AMD�̎�����APU/CPU/SoC�ɂ��Č�낤 206����©2ch.net
�_.�Q�@ | �r�炵�E����E�~�[�͕��u����ԁB
�^|�Q|�@| �ނ�ꂸ�ɃX���[���܂��傤�B
|�Q�^�_! sage�i�s�Ń}�^�[�������܂���
�r�炵��W�Ȃ��R�s�y�Ȑl��NG�ɓ���Ė������܂��傤�B
�����AMD�n�X���b�h�ߋ����O�ۑ��T�C�g
http://amd.jisakuita.net/
�O�X��
AMD�̎�����APU/CPU/SoC�ɂ��Č�낤 205����(c)2ch.net
http://anago.2ch.net/test/read.cgi/jisaku/1418944493/
�^|�Q|�@| �ނ�ꂸ�ɃX���[���܂��傤�B
|�Q�^�_! sage�i�s�Ń}�^�[�������܂���
�r�炵��W�Ȃ��R�s�y�Ȑl��NG�ɓ���Ė������܂��傤�B
�����AMD�n�X���b�h�ߋ����O�ۑ��T�C�g
http://amd.jisakuita.net/
�O�X��
AMD�̎�����APU/CPU/SoC�ɂ��Č�낤 205����(c)2ch.net
http://anago.2ch.net/test/read.cgi/jisaku/1418944493/
|
|
|
�Q
�� 2014�N �����̔��ド���L���O
http://eetimes.jp/ee/articles/1412/25/news147.html
��AMD�A2014�N�x��4���h���̐Ԏ�
http://pc.watch.impress.co.jp/docs/news/20150121_684660.html
AMD�̏��ʃ_�P���}�~���ЂƂ蕉���_(^o^)�^
http://eetimes.jp/ee/articles/1412/25/news147.html
��AMD�A2014�N�x��4���h���̐Ԏ�
http://pc.watch.impress.co.jp/docs/news/20150121_684660.html
AMD�̏��ʃ_�P���}�~���ЂƂ蕉���_(^o^)�^
4 �FSocket774�F2015/01/30(��) 19:19:30.53 ID:MAc8n8mn
���̃X���ł̎���͋֎~�Ƃ��܂��B
����֎~�Ƃ���ꂽ�����玿��i�Ƃ������^��j
���邳��̎��s���j�b�g�̋��L���Ƃ����͎̂�������Ǝv���H
Pile�@���@steam �Ńf�R�[�_�[�𑽏d�������Ȃ��玟�́A����ɏ㗬�̃������A�N�Z�X������܂ŕ����i�o�b�N�G���h�����łɁj�A
���\�𑩔����Ă��鑽�d�����ꂽ���s���j�b�g�͈�ɗZ���ɂ���SMT���s�B
����Ȃ琫�\�͏グ�_�C�ʐς���ꂻ�������ǎ������������ȁH
���邳��̎��s���j�b�g�̋��L���Ƃ����͎̂�������Ǝv���H
Pile�@���@steam �Ńf�R�[�_�[�𑽏d�������Ȃ��玟�́A����ɏ㗬�̃������A�N�Z�X������܂ŕ����i�o�b�N�G���h�����łɁj�A
���\�𑩔����Ă��鑽�d�����ꂽ���s���j�b�g�͈�ɗZ���ɂ���SMT���s�B
����Ȃ琫�\�͏グ�_�C�ʐς���ꂻ�������ǎ������������ȁH
6 �FSocket774�F2015/01/30(��) 23:39:58.65 ID:UW0v4kdb
>>5
�x���ŗ��ĉ������������̂��������ς�킩��Ȃ��B
�x���ŗ��ĉ������������̂��������ς�킩��Ȃ��B
>>4
�����͉����X������Ȃ���
�����͉����X������Ȃ���
�����R�A�Ԃł̎��s���j�b�g�̋��L���͎�������i�ł���́j���ǂ���
http://www.ne.jp/asahi/comp/tarusan/main136.htm
http://www.ne.jp/asahi/comp/tarusan/main214.htm
�߂�ǂ����������̂Ń^�C�g���͗�
http://www.ne.jp/asahi/comp/tarusan/main136.htm
http://www.ne.jp/asahi/comp/tarusan/main214.htm
�߂�ǂ����������̂Ń^�C�g���͗�
9 �FSocket774�F2015/01/31(�y) 01:21:29.86 ID:tvpN2wze
>>8
�w�y�����Q�{�g���Č��e�̎��M���x���グ��x���x���̎����������肻�����ˁB
�u�R�A�����ōs���Ă������lj����j�b�g�����A�I�[�o�[�w�b�h�����ŃR�A�O���ōs�����v�ƌ����Ă�悤�ɂ��������Ȃ��B
�w�y�����Q�{�g���Č��e�̎��M���x���グ��x���x���̎����������肻�����ˁB
�u�R�A�����ōs���Ă������lj����j�b�g�����A�I�[�o�[�w�b�h�����ŃR�A�O���ōs�����v�ƌ����Ă�悤�ɂ��������Ȃ��B
>>5
�����s���j�b�g�̋��L���Ƃ����͎̂�������Ǝv���H
�Ƃ����ɂ��Ă邾��
�����d��
�ςȌ��t����
���㗬�̃������A�N�Z�X
�������A�N�Z�X����͖̂��߂̃L���b�V�����g�����Ď��̂������Ă��邩
����Ƃ��f�[�^�L���b�V���~�X���ĕʂ̂�����������ǂݍ��ޏꍇ�܂艺����
�������i�o�b�N�G���h�����łɁj
�����炾��
�����d�����ꂽ���s���j�b�g�͈�ɗZ���ɂ���
���ɑ������d�Ȃ��i�Z���j�����̂��V���ɗZ���H�ǂ��������t�̒�`��
�����s���j�b�g�̋��L���Ƃ����͎̂�������Ǝv���H
�Ƃ����ɂ��Ă邾��
�����d��
�ςȌ��t����
���㗬�̃������A�N�Z�X
�������A�N�Z�X����͖̂��߂̃L���b�V�����g�����Ď��̂������Ă��邩
����Ƃ��f�[�^�L���b�V���~�X���ĕʂ̂�����������ǂݍ��ޏꍇ�܂艺����
�������i�o�b�N�G���h�����łɁj
�����炾��
�����d�����ꂽ���s���j�b�g�͈�ɗZ���ɂ���
���ɑ������d�Ȃ��i�Z���j�����̂��V���ɗZ���H�ǂ��������t�̒�`��
11 �FSocket774�F2015/01/31(�y) 12:37:02.46 ID:rYBr6N7Y
2000�N �f���A���R�APOWER4
��
2005�N�̓f���A���R�A���N�I���E���f���A���R�AAthlon64 X2�I
2003�N �N�A�b�h�R�APOWER5�A1�R�A2�X���b�hSMT
��
2007�N�A���ɃN�A�b�h�R�ACPU���o��IPhenom X4�I
2010�N2�� TurboCore���[�h�������POWER7�A1�R�A������4�X���b�hSMT
��
���N Turbo CORE��������Phenom II X6
2007�N �I�[�o�[5GHz POWER6
��
2013�N ���E����5GHz�AFX-9590�I(��i4.7GHz)
2014�N 12�R�A96�X���b�hSMT�APOWER8
��
2016�N(AMD����) ���E���ISMT����CPU�I�Ȃ�ƁI1�R�A������2�X���b�h�������Ă��܂��I���ꂩ���SMT�̎���IIntel�����ǂ��Ă��邩�ȁH
��
2005�N�̓f���A���R�A���N�I���E���f���A���R�AAthlon64 X2�I
2003�N �N�A�b�h�R�APOWER5�A1�R�A2�X���b�hSMT
��
2007�N�A���ɃN�A�b�h�R�ACPU���o��IPhenom X4�I
2010�N2�� TurboCore���[�h�������POWER7�A1�R�A������4�X���b�hSMT
��
���N Turbo CORE��������Phenom II X6
2007�N �I�[�o�[5GHz POWER6
��
2013�N ���E����5GHz�AFX-9590�I(��i4.7GHz)
2014�N 12�R�A96�X���b�hSMT�APOWER8
��
2016�N(AMD����) ���E���ISMT����CPU�I�Ȃ�ƁI1�R�A������2�X���b�h�������Ă��܂��I���ꂩ���SMT�̎���IIntel�����ǂ��Ă��邩�ȁH
12 �F,,�E�L�́M�E,,�j��-�������F2015/01/31(�y) 16:26:33.56 ID:e7zb0iU3
1�X���b�h�Ŏg����Ȃ����\�[�X��1�R�A�ɏW�ĕ����X���b�h�ŋ��L����Ƃ����A�v���[�`�Ȃ�
POWER8��Poulson��SMT�����ɂ���Ă邾�낤
�R�A���܂����ŋ��L���Ă̂͋������Ƃ������ASun����������AMD�����Ǔ���������B
POWER8��Poulson��SMT�����ɂ���Ă邾�낤
�R�A���܂����ŋ��L���Ă̂͋������Ƃ������ASun����������AMD�����Ǔ���������B
13 �F,,�E�L�́M�E,,�j��-�������F2015/01/31(�y) 17:03:14.42 ID:e7zb0iU3
�N���X�^�[�h���R�A�ۋ�������AMD�ɕs���Ȃ�Ă̂͌ォ��̘b��
�������������������Ԃ��������̂�AMD�������킯�ł����ǁB
AMD��CPU��1�m�[�h�ő�8CPU�ɏ�������܂��ĂāAMCM�ŕ����_�C��1�ɂ܂Ƃ߂�A
�܂Ƃ߂��������ő�\�P�b�g��������B
�ő�8�\�P�b�g�܂őΉ����Ă��̂�Magny-Cours��4�\�P�b�g�ɂȂ����̂��������������B
AMD���킭�A�\�t�g�̑����̓\�P�b�g�P�ʂ̉ۋ��Ȃ̂ŁA�\�t�g�ɂ�����R�X�g�����ɂł���A�ƁB
�����AMD�݂̂̓s���ł����āA�\�P�b�g�P�ʂ�SQL Server�Ȃǂ̃��C�Z���X���Ă�
MS�͑匃�{�ł���B�����Ŏ�v�\�t�g�x���_�[�̓R�A���ɂ��]�ʉۋ��ɂ������ĕύX�B
�ᐫ�\�R�A�����̃A�v���[�`�͋t���ɂȂ�܂����Ƃ��B
�������������������Ԃ��������̂�AMD�������킯�ł����ǁB
AMD��CPU��1�m�[�h�ő�8CPU�ɏ�������܂��ĂāAMCM�ŕ����_�C��1�ɂ܂Ƃ߂�A
�܂Ƃ߂��������ő�\�P�b�g��������B
�ő�8�\�P�b�g�܂őΉ����Ă��̂�Magny-Cours��4�\�P�b�g�ɂȂ����̂��������������B
AMD���킭�A�\�t�g�̑����̓\�P�b�g�P�ʂ̉ۋ��Ȃ̂ŁA�\�t�g�ɂ�����R�X�g�����ɂł���A�ƁB
�����AMD�݂̂̓s���ł����āA�\�P�b�g�P�ʂ�SQL Server�Ȃǂ̃��C�Z���X���Ă�
MS�͑匃�{�ł���B�����Ŏ�v�\�t�g�x���_�[�̓R�A���ɂ��]�ʉۋ��ɂ������ĕύX�B
�ᐫ�\�R�A�����̃A�v���[�`�͋t���ɂȂ�܂����Ƃ��B
14 �F,,�E�L�́M�E,,�j��-�������F2015/01/31(�y) 17:22:05.09 ID:e7zb0iU3
�u������HyperThreading������2�R�A���Ǝ咣���Ă邩�炻�̂Ƃ���̃R�A���ʼnۋ����Ă�낤���v
MS��Oracle�AIBM�Ȃǂ̎�vDB�x���_�[�́ASandy Bridge Xeon��8�R�A16�X���b�h�ɑR�ł��邩
�ǂ����̃��x���̎���16�R�A��2�{�̃��C�Z���X����������悤�ɂ����B
�T�[�o�ł���͒v���I�ŁA���̎��_��Opteron�̒������m�肵���킯�ł��B
MS��Oracle�AIBM�Ȃǂ̎�vDB�x���_�[�́ASandy Bridge Xeon��8�R�A16�X���b�h�ɑR�ł��邩
�ǂ����̃��x���̎���16�R�A��2�{�̃��C�Z���X����������悤�ɂ����B
�T�[�o�ł���͒v���I�ŁA���̎��_��Opteron�̒������m�肵���킯�ł��B
MCM�Ȃ�Dempsy��Kentsfield����ɑ��݂��Ă�����
�R�A�ۋ��ɂȂ����̂�AMD�̏��ׂƂ������Ȃ��̂ł́H
�R�A�ۋ��ɂȂ����̂�AMD�̏��ׂƂ������Ȃ��̂ł́H
16 �FSocket774�F2015/01/31(�y) 17:55:44.05 ID:32Nfw2wc
���̃R�A
17 �F,,�E�L�́M�E,,�j��-�������F2015/01/31(�y) 18:05:10.40 ID:e7zb0iU3
Intel�̓�����MCM��FSB�o�R�m�[�X�u���b�W�ɐڑ�����`�ԂŁA�ɒ[�Șb4�_�C�ł�8�_�C�ł�
�\�P�b�g������ɉe����^���Ȃ��B
���Core 2 Quad��Atom 330�ł��_���I�ɂ�1CPU������XP Home(1�\�P�b�g�܂ł����g���Ȃ�)��
���̂܂g�����킯�B
Opteron�̏ꍇ�͍ŏ����烁�����R���g���[���EHyperTransport���_�C�ɓ������Ă�
�_�C���Ƃɗq������U����̂�8�_�C����\�����ł��Ȃ�
�\�P�b�g������ɉe����^���Ȃ��B
���Core 2 Quad��Atom 330�ł��_���I�ɂ�1CPU������XP Home(1�\�P�b�g�܂ł����g���Ȃ�)��
���̂܂g�����킯�B
Opteron�̏ꍇ�͍ŏ����烁�����R���g���[���EHyperTransport���_�C�ɓ������Ă�
�_�C���Ƃɗq������U����̂�8�_�C����\�����ł��Ȃ�
AMD��ARM�n�œƎ�����낤�Ƃ��Ă邵ARM�n��APU���\�肵�Ă邵Skybridge�Ȃ�č\�z��
��Ɏ�����̓s���ŏ��i�����}���ł邵AMD�̃��\�[�X���S�ɃI�[�o�[���Ă�悤��
Zen�Ȃ�ăz���g�ɏo����̂�����
�o�����Ƃ��Ă��X�P�W���[���͂��낢��S���Y���Y���x���낤��
�K���s�K���R���V���[�}������Ɛ肵����ԂɂȂ��Ă邯�ǁA�������n�̎d������
���̊J���͒x���̂���Ԃ�����
��Ɏ�����̓s���ŏ��i�����}���ł邵AMD�̃��\�[�X���S�ɃI�[�o�[���Ă�悤��
Zen�Ȃ�ăz���g�ɏo����̂�����
�o�����Ƃ��Ă��X�P�W���[���͂��낢��S���Y���Y���x���낤��
�K���s�K���R���V���[�}������Ɛ肵����ԂɂȂ��Ă邯�ǁA�������n�̎d������
���̊J���͒x���̂���Ԃ�����
�p���I�ɃZ�~�J�X�^���i�̎d���͐��������Ă�݂��������烊�\�[�X�͑���Ȃ����낤��
�ɒ[�Șb�f�R�[�_�����ς������
>>9
���̂܂܃V���O���R�A��SMT�ɂȂ�̂��������Ⴍ�Ȃ�ˁB
steam�Ńf�R�[�_�[�����������Ȃ玟��L1I�L���b�V���Ƀt�F�b�`���������Ă����������Ȃ���
������2�R�A�Ȃ�������Ȃ����̎�2�R�A�Ŏ��s���j�b�g�����L���Ƃ��ʔ��������Ǝv���āB
���̂܂܃V���O���R�A��SMT�ɂȂ�̂��������Ⴍ�Ȃ�ˁB
steam�Ńf�R�[�_�[�����������Ȃ玟��L1I�L���b�V���Ƀt�F�b�`���������Ă����������Ȃ���
������2�R�A�Ȃ�������Ȃ����̎�2�R�A�Ŏ��s���j�b�g�����L���Ƃ��ʔ��������Ǝv���āB
����Bulldozer�n�̃��W���[����
�傫���̊��ɃV���O���X���b�h���\���Ⴂ2�X���b�h���s�\�ȃR�A
�ł����Ȃ��̂�
�R�A�����C�h�ɂ�������ɂ����W���[���𑝂₷�����ɂ��s���ɂ���
������Bulldozer�݂����ȘH���𑱂���Ȃ�
big.little����Ȃ����ǃ��C�h�ȃR�A1��jaguar�݂����ȏ����ȃR�A�����Ń��W���[���g�ނƂ��Ȃ炠�肾�Ǝv��
�܂���Ώ̂ȍ\����OS�̑Ή����ʓ|������AMD�͂��ɂ������낤����
�傫���̊��ɃV���O���X���b�h���\���Ⴂ2�X���b�h���s�\�ȃR�A
�ł����Ȃ��̂�
�R�A�����C�h�ɂ�������ɂ����W���[���𑝂₷�����ɂ��s���ɂ���
������Bulldozer�݂����ȘH���𑱂���Ȃ�
big.little����Ȃ����ǃ��C�h�ȃR�A1��jaguar�݂����ȏ����ȃR�A�����Ń��W���[���g�ނƂ��Ȃ炠�肾�Ǝv��
�܂���Ώ̂ȍ\����OS�̑Ή����ʓ|������AMD�͂��ɂ������낤����
23 �F,,�E�L�́M�E,,�j��-�������F2015/01/31(�y) 21:28:01.39 ID:e7zb0iU3
�Ƃ�����Microsoft�������Ă�
Windows RT�Ŏg���Ă�SoC��Android�ł�big.LITTTE�Ή����Ă�̂�RT�ł͖���������Ă�Ƃ�
����RT���̂�������I����Ă��܂�������ߋ��̘b�ł����ǂˁB
Windows RT�Ŏg���Ă�SoC��Android�ł�big.LITTTE�Ή����Ă�̂�RT�ł͖���������Ă�Ƃ�
����RT���̂�������I����Ă��܂�������ߋ��̘b�ł����ǂˁB
>>17
���������A�Ȃ�̂��߂Ƀl�C�e�B�u2�R�A��Pentium4�Ƃ�
�l�C�e�B�u6�R�A��Core2�Ƃ������`�b�v���I����������
���ꂽ�Ǝv���Ă�
FSB�̐����Ń_�C��ɉ����ǂ��납�\�P�b�g���ɂ����
�Ђт��čŏI�I��FSB�𑝂₷�Ƃ����͋Ƃʼn������Ă������
���������A�Ȃ�̂��߂Ƀl�C�e�B�u2�R�A��Pentium4�Ƃ�
�l�C�e�B�u6�R�A��Core2�Ƃ������`�b�v���I����������
���ꂽ�Ǝv���Ă�
FSB�̐����Ń_�C��ɉ����ǂ��납�\�P�b�g���ɂ����
�Ђт��čŏI�I��FSB�𑝂₷�Ƃ����͋Ƃʼn������Ă������
�l�C�e�B�u2�R�A��Pentium4�H
Tulsa�̎��ł�
�Ȃ�Xeon��
28 �F,,�E�L�́M�E,,�j��-�������F2015/02/01(��) 00:37:07.63 ID:lgt+ZAqg
>>24
�m�����B
FSB�����L���邱�ƂŁA�p�t�H�[�}���X��̃f�����b�g�����邾���ŁA
�\�P�b�g�����̂��̂ɐ�����킯�ł͂Ȃ��B
�v���Z�b�T�Ԃ̃������R�q�[�����V���m�[�X�u���b�W�Ɉڏ����Ă邩��
�m�[�X�u���b�W�̐������ŃR�A���𑝂₷���Ƃ��ł���B
�ł��ˁAAMD��Opteron�̏ꍇ�̓v���Z�b�T�ԍ��Ɋ��蓖�Ă���r�b�g��3�r�b�g�����Ȃ��āA
MCM�œ������Ă����ꂼ��̃_�C���ʁX�̃v���Z�b�T�ԍ������B
������S�\�P�b�g�܂ł����Ή��ł��Ȃ��B
�m�����B
FSB�����L���邱�ƂŁA�p�t�H�[�}���X��̃f�����b�g�����邾���ŁA
�\�P�b�g�����̂��̂ɐ�����킯�ł͂Ȃ��B
�v���Z�b�T�Ԃ̃������R�q�[�����V���m�[�X�u���b�W�Ɉڏ����Ă邩��
�m�[�X�u���b�W�̐������ŃR�A���𑝂₷���Ƃ��ł���B
�ł��ˁAAMD��Opteron�̏ꍇ�̓v���Z�b�T�ԍ��Ɋ��蓖�Ă���r�b�g��3�r�b�g�����Ȃ��āA
MCM�œ������Ă����ꂼ��̃_�C���ʁX�̃v���Z�b�T�ԍ������B
������S�\�P�b�g�܂ł����Ή��ł��Ȃ��B
�Ή������m�[�X�����o���Ă��̂��ł�����������
CPU�����L����͂���FSB��4�{�o����CPU1���Ԃ炳����Ƃ����قƂ����v����
CPU�����L����͂���FSB��4�{�o����CPU1���Ԃ炳����Ƃ����قƂ����v����
:473 ���O�FSocket774[sage] ���e���F2014/06/08(��) 02:14:14.40 ID:KXR8ESOI
��:774 ���O�F,,�E�L�́M�E,,�j��-������[sage] ���e���F2014/05/31(�y) 21:20:40.57
���uAMD�}�V��������LAN�Ɍq���ȁv���Č����邵��
��:778 ���O�F,,�E�L�́M�E,,�j��-������[sage] ���e���F2014/05/31(�y) 21:32:54.97
���u���m�ȗ��R���Ȃ�����AMD�̃}�V�����Г��ɓ����ȁv����B
��:780 ���O�F,,�E�L�́M�E,,�j��-������[sage] ���e���F2014/05/31(�y) 21:41:14.97 ID:+WKxBJ8a [11/36]
�����������̖��Ƃ���NEC���x�m�ʂ��@�l����PC��AMD�̃��f���Ȃ����ǂ�
��:801 ���O�FSocket774[sage] ���e���F2014/05/31(�y) 22:28:13.21
����Ƃ���Ȃ����A���I�@�ւ̑���PC�ŁA2�R�A2�X���b�h�`4�X���b�h��
���}�V�����g���ĂĂ��B�@�d�����ɃE�C���X�`�F�b�N�����ő���ƁA�Ȃ�ƁA
���Ɩ��p�V�X�e���̓��삪���f�`�j�������炵����
��:802 ���O�F,,�E�L�́M�E,,�j��-������[sage] ���e���F2014/05/31(�y) 22:34:21.61 ID:+WKxBJ8a [18/36]
������͒P���ɐ��\����ĂȂ�������
��AMD��Intel���Ȃ�đS���W�Ȃ������̘b����
���V�X�e�������ŔѐH���Ă�l�Ԃ��炷������Ԃ�t�قȘb����
��:808 ���O�FSocket774[sage] ���e���F2014/05/31(�y) 22:50:46.66
������@���@�@�L�����[�J��PC��������A�V�X�e���x���_�l��
�������炪�I������ꂽ�Ƃ���́A���[�J�l���̃v���Z�b�T�̐��\��
���n��ő���ĂȂ��E�E�E��
���ŁA���������Ƃ���ɂ́AAMD���i�͂Ȃ��c��
�����\����Ȃ����̂ŃV�X�e����g��ŁA���C�Ŕ[������̂͗c�t����
��:774 ���O�F,,�E�L�́M�E,,�j��-������[sage] ���e���F2014/05/31(�y) 21:20:40.57
���uAMD�}�V��������LAN�Ɍq���ȁv���Č����邵��
��:778 ���O�F,,�E�L�́M�E,,�j��-������[sage] ���e���F2014/05/31(�y) 21:32:54.97
���u���m�ȗ��R���Ȃ�����AMD�̃}�V�����Г��ɓ����ȁv����B
��:780 ���O�F,,�E�L�́M�E,,�j��-������[sage] ���e���F2014/05/31(�y) 21:41:14.97 ID:+WKxBJ8a [11/36]
�����������̖��Ƃ���NEC���x�m�ʂ��@�l����PC��AMD�̃��f���Ȃ����ǂ�
��:801 ���O�FSocket774[sage] ���e���F2014/05/31(�y) 22:28:13.21
����Ƃ���Ȃ����A���I�@�ւ̑���PC�ŁA2�R�A2�X���b�h�`4�X���b�h��
���}�V�����g���ĂĂ��B�@�d�����ɃE�C���X�`�F�b�N�����ő���ƁA�Ȃ�ƁA
���Ɩ��p�V�X�e���̓��삪���f�`�j�������炵����
��:802 ���O�F,,�E�L�́M�E,,�j��-������[sage] ���e���F2014/05/31(�y) 22:34:21.61 ID:+WKxBJ8a [18/36]
������͒P���ɐ��\����ĂȂ�������
��AMD��Intel���Ȃ�đS���W�Ȃ������̘b����
���V�X�e�������ŔѐH���Ă�l�Ԃ��炷������Ԃ�t�قȘb����
��:808 ���O�FSocket774[sage] ���e���F2014/05/31(�y) 22:50:46.66
������@���@�@�L�����[�J��PC��������A�V�X�e���x���_�l��
�������炪�I������ꂽ�Ƃ���́A���[�J�l���̃v���Z�b�T�̐��\��
���n��ő���ĂȂ��E�E�E��
���ŁA���������Ƃ���ɂ́AAMD���i�͂Ȃ��c��
�����\����Ȃ����̂ŃV�X�e����g��ŁA���C�Ŕ[������̂͗c�t����
:474 ���O�FSocket774[sage] ���e���F2014/06/08(��) 02:16:51.88 ID:KXR8ESOI
��:802 ���O�F,,�E�L�́M�E,,�j��-������[sage] ���e���F2014/05/31(�y) 22:34:21.61
������͒P���ɐ��\����ĂȂ�������
��:809 ���O�F,,�E�L�́M�E,,�j��-������[sage] ���e���F2014/05/31(�y) 22:54:30.30
�������������[�����ꂽ�V�X�e���ɃP�`�����Ă�n�R��z�{�{�b�^�N��
��:811 ���O�FSocket774[sage] ���e���F2014/05/31(�y) 22:58:05.62
�����I�Ȋ����Ƒϗp5�N���炢����Ȃ��́H
������Ȃ��Ƃ��m��Ȃ��́H
��:819 ���O�FSocket774[sage] ���e���F2014/05/31(�y) 23:04:25.11
���c�t�Ă�肵���̂�
�����\����ĂȂ����Ė��L�����̂�
���ϗp�E���p�N�����ƌ������̂����Ȃ��ǁH
�������̌��I�@�ւ��A���������ł�������ȂǂƎv���Ă�Ȃ�
�������͊e�Ȓ�������̏��Z�L�����e�B�|���V�[�ł��ǂ�ł���
��:827 ���O�F,,�E�L�́M�E,,�j��-������[sage] ���e���F2014/05/31(�y) 23:14:54.20
���}�V���̃X�y�b�N�����ׂ���
�����\�s�����ȂƂ�߂���
�����ł�߂��Ă����āA���l���Ȃ��ăg�����炵�����ǂ�
��:802 ���O�F,,�E�L�́M�E,,�j��-������[sage] ���e���F2014/05/31(�y) 22:34:21.61
������͒P���ɐ��\����ĂȂ�������
��AMD��Intel���Ȃ�đS���W�Ȃ������̘b����
���V�X�e�������ŔѐH���Ă�l�Ԃ��炷������Ԃ�t�قȘb����
���́A�P���ɐ��\�̑���ĂȂ������̗c�t�Șb�@���Ēf���̏ڍׂ������Ă�
���m�ȓ��A�܂�����?�@�����O�F,,�E�L�́M�E,,�j��-������
��:802 ���O�F,,�E�L�́M�E,,�j��-������[sage] ���e���F2014/05/31(�y) 22:34:21.61
������͒P���ɐ��\����ĂȂ�������
��:809 ���O�F,,�E�L�́M�E,,�j��-������[sage] ���e���F2014/05/31(�y) 22:54:30.30
�������������[�����ꂽ�V�X�e���ɃP�`�����Ă�n�R��z�{�{�b�^�N��
��:811 ���O�FSocket774[sage] ���e���F2014/05/31(�y) 22:58:05.62
�����I�Ȋ����Ƒϗp5�N���炢����Ȃ��́H
������Ȃ��Ƃ��m��Ȃ��́H
��:819 ���O�FSocket774[sage] ���e���F2014/05/31(�y) 23:04:25.11
���c�t�Ă�肵���̂�
�����\����ĂȂ����Ė��L�����̂�
���ϗp�E���p�N�����ƌ������̂����Ȃ��ǁH
�������̌��I�@�ւ��A���������ł�������ȂǂƎv���Ă�Ȃ�
�������͊e�Ȓ�������̏��Z�L�����e�B�|���V�[�ł��ǂ�ł���
��:827 ���O�F,,�E�L�́M�E,,�j��-������[sage] ���e���F2014/05/31(�y) 23:14:54.20
���}�V���̃X�y�b�N�����ׂ���
�����\�s�����ȂƂ�߂���
�����ł�߂��Ă����āA���l���Ȃ��ăg�����炵�����ǂ�
��:802 ���O�F,,�E�L�́M�E,,�j��-������[sage] ���e���F2014/05/31(�y) 22:34:21.61
������͒P���ɐ��\����ĂȂ�������
��AMD��Intel���Ȃ�đS���W�Ȃ������̘b����
���V�X�e�������ŔѐH���Ă�l�Ԃ��炷������Ԃ�t�قȘb����
���́A�P���ɐ��\�̑���ĂȂ������̗c�t�Șb�@���Ēf���̏ڍׂ������Ă�
���m�ȓ��A�܂�����?�@�����O�F,,�E�L�́M�E,,�j��-������
����A�������؋������߂��ɒf��
���̌�ّ�
�J����������A��
�ڋ��҂̖��ӔC�A�����Ȃƌ����Ă��d���Ȃ���
�����O�F,,�E�L�́M�E,,�j��-������
���̌�ّ�
�J����������A��
�ڋ��҂̖��ӔC�A�����Ȃƌ����Ă��d���Ȃ���
�����O�F,,�E�L�́M�E,,�j��-������
�܂�FX-4000��A10-8850K�ȉ��͎����ɂ��g������Ă��Ƃ�
>>33
�g���Ȃ������̂́AIntel �̃}�V�����Ǝv����
AMD�̐��i�Ȃ�ǂ����������́A����ɑ��݂��Ȃ��i�Ɩ{�l���f�����Ă�j����
����Ȃ�
FX-4000��A10-8850�������Ɏg���Ȃ��Ƃ��A���������Ƃ��Ȃ����A
�����ƑO��AMD���ł��A�茳���ᓮ��ҏW�ɂ��g���Ă��邩���
�����AAMD�ɂ����Ȃ����������߂́A�����A�Ă��Ă�G�������̗ނ��낤
���Ȃ���ID:RZjVdkoP���A���߂������ɂ͋C�����������ǂ��ł���
�g���Ȃ������̂́AIntel �̃}�V�����Ǝv����
AMD�̐��i�Ȃ�ǂ����������́A����ɑ��݂��Ȃ��i�Ɩ{�l���f�����Ă�j����
����Ȃ�
FX-4000��A10-8850�������Ɏg���Ȃ��Ƃ��A���������Ƃ��Ȃ����A
�����ƑO��AMD���ł��A�茳���ᓮ��ҏW�ɂ��g���Ă��邩���
�����AAMD�ɂ����Ȃ����������߂́A�����A�Ă��Ă�G�������̗ނ��낤
���Ȃ���ID:RZjVdkoP���A���߂������ɂ͋C�����������ǂ��ł���
����Ƃ���Ȃ����A���I�@�ւ̑���PC�ŁA2�R�A2�X���b�h�`4�X���b�h��
���}�V�����g���ĂĂ��B�@�d�����ɃE�C���X�`�F�b�N�����ő���ƁA�Ȃ�ƁA
���Ɩ��p�V�X�e���̓��삪���f�`�j�������炵����
�E�i�M�͂܂�����̏؋����o���Ȃ��ƁA�ڋ��҂̖��ӔC�A�����Ȃƌ����Ă��d���Ȃ���
���}�V�����g���ĂĂ��B�@�d�����ɃE�C���X�`�F�b�N�����ő���ƁA�Ȃ�ƁA
���Ɩ��p�V�X�e���̓��삪���f�`�j�������炵����
�E�i�M�͂܂�����̏؋����o���Ȃ��ƁA�ڋ��҂̖��ӔC�A�����Ȃƌ����Ă��d���Ȃ���
>>34
�������b��̂�������
�������b��̂�������
>>34
OS���H
Windows 8.1��7850K���Ɠ���ҏW���Ȃ��痠��G��ƃJ�N�J�N����͎̂d���Ȃ��Ǝv���Ă邪�A
10.10.2��Sandy 2�R�A2.3GHz�ł�iMovie�G���R���Ȃ���ł��J�N�J�N���Ȃ�
OS���H
Windows 8.1��7850K���Ɠ���ҏW���Ȃ��痠��G��ƃJ�N�J�N����͎̂d���Ȃ��Ǝv���Ă邪�A
10.10.2��Sandy 2�R�A2.3GHz�ł�iMovie�G���R���Ȃ���ł��J�N�J�N���Ȃ�
38 �F,,�E�L�́M�E,,�j��-�������F2015/02/01(��) 09:28:59.74 ID:lgt+ZAqg
�ϑz�E�i��͉��`
���{�l�Ȃ�C���e���Q�t�H������˂�
A-8000�̎���
A12-A 295K�Ƃ��ɂȂ�H
AMD A A 200�V���[�Y�����H
A12-A 295K�Ƃ��ɂȂ�H
AMD A A 200�V���[�Y�����H
�Ƃ肠�����O���ɂȂ�Ǝv���B
�����A-8000����Ȃ�A10�݂����Ȋ����Ő��������Ă��B
�����A-8000����Ȃ�A10�݂����Ȋ����Ő��������Ă��B
>>43
Ax-8000�Ə��������Ȃ��Ă�
Ax-8000�Ə��������Ȃ��Ă�
>>28
APIC���g�������̂�8�_�C�ȏ�͈�����悤�ɂȂ�����ł����ˁB
���́AOracle�ɔ��������Andy Bechtolsheim�����߂������Sun������A����x���_�[�ł���hp������A8�\�P�b�g�v��Ȃ��A���Č���ꂿ��������Ƃ���ˁB
APIC���g�������̂�8�_�C�ȏ�͈�����悤�ɂȂ�����ł����ˁB
���́AOracle�ɔ��������Andy Bechtolsheim�����߂������Sun������A����x���_�[�ł���hp������A8�\�P�b�g�v��Ȃ��A���Č���ꂿ��������Ƃ���ˁB
>>37
����ς�OS�̖�肾������
����ς�OS�̖�肾������
����OS�̖�肶��c�c
�s�s���o�O����A���`������
���{�l�Ȃ�C���e���Q�t�H�����
���{�l�Ȃ�C���e���Q�t�H�����
���{�l�Ȃ�Q�t�H�`�����I
�}�J�`�������������ĂăI�[���X�^�[����
Windows�M�҂͋A��
�����̓m�[�g�p�G�N�X�J�x�[�^�߂Ď��ւ���X����
�����̓m�[�g�p�G�N�X�J�x�[�^�߂Ď��ւ���X����
ISSI�݂����Ȃ�͂�����H
>>53
�ǎ��̃T�C�{�[�O���ۂ��ˁ[�����ƃ��{�����C���`�b�v��AMD������H
�ǎ��̃T�C�{�[�O���ۂ��ˁ[�����ƃ��{�����C���`�b�v��AMD������H
���{�l�Ȃ�C���e���Q�t�H�������
AMD���{�I�Ԃ�������o�g���W�T�b�J�[�Y
Llano�o��̋łɂ�
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
�����ゾ�ƁAARM cortex-A72�̂�����܂ނ̂�?
�o�ׂɖ�肪�o������̔��ł�����tegra���S����ފ�ĂɂȂ肻���ȏo���f������ȁB
�z���g�ɖ����ɏo�ׂł��邾�낤���S�z�����B
���ƁA����̑ΏۊO�̐��i�Ŕ���Ȃ̂��ő�̖�肩�B
�o�ׂɖ�肪�o������̔��ł�����tegra���S����ފ�ĂɂȂ肻���ȏo���f������ȁB
�z���g�ɖ����ɏo�ׂł��邾�낤���S�z�����B
���ƁA����̑ΏۊO�̐��i�Ŕ���Ȃ̂��ő�̖�肩�B
��݁A�j���[�X�̌�ǂ���
AMD�����Y����\��ɓ����Ă�̂�A57�ł�����A72�̗\��͏o�ĂȂ��AA72��ARM�ɂ�锭�\�������Ő��Y�x���_���肾��
AMD�����Y����\��ɓ����Ă�̂�A57�ł�����A72�̗\��͏o�ĂȂ��AA72��ARM�ɂ�锭�\�������Ő��Y�x���_���肾��
>>59
AMD�͂������Ɛ��E����ARM 64bit������
AMD�͂������Ɛ��E����ARM 64bit������
2016�N��64bit ARM���N�I
�^���薼�����͂������Ɛ��E���̘A�����X���p������
2016�N�͕�s�̘A�|���I�����N�I
2016�N�͕�s�̘A�|���I�����N�I
Seattle�̌��ARM�ł�HSA�Ή���APU��������Skybridge��������Ȃ�
AMD��Cortex-A72���̗p���Ȃ�����
AMD��Cortex-A72���̗p���Ȃ�����
���C�Z���X�͎�ł���
�킴�킴a57���V�������N����Ƃ͎v���Ȃ���
�킴�킴a57���V�������N����Ƃ͎v���Ȃ���
NVIDIA�͂���Denver�����[�X���Ă�̂�K12��2�N����ł������I�����Ƃ�����
�܂Ƃ��Ȏ��v������̂����������Ƃ�������������
�܂Ƃ��Ȏ��v������̂����������Ƃ�������������
����ς���{�l�Ȃ�C���e���Q�t�H������˂�
�S���E��Android�Q�[����Intel CPU�ɍœK����
Unity��Intel�Ɛ헪�I��g
http://m.pc.watch.impress.co.jp/docs/news/20140821_662978.html
Unity��Intel�Ɛ헪�I��g
http://m.pc.watch.impress.co.jp/docs/news/20140821_662978.html
���{�l�Ȃ�C���e���Q�t�H���
�c�ȂǂƈӖ��s���̊���グ�Ȃ���A�O���XCPU��
���Ȃ��ꂽ�l�ɐU������Ă���c
���Ȃ��ꂽ�l�ɐU������Ă���c
�S���E��Android�Q�[���̔�����
�ł͂Ȃ�
�S���E�̔�����Android�Q�[�����Ă��Ƃ�
�܂�S���E��Android�̔����Q�[���n���Q�[�����Ă��Ƃ�
����Ƃ���������������
�v���O�����̃f�[�^�̌^��������
�ł͂Ȃ�
�S���E�̔�����Android�Q�[�����Ă��Ƃ�
�܂�S���E��Android�̔����Q�[���n���Q�[�����Ă��Ƃ�
����Ƃ���������������
�v���O�����̃f�[�^�̌^��������
71 �FSocket774�F2015/02/07(�y) 13:07:51.54 ID:jbs6kDxN
radeon�H
���ł����������ꂗ�H
http://www.anandtech.com/show/8962/the-directx-12-performance-preview-amd-nvidia-star-swarm/3
http://images.anandtech.com/graphs/graph8962/71450.png
���ł����������ꂗ�H
http://www.anandtech.com/show/8962/the-directx-12-performance-preview-amd-nvidia-star-swarm/3
http://images.anandtech.com/graphs/graph8962/71450.png
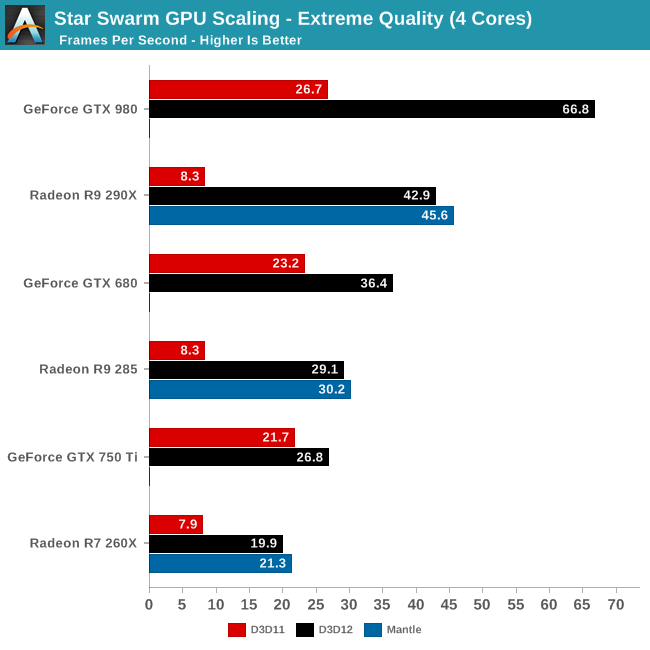{kind=link}
�ǂ�ȕs�����ȃR�[�h�Ńh���C�u����Ă邩���킩��Ȃ�
����1�Q�[���̌��ʃO���t�����������Ă��ē\��t����
�X���b�h�S�̂𝈝�����l�ȏ������݂�����
�ُ�҂̎����H��̓T�^�ł��큄�ЂƂ܂�
�������Ă�̂��āA��O�Ȃ��]������Ă��ł����˂�
����1�Q�[���̌��ʃO���t�����������Ă��ē\��t����
�X���b�h�S�̂𝈝�����l�ȏ������݂�����
�ُ�҂̎����H��̓T�^�ł��큄�ЂƂ܂�
�������Ă�̂��āA��O�Ȃ��]������Ă��ł����˂�
73 �FSocket774�F2015/02/07(�y) 13:22:13.76 ID:jbs6kDxN
74 �F,,�E�L�́M�E,,�j��-�������F2015/02/07(�y) 13:22:29.47 ID:sdijzNBq
�E�E�E�ȂǂƁA�]�����ꂽ�E�i��͂������Ă���
��͎����E�i�M���K�[
�Q�[���̍œK�������ŐL�т�Ȃ�NVIDIA��SHIELD�͂����ƃq�b�g���Ă��
�����炱�����̗͂łȂ�Ƃ����悤�Ƃ��Ă�낤����
�����炱�����̗͂łȂ�Ƃ����悤�Ƃ��Ă�낤����
���{�l�Ȃ�C���e���Q�t�H���
�܁[�Ԃ����Ⴏ�A������������܂߂��SGPU�̒��Ō�����A�Q�t�H�����f�Ɠ����x�̃V�F�A�����Ȃ��āA
Intel1���̂Ȃ��ł킸���Ȏc��V�F�A����荇���Ă邾������ȁB
�����������PC�pGPU�����Ȃ���ނ͂낭�ȃV�F�A�����Ȃ��B
Intel1���̂Ȃ��ł킸���Ȏc��V�F�A����荇���Ă邾������ȁB
�����������PC�pGPU�����Ȃ���ނ͂낭�ȃV�F�A�����Ȃ��B
79 �FSocket774�F2015/02/07(�y) 18:12:07.09 ID:8AtgoXYu
����gpu����Ă�̂ɂ낭�ɃV�F�A�Ƃ�Ȃ�nv�Ɠ����x�Ȃ��
amd�͂낭�ł��Ȃ��ł���
amd�͂낭�ł��Ȃ��ł���
�����CPU����Intel�ɕ����A�P��GPU�ł���ނɕ����Ă邩��ȁB
�����Ƃ��APC�p�̐�Ƃł͐�s�����Â��Ƃ���Ɏ���o�������o�C����tegra����킵�����Ă���ނ��A
�������̊낤���ł�AMD�ƌ݊p����
�����Ƃ��APC�p�̐�Ƃł͐�s�����Â��Ƃ���Ɏ���o�������o�C����tegra����킵�����Ă���ނ��A
�������̊낤���ł�AMD�ƌ݊p����
tegra�͂܂����\�Ńg�b�v�N���X�����炱�̐��͂��邪APU�͂Ȃ��B
82 �FSocket774�F2015/02/07(�y) 18:31:14.11 ID:8AtgoXYu
hpc,cloud,grid,mobile�����ĎԍڂȂǐV�s��J�Ă�nv��
�ꏏ�ɂ��Ȃ���
�ꏏ�ɂ��Ȃ���
���{�l�Ȃ�C���e���Q�t�H���
�����[����������ǁAAMD��x86��64�r�b�g�g���Ȃ��Ȃ������Intel�̎x�z�͂Ȃ����������ˁA
�܂����̏ꍇAMD�͂������������c���ĂȂ����������
�܂����̏ꍇAMD�͂������������c���ĂȂ����������
�x�z�Ƃ��������Ă�������
Itanium���ă}�W�Řb����Ȃ��Ȃ�����
�܂��V���i�̊J���͑����Ă�͂��Ȃ�
�܂��V���i�̊J���͑����Ă�͂��Ȃ�
���N�v���Z�X�ύX�Ȃ��̉����i�o����
���̌��Xeon�ւ̈ڍs���L�́B
���̌��Xeon�ւ̈ڍs���L�́B
AMD64�̃_��������ISA�ւ̍œK�����������Y�͔̂������ȁB
90 �F,,�E�L�́M�E,,�j��-�������F2015/02/07(�y) 22:18:22.35 ID:sdijzNBq
AMD64���Ȃ��Ƃ�Itanium�̓R���V���[�}�ɂ͍~��ė��Ȃ������Ǝv����B
���W�X�^8�{�̂܂܂�Yamhill�g�������̂܂g���Ă��͂��B
���\�����߂���͂��̂��܂�PC�Q�[���̑唼��32�r�b�g�R�[�h���B
���W�X�^16�{���ē���p�r�������Ă���ȂɕK�v�������Ȃ��̂͑���
���sx86�A�[�L�̃��W�X�^���l�[�~���O�����͂ł��邪�̂��ˁB
���Ȃ��Ƃ�������Opcode�����Ȃ��Ă�ModRM�̋����邩��AVX�g���͂ł���B
����32bit���[�h�ł�AVX�`AVX512�܂Ŏg����B
���W�X�^8�{�̂܂܂�Yamhill�g�������̂܂g���Ă��͂��B
���\�����߂���͂��̂��܂�PC�Q�[���̑唼��32�r�b�g�R�[�h���B
���W�X�^16�{���ē���p�r�������Ă���ȂɕK�v�������Ȃ��̂͑���
���sx86�A�[�L�̃��W�X�^���l�[�~���O�����͂ł��邪�̂��ˁB
���Ȃ��Ƃ�������Opcode�����Ȃ��Ă�ModRM�̋����邩��AVX�g���͂ł���B
����32bit���[�h�ł�AVX�`AVX512�܂Ŏg����B
AMD64�͒lj��̃��W�X�^�g���ƃR�[�h�̌��������̂���
�����̌݊��d���̂����Ōp�������݂̂��Ƃ��Ȃ��R�[�h�̌n
�܂ň����p�����̂͂ǂ��Ȃ�
�����̌݊��d���̂����Ōp�������݂̂��Ƃ��Ȃ��R�[�h�̌n
�܂ň����p�����̂͂ǂ��Ȃ�
Llano�o��̋łɂ�
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
�� 2014�N �����̔��ド���L���O
http://eetimes.jp/ee/articles/1412/25/news147.html
��AMD�A2014�N�x��4���h���̐Ԏ�
http://pc.watch.impress.co.jp/docs/news/20150121_684660.html
AMD�̏��ʂ������}�~���ЂƂ蕉���_(^o^)�^
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
�� 2014�N �����̔��ド���L���O
http://eetimes.jp/ee/articles/1412/25/news147.html
��AMD�A2014�N�x��4���h���̐Ԏ�
http://pc.watch.impress.co.jp/docs/news/20150121_684660.html
AMD�̏��ʂ������}�~���ЂƂ蕉���_(^o^)�^
93 �F,,�E�L�́M�E,,�j��-�������F2015/02/07(�y) 22:52:35.50 ID:sdijzNBq
��H�܂���1�o�C�g�ł�inc��dec�ɖ����ł��H
*ax, *cx, *dx, *si, *di�����g���Ă镪�ɂ�32�r�b�g�Ƃقڕς��Ȃ�
r8-r15���g���͕̂ϐ�����ʂɕK�v�Ȋ��ŁA���[�h�E�X�g�A�̕p�x��������
���b�L�[���炢�̋C�����Ŏg�����̂ł���B
*ax, *cx, *dx, *si, *di�����g���Ă镪�ɂ�32�r�b�g�Ƃقڕς��Ȃ�
r8-r15���g���͕̂ϐ�����ʂɕK�v�Ȋ��ŁA���[�h�E�X�g�A�̕p�x��������
���b�L�[���炢�̋C�����Ŏg�����̂ł���B
>>85
��AMD��x86��64�r�b�g�g���Ȃ��Ȃ������Intel�̎x�z�͂Ȃ�����������
����͂Ȃ�
IA-64�̓V���ɂȂ����\���̕����A�������̉\�����������ƍ���
���̏ꍇ�AAMD��Intel�݊�CPU�̃��[�J�[�Ƃ��Đ����c��\���͖��������͂�
>>90
�Œ���x�A��������Ԃ̑啝�g�������͊m���ɍs��ꂽ�͂��B
����x86�̃������g����MS�ɏR���Ă��܂�������A����ȊO�̕��@�łȁB
�ŁA���̃�������Ԃ�������Ǝg�����Ȃ��ɂ�32bit�����Ȃ��ėp���W�X�^�̃T�C�Y���l�b�N�ɂȂ邱�Ƃ��m��������A
�Ȃ�炩��64bit�����g���͕s���������B
>>91,93
�܂��A��قǃ��W�X�^�̊��p���I���Ȑl�ł��Ȃ�������A
�ėp���W�X�^8�{�ƃ��W�X�^�̈ꎞ�ޔ�p�̕⏕���W�X�^8�{���炢����Ζő��ɍ�����Ȃ��c�c
��AMD��x86��64�r�b�g�g���Ȃ��Ȃ������Intel�̎x�z�͂Ȃ�����������
����͂Ȃ�
IA-64�̓V���ɂȂ����\���̕����A�������̉\�����������ƍ���
���̏ꍇ�AAMD��Intel�݊�CPU�̃��[�J�[�Ƃ��Đ����c��\���͖��������͂�
>>90
�Œ���x�A��������Ԃ̑啝�g�������͊m���ɍs��ꂽ�͂��B
����x86�̃������g����MS�ɏR���Ă��܂�������A����ȊO�̕��@�łȁB
�ŁA���̃�������Ԃ�������Ǝg�����Ȃ��ɂ�32bit�����Ȃ��ėp���W�X�^�̃T�C�Y���l�b�N�ɂȂ邱�Ƃ��m��������A
�Ȃ�炩��64bit�����g���͕s���������B
>>91,93
�܂��A��قǃ��W�X�^�̊��p���I���Ȑl�ł��Ȃ�������A
�ėp���W�X�^8�{�ƃ��W�X�^�̈ꎞ�ޔ�p�̕⏕���W�X�^8�{���炢����Ζő��ɍ�����Ȃ��c�c
IA64�̓V���̉\�����̂͂���������낤���A���ۂ�葁���}���`�A�[�L���嗬�ɂȂ���arm���ȓd�́APOWER���G���^�[�v���C�Y��}���Ă�������B
����͂��Ԃ��������Ǝv��
���������Ă��ׂ������낤��
���Ƃ��A1�`�b�v�ӂ�100�h���̃}�[�W������߂��Ăł��A
�M���点�Ēׂ��ĒD������
�E�i�M�ُ�҂������Ă܂ŃX�����r�炷��Ђ��炷���
�ǂ�Ȃ��Ƃ����Ēc�q���Ǝv����
���Ƃ��A1�`�b�v�ӂ�100�h���̃}�[�W������߂��Ăł��A
�M���点�Ēׂ��ĒD������
�E�i�M�ُ�҂������Ă܂ŃX�����r�炷��Ђ��炷���
�ǂ�Ȃ��Ƃ����Ēc�q���Ǝv����
98 �F,,�E�L�́M�E,,�j��-�������F2015/02/08(��) 03:09:28.30 ID:E15V7x1F
�ǂ݂̂�Xeon��Yamhill(���W�X�^�{���g�����Ȃ���64�r�b�g��)�ɂ���Clackamas(AMD64�݊�)�ɂ���
64�r�b�g���͂���\�肾�����킯�ŁA�������̂ق����y���Ɍڋq�̃j�[�Y�͑傫�������B
���\���L�єY�݊���IBM��Sun�̎��]���Ă�IPF���T�[�o�̃��C���X�g���[���ɂȂ邱�Ƃ�
��Ȃ������͂��ł��B
IPF���ŏI�I�ɎE�����̂�Opteron�ł͂Ȃ�Intel��Xeon�Ƃ����Ă��邭�炢�ł����B
64�r�b�g���͂���\�肾�����킯�ŁA�������̂ق����y���Ɍڋq�̃j�[�Y�͑傫�������B
���\���L�єY�݊���IBM��Sun�̎��]���Ă�IPF���T�[�o�̃��C���X�g���[���ɂȂ邱�Ƃ�
��Ȃ������͂��ł��B
IPF���ŏI�I�ɎE�����̂�Opteron�ł͂Ȃ�Intel��Xeon�Ƃ����Ă��邭�炢�ł����B
�������̌݊��d���̂���
����ȊO�ړI�����ł���
�u�����̃A�v�������̂܂ܓ����v�u64bit������v
���ꗼ�������邽�߂�����x64
���{����ʖڂ�����AMD��x64��ARM���_�C�ɍ��ڂ�����
���ꂩ��̒E�p�}�낤�Ƃ��Ă���
��������Intel���߃A�[�L�̎��ӎ���Ɩ��W��
���ł�PC���X�}�z�ɐN�H����Ă邵
Intel64�̉h�Ȃ�Ė���
����ȊO�ړI�����ł���
�u�����̃A�v�������̂܂ܓ����v�u64bit������v
���ꗼ�������邽�߂�����x64
���{����ʖڂ�����AMD��x64��ARM���_�C�ɍ��ڂ�����
���ꂩ��̒E�p�}�낤�Ƃ��Ă���
��������Intel���߃A�[�L�̎��ӎ���Ɩ��W��
���ł�PC���X�}�z�ɐN�H����Ă邵
Intel64�̉h�Ȃ�Ė���
AMD�͟r��
>>99
����v�����ǒN���������
����v�����ǒN���������
����������������Ȃ甄��邵���Ȃ��Ȃ甄��Ȃ�
103 �F,,�E�L�́M�E,,�j��-�������F2015/02/08(��) 12:54:09.19 ID:E15V7x1F
���{����_���Ȃ̂�AMD�����ł���
ARM��Opteron���o���Ă�Xeon E3��Atom C2000�̓d�͌����ɏ��Ă�
���i�̗ʎY�o�ׂ�����������
�J���L�b�g�Ƃ������ڂ�2999�h���Ƃ����ӂ��������i����Ă���̂�
�����炭�܂Ƃ܂����������ڏ��������Ȃ�����
�܂��t��Atovon�͗ʎY�x�[�X�ɂ̂���x�ɔ���Ă邩��5���~��CPU�̍ڂ���
�T�[�o�p�}�U�[�ꎮ�����Ă��܂�
ARM��Opteron���o���Ă�Xeon E3��Atom C2000�̓d�͌����ɏ��Ă�
���i�̗ʎY�o�ׂ�����������
�J���L�b�g�Ƃ������ڂ�2999�h���Ƃ����ӂ��������i����Ă���̂�
�����炭�܂Ƃ܂����������ڏ��������Ȃ�����
�܂��t��Atovon�͗ʎY�x�[�X�ɂ̂���x�ɔ���Ă邩��5���~��CPU�̍ڂ���
�T�[�o�p�}�U�[�ꎮ�����Ă��܂�
�����Ȃ�x86�ɂ���̂�ARM�ɂ���̂��S����芷���悤�Ƃ����烊�X�N���ł�������B
�����������Ώ������ł��ڍs�������߂���B
x86��ARM������ȃ\�t�g���Y������A�G���h���[�U�͂��̃\�t�g��x86�ł��������Ȃ��̂�ARM�ł��������Ȃ��̂����đI�����ō����肩�A����1��łǂ����������܂��̂�������₷���Ǝv��Ȃ����H
�����������Ώ������ł��ڍs�������߂���B
x86��ARM������ȃ\�t�g���Y������A�G���h���[�U�͂��̃\�t�g��x86�ł��������Ȃ��̂�ARM�ł��������Ȃ��̂����đI�����ō����肩�A����1��łǂ����������܂��̂�������₷���Ǝv��Ȃ����H
���Ă��ɂ�iPhone�ł�Android�ł��ǂ���ł�����ł���X�}�z��~�����B
�Q����Ȃ��ƃ_���Ƃ��A�z�炵������B
���������̂�AMD������Ă������Ď����B
�Q����Ȃ��ƃ_���Ƃ��A�z�炵������B
���������̂�AMD������Ă������Ď����B
���������̂��Ă����Ă����s������
�ǂ��������Œ��r���[�ł��̂����l�i�����������Ă���
�ǂ��������Œ��r���[�ł��̂����l�i�����������Ă���
�g��Ȃ��̂�4�R�A�������Ēl�i������
�g��Ȃ��̂�IGP7���������Ēl�i������
���߃Z�b�g�o�C�����K���ǂ��������Œl�i������
�g��Ȃ��̂�IGP7���������Ēl�i������
���߃Z�b�g�o�C�����K���ǂ��������Œl�i������
108 �F,,�E�L�́M�E,,�j��-�������F2015/02/08(��) 13:39:34.12 ID:E15V7x1F
x86�ƃl�C�e�B�u���߃Z�b�g�Ƃ̃o�C�����K���A�[�L�e�N�`�����Đ�IBM�Ƃ�������Ă��i�ߋ��`�j
���ǖ��������������߂����Ȃ����
ARM��Opteron��x86��Opteron�Ńv���b�g�t�H�[���i�����j�݊��ɂ���̂����������ł���
���ǖ��������������߂����Ȃ����
ARM��Opteron��x86��Opteron�Ńv���b�g�t�H�[���i�����j�݊��ɂ���̂����������ł���
itanium��x86�G�~�����[�V�������ڂ��Ă����x���Ďg�����̂ɂȂ��̂ł������ĕ]�������������
�Ƃ������������������`�b�v��ARM��86�ڂ���Ȃ�Ęb�͖����ł���
�v���b�g�t�H�[���݊��A����悭�\�P�b�g�݊���ڎw�����Ă�����
�Ƃ������������������`�b�v��ARM��86�ڂ���Ȃ�Ęb�͖����ł���
�v���b�g�t�H�[���݊��A����悭�\�P�b�g�݊���ڎw�����Ă�����
x86��ARM�Ƃł�ISA���Ⴂ�����ă}�C�N���A�[�L�e�N�`���̋��ʉ����疳��������Ȃ��B
> �����`�b�v��ARM��86�ڂ���
�Z�L�����e�B�v���Z�b�T�Ƃ��ĂȂ�ڂ��Ă邗
�Z�L�����e�B�v���Z�b�T�Ƃ��ĂȂ�ڂ��Ă邗
112 �F,,�E�L�́M�E,,�j��-�������F2015/02/08(��) 14:00:22.54 ID:E15V7x1F
Intel��Itanium�𐄂�����Yamhill�𑁊��Ƀv�b�V�����Ă��AMD��64�r�b�g�g���Ă�
���邱�Ƃ͂Ȃ����������ˁB
�ł�����ł悩�����Ǝv���H
REX�v���t�B�N�X�͔������͂Ȃ��g�����@�Ƃ͂������W�X�^16�{�͕K�v�ȂƂ��ɂ͂���ƕ֗�����
8�{�܂ł����K�v�Ȃ��Ȃ�قƂ��x86�ƕ��ϖ��ߒ��͕ς��Ȃ�
SSE��AVX��ϋɓI�Ɏg���Ȃ�Y���̃J�E���g��4, 8, 16�Ȃǂ̑傫�ȒP�ʂɂȂ邩��
1�o�C�g��inc/dec�Ȃ�Ďc���ĂĂ��g��Ȃ��ł���B
���邱�Ƃ͂Ȃ����������ˁB
�ł�����ł悩�����Ǝv���H
REX�v���t�B�N�X�͔������͂Ȃ��g�����@�Ƃ͂������W�X�^16�{�͕K�v�ȂƂ��ɂ͂���ƕ֗�����
8�{�܂ł����K�v�Ȃ��Ȃ�قƂ��x86�ƕ��ϖ��ߒ��͕ς��Ȃ�
SSE��AVX��ϋɓI�Ɏg���Ȃ�Y���̃J�E���g��4, 8, 16�Ȃǂ̑傫�ȒP�ʂɂȂ邩��
1�o�C�g��inc/dec�Ȃ�Ďc���ĂĂ��g��Ȃ��ł���B
x86��ARM���R�[�h���[�t�B���O���O����Crusoe�Ɩ��t���悤��
�P��Intel��������Ƃ����W�J���ȁB
��������inc/dec���̂��̂�����Ȃ��B
����1�̌v�Z�������߂�1�o�C�g�Z�����Ă��Ӗ����Ȃ���add/sub���ߎg���Ώ\���B
���������Ӗ��ł�1�o�C�g���߂͑S������Ȃ��B
push/pop�������ĕ������߂��������Ƃ���������I�y�����h��1�o�C�g�g���ă��W�X�^���X�g���w�肷��悤�ɂ����������߂��Z���Ȃ邵�A
SIMD�ōL�������f�[�^�p�X���g���Ĉ�x�ɕ������W�X�^�̃f�[�^�𑀍삵�č��������邱�Ƃ��ł���Bpusha/popa�ɖ��ʂ���������Ƃ����ĒP���ɔp�~���铪�̈����͒v���I���B
����1�̌v�Z�������߂�1�o�C�g�Z�����Ă��Ӗ����Ȃ���add/sub���ߎg���Ώ\���B
���������Ӗ��ł�1�o�C�g���߂͑S������Ȃ��B
push/pop�������ĕ������߂��������Ƃ���������I�y�����h��1�o�C�g�g���ă��W�X�^���X�g���w�肷��悤�ɂ����������߂��Z���Ȃ邵�A
SIMD�ōL�������f�[�^�p�X���g���Ĉ�x�ɕ������W�X�^�̃f�[�^�𑀍삵�č��������邱�Ƃ��ł���Bpusha/popa�ɖ��ʂ���������Ƃ����ĒP���ɔp�~���铪�̈����͒v���I���B
116 �F,,�E�L�́M�E,,�j��-�������F2015/02/08(��) 14:36:42.81 ID:E15V7x1F
����pusha�Ȃ��32bit�R�[�h�ł��قƂ�ǎg���ĂȂ��ł�����i�g���Ƃ����Ēx���Ȃ�j
�R���e�N�X�g�̑ޔ���肽���Ȃ�xsave�����邵
�ނ���bound���ߔp�~�������ǃ|�C���^�͈̔̓`�F�b�N�͉ϒ��z��g���Ƃ��͑��p����邵
Skylake�œ����@�\�̖��߂�MPX�Ƃ��ĕ��������Ă邠���肪AMD64�̔����ȂƂ��B
�R���e�N�X�g�̑ޔ���肽���Ȃ�xsave�����邵
�ނ���bound���ߔp�~�������ǃ|�C���^�͈̔̓`�F�b�N�͉ϒ��z��g���Ƃ��͑��p����邵
Skylake�œ����@�\�̖��߂�MPX�Ƃ��ĕ��������Ă邠���肪AMD64�̔����ȂƂ��B
AMD64�ň�ԑʖڂȂ̂͂����Ⴎ����̊g������Ď�������܂Ƃ��ɖ��߃f�R�[�h�ł��Ȃ��Ȃ������Ƃ���B
Intel�͒��߂�Pen4��uOPS�L���b�V�����A���ǂ��č������邯�ǂ���ł��r�����Ȃ��d�ׂɂȂ��Ă���AMD�ł͂���ɑς����Ȃ��Ƃ����B
AVX�̓v���t�B�N�X����Ȃ��Ė��ߌ꒷�ϓ��v�����Œ蒷�̃w�b�_�[�ɂ܂Ƃ߂�����t�Ƀf�R�[�h���y�ɂȂ��Ă邯�ǖ{����AMD64�͂Ђǂ��B
Intel�͒��߂�Pen4��uOPS�L���b�V�����A���ǂ��č������邯�ǂ���ł��r�����Ȃ��d�ׂɂȂ��Ă���AMD�ł͂���ɑς����Ȃ��Ƃ����B
AVX�̓v���t�B�N�X����Ȃ��Ė��ߌ꒷�ϓ��v�����Œ蒷�̃w�b�_�[�ɂ܂Ƃ߂�����t�Ƀf�R�[�h���y�ɂȂ��Ă邯�ǖ{����AMD64�͂Ђǂ��B
��������X86�Ȃ�Ă������߂�����
���Y�̓G�~���ł������
���Y�̓G�~���ł������
>>109
���v���b�g�t�H�[���݊��A����悭�\�P�b�g�݊���ڎw�����Ă�����
PReP�̍ė����c�c
>>115
����1�̖��߂��āA�قڃJ�E���^�[��p����Ȃ��c�c
�X�^�b�N�|�C���^�����p�̖��߂��Z�k�`��������������Ƃ������n�߂�gdgd�ɂȂ郌�x���̖Ӓ����߂�
���v���b�g�t�H�[���݊��A����悭�\�P�b�g�݊���ڎw�����Ă�����
PReP�̍ė����c�c
>>115
����1�̖��߂��āA�قڃJ�E���^�[��p����Ȃ��c�c
�X�^�b�N�|�C���^�����p�̖��߂��Z�k�`��������������Ƃ������n�߂�gdgd�ɂȂ郌�x���̖Ӓ����߂�
68000��addq�Esubq���߂��v���o������B
1�`8�͈̔͂̐����l�����Z/���Z���閽�߁B
1�`8�͈̔͂̐����l�����Z/���Z���閽�߁B
121 �F,,�E�L�́M�E,,�j��-�������F2015/02/08(��) 15:55:29.84 ID:E15V7x1F
�X�^�b�N�Ɋ��R�[���̈����ς݉��낵���邱�Ǝ��̂��_�T���Ƃ����l������
���W�X�^16�{�ɑ��₵���킯�ł��āB
�����ɃX�^�b�N����̖��ߎc���Ă�Ε֗��݂����ȍl���͂Ȃ��B
�i����x86-64 Linux�̕W�����R�[���K��ł�4�����܂ł̓��W�X�^�n�������悤�ɂȂ��Ă�j
�ޔ����K�v�ȃf�[�^�͊��Ăяo�����ōD���ȏꏊ�ɑޔ�����Ⴆ����B
�X�[�p�[�X�J���^�̃A�[�L�e�N�`���ɂƂ��Ă͒����ς݉��낵����X�^�b�N��
���Ƃ��Ƒ����������B
���W�X�^16�{�ɑ��₵���킯�ł��āB
�����ɃX�^�b�N����̖��ߎc���Ă�Ε֗��݂����ȍl���͂Ȃ��B
�i����x86-64 Linux�̕W�����R�[���K��ł�4�����܂ł̓��W�X�^�n�������悤�ɂȂ��Ă�j
�ޔ����K�v�ȃf�[�^�͊��Ăяo�����ōD���ȏꏊ�ɑޔ�����Ⴆ����B
�X�[�p�[�X�J���^�̃A�[�L�e�N�`���ɂƂ��Ă͒����ς݉��낵����X�^�b�N��
���Ƃ��Ƒ����������B
���₢��W�X�^�̑Ҕ����ǂ��ł��ɂ���X�^�b�N����͕K�v�B
���ƂȂ��Ă�SIMD�Ŋg�������L���f�[�^�p�X���g���ĕ����̃��W�X�^���ꊇ����ł��閽�߂������������ǂ��Ȃ����B
���ƂȂ��Ă�SIMD�Ŋg�������L���f�[�^�p�X���g���ĕ����̃��W�X�^���ꊇ����ł��閽�߂������������ǂ��Ȃ����B
123 �F,,�E�L�́M�E,,�j��-�������F2015/02/08(��) 16:30:02.97 ID:E15V7x1F
�X�^�b�N����͂ǂ݂̂��K�v�����ǂ��B
�X�^�b�N�|�C���^�̑���ƃ��[�h�E�X�g�A�����܂ǂ���p��1���߂œ����ɂ��K�v�����邩�A�Ƃ����b�B
push/pop�̓��[�h�E�X�g�A�����邩�炢�܂ǂ��̃R���p�C����mov�ŃX�^�b�N�t���[����ǂݏ�������
*sp�ڑ��삷��R�[�h������B
�X�^�b�N�|�C���^�̑���ƃ��[�h�E�X�g�A�����܂ǂ���p��1���߂œ����ɂ��K�v�����邩�A�Ƃ����b�B
push/pop�̓��[�h�E�X�g�A�����邩�炢�܂ǂ��̃R���p�C����mov�ŃX�^�b�N�t���[����ǂݏ�������
*sp�ڑ��삷��R�[�h������B
amd64�̔�����j�~��������ADEC��Alpha�`�[����AMD�ɉ�������̂�j�~����Ηǂ������킯���B
���X�^�b�N�|�C���^�̑���ƃ��[�h�E�X�g�A�����܂ǂ���p��1���߂œ����ɂ��K�v�����邩�A�Ƃ����b
����͂܂��s�v���낤��
>>115
�������W�X�^�ꊇ��push�Epop����arm�ɂ͂������C������A�������? ������������SH�̂���������?
�����Ƃ��A�ꖽ�߂�push��pop���܂Ƃ߂�ƁA������������[�h�A���A�N�Z�X�ŁA�}�C�N���R�[�h�̃}�N�����߉��������ȋC������A���v�Ȃ̂�?
�Ǝv�������A���̒��x�Ń}�C�N���R�[�h���K�v�Ȃ�SSE��AVX���}�C�N���R�[�h���p�Œx�����ߌQ�ɂȂ��Ă��͂������A����Ȗ��͔������Ȃ��̂���?
����͂܂��s�v���낤��
>>115
�������W�X�^�ꊇ��push�Epop����arm�ɂ͂������C������A�������? ������������SH�̂���������?
�����Ƃ��A�ꖽ�߂�push��pop���܂Ƃ߂�ƁA������������[�h�A���A�N�Z�X�ŁA�}�C�N���R�[�h�̃}�N�����߉��������ȋC������A���v�Ȃ̂�?
�Ǝv�������A���̒��x�Ń}�C�N���R�[�h���K�v�Ȃ�SSE��AVX���}�C�N���R�[�h���p�Œx�����ߌQ�ɂȂ��Ă��͂������A����Ȗ��͔������Ȃ��̂���?
126 �F,,�E�L�́M�E,,�j��-�������F2015/02/08(��) 19:57:07.68 ID:E15V7x1F
����push/pop�͕��ʂɒx���ł����B2��ops�ɕ��������ł���B
http://stackoverflow.com/questions/12766534/cost-of-push-vs-mov-stack-vs-near-memory-and-the-overhead-of-function-calls
Fast Decode�ŏ����ł��Ȃ��Ƃ������ƁB
���_�Ƃ���mov���ߎg���ĕϗʕ������X�^�b�N�|�C���^�����������Œ��K���킹�����ق�������
���̍œK���̓R���p�C��������ɂ���Ă����B
Core 2 Duo��Stack Manager�̎d�g�݂���������āA�y�i���e�B�͂�����x�͌y�����ꂽ��
���K�V�[�R�[�h�������̈�ł����ĕʂɐ����͂���Ă��Ȃ��B
http://stackoverflow.com/questions/12766534/cost-of-push-vs-mov-stack-vs-near-memory-and-the-overhead-of-function-calls
Fast Decode�ŏ����ł��Ȃ��Ƃ������ƁB
���_�Ƃ���mov���ߎg���ĕϗʕ������X�^�b�N�|�C���^�����������Œ��K���킹�����ق�������
���̍œK���̓R���p�C��������ɂ���Ă����B
Core 2 Duo��Stack Manager�̎d�g�݂���������āA�y�i���e�B�͂�����x�͌y�����ꂽ��
���K�V�[�R�[�h�������̈�ł����ĕʂɐ����͂���Ă��Ȃ��B
32bit ARM��push/pop���ꊇ�ł�閽�߂͂���(���W�X�^16��16bit�̃t�B�[���h�g���Ďw��)
64bit���Ƃ�������push/pop���������ǔC�ӂ�2�̃��W�X�^���y�A�Ń��[�h�X�g�A���閽�߂͂���
SIMD���ƘA������4�܂őg�ɂ��ă��[�h�X�g�A���閽�߂�����
�܂��ǂ��������ł͕��ʂ̃��[�h�X�g�A�����ɓW�J����Ă�낤����
64bit���Ƃ�������push/pop���������ǔC�ӂ�2�̃��W�X�^���y�A�Ń��[�h�X�g�A���閽�߂͂���
SIMD���ƘA������4�܂őg�ɂ��ă��[�h�X�g�A���閽�߂�����
�܂��ǂ��������ł͕��ʂ̃��[�h�X�g�A�����ɓW�J����Ă�낤����
����A���ʂ�push�Epop��2��op�ōςނ��ǃ��W�X�^���������邲�Ƃɒlj��Ń�op���ЂƂ������Ȃ����Ǝv������ŁB
�����_�Ƃ���mov���ߎg���ĕϗʕ������X�^�b�N�|�C���^�����������Œ��K���킹�����ق�������
�܂��A������O�̌��_�ł͂���܂��ȁ[
�������傭�K�v�Ȃ̂́A���W�X�^���X�g�w���push pop����Ȃ��ă��W�X�^���X�g�w���mov�Ald���store�Ȃȁ[
�����_�Ƃ���mov���ߎg���ĕϗʕ������X�^�b�N�|�C���^�����������Œ��K���킹�����ق�������
�܂��A������O�̌��_�ł͂���܂��ȁ[
�������傭�K�v�Ȃ̂́A���W�X�^���X�g�w���push pop����Ȃ��ă��W�X�^���X�g�w���mov�Ald���store�Ȃȁ[
���p��̓��W�X�^���X�g�w��ł͂Ȃ����W�X�^�͈͎w��ŏ\���B
�����Ă����������߃Z�b�g��ς����̂ɃX�^�b�N�𑽗p�������钆�r���[�Ȋg�������ł��Ȃ�����AMD64�̓S�~�Ƃ������Ƃ��ˁB
�����Ă����������߃Z�b�g��ς����̂ɃX�^�b�N�𑽗p�������钆�r���[�Ȋg�������ł��Ȃ�����AMD64�̓S�~�Ƃ������Ƃ��ˁB
���W�X�^8�Ń��X�g�w��Ȃ�8bit�A�͈͎w��Ȃ�6bit�B����łǂ��̐ߖ�ɂȂ���
���W�X�^16�Ȃ烊�X�g�w���16bit�A�͈͎w���8bit���B���ꂮ�炢�Ȃ�A�����͏������G�ɂȂ邪�A�I�y�R�[�h�̃T�C�Y�̐ߖ�ɂȂ邩
XMM�Ƃ�FPU�Ƃ��̃��W�X�^�܂œ����Ȃ�A�����ԕ��G�ɂȂ��Ă��邯�ǁA�ėp���W�X�^�����Ȃ�債�����ł͂Ȃ��C������
���W�X�^16�Ȃ烊�X�g�w���16bit�A�͈͎w���8bit���B���ꂮ�炢�Ȃ�A�����͏������G�ɂȂ邪�A�I�y�R�[�h�̃T�C�Y�̐ߖ�ɂȂ邩
XMM�Ƃ�FPU�Ƃ��̃��W�X�^�܂œ����Ȃ�A�����ԕ��G�ɂȂ��Ă��邯�ǁA�ėp���W�X�^�����Ȃ�債�����ł͂Ȃ��C������
PowerPC��rN����r31�܂ł܂Ƃ߂ă��[�h�X�g�A���閽�߂�����
���̎�̖��߂��ăR�[�h�T�C�Y���k��������A�Z���u���v���O���~���O����ɂ͕֗�������
���x����Ɋ�^����́H�ƌ������
���̎�̖��߂��ăR�[�h�T�C�Y���k��������A�Z���u���v���O���~���O����ɂ͕֗�������
���x����Ɋ�^����́H�ƌ������
���x�ʂł͌ʃ��[�h/�X�g�A���߂̕����������?
