x86命令の所要クロック計測スレPart4
Penrynとあんま変わってないじゃないか。
良くも悪くも
こっちはいい傾向だな
http://www.freeweb.hu/instlatx64/MemLatX64_GenuineIntel00106A2_GainestownES_2666MHz.txt
良くも悪くも
こっちはいい傾向だな
http://www.freeweb.hu/instlatx64/MemLatX64_GenuineIntel00106A2_GainestownES_2666MHz.txt
|
|
|
290 :,,・´∀`・,,)っ-●◎○:2008/11/13(木) 20:40:54
Penryn
http://www.freeweb.hu/instlatx64/InstLatX64_GenuineIntel0010676_Core_Harpertown_2800MHz.txt
1153 SSSE3 :PHADDD xmm, xmm L: 1.07ns= 3.0c T: 0.72ns= 2.00c
1170 SSE4.1:MPSADBW xmm, xmm, imm8 L: 1.79ns= 5.0c T: 0.72ns= 2.00c
1171 SSE4.1:PHMINPOSUW xmm, xmm L: 1.43ns= 4.0c T: 1.43ns= 4.00c
Nehalem
Inst 1153 SSSE3 : PHADDD xmm, xmm L: 1.06ns= 2.8c T: 0.56ns= 1.50c
Inst 1170 SSE4.1: MPSADBW xmm, xmm, imm8 L: 1.81ns= 4.8c T: 0.37ns= 1.00c
Inst 1171 SSE4.1: PHMINPOSUW xmm, xmm L: 1.12ns= 3.0c T: 0.37ns= 1.00c
シャッフル命令強化?
さて、まるもに投稿してくるか
http://www.freeweb.hu/instlatx64/InstLatX64_GenuineIntel0010676_Core_Harpertown_2800MHz.txt
1153 SSSE3 :PHADDD xmm, xmm L: 1.07ns= 3.0c T: 0.72ns= 2.00c
1170 SSE4.1:MPSADBW xmm, xmm, imm8 L: 1.79ns= 5.0c T: 0.72ns= 2.00c
1171 SSE4.1:PHMINPOSUW xmm, xmm L: 1.43ns= 4.0c T: 1.43ns= 4.00c
Nehalem
Inst 1153 SSSE3 : PHADDD xmm, xmm L: 1.06ns= 2.8c T: 0.56ns= 1.50c
Inst 1170 SSE4.1: MPSADBW xmm, xmm, imm8 L: 1.81ns= 4.8c T: 0.37ns= 1.00c
Inst 1171 SSE4.1: PHMINPOSUW xmm, xmm L: 1.12ns= 3.0c T: 0.37ns= 1.00c
シャッフル命令強化?
さて、まるもに投稿してくるか
291 :デフォルトの名無しさん:2008/11/13(木) 20:52:53
http://pc11.2ch.net/test/read.cgi/avi/1225343648/236
http://pc11.2ch.net/test/read.cgi/avi/1225343648/281
http://pc11.2ch.net/test/read.cgi/avi/1225343648/281
292 :デフォルトの名無しさん:2008/11/13(木) 21:20:09
>>290
> シャッフル命令強化?
Integer Shufflesが倍になった
ttp://pc.watch.impress.co.jp/docs/2008/0403/kaigai13.jpg
punpck/pack/pshufのスループットが(packのMMXレジスタ版を除き)倍になっている
> シャッフル命令強化?
Integer Shufflesが倍になった
ttp://pc.watch.impress.co.jp/docs/2008/0403/kaigai13.jpg
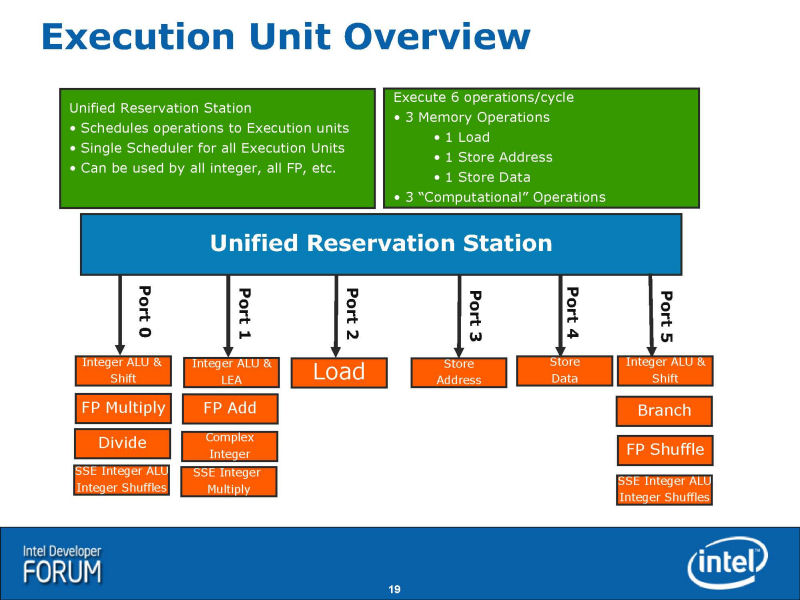{kind=link}
punpck/pack/pshufのスループットが(packのMMXレジスタ版を除き)倍になっている
293 :,,・´∀`・,,)っ-●◎○:2008/11/13(木) 21:23:37
やっぱりそうか
Radix-16 Dividerとシャッフルユニットって回路共有できるんじゃないかと思ってたけど
Penrynではなぜか別々だったんだよな
Radix-16 Dividerとシャッフルユニットって回路共有できるんじゃないかと思ってたけど
Penrynではなぜか別々だったんだよな
294 :デフォルトの名無しさん:2008/11/14(金) 21:04:03
PADDQのスループットレイテンシが良くなってるな。
295 :デフォルトの名無しさん:2008/11/14(金) 21:46:14
>Radix-16 Dividerとシャッフルユニットって回路共有できるんじゃないかと思ってたけど
できねーよw
できねーよw
296 :,,・´∀`・,,)っ-○◎●:2008/11/14(金) 21:50:43
pshufbを1サイクルでやるのに必要な回路って4ビット(16Way)のテーブル参照じゃん。
Radix-16も原理的には同じクロスバースイッチによる実装だよ。
まあ実際に回路共有してるかどうかは知らんがどちらもIntelでは45nmプロセスで初めて実装された
同水準の技術というのは事実だな。
Radix-16も原理的には同じクロスバースイッチによる実装だよ。
まあ実際に回路共有してるかどうかは知らんがどちらもIntelでは45nmプロセスで初めて実装された
同水準の技術というのは事実だな。
297 :デフォルトの名無しさん:2008/11/15(土) 20:10:49
団子はプログラムだけかたってりゃいい。
無理に回路の話するな。
無理に回路の話するな。
298 :,,・´∀`・,,)っ-●◎○:2008/11/15(土) 20:17:30
どっちも4ビットのテーブル参照ユニットだよ。
radix-16の実装についての論文は嗜んでおります。多分君らよりはモノ読んでるから。
radix-16の実装についての論文は嗜んでおります。多分君らよりはモノ読んでるから。
299 :デフォルトの名無しさん:2008/11/15(土) 20:25:21
もの読んでも理解できてないんじゃ意味ないし、読んだうちにはいりませんよ。
あるレジスタ値をシャッフルするようなネットワークなんて今時のプロセッサ内には沢山ある。
回路の世界では、実装は共通化しないで分離、専用化した方が高速なのが普通。
むりにハードを語る必要はない。
あるレジスタ値をシャッフルするようなネットワークなんて今時のプロセッサ内には沢山ある。
回路の世界では、実装は共通化しないで分離、専用化した方が高速なのが普通。
むりにハードを語る必要はない。
300 :,,・´∀`・,,)っ-●◎○:2008/11/15(土) 20:56:50
専用化(笑)
除算命令をパイプラインのどこでマイクロコードに分解してると思う?
無理にハード語るなよ
除算命令をパイプラインのどこでマイクロコードに分解してると思う?
無理にハード語るなよ
301 :デフォルトの名無しさん:2008/11/15(土) 21:11:53
ダンコ″さんが饒舌になるとスレが湧き上がるな
302 :デフォルトの名無しさん:2008/11/15(土) 21:26:16
>除算命令をパイプラインのどこでマイクロコードに分解してると思う?
>無理にハード語るなよ
団子ワラタ
こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>無理にハード語るなよ
団子ワラタ
こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
303 :,,・´∀`・,,)っ-●◎○:2008/11/15(土) 22:13:14
304 :,,・´∀`・,,)っ-●◎○:2008/11/15(土) 22:14:50
>>302←恥ずかしい奴だな。無知なら黙っておけばいいものを。
http://www.agner.org/optimize/instruction_tables.pdf
http://www.agner.org/optimize/instruction_tables.pdf
http://www.agner.org/optimize/instruction_tables.pdf
http://www.agner.org/optimize/instruction_tables.pdf
http://www.agner.org/optimize/instruction_tables.pdf
http://www.agner.org/optimize/instruction_tables.pdf
http://www.agner.org/optimize/instruction_tables.pdf
http://www.agner.org/optimize/instruction_tables.pdf
305 :デフォルトの名無しさん:2008/11/15(土) 22:35:46
おいおい、団子よ、誤魔化そうとするなよ。
おれはシングルuopとはいってない。
だが、団子は、uopに細かくばらすことで回路を共用にできると思ってるんだろw
おれはシングルuopとはいってない。
だが、団子は、uopに細かくばらすことで回路を共用にできると思ってるんだろw
306 :,,・´∀`・,,)っ-●◎○:2008/11/15(土) 22:38:12
はいはい、恥ずかしいから帰っていいよ。
307 :,,・´∀`・,,)っ-●◎○:2008/11/15(土) 22:43:50
次来るときは共用してない根拠を示してね
その逆の説明は、多くのx86アーキテクチャで除算命令とシャッフル命令の発行ポートが同一な
理由の説明にもなってしまう
その逆の説明は、多くのx86アーキテクチャで除算命令とシャッフル命令の発行ポートが同一な
理由の説明にもなってしまう
308 :デフォルトの名無しさん:2008/11/15(土) 22:44:23
>除算命令をパイプラインのどこでマイクロコードに分解してると思う?
この答えは猿でもわかるデコーダだが、団子はこの先何を言いたいのでしょう?
無知をさらしたくないならレスをしない方が身のためかもよ。
この答えは猿でもわかるデコーダだが、団子はこの先何を言いたいのでしょう?
無知をさらしたくないならレスをしない方が身のためかもよ。
309 :デフォルトの名無しさん:2008/11/15(土) 22:46:14
>次来るときは共用してない根拠を示してね
やっぱマジでuop効果だとおもってるんだな団子先生は。
偉大だ。自分で提示しているソースにそもそもそれを否定する内容がかかれているともいざ知らず。
除算命令はuopを一体何個生成しているのでしょう?
ハードはなるべく語らない方が身のためだ。これが僕からのアドバイスです。
やっぱマジでuop効果だとおもってるんだな団子先生は。
偉大だ。自分で提示しているソースにそもそもそれを否定する内容がかかれているともいざ知らず。
除算命令はuopを一体何個生成しているのでしょう?
ハードはなるべく語らない方が身のためだ。これが僕からのアドバイスです。
310 :,,・´∀`・,,)っ-●◎○:2008/11/15(土) 22:46:16
もう恥ずかしいから出てくるなよ。
マイクロオペレーション数とかかってるクロック数数えてみな。
馬鹿にはわからない真実がある。
アー馬鹿には理解不能だけどな
マイクロオペレーション数とかかってるクロック数数えてみな。
馬鹿にはわからない真実がある。
アー馬鹿には理解不能だけどな
311 :デフォルトの名無しさん:2008/11/15(土) 22:48:50
>マイクロオペレーション数とかかってるクロック数数えてみな。
自分で自分の間違いに気づいたのか、単なる電波なのか。
お団子くんの必死の弁解ショーがこれから始まります。
自分で自分の間違いに気づいたのか、単なる電波なのか。
お団子くんの必死の弁解ショーがこれから始まります。
312 :,,・´∀`・,,)っ-●◎○:2008/11/15(土) 22:51:57
別ユニットであると自信を持って言える根拠ってなんだろうね
1.俺の脳内アーキテクチャではそうだ
2.俺はIntelの中の人だ
3.とりあえず団子の言うことだから苦し紛れでも否定しとけ
俺は断定も否定もしてないが、ただ、μOP数に着目すれば
シャッフルユニットと辞書引き用のユニットで別々に持つ必然性もないことだけはわかるな。
1.俺の脳内アーキテクチャではそうだ
2.俺はIntelの中の人だ
3.とりあえず団子の言うことだから苦し紛れでも否定しとけ
俺は断定も否定もしてないが、ただ、μOP数に着目すれば
シャッフルユニットと辞書引き用のユニットで別々に持つ必然性もないことだけはわかるな。
313 :,,・´∀`・,,)っ-●◎○:2008/11/15(土) 22:53:55
つーかpshufbが辞書引きでなくてなんだって話になるけどな。
辞書引きする値の供給元が定数ROMかレジスタかって違いか
辞書引きする値の供給元が定数ROMかレジスタかって違いか
314 :,,・´∀`・,,)っ-●◎○:2008/11/15(土) 22:57:17
とりあえずSSE4.2のテキストサーチが汎用のシャッフルユニットの組み合わせで実装されてる程度には
除算命令も汎用ユニットに対するマイクロオペレーションの組み合わせで実装されてるよ
除算命令も汎用ユニットに対するマイクロオペレーションの組み合わせで実装されてるよ
315 :デフォルトの名無しさん:2008/11/15(土) 23:24:34
タ″ンゴさんの連投れスレが猛烈にヒートアップしたな
316 :,,・´∀`・,,)っ-●◎○:2008/11/15(土) 23:50:22
DIV/IDIVの32bit版ですよ
・Core 2(65nm)
μOPs=4
L=18-42 T=12-36
・Core 2(45nm) (Super Shuffle Engine / Radix-16搭載)
μOps=7
L=14-23 T=??
45nmでは大幅に除算の性能上がってるのにμOPsが増えてるのはなんでだろうね?
むしろ7μOPsの内訳はなんだろうね?
はい、これ宿題ね。
・Core 2(65nm)
μOPs=4
L=18-42 T=12-36
・Core 2(45nm) (Super Shuffle Engine / Radix-16搭載)
μOps=7
L=14-23 T=??
45nmでは大幅に除算の性能上がってるのにμOPsが増えてるのはなんでだろうね?
むしろ7μOPsの内訳はなんだろうね?
はい、これ宿題ね。
317 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 00:06:38
7μOpsの内訳、資料に書いてあるわ
Port 0: 2
Port 1: 3
Port 5: 2
うん、確かにばら撒いてるな
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
馬鹿丸出しだな
Port 0: 2
Port 1: 3
Port 5: 2
うん、確かにばら撒いてるな
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
馬鹿丸出しだな
318 :デフォルトの名無しさん:2008/11/16(日) 00:12:33
↓↓↓ダンゴ先生(NGワード)の勝利宣言が続きます↓↓↓
319 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 00:18:32
ヲーーーーーーーーーーーーーウィWWWWWWWWW
「除算は除算専用ユニットで処理される」とか恥ずかしい事言ってたフェンス君出てコーーーーーーーーーウィWWWWWWWW
ああどうしてフェンス君はこんなにも脳内がお花畑なんだWWWWWWWW
チクショオオオオオオオオオオオオオオオオWWWWWWWWW
「除算は除算専用ユニットで処理される」とか恥ずかしい事言ってたフェンス君出てコーーーーーーーーーウィWWWWWWWW
ああどうしてフェンス君はこんなにも脳内がお花畑なんだWWWWWWWW
チクショオオオオオオオオオオオオオオオオWWWWWWWWW
320 :デフォルトの名無しさん:2008/11/16(日) 00:21:43
おれはフェンス君じゃないよw
団子の脳内CPUにはユニット未満の回路構成単位はないみたいでワラタ。
複数サイクルかかるのはなんでもuopに分解されてるからとでもおもってんのか、こいつはw
団子の脳内CPUにはユニット未満の回路構成単位はないみたいでワラタ。
複数サイクルかかるのはなんでもuopに分解されてるからとでもおもってんのか、こいつはw
321 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 00:22:41
事実複数μOPsに分解されてるジャン。
言い訳になってないよ。
言い訳になってないよ。
322 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 00:25:16
レイテンシチェインがあり複数命令をインターリーブできない場合はスループットも内部OPs数以上になることはあるね。
P5までのx87命令が代表例。
P5までのx87命令が代表例。
323 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 00:26:24
【7μOpsの内訳】
Port 0: 2
Port 1: 3
Port 5: 2
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
恥ずかしくないですか?
Port 0: 2
Port 1: 3
Port 5: 2
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
恥ずかしくないですか?
324 :デフォルトの名無しさん:2008/11/16(日) 00:27:12
>>321
で、自分でuop数と実行レイテンシを比較した考察はどうだったんだ?
お前の頭には1uopで動く一般的な"除算器"(もちろん実行ユニットやポートと1対1とは限らない)という概念がないのね。
知らないからw
で、自分でuop数と実行レイテンシを比較した考察はどうだったんだ?
お前の頭には1uopで動く一般的な"除算器"(もちろん実行ユニットやポートと1対1とは限らない)という概念がないのね。
知らないからw
325 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 00:30:10
>お前の頭には1uopで動く一般的な"除算器"(もちろん実行ユニットやポートと1対1とは限らない)という概念がないのね。
PenPro/2/3でDIVが1μOPなのは知ってるよ。
しかし、少なくともCore 2以降のx86には無いし今後実装されることもないでしょう
PenPro/2/3でDIVが1μOPなのは知ってるよ。
しかし、少なくともCore 2以降のx86には無いし今後実装されることもないでしょう
326 :デフォルトの名無しさん:2008/11/16(日) 00:30:19
>>323
おれは除算専用ではない汎用的な"ユニット"にばらまくと団子が思っていると書いているが?
団子は"命令ポート"に数命令が渡されるのを、除算中のRadix単位の反復処理に対応するものだと勘違いしている
(必死に今ごまかそうとしている)。
おれは除算専用ではない汎用的な"ユニット"にばらまくと団子が思っていると書いているが?
団子は"命令ポート"に数命令が渡されるのを、除算中のRadix単位の反復処理に対応するものだと勘違いしている
(必死に今ごまかそうとしている)。
327 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 00:33:17
Penrynには【除算専用ユニット】が全ALUポートに2:3:2で存在するのか
すげーな
すげーな
328 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 00:34:42
329 :デフォルトの名無しさん:2008/11/16(日) 00:35:35
↑団子がここまで馬鹿だとは最初に書いたおれも思わなかった。
除算専用ユニットか、それよりも汎用的なユニットに除算器で処理するような内容を分解しているのか?
という話で元々かいていて、uop数とレイテンシを比較してどう団子は考えたの?
ときいているんだよ。お前は一体何様なんだ? 話をこじらして逃げようとしているだけ。
除算専用ユニットか、それよりも汎用的なユニットに除算器で処理するような内容を分解しているのか?
という話で元々かいていて、uop数とレイテンシを比較してどう団子は考えたの?
ときいているんだよ。お前は一体何様なんだ? 話をこじらして逃げようとしているだけ。
330 :デフォルトの名無しさん:2008/11/16(日) 00:37:18
ちゃんと読み返せばわかるとおり、
おれは2つ以上のuopに除算命令が分解されることはない
なんて一切かいてない。適当な団子よりも言葉を選んでいるし、あと百回読んでからレスしろよ。
おれは2つ以上のuopに除算命令が分解されることはない
なんて一切かいてない。適当な団子よりも言葉を選んでいるし、あと百回読んでからレスしろよ。
331 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 00:37:36
馬鹿はお前だ。
除算専用ユニットでの1μOPで完結してるとして残りの6μOPsは何のために何の命令を発行してるんだ
答 え て み ろ よ
お前の間違いはそこにある。
除算専用ユニットでの1μOPで完結してるとして残りの6μOPsは何のために何の命令を発行してるんだ
答 え て み ろ よ
お前の間違いはそこにある。
332 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 00:38:32
「おれ」を漢字で書かないのはフェンス症候群
333 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 00:39:38
言っておくけど、NOPは、発行せずにリタイヤだよ。
334 :デフォルトの名無しさん:2008/11/16(日) 00:46:48
>>331
詳細はわからないが、
通常プログラマから見えない内部フラグとか例外検出のための処理とかじゃね?
で、団子はuopに分解するのにスループットが悪かったり、そもそもレイテンシが
一致しないのをどう説明するんだ?
詳細はわからないが、
通常プログラマから見えない内部フラグとか例外検出のための処理とかじゃね?
で、団子はuopに分解するのにスループットが悪かったり、そもそもレイテンシが
一致しないのをどう説明するんだ?
335 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 00:47:22
パイプライン化されてない命令が複数サイクルかかるのは一つの事実だけど
除算命令が複数μOPsに分解される事実を否定するものでは無いな
除算命令が複数μOPsに分解される事実を否定するものでは無いな
336 :デフォルトの名無しさん:2008/11/16(日) 00:49:15
だから複数uopを生成しないなんておれは書いてないだろ。
>どっちも4ビットのテーブル参照ユニットだよ。
>radix-16の実装についての論文は嗜んでおります。多分君らよりはモノ読んでるから。
>俺は断定も否定もしてないが、ただ、μOP数に着目すれば
>シャッフルユニットと辞書引き用のユニットで別々に持つ必然性もないことだけはわかるな。
はやくこの大風呂敷を説明しろよ。
>どっちも4ビットのテーブル参照ユニットだよ。
>radix-16の実装についての論文は嗜んでおります。多分君らよりはモノ読んでるから。
>俺は断定も否定もしてないが、ただ、μOP数に着目すれば
>シャッフルユニットと辞書引き用のユニットで別々に持つ必然性もないことだけはわかるな。
はやくこの大風呂敷を説明しろよ。
337 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 00:50:28
>通常プログラマから見えない内部フラグとか例外検出のための処理とかじゃね?
何の例外だよ。何のフラグだよ。
お前は何も具体的なこと理解してないのに思い込みでモノをいうんだな。
結局お前はRadix-16の論文読んでないんだな。
ちなみに8ビットの除算だと4μOPsで済んでるし
64ビットだとより多くのμOPs数がかかってる
何の例外だよ。何のフラグだよ。
お前は何も具体的なこと理解してないのに思い込みでモノをいうんだな。
結局お前はRadix-16の論文読んでないんだな。
ちなみに8ビットの除算だと4μOPsで済んでるし
64ビットだとより多くのμOPs数がかかってる
338 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 00:50:48
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
339 :デフォルトの名無しさん:2008/11/16(日) 00:56:52
逃げようとしても無駄だよ。
>お前は何も具体的なこと理解してないのに思い込みでモノをいうんだな。
それはお前の方。uopが複数かかる要因は色々考えられる。Intelが詳細を公開しているわけでもないし、
正直、具体的にはわからない。何ビットかの単位でuopを分けているのかもしれないが、そもそもraidx-16の実装は
ユニット内部の話なので関係がない。
偉大なる団子さんは、具体的かつ断定的事実をuop数とレイテンシの数字から
発見したらしいからそれを説明して欲しい。
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
前後の流れをみて読めばわかるとおり、除算専用のユニットではなく、汎用的なユニットにばらまいて処理している
と書いているのであって、複数のuopそのものを否定しているわけではない。
以前から知っていることだし、そんなことは今更書くわけない。
>お前は何も具体的なこと理解してないのに思い込みでモノをいうんだな。
それはお前の方。uopが複数かかる要因は色々考えられる。Intelが詳細を公開しているわけでもないし、
正直、具体的にはわからない。何ビットかの単位でuopを分けているのかもしれないが、そもそもraidx-16の実装は
ユニット内部の話なので関係がない。
偉大なる団子さんは、具体的かつ断定的事実をuop数とレイテンシの数字から
発見したらしいからそれを説明して欲しい。
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
前後の流れをみて読めばわかるとおり、除算専用のユニットではなく、汎用的なユニットにばらまいて処理している
と書いているのであって、複数のuopそのものを否定しているわけではない。
以前から知っていることだし、そんなことは今更書くわけない。
340 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 00:58:28
逃げてるのはお前だろ。
自分では具体的な証拠も示さないくせに
無根拠な主張だけは延々やるんだな
自分では具体的な証拠も示さないくせに
無根拠な主張だけは延々やるんだな
341 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 00:59:55
負け犬よ。ごたくはいいからμOPsの内訳を答えろよ。
答えられないなら赤い顔に水でもかぶってさっさと寝ろ
答えられないなら赤い顔に水でもかぶってさっさと寝ろ
342 :デフォルトの名無しさん:2008/11/16(日) 01:01:30
>無根拠な主張だけは延々やるんだな
だから団子は根拠をいつになったら説明するんだよw
あの.pdf資料だってここにいるやつは観てるだろ。
今更なにを説明しろと。
http://pc.watch.impress.co.jp/docs/2007/0524/mpf01_04.jpg
この図をみて、radix-16が実行ユニットの実装の話であり、
シャッフルユニットとの共有とかuopの分割はレベルの違う話である。
ただそれだけのこと。団子はそれがわかってないから、おれの文意味すらわからない。
だから団子は根拠をいつになったら説明するんだよw
あの.pdf資料だってここにいるやつは観てるだろ。
今更なにを説明しろと。
http://pc.watch.impress.co.jp/docs/2007/0524/mpf01_04.jpg
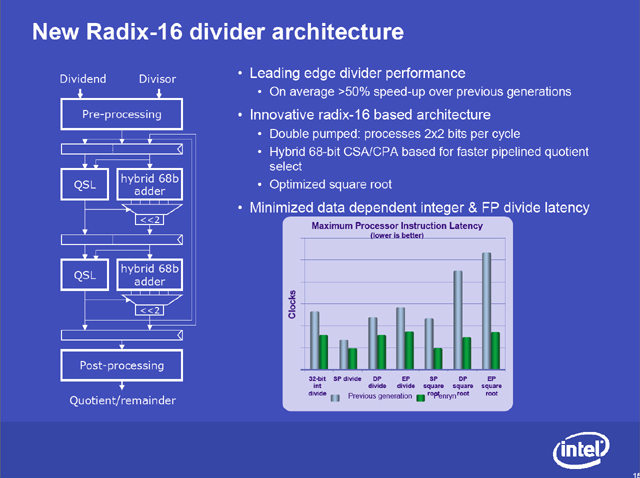{kind=link}
この図をみて、radix-16が実行ユニットの実装の話であり、
シャッフルユニットとの共有とかuopの分割はレベルの違う話である。
ただそれだけのこと。団子はそれがわかってないから、おれの文意味すらわからない。
343 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 01:05:43
整数除算で起きる特殊例外なんてせいぜいdivide by zeroくらいだぞ?
フラグ更新なんて分岐条件フラグを更新するaddやandが1μOPで済んでる程度に低コスト。
6μOPの内訳の妄想としては稚拙すぎる。
フラグ更新なんて分岐条件フラグを更新するaddやandが1μOPで済んでる程度に低コスト。
6μOPの内訳の妄想としては稚拙すぎる。
344 :デフォルトの名無しさん:2008/11/16(日) 01:07:09
他にもスケジューリング単純化の都合で使わないALUを麻痺るとか?
345 :デフォルトの名無しさん:2008/11/16(日) 01:08:12
Fused uopな故に、実際にはuopなんて生成していないが、
ポートが使えずに、uopが生成されたかのように見えるとか?
ポートが使えずに、uopが生成されたかのように見えるとか?
346 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 01:16:03
結局これがすべて最初から最後までハードワイヤードロジックで実装されてると思ってるんだろ
http://pc.watch.impress.co.jp/docs/2007/0524/mpf01_04.jpg
それが大間違いだよ
http://pc.watch.impress.co.jp/docs/2007/0524/mpf01_04.jpg
それが大間違いだよ
347 :デフォルトの名無しさん:2008/11/16(日) 01:21:07
風呂敷あと何枚ひろげたら気が済むんだ?
そろそろたたまないとエヴァ●ゲリオンの二の舞だよ。
そろそろたたまないとエヴァ●ゲリオンの二の舞だよ。
348 :デフォルトの名無しさん:2008/11/16(日) 07:21:03
>>341
人に答えさせようとするよりも、自分からビシッと示して、話をスパッと終わらせたほうがいいと思う。
人に答えさせようとするよりも、自分からビシッと示して、話をスパッと終わらせたほうがいいと思う。
349 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 11:03:27
俺がやる必要ないし
すべてハードワイヤードロジックで実装されてるっていう思い込みありきだから
現実世界の事実と照合したときに矛盾ばかりが浮上する。それだけ。
で、自説のほうが間違いだから、現実のほうに対して思い込みありきの矛盾解消を求めてくる←今ココ
無理だって。だって思い込みの時点で間違ってるんだもん。
一応フォローしておくけどQSL=テーブル参照
つーかさ、ADD/SUBもAND/OR/XORも専用のサブユニット用意してるわけじゃないんだぜ。
出来るだけ共用化することでトランジスタ数を抑えられる。クロックゲーティングに必要なトランジスタ数もね。
実際どういう構成になってるかは中の人しか知りえないことだよ。
中の人でないと自ら白状してるから、まあ脳内アーキテクチャが根拠なんだろうけど
案の定、現実世界の事実との矛盾にぶち当たってる。
すべてハードワイヤードロジックで実装されてるっていう思い込みありきだから
現実世界の事実と照合したときに矛盾ばかりが浮上する。それだけ。
で、自説のほうが間違いだから、現実のほうに対して思い込みありきの矛盾解消を求めてくる←今ココ
無理だって。だって思い込みの時点で間違ってるんだもん。
一応フォローしておくけどQSL=テーブル参照
つーかさ、ADD/SUBもAND/OR/XORも専用のサブユニット用意してるわけじゃないんだぜ。
出来るだけ共用化することでトランジスタ数を抑えられる。クロックゲーティングに必要なトランジスタ数もね。
実際どういう構成になってるかは中の人しか知りえないことだよ。
中の人でないと自ら白状してるから、まあ脳内アーキテクチャが根拠なんだろうけど
案の定、現実世界の事実との矛盾にぶち当たってる。
350 :デフォルトの名無しさん:2008/11/16(日) 11:31:33
ダンゴさんのエスプリの効いたレスでスレがあふれ返っているな
いや、自分は団子さんが正しいと思ってる。
このスレでカマッテチャンの相手をしてスレをハイペースで延ばすくらいなら、ズバリ説明してトドメさしたほうが、再発しなくていいかな、と。
このスレでカマッテチャンの相手をしてスレをハイペースで延ばすくらいなら、ズバリ説明してトドメさしたほうが、再発しなくていいかな、と。
352 :デフォルトの名無しさん:2008/11/16(日) 12:25:40
ダンゴさんの自演でスレの信憑性が一気に高まったな
353 :デフォルトの名無しさん:2008/11/16(日) 12:33:30
そもそも団子はハードワイヤードロジックって言葉が
何を指しているかもわからないんだろうけどなw
ハードに関しては素人以下の妄想レベル。
何を指しているかもわからないんだろうけどなw
ハードに関しては素人以下の妄想レベル。
354 :デフォルトの名無しさん:2008/11/16(日) 12:36:29
テーブル参照がマイクロコードなしでは実装できないという電波説も新たに披露してくれるのか。
配列やハッシュに相当する機能はハードだけで実現できるのをしらないんだねw
配列やハッシュに相当する機能はハードだけで実現できるのをしらないんだねw
355 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 13:34:34
現実問題として、整数DIV/IDIVで複数μOPかかってる。
除算回路がマルチサイクルかけてループ処理する機構になっていることと、
分解の必要有無は別問題なんだよ。
っつーか、PenrynでもSSE浮動小数の除算や平方根は1μOPで済んでる。
ちゃんと資料を読んでればわかること
つまるところ整数に余分にμOPsがかかるのはなぜか?ってことなんだが。
おそらく浮動小数演算にチューンされて、整数だと余分にオペレーションがかかる構造になったため。
たとえばDIV/IDIVは商をEAXに格納するほかに、【剰余】をEDXレジスタに格納する。
たとえば、除算機から剰余を吐き出す回路が端折られた場合、どうやって剰余を求めると思う?
一番わかりやすいのが、
剰余 = 被除数−(商×除数)
被除数のシャドウレジスタへの退避+除数と商の乗算+被除数からの減算
で3μOPs。8ビット版の除算の内訳としてはちょうど数があう。
ハイこれで一つ解決だね。
32ビットの7μOPsは単精度の仮数が24ビットしか表現できないから除算の段階でも4μOpsに分解するようにしたんだろ。
この点は4μOPのMeromから劣化してるっぽいが平均的に除算性能が上がったぶん端折ったと思われる
16ビットは実装が内部32ビットで出力時に下位16ビットを書き込むからだと思ってるが。
ホントは最適化すれば8ビットと同じ4μOPsで済むと思うが、端折ったんだろ
8ビット除算はレガシーとはいえAscii Adjust〜でたまに使うけど16ビットはそんなに使う機会ないからね。
64ビットは倍精度の53ビットにすら収まらない。増えるのは道理。
まあ、「よくわからないフラグ」と「よくわからない例外」なんて珍説よりは辻褄があってると思うが。
除算用のテーブルルックアップ用サブユニットが除算専用化されてて
他の演算に使いまわし出来ないという仮説に至る理由はよくわからんけどな。
もちろん、複数μOPsかかる事実は、仮説の反証としても成立してないよ。
Penrynでは少なくともやってないのは事実としてあるし。
除算回路がマルチサイクルかけてループ処理する機構になっていることと、
分解の必要有無は別問題なんだよ。
っつーか、PenrynでもSSE浮動小数の除算や平方根は1μOPで済んでる。
ちゃんと資料を読んでればわかること
つまるところ整数に余分にμOPsがかかるのはなぜか?ってことなんだが。
おそらく浮動小数演算にチューンされて、整数だと余分にオペレーションがかかる構造になったため。
たとえばDIV/IDIVは商をEAXに格納するほかに、【剰余】をEDXレジスタに格納する。
たとえば、除算機から剰余を吐き出す回路が端折られた場合、どうやって剰余を求めると思う?
一番わかりやすいのが、
剰余 = 被除数−(商×除数)
被除数のシャドウレジスタへの退避+除数と商の乗算+被除数からの減算
で3μOPs。8ビット版の除算の内訳としてはちょうど数があう。
ハイこれで一つ解決だね。
32ビットの7μOPsは単精度の仮数が24ビットしか表現できないから除算の段階でも4μOpsに分解するようにしたんだろ。
この点は4μOPのMeromから劣化してるっぽいが平均的に除算性能が上がったぶん端折ったと思われる
16ビットは実装が内部32ビットで出力時に下位16ビットを書き込むからだと思ってるが。
ホントは最適化すれば8ビットと同じ4μOPsで済むと思うが、端折ったんだろ
8ビット除算はレガシーとはいえAscii Adjust〜でたまに使うけど16ビットはそんなに使う機会ないからね。
64ビットは倍精度の53ビットにすら収まらない。増えるのは道理。
まあ、「よくわからないフラグ」と「よくわからない例外」なんて珍説よりは辻褄があってると思うが。
除算用のテーブルルックアップ用サブユニットが除算専用化されてて
他の演算に使いまわし出来ないという仮説に至る理由はよくわからんけどな。
もちろん、複数μOPsかかる事実は、仮説の反証としても成立してないよ。
Penrynでは少なくともやってないのは事実としてあるし。
356 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 13:35:54
357 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 13:38:30
ちなみに>>346の図には剰余の出力が描かれてないね。
358 :デフォルトの名無しさん:2008/11/16(日) 13:40:34
ちゃんばば臭い。
命令としては剰余は必ず求めなければならないので、その回路を削るとは思えないんだが。
削ったほうが、どれくらい回路が節約できるのかな。
まぁ剰余を誰も使っていないのなら計算を省けるか。
命令としては剰余は必ず求めなければならないので、その回路を削るとは思えないんだが。
削ったほうが、どれくらい回路が節約できるのかな。
まぁ剰余を誰も使っていないのなら計算を省けるか。
359 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 13:45:55
除算ロジックから剰余出力を端折る理由:だって浮動小数に必要ないじゃん。
商だけわかれば剰余を汎用のユニットで求められるだろ。
それとも、よくわからないフラグとよくわからない例外処理のほうが説得力あるのか?w
商だけわかれば剰余を汎用のユニットで求められるだろ。
それとも、よくわからないフラグとよくわからない例外処理のほうが説得力あるのか?w
360 :デフォルトの名無しさん:2008/11/16(日) 13:57:30
団子も徹夜の学習でまともになってきたせいか>>355の考察はよいが、
団子が自分で広げた大風呂敷を結局回収できてないことは事実だな。
なにしろ除算専用の演算器の存在をCore 2で否定したんだからな。
そしてシャッフルユニットとRadix-16除算器の共用化に関しては
未だに説明がない。これ以上ごまかしと話題そらしをつづけるなら、
除算ネタを今後の煽りネタとしてつかいつづけちゃうぞ。
300 :,,・´∀`・,,)っ-●◎○ [↓] :2008/11/15(土) 20:56:50
専用化(笑)
除算命令をパイプラインのどこでマイクロコードに分解してると思う?
無理にハード語るなよ
296 :,,・´∀`・,,)っ-○◎● [↓] :2008/11/14(金) 21:50:43
pshufbを1サイクルでやるのに必要な回路って4ビット(16Way)のテーブル参照じゃん。
Radix-16も原理的には同じクロスバースイッチによる実装だよ。
団子が自分で広げた大風呂敷を結局回収できてないことは事実だな。
なにしろ除算専用の演算器の存在をCore 2で否定したんだからな。
そしてシャッフルユニットとRadix-16除算器の共用化に関しては
未だに説明がない。これ以上ごまかしと話題そらしをつづけるなら、
除算ネタを今後の煽りネタとしてつかいつづけちゃうぞ。
300 :,,・´∀`・,,)っ-●◎○ [↓] :2008/11/15(土) 20:56:50
専用化(笑)
除算命令をパイプラインのどこでマイクロコードに分解してると思う?
無理にハード語るなよ
296 :,,・´∀`・,,)っ-○◎● [↓] :2008/11/14(金) 21:50:43
pshufbを1サイクルでやるのに必要な回路って4ビット(16Way)のテーブル参照じゃん。
Radix-16も原理的には同じクロスバースイッチによる実装だよ。
361 :デフォルトの名無しさん:2008/11/16(日) 14:00:42
362 :デフォルトの名無しさん:2008/11/16(日) 14:17:26
363 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 15:08:28
>>360
お前は頭も悪いし勉強できてないな。
俺の理解を曲解することしか
俺がいつ、シャッフル命令+αの命令単位に分解するなんて言ったよ?
