���K�\������
1 �Fnobody�����F
�y���K�\������̝|�z
�E����s��
�E������劽�}�B�g�p����������̂�Y�ꂸ�ɁB
���K�\���ƊW�Ȃ��b�E����͑��X���ւǂ����B
�E����s��
�E������劽�}�B�g�p����������̂�Y�ꂸ�ɁB
���K�\���ƊW�Ȃ��b�E����͑��X���ւǂ����B
|
|
|
2 �Fnobody�����F2007/01/11(��) 03:10:51 ID:???
3 �F1�F2007/01/15(��) 00:57:08 ID:/DToo9Jn
����ɏI������ȃf�u
�����͂����ł�����
�ĊJ����
�����͂����ł�����
�ĊJ����
4 �Fnobody�����F2007/01/15(��) 20:06:50 ID:???
>>2�͓���j��H
5 �Fnobody�����F2007/01/15(��) 22:01:26 ID:???
��N�Ԃ�̕����������Ȃ�ߋ��X�����炢��������('A`)
�ߋ��X��
���K�\������@2ch
�@http://pc.2ch.net/test/read.cgi/php/996105815/
���K�\������@2ch Part2
�@http://pc5.2ch.net/test/read.cgi/php/1038146241/
���K�\������@2ch Part3 s/����|�r�炵/���ځ[��/g
�@http://pc5.2ch.net/test/read.cgi/php/1069245758/
���K�\������@2ch Part4
�@http://pc8.2ch.net/test/read.cgi/php/1105930285/
�ߋ��X���̃e���v���ɂ������Q�l�T�C�g����
Perl����
�@http://www.din.or.jp/~ohzaki/perl.htm
���K�\������
�@http://www.kt.rim.or.jp/~kbk/regex/regex.html
Regex::Diagram.pm
�@http://www.cc.rim.or.jp/~midorin/mad-p/RegexDiagram.html
���K�\��
�@http://www.cc.rim.or.jp/~midorin/mad-p/perl/benkyou/PRC2kRegex/
UNIX���K�\������
�@http://web.archive.org/web/20021219021503/http://www01.u-page.so-net.ne.jp/jc4/hiroyuki/rex_index.html
Regular Expression(Riue �����̐��K�\���u��)
�@http://www.sixnine.net/regexp/
�قƂ�ǂ́��̃����N�W�ɂ܂Ƃ܂��Ă��܂��B
���K�\��/�����R�[�h�ŐV�����N2005
�@http://www2.famille.ne.jp/~akio1998/l_grep.html
�ߋ��X��
���K�\������@2ch
�@http://pc.2ch.net/test/read.cgi/php/996105815/
���K�\������@2ch Part2
�@http://pc5.2ch.net/test/read.cgi/php/1038146241/
���K�\������@2ch Part3 s/����|�r�炵/���ځ[��/g
�@http://pc5.2ch.net/test/read.cgi/php/1069245758/
���K�\������@2ch Part4
�@http://pc8.2ch.net/test/read.cgi/php/1105930285/
�ߋ��X���̃e���v���ɂ������Q�l�T�C�g����
Perl����
�@http://www.din.or.jp/~ohzaki/perl.htm
���K�\������
�@http://www.kt.rim.or.jp/~kbk/regex/regex.html
Regex::Diagram.pm
�@http://www.cc.rim.or.jp/~midorin/mad-p/RegexDiagram.html
���K�\��
�@http://www.cc.rim.or.jp/~midorin/mad-p/perl/benkyou/PRC2kRegex/
UNIX���K�\������
�@http://web.archive.org/web/20021219021503/http://www01.u-page.so-net.ne.jp/jc4/hiroyuki/rex_index.html
Regular Expression(Riue �����̐��K�\���u��)
�@http://www.sixnine.net/regexp/
�قƂ�ǂ́��̃����N�W�ɂ܂Ƃ܂��Ă��܂��B
���K�\��/�����R�[�h�ŐV�����N2005
�@http://www2.famille.ne.jp/~akio1998/l_grep.html
6 �Fnobody�����F2007/01/16(��) 02:57:15 ID:???
>>5
����J�l�ł�
����J�l�ł�
7 �F()��(?:)�̈Ⴂ�F2007/01/21(��) 14:23:29 ID:HARdTCVv
�Ώە����� //abca
���K�\�� ^(/([a-z]*))*$ �� �}�b�`
���K�\�� ^(/(?:[a-z]*))*$ �� �}�b�`���Ȃ�
����Q�Ƃ��������ʂ������łȂ����Ō��ʂ��Ⴄ�̂͂Ȃ��ł��傤���H
�����n�� PHP 5.2.0-8�AOS �� Debian GNU/Linux etch
�g�p�������� preg_match() �ł��B
��̓I�ɂ�
preg_match('"^(/(?:[a-z]*))*$"', "//abca", &$m);
var_dump($m);
�Ƃ���� $m[0] ������ɂȂ�܂��B
���Ȃ킿�}�b�`���܂���B
���K�\�� ^(/([a-z]*))*$ �� �}�b�`
���K�\�� ^(/(?:[a-z]*))*$ �� �}�b�`���Ȃ�
����Q�Ƃ��������ʂ������łȂ����Ō��ʂ��Ⴄ�̂͂Ȃ��ł��傤���H
�����n�� PHP 5.2.0-8�AOS �� Debian GNU/Linux etch
�g�p�������� preg_match() �ł��B
��̓I�ɂ�
preg_match('"^(/(?:[a-z]*))*$"', "//abca", &$m);
var_dump($m);
�Ƃ���� $m[0] ������ɂȂ�܂��B
���Ȃ킿�}�b�`���܂���B
8 �Fnobody�����F2007/01/21(��) 15:16:09 ID:???
>>7
preg_match�ɗ^���鐳�K�\����/�Ŋ���K�v�����邯�ǁA�����͂��ꂶ��Ȃ�?
���K�\��re��preg_match�ɗ^����Ƃ���
preg_match("/re/", $baka);
�Ƃ������ǂ��B
preg_match�ɗ^���鐳�K�\����/�Ŋ���K�v�����邯�ǁA�����͂��ꂶ��Ȃ�?
���K�\��re��preg_match�ɗ^����Ƃ���
preg_match("/re/", $baka);
�Ƃ������ǂ��B
9 �F()��(?:)�̈Ⴂ�F2007/01/21(��) 15:25:20 ID:HARdTCVv
>>8
�������� '@^(/(?:[a-z]*))*$@' �ȂǂƂ��ċ�蕶����
@ �ɂ���ȂNjC�����Ă���̂ł����E�E�E
()��(?:)�ɂ�苓�����Ⴄ�Ƃ����̂������܂���E�E�E
���������������Ă݂܂��Bereg �n�Ŏ����Ƃ܂�
���ʂ�����Ă��邩���m��Ȃ��̂ŁB
�������� '@^(/(?:[a-z]*))*$@' �ȂǂƂ��ċ�蕶����
@ �ɂ���ȂNjC�����Ă���̂ł����E�E�E
()��(?:)�ɂ�苓�����Ⴄ�Ƃ����̂������܂���E�E�E
���������������Ă݂܂��Bereg �n�Ŏ����Ƃ܂�
���ʂ�����Ă��邩���m��Ȃ��̂ŁB
10 �Fnobody�����F2007/01/21(��) 20:27:33 ID:???
����́cPCRE�̃o�O������\�������\�������ȁc
echo preg_match('{^(?:/(?:[a-z]*))*$}', "//abca");
=> 0
Perl�݊����K�\���ƌ������炢�Ȃ̂�Perl�Ƃ̔�r�����Ă݂Ă��ܘ_���̂Ƃ���
$ perl -e 'print scalar "//abca" =~ m{^(?:/(?:[a-z]*))*$};'
=> 1
��ŔO�̂���PCRE���ڒ@���Ă݂悤
echo preg_match('{^(?:/(?:[a-z]*))*$}', "//abca");
=> 0
Perl�݊����K�\���ƌ������炢�Ȃ̂�Perl�Ƃ̔�r�����Ă݂Ă��ܘ_���̂Ƃ���
$ perl -e 'print scalar "//abca" =~ m{^(?:/(?:[a-z]*))*$};'
=> 1
��ŔO�̂���PCRE���ڒ@���Ă݂悤
11 �F()��(?:)�̈Ⴂ�F2007/01/21(��) 21:20:40 ID:HARdTCVv
>>10
�ӂ��ށA�o�O�̉\���������ł����`
//abca ����Ȃ��� /abca/abca �Ƃ��Ȃ�}�b�`�����ł���ˁB
���̓p�X���f�B���N�g���ɕ������悤�Ƃ������܂��āA
���̓r���� // �������Ă���悤�ȃP�[�X�ŋ��������������̂Œ��ׂĂ܂����B
//abcde �� / �� /abcde �ɕ���������������ł��B
�ӂ��ށA�o�O�̉\���������ł����`
//abca ����Ȃ��� /abca/abca �Ƃ��Ȃ�}�b�`�����ł���ˁB
���̓p�X���f�B���N�g���ɕ������悤�Ƃ������܂��āA
���̓r���� // �������Ă���悤�ȃP�[�X�ŋ��������������̂Œ��ׂĂ܂����B
//abcde �� / �� /abcde �ɕ���������������ł��B
�ӂ��APCRE�t����pcretest�Ńo�[�W�����ʌ��B
[PCRE version 6.6 06-Feb-2006]
re> /^(?:a(?:b*))*$/
data> aa
0: aa
[PCRE version 6.7 04-Jul-2006]
re> /^(?:a(?:b*))*$/
data> aa
No match
[PCRE version 7.0 18-Dec-2006]
re> /^(?:a(?:b*))*$/
data> aa
0: aa
ver6.7�̂ݏ�肭�}�b�`���Ȃ��ƌ������ʂɂȂ����B
changelog��7.0���݂Ă�������ۂ��̂��������Ȃ�����ǁA38�ӂ肩�Ȃ��c
���Ȃ݂�PHP�Ŏg���Ă�PCRE�̃o�[�W�����́A
phpinfo��pcre��PCRE Library Version�Ŋm�F�ł���
[PCRE version 6.6 06-Feb-2006]
re> /^(?:a(?:b*))*$/
data> aa
0: aa
[PCRE version 6.7 04-Jul-2006]
re> /^(?:a(?:b*))*$/
data> aa
No match
[PCRE version 7.0 18-Dec-2006]
re> /^(?:a(?:b*))*$/
data> aa
0: aa
ver6.7�̂ݏ�肭�}�b�`���Ȃ��ƌ������ʂɂȂ����B
changelog��7.0���݂Ă�������ۂ��̂��������Ȃ�����ǁA38�ӂ肩�Ȃ��c
���Ȃ݂�PHP�Ŏg���Ă�PCRE�̃o�[�W�����́A
phpinfo��pcre��PCRE Library Version�Ŋm�F�ł���
13 �Fnobody�����F2007/01/22(��) 00:49:01 ID:???
������Ƃ������ȁB
>>12 �̌��ʂɋ^��͂Ȃ��̂����ǁA
>>7 ��
> preg_match('"^(/(?:[a-z]*))*$"', "//abca", &$m);
�͋���Ƀ}�b�`�Ő�������Ȃ���?
�����āA�Ώە�����ɂ� // �ƍs���ɓ�X���b�V��������ł��邯�ǁA
���K�\���� ^/ �ƈ�����Ȃ���?
���Ɂ@$ ���u���ꂿ����Ă邩��A
//hogehoge �Ƃ����p�^�[���ɂ͋�ȊO�}�b�`���悤���Ȃ��Ǝv������
���A�������Ⴂ���Ă�?
>>12 �̌��ʂɋ^��͂Ȃ��̂����ǁA
>>7 ��
> preg_match('"^(/(?:[a-z]*))*$"', "//abca", &$m);
�͋���Ƀ}�b�`�Ő�������Ȃ���?
�����āA�Ώە�����ɂ� // �ƍs���ɓ�X���b�V��������ł��邯�ǁA
���K�\���� ^/ �ƈ�����Ȃ���?
���Ɂ@$ ���u���ꂿ����Ă邩��A
//hogehoge �Ƃ����p�^�[���ɂ͋�ȊO�}�b�`���悤���Ȃ��Ǝv������
���A�������Ⴂ���Ă�?
14 �Fnobody�����F2007/01/22(��) 01:56:13 ID:???
>>13
�����A���̃A���t�@�x�b�g�ɑ���ʎw��q���l���ɓ���ĂȂ���łȂ������H
^�@# ������̍ŏ�
(
/(?:[a-z]*)�@# /�̌��[a-z]��0�����ȏ�
)*�@�@�@ �@�@�@# ��0��ȏ�J��Ԃ�
$�@# ������(�s)�̍Ō�
//abca�́A<�X���b�V���A[a-z]��"0����"�A�X���b�V���A[a-z]��4����>�ƂȂ��ă}�b�`���Ȃ���Ȃ�Ȃ��B�͂��B
>>11
���̖ړI����preg_match����ʖڂ��Ǝv���B
��ڂ̃L���v�`�����J��Ԃ���S�ċL�^���邱�Ƃ����҂����Ǝv�����A����㏑������Ă��܂��B
�p�X�����Ó��Ȃ��̂����}�b�`���O�Ō����邽�߂�preg_match��p���āA
���ۂ̐蕪����explode�����g�����ق���������Ȃ����ȁB�X���Ⴂ�ɂȂ邪�B
�}�b�`���O�Ő蕪����Ƃ���Ȃ�preg_match_all��p����
preg_match_all('{\G/[a-z]*}', "//abca", $m)
�Ƃ�����������
�����A���̃A���t�@�x�b�g�ɑ���ʎw��q���l���ɓ���ĂȂ���łȂ������H
^�@# ������̍ŏ�
(
/(?:[a-z]*)�@# /�̌��[a-z]��0�����ȏ�
)*�@�@�@ �@�@�@# ��0��ȏ�J��Ԃ�
$�@# ������(�s)�̍Ō�
//abca�́A<�X���b�V���A[a-z]��"0����"�A�X���b�V���A[a-z]��4����>�ƂȂ��ă}�b�`���Ȃ���Ȃ�Ȃ��B�͂��B
>>11
���̖ړI����preg_match����ʖڂ��Ǝv���B
��ڂ̃L���v�`�����J��Ԃ���S�ċL�^���邱�Ƃ����҂����Ǝv�����A����㏑������Ă��܂��B
�p�X�����Ó��Ȃ��̂����}�b�`���O�Ō����邽�߂�preg_match��p���āA
���ۂ̐蕪����explode�����g�����ق���������Ȃ����ȁB�X���Ⴂ�ɂȂ邪�B
�}�b�`���O�Ő蕪����Ƃ���Ȃ�preg_match_all��p����
preg_match_all('{\G/[a-z]*}', "//abca", $m)
�Ƃ�����������
15 �F()��(?:)�̈Ⴂ�F2007/01/22(��) 04:08:40 ID:???
>>12
�r���S�̂悤�ł��B
�茳�̓��Linux�}�V���Ŏ����Ă݂܂����B
preg_match('"^(/(?:[a-z]*))*$"', "//abca", &$m);
Debian GNU/Linux etch
PHP 5.2.0-8 PCRE 6.7 04-Jul-2006
�}�b�`���Ȃ��B
Fedora Core 4
PHP 5.1.6 PCRE 6.3 15-Aug-2005
�}�b�`����B
�r���S�̂悤�ł��B
�茳�̓��Linux�}�V���Ŏ����Ă݂܂����B
preg_match('"^(/(?:[a-z]*))*$"', "//abca", &$m);
Debian GNU/Linux etch
PHP 5.2.0-8 PCRE 6.7 04-Jul-2006
�}�b�`���Ȃ��B
Fedora Core 4
PHP 5.1.6 PCRE 6.3 15-Aug-2005
�}�b�`����B
16 �F()��(?:)�̈Ⴂ�F2007/01/22(��) 07:00:19 ID:???
>>12
TurboLinux Server 8.0 (Viper) �ł̋��������ׂĂ݂܂����B
preg_match('"^(/(?:[a-z]*))*$"', "//abca", &$m);
preg_match('"^(/(?:[a-z]*))*$"', "/a/abca", &$m);
��������}�b�`���܂��B
PHP 4.2.3 PCRE 3.4 22-Aug-2000 �ł��B
��͂� Debian GNU/Linux etch �� PHP5 5.2.0-8 ������
PCRE 6.7 04-Jul-2006 ���g���Ă��ċ������ς݂����Ȃ�ŁA
Debian GNU/Linux �� BTS �i�o�O�j�ɋ����悤�Ƃ�������ł����A
>>12 �̌��ʂ����p�����Ă�����č\���܂���ł��傤���H
TurboLinux Server 8.0 (Viper) �ł̋��������ׂĂ݂܂����B
preg_match('"^(/(?:[a-z]*))*$"', "//abca", &$m);
preg_match('"^(/(?:[a-z]*))*$"', "/a/abca", &$m);
��������}�b�`���܂��B
PHP 4.2.3 PCRE 3.4 22-Aug-2000 �ł��B
��͂� Debian GNU/Linux etch �� PHP5 5.2.0-8 ������
PCRE 6.7 04-Jul-2006 ���g���Ă��ċ������ς݂����Ȃ�ŁA
Debian GNU/Linux �� BTS �i�o�O�j�ɋ����悤�Ƃ�������ł����A
>>12 �̌��ʂ����p�����Ă�����č\���܂���ł��傤���H
>>14
���肪�Ƃ��B�w�E�ʂ��ǂ��Ă����B
�g���\�L���݂Ă킩������B
�����Larry�͈̂��ȁB
�Ƃ���ł������̓��ƊO�ŌJ��Ԃ��w�肪
�A������p�^�[���͑g�ݍ��킹�̔�����
�|���Ď����͂ł���Ȃ�g��Ȃ��悤��
���Ă�����ǁA�݂�Ȃ͂���Ȃ���
�C�ɂ��Ȃ�?
���肪�Ƃ��B�w�E�ʂ��ǂ��Ă����B
�g���\�L���݂Ă킩������B
�����Larry�͈̂��ȁB
�Ƃ���ł������̓��ƊO�ŌJ��Ԃ��w�肪
�A������p�^�[���͑g�ݍ��킹�̔�����
�|���Ď����͂ł���Ȃ�g��Ȃ��悤��
���Ă�����ǁA�݂�Ȃ͂���Ȃ���
�C�ɂ��Ȃ�?
18 �F()��(?:)�̈Ⴂ�F2007/01/22(��) 12:31:13 ID:???
>>17
DFA������Ƃ肠�������炢���ƂɂȂ�Ȃ������ɒ�~���邾�낤�A
�Ƃ������ł͎v������ł��ł����ANFA�Ȃ牄�X�ƃo�b�N�g���b�N
���Ȃ���͂܂荞�ނƂ������ł����ˁB
DFA������Ƃ肠�������炢���ƂɂȂ�Ȃ������ɒ�~���邾�낤�A
�Ƃ������ł͎v������ł��ł����ANFA�Ȃ牄�X�ƃo�b�N�g���b�N
���Ȃ���͂܂荞�ނƂ������ł����ˁB
20 �F()��(?:)�̈Ⴂ�F2007/01/22(��) 21:51:33 ID:???
>>19
���肪�Ƃ��������܂��B
�ނ��� PHP �̃o�[�W�������Ƃ����Ă��炦��ƁB
���āA�ŐV�o�[�W�����̃\�[�X�ɓ����Ă�̂� orz
������� PHP �̃\�[�X���߂Ȃ���v�Ă��Ă݂܂��B
���肪�Ƃ��������܂��B
�ނ��� PHP �̃o�[�W�������Ƃ����Ă��炦��ƁB
���āA�ŐV�o�[�W�����̃\�[�X�ɓ����Ă�̂� orz
������� PHP �̃\�[�X���߂Ȃ���v�Ă��Ă݂܂��B
>>19
I've reported this issue to PHP bug report.
http://bugs.php.net/bug.php?id=40195
Complete report and examination results are in
http://geeklog.windy.cx/article.php/20070122224722545
I'm in my Linux box without Japanese environment :-p
I've reported this issue to PHP bug report.
http://bugs.php.net/bug.php?id=40195
Complete report and examination results are in
http://geeklog.windy.cx/article.php/20070122224722545
I'm in my Linux box without Japanese environment :-p
Nuno Lopes ���烊�v���C������A�C���ΏۂƂȂ�܂����B
[22 Jan 9:43pm UTC] [email protected]
I confirm this is a bug in pcre. so let's ask Andrei to
upgrade PCRE to version 7, maybe for PHP 5.2.2
(assign back to me if you want me to do it).
[22 Jan 9:43pm UTC] [email protected]
I confirm this is a bug in pcre. so let's ask Andrei to
upgrade PCRE to version 7, maybe for PHP 5.2.2
(assign back to me if you want me to do it).
23 �Fnobody�����F2007/01/23(��) 17:36:48 ID:???
>>21-22
����͖͔͂Ƃ������o�O�B���ł��B
����͖͔͂Ƃ������o�O�B���ł��B
24 �Fnobody�����F2007/01/23(��) 21:15:28 ID:EGIjqz4P
perl����~��낵���ł��B
@array = split(/(hoge(.))\2/, $line);
����2�Ԗڂ̊��ʂ���@array�Ɋ܂߂Ȃ����Ƃ͂ł��܂����H
'----hoge11-----'
��
('----', 'hoge1', '-----')
�Ƃ������Ɏ��o�������̂ł��B
@array = split(/(hoge(.))\2/, $line);
����2�Ԗڂ̊��ʂ���@array�Ɋ܂߂Ȃ����Ƃ͂ł��܂����H
'----hoge11-----'
��
('----', 'hoge1', '-----')
�Ƃ������Ɏ��o�������̂ł��B
25 �Fnobody�����F2007/01/23(��) 22:31:38 ID:???
�����܂���B�ʂ̕��@�ʼn������܂����B
26 �Fnobody�����F2007/02/01(��) 17:35:44 ID:???
[9 Feb 7:58pm UTC] [email protected]
bundled pcre upgrade to version 7.0.
bundled pcre upgrade to version 7.0.
28 �Fnobody�����F2007/02/17(�y) 11:34:20 ID:???
29 �Fnobody�����F2007/02/18(��) 02:46:46 ID:???
�}���`��`��?
30 �Fnobody�����F2007/02/20(��) 02:12:09 ID:???
�����낵�����肢���܂�
ABC�Ƒ����ꍇ������AB�Ƃ�����������w�肵�����ꍇ��
�ǂ̂悤�ɏ�������悢�ł��傤���E�E�E
ABC�Ƒ����ꍇ������AB�Ƃ�����������w�肵�����ꍇ��
�ǂ̂悤�ɏ�������悢�ł��傤���E�E�E
31 �Fnobody�����F2007/02/20(��) 02:21:35 ID:???
���K�\�����Ăǂ�ȃ����b�g����́H
�o���Ȃ��Ă��ǂ���ł���H
�悭�A�����s��������˃f�o�b�O�̎��Ɋy���Č������ǁA
���W�b�N�v�������ɂ���ق����厖����Ȃ����ȁ[�ȂǂƎv���Ă��܂��܂��i�h�V���E�g�ł����j
����Ȃ̂Ƃ��Ɋ������Đl���`�������W���邱�ƂȂ�ł����ˁ[
�o���Ȃ��Ă��ǂ���ł���H
�悭�A�����s��������˃f�o�b�O�̎��Ɋy���Č������ǁA
���W�b�N�v�������ɂ���ق����厖����Ȃ����ȁ[�ȂǂƎv���Ă��܂��܂��i�h�V���E�g�ł����j
����Ȃ̂Ƃ��Ɋ������Đl���`�������W���邱�ƂȂ�ł����ˁ[
32 �Fnobody�����F2007/02/20(��) 02:23:50 ID:???
33 �Fnobody�����F2007/02/20(��) 02:26:48 ID:???
>>31
������̃p�^�[�����L�q���邽�߂ɓ�����������Ȃ̂ŁA
�o����Δ��Ɋy���ł���B
���W�b�N��100�s�Ƃ���₷�悤�ȃp�^�[�����A
���K�\���ł�1�s�ŕ\�����Ƃ��\(��������Ȃ�)�B
�o���Ȃ��Ă��������A�o���������͂邩�Ɋy���ł����B
������̃p�^�[�����L�q���邽�߂ɓ�����������Ȃ̂ŁA
�o����Δ��Ɋy���ł���B
���W�b�N��100�s�Ƃ���₷�悤�ȃp�^�[�����A
���K�\���ł�1�s�ŕ\�����Ƃ��\(��������Ȃ�)�B
�o���Ȃ��Ă��������A�o���������͂邩�Ɋy���ł����B
34 �Fnobody�����F2007/02/20(��) 07:20:03 ID:???
>>31
���W�b�N�g�߂Ȃ�����y�����邽�߂���
�����琔���̕������������o���ĕ\���Ƃ����K�\���Ȃ�ȒP�ɏo���邪
�g��Ȃ��ł��Ƃ�����ꂽ�玞�Ԃ�������B���܂��Ƀo�O��B
���W�b�N�g�߂Ȃ�����y�����邽�߂���
�����琔���̕������������o���ĕ\���Ƃ����K�\���Ȃ�ȒP�ɏo���邪
�g��Ȃ��ł��Ƃ�����ꂽ�玞�Ԃ�������B���܂��Ƀo�O��B
35 �Fnobody�����F2007/02/20(��) 08:24:42 ID:???
�������������o���̂��������̂��������@�̂悤�ȋZ�p�̂悤�Ɏv���Ă���炵��w
36 �Fnobody�����F2007/02/20(��) 08:27:41 ID:???
���邢�́u������Ă������C�̗��������ƌ�����?�v�Ƃ��v���Ă�̂���www
37 �Fnobody�����F2007/02/20(��) 08:35:59 ID:???
�y�S�́z�U�߂ɂ͐�Ό����Ȃ��ߋ�4�y���Ɂz����������
http://human6.2ch.net/test/read.cgi/ms/1168957905/
7 ���O�F�������l[] ���e���F2007/01/18(��) 03:03:54 ID:iE8GVdnP
����10��A����Q��A����فA���߂P�N�A���`�Q����
12 ���O�F�������l[] ���e���F2007/01/19(��) 22:43:01 ID:s7dkuHKN0
���Z���̍�����i���B�s�όo������B
�U�߂͎��ɂƂ��ĂV�l�ڂ̔ގ��B�i�U�߂ɂ͂R�l�ڂƉR�����j
���ɐ����������Ń����i�C�g���u�̌o������B
25 ���O�F�������l[] ���e���F2007/01/26(��) 04:08:25 ID:IfNo5kNWO
����4��A�Ҹ�N�A��d���`�A��w���ށA���a2��A����3��B
45 ���O�F�������l[sage] ���e���F2007/02/04(��) 14:24:40 ID:PBhJa6V+0
�����̗a�����U�߂̔N���̂V�{���炢���邱�ƁB
�w���̂Ƃ��A������Ƃ������ƋN�����đ听�����@���̂��Ƃ��b���ĂȂ��B
47 ���O�F�������l[] ���e���F2007/02/04(��) 17:16:59 ID:CaAW9Ko50
���[��B�فB��q�蒠�ɋL�ڂ��Ȃ��Ƃ����Ȃ�����c�����͌Ђœ\�t�����B
�`��ɂ̓o���Ă��邾�낤�B�ł����c�P���Ƃ́c�i���̔閧�B
92 ���O�F�������l[] ���e���F2007/02/09(��) 23:46:04 ID:QRXcETQYO
�Z�N�L���o�Ńo�C�g�o������B�������܂��莞�������B���b������100�l���炢�B
���o�c�C�`�ō��̒U�߂ɂ͌��v�̕��C�������ŗ��������́B�Ƃ����������ǂق�Ƃ͋t�B
�D���Ȑl�ł��ĕv�̂ĂĂ̂肩�����B���C���܂��肾�����B
�����������v�������̂ɂ������Œ�Ȏ��������Ďv���B
106 ���O�F�������l[] ���e���F2007/02/18(��) 09:56:13 ID:wIf/65Md0
���N�O�A���������ĕ߂܂������B�R�������ē������Ă������(^^v
http://human6.2ch.net/test/read.cgi/ms/1168957905/
7 ���O�F�������l[] ���e���F2007/01/18(��) 03:03:54 ID:iE8GVdnP
����10��A����Q��A����فA���߂P�N�A���`�Q����
12 ���O�F�������l[] ���e���F2007/01/19(��) 22:43:01 ID:s7dkuHKN0
���Z���̍�����i���B�s�όo������B
�U�߂͎��ɂƂ��ĂV�l�ڂ̔ގ��B�i�U�߂ɂ͂R�l�ڂƉR�����j
���ɐ����������Ń����i�C�g���u�̌o������B
25 ���O�F�������l[] ���e���F2007/01/26(��) 04:08:25 ID:IfNo5kNWO
����4��A�Ҹ�N�A��d���`�A��w���ށA���a2��A����3��B
45 ���O�F�������l[sage] ���e���F2007/02/04(��) 14:24:40 ID:PBhJa6V+0
�����̗a�����U�߂̔N���̂V�{���炢���邱�ƁB
�w���̂Ƃ��A������Ƃ������ƋN�����đ听�����@���̂��Ƃ��b���ĂȂ��B
47 ���O�F�������l[] ���e���F2007/02/04(��) 17:16:59 ID:CaAW9Ko50
���[��B�فB��q�蒠�ɋL�ڂ��Ȃ��Ƃ����Ȃ�����c�����͌Ђœ\�t�����B
�`��ɂ̓o���Ă��邾�낤�B�ł����c�P���Ƃ́c�i���̔閧�B
92 ���O�F�������l[] ���e���F2007/02/09(��) 23:46:04 ID:QRXcETQYO
�Z�N�L���o�Ńo�C�g�o������B�������܂��莞�������B���b������100�l���炢�B
���o�c�C�`�ō��̒U�߂ɂ͌��v�̕��C�������ŗ��������́B�Ƃ����������ǂق�Ƃ͋t�B
�D���Ȑl�ł��ĕv�̂ĂĂ̂肩�����B���C���܂��肾�����B
�����������v�������̂ɂ������Œ�Ȏ��������Ďv���B
106 ���O�F�������l[] ���e���F2007/02/18(��) 09:56:13 ID:wIf/65Md0
���N�O�A���������ĕ߂܂������B�R�������ē������Ă������(^^v
38 �Fnobody�����F2007/02/20(��) 19:16:13 ID:W7lgDSO2
/tatakanamk/
�ƌ�������������/����/�܂ł̌��o������ɂ͂ǂ������悢�ł��傤���H
/��/���܂߂ĂP�Q���������o�������̂ł��B
�������I�ł�����낵�����肢���܂��B
�ƌ�������������/����/�܂ł̌��o������ɂ͂ǂ������悢�ł��傤���H
/��/���܂߂ĂP�Q���������o�������̂ł��B
�������I�ł�����낵�����肢���܂��B
39 �Fnobody�����F2007/02/20(��) 19:38:28 ID:???
40 �Fnobody�����F2007/02/20(��) 19:56:10 ID:???
�G�X�p�[���K���̘R�ꂪ�g�p����� Perl �Ɛ����B
�o�b�N�X���b�V����O�u���ăG�X�P�[�v����B
/\/tatakanamk\//
�o�b�N�X���b�V����O�u���ăG�X�P�[�v����B
/\/tatakanamk\//
41 �Fnobody�����F2007/02/20(��) 22:52:27 ID:???
>>32
���肪�Ƃ��������܂����I
���肪�Ƃ��������܂����I
42 �Fnobody�����F2007/02/21(��) 02:10:45 ID:???
43 �Fnobody�����F2007/02/21(��) 03:35:33 ID:???
�G�X�P�[�v��m��Ȃ��̂���肾���痼��������ׂ����Ƃ���
�����Ă������̌��ꂾ�����Ƃ��Ă����p����Ԍ������������B
�ƌ�����B
�ƌ�����B
>>43
�����m���ɂ������ˁB
�K�v�̂Ȃ��Ƃ���܂ŃG�X�P�[�v���Ă���悤�Ȑ��K�\�����Ă��
�������������w
>>44
�킩�����A�킩����w
�����m���ɂ������ˁB
�K�v�̂Ȃ��Ƃ���܂ŃG�X�P�[�v���Ă���悤�Ȑ��K�\�����Ă��
�������������w
>>44
�킩�����A�킩����w
46 �Fnobody�����F2007/03/02(��) 01:04:13 ID:???
�ێ�
47 �Fnobody�����F2007/03/10(�y) 16:03:45 ID:VXyj5Dh3
<?
$str = "/get/data/&country=2&url=http://www.example.com/?url=http://www.example.com";
���̃f�[�^�̒��ł͂��߂� url= �ȍ~�̕�������擾����ɂ͂ǂ���������̂ł��傤���H���Ȃ݂�url=�ȍ~�̕�����ɂ��ēxurl=���܂܂�Ă��܂����A��������Ă��ׂĎ擾�������ł��B
�ǂ�����낵�����肢���܂��B
$str = "/get/data/&country=2&url=http://www.example.com/?url=http://www.example.com";
���̃f�[�^�̒��ł͂��߂� url= �ȍ~�̕�������擾����ɂ͂ǂ���������̂ł��傤���H���Ȃ݂�url=�ȍ~�̕�����ɂ��ēxurl=���܂܂�Ă��܂����A��������Ă��ׂĎ擾�������ł��B
�ǂ�����낵�����肢���܂��B
48 �Fnobody�����F2007/03/11(��) 04:44:19 ID:???
>>47
url=http://www.example.com/?url=http://www.example.com
���Ƃ��Ⴀ�����̂�?
url=.*$
�ʼn����s�s������?
url=http://www.example.com/?url=http://www.example.com
���Ƃ��Ⴀ�����̂�?
url=.*$
�ʼn����s�s������?
49 �Fnobody�����F2007/03/12(��) 12:20:51 ID:DmSqMrCU
php�g���Ă܂��B
������?�𒊏o����ɂ͂ǂ��L�q�����炢���̂ł��傤�H
¥?
���Ⴞ�߂Ȃ��Ƃ͂킩��܂���orz
������?�𒊏o����ɂ͂ǂ��L�q�����炢���̂ł��傤�H
¥?
���Ⴞ�߂Ȃ��Ƃ͂킩��܂���orz
50 �Fnobody�����F2007/03/12(��) 12:48:47 ID:???
�o�b�N�X���b�V����O�ɒu���B
51 �Fnobody�����F2007/03/12(��) 14:27:04 ID:DmSqMrCU
�����ł����I
52 �Fnobody�����F2007/03/18(��) 21:25:07 ID:7HFdTRo7
�������������B
$in=���[�U�[����̓���
$str='abc%ghi';
$str=preg_replace('/(\w+)%(\w+)/',"\1$in\2",$str);
���[�U�[����̓��͂�'def'�ɂ��Ă����ƁAabcdefghi�ɂȂ�܂��B
�ł������[�U�[����̓��͂�'123'�̏ꍇ�Aghi�ɂȂ�܂��B
���Ԃ�A�u����̕����u\1123\2�v�ƁA�q�����ĉ��߂���Ă��邩�炾�Ǝv���܂��B
{\1}�̂悤�Ɉ͂ނƂ��A�Ȃɂ��q����Ȃ��悤�ɉ��߂��Ă��炤���@�͂Ȃ��ł����H
��i�K�ɕ����Ēu������Ƃ�����Ή���ł��Ȃ��͂Ȃ��ł����X�}�[�g�ł͂Ȃ������Ȃ̂ŁB
$in=���[�U�[����̓���
$str='abc%ghi';
$str=preg_replace('/(\w+)%(\w+)/',"\1$in\2",$str);
���[�U�[����̓��͂�'def'�ɂ��Ă����ƁAabcdefghi�ɂȂ�܂��B
�ł������[�U�[����̓��͂�'123'�̏ꍇ�Aghi�ɂȂ�܂��B
���Ԃ�A�u����̕����u\1123\2�v�ƁA�q�����ĉ��߂���Ă��邩�炾�Ǝv���܂��B
{\1}�̂悤�Ɉ͂ނƂ��A�Ȃɂ��q����Ȃ��悤�ɉ��߂��Ă��炤���@�͂Ȃ��ł����H
��i�K�ɕ����Ēu������Ƃ�����Ή���ł��Ȃ��͂Ȃ��ł����X�}�[�g�ł͂Ȃ������Ȃ̂ŁB
�����܂���php4�ł��B
54 �Fnobody�����F2007/03/18(��) 22:00:48 ID:???
���������炱���Ȃ���Č��ʂ���s�ɂ܂Ƃ߂�
55 �Fnobody�����F2007/03/19(��) 08:43:07 ID:???
>55
>���ʂ�\\1��\1��
�����܂���ԈႢ�ł����B�i�����ɓ\�������ƒ����܂���������ς�炸�B�j
���̂������������Ăĉ������܂����B��Ԏ�点�Ă����܂���B
$in='123';
$str=preg_replace('/(abc)%(def)/',"\\1$in\\2",$str); //���ꂪ
$str=preg_replace('/(abc)%(def)/',"\\1123\\2",$str); //�����Ȃ��Ă��܂��̂�
$str=preg_replace('/(abc)%(def)/',"def",$str); //\\1123�͂Ȃ��̂ŏ�����\\2�����u������
print $str; //def���o�͂����
�Ǝv���̂ŁA{$in}�ł������Ă����ʂ͓����ł����B
��Ԃ����̂�\\1����{\\1}��������@���Ǝv���̂ł����B
��php����\\1��\$1�ł������̂ŁA"\${1}$in\$2"�ʼn������܂����B�ق�Ƃ����܂���B
>���ʂ�\\1��\1��
�����܂���ԈႢ�ł����B�i�����ɓ\�������ƒ����܂���������ς�炸�B�j
���̂������������Ăĉ������܂����B��Ԏ�点�Ă����܂���B
$in='123';
$str=preg_replace('/(abc)%(def)/',"\\1$in\\2",$str); //���ꂪ
$str=preg_replace('/(abc)%(def)/',"\\1123\\2",$str); //�����Ȃ��Ă��܂��̂�
$str=preg_replace('/(abc)%(def)/',"def",$str); //\\1123�͂Ȃ��̂ŏ�����\\2�����u������
print $str; //def���o�͂����
�Ǝv���̂ŁA{$in}�ł������Ă����ʂ͓����ł����B
��Ԃ����̂�\\1����{\\1}��������@���Ǝv���̂ł����B
��php����\\1��\$1�ł������̂ŁA"\${1}$in\$2"�ʼn������܂����B�ق�Ƃ����܂���B
57 �Fnobody�����F2007/03/23(��) 00:39:31 ID:P+rVOV8A
$str = "foo@=barfoo@=bar";
$str = preg_replace('/foo.*(=)bar/', "a\\1b", $str);
�����s�����ꍇ�̌��ʂ�a=ba=b�ɂ������̂ł����A
���ۂ�a=b�ɂȂ��Ă��܂��܂��B
�ǂ����Ԉ���Ă���̂ł��傤���H
$str = preg_replace('/foo.*(=)bar/', "a\\1b", $str);
�����s�����ꍇ�̌��ʂ�a=ba=b�ɂ������̂ł����A
���ۂ�a=b�ɂȂ��Ă��܂��܂��B
�ǂ����Ԉ���Ă���̂ł��傤���H
58 �Fnobody�����F2007/03/23(��) 02:15:09 ID:???
59 �F57�F2007/03/23(��) 10:16:39 ID:P+rVOV8A
>>58
.*�� bar �Ƒ���������ȊO�̔C�ӂ̕�����ɕς�������Ƃ����̂͂킩��̂ł����A
$str = preg_replace('/foo[^(bar)]*(=)bar/', "a\\2b", $str);
�Ƃ��Ă����܂������܂���B
�G���C�l��낵�����肢���܂��B
.*�� bar �Ƒ���������ȊO�̔C�ӂ̕�����ɕς�������Ƃ����̂͂킩��̂ł����A
$str = preg_replace('/foo[^(bar)]*(=)bar/', "a\\2b", $str);
�Ƃ��Ă����܂������܂���B
�G���C�l��낵�����肢���܂��B
60 �Fnobody�����F2007/03/23(��) 10:45:01 ID:???
�u���镶������܂܂Ȃ�������v�̐��K�\���͂߂�ǂ��̂ōŒZ�}�b�` .*? �ŁB
62 �Fnobody�����F2007/03/24(�y) 01:11:05 ID:???
>>59
foo[^(bar)]*(=)bar
�u���P�b�g�̒��Ƃ��ǂ��ł���ȏ������o���Ă����c
����̏ꍇ�Abar�܂Ō��Ȃ��ł� = �܂ł݂�Ⴀ������Ȃ���?
�s�p�ӂɍŒZ�}�b�`�g���Ă�ƃp�t�H�[�}���X�ŋ�����?
foo[^=]*=bar �� a=b �ɒu���ł��������B
=���L���v�`������̂��Ӑ}���킩���B
foo[^(bar)]*(=)bar
�u���P�b�g�̒��Ƃ��ǂ��ł���ȏ������o���Ă����c
����̏ꍇ�Abar�܂Ō��Ȃ��ł� = �܂ł݂�Ⴀ������Ȃ���?
�s�p�ӂɍŒZ�}�b�`�g���Ă�ƃp�t�H�[�}���X�ŋ�����?
foo[^=]*=bar �� a=b �ɒu���ł��������B
=���L���v�`������̂��Ӑ}���킩���B
63 �Fnobody�����F2007/03/24(�y) 12:15:47 ID:yU007f6l
<html>
<head>
<title>�e�X�g</title>
</head>
<body>
<!-- �������� -->
����������������������<br />
����������������������<br />
����������������������<br />
����������������������<br />
����������������������
<!-- �����܂� -->
</body>
</html>
���̂悤��html��PHP5��file_get_contents�œǂݍ����
<!-- �������� -->�`<!-- �����܂� -->���擾�������̂ł���
�ǂ�����Ηǂ��ł����H
"/<!-- �������� -->(.*)<!-- �����܂� -->/"
�œǂ߂܂���ł���
<head>
<title>�e�X�g</title>
</head>
<body>
<!-- �������� -->
����������������������<br />
����������������������<br />
����������������������<br />
����������������������<br />
����������������������
<!-- �����܂� -->
</body>
</html>
���̂悤��html��PHP5��file_get_contents�œǂݍ����
<!-- �������� -->�`<!-- �����܂� -->���擾�������̂ł���
�ǂ�����Ηǂ��ł����H
"/<!-- �������� -->(.*)<!-- �����܂� -->/"
�œǂ߂܂���ł���
64 �Fnobody�����F2007/03/24(�y) 13:41:28 ID:???
65 �Fnobody�����F2007/03/24(�y) 16:11:22 ID:???
$text = file_get_contents(�Ȃ�炩���);
mb_ereg("<!-- �������� -->(.*)<!-- �����܂� -->", $text, $data);
echo $data[1];
���s�Ɏז�����Ă�낤
mb_ereg("<!-- �������� -->(.*)<!-- �����܂� -->", $text, $data);
echo $data[1];
���s�Ɏז�����Ă�낤
66 �Fnobody�����F2007/03/25(��) 02:07:05 ID:???
>>65
���̋L�q���ƃp�^�[���̕����ŃG���[���łȂ��H
���̋L�q���ƃp�^�[���̕����ŃG���[���łȂ��H
67 �Fnobody�����F2007/04/07(�y) 00:58:14 ID:YCq54Nw2
�n�߂܂��āB
C#�ŁA���K�\����yyyy/mm/dd�������ǂ��\������̂ł��傤��?
���Ȃ݂ɁA.NET�̐��K�\����Perl�݊��������ł��B
C#�ŁA���K�\����yyyy/mm/dd�������ǂ��\������̂ł��傤��?
���Ȃ݂ɁA.NET�̐��K�\����Perl�݊��������ł��B
68 �Fnobody�����F2007/04/07(�y) 04:03:00 ID:???
>>67
Datte�N���X���Ȃɕ�����H�킹�āA��O��Ԃ��ǂ�����
���肵����?
���K�\���ł��� 9999�N13��35�����������Ă��������Ă̂Ȃ�
\d{4}/\d{2}/\d{2}
���ȁB
���Ɠ��͊撣��Ȃ�Ƃ��ł��邯�ǂ߂�ǂ�����������Ȃ��B
Datte�N���X���Ȃɕ�����H�킹�āA��O��Ԃ��ǂ�����
���肵����?
���K�\���ł��� 9999�N13��35�����������Ă��������Ă̂Ȃ�
\d{4}/\d{2}/\d{2}
���ȁB
���Ɠ��͊撣��Ȃ�Ƃ��ł��邯�ǂ߂�ǂ�����������Ȃ��B
69 �Fnobody�����F2007/04/08(��) 02:12:40 ID:EVMLEL7f
70 �Fnobody�����F2007/04/08(��) 16:37:48 ID:???
>>68
�����A�����������ƂȂ̂ˁB
�ꉞ���ӂ��Ă������ǁAC#�̕�����̃G�X�P�[�v��\���g���̂�
�v���O�����ɏ����Ƃ���
"\\d{4}..."
�̂悤��\���d�˂邩�A
@"\d{4}.."
�̂悤��\�����ʈ�������Ȃ��`���ɂ��ĂˁB
�����A�����������ƂȂ̂ˁB
�ꉞ���ӂ��Ă������ǁAC#�̕�����̃G�X�P�[�v��\���g���̂�
�v���O�����ɏ����Ƃ���
"\\d{4}..."
�̂悤��\���d�˂邩�A
@"\d{4}.."
�̂悤��\�����ʈ�������Ȃ��`���ɂ��ĂˁB
71 �Fnobody�����F2007/04/15(��) 02:12:22 ID:v7Ys668x
php5�ł��B�t�@�C���̃t���p�X���f�B���N�g��,�t�@�C����,�g���q�ɕ������Ă��̔z���Ԃ������Ă��������܂����B
$pattern1 = '`^(.*)(?:[/\\\](.*)){1}$`';
preg_match($pattern1, $fullpath, $match1);
$pos = strpos($match1[2], '.');
if($pos === false){
return array($match1[1], $match1[2]);
}else{
$pattern2='`^(.*?)\.(.*)$`';
preg_match($pattern2, $match1[2], $match2);
return array($match1[1], $match2[1], $match2[2]);
}
�K���g���q������Ȃ��x��preg_match�ŃL���v�`���o�����̂ł���
�g���q�����t�@�C�������肾�����ꍇ�̐��K�\�������܂��v�������ɓ�i�K�i�O�i�K�H�j�ɂȂ��Ă��܂��܂���
�ł�preg_match����Ă��̒���'.'�T���āA�������炳���preg_match�Ƃ����̂͂܂�肭�ǂ��悤�Ɏv���܂�
���̏�������x�ɂ��Ȃ����K�\���̍l�����̃q���g����������
$pattern1 = '`^(.*)(?:[/\\\](.*)){1}$`';
preg_match($pattern1, $fullpath, $match1);
$pos = strpos($match1[2], '.');
if($pos === false){
return array($match1[1], $match1[2]);
}else{
$pattern2='`^(.*?)\.(.*)$`';
preg_match($pattern2, $match1[2], $match2);
return array($match1[1], $match2[1], $match2[2]);
}
�K���g���q������Ȃ��x��preg_match�ŃL���v�`���o�����̂ł���
�g���q�����t�@�C�������肾�����ꍇ�̐��K�\�������܂��v�������ɓ�i�K�i�O�i�K�H�j�ɂȂ��Ă��܂��܂���
�ł�preg_match����Ă��̒���'.'�T���āA�������炳���preg_match�Ƃ����̂͂܂�肭�ǂ��悤�Ɏv���܂�
���̏�������x�ɂ��Ȃ����K�\���̍l�����̃q���g����������
72 �Fnobody�����F2007/04/15(��) 02:14:51 ID:???
�������p�̘A���_���Ȃ����@�C���f���g�������Ⴝ
73 �Fnobody�����F2007/04/15(��) 03:03:32 ID:???
���A���߂�B���K�\���X���������ˁB�������āB
�ŁA�l���Ă݂����ǁA
$path = '/abc/def.g/eee.txt';
preg_match('/(.*?)¥/([^¥/]*)¥.([^¥/.]*$)/', $path, $match);
print_r($match);
����Ȋ����łǂ�?
$path = '/abc/def.g/eee.txt';
preg_match('/(.*?)¥/([^¥/]*)¥.([^¥/.]*$)/', $path, $match);
print_r($match);
����Ȋ����łǂ�?
���ꂶ��g���q�̂Ȃ��ꍇ�ɑΉ��ł��Ȃ����B
/(.*?)¥/([^¥/]*?)(¥.[^¥/.]*)?$/
�łǂ����ȁB�X���������Ă��܂��Ă��܂�B
/(.*?)¥/([^¥/]*?)(¥.[^¥/.]*)?$/
�łǂ����ȁB�X���������Ă��܂��Ă��܂�B
77 �Fnobody�����F2007/04/15(��) 09:05:07 ID:???
PHP�Ȃ�Adirname��basename�����ΐ��K�\���Ȃg���K�v��Ȃ�����
78 �Fnobody�����F2007/04/15(��) 11:13:03 ID:???
���K�\���������Ƃ���Ȋ����ł���
$p = pathinfo($fullpath);
$temp = explode('.',$p['basename'],2);
$p['name'] = $temp[0];
if(isset($temp[1])){
�@$p['ext'] = $temp[1];
}
>>76���Q�l�ɂ��Đ��K�\���ŏ����܂���
$pattern = '`^(.*)[/\\\]([^.]*?)(?:\.(.*))?$`';
preg_match($pattern, $fullpath, $match);
���肪�Ƃ��������܂���
$p = pathinfo($fullpath);
$temp = explode('.',$p['basename'],2);
$p['name'] = $temp[0];
if(isset($temp[1])){
�@$p['ext'] = $temp[1];
}
>>76���Q�l�ɂ��Đ��K�\���ŏ����܂���
$pattern = '`^(.*)[/\\\]([^.]*?)(?:\.(.*))?$`';
preg_match($pattern, $fullpath, $match);
���肪�Ƃ��������܂���
80 �Fnobody�����F2007/05/03(��) 19:11:49 ID:meD6A7ah
php�Ōg�ѓd�b�̊G��������菜���悤preg_replace���g���Ă���̂ł����A
�G�����������܂܂ꂽ������H�Ȃǂł��܂���菜���܂���B
����Ȋ����ɂ��Ă���̂ł��������₨�����ȓ_�Ȃǂ��������������B���肢���܂��B
$str = '�G�������܂܂�镶����';
$emojiSjisChars = '(?:[\x00-\x7F\xA1-\xDF]|(?:[\x81-\x9F\xE0-\xFC][\x40-\x7E\x80-\xFC]))';
#DoCoMo�̏ꍇ
$str = preg_replace('/\G(' .$emojiSjisChars. '*?)(?:\xF8[\x9F-\xFC]|\xF9[\x40-\x49\x50-\x52\x55-\x57\x5B-\x5E\x72-\x7E\x80-\xB0])|(?:\xF9[\xB1-\xFC])/', '$1', $str);
#AU�̏ꍇ
$str = preg_replace('/\G(' .$emojiSjisChars. '*?)(?:[\xf3\xf6\xf7][\x40-\xfc]|\xf4[\x40-\x8d])/', '$1', $str);
#Softbank�̏ꍇ
$str = preg_replace('/\G(' .$emojiSjisChars. '*?)\x1B\x24[E-G].*?\x0F/', '$1', $str);
�G�����������܂܂ꂽ������H�Ȃǂł��܂���菜���܂���B
����Ȋ����ɂ��Ă���̂ł��������₨�����ȓ_�Ȃǂ��������������B���肢���܂��B
$str = '�G�������܂܂�镶����';
$emojiSjisChars = '(?:[\x00-\x7F\xA1-\xDF]|(?:[\x81-\x9F\xE0-\xFC][\x40-\x7E\x80-\xFC]))';
#DoCoMo�̏ꍇ
$str = preg_replace('/\G(' .$emojiSjisChars. '*?)(?:\xF8[\x9F-\xFC]|\xF9[\x40-\x49\x50-\x52\x55-\x57\x5B-\x5E\x72-\x7E\x80-\xB0])|(?:\xF9[\xB1-\xFC])/', '$1', $str);
#AU�̏ꍇ
$str = preg_replace('/\G(' .$emojiSjisChars. '*?)(?:[\xf3\xf6\xf7][\x40-\xfc]|\xf4[\x40-\x8d])/', '$1', $str);
#Softbank�̏ꍇ
$str = preg_replace('/\G(' .$emojiSjisChars. '*?)\x1B\x24[E-G].*?\x0F/', '$1', $str);
81 �F80�F2007/05/03(��) 19:17:55 ID:meD6A7ah
�����܂���B����$emojiSjisChars��$sjisChars�̖����ԈႦ�ł��B
82 �Fnobody�����F2007/05/03(��) 19:26:15 ID:???
�����Ɠǂ�łȂ�����
(?:�G�����̃R�[�h) �ȕ����� (?:�G�����̃R�[�h)+ �ɂ��邾���ł͂Ȃ��́H
(?:�G�����̃R�[�h) �ȕ����� (?:�G�����̃R�[�h)+ �ɂ��邾���ł͂Ȃ��́H
83 �F80�F2007/05/03(��) 20:24:41 ID:meD6A7ah
>>82
���X���肪�Ƃ��������܂��B
���̂悤��+�����܂������_���ł����B
�F�X�l���Ă���Ƃǂ�ǂ���Ȃ��Ȃ��Ă��܂���...
�������ȓ_������Έ����������������肢���܂��B
#DoCoMo�̏ꍇ�@�����ɂ����̂ŕ\������s���܂��B
$str = preg_replace(
'/\G(' .$emojiSjisChars.'*?)
(?:\xF8[\x9F-\xFC]|\xF9[\x40-\x49\x50-\x52\x55-\x57\x5B-\x5E\x72-\x7E\x80-\xB0])+|
(?:\xF9[\xB1-\xFC])+/', '$1', $str);
���X���肪�Ƃ��������܂��B
���̂悤��+�����܂������_���ł����B
�F�X�l���Ă���Ƃǂ�ǂ���Ȃ��Ȃ��Ă��܂���...
�������ȓ_������Έ����������������肢���܂��B
#DoCoMo�̏ꍇ�@�����ɂ����̂ŕ\������s���܂��B
$str = preg_replace(
'/\G(' .$emojiSjisChars.'*?)
(?:\xF8[\x9F-\xFC]|\xF9[\x40-\x49\x50-\x52\x55-\x57\x5B-\x5E\x72-\x7E\x80-\xB0])+|
(?:\xF9[\xB1-\xFC])+/', '$1', $str);
84 �Fnobody�����F2007/05/04(��) 00:29:52 ID:???
�I���C���[�̏ڍא��K�\���̖{����
�ʏ�̂Ƒ�Q�ł��Ă̂����邯�ǂǂ����������̂�H
�ʏ�̂Ƒ�Q�ł��Ă̂����邯�ǂǂ����������̂�H
85 �Fnobody�����F2007/05/04(��) 03:16:56 ID:???
>>84
�ʏ�̂��ď��ł̂��Ƃ���?
����Ⴀ�V���������B
��̓I�ɂǂ��ς�������o���ĂȂ��̂ŃI���C���[�̃T�C�g���������ǁA
Perl�̑Ώۂ�5.8�ɂ������Ă���̂ƁA.JAVA��NET�̐������������Ƃ��炵���B
�ʏ�̂��ď��ł̂��Ƃ���?
����Ⴀ�V���������B
��̓I�ɂǂ��ς�������o���ĂȂ��̂ŃI���C���[�̃T�C�g���������ǁA
Perl�̑Ώۂ�5.8�ɂ������Ă���̂ƁA.JAVA��NET�̐������������Ƃ��炵���B
86 �Fnobody�����F2007/05/10(��) 19:57:43 ID:???
php4.3.11�ł�
---------------------------------
$str = <<< DOC_END
����������
����������
<html_start>
����������
����������
<html_end>
����������
DOC_END;
$pattern = "/<html_start>(.*)<html_end>/";
$replacement = 'aaaabbbb';
$res = preg_replace($pattern, $replacement, $str);
print_r($res);
---------------------------------
�Əo�͂��Ă݂܂����������\������܂���ł����B
�z���g�́u��������������������aaaabbbb�����������v�Əo�ė~���������̂ł����c�B
�ŏI�I�ɂ�<html_start><html_end>�ň͂܂ꂽ�͈͂�
PHP��htmlspecialchars()��nl2br()����K�p���ďo�͂������ł��B
---------------------------------
$str = <<< DOC_END
����������
����������
<html_start>
����������
����������
<html_end>
����������
DOC_END;
$pattern = "/<html_start>(.*)<html_end>/";
$replacement = 'aaaabbbb';
$res = preg_replace($pattern, $replacement, $str);
print_r($res);
---------------------------------
�Əo�͂��Ă݂܂����������\������܂���ł����B
�z���g�́u��������������������aaaabbbb�����������v�Əo�ė~���������̂ł����c�B
�ŏI�I�ɂ�<html_start><html_end>�ň͂܂ꂽ�͈͂�
PHP��htmlspecialchars()��nl2br()����K�p���ďo�͂������ł��B
87 �Fnobody�����F2007/05/10(��) 20:35:51 ID:???
>>86
> $pattern = "/<html_start>(.*)<html_end>/";
�u ^ �� $ ��������Ă��Ƃ͐��K�\�����čs�P�ʁH�����s�̏ꍇ�́H�v�Ƃ��v���Ȃ���
$pattern = "/<html_start>(.*)<html_end>/s";
�ɂ��Ď����B�ŁA�us ���ĉ�����A����ɂ��v�Ǝv���Ȃ���}�j���A���́u�p�^�[���C���q�v�̂Ƃ���ǂށB
������PHP5����ł͌��̃R�[�h�ł��u�����\������Ȃ��v�ɂ͂Ȃ�Ȃ������ȁB
�@
�u���E�U�o��: �������������������� �������������������� ����������
�\�[�X: print_r($str) �Ȋ���
> $pattern = "/<html_start>(.*)<html_end>/";
�u ^ �� $ ��������Ă��Ƃ͐��K�\�����čs�P�ʁH�����s�̏ꍇ�́H�v�Ƃ��v���Ȃ���
$pattern = "/<html_start>(.*)<html_end>/s";
�ɂ��Ď����B�ŁA�us ���ĉ�����A����ɂ��v�Ǝv���Ȃ���}�j���A���́u�p�^�[���C���q�v�̂Ƃ���ǂށB
������PHP5����ł͌��̃R�[�h�ł��u�����\������Ȃ��v�ɂ͂Ȃ�Ȃ������ȁB
�@
�u���E�U�o��: �������������������� �������������������� ����������
�\�[�X: print_r($str) �Ȋ���
88 �Fnobody�����F2007/05/10(��) 20:51:04 ID:???
>>87
s�C���q�œ��삵�܂����I���肪�Ƃ��������܂��B
���us ���ĉ�����A����ɂ��v�Ǝv���Ȃ���}�j���A���́u�p�^�[���C���q�v�̂Ƃ���ǂށB
���̃y�[�W����݂�
http://jp.php.net/manual/ja/ref.pcre.php
http://jp.php.net/manual/ja/reference.pcre.pattern.modifiers.php
�̃y�[�W�̑��݂ɋC�����܂���ł����c�B
���Ƃ͊���K�p������@��T���Ă݂܂����I
s�C���q�œ��삵�܂����I���肪�Ƃ��������܂��B
���us ���ĉ�����A����ɂ��v�Ǝv���Ȃ���}�j���A���́u�p�^�[���C���q�v�̂Ƃ���ǂށB
���̃y�[�W����݂�
http://jp.php.net/manual/ja/ref.pcre.php
http://jp.php.net/manual/ja/reference.pcre.pattern.modifiers.php
�̃y�[�W�̑��݂ɋC�����܂���ł����c�B
���Ƃ͊���K�p������@��T���Ă݂܂����I
89 �Fnobody�����F2007/05/10(��) 21:18:19 ID:???
�ĊO���̎�̎��₵�����l�������
����u�����鎞�Ɋ����܂������}�j���A�����߂Ă���ue�C���q�v���݂����̂ł���
>>87�́uS�C���q�v�Ɠ����Ɏg������
$pattern = "/(.*?)<html_start>(.*)<html_end>(.*?)/se";
$replacement = "'\\2''\\1''\\3'";
����ȃR�[�h�������Ă݂���
Parse error: syntax error, unexpected T_CONSTANT_ENCAPSED_STRING
Failed evaluating code:
�Ƃ����������œ{���܂�
�C���q2�͓����Ɏg���Ȃ��̂ł��傤���c�H
>>87�́uS�C���q�v�Ɠ����Ɏg������
$pattern = "/(.*?)<html_start>(.*)<html_end>(.*?)/se";
$replacement = "'\\2''\\1''\\3'";
����ȃR�[�h�������Ă݂���
Parse error: syntax error, unexpected T_CONSTANT_ENCAPSED_STRING
Failed evaluating code:
�Ƃ����������œ{���܂�
�C���q2�͓����Ɏg���Ȃ��̂ł��傤���c�H
>>86�ł���
�����Ō��Ԃ��Ă��炱��͊��ɐ��K�\���łȂ�PHP�̎���ȋC�����Ă��܂����̂ŊY���X����
�ړ����܂��ł��B
�X����A�\����܂���ł����B
�����Ō��Ԃ��Ă��炱��͊��ɐ��K�\���łȂ�PHP�̎���ȋC�����Ă��܂����̂ŊY���X����
�ړ����܂��ł��B
�X����A�\����܂���ł����B
92 �Fnobody�����F2007/05/17(��) 13:08:20 ID:???
IP�𐳋K�\���Ń`�F�b�N�������̂ł���
210.000.111.1�`210.000.111.255
215.100.000.1�`215.100.000.255
�̂Q�ɓ��Ă͂܂�ꍇ�ATRUE�iint1�j���������ɂ͂ǂ���������ł��傤���H
�ȉ��̂悤�ɂ���Ă݂��̂ł�������IP�ł�int(1)���������Ă��܂��B
preg_match('/^210\.000\.111\.([0-9]{2}|1[0-9]{2}|2[0-4][0-9]|25[0-5])$ || ^215\.100\.000\.([0-9]{2}|1[0-9]{2}|2[0-4][0-9]|25[0-5])$/', $_SERVER['REMOTE_ADDR'])
210.000.111.1�`210.000.111.255
215.100.000.1�`215.100.000.255
�̂Q�ɓ��Ă͂܂�ꍇ�ATRUE�iint1�j���������ɂ͂ǂ���������ł��傤���H
�ȉ��̂悤�ɂ���Ă݂��̂ł�������IP�ł�int(1)���������Ă��܂��B
preg_match('/^210\.000\.111\.([0-9]{2}|1[0-9]{2}|2[0-4][0-9]|25[0-5])$ || ^215\.100\.000\.([0-9]{2}|1[0-9]{2}|2[0-4][0-9]|25[0-5])$/', $_SERVER['REMOTE_ADDR'])
93 �Fnobody�����F2007/05/17(��) 13:53:20 ID:???
>>92
���K�\���� foo || bar �݂����Ȃ̂͂Ȃ�������B
/^(210...(����)...|215...(����)...)$/ �݂����ȁB
�A�h���X�͈̔͂̃`�F�b�N������Ȃ琳�K�\���g��Ȃ������ǂ��Ǝv�����ǂˁB
���K�\���� foo || bar �݂����Ȃ̂͂Ȃ�������B
/^(210...(����)...|215...(����)...)$/ �݂����ȁB
�A�h���X�͈̔͂̃`�F�b�N������Ȃ琳�K�\���g��Ȃ������ǂ��Ǝv�����ǂˁB
94 �F���Ȃ������܂��F2007/06/06(��) 13:28:10 ID:iKhV2zih
���݂܂��A���i�Ƀ}�b�`���鐳�K�\���������Ă��������Ȃ��ł��傤���B
��
\1,000,000,000
\12,345
\1,230
\200
\10
����3���ƂɁA�J���}������A�擪�ɉ~�}�[�N�i\�j�̂�����̂ł��B
����Ȃ����߃O�O�b���̂ł����A���K�\���Ɋւ���{���茟�����ʂƂ��ďo�Ă��܂��āc�B
��
\1,000,000,000
\12,345
\1,230
\200
\10
����3���ƂɁA�J���}������A�擪�ɉ~�}�[�N�i\�j�̂�����̂ł��B
����Ȃ����߃O�O�b���̂ł����A���K�\���Ɋւ���{���茟�����ʂƂ��ďo�Ă��܂��āc�B
95 �F���Ȃ������܂��F2007/06/06(��) 13:29:35 ID:iKhV2zih
���>>94�ł����A�g�p�����PHP�ł��B
96 �Fnobody�����F2007/06/06(��) 13:41:59 ID:???
����́A�u\12,1232,32�v�݂����Ȃ̂͂͂��������́H
97 �Fnobody�����F2007/06/06(��) 13:49:54 ID:???
�u���K�\�� �J���}�v�Ƃ��ł������Ă݂�ƁE�E�E
98 �Fnobody�����F2007/06/06(��) 14:54:17 ID:???
>>98
�����炯�����ǂ���Ȃ�̂��ƁH
$hoge = "\1,000";
if(ereg(".*[0-9,\\]",$hoge)):
echo "ok";
else:
echo "ng";
endif;
�����炯�����ǂ���Ȃ�̂��ƁH
$hoge = "\1,000";
if(ereg(".*[0-9,\\]",$hoge)):
echo "ok";
else:
echo "ng";
endif;
99 �Fnobody�����F2007/06/06(��) 15:08:26 ID:???
>>98
��[ http://www.google.co.jp/search?hl=ja&q=%E9%87%91%E9%A1%8D%E3%80%80%E6%AD%A3%E8%A6%8F%E8%A1%A8%E7%8F%BE&lr= ]
��[ http://www.google.co.jp/search?hl=ja&q=%E9%87%91%E9%A1%8D%E3%80%80%E6%AD%A3%E8%A6%8F%E8%A1%A8%E7%8F%BE&lr= ]
>>96 >>97 >>98 >>99
�F�l�A���肪�Ƃ�������܂����B
�u���i�@���K�\���v�A�u�l�i�@���K�\���v�ŃO�O���Ă܂����i���j
�F�l�A���肪�Ƃ�������܂����B
�u���i�@���K�\���v�A�u�l�i�@���K�\���v�ŃO�O���Ă܂����i���j
101 �Fnobody�����F2007/06/30(�y) 13:42:20 ID:???
(?:pattern),�����(?>=pattern)���F������Ȃ��G�f�B�^�ɂ����āA
$obj->method();�́umethod�v�݂̂Ƀ}�b�`������ɂ͂ǂ���������ł��傤���B
���Ȃ݂�(?=pattern)�͎g���܂��B
$obj->method();�́umethod�v�݂̂Ƀ}�b�`������ɂ͂ǂ���������ł��傤���B
���Ȃ݂�(?=pattern)�͎g���܂��B
102 �Fnobody�����F2007/07/09(��) 23:51:58 ID:jN4+J6ks
VB.NET�Ő��K�\���������Ă��܂��B
�����Ƃ��ẮA�uA0123�v�̂悤�ɁA�擪���A���t�@�x�b�g��A�ł��̑�������4���Ƃ������K�\���ƁA
�u01234�v�̂悤�Ȑ���5���Ƃ������ނ̂ǂ��炩�Ƀ}�b�`���鐳�K�\��������Ă��܂��B
���K�\���͋��ō����Ă��܂��B
�ǂȂ����������������B
��낵�����肢���܂��B
�����Ƃ��ẮA�uA0123�v�̂悤�ɁA�擪���A���t�@�x�b�g��A�ł��̑�������4���Ƃ������K�\���ƁA
�u01234�v�̂悤�Ȑ���5���Ƃ������ނ̂ǂ��炩�Ƀ}�b�`���鐳�K�\��������Ă��܂��B
���K�\���͋��ō����Ă��܂��B
�ǂȂ����������������B
��낵�����肢���܂��B
103 �Fnobody�����F2007/07/10(��) 01:52:51 ID:???
104 �Fnobody�����F2007/07/13(��) 17:31:53 ID:lsKPRG81
php�ŕ����̗X�֔ԍ��̕�����u�������鐳�K�\���������Ă���̂ł���
�d�b�ԍ�(�g�тȂ�)�������������Ă��܂��܂�
�ǂ̂悤�ɒ��������̂ł��傤���H
mb_ereg_replace('([0-9�O-�X]{3}[\-�|�[�]]+[0-9�O-�X]{4}|[0-9�O-�X]{7})',"�X�֔ԍ�",$data)
�d�b�ԍ�(�g�тȂ�)�������������Ă��܂��܂�
�ǂ̂悤�ɒ��������̂ł��傤���H
mb_ereg_replace('([0-9�O-�X]{3}[\-�|�[�]]+[0-9�O-�X]{4}|[0-9�O-�X]{7})',"�X�֔ԍ�",$data)
105 �Fnobody�����F2007/07/14(�y) 04:11:15 ID:???
mb_ereg ���Ė߂�ǂݎg���Ȃ���������?
(\D)\d{3}-\d{4}(\d{3})?(?!\D) �� \1�X�֔ԍ� �Œu���B�łǂ�?
�ʓ|�������̂őS�p�����Ƃ��n�C�t���̗ނ͎����Œ������āB
(\D)\d{3}-\d{4}(\d{3})?(?!\D) �� \1�X�֔ԍ� �Œu���B�łǂ�?
