GPGPU#2
207 :デフォルトの名無しさん:
ノートPCでCUDAに向いてる機種って何?
浦島太郎なので、グラフィックchipの型番
とかワカンネ。
出張用に、軽くて携帯性と電池の持ちが良い
方が嬉しいけど。
あっ、もちろんLinux動くこと。
浦島太郎なので、グラフィックchipの型番
とかワカンネ。
出張用に、軽くて携帯性と電池の持ちが良い
方が嬉しいけど。
あっ、もちろんLinux動くこと。
|
|
|
208 :デフォルトの名無しさん:2008/05/11(日) 20:13:56
>>207
軽くて大きくなくて消費電力も少なめで、できればNVIDIAのGeForce8600MGS以上のVGAを搭載している機種。
軽くて大きくなくて消費電力も少なめで、できればNVIDIAのGeForce8600MGS以上のVGAを搭載している機種。
209 :デフォルトの名無しさん:2008/05/12(月) 05:38:10
>VGAを搭載している機種。
そんなスペック作ってネーヨ
そんなスペック作ってネーヨ
210 :デフォルトの名無しさん:2008/05/12(月) 07:30:43
VideoGraphicAdapterですね。
211 :デフォルトの名無しさん:2008/05/12(月) 09:46:54
Acceleratorとも言う
Folding@Homeのdllではなぜか駄目で元のsdkについてきたものに戻すと、
とりあえずエラーはでないみたいです。
VisualStudioでx64としてBrook+のGuideにあるサンプル(Sum.br)をコンパイルすることはできているのですが、
実行をしてもプロンプトが一瞬現れるだけでなんの結果も得られない状況です。
(他の元から入っているサンプルの.exeを実行しても同じ)
printfの結果さえプロンプトに表示されていないので、どう見ても実行されていないように見えるのですが
どうなんでしょうか…
とりあえずエラーはでないみたいです。
VisualStudioでx64としてBrook+のGuideにあるサンプル(Sum.br)をコンパイルすることはできているのですが、
実行をしてもプロンプトが一瞬現れるだけでなんの結果も得られない状況です。
(他の元から入っているサンプルの.exeを実行しても同じ)
printfの結果さえプロンプトに表示されていないので、どう見ても実行されていないように見えるのですが
どうなんでしょうか…
213 :デフォルトの名無しさん:2008/05/12(月) 14:36:07
プロンプトが一瞬現れるのなら、結果も一瞬現れているのではないか?
ダブルクリックで起動せずに、コマンドプロンプトから実行してみては?
ダブルクリックで起動せずに、コマンドプロンプトから実行してみては?
214 :199:2008/05/12(月) 14:40:22
コマプロ上からもやってみたのだけれど、一切のエラー・警告もなく静かに終わるんです。
Sum.br内のreturn 0; の前にprintf("test"); を入れてるのでちゃんと実行されてるなら
最低testが表示されるはずなのにされないんですよ。
ドウナッテルノ?
Sum.br内のreturn 0; の前にprintf("test"); を入れてるのでちゃんと実行されてるなら
最低testが表示されるはずなのにされないんですよ。
ドウナッテルノ?
215 :デフォルトの名無しさん:2008/05/12(月) 18:00:30
Brook+の中かCALの中でexitでも呼んでるんでしょ。
俺のやった方法は以下の通り
1.64ビット版Vista SP1をセットアップ,ドライバインストール
2.F@Hをインストール
3.F@Hを起動してamdcalrt.dll,amdcalcl.dllがDLされていることを確認したら終了する
4.適当にディレクトリを作成してXP64にインストールしたSDKからサンプルのバイナリ,Brook+のdllをコピー
(VistaにSDKは入れてない)
5.F@Hのamdcalrt.dll,amdcalcl.dllもコピー
6.実行
俺のやった方法は以下の通り
1.64ビット版Vista SP1をセットアップ,ドライバインストール
2.F@Hをインストール
3.F@Hを起動してamdcalrt.dll,amdcalcl.dllがDLされていることを確認したら終了する
4.適当にディレクトリを作成してXP64にインストールしたSDKからサンプルのバイナリ,Brook+のdllをコピー
(VistaにSDKは入れてない)
5.F@Hのamdcalrt.dll,amdcalcl.dllもコピー
6.実行
4.の(VistaにSDKは入れてない)というところが違う所ではあるのですが、
Vista x64 SP1にSDKをインストールして、後はそこから1〜6に沿ってやってみましたが
真っ黒なプロンプトが一瞬立ち上がるだけで前と変わらないみたいです。
(コマンドプロンプト上から実行しても同じ)
手詰まりなので、正式版でるまでしばらく待ってみます。
アドバイスして頂き、ありがとうございます。
Vista x64 SP1にSDKをインストールして、後はそこから1〜6に沿ってやってみましたが
真っ黒なプロンプトが一瞬立ち上がるだけで前と変わらないみたいです。
(コマンドプロンプト上から実行しても同じ)
手詰まりなので、正式版でるまでしばらく待ってみます。
アドバイスして頂き、ありがとうございます。
217 :デフォルトの名無しさん:2008/05/12(月) 21:40:50
>>216
多分SDKをインストールすると環境変数を頼りにSDKのdllを参照しに行かされてるんじゃないかなぁ。
コマンドプロンプトから
>set CALROOT=
>hoge.exe
でやってみたらいけそうな匂いがするけど。もしくはSDKの方のdllをリネームしておくとか。
あとはCatalystのバージョンくらいか。役に立てずすまんね。
多分SDKをインストールすると環境変数を頼りにSDKのdllを参照しに行かされてるんじゃないかなぁ。
コマンドプロンプトから
>set CALROOT=
>hoge.exe
でやってみたらいけそうな匂いがするけど。もしくはSDKの方のdllをリネームしておくとか。
あとはCatalystのバージョンくらいか。役に立てずすまんね。
インストールフォルダのlib中にあるdllファイルをF@Hのものに置き換えると
dllが見つからないというエラーがでるようになったので駄目な気がします。
>217 のようにしてプロンプトから実行してみましたがやはり駄目でした…
Catalystは現最新の8.4なのですが、どうでしょう。
ちなみに、VisualStudio上から強引にCPUエミュレートでコードを走らせるように設定したら
想定どうりの動きをしたのでコードの間違いや.brファイルの変換までは問題ない
と思われます。たぶん
ムゥ〜
dllが見つからないというエラーがでるようになったので駄目な気がします。
>217 のようにしてプロンプトから実行してみましたがやはり駄目でした…
Catalystは現最新の8.4なのですが、どうでしょう。
ちなみに、VisualStudio上から強引にCPUエミュレートでコードを走らせるように設定したら
想定どうりの動きをしたのでコードの間違いや.brファイルの変換までは問題ない
と思われます。たぶん
ムゥ〜
219 :デフォルトの名無しさん:2008/05/12(月) 23:59:40
うーん、何で俺の環境だと動いてんだろ。むしろこっちがおかしいのか?
なんか特別なことやったかなぁ。
なんか特別なことやったかなぁ。
220 :デフォルトの名無しさん:2008/05/13(火) 12:26:10
>>214
問題の切り分けがヘタだな。
printf() だけなら表示されるのか?ダメならそれ以前の問題。
printf() を先頭に持っていって表示されるか?されないならちょっと面倒かも。
表示されるなら、printf() の位置を移動して、表示されなくなる境界を探すとその近辺に(間接的かもしれないが)問題がある。
問題の切り分けがヘタだな。
printf() だけなら表示されるのか?ダメならそれ以前の問題。
printf() を先頭に持っていって表示されるか?されないならちょっと面倒かも。
表示されるなら、printf() の位置を移動して、表示されなくなる境界を探すとその近辺に(間接的かもしれないが)問題がある。
221 :199:2008/05/13(火) 14:34:48
>220
printf()のみソースに記述した場合も変数宣言直後にprintf()をした場合ともに、状況は
変わらないようでした...
CPUエミュの場合と、GPUの場合とでログをとってみました、こんな感じです。
CPU:
Runtime::CreateInstance((null), 0000000000000000, 1)
Brook Runtime starting up
Runtime::Runtime()
stream::stream(000000014001C228, ...)
Runtime::GetInstance((null), 0000000000000000, 0)
Runtime::GetInstanceRef()
CPURuntime::CreateStream(1, 000000000027A360, 2, 000000000027A440, 0)
CPUStream::CPUStream(1, 000000000027A360, 2, 000000000027A440)
StreamInterface::getElementSize()
CPUStream::getFieldCount()
........続く
GPU:
Runtime::CreateInstance((null), 0000000000000000, 1)
Brook Runtime starting up
CALRuntime::create(0000000000000000)
Runtime::Runtime()
CALRuntime::CALRuntime()
CALContext::create(0000000000000000)
CALContext::CALContext()
CALContext::initialize(0000000000000000, 0)
これだけ
GPUの方は、初期化処理で止まってしまっていたので、やはり環境面で何かありそうな感じです。
CPUStream::getIndexedFieldType(0)
getElementSize(1)
printf()のみソースに記述した場合も変数宣言直後にprintf()をした場合ともに、状況は
変わらないようでした...
CPUエミュの場合と、GPUの場合とでログをとってみました、こんな感じです。
CPU:
Runtime::CreateInstance((null), 0000000000000000, 1)
Brook Runtime starting up
Runtime::Runtime()
stream::stream(000000014001C228, ...)
Runtime::GetInstance((null), 0000000000000000, 0)
Runtime::GetInstanceRef()
CPURuntime::CreateStream(1, 000000000027A360, 2, 000000000027A440, 0)
CPUStream::CPUStream(1, 000000000027A360, 2, 000000000027A440)
StreamInterface::getElementSize()
CPUStream::getFieldCount()
........続く
GPU:
Runtime::CreateInstance((null), 0000000000000000, 1)
Brook Runtime starting up
CALRuntime::create(0000000000000000)
Runtime::Runtime()
CALRuntime::CALRuntime()
CALContext::create(0000000000000000)
CALContext::CALContext()
CALContext::initialize(0000000000000000, 0)
これだけ
GPUの方は、初期化処理で止まってしまっていたので、やはり環境面で何かありそうな感じです。
CPUStream::getIndexedFieldType(0)
getElementSize(1)
>221 の下の2行はミスです。
ちなみに、GPUはRadeon HD3470を使っています。(Vista HomePremium x64 SP1)
ちなみに、GPUはRadeon HD3470を使っています。(Vista HomePremium x64 SP1)
223 :デフォルトの名無しさん:2008/05/21(水) 00:46:01
brook+ってなんでLinuxじゃ使えないの?
224 :デフォルトの名無しさん:2008/05/21(水) 01:24:19
Brook+のrelease-notes-mar-08.txtより
> Compiler Support
> ----------------
>
> We only support Visual Studio 2005 (for Windows builds) and gcc 4.1.2 (for
> Linux builds).
> Compiler Support
> ----------------
>
> We only support Visual Studio 2005 (for Windows builds) and gcc 4.1.2 (for
> Linux builds).
225 :デフォルトの名無しさん:2008/05/21(水) 02:59:59
226 :デフォルトの名無しさん:2008/05/21(水) 15:32:05
cudaはGeforce8xxx以上だよ
8系でオンボードチップってあるんかいな
8系でオンボードチップってあるんかいな
227 :デフォルトの名無しさん:2008/05/21(水) 17:50:08
228 :デフォルトの名無しさん:2008/05/21(水) 20:37:49
何でこのご時世にMP3・・・
せめてAACにしろよ
せめてAACにしろよ
229 :デフォルトの名無しさん:2008/05/21(水) 21:44:19
コンテストってことは
最適化か何かかね
めざせUS$5,000.00
と思ったら人種差別化ね
Resident in the United States or Canada
最適化か何かかね
めざせUS$5,000.00
と思ったら人種差別化ね
Resident in the United States or Canada
230 :デフォルトの名無しさん:2008/05/21(水) 22:21:53
>>226
オンボードかどうかは知らんが、GeForce8系を積んだノートPCなら腐るほどある。
オンボードかどうかは知らんが、GeForce8系を積んだノートPCなら腐るほどある。
231 :デフォルトの名無しさん:2008/05/22(木) 01:25:47
>>227
既にhydrogenaudioのスレでも指摘されてるけど、LAMEで大半の時間を食ってるのは
ベクトル化の難しい心理音響解析であって、最適化の効果が大きいFFTやらMDCTではないんだよな
あまり最適化に向いた問題じゃない
既にhydrogenaudioのスレでも指摘されてるけど、LAMEで大半の時間を食ってるのは
ベクトル化の難しい心理音響解析であって、最適化の効果が大きいFFTやらMDCTではないんだよな
あまり最適化に向いた問題じゃない
232 :デフォルトの名無しさん:2008/05/22(木) 15:11:57
>>226
8100と8200のチップセットが出たがな
8100と8200のチップセットが出たがな
233 :デフォルトの名無しさん:2008/05/22(木) 23:17:04
月刊Catalyst2008年5月号では現行のAMD Stream SDK、F@HのCAL共に動きません。
気をつけましょう。
気をつけましょう。
234 :デフォルトの名無しさん:2008/05/22(木) 23:50:55
Catalyst腐りすぎ
だんだんコード悪くなってる
なぜNvidiaが金出してコンサル
してやるって言うのに応諾しねーのよ?
だんだんコード悪くなってる
なぜNvidiaが金出してコンサル
してやるって言うのに応諾しねーのよ?
235 :デフォルトの名無しさん:2008/05/23(金) 00:13:24
Vistaじゃ動くそうだよ。
> だんだんコード悪くなってる
お前はAMDの中の人なのか?w
> だんだんコード悪くなってる
お前はAMDの中の人なのか?w
236 :デフォルトの名無しさん:2008/05/23(金) 07:05:54
fahはvistaだと問題ないな8.5は
237 :デフォルトの名無しさん:2008/05/25(日) 11:57:17
AMD Stream SDK v1.1-betaきてた
238 :デフォルトの名無しさん:2008/05/25(日) 12:00:04
Linuxまだ対応してねーよ
もうAMDなんていらねーから
業界標準をCudaにしろ
もうAMDなんていらねーから
業界標準をCudaにしろ
239 :デフォルトの名無しさん:2008/05/25(日) 12:08:46
Linux向けSDK公開されてますけど?
240 :デフォルトの名無しさん:2008/05/25(日) 12:10:14
http://journal.mycom.co.jp/special/2008/cuda/008.html
希望的観測ぽいけど、GPGPU以外でも使えるモデルと思ってるみたい
希望的観測ぽいけど、GPGPU以外でも使えるモデルと思ってるみたい
241 :デフォルトの名無しさん:2008/05/25(日) 13:21:55
242 :デフォルトの名無しさん:2008/05/25(日) 13:37:27
キターーー
LinuxキタけどこれDebianはいらねーじゃん
AMD shitだな
LinuxキタけどこれDebianはいらねーじゃん
AMD shitだな
243 :デフォルトの名無しさん:2008/05/25(日) 13:48:20
244 :デフォルトの名無しさん:2008/05/25(日) 17:10:46
245 :デフォルトの名無しさん:2008/05/25(日) 18:46:25
Xenの上でも動く?
246 :デフォルトの名無しさん:2008/05/25(日) 18:50:40
debian用のパッチ作ったぉ
だれもいらんよね
だれもいらんよね
247 :デフォルトの名無しさん:2008/05/25(日) 18:57:59
>>246
いらねーよ消えろボケ
いらねーよ消えろボケ
248 :デフォルトの名無しさん:2008/05/25(日) 20:25:29
まぁ待て、煽るんじゃない。
でも俺も要らんわ。
でも俺も要らんわ。
249 :デフォルトの名無しさん:2008/05/25(日) 20:35:26
250 :デフォルトの名無しさん:2008/05/25(日) 21:08:04
要る
251 :デフォルトの名無しさん:2008/05/25(日) 22:39:34
252 :デフォルトの名無しさん:2008/05/27(火) 11:43:25
Core2Quad Q9450でPS2エミュをやると、実機と違い処理オチせず、激ムズになることが判明
http://namidame.2ch.net/test/read.cgi/news/1211740649/l50
http://namidame.2ch.net/test/read.cgi/news/1211740649/l50
253 :デフォルトの名無しさん:2008/05/28(水) 00:08:53
AMDの方言語って
CUDAと比較して半端じゃなく
使い勝手悪くない?
CUDAと比較して半端じゃなく
使い勝手悪くない?
254 :デフォルトの名無しさん:2008/05/28(水) 05:13:09
いやゼンゼン
255 :デフォルトの名無しさん:2008/05/28(水) 17:15:13
言語はAMDが作った仕様ってわけじゃないんだよな
256 :デフォルトの名無しさん:2008/05/28(水) 23:08:16
AMDの奴ってなんていうか
学生向け言語って感じで
実用性まったくない言語
になってるね
もともとが学生向けのおもちゃ
言語をベースにしているのが原因かもしれないけど
学生向け言語って感じで
実用性まったくない言語
になってるね
もともとが学生向けのおもちゃ
言語をベースにしているのが原因かもしれないけど
257 :デフォルトの名無しさん:2008/05/28(水) 23:38:15
同じ問題を解いた時ほぼ100%
CUDAに負けるね
Radeon 3870と
Geforce 9800GTXでやってるけど
Radeon遅すぎてお話にならない
CUDAに負けるね
Radeon 3870と
Geforce 9800GTXでやってるけど
Radeon遅すぎてお話にならない
258 :デフォルトの名無しさん:2008/05/29(木) 05:51:48
必死な奴が常駐してるな
259 :デフォルトの名無しさん:2008/05/29(木) 07:39:16
N社の工作員なの?
260 :デフォルトの名無しさん:2008/05/29(木) 12:31:16
こんなとこでやっても見てるやつがどれだけいることやら・・
261 :デフォルトの名無しさん:2008/05/29(木) 15:13:10
価格帯違うGPUで比べたらそりゃ遅いわな
262 :デフォルトの名無しさん:2008/06/01(日) 12:33:25
CUDAとAMDのSDKってどっちが
簡単ですか?
OpenMPみたいにらくらくにできますか?
簡単ですか?
OpenMPみたいにらくらくにできますか?
263 :デフォルトの名無しさん:2008/06/01(日) 13:24:31
AMD Stream SDKのv1.1betaって登録しないと落とせないの?
不便だなぁ
不便だなぁ
264 :デフォルトの名無しさん:2008/06/01(日) 14:34:51
は?
265 :デフォルトの名無しさん:2008/06/01(日) 14:41:20
266 :デフォルトの名無しさん:2008/06/01(日) 14:57:59
普通に落とせるよ
267 :デフォルトの名無しさん:2008/06/01(日) 15:20:54
普通に落とせるよ
268 :デフォルトの名無しさん:2008/06/02(月) 15:03:01
269 :デフォルトの名無しさん:2008/06/02(月) 21:27:45
270 :デフォルトの名無しさん:2008/06/02(月) 21:50:38
CALを生で使う根性があればAMDの方は自由度高いし面白いと思うよ。
グローバルバッファとか使えるし、適用できる問題の幅も広い。
ただCAL側のリソースをテクスチャにしたり頂点バッファにするみたいな
DirectXやOpenGLとの協調はまだ未実装だから、完全に計算しか出来ないけど。
Brook+ははっきり言ってまだ使い物にならない。CPUコード吐かせると
数値リテラルが全部floatになって生成されたcppファイルがコンパイルできないとか。
CALコードだけにすればまぁ何とか使えなくもないけど、CUDAの方が実用的。
グローバルバッファとか使えるし、適用できる問題の幅も広い。
ただCAL側のリソースをテクスチャにしたり頂点バッファにするみたいな
DirectXやOpenGLとの協調はまだ未実装だから、完全に計算しか出来ないけど。
Brook+ははっきり言ってまだ使い物にならない。CPUコード吐かせると
数値リテラルが全部floatになって生成されたcppファイルがコンパイルできないとか。
CALコードだけにすればまぁ何とか使えなくもないけど、CUDAの方が実用的。
271 :デフォルトの名無しさん:2008/06/02(月) 23:12:37
272 :デフォルトの名無しさん:2008/06/02(月) 23:22:28
まぁ機能すらフルに実装されていないβVerだから速度に期待するのは酷だね
273 :デフォルトの名無しさん:2008/06/02(月) 23:33:07
速度やバグあるのはまぁCUDAも
0.xxxははんぱねぇw状態だったから
別段いいんだけど
Brook+の自由度がどの程度なのか
いまいち図りきれないのが残念
すぐコンパイルエラーばっかり
0.xxxははんぱねぇw状態だったから
別段いいんだけど
Brook+の自由度がどの程度なのか
いまいち図りきれないのが残念
すぐコンパイルエラーばっかり
274 :デフォルトの名無しさん:2008/06/03(火) 00:44:32
>>271
まぁちと言い過ぎだけどね。
言語としてはシンプルでそれほど悪いわけじゃないし(でも3DAPIと協調するときどーすんだって気はする。ドキュメントにすら記載ないし)
CALコードだけならとりあえず動くコードは吐いてくれる。遅いけど。
v1.1-betaなんてバージョンにしちゃったから印象が悪いわけで、実際のところは熟成待ち。
>>373
秋葉原で3850が1万チョイって話もあるし、とりあえず3xxx1枚買ってbrcc -p calオススヌ。
CALバックエンドなCUDAコンパイラを誰かが作ってくれないもんかねぇ
まぁちと言い過ぎだけどね。
言語としてはシンプルでそれほど悪いわけじゃないし(でも3DAPIと協調するときどーすんだって気はする。ドキュメントにすら記載ないし)
CALコードだけならとりあえず動くコードは吐いてくれる。遅いけど。
v1.1-betaなんてバージョンにしちゃったから印象が悪いわけで、実際のところは熟成待ち。
>>373
秋葉原で3850が1万チョイって話もあるし、とりあえず3xxx1枚買ってbrcc -p calオススヌ。
CALバックエンドなCUDAコンパイラを誰かが作ってくれないもんかねぇ
275 :デフォルトの名無しさん:2008/06/03(火) 00:47:51
おっと、書き込んでから思い出した。
ドキュメントにはないけどVC用のusertype.datにこんな文字列があったんだった。
streamToD3D
streamFromD3D
streamToGL
streamFromGL
一応Brook+と3DAPIのやり取りを実装する気ではいる様だ。いつになるか知らないけどw
ドキュメントにはないけどVC用のusertype.datにこんな文字列があったんだった。
streamToD3D
streamFromD3D
streamToGL
streamFromGL
一応Brook+と3DAPIのやり取りを実装する気ではいる様だ。いつになるか知らないけどw
276 :デフォルトの名無しさん:2008/06/03(火) 00:50:48
277 :デフォルトの名無しさん:2008/06/03(火) 12:17:43
4850は18日
278 :デフォルトの名無しさん:2008/06/03(火) 13:06:50
ときに次のPhotoshopがGPU使うそうですが。
279 :デフォルトの名無しさん:2008/06/05(木) 03:12:09
280 :デフォルトの名無しさん:2008/06/05(木) 07:28:21
みんなCUDAで200Wとか280W
電力消費すれよw
電力消費すれよw
281 :デフォルトの名無しさん:2008/06/05(木) 10:05:45
>>279
β版の開発環境でプラグイン作るなんてAdobeもATiも迷惑だろ
β版の開発環境でプラグイン作るなんてAdobeもATiも迷惑だろ
282 :デフォルトの名無しさん:2008/06/05(木) 16:49:45
CUDAは上位互換が保障されてます
283 :デフォルトの名無しさん:2008/06/05(木) 21:44:13
CUDAは全ての変更が上位と将来版で
継承されることが保障されている
Computexで聞いてきたがAMDの方は
1.5からまた全く違う内容になる。
CLIの実装方式が変更されるから意味
ないんだよな
継承されることが保障されている
Computexで聞いてきたがAMDの方は
1.5からまた全く違う内容になる。
CLIの実装方式が変更されるから意味
ないんだよな
284 :デフォルトの名無しさん:2008/06/05(木) 23:49:12
つまり大幅なハードの変更がある訳かね?
285 :デフォルトの名無しさん:2008/06/06(金) 00:17:19
また変な改行の人か
286 :デフォルトの名無しさん:2008/06/06(金) 02:10:54
この流れでいくとCUDAが圧勝するわけだけど
そうなると当然対応ソフトの多さによってnVidiaカードのシェアが伸びる
下手すれば完全に独占してしまうかもしれない
AMDはCUDAに対応させるために改造するのだろうか
そうなるとnVidiaがすべての仕様をこれから先ずっと作っていくことになってしまう
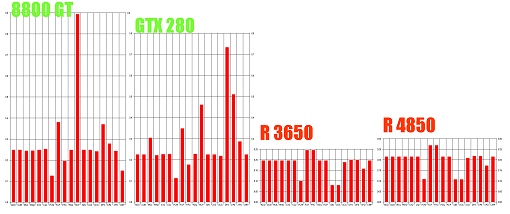
使い勝手の悪いものが出来たり、上位互換を自分勝手に切り捨てたりするかもしれん
ISOのような公式な機関が介入出来る情勢でもないし
混沌としてきそうで嫌だね
洗練された仕様がどのメーカーのVGAでも一様に動作するというのが
ユーザーとしては最も望ましいわけだけど
このままだとそれは永遠に無いかもね
そうなると当然対応ソフトの多さによってnVidiaカードのシェアが伸びる
下手すれば完全に独占してしまうかもしれない
AMDはCUDAに対応させるために改造するのだろうか
そうなるとnVidiaがすべての仕様をこれから先ずっと作っていくことになってしまう
使い勝手の悪いものが出来たり、上位互換を自分勝手に切り捨てたりするかもしれん
ISOのような公式な機関が介入出来る情勢でもないし
混沌としてきそうで嫌だね
洗練された仕様がどのメーカーのVGAでも一様に動作するというのが
ユーザーとしては最も望ましいわけだけど
このままだとそれは永遠に無いかもね
287 :デフォルトの名無しさん:2008/06/06(金) 07:36:28
>>286
いやそれは無い。もう、Intel互換のチプセトも
AMD互換のチプセトも作らせて貰えない可能性
高い。本業のグラボも1のつの巨大コアで全部
ぶん回す旧世代のアーキテクチャだよ
弱ったら買い叩かれるのがオチだよ
いやそれは無い。もう、Intel互換のチプセトも
AMD互換のチプセトも作らせて貰えない可能性
高い。本業のグラボも1のつの巨大コアで全部
ぶん回す旧世代のアーキテクチャだよ
弱ったら買い叩かれるのがオチだよ
288 :デフォルトの名無しさん:2008/06/06(金) 12:33:06
だから今余裕のあるうちに逃げ道を探して奔走してる訳だね
289 :デフォルトの名無しさん:2008/06/06(金) 16:04:53
>本業のグラボも1のつの巨大コアで全部
>ぶん回す旧世代のアーキテクチャだよ
新世代のアーキテクチャのグラボはどれですか?
>ぶん回す旧世代のアーキテクチャだよ
新世代のアーキテクチャのグラボはどれですか?
290 :デフォルトの名無しさん:2008/06/06(金) 16:09:56
RadeonはデュアルコアGPUの4870X2が次世代のフラッグシップモデル
性能もnVidia最上位のGTX280より上らしい
ttp://www.vr-zone.com/articles/Radeon_HD_4870_X2_R700_Beats_GeForce_GTX_280/5851.html
これでStream SDKさえ完成版が出ていたら…
性能もnVidia最上位のGTX280より上らしい
ttp://www.vr-zone.com/articles/Radeon_HD_4870_X2_R700_Beats_GeForce_GTX_280/5851.html
これでStream SDKさえ完成版が出ていたら…
291 :デフォルトの名無しさん:2008/06/06(金) 18:44:28
Streaming Computing用途の性能なら
単精度で2倍あるはずだしな。
単精度で2倍あるはずだしな。
292 :デフォルトの名無しさん:2008/06/06(金) 19:11:06
Stream SDKは1.0β→1.1βまで2か月しか掛かってないし、
4870X2が出る予定の8月までには完成できるんじゃないかな
4870X2が出る予定の8月までには完成できるんじゃないかな
293 :デフォルトの名無しさん:2008/06/06(金) 19:58:57
4870X2ってただのCrossFire接続だろ?