たとえるなら積和算ユニットの一部を単体の乗算と加算で使えるってレベルの話しかやってない。
複数μOPsに分解される理由を曲解してるからそういう妄想にたどり着くんだろうな。
すぐ下を見れば浮動小数除算が1μOPで処理されてることくらいわかるし
散々ヒント与えたのに相変わらず電波飛ばしてるのはお前だけ
お前は頭も悪いし勉強できてないな。
俺の理解を曲解することしか
俺がいつ、シャッフル命令+αの命令単位に分解するなんて言ったよ?
たとえるなら積和算ユニットの一部を単体の乗算と加算で使えるってレベルの話しかやってない。
複数μOPsに分解される理由を曲解してるからそういう妄想にたどり着くんだろうな。
すぐ下を見れば浮動小数除算が1μOPで処理されてることくらいわかるし
散々ヒント与えたのに相変わらず電波飛ばしてるのはお前だけ
364 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 15:12:10
>>362
不正解。
おそらく、剰余を端折れるか判定してさぼるための機構のほうが
まじめに剰余出力するよりコストかかることだろう
回路からは端折ってるがマイクロオペレーションで実装してるだろって話。
(だから1μOPで済んでいない)
不正解。
おそらく、剰余を端折れるか判定してさぼるための機構のほうが
まじめに剰余出力するよりコストかかることだろう
回路からは端折ってるがマイクロオペレーションで実装してるだろって話。
(だから1μOPで済んでいない)
365 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 15:15:08
複数マイクロオペレーションかかる理由
・わけもわからないフラグ更新
・わけもわからない例外処理
・演算ポートに「フェンス」(←得意のwww)
自分が一番わかってないのにいい加減気づけよ
・わけもわからないフラグ更新
・わけもわからない例外処理
・演算ポートに「フェンス」(←得意のwww)
自分が一番わかってないのにいい加減気づけよ
366 :デフォルトの名無しさん:2008/11/16(日) 15:44:07
伝搬速度がクリティカルなので回路を使いまわせません!
367 :デフォルトの名無しさん:2008/11/16(日) 16:11:13
「勝ち」を確信したダンゴさんのアゲ荒らしは凄惨極まりないな
368 :デフォルトの名無しさん:2008/11/16(日) 16:21:27
ダンゴさんの書き込み頻度を見てみると
どうも時々発作が出るみたいだな
どうも時々発作が出るみたいだな
369 :デフォルトの名無しさん:2008/11/16(日) 16:24:49
団子さんは初めに自分の考えが誤っていることを認めるべきだった。
間違いは直ぐに認めて訂正した方が良い。
だから無駄に書き込みの回数が多くなるんだよ。
293 :,,・´∀`・,,)っ-●◎○ [↓] :2008/11/13(木) 21:23:37
やっぱりそうか
Radix-16 Dividerとシャッフルユニットって回路共有できるんじゃないかと思ってたけど
Penrynではなぜか別々だったんだよな
出だしと最終的な結論が一致してない。
間違いは直ぐに認めて訂正した方が良い。
だから無駄に書き込みの回数が多くなるんだよ。
293 :,,・´∀`・,,)っ-●◎○ [↓] :2008/11/13(木) 21:23:37
やっぱりそうか
Radix-16 Dividerとシャッフルユニットって回路共有できるんじゃないかと思ってたけど
Penrynではなぜか別々だったんだよな
出だしと最終的な結論が一致してない。
370 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 16:27:15
俺の撒いた風呂敷に足を滑らせてフェンスに激突
371 :デフォルトの名無しさん:2008/11/16(日) 16:30:45
>>365
おれは、シャッフル演算器と除算器の共用化の話をしているので。
脱線話の1レスに粘着して、自分の汚点を体力勝負の罵倒書き込みで覆い隠そうなんて魂胆、
バレバレだし、はずかしいんでヤメテ欲しいです。
おれは、シャッフル演算器と除算器の共用化の話をしているので。
脱線話の1レスに粘着して、自分の汚点を体力勝負の罵倒書き込みで覆い隠そうなんて魂胆、
バレバレだし、はずかしいんでヤメテ欲しいです。
372 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 16:31:17
>>369
何も公式な解説が出てないので実際共有してるかしてないかは
Dividerと追加されたシャッフルユニットが同じポートに追加されたのは一つの事実だ。
俺は何一つ断定したことは言ってない。
DIV/IDIVが1μOPではなく複数の内部命令に分解されて実行される事実を提示したら
一人で混乱してた馬鹿がいただけの話
何も公式な解説が出てないので実際共有してるかしてないかは
Dividerと追加されたシャッフルユニットが同じポートに追加されたのは一つの事実だ。
俺は何一つ断定したことは言ってない。
DIV/IDIVが1μOPではなく複数の内部命令に分解されて実行される事実を提示したら
一人で混乱してた馬鹿がいただけの話
373 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 16:31:51
374 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 16:32:38
・わけもわからないフラグ更新
・わけもわからない例外処理
・演算ポートに「フェンス」(←得意のwww)
・わけもわからない例外処理
・演算ポートに「フェンス」(←得意のwww)
375 :デフォルトの名無しさん:2008/11/16(日) 16:33:37
スレタイ読めよ。
中身なんてどうでもいいんだよ。
中身なんてどうでもいいんだよ。
376 :デフォルトの名無しさん:2008/11/16(日) 16:33:41
>DIV/IDIVが1μOPではなく複数の内部命令に分解されて実行される事実を提示したら
>一人で混乱してた馬鹿がいただけの話
何度もいうが、おれは全く1uopのみだと思っていなかったし、1uopしか生成しないなんて
いったことはないが。
団子の書き込みは話の前提がテーブル参照をマイクロコードで云々だったから、
汎用的なユニットにばらまく云々の書き込みは、それを否定したまでだ。
>一人で混乱してた馬鹿がいただけの話
何度もいうが、おれは全く1uopのみだと思っていなかったし、1uopしか生成しないなんて
いったことはないが。
団子の書き込みは話の前提がテーブル参照をマイクロコードで云々だったから、
汎用的なユニットにばらまく云々の書き込みは、それを否定したまでだ。
377 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 16:33:44
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
馬鹿は死ななきゃ直らない
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
馬鹿は死ななきゃ直らない
378 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 16:34:12
何度もいうが、おれは全く1uopのみだと思っていなかったし、1uopしか生成しないなんて
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
>こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw
379 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 16:35:02
>何度もいうが、おれは全く1uopのみだと思っていなかったし、1uopしか生成しないなんて
>いったことはないが。
復唱しましょう
【こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw】
【こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw】
【こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw】
【こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw】
【こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw】
>いったことはないが。
復唱しましょう
【こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw】
【こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw】
【こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw】
【こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw】
【こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw】
380 :デフォルトの名無しさん:2008/11/16(日) 16:35:14
だから、前後の流れをみずに都合の良いように1行だけ引用するな
クズ団子が。
クズ団子が。
381 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 16:36:17
何度もいうが、この馬鹿はこの発言をした時点では、全く1uopのみだと思っていた。
【こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw】
【こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw】
【こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw】
【こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw】
【こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw】
【こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw】
【こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw】
【こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw】
【こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw】
【こいつは除算命令をuopに分解して、汎用的なユニットにバラまいてると思ってるらしいぞw】
382 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 16:37:29
>>380
前後の流れを見てもお前の勘違いは確実だが
だって、除算の出力に何の意味も無いオペレーションという仮説を3つも4つも出てくるんだもん。
いまさら撤回するなんて言うなよ。
一番理解してなかったのはお前。
前後の流れを見てもお前の勘違いは確実だが
だって、除算の出力に何の意味も無いオペレーションという仮説を3つも4つも出てくるんだもん。
いまさら撤回するなんて言うなよ。
一番理解してなかったのはお前。
383 :デフォルトの名無しさん:2008/11/16(日) 16:37:38
普通によめば
除算器をもちいずに汎用的な他の演算ユニットで処理していると読める
団子は鬼の首をとったように持ち上げているが、団子理論では
除算器なんていらないんだもんなw
除算器をもちいずに汎用的な他の演算ユニットで処理していると読める
団子は鬼の首をとったように持ち上げているが、団子理論では
除算器なんていらないんだもんなw
384 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 16:38:58
恥ずかしい発言だね
>通常プログラマから見えない内部フラグとか例外検出のための処理とかじゃね?
>通常プログラマから見えない内部フラグとか例外検出のための処理とかじゃね?
385 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 16:39:53
386 :デフォルトの名無しさん:2008/11/16(日) 16:41:14
>だって、除算の出力に何の意味も無いオペレーションという仮説を3つも4つも出てくるんだもん。
>いまさら撤回するなんて言うなよ。
おれは撤回してもぜんぜん良いが何か? 間違いを訂正できないどっかの物量書き込みの糞野郎と
同じにしないで欲しい。
あと、脱線話の手抜き1レスに粘着して話をごまかそうとするはバレバレだからやめようよw
>いまさら撤回するなんて言うなよ。
おれは撤回してもぜんぜん良いが何か? 間違いを訂正できないどっかの物量書き込みの糞野郎と
同じにしないで欲しい。
あと、脱線話の手抜き1レスに粘着して話をごまかそうとするはバレバレだからやめようよw
387 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 16:41:17
っていうか、鬼の首をとる?蛆虫を靴で踏み潰すの間違いだろ。
388 :デフォルトの名無しさん:2008/11/16(日) 16:41:54
そんなことよりも、Core i7買ったのか? おまえら。
389 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 16:43:12
390 :デフォルトの名無しさん:2008/11/16(日) 16:43:26
296 :,,・´∀`・,,)っ-○◎● [↓] :2008/11/14(金) 21:50:43
pshufbを1サイクルでやるのに必要な回路って4ビット(16Way)のテーブル参照じゃん。
Radix-16も原理的には同じクロスバースイッチによる実装だよ。
300 :,,・´∀`・,,)っ-●◎○ [↓] :2008/11/15(土) 20:56:50
専用化(笑)
除算命令をパイプラインのどこでマイクロコードに分解してると思う?
無理にハード語るなよ
ログ流そうとしても無駄だよ。定期的に説明つきで張り直してやろうか?w
pshufbを1サイクルでやるのに必要な回路って4ビット(16Way)のテーブル参照じゃん。
Radix-16も原理的には同じクロスバースイッチによる実装だよ。
300 :,,・´∀`・,,)っ-●◎○ [↓] :2008/11/15(土) 20:56:50
専用化(笑)
除算命令をパイプラインのどこでマイクロコードに分解してると思う?
無理にハード語るなよ
ログ流そうとしても無駄だよ。定期的に説明つきで張り直してやろうか?w
391 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 16:45:04
別に間違ったことは言ってないね
392 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 16:46:32
>通常プログラマから見えない内部フラグとか例外検出のための処理とかじゃね?
これは間違ったことだね
これは間違ったことだね
393 :デフォルトの名無しさん:2008/11/16(日) 16:47:48
それでは団子先生、
除算命令をパイプラインのどこでマイクロコードに分解しているのか
という質問の意図はいったい何だったのでしょう?
そして、何故シャッフルユニットと除算器の共用化で高速化が可能になるのでしょう?
除算命令をパイプラインのどこでマイクロコードに分解しているのか
という質問の意図はいったい何だったのでしょう?
そして、何故シャッフルユニットと除算器の共用化で高速化が可能になるのでしょう?
394 :デフォルトの名無しさん:2008/11/16(日) 16:47:53
395 :デフォルトの名無しさん:2008/11/16(日) 16:48:23
>>392
間違いだとは残念ながら団子君の根拠だけでは説明しきれてないが何か?
間違いだとは残念ながら団子君の根拠だけでは説明しきれてないが何か?
396 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 16:49:52
×高速化
○回路の節約
○回路の節約
397 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 16:51:22
398 :デフォルトの名無しさん:2008/11/16(日) 16:53:33
399 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 16:56:39
それがそもそもの間違いはそこから始まってるようだな。
シャッフルを発行できるポートが2基に増えてるだろ。図を見れば判るとおり。
問題になるのは、いかに低コストで実装出来るかという話。
既存の除算ユニットの一部分と共用化できれば低コストで実装できるわけだ。
しかも、2段階のシャッフルが出来るユニットとして。
シャッフルを発行できるポートが2基に増えてるだろ。図を見れば判るとおり。
問題になるのは、いかに低コストで実装出来るかという話。
既存の除算ユニットの一部分と共用化できれば低コストで実装できるわけだ。
しかも、2段階のシャッフルが出来るユニットとして。
400 :デフォルトの名無しさん:2008/11/16(日) 17:07:34
-‐ '' " ",. ̄'' ̄` ''‐、
,.-' ,r'' _,,.. - 、 ` 、
,.r'/// / ,.-' `' 、. \
/ ,r' ,r' \ '、
/ ///// ,' ,' ヽ ',
i ,.ァ .i r=ァ. ',. ',
| ,.r '" |. { r=- ', ',
| .,.r' | ! i .i
|,' ', ', .ー=‐' | .|
| ', `、 } .}
', ', '、 ! .|
'、 `、 \ ,' !
`、 '、 ' 、 / .,'
'、'-..,,_____ ___`、 `''‐- ..,, ,,.. r' /
\ ヾヾヾヾヾ \ /
` 、 、、、、、、、、 ` - ..,,, _ _,.r'゙
`' - .,,_ _,. - ''"
`"'' '' '' ""
,.-' ,r'' _,,.. - 、 ` 、
,.r'/// / ,.-' `' 、. \
/ ,r' ,r' \ '、
/ ///// ,' ,' ヽ ',
i ,.ァ .i r=ァ. ',. ',
| ,.r '" |. { r=- ', ',
| .,.r' | ! i .i
|,' ', ', .ー=‐' | .|
| ', `、 } .}
', ', '、 ! .|
'、 `、 \ ,' !
`、 '、 ' 、 / .,'
'、'-..,,_____ ___`、 `''‐- ..,, ,,.. r' /
\ ヾヾヾヾヾ \ /
` 、 、、、、、、、、 ` - ..,,, _ _,.r'゙
`' - .,,_ _,. - ''"
`"'' '' '' ""
401 :デフォルトの名無しさん:2008/11/16(日) 17:11:25
そもそも>>292の図はCore 2とかわってないんだが。
Nehalemのブロック図がでたときに一応比較確認したから。
それでおれは>>292はスルーしてたわけ。
http://www.intel.com/design/processor/manuals/248966.pdf
この37ページをみれば、シャッフルユニットはもとから2つあるのさ。
Nehalemのブロック図がでたときに一応比較確認したから。
それでおれは>>292はスルーしてたわけ。
http://www.intel.com/design/processor/manuals/248966.pdf
この37ページをみれば、シャッフルユニットはもとから2つあるのさ。
402 :デフォルトの名無しさん:2008/11/16(日) 17:16:54
ポートじゃないや実行ユニット。
403 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 17:17:25
pshuf* shufp*が発行できるユニットは1基から2基に増えた
404 :デフォルトの名無しさん:2008/11/16(日) 17:17:58
まちがいw
実行ユニットじゃなくてポートは2つある。
実行ユニットじゃなくてポートは2つある。
405 :デフォルトの名無しさん:2008/11/16(日) 17:20:08
よくよむと、PenrynのPort0とPort5のQW Shuffleは、ポートは別だけど実行ユニットが共通っていう
変態実装らしいな。Nehalemのはマニュアルが更新されるまで本当のところどうかわからない。
マジで2つに増えたのかも。
変態実装らしいな。Nehalemのはマニュアルが更新されるまで本当のところどうかわからない。
マジで2つに増えたのかも。
406 :,,・´∀`・,,)っ-●◎○:2008/11/16(日) 22:22:16
> よくよむと、PenrynのPort0とPort5のQW Shuffleは、ポートは別だけど実行ユニットが共通っていう
> 変態実装らしいな。
んぁ?どこに書いてあるんだそんなアホな間違いは
Port0で発行できる?
ならPort 5でしか実行できないスループット1の何からの命令とpshufbでもインターリーブして実行してみろよ。
よくそんな5分で検証可能な間違いを検証もせずに書けるもんだな。
スループットが0.5だと、シャッフル命令を並列発行可能なユニットが少なくとも2基あるのは確定だ。jk
あとはユニットが倍速って可能性もあるかもな。
> 変態実装らしいな。
んぁ?どこに書いてあるんだそんなアホな間違いは
Port0で発行できる?
ならPort 5でしか実行できないスループット1の何からの命令とpshufbでもインターリーブして実行してみろよ。
よくそんな5分で検証可能な間違いを検証もせずに書けるもんだな。
スループットが0.5だと、シャッフル命令を並列発行可能なユニットが少なくとも2基あるのは確定だ。jk
あとはユニットが倍速って可能性もあるかもな。
407 :,,・´∀`・,,)っ-○◎●:2008/11/16(日) 23:47:24
> Port 5でしか実行できないスループット1の何からの命令
ま、これでSuper Shuffle Engineが絡まなそうなのはjmp/jccくらいしかないんだけどな。
jmpやjccが演算ポートが重複しない限り他の命令と並列実行できるのは
大原ちゃんだって何度も検証してるくらい、このスレでは常識だし何の問題もないな。
結論から言うとjmp/jccはPort 0/1で発行可能な加算や乗算とは同時実行可能だが
シャッフルが絡む命令だけは絶対に同時実行不可能だ。
ったく、最初から最後まで馬鹿を晒すしか能がないな。
で、だ。
NehalemがCore MAのパイプラインの拡張であることを前提として、
2個目のPacked Shuffleユニットが追加されたのは間違いなく【Dividerと同じく】Port 0。
2回のシャッフルと1回のSADのマイクロオペレーションで構成されるMPSADBWのスループットが1になるには、
Port 0とPort 5の両方でシャッフル命令が発行可能である必要がある。
また、PHADD*/PHSUB*はShuffle×2+Add×1の計3μOPsだが、AddもPort0とPort5でしか発行出来ないので
スループット1.5。計測と一致するだろ?
これがもしPort0でなくてPort1だとMPSADBWのスループットが1.5、PHADD*が1になる。
もちろん0と1の両方つまり全ALUポートで発行だとshuffle系命令のスループットはほぼ全て0.33になる。
ま、これでSuper Shuffle Engineが絡まなそうなのはjmp/jccくらいしかないんだけどな。
jmpやjccが演算ポートが重複しない限り他の命令と並列実行できるのは
大原ちゃんだって何度も検証してるくらい、このスレでは常識だし何の問題もないな。
結論から言うとjmp/jccはPort 0/1で発行可能な加算や乗算とは同時実行可能だが
シャッフルが絡む命令だけは絶対に同時実行不可能だ。
ったく、最初から最後まで馬鹿を晒すしか能がないな。
で、だ。
NehalemがCore MAのパイプラインの拡張であることを前提として、
2個目のPacked Shuffleユニットが追加されたのは間違いなく【Dividerと同じく】Port 0。
2回のシャッフルと1回のSADのマイクロオペレーションで構成されるMPSADBWのスループットが1になるには、
Port 0とPort 5の両方でシャッフル命令が発行可能である必要がある。
また、PHADD*/PHSUB*はShuffle×2+Add×1の計3μOPsだが、AddもPort0とPort5でしか発行出来ないので
スループット1.5。計測と一致するだろ?
これがもしPort0でなくてPort1だとMPSADBWのスループットが1.5、PHADD*が1になる。
もちろん0と1の両方つまり全ALUポートで発行だとshuffle系命令のスループットはほぼ全て0.33になる。
408 :デフォルトの名無しさん:2008/11/17(月) 00:05:45
馬鹿だな団子は。
どこまでも馬鹿なやつだ。
すぐしたに書いてあるだろう。
QW shuffleはPort0,5で扱えるが、
処理するのはPort5にぶら下がってる128bit shufflerって。
それで2つ分って意味。
自分のしっていることが全てだと思っているから、
こんな初歩的なところで誤解したまま能書きをたれるだけのクズになってしまう。
それでだまされる連中が多いってのも問題だが。
どこまでも馬鹿なやつだ。
すぐしたに書いてあるだろう。
QW shuffleはPort0,5で扱えるが、
処理するのはPort5にぶら下がってる128bit shufflerって。
それで2つ分って意味。
自分のしっていることが全てだと思っているから、
こんな初歩的なところで誤解したまま能書きをたれるだけのクズになってしまう。
それでだまされる連中が多いってのも問題だが。
409 :,,・´∀`・,,)っ-○◎●:2008/11/17(月) 00:06:24
>QW shuffleはPort0,5で扱えるが、
無理
無理
410 :,,・´∀`・,,)っ-○◎●:2008/11/17(月) 00:06:54
> QW shuffleはPort0,5で扱えるが、
ソース出せソースwww
ソース出せソースwww
411 :,,・´∀`・,,)っ-○◎●:2008/11/17(月) 00:07:45
せっかくPort 5でしか発行出来ないことを証明する方法提示してやったのに
アホ晒せよ
アホ晒せよ
412 :デフォルトの名無しさん:2008/11/17(月) 00:08:54
>>401の34ページにかいてあるよ。
413 :デフォルトの名無しさん:2008/11/17(月) 00:10:00
マニュアルではPort1だけどね。
Port1とPort5から受け入れて、実際に処理するのはPort5の128bitのshuffleユニット。
そう書いてある。団子の計測結果の誤解釈ではなくマニュアルにねw
Port1とPort5から受け入れて、実際に処理するのはPort5の128bitのshuffleユニット。
そう書いてある。団子の計測結果の誤解釈ではなくマニュアルにねw
414 :,,・´∀`・,,)っ-○◎●:2008/11/17(月) 00:10:11
[QW shuffle]
この言い回しがアホ臭いんだよね
そもそもQWは64ビットなのか?128bitなのか?
x86の世界ではWord=16ビットだが。
この言い回しがアホ臭いんだよね
そもそもQWは64ビットなのか?128bitなのか?
x86の世界ではWord=16ビットだが。
415 :デフォルトの名無しさん:2008/11/17(月) 00:11:08
34ページじゃなくて37ページだな。
416 :,,・´∀`・,,)っ-○◎●:2008/11/17(月) 00:12:58
また例によってマニュアルの誤読のようだな。
あほらしい
恥の上塗り
あほらしい
恥の上塗り
417 :デフォルトの名無しさん:2008/11/17(月) 00:13:04
64bitに決まってるだろw
いい加減に間違いを訂正して謝罪しろよw
いい加減に間違いを訂正して謝罪しろよw
418 :,,・´∀`・,,)っ-○◎●:2008/11/17(月) 00:17:49
ああようやく意味がわかった
QW=汎用レジスタ用≠非SIMD
なにがPort5で処理されるだ?
あほくさ
QW=汎用レジスタ用≠非SIMD
なにがPort5で処理されるだ?
あほくさ
419 :デフォルトの名無しさん:2008/11/17(月) 00:22:20
>>418
3. Uses 128-bit shuffle unit in port 5.
3. Uses 128-bit shuffle unit in port 5.
420 :,,・´∀`・,,)っ-○◎●:2008/11/17(月) 00:22:44
確かにAgnerとIntelの資料だとport1と0が入れ替わってるな
まあ記号でしかないのでどうでもいいが。
FPmul側とFPadd側で通じるし
Packed ShuffleでないInteger ShuffleはBSWAPとかで使われるんだよ。
で、Port5で処理されるなんてどこに書いてあった?脳内?
まあ記号でしかないのでどうでもいいが。
FPmul側とFPadd側で通じるし
Packed ShuffleでないInteger ShuffleはBSWAPとかで使われるんだよ。
で、Port5で処理されるなんてどこに書いてあった?脳内?
421 :デフォルトの名無しさん:2008/11/17(月) 00:23:43
見事に団子さんが一番脳内アーキテクチャでしかないことが発覚してしまったな。
422 :デフォルトの名無しさん:2008/11/17(月) 00:27:34
みたところスケジューラをいじらずに、Super Shuffle Engineを実装するため、
Meromからの使用ポートはそのままで、128bit Unitを使うようにしたっぽい。
Meromからの使用ポートはそのままで、128bit Unitを使うようにしたっぽい。
423 :,,・´∀`・,,)っ-○◎●:2008/11/17(月) 00:28:03
>>419
QW Shuffle(笑)を使う唯一?の命令であるBSWAPは
元々2μOps発行でPort5に発行される。
Agnerのp30でも嫁
別に2つのポートから1つのユニットを共有してるわけではない
QW Shuffle(笑)を使う唯一?の命令であるBSWAPは
元々2μOps発行でPort5に発行される。
Agnerのp30でも嫁
別に2つのポートから1つのユニットを共有してるわけではない
424 :デフォルトの名無しさん:2008/11/17(月) 00:30:56
関係ないけどAgnerだって計測結果からの考察をしているだけで、
予想にすぎないということはお忘れなく。
具体的にどんな実装かはIntelの中の人でなければ正確なところはわからない。
予想にすぎないということはお忘れなく。
具体的にどんな実装かはIntelの中の人でなければ正確なところはわからない。
425 :,,・´∀`・,,)っ-○◎●:2008/11/17(月) 00:33:28
大丈夫、お前の妄想通りのこれだけは絶対ないから
Port 0 Port5
+→ 128-bit Shuffle←+
Port 0 Port5
+→ 128-bit Shuffle←+
426 :デフォルトの名無しさん:2008/11/17(月) 00:34:43
で、団子はマニュアル読んだことあるのかな?
427 :,,・´∀`・,,)っ-○◎●:2008/11/17(月) 00:35:16
μOPs数なんてRDPMCでカウント出来るの知ってるよね?
ちなみにIntelのマニュアルは結構誤植多いよ
AVXのリファレンスなんて数カ所間違い指摘してやったよ。
ちなみにIntelのマニュアルは結構誤植多いよ
AVXのリファレンスなんて数カ所間違い指摘してやったよ。
428 :,,・´∀`・,,)っ-○◎●:2008/11/17(月) 00:35:56
>>426
お前の脳内マニュアルなら無い
お前の脳内マニュアルなら無い
429 :デフォルトの名無しさん:2008/11/17(月) 00:36:22
ちなみにマニュアルにはPort1とPort5がQW shuffleに割り当てられていて、
Penrynでは注意書きの3でport 5の128bitユニットを使用するとかかれています。
以上
Penrynでは注意書きの3でport 5の128bitユニットを使用するとかかれています。
以上
430 :,,・´∀`・,,)っ-○◎●:2008/11/17(月) 00:41:09
それを曲解してこうなってると勘違いしたのか。馬鹿丸出しだな
Port 0 Port5
+→ 128-bit Shuffle←+
Port 0 Port5
+→ 128-bit Shuffle←+
431 :デフォルトの名無しさん:2008/11/17(月) 00:41:57
煽りすぎ荒らしすぎ
自分に自信があるならどんと構えてろよ団子
自分に自信があるならどんと構えてろよ団子
432 :デフォルトの名無しさん:2008/11/17(月) 00:42:50
レスはなるべくまとめろ
レス番つけるのも基本
レス番つけるのも基本
433 :,,・´∀`・,,)っ-○◎●:2008/11/17(月) 00:54:45
Agnerをして「嘘が書いてある」と評したIntelの最適化マニュアルがソース
検証無し
仕事になりませんな
検証無し
仕事になりませんな
434 :デフォルトの名無しさん:2008/11/17(月) 01:08:09
いさぎ悪いですよ。黙って今日はねる。
そして明日から別のネタで書け。
そして明日から別のネタで書け。
435 :デフォルトの名無しさん:2008/11/17(月) 01:08:34
CPUのパフォーマンスんカウンターの使い方、どこかに解説ない?
とくにWindowsのユーザーモードから触りたい。
とくにWindowsのユーザーモードから触りたい。
436 :,,・´∀`・,,)っ-○◎●:2008/11/17(月) 01:11:08
AVXのマニュアルなんてまだ実装した処理系がないのに2回も改訂されてるんだぜ。
マニュアルよりもIntrinsic Guideの間違いのほうが酷かったな。
今のは直ってるが8月くらいに落としたときには平気で、存在しないニーモニックが俺が見つけた限り5つくらいは記述されてた。
その程度の品質だ。察しろよ。
誤植を誤植と見抜ける人でないと(Intelのマニュアルを正しく読むのは)難しい
マニュアルよりもIntrinsic Guideの間違いのほうが酷かったな。
今のは直ってるが8月くらいに落としたときには平気で、存在しないニーモニックが俺が見つけた限り5つくらいは記述されてた。
その程度の品質だ。察しろよ。
誤植を誤植と見抜ける人でないと(Intelのマニュアルを正しく読むのは)難しい
437 :,,・´∀`・,,)っ-○◎●:2008/11/17(月) 01:12:19
いさぎ悪い
いさぎ悪い
いさぎ悪い
いさぎ悪い
いさぎ悪い
いさぎ悪い
いさぎ悪い
いさぎ悪い
いさぎ悪い
フェンス語録に追加だなこれ
いさぎ悪い
いさぎ悪い
いさぎ悪い
いさぎ悪い
いさぎ悪い
いさぎ悪い
いさぎ悪い
いさぎ悪い
フェンス語録に追加だなこれ
438 :デフォルトの名無しさん:2008/11/17(月) 01:15:29
IJKKにでも入社すればいいのに。
439 :デフォルトの名無しさん:2008/11/17(月) 01:18:56
誤植呼ばわりでごまかしか。
結局団子の語る計測万能論なんて机上の空論の人たちの考えと何も変わってないわけで。
むしろ恣意的にそれっぽいデータを並べてくるあたり、信用できないやつがやると
たちが悪い。
結局団子の語る計測万能論なんて机上の空論の人たちの考えと何も変わってないわけで。
むしろ恣意的にそれっぽいデータを並べてくるあたり、信用できないやつがやると
たちが悪い。
440 :デフォルトの名無しさん:2008/11/17(月) 01:21:49
団子さんの脳内アーキテクチャではすごいことになっていることが証明されたな
441 :,,・´∀`・,,)っ-○◎●:2008/11/17(月) 01:22:25
実験するだけの能力もないフェンス級のヴァカ机上論者が論拠として使うには
品質が悪いよ、少なくとも
品質が悪いよ、少なくとも
442 :,,・´∀`・,,)っ-○◎●:2008/11/17(月) 01:23:34
品質の問題じゃなくて解釈の問題だけどな。
こうなってるなんてどこにも書いてない
Port1 Port5
+→ 128-bit Shuffle←+
こうなってるなんてどこにも書いてない
Port1 Port5
+→ 128-bit Shuffle←+
443 :,,・´∀`・,,)っ-○◎●:2008/11/17(月) 01:24:53
「潔い」で1語
イサギって何だよ。
日本語もできないんだな
イサギって何だよ。
日本語もできないんだな
444 :デフォルトの名無しさん:2008/11/17(月) 01:25:48
実験者の能力が低いと実験してもろくな結果が得られないのは
どこの世界でも同じだな。実験でわかることととわからないことの線引きができてないやつが
計測結果から導き出したと称して、関係のないことまで妄想で語りだすというのが某さんの実態なんです。
まあ、そろそろスレの無駄だからやめようよ。
どこの世界でも同じだな。実験でわかることととわからないことの線引きができてないやつが
計測結果から導き出したと称して、関係のないことまで妄想で語りだすというのが某さんの実態なんです。
まあ、そろそろスレの無駄だからやめようよ。
445 :,,・´∀`・,,)っ-○◎●:2008/11/17(月) 01:26:38
実験する能力もなくて脳内アーキテクチャを語る
それが「フェンス」くん
それが「フェンス」くん
446 :,,・´∀`・,,)っ-○◎●:2008/11/17(月) 01:29:01
イサギ悪いぞ
447 :,,・´∀`・,,)っ-○◎●:2008/11/17(月) 01:32:19
そもそもここは「計測スレ」ですよ
まずIntelのマニュアルに誤植があったり不完全な記述があることから
自分たちで補完しようという意図があって成り立ってます。
計測をせずマニュアルを鵜呑みにするスレではありません。
フェンス君は未来永劫蚊帳の外
まずIntelのマニュアルに誤植があったり不完全な記述があることから
自分たちで補完しようという意図があって成り立ってます。
計測をせずマニュアルを鵜呑みにするスレではありません。
フェンス君は未来永劫蚊帳の外
448 :デフォルトの名無しさん:2008/11/17(月) 01:34:39
自ら本丸乗り込んでやればいいじゃないか。
449 :デフォルトの名無しさん:2008/11/17(月) 01:37:20
>>447
その割にはAgnerとかIntelの資料好きだな。
詭弁はよそうぜ。もちろん完璧な計測データを羅列して、
こうこうこうだ、だからIntelの資料は間違っている。
と、説明できれば誰も文句はない。それが本来の計測というものだ。
その割にはAgnerとかIntelの資料好きだな。
詭弁はよそうぜ。もちろん完璧な計測データを羅列して、
こうこうこうだ、だからIntelの資料は間違っている。
と、説明できれば誰も文句はない。それが本来の計測というものだ。
450 :,,・´∀`・,,)っ-○◎●:2008/11/17(月) 01:42:02
Agnerは計測してるじゃん
当然ながら俺は自分である程度正当性は検証してるよ。その上で使えるって言ってる。
AgnerがPenrynのDIV/IDIVのスループット欄空白にした理由わかる?
俺はわかった
イサギ悪いお前には死んでもわからないだろうけどな
当然ながら俺は自分である程度正当性は検証してるよ。その上で使えるって言ってる。
AgnerがPenrynのDIV/IDIVのスループット欄空白にした理由わかる?
俺はわかった
イサギ悪いお前には死んでもわからないだろうけどな
451 :,,・´∀`・,,)っ-○◎● ◆ISAGIW0/wI :2008/11/17(月) 01:57:49
イサギw
452 :デフォルトの名無しさん:2008/11/17(月) 08:43:42
胃詐欺悪い
453 :デフォルトの名無しさん:2008/11/17(月) 09:36:03
ダンゴさんのsage連打で分が悪くなったことが証明されたな
454 :デフォルトの名無しさん:2008/11/17(月) 11:20:42
じゃあ計測によってbswap等のスカラなシャッフル命令がAgnerさんの示すとおり
Port5を経由した2ポート発行であることの裏付けでもやろうか
命令を繰り返し実行しRDTSCでスループットを計測することでわかる
1. and/or/xorなどの最大3命令同時発行可能な命令のうち1命令とは並列実行できるが
2命令以上だと並列実行できない(スループット低下)。
2μops発行&2ポート占有は確定。
2.
bswap eax
jmp dmy1
dmy1:
bswap edx
jmp dmy2
dmy2:
:
のようにbswapとjmpを交互に並べたシーケンスを実行し、かかったクロックを数えると
jmp単体/bswap単体のスループットの半分まで落ち込む。
どうやらbswapの使用するポートはjmp命令を発行できるポート(port5)と
競合しているらしいことがわかる。
(逆にaddpsなどはbswapと並列実行できる)
Agnerの資料は矛盾しないし、シャッフルユニットを2つのポートで共有してるという仮説は不成立。
てかIntelの資料自体が悪いんじゃなくて解釈がデムパなだけ。
マイクロオペレーションをport5に発行するって意味で考えてれば良かった。
Port5を経由した2ポート発行であることの裏付けでもやろうか
命令を繰り返し実行しRDTSCでスループットを計測することでわかる
1. and/or/xorなどの最大3命令同時発行可能な命令のうち1命令とは並列実行できるが
2命令以上だと並列実行できない(スループット低下)。
2μops発行&2ポート占有は確定。
2.
bswap eax
jmp dmy1
dmy1:
bswap edx
jmp dmy2
dmy2:
:
のようにbswapとjmpを交互に並べたシーケンスを実行し、かかったクロックを数えると
jmp単体/bswap単体のスループットの半分まで落ち込む。
どうやらbswapの使用するポートはjmp命令を発行できるポート(port5)と
競合しているらしいことがわかる。
(逆にaddpsなどはbswapと並列実行できる)
Agnerの資料は矛盾しないし、シャッフルユニットを2つのポートで共有してるという仮説は不成立。
てかIntelの資料自体が悪いんじゃなくて解釈がデムパなだけ。
マイクロオペレーションをport5に発行するって意味で考えてれば良かった。
455 :,,・´∀`・,,)っ-□△○:2008/11/17(月) 11:45:36
イサギ悪いフェンス馬鹿は、マニュアルに書いてないことは信用しないらしいから無意味だよ。
たぶん三平方の定理も教科書に書いてあるから正しいんだと思うよwwwww
円周率も3と書いてあれば3。円周は正六角形の外周さ。
彼の辞書にreductionとかexperimentの文字はない。
たぶん三平方の定理も教科書に書いてあるから正しいんだと思うよwwwww
円周率も3と書いてあれば3。円周は正六角形の外周さ。
彼の辞書にreductionとかexperimentの文字はない。
456 :デフォルトの名無しさん:2008/11/17(月) 18:15:45
よし、俺がジャッジしてやる。
団子と、それと対立している二者、それぞれ計測のためのプログラムを作成せよ。
公平を期するために、パスワード付きのZIPでupし、両者がupした後に、パスワードを公開せよ。
それを実際に実機で実行してみて、判定しようじゃないか。
団子と、それと対立している二者、それぞれ計測のためのプログラムを作成せよ。
公平を期するために、パスワード付きのZIPでupし、両者がupした後に、パスワードを公開せよ。
それを実際に実機で実行してみて、判定しようじゃないか。
457 :デフォルトの名無しさん:2008/11/17(月) 18:32:32
二人でオープンソースなx86 cpuエミュレータ作成して意見が割れた所だけbranch切ればおk。
458 :,,・´∀`・,,)っ:2008/11/17(月) 19:17:00
イサギ=フェンス氏はCore2実機どころかAtomすら買えない貧乏人なので勝負以前の問題でし
459 :,,・´∀`・,,)っ[うんこ]:2008/11/17(月) 19:28:41
「こう書いてあるからこうに違いない」
なんら裏付けはありません。
「仕様書にはこう書いてあるから」の一転張りで通します。
解釈の間違いはあっても認めてはいけません。自分の思いこみはあらゆる実験を超越した絶対の真理です。
もし矛盾点を指摘されれば「Intelが公開してない情報なのでわかるはずがない」で逃げる。
これであなたも今日からイサギ君。
なんら裏付けはありません。
「仕様書にはこう書いてあるから」の一転張りで通します。
解釈の間違いはあっても認めてはいけません。自分の思いこみはあらゆる実験を超越した絶対の真理です。
もし矛盾点を指摘されれば「Intelが公開してない情報なのでわかるはずがない」で逃げる。
これであなたも今日からイサギ君。
460 :デフォルトの名無しさん:2008/11/17(月) 19:37:17
団子君、いい加減いざぎ悪いよ。
まだやってんのかよって。
まだやってんのかよって。
461 :,,・´∀`・,,)っ:2008/11/17(月) 19:44:57
イサギいぇーいいぇーい♪
462 :デフォルトの名無しさん:2008/11/17(月) 19:52:43
最近せっかくあるスレで団子が大人しくなったと思ったら
また別のスレに顔出してて正直荒れないかヒヤヒヤしてる。
また別のスレに顔出してて正直荒れないかヒヤヒヤしてる。
463 :デフォルトの名無しさん:2008/11/17(月) 20:02:42
団子君、いい加減いざぎおいしいよ。
464 :,,・´∀`・,,)っ[だんごないよ]:2008/11/17(月) 20:10:12
さては子鮒釣り師だな?!