�ʓ|�������̂őS�p�����Ƃ��n�C�t���̗ނ͎����Œ������āB
106 �Fnobody�����F2007/07/20(��) 05:15:36 ID:wp5plGkY
$text��HTML�^�O���܂��������Ă��āA
<>�O����< > " �����ꂼ�� < > " �ɒu���������i<>�����͂��̂܂܁j
�̂ł��B�ȉ��̂悤�ɁA�܂��S�Ă�<>"��u�����AHTML�^�O��<>������
���ɖ߂��Ă݂܂������A���܂������܂���B�ǂȂ����������肢�܂��B
����͂��Ƃ�PHP�ł����l�̂��̂��쐬����\��ł����A����Perl�ł��B
$text = "tt\"tt<3bbb\nst<a gg&tg;gg href=\"aaa\">bbb<\n";
print "before=\n";
print $text."\n\n";
$text =~ s/</</g; $text =~ s/>/>/g; $text =~ s/\"/"/g;
$text =~ s/<([^(>)]*)>/<$1>/g;
while ($text =~ /<([^>]*)\"\;([^>]*)>/) {
$text =~ s/<([^>]*)\"\;([^>]*)>/<$1\"$2>/g;
}
print "after=\n";
print $text."\n";
�����̂悤�ɒu������邱�Ƃ�z�肵�Ă��܂��B
tt"tt<3bbb
st<a gg&tg;gg href="aaa">bbb<
<>�O����< > " �����ꂼ�� < > " �ɒu���������i<>�����͂��̂܂܁j
�̂ł��B�ȉ��̂悤�ɁA�܂��S�Ă�<>"��u�����AHTML�^�O��<>������
���ɖ߂��Ă݂܂������A���܂������܂���B�ǂȂ����������肢�܂��B
����͂��Ƃ�PHP�ł����l�̂��̂��쐬����\��ł����A����Perl�ł��B
$text = "tt\"tt<3bbb\nst<a gg&tg;gg href=\"aaa\">bbb<\n";
print "before=\n";
print $text."\n\n";
$text =~ s/</</g; $text =~ s/>/>/g; $text =~ s/\"/"/g;
$text =~ s/<([^(>)]*)>/<$1>/g;
while ($text =~ /<([^>]*)\"\;([^>]*)>/) {
$text =~ s/<([^>]*)\"\;([^>]*)>/<$1\"$2>/g;
}
print "after=\n";
print $text."\n";
�����̂悤�ɒu������邱�Ƃ�z�肵�Ă��܂��B
tt"tt<3bbb
st<a gg&tg;gg href="aaa">bbb<
107 �Fnobody�����F2007/07/20(��) 05:26:31 ID:???
�v���Ԃ�Ɏ��̎Q�Ƃ̒n���݂܂����Ă铊�e�������B
108 �F106�F2007/07/20(��) 05:38:28 ID:wp5plGkY
�u���̂悤�ɒu������邱�Ƃ�z�肵�Ă��܂��B �v�̕�����
���̎Q�Ƃ̕��������̂܂ܕ\������Ă��܂����̂őS�p�ŏC�����܂��B
��낵�����肢���܂��B
tt�����������Gtt�������G3bbb
st<a gg&tg;gg href="aaa">bbb�������G
���̎Q�Ƃ̕��������̂܂ܕ\������Ă��܂����̂őS�p�ŏC�����܂��B
��낵�����肢���܂��B
tt�����������Gtt�������G3bbb
st<a gg&tg;gg href="aaa">bbb�������G
109 �Fnobody�����F2007/07/20(��) 08:47:21 ID:???
������肽���̂������ς肾�B
�ǂ��܂ł��^�O����͂��ă^�O�ȊO�̃^�O���������̎Q�Ɖ��������Ƃ������ƁH
���ꌳ�̃e�L�X�g�����Ă鎞�_�ʼn����Ԉ���Ă邾��
�ǂ��܂ł��^�O����͂��ă^�O�ȊO�̃^�O���������̎Q�Ɖ��������Ƃ������ƁH
���ꌳ�̃e�L�X�g�����Ă鎞�_�ʼn����Ԉ���Ă邾��
110 �Fnobody�����F2007/07/20(��) 12:57:58 ID:???
�����̓����ƊO���肷��̂͌��\�ʓ|����Ȃ��B���Ȃ���<a �`>����</a>�܂ł�
�Ԃ����𑀍삵�悤��3���l���āA�l�X�g�����肦�邱�ƂɋC�t���č��܂����B
�Ԃ����𑀍삵�悤��3���l���āA�l�X�g�����肦�邱�ƂɋC�t���č��܂����B
111 �Fnobody�����F2007/07/20(��) 13:08:08 ID:???
����>>106�ǂ�łȂ������B>>109�ɓ����B
���ꂶ�Ⴀ�ǂ�����ǂ��܂Ő�Ηǂ��̂��킩��Ȃ��B
xxx<abcd<ddeg<eee<g<fhg>degh><qq>zzz
�̎��A�����ۏ���Ă��āA�ǂ�����ǂ��܂ł��^�O�ƌ��Ȃ������́B
���ꂶ�Ⴀ�ǂ�����ǂ��܂Ő�Ηǂ��̂��킩��Ȃ��B
xxx<abcd<ddeg<eee<g<fhg>degh><qq>zzz
�̎��A�����ۏ���Ă��āA�ǂ�����ǂ��܂ł��^�O�ƌ��Ȃ������́B
112 �F106�F2007/07/21(�y) 01:21:27 ID:VYWED9XA
���߂�Ȃ����B����������܂���ł����B
�f���œ��e���ꂽ�������݂ɑ��āA��L�̂悤�ȏ������������ƍl���Ă��܂��B
>>106�̃X�N���v�g�͏������f���ɑg�ݍ��ޑO�ɏ����̕��������e�X�g���邽�߂ɍ쐬�������̂ł��B
$text�͏������ݓ��e�Ƒz�肵�Ă��܂��B
��ԓ�����<>���^�O�ƌ��Ȃ������ł��B
xxx<abcd<ddeg<eee<g<fhg>degh><qq>zzz
���̏ꍇ�ł��ƁA<fhg>��<qq>���^�O�Ƃ݂Ȃ��A���͎��̎Q�Ɖ��������ƍl���Ă��܂��B
�f���œ��e���ꂽ�������݂ɑ��āA��L�̂悤�ȏ������������ƍl���Ă��܂��B
>>106�̃X�N���v�g�͏������f���ɑg�ݍ��ޑO�ɏ����̕��������e�X�g���邽�߂ɍ쐬�������̂ł��B
$text�͏������ݓ��e�Ƒz�肵�Ă��܂��B
��ԓ�����<>���^�O�ƌ��Ȃ������ł��B
xxx<abcd<ddeg<eee<g<fhg>degh><qq>zzz
���̏ꍇ�ł��ƁA<fhg>��<qq>���^�O�Ƃ݂Ȃ��A���͎��̎Q�Ɖ��������ƍl���Ă��܂��B
113 �Fnobody�����F2007/07/21(�y) 02:45:37 ID:???
�܂�^�O�̒�`��
<[^>]*>
�Ƃ������Ƃł��ˁB
<[^>]*>
�Ƃ������Ƃł��ˁB
114 �F106�F2007/07/21(�y) 08:55:35 ID:VYWED9XA
115 �Fnobody�����F2007/07/21(�y) 09:30:47 ID:???
�Ⴄ����A<[^<]*?>����A112�̒�`�Ȃ�B
����ȑO��106�̓G�X�P�[�v�A�G���R�[�h�A�T�j�^�C�Y�����ʼn����Ԉ���Ă�
use HTML::Entities;
$tag_re = qr/<[^<]*?>/;
$text =~ s/($tag_re)|(.)/$1||encode_entities($2)/eg;
print $text;
����ȑO��106�̓G�X�P�[�v�A�G���R�[�h�A�T�j�^�C�Y�����ʼn����Ԉ���Ă�
use HTML::Entities;
$tag_re = qr/<[^<]*?>/;
$text =~ s/($tag_re)|(.)/$1||encode_entities($2)/eg;
print $text;
116 �Fnobody�����F2007/07/21(�y) 13:10:23 ID:7GHIEbSO
PHP��
http://localhost/index.htm
https://localhost/index.htm
http://test.com/index.htm
����
/index.htm
/index.htm
/index.htm
������o�͂������ꍇ
ereg_replace('^https?://(localhost|test.com)' ,'' ,$line);
����ł͊Ԉ���Ă�ł��傤���H
�ǂȂ��������ĉ������B���肢���܂�
http://localhost/index.htm
https://localhost/index.htm
http://test.com/index.htm
����
/index.htm
/index.htm
/index.htm
������o�͂������ꍇ
ereg_replace('^https?://(localhost|test.com)' ,'' ,$line);
����ł͊Ԉ���Ă�ł��傤���H
�ǂȂ��������ĉ������B���肢���܂�
117 �F�������[�F2007/07/27(��) 23:18:07 ID:boPeFaxI
PHP�ł��B
�A�E���|6���i���̑S�p�|���j���p�ɕς������ł��B
$a = ereg_replace("[�|]", "-", $a);
�ǂ������炢���ł��傤���H
�A�E���|6���i���̑S�p�|���j���p�ɕς������ł��B
$a = ereg_replace("[�|]", "-", $a);
�ǂ������炢���ł��傤���H
118 �Fnobody�����F2007/07/28(�y) 02:31:21 ID:k6nESKD8
ereg_* �̓}���`�o�C�g����(�S�p����)�ɑΉ����Ă��Ȃ��B
mb_ereg_* �� preg_* ���g���Ƃ����B
������preg_*�̂ق���UTF-8�łȂ��ƃ_���������Ǝv���B
mb_ereg_* �� preg_* ���g���Ƃ����B
������preg_*�̂ق���UTF-8�łȂ��ƃ_���������Ǝv���B
119 �F�������[�F2007/07/28(�y) 15:25:04 ID:9w1k0jgB
PHP�ł��B
�A�E���|6���i���̑S�p�|���j���p�ɕς������ł��B
$a = mb_ereg_replace("[�|]", "-", $a);
mb_�ł����߂ł����B
�ǂ������炢���ł��傤���H
�A�E���|6���i���̑S�p�|���j���p�ɕς������ł��B
$a = mb_ereg_replace("[�|]", "-", $a);
mb_�ł����߂ł����B
�ǂ������炢���ł��傤���H
120 �Fnobody�����F2007/07/28(�y) 15:37:30 ID:???
�����R�[�h�Ƃ��ǂ��Ȃ��Ƃ��H
121 �F�������[�F2007/07/28(�y) 16:32:13 ID:9w1k0jgB
�����R�[�h�̈Ӗ������܂����킩��Ȃ���ł��A�e�L�X�g�f�B�^��
Shift-JIS�ł��A
Shift-JIS�ł��A
122 �F���������������I���ɍs�����F2007/07/29(��) 01:50:43 ID:???
PHP�͖{�E����Ȃ���ŗǂ��m���̂����APHP���̂��f�t�H���g��
�G���R�[�f�B���O�������Ă��āA�����w�肵�Ȃ��Ƃ���g���͂�������A
������SJIS�w�肵�Ă������ł��A�����łȂ��\����������Ă��ƁB
<?php
echo mb_internal_encoding() . "\n";
echo mb_regex_encoding() . "\n";
$v = "�A�E���|6��";
mb_regex_encoding("sjis");
echo mb_regex_encoding() . "\n";
$v = mb_ereg_replace("[�|]", "-", $v);
echo $v;
����Ȃ�Œu���͂ł������ۂ��B
echo ���Ă���̂͊m�F�̂��߂Ȃ�ŋC�ɂ��Ȃ��ł����B
������ɂ��� mb_regex_encoding�Őݒ肵�Ȃ��ƃ_���������B
�G���R�[�f�B���O�������Ă��āA�����w�肵�Ȃ��Ƃ���g���͂�������A
������SJIS�w�肵�Ă������ł��A�����łȂ��\����������Ă��ƁB
<?php
echo mb_internal_encoding() . "\n";
echo mb_regex_encoding() . "\n";
$v = "�A�E���|6��";
mb_regex_encoding("sjis");
echo mb_regex_encoding() . "\n";
$v = mb_ereg_replace("[�|]", "-", $v);
echo $v;
����Ȃ�Œu���͂ł������ۂ��B
echo ���Ă���̂͊m�F�̂��߂Ȃ�ŋC�ɂ��Ȃ��ł����B
������ɂ��� mb_regex_encoding�Őݒ肵�Ȃ��ƃ_���������B
123 �F�������[�F2007/07/30(��) 07:40:51 ID:DqqhKvmn
�����������܂�����
���肪�Ƃ��������܂���
���肪�Ƃ��������܂���
124 �F�������[�F2007/07/30(��) 21:23:25 ID:TD8Lc2Id
���������͂������
file(http://)�Ŏ擾����������UTF-8��
UTF-8����sjis�ɂ�����S�p�}�C�i�X�������Ă��܂��܂��B
�����āA���s����Ă��܂����
�e�X�g�\�[�X�ł��̂�
mb_ereg_replace
�ȂǂŒu�������Ȃǂ͈���Ă܂���B
�ǂ����Ăł��傤���H
file(http://)�Ŏ擾����������UTF-8��
UTF-8����sjis�ɂ�����S�p�}�C�i�X�������Ă��܂��܂��B
�����āA���s����Ă��܂����
�e�X�g�\�[�X�ł��̂�
mb_ereg_replace
�ȂǂŒu�������Ȃǂ͈���Ă܂���B
�ǂ����Ăł��傤���H
125 �Fnobody�����F2007/07/30(��) 23:11:52 ID:???
�����m���Ă邯�ǐ��K�\���ɉ��̊W��
126 �Fnobody�����F2007/07/30(��) 23:54:01 ID:???
>>125
�U�����Ă���Ă���B(PHP�킩���)
�U�����Ă���Ă���B(PHP�킩���)
127 �Fnobody�����F2007/07/31(��) 01:38:26 ID:???
���Ȃ݂�Perl������������B���K�\���͊W�Ȃ����ǂˁB
128 �Fnobody�����F2007/07/31(��) 02:17:21 ID:???
>>126
�ϊ��Ɏg���Ă���ϊ��\�̖��i�Ȃ̂Ő��K�\���̖�肶��Ȃ��j�B
PHP�Ŏg���Ă���ϊ��\�̑f���͂킩���B
������u�g�_�b�V�����v������ƂȂ��Ō�����Ǝv������
�ǂ����̃X���Řb��ɂȂ������A����?
http://www.google.com/search?sourceid=mozclient&ie=utf-8&oe=utf-8&q=utf8+%E5%A4%89%E6%8F%9B+%E5%85%A8%E8%A7%92%E3%83%9E%E3%82%A4%E3%83%8A%E3%82%B9+%E5%8C%96%E3%81%91%E3%82%8B
�܁A�����Ē��ׂĂ��� ���������[
�ϊ��Ɏg���Ă���ϊ��\�̖��i�Ȃ̂Ő��K�\���̖�肶��Ȃ��j�B
PHP�Ŏg���Ă���ϊ��\�̑f���͂킩���B
������u�g�_�b�V�����v������ƂȂ��Ō�����Ǝv������
�ǂ����̃X���Řb��ɂȂ������A����?
http://www.google.com/search?sourceid=mozclient&ie=utf-8&oe=utf-8&q=utf8+%E5%A4%89%E6%8F%9B+%E5%85%A8%E8%A7%92%E3%83%9E%E3%82%A4%E3%83%8A%E3%82%B9+%E5%8C%96%E3%81%91%E3%82%8B
�܁A�����Ē��ׂĂ��� ���������[
129 �Fnobody�����F2007/07/31(��) 02:24:36 ID:???
�����@WebProg ���S�҂̎��� Part15�@����
http://pc11.2ch.net/test/read.cgi/php/1169725490/
�����A���Ȃ��B
�[���A���̗v���ł����̃X���Ɩ��W�� str_replace �ōςނ����B
http://pc11.2ch.net/test/read.cgi/php/1169725490/
�����A���Ȃ��B
�[���A���̗v���ł����̃X���Ɩ��W�� str_replace �ōςނ����B
130 �Fnobody�����F2007/08/10(��) 10:21:28 ID:dRcI3VfS
PHP�Ƃ��S���m��Ȃ��҂Ȃ̂ł����A���p���Ă���BBS�̃A�N�Z�X�֎~�ݒ肪
���K�\���Ŏw�肵��ƌ�����ł��B�ܘ_���K�\���͒m��Ȃ��ǂ��납���߂Ď��ɂ��܂����B
a00abcd1.kngwnt01.ap.so-net.ne.jp
123.123.123.123.ap.yournet.ne.jp
�O�҂�IP�����炩�̃R�[�h1�ɕϊ������^�C�v�ƌ�҂�IP�����̂܂o��^�C�v��
�����z�����ꂼ��z�X�g�P�ʂőS�āu���K�\���Ŏw��v����Ƃ���ǂ������\�L�ɂȂ�̂ł��傤�H
���K�\���Ŏw�肵��ƌ�����ł��B�ܘ_���K�\���͒m��Ȃ��ǂ��납���߂Ď��ɂ��܂����B
a00abcd1.kngwnt01.ap.so-net.ne.jp
123.123.123.123.ap.yournet.ne.jp
�O�҂�IP�����炩�̃R�[�h1�ɕϊ������^�C�v�ƌ�҂�IP�����̂܂o��^�C�v��
�����z�����ꂼ��z�X�g�P�ʂőS�āu���K�\���Ŏw��v����Ƃ���ǂ������\�L�ɂȂ�̂ł��傤�H
131 �Fnobody�����F2007/08/10(��) 10:29:11 ID:???
�z�X�g�������Ȃ��Ȃ����Ⴂ����ˁB
(xxx.example1.jp|xxx.example2.jp|xxx.example3.jp)
(xxx.example1.jp|xxx.example2.jp|xxx.example3.jp)
132 �Fnobody�����F2007/08/10(��) 13:25:55 ID:???
���肪�Ƃ��������܂�
�Ȃ�قǁc�ЂƂ��s���|�C���g�Ŏw�肷��ꍇ��
���K�\���Ƃ����̂��g��Ȃ��Ă��ǂ��Ƃ������Ȃ̂ł��傤���c
130�̑O�҂����Ȃ�
a00abcd1.kngwnt01.ap.so-net.ne.jp
�ƁA���̂܂w��A�����̓�Ȃ�
(a00abcd1.kngwnt01.ap.so-net.ne.jp|123.123.123.123.ap.yournet.ne.jp)
�ƂȂ��ł��傤���H
�Ȃ�قǁc�ЂƂ��s���|�C���g�Ŏw�肷��ꍇ��
���K�\���Ƃ����̂��g��Ȃ��Ă��ǂ��Ƃ������Ȃ̂ł��傤���c
130�̑O�҂����Ȃ�
a00abcd1.kngwnt01.ap.so-net.ne.jp
�ƁA���̂܂w��A�����̓�Ȃ�
(a00abcd1.kngwnt01.ap.so-net.ne.jp|123.123.123.123.ap.yournet.ne.jp)
�ƂȂ��ł��傤���H
133 �Fnobody�����F2007/08/10(��) 18:16:54 ID:???
>>132
���̂��̂���Ƃ����̂����K�\���̈�킾��B
�@a00abcd1.kngwnt01.ap.so-net.ne.jp
�Ƃ����̂����K�\������B
���ƍׂ����b�������ƁA�s���I�h�u.�v�͐��K�\���ɂ����ĔC�ӂ�1�����Ƀ}�b�`���郁�^�����Ȃ̂ŁA
�s���I�h���̂��̂Ƀ}�b�`��������(���̕����ɂ̓}�b�`���������Ȃ�)�Ƃ��ɂ́u.�v�̑���Ɂu¥.�v���g���B
�@a00abcd1¥.kngwnt01¥.ap.so-net¥.ne¥.jp
��ł��A���̏ꍇ�͂����܂ł��Ȃ��Ă����͂Ȃ����������ǂˁB
���̂��̂���Ƃ����̂����K�\���̈�킾��B
�@a00abcd1.kngwnt01.ap.so-net.ne.jp
�Ƃ����̂����K�\������B
���ƍׂ����b�������ƁA�s���I�h�u.�v�͐��K�\���ɂ����ĔC�ӂ�1�����Ƀ}�b�`���郁�^�����Ȃ̂ŁA
�s���I�h���̂��̂Ƀ}�b�`��������(���̕����ɂ̓}�b�`���������Ȃ�)�Ƃ��ɂ́u.�v�̑���Ɂu¥.�v���g���B
�@a00abcd1¥.kngwnt01¥.ap.so-net¥.ne¥.jp
��ł��A���̏ꍇ�͂����܂ł��Ȃ��Ă����͂Ȃ����������ǂˁB
134 �Fnobody�����F2007/08/10(��) 22:15:38 ID:???
135 �Fnobody�����F2007/08/11(�y) 01:30:22 ID:2Sf3pkhN
.*
��
.+
�́A���S�ɓ����Ӗ��ƍl���Ă�OK�ł����H
����Ƃ��A�����������ς���Ă��邱�Ƃ͂��肦�܂����H
��
.+
�́A���S�ɓ����Ӗ��ƍl���Ă�OK�ł����H
����Ƃ��A�����������ς���Ă��邱�Ƃ͂��肦�܂����H
136 �Fnobody�����F2007/08/11(�y) 02:02:02 ID:???
.+ 1�����ȏ�̔C�ӂ̕�����
.* 0�����ȏ�̔C�ӂ̕�����
�ōŏ��������Ă܂�����
��ʁc
.* 0�����ȏ�̔C�ӂ̕�����
�ōŏ��������Ă܂�����
��ʁc
137 �F ��xIL6SyuS5U �F2007/08/11(�y) 02:39:04 ID:???
a
138 �Fnobody�����F2007/08/14(��) 22:01:22 ID:???
perl�݊���PHP���K�\��������n�߂��̂ł����A
3.3�ȏ�ɊY������̕�������Ă����̂́A�ł��܂��ł��傤���H
���Ƃ���3.3.4��3.5�A9.0�Ȃǂł��B
�o�[�W�����̂悤�Ȃ��̂ł��B
��͂萔�l�^�łȂ��Ɠ���̂ł��傤���B
3.3�ȏ�ɊY������̕�������Ă����̂́A�ł��܂��ł��傤���H
���Ƃ���3.3.4��3.5�A9.0�Ȃǂł��B
�o�[�W�����̂悤�Ȃ��̂ł��B
��͂萔�l�^�łȂ��Ɠ���̂ł��傤���B
139 �Fnobody�����F2007/08/14(��) 22:20:59 ID:???
�o�[�W�����ԍ���������Đ��l�^�ɂ��Ă��߂�ǂ�������ˁB
3.10.0 �Ƃ��ˁA�^�ʖڂɂ�낤�Ƃ���ƁA
'.' �� split ���āA��̌����珇�ɐ����l�Ƃ��Ĕ�r���Ă����A
�݂����ɂ��Ȃ��Ƃ����Ȃ������肵�āB
3.10.0 �Ƃ��ˁA�^�ʖڂɂ�낤�Ƃ���ƁA
'.' �� split ���āA��̌����珇�ɐ����l�Ƃ��Ĕ�r���Ă����A
�݂����ɂ��Ȃ��Ƃ����Ȃ������肵�āB
140 �Fnobody�����F2007/08/14(��) 23:03:21 ID:???
141 �Fnobody�����F2007/08/15(��) 00:01:44 ID:???
/\A(?:(?:[1-9]\d+|[4-9])(?:\.(?:[1-9]\d*|0))*|3\.(?:[3-9](?:\.(?:[1-9]\d*|0))*))\z/
142 �Fnobody�����F2007/08/15(��) 00:28:29 ID:???
3.10 �� 3.20 ���R���Ă����́H
����{�P���A����B
/\A(?:(?:[1-9]\d+|[4-9])(?:\.(?:[1-9]\d*|0))*|3\.(?:(?:[1-9]\d+|[3-9])(?:\.(?:[1-9]\d*|0))*))\z/
/\A(?:(?:[1-9]\d+|[4-9])(?:\.(?:[1-9]\d*|0))*|3\.(?:(?:[1-9]\d+|[3-9])(?:\.(?:[1-9]\d*|0))*))\z/
144 �Fnobody�����F2007/08/15(��) 22:05:09 ID:???
>>141
���肪�Ɓ[�I������ƌ��Ă݂܂��I
>>142
�����ɂǂ��������l�����蓾��̂���������Ȃ��̂ł����܂ōׂ������Ȃ��Ă��������ȂƂ��������ł��B
�o�[�W�����Ƃ������A���[�U�[�G�[�W�F���g�̌�ɂ悭���Ă��鐔�l�Ȃ�ł����B
���肪�Ɓ[�I������ƌ��Ă݂܂��I
>>142
�����ɂǂ��������l�����蓾��̂���������Ȃ��̂ł����܂ōׂ������Ȃ��Ă��������ȂƂ��������ł��B
�o�[�W�����Ƃ������A���[�U�[�G�[�W�F���g�̌�ɂ悭���Ă��鐔�l�Ȃ�ł����B
145 �Fnobody�����F2007/09/01(�y) 14:16:44 ID:tMwZKBAJ
"*"��Web�Œ��ׂ�Ɓu���O�̕����O��ȏ�̌J��Ԃ��Ƀ}�b�`�v�ƂłĂ���B
UNIX��
% ls
a0/ a1/ a2/
�̂Ƃ�
% cd *1
���ł��邯��*�͉��̌J��Ԃ��H�H�H
*�͉��ł��}�b�`�Ǝv���Ă����̂͊ԈႢ�ł����H�H�H
UNIX��
% ls
a0/ a1/ a2/
�̂Ƃ�
% cd *1
���ł��邯��*�͉��̌J��Ԃ��H�H�H
*�͉��ł��}�b�`�Ǝv���Ă����̂͊ԈႢ�ł����H�H�H
146 �Fnobody�����F2007/09/01(�y) 15:26:18 ID:epTGamb+
>>145
Perl�݊��̐��K�\���ł� �*� �͗ʎw��q�Ƃ������̂̈��ł���܂��Ĥ ����� �����N���X� �O���[�v�̒���ɕt���
������0��ȏ�̌J��Ԃ��Ƃ����Ӗ�����������̂ł���� ���K�\���̌n���Ⴆ�� �*� ���Ⴄ���Ƃ��Ӗ����邱�Ƃ�����܂��傤�
Perl�݊��̐��K�\���ł� �*� �͗ʎw��q�Ƃ������̂̈��ł���܂��Ĥ ����� �����N���X� �O���[�v�̒���ɕt���
������0��ȏ�̌J��Ԃ��Ƃ����Ӗ�����������̂ł���� ���K�\���̌n���Ⴆ�� �*� ���Ⴄ���Ƃ��Ӗ����邱�Ƃ�����܂��傤�
147 �Fnobody�����F2007/09/01(�y) 15:34:18 ID:epTGamb+
�v����ɤ ���K�\���̌n���Ⴆ�L���̈Ӗ����قȂ�Ƃ������Ƃł��
148 �Fnobody�����F2007/09/01(�y) 15:58:40 ID:tMwZKBAJ
149 �Fnobody�����F2007/09/01(�y) 16:54:59 ID:fGUplrri
[2ch�����L��]
��u�A�n�[�o�[���C�t�ƊԈႦ��Ƃ��낾�����B�B
�Ⴄ��A�R���́B
���t�I�N�֘A�̍ŋ����
�����m�炸���āA���t�I�N�ʼn҂����Ƃ͏o���Ȃ��B�i�L�b�p���j
http://2ch2.net/.l?=jd2e
��u�A�n�[�o�[���C�t�ƊԈႦ��Ƃ��낾�����B�B
�Ⴄ��A�R���́B
���t�I�N�֘A�̍ŋ����
�����m�炸���āA���t�I�N�ʼn҂����Ƃ͏o���Ȃ��B�i�L�b�p���j
http://2ch2.net/.l?=jd2e
150 �Fnobody�����F2007/09/02(��) 03:27:50 ID:???
151 �Fnobody�����F2007/09/02(��) 03:54:38 ID:???
152 �Fnobody�����F2007/09/02(��) 09:50:38 ID:RtluGpKC
192.168.50.5 //OK
192.168.*.* //OK
1000.1000.1000.1000/OK
*.168.50.5 //NG
(\d+)(\.([*(\d+)])){3}
�Ȃ�����Ń_���H
192.168.*.* //OK
1000.1000.1000.1000/OK
*.168.50.5 //NG
(\d+)(\.([*(\d+)])){3}
�Ȃ�����Ń_���H
153 �Fnobody�����F2007/09/02(��) 11:04:51 ID:tGLa/mAn
154 �Fnobody�����F2007/09/02(��) 11:20:25 ID:tGLa/mAn
>>152
> (\d+)(\.([*(\d+)])){3}
����͐��������� ���̌�s���I�h�� �*�� �(�� ����� �)�� �+� �̂ǂꂩ�̑g��3��J��Ԃ�������Q�̕\���ł��
> *.168.50.5
����͐����̌� �s���I�h�� �*�� �(�� ����� �)�� �+� �̂ǂꂩ�̑g��2���J��Ԃ��Ă��Ȃ��̂Ť
��قǂ̐��K�\���Ƀ}�b�`���܂���
> (\d+)(\.([*(\d+)])){3}
����͐��������� ���̌�s���I�h�� �*�� �(�� ����� �)�� �+� �̂ǂꂩ�̑g��3��J��Ԃ�������Q�̕\���ł��
> *.168.50.5
����͐����̌� �s���I�h�� �*�� �(�� ����� �)�� �+� �̂ǂꂩ�̑g��2���J��Ԃ��Ă��Ȃ��̂Ť
��قǂ̐��K�\���Ƀ}�b�`���܂���
155 �Fnobody�����F2007/09/02(��) 11:40:01 ID:tGLa/mAn
���� �҂��Ă��������
> (\d+)(\.([*(\d+)])){3}
���Ƥ
> 192.168.50.5
> 192.168.*.*
> 1000.1000.1000.1000
> *.168.50.5
�̂��ׂĂɃ}�b�`���Ȃ��͂��ł�� ��ق�
> ����͐��������� ���̌�s���I�h�� �*�� �(�� ����� �)�� �+� �̂ǂꂩ�̑g��3��J��Ԃ�������Q�̕\���ł��
�Ɛ\���܂������ ��萳�m�ɂͤ
� ������1�ȏ゠�� ���̌�s���I�h�� �*�� �(�� ����1�¤ �)�� �+� �̂ǂꂩ�̑g��3��J��Ԃ�������Q�̕\��
�ł���܂��Ĥ
> 192.168.50.5
> 192.168.*.*
> 1000.1000.1000.1000
> *.168.50.5
�̂ǂ�����̂悤�ȕ�����ł͂Ȃ�����ł��
> (\d+)(\.([*(\d+)])){3}
���Ƥ
> 192.168.50.5
> 192.168.*.*
> 1000.1000.1000.1000
> *.168.50.5
�̂��ׂĂɃ}�b�`���Ȃ��͂��ł�� ��ق�
> ����͐��������� ���̌�s���I�h�� �*�� �(�� ����� �)�� �+� �̂ǂꂩ�̑g��3��J��Ԃ�������Q�̕\���ł��
�Ɛ\���܂������ ��萳�m�ɂͤ
� ������1�ȏ゠�� ���̌�s���I�h�� �*�� �(�� ����1�¤ �)�� �+� �̂ǂꂩ�̑g��3��J��Ԃ�������Q�̕\��
�ł���܂��Ĥ
> 192.168.50.5
> 192.168.*.*
> 1000.1000.1000.1000
> *.168.50.5
�̂ǂ�����̂悤�ȕ�����ł͂Ȃ�����ł��
156 �Fnobody�����F2007/09/02(��) 12:28:15 ID:???
\.
157 �Fnobody�����F2007/09/02(��) 13:10:37 ID:???
�ǂ���1000���������Ęb�Ȃ낤���ǁA0����255�܂ł�
�����������}�b�`���鐳�K�\�����Ăނ����ˁH
[0-9]|[12][0-2]?[0-9]|[12]?[34][0-9]|1?[5-9][0-9]|25[0-5]
�Ƃ�
[0-9]|1[0-9][0-9]?|2[0-4]?[0-9]|[3-9][0-9]|25[0-5]
�Ƃ�
�����������}�b�`���鐳�K�\�����Ăނ����ˁH
[0-9]|[12][0-2]?[0-9]|[12]?[34][0-9]|1?[5-9][0-9]|25[0-5]
�Ƃ�
[0-9]|1[0-9][0-9]?|2[0-4]?[0-9]|[3-9][0-9]|25[0-5]
�Ƃ�
158 �Fnobody�����F2007/09/02(��) 19:09:05 ID:???
PHP��Perl�݊��̐��K�\���̂��ƂŎ���ł��B
���̂悤�ȕ��͂��������Ƃ��܂��B
���͍̂s�ԍ��ŁA���ۂ̕��͒��ɂ͂���܂���B
01.<div>
02.text
03.<img>
04.</div>
05.
06.<div>
07.text1
08.text2
09.</div>
10.
11.<div>
12.hoge
13.<img>
14.</div>
���Ȃ݂Ƀh�b�g�͉��s�ɂ��}�b�`����悤�ɂ��Ă����܂��B
����ɑ��ăp�^�[���u<div>\n(.+)\n</div>�v���ŏ��}�b�`������ƁA
�T�u�p�^�[����02,03��07,08��12,13��17,18,19,20�s�ڂ����ꂼ�ꂫ����ƃ}�b�`���Ă�����ł����A
���x��<img>���܂�div�������}�b�`�����悤�Ƃ��āA�u<div>\n(.+\n<img>)\n<div>�v�ōŏ��}�b�`��������ƁA
02,03��07,08,09,10,11,12,13�s�ڂɃ}�b�`���Ă��܂��܂��B
������02,03��12,13�s�ڂ����Ƀ}�b�`������ɂ͂ǂ���������̂ł��傤���H
���낢��l�����̂ł����悭�킩��܂���B
�ǂȂ�����낵�����肢���܂��B
���̂悤�ȕ��͂��������Ƃ��܂��B
���͍̂s�ԍ��ŁA���ۂ̕��͒��ɂ͂���܂���B
01.<div>
02.text
03.<img>
04.</div>
05.
06.<div>
07.text1
08.text2
09.</div>
10.
11.<div>
12.hoge
13.<img>
14.</div>
���Ȃ݂Ƀh�b�g�͉��s�ɂ��}�b�`����悤�ɂ��Ă����܂��B
����ɑ��ăp�^�[���u<div>\n(.+)\n</div>�v���ŏ��}�b�`������ƁA
�T�u�p�^�[����02,03��07,08��12,13��17,18,19,20�s�ڂ����ꂼ�ꂫ����ƃ}�b�`���Ă�����ł����A
���x��<img>���܂�div�������}�b�`�����悤�Ƃ��āA�u<div>\n(.+\n<img>)\n<div>�v�ōŏ��}�b�`��������ƁA
02,03��07,08,09,10,11,12,13�s�ڂɃ}�b�`���Ă��܂��܂��B
������02,03��12,13�s�ڂ����Ƀ}�b�`������ɂ͂ǂ���������̂ł��傤���H
���낢��l�����̂ł����悭�킩��܂���B
�ǂȂ�����낵�����肢���܂��B
159 �Fnobody�����F2007/09/02(��) 19:35:53 ID:/HflMMhV
��
�����܂���
�u02,03��07,08��12,13��17,18,19,20�s�ڂ����ꂼ�ꂫ����ƃ}�b�`���Ă����v��
02,03��07,08��12,13�̊ԈႢ�ł���
�����܂���
�u02,03��07,08��12,13��17,18,19,20�s�ڂ����ꂼ�ꂫ����ƃ}�b�`���Ă����v��
02,03��07,08��12,13�̊ԈႢ�ł���
160 �Fnobody�����F2007/09/02(��) 20:08:53 ID:???
�����܂��ȉ������܂���
�u<div>\n((?:[^<]|<(?!div))+\n<img>)\n<div>�v
����ł������ł���
�u<div>\n((?:[^<]|<(?!div))+\n<img>)\n<div>�v
����ł������ł���
161 �Fnobody�����F2007/09/04(��) 05:14:07 ID:p30GnV0e
IP�A�h���X�̐��K�\���ɂ��Ă���ς�킩��Ȃ������ł��B
2�I�N�e�b�h�ڈȍ~��*�����Ă�OK�Ƃ���ɂ͂ǂ�����悢�ł��傤���H
192.168.50.*
192.168.*.*
192.*.*.*
192.168.50.5
1000.1000.1000.1000
�����͂��ׂ�OK�Ƃ��܂��B
2�I�N�e�b�h�ڈȍ~��*�����Ă�OK�Ƃ���ɂ͂ǂ�����悢�ł��傤���H
192.168.50.*
192.168.*.*
192.*.*.*
192.168.50.5
1000.1000.1000.1000
�����͂��ׂ�OK�Ƃ��܂��B
162 �Fnobody�����F2007/09/04(��) 09:42:52 ID:???
>>161
> 2�I�N�e�b�h�ڈȍ~��*�����Ă�OK�Ƃ���ɂ͂ǂ�����悢�ł��傤���H
�����Ɍ�����I
�ǂ��������ʂ��~�����āA�ǂ���������A�ǂ��_�����������A����̓I�ɏ�����ƁB
���ƁA�g�p���Ă鏈���n (�����\�t�g�E�F�A) ���B
�ŁA�_�����������K�\������ [*(\d+)] �����ǁA
[] �́u�����N���X�v�̐��K�\���Ȃ̂ŁA
>>154 �̌����Ă���悤�� * ( ���� + ) �̂����ꂩ�́u�����v��\���B
�u* �܂��͐����v��\���������̂ł���A (\*|\d+) �݂����ɂ���B
�̂ŁA�������ȁB
(\d+)(\.(\*|\d+)){3}
> 2�I�N�e�b�h�ڈȍ~��*�����Ă�OK�Ƃ���ɂ͂ǂ�����悢�ł��傤���H
�����Ɍ�����I
�ǂ��������ʂ��~�����āA�ǂ���������A�ǂ��_�����������A����̓I�ɏ�����ƁB
���ƁA�g�p���Ă鏈���n (�����\�t�g�E�F�A) ���B
�ŁA�_�����������K�\������ [*(\d+)] �����ǁA
[] �́u�����N���X�v�̐��K�\���Ȃ̂ŁA
>>154 �̌����Ă���悤�� * ( ���� + ) �̂����ꂩ�́u�����v��\���B
�u* �܂��͐����v��\���������̂ł���A (\*|\d+) �݂����ɂ���B
�̂ŁA�������ȁB
(\d+)(\.(\*|\d+)){3}
163 �Fnobody�����F2007/09/04(��) 11:21:03 ID:/G1gxUUQ
$` �i�}�b�`����������̑O�ɂ��邷�ׂĂ̕����� �j
������̎g�����������Ă��������B�����Perl�ł��B
������̎g�����������Ă��������B�����Perl�ł��B
164 �Fnobody�����F2007/09/04(��) 11:29:12 ID:???
>>163
"hoge" =~ /og/;
print join(",", $`, $&, $'), "\n";
������Ȋ����ŁA���̏ꍇ�� "hoge" �ɑ��� "og" ���}�b�`����̂ŁA
$`, $&, $' �ɂ͂��ꂼ�� "og" �̑O�� "h", "og", "og" �̌��� "e" ���i�[�����B
"hoge" =~ /og/;
print join(",", $`, $&, $'), "\n";
������Ȋ����ŁA���̏ꍇ�� "hoge" �ɑ��� "og" ���}�b�`����̂ŁA
$`, $&, $' �ɂ͂��ꂼ�� "og" �̑O�� "h", "og", "og" �̌��� "e" ���i�[�����B
165 �Fnobody�����F2007/09/04(��) 11:54:02 ID:/G1gxUUQ
>>164
�ł��܂����B���肪�Ƃ��������܂��B
�ł��܂����B���肪�Ƃ��������܂��B
166 �Fnobody�����F2007/09/09(��) 01:04:12 ID:???
***.com�i[0-9]��������[a-z]�̕�����3���сA���̌��.com)�̕\�L���@�������Ă�������
167 �Fnobody�����F2007/09/10(��) 21:26:12 ID:lrmAiBXN
168 �Fnobody�����F2007/09/12(��) 05:01:53 ID:???
>>166
\w{3}\.com
\w{3}\.com
169 �Fnobody�����F2007/09/12(��) 11:22:48 ID:DkIOyoGe
>>168
���ꂾ�Ƒ啶���ƃA���_�[�X�R�A�ɂ��}�b�`���Ă��܂��܂��
���ꂾ�Ƒ啶���ƃA���_�[�X�R�A�ɂ��}�b�`���Ă��܂��܂��
170 �Fnobody�����F2007/09/15(�y) 15:32:58 ID:???
<title>�ق��ق�</title>
�́u�ق��ق��v�������o���̂ɂ͂ǂ��\�L��������̂ł��傤���H
�́u�ق��ق��v�������o���̂ɂ͂ǂ��\�L��������̂ł��傤���H
171 �Fnobody�����F2007/09/15(�y) 16:48:18 ID:???
/<title>([^<]+)<\/title>/
172 �Fnobody�����F2007/09/15(�y) 17:17:54 ID:???
>>171
���肪�Ƃ��������܂��B
���肪�Ƃ��������܂��B
173 �Fnobody�����F2007/09/16(��) 01:35:56 ID:6P4HpCmY
PHP 4.4.7��
hoge
hage
123.txt
�̒����� 123 ���o����������
"/^(.+?).txt/"
���Ɠ��R
hoge
hage
123
���}�b�`���Ă��܂��B
hoge �� hage �͔C�ӂ̕�����Ő���������\��������̂����ǁA�ǂ�����Ē��o�����炢����ł��傤�B
hoge
hage
123.txt
�̒����� 123 ���o����������
"/^(.+?).txt/"
���Ɠ��R
hoge
hage
123
���}�b�`���Ă��܂��B
hoge �� hage �͔C�ӂ̕�����Ő���������\��������̂����ǁA�ǂ�����Ē��o�����炢����ł��傤�B
�}�b�`�����������
strrev()
�ŋt���ɂ��āA���x��
txt. �ōēx�}�b�`���O��������Ƃ肠�������o�ł��܂����B�����������x�t���ɁB
����ȗ͋Ƃ���Ȃ��đ��ɕ��@������낤�ȁc�c�B
strrev()
�ŋt���ɂ��āA���x��
txt. �ōēx�}�b�`���O��������Ƃ肠�������o�ł��܂����B�����������x�t���ɁB
����ȗ͋Ƃ���Ȃ��đ��ɕ��@������낤�ȁc�c�B
175 �Fnobody�����F2007/09/16(��) 02:19:07 ID:???
^^
176 �Fnobody�����F2007/09/16(��) 03:52:16 ID:vOvwrq99
>>173
�O��Ƀf���~�^ (�/�) ���t���Ă���Ƃ�������Perl�݊��̐��K�\�������g���̂ł���܂��傤���
�����ł���� �.� ��s�C���q���Ȃ�������s�Ƀ}�b�`����� �����
/^(.+?).txt/
��
hoge
hage
123.txt
�Ƀ}�b�`����� ����������
hoge
hage
123
���L���v�`������邱�Ƃ͂Ȃ��͂��ł��
�O��Ƀf���~�^ (�/�) ���t���Ă���Ƃ�������Perl�݊��̐��K�\�������g���̂ł���܂��傤���
�����ł���� �.� ��s�C���q���Ȃ�������s�Ƀ}�b�`����� �����
/^(.+?).txt/
��
hoge
hage
123.txt
�Ƀ}�b�`����� ����������
hoge
hage
123
���L���v�`������邱�Ƃ͂Ȃ��͂��ł��
177 �Fnobody�����F2007/09/16(��) 12:32:40 ID:???
>>173
�܂��Ƃɂ����u�}�b�`���Ă��܂��v�Ƃ��������̃R�[�h���N���Ă݁B
�܂��Ƃɂ����u�}�b�`���Ă��܂��v�Ƃ��������̃R�[�h���N���Ă݁B
178 �Fnobody�����F2007/09/16(��) 13:59:22 ID:G/qusHMm
$bairitsu = 0.5;�Ƃ�������$bairitsu�ɔ{�������Ă�����
height:244pt �� height:122pt�c
height:244pt �� height="150"��
�Ƃ��������height:����pt��height="����"�̐��l������
$bairitsu�{���Ēu������ɂ͂ǂ̂悤�ɂ�������ł����ˁH
��낤�Ƃ��Ă邱�Ƃ́A�G�N�Z���ō����HTML�ŕۑ��������̂��A
A4�T�C�Y�̗p���ɍ����悤��HTML�̒��ɂ���T�C�Y�w���ύX�������ł��B
�g�p�����Perl�ł��B��낵�����肢���܂��B
height:244pt �� height:122pt�c
height:244pt �� height="150"��
�Ƃ��������height:����pt��height="����"�̐��l������
$bairitsu�{���Ēu������ɂ͂ǂ̂悤�ɂ�������ł����ˁH
��낤�Ƃ��Ă邱�Ƃ́A�G�N�Z���ō����HTML�ŕۑ��������̂��A
A4�T�C�Y�̗p���ɍ����悤��HTML�̒��ɂ���T�C�Y�w���ύX�������ł��B
�g�p�����Perl�ł��B��낵�����肢���܂��B
179 �F173�F2007/09/16(��) 15:18:36 ID:6P4HpCmY
>>175
����́c�c�q���g�H�@����Ƃ�AA�H
>>176
����B�p�^�[�����s���ɂ�����s���ɂ�������s�����ɂ����肵�Ă邤���ɂ��炩���Ă��܂����݂����B
���m�ɂ�
"/^(.+?).txt/"
�Ń}�b�`���܂����B
>>177
�R�[�h�I�ɂ͂���Ȋ����B
$string = "
hoge
hage
123.txt
";
preg_match("/^(.+?).txt/", $string, $matches);
preg_match("/txt.(.*?)\r/", strrev($matches[0]), $matches);
echo strrev($matches[1]);
// ���� 123
PHP�����K�\�������S�҂Ȃ̂ŕςȏ��������Ă邩�������ǁc�c�B
����́c�c�q���g�H�@����Ƃ�AA�H
>>176
����B�p�^�[�����s���ɂ�����s���ɂ�������s�����ɂ����肵�Ă邤���ɂ��炩���Ă��܂����݂����B
���m�ɂ�
"/^(.+?).txt/"
�Ń}�b�`���܂����B
>>177
�R�[�h�I�ɂ͂���Ȋ����B
$string = "
hoge
hage
123.txt
";
preg_match("/^(.+?).txt/", $string, $matches);
preg_match("/txt.(.*?)\r/", strrev($matches[0]), $matches);
echo strrev($matches[1]);
// ���� 123
PHP�����K�\�������S�҂Ȃ̂ŕςȏ��������Ă邩�������ǁc�c�B
����H���m�ɂ͂������ŏ��ɏ������̂ł����Ă�Ȃ��B
�Ȃ�Łu�}�b�`���Ă��܂��v�̂��낤�B
�Ȃ�Łu�}�b�`���Ă��܂��v�̂��낤�B
181 �Fnobody�����F2007/09/16(��) 21:38:24 ID:YMkvDZNb
>>179
����� ���s�R�[�h��CR�ɂ��Ă���̂ł��ˡ
����
> �.� ��s�C���q���Ȃ�������s�Ƀ}�b�`����
�Ɛ\���܂������ ���m�ɂ� �LF�Ƀ}�b�`����� �ł���܂��Ĥ CR�ɂ̓}�b�`���܂��
���ʂ̓X�N���v�g�̓����ł͕�����̉��s�R�[�h��LF�ɂ�����̂ł����
�������R��������CR�ɂ��Ă���̂ł����
����� ���s�R�[�h��CR�ɂ��Ă���̂ł��ˡ
����
> �.� ��s�C���q���Ȃ�������s�Ƀ}�b�`����
�Ɛ\���܂������ ���m�ɂ� �LF�Ƀ}�b�`����� �ł���܂��Ĥ CR�ɂ̓}�b�`���܂��
���ʂ̓X�N���v�g�̓����ł͕�����̉��s�R�[�h��LF�ɂ�����̂ł����
�������R��������CR�ɂ��Ă���̂ł����
182 �Fnobody�����F2007/09/16(��) 21:48:57 ID:YMkvDZNb
���s�R�[�h��LF�Ȃ� m�C���q���g�����Ƃɂ�� �^� ���s���Ƀ}�b�`����悤�ɂȂ�̂ł��
183 �F173�F2007/09/17(��) 00:37:12 ID:/5o1hJUZ
>>181
> �Ɛ\���܂������ ���m�ɂ� �LF�Ƀ}�b�`����� �ł���܂��Ĥ CR�ɂ̓}�b�`���܂��
���[�A�����������Ȃ̂��c�c�B
���ɂȂ�܂��B
> �������R��������CR�ɂ��Ă���̂ł����
���͂������܂����`���œ��e�����e�L�X�g���e�����܂����`����HTML�ɂ��邾���̎d��������œ����Ă����ł��B
�ŁA����R�s�y�ɂ��R�s�y�őΉ���������̂��o�J�������̂ŋɗ͎��������悤�Ǝv���APHP�ŃV�R�V�R�����Ă��鎟��B
���̃v���O�����ɐH�킹�邨�q����̓��e���e�����ɍ���Ă��̂�CR�ɂȂ��Ă܂����B
�����ɉ��s�R�[�h��LF�ɂ���m�C���q�Ƃ����̂��������炤�܂������܂����B
�Ȃ�قǂ���������e��LF�ɕϊ����Ă���g�������킯���ȁB
���肪�Ɓ[�������܂����I
> �Ɛ\���܂������ ���m�ɂ� �LF�Ƀ}�b�`����� �ł���܂��Ĥ CR�ɂ̓}�b�`���܂��
���[�A�����������Ȃ̂��c�c�B
���ɂȂ�܂��B
> �������R��������CR�ɂ��Ă���̂ł����
���͂������܂����`���œ��e�����e�L�X�g���e�����܂����`����HTML�ɂ��邾���̎d��������œ����Ă����ł��B
�ŁA����R�s�y�ɂ��R�s�y�őΉ���������̂��o�J�������̂ŋɗ͎��������悤�Ǝv���APHP�ŃV�R�V�R�����Ă��鎟��B
���̃v���O�����ɐH�킹�邨�q����̓��e���e�����ɍ���Ă��̂�CR�ɂȂ��Ă܂����B
�����ɉ��s�R�[�h��LF�ɂ���m�C���q�Ƃ����̂��������炤�܂������܂����B
�Ȃ�قǂ���������e��LF�ɕϊ����Ă���g�������킯���ȁB
���肪�Ɓ[�������܂����I
184 �Fnobody�����F2007/09/17(��) 01:05:58 ID:T68tRmUw
����1�w�E���܂��Ƥ �.txt� �� �\.txt� �ɂ��ׂ��ł��ˡ
185 �F173�F2007/09/17(��) 15:37:44 ID:/5o1hJUZ
> ����1�w�E���܂��Ƥ �.txt� �� �\.txt� �ɂ��ׂ��ł��ˡ
���[�Ȃ�قǁB���肪�Ƃ��������܂��B
���[�Ȃ�قǁB���肪�Ƃ��������܂��B
186 �Fnobody�����F2007/09/18(��) 14:10:13 ID:hpuf++fz
Perl���g���āA�A�t�B���G�C�g�̃R�[�h��JavaScript�Ȃǂ��܂ރR�����g�^�O���Ȃ����폜�ł��܂���B
��j
<!--
�@�R�[�h
�@�@�E
�@�@�E
-->
HTML�^�O�� s/<.*?>//sg; �Ƃ���폜�ł��܂���
�Ȃ����R�����g�^�O�������c���Ă��܂��܂��B
�R�����g�^�O�̊J�n�u<�v�ƏI���u>�v�ȊO�̑S�Ă̕�����E�L���E���s�R�[�h���폜����������
s/<>//g; �Ƃ��Ă݂܂������폜���邱�Ƃ��ł��܂���B
s/<//g;
s/>//g;
�Ƃ���ƂȂ����폜�ł��܂��B
���܂��폜�ł�����@�������m�̕��������狳���ĉ������B
��j
<!--
�@�R�[�h
�@�@�E
�@�@�E
-->
HTML�^�O�� s/<.*?>//sg; �Ƃ���폜�ł��܂���
�Ȃ����R�����g�^�O�������c���Ă��܂��܂��B
�R�����g�^�O�̊J�n�u<�v�ƏI���u>�v�ȊO�̑S�Ă̕�����E�L���E���s�R�[�h���폜����������
s/<>//g; �Ƃ��Ă݂܂������폜���邱�Ƃ��ł��܂���B
s/<//g;
s/>//g;
�Ƃ���ƂȂ����폜�ł��܂��B
���܂��폜�ł�����@�������m�̕��������狳���ĉ������B
187 �Fnobody�����F2007/09/18(��) 16:31:55 ID:???
�O�����Ƃ��Ă܂� s/<!--.*?-->//gs ����Ă݂���H
�R�����g�^�O�̃l�X�g�͂Ȃ����낤���iJavaScript�Ƃ��ŏ����o���Ă���ʂ����ǁE�E�j
�R�����g�^�O�̃l�X�g�͂Ȃ����낤���iJavaScript�Ƃ��ŏ����o���Ă���ʂ����ǁE�E�j
188 �Fnobody�����F2007/09/19(��) 07:54:55 ID:???
>>187
���X�ǂ������肪�Ƃ��B
s/<!--.*?-->//gs�ł��Ȃ������܂������Ȃ��̂�
�R�����g�s�����ꂽ��if���ŃX���[����悤�ɂ��܂����B
���X�ǂ������肪�Ƃ��B
s/<!--.*?-->//gs�ł��Ȃ������܂������Ȃ��̂�
�R�����g�s�����ꂽ��if���ŃX���[����悤�ɂ��܂����B
189 �Fnobody�����F2007/09/19(��) 21:54:47 ID:???
PHP�Ő��K�\������������ł����A�I���C���[�̂ӂ��낤�{��ǂ߂�ł��傤���H
�������{�l�̋Z�ʂɂ����Ǝv���܂����APerl���܂������m��Ȃ��l�Ԃ��Ƃ������߂ł��肢���܂��B
�t�ɕ��������������Ȃ�APerl���ꂩ�����Ƃ��݂����Ȃ̂�����ł��B
�������{�l�̋Z�ʂɂ����Ǝv���܂����APerl���܂������m��Ȃ��l�Ԃ��Ƃ������߂ł��肢���܂��B
�t�ɕ��������������Ȃ�APerl���ꂩ�����Ƃ��݂����Ȃ̂�����ł��B
190 �Fnobody�����F2007/09/20(��) 00:20:26 ID:???
>>189
preg_.*�n���Ȃ�Perl�݊��Ȃ̂łӂ��낤�{�̋L�q���g����Ǝv���B
�Ƃ������ˁA�ӂ��낤�{�̃L���͏����n�ɂقƂ�Ljˑ����Ȃ�3�͂�4�͂ŁA
����ȊO�͂��܂����B�n�ǂ��ׂ��B
preg_.*�n���Ȃ�Perl�݊��Ȃ̂łӂ��낤�{�̋L�q���g����Ǝv���B
�Ƃ������ˁA�ӂ��낤�{�̃L���͏����n�ɂقƂ�Ljˑ����Ȃ�3�͂�4�͂ŁA
����ȊO�͂��܂����B�n�ǂ��ׂ��B
191 �Fnobody�����F2007/09/20(��) 01:57:42 ID:???
���肪�Ƃ��B���������v����čw�������B��O�ŏo��݂�������
192 �Fnobody�����F2007/09/20(��) 02:42:28 ID:???
193 �Fnobody�����F2007/09/20(��) 13:36:17 ID:KlmMrt1+
<TD width="52" height="25" bordercolor="#CCCCCC" valign="middle">
<div align="center">F8FA</div>
</TD>
�����
�uF8FA�v�̕�����preg_match_all�擾�������̂ł����A
'/<TD .*><div .*>(.*)</div><\/TD>/Ums'
�Ƃ����̂ł����A�����擾����܂���B
�ǂ̂悤�ɕ\�L����Ηǂ��̂ł��傤���H
<div align="center">F8FA</div>
</TD>
�����
�uF8FA�v�̕�����preg_match_all�擾�������̂ł����A
'/<TD .*><div .*>(.*)</div><\/TD>/Ums'
�Ƃ����̂ł����A�����擾����܂���B
�ǂ̂悤�ɕ\�L����Ηǂ��̂ł��傤���H
194 �Fnobody�����F2007/09/20(��) 13:42:18 ID:???
/<TD.*?><div.*?>(.*)?</div><\/TD>/
����Ȋ����H
����Ȋ����H
195 �Fnobody�����F2007/09/20(��) 13:44:34 ID:???
�����ĂȂ����ǂЂƂ܂��p�b�ƌ��ł����������Ȃ̂��Ƃ����H
'/<TD .*>\s*<div .*>(.*)<\/div>\s*<\/TD>/Ums'
'/<TD .*>\s*<div .*>(.*)<\/div>\s*<\/TD>/Ums'
196 �Fnobody�����F2007/09/20(��) 17:00:54 ID:SqIRO2nC
'#<TD(?:\s[^>]*)?>\s*<div(?:\s[^>]*)?>(.*)</div>\s*</TD>#ms'
197 �Fnobody�����F2007/09/20(��) 19:58:25 ID:???
>>193
���K�\���͓��o�Ă邩�玟����N�����������o�邩�ȂƂ����\�z���݂����Ǐo�Ȃ�������o�Ȃ��̂��^�C�~���O���ȂƁB
���K�\���͓��o�Ă邩�玟����N�����������o�邩�ȂƂ����\�z���݂����Ǐo�Ȃ�������o�Ȃ��̂��^�C�~���O���ȂƁB
198 �Fnobody�����F2007/09/20(��) 22:27:42 ID:???
>>197
���{��ł���
���{��ł���
199 �Fnobody�����F2007/09/20(��) 23:09:32 ID:???
>>198
����!�����{��
����!�����{��
200 �Fnobody�����F2007/09/21(��) 00:43:48 ID:???
>>191
�\�[�X�́H
�\�[�X�́H
201 �Fnobody�����F2007/10/02(��) 19:12:55 ID:DsttFroa
PHP�̐��K�\���Ń��[�U�[�G�[�W�F���g(IE����)����
�u���E�U�o�[�W������OS�̃o�[�W�������擾���邽��
�ȉ����쐬���܂���
preg_match('/Mozilla\/.*(MSIE [0-9\.]+);.*(Win[^;\)]+|Mac[^;\)]+).*/i', $lua, $match)
�قڊԈႢ�Ȃ��擾�ł���̂ł����B��ȉ��`���̃G�[�W�F���g�̂�
���s���܂�
Mozilla/4.0 (compatible; MSIE 5.0; Windows 98; Yahoo! JAPAN Version Windows 95/NT CD-ROM Edition 1.0.; DigExt)
�Â��o�[�W�����Ȃ̂Ő�̂ĂĂ��ǂ��Ƃ͎v���̂ł����������̂�
�ǂ�����ΐ������擾�ł��邩�����Ă��������Ȃ��ł��傤���H
��L�̐��K�\���ł�
MSIE 5.0
Windows 95/NT CD-ROM Edition 1.0.
�ق����͈̂ȉ�
MSIE 5.0
Windows 98
�u���E�U�o�[�W������OS�̃o�[�W�������擾���邽��
�ȉ����쐬���܂���
preg_match('/Mozilla\/.*(MSIE [0-9\.]+);.*(Win[^;\)]+|Mac[^;\)]+).*/i', $lua, $match)
�قڊԈႢ�Ȃ��擾�ł���̂ł����B��ȉ��`���̃G�[�W�F���g�̂�
���s���܂�
Mozilla/4.0 (compatible; MSIE 5.0; Windows 98; Yahoo! JAPAN Version Windows 95/NT CD-ROM Edition 1.0.; DigExt)
�Â��o�[�W�����Ȃ̂Ő�̂ĂĂ��ǂ��Ƃ͎v���̂ł����������̂�
�ǂ�����ΐ������擾�ł��邩�����Ă��������Ȃ��ł��傤���H
��L�̐��K�\���ł�
MSIE 5.0
Windows 95/NT CD-ROM Edition 1.0.
�ق����͈̂ȉ�
MSIE 5.0
Windows 98
202 �Fnobody�����F2007/10/02(��) 19:26:37 ID:???
m#(MSIE\D*[\d\.]+).*?((?:Win|Mac)\D+\d+)#
����ȕ��łǂ��H
����ȕ��łǂ��H
203 �Fnobody�����F2007/10/02(��) 19:34:02 ID:DsttFroa
204 �Fnobody�����F2007/10/05(��) 23:08:47 ID:ivRnBDKk
����ł�
$text = "��41���@[����]�́A[����]�̍ō��@�ւł��āA���̗B���[���@�@��]�ł���B";
�Ƃ����e�L�X�g��[]�ł�����ꂽ�����������G���W���ɔ�����߂̃����N�ɏ��������邽�߂̒u���������s�������ƍl���Ă��܂��B
�����ʼn��̂悤�ɑg��ł݂��Ƃ���
$text =~ s/\[(.*)\]/(<a href=\/http:\/\/foo.bar?query=\"$1\">$1<\/a>)/;
�u���̑ΏۂƂȂ�J�b�R�͍s�̐擪��[����s�̍Ō��]�܂ł��ΏۂƂȂ��Ă��܂��B��肭�@�\���܂���B
���̒u�������͂ǂ������A�����̂ł��傤���H
$text = "��41���@[����]�́A[����]�̍ō��@�ւł��āA���̗B���[���@�@��]�ł���B";
�Ƃ����e�L�X�g��[]�ł�����ꂽ�����������G���W���ɔ�����߂̃����N�ɏ��������邽�߂̒u���������s�������ƍl���Ă��܂��B
�����ʼn��̂悤�ɑg��ł݂��Ƃ���
$text =~ s/\[(.*)\]/(<a href=\/http:\/\/foo.bar?query=\"$1\">$1<\/a>)/;
�u���̑ΏۂƂȂ�J�b�R�͍s�̐擪��[����s�̍Ō��]�܂ł��ΏۂƂȂ��Ă��܂��B��肭�@�\���܂���B
���̒u�������͂ǂ������A�����̂ł��傤���H
205 �Fnobody�����F2007/10/06(�y) 00:06:57 ID:???
>>204
* �� + �́A���̂܂܂��ƍŒ��̕�����Ń}�b�`���Ă��܂��̂ŁA
�ŒZ�}�b�`�ɂ��邽�߂� .*? �݂����ɂ���Ɨǂ��B
���ƁA�J��Ԃ����������邽�߂ɁA g �I�v�V���� (/.../g �݂�����) ��t�����낵�B
* �� + �́A���̂܂܂��ƍŒ��̕�����Ń}�b�`���Ă��܂��̂ŁA
�ŒZ�}�b�`�ɂ��邽�߂� .*? �݂����ɂ���Ɨǂ��B
���ƁA�J��Ԃ����������邽�߂ɁA g �I�v�V���� (/.../g �݂�����) ��t�����낵�B
206 �Fnobody�����F2007/10/06(�y) 00:07:46 ID:???
$text=~ s#\[(.*?)\]#my$r=$1;(my$s=$1)=~s/([^\w ])/'%'.unpack('H2',$1)/ge;
$s=~tr/ /+/;'[<a href="http://foo.bar?query='.$s."\">$r</a>]"#ges;
����ȕ��łǂ��H
$s=~tr/ /+/;'[<a href="http://foo.bar?query='.$s."\">$r</a>]"#ges;
����ȕ��łǂ��H
207 �Fnobody�����F2007/10/06(�y) 00:35:40 ID:1+GhnPpX
208 �Fnobody�����F2007/10/06(�y) 16:42:21 ID:kTx5Crj6
���ʂ̕����Ƃ���\��\������ɂ͂ǂ���������ł����H
C���ꕗ�ɂ́A'\\'�݂����Ȃ�ł�
C���ꕗ�ɂ́A'\\'�݂����Ȃ�ł�
209 �Fnobody�����F2007/10/06(�y) 17:45:43 ID:???
�܂��͂���������Ă݂Ă�������
210 �Fnobody�����F2007/10/06(�y) 17:50:21 ID:kTx5Crj6
���߂������ǁA�ʖڂł����B
\\\�����������F�������B
�ł�\\���ĘA�����镶����́A\\\\\\���Ƒʖڂ������B
��
�����Ɏg���Ă�G�f�B�^�́AUnEditor�ł�
\\\�����������F�������B
�ł�\\���ĘA�����镶����́A\\\\\\���Ƒʖڂ������B
��
�����Ɏg���Ă�G�f�B�^�́AUnEditor�ł�
211 �Fnobody�����F2007/10/06(�y) 18:29:58 ID:C0xnGICK
>>210
�\\\\� �Ƃ����G�X�P�[�v�V�[�P���X�����߂���ĕ����� �\\� �ɂȂ� ������ �\\� �����K�\���Ƃ��ĉ��߂���� �\� ��\���ƌ����
���̐������炷��Ƥ �\\� ��\���ɂ� �\\\\\\\\� �ƑłĂ悢�
�\\\\� �Ƃ����G�X�P�[�v�V�[�P���X�����߂���ĕ����� �\\� �ɂȂ� ������ �\\� �����K�\���Ƃ��ĉ��߂���� �\� ��\���ƌ����
���̐������炷��Ƥ �\\� ��\���ɂ� �\\\\\\\\� �ƑłĂ悢�
212 �Fnobody�����F2007/10/06(�y) 18:34:59 ID:kTx5Crj6
213 �Fnobody�����F2007/10/07(��) 17:23:56 ID:bdyGFUK8
���p�p����������>>205�̕��@��OK�Ȃł����A���{��̕�����̏ꍇ�A�G���R�[�h����K�v������̂�
>>206�̂悤�ɂ��Ȃ���Ȃ�Ȃ��킯�ł��ˁB���A�C�����܂�����B
>>206�̂悤�ɂ��Ȃ���Ȃ�Ȃ��킯�ł��ˁB���A�C�����܂�����B
214 �Fnobody�����F2007/10/25(��) 15:30:25 ID:???
php�ŁA�ϐ��Ƀt�@�C���������ď�����������ł���
���K�\���ŕ���������������ꍇ�ǂ̂悤�ɏ����悢�ł��傤���H
���{����܂܂Ȃ���ΊȒP�����ł����A�A�A�A
���K�\���ŕ���������������ꍇ�ǂ̂悤�ɏ����悢�ł��傤���H
���{����܂܂Ȃ���ΊȒP�����ł����A�A�A�A
215 �Fnobody�����F2007/10/25(��) 16:34:35 ID:???
>>214
�ǂ䂱�ƁH�ǂ�Ȑ��������������H
�ǂ䂱�ƁH�ǂ�Ȑ��������������H
216 �Fnobody�����F2007/10/27(�y) 01:42:21 ID:???
>>214
�}���`�o�C�g
�}���`�o�C�g
217 �Fnobody�����F2007/11/05(��) 12:34:21 ID:???
(��������) [���Lku����] sa���f���� [07.07.07]
���̗l�Ƀt�@�C���ɖ��O�����Ă���̂ł����A��������̂悤�Ƀ��l�[���������̂ł��B
(��������) [07.07.07] [���Lku����] sa���f����
[07.07.07]�͓��t�ł��B2006/10/15�Ȃ�[06.10.15]�ƂȂ�܂��B
���K�\���łǂ̂悤�ɕ\��������ꊇ�ϊ��ł���ł��傤���H
�ǂȂ����䋳�����������B
���̗l�Ƀt�@�C���ɖ��O�����Ă���̂ł����A��������̂悤�Ƀ��l�[���������̂ł��B
(��������) [07.07.07] [���Lku����] sa���f����
[07.07.07]�͓��t�ł��B2006/10/15�Ȃ�[06.10.15]�ƂȂ�܂��B
���K�\���łǂ̂悤�ɕ\��������ꊇ�ϊ��ł���ł��傤���H
�ǂȂ����䋳�����������B
218 �Fnobody�����F2007/11/05(��) 12:38:12 ID:EztAcqYR
�����X���Ⴂ�ł�����ē����Ă���������Ə�����܂�
219 �Fnobody�����F2007/11/05(��) 12:47:34 ID:???
220 �F217�F2007/11/05(��) 13:09:25 ID:EztAcqYR
>>219
���炵�܂���Perl5�ł��B
http://www.hi-ho.ne.jp/~babaq/bregexp.html�̂c�k�k���g����
Namery�Ń��l�[���������ł��B
�I�O��ȃ��X�������炷�݂܂���
���炵�܂���Perl5�ł��B
http://www.hi-ho.ne.jp/~babaq/bregexp.html�̂c�k�k���g����
Namery�Ń��l�[���������ł��B
�I�O��ȃ��X�������炷�݂܂���
221 �Fnobody�����F2007/11/05(��) 13:59:05 ID:???
