AMDの次世代APU/CPUについて語ろう195世代
1 :Socket774:
\._ | 荒らし・煽り・厨房は放置が一番。
/|_| | 釣られずにスルーしましょう。
|_/\! sage進行でマターリいきますお
荒らしや関係ないコピペな人はNGに入れて無視しましょう。
自作板AMD系スレッド過去ログ保存サイト
ttp://amd.jisakuita.net/
Intelの次世代CPU/SoCについて語ろう 75
http://anago.2ch.net/test/read.cgi/jisaku/1397746780/
CPUアーキテクチャについて語れ 26
http://anago.2ch.net/test/read.cgi/jisaku/1395873247/
☆ARMの次世代core, SoCについて語るスレ #002☆
http://anago.2ch.net/test/read.cgi/jisaku/1362032148/
Your processor's IQ: An Intro to HSA
http://www.youtube.com/watch?v=i6BWzL12KMI
Revolutionizing computing with HSA-enabled APUs
http://www.youtube.com/watch?v=4YV6z6Fgw48
2014 AMD at CES Highlights:
ttp://www.techpowerup.com/196536/amd-surrounds-2014-ces-visitors-with-breakthrough-visual-and-audio-experiences.html
AMDの次世代APU/CPUについて語ろう194世代
http://anago.2ch.net/test/read.cgi/jisaku/1398812936/
テンプレ以上
∧_∧
|´・ω・) 。・゚・⌒)
| ノつ━ヽニニフ))
/|_| | 釣られずにスルーしましょう。
|_/\! sage進行でマターリいきますお
荒らしや関係ないコピペな人はNGに入れて無視しましょう。
自作板AMD系スレッド過去ログ保存サイト
ttp://amd.jisakuita.net/
Intelの次世代CPU/SoCについて語ろう 75
http://anago.2ch.net/test/read.cgi/jisaku/1397746780/
CPUアーキテクチャについて語れ 26
http://anago.2ch.net/test/read.cgi/jisaku/1395873247/
☆ARMの次世代core, SoCについて語るスレ #002☆
http://anago.2ch.net/test/read.cgi/jisaku/1362032148/
Your processor's IQ: An Intro to HSA
http://www.youtube.com/watch?v=i6BWzL12KMI
Revolutionizing computing with HSA-enabled APUs
http://www.youtube.com/watch?v=4YV6z6Fgw48
2014 AMD at CES Highlights:
ttp://www.techpowerup.com/196536/amd-surrounds-2014-ces-visitors-with-breakthrough-visual-and-audio-experiences.html
AMDの次世代APU/CPUについて語ろう194世代
http://anago.2ch.net/test/read.cgi/jisaku/1398812936/
テンプレ以上
∧_∧
|´・ω・) 。・゚・⌒)
| ノつ━ヽニニフ))
|
|
|
ここはAMDの次世代APU/CPUについて語るスレです
intelの宣伝用のスレではありませんので
intelの宣伝は他でしてください
AMDの自作用限定ではありません
AMDなら何でもござれです
intelの宣伝用のスレではありませんので
intelの宣伝は他でしてください
AMDの自作用限定ではありません
AMDなら何でもござれです
■AMD製品の欠陥内蔵温度計問題まとめ
・計測が不正確で狂っており実態からかけ離れた30度以上低い値となる為熱暴走になりやすい。
・温度計がたったのひとつしか無い為コア毎の温度がまったく判らず信頼性が皆無。
・AMD製CPU(x2/x3/x4/x6/4m8t)の全てに問題が有る。
・がっかりブル土下座、室温28度でコア温度13.4度w 室温以下の低温を実現!
・温度監視ソフトを複数起動していると0℃に
・特定1コアにスレッド指定して負荷かけても1箇所しか計測できないので全コアが同じ温度を示す(時間差で割振りして複数に見せかけてるだけ笑) ←new
( ゚д゚)
・計測が不正確で狂っており実態からかけ離れた30度以上低い値となる為熱暴走になりやすい。
・温度計がたったのひとつしか無い為コア毎の温度がまったく判らず信頼性が皆無。
・AMD製CPU(x2/x3/x4/x6/4m8t)の全てに問題が有る。
・がっかりブル土下座、室温28度でコア温度13.4度w 室温以下の低温を実現!
・温度監視ソフトを複数起動していると0℃に
・特定1コアにスレッド指定して負荷かけても1箇所しか計測できないので全コアが同じ温度を示す(時間差で割振りして複数に見せかけてるだけ笑) ←new
( ゚д゚)
おつ
5 :Socket774:2014/05/08(木) 17:30:16.76 ID:mPYpxMnf
CPU内蔵温度計なんて、Tj Max-20℃〜Tj Maxくらいの間である程度正確なら
それ以外の温度の精度なんてどうでもいいよ
それ以外の温度の精度なんてどうでもいいよ
乙
ぜんじ―のAPUでちょっと面白い実用例の記事があった
ちょっと古いけどw
//www.mouse-jp.co.jp/abest/interview/tatsunoko_production/
ぜんじ―のAPUでちょっと面白い実用例の記事があった
ちょっと古いけどw
//www.mouse-jp.co.jp/abest/interview/tatsunoko_production/
タイトルも一緒に書いとくといいね
アニメ制作スタジオの名門 タツノコプロがAMD APU搭載マシンを選んだ理由
ttp://www.mouse-jp.co.jp/abest/interview/tatsunoko_production/
AMD Application Showcase
ttp://developer.amd.com/community/application-showcase/
アニメ制作スタジオの名門 タツノコプロがAMD APU搭載マシンを選んだ理由
ttp://www.mouse-jp.co.jp/abest/interview/tatsunoko_production/
AMD Application Showcase
ttp://developer.amd.com/community/application-showcase/
8 :Socket774:2014/05/08(木) 18:31:37.47 ID:mPYpxMnf
タツノコプロはコア課金のソフトを導入してないからAMDでも大丈夫だったんだろ
映画大コケで貧乏だからAMDしか選択肢が無かったダケですよ(笑)
>>5
低温火傷したらどうすんだよ!
低温火傷したらどうすんだよ!
MSとnVIDIAの間に溝、Qualcommに乗り換え
ttp://wccftech.com/microsoft-nvidia-tegra-surface-tablet/
Tegra K1もTAITAN ZもコケてnVIDIAは今年いっぱい話題無し決定かな?
ttp://wccftech.com/microsoft-nvidia-tegra-surface-tablet/
Tegra K1もTAITAN ZもコケてnVIDIAは今年いっぱい話題無し決定かな?
コケてる印象なのになぜか増収増益なんだよな
AMD、ARMベースのサーバプロセッサSeattle公開デモ
ttp://www.guru3d.com/news_story/amd_shows_seattle_arm_based_server_chip_for_first_time.html
ttp://techreport.com/news/26419/amd-demos-seattle-its-first-arm-based-server-chip
ttp://www.guru3d.com/news_story/amd_shows_seattle_arm_based_server_chip_for_first_time.html
ttp://techreport.com/news/26419/amd-demos-seattle-its-first-arm-based-server-chip
米AMDは5月5日(現地時間)、2015年〜2016年の低消費電力向けプロセッサのロードマップを発表した。
現在、同社はメインストリーム向けx86 APUとして「Kaveri」、低電力向けx86 APUとして「Beema」、「Mullins」、サーバー向け高性能ARMコア「Seattle」の4製品を用意しているが、
その後継として、2015年にはx86とARMがピン互換となった「Project SkyBridge」をリリースする。
x86とARMがピン互換のデザインプラットフォームとなることを、AMDでは「Ambidextorus(両手の利く、と言った意味) Computing」と呼んでいる。
これにより高密度サーバー、組み込み、セミカスタム化分野、超低消費電力クライアント分野におけるリーダーシップを獲得していく考え。
SkyBridgeは20nmで製造され、GPUコアにGCN(Graphics Core Next)アーキテクチャを採用し、HSA技術をサポート。
CPUコアは、x86版が「Puma+」、ARM版がCortex-A57ベースの64bitコアを採用。ARM版はAMDにとって初めてAndroid向けプラットフォームでHSAをサポートする。
また、2016年以降には、ARMからライセンスを受けつつも独自の64bit対応の高性能ARMコア「K12」を開発する。
開発チームはCPUアーキテクトのJim Keller氏が率いる。同氏は過去にAMD K8シリーズのほか、AppleのA4/A5プロセッサの設計を担当した。
同時に、x86プロセッサの開発も継続していく。
http://pc.watch.impress.co.jp/docs/news/20140506_647078.html
現在、同社はメインストリーム向けx86 APUとして「Kaveri」、低電力向けx86 APUとして「Beema」、「Mullins」、サーバー向け高性能ARMコア「Seattle」の4製品を用意しているが、
その後継として、2015年にはx86とARMがピン互換となった「Project SkyBridge」をリリースする。
x86とARMがピン互換のデザインプラットフォームとなることを、AMDでは「Ambidextorus(両手の利く、と言った意味) Computing」と呼んでいる。
これにより高密度サーバー、組み込み、セミカスタム化分野、超低消費電力クライアント分野におけるリーダーシップを獲得していく考え。
SkyBridgeは20nmで製造され、GPUコアにGCN(Graphics Core Next)アーキテクチャを採用し、HSA技術をサポート。
CPUコアは、x86版が「Puma+」、ARM版がCortex-A57ベースの64bitコアを採用。ARM版はAMDにとって初めてAndroid向けプラットフォームでHSAをサポートする。
また、2016年以降には、ARMからライセンスを受けつつも独自の64bit対応の高性能ARMコア「K12」を開発する。
開発チームはCPUアーキテクトのJim Keller氏が率いる。同氏は過去にAMD K8シリーズのほか、AppleのA4/A5プロセッサの設計を担当した。
同時に、x86プロセッサの開発も継続していく。
http://pc.watch.impress.co.jp/docs/news/20140506_647078.html
>>12
Denverのハードの作りやCPUとしての性能には興味あったんで残念
Denverのハードの作りやCPUとしての性能には興味あったんで残念
17 :,,・´∀`・,,)っ-○○○:2014/05/08(木) 20:17:35.93 ID:GwvP3VTG
>>10
Dreamworksみたいな大型予算かけられるところは
レンダリング専用のデータセンター作ってたりするからなー
http://ascii.jp/elem/000/000/510/510912/
どうやら今はXeon Phiでレンダリングしてるらしい
http://waskul.tv/portfolio/steve-waskul-matt-walsh/
FireProってどこで使われてるのかマジで疑問なんだが。
分岐に弱い行列積番長にはラジオシティは荷が重いのかな
売れてないからQ1赤字なんだろうけど
Dreamworksみたいな大型予算かけられるところは
レンダリング専用のデータセンター作ってたりするからなー
http://ascii.jp/elem/000/000/510/510912/
どうやら今はXeon Phiでレンダリングしてるらしい
http://waskul.tv/portfolio/steve-waskul-matt-walsh/
FireProってどこで使われてるのかマジで疑問なんだが。
分岐に弱い行列積番長にはラジオシティは荷が重いのかな
売れてないからQ1赤字なんだろうけど
18 :,,・´∀`・,,)っ-○○○:2014/05/08(木) 20:23:18.34 ID:GwvP3VTG
K1はとりあえず自作市場に出てきたから物好きは何かソフト作って
試してみればいいんじゃないの?