465 :デフォルトの名無しさん:2008/11/17(月) 20:16:48
あげて煽る方が悪い
これが俺のジャスティス
これが俺のジャスティス
466 :デフォルトの名無しさん:2008/11/17(月) 20:21:32
×子鮒
○伊佐木
○伊佐木
467 :デフォルトの名無しさん:2008/11/17(月) 22:34:03
なんだこのスレ
おもしれえ
おもしれえ
468 :デフォルトの名無しさん:2008/11/18(火) 00:09:59
ダンゴさんの本拠地はゲハ板じゃないのか
469 :デフォルトの名無しさん:2008/11/19(水) 01:31:13
ああ、遂にあっちのスレでもウザくなってきた。
人の優位に立った気になって自慢するってどこの厨房だよ。
人の優位に立った気になって自慢するってどこの厨房だよ。
470 :デフォルトの名無しさん:2008/11/19(水) 02:15:26
実際厨房なんだから仕方ない
とは言えウザイけど
とは言えウザイけど
471 :デフォルトの名無しさん:2008/11/21(金) 16:24:48
馬鹿発言連発で笑えるだけまだ救いがある
472 :デフォルトの名無しさん:2008/11/21(金) 16:49:12
笑えるか?アレ
473 :,,・´∀`・,,)っ-○◎● ◆ISAGIW0/wI :2008/11/26(水) 19:40:24
諫木悪いくんは頭の角をフェンス(笑)にぶつけて氏ね
474 :デフォルトの名無しさん:2008/11/26(水) 21:26:54
ちょっとスレ違いだけどWindows7発売にするなら64bitを標準にしてくれよー
32bitのメモリ空間じゃもう狭すぎるだろ
32bitのメモリ空間じゃもう狭すぎるだろ
475 :,,・´∀`・,,)っ-○◎● ◆ISAGIW0/wI :2008/11/26(水) 22:23:01
Core i7搭載PCはもうDellやショップブランドのBTOで購入できるけどメモリ6GB Vista x64が標準だよ。
でも、一方でミッドレンジはデュアルチャネルで2GB×2で実効3GBでしばらく粘りそうな。
一方ではミッドレンジ以下はNehalemでもデュアルチャンネルだから4GBまで→32ビットで十分
って流れにもってかれそうな気もせんでもない。
問題はBuffaloやIODATAあたりが64ビット用ドライバ開発やる気無いことだ。
特にBuffalo64bit版ドライバ作らないからVistaのロゴ認証受けられない
→勝手にVistaのロゴでっちあげて「Vista対応」をうたう暴挙
いいかげんにしる
でも、一方でミッドレンジはデュアルチャネルで2GB×2で実効3GBでしばらく粘りそうな。
一方ではミッドレンジ以下はNehalemでもデュアルチャンネルだから4GBまで→32ビットで十分
って流れにもってかれそうな気もせんでもない。
問題はBuffaloやIODATAあたりが64ビット用ドライバ開発やる気無いことだ。
特にBuffalo64bit版ドライバ作らないからVistaのロゴ認証受けられない
→勝手にVistaのロゴでっちあげて「Vista対応」をうたう暴挙
いいかげんにしる
476 :デフォルトの名無しさん:2008/11/27(木) 00:13:35
個人的にはAVXが境目かなと思ってる
477 :デフォルトの名無しさん:2008/11/27(木) 14:22:04
>>475
その手の会社って、社内で開発してないからね。
他所に作らせているので、既存のものを64bit対応させようにも、ドライバのソースコードにアクセスできない。
もう一つ64bit対応したくなり理由が、
64bitアドレッシングに対応していないデバイスにはバウンスバッファが必要なこと。
PCIバス自体は32ビットバスでも、
オプションのDAC(dual address cycleの略だったかな)によって
64bitアドレッシングが可能なのだけれども、デバイスが実装してなかったり。
その手の会社って、社内で開発してないからね。
他所に作らせているので、既存のものを64bit対応させようにも、ドライバのソースコードにアクセスできない。
もう一つ64bit対応したくなり理由が、
64bitアドレッシングに対応していないデバイスにはバウンスバッファが必要なこと。
PCIバス自体は32ビットバスでも、
オプションのDAC(dual address cycleの略だったかな)によって
64bitアドレッシングが可能なのだけれども、デバイスが実装してなかったり。
478 :デフォルトの名無しさん:2008/11/27(木) 22:47:08
そんな大それた理由ではなく、単にやる気がないだけの予感。
OEM元のリファレンスドライバには64bit版がきっとあったはず。
海外での64bit普及率を考えれば無い方がおかしい。
OEM元のリファレンスドライバには64bit版がきっとあったはず。
海外での64bit普及率を考えれば無い方がおかしい。
479 :デフォルトの名無しさん:2008/11/27(木) 22:52:50
今時DAC未サポートのデバイスなんて少ないからね。
480 :,,・´∀`・,,)っ-●◎○:2008/11/27(木) 23:07:05
32bit版のドライバすら未署名だし。
「警告出るけど飛ばしてください」
Vista x64は未署名のドライバはそもそも弾かれます。
個人開発者ですら年間3万程度でドライバに署名を入れることは可能。
企業にできないわけがないんだけどね。
「警告出るけど飛ばしてください」
Vista x64は未署名のドライバはそもそも弾かれます。
個人開発者ですら年間3万程度でドライバに署名を入れることは可能。
企業にできないわけがないんだけどね。
481 :デフォルトの名無しさん:2008/11/27(木) 23:09:59
残念ながら、団子に同意。
マニュアルに「警告を無視しろ」なんて書くのは恥だと思わないもんかねぇ。
まるでVeriSignが期限切れになっている某通販サイトのようだ。
マニュアルに「警告を無視しろ」なんて書くのは恥だと思わないもんかねぇ。
まるでVeriSignが期限切れになっている某通販サイトのようだ。
482 :デフォルトの名無しさん:2008/11/27(木) 23:27:49
未署名ドライバが必要な売り物ってのはどうかと思うが、未署名ドライバを
強制的に制限しているMSもどうかと思う。俺が買ったOSで俺が書いたドライバを
F8無しでロードできないってふざけるなよ。
強制的に制限しているMSもどうかと思う。俺が買ったOSで俺が書いたドライバを
F8無しでロードできないってふざけるなよ。
483 :デフォルトの名無しさん:2008/11/28(金) 00:23:31
MSからよくOSを買えたな
俺は貧乏だから使用権のライセンスくらいしか買えねえや
俺は貧乏だから使用権のライセンスくらいしか買えねえや
484 :デフォルトの名無しさん:2008/11/28(金) 00:51:06
団子さんの自演でスレに火が灯ったな
485 : ◆0uxK91AxII :2008/11/28(金) 03:25:58
エロデータが外注丸投げをしているのは、事実。
Vistaの署名云々は、著作権保護がどうのこうのという理由からのモノだった気がするする。
Vistaの署名云々は、著作権保護がどうのこうのという理由からのモノだった気がするする。
486 :デフォルトの名無しさん:2008/11/28(金) 04:47:42
>>478
64bitに対応しなくても売れるうちは、対応しないと思う。
過去の製品のドライバをアップデートするなんて無償サービスも、やらないっしょ。
競合他社が64bit対応で将来も安心とか差別化をはかってきたら追従するだろうが、
64bit対応しないでどこまで行けるかチキンレースしているような状況。
>>481
ユーザもまた、警告を無視するのに慣れてるから。
セキュリティを外すことに抵抗感ない人が多すぎる。
セキュリティを守ろうとすると、できるのにやろうとしない怠け者扱いされるし。
>>482
>>485
ドライバに電子署名が必要な2つの側面
1つは、ウィルス等の悪意あるプログラムへの対策。ドライバにはセキュリティが及ばないからね。
もう1つは、著作権保護のため。ちゃんと約束を守るドライバにしかデータにアクセスさせたくない。
そのうち、DRMで保護されているコンテンツを再生する場合には、
マイクロソフトがソースレビューしたドライバしかロードできません、
ってことになったりして。
64bitに対応しなくても売れるうちは、対応しないと思う。
過去の製品のドライバをアップデートするなんて無償サービスも、やらないっしょ。
競合他社が64bit対応で将来も安心とか差別化をはかってきたら追従するだろうが、
64bit対応しないでどこまで行けるかチキンレースしているような状況。
>>481
ユーザもまた、警告を無視するのに慣れてるから。
セキュリティを外すことに抵抗感ない人が多すぎる。
セキュリティを守ろうとすると、できるのにやろうとしない怠け者扱いされるし。
>>482
>>485
ドライバに電子署名が必要な2つの側面
1つは、ウィルス等の悪意あるプログラムへの対策。ドライバにはセキュリティが及ばないからね。
もう1つは、著作権保護のため。ちゃんと約束を守るドライバにしかデータにアクセスさせたくない。
そのうち、DRMで保護されているコンテンツを再生する場合には、
マイクロソフトがソースレビューしたドライバしかロードできません、
ってことになったりして。
487 :デフォルトの名無しさん:2008/11/28(金) 04:58:18
まあ、未署名のドライバを使っているような糞製品は、俺は、買わないのでどうでもいいんだが。
488 :デフォルトの名無しさん:2008/11/28(金) 08:07:19
VeriSignみたいな信頼すべきできない外道企業が認証局なのが気に入らない
いつSite Finderみたいな阿呆な事をやるかわかったものではない
いつSite Finderみたいな阿呆な事をやるかわかったものではない
489 :デフォルトの名無しさん:2008/11/28(金) 12:41:55
VeriSign一択ではないだろ。
490 :デフォルトの名無しさん:2008/12/06(土) 23:48:43
Windows上でCPUのCR4レジスタのPCEを1にセットしたら、
ユーザーモードのプログラムでCPUのパフォーマンスカウンタをいじることができるの?
ユーザーモードのプログラムでCPUのパフォーマンスカウンタをいじることができるの?
491 : ◆0uxK91AxII :2008/12/07(日) 07:27:12
>>490
can NOT.
can NOT.
492 :デフォルトの名無しさん:2008/12/07(日) 10:38:23
できないのか、残念。
493 :デフォルトの名無しさん:2008/12/07(日) 21:58:23
設定するためのRDMSR & WRMSR に特権モード(リング0)が必要。
カウンタの値を読むだけなら PCE=1 の場合、RDPMC が許可。
カウンタの設定とPCE=1にする、適当なドライバをでっちあげたらいいのか?
----
あー、俺ってバカ。
dd 0fh
dd 31h
とか書いてやんの。
しかも間違いに辿り着くまで1時間も関係ないところを確認してた。
カウンタの値を読むだけなら PCE=1 の場合、RDPMC が許可。
カウンタの設定とPCE=1にする、適当なドライバをでっちあげたらいいのか?
----
あー、俺ってバカ。
dd 0fh
dd 31h
とか書いてやんの。
しかも間違いに辿り着くまで1時間も関係ないところを確認してた。
494 :デフォルトの名無しさん:2008/12/26(金) 14:10:02
O腹のかいしんのいちげきは無視かよ!
http://journal.mycom.co.jp/special/2008/nehalem02/
ああ、貧乏人はCore i7を買えないんですね?
# 本人乙の予感
http://journal.mycom.co.jp/special/2008/nehalem02/
ああ、貧乏人はCore i7を買えないんですね?
# 本人乙の予感
495 :,,・´∀`・,,)っ-○◎● ◆ISAGIW0/wI :2008/12/26(金) 19:13:40
イサギ悪いので嫌いです
496 :デフォルトの名無しさん:2008/12/26(金) 20:11:23
>>493
そう、あなたは馬鹿です。
そう、あなたは馬鹿です。
497 :デフォルトの名無しさん:2008/12/27(土) 00:39:48
498 :デフォルトの名無しさん:2008/12/27(土) 00:42:22
あのページ数であの糞重いサイトは苦痛
499 :,,・´∀`・,,)っ-○◎● ◆ISAGIW0/wI :2008/12/27(土) 03:27:05
{kind=link}
500 :デフォルトの名無しさん:2008/12/27(土) 04:09:09
Oの人は文面からintel嫌いを臭わせる才能だけ褒めてあげたい。
501 :デフォルトの名無しさん:2008/12/27(土) 15:25:35
低脳コテの執念深ささえあればあるいは
502 :デフォルトの名無しさん:2008/12/27(土) 18:21:40
大原君へ
http://journal.mycom.co.jp/photo/special/2008/nehalem02/images/graph021l.gif
これ小命令でのループ時に誤動作の可能性を考慮した対策結果だろ・・・
その為、Util29.exeも検証用ソフトとしては役に立っていない・・・
http://journal.mycom.co.jp/photo/special/2008/nehalem02/images/graph020l.gif
大原君はもっとちゃんと情報を収集したほうがいいと思うんだよ、妄想が君をダメにしている・・・
http://journal.mycom.co.jp/photo/special/2008/nehalem02/images/graph021l.gif
{kind=link}
これ小命令でのループ時に誤動作の可能性を考慮した対策結果だろ・・・
その為、Util29.exeも検証用ソフトとしては役に立っていない・・・
http://journal.mycom.co.jp/photo/special/2008/nehalem02/images/graph020l.gif
{kind=link}
大原君はもっとちゃんと情報を収集したほうがいいと思うんだよ、妄想が君をダメにしている・・・
503 :デフォルトの名無しさん:2008/12/27(土) 18:36:36
504 :デフォルトの名無しさん:2008/12/28(日) 04:54:09
>>494
大原さんはデタラメなのでスルー。
大原さんはデタラメなのでスルー。
505 :デフォルトの名無しさん:2008/12/28(日) 04:57:01
大原さん、Xeonをファンレスで動かして
熱暴走する
っていう苦言を呈すのは勘弁してください。
熱暴走する
っていう苦言を呈すのは勘弁してください。
506 :デフォルトの名無しさん:2008/12/28(日) 14:03:11
なんか、CPUのパフォーマンスカウンタをユーザーモードから使えるようにしよう、っていう動きがあるみたいね。
OSがコンテキストスイッチするときにカウンタの値も退避・復帰させることで、
システム全体ではなくスレッドごとにカウントできるようになるとか。
OSがコンテキストスイッチするときにカウンタの値も退避・復帰させることで、
システム全体ではなくスレッドごとにカウントできるようになるとか。
507 :,,・´∀`・,,)っ-○◎● ◆ISAGIW0/wI :2008/12/28(日) 16:51:20
RDPMCのことだね?
有志開発者が動いてもIntelが動いてないんですが。。。。
有志開発者が動いてもIntelが動いてないんですが。。。。
508 :デフォルトの名無しさん:2008/12/28(日) 17:06:51
509 :,,・´∀`・,,)っ-○◎● ◆ISAGIW0/wI :2008/12/28(日) 17:32:54
510 :デフォルトの名無しさん:2008/12/28(日) 17:47:25
ttp://crystaldew.info/2008/09/29/digital-sign/
>Windows 7 では動作しないというレポートも受けています
>Windows 7 では動作しないというレポートも受けています
511 :デフォルトの名無しさん:2008/12/28(日) 17:58:42
とりあえず落としとくわ
512 :デフォルトの名無しさん:2008/12/29(月) 02:51:00
>>509
ドライバ作ってそこでPMCを設定するってなのは既に誰かやってるだろう。
問題は、PMCはシステム全体で1つだってこと。
AMDのCodeAnalyst(無料)を使ってみればわかるけれども、
けっこうエゲツナイ。
ドライバ作ってそこでPMCを設定するってなのは既に誰かやってるだろう。
問題は、PMCはシステム全体で1つだってこと。
AMDのCodeAnalyst(無料)を使ってみればわかるけれども、
けっこうエゲツナイ。
513 :デフォルトの名無しさん:2008/12/30(火) 06:12:31
codeanalystってoprofileとほぼ同じになったの?ぃぬx版だけ?
スレッド毎って別に既にあるプロファイラはやってる、、、よね?
あとpmcは複数あるシステムもあるらしいよ。
資源としてどう提供されうるかの枠組みは個々あると思うけど、
枠組み自体をcpuが提供してしまおうってのは仮想化の流れかね。
スレッド毎って別に既にあるプロファイラはやってる、、、よね?
あとpmcは複数あるシステムもあるらしいよ。
資源としてどう提供されうるかの枠組みは個々あると思うけど、
枠組み自体をcpuが提供してしまおうってのは仮想化の流れかね。
514 :デフォルトの名無しさん:2008/12/30(火) 09:02:11
CPUのコアごとにあるな。
スレッドごとに統計を出すのは、えげつない方法で実現している。よろしくない。
スレッドごとに統計を出すのは、えげつない方法で実現している。よろしくない。
515 :デフォルトの名無しさん:2008/12/30(火) 09:38:18
そこらへん綺麗にならないかなぁ
516 :デフォルトの名無しさん:2008/12/30(火) 10:00:35
どうせx86はマイクロコードを使うのだから、コンテキストの退避・復帰を専用命令で行うようにしたらいいんだよ。
そしたらCPU作るほうは、自由にコンテキストを増減できるっしょ。
そしたらCPU作るほうは、自由にコンテキストを増減できるっしょ。
517 :,,・´∀`・,,)っ-●◎○:2008/12/30(火) 10:08:02
だから、それがXSAVE/XRSTORなんだが
518 :デフォルトの名無しさん:2008/12/30(火) 11:05:50
しかし、なんでそいつはPMCをやってくれないのだ・・・
519 : ◆0uxK91AxII :2008/12/30(火) 12:26:02
MSRとして、実装したから。
520 :デフォルトの名無しさん:2008/12/30(火) 15:55:04
ダンゴさんがアゲはじめたな
521 :,,・´∀`・,,)っ-○◎● ◆ISAGIW0/wI :2008/12/30(火) 16:07:18
ハイハイいさぎ悪いいさぎ悪い
522 :デフォルトの名無しさん:2008/12/30(火) 18:41:54
きもい
523 :デフォルトの名無しさん:2009/01/06(火) 20:44:27
さーて、久々にイサギことおれの登場ですよ。
>>454君、計測ご苦労。
だが、その計測結果はおれが主張していることと全く矛盾しませんよ。
port1でuopを受け入れport5の128bit shuffle unitで処理する。
Penrynでは65nm Core 2との互換性のため、このような実装になっていると思われる。
内部的にはport1とport5をbusy状態にするため、
プログラマからみるとあたかもuopを2つのportにディスパッチしているのと同じような動作にみえる。
Intelの資料には、Penryn限定で、128bit shuffle unitを使用するとはっきりかかれており、
計測結果と矛盾せず、2portを使用するところまではわかるが、
残念ながらどこにも2uopを発行するとはかかれていません。
>>454君、計測ご苦労。
だが、その計測結果はおれが主張していることと全く矛盾しませんよ。
port1でuopを受け入れport5の128bit shuffle unitで処理する。
Penrynでは65nm Core 2との互換性のため、このような実装になっていると思われる。
内部的にはport1とport5をbusy状態にするため、
プログラマからみるとあたかもuopを2つのportにディスパッチしているのと同じような動作にみえる。
Intelの資料には、Penryn限定で、128bit shuffle unitを使用するとはっきりかかれており、
計測結果と矛盾せず、2portを使用するところまではわかるが、
残念ながらどこにも2uopを発行するとはかかれていません。
525 :,,・´∀`・,,)っ-●◎○:2009/01/07(水) 01:12:45
RDPMCで噛ませたμOPs数取れるのも知らないらしいなロートルはプッ
526 :デフォルトの名無しさん:2009/01/07(水) 18:34:15
伊佐木悪いスレ
527 :デフォルトの名無しさん:2009/01/10(土) 12:46:35
脳がいさぎたないコテ
528 :デフォルトの名無しさん:2009/01/22(木) 19:26:16
いさぎもい池沼コテのせいで過疎ったな
529 :デフォルトの名無しさん:2009/01/22(木) 19:58:57
人生いさぎ過ぎたスレだなぁ
530 :デフォルトの名無しさん:2009/01/24(土) 02:15:42
Core i7 920
vender:GenuineIntel CPUID:6A4
x87 SSE SSE2
2.9 2.9 2.9 clk : 正規化数 + 正規化数 = 正規化数
4.8 3.8 4.8 clk : 正規化数 * 正規化数 = 正規化数
21.0 13.3 21.0 clk : 正規化数 / 正規化数 = 正規化数
239.4 2.9 2.9 clk : 非数 + 正規化数 = 非数
241.3 3.8 4.8 clk : 非数 * 正規化数 = 非数
243.2 6.7 6.7 clk : 非数 / 正規化数 = 非数
251.7 2.9 2.9 clk : 非数 + 非数 = 非数
253.6 3.8 4.8 clk : 非数 * 非数 = 非数
256.6 6.7 6.7 clk : 非数 / 非数 = 非数
248.9 161.4 161.2 clk : 正規化数 + 非正規化数 = 正規化数
456.6 161.4 161.4 clk : 非正規化数 + 非正規化数 = 非正規化数
460.2 162.1 163.4 clk : 非正規化数 * 正規化数 = 非正規化数
491.7 171.0 178.6 clk : 非正規化数 / 正規化数 = 非正規化数
234.6 2.9 2.9 clk : +∞ + 正規化数 = +∞
232.6 3.8 4.8 clk : +∞ * 正規化数 = +∞
239.4 6.7 6.7 clk : +∞ / 正規化数 = +∞
234.6 2.9 2.9 clk : +∞ + +∞ = +∞
232.6 3.8 4.8 clk : +∞ * +∞ = +∞
vender:GenuineIntel CPUID:6A4
x87 SSE SSE2
2.9 2.9 2.9 clk : 正規化数 + 正規化数 = 正規化数
4.8 3.8 4.8 clk : 正規化数 * 正規化数 = 正規化数
21.0 13.3 21.0 clk : 正規化数 / 正規化数 = 正規化数
239.4 2.9 2.9 clk : 非数 + 正規化数 = 非数
241.3 3.8 4.8 clk : 非数 * 正規化数 = 非数
243.2 6.7 6.7 clk : 非数 / 正規化数 = 非数
251.7 2.9 2.9 clk : 非数 + 非数 = 非数
253.6 3.8 4.8 clk : 非数 * 非数 = 非数
256.6 6.7 6.7 clk : 非数 / 非数 = 非数
248.9 161.4 161.2 clk : 正規化数 + 非正規化数 = 正規化数
456.6 161.4 161.4 clk : 非正規化数 + 非正規化数 = 非正規化数
460.2 162.1 163.4 clk : 非正規化数 * 正規化数 = 非正規化数
491.7 171.0 178.6 clk : 非正規化数 / 正規化数 = 非正規化数
234.6 2.9 2.9 clk : +∞ + 正規化数 = +∞
232.6 3.8 4.8 clk : +∞ * 正規化数 = +∞
239.4 6.7 6.7 clk : +∞ / 正規化数 = +∞
234.6 2.9 2.9 clk : +∞ + +∞ = +∞
232.6 3.8 4.8 clk : +∞ * +∞ = +∞
531 :,,・´∀`・,,)っ-●◎○:2009/01/24(土) 04:30:32
>>520を見て、Atomの結果貼っておくか、と思ってテンプレ見ようと思ったら、
見逃してた>6あたりを見てこれはひどいと思いました。今更だけど見逃してたわ。
わかってる人はわかってることだけど、*((void*)p + x* sizeof(int))なんてx86にとっちゃなんでもないです。
sizeof (__m128i)とかになっちゃうと困るんだけど。
AVXの予約ビットいっぱいあるんだから、Scaleフィールドの拡張して欲しいんだよね。
1ビット使えばx16, x32, x64, x128くらいまで使える。
というわけで、軽作業用のN270@1.6GHz
vender:GenuineIntel CPUID:6C2
x87 SSE SSE2
5.2 5.2 5.2 clk : 正規化数 + 正規化数 = 正規化数
5.3 4.1 5.3 clk : 正規化数 * 正規化数 = 正規化数
60.9 32.5 61.5 clk : 正規化数 / 正規化数 = 正規化数
401.8 5.3 5.2 clk : 非数 + 正規化数 = 非数
391.1 4.0 5.2 clk : 非数 * 正規化数 = 非数
406.4 16.6 17.0 clk : 非数 / 正規化数 = 非数
424.8 5.2 5.1 clk : 非数 + 非数 = 非数
423.5 4.0 5.2 clk : 非数 * 非数 = 非数
436.6 17.1 16.6 clk : 非数 / 非数 = 非数
456.6 245.0 205.4 clk : 正規化数 + 非正規化数 = 正規化数
769.2 199.4 205.4 clk : 非正規化数 + 非正規化数 = 非正規化数
773.3 199.3 205.4 clk : 非正規化数 * 正規化数 = 非正規化数
856.9 281.4 314.6 clk : 非正規化数 / 正規化数 = 非正規化数
404.0 5.2 5.2 clk : +∞ + 正規化数 = +∞
386.1 4.1 5.3 clk : +∞ * 正規化数 = +∞
426.4 17.1 16.8 clk : +∞ / 正規化数 = +∞
408.0 5.2 5.1 clk : +∞ + +∞ = +∞
387.6 4.0 5.3 clk : +∞ * +∞ = +∞
見逃してた>6あたりを見てこれはひどいと思いました。今更だけど見逃してたわ。
わかってる人はわかってることだけど、*((void*)p + x* sizeof(int))なんてx86にとっちゃなんでもないです。
sizeof (__m128i)とかになっちゃうと困るんだけど。
AVXの予約ビットいっぱいあるんだから、Scaleフィールドの拡張して欲しいんだよね。
1ビット使えばx16, x32, x64, x128くらいまで使える。
というわけで、軽作業用のN270@1.6GHz
vender:GenuineIntel CPUID:6C2
x87 SSE SSE2
5.2 5.2 5.2 clk : 正規化数 + 正規化数 = 正規化数
5.3 4.1 5.3 clk : 正規化数 * 正規化数 = 正規化数
60.9 32.5 61.5 clk : 正規化数 / 正規化数 = 正規化数
401.8 5.3 5.2 clk : 非数 + 正規化数 = 非数
391.1 4.0 5.2 clk : 非数 * 正規化数 = 非数
406.4 16.6 17.0 clk : 非数 / 正規化数 = 非数
424.8 5.2 5.1 clk : 非数 + 非数 = 非数
423.5 4.0 5.2 clk : 非数 * 非数 = 非数
436.6 17.1 16.6 clk : 非数 / 非数 = 非数
456.6 245.0 205.4 clk : 正規化数 + 非正規化数 = 正規化数
769.2 199.4 205.4 clk : 非正規化数 + 非正規化数 = 非正規化数
773.3 199.3 205.4 clk : 非正規化数 * 正規化数 = 非正規化数
856.9 281.4 314.6 clk : 非正規化数 / 正規化数 = 非正規化数
404.0 5.2 5.2 clk : +∞ + 正規化数 = +∞
386.1 4.1 5.3 clk : +∞ * 正規化数 = +∞
426.4 17.1 16.8 clk : +∞ / 正規化数 = +∞
408.0 5.2 5.1 clk : +∞ + +∞ = +∞
387.6 4.0 5.3 clk : +∞ * +∞ = +∞
532 :,,・´∀`・,,)っ-●◎○:2009/01/24(土) 04:31:06
530の間違い
533 :デフォルトの名無しさん:2009/01/24(土) 09:28:43
> *((void*)p + x* sizeof(int))なんてx86にとっちゃなんでもないです。
この計算毎回やると思うなんてどうかしてる
この計算毎回やると思うなんてどうかしてる
534 :,,・´∀`・,,)っ-●◎○:2009/01/24(土) 09:46:13
VCの場合はどっちかというとこんな感じに勝手に展開するわけだが。
今は違うかもしれない。
int i = count
char * base = (char*)p;
int offset = 0;
do {
sum += *((int*)(base + offset);
offset += 4;
} while (--count > 0);
今は違うかもしれない。
int i = count
char * base = (char*)p;
int offset = 0;
do {
sum += *((int*)(base + offset);
offset += 4;
} while (--count > 0);
535 :デフォルトの名無しさん:2009/01/24(土) 10:35:57
ためしたら以下相当になってた(vs2008,/O2)
int sum1=0; sum2=0; tmp=0;
int i;
int g = count - 1;
for ( i = 0 ; i < g ; i += 2 ) {
sum1 += p[i*2]; ☆
sum2 += p[i*2+1]; ☆
}
if ( i < count ) {
tmp = p[i*2];
}
return sum1 + sum2 + tmp;
☆ではleaで*4やってたぞ
関係ないけど、今って途中でpush/popやるんだねえ
あ、こっちのほうがスレ的には関係あるか
int sum1=0; sum2=0; tmp=0;
int i;
int g = count - 1;
for ( i = 0 ; i < g ; i += 2 ) {
sum1 += p[i*2]; ☆
sum2 += p[i*2+1]; ☆
}
if ( i < count ) {
tmp = p[i*2];
}
return sum1 + sum2 + tmp;
☆ではleaで*4やってたぞ
関係ないけど、今って途中でpush/popやるんだねえ
あ、こっちのほうがスレ的には関係あるか
536 :デフォルトの名無しさん:2009/01/25(日) 23:05:49
そのあたりが、RISCより速い理由?
537 :,,・´∀`・,,)っ-●◎○:2009/01/25(日) 23:40:49
とりわけメモリロードを繰り返すプログラムは強いと思う。
ベースアドレス+オフセット*スケーリング+32ビットまでの即値、なんて複雑なアドレッシングを1命令でこなせる。
かつてRISCと呼ばれたアーキテクチャなんて今は産廃みたいなもんだよ。
抽象化しにくいハードウェア機能をISAに組み込んでしまったために
モダンな実装方法を適用することが困難になったんだ。
MIPSやSPARCはディレイスロットだのレジスタウィンドウだの、リソースに余裕が出来たときに
性能を引き上げる上で邪魔になるような、アホな機能を組み込んでしまった。
所詮は1個のCPUに何億トランジスタなんて時代がくるなんて思ってなかった時代の産物だ。
x86は命令セット上そんな厄介なものないから内部的にモダンなテクニックを使っても
ソフト側からは透過的に使える。
しかしx86が勝ち残ったのもIntelとしても予定外のこと。
i960とか今で言うItaniumとかに莫大なリソース割いてたのは知ってるだろ。
市場が求めるからx86作ってきただけで、中の人は本音は嫌いだったんだよ。
「俺らのCPUって案外いけてるんじゃね?」と思ってモバイルやGPU市場に殴りこみかけてるのが
今の状態。
ベースアドレス+オフセット*スケーリング+32ビットまでの即値、なんて複雑なアドレッシングを1命令でこなせる。
かつてRISCと呼ばれたアーキテクチャなんて今は産廃みたいなもんだよ。
抽象化しにくいハードウェア機能をISAに組み込んでしまったために
モダンな実装方法を適用することが困難になったんだ。
MIPSやSPARCはディレイスロットだのレジスタウィンドウだの、リソースに余裕が出来たときに
性能を引き上げる上で邪魔になるような、アホな機能を組み込んでしまった。
所詮は1個のCPUに何億トランジスタなんて時代がくるなんて思ってなかった時代の産物だ。
x86は命令セット上そんな厄介なものないから内部的にモダンなテクニックを使っても
ソフト側からは透過的に使える。
しかしx86が勝ち残ったのもIntelとしても予定外のこと。
i960とか今で言うItaniumとかに莫大なリソース割いてたのは知ってるだろ。
市場が求めるからx86作ってきただけで、中の人は本音は嫌いだったんだよ。
「俺らのCPUって案外いけてるんじゃね?」と思ってモバイルやGPU市場に殴りこみかけてるのが
今の状態。
538 :デフォルトの名無しさん:2009/01/25(日) 23:47:26
> 1命令でこなせる。
今やその1命令が複雑すぎるからAVXが待たれているわけだが。
結局RISCが悪いんじゃなくてIntelの諦めない最適化努力が偉かっただけ。
それも資本にものを言わせて出来たわけだけどな。
今やその1命令が複雑すぎるからAVXが待たれているわけだが。
結局RISCが悪いんじゃなくてIntelの諦めない最適化努力が偉かっただけ。
それも資本にものを言わせて出来たわけだけどな。
539 :デフォルトの名無しさん:2009/01/26(月) 00:02:56
540 :,,・´∀`・,,)っ-●◎○:2009/01/26(月) 00:03:36
は?AVXのメモリアドレッシングってx86そのまんまだけど?命令フォーマットのマニュアル読んだことあるのアンタ?
プリフィクスバイトからOpcodeまでの長さが固定化されるからデコーダにやさしいわけであって
アドレッシングモードは
メモリアドレッシングの整理はMMXの段階で終わってる。
dispを8bitか32bitまで、immは8ビットに仕様を固定化することでデコード負荷がかからないようにした。
AVXがやるのは、プリフィクスバイトの整理と、レジスタオペランドの拡張。
メモリアドレッシングは10年以上前にとっくに終わってる。
ちなみにModRM, SIBがそれぞれ1バイトですむのは8本=3ビット分のレジスタしか用意しなかったから。
大半のRISCは、命令長が固定で、オペランドサイズの制約で複雑なアドレッシングモードを持つことができなかった。
プリフィクスバイトからOpcodeまでの長さが固定化されるからデコーダにやさしいわけであって
アドレッシングモードは
メモリアドレッシングの整理はMMXの段階で終わってる。
dispを8bitか32bitまで、immは8ビットに仕様を固定化することでデコード負荷がかからないようにした。
AVXがやるのは、プリフィクスバイトの整理と、レジスタオペランドの拡張。
メモリアドレッシングは10年以上前にとっくに終わってる。
ちなみにModRM, SIBがそれぞれ1バイトですむのは8本=3ビット分のレジスタしか用意しなかったから。
大半のRISCは、命令長が固定で、オペランドサイズの制約で複雑なアドレッシングモードを持つことができなかった。
541 :,,・´∀`・,,)っ-●◎○:2009/01/26(月) 00:05:11
542 :デフォルトの名無しさん:2009/01/26(月) 00:05:32
AVXってダサくね?
命令が1バイト短くなるかどうか、ちょっとデコードがシンプルになるだけじゃん。
良く使う命令が長ったらしくて、使わない命令が1バイトなのは、どうかしてるぜ。
命令が1バイト短くなるかどうか、ちょっとデコードがシンプルになるだけじゃん。
良く使う命令が長ったらしくて、使わない命令が1バイトなのは、どうかしてるぜ。
543 :デフォルトの名無しさん:2009/01/26(月) 00:10:46
960は成功したけど、DECからStrongARMを取得したので、いらない子になっちゃった。
UNIXワークステーション向け汎用プロセッサとして860と960がインテル社内で競合して、
860が勝ったというのは、どういうことなんだろうね。960では他のプロセッサに勝てないと
思ったのかな。
UNIXワークステーション向け汎用プロセッサとして860と960がインテル社内で競合して、
860が勝ったというのは、どういうことなんだろうね。960では他のプロセッサに勝てないと
思ったのかな。
544 :,,・´∀`・,,)っ-●◎○:2009/01/26(月) 00:17:15
>>542
その「使わない命令」(LDS, LES)のOpcode空間を整理したんじゃん。
先頭バイトのC4, C5をスキャンしただけでModRMの位置を推定できる。
もしLDS, LESが現役でバリバリ使われてる命令ならプリデコードのたびにストールしまくるよ。
その「使わない命令」(LDS, LES)のOpcode空間を整理したんじゃん。
先頭バイトのC4, C5をスキャンしただけでModRMの位置を推定できる。
もしLDS, LESが現役でバリバリ使われてる命令ならプリデコードのたびにストールしまくるよ。
545 :デフォルトの名無しさん:2009/01/26(月) 00:21:14
546 :,,・´∀`・,,)っ-●◎○:2009/01/26(月) 00:36:08
まあ諦めない努力だけで報われるならIA64はあんな惨状になってねーしなぁ
AMDがx86-64を出してこなきゃIntelはPentium シリーズの後継はItaniumにする予定だった。
AMDがx86-64を出してこなきゃIntelはPentium シリーズの後継はItaniumにする予定だった。
547 :デフォルトの名無しさん:2009/01/26(月) 00:36:20
>>544
それでも長いじゃん。
ぶっちゃけAMDが悪いんだけどさ、
命令の使用頻度に応じた命令長割り当てを、真っ新からやり直すべきだったのよ。
最初のうちはデコーダが2つになってアレだが、長い目でみれば、そのほうが良いのよ。
どうせ、最初は64bitのコードを速く実行する必要なかったんだしさ。
それでも長いじゃん。
ぶっちゃけAMDが悪いんだけどさ、
命令の使用頻度に応じた命令長割り当てを、真っ新からやり直すべきだったのよ。
最初のうちはデコーダが2つになってアレだが、長い目でみれば、そのほうが良いのよ。
どうせ、最初は64bitのコードを速く実行する必要なかったんだしさ。
548 :デフォルトの名無しさん:2009/01/26(月) 00:37:15
549 :,,・´∀`・,,)っ-●◎○:2009/01/26(月) 00:43:10
IA64命令セットって全然コンパクトじゃないよ。
3命令分で16byte。Itanium 2は2バンドルだから32byte/clkの命令帯域だ。
その上でNOPだらけという悲しい罠。
片やCore 2は16byte/clkの命令フェッチ帯域で4issueやってるわけで。
#レジスタ本数なんて性能の本質じゃないことはCellで遊んでみて悟ったよ。
3命令分で16byte。Itanium 2は2バンドルだから32byte/clkの命令帯域だ。
その上でNOPだらけという悲しい罠。
片やCore 2は16byte/clkの命令フェッチ帯域で4issueやってるわけで。
#レジスタ本数なんて性能の本質じゃないことはCellで遊んでみて悟ったよ。
550 :デフォルトの名無しさん:2009/01/26(月) 00:43:43
AMDは切り替えたくてたまらなかったろう。
でもアグレッシブな事やるとIntelがついてこないから3D Now!とかAMD64とかSSE5とかで歩み寄る。
そうするとIntelの尻に火が付くからIntelがアグレッシブな事をやって、結果AMDは置いて行かれる。
でもアグレッシブな事やるとIntelがついてこないから3D Now!とかAMD64とかSSE5とかで歩み寄る。
そうするとIntelの尻に火が付くからIntelがアグレッシブな事をやって、結果AMDは置いて行かれる。
551 :デフォルトの名無しさん:2009/01/26(月) 00:52:01
552 :デフォルトの名無しさん:2009/01/26(月) 00:53:41
そーか?