�u�A���u���E�}�N���v�Ƀ`�F�b�N���āA����Ȃ�łǂ��H
s/^(\(.+?\))( \[.+?\] .+?)( \[.+?\])/\1\3\2/
�̏����Ƃ��K���Ȃ̂ŁA���Ƃ͎����Œ��ׂĂ��낢�낢�����Ă݂Ă���B
s/^(\(.+?\))( \[.+?\] .+?)( \[.+?\])/\1\3\2/
�̏����Ƃ��K���Ȃ̂ŁA���Ƃ͎����Œ��ׂĂ��낢�낢�����Ă݂Ă���B
222 �Fnobody�����F2007/11/05(��) 14:37:50 ID:EztAcqYR
>>221
�o�b�`���ł��܂����I���肪�Ƃ��������܂���
�������˗�����J�^�`���ԈႦ�Ă��܂���orz
gomennnasaigomennnasaigomennnasai
(��������) [07.07.07] [���Lku����] sa���f����
���ł͂Ȃ����ɂ���ɂ͂ǂ�����E�E�E
(��������) [���Lku����] [07.07.07] sa���f����
�o�b�`���ł��܂����I���肪�Ƃ��������܂���
�������˗�����J�^�`���ԈႦ�Ă��܂���orz
gomennnasaigomennnasaigomennnasai
(��������) [07.07.07] [���Lku����] sa���f����
���ł͂Ȃ����ɂ���ɂ͂ǂ�����E�E�E
(��������) [���Lku����] [07.07.07] sa���f����
223 �Fnobody�����F2007/11/05(��) 14:41:33 ID:EztAcqYR
224 �Fnobody�����F2007/11/12(��) 05:47:51 ID:Kg6xKnVX
�u����������ABC+F481ABC+F485����������ABC+F7A5����������ABC+F3F0ABC+F39E�����Ă�ABC+F65A�Ȃɂʂ˂�ABC+F485ABC+F7A5�͂Ђӂւ�ABC+F7A5ABC+F39E�܂݂ނ߂��v
��L�̒��ɁA�uABC+16�i��x2��v�������܂܂�Ă��邩��PHP�̐��K�\���ŕ\���ɂ͂ǂ�������낵���ł��傤���H
���ڝ���낵�����肢�������܂��B
��L�̒��ɁA�uABC+16�i��x2��v�������܂܂�Ă��邩��PHP�̐��K�\���ŕ\���ɂ͂ǂ�������낵���ł��傤���H
���ڝ���낵�����肢�������܂��B
225 �Fnobody�����F2007/11/12(��) 10:41:44 ID:???
>>224
���K�\���͂��܂ЂƂȂ̂ł����Ə�肢���������邩������Ȃ������
$input_str = "����������ABC+F481ABC+F485����������ABC+F7A5����������ABC+F3F0ABC+F39E�����Ă�ABC+F65A�Ȃɂʂ˂�ABC+F485ABC+F7A5�͂Ђӂւ�ABC+F7A5ABC+F39E�܂݂ނ߂�";
echo preg_match_all("/ABC\+[A-F\d]{4}/",$input_str,$out_ary);
��$out_ary�͖����ƃG���[�ɂȂ�̂ŏ����Ȃ���
���K�\���͂��܂ЂƂȂ̂ł����Ə�肢���������邩������Ȃ������
$input_str = "����������ABC+F481ABC+F485����������ABC+F7A5����������ABC+F3F0ABC+F39E�����Ă�ABC+F65A�Ȃɂʂ˂�ABC+F485ABC+F7A5�͂Ђӂւ�ABC+F7A5ABC+F39E�܂݂ނ߂�";
echo preg_match_all("/ABC\+[A-F\d]{4}/",$input_str,$out_ary);
��$out_ary�͖����ƃG���[�ɂȂ�̂ŏ����Ȃ���
226 �Fnobody�����F2007/11/13(��) 16:45:36 ID:KDxCSN/c
����ł�
PHP�X�N���v�g��preg_match("/^[^@]+@[^.]+\..+/", $superunkoman))
�Ƃ������K�\�����������̂ł���
^[^@]+ �@�@���ŏ��̕�����@�ȊO�̕����̈��ȏ�̌J��Ԃ�
@�@�@�@�@�@�@���ŁA@������
[^.]�@�@�@�@�@�����̕����������ł��܂���B
������������
PHP�X�N���v�g��preg_match("/^[^@]+@[^.]+\..+/", $superunkoman))
�Ƃ������K�\�����������̂ł���
^[^@]+ �@�@���ŏ��̕�����@�ȊO�̕����̈��ȏ�̌J��Ԃ�
@�@�@�@�@�@�@���ŁA@������
[^.]�@�@�@�@�@�����̕����������ł��܂���B
������������
227 �Fnobody�����F2007/11/13(��) 17:15:59 ID:???
228 �Fnobody�����F2007/11/13(��) 17:39:32 ID:???
>>227
���肪�Ƃ��������܂����B���̂Ƃ���ł���
���肪�Ƃ��������܂����B���̂Ƃ���ł���
229 �Fnobody�����F2007/11/13(��) 22:44:37 ID:???
����ł�
php�X�N���v�g��
$str = ereg_replace(
"(https?|ftp)(://[[:alnum:]\+\$\;\?\.%,!#~*/:@&=_-]+)",
"<a href=\"\\1\\2\">\\1\\2</a>",
$str);
���̐��K�\����(://[[:alnum:]\+\$\;\?\.%,!#~*/:@&=_-]+)�̕�����href=\"\\1\\2\">\\1\\2</a>���̕�����
����\���Ă���̂������Ă���܂��H
php�X�N���v�g��
$str = ereg_replace(
"(https?|ftp)(://[[:alnum:]\+\$\;\?\.%,!#~*/:@&=_-]+)",
"<a href=\"\\1\\2\">\\1\\2</a>",
$str);
���̐��K�\����(://[[:alnum:]\+\$\;\?\.%,!#~*/:@&=_-]+)�̕�����href=\"\\1\\2\">\\1\\2</a>���̕�����
����\���Ă���̂������Ă���܂��H
230 �Fnobody�����F2007/11/14(��) 12:22:47 ID:E8xVrSo0
�����킷��
231 �Fnobody�����F2007/11/14(��) 13:37:57 ID:???
>>230
����͂܂��}�j���A����
PHP�}�j���A�������p
string ereg_replace ( string pattern, string replacement, string string )
pattern �̒��Ɋ��ʂł�����ꂽ���� �����܂܂�Ă���ꍇ�A
replacement �̒��� \\���� �̂悤�ȕ���������ߍ��ނ��Ƃ�
�ł��܂��B���̕����́A �u�����v�Ԗڂ̊��ʂł�����ꂽ�����������
�}�b�`���镶����� �u���������܂��B�܂��A\\0 �͕�����S�̂�
�w���܂��B9 �܂ł̕�����������g�����Ƃ��ł��܂��B���ʂ�
����q�ɂȂ��Ă��Ă��\���܂���B���̏ꍇ�͊J������ '(' ��
�ő� 9 �܂Ŏg�p�\�ł��B
����͂܂��}�j���A����
PHP�}�j���A�������p
string ereg_replace ( string pattern, string replacement, string string )
pattern �̒��Ɋ��ʂł�����ꂽ���� �����܂܂�Ă���ꍇ�A
replacement �̒��� \\���� �̂悤�ȕ���������ߍ��ނ��Ƃ�
�ł��܂��B���̕����́A �u�����v�Ԗڂ̊��ʂł�����ꂽ�����������
�}�b�`���镶����� �u���������܂��B�܂��A\\0 �͕�����S�̂�
�w���܂��B9 �܂ł̕�����������g�����Ƃ��ł��܂��B���ʂ�
����q�ɂȂ��Ă��Ă��\���܂���B���̏ꍇ�͊J������ '(' ��
�ő� 9 �܂Ŏg�p�\�ł��B
232 �Fnobody�����F2007/11/23(��) 11:29:24 ID:OIbrK2sw
���K�\�����y���狳���Ă�������̂ł����A
������@[�S�Ă̕���]�@���@���K�\���@[[]([^\]]+)]�@�Ł@�S�Ă̕����@�����o
�����Ƃ��ł��܂����A
������@{�S�Ă̕���}�@�Ł@�S�Ă̕����@�����o�����K�\���������Ă��������B
������@[�S�Ă̕���]�@���@���K�\���@[[]([^\]]+)]�@�Ł@�S�Ă̕����@�����o
�����Ƃ��ł��܂����A
������@{�S�Ă̕���}�@�Ł@�S�Ă̕����@�����o�����K�\���������Ă��������B
233 �Fnobody�����F2007/11/23(��) 15:30:11 ID:???
234 �Fnobody�����F2007/11/23(��) 20:53:35 ID:tvqFA7ba
����͖����ł���
���ׂĂ̕���
�����o������
���ׂĂ̕���
�����o������
235 �Fnobody�����F2007/11/27(��) 18:05:34 ID:fIXcwnBh
D�J�b�v�ȏ��25�Έȉ��Œ��o�������ł�
PHP5�ł�
PHP5�ł�
236 �Fnobody�����F2007/11/27(��) 19:15:14 ID:???
[D-Z]�J�b�v.*(1?[0-9]|2[0-5])��
237 �Fnobody�����F2007/11/28(��) 13:29:18 ID:fpWBgokp
PHP�Ő��K�\���ł���₱���Ƌ�킵�Ă܂��B
�ŁA���K�\���`�F�b�J�[
�@ttp://www.asterworld.com/ja/soft/regexchk.html
�@�Ƃ��������݂��āA�����֗����I�Ǝv���Ă��̂ł���
�쐬�������K�\�����@preg_replace�@�ɐݒ肵�Ă��}�b�`���Ă���܂���B
����Ȃɕ���������Ƃ��v���Ȃ��̂ł���...
C#2005�̐��K�\���̂悤�Ȃ̂ł���Perl�̐��K�\���Ɖ����������̂ł��傤���B
C#2005�̐��K�\����Perl�̐��K�\���ɕύX����ɂ͖����Ȃ̂ł��傤���B
Perl�̐��K�\�����쐬����悤�ȃ\�t�g�͂���̂ł��傤���H
�������܂����ǂȂ��������Ă��������@�����S�`���S�`�����Ă���..
�ŁA���K�\���`�F�b�J�[
�@ttp://www.asterworld.com/ja/soft/regexchk.html
�@�Ƃ��������݂��āA�����֗����I�Ǝv���Ă��̂ł���
�쐬�������K�\�����@preg_replace�@�ɐݒ肵�Ă��}�b�`���Ă���܂���B
����Ȃɕ���������Ƃ��v���Ȃ��̂ł���...
C#2005�̐��K�\���̂悤�Ȃ̂ł���Perl�̐��K�\���Ɖ����������̂ł��傤���B
C#2005�̐��K�\����Perl�̐��K�\���ɕύX����ɂ͖����Ȃ̂ł��傤���B
Perl�̐��K�\�����쐬����悤�ȃ\�t�g�͂���̂ł��傤���H
�������܂����ǂȂ��������Ă��������@�����S�`���S�`�����Ă���..
238 �Fnobody�����F2007/11/28(��) 15:10:44 ID:???
�����Ƃ��Ȃ��{�I�ȂƂ���Ŋ��Ⴂ���Ă����ł͂Ȃ����Ƒz���B
�܂��́A����ȏ�Ȃ����Ă��炢�P���Ȑ��K�\���ŋ������r���Ă݂āA
�������珇�����G�Ȑ��K�\���ɂ��Ă����č��ق����Ă݂ẮB
�܂��́A����ȏ�Ȃ����Ă��炢�P���Ȑ��K�\���ŋ������r���Ă݂āA
�������珇�����G�Ȑ��K�\���ɂ��Ă����č��ق����Ă݂ẮB
�l�b�g�Œ��ׂĂ��A�ǂ̌���̐��K�\���Ȃ̂����ЂƂ���Ȃ��̂�
��荇�����A�}�]���Ŗ{�𒍕����܂����B
���ꂲ�Ƃ̍�������悤�Ȃ��̂������...
��荇�����A�}�]���Ŗ{�𒍕����܂����B
���ꂲ�Ƃ̍�������悤�Ȃ��̂������...
C# �Ȃ� .NET �Ȃ낤���ǁA�u�ڐ� ���K�\�� (��2��)�v�ɂ͍��قȂǂ��ڂ��Ă�B
����ŁA�ς��ƌ��ŁA��{�I�ȂƂ���� Perl �� .NET �Ƃő債�����͖����Ǝv���B
����ŁA�ς��ƌ��ŁA��{�I�ȂƂ���� Perl �� .NET �Ƃő債�����͖����Ǝv���B
�u���K�\���̒B�l�v���Ė{����ɂ��č��A�ǂ�ł܂����A
�����H�ׂ���Ȃ�Ŗ����Ė����ā@�t���@�@(/ 0�P)~�K
������Ă݂܂��B�B
�����H�ׂ���Ȃ�Ŗ����Ė����ā@�t���@�@(/ 0�P)~�K
������Ă݂܂��B�B
242 �Fnobody�����F2007/12/11(��) 20:35:33 ID:???
���݂܂���A�w���v�����肢���܂��B
PHP�ɂāA����̉摜�t�@�C����������<IMG>�^�O�𒊏o����Ƃ������K�\������肽���̂ł���
��肭�s���Ȃ��č����Ă���܂��B
�ǂȂ����A���������������B�B�B
PHP�ɂāA����̉摜�t�@�C����������<IMG>�^�O�𒊏o����Ƃ������K�\������肽���̂ł���
��肭�s���Ȃ��č����Ă���܂��B
�ǂȂ����A���������������B�B�B
243 �Fnobody�����F2007/12/12(��) 01:18:37 ID:???
>>242
�������Ƃ��킵���Bsrc�����ȊO�ɑ��������̂��Ƃ��B
����alt���������Ă����������ǁB
preg_match('/<img .*?src=(["¥'])����̃t�@�C������\�����K�\��¥¥1 .*?>/', src);
�Ƃ����B���K���ɍ�����̂ł��܂��������ǂ����͂킩���
�������Ƃ��킵���Bsrc�����ȊO�ɑ��������̂��Ƃ��B
����alt���������Ă����������ǁB
preg_match('/<img .*?src=(["¥'])����̃t�@�C������\�����K�\��¥¥1 .*?>/', src);
�Ƃ����B���K���ɍ�����̂ł��܂��������ǂ����͂킩���
244 �Fnobody�����F2007/12/19(��) 16:38:31 ID:H15tWjcK
PHP��preg_replace�Ȃ�ł����A�����������肢�܂��B
����̕�����ň͂܂ꂽ�������ϊ����Ȃ����K�\���������Ă��������B
���Ƃ���
preg_replace("/aaa/", "[\1]", "aaa aaa aaa aaa aaa")
���ƌ��ʂ� "[aaa] [aaa] [aaa] [aaa] [aaa]" �ɂȂ�܂���
preg_replace("/aaa/", "[\1]", "aaa{{{aaa aaa aaa}}}aaa")
�ƂȂ��Ă����Ƃ���
"[aaa]{{{aaa aaa aaa}}}[aaa]" �Ƃ������ʂ��擾��������ł���
�v���悤�ɏo���܂���B
�����ڏo�Ȃ��Ă������̂Ńq���g�����ł������Ă��������B
����̕�����ň͂܂ꂽ�������ϊ����Ȃ����K�\���������Ă��������B
���Ƃ���
preg_replace("/aaa/", "[\1]", "aaa aaa aaa aaa aaa")
���ƌ��ʂ� "[aaa] [aaa] [aaa] [aaa] [aaa]" �ɂȂ�܂���
preg_replace("/aaa/", "[\1]", "aaa{{{aaa aaa aaa}}}aaa")
�ƂȂ��Ă����Ƃ���
"[aaa]{{{aaa aaa aaa}}}[aaa]" �Ƃ������ʂ��擾��������ł���
�v���悤�ɏo���܂���B
�����ڏo�Ȃ��Ă������̂Ńq���g�����ł������Ă��������B
245 �Fnobody�����F2007/12/19(��) 18:16:44 ID:???
>>244
��ǂݕ\���͗ʎw��q���܂߂��Ȃ�����A����preg_replace�����ł�낤�Ƃ���Ȃ�A
����ȊO�̕�����H�킹�Ă����Ēu�������Ƃ����A���C�����������ƂɂȂ�Ǝv���B
�Ⴆ����Ȃӂ���
preg_replace('/(.*?(?:\\Q{{{\\E.*?\\Q}}}\\E.*?)*)(aaa)/', '$1[$2]', "aaa{{{aaa aaa aaa}}}aaa");
�������Ă���Ώۂ̕��������������铙�̕��@���������������X�������ƁB
��ǂݕ\���͗ʎw��q���܂߂��Ȃ�����A����preg_replace�����ł�낤�Ƃ���Ȃ�A
����ȊO�̕�����H�킹�Ă����Ēu�������Ƃ����A���C�����������ƂɂȂ�Ǝv���B
�Ⴆ����Ȃӂ���
preg_replace('/(.*?(?:\\Q{{{\\E.*?\\Q}}}\\E.*?)*)(aaa)/', '$1[$2]', "aaa{{{aaa aaa aaa}}}aaa");
�������Ă���Ώۂ̕��������������铙�̕��@���������������X�������ƁB
246 �Fnobody�����F2007/12/19(��) 18:44:19 ID:???
��c��z�[���y�[�W�F�E���̕s�ˎ��ɂ��āi�����̌��\�j
http://www.city.ota.tokyo.jp/oshirase/mokutekibetsu/other/fusyouji_syobun/index.html
����E�������Q�̗e�^�őߕ߂����Ƃ��������ɂ��܂��ẮA�V�����ł̕�z�[���[�y�[�W�Ō��\�����Ƃ���ł����A����A�����W�����炩�ɂȂ�A�ȉ��̂Ƃ��蒦���������s���܂����̂Ō��\�������܂��B
�@�斯�̊F�l�̐M���𗠐邱�ƂƂȂ�A���ɐ\����܂���B���炽�߂āA���l�т������܂��B
���������Ƃ�
�@�E�������̋`���ᔽ��Ƃ����ꍇ�ɁA�����̋K���ƒ������ێ����邱�Ƃ�ړI�Ƃ��āA���̐ӔC��Njy���邽�߂ɐ��قƂ��čs�������ł��B
�@��c��ł͒��������̌��\��Ɋ�Â��A�ƐE�����������ꍇ����ɋ斯�̊S���傫�����Ė��͎Љ�I�e�����傫�����Ăɂ��āA�ʂ̒������������\���܂��B
�i���������̐��x�̏ڍׂ́A��c��l�����������Q�Ƃ��������B�j
�������ߓ�
�@����19�N12��19��
�폈���Ҏ���
�@���z�����ہ@�g���@�K��
�����̓��e
�@��E3��
�����̗��R
�@��ʔ�s�W�i�@�߂Ɉᔽ���A�S�̂̕�d�҂���ɂӂ��킵���Ȃ���s�����������߁j
�����̊T�v
�@���̐E���́A����19�N11��16���i���j���j�A�Ζ����ԏI����A���_�ސ�w���ӂň��H������A�A��r����JR���l���k�����\���c�Ԃ̓d�ԓ��ɂ����āA��q�j���ɑS��4�T�Ԃ̉���킹��\�s���A���Q�̗e�^�ɂ�芗�c�x�@���Ɍ��s�Ƒߕ߂���܂����B
�@���E���́A�����ȈՍٔ����ɋN�i����A�����Y��\���n����Ă��܂��B
http://www.city.ota.tokyo.jp/oshirase/mokutekibetsu/other/fusyouji_syobun/index.html
����E�������Q�̗e�^�őߕ߂����Ƃ��������ɂ��܂��ẮA�V�����ł̕�z�[���[�y�[�W�Ō��\�����Ƃ���ł����A����A�����W�����炩�ɂȂ�A�ȉ��̂Ƃ��蒦���������s���܂����̂Ō��\�������܂��B
�@�斯�̊F�l�̐M���𗠐邱�ƂƂȂ�A���ɐ\����܂���B���炽�߂āA���l�т������܂��B
���������Ƃ�
�@�E�������̋`���ᔽ��Ƃ����ꍇ�ɁA�����̋K���ƒ������ێ����邱�Ƃ�ړI�Ƃ��āA���̐ӔC��Njy���邽�߂ɐ��قƂ��čs�������ł��B
�@��c��ł͒��������̌��\��Ɋ�Â��A�ƐE�����������ꍇ����ɋ斯�̊S���傫�����Ė��͎Љ�I�e�����傫�����Ăɂ��āA�ʂ̒������������\���܂��B
�i���������̐��x�̏ڍׂ́A��c��l�����������Q�Ƃ��������B�j
�������ߓ�
�@����19�N12��19��
�폈���Ҏ���
�@���z�����ہ@�g���@�K��
�����̓��e
�@��E3��
�����̗��R
�@��ʔ�s�W�i�@�߂Ɉᔽ���A�S�̂̕�d�҂���ɂӂ��킵���Ȃ���s�����������߁j
�����̊T�v
�@���̐E���́A����19�N11��16���i���j���j�A�Ζ����ԏI����A���_�ސ�w���ӂň��H������A�A��r����JR���l���k�����\���c�Ԃ̓d�ԓ��ɂ����āA��q�j���ɑS��4�T�Ԃ̉���킹��\�s���A���Q�̗e�^�ɂ�芗�c�x�@���Ɍ��s�Ƒߕ߂���܂����B
�@���E���́A�����ȈՍٔ����ɋN�i����A�����Y��\���n����Ă��܂��B
247 �Fnobody�����F2007/12/22(�y) 08:43:52 ID:KKfYoqPi
���݂܂���A�����Ă��������B
PHP�Ōg�ѓd�b�ɕ������\������ۂɁA
�d�b�ԍ��̕�����telto�����N�ɂ������Ǝv���ȉ��̂悤�ɏ����܂����B
$bodySTR = preg_replace('/([-0123456789]+)/', '<a href="tel:\\1">\\1</a>',$bodySTR);
���R�Ȃ��炱�ꂾ�ƁA�u100�~�v��u��123-4567�v�ɂ��������Ă��܂��܂��B
�����ŁA
�u03-1234-5678�v�u090-1234-5678�v�u�O�R�|�P�Q�R�S�|�T�U�V�W�v���Ƀ}�b�`����
�u100�v��u123-4567�v�ɂ̓}�b�`���Ȃ����K�\���͉\�ł��傤���H
PHP�Ōg�ѓd�b�ɕ������\������ۂɁA
�d�b�ԍ��̕�����telto�����N�ɂ������Ǝv���ȉ��̂悤�ɏ����܂����B
$bodySTR = preg_replace('/([-0123456789]+)/', '<a href="tel:\\1">\\1</a>',$bodySTR);
���R�Ȃ��炱�ꂾ�ƁA�u100�~�v��u��123-4567�v�ɂ��������Ă��܂��܂��B
�����ŁA
�u03-1234-5678�v�u090-1234-5678�v�u�O�R�|�P�Q�R�S�|�T�U�V�W�v���Ƀ}�b�`����
�u100�v��u123-4567�v�ɂ̓}�b�`���Ȃ����K�\���͉\�ł��傤���H
248 �Fnobody�����F2007/12/22(�y) 14:06:28 ID:???
�\�ł�
249 �Fnobody�����F2007/12/22(�y) 16:17:35 ID:???
/(0¥d+-¥d{1,4}-¥d{4})/
�łǂ���
�łǂ���
250 �Fnobody�����F2007/12/22(�y) 17:39:05 ID:6MoMAQ1+
perl�̐��K�\���ɂ��Ď���ł��B
>>244�̕��Ɠ����l�Ȃ��̂Ȃ̂ł���
"test <a href="http://test.jp"> test"
�̗l�ȕ����������ꍇ�A�^�O����test�͕ύX������
"[test]<a href="http://test.jp">[test]"
�Ƃ����`�ɂ������̂ł����A�ǂ̂悤�ɂ���X�����ł��傤���B
��x�u��������A<>�^�O���̕���[]���O�����@���l���Ă݂͂��̂ł����A
�v���悤�ɓ��삳���鎖���o�����B�������̒��A�X�������肢�v���܂��B
>>244�̕��Ɠ����l�Ȃ��̂Ȃ̂ł���
"test <a href="http://test.jp"> test"
�̗l�ȕ����������ꍇ�A�^�O����test�͕ύX������
"[test]<a href="http://test.jp">[test]"
�Ƃ����`�ɂ������̂ł����A�ǂ̂悤�ɂ���X�����ł��傤���B
��x�u��������A<>�^�O���̕���[]���O�����@���l���Ă݂͂��̂ł����A
�v���悤�ɓ��삳���鎖���o�����B�������̒��A�X�������肢�v���܂��B
251 �Fnobody�����F2007/12/22(�y) 17:52:18 ID:???
s/(<.*?>|test)/$1?$1:"[$2]"/ges
>>251
�Ȃ�قǁA�ǂ����L�������܂����I
�Ȃ�قǁA�ǂ����L�������܂����I
253 �Fnobody�����F2008/01/14(��) 12:16:38 ID:6AXqvVgD
����(13:00:00�`18:00:00)�܂ł𐳋K�\���ł���킵�����̂ł����A
1[3-8]:[0-5][0-9]:[0-5][0-9]
�Ƃ��������ɍ��Ȃ��Ă��܂�
�N�����Ă��킩��₷��������ł������̂ł����A�����ƒZ���������͂Ȃ����̂ł��傤���H
[0-5][0-9]�����������Ȃ̂ŁA([0-5][0-9]:?){2}�Ƃ��v�����̂ł����A
���ꂾ�ƍŌ�ɃR�����������ĂĂ��}�b�`���Ă��܂��̂ʼn���ł���悤�ȏ������͂Ȃ����̂��Ȃ��ƁB
1[3-8]:[0-5][0-9]:[0-5][0-9]
�Ƃ��������ɍ��Ȃ��Ă��܂�
�N�����Ă��킩��₷��������ł������̂ł����A�����ƒZ���������͂Ȃ����̂ł��傤���H
[0-5][0-9]�����������Ȃ̂ŁA([0-5][0-9]:?){2}�Ƃ��v�����̂ł����A
���ꂾ�ƍŌ�ɃR�����������ĂĂ��}�b�`���Ă��܂��̂ʼn���ł���悤�ȏ������͂Ȃ����̂��Ȃ��ƁB
254 �Fnobody�����F2008/01/14(��) 13:51:53 ID:???
1[3-8](?::[0-5]\d){2}
255 �Fnobody�����F2008/01/15(��) 02:35:00 ID:HyHnFj45
�������w���̍��A
���{���Ńm�X�g���_���X�̗\�����嗬�s���Ă����B
�u1999�N��7���ɐl�ނ͖ŖS����I�v
�Ƃ�����̂��������I���\���ł���B
��l�ɂȂ��ĎЉ�ɏo�ē��������āA
���������ƖZ�������X���߂����Ȃ���A
1999�N�́A
����ӂꂽ����̒��ł�������Ɖ߂��Ă������B
�l�ނ͖łȂ������B
���ꂩ�炱���ŁA
1999�N�ɋN���邩������Ȃ������l�ނ̉�œI�j�ǂ��A
�N�ɂ��m��ꂸ�ɂ�������Ɖ���������l����������...
�Ƃ����ݒ�ŁA
�r�����m�ȃX�g�[���[��`���Ă݂����B
���_�A100%���S�ȃt�B�N�V�����ł���B
http://www5.diary.ne.jp/logdisp.cgi?user=532063&log=200705
256 �Fnobody�����F2008/01/20(��) 11:20:53 ID:TPbCvsXG
/([^>|\+|\s]+)\s*([>|\+]?)\s*/g
���̐��K�\���͂ǂ��������Ƃł��傤�H
���Ƀ}�b�`�����悤�Ƃ��Ă���̂ł��傤���B
JavaScript�ł��B
���̐��K�\���͂ǂ��������Ƃł��傤�H
���Ƀ}�b�`�����悤�Ƃ��Ă���̂ł��傤���B
JavaScript�ł��B
257 �Fnobody�����F2008/01/20(��) 11:37:26 ID:???
[]�̒���|���g���Ăn�q�����ɂ��Ă邩�珑�����l�͊��Ⴂ���Ă�
258 �Fnobody�����F2008/01/20(��) 12:50:55 ID:TPbCvsXG
�{���Ȃɂ�������������ł��傤���E�E�E�B
259 �Fnobody�����F2008/01/21(��) 16:00:34 ID:???
PHP�̐��K�\���ɂ��Ă̎���ł��B
2ch��dat���e�v�f���ɃL���v�`���������̂ł����A
preg_math_all('/((.*)<>)*/', $dat, $match);
�Ə����Ď��s����ƑS�̂��ہX$match�֊i�[����܂��B
$dat�ւ́u�@�v�f1<>�v�f2<>�v�f3<>�v�f4<>�v�f5�@�v�Ƃ����`���̃f�[�^�������Ă���v�f5��1�s�ڂɂ̂ݑ��݂��܂��B
�܂��A�e�v�f�͋̏ꍇ������܂��B
�����I�Ȏ���Ő\����܂��A��낵�����肢���܂��B
2ch��dat���e�v�f���ɃL���v�`���������̂ł����A
preg_math_all('/((.*)<>)*/', $dat, $match);
�Ə����Ď��s����ƑS�̂��ہX$match�֊i�[����܂��B
$dat�ւ́u�@�v�f1<>�v�f2<>�v�f3<>�v�f4<>�v�f5�@�v�Ƃ����`���̃f�[�^�������Ă���v�f5��1�s�ڂɂ̂ݑ��݂��܂��B
�܂��A�e�v�f�͋̏ꍇ������܂��B
�����I�Ȏ���Ő\����܂��A��낵�����肢���܂��B
260 �Fnobody�����F2008/01/21(��) 16:01:39 ID:???
>>258
�����Ƃ炨�O����ɂ�����Ă����炢����B
�����Ƃ炨�O����ɂ�����Ă����炢����B
261 �Fnobody�����F2008/01/21(��) 16:03:38 ID:???
>>259
preg_split �� "<>" �Ŕz��ɂ炵�����������₷�������B
preg_split �� "<>" �Ŕz��ɂ炵�����������₷�������B
>>261
���X���肪�Ƃ��������܂��B
�m����php�ɂ͗v�f������ׂ֗̕��Ȋ����n�߂���p�ӂ���Ă���܂����A����͂�����preg_match��p���Ď��g�ŕ������Ă݂����v���܂��B
�����ɂ̓n�[�h���������C������̂ŁA��n�߂ɗv�f�T���������o�����ƒ��킵�Ă݂��̂ł����A
/<>(.+)$/�@�Ə����Ɨv�f3<>�v�f4<>�v�f5���L���v�`������Ă��܂��܂��B
��͂蓖���̐��K�\���ɑ�����߂����{�I�ɊԈ���Ă���̂ł��傤���B
�A���ɂȂ��ϐ\����Ȃ��̂ł����A������̎���ւ݂̂����肢�������܂��B
�i>>259�͉܂��Ă������ɂ͗����̔��e���Ă���Ɣ��f���܂����̂Łj
���X���肪�Ƃ��������܂��B
�m����php�ɂ͗v�f������ׂ֗̕��Ȋ����n�߂���p�ӂ���Ă���܂����A����͂�����preg_match��p���Ď��g�ŕ������Ă݂����v���܂��B
�����ɂ̓n�[�h���������C������̂ŁA��n�߂ɗv�f�T���������o�����ƒ��킵�Ă݂��̂ł����A
/<>(.+)$/�@�Ə����Ɨv�f3<>�v�f4<>�v�f5���L���v�`������Ă��܂��܂��B
��͂蓖���̐��K�\���ɑ�����߂����{�I�ɊԈ���Ă���̂ł��傤���B
�A���ɂȂ��ϐ\����Ȃ��̂ł����A������̎���ւ݂̂����肢�������܂��B
�i>>259�͉܂��Ă������ɂ͗����̔��e���Ă���Ɣ��f���܂����̂Łj
263 �Fnobody�����F2008/01/21(��) 19:42:35 ID:???
[^<>]
���ȉ������܂���
265 �Fnobody�����F2008/01/21(��) 22:14:14 ID:???
>>264
�ǂ��������������炢�͏����Ă��o�`�͓�����Ȃ����Ă�B
�ǂ��������������炢�͏����Ă��o�`�͓�����Ȃ����Ă�B
266 �Fnobody�����F2008/01/30(��) 11:50:28 ID:???
perl��grep�ő啶���������̋�ʂ����Č����������ł��B
@hitlist = grep(/$search_word/i, @search_list);
������A
@hitlist = grep(/$search_word/$serch_option, @search_list);
($serch_option�ɂ�i��g�����O�ɐݒ�)
����Ȋ����ɂ������̂ł����A�Ȃ����Ă͂���܂����H
if���ŕ����邵���Ȃ��ł����H
@hitlist = grep(/$search_word/i, @search_list);
������A
@hitlist = grep(/$search_word/$serch_option, @search_list);
($serch_option�ɂ�i��g�����O�ɐݒ�)
����Ȋ����ɂ������̂ł����A�Ȃ����Ă͂���܂����H
if���ŕ����邵���Ȃ��ł����H
267 �Fnobody�����F2008/01/30(��) 13:19:43 ID:???
�召������ʂ��Č����������Ȃ�I�v�V�����Ȃ��ŌŒ�ł����ł���
�����ł��I�v�V�����g���P�[�X�Ȃ�ĂȂ��ł���
�����ł��I�v�V�����g���P�[�X�Ȃ�ĂȂ��ł���
268 �Fnobody�����F2008/01/30(��) 16:28:40 ID:???
>>266
���₪�v�̂ĂȂ��낤���ǁA
�啶����������ʂ��邩���Ȃ������ւ������A���Ęb�ł͂Ȃ����ƁB
�ǂ�����Ηǂ��̂��͒m��Ȃ����ǁB
���₪�v�̂ĂȂ��낤���ǁA
�啶����������ʂ��邩���Ȃ������ւ������A���Ęb�ł͂Ȃ����ƁB
�ǂ�����Ηǂ��̂��͒m��Ȃ����ǁB
����̗v�̂������Đ\����܂���B
���K�\���̃I�v�V���������܂����Ɛ���ł��Ȃ����ȂƎv���܂��āB
���ɑ啶���������ɂ�������Ă�킯�ł͂Ȃ��ł��B
���K�\���̃I�v�V���������܂����Ɛ���ł��Ȃ����ȂƎv���܂��āB
���ɑ啶���������ɂ�������Ă�킯�ł͂Ȃ��ł��B
270 �Fnobody�����F2008/01/31(��) 03:02:38 ID:???
>>269
�召�����̈Ⴂ�����Č����������Ƃ��ɁA�p�^�[���̐擪�� (?i) ���߂Ƃ��Ⴂ���B
$pat = ($icase ? "(?i)" : "") . $search_word;
@hitlist = grep /$pat/, @search_list;
�Ƃ�
�召�����̈Ⴂ�����Č����������Ƃ��ɁA�p�^�[���̐擪�� (?i) ���߂Ƃ��Ⴂ���B
$pat = ($icase ? "(?i)" : "") . $search_word;
@hitlist = grep /$pat/, @search_list;
�Ƃ�
271 �Fnobody�����F2008/01/31(��) 15:56:15 ID:???
proxomitron �̐��K�\���i�H�j���Ǝ��߂��āA�C���C�����Ă�����c
272 �Fnobody�����F2008/02/25(��) 06:25:28 ID:PeKKba69
2008-03 ����(�\��)
�u�ڐ� ���K�\�� ��3�Łv (Jeffrey E.F. Friedl �� / �������O ��)
ISBN 978-4-87311-359-3 �艿 5,040�~
�u�ڐ� ���K�\�� ��3�Łv (Jeffrey E.F. Friedl �� / �������O ��)
ISBN 978-4-87311-359-3 �艿 5,040�~
273 �Fnobody�����F2008/02/25(��) 12:38:04 ID:???
�����ˁB���� Web �Ō��������������˂��c���X����Ȃ̏o���Ĕ����̂��B
274 �Fnobody�����F2008/03/03(��) 22:23:33 ID:3LUWkmBW
����ł��I
PHP 5.2.5�ŁA<br>�ȊO�̃^�O�폜�����L�̂悤�ɂ����Ƃ���
do {
$res = str_replace( $result_tag[1], '', $res );
} while ( mb_ereg( '(<[a/][^>]+>)', $res, $result_tag ) );
���X�Ō����Ă܂���B
�O�̃T�[�o�[�iPHP�@4.4.4�j�ł͐���ɓ����Ă��܂����B
��낵����w�삭�������B
PHP 5.2.5�ŁA<br>�ȊO�̃^�O�폜�����L�̂悤�ɂ����Ƃ���
do {
$res = str_replace( $result_tag[1], '', $res );
} while ( mb_ereg( '(<[a/][^>]+>)', $res, $result_tag ) );
���X�Ō����Ă܂���B
�O�̃T�[�o�[�iPHP�@4.4.4�j�ł͐���ɓ����Ă��܂����B
��낵����w�삭�������B
275 �Fnobody�����F2008/03/03(��) 23:15:55 ID:???
276 �Fnobody�����F2008/03/04(��) 02:59:10 ID:???
277 �Fnobody�����F2008/03/05(��) 17:20:52 ID:???
<a href="http://jumpres/read.cgi/newsplus/1204390523/1">>>1</a>
<a href="http://jumpres/read.cgi/dqnplus/22043905235/34">>>34</a>
�X���b�h�܂Ƃ߃T�C�g�̍쐬�ɂ����ăA���J�[�̃^�O�����O�������̂ł�
��낵�����肢���܂�
<a href="http://jumpres/read.cgi/dqnplus/22043905235/34">>>34</a>
�X���b�h�܂Ƃ߃T�C�g�̍쐬�ɂ����ăA���J�[�̃^�O�����O�������̂ł�
��낵�����肢���܂�
278 �Fnobody�����F2008/03/05(��) 18:23:39 ID:???
>>277
�������ꂪ Perl �Ɖ��肵�� (Perl �łȂ���� >>1 ��ǂ�ł���) �A����Ȃ��H
s/<a href=".+?">(.+?)<\/a>/$1/g;
�������ꂪ Perl �Ɖ��肵�� (Perl �łȂ���� >>1 ��ǂ�ł���) �A����Ȃ��H
s/<a href=".+?">(.+?)<\/a>/$1/g;
279 �Fnobody�����F2008/03/05(��) 18:52:35 ID:???
���肪�Ƃ��������܂�
280 �Fnobody�����F2008/03/16(��) 09:40:37 ID:???
PHP�̐��K�\���̓o�O�o�O�Ȃ̂Ńo�[�W�������Ⴆ�Γ��삪�ς���ɁA����p�^�[���ɂȂ�Ƃ���������B
281 �Fnobody�����F2008/03/16(��) 12:34:04 ID:???
�R�����Ȃ�B
282 �Fnobody�����F2008/03/16(��) 20:44:54 ID:???
�p�^�[���C���q�Ƀp�����[�^��n���āA�������������������ƃ{���{��������B�펯����B
283 �Fnobody�����F2008/03/17(��) 06:09:10 ID:???
ruby��utf-8����Ƃ������������
284 �Fnobody�����F2008/03/17(��) 08:59:29 ID:???
pcre�̃o�O���ˁB
pcre-dev�̃��[�����O���X�g�ł����ǂ��đ��͂Ȃ�
ttp://www.exim.org/lurker/list/pcre-dev.ja.html
pcre-dev�̃��[�����O���X�g�ł����ǂ��đ��͂Ȃ�
ttp://www.exim.org/lurker/list/pcre-dev.ja.html
285 �Fnobody�����F2008/03/19(��) 14:02:11 ID:6LA3ff9b
���߂ď������݂����Ă��������܂��B
���Ƃ��Ε�����
{if(a)}
������
{if(b)}
������
{/if}
{/if}
�Ɠ���q���������Ƃ��͂ǂ̂悤�Ƀ}�b�`�������炢���ł��傤���H
PHP�ł��肢���܂��B
���Ƃ��Ε�����
{if(a)}
������
{if(b)}
������
{/if}
{/if}
�Ɠ���q���������Ƃ��͂ǂ̂悤�Ƀ}�b�`�������炢���ł��傤���H
PHP�ł��肢���܂��B
286 �Fnobody�����F2008/03/19(��) 15:32:59 ID:???
����q�̃}�b�`�͐��K�\�� (����) �ł͖����B�Ɖ����Ă����Ɨǂ����Ƃ�����炵���B
287 �F�W���A���F2008/03/28(��) 16:46:01 ID:FsCFbn2K
perl �̐��K�\����PHP�ɏ��������Ă���̂ł����A�ǂ����Ă��킩��܂���B
Perl�ł̓}�b�`�����O��� $` $' �Ŏ擾�ł��܂���PHP�ł͂ǂ����Ď擾����̂ł��傤���H
Perl�ł̓}�b�`�����O��� $` $' �Ŏ擾�ł��܂���PHP�ł͂ǂ����Ď擾����̂ł��傤���H
288 �Fnobody�����F2008/03/29(�y) 12:12:17 ID:???
�}�j���A��
289 �Fnobody�����F2008/04/12(�y) 11:24:34 ID:???
�� ���
290 �Fnobody�����F2008/04/13(��) 12:03:16 ID:???
>>287
����
����
291 �Fnobody�����F2008/04/26(�y) 13:57:41 ID:???
age
292 �Fnobody�����F2008/05/04(��) 23:26:54 ID:???
�I���C���[�̐��K�\���O��
�ق������Ǎ�����
�ق������Ǎ�����
293 �Fnobody�����F2008/05/19(��) 20:19:05 ID:???
php��hoge("****","*****");��****��*****��[1][2]�ɓ��ꂽ���̂ł����ǂ���������ł��傤���H
294 �Fnobody�����F2008/05/23(��) 20:19:21 ID:???
AGE
295 �Fnobody�����F2008/05/23(��) 20:19:44 ID:???
AGE
296 �Fnobody�����F2008/06/05(��) 16:44:59 ID:0yepAPED
���݂܂���AFC2�u���O��IP�u���b�N�����̂��߂ɁA���K�\���������Ȃ���Ȃ�Ȃ��Ȃ�܂����B
�����ŁA�����Ă��邩�����Ă��������[�B
IP�@61.78.0.0�`61.85.225.225�@���u���b�N�������̂ł��B
���̂��߂̕\���Ƃ��āA���̂��Ȃ��m�����g���ď����Ă݂��
^61\.[78-85]\.[0-9]+\.[0-9]+
�Ȃ̂��ȂƎv���Ă܂����A�����Ă܂����H
�ǂ�����낵�����肢���܂��B
�����ŁA�����Ă��邩�����Ă��������[�B
IP�@61.78.0.0�`61.85.225.225�@���u���b�N�������̂ł��B
���̂��߂̕\���Ƃ��āA���̂��Ȃ��m�����g���ď����Ă݂��
^61\.[78-85]\.[0-9]+\.[0-9]+
�Ȃ̂��ȂƎv���Ă܂����A�����Ă܂����H
�ǂ�����낵�����肢���܂��B
297 �Fnobody�����F2008/06/05(��) 17:25:51 ID:???
^61\.(?:7[89]|8[0-5])\.
��������Ȃ�����
��������Ȃ�����
298 �Fnobody�����F2008/06/05(��) 18:12:26 ID:0yepAPED
>>297
���肪�Ƃ��������܂��B
^61\.[78-85]\.�@�̂Ƃ��낪�A^61\.(?:7[89]|8[0-5])\.
���Č����Ӗ��ł���ˁH
�Ȃ�قǁB78-85����_���Ȃ�ł��ˁB���肪�Ƃ��������܂��I
���肪�Ƃ��������܂��B
^61\.[78-85]\.�@�̂Ƃ��낪�A^61\.(?:7[89]|8[0-5])\.
���Č����Ӗ��ł���ˁH
�Ȃ�قǁB78-85����_���Ȃ�ł��ˁB���肪�Ƃ��������܂��I
299 �Fnobody�����F2008/06/06(��) 03:25:44 ID:???
���ꂪ��Ԃ킩��₷���B�ȏ�
^61\.(78|79|80|81|82|83|84|85)\..*
^61\.(78|79|80|81|82|83|84|85)\..*
300 �Fnobody�����F2008/06/08(��) 17:41:28 ID:???
PHP�ŁA�P�y�[�W����HTML�̃\�[�X��$s�ɓ����Ă���Ƃ��܂��B
�����ŁA����$s�������̃^�O�������폜�������̂ł����A���܂������܂���B
�Ⴆ��<meta �`�`�` />�Ƃ����^�O�������������Ƃ��āA��������ׂĎ�菜�����\�[�X����肽���̂ł��B
$s = eregi_replace("<meta.*?>", "", $s);
�Ƃ���Ă݂��̂ł����A$s����ɂȂ��Ă��܂��̂ł��B
���w�삭�������B
�����ŁA����$s�������̃^�O�������폜�������̂ł����A���܂������܂���B
�Ⴆ��<meta �`�`�` />�Ƃ����^�O�������������Ƃ��āA��������ׂĎ�菜�����\�[�X����肽���̂ł��B
$s = eregi_replace("<meta.*?>", "", $s);
�Ƃ���Ă݂��̂ł����A$s����ɂȂ��Ă��܂��̂ł��B
���w�삭�������B
301 �Fnobody�����F2008/06/08(��) 22:40:27 ID:???
2�ߋ����O���炢�łƂ������t�͈ꌩ�˂������Ă���悤�Ɍ�����
���̎���̓����͂��̃X���̒��ɂ����Ƃ����A�q���g���o���Ă���킯��
�܂��A�c���f���Ȃ킯�ł��B
���̎���̓����͂��̃X���̒��ɂ����Ƃ����A�q���g���o���Ă���킯��
�܂��A�c���f���Ȃ킯�ł��B
302 �Fnobody�����F2008/06/09(��) 02:40:38 ID:???
303 �Fnobody�����F2008/06/09(��) 06:50:27 ID:???
>>300
'<meta[^>]*>'
'<meta[^>]*>'
304 �Fnobody�����F2008/06/09(��) 23:50:23 ID:???
300�ł��B
���肪�Ƃ��������܂��I
�����Ȃ�ł��A�ŒZ�}�b�`�������Ȃ��Ȃ��Ǝv���Ă��āA�܂���ereg��
�ŒZ�}�b�`�ł��Ȃ��Ƃ͎v���܂���ł����B
preg�ł���ĉ������܂����I�I
���肪�Ƃ��������܂��I
�����Ȃ�ł��A�ŒZ�}�b�`�������Ȃ��Ȃ��Ǝv���Ă��āA�܂���ereg��
�ŒZ�}�b�`�ł��Ȃ��Ƃ͎v���܂���ł����B
preg�ł���ĉ������܂����I�I
305 �Fnobody�����F2008/06/11(��) 15:58:44 ID:???
300�Ǝ��Ă邩������Ȃ��̂ł���
<a href="aa">11</a><a href="bb">22</a>�@����������������Ƃ�
11��22���������o�������Ǝv��
preg_match_all("/<a(.*)>(.*)<\/a>/", ��, $test)
�Ƃ���Ă݂��Ƃ���A���o�����̂�
href="aa">11</a><a href="bb"��22�ɂȂ��Ă��܂��܂����B
?�����Ă݂Ă����܂������܂���ł����B
�Ӑ}�����悤�Ɏ��o�������ꍇ�ǂ̂悤�ɋL�q��������̂ł��傤���H
�g�p���Ă��錾���php�ł��B
<a href="aa">11</a><a href="bb">22</a>�@����������������Ƃ�
11��22���������o�������Ǝv��
preg_match_all("/<a(.*)>(.*)<\/a>/", ��, $test)
�Ƃ���Ă݂��Ƃ���A���o�����̂�
href="aa">11</a><a href="bb"��22�ɂȂ��Ă��܂��܂����B
?�����Ă݂Ă����܂������܂���ł����B
�Ӑ}�����悤�Ɏ��o�������ꍇ�ǂ̂悤�ɋL�q��������̂ł��傤���H
�g�p���Ă��錾���php�ł��B
306 �Fnobody�����F2008/06/11(��) 21:01:33 ID:???
>>305
�F�X�ԈႦ�Ă�B
�܂��AA�^�O�ň͂�ł镔�����������o���Ȃ�( )�̃y�A�͈�ł����͂��B
����?���g���Ă݂��ƌ����������������Ⴂ���Ă�B
300�͂킩���ĂčŒZ�}�b�`�����Ă邪305�킩���ĂȂ����낤�H
*��?�ɒu���������肵�ĂȂ����H
�F�X�ԈႦ�Ă�B
�܂��AA�^�O�ň͂�ł镔�����������o���Ȃ�( )�̃y�A�͈�ł����͂��B
����?���g���Ă݂��ƌ����������������Ⴂ���Ă�B
300�͂킩���ĂčŒZ�}�b�`�����Ă邪305�킩���ĂȂ����낤�H
*��?�ɒu���������肵�ĂȂ����H
307 �Fnobody�����F2008/06/12(��) 00:47:05 ID:Hj50XmAm
JavaScript�ʼn��L�̂悤�ȃf�[�^���擾�������ł��B
hogehoge[1]��1
hogehoge[123]��123
hogehoge[1243][]��1243
[]�̒��g���擾�������A[]��2�������ꍇ�͍ŏ���[]�̒��g���擾���܂��B
�i�������A2�ڂ�[]�͏�ɋ�ł��B�j
hogehoge�͔C�ӂ̕�����ŁA[]�̒��g�͉�����������Ȃ������̌J��Ԃ��ł��B
�ȏゲ�ڝ��̒����肢���܂��B
hogehoge[1]��1
hogehoge[123]��123
hogehoge[1243][]��1243
[]�̒��g���擾�������A[]��2�������ꍇ�͍ŏ���[]�̒��g���擾���܂��B
�i�������A2�ڂ�[]�͏�ɋ�ł��B�j
hogehoge�͔C�ӂ̕�����ŁA[]�̒��g�͉�����������Ȃ������̌J��Ԃ��ł��B
�ȏゲ�ڝ��̒����肢���܂��B
308 �Fnobody�����F2008/06/12(��) 08:16:53 ID:???
>>307
����
����
309 �Fnobody�����F2008/06/12(��) 14:43:44 ID:???
/\[([1234]+)\]/
310 �Fnobody�����F2008/06/12(��) 14:53:37 ID:???
GJ
311 �Fnobody�����F2008/06/28(�y) 08:39:36 ID:9QUTsyON
PHP����X������U������Ă��܂����B
�g�p�����PHP�ł��B
�ȉ��̂悤�ȕϐ�������܂��B
$str = <<<EOM
������<br />
������<br />
������<br />
<!--S-->
������<br />
������<br />
<!--E-->
EOM;
���̂���<!--S-->��<!--E-->�ň͂܂�Ă���<br />�������폜�������̂ł����A
���K�\�����g�����Y��ɏ�����ł��傤���H
�ȉ��̂悤�Ɏ������̂ł����A<!--S-->��<!--E-->�������邾���ł����B
$str = preg_replace("/<!--S-->([\W\w]+)<!--E-->/",str_replace("<br />","","\\1"),$str);
�܂��A<!--S(E)-->�ň͂܂�Ă��镔���͉��s�┼�p�p�����Ȃǂ��܂܂��ꍇ������܂��B
�ǂȂ������������������܂��ł��傤���B��낵�����肢�������܂��B
�g�p�����PHP�ł��B
�ȉ��̂悤�ȕϐ�������܂��B
$str = <<<EOM
������<br />
������<br />
������<br />
<!--S-->
������<br />
������<br />
<!--E-->
EOM;
���̂���<!--S-->��<!--E-->�ň͂܂�Ă���<br />�������폜�������̂ł����A
���K�\�����g�����Y��ɏ�����ł��傤���H
�ȉ��̂悤�Ɏ������̂ł����A<!--S-->��<!--E-->�������邾���ł����B
$str = preg_replace("/<!--S-->([\W\w]+)<!--E-->/",str_replace("<br />","","\\1"),$str);
�܂��A<!--S(E)-->�ň͂܂�Ă��镔���͉��s�┼�p�p�����Ȃǂ��܂܂��ꍇ������܂��B
�ǂȂ������������������܂��ł��傤���B��낵�����肢�������܂��B
312 �Fnobody�����F2008/06/28(�y) 10:12:28 ID:???
substr_replace��strpos�łł������ȋC�����邪
>>312
���肪�Ƃ��������܂��A�������ʼn������܂����I
���肪�Ƃ��������܂��A�������ʼn������܂����I
314 �Fnobody�����F2008/07/02(��) 18:58:36 ID:???
,"/web/sendmail.php","10","10","2000"
�������������̕��͂�
,"2000"
�̂ݒ��o��������ł����A�ǂ�����������ł��傤���H
",".*[0-9]"$
����"10","10","2000"�܂ŏE�����Ⴄ��ł��E�E�E�B
�������������̕��͂�
,"2000"
�̂ݒ��o��������ł����A�ǂ�����������ł��傤���H
",".*[0-9]"$
����"10","10","2000"�܂ŏE�����Ⴄ��ł��E�E�E�B
315 �Fnobody�����F2008/07/02(��) 21:54:01 ID:???
,\"[0-9]{4}\"
>>315
���肪�Ƃ��������܂��B
�m���ɁA����ŗ�͏E���܂������A10��2000�̕����͕ϓ������ł��B
����4����������5����������Ɨl�X�Ȃ̂ŁA�ǂ��������ȂƁE�E�E�B
���肪�Ƃ��������܂��B
�m���ɁA����ŗ�͏E���܂������A10��2000�̕����͕ϓ������ł��B
����4����������5����������Ɨl�X�Ȃ̂ŁA�ǂ��������ȂƁE�E�E�B
317 �Fnobody�����F2008/07/03(��) 15:46:05 ID:???
,\"[1-9][0-9]*\"
>>317
���肪�Ƃ��������܂��B
���ꂾ�Ɓ@,"10","10","2000"�@�܂ŏE���Ă��܂��܂��E�E�E�B
�����Y��Ă��܂������A�G�ۂ��g���Ĉꊇ�I�����Ă��܂��B
���肪�Ƃ��������܂��B
���ꂾ�Ɓ@,"10","10","2000"�@�܂ŏE���Ă��܂��܂��E�E�E�B
�����Y��Ă��܂������A�G�ۂ��g���Ĉꊇ�I�����Ă��܂��B
319 �Fnobody�����F2008/07/03(��) 16:04:08 ID:???
> 10��2000�̕����͕ϓ������ł�
�ǂ��ϓ������
�Ƃ�o�������ꏊ�̏�������{��ŏ����Ă�
>315��5���ɂ��Ή������邾���Ȃ�
,\"[0-9]{4,5}\"
�ǂ��ϓ������
�Ƃ�o�������ꏊ�̏�������{��ŏ����Ă�
>315��5���ɂ��Ή������邾���Ȃ�
,\"[0-9]{4,5}\"
320 �Fnobody�����F2008/07/03(��) 16:05:46 ID:???
>>320
���肪�Ƃ��������܂��I�I�I�o���܂����I�I�I
���肪�Ƃ��������܂����[�B
>>319
���肪�Ƃ��������܂��B
>>320�ʼn������܂������A�ɒ[�Șb1�`99999999�̊Ԃŕϓ����܂��B
���肪�Ƃ��������܂��I�I�I�o���܂����I�I�I
���肪�Ƃ��������܂����[�B
>>319
���肪�Ƃ��������܂��B
>>320�ʼn������܂������A�ɒ[�Șb1�`99999999�̊Ԃŕϓ����܂��B
322 �Fnobody�����F2008/07/03(��) 16:21:37 ID:???
>>321
���R���ƌ���
���R���ƌ���
323 �Fnobody�����F2008/07/03(��) 18:01:39 ID:???
314 �͏�o���~�Ƃ�����������������A�͂₭����
324 �Fnobody�����F2008/07/03(��) 19:43:29 ID:???
�����������K�\���X���Łu�������������̕��́v�Ȃ�Ď��₷�鎞�_�Łi����
325 �Fnobody�����F2008/07/03(��) 20:01:56 ID:???
���ۓI�ȕ\���̎���̓X���[
326 �F�o�g�o�F2008/07/04(��) 18:37:34 ID:DM0Om0jz
PHP ���K�\��
PHP�̐��K�\��������Ă���̂ł����A�ǂ������܂������܂���B����͈�ԊȒP�Ȑ��K�\�����������̂ł����A�ǂ��������悢�̂ł��傤���B
$h = '(���O)�l�̉��ID��(abc12)�ŁA(5)�ԖڂɈ̂����ł��B';
�Ƃ�������A���O�A���ID�A�ԍ����o���ɂ́A�ǂ̂悤�ɂ�����悢�̂ł��傤���H
���ۂ�()�͎g�p���܂���B
�܂��A$1 ��@$2 �Ȃǂ��g�������̂ł����A����܂łł�����肢�������ł��B
�ꉞ�����Ȃ�ɍl���܂����B
preg_match('/^*.([a-zA-Z0-9]){2}([0-9]+)','���O$2.ID$1 $3 �ԖڂɈ̂�');
()���g���A2�}�b�`���������Ƃ��Ȃǂɕ����邱�Ƃ��ł���̂ł��傤���H
(���O)�l��(����)
��:���Y�l��5
���̂Ƃ����Y�l�Ƃ������{��̕������擾����ɂ�/^(+.)([0-9])$/
�����Ŗ��O��$1�ɂȂ�A������$2�ɂȂ�̂ł��傤���H
�ǂ̂悤�Ȏ���$1��$2���ǂ������ǂ����Ȃ̂��́A�ǂ̂悤�ɂ�����킩��̂ł��傤���H
���X�������₷���܂���B�킩�邩�������Ă��������B
PHP�̐��K�\��������Ă���̂ł����A�ǂ������܂������܂���B����͈�ԊȒP�Ȑ��K�\�����������̂ł����A�ǂ��������悢�̂ł��傤���B
$h = '(���O)�l�̉��ID��(abc12)�ŁA(5)�ԖڂɈ̂����ł��B';
�Ƃ�������A���O�A���ID�A�ԍ����o���ɂ́A�ǂ̂悤�ɂ�����悢�̂ł��傤���H
���ۂ�()�͎g�p���܂���B
�܂��A$1 ��@$2 �Ȃǂ��g�������̂ł����A����܂łł�����肢�������ł��B
�ꉞ�����Ȃ�ɍl���܂����B
preg_match('/^*.([a-zA-Z0-9]){2}([0-9]+)','���O$2.ID$1 $3 �ԖڂɈ̂�');
()���g���A2�}�b�`���������Ƃ��Ȃǂɕ����邱�Ƃ��ł���̂ł��傤���H
(���O)�l��(����)
��:���Y�l��5
���̂Ƃ����Y�l�Ƃ������{��̕������擾����ɂ�/^(+.)([0-9])$/
�����Ŗ��O��$1�ɂȂ�A������$2�ɂȂ�̂ł��傤���H
�ǂ̂悤�Ȏ���$1��$2���ǂ������ǂ����Ȃ̂��́A�ǂ̂悤�ɂ�����킩��̂ł��傤���H
���X�������₷���܂���B�킩�邩�������Ă��������B
327 �Fnobody�����F2008/07/04(��) 23:02:41 ID:???
328 �Fnobody�����F2008/07/15(��) 00:11:32 ID:PMHjKbcP
���₳���ĉ������B
PHP5���g���Ă��܂��B
PHP�̐��K�\�������g���ăf�[�^���擾���悤�Ǝv���Ă���̂ł�����肭�����܂���
<INPUT maxLength=20 name=id value="">
���̂悤�ȕ������ΏۂɁA������utype�v���܂܂�Ă��Ȃ��ꍇ�A����́umaxLength=20 name=id value=""�v
���擾�������̂ł��B
�S���ɑ��ČJ��Ԃ��擾�������̂�preg_match_all���g���Ă��܂��B
preg_match_all( "/<input (^type)[^<](.*?)>/is", $data, $matchs )
���̂悤�ɏ������̂ł����q�b�g���Ă���܂���B
�h�L�������g������ƁA���蕶���Ɋւ��Ă�[^a-z]�̂悤�ȏ������őΉ��ł���̂ł���
������Ɋւ��Ă͂ǂ̂悤�ɂ���悢�̂ł��傤���H
�A�h�o�C�X������K���ł��B
�X�������肢�v���܂��B
PHP5���g���Ă��܂��B
PHP�̐��K�\�������g���ăf�[�^���擾���悤�Ǝv���Ă���̂ł�����肭�����܂���
<INPUT maxLength=20 name=id value="">
���̂悤�ȕ������ΏۂɁA������utype�v���܂܂�Ă��Ȃ��ꍇ�A����́umaxLength=20 name=id value=""�v
���擾�������̂ł��B
�S���ɑ��ČJ��Ԃ��擾�������̂�preg_match_all���g���Ă��܂��B
preg_match_all( "/<input (^type)[^<](.*?)>/is", $data, $matchs )
���̂悤�ɏ������̂ł����q�b�g���Ă���܂���B
�h�L�������g������ƁA���蕶���Ɋւ��Ă�[^a-z]�̂悤�ȏ������őΉ��ł���̂ł���
������Ɋւ��Ă͂ǂ̂悤�ɂ���悢�̂ł��傤���H
�A�h�o�C�X������K���ł��B
�X�������肢�v���܂��B
329 �Fnobody�����F2008/07/15(��) 02:02:18 ID:???
330 �F328�F2008/07/15(��) 03:07:47 ID:PMHjKbcP
>>329
���X�L��������܂��B
��i�K�ڂ�
preg_match_all( "/(<input �utype���܂܂Ȃ�������Ƀ}�b�`����悤�Ȑ��K�\���v[^<]>)/is", $data, $matchs )
�ƂȂ�Ǝv���̂ł����A���̕����͂ǂ̂悤�ɂ��ď����悢�̂ł��傤���H
�͂��߁A��i�K���o���l�����̂ł����A����
�utype���܂܂Ȃ�������Ƀ}�b�`����悤�Ȑ��K�\���v���ǂ����Ă��킩�炸�ł����B
���X�L��������܂��B
��i�K�ڂ�
preg_match_all( "/(<input �utype���܂܂Ȃ�������Ƀ}�b�`����悤�Ȑ��K�\���v[^<]>)/is", $data, $matchs )
�ƂȂ�Ǝv���̂ł����A���̕����͂ǂ̂悤�ɂ��ď����悢�̂ł��傤���H
�͂��߁A��i�K���o���l�����̂ł����A����
�utype���܂܂Ȃ�������Ƀ}�b�`����悤�Ȑ��K�\���v���ǂ����Ă��킩�炸�ł����B
���ȃ��X�ł����A��ʂ��F�X�����Ă����炢���܂����B
�����������܂����B
��肠�����A�Y���͈͂�preg_match_all�Ŏ擾��Apreg_match��type�����邩���肵�ē�i�o���܂����B
�����������܂����B
��肠�����A�Y���͈͂�preg_match_all�Ŏ擾��Apreg_match��type�����邩���肵�ē�i�o���܂����B
332 �Fnobody�����F2008/07/17(��) 17:35:14 ID:LcfXPY+p
<<���o�Ă��āA���̌㏉�߂�<br><br>���o��Ƃ���܂ł̃}�b�`���@�������Ă��������B
preg�ł��B
�Ⴆ�A
hogehoge<<hogehogeh<br>oge<br><br>hogehoge<br><br>hoge<<hoge�@��
�@�@�@�@�@ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~�@�@ �@�̕����ł��B
preg�ł��B
�Ⴆ�A
hogehoge<<hogehogeh<br>oge<br><br>hogehoge<br><br>hoge<<hoge�@��
�@�@�@�@�@ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~�@�@ �@�̕����ł��B
333 �Fnobody�����F2008/07/17(��) 17:53:17 ID:???
�����D���H����������������
335 �Fnobody�����F2008/07/19(�y) 19:32:09 ID:???
�����y���r�����z���H����������������
336 �Fnobody�����F2008/07/20(��) 09:34:06 ID:???
�ł��܂����B�Ͽ
337 �Fnobody�����F2008/07/20(��) 11:43:35 ID:???
�g�ъG���������ׂ�
�u�G�v�ɒu���������邱�Ƃ͂ł��Ȃ��̂ł��傤���H
preg_replace("/[ - ]/","�G",$hoge);
�u�G�v�ɒu���������邱�Ƃ͂ł��Ȃ��̂ł��傤���H
preg_replace("/[ - ]/","�G",$hoge);
338 �Fnobody�����F2008/07/20(��) 12:01:15 ID:LU799vx+
>>337
�L�����A�́H
�L�����A�́H
339 �Fnobody�����F2008/07/20(��) 12:03:54 ID:???
340 �Fnobody�����F2008/07/20(��) 12:18:57 ID:???
>>337
�u�������鎖�͂ł��邯�ǁA���K�\�������ł͖���
�u�������鎖�͂ł��邯�ǁA���K�\�������ł͖���
341 �Fnobody�����F2008/07/20(��) 12:27:01 ID:???
>>340�ł́A���K�\���ȊO�̂��̂�OK�Ȃ̂ŁA
�����Ă������������ł��B
�����Ă������������ł��B
342 �Fnobody�����F2008/07/20(��) 13:09:57 ID:???
�G�����@�ϊ��@preg�@�Ƃ��ŃO�O�������ł��o�Ă��邾��B�B�B
����������100�{�����B
����������100�{�����B
343 �Fnobody�����F2008/07/24(��) 00:50:31 ID:/c2OsNI4
example.html�ɏ����ꂽ
<table>
<table>
344 �Fnobody�����F2008/07/24(��) 00:58:57 ID:/c2OsNI4
>>343
�딚�����B�B�\����Ȃ��B�B
example.html�ɏ����ꂽ
<table>
<tr><th>�Q�����˂�</th><td>WebProg��</td></tr>
</table>
��php��fopen, fgets��1�s���ǂݎ���Ă��܂��B
<tr>����n�܂����s�́u�Q�����˂�v��WebProg�uWebProg�v�����̂ݒ��o�������̂�
preg_replace("/^<tr><th>(.*?)</th><td>([a-zA-Z])</td>/i","$1$2",$str);
�Ƃ����̂ł����A���܂����o�ł��܂���B
�A�h�o�C�X��������������肪�����ł�
�딚�����B�B�\����Ȃ��B�B
example.html�ɏ����ꂽ
<table>
<tr><th>�Q�����˂�</th><td>WebProg��</td></tr>
</table>
��php��fopen, fgets��1�s���ǂݎ���Ă��܂��B
<tr>����n�܂����s�́u�Q�����˂�v��WebProg�uWebProg�v�����̂ݒ��o�������̂�
preg_replace("/^<tr><th>(.*?)</th><td>([a-zA-Z])</td>/i","$1$2",$str);
�Ƃ����̂ł����A���܂����o�ł��܂���B
�A�h�o�C�X��������������肪�����ł�
345 �Fnobody�����F2008/07/24(��) 01:43:31 ID:???
/^<tr><th>(.*?)</th><td>([a-zA-Z])</td>/i
���K�\���� / �Ŏn�܂��Ă邩�� / �ŏI��邱�ƂɂȂ�킯�����ǁA�r����</th>���Ă̂�����킯��
m#<t[dh][^>]*>(.*?)</t[dh]><t[dh][^>]*>(\w+)#i
����Ȋ����ɂȂ邩��
���K�\���� / �Ŏn�܂��Ă邩�� / �ŏI��邱�ƂɂȂ�킯�����ǁA�r����</th>���Ă̂�����킯��
m#<t[dh][^>]*>(.*?)</t[dh]><t[dh][^>]*>(\w+)#i
����Ȋ����ɂȂ邩��
346 �Fnobody�����F2008/07/24(��) 23:33:27 ID:???
�f���~�^�̖�肾������Ȃ��́H
preg_replace("/^<tr><th>(.*?)<\/th><td>([a-zA-Z])<\/td>/i","$1$2",$str);
preg_replace("/^<tr><th>(.*?)<\/th><td>([a-zA-Z])<\/td>/i","$1$2",$str);
347 �Fnobody�����F2008/07/25(��) 08:54:32 ID:???
�������[a-zA-Z]�A[a-zA-Z]+�������Ȃ��Ă������́H
348 �Fnobody�����F2008/07/27(��) 01:11:32 ID:sEx2Pn85
���₳���Ă��������B
�T�N���G�f�B�^�ɋS��5.9.1�𓋍ڂ��Đ��K�\���̕������Ă���̂ł����A�茳�ɂ���ڐ����K�\���ɂ�
(<)?\w+(?(1)>)
���̂悤�ȗႪ����A<�������>�̃}�b�`�����݂�?�Ƃ������Ƃ��ł���݂����ł��B
�����A�S�Ԃ͂��̕\�����T�|�[�g���Ă��Ȃ��݂����ł��B
http://www.geocities.jp/kosako3/oniguruma/doc/RE.ja.txt
���l�̂��Ƃ��S�Ԃł�����������@���Ă���̂ł��傤���H
�T�N���G�f�B�^�ɋS��5.9.1�𓋍ڂ��Đ��K�\���̕������Ă���̂ł����A�茳�ɂ���ڐ����K�\���ɂ�
(<)?\w+(?(1)>)
���̂悤�ȗႪ����A<�������>�̃}�b�`�����݂�?�Ƃ������Ƃ��ł���݂����ł��B
�����A�S�Ԃ͂��̕\�����T�|�[�g���Ă��Ȃ��݂����ł��B
http://www.geocities.jp/kosako3/oniguruma/doc/RE.ja.txt
���l�̂��Ƃ��S�Ԃł�����������@���Ă���̂ł��傤���H
349 �Fnobody�����F2008/07/29(��) 05:43:25 ID:???
��ԍŏ��ɏo�Ă����u=�������������ɂ͂ǂ������炢���ł��傤���B
C#�ł��B
C#�ł��B
350 �Fnobody�����F2008/07/29(��) 19:46:22 ID:???
�s����=�Ƃ����Ӗ��Ȃ�
/^=/m
������C#�ł̐��K�\���̎g�����͒m���̂ʼn�������B
/^=/m
������C#�ł̐��K�\���̎g�����͒m���̂ʼn�������B
351 �Fnobody�����F2008/08/06(��) 01:01:06 ID:hVakYDWk
PHP5�o�����Ă̏��S�҂ł�
�X���`����()��(?:)�̈Ⴂ�ɂ��Ď��₳��Ă܂�����
?:�̈Ӗ����ĂȂ�ł����H
�킩��₷������y�[�W�Ȃǂ���������Ă��������B
�X���`����()��(?:)�̈Ⴂ�ɂ��Ď��₳��Ă܂�����
?:�̈Ӗ����ĂȂ�ł����H
�킩��₷������y�[�W�Ȃǂ���������Ă��������B
352 �Fnobody�����F2008/08/06(��) 02:34:12 ID:???
google
353 �Fnobody�����F2008/08/06(��) 19:40:10 ID:???