�}�C�N���A�[�L�e�N�`�����悾���ŐV��SIMD�Ή�����
256bit�̃f�[�^�p�X���g���Ĉ�x��4��64bit���W�X�^���܂Ƃ߂ă��[�h�X�g�A�ł��邩��Œ��ꒃ�����Ȃ��B
256bit�̃f�[�^�p�X���g���Ĉ�x��4��64bit���W�X�^���܂Ƃ߂ă��[�h�X�g�A�ł��邩��Œ��ꒃ�����Ȃ��B
���X�g������n�_�I�_�������ƃf�R�[�_���l�b�N�ɂȂ�ˁH�Ƃ�
�L���b�V�����C���ׂ�����ˑ��W�������x���Ȃ��ĕs������ˁH�Ƃ�
�X�g�A���Ƃ��������X�g�A�o�b�t�@�����邵�Z�߂�ƈˑ��W�������x���Ȃ��ĕs������ˁH�Ƃ�
���낢��^��_������킯��
�L���b�V�����C���ׂ�����ˑ��W�������x���Ȃ��ĕs������ˁH�Ƃ�
�X�g�A���Ƃ��������X�g�A�o�b�t�@�����邵�Z�߂�ƈˑ��W�������x���Ȃ��ĕs������ˁH�Ƃ�
���낢��^��_������킯��
�펯�I�Ƀv���t�B�N�X���₷���̓f�R�[�_�͊y���낤�ȁB
RISC�ł킴�킴�Ή����Ă�̂������̂͂��ꂾ���̗��R��������Ă��Ƃ���B
RISC�ł킴�킴�Ή����Ă�̂������̂͂��ꂾ���̗��R��������Ă��Ƃ���B
���₻���������ł͂Ȃ�
�ϐ��̓������߂Ƀf�R�[�h����閽�߂��ă}�C�N���R�[�h�V�[�P���T�s���ł��傤
�ϐ��̓������߂Ƀf�R�[�h����閽�߂��ă}�C�N���R�[�h�V�[�P���T�s���ł��傤
���W�X�^4���炢�Ȃ��̓������߂Ŏ��s�ł��邾��B
SIMD���W�X�^���ƃL���b�V�����C���܂������[�h�X�g�A�łQ�̃��W�X�^�����ЂƂɂ܂Ƃ߂ē������ߐ����炷�Ƃ����ł���B
SIMD���W�X�^���ƃL���b�V�����C���܂������[�h�X�g�A�łQ�̃��W�X�^�����ЂƂɂ܂Ƃ߂ē������ߐ����炷�Ƃ����ł���B
138 �F,,�E�L�́M�E,,�j��-�������F2015/02/09(��) 04:38:38.56 ID:G0zVLc8h
>>131
����A�g�ݍ��݃}�C�R���̏ȃ��������ő������ɗ���������Ȃ����p�t�H�[�}���X��̃����b�g���Ȃ���
complex�f�R�[�_�p�X�Ńf�R�[�_�l�b�N�ɂȂ�Ȃ�p�t�H�[�}���X��Ȃ�烁���b�g�Ȃ���
��ops���L���b�V�����錻�score�A�[�L�e�N�`���ł����ǃ�ops������������Ȃ�Ӗ��������B
��������x86��8�{�̔ėp���W�X�^�͖��߂ɂ���Ė��������܂��Ă���̂Ő^�̈Ӗ��Ŕėp�ł͂Ȃ��B
ASM�ʼn������珑���ɂ��Ă��A��ʂɃe���|�����ϐ����K�v�ȗp�r�łȂ���ق�eax, ecx, edx��3�{������
�ς܂���悤�ɏ�������Apush, pop�Ȃ�ĂقƂ�ǎg���@��Ȃ��B
�͈͎w��ňꊇ�ޔA�Ƃ�x86��m��Ȃ��l�Ԃ̔��z���킳�B
AMD64�������g���Ȃ݂̂͂�Ȃ킩���Ă��
x86�̃R�[�h�̌^���o�b�T����̂ĂĐV�K��64�r�b�g���߃Z�b�g����āAx86�̖��߂����s�ł���n�C�u���b�hCPU
�������Ǝv����H
�@�@�@�@����Intel�����ɂ������B�厸�s����Itanium����B
�Ȃ�ɂ�����p�I�Ȍ���E�����n���Ă���������������H
C++���������p��������Ax86���߃Z�b�g�������B
�������Ƃ������_�Ȃ�B�g���Ȃ������Ď�C������Ȃ�����ɉ��l�͂Ȃ��B
����A�g�ݍ��݃}�C�R���̏ȃ��������ő������ɗ���������Ȃ����p�t�H�[�}���X��̃����b�g���Ȃ���
complex�f�R�[�_�p�X�Ńf�R�[�_�l�b�N�ɂȂ�Ȃ�p�t�H�[�}���X��Ȃ�烁���b�g�Ȃ���
��ops���L���b�V�����錻�score�A�[�L�e�N�`���ł����ǃ�ops������������Ȃ�Ӗ��������B
��������x86��8�{�̔ėp���W�X�^�͖��߂ɂ���Ė��������܂��Ă���̂Ő^�̈Ӗ��Ŕėp�ł͂Ȃ��B
ASM�ʼn������珑���ɂ��Ă��A��ʂɃe���|�����ϐ����K�v�ȗp�r�łȂ���ق�eax, ecx, edx��3�{������
�ς܂���悤�ɏ�������Apush, pop�Ȃ�ĂقƂ�ǎg���@��Ȃ��B
�͈͎w��ňꊇ�ޔA�Ƃ�x86��m��Ȃ��l�Ԃ̔��z���킳�B
AMD64�������g���Ȃ݂̂͂�Ȃ킩���Ă��
x86�̃R�[�h�̌^���o�b�T����̂ĂĐV�K��64�r�b�g���߃Z�b�g����āAx86�̖��߂����s�ł���n�C�u���b�hCPU
�������Ǝv����H
�@�@�@�@����Intel�����ɂ������B�厸�s����Itanium����B
�Ȃ�ɂ�����p�I�Ȍ���E�����n���Ă���������������H
C++���������p��������Ax86���߃Z�b�g�������B
�������Ƃ������_�Ȃ�B�g���Ȃ������Ď�C������Ȃ�����ɉ��l�͂Ȃ��B
VLIW�̎��s��ISA�ύX�������ƍl���Ă鎞�_�Ń��x�����Ⴗ���Ă��b�ɂȂ�Ȃ��ȁB
140 �FSocket774�F2015/02/09(��) 06:56:53.64 ID:uC9fSklo
x86�h���h�����悤�ɂ���ƌ���x86���C���ɍ�邱�ƂɂȂ���
���ɂȂ��Ă��Ȃ����@�H
���ɂȂ��Ă��Ȃ����@�H
���{�l�Ȃ�C���e���Q�t�H���
�u���������Ȃ�ċC�ɂ��Ȃ��G�~���ōs���v����
���ǑS���G�~���ꂸ�Ƀj�E���pWindows��点�Ă邵
x86���x���Ȃ�㏞�Ƃ��Ċ����ɍ\�����ꂽ���߃Z�b�g�̑��������߂�I
�����s���Ă邵
Intel�͌Ӎ��������Ă�����Ă�v���Z�X�����Z�p�ƃL���b�V���Z�p�̉��b�Y���
����ȊO�̕����Ŗ����߂����������ނƂ�������Ⴄ��
���ǑS���G�~���ꂸ�Ƀj�E���pWindows��点�Ă邵
x86���x���Ȃ�㏞�Ƃ��Ċ����ɍ\�����ꂽ���߃Z�b�g�̑��������߂�I
�����s���Ă邵
Intel�͌Ӎ��������Ă�����Ă�v���Z�X�����Z�p�ƃL���b�V���Z�p�̉��b�Y���
����ȊO�̕����Ŗ����߂����������ނƂ�������Ⴄ��
143 �FSocket774�F2015/02/09(��) 07:44:06.86 ID:ivtkgPui
phi�͐������Ă邪��
�v���Z�X�Z�p�K�[�Ƃ���������Fab����������Ђ�����������
�S�ł͂��ނǂ���
���{�l�Ȃ�C���e���Q�t�H������˂�
147 �F,,�E�L�́M�E,,�j��-������ ��M2TLe2H2No �F2015/02/09(��) 12:30:38.98 ID:2eQt5iEm
> ID:71CnXvKJ
���OIntel������CPU�X���ʼn��ɘ_�j����ĉ��������Ԃ��Ȃ������̂�
�܂��A�z�Ȃ��ƌ����Ă��
>>115
> ���������Ӗ��ł�1�o�C�g���߂͑S������Ȃ��B
1�o�C�gOpcode���s�v�Ƃ���������B
*AX���W�X�^�ւ̑��삪1�o�C�gOpcode�ň�����̂͗��j�I�ɂ��d�v�ȈӖ��������B
A���A�L�������[�^�ł����B�܂���ABCD�������̃��W�X�^�ԍ����Ƃł��v�������H
C�Ȃǂ�ABI�K��ł�AX�͊��̕Ԃ�l��Ԃ��悤�ɂȂ��Ă�B
�K�R�I��AX�ɏ������ޖ��߂���ԗ��p�p�x�������Ȃ�̂ŕ��σR�[�h�T�C�Y�̊ϓ_�Ō��Ă�
AX�Ɍ����ĉ����_�����Z�E�ړ���1�o�C�gopcode�ł���Ӗ����\���ɂ���̂��B
>>133
> 256bit�̃f�[�^�p�X���g���Ĉ�x��4��64bit���W�X�^���܂Ƃ߂ă��[�h�X�g�A�ł��邩��Œ��ꒃ�����Ȃ��B
��̂ǂ��̔]��CPU�̘b�ł����H
Intel CPU�Ɍ������b�łق��͂ǂ��Ȃ��Ă邩�͒��ׂĂȂ����A���s�̃�OP�̃t�H�[�}�b�g��
2�ȏ��destination�I�y�����h��\�����邱�Ƃ��ł��Ȃ��B
3�\�[�X�I�y�����h�A1�f�X�e�B�l�[�V�����i�{�t���O���W�X�^�j��Haswell����̃�OP�̃t�H�[�}�b�g�B
�����̏o�͐������x86���߂́A�Œ�ł��o�͐搔���̃�OP�ɕ��������B
>>129
> ���p��̓��W�X�^���X�g�w��ł͂Ȃ����W�X�^�͈͎w��ŏ\���B
������������Ȗ��߂����p�ɂȂ�Ȃ�
���W�X�^���l�[�~���O�̂��郂�_����CPU�ł͂ŕ����I�ȃ��W�X�^�Ԓn��x86���x���̃��W�X�^�ԍ���
��v���ĂȂ��킯�ŁAx86�ł͘A�Ԃ�������āA�o�b�N�G���h���x���ŘA�ԂɂȂ��Ă�킯�ˁ[����H
�ƁA�ȏ�܂��āA�ꊇpush/pop���߂��������Ɋ�^����v�f�����o���Ȃ��B
���������̂�f�l�̐�m�b�Ƃ����B
�܂����O�͎����������Ƃ�����͂��Ȏv�����݂��̂Ă�B
����1����10�܂Ńc�b�R�~����ꂳ���邨�O�͐��X�������炢�̔n�����B
��b�m�����Ȃ�������p�����ȁB
���OIntel������CPU�X���ʼn��ɘ_�j����ĉ��������Ԃ��Ȃ������̂�
�܂��A�z�Ȃ��ƌ����Ă��
>>115
> ���������Ӗ��ł�1�o�C�g���߂͑S������Ȃ��B
1�o�C�gOpcode���s�v�Ƃ���������B
*AX���W�X�^�ւ̑��삪1�o�C�gOpcode�ň�����̂͗��j�I�ɂ��d�v�ȈӖ��������B
A���A�L�������[�^�ł����B�܂���ABCD�������̃��W�X�^�ԍ����Ƃł��v�������H
C�Ȃǂ�ABI�K��ł�AX�͊��̕Ԃ�l��Ԃ��悤�ɂȂ��Ă�B
�K�R�I��AX�ɏ������ޖ��߂���ԗ��p�p�x�������Ȃ�̂ŕ��σR�[�h�T�C�Y�̊ϓ_�Ō��Ă�
AX�Ɍ����ĉ����_�����Z�E�ړ���1�o�C�gopcode�ł���Ӗ����\���ɂ���̂��B
>>133
> 256bit�̃f�[�^�p�X���g���Ĉ�x��4��64bit���W�X�^���܂Ƃ߂ă��[�h�X�g�A�ł��邩��Œ��ꒃ�����Ȃ��B
��̂ǂ��̔]��CPU�̘b�ł����H
Intel CPU�Ɍ������b�łق��͂ǂ��Ȃ��Ă邩�͒��ׂĂȂ����A���s�̃�OP�̃t�H�[�}�b�g��
2�ȏ��destination�I�y�����h��\�����邱�Ƃ��ł��Ȃ��B
3�\�[�X�I�y�����h�A1�f�X�e�B�l�[�V�����i�{�t���O���W�X�^�j��Haswell����̃�OP�̃t�H�[�}�b�g�B
�����̏o�͐������x86���߂́A�Œ�ł��o�͐搔���̃�OP�ɕ��������B
>>129
> ���p��̓��W�X�^���X�g�w��ł͂Ȃ����W�X�^�͈͎w��ŏ\���B
������������Ȗ��߂����p�ɂȂ�Ȃ�
���W�X�^���l�[�~���O�̂��郂�_����CPU�ł͂ŕ����I�ȃ��W�X�^�Ԓn��x86���x���̃��W�X�^�ԍ���
��v���ĂȂ��킯�ŁAx86�ł͘A�Ԃ�������āA�o�b�N�G���h���x���ŘA�ԂɂȂ��Ă�킯�ˁ[����H
�ƁA�ȏ�܂��āA�ꊇpush/pop���߂��������Ɋ�^����v�f�����o���Ȃ��B
���������̂�f�l�̐�m�b�Ƃ����B
�܂����O�͎����������Ƃ�����͂��Ȏv�����݂��̂Ă�B
����1����10�܂Ńc�b�R�~����ꂳ���邨�O�͐��X�������炢�̔n�����B
��b�m�����Ȃ�������p�����ȁB
148 �F,,�E�L�́M�E,,�j��-������ nfmv001101224.uqw.ppp.infoweb.ne.jp�F2015/02/09(��) 12:39:53.89 ID:2eQt5iEm
���[�������߂�
http://www.agner.org/optimize/instruction_tables.pdf
Sandy Bridge�ł�pusha/popa�͍������ǂ��납16��ops�ȏ�ɕ��������N�\���߂ł���
���j�I�ɂ�Intel���u�g���邯�ǁi���ɑ��x���K�v�ȏ�ʂł́j�g���ȁv�ƌ��������Ă������߂�
�Ȃ�ō������Ɋ�^����Ǝv���̂��H
http://www.agner.org/optimize/instruction_tables.pdf
Sandy Bridge�ł�pusha/popa�͍������ǂ��납16��ops�ȏ�ɕ��������N�\���߂ł���
���j�I�ɂ�Intel���u�g���邯�ǁi���ɑ��x���K�v�ȏ�ʂł́j�g���ȁv�ƌ��������Ă������߂�
�Ȃ�ō������Ɋ�^����Ǝv���̂��H
AMD64���哱�������ꂽ�̂͂����Ȏv�f����MS����������炾�낤����
HSA�ɂ��Ă�FSA�Őڋ߂��Ă�MS�����ꂽ����S�R���҂����ĂȂ�
PCwatch�ł���1�N�قǂ̊ԂɃZ�������}����AMD���̋L���𐔖{�����Ă���
���A�ڂ�CPU�҂ňꎞ��������AMD�̐��i���C���A�b�v�������Ă����I
���]���ꂽ�肵�Ă�����
�ڂɌ����閾�邢�j���[�X���ĒI�ڂ��I�ɃQ�b�g�����Q�[���@�ւ�APU�̗p�����ł���
�܂��Q�[���@�ɍ̗p�����Ƒ��̊J�����a���ɂȂ�̂����̃p�^�[��������
�����I�Ɍ��ăz���g�ɍD�ޗ��ɂł��邩�ǂ�����AMD�̎�r�Ɋ|�����Ă�Ǝv������
���Z�̒�グ�ȊO�A����ܔg�y���ʂȂ����
HSA�ɂ��Ă�FSA�Őڋ߂��Ă�MS�����ꂽ����S�R���҂����ĂȂ�
PCwatch�ł���1�N�قǂ̊ԂɃZ�������}����AMD���̋L���𐔖{�����Ă���
���A�ڂ�CPU�҂ňꎞ��������AMD�̐��i���C���A�b�v�������Ă����I
���]���ꂽ�肵�Ă�����
�ڂɌ����閾�邢�j���[�X���ĒI�ڂ��I�ɃQ�b�g�����Q�[���@�ւ�APU�̗p�����ł���
�܂��Q�[���@�ɍ̗p�����Ƒ��̊J�����a���ɂȂ�̂����̃p�^�[��������
�����I�Ɍ��ăz���g�ɍD�ޗ��ɂł��邩�ǂ�����AMD�̎�r�Ɋ|�����Ă�Ǝv������
���Z�̒�グ�ȊO�A����ܔg�y���ʂȂ����
���{�l�Ȃ�C���e���Q�t�H���
OpenCL�ɂ�����Ă�͖̂��邢�j���[�X�ƌ����Ă����B
�ɁE��2���ʖڂ������������Ax86���ߎ��s�̒x��������Ȃ��B
�ǂ����̉\�ł́APen4�������I��Ita���߂̃G�~�����[�V�������s�܂ŗ\�肵�Ă��ƌ������ǁA
���̂����ő��x����ɔ��肪�t���Ă��܂�������core�ɐ�ւ���ꂽ�킯�Łc�c
�܂��A�P��R�A�ő��x����ƌ����Ă�����������_���������\���͂��邵�A
���܂Ȃ�A�[�L�e�N�`���Ⴂ�̕ʃv���Z�b�T����̌^�ō���Ďg�����ƂŁA�����̂悤�Ȗ�肪�N���Ȃ��\�������邪�B
�ǂ����̉\�ł́APen4�������I��Ita���߂̃G�~�����[�V�������s�܂ŗ\�肵�Ă��ƌ������ǁA
���̂����ő��x����ɔ��肪�t���Ă��܂�������core�ɐ�ւ���ꂽ�킯�Łc�c
�܂��A�P��R�A�ő��x����ƌ����Ă�����������_���������\���͂��邵�A
���܂Ȃ�A�[�L�e�N�`���Ⴂ�̕ʃv���Z�b�T����̌^�ō���Ďg�����ƂŁA�����̂悤�Ȗ�肪�N���Ȃ��\�������邪�B
>>147
���͓��������Ƃ�������ς���Ȃ̊ԈႢ�ɋC�t���Ȃ���������m�������������B
���̔̕��ϓI�Z�����o���l�������͔̂F�߂邪�o���l������ςɂȂ��Ď��R�ȍl�@���ł��Ȃ��Ȃ��Ă���B
8086����g�����Ă����o�܂������ē����͌���ꂽ�I�y�����h�������Ȃ��������߂̃I�y�����h���g���������A����܂ł̖��߂��c��������1�o�C�g���߂͓����@�\��2�o�C�g���߂����邱�Ƃ������B
���������͍��ƂȂ��Ă͂��̃I�y�����h��a*���W�X�^�����g���Ȃ�1�o�C�g���߂��Ė{���ɗv��́H����Ȃ���˂Ƃ����b�B
������������H
���͓��������Ƃ�������ς���Ȃ̊ԈႢ�ɋC�t���Ȃ���������m�������������B
���̔̕��ϓI�Z�����o���l�������͔̂F�߂邪�o���l������ςɂȂ��Ď��R�ȍl�@���ł��Ȃ��Ȃ��Ă���B
8086����g�����Ă����o�܂������ē����͌���ꂽ�I�y�����h�������Ȃ��������߂̃I�y�����h���g���������A����܂ł̖��߂��c��������1�o�C�g���߂͓����@�\��2�o�C�g���߂����邱�Ƃ������B
���������͍��ƂȂ��Ă͂��̃I�y�����h��a*���W�X�^�����g���Ȃ�1�o�C�g���߂��Ė{���ɗv��́H����Ȃ���˂Ƃ����b�B
������������H
>>151
���O��Brook+��S�R�g���ĖႦ�Ȃ���OpenCL�ɂ������Ă������5�`6�N�o���Ă�̂ɁH
�W���ɏ���(�͂������ǑS�RNVIDIA��CUDA�ɑR�ł��Ă�Ƃ͎v���Ȃ�����
���O��Brook+��S�R�g���ĖႦ�Ȃ���OpenCL�ɂ������Ă������5�`6�N�o���Ă�̂ɁH
�W���ɏ���(�͂������ǑS�RNVIDIA��CUDA�ɑR�ł��Ă�Ƃ͎v���Ȃ�����
���{�Q�t�H84%�̎�����
���{�l�Ȃ�C���e���Q�t�H������˂�
���{�l�Ȃ�C���e���Q�t�H������˂�
>>148
pusha/popa��80186�Ńn���h�A�Z���u������̂ɕ֗����낤�ƒlj��������ǎ��͎g���肪�Ȃ������Ƃ����L���Ȗ��߁B
�e���W�X�^�����薽�߂̈Öق̃I�y�����h�ɗ\��Ă���x86�ł̓X�^�b�N�ɕۑ����K�v�Ȃ̂�si,di,bp��3�����Ȃ���������9�̃��W�X�^���܂Ƃ߂ĕۑ���������K�v�͂Ȃ������B
�g���Ȃ������Ԃ������č����������Ă��Ȃ��B���ꂾ���̘b�B
�g���郌�W�X�^�{����������Ί����̃��[�J���ϐ������W�X�^�Ɋ��蓖�Ċ��̓��Ń��W�X�^���ꊇ�ۑ��A�Ō�Ɉꊇ�����A�����ł̓������Q�ƂȂ��Ƃ���RISC�̎�@���g����悤�ɂȂ�B
���̎��S���W�X�^�ł͂Ȃ����Ǖ������W�X�^�̕ۑ������������Ȃ閽�߂��~�����Ȃ�B
AVX512�Ō���RISC�Ɠ���32���W�X�^3�I�y�����h�̖��ߑ̌n���̗p����̂Ȃ�ŏ����炻�����Ă����Ηǂ������̂ɂˁB
pusha/popa��80186�Ńn���h�A�Z���u������̂ɕ֗����낤�ƒlj��������ǎ��͎g���肪�Ȃ������Ƃ����L���Ȗ��߁B
�e���W�X�^�����薽�߂̈Öق̃I�y�����h�ɗ\��Ă���x86�ł̓X�^�b�N�ɕۑ����K�v�Ȃ̂�si,di,bp��3�����Ȃ���������9�̃��W�X�^���܂Ƃ߂ĕۑ���������K�v�͂Ȃ������B
�g���Ȃ������Ԃ������č����������Ă��Ȃ��B���ꂾ���̘b�B
�g���郌�W�X�^�{����������Ί����̃��[�J���ϐ������W�X�^�Ɋ��蓖�Ċ��̓��Ń��W�X�^���ꊇ�ۑ��A�Ō�Ɉꊇ�����A�����ł̓������Q�ƂȂ��Ƃ���RISC�̎�@���g����悤�ɂȂ�B
���̎��S���W�X�^�ł͂Ȃ����Ǖ������W�X�^�̕ۑ������������Ȃ閽�߂��~�����Ȃ�B
AVX512�Ō���RISC�Ɠ���32���W�X�^3�I�y�����h�̖��ߑ̌n���̗p����̂Ȃ�ŏ����炻�����Ă����Ηǂ������̂ɂˁB
158 �F,,�E�L�́M�E,,�j��-������ nfmv001111198.uqw.ppp.infoweb.ne.jp�F2015/02/09(��) 17:46:30.70 ID:4ASUIF+H
>>154
> ���͓��������Ƃ�������ς���Ȃ̊ԈႢ�ɋC�t���Ȃ���������m������������
�������肻�̂܂܂��O�ɕԂ��Ă��斳�\��
> 8086����g�����Ă����o�܂������ē����͌���ꂽ�I�y�����h�������Ȃ�����
> ���߂̃I�y�����h���g���������A����܂ł̖��߂��c��������1�o�C�g���߂�.
> �����@�\��2�o�C�g���߂����邱�Ƃ������B
�ւ��������ȍ앶���ȁB���w�Z�����蒼���B
�����H�u�����v���Ĉ�̂�����H
ModRM�t�H�[�}�b�g�Ȃ�8086���瑶�݂��āAax�^�[�Q�b�g�̖��߂�����1�o�C�g(+disp/imm)�ł�
ModRM�����ł��\���ł���悤�ɂȂ��Ă������H
AX�͈�ԗ��p�p�x�����������ԒZ���čςނ悤�ɂ���Ƃ����f�U�C������B
�ق�7�{�̃��W�X�^�ɂ��S���Ӗ�������B
�^�̈Ӗ���AX�Ɠ��l�ɔėp�I�Ɏg���郌�W�X�^�Ȃ��x86�ɂ͑��݂��Ȃ��B
R8�`R15�H����AMD�l����B
Intel��Yamhill�����������Ђǂ��āA���RREX�͂Ȃ���8���W�X�^�̂܂܁A�R�[�h�}�b�v�����̂܂܁A
64/32�r�b�g�Ԃ̃T�C�Y�ύX��1�o�C�g�̃v���t�B�b�N�X��t������Ƃ���16-32bit�ł�������Ƃ�
�܂������������Ƃ���낤�Ƃ��Ă���B
64bit�ł̓Z�O�����g�I�[�o�[���C�h��������Ȃ�����6��ނ̃v���t�B�N�X��ǂݑւ��Ɏg����B
���̏��0f38�Ƃ�0f3a�̒���SSSE3���ߍ�����̂�Intel�B
���̂�����̖��߂���Tejas�̃v���������Ă����Ƀv�����j���O���ꂽ������ˁB
��OPs�̌`�ɂ�����▽�߂������Ȃ������ĊW�Ȃ�����ȁB
�C�X���G���`�[���̃A�[�L���嗬�ɂȂ�܂ŁA�f�R�[�_�̕��ׂȂ�đS���l�����Ȃ�������B
����1�o�C�g������Ȃ�A�lj��̃��W�X�^�I�y�����h��8��16�Ɋg���ł���REX�̂ق���
�y���ɃR�[�h�����͗D��Ă���ˁB
ID:71CnXvKJ=ID:DZmZmqpo����A����Ȃ���A��w�͂ǂ���o�g�ł����H
���܂�ɔn�������Ęb�ɂȂ�Ȃ��̂ł����A�܂�����呲���Ă��Ƃ͂Ȃ���ˁH
�i���̒m�����x�����ƍH�ƍ��Z����o�Ă邩���������j
> ���͓��������Ƃ�������ς���Ȃ̊ԈႢ�ɋC�t���Ȃ���������m������������
�������肻�̂܂܂��O�ɕԂ��Ă��斳�\��
> 8086����g�����Ă����o�܂������ē����͌���ꂽ�I�y�����h�������Ȃ�����
> ���߂̃I�y�����h���g���������A����܂ł̖��߂��c��������1�o�C�g���߂�.
> �����@�\��2�o�C�g���߂����邱�Ƃ������B
�ւ��������ȍ앶���ȁB���w�Z�����蒼���B
�����H�u�����v���Ĉ�̂�����H
ModRM�t�H�[�}�b�g�Ȃ�8086���瑶�݂��āAax�^�[�Q�b�g�̖��߂�����1�o�C�g(+disp/imm)�ł�
ModRM�����ł��\���ł���悤�ɂȂ��Ă������H
AX�͈�ԗ��p�p�x�����������ԒZ���čςނ悤�ɂ���Ƃ����f�U�C������B
�ق�7�{�̃��W�X�^�ɂ��S���Ӗ�������B
�^�̈Ӗ���AX�Ɠ��l�ɔėp�I�Ɏg���郌�W�X�^�Ȃ��x86�ɂ͑��݂��Ȃ��B
R8�`R15�H����AMD�l����B
Intel��Yamhill�����������Ђǂ��āA���RREX�͂Ȃ���8���W�X�^�̂܂܁A�R�[�h�}�b�v�����̂܂܁A
64/32�r�b�g�Ԃ̃T�C�Y�ύX��1�o�C�g�̃v���t�B�b�N�X��t������Ƃ���16-32bit�ł�������Ƃ�
�܂������������Ƃ���낤�Ƃ��Ă���B
64bit�ł̓Z�O�����g�I�[�o�[���C�h��������Ȃ�����6��ނ̃v���t�B�N�X��ǂݑւ��Ɏg����B
���̏��0f38�Ƃ�0f3a�̒���SSSE3���ߍ�����̂�Intel�B
���̂�����̖��߂���Tejas�̃v���������Ă����Ƀv�����j���O���ꂽ������ˁB
��OPs�̌`�ɂ�����▽�߂������Ȃ������ĊW�Ȃ�����ȁB
�C�X���G���`�[���̃A�[�L���嗬�ɂȂ�܂ŁA�f�R�[�_�̕��ׂȂ�đS���l�����Ȃ�������B
����1�o�C�g������Ȃ�A�lj��̃��W�X�^�I�y�����h��8��16�Ɋg���ł���REX�̂ق���
�y���ɃR�[�h�����͗D��Ă���ˁB
ID:71CnXvKJ=ID:DZmZmqpo����A����Ȃ���A��w�͂ǂ���o�g�ł����H
���܂�ɔn�������Ęb�ɂȂ�Ȃ��̂ł����A�܂�����呲���Ă��Ƃ͂Ȃ���ˁH
�i���̒m�����x�����ƍH�ƍ��Z����o�Ă邩���������j
�l����J�߂��Ă悩�����Ȃ�
>>155
�u�c���o�Ă����̂����N�̍����ŁA���ꂩ���N�����Ȃ������Ɂi���łɊJ���҂�����jOpenCL�Ɉꕔ�@�\����荞�܂ꂽ�B
���ۂ�GPU���g���邩�ǂ����͂Ƃ�����OpenCL�ɐH�����߂��̂͂������ł��傤�B
�u�c���o�Ă����̂����N�̍����ŁA���ꂩ���N�����Ȃ������Ɂi���łɊJ���҂�����jOpenCL�Ɉꕔ�@�\����荞�܂ꂽ�B
���ۂ�GPU���g���邩�ǂ����͂Ƃ�����OpenCL�ɐH�����߂��̂͂������ł��傤�B
>>158
�����ɂ���������ȁB
�܂���������Yamhill��Itanium�Ȃ�Ęb�͈ꌾ�����Ă��Ȃ��B����Ȑ̂ɏI��������̂͂ǂ��ł������B
����AMD64�̖��߃}�b�v�����ĂȂ�Ɣ�����I�Ȃ��Ƃ��Ƃ���������n�܂��Ă���B
�����Đ擪����1�o�C�g���ǂ�ł����Ȃ��Ɩ��߃t�H�[�}�b�g���m�肵�Ȃ��v���t�B�N�X�����������d���ĕt���̂̓X�[�p�[�X�J���̃f�R�[�_�ɑ���ȕ��ׂ��|���Ă܂����ȂƂ������ƁB
AVX�̓v���t�B�N�X�ƌĂ�Ă͂��邪AVX���߂ɂ���ȏ㑼�̃v���t�B�N�X���t�����Ƃ͂Ȃ��̂Ŏ����̓w�b�_�ł���擪��1�o�C�g��ǂ����ŃI�y�R�[�h��ModR/W�̈ʒu���m�肷��B
�ƊE�ɒ������߂̕������̈Ⴂ�𗝉��ł��Ȃ��Ƃ͎v���Ȃ��̂��������ł��Ȃ��悤�Ȃ̂Ő��������Ă���B
�����ɂ���������ȁB
�܂���������Yamhill��Itanium�Ȃ�Ęb�͈ꌾ�����Ă��Ȃ��B����Ȑ̂ɏI��������̂͂ǂ��ł������B
����AMD64�̖��߃}�b�v�����ĂȂ�Ɣ�����I�Ȃ��Ƃ��Ƃ���������n�܂��Ă���B
�����Đ擪����1�o�C�g���ǂ�ł����Ȃ��Ɩ��߃t�H�[�}�b�g���m�肵�Ȃ��v���t�B�N�X�����������d���ĕt���̂̓X�[�p�[�X�J���̃f�R�[�_�ɑ���ȕ��ׂ��|���Ă܂����ȂƂ������ƁB
AVX�̓v���t�B�N�X�ƌĂ�Ă͂��邪AVX���߂ɂ���ȏ㑼�̃v���t�B�N�X���t�����Ƃ͂Ȃ��̂Ŏ����̓w�b�_�ł���擪��1�o�C�g��ǂ����ŃI�y�R�[�h��ModR/W�̈ʒu���m�肷��B
�ƊE�ɒ������߂̕������̈Ⴂ�𗝉��ł��Ȃ��Ƃ͎v���Ȃ��̂��������ł��Ȃ��悤�Ȃ̂Ő��������Ă���B
162 �F,,�E�L�́M�E,,�j��-������ nfmv001111198.uqw.ppp.infoweb.ne.jp�F2015/02/09(��) 18:31:08.01 ID:4ASUIF+H
> �g���郌�W�X�^�{����������Ί����̃��[�J���ϐ������W�X�^�Ɋ��蓖�Ċ��̓��Ń��W�X�^���ꊇ�ۑ��A
> �Ō�Ɉꊇ�����A�����ł̓������Q�ƂȂ��Ƃ���RISC�̎�@���g����悤�ɂȂ�B
> ���̎��S���W�X�^�ł͂Ȃ����Ǖ������W�X�^�̕ۑ������������Ȃ閽�߂��~�����Ȃ�B
> AVX512�Ō���RISC�Ɠ���32���W�X�^3�I�y�����h�̖��ߑ̌n���̗p����̂Ȃ�ŏ����炻�����Ă����Ηǂ������̂ɂˁB
�͂��H
AVX-512�͂��Ƃ���Xeon Phi�̂��߂̂��̂ŃC���I�[�_�Ń��C�e���V���B�����邽�߂ɖ��߂��A�����[������
�C���^�[���[�u����f�U�C�������炻���̃R�[�h�����Ȃ�Ėڂ��Ԃ���̂��B
���W�X�^�̑ޔA��1���߂ōςނ悤�ɂȂ邩��R�[�h�T�C�Y�̐ߖ�H
����Ȃ��ǂ�����Ă܂�����
�܂�SIMD���W�X�^�ɓn���f�[�^���X�^�b�N��ɐςނƂ������z���܂��A�z������B
�|�C���^�n���Ă�������ǂݏ����������H
AVX�Œlj����ꂽvzeroall���Ĉ�̉��̂��߂ɂ���Ǝv���Ă낤�ˁH
AVX�ł͊��̍ŏ���YMM���W�X�^��S�N���A���邱�Ƃ�O��ɂ��Ă�B
AVX-512�����킸�����ȁB
���̃p�����[�^�Ƃ��ēn�����̂������ASIMD���W�X�^�ɕۑ����K�v�ȃf�[�^��u�����܂�
���Ăяo���悤�ȃA�z�ȃR�[�h�����n�����ʂ��Ȃ�����B
�i���������|�C���^�g���p�����[�^�n���̂�SIMD���W�X�^���g���K�v�Ȃ��j
> �Ō�Ɉꊇ�����A�����ł̓������Q�ƂȂ��Ƃ���RISC�̎�@���g����悤�ɂȂ�B
> ���̎��S���W�X�^�ł͂Ȃ����Ǖ������W�X�^�̕ۑ������������Ȃ閽�߂��~�����Ȃ�B
> AVX512�Ō���RISC�Ɠ���32���W�X�^3�I�y�����h�̖��ߑ̌n���̗p����̂Ȃ�ŏ����炻�����Ă����Ηǂ������̂ɂˁB
�͂��H
AVX-512�͂��Ƃ���Xeon Phi�̂��߂̂��̂ŃC���I�[�_�Ń��C�e���V���B�����邽�߂ɖ��߂��A�����[������
�C���^�[���[�u����f�U�C�������炻���̃R�[�h�����Ȃ�Ėڂ��Ԃ���̂��B
���W�X�^�̑ޔA��1���߂ōςނ悤�ɂȂ邩��R�[�h�T�C�Y�̐ߖ�H
����Ȃ��ǂ�����Ă܂�����
�܂�SIMD���W�X�^�ɓn���f�[�^���X�^�b�N��ɐςނƂ������z���܂��A�z������B
�|�C���^�n���Ă�������ǂݏ����������H
AVX�Œlj����ꂽvzeroall���Ĉ�̉��̂��߂ɂ���Ǝv���Ă낤�ˁH
AVX�ł͊��̍ŏ���YMM���W�X�^��S�N���A���邱�Ƃ�O��ɂ��Ă�B
AVX-512�����킸�����ȁB
���̃p�����[�^�Ƃ��ēn�����̂������ASIMD���W�X�^�ɕۑ����K�v�ȃf�[�^��u�����܂�
���Ăяo���悤�ȃA�z�ȃR�[�h�����n�����ʂ��Ȃ�����B
�i���������|�C���^�g���p�����[�^�n���̂�SIMD���W�X�^���g���K�v�Ȃ��j
���dprefix�ȃt�H�[�}�b�g�����Ȃ̂͊��S���ӂ�����
����ƕ������W�X�^load/store���߂�p�ӂ���
�����I�ɂЂƂɂ܂Ƃ߂邱�Ƃ������������ǂ����͕ʂ̘b���Ǝv���̂�
���Ƃ܂������Ă�悤��1uop������̏������݃��W�X�^���͂���ɂ���
ISA���x���Ŗ��߂�p�ӂ��Ȃ��Ă�Macro fusion�I�Ȏ�@�Ŏ����\�ł͂�����
����ƕ������W�X�^load/store���߂�p�ӂ���
�����I�ɂЂƂɂ܂Ƃ߂邱�Ƃ������������ǂ����͕ʂ̘b���Ǝv���̂�
���Ƃ܂������Ă�悤��1uop������̏������݃��W�X�^���͂���ɂ���
ISA���x���Ŗ��߂�p�ӂ��Ȃ��Ă�Macro fusion�I�Ȏ�@�Ŏ����\�ł͂�����
load rA, mem
load rB, mem+4
����
load {rA, rB}, mem
�ɂ����Ƃ��A�����I��2��load�ɕ������Ȃ��ꍇmem��mem+4�ŃL���b�V�����C�����ׂ����ƂɂȂ��
rB�����[�h����܂�rA�Ɉˑ�����㑱���߂����s�ł����������C�e���V��������
store mem, rA
store mem+4, rB
����
store mem, {rA, rB}
�ɂ����Ƃ��A�����I��2��store�ɕ������Ȃ��ꍇrA��rB�̗��������܂�Ȃ���
wake up�ł����Astore�̔��s���x���
�ш悾���l����ƃn�b�s�[�ȋC�����邯�ǁA�����I�ɍl���ē����邩�͂܂��ʂ̘b�ł��傤�A��
load rB, mem+4
����
load {rA, rB}, mem
�ɂ����Ƃ��A�����I��2��load�ɕ������Ȃ��ꍇmem��mem+4�ŃL���b�V�����C�����ׂ����ƂɂȂ��
rB�����[�h����܂�rA�Ɉˑ�����㑱���߂����s�ł����������C�e���V��������
store mem, rA
store mem+4, rB
����
store mem, {rA, rB}
�ɂ����Ƃ��A�����I��2��store�ɕ������Ȃ��ꍇrA��rB�̗��������܂�Ȃ���
wake up�ł����Astore�̔��s���x���
�ш悾���l����ƃn�b�s�[�ȋC�����邯�ǁA�����I�ɍl���ē����邩�͂܂��ʂ̘b�ł��傤�A��
165 �FSocket774�F2015/02/09(��) 18:46:50.95 ID:LqTg7nYD
Raptr��AMD Gaming Evolved�̃A�J�E���g��/���A�h�Ȃǂ����o
http://pc.watch.impress.co.jp/docs/news/20150209_687521.html
AMD�̃f�B�X�v���C�h���C�o�uCatalyst Software Suite�v�ɓ�������Ă���Q�[���\�[�V�����l�b�g���[�N�uAMD Gaming Evolved�v�A
����т��̃x�[�X�ƂȂ��Ă���uRaptr�v�̃T�[�o�[���A��O�҂ɂ��s���A�N�Z�X���A�A�J�E���g���Ȃǂ����o�������Ƃ����������B
����̓T�[�r�X��W�J����Raptr�����p�҂ւ̃��[�����m�Ŗ��炩�ɂȂ������́B
��O�҂̃n�b�L���O�ɂ��A�A�J�E���g���A���[���A�h���X�A�p�X���[�h�n�b�V���A����шꕔ�̓o�^�����Ȃǂ��s���A�N�Z�X�����B
AMD����炩��������������������
���{�l�Ȃ�C���e���Q�t�H������˂�������
http://pc.watch.impress.co.jp/docs/news/20150209_687521.html
AMD�̃f�B�X�v���C�h���C�o�uCatalyst Software Suite�v�ɓ�������Ă���Q�[���\�[�V�����l�b�g���[�N�uAMD Gaming Evolved�v�A
����т��̃x�[�X�ƂȂ��Ă���uRaptr�v�̃T�[�o�[���A��O�҂ɂ��s���A�N�Z�X���A�A�J�E���g���Ȃǂ����o�������Ƃ����������B
����̓T�[�r�X��W�J����Raptr�����p�҂ւ̃��[�����m�Ŗ��炩�ɂȂ������́B
��O�҂̃n�b�L���O�ɂ��A�A�J�E���g���A���[���A�h���X�A�p�X���[�h�n�b�V���A����шꕔ�̓o�^�����Ȃǂ��s���A�N�Z�X�����B
AMD����炩��������������������
���{�l�Ȃ�C���e���Q�t�H������˂�������
�c�q�搶�ɗ����������Ă�����|�����AMDer�Ɋw�K�\�͖͂����̂��ˁH
�������炱��ȃK���N�^����Ȃ���
�������炱��ȃK���N�^����Ȃ���
167 �F,,�E�L�́M�E,,�j��-������ nfmv001111198.uqw.ppp.infoweb.ne.jp�F2015/02/09(��) 18:50:12.07 ID:4ASUIF+H
> �����Đ擪����1�o�C�g���ǂ�ł����Ȃ��Ɩ��߃t�H�[�}�b�g���m�肵�Ȃ��v���t�B�N�X��������
> ���d���ĕt���̂̓X�[�p�[�X�J���̃f�R�[�_�ɑ���ȕ��ׂ��|���Ă܂����ȂƂ������ƁB
���Ox86�̃t�����g�G���h�ǂ��Ȃ��Ă�̂�����Ȋ�{�I�Ȃ��Ƃ��m��Ȃ��ȁB
�ق�Ɗw���ˁ[
�擪����ǂ�ł��Ȃ��āA16�o�C�g��������t�F�b�`���āA16����ŃX�L�������ċ��E���i�荞��ł�����B
Opcode��ModRM�̏ꏊ�𐄒肷��Ό㑱��SIB/Disp/Imm�̒������킩��B
REX�̓t�����g�G���h�̃{�g���l�b�N�ɂȂ�Ȃ��B66��F2, F3�Ɠ����B
�O����ǂ�ł����Ƃ������z�Ȃ�āA���߂ăX�[�p�[�X�J�����̗p����P54C�̎��_�Ŋ��ɑ��݂��Ȃ��B
�i���ɂ����uPentium�����v���Ĉ�x�ł���������ǂ��Ƃ���H�j
�t�����g�G���h�œ��ɂ���prefix���{�g���l�b�N�ɂȂ�̂�disp��imm�̃T�C�Y��ύX����Ƃ�����
�i���茋�ʂ�����邩��j
�擪����V���A���ɓǂ�ł����Ɗ��Ⴂ���Ă邩�炱���������z�Ɋׂ�B
�t�ɁA����66�����d�������悤�����������t�F�b�`�ш悪��������邾���Ńv���f�R�[�_�E�f�R�[�_�̕��ׂ͕ς���B
asm�̃R�[�h�����Ă�A66����������nop�ŃW�����v��̐擪�̃R�[�h�̃A���C�������g�Ƃ邾��H
���O�̔]���ł̓v���t�B�N�X��ʂɂ��ƃy�i���e�B�ɂȂ��ȁH����Ȃ̌����ɂ͖�������B
�v���O�����g���Ɩ������O�݂����ȑf�l�ɂ͂킩��Ȃ����낤���ǂȁB
> ���d���ĕt���̂̓X�[�p�[�X�J���̃f�R�[�_�ɑ���ȕ��ׂ��|���Ă܂����ȂƂ������ƁB
���Ox86�̃t�����g�G���h�ǂ��Ȃ��Ă�̂�����Ȋ�{�I�Ȃ��Ƃ��m��Ȃ��ȁB
�ق�Ɗw���ˁ[
�擪����ǂ�ł��Ȃ��āA16�o�C�g��������t�F�b�`���āA16����ŃX�L�������ċ��E���i�荞��ł�����B
Opcode��ModRM�̏ꏊ�𐄒肷��Ό㑱��SIB/Disp/Imm�̒������킩��B
REX�̓t�����g�G���h�̃{�g���l�b�N�ɂȂ�Ȃ��B66��F2, F3�Ɠ����B
�O����ǂ�ł����Ƃ������z�Ȃ�āA���߂ăX�[�p�[�X�J�����̗p����P54C�̎��_�Ŋ��ɑ��݂��Ȃ��B
�i���ɂ����uPentium�����v���Ĉ�x�ł���������ǂ��Ƃ���H�j
�t�����g�G���h�œ��ɂ���prefix���{�g���l�b�N�ɂȂ�̂�disp��imm�̃T�C�Y��ύX����Ƃ�����
�i���茋�ʂ�����邩��j
�擪����V���A���ɓǂ�ł����Ɗ��Ⴂ���Ă邩�炱���������z�Ɋׂ�B
�t�ɁA����66�����d�������悤�����������t�F�b�`�ш悪��������邾���Ńv���f�R�[�_�E�f�R�[�_�̕��ׂ͕ς���B
asm�̃R�[�h�����Ă�A66����������nop�ŃW�����v��̐擪�̃R�[�h�̃A���C�������g�Ƃ邾��H
���O�̔]���ł̓v���t�B�N�X��ʂɂ��ƃy�i���e�B�ɂȂ��ȁH����Ȃ̌����ɂ͖�������B
�v���O�����g���Ɩ������O�݂����ȑf�l�ɂ͂킩��Ȃ����낤���ǂȁB
>>167
�@�擪����ǂ�ōs���悤�ɍ��ꂽ�o�C�g�R�[�h����������悤�Ƃ���Ɠr�����Ȃ������H���K�v�ɂȂ邩��
���ۂɂ̓p�C�v���C���������Ȃ�̂����e���Ē����v���f�R�[�_��ʂ����ʼn��i�K���ɕ����ď��������Ŗ��߃t�H�[�}�b�g���m�肵�āA�Ō�Ɏ��p�I�ȋK�͂̉�H�Ńf�R�[�h�ł���悤�ɂ�����A
���ꂪ���\��̃y�i���e�B���H�v��̕��S�ɂȂ��ĂȂ��Ƃł��H
�@����Pentium�͂�����2����Ȃ̂ɕ���f�R�[�h�ł��閽�߂Ɍ�������������������Ƀv���t�B�N�X���t���ƕ���f�R�[�h�ł��Ȃ��ă}�C�N���R�[�h�̂����b�ɂȂ��Ă����B
�@�擪����ǂ�ōs���悤�ɍ��ꂽ�o�C�g�R�[�h����������悤�Ƃ���Ɠr�����Ȃ������H���K�v�ɂȂ邩��
���ۂɂ̓p�C�v���C���������Ȃ�̂����e���Ē����v���f�R�[�_��ʂ����ʼn��i�K���ɕ����ď��������Ŗ��߃t�H�[�}�b�g���m�肵�āA�Ō�Ɏ��p�I�ȋK�͂̉�H�Ńf�R�[�h�ł���悤�ɂ�����A
���ꂪ���\��̃y�i���e�B���H�v��̕��S�ɂȂ��ĂȂ��Ƃł��H
�@����Pentium�͂�����2����Ȃ̂ɕ���f�R�[�h�ł��閽�߂Ɍ�������������������Ƀv���t�B�N�X���t���ƕ���f�R�[�h�ł��Ȃ��ă}�C�N���R�[�h�̂����b�ɂȂ��Ă����B
>>168
�܂��AAMD�����O�Ń}�g���ȊJ���������͂���������RD Now! �̂Ƃ������ċƊE�ɍL�����y���Ē蒅���Ă����낤����
���Ђ̎�_��������Ɣc���ł���悤�ɂȂ��������ł��O�i���Ǝv����B
���Ђ̎�_����������Ƃ��t�H���[�ł���̐������Ƃ��̒i�K�܂Ői�߂ĂȂ����ǂ��B
�܂��AAMD�����O�Ń}�g���ȊJ���������͂���������RD Now! �̂Ƃ������ċƊE�ɍL�����y���Ē蒅���Ă����낤����
���Ђ̎�_��������Ɣc���ł���悤�ɂȂ��������ł��O�i���Ǝv����B
���Ђ̎�_����������Ƃ��t�H���[�ł���̐������Ƃ��̒i�K�܂Ői�߂ĂȂ����ǂ��B
171 �F,,�E�L�́M�E,,�j��-������ nfmv001111198.uqw.ppp.infoweb.ne.jp�F2015/02/09(��) 19:52:11.09 ID:4ASUIF+H
�ق�ƌ��ꂵ���n������
>�@����Pentium�͂�����2����Ȃ̂ɕ���f�R�[�h�ł��閽�߂Ɍ��������������������
> �v���t�B�N�X���t���ƕ���f�R�[�h�ł��Ȃ��ă}�C�N���R�[�h�̂����b�ɂȂ��Ă����B
���ꂷ�玟�̐����Pentium Pro�ō�������3���܂ł���Ă�킯����
���̐����x86�����ɂƂ��Ă͊��Ɋ��ɕ����Ă��܂��Ă�����R�X�g��
�lj��Ŕ���������̂ł͂Ȃ��B
�t�F�b�`�ш悪32�o�C�g�ɂȂ낤��64�o�C�g�ɂȂ낤���R�X�g�̓��j�A�ɂ����������Ȃ��B
32bit��64bit���������Ă����Ȃ��Ƃ����Ȃ�x86��64bit�����ɋ��߂��Ă���̂́A
32bit�̂���ƃR�[�h�̌n��傫���ς��Ȃ����Ƃ��B
�R�[�h�̌n��ς���������̂ق����������ăt�����g�G���h�̎����R�X�g�����傷��B
����Ȃ��Ƃ��킩��Ȃ��̂��H
>�@����Pentium�͂�����2����Ȃ̂ɕ���f�R�[�h�ł��閽�߂Ɍ��������������������
> �v���t�B�N�X���t���ƕ���f�R�[�h�ł��Ȃ��ă}�C�N���R�[�h�̂����b�ɂȂ��Ă����B
���ꂷ�玟�̐����Pentium Pro�ō�������3���܂ł���Ă�킯����
���̐����x86�����ɂƂ��Ă͊��Ɋ��ɕ����Ă��܂��Ă�����R�X�g��
�lj��Ŕ���������̂ł͂Ȃ��B
�t�F�b�`�ш悪32�o�C�g�ɂȂ낤��64�o�C�g�ɂȂ낤���R�X�g�̓��j�A�ɂ����������Ȃ��B
32bit��64bit���������Ă����Ȃ��Ƃ����Ȃ�x86��64bit�����ɋ��߂��Ă���̂́A
32bit�̂���ƃR�[�h�̌n��傫���ς��Ȃ����Ƃ��B
�R�[�h�̌n��ς���������̂ق����������ăt�����g�G���h�̎����R�X�g�����傷��B
����Ȃ��Ƃ��킩��Ȃ��̂��H
32bit�͕ʂɑ�������K�v�Ȃ�ĂȂ����ǂȁB
32bit�̑��x������܂ł��x���Ȃ�Ȃ���Ηǂ������B
32bit��64bit�̊Ԃ̐��\�����傫����Α��x�̕K�v�Ȃ��̂͂�����64bit�ɐ�ւ��B
�ނ���32bit�͑����Ȃ�Ȃ��Ă������炻�̕�64bit���������̂��]�܂�Ă���B���ۂɂ̓L���b�V���̉��P�ȂǂŃf�R�[�_�̐i�����~�܂��Ă����i���x���ł͑����Ȃ��Ă����B
IA64�͂�������64bit�ł���Ȃɑ����Ȃ�������32bit���ɒ[�ɒx����������32bit����ڍs�ł����Ɏ��s���AARM-V8��32bit���x���Ȃ��ĂȂ����琬�����������̂��ƁB
386SX��AMD��286���x�������̂�286���R�U�炵�Ĉڍs�ɐ����������B
AMD64��32bit���[�h�̌݊������s�\����VB�A�v���ȂNjƖ��Ŏg���Ă���\�t�g�������Ȃ��Ⴊ�������Ė��ɂȂ��Ă���B
32bit�̑��x������܂ł��x���Ȃ�Ȃ���Ηǂ������B
32bit��64bit�̊Ԃ̐��\�����傫����Α��x�̕K�v�Ȃ��̂͂�����64bit�ɐ�ւ��B
�ނ���32bit�͑����Ȃ�Ȃ��Ă������炻�̕�64bit���������̂��]�܂�Ă���B���ۂɂ̓L���b�V���̉��P�ȂǂŃf�R�[�_�̐i�����~�܂��Ă����i���x���ł͑����Ȃ��Ă����B
IA64�͂�������64bit�ł���Ȃɑ����Ȃ�������32bit���ɒ[�ɒx����������32bit����ڍs�ł����Ɏ��s���AARM-V8��32bit���x���Ȃ��ĂȂ����琬�����������̂��ƁB
386SX��AMD��286���x�������̂�286���R�U�炵�Ĉڍs�ɐ����������B
AMD64��32bit���[�h�̌݊������s�\����VB�A�v���ȂNjƖ��Ŏg���Ă���\�t�g�������Ȃ��Ⴊ�������Ė��ɂȂ��Ă���B
173 �F,,�E�L�́M�E,,�j��-������ nfmv001111198.uqw.ppp.infoweb.ne.jp�F2015/02/09(��) 20:21:41.83 ID:4ASUIF+H
���āA���낻��ړ����邩�B
Intel��HyperThreading��32�r�b�g�̃v���O������64�r�b�g�̃v���O�����̕��삪�ł���
Bulldozer���W���[���̃f�R�[�_��2�X���b�h���������Ă��͂������A�r�b�g���̈Ⴂ�ɂ��
����ł��Ȃ��Ȃ�Đ���͕��������Ƃ��Ȃ��B
�����32�r�b�g��64�r�b�g�������t�����g�G���h�����L���Ă邩�炱���\�Ȃ��Ƃ��B
���āAThumb��Thumb2, Jazzele�Ȃǂ̕����̖��߃X�e�[�g������64bit�ł܂��R�[�h�̌n��ς���
ARM�����ǁA����SMT���̗p�����������Ė{�Ƃ�����h��������o�ĂȂ���ˁB
SMT�������o�Ă����Ƃ��āA32bit��64bit�̃R�[�h���ɑ��点�邱�Ƃ��ĉ\���낤���H
Thumb��Thumb2�ł��������ǂ��A���߃X�e�[�g��ւ���Ƃ��A���T�C�N�����X�g�[������ł���B
�Ԃ����ႯARM���āASMT��������s�\���Ǝv���Ă���B
Intel��HyperThreading��32�r�b�g�̃v���O������64�r�b�g�̃v���O�����̕��삪�ł���
Bulldozer���W���[���̃f�R�[�_��2�X���b�h���������Ă��͂������A�r�b�g���̈Ⴂ�ɂ��
����ł��Ȃ��Ȃ�Đ���͕��������Ƃ��Ȃ��B
�����32�r�b�g��64�r�b�g�������t�����g�G���h�����L���Ă邩�炱���\�Ȃ��Ƃ��B
���āAThumb��Thumb2, Jazzele�Ȃǂ̕����̖��߃X�e�[�g������64bit�ł܂��R�[�h�̌n��ς���
ARM�����ǁA����SMT���̗p�����������Ė{�Ƃ�����h��������o�ĂȂ���ˁB
SMT�������o�Ă����Ƃ��āA32bit��64bit�̃R�[�h���ɑ��点�邱�Ƃ��ĉ\���낤���H
Thumb��Thumb2�ł��������ǂ��A���߃X�e�[�g��ւ���Ƃ��A���T�C�N�����X�g�[������ł���B
�Ԃ����ႯARM���āASMT��������s�\���Ǝv���Ă���B
�O�O����������̗͂ɂȂ�����
API�₻��Ɋ֘A����N���X�̎g�������炢���낤
�܂�������d�v������v���O���}���O�O��܂���ł��S���̖����Ȃ���
�d�����Ă�ݒ�̎��ԑтɑS���l�b�g���Ȃ���������z������̂͋�����
����ʂɑ��l�̐l���Ȃ���
�ʂɕ������A�v����낤�������ɐl���q���悤������ɍ\���̂����ǂ�
�������č��̓v���O�����������ɐ_�G�`���Ă邵
API�₻��Ɋ֘A����N���X�̎g�������炢���낤
�܂�������d�v������v���O���}���O�O��܂���ł��S���̖����Ȃ���
�d�����Ă�ݒ�̎��ԑтɑS���l�b�g���Ȃ���������z������̂͋�����
����ʂɑ��l�̐l���Ȃ���
�ʂɕ������A�v����낤�������ɐl���q���悤������ɍ\���̂����ǂ�
�������č��̓v���O�����������ɐ_�G�`���Ă邵
>>172
>AMD64��32bit���[�h�̌݊������s�\����VB�A�v���ȂNjƖ��Ŏg���Ă���\�t�g�������Ȃ��Ⴊ�������Ė��ɂȂ��Ă���B
�������ċ�̓I�ɂǂ̂悤�Ȍ݊������s�\���Ȗ��Ȃ낤�B
����ŕ��������ƂȂ��̂ł��B������āAAMD64����Ȃ��āAWOW64�̎����Ɋւ�鎖�ł͂Ȃ��̂ł����H
>AMD64��32bit���[�h�̌݊������s�\����VB�A�v���ȂNjƖ��Ŏg���Ă���\�t�g�������Ȃ��Ⴊ�������Ė��ɂȂ��Ă���B
�������ċ�̓I�ɂǂ̂悤�Ȍ݊������s�\���Ȗ��Ȃ낤�B
����ŕ��������ƂȂ��̂ł��B������āAAMD64����Ȃ��āAWOW64�̎����Ɋւ�鎖�ł͂Ȃ��̂ł����H
�f�R�[�_��2�ςނȂ�f�R�[�_�����L����SMT��葬���Ȃ邾��B
x86�n�̎����Ȃ�uOPS���x���ł͕ʕ��ɕς���Ă��Ă����ɈႢ�͖�������B
����Ƀ}���`�R�A�Ȃ��L���b�V���̌������l�����1�R�A��SMT�ɂ͓���v���Z�X�̃}���`�X���b�h�����蓖�Ă�ׂ����낤�B
ARM�̓V���O���X���b�h���\���܂��Nj��d��ĂȂ����牉�Z��ɗ]�肪���Ȃ�SMT�̎|�������������B
x86�n�̎����Ȃ�uOPS���x���ł͕ʕ��ɕς���Ă��Ă����ɈႢ�͖�������B
����Ƀ}���`�R�A�Ȃ��L���b�V���̌������l�����1�R�A��SMT�ɂ͓���v���Z�X�̃}���`�X���b�h�����蓖�Ă�ׂ����낤�B
ARM�̓V���O���X���b�h���\���܂��Nj��d��ĂȂ����牉�Z��ɗ]�肪���Ȃ�SMT�̎|�������������B
178 �F,,�E�L�́M�E,,�j��-������ nfmv001146153.uqw.ppp.infoweb.ne.jp�F2015/02/09(��) 20:50:37.73 ID:6xrLWut8
>>175
�����̓��ōl���ď����Ȃ��n���ɕ����Ă����傤���Ȃ�
�����ɂ͎����ōl���铪�Ȃ�Ď������킹�Ă��Ȃ�
�@�@�`�炵���i�������Ŋm���߂����Ƃ͂Ȃ��j
VB�Ƃ������AMS-Office�Ȃǂɑg�ݍ��܂�Ă�VBA����Ȃ��́H
�v���O�C����32�r�b�g��OCX���g���āA32�r�b�gx86�ł�Office����Ȃ���
���삵�Ȃ��Ƃ�����Ȋ����ł���H
Windows RT��Office�ł����R�������͋N���āA����Ŗ@�l�Ɍ����������ꂸ
���[�J�[�����������Atom�^�u���b�g�������Ȃ��Ȃ����B
������̃��[�J�[PC�Ƀv���C���X�g�[������Ă�Office��32�r�b�g�B
3D�Q�[�������܂��唼��32�r�b�g�̂܂܂����A16��32�r�b�g�̂Ƃ��قLjڍs�͋��߂��Ă��Ȃ�
Windows3.1����95�����̂Ƃ����OS���͂邩�Ɉ��肵�Ă邵������4GB�ȏ�g���K�v�Ȃ����
�A�v����32�r�b�g�̂܂܂őS�R����Ȃ��B
���i���͋q�̋��߂���̂����킯�ŁA���i�����q��I�ʂ����Ȃ���
x86�̗��p�q��32�r�b�g�̌p���I�Ȑ��\��������߂Ă���B
�����̓��ōl���ď����Ȃ��n���ɕ����Ă����傤���Ȃ�
�����ɂ͎����ōl���铪�Ȃ�Ď������킹�Ă��Ȃ�
�@�@�`�炵���i�������Ŋm���߂����Ƃ͂Ȃ��j
VB�Ƃ������AMS-Office�Ȃǂɑg�ݍ��܂�Ă�VBA����Ȃ��́H
�v���O�C����32�r�b�g��OCX���g���āA32�r�b�gx86�ł�Office����Ȃ���
���삵�Ȃ��Ƃ�����Ȋ����ł���H
Windows RT��Office�ł����R�������͋N���āA����Ŗ@�l�Ɍ����������ꂸ
���[�J�[�����������Atom�^�u���b�g�������Ȃ��Ȃ����B
������̃��[�J�[PC�Ƀv���C���X�g�[������Ă�Office��32�r�b�g�B
3D�Q�[�������܂��唼��32�r�b�g�̂܂܂����A16��32�r�b�g�̂Ƃ��قLjڍs�͋��߂��Ă��Ȃ�
Windows3.1����95�����̂Ƃ����OS���͂邩�Ɉ��肵�Ă邵������4GB�ȏ�g���K�v�Ȃ����
�A�v����32�r�b�g�̂܂܂őS�R����Ȃ��B
���i���͋q�̋��߂���̂����킯�ŁA���i�����q��I�ʂ����Ȃ���
x86�̗��p�q��32�r�b�g�̌p���I�Ȑ��\��������߂Ă���B
>>175
AMD64�Ɍ݊������Ȃ��̂�MS��64bit���[�h�ł̌݊�������߂�XP�ł�32bit�ł葱���AWindows7�ł�XP���[�h�Ƃ������̌����G�~�����ڂ��ė�������B
office2003VBA�Ƃ�VB6�Ƃ����܂��Ɏg���Ă邩��B
���͂���e�ł��Ȃ�����V�X�e���X�V����悤�ɑ����Ă��旧���̂��Ȃ����������Ă邩��ˁB
�����m��Ȃ��c�q����ɂ͕�����Ȃ��ł��傤���ǁB
AMD64�Ɍ݊������Ȃ��̂�MS��64bit���[�h�ł̌݊�������߂�XP�ł�32bit�ł葱���AWindows7�ł�XP���[�h�Ƃ������̌����G�~�����ڂ��ė�������B
office2003VBA�Ƃ�VB6�Ƃ����܂��Ɏg���Ă邩��B
���͂���e�ł��Ȃ�����V�X�e���X�V����悤�ɑ����Ă��旧���̂��Ȃ����������Ă邩��ˁB
�����m��Ȃ��c�q����ɂ͕�����Ȃ��ł��傤���ǁB
180 �F,,�E�L�́M�E,,�j��-������ nfmv001146153.uqw.ppp.infoweb.ne.jp�F2015/02/09(��) 21:00:18.70 ID:6xrLWut8
�O�O���Ē��ׂ����Ƃ������������o���������̂悤�Ƀh����
����ȃ��x���̃��i�r�[�\���������ʂł���
����ȃ��x���̃��i�r�[�\���������ʂł���
�c�q����ĉ�ЂŘV�Q��������Ă��ł����B
182 �F,,�E�L�́M�E,,�j��-������ nfmv001146153.uqw.ppp.infoweb.ne.jp�F2015/02/09(��) 21:07:01.97 ID:6xrLWut8
�������Itanium���x86��x64���WOW64�ȑO�̖��
���}���˂����Ⴂ�܂������B���݂܂���B
����܂蓪���ł��ČÂ��b��D���������̎���̐l���ƁB
����܂蓪���ł��ČÂ��b��D���������̎���̐l���ƁB
184 �F,,�E�L�́M�E,,�j��-������ nfmv001146153.uqw.ppp.infoweb.ne.jp�F2015/02/09(��) 21:24:50.30 ID:6xrLWut8
�܂�VirtualPC�������������}�V�Ƃ������܂�Itanium��x86��OS���u�[�g���Ȃ�����
XP-mode����s�\
>>177
SMT���̗p������Ƃ�������͌��\�����A���߃X�e�[�g��ւ��̃R�X�g�ɂ��Č��y����Ă��Ȃ��ȁB
����~�܂�Ŏ��ۂ��Ƃ����b����Ȃ��B
32�r�b�g�����Ȃ�܂�������AAndroid��NDK�ł킴�킴Thumb�@���l�͋H������ȁB
A57�ȍ~�̃A�v���P�[�V�����v���Z�b�T��32�r�b�g��64�r�b�g�̃R�[�h�ʋ��������Ȃ���
�����Ȃ�����P���Șb�ł͂Ȃ��B
XP-mode����s�\
>>177
SMT���̗p������Ƃ�������͌��\�����A���߃X�e�[�g��ւ��̃R�X�g�ɂ��Č��y����Ă��Ȃ��ȁB
����~�܂�Ŏ��ۂ��Ƃ����b����Ȃ��B
32�r�b�g�����Ȃ�܂�������AAndroid��NDK�ł킴�킴Thumb�@���l�͋H������ȁB
A57�ȍ~�̃A�v���P�[�V�����v���Z�b�T��32�r�b�g��64�r�b�g�̃R�[�h�ʋ��������Ȃ���
�����Ȃ�����P���Șb�ł͂Ȃ��B
185 �F,,�E�L�́M�E,,�j��-������ nfmv001146153.uqw.ppp.infoweb.ne.jp�F2015/02/09(��) 21:26:41.07 ID:6xrLWut8
>>181
�咣���e�����Ƃ��Ƃ��ے肳��ĉ��������Ԃ��Ȃ�����l�i�U��������
�������V�Q�ƌ�����قǂ̍���Ȃ�
���O�A��w������H
�咣���e�����Ƃ��Ƃ��ے肳��ĉ��������Ԃ��Ȃ�����l�i�U��������
�������V�Q�ƌ�����قǂ̍���Ȃ�
���O�A��w������H
187 �F,,�E�L�́M�E,,�j��-������ nfmv001146153.uqw.ppp.infoweb.ne.jp�F2015/02/09(��) 21:37:09.88 ID:6xrLWut8
���������O�ɘ_�j���ꂽ�H���H
���̎w�E���e�ɂ��đS�������Ԃ��ĂȂ̂͂��O����H
�Ƃ��ƂƓ����Ă݂�{�P
���̎w�E���e�ɂ��đS�������Ԃ��ĂȂ̂͂��O����H
�Ƃ��ƂƓ����Ă݂�{�P
>>179
�����AMD64�Ɖ����ǂ��W���Ă���̂ł����H
Windows7 64bit�ł�������Ȃ���Windows7 32bit�łɂ�XP���[�h������Ă��邱�Ƃ������m�ł����H
XP���[�h�́AXP��OS�ˑ��������͐V����OS�Œ���Ă���API�Ɛe�a���̒Ⴂ������̎��Y�����ׂ̎d�g�݂Ƃ��āA
����Ă�����̂��ƔF�����Ă��܂��B
�ێ炪�\���ɓ͂��Ȃ��A�������͕ێ炷��O��ō���Ă��Ȃ��Г��ō��ꂽ�A�v�����A���ۂɎГ��ő����g���Ă���A
�����ʂ̏��u�Ƃ��ċ~�ς���ړI��������̂Ǝv���܂��B
�����AMD64�Ɖ����ǂ��W���Ă���̂ł����H
Windows7 64bit�ł�������Ȃ���Windows7 32bit�łɂ�XP���[�h������Ă��邱�Ƃ������m�ł����H
XP���[�h�́AXP��OS�ˑ��������͐V����OS�Œ���Ă���API�Ɛe�a���̒Ⴂ������̎��Y�����ׂ̎d�g�݂Ƃ��āA
����Ă�����̂��ƔF�����Ă��܂��B
�ێ炪�\���ɓ͂��Ȃ��A�������͕ێ炷��O��ō���Ă��Ȃ��Г��ō��ꂽ�A�v�����A���ۂɎГ��ő����g���Ă���A
�����ʂ̏��u�Ƃ��ċ~�ς���ړI��������̂Ǝv���܂��B
189 �F,,�E�L�́M�E,,�j��-������ nfmv001146153.uqw.ppp.infoweb.ne.jp�F2015/02/09(��) 21:44:01.44 ID:6xrLWut8
�c�O���������ɂ́uARM�͑f���炵���AAMD64�̓_���v���Ƃ������_���肫��
�O�O�������e���������ׂĂ邾���ł����ɐ[���l�@�͂Ȃ���
����8086�Ƃ��������̐��ゾ�Ƃ����������܂�Ă��狏�Ȃ�����ȁ[
�������A���`x86�̎咣�ɑ����u�Z�O�����g�I�[�o�[���C�h���ʓ|���[�v�Ȃ�Ă̂��o�����Ă��Ȃ���
�����͂킩�邪���ʂ��Ȃ��b������Ă�����
�O�O�������e���������ׂĂ邾���ł����ɐ[���l�@�͂Ȃ���
����8086�Ƃ��������̐��ゾ�Ƃ����������܂�Ă��狏�Ȃ�����ȁ[
�������A���`x86�̎咣�ɑ����u�Z�O�����g�I�[�o�[���C�h���ʓ|���[�v�Ȃ�Ă̂��o�����Ă��Ȃ���
�����͂킩�邪���ʂ��Ȃ��b������Ă�����
190 �F,,�E�L�́M�E,,�j��-������ nfmv001146153.uqw.ppp.infoweb.ne.jp�F2015/02/09(��) 22:10:18.88 ID:6xrLWut8
����AIA32�̌݊���������64�r�b�gCPU�A�[�L�e�N�`����IPF�i������܂Łj��AMD64/Intel64����
���݂��Ȃ����炻��2�҂ł̔�r�����ł��Ȃ��킯�Ȃ�
�ł����̃��i�r�[�N��AMD64���N�\���Ă����咣�̔�r�Ώۂ����A�����ɂ���CPU����Ȃ��āA
����������R�X�g�������ł���x86�݊������p�t�H�[�}���X�����S�ɃN���A�ł���
��z��̃I���I��CPU�A�[�L�e�N�`�������玸���邵��������B
����ȒN�ɂ����ĂȂ����̂�����Ȃ炨�O������Ă݂����Ă���������
���݂��Ȃ����炻��2�҂ł̔�r�����ł��Ȃ��킯�Ȃ�
�ł����̃��i�r�[�N��AMD64���N�\���Ă����咣�̔�r�Ώۂ����A�����ɂ���CPU����Ȃ��āA
����������R�X�g�������ł���x86�݊������p�t�H�[�}���X�����S�ɃN���A�ł���
��z��̃I���I��CPU�A�[�L�e�N�`�������玸���邵��������B
����ȒN�ɂ����ĂȂ����̂�����Ȃ炨�O������Ă݂����Ă���������
191 �F,,�E�L�́M�E,,�j��-������ nfmv001146153.uqw.ppp.infoweb.ne.jp�F2015/02/09(��) 22:20:25.63 ID:6xrLWut8
256bit�̃f�[�^�o�X��4��64bit���W�X�^������push/pop�ł���CPU�܂��[�H
>>172
386�̎���ɂ�286����̈ڍs�Ȃ�Ă낭�ɐi��łȂ���������
�ނ���A486���o�Ă悤�₭32bitCPU��������������Ȃ���?
>>172,175
16bit�R�[�h�����s�ł��Ȃ��_�ȊO�̖����ĉ�������������?
�Â��A�v�����C���X�g�[���Ƃ����C�u�������Ƃ��ŕ����I��16bit�R�[�h�g���Ă镨���c���ĂāA
���������A�v����x64��Windows�ł͎��s�ł��Ȃ�������Ė��ɂȂ������炢�����?
�������Ȃ��Ȃ����猰�݉�������������Ȃ���?
>>179
��office2003VBA�Ƃ�VB6�Ƃ����܂��Ɏg���Ă邩��B
�T�|�[�g����Ȃ��Ȃ����Â��V�X�e���������œ����Ă����Č������Ƃł���
�ł��A���ܓ����Ă���Ă̂́A�Â��n�[�h��T���Ă��Ȃ��Ɠ��삵�Ȃ��Ȃ��Ă��Ă�킯�����B�i����A����̎��Ⴖ��Ȃ���9801�̂���Ƃ��̘b�����ǁj
386�̎���ɂ�286����̈ڍs�Ȃ�Ă낭�ɐi��łȂ���������
�ނ���A486���o�Ă悤�₭32bitCPU��������������Ȃ���?
>>172,175
16bit�R�[�h�����s�ł��Ȃ��_�ȊO�̖����ĉ�������������?
�Â��A�v�����C���X�g�[���Ƃ����C�u�������Ƃ��ŕ����I��16bit�R�[�h�g���Ă镨���c���ĂāA
���������A�v����x64��Windows�ł͎��s�ł��Ȃ�������Ė��ɂȂ������炢�����?
�������Ȃ��Ȃ����猰�݉�������������Ȃ���?