IntelはAMDとMSに感謝してもいいぐらいだと思ってる。
使用頻度で最適化とかいっても、
移行し終わったころには陳腐化してるかもしれんし。
IntelはAMDとMSに感謝してもいいぐらいだと思ってる。
使用頻度で最適化とかいっても、
移行し終わったころには陳腐化してるかもしれんし。
553 :,,・´∀`・,,)っ-●◎○:2009/01/26(月) 00:59:21
>>548
それもAMDのx86-64つぶしのために仕方なく用意したものらしいよ
AMDがx86-64のドラフトを公表した時点ではYamhillなんざ影も形もなくて
当時のアスキーにはIA64 VS AMD x86-64なんてことが書かれてた。
Itanium(Merced)の32ビット(x86)コードの性能が悪くて、64ビットもそんなに性能よくないことは
当のIntelが認識してたから、x86そのものの64ビット拡張が出されるといろいろ都合が悪い。
Yamhillの命令セット仕様を公開してこなかった時点で、IA64を後継と位置づけてたのは明らか。
Yamhillはレジスタ拡張もない素のx86のアドレス拡張そのものだったという話がある。
「EM64T」 という名称にはただのメモリアドレス拡張技術であって、IA64ではない
まがいものの64ビットですよと、自分自身でネガキャンする意味合いがあった。
「Intel 64」に名称変更したあたりで何かしら方針に変化があったに違いない。
eのずれたIntelの伝統的ロゴマークを刷新したのもこのへんだったよな。
それもAMDのx86-64つぶしのために仕方なく用意したものらしいよ
AMDがx86-64のドラフトを公表した時点ではYamhillなんざ影も形もなくて
当時のアスキーにはIA64 VS AMD x86-64なんてことが書かれてた。
Itanium(Merced)の32ビット(x86)コードの性能が悪くて、64ビットもそんなに性能よくないことは
当のIntelが認識してたから、x86そのものの64ビット拡張が出されるといろいろ都合が悪い。
Yamhillの命令セット仕様を公開してこなかった時点で、IA64を後継と位置づけてたのは明らか。
Yamhillはレジスタ拡張もない素のx86のアドレス拡張そのものだったという話がある。
「EM64T」 という名称にはただのメモリアドレス拡張技術であって、IA64ではない
まがいものの64ビットですよと、自分自身でネガキャンする意味合いがあった。
「Intel 64」に名称変更したあたりで何かしら方針に変化があったに違いない。
eのずれたIntelの伝統的ロゴマークを刷新したのもこのへんだったよな。
554 :デフォルトの名無しさん:2009/01/26(月) 01:03:05
あんまし名前に意味はないと思うなあ。
すぐAdvancedとか付けたがる会社だし、Core (1)とかSSSE3とかもうネーミングが完全にマーケティングの道具でしかない。
単に顧客からしたら「EM64T」ってのが意味不明すぎるのとAMD64って呼ばせたくないだけでしょ。
すぐAdvancedとか付けたがる会社だし、Core (1)とかSSSE3とかもうネーミングが完全にマーケティングの道具でしかない。
単に顧客からしたら「EM64T」ってのが意味不明すぎるのとAMD64って呼ばせたくないだけでしょ。
555 :,,・´∀`・,,)っ-●◎○:2009/01/26(月) 01:12:37
>>554
Itaniumを「IA-64」ではなくて「IPF」と表記するようになったのもあのへんからだよ。
IntelはもちろんIntelの提灯持ちライターの筆頭の元麻布の記事にも表記の変化が見られる。
Itaniumを「IA-64」ではなくて「IPF」と表記するようになったのもあのへんからだよ。
IntelはもちろんIntelの提灯持ちライターの筆頭の元麻布の記事にも表記の変化が見られる。
556 :デフォルトの名無しさん:2009/01/26(月) 02:09:19
だんごサンはIA-64いじってるの?
個人的には、そんなにnop入ってないって印象よ。
もちろん最適化を切ったデバッグ用のビルドは別ね。
個人的には、そんなにnop入ってないって印象よ。
もちろん最適化を切ったデバッグ用のビルドは別ね。
557 :,,・´∀`・,,)っ-●◎○:2009/01/26(月) 02:22:22
HP-UX向けの仕事したことがあったかな。
コンパイラはIntelのもMSも(ともにWindows用)も使ったことがある。
印象としてプレディケートで分岐を減らしてるのはわかるが本物の分岐には弱い感じ。
あと、キャッシュあんだけ積むだけの余裕あるならアウトオブオーダやってもいいだろと
コンパイラはIntelのもMSも(ともにWindows用)も使ったことがある。
印象としてプレディケートで分岐を減らしてるのはわかるが本物の分岐には弱い感じ。
あと、キャッシュあんだけ積むだけの余裕あるならアウトオブオーダやってもいいだろと
558 :デフォルトの名無しさん:2009/01/26(月) 02:28:53
なるほど。
コードによっては、そうなるよね。
というか、そうならないほうが珍しいか。
アウトオブオーダやったら、EPICの自己否定にならないかな?
投機実行はコンパイラのお仕事、なのだから。
パイプラインのステージ数や実行ユニットなどが変ったら、
アウトオブオーダやらないと、古いプロセッサ向けにコンパイルされたものは、スムーズに流れなくなるか。
コードによっては、そうなるよね。
というか、そうならないほうが珍しいか。
アウトオブオーダやったら、EPICの自己否定にならないかな?
投機実行はコンパイラのお仕事、なのだから。
パイプラインのステージ数や実行ユニットなどが変ったら、
アウトオブオーダやらないと、古いプロセッサ向けにコンパイルされたものは、スムーズに流れなくなるか。
559 :,,・´∀`・,,)っ-●◎○:2009/01/26(月) 02:43:39
分岐の少ない直線的なコードならItaniumにも生きる道があるだろ?って思ったんだよね
でもそれこそPentium 4で十分やん的な。
人づての話だけど
大学の研究室にItanium2とPentium 4(Xeonだったかも?)があって
簡単なFFTですら、倍以上のクロックで動くPentium 4のほうが速かっただとか
あと、レジスタが多い分コンテクストスイッチに時間がかかりすぎるとか
(このへんがHyper-Threadingの導入のきっかけにもなった)
今のXeonは1コアで128ビットSIMD算術論理演算を、3命令同時発行とかできるから
最大2バンドル6命令同時発行の威光も、同クロックですら完全に霞んでる。
でもそれこそPentium 4で十分やん的な。
人づての話だけど
大学の研究室にItanium2とPentium 4(Xeonだったかも?)があって
簡単なFFTですら、倍以上のクロックで動くPentium 4のほうが速かっただとか
あと、レジスタが多い分コンテクストスイッチに時間がかかりすぎるとか
(このへんがHyper-Threadingの導入のきっかけにもなった)
今のXeonは1コアで128ビットSIMD算術論理演算を、3命令同時発行とかできるから
最大2バンドル6命令同時発行の威光も、同クロックですら完全に霞んでる。
560 :デフォルトの名無しさん:2009/01/26(月) 10:54:49
そしてXeonより上の信頼性が要求される用途でも、
CPU自体のRAS等の機能の充実によるメリットより、
複雑がゆえにバグが出やすいことのデメリットのほうが大きい。
いや、CPUの回路はシンプルかもしれない
(そのわりにはステッピングが異様にあるし、ハングするバグで全部交換なんて話もあった)
でも、それを正しく動作させるためのソフトが複雑怪奇すぎる。
CPU自体のRAS等の機能の充実によるメリットより、
複雑がゆえにバグが出やすいことのデメリットのほうが大きい。
いや、CPUの回路はシンプルかもしれない
(そのわりにはステッピングが異様にあるし、ハングするバグで全部交換なんて話もあった)
でも、それを正しく動作させるためのソフトが複雑怪奇すぎる。
561 :デフォルトの名無しさん:2009/01/26(月) 13:58:10
何に向かって吠えてるの?
>>540
誰もメモリアドレッシングに限定した話なんかしてないのでは?
>>549
だれもIA64命令セットがコンパクトなんて話はしてないのでは?
突然関係ないこといってごまかすこと多いよね。この人。
>>540
誰もメモリアドレッシングに限定した話なんかしてないのでは?
>>549
だれもIA64命令セットがコンパクトなんて話はしてないのでは?
突然関係ないこといってごまかすこと多いよね。この人。
562 :デフォルトの名無しさん:2009/01/26(月) 14:28:48
AMD64は命令が長くなる!
AVXを使ってもあまり短くならない!
いったんキレイサッパリ仕切りなおせばいい!
そうやって仕切り直したIA-64は命令が長いぞ!
AVXを使ってもあまり短くならない!
いったんキレイサッパリ仕切りなおせばいい!
そうやって仕切り直したIA-64は命令が長いぞ!
563 :デフォルトの名無しさん:2009/01/26(月) 14:35:05
IA64を作った頃にはAMD64もAVXも無かったと思うんだ。
そしてAVXに関しては>>544の通り、大きな恩恵がある。
そしてAVXに関しては>>544の通り、大きな恩恵がある。
564 :デフォルトの名無しさん:2009/01/26(月) 14:40:33
>>542
なんというCISC脳!
なんというCISC脳!
565 :デフォルトの名無しさん:2009/01/26(月) 14:42:37
どうせAVXで仕切り直すならモード切替でもして、命令体系と命令長を抜本的に直しても良かったと思うけどな。
566 :デフォルトの名無しさん:2009/01/26(月) 14:54:49
567 :デフォルトの名無しさん:2009/01/26(月) 16:41:52
568 :デフォルトの名無しさん:2009/01/26(月) 17:14:25
こうなったら出現頻度の統計をとってハフマンで
569 :,,・´∀`・,,)っ-●◎○:2009/01/26(月) 17:35:15
>>561 はぁ?
> > 1命令でこなせる。
> 今やその1命令が複雑すぎるからAVXが待たれているわけだが。
これどう考えてもAVXの技術を勘違いしてるようにしか見えないんだが。
たとえるなら月の表面構造の話の途中に、唐突にスッポンの話が割り込まれた感じ。
呆れるしかない。
複雑なアドレッシングモードとは言ったけど、一定のフォーマットどおりなら、ModRMをスキャンしただけで
SIB+DISPの有無とサイズを特定できるから可変長命令の中ではデコーダの負担が軽いんだよ。
厄介なのは16ビットDISPを含むようなレガシー命令フォーマット。
しかしIntelはレガシー命令のデコードにトランジスタを割いてない(だから古いコードだとLCPストールがおきる)。
そもそも新たに組まれたコードに古い形式の命令なんて基本的には含まれてないんだから
このへんはいまさら解決するに値しない問題。
AVXが解決するのはまったく別の問題だ。
・ModRMまでのサイズの推定をし易くする
・レガシー命令のOpcodeをオーバーライドすることでの新たなOpcode空間の確保
・第3のレジスタオペランドの追加
・256ビット、あるいはそれ以上のワイドベクトル命令の提供
AVXがコンパクトじゃないなんて誰の入れ知恵よ?
たとえばさ、PowerPCでAltiVecの256ビットとか512ビットとかのバージョンを作るにしても
4オペランド命令を廃止するという暴挙にでるか、8バイト命令の空間に割り当てるか
そのくらいしかないんだぜ
それ考えればAVXは充分コンパクトだよ。
新命令の追加は「R」ISCのフィロソフィにそもそもないんだから、破綻するのは当然だよ。
ARMもPowerPCも、もはやRISCでない別の何か。
> > 1命令でこなせる。
> 今やその1命令が複雑すぎるからAVXが待たれているわけだが。
これどう考えてもAVXの技術を勘違いしてるようにしか見えないんだが。
たとえるなら月の表面構造の話の途中に、唐突にスッポンの話が割り込まれた感じ。
呆れるしかない。
複雑なアドレッシングモードとは言ったけど、一定のフォーマットどおりなら、ModRMをスキャンしただけで
SIB+DISPの有無とサイズを特定できるから可変長命令の中ではデコーダの負担が軽いんだよ。
厄介なのは16ビットDISPを含むようなレガシー命令フォーマット。
しかしIntelはレガシー命令のデコードにトランジスタを割いてない(だから古いコードだとLCPストールがおきる)。
そもそも新たに組まれたコードに古い形式の命令なんて基本的には含まれてないんだから
このへんはいまさら解決するに値しない問題。
AVXが解決するのはまったく別の問題だ。
・ModRMまでのサイズの推定をし易くする
・レガシー命令のOpcodeをオーバーライドすることでの新たなOpcode空間の確保
・第3のレジスタオペランドの追加
・256ビット、あるいはそれ以上のワイドベクトル命令の提供
AVXがコンパクトじゃないなんて誰の入れ知恵よ?
たとえばさ、PowerPCでAltiVecの256ビットとか512ビットとかのバージョンを作るにしても
4オペランド命令を廃止するという暴挙にでるか、8バイト命令の空間に割り当てるか
そのくらいしかないんだぜ
それ考えればAVXは充分コンパクトだよ。
新命令の追加は「R」ISCのフィロソフィにそもそもないんだから、破綻するのは当然だよ。
ARMもPowerPCも、もはやRISCでない別の何か。
570 :,,・´∀`・,,)っ-●◎○:2009/01/26(月) 18:29:00
>>566-568
80:20ルール(あるいは90:10ルール)って知ってる?
統計的に、実行時間の大部分を担う部分は、コード全体の2割にも満たず、
それ以外の部分は別に速くなっても遅くなっても大して影響ないっていう経験則なんだけど
パフォーマンス上重要でないところほど命令を短くするのは全体のコードサイズを小さくするには合理的じゃないの。
実際、ARMのThumb命令もこの経験則にしたがって「80」(あるいは90)の部分での利用が推奨されてる。
でも、逆にパフォーマンス上重要な2割未満のところで使いたい命令が、命令長が長すぎて命令フェッチが
間に合わなくなると困る。そこで、4〜5バイト+α程度の命令長で3オペランド形式のSIMD命令が使えるように、
将来にわたって使える新たな命令セット空間を定義した、ってのがAVXだよ。
16バイトの命令フェッチ帯域あれば平均的に3命令程度は供給可能。
80:20ルール(あるいは90:10ルール)って知ってる?
統計的に、実行時間の大部分を担う部分は、コード全体の2割にも満たず、
それ以外の部分は別に速くなっても遅くなっても大して影響ないっていう経験則なんだけど
パフォーマンス上重要でないところほど命令を短くするのは全体のコードサイズを小さくするには合理的じゃないの。
実際、ARMのThumb命令もこの経験則にしたがって「80」(あるいは90)の部分での利用が推奨されてる。
でも、逆にパフォーマンス上重要な2割未満のところで使いたい命令が、命令長が長すぎて命令フェッチが
間に合わなくなると困る。そこで、4〜5バイト+α程度の命令長で3オペランド形式のSIMD命令が使えるように、
将来にわたって使える新たな命令セット空間を定義した、ってのがAVXだよ。
16バイトの命令フェッチ帯域あれば平均的に3命令程度は供給可能。
571 :,,・´∀`・,,)っ-●◎○:2009/01/26(月) 18:31:40
>>542宛が適切だったな
572 :デフォルトの名無しさん:2009/01/26(月) 20:51:57
> AVXが解決するのはまったく別の問題だ。
昨日から引き続き、勝手に別の事を話していると思う辺りが恥ずかしいな。
昨日から引き続き、勝手に別の事を話していると思う辺りが恥ずかしいな。
> 80:20ルール(あるいは90:10ルール)って知ってる?
俺計算屋なんだけどあんまこの法則に当たった事がないんだよな。
効率の悪い書き方は初めからしないというのと
今のご時世、計算は殆どボトルネックにならないという事かも知れない。
俺計算屋なんだけどあんまこの法則に当たった事がないんだよな。
効率の悪い書き方は初めからしないというのと
今のご時世、計算は殆どボトルネックにならないという事かも知れない。
574 :デフォルトの名無しさん:2009/01/26(月) 21:12:28
>今のご時世、計算は殆どボトルネックにならないという事かも知れない。
そりゃあんたがそういう計算に縁がないだけだ。
そりゃあんたがそういう計算に縁がないだけだ。
575 :,,・´∀`・,,)っ-●◎○:2009/01/26(月) 21:16:49
576 :デフォルトの名無しさん:2009/01/26(月) 21:30:21
俺のボトルネックは口だな。
頭の早さについていけない。
頭の早さについていけない。
577 :デフォルトの名無しさん:2009/01/26(月) 21:32:12
他のやつが言っていたかどうかは知らないが
メモリアドレッシングがボトルネックだなんて俺は言った事無いぞ。
団子と同じ主張しかしていない。
メモリアドレッシングがボトルネックだなんて俺は言った事無いぞ。
団子と同じ主張しかしていない。
578 :デフォルトの名無しさん:2009/01/26(月) 21:32:25
吃音なのか?
579 :デフォルトの名無しさん:2009/01/26(月) 21:35:01
>>570
命令キャッシュの大きさも考えてあげてください
3命令よりも多くの命令を実行できるようになったとき16バイトの命令フェッチでは足りないことを心配してください
たとえ単純でも、やはり長くなればなるほどデコードの負荷は高まりますので。
命令キャッシュの大きさも考えてあげてください
3命令よりも多くの命令を実行できるようになったとき16バイトの命令フェッチでは足りないことを心配してください
たとえ単純でも、やはり長くなればなるほどデコードの負荷は高まりますので。
580 :デフォルトの名無しさん:2009/01/26(月) 21:37:46
命令キャッシュに大きさは必要ない
L2→L1I$への転送はレイテンシこそ大きいものの、帯域幅は非常に広い。
だから、1キャッシュラインごとにL1I$ミスのL2ヒットなら、さほどのペナルティにはならない。
L2→L1I$への転送はレイテンシこそ大きいものの、帯域幅は非常に広い。
だから、1キャッシュラインごとにL1I$ミスのL2ヒットなら、さほどのペナルティにはならない。
581 :,,・´∀`・,,)っ-●◎○:2009/01/26(月) 21:41:29
ひとつのプロセッサに使えるトランジスタリソースが少なかった時代にはRISCはよかったんだよ。
今みたいに何億も使える時代になっちゃうと、リッチなアドレッシングモードも
複雑でもなんでもなくなる。
むしろRISCは、オペレーションの単位が細かすぎて、いくらトランジスタ注ぎ込んで
同時命令発行数を増やしたり、クロックあげたりしても、思ったように性能があげられない事態に陥ってる。
レジスタウィンドウなり遅延スロットなりを命令セットレベルで具体化してしまった
アーキテクチャはもっと悲惨で、高クロックにも高IPCにもパイプラインを抜本的に
作り変えることができなくて、性能競争から取り残された。
結局、ハードワイヤードでほとんどの命令をこなせるリッチな時代にこそ
適応できたのはx86だったという話。
1命令で扱うオペレーションを増やしたり、高級な機能を実装することで
トランジスタを有効利用するってのはVLIWにも通じる概念だが
x86の命令セットにはそういう時代に勝ち抜く素養があったってことだ。
今みたいに何億も使える時代になっちゃうと、リッチなアドレッシングモードも
複雑でもなんでもなくなる。
むしろRISCは、オペレーションの単位が細かすぎて、いくらトランジスタ注ぎ込んで
同時命令発行数を増やしたり、クロックあげたりしても、思ったように性能があげられない事態に陥ってる。
レジスタウィンドウなり遅延スロットなりを命令セットレベルで具体化してしまった
アーキテクチャはもっと悲惨で、高クロックにも高IPCにもパイプラインを抜本的に
作り変えることができなくて、性能競争から取り残された。
結局、ハードワイヤードでほとんどの命令をこなせるリッチな時代にこそ
適応できたのはx86だったという話。
1命令で扱うオペレーションを増やしたり、高級な機能を実装することで
トランジスタを有効利用するってのはVLIWにも通じる概念だが
x86の命令セットにはそういう時代に勝ち抜く素養があったってことだ。
582 :デフォルトの名無しさん:2009/01/26(月) 21:44:20
うー、異論を挟みたいが大筋では間違ってないだけに……
今となってはSparcにはなんの存在価値も残ってないもんねぇ。
今となってはSparcにはなんの存在価値も残ってないもんねぇ。
583 :,,・´∀`・,,)っ-●◎○:2009/01/26(月) 21:50:04
>>579
>3命令よりも多くの命令を実行できるようになったとき
AVXの256bit SIMDはうまく考えられてて、実行ユニットは128ビットのまんまで
2つの128ビットSIMD命令を発行する。
これが何を意味するかって、実質的に2命令分を供給できるわけだ。たった4〜5バイトで。
場所に応じて128ビットSIMDと256ビットSIMDを使い分けられる。
MMXとSSE2のときにもあったけど、ポイントは、XMMとYMMの下位は128ビットは同一レジスタなので
データ交換が簡単だということ。
SIMDユニットが256ビットになったときには、今度は512ビットのSIMD演算命令を実装する。
これで延々、命令帯域を確保し続けることができる。
>3命令よりも多くの命令を実行できるようになったとき
AVXの256bit SIMDはうまく考えられてて、実行ユニットは128ビットのまんまで
2つの128ビットSIMD命令を発行する。
これが何を意味するかって、実質的に2命令分を供給できるわけだ。たった4〜5バイトで。
場所に応じて128ビットSIMDと256ビットSIMDを使い分けられる。
MMXとSSE2のときにもあったけど、ポイントは、XMMとYMMの下位は128ビットは同一レジスタなので
データ交換が簡単だということ。
SIMDユニットが256ビットになったときには、今度は512ビットのSIMD演算命令を実装する。
これで延々、命令帯域を確保し続けることができる。
584 :,,・´∀`・,,)っ-●◎○:2009/01/26(月) 22:08:13
ちなみに、さっさと64ビットに移行すれば0F38グループも0F3Aグループも命令長を4バイトにすることが可能になるから。
AAMとかAASをオーバーライドできる。
AAMとかAASをオーバーライドできる。
585 :,,・´∀`・,,)っ-●◎○:2009/01/26(月) 22:09:02
#0F3Aは無理か。imm8があるから6バイト→5バイトだな。
586 :デフォルトの名無しさん:2009/01/26(月) 22:18:17
>>581
x86だと1命令でも、RISCだと複数の命令になってしまうので、
それらが依存関係を持つ1つのまとまった処理だというのを、
アウトオブオーダーのエンジンが自分で前後を見て判断しないといけないよね。
x86なら1命令なのだから、そういうことしなくても自明、と。
なんだ、x86はデコーダがネックだとかいうけど、RISCこそデコーダがネックじゃないか。
x86だと1命令でも、RISCだと複数の命令になってしまうので、
それらが依存関係を持つ1つのまとまった処理だというのを、
アウトオブオーダーのエンジンが自分で前後を見て判断しないといけないよね。
x86なら1命令なのだから、そういうことしなくても自明、と。
なんだ、x86はデコーダがネックだとかいうけど、RISCこそデコーダがネックじゃないか。
587 :デフォルトの名無しさん:2009/01/26(月) 22:23:13
ピコーン(AA略)
RISC→CISCにトランスコードして実行するというのを思いついたぞ
特許書くかな
RISC→CISCにトランスコードして実行するというのを思いついたぞ
特許書くかな
588 :,,・´∀`・,,)っ-●◎○:2009/01/26(月) 22:26:20
困ったことに、Atom 1.6GHz VS Cell PPE 3.2GHzですら、たいがいの処理でAtomのほうが速いんだ
同じインオーダなのに。
同じインオーダなのに。
589 :デフォルトの名無しさん:2009/01/26(月) 22:36:38
そりゃぁだってAtomは2スレッド×2コアだしょ?
Cell PPEは1コア・・・あれ?2スレッドだ。
だめじゃん!
Cell PPEは1コア・・・あれ?2スレッドだ。
だめじゃん!
590 :デフォルトの名無しさん:2009/01/26(月) 22:38:35
あれ? PPEでクロック換算したらPen4程度の性能が出た気がしたのはなんだったんだろう。
591 :デフォルトの名無しさん:2009/01/26(月) 22:56:23
Pentium4 < Atom ってオチじゃね?
592 :デフォルトの名無しさん:2009/01/26(月) 23:01:43
迷走しているな。
PPEが遅いのはRISCのせいじゃないだろう。
PPEが遅いのはRISCのせいじゃないだろう。
593 :,,・´∀`・,,)っ-●◎○:2009/01/26(月) 23:07:13
Pen4はSIMDが半速だからものによってはそんなもんになるんじゃね?
>>592
知ってる。てかAltiVec除いてほとんどG4 1.4GHz>PPEだったりするし。
問題はG4>Atomにならないことだ
>>592
知ってる。てかAltiVec除いてほとんどG4 1.4GHz>PPEだったりするし。
問題はG4>Atomにならないことだ
594 :デフォルトの名無しさん:2009/01/26(月) 23:24:41
なんだ
マカーがあんなに誉め称えていたG4が遅いだけか。
マカーがあんなに誉め称えていたG4が遅いだけか。
595 :デフォルトの名無しさん:2009/01/26(月) 23:25:31
だってモトローラだし。
596 :デフォルトの名無しさん:2009/01/26(月) 23:25:47
597 :デフォルトの名無しさん:2009/01/26(月) 23:27:25
今となってはSUNにはなんの存在価値も残ってないもんねぇ。
こういうこと?
こういうこと?
598 :,,・´∀`・,,)っ-●◎○:2009/01/26(月) 23:38:34
2000年くらいにUltraSPARC IIeのエントリマシンとか出したことあったろ?
Javaで同じプログラム動かしたら既に同クロックのCeleronにも圧倒的に負けてたという
笑い話
Javaで同じプログラム動かしたら既に同クロックのCeleronにも圧倒的に負けてたという
笑い話
599 :デフォルトの名無しさん:2009/01/26(月) 23:41:50
あれってシンクライアント用だったような。
600 :,,・´∀`・,,)っ-●◎○:2009/01/26(月) 23:46:42
これだこれ
http://ascii24.com/news/i/hard/article/2001/04/04/624913-000.html
ずいぶん大きいシンクライアントだなw
これ応用したA4ファイルサイズノートPC出してたメーカーがあって
100万くらいだったかな
どうみてもぼったくりです。本当にありがとうございました。
http://ascii24.com/news/i/hard/article/2001/04/04/624913-000.html
ずいぶん大きいシンクライアントだなw
これ応用したA4ファイルサイズノートPC出してたメーカーがあって
100万くらいだったかな
どうみてもぼったくりです。本当にありがとうございました。
601 :デフォルトの名無しさん:2009/01/26(月) 23:51:41
602 :,,・´∀`・,,)っ-●◎○:2009/01/26(月) 23:55:34
「ワークステーション」のラインナップだし
http://jp.sun.com/products/desktop/ws/
なぜかCore 2だけになってしまったな。
パソコンにXeonを採用するメーカー(Apple)もあれば、
Core 2をワークステーションだと言って売るメーカーもあり。
http://jp.sun.com/products/desktop/ws/
なぜかCore 2だけになってしまったな。
パソコンにXeonを採用するメーカー(Apple)もあれば、
Core 2をワークステーションだと言って売るメーカーもあり。
603 :,,・´∀`・,,)っ-●◎○:2009/01/27(火) 00:00:29
てか、シンクライアント用途だとなおさら高コストなSPARCを選ぶ意味自体ないじゃん。
今ならARMですら十分だね。
今ならARMですら十分だね。
604 :デフォルトの名無しさん:2009/01/27(火) 00:01:35
まあよそはよそ、うちはうちでx86以外の話は終わりにしよう。
605 :,,・´∀`・,,)っ-●◎○:2009/01/27(火) 00:05:39
Nanoはどこそこ性能駄目っぽいね。
さすがにAtomより性能良いだろうと思ってたんだけどやっぱりどこまでもVIAだった
さすがにAtomより性能良いだろうと思ってたんだけどやっぱりどこまでもVIAだった
606 :デフォルトの名無しさん:2009/01/27(火) 00:42:26
そうなのか。
提灯記事では、AtomよりNanoのほうがシングルスレッド性能が格段に良いような話だったが・・・orz
>>602
ワークステーションつってもさ、パワフルとは限らなよ。
データエントリー用の端末だって、ワークステーションだもの。
それにしても、ECCメモリをサポートしないのは、いただけないよ。
いまのIntelのデスクトップ向けのCPUやチップセットは。
メモリのチェックなんか時間すげーかかってやってらんないから、
壊れたら壊れたとわかるほうがいい。
提灯記事では、AtomよりNanoのほうがシングルスレッド性能が格段に良いような話だったが・・・orz
>>602
ワークステーションつってもさ、パワフルとは限らなよ。
データエントリー用の端末だって、ワークステーションだもの。
それにしても、ECCメモリをサポートしないのは、いただけないよ。
いまのIntelのデスクトップ向けのCPUやチップセットは。
メモリのチェックなんか時間すげーかかってやってらんないから、
壊れたら壊れたとわかるほうがいい。
607 :デフォルトの名無しさん:2009/01/27(火) 02:19:39
608 :,,・´∀`・,,)っ-●◎○:2009/01/27(火) 02:45:33
お前がな
だからさ、80:20ルールの80の部分でいちいちSSEなんか使わないだろ。
スカラ命令(1〜2バイトの命令)で済むならそっちのほうがいいんだよ。
AVXは長いけど長いのに合理的理由があるだろ?
拡張性、3つめのレジスタオペランド、etc・・・
だからさ、80:20ルールの80の部分でいちいちSSEなんか使わないだろ。
スカラ命令(1〜2バイトの命令)で済むならそっちのほうがいいんだよ。
AVXは長いけど長いのに合理的理由があるだろ?
拡張性、3つめのレジスタオペランド、etc・・・
609 :,,・´∀`・,,)っ-●◎○:2009/01/27(火) 03:41:13
CoreMAは4issueのパイプラインで、3つのSimple Decoderと1つのComplex Decorderで
実効3IPC+αの並列度を実現してるわけだけど、デコーダに命令を供給する前段階として、
命令の切り出しがネックになる。何並列ものスキャナで血眼になって命令境界を探すわけだ。
単純な命令であれば、1クロックに最大6命令の切り出しが可能だが、
命令セット拡張のためにプリフィクスを次々と増やしていったSSEは一筋縄にはいかない。
命令を並列に供給するには命令の境界をさっさと検出しないといけない
↓
ModRMの位置さえわかればSIB/DISPの長さがわかる。imm8の有無はOpcodeを見ることでわかる。
↓
ModRMの位置はどこだ?/Opcodeの位置はどこだ?
現状のSSEでは、プリフィックスを読み飛ばしながらOpcodeの位置を探っていかないといけない。
別に【命令が長いこと】自体が問題なんじゃなくて、プリフィックスが不規則に多重に付いてて
Opcode/ModRMの位置を検出しづらいのが問題なんだよ。
命令長の問題は二の次。
AVXでは、C4あるいはC5を見ただけでOpcodeとModRMの位置を推定できる。
ペイロード領域やSIB・DISPは命令境界の検出には直接関係ないので読み飛ばして構わない。(デコーダにやらせればいい)
切り出し・プリデコードの終わった命令は別にどうってことはないよ
強引な言い方をすれば、エスケープバイトに合わせたテーブルを参照して対応するμOPに変換するだけ。
実効3IPC+αの並列度を実現してるわけだけど、デコーダに命令を供給する前段階として、
命令の切り出しがネックになる。何並列ものスキャナで血眼になって命令境界を探すわけだ。
単純な命令であれば、1クロックに最大6命令の切り出しが可能だが、
命令セット拡張のためにプリフィクスを次々と増やしていったSSEは一筋縄にはいかない。
命令を並列に供給するには命令の境界をさっさと検出しないといけない
↓
ModRMの位置さえわかればSIB/DISPの長さがわかる。imm8の有無はOpcodeを見ることでわかる。
↓
ModRMの位置はどこだ?/Opcodeの位置はどこだ?
現状のSSEでは、プリフィックスを読み飛ばしながらOpcodeの位置を探っていかないといけない。
別に【命令が長いこと】自体が問題なんじゃなくて、プリフィックスが不規則に多重に付いてて
Opcode/ModRMの位置を検出しづらいのが問題なんだよ。
命令長の問題は二の次。
AVXでは、C4あるいはC5を見ただけでOpcodeとModRMの位置を推定できる。
ペイロード領域やSIB・DISPは命令境界の検出には直接関係ないので読み飛ばして構わない。(デコーダにやらせればいい)
切り出し・プリデコードの終わった命令は別にどうってことはないよ
強引な言い方をすれば、エスケープバイトに合わせたテーブルを参照して対応するμOPに変換するだけ。
610 :デフォルトの名無しさん:2009/01/27(火) 07:48:02
611 :,,・´∀`・,,)っ-●◎○:2009/01/27(火) 08:07:22
そっちか!
浮動小数オペレーションはスタック操作からレジスタ間オペレーションへ、
更に2オペランドから3オペランド、ベクタ長など、x86の変遷の中でも
もっとも1命令の意味が大きく変わってくる演算なので、サイズが
増えただの減っただの言っても一概にコード効率を論じることはできない。
というか、x86の利用シーン全体を100とした場合、浮動小数演算そのものが20側になるわけですが
浮動小数オペレーションはスタック操作からレジスタ間オペレーションへ、
更に2オペランドから3オペランド、ベクタ長など、x86の変遷の中でも
もっとも1命令の意味が大きく変わってくる演算なので、サイズが
増えただの減っただの言っても一概にコード効率を論じることはできない。
というか、x86の利用シーン全体を100とした場合、浮動小数演算そのものが20側になるわけですが
612 :デフォルトの名無しさん:2009/01/27(火) 11:18:59
>>609
> 現状のSSEでは、プリフィックスを読み飛ばしながらOpcodeの位置を探っていかないといけない。
マイクロコードで処理してるとでも? アホか。
回路の入力が増えれば増えるほど、通るゲートの数が増えるので、
トランジスタ数は食うは、遅延は大きいわで、「重い」んだよ。
決して、前からスキャンしているわけではない。
> 現状のSSEでは、プリフィックスを読み飛ばしながらOpcodeの位置を探っていかないといけない。
マイクロコードで処理してるとでも? アホか。
回路の入力が増えれば増えるほど、通るゲートの数が増えるので、
トランジスタ数は食うは、遅延は大きいわで、「重い」んだよ。
決して、前からスキャンしているわけではない。
613 :デフォルトの名無しさん:2009/01/27(火) 12:19:46
つまり回路的には128ビット(16バイト)を同時に扱うという事?
固定長ならどこからでもスキャン出来るから
完全同時にデコードできるだろうけどな。
命令が左からスキャンしないと解読できないアーキテクチャなんだから
限りなく団子の言うのに近い状態になりうると思うんだけど。
固定長ならどこからでもスキャン出来るから
完全同時にデコードできるだろうけどな。
命令が左からスキャンしないと解読できないアーキテクチャなんだから
限りなく団子の言うのに近い状態になりうると思うんだけど。
614 :デフォルトの名無しさん:2009/01/27(火) 13:26:01
>>613
実装とは違うが、概念的には、デコーダを1つのブラックボックスとして見ると、
入力、128ビット分の命令列(アライメントはキャッシュライン)、クロックのエッジで入力される
出力、デコード結果、クロックに同期して出力確定
内部に状態を保持、あり。
こんな感じ。1クロックでデコードするためには、
出力信号の1本は、入力128ビット×状態の論理演算の組み合わせで行うしかない。
行列の乗算みたいなものよ。
実装とは違うが、概念的には、デコーダを1つのブラックボックスとして見ると、
入力、128ビット分の命令列(アライメントはキャッシュライン)、クロックのエッジで入力される
出力、デコード結果、クロックに同期して出力確定
内部に状態を保持、あり。
こんな感じ。1クロックでデコードするためには、
出力信号の1本は、入力128ビット×状態の論理演算の組み合わせで行うしかない。
行列の乗算みたいなものよ。
615 :デフォルトの名無しさん:2009/01/27(火) 14:18:26
>>612
馬鹿だなお前は
マイクロコードも糞も無くて一種のステートマシン。
前のバイトがプリフィクスかリードバイトかOpcodeかもわからないのに何をもって
後続のバイトを判別するんだよ
前からしか評価できないだろ。
C4, C5を見ればAVXのリードバイトと見なすってのも32ビットモードでは「推定」でしかない。
第2バイトの上位2ビットが11ならAVXとみなすしそれ以外ならLES,LDSとして解釈しないといけない。
分岐を並列処理することはできるが、前後関係を無視した評価はできない。
66 66 66 66 66 66 NOPなんてのが許されるフォーマットだからたちが悪い。
馬鹿だなお前は
マイクロコードも糞も無くて一種のステートマシン。
前のバイトがプリフィクスかリードバイトかOpcodeかもわからないのに何をもって
後続のバイトを判別するんだよ
前からしか評価できないだろ。
C4, C5を見ればAVXのリードバイトと見なすってのも32ビットモードでは「推定」でしかない。
第2バイトの上位2ビットが11ならAVXとみなすしそれ以外ならLES,LDSとして解釈しないといけない。
分岐を並列処理することはできるが、前後関係を無視した評価はできない。
66 66 66 66 66 66 NOPなんてのが許されるフォーマットだからたちが悪い。
616 :デフォルトの名無しさん:2009/01/27(火) 14:28:16
前の命令の境界が判別して間違っていれば破棄すれば良いという観点からすれば投機的な並列スキャンは可能。
ただし、ものすごい負荷になるけど。
ただし、ものすごい負荷になるけど。
617 :デフォルトの名無しさん:2009/01/27(火) 14:37:22
Atomの場合はプリデコード専用のステージがなくて愚直にスキャンしてマイクロコードでデコードする。
デコードが完了すると、単純な命令であればプリデコードタグを付けられる。
プリデコードタグには命令長などの情報が含まれる。
2回目以降はプリデコードタグを元に2並列のXLAT/FLによってハードワイヤードでデコードされる。
デコードが完了すると、単純な命令であればプリデコードタグを付けられる。
プリデコードタグには命令長などの情報が含まれる。
2回目以降はプリデコードタグを元に2並列のXLAT/FLによってハードワイヤードでデコードされる。
618 :デフォルトの名無しさん:2009/01/27(火) 14:55:10
619 :デフォルトの名無しさん:2009/01/27(火) 14:56:36
620 :デフォルトの名無しさん:2009/01/27(火) 15:00:40
加算器を思い浮かべればいい
1クロックごとに1つ上の桁にキャリーを伝搬していく → マイクロコードに相当
キャリー先読みによってキャリーの伝搬を排除 → ハードワイヤードに相当
1クロックごとに1つ上の桁にキャリーを伝搬していく → マイクロコードに相当
キャリー先読みによってキャリーの伝搬を排除 → ハードワイヤードに相当
621 :デフォルトの名無しさん:2009/01/27(火) 15:07:35
622 :デフォルトの名無しさん:2009/01/27(火) 15:19:42
レガシーコード(16ビットDISP/IMMあり)と従来コードでアルゴリズムを切り替えてるんだから
マイクロコードベースなんじゃねーの?