354 �Fnobody�����F2008/08/21(��) 14:34:46 ID:wSsr/o3s
���₳���ĉ������B
PHP5���g�p���Ă��܂��B
��������Ƀ}���`�o�C�g��������ł��܂܂�Ă���ΐ^�ƌ������K�\�����s�������̂ł���
�ǂ̂悤�ɂ���悢�ł��傤���H
�h�L�������g�����璲�ׂĂ݂āA
mb_ereg("[�O-�X���|���`�|�y���|��A�|��]", $str )
�̂悤�ɂ��Ă݂��̂ł����A����ł͊����Ƀq�b�g���܂���B
�A�h�o�C�X������K���ł��B
�X�������肢�v���܂��B
PHP5���g�p���Ă��܂��B
��������Ƀ}���`�o�C�g��������ł��܂܂�Ă���ΐ^�ƌ������K�\�����s�������̂ł���
�ǂ̂悤�ɂ���悢�ł��傤���H
�h�L�������g�����璲�ׂĂ݂āA
mb_ereg("[�O-�X���|���`�|�y���|��A�|��]", $str )
�̂悤�ɂ��Ă݂��̂ł����A����ł͊����Ƀq�b�g���܂���B
�A�h�o�C�X������K���ł��B
�X�������肢�v���܂��B
355 �Fnobody�����F2008/08/21(��) 14:44:38 ID:???
�P���ɐ擪�r�b�g�����������Ă邩�ǂ�������悭�Ȃ��H
[\x80-\xff]
[\x80-\xff]
356 �Fnobody�����F2008/08/21(��) 15:28:45 ID:???
357 �Fnobody�����F2008/08/22(��) 02:32:16 ID:???
>>354
�P�o�C�g����������̂�ے肷���?
���ƁA�����R�[�h�ɂ���Ă͔��p�J�i���}���`�o�C�g��������
��������Ȃ������肷����ǁA�ǂ�����̂���?
�P�o�C�g����������̂�ے肷���?
���ƁA�����R�[�h�ɂ���Ă͔��p�J�i���}���`�o�C�g��������
��������Ȃ������肷����ǁA�ǂ�����̂���?
358 �Fnobody�����F2008/08/25(��) 10:35:16 ID:P/JycA8t
html�̃^�O���폜����̂ɁA�ӂ���
$line =~ s/<\/?[^>]+>//g; ----(1)
���Ǝv�����ǁA�ǂ����Ō������@�ł́A
$line =~ s/<[^>]*(>|$)//g; ----(2)
�ƂȂ��Ă��B���ꓮ��͓����Ȃ̂��ȁH(2)�̈Ӗ����C�}�C�`������Ȃ��B
$line =~ s/<\/?[^>]+>//g; ----(1)
���Ǝv�����ǁA�ǂ����Ō������@�ł́A
$line =~ s/<[^>]*(>|$)//g; ----(2)
�ƂȂ��Ă��B���ꓮ��͓����Ȃ̂��ȁH(2)�̈Ӗ����C�}�C�`������Ȃ��B
359 �Fnobody�����F2008/08/25(��) 20:52:33 ID:???
�i�P�j�� \/? �͏����Ă��Ӗ��Ȃ��i/��[^>]�Ɋ܂܂�邩��j
�i�Q�j�� (>|$)�́A$line�Ƃ����ϐ������琄������ɍs�P�ʂœǂݍ���Œ�����������
�ꍇ�ɁA�^�O�̓r���ʼn��s����Ă���>��������Ȃ��Ă��s���܂ō폜����ׁH
�ł����������玟�̍s�ŏ��������܂��s���Ȃ����悭�킩���
�s�P�ʂ��ƃ^�O�r���ʼn��s�����ꍇ�����邩��S���ǂݍ���ň�C�ɏ���������
s/<.*?>//g;
s/<[^>]*>//g;
�ȂǂȂǁE�E
�i�Q�j�� (>|$)�́A$line�Ƃ����ϐ������琄������ɍs�P�ʂœǂݍ���Œ�����������
�ꍇ�ɁA�^�O�̓r���ʼn��s����Ă���>��������Ȃ��Ă��s���܂ō폜����ׁH
�ł����������玟�̍s�ŏ��������܂��s���Ȃ����悭�킩���
�s�P�ʂ��ƃ^�O�r���ʼn��s�����ꍇ�����邩��S���ǂݍ���ň�C�ɏ���������
s/<.*?>//g;
s/<[^>]*>//g;
�ȂǂȂǁE�E
�Ԉ�����As/<.*?>//g;���Ɖ��s�ɑΉ��ł��Ȃ�����
s/<[\s\S]*?>//;�݂����ɂȂ��
s/<[\s\S]*?>//;�݂����ɂȂ��
361 �Fnobody�����F2008/08/25(��) 21:28:12 ID:???
����As�g������A���ʁB
362 �Fnobody�����F2008/08/25(��) 22:34:46 ID:???
>>358
(2)��SGML�̃V���[�g�^�O�̑Ή��Ƃ��H
ttp://www.asahi-net.or.jp/~SD5A-UCD/rec-html401j/appendix/notes.html#h-B.3.7
�J�n�^�O�őO�̃^�O�����ȊO�́A���W���[�ȃu���E�U�͑Ή����ĂȂ������͂��Ȃ̂ŁA
���܂肱�����Ȃ��Ă������Ǝv�����ǁB
(2)��SGML�̃V���[�g�^�O�̑Ή��Ƃ��H
ttp://www.asahi-net.or.jp/~SD5A-UCD/rec-html401j/appendix/notes.html#h-B.3.7
�J�n�^�O�őO�̃^�O�����ȊO�́A���W���[�ȃu���E�U�͑Ή����ĂȂ������͂��Ȃ̂ŁA
���܂肱�����Ȃ��Ă������Ǝv�����ǁB
���肪�Ƃ��������܂����B
���s�����̌��Ƃ��A���ɂȂ�܂����B
�v���O������ł́A�ǂ������������Ȃ̂ŁA�C�ɂȂ��Ă����̂ŁB
���s�����̌��Ƃ��A���ɂȂ�܂����B
�v���O������ł́A�ǂ������������Ȃ̂ŁA�C�ɂȂ��Ă����̂ŁB
364 �Fnobody�����F2008/08/27(��) 15:31:16 ID:j0h2/LpG
���K�\���ŔY��ł��܂��B
preg_match_all( "/((aaa|bbb|ccc).*?)(aaa|bbb|ccc|$)/is", $str, $maches )
���̂悤�Ȍ`�ɂĈȉ��̂悤�ȓ��e�̌J��Ԃ������I�ɔ����o�����Ƃ��Ă���̂ł����ꕔ��肭�����܂���
---------------------
aaa
����������
bbb
����������
ccc
����������
---------------------
��L���K�\���ł�
aaa
����������
bb
����������
cc
����������
�ƌ����悤�Ɉ�ڈȍ~�̃p�^�[���}�b�`������̐擪��bb��cc�Ƃ��Ĉꕶ�������Ă��܂��܂��B
�{����bbb�Accc�Ƃ����ƃq�b�g���������̂ł����A���ꂪ�s���܂���B
�}�b�`��̕�����|�C���^���u�O�������ē��������v�̂悤�ɂ��炷�������邩�A�������̃p�^�[���}�b�`�\����
���������������Ǝv���̂ł����A�ǂ��ɂ��悢���@���v�����܂���B
���͓Y��������K���ł��B
preg_match_all( "/((aaa|bbb|ccc).*?)(aaa|bbb|ccc|$)/is", $str, $maches )
���̂悤�Ȍ`�ɂĈȉ��̂悤�ȓ��e�̌J��Ԃ������I�ɔ����o�����Ƃ��Ă���̂ł����ꕔ��肭�����܂���
---------------------
aaa
����������
bbb
����������
ccc
����������
---------------------
��L���K�\���ł�
aaa
����������
bb
����������
cc
����������
�ƌ����悤�Ɉ�ڈȍ~�̃p�^�[���}�b�`������̐擪��bb��cc�Ƃ��Ĉꕶ�������Ă��܂��܂��B
�{����bbb�Accc�Ƃ����ƃq�b�g���������̂ł����A���ꂪ�s���܂���B
�}�b�`��̕�����|�C���^���u�O�������ē��������v�̂悤�ɂ��炷�������邩�A�������̃p�^�[���}�b�`�\����
���������������Ǝv���̂ł����A�ǂ��ɂ��悢���@���v�����܂���B
���͓Y��������K���ł��B
365 �Fnobody�����F2008/08/28(��) 12:04:03 ID:???
�e�X�g���Ă����邩�炻�̂܂܃R�s�y�ł���R�[�h�ɏ��������Ă����ɍڂ���
366 �Fnobody�����F2008/08/28(��) 18:14:41 ID:Gzy07epa
�����������@����������
���������@��������
�ȂɁ@�ʂ˂́@�͂Ђӂւ�
����
�u�����������v�u���������v�u�ȂɁv
���ɒu��������ɂ͂ǂ���������ł����H
(PHP)
$hoge = preg_replace("/^([^�@]+)/m","<b>\\1</b>",$hoge);
���Ⴄ�܂������܂���B�B�B
���������@��������
�ȂɁ@�ʂ˂́@�͂Ђӂւ�
����
�u�����������v�u���������v�u�ȂɁv
���ɒu��������ɂ͂ǂ���������ł����H
(PHP)
$hoge = preg_replace("/^([^�@]+)/m","<b>\\1</b>",$hoge);
���Ⴄ�܂������܂���B�B�B
�����܂���B
���ȉ������܂����B
���ȉ������܂����B
368 �Fnobody�����F2008/08/28(��) 18:44:08 ID:???
������������ĉ������B
369 �Fnobody�����F2008/08/28(��) 18:50:35 ID:???
���
$hoge = preg_replace("/^([^�@]+)/m","<b>\\1</b>",$hoge);
$hoge = str_replace("<br>","<br>\n",$hoge);
���ď����Ă܂���������
$hoge = preg_replace("/^([^�@]+)/m","<b>\\1</b>",$hoge);
$hoge = str_replace("<br>","<br>\n",$hoge);
���ď����Ă܂���������
370 �F364�F2008/08/29(��) 11:10:56 ID:rNMP0NTC
>>365
���X���肪�Ƃ��������܂��B
������x�l�������Ă݂ď��������Ƃ��̂悤�ȃR�[�h�ɂȂ�܂���PHP5�ɂȂ�܂��B
// �Ώە�����
$str = "ABCDaaaEFGaaaaHIJKaaaaa";
// ���K�\��
preg_match_all( "/([A-Z]+?aaa.*?)([A-Z]|$)/is", $str, $maches );
// ���ʕ\��
$c = count( $maches[1] );
for ( $i = 0; $i < $c; $i++ ) {
print "=> {$maches[1][$i]}\n";
}
=> ABCDaaa
=> FGaaa
=> HIJKaaa
�����
=> ABCDaaa
=> FGaaaa
=> HIJKaaaaa
�ƕ\�����������̂ł��B
�ǂ����X�������肢�v���܂��B
���X���肪�Ƃ��������܂��B
������x�l�������Ă݂ď��������Ƃ��̂悤�ȃR�[�h�ɂȂ�܂���PHP5�ɂȂ�܂��B
// �Ώە�����
$str = "ABCDaaaEFGaaaaHIJKaaaaa";
// ���K�\��
preg_match_all( "/([A-Z]+?aaa.*?)([A-Z]|$)/is", $str, $maches );
// ���ʕ\��
$c = count( $maches[1] );
for ( $i = 0; $i < $c; $i++ ) {
print "=> {$maches[1][$i]}\n";
}
=> ABCDaaa
=> FGaaa
=> HIJKaaa
�����
=> ABCDaaa
=> FGaaaa
=> HIJKaaaaa
�ƕ\�����������̂ł��B
�ǂ����X�������肢�v���܂��B
371 �Fnobody�����F2008/08/29(��) 11:57:14 ID:???
�ȑO�Ǝd�l�ς���Ă�悤�����ǁE�E�E
�ڂ����d�l�������ĂȂ�����킩���
�擪����ȏ�́H�p�啶�����Â������}�b�`����
���ɂ����������R�ȏ�H�Â������}�b�`
���J��Ԃ����Ă��ƁH�@is�I�v�V����������̂͂ǂ��������Ƃ��킩���
/([A-Z]+aaa+)/
�ڂ����d�l�������ĂȂ�����킩���
�擪����ȏ�́H�p�啶�����Â������}�b�`����
���ɂ����������R�ȏ�H�Â������}�b�`
���J��Ԃ����Ă��ƁH�@is�I�v�V����������̂͂ǂ��������Ƃ��킩���
/([A-Z]+aaa+)/
>>371
�E�E�E�I�\����܂���B
�F�X�l���Ď����Ă�����ɓ����������ėL��ʕ����ɂȂ��Ă��܂��Ă����݂����ł��B
�����Ƃ�����x�l���Ďd�l���`������悤�ɂ��Ă��珑�����܂��Ē����܂��B
����Ԃ��������������܂��Ă��݂܂���
�E�E�E�I�\����܂���B
�F�X�l���Ď����Ă�����ɓ����������ėL��ʕ����ɂȂ��Ă��܂��Ă����݂����ł��B
�����Ƃ�����x�l���Ďd�l���`������悤�ɂ��Ă��珑�����܂��Ē����܂��B
����Ԃ��������������܂��Ă��݂܂���
373 �Fnobody�����F2008/08/29(��) 12:39:10 ID:???
�V���Ј��̌��C�݂����łقق��܂����B
374 �Fnobody�����F2008/09/01(��) 15:52:31 ID:ME+mffWY
�g�p�����PHP4�ł��B
PHP�X������U������ė��܂����B��낵�����肢���܂��B
$str = '<a href="entry-1-18.html">���</a> <br /><a href="entry-2-18.html">�o�i�i</a> <br /><a href="entry-3-18.html">�p�C�i�b�v��</a> <br />';
���̕�����̒����烊���N��̓���̐����ƃ����N�e�L�X�g�𒊏o������
preg_match_all ( "/"."<a href=\"entry-(.*)-18\.html\">(.*)<\/a>"."/i", $str, $match );
���̂悤�Ȑ��K�\�����������̂ł����A���s���ʂ�
[0] => Array
(
[0] => <a href="entry-1-18.html">���</a> <br /><a href="entry-2-18.html">�o�i�i</a> <br /><a href="entry-3-18.html">�p�C�i�b�v��</a>
)
[1] => Array
(
[0] => 1-18.html">���</a> <br /><a href="entry-2-18.html">�o�i�i</a> <br /><a href="entry-3
)
[2] => Array
(
[0] => �p�C�i�b�v��
)
�ƂȂ�܂��B
PHP�X������U������ė��܂����B��낵�����肢���܂��B
$str = '<a href="entry-1-18.html">���</a> <br /><a href="entry-2-18.html">�o�i�i</a> <br /><a href="entry-3-18.html">�p�C�i�b�v��</a> <br />';
���̕�����̒����烊���N��̓���̐����ƃ����N�e�L�X�g�𒊏o������
preg_match_all ( "/"."<a href=\"entry-(.*)-18\.html\">(.*)<\/a>"."/i", $str, $match );
���̂悤�Ȑ��K�\�����������̂ł����A���s���ʂ�
[0] => Array
(
[0] => <a href="entry-1-18.html">���</a> <br /><a href="entry-2-18.html">�o�i�i</a> <br /><a href="entry-3-18.html">�p�C�i�b�v��</a>
)
[1] => Array
(
[0] => 1-18.html">���</a> <br /><a href="entry-2-18.html">�o�i�i</a> <br /><a href="entry-3
)
[2] => Array
(
[0] => �p�C�i�b�v��
)
�ƂȂ�܂��B
375 �Fnobody�����F2008/09/01(��) 15:53:28 ID:ME+mffWY
���L�̂悤�Ȏ��s���ʂɂ������̂ł����A���K�\���̏������������ĉ������B��낵�����肢���܂��B
[0] => Array
(
[0] => <a href="entry-1-18.html">���</a> <br /><a href="entry-2-18.html">�o�i�i</a> <br /><a href="entry-3-18.html">�p�C�i�b�v��</a>
)
[1] => Array
(
[0] => 1
[1] => 2
[2] => 3
)
[2] => Array
(
[0] => ���
[1] => �o�i�i
[2] => �p�C�i�b�v��
)
[0] => Array
(
[0] => <a href="entry-1-18.html">���</a> <br /><a href="entry-2-18.html">�o�i�i</a> <br /><a href="entry-3-18.html">�p�C�i�b�v��</a>
)
[1] => Array
(
[0] => 1
[1] => 2
[2] => 3
)
[2] => Array
(
[0] => ���
[1] => �o�i�i
[2] => �p�C�i�b�v��
)
376 �Fnobody�����F2008/09/02(��) 00:14:52 ID:???
<a href="entry-(\d+)-18.html">(.*?)</a>
377 �Fnobody�����F2008/09/02(��) 09:20:23 ID:gwaiq/Cc
378 �Fnobody�����F2008/09/02(��) 17:55:54 ID:IiWNBMxF
�o�C�I�C���t�H�}�e�B�b�N�X�ɏڂ�������������Ⴂ�܂����Hperl���g���ēˑR�ψّO��ɂ�����I�~�R�h���̃J�E���g����������ł����A���S�҂Ȃ̂ł܂�����������܂���E�E�E�i�܁j
379 �Fnobody�����F2008/09/02(��) 18:31:39 ID:???
�擪��http�܂���ttp���܂܂Ȃ�
�Ƃ������K�\���͂ǂ����������ł��傤��
�Ƃ������K�\���͂ǂ����������ł��傤��
380 �Fnobody�����F2008/09/02(��) 18:35:50 ID:???
!/^h?ttp/
381 �Fnobody�����F2008/09/02(��) 18:37:44 ID:???
^([^ht]|h([^t]|t([^t]|t[^p]))|t([^t]|t[^p])))
382 �Fnobody�����F2008/09/02(��) 19:18:50 ID:???
383 �Fnobody�����F2008/09/03(��) 09:02:07 ID:???
^([^ht]|h([^t]|t([^t]|t[^p]))|t([^t]|t[^p])))
����h�Ƃ�tt�Ƀ}�b�`���Ȃ�㩁B
^($|[^ht]|h($|[^t]|t($|[^t]|t($|[^p])))|t($|[^t]|t($|[^p]))))
���ʂ�380�̂悤�ɂ��邯�ǂȁB
����h�Ƃ�tt�Ƀ}�b�`���Ȃ�㩁B
^($|[^ht]|h($|[^t]|t($|[^t]|t($|[^p])))|t($|[^t]|t($|[^p]))))
���ʂ�380�̂悤�ɂ��邯�ǂȁB
384 �Fnobody�����F2008/09/04(��) 10:49:47 ID:???
^p^
385 �Fnobody�����F2008/09/04(��) 10:50:59 ID:???
^w^
386 �Fnobody�����F2008/09/04(��) 19:48:29 ID:ZxHTo/La
387 �Fnobody�����F2008/09/04(��) 21:53:09 ID:AVvRqwBM
$���m���ǂ݂Ƃ����͖̂ڂ���B
388 �Fnobody�����F2008/09/17(��) 17:44:57 ID:TGrFERMS
���₳���Ă��������B
OS��ubuntu8.04�Ő��K�\��������n�߂̎҂ł��B
�d�b�ԍ��ƗX�֔ԍ������݂��Ă���e�L�X�g�t�@�C������X�֔ԍ�����
���o����Ƃ��������Ȃ�ł����A
�X�֔ԍ���xxx-xxxx(x��0-9�̐���)�A�d�b�ԍ���xx-xxxx-xxxx(x��0-9�̐���)
�ŁAgrep -E [0-9]\{3\}-[0-9]\{4\} �Ƃ���Ă��d�b�ԍ����S�Ē��o����Ă��܂��܂��B
�ǂ����Ԉ���Ă���̂ł��傤���B
OS��ubuntu8.04�Ő��K�\��������n�߂̎҂ł��B
�d�b�ԍ��ƗX�֔ԍ������݂��Ă���e�L�X�g�t�@�C������X�֔ԍ�����
���o����Ƃ��������Ȃ�ł����A
�X�֔ԍ���xxx-xxxx(x��0-9�̐���)�A�d�b�ԍ���xx-xxxx-xxxx(x��0-9�̐���)
�ŁAgrep -E [0-9]\{3\}-[0-9]\{4\} �Ƃ���Ă��d�b�ԍ����S�Ē��o����Ă��܂��܂��B
�ǂ����Ԉ���Ă���̂ł��傤���B
389 �Fnobody�����F2008/09/17(��) 17:54:16 ID:???
���̐��K�\�����Ɠd�b�ԍ��ɂ��}�b�`�����Ⴄ����ˁB
��̓I�ɂ́A
xx-xXXX-XXXX
�̑啶��X�ł���킵���Ƃ���
�܂��h��Ȃ낤��������������ǂ��l���܂��傤�B
��̓I�ɂ́A
xx-xXXX-XXXX
�̑啶��X�ł���킵���Ƃ���
�܂��h��Ȃ낤��������������ǂ��l���܂��傤�B
390 �Fnobody�����F2008/09/17(��) 19:24:47 ID:???
391 �Fnobody�����F2008/09/22(��) 18:03:26 ID:???
����ł��B
���L�̂悤�Ȕz��̒�����A
(2)�`(4)�܂ł݂̂𒊏o�������Ǝv���Ă��܂��B
�@(1) testa@hoge
�@(2) _testb@hage
�@(3) _testc@noge
�@(4) _testd@nage
�@(5) _teste@n_ge
���[���Ƃ��ẮA
�@�E����[_]���t���Ă��鎖�A
�@�E@�̌���[n_]���t���Ă��Ȃ���
�ł��B��L�O��ʼn��L�̂悤�ɏ������̂ł����A
����ł���(2)�������o����܂���ł����B
�@$test =~ /^_.*@[^(n_)]/
@�̌��̐��K�\���������̂��Ǝv����ł����A
���̏ꍇ�ǂ̂悤�ɏ���������ł��傤���B
���������肢���܂�m(_ _)m
���L�̂悤�Ȕz��̒�����A
(2)�`(4)�܂ł݂̂𒊏o�������Ǝv���Ă��܂��B
�@(1) testa@hoge
�@(2) _testb@hage
�@(3) _testc@noge
�@(4) _testd@nage
�@(5) _teste@n_ge
���[���Ƃ��ẮA
�@�E����[_]���t���Ă��鎖�A
�@�E@�̌���[n_]���t���Ă��Ȃ���
�ł��B��L�O��ʼn��L�̂悤�ɏ������̂ł����A
����ł���(2)�������o����܂���ł����B
�@$test =~ /^_.*@[^(n_)]/
@�̌��̐��K�\���������̂��Ǝv����ł����A
���̏ꍇ�ǂ̂悤�ɏ���������ł��傤���B
���������肢���܂�m(_ _)m
392 �Fnobody�����F2008/09/22(��) 18:09:42 ID:???
>>391
���ꂶ�ᕶ���N���X����B���������Ƃ��͔ے��ǂ݂���B
���ꂶ�ᕶ���N���X����B���������Ƃ��͔ے��ǂ݂���B
393 �Fnobody�����F2008/09/22(��) 18:13:12 ID:???
/^_\w*\@\w+$/ and !/\@n_/
�擪_��@�̊Ԃ͂ǂ�ȕ����ł������̂��A@�ȍ~�͂ǂ�ȕ����ł������̂��Ƃ�
�ڂ������[���͂킩��Ȃ����A�f���ɕ������ق��������Ǝv��
�擪_��@�̊Ԃ͂ǂ�ȕ����ł������̂��A@�ȍ~�͂ǂ�ȕ����ł������̂��Ƃ�
�ڂ������[���͂킩��Ȃ����A�f���ɕ������ق��������Ǝv��
394 �Fnobody�����F2008/09/22(��) 18:18:30 ID:???
>>392-393
���肪�Ƃ��������܂��I
�Ƃ肠�����A>>392����̕��@�Œ��o�ł��܂����B
$test =~ /^_.*@(?!n_)./
���肪�Ƃ��������܂����B
���肪�Ƃ��������܂��I
�Ƃ肠�����A>>392����̕��@�Œ��o�ł��܂����B
$test =~ /^_.*@(?!n_)./
���肪�Ƃ��������܂����B
395 �Fnobody�����F2008/09/25(��) 14:22:28 ID:bEreCYy4
�g�p�����PHP5�ł�
html����img�^�O�̋L�q������xhtml�ɂ��邽�߂ɍŌ�ɃX�y�[�X�ƃX���b�V����t�����������Ǝv��
�ȉ��̒u���������s�����������̂ł����A
$html = preg_replace('{<img (.*?)>}' ,'<img $1 />' ,$html);
���Ximg�^�O���ɃX�y�[�X�ƃX���b�V�����Ō�ɓ����Ă���̂�����܂��̂ŁA����ȊO�Ƃ������Ƃ�
$html = preg_replace('{<img (.*?)^\/>}' ,'<img $1 />' ,$html);
���̂悤�ɋL�q���Ă݂܂������A����ł��ƑS����img�^�O�ɒu�������������Ȃ��Ȃ�܂���
�ǂ������L�q������悢�̂ł��傤���H
html����img�^�O�̋L�q������xhtml�ɂ��邽�߂ɍŌ�ɃX�y�[�X�ƃX���b�V����t�����������Ǝv��
�ȉ��̒u���������s�����������̂ł����A
$html = preg_replace('{<img (.*?)>}' ,'<img $1 />' ,$html);
���Ximg�^�O���ɃX�y�[�X�ƃX���b�V�����Ō�ɓ����Ă���̂�����܂��̂ŁA����ȊO�Ƃ������Ƃ�
$html = preg_replace('{<img (.*?)^\/>}' ,'<img $1 />' ,$html);
���̂悤�ɋL�q���Ă݂܂������A����ł��ƑS����img�^�O�ɒu�������������Ȃ��Ȃ�܂���
�ǂ������L�q������悢�̂ł��傤���H
396 �Fnobody�����F2008/09/25(��) 14:30:11 ID:???
/<img (.*?[^\/])>/
397 �Fnobody�����F2008/09/25(��) 14:38:21 ID:bEreCYy4
398 �Fnobody�����F2008/10/07(��) 01:09:40 ID:???
�Ώۂ�
<a href="test/index.html">������</a>
<a href="http://hogehoge1.com" target="_blank">������</a>
�̂悤�ȕ�����
test/index.html
http://hogehoge1.com
���������o���ɂ͂ǂ�����悢�̂ł��傤���H
�g�p�����PHP5�ł��B
preg_match("/<a href=\"(.*)\"\>.*/",$str,$m);
�ł�target="_blank"���c���Ă��܂����Ғʂ�̌��ʂ������܂���B
�ŒZ��v�Ƃ����̂��������Ƃ�����
preg_match("/<a href=\"(.*)\"{1}?\>.*/",$str,$m);
�Ƃ��܂������ʖڂł����B
�A�h�o�C�X��낵�����肢�������܂��B
<a href="test/index.html">������</a>
<a href="http://hogehoge1.com" target="_blank">������</a>
�̂悤�ȕ�����
test/index.html
http://hogehoge1.com
���������o���ɂ͂ǂ�����悢�̂ł��傤���H
�g�p�����PHP5�ł��B
preg_match("/<a href=\"(.*)\"\>.*/",$str,$m);
�ł�target="_blank"���c���Ă��܂����Ғʂ�̌��ʂ������܂���B
�ŒZ��v�Ƃ����̂��������Ƃ�����
preg_match("/<a href=\"(.*)\"{1}?\>.*/",$str,$m);
�Ƃ��܂������ʖڂł����B
�A�h�o�C�X��낵�����肢�������܂��B
399 �Fnobody�����F2008/10/07(��) 01:57:33 ID:???
/<a\s.*?href=\"(.*?)\"/is
400 �Fnobody�����F2008/10/07(��) 21:57:53 ID:???
401 �Fnobody�����F2008/10/09(��) 19:29:23 ID:???
PHP5�Ŏg���܂�
$num�ɂ́A
+����
-����
����
�Ƃ����悤�ȃp�^�[���̎��̂݃}�b�`���������ł�
�����̂Ƃ���� 0�`999999999�܂ł̒l�������Ă��܂����A0�ȊO�̎��ɓ���0������ꍇ0123�Ƃ��͏��O�������ł�
���s���낵�ĉ��L�̂悤�ɂ��Ă݂܂������A�v�������ʂ������܂���B�G���[�o�܂���łȂ݂��ڂł�
�ǂ�����낵�����肢���܂�
preg_match('/^(([^+]*)*(++[^-][^+]*)*)*?[^0-9]*$/',$num)
$num�ɂ́A
+����
-����
����
�Ƃ����悤�ȃp�^�[���̎��̂݃}�b�`���������ł�
�����̂Ƃ���� 0�`999999999�܂ł̒l�������Ă��܂����A0�ȊO�̎��ɓ���0������ꍇ0123�Ƃ��͏��O�������ł�
���s���낵�ĉ��L�̂悤�ɂ��Ă݂܂������A�v�������ʂ������܂���B�G���[�o�܂���łȂ݂��ڂł�
�ǂ�����낵�����肢���܂�
preg_match('/^(([^+]*)*(++[^-][^+]*)*)*?[^0-9]*$/',$num)
402 �Fnobody�����F2008/10/09(��) 19:32:07 ID:???
[\+\-]?(?:0|[1-9]\d*)
�s�\�����B�B
^[\+\-]?(?:0|[1-9]\d*)$
^[\+\-]?(?:0|[1-9]\d*)$
404 �Fnobody�����F2008/10/10(��) 00:47:33 ID:???
>>403
���肪�Ƃ��������܂�
������m�F�����Ƃ���
0�݂̂̏ꍇ�Ɛ����̕������X���ȏ�ł��}�b�`���Ă��܂��̂ŁA
^([^0]|[\+\-]?)(?:0|[1-9]\d{1, 9}?)$
���s���낵�Ă��̂悤�ɂ��Ă݂܂������A�S�������ă}�b�`���Ȃ��Ȃ��Ă��܂��܂���
�ǂ̂悤�ɏ�����낵���̂ł��傤���H
���肪�Ƃ��������܂�
������m�F�����Ƃ���
0�݂̂̏ꍇ�Ɛ����̕������X���ȏ�ł��}�b�`���Ă��܂��̂ŁA
^([^0]|[\+\-]?)(?:0|[1-9]\d{1, 9}?)$
���s���낵�Ă��̂悤�ɂ��Ă݂܂������A�S�������ă}�b�`���Ȃ��Ȃ��Ă��܂��܂���
�ǂ̂悤�ɏ�����낵���̂ł��傤���H
405 �Fnobody�����F2008/10/10(��) 00:58:41 ID:???
^[\+\-]?(?:0|[1-9]\d{0,8})$
406 �Fnobody�����F2008/10/10(��) 07:43:15 ID:???
407 �F���܂���� ��ExGQrDul2E �F2008/11/02(��) 16:02:00 ID:wDYsJgfV
URL���A�ϐ�$url�ɂ����g���Ă��邩���ׂ邽�߂�
preg_match_all���g���܂������A�����܂���B
�ǂ̂悤�ɂ�����悢�������Ă��������B
<?php
$url = <<< URL
a
http://x.x
http://
http://google.jp/
URL;
preg_match_all ("|(https?|ftp)(://[[:alnum:]\+\$\;\?\.%,!#~*/:@&=_-]+)|",$url,$out, PREG_SET_ORDER);
echo count($out);
?>
���s����:
Warning: preg_match_all() [function.preg-match-all]: Unknown modifier 'f' in /match.php on line 8
0
preg_match_all���g���܂������A�����܂���B
�ǂ̂悤�ɂ�����悢�������Ă��������B
<?php
$url = <<< URL
a
http://x.x
http://
http://google.jp/
URL;
preg_match_all ("|(https?|ftp)(://[[:alnum:]\+\$\;\?\.%,!#~*/:@&=_-]+)|",$url,$out, PREG_SET_ORDER);
echo count($out);
?>
���s����:
Warning: preg_match_all() [function.preg-match-all]: Unknown modifier 'f' in /match.php on line 8
0
408 �Fnobody�����F2008/11/02(��) 16:11:53 ID:???
�ʂ̐��K�\���\����T���Ă��ăR�s�y����
409 �Fnobody�����F2008/11/02(��) 17:38:13 ID:???
�f���~�^�b�Ŏn�߂��Ȃ炍�b�ɂ���K�v�����������
�ŁA�r����OR�̈Ӗ��Łb�g���Ă邩��ʂ̃f���~�^�ɂ����Ⴂ�Ȃ�
�ŁA�r����OR�̈Ӗ��Łb�g���Ă邩��ʂ̃f���~�^�ɂ����Ⴂ�Ȃ�
410 �F���܂���� ��ExGQrDul2E �F2008/11/02(��) 21:36:24 ID:0rYlog69
>>409
���肪�Ƃ��������܂�
�_(�E�́E)�^
�r����
https?|ftp
�Ŏg���Ă���̂ł����A
�ŏ���
||
//
�ȊO�ɁA�����g���悢�̂ł��傤���H
����Ƃ�
\(�G�X�P�[�v)������悢�̂ł��傤���H
���肪�Ƃ��������܂�
�_(�E�́E)�^
�r����
https?|ftp
�Ŏg���Ă���̂ł����A
�ŏ���
||
//
�ȊO�ɁA�����g���悢�̂ł��傤���H
����Ƃ�
\(�G�X�P�[�v)������悢�̂ł��傤���H
411 �Fnobody�����F2008/11/03(��) 20:39:21 ID:XFsZ1V0e
�����N���X�O����?�ɂ��āB
URL�̍ŒZ�}�b�`�����鐳�K�\��
(https?)
�ɂ��āA
���̏ꍇ�Ȃ�A
http
https
�����Ƀ}�b�`���܂��B
(https)
����Ȃ�A
https
�ɂ����}�b�`���܂���B
�����ŁA?�̈Ӗ��ׂ���A�w(�̈Ӗ����g���B0��܂���1��̌J��Ԃ��ŒZ�}�b�`�x�Ə����Ă���܂����B�Ȃ�
(https?)
��������邱�Ƃɂ���āAhttp��https���}�b�`��������̂ł��傤���H�ŒZ�}�b�`�Ȃ�Ahtt�ł������̂���Ȃ��ł����H
URL�̍ŒZ�}�b�`�����鐳�K�\��
(https?)
�ɂ��āA
���̏ꍇ�Ȃ�A
http
https
�����Ƀ}�b�`���܂��B
(https)
����Ȃ�A
https
�ɂ����}�b�`���܂���B
�����ŁA?�̈Ӗ��ׂ���A�w(�̈Ӗ����g���B0��܂���1��̌J��Ԃ��ŒZ�}�b�`�x�Ə����Ă���܂����B�Ȃ�
(https?)
��������邱�Ƃɂ���āAhttp��https���}�b�`��������̂ł��傤���H�ŒZ�}�b�`�Ȃ�Ahtt�ł������̂���Ȃ��ł����H
412 �Fnobody�����F2008/11/03(��) 21:26:40 ID:???
https? �Ȃ�@?�͒��O��s�ɑ��ĂO�P������ˁO�O
413 �Fnobody�����F2008/11/04(��) 00:18:26 ID:???
>>411
�ŒZ�}�b�`�ł͂Ȃ��Œ��}�b�`����Ȃ��́B
http �܂Ń}�b�`���Ă��邱�Ƃ�O��ɂ��āA����� s �ɑ��� 0 ��܂��� 1 ���
�u��蒷�����v�ɗD�悵�ă}�b�`����B
�ŒZ�}�b�`�ł͂Ȃ��Œ��}�b�`����Ȃ��́B
http �܂Ń}�b�`���Ă��邱�Ƃ�O��ɂ��āA����� s �ɑ��� 0 ��܂��� 1 ���
�u��蒷�����v�ɗD�悵�ă}�b�`����B
414 �Fnobody�����F2008/11/08(�y) 03:56:35 ID:???
�ŒZ�}�b�`�Č��t��*?�Ƃ��ʎw��q�̂��Ƃɂ���Ƃ���
������ł悭�g���邩�炻��Ƃ�������ɂȂ����������Ȃ�����
������ł悭�g���邩�炻��Ƃ�������ɂȂ����������Ȃ�����
415 �Fnobody�����F2008/11/08(�y) 14:37:01 ID:Ln3BC38n
���̓���ɂӂ��킵���L�����I�I�I
http://codezine.jp/article/detail/3039
http://codezine.jp/article/detail/2676
http://codezine.jp/article/detail/3039
http://codezine.jp/article/detail/2676
416 �Fnobody�����F2008/11/09(��) 02:37:50 ID:???
417 �Fnobody�����F2008/11/15(�y) 02:31:51 ID:???
���^�[
�ߏ��̐}���قɏڐ����K�\�������ׂ�����
�܂Ƃ��ȃI���C���{�͏ڐ��C�[�T�l�b�g�����Ȃ��Ƃ������������
�ȑO�͓d�q���[���v���g�R�������������ǁA
���Ђ���ă��T�C�N���R�[�i�[���痷�ɏo�Ă��܂�����
�ߏ��̐}���قɏڐ����K�\�������ׂ�����
�܂Ƃ��ȃI���C���{�͏ڐ��C�[�T�l�b�g�����Ȃ��Ƃ������������
�ȑO�͓d�q���[���v���g�R�������������ǁA
���Ђ���ă��T�C�N���R�[�i�[���痷�ɏo�Ă��܂�����
418 �Fnobody�����F2008/11/24(��) 00:38:36 ID:???
2�̐��K�\�����P�ɂ܂Ƃ߂���@�͂���܂����H
A����
�V���C
�Ƃ���2�X�e�b�v���Ƃł���Ă��邱�Ƃ�1�X�e�b�v�ōς܂������̂ł��B
A����
�V���C
�Ƃ���2�X�e�b�v���Ƃł���Ă��邱�Ƃ�1�X�e�b�v�ōς܂������̂ł��B
419 �Fnobody�����F2008/12/08(��) 02:09:36 ID:???
PHP�ł��B
$search="/^(.+?)<>(.*?)<>(.+)ID:(.+?)<>(.+)<>(.*)/";
preg_match($search,$res[$i],$match);
$id[$i]=$match[4];
$res��2ch��dat�t�@�C������s���Ƃɔz��ɓ��ꂽ���ł��B
Notice: Undefined offset: 4 (��) on 47
�Ƃ����G���[���o�Ă��܂��܂��B
47�s�ڂ�$id[$i]=$match[4];�ł��B
$search="/^(.+?)<>(.*?)<>(.+)ID:(.+?)<>(.+)<>(.*)/";
preg_match($search,$res[$i],$match);
$id[$i]=$match[4];
$res��2ch��dat�t�@�C������s���Ƃɔz��ɓ��ꂽ���ł��B
Notice: Undefined offset: 4 (��) on 47
�Ƃ����G���[���o�Ă��܂��܂��B
47�s�ڂ�$id[$i]=$match[4];�ł��B
420 �Fnobody�����F2008/12/08(��) 02:21:41 ID:???
421 �Fnobody�����F2008/12/19(��) 23:54:16 ID:???
���K�\���̐搶���Aphp�Ŏ��₳���Ē����܂��B
$str = '[db]name[/db] ���ׂ��� [db]email[/db]';
preg_match_all('/\[db\].*?\[\/db\]/s',$str,$match);
print_r($match);
��
[db]name[/db] ��
[db]email[/db] �������o�����̂ł����A
���� [db] [/db] ����
name �� email �������o���ɂ͂ǂ������悢�ł��傤���B
�������̂قǂ�낵�����肢���܂��B
$str = '[db]name[/db] ���ׂ��� [db]email[/db]';
preg_match_all('/\[db\].*?\[\/db\]/s',$str,$match);
print_r($match);
��
[db]name[/db] ��
[db]email[/db] �������o�����̂ł����A
���� [db] [/db] ����
name �� email �������o���ɂ͂ǂ������悢�ł��傤���B
�������̂قǂ�낵�����肢���܂��B
422 �Fnobody�����F2008/12/19(��) 23:58:55 ID:???
\](.*?)\[\/
423 �Fnobody�����F2008/12/20(�y) 00:04:41 ID:???
424 �Fnobody�����F2008/12/20(�y) 14:46:40 ID:???
�����Y��Ă邾�낗
425 �Fnobody�����F2008/12/22(��) 00:30:52 ID:EdTiga+3
Jedit��
�y�������z���y6�������z
�y�����z���y4�����z
�̂悤�Ɂy�@�z�ł͂͂��܂ꂽ������̓��ɕ������~2�̐��l��lj��������̂ł���
�ǂ̂悤�Ɍ������Ăǂ̂悤�ɒu������悢�ł��傤���H
�y�@�z�ł͂��܂ꂽ�������͂܂��܂��ł��B
��낵�����肢���܂��B
�y�������z���y6�������z
�y�����z���y4�����z
�̂悤�Ɂy�@�z�ł͂͂��܂ꂽ������̓��ɕ������~2�̐��l��lj��������̂ł���
�ǂ̂悤�Ɍ������Ăǂ̂悤�ɒu������悢�ł��傤���H
�y�@�z�ł͂��܂ꂽ�������͂܂��܂��ł��B
��낵�����肢���܂��B
426 �Fnobody�����F2008/12/22(��) 03:02:21 ID:???
orz
428 �Fnobody�����F2008/12/22(��) 15:42:49 ID:???
�}�N���g�ݍ��킹���
430 �Fnobody�����F2008/12/23(��) 02:31:08 ID:???
�}�N���g���Ă悩�����̂����!��
431 �Fnobody�����F2008/12/28(��) 04:14:06 ID:???
���炵�܂�
�g�p�����perl5�ł�
�z��ɁA�O����}�b�`�����Ƃ���܂ł̕�������J��Ԃ�����悤�Ƃ��Ă��܂�
($str = 'hogehugahage';
�Ƃ������������āAh�Ń}�b�`��������
@data = ['h', 'hogeh', 'hogehugah']
�Ƃ����z��ɂȂ邱�Ƃ�z�肵�Ă��܂�)
@data = $str =~ m/h/g;
�̂Ƃ��͗\�z�ǂ���
@data = ['h', 'h', 'h']
�ƂȂ����̂ł����A
@data = $str =~ m/^.*h/g
�̏ꍇ��
@data = ['hogehugah']
�ƂȂ���1��ő�}�b�`���邾���̂悤�ł�
�ǂ�����Η\�z�ʂ�̌��ʂɂȂ�ł��傤���H
�g�p�����perl5�ł�
�z��ɁA�O����}�b�`�����Ƃ���܂ł̕�������J��Ԃ�����悤�Ƃ��Ă��܂�
($str = 'hogehugahage';
�Ƃ������������āAh�Ń}�b�`��������
@data = ['h', 'hogeh', 'hogehugah']
�Ƃ����z��ɂȂ邱�Ƃ�z�肵�Ă��܂�)
@data = $str =~ m/h/g;
�̂Ƃ��͗\�z�ǂ���
@data = ['h', 'h', 'h']
�ƂȂ����̂ł����A
@data = $str =~ m/^.*h/g
�̏ꍇ��
@data = ['hogehugah']
�ƂȂ���1��ő�}�b�`���邾���̂悤�ł�
�ǂ�����Η\�z�ʂ�̌��ʂɂȂ�ł��傤���H
432 �Fnobody�����F2008/12/28(��) 08:21:40 ID:???
$str = 'hogehugahage';
$c= substr($str, 0, 1);
while ($str=~ /$c/go){
push(@data, substr($str, 0, pos($str)));
}
for (@data){print $_,"\n";}
���K�\���g��Ȃ��ƃ_���Ȃ́H
$c= substr($str, 0, 1);
while ($str=~ /$c/go){
push(@data, substr($str, 0, pos($str)));
}
for (@data){print $_,"\n";}
���K�\���g��Ȃ��ƃ_���Ȃ́H
>>432
���肪�Ƃ��������܂�
����ł��������ł�
���͐��K�\����K���g��Ȃ��Ⴂ���Ȃ��Ƃ����킯�ł͂Ȃ��A
�����ƊȌ��ɂ�����Ȃ�Ȃ�ł����v�ł�
���肪�Ƃ��������܂�
����ł��������ł�
���͐��K�\����K���g��Ȃ��Ⴂ���Ȃ��Ƃ����킯�ł͂Ȃ��A
�����ƊȌ��ɂ�����Ȃ�Ȃ�ł����v�ł�
434 �Fnobody�����F2009/01/01(��) 19:19:28 ID:???
��B�݂̂Ȃ��܁APerl5+EUC���Ŏ��₳���Ă�������
������̒��ŁA�������̂������S�p�����i�S�p�����A�S�p�A���t�@�x�b�g�A�S�p�J�^�J�i�j��
�ꕔ�L���i�ۊ��ʂ�S�p�X�y�[�X�Ȃǁj�ȊO�������Ă�����}�b�`������A�Ƃ�����������낤�Ƃ��Ă��܂�
�����N���X�ɋ����镶���R�[�h���ׂ��������āA���̔ے�Ŏ��邩�Ǝv������ł���
$txt =~ /[^xA3\xB0-\xB9]/
�̂悤�ȏ������܂ŗ��āA�l�܂��Ă��܂��܂���
$txt =~ /[^a-zA-Z0-1!#$ @]/
�݂����Ȋ����ŁA�����̕����R�[�h�������ɂ͂ǂ������炢����ł��傤���H
���������肢�������܂�
������̒��ŁA�������̂������S�p�����i�S�p�����A�S�p�A���t�@�x�b�g�A�S�p�J�^�J�i�j��
�ꕔ�L���i�ۊ��ʂ�S�p�X�y�[�X�Ȃǁj�ȊO�������Ă�����}�b�`������A�Ƃ�����������낤�Ƃ��Ă��܂�
�����N���X�ɋ����镶���R�[�h���ׂ��������āA���̔ے�Ŏ��邩�Ǝv������ł���
$txt =~ /[^xA3\xB0-\xB9]/
�̂悤�ȏ������܂ŗ��āA�l�܂��Ă��܂��܂���
$txt =~ /[^a-zA-Z0-1!#$ @]/
�݂����Ȋ����ŁA�����̕����R�[�h�������ɂ͂ǂ������炢����ł��傤���H
���������肢�������܂�
435 �Fnobody�����F2009/01/02(��) 02:24:41 ID:???
>>434
�ǂ������炢�����Ă�����ė�����Ȃ��Ǝv����B
2byte�̂Ȃ�т̂���p�^�[�������O�������Ƃ����b���낤����A^ ���g�����`�ł�
�����ȒP�ɂ͂����Ȃ��Ǝv�����ǁB
�ǂ������炢�����Ă�����ė�����Ȃ��Ǝv����B
2byte�̂Ȃ�т̂���p�^�[�������O�������Ƃ����b���낤����A^ ���g�����`�ł�
�����ȒP�ɂ͂����Ȃ��Ǝv�����ǁB
437 �Fnobody�����F2009/01/15(��) 22:57:08 ID:???
PHP5���g�p���Ă��܂��B
<pre>�^�O�ň͂܂ꂽ������̒���<br />���폜�������̂ł����A�ǂ̂悤�ɂȂ�܂��ł��傤���B
��j
�u���O
<pre>
aaa<br />
bbbb<br />
</pre>
�u����
<pre>
aaa
bbbb
</pre>
�X�������肢���܂��B
<pre>�^�O�ň͂܂ꂽ������̒���<br />���폜�������̂ł����A�ǂ̂悤�ɂȂ�܂��ł��傤���B
��j
�u���O
<pre>
aaa<br />
bbbb<br />
</pre>
�u����
<pre>
aaa
bbbb
</pre>
�X�������肢���܂��B
438 �Fnobody�����F2009/01/15(��) 23:33:28 ID:???
$s= <<<EOT
�u���O
<pre>
aaa<br />
bbbb<br />
</pre>
�u����
<pre>
aaa
bbbb
</pre>
EOT;
echo preg_replace("#(<pre>.*?</pre>)#es", "str_replace('<br />', '', '$1')", $s);
�u���O
<pre>
aaa<br />
bbbb<br />
</pre>
�u����
<pre>
aaa
bbbb
</pre>
EOT;
echo preg_replace("#(<pre>.*?</pre>)#es", "str_replace('<br />', '', '$1')", $s);
preg_replace("#<pre>.*?</pre>#es", "str_replace('<br />', '', '$0')", $s);
���ʂ͗v��Ȃ���
���ʂ͗v��Ȃ���
�o���܂����I�������B
441 �Fnobody�����F2009/01/19(��) 01:18:40 ID:???
Irvine������URL�W�J�A���S���Y�����������������B
�E[?-?]�\�L�ɂ�鐔�l�E�A���t�@�x�b�g�̘A��
�E[]��1�R�߂�?�̌����ɉ�����0����
�E[]���̓W�J�ӏ��͕�����
�Ƃ������Ƃ���ł��B
����͏o�����perl�A���_��js��vbs�ł������ɖ₢�܂���B
�ȉ��̂悤�ϊ�����邩�ł��B��낵�����肢���܂��B
>http://abc[1-2].jpg
http://abc1.jpg
http://abc2.jpg
>http://abc[09-10].jpg
http://abc09.jpg
http://abc10.jpg
>http://abc[1-2]de[099-101].jpg
http://abc1de099.jpg
http://abc1de100.jpg
http://abc1de101.jpg
http://abc2de99.jpg
http://abc2de100.jpg
http://abc2de101.jpg
>http://[a-b][01-02][4-5].jpg
http://a014.jpg
http://a015.jpg
http://a024.jpg
http://a025.jpg
http://b014.jpg
http://b015.jpg
http://b024.jpg
http://b025.jpg
�E[?-?]�\�L�ɂ�鐔�l�E�A���t�@�x�b�g�̘A��
�E[]��1�R�߂�?�̌����ɉ�����0����
�E[]���̓W�J�ӏ��͕�����
�Ƃ������Ƃ���ł��B
����͏o�����perl�A���_��js��vbs�ł������ɖ₢�܂���B
�ȉ��̂悤�ϊ�����邩�ł��B��낵�����肢���܂��B
>http://abc[1-2].jpg
![http://abc[1-2].jpg](http://abc[1-2].jpg){kind=link}
http://abc1.jpg
{kind=link}
http://abc2.jpg
{kind=link}
>http://abc[09-10].jpg
![http://abc[09-10].jpg](http://abc[09-10].jpg){kind=link}
http://abc09.jpg
{kind=link}
http://abc10.jpg
{kind=link}
>http://abc[1-2]de[099-101].jpg
![http://abc[1-2]de[099-101].jpg](http://abc[1-2]de[099-101].jpg){kind=link}
http://abc1de099.jpg
{kind=link}
http://abc1de100.jpg
{kind=link}
http://abc1de101.jpg
{kind=link}
http://abc2de99.jpg
{kind=link}
http://abc2de100.jpg
{kind=link}
http://abc2de101.jpg
{kind=link}
>http://[a-b][01-02][4-5].jpg
![http://[a-b][01-02][4-5].jpg](http://[a-b][01-02][4-5].jpg){kind=link}
http://a014.jpg
{kind=link}
http://a015.jpg
{kind=link}
http://a024.jpg
{kind=link}
http://a025.jpg
{kind=link}
http://b014.jpg
{kind=link}
http://b015.jpg
{kind=link}
http://b024.jpg
{kind=link}
http://b025.jpg
{kind=link}
442 �Fnobody�����F2009/01/19(��) 03:14:04 ID:???
>>441
�Ƃ͑S�R�W�Ȃ��ł����ǁA
h����ttp://�ƂȂ��ď������A
�����G���W�����̃N���[���������>>441�̃����N��S�ĂȂ߂�̂ŁA
�l�b�g���[�N���\�[�X�I�ɂ��܂��낵���Ȃ��ł��c
���セ�̂悤�ɗᎦ�����ۂɂ�
h������啶���ɂ����蓙�A
�����N�ɂȂ�Ȃ��悤�H�v������������������ƁA
��C���^�[�l�b�g���p�҂Ƃ��Ă͊���������ł�
�Ƃ͑S�R�W�Ȃ��ł����ǁA
h����ttp://�ƂȂ��ď������A
�����G���W�����̃N���[���������>>441�̃����N��S�ĂȂ߂�̂ŁA
�l�b�g���[�N���\�[�X�I�ɂ��܂��낵���Ȃ��ł��c
���セ�̂悤�ɗᎦ�����ۂɂ�
h������啶���ɂ����蓙�A
�����N�ɂȂ�Ȃ��悤�H�v������������������ƁA
��C���^�[�l�b�g���p�҂Ƃ��Ă͊���������ł�
443 �Fnobody�����F2009/01/19(��) 03:23:29 ID:???
���܂��낵���Ȃ����Đ����Ō����Ƃǂꂭ�炢�H
444 �Fnobody�����F2009/01/19(��) 03:24:54 ID:???
��݁I
445 �Fnobody�����F2009/01/19(��) 04:50:02 ID:cs1ls7yv
�O�O�����̂ł����A������Ȃ������̂Ŏ��₳���Ă��������B
align=left>1234567891011121345
��L��
align=left>1011121345
�����u���������̂ł���
left>.*?1011121345
�������Ă݂��̂ł����A�o���܂���ł����B
�ǂ��u������A�ǂ��̂ł��傤���A��낵�����肢���܂��B
align=left>1234567891011121345
��L��
align=left>1011121345
�����u���������̂ł���
left>.*?1011121345
�������Ă݂��̂ł����A�o���܂���ł����B
�ǂ��u������A�ǂ��̂ł��傤���A��낵�����肢���܂��B
446 �Fnobody�����F2009/01/19(��) 05:23:37 ID:???
>>445
left>.*1011121345
left>.*1011121345
447 �Fnobody�����F2009/01/19(��) 09:02:38 ID:???
s/>\d*1011121345//
�Ȃ��I�[�v���\�[�X�������悤�Ŏ��ȉ������܂����B
>>442
���܂���h���������v����l���Ă���ˁB
�����m�炸�̑��l��l��l���[�ւ��Ă�������
�Ǘ��҂�[http://�v��NG���[�h�ɒlj����Ă����悤������������������Ȃ��́H
�L�v�ł���Ύ���Ă����͂��B
>>442
���܂���h���������v����l���Ă���ˁB
�����m�炸�̑��l��l��l���[�ւ��Ă�������
�Ǘ��҂�[http://�v��NG���[�h�ɒlj����Ă����悤������������������Ȃ��́H
�L�v�ł���Ύ���Ă����͂��B
449 �Fnobody�����F2009/01/19(��) 14:46:18 ID:???
�L�~�͎��������悯��Α��͂ǂ��ł������ˁB
�܂�������Ă�B
�܂�������Ă�B
450 �Fnobody�����F2009/01/20(��) 02:49:36 ID:???
>>442�����v�Ɍ�����悤�����J����������
451 �Fnobody�����F2009/01/20(��) 03:53:44 ID:TjAtrikI
�����ƒ��߂���������
http�`�����N�����邽�юw�E�i�v�]�j���Ă��܂�442
���̎w�E�i�v�]�j�����v�Ɍ����Ă��܂�441
�ǂ����2ch�Ɍ����Ȃ��^�C�v�ł͂��邪
�p�x�̓x�������炵�ċ�J����̂�441�̕����ゾ��
���O�֏��̃g�C���b�g�y�[�p�[���O�p�ɐ܂�ĂȂ�������C�����Ƃ����Ⴄ�^�C�v�ł�
http�`�����N�����邽�юw�E�i�v�]�j���Ă��܂�442
���̎w�E�i�v�]�j�����v�Ɍ����Ă��܂�441
�ǂ����2ch�Ɍ����Ȃ��^�C�v�ł͂��邪
�p�x�̓x�������炵�ċ�J����̂�441�̕����ゾ��
���O�֏��̃g�C���b�g�y�[�p�[���O�p�ɐ܂�ĂȂ�������C�����Ƃ����Ⴄ�^�C�v�ł�
452 �Fnobody�����F2009/01/20(��) 04:11:05 ID:???
���`�n�C�n�C�����~vs���Γc���̍\�}��
�X���Ⴂ�����瑼�ł���Ă���
�X���Ⴂ�����瑼�ł���Ă���
453 �Fnobody�����F2009/01/22(��) 00:53:40 ID:2qACQkO/
���K�\����$�������܂ތ�����u�����Ăǁ`���Ă܂��H
454 �Fnobody�����F2009/01/22(��) 01:00:03 ID:???
���O�͉��������Ă��
455 �Fnobody�����F2009/01/22(��) 02:57:05 ID:???
456 �Fnobody�����F2009/01/22(��) 03:22:48 ID:???
>>455
������������
������������
457 �Fnobody�����F2009/01/22(��) 17:35:54 ID:???
<br>***********
-----
��L�̂悤�ȕ�����Łu*�v�ɂ͓��{��Ɖp�ꂪ�������Ă��܂��B
�����ŁA�A<br>����-�܂ł̊Ԃ���A�p�ꕶ���������폜����悤�Ȑ��K�\�����Ė����ł��傤���H
<br>����-�̕����͉��s�������Ă܂��B
�����m�̕������܂�����A��낵�����肢���܂��B
-----
��L�̂悤�ȕ�����Łu*�v�ɂ͓��{��Ɖp�ꂪ�������Ă��܂��B
�����ŁA�A<br>����-�܂ł̊Ԃ���A�p�ꕶ���������폜����悤�Ȑ��K�\�����Ė����ł��傤���H
<br>����-�̕����͉��s�������Ă܂��B
�����m�̕������܂�����A��낵�����肢���܂��B
458 �Fnobody�����F2009/01/22(��) 17:45:32 ID:???
459 �Fnobody�����F2009/01/22(��) 17:56:19 ID:???
460 �Fnobody�����F2009/02/01(��) 00:44:32 ID:???
461 �FOraOra�F2009/02/01(��) 01:57:15 ID:2VNzjYUZ
���������̒��ł���p�^�[���̌����̎d����
�����炸�����Ă��܂��B
�ǂȂ����䋳�����肢���܂��B
�v���b�g�t�H�[����Oracle��PL/SQL�ł��B
�����Ώۂ͈ȉ��̓��t�����̕����ł��B
'yyyymmdd hh24:mi:ss'
�ȉ��̂悤�ɐ��K�\���̌��ʂ����Ŏ���
���̌��ʂ��`�F�b�N���Ă��܂��B
bool_result := regexp_like('20080230 11:20:22','(20)[0-9]{2}(0[1-9])|1[0-2])(0[1-9]|[12][0-9]|3[01]) (0[0-9]|1[0-9]|2[0-4]):([0-5][0-9]):([0-5][0-9])');
if bool_result then
dbms_output.put_line('OK');
else
dbms_output.put_line('NG');
end if;
����ł͏�L�̐��K�\����'0230'�A'0231'�̃`�F�b�N���o���������Ă��܂��B
��L�̐��K�\���̒���'0230'�A'0231'���܂߂ă`�F�b�N������@��
�����m�̕����܂�����ǂȂ����䋳�����肢���܂��B
�����炸�����Ă��܂��B
�ǂȂ����䋳�����肢���܂��B
�v���b�g�t�H�[����Oracle��PL/SQL�ł��B
�����Ώۂ͈ȉ��̓��t�����̕����ł��B
'yyyymmdd hh24:mi:ss'
�ȉ��̂悤�ɐ��K�\���̌��ʂ����Ŏ���
���̌��ʂ��`�F�b�N���Ă��܂��B
bool_result := regexp_like('20080230 11:20:22','(20)[0-9]{2}(0[1-9])|1[0-2])(0[1-9]|[12][0-9]|3[01]) (0[0-9]|1[0-9]|2[0-4]):([0-5][0-9]):([0-5][0-9])');
if bool_result then
dbms_output.put_line('OK');
else
dbms_output.put_line('NG');
end if;
����ł͏�L�̐��K�\����'0230'�A'0231'�̃`�F�b�N���o���������Ă��܂��B
��L�̐��K�\���̒���'0230'�A'0231'���܂߂ă`�F�b�N������@��
�����m�̕����܂�����ǂȂ����䋳�����肢���܂��B
462 �Fnobody�����F2009/02/02(��) 21:43:16 ID:H9hEncfV
�uid="72157612930889935" primary="3224910389" secret="be0cf48b4f" server="3468" farm="4" photos="131" videos="0"�v�Ƃ���������A
�uid=""�v�̐����������̂ł����i���̗�ł���u72157612930889935�v���~�����ł��j
$patern = 'id="(.*)" ?';
ereg($patern,$line,$id);
echo $id[1]."<br />\n";
�ł͍Ō��videos�̏I���̃_�u���R�[�e�[�V�����܂œ����Ă��܂��܂����B
>>421�ɋ߂��Ǝv���̂ł���?�ōŒZ�}�b�`�H�ɂȂ�悤�ȋC�����܂���
>>412�ɂ���悤��?��0��1��̌J��Ԃ��̂悤�ɂ��v�����c�B
OS��Cent4�n�APHP4.1.3�A����ereg���g���܂����B�ǂȂ��������ĉ�����
�uid=""�v�̐����������̂ł����i���̗�ł���u72157612930889935�v���~�����ł��j
$patern = 'id="(.*)" ?';
ereg($patern,$line,$id);
echo $id[1]."<br />\n";
�ł͍Ō��videos�̏I���̃_�u���R�[�e�[�V�����܂œ����Ă��܂��܂����B
>>421�ɋ߂��Ǝv���̂ł���?�ōŒZ�}�b�`�H�ɂȂ�悤�ȋC�����܂���
>>412�ɂ���悤��?��0��1��̌J��Ԃ��̂悤�ɂ��v�����c�B
OS��Cent4�n�APHP4.1.3�A����ereg���g���܂����B�ǂȂ��������ĉ�����
463 �Fnobody�����F2009/02/02(��) 21:51:38 ID:???
id="([0-9]*)�@�Ƃ��E�E
464 �F462�F2009/02/02(��) 21:55:09 ID:H9hEncfV
465 �Fnobody�����F2009/02/05(��) 13:33:36 ID:???
?��*�̈Ӗ���m���Ă������Ƃ��̔����ɂ͂Ȃ�Ȃ�
466 �Fnobody�����F2009/02/06(��) 11:54:32 ID:???
����ˁB
{0,1}��{0,1,2,3...}���̈Ⴂ�������B
{0,1}��{0,1,2,3...}���̈Ⴂ�������B
467 �Fnobody�����F2009/02/06(��) 16:00:49 ID:???
���₷��l�͍Œ����{�͒m���Ăė~�����Ǝv���������̍�
468 �Fnobody�����F2009/02/10(��) 00:16:26 ID:???
F, f, t, S, P �����K�\���̂Ƃ��A
FtSPPP �܂��� FfSPPPP ��
F(tS|fSP)P{3} ���Z���Ȃ�܂���?
PPP �� PPPP �ł͂Ȃ� X �� Y (F�̒���ɗ�����̂ɂ����S�̌�ɗ���ׂ����̂��܂������Ⴄ�ꍇ) �ɂ͉��p�\�ł��傤��?
FtSPPP �܂��� FfSPPPP ��
F(tS|fSP)P{3} ���Z���Ȃ�܂���?
PPP �� PPPP �ł͂Ȃ� X �� Y (F�̒���ɗ�����̂ɂ����S�̌�ɗ���ׂ����̂��܂������Ⴄ�ꍇ) �ɂ͉��p�\�ł��傤��?
469 �Fnobody�����F2009/02/10(��) 00:53:38 ID:???
F(tS|fSP)PPP
470 �Fnobody�����F2009/02/23(��) 09:51:32 ID:0L52Pp6H
.*?
����̈Ӗ��������ĉ������B
����̈Ӗ��������ĉ������B
471 �Fnobody�����F2009/02/23(��) 10:49:52 ID:???
�u�D�v�̓J�j����
�u���v�͂O�C�ȏ�̐������Ă��Ō�܂�
�܂�A�u�D���v�ŃJ�j�����邾���S����߂�s�����Ƃ����Ӗ��i�����̗��l���j
�����ŕ߂�s���������ł���Ƃ��������āu�D���H�v�Ƃ����v�z���l���o���ꂽ
�Ӗ��́A�ŏ��ɃJ�j�������炻�̈�C��߂܂��ċ����~�߂�Ƃ�������
�u���v�͂O�C�ȏ�̐������Ă��Ō�܂�
�܂�A�u�D���v�ŃJ�j�����邾���S����߂�s�����Ƃ����Ӗ��i�����̗��l���j
�����ŕ߂�s���������ł���Ƃ��������āu�D���H�v�Ƃ����v�z���l���o���ꂽ
�Ӗ��́A�ŏ��ɃJ�j�������炻�̈�C��߂܂��ċ����~�߂�Ƃ�������
472 �Fnobody�����F2009/02/23(��) 15:41:23 ID:0L52Pp6H
>>471
�ł́A .*? �� .? �̈Ⴂ�������ĉ������B
�ł́A .*? �� .? �̈Ⴂ�������ĉ������B
473 �Fnobody�����F2009/02/23(��) 17:58:21 ID:???
>>472
�u�D�v�̓J�j����
�u�H�v�͕߂�邩�Ƃ�Ȃ�������Ȃ����Ƃ肠�����w�͂���Ƃ����Ӗ�
�܂�A�u�D�H�v�Ō��̃J�j�T������Ƃ����Ӗ�
�u�D�v�̓J�j����
�u�H�v�͕߂�邩�Ƃ�Ȃ�������Ȃ����Ƃ肠�����w�͂���Ƃ����Ӗ�
�܂�A�u�D�H�v�Ō��̃J�j�T������Ƃ����Ӗ�
474 �Fnobody�����F2009/03/02(��) 19:46:41 ID:/g2x4kDh
php�ł��B
���Ƃ��Ε��ʂ�
http://google.co.jp�Ə����Ă�����̂�
<a href="http://google.co.jp">test</a>�Ə����Ă��镶������܂��B
���̕�������̃^�O�ɂȂ��ĂȂ�Url��A�^�O�Ń����N�肽����ł����ǂ������炢���ł��傤���B
���Ƃ��Ε��ʂ�
http://google.co.jp�Ə����Ă�����̂�
<a href="http://google.co.jp">test</a>�Ə����Ă��镶������܂��B
���̕�������̃^�O�ɂȂ��ĂȂ�Url��A�^�O�Ń����N�肽����ł����ǂ������炢���ł��傤���B
475 �Fnobody�����F2009/03/02(��) 21:22:30 ID:???
http����n�܂�A���p�p������.?&%���܂�ł邩�������
476 �Fnobody�����F2009/03/05(��) 18:30:50 ID:???
477 �Fnobody�����F2009/03/11(��) 00:46:27 ID:???
478 �Fnobody�����F2009/03/11(��) 01:27:39 ID:???
479 �Fnobody�����F2009/03/11(��) 11:15:58 ID:???
>>477
"{^https?://[0-9a-zA-Z]*\.2ch\.net/[0-9a-zA-Z]*/test/bbs\.cgi[0-9a-zA-Z/_-]*$}"
"{^https?://[0-9a-zA-Z]*\.2ch\.net/[0-9a-zA-Z]*/test/bbs\.cgi[0-9a-zA-Z/_-]*$}"
480 �Fnobody�����F2009/03/20(��) 02:34:11 ID:???
php�̃N���X�t�@�C���̓���̊��𐳋K�\���Ŕ����o�������̂ł����\�ł��傤���H
�� class.test.php ���� public function test($a){ �{�� }
�X�P���g���R�[�h�̏ꍇ�ȒP�ɔ����o����̂ł����A
�{������if,swich�Ȃǂ� } �����݂����ꍇ�ǂ�����Ηǂ��̂��Y��ł��܂��B
�� class.test.php ���� public function test($a){ �{�� }
�X�P���g���R�[�h�̏ꍇ�ȒP�ɔ����o����̂ł����A
�{������if,swich�Ȃǂ� } �����݂����ꍇ�ǂ�����Ηǂ��̂��Y��ł��܂��B
481 �Fnobody�����F2009/03/20(��) 04:11:43 ID:???
{���o����T��}��1���₹���������
482 �Fnobody�����F2009/03/20(��) 22:15:43 ID:???
�����
Boost���C�u����Boost.Xpressive���ABoost.Regex���ABoost.Spirit
�ł��B(�W��C++,�R���p�C��g++�B)
���ʂ̑Ή��̃o�����X���Ƃ�Ă���Ȃ�}�b�`������Ƃ������K�\���͂ǂ������܂����H
boost::xpressive::sregex parens;
parens = *( '(' >> by_ref(parens) >> ')' );
����
�@()���}�b�`
�@()()���}�b�`
�@()(()((()))())���}�b�`
�@(()))))���}�b�`���Ȃ�
�ł��B
���Ƃ��Ă�(1+3)*(4+(8-9))�̗l�Ɋ��ʈȊO�̕������܂܂�Ă��Ă����ʂ̃o�����X���Ƃ�Ă��邩����ł���悤�ɂ������̂ł����B
���������ʂƂ��Ă� ( �� ) ������z�肵�A{}[]�Ȃǂ͔���̑Ώۂɂ͂����A�����Ƃ��Đ��藧���Ă��邩�ǂ����Ȃǂ����肹���A�����܂� ( �� ) �̃o�����X�������������ł��B
Boost���C�u����Boost.Xpressive���ABoost.Regex���ABoost.Spirit
�ł��B(�W��C++,�R���p�C��g++�B)
���ʂ̑Ή��̃o�����X���Ƃ�Ă���Ȃ�}�b�`������Ƃ������K�\���͂ǂ������܂����H
boost::xpressive::sregex parens;
parens = *( '(' >> by_ref(parens) >> ')' );
����
�@()���}�b�`
�@()()���}�b�`
�@()(()((()))())���}�b�`
�@(()))))���}�b�`���Ȃ�
�ł��B
���Ƃ��Ă�(1+3)*(4+(8-9))�̗l�Ɋ��ʈȊO�̕������܂܂�Ă��Ă����ʂ̃o�����X���Ƃ�Ă��邩����ł���悤�ɂ������̂ł����B
���������ʂƂ��Ă� ( �� ) ������z�肵�A{}[]�Ȃǂ͔���̑Ώۂɂ͂����A�����Ƃ��Đ��藧���Ă��邩�ǂ����Ȃǂ����肹���A�����܂� ( �� ) �̃o�����X�������������ł��B
483 �Fnobody�����F2009/03/20(��) 22:25:59 ID:???