>>179
��office2003VBA�Ƃ�VB6�Ƃ����܂��Ɏg���Ă邩��B
�T�|�[�g����Ȃ��Ȃ����Â��V�X�e���������œ����Ă����Č������Ƃł���
�ł��A���ܓ����Ă���Ă̂́A�Â��n�[�h��T���Ă��Ȃ��Ɠ��삵�Ȃ��Ȃ��Ă��Ă�킯�����B�i����A����̎��Ⴖ��Ȃ���9801�̂���Ƃ��̘b�����ǁj
>>191
�ꎟ�f�[�^�L���b�V���̃f�[�^�o�X��256bit���Ă̂͂��łɎ�������Ă邶���AIntel�ł́B
�ꎟ�L���b�V���ւ̏������݂Ɍ���A4��64bit���W�X�^�̓��e����push/pop�ł��Ă������Ƃ͎v�����ǁA
�ʂ����Ăł��Ă�̂��Ȃ�? �悭�킩���B
�ꎟ�f�[�^�L���b�V���̃f�[�^�o�X��256bit���Ă̂͂��łɎ�������Ă邶���AIntel�ł́B
�ꎟ�L���b�V���ւ̏������݂Ɍ���A4��64bit���W�X�^�̓��e����push/pop�ł��Ă������Ƃ͎v�����ǁA
�ʂ����Ăł��Ă�̂��Ȃ�? �悭�킩���B
194 �F,,�E�L�́M�E,,�j��-������ nfmv001146153.uqw.ppp.infoweb.ne.jp�F2015/02/09(��) 22:46:40.26 ID:6xrLWut8
32�r�b�g�̐��\�͌��̂ĂĂ���������64�r�b�g�𑬂�����ƌ����o�������Ǝv����
64�r�b�g�Ɉڍs�̌����݂̂Ȃ����K�V�[�A�v���̃j�[�Y�̘b������������
�咣�̕������ő�180�x�Ԃ�Ă��
����AMD64�W�ˁ[�������
64�r�b�g�Ɉڍs�̌����݂̂Ȃ����K�V�[�A�v���̃j�[�Y�̘b������������
�咣�̕������ő�180�x�Ԃ�Ă��
����AMD64�W�ˁ[�������
195 �F,,�E�L�́M�E,,�j��-������ nfmv001146153.uqw.ppp.infoweb.ne.jp�F2015/02/09(��) 23:00:03.23 ID:6xrLWut8
>>193
�{���ɓ����ɂ��Ȃ�Load/Store���j�b�g��4�n���K�v�ɂȂ��B
��ɂ������Ă邯�ǁA���Ƃ���R8�`R11��x64�̖��߃Z�b�g��ł͈ꑱ���Ɍ����邩������Ȃ���
�������W�X�^�t�@�C����ł̓��W�X�^���l�[���őS�R���̔Ԓn�Ƀ}�b�s���O�����
�A�Ԏw�肵�Ă�����4�̃��W�X�^�ɁA�݂����ȒP���Șb����Ȃ��B
256bit��4�{�̃��W�X�^�ɕ��z����Ⴂ���ƌ��������낤���ǁA
����destination�̃f�[�^�|�[�g��1�{�����Ȃ����炻���4�{�ɑ��₳�Ȃ��Ƃ����Ȃ��B
�������}�C�N���I�y���[�V������
load dest1, dest2, dest3, dest4, [addr]
�݂����ȃN�\�����t�H�[�}�b�g��\�����Ȃ��Ƃ����Ȃ��B
����1��OP������40�o�C�g���炢���������ȁH���ꂪ�����ƒ����Ȃ����Ⴄ�ł��傤�Ȃ��B
�R���r�j�܂ŕٓ����ɍs�����肪�H�i�H����Ă��܂����x���̘b�ł��B
�{���ɓ����ɂ��Ȃ�Load/Store���j�b�g��4�n���K�v�ɂȂ��B
��ɂ������Ă邯�ǁA���Ƃ���R8�`R11��x64�̖��߃Z�b�g��ł͈ꑱ���Ɍ����邩������Ȃ���
�������W�X�^�t�@�C����ł̓��W�X�^���l�[���őS�R���̔Ԓn�Ƀ}�b�s���O�����
�A�Ԏw�肵�Ă�����4�̃��W�X�^�ɁA�݂����ȒP���Șb����Ȃ��B
256bit��4�{�̃��W�X�^�ɕ��z����Ⴂ���ƌ��������낤���ǁA
����destination�̃f�[�^�|�[�g��1�{�����Ȃ����炻���4�{�ɑ��₳�Ȃ��Ƃ����Ȃ��B
�������}�C�N���I�y���[�V������
load dest1, dest2, dest3, dest4, [addr]
�݂����ȃN�\�����t�H�[�}�b�g��\�����Ȃ��Ƃ����Ȃ��B
����1��OP������40�o�C�g���炢���������ȁH���ꂪ�����ƒ����Ȃ����Ⴄ�ł��傤�Ȃ��B
�R���r�j�܂ŕٓ����ɍs�����肪�H�i�H����Ă��܂����x���̘b�ł��B
>>170
���Ђł͈͂����݂̂��߂�Mantle�o�����Ȃ���
NVIDIA��gameworks�Ɉ����t�����肵�Ă�����S�R�����݂Ȃ�����
�l�ɂ���Ă�AMD�Ƌ�ATI�͈Ⴄ�݂����Ȍ��������邯��
�������̓��m�����������Ȃ����Ċ�������
HSA���Ȃ��Ȃ����ʏo���Ȃ����R�ɋ��Ƒ��Ђ̖W�Q��z�肷��z�����邵
�t�@���̎v�l�p�^���������x�������
���Ђł͈͂����݂̂��߂�Mantle�o�����Ȃ���
NVIDIA��gameworks�Ɉ����t�����肵�Ă�����S�R�����݂Ȃ�����
�l�ɂ���Ă�AMD�Ƌ�ATI�͈Ⴄ�݂����Ȍ��������邯��
�������̓��m�����������Ȃ����Ċ�������
HSA���Ȃ��Ȃ����ʏo���Ȃ����R�ɋ��Ƒ��Ђ̖W�Q��z�肷��z�����邵
�t�@���̎v�l�p�^���������x�������
>>194
�ߋ��̃\�t�g�E�F�A�Ƃ̊��S�Ȍ݊������K�v�ł��B
�݊����[�h�̐��\�͊����i�Ɠ����ȏ�̂��̂��K�v�ł��B
64bit���[�h�̐��\�͍���������قǗǂ��ł��B
���������t�c�[�̏���҂̐������B
�݊����[�h�̐��\��10��������64bit���[�h�̐��\��20�������ł��B
�݊����[�h�̐��\��5��������64bit���[�h�̐��\��25�������ł��B
�ǂ����������ł����B
�݊����[�h�Ŏg���\�t�g�͂��Ƃ��ƌy���̂�5�������ł��\�����K�ɓ����܂��B
64bit���[�h�̃\�t�g�͐V�������@�\�łő�K�͂ȃf�[�^����������̂̏����d���Ȃ��Ă܂��B�����ł����\���ǂ������������ł��ˁB
�ߋ��̃\�t�g�E�F�A�Ƃ̊��S�Ȍ݊������K�v�ł��B
�݊����[�h�̐��\�͊����i�Ɠ����ȏ�̂��̂��K�v�ł��B
64bit���[�h�̐��\�͍���������قǗǂ��ł��B
���������t�c�[�̏���҂̐������B
�݊����[�h�̐��\��10��������64bit���[�h�̐��\��20�������ł��B
�݊����[�h�̐��\��5��������64bit���[�h�̐��\��25�������ł��B
�ǂ����������ł����B
�݊����[�h�Ŏg���\�t�g�͂��Ƃ��ƌy���̂�5�������ł��\�����K�ɓ����܂��B
64bit���[�h�̃\�t�g�͐V�������@�\�łő�K�͂ȃf�[�^����������̂̏����d���Ȃ��Ă܂��B�����ł����\���ǂ������������ł��ˁB
�c�q�ɕ����Ă�M�ҏ�Ȃ���
�m���̂Ȃ��̂ɖ��ʂɒ��荇���Ȃ���
�m���̂Ȃ��̂ɖ��ʂɒ��荇���Ȃ���
199 �F,,�E�L�́M�E,,�j��-������ nfmv001146153.uqw.ppp.infoweb.ne.jp�F2015/02/09(��) 23:38:39.52 ID:6xrLWut8
�����܂ō��ꂵ�Ă����āA�ł��Ȃ����R����������瓦����Ƃ����肦�Ȃ���ˁH
> 133 �FSocket774 �F2015/02/09(��) 02:01:16.23 ID:71CnXvKJ
> �}�C�N���A�[�L�e�N�`�����悾���ŐV��SIMD�Ή�����
> 256bit�̃f�[�^�p�X���g���Ĉ�x��4��64bit���W�X�^���܂Ƃ߂ă��[�h�X�g�A�ł��邩��Œ��ꒃ�����Ȃ��B
> 133 �FSocket774 �F2015/02/09(��) 02:01:16.23 ID:71CnXvKJ
> �}�C�N���A�[�L�e�N�`�����悾���ŐV��SIMD�Ή�����
> 256bit�̃f�[�^�p�X���g���Ĉ�x��4��64bit���W�X�^���܂Ƃ߂ă��[�h�X�g�A�ł��邩��Œ��ꒃ�����Ȃ��B
200 �F,,�E�L�́M�E,,�j��-������ nfmv001146153.uqw.ppp.infoweb.ne.jp�F2015/02/09(��) 23:41:52.71 ID:6xrLWut8
�ʂɃ��[�h�X�g�A���j�b�g�̃|�[�g���Ȃ�ĕK�v�Ȃ瑝�₹�邵���܂ł��X�g�A���߂͕����̃��j�b�g���g���ă|�[�g�����҂��ł������A���̖����Ȃ��̂ɉ��𑛂��ł�����B
���ځ[�����ǂ܂��V�Q�������Ă���́H
203 �F,,�E�L�́M�E,,�j��-������ nfmv001146153.uqw.ppp.infoweb.ne.jp�F2015/02/09(��) 23:47:20.40 ID:6xrLWut8
AMD�̃X���Q���邯�ǁA�ǂ������{�X���H
206 �F,,�E�L�́M�E,,�j��-������ nfmv001146153.uqw.ppp.infoweb.ne.jp�F2015/02/09(��) 23:52:50.33 ID:6xrLWut8
�����܂ł̗�������Ƃ��b�ɂ��Ă݂܂���
ID:DZmZmqpo �u���̔ޏ������[���l�Ȃ��IAKB48�͕s�H�I�v
�i�������]���ޏ��j
��
,,�E�L�́M�E,,�j��-�������u����Ȃɔ��l�Ȃ�ʐ^�����Ă݂��v
��
ID:DZmZmqpo �u�E�E�E�E�v
ID:DZmZmqpo �u���̔ޏ������[���l�Ȃ��IAKB48�͕s�H�I�v
�i�������]���ޏ��j
��
,,�E�L�́M�E,,�j��-�������u����Ȃɔ��l�Ȃ�ʐ^�����Ă݂��v
��
ID:DZmZmqpo �u�E�E�E�E�v
207 �F,,�E�L�́M�E,,�j��-������ nfmv001146153.uqw.ppp.infoweb.ne.jp�F2015/02/09(��) 23:53:56.37 ID:6xrLWut8
>>204
�ŁA���O�̔]���̐V�^CPU�́A�ǂ��̉�Ђ��J�����Ă��ł����H
�ŁA���O�̔]���̐V�^CPU�́A�ǂ��̉�Ђ��J�����Ă��ł����H
208 �F,,�E�L�́M�E,,�j��-������ nfmv001146153.uqw.ppp.infoweb.ne.jp�F2015/02/10(��) 00:02:03.70 ID:odukiSa7
���s���Ԃ�R�[�h�T�C�Y��1%�ɂ������Ȃ��悤��push/pop�𑬂����邽�߂�����
�p�C�v���C���ɑ�|����ȉ��C������CPU���[�J�[�͂��Ȃ��ł��傤�Ȃ�
�����܂ŃR�X�g������Ȃ�
add eax, ecx
add eax, 1234
��1���߂ɂ܂Ƃ߂�
lea eax, [eax+ecx+1234]
�Ɠ����ɂ���݂����ȁA���A�O���b�V�u�ȃ�OPs�̗Z���Ƀ��\�[�X�������ق��������Ǝv���܂��ˁB
���ߊԂ̃��C�e���V�����k�ł��邵�A���K�V�[�R�[�h�������Ȃ�B
�p�C�v���C���ɑ�|����ȉ��C������CPU���[�J�[�͂��Ȃ��ł��傤�Ȃ�
�����܂ŃR�X�g������Ȃ�
add eax, ecx
add eax, 1234
��1���߂ɂ܂Ƃ߂�
lea eax, [eax+ecx+1234]
�Ɠ����ɂ���݂����ȁA���A�O���b�V�u�ȃ�OPs�̗Z���Ƀ��\�[�X�������ق��������Ǝv���܂��ˁB
���ߊԂ̃��C�e���V�����k�ł��邵�A���K�V�[�R�[�h�������Ȃ�B
�ʂɂ��̒c�q���Đl�Ɍ����ꂷ��킯����Ȃ����ǁA>>204�̎咣�͑f�l�ł��Ȃ����������Ďv�����E�E�E
�������ɑ��݂��Ă镨�ł�����r�ł��Ȃ��������Ⴂ���Ȃ����낤�E�E�E
�������ɑ��݂��Ă镨�ł�����r�ł��Ȃ��������Ⴂ���Ȃ����낤�E�E�E
>>209
�����ł�AMD�Ɣ�r������ĕ��ʂ���
���N�o��Zen��ϑz���Ĕ�r������AMD���叟���ōK��
���ꂪ����̈�Ԃ̂悳
�A�Z���u�����x���ŐF�X�����Ă�����AMD���[�U�[�����
���̒��x���x������Ȃ���AMD���o���Ȃ�ďo���Ȃ����낤��
�����ł�AMD�Ɣ�r������ĕ��ʂ���
���N�o��Zen��ϑz���Ĕ�r������AMD���叟���ōK��
���ꂪ����̈�Ԃ̂悳
�A�Z���u�����x���ŐF�X�����Ă�����AMD���[�U�[�����
���̒��x���x������Ȃ���AMD���o���Ȃ�ďo���Ȃ����낤��
211 �F,,�E�L�́M�E,,�j��-������ nfmv001146153.uqw.ppp.infoweb.ne.jp�F2015/02/10(��) 00:21:24.42 ID:odukiSa7
���̖��߂������I�ł���͔�����Ȃ�Ă͎̂��ۂɒ�ʓI�ȃf�[�^�������Ă͂��߂�
�c�_�ł���b�Ȃ̂ł���B
�����Ɏg���Ă�v���O�����̖��߃_���v���āApush/pop�̏o���p�x���ׂĂ݂��炢���Ǝv����
�R�[�h�T�C�Y���ǂꂾ���������Ȃ�̂��A��ʓI�ȃf�[�^�����������ۘ_�����ł��̂����̂�
1997�N������Intel CPU�����œK���}�j���A�������܂��Ƀ_�E�����[�h�ł��Ă���
http://www.intel.com/design/pentium/manuals/24281603.pdf
�v��Fpusha*/popa*��Complex�ŃR�[�h������x���B�g���ȁB
Pentium Pro�̎��ォ�烏�i�r�[�N�ꉟ���̖��߂�������������I�؋���
VC6.0�̍��ɂ͍œK����pusha/popa�͂��납�P�Ƃ�push/pop���琶�����Ȃ��悤�ɂȂ��Ă��B
SSE��AVX�g���Ă�����ق����������ǃA���C�������g�▽�߃T�|�[�g�C�ɂ����g����
�ėp����������X�g�����O�R�s�[�Ɏg��ꑱ���Ă���rep movs*��
IvyBridge�ō��������Ă̂ƑS�R�b���Ⴄ����ˁB
pusha*/popa*�͕֗����Ǝv��Ȃ�����N���g���ĂȂ������X���������Ă��N�������Ȃ��Ƃ����B
�c�_�ł���b�Ȃ̂ł���B
�����Ɏg���Ă�v���O�����̖��߃_���v���āApush/pop�̏o���p�x���ׂĂ݂��炢���Ǝv����
�R�[�h�T�C�Y���ǂꂾ���������Ȃ�̂��A��ʓI�ȃf�[�^�����������ۘ_�����ł��̂����̂�
1997�N������Intel CPU�����œK���}�j���A�������܂��Ƀ_�E�����[�h�ł��Ă���
http://www.intel.com/design/pentium/manuals/24281603.pdf
�v��Fpusha*/popa*��Complex�ŃR�[�h������x���B�g���ȁB
Pentium Pro�̎��ォ�烏�i�r�[�N�ꉟ���̖��߂�������������I�؋���
VC6.0�̍��ɂ͍œK����pusha/popa�͂��납�P�Ƃ�push/pop���琶�����Ȃ��悤�ɂȂ��Ă��B
SSE��AVX�g���Ă�����ق����������ǃA���C�������g�▽�߃T�|�[�g�C�ɂ����g����
�ėp����������X�g�����O�R�s�[�Ɏg��ꑱ���Ă���rep movs*��
IvyBridge�ō��������Ă̂ƑS�R�b���Ⴄ����ˁB
pusha*/popa*�͕֗����Ǝv��Ȃ�����N���g���ĂȂ������X���������Ă��N�������Ȃ��Ƃ����B
���{�l�Ȃ�C���e���Q�t�H���
>>212
FX�͖ϑz��肸�[���Ƃ������āA2��ڂ�Intel�̍��̍ŐV��肷�������Ċ���������ȁB
���܂�̂��A�h�o���e�[�W���傫���Ȃ��āAAMD��FX�̐i���X�g�b�v���Ă��܂����B
���N��14n�ł�PileFX�ɂ͋y�Ȃ���
Zen��FX�̂悤�Ȃ��������̂ɂȂ��Ȃ��̂���
FX�͖ϑz��肸�[���Ƃ������āA2��ڂ�Intel�̍��̍ŐV��肷�������Ċ���������ȁB
���܂�̂��A�h�o���e�[�W���傫���Ȃ��āAAMD��FX�̐i���X�g�b�v���Ă��܂����B
���N��14n�ł�PileFX�ɂ͋y�Ȃ���
Zen��FX�̂悤�Ȃ��������̂ɂȂ��Ȃ��̂���
215 �F,,�E�L�́M�E,,�j��-������ nfmv001146153.uqw.ppp.infoweb.ne.jp�F2015/02/10(��) 00:48:40.87 ID:odukiSa7
���̗₦��������FX�̒g�[�@�\�͂����܂�����
���̃I���W�͐l�̏������݂��܂Ƃ��Ɍ����ɐҐ����˂ŏ�������ł��邩�炽�܂��ȁB>>157��ǂ�ŏo�����ė����B
����Ȃ�push/pop���߂̃E�G�[�g���Ⴂ�Ȃ�rax/al���Öق̃I�y�����h�ɂ���1�o�C�g�I�y�R�[�h���Z���߂Ȃ�Ă����Ǝg�p�p�x���Ⴂ����܂Ƃ߂Ă���Ȃ������B
�ǂ����f�R�[�_�͏\����������Ă邵2�o�C�g�I�y�R�[�h���߂ŏ\���B
��������1�o�C�g�ڂ̃R�[�h��1/4�͋ɂȂ邩��R�[�h�z�u��������Ɛ���������REX�v���t�B�N�X�ɂ���2bit�lj��ł����Ⴄ�B
������66��8bit�ɑ���REX.W�ő�p����Ƃ���67�͂�������Ȃ��ł���ˁB�Ȃ�/0F/0F 38/0F 3A��2bit�Ɋ��蓖�Ă���g�����߂̃v���t�B�N�X���P�ɂ܂Ƃ܂��Ă��炷������B�������d�v���t�B�N�X�Ƃ͂������B
�ȒP�ɃR�[�h���x���オ���Ă��܂��ăf�R�[�h���y�ɂȂ��ł����Z�p�I�ɈӖ��̂��锽�_�͂���܂����B
����Ȃ�push/pop���߂̃E�G�[�g���Ⴂ�Ȃ�rax/al���Öق̃I�y�����h�ɂ���1�o�C�g�I�y�R�[�h���Z���߂Ȃ�Ă����Ǝg�p�p�x���Ⴂ����܂Ƃ߂Ă���Ȃ������B
�ǂ����f�R�[�_�͏\����������Ă邵2�o�C�g�I�y�R�[�h���߂ŏ\���B
��������1�o�C�g�ڂ̃R�[�h��1/4�͋ɂȂ邩��R�[�h�z�u��������Ɛ���������REX�v���t�B�N�X�ɂ���2bit�lj��ł����Ⴄ�B
������66��8bit�ɑ���REX.W�ő�p����Ƃ���67�͂�������Ȃ��ł���ˁB�Ȃ�/0F/0F 38/0F 3A��2bit�Ɋ��蓖�Ă���g�����߂̃v���t�B�N�X���P�ɂ܂Ƃ܂��Ă��炷������B�������d�v���t�B�N�X�Ƃ͂������B
�ȒP�ɃR�[�h���x���オ���Ă��܂��ăf�R�[�h���y�ɂȂ��ł����Z�p�I�ɈӖ��̂��锽�_�͂���܂����B
>>211
�c�q�A����Ȃ��ǂ�B
SSE��AVX���ĉ��ŃA���C�����g���Ȃ��Ɗo�����Ȃ��H
�Ȃv���O�������ق����炷��Ƃ��炢�ʓ|���Ċ����������
���ʂ�std::vector���ق�����ēn���Ċo�����ė~�������Ċ�������
�c�q�A����Ȃ��ǂ�B
SSE��AVX���ĉ��ŃA���C�����g���Ȃ��Ɗo�����Ȃ��H
�Ȃv���O�������ق����炷��Ƃ��炢�ʓ|���Ċ����������
���ʂ�std::vector���ق�����ēn���Ċo�����ė~�������Ċ�������
Llano�o��̋łɂ�
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
�� 2014�N �����̔��ド���L���O
http://eetimes.jp/ee/articles/1412/25/news147.html
��AMD�A2014�N�x��4���h���̐Ԏ�
http://pc.watch.impress.co.jp/docs/news/20150121_684660.html
AMD�̏��ʂ������}�~���ЂƂ蕉���_(^o^)�^
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
�� 2014�N �����̔��ド���L���O
http://eetimes.jp/ee/articles/1412/25/news147.html
��AMD�A2014�N�x��4���h���̐Ԏ�
http://pc.watch.impress.co.jp/docs/news/20150121_684660.html
AMD�̏��ʂ������}�~���ЂƂ蕉���_(^o^)�^
���{�l�Ȃ�C���e���Q�t�H���
�A���C�����g�N�͉������Ƃ���������ł�
����I�ɃA���C�����g���ʓ|���[�Ə������܂Ȃ��Ǝ��Ⴄ�a�C�Ȃ́H
����I�ɃA���C�����g���ʓ|���[�Ə������܂Ȃ��Ǝ��Ⴄ�a�C�Ȃ́H
221 �F,,�E�L�́M�E,,�j��-������ nfmv001146153.uqw.ppp.infoweb.ne.jp�F2015/02/10(��) 01:15:01.25 ID:odukiSa7
����Ȃ��˂��܂�����
�����R�X�g�̒�ʓI�]���͍�����l�ԂłȂ��Ɛ������ł��Ȃ�
����Ȃ��̖������Ĕ]���ł��s���悭�l����
�@�u�ڂ��̂������������傤�̂��[�ҁ[��[�v
�͂������čŋ����I
�ł�����Ȃ̎�������̂͏��w���܂łɂ����@�݂��Ƃ��Ȃ�����
���O�����ĔN��I�ɂ͂��낻��q�������Ă����������Ȃ�H���邢�͑����H
>>115
> pusha/popa�ɖ��ʂ���������Ƃ����ĒP���ɔp�~���铪�̈����͒v���I���B
���������̂́@�����܁����@����
�g���Ȃ����߂��c���Ӗ����Ȃ��Ƃ����̂͑Ó����Ǝv�����ǂ�
�{���ɕK�v�ł������ɂȂ����狌�ԈˑR�̃��K�V�[�t�H�[�}�b�g�ł͂Ȃ�
�V���߂Ƃ��Ď�����������B
8���߂�16���߂�����̂�1���߂ł��ނȂ�AVEX��EVEX�G���R�[�h��5�`6�o�C�g�������Ă�
�\���y�C�ł�����炳�B
> �g���Ȃ������Ԃ������č����������Ă��Ȃ��B���ꂾ���̘b�B
�t�ɁA�N���g��Ȃ����߂𑬂�������g����悤�ɂȂ�Ǝv���́H
CPU���Ď��ۂ̃A�v���Ɏg���閽�߂�z�肵�Ė��ߒlj����Ă����
�ꊇpush/pop���K�v�ɂȂ�قǃX�^�b�N���삵�܂���A�v������
��̂Ȃɂ�z�肵�Ă�킯�H
�����R�X�g�̒�ʓI�]���͍�����l�ԂłȂ��Ɛ������ł��Ȃ�
����Ȃ��̖������Ĕ]���ł��s���悭�l����
�@�u�ڂ��̂������������傤�̂��[�ҁ[��[�v
�͂������čŋ����I
�ł�����Ȃ̎�������̂͏��w���܂łɂ����@�݂��Ƃ��Ȃ�����
���O�����ĔN��I�ɂ͂��낻��q�������Ă����������Ȃ�H���邢�͑����H
>>115
> pusha/popa�ɖ��ʂ���������Ƃ����ĒP���ɔp�~���铪�̈����͒v���I���B
���������̂́@�����܁����@����
�g���Ȃ����߂��c���Ӗ����Ȃ��Ƃ����̂͑Ó����Ǝv�����ǂ�
�{���ɕK�v�ł������ɂȂ����狌�ԈˑR�̃��K�V�[�t�H�[�}�b�g�ł͂Ȃ�
�V���߂Ƃ��Ď�����������B
8���߂�16���߂�����̂�1���߂ł��ނȂ�AVEX��EVEX�G���R�[�h��5�`6�o�C�g�������Ă�
�\���y�C�ł�����炳�B
> �g���Ȃ������Ԃ������č����������Ă��Ȃ��B���ꂾ���̘b�B
�t�ɁA�N���g��Ȃ����߂𑬂�������g����悤�ɂȂ�Ǝv���́H
CPU���Ď��ۂ̃A�v���Ɏg���閽�߂�z�肵�Ė��ߒlj����Ă����
�ꊇpush/pop���K�v�ɂȂ�قǃX�^�b�N���삵�܂���A�v������
��̂Ȃɂ�z�肵�Ă�킯�H
>>216
������Ȃ�push/pop���߂̃E�G�[�g���Ⴂ�Ȃ�rax/al���Öق̃I�y�����h�ɂ���1�o�C�g�I�y�R�[�h���Z���߂Ȃ�Ă����Ǝg�p�p�x���Ⴂ����܂Ƃ߂Ă���Ȃ������B
���ǂ����f�R�[�_�͏\����������Ă邵2�o�C�g�I�y�R�[�h���߂ŏ\���B
����͓��ӂ����ǂ�
����������1�o�C�g�ڂ̃R�[�h��1/4�͋ɂȂ邩��R�[�h�z�u��������Ɛ���������REX�v���t�B�N�X�ɂ���2bit�lj��ł����Ⴄ�B
�����������Ȃ��ŕ��u����̂͂������Ǎ폜������_�������
�Â��v���O�����̈ꕔ�������Ȃ��Ȃ�B
x86�̑��݈Ӌ`�̍��������Ȕے肷����s����
������Ȃ�push/pop���߂̃E�G�[�g���Ⴂ�Ȃ�rax/al���Öق̃I�y�����h�ɂ���1�o�C�g�I�y�R�[�h���Z���߂Ȃ�Ă����Ǝg�p�p�x���Ⴂ����܂Ƃ߂Ă���Ȃ������B
���ǂ����f�R�[�_�͏\����������Ă邵2�o�C�g�I�y�R�[�h���߂ŏ\���B
����͓��ӂ����ǂ�
����������1�o�C�g�ڂ̃R�[�h��1/4�͋ɂȂ邩��R�[�h�z�u��������Ɛ���������REX�v���t�B�N�X�ɂ���2bit�lj��ł����Ⴄ�B
�����������Ȃ��ŕ��u����̂͂������Ǎ폜������_�������
�Â��v���O�����̈ꕔ�������Ȃ��Ȃ�B
x86�̑��݈Ӌ`�̍��������Ȕے肷����s����
>>222
�̂̂Ƃ̌݊����ێ������Ă�����x86������ȁB
���܂̍ŐV��CPU�ł��A�̐̂��̐̂�16bit����̂��̂����܂��ɃT�|�[�g���Ă����H
�̂̂Ƃ̌݊����ێ������Ă�����x86������ȁB
���܂̍ŐV��CPU�ł��A�̐̂��̐̂�16bit����̂��̂����܂��ɃT�|�[�g���Ă����H
>>222
�����inc/dec�����݊����ɕK�v��v86���[�h����荂���ȃG�~���ɕK�v��sahf/lahf�������AMD�Ɍ����Ă��������B
64bit���[�h�Ŏd�蒼���̂���������̖��߂��x�[�X�ɂ���ɂ���g��Ȃ����߂͐������ĘA���̈�ɒn�グ���ĐՒn��L�����p���������ǂ��ł��B
�����inc/dec�����݊����ɕK�v��v86���[�h����荂���ȃG�~���ɕK�v��sahf/lahf�������AMD�Ɍ����Ă��������B
64bit���[�h�Ŏd�蒼���̂���������̖��߂��x�[�X�ɂ���ɂ���g��Ȃ����߂͐������ĘA���̈�ɒn�グ���ĐՒn��L�����p���������ǂ��ł��B
225 �F,,�E�L�́M�E,,�j��-������ nfmv001146153.uqw.ppp.infoweb.ne.jp�F2015/02/10(��) 01:37:19.14 ID:odukiSa7
>>217
���\�̖�肶��Ȃ���ˁ[
�n�[�h���ߑł��Ȃ炢���������v���b�g�t�H�[���T�|�[�g����Ȃ�cpuid����
���߂��Ή����Ă邩�ǂ����݂Ȃ��Ƃ����Ȃ������B
���ƁA�A���C�������g�̂���ɂ͏d��Ȗ�肪�����āA�ʏ�̃X�g�����O���삾��
1�o�C�g�������ǂ܂Ȃ�������ɂȂ�Ȃ����A�~�X�A���C���A�N�Z�X��
���܂��ܓǂ��16�o�C�g���邢��32�o�C�g���y�[�W���E���܂����ł���
��O�������Ď��ʁB
����͉��z�L�����T�|�[�g����A�[�L�e�N�`���̏h���B
������AVX�Ń~�X�A���C�����[�h�����e�����悤�ɂȂ����Ƃ����Ă�SIMD��
�X�g�����O�����p����Ƃ��͂Ƃ肠����16�Ȃ�32�Ȃ�Ŋ�����A�h���X��
���킹�Ă����̂�����
���������̂��߂�ǂ�����rep movs*�������������̂͂��肪�����̂���
Haswell�ł���y�[�W���E�������ł�����ƍœK�����ꂽfast_memcpy�I�Ȃ��̂�
���\�ɂ͏��Ă�B�ނ���AVX2�g�����\�t�g�����̂ق��������B
complex decode�̖��߂��đS��OPs�����^�C������܂�ROB�ɋ����邩��
�����[���\�ʂŃy�i���e�B�����ˁB
���\�̖�肶��Ȃ���ˁ[
�n�[�h���ߑł��Ȃ炢���������v���b�g�t�H�[���T�|�[�g����Ȃ�cpuid����
���߂��Ή����Ă邩�ǂ����݂Ȃ��Ƃ����Ȃ������B
���ƁA�A���C�������g�̂���ɂ͏d��Ȗ�肪�����āA�ʏ�̃X�g�����O���삾��
1�o�C�g�������ǂ܂Ȃ�������ɂȂ�Ȃ����A�~�X�A���C���A�N�Z�X��
���܂��ܓǂ��16�o�C�g���邢��32�o�C�g���y�[�W���E���܂����ł���
��O�������Ď��ʁB
����͉��z�L�����T�|�[�g����A�[�L�e�N�`���̏h���B
������AVX�Ń~�X�A���C�����[�h�����e�����悤�ɂȂ����Ƃ����Ă�SIMD��
�X�g�����O�����p����Ƃ��͂Ƃ肠����16�Ȃ�32�Ȃ�Ŋ�����A�h���X��
���킹�Ă����̂�����
���������̂��߂�ǂ�����rep movs*�������������̂͂��肪�����̂���
Haswell�ł���y�[�W���E�������ł�����ƍœK�����ꂽfast_memcpy�I�Ȃ��̂�
���\�ɂ͏��Ă�B�ނ���AVX2�g�����\�t�g�����̂ق��������B
complex decode�̖��߂��đS��OPs�����^�C������܂�ROB�ɋ����邩��
�����[���\�ʂŃy�i���e�B�����ˁB
226 �F,,�E�L�́M�E,,�j��-������ nfmv001146153.uqw.ppp.infoweb.ne.jp�F2015/02/10(��) 02:31:20.86 ID:odukiSa7
>>224
���O�������̔\�͂��킫�܂������\�킸���݂��Ƃ������̓u���Ȃ��ˁB
���ꂾ���̎����S�������Ɍ�����������������Ȃ��
���ɊȒP�ɘ_�j�����悤�Ȃ��o�J���������Ȃ��Ă��ނ悤�ɂȂ邩����H
���������N��64bit�Ń��K�V�[���߂̊��蓖�Ă���錈�f���ł������H
��������Intel�͊����̖��߂��Ԃ��ċ�����Ƃ������z���̎����Ă��Ȃ��B
Intel�ɍ��C������Ȃ�BCD���얽�߂Ȃ��32�r�b�g�ڍs���_�łȂ��Ȃ��Ă�B
��������1�o�C�g��INC/DEC������ăv���t�B�b�N�X�ɕς����������
���ߋ��E�̌v�Z��32bit�Ƃ���قǕς��킯����Ȃ�����
�v���f�R�[�h�̃A���S���Y���ɂ���قǕύX�͕K�v�Ȃ���
���O�͑O���珇�Ԃɂ����f�R�[�h�ł��Ȃ��Ǝv������ł��i�����H�j����
prefix��������ƃf�R�[�_���׃K�[���̂���Ȃ��܂ʂ��������J��Ԃ��Ă��ȁH
����Ȃɕs�������������Ȃ�A���O�����z�̍ŋ��̖��߃Z�b�gOpcode Map�������Ă݂Ȃ�
�ΈĂ������Ȃ�����A�T���猩�ĂȂɂ����z�Ȃ̂��S���������̂��B
�@�@���l�̌��f��ᔻ��������A�����̌��f��M����ق����E�C�̗v�邱�Ƃ�
�@�@�@�@�@-�t�����̉��A�b�e�B��
���O�������̔\�͂��킫�܂������\�킸���݂��Ƃ������̓u���Ȃ��ˁB
���ꂾ���̎����S�������Ɍ�����������������Ȃ��
���ɊȒP�ɘ_�j�����悤�Ȃ��o�J���������Ȃ��Ă��ނ悤�ɂȂ邩����H
���������N��64bit�Ń��K�V�[���߂̊��蓖�Ă���錈�f���ł������H
��������Intel�͊����̖��߂��Ԃ��ċ�����Ƃ������z���̎����Ă��Ȃ��B
Intel�ɍ��C������Ȃ�BCD���얽�߂Ȃ��32�r�b�g�ڍs���_�łȂ��Ȃ��Ă�B
��������1�o�C�g��INC/DEC������ăv���t�B�b�N�X�ɕς����������
���ߋ��E�̌v�Z��32bit�Ƃ���قǕς��킯����Ȃ�����
�v���f�R�[�h�̃A���S���Y���ɂ���قǕύX�͕K�v�Ȃ���
���O�͑O���珇�Ԃɂ����f�R�[�h�ł��Ȃ��Ǝv������ł��i�����H�j����
prefix��������ƃf�R�[�_���׃K�[���̂���Ȃ��܂ʂ��������J��Ԃ��Ă��ȁH
����Ȃɕs�������������Ȃ�A���O�����z�̍ŋ��̖��߃Z�b�gOpcode Map�������Ă݂Ȃ�
�ΈĂ������Ȃ�����A�T���猩�ĂȂɂ����z�Ȃ̂��S���������̂��B
�@�@���l�̌��f��ᔻ��������A�����̌��f��M����ق����E�C�̗v�邱�Ƃ�
�@�@�@�@�@-�t�����̉��A�b�e�B��
>>221
RISC�ł͊����Ń��W�X�^���ꊇ�Ҕ����ă��W�X�^�ϐ��Ƃ��Ďg�p�A�Ō�Ɉꊇ�������ďI���Ƃ������Ƃ����B
���\���d������Ȃ�R�X�g�̍����������I�y�����h���Z�����炷�̂͏펯�B
>>226
�f�R�[�h�͏��Ԃɂ����ł��Ȃ���B���̂��߂ɒ����v���f�R�[�h�̃p�C�v���C�����K�v���Ǝv���Ă�B
�e�o�C�g��擪�Ƒz�肵�Ė��ߒ����f�R�[�h���鏈�������ׂđ��点�Č��ʂ��o���Ƃ���ł�����Ŗ��ߒ����}�[�N���Ė{�f�R�[�_�ɑ��閽�߂����߂�B
��H�K�͂Ƃ��Ă��ꂪ���E�B
�Ԉ���Ă��������H��1�N���b�N�Ńf�R�[�h�ł����Ȃ��B
RISC�ł͊����Ń��W�X�^���ꊇ�Ҕ����ă��W�X�^�ϐ��Ƃ��Ďg�p�A�Ō�Ɉꊇ�������ďI���Ƃ������Ƃ����B
���\���d������Ȃ�R�X�g�̍����������I�y�����h���Z�����炷�̂͏펯�B
>>226
�f�R�[�h�͏��Ԃɂ����ł��Ȃ���B���̂��߂ɒ����v���f�R�[�h�̃p�C�v���C�����K�v���Ǝv���Ă�B
�e�o�C�g��擪�Ƒz�肵�Ė��ߒ����f�R�[�h���鏈�������ׂđ��点�Č��ʂ��o���Ƃ���ł�����Ŗ��ߒ����}�[�N���Ė{�f�R�[�_�ɑ��閽�߂����߂�B
��H�K�͂Ƃ��Ă��ꂪ���E�B
�Ԉ���Ă��������H��1�N���b�N�Ńf�R�[�h�ł����Ȃ��B
228 �F,,�E�L�́M�E,,�j��-������ nfmv001146153.uqw.ppp.infoweb.ne.jp�F2015/02/10(��) 03:01:31.51 ID:odukiSa7
> RISC�ł͊����Ń��W�X�^���ꊇ�Ҕ����ă��W�X�^�ϐ��Ƃ��Ďg�p�A
> �Ō�Ɉꊇ�������ďI���Ƃ������Ƃ����B
��������x86��RISC����Ȃ��ł�
����Ȃ��Ƃ��m��Ȃ��̂ˁ@O��BA��KA��SA��N�@���c
> ���\���d������Ȃ�R�X�g�̍����������I�y�����h���Z�����炷�̂͏펯�B
���O�̔]���ł̏펯�͕����ĂȂ�
1���g��Ȃ��l�܂ł����������W�X�^�Ƀ��[�h���Ċ��蓖�ĂȂ��Ƃ����Ȃ�RISC�͕s�ւ�
x86�Ȃ�P��łł��鑀�삪�������߂ɕ�����邩�炻���Ɉˑ��W�`�F�[����������
OoO�ɂ�铮�I�œK���̑j�Q�v���ɂȂ��Ă���B
�P���g��Ȃ��l�Ȃ炢���������[�h���Ȃ��Ă��X�^�b�N�|�C���^����
�������I�y�����h�w��ʼn����Z�����ق������ߐ�����B
�����Ă��ꂪx86��RISC�̐��\��ł��j���Ă����p�t�H�[�}���X�̍����v�f���B
> �Ō�Ɉꊇ�������ďI���Ƃ������Ƃ����B
��������x86��RISC����Ȃ��ł�
����Ȃ��Ƃ��m��Ȃ��̂ˁ@O��BA��KA��SA��N�@���c
> ���\���d������Ȃ�R�X�g�̍����������I�y�����h���Z�����炷�̂͏펯�B
���O�̔]���ł̏펯�͕����ĂȂ�
1���g��Ȃ��l�܂ł����������W�X�^�Ƀ��[�h���Ċ��蓖�ĂȂ��Ƃ����Ȃ�RISC�͕s�ւ�
x86�Ȃ�P��łł��鑀�삪�������߂ɕ�����邩�炻���Ɉˑ��W�`�F�[����������
OoO�ɂ�铮�I�œK���̑j�Q�v���ɂȂ��Ă���B
�P���g��Ȃ��l�Ȃ炢���������[�h���Ȃ��Ă��X�^�b�N�|�C���^����
�������I�y�����h�w��ʼn����Z�����ق������ߐ�����B
�����Ă��ꂪx86��RISC�̐��\��ł��j���Ă����p�t�H�[�}���X�̍����v�f���B
>>228
�Ƃ����1�N���b�N�ŕ����̖��߂���ăf�R�[�h�ł���X�[�p�[����f�R�[�_�̎���������Ă�B
�Ƃ����1�N���b�N�ŕ����̖��߂���ăf�R�[�h�ł���X�[�p�[����f�R�[�_�̎���������Ă�B
230 �F,,�E�L�́M�E,,�j��-������ nfmv001146153.uqw.ppp.infoweb.ne.jp�F2015/02/10(��) 04:30:47.27 ID:odukiSa7
���n����������
�u1�T�C�N���ŏ����ł���v�ƌ����Ă�̂��X���[�v�b�g�̂��ƂȂ̂����C�e���V�̂��ƂȂ̂�
���邢�́A�����������O�̃~�j�}���]���X�ł̓��C�e���V�Ƃ����T�O���琳���������ł���Ƃ�
�v���Ȃ��̂����B
�X���[�v�b�g�Ȃ�A�p�C�v���C�������ĕ����邱�Ƃʼn\�B
���C�e���V�Ȃ�Ai486�Ƃ��̎���Ȃ�Ƃ������A��OPs������GHz�I�[�_��CPU��
decode�X�e�[�W��1�N���b�N�T�C�N���ōςނȂ�Ă����CPU�͂܂����Ȃ�
�Ƃ������u����@�f�R�[�h�v�ł��̃X���������Ă��ǂ����̃��i�r�[��
���̉��l�ۏo�����X�����q�b�g���Ȃ��̂����Ȃ����ɕ����̂��H
���ꂪ���O�̔]��CPU�̋����Ȃ킯����
> �e�o�C�g��擪�Ƒz�肵�Ė��ߒ����f�R�[�h���鏈�������ׂđ��点�Č��ʂ��o���Ƃ���ł�����Ŗ��ߒ����}�[�N���Ė{�f�R�[�_�ɑ��閽�߂����߂�B
��H�K�͂Ƃ��Ă��ꂪ���E�B
�ǂ��Œ��ׂ��̂��]���ϑz�Ō����Ă�̂��m��Ȃ����A���ʌ��@���O�ɂ������������
Prefix��O����1�o�C�g�����Ԃɓǂ�ł����K�v�Ȃ�ĂȂ���
Opcode�̈ʒu����16����ŃX�L�������Ė��߂�Opcode�ɑΉ�����r�b�g��T��
���̌���ModRM����SIB, DISP�̃T�C�Y�ʂ���Ζ��߂̖������킩��B
�������킩��Ύ��̖��߂̐擪�͂킩��B
�Ȃ�̂��߂̓��@�I�ȃX�L������
�ǂ����擪���Ȃ�Ă��ƂŊm�肷��������Ƃ�����Aprefix���܂߂��擪����ǂ�ł邱�Ƃ�
���肷��K�v�Ȃ�ĂȂ���B
������REX�̂悤�ȐV����prefix�������Ă��v���f�R�[�_�̕��ׂ��������đ�����킯�ł͂Ȃ��B
���O���A16����̃v���f�R�[�_�������Ă��ꂼ�ꂪ�V���A����prefix��O���珇�Ԃɓǂݐi�߂Ă�
�Ǝv���Ă�킯����H
66 66 66 66 66 66 66 66 66 90
�݂����ȏ璷Prefix����NOP���烋�[�v�O�̃p�f�B���O�p�Ƃ��ăR�[�h��ɓ����Ă���̂�
�O���珇�Ԃ�1�o�C�g�����߂��Ă���A3�`4�T�C�N���ŏI���킯���Ȃ����낗
1�`10�Ԗڂ�prefix�ł��邱�Ƃ��ŏ��̃T�C�N���Ō��o�ł��Ė��ߖ{�̂�11�Ԗڂɂ��邱�Ƃ͂킩��킯�B
�v����ɂ��O�����������ĂȂ����Ă��Ƃ���ȁH
�u1�T�C�N���ŏ����ł���v�ƌ����Ă�̂��X���[�v�b�g�̂��ƂȂ̂����C�e���V�̂��ƂȂ̂�
���邢�́A�����������O�̃~�j�}���]���X�ł̓��C�e���V�Ƃ����T�O���琳���������ł���Ƃ�
�v���Ȃ��̂����B
�X���[�v�b�g�Ȃ�A�p�C�v���C�������ĕ����邱�Ƃʼn\�B
���C�e���V�Ȃ�Ai486�Ƃ��̎���Ȃ�Ƃ������A��OPs������GHz�I�[�_��CPU��
decode�X�e�[�W��1�N���b�N�T�C�N���ōςނȂ�Ă����CPU�͂܂����Ȃ�
�Ƃ������u����@�f�R�[�h�v�ł��̃X���������Ă��ǂ����̃��i�r�[��
���̉��l�ۏo�����X�����q�b�g���Ȃ��̂����Ȃ����ɕ����̂��H
���ꂪ���O�̔]��CPU�̋����Ȃ킯����
> �e�o�C�g��擪�Ƒz�肵�Ė��ߒ����f�R�[�h���鏈�������ׂđ��点�Č��ʂ��o���Ƃ���ł�����Ŗ��ߒ����}�[�N���Ė{�f�R�[�_�ɑ��閽�߂����߂�B
��H�K�͂Ƃ��Ă��ꂪ���E�B
�ǂ��Œ��ׂ��̂��]���ϑz�Ō����Ă�̂��m��Ȃ����A���ʌ��@���O�ɂ������������
Prefix��O����1�o�C�g�����Ԃɓǂ�ł����K�v�Ȃ�ĂȂ���
Opcode�̈ʒu����16����ŃX�L�������Ė��߂�Opcode�ɑΉ�����r�b�g��T��
���̌���ModRM����SIB, DISP�̃T�C�Y�ʂ���Ζ��߂̖������킩��B
�������킩��Ύ��̖��߂̐擪�͂킩��B
�Ȃ�̂��߂̓��@�I�ȃX�L������
�ǂ����擪���Ȃ�Ă��ƂŊm�肷��������Ƃ�����Aprefix���܂߂��擪����ǂ�ł邱�Ƃ�
���肷��K�v�Ȃ�ĂȂ���B
������REX�̂悤�ȐV����prefix�������Ă��v���f�R�[�_�̕��ׂ��������đ�����킯�ł͂Ȃ��B
���O���A16����̃v���f�R�[�_�������Ă��ꂼ�ꂪ�V���A����prefix��O���珇�Ԃɓǂݐi�߂Ă�
�Ǝv���Ă�킯����H
66 66 66 66 66 66 66 66 66 90
�݂����ȏ璷Prefix����NOP���烋�[�v�O�̃p�f�B���O�p�Ƃ��ăR�[�h��ɓ����Ă���̂�
�O���珇�Ԃ�1�o�C�g�����߂��Ă���A3�`4�T�C�N���ŏI���킯���Ȃ����낗
1�`10�Ԗڂ�prefix�ł��邱�Ƃ��ŏ��̃T�C�N���Ō��o�ł��Ė��ߖ{�̂�11�Ԗڂɂ��邱�Ƃ͂킩��킯�B
�v����ɂ��O�����������ĂȂ����Ă��Ƃ���ȁH
>>230
���O�o�J����B
���߃R�[�h�Ƒ��l�̋�ʂ��t���Ȃ���Ԃłǂ�����ăI�y�R�[�h����肷��B
mov eax,90909090h�Ƃ��̖��߂��������炢���Ȃ�nop��4�Ńf�R�[�h�I�����B
�擪���猩�Ă��������Ȃ���B
�܂��v���t�B�N�X��p�̃f�R�[�_�������ƕ���Ŋe�o�C�g�ʒu���疽�߂��n�܂����Ɖ��肵���Ƃ����ꂼ��ǂ�ȃv���t�B�N�X���t�����ƂɂȂ邩�A�I�y�R�[�h�̈ʒu���ǂ��ɂȂ邩�m�肳����B
������CPU�̓��샂�[�h���v���t�B�N�X�ŏ㏑���������̂ŃI�y�R�[�h��ModR/W�̒�`���m�肷�邩�玟�̒i�K�ŃI�y�R�[�h��ModR/W���f�R�[�h����B
���ߒ��ɊW�Ȃ����������ăI�y�R�[�h����ModR/W�̗L���A���l�̗L���ƒ����AModR/W����SIB�̗L���A�I�t�Z�b�g�̗L���ƒ��������߂č��v����Ζ��ߒ������܂�B
�����܂ł�10�����B
���̎��̒i�K�Ŗ��ߒ����X�L�������Đ��������ߋ��E���m�肳���ăf�R�[�h���ׂ����߂��i�荞��ł���{�f�R�[�h�ɓ���킯�B
���O�o�J����B
���߃R�[�h�Ƒ��l�̋�ʂ��t���Ȃ���Ԃłǂ�����ăI�y�R�[�h����肷��B
mov eax,90909090h�Ƃ��̖��߂��������炢���Ȃ�nop��4�Ńf�R�[�h�I�����B
�擪���猩�Ă��������Ȃ���B
�܂��v���t�B�N�X��p�̃f�R�[�_�������ƕ���Ŋe�o�C�g�ʒu���疽�߂��n�܂����Ɖ��肵���Ƃ����ꂼ��ǂ�ȃv���t�B�N�X���t�����ƂɂȂ邩�A�I�y�R�[�h�̈ʒu���ǂ��ɂȂ邩�m�肳����B
������CPU�̓��샂�[�h���v���t�B�N�X�ŏ㏑���������̂ŃI�y�R�[�h��ModR/W�̒�`���m�肷�邩�玟�̒i�K�ŃI�y�R�[�h��ModR/W���f�R�[�h����B
���ߒ��ɊW�Ȃ����������ăI�y�R�[�h����ModR/W�̗L���A���l�̗L���ƒ����AModR/W����SIB�̗L���A�I�t�Z�b�g�̗L���ƒ��������߂č��v����Ζ��ߒ������܂�B
�����܂ł�10�����B
���̎��̒i�K�Ŗ��ߒ����X�L�������Đ��������ߋ��E���m�肳���ăf�R�[�h���ׂ����߂��i�荞��ł���{�f�R�[�h�ɓ���킯�B
�ǂ��݂��>>230�̏����Ă��邱�Ƃ�1���ߕ������Ȃ��ȁB
���ۂɂ̓X�[�p�[�X�J���ʼn����߂������Ƀf�R�[�h���Ȃ��Ⴂ���Ȃ��̂ɂ����������ۂ茇�����Ă���B
�����_�����B
���ۂɂ̓X�[�p�[�X�J���ʼn����߂������Ƀf�R�[�h���Ȃ��Ⴂ���Ȃ��̂ɂ����������ۂ茇�����Ă���B
�����_�����B
�����������}�C�N���R�[�h�ƍl���Ă�̂��������ȁB
�p�C�v���C���͏��������̈�`�ԂȂ̂ɁB
�����ĕ����̃p�C�v���C�������Ԃ̂��X�[�p�[�X�J��
�����̃f�R�[�_�����Ԃ͓̂�����O�B
����Ȋ�{�I�Ȃ��Ƃ����O���Ă��邾�����낤���ǂ˂��B
�p�C�v���C���͏��������̈�`�ԂȂ̂ɁB
�����ĕ����̃p�C�v���C�������Ԃ̂��X�[�p�[�X�J��
�����̃f�R�[�_�����Ԃ͓̂�����O�B
����Ȋ�{�I�Ȃ��Ƃ����O���Ă��邾�����낤���ǂ˂��B
�Ȃ�Œc�q���O��ip�����Ă�́H
235 �F,,�E�L�́M�E,,�j��-�������F2015/02/10(��) 19:10:24.13 ID:m74wgqJQ
>>231-233
�K���ōl���Ă܂��p�̏�h��ł����H�����������
> ���߃R�[�h�Ƒ��l�̋�ʂ��t���Ȃ���Ԃłǂ�����ăI�y�R�[�h����肷��B
��₾���炢����B�O�̊m�肵�����ߋ��E�Ɣ�r���Ė����������������O��������B
���ꂪ���@�I���s����H
�����ے肷��Ȃ玩���̔�������ے肷�邱�ƂɂȂ邯�ǁH
> �e�o�C�g��擪�Ƒz�肵�Ė��ߒ����f�R�[�h���鏈�������ׂđ��点�Č��ʂ��o���Ƃ���ł�����Ŗ��ߒ����}�[�N���Ė{�f�R�[�_�ɑ��閽�߂����߂�B
���߂̊J�n�o�C�g��Prefix��Opcode���͂��̃o�C�g�ׂȂ��Ƃ킩��Ȃ���
�ǂ�Ȗ��߂ɂ�Opcode�͊܂܂��B
������܂��̓t�F�b�`�����S�Ă�16�o�C�g���A�����ꂩ�̖��߂Ɋ܂܂��Opcode�o�C�g�ł���Ɖ��肷��B
�V���O���o�C�g���߂Ȃ�ModRM�̂Ȃ����̂����邪�A������Opcode�̌��ɂ�ModRM�����B
ModRM�Ǝv����o�C�g���X�L���������SIB+DISP�̃T�C�Y���킩��B
�������ł������͂͂�������邩��A�O�̖��߂̏I�[�Ɣ�r���Ė������Ȃ�
�g�ݍ��킹��I�Ԃ��ƂŌ����i�荞�ށB
���i�r�[���ꂿ���̌����ʂ�A���߂̐�[�Ɖ��肷����Ă̂́A������o���Ȃ��͂Ȃ�����
�璷��prefix�������������Ă�ꍇ��z�肵�Ȃ��Ƃ����Ȃ�����A
���[�X�g�P�[�X��x86�̍ő喽�ߒ��ł���15�o�C�g���A������15�o�C�g��S���X�L�������Ȃ���
���߂̏I�[�̐��肪�ł��Ȃ���B
��[���ǂ�������u����v�ɂ����Ȃ��̂ɁA�I�[�����m���ɒT���̂ɂ���̓R�X�g�������肷����B
Opcode���Ƃ݂Ȃ��A�����Ƃ��O�̂P�`�R�o�C�g�i��璷Prefix�̌��j��
����1�o�C�g�iModRM���j�����ŁA���̖��߂̏I�[�ʒu�̌�₪������B
���邢�͂��̃o�C�g��Opcode�ł͂Ȃ����Ƃ��킩��B
�ǂ������R�X�g��������Ȃ����͖������ˁB
������Opcode����1�`3�o�C�g���O�ɂ��邩������Ȃ��璷prefix�̃X�L�����͌�ɂł��邩��
���̂ԂʂɃT�C�N�����͐H���Ȃ��B
�K���ōl���Ă܂��p�̏�h��ł����H�����������
> ���߃R�[�h�Ƒ��l�̋�ʂ��t���Ȃ���Ԃłǂ�����ăI�y�R�[�h����肷��B
��₾���炢����B�O�̊m�肵�����ߋ��E�Ɣ�r���Ė����������������O��������B
���ꂪ���@�I���s����H
�����ے肷��Ȃ玩���̔�������ے肷�邱�ƂɂȂ邯�ǁH
> �e�o�C�g��擪�Ƒz�肵�Ė��ߒ����f�R�[�h���鏈�������ׂđ��点�Č��ʂ��o���Ƃ���ł�����Ŗ��ߒ����}�[�N���Ė{�f�R�[�_�ɑ��閽�߂����߂�B
���߂̊J�n�o�C�g��Prefix��Opcode���͂��̃o�C�g�ׂȂ��Ƃ킩��Ȃ���
�ǂ�Ȗ��߂ɂ�Opcode�͊܂܂��B
������܂��̓t�F�b�`�����S�Ă�16�o�C�g���A�����ꂩ�̖��߂Ɋ܂܂��Opcode�o�C�g�ł���Ɖ��肷��B
�V���O���o�C�g���߂Ȃ�ModRM�̂Ȃ����̂����邪�A������Opcode�̌��ɂ�ModRM�����B
ModRM�Ǝv����o�C�g���X�L���������SIB+DISP�̃T�C�Y���킩��B
�������ł������͂͂�������邩��A�O�̖��߂̏I�[�Ɣ�r���Ė������Ȃ�
�g�ݍ��킹��I�Ԃ��ƂŌ����i�荞�ށB
���i�r�[���ꂿ���̌����ʂ�A���߂̐�[�Ɖ��肷����Ă̂́A������o���Ȃ��͂Ȃ�����
�璷��prefix�������������Ă�ꍇ��z�肵�Ȃ��Ƃ����Ȃ�����A
���[�X�g�P�[�X��x86�̍ő喽�ߒ��ł���15�o�C�g���A������15�o�C�g��S���X�L�������Ȃ���
���߂̏I�[�̐��肪�ł��Ȃ���B
��[���ǂ�������u����v�ɂ����Ȃ��̂ɁA�I�[�����m���ɒT���̂ɂ���̓R�X�g�������肷����B
Opcode���Ƃ݂Ȃ��A�����Ƃ��O�̂P�`�R�o�C�g�i��璷Prefix�̌��j��
����1�o�C�g�iModRM���j�����ŁA���̖��߂̏I�[�ʒu�̌�₪������B
���邢�͂��̃o�C�g��Opcode�ł͂Ȃ����Ƃ��킩��B
�ǂ������R�X�g��������Ȃ����͖������ˁB
������Opcode����1�`3�o�C�g���O�ɂ��邩������Ȃ��璷prefix�̃X�L�����͌�ɂł��邩��
���̂ԂʂɃT�C�N�����͐H���Ȃ��B
236 �F,,�E�L�́M�E,,�j��-�������F2015/02/10(��) 19:14:54.28 ID:m74wgqJQ
�O����������Ɍ������ăX�L��������̂ƁA�^����O��ɃX�L��������̂ł�
�ǂ����������̕��ł��ăT�C�N�����ߖ�ł��邩�A����Ȃ̏펯�I�ɍl����킩���ˁH
�ǂ����������̕��ł��ăT�C�N�����ߖ�ł��邩�A����Ȃ̏펯�I�ɍl����킩���ˁH
����ȂƂ���Ŏ��̃v���O���������ӂł������������Ă��d�����Ȃ����낤
���ꂼ��t���[�\�t�g�ł��o����
��������ǂ������ォ���߂Ă���(�L�E�ցE�M)
�������Ȃ����𑜃\�t�g�Ȃ��~������
���ꂼ��t���[�\�t�g�ł��o����
��������ǂ������ォ���߂Ă���(�L�E�ցE�M)
�������Ȃ����𑜃\�t�g�Ȃ��~������
238 �F,,�E�L�́M�E,,�j��-�������F2015/02/10(��) 19:50:56.87 ID:m74wgqJQ
>>237
T�E�E�E�Ȃ����H�킷�ꂽ
John the Ripper�̊J�����͎҂̈�l�Ƃ��ē��{�l�ŗB��L�ڂ���Ă�̂͂��₳���I
http://www.openwall.com/john/doc/CREDITS.shtml
T�E�E�E�Ȃ����H�킷�ꂽ
John the Ripper�̊J�����͎҂̈�l�Ƃ��ē��{�l�ŗB��L�ڂ���Ă�̂͂��₳���I
http://www.openwall.com/john/doc/CREDITS.shtml
powerpc�������܂��́H
C#�Ő���r���̃y�C���g�\�t�g��
̫ļ��̎w��c�[���ƕ\�ʏ㓯�������ŗy���Ɍy���������o�������ɂ�
����̑������Ƃ�SSE���Ƃ��i�������w��c�[���Ńo���o���g���Ă��͂��j����
�A���S���Y�����y�ʃR���p�N�g�Ȃ̂���Ԉ̂����Ă̂�����������
�Ă�����4����8����HGPU�̑O�ɂ̓I���`���݂Ă��Ȃ���
AVX�ȂA�E�g�I�u�ᒆ�A���܂ꂽ���ăo�g�����ˁ[��
̫ļ��̎w��c�[���ƕ\�ʏ㓯�������ŗy���Ɍy���������o�������ɂ�
����̑������Ƃ�SSE���Ƃ��i�������w��c�[���Ńo���o���g���Ă��͂��j����
�A���S���Y�����y�ʃR���p�N�g�Ȃ̂���Ԉ̂����Ă̂�����������
�Ă�����4����8����HGPU�̑O�ɂ̓I���`���݂Ă��Ȃ���
AVX�ȂA�E�g�I�u�ᒆ�A���܂ꂽ���ăo�g�����ˁ[��
�T���X���А��̃e���r�A�e���r�̑O�ł̉�b��S�ċL�^���A��Ƀl�b�g����đ��M���Ă��鎖������ [�]�ڋ֎~](c)2ch.net [941145234]
http://fox.2ch.net/test/read.cgi/poverty/1423552110/
�s�s���o�O�Ă����X�y���M�X�p�C�A���`�����͂Ȃ��킗
���{�l�Ȃ�C���e���Q�t�H�����
http://fox.2ch.net/test/read.cgi/poverty/1423552110/
�s�s���o�O�Ă����X�y���M�X�p�C�A���`�����͂Ȃ��킗
���{�l�Ȃ�C���e���Q�t�H�����
242 �F,,�E�L�́M�E,,�j��-�������F2015/02/10(��) 20:08:09.63 ID:m74wgqJQ
>>239
AltiVec�G�肽�������߂�G4�����Mac mini�������̂����̃}�J�[�f�r���[
�܂�Xcode���č����̂��ς�炸���Y���N�\���ȁB
AltiVec�G�肽�������߂�G4�����Mac mini�������̂����̃}�J�[�f�r���[
�܂�Xcode���č����̂��ς�炸���Y���N�\���ȁB
244 �F,,�E�L�́M�E,,�j��-�������F2015/02/10(��) 20:19:31.49 ID:m74wgqJQ
>>240
�P��Photoshop���@�\�Ă���̕��d�����������Ⴄ�ƁE�E�E
C#�Ȃ�.NET Framework�̉摜�����nAPI���̂������I��SSE/AVX�����b�v���Ă�͂�����B
WIC�iWindows Imaging Component�j���Ă����čŋ߂�C++������g����悤�ɂȂ��Ă�
�P��Photoshop���@�\�Ă���̕��d�����������Ⴄ�ƁE�E�E
C#�Ȃ�.NET Framework�̉摜�����nAPI���̂������I��SSE/AVX�����b�v���Ă�͂�����B
WIC�iWindows Imaging Component�j���Ă����čŋ߂�C++������g����悤�ɂȂ��Ă�
>>240��������GPU(HSA?)���g�������炵���y�C���g�\�t�g�����J���Ă����̂�
�y���݂��ȁBAMD���[�U�[��>>240���������I
>>238
DES S-Box���ĉ��������ς肾���A�N�����g���Ă������̂���������т���̂�
�g���Ă����̂��p�X���[�h�N���b�N�c�[�����Č����̂��A�Ђ˂���c�q��̂��̂��Ċ���������
�y���݂��ȁBAMD���[�U�[��>>240���������I
>>238
DES S-Box���ĉ��������ς肾���A�N�����g���Ă������̂���������т���̂�
�g���Ă����̂��p�X���[�h�N���b�N�c�[�����Č����̂��A�Ђ˂���c�q��̂��̂��Ċ���������
>>244
��s�̃G�N�Z���I���̂����ɊG�ɋ��������̂�
�w��c�[���ŃO�O���
̫ļ��̃u���V��1pixel��ARGB����byte���l���Z���Ă����i�̂��������ʂ̏����j
�摜���b�N����ARGB�|�C���^�w�肵�ĂP�����Z���A�����b�N���Ċm��
�u���V�n�͂���̌J��Ԃ����i������ʓI�ɂ́j
��s�̃G�N�Z���I���̂����ɊG�ɋ��������̂�
�w��c�[���ŃO�O���
̫ļ��̃u���V��1pixel��ARGB����byte���l���Z���Ă����i�̂��������ʂ̏����j
�摜���b�N����ARGB�|�C���^�w�肵�ĂP�����Z���A�����b�N���Ċm��
�u���V�n�͂���̌J��Ԃ����i������ʓI�ɂ́j
247 �F,,�E�L�́M�E,,�j��-�������F2015/02/10(��) 20:59:33.85 ID:m74wgqJQ
����AVX�ɍœK�����ꂽ�o�������̉摜����API���ׂ�������AVX��葬���Ȃ�����
���Ⴂ����قǂ̃A�z���͂킽���͎������킹�Ă���܂���
�T�[�o�T�C�h�ł悭�g���Ă�ImageMagick��Apache������������
�L��������Ƃ����čő��Ƃ͌���Ȃ�
���Ⴂ����قǂ̃A�z���͂킽���͎������킹�Ă���܂���
�T�[�o�T�C�h�ł悭�g���Ă�ImageMagick��Apache������������
�L��������Ƃ����čő��Ƃ͌���Ȃ�
248 �F,,�E�L�́M�E,,�j��-�������F2015/02/10(��) 21:05:20.00 ID:m74wgqJQ
�\�[�X�R�[�h���J�ł���H
�摜�̃f�[�^���o������API�ƌ����邯��
��������̃f�[�^���Z��API����Ȃ����Ă�
�u���߁��f�[�^�Ńf�[�^�����߁v
�uLNI��GPU�͓���SIMT������LNI��GPU��SIMT�Ȃ킯���Ȃ��v
�Ƃ��������������c�߂�悤�Șb�͑����ł���
��������̃f�[�^���Z��API����Ȃ����Ă�
�u���߁��f�[�^�Ńf�[�^�����߁v
�uLNI��GPU�͓���SIMT������LNI��GPU��SIMT�Ȃ킯���Ȃ��v
�Ƃ��������������c�߂�悤�Șb�͑����ł���
251 �F,,�E�L�́M�E,,�j��-�������F2015/02/10(��) 21:15:55.99 ID:m74wgqJQ
�j�[�g�̔]���v���O���������͂�������ł�
�X�N���[���V���b�g�����ł��Ƃ��Ă��炵�Ă݂�H�{���ɂ���Ȃ�
�X�N���[���V���b�g�����ł��Ƃ��Ă��炵�Ă݂�H�{���ɂ���Ȃ�
253 �F,,�E�L�́M�E,,�j��-�������F2015/02/10(��) 21:29:11.58 ID:m74wgqJQ
�͈�()����������������������������������������������������������������������������ۏo��
254 �F,,�E�L�́M�E,,�j��-�������F2015/02/10(��) 21:33:21.34 ID:m74wgqJQ
C#�̃T���v���T�C�g����R�s�y���Ă��������̃R�[�h�ɃI���W�i���v�f���������������
������Ȃ�ł����\�b�h���������ɂ���̂�DQN�������
Java��C#�̃V���{����UNICODE�g����݂̂͂�Ȓm���Ă邯�ǂ���͎g���Ă������Ďg��Ȃ�
������Ȃ�ł����\�b�h���������ɂ���̂�DQN�������
Java��C#�̃V���{����UNICODE�g����݂̂͂�Ȓm���Ă邯�ǂ���͎g���Ă������Ďg��Ȃ�
�P�Ȃ�u���V�Ŕ�r����Ɖ��A�v����̫ļ��ł͍���������̫ļ��̂ق����y��
�ł��w��c�[�����ƒf�R���A�v���̂ق����y��
̫ļ��̏�����������Ă�̂�if���炯�Ȃ̂��͊F�ڕs��������
�Ƃɂ�����������������̂ق�������
�ǐ��d���A�\���̔c���d���ŃA���S���Y���˂��l�߂�̂��őP�����ďؖ������悤�Ȃ����
�ł��w��c�[�����ƒf�R���A�v���̂ق����y��
̫ļ��̏�����������Ă�̂�if���炯�Ȃ̂��͊F�ڕs��������
�Ƃɂ�����������������̂ق�������
�ǐ��d���A�\���̔c���d���ŃA���S���Y���˂��l�߂�̂��őP�����ďؖ������悤�Ȃ����
256 �F,,�E�L�́M�E,,�j��-�������F2015/02/10(��) 21:48:46.30 ID:m74wgqJQ
�����Z1��E�|���Z2��Ȃ�Č������Ⴄ���x���̖��\��
�A���S���Y���������ōl����\�͂��Ȃ��̂͒N�����Ă킩���B
�v���O�����������Ă�Ƃ����YouTube�ɂ����������Ȃ��́H�S�V�S�V�݂����ɁB
�A���S���Y���������ōl����\�͂��Ȃ��̂͒N�����Ă킩���B
�v���O�����������Ă�Ƃ����YouTube�ɂ����������Ȃ��́H�S�V�S�V�݂����ɁB
257 �F,,�E�L�́M�E,,�j��-�������F2015/02/10(��) 21:54:13.23 ID:m74wgqJQ
�l�b�g�ŏE�����T���v�����ς��������̃R�s�y�v���O������100���Ƃ�
�_���R�s�y�̏��ە����j�ł��猾��Ȃ���H
�_���R�s�y�̏��ە����j�ł��猾��Ȃ���H
258 �F,,�E�L�́M�E,,�j��-�������F2015/02/10(��) 22:01:25.49 ID:m74wgqJQ
���O�O�������e�𗝉������������Ă锚���X�̈��
465 �FSocket774 [��] �F2015/02/03(��) 22:37:36.80 ID:HrSzjo3M (7/7)
RISC�̓R���p�C���Ɋ撣���Ă��炤���Ƃŕ�����s�̕p�x���グ
�����O��Ƃ��ă��W�X�^�i�R�A�̃��\�[�X�E���j�b�g�j�𑝂₷
�i���łɖ��߂��P�������ꂽ���N���b�N���オ��Z�i�j
�����Ȃ��RISC����K�͂��Ƃ������ƂɂȂ�
�ł�����ƃX�}�z�䂦�̒����d�͋����Ƃ�
�����u���j�b�g������ƒ����d�́v�Ƃ͊��S���W
�ܘ_�m��̍��̗�����������ǂ��Ȃ邩�Ƃ������̂͒m��Ȃ���
465 �FSocket774 [��] �F2015/02/03(��) 22:37:36.80 ID:HrSzjo3M (7/7)
RISC�̓R���p�C���Ɋ撣���Ă��炤���Ƃŕ�����s�̕p�x���グ
�����O��Ƃ��ă��W�X�^�i�R�A�̃��\�[�X�E���j�b�g�j�𑝂₷
�i���łɖ��߂��P�������ꂽ���N���b�N���オ��Z�i�j
�����Ȃ��RISC����K�͂��Ƃ������ƂɂȂ�
�ł�����ƃX�}�z�䂦�̒����d�͋����Ƃ�
�����u���j�b�g������ƒ����d�́v�Ƃ͊��S���W
�ܘ_�m��̍��̗�����������ǂ��Ȃ邩�Ƃ������̂͒m��Ȃ���
�v���t�B�N�X���ォ��X�L�����ł���Ǝv���Ă鎞�_�Ř_���I�v�l�͂�����Ȃ��ȁB
�ォ��v���t�B�N�X�Ɍ�����R�[�h���������Ă����ꂪ�v���t�B�N�X���O�̖��߂�ModR/W�⑦�l�Ȃ̂��Ȃ�ĕ�����Ȃ��B�O�̖��߂̍Ōオ���܂�Ȃ����Ƃɂ͂ǂ�����v���t�B�N�X�Ƃ��ĉ��߂��ėǂ��̂�������Ȃ��B
���������ォ��v���t�B�N�X���t�����Ƃ��������Ă��I�y�R�[�h��ModR/W�̃f�R�[�h�͏I����Ă邩���蒼���͌����Ȃ��B�܂�����Ԉ���Ă��炲�߂�Ȃ���������Ă��ƁB
����Pentium�̃f�R�[�_�͒c�q����̌����Ă�悤�ȓ������Ǝv����B2���ߖڂ̓v���t�B�N�X�Ƃ��}�C�N���R�[�h���߂Ƃ��ɊY���������j�Z�ɂ��邱�Ƃ�O��ɓ��@�I�Ƀf�R�[�h���Ă邩��B
Pentium�̓p�C�v���C�����Z���ăv���f�R�[�h�i����������Ƃɂ��������Ȃ�2���ߖڂ��f�R�[�h���n�߂Ȃ����Ƃɂ͊Ԃɍ���Ȃ�����ˁB
�ł�1�N���b�N��4���߃f�R�[�h���鍡�̃v���Z�b�T�ŁA������286�ȍ~�Ɋg�����ꂽ���߂�100���v���t�B�N�X�t���Ƃ����Ńv���t�B�N�X��������S���̂ĂĂ�蒼���Ƃ��������������Ă�����ƗL�蓾�Ȃ��B
SSE�̃f�R�[�h�Ƃ��ǂ�����Ă��ł����˂��B
�v���t�B�N�X��������I�y�R�[�h�̈Ӗ����S���ʕ��ɂȂ��ł���B
�ォ��v���t�B�N�X�Ɍ�����R�[�h���������Ă����ꂪ�v���t�B�N�X���O�̖��߂�ModR/W�⑦�l�Ȃ̂��Ȃ�ĕ�����Ȃ��B�O�̖��߂̍Ōオ���܂�Ȃ����Ƃɂ͂ǂ�����v���t�B�N�X�Ƃ��ĉ��߂��ėǂ��̂�������Ȃ��B
���������ォ��v���t�B�N�X���t�����Ƃ��������Ă��I�y�R�[�h��ModR/W�̃f�R�[�h�͏I����Ă邩���蒼���͌����Ȃ��B�܂�����Ԉ���Ă��炲�߂�Ȃ���������Ă��ƁB
����Pentium�̃f�R�[�_�͒c�q����̌����Ă�悤�ȓ������Ǝv����B2���ߖڂ̓v���t�B�N�X�Ƃ��}�C�N���R�[�h���߂Ƃ��ɊY���������j�Z�ɂ��邱�Ƃ�O��ɓ��@�I�Ƀf�R�[�h���Ă邩��B
Pentium�̓p�C�v���C�����Z���ăv���f�R�[�h�i����������Ƃɂ��������Ȃ�2���ߖڂ��f�R�[�h���n�߂Ȃ����Ƃɂ͊Ԃɍ���Ȃ�����ˁB
�ł�1�N���b�N��4���߃f�R�[�h���鍡�̃v���Z�b�T�ŁA������286�ȍ~�Ɋg�����ꂽ���߂�100���v���t�B�N�X�t���Ƃ����Ńv���t�B�N�X��������S���̂ĂĂ�蒼���Ƃ��������������Ă�����ƗL�蓾�Ȃ��B
SSE�̃f�R�[�h�Ƃ��ǂ�����Ă��ł����˂��B
�v���t�B�N�X��������I�y�R�[�h�̈Ӗ����S���ʕ��ɂȂ��ł���B
�v�܂œǂ�
261 �F,,�E�L�́M�E,,�j��-�������F2015/02/10(��) 22:29:07.52 ID:m74wgqJQ
>>259
> SSE�̃f�R�[�h�Ƃ��ǂ�����Ă��ł����˂��B
> �v���t�B�N�X��������I�y�R�[�h�̈Ӗ����S���ʕ��ɂȂ��ł���B
������Ȃ�ł����p�̏�h����J��Ԃ�������̂�
SSE�͂������66,F2,F3�����Ă�Opcode���疽�ߏI�[�܂ł̒������S���������B
pre-decode�ł͖��߂́u�Ӗ��v�Ȃ�ĕK�v�Ȃ���B
�K�v�Ȃ̂͂����I�[�i���̖��߂Ƃ̋��E�j�����o���邱�ƁB
�Ӗ������߂���̂�decode�̖�ڂ�����A�O�i�͐�o���ɓO��������B
> SSE�̃f�R�[�h�Ƃ��ǂ�����Ă��ł����˂��B
> �v���t�B�N�X��������I�y�R�[�h�̈Ӗ����S���ʕ��ɂȂ��ł���B
������Ȃ�ł����p�̏�h����J��Ԃ�������̂�
SSE�͂������66,F2,F3�����Ă�Opcode���疽�ߏI�[�܂ł̒������S���������B
pre-decode�ł͖��߂́u�Ӗ��v�Ȃ�ĕK�v�Ȃ���B
�K�v�Ȃ̂͂����I�[�i���̖��߂Ƃ̋��E�j�����o���邱�ƁB
�Ӗ������߂���̂�decode�̖�ڂ�����A�O�i�͐�o���ɓO��������B
�c�q�������Tripcode���������
�����Y�ꂿ�������
�܂��ߋ��ɋƐт�������Ă��ƂŌ������Ă�낤
ID:k2tdIBHI�͂Ȃߋ��ł���������Ɛт���́H
�Ȃ��Ȃ�Ȃ�2ch�����ɂł����ɗ��t���[�\�t�g����
HSA�Ή��̂�
�����Y�ꂿ�������
�܂��ߋ��ɋƐт�������Ă��ƂŌ������Ă�낤
ID:k2tdIBHI�͂Ȃߋ��ł���������Ɛт���́H
�Ȃ��Ȃ�Ȃ�2ch�����ɂł����ɗ��t���[�\�t�g����
HSA�Ή��̂�
263 �F,,�E�L�́M�E,,�j��-�������F2015/02/10(��) 22:46:31.28 ID:m74wgqJQ
����͂����ƁASSSE3�`SSE4.x��66 0F 38 op���ăt�H�[�}�b�g������́AAMD����Ȃ���
Intel�ŁA���������̗pCPU����EM64T����CPU���ŏ��ɏo���̂�肸���ƌ�Ȃ�ł�����
�Ȃ�ł����prefix���������Ƃ�AMD64�������Ƃ������ƂɂȂ��Ă��ł����H
AMD��2011�N�܂�SSSE3�ɑΉ�����CPU����o���Ȃ�������
�ނ���|�V������SSE5��0F����n�܂�]���t�H�[�}�b�g�Ȃ���A66,F2,F3��prefix�Ȃ���
PS/SS/PD/SD��\���ł���悤�ɂȂ��Ă���A�X��REX�����̋@�\��DREX�Ƃ���
���߃t�B�[���h�ɑg�ݍ��܂�Ă���A0F���O��prefix������K�v���Ȃ�
�t�H�[�}�b�g�Ɏd�グ�Ă����B
SSSE3��66�Ȃ��̃t�H�[�}�b�g��MMX���W�X�^�ɍ�p����悤�ɂȂ��Ă�����܂�����
SSE4��66�Ȃ��̖��߂������Ɋ��蓖�ĂĂ�킯�ł��Ȃ��B
64bit���ȍ~���O���匙����prefix���N�\����SIMD���߂�lj������̂�Intel��
�t��AMD��AVX���\�������O�ɁA���������A�Z���Œ蒷�̒lj����߂����낤��
���Ă��̂ł����A���̓_�͂ǂ��ł����H
����������A���Ȃ��͂ǂ��̉�Ђ������������āA���邢�͂��Ȃ�������
����Ȑ����p���N���Ă��ł����H
Intel�ŁA���������̗pCPU����EM64T����CPU���ŏ��ɏo���̂�肸���ƌ�Ȃ�ł�����
�Ȃ�ł����prefix���������Ƃ�AMD64�������Ƃ������ƂɂȂ��Ă��ł����H
AMD��2011�N�܂�SSSE3�ɑΉ�����CPU����o���Ȃ�������
�ނ���|�V������SSE5��0F����n�܂�]���t�H�[�}�b�g�Ȃ���A66,F2,F3��prefix�Ȃ���
PS/SS/PD/SD��\���ł���悤�ɂȂ��Ă���A�X��REX�����̋@�\��DREX�Ƃ���
���߃t�B�[���h�ɑg�ݍ��܂�Ă���A0F���O��prefix������K�v���Ȃ�
�t�H�[�}�b�g�Ɏd�グ�Ă����B
SSSE3��66�Ȃ��̃t�H�[�}�b�g��MMX���W�X�^�ɍ�p����悤�ɂȂ��Ă�����܂�����
SSE4��66�Ȃ��̖��߂������Ɋ��蓖�ĂĂ�킯�ł��Ȃ��B
64bit���ȍ~���O���匙����prefix���N�\����SIMD���߂�lj������̂�Intel��
�t��AMD��AVX���\�������O�ɁA���������A�Z���Œ蒷�̒lj����߂����낤��
���Ă��̂ł����A���̓_�͂ǂ��ł����H
����������A���Ȃ��͂ǂ��̉�Ђ������������āA���邢�͂��Ȃ�������
����Ȑ����p���N���Ă��ł����H
264 �F,,�E�L�́M�E,,�j��-�������F2015/02/10(��) 23:09:16.01 ID:m74wgqJQ
> ������286�ȍ~�Ɋg�����ꂽ���߂�100���v���t�B�N�X�t���Ƃ�����
> �v���t�B�N�X��������S���̂ĂĂ�蒼���Ƃ��������������Ă�����ƗL�蓾�Ȃ��B
���́A���O���u���肦�Ȃ��v�Ǝv�������ۂɋN�����Ă��̂�Pentium Pro��LCP�X�g�[������
66h/67h�̎g�p�ɂ����disp32��imm32�̃T�C�Y��16�r�b�g���ɃI�[�o�[���C�h�����
�y�i���e�B��������悤�ɂȂ��Ă����B
Haswell�ł����܂��ɂ��̖�葶�݂����B
1536��OPs���͂ݏo���������[�v�����ă�OPs cache�����Ȃ���Ԃɂ���
�����Ă݂�킩��B
����́A���������Ă�A���S���Y����Pentium Pro�ȍ~Intel�v���Z�b�T�Ɏ�������Ă邱�Ƃ�
�؋��ɂق��Ȃ�Ȃ��B
> �v���t�B�N�X��������S���̂ĂĂ�蒼���Ƃ��������������Ă�����ƗL�蓾�Ȃ��B
���́A���O���u���肦�Ȃ��v�Ǝv�������ۂɋN�����Ă��̂�Pentium Pro��LCP�X�g�[������
66h/67h�̎g�p�ɂ����disp32��imm32�̃T�C�Y��16�r�b�g���ɃI�[�o�[���C�h�����
�y�i���e�B��������悤�ɂȂ��Ă����B
Haswell�ł����܂��ɂ��̖�葶�݂����B
1536��OPs���͂ݏo���������[�v�����ă�OPs cache�����Ȃ���Ԃɂ���
�����Ă݂�킩��B
����́A���������Ă�A���S���Y����Pentium Pro�ȍ~Intel�v���Z�b�T�Ɏ�������Ă邱�Ƃ�
�؋��ɂق��Ȃ�Ȃ��B
�P�X�e�[�W�ł�鏈�������Ȃ����āi���N���b�N���̂��߁j�A
�����Ȃ��X�e�[�W���ŁA�f�R�[�h���s��Ȃ��Ƃ����Ȃ�
����Ɉˑ��W�������ƃ`�F�b�N���āA�����������d�͂�
�������A�f�R�[�h�Ɏg���g�����W�X�^�͐̂Ɣ�ׂĂ����Ԃ����Ă����܂�Ȃ�
����Ȗ�����肨�������āA�����Ƃ���Ă�Intel�͂�������
�����Ȃ��X�e�[�W���ŁA�f�R�[�h���s��Ȃ��Ƃ����Ȃ�
����Ɉˑ��W�������ƃ`�F�b�N���āA�����������d�͂�
�������A�f�R�[�h�Ɏg���g�����W�X�^�͐̂Ɣ�ׂĂ����Ԃ����Ă����܂�Ȃ�
����Ȗ�����肨�������āA�����Ƃ���Ă�Intel�͂�������
266 �F,,�E�L�́M�E,,�j��-�������F2015/02/11(��) 09:02:57.55 ID:cRbfTUID
>>262
�����̂��ƂȂ���A�\�t�g������Ɛт̘b���o�Ă��ċ��h�S��
�u��������Ȃ������\�t�g������[�v�i�������s���n�b�^���j
�ƌ����Ă邾���B�ł��n��������Web�ŏE���Ă����v���O�����̃R�s�y������t�B
����ԃn�b�^���Œ��g�Ȃ�ĂȂ��B
���͂�����Ȃ��̂Ƀv���C�h�����͈�l�O�Ȃ�B
�v���C�h�̍����ɂȂ�悤�Ȑ��ʂȂ�Ŏ����ĂȂ�����e����ꖂ邾����
����������j�[�g�Ȃ��ǂ˂�����
�����̂��ƂȂ���A�\�t�g������Ɛт̘b���o�Ă��ċ��h�S��
�u��������Ȃ������\�t�g������[�v�i�������s���n�b�^���j
�ƌ����Ă邾���B�ł��n��������Web�ŏE���Ă����v���O�����̃R�s�y������t�B
����ԃn�b�^���Œ��g�Ȃ�ĂȂ��B
���͂�����Ȃ��̂Ƀv���C�h�����͈�l�O�Ȃ�B
�v���C�h�̍����ɂȂ�悤�Ȑ��ʂȂ�Ŏ����ĂȂ�����e����ꖂ邾����
����������j�[�g�Ȃ��ǂ˂�����
10���̑��i��t�j�ł����������̌��Ԃ薳���̂ɉ����Ă����Č����Ă�̂�
���ӂ��Ă܂Ŗ\��Ă�̂͂����P���ł��瓥�ݓ|���K�v�ɔ����Ă�ᖳ�����������
���{�����x���i�}�|���z���Ă邩��ȁ`���\�����K���l���z��
���Ȃ݂ɉ���������̂�PSD�Ή��y�C���g�\�t�g��PSD�Ή��r���[�A�ƃL���v�`���\�t�g��
�K�X�̔��Ǘ��\�t�g�Ɠd�̔��Ǘ��\�t�g�Ƀn���f�B�^�[�~�i���̑��
����ƃQ�[��������
Web�iSilverlight��Typscript�j�Ή��̂��͈̂ꉞ���J���Ă邯��
�����ڃV���{�����玩�M�����Đ����o���̂͂�����ƒp������
���P���G�͖Œ��ꒃ��肢���ǃh�b�g�G�Ƃ������f�U�C���Ƃ��͂��Ȃ�����
�ł�10����t�ƈ��������łȂ�ǂꂩ�P���̃X���Ō��J���Ă�������
���ӂ��Ă܂Ŗ\��Ă�̂͂����P���ł��瓥�ݓ|���K�v�ɔ����Ă�ᖳ�����������
���{�����x���i�}�|���z���Ă邩��ȁ`���\�����K���l���z��
���Ȃ݂ɉ���������̂�PSD�Ή��y�C���g�\�t�g��PSD�Ή��r���[�A�ƃL���v�`���\�t�g��
�K�X�̔��Ǘ��\�t�g�Ɠd�̔��Ǘ��\�t�g�Ƀn���f�B�^�[�~�i���̑��
����ƃQ�[��������
Web�iSilverlight��Typscript�j�Ή��̂��͈̂ꉞ���J���Ă邯��
�����ڃV���{�����玩�M�����Đ����o���̂͂�����ƒp������
���P���G�͖Œ��ꒃ��肢���ǃh�b�g�G�Ƃ������f�U�C���Ƃ��͂��Ȃ�����
�ł�10����t�ƈ��������łȂ�ǂꂩ�P���̃X���Ō��J���Ă�������
268 �FSocket774�F2015/02/11(��) 11:45:43.08 ID:wBhDPbDs
�h�͈́h
269 �F,,�E�L�́M�E,,�j��-�������F2015/02/11(��) 12:10:33.15 ID:cRbfTUID
�C�̂��̂Ƃ��R�̂��̂Ƃ��킩��Ȃ��A�v���ɂ����Ȃ�10����100�����o���o�J���Ȃ�����B
�R�s�y������ǂ������J�ł��Ȃ���H
�I�[�v���\�[�X�̃t���[�\�t�g�ł���t���}�̃A�v���͂�����ł����邺�H
�R�s�y������ǂ������J�ł��Ȃ���H
�I�[�v���\�[�X�̃t���[�\�t�g�ł���t���}�̃A�v���͂�����ł����邺�H
270 �F,,�E�L�́M�E,,�j��-�������F2015/02/11(��) 12:16:13.73 ID:cRbfTUID
�����\�t�g��Photoshop�̒l�i�l�����
����Ȏ��Ȗ����̎w��c�[���i�j�Ȃ�
10���̉��l������Ƃ͎v���Ȃ�����ȁB
�����������݂��邩���킩��Ȃ���
�Ȃ�Ȃ�N���𐧌������̌��łł�����Ă݂���H
����ȃ\�t�g�{���ɍ�����Ȃ�ȒP����H
����Ȏ��Ȗ����̎w��c�[���i�j�Ȃ�
10���̉��l������Ƃ͎v���Ȃ�����ȁB
�����������݂��邩���킩��Ȃ���
�Ȃ�Ȃ�N���𐧌������̌��łł�����Ă݂���H
����ȃ\�t�g�{���ɍ�����Ȃ�ȒP����H
272 �F,,�E�L�́M�E,,�j��-�������F2015/02/11(��) 12:37:40.44 ID:cRbfTUID
�����̋�����
273 �F,,�E�L�́M�E,,�j��-�������F2015/02/11(��) 12:40:40.48 ID:cRbfTUID
�u�������Ό����Ă��v�͌����������R���Ă����悭�����Z���t����ˁ`
>>271
RPG�̓E�B�U�[�h���B�P�R�s�[+����android�ō���Ă�Œ�
�퓬�͏o���邯�ǓG�f�[�^��K�w�f�[�^�₻�̑����܂��S�R
���Ƃ�SLG��RTS�Ȋ����̂��̂���
�ǂ����Ă����Č����Ȃ烁�[���ő��邯��
RPG�̓E�B�U�[�h���B�P�R�s�[+����android�ō���Ă�Œ�
�퓬�͏o���邯�ǓG�f�[�^��K�w�f�[�^�₻�̑����܂��S�R
���Ƃ�SLG��RTS�Ȋ����̂��̂���
�ǂ����Ă����Č����Ȃ烁�[���ő��邯��
275 �F,,�E�L�́M�E,,�j��-�������F2015/02/11(��) 13:04:26.93 ID:cRbfTUID
�����玟�ւƉR���o�Ă��܂�
�R�̃f�p�[�g
�n�b�^���̑�������
�R�̃f�p�[�g
�n�b�^���̑�������
������amd�������グ��̂ɂȂ�ł����܂ʼnR�����K�v������̂�
277 �F,,�E�L�́M�E,,�j��-�������F2015/02/11(��) 13:16:22.69 ID:cRbfTUID
���̂��������10�N�ȏ�AMD�X���Œm��A�Ă��Ă�Ђ������薳�E
�Ȃ�̎��т����_���Ȃ����̉�ŁA�l�b�g�Ńn�b�^�����������Ƃł���
�����̎����S�����Ȃ��̂���B
�R���Ă��̑ԓx���Ă����킩��ˁ[
�Ȃ�̎��т����_���Ȃ����̉�ŁA�l�b�g�Ńn�b�^�����������Ƃł���
�����̎����S�����Ȃ��̂���B
�R���Ă��̑ԓx���Ă����킩��ˁ[
279 �F,,�E�L�́M�E,,�j��-�������F2015/02/11(��) 13:21:40.22 ID:cRbfTUID
280 �F,,�E�L�́M�E,,�j��-�������F2015/02/11(��) 13:25:26.45 ID:cRbfTUID
�u�����Ă�����ăv���C���Ă݂����ǂ����[�v
�Ƃ������쎩�������藧��Ȃ�����
���ɂ����Ă��s���葽���Ɍ��J�ł��Ȃ����x���̃S�~�v���O���������Ȃ���
�d���Ȃ���
�Ƃ������쎩�������藧��Ȃ�����
���ɂ����Ă��s���葽���Ɍ��J�ł��Ȃ����x���̃S�~�v���O���������Ȃ���
�d���Ȃ���
ID:nkwg62dS���{���ɐF�X�J�����Ă�(��)���ǂ����̊m�F�ł͂Ȃ��āA�ɂԂ��ɃI�t���C����RPG�T���Ă������Ȃ̂ŁB
�Ȃ₽�炱����苭����������A�V�X�e���ʂɕȂ̂���̂����ҏo���邩�Ǝv�������ǖ����Ȃ炢�������B