マイクロコードベースなんじゃねーの?
623 :デフォルトの名無しさん:2009/01/27(火) 15:27:43
>>618
逆に現実世界の実装が1〜2サイクル程度で済んでると思ってるのか?
加算機の桁上げなんてたかだか1ビットだ。バイト単位だと全然話が違う。
だからAMDはL1命令キャッシュにフェッチする段階でプリデコード処理を行ってタグを付けてしまうし
Atomも省電力性と性能の両立のために>>617のようなことをやってる。
逆に現実世界の実装が1〜2サイクル程度で済んでると思ってるのか?
加算機の桁上げなんてたかだか1ビットだ。バイト単位だと全然話が違う。
だからAMDはL1命令キャッシュにフェッチする段階でプリデコード処理を行ってタグを付けてしまうし
Atomも省電力性と性能の両立のために>>617のようなことをやってる。
624 :デフォルトの名無しさん:2009/01/27(火) 15:41:09
>>622
2つの性格の異なるデコーダーを用意して、
コード種判定回路の出力に、その2つを切り替えるロジックを作れば、
別にマイクロコードで無くてもいいんじゃねーの?
実際どうなってるかは知らんけどさ。
2つの性格の異なるデコーダーを用意して、
コード種判定回路の出力に、その2つを切り替えるロジックを作れば、
別にマイクロコードで無くてもいいんじゃねーの?
実際どうなってるかは知らんけどさ。
625 :デフォルトの名無しさん:2009/01/27(火) 15:44:46
どっちにしろAVXに完全移行してSSE*がレガシーになればプリデコーダの負担も軽くなると
考えてるんだろIntelは。
AVXマニュアルにおいてSSEをOSがトラップしてソフトエミュレーションで実行することについて言及してるのは
SSEのデコードアルゴリズムの排除を前提とした話。
考えてるんだろIntelは。
AVXマニュアルにおいてSSEをOSがトラップしてソフトエミュレーションで実行することについて言及してるのは
SSEのデコードアルゴリズムの排除を前提とした話。
626 :デフォルトの名無しさん:2009/01/27(火) 16:07:20
627 :デフォルトの名無しさん:2009/01/27(火) 16:52:13
628 :デフォルトの名無しさん:2009/01/27(火) 17:07:13
629 :デフォルトの名無しさん:2009/01/28(水) 00:22:27
x86命令の所要クロック計測スレ
630 :,,・´∀`・,,)っ-●◎○:2009/01/28(水) 00:23:33
パイプラインの構造を考察することはクロックを知る上で重要だ。もっとやれ貴様ら。
631 :デフォルトの名無しさん:2009/01/28(水) 03:40:42
そう言えば IEEE Spectrum の i860 の記事に
instruction decoder の state machine を人間が作れなくて
CAD の自動生成を使ったという話が無かったっけ?
ま,それほど大変だという話
instruction decoder の state machine を人間が作れなくて
CAD の自動生成を使ったという話が無かったっけ?
ま,それほど大変だという話
632 :デフォルトの名無しさん:2009/01/28(水) 20:07:39
関係ないけど、例え人間が作れたとしても自動生成に任せるのは正しいと思った。
633 :デフォルトの名無しさん:2009/01/28(水) 20:34:58
人間が設計ツールを使うなんて普通の事なんだけど、それがどうかしたの?
自動配線ツールに与えるパラメーターを考えるのは人間だよ。
自動配線ツールに与えるパラメーターを考えるのは人間だよ。
634 :デフォルトの名無しさん:2009/01/29(木) 02:21:17
>>608
>>542
> 命令が1バイト短くなるかどうか、ちょっとデコードがシンプルになるだけじゃん。
> 良く使う命令が長ったらしくて、使わない命令が1バイトなのは、どうかしてるぜ。
元々命令長の話しかしてない。
にもかかわらず命令実行速度の話を延々としている団子は池沼。
>>542
> 命令が1バイト短くなるかどうか、ちょっとデコードがシンプルになるだけじゃん。
> 良く使う命令が長ったらしくて、使わない命令が1バイトなのは、どうかしてるぜ。
元々命令長の話しかしてない。
にもかかわらず命令実行速度の話を延々としている団子は池沼。
635 :デフォルトの名無しさん:2009/01/29(木) 02:27:06
結局は実行速度さえ満足な物なら命令長なんてねぇ…
636 :デフォルトの名無しさん:2009/01/29(木) 03:07:28
637 : ◆0uxK91AxII :2009/01/29(木) 05:43:46
Intelは時代を先取りした、と。
638 :,,・´∀`・,,)っ-●◎○:2009/01/29(木) 09:59:47
>>634
はぁ?
たかだか3命令+α程度しか並列デコードできないのに命令長がどうとか
けちくさいこと言って何になんのよ?
1命令で2μOPs分生成するなら、うまく使えば実質的に命令長が
減ったのと同じ効果が得られるだろ?
(それが256ビットAVX命令なんだが)
はぁ?
たかだか3命令+α程度しか並列デコードできないのに命令長がどうとか
けちくさいこと言って何になんのよ?
1命令で2μOPs分生成するなら、うまく使えば実質的に命令長が
減ったのと同じ効果が得られるだろ?
(それが256ビットAVX命令なんだが)
639 :,,・´∀`・,,)っ-●◎○:2009/01/29(木) 10:06:31
つか、SSEが頻繁に使うとか馬鹿じゃね?
整数スカラ命令を「使わない」とかwww
配列の添字どうやって算出すんの?
分岐もやらないのかよ?
SSEなんて現実のコードではそんなに頻繁に使「え」ません。
使えるところが限られるけど
32バイトfetchにすると熱密度が(ryってのはゲルたんが言ってるだろ。
Itanium 2のクロックが上げられないのも、Phenomが爆熱なのも、
みんな32バイト/clkのInst. fetchのせいだそうです。
依存関係ネックでどのみち上げられないケースが多いんだから
むやみに命令帯域増やしても意味ないってのがIntelの判断だよ。
俺に吠えて現実が変わりますか?ぁあ?
整数スカラ命令を「使わない」とかwww
配列の添字どうやって算出すんの?
分岐もやらないのかよ?
SSEなんて現実のコードではそんなに頻繁に使「え」ません。
使えるところが限られるけど
32バイトfetchにすると熱密度が(ryってのはゲルたんが言ってるだろ。
Itanium 2のクロックが上げられないのも、Phenomが爆熱なのも、
みんな32バイト/clkのInst. fetchのせいだそうです。
依存関係ネックでどのみち上げられないケースが多いんだから
むやみに命令帯域増やしても意味ないってのがIntelの判断だよ。
俺に吠えて現実が変わりますか?ぁあ?
640 :,,・´∀`・,,)っ-●◎○:2009/01/29(木) 10:29:29
実際問題、どんなアルゴリズム使おうと、
たとえSIMDで力業で並列演算やろうがLUT使おうがソフトウェア・ステートマシンやろうが
整数演算は常に使います。
この前提がまずおかしい
> 良く使う命令が長ったらしくて、使わない命令が1バイトなのは、どうかしてるぜ。
BCDなどのレガシー命令に関しては再割り当ての過渡期なんだから
目くじらたててもしょうがないし
たとえSIMDで力業で並列演算やろうがLUT使おうがソフトウェア・ステートマシンやろうが
整数演算は常に使います。
この前提がまずおかしい
> 良く使う命令が長ったらしくて、使わない命令が1バイトなのは、どうかしてるぜ。
BCDなどのレガシー命令に関しては再割り当ての過渡期なんだから
目くじらたててもしょうがないし
641 :デフォルトの名無しさん:2009/01/29(木) 11:34:23
>>638
デコーダの回路のコスト・消費電力・局所的な発熱・伝搬遅延のボトルネック
デコーダの回路のコスト・消費電力・局所的な発熱・伝搬遅延のボトルネック
642 :デフォルトの名無しさん:2009/01/29(木) 11:50:38
大体に、動画エンコーダなんかに代表されるSSEを積極活用したアプリは
Hyper Threadingで性能が数割上がる、つまり命令間の依存関係や
メモリレイテンシがネックになってる罠。
命令長が長すぎて命令フェッチがネックになるなんて的外れな文句垂れてる奴は
コスト分析もできない無能
Hyper Threadingで性能が数割上がる、つまり命令間の依存関係や
メモリレイテンシがネックになってる罠。
命令長が長すぎて命令フェッチがネックになるなんて的外れな文句垂れてる奴は
コスト分析もできない無能
643 :デフォルトの名無しさん:2009/01/29(木) 11:55:47
644 :デフォルトの名無しさん:2009/01/29(木) 11:58:52
>>639
Itanium2のクロックが上げられないのは、32バイト/クロックの命令フェッチのせいなのか?
短いパイプラインと、ひたすら投機実行しては結果を捨てまくるアーキテクチャがネックだと思ってた。
乱暴に言って、必要最低限の2倍の命令を実行するっしょ?
Itanium2のクロックが上げられないのは、32バイト/クロックの命令フェッチのせいなのか?
短いパイプラインと、ひたすら投機実行しては結果を捨てまくるアーキテクチャがネックだと思ってた。
乱暴に言って、必要最低限の2倍の命令を実行するっしょ?
645 :デフォルトの名無しさん:2009/01/29(木) 12:00:00
>>640
そいや、IBMはPOWERにBCD「演算」命令を追加したな。
そいや、IBMはPOWERにBCD「演算」命令を追加したな。
646 :デフォルトの名無しさん:2009/01/29(木) 12:03:04
>>642
え?
動画エンコーダ等の、拡張命令をしっかり使い倒して
*チューニングする場合は*、Hyper Threadingは使わないほうが性能が良いぞ。
命令間の依存関係が十分な距離になるようにソフトウェアパイプライニングし、
メモリレイテンシがネックにならないように適切にプリフェッチを行う。
ゆえに、Hyper Threadingを使うと、パイプラインが乱れキャッシュが汚染され、
パフォーマンスが低下するのよ。
え?
動画エンコーダ等の、拡張命令をしっかり使い倒して
*チューニングする場合は*、Hyper Threadingは使わないほうが性能が良いぞ。
命令間の依存関係が十分な距離になるようにソフトウェアパイプライニングし、
メモリレイテンシがネックにならないように適切にプリフェッチを行う。
ゆえに、Hyper Threadingを使うと、パイプラインが乱れキャッシュが汚染され、
パフォーマンスが低下するのよ。
647 :デフォルトの名無しさん:2009/01/29(木) 12:04:55
>>643
Intelの論文は、割り当てを真っ新からやり直すことはできない、というところからスタートしてるんじゃないか?
Intelの論文は、割り当てを真っ新からやり直すことはできない、というところからスタートしてるんじゃないか?
648 :デフォルトの名無しさん:2009/01/29(木) 12:05:52
どこの動画エンコーダでHTが逆効果になるか教えて下さいな
649 :デフォルトの名無しさん:2009/01/29(木) 12:14:11
>>646
知らないなら語らなくていいよ。無知蒙昧はなはだしい。
明示的なキャッシュ制御命令は程度スループット改善することはできるけど
レイテンシを埋めるには至らない。
むしろ、ライトスルー制御命令を使わないとキャッシュを取り合って性能出しにくい
逆にね。
知らないなら語らなくていいよ。無知蒙昧はなはだしい。
明示的なキャッシュ制御命令は程度スループット改善することはできるけど
レイテンシを埋めるには至らない。
むしろ、ライトスルー制御命令を使わないとキャッシュを取り合って性能出しにくい
逆にね。
650 :デフォルトの名無しさん:2009/01/29(木) 12:22:18
知ったかぶりもたいがいにしろ>>646
651 :デフォルトの名無しさん:2009/01/29(木) 12:36:06
L1とレジスタ舐め回す程度の小物ツールしか見たこと無いんだろ
ストリーミング処理のレイテンシを1スレッドだけで埋めるのはx86の少ない論理レジスタ数じゃ物理的に不可能
ストリーミング処理のレイテンシを1スレッドだけで埋めるのはx86の少ない論理レジスタ数じゃ物理的に不可能
652 :デフォルトの名無しさん:2009/01/29(木) 12:39:27
はいはい>>648-651まで、顔真っ赤にして4連投乙
653 :デフォルトの名無しさん:2009/01/29(木) 12:42:20
見えない敵と戦う知ったかぶり
654 :デフォルトの名無しさん:2009/01/29(木) 12:44:12
655 : ◆0uxK91AxII :2009/01/29(木) 12:44:29
動画のencode云々は、algorithmにもよるから、何とも言えないね。
軽い物程、CPUの外の影響が大きくなり、このスレの趣旨からハズレる。
軽い物程、CPUの外の影響が大きくなり、このスレの趣旨からハズレる。
656 :デフォルトの名無しさん:2009/01/29(木) 12:53:30
フィルタを重ねるほどオンキャッシュ処理の頻度は高くなるね
それでもL1外の読み書きのレイテンシを完全に隠蔽してしまえるような状況は知らない
論理レジスタ32本くらいあっても厳しいのに
それでもL1外の読み書きのレイテンシを完全に隠蔽してしまえるような状況は知らない
論理レジスタ32本くらいあっても厳しいのに
657 :デフォルトの名無しさん:2009/01/29(木) 13:22:20
マジレスするとメモリの帯域がネックになってSMTが効果ないケースはありうる。
なおさら命令供給ネックと関係ないが。
なおさら命令供給ネックと関係ないが。
658 :デフォルトの名無しさん:2009/01/29(木) 15:23:51
>>656
フィルタ・・・ねぇ。
フィルタを色々使うとAMDのほうが速いっていう昔の話については、
それらのフィルタの実装が悪かった、ただそれだけのことよ。
ネットでフリーで公開されてる大半のフィルタは、
処理速度を最優先したコーディングをしていない。
とにかくバグらずに目的の映像が得られれば、
ひどい非効率な処理手順でも構わない、
ないよりはマシ
というコンセプト。
それは間違ってはいないが、それをもってしてCPUを評価しちゃいかん。
フィルタ・・・ねぇ。
フィルタを色々使うとAMDのほうが速いっていう昔の話については、
それらのフィルタの実装が悪かった、ただそれだけのことよ。
ネットでフリーで公開されてる大半のフィルタは、
処理速度を最優先したコーディングをしていない。
とにかくバグらずに目的の映像が得られれば、
ひどい非効率な処理手順でも構わない、
ないよりはマシ
というコンセプト。
それは間違ってはいないが、それをもってしてCPUを評価しちゃいかん。
659 :デフォルトの名無しさん:2009/01/29(木) 17:43:16
>>639
>Itanium 2のクロックが上げられないのも、Phenomが爆熱なのも、
>みんな32バイト/clkのInst. fetchのせいだそうです。
現行のItanium 2のクロックが1.6GHzなのはFoxtonが失敗したせい。本来はTDP100Wで2GHzを超える予定だった。
デバッグも人員減らしでまともにされなかったね。その代わりに今のXeonの隆盛があるのだが。
2GHzでもクロックが低いということならそれは大容量かつ低レイテンシなL3キャッシュや短いパイプラインも関係しているのでは?
>Itanium 2のクロックが上げられないのも、Phenomが爆熱なのも、
>みんな32バイト/clkのInst. fetchのせいだそうです。
現行のItanium 2のクロックが1.6GHzなのはFoxtonが失敗したせい。本来はTDP100Wで2GHzを超える予定だった。
デバッグも人員減らしでまともにされなかったね。その代わりに今のXeonの隆盛があるのだが。
2GHzでもクロックが低いということならそれは大容量かつ低レイテンシなL3キャッシュや短いパイプラインも関係しているのでは?
660 :,,・´∀`・,,)っ-○◎●:2009/01/29(木) 17:47:47
現実世界に存在してもいない「ぼくの考えた理想のエンコソフト」をもって
HTは遅くなるとか馬鹿なの?死ぬの?
Intel CPUにいち早く対応することを売りにしてるTMPEGEncですらアレですよ。
HTは遅くなるとか馬鹿なの?死ぬの?
Intel CPUにいち早く対応することを売りにしてるTMPEGEncですらアレですよ。
661 :デフォルトの名無しさん:2009/01/30(金) 01:29:45
662 :デフォルトの名無しさん:2009/01/30(金) 20:55:57
なんでAMDのCPUは熱いの?
昔も熱かったから、K8で一時期ちょっと熱くなかったのが例外なのかも。
昔も熱かったから、K8で一時期ちょっと熱くなかったのが例外なのかも。
663 :,,・´∀`・,,)っ-○◎●:2009/01/31(土) 00:26:04
AMDってL1ヒット時のピーク性能を極端に重視する傾向があるよね。
一方Intelは昔からL2の構成にこだわりがあるようで。
一方Intelは昔からL2の構成にこだわりがあるようで。
664 :デフォルトの名無しさん:2009/01/31(土) 00:47:45
ベンチマーク対策じゃね?
665 :デフォルトの名無しさん:2009/01/31(土) 01:47:28
>>663
ターゲットの違い
Intel → サーバーまでカバーしなきゃいけないので、大きなワーキングセットでの性能確保を重視
AMD → パソコンでの性能重視
ということかと。
パソコンのユーザに喜ばれるのは、当然、AMDのほうになるよね。
ターゲットの違い
Intel → サーバーまでカバーしなきゃいけないので、大きなワーキングセットでの性能確保を重視
AMD → パソコンでの性能重視
ということかと。
パソコンのユーザに喜ばれるのは、当然、AMDのほうになるよね。
666 :,,・´∀`・,,)っ-○◎●:2009/01/31(土) 01:51:09
いま別に喜ばれてないけど。
逆にAMDのほうがサーバでしか生きられてなくね?
極端に一部の性能を重視して熱密度が上がってしまい、逆に平均性能を上げられないというジレンマは
IntelがPentium 4で、AMDは現役で経験している通り。
逆にAMDのほうがサーバでしか生きられてなくね?
極端に一部の性能を重視して熱密度が上がってしまい、逆に平均性能を上げられないというジレンマは
IntelがPentium 4で、AMDは現役で経験している通り。
667 :デフォルトの名無しさん:2009/01/31(土) 01:59:24
668 :,,・´∀`・,,)っ-○◎●:2009/01/31(土) 02:12:09
AMDは今後2年間はデスクトップCPU市場見捨ててOpteronのコア数増やす方向らしいよ。
669 :デフォルトの名無しさん:2009/01/31(土) 02:18:48
Nehalemにほぼダブルスコアで負けてるんだからコア数だけで追随しても無駄な努力
それに基本はコア数競争 = 微細化競争のバーベットゲームだし
AMDはトチ狂ったとしか思えない
最近の不況もあいまってVIAよりヤバイ状況
それに基本はコア数競争 = 微細化競争のバーベットゲームだし
AMDはトチ狂ったとしか思えない
最近の不況もあいまってVIAよりヤバイ状況
670 :デフォルトの名無しさん:2009/01/31(土) 02:40:22
671 :,,・´∀`・,,)っ-○◎●:2009/01/31(土) 03:01:31
「PhenomではSSEのために命令フェッチ帯域を2倍に増やした」(AMD談)
これはこれで方針としては正しくて、AMDの場合はロードユニット2つだから
メモリ間オペレーションを同時発行する機会を増やしたほうが性能は引き出せる。
で、メモリ間オペレーションはSIB, DISP32, imm8などをフルに使えば命令長が長くなるから、
安定供給するにはフェッチ帯域を増やさないといけない。
メリット(性能)とデメリット(熱密度・消費電力)のバランスを考えてIntelは先送りしたようだ。
AMDと違ってロードユニットの本数が少ないからそっち方面に振るメリットも相対的に小さいし。
Intelは256ビットSIMD(AVX)導入で実質的な命令サイズを節約する方向に向かってる。
AMDにとっては、SSEを使う多くのアプリケーションがIntel CPU向けに最適化される現状では
どうにもならない。それで、シェア50%を狙えるだけの生産ラインを確保なんていう、
現状を省みないプランを打ち出すにいたってると(笑)
景気が冷え込んで規模縮小しないとやっていけないご時世に
Intelにマーケティング上「勝てる」アーキテクチャと、製造キャパの両方を
求めないといけないなんて大変だな。
これはこれで方針としては正しくて、AMDの場合はロードユニット2つだから
メモリ間オペレーションを同時発行する機会を増やしたほうが性能は引き出せる。
で、メモリ間オペレーションはSIB, DISP32, imm8などをフルに使えば命令長が長くなるから、
安定供給するにはフェッチ帯域を増やさないといけない。
メリット(性能)とデメリット(熱密度・消費電力)のバランスを考えてIntelは先送りしたようだ。
AMDと違ってロードユニットの本数が少ないからそっち方面に振るメリットも相対的に小さいし。
Intelは256ビットSIMD(AVX)導入で実質的な命令サイズを節約する方向に向かってる。
AMDにとっては、SSEを使う多くのアプリケーションがIntel CPU向けに最適化される現状では
どうにもならない。それで、シェア50%を狙えるだけの生産ラインを確保なんていう、
現状を省みないプランを打ち出すにいたってると(笑)
景気が冷え込んで規模縮小しないとやっていけないご時世に
Intelにマーケティング上「勝てる」アーキテクチャと、製造キャパの両方を
求めないといけないなんて大変だな。
672 :デフォルトの名無しさん:2009/01/31(土) 03:17:28
>>671
> シェア50%を狙えるだけの生産ラインを確保
これ自体は間違っていなかった(過去形)
ただその後IntelがCoreMAを発売、それを上回る性能のCPUをAMDが用意していなかったことが敗北の要因だ
それから以降はもうグダグダでしかない
> シェア50%を狙えるだけの生産ラインを確保
これ自体は間違っていなかった(過去形)
ただその後IntelがCoreMAを発売、それを上回る性能のCPUをAMDが用意していなかったことが敗北の要因だ
それから以降はもうグダグダでしかない
673 :,,・´∀`・,,)っ-○◎●:2009/01/31(土) 03:18:06
Nehalemでは、32μOPsだっけ?長い命令を使っても命令フェッチ帯域制限を掻い潜れる
ループバッファのエントリ数は。
これ結構きついんだよなぁ
ループバッファのエントリ数は。
これ結構きついんだよなぁ
674 :デフォルトの名無しさん:2009/01/31(土) 04:19:30
>>668
どうやってコアを増やすのだろう。
ダイサイズが巨大になって歩留まりが・・・サーバ向けなら歩留まりが低くても大丈夫なのかな。
まさか、自らがマーケティングのために叩いた、複数ダイのMCMは・・・恥ずかしくて出来ないよな。
いや、恥ずかしいのはAMD厨だけで、ビジネスに徹するAMDは平然とヤルか。
どうやってコアを増やすのだろう。
ダイサイズが巨大になって歩留まりが・・・サーバ向けなら歩留まりが低くても大丈夫なのかな。
まさか、自らがマーケティングのために叩いた、複数ダイのMCMは・・・恥ずかしくて出来ないよな。
いや、恥ずかしいのはAMD厨だけで、ビジネスに徹するAMDは平然とヤルか。
675 :,,・´∀`・,,)っ-○◎●:2009/01/31(土) 05:17:28
AVXプログラミングリファレンス第5版出た
http://software.intel.com/file/10069
http://software.intel.com/file/10069
676 :デフォルトの名無しさん:2009/01/31(土) 07:53:52
>>674
モノリシック6コアなのでダイサイズは巨大化するようだな。
あとMCMの話は2年前から出ていた。
最近の発表によるとMCMでは12コアと8コアが予定されているらしい。
12コアはそのまま6*2として8コアは (6-2)*2 かな?
モノリシック6コアなのでダイサイズは巨大化するようだな。
あとMCMの話は2年前から出ていた。
最近の発表によるとMCMでは12コアと8コアが予定されているらしい。
12コアはそのまま6*2として8コアは (6-2)*2 かな?
677 :デフォルトの名無しさん:2009/01/31(土) 10:09:36
もう液浸の時代かぁ。10年前には想像さえできなかったな。
678 :デフォルトの名無しさん:2009/01/31(土) 16:19:15
GJだが直リンは遠慮しる
679 :デフォルトの名無しさん:2009/01/31(土) 22:10:32
そもそもK8のHTは、MCMのために存在すると言っても過言ではない。
IntelのFSBも、そうだがな。
IntelのFSBも、そうだがな。
680 :デフォルトの名無しさん:2009/02/01(日) 16:16:32
そんな主張は初めて聞いた
まあ確かにMulti-Agentが前提のFSBでBlackford(Woodcrest)みたいなPoint-to-Pointってのも不自然な気はしたが
どちらもChip-to-Chipの技術に過ぎないと思うが
あ、HyperTransportはバックプレーンとかにも使われているんだっけ
まあ確かにMulti-Agentが前提のFSBでBlackford(Woodcrest)みたいなPoint-to-Pointってのも不自然な気はしたが
どちらもChip-to-Chipの技術に過ぎないと思うが
あ、HyperTransportはバックプレーンとかにも使われているんだっけ
681 :,,・´∀`・,,)っ-○◎●:2009/03/13(金) 17:37:38
ageんか貴様ら!
682 :デフォルトの名無しさん:2009/03/15(日) 16:23:42
死ね
683 :デフォルトの名無しさん:2009/05/13(水) 05:33:40
落ちる
684 :デフォルトの名無しさん:2009/05/31(日) 20:04:44
VT-xやSVMにおけるGuest-Host間の切り替え時間ってどんくらい?
685 :デフォルトの名無しさん:2009/06/02(火) 11:23:55
>>684
vmrun-vmmcallでホストゲストを10往復させて計測してみました。
1往復あたり1000clkくらい@PhenomII
vmmcallのかわりにioインターセプトさせると、1080clkでした。
vmrun-vmmcallでホストゲストを10往復させて計測してみました。
1往復あたり1000clkくらい@PhenomII
vmmcallのかわりにioインターセプトさせると、1080clkでした。
686 :デフォルトの名無しさん:2009/06/02(火) 11:28:31
I/Oパターンによってはエミュレータの方が速そうだな
687 :,,・´∀`・,,)っ-○○○:2009/06/02(火) 20:34:34
ディスクフォーマットとかデフラグがアホみたいに速い
688 :デフォルトの名無しさん:2009/06/03(水) 11:23:52
その昔、メインメモリが1MBの時代にバンクメモリを10MBくらい使ったディスクのドライバを書いたことがある。
当時はdefragが標準ではなかったから、defrag相当も自作した。
HDDは持ってなかったから、できたバンクメモリディスクで開発していたわけだ。
そうして、電源を切るとバンクメモリは消えてなくなることを身を持って再確認した。
当時はdefragが標準ではなかったから、defrag相当も自作した。
HDDは持ってなかったから、できたバンクメモリディスクで開発していたわけだ。
そうして、電源を切るとバンクメモリは消えてなくなることを身を持って再確認した。
689 :1 ◆.MeromIYCE :2009/06/10(水) 18:55:25
波のシミュレーションを書いたんだけど、
SSE2のコードがC言語比で1.2倍くらいしか速くならず、おかしいと思ったら、
扱うメモリがL2キャッシュを少しはみ出していた。
L2に収まるサイズでやり直したら、一気に3倍近い差になった。
L2に収まらない場合は、プリフェッチやmovnt系など、
まずメモリ関係をやらないと話にならないんだな。
知ってたけど久しぶりだから忘れてた。
SSE2のコードがC言語比で1.2倍くらいしか速くならず、おかしいと思ったら、
扱うメモリがL2キャッシュを少しはみ出していた。
L2に収まるサイズでやり直したら、一気に3倍近い差になった。
L2に収まらない場合は、プリフェッチやmovnt系など、
まずメモリ関係をやらないと話にならないんだな。
知ってたけど久しぶりだから忘れてた。
690 :デフォルトの名無しさん:2009/07/05(日) 22:13:17
>>688
>当時はdefragが標準ではなかったから、defrag相当も自作した。
>HDDは持ってなかったから、できたバンクメモリディスクで開発していたわけだ。
ををすごい、
どこがって?
>defrag相当も自作した。
>HDDは持ってなかったから
この部分に感動を覚えた
>当時はdefragが標準ではなかったから、defrag相当も自作した。
>HDDは持ってなかったから、できたバンクメモリディスクで開発していたわけだ。
ををすごい、
どこがって?
>defrag相当も自作した。
>HDDは持ってなかったから
この部分に感動を覚えた
691 :デフォルトの名無しさん:2009/07/07(火) 09:10:11
692 :デフォルトの名無しさん:2009/07/07(火) 15:34:31
フロッピーはインターリーブ考慮せんといかんな
693 :デフォルトの名無しさん:2009/08/10(月) 20:15:17
このスレ ノネナール臭が凄い……
694 :デフォルトの名無しさん:2009/08/10(月) 22:46:09
skip sector & skew
->
track read / write + cache
->
track read / write + cache
先人がMMXアセンブラで作った関数のパフォーマンス改善をしています。
一部SSE化したり、アルゴリズム改善でだいたい1/2くらいまで縮まったので
AMD CodeAnalyst(Ver2.76)を使ってチューニングをしようとしているのですが勘所がわかりません。
Pipeline simulationを見ると、ピンク赤枠(SCHED FPU Scheduler ineligible)が貯まっていき
パイプラインの幅が広がってしまいるようです。
一般的な目安として、どのような部分に注目してチューニングすれば良いでしょうか?
とりあえずは、Notesに書かれた「Bank conflict」や「Stlf 31:12」などの部分を何とかしようかと思っています。
一部SSE化したり、アルゴリズム改善でだいたい1/2くらいまで縮まったので
AMD CodeAnalyst(Ver2.76)を使ってチューニングをしようとしているのですが勘所がわかりません。
Pipeline simulationを見ると、ピンク赤枠(SCHED FPU Scheduler ineligible)が貯まっていき
パイプラインの幅が広がってしまいるようです。
一般的な目安として、どのような部分に注目してチューニングすれば良いでしょうか?
とりあえずは、Notesに書かれた「Bank conflict」や「Stlf 31:12」などの部分を何とかしようかと思っています。
696 :デフォルトの名無しさん:2009/09/30(水) 09:42:24
一旦Cで書き直してコンパイラに任せた方が早かったりしてね。
697 :,,・´∀`・,,)っ-○○○:2009/10/11(日) 02:52:16
整数でMMXの倍出れば充分だよ
開発機のAthron64x2での評価で1/2くらいになったと言っていたんですが
実機のCore2Duoで動かしたら、元のプログラムの実行速度が上がり
相対的に2割くらいしか改善されないという情けない結果になりました。
AthronとCore2Duoの差というより、L2キャッシュの容量が512Kと2Mの差なんだと思います。
その後SSEのみで書き直し、3割改善まで進んだところで今のところギブアップです。
CodeAnalystはAMDのCPUじゃないと動かないので、V-Tune評価版で
試してみる価値があるかどうかという所です。
実機のCore2Duoで動かしたら、元のプログラムの実行速度が上がり
相対的に2割くらいしか改善されないという情けない結果になりました。
AthronとCore2Duoの差というより、L2キャッシュの容量が512Kと2Mの差なんだと思います。
その後SSEのみで書き直し、3割改善まで進んだところで今のところギブアップです。
CodeAnalystはAMDのCPUじゃないと動かないので、V-Tune評価版で
試してみる価値があるかどうかという所です。
699 :,,・´∀`・,,)っ-○○○:2009/10/11(日) 04:07:48
紹介ありがとうございます
試してみますね
試してみますね
701 :デフォルトの名無しさん:2009/10/11(日) 04:30:29
AMD用にチューニングしたコードをIntelに持っていって
果してどのくらい意味があるのだろうか?
果してどのくらい意味があるのだろうか?
702 :デフォルトの名無しさん:2009/10/11(日) 09:35:15
Intel用に最適化したのをAMD機で動かすより意味あると思うけど・・・
703 :,,・´∀`・,,)っ-○○○:2009/10/11(日) 10:27:37
どっちもない。
Intelは乗算や水平加減算以外の整数命令はほぼレイテンシ1だが
AMDのはほぼ2だから全然特性が違う。
Intelは乗算や水平加減算以外の整数命令はほぼレイテンシ1だが
AMDのはほぼ2だから全然特性が違う。
704 :1 ◆.MeromIYCE :2009/10/11(日) 11:38:24
細かいこと考えて最適化しても、
結局L2に収まるか収まらないかで全てが決まってしまう現実。
面倒だが、L2サイズを基準に処理を分割できれば
かなりのオーバーヘッドがあっても元は取れるはず。
結局L2に収まるか収まらないかで全てが決まってしまう現実。
面倒だが、L2サイズを基準に処理を分割できれば
かなりのオーバーヘッドがあっても元は取れるはず。
705 :デフォルトの名無しさん:2009/11/17(火) 08:17:58
Optimization Reference Manualの間違いなのか事実なのか知らないけど、
なんで一部のプロセッサでandpsがスループット1でとpandが0.33なんだろう。
単精度用にandpsでmmx上がりの整数用にpandってのは
命令フォーマット上は確かに一貫していて扱いやすいんだろうけれど、
たかだかビット演算で速度に違いが出てくるくらいならオペコードを複数用意しちゃいかんと思うのだが。
試してないけどコンパイラオプションでSSE2以上を指定したら
問答無用で_mm_and_ps()をpandにするくらいの責任を取って欲しい。
なんで一部のプロセッサでandpsがスループット1でとpandが0.33なんだろう。
単精度用にandpsでmmx上がりの整数用にpandってのは
命令フォーマット上は確かに一貫していて扱いやすいんだろうけれど、
たかだかビット演算で速度に違いが出てくるくらいならオペコードを複数用意しちゃいかんと思うのだが。
試してないけどコンパイラオプションでSSE2以上を指定したら
問答無用で_mm_and_ps()をpandにするくらいの責任を取って欲しい。
706 :デフォルトの名無しさん:2009/11/17(火) 10:08:49
XMMを使用するので同じ命令に見えるかもしれないが
CPU内部では整数ドメインとFPドメインに分かれていて
それぞれに作用する命令なんだ
異なるドメイン間でデータのやり取りが発生すると
ペナルティーを受けるから、命令は扱うデータに
合わせるべきだね
CPU内部では整数ドメインとFPドメインに分かれていて
それぞれに作用する命令なんだ
異なるドメイン間でデータのやり取りが発生すると
ペナルティーを受けるから、命令は扱うデータに
合わせるべきだね
707 :,,・´∀`・,,)っ-○○○:2009/11/18(水) 00:06:35
ちなみにSandy Bridgeでは{and,andn,or,xor}psを発行出来る演算ユニットだけが256ビット化される。
ビット論理演算のスループットはNehalemの1.33倍!
そして、Macro Ops Fusionが熱い!ヤバイ!間違いない!
dec + jccとか and + jccも融合可っだ。ハゲっが。
ビット論理演算のスループットはNehalemの1.33倍!
そして、Macro Ops Fusionが熱い!ヤバイ!間違いない!
dec + jccとか and + jccも融合可っだ。ハゲっが。
708 :,,・´∀`・,,)っ-○○○:2009/11/18(水) 00:39:12
正確には3オペランドになるぶんMOV*が削減できるので
1.5倍以上かも
1.5倍以上かも
709 :デフォルトの名無しさん:2010/01/22(金) 10:53:07
295 名前:Socket774[sage] 投稿日:2010/01/22(金) 09:34:39 ID:afQeCPeg
Some instruction latency numbers of Bulldozer?
http://citavia.blog.de/2010/01/21/some-instruction-latency-numbers-of-bulldozer-7850137/
命令レイテンシも出てるみたいだ
296 名前:Socket774[sage] 投稿日:2010/01/22(金) 10:16:42 ID:4TT5t9OB
ttp://svn.open64.net/filedetails.php?repname=Open64&path=%2Ftrunk%2Fosprey%2Fcommon%2Ftarg_info%2Fproc%2Fx8664%2Forochi_si.cxx&rev=2722
Any_Result_Available_Time()がレイテンシ
fp-load 2 -> 5
fadd/fmul 4 -> 6
fmadd 6
fdiv32 18 -> 27
fdiv64 20 -> 30
Some instruction latency numbers of Bulldozer?
http://citavia.blog.de/2010/01/21/some-instruction-latency-numbers-of-bulldozer-7850137/
命令レイテンシも出てるみたいだ
296 名前:Socket774[sage] 投稿日:2010/01/22(金) 10:16:42 ID:4TT5t9OB
ttp://svn.open64.net/filedetails.php?repname=Open64&path=%2Ftrunk%2Fosprey%2Fcommon%2Ftarg_info%2Fproc%2Fx8664%2Forochi_si.cxx&rev=2722
Any_Result_Available_Time()がレイテンシ
fp-load 2 -> 5
fadd/fmul 4 -> 6
fmadd 6
fdiv32 18 -> 27
fdiv64 20 -> 30
710 :デフォルトの名無しさん:2010/03/04(木) 12:42:56
最適化マニュアルに載ってないAESNIとかPCLMULのレイテンシ
DualCore Intel Core i5 650, 3600 MHz (26 x 138) (Clarkdale)
ttp://www.freeweb.hu/instlatx64/GenuineIntel0020652_Clarkdale_InstLatX64.txt
DualCore Intel Core i5 650, 3600 MHz (26 x 138) (Clarkdale)
ttp://www.freeweb.hu/instlatx64/GenuineIntel0020652_Clarkdale_InstLatX64.txt
711 :デフォルトの名無しさん:2010/03/14(日) 03:45:01
Pentium4のHyperThreadingは、
片方のコンテキストのメモリアクセスでパイプラインが止まると、
もう片方のコンテキストまで止まってしまうって本当?