HSAがどうとか粋がってた会社がARM版APUどころかGPU非内蔵SoCすら市場に
投入できてない時期に、一般個人が直接触れる64ビットARM+CUDA統合環境を
投入してきたのは意味は大きい。
(大方カーナビ市場向けの評価ボードと同じものを流してるだけだと思うけど)
試してみればいいんじゃないの?
HSAがどうとか粋がってた会社がARM版APUどころかGPU非内蔵SoCすら市場に
投入できてない時期に、一般個人が直接触れる64ビットARM+CUDA統合環境を
投入してきたのは意味は大きい。
(大方カーナビ市場向けの評価ボードと同じものを流してるだけだと思うけど)
いまのjetsonはa15でっせ
ソケット互換っていうならIntelとAMDで互換できないの?
自作業界にとって切実な問題だと思う
自作業界にとって切実な問題だと思う
NVIDIA GeForceの日本でのシェアが84%を超えました。
これも一重に皆様のお陰です。
GeForceをご愛用頂いているユーザー様、販売店様、OEM様、ありがとうございます。
これからもGeForceをよろしくお願いいたします!
https://mobile.twitter.com/NVIDIAJapan/status/452009316522807296/photo/1?screen_name=NVIDIAJapan
>NVIDIA GeForceの日本でのシェアが84%を超えました。
(・ω・)ノ
これも一重に皆様のお陰です。
GeForceをご愛用頂いているユーザー様、販売店様、OEM様、ありがとうございます。
これからもGeForceをよろしくお願いいたします!
https://mobile.twitter.com/NVIDIAJapan/status/452009316522807296/photo/1?screen_name=NVIDIAJapan
>NVIDIA GeForceの日本でのシェアが84%を超えました。
(・ω・)ノ
チップから何から全部違うものを無理やり統一ってのは無理だろうから、全部がSoCになったら業界として規格統一の芽もあるんじゃね?
24 :,,・´∀`・,,)っ-○○○:2014/05/08(木) 20:57:35.06 ID:GwvP3VTG
>>20
縦方向すら1〜2年で互換性切り捨ててるのに他社と互換なんてやると思う?
インターフェース互換でどうにかしたいならPCI Expressカードに刺さるタイプの
CPUボードならIntelプラットフォームでも使えるから出せばいいんじゃないの?
これを使うことでCellもARMもIntelプラットフォームで動かせた。
縦方向すら1〜2年で互換性切り捨ててるのに他社と互換なんてやると思う?
インターフェース互換でどうにかしたいならPCI Expressカードに刺さるタイプの
CPUボードならIntelプラットフォームでも使えるから出せばいいんじゃないの?
これを使うことでCellもARMもIntelプラットフォームで動かせた。
縦の互換がないならせめて横の互換ほしいなあ
分断されすぎて自作人口減ったんじゃないか?
まあ現実考えたら厳しいんだろうけど
分断されすぎて自作人口減ったんじゃないか?
まあ現実考えたら厳しいんだろうけど
>>24
一時期ドーターボードっていうのがあってだな
一時期ドーターボードっていうのがあってだな
{kind=link}
28 :,,・´∀`・,,)っ-○○○:2014/05/08(木) 21:26:44.53 ID:GwvP3VTG
Cell(GigaAccelなど)も今のXeon Phiのカードも一種のドーターでしょ。
OSもホストと独立して動く。
OSもホストと独立して動く。
>>29
あなたの言うメーカーってどの分野のメーカーのことかね
あなたの言うメーカーってどの分野のメーカーのことかね
しょせん消費者がグダグダ言うだけの掲示板なんだからいいじゃん
まあ現実として厳しいのはわかってますよ
まあ現実として厳しいのはわかってますよ
エヌビディアがシェア取ってもAMDより売り上げが低いとか笑えるわ
36 :,,・´∀`・,,)っ-○○○:2014/05/08(木) 22:44:56.46 ID:GwvP3VTG
なんで据え置きゲーム機全制覇してるのに赤字なん?
団子ってNVIDIA派なの?
GPUコンピューティングを否定するならNVIDIAも否定しなよ
GPUコンピューティングを否定するならNVIDIAも否定しなよ
38 :,,・´∀`・,,)っ-○○○:2014/05/08(木) 23:10:31.99 ID:GwvP3VTG
MSはともかくとして、いつ潰れてもおかしくないソニーのPS4が
大口顧客の時点で爆弾抱えてるようなものだよ
PS4が撤退したらXboxOneがその分売れるかというと
そうはならないだろうしなぁ
もはやゲーム市場も家庭用据え置きよりモバイルのほうが大きいし
>>37
ぶっちゃけNVIDIA先生の山吹色のお菓子はおいしいです。
まあ金の切れ目は縁の切れ目ですけどw
大口顧客の時点で爆弾抱えてるようなものだよ
PS4が撤退したらXboxOneがその分売れるかというと
そうはならないだろうしなぁ
もはやゲーム市場も家庭用据え置きよりモバイルのほうが大きいし
>>37
ぶっちゃけNVIDIA先生の山吹色のお菓子はおいしいです。
まあ金の切れ目は縁の切れ目ですけどw
AMDと違ってNVIDIAのGPUコンピューティングは利益も実績も出してるからなあ
エヌビディアがAMDの売り上げ抜けるの?
シェア100パーセントになっても無理なんじゃないか?
シェア100パーセントになっても無理なんじゃないか?
41 :,,・´∀`・,,)っ-○○○:2014/05/08(木) 23:25:55.51 ID:GwvP3VTG
ATiと合併してサムスンとQualcommに抜かれるまで業界2位の売上げ誇ってたAMDが
GPU専業メーカーがちょっと毛を生やしただけのNVIDIAにまで抜かれたら
それはそれで恥だろ
GPU専業メーカーがちょっと毛を生やしただけのNVIDIAにまで抜かれたら
それはそれで恥だろ
AMDはNvidiaの利益抜けるの?
43 :,,・´∀`・,,)っ-○○○:2014/05/08(木) 23:30:19.53 ID:GwvP3VTG
AMDの売上高ですが、見事なまでの右肩下がりです。
http://jp.investing.com/equities/adv-micro-device-financial-summary
AMDのCPUの出荷台数は2016年ごろまでにUltrabookの出荷台数に抜かれる見込みです。
http://jp.investing.com/equities/adv-micro-device-financial-summary
AMDのCPUの出荷台数は2016年ごろまでにUltrabookの出荷台数に抜かれる見込みです。
アムド利益率低すぎだしなぁw
ますますもうからんとこばっか手出してるし
ますますもうからんとこばっか手出してるし
そんなAMDすごく無いだろ
Intelの20パーセント未満のシェアを維持して
ずっと赤字企業なのに。
エヌビディアがずっと売り上げてるとか宣伝してる割にAMDより売り上げ低い
ウルトラブックのシェアが上がろうが
それでもエヌビディアの方が売り上げは下
Intelの20パーセント未満のシェアを維持して
ずっと赤字企業なのに。
エヌビディアがずっと売り上げてるとか宣伝してる割にAMDより売り上げ低い
ウルトラブックのシェアが上がろうが
それでもエヌビディアの方が売り上げは下
n社は今後急成長する要素あるのかね。
スパコンはXeonPhiと競争になるだろうし、モバイル向けも失速気味だ。
まだ成長する余地はあるだろうけど、そんなに明るい未来でもないと思うが。
まあAMDも相当先が暗いのでここで言っても……
スパコンはXeonPhiと競争になるだろうし、モバイル向けも失速気味だ。
まだ成長する余地はあるだろうけど、そんなに明るい未来でもないと思うが。
まあAMDも相当先が暗いのでここで言っても……
>>46だけど
レス番残ってるのは特に意味はないので気にしないでくれ。
レス番残ってるのは特に意味はないので気にしないでくれ。
48 :,,・´∀`・,,)っ-○○○:2014/05/09(金) 00:09:14.52 ID:HRt7Pt4j
HPCに関していうなら、GPGPUスパコンのピークは過ぎたと思う。
それまではGPGPUを活用することそのものが研究のテーマになったが
もうやれること、やれないこと、得意なこと不得意なことは
有意義な論文がある程度出ちゃって
もう限られた隙間狙いのテーマしか残ってないのだよね
ある程度有効な用途はわかっちゃったから、それをどう工業製品に
応用するかを考える段階。選択と集中のフェーズだね。
未だに「GPUの未知の可能性を探る!」みたいなコンピュータ科学者がいたら
三流かただの変人。
それまではGPGPUを活用することそのものが研究のテーマになったが
もうやれること、やれないこと、得意なこと不得意なことは
有意義な論文がある程度出ちゃって
もう限られた隙間狙いのテーマしか残ってないのだよね
ある程度有効な用途はわかっちゃったから、それをどう工業製品に
応用するかを考える段階。選択と集中のフェーズだね。
未だに「GPUの未知の可能性を探る!」みたいなコンピュータ科学者がいたら
三流かただの変人。
1%の変人が革新を創造する
AMD & Microsoft Game Developer Day
Monday, June 2, 2014 from 9:00 AM to 6:00 PM (CEST)
Stockholm, Sweden
Event Details
Presentation content will be primarily aimed at Graphics programmers
(The evening drinks reception from 6pm will be open to producers, artists, business folks etc, please don’t book tickets, just turn up at 6pm)
This Free Developer Day is open to all Game Developers in Europe - Publisher studios, Indie studios, small or large. Desktop / Tablet developers and Students
(studying relevant courses with enough technical skill to understand the content) are all welcome.
You will NOT need to sign a Non Disclosure Agreement to attend
All attendees to complete registration through this website.
Please note that if we run out of space, then some tickets may need to be cancelled to ensure maximum reach to community
(limiting numbers per company / course if necessary to get maximum coverage) any ticket cancelations will be made by Friday 23rd May
Guests should bring their paper tickets on the day
Agenda:
7 presentations in covering the below subjects (titles currently being finalised)
GCN Architecture
Mantle
DirectX12
Shader optimisation
Xbox One and Indi Developers
Johan Andersson from EA Frostbite and Emil Persson from Avalanche Studios are confirmed presenters
We look forward to seeing you all
Cheers, Kevin Strange - AMD EMEA Developer Relations Manager
Monday, June 2, 2014 from 9:00 AM to 6:00 PM (CEST)
Stockholm, Sweden
Event Details
Presentation content will be primarily aimed at Graphics programmers
(The evening drinks reception from 6pm will be open to producers, artists, business folks etc, please don’t book tickets, just turn up at 6pm)
This Free Developer Day is open to all Game Developers in Europe - Publisher studios, Indie studios, small or large. Desktop / Tablet developers and Students
(studying relevant courses with enough technical skill to understand the content) are all welcome.
You will NOT need to sign a Non Disclosure Agreement to attend
All attendees to complete registration through this website.
Please note that if we run out of space, then some tickets may need to be cancelled to ensure maximum reach to community
(limiting numbers per company / course if necessary to get maximum coverage) any ticket cancelations will be made by Friday 23rd May
Guests should bring their paper tickets on the day
Agenda:
7 presentations in covering the below subjects (titles currently being finalised)
GCN Architecture
Mantle
DirectX12
Shader optimisation
Xbox One and Indi Developers
Johan Andersson from EA Frostbite and Emil Persson from Avalanche Studios are confirmed presenters
We look forward to seeing you all
Cheers, Kevin Strange - AMD EMEA Developer Relations Manager
陽性かくにん!