�Ȃ₽�炱����苭����������A�V�X�e���ʂɕȂ̂���̂����ҏo���邩�Ǝv�������ǖ����Ȃ炢�������B
�Q�[���L���[�u�̃t�@���^�V�[�X�^�[�I�����C�����I�t���C���Ő��S���ԃv���C������
283 �F,,�E�L�́M�E,,�j��-�������F2015/02/11(��) 13:35:35.66 ID:cRbfTUID
������肪�����͎̂����̋��h�S�������Ƃ����ŁA
�l�ԂƂ��Ă̒��g���v���O�����̃��[�`��������ۂł���B
�l�ԂƂ��Ă̒��g���v���O�����̃��[�`��������ۂł���B
284 �F,,�E�L�́M�E,,�j��-�������F2015/02/11(��) 13:37:01.86 ID:cRbfTUID
AMD�X���o�g�̍ŋ��v���O���}�[�͉��u����E�B���X������ЎR�S��Ɍ��܂��Ă邾��I
�ق��͌������̎G��
�ق��͌������̎G��
��������ۂ̂ق������߂��߂�
286 �F,,�E�L�́M�E,,�j��-�������F2015/02/11(��) 16:18:27.09 ID:cRbfTUID
�s�s���o�O�����X�y���M�X�p�C�A���`������
���{�l�Ȃ�C���e���Q�t�H�����
���{�l�Ȃ�C���e���Q�t�H�����
>>267
�Ȃ�ŋ����o���Ȃ�H�@�����10���I
>Web�iSilverlight��Typscript�j�Ή��̂��͈̂ꉞ���J���Ă邯��
���J���Ă���Ȃ�ׂ����킸�ɂ������ďo���Ηǂ�����
�Ȃ�ŋ����o���Ȃ�H�@�����10���I
>Web�iSilverlight��Typscript�j�Ή��̂��͈̂ꉞ���J���Ă邯��
���J���Ă���Ȃ�ׂ����킸�ɂ������ďo���Ηǂ�����
�@�@�@�@ �Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q
�@�@�@�@�S�~ || || || || || || || ,l,,l,,l ��V�c|
�@�@�@�@�@V~~''-�R��''''""~ �@�@�S�jƜc|�@�@�@�@�@�@�@�o���E�E�E�E�E�E�I
�@�@�@�@ /�@��[�\''��@�@�@�@�@ �Sƃj���@�@�@�@�@�@ �o�����E�E�E
�@�@�@ <'-.,�@�@�P�P �@ �@ _,,,..-�]��@�r�j�|�@�@�@�@�@�@�@����@�܂��@���̎��Əꏊ��
�@�@�@/"''-�,�]l �@�@l`__�j-�]'''""` /�j��|�@�@�@�@�@�@�@�w��܂ł͂��Ă��Ȃ�
�@�@�@|�@==���!�@�@`��====��@�@l =����=|
.�@�@�@| `�[߁]'/�@�@ `�[�]߁\' �@�@l.=l��|~|�@�@�@�@�@�@�@���̂��Ƃ�
�@�@�@ |`�[�]/�@�@�@�@`�[�\�\�@�@H<,�r|=|�@�@�@�@�@�@�@�ǂ������N���
�@�@�@ |�@�@/�@�@�@ ��@�@ �@�@ �@ �@ l|__�m�|�@�@�@�@�@�@�@�v���o��������������
.�@�@�@| �^`�[�@~�@���@�@ �_�@�@�@.|�S.�j|�R
�@�@�@ |���@����l��l��l��l���b�@ �@|�@�S_,|�@�_�@�@�@�@�@�܂�E�E�E�E
. �@ �@ |�@�@�@�@�߁@�@�@�@�@�@�@�@�@|�@�@ `l�@�@ �___�@�@�@>>267�����̋C�ɂȂ��
�@�@�@�@!�A�@�@�@�@�@�@�@�@�@�@ _,,..-'�� �^l�@�@ �@ |�@~'''�@ �\�t�g�̒�
�]''"�P|�@`i�-..,,,�Q,,,,,....-�]'''"�@ �@ �^�@ |�@ �@ �@ |�@�@�@ 10�N��@20�N��Ƃ������Ƃ�
�@-�\|�@�@|�_�@�@�@�@�@�@�@�@�@ �^�@ �@ |�@�@�@ �@ |�@�@�@�\���낤�E�E�E�E�E�E�E�E�E�E�Ƃ������ƁE�E�E�E�I
�@ �@ |�@�@ |�@ �_�@�@�@�@�@�@�^�@ �@ �@ |�@�@�@�@�@ |
�@�@�@�@�S�~ || || || || || || || ,l,,l,,l ��V�c|
�@�@�@�@�@V~~''-�R��''''""~ �@�@�S�jƜc|�@�@�@�@�@�@�@�o���E�E�E�E�E�E�I
�@�@�@�@ /�@��[�\''��@�@�@�@�@ �Sƃj���@�@�@�@�@�@ �o�����E�E�E
�@�@�@ <'-.,�@�@�P�P �@ �@ _,,,..-�]��@�r�j�|�@�@�@�@�@�@�@����@�܂��@���̎��Əꏊ��
�@�@�@/"''-�,�]l �@�@l`__�j-�]'''""` /�j��|�@�@�@�@�@�@�@�w��܂ł͂��Ă��Ȃ�
�@�@�@|�@==���!�@�@`��====��@�@l =����=|
.�@�@�@| `�[߁]'/�@�@ `�[�]߁\' �@�@l.=l��|~|�@�@�@�@�@�@�@���̂��Ƃ�
�@�@�@ |`�[�]/�@�@�@�@`�[�\�\�@�@H<,�r|=|�@�@�@�@�@�@�@�ǂ������N���
�@�@�@ |�@�@/�@�@�@ ��@�@ �@�@ �@ �@ l|__�m�|�@�@�@�@�@�@�@�v���o��������������
.�@�@�@| �^`�[�@~�@���@�@ �_�@�@�@.|�S.�j|�R
�@�@�@ |���@����l��l��l��l���b�@ �@|�@�S_,|�@�_�@�@�@�@�@�܂�E�E�E�E
. �@ �@ |�@�@�@�@�߁@�@�@�@�@�@�@�@�@|�@�@ `l�@�@ �___�@�@�@>>267�����̋C�ɂȂ��
�@�@�@�@!�A�@�@�@�@�@�@�@�@�@�@ _,,..-'�� �^l�@�@ �@ |�@~'''�@ �\�t�g�̒�
�]''"�P|�@`i�-..,,,�Q,,,,,....-�]'''"�@ �@ �^�@ |�@ �@ �@ |�@�@�@ 10�N��@20�N��Ƃ������Ƃ�
�@-�\|�@�@|�_�@�@�@�@�@�@�@�@�@ �^�@ �@ |�@�@�@ �@ |�@�@�@�\���낤�E�E�E�E�E�E�E�E�E�E�Ƃ������ƁE�E�E�E�I
�@ �@ |�@�@ |�@ �_�@�@�@�@�@�@�^�@ �@ �@ |�@�@�@�@�@ |
290 �F,,�E�L�́M�E,,�j��-�������F2015/02/12(��) 01:35:10.46 ID:1MXGREpM
�����o���Ƃ����Ό��J�v����������߂�Ǝv������Ȃ��́H
�T���猩��A���J�ł��Ȃ��̂́u������������������ł���H�v�ƂȂ�킯�ł����ǂ�
��������g�����Ȃ���v���O���}�Ȃ�A�Z�p�f���I�ȃR�[�h�̂P��Q���炢
�T�N���ƃX�N���b�`����gist�ɂł����J���炢�]�T���Ǝv���̂����ǁH
������́u���O������Ă݂�v�ƌ�������邩�猾���Ă�B
�T���猩��A���J�ł��Ȃ��̂́u������������������ł���H�v�ƂȂ�킯�ł����ǂ�
��������g�����Ȃ���v���O���}�Ȃ�A�Z�p�f���I�ȃR�[�h�̂P��Q���炢
�T�N���ƃX�N���b�`����gist�ɂł����J���炢�]�T���Ǝv���̂����ǁH
������́u���O������Ă݂�v�ƌ�������邩�猾���Ă�B
AMD�t�@���{�[�C�͂����s���A�����̃I���p���[�h�������
������AMD�̈�ۂ������Ȃ�
AMD������Ȃ��̂̓t�@���{�[�C�̂�������
������AMD�̈�ۂ������Ȃ�
AMD������Ȃ��̂̓t�@���{�[�C�̂�������
�܂��u�������j�Z�t�Ɋ�t����i���O��������j�v���u��u�ɂ��āu�������ɕ����v�ɂȂ邵
�i�������ȗ�������Ɓj�uSIMT��SIMT�v�u���߁��f�[�^�v�u���Z�����Z�i���j�b�g������Ə���d�͌���j�v
���̂悤�ɏ�ɒm��
���܂��ɂ����������\�t�g���̂ɂ킴�킴���҂ɒ�q���肵��
���[���ł��ꂱ�ꋳ����Ă���
����u�����̐Ղ������p���̂͂��̉��������l��I�v�Ƃ�
�uGUI�ō�����͉̂������I�v�Ƃ��L���C�����A��������H�i���남�ڂ��j
����Ȉُ�҂Ƀ\�[�X�n������ԈႢ�Ȃ��p�N���邵
���s�t�@�C�������Ċ�Ȃ�����
����Ȃ�̑㏞���킹�������œn������ɂ��H����擖�R
�i�������ȗ�������Ɓj�uSIMT��SIMT�v�u���߁��f�[�^�v�u���Z�����Z�i���j�b�g������Ə���d�͌���j�v
���̂悤�ɏ�ɒm��
���܂��ɂ����������\�t�g���̂ɂ킴�킴���҂ɒ�q���肵��
���[���ł��ꂱ�ꋳ����Ă���
����u�����̐Ղ������p���̂͂��̉��������l��I�v�Ƃ�
�uGUI�ō�����͉̂������I�v�Ƃ��L���C�����A��������H�i���남�ڂ��j
����Ȉُ�҂Ƀ\�[�X�n������ԈႢ�Ȃ��p�N���邵
���s�t�@�C�������Ċ�Ȃ�����
����Ȃ�̑㏞���킹�������œn������ɂ��H����擖�R
>>292
�c�q�̓g���b�v�R�[�h�̂�̓t���[�Ō��J������
���O��������ď��������玩���I�ɒc�q�ȉ��ɂȂ邯�ǁA����ł������́H
�c�q�̓g���b�v�R�[�h�̂�̓t���[�Ō��J������
���O��������ď��������玩���I�ɒc�q�ȉ��ɂȂ邯�ǁA����ł������́H
�����̊|���Z2���Z1��N�̓��{�ꂪ�ƂĂ�����������
�Ȃɂ����Ă�̂������ς�Ȃ�
�Ȃɂ����Ă�̂������ς�Ȃ�
295 �F,,�E�L�́M�E,,�j��-������ @nfmv001185085.uqw.ppp.infoweb.ne.jp�F2015/02/12(��) 11:46:10.95 ID:L2f7IUVb
�Ă����[���ŋ���������ҁi�j���ĒN�H����Ȑl�����݂��Ȃ�����
KENJI AIKO���̃T�C�g�̃o�b�N���O�ǂ݂Ȃ���UNIX Crypt�̎��O�������@�o������
distributed.net�N���C�A���g�Ŏg���Ă���DES�̏����̕���@�͂���ɕʂ̃T�C�g����B
John the Ripper�̃R�[�h�q���������葁�����Ă̂͒��ׂĂ邤���ɂ킩������
GNU ASM�`���̃R�[�h���킯�킩����ɁA���C�Z���X��������Ȋ댯��GPL������
����͎g���Ȃ��Ǝv���āA���ǎ����Ŏ��s���낵��Visual C++�ŃR���p�C���ł���R�[�h��
0���珑�������(JtR��Visual C++�g���Ȃ�)
�N���Ƀ��[���ŕ������Ȃ�Ď����͂Ȃ����A���[�ƁA�u���m��ʍ��̃g���b�p�[�i���v�̐l�������H
������������R�A���[�`�����Ă݂��̂Ŏg���Ă݂Ă����������ĉ������[������������
�Ԏ����Ȃ���������A����UI�܂őS���A�����ŏ������Ƃ����ˁB
���͂ǂ������炩��ؗp�����R�[�h�Ȃ炿���ƌ��J�����Ɋ�Â��Č����\�L�͂��Ă邵
���f�Ńp�N��悤�ȓ��l�݂����Ȑ^���͂��Ăˁ[
��ŁAPS3��Linux��������Cell�œ����o�[�W����������Ă݂悤�Ǝv���Ă��[
����͌��Ǎ������āA���Ԑ��ʕ��͑��̍�ҁiVecTripper�̐l�Ƃ�celltripper�̐l�j�ɃR�[�h
���邾���ɂȂ������ǁAJtR�ɂ����闧��ɂȂ����̂͐���Ȃ��̂ł���B
���ꂪ����B�ŏ�����JtR�̊��ň����݊��ō���Ă邩��ȒP�ɈڐA�ł����B
http://download.openwall.net/pub/projects/john/contrib/bitslice-des/dango.chu.jp/
�ŏ���BSD���C�Z���X�Ō��J�������ǁAJtR��҂̃A���N�T���h������
�u3������BSD���C�Z���X��JtR�̃��C�Z���X�Ɩ������邩�烉�C�Z���X�ύX���Ă���v
�Ɨv�]���Ă����̂�GPL�̃o�[�W�������������ˁB�ق�Ƃ�GPL���������ǁB
�ł����̂��ƂŊ�Ƃ̋��͂ʼn��̂������Ɖ��ǂ����R�[�h��������炵����
���͉��̂�͎g���ĂȂ����ǂ�
�������A���l�̃\�[�X�p�N�邵���\���Ȃ��z�����l�Ƀp�N�点�����Ȃ��Ƃ��v���オ�范������
����ȓƑn������R�[�h������͂��Ȃ��͍̂��܂ł̔n�����X�݂Ă�킩�邶���H
KENJI AIKO���̃T�C�g�̃o�b�N���O�ǂ݂Ȃ���UNIX Crypt�̎��O�������@�o������
distributed.net�N���C�A���g�Ŏg���Ă���DES�̏����̕���@�͂���ɕʂ̃T�C�g����B
John the Ripper�̃R�[�h�q���������葁�����Ă̂͒��ׂĂ邤���ɂ킩������
GNU ASM�`���̃R�[�h���킯�킩����ɁA���C�Z���X��������Ȋ댯��GPL������
����͎g���Ȃ��Ǝv���āA���ǎ����Ŏ��s���낵��Visual C++�ŃR���p�C���ł���R�[�h��
0���珑�������(JtR��Visual C++�g���Ȃ�)
�N���Ƀ��[���ŕ������Ȃ�Ď����͂Ȃ����A���[�ƁA�u���m��ʍ��̃g���b�p�[�i���v�̐l�������H
������������R�A���[�`�����Ă݂��̂Ŏg���Ă݂Ă����������ĉ������[������������
�Ԏ����Ȃ���������A����UI�܂őS���A�����ŏ������Ƃ����ˁB
���͂ǂ������炩��ؗp�����R�[�h�Ȃ炿���ƌ��J�����Ɋ�Â��Č����\�L�͂��Ă邵
���f�Ńp�N��悤�ȓ��l�݂����Ȑ^���͂��Ăˁ[
��ŁAPS3��Linux��������Cell�œ����o�[�W����������Ă݂悤�Ǝv���Ă��[
����͌��Ǎ������āA���Ԑ��ʕ��͑��̍�ҁiVecTripper�̐l�Ƃ�celltripper�̐l�j�ɃR�[�h
���邾���ɂȂ������ǁAJtR�ɂ����闧��ɂȂ����̂͐���Ȃ��̂ł���B
���ꂪ����B�ŏ�����JtR�̊��ň����݊��ō���Ă邩��ȒP�ɈڐA�ł����B
http://download.openwall.net/pub/projects/john/contrib/bitslice-des/dango.chu.jp/
�ŏ���BSD���C�Z���X�Ō��J�������ǁAJtR��҂̃A���N�T���h������
�u3������BSD���C�Z���X��JtR�̃��C�Z���X�Ɩ������邩�烉�C�Z���X�ύX���Ă���v
�Ɨv�]���Ă����̂�GPL�̃o�[�W�������������ˁB�ق�Ƃ�GPL���������ǁB
�ł����̂��ƂŊ�Ƃ̋��͂ʼn��̂������Ɖ��ǂ����R�[�h��������炵����
���͉��̂�͎g���ĂȂ����ǂ�
�������A���l�̃\�[�X�p�N�邵���\���Ȃ��z�����l�Ƀp�N�点�����Ȃ��Ƃ��v���オ�范������
����ȓƑn������R�[�h������͂��Ȃ��͍̂��܂ł̔n�����X�݂Ă�킩�邶���H
�u�����́i�����́j�J�[�h�����ʂ̂ɂ悢�����v
���㍂55��1,000���h���@������4��300���h��
���㍂46��8,151���h���@�����v6��3,059���h��
���㍂55��1,000���h���@������4��300���h��
���㍂46��8,151���h���@�����v6��3,059���h��
ttp://fast-uploader.com/file/6979274254205/
�g���b�v��������Ă݂����ǎv��������q����
���͂�����������g���b�v�ɕϊ����镔���͌��J����Ă邩��ہX�R�s�y�ł���
�̂��Ƃ�����Perl�ŏ����ꂽ�\�[�X�������������Ǝv�����炻���]�݂̌���ɕϊ�����̂͑�����q�����낤
��]�̕����g���b�v�Ɋ܂܂�Ă邩�ǂ����̏ƍ��͐��K�\���̕��������ł���
�u������������_���ō��v�Ƃ��������͊y�����Ǝv��������
�g���b�v���͂̎d���Ƃ������[����
����char�����Ԃ��牽�Ԃ܂œo�^����Ă�̂��s���Ȃ̂œ������
���������ōő�l�ƍŏ��l������Ɍ��߂Ă�������ł悵�Ƃ���
�ł��܂����ʂ̃Q�[����A�v����1/1000���炢�̃R�[�h�ʂ���
�g���b�v��char�Ɋւ��Ă����Ə����W�����������
�g���b�v��������Ă݂����ǎv��������q����
���͂�����������g���b�v�ɕϊ����镔���͌��J����Ă邩��ہX�R�s�y�ł���
�̂��Ƃ�����Perl�ŏ����ꂽ�\�[�X�������������Ǝv�����炻���]�݂̌���ɕϊ�����̂͑�����q�����낤
��]�̕����g���b�v�Ɋ܂܂�Ă邩�ǂ����̏ƍ��͐��K�\���̕��������ł���
�u������������_���ō��v�Ƃ��������͊y�����Ǝv��������
�g���b�v���͂̎d���Ƃ������[����
����char�����Ԃ��牽�Ԃ܂œo�^����Ă�̂��s���Ȃ̂œ������
���������ōő�l�ƍŏ��l������Ɍ��߂Ă�������ł悵�Ƃ���
�ł��܂����ʂ̃Q�[����A�v����1/1000���炢�̃R�[�h�ʂ���
�g���b�v��char�Ɋւ��Ă����Ə����W�����������
298 �F,,�E�L�́M�E,,�j��-������ @nfmv001150041.uqw.ppp.infoweb.ne.jp�F2015/02/12(��) 16:34:23.89 ID:KazS4yY+
�ǂ�Ȃ��Ǝv���ăm�[�gPC�ŊJ���ē������Ă݂���
�������ɏo���Ă����͈̂Ă̒�UnixCrypt.cs���̂܂g����������
���w���ł����郌�x���̃R�s�y�v���O�����ł����Ƃ��B
�o�������̃\�[�X���l�b�g�ŏE���Ă��Đ�\�肵�č��܂����Ȃ��
�����̃v���O������菈�����x��g��������悭���邱�Ƃ����l���Ȃ���
��Ȃ���N�ł��ł����B
UnixCrypt.cs����������A���ł���܂������w����.NET�̃o�[�W����1�Ƃ��̎��ゾ��������
C#�̕����悤�Ǝv���ėV�т�C#Tripper��������Ƃ��邵�A�w�Z�A��̉ɂȂƂ���2�����炢
�g���ď����グ�����A������ƍ������̂��߂ɉ��Ǔ���Ă�Pentium M��1.5MHz�ł�
23kt/s�Ƃ����̂����肵���o�Ȃ������B���ꂪC#�̌��E���Ǝv�����ˁB
GUI�͑f���������邪�A���x���K�v�ȃR�[�h�ł�x86�l�C�e�B�u�ɂ͂͂邩�ɋy�Ȃ��B
���̒m��A�Ă�������̂́AGUI���炨�e���Ƃ������A�}���`�X���b�h��������ł��ĂȂ�����
�i���⑬�x�̕\�����Ȃ����5�������炢����ă{�^�����������猟�������܂�
��ؓ��͂��`��X�V������Ȃ��B
��Ώo�����Ȃ������w�肵����A�^�X�N�}�l�[�W�����狭���I�����Ȃ����艄�X�����������ˁH
���߂ĕʃX���b�h�œ������Ē��~�{�^���Œ��f�ł���悤�ɂ���Ƃ��Œ���̔z������ł���̂��H
���x�\�����Ȃ����珈�����ǂ��i��ł�̂����邢�͂����t���[�Y���Ă�̂����킩��Ȃ��B
�摜�����v���O�����������o����x�ł�����Ȃ�A���[�J�[�X���b�h�N�������炢
������O�ɂ��Ǝv�����̂����B
�X�ɂ͂킴�킴SHA-1�ł�DES�ł̃R�[�h�p�X�𗼕�����Ă�̂ɂǂ������������̂���
�w����ł��Ȃ��B�܂������W�I�{�^���̔z�u����킩��Ȃ��H
��L�̂��ƑS�����̂ɁAC#���Ⴝ������100�s��������Ȃ���H
����ȃA���S���Y���ɒ��ڊW���Ȃ����[�U�[�G�N�X�y���G���X����܂Ƃ��ȍS������ĂȂ��̂�
�R�[�h�ʂ����Ȃ��Ƃ��]�T�����Ă�t�������銄�ɂ́A����������Ύ�����Ⴂ���Ȃ�������
�{�����o��B
�܂Ƃ��Ƀv���O�������������ƂȂ����ăo���o���Ȃ�ȁB
�X�L���̒Ⴓ�킴�킴�����ŏؖ����Ă���Ă��肪�Ƃ��B
�͈�()
�������ɏo���Ă����͈̂Ă̒�UnixCrypt.cs���̂܂g����������
���w���ł����郌�x���̃R�s�y�v���O�����ł����Ƃ��B
�o�������̃\�[�X���l�b�g�ŏE���Ă��Đ�\�肵�č��܂����Ȃ��
�����̃v���O������菈�����x��g��������悭���邱�Ƃ����l���Ȃ���
��Ȃ���N�ł��ł����B
UnixCrypt.cs����������A���ł���܂������w����.NET�̃o�[�W����1�Ƃ��̎��ゾ��������
C#�̕����悤�Ǝv���ėV�т�C#Tripper��������Ƃ��邵�A�w�Z�A��̉ɂȂƂ���2�����炢
�g���ď����グ�����A������ƍ������̂��߂ɉ��Ǔ���Ă�Pentium M��1.5MHz�ł�
23kt/s�Ƃ����̂����肵���o�Ȃ������B���ꂪC#�̌��E���Ǝv�����ˁB
GUI�͑f���������邪�A���x���K�v�ȃR�[�h�ł�x86�l�C�e�B�u�ɂ͂͂邩�ɋy�Ȃ��B
���̒m��A�Ă�������̂́AGUI���炨�e���Ƃ������A�}���`�X���b�h��������ł��ĂȂ�����
�i���⑬�x�̕\�����Ȃ����5�������炢����ă{�^�����������猟�������܂�
��ؓ��͂��`��X�V������Ȃ��B
��Ώo�����Ȃ������w�肵����A�^�X�N�}�l�[�W�����狭���I�����Ȃ����艄�X�����������ˁH
���߂ĕʃX���b�h�œ������Ē��~�{�^���Œ��f�ł���悤�ɂ���Ƃ��Œ���̔z������ł���̂��H
���x�\�����Ȃ����珈�����ǂ��i��ł�̂����邢�͂����t���[�Y���Ă�̂����킩��Ȃ��B
�摜�����v���O�����������o����x�ł�����Ȃ�A���[�J�[�X���b�h�N�������炢
������O�ɂ��Ǝv�����̂����B
�X�ɂ͂킴�킴SHA-1�ł�DES�ł̃R�[�h�p�X�𗼕�����Ă�̂ɂǂ������������̂���
�w����ł��Ȃ��B�܂������W�I�{�^���̔z�u����킩��Ȃ��H
��L�̂��ƑS�����̂ɁAC#���Ⴝ������100�s��������Ȃ���H
����ȃA���S���Y���ɒ��ڊW���Ȃ����[�U�[�G�N�X�y���G���X����܂Ƃ��ȍS������ĂȂ��̂�
�R�[�h�ʂ����Ȃ��Ƃ��]�T�����Ă�t�������銄�ɂ́A����������Ύ�����Ⴂ���Ȃ�������
�{�����o��B
�܂Ƃ��Ƀv���O�������������ƂȂ����ăo���o���Ȃ�ȁB
�X�L���̒Ⴓ�킴�킴�����ŏؖ����Ă���Ă��肪�Ƃ��B
�͈�()
�g���b�v���������̂ɗv�������Ԃ�
�O�O�����蕶���̃R�[�h�ԍ���T������Ȃǂ̉�蓹���Ȃ���
����Ǝ��Ԃ�10���Ƃ���
�������̂��߂Ɍ����ւ�����F�X���̂ɕ�������6�{�|����Ƃ����1����
�g���b�v�����̂��߂�10�N��₵�����̒��g�͂P���ԕ��E�E�E
�������Ⴀ�啱�����ĊۂP��
����R�e���ɂ��Ȃ�Ł����������Ōv�Z���悤����Ȃ���
�{�l�ɂ����ŕs�v�ȃA�v����3��10�N�E�E�E
�O�O�����蕶���̃R�[�h�ԍ���T������Ȃǂ̉�蓹���Ȃ���
����Ǝ��Ԃ�10���Ƃ���
�������̂��߂Ɍ����ւ�����F�X���̂ɕ�������6�{�|����Ƃ����1����
�g���b�v�����̂��߂�10�N��₵�����̒��g�͂P���ԕ��E�E�E
�������Ⴀ�啱�����ĊۂP��
����R�e���ɂ��Ȃ�Ł����������Ōv�Z���悤����Ȃ���
�{�l�ɂ����ŕs�v�ȃA�v����3��10�N�E�E�E
300 �F,,�E�L�́M�E,,�j��-������ @nfmv001150041.uqw.ppp.infoweb.ne.jp�F2015/02/12(��) 17:12:08.52 ID:KazS4yY+
���������u���������v�Ȃ�Ă���ȃ��x���̖ڎw���ĂȂ���������
5�������炢���ꂽ��t���[�Y����悤�Ȃ̂��܂Ƃ��ɓ����Ă�Ƃ͌���Ȃ����낤
6�����}�b�`�ł��牴�̂���ڃX�y�b�N��50�b��8�����邼
������\�t�g���y���ɒx�����̂��h����ł����Ƃ��p���������Ȃ��ł���
http://yui.oopsup.com/browse.php/vix/%E7%84%A1%E9%A1%8C.png
5�������炢���ꂽ��t���[�Y����悤�Ȃ̂��܂Ƃ��ɓ����Ă�Ƃ͌���Ȃ����낤
6�����}�b�`�ł��牴�̂���ڃX�y�b�N��50�b��8�����邼
������\�t�g���y���ɒx�����̂��h����ł����Ƃ��p���������Ȃ��ł���
http://yui.oopsup.com/browse.php/vix/%E7%84%A1%E9%A1%8C.png
{kind=link}
�����ł��g��Ȃ����̂ɉ��̐S���𒍂��̂��H
����͂����炭�u���ꂵ���o���Ȃ��v���炾�낤
�t���ɓ`�����ꂽ10���ԃN�b�L���O�̂��̂������V�s������Ȃ�
�R���p�C����z�N�����������
���ꂩ��ʂ̌���ւ̖|��E�ڐA�Ƃ����̂̓p�^�[�������܂��Ă���
�ނ���ς�����ʕ��ɂȂ��Ă��܂��i�ς�����Ȃ��ꍇ���ܘ_����j
������u����T���v���Ȃǂ����Ȃ��낤���撣������͏o����
�������A���S���Y���̂ق��͂ǂ����H
API�̎g�����ƈ���ăA���S���Y���̂ق��͍u����T���v���͏��Ȃ�
�u���b�N������e�g���X�Ղ�Ղ悭�炢��
���̂������Ƃ����Ɓu�l����Ή��邩��v
��ʕ\��API�����m���Ă�Ό�͕ϐ��z��ȂǂȂǂ���g�����
���̂��Ƃ͕\���o���邩��
�Ȃ�u�l���Ă�����Ȃ��v�l�͂ǂ��Ȃ̂��E�E�E�H
���Ȃ݂Ƀg���b�v�����A���S���Y���̂ق��͕ς�����ʖ�
�ʂ̕����o�Ă�����g�����ɂȂ�Ȃ�����
����͂����炭�u���ꂵ���o���Ȃ��v���炾�낤
�t���ɓ`�����ꂽ10���ԃN�b�L���O�̂��̂������V�s������Ȃ�
�R���p�C����z�N�����������
���ꂩ��ʂ̌���ւ̖|��E�ڐA�Ƃ����̂̓p�^�[�������܂��Ă���
�ނ���ς�����ʕ��ɂȂ��Ă��܂��i�ς�����Ȃ��ꍇ���ܘ_����j
������u����T���v���Ȃǂ����Ȃ��낤���撣������͏o����
�������A���S���Y���̂ق��͂ǂ����H
API�̎g�����ƈ���ăA���S���Y���̂ق��͍u����T���v���͏��Ȃ�
�u���b�N������e�g���X�Ղ�Ղ悭�炢��
���̂������Ƃ����Ɓu�l����Ή��邩��v
��ʕ\��API�����m���Ă�Ό�͕ϐ��z��ȂǂȂǂ���g�����
���̂��Ƃ͕\���o���邩��
�Ȃ�u�l���Ă�����Ȃ��v�l�͂ǂ��Ȃ̂��E�E�E�H
���Ȃ݂Ƀg���b�v�����A���S���Y���̂ق��͕ς�����ʖ�
�ʂ̕����o�Ă�����g�����ɂȂ�Ȃ�����
�Ӗ��s�Ȓ�����������
>>298�Ŏw�E���ꂽ�������ǂ����̂�f�����o������ǂ������̂�
>>298�Ŏw�E���ꂽ�������ǂ����̂�f�����o������ǂ������̂�
>>302
�ǂ�H
�ǂ�H
�S��
�w�E���ꂽ����S�����ǂ����̂�30���ȓ��ɏo���Ă���
���Ȃ��Ƃ����̒��ł͂��̕]�����オ�������ǂȂ�
�w�E���ꂽ����S�����ǂ����̂�30���ȓ��ɏo���Ă���
���Ȃ��Ƃ����̒��ł͂��̕]�����オ�������ǂȂ�
AMD�X���ɔS������c�q�ɔS������>>301�Ƃ����F���ł�낵���ł����H
>>304
������ӏ������ɂ�����Č����Ă�̂�
�������͂���ɕ\�L�ւ���ς�
ttp://ufcpp.net/study/csharp/lib_parallel.html
�ʃX���b�h��Thread t;
t = new Thread(new ThreadStart(�������ʖ�));
t.IsBackground = true;
t.Start();
while�̏�����bool���₵�ĕʃX���Œl�ύX
���̂���ԉɊ|�������
������ӏ������ɂ�����Č����Ă�̂�
�������͂���ɕ\�L�ւ���ς�
ttp://ufcpp.net/study/csharp/lib_parallel.html
�ʃX���b�h��Thread t;
t = new Thread(new ThreadStart(�������ʖ�));
t.IsBackground = true;
t.Start();
while�̏�����bool���₵�ĕʃX���Œl�ύX
���̂���ԉɊ|�������
����Ȃ��ĉ��X����while�̂ق���ʃX���Ɏw�肾
308 �F,,�E�L�́M�E,,�j��-������ @nfmv001178103.uqw.ppp.infoweb.ne.jp�F2015/02/12(��) 18:59:58.89 ID:0SWhhLBZ
���������u�t���v�Ȃ�Ă��ˁ[����������������������������������������������
���X�y�N�g���Ă��Í��w�҂Ȃ炢�����ǁA�قڑS���C�O�̑�w������
�A���S���Y�����s�ςƂ����̂��Ԕ���������
DES�̃A���S���Y�����͕̂ς��Ȃ����u�����ɉ�ǂ��邽�߂̃e�N�j�b�N�v��
2008�N����܂�IEEE����{�̏���w��ł����т��ѐV�����_�����������Ă����B
Bit-slice�@���v���Z�b�T�̃T�|�[�g����_�����Z���߂̎�ނɂ���Ę_���Q�[�g����
�啝�ɍ팸�ł����肷�邩��A���ꂾ���ł��������x�������ς���Ă���B
�������ASHA-1�݂����Ȏ�������ł�n�b�V���̂�������72�r�b�g���g����12���g���b�v�Ƃ�
2ch�^�c�������������\�������ˁB���{�I�ɋ��x�̉����ɂȂ��Ăˁ[����
AES�g���Ă��x86�ł�ARM�ł��ŋ߂̃v���Z�b�T�̓n�[�h�E�F�A�����ꂽ��p���W�b�N��
�g���邩��G�l���M�[�����I�ɂ����Ȃ�܂Ƃ��ɂȂ��Ă��͂��Ȃ̂����B
���X�y�N�g���Ă��Í��w�҂Ȃ炢�����ǁA�قڑS���C�O�̑�w������
�A���S���Y�����s�ςƂ����̂��Ԕ���������
DES�̃A���S���Y�����͕̂ς��Ȃ����u�����ɉ�ǂ��邽�߂̃e�N�j�b�N�v��
2008�N����܂�IEEE����{�̏���w��ł����т��ѐV�����_�����������Ă����B
Bit-slice�@���v���Z�b�T�̃T�|�[�g����_�����Z���߂̎�ނɂ���Ę_���Q�[�g����
�啝�ɍ팸�ł����肷�邩��A���ꂾ���ł��������x�������ς���Ă���B
�������ASHA-1�݂����Ȏ�������ł�n�b�V���̂�������72�r�b�g���g����12���g���b�v�Ƃ�
2ch�^�c�������������\�������ˁB���{�I�ɋ��x�̉����ɂȂ��Ăˁ[����
AES�g���Ă��x86�ł�ARM�ł��ŋ߂̃v���Z�b�T�̓n�[�h�E�F�A�����ꂽ��p���W�b�N��
�g���邩��G�l���M�[�����I�ɂ����Ȃ�܂Ƃ��ɂȂ��Ă��͂��Ȃ̂����B
���̒��ł̂��̕]���͂����ς��Ȃ���
���Ԑ�
�ł����̃X���Z�������邾�낤��
�撣���Ċ���������H
���J�܂ł̎��Ԃɂ���Ă͕]������l�����邩����
���Ԑ�
�ł����̃X���Z�������邾�낤��
�撣���Ċ���������H
���J�܂ł̎��Ԃɂ���Ă͕]������l�����邩����
310 �FSocket774�F2015/02/12(��) 19:13:54.37 ID:gxGC9oxe
>>301
hsa�ނ��܂��[�H
hsa�ނ��܂��[�H
311 �F,,�E�L�́M�E,,�j��-�������F2015/02/12(��) 19:19:45.37 ID:0SWhhLBZ
>>306
������A����ȃO�O���ďo�Ă������ʂȂ�ē\��Ȃ��Ă������炨�O�����ۂɂ���Ă݂��
����Ȍl�^�c�̃T�C�g�Ȃ�Č�����AVS�g���Ă�Ȃ�MSDN�I�����C���}�j���A���o�Ă��邵
���ʃ��X�����Ă�ԂɃR�[�h�����邾��H
��Ԃ������������Ȃ��āA2ch�ɏ����ɂ�������w�E�ӏ������Ă݂��B
> �������͂���ɕ\�L�ւ���ς�
�Ԃ����Ⴏ��Ƃ��ꂾ���ł͉��̎w�E�������_�̉����͂ł��܂���
���ʂ�bool�l�͂��̂܂܂���X���b�h�Z�[�t�ɂȂ�Ȃ�����A���肷��ƃ��C���X���b�h��
���[�J�[�X���b�h�̔F�����Ă�l�ɂ��ꂪ�����Ė\�����邯�ǂˁB
�����X���b�h�œ����ϐ��l���Q�Ƃ���ꍇ�̓|�[�����O�p��API�����邩�炻����g��Ȃ��ƃ_������H
>>306�̃��X�̓}���`�X���b�h�̃v���O���������܂őS�����������ƂȂ��Ɣ��Ă�ɓ������B
������A����ȃO�O���ďo�Ă������ʂȂ�ē\��Ȃ��Ă������炨�O�����ۂɂ���Ă݂��
����Ȍl�^�c�̃T�C�g�Ȃ�Č�����AVS�g���Ă�Ȃ�MSDN�I�����C���}�j���A���o�Ă��邵
���ʃ��X�����Ă�ԂɃR�[�h�����邾��H
��Ԃ������������Ȃ��āA2ch�ɏ����ɂ�������w�E�ӏ������Ă݂��B
> �������͂���ɕ\�L�ւ���ς�
�Ԃ����Ⴏ��Ƃ��ꂾ���ł͉��̎w�E�������_�̉����͂ł��܂���
���ʂ�bool�l�͂��̂܂܂���X���b�h�Z�[�t�ɂȂ�Ȃ�����A���肷��ƃ��C���X���b�h��
���[�J�[�X���b�h�̔F�����Ă�l�ɂ��ꂪ�����Ė\�����邯�ǂˁB
�����X���b�h�œ����ϐ��l���Q�Ƃ���ꍇ�̓|�[�����O�p��API�����邩�炻����g��Ȃ��ƃ_������H
>>306�̃��X�̓}���`�X���b�h�̃v���O���������܂őS�����������ƂȂ��Ɣ��Ă�ɓ������B
312 �F,,�E�L�́M�E,,�j��-�������F2015/02/12(��) 19:41:06.33 ID:0SWhhLBZ
�X���b�h�̃L�����Z���̐��������@�͂���i.NET Framework 4.5�Ή��j
https://msdn.microsoft.com/ja-jp/library/dd997364(v=vs.110).aspx
����Ȋ�{�I�ȃv���O�������܂Ƃ��ɏ����Ȃ��z��
HSA�œ���GPU�̃v���O���~���O���ȒP�ɂȂ�Ƃ������Ă邩�玸���邵���Ȃ���
�v���O���~���O�̏펯�ȑO�̖��
https://msdn.microsoft.com/ja-jp/library/dd997364(v=vs.110).aspx
����Ȋ�{�I�ȃv���O�������܂Ƃ��ɏ����Ȃ��z��
HSA�œ���GPU�̃v���O���~���O���ȒP�ɂȂ�Ƃ������Ă邩�玸���邵���Ȃ���
�v���O���~���O�̏펯�ȑO�̖��
>>311
C#�͋K������������
Bitmap��f�ŕ������悤�Ƃ����IDE�ɐF�X���ӂ��ꂽ�C�����邪
bool����S�R�W�Ȃ�
���l���Z����X���b�h�Z�[�t���Ȃ��Ɛ��l�o�O�o�邾�낤���ǖ\���ȂN����킯�Ȃ�
while���邵�Ȃ��̃t���O�Ȃ�����ƗL�蓾�Ȃ�
C#�ʼn���������Ȃ�C++�Ȃ�����Ƒ��v���낤��
���܂ł��t���̃��[���ɂ����݂��ĂȂ��ŏ����͎����̓��g����
C#�͋K������������
Bitmap��f�ŕ������悤�Ƃ����IDE�ɐF�X���ӂ��ꂽ�C�����邪
bool����S�R�W�Ȃ�
���l���Z����X���b�h�Z�[�t���Ȃ��Ɛ��l�o�O�o�邾�낤���ǖ\���ȂN����킯�Ȃ�
while���邵�Ȃ��̃t���O�Ȃ�����ƗL�蓾�Ȃ�
C#�ʼn���������Ȃ�C++�Ȃ�����Ƒ��v���낤��
���܂ł��t���̃��[���ɂ����݂��ĂȂ��ŏ����͎����̓��g����
314 �F,,�E�L�́M�E,,�j��-�������F2015/02/12(��) 20:03:42.29 ID:0SWhhLBZ
> C#�ʼn���������Ȃ�C++�Ȃ�����Ƒ��v���낤��
�������A�z�����Ęb�ɂȂ�Ȃ�����
C++���Ƌ��L�ϐ���volatile�����t���邱�ƂŒl���X���b�h���ƂɕʁX�ɃL���b�V������邱�Ƃ�
�}���ł��邪�A�m���ɓǂݏ���������ۏł��Ȃ��B
���ꂪ�ʗp�����̂͂��������V���O���v���Z�b�T�̃^�C���X���C�X�݂̂Ń}���`�X���b�h
����Ă�����܂ł��B
���������蔲���v���O���������Ă����HyperThreading��f���A���R�A�Ɉڍs�����Ƃ���
����ɓ����Ȃ��Ȃǂ̖��ɑ������Ă�B
�������ւ̏������݂����S�ɏI����Ă��Ȃ��i�K�ŕʂ̃X���b�h����ǂݍ��ނ��Ƃ�
�ł��Ă��܂����琮�������j����B
C++/Win32�ł�InterlockedExchange�g����x86��lock�v���t�B�N�X��mov�ɓW�J����邩��
������g����B
x86��lock�v���t�B�N�X�����߂͗B�ꖽ�߃Z�b�g���x���Ń}���`�v���Z�b�T�Ԃ�
�������R���V�X�e���V��ۏ�����@�B
������t�����ĒN���悗������
�������A�z�����Ęb�ɂȂ�Ȃ�����
C++���Ƌ��L�ϐ���volatile�����t���邱�ƂŒl���X���b�h���ƂɕʁX�ɃL���b�V������邱�Ƃ�
�}���ł��邪�A�m���ɓǂݏ���������ۏł��Ȃ��B
���ꂪ�ʗp�����̂͂��������V���O���v���Z�b�T�̃^�C���X���C�X�݂̂Ń}���`�X���b�h
����Ă�����܂ł��B
���������蔲���v���O���������Ă����HyperThreading��f���A���R�A�Ɉڍs�����Ƃ���
����ɓ����Ȃ��Ȃǂ̖��ɑ������Ă�B
�������ւ̏������݂����S�ɏI����Ă��Ȃ��i�K�ŕʂ̃X���b�h����ǂݍ��ނ��Ƃ�
�ł��Ă��܂����琮�������j����B
C++/Win32�ł�InterlockedExchange�g����x86��lock�v���t�B�N�X��mov�ɓW�J����邩��
������g����B
x86��lock�v���t�B�N�X�����߂͗B�ꖽ�߃Z�b�g���x���Ń}���`�v���Z�b�T�Ԃ�
�������R���V�X�e���V��ۏ�����@�B
������t�����ĒN���悗������
IDE�̌x������Ȃ���
�P���̉摜���X���b�h�ŕς��悤�ƁA����Q�Ƃ��邾���ŃG���[�Ŏ~�܂��������
�f�[�^���������f����Ȃ��Ƃ�����������Ȃ��A�v�����~�܂�
�ł����l�̏ꍇ�́u�Q�ƂƉ��Z�̏��ԕϓ��ɂ�鐔�l�o�O�v���O�O���ďo�邭�炢�Ȃ̂�
�A�v�����~�܂�Ȃ�Ă��Ƃ͖������낤
�Ă��\�����ĉ�
�P���̉摜���X���b�h�ŕς��悤�ƁA����Q�Ƃ��邾���ŃG���[�Ŏ~�܂��������
�f�[�^���������f����Ȃ��Ƃ�����������Ȃ��A�v�����~�܂�
�ł����l�̏ꍇ�́u�Q�ƂƉ��Z�̏��ԕϓ��ɂ�鐔�l�o�O�v���O�O���ďo�邭�炢�Ȃ̂�
�A�v�����~�܂�Ȃ�Ă��Ƃ͖������낤
�Ă��\�����ĉ�
316 �F,,�E�L�́M�E,,�j��-�������F2015/02/12(��) 20:10:32.81 ID:0SWhhLBZ
�킩��₷���}�����邩��ǂ�ǂ����\
�����C/C++�̘b�ł���
http://itpro.nikkeibp.co.jp/article/COLUMN/20070603/273403/
�����C/C++�̘b�ł���
http://itpro.nikkeibp.co.jp/article/COLUMN/20070603/273403/
317 �F,,�E�L�́M�E,,�j��-�������F2015/02/12(��) 20:12:23.24 ID:0SWhhLBZ
�Q�ȏ�̃��[�J�[�X���b�h�ŏ����S����Ƃ��ɃA�g�~�b�N�������K�v�Ȃ���
�����A�n�������炻��Ȃ��Ƃ��킩��Ȃ��̂�
�����A�n�������炻��Ȃ��Ƃ��킩��Ȃ��̂�
318 �F,,�E�L�́M�E,,�j��-�������F2015/02/12(��) 20:16:25.91 ID:0SWhhLBZ
�v���O���~���O�̐��E�ł�wizard�͐��r�̃v���O���}�̑��̂���
���̂���������40�߂��ĕʂ̈Ӗ��ł̖��@�g��
���̂���������40�߂��ĕʂ̈Ӗ��ł̖��@�g��
�r��������
�u�����ǂ��������Ă���Ȃ��Ɩ\�������Ⴄ�I
���l�������I�v
���ďꍇ�ɕK�v�ɂȂ���̂ł�����
�Ă��\�����ĉ�
���l�̕ϓ��ɕq������Ȃ��Ă����������Ȃ�r�����������Ă���K�v������
�܂��Ă�[�U�[�������{�^���ɑ��Ĕr���������Ăǂ��\�������ł���
�u�����ǂ��������Ă���Ȃ��Ɩ\�������Ⴄ�I
���l�������I�v
���ďꍇ�ɕK�v�ɂȂ���̂ł�����
�Ă��\�����ĉ�
���l�̕ϓ��ɕq������Ȃ��Ă����������Ȃ�r�����������Ă���K�v������
�܂��Ă�[�U�[�������{�^���ɑ��Ĕr���������Ăǂ��\�������ł���
���ɂȂ�����hsa�����o���Ă�����ł�����
321 �F,,�E�L�́M�E,,�j��-�������F2015/02/12(��) 20:30:18.86 ID:0SWhhLBZ
C++�̓������������������Ȃ�����C#�������Ɩʓ|����H
���r���[�ȃX���b�h�̒��f����ƃ��������[�N�����H
���r���[�ȃX���b�h�̒��f����ƃ��������[�N�����H
322 �F,,�E�L�́M�E,,�j��-�������F2015/02/12(��) 20:33:07.30 ID:0SWhhLBZ
>>320
����ȁB����HSA Bolt�̃o�[�W�����������ԍX�V���ꂽ���A
�Ȃ����Ă݂��炢������Ȃ���
�|���Z�����Z������������Ȃ��āA���̃t�@���{�[�C��
�ȒP�Ƀv���O���~���O�ł��邱�Ƃ��I���ׂ����Ǝv����
����ȁB����HSA Bolt�̃o�[�W�����������ԍX�V���ꂽ���A
�Ȃ����Ă݂��炢������Ȃ���
�|���Z�����Z������������Ȃ��āA���̃t�@���{�[�C��
�ȒP�Ƀv���O���~���O�ł��邱�Ƃ��I���ׂ����Ǝv����
������
������������Y��Ɣr������̍���
�{�^���n���h���Ŕr������������������
�܂�����ς����Ղ��̂�SIMT��SIMT�Ƃ���������
��b���{����v��Ȃ������I�ȗ������x���̖��������
�ǂݔ���Ă镔���ɂ������ɂ��������̂���낤����
����߂��đS���E���Ă��Ȃ�
������������Y��Ɣr������̍���
�{�^���n���h���Ŕr������������������
�܂�����ς����Ղ��̂�SIMT��SIMT�Ƃ���������
��b���{����v��Ȃ������I�ȗ������x���̖��������
�ǂݔ���Ă镔���ɂ������ɂ��������̂���낤����
����߂��đS���E���Ă��Ȃ�
�܂��c�q�ɔS������ϑz�N����\�ꂩ
325 �F,,�E�L�́M�E,,�j��-�������F2015/02/12(��) 20:54:07.15 ID:0SWhhLBZ
���������AUnixCrypt.cs����10�N�ȏ�O�Ɏg�������Ƃ��邩�炿����Ǝv���o������B
����UFC Crypt��Java�ɈڐA�������̂�����Ƀx�^�ڐA�������̂�
2ch�̃T�[�o��crypt������UFC�Ɉˑ����Ă�����salt�̒l�͂��������l�ɂȂ�����B
UnixCrypt.cs���g���ꍇ�́Asalt�ɂ́Akey[1..2]�Ɠ�������������̂܂ܓn���Ă�����
�Ȃ���l���Ȃ��Ă�2ch�݊��g���b�v�ɂȂ�B
�����ˁB
private static readonly uint[] m_saltTranslation = { ... };
�����Č����Ȃ�A256�v�f�Ɋg������0x80-0xFF�Ԗڂ�S��0x00�ɂ��Ă������炢���B
�ł�ASCII�͈͊O�̕������L�[�ɂ��Ȃ���W�Ȃ���ˁH
���������[��������
����UFC Crypt��Java�ɈڐA�������̂�����Ƀx�^�ڐA�������̂�
2ch�̃T�[�o��crypt������UFC�Ɉˑ����Ă�����salt�̒l�͂��������l�ɂȂ�����B
UnixCrypt.cs���g���ꍇ�́Asalt�ɂ́Akey[1..2]�Ɠ�������������̂܂ܓn���Ă�����
�Ȃ���l���Ȃ��Ă�2ch�݊��g���b�v�ɂȂ�B
�����ˁB
private static readonly uint[] m_saltTranslation = { ... };
�����Č����Ȃ�A256�v�f�Ɋg������0x80-0xFF�Ԗڂ�S��0x00�ɂ��Ă������炢���B
�ł�ASCII�͈͊O�̕������L�[�ɂ��Ȃ���W�Ȃ���ˁH
���������[��������
326 �F,,�E�L�́M�E,,�j��-�������F2015/02/12(��) 20:58:25.95 ID:0SWhhLBZ
�Ƃ���Ŗ����̕����Ɋ����Ƃ���������ǂ���͈Ӑ}�ʂ�̓���Ȃ́H����ȓ���Ȃ́H
�ނ���distributed.net�̃N���C�A���g�͓������Ă����Ƃ����
�����Pentium4�}�V����24���ԓ������Ă�����ACPU�t�@���������ł܂���ĂƂɂ����ς�����
�����Pentium4�}�V����24���ԓ������Ă�����ACPU�t�@���������ł܂���ĂƂɂ����ς�����
CPU��_����Ȃ�AC#���A�A�Z���u����A�A�Z���u���ɋ߂�C���ꓙ�ł��Ȃ���
329 �F,,�E�L�́M�E,,�j��-������ ��utdIdpaa4jkc �F2015/02/12(��) 21:23:04.23 ID:0SWhhLBZ
>>327
����̃\�[�X��͂���Ă����A�w�u���C��w��Eli Biham�搶�̘_�����x���ǂ�[
�C�X���G���l���ă}�W�V�ˑ�����ȁB
���܂���C�X���G���l��������H
�����A�g���b�v�e�X�g���Ă݂���ꉞ�͐���ɓ��삵�Ă�݂����B
�L�[��
#!!!!!!!!!!!!!!!!!!!��
�ǂ���6bit�~12������72bit�����Ȃ����A�L�[��ASCII��printable�����݂̂�16�������炢��
�\�����Ǝv�����ǂˁB#&<>;�����菜�O���Ƃ�������ł���H
16�����ł�(2^6)^12���͂邩�ɑ�������A�����_���������Ă��L�[�̏Փ˂����g���b�v��
�Փˊm���̂ق����y���ɍ�����B
>>328
�����P�����i���炱�����˂�̌��炵�����j�̂��ADay���̂��ACPU���[�`����AVX2�g���Ă邩��
�ǂ݂̂����p���SIMD�g��Ȃ��ƃX�s�[�h�I�ɘb�ɂȂ�Ȃ��ˁB
HSA�g������CPU��SIMD�g��Ȃ��Ă����Ƃ������Ȃ�܂�����ł�������
AVX���g�����Ȃ��Ȃ����x�����Ⴛ�������������Ǝv���B
�V����Atom�ɍڂ�\���SHA�g�����߂����I�ɒ��ڊ��B
�ǂ���SHA�̃��E���h�����������ߕ��ׂȂ��Ƃ����Ȃ���H�Ƃ��v������
�T���v���R�[�h������4���E���h���܂Ƃ߂ď����ł��ĂĖ��ߐ��̏��Ȃ��ɋ�����
����̃\�[�X��͂���Ă����A�w�u���C��w��Eli Biham�搶�̘_�����x���ǂ�[
�C�X���G���l���ă}�W�V�ˑ�����ȁB
���܂���C�X���G���l��������H
�����A�g���b�v�e�X�g���Ă݂���ꉞ�͐���ɓ��삵�Ă�݂����B
�L�[��
#!!!!!!!!!!!!!!!!!!!��
�ǂ���6bit�~12������72bit�����Ȃ����A�L�[��ASCII��printable�����݂̂�16�������炢��
�\�����Ǝv�����ǂˁB#&<>;�����菜�O���Ƃ�������ł���H
16�����ł�(2^6)^12���͂邩�ɑ�������A�����_���������Ă��L�[�̏Փ˂����g���b�v��
�Փˊm���̂ق����y���ɍ�����B
>>328
�����P�����i���炱�����˂�̌��炵�����j�̂��ADay���̂��ACPU���[�`����AVX2�g���Ă邩��
�ǂ݂̂����p���SIMD�g��Ȃ��ƃX�s�[�h�I�ɘb�ɂȂ�Ȃ��ˁB
HSA�g������CPU��SIMD�g��Ȃ��Ă����Ƃ������Ȃ�܂�����ł�������
AVX���g�����Ȃ��Ȃ����x�����Ⴛ�������������Ǝv���B
�V����Atom�ɍڂ�\���SHA�g�����߂����I�ɒ��ڊ��B
�ǂ���SHA�̃��E���h�����������ߕ��ׂȂ��Ƃ����Ȃ���H�Ƃ��v������
�T���v���R�[�h������4���E���h���܂Ƃ߂ď����ł��ĂĖ��ߐ��̏��Ȃ��ɋ�����
�c�q�͊y�����V�ё���ɋ��에�����Ċ������ȁB
>>320
AMD�t�@����������Ȃ�HSA�Ńg���b�v����������Ċ��������
CPU�EGPU�������ł���HSA�Ȃ�A�ȒP�ɂ���Ȃɍ����g���b�v�����ł�����A�����[����Ȃ̂ɂ�
>>320
AMD�t�@����������Ȃ�HSA�Ńg���b�v����������Ċ��������
CPU�EGPU�������ł���HSA�Ȃ�A�ȒP�ɂ���Ȃɍ����g���b�v�����ł�����A�����[����Ȃ̂ɂ�
331 �F,,�E�L�́M�E,,�j��-�������F2015/02/12(��) 21:39:00.89 ID:0SWhhLBZ
HSA���g���ΊȒP�Ƀv���O���~���O�ł���Ƃ����A
���Ɋ������Ă郉�C�u����������̂ɂ����N���g��Ȃ����Ă̂͂ǂ��������Ƃ��낤�ˁH
Bolt�̓f�B�X�N���[�g��Radeon�ł�APU�ł��ǂ����ł��g����悤�ɂȂ��Ă��B
Bolt�͂���ȏ㍪�{�I�Ȑi���͂��Ȃ��Ǝv����B
���g������̂��g���Ȃ���͂�����o�[�W�������d�˂Ă��g���₷���Ȃ�Ȃ��Ǝv���B
�Ƃ肠����Bolt��AMD��p�̃v���O�����������p�����Ȃ��l�Ԃɂ�
�ꐶ���p�̃��C�u�����Ȃ̂͊ԈႢ�Ȃ���
�����ł���VS2010����v���W�F�N�g���Ƃ�include�p�X�Elib�p�X���w�肵�Ȃ��Ƃ����Ȃ��Ȃ����̂�
�킴�킴AMD���ł��������Ȃ����C�u�������Z�b�g�A�b�v�����Ԃ���ɂ���
AMD�̊J�����Ɍ���Ȃ����ǁA�W���O�̃��C�u�����g���ɂ̓J�X�^��AppWizard�̒���
include/lib�p�X��ݒ肷��X�N���v�g�Ԃ����ނ̂��m�����˂��B
�f�t�H���g�̃v���p�e�B�V�[�g��XML�ڂ�����ǂ��ɂł��Ȃ���ǂ��낢��ʓ|����
���Ɋ������Ă郉�C�u����������̂ɂ����N���g��Ȃ����Ă̂͂ǂ��������Ƃ��낤�ˁH
Bolt�̓f�B�X�N���[�g��Radeon�ł�APU�ł��ǂ����ł��g����悤�ɂȂ��Ă��B
Bolt�͂���ȏ㍪�{�I�Ȑi���͂��Ȃ��Ǝv����B
���g������̂��g���Ȃ���͂�����o�[�W�������d�˂Ă��g���₷���Ȃ�Ȃ��Ǝv���B
�Ƃ肠����Bolt��AMD��p�̃v���O�����������p�����Ȃ��l�Ԃɂ�
�ꐶ���p�̃��C�u�����Ȃ̂͊ԈႢ�Ȃ���
�����ł���VS2010����v���W�F�N�g���Ƃ�include�p�X�Elib�p�X���w�肵�Ȃ��Ƃ����Ȃ��Ȃ����̂�
�킴�킴AMD���ł��������Ȃ����C�u�������Z�b�g�A�b�v�����Ԃ���ɂ���
AMD�̊J�����Ɍ���Ȃ����ǁA�W���O�̃��C�u�����g���ɂ̓J�X�^��AppWizard�̒���
include/lib�p�X��ݒ肷��X�N���v�g�Ԃ����ނ̂��m�����˂��B
�f�t�H���g�̃v���p�e�B�V�[�g��XML�ڂ�����ǂ��ɂł��Ȃ���ǂ��낢��ʓ|����
���{�l�Ȃ�C���e���Q�t�H���
>>331
Bolt��c++����HSA���g���悤�ɂ��郉�C�u�����������
AMD�t�@����C#�ł����C++ + Bolt�̂ق���(���J�����)AMD�̂��߂ɂ��Ȃ邩��ǂ����
�c�q�A����Bolt�̃T���v���������߂�Bolt��Intel��OpenCL����g���悤�ɂ��Ă���
(�����Ȃ��T���v���������ACPU�㓮��Œx������)
���ł�AMD��clFFT��Nvidia��OpenCL����Ƃ肠�����g���悤�ɂ��Ă���B
Bolt��c++����HSA���g���悤�ɂ��郉�C�u�����������
AMD�t�@����C#�ł����C++ + Bolt�̂ق���(���J�����)AMD�̂��߂ɂ��Ȃ邩��ǂ����
�c�q�A����Bolt�̃T���v���������߂�Bolt��Intel��OpenCL����g���悤�ɂ��Ă���
(�����Ȃ��T���v���������ACPU�㓮��Œx������)
���ł�AMD��clFFT��Nvidia��OpenCL����Ƃ肠�����g���悤�ɂ��Ă���B
334 �F,,�E�L�́M�E,,�j��-�������F2015/02/12(��) 22:08:47.97 ID:0SWhhLBZ
boost�V�����̓��ꂽ��
���������v���p�e�B�V�[�g������̂߂�ǂ�����
���������v���p�e�B�V�[�g������̂߂�ǂ�����
�c�q�����܂����o���Ă�̂�
AMD�t�@���{�[�C�͕s�b��Ȃ��Ȃ�
AMD�t�@���{�[�C�͕s�b��Ȃ��Ȃ�
>>334
�����́H�H
�������̂��Ɠ���ɂ��ă}�X�^�[����NLMeansCL2�̍����������Ă���
http://forum.doom9.org/showthread.php?t=171379
�������ł�����}�W�ő��h���邼
�����́H�H
�������̂��Ɠ���ɂ��ă}�X�^�[����NLMeansCL2�̍����������Ă���
http://forum.doom9.org/showthread.php?t=171379
�������ł�����}�W�ő��h���邼
Zen�̓T���`�������H
http://vga.zol.com.cn/507/5074357.html
http://vga.zol.com.cn/507/5074357.html
338 �F,,�E�L�́M�E,,�j��-�������F2015/02/12(��) 22:35:10.96 ID:0SWhhLBZ
Boost�����O���œ�������̂��炭�Ԃ�ʼnY�����Y�Ȃ���
Boost.Log����AVX2�܂ŕ��ʂɑΉ����Ă�̂�
���₱�ꉽ�����郉�C�u�������āALog�Ȃ��ǂ�
�����̂��H
HSA Foundation��Boost��HSA�c�[�����˂����܂Ȃ��āH
C++�̏��W�����C�u���������H
�Ƃ�������C++11�̃��C�u�����ŏ\���������̂ŁA���炭Boost�g���ĂȂ������킯�����B
Boost.Log����AVX2�܂ŕ��ʂɑΉ����Ă�̂�
���₱�ꉽ�����郉�C�u�������āALog�Ȃ��ǂ�
�����̂��H
HSA Foundation��Boost��HSA�c�[�����˂����܂Ȃ��āH
C++�̏��W�����C�u���������H
�Ƃ�������C++11�̃��C�u�����ŏ\���������̂ŁA���炭Boost�g���ĂȂ������킯�����B
339 �F,,�E�L�́M�E,,�j��-�������F2015/02/12(��) 22:53:36.95 ID:0SWhhLBZ
Tripcode�Ȃ�Ƃ��ōŏ��̍�Boost�g���Ă���B
���Ƃ��ΐ��K�\����Regex++�Ƃ����B
�x���`�Ƃ��Ă݂���Oniguruma�̂ق������������肵�āA���ǍŌ�Ɏc�����̂�boost.mt19937����
Boost�܂��ł���Ȃ��ˁH
�r����mt19937��荂����SFMT�Ƃ��o�Ă����肵�āASFMT�����O�ŃN���X�e���v���[�g������
�usfmtplus�v�Ƃ����Ă����N�\���C�u��������āA�ł������͌���Tri�Ȃ�Ƃ��ɂ͓���Ȃ��������ǂ�
�Ă����ꉴ����u�K�v�ˁ[�ȁv�Ǝv��������
�������m��ʂƂ���̃I�[�v���\�[�X�v���W�F�N�g�Ŗ����Ɏg���Ă��肷�邩��킩������
http://slash-sandbox.googlecode.com/svn/trunk/%20slash-sandbox/nih/docs/html/sfmtrand_8h_source.html
���Ƃ��ΐ��K�\����Regex++�Ƃ����B
�x���`�Ƃ��Ă݂���Oniguruma�̂ق������������肵�āA���ǍŌ�Ɏc�����̂�boost.mt19937����
Boost�܂��ł���Ȃ��ˁH
�r����mt19937��荂����SFMT�Ƃ��o�Ă����肵�āASFMT�����O�ŃN���X�e���v���[�g������
�usfmtplus�v�Ƃ����Ă����N�\���C�u��������āA�ł������͌���Tri�Ȃ�Ƃ��ɂ͓���Ȃ��������ǂ�
�Ă����ꉴ����u�K�v�ˁ[�ȁv�Ǝv��������
�������m��ʂƂ���̃I�[�v���\�[�X�v���W�F�N�g�Ŗ����Ɏg���Ă��肷�邩��킩������
http://slash-sandbox.googlecode.com/svn/trunk/%20slash-sandbox/nih/docs/html/sfmtrand_8h_source.html
340 �F,,�E�L�́M�E,,�j��-�������F2015/02/12(��) 22:54:49.09 ID:0SWhhLBZ
��implementation�̃X�y���Ԉ���Ă邵���Â��p���������z����ȉ�
>>337
����Ƃ���̌��L���ł��낤������������A�ǂ���Fab�g�����Ȃ�Ăǂ��ɂ�������ĂȂ����H
http://www.sweclockers.com/nyhet/19954-amd-zen-forst-ut-i-summit-ridge-for-14-nanometer
����Ƃ���̌��L���ł��낤������������A�ǂ���Fab�g�����Ȃ�Ăǂ��ɂ�������ĂȂ����H
http://www.sweclockers.com/nyhet/19954-amd-zen-forst-ut-i-summit-ridge-for-14-nanometer
>>338
Boost.Compute
https://github.com/kylelutz/compute
���O���炵��Boost�����_���Ă��銴����GPGPU�_�����C�u����
Bolt��葽�����}�[�N326�I�@Thrust�͍X�ɐ�������
Kyle�����OpenCL2.0(HSA)�Ή�����ꂾ
>>337
���N�N����ł����ς肾���A�_�����ĂȂǂ��\�L����
Boost.Compute
https://github.com/kylelutz/compute
���O���炵��Boost�����_���Ă��銴����GPGPU�_�����C�u����
Bolt��葽�����}�[�N326�I�@Thrust�͍X�ɐ�������
Kyle�����OpenCL2.0(HSA)�Ή�����ꂾ
>>337
���N�N����ł����ς肾���A�_�����ĂȂǂ��\�L����
343 �F,,�E�L�́M�E,,�j��-�������F2015/02/12(��) 23:19:33.55 ID:0SWhhLBZ
nih���ă��C�u�����͂�������������Ǝv���ăg�b�v�y�[�W�����炱��̊J����NVIDIA�̎Ј�������
���ǂ�NVIDIA�ɕt���_���Ă�悗������
���ǂ�NVIDIA�ɕt���_���Ă�悗������
344 �F,,�E�L�́M�E,,�j��-�������F2015/02/12(��) 23:48:04.01 ID:0SWhhLBZ
>>342
����Sandbox�i�\���R�j�ɂ�������ĂȂ��I���I��Boost���C�u��������ˁ[��
�]�Y�搶��GPGPU������܂�D��łȂ��݂��������A�W�����͂ǂ����Ȃ��E�E�E�Ƃ��������B
�v�X�Ɏ����̐̏�����SFMTplus(��)�̃R�[�h�ǂ�ł݂āAC++��Template�@�\���Ă����[��ȂƎv�����B
���ꂽ����AMD��SSEplus�Ɉ����|���Ĕ���ł������O�Ȃ��ǂ��B
�����R�[�h�ʑ����̂�C++���Ƃ�������400�s�B
����A�N���X�ɂ܂Ƃ߂邱�ƂŁA�����̗����C���X�^���X���ɍ���̂�����Ȃ��ǂ��B
��������128�r�b�g�u���b�N���ƂɈˑ��W�����邩��AAVX�g���Ă�2�{�����Ȃ�킯����Ȃ����
SFMT�\���̂������Α������ǁA������Đ��w�I�ɂǂ��Ȃ̂��Ȃ���
boost.mt19937�́A�N���X�e���v���[�g�������C++11�̕W�����C�u��������B
����boost�g�����R���Ăǂ��ɂ��邾�낤���H�܂��Ƃ肠�����֗������Ȃ��̂�����Ύg���Ă݂悤���ȂƁB
���x�̈��萫��SFMT�̂ق����������ǁAMT��256�r�b�g�ȏ��SIMD�ł��X�P�[�����邩��
AVX2�ł�����œK������Ƌt�]����B
�Ԃ����ႯSIMD oriented�̈Ӗ����Ȃ��ˁH
�S�Ԃ̌ꌹ���ׂĂ݂��璆���̉����������B
����Sandbox�i�\���R�j�ɂ�������ĂȂ��I���I��Boost���C�u��������ˁ[��
�]�Y�搶��GPGPU������܂�D��łȂ��݂��������A�W�����͂ǂ����Ȃ��E�E�E�Ƃ��������B
�v�X�Ɏ����̐̏�����SFMTplus(��)�̃R�[�h�ǂ�ł݂āAC++��Template�@�\���Ă����[��ȂƎv�����B
���ꂽ����AMD��SSEplus�Ɉ����|���Ĕ���ł������O�Ȃ��ǂ��B
�����R�[�h�ʑ����̂�C++���Ƃ�������400�s�B
����A�N���X�ɂ܂Ƃ߂邱�ƂŁA�����̗����C���X�^���X���ɍ���̂�����Ȃ��ǂ��B
��������128�r�b�g�u���b�N���ƂɈˑ��W�����邩��AAVX�g���Ă�2�{�����Ȃ�킯����Ȃ����
SFMT�\���̂������Α������ǁA������Đ��w�I�ɂǂ��Ȃ̂��Ȃ���
boost.mt19937�́A�N���X�e���v���[�g�������C++11�̕W�����C�u��������B
����boost�g�����R���Ăǂ��ɂ��邾�낤���H�܂��Ƃ肠�����֗������Ȃ��̂�����Ύg���Ă݂悤���ȂƁB
���x�̈��萫��SFMT�̂ق����������ǁAMT��256�r�b�g�ȏ��SIMD�ł��X�P�[�����邩��
AVX2�ł�����œK������Ƌt�]����B
�Ԃ����ႯSIMD oriented�̈Ӗ����Ȃ��ˁH
�S�Ԃ̌ꌹ���ׂĂ݂��璆���̉����������B
boost�Ƃ����Ύg�������ǂ��킩���̂ł������Ă���uboost���g���Ȃ��p���������z(��)���v���O���}�����ȁv���Đ����Ă�T�C�g�������ĂȂނ����̎v���o�����B
���͂����y�ȕ��֗����Powershell�������ėp�������������ɂȂ��Ă邯�ǁAboost�Ă̂�STL���g�����ĕs�������������Č��������ŗǂ������̂��ȁB
���͂����y�ȕ��֗����Powershell�������ėp�������������ɂȂ��Ă邯�ǁAboost�Ă̂�STL���g�����ĕs�������������Č��������ŗǂ������̂��ȁB
���{�l�Ȃ�C���e���Q�t�H���
���̗���E�E���������Ė{���ɍ��������ꂻ���H
�̂�1��100���X������O�Ȃ��炢������������
�l����ԁAAVX2�����܂��g����B
�A���h�u���������C�����[�`�������ꂽ�������v
1��100���X���Ė��������z�����\���������݂��Ă����������H
�Ō�ɏ������z�������Ƃ��v������ł�̂��m���
�Ō�ɏ������z�������Ƃ��v������ł�̂��m���
���{�l�Ȃ�C���e���Q�t�H���
ARM�̂Ƃ��͐��������ȁB
���200���X���炢�L�т����ǁA���܂�̂�����Ȃ��Ɍ���̎~�߂Ă��B�B
���200���X���炢�L�т����ǁA���܂�̂�����Ȃ��Ɍ���̎~�߂Ă��B�B
AMD�͎��ЊJ����f�O����ARM�ɐ�ւ����B
�I������ȁB
�I������ȁB
(�P�\�P)�����
�c�O
������AMD�̖����͈Â�����
������AMD�̖����͈Â�����
���{�l�̓C���e���Q�t�H���
358 �F,,�E�L�́M�E,,�j��-�������F2015/02/13(��) 20:46:33.84 ID:FskOvHs4
>>345
����AC++���s�K�i���o��O��
�u�������C++�W�����C�u������₾���獡����o���Ă����v
�݂����ȃm���������Ǝv�����AC++11�K�i�ɂ߂ڂ����@�\�͎�������Ă��܂������ƂȂ��Ă�
�����R���p�C���ł�C++11�����̋@�\���g����Ƃ��A�������������b�g�����o���Ȃ�������
����قǂ��肪�������̂ł͂Ȃ��Ƃ����F���ł���
�����獡��C++�̕W�����C�u�������o����A�̂ق��ł���
Spirit�Ƃ�MPL�Ƃ��}�j�A�b�N�����ĕW��������錩���ݖ����ł��傠��
����AC++���s�K�i���o��O��
�u�������C++�W�����C�u������₾���獡����o���Ă����v
�݂����ȃm���������Ǝv�����AC++11�K�i�ɂ߂ڂ����@�\�͎�������Ă��܂������ƂȂ��Ă�
�����R���p�C���ł�C++11�����̋@�\���g����Ƃ��A�������������b�g�����o���Ȃ�������
����قǂ��肪�������̂ł͂Ȃ��Ƃ����F���ł���
�����獡��C++�̕W�����C�u�������o����A�̂ق��ł���
Spirit�Ƃ�MPL�Ƃ��}�j�A�b�N�����ĕW��������錩���ݖ����ł��傠��
>>357
�ł��̂ŁA�D�y�ɑ������x�͕�����
http://akiba-pc.watch.impress.co.jp/docs/event/tour/fukuoka.html
���܂��B
�ł��̂ŁA�D�y�ɑ������x�͕�����
http://akiba-pc.watch.impress.co.jp/docs/event/tour/fukuoka.html
���܂��B
360 �F���@�Ɏ����ݓ��X�p�C�E�n���E���N�U�F2015/02/14(�y) 10:42:14.79 ID:RIZD18D6
�}�X�R�~����ɐG��Ȃ�����
���j�����}�ȊO���ݓ�����A�������X�p�C�A�܂��͂��̉e�����ɂ���Ɖ��肵�Ă������������B
�悭������
����ꂽ�Q�O�N�@���@��Q�O�N�O�@���߂Ď����}���P�Ɖߔ���������i����̐V���}���^�}����j��
����ꂽ�P�T�N�@���@��P�T�N�O�@�����̘A���������n�܂�@�@�i�����}�̗^�}����j /
�����̂Ƃ��A���߂ĂW�O�~/�h���Ƃ������~���U������āA���{�̐����Ƃ͐��ށE��
�@�������E�؍����䓪���n�߂�B���{�̋Z�p�҂��A��ʂɊ؍��ȂǂɈ����������悤�ɂȂ�B
�@�C�I���i����}�E���c�Ɓj���^�p�`���R�X���A�n���o�ς⏤�X�X��H���Ԃ����߂́A
�@��X���n�@�������B�ݓ��p�`���R����CM�E�`���V�����ցE��^�`�F�[���W�J���n�܂�B
�@���{�̊w�͒ቺ���ړI�́u��Ƃ苳��v�̖{�i�����B�i���Q�́A�P�V�N�O�B�j
�����̂Ƃ��̉H�c�i�V���}�j�̊炪�����ɔ�����B
�����̂Ƃ��A����̐V���}��S�͂őI���x�������̂��A�n���w��Ƃ�����B
�����̂Ƃ��A�����u�P�Ɓv�����i���������̒P�ƂQ/�R�c�ȁj�̕����ɁA���|�I�s����
�@���I�����x�֖@������
2014���I���̔�ᓖ�I���@
���}�� �@�@�@�@�����@�@�����@�@����@�@�ېV�@�@���Y
����@�@�@�@�@�@68�@�@�@26�@�@�@�@35�@�@�@30�@�@�@20
���v���@�@�@�@�@ 291�@�@�@35�@�@�@�@73�@�@�@41�@�@�@21
��ᓖ�I���@�@23%�@�@�@74%�@�@�@48%�@�@73%�@�@�@95%�@�@����
���Y�E�����E�ېV�́A��ᐧ�x��p�~����Ώ��ł��@
�Q�l�j
����}�́A���~���U���Ńp�i�\�j�b�N��V���[�v�A�\�j�[��ׂ��C�������H
http://www.youtube.com/watch?v=iG_oaqU0pEM
�A�����N�l���肪�����Ƃ�ڎw�����H���{
http://www.youtube.com/watch?v=CxIGOhFT4g8 �@����
���j�����}�ȊO���ݓ�����A�������X�p�C�A�܂��͂��̉e�����ɂ���Ɖ��肵�Ă������������B
�悭������
����ꂽ�Q�O�N�@���@��Q�O�N�O�@���߂Ď����}���P�Ɖߔ���������i����̐V���}���^�}����j��
����ꂽ�P�T�N�@���@��P�T�N�O�@�����̘A���������n�܂�@�@�i�����}�̗^�}����j /
�����̂Ƃ��A���߂ĂW�O�~/�h���Ƃ������~���U������āA���{�̐����Ƃ͐��ށE��
�@�������E�؍����䓪���n�߂�B���{�̋Z�p�҂��A��ʂɊ؍��ȂǂɈ����������悤�ɂȂ�B
�@�C�I���i����}�E���c�Ɓj���^�p�`���R�X���A�n���o�ς⏤�X�X��H���Ԃ����߂́A
�@��X���n�@�������B�ݓ��p�`���R����CM�E�`���V�����ցE��^�`�F�[���W�J���n�܂�B
�@���{�̊w�͒ቺ���ړI�́u��Ƃ苳��v�̖{�i�����B�i���Q�́A�P�V�N�O�B�j
�����̂Ƃ��̉H�c�i�V���}�j�̊炪�����ɔ�����B
�����̂Ƃ��A����̐V���}��S�͂őI���x�������̂��A�n���w��Ƃ�����B
�����̂Ƃ��A�����u�P�Ɓv�����i���������̒P�ƂQ/�R�c�ȁj�̕����ɁA���|�I�s����
�@���I�����x�֖@������
2014���I���̔�ᓖ�I���@
���}�� �@�@�@�@�����@�@�����@�@����@�@�ېV�@�@���Y
����@�@�@�@�@�@68�@�@�@26�@�@�@�@35�@�@�@30�@�@�@20
���v���@�@�@�@�@ 291�@�@�@35�@�@�@�@73�@�@�@41�@�@�@21
��ᓖ�I���@�@23%�@�@�@74%�@�@�@48%�@�@73%�@�@�@95%�@�@����
���Y�E�����E�ېV�́A��ᐧ�x��p�~����Ώ��ł��@
�Q�l�j
����}�́A���~���U���Ńp�i�\�j�b�N��V���[�v�A�\�j�[��ׂ��C�������H
http://www.youtube.com/watch?v=iG_oaqU0pEM
�A�����N�l���肪�����Ƃ�ڎw�����H���{
http://www.youtube.com/watch?v=CxIGOhFT4g8 �@����
361 �F���@�Ɏ����ݓ��X�p�C�E�n���E���N�U�F2015/02/14(�y) 11:15:06.07 ID:RIZD18D6
�����@���{�Ɏ؋���������܂����̂͏����Y�i���Ԃ�ݓ��A���j�B
���S�R�O���~
���R�i���Љ�}�F���̐l���A���H�j���t���v���X�Q�O�O���~�@
�g�[�^���U�R�O���~
�i�ڂ����͓��č\�����c�Ō����j
������؋��́A����Ƃ��̗����ł́H
����́A�����}����ɓ��{�ɔ��e�������������ɁA���̃o���}�L���������œ���
�x����Ղ��������莩���}������������i���Ԃ������A�ꗣ�}�j�A
������P�Ɖߔ�������ɒǂ����B
�����āA��R�ɐ��}�i�V���}�������}�j����������A�؍���ݓ��֗��v�U�����Ă����B
���{���؋��卑�ɂ����͎̂����}���I�ƁA�����Ŏd���Ύ���}������
�Nj����鎩�쎩�����ɂ���āA����}�ւ̐������ɂȂ����B
�������}�ȊO�̋c���́A���{���𖼏��A�����N�l���A���̉e�����ɂ���Ɖ���B
�Ƃ�������ł͂Ȃ��ł��傤���B
���S�R�O���~
���R�i���Љ�}�F���̐l���A���H�j���t���v���X�Q�O�O���~�@
�g�[�^���U�R�O���~
�i�ڂ����͓��č\�����c�Ō����j
������؋��́A����Ƃ��̗����ł́H
����́A�����}����ɓ��{�ɔ��e�������������ɁA���̃o���}�L���������œ���
�x����Ղ��������莩���}������������i���Ԃ������A�ꗣ�}�j�A
������P�Ɖߔ�������ɒǂ����B
�����āA��R�ɐ��}�i�V���}�������}�j����������A�؍���ݓ��֗��v�U�����Ă����B
���{���؋��卑�ɂ����͎̂����}���I�ƁA�����Ŏd���Ύ���}������
�Nj����鎩�쎩�����ɂ���āA����}�ւ̐������ɂȂ����B
�������}�ȊO�̋c���́A���{���𖼏��A�����N�l���A���̉e�����ɂ���Ɖ���B
�Ƃ�������ł͂Ȃ��ł��傤���B
�o�u������̃c�P����B
�N��������b�ɂȂ��Ă����ʂ͓����B
���ƁA�~���Ƃ��~���̓M���V���Ƃ����[���b�p�ł̍��ۏ�̕s�������[�B
�~��Ζ����o�u���̂悤�ɍ����Ȃ��Ă邩��_��ꂽ�́B
�p�i�\�j�b�N�Ƃ��V���[�v�Ƃ��_�O�B
�N��������b�ɂȂ��Ă����ʂ͓����B
���ƁA�~���Ƃ��~���̓M���V���Ƃ����[���b�p�ł̍��ۏ�̕s�������[�B
�~��Ζ����o�u���̂悤�ɍ����Ȃ��Ă邩��_��ꂽ�́B
�p�i�\�j�b�N�Ƃ��V���[�v�Ƃ��_�O�B
>>361
���i���Ԃ�ݓ��A���j�B
���e������c�������A���o�g�́B
ttp://ja.wikipedia.org/wiki/%E5%B0%8F%E6%B2%A2%E4%BD%90%E9%87%8D%E5%96%9C
���i���Ԃ�ݓ��A���j�B
���e������c�������A���o�g�́B
ttp://ja.wikipedia.org/wiki/%E5%B0%8F%E6%B2%A2%E4%BD%90%E9%87%8D%E5%96%9C
364 �F,,�E�L�́M�E,,�j��-�������F2015/02/17(��) 02:36:52.32 ID:bw7tsr4B
http://www.linaro.org/leg/servercluster/
�Ȃ�AMD��APM��64�r�b�gARM�̃����[�g�J�����������Ŏg����炵����
�Ȃ�ꂨ�܂���
�Ȃ�AMD��APM��64�r�b�gARM�̃����[�g�J�����������Ŏg����炵����
�Ȃ�ꂨ�܂���
���{���Y�ƃX�p�C�ɊÂ����������Œ�����؍��͐�i�����݂ɂȂ��Ă����������Ŕ��������Ƀp�N�����I�ё����Ă�
���{�l�Ȃ�C���e���Q�t�H���
�ނ��������[�g�ŃV�F����������J�����Ƃ������������A
hello world�����������������
hello world�����������������
AMD�͂�������PiPO X7�݂����Ȉ�����Win�@�Ƃ��ɍ̗p����邭�炢�̂���������̂ɂ�
http://www.pipo.com/product.php?id=157
atom�f�r���[���悤����
http://www.pipo.com/product.php?id=157
atom�f�r���[���悤����
���{�l�̓C���e���Q�t�H���
ArrayFire Benchmarks: AMD Kaveri vs Intel Haswell Part-1
http://arrayfire.com/arrayfire-benchmarks-amd-kaveri-vs-intel-haswell-part-1/
http://arrayfire.com/arrayfire-benchmarks-amd-kaveri-vs-intel-haswell-part-1/
>>368
> AMD�͂�������PiPO X7�݂����Ȉ�����Win�@�Ƃ��ɍ̗p����邭�炢�̂���������̂ɂ�
Intel���o����̂�AMD�ł��o�����
�P�ɊJ�������邾���̎�����T�|�[�g���o���Ȃ�����
�Ƃ������AIntel���F�X�J�������܂����ĂāAAMD�ŊJ������]�͂������Ă邾������
> AMD�͂�������PiPO X7�݂����Ȉ�����Win�@�Ƃ��ɍ̗p����邭�炢�̂���������̂ɂ�
Intel���o����̂�AMD�ł��o�����
�P�ɊJ�������邾���̎�����T�|�[�g���o���Ȃ�����
�Ƃ������AIntel���F�X�J�������܂����ĂāAAMD�ŊJ������]�͂������Ă邾������
AMD������Ȃ��̂̓C���e���̂����i�j
���N�l���Ⴆ�Ȃ��͓̂��{�l�̂����i�j
���N�l���Ⴆ�Ȃ��͓̂��{�l�̂����i�j
���{�l�Ȃ�C���e���Q�t�H�������
>>371
AMD�ɋ����Ȃ��̂��A���[�J�[�ɗ]�͂��Ȃ��̂��ǂ����ȂH
AMD�ɋ����Ȃ��̂��A���[�J�[�ɗ]�͂��Ȃ��̂��ǂ����ȂH
����Ȃ����m�Ɋւ�肽���Ȃ�
�����Ă�n���ɋ߂Â��A�z�͒��N�l���炢���킳
>>375
������T�|�[�g���Ă��Ȃ�����AAMD�͋��]���Ă���B
x86���[�U�[���[�J�[��Intel�J���ɕK����AMD�܂Ŏg���]�͂Ȃ�����A
AMD���g�AAMD�i�͎g�����ĕ������Ă���B
������AAMD�Ј��͎��Ȗ����̃I�i�j�[���i�J�����y����ł���BTDP220W�@FX�̓I�i�j�[�����������
������T�|�[�g���Ă��Ȃ�����AAMD�͋��]���Ă���B
x86���[�U�[���[�J�[��Intel�J���ɕK����AMD�܂Ŏg���]�͂Ȃ�����A
AMD���g�AAMD�i�͎g�����ĕ������Ă���B
������AAMD�Ј��͎��Ȗ����̃I�i�j�[���i�J�����y����ł���BTDP220W�@FX�̓I�i�j�[�����������
���{�l�Ȃ�C���e���Q�t�H�������
>>375
�ߋ���Intel�̈��s��AMD�̗��v�ƃ��[�J�[�Ƃ̊W�����܂�������
������A�ǂ�ȂɗD�ꂽ���̍���Ă��A�����ł��Ȃ����A�����ł��Ȃ����A���i�J�����o���Ȃ��ɂȂ��Ă�
����AAMD��Intel�̃}�[�P�e�B���O��T�|�[�g�̍���100�{���炢���肻��������A��������Ă��S�Ēׂ�����
�܂��A���ł���@�s�ׂői�����Ă�Intel��A970��G-synk�݂����ȍ��\���炯�̃k�r���肪�����̂��؋�
�ߋ���Intel�̈��s��AMD�̗��v�ƃ��[�J�[�Ƃ̊W�����܂�������
������A�ǂ�ȂɗD�ꂽ���̍���Ă��A�����ł��Ȃ����A�����ł��Ȃ����A���i�J�����o���Ȃ��ɂȂ��Ă�
����AAMD��Intel�̃}�[�P�e�B���O��T�|�[�g�̍���100�{���炢���肻��������A��������Ă��S�Ēׂ�����
�܂��A���ł���@�s�ׂői�����Ă�Intel��A970��G-synk�݂����ȍ��\���炯�̃k�r���肪�����̂��؋�
�Ƃ������Ƃɂ�����
���{�l�Ȃ�C���e���Q�t�H���
���{�l�Ȃ�C���e���Q�t�H���
>>380
Intel�͉c�ƥ�}�[�P�e�B���O�����ׂ�������
AMD��rich��T���A���W�t�F�X�^�A��鏗�Ȃ�
�I�i�j�[�C�x���g���J�����Ƃ��ނ�ɂƂ��Ă͏d�v
AMD�Ј����ׂ���莩�������������Əo���Ă����܂������
Intel�͉c�ƥ�}�[�P�e�B���O�����ׂ�������
AMD��rich��T���A���W�t�F�X�^�A��鏗�Ȃ�
�I�i�j�[�C�x���g���J�����Ƃ��ނ�ɂƂ��Ă͏d�v
AMD�Ј����ׂ���莩�������������Əo���Ă����܂������
>>380
K6-2�̂����3D Now! �̃T�|�[�g���[�����������̂悤�ɕ���������A���������?