新世代なんて程のもんじゃ無いな。
新世代なんて程のもんじゃ無いな。
294 :デフォルトの名無しさん:2008/06/06(金) 20:02:34
295 :デフォルトの名無しさん:2008/06/06(金) 20:03:26
いや、ただのCrossFireだって・・・
二重にメモリ積んでるし。
二重にメモリ積んでるし。
296 :デフォルトの名無しさん:2008/06/06(金) 20:10:03
297 :デフォルトの名無しさん:2008/06/06(金) 20:16:24
ttp://northwood.blog60.fc2.com/blog-entry-1999.html
>Radeon HD 4870X2はATiの次世代ハイエンドカードである。
>このカードは2つのGPUを1つの基板に搭載したものである。
>Radeon HD 4870X2はATiのMulti-GPUソリューションである
>CrossFire Xによる2つのGPUをリンクさせるのでドライバのできによって性能が大きく左右される。
>Radeon HD 4870X2はATiの次世代ハイエンドカードである。
>このカードは2つのGPUを1つの基板に搭載したものである。
>Radeon HD 4870X2はATiのMulti-GPUソリューションである
>CrossFire Xによる2つのGPUをリンクさせるのでドライバのできによって性能が大きく左右される。
298 :デフォルトの名無しさん:2008/06/06(金) 20:48:26
俺らでCLIの開発してやるから
ATI仕様さらせよ
今Linux版解析してるが
実装がヒドイこれやばいだろってもんじゃないなぁ
ATI仕様さらせよ
今Linux版解析してるが
実装がヒドイこれやばいだろってもんじゃないなぁ
299 :デフォルトの名無しさん:2008/06/06(金) 20:49:07
>>297
ただのCrossFireとCrossFireXは世代が違う技術だっての…メモリ非共有ともどこにも書いてないしな
少なくとも単なる大型化のGTX280とは全く別世代のアーキテクチャだ
ttp://a96sj096.cocolog-nifty.com/weblog/2008/05/r7002_d82b.html
ttp://northwood.blog60.fc2.com/blog-entry-2000.html#more
ただのCrossFireとCrossFireXは世代が違う技術だっての…メモリ非共有ともどこにも書いてないしな
少なくとも単なる大型化のGTX280とは全く別世代のアーキテクチャだ
ttp://a96sj096.cocolog-nifty.com/weblog/2008/05/r7002_d82b.html
ttp://northwood.blog60.fc2.com/blog-entry-2000.html#more
300 :デフォルトの名無しさん:2008/06/07(土) 19:36:02
800SPの1.2Tflopsだってさ4870
あと4870X2がオンボードCFなのかどうかは不明
PLXじゃない専用ブリッジを乗せるとのうわさもある
あと4870X2がオンボードCFなのかどうかは不明
PLXじゃない専用ブリッジを乗せるとのうわさもある
301 :デフォルトの名無しさん:2008/06/07(土) 19:39:40
302 :デフォルトの名無しさん:2008/06/07(土) 19:54:12
{kind=link}
303 :デフォルトの名無しさん:2008/06/07(土) 20:00:28
つまり今まで一番もっともらしく出回ってた
480SPってのが単なる妄想スペックだったわけだ
480SPってのが単なる妄想スペックだったわけだ
304 :デフォルトの名無しさん:2008/06/07(土) 20:30:00
実製品のFLOPSが妄想スペックを20%近く上回るとか…
逆にこっちの方がフェイクじゃないかと思ってしまうな
逆にこっちの方がフェイクじゃないかと思ってしまうな
305 :デフォルトの名無しさん:2008/06/07(土) 20:39:12
フェイクだったりして
306 :デフォルトの名無しさん:2008/06/07(土) 20:42:53
4850とりあえずもう予約したから
初日にベンチしてやるから
何やってほしいか晒せ
初日にベンチしてやるから
何やってほしいか晒せ
307 :デフォルトの名無しさん:2008/06/07(土) 20:52:51
>>306
H.264エンコード
H.264エンコード
308 :デフォルトの名無しさん:2008/06/07(土) 21:13:07
309 :デフォルトの名無しさん:2008/06/07(土) 21:40:52
まぁ、フェイクとしても4870はいずれ1Tflops超えか
310 :デフォルトの名無しさん:2008/06/07(土) 22:11:20
AでもNでもどっちでもいいからはよH.264エンコーダ作ってクレー
311 :デフォルトの名無しさん:2008/06/08(日) 17:40:29
どうでもいいけどラデはム板的に意味なし
312 :デフォルトの名無しさん:2008/06/08(日) 17:43:46
CALがあるじゃない
313 :デフォルトの名無しさん:2008/06/08(日) 18:36:05
いっこうにCALの話題が無いw
誰かが試したという報告すら聞かない
CUDAはかなり普及してきてる
誰かが試したという報告すら聞かない
CUDAはかなり普及してきてる
314 :デフォルトの名無しさん:2008/06/08(日) 18:40:29
ところでDX10はストリーム演算が出来るとか聞くけど
サンプルとかぜんぜん見当たらないんだけど
DX9と比較して何がどう違うの?
DX10を使ったフレームワークとかあるの?
サンプルとかぜんぜん見当たらないんだけど
DX9と比較して何がどう違うの?
DX10を使ったフレームワークとかあるの?
315 :デフォルトの名無しさん:2008/06/08(日) 20:15:25
4870X2のCFで4.8Tflopsとかわけわかんねぇ
パフォーマンス
パフォーマンス
316 :デフォルトの名無しさん:2008/06/08(日) 20:17:24
X2で1.2TF
48レーンのPCI-EXってかなり
限定されるな
48レーンのPCI-EXってかなり
限定されるな
317 :デフォルトの名無しさん:2008/06/08(日) 20:39:08
いや、多分そうはならない
318 :デフォルトの名無しさん:2008/06/08(日) 22:40:09
CALのドキュメントどれ読めばいいの?
319 :デフォルトの名無しさん:2008/06/08(日) 22:46:22
ProgrammingGuide.pdfとcal_platform_spec.pdfとil.pdf
320 :デフォルトの名無しさん:2008/06/09(月) 17:55:47
ttp://www.pczilla.net/en/post/36.html
According to some insiders, Compute Shader technology in
DirectX1 11 will possibly terminate the future of NVIDIA's CUDA technology.
統一が望ましいわな
当然
According to some insiders, Compute Shader technology in
DirectX1 11 will possibly terminate the future of NVIDIA's CUDA technology.
統一が望ましいわな
当然
321 :デフォルトの名無しさん:2008/06/09(月) 21:01:12
Linuxはどうなるのさ?
322 :デフォルトの名無しさん:2008/06/09(月) 22:02:54
何そのいらない子
323 :デフォルトの名無しさん:2008/06/11(水) 05:05:11
結局11が出るまで何も普及しないし実験に付き合わされただけかw
324 :デフォルトの名無しさん:2008/06/11(水) 05:10:09
ATIの10.1とかもう何の為にあるのかさえ分からんw
ATI詐欺にまた引っかかったなそこの君www
ATI詐欺にまた引っかかったなそこの君www
325 :デフォルトの名無しさん:2008/06/11(水) 07:40:27
Windowsの方がどんな場合でも
処理性能300%上なのになぜ
Linuxなんて存在するんだろう
処理性能300%上なのになぜ
Linuxなんて存在するんだろう
326 :デフォルトの名無しさん:2008/06/11(水) 09:07:49
OpenCLってどうよ?
327 :デフォルトの名無しさん:2008/06/11(水) 12:39:40
>>325
タダだから。
タダだから。
328 :デフォルトの名無しさん:2008/06/11(水) 14:22:25
329 :デフォルトの名無しさん:2008/06/11(水) 15:34:51
330 :デフォルトの名無しさん:2008/06/11(水) 20:29:50
>>324
ばか
ばか
331 :デフォルトの名無しさん:2008/06/11(水) 23:05:00
10.1は知らんけど、Stream SDKが死産になりそうな感じではあるな
332 :デフォルトの名無しさん:2008/06/11(水) 23:12:23
Intelの奴が2009年の始めにでるけど
それは1枚のカードで4TFらしいね
それは1枚のカードで4TFらしいね
333 :デフォルトの名無しさん:2008/06/12(木) 01:04:38
Intel()笑
334 :デフォルトの名無しさん:2008/06/12(木) 06:18:45
なんだその関数
335 :デフォルトの名無しさん:2008/06/12(木) 14:14:08
>>334
ワラタ
ワラタ
336 :デフォルトの名無しさん:2008/06/12(木) 16:59:50
void intel()
{
delete palestinian;
}
{
delete palestinian;
}
337 :デフォルトの名無しさん:2008/06/12(木) 17:10:52
AMDはhavokか
338 :デフォルトの名無しさん:2008/06/12(木) 17:17:42
ttp://pc.watch.impress.co.jp/docs/2008/0612/amd.htm
AMDとHavok、物理演算をAMDプラットフォームに最適化
最適化はAMD Phenom X4を含むx86プロセッサが対象で、
将来的なATI Radeon GPUでの利用についても取り組む。
AMDとHavok、物理演算をAMDプラットフォームに最適化
最適化はAMD Phenom X4を含むx86プロセッサが対象で、
将来的なATI Radeon GPUでの利用についても取り組む。
339 :デフォルトの名無しさん:2008/06/12(木) 20:03:17
またAMD詐欺か
340 :デフォルトの名無しさん:2008/06/12(木) 20:04:15
どうでもいいがこのまま消費電力増え続けると地球と家計が爆発するぞ
341 :デフォルトの名無しさん:2008/06/12(木) 20:24:35
詐欺も何もCCCにはR600のころから物理処理に関するヘルプが入っていて
havokがintelに買収されてから延々と活かされないままになっていた
havokがintelに買収されてから延々と活かされないままになっていた
342 :デフォルトの名無しさん:2008/06/12(木) 22:12:36
俺のRadeon4870がねぇええええ
悪SKせいだ
悪SKせいだ
343 :デフォルトの名無しさん:2008/06/12(木) 22:46:01
vistaにcuda2.0入れてサンプルを試しているんだけど
simpleD3Dでコンパイルエラーが起きます。
エラーメッセージは以下です。
1>------ ビルド開始: プロジェクト: simpleD3D9, 構成: Debug Win32 ------
1>カスタム ビルド ステップを実行しています。
1>simpleD3D9_kernel.cu
1>C:\Program Files\Microsoft SDKs\Windows\v6.0\Include\winnt.h(11241): warning:
1> expression has no effect
1>C:\Program Files\Microsoft SDKs\Windows\v6.0\Include\winnt.h(12857): warning:
1> expression has no effect
1>C:\Program Files\Microsoft SDKs\Windows\v6.0\Include\objbase.h(240): error:
1> identifier "IUnknown" is undefined
1>1 error detected in the compilation of "C:\Users\ookawara\AppData\Local\Temp/tmpxft_000016a8_00000000-6_simpleD3D9_kernel.cpp1.ii".
1>ビルドログは "file://c:\Program Files\NVIDIA Corporation\NVIDIA CUDA SDK\projects\simpleD3D9\Debug\BuildLog.htm" に保存されました。
1>simpleD3D9 - エラー 1、警告 2
========== ビルド: 0 正常終了、1 失敗、0 更新、0 スキップ ==========
誰か教えてください。
simpleD3Dでコンパイルエラーが起きます。
エラーメッセージは以下です。
1>------ ビルド開始: プロジェクト: simpleD3D9, 構成: Debug Win32 ------
1>カスタム ビルド ステップを実行しています。
1>simpleD3D9_kernel.cu
1>C:\Program Files\Microsoft SDKs\Windows\v6.0\Include\winnt.h(11241): warning:
1> expression has no effect
1>C:\Program Files\Microsoft SDKs\Windows\v6.0\Include\winnt.h(12857): warning:
1> expression has no effect
1>C:\Program Files\Microsoft SDKs\Windows\v6.0\Include\objbase.h(240): error:
1> identifier "IUnknown" is undefined
1>1 error detected in the compilation of "C:\Users\ookawara\AppData\Local\Temp/tmpxft_000016a8_00000000-6_simpleD3D9_kernel.cpp1.ii".
1>ビルドログは "file://c:\Program Files\NVIDIA Corporation\NVIDIA CUDA SDK\projects\simpleD3D9\Debug\BuildLog.htm" に保存されました。
1>simpleD3D9 - エラー 1、警告 2
========== ビルド: 0 正常終了、1 失敗、0 更新、0 スキップ ==========
誰か教えてください。
344 :デフォルトの名無しさん:2008/06/12(木) 23:41:43
>>343
まさかとは思うが、VC6なんぞを使ってはいないだろうな。つーか、CUDAスレに逝け。
まさかとは思うが、VC6なんぞを使ってはいないだろうな。つーか、CUDAスレに逝け。
345 :デフォルトの名無しさん:2008/06/12(木) 23:59:11
割れ物のVSだとなるようなw
おっといけね
おっといけね
346 :デフォルトの名無しさん:2008/06/13(金) 00:20:42
>>344、345
vs2005expressです。
vs2005expressです。
347 :デフォルトの名無しさん:2008/06/13(金) 11:55:15
>>346
だから、ちゃんと隔離用に作ってあるんだからCUDAスレに逝け。
だから、ちゃんと隔離用に作ってあるんだからCUDAスレに逝け。
348 :デフォルトの名無しさん:2008/06/16(月) 17:47:08
TESLA、Firestreamといったボードは、3DCGでレンダーファームとして今すぐに利用できるのでしょうか?
349 :デフォルトの名無しさん:2008/06/16(月) 18:17:35
ttp://pc.watch.impress.co.jp/docs/2008/0616/amd.htm
AMD、1TFLOPSの演算性能を持つGPGPU
「FireStream 9250」
使用スロットは1スロットのみで、消費電力は150W以下
AMD、1TFLOPSの演算性能を持つGPGPU
「FireStream 9250」
使用スロットは1スロットのみで、消費電力は150W以下
350 :デフォルトの名無しさん:2008/06/18(水) 06:36:23
AMDのHD4850が2万5千円だって
ゲフォの次のやつは7万円だって
CUDAの一人勝ちかと思ったけどそうでもないかもw
ゲフォの次のやつは7万円だって
CUDAの一人勝ちかと思ったけどそうでもないかもw
351 :デフォルトの名無しさん:2008/06/18(水) 08:50:24
HavokがAMD対応を発表しててFireStream 9250が第3四半期…
その頃にはさすがにSDKもβが取れてるだろうからどうなるか分からんね
Photoshop CS4も10月頃だから年内にRadeon対応ソフトが現れたらそれほど差は付かない
その頃にはさすがにSDKもβが取れてるだろうからどうなるか分からんね
Photoshop CS4も10月頃だから年内にRadeon対応ソフトが現れたらそれほど差は付かない
352 :デフォルトの名無しさん:2008/06/18(水) 09:07:34
353 :デフォルトの名無しさん:2008/06/18(水) 10:51:26
まぁ、安いのはいいことだよなぁ
貧乏学生多そうだしな!w
貧乏学生多そうだしな!w
354 :デフォルトの名無しさん:2008/06/18(水) 11:01:43
値段はともかく発熱量を下げてもらわんと、
ラック当たりの計算量が上がらない。
ラック当たりの計算量が上がらない。
355 :デフォルトの名無しさん:2008/06/18(水) 19:51:59
FireStream 9250は値段半額で発熱同じ、性能2倍じゃん
356 :デフォルトの名無しさん:2008/06/18(水) 22:37:44
ゲロビディア氏ね
357 :デフォルトの名無しさん:2008/06/18(水) 23:35:37
GPU2 6.12 beta 6 for ATIに付いて来るCALランタイムで
今までのドキュメントとは異なるDirectX協調用拡張関数確認。
calD3D9UnmapTexture
calD3D9MapTexture
calD3D9UnmapVertexBuffer
calD3D9MapVertexBuffer
calD3D9Associate(これは今まで通り)
引数が判らないしDisassociateはどうしたとツッコミ入れたいけど、とりあえず実装したみたい。
今までのドキュメントとは異なるDirectX協調用拡張関数確認。
calD3D9UnmapTexture
calD3D9MapTexture
calD3D9UnmapVertexBuffer
calD3D9MapVertexBuffer
calD3D9Associate(これは今まで通り)
引数が判らないしDisassociateはどうしたとツッコミ入れたいけど、とりあえず実装したみたい。
358 :デフォルトの名無しさん:2008/06/20(金) 14:14:46
http://pc.watch.impress.co.jp/docs/2008/0620/kurouto.htm
RadeonHD 4850/4870 22,980円/34,980円
6月20日より順次発売
RadeonHD 4870
160sp * 2issue * 750MHz = 240GFLOPS
RadeonHD 4850/FireStream 9250
160sp * 2issue * 625MHz = 200GFLOPS
Tesla C1060
30sp * 2issue * 1500MHz = 90GFLOPS
GeForceGTX 280
30sp * 2issue * 1296MHz = 78GFLOPS
GeForceGTX 260
24sp * 2issue * 1242MHz = 60GFLOPS
RadeonHD 4850/4870 22,980円/34,980円
6月20日より順次発売
RadeonHD 4870
160sp * 2issue * 750MHz = 240GFLOPS
RadeonHD 4850/FireStream 9250
160sp * 2issue * 625MHz = 200GFLOPS
Tesla C1060
30sp * 2issue * 1500MHz = 90GFLOPS
GeForceGTX 280
30sp * 2issue * 1296MHz = 78GFLOPS
GeForceGTX 260
24sp * 2issue * 1242MHz = 60GFLOPS
359 :デフォルトの名無しさん:2008/06/20(金) 14:30:14
何その変な計算
360 :デフォルトの名無しさん:2008/06/20(金) 17:34:08
謎だな
つーか、800SPだよな
つーか、800SPだよな
361 :デフォルトの名無しさん:2008/06/21(土) 07:24:51
倍精度だろ
362 :デフォルトの名無しさん:2008/06/21(土) 09:36:09
単精度で800だよ
363 :デフォルトの名無しさん:2008/06/21(土) 10:06:34
だから>>358の算式は倍精度のパフォーマンス出す式だろ
364 :デフォルトの名無しさん:2008/06/21(土) 13:07:45
365 :デフォルトの名無しさん:2008/06/21(土) 14:32:36
PowerDirectorがAMDのビデオカードに対応するらしいから、モノ自体はあるんだろうけどね
開発環境も早く公開してくれるといいなぁ、倍精度考えると性能は段違いなんだから
開発環境も早く公開してくれるといいなぁ、倍精度考えると性能は段違いなんだから
366 :デフォルトの名無しさん:2008/06/21(土) 17:13:37
CALのIL.PDFもってる人どこか
うぷっていただけませんか?
リンク切れててとれない
うぷっていただけませんか?
リンク切れててとれない
367 :デフォルトの名無しさん:2008/06/21(土) 17:20:25
SDKに入ってるからインスコしろ。
368 :デフォルトの名無しさん:2008/06/21(土) 17:24:08
369 :デフォルトの名無しさん:2008/06/23(月) 23:42:11
CALのためだけに
Radeon4850買ってきますた
Radeon4850買ってきますた
370 :デフォルトの名無しさん:2008/06/23(月) 23:54:48
マゾだなぁ
371 :デフォルトの名無しさん:2008/06/24(火) 00:03:47
ふひひwありがと
372 :デフォルトの名無しさん:2008/06/25(水) 00:45:00
AMDの奴って専用ドライバ入れないと開発できないんだな
めんどいな
Nvidiaは別になんもいらんのにしょぼい
めんどいな
Nvidiaは別になんもいらんのにしょぼい
373 :デフォルトの名無しさん:2008/06/25(水) 03:39:04
逆ですよ。
374 :デフォルトの名無しさん:2008/06/26(木) 23:13:34
http://japan.renesas.com/fmwk.jsp?cnt=press_release20080623.htm&fp=/company_info/news_and_events/press_releases
組み込み向けだから絶対性能はGPUには勝てないけど、消費電力はずっと低そう
個人が簡単に購入できるものじゃないけど
組み込み向けだから絶対性能はGPUには勝てないけど、消費電力はずっと低そう
個人が簡単に購入できるものじゃないけど
375 :デフォルトの名無しさん:2008/06/26(木) 23:16:13
CALってなんで ATI Catalyst? 8.6では動かないの?
376 :デフォルトの名無しさん:2008/06/26(木) 23:51:49
しかもCALってドキュメント全部VisualStudio用なんだな
やる気なさ杉だな
AMDつぶれねーかなぁまじで
やる気なさ杉だな
AMDつぶれねーかなぁまじで
377 :デフォルトの名無しさん:2008/06/26(木) 23:54:42
しかもCALのILドキュメントの記法がISOの
記述を遵守していない。ここの会社はドキュメントの
書き方もしらんのか?
記述を遵守していない。ここの会社はドキュメントの
書き方もしらんのか?
378 :デフォルトの名無しさん:2008/06/27(金) 00:16:08
このスレ監視してるラデ房うぜーなぁ
ほんとATIの奴等ってキモイ
ほんとATIの奴等ってキモイ
379 :デフォルトの名無しさん:2008/06/27(金) 00:18:07
元NDIVIAユーザーですが、なんだか情けなくてしょうがない。
そんなに必死になるなよ。
考えが偏ってて、客観的に見て痛いぞ。
性能の良い製品を使えばいい。ただそれだけ。
そんなに必死になるなよ。
考えが偏ってて、客観的に見て痛いぞ。
性能の良い製品を使えばいい。ただそれだけ。
380 :デフォルトの名無しさん:2008/06/27(金) 00:21:14
>>379
お前の発言の方が痛いぞw
お前の発言の方が痛いぞw
381 :デフォルトの名無しさん:2008/06/27(金) 00:23:11
下らんアオリしてないでプログラムの話しろよ
382 :デフォルトの名無しさん:2008/06/27(金) 00:24:58
>>381
糞CALじゃなんもできませーん
糞CALじゃなんもできませーん
383 :デフォルトの名無しさん:2008/06/27(金) 00:25:06
384 :デフォルトの名無しさん:2008/06/27(金) 00:26:03
本当にnVidia工作員は醜いな
自作PC板以外のスレを荒らす前に小売店の損失を補償してやれ
自作PC板以外のスレを荒らす前に小売店の損失を補償してやれ
385 :デフォルトの名無しさん:2008/06/27(金) 00:29:04
>>384
良いこと言った。
ってかNVIDIA工作員マジUZEEEE
性能が良く、コストパフォーマンスの取れるグラボを買うべきだろ?ふつうならな。
現状のNDIVIAで2.6万以下で4850よか良い製品俺に勧めてくれ。
良いこと言った。
ってかNVIDIA工作員マジUZEEEE
性能が良く、コストパフォーマンスの取れるグラボを買うべきだろ?ふつうならな。
現状のNDIVIAで2.6万以下で4850よか良い製品俺に勧めてくれ。
386 :デフォルトの名無しさん:2008/06/27(金) 00:30:15
>>385
9800GTX+来週買えばいいだろボケw
9800GTX+来週買えばいいだろボケw
387 :デフォルトの名無しさん:2008/06/27(金) 00:31:14
以後荒らしと工作員はスルーで
388 :デフォルトの名無しさん:2008/06/27(金) 00:31:32
389 :デフォルトの名無しさん:2008/06/27(金) 00:33:24
390 :デフォルトの名無しさん:2008/06/27(金) 00:33:53
PCショップに勤めてるから、9800GTX+も9800GTXも刺して動かしたよ。
もうNVIDIA内で自爆するような製品の出し合いやめれw
一応感想だけど、9800GTX+は9800GTXとそんなにベンチマークしても思ってた通り、すばらしくなかった
その点値段的にも性能的にも4850は良かった。ファンだけ交換すれば申し分ないかな。
NVIDIAさん、店が損した分返してください
もうNVIDIA内で自爆するような製品の出し合いやめれw
一応感想だけど、9800GTX+は9800GTXとそんなにベンチマークしても思ってた通り、すばらしくなかった
その点値段的にも性能的にも4850は良かった。ファンだけ交換すれば申し分ないかな。
NVIDIAさん、店が損した分返してください
391 :デフォルトの名無しさん:2008/06/27(金) 00:34:47
>>390
つーか自作板から流れてくるなよ屑どもが
つーか自作板から流れてくるなよ屑どもが
392 :デフォルトの名無しさん:2008/06/27(金) 00:36:39
cal_platofrm_spec.pdfが24ページしか無い件についてw
さすが半導体メーカの中でもっとも屑と言われたAMDの
仕事ですねw
さすが半導体メーカの中でもっとも屑と言われたAMDの
仕事ですねw
393 :デフォルトの名無しさん:2008/06/27(金) 00:38:20
GT200がコケたせいで、まだ正式リリースされていない開発環境の
ドキュメントに不備があると叩かなきゃならないほどに追い詰められてんのか…
ドキュメントに不備があると叩かなきゃならないほどに追い詰められてんのか…
394 :デフォルトの名無しさん:2008/06/27(金) 00:38:49
いろいろなスレ見ちゃ悪いのか?
良い製品が違うメーカーから出て嫉妬してんじゃねーよ。
ATIをそんなに罵倒したいならNVIDIAがもっと良い製品出せよw
それからだなw
じゃあな
良い製品が違うメーカーから出て嫉妬してんじゃねーよ。
ATIをそんなに罵倒したいならNVIDIAがもっと良い製品出せよw
それからだなw
じゃあな
395 :デフォルトの名無しさん:2008/06/27(金) 00:39:22
GPGPU的にはATIは無いわwww
396 :デフォルトの名無しさん:2008/06/27(金) 00:41:43
397 :デフォルトの名無しさん:2008/06/27(金) 00:42:00
次はGT200+ですね、判ります。
398 :デフォルトの名無しさん:2008/06/27(金) 00:43:48
4850がコスパや3D性能的に良いようだから、ATiのGPGPU環境とやらのドキュメントちょっと見てみたがなんか分かりづらいな
Brook+のドキュメントにのってるサンプルコード見た感じじゃ、まだシェーダ言語から脱却し切れてないようだし
演算器がVLIWってのもな。最適化面倒くせえぞあれ
個人的にはATi好きだし頑張って欲しいんだが、GPGPUとしてはまだ当分nVidia一択だな
Brook+のドキュメントにのってるサンプルコード見た感じじゃ、まだシェーダ言語から脱却し切れてないようだし
演算器がVLIWってのもな。最適化面倒くせえぞあれ
個人的にはATi好きだし頑張って欲しいんだが、GPGPUとしてはまだ当分nVidia一択だな
399 :デフォルトの名無しさん:2008/06/27(金) 00:44:07
つまりAdobeは正式版と永遠のβ版を比べて
それでもRadeonに対応する価値があると判断したわけだな…
ttp://www.4gamer.net/games/045/G004578/20080625008/SS/020.jpg
それでもRadeonに対応する価値があると判断したわけだな…
ttp://www.4gamer.net/games/045/G004578/20080625008/SS/020.jpg
{kind=link}
400 :デフォルトの名無しさん:2008/06/27(金) 00:45:35
いままでのNVIDIAの実力
昔:ATI新製品高性能→ゲフォ性能更新→ATIすぐ負ける
現在:ゲフォ新製品→ゲフォマイナーチェンジ(9800GTX+)で自爆→4850トドメ→ゲフォ新製品→ATIがまた出してゲフォ死亡
昔:ATI新製品高性能→ゲフォ性能更新→ATIすぐ負ける
現在:ゲフォ新製品→ゲフォマイナーチェンジ(9800GTX+)で自爆→4850トドメ→ゲフォ新製品→ATIがまた出してゲフォ死亡
401 :デフォルトの名無しさん:2008/06/27(金) 00:48:03
>>399
違うよ、AMD2万ドル、Adobe出資0で共同開発しているから
出してるだけ。まじな話Adobeの開発者が対応したのは
CUDAだけ、CALは金もらったからやるっていってるだけ
で対応するとはAdobe自身から一切発表は無い
違うよ、AMD2万ドル、Adobe出資0で共同開発しているから
出してるだけ。まじな話Adobeの開発者が対応したのは
CUDAだけ、CALは金もらったからやるっていってるだけ
で対応するとはAdobe自身から一切発表は無い
402 :デフォルトの名無しさん:2008/06/27(金) 00:48:42
2週間前だったらGPGPUはnVidiaの圧勝だろうと胸を張って言えたけど、
ここに来てAdobeのAMD製GPU対応とnVidiaの自爆が重なってどうなるか分からない模様になってきたな…
少なくとも信者論争とは無関係のスレで
他社製品を執拗に叩くのを営業戦略と勘違いしてる所は負けるだろうけど
ここに来てAdobeのAMD製GPU対応とnVidiaの自爆が重なってどうなるか分からない模様になってきたな…
少なくとも信者論争とは無関係のスレで
他社製品を執拗に叩くのを営業戦略と勘違いしてる所は負けるだろうけど
403 :デフォルトの名無しさん:2008/06/27(金) 00:48:44
>>399
まぁAdobeの事だし、どっちにもだすんじゃないか
それに開発環境はともかくとして、現状のGPU市場はnVidia/ATiの二強なんだし
ATiのに対応しないってのはさすがにデメリットがでかい
まぁAdobeの事だし、どっちにもだすんじゃないか
それに開発環境はともかくとして、現状のGPU市場はnVidia/ATiの二強なんだし
ATiのに対応しないってのはさすがにデメリットがでかい
404 :デフォルトの名無しさん:2008/06/27(金) 00:48:45
>>375
動くよ
>>376
VCに依存してないドキュメントの方が多いよ
>>377
ISOの記法って何?バックエンドでしかないCALをISOに承認させるわけ?