>>481
�ł��܂����A���肪�Ƃ��������܂����B
����Ȋ����ŁA�ȒP�ł����ˁA�A�A
�@/function test.*?\{.*? (\{.*?\}.*?)*? \}/s
�ł��܂����A���肪�Ƃ��������܂����B
����Ȋ����ŁA�ȒP�ł����ˁA�A�A
�@/function test.*?\{.*? (\{.*?\}.*?)*? \}/s
484 �Fnobody�����F2009/03/20(��) 23:13:32 ID:???
echo���� { } �ɂ��Ή����Ă݂܂����B
����łقڊ������Ȃ��A�A�A
/public\sfunction\stest_if_text.*?\{.*?(\{.*?("(.*?\{*?.*?|.*?\}*?.*?)*?".*?)*?\}.*?)*?\}/s
����łقڊ������Ȃ��A�A�A
/public\sfunction\stest_if_text.*?\{.*?(\{.*?("(.*?\{*?.*?|.*?\}*?.*?)*?".*?)*?\}.*?)*?\}/s
485 �Fnobody�����F2009/03/20(��) 23:18:29 ID:???
�Z���X�˂���
���_��������
���_��������
486 �Fnobody�����F2009/03/20(��) 23:28:45 ID:???
���������őΉ������
/[public|private|protected]+\s+[static]?\s?function\s+����.*?\{.*?(\{.*?("(.*?\{*?.*?|.*?\}*?.*?)*?".*?)*?\}.*?)*?\}/s
����Ȋ������Ȃ�
�ǂ݂₷���D��ŋL�q���Ă邩��Z���X�͊��ق��Ă���������
/[public|private|protected]+\s+[static]?\s?function\s+����.*?\{.*?(\{.*?("(.*?\{*?.*?|.*?\}*?.*?)*?".*?)*?\}.*?)*?\}/s
����Ȋ������Ȃ�
�ǂ݂₷���D��ŋL�q���Ă邩��Z���X�͊��ق��Ă���������
487 �Fnobody�����F2009/03/24(��) 08:12:11 ID:???
>>482
���K�\���������ᖳ������ˁH
���K�\���������ᖳ������ˁH
488 �Fnobody�����F2009/03/24(��) 09:59:04 ID:???
>>482
���K�\�����ᐔ�w�I�ɕs�\�B�L����ԃI�[�g�}�g���Ȃ̂ŕ����ĂȂ�
�J���J�b�R�̐������X��Ԑ��܂ł����������Ȃ����炻����z�������_��
�A�E�g�B
Perl�̐��K�\���݂����ɍċA�I�ȃp�^�[����������悤�Ɋg������Ă��
�ʂ����ǂˁB
���K�\�����ᐔ�w�I�ɕs�\�B�L����ԃI�[�g�}�g���Ȃ̂ŕ����ĂȂ�
�J���J�b�R�̐������X��Ԑ��܂ł����������Ȃ����炻����z�������_��
�A�E�g�B
Perl�̐��K�\���݂����ɍċA�I�ȃp�^�[����������悤�Ɋg������Ă��
�ʂ����ǂˁB
>>482
Boost��Xpressive�Ȃ�by_ref()�����邩��ċA�I�ɏ����Ȃ����Ƃ��Ȃ��n�Y�B
�ł���[�킩���B
Spirit���g����Ȃ炻�����̂��y��������ˁH
Boost��Xpressive�Ȃ�by_ref()�����邩��ċA�I�ɏ����Ȃ����Ƃ��Ȃ��n�Y�B
�ł���[�킩���B
Spirit���g����Ȃ炻�����̂��y��������ˁH
490 �Fnobody�����F2009/03/24(��) 10:20:21 ID:???
�u���X��Ԑ��v�̈Ӗ����킩��܂���B
491 �Fnobody�����F2009/03/24(��) 10:38:59 ID:???
���w����悭�łĂ��邯�ǂˁA�u���X�v�Ƃ��u��Ԑ��v�Ƃ�
492 �Fnobody�����F2009/03/24(��) 10:40:15 ID:???
493 �Fnobody�����F2009/03/24(��) 12:16:31 ID:???
���O�琳�K�\���X���ɂ��ėL����ԃI�[�g�}�g�����킩���̂�...
������Ȃ�ł���Ƃ肷���邾��
������Ȃ�ł���Ƃ肷���邾��
494 �Fnobody�����F2009/03/25(��) 10:08:36 ID:???
����x��10�ȏ�ł���ꍇ�Ƀ}�b�`������̂�
x{9}x+
��
x{10}x*
�͋��ɓ�����OK���Ƃ��������A
��ʘ_�Ō����Ƃǂ��炪��������ɂȂ�H
x{9}x+
��
x{10}x*
�͋��ɓ�����OK���Ƃ��������A
��ʘ_�Ō����Ƃǂ��炪��������ɂȂ�H
495 �Fnobody�����F2009/03/25(��) 10:43:53 ID:???
�ǂ�������������Ȃ��瓯�������
������������������ǂł���Ǝv������
������������������ǂł���Ǝv������
496 �Fnobody�����F2009/03/25(��) 12:38:18 ID:???
��������ň�ʘ_�ł͂Ȃ�Ƃ������Ȃ��Ǝv����B
�ǂ�����H�킹�Ă��S�������I�[�g�}�g���ɕϊ����Ă�����s�����
�ł҂����蓯���ɂȂ�����A�Ȃ�Ă̂����邩������Ȃ����A
�t�ɂȂ���+���s���ӂȎ����Ƃ�*���s���ӂȎ����Ƃ����邩��
����Ȃ��B���m�ɂ���Ă�{..}���s���ӂ�x����ׂ��ق���������
�������Ƃ��l������ȁB
�ǂ�����H�킹�Ă��S�������I�[�g�}�g���ɕϊ����Ă�����s�����
�ł҂����蓯���ɂȂ�����A�Ȃ�Ă̂����邩������Ȃ����A
�t�ɂȂ���+���s���ӂȎ����Ƃ�*���s���ӂȎ����Ƃ����邩��
����Ȃ��B���m�ɂ���Ă�{..}���s���ӂ�x����ׂ��ق���������
�������Ƃ��l������ȁB
498 �F���R�F2009/03/29(��) 09:39:01 ID:MqxV8vA3
PHP ���K�\���ɂ���
$str = 'test1?test2/test3;test4';
���̕�����
test1
test2
test3
test4
�����o���ɂ͂ǂ�������悢�ł��傤���H
���̉���
data1=test1&data2=test2&data3=test3&data4=test4
�ƕϊ��������ł�
preg_replace���g���Ă��܂�
$str = preg_replace("�^([a-zA-Z0-9]+\?+[a-zA-Z0-9]+)\/+[a-zA-Z0-9];+[a-zA-Z0-9)$�","data1=$1&data2=$2&data3=$3&data4=$4",$str));
����ł̓_���݂����ł�
$str = 'test1?test2/test3;test4';
���̕�����
test1
test2
test3
test4
�����o���ɂ͂ǂ�������悢�ł��傤���H
���̉���
data1=test1&data2=test2&data3=test3&data4=test4
�ƕϊ��������ł�
preg_replace���g���Ă��܂�
$str = preg_replace("�^([a-zA-Z0-9]+\?+[a-zA-Z0-9]+)\/+[a-zA-Z0-9];+[a-zA-Z0-9)$�","data1=$1&data2=$2&data3=$3&data4=$4",$str));
����ł̓_���݂����ł�
499 �Fnobody�����F2009/03/29(��) 09:49:02 ID:???
�ǁ[��[�N�G���������
500 �Fnobody�����F2009/03/29(��) 09:54:22 ID:???
$str = 'test1?test2/test3;test4';
���̓��e���ǂ������p�^�[���ŕϓ������邩���킩���
������Ă��鐳�K�\�����Ă݂�Ɓ@? / ; �̏��ɋ�蕶�������邱�Ƃ͌Œ�Ō��܂��Ă�H
���̓��e���ǂ������p�^�[���ŕϓ������邩���킩���
������Ă��鐳�K�\�����Ă݂�Ɓ@? / ; �̏��ɋ�蕶�������邱�Ƃ͌Œ�Ō��܂��Ă�H
501 �F���R�F2009/03/29(��) 19:51:10 ID:MqxV8vA3
�͂��B�Œ�ł��܂��Ă܂��B
�������A
test1
�Ȃǂ̕�����͔��p�p��������ł��B
�������A
test1
�Ȃǂ̕�����͔��p�p��������ł��B
502 �Fnobody�����F2009/03/31(��) 12:09:46 ID:???
>>498
data1,data2,data3�E�E�E���߂�������
data1,data2,data3�E�E�E���߂�������
503 �Fnobody�����F2009/04/14(��) 19:16:36 ID:???
�ȉ��̂悤�ȕ������u���ł��ׂč폜�������̂ł���
�ǂ����������̂ł��傤��
onMouseOver="refPopUp(1,event)" onMouseOut="hidePop()"
onMouseOver="refPopUp(23,event)" onMouseOut="hidePop()"
onMouseOver="refPopUp(345,event)" onMouseOut="hidePop()"
��
3�s���ׂč폜
���������K�\��
onMouseOver="refPopUp(\d+{1,3}.,event)" onMouseOut="hidePop()"
�ǂ����������̂ł��傤��
onMouseOver="refPopUp(1,event)" onMouseOut="hidePop()"
onMouseOver="refPopUp(23,event)" onMouseOut="hidePop()"
onMouseOver="refPopUp(345,event)" onMouseOut="hidePop()"
��
3�s���ׂč폜
���������K�\��
onMouseOver="refPopUp(\d+{1,3}.,event)" onMouseOut="hidePop()"
504 �Fnobody�����F2009/04/14(��) 19:24:30 ID:???
�R�p�D�C�́D���ĂȂɂ�
505 �Fnobody�����F2009/04/14(��) 19:31:15 ID:???
>>504
���܂�
�ꉞ���͉������܂����B������G�f�B�^�̐��K�\���I���œ���m�F
onMouseOver="refPopUp\(\d{1,3},event\)" onMouseOut="hidePop\(\)"
���܂�
�ꉞ���͉������܂����B������G�f�B�^�̐��K�\���I���œ���m�F
onMouseOver="refPopUp\(\d{1,3},event\)" onMouseOut="hidePop\(\)"
506 �Fnobody�����F2009/04/14(��) 20:09:33 ID:???
���L��2���ɂ���font�^�O�����������ł��B
���K�\����p����1�x�̒u���ŏ����܂����H
<dd><font style="font-size:;color:;"> �e�X�g <br> �e�X�g </font><br><br></dd>
<dd><font style="font-size:;color:;"> �e�X�g2 <br> �e�X�g2 </font><br><br></dd>
�l�����Ƃ���
<dd><font style="font-size:;color:;">������s�̂���</font>���폜���A���̂���<font style="font-size:;color:;">���폜
����ōs���������Ǝv�����̂ł����A����������s�̂����������폜�A�Ƃ������K�\�����킩��܂���ł����E�E�E
���K�\����p����1�x�̒u���ŏ����܂����H
<dd><font style="font-size:;color:;"> �e�X�g <br> �e�X�g </font><br><br></dd>
<dd><font style="font-size:;color:;"> �e�X�g2 <br> �e�X�g2 </font><br><br></dd>
�l�����Ƃ���
<dd><font style="font-size:;color:;">������s�̂���</font>���폜���A���̂���<font style="font-size:;color:;">���폜
����ōs���������Ǝv�����̂ł����A����������s�̂����������폜�A�Ƃ������K�\�����킩��܂���ł����E�E�E
507 �Fnobody�����F2009/04/16(��) 23:48:40 ID:???
>>506
(.*)<font style="font-size:;color:;">(.*)<\/font>(.*)
$1$2$3
�Ƃ��������Ȃ��B
�ǂ��̐��K�\�����g�����ɂ��ł��Ȃ���������Ȃ����ǁB
$n��n�Ԗڂ̊��ʂɊY�����邩��<font style="font-size:;color:;">��</font>��������B
<font></font>���l�X�Ƃ��Ă���ȂǕ�����������ʖڂ�������Ȃ����ǁB
(.*)<font style="font-size:;color:;">(.*)<\/font>(.*)
$1$2$3
�Ƃ��������Ȃ��B
�ǂ��̐��K�\�����g�����ɂ��ł��Ȃ���������Ȃ����ǁB
$n��n�Ԗڂ̊��ʂɊY�����邩��<font style="font-size:;color:;">��</font>��������B
<font></font>���l�X�Ƃ��Ă���ȂǕ�����������ʖڂ�������Ȃ����ǁB
508 �Fnobody�����F2009/04/17(��) 04:08:26 ID:???
509 �Fnobody�����F2009/04/25(�y) 21:30:02 ID:???
�@�R('A`)Ɂ@�@�����\��!
�@�@(�@ )�@
�@�@Ƀ�|
�@�@(�@ )�@
�@�@Ƀ�|
510 �Fnobody�����F2009/04/29(��) 05:47:07 ID:???
�`�J�����܂���
511 �Fnobody�����F2009/05/12(��) 06:32:22 ID:???
12?34
12??34
�Ⴂ���o��Ƃ��͂ǂ�ȂƂ��������Ȃ���
12??34
�Ⴂ���o��Ƃ��͂ǂ�ȂƂ��������Ȃ���
512 �Fnobody�����F2009/05/18(��) 16:49:08 ID:???
$txt = aaa(�f12165;
�̂悤�ȁA�Œ蕶����aaa�̌��Ɂw(�fnnnnn;�x�in�̕����͕K�����p�����Œl�ƕ������͉ρB�f�͑S�p�j�ƂȂ�ӏ��������Ⴄ���Ⴀ��A
���̕�����̐���������ł���L��������S�č폜�������̂ł����A�������肭�鐳�K�\���������т܂���
���ĂȂ��ł��傤��
php5 or 4
�̂悤�ȁA�Œ蕶����aaa�̌��Ɂw(�fnnnnn;�x�in�̕����͕K�����p�����Œl�ƕ������͉ρB�f�͑S�p�j�ƂȂ�ӏ��������Ⴄ���Ⴀ��A
���̕�����̐���������ł���L��������S�č폜�������̂ł����A�������肭�鐳�K�\���������т܂���
���ĂȂ��ł��傤��
php5 or 4
513 �Fnobody�����F2009/05/18(��) 22:40:33 ID:???
aaa�̌��ɂ����Ⴄ�������
$txt = aaa(�f12165;
$txt = aaa(�f5445;
$txt = aba(�f13;
$txt = aaa(�f99999;
�����ȂH
���� = preg_replace('/�f(\d+);/', '$1', ����);
����
$txt = 12165
$txt = 5445
$txt = aba(�f13;
$txt = 99999
$txt = aaa(�f12165;
$txt = aaa(�f5445;
$txt = aba(�f13;
$txt = aaa(�f99999;
�����ȂH
���� = preg_replace('/�f(\d+);/', '$1', ����);
����
$txt = 12165
$txt = 5445
$txt = aba(�f13;
$txt = 99999
514 �Fnobody�����F2009/05/21(��) 08:03:14 ID:bdo2M1uu
���݂܂���A���₳���Ă��������B
�Ȗ��̃��X�g���ꊇ�u�����悤�Ƃ��Ă��܂��B��̓I�ɂ�"�` by"��
����ۊ��ʂ����l�p����"[ ]"�ɒu�����������̂ł��B
��
This is me (talk) (Composed by Johan)
��
This is me (talk) [Composed by Johan]
�ǂ̂悤�ȏ����ɂ�����������������肢���܂��B
�Ȗ��̃��X�g���ꊇ�u�����悤�Ƃ��Ă��܂��B��̓I�ɂ�"�` by"��
����ۊ��ʂ����l�p����"[ ]"�ɒu�����������̂ł��B
��
This is me (talk) (Composed by Johan)
��
This is me (talk) [Composed by Johan]
�ǂ̂悤�ȏ����ɂ�����������������肢���܂��B
515 �Fnobody�����F2009/05/21(��) 08:25:36 ID:???
���K�\���ƈꌾ�Ɍ����Ă��ˁA���K�\���ɂ����낢�날���ĂˁA�ǂ̐��K�\������
���������S�R����Ă��邩��ˁA���̎��₾������Ȃ�Ƃ������Ȃ��̂ˁB
���S�җp�̃T�C�g�ɂ����Ă�����Ⴂ�Ȃ̂ˁB
�}���ł݂鐳�K�\������
http://funcchan.blog16.fc2.com/
���������S�R����Ă��邩��ˁA���̎��₾������Ȃ�Ƃ������Ȃ��̂ˁB
���S�җp�̃T�C�g�ɂ����Ă�����Ⴂ�Ȃ̂ˁB
�}���ł݂鐳�K�\������
http://funcchan.blog16.fc2.com/
516 �Fnobody�����F2009/05/21(��) 08:34:21 ID:???
$s= "This is me (talk) (Composed by Johan)";
$s=~ s/\(([^\)]*\bby\b[^\)]*)\)/[$1]/gi;
$s=~ s/\(([^\)]*\bby\b[^\)]*)\)/[$1]/gi;
517 �Fnobody�����F2009/05/21(��) 09:43:06 ID:???
>>515-516
���肪�Ƃ��������܂��B
STEP�Ƃ����^�O�G�f�B�^��100�ȂقLjꊇ�u�����悤��
�ژ_��ł܂��B
�����Ă����������T�C�g�ƃX�N���v�g���肪�����
���݈���ꓬ���ł��B������Ɗ撣���Ă݂܂��B
���肪�Ƃ��������܂��B
STEP�Ƃ����^�O�G�f�B�^��100�ȂقLjꊇ�u�����悤��
�ژ_��ł܂��B
�����Ă����������T�C�g�ƃX�N���v�g���肪�����
���݈���ꓬ���ł��B������Ɗ撣���Ă݂܂��B
518 �Fnobody�����F2009/05/23(�y) 22:18:11 ID:???
���������Ƃ��ɂ��܂�킯��
special days(arranged by hor version.) (Composed by Ellic)
special days(arranged by hor version.) (Composed by Ellic)
519 �Fnobody�����F2009/05/27(��) 00:18:24 ID:???
���₳���ĉ������B
ABC
�cLMNO�c�c�c
�c�cLMNO�c�c
�c�c�cLMNO�c
XYZ
�Ƃ����悤�ȕ��͂��������Ƃ��܂��B
�uLMNO�v�̑O��(�u�c�v)�ɂ͕���(���{���p����)������܂��B
Perl5�݊��̐��K�\�����g����e�L�X�g�G�f�B�^��ABREGEXP.DLL���g����u�����\�t�g���g�p���A
�uABC�v����uXYZ�v�܂łɂ���uLMNO�v���uOOOO�v�ɒu�������邱�Ƃ͉\�ł��傤���H
����͈͓̔��̕���������u�������鐳�K�\�����킩�炸�A����������ƒu����������̎w��ō����Ă��܂��B
�ǂ̂悤�ɂ���Ηǂ��̂������Ē�����Ə�����܂��B��낵�����肢���܂��B
ABC
�cLMNO�c�c�c
�c�cLMNO�c�c
�c�c�cLMNO�c
XYZ
�Ƃ����悤�ȕ��͂��������Ƃ��܂��B
�uLMNO�v�̑O��(�u�c�v)�ɂ͕���(���{���p����)������܂��B
Perl5�݊��̐��K�\�����g����e�L�X�g�G�f�B�^��ABREGEXP.DLL���g����u�����\�t�g���g�p���A
�uABC�v����uXYZ�v�܂łɂ���uLMNO�v���uOOOO�v�ɒu�������邱�Ƃ͉\�ł��傤���H
����͈͓̔��̕���������u�������鐳�K�\�����킩�炸�A����������ƒu����������̎w��ō����Ă��܂��B
�ǂ̂悤�ɂ���Ηǂ��̂������Ē�����Ə�����܂��B��낵�����肢���܂��B
520 �Fnobody�����F2009/05/27(��) 22:50:49 ID:???
s/(ABC.*)LMNO(.*XYZ)/$1OOOO$2/g
���Ă��Ƃ��H
���Ă��Ƃ��H
>>520
��̓I�Ȏw��������Ē����Ă��肪�Ƃ��������܂����B
�����������̂ł����u�����ł��܂���ł����B
�uSpeeeeed�v�Ƃ����u�����\�t�g�ł�BREGEXP.DLL���g����̂ł����A����ł��u�������ʂ��[���̂܂܂ł��B
������̃X����������x�ǂݕԂ��Ă����Ɛ��K�\������������Ǝv���܂��B
��̓I�Ȏw��������Ē����Ă��肪�Ƃ��������܂����B
�����������̂ł����u�����ł��܂���ł����B
�uSpeeeeed�v�Ƃ����u�����\�t�g�ł�BREGEXP.DLL���g����̂ł����A����ł��u�������ʂ��[���̂܂܂ł��B
������̃X����������x�ǂݕԂ��Ă����Ɛ��K�\������������Ǝv���܂��B
522 �Fnobody�����F2009/06/07(��) 21:54:50 ID:???
s/(?>ABC)(.*)LMNO(.*)(?<=XYZ)/${1}0000$2/
����������������Ƃ��H
�Ȃm���g�I�v�V�������Ă����ʂ�������Ȃ�
����������������Ƃ��H
�Ȃm���g�I�v�V�������Ă����ʂ�������Ȃ�
523 �Fnobody�����F2009/06/11(��) 09:11:23 ID:???
524 �Fnobody�����F2009/06/12(��) 11:14:20 ID:???
sed �ł��g���[�H
525 �Fnobody�����F2009/06/13(�y) 23:07:31 ID:56/XckFT
Perl�̐��K�\���Ŏ��₳���ĉ������B
yyyy/mm/entry-basename/index.php
���͂ǂ̂悤�ɋL�q��������̂��A���萔�ł����������肢�܂�<(_ _)>
yyyy/mm/entry-basename/index.php
���͂ǂ̂悤�ɋL�q��������̂��A���萔�ł����������肢�܂�<(_ _)>
526 �Fnobody�����F2009/06/14(��) 09:14:31 ID:???
���K�\���ŕ\���ɂ͑O��������Ȃ��Ɠ������Ȃ�
yyyy�������S�������̐���H
mm�������Q�������̌��i�[���T�v���X�j�H
m#^\d{4}/\d\d/entry-basename/index\.php$#
yyyy�������S�������̐���H
mm�������Q�������̌��i�[���T�v���X�j�H
m#^\d{4}/\d\d/entry-basename/index\.php$#
527 �F525�F2009/06/14(��) 17:21:47 ID:Ycy68Wtw
>>526����𓀗L��������܂��B
�f�l�Ŏ��₪���肭���Ő\����L��܂���
���̏ꍇ����
"/diary/archives/yyyy/mm/entry_basename.php"
"/^\/diary\/archives\/\d{4}\/\d{2}\/(\w+)\.php/"
���̂悤�ɒu��������݂����Ȃ̂ł����A
���l�Ɂ��̏ꍇ����
"yyyy/mm/entry-basename/index.php"
�ǂ̂悤�ɒu��������̂���������Ȃ��āA���萔�ł����������������B
������ɂ����Đ\����Ȃ��ł��B
�f�l�Ŏ��₪���肭���Ő\����L��܂���
���̏ꍇ����
"/diary/archives/yyyy/mm/entry_basename.php"
"/^\/diary\/archives\/\d{4}\/\d{2}\/(\w+)\.php/"
���̂悤�ɒu��������݂����Ȃ̂ł����A
���l�Ɂ��̏ꍇ����
"yyyy/mm/entry-basename/index.php"
�ǂ̂悤�ɒu��������̂���������Ȃ��āA���萔�ł����������������B
������ɂ����Đ\����Ȃ��ł��B
528 �Fnobody�����F2009/06/14(��) 21:15:28 ID:???
���Ȃ݂Ƀ[���Ō��߂�̂́u�[���p�f�B���O�v�ˁB
> ���̂悤�ɒu��������݂����Ȃ̂ł����A
�u�u��������v���āA�����鐳�K�\���ɂ��u�������̈Ӗ�����Ȃ���
�u�����\���ɖ|��v���ĈӖ��Ȃ̂��B���܂�������킵���B
�������c�A
�ŁA�ǂ̒P�ꂪ�ϕ����Ȃ̂��������ς蕪����Ȃ���ˁB
"index.php" �͌Œ�Ȃ́H
����ƁA��̒u��������ł� "entry_basename" �ɂȂ��Ă��邯��
���q�˂̌��� "entry-basename" ����ˁB�P�Ȃ� typo ���ȁH
"\w" ���g����ł́A�����Ώە������ "_" �� "-" �Ƃ̈Ⴂ�͖{���I����B
�v����ɁA���₷��ɂ��Ă͕s�������߂��܂��B
> ���̂悤�ɒu��������݂����Ȃ̂ł����A
�u�u��������v���āA�����鐳�K�\���ɂ��u�������̈Ӗ�����Ȃ���
�u�����\���ɖ|��v���ĈӖ��Ȃ̂��B���܂�������킵���B
�������c�A
�ŁA�ǂ̒P�ꂪ�ϕ����Ȃ̂��������ς蕪����Ȃ���ˁB
"index.php" �͌Œ�Ȃ́H
����ƁA��̒u��������ł� "entry_basename" �ɂȂ��Ă��邯��
���q�˂̌��� "entry-basename" ����ˁB�P�Ȃ� typo ���ȁH
"\w" ���g����ł́A�����Ώە������ "_" �� "-" �Ƃ̈Ⴂ�͖{���I����B
�v����ɁA���₷��ɂ��Ă͕s�������߂��܂��B
529 �F525�F2009/06/14(��) 23:33:00 ID:Ycy68Wtw
>>525�ł�
�u�����\���ɖ|��v�Ƃ����Ӗ��ł��B���炵�܂���
������"index.php"�͌Œ�ŁA"entry-basename"�������ł��B
http://www.magicvox.net/archive/2005/05261744/
�����̃y�[�W�ɂ��郉���L���O�����p�������̂ł����A
�u�����L���O�W�v�������t�@�C�����Ƀ}�b�`����悤 Perl �̐��K�\��
���C�������������B�v
�����̈Ӗ���������Ȃ��č����Ă��܂��B���̃T�C�g�Ȃǂ����Ă݂�ƁA
�����̌ʃG���g���[�p�X��"/diary/archives/yyyy/mm/entry_basename.php"�Ȃ킯�ł��̂ŁA
"/^\/diary\/archives\/\d{4}\/\d{2}\/(\w+)\.php/"�Ƃ��܂����B
�Ƃ���܂��B
���̏ꍇ�A�G���g���[�p�X��"yyyy/mm/entry-basename/index.php"�ł��B
�����"/^\/diary\/archives\/\d{4}\/\d{2}\/(\w+)\.php/"�̂悤�ɋL�q
����ɂ͂ǂ���������̂ł��傤���H
�������炵�܂����B
�u�����\���ɖ|��v�Ƃ����Ӗ��ł��B���炵�܂���
������"index.php"�͌Œ�ŁA"entry-basename"�������ł��B
http://www.magicvox.net/archive/2005/05261744/
�����̃y�[�W�ɂ��郉���L���O�����p�������̂ł����A
�u�����L���O�W�v�������t�@�C�����Ƀ}�b�`����悤 Perl �̐��K�\��
���C�������������B�v
�����̈Ӗ���������Ȃ��č����Ă��܂��B���̃T�C�g�Ȃǂ����Ă݂�ƁA
�����̌ʃG���g���[�p�X��"/diary/archives/yyyy/mm/entry_basename.php"�Ȃ킯�ł��̂ŁA
"/^\/diary\/archives\/\d{4}\/\d{2}\/(\w+)\.php/"�Ƃ��܂����B
�Ƃ���܂��B
���̏ꍇ�A�G���g���[�p�X��"yyyy/mm/entry-basename/index.php"�ł��B
�����"/^\/diary\/archives\/\d{4}\/\d{2}\/(\w+)\.php/"�̂悤�ɋL�q
����ɂ͂ǂ���������̂ł��傤���H
�������炵�܂����B
530 �Fnobody�����F2009/06/15(��) 00:03:48 ID:???
'/\d{4}\/\d{2}\/(\w+)\/index\.php/'
�䂷���邯�� PHP �� preg �g���� entry_basename �� $1 �ɓ�����
�v������ł݂�
�䂷���邯�� PHP �� preg �g���� entry_basename �� $1 �ɓ�����
�v������ł݂�
531 �Fnobody�����F2009/06/15(��) 00:06:02 ID:???
�ŁA���� "entry-basename" ���Ă̂͂��̕����̂��̂ł͂Ȃ���
�u�����ɂ����ȕ�������܂��v���[�_�~�[�Ȃ낤���ǁA
�ǂ������������ō\�������́H
�u�����ɂ����ȕ�������܂��v���[�_�~�[�Ȃ낤���ǁA
�ǂ������������ō\�������́H
532 �Fnobody�����F2009/07/05(��) 16:07:10 ID:???
perl�Ńe�L�X�g�f�[�^���̓��t�������A
2009/1/1
��
2009/01/01
�Ɉ�s�Œu���������̂ł����B
s|/([0-9][^0-9])|/0$1|gm;
���ƁA2���������K�v�ɂȂ��Ă��܂��܂��B
�������@����܂���?
2009/1/1
��
2009/01/01
�Ɉ�s�Œu���������̂ł����B
s|/([0-9][^0-9])|/0$1|gm;
���ƁA2���������K�v�ɂȂ��Ă��܂��܂��B
�������@����܂���?
533 �Fnobody�����F2009/07/05(��) 16:12:40 ID:???
split��sprintf
534 �Fnobody�����F2009/07/05(��) 17:05:36 ID:???
535 �Fnobody�����F2009/07/05(��) 17:40:16 ID:???
m �͂Ȃ��Ă��悳�����Ɍ�����
536 �Fnobody�����F2009/07/05(��) 18:26:28 ID:???
537 �Fnobody�����F2009/07/05(��) 18:27:53 ID:???
���Ԃ�g������Ȃ���
538 �Fnobody�����F2009/07/08(��) 01:27:46 ID:???
$str =~ s{/([0-9])(?![0-9])}{/0$1}g;
539 �Fnobody�����F2009/07/15(��) 09:40:19 ID:???
�G�ۂŁACSS�� : �܂ł̕����������\���������̂ł����A
�ǂ��\����������̂ł��傤���B
�ȉ��̗Ⴞ�ƁAfont-size:�̕����ł��B
h1 {
font-size: 150% !important;
}
�ǂ��\����������̂ł��傤���B
�ȉ��̗Ⴞ�ƁAfont-size:�̕����ł��B
h1 {
font-size: 150% !important;
}
540 �Fnobody�����F2009/07/15(��) 13:56:52 ID:???
541 �Fnobody�����F2009/07/15(��) 14:47:39 ID:???
���肪�Ƃ��������܂��B
���₷���Ȃ�܂����I
:first-child��:not�̃Z���N�^�Ō딚���Ă����̂�
[\-a-za-z0-9]+[ \t]*:(?!\first|last|not)
�Ƃ��܂����B
�܂��ȉ��̂悤�Ȃ��̂��ƌ딚����݂����ł���
����͂قƂ�ǎg��Ȃ��̂Ŗڂ��ނ낤�Ǝv���܂���
BODY[style="width: 100%; height: 100%;"] {
font-size: 150% !important;
}
���₷���Ȃ�܂����I
:first-child��:not�̃Z���N�^�Ō딚���Ă����̂�
[\-a-za-z0-9]+[ \t]*:(?!\first|last|not)
�Ƃ��܂����B
�܂��ȉ��̂悤�Ȃ��̂��ƌ딚����݂����ł���
����͂قƂ�ǎg��Ȃ��̂Ŗڂ��ނ낤�Ǝv���܂���
BODY[style="width: 100%; height: 100%;"] {
font-size: 150% !important;
}
542 �Fnobody�����F2009/07/15(��) 15:14:34 ID:???
�ǂ��l����������ƈ�t������
[\-a-za-z0-9]+[ \t]*:(?!first|last|not|hover|focas|active|visited|link|lang|after|before)
[\-a-za-z0-9]+[ \t]*:(?!first|last|not|hover|focas|active|visited|link|lang|after|before)
543 �Fnobody�����F2009/07/15(��) 23:25:43 ID:2a7dmfqp
/(^-^;)/w(^o^)vv(-_-;)vv[^-^](^_^;)/
544 �Fnobody�����F2009/07/22(��) 16:01:40 ID:???
���݂܂��₳���Ă��������B
���K�\�����S�҂ł��B
�G�ۂŁA���K�\�����g���ĕ�����̒u�������悤�Ƃ��Ă��܂��B
��j
abcd,efag),
������ŏ���[,]������[',]�ɒu���������Ǝv���Ă��܂��B
����������F�@[^)],
�u��������F�@',
�Ƃ���ƁA
abc',efag),
�̂悤�ɕ�����̌��̂P�����܂ŏ����Ă��܂��܂��B
���������Ȃ��悤�ɁA�Ō���łȂ�[,]������u������ɂ͂ǂ̂悤�Ɏw�肷������ł��傤���B
�������������B
���K�\�����S�҂ł��B
�G�ۂŁA���K�\�����g���ĕ�����̒u�������悤�Ƃ��Ă��܂��B
��j
abcd,efag),
������ŏ���[,]������[',]�ɒu���������Ǝv���Ă��܂��B
����������F�@[^)],
�u��������F�@',
�Ƃ���ƁA
abc',efag),
�̂悤�ɕ�����̌��̂P�����܂ŏ����Ă��܂��܂��B
���������Ȃ��悤�ɁA�Ō���łȂ�[,]������u������ɂ͂ǂ̂悤�Ɏw�肷������ł��傤���B
�������������B
545 �Fnobody�����F2009/07/24(��) 05:32:15 ID:???
�G�ۂŃT�|�[�g����Ă��鐳�K�\���̋@�\���ǂꂾ���̂��̂��������Ȃ��B
��� 1(����҂̕��j�Q�l)
����������: ([^)]),
�u��������: $1',
��� 2
����������: ,(?!$)
�u��������: ',
�����Ȃ��U�u,\n�v���u,�v���܂܂Ȃ��ʂ̓K���ȕ�����ɕϊ����āA
�S�Ắu,�v���u',�v�ɕϊ����Ă��猳�ɖ߂��Ƃ��B
��� 1(����҂̕��j�Q�l)
����������: ([^)]),
�u��������: $1',
��� 2
����������: ,(?!$)
�u��������: ',
�����Ȃ��U�u,\n�v���u,�v���܂܂Ȃ��ʂ̓K���ȕ�����ɕϊ����āA
�S�Ắu,�v���u',�v�ɕϊ����Ă��猳�ɖ߂��Ƃ��B
546 �Fnobody�����F2009/08/01(�y) 13:06:24 ID:???
��� 3
����������: |-^)v!!
�u��������: (^o^)/~~
����������: |-^)v!!
�u��������: (^o^)/~~
547 �Fnobody�����F2009/09/01(��) 17:17:50 ID:???
PHP5�ŁA$txt�Ɋi�[���ꂽ
<a href="javascript:userid('123456');">�e�L�X�g</a>
���u123456�v�Ɓu�e�L�X�g�v�͕ω����܂�
�Ƃ��������т̕�����^�O���ʂ���
123456,�e�L�X�g,
�ƃJ���}���ɂ������̂ł����A�����ǂ����@�͂Ȃ��ł��傤��
<a href="javascript:userid('123456');">�e�L�X�g</a>
���u123456�v�Ɓu�e�L�X�g�v�͕ω����܂�
�Ƃ��������т̕�����^�O���ʂ���
123456,�e�L�X�g,
�ƃJ���}���ɂ������̂ł����A�����ǂ����@�͂Ȃ��ł��傤��
548 �Fnobody�����F2009/09/01(��) 17:51:35 ID:???
���ȉ������܂���
�����������Đ\����܂���
�����������Đ\����܂���
549 �Fnobody�����F2009/09/03(��) 10:54:41 ID:???
>>548�͂���H
550 �Fnobody�����F2009/09/03(��) 12:19:35 ID:54RqrMPZ
301�ŃT�C�g�ړ�������ꍇ�Ɋ��ɐF�X�Ȓl������̂����ꂼ�ꃊ�_�C���N�g���������ꍇ��
�ꋓ�ɏ����ɂ͂ǂ���������ł��傤���H
�P�P�����Ɖ��L�̂悤�Ȃ̂��P�ɂ������ł��B
Redirect 301 /index.php?a=1 "http://www.sample.jp/index?a=1"
Redirect 301 /index.php?a=2 "http://www.sample.jp/index?a=2"
Redirect 301 /index.php?a=3 "http://www.sample.jp/index?a=3"
�@�E
�@�E
�@�E
Redirect 301 /index.php?a=a1 "http://www.sample.jp/index?a=a1"
Redirect 301 /index.php?a=b2 "http://www.sample.jp/index?a=b2"
Redirect 301 /index.php?a=c3 "http://www.sample.jp/index?a=c3"
�@�E
�@�E
�@�E
�ꋓ�ɏ����ɂ͂ǂ���������ł��傤���H
�P�P�����Ɖ��L�̂悤�Ȃ̂��P�ɂ������ł��B
Redirect 301 /index.php?a=1 "http://www.sample.jp/index?a=1"
Redirect 301 /index.php?a=2 "http://www.sample.jp/index?a=2"
Redirect 301 /index.php?a=3 "http://www.sample.jp/index?a=3"
�@�E
�@�E
�@�E
Redirect 301 /index.php?a=a1 "http://www.sample.jp/index?a=a1"
Redirect 301 /index.php?a=b2 "http://www.sample.jp/index?a=b2"
Redirect 301 /index.php?a=c3 "http://www.sample.jp/index?a=c3"
�@�E
�@�E
�@�E
551 �Fnobody�����F2009/09/03(��) 12:27:59 ID:???
>>550
�U�����ŗ�������Ƃ�����Ȑl����
�U�����ŗ�������Ƃ�����Ȑl����
552 �Fnobody�����F2009/09/03(��) 12:47:58 ID:54RqrMPZ
�����Ɍ����āu�X���Ⴂ�v���Ē��̂��Ƃ��H
�Ǝv�����̂ŗ�Ȃǂ͏����Ȃ������B
�ǂ������Ƃ����Ƃ������̕����K�Ƃ͎v�����A
�y.htaccess�t�@�C��(�u���U�ݒ�t�@�C���v)�̏������E�g�����ȂǂɊւ���X���ł��B �z
���Đ����̃X���ɏ����Ă��ʂɊԈ���ĂȂ��Ǝv���B
�Ǝv�����̂ŗ�Ȃǂ͏����Ȃ������B
�ǂ������Ƃ����Ƃ������̕����K�Ƃ͎v�����A
�y.htaccess�t�@�C��(�u���U�ݒ�t�@�C���v)�̏������E�g�����ȂǂɊւ���X���ł��B �z
���Đ����̃X���ɏ����Ă��ʂɊԈ���ĂȂ��Ǝv���B
553 �Fnobody�����F2009/09/03(��) 15:52:56 ID:???
>>550
�X���Ⴂ�B
�yApache�zmod_rewrite�ɂ��Č��X��
http://pc11.2ch.net/test/read.cgi/php/1023791370/
�l�I�ɂ͗�Ƃ��ǂ��ł������Ǝv�����ǁA
�}���`���∵������Ė��Ȃ��ƂɂȂ�\��������̂ŁA
�u�������Ŏ��₵�����܂��v�Ƃ��ЂƂ��ƌ����Ă�������������Ƃ͎v���B
���ƁA�h���C���̗Ꭶ�Ɏg����̂� "example.jp" �ˁB
�X���Ⴂ�B
�yApache�zmod_rewrite�ɂ��Č��X��
http://pc11.2ch.net/test/read.cgi/php/1023791370/
�l�I�ɂ͗�Ƃ��ǂ��ł������Ǝv�����ǁA
�}���`���∵������Ė��Ȃ��ƂɂȂ�\��������̂ŁA
�u�������Ŏ��₵�����܂��v�Ƃ��ЂƂ��ƌ����Ă�������������Ƃ͎v���B
���ƁA�h���C���̗Ꭶ�Ɏg����̂� "example.jp" �ˁB
554 �Fnobody�����F2009/09/13(��) 17:57:11 ID:???
PHP��Perl�݊���preg_replace�����g�����u�����s�����Ƃ��Ă���̂ł����A
��肽�����Ƃ����܂������ł��܂���B
��肽�����Ƃ́A
�E<tagA>�Ƃ����������</tagA>�̂�������<tagInsert>�Ƃ����������}��������
�E�������A<tagA>�̒���<tagB>�Ƃ�����������ꍇ�́A����<tagB>�̉��ɑ}��������
�����s�������K�\����
$new_str = preg_replace("/<tagA(.*?)>(.*?)(<(?!tagB).)*/", '<tagA\\1>\\2<tagInsert>\\3', $str);
�������������၄
<tagA>
<tagB>
<tagB>
<tagC>
</tagA>
���u�����s
<tagA>
<tagB>
<tagB>
<tagInsert>
<tagC>
</tagA>
��肽�����Ƃ����܂������ł��܂���B
��肽�����Ƃ́A
�E<tagA>�Ƃ����������</tagA>�̂�������<tagInsert>�Ƃ����������}��������
�E�������A<tagA>�̒���<tagB>�Ƃ�����������ꍇ�́A����<tagB>�̉��ɑ}��������
�����s�������K�\����
$new_str = preg_replace("/<tagA(.*?)>(.*?)(<(?!tagB).)*/", '<tagA\\1>\\2<tagInsert>\\3', $str);
�������������၄
<tagA>
<tagB>
<tagB>
<tagC>
</tagA>
���u�����s
<tagA>
<tagB>
<tagB>
<tagInsert>
<tagC>
</tagA>
555 �Fnobody�����F2009/09/27(��) 12:15:08 ID:???
�@/�g���F(\d+)\n�̏d�F(\d+)/
�Ƃ������K�\���ɑ��A�Ⴆ��
�@"�g���F175\n�̏d�F67"
�Ƃ�������������
�@"�g���F<font color="red">175</font>\n�̏d�F<font color="blue">67</font>"
�̂悤��HTML�^�O��lj��������B
������
�@"�g���F100\n�̏d�F100"
�̂悤�ɐg���Ƒ̏d�������ꍇ���g���͐ԁA�̏d�͐ɂ������B
�����Ɨ~�������ΐ��K�\���͐g���E�̏d�����łȂ�
�@/�N��F(\d+)\n�D���ȐH�ו��F(\S+)/
�̂悤�ɉςɂ������B
�Ƃ������K�\���ɑ��A�Ⴆ��
�@"�g���F175\n�̏d�F67"
�Ƃ�������������
�@"�g���F<font color="red">175</font>\n�̏d�F<font color="blue">67</font>"
�̂悤��HTML�^�O��lj��������B
������
�@"�g���F100\n�̏d�F100"
�̂悤�ɐg���Ƒ̏d�������ꍇ���g���͐ԁA�̏d�͐ɂ������B
�����Ɨ~�������ΐ��K�\���͐g���E�̏d�����łȂ�
�@/�N��F(\d+)\n�D���ȐH�ו��F(\S+)/
�̂悤�ɉςɂ������B
556 �Fnobody�����F2009/09/27(��) 13:11:58 ID:???
�����ł���
�ǂ����������m�b��݂��Ă�������
558 �Fnobody�����F2009/09/27(��) 16:41:20 ID:???
���́H
559 �Fnobody�����F2009/09/27(��) 16:49:26 ID:???
perl�ł�ruby�ł�
�ł��邾���g���b�L�[�łȂ��ĕ��ʂ̐��K�\���̃p�^�[���}�b�`�ƒu���łł���͈͂�
�ł��邾���g���b�L�[�łȂ��ĕ��ʂ̐��K�\���̃p�^�[���}�b�`�ƒu���łł���͈͂�
560 �Fnobody�����F2009/09/27(��) 23:10:15 ID:???
��ΐ��K�\�������ŏ����Ȃ��Ⴞ�߂Ȃ́H
���ʂɊ������������I���Ǝv������
���ʂɊ������������I���Ǝv������
561 �Fnobody�����F2009/09/28(��) 01:47:40 ID:???
if�g���ĕ������
562 �Fnobody�����F2009/09/28(��) 08:53:02 ID:???
���K�\���������������ǂ����Ɨ�������ɂ������ĂȂ��l��
���K�\���ł��Ƃ������Ėʓ|�Ȏ��܂ł����悤�Ƃ��Ă���Ȃ�
��J������X��������ˁB���������Ⴆ�Ύg���������������ǂ���
���f���悤�ɂȂ���B
���K�\���ł��Ƃ������Ėʓ|�Ȏ��܂ł����悤�Ƃ��Ă���Ȃ�
��J������X��������ˁB���������Ⴆ�Ύg���������������ǂ���
���f���悤�ɂȂ���B
563 �Fnobody�����F2009/09/28(��) 10:18:45 ID:???
>>555
����Ȃ̂Ƃ��H
html = str.sub(/(.+?)(�F)(\d+)\n(.+?)(�F)(\S+)/) {
"#{$1}#{$2}��font color=\"red\"��#{$3}��/font��\n#{$4}#{$5}��font color=\"blue\"��#{$6}��/font��"
}
����Ȃ̂Ƃ��H
html = str.sub(/(.+?)(�F)(\d+)\n(.+?)(�F)(\S+)/) {
"#{$1}#{$2}��font color=\"red\"��#{$3}��/font��\n#{$4}#{$5}��font color=\"blue\"��#{$6}��/font��"
}
564 �Fnobody�����F2009/10/06(��) 22:32:03 ID:???
php��preg_match�Ȃ̂ł���
������̒���URL����z�X�g���擾����͉̂���̂ł���
�z�X�g���Ƃ��̌�ɑ����f�B���N�g�������擾������@�������ĉ������B
$url = "http://hogehoge.com/hoge/index.php";
����Ȃ��
http://hogehoge.com/hoge�̕����ł��B
���肢�������܂��B
������̒���URL����z�X�g���擾����͉̂���̂ł���
�z�X�g���Ƃ��̌�ɑ����f�B���N�g�������擾������@�������ĉ������B
$url = "http://hogehoge.com/hoge/index.php";
����Ȃ��
http://hogehoge.com/hoge�̕����ł��B
���肢�������܂��B
565 �Fnobody�����F2009/10/13(��) 11:08:03 ID:8X+N74J6
php�ŁA����������̊g���q�����t�@�C�����}�b�`���������̂ł����A
�Ō���Ӗ�����$�͉��L�̂悤�ɍŏI�I�ɂP�ł悢�ł���
if (preg_match("/\.html|\.php|\.txt$/",$value)) {
$chk = 1;
}
����Ƃ����̂悤�ɑS����$���K�v�ł����H
if (preg_match("/\.html$|\.php$|\.txt$/",$value)) {
$chk = 1;
}
�Ō���Ӗ�����$�͉��L�̂悤�ɍŏI�I�ɂP�ł悢�ł���
if (preg_match("/\.html|\.php|\.txt$/",$value)) {
$chk = 1;
}
����Ƃ����̂悤�ɑS����$���K�v�ł����H
if (preg_match("/\.html$|\.php$|\.txt$/",$value)) {
$chk = 1;
}
566 �Fnobody�����F2009/10/13(��) 11:28:58 ID:???
>>564
parse_url�g����"/(.*)\//"
>>565
����Ă݂�킩�邱�Ƃ����Ǔ��R�S���ɕK�v
������\.(html|php|txt)$�݂����Ɋ��ʂł�����̂��퓅�����ǃ}�b�`�����l���擾����K�v�Ȃ��Ȃ�
\.(?:html|php|txt)$�Ə����ď����y���ł���
parse_url�g����"/(.*)\//"
>>565
����Ă݂�킩�邱�Ƃ����Ǔ��R�S���ɕK�v
������\.(html|php|txt)$�݂����Ɋ��ʂł�����̂��퓅�����ǃ}�b�`�����l���擾����K�v�Ȃ��Ȃ�
\.(?:html|php|txt)$�Ə����ď����y���ł���
567 �F565�F2009/10/13(��) 12:34:51 ID:8X+N74J6
>>566
���肪�Ƃ��������܂����i�@�O�ցO�j
���肪�Ƃ��������܂����i�@�O�ցO�j
568 �Fnobody�����F2009/10/14(��) 08:58:15 ID:???
perl �ŁC
�u<��>�ň͂܂ꂽ��������� abc �� def �ɑS�Ēu������v
�Ƃ����̂͐��K�\���łǂ������悢�ł��傤���B
�}�b�`�����Ȃ��
"<asaabcasalaabca>" =~ /\<(.*?)(abc(.*?))*?\>/
�̂悤�ɂ��ă}�b�`��������̂ł����C�J��Ԃ�������̂Ō���Q�ƂŎ擾�ł��܂���B
�u<��>�ň͂܂ꂽ��������� abc �� def �ɑS�Ēu������v
�Ƃ����̂͐��K�\���łǂ������悢�ł��傤���B
�}�b�`�����Ȃ��
"<asaabcasalaabca>" =~ /\<(.*?)(abc(.*?))*?\>/
�̂悤�ɂ��ă}�b�`��������̂ł����C�J��Ԃ�������̂Ō���Q�ƂŎ擾�ł��܂���B
569 �Fnobody�����F2009/10/14(��) 09:18:20 ID:???
>>568
��������perl�Ńv���O�������������A
1. �u<�v�Ɓu>�v�Ɉ͂܂ꂽ����������o��
2. 1�Ŏ��o�����������abc��def�ɒu��
3. 2�̌��ʂ��u<�v�u>�v�ŋ���
�Ƃ��Γ�����Ƃ͉����Ȃ��B
��������perl�Ńv���O�������������A
1. �u<�v�Ɓu>�v�Ɉ͂܂ꂽ����������o��
2. 1�Ŏ��o�����������abc��def�ɒu��
3. 2�̌��ʂ��u<�v�u>�v�ŋ���
�Ƃ��Γ�����Ƃ͉����Ȃ��B
570 �F568�F2009/10/14(��) 10:26:28 ID:6OWMkMrw
>>569
����C�m���ɂ��������Ƃ���Ȃ̂ł����C
Perl�݊��̐��K�\�����̗p���Ă���G�f�B�^�ŕ��͂�ł��Ă���Ƃ��ɁC
���������g���̂Ă�Perl�X�N���v�g�����̂��ʓ|�ŁC
���������G�f�B�^�ɓ�������Ă��鐳�K�\���u���@�\�Œu���ł���Ε֗��Ȃ̂ɂȁc�c�Ǝv��������ł��B
����C�m���ɂ��������Ƃ���Ȃ̂ł����C
Perl�݊��̐��K�\�����̗p���Ă���G�f�B�^�ŕ��͂�ł��Ă���Ƃ��ɁC
���������g���̂Ă�Perl�X�N���v�g�����̂��ʓ|�ŁC
���������G�f�B�^�ɓ�������Ă��鐳�K�\���u���@�\�Œu���ł���Ε֗��Ȃ̂ɂȁc�c�Ǝv��������ł��B
571 �Fnobody�����F2009/10/14(��) 10:46:05 ID:???
����Ⴛ�̃G�f�B�^�̐������ɏ����Ă��邾��
572 �Fnobody�����F2009/10/14(��) 16:45:59 ID:???
�u< �� > �ň͂܂ꂽ��������̂����� abc �� def �ɒu������v���A
���̃G�f�B�^�̃L�[�{�[�h�}�N���@�\�ŌJ��Ԃ��K�p����悭�ˁH
���̃G�f�B�^�̃L�[�{�[�h�}�N���@�\�ŌJ��Ԃ��K�p����悭�ˁH
573 �Fnobody�����F2009/10/14(��) 17:59:48 ID:???
����A���̃G�f�B�^�ɐ��K�\���ł̒u���@�\�����邾��A����
574 �Fnobody�����F2009/10/14(��) 18:10:49 ID:???
�u���Ƃ������⊮����ˁH
>>573
�G�f�B�^�̒u���@�\���ƕ��G�Ȃ��Ƃ��ł��Ȃ� (���̏ꍇ < �� > �̊Ԃ��J��Ԃ��u��)
����ǂ���������́H���Ă������₾�Ǝv�������A�Ⴄ�̂��ȁH
�ǂ̃G�f�B�^�g���Ă�Ƃ��N���Ă����Ƃ����ƓI�m�ɓ�����鍁��t�������������B
�G�f�B�^�̒u���@�\���ƕ��G�Ȃ��Ƃ��ł��Ȃ� (���̏ꍇ < �� > �̊Ԃ��J��Ԃ��u��)
����ǂ���������́H���Ă������₾�Ǝv�������A�Ⴄ�̂��ȁH
�ǂ̃G�f�B�^�g���Ă�Ƃ��N���Ă����Ƃ����ƓI�m�ɓ�����鍁��t�������������B
>>571-574
�����C�ł�����C�G�f�B�^�iMac OS X �� Jedit X �ł��j�ɐ��K�\���u���@�\��������Ă��邱�Ƃ͕������Ă��܂��B
���̐��K�\���̏�������m�肽���̂ł��B
�u< �� > �̊Ԃ̌J��Ԃ��u���v�͐��K�\���ł͎����s�\�C�Ƃ������Ƃł���C
��ނ��X�N���v�g��g�݂܂��iPerl ���邢�� Jedit X �̃}�N������ł��� AppleScript�j���C
�\�ł���ΐ��K�\���u���Ŏ����������̂ł��B
��͂�G�f�B�^�E�B���h�E���Ŋ�������͎̂�y�ł��̂ŁB
��ǂ݁E��ǂ݂�ċA�𗘗p��������Z�I�I���K�\���ł��\���܂���B�A�C�f�A�����߂Ă��܂��B
�����C�ł�����C�G�f�B�^�iMac OS X �� Jedit X �ł��j�ɐ��K�\���u���@�\��������Ă��邱�Ƃ͕������Ă��܂��B
���̐��K�\���̏�������m�肽���̂ł��B
�u< �� > �̊Ԃ̌J��Ԃ��u���v�͐��K�\���ł͎����s�\�C�Ƃ������Ƃł���C
��ނ��X�N���v�g��g�݂܂��iPerl ���邢�� Jedit X �̃}�N������ł��� AppleScript�j���C
�\�ł���ΐ��K�\���u���Ŏ����������̂ł��B
��͂�G�f�B�^�E�B���h�E���Ŋ�������͎̂�y�ł��̂ŁB
��ǂ݁E��ǂ݂�ċA�𗘗p��������Z�I�I���K�\���ł��\���܂���B�A�C�f�A�����߂Ă��܂��B
577 �Fnobody�����F2009/10/15(��) 00:24:07 ID:???
>>568=570=576
�e�L�X�g�G�f�B�^�̎������鐳�K�\���ɂ͕���������B
�����Őq�˂Ă����������Ȃ��\������Ȃ̂ŁA�VMac�̐�p�X���b�h�Ɉ����z�����Ƃ𐄏��B
Mac�p�e�L�X�g�G�f�B�^ Jedit X / 1.0�`4.0
http://pc11.2ch.net/test/read.cgi/mac/1248500724/
�e�L�X�g�G�f�B�^�̎������鐳�K�\���ɂ͕���������B
�����Őq�˂Ă����������Ȃ��\������Ȃ̂ŁA�VMac�̐�p�X���b�h�Ɉ����z�����Ƃ𐄏��B
Mac�p�e�L�X�g�G�f�B�^ Jedit X / 1.0�`4.0
http://pc11.2ch.net/test/read.cgi/mac/1248500724/
578 �Fnobody�����F2009/10/15(��) 13:12:35 ID:???
>>576
Perl�ł��Ă݂��B
���̃G�f�B�^�͌���Q�Ƃ͂ł���ȁH
my $str = "<asaabcasalaabca>";
print $str, "\n";
$str =~ s/((?:<|\G).*?)abc(?=.*?>)/\1def/g;
print $str, "\n";
Perl�ł��Ă݂��B
���̃G�f�B�^�͌���Q�Ƃ͂ł���ȁH
my $str = "<asaabcasalaabca>";
print $str, "\n";
$str =~ s/((?:<|\G).*?)abc(?=.*?>)/\1def/g;
print $str, "\n";
>>568�̃P�[�X�����Ȃ���v�����ǁA�ėp�I�ɂ͕s������肻���Ȃ̂Ŏ�����
���s���낵�����ʁA�ȉ��ł��������Ȋ��������ǁA�ǂ����낤�H
$str =~ s/((?:<|\G)[^<>]*?)abc(?=[^<>]*>)/\1def/g;
$str =~ s/((?:<|\G)[^<>]*?)abc(?=[^<>]*>)/\1def/g;
581 �Fnobody�����F2009/10/15(��) 13:51:05 ID:???
utf-8�̕����R�[�h���ɂȂ�������T���ɂ͂ǂ�Ȋ����ɂ��������ł��傤���H
javascript�ł��B
javascript�ł��B
582 �Fnobody�����F2009/10/15(��) 20:38:57 ID:???
>>568
Perl��������B
s/<(.*?)>/(my $s = $1) =~ s{abc}{def}g; "<$s>"/ges;
�G�f�B�^�̃}�N���ł��̂��������ȂƎv�����ǁA������Ɩʓ|�B
Perl��������B
s/<(.*?)>/(my $s = $1) =~ s{abc}{def}g; "<$s>"/ges;
�G�f�B�^�̃}�N���ł��̂��������ȂƎv�����ǁA������Ɩʓ|�B
583 �Fnobody�����F2009/10/19(��) 23:25:42 ID:/Zspq1xO
�o�g�o�łƂ���t�@�C����ǂݍ���ŁA�ǂݍ��t�@�C���̒��ɉ��L�̋L�q
������ΐ��K�\��(preg_replace��)�ŋɒu�����������ƍl���Ă��܂��B
���K�\���Ő��K�\���������L�q�̎d�����킩��܂���orz
�ǂ̂悤�Ȑ��K�\�����L�ڂ���悢�ł��傤���B
���݂܂���������ɂȂ�����������܂����炲������낵�����肢�������܂��B
���������������L�q���̂P������
if ( /^(To|Cc): admin@admin\.com$/:h || /^(To|Cc): .*\<admin@admin\.com\>/:h )
{
cc \"| /usr/bin/nextbb -c ISO-2022-JP -s 'xxxxx' -A 'From:yyyyy <[email protected]>' -t
/home/sendmail -t\"
}
���������������L�q���̂Q������
/^[a-zA-Z0-9\-\.\/\[\]\(\)\{\}\|@`:<>,!?\"'#\$%&*+;\\=^_~ ]*?$/"
������ΐ��K�\��(preg_replace��)�ŋɒu�����������ƍl���Ă��܂��B
���K�\���Ő��K�\���������L�q�̎d�����킩��܂���orz
�ǂ̂悤�Ȑ��K�\�����L�ڂ���悢�ł��傤���B
���݂܂���������ɂȂ�����������܂����炲������낵�����肢�������܂��B
���������������L�q���̂P������
if ( /^(To|Cc): admin@admin\.com$/:h || /^(To|Cc): .*\<admin@admin\.com\>/:h )
{
cc \"| /usr/bin/nextbb -c ISO-2022-JP -s 'xxxxx' -A 'From:yyyyy <[email protected]>' -t
/home/sendmail -t\"
}
���������������L�q���̂Q������
/^[a-zA-Z0-9\-\.\/\[\]\(\)\{\}\|@`:<>,!?\"'#\$%&*+;\\=^_~ ]*?$/"
584 �Fnobody�����F2009/10/19(��) 23:36:46 ID:???
Linux�R�}���h�����͂����C���v�b�g�{�b�N�X�̓��̓`�F�b�N������
���K�\���ł�肽���̂ł����A�ǂ̂悤�ȃ`�F�b�N���s�������ł��傤���H
���K�\���ł�肽���̂ł����A�ǂ̂悤�ȃ`�F�b�N���s�������ł��傤���H
585 �Fnobody�����F2009/10/20(��) 09:19:58 ID:???
����̓L�~���ǂ̂悤�ȓ��͂��������������킩��Ȃ����瓚���悤���Ȃ�
586 �Fnobody�����F2009/10/23(��) 15:06:47 ID:???
������Ă����Ȃ��̂�
587 �Fnobody�����F2009/10/23(��) 17:07:26 ID:???
Linux�R�}���h�Ƃ��A�C���v�b�g�{�b�N�X���ĉ��H
588 �Fnobody�����F2009/10/24(�y) 13:30:39 ID:???
<input>�ʼn��������submit����ƁA���ꂪ���s�����̂��H
�ȂI���ɂ��܂����܂����Ċ댯�ȃR�}���h���s���ꂻ�����ȁB
�������̒m���ł͒m���B
�ǂ�ȃR�}���h���t�������Ȃ��ȁB
���������R�}���h�ɂ���ă`�F�b�N���e�͕ς���Ȃ��́H
�ȂI���ɂ��܂����܂����Ċ댯�ȃR�}���h���s���ꂻ�����ȁB
�������̒m���ł͒m���B
�ǂ�ȃR�}���h���t�������Ȃ��ȁB
���������R�}���h�ɂ���ă`�F�b�N���e�͕ς���Ȃ��́H
589 �Fnobody�����F2009/10/24(�y) 18:23:59 ID:???
<input name="cmd" type="text" value="rm -rf ." />
590 �Fnobody�����F2009/10/25(��) 08:12:45 ID:???
>>584
���͂��ꂩ��ǂ̂悤�ɐ����Ă��������ł��傤���H
���炢�ɔ��R�Ƃ������₾�Ȃ����B
�\���I�� shell ���\���ǂ����Ȃ� Perl �Ȃ� shellwords.pl �g���Ƃ��ȁB
���͂��ꂩ��ǂ̂悤�ɐ����Ă��������ł��傤���H
���炢�ɔ��R�Ƃ������₾�Ȃ����B
�\���I�� shell ���\���ǂ����Ȃ� Perl �Ȃ� shellwords.pl �g���Ƃ��ȁB
591 �Fnobody�����F2009/12/09(��) 19:11:48 ID:???
�܂����K�\�����f�l�Ȃ̂ŋ����Ă��������B
���Ƃ��Έȉ��̂悤�Ɏl�s�̕��͂�������
����當�͂̍ŏ�(��Ԗ�)�̋�����������������ɂ�
�ǂ���������̂ł����H
The environment of contents industries is so drastically changing,
though Japan has not fully.
taken advantage of the changes to develop.
its presence in the global market.
The ��environment�̊Ԃ̋����@�Athough�@�� Japan�̊�
taken ��advantage�@�̊Ԃ̋��ȂǂȂǂł�
���Ƃ��Έȉ��̂悤�Ɏl�s�̕��͂�������
����當�͂̍ŏ�(��Ԗ�)�̋�����������������ɂ�
�ǂ���������̂ł����H
The environment of contents industries is so drastically changing,
though Japan has not fully.
taken advantage of the changes to develop.
its presence in the global market.
The ��environment�̊Ԃ̋����@�Athough�@�� Japan�̊�
taken ��advantage�@�̊Ԃ̋��ȂǂȂǂł�
592 �Fnobody�����F2009/12/09(��) 21:08:56 ID:???
Perl�Ŋ��̊��ʂ��h���h������q�ɂ��Ă������K�\�������Ă邾����
(\([^()]*(((\([^()]*\)[^()]*))*\)[^()]*)*)*\)
������Ɍ��͖�����ȁI�H
�ǂ�Ȃɓ���q�ɂ��Ă��A�G���[�͂łȂ�����
���߂č�������K�\���Ȃ��B���w��A���
(\([^()]*(((\([^()]*\)[^()]*))*\)[^()]*)*)*\)
������Ɍ��͖�����ȁI�H
�ǂ�Ȃɓ���q�ɂ��Ă��A�G���[�͂łȂ�����
���߂č�������K�\���Ȃ��B���w��A���
593 �Fnobody�����F2009/12/20(��) 20:33:27 ID:fe9ijwb+
0*(\d+)
����̈Ӗ��������Ă�������
()�̒��͂킩��̂ł����O���悭�킩��܂���
����̈Ӗ��������Ă�������
()�̒��͂킩��̂ł����O���悭�킩��܂���
594 �Fnobody�����F2009/12/20(��) 20:38:26 ID:???
�����̕��т���擪�̂O����菜���Ă�
595 �Fnobody�����F2009/12/20(��) 20:44:43 ID:fe9ijwb+
�Ȃ�ق�
00200 �Ƃ��̑O��0�����Č����ł���Ƃ��������ł���
00200 �Ƃ��̑O��0�����Č����ł���Ƃ��������ł���
596 �Fnobody�����F2009/12/21(��) 08:18:48 ID:???
>> 0*(\d+)
0��0�ȏ����ɁA0�`9��1�ȏ���ԁB
0��0�ȏ����ɁA0�`9��1�ȏ���ԁB
597 �Fnobody�����F2009/12/21(��) 20:42:38 ID:???
598 �Fnobody�����F2009/12/23(��) 22:25:52 ID:Hajqsr0G
HTML�^�O�� <ul> <li> �ɂ��āA����q�\���ɂȂ��Ă����ꍇ���l������ Pukiwiki���̋L�@�ɕϊ����悤�ƍl���Ă��܂�
<ul>
�@ <li>1�s�ځ�1�i��
�@ <li>2�s�ځ�1�i��
�@ <ul>
�@ �@ <li>3�s�ځ�2�i��
�@ �@ <li>4�s�ځ�2�i��
�@ </ul>
�@ <li>5�s�ځ�1�i��
</ul>
�����
- 1�s�ځ�1�i��
- 2�s�ځ�1�i��
-- 3�s�ځ�2�i��
-- 4�s�ځ�2�i��
- 5�s�ځ�1�i��
����Ȋ����ɂ��悤�Ǝl�ꔪ�ꂵ�Ă���̂ł����ǂ��ɂ�����c
�q���g�����ł��ǂ��̂ŃA�h�o�C�X�����肢���܂��B
���́A<ul>�����݂������
<ul>( <ul>�ȊO )<\/ul> ���o����
���̒��� /<li>(.*?)<\/li>/s �Œu�������āA�����o�����ƍ����ւ���
�ŏ��Ɍ�������<ul>(.*?)<\/ul>�ɂ��� <ul> �� </ul>���폜�A�ƍl���Ă��܂���
�ŏ��� <ul>�ȊO �̎��_�Ŋ��ɂ܂Â��Ă���n���ł��B
<ul>
�@ <li>1�s�ځ�1�i��
�@ <li>2�s�ځ�1�i��
�@ <ul>
�@ �@ <li>3�s�ځ�2�i��
�@ �@ <li>4�s�ځ�2�i��
�@ </ul>
�@ <li>5�s�ځ�1�i��
</ul>
�����
- 1�s�ځ�1�i��
- 2�s�ځ�1�i��
-- 3�s�ځ�2�i��
-- 4�s�ځ�2�i��
- 5�s�ځ�1�i��
����Ȋ����ɂ��悤�Ǝl�ꔪ�ꂵ�Ă���̂ł����ǂ��ɂ�����c
�q���g�����ł��ǂ��̂ŃA�h�o�C�X�����肢���܂��B
���́A<ul>�����݂������
<ul>( <ul>�ȊO )<\/ul> ���o����
���̒��� /<li>(.*?)<\/li>/s �Œu�������āA�����o�����ƍ����ւ���
�ŏ��Ɍ�������<ul>(.*?)<\/ul>�ɂ��� <ul> �� </ul>���폜�A�ƍl���Ă��܂���
�ŏ��� <ul>�ȊO �̎��_�Ŋ��ɂ܂Â��Ă���n���ł��B
599 �Fnobody�����F2009/12/23(��) 23:13:19 ID:???
$head= '';
$s=~ s/(<ul>)\s*|(<\/ul>)\s*|<li>(.*)(?:<\/li>)?\s*/$1?scalar($head.='-',''):$2?scalar(($head=substr($head,1)),''):"$head $3\n"/gei;
print $s;
$s=~ s/(<ul>)\s*|(<\/ul>)\s*|<li>(.*)(?:<\/li>)?\s*/$1?scalar($head.='-',''):$2?scalar(($head=substr($head,1)),''):"$head $3\n"/gei;
print $s;
600 �Fnobody�����F2009/12/29(��) 00:08:08 ID:F3P1tBWB
������̒��ɂ��遏�����������������̂ł����Apreg_replace('/��/')��
preg_replace('/����/')�ł͍폜�ł��Ȃ������̂ł����Apreg_replace('/������/')���ƍ폜�ł��܂����E�E�E
����͂Ȃ��ł��傤���B
���͎��ɗL�镶�����G�X�P�[�v����킯�ł�����Apreg_replace('/����/')�ł��������ȋC������̂ł����B�B�B
���K�\�����S�҂ɂ��A��x���ł�����������낵�����肢�������܂��B
�i��L�́A�����Ĕ��p�ł͂Ȃ��A�S�p�́��Ő������Ă��܂��B�j
preg_replace('/����/')�ł͍폜�ł��Ȃ������̂ł����Apreg_replace('/������/')���ƍ폜�ł��܂����E�E�E
����͂Ȃ��ł��傤���B
���͎��ɗL�镶�����G�X�P�[�v����킯�ł�����Apreg_replace('/����/')�ł��������ȋC������̂ł����B�B�B
���K�\�����S�҂ɂ��A��x���ł�����������낵�����肢�������܂��B
�i��L�́A�����Ĕ��p�ł͂Ȃ��A�S�p�́��Ő������Ă��܂��B�j
601 �Fnobody�����F2009/12/29(��) 12:06:00 ID:???