K6-2�̂����3D Now! �̃T�|�[�g���[�����������̂悤�ɕ���������A���������?
�ӂ�AMD�̃T�C�g���Ă������ǁA����������ƃ����C���o���ĉ^�c���Ă����Ǝv���B
�����N��͂������ɍ������E�E�E
�����N��͂������ɍ������E�E�E
AMD�T�C�g�̕s����intel�̉A�d
�����10�N�ȏ��@�Ȉ��͂�ז�����āA���v��V�F�A�����������D���āA��邱�ƂȂ����ז����ꂽ��ɃX�e�}�L��������܂����Ă�����
���ʂȂ�Ƃ����ɊJ���͖����Ȃ��Ēׂ�Ă��
�����ɖ��N�V�R�A�J�����āA�n�C�G���h�ŏ����ł��鐻�i���Ă�̂���Ղ���
APU����āAHSA���肵�āAMantle����āAARM����āASkyBridge����āAHBM����āAPS4�Ɣ�1�ɍ̗p����āAGREEN500 TOP�������
��Ԏ������Ȃ̂ɊJ���͌���ǂ��납�������Ă����Ă�̂��M������
�ɂ��ނ炭�́A�v���Z�X���S���ǂ����ĂȂ����Ƃ���
Nvidia�͂Ƃ��Ƃ����\���o������GPGPU����ăO���t�B�b�N������Maxwell��邵�AIntel��14nm��q���Ă��Ƀu���[�h���X�J�C���債�����Ɩ���
Nvidia��Intel�̒�͒m�ꂽ����A��������ł�����������
���ʂȂ�Ƃ����ɊJ���͖����Ȃ��Ēׂ�Ă��
�����ɖ��N�V�R�A�J�����āA�n�C�G���h�ŏ����ł��鐻�i���Ă�̂���Ղ���
APU����āAHSA���肵�āAMantle����āAARM����āASkyBridge����āAHBM����āAPS4�Ɣ�1�ɍ̗p����āAGREEN500 TOP�������
��Ԏ������Ȃ̂ɊJ���͌���ǂ��납�������Ă����Ă�̂��M������
�ɂ��ނ炭�́A�v���Z�X���S���ǂ����ĂȂ����Ƃ���
Nvidia�͂Ƃ��Ƃ����\���o������GPGPU����ăO���t�B�b�N������Maxwell��邵�AIntel��14nm��q���Ă��Ƀu���[�h���X�J�C���債�����Ɩ���
Nvidia��Intel�̒�͒m�ꂽ����A��������ł�����������
��芸�����A390x��Nvidia��ׂ��ɂ�����
���܂Ŋ�Ȃ�500mm2������r�b�O�_�C�J�����ė��Ȃ������̂ɁA�����ɗ��ăr�b�O�_�C+HBM�̃n�C�G���h�\���������Ă���
���܂ł́A�ŏ�ʂł�350mm2�Ƃ��ŁA�Q�t�H��550mm2�N���X�Ɛ���ė����������
�n�C�G���h�ł������̃_�C�T�C�Y�ɂȂ�Ȃ�A���܂ł݂����Ȑ��\�ň��|����邱�Ƃ������Ȃ�
�I�}�P�ɁAFruidmotion��FreeSync�APS4�Ƃ̗ގ����Ƃ����Ǝ��̋@�\�������Ă�
390x�̐��\��FreeSync�̑g�����́A���\����������GM200�Ƃ̋����ɗL���Ȃ̂͊m�����낤
������GM200�Ŕ�Ή���64bit�ɑΉ����Ă���AHPC����ł��������͂Ȑ��i������
���܂Ŋ�Ȃ�500mm2������r�b�O�_�C�J�����ė��Ȃ������̂ɁA�����ɗ��ăr�b�O�_�C+HBM�̃n�C�G���h�\���������Ă���
���܂ł́A�ŏ�ʂł�350mm2�Ƃ��ŁA�Q�t�H��550mm2�N���X�Ɛ���ė����������
�n�C�G���h�ł������̃_�C�T�C�Y�ɂȂ�Ȃ�A���܂ł݂����Ȑ��\�ň��|����邱�Ƃ������Ȃ�
�I�}�P�ɁAFruidmotion��FreeSync�APS4�Ƃ̗ގ����Ƃ����Ǝ��̋@�\�������Ă�
390x�̐��\��FreeSync�̑g�����́A���\����������GM200�Ƃ̋����ɗL���Ȃ̂͊m�����낤
������GM200�Ŕ�Ή���64bit�ɑΉ����Ă���AHPC����ł��������͂Ȑ��i������
���łɌ����ƁAGPU�Ńr�b�O�_�C���ւ����Ƃ������Ƃ́AAPU��CPU�ł����ւ����\���������Ƃ�������
Intel��Xeon��500mm2�̃r�b�O�R�A������A�R�Ƃ��ď���Zen�R�A�̃r�b�O�R�A�̉\�������邩��
���̂Ƃ���}�C�N���T�[�o�[�����炵������A��������100�`200mm2�����m��ǂ�
Zen�̃r�b�O�_�C������Ƃ�����Phi�ɋ߂����̂ɂȂ邾�낤���A�X���[���R�A100�Ƃ�
AMD������ǂ��Ȃ邩�́A���N��16/14nm���炾��
SkyBridge�A���f4xx�ADX12/OpenCL2.0�\�t�g�Ƃ��̏o�����悾�낤���A
�ʂ�����Zen APU������ł��邩�APS4�Ɣ�1�̕��y�͂ǂ��Ȃ̂��ADX12/Mantle��iGPU+dGPU���o����̂��A
����������HSA�Ή���Java9�͂ǂ��Ȃ��Ă�AFX�Ƃ���300�`500mm2��APU+HBM�Ƃ��o��̂�
�m���V�Q�[���@��APU��������b���������AFreeSync�f�B�X�v���C��������
�܂��A�������ŗ��N��Carrizo��28nm�Ƃ͌������ꂻ���ȋC�͂���
�����AL3�L���b�V���ς�ł�Kaveri��5���������炢�炵����
�X�J�C���[�N�̓n�X�E�F���Ƒ債�ĕς���炵�������\�őR���o��������
Intel��Xeon��500mm2�̃r�b�O�R�A������A�R�Ƃ��ď���Zen�R�A�̃r�b�O�R�A�̉\�������邩��
���̂Ƃ���}�C�N���T�[�o�[�����炵������A��������100�`200mm2�����m��ǂ�
Zen�̃r�b�O�_�C������Ƃ�����Phi�ɋ߂����̂ɂȂ邾�낤���A�X���[���R�A100�Ƃ�
AMD������ǂ��Ȃ邩�́A���N��16/14nm���炾��
SkyBridge�A���f4xx�ADX12/OpenCL2.0�\�t�g�Ƃ��̏o�����悾�낤���A
�ʂ�����Zen APU������ł��邩�APS4�Ɣ�1�̕��y�͂ǂ��Ȃ̂��ADX12/Mantle��iGPU+dGPU���o����̂��A
����������HSA�Ή���Java9�͂ǂ��Ȃ��Ă�AFX�Ƃ���300�`500mm2��APU+HBM�Ƃ��o��̂�
�m���V�Q�[���@��APU��������b���������AFreeSync�f�B�X�v���C��������
�܂��A�������ŗ��N��Carrizo��28nm�Ƃ͌������ꂻ���ȋC�͂���
�����AL3�L���b�V���ς�ł�Kaveri��5���������炢�炵����
�X�J�C���[�N�̓n�X�E�F���Ƒ債�ĕς���炵�������\�őR���o��������
2014
Kaveri�@��New�I
Beema�@��New�I
Mullins�@��New�I
�Ԏ�4���h��
2015
Kaveri Refresh�iGodavari�j �f�X�N�g�b�v
Carrizo �m�[�g�@��New�I
Carrizo-L�iBeema���l�[���j
Mullins
���N�͂ǂ��ߎS�Ȃ��ƂɂȂ��Ă��܂��H
Kaveri�@��New�I
Beema�@��New�I
Mullins�@��New�I
�Ԏ�4���h��
2015
Kaveri Refresh�iGodavari�j �f�X�N�g�b�v
Carrizo �m�[�g�@��New�I
Carrizo-L�iBeema���l�[���j
Mullins
���N�͂ǂ��ߎS�Ȃ��ƂɂȂ��Ă��܂��H
�S�Ċ��Ғʂ�ɍs�����͂킩��Ȃ����AAMD�����앪��̊������ɍv�����Ă����Ȃ�劽�}
���N��NVIDIA�X�L�����_���݂����Ȃ̂͂���
���N��NVIDIA�X�L�����_���݂����Ȃ̂͂���
amd�͌������
�h�����r���[����o�J�������B
����f�X�N�g�b�v�̃n�C�G���h�ƃm�[�g�p�\�R���̈�ʓI��HDD�i�Ɣ�r���Ă����肩�x���Ƃ��A�͂�����݂�Ƃǂ��ł������@�\��1���Ȃ��Ɖ��X��������Ő���1�Ƃ��B
�������]���������Ȃ�����A�悭�킩���ĂȂ��z��������ǂ����i�Ȃ̂Ɉ����̂��Ɗ��Ⴂ���Čh������B
�����������炻��_���Ă킴�ƈӖ��킩���h�����r���[�����Ă�̂����Ƌ^�������Ȃ�B
����f�X�N�g�b�v�̃n�C�G���h�ƃm�[�g�p�\�R���̈�ʓI��HDD�i�Ɣ�r���Ă����肩�x���Ƃ��A�͂�����݂�Ƃǂ��ł������@�\��1���Ȃ��Ɖ��X��������Ő���1�Ƃ��B
�������]���������Ȃ�����A�悭�킩���ĂȂ��z��������ǂ����i�Ȃ̂Ɉ����̂��Ɗ��Ⴂ���Čh������B
�����������炻��_���Ă킴�ƈӖ��킩���h�����r���[�����Ă�̂����Ƌ^�������Ȃ�B
http://wccftech.com/amds-fiji-gpu-chip-upcoming-radeon-300-series-lineup-rest-cards-feature-current-gcn-cores/
���l�[���Ղ�N���[�H
���l�[���Ղ�N���[�H
���{�l�Ȃ�C���e���Q�t�H���
�V���ɏo��GPU��2��ނ��炢�����Ȃ����A���l�[���I�����[�̌^�Ԃ��o��\�����Ȃ��͂Ȃ�
�����炭OEM�������낤����
��Ƃ���HD9000�V���[�Y
�����炭OEM�������낤����
��Ƃ���HD9000�V���[�Y
���l�[���̍ŏ�����7000��9100�����肾��������?
�����ԍ�������ȏ����������
�����ԍ�������ȏ����������
7000��7200�����ナ�l�[��Radeon
���{�l�̓C���e���Q�t�H���
https://www.linkedin.com/pub/srinivas-choudary/6/417/397?trk=pub-pbmap
>Involved in 3 very successful projects: Kabini (TSMC28HP), Bhavani (GF28A) and Nolan
(GF20LPM).
Nolan��GF��20nmLPM�g���炵��
>Involved in 3 very successful projects: Kabini (TSMC28HP), Bhavani (GF28A) and Nolan
(GF20LPM).
Nolan��GF��20nmLPM�g���炵��
401 �FSocket774�F2015/02/19(��) 17:16:08.23 ID:oJpngAkN
�ʂɃ��l�[���ł���������Ȃ�
���͒l�i�Ȃ�̐��\���o�邩�ǂ�����
���͒l�i�Ȃ�̐��\���o�邩�ǂ�����
�ă��l�[�����Ƃ��l������A���l�[��1��̕��Ȃ�ăJ���C�C������
�Q�t�H��8800GTS����9800�AGTS250�ƕς���������A������āB
���l�[��1���Ȃ�A�������Ďv���o���Ȃ��قǂ��邯�ǁB2��̂��̂͏��Ȃ���ȁB
�Q�t�H��8800GTS����9800�AGTS250�ƕς���������A������āB
���l�[��1���Ȃ�A�������Ďv���o���Ȃ��قǂ��邯�ǁB2��̂��̂͏��Ȃ���ȁB
�ʂɃ��l�[���ł���������Ȃ�
���͎g�p�ǂ���̐��\���o�邩�ǂ�����
���͎g�p�ǂ���̐��\���o�邩�ǂ�����
�Ԉ����
�ʂɃ��l�[���ł���������Ȃ�
���͎d�l�ǂ���̐��\���o�邩�ǂ�����
�ʂɃ��l�[���ł���������Ȃ�
���͎d�l�ǂ���̐��\���o�邩�ǂ�����
>>395
���l�[���Ƃ������A�i�K�I�ȃ��C���i�b�v�̋������낤
2012�N��HD7000�V���[�Y(GCN1.0)���o�āA
2013�N�Ƀn�C�G���h��290x(GCN1.1)�lj��A
2014�N�Ƀ~�h����285(GCN1.2)�lj��A
2015�N�ɍŏ��390x(GCN1.3)�lj��A
28nm�������v���Z�X�ɂȂ��Ă邩��A�������⋭���Ă邾��
��V����̂�16nm�ɂȂ��Ă��炾��
���l�[���Ƃ������A�i�K�I�ȃ��C���i�b�v�̋������낤
2012�N��HD7000�V���[�Y(GCN1.0)���o�āA
2013�N�Ƀn�C�G���h��290x(GCN1.1)�lj��A
2014�N�Ƀ~�h����285(GCN1.2)�lj��A
2015�N�ɍŏ��390x(GCN1.3)�lj��A
28nm�������v���Z�X�ɂȂ��Ă邩��A�������⋭���Ă邾��
��V����̂�16nm�ɂȂ��Ă��炾��
AMD�͂��܂�Nv�����|���Ă��邩�班�����⋭�ŏ\���������
Nv���ӂ����Ȃ��Ƃ����Ȃ���
Nv���ӂ����Ȃ��Ƃ����Ȃ���
���{�Q�t�H84%�̎�����
����A���`�����t�@���{�[�C���_�a����
���{�l�Ȃ�C���e���Q�t�H������˂�
����A���`�����t�@���{�[�C���_�a����
���{�l�Ȃ�C���e���Q�t�H������˂�
���Hnv��amd�����|���ĂˁH
amd���āAlinpack�v�Z���Í��ʉ݂̌v�Z�A�g���b�v�����ł�nv���ゾ���ǁA
GPU�Ƃ��Ďg�����Ƃ��ɂ�nvidia��肩�Ȃ���
amd���āAlinpack�v�Z���Í��ʉ݂̌v�Z�A�g���b�v�����ł�nv���ゾ���ǁA
GPU�Ƃ��Ďg�����Ƃ��ɂ�nvidia��肩�Ȃ���
�E���g���n�C�G���h��HBM���ʂŃt���b�O�V�b�v�͎�ꂻ��������
���~�h���n�C�`�~�h�����[�����s�̃��l�[��������Maxwell��GM204/GM206/GM107����ɏ��ĂȂ��C������
�Ƃ�����Tonga���X�ɍ����6Pin�����œ�������悤�ɂ���R7 365�݂����ȃR�A���o����
���~�h���n�C�`�~�h�����[�����s�̃��l�[��������Maxwell��GM204/GM206/GM107����ɏ��ĂȂ��C������
�Ƃ�����Tonga���X�ɍ����6Pin�����œ�������悤�ɂ���R7 365�݂����ȃR�A���o����
���{�l�Ȃ�C���e���Q�t�H���
413 �FSocket774�F2015/02/20(��) 05:26:54.94 ID:lON4Ud/B
>>410
http://www.phoronix.com/scan.php?page=article&item=nvidia_gtx980_opencl&num=2
�z���f�I�������Ă�͓̂d�C�Ɖ��x�̍������炢���悗
http://www.phoronix.com/scan.php?page=article&item=nvidia_gtx980_opencl&num=2
�z���f�I�������Ă�͓̂d�C�Ɖ��x�̍������炢���悗
���{�Q�t�H84%�̎���
>>410
NVIDIA�����������̂�Fermi�܂�
���b�p�Ƃ������o����Kepler���炨�������Ȃ�n�߂āA�����ᗧ�h�ȃx���`�}�[�N���\�r�f�B�A
http://www.pcper.com/files/review/2014-09-18/G1-Bioshock_2560x1440_PLOT.png
NVIDIA�����������̂�Fermi�܂�
���b�p�Ƃ������o����Kepler���炨�������Ȃ�n�߂āA�����ᗧ�h�ȃx���`�}�[�N���\�r�f�B�A
http://www.pcper.com/files/review/2014-09-18/G1-Bioshock_2560x1440_PLOT.png
{kind=link}
���{�l�Ȃ�C���e���Q�t�H���
http://www.pcper.com/files/review/2014-09-18/power.png
http://www.pcper.com/files/review/2014-09-18/G3-power.png
GTX 980�@Load291W�@SLI392W
R9 290X Load422W CFX668W
GTX 980 SLI���d�͐H���Ă�R9 290X��炽
{kind=link}
http://www.pcper.com/files/review/2014-09-18/G3-power.png
{kind=link}
GTX 980�@Load291W�@SLI392W
R9 290X Load422W CFX668W
GTX 980 SLI���d�͐H���Ă�R9 290X��炽
GTX980��101W�Ȃ킯�Ȃ�����
�펯�I�ɍl����
�펯�I�ɍl����
���{�l�Ȃ�C���e���Q�t�H���
�A���z�ꁄ���܁AAPU�A�}���g��GPU�A�Q�[����AMD�͂������D���B
�A���z�ꁄ���̍D���͍��㐔�N�͌p�����邾�낤�B
���ϑz
������
AMD�A�S�]�ƈ���7�����ꎞ���قցB
2014�N��4�l�����i10�`12�����j�̔��㍂�͂����13���������錩���݁B
http://eetimes.jp/ee/articles/1410/22/news055.html
>> �����13���������錩���݂��Ƃ���
>> 13���������錩����
>> 13������
�A���z�ꁄ���̍D���͍��㐔�N�͌p�����邾�낤�B
���ϑz
������
AMD�A�S�]�ƈ���7�����ꎞ���قցB
2014�N��4�l�����i10�`12�����j�̔��㍂�͂����13���������錩���݁B
http://eetimes.jp/ee/articles/1410/22/news055.html
>> �����13���������錩���݂��Ƃ���
>> 13���������錩����
>> 13������
Fermi�ŎS�s���Ă�nvidia��AMD5000�`6000�V���[�Y�̂悤�ɃQ�[���ɓ���������i
�t��AMD��GPU�ʼn��ł���낤�Ɨ]�v�Ȃ��Ƃ��Ē��
Fermi�̎��s�݂Ă��낤�Ɉ�ʌ�����5000�`6000�V���[�Y�̂悤�ɂ�������̂�
�命�����g��Ȃ��@�\�͂�����
�t��AMD��GPU�ʼn��ł���낤�Ɨ]�v�Ȃ��Ƃ��Ē��
Fermi�̎��s�݂Ă��낤�Ɉ�ʌ�����5000�`6000�V���[�Y�̂悤�ɂ�������̂�
�命�����g��Ȃ��@�\�͂�����
422 �FSocket774�F2015/02/20(��) 16:02:57.54 ID:6bZ3mJ4G
kepler,maxwell�͕ʂɃQ�[����������Ȃ����ǂ˂�
���{�l�Ȃ�C���e���Q�t�H�������
FireProW7100���Ă̂������Ă��ȁE�E�E
NVIDIA �����ƃ}�V�Ȏʐ^�Ȃ������̂���
http://akiba-pc.watch.impress.co.jp/img/ah/docs/682/313/nv1.jpg
AMD ����������a�m�X�{��
http://akiba-pc.watch.impress.co.jp/img/ah/docs/682/313/amd1.jpg
PC�p�[�c�e�Ђɕ����u���N�̈ӋC���݁v�Ɓu���N�̔���v
http://akiba-pc.watch.impress.co.jp/docs/sp/20150101_682313.html
http://akiba-pc.watch.impress.co.jp/img/ah/docs/682/313/nv1.jpg
{kind=link}
AMD ����������a�m�X�{��
http://akiba-pc.watch.impress.co.jp/img/ah/docs/682/313/amd1.jpg
{kind=link}
PC�p�[�c�e�Ђɕ����u���N�̈ӋC���݁v�Ɓu���N�̔���v
http://akiba-pc.watch.impress.co.jp/docs/sp/20150101_682313.html
{kind=link}
{kind=link}
{kind=link}
{kind=link}
���{�Q�t�H84%�̎���
���{�l�Ȃ�C���e���Q�t�H���
���{�l�Ȃ�C���e���Q�t�H���
>>420
AMD��APU(HSA)�A�}���g��GPU�A�Q�[���ł������D��(���A�����w���čD�����Č����Ă���̂��m��Ȃ���)����Ȃ��̂���
���㍂�̂��Ƃ��w���Ă���̂��H
AMD��APU(HSA)�A�}���g��GPU�A�Q�[���ł������D��(���A�����w���čD�����Č����Ă���̂��m��Ȃ���)����Ȃ��̂���
���㍂�̂��Ƃ��w���Ă���̂��H
433 �FSocket774�F2015/02/20(��) 23:58:35.24 ID:SunMopX/
AMD�̏ꍇ
��2015�N�̈ӋC���݂������ĉ�����
�@���o�C�������ɏȓd�͐���啝�ɍ��߂����o�C��APU�t�@�~���[�uCarrizo�v���n�߂Ƃ��鎟����APU��A
���s��GPU���\���X�ɍ��߂����i�Ȃǂ̓����ɒ��͂��Ă����܂��B
�d�͌�������O���t�B�b�N�X���\���啝�Ɍ��シ��AMD���i��OEM���[�J�[���̗p���₷�����邱�ƂŁA
���L�����\�Ɖ��i�|�C���g���J�o�[����ŏI���i���F�l�ɂ��͂��������Ǝv���܂��B
���ǎ҂Ɉꌾ�ǂ���
�@���N��Mantle��TrueAudio�A�є������_�����O�Z�p��TressFX Hair�Ƃ������ŐV�Z�p�ւ̃Q�[���̍œK�����܂��܂��i�݁AAMD���i�����p�����Q�[���̌�������Ƀp���[�A�b�v���܂��I
�l�X�ȍŐV�Q�[�����o���h������uNever Settle�v��A�l�X�ȃL�����y�[���A�H�t���ł̃C�x���g�ȂǁA�F�l�Ɋ��Œ�����������{���Ă��������Ǝv���܂��B
�ŐV����AMD��Facebook�y�[�W�Ő������ē����܂��̂ł��Ѓ`�F�b�N���Ă݂Ă��������B
�Q�t�H�~�[�̏ꍇ
��2015�N�̈ӋC���݂������ĉ�����
�@�V�F�A100%��ڎw���Ĉ��������撣��܂��i�j�B
���N���F�l�Ɉ������NVIDIA�ƂȂ�悤�ɐ��i���Ă܂���܂��̂ŁA�X�������肢�܂��B
���ǎ҂Ɉꌾ�ǂ���
�@2015�N���F�l�̂����҂ɂ������ł���GeForce���i�����ĐV���ȋZ�p�����͂��ł���悤�ɓw�͂��Ă��������ł��B���N�����[�U�[�̊F�l�Ƃ̐G�ꍇ�����厖�ɂ��Ă��������Ǝv���܂��B
�\�[�X
http://akiba-pc.watch.impress.co.jp/docs/sp/20150101_682313.html
��2015�N�̈ӋC���݂������ĉ�����
�@���o�C�������ɏȓd�͐���啝�ɍ��߂����o�C��APU�t�@�~���[�uCarrizo�v���n�߂Ƃ��鎟����APU��A
���s��GPU���\���X�ɍ��߂����i�Ȃǂ̓����ɒ��͂��Ă����܂��B
�d�͌�������O���t�B�b�N�X���\���啝�Ɍ��シ��AMD���i��OEM���[�J�[���̗p���₷�����邱�ƂŁA
���L�����\�Ɖ��i�|�C���g���J�o�[����ŏI���i���F�l�ɂ��͂��������Ǝv���܂��B
���ǎ҂Ɉꌾ�ǂ���
�@���N��Mantle��TrueAudio�A�є������_�����O�Z�p��TressFX Hair�Ƃ������ŐV�Z�p�ւ̃Q�[���̍œK�����܂��܂��i�݁AAMD���i�����p�����Q�[���̌�������Ƀp���[�A�b�v���܂��I
�l�X�ȍŐV�Q�[�����o���h������uNever Settle�v��A�l�X�ȃL�����y�[���A�H�t���ł̃C�x���g�ȂǁA�F�l�Ɋ��Œ�����������{���Ă��������Ǝv���܂��B
�ŐV����AMD��Facebook�y�[�W�Ő������ē����܂��̂ł��Ѓ`�F�b�N���Ă݂Ă��������B
�Q�t�H�~�[�̏ꍇ
��2015�N�̈ӋC���݂������ĉ�����
�@�V�F�A100%��ڎw���Ĉ��������撣��܂��i�j�B
���N���F�l�Ɉ������NVIDIA�ƂȂ�悤�ɐ��i���Ă܂���܂��̂ŁA�X�������肢�܂��B
���ǎ҂Ɉꌾ�ǂ���
�@2015�N���F�l�̂����҂ɂ������ł���GeForce���i�����ĐV���ȋZ�p�����͂��ł���悤�ɓw�͂��Ă��������ł��B���N�����[�U�[�̊F�l�Ƃ̐G�ꍇ�����厖�ɂ��Ă��������Ǝv���܂��B
�\�[�X
http://akiba-pc.watch.impress.co.jp/docs/sp/20150101_682313.html
>>426
�f���炵���A�Q�t�H�L�`�̐��_���`�ɂȂ����悤��
�f���炵���A�Q�t�H�L�`�̐��_���`�ɂȂ����悤��
>>433
AMD:�Z�p
Nv:�V�F�A
AMD�͎�ł���Ă��邩��A�Z�p�A�s�[���ɕK���Ŕ���グ��V�F�A���ċC�ɂ��Ȃ������
����ᔄ��グ��V�F�A�������Nv�����ׂ��ł�����
AMD:�Z�p
Nv:�V�F�A
AMD�͎�ł���Ă��邩��A�Z�p�A�s�[���ɕK���Ŕ���グ��V�F�A���ċC�ɂ��Ȃ������
����ᔄ��グ��V�F�A�������Nv�����ׂ��ł�����
5350�ň��������ł�����directx���Ȃ��ƃQ�[�����Ăł��܂����ˁH
Windows update����Ύ����œ�������ł����H
AMD���߂ĂŁE�E�E
Windows update����Ύ����œ�������ł����H
AMD���߂ĂŁE�E�E
microsoft�ɕ���
HardwareTnL�͂ǂ��Ń_�E�����[�h�ł��܂����H
�ڂ����t�@�C�t�@���P�P����肽���ł�
�ڂ����t�@�C�t�@���P�P����肽���ł�
>>436
����AMD�W�Ȃ�
����AMD�W�Ȃ�
440 �FSocket774�F2015/02/21(�y) 05:41:17.72 ID:U/li4UnG
gameworks�ŋZ�p�A�s�[�����܂���nv
���N��X�I��gtc�Ƃ����������\�C�x���g���J��nv
mantle? hsa?�Ȃɂ���H���������́H��Ԃ�amd
���N��X�I��gtc�Ƃ����������\�C�x���g���J��nv
mantle? hsa?�Ȃɂ���H���������́H��Ԃ�amd
AMD�̓Q�[���̃\�[�X�R�[�h�����Ȃ��ƃh���C�o�̍œK�����ł��Ȃ������H
�Z�p�́i�j
�Z�p�́i�j
�h���������ɐ��܂�Ǝ��n������l�ς������������t�]���܂�
443 �FSocket774�F2015/02/21(�y) 07:57:53.00 ID:W7/OU8fI
intel��14nm���ォ������CPU���\�̂Ăē���GPU�̐��\���グ�Ă����ˁB
AMD��32nm�v���Z�X���炻�������Ă���intel�͎���x��B
AMD��32nm�v���Z�X���炻�������Ă���intel�͎���x��B
444 �FSocket774�F2015/02/21(�y) 08:21:37.51 ID:U/li4UnG
cpu���\���ĂĂˁ[���ǂ�
skl�Ŗ��߂̎��s���C�e���V�܂��k�߂Ă��Ă邵
skl�Ŗ��߂̎��s���C�e���V�܂��k�߂Ă��Ă邵
445 �FSocket774�F2015/02/21(�y) 08:45:14.73 ID:cMOR0EAh
>>442
�����A���n��t�]�Z�p��AMD�̋Z�p����I
2000�N �f���A���R�APOWER4
��
2005�N�̓f���A���R�A���N�I���E���f���A���R�AAthlon64 X2�I
2003�N �N�A�b�h�R�APOWER5�A1�R�A2�X���b�hSMT
��
2007�N�A���ɃN�A�b�h�R�ACPU���o��IPhenom X4�I
2010�N2�� TurboCore���[�h�������POWER7�A1�R�A������4�X���b�hSMT
��
���N Turbo CORE��������Phenom II X6
2007�N �I�[�o�[5GHz POWER6
��
2013�N ���E����5GHz�AFX-9590�I(��i4.7GHz)
2014�N 12�R�A96�X���b�hSMT�APOWER8
��
2016�N(AMD����) ���E���ISMT����CPU�I�Ȃ�ƁI1�R�A������2�X���b�h�������Ă��܂��I���ꂩ���SMT�̎���IIntel�����ǂ��Ă��邩�ȁH
�����A���n��t�]�Z�p��AMD�̋Z�p����I
2000�N �f���A���R�APOWER4
��
2005�N�̓f���A���R�A���N�I���E���f���A���R�AAthlon64 X2�I
2003�N �N�A�b�h�R�APOWER5�A1�R�A2�X���b�hSMT
��
2007�N�A���ɃN�A�b�h�R�ACPU���o��IPhenom X4�I
2010�N2�� TurboCore���[�h�������POWER7�A1�R�A������4�X���b�hSMT
��
���N Turbo CORE��������Phenom II X6
2007�N �I�[�o�[5GHz POWER6
��
2013�N ���E����5GHz�AFX-9590�I(��i4.7GHz)
2014�N 12�R�A96�X���b�hSMT�APOWER8
��
2016�N(AMD����) ���E���ISMT����CPU�I�Ȃ�ƁI1�R�A������2�X���b�h�������Ă��܂��I���ꂩ���SMT�̎���IIntel�����ǂ��Ă��邩�ȁH
>>440
gtc���ĂȂƎv���ANv�M�ҏW��B�ł��������ȁA����Ȃ̂���{�ŊJ�������
����ȂƂ��낪�Ԏ������ʂ̉�ЂƂ̈Ⴂ���낤
AMD�͂���Ȃ̓��{�ŊJ���̖������낤�ȁB��ƁA�Z�p�ҥ�����҂̐M�҂͓��{�ɂقƂ�ǂ��Ȃ����낤����ȁB
gtc���ĂȂƎv���ANv�M�ҏW��B�ł��������ȁA����Ȃ̂���{�ŊJ�������
����ȂƂ��낪�Ԏ������ʂ̉�ЂƂ̈Ⴂ���낤
AMD�͂���Ȃ̓��{�ŊJ���̖������낤�ȁB��ƁA�Z�p�ҥ�����҂̐M�҂͓��{�ɂقƂ�ǂ��Ȃ����낤����ȁB
>>440-441
�Z�p�A�s�[���ƃh���C�o�œK�����܂���NV
https://www.youtube.com/watch?v=NYfYekrAPAE
�@��
���̌��ʂ����ꂗ
http://www.4gamer.net/games/251/G025157/20141127026/
�Z�p�A�s�[���ƃh���C�o�œK�����܂���NV
https://www.youtube.com/watch?v=NYfYekrAPAE
�@��
���̌��ʂ����ꂗ
http://www.4gamer.net/games/251/G025157/20141127026/
Llano�o��̋łɂ�
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
�� 2014�N �����̔��ド���L���O
http://eetimes.jp/ee/articles/1412/25/news147.html
��AMD�A2014�N�x��4���h���̐Ԏ�
http://pc.watch.impress.co.jp/docs/news/20150121_684660.html
AMD�̏��ʂ������}�~���ЂƂ蕉���_(^o^)�^
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
�� 2014�N �����̔��ド���L���O
http://eetimes.jp/ee/articles/1412/25/news147.html
��AMD�A2014�N�x��4���h���̐Ԏ�
http://pc.watch.impress.co.jp/docs/news/20150121_684660.html
AMD�̏��ʂ������}�~���ЂƂ蕉���_(^o^)�^
449 �FSocket774�F2015/02/21(�y) 11:20:36.61 ID:W7/OU8fI
�уE�}�I
�Ƃ������ĐH�߂���NVIDIA
�܂�ʼn^���s���łԂ��Ԃ��̎��b�̉�B
����NVIDIA���ے����Ă邩�̂悤���B
���ł����P�l�Ń}�C�N�����Ă�́H
�̂ł��������Ă�̂���H
�����͎���O�H
http://akiba-pc.watch.impress.co.jp/img/ah/docs/682/313/nv1.jpg
�Ƃ������ĐH�߂���NVIDIA
�܂�ʼn^���s���łԂ��Ԃ��̎��b�̉�B
����NVIDIA���ے����Ă邩�̂悤���B
���ł����P�l�Ń}�C�N�����Ă�́H
�̂ł��������Ă�̂���H
�����͎���O�H
http://akiba-pc.watch.impress.co.jp/img/ah/docs/682/313/nv1.jpg
http://www.geocities.jp/andosprocinfo/wadai15/20150221.htm
�Q�DAMD��HPC������APU�̊J���ɂ��Ĕ��\
�@�@2015�N2��20���ɑ��ŊJ�Â��ꂽPC Cluster Consortium�̃��[�N�V���b�v
�ɂ����āCAMD�̗ю����u���̒��ŁCAMD���n�C�G���h��GPU���W�ς���HPC
������APU�̊J������Ɣ��\���܂����B���݂�APU�́C�f�X�N�g�b�v�����̍ō�
���\�̂��̂ł�����d�͂�100W���x�ŁC200W����n�C�G���h��GPU�͏W��
�ł��܂���B
����ɑ��āC�n�C�G���h��GPU���W�ς����C200�`300W�̏���d�͂�HPC����
��APU���J������Ƃ̂��Ƃł��B
�@���݂�Hawaii GPU�̎������GPU��2016�N�ɏo���C������W�ς���n�C�G���h
APU��2017�N�ɏo���v��ł��B����APU�ɂ�FirePro���̃n�C�G���hGPU�Ǝ�����
Opteron�̃T�[�o�p�����\CPU���W�ς��܂��B
�@���������C2018�N�ɂ͂��̎��̐����GPU�C2019�N�ɂ͂�����W�ς���n�C�G��
�hAPU���J������v��ŁC2019�N��APU�̓}���`TFlops�̐��\�����Ƃ̂��Ƃł��B
�R�DAMD��32�R�A�C64�X���b�h��ARM��x86�v���Z�T�i������v��
�@�@2015�N2��20���ɑ��ŊJ�Â��ꂽPC Cluster Consortium�̃��[�N�V���b�v��
�����āCAMD�̗ю����C�u���̒��ŁCAMD��2016�N�ɂ�Cortex-A57�̉��{����
���\������ARM v8�A�[�L�e�N�`����K12�R�A��Ǝ��J�����C�T�[�o�p�v���Z�T�Ƃ���
���i������Ƃ����v��\���܂����B
�@�@����K12�Ɠ������x86�v���Z�T�Ƃ̓s���݊��ƂȂ�Ƃ̂��Ƃł��B�܂��C������
�v���Z�T��32�R�A���W�ς��C����܂�AMD�ł͍̗p���Ă��Ȃ������}���`�X���b�h��
�T�|�[�g����Ƃ̂��ƂŁC64�X���b�h�������s����v���Z�T�ƂȂ�Ƃ̂��Ƃł��B
�Q�DAMD��HPC������APU�̊J���ɂ��Ĕ��\
�@�@2015�N2��20���ɑ��ŊJ�Â��ꂽPC Cluster Consortium�̃��[�N�V���b�v
�ɂ����āCAMD�̗ю����u���̒��ŁCAMD���n�C�G���h��GPU���W�ς���HPC
������APU�̊J������Ɣ��\���܂����B���݂�APU�́C�f�X�N�g�b�v�����̍ō�
���\�̂��̂ł�����d�͂�100W���x�ŁC200W����n�C�G���h��GPU�͏W��
�ł��܂���B
����ɑ��āC�n�C�G���h��GPU���W�ς����C200�`300W�̏���d�͂�HPC����
��APU���J������Ƃ̂��Ƃł��B
�@���݂�Hawaii GPU�̎������GPU��2016�N�ɏo���C������W�ς���n�C�G���h
APU��2017�N�ɏo���v��ł��B����APU�ɂ�FirePro���̃n�C�G���hGPU�Ǝ�����
Opteron�̃T�[�o�p�����\CPU���W�ς��܂��B
�@���������C2018�N�ɂ͂��̎��̐����GPU�C2019�N�ɂ͂�����W�ς���n�C�G��
�hAPU���J������v��ŁC2019�N��APU�̓}���`TFlops�̐��\�����Ƃ̂��Ƃł��B
�R�DAMD��32�R�A�C64�X���b�h��ARM��x86�v���Z�T�i������v��
�@�@2015�N2��20���ɑ��ŊJ�Â��ꂽPC Cluster Consortium�̃��[�N�V���b�v��
�����āCAMD�̗ю����C�u���̒��ŁCAMD��2016�N�ɂ�Cortex-A57�̉��{����
���\������ARM v8�A�[�L�e�N�`����K12�R�A��Ǝ��J�����C�T�[�o�p�v���Z�T�Ƃ���
���i������Ƃ����v��\���܂����B
�@�@����K12�Ɠ������x86�v���Z�T�Ƃ̓s���݊��ƂȂ�Ƃ̂��Ƃł��B�܂��C������
�v���Z�T��32�R�A���W�ς��C����܂�AMD�ł͍̗p���Ă��Ȃ������}���`�X���b�h��
�T�|�[�g����Ƃ̂��ƂŁC64�X���b�h�������s����v���Z�T�ƂȂ�Ƃ̂��Ƃł��B
GPU��HPC�����ɔ������̒��߂���
452 �FSocket774�F2015/02/21(�y) 13:31:09.14 ID:0C0q1sir
�ł���gpu����apu������Ă����Ă���
�����SoC��20mm�X�L�b�v����Ƃ����b���o�Ă��
GPU�Ŏg�p����邩�܂��܂��������Ȃ��Ă����ȁB
GPU�Ŏg�p����邩�܂��܂��������Ȃ��Ă����ȁB
���������ǂ�����ł���
DDR4�ł��܂��x�����AHBM�H�ʼn��Ƃ�����C�Ȃ̂���
DDR4�ł��܂��x�����AHBM�H�ʼn��Ƃ�����C�Ȃ̂���
2000�N �f���A���R�APOWER4
��
2005�N�̓f���A���R�A���N�I���E���f���A���R�AAthlon64 X2�I
2003�N �N�A�b�h�R�APOWER5�A1�R�A2�X���b�hSMT
��
2007�N�A���ɃN�A�b�h�R�ACPU���o��IPhenom X4�I
2010�N2�� TurboCore���[�h�������POWER7�A1�R�A������4�X���b�hSMT
��
���N Turbo CORE��������Phenom II X6
2007�N �I�[�o�[5GHz POWER6
��
2013�N ���E����5GHz�AFX-9590�I(��i4.7GHz)
2014�N 12�R�A96�X���b�hSMT�APOWER8
��
2016�N(AMD����) ���E���ISMT����CPU�I�Ȃ�ƁI1�R�A������2�X���b�h�������Ă��܂��I���ꂩ���SMT�̎���IIntel�����ǂ��Ă��邩�ȁH
��
2005�N�̓f���A���R�A���N�I���E���f���A���R�AAthlon64 X2�I
2003�N �N�A�b�h�R�APOWER5�A1�R�A2�X���b�hSMT
��
2007�N�A���ɃN�A�b�h�R�ACPU���o��IPhenom X4�I
2010�N2�� TurboCore���[�h�������POWER7�A1�R�A������4�X���b�hSMT
��
���N Turbo CORE��������Phenom II X6
2007�N �I�[�o�[5GHz POWER6
��
2013�N ���E����5GHz�AFX-9590�I(��i4.7GHz)
2014�N 12�R�A96�X���b�hSMT�APOWER8
��
2016�N(AMD����) ���E���ISMT����CPU�I�Ȃ�ƁI1�R�A������2�X���b�h�������Ă��܂��I���ꂩ���SMT�̎���IIntel�����ǂ��Ă��邩�ȁH
AMD Carrizo APU ISSCC 2015 Presentation Leaked ? 5% IPC Gain With x86 Excavator, Die Consists of 3.1 Billion Transistors
http://wccftech.com/amd-carrizo-apu-isscc-2015-presentation-leaked-5-ipc-gain-x86-steamroller-die-consists-31-billion-transistors/
http://wccftech.com/amd-carrizo-apu-isscc-2015-presentation-leaked-5-ipc-gain-x86-steamroller-die-consists-31-billion-transistors/
>>456
�������E�E�ނ����Ꮼ�����Ⴍ�Ȃ��Ă�
�������E�E�ނ����Ꮼ�����Ⴍ�Ȃ��Ă�
HPC�ƊE������Ă�̂́A
��������AMD���g���ĊJ�����Ă��A���[�J�[�̓s���őł����Ă��������̓��������ʂɂȂ邱�ƂƁA
�T�[�h�p�[�e�B��HPC�\�t�g�E�F�A�E���C�u�����̕s��
��������AMD���g���ĊJ�����Ă��A���[�J�[�̓s���őł����Ă��������̓��������ʂɂȂ邱�ƂƁA
�T�[�h�p�[�e�B��HPC�\�t�g�E�F�A�E���C�u�����̕s��
����͐���ł��Ă�B�����ɂ킩��
2000�N �f���A���R�APOWER4
��
2005�N�̓f���A���R�A���N�I���E���f���A���R�AAthlon64 X2�I
���N�A�j�R�C�`�����f���A���R�ACPU PentiumD����
��
�x��āA�悤�₭�{���̃f���A���R�ACPU CoreDuo�o��
PenD�̓j�R�C�`�Ƃ����_�����邱�ƂȂ���A�R�A�Ԃ̒ʐM�i�L���b�V�����@�Ȃǂ̂��߂ɃR�A�ԒʐM���K�v�j���`�b�v�Z�b�g�o�R�ŁA
CPU�p�b�P�[�W���ł̒��ڒʐM���ł��Ȃ�����
2007�N �I�[�o�[5GHz POWER6
��
Intel���A�͂�o����
2014�N 12�R�A96�X���b�hSMT�APOWER8
��
2016�N(AMD����) ���E���ISMT����CPU�I�Ȃ�ƁI1�R�A������2�X���b�h�������Ă��܂��I���ꂩ���SMT�̎���IIntel�����ǂ��Ă��邩�ȁH
POWER5�Ƃ��APen4��HTT�Ƃ��͈�����̂�?
��NetBurst�}�C�N���A�[�L�e�N�`����Xeon��Pentium 4��SMT���̗p�����ŏ��̏��p�v���Z�b�T�ŁA�ȍ~���܂��܂ȃ��f����
�����@�\�����ڂ���Ă���B�C���e���͂��̋@�\���u�n�C�p�[�X���b�f�B���O�E�e�N�m���W�[ (Hyper-Threading Technology)�v�ƌĂсA
�����̓��e�͊�{�I��2�X���b�h��SMT�G���W���ł���
�Ƃ���ŁA
��DEC Alpha EV8�͂���Ƀp���t����4�X���b�hSMT�G���W���𓋍ڂ���\��ł�����
�炵�����AAMD�̂͂��̕ӂ̋Z�p���˂�?
��
2005�N�̓f���A���R�A���N�I���E���f���A���R�AAthlon64 X2�I
���N�A�j�R�C�`�����f���A���R�ACPU PentiumD����
��
�x��āA�悤�₭�{���̃f���A���R�ACPU CoreDuo�o��
PenD�̓j�R�C�`�Ƃ����_�����邱�ƂȂ���A�R�A�Ԃ̒ʐM�i�L���b�V�����@�Ȃǂ̂��߂ɃR�A�ԒʐM���K�v�j���`�b�v�Z�b�g�o�R�ŁA
CPU�p�b�P�[�W���ł̒��ڒʐM���ł��Ȃ�����
2007�N �I�[�o�[5GHz POWER6
��
Intel���A�͂�o����
2014�N 12�R�A96�X���b�hSMT�APOWER8
��
2016�N(AMD����) ���E���ISMT����CPU�I�Ȃ�ƁI1�R�A������2�X���b�h�������Ă��܂��I���ꂩ���SMT�̎���IIntel�����ǂ��Ă��邩�ȁH
POWER5�Ƃ��APen4��HTT�Ƃ��͈�����̂�?
��NetBurst�}�C�N���A�[�L�e�N�`����Xeon��Pentium 4��SMT���̗p�����ŏ��̏��p�v���Z�b�T�ŁA�ȍ~���܂��܂ȃ��f����
�����@�\�����ڂ���Ă���B�C���e���͂��̋@�\���u�n�C�p�[�X���b�f�B���O�E�e�N�m���W�[ (Hyper-Threading Technology)�v�ƌĂсA
�����̓��e�͊�{�I��2�X���b�h��SMT�G���W���ł���
�Ƃ���ŁA
��DEC Alpha EV8�͂���Ƀp���t����4�X���b�hSMT�G���W���𓋍ڂ���\��ł�����
�炵�����AAMD�̂͂��̕ӂ̋Z�p���˂�?