>>392
1ページ1関数のCudaReferenceManual.pdfを詰めて、3DAPIとの協調用関数をなくして、
ILの機能にあたる部分を削除して、CALでは分ける必要のない関数をまとめれば似たようなものになるね。
動くよ
>>376
VCに依存してないドキュメントの方が多いよ
>>377
ISOの記法って何?バックエンドでしかないCALをISOに承認させるわけ?
>>392
1ページ1関数のCudaReferenceManual.pdfを詰めて、3DAPIとの協調用関数をなくして、
ILの機能にあたる部分を削除して、CALでは分ける必要のない関数をまとめれば似たようなものになるね。
405 :デフォルトの名無しさん:2008/06/27(金) 00:50:29
406 :デフォルトの名無しさん:2008/06/27(金) 00:52:03
2万ドルももらって出しませんとは本当でも言えんよな
ほんとうAMDってなりふりかまわず汚いですね
ほんとうAMDってなりふりかまわず汚いですね
407 :デフォルトの名無しさん:2008/06/27(金) 00:53:39
>>405
Adobeが対応するからといって、CUDAの優位は揺るがないだろw
確かにATiのはまだβ段階でしかないが、それを差し引いてもちょっと使いづらい
まぁ使う側としてはどっちでもいいからとっとと統一して貰いたいもんだが
トランスレーター作るっていうのでもいいけど
Adobeが対応するからといって、CUDAの優位は揺るがないだろw
確かにATiのはまだβ段階でしかないが、それを差し引いてもちょっと使いづらい
まぁ使う側としてはどっちでもいいからとっとと統一して貰いたいもんだが
トランスレーター作るっていうのでもいいけど
408 :デフォルトの名無しさん:2008/06/27(金) 00:54:39
プログラマーが環境を選ぶんじゃなくて、
与えられた環境で組むのがプログラマーだろ
それを理解できないからと言ってだだをこねるのはタダの無能
与えられた環境で組むのがプログラマーだろ
それを理解できないからと言ってだだをこねるのはタダの無能
409 :デフォルトの名無しさん:2008/06/27(金) 00:55:18
お前ら自作板から援軍派兵するのやめろよw
410 :デフォルトの名無しさん:2008/06/27(金) 00:55:36
411 :デフォルトの名無しさん:2008/06/27(金) 00:56:59
nVidiaが勝てるように作られたVantageで負けちゃ世話無いわな
412 :デフォルトの名無しさん:2008/06/27(金) 00:58:57
>>398
Brook+はBrookGPUをちょっと改造しただけの代物だから使いにくいよ。
未実装な部分が残ってたりでコンパイラがASSERTで落ちたりする。OpenCLが出ればそっちに統一でしょ。
VLIWはHLSLコンパイラの蓄積があるから差ほど大変じゃない。
今はBrook+ -> 独自拡張版HLSL -> CAL ILでコンパイルしてる。
>>401
Adobeからの「発表」であればCUDAを使うとは一言もなかったりする。
単にデモでGeForceを使っていて多分CUDAで書いたんだろうというだけ。
後はNVIDIAからの発表。
>>410
CALを使ったゲームが実際にあるなら教えてくれ。
Brook+はBrookGPUをちょっと改造しただけの代物だから使いにくいよ。
未実装な部分が残ってたりでコンパイラがASSERTで落ちたりする。OpenCLが出ればそっちに統一でしょ。
VLIWはHLSLコンパイラの蓄積があるから差ほど大変じゃない。
今はBrook+ -> 独自拡張版HLSL -> CAL ILでコンパイルしてる。
>>401
Adobeからの「発表」であればCUDAを使うとは一言もなかったりする。
単にデモでGeForceを使っていて多分CUDAで書いたんだろうというだけ。
後はNVIDIAからの発表。
>>410
CALを使ったゲームが実際にあるなら教えてくれ。
413 :デフォルトの名無しさん:2008/06/27(金) 01:04:51
OpenCLはAMD不参加だし
Intelから絶対参加することは認めないと
通告されてるしなw
まぁ捏造ベンチで喜ぶラデ房は本当おめでたいよw
Intelから絶対参加することは認めないと
通告されてるしなw
まぁ捏造ベンチで喜ぶラデ房は本当おめでたいよw
414 :デフォルトの名無しさん:2008/06/27(金) 01:05:05
頼みの綱はうんこCUDAだけか
415 :デフォルトの名無しさん:2008/06/27(金) 01:06:32
>>413
大嘘こいて楽しい?
大嘘こいて楽しい?
416 :デフォルトの名無しさん:2008/06/27(金) 01:11:03
417 :デフォルトの名無しさん:2008/06/27(金) 01:13:37
妄想もココまでくると病気だな
418 :デフォルトの名無しさん:2008/06/27(金) 01:15:19
>>416
ATiが嫌いなのはよく分かったから、後は日記帳にでも妄想書いとけ
ATiが嫌いなのはよく分かったから、後は日記帳にでも妄想書いとけ
419 :デフォルトの名無しさん:2008/06/27(金) 01:16:26
Intel の誰が,Apple のどんな立場の人間がそんなこと言ってるんだ?w
420 :デフォルトの名無しさん:2008/06/27(金) 01:16:40
421 :デフォルトの名無しさん:2008/06/27(金) 01:17:54
今のMACに搭載されているVGA調べてみろ
どっちのVGAが載ってる?ん?
どっちのVGAが載ってる?ん?
422 :デフォルトの名無しさん:2008/06/27(金) 01:22:56
ここはム板なので、それ以上は自作PC板でやってくれ。
まぁ、元々プログラミングの話なんてほとんど出てないけどな。
まぁ、元々プログラミングの話なんてほとんど出てないけどな。
423 :デフォルトの名無しさん:2008/06/27(金) 01:24:05
CALなんてそもそも存在しないし
424 :デフォルトの名無しさん:2008/06/27(金) 05:40:55
>OpenCLはAMD不参加だし
ttp://www.amd.com/us-en/Corporate/VirtualPressRoom/0,,51_104_543~126593,00.html
“We believe that OpenCL is a step in the right direction and we fully support this effort.
AMD intends to ensure that the AMD Stream SDK rapidly evolves to comply with open industry standards as they emerge.”
てか、なんでmacむけ3870が出たのか考えてみれば・・
ほんと必死だな
ttp://www.amd.com/us-en/Corporate/VirtualPressRoom/0,,51_104_543~126593,00.html
“We believe that OpenCL is a step in the right direction and we fully support this effort.
AMD intends to ensure that the AMD Stream SDK rapidly evolves to comply with open industry standards as they emerge.”
てか、なんでmacむけ3870が出たのか考えてみれば・・
ほんと必死だな
425 :デフォルトの名無しさん:2008/06/27(金) 06:17:03
CUDA最強だなやっぱりCALなんてゴミもいいところ
所詮ATiの残党が作ったゴミ
所詮ATiの残党が作ったゴミ
426 :デフォルトの名無しさん:2008/06/27(金) 08:13:24
427 :デフォルトの名無しさん:2008/06/27(金) 08:20:00
>>426
嘘書くんじゃねーぼけ
このドキュメントは素晴らしいな
AMDには真似の出来ない品質だ
http://www.nvidia.co.jp/docs/IO/51174/NVIDIA_CUDA_Programming_Guide_1.1_JPN.pdf
嘘書くんじゃねーぼけ
このドキュメントは素晴らしいな
AMDには真似の出来ない品質だ
http://www.nvidia.co.jp/docs/IO/51174/NVIDIA_CUDA_Programming_Guide_1.1_JPN.pdf
428 :デフォルトの名無しさん:2008/06/27(金) 08:22:40
理解もすごい進むしいい資料だ
429 :デフォルトの名無しさん:2008/06/27(金) 08:37:09
ああ、誤訳だらけで鬱になれるね。
英語版を訳しながら読む方が未だましだし、それも前提となる知識があってのことだ。
それでも、ないよりはずっと有り難いのだけれどね。
英語版を訳しながら読む方が未だましだし、それも前提となる知識があってのことだ。
それでも、ないよりはずっと有り難いのだけれどね。
430 :デフォルトの名無しさん:2008/06/27(金) 08:38:00
>>429
>428のようにまともに日本語も扱えないような香具師には読んだ積もりになれるという点で丁度いいのだろ。
>428のようにまともに日本語も扱えないような香具師には読んだ積もりになれるという点で丁度いいのだろ。
431 :デフォルトの名無しさん:2008/06/27(金) 09:03:36
「エラー!ブックマークが定義されていません。」が多すぎてワロタ
こりゃAMDどころかどこも真似できんわw
これで正式版wwwww
こりゃAMDどころかどこも真似できんわw
これで正式版wwwww
432 :デフォルトの名無しさん:2008/06/27(金) 09:35:09
433 :デフォルトの名無しさん:2008/06/27(金) 09:43:37
どうせOpenCLになるんだろうし、どっちでもよかろうに・・・
今の乱立状態がユーザーにとってもデメリットしかないってのは確かなんだから
歓迎すべき事だと思うんだけどなぁ、各社の参加は
今の乱立状態がユーザーにとってもデメリットしかないってのは確かなんだから
歓迎すべき事だと思うんだけどなぁ、各社の参加は
434 :デフォルトの名無しさん:2008/06/27(金) 10:39:34
「OpenCLにはMicrosoftが加わっていない」
「DirectX11でGPGPUをサポートするらしい」
とかでOpenCLはOpenGLみたいな立場になるとか言われてるみたいd
「DirectX11でGPGPUをサポートするらしい」
とかでOpenCLはOpenGLみたいな立場になるとか言われてるみたいd
435 :デフォルトの名無しさん:2008/06/27(金) 10:47:04
問題は現状のリソースがそのまま利用出来るのか
買い替えが必要なのかだな
買い替えが必要なのかだな
436 :デフォルトの名無しさん:2008/06/27(金) 18:12:08
Microsoftは独自にDirectX用のCLを作るよ
OpenGLみたいに誰も使わない規格を使う
理由がないからねぇ
OpenGLみたいに誰も使わない規格を使う
理由がないからねぇ
437 :デフォルトの名無しさん:2008/06/27(金) 18:28:14
Radeonの存在意義も解らないよね?
438 :デフォルトの名無しさん:2008/06/27(金) 18:42:06
ID出ない板だとほんと特定個人が暴れ放題だな…
そんなに必死になっても現実はNVのシェアが落ちていく一方ですよっと
そんなに必死になっても現実はNVのシェアが落ちていく一方ですよっと
439 :デフォルトの名無しさん:2008/06/27(金) 18:52:34
>>438
FUD流して何面白いの?頭おかしいにもほどがあるな
FUD流して何面白いの?頭おかしいにもほどがあるな
440 :デフォルトの名無しさん:2008/06/27(金) 19:55:23
これだからATI厨は困る・・・
捏造までして叩くのか・・・
捏造までして叩くのか・・・
441 :デフォルトの名無しさん:2008/06/27(金) 20:15:05
アチは本当すぐ捏造するしねぇ
チートドライバ作り出すし
チートドライバ作り出すし
442 :デフォルトの名無しさん:2008/06/27(金) 20:35:34
おまいら頼むから自作板のvsスレでやってください。
443 :デフォルトの名無しさん:2008/06/27(金) 20:36:55
ベンチスコアは捏造。ドライバは糞。字も書けない。
ATI最悪!
ATI最悪!
444 :デフォルトの名無しさん:2008/06/27(金) 20:51:43
445 :デフォルトの名無しさん:2008/06/27(金) 20:56:20
Nvidiaさん、ボイド復帰型何よこれ?
446 :デフォルトの名無しさん:2008/06/27(金) 21:02:18
447 :デフォルトの名無しさん:2008/06/27(金) 21:08:50
nVidia工作員を装ったATi信者を装ったnVidia工作員を装ったATi信者を装った…(ry
以下無限ループ
以下無限ループ
448 :デフォルトの名無しさん:2008/06/28(土) 11:49:55
ここの人間にとっては、描画性能では明らかに劣っているnVIDIAのカードが
描画性能相応に暴落してくれる、というのは非常にありがたい状況だな。
市販のHD 4xxxは倍精度演算を殺してるし、開発環境もnVIDIAの方が整っている。
他の板ではどんどんnVIDIAを叩いてほしい。
が、ここでは邪魔だから止めてね。
描画性能相応に暴落してくれる、というのは非常にありがたい状況だな。
市販のHD 4xxxは倍精度演算を殺してるし、開発環境もnVIDIAの方が整っている。
他の板ではどんどんnVIDIAを叩いてほしい。
が、ここでは邪魔だから止めてね。
449 :デフォルトの名無しさん:2008/06/28(土) 11:54:34
GPUで整数演算がしたいです。
450 :デフォルトの名無しさん:2008/06/28(土) 11:59:09
整数演算ってどうやってするの?
451 :デフォルトの名無しさん:2008/06/28(土) 12:15:06
別にnVIDIAの話は専用にスレあるからここではいくら暴れてくれも平気だよ
452 :デフォルトの名無しさん:2008/06/28(土) 12:19:36
>>448
殺してるって証拠はある?
殺してるって証拠はある?
453 :デフォルトの名無しさん:2008/06/28(土) 12:47:14
>>452
ttp://pc.watch.impress.co.jp/docs/2008/0616/amd.htm
って記事があるけど単精度1TFLOPS以上と書いてあるので使われてるコアはHD4xxx系のはず
BIOSレベルで隠蔽してるのか、回路焼いてるのかは不明
MODで倍精度ONに出来れば… ゴクリ…
ttp://pc.watch.impress.co.jp/docs/2008/0616/amd.htm
って記事があるけど単精度1TFLOPS以上と書いてあるので使われてるコアはHD4xxx系のはず
BIOSレベルで隠蔽してるのか、回路焼いてるのかは不明
MODで倍精度ONに出来れば… ゴクリ…
454 :デフォルトの名無しさん:2008/06/28(土) 12:52:54
>>452
ttp://pc.watch.impress.co.jp/docs/2008/0626/kaigai450.htm
>AMDはグラフィックス製品では倍精度は有効にせず、GPGPU向けの「FireStream」系列でのみ倍精度をサポートする見込みだ。これは、グラフィックス製品で倍精度をサポートするNVIDIAとの大きな戦略の違いだ。
ttp://pc.watch.impress.co.jp/docs/2008/0626/kaigai450.htm
>AMDはグラフィックス製品では倍精度は有効にせず、GPGPU向けの「FireStream」系列でのみ倍精度をサポートする見込みだ。これは、グラフィックス製品で倍精度をサポートするNVIDIAとの大きな戦略の違いだ。
455 :デフォルトの名無しさん:2008/06/28(土) 12:58:35
>>453
それRV670でも同じこと言われてたけど、結局FireStream化どころか何もせずにHD3xxxで倍精度演算できるよ。
それRV670でも同じこと言われてたけど、結局FireStream化どころか何もせずにHD3xxxで倍精度演算できるよ。
457 :デフォルトの名無しさん:2008/06/28(土) 16:14:07
Nvidiaがハードレベルで圧倒的に優れている証拠を見せてやろう
http://www.4gamer.net/games/050/G005004/20080627060/TN/018.jpg
Radeonなんてゴミもいいところw
http://www.4gamer.net/games/050/G005004/20080627060/TN/018.jpg
{kind=link}
Radeonなんてゴミもいいところw
458 :デフォルトの名無しさん:2008/06/28(土) 16:28:45
>>457
Geforce最強すぎる
Geforce最強すぎる
459 :デフォルトの名無しさん:2008/06/28(土) 16:58:18
GTX280ってあんだけ高いのに8800GTより性能低いのか…
買う価値無いな
買う価値無いな
460 :デフォルトの名無しさん:2008/06/28(土) 17:06:51
>>457-459
その画像はSP1個当たりの性能な
ttp://www.4gamer.net/games/050/G005004/20080627060/
8800GTは112基
GTX280は240基
HD3650は120基
HD4850は800基だから
実際の演算能力は
HD4850>GTX280>8800GT>HD3650
その画像はSP1個当たりの性能な
ttp://www.4gamer.net/games/050/G005004/20080627060/
8800GTは112基
GTX280は240基
HD3650は120基
HD4850は800基だから
実際の演算能力は
HD4850>GTX280>8800GT>HD3650
461 :デフォルトの名無しさん:2008/06/28(土) 17:10:20
>>460
SP800?ダントツじゃん
SP800?ダントツじゃん
462 :デフォルトの名無しさん:2008/06/28(土) 17:30:53
その記事の誤差のところのHD3650どうなってるんだろ?
これって繰り返し計算の累積誤差じゃなくて、1回計算しただけの誤差かな?
赤と緑のグラフの意味もその記事じゃ分からんな。
(ググってみたら最大誤差と平均誤差らしい)
AMDがGPGPUに消極的だったのは、この辺が関係してそうだね。
これって繰り返し計算の累積誤差じゃなくて、1回計算しただけの誤差かな?
赤と緑のグラフの意味もその記事じゃ分からんな。
(ググってみたら最大誤差と平均誤差らしい)
AMDがGPGPUに消極的だったのは、この辺が関係してそうだね。
463 :デフォルトの名無しさん:2008/06/28(土) 17:33:47
とりあえずGeforce最強これは紛れも無い事実
そしてRadeonは捏造ベンチ+精度落とした偽造
ドライバ利用が確定した
そしてRadeonは捏造ベンチ+精度落とした偽造
ドライバ利用が確定した
464 :デフォルトの名無しさん:2008/06/28(土) 17:37:29
とりあえず
GPGPUやってない奴は消えろ
GPGPUやってない奴は消えろ
465 :デフォルトの名無しさん:2008/06/28(土) 17:38:57
やってるよー
倍精度も計算できない糞Radeonなんて使いませんがwwww
倍精度も計算できない糞Radeonなんて使いませんがwwww
466 :デフォルトの名無しさん:2008/06/28(土) 17:41:48
だから出来るってば。
467 :デフォルトの名無しさん:2008/06/28(土) 17:43:35
できねーよ。ソース出してみろやw
嘘つくのやめてほしいなぁ
嘘つくのやめてほしいなぁ
468 :デフォルトの名無しさん:2008/06/28(土) 17:46:26
ほら出てこないw
469 :デフォルトの名無しさん:2008/06/28(土) 17:50:18
出来ないソースを出す方が先だろ
470 :デフォルトの名無しさん:2008/06/28(土) 17:56:58
{kind=link}
471 :デフォルトの名無しさん:2008/06/28(土) 17:58:31
画像なんて合成できるしねぇ
おっと用事思い出した
おっと用事思い出した
472 :デフォルトの名無しさん:2008/06/28(土) 18:00:50
はいさようなら。邪魔だからもう来なくていいよ。
473 :デフォルトの名無しさん:2008/06/28(土) 18:48:17
これfloatで出してるだけじゃねーかw
危うく騙されるところだった
危うく騙されるところだった
474 :デフォルトの名無しさん:2008/06/28(土) 19:05:35
は?
475 :デフォルトの名無しさん:2008/06/28(土) 19:07:35
そのうさんくせーサンプルで小数点7桁まで
出してみろやwでねーだろ?謝っちまえよ?
出してみろやwでねーだろ?謝っちまえよ?
476 :デフォルトの名無しさん:2008/06/28(土) 19:16:18
> そのうさんくせーサンプルで小数点7桁まで
ソース読んだのならツッコミどころ間違ってると思うよ。
ソース読んだのならツッコミどころ間違ってると思うよ。
477 :デフォルトの名無しさん:2008/06/28(土) 19:19:47
久しぶりに声出して笑えた
ありがとう
ありがとう
478 :デフォルトの名無しさん:2008/06/28(土) 21:16:22
>>475
printfの内容は%fじゃないよな?
printfの内容は%fじゃないよな?
479 :デフォルトの名無しさん:2008/06/28(土) 21:39:22
これだからNV厨はダメだね
480 :デフォルトの名無しさん:2008/06/28(土) 22:35:52
CAL書きやすくね?とか思う俺は変態?
481 :デフォルトの名無しさん:2008/06/28(土) 23:22:05
バイナリアンか何かですか?
482 :デフォルトの名無しさん:2008/06/28(土) 23:57:51
まあどうせDX11までGPGPUは日陰の存在
483 :デフォルトの名無しさん:2008/06/28(土) 23:59:50
焼き直しで古い論文実装するだけで
予算も付くし美味しいんだけどね
予算も付くし美味しいんだけどね
484 :デフォルトの名無しさん:2008/06/29(日) 01:38:29
画像処理目的でAMDのStream SDKを触り始めたんだけど
1ピクセル=8ビット
でWidth x Heightみたいなデータを扱う事って出来ないのかな??
なんかBrook+を使う時点で32ビット縛りで、CALを見てみたら非常に難しくて・・・
1ピクセル=8ビット
でWidth x Heightみたいなデータを扱う事って出来ないのかな??
なんかBrook+を使う時点で32ビット縛りで、CALを見てみたら非常に難しくて・・・
485 :デフォルトの名無しさん:2008/06/29(日) 04:25:19
Cg≒HLSL見たいに上手く良くか
intelが横槍入れそうだな
Nvidiaの最高経営責任者(CEO)であるJen-Hsun Huang氏は先週インタビューで、
AppleにはWWDCを盛り上げるための一環として、NvidiaのCUDAテクノロジに関する計画があるかもしれないことを示唆した。
Huang氏は、「AppleはCUDAについて熟知している」と述べ、
同社が、Macでのグラフィックスチップの活用をより簡単にするため、
このNvidiaの技術を正式に採用する準備が整っている可能性を示唆した。
Appleは同技術を実装する際、「CUDAとは呼ばず、別の呼び名を付けるだろう」とHuang氏は、
4日にNvidiaの本社で行われたインタビューで述べた。
http://japan.cnet.com/news/ent/story/0,2000056022,20374870,00.htm
Apple社,「Mac OS X」の次期バージョン「Snow Leopard」も公開,GPGPUに対応へ
GPUで汎用計算を行うアプリケーション・ソフトウエアの開発には,
C言語を拡張した新しい言語「OpenCL(open computing language)」を利用する。
http://techon.nikkeibp.co.jp/article/NEWS/20080610/153055/
Khronos Groupが「Compute Working Group」を設置,メーカー非依存のGPGPUを目指す
Khronos Groupは既に米Apple Inc.が,さまざまな用途でGPUとマイクロプロセサの
計算資源を活用するためのC言語に基づくプログラミング言語
「Open Computing Language(OpenCL)」を提案済みであることを明らかにした。
http://techon.nikkeibp.co.jp/article/NEWS/20080617/153397/
ハードウェアベンダーと繋がり無くGPGPU対応は難しいから
MS単独で変な言語作ることはないだろう
AMDはOpenCLをバックアップしてるから
あとはCtを提唱してるintelがどうなるかだけ
MSがintelと組んだらややこしくなる
intelが横槍入れそうだな
Nvidiaの最高経営責任者(CEO)であるJen-Hsun Huang氏は先週インタビューで、
AppleにはWWDCを盛り上げるための一環として、NvidiaのCUDAテクノロジに関する計画があるかもしれないことを示唆した。
Huang氏は、「AppleはCUDAについて熟知している」と述べ、
同社が、Macでのグラフィックスチップの活用をより簡単にするため、
このNvidiaの技術を正式に採用する準備が整っている可能性を示唆した。
Appleは同技術を実装する際、「CUDAとは呼ばず、別の呼び名を付けるだろう」とHuang氏は、
4日にNvidiaの本社で行われたインタビューで述べた。
http://japan.cnet.com/news/ent/story/0,2000056022,20374870,00.htm
Apple社,「Mac OS X」の次期バージョン「Snow Leopard」も公開,GPGPUに対応へ
GPUで汎用計算を行うアプリケーション・ソフトウエアの開発には,
C言語を拡張した新しい言語「OpenCL(open computing language)」を利用する。
http://techon.nikkeibp.co.jp/article/NEWS/20080610/153055/
Khronos Groupが「Compute Working Group」を設置,メーカー非依存のGPGPUを目指す
Khronos Groupは既に米Apple Inc.が,さまざまな用途でGPUとマイクロプロセサの
計算資源を活用するためのC言語に基づくプログラミング言語
「Open Computing Language(OpenCL)」を提案済みであることを明らかにした。
http://techon.nikkeibp.co.jp/article/NEWS/20080617/153397/
ハードウェアベンダーと繋がり無くGPGPU対応は難しいから
MS単独で変な言語作ることはないだろう
AMDはOpenCLをバックアップしてるから
あとはCtを提唱してるintelがどうなるかだけ
MSがintelと組んだらややこしくなる
486 :デフォルトの名無しさん:2008/06/29(日) 09:41:45
IntelはLarrabeeでMSと組んで汎用GPU言語作るだろ
IntelもMSもOpenなんちゃらって儲けが薄くならないと
やらないし
IntelもMSもOpenなんちゃらって儲けが薄くならないと
やらないし
487 :デフォルトの名無しさん:2008/06/29(日) 09:44:09
このスレ住人にとっては驚きの週末だなぁ。
488 :デフォルトの名無しさん:2008/06/29(日) 10:50:30
急に沸いてきたな
489 :デフォルトの名無しさん:2008/06/29(日) 12:00:32
Folding@HomeのGPU版をしている人居ます?
PS3の280GTXは6倍以上をこなしているようですが。
ベータ版が公開されているが時間がなくてまだ何もしていない(困った。)
PS3の280GTXは6倍以上をこなしているようですが。
ベータ版が公開されているが時間がなくてまだ何もしていない(困った。)
490 :デフォルトの名無しさん:2008/06/29(日) 22:56:14
>>485
噂レベルだけどMSは.NET上に
GPU用のIL言語構築するみたい
JATで最適化かけて走らせるイメージを
持っているみたいだよ。
基本的に今のワーキンググループとは
まったく発想がことなってるらしいね
噂レベルだけどMSは.NET上に
GPU用のIL言語構築するみたい
JATで最適化かけて走らせるイメージを
持っているみたいだよ。
基本的に今のワーキンググループとは
まったく発想がことなってるらしいね
491 :デフォルトの名無しさん:2008/06/29(日) 23:26:52
>>490
噂のソースうp
噂のソースうp
492 :デフォルトの名無しさん:2008/06/29(日) 23:31:51
493 :デフォルトの名無しさん:2008/06/30(月) 01:10:57
CALでreduction bufferってどう使うの?
scratch bufferは名前だけはドキュメントに載ってるし
サンプルみるとdcl_indexed_temp_arrayでx#っぽいけど、
reduction bufferはさっぱりわからん。ISAで書かないと無理?
scratch bufferは名前だけはドキュメントに載ってるし
サンプルみるとdcl_indexed_temp_arrayでx#っぽいけど、
reduction bufferはさっぱりわからん。ISAで書かないと無理?
494 :デフォルトの名無しさん:2008/06/30(月) 01:47:18
brccのコードでreductionFactorってあるけどあれが
何吐くか見てみれば?
何吐くか見てみれば?
495 :デフォルトの名無しさん:2008/06/30(月) 02:14:18
Brook+のreductionってreduction buffer使ってないんだよ。
だから参考にならないんだ。
だから参考にならないんだ。
496 :デフォルトの名無しさん:2008/06/30(月) 07:41:45
497 :デフォルトの名無しさん:2008/06/30(月) 23:44:51
brookのscatter/gatherの使いどころが判らないんだけど、誰か詳しい人いますか?
498 :デフォルトの名無しさん:2008/06/30(月) 23:45:34
499 :デフォルトの名無しさん:2008/06/30(月) 23:49:02
>>498
ここで日本語のログ置いとくと後々、参照する時楽なんで一緒に勉強&情報交換できると助かります。
私はとりあえず付属のBrook周りのドキュメントは読んだんですが。。。
今までになく最悪な英語でムキーってなってるところです。
ここで日本語のログ置いとくと後々、参照する時楽なんで一緒に勉強&情報交換できると助かります。
私はとりあえず付属のBrook周りのドキュメントは読んだんですが。。。
今までになく最悪な英語でムキーってなってるところです。
500 :デフォルトの名無しさん:2008/07/01(火) 00:03:38
>>499
じゃあ何かおいておきます
こっちは、Linux上のクライアント+Radeon 4870
WindowsXP64bit + Radeon 3870で開発を始めてみました。
現在、付属のヘッダやサンプルなどの解析をかけているところです。
じゃあ何かおいておきます
こっちは、Linux上のクライアント+Radeon 4870
WindowsXP64bit + Radeon 3870で開発を始めてみました。
現在、付属のヘッダやサンプルなどの解析をかけているところです。
501 :デフォルトの名無しさん:2008/07/01(火) 20:52:29
CALランタイムってVistaじゃ完全に使えないの?