よかった。
よかった。
バイオ粒子反応確認!!!
53 :Socket774:2014/05/09(金) 02:38:46.00 ID:ti+LnyED
UFC 128 - エリック・コク vs. ハファエル・アスンサオ
https://www.youtube.com/watch?v=n2CcU1A1i-0
UFC 134 - エリック・シウバ vs. ルイス・ラモス
https://www.youtube.com/watch?v=x25xIpNmhCo
UFC 140 - コスタ・フィリッポウ vs. ジャレッド・ハマン
https://www.youtube.com/watch?v=etC-LdvIe8A
UFC on Fox 5 - マット・ブラウン vs. マイク・スウィック
https://www.youtube.com/watch?v=HvWDkItV20s
https://www.youtube.com/watch?v=n2CcU1A1i-0
UFC 134 - エリック・シウバ vs. ルイス・ラモス
https://www.youtube.com/watch?v=x25xIpNmhCo
UFC 140 - コスタ・フィリッポウ vs. ジャレッド・ハマン
https://www.youtube.com/watch?v=etC-LdvIe8A
UFC on Fox 5 - マット・ブラウン vs. マイク・スウィック
https://www.youtube.com/watch?v=HvWDkItV20s
54 :Socket774:2014/05/09(金) 03:39:56.39 ID:Vpxtq18S
Tegra K1 vs AMD K12
http://anago.2ch.net/test/read.cgi/jisaku/1399586603/
http://anago.2ch.net/test/read.cgi/jisaku/1399586603/
56 :,,・´∀`・,,)っ-○○○:2014/05/09(金) 07:41:53.66 ID:HRt7Pt4j
わざわざスレ立てるほどか
既に市場投入されてるK1と、絵に描いた餅
どっちが強いですか?
既に市場投入されてるK1と、絵に描いた餅
どっちが強いですか?
個人の体感によりその強さは無限大なので絵餅の大勝利です
58 :Socket774:2014/05/09(金) 08:26:56.71 ID:VdbRqiGF
http://ameblo.jp/kosengadaisuki/entry-11830858729.html
ヤフオクで簡単にできる吊り上げ方法。悪用するなとはいいません。自己防衛のために利用してくれ。
ヤフオクで簡単にできる吊り上げ方法。悪用するなとはいいません。自己防衛のために利用してくれ。
Ontario
C-50 2コア 1GHz GPU 80SP 276MHz
Temash
A4-1200 2コア1GHz GPU 128SP 225MHz
Beema
E1-6010 2コア 1.35GHz GPU 128SP 350MHz
それぞれ体感で1.4倍
搭載HDDのプラッタ容量
750GB
1TB
1.25TB
それぞれ体感で1.2倍高速化
Windows7
Windows8
Windows8.1Update1
それぞれ体感で1.2倍高速化
2011年のC-50搭載ノート→2014年E1-6010搭載ノートの体感差が理論上4倍になる
楽しみになってきた
C-50 2コア 1GHz GPU 80SP 276MHz
Temash
A4-1200 2コア1GHz GPU 128SP 225MHz
Beema
E1-6010 2コア 1.35GHz GPU 128SP 350MHz
それぞれ体感で1.4倍
搭載HDDのプラッタ容量
750GB
1TB
1.25TB
それぞれ体感で1.2倍高速化
Windows7
Windows8
Windows8.1Update1
それぞれ体感で1.2倍高速化
2011年のC-50搭載ノート→2014年E1-6010搭載ノートの体感差が理論上4倍になる
楽しみになってきた
>>59
どういう計算だよ
どういう計算だよ
Q1 CPU Marktshare data
http://www.investorvillage.com/smbd.asp?mb=476&mn=283437&pt=msg&mid=13808248
http://www.investorvillage.com/smbd.asp?mb=476&mn=283437&pt=msg&mid=13808248
全部掛けちゃいかんだろ。一番遅い方に引っ張られるからせいぜい1.2倍だろ?
64 :Socket774:2014/05/09(金) 10:21:04.17 ID:bl7CGDBJ
ノートPCはSSD化するのがいちばん体感速度が上がる
ノートPCに乗ってるHDDは糞遅いからね
次はOSをWindows8.x化すると体感速度が上がる
Windows8.xはWindows7やVistaに比べて軽くなってサクサク動くから
ノートPCに乗ってるHDDは糞遅いからね
次はOSをWindows8.x化すると体感速度が上がる
Windows8.xはWindows7やVistaに比べて軽くなってサクサク動くから
APU以外の部分でも2倍高速化するのか
APUとはなんだったのか
APUとはなんだったのか
>>61
本気で言ってるなら小学校からやり直そう
本気で言ってるなら小学校からやり直そう
ウォーズマンもびっくりか
まあ、ontario HDDからmullins SSDなら倍以上の性能や体感アップは余裕であるだろうな
>>69
土下座アーキとAPUがどれだけ嫌われてるかがわかるな
土下座アーキとAPUがどれだけ嫌われてるかがわかるな
●●
復活も何もIntelじゃ真似できない高性能GPU統合プロセッサで需要を得られているから、供給が一気に増えるTrinityでシェアを増やすのは確定なんだが
Trinityがダメとか夢見るのはやめたら?
去年は、出来立てで歩留まり悪いAMDの32nm SOI vs 安定して歩留まり高い Intel 32nmで圧倒的に部が悪かったうえで、現状維持できたのはわかるよね?
今年は、安定して歩留まり高い AMD 32nm vs 出来立てで歩留まり悪い Intel 22nmの勝負で、昨年よりかなり状況は良くなってる
出荷量でかなり差を詰めるから今年はシェア増えるよ、特にモバイル向けがね
2012/02/28(火) 00:20 | URL | LGA774 #-[ 編集]
●●
復活も何もIntelじゃ真似できない高性能GPU統合プロセッサで需要を得られているから、供給が一気に増えるTrinityでシェアを増やすのは確定なんだが
Trinityがダメとか夢見るのはやめたら?
去年は、出来立てで歩留まり悪いAMDの32nm SOI vs 安定して歩留まり高い Intel 32nmで圧倒的に部が悪かったうえで、現状維持できたのはわかるよね?
今年は、安定して歩留まり高い AMD 32nm vs 出来立てで歩留まり悪い Intel 22nmの勝負で、昨年よりかなり状況は良くなってる
出荷量でかなり差を詰めるから今年はシェア増えるよ、特にモバイル向けがね
2012/02/28(火) 00:20 | URL | LGA774 #-[ 編集]
●●
Llano登場の暁には
Trinity登場の暁には
Richland登場の暁には
Kaveri登場の暁には ← new!
▼無慈悲な現実
ttp://www.cpubenchmark.net/market_share.html
↑
期待の2014Q1でなんと 過去最低 を記録!(笑)
Trinity登場の暁には
Richland登場の暁には
Kaveri登場の暁には ← new!
▼無慈悲な現実
ttp://www.cpubenchmark.net/market_share.html
↑
期待の2014Q1でなんと 過去最低 を記録!(笑)
今日もアンチが必死なスレだなー
団子をNGにする理由
・GPGPUの話→CPUしか使わないことにしたいのでCPUの話にする
・GPUの話→なぜかCPUの話になっている
・Mantleの話→DX12の話になっている
・HSAの話→なぜかMantleの話になる
・AVXの話→幅広いソフト分野の中で、商用コンピューティングに絞って話す
・内蔵GPUの話→CPUの話になっている
・APUの話→CPU性能だけ話す
・ゲームソフトの話→インテルとNvidiaの話にする
・ゲームハードの話→なぜかGPGPUが出てくる→CPUの話になる
・AMDの話→不得意分野の実績(マイナス)だけ語る
・インテルの話→得意分野の実績(プラス)だけ語る
肉団子が来ると全部これになる
だから団子はNGしとけ
・GPGPUの話→CPUしか使わないことにしたいのでCPUの話にする
・GPUの話→なぜかCPUの話になっている
・Mantleの話→DX12の話になっている
・HSAの話→なぜかMantleの話になる
・AVXの話→幅広いソフト分野の中で、商用コンピューティングに絞って話す
・内蔵GPUの話→CPUの話になっている
・APUの話→CPU性能だけ話す
・ゲームソフトの話→インテルとNvidiaの話にする
・ゲームハードの話→なぜかGPGPUが出てくる→CPUの話になる
・AMDの話→不得意分野の実績(マイナス)だけ語る
・インテルの話→得意分野の実績(プラス)だけ語る
肉団子が来ると全部これになる
だから団子はNGしとけ
ダンゴ先生がいなくなったら廃墟ですよこんなスレ
見るべき情報がない時期は廃墟で構わないと思うけどね。
それよりA8-7600はいつになったら市場に出てくるんだよ・・・
こんなに遅れるほど製造が難しいわけでもなさそうだけど。
それよりA8-7600はいつになったら市場に出てくるんだよ・・・
こんなに遅れるほど製造が難しいわけでもなさそうだけど。
団子はな、CPU/AVXマンセー、iGPUはゴミが基本思想だから話が全くかみ合わない
毎月新情報が出てくるから廃墟とかありえないな
intel次世代スレのほうがよほど廃墟だろ、AMD批判と過去の栄光しか話してないからな
intel次世代スレのほうがよほど廃墟だろ、AMD批判と過去の栄光しか話してないからな
今年だけでkaveri発売、シアトル発表、AM1発売、mullins/Beema発表、K12発表、Sky Bridge発表だからなあ
どれもこれも興味深くて話したいことだらけだし、今後も20/14nmやHSA、Mantleゲームとか話題は尽きない
どれもこれも興味深くて話したいことだらけだし、今後も20/14nmやHSA、Mantleゲームとか話題は尽きない
>>78
そもそも、CPUにSSE/AVXがある以上、しょぼい性能のiGPU使ったGPGPUに意味なんて無いだろ?
処理によってはCPU+SSE/AVXよりはるかに速度が出せるdGPUによるGPGPUなら意味があるけどね
そもそも、CPUにSSE/AVXがある以上、しょぼい性能のiGPU使ったGPGPUに意味なんて無いだろ?