Llano�o��̋łɂ�
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
�� 2014�N �����̔��ド���L���O
http://eetimes.jp/ee/articles/1412/25/news147.html
��AMD�A2014�N�x��4���h���̐Ԏ�
http://pc.watch.impress.co.jp/docs/news/20150121_684660.html
AMD�̏��ʂ������}�~���ЂƂ蕉���_(^o^)�^
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
�� 2014�N �����̔��ド���L���O
http://eetimes.jp/ee/articles/1412/25/news147.html
��AMD�A2014�N�x��4���h���̐Ԏ�
http://pc.watch.impress.co.jp/docs/news/20150121_684660.html
AMD�̏��ʂ������}�~���ЂƂ蕉���_(^o^)�^
462 �F,,�E�L�́M�E,,�j��-�������F2015/02/21(�y) 17:06:11.15 ID:qVwlS5W5
�˂����݂ǂ����FP/SIMD���j�b�g�̃T�C�Y���������ĂȂ����Ƃ�
Carrizo��AVX2���A�����݊�����邽�߁i128bit SIMD��2��܂킷�����j�̂���������ɂƂǂ܂�̂�
�z���ɓ�Ȃ��ƁB
Carrizo��AVX2���A�����݊�����邽�߁i128bit SIMD��2��܂킷�����j�̂���������ɂƂǂ܂�̂�
�z���ɓ�Ȃ��ƁB
�T�E�X���������ꂽ�������A���R�A�������\�傫�Ȗʐς��߂Ă���悤�Ɍ�����
�Z�����C�u�����������^���獂���x�^�ɂȂ����̂ŃN���b�N�̏���͍����������ԉ����邾�낤
��N���b�N�ȓd�͂ɓ�����������3GHz�I�[�o�[�̃f�X�N�g�b�v�p�͏o���Ȃ��킯��
�Z�����C�u�����������^���獂���x�^�ɂȂ����̂ŃN���b�N�̏���͍����������ԉ����邾�낤
��N���b�N�ȓd�͂ɓ�����������3GHz�I�[�o�[�̃f�X�N�g�b�v�p�͏o���Ȃ��킯��
�f�X�N�g�b�v�p�͗��N�o�����������H
������ƑO�Ƀf�X�N�g�b�v�p��kaveri refresh�ʼn��Ƃ�������Č������nj��ǃf�X�N�g�b�v�pcarrizo�͏o��̂�
>>462
�� �VCPU�R�A
���@����APU�ɂ�FirePro���̃n�C�G���hGPU�Ǝ�����Opteron�̃T�[�o�p�����\CPU���W�ς��܂��B
�悭�ǂ�����
�� �VCPU�R�A
���@����APU�ɂ�FirePro���̃n�C�G���hGPU�Ǝ�����Opteron�̃T�[�o�p�����\CPU���W�ς��܂��B
�悭�ǂ�����
�f�X�N������95W��SKU�͊m���ɏo�Ȃ����낤��
cTDP�ŗV�Ԃɂ͂����ɂȂ�Ǝv������
cTDP�ŗV�Ԃɂ͂����ɂȂ�Ǝv������
�ő�N���b�N���オ��Ȃ�����ˁE�E�B
IPC5%���㕪��������Ă��ɐ��B
IPC5%���㕪��������Ă��ɐ��B
469 �F,,�E�L�́M�E,,�j��-�������F2015/02/21(�y) 20:44:31.10 ID:qVwlS5W5
>>466
���O���悭�ǂ߁B���������̂�Carrizo�̘b�ł����ĐV�R�A�̘b�Ȃ�Ă��ĂȂ����B
���O���悭�ǂ߁B���������̂�Carrizo�̘b�ł����ĐV�R�A�̘b�Ȃ�Ă��ĂȂ����B
>>465
���N��Kaveri Refresh�ŗ���
���N�̓f�X�N�g�b�v�pCarrizo��ZenCPU
�ė��N��ZenAPU
>>466
Carrizo�̃_�C�ʐ^�̘b�肾���炻���炱���悭�ǂ�����
���N��Kaveri Refresh�ŗ���
���N�̓f�X�N�g�b�v�pCarrizo��ZenCPU
�ė��N��ZenAPU
>>466
Carrizo�̃_�C�ʐ^�̘b�肾���炻���炱���悭�ǂ�����
471 �F,,�E�L�́M�E,,�j��-�������F2015/02/21(�y) 21:09:47.15 ID:qVwlS5W5
�܂�Zen�̂ق����ő�32�R�A�Ƃ�����o�Ă��Ă邩��4IPC�ȏ�̑�^�R�A�ł���\���͂��Ȃ�Ⴂ���ǂ�
Density Server�������������ȏ�A�N���b�N�����萫�\��Atom�Ɠ�������������x�̐����Ȃ̂ł́H
Density Server�������������ȏ�A�N���b�N�����萫�\��Atom�Ɠ�������������x�̐����Ȃ̂ł́H
�m���ɁE�E����I��HPC���Ǝv������ł��B
���ꂩ���ARM���̒ᐫ�\�ŏ\���Ȃ�B
�R�A������Ȃɑ傫���Ȃ����Ď���8�R�AAPU�f�X�N�����ɗ���Ƃ����Ȃ��B
14nm�Ȃ�sandybridge�N���X�̃R�A�ł�32�R�A��400mm2���x�ɗ}�������
Zen�͐V�K�R�A�����Ęb������Bobcat�n��
���ǔŒ��x�̑㕨���łĂ���\���������Ȃ�
���ǔŒ��x�̑㕨���łĂ���\���������Ȃ�
477 �F,,�E�L�́M�E,,�j��-�������F2015/02/22(��) 00:32:14.83 ID:/mEdeDGD
�R�A���W�ς���قǃ������̋������ɘa���邽�߂ɑ�e�ʂ̃L���b�V�������邢�͍L�ш惁������
�K�v�ɂȂ�̂ł����ȒP�Ȃ��̂���Ȃ���
�_�C�T�C�Y�̖��Ȃ�Ƃ肠�����V���O���_�C�Ȃ̂�MCM�Ȃ̂����킩��Ȃ����������邱�Ƃ���Ȃ��B
��ԃN���e�B�J���Ȃ̂͏���d�͂��Ǝv����B
���Ƃ���Broadwell��2GHz��1�R�A������5W���x�Ɖ��肵�Ă��A32�R�A���ς߂�160W
����ȋK�͂�CPU�������x�T�[�o�ɐς߂�킯���Ȃ����낤�H
�K�v�ɂȂ�̂ł����ȒP�Ȃ��̂���Ȃ���
�_�C�T�C�Y�̖��Ȃ�Ƃ肠�����V���O���_�C�Ȃ̂�MCM�Ȃ̂����킩��Ȃ����������邱�Ƃ���Ȃ��B
��ԃN���e�B�J���Ȃ̂͏���d�͂��Ǝv����B
���Ƃ���Broadwell��2GHz��1�R�A������5W���x�Ɖ��肵�Ă��A32�R�A���ς߂�160W
����ȋK�͂�CPU�������x�T�[�o�ɐς߂�킯���Ȃ����낤�H
Zen��8�R�A�ł���
Bobcat �Ƃ����� TOUGH GUY
480 �FSocket774�F2015/02/22(��) 02:07:36.67 ID:IZwX/Pb/
�����̓X�^�b�N�h�������łȂ�Ƃ��Ȃ�Ƃ��āA
32�R�A�Ɩ������Ă���Ă��Ƃ͏���d�͘g���ꉞ�ڏ��͂��Ă�낤
skybridge�̓��j�[�R�A�I�ȕ������Ȃ�A�V���O���X���b�h���\�͋��߂Ȃ��낤��
arm��x64�ŃR�A�����������Ă��Ƃ́A�f�R�[�_�[�̌��͋��ʉ��Ƃ�������̂�����
32�R�A�Ɩ������Ă���Ă��Ƃ͏���d�͘g���ꉞ�ڏ��͂��Ă�낤
skybridge�̓��j�[�R�A�I�ȕ������Ȃ�A�V���O���X���b�h���\�͋��߂Ȃ��낤��
arm��x64�ŃR�A�����������Ă��Ƃ́A�f�R�[�_�[�̌��͋��ʉ��Ƃ�������̂�����
������X�[�p�[�R���s���[�^�[�́A
�`���I��CPU�E���������{�[�h�Ƀn���_�Œ��t����������O�������̂ŁA
HMC���������n���_���t���Ƃ��ł�������邾�낤���A
�`���I��CPU�����������\�P�b�g���������T�[�o�ɂ����āA
�͂��t���Ƃ��������̂��낤���H
�`���I��CPU�E���������{�[�h�Ƀn���_�Œ��t����������O�������̂ŁA
HMC���������n���_���t���Ƃ��ł�������邾�낤���A
�`���I��CPU�����������\�P�b�g���������T�[�o�ɂ����āA
�͂��t���Ƃ��������̂��낤���H
482 �F,,�E�L�́M�E,,�j��-�������F2015/02/22(��) 02:39:03.88 ID:/mEdeDGD
HMC�ɂ��Ă͏����搶�������[���c�C�[�g���Ă��
https://twitter.com/prof_hrk/status/319628318309769216
https://twitter.com/prof_hrk/status/319628318309769216
�l�I�ɂ́A�Ƃ肠�����Ȃ���HMC���g�����n�C�G���h����ŁA
HMC���Ȃ��̒Z���Ԃ���Ȃ��āA���Ȃ蒷���Ԃ�����C�������
HMC���Ȃ��̒Z���Ԃ���Ȃ��āA���Ȃ蒷���Ԃ�����C�������
HMC�Ȃg��Ȃ���BHBM�Ȃ�g����
>>450
��������Ȋ���
�E500mm2��HPC�����n�C�G���hAPU
����16�R�A32�X���b�h+4096sp�� + HBM 8GB + DDR4 64GB
HBM�������Ƒ����������e�ʂ�����Ȃ�����ADDR4�ŗe�ʉ҂�����
�������Ǘ�������������ǁA�܂����Ƃ����邾�낤
�E32�R�A64�X���b�h�̃n�C�G���hCPU
�����N���b�N��3Ghz��
AVX��2�܂ł�512bit�͖��ʂȂ̂Ŕ�Ή�
���ł�Fabric�Ή��Ń}���`�v���Z�b�T�ɍœK��
�����ċ��炭���̃��j�[�R�ACPU�Ƒ��Ȃ��n�C�G���hGPU�����݂��邾�낤
����8096sp+HBM 16GB�@�{���x7T�ʂ�
�����������琧��p��4�R�A���炢CPU�悹�Ă��邩��
CPU�AGPU�AAPU��Fabric�Ōq���̂��A����}�U�[����HT�݂����ȃR�q�[�����g�o�X�Ōq�����͕������
���܂�500mm2���̃n�C�G���h�`�b�v�s�݂ŃC���e���Q�t�H�Ƀn�C�G���h�ł���Ă�������A�R���ŋt�P�������Ȃ낤��
��������Ȋ���
�E500mm2��HPC�����n�C�G���hAPU
����16�R�A32�X���b�h+4096sp�� + HBM 8GB + DDR4 64GB
HBM�������Ƒ����������e�ʂ�����Ȃ�����ADDR4�ŗe�ʉ҂�����
�������Ǘ�������������ǁA�܂����Ƃ����邾�낤
�E32�R�A64�X���b�h�̃n�C�G���hCPU
�����N���b�N��3Ghz��
AVX��2�܂ł�512bit�͖��ʂȂ̂Ŕ�Ή�
���ł�Fabric�Ή��Ń}���`�v���Z�b�T�ɍœK��
�����ċ��炭���̃��j�[�R�ACPU�Ƒ��Ȃ��n�C�G���hGPU�����݂��邾�낤
����8096sp+HBM 16GB�@�{���x7T�ʂ�
�����������琧��p��4�R�A���炢CPU�悹�Ă��邩��
CPU�AGPU�AAPU��Fabric�Ōq���̂��A����}�U�[����HT�݂����ȃR�q�[�����g�o�X�Ōq�����͕������
���܂�500mm2���̃n�C�G���h�`�b�v�s�݂ŃC���e���Q�t�H�Ƀn�C�G���h�ł���Ă�������A�R���ŋt�P�������Ȃ낤��
�����n�C�G���h��HMC�̓ƒd��ł��傤�B
���͒l�i�I�E�\���I�Ȑ�������_�B
����HMC��2.5D�\�����[�V�����ƌ����̂͂ȂႤ�C���E�E
�iEMIB�ł̎����̂��Ƃ������Ă�̂��ȁH�j
���͒l�i�I�E�\���I�Ȑ�������_�B
����HMC��2.5D�\�����[�V�����ƌ����̂͂ȂႤ�C���E�E
�iEMIB�ł̎����̂��Ƃ������Ă�̂��ȁH�j
>>456
�n�C�p�t�H�[�}���X�v���Z�X���烂�o�C���p�̍����x�v���Z�X�ɂ����珬�����Ȃ������Ċ�������
����ō����N���b�N�̃n�C�p�t�H�[�}���X���̂��ł��Ȃ��āA�f�X�N�g�b�v�p��������Ċ����ɂȂ��č���̓p�X�ł��Ċ������B
>>458
���ƁA���\�ǂ��Ă����L����\�t�g���Y(HPC�̃��W���[��CUDA�H)�����p�ł��Ȃ����ĂȂ�ƁA�ڍs�����炩���
���\���炵�����ǁA�V����OpenCL�ł���Ă����
AMD�ł�CUDA�Ŏg����悤�ɂ��Ȃ��Ƃ���܂���҂ł��Ȃ���������
�n�C�p�t�H�[�}���X�v���Z�X���烂�o�C���p�̍����x�v���Z�X�ɂ����珬�����Ȃ������Ċ�������
����ō����N���b�N�̃n�C�p�t�H�[�}���X���̂��ł��Ȃ��āA�f�X�N�g�b�v�p��������Ċ����ɂȂ��č���̓p�X�ł��Ċ������B
>>458
���ƁA���\�ǂ��Ă����L����\�t�g���Y(HPC�̃��W���[��CUDA�H)�����p�ł��Ȃ����ĂȂ�ƁA�ڍs�����炩���
���\���炵�����ǁA�V����OpenCL�ł���Ă����
AMD�ł�CUDA�Ŏg����悤�ɂ��Ȃ��Ƃ���܂���҂ł��Ȃ���������
488 �F,,�E�L�́M�E,,�j��-�������F2015/02/22(��) 11:04:30.27 ID:/mEdeDGD
>>485
> AVX��2�܂ł�512bit�͖��ʂȂ̂Ŕ�Ή�
�܂������j�ɂȂ�悤�Ȕ�������ˁ[�悗����
���O�ACarrizo�̖��߃Z�b�g�Ή����o��܂�AVX2���v��Ȃ��Ƃ������Ă����낗������
�Ƃ肠����Win10��AVX-512�Ή��͊��Ɋm�肾��
128�r�b�g���Z���4��܂킵�ł����Ă��Ƃ肠�����Ή����Ƃ�������Ȃ��ł�����
Xeon Phi�ւ̔s�k���Ӗ�����Ƃ�����Ȃ��ƋC�ɂ��Ȃ��Ă�������
�ǂ݂̂�����FirePro�͕����Ă邶��Ȃ���
> AVX��2�܂ł�512bit�͖��ʂȂ̂Ŕ�Ή�
�܂������j�ɂȂ�悤�Ȕ�������ˁ[�悗����
���O�ACarrizo�̖��߃Z�b�g�Ή����o��܂�AVX2���v��Ȃ��Ƃ������Ă����낗������
�Ƃ肠����Win10��AVX-512�Ή��͊��Ɋm�肾��
128�r�b�g���Z���4��܂킵�ł����Ă��Ƃ肠�����Ή����Ƃ�������Ȃ��ł�����
Xeon Phi�ւ̔s�k���Ӗ�����Ƃ�����Ȃ��ƋC�ɂ��Ȃ��Ă�������
�ǂ݂̂�����FirePro�͕����Ă邶��Ȃ���
�Ƃ肠�����ł�AVX-512�Ή����Ă�����Phi�ȊO��Intel���{�i�Ή�����̂�17�N�ȍ~�̗\�肾����
�n�b�^���ł��Z�[���X�|�C���g�ɂ͂Ȃ�ȁB
�n�b�^���ł��Z�[���X�|�C���g�ɂ͂Ȃ�ȁB
490 �FSocket774�F2015/02/22(��) 11:23:56.47 ID:zAsl/1n6
sse6�ł��o�������̂�
FirePRO�����Ă�Ƃ�����HPC�ƊE�ő��݊����Ȃ��悤��
GPGPU�����̃A�s�[�����n�߂�������NVIDIA�Ƒ卷�Ȃ������̂�
��ATI���Č����Ă��́H
GPGPU�����̃A�s�[�����n�߂�������NVIDIA�Ƒ卷�Ȃ������̂�
��ATI���Č����Ă��́H
�������̔ɖ߂��ė������|��������FirePRO�HAMDGPU��HPC������TOP��������炾��
���Z�\�͂Ŗ�薳���̂Ƀ\�t�g�ʂł�CUDA�Ȃǂ̔ėp�����Ր��Ɍ�����
���̂��߂�HSA��������Ǒ��͖{�肾���܂��i��łȂ�
���Z�\�͂Ŗ�薳���̂Ƀ\�t�g�ʂł�CUDA�Ȃǂ̔ėp�����Ր��Ɍ�����
���̂��߂�HSA��������Ǒ��͖{�肾���܂��i��łȂ�
green500��1�ʂɂȂ�����̓x���`�̉�͂��s����
���n���gpu��cpu�ǂ����g������L�����͂�������
hdd����ς�łȂ��������
�ق�Ƃ��̃x���`�̂��߂����ɍ�����悤�Ȃ���
���n���gpu��cpu�ǂ����g������L�����͂�������
hdd����ς�łȂ��������
�ق�Ƃ��̃x���`�̂��߂����ɍ�����悤�Ȃ���
���V�X�e���Ńg�b�v�ɂȂ��Ƃ���قǃA�N�Z�����[�^�̌������ǂ��Ȃ��ƒB���ł��낤����
>>493
�x���`�p�V�X�e���Ȃ�đ�T����Ȃ���
���������A���菈���ɍœK������͕̂��ʂ���
2017�N�ȂA500mm2�T�C�Y�̃}���`�R�A+�n�C�G���hGPU��APU�o�����AHBM��8G��16G�Ƃ��悹�Ă��邩���
HSA��OpenCL2.0��CPU��GPGPU�̕��ו��z���ȒP�ɂł��邵�A�L�ш惁�����������|�C���^�ŋ��L������A
���ȏ�ɍœK�����ꂽ���̏o����TOP�Ƒ��Ԑ��ɓ�������
�x���`�p�V�X�e���Ȃ�đ�T����Ȃ���
���������A���菈���ɍœK������͕̂��ʂ���
2017�N�ȂA500mm2�T�C�Y�̃}���`�R�A+�n�C�G���hGPU��APU�o�����AHBM��8G��16G�Ƃ��悹�Ă��邩���
HSA��OpenCL2.0��CPU��GPGPU�̕��ו��z���ȒP�ɂł��邵�A�L�ш惁�����������|�C���^�ŋ��L������A
���ȏ�ɍœK�����ꂽ���̏o����TOP�Ƒ��Ԑ��ɓ�������
�Q�t�H�̕������N���O������g��\�t�g�E�F�A�J�����Ȃ�������GPGPU�s�ꂪ�L�т�����Ƃ����Čォ��ȒP�ɎQ���ł���قNJÂ��Ȃ��������Ă��Ƃ���B
LINPACK��p�x���`�V�X�e��
501 �F,,�E�L�́M�E,,�j��-�������F2015/02/22(��) 17:55:37.10 ID:/mEdeDGD
�X�p�R�����ăx���`�}�[�N�̂��߂ɂ���킯����Ȃ���
GPU�ڈ�������͑�������Ƃ��ώG����
������V�X�e�������Z��p
�u����o���Ė��ɗ��́H�v�u��J���đg��Ŗ��ɗ��́H�v
�����������O�������Ƃ��ĉ��
����Չ�������̂�HSA
���C����������Ń��C���v���Z�b�T�Ɠ����f�[�^���g��
���ߌ`�����Ⴄ������GPU��CPU�Ɠ����悤�ȃR�A�Ƃ��Ĉ���
�O���{�p�̌���Ƃ͈Ⴄ�����Ղ��v���O���~���O�����
������V�X�e�������Z��p
�u����o���Ė��ɗ��́H�v�u��J���đg��Ŗ��ɗ��́H�v
�����������O�������Ƃ��ĉ��
����Չ�������̂�HSA
���C����������Ń��C���v���Z�b�T�Ɠ����f�[�^���g��
���ߌ`�����Ⴄ������GPU��CPU�Ɠ����悤�ȃR�A�Ƃ��Ĉ���
�O���{�p�̌���Ƃ͈Ⴄ�����Ղ��v���O���~���O�����
>>502
Intel��Knights Landing��NIVIDIA��NVLink�œ����A�v���[�`��邩�狣�����������ǂˁB
HSA�y�����鑫�����肪����Q�[�������Ȃ��̂�����������������~�������B
Intel��Knights Landing��NIVIDIA��NVLink�œ����A�v���[�`��邩�狣�����������ǂˁB
HSA�y�����鑫�����肪����Q�[�������Ȃ��̂�����������������~�������B
HPC�̐��\�E���b�p��Linpack���\�݂̂ŕ]��������āA
���Ƃ��I�����s�b�N�Ō����A�}���\���I������j�I���100m���̐��тőI�l����悤�Ȃ���
���Ƃ��I�����s�b�N�Ō����A�}���\���I������j�I���100m���̐��тőI�l����悤�Ȃ���
�C���e���Q�t�H��LINPACK��p�x���`�V�X�e�������ǂ�
>>504
PC������Kaveri��Mantle��OpenCL2.0
�����ɑ��݂��āA����Carrizo�ADX12�AJava9������邵
�ȓd�͌�����SkyBridge��x86��ARM�̗��Ή��i�߂�
�I��N���E�h�AHPC�����ɂ�32�R�A��n�C�G���hAPU�����\��
�������ǂ��납5�肭�炢������
PC������Kaveri��Mantle��OpenCL2.0
�����ɑ��݂��āA����Carrizo�ADX12�AJava9������邵
�ȓd�͌�����SkyBridge��x86��ARM�̗��Ή��i�߂�
�I��N���E�h�AHPC�����ɂ�32�R�A��n�C�G���hAPU�����\��
�������ǂ��납5�肭�炢������
>>505
LINPACK�͊�����CPU��GPU���ʃA�h���X���ʃ������ŘA�g���Â炢�V�X�e�������ȃC���[�W
APU�̓��������L���A�h���X���L������ALINPACK����t�ɐ��\�𑪂�Ȃ��C������
APU�݂����ȃA�h���X���L���������\Soc�̃}���`�v���Z�b�T�ȍ����x�T�[�o�[�̐��\�]���́A�V�������Ȃ��Əo���Ȃ����낤��
LINPACK�͊�����CPU��GPU���ʃA�h���X���ʃ������ŘA�g���Â炢�V�X�e�������ȃC���[�W
APU�̓��������L���A�h���X���L������ALINPACK����t�ɐ��\�𑪂�Ȃ��C������
APU�݂����ȃA�h���X���L���������\Soc�̃}���`�v���Z�b�T�ȍ����x�T�[�o�[�̐��\�]���́A�V�������Ȃ��Əo���Ȃ����낤��
HSA�̑O������ɂȂ���APU��GPU�R�A��CPU�p��L2�L���b�V�����g����
�O���{�̂悤�Ɂu���������Ńh�o�b�ƌv�Z���邩����ăf�[�^�p�ӂ���̒x�߂��v�ł��Ȃ�
SSE���̂悤�ɁuSIMD�ŃR�A��傗����SIMD��GHz�Ŗ��ʂɃu���������v�ł��Ȃ�
�}���`�X���b�h�̂悤�Ȋ��o��GPGPU�o����̂�����
�O���{�̂悤�Ɂu���������Ńh�o�b�ƌv�Z���邩����ăf�[�^�p�ӂ���̒x�߂��v�ł��Ȃ�
SSE���̂悤�ɁuSIMD�ŃR�A��傗����SIMD��GHz�Ŗ��ʂɃu���������v�ł��Ȃ�
�}���`�X���b�h�̂悤�Ȋ��o��GPGPU�o����̂�����
firepro���ĔN�ɓ���linpack�x���`��2-3�V�X�e�������݂�@��Ȃ�
513 �F,,�E�L�́M�E,,�j��-�������F2015/02/22(��) 19:22:18.12 ID:/mEdeDGD
�����ĐV�K�̗p�������邾���̖��͂��Ȃ�����
514 �FSocket774�F2015/02/22(��) 19:24:53.98 ID:0tYt+uqR
>>510
�wSIMD����K�͂�GPU��SIMD���̃��C�e���V��SIMD�̂悤�Ȋ��o�Łx�Ȃ狭�݂����A�w�}���`�X���b�h�̂悤�Ȋ��o�Łx���Ǝ�݂����B
�wSIMD����K�͂�GPU��SIMD���̃��C�e���V��SIMD�̂悤�Ȋ��o�Łx�Ȃ狭�݂����A�w�}���`�X���b�h�̂悤�Ȋ��o�Łx���Ǝ�݂����B
515 �F,,�E�L�́M�E,,�j��-�������F2015/02/22(��) 19:31:09.56 ID:/mEdeDGD
�{���̃}���`�X���b�h�Ȃ番��ł��ăv���Z�b�T�R�A���ƂɕʁX�̃v���V�[�W�����Ɏ��s�ł��邪
GPGPU�͏��FSIMD�ɔ�킹�Ă邾��������ȁB
����͂����̃v���f�B�P�[�g
GPGPU�͏��FSIMD�ɔ�킹�Ă邾��������ȁB
����͂����̃v���f�B�P�[�g
516 �F,,�E�L�́M�E,,�j��-�������F2015/02/22(��) 19:42:20.67 ID:/mEdeDGD
GPGPU����if �`�@else if�@�` else�E�E�E��S�����s���āA���s���ʂ�I������ł���
���̂������ƁA����悪�������������d�͌�����������B
LINPACK�͕���炵�����Ȃ��̂�GPU�݂����ȃu���[�g�t�H�[�X�^�\���ł�
����قǎ��s�����͗����Ȃ����A�����̃A�v���ł͂����͂����Ȃ��B
�X�J��CPU�Ƀx�N�g�����j�b�g���Ԃ牺�������\����Xeon Phi�́A�K�v�ɉ�����
�{���̃X�J�������╪�ł���̂ŁA�����̖��ʂ��Ȃ��AGPU�̓d�͌��������邱�Ƃ��ł���B
Phi��LINPACK�ł͊���H���Ă邪�A���p�ɋ�������Top500��20�V�X�e���ȏ�ō̗p����Ă�B
���̂������ƁA����悪�������������d�͌�����������B
LINPACK�͕���炵�����Ȃ��̂�GPU�݂����ȃu���[�g�t�H�[�X�^�\���ł�
����قǎ��s�����͗����Ȃ����A�����̃A�v���ł͂����͂����Ȃ��B
�X�J��CPU�Ƀx�N�g�����j�b�g���Ԃ牺�������\����Xeon Phi�́A�K�v�ɉ�����
�{���̃X�J�������╪�ł���̂ŁA�����̖��ʂ��Ȃ��AGPU�̓d�͌��������邱�Ƃ��ł���B
Phi��LINPACK�ł͊���H���Ă邪�A���p�ɋ�������Top500��20�V�X�e���ȏ�ō̗p����Ă�B
518 �F,,�E�L�́M�E,,�j��-�������F2015/02/22(��) 20:24:25.47 ID:/mEdeDGD
�I�t���[�h���f������Ȃ��Ď����쓮�O��Ō����Ă���ǁH
��������800MHz�O���SIMD�^�v���Z�b�T��4�T�C�N�������������s����������I�X�J�����\��200MHz���x�����B
Phi�͋Ȃ���Ȃ�ɂ�1GHz�ȏ�ŋ쓮����X�[�p�[�X�J���^�v���Z�b�T�B
���Ƃ��}�X�N���W�X�^��1�������Ă�v�f�������}�[�W���閽�߂��邶���B
�A�N�e�B�u�ȗv�f�������ăp�b�N���ăx�N�g�����Z���j�b�g�̎����ғ��������߂邱�Ƃ��ł���B
�����GPU�̂悤��SPMD�^�̃v���O���~���O���f���ł͐�ɕs�\�B
��������800MHz�O���SIMD�^�v���Z�b�T��4�T�C�N�������������s����������I�X�J�����\��200MHz���x�����B
Phi�͋Ȃ���Ȃ�ɂ�1GHz�ȏ�ŋ쓮����X�[�p�[�X�J���^�v���Z�b�T�B
���Ƃ��}�X�N���W�X�^��1�������Ă�v�f�������}�[�W���閽�߂��邶���B
�A�N�e�B�u�ȗv�f�������ăp�b�N���ăx�N�g�����Z���j�b�g�̎����ғ��������߂邱�Ƃ��ł���B
�����GPU�̂悤��SPMD�^�̃v���O���~���O���f���ł͐�ɕs�\�B
����\���Ɋւ��Ă�
�uIntelCPU�n�m�C�ŗ\���A���������v�݂����Ȋ댯��
�ܘ_���\�[�X�Ɩʐς�\�����j�b�g�Ɋ��������b�g��
�f�[�^�̈��ʊW�i�p��Y�ꂽ�j�������������₷�������ŏd�v�Ȃ̂��ǂ���
�R�[�h�̏������Ƃ����̂͂P�ʂ肵���Ȃ��Ȃ�Ă��Ƃ͂Ȃ�
if���炯�̏��������čH�v����ΐ��l���Z�����ōςނ悤�ɂȂ�ꍇ������
Phi�}���Z�[�̋L���Łu��������Ȃ��ƃh����Ō���Ĕn������Ȃ��̂��v���Ă̂���������
���������P�[�X�͏��Ȃ��Ȃ���������Ȃ���
�uIntelCPU�n�m�C�ŗ\���A���������v�݂����Ȋ댯��
�ܘ_���\�[�X�Ɩʐς�\�����j�b�g�Ɋ��������b�g��
�f�[�^�̈��ʊW�i�p��Y�ꂽ�j�������������₷�������ŏd�v�Ȃ̂��ǂ���
�R�[�h�̏������Ƃ����̂͂P�ʂ肵���Ȃ��Ȃ�Ă��Ƃ͂Ȃ�
if���炯�̏��������čH�v����ΐ��l���Z�����ōςނ悤�ɂȂ�ꍇ������
Phi�}���Z�[�̋L���Łu��������Ȃ��ƃh����Ō���Ĕn������Ȃ��̂��v���Ă̂���������
���������P�[�X�͏��Ȃ��Ȃ���������Ȃ���
����
IntelCPU�n�m�C�ŗ\���h���s�h�A��
IntelCPU�n�m�C�ŗ\���h���s�h�A��
PCie�o�R�Ń������R�s�[�K�{�̍���GPGPU�ƁA
�����o�X�ڑ��ŃA�h���X���L��APU���ƁA���C�e���V��ш�ŃP�^�Ⴂ�̍��������}���Ǝv��
����CPU������AVX�ɂ͏��ĂȂ����낤���A���Z���\�ɍ������邩�狤���͂ł���
���Ȃ݂ɁA���̃��f�ɂ͊ȈՓI�ȃX�J���R�A�����ڂ���Ă�
http://pc.watch.impress.co.jp/img/pcw/docs/668/620/html/08.png.html
�ǂ̒��x�̐��\���͒m��Ȃ����A�����̕����Ȃ���͂Ȃ�
�����o�X�ڑ��ŃA�h���X���L��APU���ƁA���C�e���V��ш�ŃP�^�Ⴂ�̍��������}���Ǝv��
����CPU������AVX�ɂ͏��ĂȂ����낤���A���Z���\�ɍ������邩�狤���͂ł���
���Ȃ݂ɁA���̃��f�ɂ͊ȈՓI�ȃX�J���R�A�����ڂ���Ă�
http://pc.watch.impress.co.jp/img/pcw/docs/668/620/html/08.png.html
{kind=link}
�ǂ̒��x�̐��\���͒m��Ȃ����A�����̕����Ȃ���͂Ȃ�
522 �F,,�E�L�́M�E,,�j��-�������F2015/02/22(��) 20:48:55.74 ID:/mEdeDGD
���p�Ńn�m�C�̓��ɋߎ�����悤�ȉ��Z�������g����Ȃ�ĕ��������Ƃ͂Ȃ���
����Ȃ��̉��Ɏg���H
����A�A�N�e�B�u�v�f�̍ăp�b�L���O�́A�a�s����ŗL�p������Xeon Phi������
�i�|�X�gLINPACK�̍ŗL�͌�������j
�ȕ��@�ł̓x�N�g���v�f�̑唼�ɗV�т��ł��邵�AGPU�̓��_�N�V�������x������B
����Ȃ��̉��Ɏg���H
����A�A�N�e�B�u�v�f�̍ăp�b�L���O�́A�a�s����ŗL�p������Xeon Phi������
�i�|�X�gLINPACK�̍ŗL�͌�������j
�ȕ��@�ł̓x�N�g���v�f�̑唼�ɗV�т��ł��邵�AGPU�̓��_�N�V�������x������B
523 �F,,�E�L�́M�E,,�j��-�������F2015/02/22(��) 20:59:17.24 ID:/mEdeDGD
�uScalar Integer ALU�v
��
�������������ł��Ȃ�
AVX*�����p���đa�s����������Ȃ炢�낢�댤������ĂĂ�
�����}�g�̃|�X�gT2K��Knights Landing�O��Řb���i��ł���B
http://www.slis.tsukuba.ac.jp/~hasegawa.hidehiko.ga/GYOSEKI/hishinuma_MPcomp4.pdf
LINPACK�̐������������Ȃ��悤�Ȓ�w�������}���Z�[���ĂȂ�FirePro���Ⴂ����̂ł���B
��
�������������ł��Ȃ�
AVX*�����p���đa�s����������Ȃ炢�낢�댤������ĂĂ�
�����}�g�̃|�X�gT2K��Knights Landing�O��Řb���i��ł���B
http://www.slis.tsukuba.ac.jp/~hasegawa.hidehiko.ga/GYOSEKI/hishinuma_MPcomp4.pdf
LINPACK�̐������������Ȃ��悤�Ȓ�w�������}���Z�[���ĂȂ�FirePro���Ⴂ����̂ł���B
524 �F,,�E�L�́M�E,,�j��-�������F2015/02/22(��) 21:03:33.24 ID:/mEdeDGD
��������Radeon��FirePro�̔]�݂��ɃE���R�l�܂����悤�ȍ\�����ᑬ���x���ȑO��Hanoi�����s�ł��Ȃ��Ǝv��
�f�[�^�Ɉ��ʂ̋���CPU�p�ɋ������ꂽ�\�����j�b�g��
�����_���I�𖢖��̗\�����ʂ��o���̂��Ռ���������
�u���ꂪIntel�̎��R�̂��I�v���ăX����i�����ҁj���L���V�������̂͂����ƏՌ��I������
�����_���I�𖢖��̗\�����ʂ��o���̂��Ռ���������
�u���ꂪIntel�̎��R�̂��I�v���ăX����i�����ҁj���L���V�������̂͂����ƏՌ��I������
radeon�̃X�J�����Z�������wavefront�P�ʂł��������ł��˂�ˁ[��
527 �F,,�E�L�́M�E,,�j��-�������F2015/02/22(��) 21:19:08.71 ID:/mEdeDGD
�v���O���~���O�f�l�̑����Z1��|���Z2������L�����ς�������ł��o���o���Ƃ�������
529 �F,,�E�L�́M�E,,�j��-�������F2015/02/22(��) 21:26:12.36 ID:/mEdeDGD
>>526
������ƈႤ����Phi�Ɣ�ׂ�Ƙ_�O�ȍ\���Ȃ̂͊ԈႢ�Ȃ���
���ꂶ��LINPACK�݂����Ȗ��s�Z����Ȃ��Ɛ�ɐ��\�o�Ȃ�
http://pc.watch.impress.co.jp/docs/column/kaigai/20130318_592131.html
APU�i�j��hUMA�i�j���ǂ��̂����̂���Ȃ���GPU�̉��Z���j�b�g���̂��̂�
���܂ǂ��̃X�p�R���̃��[�N���[�h�Ɍ����ĂȂ��B
������ƈႤ����Phi�Ɣ�ׂ�Ƙ_�O�ȍ\���Ȃ̂͊ԈႢ�Ȃ���
���ꂶ��LINPACK�݂����Ȗ��s�Z����Ȃ��Ɛ�ɐ��\�o�Ȃ�
http://pc.watch.impress.co.jp/docs/column/kaigai/20130318_592131.html
APU�i�j��hUMA�i�j���ǂ��̂����̂���Ȃ���GPU�̉��Z���j�b�g���̂��̂�
���܂ǂ��̃X�p�R���̃��[�N���[�h�Ɍ����ĂȂ��B
���Ƃ�warp�g�ݒ��������Ę_���͐��N�O�͂�������
dynamic warp formation��subdivision�����
����nvidia�̓r���_���[�搶�����Ă����
�K�w�^�̃X�P�W���[�����O�ƃ��W�X�^�t�@�C���i�L���b�V���j��
���Ȃ��Ƃ����s����warp�T�C�Y�����������Ă��܂������ɂȂ�悤�ł�
pascal�������
dynamic warp formation��subdivision�����
����nvidia�̓r���_���[�搶�����Ă����
�K�w�^�̃X�P�W���[�����O�ƃ��W�X�^�t�@�C���i�L���b�V���j��
���Ȃ��Ƃ����s����warp�T�C�Y�����������Ă��܂������ɂȂ�悤�ł�
pascal�������
> AVX*�����p���đa�s����������Ȃ炢�낢�댤������ĂĂ�
> �����}�g�̃|�X�gT2K��Knights Landing�O��Řb���i��ł���B
> http://www.slis.tsukuba.ac.jp/~hasegawa.hidehiko.ga/GYOSEKI/hishinuma_MPcomp4.pdf
> LINPACK�̐������������Ȃ��悤�Ȓ�w�������}���Z�[���ĂȂ�FirePro���Ⴂ����̂ł���B
���̕ӂ�32�R�A64�X���b�h�̐VOpteron������Ă�����
AMD�͂Ƃ����ɒELINPACK�̏����o���ĂāA��͐V�v���Z�X�ڍs��҂��Ă��
> �����}�g�̃|�X�gT2K��Knights Landing�O��Řb���i��ł���B
> http://www.slis.tsukuba.ac.jp/~hasegawa.hidehiko.ga/GYOSEKI/hishinuma_MPcomp4.pdf
> LINPACK�̐������������Ȃ��悤�Ȓ�w�������}���Z�[���ĂȂ�FirePro���Ⴂ����̂ł���B
���̕ӂ�32�R�A64�X���b�h�̐VOpteron������Ă�����
AMD�͂Ƃ����ɒELINPACK�̏����o���ĂāA��͐V�v���Z�X�ڍs��҂��Ă��
�n�m�C�̓��������v���O�����ł̕���\���̓I�������āA
�����_���I���Ƒ卷�Ȃ����ɗ��������̂����ʂ���Ȃ���? �m��ǁB
�����_���I���Ƒ卷�Ȃ����ɗ��������̂����ʂ���Ȃ���? �m��ǁB
2CU���Ƃ�1��ARM���ڂ��i��GPU���R���g���[�������j��Ȃ�ĉ\�����邪�E�E�B
534 �F,,�E�L�́M�E,,�j��-�������F2015/02/22(��) 23:03:06.65 ID:/mEdeDGD
> dynamic warp formation��subdivision�����
x86�Ȃ�f�[�^�̍ăp�b�L���O�𖽗߃X�g���[�����ŏo���Ă��܂������
�������Ԃ����Ⴏ���b�AKnights Corner + MKL������܂肤�܂��s���ĂȂ����ۂ��̂�
���O�Ŋ撣���Ă�Haswell Xeon�ɕ�����Ƃ��]�X�B
����Top500��8���ȏ��Xeon�I�����[�̃z���W�j�A�X�\������
Phi������Ă�����Ȃ��Ă�Intel�I�ɂ͂���قǍ���Ȃ��̂��낤����
x86�Ȃ�f�[�^�̍ăp�b�L���O�𖽗߃X�g���[�����ŏo���Ă��܂������
�������Ԃ����Ⴏ���b�AKnights Corner + MKL������܂肤�܂��s���ĂȂ����ۂ��̂�
���O�Ŋ撣���Ă�Haswell Xeon�ɕ�����Ƃ��]�X�B
����Top500��8���ȏ��Xeon�I�����[�̃z���W�j�A�X�\������
Phi������Ă�����Ȃ��Ă�Intel�I�ɂ͂���قǍ���Ȃ��̂��낤����
>>534
�ŏ����炻�̂Ԃ����Ⴏ���b���Ă��̂ɂȂ�Œc�q���͍��܂�Phi�i�삵�Ă��H
�ŏ����炻�̂Ԃ����Ⴏ���b���Ă��̂ɂȂ�Œc�q���͍��܂�Phi�i�삵�Ă��H
2CU��ARM1�R�A���ƁA64CU�ʂ���390x�N���X����32�R�A�K�v�ɂȂ邼
����ɁARadeon�̃R�}���h�v���Z�b�T�͓Ǝ���RISC CPU�����A
ACE��GPGPU�̐��䃆�j�b�g�ŁA���Z�p�R�}���h�v���Z�b�T�݂����Ȃ���
����p�v���Z�b�T�͂Ƃ����ɓ��ڍς݂�����A�R���ȏ�͊g�����Ȃ��Ǝv��
����ɁARadeon�̃R�}���h�v���Z�b�T�͓Ǝ���RISC CPU�����A
ACE��GPGPU�̐��䃆�j�b�g�ŁA���Z�p�R�}���h�v���Z�b�T�݂����Ȃ���
����p�v���Z�b�T�͂Ƃ����ɓ��ڍς݂�����A�R���ȏ�͊g�����Ȃ��Ǝv��
�͂����߂̒c�q�̃��X���Ă݂����ǁATesla���X�p�R���ƊE�x�z���Ă��闝�R�ɂȂ��ĂȂ���
�c�q�͂܂�GPGPU�����|�I�V�F�A�������Ă����������ׂ����낤
�����āA�^�_�Ńo���܂������������y���ĂȂ�Phi�̎�_����
�D��Ă���Phi��Intel�u�����h�ƃ}�[�P�e�B���O�ł����y���Ȃ��̂́A�X�}�t�H�Ɠ������R�Ȃ��������
�����A�N�Z�����[�^�Ƃ��Ă�x86���K�v�Ƃ���ĂȂ��̂ɃS���������Ă邾�������猩����������ĂȂ��낤
�c�q�͂܂�GPGPU�����|�I�V�F�A�������Ă����������ׂ����낤
�����āA�^�_�Ńo���܂������������y���ĂȂ�Phi�̎�_����
�D��Ă���Phi��Intel�u�����h�ƃ}�[�P�e�B���O�ł����y���Ȃ��̂́A�X�}�t�H�Ɠ������R�Ȃ��������
�����A�N�Z�����[�^�Ƃ��Ă�x86���K�v�Ƃ���ĂȂ��̂ɃS���������Ă邾�������猩����������ĂȂ��낤
>>536
����APU�iCheetah�j�̘b�Ȃ�ŁE�E�B
ACE�̐e���݂����Ȋ����ɂȂ��Ȃ����ƁB
CPU�i�v���O�����j����GPU�ւ̂̑����Ƃ����B
����APU�iCheetah�j�̘b�Ȃ�ŁE�E�B
ACE�̐e���݂����Ȋ����ɂȂ��Ȃ����ƁB
CPU�i�v���O�����j����GPU�ւ̂̑����Ƃ����B
�c�q�����g��>>534�ŏ����Ă鎖����B
Knights Corner����GPU�Ɠ����悤�Ȏ������ł��Ȃ��̂�
���������Tesla�̕������\�������ł���B
Knights Corner����GPU�Ɠ����悤�Ȏ������ł��Ȃ��̂�
���������Tesla�̕������\�������ł���B
540 �F,,�E�L�́M�E,,�j��-�������F2015/02/23(��) 00:00:13.90 ID:wmndRWZg
GPU�X�p�R���̐�삯��TSUBAME����A�N�Z�����[�^�ڃm�[�h�������������
�ʂ�Tesla�����Ď�_���Ȃ��킯�ł͂Ȃ��B
���l�v�Z�\�t�g�E�F�A�̃P�c�@���Ă������Ԓ�������������Tesla�̂ق����\�t�g���[�����Ă�
�Ƃ����̂͂���Ǝv���B�����Ă邱�Ƃ�����点���Tesla�����ď\�������B
�i����͕ʂɉ����w�E���Ă�a�s����ɋ����ƌ����Ă�킯�ł͂Ȃ��j
�ʂ�Tesla�����Ď�_���Ȃ��킯�ł͂Ȃ��B
���l�v�Z�\�t�g�E�F�A�̃P�c�@���Ă������Ԓ�������������Tesla�̂ق����\�t�g���[�����Ă�
�Ƃ����̂͂���Ǝv���B�����Ă邱�Ƃ�����点���Tesla�����ď\�������B
�i����͕ʂɉ����w�E���Ă�a�s����ɋ����ƌ����Ă�킯�ł͂Ȃ��j
�����܂��A�X�p�R������GPGPU�O��ŃA���S���Y����c�[���ނ��J������ĉ^�p����Ă邩���
������x86��AVX512��玝���Ă��Ă��A����ɍœK���������Z���ł���킯���Ȃ�
���ǂ�GPGPU�����̃\�t�g��GPGPU���ۂ����������Ƃ����o���Ȃ��͓̂��R
�X�}�t�H��x86���y�����悤�Ƃ���x86 Android��������ǃT�b�p������ĂȂ��̂ƈꏏ����
���Ɋm����G�R�V�X�e�����ł��Ă�Ƃ���ɁA�ʕ��삩��S���ʂ̃V�X�e���������t���悤�Ƃ��Ă��A����ᖳ������
������x86��AVX512��玝���Ă��Ă��A����ɍœK���������Z���ł���킯���Ȃ�
���ǂ�GPGPU�����̃\�t�g��GPGPU���ۂ����������Ƃ����o���Ȃ��͓̂��R
�X�}�t�H��x86���y�����悤�Ƃ���x86 Android��������ǃT�b�p������ĂȂ��̂ƈꏏ����
���Ɋm����G�R�V�X�e�����ł��Ă�Ƃ���ɁA�ʕ��삩��S���ʂ̃V�X�e���������t���悤�Ƃ��Ă��A����ᖳ������
�������FirePro��APU������AGPU���s���ӂȐ������Z�╪����CPU�ɂ�点�邾��
��������GCN�̐������Z���\��Kepler��Maxwell�̐��{�ゾ����A�����܂Ń{�g���l�b�N�ɂ͂Ȃ��
��́A�قƂ�ǂ̃X�p�R����x86+GPGPU�Œ蒅���ăG�R�V�X�e������Ă邩��A���Ƃ�Intel�ł������͖̂���
�����A�G�N�T�X�P�[���ŃC���e���k�r�͕ʕ����Ɍ�����������A�����̃V�X�e�����p���ł����p���f�������݂��Ȃ�
�B��Ax86+GPU��APU�������Ă�AMD������������X�p�R���������ł���
�����悤�Ȏ���͉ߋ��ɂ������
x86��64bit���Ō݊����Ȃ�����IA64�Ɍ�������Intel�ƁA�݊������ێ�����x64���J������AMD
���ǕW���ɂȂ����̂́A�݊������ێ�����x64����AMD64������
��������GCN�̐������Z���\��Kepler��Maxwell�̐��{�ゾ����A�����܂Ń{�g���l�b�N�ɂ͂Ȃ��
��́A�قƂ�ǂ̃X�p�R����x86+GPGPU�Œ蒅���ăG�R�V�X�e������Ă邩��A���Ƃ�Intel�ł������͖̂���
�����A�G�N�T�X�P�[���ŃC���e���k�r�͕ʕ����Ɍ�����������A�����̃V�X�e�����p���ł����p���f�������݂��Ȃ�
�B��Ax86+GPU��APU�������Ă�AMD������������X�p�R���������ł���
�����悤�Ȏ���͉ߋ��ɂ������
x86��64bit���Ō݊����Ȃ�����IA64�Ɍ�������Intel�ƁA�݊������ێ�����x64���J������AMD
���ǕW���ɂȂ����̂́A�݊������ێ�����x64����AMD64������
�I�p��PC�p�ɕʃA�[�L�e�N�`���ŋ����ł���Intel�͖`���������A
�������A�[�L�e�N�`���ɓ��ꂵ�Ȃ��ƊJ���܂��͐��Y�ł��Ȃ��i�J�������Ȃ����A
�H����ו����������č���jAMD�͎I�ɂ����p�ł���PC�pCPU���K�v�s����������
��������A���̎����܂ő��݂��Ȃ������V�s�ꂪ�J���x86�I���}�L����
��ŁA���̃A�[�L�e�N�`����PC�ł������肠�܂���MS�̔쉺�ɓ����ĕW��������
�������A�[�L�e�N�`���ɓ��ꂵ�Ȃ��ƊJ���܂��͐��Y�ł��Ȃ��i�J�������Ȃ����A
�H����ו����������č���jAMD�͎I�ɂ����p�ł���PC�pCPU���K�v�s����������
��������A���̎����܂ő��݂��Ȃ������V�s�ꂪ�J���x86�I���}�L����
��ŁA���̃A�[�L�e�N�`����PC�ł������肠�܂���MS�̔쉺�ɓ����ĕW��������
���ǂ̂Ƃ���A�����V�X�e���Ƃ̌݊��́A�����̍����\�ȐV�V�X�e�������v������̂̓h�R���ꏏ���Ă��Ƃ���
Tesla��FirePro�ɔ�ׂ�Phi���D��Ă���̂́A���\����Ȃ�x86�ŊJ�����₷�����Ă��Ƃ炵�����ǁA
�����V�X�e����GPGPU���肫�łł��Ă���AVX512��GPGPU���ɒ������������D�ʐ����N�\���Ȃ�
�X�ɐ��\��������������Ă���ꍇ������Phi�Ɏ��v�Ȃ����߂Ȃ���
���łɌ����ƁATesla��FirePro�̓e�N�X�`�����j�b�g�ς�ł邩��APC��[�N�X�e�[�V���������ƃ_�C�����ʉ��o���邯�ǁAPhi�ɂ͂Ȃ����疳��
�X�Ɍ����ƁA���f���ƃO���t�B�b�N��GPGPU�����������ł��邯�ǁA�Q�t�H�ł͖���������A�f����O���t�B�b�N�̍��x�ȏ����̓��f�����o���Ȃ�
�܂�AAPU�ŃN���E�h�g�߂A�ėp���Z���O���t�B�b�N���Q�[����CAD�������������S�Ęd����Ƃ�������
���ɏd�v�Ȃ̂́A������x86+GPGPU�Ƃ����G�R�V�X�e���Ƃ̌݊������ێ������܂ܑg�߂�̂��傫��
�܂�A�����̃\�t�g�E�F�A�����̂܂ܓ��������ɁA�œK������ΐ��{���琔�\�{�̐��\���o����
Tesla��FirePro�ɔ�ׂ�Phi���D��Ă���̂́A���\����Ȃ�x86�ŊJ�����₷�����Ă��Ƃ炵�����ǁA
�����V�X�e����GPGPU���肫�łł��Ă���AVX512��GPGPU���ɒ������������D�ʐ����N�\���Ȃ�
�X�ɐ��\��������������Ă���ꍇ������Phi�Ɏ��v�Ȃ����߂Ȃ���
���łɌ����ƁATesla��FirePro�̓e�N�X�`�����j�b�g�ς�ł邩��APC��[�N�X�e�[�V���������ƃ_�C�����ʉ��o���邯�ǁAPhi�ɂ͂Ȃ����疳��
�X�Ɍ����ƁA���f���ƃO���t�B�b�N��GPGPU�����������ł��邯�ǁA�Q�t�H�ł͖���������A�f����O���t�B�b�N�̍��x�ȏ����̓��f�����o���Ȃ�
�܂�AAPU�ŃN���E�h�g�߂A�ėp���Z���O���t�B�b�N���Q�[����CAD�������������S�Ęd����Ƃ�������
���ɏd�v�Ȃ̂́A������x86+GPGPU�Ƃ����G�R�V�X�e���Ƃ̌݊������ێ������܂ܑg�߂�̂��傫��
�܂�A�����̃\�t�g�E�F�A�����̂܂ܓ��������ɁA�œK������ΐ��{���琔�\�{�̐��\���o����
�܂��A�v����ɁA2017�N�\��̃n�C�G���hGPU���ڂ����n�C�G���hAPU��HPC�s���Ȋ�����Ƃ�������
�����܂��ASMT�Ή���x86�R�A��16�Ƃ��ς�łāA390x����GPU�ς�ŁA�X�ɃA�h���X���L���o���āAHBM��16G�ς�ł���A�����̒N�����匾����
�����܂��ASMT�Ή���x86�R�A��16�Ƃ��ς�łāA390x����GPU�ς�ŁA�X�ɃA�h���X���L���o���āAHBM��16G�ς�ł���A�����̒N�����匾����
�ł�Tesla��FirePro���_���Z�O�����g��x86�I�����łɓ��荞��ł�Z�O�����g�̊Ԃɖ��m�̐V�s�ꂪ�B��ĂāA
������Phi�����荞��ł����Ƃ����\�����Ȃ��킯�ł͂Ȃ����璧�킵�悤���Ď�����A���Ԃ�B
������Phi�����荞��ł����Ƃ����\�����Ȃ��킯�ł͂Ȃ����璧�킵�悤���Ď�����A���Ԃ�B
GPGPU�����|�I�V�F�A���Ă����̂́ATOP500�̕]�����@��LINPACK������A
LINPACK�v�Z�����ӂ�GPGPU�����V�F�A�Ɍ�������Ă̂�����Ƃ�������
LINPACK�v�Z�����ӂ�GPGPU�����V�F�A�Ɍ�������Ă̂�����Ƃ�������
Tesla��FirePro�Ƃ������AGPU���S���Ă���s��̍L�������[�Ȃ��L�������
PC��Q�[���O���t�B�b�N�ɁACAD�Ƃ��̃��[�N�X�e�[�V�����AHPC�Ƃ��̉Ȋw���Z�̃A�N�Z�����[�^
APU���ƁA�X��CPU�Ƃ��Ă̐��\������邩��AGPU�������ƕ₦�Ȃ�������J���n���Ή��ł���
Phi��Atom�n�ŃV���O�����\���n�ゾ����A���Ǖ��Z�̃A�N�Z�����[�^�Ƃ��Ă����g���Ȃ�����A�V�s�ꂪ�����߂�Ƃ��v���Ȃ�
���������ACore�n��Phi����������Ęb�͂ǂ��Ȃ�������
���Lj�ʌ�����i7�Ƃ�����Core CPU��HD�O���t�B�b�N�ŏꏊ�������ς�������APhi�R�A��ςނ��Ƃ͏o���Ȃ���
Xeon�ɐςނɂ��Ă��A����20�R�A���炢�ς�łāAPhi��ςރ����b�g�������������疳�����ۂ�
��������Core��Phi�̋K�͂������������ɈႤ�R�A�����Ă��A��������܂��X�P�W���[���ł���Ƃ��v���Ȃ����
����������biglittle�݂����ɁA���݂Ɏg�������邭�炢���ւ̎R���낤
PC��Q�[���O���t�B�b�N�ɁACAD�Ƃ��̃��[�N�X�e�[�V�����AHPC�Ƃ��̉Ȋw���Z�̃A�N�Z�����[�^
APU���ƁA�X��CPU�Ƃ��Ă̐��\������邩��AGPU�������ƕ₦�Ȃ�������J���n���Ή��ł���
Phi��Atom�n�ŃV���O�����\���n�ゾ����A���Ǖ��Z�̃A�N�Z�����[�^�Ƃ��Ă����g���Ȃ�����A�V�s�ꂪ�����߂�Ƃ��v���Ȃ�
���������ACore�n��Phi����������Ęb�͂ǂ��Ȃ�������
���Lj�ʌ�����i7�Ƃ�����Core CPU��HD�O���t�B�b�N�ŏꏊ�������ς�������APhi�R�A��ςނ��Ƃ͏o���Ȃ���
Xeon�ɐςނɂ��Ă��A����20�R�A���炢�ς�łāAPhi��ςރ����b�g�������������疳�����ۂ�
��������Core��Phi�̋K�͂������������ɈႤ�R�A�����Ă��A��������܂��X�P�W���[���ł���Ƃ��v���Ȃ����
����������biglittle�݂����ɁA���݂Ɏg�������邭�炢���ւ̎R���낤
>>548
> GPGPU�����|�I�V�F�A���Ă����̂́ATOP500�̕]�����@��LINPACK������A
> LINPACK�v�Z�����ӂ�GPGPU�����V�F�A�Ɍ�������Ă̂�����Ƃ�������
��������邯�ǁA�ł�����͈̂����Ă�������g���āA�o���G�[�V�������L�x�����炾�낤
��{�I��PC����GPU�̍��i���ł�����A��p�A�N�Z�����[�^�Ɗr�ׂĔ�������Ƃ��Ă��A������`�����ɏo����قLj����Đ��𑵂��邱�Ƃ��o����
�����Quadro��Q�t�H���g���č\�z���邱�Ƃ��\�ȂقǏ_�������
�܂��A����ȃQ�t�H���A�����ザ��Power�Ƃ����������������Ax86�����̃n�C�G���h�͐�]�I
> GPGPU�����|�I�V�F�A���Ă����̂́ATOP500�̕]�����@��LINPACK������A
> LINPACK�v�Z�����ӂ�GPGPU�����V�F�A�Ɍ�������Ă̂�����Ƃ�������
��������邯�ǁA�ł�����͈̂����Ă�������g���āA�o���G�[�V�������L�x�����炾�낤
��{�I��PC����GPU�̍��i���ł�����A��p�A�N�Z�����[�^�Ɗr�ׂĔ�������Ƃ��Ă��A������`�����ɏo����قLj����Đ��𑵂��邱�Ƃ��o����
�����Quadro��Q�t�H���g���č\�z���邱�Ƃ��\�ȂقǏ_�������
�܂��A����ȃQ�t�H���A�����ザ��Power�Ƃ����������������Ax86�����̃n�C�G���h�͐�]�I
���͂Ȃ���
�u���C���X�g�[�~���O��4����
���f�E���_���o���Ȃ��i���_���ցj
�e��ȍl�������}����i���R�z���j
�ʂ��d������i�����ʁj
�A�C�f�B�A�����������W������i�������P�j
���f�E���_���o���Ȃ��i���_���ցj
�e��ȍl�������}����i���R�z���j
�ʂ��d������i�����ʁj
�A�C�f�B�A�����������W������i�������P�j
IGP�u�́H�ׂ�CPU���邾�낻�����ɗ��߁v
APU�����炱���o���镪�Ɖ�
���̂��߂�AMD��GPU�̃X�J���������L���b�V���Ɏ�����Ă�
http://pc.watch.impress.co.jp/docs/column/kaigai/20140129_632794.html
�����ɂ͗L�v�ł��O�t���ɂ͊��S�Ȏ֑��Ȃ����̉���
AMD���f�J�����ʃA�[�L�J������낤���ǂ܂��d��������
APU�����炱���o���镪�Ɖ�
���̂��߂�AMD��GPU�̃X�J���������L���b�V���Ɏ�����Ă�
http://pc.watch.impress.co.jp/docs/column/kaigai/20140129_632794.html
�����ɂ͗L�v�ł��O�t���ɂ͊��S�Ȏ֑��Ȃ����̉���
AMD���f�J�����ʃA�[�L�J������낤���ǂ܂��d��������
dGPU��SIMD�Ɣ�r����CPU�Ƃ̊Ԃ̃f�[�^�̂���肪1000�{�x������ǂ����Z�\�͂�10�{�ȏ㍂�����瑶�݉��l���F�߂��Ă���B
APU��HSA�Ńf�[�^�̂���肪100�{�x�����܂Ō��Ⴂ�ɉ��P���ꂽ�����Z�\�͂�SIMD�Ƒ卷�Ȃ��̂�iGPU�̃��\�[�X��L�����p���Ĉ��オ��ȃV�X�e�����\�z�ł���ȊO�̃����b�g�������B
APU��HSA�Ńf�[�^�̂���肪100�{�x�����܂Ō��Ⴂ�ɉ��P���ꂽ�����Z�\�͂�SIMD�Ƒ卷�Ȃ��̂�iGPU�̃��\�[�X��L�����p���Ĉ��オ��ȃV�X�e�����\�z�ł���ȊO�̃����b�g�������B
556 �FSocket774�F2015/02/23(��) 10:57:54.87 ID:9yTMDHtg
1000�{�Ƃ�10�{�Ƃ��ǂ��\�[�X�H
557 �FSocket774�F2015/02/23(��) 11:02:48.48 ID:mnIxt4vb
��������
>>���オ��ȃV�X�e�����\�z�ł���ȊO�̃����b�g������
�`�l�c�̑��݈Ӌ`���̂��̂���Ȃ�
�����܂�ɂ`�o�t�̗p�v�r�Ⴊ������x�ŏ\���B
����p�[�c�͎�őI�Ԃ����B
�`�l�c�̑��݈Ӌ`���̂��̂���Ȃ�
�����܂�ɂ`�o�t�̗p�v�r�Ⴊ������x�ŏ\���B
����p�[�c�͎�őI�Ԃ����B
��86SIMD��IGP�ƈ����L1�̃f�[�^�Q�Əo����̂�
����Ɏ��܂�K�͂ł͐�������
�l�g�o���g���X�L���b�V���Ɏ��܂�K�͂̃��[�v�Ȃ痝�_�㐦�������悤��
SSE��AVX�����Z�̂������ē����f�[�^���艄�X�g�������Ȃ琦������
���ƃ��j�b�g���₷�ƃR�A����������
�u���j�b�g���₷�ƒ����d�́v�Ȑ��E�ł͑������ꂪ���x�ɂ����f����邩�琦������
����Ɋւ��Ă�GPU�͗]�胆�j�b�g��S�Ď��s���邱�Ƃ�
�\���₻�̐��x�Ɋւ�炸�����Ɏ��s�o���邪
�ʂ̐��E�ł͗\���~�X�A�������ق����Ԃ���Intel���R�̂Ȃ̂łނ��됦��������GPU�̓G���Ƃ���ł͂Ȃ�
����Ɏ��܂�K�͂ł͐�������
�l�g�o���g���X�L���b�V���Ɏ��܂�K�͂̃��[�v�Ȃ痝�_�㐦�������悤��
SSE��AVX�����Z�̂������ē����f�[�^���艄�X�g�������Ȃ琦������
���ƃ��j�b�g���₷�ƃR�A����������
�u���j�b�g���₷�ƒ����d�́v�Ȑ��E�ł͑������ꂪ���x�ɂ����f����邩�琦������
����Ɋւ��Ă�GPU�͗]�胆�j�b�g��S�Ď��s���邱�Ƃ�
�\���₻�̐��x�Ɋւ�炸�����Ɏ��s�o���邪
�ʂ̐��E�ł͗\���~�X�A�������ق����Ԃ���Intel���R�̂Ȃ̂łނ��됦��������GPU�̓G���Ƃ���ł͂Ȃ�
��̃v���O�����������n�߂�܂ł̏������Ԃ�0��SIMD�ƋC�������Ȃ�N���b�N�̊|����GPGPU�œ������Ƃ��ł���킯�����̂ɂȁB
562 �FSocket774�F2015/02/23(��) 11:40:21.06 ID:9yTMDHtg
�v���O�����������n�߂�܂ł̏������Ԃ�0�̃\�[�X�́H
>>562
�������߂̎���SIMD���߂������o���܂ł̑҂����Ԃ����B
�X�[�p�[�X�J����SIMD�̕�����ɓ����o��������Ă邩�������B
�������߂̎���SIMD���߂������o���܂ł̑҂����Ԃ����B
�X�[�p�[�X�J����SIMD�̕�����ɓ����o��������Ă邩�������B
>>562
�e�ƋT�̗��_
�f�[�^�A�h���X���L��IGP�ł�VRAM�f�[�^�]�����̏����s�v��
���ʂɖ��߃f�R�[�h����̕��Z�����Ȃ��邪
���������߂̕��G��CISC��x86�f�R�[�_�͂��̕s����҉悤�ƐF�X�肪������Ă���
�t��ARM��GPU���߂Ȃǂ̃f�R�[�_�͖��f����Intel�v�`�t���Č��Ȃǂ��ėV��ł��܂�
���̂܂ܐQ�Ă��܂��Đl�Ԃɂ����郌�x���̒x����������
�ܘ_�n����̘b�ł͂Ȃ����������n�������f�͋֕���
�e�ƋT�̗��_
�f�[�^�A�h���X���L��IGP�ł�VRAM�f�[�^�]�����̏����s�v��
���ʂɖ��߃f�R�[�h����̕��Z�����Ȃ��邪
���������߂̕��G��CISC��x86�f�R�[�_�͂��̕s����҉悤�ƐF�X�肪������Ă���
�t��ARM��GPU���߂Ȃǂ̃f�R�[�_�͖��f����Intel�v�`�t���Č��Ȃǂ��ėV��ł��܂�
���̂܂ܐQ�Ă��܂��Đl�Ԃɂ����郌�x���̒x����������
�ܘ_�n����̘b�ł͂Ȃ����������n�������f�͋֕���
�ƌ����Ă��A�����ȃx���`�}�[�N������Ō��܂�킯�ł��������ăI�`�B
�傫�ȉ摜�A�f���f�[�^�[�̘A���������炢�����D�ʂ��������A�u�o�t�ɔėp����b�o�t�̑�ւȂ�ċ��߂��Ă��Ȃ��B
�傫�ȉ摜�A�f���f�[�^�[�̘A���������炢�����D�ʂ��������A�u�o�t�ɔėp����b�o�t�̑�ւȂ�ċ��߂��Ă��Ȃ��B
>>555
�ėp���W�X�^����SIMD���W�X�^�Ƀf�[�^��]�����閽�߂����Ă݂悤
vmovdqa ymm0, eax
�͂�������1�N���b�N�T�C�N���̃��C�e���V��
�X��CPU�̖��߃X�g���[�����炻�̂܂��s�ł���̂ŁA��ւ��R�X�g�͎�����0�T�C�N��
CPU����GPU�ɏ���������̂�1000�T�C�N�����x�ōςނ킯���Ȃ�����H
�J�[�l���R�[�����ăh���C�o�Ăяo���āE�E�E�Ń}�C�N���b�`�~���b�I�[�_�iCPU�̃N���b�N�T�C�N������0.x�i�m�b�I�[�_�j�̎��Ԃ�v����B
����͕ʂɃz�X�g������-�f�o�C�X�������Ԃ�*memcpy�̎��Ԃ������ƌ����Ă�킯�ł͂Ȃ�
�i����͕ʓr������j
�ėp���W�X�^����SIMD���W�X�^�Ƀf�[�^��]�����閽�߂����Ă݂悤
vmovdqa ymm0, eax
�͂�������1�N���b�N�T�C�N���̃��C�e���V��
�X��CPU�̖��߃X�g���[�����炻�̂܂��s�ł���̂ŁA��ւ��R�X�g�͎�����0�T�C�N��
CPU����GPU�ɏ���������̂�1000�T�C�N�����x�ōςނ킯���Ȃ�����H
�J�[�l���R�[�����ăh���C�o�Ăяo���āE�E�E�Ń}�C�N���b�`�~���b�I�[�_�iCPU�̃N���b�N�T�C�N������0.x�i�m�b�I�[�_�j�̎��Ԃ�v����B
����͕ʂɃz�X�g������-�f�o�C�X�������Ԃ�*memcpy�̎��Ԃ������ƌ����Ă�킯�ł͂Ȃ�
�i����͕ʓr������j
�ނ���CPU�ƓƗ����ē����A�N�Z�����[�^�Ƃ��ă������o�X���Ɨ����Ă�������\���グ�₷���Ă����ȃV�[���ŗL�����낤�ɂȁB
�ǂ����g�����͉摜�������V�~�����[�V���������Ȃ����B
�ǂ����g�����͉摜�������V�~�����[�V���������Ȃ����B
>>566
���������O�������I����ăv���O�����������o������̘b��1000�{�Ȃ��B�ǂ����݂�������1�b�|�����Ă�SIMD��10�b�|���鏈�����������dGPU�̕��������Ȃ�B�Ƃ��낪iGPU���Ƃ���������Ō��ǎg�������Ȃ��B
���������O�������I����ăv���O�����������o������̘b��1000�{�Ȃ��B�ǂ����݂�������1�b�|�����Ă�SIMD��10�b�|���鏈�����������dGPU�̕��������Ȃ�B�Ƃ��낪iGPU���Ƃ���������Ō��ǎg�������Ȃ��B
Haswell��Xeon�ŏ�ʃN���X�͊��ɒP���x2TFLOPS�I�[�o�[�̗��_���\���邩���
�i�����Ă�������S�ɎJ������邾���̃������ш悪����ƌ����Ă�킯�ł͂Ȃ��j
�i�����Ă�������S�ɎJ������邾���̃������ш悪����ƌ����Ă�킯�ł͂Ȃ��j
>>568
dGPU�̋��݂͌��ǁA�Ǝ��̍L�ш惁�����ƁACPU�Ƃ͓Ɨ����ė^�����Ă�M�v��
����GPU�ɂ͂��ꂪ�Ȃ��A�Ƃ����b�����Ă���̂Ȃ炻�̒ʂ肾�B
�������̂���CPU��GDDR5�Ȃ݂�����ȏ�̃������ш��^���Ă݂���ǂ����낤�H
�Ƃ����̂����̃X�e�b�v����
>>549
> Phi��Atom�n�ŃV���O�����\���n�ゾ����A���Ǖ��Z�̃A�N�Z�����[�^�Ƃ��Ă����g���Ȃ�����A�V�s�ꂪ�����߂�Ƃ��v���Ȃ�
Atom�̐��\��n���ɂ��Ă�悤�����A8�R�A�ETDP20W�i�T�E�X�u���b�W���݂�SoC�j��
������8�R�A��TDP65W�i�m�[�X�E�T�E�X�͕ʁj��Opteron 3380�ɔ��鐫�\�����Ă�̂����sAtom�Ȃ��H
http://www.servethehome.com/Server-detail/intel-atom-c2750-8-core-avoton-rangeley-benchmarks-fast-power/
�������Knights Landing�͂��ꂪ72�R�A�W�ς����AVX-512���j�b�g���ς܂��B
AMD��CPU�����j�[�R�A�H���ɑǂ��������ȏ�A1�R�A������̐��\�͎���Atom�̐��\����
�啝�ɒ������邩�͔������B
dGPU�̋��݂͌��ǁA�Ǝ��̍L�ш惁�����ƁACPU�Ƃ͓Ɨ����ė^�����Ă�M�v��
����GPU�ɂ͂��ꂪ�Ȃ��A�Ƃ����b�����Ă���̂Ȃ炻�̒ʂ肾�B
�������̂���CPU��GDDR5�Ȃ݂�����ȏ�̃������ш��^���Ă݂���ǂ����낤�H
�Ƃ����̂����̃X�e�b�v����
>>549
> Phi��Atom�n�ŃV���O�����\���n�ゾ����A���Ǖ��Z�̃A�N�Z�����[�^�Ƃ��Ă����g���Ȃ�����A�V�s�ꂪ�����߂�Ƃ��v���Ȃ�
Atom�̐��\��n���ɂ��Ă�悤�����A8�R�A�ETDP20W�i�T�E�X�u���b�W���݂�SoC�j��
������8�R�A��TDP65W�i�m�[�X�E�T�E�X�͕ʁj��Opteron 3380�ɔ��鐫�\�����Ă�̂����sAtom�Ȃ��H
http://www.servethehome.com/Server-detail/intel-atom-c2750-8-core-avoton-rangeley-benchmarks-fast-power/
�������Knights Landing�͂��ꂪ72�R�A�W�ς����AVX-512���j�b�g���ς܂��B
AMD��CPU�����j�[�R�A�H���ɑǂ��������ȏ�A1�R�A������̐��\�͎���Atom�̐��\����
�啝�ɒ������邩�͔������B
571 �FSocket774�F2015/02/23(��) 12:40:45.53 ID:Rits9GXJ
�����ザ��n�C�G���hGPU�������邩����Ȃ���
���C�e���V�Ƃ���AVX��10�{�x���āAdGPU��100�{�������炢����
���C�e���V�Ƃ���AVX��10�{�x���āAdGPU��100�{�������炢����
CPU�ɁAdGPU���݂̐��\��iGPU��ς݁A
�������C���^�t�F�[�X��GDDR5�ɂł����ă}�U�[�{�[�h���t���ɂ���A
�킴�킴CPU��dGPU�𗼕��ς܂Ȃ��Ă�����
�ŁA1PC�ɑ�������{�[�h��1➑̂ɂ�������ς߂�悤�ɂ���
�������x���グ��Ƃ���
�������C���^�t�F�[�X��GDDR5�ɂł����ă}�U�[�{�[�h���t���ɂ���A
�킴�킴CPU��dGPU�𗼕��ς܂Ȃ��Ă�����
�ŁA1PC�ɑ�������{�[�h��1➑̂ɂ�������ς߂�悤�ɂ���
�������x���グ��Ƃ���
HSA�̒��̃w�e��Q�ł�GPU����CPU�Ƀ^�X�N��n��������
�����Ȃ��x86SIMD�Ȃ�GPU�����̑��x�ɂȂ��Ă��܂��悤�Ɏv���邪
�����͂Ȃ�Ȃ�
���̂Ȃ疽�߁��f�[�^�Ńf�[�^�����߂����炾
���ꂪ�����炭�e�ƋT�̗��_�ɖ��ڂɊW���Ă���͂�
�����Ȃ��x86SIMD�Ȃ�GPU�����̑��x�ɂȂ��Ă��܂��悤�Ɏv���邪
�����͂Ȃ�Ȃ�
���̂Ȃ疽�߁��f�[�^�Ńf�[�^�����߂����炾
���ꂪ�����炭�e�ƋT�̗��_�ɖ��ڂɊW���Ă���͂�
> �������C���^�t�F�[�X��GDDR5�ɂł����ă}�U�[�{�[�h���t���ɂ���A
> �킴�킴CPU��dGPU�𗼕��ς܂Ȃ��Ă�����
�ėp�������Ȃ��邵�A4�`8GB���x�����ς߂Ȃ��Ȃ�_�O�B
��ʂ̃T�[�o�̃{�g���l�b�N�͂ނ���HDD��l�b�g���[�N�g���t�B�b�N�̂ق��ɂ��邵
�ނ��냁�����ш���]���ɂ��Ă��e�ʂ��m�ۂ�������B
> �킴�킴CPU��dGPU�𗼕��ς܂Ȃ��Ă�����
�ėp�������Ȃ��邵�A4�`8GB���x�����ς߂Ȃ��Ȃ�_�O�B
��ʂ̃T�[�o�̃{�g���l�b�N�͂ނ���HDD��l�b�g���[�N�g���t�B�b�N�̂ق��ɂ��邵
�ނ��냁�����ш���]���ɂ��Ă��e�ʂ��m�ۂ�������B
575 �FSocket774�F2015/02/23(��) 12:50:18.49 ID:Rits9GXJ
APU��AVX��GPGPU���������ĂāA������o���邩��D���Ȃ悤�Ɏg����������
�������� AVX vs iGPU�͖O��������ڒ����ț������͂���������
�������� AVX vs iGPU�͖O��������ڒ����ț������͂���������
>>571
CPU��L2���L���Ă�10�{�͖���������B�����ɋ��L������L2���x���Ȃ邾�������B�撣����100�{�O�オ���_���E����B����GPU�̃v���O�������ҋ@���Ă��Ԃ�CPU�ƃf�[�^������肷��X�s�[�h�̘b�ˁB
����ȏ��ڎw�����炻��͔ėpGPU�ł͂Ȃ���p�o�X�łȂ������R�v���Z�b�T�Ƃ��Đv���Ȃ��Ɩ����B
CPU��L2���L���Ă�10�{�͖���������B�����ɋ��L������L2���x���Ȃ邾�������B�撣����100�{�O�オ���_���E����B����GPU�̃v���O�������ҋ@���Ă��Ԃ�CPU�ƃf�[�^������肷��X�s�[�h�̘b�ˁB
����ȏ��ڎw�����炻��͔ėpGPU�ł͂Ȃ���p�o�X�łȂ������R�v���Z�b�T�Ƃ��Đv���Ȃ��Ɩ����B
578 �FSocket774�F2015/02/23(��) 12:53:37.48 ID:9yTMDHtg
���ꌩ���CPU�Ԃł��x�����������邱�Ƃ����グ�Ă�킯�����H
http://m.pc.watch.impress.co.jp/docs/news/20150223_689447.html
http://m.pc.watch.impress.co.jp/docs/news/20150223_689447.html
>>578
����͂����܂�CPU���܂������ꍇ�̘b���ˁB
x86��SIMD���߂͓����R�A���̃��j�b�g��������������`���x���͔������Ȃ���B
���ɖ��߃X�g���[���̒��ɑg�ݍ��܂�Ă���̂ɁA�ʓr�v�シ��悤�ȏ������ԂȂ�Ă���킯���Ȃ��B
����͂����܂�CPU���܂������ꍇ�̘b���ˁB
x86��SIMD���߂͓����R�A���̃��j�b�g��������������`���x���͔������Ȃ���B
���ɖ��߃X�g���[���̒��ɑg�ݍ��܂�Ă���̂ɁA�ʓr�v�シ��悤�ȏ������ԂȂ�Ă���킯���Ȃ��B
GPU�͔ėp�����R�����A�������삪�s�\�ŁA�����V�����d������邽�т�
�s�xCPU�ɂ�邨�V���Ă��K�v�Ȃ̂ɂ���CPU�������Ƃ����̂����Ȃ킯��
����GPU�Ȃ瑽���߂��Ȃ�E�E�E�Ƃ����Ă�����CPU�����V���Ă��Ȃ��Ⴂ���Ȃ����Ƃ͕ς��Ȃ�
�s�xCPU�ɂ�邨�V���Ă��K�v�Ȃ̂ɂ���CPU�������Ƃ����̂����Ȃ킯��
����GPU�Ȃ瑽���߂��Ȃ�E�E�E�Ƃ����Ă�����CPU�����V���Ă��Ȃ��Ⴂ���Ȃ����Ƃ͕ς��Ȃ�
>>580
����AMD�̃X��������
����AMD�̃X��������
�@���l�i
http://www.pcper.com/news/Graphics-Cards/GPU-Market-sees-20-point-swing-2014-NVIDIA-gains-AMD-falls
����1�N�ŁA�����ł������Ȃ�����RADEON���[�U�[��3�l��1�l��GeForce�ɏ�芷�����킯��
CS�@���e�Ƃ́AMantle�Ƃ́A���������ʓ��Ƃ͂Ȃ����̂�
����1�N�ŁA�����ł������Ȃ�����RADEON���[�U�[��3�l��1�l��GeForce�ɏ�芷�����킯��
CS�@���e�Ƃ́AMantle�Ƃ́A���������ʓ��Ƃ͂Ȃ����̂�
���莩�́A�A���`�̎��쎩�������A�������˂���Ȃ�
�P���ɋ����ʂ������ɓ�����AMD�@VGA�̃V�F�A�Ȃ�đ�����v�f���Ȃ��B
�ȏ�A�X���`�B
�P���ɋ����ʂ������ɓ�����AMD�@VGA�̃V�F�A�Ȃ�đ�����v�f���Ȃ��B
�ȏ�A�X���`�B
���Y���C���̂����ɂ��n�߂܂���
�����������GeForce��TSMC�Ő��Y���Ă�̂�
�����������GeForce��TSMC�Ő��Y���Ă�̂�
�s��V�F�A�ƃ��[�U�[���̈Ⴂ�𗝉��ł��Ȃ��r�����c�c
�̔����̃f�[�^����ǂ��Ďg�p�Ґ��Ǝv������ł�ȁB����ȃ��c�c�c
�̔����̃f�[�^����ǂ��Ďg�p�Ґ��Ǝv������ł�ȁB����ȃ��c�c�c
AMD�͎s��V�F�A�����Ȃ��Ă��̔��������Ȃ��Ă����[�U�[�͑������Ă��Ƃ�
�ǂ��������Ƃ���
�ǂ��������Ƃ���
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20140129_632794.html
AMDGPU�̋�������CPU�_�C�����O��̂������ł���
�����ʃA�[�L�e�N�`������Ȃ�����Ɠ������̂œ����p�@�\���Ă�킯�ł���
���̃A�[�L�e�N�`�����X�J���R�A�Ƃ̕��p�O��Ńx�N�^�������߂̂܂�
GPU�����őS����낤�Ƃ��Ă�NV�ƃJ�[�h�������悤�Ƃ���Ɣėp���Ƃ�������
AMDGPU�̋�������CPU�_�C�����O��̂������ł���
�����ʃA�[�L�e�N�`������Ȃ�����Ɠ������̂œ����p�@�\���Ă�킯�ł���
���̃A�[�L�e�N�`�����X�J���R�A�Ƃ̕��p�O��Ńx�N�^�������߂̂܂�
GPU�����őS����낤�Ƃ��Ă�NV�ƃJ�[�h�������悤�Ƃ���Ɣėp���Ƃ�������
590 �FSocket774�F2015/02/23(��) 20:09:41.59 ID:KA4QqN66
>>582
8GBit�`�b�v�͂܂�32bit�o�X���i�����ʎY����Ă��Ȃ�����A16GB���ڂ���ɂ�512bit�����R�����K�v�ɂȂ�B(���s��Opteron�̃����R����128bit)
���������A�T�[�o�[��16GB�Ȃ�ď��Ȃ����Ę_�O�B
8GBit�`�b�v�͂܂�32bit�o�X���i�����ʎY����Ă��Ȃ�����A16GB���ڂ���ɂ�512bit�����R�����K�v�ɂȂ�B(���s��Opteron�̃����R����128bit)
���������A�T�[�o�[��16GB�Ȃ�ď��Ȃ����Ę_�O�B
591 �F,,�E�L�́M�E,,�j��-�������F2015/02/23(��) 20:28:51.46 ID:Mne6GXgt
�܂��\��Ă�̂��@�͈́i�j
>>584
���̋�������̈�Ђ̓y�e���������ʂ����Ƃ��āA����J�E���g�_�E��������B
���̋�������̈�Ђ̓y�e���������ʂ����Ƃ��āA����J�E���g�_�E��������B
>>589
�ėp�����Ă̂́A�v�����CPU�ɋ߂Â�����Ă��Ƃ���
OS������悤�ɁACPU�݂����Ȑ������\�≼�z�������Ƃ��̐���@�\������邱�Ƃ��낤���ǁA
AMD�́AOS��������A�������\��CPU���ɂ������͂Ȃ��A
CPU�Ɠ����̐���@�\������悤�Ƃ��Ă��邾��
GCN��������d�˂閈�ɐi�����āATonga�ŃR���e�L�X�g�X�C�b�`�ɑΉ����āACPU�ɂ��Ȃ�߂�����@�\�������Ɏ�����
Nvidia�́AMaxwell�ł��^�X�N�X�C�b�`�ɂ��Ή��ł��ĂȂ����A�O���t�B�b�N��GPGPU�̓��������ɂ��Ή��ł��ĂȂ�
Fermi�ȍ~GPGPU�I�ɂ͉����i�����ĂȂ���
�����ėp���ł́A���f�ɑ��ăQ�t�H�͎���x��ǂ��납�A�X�^�[�g���C���ɗ��ĂĂ邾���ł����Ȃ�
�P�ɁACUDA��GPGPU�v���O����������葽���y�Ƃ�������
�ėp�����Ă̂́A�v�����CPU�ɋ߂Â�����Ă��Ƃ���
OS������悤�ɁACPU�݂����Ȑ������\�≼�z�������Ƃ��̐���@�\������邱�Ƃ��낤���ǁA
AMD�́AOS��������A�������\��CPU���ɂ������͂Ȃ��A
CPU�Ɠ����̐���@�\������悤�Ƃ��Ă��邾��
GCN��������d�˂閈�ɐi�����āATonga�ŃR���e�L�X�g�X�C�b�`�ɑΉ����āACPU�ɂ��Ȃ�߂�����@�\�������Ɏ�����
Nvidia�́AMaxwell�ł��^�X�N�X�C�b�`�ɂ��Ή��ł��ĂȂ����A�O���t�B�b�N��GPGPU�̓��������ɂ��Ή��ł��ĂȂ�
Fermi�ȍ~GPGPU�I�ɂ͉����i�����ĂȂ���
�����ėp���ł́A���f�ɑ��ăQ�t�H�͎���x��ǂ��납�A�X�^�[�g���C���ɗ��ĂĂ邾���ł����Ȃ�
�P�ɁACUDA��GPGPU�v���O����������葽���y�Ƃ�������
�܂�amd��y�͎g�������Ȃ��R���h�[������������
�����A���������킯�ł�
�����A���������킯�ł�
595 �F,,�E�L�́M�E,,�j��-�������F2015/02/23(��) 21:23:30.51 ID:Mne6GXgt
�S�����D�Ɏg���邶��Ȃ���
���ƃv�����g���߂���̂ɂ��g���邩��
���ƃv�����g���߂���̂ɂ��g���邩��
�J���]�[�̏ڍה��\�܂��H
�lj���7���g�����W�X�^�̗p�r���C�ɂȂ��
28nm�ɂ��Ă̓g�����W�X�^���x���ُ�ɍ�������A�V�v���Z�X�̏ڍׂ��������~����
28nm�ɂ��Ă̓g�����W�X�^���x���ُ�ɍ�������A�V�v���Z�X�̏ڍׂ��������~����
AMD�̕����̔��������Ȃ����ǁANVIDIA��胆�[�U�[�������Ƃ����̎������ƁA
AMD�̍w���w��GPU����x�����Ɖ��N���������Ȃ��̂������āA
NVIDIA�̍w���w�͂f�o�t��Z���Ԃɉ������A����ӗ~��������
���[�J�[�ɂ͂��肪�����^�C�v���������Ă��ƂɂȂ�̂��H
AMD�̍w���w��GPU����x�����Ɖ��N���������Ȃ��̂������āA
NVIDIA�̍w���w�͂f�o�t��Z���Ԃɉ������A����ӗ~��������
���[�J�[�ɂ͂��肪�����^�C�v���������Ă��ƂɂȂ�̂��H
>>588
���[�U�[���͌��݂̃V�F�A��������Ȃ��ߋ������炩�̃V�F�A���e������B
��N�O�ɔ��ꂽ�r�f�I�J�[�h�̂����A�����łɎg���Ă��Ȃ����͂����ꕔ�ŁA�唼�͂܂��g���Ă�B
���[�U�[���͌��݂̃V�F�A��������Ȃ��ߋ������炩�̃V�F�A���e������B
��N�O�ɔ��ꂽ�r�f�I�J�[�h�̂����A�����łɎg���Ă��Ȃ����͂����ꕔ�ŁA�唼�͂܂��g���Ă�B
>>598
���������p�x�������l�̈�ތ^�ł���n�C�G���h�Q�[�}�[�w����ނ̃��[�U�[�����������A�Ƃ͌�����
�ȂA�ŏ�ʃ��f���̃n�C�G���hGPU�����Ǝv������Q�t�H�����Ȃ����ă^�C�~���O�����ƍP��I�ɒ蒅���ĂāA
�Q�t�H�ł����f�ł��������Ď����͒Z������ȁB
�����Ƃ��A���������w�̐l���͏��Ȃ�����A���z�I�ɂ͔�d���傫���Ă��o�א��ł͌덷�����m���ȁB
���������p�x�������l�̈�ތ^�ł���n�C�G���h�Q�[�}�[�w����ނ̃��[�U�[�����������A�Ƃ͌�����
�ȂA�ŏ�ʃ��f���̃n�C�G���hGPU�����Ǝv������Q�t�H�����Ȃ����ă^�C�~���O�����ƍP��I�ɒ蒅���ĂāA
�Q�t�H�ł����f�ł��������Ď����͒Z������ȁB
�����Ƃ��A���������w�̐l���͏��Ȃ�����A���z�I�ɂ͔�d���傫���Ă��o�א��ł͌덷�����m���ȁB
>>597
�펯�I�ɍl����Ɠ������ꂽ�T�E�X�u���b�W�̕��Ȃ낤���ǁA����ɂ��Ă͂�����Ƒ傫������
�펯�I�ɍl����Ɠ������ꂽ�T�E�X�u���b�W�̕��Ȃ낤���ǁA����ɂ��Ă͂�����Ƒ傫������
steam�̃��[�U�[����Geforce��Radeon��2:1���炢�̔䗦�ɂȂ��Ă���
�����[�U�[���ł�NVIDIA�̈�������
�����[�U�[���ł�NVIDIA�̈�������
�̊��ł�AMD�̂̕���������
�V�F�A��[�U�[���́A��`��i���ɔ�Ⴗ�邩��A��������r������Ă�AMD�ɏ����ڂ͂Ȃ���
�l�T��ASCII��PCWatch����Ε����邾��A�قƂ�ǖ����C���e���Q�t�H�̐�`����ŁA
AMD�̋L���Ȃ��1���Ԃ�1���邩�ǂ����Ƃ����̂��炭
����ȏŔ����͂����Ȃ�
���̂��Ă��炤���߂ɂ͑I�����Ƃ��đ��݂��Ȃ��Ƃ����Ȃ����ǁA����͋L�����Ȃ�����I�����悤���Ȃ�
�l�T��ASCII��PCWatch����Ε����邾��A�قƂ�ǖ����C���e���Q�t�H�̐�`����ŁA
AMD�̋L���Ȃ��1���Ԃ�1���邩�ǂ����Ƃ����̂��炭
����ȏŔ����͂����Ȃ�
���̂��Ă��炤���߂ɂ͑I�����Ƃ��đ��݂��Ȃ��Ƃ����Ȃ����ǁA����͋L�����Ȃ�����I�����悤���Ȃ�
���i����������I�����悤���Ȃ��A�Ȃ�킩�邪�A�L������������I�����悤���Ȃ��j�_��
606 �FSocket774�F2015/02/24(��) 00:03:26.55 ID:DHJJQMvC
Radeon�ŐV���i���Ĕ��N�ȏ�O��285�܂ők��Ȃ��ƂȂ���
�����Ȃ��̂ɋL���Ȃ�ď�����킯�Ȃ������
9�������̃C�x���g���A4�T�̃C���^�r���[�̍Ō��
���͂���܂������Ď����1�������݂����ɓ����Ă�����
��������������H
���̋L���ǂƂ��͉����V���i��\�肵�Ă�̂��Ǝv�����̂�
�����Ȃ��������
�����Ȃ��̂ɋL���Ȃ�ď�����킯�Ȃ������
9�������̃C�x���g���A4�T�̃C���^�r���[�̍Ō��
���͂���܂������Ď����1�������݂����ɓ����Ă�����
��������������H
���̋L���ǂƂ��͉����V���i��\�肵�Ă�̂��Ǝv�����̂�
�����Ȃ��������
�r�����h�A�[�X���������ꂽ����Mantle�Ή����Ă��Ƃł������L�����łĂ�����
�A�����������������́H
Radeon���₽�玝���グ�Ă�A���͓��R����Ă��ˁH
�A�����������������́H
Radeon���₽�玝���グ�Ă�A���͓��R����Ă��ˁH
609 �F,,�E�L�́M�E,,�j��-�������F2015/02/24(��) 00:43:48.30 ID:MMHemARs
3�����x��Ō�������X�p��Ƀ��r���[�˗�������悤�ȃ��x���Ȃ̂�
���@�����������B
���@�����������B
>>607
������GTX750�̐VPC�̐�`������Ă邭�炢�Ȃ�
���i�Ɛ�`�͂ǂ�������Ƃ�����Ȃ��A�������s�݂����Ȃ���
����ɔN����̃C�x���g�łǂ������Ƃ�����Ȗ�肶��Ȃ���
�~�������Ɍ����������ɁA�V���i�̐�`��A�������i�̔�r�A�����L���O�Ƃ����Ĕ�������
�����S�Ă��C���e���Q�t�H�Ő�߂��Ă邩��AAMD�������邱�Ƃ͂Ȃ�
�ߋ��̃C���e���̈��s���A���ɍ��t���Ē蒅���Ă邩��A�a��������P����Ȃ��܂܍��Ɏ����Ă邾��
�a��O�̈����ȖW�Q�ŁA���v��c�ƖԂ����������D���Ă邩��A�ǂ�����Ă��҉�ł��ĂȂ���
����ł��J�������͈ێ����Ă邩��A
APU���J������PS4�┠1�ɍ̗p����邵�A390x������ăQ�t�H�Ɠn�荇���邵�ASkyBridge�Ƃ�����x86��ARM�̐V�R�A�ƃv���b�g�t�H�[�������邵�A2017�N�ɂ́A�n�C�G���hAPU��32�R�AOpteron�Ƃ������Ă�
SkyBridge�ƁA�n�C�G���hAPU�́AAMD��ATI�������Ă����Fusion�\�z�̓��B�_������A�J���𑱂��Ă����Ǝv��
�n�C�G���hAPU�́A����APU�̎�_��S�ĉ���������������A���Ȃ苣���͂͂���
����ɍ~��Ă��邩�͔��������ǁAHPC��X�p�R���ɍ̗p����Ă����̂��y���݂���
������GTX750�̐VPC�̐�`������Ă邭�炢�Ȃ�
���i�Ɛ�`�͂ǂ�������Ƃ�����Ȃ��A�������s�݂����Ȃ���
����ɔN����̃C�x���g�łǂ������Ƃ�����Ȗ�肶��Ȃ���
�~�������Ɍ����������ɁA�V���i�̐�`��A�������i�̔�r�A�����L���O�Ƃ����Ĕ�������
�����S�Ă��C���e���Q�t�H�Ő�߂��Ă邩��AAMD�������邱�Ƃ͂Ȃ�
�ߋ��̃C���e���̈��s���A���ɍ��t���Ē蒅���Ă邩��A�a��������P����Ȃ��܂܍��Ɏ����Ă邾��
�a��O�̈����ȖW�Q�ŁA���v��c�ƖԂ����������D���Ă邩��A�ǂ�����Ă��҉�ł��ĂȂ���
����ł��J�������͈ێ����Ă邩��A
APU���J������PS4�┠1�ɍ̗p����邵�A390x������ăQ�t�H�Ɠn�荇���邵�ASkyBridge�Ƃ�����x86��ARM�̐V�R�A�ƃv���b�g�t�H�[�������邵�A2017�N�ɂ́A�n�C�G���hAPU��32�R�AOpteron�Ƃ������Ă�
SkyBridge�ƁA�n�C�G���hAPU�́AAMD��ATI�������Ă����Fusion�\�z�̓��B�_������A�J���𑱂��Ă����Ǝv��
�n�C�G���hAPU�́A����APU�̎�_��S�ĉ���������������A���Ȃ苣���͂͂���
����ɍ~��Ă��邩�͔��������ǁAHPC��X�p�R���ɍ̗p����Ă����̂��y���݂���
>>608
�������L��������������
����Ȃ���A�c��ȑ��̃Q�[���̋L���ŏ����Ă�������
����I�ɓ��W�������A����PC�o�������Ȃ��ƈӖ��͖���
BF4��h���S���G�b�W�ATheif�Ƃ��������A�����O��ŏ����L���������������ŁA�����ጇ�Ђ�����ȋL���͂Ȃ�
�������L��������������
����Ȃ���A�c��ȑ��̃Q�[���̋L���ŏ����Ă�������
����I�ɓ��W�������A����PC�o�������Ȃ��ƈӖ��͖���
BF4��h���S���G�b�W�ATheif�Ƃ��������A�����O��ŏ����L���������������ŁA�����ጇ�Ђ�����ȋL���͂Ȃ�
2000�N �f���A���R�APOWER4
��
2005�N�̓f���A���R�A���N�I���E���f���A���R�AAthlon64 X2�I
2003�N �N�A�b�h�R�APOWER5�A1�R�A2�X���b�hSMT
��
2007�N�A���ɃN�A�b�h�R�ACPU���o��IPhenom X4�I
2010�N2�� TurboCore���[�h�������POWER7�A1�R�A������4�X���b�hSMT
��
���N Turbo CORE��������Phenom II X6
2007�N �I�[�o�[5GHz POWER6
��
2013�N ���E����5GHz�AFX-9590�I(��i4.7GHz)
2014�N 12�R�A96�X���b�hSMT�APOWER8
��
2016�N(AMD����) ���E���ISMT����CPU�I�Ȃ�ƁI1�R�A������2�X���b�h�������Ă��܂��I���ꂩ���SMT�̎���IIntel�����ǂ��Ă��邩�ȁH
��
2005�N�̓f���A���R�A���N�I���E���f���A���R�AAthlon64 X2�I
2003�N �N�A�b�h�R�APOWER5�A1�R�A2�X���b�hSMT
��
2007�N�A���ɃN�A�b�h�R�ACPU���o��IPhenom X4�I
2010�N2�� TurboCore���[�h�������POWER7�A1�R�A������4�X���b�hSMT
��
���N Turbo CORE��������Phenom II X6
2007�N �I�[�o�[5GHz POWER6
��
2013�N ���E����5GHz�AFX-9590�I(��i4.7GHz)
2014�N 12�R�A96�X���b�hSMT�APOWER8
��
2016�N(AMD����) ���E���ISMT����CPU�I�Ȃ�ƁI1�R�A������2�X���b�h�������Ă��܂��I���ꂩ���SMT�̎���IIntel�����ǂ��Ă��邩�ȁH
�~�b�h�R�A�Ȃ�ăn�C�G���h���Ȃ��n�R�l�̎M�ɂ������
�n�C�G���h������邩��~�h�������W������Ă�������
����AMD�ɂ͔����n�C�G���h���Ȃ�����A�~�h���R�A�������Ă��ǂ�������Ȃ���
�����炱���A290x���o�������̓��l�[���ł����Ȃ�280x�����łɔ���Ă�
290x�����݂���������A285�����ꂽ
����ǁA290x��980�ɗ����甄��Ȃ��Ȃ���
���o���ׂ��Ȃ̂́A����Ȃ��~�h������Ȃ��A�R�ł���n�C�G���h�Ȃ�
390x��SM200�ƌ݊p�ȏ�Ȃ�A���ł�290x��285������Ă������낤��
�n�C�G���h������邩��~�h�������W������Ă�������
����AMD�ɂ͔����n�C�G���h���Ȃ�����A�~�h���R�A�������Ă��ǂ�������Ȃ���
�����炱���A290x���o�������̓��l�[���ł����Ȃ�280x�����łɔ���Ă�
290x�����݂���������A285�����ꂽ
����ǁA290x��980�ɗ����甄��Ȃ��Ȃ���
���o���ׂ��Ȃ̂́A����Ȃ��~�h������Ȃ��A�R�ł���n�C�G���h�Ȃ�
390x��SM200�ƌ݊p�ȏ�Ȃ�A���ł�290x��285������Ă������낤��
615 �F,,�E�L�́M�E,,�j��-�������F2015/02/24(��) 02:25:19.72 ID:MMHemARs
�~�b�h�����W���x���̐ݒ�Ȃ�Intel HD Graphics�ŗ]�T�œ������Ă��܂�
�Ƃ������ނ���Civ5 BNW�����y��
���삪�y����������Ȃ��Đ��E�ς��V�X�e�����y��
Civ5 BNW���獡�܂ł�Civ�̕��@�I�v�f�Ɨ��j�I�̐l�E����������蕥�����c��J�X��
SF�v�f�𑫂����̂�BE
�Ƃ������ނ���Civ5 BNW�����y��
���삪�y����������Ȃ��Đ��E�ς��V�X�e�����y��
Civ5 BNW���獡�܂ł�Civ�̕��@�I�v�f�Ɨ��j�I�̐l�E����������蕥�����c��J�X��
SF�v�f�𑫂����̂�BE
�c�q�͓��{�ꂪ�s���R�݂�������
613��614�̃~�b�h�̓~�h�������WGPU���ĈӖ�����
�Q�[���̃~�h���ݒ肶��Ȃ������
���łɌ����ƁA�o�O���炯�Ŋo�����\�����HD�O���t�B�b�N�Ƃ��C���e���g���ł��S�~����������
���܂�ɂ��c�O�����ĒN���g��Ȃ�����A��Q���Ȃ��đi�ׂɂȂ�Ȃ������̑㕨
DX12�Ή��̂܂Ƃ��ȃh���C�o����ꂽ�炻�̎��Ɏ������Ă���
613��614�̃~�b�h�̓~�h�������WGPU���ĈӖ�����
�Q�[���̃~�h���ݒ肶��Ȃ������
���łɌ����ƁA�o�O���炯�Ŋo�����\�����HD�O���t�B�b�N�Ƃ��C���e���g���ł��S�~����������
���܂�ɂ��c�O�����ĒN���g��Ȃ�����A��Q���Ȃ��đi�ׂɂȂ�Ȃ������̑㕨
DX12�Ή��̂܂Ƃ��ȃh���C�o����ꂽ�炻�̎��Ɏ������Ă���
617 �F,,�E�L�́M�E,,�j��-�������F2015/02/24(��) 02:48:00.26 ID:MMHemARs
618 �F,,�E�L�́M�E,,�j��-�������F2015/02/24(��) 02:55:28.89 ID:MMHemARs
HD4000��CivBE�v���C���Ă铮�悠�邩�猩�Ă݂���H
https://www.youtube.com/watch?v=6TQq6WyfSM0
Haswell�Ȃ�t��HD�ł����̃N�I���e�B�ł������
���̓_�AAPU����CPU���\���Ⴂ��AI�̑҂����Ԃ��������i����ȃC���[�W
�Ƃ�����YouTube�Ƀv���C���|�[�g�������Ă��
Mantle�Ή��Ńv���C���Ă�z�قƂ�ǂ��Ȃ��Ƃ���������������
https://www.youtube.com/watch?v=6TQq6WyfSM0
Haswell�Ȃ�t��HD�ł����̃N�I���e�B�ł������
���̓_�AAPU����CPU���\���Ⴂ��AI�̑҂����Ԃ��������i����ȃC���[�W
�Ƃ�����YouTube�Ƀv���C���|�[�g�������Ă��
Mantle�Ή��Ńv���C���Ă�z�قƂ�ǂ��Ȃ��Ƃ���������������
raptr��Mantle�ł��^��ł���悤�ɂȂ����̂����ŋ߂������
�����ɒm��Ȃ��l�����邩������Ȃ���
�����ɒm��Ȃ��l�����邩������Ȃ���
620 �F,,�E�L�́M�E,,�j��-�������F2015/02/24(��) 03:05:26.94 ID:MMHemARs
�Ă�7850K���ăm�[�gPC��i3���V���O���X���b�h���\�Ⴂ����
Civ��AI��Lua���Ă����X�N���v�g����őg�܂�Ă邩���
�x��CPU�͂܂��_�O
AI�^�[���̑҂����ԂŃX�g���X���܂��
Civ��AI��Lua���Ă����X�N���v�g����őg�܂�Ă邩���
�x��CPU�͂܂��_�O
AI�^�[���̑҂����ԂŃX�g���X���܂��
FX-8800P
http://www.3dmark.com/3dm11/9453670
FX-7600P�̃X�R�A�Ɣ�r����Ə����ɏオ���Ă���݂�������
http://www.legitreviews.com/wp-content/uploads/2014/06/3dmark11-645x407.jpg
http://www.3dmark.com/3dm11/9453670
FX-7600P�̃X�R�A�Ɣ�r����Ə����ɏオ���Ă���݂�������
http://www.legitreviews.com/wp-content/uploads/2014/06/3dmark11-645x407.jpg
{kind=link}
The Industrial Internet is transforming businesses
http://community.amd.com/community/amd-blogs/amd-business/blog/2015/02/23/
http://community.amd.com/community/amd-blogs/amd-business/blog/2015/02/23/
>>621
�����X�R�A�ƃO���t�B�b�N�X�R�A��2400�g����A10-7850k���ザ��Ȃ���
http://www.technic3d.com/review/cpu-s/1648-amd-a10-7850k-kaveri-apu-im-test/11.htm
AMD FX-8800P
Score P2645
Graphics Score 2700
Physics Score 3128
A0-7850k
Score P2577
Graphics Score 2391
Physics Score ?