��肽�����Ǝ��̂�str_replace�łł��邾�낤����php�̐��K�\�����Ȃ��������ȁB
perl�Ȃ炻��Œʂ�͂������ǁB
perl�Ȃ炻��Œʂ�͂������ǁB
602 �Fnobody�����F2009/12/29(��) 12:38:00 ID:???
������Ƃ��ẴG�X�P�[�v�Ɛ��K�\���Ƃ��ẴG�X�P�[�v�͕ʁB
'/\\/' �́@/\/ '/\\\/' �́@ /\\/ '/\\\\/' �� /\\/�@�@
'/\\/' �́@/\/ '/\\\/' �́@ /\\/ '/\\\\/' �� /\\/�@�@
603 �F600�F2009/12/29(��) 22:52:30 ID:F3P1tBWB
604 �Fnobody�����F2009/12/30(��) 09:01:55 ID:???
�����������Aphp���ƃV���O���N�I�[�g�ň͂�ł�\�̓G�X�P�[�v�ɉ��߂����̂��B
605 �Fnobody�����F2010/01/24(��) 19:36:14 ID:???
<a href="test.php?id=0001">����������</a>
<div class="id">0001</div>
<div class="time">20100101010101</div>
<div class="name">�Ȃ܂�</div>
<div class="body">�R�����g</div>
��L�̃^�O���������Ƃ��āA
preg_match_all("/<a href=\"test.php\?id=0001\">(.*)/<\/div>\" style=\"display: none;\">/", $hoge, $data);
�̂悤�ɏ����ƁA�w�肵��ID��a�^�O���̕������Ƃ��̂ł����A���̉���<div class="id">����<div class="body">�̌��</div>�܂ł̃^�O�A
�������͂��̃^�O���̕�����𒊏o�������̂ł������܂������܂���B
���ꂼ��̃^�O��1�s�łȂ����Ă���̂Ƃ��āA�����^�O�͈͓̔������͉̂\�Ȃ̂ł��傤���H
<div class="id">0001</div>
<div class="time">20100101010101</div>
<div class="name">�Ȃ܂�</div>
<div class="body">�R�����g</div>
��L�̃^�O���������Ƃ��āA
preg_match_all("/<a href=\"test.php\?id=0001\">(.*)/<\/div>\" style=\"display: none;\">/", $hoge, $data);
�̂悤�ɏ����ƁA�w�肵��ID��a�^�O���̕������Ƃ��̂ł����A���̉���<div class="id">����<div class="body">�̌��</div>�܂ł̃^�O�A
�������͂��̃^�O���̕�����𒊏o�������̂ł������܂������܂���B
���ꂼ��̃^�O��1�s�łȂ����Ă���̂Ƃ��āA�����^�O�͈͓̔������͉̂\�Ȃ̂ł��傤���H
606 �Fnobody�����F2010/01/24(��) 20:12:18 ID:???
�����Ȃ�preg_match_all()�g�����Lj�Ȃ�preg_match()�ňȉ��̂悤��
preg_match('/\bid=(\d+)[^>]+>([^<]*)<\/a>.*?"id">\1<.*?"time">(\d+)<.*?"name">([^<]*)<.*?"body">([^<]*)</is', $s, $match);
preg_match('/\bid=(\d+)[^>]+>([^<]*)<\/a>.*?"id">\1<.*?"time">(\d+)<.*?"name">([^<]*)<.*?"body">([^<]*)</is', $s, $match);
607 �Fnobody�����F2010/01/24(��) 21:01:02 ID:???
�L��������܂��B
ID��0001�ȊO�̃R�����g���Ђ��������Ă��܂����A���Ȃ��]����̂ɋ߂Â��Ă��܂����B
���������ׂ��������ׂ��ł������A������ID������A����ID�ł̃R�����g�������������ꍇ�ł��B
��L�̃^�O����̃Z�b�g�Ƃ��āA���������钆��
<a href="test.php?id=0001">����������</a>�̃^�O�ƃR�����g�������܂Ƃ߂ĕ\�����������Ǝv���Ă��܂��B
id=�̕��������ς��Ē���0001���w�肵���炾�߂������E�E�E
ID��0001�ȊO�̃R�����g���Ђ��������Ă��܂����A���Ȃ��]����̂ɋ߂Â��Ă��܂����B
���������ׂ��������ׂ��ł������A������ID������A����ID�ł̃R�����g�������������ꍇ�ł��B
��L�̃^�O����̃Z�b�g�Ƃ��āA���������钆��
<a href="test.php?id=0001">����������</a>�̃^�O�ƃR�����g�������܂Ƃ߂ĕ\�����������Ǝv���Ă��܂��B
id=�̕��������ς��Ē���0001���w�肵���炾�߂������E�E�E
608 �Fnobody�����F2010/01/25(��) 01:28:52 ID:???
���s���낵����Ȃ�Ƃ���]�ʂ�̂��̂��ł��܂����B
���K�\�������Ɏ����Ăăv���O��������낵���Ȃ������c
���K�\�������Ɏ����Ăăv���O��������낵���Ȃ������c
609 �Fnobody�����F2010/02/03(��) 12:34:08 ID:???
�搶����ł�
Rewrite�œ��IURL��ÓIURL�ɂ������̂ł�
��肽�����Ƃ�6�̃N�G�����������������̂ł���
6�̂���1�̂Ƃ��A�Q�̂Ƃ��A�E�E�E�U�̂Ƃ��Ƃ����悤�ɑg�ݍ��킹�����Ȃ�̐��ɂȂ��Ă��܂��Ǝv���̂ł���
����� 6P1 + 6P2 + 6P3 + 6P4 + 6P5 + 6P6 �ƍl���Ă悢�̂ł��傤���H
6�����������Ȃ�Ă���ϖ����ł��傤���H
Rewrite�œ��IURL��ÓIURL�ɂ������̂ł�
��肽�����Ƃ�6�̃N�G�����������������̂ł���
6�̂���1�̂Ƃ��A�Q�̂Ƃ��A�E�E�E�U�̂Ƃ��Ƃ����悤�ɑg�ݍ��킹�����Ȃ�̐��ɂȂ��Ă��܂��Ǝv���̂ł���
����� 6P1 + 6P2 + 6P3 + 6P4 + 6P5 + 6P6 �ƍl���Ă悢�̂ł��傤���H
6�����������Ȃ�Ă���ϖ����ł��傤���H
610 �Fnobody�����F2010/02/03(��) 13:22:42 ID:???
���傗
611 �Fnobody�����F2010/03/02(��) 21:59:18 ID:???
�@
612 �Fnobody�����F2010/03/02(��) 22:11:34 ID:???
test
613 �Fnobody�����F2010/03/08(��) 15:33:08 ID:???
MySQL�_���v����
/*------------------��������--------------------*/
DROP TABLE IF EXISTS `table100`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!40101 SET character_set_client = utf8 */;
CREATE TABLE `table100` (
`code1` varchar(5) default NULL,
`zip1` varchar(7) default NULL,
`address1` varchar(250) default NULL,
`address2` varchar(250) default NULL,
`div_1` varchar(1) default NULL,
`div_2` varchar(1) default NULL,
`import_date` timestamp NULL default NULL,
`rec_key1` int(10) unsigned NOT NULL auto_increment,
PRIMARY KEY (`rec_key1`)
) ENGINE=InnoDB AUTO_INCREMENT=121471 DEFAULT CHARSET=eucjpms;
/*!40101 SET character_set_client = @saved_cs_client */;
/*------------------�����܂�--------------------*/
`table100` �� `TABLE100`
`code1` �� `CODE1`
�ȂNjt�N�H�[�g�ň͂܂ꂽ���������啶���ϊ����ꊇ�ōs�������ł��B�B
�ł����linux �R�}���h���C���Aperl �Ȃǂł��肢���܂��B�B
/*------------------��������--------------------*/
DROP TABLE IF EXISTS `table100`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!40101 SET character_set_client = utf8 */;
CREATE TABLE `table100` (
`code1` varchar(5) default NULL,
`zip1` varchar(7) default NULL,
`address1` varchar(250) default NULL,
`address2` varchar(250) default NULL,
`div_1` varchar(1) default NULL,
`div_2` varchar(1) default NULL,
`import_date` timestamp NULL default NULL,
`rec_key1` int(10) unsigned NOT NULL auto_increment,
PRIMARY KEY (`rec_key1`)
) ENGINE=InnoDB AUTO_INCREMENT=121471 DEFAULT CHARSET=eucjpms;
/*!40101 SET character_set_client = @saved_cs_client */;
/*------------------�����܂�--------------------*/
`table100` �� `TABLE100`
`code1` �� `CODE1`
�ȂNjt�N�H�[�g�ň͂܂ꂽ���������啶���ϊ����ꊇ�ōs�������ł��B�B
�ł����linux �R�}���h���C���Aperl �Ȃǂł��肢���܂��B�B
614 �Fnobody�����F2010/03/08(��) 18:01:54 ID:???
���Ԃ�s/`(\w+)`/`\U$1`/g
615 �Fnobody�����F2010/04/11(��) 00:10:39 ID:???
ereg�Ŕ��p�L���݂̂��}�b�`������false��Ԃ�������g��ł���̂ł����A
���̂��ꕔ�̊����������|�����Ă��܂��܂��c�m�F�������ł͗[�Ă��́u�[�v��
�����Ȃǂł��B
if(ereg ("[[:punct:]]",$_POST['���O']))
����Ȋ����ł��B���܂ł͕��ʂɋ@�\���Ă�����ł����c
�ǂȂ����A�h�o�C�X�����Ȃ��ł��傤���H
���̂��ꕔ�̊����������|�����Ă��܂��܂��c�m�F�������ł͗[�Ă��́u�[�v��
�����Ȃǂł��B
if(ereg ("[[:punct:]]",$_POST['���O']))
����Ȋ����ł��B���܂ł͕��ʂɋ@�\���Ă�����ł����c
�ǂȂ����A�h�o�C�X�����Ȃ��ł��傤���H
616 �Fnobody�����F2010/04/11(��) 02:49:42 ID:???
617 �Fnobody�����F2010/04/12(��) 09:23:26 ID:???
ereg��PHP5.3.0������ɂȂ��Ă�̂ŐV���������v���O�����ł�
�g��Ȃ��ق���������Bperl�݊����K�\��(PCRE)�����g�����������B
�g��Ȃ��ق���������Bperl�݊����K�\��(PCRE)�����g�����������B
618 �Fnobody�����F2010/05/02(��) 00:32:33 ID:???
:wink:, :lol:, :cry:, :evil:, :twisted:, :roll:, :idea:, :arrow:, :mrgreen:, :),
:-(, :!:, :?:, :oops:, :-o,:-D,8-|,8-), :??, :x:, :-P, :ase:, =:[, :ahhh:,
:star0.0:, :star0.0:, :star0.5:, :star1.0:, :!!!:, :**:,
:heart:, :!!:, :hahaha:, :chin:, :[], :|
����Ȋ����̃X�}�C���[�R�[�h���}�b�`������̂ɁA
$string = '{[:\*8=][(^:|*|a-zA-Z\-!?_\.\d\[)]*[(.*:)(.*\*)(.?)(:*[)(\])PoD\|]};
����Ȋ����̃R�[�h�ɂ��Ă݂����ǁA�����ƃX�}�[�g�ɏo���܂���?
�������A���K�\���̓p�Y���݂����Ŗʔ����ˁB
:-(, :!:, :?:, :oops:, :-o,:-D,8-|,8-), :??, :x:, :-P, :ase:, =:[, :ahhh:,
:star0.0:, :star0.0:, :star0.5:, :star1.0:, :!!!:, :**:,
:heart:, :!!:, :hahaha:, :chin:, :[], :|
����Ȋ����̃X�}�C���[�R�[�h���}�b�`������̂ɁA
$string = '{[:\*8=][(^:|*|a-zA-Z\-!?_\.\d\[)]*[(.*:)(.*\*)(.?)(:*[)(\])PoD\|]};
����Ȋ����̃R�[�h�ɂ��Ă݂����ǁA�����ƃX�}�[�g�ɏo���܂���?
�������A���K�\���̓p�Y���݂����Ŗʔ����ˁB
619 �Fnobody�����F2010/05/02(��) 04:08:13 ID:???
>>618
�X�}�[�g���ł͂������̂��ゾ�� :P
(:(wink|lol|cry|evil|twisted|roll|idea|arrow|mrgreen|\!|\?|oops|x|ase|ahhh|star0.0|star0.5|star1.0|\!\!\!|\*\*|heart|\!\!|hahaha|chin):)
|(:)|:-(|:-o|:-D|8-\||8-)|:??|:-P|=:[|:[]|:\|)
�X�}�[�g���ł͂������̂��ゾ�� :P
(:(wink|lol|cry|evil|twisted|roll|idea|arrow|mrgreen|\!|\?|oops|x|ase|ahhh|star0.0|star0.5|star1.0|\!\!\!|\*\*|heart|\!\!|hahaha|chin):)
|(:)|:-(|:-o|:-D|8-\||8-)|:??|:-P|=:[|:[]|:\|)
620 �Fnobody�����F2010/05/02(��) 04:53:21 ID:???
>>619
�F�X�o�O����
my @g = $str =~ /(
(?: \:
(?: ahhh | arrow | ase | chin | cry | evil | hahaha | heart | idea | lol | mrgreen | oops | roll | star0\.0 | star0\.0 | star0\.5 | star1\.0 | twisted | wink | x | \!\!\! | \!\! | \! | \*\* | \? )
\:)
|
(?: \:-\) | \:\-\( | \:\-D | \:\-P | \:\-o | \:\?\? | \:\[\] | 8\-\| | 8\-\) | \=\:\[ )
)/gx;
�F�X�o�O����
my @g = $str =~ /(
(?: \:
(?: ahhh | arrow | ase | chin | cry | evil | hahaha | heart | idea | lol | mrgreen | oops | roll | star0\.0 | star0\.0 | star0\.5 | star1\.0 | twisted | wink | x | \!\!\! | \!\! | \! | \*\* | \? )
\:)
|
(?: \:-\) | \:\-\( | \:\-D | \:\-P | \:\-o | \:\?\? | \:\[\] | 8\-\| | 8\-\) | \=\:\[ )
)/gx;
621 �Fnobody�����F2010/05/02(��) 10:16:16 ID:???
>>618�̂���:aaaaa:�Ƃ����݂��Ȃ����̂܂Ń}�b�`�����Ⴄ��H
((?:\:(?:(?:ahhh|arrow|ase|chin|cry|evil|hahaha|heart|idea|lol|mrgreen|oops|roll|star(?:0\.[05]|1\.0)|twisted|wink|x|\!{1,3}|\*{2})\:|\?[:?]|(?:\)|\[\]|\||\-[(oDP])))|(?:8\-[|)])|=\:\[)
((?:\:(?:(?:ahhh|arrow|ase|chin|cry|evil|hahaha|heart|idea|lol|mrgreen|oops|roll|star(?:0\.[05]|1\.0)|twisted|wink|x|\!{1,3}|\*{2})\:|\?[:?]|(?:\)|\[\]|\||\-[(oDP])))|(?:8\-[|)])|=\:\[)
622 �Fnobody�����F2010/05/02(��) 11:44:31 ID:???
>>619-621
�������A�����̊g�����l���Ċɂ��������ǁA
2�o�C�g�����ȊO�̃u���O����L���}�b�`����������Ď����B�B�B
���ꂶ��X�}�C���[�R�[�h�̕��Ɍ��i�ȃ��[����...
�Ȃ���čl����̂����[�U�[�ɗD�����Ȃ����B
�܂荇������̓���� :|
�������A�����̊g�����l���Ċɂ��������ǁA
2�o�C�g�����ȊO�̃u���O����L���}�b�`����������Ď����B�B�B
���ꂶ��X�}�C���[�R�[�h�̕��Ɍ��i�ȃ��[����...
�Ȃ���čl����̂����[�U�[�ɗD�����Ȃ����B
�܂荇������̓���� :|
623 �Fnobody�����F2010/05/02(��) 19:52:37 ID:???
624 �Fnobody�����F2010/05/02(��) 20:21:19 ID:???
625 �Fnobody�����F2010/05/02(��) 22:35:26 ID:???
>>624
�����琄������ƁA�O��Ƃ��ĕ��ʂ̋L���̏ꍇ�̓X�}�C���[�R�[�h�Ƃ�炪�摜�ɕϊ������Ƃ������Ƃ������āA
���̋L�������p����Ă�ꍇ�͂����������������Ƃ������Ƃ��H
�O�������Ȃ�X�}�C���[�R�[�h���摜�ɕϊ����鎞�Ɏg���Ă郋�[�������i�Ɏg���ׂ������A
�������Ȃ��Ȃ烊���N�ł��摜�ł��Ȃ��X�}�C���[�R�[�h����������K�v���Ȃ��Ǝv����
�����琄������ƁA�O��Ƃ��ĕ��ʂ̋L���̏ꍇ�̓X�}�C���[�R�[�h�Ƃ�炪�摜�ɕϊ������Ƃ������Ƃ������āA
���̋L�������p����Ă�ꍇ�͂����������������Ƃ������Ƃ��H
�O�������Ȃ�X�}�C���[�R�[�h���摜�ɕϊ����鎞�Ɏg���Ă郋�[�������i�Ɏg���ׂ������A
�������Ȃ��Ȃ烊���N�ł��摜�ł��Ȃ��X�}�C���[�R�[�h����������K�v���Ȃ��Ǝv����
626 �Fnobody�����F2010/05/02(��) 23:09:45 ID:???
>>625
�����ł��B
�ʏ�L���ł̓X�}�C���[�R�[�h���摜�ɕϊ�����܂��B
�ŁA���p���ɂ́A�����(���s,�X�y�[�X,�^�u,�摜,�����N��)����������
�R���p�N�g�ɂ������̂ł��B
���p���ɃX�}�C���[�������Ă�������ł����A
�L�����ۂ߂�ߒ���<img>�^�O���ז������̂ŁA����������d�l�Ƃ��܂����B
�����ł��B
�ʏ�L���ł̓X�}�C���[�R�[�h���摜�ɕϊ�����܂��B
�ŁA���p���ɂ́A�����(���s,�X�y�[�X,�^�u,�摜,�����N��)����������
�R���p�N�g�ɂ������̂ł��B
���p���ɃX�}�C���[�������Ă�������ł����A
�L�����ۂ߂�ߒ���<img>�^�O���ז������̂ŁA����������d�l�Ƃ��܂����B
627 �Fnobody�����F2010/05/03(��) 00:05:08 ID:???
>>626
��ximg�v�f�ɒu���������̂��x�[�X�ɂ���Ƃ����̂������������������̂ł́H
���������ĕ\�����钼�O�ɒu�����Ă��Ȃ��āADB�ɓ˂����ޒi�K�Œu����������Ă�Ƃ��H
���ꂾ������v�����������ق��������Ǝv������
��ximg�v�f�ɒu���������̂��x�[�X�ɂ���Ƃ����̂������������������̂ł́H
���������ĕ\�����钼�O�ɒu�����Ă��Ȃ��āADB�ɓ˂����ޒi�K�Œu����������Ă�Ƃ��H
���ꂾ������v�����������ق��������Ǝv������
628 �Fnobody�����F2010/05/03(��) 00:07:04 ID:???
>>626
���Ⴀ����ς� >�X�}�C���[�R�[�h���摜�ɕϊ����鎞�Ɏg���Ă郋�[�������i�Ɏg�� ����ԃX�}�[�g�Ȃ�Ȃ���
���ꂪ�ł��Ȃ��Ȃ��U���p����Ă��Ȃ��L���Ƃ��ď������āA��������img�^�O����������Ƃ�
���K�\���̘b����͂����Ԃ��ꂽ�̂ʼn��͂���ȏ㉽������Ȃ����Ƃɂ���� :P
���Ⴀ����ς� >�X�}�C���[�R�[�h���摜�ɕϊ����鎞�Ɏg���Ă郋�[�������i�Ɏg�� ����ԃX�}�[�g�Ȃ�Ȃ���
���ꂪ�ł��Ȃ��Ȃ��U���p����Ă��Ȃ��L���Ƃ��ď������āA��������img�^�O����������Ƃ�
���K�\���̘b����͂����Ԃ��ꂽ�̂ʼn��͂���ȏ㉽������Ȃ����Ƃɂ���� :P
629 �Fnobody�����F2010/05/03(��) 00:36:11 ID:???
>>627-628
�X�}�C���[�R�[�h���u�������̂�DB������������Ă���ł����A
�lj��v���O�����̓���ID�ɂ���ėD�揇�ʂ�����̂ŒP���ł͂Ȃ���ł��B�B�B
�ŁA�������K�\������E���������Ȃ̂ł��ꂪ�Ō�B
�E�����łɁA�^�C���Y�X�N�E�F�A�Ŕ�������ς�ł��Ԃ��āB�B�B
�Ƃ̎Ԃ����K�\���Ń}�b�`�����Ⴄ������
�X�}�C���[�R�[�h���u�������̂�DB������������Ă���ł����A
�lj��v���O�����̓���ID�ɂ���ėD�揇�ʂ�����̂ŒP���ł͂Ȃ���ł��B�B�B
�ŁA�������K�\������E���������Ȃ̂ł��ꂪ�Ō�B
�E�����łɁA�^�C���Y�X�N�E�F�A�Ŕ�������ς�ł��Ԃ��āB�B�B
�Ƃ̎Ԃ����K�\���Ń}�b�`�����Ⴄ������
630 �Fnobody�����F2010/05/19(��) 16:47:15 ID:t/z/xcK5
���₳���Ă��������I
������������ @ ABCD @ abcd
�Ƃ���������
<b>������������</b> @ ABCD @ <em>abcd</em>
�̂悤�ɒu�����������͂ǂ��������K�\�����g�������̂ł��傤���H
��낵�����肢�������܂�
������������ @ ABCD @ abcd
�Ƃ���������
<b>������������</b> @ ABCD @ <em>abcd</em>
�̂悤�ɒu�����������͂ǂ��������K�\�����g�������̂ł��傤���H
��낵�����肢�������܂�
631 �Fnobody�����F2010/05/19(��) 17:44:20 ID:???
���̗�ɂ��邽�߂̏������ĉ��H
�X�y�[�X @ �X�y�[�X �����Ƃ��H
�X�y�[�X @ �X�y�[�X �����Ƃ��H
632 �Fnobody�����F2010/05/20(��) 19:43:15 ID:avs5qFDL
���₳���Ă��������B
<table>
<tr>
<th>���̂P</th>
<td>
�l�P
</td>
</tr>
<tr>
<th>���̂Q</th>
<td>
�l�Q
</td>
</tr>
</table>
�̂悤��HTML������܂��B
���ۂɂ͑S�Ẳ��s�ƃC���f���g�̓g��������Ă܂��B
���̒l�P�̕������Ƃ�ɂ͂ǂ̂悤�Ȑ��K�\�����g���Ηǂ��ł��傤���H
<th>���̂P</th><td>([^<]*)</td>
�̂悤�ɍl���Ă܂������l�P�ɂ�<img>�^�O������ꍇ������܂��B
<table>��<td>�����邱�Ƃ͂���܂���B
<table>
<tr>
<th>���̂P</th>
<td>
�l�P
</td>
</tr>
<tr>
<th>���̂Q</th>
<td>
�l�Q
</td>
</tr>
</table>
�̂悤��HTML������܂��B
���ۂɂ͑S�Ẳ��s�ƃC���f���g�̓g��������Ă܂��B
���̒l�P�̕������Ƃ�ɂ͂ǂ̂悤�Ȑ��K�\�����g���Ηǂ��ł��傤���H
<th>���̂P</th><td>([^<]*)</td>
�̂悤�ɍl���Ă܂������l�P�ɂ�<img>�^�O������ꍇ������܂��B
<table>��<td>�����邱�Ƃ͂���܂���B
�r���œ��e���Ă��܂��܂����B
���萔�ł�����������낵�����肢���܂��B
�Ȃ��A����18�Ώ��q�ɂȂ�܂��B
���萔�ł�����������낵�����肢���܂��B
�Ȃ��A����18�Ώ��q�ɂȂ�܂��B
634 �Fnobody�����F2010/05/20(��) 19:54:06 ID:???
<th>���̂P</th><td>(.*?)</td>
635 �Fnobody�����F2010/05/20(��) 20:40:36 ID:a5arSWsA
http://www19.atpages.jp/imagelinkget/get.php?t=v&u=www.phpbook.jp/regexp/ini/img/p1-1.png
http://ukiya.sakura.ne.jp/index.php?plugin=ref&page=%E6%AD%A3%E8%A6%8F%E8%A1%A8%E7%8F%BE%E8%AC%9B%E5%BA%A7%2F1&src=regex1.png
http://ukiya.sakura.ne.jp/index.php?plugin=ref&page=%E6%AD%A3%E8%A6%8F%E8%A1%A8%E7%8F%BE%E8%AC%9B%E5%BA%A7%2F8&src=regex8.png
{kind=link}
http://ukiya.sakura.ne.jp/index.php?plugin=ref&page=%E6%AD%A3%E8%A6%8F%E8%A1%A8%E7%8F%BE%E8%AC%9B%E5%BA%A7%2F1&src=regex1.png
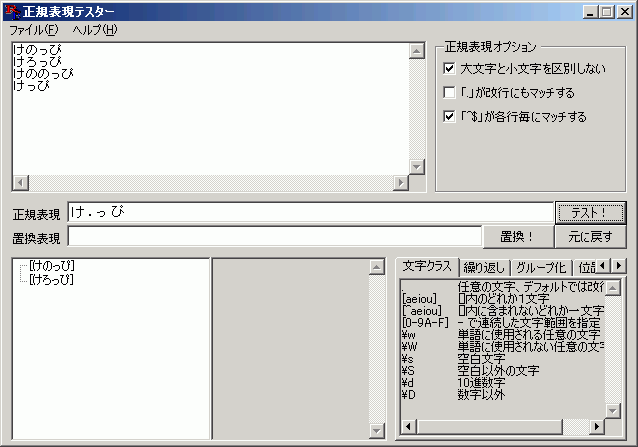{kind=link}
http://ukiya.sakura.ne.jp/index.php?plugin=ref&page=%E6%AD%A3%E8%A6%8F%E8%A1%A8%E7%8F%BE%E8%AC%9B%E5%BA%A7%2F8&src=regex8.png
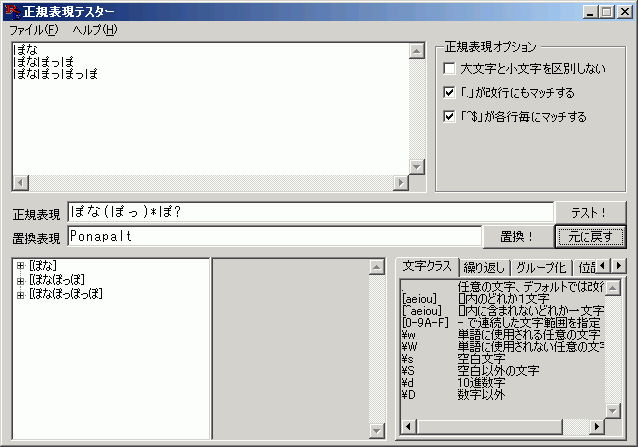{kind=link}
636 �Fnobody�����F2010/05/20(��) 21:13:11 ID:???
<th>���̂P</th><td>(�l�P|<img>)</td>
637 �F632�F2010/05/21(��) 22:05:20 ID:E8tDrX2s
���肪�Ƃ��������܂����B
�����ɉ����ł��܂����B
������x��ɍs���̂ł���ɂĎ���v���܂��B
�����ɉ����ł��܂����B
������x��ɍs���̂ł���ɂĎ���v���܂��B
638 �Fnobody�����F2010/05/24(��) 12:25:48 ID:???
�֏悾����
<table>
<tr>
<th>���̂P</th>
<td class="abc">
�l�P
</td>
</tr>
<tr>
<th>���̂Q</th>
<td class="def">
�l�Q
</td>
</tr>
...���Ɖ�������
���̏ꍇ�@<th>���̂P</th><td .*>(.*?)</td>�@�ɂ����̂ł���
���̂����܂��@�l�P �����擾�ł��܂���
�ǂ��� .*�ŗ]�v�Ȃ��̂��擾���Ă���悤�ł�
�ǂ����������ł��傤��
�����i�j�ł��B
<table>
<tr>
<th>���̂P</th>
<td class="abc">
�l�P
</td>
</tr>
<tr>
<th>���̂Q</th>
<td class="def">
�l�Q
</td>
</tr>
...���Ɖ�������
���̏ꍇ�@<th>���̂P</th><td .*>(.*?)</td>�@�ɂ����̂ł���
���̂����܂��@�l�P �����擾�ł��܂���
�ǂ��� .*�ŗ]�v�Ȃ��̂��擾���Ă���悤�ł�
�ǂ����������ł��傤��
�����i�j�ł��B
639 �Fnobody�����F2010/05/24(��) 14:40:31 ID:???
<th>���̂P</th><td .*?>(.*?)</td>
640 �Fnobody�����F2010/06/10(��) 09:40:35 ID:???
���݁AHTML��img�^�O���g���āu/img/jpg/�v�f�B���N�g���ɂ���摜�t�@�C�����\�����Ă��܂��B
��j
<img src="/img/jpg/1111.jpg" >
<img src="/img/jpg/mm2222.jpg" >
<img src="/img/jpg/kkkkk3333.jpg" >
��������ꂼ��A�ȉ��̂悤�ɒu���������ƍl���Ă��܂��B
��j
<a href="http://www.xxxxx.jp/1111.jpg"><img src="/img/jpg/1111.jpg" width="240px"></a>
<a href="http://www.xxxxx.jp/mm2222.jpg"><img src="/img/jpg/mm2222.jpg" width="240px"></a>
<a href="http://www.xxxxx.jp/kkkkk3333.jpg"><img src="/img/jpg/kkkkk3333.jpg" width="240px"></a>
img�^�O�������N�^�O�ň͂ނ̂ł����A�����N��URL�ɂ͌��X�̉摜�t�@�C�������g���Ă��܂��B�܂��Aimg�^�O�ɂ́uwidth="240px"�v���t������Ă��܂��B
���̂悤�Ȓu����PHP5�ōs���ɂ́A�ǂ̂悤�Ȑ��K�\�����g�p�������낵���ł��傤���B
�X�������肢�v���܂��B
��j
<img src="/img/jpg/1111.jpg" >
<img src="/img/jpg/mm2222.jpg" >
<img src="/img/jpg/kkkkk3333.jpg" >
��������ꂼ��A�ȉ��̂悤�ɒu���������ƍl���Ă��܂��B
��j
<a href="http://www.xxxxx.jp/1111.jpg"><img src="/img/jpg/1111.jpg" width="240px"></a>
{kind=link}
<a href="http://www.xxxxx.jp/mm2222.jpg"><img src="/img/jpg/mm2222.jpg" width="240px"></a>
{kind=link}
<a href="http://www.xxxxx.jp/kkkkk3333.jpg"><img src="/img/jpg/kkkkk3333.jpg" width="240px"></a>
{kind=link}
img�^�O�������N�^�O�ň͂ނ̂ł����A�����N��URL�ɂ͌��X�̉摜�t�@�C�������g���Ă��܂��B�܂��Aimg�^�O�ɂ́uwidth="240px"�v���t������Ă��܂��B
���̂悤�Ȓu����PHP5�ōs���ɂ́A�ǂ̂悤�Ȑ��K�\�����g�p�������낵���ł��傤���B
�X�������肢�v���܂��B
641 �Fnobody�����F2010/06/10(��) 16:43:49 ID:???
�f�l�ł��B
s/<img src="\/img\/jpg\/(.+)\.jpg" >/<a href="http:\/\/www\.xxxxx\.jp\/\1\.jpg"><img src="\/img\/jpg\/\1\.jpg" width="240px"><\/a>/;
����Ȋ����ɂȂ�̂��Ǝv���܂����ǂ��ł��傤���H
s/<img src="\/img\/jpg\/(.+)\.jpg" >/<a href="http:\/\/www\.xxxxx\.jp\/\1\.jpg"><img src="\/img\/jpg\/\1\.jpg" width="240px"><\/a>/;
{kind=link}
����Ȋ����ɂȂ�̂��Ǝv���܂����ǂ��ł��傤���H
642 �Fnobody�����F2010/07/01(��) 16:19:28 ID:qVVuQ4W9
Perl 5.8 /5.10�Ŏg�p���܂��B
HTML�\�[�X�̒���img�^�O�̃t�@�C�����𐳋K�\���Ȃǂňꊇ�ŕς������ł��B
<img src="http://www.hoge.com/aaa/bb/ccc/ddd.jpg" alt="sss">
<img src="/xxx/yyy.png">
<img src="../aaa/fff/xxx/ccc.gif" width="32" height="16">
�@�@�@�@�@�@�@�@�@�@�@��
<img src="/images/ddd.jpg" alt="sss">
<img src="/images/yyy.png">
<img src="/images/ccc.gif" width="32" height="16">
����Ȋ����ł��B�ǂ̗l�ɂ�����悢�ł��傤���B
HTML�\�[�X�̒���img�^�O�̃t�@�C�����𐳋K�\���Ȃǂňꊇ�ŕς������ł��B
<img src="http://www.hoge.com/aaa/bb/ccc/ddd.jpg" alt="sss">
{kind=link}
<img src="/xxx/yyy.png">
<img src="../aaa/fff/xxx/ccc.gif" width="32" height="16">
�@�@�@�@�@�@�@�@�@�@�@��
<img src="/images/ddd.jpg" alt="sss">
<img src="/images/yyy.png">
<img src="/images/ccc.gif" width="32" height="16">
����Ȋ����ł��B�ǂ̗l�ɂ�����悢�ł��傤���B
643 �Fnobody�����F2010/07/01(��) 17:11:08 ID:???
>>642
s|(<img[^>]* src=")[^"]*/([^/"]+"[^>]*>)|$1/images/$2|ig
s|(<img[^>]* src=")[^"]*/([^/"]+"[^>]*>)|$1/images/$2|ig
644 �Fnobody�����F2010/09/13(��) 00:25:36 ID:BUnMGSIw
php5.3�ł��B
%�ł����܂ꂽ(%test%)������preg_match�Ńq�b�g����������ł����A�ǂ�����������ɂ��������ł��傤���H
���Ȃ݂ɁA'/%%([^%])%%/'�ł͂��߂ł����B
%�ł����܂ꂽ(%test%)������preg_match�Ńq�b�g����������ł����A�ǂ�����������ɂ��������ł��傤���H
���Ȃ݂ɁA'/%%([^%])%%/'�ł͂��߂ł����B
645 �Fnobody�����F2010/09/13(��) 00:27:10 ID:???
�ԈႦ���B
'/%%([^%]*)%%/'�ł��B
'/%%([^%]*)%%/'�ł��B
646 �Fnobody�����F2010/09/13(��) 00:33:05 ID:???
%%test%% �Ə�����Ă��� %test% ���L���v�`������悤�ɂ������̂�
%test% �Ə�����Ă��� test ���L���v�`������̂��ǂ����H
��҂��Ə���Ɍ��ߕt����B'/%([^%]+)%/'
%test% �Ə�����Ă��� test ���L���v�`������̂��ǂ����H
��҂��Ə���Ɍ��ߕt����B'/%([^%]+)%/'
647 �Fnobody�����F2010/09/23(��) 15:56:42 ID:???
find . -type f -iregex ".*[^html|htm|gif|jpg|jpeg|png|css|js|swf|xml]" -print
�ŃE�F�u�֘A�ȊO�̃t�@�C�����o�����̂�����ǁA
�Ȃ����݂�͂��́y*.pdf�z���o�Ă��܂���B
���������s�����̂ł��傤���B
�ŃE�F�u�֘A�ȊO�̃t�@�C�����o�����̂�����ǁA
�Ȃ����݂�͂��́y*.pdf�z���o�Ă��܂���B
���������s�����̂ł��傤���B
648 �Fnobody�����F2010/09/24(��) 17:04:12 ID:???
[^html|htm|gif|jpg|jpeg|png|css|js|swf|xml] �� [^cefghijlmnpstwx|]
��648
find . -type f ! \( -name \*.html -o -name \*.htm -o -name \*.css -o -name \*.js -o -name \*.gif -o -name \*.jpg -o -name \*.png -o -name \*.swf -o -name \*.xml -o -name \*.pdf \) -print
���A-iregex�g���ĒZ������ɂ͂ǂ�����������̂ł��傤���B
find . -type f ! \( -name \*.html -o -name \*.htm -o -name \*.css -o -name \*.js -o -name \*.gif -o -name \*.jpg -o -name \*.png -o -name \*.swf -o -name \*.xml -o -name \*.pdf \) -print
���A-iregex�g���ĒZ������ɂ͂ǂ�����������̂ł��傤���B
650 �Fnobody�����F2010/09/26(��) 06:42:01 ID:JLVe9rj0
Firebug��"aaaaaaaaaaaaaaaaaaaa".match(/(a)/)�Ƃ����2�����q�b�g���Ȃ���ł����A
�S����a���q�b�g������ɂ͂ǂ������炢����ł��傤���H
�S����a���q�b�g������ɂ͂ǂ������炢����ł��傤���H
651 �Fnobody�����F2010/09/26(��) 22:12:08 ID:???
652 �Fnobody�����F2010/10/03(��) 17:27:45 ID:???
�wa*a/a/*/a*a/a/*/a*a/a*a/a/*/a*a/a/*/a*a/a*a/a/*/a*a/a/*/a*a/a*a/a/*/a*a/a/*/a*a/a�x
���̕������
/* ~~~ */ �ň͂܂ꂽ�������ꂼ���S�Đ��K�\���Ŕ����o����̂ł����H
���̕������
/* ~~~ */ �ň͂܂ꂽ�������ꂼ���S�Đ��K�\���Ŕ����o����̂ł����H
�����܂���B�g�p�����PHP5.1.6�ł��B
���̉������܂����B
655 �Fnobody�����F2010/10/20(��) 18:27:58 ID:???
�u/index.php/blog/new/id/17�v
����Aphp�t�@�C����(/index.php)�̂ݍ폜����ɂ͂ǂ���������ł��傤���H
�t�@�C�����͕ς�邱�Ƃ�����܂��B
����Aphp�t�@�C����(/index.php)�̂ݍ폜����ɂ͂ǂ���������ł��傤���H
�t�@�C�����͕ς�邱�Ƃ�����܂��B
656 �Fnobody�����F2010/10/20(��) 22:18:19 ID:???
s{/[^/]+?\.php}{}
PHP��preg_replace()�ɓn���Ă݂��̂ł����A
��Warning: preg_replace() [function.preg-replace]: Delimiter must not be alphanumeric or backslash in
�ƌ����Ă��܂��܂��B�B�B
��Warning: preg_replace() [function.preg-replace]: Delimiter must not be alphanumeric or backslash in
�ƌ����Ă��܂��܂��B�B�B
�ǂ�����������n�����̂�������ƒm�肽���B
<?php
$str = '/index.php/blog/new/id/17';
// $pattern = '/\/[^\/]+?\.php/'; // �f���~�^�� / �̂Ƃ��̓G�X�P�[�v
$pattern = '{/[^/]+?\.php}'; // �f���~�^�� { �� }
$replace = '';
echo preg_replace($pattern, $replace, $str);
?>
<?php
$str = '/index.php/blog/new/id/17';
// $pattern = '/\/[^\/]+?\.php/'; // �f���~�^�� / �̂Ƃ��̓G�X�P�[�v
$pattern = '{/[^/]+?\.php}'; // �f���~�^�� { �� }
$replace = '';
echo preg_replace($pattern, $replace, $str);
?>
659 �Fnobody�����F2010/11/13(�y) 19:09:08 ID:peMm7xtt
PHP�ŁA�Ⴆ��
�������������͂��l����̂́A���̂����B
�킽���́A�u����ɂ��́v�ƌ����܂����B
�u���̕��͂́A�Ȃ��Ȃ��ʔ����ł��ˁB�ƂĂ����m�Ȑ��K�\�����l����K�v�������ł��B�v
�u�ł́A����Ȑ��K�\�����ǂ�����Č�����̂ł��傤���H�������A���₵�Ă݂܂��傤��I�B�v
�u�Ȃ�قǁH�B����͖ʔ����A�C�f�B�A���B�v�ƁA������l�͌������B
�Ƃ������͂��������Ƃ��ɁA
"�������������͂��l����̂́A���̂����B",
"�킽���́A","�u����ɂ��́v","�ƌ����܂����B",
"�u���̕��͂́A�Ȃ��Ȃ��ʔ����ł��ˁB","�ƂĂ����m�Ȑ��K�\�����l����K�v�������ł��B�v",
"�u�ł́A����Ȑ��K�\�����ǂ�����Č�����̂ł��傤���H","�������A���₵�Ă݂܂��傤��I�B�v",
"�u�Ȃ�قǁH�B","����͖ʔ����A�C�f�B�A���B�v","�ƁA������l�͌������B"
�Ƃ��������ɕ������Ĕz��ɂ������Ǝv���Ă��܂��B
���ݎg���Ă��鐳�K�\����
$contents = array();
preg_match_all('/.*?�B|.*?�u/m',$content,$contents);
�Ƃ��������ŏ����Ă݂܂����B
$content�����Ƃ̕��͂ŁA$contents���V��������z��ł��B
�ǂ������G�łǂ�������ǂ��̂��킩��Ȃ��̂Ŏ��₳���Ă��������܂��B��낵�����肢���܂��B
�������������͂��l����̂́A���̂����B
�킽���́A�u����ɂ��́v�ƌ����܂����B
�u���̕��͂́A�Ȃ��Ȃ��ʔ����ł��ˁB�ƂĂ����m�Ȑ��K�\�����l����K�v�������ł��B�v
�u�ł́A����Ȑ��K�\�����ǂ�����Č�����̂ł��傤���H�������A���₵�Ă݂܂��傤��I�B�v
�u�Ȃ�قǁH�B����͖ʔ����A�C�f�B�A���B�v�ƁA������l�͌������B
�Ƃ������͂��������Ƃ��ɁA
"�������������͂��l����̂́A���̂����B",
"�킽���́A","�u����ɂ��́v","�ƌ����܂����B",
"�u���̕��͂́A�Ȃ��Ȃ��ʔ����ł��ˁB","�ƂĂ����m�Ȑ��K�\�����l����K�v�������ł��B�v",
"�u�ł́A����Ȑ��K�\�����ǂ�����Č�����̂ł��傤���H","�������A���₵�Ă݂܂��傤��I�B�v",
"�u�Ȃ�قǁH�B","����͖ʔ����A�C�f�B�A���B�v","�ƁA������l�͌������B"
�Ƃ��������ɕ������Ĕz��ɂ������Ǝv���Ă��܂��B
���ݎg���Ă��鐳�K�\����
$contents = array();
preg_match_all('/.*?�B|.*?�u/m',$content,$contents);
�Ƃ��������ŏ����Ă݂܂����B
$content�����Ƃ̕��͂ŁA$contents���V��������z��ł��B
�ǂ������G�łǂ�������ǂ��̂��킩��Ȃ��̂Ŏ��₳���Ă��������܂��B��낵�����肢���܂��B
660 �Fnobody�����F2010/11/14(��) 09:26:59 ID:???
��x�ɂ�낤�Ƃ��Ȃ��ŕ����Ă������Ǝv����
661 �Fnobody�����F2010/11/14(��) 22:54:16 ID:xJLLsuw0
���K�\���ł̏d���s�̍폜�ɂ���
���₳���Ă�������
�݂���@�@�@�݂���
�݂���@�@�@�i�s�j
��@���@���
�Ȃ��@�@�@�@�Ȃ�
�Ȃ��@�@�@�@�i�s�j
�Ȃ��@�@�@�@�i�s�j
�����@�@�@�@����
�Ƃ�������
�d���s�͋̂܂܂Ŏc�������̂ł���
�ǂ����ׂ��ł��傤���H
���₳���Ă�������
�݂���@�@�@�݂���
�݂���@�@�@�i�s�j
��@���@���
�Ȃ��@�@�@�@�Ȃ�
�Ȃ��@�@�@�@�i�s�j
�Ȃ��@�@�@�@�i�s�j
�����@�@�@�@����
�Ƃ�������
�d���s�͋̂܂܂Ŏc�������̂ł���
�ǂ����ׂ��ł��傤���H
662 �Fnobody�����F2010/11/14(��) 22:55:28 ID:???
�X�N���v�g����ł�����ق����y����ˁH
663 �Fnobody�����F2010/11/14(��) 23:35:35 ID:xJLLsuw0
664 �Fnobody�����F2010/11/15(��) 00:12:15 ID:???
�ł��ۂ�
�݂���
���
���
�݂���
�݂���
���
�ł��ۂ�
����ȕ��ɗ��ꂽ�s�ɏd��������ꍇ�͂ǂ�����H�\�[�g�ς݂Ȃ̂��ȁB
�݂���
���
���
�݂���
�݂���
���
�ł��ۂ�
����ȕ��ɗ��ꂽ�s�ɏd��������ꍇ�͂ǂ�����H�\�[�g�ς݂Ȃ̂��ȁB
665 �Fnobody�����F2010/11/15(��) 00:48:49 ID:AfSBC14n
�G�N�Z���Ń\�[�g���Ă���܂�
666 �Fnobody�����F2010/12/06(��) 23:51:24 ID:k5Tua1Td
���[���A�h���X�����������}�b�`���O�B
�������A@gmail.com�A@googlemail.com�A@livedoor.com�̏ꍇ��
@�̑O�Ɂu+�v�u.�v���܂܂�Ă���ꍇ�͏��O����B
������Đ��K�\���P���łł����肵�܂����H
�������A@gmail.com�A@googlemail.com�A@livedoor.com�̏ꍇ��
@�̑O�Ɂu+�v�u.�v���܂܂�Ă���ꍇ�͏��O����B
������Đ��K�\���P���łł����肵�܂����H
667 �Fnobody�����F2010/12/06(��) 23:53:00 ID:???
yes
668 �Fnobody�����F2010/12/08(��) 14:11:59 ID:???
���[���A�h���X�̑Ó����̔���͂ǂ̂��炢�����ɂ��̂��낤
669 �Fnobody�����F2010/12/20(��) 16:51:11 ID:Qb400/Ia
php5�ŁAtable�^�O���̉��s�i<br />�j��S�č폜�������̂ł��B
�ǂ�������ǂ���ł��傤�B
���u���O
<table border="1" cellpadding="5" cellspacing="0" class="xx" id="xx"><br />
<tbody><br />
<tr><br />
<td><br />
</td><br />
</tr><br />
</tbody><br />
</table>
���u����
<table border="1" cellpadding="5" cellspacing="0" class="xx" id="xx">
<tbody>
<tr>
<td>
</td>
</tr>
</tbody>
</table>
�ǂ�������ǂ���ł��傤�B
���u���O
<table border="1" cellpadding="5" cellspacing="0" class="xx" id="xx"><br />
<tbody><br />
<tr><br />
<td><br />
</td><br />
</tr><br />
</tbody><br />
</table>
���u����
<table border="1" cellpadding="5" cellspacing="0" class="xx" id="xx">
<tbody>
<tr>
<td>
</td>
</tr>
</tbody>
</table>
670 �Fnobody�����F2010/12/20(��) 20:03:43 ID:???
>>669
str_replace�ł���
str_replace�ł���
671 �Fnobody�����F2010/12/20(��) 20:48:53 ID:???
���ʂ�strip_tags����ˁH
672 �Fnobody�����F2010/12/21(��) 08:13:01 ID:???
�e�[�u���O��br�͍폜�������Ȃ���
673 �Fnobody�����F2010/12/24(��) 08:47:52 ID:???
���̎�̂��Ƃ���肽���l�͑�R����Ǝv���̂�
�U�X���o�̉\��������܂����A
�Q�l�y�[�W�ł��\���܂���̂ŋ����Ă�������
UWSC�̃R�[�h�������̂�K2Editor���g���Ă��܂�
�d�グ���R�[�h�̉ǐ��������邽�߂�
���Z�q�̑O��ɃX�y�[�X����ꂽ���ł�
��@x+y=z
�@�@x + y = z
K2Editor�̐��K�\����BREGEXP.DLL���g���Ă��܂�
�ȉ��̒u�����}�N���ōs���܂�
"([^ ])([\+\-\*<])","$1 $2"
"([^ <])>","$1 >"
"([\+\-\*=])([^ ])","$1 $2"
"([^ <>])=","$1 ="
"<([^ =>])","< $1"
">([^ =])","> $1"
"([^ \/])\/([^\/])","$1 /$3"
"([^\/])\/([^ \/])","$1/ $3"
"�@"," "
" +"," "
"([,=\+\-\*\/\(<>]|mod|and|or|xor) - ","$1 -"
���K�\���̓h�f�l�Ńl�b�g�Ō������Ȃ��珑�����̂�
�܂��������������Ǝv���܂�������͒u���Ƃ��āA
�{��̓_�u���R�[�e�[�V�����Ŋ���ꂽ���������
�u���������Ȃ��̂ł����A�������@�͂���܂����H
�U�X���o�̉\��������܂����A
�Q�l�y�[�W�ł��\���܂���̂ŋ����Ă�������
UWSC�̃R�[�h�������̂�K2Editor���g���Ă��܂�
�d�グ���R�[�h�̉ǐ��������邽�߂�
���Z�q�̑O��ɃX�y�[�X����ꂽ���ł�
��@x+y=z
�@�@x + y = z
K2Editor�̐��K�\����BREGEXP.DLL���g���Ă��܂�
�ȉ��̒u�����}�N���ōs���܂�
"([^ ])([\+\-\*<])","$1 $2"
"([^ <])>","$1 >"
"([\+\-\*=])([^ ])","$1 $2"
"([^ <>])=","$1 ="
"<([^ =>])","< $1"
">([^ =])","> $1"
"([^ \/])\/([^\/])","$1 /$3"
"([^\/])\/([^ \/])","$1/ $3"
"�@"," "
" +"," "
"([,=\+\-\*\/\(<>]|mod|and|or|xor) - ","$1 -"
���K�\���̓h�f�l�Ńl�b�g�Ō������Ȃ��珑�����̂�
�܂��������������Ǝv���܂�������͒u���Ƃ��āA
�{��̓_�u���R�[�e�[�V�����Ŋ���ꂽ���������
�u���������Ȃ��̂ł����A�������@�͂���܂����H
674 �Fnobody�����F2010/12/29(��) 07:28:15 ID:???
����\��������
675 �Fnobody�����F2011/01/06(��) 22:08:59 ID:y0rS3N6j
����ł��BPHP5.3��preg_match���g���Ă���̂ł����A�Ⴆ��
�u����(��20����3�A��1�߂�3�A�E�E�E�����A���z��@��80����2�ɂ����ẮE�E�E�v
�Ƃ������͂��@�����̂���Ȃǂ�while���[�v�ŏE���グ�����̂ł����A
/([��]*)([1-9]+[0-9]*)([������]+)[��]*([1-9]+[0-9]*)*[��]*([1-9]+[0-9]*)*(.*)/
�ŏE���グ��ƁA�@�����́i��̕��͂��Ɓu���z��@�v�j�������Ă��܂��̂�
/([���z��@|���z��@�{�s��]*)([��]*)([1-9]+[0-9]*)([������]+)[��]*([1-9]+[0-9]*)*[��]*([1-9]+[0-9]*)*(.*)/
�ƌ����`�ŏE���ƁA�Ȃ���preg_match($match, $text, $arr)��$arr�̒��ɁA�Ȃ����u��v�Ƃ����������E���Ă��܂���B
����͉��̂Ȃ�ł��傤���H�H
�������R�������������������������A�������肢�܂��B
�u����(��20����3�A��1�߂�3�A�E�E�E�����A���z��@��80����2�ɂ����ẮE�E�E�v
�Ƃ������͂��@�����̂���Ȃǂ�while���[�v�ŏE���グ�����̂ł����A
/([��]*)([1-9]+[0-9]*)([������]+)[��]*([1-9]+[0-9]*)*[��]*([1-9]+[0-9]*)*(.*)/
�ŏE���グ��ƁA�@�����́i��̕��͂��Ɓu���z��@�v�j�������Ă��܂��̂�
/([���z��@|���z��@�{�s��]*)([��]*)([1-9]+[0-9]*)([������]+)[��]*([1-9]+[0-9]*)*[��]*([1-9]+[0-9]*)*(.*)/
�ƌ����`�ŏE���ƁA�Ȃ���preg_match($match, $text, $arr)��$arr�̒��ɁA�Ȃ����u��v�Ƃ����������E���Ă��܂���B
����͉��̂Ȃ�ł��傤���H�H
�������R�������������������������A�������肢�܂��B
676 �Fnobody�����F2011/01/07(��) 03:55:37 ID:???
����\���Œs������
677 �Fnobody�����F2011/01/07(��) 03:58:44 ID:???
$text = '����(��20����3�A��1�߂�3�A�E�E�E�����A���z��@��80����2�ɂ����Ă�';
$pat1 = '/([��]*)([1-9]+[0-9]*)([������]+)[��]*([1-9]+[0-9]*)*[��]*([1-9]+[0-9]*)*(.*)/';
$pat2 = '/([���z��@|���z��@�{�s��]*)([��]*)([1-9]+[0-9]*)([������]+)[��]*([1-9]+[0-9]*)*[��]*([1-9]+[0-9]*)*(.*)/';
preg_match($pat1, $text, $arr);
var_dump($arr);
preg_match($pat2, $text, $arr);
var_dump($arr);
array(7) {
[0]=> string(62) "��20����3�A��1�߂�3�A�E�E�E�����A���z��@��80����2�ɂ����Ă�"
[1]=> string(2) "��"
[2]=> string(2) "20"
[3]=> string(2) "��"
[4]=> string(1) "3"
[5]=> string(0) ""
[6]=> string(53) "�A��1�߂�3�A�E�E�E�����A���z��@��80����2�ɂ����Ă�"
}
array(8) {
[0]=> string(62) "��20����3�A��1�߂�3�A�E�E�E�����A���z��@��80����2�ɂ����Ă�"
[1]=> string(0) ""
[2]=> string(2) "��"
[3]=> string(2) "20"
[4]=> string(2) "��"
[5]=> string(1) "3"
[6]=> string(0) ""
[7]=> string(53) "�A��1�߂�3�A�E�E�E�����A���z��@��80����2�ɂ����Ă�"
}
�悪�E���Ȃ����Ăǂ��̘b�H
���ƊW�Ȃ����Ǖ����E�������Ȃ�preg_match_all
$pat1 = '/([��]*)([1-9]+[0-9]*)([������]+)[��]*([1-9]+[0-9]*)*[��]*([1-9]+[0-9]*)*(.*)/';
$pat2 = '/([���z��@|���z��@�{�s��]*)([��]*)([1-9]+[0-9]*)([������]+)[��]*([1-9]+[0-9]*)*[��]*([1-9]+[0-9]*)*(.*)/';
preg_match($pat1, $text, $arr);
var_dump($arr);
preg_match($pat2, $text, $arr);
var_dump($arr);
array(7) {
[0]=> string(62) "��20����3�A��1�߂�3�A�E�E�E�����A���z��@��80����2�ɂ����Ă�"
[1]=> string(2) "��"
[2]=> string(2) "20"
[3]=> string(2) "��"
[4]=> string(1) "3"
[5]=> string(0) ""
[6]=> string(53) "�A��1�߂�3�A�E�E�E�����A���z��@��80����2�ɂ����Ă�"
}
array(8) {
[0]=> string(62) "��20����3�A��1�߂�3�A�E�E�E�����A���z��@��80����2�ɂ����Ă�"
[1]=> string(0) ""
[2]=> string(2) "��"
[3]=> string(2) "20"
[4]=> string(2) "��"
[5]=> string(1) "3"
[6]=> string(0) ""
[7]=> string(53) "�A��1�߂�3�A�E�E�E�����A���z��@��80����2�ɂ����Ă�"
}
�悪�E���Ȃ����Ăǂ��̘b�H
���ƊW�Ȃ����Ǖ����E�������Ȃ�preg_match_all
678 �Fnobody�����F2011/01/07(��) 08:16:20 ID:???
[�}���`�o�C�g] ���̎��_�ł����������
679 �Fnobody�����F2011/01/07(��) 08:35:43 ID:???
u �C���q������Ȃ��̂��ȁH
[��]* �͗ʎw��q���܂߂Ăǂ����Ǝv�����ǂˁB
[��]* �͗ʎw��q���܂߂Ăǂ����Ǝv�����ǂˁB
680 �Fnobody�����F2011/01/07(��) 11:13:33 ID:???
PHP��Perl�݊����K�\���ŁA�A�����������肵�����i3�����ȏ�j
���̂ł͂��߁H
preg_match("/(.)\1{3,}/", $hoge)
�ၨAAA�Abbb�A111�A���������Ȃ����������悤�ɂ������A�Ƃ�������
���̂ł͂��߁H
preg_match("/(.)\1{3,}/", $hoge)
�ၨAAA�Abbb�A111�A���������Ȃ����������悤�ɂ������A�Ƃ�������
681 �Fnobody�����F2011/01/07(��) 11:42:34 ID:???
682 �Fnobody�����F2011/01/07(��) 12:06:39 ID:???
>>681
4�����ȏ�A�������������Ƃ��Ă��A�z�肵���悤�ɓ����Ȃ��E�E�E
��OK�iPerl�j
my $hoge = 'aaaa'; if ($hoge =~ /(.)\1{3,}/) { print 'OK'; } else { print 'NG'; }
��NG�iPHP�j
$hoge = 'aaaa'; if (preg_match("/(.)\1{3,}/", $hoge)) { echo 'OK'; } else { echo 'NG'; }
PHP��\1���ĕ\���ł��Ȃ��H
4�����ȏ�A�������������Ƃ��Ă��A�z�肵���悤�ɓ����Ȃ��E�E�E
��OK�iPerl�j
my $hoge = 'aaaa'; if ($hoge =~ /(.)\1{3,}/) { print 'OK'; } else { print 'NG'; }
��NG�iPHP�j
$hoge = 'aaaa'; if (preg_match("/(.)\1{3,}/", $hoge)) { echo 'OK'; } else { echo 'NG'; }
PHP��\1���ĕ\���ł��Ȃ��H
683 �Fnobody�����F2011/01/07(��) 12:28:18 ID:???
"..."�̒�������¥¥1�Ə����Ȃ��Ƒʖڂ���B
684 �Fnobody�����F2011/01/07(��) 13:39:43 ID:???
$hoge = 'aaaa';
echo preg_match('/(.)\1{3,}/', $hoge) ? 'OK' : 'NG'; // OK
"\\1" �� '\1' ����ˁB
echo preg_match('/(.)\1{3,}/', $hoge) ? 'OK' : 'NG'; // OK
"\\1" �� '\1' ����ˁB
����������ˁE�E�E
���肪�Ƃ��������܂���
u���t���Ċ����ł�
���肪�Ƃ��������܂���
u���t���Ċ����ł�
686 �F675�F2011/01/08(�y) 22:00:49 ID:GTa36OYO
�Ԏ��x���Ȃ�܂��Đ\����܂���B
/u��lj������猩���ɋ@�\���܂����B
�Ƃ������A���܂ł��K�\������{��ɓK�p���Ă����̂ł����A/u�̂��Ƃ�S���m��܂���ł����B
���p������������ł��B
���������������A���肪�Ƃ��������܂����B
/u��lj������猩���ɋ@�\���܂����B
�Ƃ������A���܂ł��K�\������{��ɓK�p���Ă����̂ł����A/u�̂��Ƃ�S���m��܂���ł����B
���p������������ł��B
���������������A���肪�Ƃ��������܂����B
687 �F675�F2011/01/17(��) 22:15:13 ID:Br3WLX+O
�X�Ɏ���ł��B
�u...�ɂ����Ă͍��y��ʑ�b����߂����S��K�v�ȋZ�p�I�̂������̎w�肷��ɌW�镔���Ɍ���B)�A��119���A��5�͂�4(��129����2��5��1����2��6��...�v
�Ƃ������͂���A�恛�����́����́����Ȃǂ����A�����̑O��̕��͂��擾�������ƍl���Ă��܂��B
������
�u/^(.+)*([��])([1-9]+[0-9]*)*([��]+)[��]*([1-9]+[0-9]*)*[��]*([1-9]+[0-9]*)*(.*)/u�v
�Ƃ����p�^�[����preg_match�ŏE���������Ǝv���̂ł����A�S���v���悤�ɏE�������܂���B
�������Ȃ̂ł��傤���H�H
�v���O�����Ƃ��ẮA
<?php
$text = '�ɂ����Ă͍��y��ʑ�b����߂����S��K�v�ȋZ�p�I�̂������̎w�肷��ɌW�镔���Ɍ���B)�A��119���A��5�͂�4(��129����2��5��1����2��6���̕���';
print 'text : ' . $text . '<br>';
$match = '/^(.+)*([��])([1-9]+[0-9]*)*([��]+)[��]*([1-9]+[0-9]*)*[��]*([1-9]+[0-9]*)*(.*)/u';
print 'match : ' . $match . '<br>';
preg_match($match,$text,$arr);
print 'arr : ';
print_r($arr);
print '<br>';
?>
����Ȋ����ł��B
���������������������������A�������肢�܂��B
�u...�ɂ����Ă͍��y��ʑ�b����߂����S��K�v�ȋZ�p�I�̂������̎w�肷��ɌW�镔���Ɍ���B)�A��119���A��5�͂�4(��129����2��5��1����2��6��...�v
�Ƃ������͂���A�恛�����́����́����Ȃǂ����A�����̑O��̕��͂��擾�������ƍl���Ă��܂��B
������
�u/^(.+)*([��])([1-9]+[0-9]*)*([��]+)[��]*([1-9]+[0-9]*)*[��]*([1-9]+[0-9]*)*(.*)/u�v
�Ƃ����p�^�[����preg_match�ŏE���������Ǝv���̂ł����A�S���v���悤�ɏE�������܂���B
�������Ȃ̂ł��傤���H�H
�v���O�����Ƃ��ẮA
<?php
$text = '�ɂ����Ă͍��y��ʑ�b����߂����S��K�v�ȋZ�p�I�̂������̎w�肷��ɌW�镔���Ɍ���B)�A��119���A��5�͂�4(��129����2��5��1����2��6���̕���';
print 'text : ' . $text . '<br>';
$match = '/^(.+)*([��])([1-9]+[0-9]*)*([��]+)[��]*([1-9]+[0-9]*)*[��]*([1-9]+[0-9]*)*(.*)/u';
print 'match : ' . $match . '<br>';
preg_match($match,$text,$arr);
print 'arr : ';
print_r($arr);
print '<br>';
?>
����Ȋ����ł��B
���������������������������A�������肢�܂��B
688 �Fnobody�����F2011/01/17(��) 22:47:22 ID:???
����蕪���Ă��玿�₵�Ă���
689 �F�}�b�`������������������ɂ������F2011/01/17(��) 22:59:46 ID:e71m2/yA
PHP�ɂ����鐳�K�\���Ɋւ��鎿��ł��B
���̃T���v���v���O�����ł�$3�������Ƃ��啶���́uUS�v�ɂȂ�܂����A
�ŏ���$3�������������́uus�v�ɂ�����@����������Ă��������B
OS��Windows�APHP��5.3�ł��B
���̕�����̗�
Country: US
�ϊ���ɓ�����������̗�
Country: <a href="http://ja.wikipedia.org/wiki/.us">US</a>
�T���v���v���O����
<?php
$result = '';
$text = 'Country: US';
$pattern = '/(Country):(\s+)([A-Z]{2})/i';
$replace = "$1:$2<a href=\"http://ja.wikipedia.org/wiki/.$3\">$3</a>";
$result = preg_replace($pattern, $replace, $text);
echo $result;
?>
���̃T���v���v���O�����ł�$3�������Ƃ��啶���́uUS�v�ɂȂ�܂����A
�ŏ���$3�������������́uus�v�ɂ�����@����������Ă��������B
OS��Windows�APHP��5.3�ł��B
���̕�����̗�
Country: US
�ϊ���ɓ�����������̗�
Country: <a href="http://ja.wikipedia.org/wiki/.us">US</a>
�T���v���v���O����
<?php
$result = '';
$text = 'Country: US';
$pattern = '/(Country):(\s+)([A-Z]{2})/i';
$replace = "$1:$2<a href=\"http://ja.wikipedia.org/wiki/.$3\">$3</a>";
$result = preg_replace($pattern, $replace, $text);
echo $result;
?>
690 �Fnobody�����F2011/01/17(��) 23:51:56 ID:???
�茳�̃G�f�B�^�ł�\L�łł�����ǂ�
PHP�Ŏg����u���p�^�[�����ǂ�������Ȃ�
e�C���q�����Ⴄ�Ƃ�
PHP�Ŏg����u���p�^�[�����ǂ�������Ȃ�
e�C���q�����Ⴄ�Ƃ�
�����ł��ˁBPerl����\l�Ŏ��̕������������ɂȂ�Ƃ�����݂����ł����A
PHP�ɂ͂Ȃ���ł����ˁH
�ق��̕��@�ł����܂��܂���̂ŁA
���������A�����҂����Ă���܂��B
PHP�ɂ͂Ȃ���ł����ˁH
�ق��̕��@�ł����܂��܂���̂ŁA
���������A�����҂����Ă���܂��B
692 �Fnobody�����F2011/01/18(��) 01:17:36 ID:???
>>689
$pattern = '/(Country):(\s+)([A-Z]{2})/ie';
$replace = '"$1:$2<a href=\"http://ja.wikipedia.org/wiki/." .strtolower($3). "\">$3</a>"';
�����Ă݂�����p�����������肵�Ȃ������ɂȂ��Ă��܂����B
$pattern = '/(Country):(\s+)([A-Z]{2})/ie';
$replace = '"$1:$2<a href=\"http://ja.wikipedia.org/wiki/." .strtolower($3). "\">$3</a>"';
�����Ă݂�����p�����������肵�Ȃ������ɂȂ��Ă��܂����B
693 �Fnobody�����F2011/01/18(��) 19:32:41 ID:sm74ERjN
���̐��K�\���ł����A���܂ł��܂������Ă��Ȃ��Ƃ���������
�ł��B�ŁA�����悤�Ǝv���̂ł����A
�����w�K�\�t�g�t�� ���K�\���������h����
���ꂢ���ł����ˁH
�I���C���[�Ƃǂ������������Ȃ��Ďv����ł����ǁB
�ł��B�ŁA�����悤�Ǝv���̂ł����A
�����w�K�\�t�g�t�� ���K�\���������h����
���ꂢ���ł����ˁH
�I���C���[�Ƃǂ������������Ȃ��Ďv����ł����ǁB
694 �Fnobody�����F2011/01/18(��) 22:59:06 ID:???
>>693
Web�ł���
Web�ł���
695 �Fnobody�����F2011/01/19(��) 10:36:15 ID:???
>>692
�ł��܂����B
�����A�uDO�v�Ƃ����h�~�j�J�̍��ʃR�[�h�̎��A�\���Əd�Ȃ��ăG���[�ɂȂ����̂ŁA
�_�u���N�H�[�g�ɂ��܂����B
$pattern = '/(Country):(\s+)([A-Z]{2})/ie';
$replace = '"$1:$2<a href=\"http://ja.wikipedia.org/wiki/." .strtolower("$3"). "\">$3</a>"';
�ǂ������肪�Ƃ��������܂����B
�ł��܂����B
�����A�uDO�v�Ƃ����h�~�j�J�̍��ʃR�[�h�̎��A�\���Əd�Ȃ��ăG���[�ɂȂ����̂ŁA
�_�u���N�H�[�g�ɂ��܂����B
$pattern = '/(Country):(\s+)([A-Z]{2})/ie';
$replace = '"$1:$2<a href=\"http://ja.wikipedia.org/wiki/." .strtolower("$3"). "\">$3</a>"';
�ǂ������肪�Ƃ��������܂����B
697 �Fnobody�����F2011/01/19(��) 21:48:50 ID:???
>>690��e�C���q�ƌ����Ă���̂�
698 �Fnobody�����F2011/01/19(��) 23:40:21 ID:zqG6AlFK
���ۓI�Ȏ���Ő\����Ȃ���ł����A�{�̘b���o���̂ł��łɎf��������ł����B
���܂ŕ\�v�Z�\�t�g��f�[�^�x�[�X�\�t�g�ȂǕ��ʂɏK�����A
�X�ɋ������o�Ă����̂�MySQL��PHP���g���ăv���O���~���O������A
apache��PostFix�Ȃǂ����Ƃ��g����悤�ɂȂ�A���ƂȂ��������Ă������������Ă�̂ł����A
���K�\���Ɋւ��ẮA�����Ɂu�ǂ��ɂ��g���Ă��邯�ǁA�����͏o���Ă��Ȃ������v�����܂��B
�Ƃ肠��������Ă݂āA���߂ňႤ��������Ă݂��肵��....