そして、AtomやNehalem以降の同名の別モノでは、どうなの?
片方のコンテキストのメモリアクセスでパイプラインが止まると、
もう片方のコンテキストまで止まってしまうって本当?
そして、AtomやNehalem以降の同名の別モノでは、どうなの?
712 :デフォルトの名無しさん:2010/03/14(日) 20:25:07
聞いた所で聞けよ
713 :デフォルトの名無しさん:2010/03/14(日) 21:33:46
HyperThreadingはまやかし
714 :デフォルトの名無しさん:2010/03/14(日) 21:42:27
Pentium4の偏見で凝り固まった人は案外と多い
HyperThreadingと聞いただけでイラネーヨという
Pentium4がK7 Athlonよりも省電力とかいうと
キチガイを見る目で聞く耳を持たない人とかも
HyperThreadingと聞いただけでイラネーヨという
Pentium4がK7 Athlonよりも省電力とかいうと
キチガイを見る目で聞く耳を持たない人とかも
715 :デフォルトの名無しさん:2010/03/14(日) 23:14:53
国母のアンチみたいなもん
716 :デフォルトの名無しさん:2010/03/14(日) 23:21:11
>>714
俺もその口だが、HyperThreadingっていくつかの条件がついた状況でしか使えないから
結局動画のエンコードぐらいしか役に立たないと思ってる。
また、XPも対応が不十分だったりしたと思ったが最近はそうでもないのか?
XPに固執するほど結果は出ないみたいな。
俺もその口だが、HyperThreadingっていくつかの条件がついた状況でしか使えないから
結局動画のエンコードぐらいしか役に立たないと思ってる。
また、XPも対応が不十分だったりしたと思ったが最近はそうでもないのか?
XPに固執するほど結果は出ないみたいな。
717 :デフォルトの名無しさん:2010/03/14(日) 23:22:52
なんで欲張ってSMTなんかやるんだろ
Itanium2のようにCGMTでいいじゃんか
Itanium2のようにCGMTでいいじゃんか
718 :デフォルトの名無しさん:2010/03/14(日) 23:24:21
実装に必要なハードウェアリソースはごくわずかだから
719 :デフォルトの名無しさん:2010/03/14(日) 23:26:26
HyperThreadingが狙いとしていたのは動画のエンコードのように、
パイプラインにファイン・チューニングできる(された)コードではなく、
パイプラインがスカスカになるような駄コードを2つまとめて流せば、
実行ユニットが遊ばずに有効活用できて性能が上がりますよ
ということだったと思う
パイプラインにファイン・チューニングできる(された)コードではなく、
パイプラインがスカスカになるような駄コードを2つまとめて流せば、
実行ユニットが遊ばずに有効活用できて性能が上がりますよ
ということだったと思う
720 :デフォルトの名無しさん:2010/03/15(月) 00:10:30
>>719
そんなコンパイラはどこにあるのだ。
ああ、gcc, bcc, java辺りか?
ADDが倍速だったりその他諸々、チューニングされていないようなプログラムが使う命令はスカスカになりにくいと思うんだが。
そんなコンパイラはどこにあるのだ。
ああ、gcc, bcc, java辺りか?
ADDが倍速だったりその他諸々、チューニングされていないようなプログラムが使う命令はスカスカになりにくいと思うんだが。
721 :デフォルトの名無しさん:2010/03/15(月) 00:31:05
Pentium4はOOO性能が低いっぽくて、命令の並び順を変えると速度が変ったりするんで、普通のコードはスカスカになるんじゃないかと。
722 :デフォルトの名無しさん:2010/03/15(月) 14:29:20
>>711
初期のPentium4 with HTでは、(PentiumProと同じで)
L1Dキャッシュミスを4つまでしか保持できないので、
片方のスレッドで5つのキャッシュミスを起こすとロードユニットが完全停止して、
もう片方のスレッドも実質止まってしまうという事はあると思う。
その後のCPUではキャッシュミス保持数が倍増されている。
初期のPentium4 with HTでは、(PentiumProと同じで)
L1Dキャッシュミスを4つまでしか保持できないので、
片方のスレッドで5つのキャッシュミスを起こすとロードユニットが完全停止して、
もう片方のスレッドも実質止まってしまうという事はあると思う。
その後のCPUではキャッシュミス保持数が倍増されている。
723 :,,・´∀`・,,)っ-○○○:2010/03/16(火) 12:58:55
NetBurstの設計者が自ら言ってるようにL1Dの容量が絶対的に少ないだろう
724 :デフォルトの名無しさん:2010/03/16(火) 15:02:19
ttp://ja.wikipedia.org/wiki/%E3%83%AA%E3%83%97%E3%83%AC%E3%82%A4%E3%82%B7%E3%82%B9%E3%83%86%E3%83%A0
L1D$ミスすると両方のコンテキストがストールする
L1D$ミスすると両方のコンテキストがストールする
725 :デフォルトの名無しさん:2010/03/16(火) 15:05:43
キャッシュミスで全部とまっちゃぁ、DRAMのレイテンシの隠蔽にはならないなぁ。
もしキャッシュミスで止まらなければ、DRAMのレイテンシは数百クロック分にもなるわけで、1000命令くらい実行できる。
で、AtomやCore iはどうなんでしょう?
もしキャッシュミスで止まらなければ、DRAMのレイテンシは数百クロック分にもなるわけで、1000命令くらい実行できる。
で、AtomやCore iはどうなんでしょう?
726 :デフォルトの名無しさん:2010/03/16(火) 19:02:58
メモコンをCPUに持ってきた
727 :デフォルトの名無しさん:2010/03/16(火) 22:10:52
ということは、それらのHTも相変わらずメモリのレイテンシを隠蔽できない、ってことか。
728 :デフォルトの名無しさん:2010/03/16(火) 23:09:23
なんで「ということは」でそういう結論になるのかさっぱり分からん。
729 :デフォルトの名無しさん:2010/03/16(火) 23:18:22
アム虫だから
730 :デフォルトの名無しさん:2010/03/16(火) 23:20:29
だからお前らFB-DIMMが流行るまで我慢しろって
731 :デフォルトの名無しさん:2010/03/16(火) 23:24:52
レイテンシ激増じゃねえか
732 :デフォルトの名無しさん:2010/03/16(火) 23:33:50
わかってねえなあ
FB-DIMMはクロック数や容量を上げるのが簡単なんだよ
FB-DIMMはクロック数や容量を上げるのが簡単なんだよ
733 :デフォルトの名無しさん:2010/03/16(火) 23:36:25
レイテンシーが増えるという指摘にそういう的外れな返答しかできない辺り
「わかってねえなあ」
「わかってねえなあ」
734 :デフォルトの名無しさん:2010/03/16(火) 23:39:24
消費電力と温度を上げるのも簡単
735 :デフォルトの名無しさん:2010/03/16(火) 23:41:44
Pen4の悪夢再び?
736 :デフォルトの名無しさん:2010/03/16(火) 23:43:33
FB-DIMMは終わったから悪夢はもう来ない
737 :デフォルトの名無しさん:2010/03/16(火) 23:46:19
まだ終わってないけど一般人には関係ない
738 :デフォルトの名無しさん:2010/03/16(火) 23:47:05
レイテンシが増えてもFSBを上げればいいじゃない
739 :デフォルトの名無しさん:2010/03/16(火) 23:47:53
740 :デフォルトの名無しさん:2010/03/16(火) 23:49:09
>>738
そんなもんもう無い
そんなもんもう無い
741 :デフォルトの名無しさん:2010/03/17(水) 00:09:33
FB-DIMMはレイテンシは大きいけどランダムアクセスでのバンド幅が大きいんじゃなかったっけ?
普通のDDR2やDDR3は、ちょっとした並列処理はしてくれるけれども、
メモリコントローラとDRAMがピッタリ歩調を合わせて動作しないといけないので、
DIMMを何枚積んでも、容量方向の拡張でしかなかった。
しかしFB-DIMMは、パケットベースでインテリジェントに動作するので、
DIMMを詰めば積むほど、並行してアクセスできるメモリが増えて行く。
また、ライトバックが許される書き込みをキューに入れて後回しにして、
早くデータを返すべき読み込みを先に行うとかも、やれるとか。
それで、
SunのNiagara2っていう1チップで8スレッドSMT×8コアで64スレッドも同時に走るCPUは、
FB-DIMMを大量に積むことでパフォーマンスを確保しているとか。
普通のDDR2やDDR3は、ちょっとした並列処理はしてくれるけれども、
メモリコントローラとDRAMがピッタリ歩調を合わせて動作しないといけないので、
DIMMを何枚積んでも、容量方向の拡張でしかなかった。
しかしFB-DIMMは、パケットベースでインテリジェントに動作するので、
DIMMを詰めば積むほど、並行してアクセスできるメモリが増えて行く。
また、ライトバックが許される書き込みをキューに入れて後回しにして、
早くデータを返すべき読み込みを先に行うとかも、やれるとか。
それで、
SunのNiagara2っていう1チップで8スレッドSMT×8コアで64スレッドも同時に走るCPUは、
FB-DIMMを大量に積むことでパフォーマンスを確保しているとか。
742 :デフォルトの名無しさん:2010/03/17(水) 00:21:21
>>741
そうだよよくわかってるじゃないか
問題はDIMMがあまりにも流行りすぎてFB-DIMMが高価なままって
所にあるんだ
もちろんバッファリングするのでレイテンシは増えるが、動作は安定化
するので電気的にいろいろ無理させやすい
そうだよよくわかってるじゃないか
問題はDIMMがあまりにも流行りすぎてFB-DIMMが高価なままって
所にあるんだ
もちろんバッファリングするのでレイテンシは増えるが、動作は安定化
するので電気的にいろいろ無理させやすい
743 :デフォルトの名無しさん:2010/03/17(水) 00:25:26
自演してデタラメをまき散らすのってどうなんだろう。
744 :デフォルトの名無しさん:2010/03/17(水) 00:25:59
自演じゃねーよ
運営に頼んでホスト教えてもらえ
運営に頼んでホスト教えてもらえ
745 :デフォルトの名無しさん:2010/03/17(水) 00:27:15
あ、ageになってた
sageに変えた
上がってると書きこみが余計糞に見えやすいしな
sageに変えた
上がってると書きこみが余計糞に見えやすいしな
746 :デフォルトの名無しさん:2010/03/17(水) 00:54:30
747 :デフォルトの名無しさん:2010/03/17(水) 01:53:00
しかしアレだよな
Core2もi7もL2キャッシュにバカでかいメモリを積んでようやく性能を
確保している事を考えると、メインメモリのレイテンシって本当に動作
速度の足を引っ張っているんだな
Core2もi7もL2キャッシュにバカでかいメモリを積んでようやく性能を
確保している事を考えると、メインメモリのレイテンシって本当に動作
速度の足を引っ張っているんだな
748 :,,・´∀`・,,)っ-○○○:2010/03/17(水) 03:14:59
演算ユニット当たりのバンド幅考えるとGPUのほうが状況は酷いけどね
749 :デフォルトの名無しさん:2010/03/17(水) 03:25:31
たとえば3%のキャッシュミスを減らそうとしたら大変よ。
繰り返し実行されるような部分ではない部分がキャッシュミスしやすく、
そういうところは予測が付きにくく十分早期にプリフェッチかけるのも困難。
だから、CGMTで。
繰り返し実行されるような部分ではない部分がキャッシュミスしやすく、
そういうところは予測が付きにくく十分早期にプリフェッチかけるのも困難。
だから、CGMTで。
750 :,,・´∀`・,,)っ-○○○:2010/03/17(水) 03:29:40
>>917
コード希望
コード希望
751 :デフォルトの名無しさん:2010/03/17(水) 04:07:32
wrong pathキタ━━━━━━(゚∀゚)━━━━━━ッ!!!
752 :,,・´∀`・,,)っ-○○○:2010/03/17(水) 23:55:23
x86のようなレジスタ本数が少なく依存関係のチェインを抱えがちな命令セットには
SMTはかなり有効なんだけどな。
IPFがSMTではなくCGMTを採用してるのはは、コンパイル時に依存関係が明示されてるから
リソース競合は起こりえない(けどキャッシュミスは起こる)ってVLIWらしい発想だと思うけどなー。
SMTはかなり有効なんだけどな。
IPFがSMTではなくCGMTを採用してるのはは、コンパイル時に依存関係が明示されてるから
リソース競合は起こりえない(けどキャッシュミスは起こる)ってVLIWらしい発想だと思うけどなー。
753 :デフォルトの名無しさん:2010/03/18(木) 00:36:32
SMTやるかわりにOOOやらない → あとむ
SMTやるくらいなら実行ユニット減らしてコア増やす → ぶるどーざー
なんだかx86でSMTは贅沢な気がする
IPFがCGMTなのは、シングルスレッド性能追求のアーキテクチャだからだと思う。
マルチスレッドでスループットが出ればいいっていうのなら、投機実行とかゴッソリいらないし。
SMTやるくらいなら実行ユニット減らしてコア増やす → ぶるどーざー
なんだかx86でSMTは贅沢な気がする
IPFがCGMTなのは、シングルスレッド性能追求のアーキテクチャだからだと思う。
マルチスレッドでスループットが出ればいいっていうのなら、投機実行とかゴッソリいらないし。
754 :,,・´∀`・,,)っ-○○○:2010/03/18(木) 02:23:02
BulldozerのIntegerクラスタはスレッド毎に持ってるからSMTとは言えないけど
FPクラスタは共有だから部分的にはSMTそのものだろ
FPクラスタは共有だから部分的にはSMTそのものだろ
755 :デフォルトの名無しさん:2010/03/18(木) 02:29:59
そうだね。
IPFはシングルスレッド性能追求という、時代の流れに反するアーキテクチャだが、どーするんだろ。
実際、IPFのシングルスレッド性能っていうのは、どれくらいx86よりも速いんだ?
IPFはシングルスレッド性能追求という、時代の流れに反するアーキテクチャだが、どーするんだろ。
実際、IPFのシングルスレッド性能っていうのは、どれくらいx86よりも速いんだ?
756 :,,・´∀`・,,)っ-○○○:2010/03/18(木) 02:36:09
ベストケースで6オペレーション同時発行だから、はまればクロック当たりでx86を越えるけど
3GHzのCore i7の方が速いという現実。
速さは売りにしちゃ駄目。
あとは信頼性(笑)か。
うに死すは取るに足らない物としてItanium引き上げてXeon MPに枕替えしたけどね。
HP-UX使いたい人向けのプラットフォームだね。
3GHzのCore i7の方が速いという現実。
速さは売りにしちゃ駄目。
あとは信頼性(笑)か。
うに死すは取るに足らない物としてItanium引き上げてXeon MPに枕替えしたけどね。
HP-UX使いたい人向けのプラットフォームだね。
757 :デフォルトの名無しさん:2010/03/18(木) 02:58:03
信頼性つっても後づけじゃね?
アーキテクチャ的に信頼性を高めているわけではないよね。
どうせ後づけならXeon・・・は複雑すぎてどーにもならんか。
アーキテクチャ的に信頼性を高めているわけではないよね。
どうせ後づけならXeon・・・は複雑すぎてどーにもならんか。
758 :,,・´∀`・,,)っ-○○○:2010/03/18(木) 03:03:33
一応IPFはチップレベルで多数決冗長系が組める
759 :デフォルトの名無しさん:2010/03/18(木) 03:10:55
IPFに興味があるならWindowsのWDK(旧名、DDK)に入ってるIA64用のコンパイラで
/FAcsオプション付けてコンパイルして出力される.CODを除いてみると、面白いぞ
x86環境でのクロスコンパイラだから実機なくても動くから
nopが挿入されまくりだから
/FAcsオプション付けてコンパイルして出力される.CODを除いてみると、面白いぞ
x86環境でのクロスコンパイラだから実機なくても動くから
nopが挿入されまくりだから
760 :デフォルトの名無しさん:2010/03/18(木) 03:12:17
761 :,,・´∀`・,,)っ-○○○:2010/03/18(木) 03:27:08
前提となるメモリコヒーレントモデルが異なる(従来x86では不向き)ので
仮にできても既存のx86資産捨ててまでやる意味がどこまであるかと言う謎
(その点例の試作品48コアのSCCではある意味禁忌をおかしてるわけだが)
仮にできても既存のx86資産捨ててまでやる意味がどこまであるかと言う謎
(その点例の試作品48コアのSCCではある意味禁忌をおかしてるわけだが)
762 :デフォルトの名無しさん:2010/03/18(木) 04:01:24
むー、それなりに理由があるのか。
あんまり普遍的ではないコードで申し訳ないが↓をコンパイルしてみた
bool IsStringAllXdigit(const char* pBuf, int len) {
if (0 < len) {
for (int i=0; i<len; i++) {
if (isxdigit(pBuf[i])) {
// ok
} else {
return false ;
}
}
} else {
return false ;
}
// ここに到達するときには全ての文字が isxdigit で true ;
return true ;
}
最適化は/O2で、
x86 → 30命令
IA64 → 10バンドル(=30命令)だがnopを5つ含む
nopが入っても命令数は同じだし、5/30で入りまくりというのも過敏なような
あんまり普遍的ではないコードで申し訳ないが↓をコンパイルしてみた
bool IsStringAllXdigit(const char* pBuf, int len) {
if (0 < len) {
for (int i=0; i<len; i++) {
if (isxdigit(pBuf[i])) {
// ok
} else {
return false ;
}
}
} else {
return false ;
}
// ここに到達するときには全ての文字が isxdigit で true ;
return true ;
}
最適化は/O2で、
x86 → 30命令
IA64 → 10バンドル(=30命令)だがnopを5つ含む
nopが入っても命令数は同じだし、5/30で入りまくりというのも過敏なような
763 :デフォルトの名無しさん:2010/03/19(金) 02:00:53
ユーザーモードの互換性は確保するけど
特権モードの互換性は取らない
っていうのもアリじゃない?
ページ単位にコアが占有していればアクセスできるけど、
占有してなければページフォルト発生して特権モードで処理するとかすれば。
特権モードの互換性は取らない
っていうのもアリじゃない?
ページ単位にコアが占有していればアクセスできるけど、
占有してなければページフォルト発生して特権モードで処理するとかすれば。
764 :デフォルトの名無しさん:2010/03/20(土) 02:43:36
各種CPUのパイプラインをシミュレーションするツールが欲しくなるなぁ
765 :デフォルトの名無しさん:2010/03/23(火) 03:38:22
TLBキャッシュミスやレジスタウィンドウのオーバーフローをトラップで処理しているCPUがあったが、遅かったぞー
766 :デフォルトの名無しさん:2010/04/01(木) 06:56:11
Corei7の動作クロックを取得する方法ってないんですか?
rdtscを使ってクロック数を取得して、実行時間を掛けても、
設定クロックにしかなりません。
TurboBoostがかかっているかどうか知りたいのですが・・・。
rdtscを使ってクロック数を取得して、実行時間を掛けても、
設定クロックにしかなりません。
TurboBoostがかかっているかどうか知りたいのですが・・・。
767 :デフォルトの名無しさん:2010/04/01(木) 08:28:44
768 :デフォルトの名無しさん:2010/04/02(金) 03:39:48
>>767
ありがとうございます。
msrの値を読まなければいけないので、特権モードでないとだめですね。
msr-toolsのソースを眺めていたら、
sprintf(msr_file_name, "/dev/cpu/%d/msr", cpu);
fd = open(msr_file_name, O_RDONLY);
pread(fd, &data, sizeof data, reg);
こんな感じで値を読んでいたので、
多少遅延がありそうですが、何とか出来そうです。
ありがとうございます。
msrの値を読まなければいけないので、特権モードでないとだめですね。
msr-toolsのソースを眺めていたら、
sprintf(msr_file_name, "/dev/cpu/%d/msr", cpu);
fd = open(msr_file_name, O_RDONLY);
pread(fd, &data, sizeof data, reg);
こんな感じで値を読んでいたので、
多少遅延がありそうですが、何とか出来そうです。
769 :デフォルトの名無しさん:2010/04/23(金) 08:29:45
perfってツールが便利そうなのでメモ。
Ubuntu Lucid (10.04)でperfを使うにはlinux-toolsを入れれば良い。Linux 2.6.32なので対応CPUはまだ少ない。
http://morihyphen.hp.infoseek.co.jp/txt/perf.html
http://shuns.sblo.jp/article/33050692.html
http://shuns.sblo.jp/article/33068050.html
http://blog.fenrus.org/?p=5
Ubuntu Lucid (10.04)でperfを使うにはlinux-toolsを入れれば良い。Linux 2.6.32なので対応CPUはまだ少ない。
http://morihyphen.hp.infoseek.co.jp/txt/perf.html
http://shuns.sblo.jp/article/33050692.html
http://shuns.sblo.jp/article/33068050.html
http://blog.fenrus.org/?p=5
770 :デフォルトの名無しさん:2010/08/26(木) 01:40:22
SandyBridgeでSIMDを256bit幅に拡張するというけど、
なぜ128bit幅のまま実行ユニットを倍加する、
という選択肢を取らなかったの?
・同時に実行する命令数が増える=そのハンドリングのための回路で消費電力アップ
・実行ユニットを倍にしても、現状のレイテンシ・スループットに合わせて書かれたコードでは実行ユニットが遊んでしまう
あたり?
なぜ128bit幅のまま実行ユニットを倍加する、
という選択肢を取らなかったの?
・同時に実行する命令数が増える=そのハンドリングのための回路で消費電力アップ
・実行ユニットを倍にしても、現状のレイテンシ・スループットに合わせて書かれたコードでは実行ユニットが遊んでしまう
あたり?
771 :デフォルトの名無しさん:2010/08/27(金) 12:03:26
>>770
大体そう
スケジューリングをはじめとしたコントロールのコストがデータフローに関わるコストを遙かに上回ってるから。
SIMDユニットそのものの幅を倍に増やす方式だと、データ幅が256ビットに増えても、
内部データバスを256ビットにするだけで、パイプライン構造はCore MAとほぼ同じでいける。
だから消費電力あたりのSIMD演算性能はほぼ倍になる。
128ビットの演算ユニットを倍に増やす方式だと演算ユニットを増やした分だけ制御ブロックが肥大化するので
電力効率的にも美味しくないと思われる。
大体そう
スケジューリングをはじめとしたコントロールのコストがデータフローに関わるコストを遙かに上回ってるから。
SIMDユニットそのものの幅を倍に増やす方式だと、データ幅が256ビットに増えても、
内部データバスを256ビットにするだけで、パイプライン構造はCore MAとほぼ同じでいける。
だから消費電力あたりのSIMD演算性能はほぼ倍になる。
128ビットの演算ユニットを倍に増やす方式だと演算ユニットを増やした分だけ制御ブロックが肥大化するので
電力効率的にも美味しくないと思われる。
772 :デフォルトの名無しさん:2010/08/28(土) 10:20:10
ありがとう
ちなみにAMDのBulldozerは実行ユニットを256bit幅にせず、128bit幅×2個の構成にしてる・・・どうなんでしょう。
ちなみにAMDのBulldozerは実行ユニットを256bit幅にせず、128bit幅×2個の構成にしてる・・・どうなんでしょう。
773 :デフォルトの名無しさん:2010/08/28(土) 16:08:35
もともとが128ビットSSE5を想定した設計で急遽256ビットAVX対応に作り替えたからでは。
まあ、FMAの実装ではAMDが先行してるし、ゆくゆくはAMDが256ビット化、IntelがFMA対応で
実質的な差が無くなるのではないかと。
まあ、FMAの実装ではAMDが先行してるし、ゆくゆくはAMDが256ビット化、IntelがFMA対応で
実質的な差が無くなるのではないかと。
774 :デフォルトの名無しさん:2010/08/29(日) 06:08:06
なるほど。
BulldozerのFPUは2つのコアで共有されるから、
128ビット×2個といっても、1コアあたりでは1個。
もし、256ビット×1個にすると、1コアあたりでは0.5個
既存の128ビットの命令を使ったコードの速度が遅いのだろう。
新命令の追加タイミングと、演算器の強化タイミングは、一緒とは限らず、
128ビットのSSE2命令が追加された当初は、64ビット×2回で処理してた
せっかく新命令を使って書いたのに速くならない・・・っていう不満があると、
AVXを使ってもらえないので、新命令と同時に演算器強化するのかな
ソフトの互換性という点では、新命令は速くなくていいから早めに実装してほしい
BulldozerのFPUは2つのコアで共有されるから、
128ビット×2個といっても、1コアあたりでは1個。
もし、256ビット×1個にすると、1コアあたりでは0.5個
既存の128ビットの命令を使ったコードの速度が遅いのだろう。
新命令の追加タイミングと、演算器の強化タイミングは、一緒とは限らず、
128ビットのSSE2命令が追加された当初は、64ビット×2回で処理してた
せっかく新命令を使って書いたのに速くならない・・・っていう不満があると、
AVXを使ってもらえないので、新命令と同時に演算器強化するのかな
ソフトの互換性という点では、新命令は速くなくていいから早めに実装してほしい
775 :1 ◆.MeromIYCE :2010/08/29(日) 09:11:19
128bitが256bitになると、論理レジスタが倍増したことになる。
だからその分は速くなると思うよ(並列実行できるという意味で)。
スループットが糞悪いPentiumMのSSE2浮動小数点も効果あったし。
だからその分は速くなると思うよ(並列実行できるという意味で)。
スループットが糞悪いPentiumMのSSE2浮動小数点も効果あったし。
776 :,,・´∀`・,,)っ-○○○:2010/08/31(火) 00:19:05
YMM上位だけを更新する命令とかあるなら32本のXMMレジスタとしても活用しようがあるんだけど
上ゼロクリアか、上下同じ操作か、しかない。
このへんはMMレジスタとXMMレジスタが独立してたのとちと扱いが違う
上ゼロクリアか、上下同じ操作か、しかない。
このへんはMMレジスタとXMMレジスタが独立してたのとちと扱いが違う
777 :デフォルトの名無しさん:2010/08/31(火) 03:30:24
全部レジスタに乗るような順番で計算するよりも、
L1D$との間で出し入れをしてでも、依存関係のある命令間の距離を長くしたほうが、
スループットが出たりするんだよねぇ。
L1D$との間で出し入れをしてでも、依存関係のある命令間の距離を長くしたほうが、
スループットが出たりするんだよねぇ。
778 :デフォルトの名無しさん:2010/08/31(火) 10:41:36
>>777
mov(load or reg2reg)命令でdestオペランドを上書きしながら反復処理をアンロールすれば
空いてる物理レジスタに自動的に割り振ってくれるから
ほどほどにやっておけばいいよ。
どのみち同時に読み出せるオペランド数に制限があるからそこで頭打ちになる。
まあ、AVXでdest独立になったのは美味しいな(ほぼ全部の命令がリネーミングのヒントになりうる)
mov(load or reg2reg)命令でdestオペランドを上書きしながら反復処理をアンロールすれば
空いてる物理レジスタに自動的に割り振ってくれるから
ほどほどにやっておけばいいよ。
どのみち同時に読み出せるオペランド数に制限があるからそこで頭打ちになる。
まあ、AVXでdest独立になったのは美味しいな(ほぼ全部の命令がリネーミングのヒントになりうる)
SSE4.1に対応したVIA CNB
http://www.freeweb.hu/instlatx64/CentaurHauls00006F8_CNB_Isaiah_InstLatX64.txt
Intel 最適化マニュアル AESNIとPCLMULQDQ追加
http://www.intel.com/Assets/PDF/manual/248966.pdf
http://www.freeweb.hu/instlatx64/CentaurHauls00006F8_CNB_Isaiah_InstLatX64.txt
Intel 最適化マニュアル AESNIとPCLMULQDQ追加
http://www.intel.com/Assets/PDF/manual/248966.pdf
780 :デフォルトの名無しさん:2010/09/11(土) 23:20:30
781 :デフォルトの名無しさん:2010/09/13(月) 09:37:39
L1D$のレイテンシが2→3→4と拡大してるんだが、どーにかならんの?
782 :デフォルトの名無しさん:2010/09/18(土) 14:28:35
AMDのCPUID Specificationが更新されました
http://support.amd.com/us/Processor_TechDocs/25481.pdf
BMI(Bit Manipulation Instruction)は未公開の新命令でしょうか?
http://support.amd.com/us/Processor_TechDocs/25481.pdf
BMI(Bit Manipulation Instruction)は未公開の新命令でしょうか?
783 :,,・´∀`・,,)っ-○○○:2010/11/03(水) 16:50:07
こんにちのOoOEなCPUにおいてL1キャッシュのレイテンシそのものは本質的な問題なのかね?
現代のCPUはL1ヒットを前提にスケジューリングされる。
アドレス解決さえ先行してできれば、どんどん空いた物理レジスタ(orメモリフォワーディングバッファ)
に先読みしておけるということ。
レイテンシが大きくなればなった分だけそのサイクル数ぶん先読みをしておく必要があるけどね。
Memory DisambiguationとかRAWハザードを回避するためのテクニックがどんどん採用されて
L1のレイテンシが性能に響くケースは少なくなりつつある。
L2以下は別。理由はまったく同じで、L1キャッシュヒットを前提にスケジューリングされてるから。
つまりL2キャッシュのロードレイテンシは隠蔽できない。
現代のCPUはL1ヒットを前提にスケジューリングされる。
アドレス解決さえ先行してできれば、どんどん空いた物理レジスタ(orメモリフォワーディングバッファ)
に先読みしておけるということ。
レイテンシが大きくなればなった分だけそのサイクル数ぶん先読みをしておく必要があるけどね。
Memory DisambiguationとかRAWハザードを回避するためのテクニックがどんどん採用されて
L1のレイテンシが性能に響くケースは少なくなりつつある。
L2以下は別。理由はまったく同じで、L1キャッシュヒットを前提にスケジューリングされてるから。
つまりL2キャッシュのロードレイテンシは隠蔽できない。
784 :デフォルトの名無しさん:2010/11/03(水) 21:24:27
お、団子さんひさしぶり
785 :デフォルトの名無しさん:2010/11/04(木) 14:47:31
団子さんはどうしてそんなに詳しいのだろうか・・・
786 :,,・´∀`・,,)っ-○○○:2010/11/07(日) 08:13:17
アドレス解決が先に行えないケースを反例としてだしておくれ。
暗号化のテーブルルックアップ処理を頻繁に行うものはパフォーマンス総崩れかもね
AESNIを使えということだろうが。
暗号化のテーブルルックアップ処理を頻繁に行うものはパフォーマンス総崩れかもね
AESNIを使えということだろうが。
787 :デフォルトの名無しさん:2010/11/08(月) 02:15:08
OOOは、
後続の命令で実行できるものをどんどん実行するのではなく、
先方にある命令で実行できるものをどんどん実行するの?
後続の命令で実行できるものをどんどん実行するのではなく、
先方にある命令で実行できるものをどんどん実行するの?
788 :デフォルトの名無しさん:2011/01/07(金) 08:06:53
http://www.freeweb.hu/instlatx64/GenuineIntel00206A7_SandyBridge_InstLatX64.txt
VI-MULがFP-MULに統合されたので、整数SIMD乗算のレイテンシが3から5になったようだ
http://pc.watch.impress.co.jp/img/pcw/docs/395/394/html/4.jpg.html
http://pc.watch.impress.co.jp/img/pcw/docs/395/394/html/5.jpg.html
VI-MULがFP-MULに統合されたので、整数SIMD乗算のレイテンシが3から5になったようだ
http://pc.watch.impress.co.jp/img/pcw/docs/395/394/html/4.jpg.html
{kind=link}
http://pc.watch.impress.co.jp/img/pcw/docs/395/394/html/5.jpg.html
{kind=link}
789 :デフォルトの名無しさん:2011/01/07(金) 11:15:31
最適化マニュアルにSandy Bridgeの情報が追加された
http://www.intel.com/Assets/PDF/manual/248966.pdf
http://www.intel.com/Assets/PDF/manual/248966.pdf
790 :,,・´∀`・,,)っ-○○○:2011/01/07(金) 14:27:08
SSE4が全面的に速くなってる。
AES-NIレイテンシが増えてる。
これによってCBC/CFBなどのブロック依存関係のある暗号化形式が遅くなるが十分速いのでさして問題ないか。
そしてスループット1になったことでECBが倍ほど速くなるわけだが・・・
AES-NIレイテンシが増えてる。
これによってCBC/CFBなどのブロック依存関係のある暗号化形式が遅くなるが十分速いのでさして問題ないか。
そしてスループット1になったことでECBが倍ほど速くなるわけだが・・・
leaがついに劣化してしまった
792 :デフォルトの名無しさん:2011/01/07(金) 17:43:48
Fast-LEA 1-cycle; [r+r], [r+r*n]
Slow-LEA 3-cycle; [r+r+disp], [r+r*n+disp]
[r+disp]はどっち?
ロードはoffsetの値でレイテンシが変わるみたいだけど
0〜2047なのかそれとも-2048〜2047なのか
Slow-LEA 3-cycle; [r+r+disp], [r+r*n+disp]
[r+disp]はどっち?
ロードはoffsetの値でレイテンシが変わるみたいだけど
0〜2047なのかそれとも-2048〜2047なのか
793 :デフォルトの名無しさん:2011/01/08(土) 02:14:31
794 :デフォルトの名無しさん:2011/01/08(土) 07:24:03
ttp://www.freeweb.hu/instlatx64/CentaurHauls00006F8_CNB_Isaiah_InstLatX64.txt
名ばかり実装かと思いきや、nanoは結構まじめにSSE4.1実装してるね
名ばかり実装かと思いきや、nanoは結構まじめにSSE4.1実装してるね
795 :デフォルトの名無しさん:2011/01/08(土) 07:27:29
ああ、nanoはメモリの書き込みは速いけど
読み込みが遅い
それが改善されれば、SSE関連ではもっとパフォーマンスあがるはずだ
Padlockはメモリアクセスで頭打ちになってる
読み込みが遅い
それが改善されれば、SSE関連ではもっとパフォーマンスあがるはずだ
Padlockはメモリアクセスで頭打ちになってる
796 :デフォルトの名無しさん:2011/01/08(土) 10:29:22
SSE4.1の速さをもてはやす理由が分からん。
例えばROUNDPSなんてIntelが手抜きでオペコード作ってなかっただけで、初代SSEに入っていておかしくない基本的な命令だろ。
ソフトウェアで書くとややこしく遅いが原理は簡単。むしろハードウェアで作って他の命令より大幅に遅くなる事なんて考えられん。
例えばROUNDPSなんてIntelが手抜きでオペコード作ってなかっただけで、初代SSEに入っていておかしくない基本的な命令だろ。
ソフトウェアで書くとややこしく遅いが原理は簡単。むしろハードウェアで作って他の命令より大幅に遅くなる事なんて考えられん。
797 :デフォルトの名無しさん:2011/01/08(土) 14:29:43
別にroundは速くなってないよ。元々スループット1だし。
例えばblendvはプレディケーションちっくな事をやる時に
and-andn-orとやってたのが1命令で済むので、
スループット1になったのは嬉しいと思うけどね。
例えばblendvはプレディケーションちっくな事をやる時に
and-andn-orとやってたのが1命令で済むので、
スループット1になったのは嬉しいと思うけどね。
798 :,,・´∀`・,,)っ-○○○:2011/01/08(土) 18:11:56
dppsが速いのは3Dでは結構重要。
なによりmpsadbw/pminposuwが速い。
なによりmpsadbw/pminposuwが速い。
799 :デフォルトの名無しさん:2011/01/08(土) 18:22:59
mpsadbw/pminposuwはスループット変わらず、
レイテンシの分遅くなっているように見えるけど
レイテンシの分遅くなっているように見えるけど
800 :,,・´∀`・,,)っ-○○○:2011/01/08(土) 18:36:02
ああNehalemの時点で速かったんだねこの命令
大きな変化はこのへんか。
Westmere
1197 SSE4.2:PCMPESTRI xmm, xmm, imm8 L: 1.88ns= 6.0c T: 1.88ns= 6.00c
1198 SSE4.2:PCMPESTRM xmm, xmm, imm8 L: 1.88ns= 6.0c T: 1.88ns= 6.00c
1199 SSE4.2:PCMPISTRI xmm, xmm, imm8 L: 0.63ns= 2.0c T: 0.63ns= 2.00c
1200 SSE4.2:PCMPISTRM xmm, xmm, imm8 L: 0.63ns= 2.0c T: 0.63ns= 2.00c
1201 CLMUL :PCLMULQDQ xmm, xmm, imm8 L: 4.71ns= 15.1c T: 3.13ns= 10.00c
1202 AESNI :AESENC xmm, xmm L: 1.88ns= 6.0c T: 0.63ns= 2.00c
1203 AESNI :AESENCLAST xmm, xmm L: 1.88ns= 6.0c T: 0.63ns= 2.00c
1204 AESNI :AESDEC xmm, xmm L: 1.88ns= 6.0c T: 0.63ns= 2.00c
1205 AESNI :AESDECLAST xmm, xmm L: 1.88ns= 6.0c T: 0.63ns= 2.00c
1206 AESNI :AESIMC xmm, xmm L: 1.88ns= 6.0c T: 0.63ns= 2.00c
1207 AESNI :AESKEYGEN xmm, xmm, imm8 L: 1.88ns= 6.0c T: 0.63ns= 2.00c
Sandy Bridge
1197 SSE4.2:PCMPESTRI xmm, xmm, imm8 L: 1.29ns= 4.0c T: 1.29ns= 4.00c
1198 SSE4.2:PCMPESTRM xmm, xmm, imm8 L: 1.29ns= 4.0c T: 1.29ns= 4.00c
1199 SSE4.2:PCMPISTRI xmm, xmm, imm8 L: 0.97ns= 3.0c T: 0.97ns= 3.00c
1200 SSE4.2:PCMPISTRM xmm, xmm, imm8 L: 0.97ns= 3.0c T: 0.97ns= 3.00c
1201 CLMUL :PCLMULQDQ xmm, xmm, imm8 L: 4.39ns= 13.6c T: 2.59ns= 8.00c
1202 AESNI :AESENC xmm, xmm L: 2.59ns= 8.0c T: 0.32ns= 1.00c
1203 AESNI :AESENCLAST xmm, xmm L: 2.59ns= 8.0c T: 0.32ns= 1.00c
1204 AESNI :AESDEC xmm, xmm L: 2.59ns= 8.0c T: 0.32ns= 1.00c
1205 AESNI :AESDECLAST xmm, xmm L: 2.59ns= 8.0c T: 0.32ns= 1.00c
1206 AESNI :AESIMC xmm, xmm L: 4.53ns= 14.0c T: 0.65ns= 2.00c
1207 AESNI :AESKEYGEN xmm, xmm, imm8 L: 3.23ns= 10.0c T: 2.59ns= 8.00c
速くなったり遅くなったりわけわかめ
大きな変化はこのへんか。
Westmere
1197 SSE4.2:PCMPESTRI xmm, xmm, imm8 L: 1.88ns= 6.0c T: 1.88ns= 6.00c
1198 SSE4.2:PCMPESTRM xmm, xmm, imm8 L: 1.88ns= 6.0c T: 1.88ns= 6.00c
1199 SSE4.2:PCMPISTRI xmm, xmm, imm8 L: 0.63ns= 2.0c T: 0.63ns= 2.00c
1200 SSE4.2:PCMPISTRM xmm, xmm, imm8 L: 0.63ns= 2.0c T: 0.63ns= 2.00c
1201 CLMUL :PCLMULQDQ xmm, xmm, imm8 L: 4.71ns= 15.1c T: 3.13ns= 10.00c
1202 AESNI :AESENC xmm, xmm L: 1.88ns= 6.0c T: 0.63ns= 2.00c
1203 AESNI :AESENCLAST xmm, xmm L: 1.88ns= 6.0c T: 0.63ns= 2.00c
1204 AESNI :AESDEC xmm, xmm L: 1.88ns= 6.0c T: 0.63ns= 2.00c
1205 AESNI :AESDECLAST xmm, xmm L: 1.88ns= 6.0c T: 0.63ns= 2.00c
1206 AESNI :AESIMC xmm, xmm L: 1.88ns= 6.0c T: 0.63ns= 2.00c
1207 AESNI :AESKEYGEN xmm, xmm, imm8 L: 1.88ns= 6.0c T: 0.63ns= 2.00c
Sandy Bridge
1197 SSE4.2:PCMPESTRI xmm, xmm, imm8 L: 1.29ns= 4.0c T: 1.29ns= 4.00c
1198 SSE4.2:PCMPESTRM xmm, xmm, imm8 L: 1.29ns= 4.0c T: 1.29ns= 4.00c
1199 SSE4.2:PCMPISTRI xmm, xmm, imm8 L: 0.97ns= 3.0c T: 0.97ns= 3.00c
1200 SSE4.2:PCMPISTRM xmm, xmm, imm8 L: 0.97ns= 3.0c T: 0.97ns= 3.00c
1201 CLMUL :PCLMULQDQ xmm, xmm, imm8 L: 4.39ns= 13.6c T: 2.59ns= 8.00c
1202 AESNI :AESENC xmm, xmm L: 2.59ns= 8.0c T: 0.32ns= 1.00c
1203 AESNI :AESENCLAST xmm, xmm L: 2.59ns= 8.0c T: 0.32ns= 1.00c
1204 AESNI :AESDEC xmm, xmm L: 2.59ns= 8.0c T: 0.32ns= 1.00c
1205 AESNI :AESDECLAST xmm, xmm L: 2.59ns= 8.0c T: 0.32ns= 1.00c
1206 AESNI :AESIMC xmm, xmm L: 4.53ns= 14.0c T: 0.65ns= 2.00c
1207 AESNI :AESKEYGEN xmm, xmm, imm8 L: 3.23ns= 10.0c T: 2.59ns= 8.00c
速くなったり遅くなったりわけわかめ
801 :デフォルトの名無しさん:2011/01/08(土) 21:43:14
http://journal.mycom.co.jp/special/2011/sandybridge/002.html
Sandra 2011 Multi-Media Bench
>AVXの拡張にあたって実行ユニットのデータ幅そのものは増やされていないし
FP性能が倍になっている理由がレイテンシだけでは厳しい
http://journal.mycom.co.jp/special/2011/sandybridge/004.html
>命令L1→Fetchの帯域幅も32Bytes/cycleに増量された。
32Bytes/cycleはDecoded ICacheの帯域ではないのか?