サンプルを実行したら初期化エラーが出るんだが
今更XP64を入れる気にはならんし…
サンプルを実行したら初期化エラーが出るんだが
今更XP64を入れる気にはならんし…
502 :デフォルトの名無しさん:2008/07/01(火) 21:43:42
fahについてくるやつは?
503 :デフォルトの名無しさん:2008/07/05(土) 03:10:32
誰もCALチェッカー使ってくれなかったから自分で4850買っちゃったよ。
ttp://www1.axfc.net/uploader/Img/so/15302.png
右:4850
左:3850
2枚挿し
ttp://www7.axfc.net/uploader/Img/so/14467.png
3850単体
3850は256MB版なはずなのに4850に引きずられるように512MBってことになってるのは何でだ?
SIMD数は公開されたデータどおりだけど、相変わらずクロックの部分はへんてこ。
ttp://www1.axfc.net/uploader/Img/so/15302.png
{kind=link}
右:4850
左:3850
2枚挿し
ttp://www7.axfc.net/uploader/Img/so/14467.png
{kind=link}
3850単体
3850は256MB版なはずなのに4850に引きずられるように512MBってことになってるのは何でだ?
SIMD数は公開されたデータどおりだけど、相変わらずクロックの部分はへんてこ。
504 :デフォルトの名無しさん:2008/07/05(土) 23:40:30
>>503
俺のところはこんな感じ
Locking assertion failure. Backtrace:
#0 /usr/lib/libxcb-xlib.so.0 [0xb751e767]
#1 /usr/lib/libxcb-xlib.so.0(xcb_xlib_lock+0x2e) [0xb751e81e]
#2 /usr/lib/libX11.so.6 [0xb7562518]
#3 /usr/lib/libX11.so.6(XFreeGC+0x26) [0xb753e9d6]
Avail Local RAM 488MB
Avail Uncached Remove RAM 114MB
Avail Cached Remove RAM 59MB
Local GPU RAM 512 MB
Uncached Remote RAM 191 MB
Cached Remote RAM 59 MB
GPU Clock 337 MHz
Memory 625 MHz
Wavefront 64
SIMD 10
Double Precision Artithmetic : YES
Reserved1 : YES
Reserved2 : NO
Reserved3 : YES
Reserved4 : YES
MemExport : YES
Device Type : R770
Maximum width of one-dimensional resource 8192
Maximum width of two-dimensional resource 8192
Maximum height above rail level of two-dimensional resource 8192
The system has one device
CAL Runtime version 1.1.1
俺のところはこんな感じ
Locking assertion failure. Backtrace:
#0 /usr/lib/libxcb-xlib.so.0 [0xb751e767]
#1 /usr/lib/libxcb-xlib.so.0(xcb_xlib_lock+0x2e) [0xb751e81e]
#2 /usr/lib/libX11.so.6 [0xb7562518]
#3 /usr/lib/libX11.so.6(XFreeGC+0x26) [0xb753e9d6]
Avail Local RAM 488MB
Avail Uncached Remove RAM 114MB
Avail Cached Remove RAM 59MB
Local GPU RAM 512 MB
Uncached Remote RAM 191 MB
Cached Remote RAM 59 MB
GPU Clock 337 MHz
Memory 625 MHz
Wavefront 64
SIMD 10
Double Precision Artithmetic : YES
Reserved1 : YES
Reserved2 : NO
Reserved3 : YES
Reserved4 : YES
MemExport : YES
Device Type : R770
Maximum width of one-dimensional resource 8192
Maximum width of two-dimensional resource 8192
Maximum height above rail level of two-dimensional resource 8192
The system has one device
CAL Runtime version 1.1.1
505 :デフォルトの名無しさん:2008/07/05(土) 23:45:15
506 :デフォルトの名無しさん:2008/07/05(土) 23:46:05
>>505
今自分で作りました
今自分で作りました
507 :デフォルトの名無しさん:2008/07/05(土) 23:50:35
508 :デフォルトの名無しさん:2008/07/06(日) 00:02:51
509 :デフォルトの名無しさん:2008/07/06(日) 00:04:46
あーしまった。CALdevicestatusをリアルタイム更新できるように弄った名残がそのままでした。
お目汚し失礼。
お目汚し失礼。
510 :デフォルトの名無しさん:2008/07/06(日) 00:27:01
511 :デフォルトの名無しさん:2008/07/06(日) 00:45:17
512 :デフォルトの名無しさん:2008/07/06(日) 08:41:35
513 :デフォルトの名無しさん:2008/07/06(日) 10:39:01
514 :デフォルトの名無しさん:2008/07/06(日) 10:42:05
売ってることに驚いた
515 :デフォルトの名無しさん:2008/07/06(日) 10:59:40
516 :デフォルトの名無しさん:2008/07/06(日) 11:28:42
517 :デフォルトの名無しさん:2008/07/06(日) 11:42:21
>>516
そんなどこぞのチラ裏日記見せられてもw
そんなどこぞのチラ裏日記見せられてもw
518 :デフォルトの名無しさん:2008/07/06(日) 11:59:00
>>516
牧野は8800が出たとき降参宣言してたはずだが。
牧野は8800が出たとき降参宣言してたはずだが。
519 :デフォルトの名無しさん:2008/07/06(日) 12:01:13
GPUにしか興味ないんだからね
520 :デフォルトの名無しさん:2008/07/06(日) 20:50:09
GPU Gems 3 日本語版
今週出るねでもやっぱ値段はるな
今週出るねでもやっぱ値段はるな
521 :デフォルトの名無しさん:2008/07/06(日) 22:26:26
ここで聞いてみてもいいのか解らないんだが
CALとBrook2つ存在する理由ってなんなのでしょうか
CALとBrook2つ存在する理由ってなんなのでしょうか
522 :デフォルトの名無しさん:2008/07/07(月) 09:13:52
CAL = API
Brook+ = オープンソース・フリーで提供される開発言語の1つ
Brook+ = オープンソース・フリーで提供される開発言語の1つ
523 :デフォルトの名無しさん:2008/07/07(月) 19:37:49
>>521
.NET Frameworkも中間アセンブリを弄れるわけだが
.NET Frameworkも中間アセンブリを弄れるわけだが
524 :デフォルトの名無しさん:2008/07/07(月) 20:07:16
>>522
いや全然違うだろ
いや全然違うだろ
525 :デフォルトの名無しさん:2008/07/07(月) 21:57:40
AMDの中の人に
なんでCAL作ってるのさ
LLVMしろよゴルァってメールしたら
めっさ怒られました。
AMDの中の人ごめんなさい
なんでCAL作ってるのさ
LLVMしろよゴルァってメールしたら
めっさ怒られました。
AMDの中の人ごめんなさい
526 :デフォルトの名無しさん:2008/07/07(月) 22:07:43
ttp://forums.amd.com/devforum/messageview.cfm?catid=328&threadid=97024&enterthread=y
sgratton氏にマジ禿同。
後で仕様が変わったりしてもいいからひとまず今の仕様をドキュメントで網羅して欲しい。
sgratton氏にマジ禿同。
後で仕様が変わったりしてもいいからひとまず今の仕様をドキュメントで網羅して欲しい。
527 :デフォルトの名無しさん:2008/07/07(月) 22:28:31
予算5万ドルじゃこれが限界だと思うけどね
528 :デフォルトの名無しさん:2008/07/09(水) 20:07:41
NVIDIA GeForce 8シリーズ、ソフトウェア更新でPhysXに対応
http://blogs.wankuma.com/shannon/archive/2008/02/19/123885.aspx
もうATIはスレ違いに近いな
http://blogs.wankuma.com/shannon/archive/2008/02/19/123885.aspx
もうATIはスレ違いに近いな
529 :デフォルトの名無しさん:2008/07/09(水) 20:57:10
>>528
その「2月」の記事が、どうかしたか?
その「2月」の記事が、どうかしたか?
530 :デフォルトの名無しさん:2008/07/09(水) 21:08:23
>>528
自作板のゲロビディアすれ帰れ
自作板のゲロビディアすれ帰れ
531 :デフォルトの名無しさん:2008/07/10(木) 01:41:52
>>528
お前自身が板違い。
お前自身が板違い。
532 :デフォルトの名無しさん:2008/07/11(金) 00:56:14
CALってCUDAと比べて10倍以上遅くね?
4870とGe8600が同じぐらいなんだが?
汎用処理は全然できないっぽいな
4870とGe8600が同じぐらいなんだが?
汎用処理は全然できないっぽいな
533 :デフォルトの名無しさん:2008/07/11(金) 12:12:15
そりゃまぁ、グラフィックスに特化したVLIWだしな・・・
コンパイラの最適化でも限界がある罠。
コンパイラの最適化でも限界がある罠。
534 :デフォルトの名無しさん:2008/07/11(金) 12:18:55
chrome400に比べればみんな遅い
535 :デフォルトの名無しさん:2008/07/12(土) 17:37:37
536 :デフォルトの名無しさん:2008/07/12(土) 17:48:17
どこぞの糞CPUメーカみたいに
消費電力言い出す奴は大抵糞だw
消費電力言い出す奴は大抵糞だw
537 :デフォルトの名無しさん:2008/07/12(土) 20:35:31
はぁ?
538 :デフォルトの名無しさん:2008/07/12(土) 22:02:20
今消費電力の事を語らないメーカーなんて存在するのかな
539 :デフォルトの名無しさん:2008/07/12(土) 22:14:01
あMD
540 :デフォルトの名無しさん:2008/07/12(土) 22:19:40
消費電力を一番問題だと思っているのは利用者だろ
541 :デフォルトの名無しさん:2008/07/12(土) 22:21:40
つまり利用者のことを考えないメーカ?
542 :デフォルトの名無しさん:2008/07/12(土) 22:54:55
48xxが出てから急にこのスレに必死な人が増えたね
543 :デフォルトの名無しさん:2008/07/13(日) 01:32:53
不思議なことに、何か良い新製品が出ると、自分が偉くなった
と思い込む変な人がいっぱい湧くよな。
不思議だ。
と思い込む変な人がいっぱい湧くよな。
不思議だ。
544 :デフォルトの名無しさん:2008/07/13(日) 02:17:58
勝ち負けに興味ある人隔離スレとして機能してくれるならそれはそれで。
545 :デフォルトの名無しさん:2008/07/13(日) 11:10:53
NV使っている奴よりATI使っている俺の方が偉い
546 :デフォルトの名無しさん:2008/07/13(日) 11:15:42
ゲロビディアは小売店を潰そうと画策した糞会社だ
547 :デフォルトの名無しさん:2008/07/13(日) 17:27:54
なんでGPGPUスレに沸くんだ
548 :デフォルトの名無しさん:2008/07/13(日) 17:36:35
GPGPUでは、nVidiaがAMDに勝ってると思ってるんだろ。
いわゆる、語るに落ちるって奴w
いわゆる、語るに落ちるって奴w
549 :デフォルトの名無しさん:2008/07/13(日) 17:47:06
実際ATIのVLIWは汎用処理では
遅くて使い物にならないけどね
理論値倍精度で500Gが4、5G程度しか
でなくなっちゃうからねぇ
まぁ3Dでは高速だがGPGPUではゴミだ
遅くて使い物にならないけどね
理論値倍精度で500Gが4、5G程度しか
でなくなっちゃうからねぇ
まぁ3Dでは高速だがGPGPUではゴミだ
550 :デフォルトの名無しさん:2008/07/13(日) 18:05:31
倍精度の理論値は短精度の1/5じゃないの?
倍精度だと倍精度積和+整数演算の組み合わせしかできないから
VLIWコンパイラの不出来の所為で性能が落ちる部分は少ない。
整数演算使わなきゃ殆どスカラプロセッサだし。
倍精度だと倍精度積和+整数演算の組み合わせしかできないから
VLIWコンパイラの不出来の所為で性能が落ちる部分は少ない。
整数演算使わなきゃ殆どスカラプロセッサだし。
551 :デフォルトの名無しさん:2008/07/13(日) 18:09:00
あのー質問してもいいでつか?
552 :デフォルトの名無しさん:2008/07/13(日) 20:46:25
>>551
消えろカス
消えろカス
553 :デフォルトの名無しさん:2008/07/13(日) 20:56:28
>>551
いや、そんなことより俺の質問を聞いてくれ。
いや、そんなことより俺の質問を聞いてくれ。
554 :デフォルトの名無しさん:2008/07/13(日) 22:57:49
お兄ちゃんたちってどうして変な臭いがするの???
555 :デフォルトの名無しさん:2008/07/13(日) 23:00:22
俺はおじさんだヴォケ
556 :デフォルトの名無しさん:2008/07/13(日) 23:07:14
カレー臭がするのか
557 :デフォルトの名無しさん:2008/07/13(日) 23:13:13
そうそう最近脱いだ服が臭くてな。
558 :デフォルトの名無しさん:2008/07/14(月) 06:49:02
おや汁対策で、俺の服だけ別に洗濯機回されてる。
559 :デフォルトの名無しさん:2008/07/15(火) 05:37:32
>>558
最近の洗剤なめんなw お前が嫌われてるだけだw
最近の洗剤なめんなw お前が嫌われてるだけだw
560 :デフォルトの名無しさん:2008/07/15(火) 13:14:02
>>559
なんでお前が偉そうなのw
なんでお前が偉そうなのw
561 :デフォルトの名無しさん:2008/07/15(火) 16:02:07
しかし、NL-MeansはCUDA遅くて使い物にならなかったみたいだね
得意不得意がハッキリしてて面白いね
得意不得意がハッキリしてて面白いね
562 :デフォルトの名無しさん:2008/07/15(火) 16:02:27
ここでやるな、よそでやれ
563 :デフォルトの名無しさん:2008/07/15(火) 22:57:02
正直nVidiaの超スカラプロセッサ化は、面白味に欠けるなぁ
GPUはあくまでベクトルプロセッサであって欲しいが
GPUはあくまでベクトルプロセッサであって欲しいが
564 :デフォルトの名無しさん:2008/07/16(水) 02:09:27
Larrabeeに追われるNVIDIAがGT200に施したGPGPU向け拡張
ttp://pc.watch.impress.co.jp/docs/2008/0716/kaigai453.htm
ttp://pc.watch.impress.co.jp/docs/2008/0716/kaigai453.htm
565 :デフォルトの名無しさん:2008/07/17(木) 05:16:15
>>563
超同意だけど、グラフィック用途でも粒度が細かくなりつつあるので仕方ないと思う。階層化シャドウマップとか、その半影とか、双半球環境マップとか。
超同意だけど、グラフィック用途でも粒度が細かくなりつつあるので仕方ないと思う。階層化シャドウマップとか、その半影とか、双半球環境マップとか。
566 :デフォルトの名無しさん:2008/07/18(金) 19:20:21
今朝の日経産業新聞で読み仮名が「CUDA(クーダ)」だった。
彼らは専門知識が無くてもインタビューとかするだろうし、こっちが正しいんだよな?
彼らは専門知識が無くてもインタビューとかするだろうし、こっちが正しいんだよな?
567 :デフォルトの名無しさん:2008/07/18(金) 20:27:00
>>566
大分まえからクーダだが。。今までなんて呼んでたの?
大分まえからクーダだが。。今までなんて呼んでたの?
568 :デフォルトの名無しさん:2008/07/18(金) 20:34:12
>>566
クーダじゃないの?
クーダじゃないの?
569 :デフォルトの名無しさん:2008/07/18(金) 20:39:46
570 :デフォルトの名無しさん:2008/07/18(金) 21:45:58
アニメのキャラみたいだな、クーちゃん
571 :デフォルトの名無しさん:2008/07/18(金) 22:03:13
読み方ネタなんかでスレ消費するのはやめてくーださい
572 :デフォルトの名無しさん:2008/07/19(土) 00:16:36
【審議拒否】
573 :デフォルトの名無しさん:2008/07/19(土) 00:18:44
ヌーダだろ
574 :デフォルトの名無しさん:2008/07/19(土) 08:03:36
クター
575 :デフォルトの名無しさん:2008/07/19(土) 15:12:25
きゅうううううううううううううううううううううううううううううううううううううううううううううううううううううううううううううううだぁ
だろ
だろ
576 :デフォルトの名無しさん:2008/07/19(土) 15:49:42
Geodeじゃないんだから
577 :デフォルトの名無しさん:2008/07/20(日) 03:40:41
管
578 :デフォルトの名無しさん:2008/07/21(月) 20:17:11
/\ ,r‐''''" ~'~"''-、
〈 /,!,!,' ./, r‐i'i~'、
>,'./:/,' / i i、 i, ',i ヽ,_!,!'、
_,,,_ くi'./ /ii、,!!,' '、!、!,、ャ , ,!,,!、,!
\ ~'‐、i'、_ レ',',!'i:|了5 'iテヤ, i i:;:;::ヽ,
つ、. | "'''i-!,,!,,!、゙'''',_,,--、''イ. i i:;:;::',、ヽ, 問おう、
~‐'、| 'i, : :~"''‐'--、,!'~'、. i i:;:;:::',ヽヽ, あなたがわたしのおにいちゃんか
'! /: : : : . : : : . . :~"'ヽ;:i: !,::;::ヽヽ,`ヽ、_
フ''フ'''' フ''‐、--;,;,; : : : : : /, !, ヽ;:::::ヽ,`ヽ、'、''''''‐‐、
/ /,'i /'i ll i〉: : !: :"'''-.,,_';;ヽヽ;: ヽ、:::`ヽ、 ヽヽ 'i
/ ヽ,i.'/ ‐‐'、!/: : ∞: : : : i:/:;;:;:'i ::;i:::::,,_..ヽ::::ヽ し、_
( / !(',_ /: : :.∞ : : : :/',:::;:/ ::/'、::::;:ヽ,!::::ノ、 !,,_
)( !, ,、''-/: : : :∞: : : :(;:',:::/__::ヽ `ヽ::::);:::l し、
. ' ) /, ,!)/ : : : :.∞ : : : : ヽ,i' 7/ !::',, ',,!、 !
( "'/: : : : : : i: : : : : : '、_、 ξ ζ く
く,;,;,;_: : : : l : : :_;,;-'"\
く ~"'''''"''i''".__ /
/"'-、,_,,,,-‐' ̄\ ̄ '、
/ /. \. \
/ / \ ヽ
/ / i二ニi_,,,
i'i'" ,__ / ...................,,!_∞_ニ、i|:::........
_! 'ヽ! ~'i ...............::::::::::::( ‐-‐''i=ヽ:::
.l、lヾ_,,,∞(i,,:::::::::::::::::::::::::::::::::::::"====='''
し、<、/、三ニ'、;::::::::::::::::::::::
`ヽ、_,,,,,,,,,,-i;::::::::::::::::....
〈 /,!,!,' ./, r‐i'i~'、
>,'./:/,' / i i、 i, ',i ヽ,_!,!'、
_,,,_ くi'./ /ii、,!!,' '、!、!,、ャ , ,!,,!、,!
\ ~'‐、i'、_ レ',',!'i:|了5 'iテヤ, i i:;:;::ヽ,
つ、. | "'''i-!,,!,,!、゙'''',_,,--、''イ. i i:;:;::',、ヽ, 問おう、
~‐'、| 'i, : :~"''‐'--、,!'~'、. i i:;:;:::',ヽヽ, あなたがわたしのおにいちゃんか
'! /: : : : . : : : . . :~"'ヽ;:i: !,::;::ヽヽ,`ヽ、_
フ''フ'''' フ''‐、--;,;,; : : : : : /, !, ヽ;:::::ヽ,`ヽ、'、''''''‐‐、
/ /,'i /'i ll i〉: : !: :"'''-.,,_';;ヽヽ;: ヽ、:::`ヽ、 ヽヽ 'i
/ ヽ,i.'/ ‐‐'、!/: : ∞: : : : i:/:;;:;:'i ::;i:::::,,_..ヽ::::ヽ し、_
( / !(',_ /: : :.∞ : : : :/',:::;:/ ::/'、::::;:ヽ,!::::ノ、 !,,_
)( !, ,、''-/: : : :∞: : : :(;:',:::/__::ヽ `ヽ::::);:::l し、
. ' ) /, ,!)/ : : : :.∞ : : : : ヽ,i' 7/ !::',, ',,!、 !
( "'/: : : : : : i: : : : : : '、_、 ξ ζ く
く,;,;,;_: : : : l : : :_;,;-'"\
く ~"'''''"''i''".__ /
/"'-、,_,,,,-‐' ̄\ ̄ '、
/ /. \. \
/ / \ ヽ
/ / i二ニi_,,,
i'i'" ,__ / ...................,,!_∞_ニ、i|:::........
_! 'ヽ! ~'i ...............::::::::::::( ‐-‐''i=ヽ:::
.l、lヾ_,,,∞(i,,:::::::::::::::::::::::::::::::::::::"====='''
し、<、/、三ニ'、;::::::::::::::::::::::
`ヽ、_,,,,,,,,,,-i;::::::::::::::::....
579 :デフォルトの名無しさん:2008/07/21(月) 20:18:33
なんの誤爆だw
580 :デフォルトの名無しさん:2008/07/28(月) 16:09:11
誰かBlenderでCUDA使ったレンダ作ってくれ
ほめられるよ
ほめられるよ
581 :デフォルトの名無しさん:2008/07/28(月) 22:53:23
自分でやるかちゃんと金払え
582 :デフォルトの名無しさん:2008/07/28(月) 23:04:39
あんな汚いソースじゃ移植したくない
583 :デフォルトの名無しさん:2008/07/28(月) 23:44:30
レンダ部分のソースの範囲だけ教えてくれれば
みなくもない
みなくもない
584 :デフォルトの名無しさん:2008/07/29(火) 12:29:39
ヒントつオープンソース
585 :デフォルトの名無しさん:2008/07/29(火) 16:54:09
ヒントツ・オープンソース
586 :デフォルトの名無しさん:2008/07/29(火) 23:55:13
解析するのめんどうだから
レンダの部分だけここにソースリストあげて
それくらいしてくれてもいいよね?
レンダの部分だけここにソースリストあげて
それくらいしてくれてもいいよね?
587 :デフォルトの名無しさん:2008/07/30(水) 10:25:46
まぁ、他人に頼むのならそれくらいしてもいいよな
588 :デフォルトの名無しさん:2008/07/30(水) 13:22:00
589 :デフォルトの名無しさん:2008/07/31(木) 10:59:57
WME対応してくれないかな・・・
590 :デフォルトの名無しさん:2008/07/31(木) 15:07:56
F@H落として動かしてるのにamdcalcl.dllとamdcalrt.dllがDLされないぞ…
まさかスタティックリンクになったのか…
まさかスタティックリンクになったのか…
591 :デフォルトの名無しさん:2008/08/01(金) 00:32:34
見るフォルダ間違ってるとか。
そもそも最近のはインストーラに付いてくる。
そもそも最近のはインストーラに付いてくる。
592 :デフォルトの名無しさん:2008/08/02(土) 02:23:24
3DCGのレンダリングには向いてない?
593 :デフォルトの名無しさん:2008/08/02(土) 02:44:50
レイトレやるならアリだろ。
594 :デフォルトの名無しさん:2008/08/02(土) 15:33:38
じゃあ>>588のソース改変してCUDA対応きぼん
595 :デフォルトの名無しさん:2008/08/02(土) 16:52:45
>>594
CUDAスレに行け
CUDAスレに行け
596 :デフォルトの名無しさん:2008/08/02(土) 16:53:47
>>591
Vista対応のDLLが欲しいんだ…
Vista対応のDLLが欲しいんだ…
597 :デフォルトの名無しさん:2008/08/02(土) 17:21:10
598 :デフォルトの名無しさん:2008/08/05(火) 22:12:13
Vista用のGPU2クライアント落とせば入ってるよ
DLページをもう一回見たらVistaマークのzipから落とせた\(^o^)/
でも当然だがこのDLLじゃ64bit版のサンプルは実行できないな…(´・ω・`)
どうせ2GB超えるようなプログラムは作ってないし素直に本家更新待つか
でも当然だがこのDLLじゃ64bit版のサンプルは実行できないな…(´・ω・`)
どうせ2GB超えるようなプログラムは作ってないし素直に本家更新待つか
600 :デフォルトの名無しさん:2008/08/09(土) 09:14:54
CPUで流体シミュレーションやって遊んでるけど
ぶっちゃけGPGPUと速度変わりませんwwww
プログラムを最適化したらむしろ早いかもwwww
ぶっちゃけGPGPUと速度変わりませんwwww
プログラムを最適化したらむしろ早いかもwwww
601 :デフォルトの名無しさん:2008/08/09(土) 17:13:49
つまりショボイプログラムなんですね
分かります
分かります
602 :デフォルトの名無しさん:2008/08/09(土) 19:39:05
601の言い方は悪いが同意。俺も詳しくは無いがそこらの記事から察するに、
今のCPUだって遅いわけではないんだから
複数のオブジェクトに対して或る程度の高負荷がかかる処理でないと
差が出ないと思うんだが。
今のCPUだって遅いわけではないんだから
複数のオブジェクトに対して或る程度の高負荷がかかる処理でないと
差が出ないと思うんだが。
603 :デフォルトの名無しさん:2008/08/10(日) 01:44:48
ちらっと触って思ったこと。
計算は速いけど、なんかデータのCPU<->GPU間転送が超遅い。
んで、大体の人が期待しているGPGPU使用のh.264エンコって現実味がない気がしてきた。
入力がまず間違いなく、1フレームごとに発生するわけだからその分のデータ転送は必須。
普通にCPUのSIMD使ったほうが早いかと。
計算は速いけど、なんかデータのCPU<->GPU間転送が超遅い。
んで、大体の人が期待しているGPGPU使用のh.264エンコって現実味がない気がしてきた。
入力がまず間違いなく、1フレームごとに発生するわけだからその分のデータ転送は必須。
普通にCPUのSIMD使ったほうが早いかと。
604 :デフォルトの名無しさん:2008/08/10(日) 01:52:19
自分の能力を過信するとそう思っちゃうよね。
もっと調べると、使いこなせない俺はヘボプログラマなんだと実感する。
NVIDIA、GPUによるH.264エンコードをデモ
http://journal.mycom.co.jp/news/2008/04/16/020/
http://www.elementaltechnologies.com/how_it_works.php
もっと調べると、使いこなせない俺はヘボプログラマなんだと実感する。
NVIDIA、GPUによるH.264エンコードをデモ
http://journal.mycom.co.jp/news/2008/04/16/020/
http://www.elementaltechnologies.com/how_it_works.php
605 :デフォルトの名無しさん:2008/08/10(日) 02:00:22
まあ一口にH264と言っても自由度高いし、と言うかいろんな圧縮処理が規格化されてるんだっけ、
この記事のやつはどの位圧縮できるんだろうね
この記事のやつはどの位圧縮できるんだろうね
606 :デフォルトの名無しさん:2008/08/10(日) 02:01:47
>>604
使いこなせないのが全て実装側にあるって考えはどうも嫌です。
道具を使う側が、使いにくいと思う場合はやっぱり道具側を改善すべきかと。
いまだにGPGPU向け言語とゆうか、インターフェースとゆうかそれが不十分な気がします。
CUDAはまだ使いやすいほうだけど。。。
だって教えてくれた記事が4月なのに、まだ現物ソフトないじゃん
使いこなせないのが全て実装側にあるって考えはどうも嫌です。
道具を使う側が、使いにくいと思う場合はやっぱり道具側を改善すべきかと。
いまだにGPGPU向け言語とゆうか、インターフェースとゆうかそれが不十分な気がします。
CUDAはまだ使いやすいほうだけど。。。
だって教えてくれた記事が4月なのに、まだ現物ソフトないじゃん
607 :デフォルトの名無しさん:2008/08/10(日) 02:09:53
明後日から始まるSIGGRAPHにElemental Technologiesが出展するみたいだね
これで公開時期が発表されなかったり>>604より速くなってなかったら…
これで公開時期が発表されなかったり>>604より速くなってなかったら…
608 :デフォルトの名無しさん:2008/08/10(日) 09:25:37
609 :デフォルトの名無しさん:2008/08/10(日) 09:44:23
まぁIntelが金注ぎまくるまで待っていても
いいと思うけどね
いいと思うけどね
610 :デフォルトの名無しさん:2008/08/10(日) 10:43:01
>使いこなせないのが全て実装側にあるって考えはどうも嫌です
痛い,痛過ぎる
痛い,痛過ぎる
611 :デフォルトの名無しさん:2008/08/10(日) 11:07:18
半年後にはOpenCA出るしDirectCA(仮称)
そろそろ発表されるのにCUDAに縛られる
意味無いなぁ
そろそろ発表されるのにCUDAに縛られる
意味無いなぁ
612 :デフォルトの名無しさん:2008/08/10(日) 12:43:12
まーねー、俺みたいにぬるいプログラマは
DirectXくらい楽になってくれるとうれしー
DirectXくらい楽になってくれるとうれしー
613 :デフォルトの名無しさん:2008/08/10(日) 19:42:41
614 :デフォルトの名無しさん:2008/08/15(金) 21:42:11
SIGGRAPH 2008のAMDの資料にCALとDirectXの協調のさせ方が微妙に出てるね。
ttp://s08.idav.ucdavis.edu/
関数ポインタの取得の部分が書いてないもんだから>>357の関数名で合ってるのかさっぱりわからない。
まぁとりあえず試してみるかね。
ttp://s08.idav.ucdavis.edu/
関数ポインタの取得の部分が書いてないもんだから>>357の関数名で合ってるのかさっぱりわからない。
まぁとりあえず試してみるかね。
615 :デフォルトの名無しさん:2008/08/15(金) 22:28:37
今GPGPUやっても仕方がないきがしてならん
Intelの発表見ると微妙過ぎる気がしてならん
Intelの発表見ると微妙過ぎる気がしてならん
616 :デフォルトの名無しさん:2008/08/16(土) 12:56:04
>>615
分野によってドチラがコストパフォーマンスが高いかが違うので、やっても仕方ないかどうかは、分野による。
分野によってドチラがコストパフォーマンスが高いかが違うので、やっても仕方ないかどうかは、分野による。
617 :デフォルトの名無しさん:2008/08/16(土) 21:01:35
分野と言うか目的が一番問題だろうな
618 :デフォルトの名無しさん:2008/08/16(土) 21:18:53
>>613
それってかなりがっかりなお知らせなんじゃ…つかなんのためのGPGPUよ
それってかなりがっかりなお知らせなんじゃ…つかなんのためのGPGPUよ
619 :デフォルトの名無しさん:2008/08/16(土) 23:43:43
しかもBaselineプロファイルなんてBないから圧縮率悪いし、わざわざ、GPU最適化して作る意味ないです。。。
620 :デフォルトの名無しさん:2008/08/17(日) 00:32:06
そうでなく、そのプロファイルでの報告だってのが、ってことじゃね
621 :デフォルトの名無しさん:2008/08/22(金) 07:29:34
GPUを用いた映像のリアルタイム手ぶれ補正ソフトウェアの開発
いいなGPU使うだけで税金おりるのって
いいなGPU使うだけで税金おりるのって
622 :デフォルトの名無しさん:2008/08/22(金) 11:39:13
マルチする奴って馬鹿だな、まで読んだ
623 :デフォルトの名無しさん:2008/08/22(金) 14:44:20
CUDA2正式版が出たな
それに対してAMDは4850が出てから一度も…
それに対してAMDは4850が出てから一度も…
624 :デフォルトの名無しさん:2008/08/23(土) 01:04:22
4850以前に3000シリーズもStream SDKのドキュメントに出てないぞ
625 :デフォルトの名無しさん:2008/08/23(土) 01:53:12
>>624
全然汎用的に使えないから、いいんじゃない?