処理によってはCPU+SSE/AVXよりはるかに速度が出せるdGPUによるGPGPUなら意味があるけどね
>>81
ま、それがIntel GPUの限界だよね
ま、それがIntel GPUの限界だよね
ああ、 ID:Ax8FCWYcは全部わかってて褒め殺ししてるから
新製品が発売されるのと、新製品の性能が優れてるのと、新製品が商業的に成功するのは別だからな
AMDのPC事業がNVIDIAに負けるレベルだもんなぁ>過疎化
Intelもクライアント部門は減少続いてるし、完全に停滞しとる
Intelもクライアント部門は減少続いてるし、完全に停滞しとる
87 :Socket774:2014/05/09(金) 14:11:27.27 ID:eZIr0XDM
サンプルもあるからやってみ
http://neareal.net/index.php?Programming%2FOpenCL%2FOpenCLSharp%2FTutorial%2F5_TimeOfSimpleOpenCLTask
最もシンプルなOpenCLによる演算の実行 - 実行時間
OpenCL を利用しない場合:10
OpenCL を利用した場合 : 640
---------------
OpenCL Setup Time - 1 : 279.0702
OpenCL Setup Time - 2 : 8.7545
OpenCL Calc Time : 341.7137
OpenCL End Time : 9.1246
OpenCL Total Time : 638.6596
うちの場合
(intel opencl rumtimeでSSEをデバイスとして使っていると思われる)
(calc timeが小さいので)
---------------------------
OpenCL Setup Time - 1 : 352.8661
OpenCL Setup Time - 2 : 0.9382
OpenCL Calc Time : 3.9298
OpenCL End Time : 3.6446
OpenCL Total Time : 361.3758
非openclの場合は 6
総じておよそ60倍の時間がかかるわけだ
この差を埋められるほどの計算内容でないと
無駄だよ
http://neareal.net/index.php?Programming%2FOpenCL%2FOpenCLSharp%2FTutorial%2F5_TimeOfSimpleOpenCLTask
最もシンプルなOpenCLによる演算の実行 - 実行時間
OpenCL を利用しない場合:10
OpenCL を利用した場合 : 640
---------------
OpenCL Setup Time - 1 : 279.0702
OpenCL Setup Time - 2 : 8.7545
OpenCL Calc Time : 341.7137
OpenCL End Time : 9.1246
OpenCL Total Time : 638.6596
うちの場合
(intel opencl rumtimeでSSEをデバイスとして使っていると思われる)
(calc timeが小さいので)
---------------------------
OpenCL Setup Time - 1 : 352.8661
OpenCL Setup Time - 2 : 0.9382
OpenCL Calc Time : 3.9298
OpenCL End Time : 3.6446
OpenCL Total Time : 361.3758
非openclの場合は 6
総じておよそ60倍の時間がかかるわけだ
この差を埋められるほどの計算内容でないと
無駄だよ
FXの後継が出なくなったりOpteronが少なくとも4年間は
32nm止まりだったり
たいがいBulldozerで要らぬ野心を抱いたせい
32nm止まりだったり
たいがいBulldozerで要らぬ野心を抱いたせい
FXの後継はExcavatorで出てくると思う
2012年にでもKomodoと言う10コアのCPUがDDR4で出す予定だったのに
DDR4が難航したせいでキャンセルされた
代わりにVisheraと言う8コアの中途半端な物しか出せなかった
それは4gamerの記事にでも取上げられている
「komodo DDR4」とかで検索すればいい
Excavator世代になるとDDR3/4世代となり
ここでもう一度FXを出すかどうかを検討するレベルになる
2012年にでもKomodoと言う10コアのCPUがDDR4で出す予定だったのに
DDR4が難航したせいでキャンセルされた
代わりにVisheraと言う8コアの中途半端な物しか出せなかった
それは4gamerの記事にでも取上げられている
「komodo DDR4」とかで検索すればいい
Excavator世代になるとDDR3/4世代となり
ここでもう一度FXを出すかどうかを検討するレベルになる
>>87
そんなシンプルな処理にGPU使うなやってだけでしょ。
それに旧来のOpenCLでパフォーマンスが上がらないのは既出だよ。
>>89
俺もそう思う。
プロセスルールの刷新は遅れるし、一年ごとにアーキテクチャを更新する予定だったしでコスパ(AMDにとって)悪すぎたからね。
そんなシンプルな処理にGPU使うなやってだけでしょ。
それに旧来のOpenCLでパフォーマンスが上がらないのは既出だよ。
>>89
俺もそう思う。
プロセスルールの刷新は遅れるし、一年ごとにアーキテクチャを更新する予定だったしでコスパ(AMDにとって)悪すぎたからね。
91 :Socket774:2014/05/09(金) 14:39:40.78 ID:eZIr0XDM
だからGPGPUの使い道なんてほとん無いってことだわ
いまさらFXとかやったってもう客いないだろうに。
ちょっと成功するといい気になってお客様をないがしろにする。
そのお客様は二度と戻って来ない。
昔から同じことの繰り返しだ。
ちょっと成功するといい気になってお客様をないがしろにする。
そのお客様は二度と戻って来ない。
昔から同じことの繰り返しだ。
熱処理大変だろうけど、FM2で8コアとかあると嬉しいんだけどなぁ。
FireProW8100 (2048SP 32C 600MHz, 3GB DDR5 5.5GHz 256-bit)
http://www.sisoftware.eu/rank2011d/show_run.php?q=c2ffcdf4d2b3d2efddebd9efddeec8ba87b791f491ac9cbac9f4cc&l=jp
例のTongaってGPUだろうか
こいつもクロックがずいぶんと低い
http://www.sisoftware.eu/rank2011d/show_run.php?q=c2ffcdf4d2b3d2efddebd9efddeec8ba87b791f491ac9cbac9f4cc&l=jp
例のTongaってGPUだろうか
こいつもクロックがずいぶんと低い
CUDAやOpenCLみたいなのはセットアップに時間かかるしメモリロードが発生するので限定的にしか使えない
膨大なデータを扱うには不向き
それを克服するのがHSA構想でしょ
膨大なデータを扱うには不向き
それを克服するのがHSA構想でしょ
AMD Kaveri Mobile APUs Vs. ULV Haswell Benchmarks ? Flagship APU FX-7600P Takes Home the Crown
http://wccftech.com/amd-kaveri-mobile-apus-vs-ulv-haswell-benchmarks/
http://cdn.wccftech.com/wp-content/uploads/2014/05/AMD-Mobile-Kaveri-APUs-Gaming-Performance.png
http://cdn3.wccftech.com/wp-content/uploads/2014/05/AMD-Mobile-Kaveri-APUs-Compute.png
http://wccftech.com/amd-kaveri-mobile-apus-vs-ulv-haswell-benchmarks/
http://cdn.wccftech.com/wp-content/uploads/2014/05/AMD-Mobile-Kaveri-APUs-Gaming-Performance.png
{kind=link}
http://cdn3.wccftech.com/wp-content/uploads/2014/05/AMD-Mobile-Kaveri-APUs-Compute.png
{kind=link}
克服するという売り文句で情弱を騙して売るという商法
サードパーティ製アプリなんて出てくる気配ないしな
温度差がわからないって幸せだな
サードパーティ製アプリなんて出てくる気配ないしな
温度差がわからないって幸せだな
98 :Socket774:2014/05/09(金) 15:26:18.41 ID:eZIr0XDM
>>95
fa?
fa?
仮に特定条件で使わない場合の⚪︎倍速くなるとしても
APUはシェアがとれてないのでソフト開発者は
AMD専用APIを使いたがらない。採算性がないから。
SSE4aやXOP対応ソフトがほとんど無いことからもわかる。
APUはシェアがとれてないのでソフト開発者は
AMD専用APIを使いたがらない。採算性がないから。
SSE4aやXOP対応ソフトがほとんど無いことからもわかる。
GPU性能なw
>>100
とりあえず・・ つOpenCL 2.0
とりあえず・・ つOpenCL 2.0
HSAやMantleは抜きにしても、その技術を一部使ってるDX12、OpenCL2.0が出てくる来年以降はAMDにとってソフト的に面白くなりそう
DirectX12はWindows 9で対応だな
そんでもってGCNは既に対応済み
恐らくOSのどの部分かにもDX12で高速化っつうかGPUを使うので
CPU負荷軽減がなされるだろうからCPU性能の差もどんどんなくなる
そんでもってGCNは既に対応済み
恐らくOSのどの部分かにもDX12で高速化っつうかGPUを使うので
CPU負荷軽減がなされるだろうからCPU性能の差もどんどんなくなる
>>80
別にソフトがどうとかあんま興味ない
面白いCPU/GPUハードがでてくれればオレは何でも楽しめるんでw
HaswellのGT3e、Baytrail、Kabini、TegraK1等々のSOCものはオモロイ
Kaveriはメモリ帯域がボトルネックになってモッタイナイけど
改良されたSteamrollerコアによるIPCの改善やGCNの採用等
目新しさも多く楽しめた
別にソフトがどうとかあんま興味ない
面白いCPU/GPUハードがでてくれればオレは何でも楽しめるんでw
HaswellのGT3e、Baytrail、Kabini、TegraK1等々のSOCものはオモロイ
Kaveriはメモリ帯域がボトルネックになってモッタイナイけど
改良されたSteamrollerコアによるIPCの改善やGCNの採用等
目新しさも多く楽しめた
最近のAMDは常に期待を下回るからつまらないな
7500も思ったほど伸びてくれなかったしirisに負けるし
コスパとか無視していいからDDR4で動くFXシリーズをintelより先に出してくれよ
7500も思ったほど伸びてくれなかったしirisに負けるし
コスパとか無視していいからDDR4で動くFXシリーズをintelより先に出してくれよ
TSMC extends 28nm production lead time to 16 weeks
http://www.digitimes.com/news/a20140509PD207.html
http://www.digitimes.com/news/a20140509PD207.html
{kind=link}
110 :,,・´∀`・,,)っ-○○○:2014/05/09(金) 19:37:58.36 ID:HRt7Pt4j
>>102
C/C++で書かれてるコードをわざわざOpenCLで書き直す必要があるの?
CPUで問題なく動いてるものを、マーケットの小さいAPUに配慮して
書き直すなんて、かかる工数を考えればありえないことだよ。
C/C++で書かれてるコードをわざわざOpenCLで書き直す必要があるの?
CPUで問題なく動いてるものを、マーケットの小さいAPUに配慮して
書き直すなんて、かかる工数を考えればありえないことだよ。
AMD独自APIは〜に対するレスなので
pc程度ではgpgpuの使い道はない
オーバーヘッドで60倍も時間かかるんじゃ
オーバーヘッドで60倍も時間かかるんじゃ
113 :,,・´∀`・,,)っ-○○○:2014/05/09(金) 20:13:23.53 ID:HRt7Pt4j
>>111
既に並列化してあるCPU向けコードをOpenCLで書き直す意味は無いよ。
OpenCLは初動時にコンパイルするからネイティブコードより遅いし、
そのコンパイル自体も事前コンパイルのC/C++より最適化が浅い。
SSEやAVXの特性に合わせたソースコードレベルの最適化ができない。
そしてまだ並列化してないコードを並列化する際だが、これもあえてOpenCLを
選ぶ意味は無い。
Pure C++コード資産を簡単に移行できる処理系としてCilkPlusやTBBがある。
これらはgccとかにもポーティングされてるからIntelコンパイラ以外でも利用できる。
これらはもちろんゲーム業界でも多くの利用実績がある。
既に並列化してあるCPU向けコードをOpenCLで書き直す意味は無いよ。
OpenCLは初動時にコンパイルするからネイティブコードより遅いし、
そのコンパイル自体も事前コンパイルのC/C++より最適化が浅い。
SSEやAVXの特性に合わせたソースコードレベルの最適化ができない。
そしてまだ並列化してないコードを並列化する際だが、これもあえてOpenCLを
選ぶ意味は無い。
Pure C++コード資産を簡単に移行できる処理系としてCilkPlusやTBBがある。
これらはgccとかにもポーティングされてるからIntelコンパイラ以外でも利用できる。
これらはもちろんゲーム業界でも多くの利用実績がある。
>>113
Intelには無理だからOpenCL普及しちゃ困ると素直に言えんか?