�����X�R�A�ƃO���t�B�b�N�X�R�A��2400�g����A10-7850k���ザ��Ȃ���
http://www.technic3d.com/review/cpu-s/1648-amd-a10-7850k-kaveri-apu-im-test/11.htm
AMD FX-8800P
Score P2645
Graphics Score 2700
Physics Score 3128
A0-7850k
Score P2577
Graphics Score 2391
Physics Score ?
>>593
�j���A���X�̖�肾���ǂ���͔ėp������Ȃ���
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20131025_620789.html
�����̌��t������hQ��GPU��CPU�̃X���[�u����}�X�^�[�ւƉ�������ʂ�������
���Z�̂ق��̍\����ς��Ȃ��ᓾ�ӕ���E�u�p�v�r�͕ς��Ȃ�
�i���[�U�[���_�̘b�ł�����PC���_���炾�ƃ}�X�^�[���ėp���낤���ǁj
�g���X�L���b�V�����݂̃E�B�����b�g���}�X�^�[CPU������
�c�{�ɛƂ镨���������X�L�}�ȊO�ł͑S�R���\���o��
SSE2�Ō떂�����ĉ��Ƃ�����ɏo�����̂Ɏ��Ă���
������AMD��x86�EARM�EGPU���߂�3�{���Ă������
���N���N���̂���
�j���A���X�̖�肾���ǂ���͔ėp������Ȃ���
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20131025_620789.html
�����̌��t������hQ��GPU��CPU�̃X���[�u����}�X�^�[�ւƉ�������ʂ�������
���Z�̂ق��̍\����ς��Ȃ��ᓾ�ӕ���E�u�p�v�r�͕ς��Ȃ�
�i���[�U�[���_�̘b�ł�����PC���_���炾�ƃ}�X�^�[���ėp���낤���ǁj
�g���X�L���b�V�����݂̃E�B�����b�g���}�X�^�[CPU������
�c�{�ɛƂ镨���������X�L�}�ȊO�ł͑S�R���\���o��
SSE2�Ō떂�����ĉ��Ƃ�����ɏo�����̂Ɏ��Ă���
������AMD��x86�EARM�EGPU���߂�3�{���Ă������
���N���N���̂���
AMD�C����APU�uCarrizo�v�̏ڍ������J�BKaveri�Ɠ���28nm�v���Z�X�Z�p���̗p���Ȃ���g�����W�X�^����29�����ʂł����閧�Ƃ�
ttp://www.4gamer.net/games/282/G028229/20150223061/
ttp://www.4gamer.net/games/282/G028229/20150223061/
CPU�̃V���O���X���b�h���\�̌���͑����Ë����āA
�`�b�v�S�̂̐��\�A�b�v�A�d�͂Ƃ̃o�����X�ɗ͂����������ɕς�������Ă��Ƃ���
����AMD���咣����悤�ɃG���h���[�U�[�̗p�r��
GPU�����p����A�v���������邩�ǂ���������
�`�b�v�S�̂̐��\�A�b�v�A�d�͂Ƃ̃o�����X�ɗ͂����������ɕς�������Ă��Ƃ���
����AMD���咣����悤�ɃG���h���[�U�[�̗p�r��
GPU�����p����A�v���������邩�ǂ���������
627 �FSocket774�F2015/02/24(��) 12:17:21.61 ID:JpOCh2cY
�`�o�t�̂f�o�t���\�Ȃ�Ă��܂����x�������ȁB
628 �FSocket774�F2015/02/24(��) 15:16:32.15 ID:BvNXgNsM
�m�[�g�p�\�R����➑̂��ƁA�O���{���ڂ���Ƃ��炭�͂������A
���̂�15�����x�ł��������ĉΏ������܂�����ȁB
APU�ŗ₦�₦�Ȃ炻�̕������K�B
���̂�15�����x�ł��������ĉΏ������܂�����ȁB
APU�ŗ₦�₦�Ȃ炻�̕������K�B
GX60�AE455�Ƃ��ɁA�ɒ[�ȉ��M�Ȃ�Ĕ������Ȃ�����
����GPU�̐��\�Ȃ�Ă�������ꂽ�w�ɂ����Ȃ�����
GPU��������č����i�т�intel�ɂ͐^���ł��Ȃ�6�`8�R�A�����Ă�
�������̂ق����A�s�[���ɂȂ�A�u���n�A�[�L�̓R�A���₵�ĂȂ��
GPU��������č����i�т�intel�ɂ͐^���ł��Ȃ�6�`8�R�A�����Ă�
�������̂ق����A�s�[���ɂȂ�A�u���n�A�[�L�̓R�A���₵�ĂȂ��
631 �FSocket774�F2015/02/24(��) 18:58:50.70 ID:JpOCh2cY
�u�I�[�o�N���b�N�������ŁA�����f�o�t�̐��\���オ�������v�Ȃ�āA
���S�Ȃ`�l�c�M�҂̃I�i�j�[
���S�Ȃ`�l�c�M�҂̃I�i�j�[
�� CPU Hierarchy Chart 2015
AMD�ߎS�������
�܂�ŏ����ɂȂ��ĂȂ���
6�N�O�̐ɂ��畉���Ă��
������x��Ȃ���
http://www.tomshardware.com/reviews/gaming-cpu-review-overclock,3106-5.html
AMD�ߎS�������
�܂�ŏ����ɂȂ��ĂȂ���
6�N�O�̐ɂ��畉���Ă��
������x��Ȃ���
http://www.tomshardware.com/reviews/gaming-cpu-review-overclock,3106-5.html
Carrizo�����\���ꂽ�Ƃ��͍��N�̍��������[�X�����e���Ǝv���Ă��̂�
�܂���Windows10���킹�Ƃ͎v��Ȃ�������
�܂���Windows10���킹�Ƃ͎v��Ȃ�������
634 �FSocket774�F2015/02/24(��) 20:14:45.55 ID:endjnTMt
���ŁH
�m�[�g�p����H
�m�[�g�p����H
Llano�o��̋łɂ�
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
�� 2014�N �����̔��ド���L���O
http://eetimes.jp/ee/articles/1412/25/news147.html
��AMD�A2014�N�x��4���h���̐Ԏ�
http://pc.watch.impress.co.jp/docs/news/20150121_684660.html
AMD�̏��ʂ������}�~���ЂƂ蕉���_(^o^)�^
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
�� 2014�N �����̔��ド���L���O
http://eetimes.jp/ee/articles/1412/25/news147.html
��AMD�A2014�N�x��4���h���̐Ԏ�
http://pc.watch.impress.co.jp/docs/news/20150121_684660.html
AMD�̏��ʂ������}�~���ЂƂ蕉���_(^o^)�^
AMD�̒��̐l�͋C�Â��Ȃ��̂���
Carrizo�͂�������kaveri���X�y�[�X�ł����Ȃ�
���̕�����GDDR5 512MB���炢������ΊԈႢ�Ȃ�����GPU�͍��x���`�}�[�N�o����̂ɂ�
�Ȃ��������[�����Ȃ��낤��
Carrizo�͂�������kaveri���X�y�[�X�ł����Ȃ�
���̕�����GDDR5 512MB���炢������ΊԈႢ�Ȃ�����GPU�͍��x���`�}�[�N�o����̂ɂ�
�Ȃ��������[�����Ȃ��낤��
>>636
APU�Ƃ��̃��W�b�N�����v���Z�X�ƁAGDDR5�Ƃ���DRAM�v���Z�X�͑S���Ⴄ
APU�Ƃ��̃��W�b�N�����v���Z�X�ƁAGDDR5�Ƃ���DRAM�v���Z�X�͑S���Ⴄ
512MB��GDDR5����bit�Őڑ�������Ă����c
GDDR5�ɖ������Ă�ӂ�A�Q�n����̂��q����Ȃ�Ȃ�����
��������GDDR5���ŐV�Ŋ��S�����Ȗ��@�̃�������������Ă邩��
��������GDDR5���ŐV�Ŋ��S�����Ȗ��@�̃�������������Ă邩��
>>638
32bit
32bit
8Gbit/32bit�ڑ���GDDR5�`�b�v�Ȃ�A
8�g�����傤��8GByte�Ńg�[�^��256bit�ڑ�
8�g�����傤��8GByte�Ńg�[�^��256bit�ڑ�
���{�l�Ȃ�C���e���Q�t�H������˂�
>>639
APU�Ńl�b�N�ɂȂ��Ă�̂͌��ǃ������[�����
DDR4�Ή����Ă�킯����Ȃ�
�g���v���N�A�g���`�����l���Ή����Ă�킯����Ȃ�
APU�P�̂̐��\���ǂ��Ă��������[�ňӖ����Ȃ��Ȃ�C������
�����炱��APU�{�̂�GDDR5�����Ē��Ōq����Ζ��������Ǝv��
APU�Ńl�b�N�ɂȂ��Ă�̂͌��ǃ������[�����
DDR4�Ή����Ă�킯����Ȃ�
�g���v���N�A�g���`�����l���Ή����Ă�킯����Ȃ�
APU�P�̂̐��\���ǂ��Ă��������[�ňӖ����Ȃ��Ȃ�C������
�����炱��APU�{�̂�GDDR5�����Ē��Ōq����Ζ��������Ǝv��
>>643
GDDR5�̃`�b�v1������28GB/sec�����ςނ́H
GDDR5�̃`�b�v1������28GB/sec�����ςނ́H
�����炱��HBM���o�Ă�����Ȃ��̂���
�f���ɂ��������҂��Ă�����Ǝv����
�f���ɂ��������҂��Ă�����Ǝv����
���ʂɃ��W���[���𑝂₵�ė~����
DDR4�Ή����Ă��ꂽ������O���b�t�B�N�������Ɛ��\�オ�邾�낤�Ȃ�
DDR4-3300���g������g���Ă݂�����
DDR4-3300���g������g���Ă݂�����
DDR4�ɂ��Ή����邵���W���[�����{�ɂȂ�
������2016�N�ɂ�
������2016�N�ɂ�
>>641
�\�P�b�g�ɂ͎��܂��APU�h�[�^�[�{�[�h��
�\�P�b�g�ɂ͎��܂��APU�h�[�^�[�{�[�h��
Nvidia���V�F�A76%���l���B 2014�N�̃r�f�I�J�[�h�s��
http://hibisaca.seesaa.net/article/414630595.html
http://hibisaca.seesaa.net/article/414630595.html
���{�Q�t�H84%�̎���
���{�l�Ȃ�C���e���Q�t�H���
���{�l�Ȃ�C���e���Q�t�H���
DDR4�|FX�|APU�|HBM
�@�@�@�@�b
�@�@�@�@�b
�@�@�@�@�b
�@�@�@�@GPU�iHBM�j
����Ȋ����ɂ�����ʔ������Ȃ��ȁ[
�@�@�@�@
�@�@�@�@�b
�@�@�@�@�b
�@�@�@�@�b
�@�@�@�@GPU�iHBM�j
����Ȋ����ɂ�����ʔ������Ȃ��ȁ[
�@�@�@�@
653 �FSocket774�F2015/02/25(��) 13:27:45.47 ID:4vhbBHvR
DDR4�ɑΉ�����Ȃ�n�߂�2133����Ȃ��́H
655 �FSocket774�F2015/02/25(��) 15:52:31.50 ID:lQ7ZMsaH
�Q�t�H�ƌ����Ă��A�s���L���������
�@TITAN Z�@�`�@210
�@TITAN Z�@�`�@210
�k�r���\�̓z�ꂪ76%������̂�
���̒���8���̓{���N���Ƃ������ǁA�m���ɂ�������
���̒���8���̓{���N���Ƃ������ǁA�m���ɂ�������
APU�̃������̑ш�s���͐[��������AHBM��DDR�̃n�C�u���b�g�������ɂ��낻�낵�ė~����
HBM���ƍ��������ǃR�X�g��������A�i�V�A1G�A2G�Ƃ��}�U�[�̃O���[�h�œ��ڗʂ��ς�����
�\�P�b�g7�̎��̊O��TAG RAM��L2�L���b�V����AGPU�����`�b�v�Z�b�g�̃o�b�t�@�������݂����Ȋ����ŏo���Ă����
HBM���ƍ��������ǃR�X�g��������A�i�V�A1G�A2G�Ƃ��}�U�[�̃O���[�h�œ��ڗʂ��ς�����
�\�P�b�g7�̎��̊O��TAG RAM��L2�L���b�V����AGPU�����`�b�v�Z�b�g�̃o�b�t�@�������݂����Ȋ����ŏo���Ă����
DDR3 2400 8GBx2�ȃ��������g���Ă���
�Е��Ƀ������G���[���o�Ă��܂������̂��̐�]���͂Ȃ��Ȃ��B
�������͊�{�I�ɉi�v�ۏ����烁�[�J���肷���������
�߂��Ă���܂ł̑ւ��������������Ƃ��͂ق�Ǝ��ʂ�ȁB
�Е��Ƀ������G���[���o�Ă��܂������̂��̐�]���͂Ȃ��Ȃ��B
�������͊�{�I�ɉi�v�ۏ����烁�[�J���肷���������
�߂��Ă���܂ł̑ւ��������������Ƃ��͂ق�Ǝ��ʂ�ȁB
659 �FSocket774�F2015/02/25(��) 21:18:09.64 ID:EP5mbbmL
�ނ���HBM�ɂ���Ȃ�DDR4�����̂���ˁH
�u�i�v�ۏv���Ă����ƋK��ǂق���������
�{���ɉi�v�ۏ����킯����Ȃ�
�{���ɉi�v�ۏ����킯����Ȃ�
661 �FSocket774�F2015/02/25(��) 21:55:49.64 ID:lQ7ZMsaH
�ǂ��܂œd�����グ�����L�^����郁�����ɓ���ȗ̈悪���邩���
662 �FSocket774�F2015/02/26(��) 01:38:08.92 ID:bZEhGSib
> AMD��Analyst Day�̓x�ɁA�O�N��Analyst Day�Ŕ��\�����R�[�h�l�[���̔�����j���A
> �V���ɑ����̃R�[�h�l�[���\����B
http://pc.watch.impress.co.jp/docs/column/kaigai/20120203_509658.html
�E�\�A��U���A�}�M�����V�C
�n�i�V�����̍��\�t�A���h_��(�_�
> �V���ɑ����̃R�[�h�l�[���\����B
http://pc.watch.impress.co.jp/docs/column/kaigai/20120203_509658.html
�E�\�A��U���A�}�M�����V�C
�n�i�V�����̍��\�t�A���h_��(�_�
����AMD��20nm�Ή���Amur�������楥�Nolan���疳�����Ƃ�
Amur��TegraX1���Ƃ͌���Ȃ�����K1���x�̐��\�͂���낤�ȁH
Amur��TegraX1���Ƃ͌���Ȃ�����K1���x�̐��\�͂���낤�ȁH
Amul�Ƈ�lan��SkyBridge�̎o���R�A�̂͂�����
�����ʃv���Z�X�Ƃ����肦�Ȃ�����
Tegra�Ƃ��������X���J�X�Ƃ��ǂ��ł�������
�����ʃv���Z�X�Ƃ����肦�Ȃ�����
Tegra�Ƃ��������X���J�X�Ƃ��ǂ��ł�������
AMD�́A�����炭������Bull�nx86MA�����ǂ��Ȃ���A
Bull�n����Ȃ��Vx86MA���J�����Ă�͂�
�ŁA�Vx86MA�̂߂ǂ�������ABull�nMA���I��������
�Vx86MA�Ɉڍs�����Ȃ�����
����Bull�nMA���j�����ꂽ�Ȃ�A�Vx86MA�̊J�������������I�����
�����[�X�������ł����Ƃ������ƂȋC�������
Bull�n����Ȃ��Vx86MA���J�����Ă�͂�
�ŁA�Vx86MA�̂߂ǂ�������ABull�nMA���I��������
�Vx86MA�Ɉڍs�����Ȃ�����
����Bull�nMA���j�����ꂽ�Ȃ�A�Vx86MA�̊J�������������I�����
�����[�X�������ł����Ƃ������ƂȋC�������
���O���N�Q�����H
Zen��K12�ŃO�O��A�b�͂��ꂩ�炾
Zen��K12�ŃO�O��A�b�͂��ꂩ�炾
AMD��������APU�uCarrizo�v�̒����d�͂̔閧�����J
http://pc.watch.impress.co.jp/docs/column/kaigai/20150226_690092.html
http://pc.watch.impress.co.jp/docs/column/kaigai/20150226_690092.html
oh
�����݂��炳�肰�Ȃ�DDR4�T�|�[�g�Ə����Ă���ެ�
�z���g���肰�Ȃ������ăX���[����Ƃ��낾����
�����݂��炳�肰�Ȃ�DDR4�T�|�[�g�Ə����Ă���ެ�
�z���g���肰�Ȃ������ăX���[����Ƃ��낾����
AMD�̎�����APU�ł���gNolan�h�ƁgAmur�h��AMD�Ƃ��Ă͏���20nm�v���Z�X�Ő��������APU�ƂȂ�ƌ����Ă����B
�������AWCCF Tech���̐V���ȏ��ɂ��ƁgNolan�h��28nm�v���Z�X�Ő�������A20nm�v���Z�X�Ő��������̂́gAmur�h�݂̂ƂȂ�B
http://northwood.blog60.fc2.com/blog-entry-7961.html
�������AWCCF Tech���̐V���ȏ��ɂ��ƁgNolan�h��28nm�v���Z�X�Ő�������A20nm�v���Z�X�Ő��������̂́gAmur�h�݂̂ƂȂ�B
http://northwood.blog60.fc2.com/blog-entry-7961.html
>>669
https://www.linkedin.com/pub/srinivas-choudary/6/417/397?trk=pub-pbmap
>Involved in 3 very successful projects: Kabini (TSMC28HP), Bhavani (GF28A) and Nolan
(GF20LPM).
https://www.linkedin.com/pub/srinivas-choudary/6/417/397?trk=pub-pbmap
>Involved in 3 very successful projects: Kabini (TSMC28HP), Bhavani (GF28A) and Nolan
(GF20LPM).
Llano�o��̋łɂ�
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
�� 2014�N �����̔��ド���L���O
http://eetimes.jp/ee/articles/1412/25/news147.html
��AMD�A2014�N�x��4���h���̐Ԏ�
http://pc.watch.impress.co.jp/docs/news/20150121_684660.html
AMD�̏��ʂ������}�~���ЂƂ蕉���_(^o^)�^
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
�� 2014�N �����̔��ド���L���O
http://eetimes.jp/ee/articles/1412/25/news147.html
��AMD�A2014�N�x��4���h���̐Ԏ�
http://pc.watch.impress.co.jp/docs/news/20150121_684660.html
AMD�̏��ʂ������}�~���ЂƂ蕉���_(^o^)�^
�v���Ԃ�ɗ�������>620�����������߂ċA���B
Carrizo�o������X���ɗ��Ă݂����ǂȁB
Carrizo�o������X���ɗ��Ă݂����ǂȁB
>>667
Carrizo�iexcavator�j�������グ�Ă邯��25w���x��steamrollor�Ɠ����ɂȂ����Ⴄ�̂�
�f�X�N�����Ƃ��Ăǂ��Ȃ낤�E�E�B
Carrizo�iexcavator�j�������グ�Ă邯��25w���x��steamrollor�Ɠ����ɂȂ����Ⴄ�̂�
�f�X�N�����Ƃ��Ăǂ��Ȃ낤�E�E�B
���{�l�Ȃ�C���e���Q�t�H������˂�
�㓡�����ŋ߃n�[�h�̋L���������悤�ɂȂ��Ă��Ɗ������B
�v���Z�X�̘b�͐��Y����ɂ������đ厖�����AIoT�̉���ƕ����ď��Ȗڂł悢�B
�v���Z�X�̘b�͐��Y����ɂ������đ厖�����AIoT�̉���ƕ����ď��Ȗڂł悢�B
>667
> 9T�Z���ɕύX����A���̕��A�����d�����̓�����g���͗�����BAMD�ɂ��ƁA
> ���g���ɑ���e����10%���x�܂ł��Ƃ����B�������AAPU�̏ꍇ��
> ����d�͂������邱�ƂŁA�t�ɓ�����g�����グ��]�T���ł���ƌ����B
> ��荂�d���ŋ쓮���Ď��g�����グ�邱�Ƃ��\�ɂȂ邩�炾�B
> 9T�Z���ɕύX����A���̕��A�����d�����̓�����g���͗�����BAMD�ɂ��ƁA
> ���g���ɑ���e����10%���x�܂ł��Ƃ����B�������AAPU�̏ꍇ��
> ����d�͂������邱�ƂŁA�t�ɓ�����g�����グ��]�T���ł���ƌ����B
> ��荂�d���ŋ쓮���Ď��g�����グ�邱�Ƃ��\�ɂȂ邩�炾�B
�匴�̓��o�C�������v���Z�X���g���ȏ�A��ΐ��\��Carrizo��Kaveri�ɋy�Ȃ�
�\�����傫���Ɨ\�����Ă����ǂǂ��Ȃ邱�Ƃ��
�\�����傫���Ɨ\�����Ă����ǂǂ��Ȃ邱�Ƃ��
���ہA�f�X�N�������L�����Z�����ꂽ���R���A�p�t�H�[�}���X�̍������҂����قǖ������炾�낤��
FullHD14�C���`�m�[�g�p�Ƃ��Ċ��҂��Ă邯�ǁA��������ɂ͗��N�ȍ~�Ɋ��҂��ȁB
FullHD14�C���`�m�[�g�p�Ƃ��Ċ��҂��Ă邯�ǁA��������ɂ͗��N�ȍ~�Ɋ��҂��ȁB
679 �FSocket774�F2015/02/26(��) 20:11:57.12 ID:mruFzKS9
28�ƌ������l���x����߂��B
�Ⴆ�A20nm��14nm�ł͐��l�������Ă邪�ς���ĂȂ��B
20nm�v���Z�X��FinFET�ɉ��ǂ����̂�16nn��������14nm�������肷��B
���ۂ�intel14nm�v���Z�X�Ɣ�r���Ă��������č����Ȃ��B
�Ⴆ�A20nm��14nm�ł͐��l�������Ă邪�ς���ĂȂ��B
20nm�v���Z�X��FinFET�ɉ��ǂ����̂�16nn��������14nm�������肷��B
���ۂ�intel14nm�v���Z�X�Ɣ�r���Ă��������č����Ȃ��B
{kind=link}
Intel�͕ʊi�����ǁATSMC�i16nm+�j/�T���X���Ƃ���finfet���ň��菬�����Ȃ��Ă�ˁB
>>679
���̘b���Ɨ]�v�A����28nm��Carrizo�����҂ł��Ȃ��Ƃ����b�ɂȂ邾����
���̘b���Ɨ]�v�A����28nm��Carrizo�����҂ł��Ȃ��Ƃ����b�ɂȂ邾����
>>679�搶�ɂ��ƁAZen���債�����Ƃ��Ȃ��炵����
Carrizo��28nm�́A�o�����ǂ����čő�28nm����Ȃ����
����AAMD�̖��������D�G������̂��낤����
http://pc.watch.impress.co.jp/img/pcw/docs/664/921/11.jpg
���̐}�ł����Ƃǂꂭ�炢�̂��낤��
����AAMD�̖��������D�G������̂��낤����
http://pc.watch.impress.co.jp/img/pcw/docs/664/921/11.jpg
���̐}�ł����Ƃǂꂭ�炢�̂��낤��
�����v���Z�X�ŋƊE�ɒx����Ƃ��Ă�Ƃ���GF�ɎӍ߂Ɣ�����v��
GF�̐����v���Z�X���]��������AMD�̃v���Z�X�݂����Ȉ���
GF�̐����v���Z�X���]��������AMD�̃v���Z�X�݂����Ȉ���
�}�U�[��CPU���F�X��������Ȃ���
VGA��CPU������čs�������낤�Ȃ����Ďv��
VGA��CPU������čs�������낤�Ȃ����Ďv��
�Q�[�g�Ƃ��̃s�b�`�͕ς���ĂȂ���Ȃ���
GF�͌�AMD������ȁA���łɌ�����APU��28nm�v���Z�X��AMD���J���ɖ��ڂɊւ���Ă�
689 �FSocket774�F2015/02/26(��) 21:11:30.47 ID:mruFzKS9
>>680
������pcwatch���A�\�[�X�Ȃ̂͂����������Č����Ă�́B
�_�C�T�C�Y�ӂ�ɂǂꂾ���̃g�����W�X�^�[��ς߂邩�H
���ꂪ�{���̈Ӗ��̐����v���Z�X�B
������pcwatch���A�\�[�X�Ȃ̂͂����������Č����Ă�́B
�_�C�T�C�Y�ӂ�ɂǂꂾ���̃g�����W�X�^�[��ς߂邩�H
���ꂪ�{���̈Ӗ��̐����v���Z�X�B
�v���Z�X���オ���Ă��A�̂ƈ���ĒP���ȃV�������N�͏o���Ȃ���
���������v���Z�X�ł��v�Z�p�ŏW�ϓx�͂������邵
�t�ɍŐV�̃v���Z�X�ł��v�Z�p�̐ςݏd�˂��Ȃ���ΐ����ʂ�̏W�ϓx����͓����Ȃ��B
�ʂɂ������Șb�ł����ł��Ȃ��悤�ȋC�����邪��
���������v���Z�X�ł��v�Z�p�ŏW�ϓx�͂������邵
�t�ɍŐV�̃v���Z�X�ł��v�Z�p�̐ςݏd�˂��Ȃ���ΐ����ʂ�̏W�ϓx����͓����Ȃ��B
�ʂɂ������Șb�ł����ł��Ȃ��悤�ȋC�����邪��
����nm���ՂƏI�Ղ̍����傫���AAMD�͐̂��炻�����������ƁB
�����珘�ՂɃV�������N�����̂ɍ����������ƌ�����
�����珘�ՂɃV�������N�����̂ɍ����������ƌ�����
�����A���ꌋ�Njꂵ����ɂ����܂����E�E�E�Ȃ�Ȃ��A�����B
IPC����+5%�A�N���b�N�ɑ���y�i10%
������Ɠd���グ�āAKaveri�Ɠ����܂ł͎����Ă���悤�ɂ��Ċ����Ȃ낤���ǁA
����قƂ��OC�ł��ˁ[��˂��H
�N���b�N���������ɂ��悤�Ƃ���ƁA�d�����������ɂ���K�v�������āA
�ł��z���ׂ��Ȃ��Ă邩��A�ψ��������A�z����R�����Ă��ŁA
���M�����������ɂȂ肻���Ȉ����B
�܂��A�����d�͌����̃v���Z�X/�Z���v�g���Ă鎞�_�ŁA
���N���b�N�_���A�ǂ���������Ă����Ȃ���ǁB
����Ȑv����R�A�Ƀu���R���̕����܂��g�킴��Ȃ����_�ŁA
�F�X�I���������Ă�C�����邪�E�E�E
IPC����+5%�A�N���b�N�ɑ���y�i10%
������Ɠd���グ�āAKaveri�Ɠ����܂ł͎����Ă���悤�ɂ��Ċ����Ȃ낤���ǁA
����قƂ��OC�ł��ˁ[��˂��H
�N���b�N���������ɂ��悤�Ƃ���ƁA�d�����������ɂ���K�v�������āA
�ł��z���ׂ��Ȃ��Ă邩��A�ψ��������A�z����R�����Ă��ŁA
���M�����������ɂȂ肻���Ȉ����B
�܂��A�����d�͌����̃v���Z�X/�Z���v�g���Ă鎞�_�ŁA
���N���b�N�_���A�ǂ���������Ă����Ȃ���ǁB
����Ȑv����R�A�Ƀu���R���̕����܂��g�킴��Ȃ����_�ŁA
�F�X�I���������Ă�C�����邪�E�E�E
����prescott�ł���
�������Zen�����݂��邵�AAPU�Ƃ��ďȓd�͒Nj��������ʂ����A35W��95W��Kaveri�Ɠ����Ȃ�o���߂��Ȃ��炢����
OC����CPU���\��������Əオ����AHSA�Ɍ�����APU�̃o�����X�����Ă����ق����A���[�U�[�Ƃ��Ă͐�̊y���݂������Ċ��������ǂ�
OC����CPU���\��������Əオ����AHSA�Ɍ�����APU�̃o�����X�����Ă����ق����A���[�U�[�Ƃ��Ă͐�̊y���݂������Ċ��������ǂ�
�c�O�Ȃ��獡��AMD�ɂ͋������Ȃ����NJ��҂��Ă�
Nolan��Amur�̏ڍׂ��ĉ������o�邩��
Carrizo�������d�͂̃����W�����Ă݂������ǂǂ̈ʐ��\�o�邩
Carrizo�������d�͂̃����W�����Ă݂������ǂǂ̈ʐ��\�o�邩
>>694
HSA���āA���l�̂��Ƃ�intel���͓���Ă��Ă邵�A�\�t�g�̊J�����ԊJ���͎̂b����ŁA
���̍��ɂ͔��������Ƃ������Ă��ꂻ���Ȋ������ˁB
HSA���āA���l�̂��Ƃ�intel���͓���Ă��Ă邵�A�\�t�g�̊J�����ԊJ���͎̂b����ŁA
���̍��ɂ͔��������Ƃ������Ă��ꂻ���Ȋ������ˁB
>>689
���̈Ӗ��Ń��j�A�ɉ�H���k���ł����̂͂�������130nm������܂ł���
90nm�̎��_�ł��A���S�ɂ̓��j�A�ȏk�����ł��Ȃ��Ȃ��Ă������
>>692
180nm��Palomino����130nm��Thoroughbred�ɐ�ւ����Ƃ�������N���b�N���قƂ�nj��サ�Ȃ��āA
�}�C�i�[�o�[�W�����A�b�v����A�}�[�N�t���ɂȂ��Ă���N���b�N���オ�����C������
���̈Ӗ��Ń��j�A�ɉ�H���k���ł����̂͂�������130nm������܂ł���
90nm�̎��_�ł��A���S�ɂ̓��j�A�ȏk�����ł��Ȃ��Ȃ��Ă������
>>692
180nm��Palomino����130nm��Thoroughbred�ɐ�ւ����Ƃ�������N���b�N���قƂ�nj��サ�Ȃ��āA
�}�C�i�[�o�[�W�����A�b�v����A�}�[�N�t���ɂȂ��Ă���N���b�N���オ�����C������
>>697�@�܂�OpenCL2.0�ł����������L�ł��邩��ȁA��������AMD�ւ���Ă邯��
���̕�Intel����Skylake�̋Z�p����Ă�炵�����AALU�Ɍ���Ό��X����ȂɈ����Ȃ�����
CPU���\��x86��2�Ԏ肾�I�Ƒ���U��鐫�\�ɂȂ��Ȃ����ˁH
���������Η]�T�����ēG�ɋZ�p�n���āA�t���{�b�R�ɂ��ꂽ�����R���卲�������悤�ȁc�c
FX�Ɋ��ҁI���Ă����ǁAMS��8.1�ʼn摜�o�͂̂��Ȃ�iGPU���p�@�\�t���Ă邵�iQSV�ׂ̈�������j
�O���{�ς�ł�PC�ł�iGPU�t���ɂԂ���オ����̂����˂�
���̕�Intel����Skylake�̋Z�p����Ă�炵�����AALU�Ɍ���Ό��X����ȂɈ����Ȃ�����
CPU���\��x86��2�Ԏ肾�I�Ƒ���U��鐫�\�ɂȂ��Ȃ����ˁH
���������Η]�T�����ēG�ɋZ�p�n���āA�t���{�b�R�ɂ��ꂽ�����R���卲�������悤�ȁc�c
FX�Ɋ��ҁI���Ă����ǁAMS��8.1�ʼn摜�o�͂̂��Ȃ�iGPU���p�@�\�t���Ă邵�iQSV�ׂ̈�������j
�O���{�ς�ł�PC�ł�iGPU�t���ɂԂ���オ����̂����˂�
>>697
Intel���͓���Ă�̂�x86�����̕��Z����
iGPU��dGPU�Ƃ��َ̈�v���Z�b�T�Ԃ̏����͂���C�͂Ȃ����A�����������I��FPGA�������炢
�w�e���W�j�A�X�́AiGPU���アIntel�ɂƂ��Ă͋S�傾����A���������Ƃ����ǂ��납�A��������AMD�ɒD����
��������iGPU���p�ɂȂ��Ă���OpenCL��DX12��Intel�ɂƂ��Ă͎ז����m�ł���������
CPU�����������AiGPU���p����邵�AdGPU�ƘA�g�������Ƃ����AAMD�������L���ɂȂ郂�m����
Intel�ɂƂ��Ẵ����b�g�͑S���Ȃ��ǂ��납�f�����b�g���������㕨
Intel���͓���Ă�̂�x86�����̕��Z����
iGPU��dGPU�Ƃ��َ̈�v���Z�b�T�Ԃ̏����͂���C�͂Ȃ����A�����������I��FPGA�������炢
�w�e���W�j�A�X�́AiGPU���アIntel�ɂƂ��Ă͋S�傾����A���������Ƃ����ǂ��납�A��������AMD�ɒD����
��������iGPU���p�ɂȂ��Ă���OpenCL��DX12��Intel�ɂƂ��Ă͎ז����m�ł���������
CPU�����������AiGPU���p����邵�AdGPU�ƘA�g�������Ƃ����AAMD�������L���ɂȂ郂�m����
Intel�ɂƂ��Ẵ����b�g�͑S���Ȃ��ǂ��납�f�����b�g���������㕨
�v�Z����v���Z�b�T���Ⴆ�w�e���W�j�A�X�𖼏���Ă������B
Blldozer2M�{Jaguar16C�Ƃ��ł���
Blldozer2M�{Jaguar16C�Ƃ��ł���
702 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 00:05:29.87 ID:Aw/UAy+U
AMD�����w�e���W�j�A�X�̊J������Intel�ȏ�̃\�t�g�J���҂̎x�����l��������ł�����
�Q���͐Q�ĉ�
�Q���͐Q�ĉ�
Carrizo�̉z����ׂ��n�[�h�������̐��������ō����Ȃ��Ă邯��
���ۂɃ����[�X����鍠�ɂ͂Ȃ��������ƂɂȂ��Ă�Zen������ް��
�Ȃ��Ă�낤��
���ۂɃ����[�X����鍠�ɂ͂Ȃ��������ƂɂȂ��Ă�Zen������ް��
�Ȃ��Ă�낤��
704 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 00:32:52.76 ID:Aw/UAy+U
HSA��Kaveri�Ŋ�������ƌ����Ă��̂ɂ��̊Ԃɂ�Carrizo�ɂ����ւ���Ă���
Bulldozer����������Ƃ����O���2014�N�܂ł�x86�̃V�F�A50%��������
���̃V�F�A50%�̑O��̂��Ƃ�HSA���������̂�
�uHSA�ŃV�F�A�����Ԃ��v�Ƃ������ꖳ���Ȃ��Ƃ������o���n���ł���
�\�t�g�J���҂��S�����Ă��ĂȂ�����Ȃ��ł���
Bulldozer����������Ƃ����O���2014�N�܂ł�x86�̃V�F�A50%��������
���̃V�F�A50%�̑O��̂��Ƃ�HSA���������̂�
�uHSA�ŃV�F�A�����Ԃ��v�Ƃ������ꖳ���Ȃ��Ƃ������o���n���ł���
�\�t�g�J���҂��S�����Ă��ĂȂ�����Ȃ��ł���
�����P�Ȃ�bigLITTLE����
�X�}�t�H�ł��Ή����Ă�
Intel��Core��Atom��Phi�������ăw�e���W�j�A�X����Ƃ������Ă����ǂ�߂�����
����Core��AVX�̋��������Ă��������Ȃ낤��
�X�}�t�H�ł��Ή����Ă�
Intel��Core��Atom��Phi�������ăw�e���W�j�A�X����Ƃ������Ă����ǂ�߂�����
����Core��AVX�̋��������Ă��������Ȃ낤��
706 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 00:40:08.96 ID:Aw/UAy+U
�㓡�O���\���̈�Ƃ��Č�����������Intel�͈ꌾ���������ĂȂ���
��������Windows����Ώ̃}���`�R�A�ɑΉ����Ă��Ȃ�
�ibig.LITTLE�Ή���SoC��Windows RT�}�V���ł͏ȓd�͗p�R�A���E����Ă�j
��������Windows����Ώ̃}���`�R�A�ɑΉ����Ă��Ȃ�
�ibig.LITTLE�Ή���SoC��Windows RT�}�V���ł͏ȓd�͗p�R�A���E����Ă�j
����Intel�k�r�̎�������2�N���Ċm�肵������A�X�e�}���Ă�����
Carrizo��h265�G���R�ɑΉ��������������A�G���R���[�͒ʗp���Ȃ���
DX12�̓}���`GPU������iGPU���p����APU�̓V������
���������APascal��ARM�R�A�����������H
�V�F�[�_�[���Ȃ��Ȃ��Ă��Ȃ萫�\�������
������C���e���Q�t�H���āAIntel HD�ƃQ�t�H��ARM���ז����Đ��\�o���������Ŕ��Ɋy���݂���
Carrizo��h265�G���R�ɑΉ��������������A�G���R���[�͒ʗp���Ȃ���
DX12�̓}���`GPU������iGPU���p����APU�̓V������
���������APascal��ARM�R�A�����������H
�V�F�[�_�[���Ȃ��Ȃ��Ă��Ȃ萫�\�������
������C���e���Q�t�H���āAIntel HD�ƃQ�t�H��ARM���ז����Đ��\�o���������Ŕ��Ɋy���݂���
708 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 00:54:59.98 ID:Aw/UAy+U
AMD������2�N�œ|�Y�����
709 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 00:57:07.24 ID:Aw/UAy+U
AMD�A2014�N�x�͑�����4���h���̐Ԏ�
��AMD��20��(���n����)�A2014�N�x��4�l��������ђʔN�̌��Z�\�����B
�@��4�l�����̔��㍂��12��4,000���h���A�c�Ƒ�����3��3,000���h���A��������3��6,400���h���ƂȂ����B
1��������̑�����0.47�h���B���㍂�͑O�N�����Ɣ�r����22%���Ƃ��Ȃ�̕s���ŁA�������Ԏ��ɓ]�����B
�@2014�N�ʔN�̔��㍂��55��1,000���h���ƁA2013�N�x�Ɣ�r����4%�����������̂́A
�c�Ƒ�����1��5,500���h���A��������4��300���h���A1��������̑�����0.53�h���ƂȂ����B
�@��4�l�����̓R���s���[�e�B���O�ƃO���t�B�b�N�X���傪���ɕs���ŁA�O�N�����Ɣ�r����16%���ƂȂ����B
���Ƀf�X�N�g�b�vGPU���s���������Ƃ��Ă���B
�@����G���^�[�v���C�Y/�g�ݍ���/�Z�~�J�X�^�������PlayStation 4��Xbox One�Ɏx�����A
�O�N������51%���̑����ƂȂ������̂́A���O����11%���ŁA�c�Ɨ��v�������Ă���B
���̂ق��̕����3��8,300���h���̉c�Ƒ������v�サ�Ă���B
�@Lisa Su�В���CEO�̓����[�X�̒��ŁA�u�Z�~�J�X�^����g�ݍ�������50%���̎����čD�������A
2015�N��2�l�����ɃR���s���[�e�B���O�ƃO���t�B�b�N�X�̃Z�O�����g�ɂ����Č��S�ȋO���ɖ߂���悤簐i���Ă���i�K���v�Əq�ׂ��B
�@2015�N��1�l������15%�̔��㌸��\�����Ă���B
http://pc.watch.impress.co.jp/docs/news/20150121_684660.html
��AMD��20��(���n����)�A2014�N�x��4�l��������ђʔN�̌��Z�\�����B
�@��4�l�����̔��㍂��12��4,000���h���A�c�Ƒ�����3��3,000���h���A��������3��6,400���h���ƂȂ����B
1��������̑�����0.47�h���B���㍂�͑O�N�����Ɣ�r����22%���Ƃ��Ȃ�̕s���ŁA�������Ԏ��ɓ]�����B
�@2014�N�ʔN�̔��㍂��55��1,000���h���ƁA2013�N�x�Ɣ�r����4%�����������̂́A
�c�Ƒ�����1��5,500���h���A��������4��300���h���A1��������̑�����0.53�h���ƂȂ����B
�@��4�l�����̓R���s���[�e�B���O�ƃO���t�B�b�N�X���傪���ɕs���ŁA�O�N�����Ɣ�r����16%���ƂȂ����B
���Ƀf�X�N�g�b�vGPU���s���������Ƃ��Ă���B
�@����G���^�[�v���C�Y/�g�ݍ���/�Z�~�J�X�^�������PlayStation 4��Xbox One�Ɏx�����A
�O�N������51%���̑����ƂȂ������̂́A���O����11%���ŁA�c�Ɨ��v�������Ă���B
���̂ق��̕����3��8,300���h���̉c�Ƒ������v�サ�Ă���B
�@Lisa Su�В���CEO�̓����[�X�̒��ŁA�u�Z�~�J�X�^����g�ݍ�������50%���̎����čD�������A
2015�N��2�l�����ɃR���s���[�e�B���O�ƃO���t�B�b�N�X�̃Z�O�����g�ɂ����Č��S�ȋO���ɖ߂���悤簐i���Ă���i�K���v�Əq�ׂ��B
�@2015�N��1�l������15%�̔��㌸��\�����Ă���B
http://pc.watch.impress.co.jp/docs/news/20150121_684660.html
�ƃQ�ƊE�������͂������Ɗ撣��ł���
�G���s�݂����ɑ�p�i�̂���ėp���i�̕��삶��Ȃ���
�A�|�̓G���s�ɓ|�Y���ė~�����Ȃ������݂���������
�G���s�݂����ɑ�p�i�̂���ėp���i�̕��삶��Ȃ���
�A�|�̓G���s�ɓ|�Y���ė~�����Ȃ������݂���������
711 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 01:02:06.96 ID:Aw/UAy+U
XboxOne��PS4������IP�͊��Ɋ������Ă�킯������
�ʂ�AMD�̐��i�J�����X�g�b�v�����Ƃ���ʼn��̉e�����Ȃ�
�j�Y�Ǎ��l���������������p���łǂ�������ɐ蔄�肷�邾���ł���
�ʂ�AMD�̐��i�J�����X�g�b�v�����Ƃ���ʼn��̉e�����Ȃ�
�j�Y�Ǎ��l���������������p���łǂ�������ɐ蔄�肷�邾���ł���
AMD���Ȃ��Ȃ�����Ƀk�r��C���e�������Q�[���@�Â�������[�h�o����Ƃ͎v���Ȃ������
�C���e���ɂ�AVX�Ȃ�炢�����A�v���ł͑債�Đ��\�オ�炸�����b�g���Ȃ��g�����߂ł̃n�C�v��
�k�r�ɂ̓X�y�b�N���\�����ꂼ��撣���Ă��炢�����g�R����
�C���e���ɂ�AVX�Ȃ�炢�����A�v���ł͑債�Đ��\�オ�炸�����b�g���Ȃ��g�����߂ł̃n�C�v��
�k�r�ɂ̓X�y�b�N���\�����ꂼ��撣���Ă��炢�����g�R����
713 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 01:07:38.06 ID:eKNrnP9T
WiiU��eDRAM��NEC�̒߉��������Ȃ����Č����Ă�����
�\�j�[�ɔ���ꂽ������lj��Ƃ����Ă邶��Ȃ���
�C�V������������NEC�Ɏ������������Ȃ�Ęb���Ȃ�
�Q�[���ƊE��AMD���~�ς��Ă����Ȃ�ď펯�I�ɂ��肦�Ȃ�����
�\�j�[�ɔ���ꂽ������lj��Ƃ����Ă邶��Ȃ���
�C�V������������NEC�Ɏ������������Ȃ�Ęb���Ȃ�
�Q�[���ƊE��AMD���~�ς��Ă����Ȃ�ď펯�I�ɂ��肦�Ȃ�����
714 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 01:08:41.65 ID:eKNrnP9T
����AMD�͓|�Y����ׂ����Ǝv����
715 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 01:09:44.17 ID:eKNrnP9T
�͉����ǂ��Ȃ��ĂȂ��A�Ƃ��������z�͂��̍���葝���Ă���
http://www.fukeiki.com/2009/09/bankruptcy-risk-20-us-companes.html
http://www.fukeiki.com/2009/09/bankruptcy-risk-20-us-companes.html
Intel�������ՁX�Ƒ��Ђ�x86�̌��������n���邱�Ƃ�F�߂邩��
�������ꂽ�艽������AMD�͎c��Ǝv����
�������ꂽ�艽������AMD�͎c��Ǝv����
�C���e���̂������肩����CPU�������ԂɂȂ��Ȃ邵
�v����{�b�Ă��邾�낤��
DX12�̂��ƂɂȂ����}���g���݂�����
�C�m�x�[�V������u���[�N�X���[�̔��M�����Ȃ��Ȃ邩��
�����Ƃ����Ԃ�windows�̃X�y�b�N�����������Ⴄ��
�k�r��GPU�R�A��IP����������ĂȂ����F�X�I����
�I�����Sun����������C�m�x�[�V�������Ȃ��Ȃ����悤��
�N���C�A���g�R���s���[�e�B���O���Í��̒����̂悤�Ȑ��E�ɕ����߂邱�ƂɂȂ�
�v����{�b�Ă��邾�낤��
DX12�̂��ƂɂȂ����}���g���݂�����
�C�m�x�[�V������u���[�N�X���[�̔��M�����Ȃ��Ȃ邩��
�����Ƃ����Ԃ�windows�̃X�y�b�N�����������Ⴄ��
�k�r��GPU�R�A��IP����������ĂȂ����F�X�I����
�I�����Sun����������C�m�x�[�V�������Ȃ��Ȃ����悤��
�N���C�A���g�R���s���[�e�B���O���Í��̒����̂悤�Ȑ��E�ɕ����߂邱�ƂɂȂ�
718 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 01:15:35.57 ID:eKNrnP9T
>>716
AMD�����Ђɔ��p���ꂽ��x86�̐������C�Z���X����������Ƃ����_��
AMD�����Ђɔ��p���ꂽ��x86�̐������C�Z���X����������Ƃ����_��
���߂�GF�ȊO�ł�x86�݊�CPU�������F�߂��ĂȂ��������
x86����������Ƃ������Ƃ̓A�����J�̔e���������Ƃ������Ƃ�����
���������g���ăS�������ʼn��������邾�낤��
x86����������Ƃ������Ƃ̓A�����J�̔e���������Ƃ������Ƃ�����
���������g���ăS�������ʼn��������邾�낤��
720 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 01:18:27.76 ID:eKNrnP9T
Qualcomm��x86���������Ǝv����
������Ƃ��ƂƓ|�Y���Ă��ꗊ��
������Ƃ��ƂƓ|�Y���Ă��ꗊ��
�N�A���R���͒P�Ȃ郂�f����
���͑S���悻���甃���ė�������
����AMD��CPU�����`���I�ɑ�����GPU���ɏ����ւ����Ă�̂Ƃ͖{���I�ɈႤ
���͑S���悻���甃���ė�������
����AMD��CPU�����`���I�ɑ�����GPU���ɏ����ւ����Ă�̂Ƃ͖{���I�ɈႤ
722 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 01:22:12.37 ID:eKNrnP9T
Krait CPU�R�A�͈ꉞ���ЊJ���Ȃ�ł��������
>>718
����A�����琻�����̐蔄��Ȃ�ďo���Ȃ����A�������Ő����c��ł���
����A�����琻�����̐蔄��Ȃ�ďo���Ȃ����A�������Ő����c��ł���
724 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 01:27:18.10 ID:eKNrnP9T
AMD64�֘A�̓��������邵Intel���ꎞ�I�ɔ�������ˁH
���̌�̓|�C��
Windows 10��Xbox�������邵�AOne���������~�ɂȂ��Ă����ƌp���ł���̐��𐮂�����
���̌�̓|�C��
Windows 10��Xbox�������邵�AOne���������~�ɂȂ��Ă����ƌp���ł���̐��𐮂�����
725 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 01:35:56.09 ID:eKNrnP9T
�ǂ݂̂��Q�[���n�[�h�Ȃ��5�`6�N�̃��C�t�T�C�N���Ȃ�
�����ᖳ���ŕʂ̏����l����̂����[�J�[�ł���
���i�����̓s���Ő����ł���Ȃ�ă\�j�[�̗��j�l�����
�ʂɓ��قȂ��Ƃł��Ȃ���
���������\�j�[���̂�������������
�����ᖳ���ŕʂ̏����l����̂����[�J�[�ł���
���i�����̓s���Ő����ł���Ȃ�ă\�j�[�̗��j�l�����
�ʂɓ��قȂ��Ƃł��Ȃ���
���������\�j�[���̂�������������
�Q�[���N���C�A���g����邽�߂̃n�[�h�E�F�A�Z�p���Ȃ��Ȃ��
�S���I����̃X�g���[�~���O�ł��܂��Ƃ����̂͂��蓾�邩����
�S���I����̃X�g���[�~���O�ł��܂��Ƃ����̂͂��蓾�邩����
AMD��x86���߂鏀���������ɐi�߂Ă��
SkyBridge��Zen��K12���Ax86��ARM�����̐v��@�����p���č���Ă邩��Apin�݊��ǂ��납�A
�����\����������\��������
CPU�R�A�ȊO�̃A���R�A���͊��ɗ��Ή�������A���Ƃ�PS4�Ɣ�1�̎����������Ȃ�5�N�キ�炢�ɁA
��p��PS5�Ƌ���x86���߂����ȋC������
5�N������AARM�������\�����āAx86�̃m�E�n�E�⎑�Y���z�����āA�Ƃ����ɒǂ��z���Ă���������
SkyBridge��Zen��K12���Ax86��ARM�����̐v��@�����p���č���Ă邩��Apin�݊��ǂ��납�A
�����\����������\��������
CPU�R�A�ȊO�̃A���R�A���͊��ɗ��Ή�������A���Ƃ�PS4�Ɣ�1�̎����������Ȃ�5�N�キ�炢�ɁA
��p��PS5�Ƌ���x86���߂����ȋC������
5�N������AARM�������\�����āAx86�̃m�E�n�E�⎑�Y���z�����āA�Ƃ����ɒǂ��z���Ă���������
�C���e���̃L���b�V���������Z�p��ǂ��z���̂͑�����������˂����ȁc
�x���`()�����Ŗ@�����̂̓A���̂����ł���
�x���`()�����Ŗ@�����̂̓A���̂����ł���
5�N��ƌ�������10nm��7nm�Ƃ�����
28nm��30���g�����W�X�^��APU�����AMD�Ȃ�A100���g�����W�X�^���炢�̍�肻����
�m��290x��60���������A�c��30����CPU�R�A���A������Zen��k12�Ȃ�16�R�A���炢�]�T���낤��
5�N���16�R�A+290x�Ƃ���APU��3���~���炢�Ŕ�����Ȃ�A�C���e���Q�t�H�Ƃ�����Ȃ�����
28nm��30���g�����W�X�^��APU�����AMD�Ȃ�A100���g�����W�X�^���炢�̍�肻����
�m��290x��60���������A�c��30����CPU�R�A���A������Zen��k12�Ȃ�16�R�A���炢�]�T���낤��
5�N���16�R�A+290x�Ƃ���APU��3���~���炢�Ŕ�����Ȃ�A�C���e���Q�t�H�Ƃ�����Ȃ�����
730 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 02:29:36.92 ID:eKNrnP9T
�Q���͐Q�Č�������
http://jp.investing.com/equities/adv-micro-device-income-statement
http://jp.investing.com/equities/adv-micro-device-income-statement
731 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 02:34:22.11 ID:eKNrnP9T
�������̂ق���������
�����{��187
���{��]�� 6949�ɑ��āA�ݐϐԎ��@6646
�����߁@SU��N��ZE��N
http://jp.investing.com/equities/adv-micro-device-balance-sheet
�����{��187
���{��]�� 6949�ɑ��āA�ݐϐԎ��@6646
�����߁@SU��N��ZE��N
http://jp.investing.com/equities/adv-micro-device-balance-sheet
732 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 02:36:00.37 ID:eKNrnP9T
�\�j�[��MS�̃Q�[�����Ƃ̔����y���ɒ�����AMD�̗ݐϐԎ����U���Ă����Ȃ��
����Ȓ��̂����b������킯���Ȃ�����n���Ȃ́H
����Ȓ��̂����b������킯���Ȃ�����n���Ȃ́H
���[�A�̖@���������I�ɔj���Ă���Ƃ���MS��DX12�����ꂽ�Z�p�I�w�i��
�I�C���}�l�[�����ꂽ�Ƃ������Ƃ���
�������Q�[���ƊE������
�C���e����k�r�͎l�ʑ^�̂���
�I�C���}�l�[�����ꂽ�Ƃ������Ƃ���
�������Q�[���ƊE������
�C���e����k�r�͎l�ʑ^�̂���
734 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 02:41:35.59 ID:eKNrnP9T
http://fox.2ch.net/test/read.cgi/poverty/1421818663/l50
195 �F�ԑg�̓r���ł����A�t�B�T�C�g�ւ̓]�ڂ͋֎~�ł��F2015/01/23(��) 04:56:32.84 ID:bErimHen0
>>193
���̍��ƈꏏ�ō����߈����O�捡
������H������Fab�����ĂȂ����炻�����������Ƃ͎v������
�����Y����
2008�@*1��2700���@���
2009�@*6��4800���@Q3�܂ō����߁A�H�ꔄ���ăA�u�_�r����̂��������ʼn�
2010�@10��1300���@������AMD�A�Ɛт��D��
2011�@15��9000���@������������Q4��Bulldozer���a
2012�@*5��3800���@����E��������
2013�@*5��4400���@Q2�܂ʼnE���AQ3����PS4/��1�h�[�s���O�Ŏ�������
2014�@*1��8700���@Q4��PS4/��1�h�[�s���O�̌��ʂ���ĂщE��
2015Q1���Z�������̂͌����Ă�Ƃ��Ė���Q2�̌��ʂ�
���҂̃J���]��HBM���f������͂�������
����Â�����������ǂ����悤���Ȃ�
Fab�����ăA�u�_�r�ɋ��o���Ă�����Ă������������������̂�
Bulldozer��R�P�ł܁`���ꋫ�Ɋׂ��Ă�
195 �F�ԑg�̓r���ł����A�t�B�T�C�g�ւ̓]�ڂ͋֎~�ł��F2015/01/23(��) 04:56:32.84 ID:bErimHen0
>>193
���̍��ƈꏏ�ō����߈����O�捡
������H������Fab�����ĂȂ����炻�����������Ƃ͎v������
�����Y����
2008�@*1��2700���@���
2009�@*6��4800���@Q3�܂ō����߁A�H�ꔄ���ăA�u�_�r����̂��������ʼn�
2010�@10��1300���@������AMD�A�Ɛт��D��
2011�@15��9000���@������������Q4��Bulldozer���a
2012�@*5��3800���@����E��������
2013�@*5��4400���@Q2�܂ʼnE���AQ3����PS4/��1�h�[�s���O�Ŏ�������
2014�@*1��8700���@Q4��PS4/��1�h�[�s���O�̌��ʂ���ĂщE��
2015Q1���Z�������̂͌����Ă�Ƃ��Ė���Q2�̌��ʂ�
���҂̃J���]��HBM���f������͂�������
����Â�����������ǂ����悤���Ȃ�
Fab�����ăA�u�_�r�ɋ��o���Ă�����Ă������������������̂�
Bulldozer��R�P�ł܁`���ꋫ�Ɋׂ��Ă�
735 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 02:50:07.80 ID:eKNrnP9T
2010-2011�ɏ����Y�����������̂���Intel�̘a��������
���ꂷ��S�������ĉc�Ɨ��v���o�Ă��������̎Ѝ������H���A���\��
���ꂷ��S�������ĉc�Ɨ��v���o�Ă��������̎Ѝ������H���A���\��
�ڐ�̃J�l�̘b�悩���i�̒��Ă���@�\�⎿�����������C�C��
�N���X�}�X����ŏ��ނ��Ĕ���グ�𑝂₻����
�ǂ����̃O���{���[�J�[�݂����ɃX�y�b�N���\�ɑ�����}�V����
�N���X�}�X����ŏ��ނ��Ĕ���グ�𑝂₻����
�ǂ����̃O���{���[�J�[�݂����ɃX�y�b�N���\�ɑ�����}�V����
737 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 02:55:32.70 ID:eKNrnP9T
��������Fab���c���ĂȂ������͉����ł��傤��
�����������߂�HSA�o���ł��˂킩��܂�
�����������߂�HSA�o���ł��˂킩��܂�
APU�ɂ͗]����҂��ĂȂ����ǃ��f�������Ȃ����獢���
�A�j���ׂ̈�����285X�������Ƃ����̂ɂ�
�Q�[���͂��܁`�ɂ����x������Q�t�H�͗v��Ȃ��̂�ˁA�n�[�h�E�F�A�G���R��QSV���邵
���f�̂S���A�b�v�X�P�[�����O�͌��\�Y�킾���A�f�m�C�Y�͋��͂����{���⊮�����邵
����ZerocorePower���l�I�ɂ͕K�{���ˁA��GPU�ς�PC�����̂܂܉ƎI�Ƃ��Ă��^�p���Ă邩��
�A�C�h��������d�͂͏������ɉz�������Ƃ͂Ȃ����A�Q�[��&�A�j���ȊO�̎��͐Q������iGPU�ɐ�ւ��Ă�������
�܂�������HSA�݂����ȕϑԂ��ۂ��̂ɂ����҂������Ȃ�C�����͕�����Ȃ����Ȃ���
�A�j���ׂ̈�����285X�������Ƃ����̂ɂ�
�Q�[���͂��܁`�ɂ����x������Q�t�H�͗v��Ȃ��̂�ˁA�n�[�h�E�F�A�G���R��QSV���邵
���f�̂S���A�b�v�X�P�[�����O�͌��\�Y�킾���A�f�m�C�Y�͋��͂����{���⊮�����邵
����ZerocorePower���l�I�ɂ͕K�{���ˁA��GPU�ς�PC�����̂܂܉ƎI�Ƃ��Ă��^�p���Ă邩��
�A�C�h��������d�͂͏������ɉz�������Ƃ͂Ȃ����A�Q�[��&�A�j���ȊO�̎��͐Q������iGPU�ɐ�ւ��Ă�������
�܂�������HSA�݂����ȕϑԂ��ۂ��̂ɂ����҂������Ȃ�C�����͕�����Ȃ����Ȃ���
739 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 03:00:13.10 ID:eKNrnP9T
��ATI�Љ����Ăǂ�������ɔ��p���邱�Ƃ��炢�͑z�肳��܂��Ȃ�
740 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 03:01:41.37 ID:eKNrnP9T
�]�ƈ��ǂ��܂ō팸����̂����y���݂ł�
����Ȃ͂������A�Ȃ�̖��ɂ��o���ĂȂ���
�����ݔ����p���Ă�TSMC�Ƃ��ł������ł��邱�ƂɂȂ����̂��������v�݂����Ȃ���
��������AMD�̏����̋@���D���܂����ĐԎ����炯�ɂ��Ă�Intel�̈��������ė��v���ǂ��Ƃ����C����Ȃ���Ȃ��O���������
�܂��A�Ԏ����炯�ŕ����炯�Ȃ̂ɁA�|�Y�̋C�z���Ȃ��ǂ��납�A���ʂɃR�X�g�����鋐��_�C�⎟����Ƃ��������J�����Ă邩��A
�ׂ�Ȃ��d�g�݂��������瓭���Ă�낤��
�����ݔ����p���Ă�TSMC�Ƃ��ł������ł��邱�ƂɂȂ����̂��������v�݂����Ȃ���
��������AMD�̏����̋@���D���܂����ĐԎ����炯�ɂ��Ă�Intel�̈��������ė��v���ǂ��Ƃ����C����Ȃ���Ȃ��O���������
�܂��A�Ԏ����炯�ŕ����炯�Ȃ̂ɁA�|�Y�̋C�z���Ȃ��ǂ��납�A���ʂɃR�X�g�����鋐��_�C�⎟����Ƃ��������J�����Ă邩��A
�ׂ�Ȃ��d�g�݂��������瓭���Ă�낤��
�������s�K������Ƃ����đ��l�̕s�K�܂Ŋ��Ȃ��Ă��C�C�Ǝv���܂����ǂ�
�܂������͂�������������f�����Ȃ낤���ǂ���
�܂������͂�������������f�����Ȃ낤���ǂ���
743 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 03:06:17.29 ID:eKNrnP9T
744 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 03:07:48.26 ID:eKNrnP9T
>>742
> �������s�K������Ƃ����đ��l�̕s�K�܂Ŋ��Ȃ��Ă��C�C�Ǝv���܂����ǂ�
��
> �������Q�[���ƊE������
> �C���e����k�r�͎l�ʑ^�̂���
> �������s�K������Ƃ����đ��l�̕s�K�܂Ŋ��Ȃ��Ă��C�C�Ǝv���܂����ǂ�
��
> �������Q�[���ƊE������
> �C���e����k�r�͎l�ʑ^�̂���
�ƃQ��AMD�̋Z�p�I�����Ō������t�����̂ɂ�����Ȃ߂悤�ƃJ�l�̘b����
�{�C�Œp���������N�Y����
�{�C�Œp���������N�Y����
746 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 03:10:20.40 ID:eKNrnP9T
�ׂ���Ђ̋Z�p�ɏ����Ȃ�ĂȂ���
>>743
�l�ʑ^�̂ł��J�l��������n�b�s�[
������X�y�b�N���\�ŋq���x���Ă��C�C��H
�Њ���͌������|���̃x���`()�ō��������ւ邵���Ȃ��\�����Ȃ̂��܂��ꋻ
�l�ʑ^�̂ł��J�l��������n�b�s�[
������X�y�b�N���\�ŋq���x���Ă��C�C��H
�Њ���͌������|���̃x���`()�ō��������ւ邵���Ȃ��\�����Ȃ̂��܂��ꋻ
>>746
AIX�̕���Solaris���D�G�Ƃ��v���Ă܂��H���Ƃ�����Z�p���s����
AIX�̕���Solaris���D�G�Ƃ��v���Ă܂��H���Ƃ�����Z�p���s����
Linux�̓t���[UNIX�̒��ōł��g���Ă���
������ł����\������
���������M���O�����҂�����
������ł����\������
���������M���O�����҂�����
750 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 03:12:21.14 ID:eKNrnP9T
Sun�Ȃ�ăS�~���낗����
�łȂ���Oracle�����O��RHEL�t�H�[�N��Oracle Linux���Ȃ�
�łȂ���Oracle�����O��RHEL�t�H�[�N��Oracle Linux���Ȃ�
751 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 03:13:35.38 ID:eKNrnP9T
Oracle�������œ������̂�Java�ƁAUNIX�_�b�ɂ�����V�Q�ڋq
>>741�@�������Ƀu���n�A�[�L�̎��s�͒ɂ�����
�u���n���n���ɐl�C���������ǁA����Steamroller�̂W�R�A���o�����A32nm������Ō떂����
�j�b�`��������Ȃ獂�P���ȏ��i�o���Ȃ��ƃL�c�C��ADevils�@Conyan�Ȃ�Ă킴�킴���t�����O���X���P����
i5�Ai7�ʼnߋ��ō��̔����������H���̎s��͒n���ɐ�������Ǝv������
�܂�14nm����ōĐv�����炻��Ɋ��҂��ʁA��P�`�Q�N�ł͂������ɒׂ�Ȃ���
�u���n���n���ɐl�C���������ǁA����Steamroller�̂W�R�A���o�����A32nm������Ō떂����
�j�b�`��������Ȃ獂�P���ȏ��i�o���Ȃ��ƃL�c�C��ADevils�@Conyan�Ȃ�Ă킴�킴���t�����O���X���P����
i5�Ai7�ʼnߋ��ō��̔����������H���̎s��͒n���ɐ�������Ǝv������
�܂�14nm����ōĐv�����炻��Ɋ��҂��ʁA��P�`�Q�N�ł͂������ɒׂ�Ȃ���
�I���N����RHEL�N���[��������Ă���̂�Linux�Ń����X�g�b�v�T�[�r�X�������Ƃ����q�̗v�]�����邩��
Sun���S�~�Ƃ��A�z������
�I�����Ă��Ђ͂��܂��ɂǂ���Sun�̈�Y��JAVA�ŐH���Ȃ��ł�
Sun���S�~�Ƃ��A�z������
�I�����Ă��Ђ͂��܂��ɂǂ���Sun�̈�Y��JAVA�ŐH���Ȃ��ł�
754 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 03:15:03.74 ID:eKNrnP9T
�����߂��Ăǂ��������Ƃ��킩���ĂȂ��炵��
�Z�p�I�Ƀk�r��C���e���������s�\�ȃn�[�h�E�F�A��v�ł����Ђ������߂܂Œǂ����ނƂ�
�C���e���̂�����͕̂��ʂ̌����点����˂���
���N�U���r�b�N���̃��_�����@
�C���e���̂�����͕̂��ʂ̌����点����˂���
���N�U���r�b�N���̃��_�����@
756 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 03:17:11.62 ID:eKNrnP9T
�ׂ��Ⴂ����S�~���AMD
����AMD���O�ɂ��O�����ʂ�
����͊|���Ă��C�C
����͊|���Ă��C�C
758 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 03:19:09.78 ID:eKNrnP9T
Qualcomm�͑���i������Apple�͓|�Y���O���玝��������
AMD�̌o�c�\�͂��Ȃ���������Ȃ��ł����H
�Z�p�Z�p���đ�̂ɑ������甃���Ă������Y�ɗ����Ă邾�������
AMD�̌o�c�\�͂��Ȃ���������Ȃ��ł����H
�Z�p�Z�p���đ�̂ɑ������甃���Ă������Y�ɗ����Ă邾�������
759 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 03:19:42.02 ID:eKNrnP9T
�����߂��鎞����\�z���悤��
�����������ė���3Dlabs�̎��Y�͂ǂ��ɐ�������
�J���`�[�����Ɣ������̂ɉ������Ȃ�����˂���
�k�r��ATI�ւ̌����点�ő�p�̃`�b�v�Z�b�g�x���_�����Ă���
�J���`�[�����Ɣ������̂ɉ������Ȃ�����˂���
�k�r��ATI�ւ̌����点�ő�p�̃`�b�v�Z�b�g�x���_�����Ă���
������X���Ŏ�������Ȃ����_�Ń^�_�̕���������c�q��
�������A35w�ȉ��̃��o�C��������28nm�̂܂܃��b�g�p�t�H�[�}���X�{���ŁA�X�ɃT�E�X�����Ƃ������Ȑv���Ă���Carrizo
���ʂɃu���[�h�E�F���Ƌ��������Ȃ��炢�������\���������A���肷���Skylake�����Ƃ��Ȃ肻����
�N���ɂ�DX12���o�邵�A�Q�[�������K�Ȃ낤��
����ȗD�ꂽAPU���f�X�N�g�b�v�����ɏo���Ȃ��قǒǂ�����Intel�̓}�W�������
�������A35w�ȉ��̃��o�C��������28nm�̂܂܃��b�g�p�t�H�[�}���X�{���ŁA�X�ɃT�E�X�����Ƃ������Ȑv���Ă���Carrizo
���ʂɃu���[�h�E�F���Ƌ��������Ȃ��炢�������\���������A���肷���Skylake�����Ƃ��Ȃ肻����
�N���ɂ�DX12���o�邵�A�Q�[�������K�Ȃ낤��
����ȗD�ꂽAPU���f�X�N�g�b�v�����ɏo���Ȃ��قǒǂ�����Intel�̓}�W�������
762 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 03:22:53.69 ID:eKNrnP9T
Intel�������������_��ZiiLABS���Ă���SoC���ɐ��艺�����Ă���H
Atom�̊J���`�[���ƍ���������������ˁH
Atom�̊J���`�[���ƍ���������������ˁH
763 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 03:23:35.41 ID:eKNrnP9T
>>761
�������������������Ă������R�R���ł��̂��Ȃ���
�������������������Ă������R�R���ł��̂��Ȃ���
�A���̖{����GPU������
SoC��IP����ł͂Ȃ��R���v���[�g�Ȑ��i�������[�X���邽�߂ɑI����
SoC��IP����ł͂Ȃ��R���v���[�g�Ȑ��i�������[�X���邽�߂ɑI����
������
�Z�N�g��`�ŃS���S���̃C���e���������Ȃ�Ă����Ă������̂�
�T���ɑ����瑦�ގЂ̗⍓����ȃL�`�K�C�ǂ����낤��
�Z�N�g��`�ŃS���S���̃C���e���������Ȃ�Ă����Ă������̂�
�T���ɑ����瑦�ގЂ̗⍓����ȃL�`�K�C�ǂ����낤��
766 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 03:25:45.89 ID:eKNrnP9T
�f�B�X�N���[�g�J�[�h����P�ނ������ɔ����ς����������Ɍ��܂��Ă邾��
�g�������Ȃ��l�ގc���Ă����킯�ˁ[����
���_����Ȃ�ߋ��̍����f�[�^�ł��p�ӂ��Ă݁H
�g�������Ȃ��l�ގc���Ă����킯�ˁ[����
���_����Ȃ�ߋ��̍����f�[�^�ł��p�ӂ��Ă݁H
>>752
2016�N��32�R�A�A2017�N��290x���炢�̃n�C�G���hGPU���������n�C�G���hAPU���o���炵�����A�n�C�G���h�̈�ŃK�`�ɉ��肠���C���X����
DX12��OpenCL2.0���㉟�����邩��A�����ň�C�ɍU�߂�C���낤��
2016�N��32�R�A�A2017�N��290x���炢�̃n�C�G���hGPU���������n�C�G���hAPU���o���炵�����A�n�C�G���h�̈�ŃK�`�ɉ��肠���C���X����
DX12��OpenCL2.0���㉟�����邩��A�����ň�C�ɍU�߂�C���낤��
3Dlabs��GPU���Y����؍����������ĉ��̐��ʂ��Ȃ�
�t�ɐ����Ǝv����
�N�A���R���ɔ�������Ȃ��悤�����E���ړI�������낤����
�t�ɐ����Ǝv����
�N�A���R���ɔ�������Ȃ��悤�����E���ړI�������낤����
769 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 03:28:48.90 ID:eKNrnP9T
> �T���ɑ����瑦�ގЂ̗⍓����ȃL�`�K�C�ǂ����낤��
�A�n�n�A�T���ǂ��납��͋��̃G���W�j�A���烊�X�g������AMD�ɂ͓���������܂���
Apple����AMD�G���W�j�A���W�߂āA�V�^�v���Z�b�T��v���H
http://kettya.com/2012/log07219775.htm
�̂̋L�������Ǎ��������Ă�X��
�i���Ȃ������܂�4���̃��X�g�����\������j
�A�n�n�A�T���ǂ��납��͋��̃G���W�j�A���烊�X�g������AMD�ɂ͓���������܂���
Apple����AMD�G���W�j�A���W�߂āA�V�^�v���Z�b�T��v���H
http://kettya.com/2012/log07219775.htm
�̂̋L�������Ǎ��������Ă�X��
�i���Ȃ������܂�4���̃��X�g�����\������j
770 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 03:31:06.63 ID:eKNrnP9T
�A�b�v���AARM�AQualcomm�A��IBM�̃`�b�v�f�U�C�i�[�𐔑����̗p
http://iphone-mania.jp/news-34980/
> �A�����J�A�I�[�X�e�B���̃`�b�v�v�҂̋��l�s��͂���2�N�ԁA
> ���Ɋ�����ттĂ���A�A�b�v���AARM�AQualcomm�̊e�Ђ�
> �ϋɓI��IBM��AMD�AFreescale�̂悤�ȃ`�b�v���[�J�[�o�g��
> �����̗D�G�ȃX�^�b�t���̗p���Ă���ƌ�IBM�̏]�ƈ����q�ׂĂ��܂��B
http://iphone-mania.jp/news-34980/
> �A�����J�A�I�[�X�e�B���̃`�b�v�v�҂̋��l�s��͂���2�N�ԁA
> ���Ɋ�����ттĂ���A�A�b�v���AARM�AQualcomm�̊e�Ђ�
> �ϋɓI��IBM��AMD�AFreescale�̂悤�ȃ`�b�v���[�J�[�o�g��
> �����̗D�G�ȃX�^�b�t���̗p���Ă���ƌ�IBM�̏]�ƈ����q�ׂĂ��܂��B
>>712
Intel�ɂ͂낭��GPU���Ȃ��A�Q�[���@�Ɏg���郌�x���ɒB����\�肪�Ȃ��B
��ނɂ͂낭��CPU���Ȃ��B
�����A���OCPU�ł͂Ȃ��Ƃ͌����ACortex-A57���炢�̃��x���Ȃ�Ȃ�Ƃ��B���āA���ꌻ�s���f����SoC���
�ł�����XBOX��玟��PS�Ŏg����悤�ȁAPS4��CPU�R�A�����鐫�\��ARM CPU�����N���ɏo�Ă���Ƃ͎v���ɂ����̂ŁA����ς�l�b�N�B
>>720
���肦�Ȃ����ƌ����Ă������ł��Ȃ�����B
>>724
�Ƌ֖@�ᔽ�őj�~����邾��B���̔����͐����̗]�n�Ȃ��B
>>728
�L���b�V���������ƃ����R���̑��x�ł͏��x86�݊�CPU�����������ēƑ��������Ă�������ȁA���Ȃ��Ƃ5����Ȍ�́B
����ȑO�͒m��ǁA���ꂱ��20�N���炢�͓Ƒ���Ԃ̂悤�ȁB
�����Ƃ��A������PC�ȊO�̏�ʋ@���������\CPU��x86����ɂ�������A�z���g�ɓƑ��������킯����Ȃ����ǁB
Intel�ɂ͂낭��GPU���Ȃ��A�Q�[���@�Ɏg���郌�x���ɒB����\�肪�Ȃ��B
��ނɂ͂낭��CPU���Ȃ��B
�����A���OCPU�ł͂Ȃ��Ƃ͌����ACortex-A57���炢�̃��x���Ȃ�Ȃ�Ƃ��B���āA���ꌻ�s���f����SoC���
�ł�����XBOX��玟��PS�Ŏg����悤�ȁAPS4��CPU�R�A�����鐫�\��ARM CPU�����N���ɏo�Ă���Ƃ͎v���ɂ����̂ŁA����ς�l�b�N�B
>>720
���肦�Ȃ����ƌ����Ă������ł��Ȃ�����B
>>724
�Ƌ֖@�ᔽ�őj�~����邾��B���̔����͐����̗]�n�Ȃ��B
>>728
�L���b�V���������ƃ����R���̑��x�ł͏��x86�݊�CPU�����������ēƑ��������Ă�������ȁA���Ȃ��Ƃ5����Ȍ�́B
����ȑO�͒m��ǁA���ꂱ��20�N���炢�͓Ƒ���Ԃ̂悤�ȁB
�����Ƃ��A������PC�ȊO�̏�ʋ@���������\CPU��x86����ɂ�������A�z���g�ɓƑ��������킯����Ȃ����ǁB
��͂Ȃ������������
�^�u�p��ARM�R�A��M���Đ��\�����ڎw���̂������˂�
���̃A�|�M�҂̓S�~�ł���������ŐV��ARM�R�A�����Ă����Ă����Ώ\���Ǝv����
�^�u�p��ARM�R�A��M���Đ��\�����ڎw���̂������˂�
���̃A�|�M�҂̓S�~�ł���������ŐV��ARM�R�A�����Ă����Ă����Ώ\���Ǝv����
773 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 03:33:04.54 ID:eKNrnP9T
���O�ō����K12�̐��\��ARM�{�Ƃ�Qualcomm���̑������J����A72�ɕ�����Ƃ����M���O�Ɋ���
774 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 03:35:03.24 ID:eKNrnP9T
>>772
�n�R������D�G�ȋZ�p�҂ɕ���������Ȃ��낗����
�n�R������D�G�ȋZ�p�҂ɕ���������Ȃ��낗����
>>767�@
�܂�����͂������ǁA�l�I�Ƀ��C��CPU�͋Ă����Ăق�������
HSA����OpenCL2.0���̎g���Ȃ�APCIe��APU�o���Ăق�������
���XGPGPU�͕��U�R���s���[�e�B���O�ׂ̈̕��Ȃ̂ɂ��̃��j�b�g��ɏW�����Ăǁ[����̂悗
�Ƃ������R���V���[�}�Ń��j�[�R�A�H���͖��ɗ����Ȃ����Ă̂�Sandy��bull�ł���H
���j�[�R�A�̂܂܂łǁ[����̂悗��̃��[�t�R�A���ēz���H�WC32T�Ƃ�������ł͂���炵������
�܂�����͂������ǁA�l�I�Ƀ��C��CPU�͋Ă����Ăق�������
HSA����OpenCL2.0���̎g���Ȃ�APCIe��APU�o���Ăق�������
���XGPGPU�͕��U�R���s���[�e�B���O�ׂ̈̕��Ȃ̂ɂ��̃��j�b�g��ɏW�����Ăǁ[����̂悗
�Ƃ������R���V���[�}�Ń��j�[�R�A�H���͖��ɗ����Ȃ����Ă̂�Sandy��bull�ł���H
���j�[�R�A�̂܂܂łǁ[����̂悗��̃��[�t�R�A���ēz���H�WC32T�Ƃ�������ł͂���炵������
>>755
�����ƁA�݊��`�b�v�Z�b�g���[�J�[��VIA��SiS���ׂꂽ�̂�Intel���i�U���Ő��i�̔���W�Q��������Ƃ������Ă��?