Sandra 2011 Multi-Media Bench
>AVXの拡張にあたって実行ユニットのデータ幅そのものは増やされていないし
FP性能が倍になっている理由がレイテンシだけでは厳しい
http://journal.mycom.co.jp/special/2011/sandybridge/004.html
>命令L1→Fetchの帯域幅も32Bytes/cycleに増量された。
32Bytes/cycleはDecoded ICacheの帯域ではないのか?
802 :デフォルトの名無しさん:2011/01/08(土) 21:47:31
まあまあw
いつもの大原節です
いつもの大原節です
803 :デフォルトの名無しさん:2011/01/09(日) 23:35:02
たしかにWriteだけ速いな
------[ CPU Info ]------
CPU Type : VIA Nano U3100, 1600 MHz (8 x 200)
------[ Memory Bandwidth ]------
CPU Clock : 1596.0 MHz
CPU Multiplier: 8x
CPU FSB : 199.5 MHz (original: 200 MHz)
Memory Bus : 532.0 MHz
DRAM:FSB Ratio: 16:6
Memory Type : Single Channel DDR3-1066 SDRAM
FSB Bandwidth : 6400 MB/s
Mem Bandwidth : 8533 MB/s
Max. NUMA Node: 0
Logical CPUs : 1
------------------------------------------------------------------------------------------------
CPU Mask | Read | Write | Copy | CacheFR | CacheFW | Time |
| Normal| Common| Normal| Normal| Common| Normal| Common| Normal | |
--------------------|-------|-------|-------|-------|-------|-------|-------|---------|--------|
0000000000000001 | 3235 | 3230 | 5814 | 3933 | 3925 | 3659 | 3657 | 0 | 40.2 |
----------------------------------------------------------------------------------------
-----------------------------------------------------------------------------------------
Typ| Read | Write | Copy | CacheFR | CacheFW |
| MB/s | Time | MB/s | Time | MB/s | Time | MB/s | Time | MB/s | Time |
---|-------|--------|-------|--------|-------|--------|-------|--------|-------|--------|
ST | 3236 | 4.6 | 5826 | 7.4 | 3917 | 2.6 | 3658 | 7.0 | 0 | 2.6 |
MT | 3258 | 2.3 | 5810 | 6.6 | 3949 | 3.4 | 3658 | 7.6 | 0 | 1.8 |
-----------------------------------------------------------------------------------------
------[ CPU Info ]------
CPU Type : VIA Nano U3100, 1600 MHz (8 x 200)
------[ Memory Bandwidth ]------
CPU Clock : 1596.0 MHz
CPU Multiplier: 8x
CPU FSB : 199.5 MHz (original: 200 MHz)
Memory Bus : 532.0 MHz
DRAM:FSB Ratio: 16:6
Memory Type : Single Channel DDR3-1066 SDRAM
FSB Bandwidth : 6400 MB/s
Mem Bandwidth : 8533 MB/s
Max. NUMA Node: 0
Logical CPUs : 1
------------------------------------------------------------------------------------------------
CPU Mask | Read | Write | Copy | CacheFR | CacheFW | Time |
| Normal| Common| Normal| Normal| Common| Normal| Common| Normal | |
--------------------|-------|-------|-------|-------|-------|-------|-------|---------|--------|
0000000000000001 | 3235 | 3230 | 5814 | 3933 | 3925 | 3659 | 3657 | 0 | 40.2 |
----------------------------------------------------------------------------------------
-----------------------------------------------------------------------------------------
Typ| Read | Write | Copy | CacheFR | CacheFW |
| MB/s | Time | MB/s | Time | MB/s | Time | MB/s | Time | MB/s | Time |
---|-------|--------|-------|--------|-------|--------|-------|--------|-------|--------|
ST | 3236 | 4.6 | 5826 | 7.4 | 3917 | 2.6 | 3658 | 7.0 | 0 | 2.6 |
MT | 3258 | 2.3 | 5810 | 6.6 | 3949 | 3.4 | 3658 | 7.6 | 0 | 1.8 |
-----------------------------------------------------------------------------------------
804 :デフォルトの名無しさん:2011/01/13(木) 02:08:15
Optimization Reference Manualのスループットを見る限り、VDIVPS/PDは128ビットずつ計算してるのか?
そしたらVRCPPS使った方が速くなったりするのだろうか。
実機がないから分からん。
そしたらVRCPPS使った方が速くなったりするのだろうか。
実機がないから分からん。
805 :,,・´∀`・,,)っ-○○○:2011/01/13(木) 03:13:10
VRCPPSも128ビットずつだよ。
11ビット精度で十分ならそれでいい。
11ビット精度で十分ならそれでいい。
806 :デフォルトの名無しさん:2011/01/13(木) 07:36:04
いや十分な精度が欲しい場合にNehalemではDIVPSが速すぎて
RCPPSがいらない子だった、というか正常進化でお役御免だったわけだけど
Sandy BridgeではまたNewton-Raphson使った方が良かったりするの?
旧石器時代に逆戻りなら勘弁してほしいなあ、というお話。
RCPPSがいらない子だった、というか正常進化でお役御免だったわけだけど
Sandy BridgeではまたNewton-Raphson使った方が良かったりするの?
旧石器時代に逆戻りなら勘弁してほしいなあ、というお話。
807 :デフォルトの名無しさん:2011/01/13(木) 07:48:55
RCPPSが12ビットならNewton-Raphsonでもいいんだけどな。
可能な限り精度が欲しい場合に、2ビットの精度を求めてVDIVPS使うと
ものすごい遅くなるというのが解せない。
可能な限り精度が欲しい場合に、2ビットの精度を求めてVDIVPS使うと
ものすごい遅くなるというのが解せない。
808 :,,・´∀`・,,)っ-○○○:2011/01/14(金) 17:00:10
その可能な限りってのがどんなケースかによるな。
たとえばA±B/CをやるとしてAとB/Cで絶対値が2ビット以上違う場合は2段のNewton-Raphsonで十分だし。
たとえばA±B/CをやるとしてAとB/Cで絶対値が2ビット以上違う場合は2段のNewton-Raphsonで十分だし。
809 :デフォルトの名無しさん:2011/01/16(日) 15:18:31
>>790
ソフトウェア屋としては、
新命令は(従来命令を使った場合と同程度の速度であれば)速くなくてもいいから、とにかく実行できる段階
を経てから
新命令が速く実行できる段階
にシフトするのが良いと思うから、Intelの導入の仕方は歓迎だよ。
ソフトウェア屋としては、
新命令は(従来命令を使った場合と同程度の速度であれば)速くなくてもいいから、とにかく実行できる段階
を経てから
新命令が速く実行できる段階
にシフトするのが良いと思うから、Intelの導入の仕方は歓迎だよ。
810 :デフォルトの名無しさん:2011/01/16(日) 15:20:55
>>791
8086の頃から、LEA命令の存在は疑問に思ってた。
実行時にアドレスを計算せずとも、
アセンブル時にアドレスが決まるものはそうすべきだし、
そうでないにしても普通に計算すりゃいいじゃん、と。
8086の頃から、LEA命令の存在は疑問に思ってた。
実行時にアドレスを計算せずとも、
アセンブル時にアドレスが決まるものはそうすべきだし、
そうでないにしても普通に計算すりゃいいじゃん、と。
811 :デフォルトの名無しさん:2011/01/16(日) 15:25:03
LEA を使えば、一度に 3 つ以上の数を足し込める。
アドレス計算のためにたくさん積んでる加算器を有効に使えるわけさ。
アドレス計算のためにたくさん積んでる加算器を有効に使えるわけさ。
812 :デフォルトの名無しさん:2011/01/16(日) 17:04:38
そっか、
LEA BX, [BX + SI + imm8/16]
とか、
LEA EDX, [EBX + EAX*4 + imm]
とか、
できるんだ。
CISCすげー
LEA BX, [BX + SI + imm8/16]
とか、
LEA EDX, [EBX + EAX*4 + imm]
とか、
できるんだ。
CISCすげー
813 :,,・´∀`・,,)っ-○○○:2011/01/16(日) 19:32:01
たとえば3n + 1問題を高速に解くとか?
lea eax, [eax + eax*2 + 1]
整数即値の乗算も2倍、3倍、5倍、8倍、9倍あたりならLEA使ったほうが速いです。
さらに言うとsource, dest独立なので命令数も少なくなる
lea eax, [eax + eax*2 + 1]
整数即値の乗算も2倍、3倍、5倍、8倍、9倍あたりならLEA使ったほうが速いです。
さらに言うとsource, dest独立なので命令数も少なくなる
814 :デフォルトの名無しさん:2011/01/16(日) 21:45:27
どうりでIA-64が同クロックのx86に勝てないわけだ。
MIPSと比べるとIA-64は強力だけど、x86には及ばないな。
もはや加算器やシフタなんてタダ同然なんだなー。
MIPSと比べるとIA-64は強力だけど、x86には及ばないな。
もはや加算器やシフタなんてタダ同然なんだなー。
815 :デフォルトの名無しさん:2011/01/16(日) 23:50:34
RISCを擁護する気はないけど、CISCだから凄いってのも違う気がする。
レジスタ数が128本も無くてオペコードに余裕があったら4バイト即値は不可能としても、似たようなのがCell辺りに入っていてもおかしく無さそうだし。
ま、歴史的な経緯とか色々理由はあるだろうけれど
当時需要があって、今でも十分使える遺産って事でしょ。
SSE/AVXのある今となっては16倍や32倍もあれば便利だったねってところ。
レジスタ数が128本も無くてオペコードに余裕があったら4バイト即値は不可能としても、似たようなのがCell辺りに入っていてもおかしく無さそうだし。
ま、歴史的な経緯とか色々理由はあるだろうけれど
当時需要があって、今でも十分使える遺産って事でしょ。
SSE/AVXのある今となっては16倍や32倍もあれば便利だったねってところ。
816 :,,・´∀`・,,)っ-○○○:2011/01/17(月) 00:39:13
> SSE/AVXのある今となっては16倍や32倍もあれば便利だったねってところ。
これはたしかに。64ビット拡張とかのタイミングでscaleをもう1ビット増やして欲しかったな。
もっとも今カウンタ変数の更新にinc/dec使わないからあまり意味無いんだけど。
ただ、8倍まで表現できれば64ビットスカラ整数のオフセット算出を「タダ」でできることになる。
RISCの大半はアドレス計算もALUでやるものが多いからなあ。
Cell SPEはいちいち「積和算」が必要なんだぜ
ARMは論理レジスタを16本に抑えてプレディケートやバレルシフタにコード空間を割いてるから
多少マシという程度。
これはたしかに。64ビット拡張とかのタイミングでscaleをもう1ビット増やして欲しかったな。
もっとも今カウンタ変数の更新にinc/dec使わないからあまり意味無いんだけど。
ただ、8倍まで表現できれば64ビットスカラ整数のオフセット算出を「タダ」でできることになる。
RISCの大半はアドレス計算もALUでやるものが多いからなあ。
Cell SPEはいちいち「積和算」が必要なんだぜ
ARMは論理レジスタを16本に抑えてプレディケートやバレルシフタにコード空間を割いてるから
多少マシという程度。
817 :デフォルトの名無しさん:2011/01/17(月) 14:32:58
え?
mov eax, dword ptr[ebx + edx*4]
って、scale値4なの? もったいない。
scaleは2ビットしかなくて4通りしかないんだから、
アクセス幅によらずに1,2,4,8ではなく、
dwordなら4,8,12,16
qwordなら8,16,24,32
ってな具合にしてくれればよかったのにね。
mov eax, dword ptr[ebx + edx*4]
って、scale値4なの? もったいない。
scaleは2ビットしかなくて4通りしかないんだから、
アクセス幅によらずに1,2,4,8ではなく、
dwordなら4,8,12,16
qwordなら8,16,24,32
ってな具合にしてくれればよかったのにね。
818 :,,・´∀`・,,)っ-○○○:2011/01/17(月) 17:31:52
それはそれで困るけど・・・
indexを4の倍数、8の倍数にしとけば良い話だしな。
x64では1バイトOpcode空間から削除されてしまったinc/decをつかおうってんじゃないだろ?
indexを4の倍数、8の倍数にしとけば良い話だしな。
x64では1バイトOpcode空間から削除されてしまったinc/decをつかおうってんじゃないだろ?
819 :デフォルトの名無しさん:2011/01/19(水) 23:49:56
820 :デフォルトの名無しさん:2011/01/27(木) 00:28:28
ItaniumにはClassic Pentiumが丸ごと入っているっていう噂を見かけたのだが、本当?
Intelの資料には、
命令フェッチやデコード、スケジューラやリタイアメント等はIA-32専用だが、
レジスタや実行ユニットはIA-64用と共用されていると書いてあるらしいのだが。
Intelの資料には、
命令フェッチやデコード、スケジューラやリタイアメント等はIA-32専用だが、
レジスタや実行ユニットはIA-64用と共用されていると書いてあるらしいのだが。
821 :デフォルトの名無しさん:2011/01/27(木) 21:54:57
822 :デフォルトの名無しさん:2011/01/27(木) 23:05:16
命令の所要クロックを比較すれば、噂が本当かどうか、分かるのかな。
823 :デフォルトの名無しさん:2011/01/27(木) 23:21:05
64bit化の時に、
andn, xnor, nand とかの整数命令をもうちょっと強化してもよかった気がするなあ。
回路的には大したことないはずだし。
andn, xnor, nand とかの整数命令をもうちょっと強化してもよかった気がするなあ。
回路的には大したことないはずだし。
824 :,,・´∀`・,,)っ-○○○:2011/01/28(金) 00:06:50
andnはVEXフォーマット採用で3オペランド形式になりますよ
825 :デフォルトの名無しさん:2011/01/28(金) 04:12:34
826 :デフォルトの名無しさん:2011/01/28(金) 05:04:50
アウトオブオーダ実行しておきながら800MHzで200MHz相当の速度しかでないって、どんだけ・・・。
827 :デフォルトの名無しさん:2011/01/28(金) 07:38:04
828 :,,・´∀`・,,)っ-○○○:2011/01/28(金) 07:50:02
いや、その汎用レジスタ版のandnがVEXフォーマットなのよ。
http://gcc.gnu.org/ml/gcc-patches/2010-10/msg01766.html
AMD独自命令かと思いきやBMIのCPUID Feature FlagはIntel側の空間にある。
http://gcc.gnu.org/ml/gcc-patches/2010-10/msg01766.html
AMD独自命令かと思いきやBMIのCPUID Feature FlagはIntel側の空間にある。
829 :デフォルトの名無しさん:2011/01/28(金) 21:00:16
まぢか?
Haswellとかに載るのか?
でもやっぱり64bitになった時に見直すべきだったと思うな。
途中からじゃほとんど使われないままになってしまう。
Haswellとかに載るのか?
でもやっぱり64bitになった時に見直すべきだったと思うな。
途中からじゃほとんど使われないままになってしまう。
830 :デフォルトの名無しさん:2011/01/28(金) 23:47:56
AMD64は悪貨ですから。未来に負の遺産を残すことなんか、気にしちゃイネエ。
IA-32からの変更を少なく抑えることで、ローコストに32bitと64bitの両対応とし、
IA-64を叩き割るのが、AMDの取った貧者の核兵器的な戦略ですから。
IA-32からの変更を少なく抑えることで、ローコストに32bitと64bitの両対応とし、
IA-64を叩き割るのが、AMDの取った貧者の核兵器的な戦略ですから。
831 :デフォルトの名無しさん:2011/01/29(土) 03:07:21
AMDのくせに生意気だ!
ってことですね。わかりますw
ってことですね。わかりますw
832 :デフォルトの名無しさん:2011/01/29(土) 04:51:10
どうした? 意味がワカラン。
833 :デフォルトの名無しさん:2011/01/29(土) 07:52:38
834 :デフォルトの名無しさん:2011/01/29(土) 10:43:26
intelにゃ最初からできないだろう。SSEのように後からダラダラ醜い建て増しをしていくのが目に見えてる。
835 :デフォルトの名無しさん:2011/01/29(土) 15:12:08
でも結果オーライだったじゃん
OSやコンパイラの大きな変更無しに64bitに移行出来たんだから
かたやItanium2の凋落はどうだ?ひどいもんだろう
いくら最新のVLIWで御座いますって言ってもソフト資産が無い事には
流行らないってはっきりわかってしまったからな
OSやコンパイラの大きな変更無しに64bitに移行出来たんだから
かたやItanium2の凋落はどうだ?ひどいもんだろう
いくら最新のVLIWで御座いますって言ってもソフト資産が無い事には
流行らないってはっきりわかってしまったからな
836 :デフォルトの名無しさん:2011/01/29(土) 16:54:57
>>834
インテルは実際にやったじゃん、IA-64を。
>>835
> OSやコンパイラの大きな変更無しに64bitに移行出来たんだから
WindowsやLinuxは、AMD64よりも先にIA-64に移植されましたよ。
Windowsに関して言えば、AMD64版はx86版からの移植というよりは、IA-64版からの移植ですよ。
Itaniumはx86命令の実行速度が遅いのが問題だった。
x86の膨大なソフト資産がそのまま走るのに、それが遅いことをさして「互換性がない」とまで言われる始末。
初代Itaniumに関しては、消費電力的にもコスト的にも、Pentium3のダイをMCMする余裕があったのだから、
なりふりかまわず、そうしていればよかったのにね。
インテルは実際にやったじゃん、IA-64を。
>>835
> OSやコンパイラの大きな変更無しに64bitに移行出来たんだから
WindowsやLinuxは、AMD64よりも先にIA-64に移植されましたよ。
Windowsに関して言えば、AMD64版はx86版からの移植というよりは、IA-64版からの移植ですよ。
Itaniumはx86命令の実行速度が遅いのが問題だった。
x86の膨大なソフト資産がそのまま走るのに、それが遅いことをさして「互換性がない」とまで言われる始末。
初代Itaniumに関しては、消費電力的にもコスト的にも、Pentium3のダイをMCMする余裕があったのだから、
なりふりかまわず、そうしていればよかったのにね。
837 :デフォルトの名無しさん:2011/01/29(土) 17:23:01
838 :デフォルトの名無しさん:2011/01/29(土) 17:28:43
戦略というより実装だな
今後の事なんだからもっとすり合わせても良かった
今後の事なんだからもっとすり合わせても良かった
839 :デフォルトの名無しさん:2011/01/29(土) 18:31:23
もしintelがIA64を投入せず代わりにAMD64のような64bit拡張をしていたら、
80286→80386
の時と同じように、intelは散々に叩かれただろうな。
80286→80386
の時と同じように、intelは散々に叩かれただろうな。
840 :デフォルトの名無しさん:2011/01/29(土) 19:18:25
Yamhill拡張よりはamd64拡張の方がよかったとおもうけどね。
レジスタ増やしたし。
レジスタ増やしたし。
841 :デフォルトの名無しさん:2011/01/29(土) 19:49:25
IA-64がなければ、Yamhillもなかった・・・また違った64bit拡張になったと思うよ。
842 :デフォルトの名無しさん:2011/01/29(土) 22:07:02
AMDがやることは良いこと
Intelがやることは悪いことですから
Intelがやることは悪いことですから
843 :デフォルトの名無しさん:2011/01/30(日) 00:05:56
IA64が売れていたらYamhillはなかった。だろ。
844 :デフォルトの名無しさん:2011/01/30(日) 00:14:11
IA64がなかったら・・・・Yamhillとは違う64bit拡張
IA64が売れていたら・・・・Yamhillは出番なし
IA64が売れなかった・・・・簡易64bit拡張のYamhillが作られたが、お蔵入りさせてAMD64を採用
IA64が売れていたら・・・・Yamhillは出番なし
IA64が売れなかった・・・・簡易64bit拡張のYamhillが作られたが、お蔵入りさせてAMD64を採用
845 :デフォルトの名無しさん:2011/01/31(月) 19:10:07
Optimization manuals更新
http://www.agner.org/optimize/
Sandy Bridgeの情報が追加されたようだ
Intel(R) 64 and IA-32 Architectures Optimization Reference Manual
http://www.intel.com/Assets/PDF/manual/248966.pdf
248966-023から248966-023aの変更点がわからない
http://www.agner.org/optimize/
Sandy Bridgeの情報が追加されたようだ
Intel(R) 64 and IA-32 Architectures Optimization Reference Manual
http://www.intel.com/Assets/PDF/manual/248966.pdf
248966-023から248966-023aの変更点がわからない
846 :デフォルトの名無しさん:2011/02/08(火) 08:33:22
メモリのゼロフィルに要する時間が気になる。
ゼロフィルするときの動作って、もしかして、
1、あるメモリへの書き込みがキューに入り、キャッシュに送られる
2、キャッシュはキャッシュライン分をDRAMから読む
3、キャッシュライン上で、1の書き込みの処理を行う
4、キャッシュからDRAMに書き込みが行われる
といった具合になっていて、
キャッシュラインが全て塗りつぶされるような場合でも、
DRAMからの読み込みが発生してしまう、ってことなの?
ゼロフィルするときの動作って、もしかして、
1、あるメモリへの書き込みがキューに入り、キャッシュに送られる
2、キャッシュはキャッシュライン分をDRAMから読む
3、キャッシュライン上で、1の書き込みの処理を行う
4、キャッシュからDRAMに書き込みが行われる
といった具合になっていて、
キャッシュラインが全て塗りつぶされるような場合でも、
DRAMからの読み込みが発生してしまう、ってことなの?
847 :デフォルトの名無しさん:2011/02/08(火) 08:59:32
メモリの一部に書き込むと言うことは、その周辺もまとめて書き込まないといけないからどうしても読み込みが発生するのでは?
Intelの講習会ではそう言ってたと思った。
Intelの講習会ではそう言ってたと思った。
848 :デフォルトの名無しさん:2011/02/08(火) 09:31:00
部分的に書き込むときは、読んで・変更して・書き込む、っていう動作になるのは仕方ないにしても、
キャッシュライン丸ごと全部が書き換わるときには、読む必要ないと思うんだけど、読んでるクサイのよね。
キャッシュライン丸ごと全部が書き換わるときには、読む必要ないと思うんだけど、読んでるクサイのよね。
849 : ◆0uxK91AxII :2011/02/08(火) 13:07:30
嫌ならmovnt*を使えばっていう。
850 :デフォルトの名無しさん:2011/02/08(火) 16:19:42
movnt*は、
キャッシュから優先的に追い出して構わないというヒント
ではなく、
キャッシュラインと同じサイズのコンバイン用のバッファを介して、ライトスルーでメモリに書き込め
っていう命令なのね。
キャッシュラインの境界に合わせてシーケンシャルに書き込めば、
メモリへの書き込みはキャッシュラインのサイズでのバースト・ライトになる、と。
キャッシュから優先的に追い出して構わないというヒント
ではなく、
キャッシュラインと同じサイズのコンバイン用のバッファを介して、ライトスルーでメモリに書き込め
っていう命令なのね。
キャッシュラインの境界に合わせてシーケンシャルに書き込めば、
メモリへの書き込みはキャッシュラインのサイズでのバースト・ライトになる、と。
851 :デフォルトの名無しさん:2011/02/08(火) 16:26:35
んーでも、NTでmovしても、readに対してwriteは8割程度の速度しか出ないんだよなー。
852 :デフォルトの名無しさん:2011/02/11(金) 16:19:28
>>24
コンパイラにマルチスレッドの指定はないの?
コンパイラにマルチスレッドの指定はないの?
853 :デフォルトの名無しさん:2011/02/11(金) 20:18:43
854 :デフォルトの名無しさん:2011/02/11(金) 20:26:24
クリティカルではないコードでは無問題。
このスレの人は古すぎる。
このスレの人は古すぎる。
855 :デフォルトの名無しさん:2011/02/11(金) 20:58:17
個人でのプログラムでクリティカルでないことがあらかじめわかってるなら
良いんじゃない?
集団でのプログラム、業務でのプログラムなら、
クリティカルにならなくても避けるべき。
そういうコードが残ってると後々悪さをするんだよ。
想定外のところからのコール、移植、ソースの流用、.....などなどで。
計算オーダーの違いは明らかで、
コード量はほぼ同じ。
見やすさもほとんど変わらず。
あえて >>24 のように書く意味がない。
良いんじゃない?
集団でのプログラム、業務でのプログラムなら、
クリティカルにならなくても避けるべき。
そういうコードが残ってると後々悪さをするんだよ。
想定外のところからのコール、移植、ソースの流用、.....などなどで。
計算オーダーの違いは明らかで、
コード量はほぼ同じ。
見やすさもほとんど変わらず。
あえて >>24 のように書く意味がない。
856 :デフォルトの名無しさん:2011/02/11(金) 21:06:11
メンテナンスを想定していて、
現状のコードで問題ない部分は修正すべきではないよ。
修正するなら関係者の合意をとってからにすべきだし、
修正したコードの有益性を明確に説明すべき。
勝手に直すのは論外。
オタクプログラマが嫌われる理由を作らないようにしましょう。
現状のコードで問題ない部分は修正すべきではないよ。
修正するなら関係者の合意をとってからにすべきだし、
修正したコードの有益性を明確に説明すべき。
勝手に直すのは論外。
オタクプログラマが嫌われる理由を作らないようにしましょう。
857 :デフォルトの名無しさん:2011/02/11(金) 21:24:46
新規でそういうコードを作るなって話だよ
858 :デフォルトの名無しさん:2011/02/11(金) 22:24:54
strlenしている先がvolatileなポインタだったら、動き変わるからなぁ。
あえて>>24のような書き方をしている可能性もある。
あえて>>24のような書き方をしている可能性もある。
859 :デフォルトの名無しさん:2011/02/11(金) 22:40:44
volatileがついてないタダのキャラポじゃんか。
constもなぜかついてないが。
そんなこと言い出したら
strlenが標準ライブラリじゃなく全然関係ない関数かもしれない
とかそういう心配も
constもなぜかついてないが。
そんなこと言い出したら
strlenが標準ライブラリじゃなく全然関係ない関数かもしれない
とかそういう心配も
860 :デフォルトの名無しさん:2011/02/12(土) 01:10:57
#include してないしな。
861 :デフォルトの名無しさん:2011/02/12(土) 10:30:13
862 :デフォルトの名無しさん:2011/02/12(土) 10:39:31
いまどきこんなんでやばくなる全体の設計の悪さなんとかしろよw
863 :デフォルトの名無しさん:2011/02/12(土) 22:37:04
864 :デフォルトの名無しさん:2011/02/12(土) 22:39:13
こういうコードを書くヤツや
こういうコードを肯定するヤツ
と一緒に仕事したくない
こういうコードを肯定するヤツ
と一緒に仕事したくない
まさか二年以上も経ってから突き回される事になるとは思わなかったw
単に、x64の方だけ空気読んでいて興味深いなあ位の意味しかなかったのになあ。
処理内容も、ループ自体が最適化で省略されないようにしたかっただけだし。
単に、x64の方だけ空気読んでいて興味深いなあ位の意味しかなかったのになあ。
処理内容も、ループ自体が最適化で省略されないようにしたかっただけだし。
866 :デフォルトの名無しさん:2011/02/12(土) 23:31:52
オーダー違うって言ってるやついるけど、
オーダーは同じだよ。
どのみちbufの長さに対して2乗のループだからな。
オーダーは同じだよ。
どのみちbufの長さに対して2乗のループだからな。
867 :デフォルトの名無しさん:2011/02/12(土) 23:33:08
>>263
何らかの処理の部分も2億回になるから、遅けりゃわかる。
何らかの処理の部分も2億回になるから、遅けりゃわかる。
868 :デフォルトの名無しさん:2011/02/13(日) 00:39:17
>>16
のコードを見て実害出るほどに速度差が容易にでると思えるやつはまだまだ素人。
のコードを見て実害出るほどに速度差が容易にでると思えるやつはまだまだ素人。
869 :デフォルトの名無しさん:2011/02/13(日) 01:21:40
strlen(buf) があると最適化出来ないんじゃないの?
870 :デフォルトの名無しさん:2011/02/13(日) 01:40:57
インライン展開できるのにそれを最適化できないっていうのは少し悲しい
871 :デフォルトの名無しさん:2011/02/13(日) 02:19:01
>>852-870
スレ違い
スレ違い
872 :デフォルトの名無しさん:2011/02/13(日) 02:20:49
多少マナーのあるひとなら
こう書くでしょ
for (int i=strlen(buf1); --i >= 0; ) {
for (int j=strlen(buf2); --j >= 0; ) {
何かの処理
}
}
こう書くでしょ
for (int i=strlen(buf1); --i >= 0; ) {
for (int j=strlen(buf2); --j >= 0; ) {
何かの処理
}
}
873 :デフォルトの名無しさん:2011/02/13(日) 09:56:44
874 :デフォルトの名無しさん:2011/02/13(日) 10:38:13
>>872はある種のジョークなんだろ。
全くおもしろくはないが
全くおもしろくはないが
875 :デフォルトの名無しさん:2011/02/13(日) 10:41:10
876 :デフォルトの名無しさん:2011/02/13(日) 10:50:13
>>865
x86とx64で生成するコードが違うのは、バグの互換性のためだと思う。
>>866
strlenを毎回やると、ループが3重になるからO(N^3)
strlenを最初だけにすると、ループは2重になるからO(N^2)
オーダー、違いますね。
x86とx64で生成するコードが違うのは、バグの互換性のためだと思う。
>>866
strlenを毎回やると、ループが3重になるからO(N^3)
strlenを最初だけにすると、ループは2重になるからO(N^2)
オーダー、違いますね。
877 :デフォルトの名無しさん:2011/02/13(日) 10:50:36
>>873
Visual Studio 2010 Win32 Releaseのデフォルト設定
CPU core i7 2600
buf1, buf2 とも10000文字の文字列
「何らかの処理」の部分は >>24 と同等
>>16 のまま
389.8秒
strlenをループの外に
0.028秒
Visual Studio 2010 Win32 Releaseのデフォルト設定
CPU core i7 2600
buf1, buf2 とも10000文字の文字列
「何らかの処理」の部分は >>24 と同等
>>16 のまま
389.8秒
strlenをループの外に
0.028秒
878 :デフォルトの名無しさん:2011/02/13(日) 10:52:44
>>873みたく、10秒位差がでない限り気にしない人ばかりなら
色々楽だろうなあ、と思った。
色々楽だろうなあ、と思った。
879 :デフォルトの名無しさん:2011/02/13(日) 10:54:44
>CPU core i7 2600
うわ・・・厨房臭い・・・。
うわ・・・厨房臭い・・・。
880 :デフォルトの名無しさん:2011/02/13(日) 11:11:13
>>879
ツッコミ入れるポイントにセンスがないな、お前。
俺が仕事で書くコードでは、C++で文字列クラスを使うので、strlenを毎回呼ぶようなことにはならない。
それは遅いからではなく、strlenを使うような書き方をしてたらミスが怖いので、やらない。
速度の話だと、毎回strlenを呼ぶような遅いコードを書くのは全然OKというよりも、むしろ推奨。
最初から最短コース的な速度だと、
営業からは、安い1ソケットのサーバで済むのは儲からない、などと嫌味を言われるし、
様々な変更や改修で遅くなっていくとマズい。
だから、簡単に直せる遅いコードを散りばめておいて、必要に応じて速いコードに直すのがいい。
ツッコミ入れるポイントにセンスがないな、お前。
俺が仕事で書くコードでは、C++で文字列クラスを使うので、strlenを毎回呼ぶようなことにはならない。
それは遅いからではなく、strlenを使うような書き方をしてたらミスが怖いので、やらない。
速度の話だと、毎回strlenを呼ぶような遅いコードを書くのは全然OKというよりも、むしろ推奨。
最初から最短コース的な速度だと、
営業からは、安い1ソケットのサーバで済むのは儲からない、などと嫌味を言われるし、
様々な変更や改修で遅くなっていくとマズい。
だから、簡単に直せる遅いコードを散りばめておいて、必要に応じて速いコードに直すのがいい。
881 :デフォルトの名無しさん:2011/02/13(日) 11:15:17
882 :デフォルトの名無しさん:2011/02/13(日) 11:39:06
883 :デフォルトの名無しさん:2011/02/13(日) 11:40:25
アホな命令がくるときに備えて、
いざというときに逃げられるギミックを仕込んでおくのは
プロの常識。
いざというときに逃げられるギミックを仕込んでおくのは
プロの常識。
884 :デフォルトの名無しさん:2011/02/13(日) 11:45:55
ギミックw
885 :デフォルトの名無しさん:2011/02/13(日) 11:50:34
886 :デフォルトの名無しさん:2011/02/13(日) 13:42:11
887 :デフォルトの名無しさん:2011/02/13(日) 14:20:26
同じ値の引数でも、中身が変ってるかもしれんだろ。
888 :デフォルトの名無しさん:2011/02/14(月) 01:05:06
strlenがただのライブラリ内の一関数という扱いであれば
コンパイラがpure関数かどうか知るすべがない。
strlenに対してコンパイラが特別扱いしていれば
最適化されるかも知れないが、
特別扱いするほど良く使われる関数でもない。
コンパイラがpure関数かどうか知るすべがない。
strlenに対してコンパイラが特別扱いしていれば
最適化されるかも知れないが、
特別扱いするほど良く使われる関数でもない。
889 :デフォルトの名無しさん:2011/02/14(月) 01:08:30
890 :デフォルトの名無しさん:2011/02/14(月) 01:11:06
pure関数って何?
内部に状態を持たず、引数に対して一意の返り値を返す関数?
だとしたら、strlenはpure関数になるわけがない。
たとえば
n1a = strlen(buf1);
strcpy(buf1, buf2);
n1b = strlen(buf1);
どちらのstrlenもbuf1という同じ値を引数にしているが、返り値の値は同じとは限らない。
内部に状態を持たず、引数に対して一意の返り値を返す関数?