Intelには無理だからOpenCL普及しちゃ困ると素直に言えんか?
INTEL自身はopenCLを肯定してたと思うけど
>>75
ほんとこれ
ほんとこれ
じゃ、団子には煽りレス以外禁止で
119 :,,・´∀`・,,)っ-○○○:2014/05/09(金) 20:44:27.79 ID:HRt7Pt4j
Intelは定番の並列化処理系はおさえてるから好きなものを選べ
というスタンスでしょ(もちろん選ばせたいものは生産性の悪いOpenCLじゃない)
プログラム初期化のたびにコンパイル時間のかかるもっさりプログラム
ばっかりになったら俺は嫌だけどね。
iGPUでGPGPUは基本的に無意味だと思ってる。
SkylakeでCPUだけで900GFLOPS出るならiGPU使ってまで汎用演算やる
意味ないでしょ?(どうせメモリ帯域が飽和したら頭打ちになるんだし)
「CPUが遅いAMDに配慮してHSAを使おう」
っていう議論をしたいなら、APU搭載PCの販売台数なんかも考えて
費用対効果を考えないといけないね。
俺はAMDを選ぶバカが悪いってことで無視しても差し支えないんじゃないかと思ってるけど。
BoltはCilkPlusやTBBより遥かに生産性は悪いよ。
既にバージョンは1.1になってるのにどこかしらのソフトで利用されてるなんていう
実績を寡聞にして知らない。
あとJavaのSumatraAPI?あれも大して生産性高くないのよ。
大体にJavaで組まれたクライアントPC向けアプリケーションって何があるのさ?
俺はEclipseとV2C(2chブラウザ)くらいしか使ってないよ。
Webブラウザ向けプラグインもFlash以上にセキュリティホールのすくつだから
最近はまったくといっていいほど見かけなくなった。
というスタンスでしょ(もちろん選ばせたいものは生産性の悪いOpenCLじゃない)
プログラム初期化のたびにコンパイル時間のかかるもっさりプログラム
ばっかりになったら俺は嫌だけどね。
iGPUでGPGPUは基本的に無意味だと思ってる。
SkylakeでCPUだけで900GFLOPS出るならiGPU使ってまで汎用演算やる
意味ないでしょ?(どうせメモリ帯域が飽和したら頭打ちになるんだし)
「CPUが遅いAMDに配慮してHSAを使おう」
っていう議論をしたいなら、APU搭載PCの販売台数なんかも考えて
費用対効果を考えないといけないね。
俺はAMDを選ぶバカが悪いってことで無視しても差し支えないんじゃないかと思ってるけど。
BoltはCilkPlusやTBBより遥かに生産性は悪いよ。
既にバージョンは1.1になってるのにどこかしらのソフトで利用されてるなんていう
実績を寡聞にして知らない。
あとJavaのSumatraAPI?あれも大して生産性高くないのよ。
大体にJavaで組まれたクライアントPC向けアプリケーションって何があるのさ?
俺はEclipseとV2C(2chブラウザ)くらいしか使ってないよ。
Webブラウザ向けプラグインもFlash以上にセキュリティホールのすくつだから
最近はまったくといっていいほど見かけなくなった。
121 :,,・´∀`・,,)っ-○○○:2014/05/09(金) 20:51:18.88 ID:HRt7Pt4j
「AMD向けのコード最適化をしない」ってことよ
午後のこ〜だで3DNow!を使い倒してたへるみ先生は
AMD XOPもSSE4aもガン無視の現実↓
https://github.com/herumi/xbyak
午後のこ〜だで3DNow!を使い倒してたへるみ先生は
AMD XOPもSSE4aもガン無視の現実↓
https://github.com/herumi/xbyak
オープンCLでもなんでも4Kとかだったら処理が2の何乗になるじゃないっすか
それを影だとかなんだとかやってたらおいつかないっすよ
それを影だとかなんだとかやってたらおいつかないっすよ
123 :,,・´∀`・,,)っ-○○○:2014/05/09(金) 21:05:13.77 ID:HRt7Pt4j
これは火病を起こさせるのが楽しいからあえて言うんだけど
AMDがCPUシェア2割を切ったこと自体が
ソフト屋にとってはコスト削減効果を生み出してるんだよね。
「AMDを無視する」
これだけでソフト開発工数を確実に減らすことができる。
2割未満なんて無視しても差し支えないからだ。
Intelに買い換えられない貧乏はほっとけ。
どうせソフトも買う金も持ってないからな!
>>122
H.265なんて必要になったときには固定ハードでやればよくね?
Snapdragonとかにも支援回路載ってるのにPCに載せちゃいけない理由ないよね?
AMDがCPUシェア2割を切ったこと自体が
ソフト屋にとってはコスト削減効果を生み出してるんだよね。
「AMDを無視する」
これだけでソフト開発工数を確実に減らすことができる。
2割未満なんて無視しても差し支えないからだ。
Intelに買い換えられない貧乏はほっとけ。
どうせソフトも買う金も持ってないからな!
>>122
H.265なんて必要になったときには固定ハードでやればよくね?
Snapdragonとかにも支援回路載ってるのにPCに載せちゃいけない理由ないよね?
openCLの話にCPUシェアが関係するのかよw
じゃあC++AMPで書けばどのGPUでも動くって事は有利なわけだな
なにせシェアの問題らしいから
そろそろHPCと金の話に逃げ込んだ方がいいんじゃないのか
じゃあC++AMPで書けばどのGPUでも動くって事は有利なわけだな
なにせシェアの問題らしいから
そろそろHPCと金の話に逃げ込んだ方がいいんじゃないのか
125 :,,・´∀`・,,)っ-○○○:2014/05/09(金) 21:18:53.16 ID:HRt7Pt4j
> じゃあC++AMPで書けばどのGPUでも動くって事は有利なわけだな
> なにせシェアの問題らしいから
C++AMPなんて使ってるプロジェクト知らないよ?
勉強会でも全くといっていいほど話題に出ない
> なにせシェアの問題らしいから
C++AMPなんて使ってるプロジェクト知らないよ?
勉強会でも全くといっていいほど話題に出ない
127 :,,・´∀`・,,)っ-○○○:2014/05/09(金) 21:20:26.84 ID:HRt7Pt4j
C++AMPで書かれた有名ソフトを10個挙げて
128 :Socket774:2014/05/09(金) 21:24:55.44 ID:9v0Js4BS
その、(AMDにとって)期待のKaveriが高いからシェア現象に歯止めがかからないんだよ。
GPU性能を要求するユーザーは全体からすると僅かなんだから、Core i3と競える価格にしないと一般ユーザー向け製品では勝負にならないだろ。
GPU性能を要求するユーザーは全体からすると僅かなんだから、Core i3と競える価格にしないと一般ユーザー向け製品では勝負にならないだろ。
129 :,,・´∀`・,,)っ-○○○:2014/05/09(金) 21:30:29.76 ID:HRt7Pt4j
聞くところによると、Llano立ち上げ時
「うちはRadeon持ってるからこいつを投入すればシェア50%狙える」
みたいな、かなり楽観的な予測をしてたらしい
でもすごいよAMDって
今やってることが5年前とほとんど変わってない
http://www.itmedia.co.jp/pcuser/articles/0908/30/news002.html
オンボードGPUで比較して勝てるものだけピックアップして
ホルホル。イベントに足を運ぶやつもよく飽きないよな。
それでシェア伸ばせた実績なんて今まであったのかと
この5年で累積赤字だけが増えただけじゃないの
「うちはRadeon持ってるからこいつを投入すればシェア50%狙える」
みたいな、かなり楽観的な予測をしてたらしい
でもすごいよAMDって
今やってることが5年前とほとんど変わってない
http://www.itmedia.co.jp/pcuser/articles/0908/30/news002.html
オンボードGPUで比較して勝てるものだけピックアップして
ホルホル。イベントに足を運ぶやつもよく飽きないよな。
それでシェア伸ばせた実績なんて今まであったのかと
この5年で累積赤字だけが増えただけじゃないの
>>96
>>109
こうして見るとKaveriの圧勝みたいだな
この数値見る限りi7-4700UよりもCPU性能は上だな
>>99
FX7500は384SPだがFX7600は512SPだからA10-6800Kぐらいは軽く抜きさる
intelは、さっさと14nmプロセス出せ
>>109
こうして見るとKaveriの圧勝みたいだな
この数値見る限りi7-4700UよりもCPU性能は上だな
>>99
FX7500は384SPだがFX7600は512SPだからA10-6800Kぐらいは軽く抜きさる
intelは、さっさと14nmプロセス出せ
132 :,,・´∀`・,,)っ-○○○:2014/05/09(金) 21:34:51.35 ID:HRt7Pt4j
現実から目を逸らすって素敵
>>125
おかしなことを言うね、C++AMP自体がDX(DirectCompute)ベースでGPGPUをやるっていうMSのプロジェクトだろ?
wiondows7とwindows8ではDXの違いにより倍精度演算でやれることが違うしDX12でも当然拡張されるでしょうよ
DXでできることはほとんど代替可能だというMantleでも使えるかもしれんなぁ
おかしなことを言うね、C++AMP自体がDX(DirectCompute)ベースでGPGPUをやるっていうMSのプロジェクトだろ?
wiondows7とwindows8ではDXの違いにより倍精度演算でやれることが違うしDX12でも当然拡張されるでしょうよ
DXでできることはほとんど代替可能だというMantleでも使えるかもしれんなぁ
>>121
ま、別にいいかな。。
声優買いするオタクならぬ拡張命令買いするオタクがいるなら傑作だが。。
>>123
ま、AMDに最適化されてなくてもSSE2に対応したx86プロセッサなら互換性で困ることはないし
そんな大規模なプロジェクトで作られたアプリなんて使ってないから無問題
ま、別にいいかな。。
声優買いするオタクならぬ拡張命令買いするオタクがいるなら傑作だが。。
>>123
ま、AMDに最適化されてなくてもSSE2に対応したx86プロセッサなら互換性で困ることはないし
そんな大規模なプロジェクトで作られたアプリなんて使ってないから無問題
団子がC++AMPに無関心なのはC++AMPがDXベースな故にwindowsでしか使えないという致命的な弱点を持ってるからだよ
だからHPC界隈では最初から候補に上がらない、しかしその弱点もなんとなく解決できそうな目処はついてきたなぁ
だからHPC界隈では最初から候補に上がらない、しかしその弱点もなんとなく解決できそうな目処はついてきたなぁ
136 :,,・´∀`・,,)っ-○○○:2014/05/09(金) 21:42:04.10 ID:HRt7Pt4j
> おかしなことを言うね、C++AMP自体がDX(DirectCompute)ベースでGPGPUをやるっていうMSのプロジェクトだろ?
それを使ったソフトを10個でいいから挙げろと言ってるのだが
そんなすごい開発環境なら挙げられるだろ?
それを使ったソフトを10個でいいから挙げろと言ってるのだが
そんなすごい開発環境なら挙げられるだろ?