�����ƁA�݊��`�b�v�Z�b�g���[�J�[��VIA��SiS���ׂꂽ�̂�Intel���i�U���Ő��i�̔���W�Q��������Ƃ������Ă��?
Windows�𑖂点���H/W�ł̉��z�����I�t�ɂȂ�MacPro���������āH��
�A�|�͒N���ق����Ƃ��̃m���Ńv���Z�b�T��v���邩��AMD�̋��Ђɂ͂Ȃ肦�Ȃ�
�A�|�͒N���ق����Ƃ��̃m���Ńv���Z�b�T��v���邩��AMD�̋��Ђɂ͂Ȃ肦�Ȃ�
���肷���Carrizo��Broadwell���쒀���邩��������
Qualcomm��snapdragon�����^��Intel���甃�����ꂽStrongARM���������
������āA���Ƃ���Intel�͂ǂ����甃������Ă����������B�Y�ꂽ���B
�������ꂽ���Y�ł��L���Ɋ��p���āA����W�����Ă����Ă���[���B
�܂�AMD�͔������ꂽ���Y���S�~���Ɏ̂Ă��O�Ⴊ���Ȃ��Ȃ����牽�Ƃ������Ȃ����c�c
������āA���Ƃ���Intel�͂ǂ����甃������Ă����������B�Y�ꂽ���B
�������ꂽ���Y�ł��L���Ɋ��p���āA����W�����Ă����Ă���[���B
�܂�AMD�͔������ꂽ���Y���S�~���Ɏ̂Ă��O�Ⴊ���Ȃ��Ȃ����牽�Ƃ������Ȃ����c�c
>>780
DEC�̈�Y
DEC�̈�Y
782 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 03:42:27.81 ID:eKNrnP9T
�n�C�G���h�̈�˂��B
�܂����R�A�̐������\���Ƃ��������肩�ˁH
Density Server�Ɩ������Ă�ȏ�Xeon�ƒ��荇�������W�͂܂����肦�Ȃ��Ǝv���̂���
Avoton�̌�p��Denverton�̃R�A�����킩��Ȃ�����12�`16�R�A���炢�悹�Ă���C�͂���
http://pc.watch.impress.co.jp/img/pcw/docs/614/543/html/03.png.html
AMD���ӂ̃j�R�C�`�Ȃ�16�R�A�~2�ł������������B
����d�͎���ł͏����ڂ��邩���ˁI
�܂����R�A�̐������\���Ƃ��������肩�ˁH
Density Server�Ɩ������Ă�ȏ�Xeon�ƒ��荇�������W�͂܂����肦�Ȃ��Ǝv���̂���
Avoton�̌�p��Denverton�̃R�A�����킩��Ȃ�����12�`16�R�A���炢�悹�Ă���C�͂���
http://pc.watch.impress.co.jp/img/pcw/docs/614/543/html/03.png.html
{kind=link}
AMD���ӂ̃j�R�C�`�Ȃ�16�R�A�~2�ł������������B
����d�͎���ł͏����ڂ��邩���ˁI
ARM�Ɋւ��ẮAAMD�͂�������v���[���̂P���Ă����Ȃ̂ɁA
�Ȃɂ�����ȂɊ��҂��Ă��
AMD�ɂ������Ȃ�������ARM�T�[�o�p�`�b�v��AMD�ɍ���Ƃ͎v���Ȃ�
AMD�ɍ���Ȃ�A���̃��[�J�[���������A
ARM��������ARM�T�[�o����IP���������肷�邾��
�Ȃɂ�����ȂɊ��҂��Ă��
AMD�ɂ������Ȃ�������ARM�T�[�o�p�`�b�v��AMD�ɍ���Ƃ͎v���Ȃ�
AMD�ɍ���Ȃ�A���̃��[�J�[���������A
ARM��������ARM�T�[�o����IP���������肷�邾��
784 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 03:44:01.54 ID:eKNrnP9T
>>780
XScale���Ɣ������̂�Qualcomm����Ȃ���Marvell�����Ă�
XScale���Ɣ������̂�Qualcomm����Ȃ���Marvell�����Ă�
�����AStrongARM����DEC���甃�������c�������̂��B��������Y��Ă�
DEC���ăz���g�Ƀo�����肳�ꂿ����Ă��ȁc�c
DEC���ăz���g�Ƀo�����肳�ꂿ����Ă��ȁc�c
MacPro��Windows�𑖂点��Ɖ��z���x�����I�t�ɂȂ錏�Ɋւ���
�T�|�[�g�͈�؏����o���Ȃ��Ƃ�
����ȃ��[�J�[�̐��i���I�Ŏg���邩�H
�܂����A�|��ARM�I��iOS�ł��g���̂��悗
�T�|�[�g�͈�؏����o���Ȃ��Ƃ�
����ȃ��[�J�[�̐��i���I�Ŏg���邩�H
�܂����A�|��ARM�I��iOS�ł��g���̂��悗
787 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 03:46:02.92 ID:eKNrnP9T
>>783
�A�v���C�h�}�C�N�������ɂ���B������IP���Ǝ��v���Ă�B
40nm�̎��_��28nm��AMD Seattle�ȏ�̐��\
�ǂ�����
�A�v���C�h�}�C�N�������ɂ���B������IP���Ǝ��v���Ă�B
40nm�̎��_��28nm��AMD Seattle�ȏ�̐��\
�ǂ�����
>>785
DEC���Z�p�I�ɂ̓X�Q�G��Ђ���������
Gb�l�b�g���[�N����OS����Alpha CPU����Ȃ�Ă������Ă�
�C���e����QPI�Ƃ���DEC�g�̍�i����
�����C���e���ɍ����o�X���J������Z�p�Ȃ�ĂȂ�
DEC���Z�p�I�ɂ̓X�Q�G��Ђ���������
Gb�l�b�g���[�N����OS����Alpha CPU����Ȃ�Ă������Ă�
�C���e����QPI�Ƃ���DEC�g�̍�i����
�����C���e���ɍ����o�X���J������Z�p�Ȃ�ĂȂ�
789 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 03:55:37.25 ID:eKNrnP9T
DIX��DEC/Intel/Xerox
���[����HyperTransport����DEC�g��������
Intel�哱��PCIe�Ɏ����㕉��������
���[����HyperTransport����DEC�g��������
Intel�哱��PCIe�Ɏ����㕉��������
>>783
> ARM�Ɋւ��ẮAAMD�͂�������v���[���̂P���Ă����Ȃ̂ɁA
> �Ȃɂ�����ȂɊ��҂��Ă��
�@Opteron�̃m�E�n�E��FirePro�Ƃ̘A�g�ƁAx86�̃\�t�g��J�����Y�̗��p��AMD�ɂ����o�����
> AMD�ɂ������Ȃ�������ARM�T�[�o�p�`�b�v��AMD�ɍ���Ƃ͎v���Ȃ�
x86�̃m�E�n�E�������ꂽK12���J������Ă邯�ǂ�
���̐��\�͖��m�������ǁAZen���lSMT�Ή��̉\��������
> AMD�ɍ���Ȃ�A���̃��[�J�[���������A
> ARM��������ARM�T�[�o����IP���������肷�邾��
�`�b�v������������łǂ��Ȃ����ł��Ȃ���
�i���ƐM�����̂��߂ɁA���Ɏ��ԂƃJ�l��������o���f�[�V�������K�v�����AARM�I�̓\�t�g���F��������A�����̖ʓ|�����Ȃ��Ƃ����Ȃ�
AMD�Ȃ炻�̕ӂ̖ʓ|�����S�ă`�����ɏo���邩����҂���Ă��
�܂��Ax64����āA�{�i�Ix64�I�����AMD���炷��A�����̃m�E�n�E���g����ARM�I�͊y�ȃ~�b�V�������낤
> ARM�Ɋւ��ẮAAMD�͂�������v���[���̂P���Ă����Ȃ̂ɁA
> �Ȃɂ�����ȂɊ��҂��Ă��
�@Opteron�̃m�E�n�E��FirePro�Ƃ̘A�g�ƁAx86�̃\�t�g��J�����Y�̗��p��AMD�ɂ����o�����
> AMD�ɂ������Ȃ�������ARM�T�[�o�p�`�b�v��AMD�ɍ���Ƃ͎v���Ȃ�
x86�̃m�E�n�E�������ꂽK12���J������Ă邯�ǂ�
���̐��\�͖��m�������ǁAZen���lSMT�Ή��̉\��������
> AMD�ɍ���Ȃ�A���̃��[�J�[���������A
> ARM��������ARM�T�[�o����IP���������肷�邾��
�`�b�v������������łǂ��Ȃ����ł��Ȃ���
�i���ƐM�����̂��߂ɁA���Ɏ��ԂƃJ�l��������o���f�[�V�������K�v�����AARM�I�̓\�t�g���F��������A�����̖ʓ|�����Ȃ��Ƃ����Ȃ�
AMD�Ȃ炻�̕ӂ̖ʓ|�����S�ă`�����ɏo���邩����҂���Ă��
�܂��Ax64����āA�{�i�Ix64�I�����AMD���炷��A�����̃m�E�n�E���g����ARM�I�͊y�ȃ~�b�V�������낤
CPU��DEC�AGPU��SGI����������
����CPU��GPU�̐v�`�[���̌��������ǂ�Ƃ�����������2�Ђɍs����
����CPU��GPU�̐v�`�[���̌��������ǂ�Ƃ�����������2�Ђɍs����
PCIe�͊O���o�X
HT�̓V�X�e���o�X(CPU�ȊO�̃��m���q����ėp���͂��邪)
�����킩���ĂȂ���
HT�̓V�X�e���o�X(CPU�ȊO�̃��m���q����ėp���͂��邪)
�����킩���ĂȂ���
Innovative AMD FirePro? Server GPU Supports Intense Compute Workloads on HP ProLiant DL380 Gen9 Servers
http://www.amd.com/en-us/press-releases/Pages/innovative-amd-firepro-2015feb26.aspx
http://www.amd.com/en-us/press-releases/Pages/innovative-amd-firepro-2015feb26.aspx
>>791
DEC�Ɍ����Ă����̂�����Ƃ���ΐ�p�n�[�h�E�F�A��p����������3D�Z�p���낤��
DEC�ɂȂ���SGI�ɂ��������̂�����
������DEC�g�ɂƂ��Ă̐��t�̓O���t�B�b�N�X�ł���
AMD�̒��̐l�ɂȂ���DEC�̘A���ɂƂ���
���̐��t�������\�ȃ`�����X�Ƃ��Ă������̂����܂���ATI�������낤�Ǝv��
ATI��3D��������ArtX�ł��茳SGI�ɂȂ邪
DEC�Ɍ����Ă����̂�����Ƃ���ΐ�p�n�[�h�E�F�A��p����������3D�Z�p���낤��
DEC�ɂȂ���SGI�ɂ��������̂�����
������DEC�g�ɂƂ��Ă̐��t�̓O���t�B�b�N�X�ł���
AMD�̒��̐l�ɂȂ���DEC�̘A���ɂƂ���
���̐��t�������\�ȃ`�����X�Ƃ��Ă������̂����܂���ATI�������낤�Ǝv��
ATI��3D��������ArtX�ł��茳SGI�ɂȂ邪
795 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 04:01:35.63 ID:eKNrnP9T
�n���ł����H
����QPI��DMI��PCIe�v���g�R���x�[�X��
����QPI��DMI��PCIe�v���g�R���x�[�X��
797 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 04:03:34.23 ID:eKNrnP9T
�U�R�A�i�j���ď��Ă�SMT�����X�h����œ�������AMD���ǂ��v�����H
798 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 04:07:52.77 ID:eKNrnP9T
SGISGI���ė�̒r�c���l���q���c�ł���
�s�b�g�N���[�̃o�C�g������ł�
�s�b�g�N���[�̃o�C�g������ł�
�P�Ƀx���`��Əȓd�͖ړI�Ȃ��
�v�҂��U�R�A�ł͎I�ɂ͕s�\���Ɣ��f���Ă�
���p�\�t�g�ł̃R�A�W���̃R�X�p��������ߏ葕���Ƃ��ꂽ��
�M�d�ȃ_�C�������Ă܂ŃR�A����������K�v���Ȃ��ł���
�����R�A���ł̃y�i���e�B���Ȃ�OSS�ȊO�ł�CPU�̃��W���[���Z�p�͕s�K���Ǝv����
�v�҂��U�R�A�ł͎I�ɂ͕s�\���Ɣ��f���Ă�
���p�\�t�g�ł̃R�A�W���̃R�X�p��������ߏ葕���Ƃ��ꂽ��
�M�d�ȃ_�C�������Ă܂ŃR�A����������K�v���Ȃ��ł���
�����R�A���ł̃y�i���e�B���Ȃ�OSS�ȊO�ł�CPU�̃��W���[���Z�p�͕s�K���Ǝv����
�t��Win��ł�x264�݂�����OSS�ł̓R�A���̃����b�g���o��
�o�b�N�O���E���h�ő��点�Ă��C���e��CPU�݂����ɂ������肩�����Ȃ������
�P��CPU����D��x�𗎂Ƃ��悢�ƍl����̂͏��
�o�b�N�O���E���h�ő��点�Ă��C���e��CPU�݂����ɂ������肩�����Ȃ������
�P��CPU����D��x�𗎂Ƃ��悢�ƍl����̂͏��
SGI��WindowsNT4.0Workstation�̗p�����O���t�B�b�N���[�N�X�e�[�V�����Ɋ����Ȃ��܂łɒׂ��ꂽ����
>>795
�㓡��QPI�̓V���A���o�X����Ȃ����Č����Ă܂���
�㓡��QPI�̓V���A���o�X����Ȃ����Č����Ă܂���
>>801
Diamondmm�P����FireGL�Ƃ��}�W�ŃS�~���������ǒl�i��SGI��EWS���S�R��������
����Ƀt�@�����n�C�g�Ƃ�M$�Ƀ������^�����n���p�Ȃ�
�k�r�̓��������Ƃ������E�͊��͂��̕ӌo�����Ă���̎��a�Ǝv����
Diamondmm�P����FireGL�Ƃ��}�W�ŃS�~���������ǒl�i��SGI��EWS���S�R��������
����Ƀt�@�����n�C�g�Ƃ�M$�Ƀ������^�����n���p�Ȃ�
�k�r�̓��������Ƃ������E�͊��͂��̕ӌo�����Ă���̎��a�Ǝv����
804 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 04:41:25.80 ID:eKNrnP9T
����ǂ̓I���I���V���A�����悗
�R�[���t���X�e�B���t���O���ł��H���ĐQ��
�R�[���t���X�e�B���t���O���ł��H���ĐQ��
806 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 04:53:04.29 ID:eKNrnP9T
>>733
��̂��̕��n���̓A�u�_�r�����������P���Ƃ�AMD�ɋ��n����
�Ȃ���������ʓ|���Ă��炦��Ǝv���Ă邩�獢��
�܂��œ����v�N���Ă��Ȃ��́H
ATIC��Fab���Ƃ��n�߂����āA�葁��Fab�𗧂��グ�邽�߂ɂ܂�Fab�����ė]���Ă��Ђ���Fab�����Ƃ���
���ꂪAMD�ł���`���[�^�[�h
�ނ�͍Ő�[�N���X��Fab�Ɠ����ɁAAMD���ڋq�Ƃ��Ď�ɓ���邱�Ƃ��ł���
Fab�����グ����AMD�̎��Y���������̂́A�����グ���琔�N�ɂ킽����
���Y���C����\��Ƃ����m��̌��Ԃ肾�B
�܂薢���̋���O�肵�������ɂ����Ȃ��B
AMD�͂��̌_���j�����A�����Ƃ��Ď莝����GF�̊����S���Ǝ莝���̌�����
GF�ɕ������B���̎��_��AMD�͂���ATIC�Ƃ͂Ȃ�̂������̂Ȃ���ЂɂȂ����B
���������ɋ������֗��ȃh��������͂������Ȃ���B
������������ɂ͋�ATI����������炢�����Ȃ���Ȃ��́H
��̂��̕��n���̓A�u�_�r�����������P���Ƃ�AMD�ɋ��n����
�Ȃ���������ʓ|���Ă��炦��Ǝv���Ă邩�獢��
�܂��œ����v�N���Ă��Ȃ��́H
ATIC��Fab���Ƃ��n�߂����āA�葁��Fab�𗧂��グ�邽�߂ɂ܂�Fab�����ė]���Ă��Ђ���Fab�����Ƃ���
���ꂪAMD�ł���`���[�^�[�h
�ނ�͍Ő�[�N���X��Fab�Ɠ����ɁAAMD���ڋq�Ƃ��Ď�ɓ���邱�Ƃ��ł���
Fab�����グ����AMD�̎��Y���������̂́A�����グ���琔�N�ɂ킽����
���Y���C����\��Ƃ����m��̌��Ԃ肾�B
�܂薢���̋���O�肵�������ɂ����Ȃ��B
AMD�͂��̌_���j�����A�����Ƃ��Ď莝����GF�̊����S���Ǝ莝���̌�����
GF�ɕ������B���̎��_��AMD�͂���ATIC�Ƃ͂Ȃ�̂������̂Ȃ���ЂɂȂ����B
���������ɋ������֗��ȃh��������͂������Ȃ���B
������������ɂ͋�ATI����������炢�����Ȃ���Ȃ��́H
��ATI�Ȃ�Ă��̂͂����Ȃ���o�J��
����AMD�͋�ATI���̂��̂�
����Ȃ̂͂��O����o�J�Ȏ����藣���Ƃ��O���̂��Ȃ��Ȃ邮�炢���R�̂���
����AMD�͋�ATI���̂��̂�
����Ȃ̂͂��O����o�J�Ȏ����藣���Ƃ��O���̂��Ȃ��Ȃ邮�炢���R�̂���
808 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 04:58:32.86 ID:eKNrnP9T
���Ⴀ�uGPU���Ɓv
�����~���������˂Ƃ���
810 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 05:00:10.99 ID:eKNrnP9T
AMD�ׂꂽ��j���p�[�e�B�J����������
���p�\�R���̓X�}�z�ŎB�肽�߂��ʐ^�̓��ꕨ����
���ق��ł��Ȃ�PC���[�J�[�����������������]��ł�B
AMD��肱�������A�z���ׂ��Ă���܂��˂��H
�X�}�z���y������i���ŒႾ���A�ǂ��l���Ă�AMD���c�q�݂����ȘA���̕����Q��
���ق��ł��Ȃ�PC���[�J�[�����������������]��ł�B
AMD��肱�������A�z���ׂ��Ă���܂��˂��H
�X�}�z���y������i���ŒႾ���A�ǂ��l���Ă�AMD���c�q�݂����ȘA���̕����Q��
��̂ǂ�����GPU��IP��J���������������Ă����̖��ɂ������˂���
3Dlabs�ȑO�ɂ�Chips & Technology�Ƃ����������Ǔ������牽��̐i�����Ȃ�
�A�|�ɗv�������GPU���������X����Ă�̂��~�G�~�G
3Dlabs�ȑO�ɂ�Chips & Technology�Ƃ����������Ǔ������牽��̐i�����Ȃ�
�A�|�ɗv�������GPU���������X����Ă�̂��~�G�~�G
�I�ł���AMD����`�b�v�̊O�̂��Ă�
�Ȃ�ŃC���e����Xeon�t�@�C()�̊O�̂�v�����Ȃ������낤�ˁH
����GPU�̂ł������Ȃ������炩��
�Ȃ�ŃC���e����Xeon�t�@�C()�̊O�̂�v�����Ȃ������낤�ˁH
����GPU�̂ł������Ȃ������炩��
>>811
�X�}�z�{�̂������ƃ\�t�g�E�F�A�L�[�{�[�h�����Ȃ�����g���ɂ�����ˁc
������K���P�[���v�͍���������Ǝv���܂���
�X�}�z�{�̂������ƃ\�t�g�E�F�A�L�[�{�[�h�����Ȃ�����g���ɂ�����ˁc
������K���P�[���v�͍���������Ǝv���܂���
815 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 05:16:34.87 ID:eKNrnP9T
> �j�b�`��������Ȃ獂�P���ȏ��i�o���Ȃ��ƃL�c�C��ADevils�@Conyan�Ȃ�Ă킴�킴���t�����O���X���P����
> i5�Ai7�ʼnߋ��ō��̔����������H���̎s��͒n���ɐ�������Ǝv������
Reflesh�O�ɂ��Ƃ��Ɣ̔���1�ʁ`2�ʏ�A������4770K�̌�p���i�����甄�ꂽ������
�ǂ݂̂�OC�ɍS��l�͊k�����Ăł�OC�������B
�������z�����T���������B
LGA2011�Ŕ��������̂ɁA�킴�킴�����肪�o��܂Ŕ���������OC�n���Ƃ����B
�ł�����͌���x86�ō����\���ւ�A�[�L�e�N�`���ōō��N���b�N���ւ鐻�i�����炱��
�������������𖣗����Ă���B
���[���`�������̓g�b�v10�����ɓ����Ă����̌�͔̔�������Ƃ����s��ȏo������������
���\��2�R�A�Ȃ݁A����d�͂͂�������4�R�A���̂ǂ�����7850K�݂����Ȑ��i�������Ȃ�AMD�ɂ�
�A�����b�N�Ȃ璷�������Ȃ�Ă̂͒ʗp���Ȃ����ƁB
�ނ���Athlon5350����������Ă邶��Ȃ���
�K�v�Ȃ̂͂��̃����W����Ȃ��́H
> i5�Ai7�ʼnߋ��ō��̔����������H���̎s��͒n���ɐ�������Ǝv������
Reflesh�O�ɂ��Ƃ��Ɣ̔���1�ʁ`2�ʏ�A������4770K�̌�p���i�����甄�ꂽ������
�ǂ݂̂�OC�ɍS��l�͊k�����Ăł�OC�������B
�������z�����T���������B
LGA2011�Ŕ��������̂ɁA�킴�킴�����肪�o��܂Ŕ���������OC�n���Ƃ����B
�ł�����͌���x86�ō����\���ւ�A�[�L�e�N�`���ōō��N���b�N���ւ鐻�i�����炱��
�������������𖣗����Ă���B
���[���`�������̓g�b�v10�����ɓ����Ă����̌�͔̔�������Ƃ����s��ȏo������������
���\��2�R�A�Ȃ݁A����d�͂͂�������4�R�A���̂ǂ�����7850K�݂����Ȑ��i�������Ȃ�AMD�ɂ�
�A�����b�N�Ȃ璷�������Ȃ�Ă̂͒ʗp���Ȃ����ƁB
�ނ���Athlon5350����������Ă邶��Ȃ���
�K�v�Ȃ̂͂��̃����W����Ȃ��́H
>�킴�킴�����肪�o��܂Ŕ���������OC�n��
���ȖړI�����Ă��
���O�݂����ɂ�
BX�`�b�v�Z�b�g��FSB133MHz�ŏ�p�o�����牽�N�킦��Ƃ������Ă��A�z�ȘA���Ƃ��ǂ����Ă��
���Ă������Ƃ����������Ă��o�J��������
���ȖړI�����Ă��
���O�݂����ɂ�
BX�`�b�v�Z�b�g��FSB133MHz�ŏ�p�o�����牽�N�킦��Ƃ������Ă��A�z�ȘA���Ƃ��ǂ����Ă��
���Ă������Ƃ����������Ă��o�J��������
����150MHz���������ȁH��
���Ƃ����Ԃ̗���͎c����
���LGA2011�Ȃ�Ĕ��M�̃S�~����Ȃ��ł���
�������`���l���������Ƃ���ł�������������������P���˂�
���Ƃ����Ԃ̗���͎c����
���LGA2011�Ȃ�Ĕ��M�̃S�~����Ȃ��ł���
�������`���l���������Ƃ���ł�������������������P���˂�
ID:rQWsaD1A�͂Ȃ��>>796�Ŏ����Ƀ��X���Ă�́H
>>818
typo�̒�������
typo�̒�������
820 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 05:27:51.31 ID:eKNrnP9T
�X�}�z����K���P�[�ɖ߂������[�U�[������Ȃ�ɂ���̂͂����P��3��L�����A��
�X�}�z�̒�z�����������炾
�����ăK���P�[���ނ���i��MVNO��Ё{SIM�t���[�X�}�z�̌_���L�тĂ�㩁B
docomo��au��Android���̗p�����u�K���z�v�Ƃ����������
GooglePlay�ɂ͔�Ή���i-mode/ezweb�̑Ή��R���e���c���g���Ȃ��B
���̏�ł�������LTE�̗����v�����ɉ�������������Ƃ����
��Ȃ���˂����낗����
au��2011�N���炢�܂�Wi-Fi�o�R�ŃC���^�[�l�b�g�ɂȂ���K���P�[�[���Ƃ��̃T�[�r�X
����Ă����ǂƂ����Ɏ��߂��������B
�X�}�z�̃p�P�b�g�ʐM���œ����闘�v�������ɂ����������킩��ˁB
�X�}�z�̒�z�����������炾
�����ăK���P�[���ނ���i��MVNO��Ё{SIM�t���[�X�}�z�̌_���L�тĂ�㩁B
docomo��au��Android���̗p�����u�K���z�v�Ƃ����������
GooglePlay�ɂ͔�Ή���i-mode/ezweb�̑Ή��R���e���c���g���Ȃ��B
���̏�ł�������LTE�̗����v�����ɉ�������������Ƃ����
��Ȃ���˂����낗����
au��2011�N���炢�܂�Wi-Fi�o�R�ŃC���^�[�l�b�g�ɂȂ���K���P�[�[���Ƃ��̃T�[�r�X
����Ă����ǂƂ����Ɏ��߂��������B
�X�}�z�̃p�P�b�g�ʐM���œ����闘�v�������ɂ����������킩��ˁB
>>819
���������Ƃ��눫������
HT��HyperTransport�ł����Ă��H
����er�Ȃ�펯
http://ja.wikipedia.org/wiki/HyperTransport
http://ja.broadcom.com/products/HT-2100
http://www.gigabyte.us/products/list.aspx?s=42&jid=13&p=2&v=2
���������Ƃ��눫������
HT��HyperTransport�ł����Ă��H
����er�Ȃ�펯
http://ja.wikipedia.org/wiki/HyperTransport
http://ja.broadcom.com/products/HT-2100
http://www.gigabyte.us/products/list.aspx?s=42&jid=13&p=2&v=2
google play�ɔ�Ή��Ȃ͉̂�ʃ^�b�`�ɑΉ����Ȃ��������炾
�Ӑ}�I�ɐ�̂Ă��Z�p
�����WiFi�o�R�Ńl�b�g�ɂȂ��肽����ΒP�ɓD�^�u�g����������
WiFi�o�R�Ŗ����œd�b��������ꂽ���P���Ⴀ��܂���
�Ӑ}�I�ɐ�̂Ă��Z�p
�����WiFi�o�R�Ńl�b�g�ɂȂ��肽����ΒP�ɓD�^�u�g����������
WiFi�o�R�Ŗ����œd�b��������ꂽ���P���Ⴀ��܂���
>>821
���`���肪�ƁI
���`���肪�ƁI
���āA���Ƃ͎v�����������Ă���
����1���Ԕ����炢�����ǐQ�悤
����1���Ԕ����炢�����ǐQ�悤
825 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 05:38:49.92 ID:eKNrnP9T
�₾�悱�̓��储������̓S�V�S�V�ƌ��������ĂĂق�����
Sun��D���̒s���
Sun��D���̒s���
2chMate 0.8.6.21 dev/SHARP/SHF31/4.4.4/LT
�Ăꂽ�C������
�Ăꂽ�C������
�������������������
�����Ă��悤���Ȃ�
����͎����Ŏn���t���Ă���
�����Ă��悤���Ȃ�
����͎����Ŏn���t���Ă���
>>815�@����OC���Ȃ�����4790�����������H4770���͒�iAVX�Q���s���Ɏ���20����CPU90���߂��Ƃ����ĕ�����������
Haswell-E�����Ȃ����Ȃ��Ǝv���Ă��Ƃ����Devils Conyan�ŁA�k���肵�Ȃ��Ă��������M�}�V�ɂȂ��Ă���
Haswell��QSV��C7�X�e�[�g�͗~������������
��Haswell�̎���OC������i�Œ�d�����Ƃ������s���Ă��L�K�X�A�������M���}�V�ɂȂ�݂���������
skylake�҂����Ă���Haswell Reflesh��IYH������������A�����������鍠�i�����܂��S�`�T�N�ギ�炢���H�j
AMD�������傢�撣���Ă���Ă�Ɗ������Ȃ���
Haswell-E�����Ȃ����Ȃ��Ǝv���Ă��Ƃ����Devils Conyan�ŁA�k���肵�Ȃ��Ă��������M�}�V�ɂȂ��Ă���
Haswell��QSV��C7�X�e�[�g�͗~������������
��Haswell�̎���OC������i�Œ�d�����Ƃ������s���Ă��L�K�X�A�������M���}�V�ɂȂ�݂���������
skylake�҂����Ă���Haswell Reflesh��IYH������������A�����������鍠�i�����܂��S�`�T�N�ギ�炢���H�j
AMD�������傢�撣���Ă���Ă�Ɗ������Ȃ���
829 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 05:46:31.91 ID:eKNrnP9T
830 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 05:47:28.85 ID:eKNrnP9T
>>828
Conyan���ĂȂ�
Conyan���ĂȂ�
�x���`���C���e��CPU�������Ƃ��ɕʃ��[�`���ɕ��Ă���
AMD���ǂ��撣�����Ƃ���ňӖ��˂���
QSV��C7���~����������Ȃ炻��ł�����˂���
AMD���ǂ��撣�����Ƃ���ňӖ��˂���
QSV��C7���~����������Ȃ炻��ł�����˂���
832 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 05:49:05.14 ID:eKNrnP9T
> �x���`���C���e��CPU�������Ƃ��ɕʃ��[�`���ɕ��Ă���
> AMD���ǂ��撣�����Ƃ���ňӖ��˂���
Visual C++�ɂ���ȋ@�\�͎�������ĂȂ�����
���Ƃ��Ă�����Ȃ���炵���f�B�X�p�b�`�@�\���͉̂��݂����ȂЂ˂��ꂽ�J����
> AMD���ǂ��撣�����Ƃ���ňӖ��˂���
Visual C++�ɂ���ȋ@�\�͎�������ĂȂ�����
���Ƃ��Ă�����Ȃ���炵���f�B�X�p�b�`�@�\���͉̂��݂����ȂЂ˂��ꂽ�J����
833 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 05:53:43.45 ID:eKNrnP9T
�x���`�}�[�N���s�����Ă�Ƃ����Ȃ�A���̃x���`�}�[�N��disassemble����cpuid�̎��s���ʂ�
���Ă邱�Ƃ���������ǂ�����
���͂���H
�́AIntel�ސ���TAT�̃N���b�N�p�b�`��������Ƃ����邵��������
���Ă邱�Ƃ���������ǂ�����
���͂���H
�́AIntel�ސ���TAT�̃N���b�N�p�b�`��������Ƃ����邵��������
���Ⴊ���邩���
PC�֘A�̃x���`�̓k�r�ƃC���e���̑��̂������Ă�\�������邩��S�ċ^���Ă����邵���˂�
�܂����ێg���ă_���Ȃ炷������Ⴂ����GTX970�݂����ɔ��蔲�����Ȃ��ƔߎS����
PC�֘A�̃x���`�̓k�r�ƃC���e���̑��̂������Ă�\�������邩��S�ċ^���Ă����邵���˂�
�܂����ێg���ă_���Ȃ炷������Ⴂ����GTX970�݂����ɔ��蔲�����Ȃ��ƔߎS����
���C���̓e�U�����O�Ȃ̂�
�o�b�e���[�e�ʂ̊��ɂ�����
�o�A����v1���Ԓ��x�ԉ^�]���Ȃ���
�^�u���b�g��youtube�Đ����邭�炢����3�����炢�����܂���
�^�b�`�N���[�U�[��e�U�����O���{�^���ŋN����~�ł���̂Ŋy
���̓K���P�[�ƈꏏ
����gmail�͂Ȃ��ł�
�X�}�z����Ȃ���K���P�[����
�K���P�[�������
�o�b�e���[�e�ʂ̊��ɂ�����
�o�A����v1���Ԓ��x�ԉ^�]���Ȃ���
�^�u���b�g��youtube�Đ����邭�炢����3�����炢�����܂���
�^�b�`�N���[�U�[��e�U�����O���{�^���ŋN����~�ł���̂Ŋy
���̓K���P�[�ƈꏏ
����gmail�͂Ȃ��ł�
�X�}�z����Ȃ���K���P�[����
�K���P�[�������
836 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 05:58:01.44 ID:eKNrnP9T
���̃X�����B��������������
http://�@2ch�@.�@ac�@�@.la�@/read.php/jisaku/1187603220/770n-
http://�@2ch�@.�@ac�@�@.la�@/read.php/jisaku/1187603220/770n-
837 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 06:09:00.37 ID:eKNrnP9T
CPUID�`�F�b�N���ăx���_�[�X�g�����O�ŕ��Ă�^���̂���v���O����
������ƒN���グ�Ă݂Ă���Ȃ����H
�����p�b�`�������H
������ƒN���グ�Ă݂Ă���Ȃ����H
�����p�b�`�������H
838 �FSocket774�F2015/02/27(��) 06:09:02.04 ID:OTAI4ooD
>>815
AMD�̌��s���i�ň�ԗL�]�Ȃ̂�Athlon5350���Beema���ˁB(����������i�ł͖�����)
�ቿ�i�m�[�g�����Ƃ��Č������Ă���B
AMD�̌��s���i�ň�ԗL�]�Ȃ̂�Athlon5350���Beema���ˁB(����������i�ł͖�����)
�ቿ�i�m�[�g�����Ƃ��Č������Ă���B
�Ǝ҂Ȃ�CPUID�݂����Ȃ����o����������Ȃ��Ă���������Ǝ�̍������ł��邾�낤��
840 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 06:15:08.35 ID:eKNrnP9T
CPUID����Ȃ���ǂ������AMD��CPU�����Ď��ʂ����ł���������
�܂���OS�̊��ϐ����H
����Ȃ�BAT�t�@�C�����点�邾���ŋU���ł��邾�낪������
�����IT���s��Sun���f���炵���Ƃ��܂��Œs��҂���
�܂���OS�̊��ϐ����H
����Ȃ�BAT�t�@�C�����点�邾���ŋU���ł��邾�낪������
�����IT���s��Sun���f���炵���Ƃ��܂��Œs��҂���
841 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 06:18:31.44 ID:eKNrnP9T
���ϐ� PROCESSOR_IDENTIFIER
Haswell���Ƃ����Ȃ�
Intel64 Family 6 Model 60 Stepping 3, GenuineIntel
������P��OS����CPUID���߂̎��s���ʂ��Z�b�g���Ă邾���ɉ߂���̂����B
Haswell���Ƃ����Ȃ�
Intel64 Family 6 Model 60 Stepping 3, GenuineIntel
������P��OS����CPUID���߂̎��s���ʂ��Z�b�g���Ă邾���ɉ߂���̂����B
�����ɉ����߂������Ǝ����ōl����悗
843 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 06:25:14.30 ID:eKNrnP9T
�m�����Ȃ��l�Ԃ������������R�������Ă邾���ɂ����݂���̂��A�s��҂�
�O�Ⴊ����Ƃ����̂Ȃ炻�́u�O��v������
���R���������ȁH
�O�Ⴊ����Ƃ����̂Ȃ炻�́u�O��v������
���R���������ȁH
>>843
ttp://arstechnica.com/gadgets/2008/07/atom-nano-review/6/
�߂�ǂ������ȁc
���ނ��炮������Ă��Ƃ��o���Ă����
ttp://arstechnica.com/gadgets/2008/07/atom-nano-review/6/
�߂�ǂ������ȁc
���ނ��炮������Ă��Ƃ��o���Ă����
845 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 06:35:42.15 ID:eKNrnP9T
>>844
PCMark2005���o�������́ASSE3�̃t���O��Intel�����d�l��`����Ă��Ȃ�����
�x���_�[�X�g�����O��GenuineIntel�łȂ���SSE3�����o���Ȃ�����
Feature�t���O���h���Ӗ��̓x���_�[���ƂɈقȂ�ꍇ������̂ŏ����
�uSSE3���g����v�Ɣ��f���邱�Ƃ͂ł��Ȃ��B
���̈Ӗ���PCMark�̓���͐������B
AMD��VIA��SSE3���d�l���ɒ�`�����̂�PCMark2005��肸���ƌ�B
���ꂪ�Ȃɂ���肪���邩�H
PCMark2005���o�������́ASSE3�̃t���O��Intel�����d�l��`����Ă��Ȃ�����
�x���_�[�X�g�����O��GenuineIntel�łȂ���SSE3�����o���Ȃ�����
Feature�t���O���h���Ӗ��̓x���_�[���ƂɈقȂ�ꍇ������̂ŏ����
�uSSE3���g����v�Ɣ��f���邱�Ƃ͂ł��Ȃ��B
���̈Ӗ���PCMark�̓���͐������B
AMD��VIA��SSE3���d�l���ɒ�`�����̂�PCMark2005��肸���ƌ�B
���ꂪ�Ȃɂ���肪���邩�H
846 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 06:37:36.87 ID:eKNrnP9T
���ǁA���储������iID:rQWsaD1A �j���܂����m���N����������
via cpu�̓}�C�i�[�����ăT�|�[�g����ĂȂ������Ƃ���
64bit vista������sp1�܂Ŏg���Ȃ�������
64bit vista������sp1�܂Ŏg���Ȃ�������
>Feature�t���O���h���Ӗ��̓x���_�[���ƂɈقȂ�ꍇ������̂ŏ����
>�uSSE3���g����v�Ɣ��f���邱�Ƃ͂ł��Ȃ���
�܂�\�t�g�E�F�A�̃����[�X��ɃC���e���ȊO��CPU�x���_��
��ǂ��Ŋg�����߂��T�|�[�g���Ă���������������disable�o������Ęb����
GTX970�Ȃ݂ɏ������̂Ȃ��v���_�N�g���Ǝv��Ȃ����H
>�uSSE3���g����v�Ɣ��f���邱�Ƃ͂ł��Ȃ���
�܂�\�t�g�E�F�A�̃����[�X��ɃC���e���ȊO��CPU�x���_��
��ǂ��Ŋg�����߂��T�|�[�g���Ă���������������disable�o������Ęb����
GTX970�Ȃ݂ɏ������̂Ȃ��v���_�N�g���Ǝv��Ȃ����H
849 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 06:42:52.70 ID:eKNrnP9T
Carrizo�͂���VIA��PadLock�T�|�[�g�����
�N��������̂��͒m���
�N��������̂��͒m���
via�̑g�ݍ������̌㊘�_���Ă�Ȃ�
via����cpu�o���C�z�͂Ȃ���
via����cpu�o���C�z�͂Ȃ���
851 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 06:48:27.32 ID:eKNrnP9T
>>848
PCMark Vantage�����Intel�ȊO�ł�SSE3���o����悤�ɂȂ�������
��肠��̂��ˁH
> ��ǂ��Ŋg�����߂��T�|�[�g���Ă���������������disable�o������Ęb����
�������܂��c����Ƃ�����
�������Ď��Ђ�GPGPU�ɃX�y�V�����`���[������LibreOffice Calc�̉�͋@�\��
������PCMark8�ɂ˂�����ł��|�C���g�̔�d�������Ȃ�悤�ɂ����ǂ�����
����A�Ђ݂����ȊO���H��͘d�G����ł͉\���Ƃ͎v����
UL�ɔ������ꂽ����������������^���͒ʗp���Ȃ��Ǝv�������ǂ�
PCMark Vantage�����Intel�ȊO�ł�SSE3���o����悤�ɂȂ�������
��肠��̂��ˁH
> ��ǂ��Ŋg�����߂��T�|�[�g���Ă���������������disable�o������Ęb����
�������܂��c����Ƃ�����
�������Ď��Ђ�GPGPU�ɃX�y�V�����`���[������LibreOffice Calc�̉�͋@�\��
������PCMark8�ɂ˂�����ł��|�C���g�̔�d�������Ȃ�悤�ɂ����ǂ�����
����A�Ђ݂����ȊO���H��͘d�G����ł͉\���Ƃ͎v����
UL�ɔ������ꂽ����������������^���͒ʗp���Ȃ��Ǝv�������ǂ�
�Z�p�I�ɉ\�������p���i�ł����������G�Ȏ�@���̗p���ꂽ�Ƃ�������o�����܂�
�Ȃ�ł���ȃP���J���Ȃ������˂�
�Ȃ�ł���ȃP���J���Ȃ������˂�
853 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 06:52:02.22 ID:eKNrnP9T
�̈ӂɎ��Ђ̃x���`�}�[�N�X�R�A�������Ȃ�悤�ɍH�삵�������AMD�̂ق����낤�H
�����Ă���Ăƌ�����ނ������Ă�����������낤��
�������̑ԓx��
�P��Intel��Calc�̉�͂�H/W�T�|�[�g����悢�����̘b����
�������̑ԓx��
�P��Intel��Calc�̉�͂�H/W�T�|�[�g����悢�����̘b����
855 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 06:57:21.10 ID:eKNrnP9T
�����x���`�}�[�N�\�t�g�uPCMark 8�v�����W���[�A�b�v�f�[�g
�I�[�v���\�[�X���i�𗘗p�����V�����e�X�g���lj��A�X�R�A�̌݊����͂Ȃ�
http://www.forest.impress.co.jp/docs/news/20140120_631438.html
> ���Ƃ��A�gHome�h����сgCreative�h�̗��x���`�}�[�N�ł̓I�[�v���\�[�X��
> �O���t�B�b�N�X���C�u�����gImageMagick�h�𗘗p�����摜�����e�X�g���lj����ꂽ�B
> �܂��A�gWork�h�x���`�}�[�N�ł̓I�[�v���\�[�X�̕\�v�Z�\�t�g�uLibreOffice Calc�v�𗘗p����
> �p�t�H�[�}���X�e�X�g�Ȃǂ��V���ɒlj����ꂽ�B
AMD���X�y�V�����`���[������Calc�̉�͋@�\���s���|�C���g�Œlj�����
�Ȃ����A�O�̃o�[�W�����Ƃ̃X�R�A�̌݊������Ȃ��Ȃ�ƁB
����͕��s������Ƃ̂�邱�Ƃ��낤
�I�[�v���\�[�X���i�𗘗p�����V�����e�X�g���lj��A�X�R�A�̌݊����͂Ȃ�
http://www.forest.impress.co.jp/docs/news/20140120_631438.html
> ���Ƃ��A�gHome�h����сgCreative�h�̗��x���`�}�[�N�ł̓I�[�v���\�[�X��
> �O���t�B�b�N�X���C�u�����gImageMagick�h�𗘗p�����摜�����e�X�g���lj����ꂽ�B
> �܂��A�gWork�h�x���`�}�[�N�ł̓I�[�v���\�[�X�̕\�v�Z�\�t�g�uLibreOffice Calc�v�𗘗p����
> �p�t�H�[�}���X�e�X�g�Ȃǂ��V���ɒlj����ꂽ�B
AMD���X�y�V�����`���[������Calc�̉�͋@�\���s���|�C���g�Œlj�����
�Ȃ����A�O�̃o�[�W�����Ƃ̃X�R�A�̌݊������Ȃ��Ȃ�ƁB
����͕��s������Ƃ̂�邱�Ƃ��낤
�Z�p�v�V��^�����ے肳��Ă�����̂���
�撣���ăC���e����Calc�̍������ɂ܂��i�V�^�}�G��
�撣���ăC���e����Calc�̍������ɂ܂��i�V�^�}�G��
857 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 06:59:44.44 ID:eKNrnP9T
�����Ă���g��Ȃ������
�{�Ƃ�Apache Open Office�ɂ��Ȃ����MS Office�ɂ��Ȃ�
C++�W�����ψ���̍]���������āA�uLibreOffice�ł�邱�Ƃ���Ȃ��v�Ƃ����Ă�@�\��
�킴�킴��Ԃ�����̂�AMD���炢�ł���B
��c�����ɂ܂��
�{�Ƃ�Apache Open Office�ɂ��Ȃ����MS Office�ɂ��Ȃ�
C++�W�����ψ���̍]���������āA�uLibreOffice�ł�邱�Ƃ���Ȃ��v�Ƃ����Ă�@�\��
�킴�킴��Ԃ�����̂�AMD���炢�ł���B
��c�����ɂ܂��
�ʂɂ���Ă��\��Ȃ���Ȃ��ł����H�Z�p�̉\���͖�����ł���
859 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 07:01:59.19 ID:eKNrnP9T
�J������ł������储�������
PCMark 8���K����������Ⴂ����Ȃ������H
���܂ŃC���e��������Ă������AMD�ɋt�ɂ��Ԃ��ꂽ�C���͂ǂ���
���܂ŃC���e��������Ă������AMD�ɋt�ɂ��Ԃ��ꂽ�C���͂ǂ���
Calc���ăx���_�`�F�b�N�͂��ĂȂ���Ȃ���
862 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 07:17:22.99 ID:eKNrnP9T
�ʂɂ�����Ȃ��ł���
����͂܂�u�X�R�A�̌݊������Ȃ��Ȃ����v�Ƃ������R��PCMark8���g��Ȃ�
�A�X�L�[�Ȃǂ̎G������邢�����Ȃ��킯�ł���ˁB
IT�v�����Q�l�ɂ��Ă�̂�SPEC�݂����Ȕ�c���̑�O�ҋ@�ւ̃x���`�}�[�N����
�R�b�`���ʂł�Intel�̓����O�ɏオ���Ă�����ƒ������
ASUSTeK Computer Inc. (Test Sponsor: Intel Corporation)
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@~~~~~~~~~~~~~~~~~~
ASUS A88X-PRO Motherboard (AMD A10-7850K APU with Radeon R7 Graphics)
SPECint?_rate2006 = 93.7
SPECint_rate_base2006 = 90.3
https://www.spec.org/cpu2006/results/res2014q3/cpu2006-20140715-30428.html
Intel Corporation
ASUS H97M-PLUS Motherboard (Intel Core i3-4150)
SPECint?_rate2006 = 109
SPECint_rate_base2006 = 103
https://www.spec.org/cpu2006/results/res2014q3/cpu2006-20140715-30472.html
����͂܂�u�X�R�A�̌݊������Ȃ��Ȃ����v�Ƃ������R��PCMark8���g��Ȃ�
�A�X�L�[�Ȃǂ̎G������邢�����Ȃ��킯�ł���ˁB
IT�v�����Q�l�ɂ��Ă�̂�SPEC�݂����Ȕ�c���̑�O�ҋ@�ւ̃x���`�}�[�N����
�R�b�`���ʂł�Intel�̓����O�ɏオ���Ă�����ƒ������
ASUSTeK Computer Inc. (Test Sponsor: Intel Corporation)
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@~~~~~~~~~~~~~~~~~~
ASUS A88X-PRO Motherboard (AMD A10-7850K APU with Radeon R7 Graphics)
SPECint?_rate2006 = 93.7
SPECint_rate_base2006 = 90.3
https://www.spec.org/cpu2006/results/res2014q3/cpu2006-20140715-30428.html
Intel Corporation
ASUS H97M-PLUS Motherboard (Intel Core i3-4150)
SPECint?_rate2006 = 109
SPECint_rate_base2006 = 103
https://www.spec.org/cpu2006/results/res2014q3/cpu2006-20140715-30472.html
�@�@�@�@�@�@ �@ �@ �@ �@ �@ �@ �A�� , , _
�@�@ �@ ,. -��i�Oi�._�@�@ �@ �`,�,�,�,�,.�A'�A
.�@�@ /�@ �@ | | .|=�U=��@__��/�_�@v~�^!|
�@�@ l.�@�@�@ �� �� l�@�_�_{f�a�~�U, ,���:lf�Oi
�@�^�R.�@�@ ɢ,Ĥ�.ĺ]i�S|r�~r�r�r�C��l�'
/�@ �@ �M�R//| Ĥ�R���| |/|{��������}Ĥ
|�@�@�@ �@ ��| lƁT�q! l!L_, , ,�, , , ,_���f�A
�R�@�@�@ __|�[L|���O��R��'�O�S��O�V�L�_�_
�@,�T,�^�@ .}���������R.�@ �R �_
l/�@|Ĥ.�^�L�_�@�@�@�@�@�@�@�@ �@ �@ ||.�@��'�L�P�M�R
�@�@||�@!�@ �@ ��_�@�@�@�@�@ �@ �@ �@ ||. /�@�@�@ �@ :|
�@�@||�@|.l l�!.|�� |�R)�@�@�@�@�@�@�@�@�@ |l/�@�@ �@ �@ /
�@�@||�@`�)U'J�@�@�@�@�@�@�@�@�@�@�@/-���@�@�@,�.|
�@�@||�@�@ �@ �Q�@�@�@�@�@�@�@�@ �@ /-���@�@�@/ �R|
�@�@||�@ r�]-�=���M�R,.--r-�� ''"�L�P�M�R�@�@ /�@�@ }
�@�@||.�@{�O��@ �@ |�@���@�@�@�@�@�@�@�@�@ /�@�@ /
�@�@||.�@ �S��--��'`�[�T�@�@�@�@�@ �@ _,. �� �@ �m|
�@�@ �@ ,. -��i�Oi�._�@�@ �@ �`,�,�,�,�,.�A'�A
.�@�@ /�@ �@ | | .|=�U=��@__��/�_�@v~�^!|
�@�@ l.�@�@�@ �� �� l�@�_�_{f�a�~�U, ,���:lf�Oi
�@�^�R.�@�@ ɢ,Ĥ�.ĺ]i�S|r�~r�r�r�C��l�'
/�@ �@ �M�R//| Ĥ�R���| |/|{��������}Ĥ
|�@�@�@ �@ ��| lƁT�q! l!L_, , ,�, , , ,_���f�A
�R�@�@�@ __|�[L|���O��R��'�O�S��O�V�L�_�_
�@,�T,�^�@ .}���������R.�@ �R �_
l/�@|Ĥ.�^�L�_�@�@�@�@�@�@�@�@ �@ �@ ||.�@��'�L�P�M�R
�@�@||�@!�@ �@ ��_�@�@�@�@�@ �@ �@ �@ ||. /�@�@�@ �@ :|
�@�@||�@|.l l�!.|�� |�R)�@�@�@�@�@�@�@�@�@ |l/�@�@ �@ �@ /
�@�@||�@`�)U'J�@�@�@�@�@�@�@�@�@�@�@/-���@�@�@,�.|
�@�@||�@�@ �@ �Q�@�@�@�@�@�@�@�@ �@ /-���@�@�@/ �R|
�@�@||�@ r�]-�=���M�R,.--r-�� ''"�L�P�M�R�@�@ /�@�@ }
�@�@||.�@{�O��@ �@ |�@���@�@�@�@�@�@�@�@�@ /�@�@ /
�@�@||.�@ �S��--��'`�[�T�@�@�@�@�@ �@ _,. �� �@ �m|
�ؑ��̑��肵�Ă�˂���
Calc����HSA���ǂ��̂Ƃ������ł��z����Ȃ���������
866 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 07:37:48.23 ID:eKNrnP9T
AMD���蔲�������l��AMD��K�v�ȏ�Ɏ����グ�Ă�̂���
867 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 07:39:50.67 ID:eKNrnP9T
>>865
��������B
AMD�̃S��������LibreOffice�ɂ˂����݁A����������PCMark�ɂ��˂�����
��邱�Ƃ��b��X�^�C���N�I���e�B
��������B
AMD�̃S��������LibreOffice�ɂ˂����݁A����������PCMark�ɂ��˂�����
��邱�Ƃ��b��X�^�C���N�I���e�B
�����x���`�Ȃ��X�N���Q�l�ɂ��ĂȂ�����
869 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 07:57:07.87 ID:eKNrnP9T
Calc�̗��p�p�x�̍�����ʓI�ȋ@�\���g���Ȃ�킩����A
�����炭�N���g���ĂȂ��ł��낤HSA�ɓ���������͋@�\������
�s���|�C���g��PCMark8�ɍ̗p����Ă���
�����炭�N���g���ĂȂ��ł��낤HSA�ɓ���������͋@�\������
�s���|�C���g��PCMark8�ɍ̗p����Ă���
INTEL��NVIDIA�g���[���ɂ����Ă��
871 �FSocket774�F2015/02/27(��) 08:03:45.20 ID:Iy3nL8ws
hsa���Ă�����́H
872 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 08:06:42.74 ID:eKNrnP9T
SPEC�͕�����PC�E�T�[�o�x���_�[���F�̂����Ƃ����Ђ���x���`�}�[�N������
SPEC�̃X�R�A���Ƃ��ΊԈႢ�Ȃ�
�������AMD�����ЃT�C�g�œ��X�ƌ��J���Ă邭�炢�����當��͂Ȃ����낤
http://www.amd.com/en-us/products/server/benchmarks
�E�E�E���Ă����ǁA2013�N�ȍ~�A�s�[�����Ȃ��Ȃ���
�i���R�̓v���Z�X���[���ō��������Intel���i�ɑ�s����悤�ɂȂ�������j
SPEC�̃X�R�A���Ƃ��ΊԈႢ�Ȃ�
�������AMD�����ЃT�C�g�œ��X�ƌ��J���Ă邭�炢�����當��͂Ȃ����낤
http://www.amd.com/en-us/products/server/benchmarks
�E�E�E���Ă����ǁA2013�N�ȍ~�A�s�[�����Ȃ��Ȃ���
�i���R�̓v���Z�X���[���ō��������Intel���i�ɑ�s����悤�ɂȂ�������j
873 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 08:09:53.68 ID:eKNrnP9T
�ŋ߂�intel��itanium�̃X�R�A��SPEC�ɂ̂��Ȃ��Ȃ��Ă��܂���
����itanium�͏I���Ȃ̂�
����itanium�͏I���Ȃ̂�
875 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 08:14:21.90 ID:eKNrnP9T
Windows��RHEL��������HP-UX/NonStopOS�����c���ĂȂ��̂ɂ��Ӗ����������
�K�v�Ȃ�HP�����ł���
�K�v�Ȃ�HP�����ł���
�c�q�I��Nolan��Amur���ĉ���肽����������H
���X�^�u���b�g�ɎQ�����Ă����ꏊ����̂���
���X�^�u���b�g�ɎQ�����Ă����ꏊ����̂���
������^�u���b�g����w
����Watch�Ƃ��n�܂��Ă�̂ɂ���ȃ��[�J�[�g�������Ώ��ɂȂ��w
����Watch�Ƃ��n�܂��Ă�̂ɂ���ȃ��[�J�[�g�������Ώ��ɂȂ��w
���sGCN�̃��b�g�p�t�H�[�}���X����Ɖ����ɍ̗p���Ă��炤����Ȃ̂���
INTEL��iGPU��DX12�Ή���搂��Ă�͂��Ȃ������
http://www.anandtech.com/show/8998/directx-12-star-swarm-intel-igpu-performance-preview
http://www.anandtech.com/show/8998/directx-12-star-swarm-intel-igpu-performance-preview
���{�l�Ȃ�C���e���Q�t�H���
>>840
Sun�Ȃ�Ă��܂ǂ��A�ɓ����Ƃ������̂����Ђ���������Ƃ��A
���V�X�e����Sun������V�V�X�e����Sun�݂����ȂƂ������ȋC�������
Sun�Ȃ�Ă��܂ǂ��A�ɓ����Ƃ������̂����Ђ���������Ƃ��A
���V�X�e����Sun������V�V�X�e����Sun�݂����ȂƂ������ȋC�������
>>879
AMD��CPU���l�b�N������DX12�ŐL�т�AIntel��GPU���l�b�N������DX12�ɂȂ��Ă��L�тȂ�
�Ƃ����b�Ȃ낤���ǁA����ɂ�����GT3e�����߂���
����ς�eDRAM���Čy�ʃx���`�̓_���҂��ɂ������ɗ����Ȃ��ȁc
AMD��CPU���l�b�N������DX12�ŐL�т�AIntel��GPU���l�b�N������DX12�ɂȂ��Ă��L�тȂ�
�Ƃ����b�Ȃ낤���ǁA����ɂ�����GT3e�����߂���
����ς�eDRAM���Čy�ʃx���`�̓_���҂��ɂ������ɗ����Ȃ��ȁc
eDRAM��DX11�̃{�g���l�b�N�߂�悤�Ȏ������Ă����̂�
DX12�ł��̃{�g���l�b�N���̂��̂������Ȃ����̂�eDRAM�̓��������͉������Ƃ��ł�
DX12�ł��̃{�g���l�b�N���̂��̂������Ȃ����̂�eDRAM�̓��������͉������Ƃ��ł�
���{�Q�t�H84%�̎���
���{�l�Ȃ�Q�t�H�������
���{�l�Ȃ�Q�t�H�������
886 �F,,�E�L�́M�E,,�j��-�������F2015/02/27(��) 14:08:17.65 ID:EydzbDX3
>>876
�ǂ������^�u���b�g��ڎw���Ă���̂��A�����r�W���������Ȃ����AMD��
���Ƃ���Intel����Venue8�Ƃ��̃^�u���b�g��RealSense�Ή��̃J�������ڂ����Ă���
���p�����\�t�g�ɕ����R���e�X�g�Ƃ��J����RealSense�Ή��R���e���c�g���
�Ƃ߂Ă���B
���ꂪ�^�u���b�g�s�ꊈ�����̐�D�ɂȂ邩�͒m��A�V�s��n�o�̂��߂̋ؓ����A
�Ԏ��o���Ă��ς����邾���̗̑͂����邩��A����Ӗ��x���`���[�����S���Ă��Ă�����
�Ǝv���̂ł��B
�c�O������AMD�ɂ͂��ꂪ�Ȃ�
�ǂ�������ł���A��������Ă邩�牴�����낤���A�݂�����
���\���甼�N�Ԃ܂���������ɂ��ꂸ�A���낤���č̗p������������̂���p��
�@�@�o���o���Q�[���Y�i�j
�����Ƃ���Mullins�̎��s������邵�A�����́uAMD�łȂ�������Ȃ����R�v
�݂����Ȃ̂������Ăق����Ǝv���܂���
�����AMD�ł̓_���ȗ��R�̂ق�����������
�iLPDDR3��Ή��Ƃ��A7�`8�C���`➑̂Ɏ��܂�Ȃ��Ƃ��j
Cell B.E.�ɐ^����ɐH������CUDA��FPGA��Xeon Phi���Ȃ�ł����
�}���`�R�A�œK���̃��[�f�B���O�J���p�j�[�ɏ��l�߂�Fixstars���A
AMD�EHSA�Ɍ����ẮA�܂����������������Ă��Ȃ��Ƃ����������
���̏����͌���Â����Ă���Ǝv���܂�
�ǂ������^�u���b�g��ڎw���Ă���̂��A�����r�W���������Ȃ����AMD��
���Ƃ���Intel����Venue8�Ƃ��̃^�u���b�g��RealSense�Ή��̃J�������ڂ����Ă���
���p�����\�t�g�ɕ����R���e�X�g�Ƃ��J����RealSense�Ή��R���e���c�g���
�Ƃ߂Ă���B
���ꂪ�^�u���b�g�s�ꊈ�����̐�D�ɂȂ邩�͒m��A�V�s��n�o�̂��߂̋ؓ����A
�Ԏ��o���Ă��ς����邾���̗̑͂����邩��A����Ӗ��x���`���[�����S���Ă��Ă�����
�Ǝv���̂ł��B
�c�O������AMD�ɂ͂��ꂪ�Ȃ�
�ǂ�������ł���A��������Ă邩�牴�����낤���A�݂�����
���\���甼�N�Ԃ܂���������ɂ��ꂸ�A���낤���č̗p������������̂���p��
�@�@�o���o���Q�[���Y�i�j
�����Ƃ���Mullins�̎��s������邵�A�����́uAMD�łȂ�������Ȃ����R�v
�݂����Ȃ̂������Ăق����Ǝv���܂���
�����AMD�ł̓_���ȗ��R�̂ق�����������
�iLPDDR3��Ή��Ƃ��A7�`8�C���`➑̂Ɏ��܂�Ȃ��Ƃ��j
Cell B.E.�ɐ^����ɐH������CUDA��FPGA��Xeon Phi���Ȃ�ł����
�}���`�R�A�œK���̃��[�f�B���O�J���p�j�[�ɏ��l�߂�Fixstars���A
AMD�EHSA�Ɍ����ẮA�܂����������������Ă��Ȃ��Ƃ����������
���̏����͌���Â����Ă���Ǝv���܂�
���{�l�Ȃ�C���e���Q�t�H�������
>>886
���ꂩ���DDR3�̎��ゾ����(�k����
���ꂩ���DDR3�̎��ゾ����(�k����
889 �FSocket774�F2015/02/27(��) 14:39:51.70 ID:RTMEoTMD
DDR4�̓��C�e���V�[���������瓯�����g���Ȃ�DDR3�̂������B
DDR3-3200�܂ł͍����ɂȂ�B
DDR3-3200�܂ł͍����ɂȂ�B
���{�l�Ȃ�C���e���Q�t�H���
>>889
DDR3�܂łƈ���āADDR4��Prefetch�����L�����ɁA
�����̃o���N�O���[�v����đ��x�҂��ł邩��A�K���x���Ȃ��Ȃ���B
���Ƀ����_���A�N�Z�X����DDR4�̕���latency�Ⴍ�Ȃ��Ă��肷�邯�ǁB
DDR3�܂łƈ���āADDR4��Prefetch�����L�����ɁA
�����̃o���N�O���[�v����đ��x�҂��ł邩��A�K���x���Ȃ��Ȃ���B
���Ƀ����_���A�N�Z�X����DDR4�̕���latency�Ⴍ�Ȃ��Ă��肷�邯�ǁB
�H�t�� ZOA���S�@��҂̎���PC���ꂪ�[��
http://akiiaok.blog.fc2.com/blog-entry-138.html
http://akiiaok.blog.fc2.com/blog-entry-138.html
�T�[�h�E�F�[�u�݂����ɖ@�l����̕Ў�Ԃł���Ă�Ƃ��납
���j�b�g�R���O���[�v�ȊO�͕m����
���j�b�g�R���O���[�v�ȊO�͕m����
894 �FSocket774�F2015/02/27(��) 15:55:37.71 ID:OTAI4ooD
>>889
���g���������Ȃ烌�C�e���V(�x������)�͓����x�őш��DDR4��DDR3�̂Q�{����B
DDR3-1066(CL7�̐��i������)��DDR4-2133(CL15�̐��i������)������133MHz����B
���g���������Ȃ烌�C�e���V(�x������)�͓����x�őш��DDR4��DDR3�̂Q�{����B
DDR3-1066(CL7�̐��i������)��DDR4-2133(CL15�̐��i������)������133MHz����B
>>788
Athlon������AthlonXP�܂Ő��N�Ԏg���Ă�EV6�o�X��DEC������������
Athlon������AthlonXP�܂Ő��N�Ԏg���Ă�EV6�o�X��DEC������������
>>794
�������ŏ�����ނ��������Ēf��ꂽ����ATI�ɘb�������Ă������������?
�������ŏ�����ނ��������Ēf��ꂽ����ATI�ɘb�������Ă������������?
�H�t���Œׂ�Ȃ��X�́A
�E���͏��Ђ�����ĂĂ��܂��ŏ����������Ă�
�E���͕s���Y�I�[�i�[
����ȃC���[�W������
���������Ƃ������X�őS�R�ׂ�Ȃ��̂́A
���̓y�n�E�r�����̂����O�̕����Ńe�i���g�������Ă���Ƃ���
�E���͏��Ђ�����ĂĂ��܂��ŏ����������Ă�
�E���͕s���Y�I�[�i�[
����ȃC���[�W������
���������Ƃ������X�őS�R�ׂ�Ȃ��̂́A
���̓y�n�E�r�����̂����O�̕����Ńe�i���g�������Ă���Ƃ���
�c�N���Ɍ����Ă͕s���Y�n�������������ă��}�_�ɔ������ꂽ���ǂˁB
���̓A�[�N�ӂ肪���o�C�̂��Ȃ�
�H�����̃������ǂ����悤
�H�����̃������ǂ����悤