全然汎用的に使えないから、いいんじゃない?
626 :デフォルトの名無しさん:2008/08/23(土) 15:40:08
CUDAとCALに両方対応するプリコンパイラを誰か作らないのか
627 :デフォルトの名無しさん:2008/08/23(土) 15:59:30
>>626
抽象度が違うから無理だし、作ったって使いやすいものじゃない。
抽象度が違うから無理だし、作ったって使いやすいものじゃない。
628 :デフォルトの名無しさん:2008/08/24(日) 00:14:04
629 :デフォルトの名無しさん:2008/08/24(日) 00:30:24
>>628
ものすごい今更感が
ものすごい今更感が
630 :デフォルトの名無しさん:2008/08/24(日) 03:46:37
そもそも、なぜこのスレ?
631 :デフォルトの名無しさん:2008/08/28(木) 01:47:18
CUDA最強だね
AMDはBroadcomに身売りしたし終わりだね
AMDはBroadcomに身売りしたし終わりだね
632 :デフォルトの名無しさん:2008/08/28(木) 02:58:25
今の時点でCUDA最強なんて言ってるのを、10年後の人間に見せたら
牛乳吹くぞきっとw
牛乳吹くぞきっとw
633 :デフォルトの名無しさん:2008/08/28(木) 04:55:44
現時点じゃCUDA(笑)だもんな。
インテルがGPGPUは失敗するって言ってたけど今のままじゃ
その通りになりそうだし。
インテルがGPGPUは失敗するって言ってたけど今のままじゃ
その通りになりそうだし。
634 :デフォルトの名無しさん:2008/08/28(木) 05:52:06
ゲーム屋(の一部)から言わせて貰えば、GPGPUはとても魅力的。
巨大な配列に適当な関数を map するような用途は沢山あるから。
だから逆に、あんまりCPUよりになって欲しくないね。
巨大な配列に適当な関数を map するような用途は沢山あるから。
だから逆に、あんまりCPUよりになって欲しくないね。
635 :デフォルトの名無しさん:2008/09/01(月) 23:27:31
GPGPUって今どういう状態?
1.GPUメーカーが必死に煽って、好き者PGだけが遊びでいじってる状態?
2.先進的PGが名もなきゲームや特殊なソフトで、こっそり実用する奴がいる状態?
3.先進的なメーカーが、名もなきゲームや特殊なソフトで使う事もある状態?
4.ゲームや特殊なソフトでは、たまに使ってるソフトもある位の状態?
5.有名実用ソフトがみんな当たり前のように使用している状態?
6.Windowsのカーネルも含めてほとんどのソフトがGPUで動いてる状態?
1.GPUメーカーが必死に煽って、好き者PGだけが遊びでいじってる状態?
2.先進的PGが名もなきゲームや特殊なソフトで、こっそり実用する奴がいる状態?
3.先進的なメーカーが、名もなきゲームや特殊なソフトで使う事もある状態?
4.ゲームや特殊なソフトでは、たまに使ってるソフトもある位の状態?
5.有名実用ソフトがみんな当たり前のように使用している状態?
6.Windowsのカーネルも含めてほとんどのソフトがGPUで動いてる状態?
636 :デフォルトの名無しさん:2008/09/01(月) 23:35:25
2じゃね
637 :デフォルトの名無しさん:2008/09/02(火) 00:41:29
カーネルが動いたらむしろCPU要らない気がするw
638 :デフォルトの名無しさん:2008/09/02(火) 00:53:17
それは、もうGPUじゃない。
639 :デフォルトの名無しさん:2008/09/02(火) 08:54:34
このスレだと微妙にスレ違いなネタなんだけど
物理シュミレーションスレ誰か立ててくれませんか?
物理シュミレーションスレ誰か立ててくれませんか?
640 :デフォルトの名無しさん:2008/09/02(火) 13:18:00
自分で立てろや
641 :デフォルトの名無しさん:2008/09/02(火) 13:31:43
立てられないんです
642 :デフォルトの名無しさん:2008/09/02(火) 14:56:12
643 :デフォルトの名無しさん:2008/09/03(水) 00:32:20
>>635
photoshopや有名エンコーダで利用されるようになったら、晴れて一般技術の仲間入りって所か?
photoshopや有名エンコーダで利用されるようになったら、晴れて一般技術の仲間入りって所か?
644 :デフォルトの名無しさん:2008/09/05(金) 04:19:58
"一般技術"って何だ?
645 :デフォルトの名無しさん:2008/09/06(土) 11:18:09
電話が使えるとか電卓が使えるとかそういう技術の事ジャマイカ?
646 :デフォルトの名無しさん:2008/09/06(土) 23:20:29
っつーか、それ以前に、そんな日が本当に来るのかよ。
647 :デフォルトの名無しさん:2008/09/06(土) 23:41:40
来ません
648 :デフォルトの名無しさん:2008/09/07(日) 11:55:08
AthronとNvidia好きな俺にとっちゃ
649 :デフォルトの名無しさん:2008/09/07(日) 12:34:13
Athron
Athron
Athron
Athron
Athron
Athron
Athron
Athron
Athron
Athron
Athron
Athron
Athron
Athron
Athron
Athron
Athron
Athron
Athron
Athron
Athron
Athron
Athron
Athron
Athron
Athron
Athron
650 :デフォルトの名無しさん:2008/09/07(日) 13:14:18
ソフトウェア環境が整う速度よりも
CPUのコア数が増える速度の方が早いでしょ
GPUをCPU並みに複雑な処理に対応させるって
それって単にマルチコアなCPUを作るだけでしょって話なわけで
結局メーカーの入れ替わりなんかが発生するかもはしれんけど
行き着く先はCPUとGPUの統合なわけ
プログラムはマルチスレッドなものを作っとけばいいだけ
CUDAだのCALだのは要らない
CPUのコア数が増える速度の方が早いでしょ
GPUをCPU並みに複雑な処理に対応させるって
それって単にマルチコアなCPUを作るだけでしょって話なわけで
結局メーカーの入れ替わりなんかが発生するかもはしれんけど
行き着く先はCPUとGPUの統合なわけ
プログラムはマルチスレッドなものを作っとけばいいだけ
CUDAだのCALだのは要らない
651 :デフォルトの名無しさん:2008/09/07(日) 13:20:41
単純にMAP関数アクセラレータとして使えるくらい
GPUがCPUに近くなればいいんだよ。
stlっぽくunordered_for_eachにkernel関数渡せば
ハードに合った並列処理されるみたいな。
GPUがCPUに近くなればいいんだよ。
stlっぽくunordered_for_eachにkernel関数渡せば
ハードに合った並列処理されるみたいな。
652 :デフォルトの名無しさん:2008/09/07(日) 13:21:24
pentium-mクラスの256コアCPU速く出ないかなぁ
653 :デフォルトの名無しさん:2008/09/07(日) 13:22:48
バカだから並列プログラムできません><
と素直に言えばいいのに
と素直に言えばいいのに
654 :デフォルトの名無しさん:2008/09/07(日) 13:25:14
並列プログラミングできないって、それが理解できないですよ。
単にコア分のスレッド使って、処理を分ければ良いだけのことでしょ?
単にコア分のスレッド使って、処理を分ければ良いだけのことでしょ?
655 :デフォルトの名無しさん:2008/09/07(日) 13:26:44
>>650
いるいる。
現状CPUのSIMDだってコンパイラはまともに最適化してくれなくて
自分で専用のコード書かなきゃいけない。
マルチスレッドだってOSによってAPIが当然違うし同期とか面倒くさい。
CUDAだろうがその他の開発環境だろうが構わないが
もっと並列性の高い言語を用意してくれなきゃ
多くのヘタレPGが書いたコードは現状のCPUだって1/10くらいしか性能が出てない。
いるいる。
現状CPUのSIMDだってコンパイラはまともに最適化してくれなくて
自分で専用のコード書かなきゃいけない。
マルチスレッドだってOSによってAPIが当然違うし同期とか面倒くさい。
CUDAだろうがその他の開発環境だろうが構わないが
もっと並列性の高い言語を用意してくれなきゃ
多くのヘタレPGが書いたコードは現状のCPUだって1/10くらいしか性能が出てない。
656 :デフォルトの名無しさん:2008/09/07(日) 13:38:17
手続き型の記述法がアホ臭いことが結構あるだろ。
forループでわざわざどうでもいい処理順序まで記述した挙句
OpenMPのプラグマで実は並列に処理できますよとヒント書くとか。
並列構文作って無意味な制御変数のデータ依存省いた
本当に必要な依存だけ記述されたRTLをコンパイラに素直に渡せないから
人間は無駄に処理順序を記述する羽目になり、
コンパイラは無駄に不完全な並列化解析することになる。
forループでわざわざどうでもいい処理順序まで記述した挙句
OpenMPのプラグマで実は並列に処理できますよとヒント書くとか。
並列構文作って無意味な制御変数のデータ依存省いた
本当に必要な依存だけ記述されたRTLをコンパイラに素直に渡せないから
人間は無駄に処理順序を記述する羽目になり、
コンパイラは無駄に不完全な並列化解析することになる。
657 :デフォルトの名無しさん:2008/09/08(月) 10:55:02
フォトショやエンコーダのCUDAに対応するのがあるよ
3DCGレンダで対応するのが出るのは時間の問題じゃねーか
3DCGレンダで対応するのが出るのは時間の問題じゃねーか
658 :デフォルトの名無しさん:2008/09/09(火) 10:23:51
AMDの新しいSDK出るのって今週の予定だったな。
659 :デフォルトの名無しさん:2008/09/10(水) 10:11:09
密かにftpサーバに新版アップされているな。
660 :デフォルトの名無しさん:2008/09/10(水) 12:18:27
vista用も用意されてるね
661 :デフォルトの名無しさん:2008/09/10(水) 12:26:26
662 :デフォルトの名無しさん:2008/09/10(水) 13:38:46
1.2.βの更新日が7月23日?
今週の新版は1.3βなのかついに正式版なのか
今週の新版は1.3βなのかついに正式版なのか
663 :デフォルトの名無しさん:2008/09/10(水) 16:24:44
1.2βですじゃ
664 :デフォルトの名無しさん:2008/09/10(水) 16:26:29
665 :デフォルトの名無しさん:2008/09/10(水) 23:45:31
ぱっとドキュ見てみたけど、相変わらずCALの方が。。。
フォーラムでも叩かれてたのに、見た目綺麗でも中身変わらず。。。。
フォーラムでも叩かれてたのに、見た目綺麗でも中身変わらず。。。。
666 :デフォルトの名無しさん:2008/09/11(木) 05:48:50
667 :デフォルトの名無しさん:2008/09/11(木) 06:31:14
余裕で出来るwww
668 :デフォルトの名無しさん:2008/09/11(木) 07:05:19
669 :デフォルトの名無しさん:2008/09/11(木) 09:59:14
ttp://pc.watch.impress.co.jp/docs/2008/0910/leadtek.htm
これGPGPUみたくユーザが使えたら面白そう
これGPGPUみたくユーザが使えたら面白そう
670 :デフォルトの名無しさん:2008/09/11(木) 11:24:47
性能と価格と消費電力次第だけど、数が出ないだろうからGPUに比べてとても割に合わなそう。
いつぞやの物理演算プロセッサの路線。
いつぞやの物理演算プロセッサの路線。
671 :デフォルトの名無しさん:2008/09/11(木) 14:18:41
5000-10000円程度か、対応ソフトウェアにバンドルして発売すればそこそこ需要はあるかと。
まぁSD解像度を主眼に置いている時点でワゴン逝き確定。ワゴンに行ったら救出しまつ。
まぁSD解像度を主眼に置いている時点でワゴン逝き確定。ワゴンに行ったら救出しまつ。
初物だから10万くらいするんじゃないか?
673 :デフォルトの名無しさん:2008/09/11(木) 20:02:34
やっとVista対応か
これでXP64消せる
これでXP64消せる
674 :デフォルトの名無しさん:2008/09/11(木) 20:20:40
675 :デフォルトの名無しさん:2008/09/12(金) 02:31:56
HD3450(Cat8.8)でBrook+のサンプルは動くのに
CALのサンプルが
Current hardware does not support this kernel.
やら
This program cannot be run on the present graphics hardware.
Exiting!
と表示されて全然動かないなぁ
Brook+の方はNLM_Denoise.bmpも出力できるからCALのバージョンチェックが厳しいだけだろうな
明日4850の方でも試してみよう
CALのサンプルが
Current hardware does not support this kernel.
やら
This program cannot be run on the present graphics hardware.
Exiting!
と表示されて全然動かないなぁ
Brook+の方はNLM_Denoise.bmpも出力できるからCALのバージョンチェックが厳しいだけだろうな
明日4850の方でも試してみよう
676 :デフォルトの名無しさん:2008/09/12(金) 02:59:10
>>675
Brook+の方はちゃんとGPUで動いてるの?CPUエミュになってない?
Brook+の方はちゃんとGPUで動いてるの?CPUエミュになってない?
677 :デフォルトの名無しさん:2008/09/12(金) 03:00:55
678 :デフォルトの名無しさん:2008/09/12(金) 09:10:19
>>675
単にMEM_EXPORTの機能がないカード使ってるだけだろ?
単にMEM_EXPORTの機能がないカード使ってるだけだろ?
679 :デフォルトの名無しさん:2008/09/15(月) 12:58:24
Stream SDK 1.2になったけど
なんか変わった?ドキュメントがさらにカオスに
なった以外変更ないみたいなんだが
なんか変わった?ドキュメントがさらにカオスに
なった以外変更ないみたいなんだが
680 :デフォルトの名無しさん:2008/09/15(月) 13:17:25
shader analyzerで見る限り
brook+のreduceで高速化のためか
複数のILプログラム出力しているみたい。
brook+のreduceで高速化のためか
複数のILプログラム出力しているみたい。
681 :デフォルトの名無しさん:2008/09/15(月) 14:30:12
682 :デフォルトの名無しさん:2008/09/17(水) 07:36:18
683 :デフォルトの名無しさん:2008/09/17(水) 08:54:40
なにげにクイックソートライブラリとか探せばごろごろすぐに使えるものがある
684 :デフォルトの名無しさん:2008/09/17(水) 11:50:31
初心者ですみません。
一般的なスペック高めのPC(現状ではC2D E8x00系,GeForce 9800系あたりを想定)で、
現状、あるいは今後のロードマップで、
CPUでやるより最大で何倍位の性能出るんでしょうか?
もちろん、課題に大きく依存すると思いますが、とりあえず最大(GPGPUに適した課題)で。
あと、性能を大きく上げる手軽な増設・改造などありますでしょうか。
一般的なスペック高めのPC(現状ではC2D E8x00系,GeForce 9800系あたりを想定)で、
現状、あるいは今後のロードマップで、
CPUでやるより最大で何倍位の性能出るんでしょうか?
もちろん、課題に大きく依存すると思いますが、とりあえず最大(GPGPUに適した課題)で。
あと、性能を大きく上げる手軽な増設・改造などありますでしょうか。
あ、別にnVidiaでなくてもPCショップで普通に買えるものならどこのでも良いです。
686 :デフォルトの名無しさん:2008/09/17(水) 15:25:56
GPGPUがらみですが、ちょっと離れてしまう話でもあり
でもどこで聴けばいいのかわからないので、ここで聞かせてください。
セカンドディスプレイを繋ぐ2つ目のDVIから
GPUで処理したデータをデジタル出力(映像ではないです)させたいのです。
どちらのディスプレイからデータを出力させるか
や
どこのピンからどんなデータを出すか。
などの資料は、無いでしょうか?
そういう制御が無理な気もしますし、少なくともATiとnVIDIAでは別な気もしますし。
でもどこで聴けばいいのかわからないので、ここで聞かせてください。
セカンドディスプレイを繋ぐ2つ目のDVIから
GPUで処理したデータをデジタル出力(映像ではないです)させたいのです。
どちらのディスプレイからデータを出力させるか
や
どこのピンからどんなデータを出すか。
などの資料は、無いでしょうか?
そういう制御が無理な気もしますし、少なくともATiとnVIDIAでは別な気もしますし。
687 :デフォルトの名無しさん:2008/09/17(水) 17:05:33
688 :デフォルトの名無しさん:2008/09/17(水) 22:08:23
689 :デフォルトの名無しさん:2008/09/17(水) 22:09:56
たとえば音声認識とか。
690 :デフォルトの名無しさん:2008/09/17(水) 22:43:55
CALの場合悩みは結局
痛nium2と同じだしな
CUDAは結局SSEの延長
痛nium2と同じだしな
CUDAは結局SSEの延長
691 :デフォルトの名無しさん:2008/09/17(水) 23:00:22
692 :デフォルトの名無しさん:2008/09/17(水) 23:17:48
去年はCell
今年はCUDA
来年は?
今年はCUDA
来年は?
693 :デフォルトの名無しさん:2008/09/17(水) 23:18:26
OpenCL
694 :デフォルトの名無しさん:2008/09/17(水) 23:23:56
Larrabee
695 :デフォルトの名無しさん:2008/09/18(木) 01:38:11
696 :デフォルトの名無しさん:2008/09/27(土) 18:03:14
NVIDIA製GPUが「Photoshop」「After Effects」「Premiere Pro」の最新版「CS4」アクセラレーションをサポート。
http://www.4gamer.net/games/032/G003263/20080925009/
>Adobe Photoshop CS4はQuadroとGeForceのどちらでも利用可能だが,
>残る二つはQuadroのみが認証&推奨されている――を搭載したシステムでは,自動的に有効化されるとのことだ。
Geforceで動くAE、Premiereプラグインを開発して売り出せば(ry
http://www.4gamer.net/games/032/G003263/20080925009/
>Adobe Photoshop CS4はQuadroとGeForceのどちらでも利用可能だが,
>残る二つはQuadroのみが認証&推奨されている――を搭載したシステムでは,自動的に有効化されるとのことだ。
Geforceで動くAE、Premiereプラグインを開発して売り出せば(ry
697 :デフォルトの名無しさん:2008/09/27(土) 20:01:41
ぬか喜びしてるのか色んなところにコピペしまくってるね君
698 :デフォルトの名無しさん:2008/09/30(火) 08:09:32
GPGPUでDSP作って
ディスプレイ繋いでない方のDVI端子にDVI->COAXIAL出力つけて
サウンドカード化とか、ちょっと妄想してみた。
DViだったら、多chも余裕な気もする。
ディスプレイ繋いでない方のDVI端子にDVI->COAXIAL出力つけて
サウンドカード化とか、ちょっと妄想してみた。
DViだったら、多chも余裕な気もする。
699 :デフォルトの名無しさん:2008/09/30(火) 11:52:40
それHDMIじゃダメなん?
700 :デフォルトの名無しさん:2008/09/30(火) 11:59:05
HDMI端子の普及率はまだそこまで高くないでしょ。
どうせGPGPUを使うなら、コンセプト的には、あまった●●で××を・・・
って感じだろうから、もう1個のDVI端子を何か有効に使いたい所。
どうせGPGPUを使うなら、コンセプト的には、あまった●●で××を・・・
って感じだろうから、もう1個のDVI端子を何か有効に使いたい所。
701 :デフォルトの名無しさん:2008/09/30(火) 22:34:53
702 :デフォルトの名無しさん:2008/10/10(金) 01:20:34
703 :デフォルトの名無しさん:2008/10/20(月) 23:57:16
結局、CS4もCUDAじゃなくてOpenGLだったわけだけど
何で今頃DX9のSM3.0対応のソフトが増えてるんだろ?
誰かわかる人教えてくれw
何で今頃DX9のSM3.0対応のソフトが増えてるんだろ?
誰かわかる人教えてくれw
704 :デフォルトの名無しさん:2008/10/21(火) 12:25:27
34 名前: Socket774 [sage] 投稿日: 2008/10/18(土) 01:45:03 ID:6Ti8WTwL
こっこれはGTX260じゃなくてQuadroCXなんだからね!
http://dc.watch.impress.co.jp/cda/accessories/2008/10/17/9443.html
約3万円→約20万円
こっこれはGTX260じゃなくてQuadroCXなんだからね!
http://dc.watch.impress.co.jp/cda/accessories/2008/10/17/9443.html
約3万円→約20万円
705 :デフォルトの名無しさん:2008/10/21(火) 12:44:04
NVIDIA社員が打ち合わせに来た際に言った台詞:
--
ボードメーカさんのボードは部品の品質も低いし検査もろくにしていない。
業務で使うのならそんなアキバ的発想はやめてQuadroFXを使うべきです。
--
その場にいたボードメーカさんの苦笑が忘れられない。
# GeForce8800GT vs. QuadroFX3700だけどね。
--
ボードメーカさんのボードは部品の品質も低いし検査もろくにしていない。
業務で使うのならそんなアキバ的発想はやめてQuadroFXを使うべきです。
--
その場にいたボードメーカさんの苦笑が忘れられない。
# GeForce8800GT vs. QuadroFX3700だけどね。
706 :デフォルトの名無しさん:2008/10/21(火) 20:38:40
707 :デフォルトの名無しさん:2008/10/21(火) 20:49:53
いつの間にかStreamSDKの1.2.1が出てたんだな
Radeon4xxxシリーズがOpenCloseDeviceでUnknownだったのがちゃんとR700系として認識されるようになった
Radeon4xxxシリーズがOpenCloseDeviceでUnknownだったのがちゃんとR700系として認識されるようになった
708 :デフォルトの名無しさん:2008/10/21(火) 22:08:51
>>705
おまいさんの仕事がなんなのかすんごい気になる
おまいさんの仕事がなんなのかすんごい気になる
710 :デフォルトの名無しさん:2008/10/21(火) 23:06:56
711 :デフォルトの名無しさん:2008/10/23(木) 05:35:44
同じ石なのに値段がどれだけ違うんだ、と思っていた時期が俺にもありました。
もう変わったらしいので当てはまらなくなっただけだが。
どちらにしろ利益率からいったら売れるところには売りたいのは当然だわな。
アキバ的発想で予備買ってもおつりがくるよな。
もう変わったらしいので当てはまらなくなっただけだが。
どちらにしろ利益率からいったら売れるところには売りたいのは当然だわな。
アキバ的発想で予備買ってもおつりがくるよな。
712 :デフォルトの名無しさん:2008/10/23(木) 07:34:30
>>711
まったくだ
まったくだ
713 :デフォルトの名無しさん:2008/10/23(木) 08:55:56
NVIDIAはブランド詐欺専門だからな
いっぱいあっても現役チップは3種類程度w
いっぱいあっても現役チップは3種類程度w
714 :デフォルトの名無しさん:2008/10/25(土) 16:23:33
さすがに3世代またいでリネームされると、ちょっとNV見限りたくなってきてるw
715 :デフォルトの名無しさん:2008/10/31(金) 01:28:36
CUDAのVS2008対応は年末か
716 :デフォルトの名無しさん:2008/11/01(土) 01:39:14
そんなことより、先にFreeBSDに対応してくれよ。
できればamd64で。
できればamd64で。
717 :デフォルトの名無しさん:2008/11/04(火) 22:39:56
http://www.hpcwire.com/blogs/OpenCL_On_the_Fast_Track_33608199.html
OpenCL on the Fast Track
Version 1.0 of OpenCL is currently scheduled to be released in early December at SIGGRAPH Asia 2008 in Singapore.
OpenCL on the Fast Track
Version 1.0 of OpenCL is currently scheduled to be released in early December at SIGGRAPH Asia 2008 in Singapore.
718 :デフォルトの名無しさん:2008/11/04(火) 23:28:14
キタ━━━━(゚∀゚)━━━━!!
719 :デフォルトの名無しさん:2008/11/12(水) 23:48:12
最近何か情報ないのかね?
相変わらずプログラム作りにくくて難儀なんだけどさ
相変わらずプログラム作りにくくて難儀なんだけどさ
720 :デフォルトの名無しさん:2008/11/13(木) 02:00:12
NVIDIAがシェーダデバッガを期間限定割引販売してるけど
GPGPU的には関係ないのかな。
GPGPU的には関係ないのかな。
721 :デフォルトの名無しさん:2008/11/13(木) 07:46:49
開発ツールアホみたいに高く売るのは
バカ会社の典型だな
ゲロビディア潰れろ
バカ会社の典型だな
ゲロビディア潰れろ
722 :,,・´∀`・,,)っ-●◎○:2008/11/13(木) 10:20:22
非業務用は無償じゃん
なに切れてんだ?
なに切れてんだ?
723 :デフォルトの名無しさん:2008/11/13(木) 11:02:44
AMDのシェーダデバッガは無料会員登録で手に入るな
724 :デフォルトの名無しさん:2008/11/13(木) 20:25:38
228 :Socket774 [↓] :2008/11/13(木) 20:16:24 ID:DqWrARXH
ttp://www.pcper.com/article.php?aid=638
ATI Stream Computing: From the desktop to the datacenter
ttp://www.pcper.com/images/reviews/638/07.jpg
ttp://www.pcper.com/images/reviews/638/08.jpg
ttp://www.pcper.com/images/reviews/638/09.jpg
ttp://www.pcper.com/images/reviews/638/10.jpg
ttp://www.businesswire.com/portal/site/home/permalink/?ndmViewId=news_view&newsId=20081112006601&newsLang=en
AMD Set to Release Free Software Giving Millions of ATI Radeon? Owners
New Way to Run Demanding Computing Tasks Faster than Ever
December ATI Catalyst? Driver Release Automatically Switches on ATI Stream Acceleration
in ATI Radeon? Graphics Cards Found in Millions of PCs
To Enable Instant Benefit, Users Will Also Be Able to Download Free Avivo? Video Converter
That Makes High-Definition Video Conversion up to 17x Faster
ttp://www.pcper.com/article.php?aid=638
ATI Stream Computing: From the desktop to the datacenter
ttp://www.pcper.com/images/reviews/638/07.jpg
{kind=link}
ttp://www.pcper.com/images/reviews/638/08.jpg
{kind=link}
ttp://www.pcper.com/images/reviews/638/09.jpg
{kind=link}
ttp://www.pcper.com/images/reviews/638/10.jpg
{kind=link}
ttp://www.businesswire.com/portal/site/home/permalink/?ndmViewId=news_view&newsId=20081112006601&newsLang=en
AMD Set to Release Free Software Giving Millions of ATI Radeon? Owners
New Way to Run Demanding Computing Tasks Faster than Ever
December ATI Catalyst? Driver Release Automatically Switches on ATI Stream Acceleration
in ATI Radeon? Graphics Cards Found in Millions of PCs
To Enable Instant Benefit, Users Will Also Be Able to Download Free Avivo? Video Converter
That Makes High-Definition Video Conversion up to 17x Faster
725 :デフォルトの名無しさん:2008/11/13(木) 22:16:27
今度こそGPUアクセラレートなAVIVO Converterが出るのか。
本当に出るのか心配だが、期待はしておこう。
COBRAとAVTはどこ行っちゃったのかよくわからんし、
*の文が小さい上に肝心のスライドは転載されてないのはアレだがw
本当に出るのか心配だが、期待はしておこう。
COBRAとAVTはどこ行っちゃったのかよくわからんし、
*の文が小さい上に肝心のスライドは転載されてないのはアレだがw
726 :デフォルトの名無しさん:2008/11/14(金) 22:05:16
AMD Stream対応のプログラムって
CAL直書きなの?