137 :,,・´∀`・,,)っ-○○○:2014/05/09(金) 21:43:12.58 ID:HRt7Pt4j
> C++AMPに無関心なのはC++AMPがDXベースな故にwindowsでしか使えないという
> 致命的な弱点を持ってるからだよ
違うよ単純に案件がないから。
金にならない技術に人は寄り付かない
> 致命的な弱点を持ってるからだよ
違うよ単純に案件がないから。
金にならない技術に人は寄り付かない
HSAで作られると内蔵GPUが強力なAMDに負けちゃうからintelから作らないでくれってお願いされてるんだろう
139 :,,・´∀`・,,)っ-○○○:2014/05/09(金) 21:50:45.74 ID:HRt7Pt4j
> HSAで作られると内蔵GPUが強力なAMDに負けちゃうからintelから作らないでくれってお願いされてるんだろう
またつまらん言いがかりだな
AMDはAPUでCilkPlusが動くように移植すればいいんじゃね?(鼻ホジホジ
またつまらん言いがかりだな
AMDはAPUでCilkPlusが動くように移植すればいいんじゃね?(鼻ホジホジ
2014年
http://akiba-pc.watch.impress.co.jp/docs/news/news/20140118_631297.html
Core i5-4670Kと比べてA10-7850Kがパフォーマンスに優れるとアピール。「いまさらSuper Pi(だけ)ですか?」
2011年
http://www.4gamer.net/games/100/G010001/20110629001/
これらGPUコアは,Sandy Bridge世代のCore iシリーズが統合しているグラフィックス機能を3D性能で大きく上回り
2008年
http://ascii.jp/elem/000/000/114/114301/
米インテル社のGPU内蔵チップセット(Intel G35 Expressなど)と比べて、2倍を超える性能を発揮
番外編
2002年
http://pc.watch.impress.co.jp/docs/2002/0717/nvidia.htm
nForce2のシステムは、Pentium 4 2.53GHz+Intel 845Gに比べてQuakeIII Arenaで5倍以上
やってることが変わらないというか、性能差はむしろ昔のほうが大きかったんだよねえ
http://akiba-pc.watch.impress.co.jp/docs/news/news/20140118_631297.html
Core i5-4670Kと比べてA10-7850Kがパフォーマンスに優れるとアピール。「いまさらSuper Pi(だけ)ですか?」
2011年
http://www.4gamer.net/games/100/G010001/20110629001/
これらGPUコアは,Sandy Bridge世代のCore iシリーズが統合しているグラフィックス機能を3D性能で大きく上回り
2008年
http://ascii.jp/elem/000/000/114/114301/
米インテル社のGPU内蔵チップセット(Intel G35 Expressなど)と比べて、2倍を超える性能を発揮
番外編
2002年
http://pc.watch.impress.co.jp/docs/2002/0717/nvidia.htm
nForce2のシステムは、Pentium 4 2.53GHz+Intel 845Gに比べてQuakeIII Arenaで5倍以上
やってることが変わらないというか、性能差はむしろ昔のほうが大きかったんだよねえ
142 :,,・´∀`・,,)っ-○○○:2014/05/09(金) 22:00:48.41 ID:HRt7Pt4j
だが安心しる
Intelがコスト高くて避けてるメモリをAMDが先に使える理由が無いから
Intelがコスト高くて避けてるメモリをAMDが先に使える理由が無いから
>>75
次回からのテンプレに入れたほうが良いね。
次回からのテンプレに入れたほうが良いね。
DS:ダンゴソフト 団子の資産6兆円
146 :,,・´∀`・,,)っ-○○○:2014/05/09(金) 22:04:16.93 ID:HRt7Pt4j
山吹色のお菓子は甘くて甘くておいしいよー
147 :,,・´∀`・,,)っ-○○○:2014/05/09(金) 22:05:13.29 ID:HRt7Pt4j
そーいえばセレブオーク先生ってすげーよな
>>144
先行者利益って用語の意味を調べた方がいい
先行者利益って用語の意味を調べた方がいい
149 :,,・´∀`・,,)っ-○○○:2014/05/09(金) 22:09:31.80 ID:HRt7Pt4j
貧乏空想集団有限公司
「おさわり禁止 ウナギ銀河養殖キット」
「おさわり禁止 ウナギ銀河養殖キット」
150 :Socket774:2014/05/09(金) 22:09:49.54 ID:9v0Js4BS
結局の所、大多数のユーザーにとってはiGPUの性能向上はオマケにしかすぎないんだよね。
iGPUの始まりは、『大多数のユーザーは高いグラフィック性能を必要としないから、チップセットに内蔵した方が安くなる』からだからな。
CPUの価格据え置きでiGPU性能が上がればユーザーは喜ぶけど、CPUの価格が上がってまでiGPU性能の向上を喜ぶユーザーは一握りしかいない。
最初から一握りのユーザーにしかうけない仕様で開発を始めたら、AMDの技術者がどれだけ頑張ってもシェアを増やすなんて無理だわな。
iGPUの始まりは、『大多数のユーザーは高いグラフィック性能を必要としないから、チップセットに内蔵した方が安くなる』からだからな。
CPUの価格据え置きでiGPU性能が上がればユーザーは喜ぶけど、CPUの価格が上がってまでiGPU性能の向上を喜ぶユーザーは一握りしかいない。
最初から一握りのユーザーにしかうけない仕様で開発を始めたら、AMDの技術者がどれだけ頑張ってもシェアを増やすなんて無理だわな。
>>141
もともと、GDDR5で性能発揮するようにしたGPUをCPUと一緒にしたから
DDR3じゃフルに力発揮できないだろう。DDR4でもiGPUは遊んでいるってなるだろう
iGPUの性能出すために高価なメモリを使うって、GPGPUが普及していない状況ではアホだし
もともと、GDDR5で性能発揮するようにしたGPUをCPUと一緒にしたから
DDR3じゃフルに力発揮できないだろう。DDR4でもiGPUは遊んでいるってなるだろう
iGPUの性能出すために高価なメモリを使うって、GPGPUが普及していない状況ではアホだし
152 :,,・´∀`・,,)っ-○○○:2014/05/09(金) 22:11:36.77 ID:HRt7Pt4j
>>148
侍魂のPV数的な意味で?
侍魂のPV数的な意味で?
153 :,,・´∀`・,,)っ-○○○:2014/05/09(金) 22:17:19.18 ID:HRt7Pt4j
そもそも先行者利益というのは新興市場に対して言うものだ
プログラミング言語を変えた程度で衰退市場が活性化するなんて
そんなバカな事例は無い
プログラミング言語を変えた程度で衰退市場が活性化するなんて
そんなバカな事例は無い
AMD Athlon 5350 quad-core, 2.0 GHz GPU 600MHz 28nmプロセス ダイサイズ107mm2前後
Intel Celeron J1900, quad-core, 2.42 GHz GPU 854MHz 22nmプロセス ダイサイズ107mm2前後
Higer is betterの項目
PCMark 8
http://media.bestofmicro.com/B/9/430677/original/pcmark.png
Sandra Arithmetic
http://media.bestofmicro.com/B/E/430682/original/sandra-arith.png
GPGPU Processor Cryptography
http://media.bestofmicro.com/C/H/430721/original/sandra-GPGPU-crypt.png
3DMark2013
http://media.bestofmicro.com/B/1/430669/original/3dmark.png
Peacekeeper
http://media.bestofmicro.com/B/B/430679/original/peacekeeper.png
Dota 2
http://media.bestofmicro.com/C/K/430724/original/Dota2.png
Grid 2
http://media.bestofmicro.com/B/5/430673/original/Grid2.png
Lower is betterの項目
Adobi Acrobat XI
http://media.bestofmicro.com/B/0/430668/original/acrobat.png
ABBYY FineReader
http://media.bestofmicro.com/B/2/430670/original/abbyy.png
JPEG Dedoder
http://media.bestofmicro.com/B/7/430675/original/JPEG-decoder.png
iTunes x64
http://media.bestofmicro.com/B/6/430674/original/iTunes.png
Lame MP3
http://media.bestofmicro.com/B/8/430676/original/lame.png
HandBrake CLI
http://media.bestofmicro.com/B/A/430678/original/handbrake.png
TotalCodeStudio
http://media.bestofmicro.com/B/I/430686/original/totalcode.png
Zip 9.28
http://media.bestofmicro.com/B/3/430671/original/7zip.png
WinRAR 5.10
http://media.bestofmicro.com/B/J/430687/original/winRAR.png
Processor Temperature
http://media.bestofmicro.com/B/H/430685/original/temp.png
Celeronの方がクロック高いだけあって優秀なのかと思ったら違ってたなwwww
Intel Celeron J1900, quad-core, 2.42 GHz GPU 854MHz 22nmプロセス ダイサイズ107mm2前後
Higer is betterの項目
PCMark 8
http://media.bestofmicro.com/B/9/430677/original/pcmark.png
{kind=link}
Sandra Arithmetic
http://media.bestofmicro.com/B/E/430682/original/sandra-arith.png
{kind=link}
GPGPU Processor Cryptography
http://media.bestofmicro.com/C/H/430721/original/sandra-GPGPU-crypt.png
{kind=link}
3DMark2013
http://media.bestofmicro.com/B/1/430669/original/3dmark.png
{kind=link}
Peacekeeper
http://media.bestofmicro.com/B/B/430679/original/peacekeeper.png
{kind=link}
Dota 2
http://media.bestofmicro.com/C/K/430724/original/Dota2.png
{kind=link}
Grid 2
http://media.bestofmicro.com/B/5/430673/original/Grid2.png
{kind=link}
Lower is betterの項目
Adobi Acrobat XI
http://media.bestofmicro.com/B/0/430668/original/acrobat.png
{kind=link}
ABBYY FineReader
http://media.bestofmicro.com/B/2/430670/original/abbyy.png
{kind=link}
JPEG Dedoder
http://media.bestofmicro.com/B/7/430675/original/JPEG-decoder.png
{kind=link}
iTunes x64
http://media.bestofmicro.com/B/6/430674/original/iTunes.png
{kind=link}
Lame MP3
http://media.bestofmicro.com/B/8/430676/original/lame.png
{kind=link}
HandBrake CLI
http://media.bestofmicro.com/B/A/430678/original/handbrake.png
{kind=link}
TotalCodeStudio
http://media.bestofmicro.com/B/I/430686/original/totalcode.png
{kind=link}
Zip 9.28
http://media.bestofmicro.com/B/3/430671/original/7zip.png
{kind=link}
WinRAR 5.10
http://media.bestofmicro.com/B/J/430687/original/winRAR.png
{kind=link}
Processor Temperature
http://media.bestofmicro.com/B/H/430685/original/temp.png
{kind=link}
Celeronの方がクロック高いだけあって優秀なのかと思ったら違ってたなwwww
オランダ妻は銀河ウナギの夢をみるか?