�܂�ŕʎ�ނȍl�������K�v�ȋC�����܂��B
�Ȃ̂Ŏ���Ȃ̂ł����A���K�\���𗝉�����̂Ɉ�ԗǂ��{�Ƃ��A
���K�\���ɂ��āu�ڂ�����������I�I���ނ����I�I�������[�܂����v
���Ďv����悤�Ȗ{�Ƃ���������A�Љ�������Ȃ��ł��傤���H�H
����Ƃ��E�ϋ����A���s���Ă͍l����J��Ԃ��łȂ���A�K���ł��Ȃ����Ȃ̂ł��傤���H�H
�������N�ŎO�\�H�Ȃ̂ŁA�����ł��Ȃ��Ă��Ă�̂�������܂��A���܂������ɂ��ݍ��݂ɂ����Ȃ��Ă�悤�ȋC�����Ă܂��B
������낵����������肢�܂��B
���܂ŕ\�v�Z�\�t�g��f�[�^�x�[�X�\�t�g�ȂǕ��ʂɏK�����A
�X�ɋ������o�Ă����̂�MySQL��PHP���g���ăv���O���~���O������A
apache��PostFix�Ȃǂ����Ƃ��g����悤�ɂȂ�A���ƂȂ��������Ă������������Ă�̂ł����A
���K�\���Ɋւ��ẮA�����Ɂu�ǂ��ɂ��g���Ă��邯�ǁA�����͏o���Ă��Ȃ������v�����܂��B
�Ƃ肠��������Ă݂āA���߂ňႤ��������Ă݂��肵��....
�܂�ŕʎ�ނȍl�������K�v�ȋC�����܂��B
�Ȃ̂Ŏ���Ȃ̂ł����A���K�\���𗝉�����̂Ɉ�ԗǂ��{�Ƃ��A
���K�\���ɂ��āu�ڂ�����������I�I���ނ����I�I�������[�܂����v
���Ďv����悤�Ȗ{�Ƃ���������A�Љ�������Ȃ��ł��傤���H�H
����Ƃ��E�ϋ����A���s���Ă͍l����J��Ԃ��łȂ���A�K���ł��Ȃ����Ȃ̂ł��傤���H�H
�������N�ŎO�\�H�Ȃ̂ŁA�����ł��Ȃ��Ă��Ă�̂�������܂��A���܂������ɂ��ݍ��݂ɂ����Ȃ��Ă�悤�ȋC�����Ă܂��B
������낵����������肢�܂��B
699 �Fnobody�����F2011/01/20(��) 00:05:42 ID:???
>>698
���ƂȂ����������C�ɂȂ��Ă��鎞�͉����������ĂȂ���������ƊȒP�Ȃ̂�����
���ƂȂ����������C�ɂȂ��Ă��鎞�͉����������ĂȂ���������ƊȒP�Ȃ̂�����
700 �F693�F2011/01/20(��) 01:01:52 ID:973KUxXQ
701 �Fnobody�����F2011/01/20(��) 13:16:18 ID:???
���K�\���̃X�� (�v���O������ UNIX �ɂ�����) �̃��O�����āA
����̂����Ђ��[��������Ă����ƁA���\�ǂ����K�ɂȂ�Ǝv���B
����̂����Ђ��[��������Ă����ƁA���\�ǂ����K�ɂȂ�Ǝv���B
702 �Fnobody�����F2011/01/20(��) 23:13:37 ID:LxK6uyro
���̐��K�\����hoge�t�H���_�ȉ��̍Ō�́u/�v�̌�Ɂui/�v�����܂�悤��URL��ϊ����Ă���܂��B
RewriteRule ^/hoge(.*)/(.*).html$ http://example.com/hoge/$1/i/$2.html�@[L]
���L�̂悤�ȏꍇ�͖��Ȃ��̂ł���
http://example.com/hoge�@���@http://example.com/hoge/i/
http://example.com/hoge/saitama/2011/01/index.html�@���@http://example.com/hoge/saitama/2011/01/i/index.html
���̂悤��hoge�Ŏn�܂�f�B���N�g���܂ł��ϊ�����Ă��܂��܂��B
http://example.com/hogehoge/kankeinai.html
hoge�t�H���_�z���̂ݕϊ������悤�ɂ���ɂ́A�ǂ������炢���ł��傤���H
����
CentOS�T
Apache�Q
RewriteRule ^/hoge(.*)/(.*).html$ http://example.com/hoge/$1/i/$2.html�@[L]
���L�̂悤�ȏꍇ�͖��Ȃ��̂ł���
http://example.com/hoge�@���@http://example.com/hoge/i/
http://example.com/hoge/saitama/2011/01/index.html�@���@http://example.com/hoge/saitama/2011/01/i/index.html
���̂悤��hoge�Ŏn�܂�f�B���N�g���܂ł��ϊ�����Ă��܂��܂��B
http://example.com/hogehoge/kankeinai.html
hoge�t�H���_�z���̂ݕϊ������悤�ɂ���ɂ́A�ǂ������炢���ł��傤���H
����
CentOS�T
Apache�Q
703 �Fnobody�����F2011/01/21(��) 00:15:43 ID:???
/hoge/(.*)�`�ɂ�����������
704 �Fnobody�����F2011/01/21(��) 18:26:53 ID:???
>>698
���̗ǂ��l���Ƃ܂��Ⴄ�̂�������Ȃ����ǁA
��X�̂悤�Ȗ}�l�͌J��Ԃ�����Čo���l��ςނ����Ȃ����Ȃ��A���ċC������B
�ŁA�����ǂ�ň�R���z�������Ȃ�A����ł̓I���C���[�{�̈�����������Ǝv���B
���̗ǂ��l���Ƃ܂��Ⴄ�̂�������Ȃ����ǁA
��X�̂悤�Ȗ}�l�͌J��Ԃ�����Čo���l��ςނ����Ȃ����Ȃ��A���ċC������B
�ŁA�����ǂ�ň�R���z�������Ȃ�A����ł̓I���C���[�{�̈�����������Ǝv���B
705 �Fnobody�����F2011/02/10(��) 13:57:44 ID:???
�Ώۂ̕�����Ƀn���O���������܂܂�邩�ǂ����f�������̂ł���
�悢���@���v�������т܂���B
javascript�ł��B
�悢���@���v�������т܂���B
javascript�ł��B
706 �Fnobody�����F2011/02/27(��) 08:37:54.94 ID:GexZY7hJ
�P�D preg_match('/[\(]{2}?(.*?)\:(.*?)[\)]{2}?/', $text, $match)
���̕ϊ���ϐ��W�J�Ŏ��s�������̂ł����A
���K�\���Ŏg����L���̕ϐ��W�J�̂�肩���������Ă��������B
�Q�D$exprString = '/[\(]{2}?(.*?)\:(.*?)[\)]{2}?/';
�@�@preg_match("/$exprString/", $text, $match);
���ꂾ�Ƃ��܂��s���܂���B
���̕ϊ���ϐ��W�J�Ŏ��s�������̂ł����A
���K�\���Ŏg����L���̕ϐ��W�J�̂�肩���������Ă��������B
�Q�D$exprString = '/[\(]{2}?(.*?)\:(.*?)[\)]{2}?/';
�@�@preg_match("/$exprString/", $text, $match);
���ꂾ�Ƃ��܂��s���܂���B
707 �Fnobody�����F2011/02/27(��) 09:01:28.34 ID:???
"/$exprString/"��W�J������"//[\(]{2}?(.*?)\:(.*?)[\)]{2}?//"�ɂȂ邺�H
>>707
�������܂����B�S���C�������ɔY��ł܂����B���肪�Ƃ��������܂��B
�������܂����B�S���C�������ɔY��ł܂����B���肪�Ƃ��������܂��B
709 �Fnobody�����F2011/02/27(��) 16:36:06.93 ID:KOnmSusx
�����w�K�\�t�g�t�� ���K�\���������h����
���܂����B
���ɕ��ɂȂ�܂����B�y�����������A�Ȃp�Y�����Ƃ��Ă���
�݂����ŁA�����c�O�Ȃ���\�t�g�͂������܂���ł����B
���܂����B
���ɕ��ɂȂ�܂����B�y�����������A�Ȃp�Y�����Ƃ��Ă���
�݂����ŁA�����c�O�Ȃ���\�t�g�͂������܂���ł����B
710 �Fnobody�����F2011/03/03(��) 19:14:51.88 ID:v/2VFVai
�ȉ���qdmail_receiver.php�Ƃ������[����M�̃v���O�����̈ꕔ�ŁA
�Y�t�t�@�C���̃t�@�C�������擾���Ă��镔���ɂȂ�܂��B
�������A�t�@�C�����ɔ��p�X�y�[�X������ƁA���p�X�y�[�X�ŕ�����Ă��܂�
�Ƃ������ۂ�����܂��B
���p�X�y�[�X�œr��Ȃ��悤�ɂ���̂͂ǂ̂悤�ɂ���悢�̂ł��傤���H
preg_match('/name\s*=\s*"?([^"\s\r\n]+)"?\r?\n?/is',$header['content-type'] , $matches )
��낵�����肢���܂��B
�Y�t�t�@�C���̃t�@�C�������擾���Ă��镔���ɂȂ�܂��B
�������A�t�@�C�����ɔ��p�X�y�[�X������ƁA���p�X�y�[�X�ŕ�����Ă��܂�
�Ƃ������ۂ�����܂��B
���p�X�y�[�X�œr��Ȃ��悤�ɂ���̂͂ǂ̂悤�ɂ���悢�̂ł��傤���H
preg_match('/name\s*=\s*"?([^"\s\r\n]+)"?\r?\n?/is',$header['content-type'] , $matches )
��낵�����肢���܂��B
711 �Fnobody�����F2011/03/03(��) 20:18:10.39 ID:???
[^"\s\r\n]+
"�ł��X�y�[�X�ł����s�ł��Ȃ���������������`
���Ď����ŏ����Ă���
"�ł��X�y�[�X�ł����s�ł��Ȃ���������������`
���Ď����ŏ����Ă���
712 �Fnobody�����F2011/03/04(��) 10:24:26.15 ID:???
�����ŕ����Ă邭�炢������@[^"\r\n]+�@����������������ċ����Ȃ���
713 �F710�F2011/03/04(��) 13:32:58.16 ID:8WvXj1g+
���܂��������Ȃ炢�����ǁA�t�@�C���������o�������̌㑱�����ׂ�?������
����"�ň͂܂�ĂȂ��̂�������A�E�g�����ǂ�
/name=(?:"([^"\r\n]+)"|([^\s\r\n]+))/i �Ń}�b�`������
if (empty($matches[1])) $matches[1] = $matches[2];
�݂����ɂ����ق����茘��������
����"�ň͂܂�ĂȂ��̂�������A�E�g�����ǂ�
/name=(?:"([^"\r\n]+)"|([^\s\r\n]+))/i �Ń}�b�`������
if (empty($matches[1])) $matches[1] = $matches[2];
�݂����ɂ����ق����茘��������
715 �Fnobody�����F2011/03/06(��) 18:00:58.46 ID:???
�y����zPHP5.3
�yOS�zXP
���O��BBS�������Ă��܂����A�ŋ߁A���X�ԍ��Ƀ����N���������v���A�u>>1�v�̂悤�ȃ��X��preg_match�Ń����N�^�O�������悤�Ǝ��݂܂����B
preg_match('/>>[0-9]+/',$text,$link);
preg_replace('/>>[0-9]+/','<a href="#">'.$link[$n].'</a>',$text);
���̊��ł͍ŏ��Ƀ}�b�`���郌�X�����ϊ��ł��܂���ł����B
�����悢�Ă�����܂����炨�肢���܂��B
�yOS�zXP
���O��BBS�������Ă��܂����A�ŋ߁A���X�ԍ��Ƀ����N���������v���A�u>>1�v�̂悤�ȃ��X��preg_match�Ń����N�^�O�������悤�Ǝ��݂܂����B
preg_match('/>>[0-9]+/',$text,$link);
preg_replace('/>>[0-9]+/','<a href="#">'.$link[$n].'</a>',$text);
���̊��ł͍ŏ��Ƀ}�b�`���郌�X�����ϊ��ł��܂���ł����B
�����悢�Ă�����܂����炨�肢���܂��B
716 �Fnobody�����F2011/03/08(��) 00:32:23.62 ID:???
preg_match_all �g���H
717 �Fnobody�����F2011/06/04(�y) 18:19:07.23 ID:GeFi3irL
<html>......<div class="list">�摜���X�g<br>1����<br><img src="http://example.com/aaa.jpg"><br>
2����<br><img src="http://example.com/bbb.jpg"><br>
3����<br><img src="http://example.com/ccc.jpg"><br>�����ƌ���<br></div>........</html>
�����<div class="list">��</div>�̊Ԃ̃A�h���X���������o���̂��Ăǂ����܂����H
........�̒��ɂ��摜�A�h���X������܂��B�������̓}�b�`�����Ȃ��悤�ɂ������B
preg_match_all("/list\".+?src=\"(.+)\".+</div>/", $html, $m);
{kind=link}
2����<br><img src="http://example.com/bbb.jpg"><br>
{kind=link}
3����<br><img src="http://example.com/ccc.jpg"><br>�����ƌ���<br></div>........</html>
{kind=link}
�����<div class="list">��</div>�̊Ԃ̃A�h���X���������o���̂��Ăǂ����܂����H
........�̒��ɂ��摜�A�h���X������܂��B�������̓}�b�`�����Ȃ��悤�ɂ������B
preg_match_all("/list\".+?src=\"(.+)\".+</div>/", $html, $m);
718 �Fnobody�����F2011/06/04(�y) 19:29:38.67 ID:???
�Q�i�K�ɕ�����ׂ�
719 �Fnobody�����F2011/06/04(�y) 19:32:39.30 ID:???
>>717
�Ȃ�ł���𐳋K�\���ł�낤�Ƃ���̂����킩���B���싷�B
�Ȃ�ł���𐳋K�\���ł�낤�Ƃ���̂����킩���B���싷�B
720 �Fnobody�����F2011/06/04(�y) 22:11:24.15 ID:???
721 �F �E�@���yLv=4,xxxP�z �F2011/06/04(�y) 22:38:07.91 ID:???
����҂�������w�肵�Ă��Ȃ����_�ł��@�����������x���B
722 �Fnobody�����F2011/06/04(�y) 23:04:45.68 ID:???
preg_match_all �� PHP �̊�
723 �Fnobody�����F2011/06/05(��) 14:02:49.98 ID:uEzVCQDA
>>717
���K�\���ꔭ�łł������ȋC�������ł����A�����ł����H
�Œ�P��---�@���̒������� ---�Œ�P��
����ȏ�ʂĂ悭����悤��
���K�\���ꔭ�łł������ȋC�������ł����A�����ł����H
�Œ�P��---�@���̒������� ---�Œ�P��
����ȏ�ʂĂ悭����悤��
724 �Fnobody�����F2011/06/06(��) 08:01:30.97 ID:???
>>709
win7HP�H
win7HP�H
725 �Fnobody�����F2011/06/16(��) 23:36:27.10 ID:SYj2PUn3
php��preg�g���Ă��܂��B
����t�@�C������
<td width="71%" valign="top" align="center"><div align = "center">
��
<td width="71%" valign="top" align="center">
�����ɕϊ��������Ƃ�����
$regTxt = "/<td ([a-z0-9\"=\s\%]+)><div ([a-z0-9\"=\s\%]+)>/is";
preg_match($regTxt,$x,$exchangeArr);
��$exchangeArr[1]���폜���邽�߁Apreg_replace���g�����Ǝv���Ă��܂��B
�����A�ŏ���preg_match�Ń}�b�`���܂���B
�ǂ�������o����̂ł��傤���H�H
�ǂȂ������������������B���肢���܂��B
����t�@�C������
<td width="71%" valign="top" align="center"><div align = "center">
��
<td width="71%" valign="top" align="center">
�����ɕϊ��������Ƃ�����
$regTxt = "/<td ([a-z0-9\"=\s\%]+)><div ([a-z0-9\"=\s\%]+)>/is";
preg_match($regTxt,$x,$exchangeArr);
��$exchangeArr[1]���폜���邽�߁Apreg_replace���g�����Ǝv���Ă��܂��B
�����A�ŏ���preg_match�Ń}�b�`���܂���B
�ǂ�������o����̂ł��傤���H�H
�ǂȂ������������������B���肢���܂��B
726 �Fnobody�����F2011/06/16(��) 23:41:03.98 ID:???
preg_match��$exchangeArr[1]���폜���邽��preg_replace�H
���{��ł���
���{��ł���
727 �Fnobody�����F2011/06/16(��) 23:44:03.44 ID:SYj2PUn3
<div align = "center"> ���폜���邽��
�ł��肢���܂��B
�ł��肢���܂��B
728 �Fnobody�����F2011/06/16(��) 23:45:43.17 ID:???
preg_match��preg_replace�p����K�v������́H
729 �Fnobody�����F2011/06/16(��) 23:52:34.42 ID:SYj2PUn3
<td....>���l�X�Ȍ`���Ƃ��Ă��邽�߁A�܂��͂��������o���K�v�����邩�Ǝv���A�������Ă܂��B
<td....><div...>�Ƃ����`�ŁA<td...>��<div...>�̂��ꂼ���...���A�l�X�Ȍ`���Ƃ��Ă��邯�ǁA<td...>���������ꂢ�Ɏc�������̂ł��B
�����A<div...>�����̂��́i�O��<td...>�����Ă��Ȃ��j�͕ϊ��������Ȃ��̂ł��B
����Ȑ����ł킩��܂��H
<td....><div...>�Ƃ����`�ŁA<td...>��<div...>�̂��ꂼ���...���A�l�X�Ȍ`���Ƃ��Ă��邯�ǁA<td...>���������ꂢ�Ɏc�������̂ł��B
�����A<div...>�����̂��́i�O��<td...>�����Ă��Ȃ��j�͕ϊ��������Ȃ��̂ł��B
����Ȑ����ł킩��܂��H
730 �Fnobody�����F2011/06/16(��) 23:56:08.62 ID:???
���K�\�����ו������Ė��̐蕪�����Ă݂�Ƃ����Ǝv����
731 �Fnobody�����F2011/06/18(�y) 14:34:02.52 ID:???
>>725,729
���̗l�X�Ȍ`�𐳋K�\���Ŏw�肷������Ǝv�����ǂˁB
$string = '<td width="71%" valign="top" align="center"><div align = "center">';
$string = preg_replace('/(<td [^>]+><div) [^>]+/', '$1', $string);
���̗l�X�Ȍ`�𐳋K�\���Ŏw�肷������Ǝv�����ǂˁB
$string = '<td width="71%" valign="top" align="center"><div align = "center">';
$string = preg_replace('/(<td [^>]+><div) [^>]+/', '$1', $string);
732 �Fnobody�����F2011/06/18(�y) 14:41:26.83 ID:???
���^�O�̂��Ƃ͖�������
734 �Fnobody�����F2011/06/30(��) 00:52:32.34 ID:hWRw8zI0
PHP5.3��preg_replace��
/<td[^>]+><div[^>]+/�Ƃ��Ő��K�\��������Ă��A�S���ύX����܂���B
preg_match�ł���Ă݂��<td[^>]+>�܂łȂ�match���邯�ǁA�u<�v�ȍ~������ƁA�S�������������Ă��܂���B
�����v�������邱�ƁA�Ȃ��ł��傤���H
/<td[^>]+><div[^>]+/�Ƃ��Ő��K�\��������Ă��A�S���ύX����܂���B
preg_match�ł���Ă݂��<td[^>]+>�܂łȂ�match���邯�ǁA�u<�v�ȍ~������ƁA�S�������������Ă��܂���B
�����v�������邱�ƁA�Ȃ��ł��傤���H
735 �Fnobody�����F2011/06/30(��) 06:05:38.15 ID:???
�ΏۂƂ��Ă��镶����ɂ��̐��K�\���Ƀ}�b�`���镔�������݂��Ȃ�
736 �Fnobody�����F2011/06/30(��) 07:23:46.62 ID:???
�������Ⴂ���Ă���Ƃ������Ƃ��Ă���Ƃ����v���Ȃ�
737 �Fnobody�����F2011/06/30(��) 21:31:52.67 ID:???
�ʎw��q��'+'����'*'�ɂ��Ă݂���}�b�`���܂����A�݂����Șb�ȋC�����ĂȂ�Ȃ��B
738 �F734�F2011/07/03(��) 22:32:36.09 ID:8QAPbG3u
�ǂ���琳�K�\���͖��Ȃ������݂����ł��B
php�Ńt�@�C����fopen�œǂݍ���ŁA
while ($x = fgets($fp,1092)) {...}�ŕϊ��������Ă�����ǁA
<td..>������<div..>�����̊Ԃɉ��s�������Ă��邩��A�ϊ��ł��Ȃ��炵���B
�ǂ������炢���ł��傤�H�H
php�Ńt�@�C����fopen�œǂݍ���ŁA
while ($x = fgets($fp,1092)) {...}�ŕϊ��������Ă�����ǁA
<td..>������<div..>�����̊Ԃɉ��s�������Ă��邩��A�ϊ��ł��Ȃ��炵���B
�ǂ������炢���ł��傤�H�H
739 �Fnobody�����F2011/07/03(��) 22:39:11.31 ID:???
�H�v����H
740 �Fnobody�����F2011/07/03(��) 23:37:07.72 ID:ypX399q3
$string = preg_replace('/<div align = \"center\"> /', '', $string);
$string = preg_replace('/<\/div>/', '', $string);
���A
$string = preg_replace('/<div(.*?)> /', '', $string);
$string = preg_replace('/<\/div>/', '', $string);
����˂���
$string = preg_replace('/<\/div>/', '', $string);
���A
$string = preg_replace('/<div(.*?)> /', '', $string);
$string = preg_replace('/<\/div>/', '', $string);
����˂���
741 �F734�F2011/07/03(��) 23:45:10.46 ID:8QAPbG3u
�S�Ă�div���폜��������łȂ��A<td....></td>�Ԃɂ���<div></div>���폜�������̂ł��B
<td....></td>�Ԃɂ�����͍̂폜���āA����ȊO�͉��s�������̂ł��B
<td....></td>�Ԃɂ�����͍̂폜���āA����ȊO�͉��s�������̂ł��B
742 �Fnobody�����F2011/07/05(��) 00:46:35.42 ID:???
preg_replace��A�ł��Ď�肽���̂������������
743 �Fnobody�����F2011/07/16(�y) 18:02:18.22 ID:???
744 �Fnobody�����F2011/07/16(�y) 22:16:17.55 ID:???
/http:\/\/[^ ]* /
745 �Fnobody�����F2011/07/23(�y) 20:12:09.44 ID:lXdqpzgT
A�̌J��Ԃ���A+�Ƃ�A{m,n}�Ń}�b�`�ł��܂����A
�J��Ԃ��ꂽ��������AAAAA��A*5�Ȃǂɒu������u���܂��v���@�͂���ł��傤���B
����͂Ƃ肠����JavaScript�ōl���Ă��܂��B
replace(/A+/g, 'A*'); //����������i�܂Ȃ��B
�J��Ԃ��ꂽ��������AAAAA��A*5�Ȃǂɒu������u���܂��v���@�͂���ł��傤���B
����͂Ƃ肠����JavaScript�ōl���Ă��܂��B
replace(/A+/g, 'A*'); //����������i�܂Ȃ��B
746 �Fnobody�����F2011/07/23(�y) 20:22:41.87 ID:???
>>745
���K�\���ɂ͂Ȃ��̂�JavaScript�X����
���K�\���ɂ͂Ȃ��̂�JavaScript�X����
747 �Fnobody�����F2011/07/23(�y) 20:34:12.11 ID:lXdqpzgT
748 �Fnobody�����F2011/07/24(��) 19:06:14.31 ID:/DoWXp9n
�u���̐l�v�܂��́u�O�̐l�v�Ƃ���������͓�����E���ꍇ�A�ǂ̗l�ȏ��������ǂ��̂ł��傤��??
[���̐l | �O�̐l] ���Ɓu�́v�ꕶ�������ł��E���Ă��܂��܂��c
[���̐l | �O�̐l] ���Ɓu�́v�ꕶ�������ł��E���Ă��܂��܂��c
749 �Fnobody�����F2011/07/24(��) 21:04:07.81 ID:???
"[abc]"�́u�wa�x���wb�x���wc�x�Ƀ}�b�`�v�����c�B
�N�̏��������K�\���́u�w���x���w�O�x���w�́x���w�l�x���w|�x���w �x�Ƀ}�b�`�v���B
����"(���̐l|�O�̐l)"�݂����Ȃ��Ƃ������������낤���ǁA
"[���O]�̐l"�ł����Ǝv���B
�N�̏��������K�\���́u�w���x���w�O�x���w�́x���w�l�x���w|�x���w �x�Ƀ}�b�`�v���B
����"(���̐l|�O�̐l)"�݂����Ȃ��Ƃ������������낤���ǁA
"[���O]�̐l"�ł����Ǝv���B
750 �Fnobody�����F2011/07/24(��) 21:07:51.65 ID:???
���ƁA�����悤�Ȃ̂ł��肪���Ȃ̂�
"[^hogehoge]"�ŕ�����̔ے���w�肵������ɂȂ����Ⴄ�l�B
�������ԈႢ�B�O�ׁ̈B
"[^hogehoge]"�ŕ�����̔ے���w�肵������ɂȂ����Ⴄ�l�B
�������ԈႢ�B�O�ׁ̈B
751 �Fnobody�����F2011/07/24(��) 22:38:19.38 ID:X7IDpmYo
>>750
�ł͉����������̂ł��傤���H
�ł͉����������̂ł��傤���H
752 �Fnobody�����F2011/07/24(��) 22:54:58.14 ID:???
>>751
[���O]�̐l
[���O]�̐l
753 �Fnobody�����F2011/07/24(��) 23:02:35.46 ID:???
���A�Ƃ����B
������̔ے��
(?!.*������.*).*
�݂����̂��Ȃ�
������̔ے��
(?!.*������.*).*
�݂����̂��Ȃ�
754 �Fnobody�����F2011/07/25(��) 21:55:36.12 ID:RVWZInKC
form����̏���ҏW���Ă����ł����P�[�^�C�G����(5�Ђ�)��������������Ƃ����̂͂ł��܂����H
PHP5�ł��B
PHP5�ł��B
755 �Fnobody�����F2011/07/25(��) 22:46:11.52 ID:???
756 �Fnobody�����F2011/07/25(��) 23:06:55.26 ID:RVWZInKC
757 �Fnobody�����F2011/07/27(��) 20:41:33.29 ID:PkulA4Dr
40�߂����I�b�T�����A�P���Z�o��Web�œƗ�����Ƃ��Q�������Ă܂�wwwwww
�T�����[�}���ɁA�������Ǝw�E���ꔭ����wwww
�v�����f�U�C���̊���P������u���Ă�l�@Part2
http://yuzuru.2ch.net/test/read.cgi/dame/1308059991
>>505
����40��Ŋ���P���āA���ꂩ��Ɨ����悤�ƍl���Ă邪�ȁB
�܂���o�����邩�炻�̕��ʂł̘b�����ǁB
����P���͒P�Ɂu�o�i�[���炢���܂���v���Č��������̂��߂Ɏ��B
30��Ȃ�f�W�n���ɂ������ς����邼�A�]�T����B
�����Ƃ����Љ�l�o������������B
�T�����[�}���ɁA�������Ǝw�E���ꔭ����wwww
�v�����f�U�C���̊���P������u���Ă�l�@Part2
http://yuzuru.2ch.net/test/read.cgi/dame/1308059991
>>505
����40��Ŋ���P���āA���ꂩ��Ɨ����悤�ƍl���Ă邪�ȁB
�܂���o�����邩�炻�̕��ʂł̘b�����ǁB
����P���͒P�Ɂu�o�i�[���炢���܂���v���Č��������̂��߂Ɏ��B
30��Ȃ�f�W�n���ɂ������ς����邼�A�]�T����B
�����Ƃ����Љ�l�o������������B
758 �Fnobody�����F2011/07/30(�y) 14:00:39.72 ID:???
>>757
ID:1gQ87Cnm ������������
ID:1gQ87Cnm ������������
759 �Fnobody�����F2011/08/01(��) 07:47:20.91 ID:???
^(\d{3},)*\d{3}$
��L���K�\����123���q�b�g���闝�R��������܂���
�J���}���Ȃ��Ă����̃q�b�g�����ł����H
*�̑O��()������ł����Ă܂����H
���Ώە�����
123
123,456
987,654,321
123,789,456,012
9876,543
123,456,
��HIT������
123
123,456
987,654,321
123,789,456,012
��L���K�\����123���q�b�g���闝�R��������܂���
�J���}���Ȃ��Ă����̃q�b�g�����ł����H
*�̑O��()������ł����Ă܂����H
���Ώە�����
123
123,456
987,654,321
123,789,456,012
9876,543
123,456,
��HIT������
123
123,456
987,654,321
123,789,456,012
760 �Fnobody�����F2011/08/01(��) 07:59:48.61 ID:???
>>759
*�̈Ӗ��ׂ悤
*�̈Ӗ��ׂ悤
761 �Fnobody�����F2011/08/01(��) 07:59:51.56 ID:???
* �� + �ʼn������Ȃ��H
*�̓[���ȏ�Ń}�b�`������B
*�̓[���ȏ�Ń}�b�`������B
>>760
���ׂȂ��Ă��������Ă܂���()*�����l�Ȃ̂��Ǝv���܂���
>>761
�����Annn�̏ꍇ���q�b�g�������������̂�*�ł����̂ł�
�d�l�Ƃ����������̊m�F�������ړI�ŏ������̂�
���ׂȂ��Ă��������Ă܂���()*�����l�Ȃ̂��Ǝv���܂���
>>761
�����Annn�̏ꍇ���q�b�g�������������̂�*�ł����̂ł�
�d�l�Ƃ����������̊m�F�������ړI�ŏ������̂�
763 �Fnobody�����F2011/08/01(��) 09:39:13.59 ID:3IgNAOvk
>>759�̈Ӑ}�����܂����悭�킩��A
�ua*�v�̎��Ɓu(abc)*�v�̎��Ƃ�*�̋@�\���ς��Ȃ����Ƃ��m�F�����������́H
���Ǝ���t�����ɔg���������͋C�������Ă��܂��̂̓I�������i�j�H
�ua*�v�̎��Ɓu(abc)*�v�̎��Ƃ�*�̋@�\���ς��Ȃ����Ƃ��m�F�����������́H
���Ǝ���t�����ɔg���������͋C�������Ă��܂��̂̓I�������i�j�H
764 �Fnobody�����F2011/08/01(��) 09:43:31.28 ID:???
�q���g�FID�B��
765 �Fnobody�����F2011/08/01(��) 09:48:49.11 ID:???
����������ƃC���b�Ƃ���
766 �Fnobody�����F2011/08/01(��) 09:52:47.51 ID:???
(\d{3},)*�@�W�Ȃ������
767 �Fnobody�����F2011/08/01(��) 10:28:45.34 ID:???
>>762
�ǂ����Ă��킩���ĂȂ����낗
�ǂ����Ă��킩���ĂȂ����낗
768 �Fnobody�����F2011/08/01(��) 17:56:48.08 ID:???
>>763
> >>759�̈Ӑ}�����܂����悭�킩��A
> �ua*�v�̎��Ɓu(abc)*�v�̎��Ƃ�*�̋@�\���ς��Ȃ����Ƃ��m�F�����������́H
�͂�
> ���Ǝ���t�����ɔg���������͋C�������Ă��܂��̂̓I�������i�j�H
�C���b��
> >>759�̈Ӑ}�����܂����悭�킩��A
> �ua*�v�̎��Ɓu(abc)*�v�̎��Ƃ�*�̋@�\���ς��Ȃ����Ƃ��m�F�����������́H
�͂�
> ���Ǝ���t�����ɔg���������͋C�������Ă��܂��̂̓I�������i�j�H
�C���b��
769 �Fnobody�����F2011/08/01(��) 17:59:56.76 ID:???
�@�\���ς��Ȃ����̊m�F�Ȃ̂Ɏ�����e��
���q�b�g���闝�R���킩��܂���
���Ă����������낗
���q�b�g���闝�R���킩��܂���
���Ă����������낗
770 �Fnobody�����F2011/08/01(��) 18:00:59.64 ID:???
>>766
�ǂ��������ł��傤���H
�����ƃX�}�[�g�ȕ��@������̂ł���ΐ������肢�܂�
>>767
���������Ȃ��̂������ς�ł�
���ߕ�����0��ȏ��hit���Ď��łȂ��́H
�ǂ��������ł��傤���H
�����ƃX�}�[�g�ȕ��@������̂ł���ΐ������肢�܂�
>>767
���������Ȃ��̂������ς�ł�
���ߕ�����0��ȏ��hit���Ď��łȂ��́H
771 �Fnobody�����F2011/08/01(��) 18:02:51.58 ID:???
772 �Fnobody�����F2011/08/01(��) 18:11:52.38 ID:3IgNAOvk
���͂���������ł悩����(�L��`)�c�B
773 �Fnobody�����F2011/08/01(��) 18:44:25.32 ID:???
���߁u�����v�Ƃ͌���Ȃ�����B
(����̂���Ȃ̂Ƃ�)*(?:�ق��ɂ�����Ȃ̂Ƃ�)*[����]*����ł��傤�B
(����̂���Ȃ̂Ƃ�)*(?:�ق��ɂ�����Ȃ̂Ƃ�)*[����]*����ł��傤�B
774 �Fnobody�����F2011/08/01(��) 19:21:33.25 ID:???
775 �Fnobody�����F2011/08/01(��) 22:22:11.88 ID:???
776 �Fnobody�����F2011/08/01(��) 22:37:10.25 ID:3IgNAOvk
>>774�̎w�E�������܂œI�m�Ȃ��̂��������Ă̂����܂����s���Ɨ��Ȃ����i�j
�܂��悩������( �L�́M)
�܂��悩������( �L�́M)
777 �Fnobody�����F2011/08/01(��) 22:54:31.04 ID:???
��낽
778 �Fnobody�����F2011/08/02(��) 11:07:19.68 ID:???
���ǂ킩���ĂȂ��������
779 �Fnobody�����F2011/08/03(��) 19:33:03.57 ID:???
762 ���O�F 759 [sage] ���e���F 2011/08/01(��) 08:58:25.47 ID:???
>>760
���ׂȂ��Ă��������Ă܂���()*�����l�Ȃ̂��Ǝv���܂���
>>761
�����Annn�̏ꍇ���q�b�g�������������̂�*�ł����̂ł�
�d�l�Ƃ����������̊m�F�������ړI�ŏ������̂�
>>760
���ׂȂ��Ă��������Ă܂���()*�����l�Ȃ̂��Ǝv���܂���
>>761
�����Annn�̏ꍇ���q�b�g�������������̂�*�ł����̂ł�
�d�l�Ƃ����������̊m�F�������ړI�ŏ������̂�
780 �Fnobody�����F2011/08/04(��) 09:41:51.16 ID:???
�����̊m�F�Ȃ�p�^�[���o���ăe�X�g����Ⴂ�����������
�ȂC���b�Ƃ����
�ȂC���b�Ƃ����
781 �Fnobody�����F2011/08/04(��) 12:34:18.67 ID:???
>>780
�C���b��
�C���b��
782 �Fnobody�����F2011/08/26(��) 08:02:24.21 ID:???
test
783 �Fnobody�����F2011/09/02(��) 00:33:38.37 ID:???
>>782
�C���b��
�C���b��
784 �Fnobody�����F2011/09/06(��) 00:06:31.30 ID:???
ttp//aaa.co.jp:8888
http//bbb.com:9999/
�����O����
����
h?ttp//������.������.������:������/?
�@�@�@�@ ����������@�@�@�@�@ �����܂Ł�
���q�b�g���������̂ł����F�X�������̂ł����o���܂���ł���
�������@������܂��ł��傤���H
http//bbb.com:9999/
�����O����
����
h?ttp//������.������.������:������/?
�@�@�@�@ ����������@�@�@�@�@ �����܂Ł�
���q�b�g���������̂ł����F�X�������̂ł����o���܂���ł���
�������@������܂��ł��傤���H
785 �Fnobody�����F2011/09/06(��) 00:20:00.51 ID:???
h?ttp:\/\/(?!aaa.co.jp:8888|bbb.com:9999)(\w+\.)+\w+(:\d+)?\/?
786 �Fnobody�����F2011/09/06(��) 00:28:37.10 ID:???
787 �Fnobody�����F2011/09/14(��) 01:54:57.08 ID:???
2ch��dat�̂P�i�P�s�ځj�̃��X���Ƀg���b�v�i10���ȏ�ł�10�`12���ł�ok�j��
�܂܂�Ă�ꍇ�Ƀq�b�g���������̂ł����A�ꕔ���O�������g���b�v����܂�
��(?!5s5hPZiJeU|ozOtJW9BFA).{10}
�܂ł͂ł����悤�ȋC������̂ł����P�s�ڂɃ}�b�`������ɂ͂ǂ�������ǂ��ł��傤��
SJIS�ł��B
�܂܂�Ă�ꍇ�Ƀq�b�g���������̂ł����A�ꕔ���O�������g���b�v����܂�
��(?!5s5hPZiJeU|ozOtJW9BFA).{10}
�܂ł͂ł����悤�ȋC������̂ł����P�s�ڂɃ}�b�`������ɂ͂ǂ�������ǂ��ł��傤��
SJIS�ł��B
788 �Fnobody�����F2011/09/14(��) 08:26:15.86 ID:???
>>787
^?d�Ƃ�
^?d�Ƃ�
789 �Fnobody�����F2011/09/14(��) 13:20:15.86 ID:???
790 �Fnobody�����F2011/09/15(��) 22:42:04.53 ID:???
>>789
���肪�Ƃ��������܂�
�悭������Ȃ������̂Œ��ׂĂ݂�ƕ����s�̍s���A�����Ƀ}�b�`�����邱�Ƃ��ł���̂ł���
�c�O�Ȃ���s���A�����Ƀg���b�v������킯�łȂ��̂ł��܂��Ȃ��悤�ł��B�B
���肪�Ƃ��������܂�
�悭������Ȃ������̂Œ��ׂĂ݂�ƕ����s�̍s���A�����Ƀ}�b�`�����邱�Ƃ��ł���̂ł���
�c�O�Ȃ���s���A�����Ƀg���b�v������킯�łȂ��̂ł��܂��Ȃ��悤�ł��B�B
791 �Fnobody�����F2011/09/16(��) 01:40:23.90 ID:???
792 �Fnobody�����F2011/09/16(��) 01:49:30.98 ID:???
�����n�������Ȃ�����ł���B
>>789�̂���m�I�v�V�����́u���s����������P��s���[�h�v�̈Ӗ�
(Ruby���̗��V)�ŏ����Ă��āA
>>790�͂�����u�����s���[�h�v�̈Ӗ�(Perl���̗��V)�Ɏ���Ă���B
>>789�̂���m�I�v�V�����́u���s����������P��s���[�h�v�̈Ӗ�
(Ruby���̗��V)�ŏ����Ă��āA
>>790�͂�����u�����s���[�h�v�̈Ӗ�(Perl���̗��V)�Ɏ���Ă���B
793 �Fnobody�����F2011/09/22(��) 02:27:55.73 ID:???
>>790
�擪����A�ŏ��ɉ��s�R�[�h���o�Ă���܂ł�1�s�ڂ���
�擪����A�ŏ��ɉ��s�R�[�h���o�Ă���܂ł�1�s�ڂ���
794 �Fnobody�����F2011/10/02(��) 19:26:42.05 ID:Tnal10Vi
abcdefgfedcba �Ƃ���������
def�Ƃ�����������������Əo����̂ł����A
def�ȊO�������ɂ͂ǂ���������̂ł��傤���H
def�Ƃ�����������������Əo����̂ł����A
def�ȊO�������ɂ͂ǂ���������̂ł��傤���H
795 �Fnobody�����F2011/10/02(��) 20:09:22.37 ID:zbShr9jh
���R�Ƃ�����
796 �Fnobody�����F2011/10/03(��) 06:19:41.91 ID:???
>>794
�悭�킩��ے�͂߂�ǂ��������B
([^def]|d(?!ef)|(?<!d)e(?!f)|(?<!de)f)
��def�̈ꕔ�ł���d,e,f�ȊO�̔C�ӂ�1�����Ƀ}�b�`���邩��
����łȂ�Ƃ��Ȃ邾�낤�B
�悭�킩��ے�͂߂�ǂ��������B
([^def]|d(?!ef)|(?<!d)e(?!f)|(?<!de)f)
��def�̈ꕔ�ł���d,e,f�ȊO�̔C�ӂ�1�����Ƀ}�b�`���邩��
����łȂ�Ƃ��Ȃ邾�낤�B
797 �Fnobody�����F2011/10/03(��) 21:56:35.04 ID:???
>>794
���ɂ�邯�ǁA(def)�ł��ׂĂɃ}�b�`�����āA���Ƃ���擾����$1�I�Ȃ��̂ɒu����������̂ł�
���ɂ�邯�ǁA(def)�ł��ׂĂɃ}�b�`�����āA���Ƃ���擾����$1�I�Ȃ��̂ɒu����������̂ł�
798 �Fnobody�����F2011/10/07(��) 11:38:20.62 ID:???
799 �Fnobody�����F2011/10/10(��) 10:36:17.70 ID:???
PHP�ɂ�HTML�^�O�ȊO�̑S�Ă̕����ɂ��āA�S�p�E���p�̓���Ȃǂ̏�����
�������Ǝv���̂ł����A�Ⴆ�Ήp����S�p�œ��ꂵ�����ꍇ�A�f�l�l���ł�
�ł��P���ɍ�Ƃ�����ɂ́u�S�Ẳp����S�p�Ɂv���u�^�O�̂ݔ��p�Ɂv�Ƃ���
�Q��ɕ������������x�X�g���Ǝv���̂ł����A�����ƌ����̗ǂ������̕��@��
����܂��ł��傤���H
�������Ǝv���̂ł����A�Ⴆ�Ήp����S�p�œ��ꂵ�����ꍇ�A�f�l�l���ł�
�ł��P���ɍ�Ƃ�����ɂ́u�S�Ẳp����S�p�Ɂv���u�^�O�̂ݔ��p�Ɂv�Ƃ���
�Q��ɕ������������x�X�g���Ǝv���̂ł����A�����ƌ����̗ǂ������̕��@��
����܂��ł��傤���H
800 �Fnobody�����F2011/10/10(��) 11:10:33.30 ID:???
PHP�Ȃ�����ɂ��������A�����e�i���X�����d���������������Ǝv���B
801 �Fnobody�����F2011/10/10(��) 16:07:33.02 ID:gughiUX1
"<"�ɑ�������(">"��������I��)�͑S�����p��
����ȊO�͂ǂ��ǂ��S�p��
�ł���
����͂��Ă����A��ƂȂ����R�����Ȃ���Γ��ꂷ��Ȃ�S�p����Ȃ����p�ɂ��Ƃ��B
����ȊO�͂ǂ��ǂ��S�p��
�ł���
����͂��Ă����A��ƂȂ����R�����Ȃ���Γ��ꂷ��Ȃ�S�p����Ȃ����p�ɂ��Ƃ��B
802 �Fnobody�����F2011/10/11(��) 00:33:04.23 ID:???
>>799
DOM�ŏ�������̂���������
DOM�ŏ�������̂���������
803 �Fnobody�����F2011/10/11(��) 00:36:07.74 ID:???
>>801
<input type="button" value="��������������">
<input type="button" value="��������������">
804 �Fnobody�����F2011/10/11(��) 23:11:43.85 ID:???
>>800
�����e�i���X���ɂ������Ƃǂ�Ȋ����ɂȂ邩�c�c�܂�ŃC���[�W�ł��܂���c�corz
>>801
�����܂���A��ƂȂ����R�őS�p�����˂Ȃ�Ȃ��̂ł��c�B
�Ƃ���ł��̕��@�͐��K�\���͓��Ɏg�킸�A1�������`�F�b�N���Ă��������ł��傤���H
>>802
DOM���g���Ƃ����Ɓc�c��͂肱������K�\���͎g��Ȃ������ł����H
>>803
����͓��Ƀ^�O�̒��g�܂ł͂�����Ȃ��\��Ȃ̂őS�pvalue�ł�ok�ł��B
�����e�i���X���ɂ������Ƃǂ�Ȋ����ɂȂ邩�c�c�܂�ŃC���[�W�ł��܂���c�corz
>>801
�����܂���A��ƂȂ����R�őS�p�����˂Ȃ�Ȃ��̂ł��c�B
�Ƃ���ł��̕��@�͐��K�\���͓��Ɏg�킸�A1�������`�F�b�N���Ă��������ł��傤���H
>>802
DOM���g���Ƃ����Ɓc�c��͂肱������K�\���͎g��Ȃ������ł����H
>>803
����͓��Ƀ^�O�̒��g�܂ł͂�����Ȃ��\��Ȃ̂őS�pvalue�ł�ok�ł��B
805 �Fnobody�����F2011/10/12(��) 00:03:54.71 ID:???
>>801
�����܂���A�X���Ⴂ�ɂȂ��Ă��܂��܂������A�ЂƂ܂����̕��@�������Ă݂܂����B
���A���̎Q�Ɓi&anp�Ƃ��j���o�Ă����Ƃ��ɂ�₱�������ƂɂȂ肻���ł��corz
���̏ꍇ�����͋Z�Ő蔲���邩�A�������͂�͂肠����x���K�\���ŏ�����
���������ǂ������ȋC�����܂����ǂ��ł��傤���B
���邢��DOM�̕����ȒP�Ȃ̂ł��傤���c�H
�ǂ��^�O�̒��g�����o����̂����܂ЂƂ킩��Ȃ��ł��B�B�B
�����܂���A�X���Ⴂ�ɂȂ��Ă��܂��܂������A�ЂƂ܂����̕��@�������Ă݂܂����B
���A���̎Q�Ɓi&anp�Ƃ��j���o�Ă����Ƃ��ɂ�₱�������ƂɂȂ肻���ł��corz
���̏ꍇ�����͋Z�Ő蔲���邩�A�������͂�͂肠����x���K�\���ŏ�����
���������ǂ������ȋC�����܂����ǂ��ł��傤���B
���邢��DOM�̕����ȒP�Ȃ̂ł��傤���c�H
�ǂ��^�O�̒��g�����o����̂����܂ЂƂ킩��Ȃ��ł��B�B�B
806 �Fnobody�����F2011/10/12(��) 00:21:33.58 ID:???
���[�c�ォ��S�p��XXX�G�p�ɂ�����ĕ��@������܂��˂��c�B
���[��B
���[��B
807 �Fnobody�����F2011/10/14(��) 09:47:43.56 ID:+/AP5o7r
html�̃\�[�X����^�O�����O����̂ɒ��킵�ĂĈȉ��̂悤�ɂ�����ł���
�����ƌ���������������ł��傤���H
\<[a-zA-Z0-9\"\<\>\ \=\;\:\/\.\_\-\(\)\#\!\'\&\%]+
�����ƌ���������������ł��傤���H
\<[a-zA-Z0-9\"\<\>\ \=\;\:\/\.\_\-\(\)\#\!\'\&\%]+
808 �Fnobody�����F2011/10/14(��) 15:25:07.10 ID:???
�ǂ��~�������Ȃ̂��Ƃ�
809 �Fnobody�����F2011/10/14(��) 15:26:32.18 ID:i4T0D1ix
>>807
�����ƁuHello�v���Ə����Ă����Ȃ����H
<p>Hello</p>
�����Ɓu�calt="�v�Ŏ~�܂��Ă��܂�Ȃ����H
<img src="hello.png" alt="����ɂ���">
���Ƃ����킯�ł���ł�����Ȃ��́B
<[^>]>
�����ƁuHello�v���Ə����Ă����Ȃ����H
<p>Hello</p>
�����Ɓu�calt="�v�Ŏ~�܂��Ă��܂�Ȃ����H
<img src="hello.png" alt="����ɂ���">
���Ƃ����킯�ł���ł�����Ȃ��́B
<[^>]>
810 �Fnobody�����F2011/10/14(��) 15:28:56.11 ID:i4T0D1ix
����u+�v��������
<[^>]+>
<[^>]+>
811 �Fnobody�����F2011/10/15(�y) 02:18:16.86 ID:pl58b8lQ
�t�W�e���r�f��
�ԉ��f��
�v�`�F�b�N
�ԉ��f��
�v�`�F�b�N
812 �Fnobody�����F2011/10/15(�y) 15:28:36.48 ID:???
>>809
����͕֗��B���肪�Ƃ�
����͕֗��B���肪�Ƃ�
813 �Fnobody�����F2011/10/15(�y) 16:07:18.81 ID:???
�������Ă��Ƃ�
814 �F809�F2011/10/15(�y) 18:11:07.01 ID:5td5CFAR
>>813������
815 �Fnobody�����F2011/11/01(��) 16:59:25.75 ID:???
�s�P�ʂ��_�u���N�I�[�g�ň͂ސ��K�\����
������������������
������������������
����
/^.*$/m
�u������
"$0"
�Ƃ����ꍇ��
"������������������
"
"������������������
"
�ƂȂ��Ă��܂��܂��B"������������������"�Ƃ������̂ł����A�ǂ̂悤�ɂ���Ηǂ��ł��傤��
PHP��preg_replace���g���Ă��܂��B��낵�����肢���܂��B
������������������
������������������
����
/^.*$/m
�u������
"$0"
�Ƃ����ꍇ��
"������������������
"
"������������������
"
�ƂȂ��Ă��܂��܂��B"������������������"�Ƃ������̂ł����A�ǂ̂悤�ɂ���Ηǂ��ł��傤��
PHP��preg_replace���g���Ă��܂��B��낵�����肢���܂��B
816 �Fnobody�����F2011/11/01(��) 17:49:42.69 ID:???
�}�b�`����Ȃ��悤�ɉ��s���܂܂�Ă邩��B
817 �Fnobody�����F2011/11/01(��) 18:23:24.87 ID:???
818 �Fnobody�����F2011/11/01(��) 22:17:43.68 ID:???
819 �Fnobody�����F2011/11/01(��) 22:40:47.00 ID:???
>>818
>>816��
> �}�b�`����Ȃ��悤�ɉ��s���܂܂�Ă邩��B
�ł͂Ȃ���
�}�b�`����Ȃ��悤�ɉ��s���܂܂�Ă��Ȃ��Ă�\x0D���t������邩��
�����ł͂���܂���B
>>816��
> �}�b�`����Ȃ��悤�ɉ��s���܂܂�Ă邩��B
�ł͂Ȃ���
�}�b�`����Ȃ��悤�ɉ��s���܂܂�Ă��Ȃ��Ă�\x0D���t������邩��
�����ł͂���܂���B
820 �F816 != 818�F2011/11/01(��) 23:45:06.62 ID:???
>>819
�����������������̂��ȁBCR���܂܂�Ă邩��B
�ʂ�CR�͕t�����ꂽ�肵�Ȃ���B
preg_replace("/^([^\r]*)\r?$/m", "\\1", $text);
�Ƃ��邩�ALF�݂̂ɕϊ����Ă��珈�����邩�B
�����������������̂��ȁBCR���܂܂�Ă邩��B
�ʂ�CR�͕t�����ꂽ�肵�Ȃ���B
preg_replace("/^([^\r]*)\r?$/m", "\\1", $text);
�Ƃ��邩�ALF�݂̂ɕϊ����Ă��珈�����邩�B
821 �Fnobody�����F2011/11/07(��) 22:53:15.08 ID:???
�Z���ƔԒn�̊Ԃɂ�����폜����ꍇ�ǂ��������ł���?
�u�����s ���� 123�Ԓn�v���̕������
�u�����s ����123�Ԓn�v�Ƃ������ł�
�u�����s�v�Ɓu�����v�̊Ԃ̋͂��̂܂܂Ƃ��������t�ł�
�u�����s ���� 123�Ԓn�v���̕������
�u�����s ����123�Ԓn�v�Ƃ������ł�
�u�����s�v�Ɓu�����v�̊Ԃ̋͂��̂܂܂Ƃ��������t�ł�
822 �Fnobody�����F2011/11/08(��) 00:28:51.98 ID:???
�������K������O��ŁA
\s[\d]
\s[\d]
823 �Fnobody�����F2011/11/08(��) 01:11:57.96 ID:???
(?!�s).\s
824 �Fnobody�����F2011/11/08(��) 08:57:43.48 ID:???
825 �Fnobody�����F2011/11/08(��) 10:58:00.13 ID:???
(�����s|�k�C��|(?:���s|���)�{|[���s��Q])\s+
��
\1
��
\1
826 �Fnobody�����F2011/11/08(��) 10:58:59.04 ID:???
�����A���Ⴂ����
>>825�͗����Ă���
>>825�͗����Ă���
827 �Fnobody�����F2011/11/08(��) 12:21:27.42 ID:???
>>821
(?![�s�撬��]).\s
(?![�s�撬��]).\s
828 �F816 != 818�F2011/11/08(��) 13:46:47.91 ID:???
�S�A�ȁB
829 �Fnobody�����F2011/11/08(��) 20:01:17.27 ID:???
���キ���傭
830 �Fnobody�����F2011/11/09(��) 02:32:34.16 ID:???
831 �Fnobody�����F2011/11/23(��) 06:53:59.84 ID:V5f5mApl
![[
�@������
�@![[�ʂ̕���]]
�@![[�ق��ق�]]
]]
![[����]]�����ꂪ�P�P�ʂŁA������Ȃ̒�����ŒZ�}�b�`�Œ��o�������A�ȉ��̂悤�ɂ��܂����B
$pattern = '/!\[\[([^\[\]]+)\]{2,2}?/';
���������̏ꍇ�A�u���P�b�g���g���Ȃ��̂ō����Ă��܂��B
![[ ���̒���[���Ƃ�]��������Ǝg���Ȃ� ]]
�ŒZ�}�b�`������ɂ͂ǂ����������ł��傤���H
�@������
�@![[�ʂ̕���]]
�@![[�ق��ق�]]
]]
![[����]]�����ꂪ�P�P�ʂŁA������Ȃ̒�����ŒZ�}�b�`�Œ��o�������A�ȉ��̂悤�ɂ��܂����B
$pattern = '/!\[\[([^\[\]]+)\]{2,2}?/';
���������̏ꍇ�A�u���P�b�g���g���Ȃ��̂ō����Ă��܂��B
![[ ���̒���[���Ƃ�]��������Ǝg���Ȃ� ]]
�ŒZ�}�b�`������ɂ͂ǂ����������ł��傤���H
832 �Fnobody�����F2011/11/23(��) 07:02:11.30 ID:???
$pattern = '/!\[\[.+?]]{2,2}?/';
833 �Fnobody�����F2011/11/23(��) 09:23:16.47 ID:V5f5mApl
>>832
���肪�Ƃ��������܂��B
���Ȃ݂Ɂ������ł��傤���H
$pattern = '/!\[\[.+?\]{2,2}?/';
�������Ȃ���A��͂�Œ��}�b�`�ɂȂ��Ă��܂��܂��B
�������菑���Y�ꂽ�̂ł����APHP��preg_match�ōs�Ȃ��Ă��܂��B
PCRE�����iPrel�݊��j�炵���ł��B
���肪�Ƃ��������܂��B
���Ȃ݂Ɂ������ł��傤���H
$pattern = '/!\[\[.+?\]{2,2}?/';
�������Ȃ���A��͂�Œ��}�b�`�ɂȂ��Ă��܂��܂��B
�������菑���Y�ꂽ�̂ł����APHP��preg_match�ōs�Ȃ��Ă��܂��B
PCRE�����iPrel�݊��j�炵���ł��B
834 �Fnobody�����F2011/11/23(��) 09:52:54.59 ID:V5f5mApl
���A���݂܂���A�ł��܂����I
���A1�s���Ƃ�����̂ł����A�����s�ɂ܂��������ꍇ���s���܂����B
�����̂悤�ȏꍇ
![[
�@��[��]��
�@![[�ʂ̕���]]
�@![[�ق��ق�]]
]]
�I�v�V������m��s��t���Ă݂܂������_���ł��B
���A1�s���Ƃ�����̂ł����A�����s�ɂ܂��������ꍇ���s���܂����B
�����̂悤�ȏꍇ
![[
�@��[��]��
�@![[�ʂ̕���]]
�@![[�ق��ق�]]
]]
�I�v�V������m��s��t���Ă݂܂������_���ł��B
835 �Fnobody�����F2011/11/24(��) 01:59:39.52 ID:???
>>834
����q�̑Ή��Ƃ�}�b�`����ɂ�
Subroutine References���g���Ηǂ���B
<?php
$re = '/(?:!\[\[(?:(?!!\[\[)(?!\]\]).|(?R))*\]\])/s';
$text = "![[
��[��]��
![[�ʂ̕���]]
![[�ق��ق�]]
]]";
$position = array();
for ($i = 0; $i < strlen($text); $i++) {
$pos = strpos($text, '!', $i);
if (end($position) !== $pos)
$position[] = $pos;
}
foreach ($position as $pos) {
$t = substr($text, $pos);
if (($pos === 0 || $pos) && preg_match_all($re, $t, $match, PREG_SET_ORDER)) {
var_dump($pos); var_dump($t); var_dump($match); print "----\n";
}
}
?>
����q�̑Ή��Ƃ�}�b�`����ɂ�
Subroutine References���g���Ηǂ���B
<?php
$re = '/(?:!\[\[(?:(?!!\[\[)(?!\]\]).|(?R))*\]\])/s';
$text = "![[
��[��]��
![[�ʂ̕���]]
![[�ق��ق�]]
]]";
$position = array();
for ($i = 0; $i < strlen($text); $i++) {
$pos = strpos($text, '!', $i);
if (end($position) !== $pos)
$position[] = $pos;
}
foreach ($position as $pos) {
$t = substr($text, $pos);
if (($pos === 0 || $pos) && preg_match_all($re, $t, $match, PREG_SET_ORDER)) {
var_dump($pos); var_dump($t); var_dump($match); print "----\n";
}
}
?>
836 �Fnobody�����F2011/11/25(��) 00:51:55.86 ID:7pZprZ8q
>>835
�����I�H���肪�Ƃ��������܂��I
�����I�H���肪�Ƃ��������܂��I
837 �Fnobody�����F2011/11/25(��) 01:08:56.26 ID:???
838 �Fnobody�����F2011/11/27(��) 21:48:09.61 ID:ZbhJICcu
json�̌`����z��ɕϊ����邱�Ƃ͏o���Ȃ��ł��傤���H
php��json_decode���ƁA�ǂ����ϊ��G���[���o��悤�ŁA���K�\���ʼn����ł���Ǝv���̂ł����B
{"xType":{"0":"main","1":"main","2":"main","3":"main","4":"main"},"xNum":{"0":"6","1":"6","2":"5","3":"5","4":"6"},"yType":{"0":"main","1":"main","2":"main","3":"main","4":"main"},"yNum":{"0":"5","1":"4","2":"4","3":"5","4":"5"}}
��[xType][0]=main,[xType][1]=main�E�E�E�E�E�I�Ȋ����Ȃ�ł����B
�ǂȂ������肢�������܂��B
php��json_decode���ƁA�ǂ����ϊ��G���[���o��悤�ŁA���K�\���ʼn����ł���Ǝv���̂ł����B
{"xType":{"0":"main","1":"main","2":"main","3":"main","4":"main"},"xNum":{"0":"6","1":"6","2":"5","3":"5","4":"6"},"yType":{"0":"main","1":"main","2":"main","3":"main","4":"main"},"yNum":{"0":"5","1":"4","2":"4","3":"5","4":"5"}}
��[xType][0]=main,[xType][1]=main�E�E�E�E�E�I�Ȋ����Ȃ�ł����B
�ǂȂ������肢�������܂��B
839 �Fnobody�����F2011/11/27(��) 23:58:55.08 ID:???
>>838
json_decode�ŃG���[���o�Ȃ�����
json_decode�ŃG���[���o�Ȃ�����
840 �Fnobody�����F2011/11/28(��) 08:12:12.66 ID:NxvSoLFs
>>839
�S�̂͂����ƒ����̂ł���...
�S�̂͂����ƒ����̂ł���...
841 �Fnobody�����F2011/11/28(��) 11:38:12.26 ID:???
�[���G���[�ɂȂ�悤��json���h�L��f�������Ȃ�Ƃ������B
842 �Fnobody�����F2011/11/28(��) 11:51:50.21 ID:???
>>840
�Ȃ��G���[�̌�������肵�Ȃ��̂ł���...
�Ȃ��G���[�̌�������肵�Ȃ��̂ł���...
843 �Fnobody�����F2011/11/28(��) 11:52:31.97 ID:???
���ƁAjson�`���łȂ����̂��Ajson�`�����Ǝv������Ő��K�\�������Ă����ǂ��܂������Ȃ��Ƃ������B
844 �Fnobody�����F2011/11/28(��) 20:38:17.18 ID:cgQZB7ih
{"1":{"0":{"n":{"xType":{"0":"main","1":"main","2":"main","3":"main","4":"main"},"xNum":{"0":"3","1":"5","2":"5","3":"3","4":"3"},"yType":{"0":"main","1":"main","2":"main","3":"main","4":"main"},
"yNum":{"0":"5","1":"5","2":"3","3":"3","4":"5"}}},"1":{"b":{"xType":{"0":"main","1":"main","2":"main","3":"main","4":"main"},"xNum":{"0":"5","1":"6","2":"6","3":"5","4":"5"},"yType":{"0":"main","1":"main","2":"main","3":"main","4":"main"},
"yNum":{"0":"5","1":"5","2":"4","3":"4","4":"5"}}},"2":{"l":{"xType":{"0":"main","1":"main","2":"main","3":"main","4":"main"},"xNum":{"0":"4","1":"5","2":"5","3":"4","4":"4"},"yType":{"0":"main","1":"main","2":"main","3":"main","4":"main"},
"yNum":{"0":"5","1":"5","2":"4","3":"4","4":"5"}}}}}
�ꉞ����Ȋ����̃f�[�^�ł��B
json�`�����Ǝv����ł����Aphp�̂ق��ł�
Syntax error, malformed JSON
�Ƃ�Ȃ��ł��B
"yNum":{"0":"5","1":"5","2":"3","3":"3","4":"5"}}},"1":{"b":{"xType":{"0":"main","1":"main","2":"main","3":"main","4":"main"},"xNum":{"0":"5","1":"6","2":"6","3":"5","4":"5"},"yType":{"0":"main","1":"main","2":"main","3":"main","4":"main"},
"yNum":{"0":"5","1":"5","2":"4","3":"4","4":"5"}}},"2":{"l":{"xType":{"0":"main","1":"main","2":"main","3":"main","4":"main"},"xNum":{"0":"4","1":"5","2":"5","3":"4","4":"4"},"yType":{"0":"main","1":"main","2":"main","3":"main","4":"main"},
"yNum":{"0":"5","1":"5","2":"4","3":"4","4":"5"}}}}}
�ꉞ����Ȋ����̃f�[�^�ł��B
json�`�����Ǝv����ł����Aphp�̂ق��ł�
Syntax error, malformed JSON
�Ƃ�Ȃ��ł��B
845 �Fnobody�����F2011/11/28(��) 21:06:49.29 ID:???
>>844
�f�R�[�h�ł�����(PHP 5.3.2)
�f�R�[�h�ł�����(PHP 5.3.2)
846 �Fnobody�����F2011/11/28(��) 21:16:33.29 ID:cgQZB7ih
�}�W�������H�H
�f�R�[�h�̎d���������̂ł��傤���H�H
�ł�������������Ă��������B
�f�R�[�h�̎d���������̂ł��傤���H�H
�ł�������������Ă��������B
847 �Fnobody�����F2011/11/28(��) 22:13:12.05 ID:???
�����Ȃ�Ȃ����߂ɂ��ǂ�ȃf�[�^���ǂ��������G���[�ɂȂ������������̂��d�v�Ȃ��ǁB
848 �Fnobody�����F2011/11/28(��) 22:14:25.01 ID:???
849 �F846�F2011/11/28(��) 22:41:14.25 ID:NxvSoLFs
�P����javascript�̔z���json�ɕϊ������Ă���hidden�����ɓ��́B
�����POST�ő�����PHP�t�@�C����
json_decode($_POST['hidden'])
���Č`�ł���Ă܂��Bhidden�ő��邱�Ǝ��̂��ԈႢ�H�H
����Ƃ�hidden�������ɕϊ����Ȃ�������Ȃ��́H�H
�����POST�ő�����PHP�t�@�C����
json_decode($_POST['hidden'])
���Č`�ł���Ă܂��Bhidden�ő��邱�Ǝ��̂��ԈႢ�H�H
����Ƃ�hidden�������ɕϊ����Ȃ�������Ȃ��́H�H
850 �Fnobody�����F2011/11/28(��) 23:04:04.57 ID:???
hidden�����Ƃ�$_POST['hidden']�Ƃ��ӎU�L�����Ȃ̂��������Ă邵�B
���̐蕪���̎d���ɂ��đ��������Ȃ�A�������Ƃ��A�����S�҃X���݂����ȂƂ���łǂ���
���̐蕪���̎d���ɂ��đ��������Ȃ�A�������Ƃ��A�����S�҃X���݂����ȂƂ���łǂ���
851 �Fnobody�����F2011/11/29(��) 23:04:45.51 ID:gKGxmzY9
838�͏o�������ǁA844�͏o���Ȃ������B
����t�@�C����ŕϐ������Ă݂����ʂƂ��āB
����t�@�C����ŕϐ������Ă݂����ʂƂ��āB
852 �Fnobody�����F2012/01/01(��) 16:05:26.90 ID:vpch3S2x
�����̌�������Ȃ��A�����_�ȉ�2�ʂ܂ł̏������}�b�`���������̂ł������܂������܂���B
str.match(/[0-9]*.[0-9][1-9]/g)
�ǂ����Ԉ���Ă���̂������Ă��������܂��ł��傤���B
PHP Version 5.2.16�ł�
�X�������肢�v���܂��B
str.match(/[0-9]*.[0-9][1-9]/g)
�ǂ����Ԉ���Ă���̂������Ă��������܂��ł��傤���B
PHP Version 5.2.16�ł�
�X�������肢�v���܂��B
853 �Fnobody�����F2012/01/01(��) 17:00:46.35 ID:???
�����JavaScript�ɂ��������Ȃ�����
854 �Fnobody�����F2012/01/01(��) 18:04:13.68 ID:Zget/7Sh
>>852
�{����PHP���Ƃ���A�����Ă�Ƃ���̂ق������Ȃ���
preg_match_all('/[0-9]*\.[0-9][0-9]/');
1/100�̈ʂ͐ϋɓI�Ƀ[�����Ȃ��Ȃ���Ȃ�Ȃ��́H[0-9]�ł悭�ˁH
���ƁA�P�Ȃ鐮���Ƃ��A�����_�ȉ�3�ʈȏ�̐������ǂ����������̂��ɂ���Ă��ς���Ă���B
�����������ۂ̂Ƃ���́uPHP�ŏo�͂���HTML�ɏ����ꂽJavaScript�v�����肩�ȁH
�{����PHP���Ƃ���A�����Ă�Ƃ���̂ق������Ȃ���
preg_match_all('/[0-9]*\.[0-9][0-9]/');
1/100�̈ʂ͐ϋɓI�Ƀ[�����Ȃ��Ȃ���Ȃ�Ȃ��́H[0-9]�ł悭�ˁH
���ƁA�P�Ȃ鐮���Ƃ��A�����_�ȉ�3�ʈȏ�̐������ǂ����������̂��ɂ���Ă��ς���Ă���B
�����������ۂ̂Ƃ���́uPHP�ŏo�͂���HTML�ɏ����ꂽJavaScript�v�����肩�ȁH
855 �F �y��g�z �y1107�~�z �F2012/01/01(��) 19:46:02.61 ID:???
>>852
�}�b�`�����镶�����l�݂̂ł���A
���l������������������̂ł́H
�����ł����Ă������I�ɐ��l�ɕϊ����铙���\�ł���A
���Ȃ�y�ł��B
�}�b�`�����镶�����l�݂̂ł���A
���l������������������̂ł́H
�����ł����Ă������I�ɐ��l�ɕϊ����铙���\�ł���A
���Ȃ�y�ł��B
>853,854,855
��ώ��炵�܂����B
854����̂��������ʂ�A�uPHP�ŏo�͂���HTML�ɏ����ꂽJavaScript�v�ł����B
���̗�������s�\���ł����B�\�������܂���ł����B
��ώ��炵�܂����B
854����̂��������ʂ�A�uPHP�ŏo�͂���HTML�ɏ����ꂽJavaScript�v�ł����B
���̗�������s�\���ł����B�\�������܂���ł����B
857 �Fnobody�����F2012/01/02(��) 17:24:24.78 ID:???
>>852
// 1 of 2
// ��Ƃ��ĉ~����pi
var value = "3.1415926";
var target = value;
// ��������������A�lj�����
if (target.indexOf(".") < 0) {
�@target = target.concat(".00");
}
var integral_part_1 = 0;
if (target > 0){
�@integral_part_1 = Math.floor(target);
}else{
�@integral_part_1 = Math.ceil(target);
}
//document.write(value," �̐������� ", integral_part_1, "<br>");
// 1 of 2
// ��Ƃ��ĉ~����pi
var value = "3.1415926";
var target = value;
// ��������������A�lj�����
if (target.indexOf(".") < 0) {
�@target = target.concat(".00");
}
var integral_part_1 = 0;
if (target > 0){
�@integral_part_1 = Math.floor(target);
}else{
�@integral_part_1 = Math.ceil(target);
}
//document.write(value," �̐������� ", integral_part_1, "<br>");
858 �Fnobody�����F2012/01/02(��) 17:25:16.42 ID:???