それともなんか違うもの使ってるの?
CAL直書きなの?
それともなんか違うもの使ってるの?
727 :デフォルトの名無しさん:2008/11/14(金) 22:07:37
>>724
これで年内にStream SDKの正式版が出なかったら怒るぞ
これで年内にStream SDKの正式版が出なかったら怒るぞ
728 :デフォルトの名無しさん:2008/11/14(金) 22:19:27
出なくてもいいけどもっとまともに
プログラム作れるようにしてくれよw
プログラム作れるようにしてくれよw
729 :,,・´∀`・,,)っ-○◎●:2008/11/14(金) 22:24:17
キャッシュの小ささはどうにもならない。
CUDAですらDirectXでできることと大して変わらん。
CUDAですらDirectXでできることと大して変わらん。
730 :デフォルトの名無しさん:2008/11/15(土) 00:02:34
>>726
確かBrook+が使えるんじゃなかった?
確かBrook+が使えるんじゃなかった?
731 :デフォルトの名無しさん:2008/11/15(土) 06:33:39
732 :デフォルトの名無しさん:2008/11/15(土) 12:39:24
733 :デフォルトの名無しさん:2008/11/15(土) 12:57:37
734 :デフォルトの名無しさん:2008/11/15(土) 13:13:53
ATI Stream正式発表っていってるけど
糞ドキュメントと仕様不備だらけ
糞ドキュメントと仕様不備だらけ
735 :,,・´∀`・,,)っ-●◎○:2008/11/15(土) 13:18:29
逆に今までのなんだったんだよって感じ
736 :デフォルトの名無しさん:2008/11/15(土) 13:32:22
あの言語仕様で汎用的に使えるのって
SSEの置換程度だしついでに出たフォーラムで
言った正式リリース時には一定の制約はあるものの
FPGAのような汎用ソリューションにするっていうのは
まるっきり嘘だったな
やっぱりIntelに期待するしかないな
SSEの置換程度だしついでに出たフォーラムで
言った正式リリース時には一定の制約はあるものの
FPGAのような汎用ソリューションにするっていうのは
まるっきり嘘だったな
やっぱりIntelに期待するしかないな
737 :デフォルトの名無しさん:2008/11/15(土) 13:50:17
CUDAの糞っぷりでみんな懲りてるからなぁ
先駆者が大失敗した影響はでかいな
ホント、DirectXに組み込まれるまで手を出せない感じ
先駆者が大失敗した影響はでかいな
ホント、DirectXに組み込まれるまで手を出せない感じ
738 :デフォルトの名無しさん:2008/11/15(土) 13:51:14
俺、CUDAの仕様は結構気に入ってるんだけどな。まぁ慣れただけなのかもしれんが
739 :デフォルトの名無しさん:2008/11/15(土) 13:58:11
Pthreadみたいに使えないといらんよ
740 :デフォルトの名無しさん:2008/11/15(土) 14:37:27
>>733
中身のDLLのバージョン変わってないけどね。
中身のDLLのバージョン変わってないけどね。
741 :デフォルトの名無しさん:2008/11/15(土) 14:41:30
742 :デフォルトの名無しさん:2008/11/15(土) 16:02:21
>>732
発表したのが07年ってだけだろw
発表したのが07年ってだけだろw
743 :デフォルトの名無しさん:2008/11/15(土) 16:17:49
で、COBRA使ってるってソースはまだですか?
744 :デフォルトの名無しさん:2008/11/15(土) 16:31:19
>>743
grepでもかければ?
grepでもかければ?
745 :デフォルトの名無しさん:2008/11/15(土) 19:45:04
COBRAは昔からあるATIのマルチメディア向けライブラリだよ
ttp://www.rage3d.com/print.php?article=/reviews/video/aiw9800p
で、それが今日まで更新されてきたわけだ
ttp://ati.amd.com/products/firepro/Siggraph_2008_video_encode_final.pdf
About AMD’s Accelerated Video Transcoding
AVT (aka Cobra) first developed for ATI TV tuners.
software encode = cheaper tuners.
Still deployed this way
Cobra team serves as R&D centre for video futures:
Shader-based video processing
Arrival of HD
Optical disc formats
GPU Video encode
GPU-accelerated decode and encode work continues…
ttp://www.rage3d.com/print.php?article=/reviews/video/aiw9800p
で、それが今日まで更新されてきたわけだ
ttp://ati.amd.com/products/firepro/Siggraph_2008_video_encode_final.pdf
About AMD’s Accelerated Video Transcoding
AVT (aka Cobra) first developed for ATI TV tuners.
software encode = cheaper tuners.
Still deployed this way
Cobra team serves as R&D centre for video futures:
Shader-based video processing
Arrival of HD
Optical disc formats
GPU Video encode
GPU-accelerated decode and encode work continues…
746 :デフォルトの名無しさん:2008/11/15(土) 23:17:38
Cobra 9.15.0.20713
747 :デフォルトの名無しさん:2008/11/15(土) 23:58:14
ごめんなさいずっとCORBAのtypoだと思い込んでましたw
748 :デフォルトの名無しさん:2008/11/16(日) 00:10:21
XPIDLの元になったやつか
749 :デフォルトの名無しさん:2008/11/19(水) 18:47:19
OpenCLのプレゼン資料
ttp://khronos.org/opencl/
Mathematicaが来年初頭CUDAに対応するって話
ttp://www.nvidia.com/object/io_1227010734073.html
ttp://khronos.org/opencl/
Mathematicaが来年初頭CUDAに対応するって話
ttp://www.nvidia.com/object/io_1227010734073.html
750 :デフォルトの名無しさん:2008/11/26(水) 12:18:50
ベールが剥がれた? OpenCLの概要を確認する
http://journal.mycom.co.jp/column/osx/301/index.html
DirectX 11はWindows 7とともにリリースされる
http://northwood.blog60.fc2.com/blog-entry-2450.html
http://journal.mycom.co.jp/column/osx/301/index.html
DirectX 11はWindows 7とともにリリースされる
http://northwood.blog60.fc2.com/blog-entry-2450.html
751 :デフォルトの名無しさん:2008/12/02(火) 15:04:18
GPUについて半分質問な感じだけど、聞いてくれ。
nVIDAのグラボの発熱量+消費電力が気になったんだが、
ATIの奴らでも似たようなもん?
昔はATIは省エネ的な感じで、コスパ良かった気がしたんだが
近頃ノートパソコンばっかり使ってて、グラボの良し悪しや
どれが最新のハイエンドで、どれが普及品で、どいつらが省エネタイプか
さっぱり分らんので、ご教授願いたい。
GPGPUでガリガリと計算させ続けようと考えてて、
さすがに、下手な発熱量と消費電力は抑えられれば抑えられる方が好ましいと思ってるんだが、
現状ではまだ、CUDA以外はダメぽな感じ?
もしも、ATIの方が電力抑えめでこっち使いたいなら、DirectX11待ちが正解そう?
nVIDAのグラボの発熱量+消費電力が気になったんだが、
ATIの奴らでも似たようなもん?
昔はATIは省エネ的な感じで、コスパ良かった気がしたんだが
近頃ノートパソコンばっかり使ってて、グラボの良し悪しや
どれが最新のハイエンドで、どれが普及品で、どいつらが省エネタイプか
さっぱり分らんので、ご教授願いたい。
GPGPUでガリガリと計算させ続けようと考えてて、
さすがに、下手な発熱量と消費電力は抑えられれば抑えられる方が好ましいと思ってるんだが、
現状ではまだ、CUDA以外はダメぽな感じ?
もしも、ATIの方が電力抑えめでこっち使いたいなら、DirectX11待ちが正解そう?
752 :デフォルトの名無しさん:2008/12/02(火) 16:39:59
消費電力に関しては、今の世代ではATIがひとつ抜けた感がある。
とくにこの、補助電源が不要なクラス
http://www.coneco.net/special/d066/
ところがソフトウェア的にはATIが1年以上遅れてる。
http://pc.watch.impress.co.jp/docs/2008/1114/amd.htm
>>727-729 >>734-738
トレードオフだな。…あとはどう判断するかだ
DirectX11は先の話だと思うけど
とくにこの、補助電源が不要なクラス
http://www.coneco.net/special/d066/
ところがソフトウェア的にはATIが1年以上遅れてる。
http://pc.watch.impress.co.jp/docs/2008/1114/amd.htm
>>727-729 >>734-738
トレードオフだな。…あとはどう判断するかだ
DirectX11は先の話だと思うけど
>>752 A lot of thanks.
やっぱし、微妙なラインを判断しなきゃならないのかぁ。
CUDAの方はdocumentサクッと見つかったけど、
AMDStreamの方はSDKをダウンロードしてsetupしないと見る事もできないのね・・・。
(結局setupして、今document見てるけどwww)
DirectX11については下記のリンク先で2009年とあったから、てっきりもうすぐ、
遅くともあと1年半待てば…とか思ってたんだけど、
甘い見通しだった??
ttp://www.xbitlabs.com/news/video/display/20081002034817_ATI_Plans_Expects_DirectX_11_Chips_Next_Year.html
やっぱし、微妙なラインを判断しなきゃならないのかぁ。
CUDAの方はdocumentサクッと見つかったけど、
AMDStreamの方はSDKをダウンロードしてsetupしないと見る事もできないのね・・・。
(結局setupして、今document見てるけどwww)
DirectX11については下記のリンク先で2009年とあったから、てっきりもうすぐ、
遅くともあと1年半待てば…とか思ってたんだけど、
甘い見通しだった??
ttp://www.xbitlabs.com/news/video/display/20081002034817_ATI_Plans_Expects_DirectX_11_Chips_Next_Year.html
754 :デフォルトの名無しさん:2008/12/02(火) 18:57:59
755 :デフォルトの名無しさん:2008/12/03(水) 00:04:17
世代ごとにターンが入れ替わってる。
コストから言うと、別スレで挙げられてる
HP ML115 +GF8400GSがぶっち切りで安上がり
じゃないかな。
コストから言うと、別スレで挙げられてる
HP ML115 +GF8400GSがぶっち切りで安上がり
じゃないかな。
756 :デフォルトの名無しさん:2008/12/03(水) 07:54:21
>>753
製品のよしあしは世代ごとに変わるから、使いたくなったときが買い時
でもCUDAやATI Streamに縛られたくなかったら、待てば?
http://pc.watch.impress.co.jp/docs/2008/1202/kaigai478.htm
製品のよしあしは世代ごとに変わるから、使いたくなったときが買い時
でもCUDAやATI Streamに縛られたくなかったら、待てば?
http://pc.watch.impress.co.jp/docs/2008/1202/kaigai478.htm
757 :デフォルトの名無しさん:2008/12/03(水) 14:40:21
まあCUDAにしろStreamSDKにしろOpenCL用のライブラリ作ればそれまでなわけで
758 :デフォルトの名無しさん:2008/12/03(水) 15:52:38
OpenCLなんて持ち上げてるのはマカーだけだよ。
XcodeがWindowsやLinuxで提供されてないのと同じレベルで、Snow Leopard専用言語。
「C#」や「C++/CLI」だって言語処理系自体はECMA標準規格だが事実上Windows .NET専用だろ?
どのみちCUDAの言語処理系に酷似してるなら簡単に移植できるだろうけど。
XcodeがWindowsやLinuxで提供されてないのと同じレベルで、Snow Leopard専用言語。
「C#」や「C++/CLI」だって言語処理系自体はECMA標準規格だが事実上Windows .NET専用だろ?
どのみちCUDAの言語処理系に酷似してるなら簡単に移植できるだろうけど。
759 :デフォルトの名無しさん:2008/12/03(水) 17:11:36
OpenCLはGPUだけをターゲットにしたものじゃないのだが
760 :デフォルトの名無しさん:2008/12/03(水) 17:22:15
CPUのコードも生成できるって言いたいんだろ?知ってるよ。
CUDAもホストCPU用のコード生成できるようになるよ。
OpenCLは、少なくとも当面「Snow Leopardだけをターゲット」だけどな。
CUDAもホストCPU用のコード生成できるようになるよ。
OpenCLは、少なくとも当面「Snow Leopardだけをターゲット」だけどな。
761 :デフォルトの名無しさん:2008/12/03(水) 17:54:22
いつもどおりMSがDirectXでWindows上のデファクトスタンダードを打ち出して普及を阻害するんだよな。
OpenGLがそうであったように。
OpenGLがそうであったように。
762 :デフォルトの名無しさん:2008/12/03(水) 19:25:51
>>761
でもそれは元々OpenGLがとっつきづらくて普及進んでなかったんじゃ。
でもそれは元々OpenGLがとっつきづらくて普及進んでなかったんじゃ。
763 :デフォルトの名無しさん:2008/12/03(水) 19:30:16
CUDA(笑)
764 :デフォルトの名無しさん:2008/12/03(水) 19:35:02
今のOpenGLは自滅してない?
765 :デフォルトの名無しさん:2008/12/03(水) 20:17:14
NVIDIA自体は特にこだわりは無いそうだ。
MSあたりがデファクトスタンダードを作ってくれるならそれでいいと。
CgをベースにHLSLが生まれたように。
CUDAはGPGPU用言語処理系としては頭一つ抜けてると思うが。
現時点で「使える」という点でね。
そんなに普及してないじゃないかって思うだろうけど、GPGPU自体がそんなもんだよ
MSあたりがデファクトスタンダードを作ってくれるならそれでいいと。
CgをベースにHLSLが生まれたように。
CUDAはGPGPU用言語処理系としては頭一つ抜けてると思うが。
現時点で「使える」という点でね。
そんなに普及してないじゃないかって思うだろうけど、GPGPU自体がそんなもんだよ
766 :デフォルトの名無しさん:2008/12/03(水) 20:28:21
でも、糞
767 :デフォルトの名無しさん:2008/12/03(水) 20:29:11
ハード屋はどこもそんなもんだと思うよ
ソフト屋もどこもそんなもんだと思うよ
自分とこの製品買ってくれるならなんでもいいわけで
ソフト屋もどこもそんなもんだと思うよ
自分とこの製品買ってくれるならなんでもいいわけで
768 :デフォルトの名無しさん:2008/12/03(水) 20:31:15
まぁ、このままだと下手したらIntelに全部もっていかれかねないんだから
769 :デフォルトの名無しさん:2008/12/03(水) 21:29:14
ぶっちゃけ、Intelに全部もっていかれるのが一番いいなぁ。
770 :デフォルトの名無しさん:2008/12/03(水) 21:37:47
Intelが全部持ってっちゃうと企業努力しなくなるだろ
771 :デフォルトの名無しさん:2008/12/03(水) 21:43:04
CUDA類似の奴が他のチップ(まぁATiだけど)でも使えるようになるという点でOpenCLには期待してる
まぁ何でもいいから使いやすいデファクトスタンダードを早く作ってくれ
まぁ何でもいいから使いやすいデファクトスタンダードを早く作ってくれ
772 :デフォルトの名無しさん:2008/12/03(水) 22:12:05
まあMacOS上のデファクトスタンダードは間違いないだろうが
それ以上でもそれ以下でもないな。
OpenCLワーキンググループはにはNVIDIAもIntelも名を連ねてるが
結局はAppleは自社製品買ってくれる上客だからなわけで。
当然ながらMSは不支持。メリットが無いから。
となると、Windows用の「OpenCL」公式ランタイム環境をどこの会社が用意する?
ベンダーごとに用意する?
それじゃOpenGLのgdgdの二の舞だな。
DX11 Compute ShaderとOpenCL、どっちかを選べと言われたら
NVIDIAもAMDもIntelも圧倒的に前者を選ぶだろうよ。
それとは別にCUDAなりCALなりCtなり各ベンダープロプライエタリな処理系は並行して
サポートしていくだろうし。
MacOS専用同然になる公算はでかいわ。
まあ、MacもデスクトップではLinux以上には影響力あるしデザイン業界には
相変わらず強いからそれなりには支持されるかもしれないけどさ。
それ以上でもそれ以下でもないな。
OpenCLワーキンググループはにはNVIDIAもIntelも名を連ねてるが
結局はAppleは自社製品買ってくれる上客だからなわけで。
当然ながらMSは不支持。メリットが無いから。
となると、Windows用の「OpenCL」公式ランタイム環境をどこの会社が用意する?
ベンダーごとに用意する?
それじゃOpenGLのgdgdの二の舞だな。
DX11 Compute ShaderとOpenCL、どっちかを選べと言われたら
NVIDIAもAMDもIntelも圧倒的に前者を選ぶだろうよ。
それとは別にCUDAなりCALなりCtなり各ベンダープロプライエタリな処理系は並行して
サポートしていくだろうし。
MacOS専用同然になる公算はでかいわ。
まあ、MacもデスクトップではLinux以上には影響力あるしデザイン業界には
相変わらず強いからそれなりには支持されるかもしれないけどさ。
773 :デフォルトの名無しさん:2008/12/03(水) 23:12:59
DirectCAの開発資金が200億円
OpenCAの開発資金が8億円
絶対OpenCAは流行らないし潰れる
OpenCAの開発資金が8億円
絶対OpenCAは流行らないし潰れる
774 :デフォルトの名無しさん:2008/12/03(水) 23:16:28
>>772
>それとは別にCUDAなりCALなりCtなり各ベンダープロプライエタリな処理系は並行してサポートしていくだろうし。
これって使う側(プログラマとしてのな)からすりゃ鬱陶しいだけなんだよ
MacなんてゴミOSはどうでもいいから、最低WinとUnix/LinuxについてはこれがGPGPUの標準ってのを作ってくれなきゃこれ以上広まらんぞ
>それとは別にCUDAなりCALなりCtなり各ベンダープロプライエタリな処理系は並行してサポートしていくだろうし。
これって使う側(プログラマとしてのな)からすりゃ鬱陶しいだけなんだよ
MacなんてゴミOSはどうでもいいから、最低WinとUnix/LinuxについてはこれがGPGPUの標準ってのを作ってくれなきゃこれ以上広まらんぞ
775 :デフォルトの名無しさん:2008/12/03(水) 23:18:53
なんだかんだで
糞MSのデファクトスタンダードって対応早いしトータルで見ると良いと思うんだよね
OpenGLだけならここまで進まなかったでしょ、実際
糞MSのデファクトスタンダードって対応早いしトータルで見ると良いと思うんだよね
OpenGLだけならここまで進まなかったでしょ、実際
776 :デフォルトの名無しさん:2008/12/03(水) 23:20:20
Linuxはサポートする必要ないだろ
糞リーナスのオナチラOSなんて不要だろw
糞リーナスのオナチラOSなんて不要だろw
777 :デフォルトの名無しさん:2008/12/03(水) 23:22:34
>>776
常時稼働させる演算用鯖(GPUGRIDとか)としてや、GPUクラスタとしてLinuxは必要
常時稼働させる演算用鯖(GPUGRIDとか)としてや、GPUクラスタとしてLinuxは必要
778 :デフォルトの名無しさん:2008/12/03(水) 23:26:32
779 :デフォルトの名無しさん:2008/12/03(水) 23:27:51
Linuxの方が軽いだろう。それにクラスタを構成する全ノードに一々Win鯖入れんのか?
保守もそうだし、入れる手間を考えたらLinuxの方が遥かに楽
保守もそうだし、入れる手間を考えたらLinuxの方が遥かに楽
780 :デフォルトの名無しさん:2008/12/03(水) 23:31:52
MSCS入れた方が管理楽だろ
Linuxでまともにクラスタ管理できるソフトなんてみたことないけどなw
釣りだと思うが、あったら教えてくれよw
Linuxでまともにクラスタ管理できるソフトなんてみたことないけどなw
釣りだと思うが、あったら教えてくれよw
781 :デフォルトの名無しさん:2008/12/03(水) 23:38:04
Windows 95の頃はOpenGLって割とメジャーだったんだけどね。
OpenGLなスクリーンセーバーが標準で入ってたりした。
Visual Studioで標準でサポートされてたのも大きい。
MSがOpenCLをサポートすらしないとなると、事実上Windows環境からは捨てられたも当然。
CUDA 3.0がOpenCLの言語機能に準拠する可能性もあるが、ハードベンダー頼りになっちゃうと
好き勝手に拡張して分裂の流れなんだよな。OpenGLのそれみたいな。
ハードウェア非依存の処理系が成功するにはどこかしら独裁やってくれるリーダーが必要だ。
MSは十分強いが、Appleは弱すぎる。
DX11はWindow 7からって言われてたけどCompute Shaderは従来OSでも使えるようにする
方針打ち出した(DirectX10の機能も実はXPでも使えましたって落ちだったし)
一方でOpenCLは、当のAppleすらSnow Leopardの目玉機能としてる(旧OSユーザーは無視?)
OpenGLなスクリーンセーバーが標準で入ってたりした。
Visual Studioで標準でサポートされてたのも大きい。
MSがOpenCLをサポートすらしないとなると、事実上Windows環境からは捨てられたも当然。
CUDA 3.0がOpenCLの言語機能に準拠する可能性もあるが、ハードベンダー頼りになっちゃうと
好き勝手に拡張して分裂の流れなんだよな。OpenGLのそれみたいな。
ハードウェア非依存の処理系が成功するにはどこかしら独裁やってくれるリーダーが必要だ。
MSは十分強いが、Appleは弱すぎる。
DX11はWindow 7からって言われてたけどCompute Shaderは従来OSでも使えるようにする
方針打ち出した(DirectX10の機能も実はXPでも使えましたって落ちだったし)
一方でOpenCLは、当のAppleすらSnow Leopardの目玉機能としてる(旧OSユーザーは無視?)
782 :デフォルトの名無しさん:2008/12/03(水) 23:45:45
>>780
SCoreで十分。それにWin鯖使うとしてライセンスどんだけ必要になると思ってんだ
つーか、「Linuxを無理でも勧めようとするのはよくない」とか言ってるお前こそ
Windowsを無理でも勧めようとしてるんだろうが
SCoreで十分。それにWin鯖使うとしてライセンスどんだけ必要になると思ってんだ
つーか、「Linuxを無理でも勧めようとするのはよくない」とか言ってるお前こそ
Windowsを無理でも勧めようとしてるんだろうが
783 :デフォルトの名無しさん:2008/12/03(水) 23:50:39
>>782
LinuxなんてOSがタダってだけでしょう
安かろう悪かろうで大学や大企業などの
公益性の高いところでLinux利用するのは
まずいだろう
バグだらけでMyrunetとか未だに動かないSCoreの
名前出されるなんて思ってもみなかったけどw
LinuxなんてOSがタダってだけでしょう
安かろう悪かろうで大学や大企業などの
公益性の高いところでLinux利用するのは
まずいだろう
バグだらけでMyrunetとか未だに動かないSCoreの
名前出されるなんて思ってもみなかったけどw
784 :デフォルトの名無しさん:2008/12/03(水) 23:58:47
大学は安くてナンボだろ。慶應みたいな大学ですらPS3を何台も買いあさったりしてるわけで。
785 :デフォルトの名無しさん:2008/12/04(木) 00:02:58
Myrinet使えないって何言ってんだ。現にSCore+Myrinetで稼働してるクラスタあるだろう
それに784も書いてるように、湯水の如く研究予算あるわけじゃねえんだから、クラスタのOSにWin鯖なんて導入できる訳ねえだろ
それに784も書いてるように、湯水の如く研究予算あるわけじゃねえんだから、クラスタのOSにWin鯖なんて導入できる訳ねえだろ
786 :デフォルトの名無しさん:2008/12/04(木) 00:04:27
>>784
どこの大学とは言わないけど
金なさげなフリして結構飲み代多かったり
卒業生が勤めている会社から研究費出してもらって
自分の権力的な実績作りにご執心だったりと
講義は休講が多かったり内容スカスカだったりと
どこの大学とは言わないけど
金なさげなフリして結構飲み代多かったり
卒業生が勤めている会社から研究費出してもらって
自分の権力的な実績作りにご執心だったりと
講義は休講が多かったり内容スカスカだったりと
787 :デフォルトの名無しさん:2008/12/04(木) 00:17:19
どこの国公立大学でもありがちだな。
金は上から振ってくるから年度末までに昇華しないといけないって考え。
金は上から振ってくるから年度末までに昇華しないといけないって考え。
788 :デフォルトの名無しさん:2008/12/04(木) 00:19:02
まずはFreeBSDに対応してくれ
789 :デフォルトの名無しさん:2008/12/04(木) 23:29:37
禿同。
デス鳥乱立で互換性の取れないLinuxに
完成度の低いToolkit乱れ撃ちするのに
無駄な労力使ってないで、FreeBSD/amd64
に対応してくれ。5.xに対応すれば、6.x,
7.xにも自動的に対応するのに。
デス鳥乱立で互換性の取れないLinuxに
完成度の低いToolkit乱れ撃ちするのに
無駄な労力使ってないで、FreeBSD/amd64
に対応してくれ。5.xに対応すれば、6.x,
7.xにも自動的に対応するのに。
790 :,,・´∀`・,,)っ-●◎○:2008/12/04(木) 23:35:51
だいぶ淘汰されてDebian系:Ubuntu、RPM系:Fedora/Redhatで纏まりつつあるけどな
791 :デフォルトの名無しさん:2008/12/04(木) 23:39:30
とゆうかDebian系、RHEL系以外のディストリってほぼ使われてないだろ
792 :デフォルトの名無しさん:2008/12/05(金) 00:01:24
ミラクソLinuxの中の人間が
痛すぎるあいつ等人間として生き恥を晒しながら
生き続けることに疑問を感じないのだろうか
痛すぎるあいつ等人間として生き恥を晒しながら
生き続けることに疑問を感じないのだろうか
793 :デフォルトの名無しさん:2008/12/05(金) 02:16:11
suseは?
794 :デフォルトの名無しさん:2008/12/05(金) 23:54:44
ミラクルのおっさんが賞取ったからって嫉妬すんなや。
795 :デフォルトの名無しさん:2008/12/07(日) 04:09:46
月刊Catalyst12月号の早売りでCALのランタイムが6.14.10.103から6.14.10.145にジャンプアップしてた。
dllの構成も変わって、今までのamdcalrt.dllとamdcalcl.dllは中身がすっからかん。
amdcaldd.dllが実際の処理を担当するみたい。
amdpcom32/64.dllはよくわからないけど、DXVAとDirectXに関連するっぽい。
dllの構成も変わって、今までのamdcalrt.dllとamdcalcl.dllは中身がすっからかん。
amdcaldd.dllが実際の処理を担当するみたい。
amdpcom32/64.dllはよくわからないけど、DXVAとDirectXに関連するっぽい。
796 :デフォルトの名無しさん:2008/12/08(月) 19:55:00
>>783 フランスは政府が中心になって Ubuntu を推進してるが?
797 :デフォルトの名無しさん:2008/12/08(月) 20:01:58
linux嫌われすぎだな
798 :デフォルトの名無しさん:2008/12/08(月) 20:27:49
http://www.computerbase.de/artikel/hardware/grafikkarten/2008/kurztest_ati_video_converter_benchmarks/3/
ATi Video Converter Benchmarks
AVIVO converterはshaderの差がはっきり出るが
BadaBOOMは何だこりゃ?
nvは9600GTで良いじゃん
ATi Video Converter Benchmarks
AVIVO converterはshaderの差がはっきり出るが
BadaBOOMは何だこりゃ?
nvは9600GTで良いじゃん
799 :デフォルトの名無しさん:2008/12/08(月) 23:57:40
800 :デフォルトの名無しさん:2008/12/09(火) 01:00:41
>アメリカ以外の多くのEU加盟国から
???