{kind=link}
157 :,,・´∀`・,,)っ-○○○:2014/05/09(金) 22:27:20.58 ID:HRt7Pt4j
大体に世の中のソフト開発プロジェクトの8割以上がCより何倍も
実行速度が遅い(けど手軽な)プログラミング言語を使ってるのに
いまさら速度だけを売りにしてCより面倒な言語が受け入れられると
思うほうが間違いだよ
ただ俺はOpenCLそのものは否定しないよ
JavaScriptをOpenCLバックエンドに使って高速化しようと試みてる
プロジェクトをIntelがやってるじゃん。
逆になんでそういうのをAMDがやらないのか疑問なんだが。
JavaScriptってある意味一番身近なプログラミング言語だぞ。
実行速度が遅い(けど手軽な)プログラミング言語を使ってるのに
いまさら速度だけを売りにしてCより面倒な言語が受け入れられると
思うほうが間違いだよ
ただ俺はOpenCLそのものは否定しないよ
JavaScriptをOpenCLバックエンドに使って高速化しようと試みてる
プロジェクトをIntelがやってるじゃん。
逆になんでそういうのをAMDがやらないのか疑問なんだが。
JavaScriptってある意味一番身近なプログラミング言語だぞ。
>>156
CPU+GPUの場合に消費電力1.3倍の差がある
CPU+GPUの場合ってどれかと思ったらこれか?
GPGPU Processor Cryptography
http://media.bestofmicro.com/C/H/430721/original/sandra-GPGPU-crypt.png
性能さどんだけーw
CPU+GPUの場合に消費電力1.3倍の差がある
CPU+GPUの場合ってどれかと思ったらこれか?
GPGPU Processor Cryptography
http://media.bestofmicro.com/C/H/430721/original/sandra-GPGPU-crypt.png
性能さどんだけーw
159 :,,・´∀`・,,)っ-○○○:2014/05/09(金) 22:34:10.23 ID:HRt7Pt4j
暗号処理はRangeleyが専用ハードウェアを積んでるしな
クライアント用途ではそんなに大量の暗号処理なんて想定してるわけが無い
それこそ電力の無駄になるからな。
クライアント用途ではそんなに大量の暗号処理なんて想定してるわけが無い
それこそ電力の無駄になるからな。
intelではGPUがクソだから
NVIDIAの力借りないと無理なんだが
こういう低消費電力向けはION2以降出せて無いんだよな
NVIDIAの力借りないと無理なんだが
こういう低消費電力向けはION2以降出せて無いんだよな
>Javaで書いたデータ並列プログラムをGPUを使って高速化するというAparapi(A PARallel API)という方法がある。
Aparapiは実行時にバイトコードを見て、OpenCLに変換できる部分はGPUに実行させることにより、性能を改善する。
このAparapiの実装には、次のようなロードマップを考えており、最終的には、Sumatraと呼ぶHSA用のJVMを開発し、
GPUで実行できる部分は最適化されたHSAILコードを出力する。
OpenClできない人はこっちでやると簡単ですよ〜(仮)あ、でもHSA専用ですwww
Aparapiは実行時にバイトコードを見て、OpenCLに変換できる部分はGPUに実行させることにより、性能を改善する。
このAparapiの実装には、次のようなロードマップを考えており、最終的には、Sumatraと呼ぶHSA用のJVMを開発し、
GPUで実行できる部分は最適化されたHSAILコードを出力する。
OpenClできない人はこっちでやると簡単ですよ〜(仮)あ、でもHSA専用ですwww
162 :,,・´∀`・,,)っ-○○○:2014/05/09(金) 22:54:04.39 ID:HRt7Pt4j
いまどきJavaなんてPCに入れてる人のほうが少ないから
さて、そのSumatraだが・・・
https://wikis.oracle.com/display/HotSpotInternals/Sumatra
> ・mitigate the complexities of present-day GPU backends and layered standards
> ・standards include: OpenCL, CUDA, Intel Phi, PTX, HSA (forthcoming), ...
~~~~~~~~~~~~~~~~~~
残念、HSAがドンケツでした
さて、そのSumatraだが・・・
https://wikis.oracle.com/display/HotSpotInternals/Sumatra
> ・mitigate the complexities of present-day GPU backends and layered standards
> ・standards include: OpenCL, CUDA, Intel Phi, PTX, HSA (forthcoming), ...
~~~~~~~~~~~~~~~~~~
残念、HSAがドンケツでした
HSAは6月のドライバ待ちだろ
164 :,,・´∀`・,,)っ-○○○:2014/05/09(金) 22:55:35.24 ID:HRt7Pt4j
> build a low-level library of vector intrinsics (e.g., AVX-style) that can be called (manually) from Java
って書いてあるからAVXのほうが有利っぽいですね
って書いてあるからAVXのほうが有利っぽいですね
そら効率おとしてるんだからいいんじゃね。
可能性を探る開発ソフトだろw
いけると思えば最適化すればいいだけだし。
可能性を探る開発ソフトだろw
いけると思えば最適化すればいいだけだし。
166 :,,・´∀`・,,)っ-○○○:2014/05/09(金) 23:02:00.96 ID:HRt7Pt4j
頭に刺さったブーメランが痛々しい
ホント団子は現状しかみない老害だなw
168 :,,・´∀`・,,)っ-○○○:2014/05/09(金) 23:07:19.20 ID:HRt7Pt4j
今を見ないから>>72みたいな発言が歴史に残るのだよ
Intelすげー≠団子すげー
アーカイブされてるのはコテハン発言の方だぞ
171 :,,・´∀`・,,)っ-○○○:2014/05/09(金) 23:15:13.75 ID:HRt7Pt4j
172 :,,・´∀`・,,)っ-○○○:2014/05/09(金) 23:17:44.12 ID:HRt7Pt4j
名無しだからって2015年以降のの自分が見て恥ずかしくない発言をしような
たぶん東京オリンピックの年にもVisualBasicとかPHPのくそプログラムは
普通に存在すると思います。
たぶん東京オリンピックの年にもVisualBasicとかPHPのくそプログラムは
普通に存在すると思います。
AMDは倒産するんだろ?w
15年まで生き残ってたらこっちにくるなよwww
15年まで生き残ってたらこっちにくるなよwww
174 :,,・´∀`・,,)っ-○○○:2014/05/09(金) 23:26:21.28 ID:HRt7Pt4j
社債償還のために何を現金化するのか楽しみですわ
>>162
HadoopはJavaで組まれてるといったのはお前じゃなかったか?
HadoopはJavaで組まれてるといったのはお前じゃなかったか?
177 :,,・´∀`・,,)っ-○○○:2014/05/09(金) 23:35:07.37 ID:HRt7Pt4j
>>161
絵に描いた餅じゃなく、本物の餅が出来てから自慢してね
絵に描いた餅じゃなく、本物の餅が出来てから自慢してね
ばかかww
想像しなければ実現すらしないんだよwww
想像しなければ実現すらしないんだよwww
180 :,,・´∀`・,,)っ-○○○:2014/05/09(金) 23:39:04.10 ID:HRt7Pt4j
AMDが実際に作ってないものを勝手に妄想しても不毛なのだが
182 :,,・´∀`・,,)っ-○○○:2014/05/09(金) 23:43:47.87 ID:HRt7Pt4j
そういう発言はたいがい皮肉で言ってる
164 名前:,,・´∀`・,,)っ-○○○[sage] 投稿日:2014/05/09(金) 22:55:35.24 ID:HRt7Pt4j [24/32]
> build a low-level library of vector intrinsics (e.g., AVX-style) that can be called (manually) from Java
って書いてあるからAVXのほうが有利っぽいですね
これまったく意味わからんけどな。どこが有利って?ww
> build a low-level library of vector intrinsics (e.g., AVX-style) that can be called (manually) from Java
って書いてあるからAVXのほうが有利っぽいですね
これまったく意味わからんけどな。どこが有利って?ww
184 :,,・´∀`・,,)っ-○○○:2014/05/10(土) 00:17:30.97 ID:1jDHUPL0
ぷ
この程度も理解できないのか
OpenCLのようなSPMDスタイルの欠点は
レジスタ上でのシフトやシャッフルを簡単に表現できないことなんだよ
別のスレッドが持ってるものとみなして都度メモリから読み直すことになる。
こういう命令はx86にはSSEからもともとあるから対応が容易。
レジスタ間シャッフルを活用するコードを書きたい場合は
GPGPUのようなSPMD強制のコード体系は百害あって一利なし。
この程度も理解できないのか
OpenCLのようなSPMDスタイルの欠点は
レジスタ上でのシフトやシャッフルを簡単に表現できないことなんだよ
別のスレッドが持ってるものとみなして都度メモリから読み直すことになる。
こういう命令はx86にはSSEからもともとあるから対応が容易。
レジスタ間シャッフルを活用するコードを書きたい場合は
GPGPUのようなSPMD強制のコード体系は百害あって一利なし。
ID:OgGXZsp、必死に基地印つけるなよ
お前、AMDユーザーじゃなくIntelユーザーだろ
お前、AMDユーザーじゃなくIntelユーザーだろ
は?w
どこに有利って単語があるのか聞いてるww
どこに有利って単語があるのか聞いてるww
まぁ、荒らし目的なのは昔からだろw
最近ここのスレでもどんな奴かってのが浸透してるようだし、ただの老害だからスルーでも
いいんだけどな。 暇つぶしに絡んでるだけだけどw
最近ここのスレでもどんな奴かってのが浸透してるようだし、ただの老害だからスルーでも
いいんだけどな。 暇つぶしに絡んでるだけだけどw
ID:9e8+WWos、必死に基地るなよ
暇つぶしの場所だろww
191 :,,・´∀`・,,)っ-○○○:2014/05/10(土) 00:30:22.95 ID:1jDHUPL0
GPUでAVXスタイルのintrinsicsでのプログラミングをサポートしてるデバイスは
基本的に無いからx86やXeon Phiをお手本にするということだよ。
基本スカラで書いて必要なところだけintrinsicsを使ったベクトル操作を記述する
従来のCPUでのSIMD記述スタイルが実現できる。
当然ながらCPUやXeon PhiのSIMDの特性に合ったプログラミングスタイルだ。
NECスパコンも1スカラユニットに対して1つの512ビット幅のベクトルユニットだし
AVX-512はHPC用しては理想系なのだ。
どっかの2048ビットレジスタとか粒度荒すぎて汎用処理は向いてないでしょw
基本的に無いからx86やXeon Phiをお手本にするということだよ。
基本スカラで書いて必要なところだけintrinsicsを使ったベクトル操作を記述する
従来のCPUでのSIMD記述スタイルが実現できる。
当然ながらCPUやXeon PhiのSIMDの特性に合ったプログラミングスタイルだ。
NECスパコンも1スカラユニットに対して1つの512ビット幅のベクトルユニットだし
AVX-512はHPC用しては理想系なのだ。
どっかの2048ビットレジスタとか粒度荒すぎて汎用処理は向いてないでしょw
お前ら団子すきやなぁ
ほとんどはNGしてるというのに餌やるな
amd自体もなにもなくて暇だとはいえ、見るに耐えない
前日1 位/1812 ID中の書き込む単なるあらしだぞ
ほとんどはNGしてるというのに餌やるな
amd自体もなにもなくて暇だとはいえ、見るに耐えない
前日1 位/1812 ID中の書き込む単なるあらしだぞ
194 :,,・´∀`・,,)っ-○○○:2014/05/10(土) 00:38:11.15 ID:1jDHUPL0
そもそもあぱらぴ(爆笑)自体jcudaの二番煎じだし
別にJavaでGPUを呼び出せても今までのJavaコード資産が
GPUで動くわけじゃないしカーネルコードを新規に書き起こす量を
考えたらぶっちゃけわずらわしさはOpenCLと大して変わらんのよ
別にJavaでGPUを呼び出せても今までのJavaコード資産が
GPUで動くわけじゃないしカーネルコードを新規に書き起こす量を
考えたらぶっちゃけわずらわしさはOpenCLと大して変わらんのよ
195 :,,・´∀`・,,)っ-○○○:2014/05/10(土) 00:42:29.24 ID:1jDHUPL0
https://code.google.com/p/aparapi/downloads/list
なぜかMacOS用バイナリがあるね。つまりIntelCPUでも動くようだ。
こんなポンコツコード使う気にもならないけどな。
なぜかMacOS用バイナリがあるね。つまりIntelCPUでも動くようだ。
こんなポンコツコード使う気にもならないけどな。
質問理解してないな。
HSAはCPUとGPUを使ったプログラムな訳で効率のいいほうを使うだけの話だろ。
GPUよりCPUを使ったほうが有利って言いたいのか?w
仮にそうゆう意図なら物によってが抜けてるww
HSAはCPUとGPUを使ったプログラムな訳で効率のいいほうを使うだけの話だろ。
GPUよりCPUを使ったほうが有利って言いたいのか?w
仮にそうゆう意図なら物によってが抜けてるww
198 :,,・´∀`・,,)っ-○○○:2014/05/10(土) 01:02:43.38 ID:1jDHUPL0
CPU110GFLOPS + GPU720GFLOPSじゃGPU使わないと遅いけど
CPU440GFLOPS + GPU400GFLOPSなら別にiGPU使わなくてもよくね?