>>852
// 2 of 2
// ������1�ʂ��擾
target = target - integral_part_1;
target = target * 10;
var integral_part_2 = 0;
if (target > 0){
�@integral_part_2 = Math.floor(target);
}else{
�@integral_part_2 = Math.ceil(target);
}
//document.write(value," �̏�����1�ʕ����� ", integral_part_2, "<br>");
// ������2�ʂ��擾
target = target - integral_part_2;
target = target * 10;
var integral_part_3 = 0;
if (target > 0){
�@integral_part_3 = Math.floor(target);
}else{
�@integral_part_3 = Math.ceil(target);
}
document.write(value," �̏�����2�ʕ����� ", integral_part_3, "<br>");
// 2 of 2
// ������1�ʂ��擾
target = target - integral_part_1;
target = target * 10;
var integral_part_2 = 0;
if (target > 0){
�@integral_part_2 = Math.floor(target);
}else{
�@integral_part_2 = Math.ceil(target);
}
//document.write(value," �̏�����1�ʕ����� ", integral_part_2, "<br>");
// ������2�ʂ��擾
target = target - integral_part_2;
target = target * 10;
var integral_part_3 = 0;
if (target > 0){
�@integral_part_3 = Math.floor(target);
}else{
�@integral_part_3 = Math.ceil(target);
}
document.write(value," �̏�����2�ʕ����� ", integral_part_3, "<br>");
859 �Fnobody�����F2012/01/06(��) 21:48:56.02 ID:b1y0AA6H
�����̊F����̃��x���ł͊ȒP������̂����킩��܂������Ă�������
Firefox�u���E�U�̃X�N���v�g�ŁuGoogle Reader NG Filter�v�Ƃ������̂�����܂�
�����RSS�����ɓ���̃L�[���[�h����v���Ă���Ύ����I�ɍ폜������̂ł�
�T���v���Ƃ���AD��PR���������K�\�����͂��߂�������Ă��܂�
^\W?(?:ADV?|PR)\b
�����������̂ł�
�擪��AD��PR������L�������Ȃ��Ă����ނ킯�ł�
��������p���Č������Ȃ��L�[���[�h���܂܂�Ă�����̂������ׂ�
�����Ȃ�Ɏ��s���낵�Ă���̂ł�����肭�����܂���
�����̃L�[���[�h�Ȃ̂œ��R^�͕s�v�ł����A���K�\���̃T�C�g�ŕ����ĉ��ς��Ă�
�����Ȃ��̂ł�
iPhone��Android�Ƃ����L�[���[�h���܂܂�Ă�����폜����Ƃ����\�������肢���܂�
Firefox�u���E�U�̃X�N���v�g�ŁuGoogle Reader NG Filter�v�Ƃ������̂�����܂�
�����RSS�����ɓ���̃L�[���[�h����v���Ă���Ύ����I�ɍ폜������̂ł�
�T���v���Ƃ���AD��PR���������K�\�����͂��߂�������Ă��܂�
^\W?(?:ADV?|PR)\b
�����������̂ł�
�擪��AD��PR������L�������Ȃ��Ă����ނ킯�ł�
��������p���Č������Ȃ��L�[���[�h���܂܂�Ă�����̂������ׂ�
�����Ȃ�Ɏ��s���낵�Ă���̂ł�����肭�����܂���
�����̃L�[���[�h�Ȃ̂œ��R^�͕s�v�ł����A���K�\���̃T�C�g�ŕ����ĉ��ς��Ă�
�����Ȃ��̂ł�
iPhone��Android�Ƃ����L�[���[�h���܂܂�Ă�����폜����Ƃ����\�������肢���܂�
860 �Fnobody�����F2012/01/06(��) 23:01:27.07 ID:pwr91DzE
(?:iPhone|Android)�ł�������B
��L�Ƀ}�b�`������ŁA�{�����폜���镔�����T���v������R�s�y���Ȃ��ƃ_�������B
��L�Ƀ}�b�`������ŁA�{�����폜���镔�����T���v������R�s�y���Ȃ��ƃ_�������B
861 �Fnobody�����F2012/01/06(��) 23:25:15.04 ID:???
.*(iPhone|Android).*
862 �Fnobody�����F2012/01/06(��) 23:26:11.05 ID:???
863 �Fnobody�����F2012/01/07(�y) 00:03:18.47 ID:n5aAiFGN
>>862
���⏭�Ȃ��Ƃ�>>860�̐��K�\���̓}�b�`����͂��Ȃ̂ŁA���Ƃ���
1. �}�b�`������Ώۂ��{���ł͂Ȃ��^�C�g���ɂȂ��Ă���
2. �폜���鏈�����ǂ��ɂ��Ȃ��Ă���
3. ���̑�
���⏭�Ȃ��Ƃ�>>860�̐��K�\���̓}�b�`����͂��Ȃ̂ŁA���Ƃ���
1. �}�b�`������Ώۂ��{���ł͂Ȃ��^�C�g���ɂȂ��Ă���
2. �폜���鏈�����ǂ��ɂ��Ȃ��Ă���
3. ���̑�
864 �Fnobody�����F2012/01/07(�y) 00:05:14.52 ID:???
>>859
���ꂩ
http://userscripts.org/scripts/show/67840
�e���[��,URL,���̏����Ƀ}�b�`���ĂȂ���Ȃ����H
���ƁA�啶�����������`�F�b�N���Ă���Ƃ�
���ꂩ
http://userscripts.org/scripts/show/67840
�e���[��,URL,���̏����Ƀ}�b�`���ĂȂ���Ȃ����H
���ƁA�啶�����������`�F�b�N���Ă���Ƃ�
865 �Fnobody�����F2012/01/07(�y) 00:56:55.41 ID:???
>�����̊F����̃��x���ł͊ȒP������̂����킩��܂������Ă�������
����Ȗ����͂����B
����Ȗ����͂����B
866 �Fnobody�����F2012/01/13(��) 15:32:24.50 ID:QW0sWV6a
<a href="http://example.com/aaa.jpg"><img src="http://examle.com/bbb.jpg"></a>
�����<a href���Ȃ��ꍇ�Ɍ���<img src�Ƀ}�b�`������URI���擾����ɂ͂ǂ���������H
preg_match_all('/(?:(?(?=<a href)|src))="([^"]+)/si', $html, $m);
����<a href������Ƃ���<a href�̕����͉����}�b�`���Ȃ���src�̕����}�b�`����݂���
{kind=link}
�����<a href���Ȃ��ꍇ�Ɍ���<img src�Ƀ}�b�`������URI���擾����ɂ͂ǂ���������H
preg_match_all('/(?:(?(?=<a href)|src))="([^"]+)/si', $html, $m);
����<a href������Ƃ���<a href�̕����͉����}�b�`���Ȃ���src�̕����}�b�`����݂���
867 �Fnobody�����F2012/01/13(��) 21:09:54.88 ID:???
�܂�<a href���Ȃ��Ƃ����̂������ɂȂ��̂��A�y����͂����肳���Ȃ���
868 �Fnobody�����F2012/01/14(�y) 00:24:14.06 ID:???
>>866
preg_match_all('|<img src="([^"]*)">(?!</a>)|')
preg_match_all('|<img src="([^"]*)">(?!</a>)|')
869 �Fnobody�����F2012/01/15(��) 00:11:37.39 ID:???
>>866
xhtml���z��ł���Ȃ�A���K�\�����xpath�g���������ǂ���B
php.net�ɂ��������ς���A$string�ɕ�������������Ă�Ƃ��āA
$xml = new SimpleXMLElement($string);
$result = $xml->xpath('//img[name(..)!="a"]/@src');
while(list( , $node) = each($result)) {
echo $node,"\n";
}
���̏ꍇ���Ɛe�v�f��a�ł͂Ȃ�img�v�f��src�������Ă��Ƃ�
���ڕ\���ł��邩��ˁB
xhtml���z��ł���Ȃ�A���K�\�����xpath�g���������ǂ���B
php.net�ɂ��������ς���A$string�ɕ�������������Ă�Ƃ��āA
$xml = new SimpleXMLElement($string);
$result = $xml->xpath('//img[name(..)!="a"]/@src');
while(list( , $node) = each($result)) {
echo $node,"\n";
}
���̏ꍇ���Ɛe�v�f��a�ł͂Ȃ�img�v�f��src�������Ă��Ƃ�
���ڕ\���ł��邩��ˁB
870 �Fnobody�����F2012/02/04(�y) 12:29:11.76 ID:???
������̃X���b�h�ɂ͂��߂ē��~���܂��B��낵�����肢���܂��B
�E�g�p����Fjava
�E������e�F������]�����ƂȂ��E�������B
���������E���o�����K�\�����l�b�g�Œ��ׂĂ����̂ł����A
�Ȃɂ��V�����āA�Ȃɂ��s�\���ŁA�Ȃɂ������Ȃ̂��킩��Ȃ��Ȃ��Ă��܂��܂����B
�E�g�p����Fjava
�E������e�F������]�����ƂȂ��E�������B
���������E���o�����K�\�����l�b�g�Œ��ׂĂ����̂ł����A
�Ȃɂ��V�����āA�Ȃɂ��s�\���ŁA�Ȃɂ������Ȃ̂��킩��Ȃ��Ȃ��Ă��܂��܂����B
871 �Fnobody�����F2012/02/04(�y) 18:34:56.81 ID:???
�����ȊO
872 �Fnobody�����F2012/02/04(�y) 20:48:16.26 ID:???
[\p{InCJKUnifiedIdeographs}
���������̂��݂����̂ł����A����Ŗԗ�����Ă���̂ł��傤���B
���������̂��݂����̂ł����A����Ŗԗ�����Ă���̂ł��傤���B
873 �Fnobody�����F2012/02/05(��) 12:00:52.66 ID:???
http://code.cside.com/3rdpage/jp/utf-8/indexEastAsian.html
����������Ċ����̊܂܂�Ă���O���[�v���������炢����Ȃ�������B�E���Ă͍��镶��������Ȃ�
�E�����������̃R�[�h�|�C���g����邵���Ȃ���Ȃ�������
�u���������ʓ| ! Unicode�Ɋ܂܂����{��Ŏg���Ă��銿���������E�����K�\���������ɏ����Ă���� !�v����
���ƂȂ瓚���Ă��炦�Ȃ��Ǝv������
����������Ċ����̊܂܂�Ă���O���[�v���������炢����Ȃ�������B�E���Ă͍��镶��������Ȃ�
�E�����������̃R�[�h�|�C���g����邵���Ȃ���Ȃ�������
�u���������ʓ| ! Unicode�Ɋ܂܂����{��Ŏg���Ă��銿���������E�����K�\���������ɏ����Ă���� !�v����
���ƂȂ瓚���Ă��炦�Ȃ��Ǝv������
874 �Fnobody�����F2012/02/05(��) 13:17:26.57 ID:???
>>873
�ʓ|�B�B�B�Ƃ����Ӗ��ł͂Ȃ��A�������܂ޕ��͂����グ�鐳�K�\����T���Ă����̂ł����A
���ׂ�Β��ׂ�قǎ�ނ�����A���L����Ήߕs���Ȃ������Ȍ��ʂ���̂�������Ȃ��Ȃ����̂�
���₵������ł��B
�ʓ|�B�B�B�Ƃ����Ӗ��ł͂Ȃ��A�������܂ޕ��͂����グ�鐳�K�\����T���Ă����̂ł����A
���ׂ�Β��ׂ�قǎ�ނ�����A���L����Ήߕs���Ȃ������Ȍ��ʂ���̂�������Ȃ��Ȃ����̂�
���₵������ł��B
875 �Fnobody�����F2012/02/05(��) 13:35:14.15 ID:???
>>870
JIS X 0208�܂���JIS X 0213�����̊����R�[�h�ł�����Ȃ��H
JIS X 0208�����Ȃ� http://charset.7jp.net/unicode2.html �ɂ�������B
JIS X 0208�܂���JIS X 0213�����̊����R�[�h�ł�����Ȃ��H
JIS X 0208�����Ȃ� http://charset.7jp.net/unicode2.html �ɂ�������B
876 �Fnobody�����F2012/02/05(��) 17:49:14.26 ID:???
>>875
���肪�Ƃ��������܂��B[��-�r��-�]�ɉ�����[�\-�K]������悤�ł����A
\p{InCJKUnifiedIdeographs} �܂���[��-�]�Ƃ͔�ׂėʂ��قȂ�̂��ۂ�
�g���Ă͂����Ȃ��̂��ǂ��Ȃ̂��A�����Ă���������Ɗ������ł��B
���Ȃ݂�windows7�AMicrosoft(R) Office IME 2007 �����c�[�� ���g���Ă��܂��B
���肪�Ƃ��������܂��B[��-�r��-�]�ɉ�����[�\-�K]������悤�ł����A
\p{InCJKUnifiedIdeographs} �܂���[��-�]�Ƃ͔�ׂėʂ��قȂ�̂��ۂ�
�g���Ă͂����Ȃ��̂��ǂ��Ȃ̂��A�����Ă���������Ɗ������ł��B
���Ȃ݂�windows7�AMicrosoft(R) Office IME 2007 �����c�[�� ���g���Ă��܂��B
877 �Fnobody�����F2012/02/05(��) 19:33:01.78 ID:???
>>876
�R�[�h�\���猟����������킩��Ǝv�����ǁc�B
"��" �Ō�������� 4e00 �ɂ���A"�" �Ō�������� 9fa0 �ɂ��邱�Ƃ��킩��B
\p{InCJKUnifiedIdeographs} �͎����Ɉˑ����邩��Java�̎d�l����ǂ�ŁA�Ƃ����B
�g���Ă͂����Ȃ��A�Ȃ�Ĕ��f�w�W���Ȃ��ɔ��f�ł���킯���Ȃ��B
�R�[�h�\���猟����������킩��Ǝv�����ǁc�B
"��" �Ō�������� 4e00 �ɂ���A"�" �Ō�������� 9fa0 �ɂ��邱�Ƃ��킩��B
\p{InCJKUnifiedIdeographs} �͎����Ɉˑ����邩��Java�̎d�l����ǂ�ŁA�Ƃ����B
�g���Ă͂����Ȃ��A�Ȃ�Ĕ��f�w�W���Ȃ��ɔ��f�ł���킯���Ȃ��B
878 �Fnobody�����F2012/02/05(��) 19:41:04.69 ID:???
"JavaTM Platform Standard Ed. 6" �ɂ� \p{InCJKUnifiedIdeographs} ���Ȃ��ˁB
http://java.sun.com/javase/ja/6/docs/ja/api/java/util/regex/Pattern.html
http://java.sun.com/javase/ja/6/docs/ja/api/java/util/regex/Pattern.html
879 �Fnobody�����F2012/02/05(��) 20:32:59.67 ID:???
>>877>>878
�ԓ��A���ɂ��肪�Ƃ��������܂����B
�����̏o�������_�Ƃ��ẮA\p{InCJKUnifiedIdeographs}���N���X Pattern�ɂ͂Ȃ����ƁA
����4E9C�A�K��9ED1�ɂ���A���Ꞃ̈ʒu�����������Ƃ���(���т̏������Ⴄ�̂ň�T�ɂ͌����܂���)�A
[��-�]���g���̂���ԑÓ��Ɣ��f���܂����B
�F�l�A�{���ɂ��肪�Ƃ��������܂����B
�ԓ��A���ɂ��肪�Ƃ��������܂����B
�����̏o�������_�Ƃ��ẮA\p{InCJKUnifiedIdeographs}���N���X Pattern�ɂ͂Ȃ����ƁA
����4E9C�A�K��9ED1�ɂ���A���Ꞃ̈ʒu�����������Ƃ���(���т̏������Ⴄ�̂ň�T�ɂ͌����܂���)�A
[��-�]���g���̂���ԑÓ��Ɣ��f���܂����B
�F�l�A�{���ɂ��肪�Ƃ��������܂����B
880 �Fnobody�����F2012/02/17(��) 21:31:06.69 ID:???
����ł��BABCDE��5�̕���������A�����̕����E�����ɓ_�݂��Ă��܂��B
�����E�����ɂ���ABCDE���}�b�`�����鐳�K�\���������Ă��������B
�����͂̂��������ł��B
�l�b�g�Œ��ׂ��肵���̂ł����A�ǂ̌��t��p����Ǝ����̗v�����铚����
������̂�������Ȃ������̂ŏ������݂��܂����B
�܂������Œ��ׂ邽�߂ɂ����ȉ����ł���悤��HP�������Ă���������Ɗ������ł��B
��낵�����肢���܂��B
JAVA��p���Ă��܂��B
�����E�����ɂ���ABCDE���}�b�`�����鐳�K�\���������Ă��������B
�����͂̂��������ł��B
�l�b�g�Œ��ׂ��肵���̂ł����A�ǂ̌��t��p����Ǝ����̗v�����铚����
������̂�������Ȃ������̂ŏ������݂��܂����B
�܂������Œ��ׂ邽�߂ɂ����ȉ����ł���悤��HP�������Ă���������Ɗ������ł��B
��낵�����肢���܂��B
JAVA��p���Ă��܂��B
881 �Fnobody�����F2012/02/18(�y) 01:29:01.30 ID:???
882 �Fnobody�����F2012/02/18(�y) 07:45:28.55 ID:???
>>881
�}���`���C�����[�hON���Ǝv���܂��B
���ꂼ��̕��͂��ƂɓK�p�������Ǝv���Ă��܂��B
�NjL�Ȃ̂ł����A
ABCDE���܂܂�Ă��Ȃ����͂����������ƍl���Ă��܂��B
��낵�����肢���܂��B
�}���`���C�����[�hON���Ǝv���܂��B
���ꂼ��̕��͂��ƂɓK�p�������Ǝv���Ă��܂��B
�NjL�Ȃ̂ł����A
ABCDE���܂܂�Ă��Ȃ����͂����������ƍl���Ă��܂��B
��낵�����肢���܂��B
883 �Fnobody�����F2012/02/18(�y) 10:11:57.59 ID:???
884 �Fnobody�����F2012/02/18(�y) 10:58:37.64 ID:???
>>883
���肪�Ƃ��������܂����B
���肪�Ƃ��������܂����B
885 �Fnobody�����F2012/02/22(��) 10:20:21.24 ID:???
����ł��Bjava�����悤���Ă��܂��B
�Ђ炪�ȁE�J�^�J�i�E�A���t�@�x�b�g�E�L���ŁA�A���ł͂Ȃ��K���܂��肠����4�����ȏ�̕���
���o�����K�\���������Ē����Ȃ��ł��傤���B��낵�����肢���܂��B
�Ђ炪�ȁE�J�^�J�i�E�A���t�@�x�b�g�E�L���ŁA�A���ł͂Ȃ��K���܂��肠����4�����ȏ�̕���
���o�����K�\���������Ē����Ȃ��ł��傤���B��낵�����肢���܂��B
886 �Fnobody�����F2012/02/22(��) 22:58:11.24 ID:???
�A���ł͂Ȃ��܂��肠������Ԃ��ǂ��������ƂȂ낤�B
����4���p���Ă���܂��肠�������ȁB
���As# �͂ǂ��Ȃ́B
����4���p���Ă���܂��肠�������ȁB
���As# �͂ǂ��Ȃ́B
887 �Fnobody�����F2012/02/22(��) 23:26:26.77 ID:???
>>886
�A���ł͂Ȃ��K�������肠����4�����ȏ�̕��͂Ƃ�
�u���������v�u�A�A�A�A�v�uaaaa�v�u���������v���A���������͂ł͂Ȃ�
�u���A�Aa�v�Ƃ��uaaa�́v�Ƃ��u�����A�A�v���̕��͂̂��Ƃł��B
������Â炭�����܂���B
�A���ł͂Ȃ��K�������肠����4�����ȏ�̕��͂Ƃ�
�u���������v�u�A�A�A�A�v�uaaaa�v�u���������v���A���������͂ł͂Ȃ�
�u���A�Aa�v�Ƃ��uaaa�́v�Ƃ��u�����A�A�v���̕��͂̂��Ƃł��B
������Â炭�����܂���B
888 �Fnobody�����F2012/02/22(��) 23:50:16.43 ID:???
889 �Fnobody�����F2012/02/22(��) 23:59:54.01 ID:???
>>888
�u�Ђ炪�Ȃ����v�u�J�^�J�i�����v�u�A���t�@�x�b�g�����v�u�L�������v�̕��͂ł͂Ȃ��̂Ń}�b�`���܂��B
�u�����������v�͂Ђ炪�Ȃ��A�����Ă���̂Ń}�b�`���Ȃ��悤�ɂ��肢���܂��B
�u�Ђ炪�Ȃ����v�u�J�^�J�i�����v�u�A���t�@�x�b�g�����v�u�L�������v�̕��͂ł͂Ȃ��̂Ń}�b�`���܂��B
�u�����������v�͂Ђ炪�Ȃ��A�����Ă���̂Ń}�b�`���Ȃ��悤�ɂ��肢���܂��B
890 �Fnobody�����F2012/02/23(��) 00:39:32.26 ID:???
>>889
����Ȋ����H
^(?:[a-zA-Z��-�U�@-�S�A-��].{4,}|[a-zA-Z��-�U�@-�S].{4,}|[a-zA-Z��-�U].{4,}|[��-�U�@-�S�A-��].{4,}|[��-�U�@-�S].{4,}|[�@-�S�A-��].{4,})$
����Ȋ����H
^(?:[a-zA-Z��-�U�@-�S�A-��].{4,}|[a-zA-Z��-�U�@-�S].{4,}|[a-zA-Z��-�U].{4,}|[��-�U�@-�S�A-��].{4,}|[��-�U�@-�S].{4,}|[�@-�S�A-��].{4,})$
891 �Fnobody�����F2012/02/23(��) 00:45:45.26 ID:???
892 �Fnobody�����F2012/02/23(��) 01:57:09.70 ID:???
893 �Fnobody�����F2012/02/23(��) 02:20:18.23 ID:???
>>892
���������A�ӂ��邱�ƂȂ�āB
���������A�ӂ��邱�ƂȂ�āB
894 �Fnobody�����F2012/02/23(��) 09:38:55.66 ID:???
1�̕����킾���łȂ��Ȃ�ǂ����ɈقȂ�2�̕����킪���ԂƂ��낪���锤
�Ȃ̂ŁA���Ƃ�4�����ȏ�̏��������ɂ͂��̕��ԂƂ���̑O��2�����ȏ�
���邩�A�O�ƌ���1�����ȏジ���邩�A����2�����ȏ゠�邩�̂����ꂩ
�ł���B
�����N���X���������������̂͂��邢�̂ł�,�A,a,���ő�\�������
[���Aa��]{2,}���A[���Aa��]*
�݂����̂�^�̕�����̏���~�O�ƌ��̌J��Ԃ����̃p�^�[��������
������|�ŕ��ׂ��OK
�Ȃ̂ŁA���Ƃ�4�����ȏ�̏��������ɂ͂��̕��ԂƂ���̑O��2�����ȏ�
���邩�A�O�ƌ���1�����ȏジ���邩�A����2�����ȏ゠�邩�̂����ꂩ
�ł���B
�����N���X���������������̂͂��邢�̂ł�,�A,a,���ő�\�������
[���Aa��]{2,}���A[���Aa��]*
�݂����̂�^�̕�����̏���~�O�ƌ��̌J��Ԃ����̃p�^�[��������
������|�ŕ��ׂ��OK
895 �Fnobody�����F2012/02/23(��) 10:34:55.79 ID:???
>>894
�u[���Aa��]{2,}���A[���Aa��]*�v�̐^�́u���A�v�̕�����
�u���A�v�u��a�v�u�����v�u�A���v�u�Aa�v�u�A���v�ua���v�ua�A�v�ua���v
�u�����v�u���A�v�u��a�v��12�ʂ�����|�ŕ��ׂ�Ɖ��߂��܂�������낵�������ł��傤���B
����{���ɂ��肪�Ƃ��������܂����B
�u[���Aa��]{2,}���A[���Aa��]*�v�̐^�́u���A�v�̕�����
�u���A�v�u��a�v�u�����v�u�A���v�u�Aa�v�u�A���v�ua���v�ua�A�v�ua���v
�u�����v�u���A�v�u��a�v��12�ʂ�����|�ŕ��ׂ�Ɖ��߂��܂�������낵�������ł��傤���B
����{���ɂ��肪�Ƃ��������܂����B
896 �Fnobody�����F2012/02/23(��) 12:00:24.74 ID:???
����ɑO��̌J��Ԃ����̏ꍇ�킯��
[���Aa��]{2,}���A[���Aa��]*
[���Aa��]{1,}���A[���Aa��]{1,}
[���Aa��]*���A[���Aa��]{2,}
�c
���K�v������12�~3=36�ʂ����ĕ��ׂ�
[���Aa��]{2,}���A[���Aa��]*
[���Aa��]{1,}���A[���Aa��]{1,}
[���Aa��]*���A[���Aa��]{2,}
�c
���K�v������12�~3=36�ʂ����ĕ��ׂ�
897 �Fnobody�����F2012/02/23(��) 12:03:30.20 ID:???
�^�����Ⴄ����
[���Aa��]{2,}(���A|��a|�c.)[���Aa��]*
[���Aa��]{1,}(���A|��a|�c.)[���Aa��]{1,}
[���Aa��]*(���A|��a|�c.)[���Aa��]{2,}
�Ƃ��������y����
[���Aa��]{2,}(���A|��a|�c.)[���Aa��]*
[���Aa��]{1,}(���A|��a|�c.)[���Aa��]{1,}
[���Aa��]*(���A|��a|�c.)[���Aa��]{2,}
�Ƃ��������y����
898 �Fnobody�����F2012/02/23(��) 14:37:23.71 ID:???
899 �Fnobody�����F2012/02/23(��) 17:00:23.37 ID:???
PHP�F5.3�ł��B
URL�̒u���̎���ł��B
�ipreg_replace()�ł�����j
ttp://aa.com/index.php?(�K���ȕ�����)�@��������
��
ttp://aa.com/index.html
�̂悤�ɂ������̂ł����A�ǂ̂悤�Ȑ��K�\�����g�����炢���ł��傤���H
��낵�����肢���܂��B
URL�̒u���̎���ł��B
�ipreg_replace()�ł�����j
ttp://aa.com/index.php?(�K���ȕ�����)�@��������
��
ttp://aa.com/index.html
�̂悤�ɂ������̂ł����A�ǂ̂悤�Ȑ��K�\�����g�����炢���ł��傤���H
��낵�����肢���܂��B
900 �Fnobody�����F2012/02/23(��) 21:26:51.99 ID:???
>>899
�����Ώ�
index\.php[\?]+.+$
�u��������
index.html
URL�Ɋ܂܂��php�t�@�C�����������݂���ꍇ�AGET�ϐ��i?�ȍ~�̕�����j�������I�ɏ����������ꍇ
�������A�����̂�����u?�v����n�܂�P�ꂪ�����ΏۂƂȂ��Ă��܂��B
�����Ώ�
[\?]+.+$
�u��������
index.html
�����Ώ�
index\.php[\?]+.+$
�u��������
index.html
URL�Ɋ܂܂��php�t�@�C�����������݂���ꍇ�AGET�ϐ��i?�ȍ~�̕�����j�������I�ɏ����������ꍇ
�������A�����̂�����u?�v����n�܂�P�ꂪ�����ΏۂƂȂ��Ă��܂��B
�����Ώ�
[\?]+.+$
�u��������
index.html
901 �Fnobody�����F2012/02/26(��) 21:16:58.77 ID:???
javascript�ł��B
����������"manga_index[0-9]+\.html"��"manga_ban_index[0-9]+\.html"
�i��:manga_index52342.html��manga_ban_index2.html�Ńq�b�g�j
manga_index[0-9]+\.html�̏ꍇ��manga_ban_index[0-9]+\.html��ban_��lj���
manga_ban_index[0-9]+\.html�̏ꍇ��manga_ban_index[0-9]+\.html�Ƃ��̂܂܂ɂ������̂ł����ǂ���������̂ł��傤���H
����������"manga_index[0-9]+\.html"��"manga_ban_index[0-9]+\.html"
�i��:manga_index52342.html��manga_ban_index2.html�Ńq�b�g�j
manga_index[0-9]+\.html�̏ꍇ��manga_ban_index[0-9]+\.html��ban_��lj���
manga_ban_index[0-9]+\.html�̏ꍇ��manga_ban_index[0-9]+\.html�Ƃ��̂܂܂ɂ������̂ł����ǂ���������̂ł��傤���H
902 �Fnobody�����F2012/02/27(��) 16:13:34.47 ID:???
manga_index �� manga_ban_index �ɒu�����������Ȃ���
903 �Fnobody�����F2012/02/29(��) 06:23:11.44 ID:???
�g�p�����킸(?:foo|bar)��(foo|bar)�̈Ⴂ������܂���
�������ǂރX�N���v�g����̎Q�l���ł͓��ɒ��߂��Ȃ���foo��bar���ǂ��炩�ɓ��Ă͂܂���̂�(?:foo|bar)�Ə�����܂���
���S�Ҍ����̐��K�\���ɂ��ẴT���v���Ȃnj����(foo|bar)�������C�����܂�
�ǂ������Ⴂ�Ȃ̂ł��傤�H�����I�Ȏ���ł�����낵�����肢���܂�
�������ǂރX�N���v�g����̎Q�l���ł͓��ɒ��߂��Ȃ���foo��bar���ǂ��炩�ɓ��Ă͂܂���̂�(?:foo|bar)�Ə�����܂���
���S�Ҍ����̐��K�\���ɂ��ẴT���v���Ȃnj����(foo|bar)�������C�����܂�
�ǂ������Ⴂ�Ȃ̂ł��傤�H�����I�Ȏ���ł�����낵�����肢���܂�
904 �Fnobody�����F2012/02/29(��) 14:42:57.64 ID:???
>>903
()�ň͂ނƂ��Ƃ���\1�ȂǂŎQ�Ƃł��܂��B
(?:�j�Ƃ���Ƃ��̎Q�Ƃ�邱�Ƃ��ł��܂��B
()�ŃO���[�v���������������ǎQ�Ƃ͂��Ȃ��A�Ƃ����Ƃ��ɂ��̐ݒ������Ɩ��ʂ��Ȃ��Ȃ�܂��B
()�ň͂ނƂ��Ƃ���\1�ȂǂŎQ�Ƃł��܂��B
(?:�j�Ƃ���Ƃ��̎Q�Ƃ�邱�Ƃ��ł��܂��B
()�ŃO���[�v���������������ǎQ�Ƃ͂��Ȃ��A�Ƃ����Ƃ��ɂ��̐ݒ������Ɩ��ʂ��Ȃ��Ȃ�܂��B
905 �Fnobody�����F2012/03/01(��) 17:23:10.26 ID:???
906 �Fnobody�����F2012/03/05(��) 00:36:21.70 ID:???
php�̐��K�\���ŁA���ꕶ���A����Ȃ́�(�H�H�H�H�H)����ʂ�������ł����A�ǂ�����悢�ł��傤���B
�������肵������ł��̂ŁA�Q�l�ɂȂ�T�C�g�������Ă���������x�ł��\���܂���B
�������肵������ł��̂ŁA�Q�l�ɂȂ�T�C�g�������Ă���������x�ł��\���܂���B
�����������Ă܂��ˁB���݂܂���B
���ꕶ���Ƃ����̂́A�~���Ƃ����b�g���Ƃ��A����當���i�ǂݕ����킩��܂���B�n�[�g�Ƃ��B�j�Ŏg������̂ł��B
���ꕶ���Ƃ����̂́A�~���Ƃ����b�g���Ƃ��A����當���i�ǂݕ����킩��܂���B�n�[�g�Ƃ��B�j�Ŏg������̂ł��B
908 �Fnobody�����F2012/03/05(��) 01:55:25.02 ID:???
>>906
UTF-8��
UTF-8��
909 �Fnobody�����F2012/03/05(��) 09:22:56.91 ID:???
�S�����ׂĕ����N���X�ɂ���Ⴂ������B���K�\���ȑO�̖�肾�ȁB
910 �Fnobody�����F2012/03/10(�y) 02:43:47.72 ID:???
479 ���O�Fnobody����[] ���e���F2012/03/10(�y) 02:34:43.14 ID:/aJUja8G
������̐��K�\����
�u���l�Ɖp��� .�@�Ɓ@/�@�� hoge�@�ȊO�Ƀ}�b�`�v
�Ƃ����̂���肽���̂ł����ǂ������s���Ă��܂��܂��B�ꔭ�ł̉������@�Ƃ�����̂ł��傤���H
\D��������Ƃ܂�\W�Ń}�b�`���O�A���̌�h�b�g�Ń}�b�`���O�ƕ����������������@�����v�����Ȃ������̂ł���
������̐��K�\����
�u���l�Ɖp��� .�@�Ɓ@/�@�� hoge�@�ȊO�Ƀ}�b�`�v
�Ƃ����̂���肽���̂ł����ǂ������s���Ă��܂��܂��B�ꔭ�ł̉������@�Ƃ�����̂ł��傤���H
\D��������Ƃ܂�\W�Ń}�b�`���O�A���̌�h�b�g�Ń}�b�`���O�ƕ����������������@�����v�����Ȃ������̂ł���
911 �Fnobody�����F2012/03/10(�y) 02:56:04.76 ID:???
����Ԃ��u���l���p�ꂩ .�@���@/�@�� hoge�@�Ƀ}�b�`�v ������not�}�b�`
912 �Fnobody�����F2012/03/10(�y) 03:17:32.46 ID:???
913 �Fnobody�����F2012/03/20(��) 19:40:54.01 ID:Z+BjIxhL
java�̕\�����@��
�a������폜�A���������O���`�Ȃ�폜���Ȃ��A���a�P�̂ł��폜
�Ƃ����\�����@�͂���܂����H
^[�`]�a���ƑS�̂�2�������邱�Ƃ��O��̂悤�ɉ��߂��Ă��܂����Ԉ���Ă��܂��ł��傤���B
�a������폜�A���������O���`�Ȃ�폜���Ȃ��A���a�P�̂ł��폜
�Ƃ����\�����@�͂���܂����H
^[�`]�a���ƑS�̂�2�������邱�Ƃ��O��̂悤�ɉ��߂��Ă��܂����Ԉ���Ă��܂��ł��傤���B
914 �Fnobody�����F2012/03/20(��) 19:59:11.06 ID:???
>>913
[^A]?B����
[^A]?B����
915 �Fnobody�����F2012/03/20(��) 20:10:18.04 ID:Z+BjIxhL
>>914
�}�b�`���܂����B���肪�Ƃ��������܂��B
�}�b�`���܂����B���肪�Ƃ��������܂��B
916 �Fnobody�����F2012/03/21(��) 02:09:27.32 ID:???
[^A]
��
�����������̐l�������Ă�悤�Řa��
��
�����������̐l�������Ă�悤�Řa��
917 �Fnobody�����F2012/03/21(��) 12:29:51.49 ID:???
�����A�Ȃ�قǁB�Ǝv�������� ?�����邩��u�͂�?�v���Č����Ă�Ƃ��z�����Ă��܂�����
[^A]?
[^A]?
918 �Fnobody�����F2012/03/26(��) 23:29:49.84 ID:???
�u�����������v�̂����ꂩ��3��ȏ�A��������}�b�`���Ăǂ���������ł��傤�H
[����������]{3,}���Ɓu�������v�Ƃ��ɂ��}�b�`��������đʖڂ������B
[����������]{3,}���Ɓu�������v�Ƃ��ɂ��}�b�`��������đʖڂ������B
919 �Fnobody�����F2012/03/26(��) 23:37:31.05 ID:???
>>918
([����������])\1{2,}
([����������])\1{2,}
920 �Fnobody�����F2012/03/26(��) 23:41:15.88 ID:???
921 �Fnobody�����F2012/03/28(��) 18:04:07.49 ID:???
922 �Fnobody�����F2012/03/28(��) 18:26:58.68 ID:???
>>914����
923 �Fnobody�����F2012/03/28(��) 18:57:52.69 ID:???
924 �Fnobody�����F2012/03/28(��) 18:59:57.97 ID:???
925 �Fnobody�����F2012/03/29(��) 12:43:34.53 ID:UbmjoR9L
���e�L�X�g:
https://www.google.co.jp/search?hl=ja&safe=off&site=&source=hp&q=test&oq=test&aq=f&aqi=g10&aql=&gs_l=hp.3..0l10.1783l3806l0l4057l7l7l0l0l0l0l145l766l2j5l7l0.frgbld.
https://www.google.co.jp/search?q=test&oe=utf-8&rls=org.mozilla:ja:official&hl=ja&client=firefox-a&um=1&ie=UTF-8&tbm=isch&source=og&sa=N&tab=wi&ei=n8BzT-uaHqaimQWZweD8Bw&biw=1064&bih=964&sei=ocBzT4e7FqOimQWq3IH5Bw
https://www.google.co.jp/search?q=test&hl=ja&safe=off&prmd=imvnsz&source=lnms&tbm=nws&ei=18lzT6GLE_HTmAXK8N2CCA&sa=X&oi=mode_link&ct=mode&cd=5&ved=0CBsQ_AUoBA&biw=1064&bih=931
http://maps.google.co.jp/maps?q=test&oe=utf-8&rls=org.mozilla:ja:official&hl=ja&client=firefox-a&um=1&biw=1064&bih=964&ie=UTF-8&sa=N&tab=il
C#:
using System.Text.RegularExpressions;
text = Regex.Replace(text, @"(https?://[a-z.]+\.google\.[a-z.]+/[a-z]+\?).*?(q=[^&]*).*?(&tbm=[^&]*)?[a-zA-Z0-9-_./~*%$@:;,!?&=+#]*", "$1$2$3");
Google��URL���V���v�����������̂ł����A��L�R�[�h���Ɓu(&tbm=[^&]*)?�v�̕������E���܂���B
�Ō��?������&tbm���܂܂Ȃ��N�G���Ń}�b�`���Ȃ��Ȃ�܂��B
�ǂ������炢���ł��傤���B
https://www.google.co.jp/search?hl=ja&safe=off&site=&source=hp&q=test&oq=test&aq=f&aqi=g10&aql=&gs_l=hp.3..0l10.1783l3806l0l4057l7l7l0l0l0l0l145l766l2j5l7l0.frgbld.
https://www.google.co.jp/search?q=test&oe=utf-8&rls=org.mozilla:ja:official&hl=ja&client=firefox-a&um=1&ie=UTF-8&tbm=isch&source=og&sa=N&tab=wi&ei=n8BzT-uaHqaimQWZweD8Bw&biw=1064&bih=964&sei=ocBzT4e7FqOimQWq3IH5Bw
https://www.google.co.jp/search?q=test&hl=ja&safe=off&prmd=imvnsz&source=lnms&tbm=nws&ei=18lzT6GLE_HTmAXK8N2CCA&sa=X&oi=mode_link&ct=mode&cd=5&ved=0CBsQ_AUoBA&biw=1064&bih=931
http://maps.google.co.jp/maps?q=test&oe=utf-8&rls=org.mozilla:ja:official&hl=ja&client=firefox-a&um=1&biw=1064&bih=964&ie=UTF-8&sa=N&tab=il
C#:
using System.Text.RegularExpressions;
text = Regex.Replace(text, @"(https?://[a-z.]+\.google\.[a-z.]+/[a-z]+\?).*?(q=[^&]*).*?(&tbm=[^&]*)?[a-zA-Z0-9-_./~*%$@:;,!?&=+#]*", "$1$2$3");
Google��URL���V���v�����������̂ł����A��L�R�[�h���Ɓu(&tbm=[^&]*)?�v�̕������E���܂���B
�Ō��?������&tbm���܂܂Ȃ��N�G���Ń}�b�`���Ȃ��Ȃ�܂��B
�ǂ������炢���ł��傤���B
926 �F925�F2012/03/29(��) 19:25:30.17 ID:UbmjoR9L
>>925�̖����������A�����i�W���܂����B
text:
https://www.google.co.jp/search?hl=ja&safe=off&site=&source=hp&q=test&oq=test&aq=f&aqi=g10&aql=&gs_l=hp.3..0l10.1783l3806l0l4057l7l7l0l0l0l0l145l766l2j5l7l0.frgbld.
https://www.google.co.jp/search?q=test&oe=utf-8&rls=org.mozilla:ja:official&hl=ja&client=firefox-a&um=1&ie=UTF-8&tbm=isch&source=og&sa=N&tab=wi&ei=n8BzT-uaHqaimQWZweD8Bw&biw=1064&bih=964&sei=ocBzT4e7FqOimQWq3IH5Bw
https://www.google.co.jp/search?tbm=isch&hl=ja&source=hp&biw=1064&bih=931&q=test&gbv=2&oq=test&aq=f&aqi=g9g-r1&aql=&gs_l=img.3..0l9j0i4.2370l3015l0l3824l4l4l0l0l0l0l111l406l2j2l4l0.frgbld.
https://www.google.co.jp/search?q=test&hl=ja&safe=off&prmd=imvnsz&source=lnms&tbm=nws&ei=18lzT6GLE_HTmAXK8N2CCA&sa=X&oi=mode_link&ct=mode&cd=5&ved=0CBsQ_AUoBA&biw=1064&bih=931
http://maps.google.co.jp/maps?q=test&oe=utf-8&rls=org.mozilla:ja:official&hl=ja&client=firefox-a&um=1&biw=1064&bih=964&ie=UTF-8&sa=N&tab=il
C#:
text = Regex.Replace(text, @"(https?://[a-z.]+\.google\.[a-z.]+/[a-z]+)(?=.*[?&](q=[^&\s]*))(?=.*[?&](tbm=[^&\s]*))?[a-zA-Z0-9-_./~*%$@:;,!?&=+#]*", "$1?$2&$3");
��肽������:
google��URL�̂����A�uq=�v�Ɓutbm=�v��2��ނ̕ϐ��������o���Ďc����킬���Ƃ��B
�������Aq/tbm�̓o��͏��s���ɂ��Ή�����B
�����Ă��邱��:
�utbm=�v���Ȃ�URL�ł��A�u���̑�3�����Ɂu&$3�v��t���Ă��邽�߂Ɂu&�v�����t���Ă��܂��B
�O�����Z�q�� ("$3"=="")?"":"&$3" �Ƃ���낤�Ƃ������Ǎŏ���"$3"��W�J���Ă���Ȃ��悤�ō��܁B
1�s�lj����āA�u�Ō��&�������t���Ă����菜���v�����Ȃ��ł��傤���B
text:
https://www.google.co.jp/search?hl=ja&safe=off&site=&source=hp&q=test&oq=test&aq=f&aqi=g10&aql=&gs_l=hp.3..0l10.1783l3806l0l4057l7l7l0l0l0l0l145l766l2j5l7l0.frgbld.
https://www.google.co.jp/search?q=test&oe=utf-8&rls=org.mozilla:ja:official&hl=ja&client=firefox-a&um=1&ie=UTF-8&tbm=isch&source=og&sa=N&tab=wi&ei=n8BzT-uaHqaimQWZweD8Bw&biw=1064&bih=964&sei=ocBzT4e7FqOimQWq3IH5Bw
https://www.google.co.jp/search?tbm=isch&hl=ja&source=hp&biw=1064&bih=931&q=test&gbv=2&oq=test&aq=f&aqi=g9g-r1&aql=&gs_l=img.3..0l9j0i4.2370l3015l0l3824l4l4l0l0l0l0l111l406l2j2l4l0.frgbld.
https://www.google.co.jp/search?q=test&hl=ja&safe=off&prmd=imvnsz&source=lnms&tbm=nws&ei=18lzT6GLE_HTmAXK8N2CCA&sa=X&oi=mode_link&ct=mode&cd=5&ved=0CBsQ_AUoBA&biw=1064&bih=931
http://maps.google.co.jp/maps?q=test&oe=utf-8&rls=org.mozilla:ja:official&hl=ja&client=firefox-a&um=1&biw=1064&bih=964&ie=UTF-8&sa=N&tab=il
C#:
text = Regex.Replace(text, @"(https?://[a-z.]+\.google\.[a-z.]+/[a-z]+)(?=.*[?&](q=[^&\s]*))(?=.*[?&](tbm=[^&\s]*))?[a-zA-Z0-9-_./~*%$@:;,!?&=+#]*", "$1?$2&$3");
��肽������:
google��URL�̂����A�uq=�v�Ɓutbm=�v��2��ނ̕ϐ��������o���Ďc����킬���Ƃ��B
�������Aq/tbm�̓o��͏��s���ɂ��Ή�����B
�����Ă��邱��:
�utbm=�v���Ȃ�URL�ł��A�u���̑�3�����Ɂu&$3�v��t���Ă��邽�߂Ɂu&�v�����t���Ă��܂��B
�O�����Z�q�� ("$3"=="")?"":"&$3" �Ƃ���낤�Ƃ������Ǎŏ���"$3"��W�J���Ă���Ȃ��悤�ō��܁B
1�s�lj����āA�u�Ō��&�������t���Ă����菜���v�����Ȃ��ł��傤���B
927 �Fnobody�����F2012/03/29(��) 20:25:45.43 ID:???
�Ȃ�ς������Ȃ��B
���Ȃ�?�ŕ������āA2�ɂȂ�����2�ڂ�&�ŕ������āAq=��tbm=�����o���ďI����
���Ȃ�?�ŕ������āA2�ɂȂ�����2�ڂ�&�ŕ������āAq=��tbm=�����o���ďI����
928 �Fnobody�����F2012/03/30(��) 00:45:36.69 ID:???
�f���Ƀ��C�u�����g���������B
see HttpUtility.ParseQueryString()
see HttpUtility.ParseQueryString()
929 �F925�F2012/03/30(��) 13:55:15.20 ID:Wpf4JXLP
>>927-928�̌����Ƃ���Ƃ����C�����Ă��܂������A�ǂ�����肭�������̂ł����܂��B
C#:
text = Regex.Replace(text, @"(https?://[a-z.]+\.google\.[a-z.]+/[a-z]+)(?(?=\?tbm=)(\?(tbm=[^&\s]*).*?(&q=[^&\s]*))|((?=.*?[?&](q=[^&\s]*))(?=.*?(&tbm=[^&\s]*))?))[a-zA-Z0-9-_./~*%$@:;,!?&=+#]*", "$1?$2$3$5$6");
�L���v�`�����ʂł͂Ȃ����K�\���̂ق��ɏ����������Ăǂ��ɂ��ł��܂����B
���������������G�ɂȂ�Ə��������ǂ�ǂ�ώG�ɂȂ�̂Ŋg�����͂Ȃ���������܂���B
���ƁA�ǂ�������������������������$4��$7���L���v�`��(�����Ƃ���ɋ�)���Ă���悤�ł����A
������(?:�𑫂��Ɠ���q�̃J�b�R�����S���L���v�`������Ȃ��Ȃ��Ă��܂����̂ŁA�Ƃ肠�������̂܂܁B
C#:
text = Regex.Replace(text, @"(https?://[a-z.]+\.google\.[a-z.]+/[a-z]+)(?(?=\?tbm=)(\?(tbm=[^&\s]*).*?(&q=[^&\s]*))|((?=.*?[?&](q=[^&\s]*))(?=.*?(&tbm=[^&\s]*))?))[a-zA-Z0-9-_./~*%$@:;,!?&=+#]*", "$1?$2$3$5$6");
�L���v�`�����ʂł͂Ȃ����K�\���̂ق��ɏ����������Ăǂ��ɂ��ł��܂����B
���������������G�ɂȂ�Ə��������ǂ�ǂ�ώG�ɂȂ�̂Ŋg�����͂Ȃ���������܂���B
���ƁA�ǂ�������������������������$4��$7���L���v�`��(�����Ƃ���ɋ�)���Ă���悤�ł����A
������(?:�𑫂��Ɠ���q�̃J�b�R�����S���L���v�`������Ȃ��Ȃ��Ă��܂����̂ŁA�Ƃ肠�������̂܂܁B
930 �Fnobody�����F2012/03/30(��) 17:40:03.01 ID:???
���K�\���ł����Ȃ�����߂ȗ��R������ɈႢ�Ȃ��Ƃ����ƕ��u�����R�[�h�Ђ����܂��ɐ��܂ꂽ�̂ł���B
931 �Fnobody�����F2012/04/12(��) 15:38:18.00 ID:nr7fN3uJ
�l�̏��������[���}�K�W���X�^���h������Ă���̂ł���
�G�ۃG�f�B�^�̐��K�\���𗘗p���ċA���Ă����G���[���[�����X�g����
�A�h���X�������o�������̂ł����ǂ���������ł��傤���H
��̓I�ɂ�
---------------------------
���[���w�b�_�[
<[email protected]>
---------------------------
�Ƃ����e�L�X�g��������
<[email protected]>�̕�����
[email protected]�݂̂����o�������Ǝv���Ă��܂�
��낵�����肢�v���܂�
�G�ۃG�f�B�^�̐��K�\���𗘗p���ċA���Ă����G���[���[�����X�g����
�A�h���X�������o�������̂ł����ǂ���������ł��傤���H
��̓I�ɂ�
---------------------------
���[���w�b�_�[
<[email protected]>
---------------------------
�Ƃ����e�L�X�g��������
<[email protected]>�̕�����
[email protected]�݂̂����o�������Ǝv���Ă��܂�
��낵�����肢�v���܂�
932 �Fnobody�����F2012/04/13(��) 14:15:11.85 ID:???
933 �Fnobody�����F2012/04/16(��) 12:27:42.62 ID:???
>>931
�G�ۂ̐��K�\���X�^�C������Ȃ����ǁA
�G�f�B�^�̌������œ���̏ꏊ���������o�����Č��\��ς���B
�������Aperl�Aphp�Ajavascript�ŏ����������ǂ��Ǝv��
�G�ۂ̐��K�\���X�^�C������Ȃ����ǁA
�G�f�B�^�̌������œ���̏ꏊ���������o�����Č��\��ς���B
�������Aperl�Aphp�Ajavascript�ŏ����������ǂ��Ǝv��
934 �F�[�b�P���V�V�S�����X�g�R�[���F2012/05/09(��) 21:57:54.68 ID:BzXqVbz5
�s��
935 �Fnobody�����F2012/05/10(��) 11:31:59.11 ID:uA0oypVx
����ł��Bjava���g�p���Ă��܂��B
(?:[\(�i][��-�]+[\)�j]*)
�Ƃ������K�\���������ہA���ʓ��ɂЂ炪�Ȃ��܂܂�Ă��܂��̂ł����A
�܂܂�Ȃ������̂݊��ʓ��ɑ��݂���\�����@�������Ă��������Ȃ��ł��傤���B
���肢���܂��B
(?:[\(�i][��-�]+[\)�j]*)
�Ƃ������K�\���������ہA���ʓ��ɂЂ炪�Ȃ��܂܂�Ă��܂��̂ł����A
�܂܂�Ȃ������̂݊��ʓ��ɑ��݂���\�����@�������Ă��������Ȃ��ł��傤���B
���肢���܂��B
936 �Fnobody�����F2012/05/12(�y) 18:10:34.44 ID:???
[\(�i](?!.*[��-��@-���-�0-9a-zA-Z��-���`-�y�O-�X])�͂ǂ����낤�B
�������A�u�i�j�������v�Ƃ����߂���Ȃ��B
�������A�u�i�j�������v�Ƃ����߂���Ȃ��B
937 �Fnobody�����F2012/05/13(��) 01:45:46.19 ID:???
�U������ė�����ł����ǁA
����ȃX���������̂ˁB
����ȃX���������̂ˁB
938 �Fnobody�����F2012/05/14(��) 16:10:42.62 ID:???
939 �Fnobody�����F2012/05/15(��) 00:03:15.70 ID:???
���K�\���ł悭�������遫�̃R�[�h�̂���
[L]�@���Ăǂ������Ӗ��Ȃ�ł��傤���H
RewriteRule (.*) app/webroot/$1 [L]
[L]�@���Ăǂ������Ӗ��Ȃ�ł��傤���H
RewriteRule (.*) app/webroot/$1 [L]
940 �Fnobody�����F2012/05/15(��) 09:36:17.08 ID:CSpkYc1K
941 �Fnobody�����F2012/05/27(��) 23:18:00.45 ID:HwDNoFBJ
linux��grep��green�Ƃ��P��������������̂ł����A�ǂ��������K�\�����g���悢�̂ł��傤��
942 �Fnobody�����F2012/05/28(��) 12:18:36.34 ID:???
�ނ�ł����H
943 �Fnobody�����F2012/05/29(��) 22:34:21.81 ID:???
>>941
grep *green*
grep *green*
944 �Fnobody�����F2012/05/30(��) 19:02:44.43 ID:???
����̘A�����邗�����O���A�P�̂̂����}�b�`���������̂ł�����肭�����܂���B
[��|w|�v]$(?![��|w|�v])
�ł͕������K���}�b�`���Ă��܂��܂��B
���ꕶ���͖����Ȃ̂ł��傤���B
[��|w|�v]$(?![��|w|�v])
�ł͕������K���}�b�`���Ă��܂��܂��B
���ꕶ���͖����Ȃ̂ł��傤���B
945 �Fnobody�����F2012/05/30(��) 21:52:23.72 ID:???
(?<![W|w|�v|��])[W|w|�v|��](?![W|w|�v|��])
946 �Fnobody�����F2012/06/01(��) 06:28:07.98 ID:???
�P�ł��łт����I���肪�Ƃ��������܂����B
947 �Fnobody�����F2012/06/01(��) 11:21:23.01 ID:5OXqp69a
www.�Ƃ��ǂ������
948 �Fnobody�����F2012/06/02(�y) 14:54:43.21 ID:???
http://hoge.example/w/ �͂ǂ�����H
949 �Fnobody�����F2012/06/02(�y) 19:04:48.56 ID:???
$
950 �Fnobody�����F2012/06/03(��) 15:01:25.61 ID:+b3NOtvy
>>944-945
�����N���X��[]���ŁA|���g���Ă�or�����̈Ӗ��ɂ͂Ȃ炸��
|�Ƃ��������ɂ��}�b�`���鐳�K�\���ɂȂ��Ă��܂��Ǝv������
�����N���X��[]���ŁA|���g���Ă�or�����̈Ӗ��ɂ͂Ȃ炸��
|�Ƃ��������ɂ��}�b�`���鐳�K�\���ɂȂ��Ă��܂��Ǝv������
951 �Fnobody�����F2012/06/05(��) 13:25:40.03 ID:???
>>950
���܂܂ŒN���˂����܂Ȃ������̂��ʔ������
���܂܂ŒN���˂����܂Ȃ������̂��ʔ������
952 �Fnobody�����F2012/06/05(��) 17:29:38.47 ID:???
java�����悤���Ă��܂��B
����̘A������3�̕����̂Ȃ��肪2��ȏ�A
�������������������A��
�������������������������A�ȂǂɃ}�b�`���鐳�K�\���������Ă��������B
��낵�����肢���܂��B
����̘A������3�̕����̂Ȃ��肪2��ȏ�A
�������������������A��
�������������������������A�ȂǂɃ}�b�`���鐳�K�\���������Ă��������B
��낵�����肢���܂��B
953 �Fnobody�����F2012/06/05(��) 19:13:00.94 ID:???
((.)\2\2){2,}�@
�łǂ��H
�łǂ��H
954 �Fnobody�����F2012/06/05(��) 19:33:19.22 ID:???
955 �Fnobody�����F2012/06/06(��) 08:57:42.95 ID:???
>>953
�X�T�S�ł��B
>>953�������ƁA���6�����ȏ�ɂȂ��3�̔{�����ƂɂƂ�����}�b�`
���Ă��܂��̂ł����A���������邱�Ƃ��ł��܂��ł��傤���B
���т��т����f�����Ă����܂���B
��낵�����肢���܂��B
�X�T�S�ł��B
>>953�������ƁA���6�����ȏ�ɂȂ��3�̔{�����ƂɂƂ�����}�b�`
���Ă��܂��̂ł����A���������邱�Ƃ��ł��܂��ł��傤���B
���т��т����f�����Ă����܂���B
��낵�����肢���܂��B
956 �Fnobody�����F2012/06/06(��) 11:01:47.54 ID:???
((.)\2\2(?!\2)){2,}
���߂Ă�����������Ă�̂�������Ȃ�����
���߂Ă�����������Ă�̂�������Ȃ�����
957 �Fnobody�����F2012/06/06(��) 15:54:28.31 ID:???
>>956
���߂Ă��邻�̂��̂ł����B�{���ɂ��肪�Ƃ��������܂����I
���߂Ă��邻�̂��̂ł����B�{���ɂ��肪�Ƃ��������܂����I
958 �Fnobody�����F2012/06/07(��) 23:23:40.40 ID:???
../../../../aaa
../../aaa
../////bbb
/asdaii/daia/aaaa
�̏ꍇ�Ɉ�ԉE��/���獶�������o����悤�ɂ���ɂ͂ǂ���������ł����H
../../../../
../../
../////
/asdaii/daia/
../../aaa
../////bbb
/asdaii/daia/aaaa
�̏ꍇ�Ɉ�ԉE��/���獶�������o����悤�ɂ���ɂ͂ǂ���������ł����H
../../../../
../../
../////
/asdaii/daia/
959 �Fnobody�����F2012/06/07(��) 23:56:12.45 ID:WHczB1bW
(.*\/)[^\/]*$
960 �Fnobody�����F2012/06/08(��) 10:21:58.59 ID:???
�P���Ɂ@.*/�@�@ �i ���ɂ���Ắ@�@.*\/�@�@�j
����ʖڂȂ́H
����ʖڂȂ́H
961 �F959�F2012/06/08(��) 11:55:23.48 ID:+g+yLQod
����ȋC�����Ă�������������
962 �Fnobody�����F2012/07/10(��) 01:04:31.08 ID:???
���@���@���@���@���@���@���@���@���@���@���@���@���@���@���@���@��
�f�l�n�C���^�[�l�b�g�@�悵���� �������@�@�܂��ł�������ł����ǁB
���@���@���@���@���@���@���@���@���@���@���@���@���@���@���@���@��
�f�l�n�C���^�[�l�b�g�@�悵���� �������@�@�܂��ł�������ł����ǁB
���@���@���@���@���@���@���@���@���@���@���@���@���@���@���@���@��
�f�l�n�C���^�[�l�b�g�@�悵���� �������@�@�܂��ł�������ł����ǁB
���@���@���@���@���@���@���@���@���@���@���@���@���@���@���@���@��
�f�l�n�C���^�[�l�b�g�@�悵���� �������@�@�܂��ł�������ł����ǁB
���@���@���@���@���@���@���@���@���@���@���@���@���@���@���@���@��
�f�l�n�C���^�[�l�b�g�@�悵���� �������@�@�܂��ł�������ł����ǁB
���@���@���@���@���@���@���@���@���@���@���@���@���@���@���@���@��
�f�l�n�C���^�[�l�b�g�@�悵���� �������@�@�܂��ł�������ł����ǁB
���@���@���@���@���@���@���@���@���@���@���@���@���@���@���@���@��
�f�l�n�C���^�[�l�b�g�@�悵���� �������@�@�܂��ł�������ł����ǁB
���@���@���@���@���@���@���@���@���@���@���@���@���@���@���@���@��
�f�l�n�C���^�[�l�b�g�@�悵���� �������@�@�܂��ł�������ł����ǁB
���@���@���@���@���@���@���@���@���@���@���@���@���@���@���@���@��
963 �Fnobody�����F2012/07/19(��) 13:22:33.53 ID:???
>>943
grep -e "*+green+*"
grep -e "*+green+*"
964 �Fnobody�����F2012/07/25(��) 19:18:05.52 ID:???
�@
965 �Fnobody�����F2012/07/28(�y) 09:37:57.75 ID:???
tes
966 �Fnobody�����F2012/07/30(��) 10:55:07.56 ID:???
PHP��preg_match��replace��
ABCDE���Ă���������FGHIJ���Ă��������ŏ��ɂ����āA
���ɐ���������������ł���Ƃ������K�\���͂ǂ����������ł��傤���H
or�́@| �ł���킷�Ǝv�����̂ł���������ɂȂ�Ƃǂ����������̂��킩��Ȃ������̂ŁB�B
��낵�����肢�v���܂��B
ABCDE���Ă���������FGHIJ���Ă��������ŏ��ɂ����āA
���ɐ���������������ł���Ƃ������K�\���͂ǂ����������ł��傤���H
or�́@| �ł���킷�Ǝv�����̂ł���������ɂȂ�Ƃǂ����������̂��킩��Ȃ������̂ŁB�B
��낵�����肢�v���܂��B
967 �Fnobody�����F2012/07/30(��) 13:41:05.40 ID:???
>>966
'/\A(ABCDE|FGHIJ)\d+/'
'/\A(ABCDE|FGHIJ)\d+/'
968 �Fnobody�����F2012/07/30(��) 13:44:19.19 ID:???
>>967
���肪�Ƃ��������܂��B
\A���Ăǂ������Ӗ��������ł��傤�H
�����()���ăL���v�`�����鎞�ɂ����g��Ȃ��Ǝv������ł������ɈӖ��������ł����H
���肪�Ƃ��������܂��B
\A���Ăǂ������Ӗ��������ł��傤�H
�����()���ăL���v�`�����鎞�ɂ����g��Ȃ��Ǝv������ł������ɈӖ��������ł����H
969 �Fnobody�����F2012/07/31(��) 17:44:18.81 ID:???
>>968
>>5�ɐ��K�\���֘A�̃T�C�g�ւ̃����N�������B
\A ������擪�ʒu�Ƀ}�b�`
^ �s���Ƀ}�b�`
���s�C���qm���g���ĂȂ��Ƃ��͓����Ӗ������ǁA���s�}�b�`�ł͈Ⴄ�B
���s�}�b�`�ł̉��s�����^�̓}�b�`���邯�ǁA\A�̓}�b�`���Ȃ��B
�ŁA�h�q�I�ɕ�����擪�Ƃ����Ӗ��̎���\A�̕����D�܂����B
�J�b�R�ɂ��Ă͂��̒ʂ�ŁA�L���v�`������Ƃ����@�\��������ǁA
�����ЂƂO���[�v���Ƃ����@�\������B�Ⴆ�A(AB)+�Ƃ��B�����
AB�AABAB�AABABAB�A�c�Ƀ}�b�`����B�����A�L���v�`���ۑ��̕��I�[�o�[
�w�b�h�Ƃ��������g�p�ʂ������Ȃ�Ƃ������ʂŖ�肠��̂����B
���̏ꍇ�A�O���[�v�������̋@�\������(?:�`)���g����B�Ȃ̂ŁA>>967�́A
\A(?:ABCDE|FGHIJ)\d+
�̕����ǂ��̂����B
>>5�ɐ��K�\���֘A�̃T�C�g�ւ̃����N�������B
\A ������擪�ʒu�Ƀ}�b�`
^ �s���Ƀ}�b�`
���s�C���qm���g���ĂȂ��Ƃ��͓����Ӗ������ǁA���s�}�b�`�ł͈Ⴄ�B
���s�}�b�`�ł̉��s�����^�̓}�b�`���邯�ǁA\A�̓}�b�`���Ȃ��B
�ŁA�h�q�I�ɕ�����擪�Ƃ����Ӗ��̎���\A�̕����D�܂����B
�J�b�R�ɂ��Ă͂��̒ʂ�ŁA�L���v�`������Ƃ����@�\��������ǁA
�����ЂƂO���[�v���Ƃ����@�\������B�Ⴆ�A(AB)+�Ƃ��B�����
AB�AABAB�AABABAB�A�c�Ƀ}�b�`����B�����A�L���v�`���ۑ��̕��I�[�o�[
�w�b�h�Ƃ��������g�p�ʂ������Ȃ�Ƃ������ʂŖ�肠��̂����B
���̏ꍇ�A�O���[�v�������̋@�\������(?:�`)���g����B�Ȃ̂ŁA>>967�́A
\A(?:ABCDE|FGHIJ)\d+
�̕����ǂ��̂����B
970 �Fnobody�����F2012/07/31(��) 17:50:50.74 ID:???
971 �Fnobody�����F2012/08/01(��) 23:55:05.65 ID:7jlH6jTD
���݂܂���APHP�X������U������Ă��܂���
PHP Version 5.3.14���g���Ă��܂�
preg_match(���K�\��, $text)��$text���S�p�����܂��͔��p�p�����ō\������Ă��邱�Ƃ�
�`�F�b�N�������̂ł����A�ǂ�������ǂ��ł��傤��
�L���͈�ؔr���������Ǝv���Ă��܂�
��낵�����肢���܂�
�i�ȑO����Ă������@�@preg_match('/^w+$/u', $text)������Ƃ�����S�p�������G���[�ŕԂ��悤�ɂȂ��Ă��܂�
�Ή��ł��Ȃ��Ȃ��Ă��܂��܂����j
PHP Version 5.3.14���g���Ă��܂�
preg_match(���K�\��, $text)��$text���S�p�����܂��͔��p�p�����ō\������Ă��邱�Ƃ�
�`�F�b�N�������̂ł����A�ǂ�������ǂ��ł��傤��
�L���͈�ؔr���������Ǝv���Ă��܂�
��낵�����肢���܂�
�i�ȑO����Ă������@�@preg_match('/^w+$/u', $text)������Ƃ�����S�p�������G���[�ŕԂ��悤�ɂȂ��Ă��܂�
�Ή��ł��Ȃ��Ȃ��Ă��܂��܂����j
972 �Fnobody�����F2012/08/02(��) 01:19:42.46 ID:???
>>971
�ȑO����Ă������@���āA
/^w+$/u
����Ȃ���
/^\w+$/u
����ȁH
���鎞����G�X�P�[�v�V�[�P���X��Unicode�v���p�e�B������悤�Ɏd�l�ύX�����͂��B
�����php�����p���Ă���PCRE�������Ȃ������炾�����Ǝv���B
�S�p�������Ă̂͂Ђ炪�ȁE�J�^�J�i�E�������Ă��Ƃ�OK����ȁH
�Ȃ炱��ł��܂��s���͂��B
/^[0-9a-zA-Z\x{3040}-\x{309F}\x{30A0}-\x{30FF}\x{4E00}-\x{9FFF}]+$/u
�ȑO����Ă������@���āA
/^w+$/u
����Ȃ���
/^\w+$/u
����ȁH
���鎞����G�X�P�[�v�V�[�P���X��Unicode�v���p�e�B������悤�Ɏd�l�ύX�����͂��B
�����php�����p���Ă���PCRE�������Ȃ������炾�����Ǝv���B
�S�p�������Ă̂͂Ђ炪�ȁE�J�^�J�i�E�������Ă��Ƃ�OK����ȁH
�Ȃ炱��ł��܂��s���͂��B
/^[0-9a-zA-Z\x{3040}-\x{309F}\x{30A0}-\x{30FF}\x{4E00}-\x{9FFF}]+$/u
973 �Fnobody�����F2012/08/02(��) 08:26:03.28 ID:???
>>972
���܂������܂����I
�O�̂������_���ɂȂ������R�̉���܂ł��Ă��������Ă��肪�Ƃ��������܂�
�}�ɂ���Ȏd�l���ύX�����Ȃ�ċ��낵����ł����A�����Ă����������悤��
���J�ɍ�������������݂����ł���
���肪�Ƃ��������܂���
���܂������܂����I
�O�̂������_���ɂȂ������R�̉���܂ł��Ă��������Ă��肪�Ƃ��������܂�
�}�ɂ���Ȏd�l���ύX�����Ȃ�ċ��낵����ł����A�����Ă����������悤��
���J�ɍ�������������݂����ł���
���肪�Ƃ��������܂���
974 �Fnobody�����F2012/08/11(�y) 14:03:27.69 ID:???
t
975 �Fnobody�����F2012/08/23(��) 12:27:54.97 ID:???
age
976 �F �E�@���yLv=2,xxxP�z(1+0�F8) �F2012/09/05(��) 09:36:06.11 ID:???
test
977 �Fnobody�����F2012/09/07(��) 03:22:20.21 ID:???
���K�\���ł�邱�Ƃ���߂�̂�
�ǂ��������肪�o�����ł����H
�P�D���K�\���ł͕s�\
��E�E�E����
�Q�D���K�\���Ŋ撣����邪�A���G�ɂȂ邩����Ȃ��B
��E�E�E����
�P�C�Q�̗�̕����������ĉ������B
�ǂ��������肪�o�����ł����H
�P�D���K�\���ł͕s�\
��E�E�E����
�Q�D���K�\���Ŋ撣����邪�A���G�ɂȂ邩����Ȃ��B
��E�E�E����
�P�C�Q�̗�̕����������ĉ������B
978 �Fnobody�����F2012/09/07(��) 10:01:53.39 ID:???
�s�\���ǂ����͐��w�I�ɂ킩���Ă�̂ł����ƕ����Ă��������B
�ł���͂������Ǖ��G��������Ȃ��̂͏����ɔے肪����Ƃ��B
���ۂɂ͉������ł��g�����Ƃ��Ă���ꍇ�͒��߂���Č������́A
�g���ĊȒP�ɂł������ȂƂ��Ɏg�����Ċ������Ȃ��B
�ł���͂������Ǖ��G��������Ȃ��̂͏����ɔے肪����Ƃ��B
���ۂɂ͉������ł��g�����Ƃ��Ă���ꍇ�͒��߂���Č������́A
�g���ĊȒP�ɂł������ȂƂ��Ɏg�����Ċ������Ȃ��B
979 �F �E�@���yLv=3,xxxP�z(1+0�F8) �F2012/09/14(��) 10:37:26.72 ID:???
!ninja
980 �Fnobody�����F2012/09/18(��) 03:34:48.70 ID:8HJfmbgZ
���낻�뎟�X���H
981 �Fnobody�����F