???
801 :デフォルトの名無しさん:2008/12/09(火) 09:06:49
政府をアホ呼ばわりすると賢く見えるライフハックですね。わかります。
802 :デフォルトの名無しさん:2008/12/09(火) 12:00:03
OpenCLの仕様公開ktkr
ttp://www.khronos.org/registry/cl/
ttp://www.khronos.org/registry/cl/
803 :デフォルトの名無しさん:2008/12/09(火) 13:26:17
☆ チン マチクタビレタ〜
マチクタビレタ〜
☆ チン 〃 ∧_∧ / ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄
ヽ ___\(\・∀・) < NVIDIAとAMDと東芝のインプリメントまだ〜?
\_/⊂ ⊂_ ) \__________________
/ ̄ ̄ ̄ ̄ ̄ ̄ /|
| ̄ ̄ ̄ ̄ ̄ ̄ ̄| |
| 愛媛みかん |/
マチクタビレタ〜
☆ チン 〃 ∧_∧ / ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄
ヽ ___\(\・∀・) < NVIDIAとAMDと東芝のインプリメントまだ〜?
\_/⊂ ⊂_ ) \__________________
/ ̄ ̄ ̄ ̄ ̄ ̄ /|
| ̄ ̄ ̄ ̄ ̄ ̄ ̄| |
| 愛媛みかん |/
804 :デフォルトの名無しさん:2008/12/09(火) 19:58:05
PDF読むとAMD, Apple, Intel, NVIDIAは凄い人数投入してるけど
東芝は入って無いんだよな。
強いて言うとSonyが一人だけ。
東芝は入って無いんだよな。
強いて言うとSonyが一人だけ。
805 :デフォルトの名無しさん:2008/12/09(火) 22:10:12
>>804
東芝は社員が個人的にOpenCLに対応させようとがんばってるだけじゃなかったっけ?
東芝は社員が個人的にOpenCLに対応させようとがんばってるだけじゃなかったっけ?
806 :デフォルトの名無しさん:2008/12/09(火) 22:28:13
じゃあ俺はATi用インプリするから
>>804はNvidiaヨロ〜
>>804はNvidiaヨロ〜
807 :デフォルトの名無しさん:2008/12/10(水) 11:11:23
808 :デフォルトの名無しさん:2008/12/10(水) 14:11:37
809 :デフォルトの名無しさん:2008/12/10(水) 15:52:04
は???
AVIVO Video Converter出したのにまだβかよ
しかもまた旧Verをアンインストールしないとインストールできない糞インストーラかよ
AVIVO Video Converter出したのにまだβかよ
しかもまた旧Verをアンインストールしないとインストールできない糞インストーラかよ
810 :デフォルトの名無しさん:2008/12/10(水) 20:36:10
当然じゃないか
SDKとかも上書してんのかおまえはw
SDKとかも上書してんのかおまえはw
811 :デフォルトの名無しさん:2008/12/10(水) 20:36:45
むしろ不用意に上書き出来ない方が安心できるな
812 :デフォルトの名無しさん:2008/12/10(水) 20:45:18
813 :デフォルトの名無しさん:2008/12/10(水) 20:46:35
ただのソフトならともかく、SDKみたいなもんについては勝手に消して欲しくないから
自分で消せって方式の方が良い。少なくとも俺はな
自分で消せって方式の方が良い。少なくとも俺はな
814 :デフォルトの名無しさん:2008/12/10(水) 20:47:19
今時
普通
何年前
お薬飲んだ?
普通
何年前
お薬飲んだ?
815 :デフォルトの名無しさん:2008/12/10(水) 21:18:19
OpenCLって将来的には
コンソーシアム加盟員だけが商業ビジネスできる
ようにするんだな。それも1ライセンス1000ドルから5000ドルって高すぎだろ
コンソーシアム加盟員だけが商業ビジネスできる
ようにするんだな。それも1ライセンス1000ドルから5000ドルって高すぎだろ
816 :デフォルトの名無しさん:2008/12/10(水) 23:51:34
貧乏人はMSに期待しろ
結局それが一番堅い
結局それが一番堅い
817 :デフォルトの名無しさん:2008/12/11(木) 11:11:46
ShaderAnalyzerからGPGPU分を分離したようです。
Stream KernelAnalyzer
ttp://developer.amd.com/gpu/ska/Pages/default.aspx
Stream KernelAnalyzer
ttp://developer.amd.com/gpu/ska/Pages/default.aspx
818 :デフォルトの名無しさん:2008/12/11(木) 23:34:54
CALでASCIIだけは
処理できそうなんだけど
うまくいかねぇw
詰めが甘いんだよなぁ
うーん
処理できそうなんだけど
うまくいかねぇw
詰めが甘いんだよなぁ
うーん
819 :デフォルトの名無しさん:2008/12/12(金) 00:09:20
StreamSDK 1.3
完全にDebianでは動かなくなった
Debian見捨てたなこりゃ
完全にDebianでは動かなくなった
Debian見捨てたなこりゃ
820 :デフォルトの名無しさん:2008/12/12(金) 01:36:45
それ以前にDebianだとfglrxが随分前からインストール出来ないだろ。
experimentalですら11月に10月号が出てそのまま足踏みって時点でDebian側も投げてる。
つまりは素直にUbuntuにしろって事だ。
experimentalですら11月に10月号が出てそのまま足踏みって時点でDebian側も投げてる。
つまりは素直にUbuntuにしろって事だ。
821 :デフォルトの名無しさん:2008/12/16(火) 00:24:33
822 :デフォルトの名無しさん:2008/12/16(火) 00:34:22
「ATI Stream SDK 1.3」の大幅な機能強化をベースとするバージョン1.4は、
より細分化されたデータタイプのサポート、グラフィックスAPIの相互運用性、
マルチGPUのサポート、Brook+へのスレッドレベルのデータ共有を追加できるよう設計されています。
このほか、「ATI Radeon HD 4870 X2グラフィックス」へのサポートの向上や、
複数の「ATI FirePro 3Dグラフィックス・アクセラレータ」のサポートなどの機能強化が図られています。
「ATI Stream SDK」のバージョン1.4の公開は2009年第1四半期中を予定しています。
1.4でようやくマルチGPU対応か
サイドポートも有効になるか?
より細分化されたデータタイプのサポート、グラフィックスAPIの相互運用性、
マルチGPUのサポート、Brook+へのスレッドレベルのデータ共有を追加できるよう設計されています。
このほか、「ATI Radeon HD 4870 X2グラフィックス」へのサポートの向上や、
複数の「ATI FirePro 3Dグラフィックス・アクセラレータ」のサポートなどの機能強化が図られています。
「ATI Stream SDK」のバージョン1.4の公開は2009年第1四半期中を予定しています。
1.4でようやくマルチGPU対応か
サイドポートも有効になるか?
823 :デフォルトの名無しさん:2008/12/16(火) 01:19:38
マルチGPUのサポートと4870X2のサポート向上を別表記してるんだからやってくれるだろう。
本当にサイドポートという機構が存在すればの話だが。
本当にサイドポートという機構が存在すればの話だが。
824 :デフォルトの名無しさん:2008/12/16(火) 06:09:14
結局マルチコアCPUで落ち着きそうだな
825 :デフォルトの名無しさん:2008/12/16(火) 08:45:23
結局4670でもDP対応しているようだな。
826 :デフォルトの名無しさん:2008/12/16(火) 10:10:07
だってVLIWの問題だもの
どうにでもなる
どうにでもなる
827 :デフォルトの名無しさん:2008/12/18(木) 10:25:18
なんか、CUDAもAMD Streamもスルーして、OpenCLに絞った方がいいのかなぁ
開発リソースが有り余ってる訳じゃないし…
開発リソースが有り余ってる訳じゃないし…
828 :デフォルトの名無しさん:2008/12/18(木) 15:04:18
専用ので作った方がピークパフォーマンスは高いかもしれないけど
ATiもヌビもOpenCLに全面対応すると言ってるんだからそう違いはないだろうな。
ATiもヌビもOpenCLに全面対応すると言ってるんだからそう違いはないだろうな。
829 :デフォルトの名無しさん:2008/12/18(木) 15:11:35
OpenGLでQuadroとFireGLが既にやっているように、
FireStreamやTeslaを売るためにGeForceやRadeonでOpenCL対応が制限されそうで嫌だ
結果的にDirectXのComputeShaderの方が遥かにアベレージパフォーマンス良かったりしてな
FireStreamやTeslaを売るためにGeForceやRadeonでOpenCL対応が制限されそうで嫌だ
結果的にDirectXのComputeShaderの方が遥かにアベレージパフォーマンス良かったりしてな
830 :デフォルトの名無しさん:2008/12/18(木) 22:10:42
>>829
> OpenGLでQuadroとFireGLが既にやっているように、
FireStreamとRadeonってどこが違うのって聞かれたAMDの中の人は
サポート(供給期間の保証とか)が違うだけだよって普通に言っちゃってたよ。
> OpenGLでQuadroとFireGLが既にやっているように、
FireStreamとRadeonってどこが違うのって聞かれたAMDの中の人は
サポート(供給期間の保証とか)が違うだけだよって普通に言っちゃってたよ。
831 :デフォルトの名無しさん:2008/12/18(木) 23:35:25
832 :デフォルトの名無しさん:2008/12/19(金) 01:23:59
833 :,,・´∀`・,,)っ-●◎○:2008/12/19(金) 01:38:26
9600GTで2GBのネタみたいな仕様のカードあったな。
Tesla代わりに使えるんじゃないかと思ったもんだ。
VRAM大容量=64ビット専用と認識してるが
Tesla代わりに使えるんじゃないかと思ったもんだ。
VRAM大容量=64ビット専用と認識してるが
834 :デフォルトの名無しさん:2008/12/27(土) 18:33:42
AMDのサイトで"R6xx Family Instruction Set Architecture"読んでるんだが、
普通のプロセッサの資料と勝手が違って違って読みにくい。
なんか、アーキテクチャの概略がわかる資料とか知ってる心やらしい人がいたら
教えてください。
普通のプロセッサの資料と勝手が違って違って読みにくい。
なんか、アーキテクチャの概略がわかる資料とか知ってる心やらしい人がいたら
教えてください。
835 :,,・´∀`・,,)っ-●◎○:2008/12/27(土) 22:32:56
1つのストリームプロセッサエレメントがX, Y, Z, W, Transからなる5-WayのALUがぶら下がったVLIWで構成されてる。
836 :デフォルトの名無しさん:2008/12/28(日) 03:35:37
837 :デフォルトの名無しさん:2008/12/28(日) 10:25:21
>>835
thx
でも、さすがにそれはネットメディアの解説記事で知ってたw
>>836
thx
早速読んでみる。
しかし、ブロックダイアグラムだけ見ると癖の強いアーキテクチャだな>R6xx
演算器の間の連携手段が小容量のR/Wキャッシュだけってのはこの規模の
SIMDマシンとしてかなり弱い気がする。
thx
でも、さすがにそれはネットメディアの解説記事で知ってたw
>>836
thx
早速読んでみる。
しかし、ブロックダイアグラムだけ見ると癖の強いアーキテクチャだな>R6xx
演算器の間の連携手段が小容量のR/Wキャッシュだけってのはこの規模の
SIMDマシンとしてかなり弱い気がする。
838 :デフォルトの名無しさん:2008/12/29(月) 13:07:13
PV、PSあたりの仕様を見ると
ALU Clauseの存在意義が分かって面白い。
ALU Clauseの存在意義が分かって面白い。
839 :デフォルトの名無しさん:2008/12/29(月) 13:34:55
GSが入った所にDmaCopyってのが入ってるけどなんか厄介そうだな。
ジオメトリシェーダーって全然ノータッチなのだが、結構面倒なのかな?
this program type is optionalなので意味分からない時は無視するが勝ちかorz
ジオメトリシェーダーって全然ノータッチなのだが、結構面倒なのかな?
this program type is optionalなので意味分からない時は無視するが勝ちかorz
840 :デフォルトの名無しさん:2008/12/29(月) 13:57:16
ILじゃなくてISAで何を作ろうとしてるのかね?
841 :,,・´∀`・,,)っ-○◎●:2008/12/29(月) 17:18:29
ネイティブアセンブラじゃね?
俺もCUDAのPTXが嫌いなんだが
俺もCUDAのPTXが嫌いなんだが
842 :デフォルトの名無しさん:2009/01/07(水) 08:20:20
amdのstream kernelanalyzerて走らせるのにstream sdk以外になんかいる?
もらってきた実行ファイル叩いてもコンソールが数秒開く以外反応がないんだが。
もらってきた実行ファイル叩いてもコンソールが数秒開く以外反応がないんだが。
843 :デフォルトの名無しさん:2009/01/07(水) 08:25:25
コンソールアプリなら、コンソールで使えよ。
844 :デフォルトの名無しさん:2009/01/08(木) 00:11:48
amdユーザなんて所詮このレベルw
845 :デフォルトの名無しさん:2009/01/10(土) 19:58:38
>>844
どこからどうみても、一番レベルの低いレスをどうも。
どこからどうみても、一番レベルの低いレスをどうも。
846 :デフォルトの名無しさん:2009/01/13(火) 03:18:18
よくわからんのだけども、折角だから流行りそうなの勉強したいなと思ったんですが
調べてみて
-AMD-
CTM
Havok
-NVIDIA-
CUDA
Physx
-他-
BrookGPU
PeakStream
RapidMind
こんんあ感じかな?
今のところCUDAが流行ってるんですか?
あと、今後PhysxとかHavokとかの物理エンジンがCUDAやCTMなんかに統合されるとかいう可能性とか
あったりするんでしょうか?
調べてみて
-AMD-
CTM
Havok
-NVIDIA-
CUDA
Physx
-他-
BrookGPU
PeakStream
RapidMind
こんんあ感じかな?
今のところCUDAが流行ってるんですか?
あと、今後PhysxとかHavokとかの物理エンジンがCUDAやCTMなんかに統合されるとかいう可能性とか
あったりするんでしょうか?
847 :デフォルトの名無しさん:2009/01/13(火) 04:16:02
今年はIntelもメニーコアの汎用GPUを出すし先のことは分からない
Intelはx86命令セットを実装するからたぶんこれが生き残る
現状一番扱いやすくて普及してるのがCUDAとphysx
AMDは資料もろくにないし言語仕様もぐちゃぐちゃで使い物にならない
Intelはx86命令セットを実装するからたぶんこれが生き残る
現状一番扱いやすくて普及してるのがCUDAとphysx
AMDは資料もろくにないし言語仕様もぐちゃぐちゃで使い物にならない
848 :デフォルトの名無しさん:2009/01/13(火) 04:45:32
つ[OpenCL]
849 :デフォルトの名無しさん:2009/01/13(火) 08:06:00
ハードよりの資料はAMDの方が充実しているだろ。
Brook+が微妙なだけでCALの仕様はまとも。
まあ、CALはほぼアセンブリだから、高級言語で記述したいなら
Brook+でどうにかするしかないのが最大の難点だが。
Brook+が微妙なだけでCALの仕様はまとも。
まあ、CALはほぼアセンブリだから、高級言語で記述したいなら
Brook+でどうにかするしかないのが最大の難点だが。
850 :デフォルトの名無しさん:2009/01/13(火) 23:38:04
>>847
Larrabeeは確かにx86命令+αを実装するみたいだが、果たして普及するかは別問題だぞ
パフォーマンスが出ないんじゃHPC分野からは見向きもされない
そもそもアセンブリレベルでコーディングなんてしないわけで、CUDAなりBrook+なりの高級言語使うのが当たり前になってるんだから
結局はどこまでLarrabee用の言語を構築できるかでしょ
Larrabeeは確かにx86命令+αを実装するみたいだが、果たして普及するかは別問題だぞ
パフォーマンスが出ないんじゃHPC分野からは見向きもされない
そもそもアセンブリレベルでコーディングなんてしないわけで、CUDAなりBrook+なりの高級言語使うのが当たり前になってるんだから
結局はどこまでLarrabee用の言語を構築できるかでしょ
851 :デフォルトの名無しさん:2009/01/14(水) 00:00:51
Intelは言語レベルではなく、OpenMPのようなライブラリっぽいものでLarrabeeサポートしていく方針だったかと。
で、同じコードでマルチCPUやなんかにも対応させるようなことを言ってたような希ガス。
で、同じコードでマルチCPUやなんかにも対応させるようなことを言ってたような希ガス。
852 :デフォルトの名無しさん:2009/01/14(水) 00:18:08
Larrabeeがどうなるかは知らないけどIntelは独自言語も作ってるし、OpenCLにも対応する予定だよ。
ま、開発はどうにかなるとしてもLarrabeeは消費電力気にしてキャッシュを
強化する代わりに絶対的なメモリ帯域が足りないっぽいのがなあ。
実際のコードはそんなに局所性が高くないものも多いんだよ。
ま、開発はどうにかなるとしてもLarrabeeは消費電力気にしてキャッシュを
強化する代わりに絶対的なメモリ帯域が足りないっぽいのがなあ。
実際のコードはそんなに局所性が高くないものも多いんだよ。
853 :デフォルトの名無しさん:2009/01/14(水) 00:46:03
別に流行ってないよ。
マニアのみ。
マニアのみ。
854 :デフォルトの名無しさん:2009/01/14(水) 07:11:14
Larrabee 300W
アホだろw
アホだろw
855 :,,・´∀`・,,)っ-●◎○:2009/01/14(水) 15:23:02
>>852
実はリアルタイムレイトレーシングに最適化されてるとか。
キャッシュの利用によって外部バスの負荷を軽減することで、結果的に省電力化を図れる
みたいな話で、このへんはイスラエルのキャッシュ大容量CPUの設計思想のフィードバックだよ。
メモリコントローラに帯域を狭くするなんて言ってない訳だが、誰が言ったんだ?
しかし、メモリ云々はGeForceあたりでも切実な問題じゃないの?
SMあたりのレジスタファイル倍増したかわりにGeForce8なんかと比べてメモリ帯域減らしてるじゃないの。
>>852
「ハイエンドでも300W以内に収める」とは言ってるが300Wになるなんて誰も言ってないだろ
480SPのGTX295が300一歩手前の状態だから上位はそんなもんだろ
Larrabeeは16Way SIMDユニット搭載だから、32コアでGT100/200換算512SP程度。
実はリアルタイムレイトレーシングに最適化されてるとか。
キャッシュの利用によって外部バスの負荷を軽減することで、結果的に省電力化を図れる
みたいな話で、このへんはイスラエルのキャッシュ大容量CPUの設計思想のフィードバックだよ。
メモリコントローラに帯域を狭くするなんて言ってない訳だが、誰が言ったんだ?
しかし、メモリ云々はGeForceあたりでも切実な問題じゃないの?
SMあたりのレジスタファイル倍増したかわりにGeForce8なんかと比べてメモリ帯域減らしてるじゃないの。
>>852
「ハイエンドでも300W以内に収める」とは言ってるが300Wになるなんて誰も言ってないだろ
480SPのGTX295が300一歩手前の状態だから上位はそんなもんだろ
Larrabeeは16Way SIMDユニット搭載だから、32コアでGT100/200換算512SP程度。
856 :デフォルトの名無しさん:2009/01/14(水) 17:00:17
まあWindowsがlarrabeeにカスタマイズされただ嫌でも買うでしょ
857 :デフォルトの名無しさん:2009/01/19(月) 05:19:28
3Dゲームしている時以外は
GPUパワー余っているから
今こそ分散コンピューティングの時
GPUパワー余っているから
今こそ分散コンピューティングの時
stream Kernelanalyzerだが動いた。
もらってきたファイルの拡張子が.exeだったんでそのまま走らせるのかと思ってたら、実は.MSI形式だった。
恥ずかしい。
もらってきたファイルの拡張子が.exeだったんでそのまま走らせるのかと思ってたら、実は.MSI形式だった。
恥ずかしい。
859 :デフォルトの名無しさん:2009/01/27(火) 09:29:34
>>858
あげてみる
あげてみる
860 :デフォルトの名無しさん:2009/02/05(木) 02:43:34
861 :デフォルトの名無しさん:2009/02/05(木) 05:23:02
OpenCLはマルチコア対応でしかもSSEなんかで最適化されてるから
GPUよりクアッドコアCPUのが早いというw
GPUよりクアッドコアCPUのが早いというw
862 :デフォルトの名無しさん:2009/02/05(木) 09:02:03
手軽に複数枚増設できるgpuに対して、cpuを複数つけることは難しいだろう。
それに行き詰まってるcpuよりは、gpuのほうがまだまだ速くなるし、
計算/表示まで1つのハードウェア内で完結したほうがいいだろう?
cpuの仕事ってioと制御だけでもいいくらい。
それに行き詰まってるcpuよりは、gpuのほうがまだまだ速くなるし、
計算/表示まで1つのハードウェア内で完結したほうがいいだろう?
cpuの仕事ってioと制御だけでもいいくらい。
863 :デフォルトの名無しさん:2009/02/05(木) 09:12:51
GPUメモリからシステムメモリへの転送が早ければなあ
864 :デフォルトの名無しさん:2009/02/05(木) 09:19:14
GPUからプロセッサキャッシュへ直接転送できればいいのにな。
865 :デフォルトの名無しさん:2009/02/05(木) 23:26:29
>>計算/表示まで1つのハードウェア内で完結したほうがいいだろう?
それこそCPU有利じゃないかw
それこそCPU有利じゃないかw
866 :,,・´∀`・,,)っ-○◎●:2009/02/06(金) 13:17:48
867 :デフォルトの名無しさん:2009/02/06(金) 13:55:53
>>866
乙
乙
868 :デフォルトの名無しさん:2009/02/07(土) 11:18:29
4亀のGPGPU記事、突っ込みどころが多すぎてもうどうしたものやら。
誰か頼むわ。
誰か頼むわ。
869 :デフォルトの名無しさん:2009/02/07(土) 15:20:21
ざっと流し読みした限り、そんなに変な箇所は無かったように思うが
ゲーマー向けのGPGPU解説ならあんなもんじゃねーの?
ゲーマー向けのGPGPU解説ならあんなもんじゃねーの?
870 :デフォルトの名無しさん:2009/02/07(土) 16:54:42
超解像のような考え方は昔からあるようだな
フリーソフトImageD2
http://www.tiu.ac.jp/~zohzemi/imgD2/index.html
これは時間軸方向にも参照するものだ。
NVIDIAのMOTIONDSPと同じ考え方だな。
西川善司の大画面☆マニア 第113回 超解像
http://av.watch.impress.co.jp/docs/20090120/dg113.htm
この方法は数フレームを参照することで低解像な映像のブレから情報量をアップさせるようだが、
この方法だとシーンチェンジやめまぐるしく動く映像では逆効果でめちゃくちゃな映像になるのではないか?
(これは上記のフリーソフトの別ページでも注意点として載っていた)
でも東芝などの日本の各社がやってる1フレームだけで行う超解像はそもそも無理がある。だから不自然な画質になったり、情報量が逆に消失したりする。
Lanczosなどでそのままアプコンしたほうがずっと情報量あるし自然な画質だ。比較してみれば一発で分かる。
http://plusd.itmedia.co.jp/lifestyle/articles/0812/24/news031_2.html
ここの元画像を720×480にし、それをAVIUTLなどでLanczosでフルHDにしたもののほうがずっと綺麗。
超解像は単純な処理だから柵とか崩れてるし、文字も駄目だし、元からあった情報を処理によって消しちゃう副作用のほうが強い。
超解像、超解像と目新しくいって盛り上げようとしたいのは分かるが、こんなのはまやかしだよ。
http://www1.axfc.net/uploader/Li/so/24824.zip&key=pass
比較用画像もうpしておいた
一方、数フレームでやる方法は計算が大変だが、シーンチェンジや盛大な動きの問題さえクリアすればかなり使えそうではある。
MOTIONDSPや↓はそのあたりちゃんとクリアしているのだろうか?
http://www.flashbackj.com/red_giant/instant_hd_advanced/
フリーソフトImageD2
http://www.tiu.ac.jp/~zohzemi/imgD2/index.html
これは時間軸方向にも参照するものだ。
NVIDIAのMOTIONDSPと同じ考え方だな。
西川善司の大画面☆マニア 第113回 超解像
http://av.watch.impress.co.jp/docs/20090120/dg113.htm
この方法は数フレームを参照することで低解像な映像のブレから情報量をアップさせるようだが、
この方法だとシーンチェンジやめまぐるしく動く映像では逆効果でめちゃくちゃな映像になるのではないか?
(これは上記のフリーソフトの別ページでも注意点として載っていた)
でも東芝などの日本の各社がやってる1フレームだけで行う超解像はそもそも無理がある。だから不自然な画質になったり、情報量が逆に消失したりする。
Lanczosなどでそのままアプコンしたほうがずっと情報量あるし自然な画質だ。比較してみれば一発で分かる。
http://plusd.itmedia.co.jp/lifestyle/articles/0812/24/news031_2.html
ここの元画像を720×480にし、それをAVIUTLなどでLanczosでフルHDにしたもののほうがずっと綺麗。
超解像は単純な処理だから柵とか崩れてるし、文字も駄目だし、元からあった情報を処理によって消しちゃう副作用のほうが強い。
超解像、超解像と目新しくいって盛り上げようとしたいのは分かるが、こんなのはまやかしだよ。
http://www1.axfc.net/uploader/Li/so/24824.zip&key=pass
比較用画像もうpしておいた
一方、数フレームでやる方法は計算が大変だが、シーンチェンジや盛大な動きの問題さえクリアすればかなり使えそうではある。
MOTIONDSPや↓はそのあたりちゃんとクリアしているのだろうか?
http://www.flashbackj.com/red_giant/instant_hd_advanced/
871 :デフォルトの名無しさん:2009/02/07(土) 20:20:03
なるほどマルチでしたwww
ていうかコピペなのね。
http://gimpo.2ch.net/test/read.cgi/av/1201962634/275
が初出なのかな? Google によるとだけど。
ていうかコピペなのね。
http://gimpo.2ch.net/test/read.cgi/av/1201962634/275
が初出なのかな? Google によるとだけど。
872 :デフォルトの名無しさん:2009/02/08(日) 03:03:55
>>869
「標準的なプラットフォームの登場」という要望に答えたCUDAって書き方してるのは笑うしかないでしょ。
こことかも
> しかも,CUDAソフトウェアのパフォーマンスは,GPUの世代やモデルに応じてスケーラブルとなるため,
> 開発者もプログラム側も,「動作対象となる GPUがGeForce 8800 GTXなのか,(中略)」といったことを気にする必要がない。
気にしなければ確かにスケーラブルだけどパフォーマンスはでないわけで。
CUDAアプリの殆どがGPUの仕様に合わせてガチガチに最適化してるのを黙ってるのはどうかと。
PTXトランスレータがGPUの個数を考慮してるってのは完全に嘘だ。
NVIDIA PhysXのRadeon制限も自分の妄想語るのに夢中でさっぱり忘れてるみたいだし。
ATI Streamに関してもCTMとCAL ILとHDシリーズのISAをごっちゃにした解説をしてる。
絵の説明のところでATI Stream解禁の本質がCALをドライバに含めることだと正しく説明してるのは評価できるけどね。
CSとOpenCLに関しては、3DAPIとリソースの共有が出来ることが重要なポイントだというのなら
CUDAが両APIのリソースを扱えるってことを説明しないとまずいでしょ。
OpenCL 1.0の仕様はもう公開されてるのに仕様確定が09年6月ごろとかは意味不明だ。
「標準的なプラットフォームの登場」という要望に答えたCUDAって書き方してるのは笑うしかないでしょ。
こことかも
> しかも,CUDAソフトウェアのパフォーマンスは,GPUの世代やモデルに応じてスケーラブルとなるため,
> 開発者もプログラム側も,「動作対象となる GPUがGeForce 8800 GTXなのか,(中略)」といったことを気にする必要がない。
気にしなければ確かにスケーラブルだけどパフォーマンスはでないわけで。
CUDAアプリの殆どがGPUの仕様に合わせてガチガチに最適化してるのを黙ってるのはどうかと。
PTXトランスレータがGPUの個数を考慮してるってのは完全に嘘だ。
NVIDIA PhysXのRadeon制限も自分の妄想語るのに夢中でさっぱり忘れてるみたいだし。
ATI Streamに関してもCTMとCAL ILとHDシリーズのISAをごっちゃにした解説をしてる。
絵の説明のところでATI Stream解禁の本質がCALをドライバに含めることだと正しく説明してるのは評価できるけどね。
CSとOpenCLに関しては、3DAPIとリソースの共有が出来ることが重要なポイントだというのなら
CUDAが両APIのリソースを扱えるってことを説明しないとまずいでしょ。
OpenCL 1.0の仕様はもう公開されてるのに仕様確定が09年6月ごろとかは意味不明だ。
873 :デフォルトの名無しさん:2009/02/08(日) 03:08:54
MOTIONDSPで検索したらモザイク消しの話題があった
それは思いつかなかったw
確かに超解像はモザイクが消せるw
それは思いつかなかったw
確かに超解像はモザイクが消せるw
874 :デフォルトの名無しさん:2009/02/08(日) 08:11:31
前後のフレームを参照してモザイクを消そうなんて
プログラムのプの字も知らなかった小学生の頃に思いついたけどな。
みんなそんなもんだろ?