だとしたら、strlenはpure関数になるわけがない。
たとえば
n1a = strlen(buf1);
strcpy(buf1, buf2);
n1b = strlen(buf1);
どちらのstrlenもbuf1という同じ値を引数にしているが、返り値の値は同じとは限らない。
891 : ◆0uxK91AxII :2011/02/14(月) 08:07:31
スレ違いな上に阿呆がpopしまくっていて酷いね。
892 :デフォルトの名無しさん:2011/02/14(月) 12:45:12
volatileへのポインターでなければ、
ポインターの示す先が変わっていないと判断したときは、
勝手にstrlenの結果をキャッシュしても規格上は問題無いと思う。
規格と実装を混同してないか?
ポインターの示す先が変わっていないと判断したときは、
勝手にstrlenの結果をキャッシュしても規格上は問題無いと思う。
規格と実装を混同してないか?
893 :デフォルトの名無しさん:2011/02/14(月) 13:25:30
おまえらコンパイラ最適化の井戸端会議はどうでもいいので所要クロック(笑)でも数えててください(笑)
894 :,,・´∀`・,,)っ-○○○:2011/02/14(月) 19:47:27
strlenをSSE2でチューンしたコードならあるけどwwww
もちろんCじゃあれなんでフルアセンブラで書き直した。
てかさx86-Win32のABIってなんで__fastcallデフォルトにしなかったんだろうって思ったよ。
もちろんCじゃあれなんでフルアセンブラで書き直した。
てかさx86-Win32のABIってなんで__fastcallデフォルトにしなかったんだろうって思ったよ。
895 :デフォルトの名無しさん:2011/02/14(月) 20:11:01
896 :デフォルトの名無しさん:2011/02/14(月) 20:20:56
897 :デフォルトの名無しさん:2011/02/14(月) 20:25:17
VisualBasicへの配慮だったりして
898 :,,・´∀`・,,)っ-○○○:2011/02/14(月) 20:35:27
eax, ecx, edxはどのみちcaller-saveなんだからレジスタ渡しにしてくれたほうがいいんだけどね
10文字以内の文字列で自作strlenを使うとfastcall版とcdecl版でかなり性能が変わってるんで
これはどうしたものかと。
10文字以内の文字列で自作strlenを使うとfastcall版とcdecl版でかなり性能が変わってるんで
これはどうしたものかと。
899 :デフォルトの名無しさん:2011/02/14(月) 21:14:09
独禁法に違反する恐れがあった、というのは考えすぎかw
fastcall、というかレジスタ経由の呼び出しは、
元々コンパイラ依存で各社好き勝手やっていたから、
仕様の決め方によっては他社への嫌がらせと取られかねない、とか。
fastcall、というかレジスタ経由の呼び出しは、
元々コンパイラ依存で各社好き勝手やっていたから、
仕様の決め方によっては他社への嫌がらせと取られかねない、とか。
900 :デフォルトの名無しさん:2011/02/14(月) 21:20:49
>>898
わざと性能落として、より高い CPU 買わせようっていう
wintel の謀略だったのかもね。
> これはどうしたものかと。
だんごさんのスーパーなライブラリでもかまして、なんとかしのいでくださいwww
わざと性能落として、より高い CPU 買わせようっていう
wintel の謀略だったのかもね。
> これはどうしたものかと。
だんごさんのスーパーなライブラリでもかまして、なんとかしのいでくださいwww
901 :デフォルトの名無しさん:2011/02/14(月) 21:21:21
8085(Z80)からの移植性を考慮して、だと思うが。
902 :デフォルトの名無しさん:2011/02/14(月) 21:50:48
903 :デフォルトの名無しさん:2011/02/14(月) 22:06:54
呼び出し規約なんて、関数単位で選べるんだから、選べばいいじゃん。
904 : ◆0uxK91AxII :2011/02/14(月) 22:07:42
歴史的にお約束のsyscallに合わせたからとか。
905 :デフォルトの名無しさん:2011/02/14(月) 22:54:12
64bitだと過去に縛られないからレジスタ渡しだね。
レジスタが多いからってのもあるだろうけど。
レジスタが多いからってのもあるだろうけど。
906 :デフォルトの名無しさん:2011/02/14(月) 22:57:13
VS2010 の浮動小数点の関数を見たら、
コールのたびにSSE2対応かどうかの判断をして呼び分けてた。
sinとかx87 1命令で出来る関数でも、本当にSSE2の方が速いんだろうか.....
コールのたびにSSE2対応かどうかの判断をして呼び分けてた。
sinとかx87 1命令で出来る関数でも、本当にSSE2の方が速いんだろうか.....
907 :デフォルトの名無しさん:2011/02/14(月) 23:14:21
908 :デフォルトの名無しさん:2011/02/14(月) 23:39:37
909 :デフォルトの名無しさん:2011/02/14(月) 23:43:01
>>907
x87FPUは、レジスタがスタックだし、例外とかの処理の都合上、スーパースカラーやパイプライン実行に向いてないのよ。
SSE2は、その2つのハンデを負ってないので、それだけで高速。
昔はx87FPUの例外処理を端折ることで高速化したサードパーティのFPUとか、あったんだよー。
x87FPUは、レジスタがスタックだし、例外とかの処理の都合上、スーパースカラーやパイプライン実行に向いてないのよ。
SSE2は、その2つのハンデを負ってないので、それだけで高速。
昔はx87FPUの例外処理を端折ることで高速化したサードパーティのFPUとか、あったんだよー。
910 :デフォルトの名無しさん:2011/02/15(火) 00:09:07
試しにsin 100000000回で実験したら
xmmが有利な64bitでも
x87の方が倍くらい速かった。
>>909
x87の方は実行時間のほとんどがfsinなので、
スーパースカラーやパイプラインは関係ないかと。
xmmが有利な64bitでも
x87の方が倍くらい速かった。
>>909
x87の方は実行時間のほとんどがfsinなので、
スーパースカラーやパイプラインは関係ないかと。
911 :デフォルトの名無しさん:2011/02/15(火) 00:12:16
ちなみに、x87を使ったコードは以下
昔の32bitコンパイラならインラインでそのままfsinが使われてたはず
sin_x87 proc
movlpd qword ptr data, xmm0
fld qword ptr data
fsin
fstp qword ptr data
movlpd xmm0, qword ptr data0
ret
sin_x87 endp
昔の32bitコンパイラならインラインでそのままfsinが使われてたはず
sin_x87 proc
movlpd qword ptr data, xmm0
fld qword ptr data
fsin
fstp qword ptr data
movlpd xmm0, qword ptr data0
ret
sin_x87 endp
912 :デフォルトの名無しさん:2011/02/15(火) 00:14:12
Core i7で地味にFPUも改良してる可能性はあるな
913 :デフォルトの名無しさん:2011/02/15(火) 00:49:44
あ、ごめんなさい。逆だった。
xmmの方が倍くらい速い。
の間違いでした。
失礼しました。
fsinとかって本当互換性のためだけについてるって感じですかね。
xmmの方が倍くらい速い。
の間違いでした。
失礼しました。
fsinとかって本当互換性のためだけについてるって感じですかね。
914 :デフォルトの名無しさん:2011/02/15(火) 01:19:27
VC++2008 Express EditionとNorthwood、Clarkdaleで試してみた
/fp:fast
/arch:SSE2ではcall ___libm_sse2_sin
/arch無しではcall _sin
SSE2は75%の時間で終了
/fp:precise
/arch:SSE2ではcall __CIsin
/arch無しではcall _sin
速度差ほとんど無し
そっか、いまどきのCPUだと倍も違うのか。
/fp:fast
/arch:SSE2ではcall ___libm_sse2_sin
/arch無しではcall _sin
SSE2は75%の時間で終了
/fp:precise
/arch:SSE2ではcall __CIsin
/arch無しではcall _sin
速度差ほとんど無し
そっか、いまどきのCPUだと倍も違うのか。
915 :デフォルトの名無しさん:2011/02/15(火) 01:45:54
たびたびすまん。
値によってはやっぱりx86の方が倍速いみたい。
SSE2だと条件分岐が多いんで、
いろんな値でsinを行うと分岐予測が外れて遅くなる。
逆にほとんど同じ値ばかりだとSSE2の方が倍速い。
値によってはやっぱりx86の方が倍速いみたい。
SSE2だと条件分岐が多いんで、
いろんな値でsinを行うと分岐予測が外れて遅くなる。
逆にほとんど同じ値ばかりだとSSE2の方が倍速い。
916 :デフォルトの名無しさん:2011/02/15(火) 10:01:13
sse2なら、ベクタ化コードとも共存できるね
917 :デフォルトの名無しさん:2011/02/15(火) 18:25:25
918 :デフォルトの名無しさん:2011/02/15(火) 21:44:54
速さじゃなく結果の精度に一貫性持たせる為だと思うよ
919 :デフォルトの名無しさん:2011/02/15(火) 21:58:57
結果の一貫性が必要な用途なんてネットゲーくらいしか無いのに...
ほとんどの用途では速度と精度の方が重要だろうに。
この先もっと速い命令や速いアルゴリズムが出ても
一貫性の為に同じ方法を維持する?
そんな.....
ほとんどの用途では速度と精度の方が重要だろうに。
この先もっと速い命令や速いアルゴリズムが出ても
一貫性の為に同じ方法を維持する?
そんな.....
920 :デフォルトの名無しさん:2011/02/15(火) 22:06:25
VS2010は持ってないけど、VS2010のSSE2 sinってそんなに遅いのか?
インテルコンパイラだとSSE2 sinがx87 fsinに負けることなんてまずないけどな。
例えば次のようなコードだとSSE2 sinの方がx87 fsinより40%速い。
double sum=0.0; srand(1);
for(int i=0;i<100000000;i++) sum+=sin((rand()-RAND_MAX/2)/10.0);
ループが自動ベクトル化されていないことも確認した。
インテルコンパイラだとSSE2 sinがx87 fsinに負けることなんてまずないけどな。
例えば次のようなコードだとSSE2 sinの方がx87 fsinより40%速い。
double sum=0.0; srand(1);
for(int i=0;i<100000000;i++) sum+=sin((rand()-RAND_MAX/2)/10.0);
ループが自動ベクトル化されていないことも確認した。
921 :デフォルトの名無しさん:2011/02/15(火) 22:17:55
一貫性の為ならx87とSSE2を実行時に使い分けるなんてことはしないはず
922 :デフォルトの名無しさん:2011/02/15(火) 22:37:01
VS2010 Release デフォルト設定
コードは>>920
○ SSE2を用いたsin
x86 3.66秒
x64 3.95秒
※標準ライブラリのsin使用
※実行時にSSE2とx87を使い分けているようなのでオーバーヘッドがある
○ x87のfsin使用
x86 5.69秒
x64 4.96秒
※アセンブラ記述の関数をコール
普通の値ならSSE2の方が速い
コードは>>920
○ SSE2を用いたsin
x86 3.66秒
x64 3.95秒
※標準ライブラリのsin使用
※実行時にSSE2とx87を使い分けているようなのでオーバーヘッドがある
○ x87のfsin使用
x86 5.69秒
x64 4.96秒
※アセンブラ記述の関数をコール
普通の値ならSSE2の方が速い
923 :デフォルトの名無しさん:2011/02/15(火) 22:37:02
___libm_sse2_sinのコードを見たが、ほぼ分岐なしで一本道。
しかし、レジスタの依存関係があるので、あまり速くなさそう。
SIMDしないのはモッタイナイし、ソフトウェア・パイプライニングで2セット同時に計算したほうが良さそう。
しかし、レジスタの依存関係があるので、あまり速くなさそう。
SIMDしないのはモッタイナイし、ソフトウェア・パイプライニングで2セット同時に計算したほうが良さそう。
924 :デフォルトの名無しさん:2011/02/15(火) 22:42:12
>>923
VS2010のはテーブルを使ってるけど、
インテルコンパイラでは使ってない?
一周(2π)を64分割した点からの角度差を求め、
そのsin, cosを求めてから、
64点の値と加法定理を用いて結果を出してる模様。
64点の値にテーブルを用いている。
その過程でSSE2による2セットの演算を多様している。
VS2010のはテーブルを使ってるけど、
インテルコンパイラでは使ってない?
一周(2π)を64分割した点からの角度差を求め、
そのsin, cosを求めてから、
64点の値と加法定理を用いて結果を出してる模様。
64点の値にテーブルを用いている。
その過程でSSE2による2セットの演算を多様している。
925 :デフォルトの名無しさん:2011/02/15(火) 23:07:12
角度が近ければベクタ化できるけど、
ぜんぜん関係のない複数の角度のsinを求めるのだと
条件分岐やテーブルを使わなきゃならないんで
ベクタ化は難しいと思う。
ぜんぜん関係のない複数の角度のsinを求めるのだと
条件分岐やテーブルを使わなきゃならないんで
ベクタ化は難しいと思う。
926 :デフォルトの名無しさん:2011/02/15(火) 23:15:47
927 :デフォルトの名無しさん:2011/02/15(火) 23:18:29
928 :デフォルトの名無しさん:2011/02/15(火) 23:19:12
929 :デフォルトの名無しさん:2011/02/15(火) 23:24:19
>>922
VS2010でもSSE2の方が速いじゃん。
x87 fsinの方が速いのってどんな場合??と思ったら、
こういう引数がでかい場合か。
double sum=0.0; srand(1);
for(int i=0;i<100000000;i++) sum+=sin((rand()-RAND_MAX/2)*1e10);
この場合なら確かにSSE2はx87 fsinより倍以上遅い。
>>924
インテルコンパイラでも64分割してテーブル引いてる。
VS2010でもSSE2の方が速いじゃん。
x87 fsinの方が速いのってどんな場合??と思ったら、
こういう引数がでかい場合か。
double sum=0.0; srand(1);
for(int i=0;i<100000000;i++) sum+=sin((rand()-RAND_MAX/2)*1e10);
この場合なら確かにSSE2はx87 fsinより倍以上遅い。
>>924
インテルコンパイラでも64分割してテーブル引いてる。
>>929
32bit
__libm_sse2_sin:
00401234 pextrw eax,xmm0,3
00401239 and ax,7FFFh
0040123D sub ax,3030h
00401241 cmp ax,10C5h
00401245 ja special (401381h)
0040124B movsd xmm1,mmword ptr [PI32INV (40EA20h)]
00401253 mulsd xmm1,xmm0
00401257 movsd xmm2,mmword ptr [SHIFTER (40EA28h)]
0040125F cvtsd2si edx,xmm1
00401263 addsd xmm1,xmm2
00401267 movsd xmm3,mmword ptr [P_1 (40EA10h)]
0040126F subsd xmm1,xmm2
00401273 movapd xmm2,xmmword ptr [P_2 (40EA00h)]
0040127B mulsd xmm3,xmm1
0040127F unpcklpd xmm1,xmm1
00401283 add edx,1C7600h
00401289 movsd xmm4,xmm0
0040128D and edx,3Fh
00401290 movapd xmm5,xmmword ptr [SC_4 (40E9F0h)]
00401298 lea eax,[Ctable (40E1C0h)]
0040129E shl edx,5
004012A1 add eax,edx
004012A3 mulpd xmm2,xmm1
004012A7 subsd xmm0,xmm3
004012AB mulsd xmm1,mmword ptr [P_3 (40EA18h)]
004012B3 subsd xmm4,xmm3
32bit
__libm_sse2_sin:
00401234 pextrw eax,xmm0,3
00401239 and ax,7FFFh
0040123D sub ax,3030h
00401241 cmp ax,10C5h
00401245 ja special (401381h)
0040124B movsd xmm1,mmword ptr [PI32INV (40EA20h)]
00401253 mulsd xmm1,xmm0
00401257 movsd xmm2,mmword ptr [SHIFTER (40EA28h)]
0040125F cvtsd2si edx,xmm1
00401263 addsd xmm1,xmm2
00401267 movsd xmm3,mmword ptr [P_1 (40EA10h)]
0040126F subsd xmm1,xmm2
00401273 movapd xmm2,xmmword ptr [P_2 (40EA00h)]
0040127B mulsd xmm3,xmm1
0040127F unpcklpd xmm1,xmm1
00401283 add edx,1C7600h
00401289 movsd xmm4,xmm0
0040128D and edx,3Fh
00401290 movapd xmm5,xmmword ptr [SC_4 (40E9F0h)]
00401298 lea eax,[Ctable (40E1C0h)]
0040129E shl edx,5
004012A1 add eax,edx
004012A3 mulpd xmm2,xmm1
004012A7 subsd xmm0,xmm3
004012AB mulsd xmm1,mmword ptr [P_3 (40EA18h)]
004012B3 subsd xmm4,xmm3
932 :デフォルトの名無しさん:2011/02/15(火) 23:35:36
>>927
> テーブル参照の部分だけ別に分けてやればいいと思う。
そうだね。
>>930
そうそう。
私はこんな感じのコードでやった。
double sum=0.0; srand(1);
for(int i=0;i<100000000;i++) sum+=sin((double)i);
実際に良く使うのは±2πの範囲だと思うので、
通常はSSE2の方が速い。
-----
sinとcosを同時に求める必要があるなら、
セットで求めるのが効率的だね。
共通の処理がすごく多いから。
x87にもfsincosとかいうのがあったような気がする。
> テーブル参照の部分だけ別に分けてやればいいと思う。
そうだね。
>>930
そうそう。
私はこんな感じのコードでやった。
double sum=0.0; srand(1);
for(int i=0;i<100000000;i++) sum+=sin((double)i);
実際に良く使うのは±2πの範囲だと思うので、
通常はSSE2の方が速い。
-----
sinとcosを同時に求める必要があるなら、
セットで求めるのが効率的だね。
共通の処理がすごく多いから。
x87にもfsincosとかいうのがあったような気がする。
933 :デフォルトの名無しさん:2011/02/15(火) 23:38:03
004012B7 movsd xmm7,mmword ptr [eax+8]
004012BC unpcklpd xmm0,xmm0
004012C0 movsd xmm3,xmm4
004012C4 subsd xmm4,xmm2
004012C8 mulpd xmm5,xmm0
004012CC subpd xmm0,xmm2
004012D0 movapd xmm6,xmmword ptr [SC_2 (40E9D0h)]
004012D8 mulsd xmm7,xmm4
004012DC subsd xmm3,xmm4
004012E0 mulpd xmm5,xmm0
004012E4 mulpd xmm0,xmm0
004012E8 subsd xmm3,xmm2
004012EC movapd xmm2,xmmword ptr [eax]
004012F0 subsd xmm1,xmm3
004012F4 movsd xmm3,mmword ptr [eax+18h]
004012F9 addsd xmm2,xmm3
004012FD subsd xmm7,xmm2
00401301 mulsd xmm2,xmm4
00401305 mulpd xmm6,xmm0
00401309 mulsd xmm3,xmm4
0040130D mulpd xmm2,xmm0
00401311 mulpd xmm0,xmm0
004012BC unpcklpd xmm0,xmm0
004012C0 movsd xmm3,xmm4
004012C4 subsd xmm4,xmm2
004012C8 mulpd xmm5,xmm0
004012CC subpd xmm0,xmm2
004012D0 movapd xmm6,xmmword ptr [SC_2 (40E9D0h)]
004012D8 mulsd xmm7,xmm4
004012DC subsd xmm3,xmm4
004012E0 mulpd xmm5,xmm0
004012E4 mulpd xmm0,xmm0
004012E8 subsd xmm3,xmm2
004012EC movapd xmm2,xmmword ptr [eax]
004012F0 subsd xmm1,xmm3
004012F4 movsd xmm3,mmword ptr [eax+18h]
004012F9 addsd xmm2,xmm3
004012FD subsd xmm7,xmm2
00401301 mulsd xmm2,xmm4
00401305 mulpd xmm6,xmm0
00401309 mulsd xmm3,xmm4
0040130D mulpd xmm2,xmm0
00401311 mulpd xmm0,xmm0
934 :デフォルトの名無しさん:2011/02/15(火) 23:39:56
00401315 addpd xmm5,xmmword ptr [SC_3 (40E9E0h)]
0040131D mulsd xmm4,mmword ptr [eax]
00401321 addpd xmm6,xmmword ptr [SC_1 (40E9C0h)]
00401329 mulpd xmm5,xmm0
0040132D movsd xmm0,xmm3
00401331 addsd xmm3,mmword ptr [eax+8]
00401336 mulpd xmm1,xmm7
0040133A movsd xmm7,xmm4
0040133E addsd xmm4,xmm3
00401342 addpd xmm6,xmm5
00401346 movsd xmm5,mmword ptr [eax+8]
0040134B subsd xmm5,xmm3
0040134F subsd xmm3,xmm4
00401353 addsd xmm1,mmword ptr [eax+10h]
00401358 mulpd xmm6,xmm2
0040135C addsd xmm5,xmm0
00401360 addsd xmm3,xmm7
00401364 addsd xmm1,xmm5
00401368 addsd xmm1,xmm3
0040136C addsd xmm1,xmm6
00401370 unpckhpd xmm6,xmm6
00401374 addsd xmm1,xmm6
00401378 addsd xmm4,xmm1
0040137C movapd xmm0,xmm4
00401380 ret
こんな感じ。
0040131D mulsd xmm4,mmword ptr [eax]
00401321 addpd xmm6,xmmword ptr [SC_1 (40E9C0h)]
00401329 mulpd xmm5,xmm0
0040132D movsd xmm0,xmm3
00401331 addsd xmm3,mmword ptr [eax+8]
00401336 mulpd xmm1,xmm7
0040133A movsd xmm7,xmm4
0040133E addsd xmm4,xmm3
00401342 addpd xmm6,xmm5
00401346 movsd xmm5,mmword ptr [eax+8]
0040134B subsd xmm5,xmm3
0040134F subsd xmm3,xmm4
00401353 addsd xmm1,mmword ptr [eax+10h]
00401358 mulpd xmm6,xmm2
0040135C addsd xmm5,xmm0
00401360 addsd xmm3,xmm7
00401364 addsd xmm1,xmm5
00401368 addsd xmm1,xmm3
0040136C addsd xmm1,xmm6
00401370 unpckhpd xmm6,xmm6
00401374 addsd xmm1,xmm6
00401378 addsd xmm4,xmm1
0040137C movapd xmm0,xmm4
00401380 ret
こんな感じ。
935 :デフォルトの名無しさん:2011/02/15(火) 23:44:48
>>931
ごめん。間に割り込んじゃった。
中心部分は2010の32bitと同じみたい。
2010だとその前にCPUによる分岐や、stからxmm0へのコピーなんかの処理がある。
00401283 add edx,1C7600h
これの意味がどうしてもわからないんだけど、
わかります?
なくても何も変わらないと思うんだけど......
ごめん。間に割り込んじゃった。
中心部分は2010の32bitと同じみたい。
2010だとその前にCPUによる分岐や、stからxmm0へのコピーなんかの処理がある。
00401283 add edx,1C7600h
これの意味がどうしてもわからないんだけど、
わかります?
なくても何も変わらないと思うんだけど......
936 :デフォルトの名無しさん:2011/02/15(火) 23:57:37
937 :デフォルトの名無しさん:2011/02/16(水) 00:04:08
そういうことか
他の関数でも探してみようかな
他の関数でも探してみようかな
938 :デフォルトの名無しさん:2011/02/16(水) 05:50:51
codepadとか使おうyo
939 :デフォルトの名無しさん:2011/02/16(水) 13:07:38
そうそう。あとできればThis code is public domain.ってコメントに入れてくれると嬉しい。
940 :デフォルトの名無しさん:2011/02/16(水) 13:22:00
つまらない釣りは辞めろ
941 :デフォルトの名無しさん:2011/02/17(木) 02:23:26
>589
2スレッドだけど、クロック単位でスレッドを切り替えてるだけだから1スレッドあたりのIPCは...
2スレッドだけど、クロック単位でスレッドを切り替えてるだけだから1スレッドあたりのIPCは...
942 :デフォルトの名無しさん:2011/02/17(木) 19:32:47
クロック単位でスレッドを切り換えるだけでも、実効IPCは改善しますぜ。
943 :デフォルトの名無しさん:2011/02/17(木) 20:33:25
>>919
お前ってアホだね
お前ってアホだね
944 :デフォルトの名無しさん:2011/02/17(木) 22:40:23
どうしたとつぜん
945 :デフォルトの名無しさん:2011/03/03(木) 21:40:49.98
946 :デフォルトの名無しさん:2011/03/03(木) 21:57:03.56
947 :デフォルトの名無しさん:2011/03/03(木) 21:59:51.36
948 :デフォルトの名無しさん:2011/03/03(木) 22:06:50.35
和訳ってあるの?
949 :デフォルトの名無しさん:2011/03/03(木) 22:11:59.02
この内容をふつうに理解しているレベルになると、
この程度の英語くらい普通に読めるから訳なんていらない。
この程度の英語くらい普通に読めるから訳なんていらない。
950 :デフォルトの名無しさん:2011/03/03(木) 23:03:45.56
テンプレェ・・・
951 :デフォルトの名無しさん:2011/03/04(金) 02:09:10.18
952 :デフォルトの名無しさん:2011/03/04(金) 04:54:58.57
再配布禁止でなけりゃちとうpしてもらえんだろか?
953 :デフォルトの名無しさん:2011/03/04(金) 07:13:31.43
そこのnano CPUID偽装ネタおもしろいな
954 :,,・´∀`・,,)っ-○○○:2011/03/04(金) 16:57:46.17
和訳ってソニーCSLの中の人か
955 :デフォルトの名無しさん:2011/03/05(土) 13:23:29.70
>838
またそれに何年かかかって〜、下手すりゃ先に実装されて〜、とAMD的に美味しい展開にはならないと思われ。
ましちゃIntelはx64に乗り気じゃなかったわけだし。
またそれに何年かかかって〜、下手すりゃ先に実装されて〜、とAMD的に美味しい展開にはならないと思われ。
ましちゃIntelはx64に乗り気じゃなかったわけだし。
956 :デフォルトの名無しさん:2011/03/05(土) 14:07:32.02
Intelにすりゃ「AMDにやられた〜」って感じなのかな
957 :デフォルトの名無しさん:2011/03/05(土) 16:28:52.02
むしろMSにやられた。だろ。
958 :,,・´∀`・,,)っ-○○○:2011/03/05(土) 22:38:17.49
浮動小数点演算命令はAMDオリジナルプランは破棄されてIntel SSE*互換だしね。
実質「MS64」だよ
実質「MS64」だよ
959 :デフォルトの名無しさん:2011/03/05(土) 23:10:21.88
やっぱり普通の整数命令がマズイよな x86, x64は。
960 :デフォルトの名無しさん:2011/03/06(日) 01:13:12.26
AVXで整理したといってもAVXを使わない粒度の細かい命令はそのまま残るわけで
961 : ◆0uxK91AxII :2011/03/06(日) 13:09:26.41
AVXとは何だったのか。
962 :デフォルトの名無しさん:2011/03/08(火) 16:13:29.36
命令(およびprefix)の前に、
prefix長と命令長を示す1バイトを付ける
っていうのは、割りに合わないっていう判断がされたのかな。
prefix長と命令長を示す1バイトを付ける
っていうのは、割りに合わないっていう判断がされたのかな。
963 :デフォルトの名無しさん:2011/03/10(木) 17:52:04.28
AMDはL1I$上でマーカー付けてる。
下手にISAをいじるよりも良いという判断なのだろう。
下手にISAをいじるよりも良いという判断なのだろう。
964 :,,・´∀`・,,)<一番良い -○○○ を頼む:2011/03/11(金) 14:29:39.13
Pentium 4はトレースキャッシュミスしてL2からのフェッチになると1クロック1命令までスループットが低下したけど
AMDの場合もL1Iキャッシュミスをすればプリデコーダの性能がボトルネックになる。
命令ストリーム+プリデコードタグで1サイクルに400bit以上もフェッチするくらいなら
全部デコード済みのキャッシュをL1Iとは別に持ったほうがましじゃね?
・・・と思ったらSandy Bridgeがそれをやった。
AMDの場合もL1Iキャッシュミスをすればプリデコーダの性能がボトルネックになる。
命令ストリーム+プリデコードタグで1サイクルに400bit以上もフェッチするくらいなら
全部デコード済みのキャッシュをL1Iとは別に持ったほうがましじゃね?
・・・と思ったらSandy Bridgeがそれをやった。
965 :デフォルトの名無しさん:2011/03/14(月) 00:37:40.36
思うだけじゃ駄目で、使えるトランジスタ数等を考えた定量的な解析が必要だろう
966 :デフォルトの名無しさん:2011/03/14(月) 01:12:27.42
ここは計測スレ
967 :デフォルトの名無しさん:2011/03/14(月) 16:52:23.37
Itaniumもらったんだが、どうやって計測するん?
RDTSCなんて命令ないぞ?
RDTSCなんて命令ないぞ?
968 :デフォルトの名無しさん:2011/03/14(月) 19:32:31.99
AR44レジスタを見るらしいよ。
レジスタの仕様自体はよく知らないけど。
レジスタの仕様自体はよく知らないけど。
969 :デフォルトの名無しさん:2011/03/14(月) 22:21:58.71
スレタイ見ろよこの糞虫どもが。
970 :デフォルトの名無しさん:2011/03/15(火) 20:06:21.27
>>968
サンクス・・・レジスタ読むまでの道のりは長そうだ。
サンクス・・・レジスタ読むまでの道のりは長そうだ。
971 :デフォルトの名無しさん:2011/03/25(金) 23:39:40.29
今回の災害にまつわる節電のため、Itaniumは電源を入れられなくなりました
エアコンよりも電気食うって、どういうことよ
エアコンよりも電気食うって、どういうことよ
972 :デフォルトの名無しさん:2011/04/07(木) 21:38:03.74
Software Optimization Guide for AMD Family 15h Processors
http://support.amd.com/us/Processor_TechDocs/47414.pdf
http://support.amd.com/us/Processor_TechDocs/47414.pdf
973 :,,・´∀`・,,)<一番良い -○○○ を頼む:2011/04/07(木) 23:21:37.04
FP/SIMDのポート配分がかなり嫌だな。
使いこなせる変態いたらまじで尊敬するわ。
使いこなせる変態いたらまじで尊敬するわ。
974 :デフォルトの名無しさん:2011/04/08(金) 00:13:39.28
>>973
いるじゃん。ここに一人。そんk
いるじゃん。ここに一人。そんk
975 :デフォルトの名無しさん:2011/04/08(金) 00:23:14.37
既定に餌を与える奴は既定
976 :,,・´∀`・,,)<一番良い -○○○ を頼む:2011/04/08(金) 00:43:28.63
何が嫌かって、簡単にいうと、行列積演算でかなり使えそうな、それこそIntelのAVXオリジナルよりリッチな
シャッフル・転置命令が実装されてるけど、FMACをフルに使う場合はその命令は使うなという、罰ゲーム仕様です。
なぜならFMACの1つとXBARユニットがPort1を共有してるから。
Port2, Port3側で実行できるPack/Unpack命令複数で代用してうまくポート競合を回避してくださいってこと。
この点に関してはSandy Bridgeのポート構成の美点を再確認できました。
シャッフル・転置命令が実装されてるけど、FMACをフルに使う場合はその命令は使うなという、罰ゲーム仕様です。
なぜならFMACの1つとXBARユニットがPort1を共有してるから。
Port2, Port3側で実行できるPack/Unpack命令複数で代用してうまくポート競合を回避してくださいってこと。
この点に関してはSandy Bridgeのポート構成の美点を再確認できました。
977 :デフォルトの名無しさん:2011/04/08(金) 00:49:21.44
Pack/UnpackもXBARだけじゃね?
978 :,,・´∀`・,,)<一番良い -○○○ を頼む:2011/04/08(金) 00:54:34.17
よくみたらそうだった。
なんでこのマニュアルのサンプルVPERMIL2PS使えば命令数減らせるものをUNPACKとかDUPとか使ってるんだろ?
なんでこのマニュアルのサンプルVPERMIL2PS使えば命令数減らせるものをUNPACKとかDUPとか使ってるんだろ?
979 :,,・´∀`・,,)<一番良い -○○○ を頼む:2011/04/08(金) 01:04:14.99
いや、そんなに減らないわ。失礼。
980 :デフォルトの名無しさん:2011/04/08(金) 01:38:34.38
遅くなる理由は異なれ、初期実装においてリッチなのが遅いのはIntelだってSSEの頃からそうだったろ。
初期実装は動く事が大事、まずは周知っていう発想は正直やめてほしいけど。
後から速くなるも知れないから、とかいう理由で今からわざわざ遅くなる選択をするかってのな。
速くなったら速くなったで新旧用にバイナリ2つ用意しなきゃならないし。
初期実装は動く事が大事、まずは周知っていう発想は正直やめてほしいけど。
後から速くなるも知れないから、とかいう理由で今からわざわざ遅くなる選択をするかってのな。
速くなったら速くなったで新旧用にバイナリ2つ用意しなきゃならないし。
981 :デフォルトの名無しさん:2011/04/08(金) 01:52:18.91
連投失礼。
どうせ動くの最優先にするなら、多少無理してでも豊富な命令を用意して、かつ固定しておいてほしかった。
128ビットだけでSSEからSSE4.2、しかも間にSSSE3とか変態ネーミングも絡めて6世代もバリエーションがあるのは多すぎる。
どうせ動くの最優先にするなら、多少無理してでも豊富な命令を用意して、かつ固定しておいてほしかった。
128ビットだけでSSEからSSE4.2、しかも間にSSSE3とか変態ネーミングも絡めて6世代もバリエーションがあるのは多すぎる。
982 :,,・´∀`・,,)<一番良い -○○○ を頼む:2011/04/08(金) 01:58:14.01
いやべつに遅くは無いと思う。ただポート構成が悪い。
これどういう風に進化するんだろうね?
FMACの256ビット化はいうまでもないけど、Port0, Port1にもMMX_ALUを持たせて
XBARはPort2に移動かな。
最初に(V)PPERM見たときスゲー協力だと思ったけど、1個だとわかった時点で
PSHUFBを2個発行できるSandy Bridgeのほうがいいわと思いました。
というか、どのみちSandy Bridge用とBulldozer用で別々のAVXコードが必要になるよ。
これどういう風に進化するんだろうね?
FMACの256ビット化はいうまでもないけど、Port0, Port1にもMMX_ALUを持たせて
XBARはPort2に移動かな。
最初に(V)PPERM見たときスゲー協力だと思ったけど、1個だとわかった時点で
PSHUFBを2個発行できるSandy Bridgeのほうがいいわと思いました。
というか、どのみちSandy Bridge用とBulldozer用で別々のAVXコードが必要になるよ。
983 :デフォルトの名無しさん:2011/04/08(金) 02:09:18.62
984 :,,・´∀`・,,)<一番良い -○○○ を頼む:2011/04/08(金) 02:10:01.79
あとVPCMOVと(V)PBLENDVBがVPERM*と同じポートなのが嫌だね。
32要素を超えるテーブル参照をしたいときにスループットでないいよ。
(Altivecではこれに相当する命令を並列実行できました)
32要素を超えるテーブル参照をしたいときにスループットでないいよ。
(Altivecではこれに相当する命令を並列実行できました)
985 :デフォルトの名無しさん:2011/04/08(金) 15:44:05.74
986 :デフォルトの名無しさん:2011/04/08(金) 16:01:26.31
なにかコンプレックスでもあるの?w
987 :デフォルトの名無しさん:2011/04/08(金) 16:25:24.61
This code is in the public domain.
988 :,,・´∀`・,,)<一番良い -○○○ を頼む:2011/04/08(金) 17:12:48.75
この人はドイツの人っぽいけどこういう一例も
http://www.sqlite.org/cvstrac/wiki?p=SampleCode
公共物ですと言いたいならinは必要だが
いわゆるPDS(著作権を放棄したソフトウェア)ですって意味なら不要かと
http://www.sqlite.org/cvstrac/wiki?p=SampleCode
公共物ですと言いたいならinは必要だが
いわゆるPDS(著作権を放棄したソフトウェア)ですって意味なら不要かと
989 :デフォルトの名無しさん:2011/04/09(土) 01:45:08.48
>>985 はアスペ
990 :デフォルトの名無しさん:2011/04/09(土) 02:52:25.02
>>985
バカだなお前。あれが未来の英語の姿だぞ?
バカだなお前。あれが未来の英語の姿だぞ?
991 :,,・´∀`・,,)<一番良い -○○○ を頼む:2011/04/09(土) 03:42:17.06
アルファベットで書かれた言語で英語ほど文法が加減なものは無いな。
992 :デフォルトの名無しさん:2011/04/09(土) 04:57:31.29
>>980
> 初期実装は動く事が大事
それが効力を発揮するのは、そのCPUが世代遅れになった時、だ。
後から速くなるかもしれないから使ってくださいではなく、
後から速くなったときに(古いCPUで動かないという理由で)使うのを躊躇させないために、あるのだと思う。
> 初期実装は動く事が大事
それが効力を発揮するのは、そのCPUが世代遅れになった時、だ。
後から速くなるかもしれないから使ってくださいではなく、
後から速くなったときに(古いCPUで動かないという理由で)使うのを躊躇させないために、あるのだと思う。
993 :デフォルトの名無しさん:2011/04/09(土) 05:17:16.68
My private parts are in the public domain :D
994 :デフォルトの名無しさん:2011/04/09(土) 12:19:50.18
a
995 :デフォルトの名無しさん:2011/04/09(土) 16:12:55.30
Lvが足りなくて次スレ立てられなかった
↓たのむ
↓たのむ
996 :デフォルトの名無しさん:2011/04/09(土) 16:45:23.50
997 :デフォルトの名無しさん:2011/04/09(土) 17:27:51.46
998 :デフォルトの名無しさん:2011/04/09(土) 17:44:30.87
x86命令の所要クロック計測スレPart5
http://hibari.2ch.net/test/read.cgi/tech/1302334991/
http://hibari.2ch.net/test/read.cgi/tech/1302334991/
999 :デフォルトの名無しさん:2011/04/09(土) 17:52:08.33
x86命令の所要クロック計測スレPart5
http://hibari.2ch.net/test/read.cgi/tech/1302334991/
http://hibari.2ch.net/test/read.cgi/tech/1302334991/
1000 :デフォルトの名無しさん:2011/04/09(土) 18:02:40.02
何も無理矢理埋めんでも
1001 :1001:
このスレッドは1000を超えました。
もう書けないので、新しいスレッドを立ててくださいです。。。
もう書けないので、新しいスレッドを立ててくださいです。。。