プログラムのプの字も知らなかった小学生の頃に思いついたけどな。
みんなそんなもんだろ?
875 :デフォルトの名無しさん:2009/02/08(日) 09:55:43
>>872
所詮ユーザー向けのバラ色セールストークなんだから気にするなよ。
所詮ユーザー向けのバラ色セールストークなんだから気にするなよ。
876 :デフォルトの名無しさん:2009/02/08(日) 16:26:50
877 :デフォルトの名無しさん:2009/02/08(日) 19:09:29
>>872
ユーザー向けとしてはその程度でいいだろ
確かに普段書いてるCUDAプログラムなんて、使ってるGPU毎にブロックサイズとかを全部最適化し直してるけど
一般ユーザーにそこまで説明する必要はない
とりあえずGPGPUすげーなって程度の認識を持たせれば十分でしょ
逆にそこまで説明しちゃうと「なんだ役にたたねーじゃん」って印象を与えかねない
まぁ実際問題としてはまだアカデミックな用途がほとんどだけどな
ユーザー向けとしてはその程度でいいだろ
確かに普段書いてるCUDAプログラムなんて、使ってるGPU毎にブロックサイズとかを全部最適化し直してるけど
一般ユーザーにそこまで説明する必要はない
とりあえずGPGPUすげーなって程度の認識を持たせれば十分でしょ
逆にそこまで説明しちゃうと「なんだ役にたたねーじゃん」って印象を与えかねない
まぁ実際問題としてはまだアカデミックな用途がほとんどだけどな
878 :デフォルトの名無しさん:2009/02/08(日) 23:30:26
実行ポインタやら実行コンテキストはgpuだけで自律制御できるようになったのかな?
その辺の理解がもっと深まればintelやamdの変態cpuを待つ必要がなくなると思うんだけど。
その辺の理解がもっと深まればintelやamdの変態cpuを待つ必要がなくなると思うんだけど。
879 :デフォルトの名無しさん:2009/02/09(月) 05:31:06
被写体を3Dモデル化して全フレームからテクスチャを合成して
無限に超解像とか出来る日が来る
無限に超解像とか出来る日が来る
880 :デフォルトの名無しさん:2009/02/09(月) 13:34:59
881 :デフォルトの名無しさん:2009/02/16(月) 10:01:03
882 :テスラは捨てら:2009/02/16(月) 11:45:58
1個のGPUの中にSPUが数百個入ってるワケだが。
更にそういう使いかたしたいならテスラ買え、ってことでは?
普通にブレードサーバ買った方が安いけどw
更にそういう使いかたしたいならテスラ買え、ってことでは?
普通にブレードサーバ買った方が安いけどw
883 :,,・´∀`・,,)っ-●◎○:2009/02/16(月) 18:50:15
ここは、ものを比較する際に電力効率とかコストパフォーマンスで相対化することもできないインターネッツですね
884 :デフォルトの名無しさん:2009/02/16(月) 22:28:48
軸が足りないと批判する人間も実は軸が足りなかったりするからねぇ。
885 :デフォルトの名無しさん:2009/02/16(月) 23:16:50
コストパフォーマンス? テスラもAMDのなんちゃら言う奴も馬鹿高いじゃないか。
下手すりゃブレードの方が安いぞ。
下手すりゃブレードの方が安いぞ。
886 :デフォルトの名無しさん:2009/02/17(火) 11:39:19
メニーコアCPUには性能面でも価格面でも適わないという結論になりました
887 :デフォルトの名無しさん:2009/02/17(火) 12:18:55
何をもって高い安いって言ってるの?性能の指標は何?w
ブレードなんて熱密度の関係から敬遠されてるじゃんwww
たとえば単精度1TFLOPS弾き出すのにXeonやOpteronだとキロワット単位ですが。
ブレードなんて熱密度の関係から敬遠されてるじゃんwww
たとえば単精度1TFLOPS弾き出すのにXeonやOpteronだとキロワット単位ですが。
888 :デフォルトの名無しさん:2009/02/17(火) 12:43:09
ブレードサーバって設置スペースを削減したい場合に有効だが冷却コストとかの問題で結局高コストなんだよね。
導入コストだけみて運用コストを考えないのはおこちゃま
導入コストだけみて運用コストを考えないのはおこちゃま
889 :デフォルトの名無しさん:2009/02/17(火) 12:53:42
光CPUはどうなったんだ?
890 :デフォルトの名無しさん:2009/02/17(火) 13:05:53
量子CPUのが先に実用化されるんじゃないの?
891 :デフォルトの名無しさん:2009/02/17(火) 13:27:10
量子のほうは似非科学だから永遠に実用化などされない
892 :デフォルトの名無しさん:2009/02/17(火) 13:31:54
通信時間0msの通信装置が作れるかもしれんがコンピュータには使えない
893 :デフォルトの名無しさん:2009/02/17(火) 14:20:03
CPU内の配線に使えないかな?
894 :デフォルトの名無しさん:2009/02/17(火) 22:32:08
>>887
GPUで単精度1TFLOPSを引き出せるようなアプリがどれだけあるのかと。
GPUで単精度1TFLOPSを引き出せるようなアプリがどれだけあるのかと。
895 :デフォルトの名無しさん:2009/02/17(火) 22:48:57
コード書くつもりの話でないのだったらゲハなり自作なりでやれ。ム板でやるな。
896 :デフォルトの名無しさん:2009/02/17(火) 23:55:58
>>891
似非科学って・・・
似非科学って・・・
897 :デフォルトの名無しさん:2009/02/18(水) 01:04:38
量子コンピュータって重要な部分は量子のもつれという特異な現象だけ
現状では量子状態は参照しか出来ないから
極端な話同じ動作を繰り返すからくり人形使ってっていいんだよ
あとは机上の空論の世界で、0と1の両方があるので答えは0〜1なので正解とか言ってるだけ
現状では量子状態は参照しか出来ないから
極端な話同じ動作を繰り返すからくり人形使ってっていいんだよ
あとは机上の空論の世界で、0と1の両方があるので答えは0〜1なので正解とか言ってるだけ
898 :デフォルトの名無しさん:2009/02/18(水) 01:12:09
唯一実用化された量子暗号も量子もつれを利用しただけのもの
同じ動作を繰り返す量子ペアを別経路で発送して
途中で誰かが参照したらペアが壊れるので傍受されましたって
それだけw
同じ動作を繰り返す量子ペアを別経路で発送して
途中で誰かが参照したらペアが壊れるので傍受されましたって
それだけw
899 :デフォルトの名無しさん:2009/02/18(水) 01:16:51
たかだがアインシュタインもびっくりした現象たった1つを
ここまで壮大な妄想の一科学分野にまで発展させて研究資金を搾り取ってるのはすごいなw
もはや宗教の域に達してるw
ここまで壮大な妄想の一科学分野にまで発展させて研究資金を搾り取ってるのはすごいなw
もはや宗教の域に達してるw
900 :デフォルトの名無しさん:2009/02/18(水) 10:05:53
>>897
わかってなさそうだな。
わかってなさそうだな。
901 :デフォルトの名無しさん:2009/02/18(水) 12:52:47
そりゃ分かるってことは信者になるってことだからな
902 :デフォルトの名無しさん:2009/02/18(水) 14:33:34
信者とか信者じゃないとかいう話じゃないからなぁ
「現状では量子状態は参照しか出来ない」
とか
「0と1の両方があるので答えは0〜1なので正解とか言ってるだけ」
というのが、わかってなさを表してる。
「現状では量子状態は参照しか出来ない」
とか
「0と1の両方があるので答えは0〜1なので正解とか言ってるだけ」
というのが、わかってなさを表してる。
903 :デフォルトの名無しさん:2009/02/18(水) 17:29:05
904 :デフォルトの名無しさん:2009/02/19(木) 01:18:33
4コアでSSE128bitでさらに4倍の16コアあるのと同じこと
しかも3GHzとかで動いてる
しかも3GHzとかで動いてる
905 :デフォルトの名無しさん:2009/02/19(木) 01:57:56
SSE使っても処理が煩雑になるし思ったほど性能上がらんし・・・
906 :デフォルトの名無しさん:2009/02/19(木) 05:10:38
思ったほど性能上がらんのはGPUも同じだがな。
907 :デフォルトの名無しさん:2009/02/19(木) 06:58:53
SSEは使い方知らんと性能上がらんのよ
普通にプログラミングしても駄目よ
普通にプログラミングしても駄目よ
908 :デフォルトの名無しさん:2009/02/19(木) 10:00:20
GPGPUは使い方知らんと(ry
Cellは使い方知らんと(ry
SpursEngineは使い方知ってても(ry
Cellは使い方知らんと(ry
SpursEngineは使い方知ってても(ry
909 :デフォルトの名無しさん:2009/02/19(木) 10:40:56
高速計算できるよってやつは本当にクセが強いな
カリカリにチューンできるようになるころには次のが来るもんなあ
カリカリにチューンできるようになるころには次のが来るもんなあ
910 :デフォルトの名無しさん:2009/02/19(木) 11:14:31
SSE使うにはアセンブラ使わんとだめだよね?
911 :デフォルトの名無しさん:2009/02/19(木) 12:13:47
つ「組み込み関数」
912 :デフォルトの名無しさん:2009/02/19(木) 12:48:08
最近はC#からでも使えるよ
913 :デフォルトの名無しさん:2009/02/19(木) 12:55:53
最近は便利になってたのか・・・。
ちょいと調べてみるよ。
ちょいと調べてみるよ。
914 :デフォルトの名無しさん:2009/02/19(木) 13:07:45
>>912もしかしたコンパイルのプラットフォームターゲットの事?
915 :デフォルトの名無しさん:2009/02/19(木) 14:24:14
>>912
直接は使えない。
文字通りのSIMDを使うにはターゲット毎にアンマネージド(ネイティブ)なC/C++などで
コード書いてDLL化し、その関数を呼ぶ形でしかアクセスできない。
ハッキリ言ってめんどい。
浮動小数をSSEスカラに使うならCPU機能を判断して自動的に使われるようだけど
どのみち性能は出ないので期待しないほうがいい。
直接は使えない。
文字通りのSIMDを使うにはターゲット毎にアンマネージド(ネイティブ)なC/C++などで
コード書いてDLL化し、その関数を呼ぶ形でしかアクセスできない。
ハッキリ言ってめんどい。
浮動小数をSSEスカラに使うならCPU機能を判断して自動的に使われるようだけど
どのみち性能は出ないので期待しないほうがいい。
916 :デフォルトの名無しさん:2009/02/19(木) 14:36:02
Mono.Simdなんて変態があるけどなー
ターゲット依存なので使いように困るわけだが。
ターゲット依存なので使いように困るわけだが。
917 :デフォルトの名無しさん:2009/02/26(木) 00:22:40
OpenSSL-GPU
http://math.ut.ee/~uraes/openssl-gpu/
http://math.ut.ee/~uraes/openssl-gpu/
918 :デフォルトの名無しさん:2009/02/26(木) 00:37:32
SSLの計算にGPUをつかうのか・・・
919 :デフォルトの名無しさん:2009/02/26(木) 00:46:22
カッコイイが誰も使わないな・・・
920 :デフォルトの名無しさん:2009/02/26(木) 09:25:40
もうちょい速ければね。
SSLって案外計算量馬鹿にならないし。
SSLアクセラレータ代わりに安価なGPUが使えるならそれもアリかもしれない・・・
SSLって案外計算量馬鹿にならないし。
SSLアクセラレータ代わりに安価なGPUが使えるならそれもアリかもしれない・・・
921 :デフォルトの名無しさん:2009/02/26(木) 09:32:58
GPU使う場合のレイテンシは問題にならないのかね?
922 :デフォルトの名無しさん:2009/02/26(木) 11:19:15
それが問題だね・・・
そのレイテンシカバーできるくらいの、
大きなbit数でエンコードするとか?
そのレイテンシカバーできるくらいの、
大きなbit数でエンコードするとか?
923 :デフォルトの名無しさん:2009/02/26(木) 16:23:55
P4の頃ですら大してメリットなかったのに、i7とかの時代にどうしろとw
924 :デフォルトの名無しさん:2009/02/26(木) 20:06:44
padlockでおk
925 :デフォルトの名無しさん:2009/02/26(木) 21:37:15
CPU: Intel P4 640 3.2GHz
8800GTS can give 0..3% faster results compared to CPU・・・
padlockの方が圧倒的じゃないか
Pen4 3.2GHzと同等ならこんな感じだw
ttp://xs136.xs.to/xs136/09094/untitled275.jpg
8800GTS can give 0..3% faster results compared to CPU・・・
padlockの方が圧倒的じゃないか
Pen4 3.2GHzと同等ならこんな感じだw
ttp://xs136.xs.to/xs136/09094/untitled275.jpg
{kind=link}
926 :,,・´∀`・,,)っ-○◎●:2009/02/26(木) 22:06:25
IntelプロセッサにAES支援がつくのはWestmereからだから今は我慢だ
927 :デフォルトの名無しさん:2009/02/26(木) 22:47:54
団子を自作板以外で初めてみたわ
928 :デフォルトの名無しさん:2009/02/26(木) 22:56:58
プログラム板にもそこらじゅう張り付いてるぞ
おまえさん見る範囲狭すぎ
おまえさん見る範囲狭すぎ
929 :,,・´∀`・,,)っ-○◎●:2009/02/26(木) 23:10:52
このスレだけでもかなり頭の方から粘着してるな
930 :デフォルトの名無しさん:2009/02/27(金) 03:40:07
>>927
向こうでもみんなに迷惑かけてるのかい
向こうでもみんなに迷惑かけてるのかい
931 :,,・´∀`・,,)っ-○◎●:2009/02/27(金) 03:58:33
だって和スイーツ(笑)だもの。
今更気づいたんだがCUDAってさ、
x64用のToolkit, SDKを入れると
32bit用バイナリがビルドできなくね?
cutilsは32と64の両方のlibがあるのに><
せめてlib32とlib64に分けるとかしてくれよ
今更気づいたんだがCUDAってさ、
x64用のToolkit, SDKを入れると
32bit用バイナリがビルドできなくね?
cutilsは32と64の両方のlibがあるのに><
せめてlib32とlib64に分けるとかしてくれよ
932 :デフォルトの名無しさん:2009/02/27(金) 11:19:28
団子ってプログラマーだったん?
933 :,,・´∀`・,,)っ-○◎●:2009/02/27(金) 19:44:05
団子(だんご)は、米の粉に水やお湯を加えてこねて、蒸したり茹でたりしてできた餅を小さくまるめた菓子である。
http://ja.wikipedia.org/wiki/%E5%9B%A3%E5%AD%90
http://ja.wikipedia.org/wiki/%E5%9B%A3%E5%AD%90
934 :デフォルトの名無しさん:2009/02/27(金) 20:24:10
ちょっと調子にのっただけなんで許してあげて
935 :,,・´∀`・,,)っ-○◎● :2009/02/28(土) 06:43:02
おう許してやるよよしよし
936 :デフォルトの名無しさん:2009/03/13(金) 22:09:32
1.4にあがってスレッド間で使えるようになったな
OpenMPっぽい問題は解けそう
OpenMPっぽい問題は解けそう
937 :デフォルトの名無しさん:2009/03/13(金) 22:37:55
1.4って、何が?
938 :,,・´∀`・,,)っ-○◎●:2009/03/13(金) 22:43:51
CUDAのCompute Capabilityのことかと
おぃぃ?NVIDIAは新製品のサンプルくらいよこすべきだと思うんだが?
未だに8600GTでやらされてるんだが。
おぃぃ?NVIDIAは新製品のサンプルくらいよこすべきだと思うんだが?
未だに8600GTでやらされてるんだが。
939 :デフォルトの名無しさん:2009/03/13(金) 23:00:11
今日の話題で1.4ならATI Streamの方だろ。
940 :デフォルトの名無しさん:2009/03/13(金) 23:05:40
Brook+強化されてもなぁ・・・OpenCLマダー?
CALはTUがまともに動くようになったのとX2正式サポートとバグ直しか。
CAL ILの資料はドライバの中身さらけ出し度がさらに上がった感があるな。
CALはTUがまともに動くようになったのとX2正式サポートとバグ直しか。
CAL ILの資料はドライバの中身さらけ出し度がさらに上がった感があるな。
941 :,,・´∀`・,,)っ-○◎●:2009/03/13(金) 23:09:31
942 :デフォルトの名無しさん:2009/03/13(金) 23:14:39
int8使えるけど遅いな
943 :デフォルトの名無しさん:2009/03/14(土) 02:36:19
>>941
昨日のボクシングの試合は、久々に見所が有ったよな。
ところでウチのマシンでCUDA動かしてたら、マシンが超遅く
成って戻らない。超重いんだけど、落ちはせずに動き続けてる。
何が起こったんだか? 今週末は東京出張だからもう寝よ。
昨日のボクシングの試合は、久々に見所が有ったよな。
ところでウチのマシンでCUDA動かしてたら、マシンが超遅く
成って戻らない。超重いんだけど、落ちはせずに動き続けてる。
何が起こったんだか? 今週末は東京出張だからもう寝よ。
944 :デフォルトの名無しさん:2009/03/14(土) 05:57:09
>>938
新製品って何?
新製品って何?
945 :デフォルトの名無しさん:2009/03/14(土) 06:00:23
http://developer.amd.com/gpu/acmlgpu/Pages/default.aspx
AMD Core Math Library for Graphic Processors (ACML-GPU)
なにげにgpu対応版acmlが出てるのね
AMD Core Math Library for Graphic Processors (ACML-GPU)
なにげにgpu対応版acmlが出てるのね
946 :デフォルトの名無しさん:2009/03/14(土) 19:55:25
結局1.4云々はATi Streamの方なのか?
CUDA2.1のドキュメントにもCompute Cap. 1.3までしか記述はないが
CUDA2.1のドキュメントにもCompute Cap. 1.3までしか記述はないが
947 :デフォルトの名無しさん:2009/03/14(土) 20:01:44
SDKじゃなくてCCのVerUPが来たらここだけじゃなくnVidiaのニュースリリースに出てるだろ
948 :デフォルトの名無しさん:2009/03/14(土) 20:04:42
>>947
まぁそりゃそうだわな
ATi Stream見てみたら、v1.4が出たのな
What's up見る限り、CUDAで言うところの共有メモリをBrook+から扱えるようになったってことか?
Brook+をアップデートされてもな
まぁそりゃそうだわな
ATi Stream見てみたら、v1.4が出たのな
What's up見る限り、CUDAで言うところの共有メモリをBrook+から扱えるようになったってことか?
Brook+をアップデートされてもな
949 :デフォルトの名無しさん:2009/03/14(土) 20:20:01
950 :デフォルトの名無しさん:2009/03/14(土) 20:28:11
>>949
Significant feature enhancements to Brook+:
* Access to thread-level data sharing.
Brook+から扱えるって事じゃねえの?SDK User Guideの2-40
Significant feature enhancements to Brook+:
* Access to thread-level data sharing.
Brook+から扱えるって事じゃねえの?SDK User Guideの2-40
951 :デフォルトの名無しさん:2009/03/14(土) 20:32:13
これまでのBrook+はほぼCの構文だけだったけど
1.4でC++のテンプレートを使ったプログラミングが出来るようになったな
ドキュメントだとLegacyとNew APIっていう比較でコードの長さも一長一短だが
共存は出来ないんだろうか?
1.4でC++のテンプレートを使ったプログラミングが出来るようになったな
ドキュメントだとLegacyとNew APIっていう比較でコードの長さも一長一短だが
共存は出来ないんだろうか?
952 :デフォルトの名無しさん:2009/03/15(日) 21:53:50
ttp://forum.beyond3d.com/showthread.php?t=52990
ACML gpu benchmark numbers
>170 gflops for DP and 380 gflops for SP.
>Remember to run your CPU at full speed (i.e. disable powersave)!!
DPのわりにSPが速くないような
(RV770ってDP/SP=1/5だったように思うが)
ACML gpu benchmark numbers
>170 gflops for DP and 380 gflops for SP.
>Remember to run your CPU at full speed (i.e. disable powersave)!!
DPのわりにSPが速くないような
(RV770ってDP/SP=1/5だったように思うが)
953 :デフォルトの名無しさん:2009/03/15(日) 22:08:06
954 :デフォルトの名無しさん:2009/03/15(日) 23:12:21
GTX 280だと、doubleで90GFlopsぐらいまで落ちた気がするからそれだけみるとすごいな
ただ、実際問題として頭からケツまでdouble精度が必要なソフトがあんま無いってのと
floatの性能が芳しくないからそこがネックだな
ただ、実際問題として頭からケツまでdouble精度が必要なソフトがあんま無いってのと
floatの性能が芳しくないからそこがネックだな
955 :デフォルトの名無しさん:2009/03/16(月) 11:47:25
GeForceは1SMあたり、単精度MAC8器(SP)、特殊演算ユニット(SFU)2器、倍精度(DP)1器の構成。
単精度性能は8Way積和算+4Way乗算×2で24、倍精度は1Wayの積和算で、2
つまり単精度:倍精度のスループットの比率は12:1
RadeonはGeForceのSPに相当する部分を5WayのVLIWで構成し、そのうち1Wayで倍精度も実行できるようにしてる。
んで、スループットの比率は5:1なわけだけど、どっちが優れてるかは一概には言い難い。
VLIWは演算対象によって実効性能がガクっと落ちる(倍精度はもともと1Wayなので関係ないが)
ただ、倍精度演算ユニットを倍増するくらいの拡張は将来のGeForceにもできるだろうから
今は我慢のとき。
Larrabeeは16Wayの単精度と8Wayの倍精度で演算ユニットを共有することになるから
理屈の上では2:1になる。まあ、ケチってくるかもしれないけどね。
単精度性能は8Way積和算+4Way乗算×2で24、倍精度は1Wayの積和算で、2
つまり単精度:倍精度のスループットの比率は12:1
RadeonはGeForceのSPに相当する部分を5WayのVLIWで構成し、そのうち1Wayで倍精度も実行できるようにしてる。
んで、スループットの比率は5:1なわけだけど、どっちが優れてるかは一概には言い難い。
VLIWは演算対象によって実効性能がガクっと落ちる(倍精度はもともと1Wayなので関係ないが)
ただ、倍精度演算ユニットを倍増するくらいの拡張は将来のGeForceにもできるだろうから
今は我慢のとき。
Larrabeeは16Wayの単精度と8Wayの倍精度で演算ユニットを共有することになるから
理屈の上では2:1になる。まあ、ケチってくるかもしれないけどね。
956 :デフォルトの名無しさん:2009/03/16(月) 18:59:48
957 :デフォルトの名無しさん:2009/03/16(月) 23:38:14
>>956
倍精度は4つだけしか使わない。
Trans Unitで出来ないのはX,Y,Z,W Unit4つ同時使用が前提の命令とアドレスレジスタに触る命令だけ。
だからX,Y,Z,W Unit使ってDP1つ、その上でTrans Unitが残ってるからSP or INT1つも同時に出来るよ。
倍精度は4つだけしか使わない。
Trans Unitで出来ないのはX,Y,Z,W Unit4つ同時使用が前提の命令とアドレスレジスタに触る命令だけ。
だからX,Y,Z,W Unit使ってDP1つ、その上でTrans Unitが残ってるからSP or INT1つも同時に出来るよ。
958 :デフォルトの名無しさん:2009/03/17(火) 01:34:43
959 :デフォルトの名無しさん:2009/03/17(火) 10:16:34
,.、,、,..,、、.,、,、、..,_,,_ /i
;'`;、、:、. .:、:, :,.: ::`゛:.::'':,'.´ -‐i
'、;: ...: ,:. :.、... :.、.:: _;... .;;.‐'゛ ̄  ̄
ヽ(´・ω・)ノ
| /
UU
;'`;、、:、. .:、:, :,.: ::`゛:.::'':,'.´ -‐i
'、;: ...: ,:. :.、... :.、.:: _;... .;;.‐'゛ ̄  ̄
ヽ(´・ω・)ノ
| /
UU
960 :デフォルトの名無しさん:2009/03/19(木) 20:12:50
catalyst9.3が出たが「XPだとCALがうまく動かない」とさ
961 :デフォルトの名無しさん:2009/03/19(木) 21:36:57
Folding@Homeに付いてきたamdcalrt.dll 6.14.10.103は動くっぽい。
待て屋のディレクトリに放り込んだらちゃんと動いたんで多分大丈夫。
待て屋のディレクトリに放り込んだらちゃんと動いたんで多分大丈夫。
962 :デフォルトの名無しさん:2009/03/19(木) 21:44:53
CALのDLLをFolding@Homeに最適化しようとして、最適化しようとして、
XP版だけ間に合わなかったか
XP版だけ間に合わなかったか
963 :デフォルトの名無しさん:2009/03/19(木) 21:53:12
Clarkdaleとか出たら
GPUメモリに高速アクセスできるようになるんですか
GPUメモリに高速アクセスできるようになるんですか
964 :デフォルトの名無しさん:2009/03/19(木) 22:19:50
1.4からマルチGPUに対応とかになってたから
仮想化のもんだいか
仮想化のもんだいか
965 :デフォルトの名無しさん:2009/03/20(金) 09:58:49
catalystを入れ替えるときにチップセットドライバも更新しようと思って
software uninstall utilityで全ソフトの削除を選んだらstream sdkまで
消されたw
software uninstall utilityで全ソフトの削除を選んだらstream sdkまで
消されたw
966 :デフォルトの名無しさん:2009/03/20(金) 12:10:07
Web PAMが削除されることを知っていた俺にとっては想定の範囲内。
967 :,,・´∀`・,,)っ-●◎○:2009/03/21(土) 16:19:09
969 :デフォルトの名無しさん:2009/03/21(土) 18:46:32
>>970次スレよろ
970 :,,・´∀`・,,)っ-○◎●:2009/03/21(土) 19:18:35
971 :,,・´∀`・,,)っ-○◎●:2009/03/21(土) 19:35:44
ここまで全部だんごやさんの自演だよ
972 :デフォルトの名無しさん:2009/03/21(土) 20:42:38
さて、アイちゃんが立てたスレは放置して新しく立て直すか・・・
973 :デフォルトの名無しさん:2009/03/21(土) 21:31:32
974 :デフォルトの名無しさん:2009/03/21(土) 21:54:42
一応貼っとくか
ttp://www.techpowerup.com/index.php?88739
AMD to Demonstrate GPU Havok Physics Acceleration at GDC
ATI's Terry Makedon, in his Twitter-feed has revealed that AMD would put forth its “ATI GPU Physics strategy.”
He also added that the company would present a tech-demonstration of Havok technology working in conjunction with ATI hardware.
The physics API is expected to utilize OpenCL and AMD Stream.
ttp://www.techpowerup.com/index.php?88739
AMD to Demonstrate GPU Havok Physics Acceleration at GDC
ATI's Terry Makedon, in his Twitter-feed has revealed that AMD would put forth its “ATI GPU Physics strategy.”
He also added that the company would present a tech-demonstration of Havok technology working in conjunction with ATI hardware.
The physics API is expected to utilize OpenCL and AMD Stream.
975 :デフォルトの名無しさん:2009/03/21(土) 22:03:14
結局分立のまま並走かよ。
BulletがCUDAとStreamの両方に対応する事を祈るしかないか。
BulletがCUDAとStreamの両方に対応する事を祈るしかないか。
976 :デフォルトの名無しさん:2009/03/21(土) 22:19:14
だんごトリップなしかよ
977 :デフォルトの名無しさん:2009/03/22(日) 06:31:58
発言のキモさでわかるだろ
978 :,,・´∀`・,,)っ-○◎●:2009/03/22(日) 06:33:22
><
979 :デフォルトの名無しさん:2009/03/22(日) 08:52:36
FireStorm製品ではなくてグラボとしてのRadeon-HD4870+ATI Stream SDK で倍精度計算は可能ですか?
「DP計算はできないように機能を殺してある」/「RV670(<ーFireStormのこと?)でSDK入れたら計算できた」と言う
矛盾するような内容の書き込みが存在するのですが。
「DP計算はできないように機能を殺してある」/「RV670(<ーFireStormのこと?)でSDK入れたら計算できた」と言う
矛盾するような内容の書き込みが存在するのですが。
980 :デフォルトの名無しさん:2009/03/22(日) 10:09:50