MaxwellでCUDA6のほうが確実。
そもそもワールドワイドで年間200〜300万個程度しか売れてないPC向けAPU
とかより年間5000万個売れてて開発用ソフトも充実してるCUDA対応GPUの
ほうが圧倒的に市場性があるじゃん。
DDR3をCPUと共有のhUMA(笑)よりGDDR5のGPUとのNUMAのほうが確実に
性能を出せるしな。レイテンシ重視するものはAVXを使えばいい。
広いメモリ帯域が使えるわけでもなければ、CPUから見て事実上レイテンシ0の
AVXほど小回りがきくわけでもない。
ダメなところしか残らないHSAなんてAMDに固執する人しか需要ないでしょ
CPU440GFLOPS + GPU400GFLOPSなら別にiGPU使わなくてもよくね?
MaxwellでCUDA6のほうが確実。
そもそもワールドワイドで年間200〜300万個程度しか売れてないPC向けAPU
とかより年間5000万個売れてて開発用ソフトも充実してるCUDA対応GPUの
ほうが圧倒的に市場性があるじゃん。
DDR3をCPUと共有のhUMA(笑)よりGDDR5のGPUとのNUMAのほうが確実に
性能を出せるしな。レイテンシ重視するものはAVXを使えばいい。
広いメモリ帯域が使えるわけでもなければ、CPUから見て事実上レイテンシ0の
AVXほど小回りがきくわけでもない。
ダメなところしか残らないHSAなんてAMDに固執する人しか需要ないでしょ
Intel以外はどこもかしこもCPU+iGPUを連携させて使いたがっているんだよね
そりゃそうだ、CPU以上のトランジスタ使ってCPU以上の面積になっているし、
CPUよりSIMDやFMA演算が得意だからグラフィック以外にも使わないともったいない
活用するための2大ネックがメモリ帯域とコヒーレントだけど、
PS4がhUMAとGDDR5対応でネックなしの性能を見せてくれている
結果は開発者大絶賛でゲームの完成度も高く過去最大の速度で普及している
PS4か同等のシステムにWindowsかLinuxを載せられたら、
GPGPU(OpenCL、HSA等)の普及が一気に進みそうだし、AMDはその辺考えてくれないかな
そりゃそうだ、CPU以上のトランジスタ使ってCPU以上の面積になっているし、
CPUよりSIMDやFMA演算が得意だからグラフィック以外にも使わないともったいない
活用するための2大ネックがメモリ帯域とコヒーレントだけど、
PS4がhUMAとGDDR5対応でネックなしの性能を見せてくれている
結果は開発者大絶賛でゲームの完成度も高く過去最大の速度で普及している
PS4か同等のシステムにWindowsかLinuxを載せられたら、
GPGPU(OpenCL、HSA等)の普及が一気に進みそうだし、AMDはその辺考えてくれないかな
200 :,,・´∀`・,,)っ-○○○:2014/05/10(土) 01:10:57.10 ID:1jDHUPL0
考えてくれてないので普及しません
団子、さすがに
>ワールドワイドで年間200〜300万個程度しか売れてないPC向けAPU
はないだろ。年間1千万以上はいくらなんでもいくんじゃないのか
>ワールドワイドで年間200〜300万個程度しか売れてないPC向けAPU
はないだろ。年間1千万以上はいくらなんでもいくんじゃないのか
202 :Socket774:2014/05/10(土) 01:18:21.00 ID:+BNkl2vs
CPU以上のトランジスタ使ってCPU以上の面積になっているから、APUは売れないんじゃないの?
『使わないともったいない』というのは言い方を変えれば、今はほとんど使われていない=ほとんどのユーザーは無くても困らない。
無くても困らないものに高い金は払えないよ。
『使わないともったいない』というのは言い方を変えれば、今はほとんど使われていない=ほとんどのユーザーは無くても困らない。
無くても困らないものに高い金は払えないよ。
203 :,,・´∀`・,,)っ-○○○:2014/05/10(土) 01:23:15.11 ID:1jDHUPL0
200〜300万はもちろんテキトーな数字。
いずれにしてもGeForceより圧倒的にすくなく
市場性に乏しいプラットフォームであることは間違いないよ
まずは販売個数でGeForceに勝つところからでしょ
いずれにしてもGeForceより圧倒的にすくなく
市場性に乏しいプラットフォームであることは間違いないよ
まずは販売個数でGeForceに勝つところからでしょ
そうだね〜個人も企業もCPUいらないからCPUに割り当てる位ならGPU使わせろって大前提なのを忘れているけどねw
特にHasswellなんて爆熱なだけで何も生み出せない無駄の極みなんだよねw
特にHasswellなんて爆熱なだけで何も生み出せない無駄の極みなんだよねw
205 :,,・´∀`・,,)っ-○○○:2014/05/10(土) 01:28:42.27 ID:1jDHUPL0
>>202
いまだGPGPUとして活用されてないのに
何かにつけてあいつら「CPU性能は必要十分」っていうもんなー
「Core i3に負けて悔しいからHSA対応ソフト作ってください」くらい
アピールしたほうがまだソフト屋も頑張りようがあるのに、
やつらHSA対応アプリケーション欲しくないらしいぜ?
いまだGPGPUとして活用されてないのに
何かにつけてあいつら「CPU性能は必要十分」っていうもんなー
「Core i3に負けて悔しいからHSA対応ソフト作ってください」くらい
アピールしたほうがまだソフト屋も頑張りようがあるのに、
やつらHSA対応アプリケーション欲しくないらしいぜ?
206 :Socket774:2014/05/10(土) 01:34:05.61 ID:+BNkl2vs
将来ソフトが対応して始めて役に立つ機能を持った製品を普及させたい場合の鉄則は、現状では役に立たない機能は価格に転嫁しないこと。
Kaveriを広く普及させたいなら今の価格は高すぎる。
Core i3並にまで価格を落とさないと無理だよ。
Kaveriを広く普及させたいなら今の価格は高すぎる。
Core i3並にまで価格を落とさないと無理だよ。
207 :,,・´∀`・,,)っ-○○○:2014/05/10(土) 01:36:53.55 ID:1jDHUPL0
> そうだね〜個人も企業もCPUいらないから
そっかー
だからOpteronは8コアやめて4コア+GPUになったんだね
ってアホか
GPUなしでキャッシュ16MBもつんだ8コアCPUが
CPU内蔵の4コアCPUに負けたのは
GPU性能のおかげじゃなくてCPUの性能のせいだろ
そっかー
だからOpteronは8コアやめて4コア+GPUになったんだね
ってアホか
GPUなしでキャッシュ16MBもつんだ8コアCPUが
CPU内蔵の4コアCPUに負けたのは
GPU性能のおかげじゃなくてCPUの性能のせいだろ
当のIntelもHaswellのGT3が4コアCPUと同じくらいの面積になったな
ブロードウェルも4コア据え置きで、更にGPU増やしたGT4予定してる
スカイレークも4コア据え置きでGT5とか言ってさらに増やすだろうね
そんなにIntelのCPUが凄くてiGPUはどうでもいいなら、
Haswellは6コア+GT1でいいだろうし、スカイレークも8コア+GT1にしてるよな
それが何で4コア止まりなのか、何でiGPUを必死に強化してるのか団子たちは説明できるのかね
ブロードウェルも4コア据え置きで、更にGPU増やしたGT4予定してる
スカイレークも4コア据え置きでGT5とか言ってさらに増やすだろうね
そんなにIntelのCPUが凄くてiGPUはどうでもいいなら、
Haswellは6コア+GT1でいいだろうし、スカイレークも8コア+GT1にしてるよな
それが何で4コア止まりなのか、何でiGPUを必死に強化してるのか団子たちは説明できるのかね
209 :,,・´∀`・,,)っ-○○○:2014/05/10(土) 01:46:50.16 ID:1jDHUPL0
DDR3 2chは4コアで十分
コア数が多いほうがいい人は4chで6コアの上位版i7やXeonがあるからそっちを買え
コア数が多いほうがいい人は4chで6コアの上位版i7やXeonがあるからそっちを買え
210 :,,・´∀`・,,)っ-○○○:2014/05/10(土) 01:52:26.64 ID:1jDHUPL0
PCは周辺チップを取り込むことでコストダウン化をはかってきた。
ディスクリートGPUもまた、一般ユーザーにとって独立してる
必要性の低いパーツだからこそワンチップ化の波に飲まれた。
CPUがMMXを搭載したときにソフトウェア音源が台頭して
サウンドカードが廃れた流れと同じ。
もうひとつ、CPUと比べてGPUは低クロックで動くからダークシリコン
対策になるという理由もあったはずだが
頭が悪い人はそんなことも記憶できないのか
ディスクリートGPUもまた、一般ユーザーにとって独立してる
必要性の低いパーツだからこそワンチップ化の波に飲まれた。
CPUがMMXを搭載したときにソフトウェア音源が台頭して
サウンドカードが廃れた流れと同じ。
もうひとつ、CPUと比べてGPUは低クロックで動くからダークシリコン
対策になるという理由もあったはずだが
頭が悪い人はそんなことも記憶できないのか
211 :Socket774:2014/05/10(土) 01:53:11.05 ID:+BNkl2vs
AMDはKaveriと同等のCPU処理能力のFXと比べて高いのに対して、
Intelの2〜4コアCPUは前モデルから価格据え置きでiGPUの性能を上げているだろ?
つまり、IntelはiGPUに対して価格を上げてまで増強する価値は無いと考えているのだよ。
6コアはLGA2011製品と区別するためにLGA1150では出す気が無いだけだよ。
AMDのCPU性能がもっと高ければメインストリームで6コア出したかもしれないがな。
Intelの2〜4コアCPUは前モデルから価格据え置きでiGPUの性能を上げているだろ?
つまり、IntelはiGPUに対して価格を上げてまで増強する価値は無いと考えているのだよ。
6コアはLGA2011製品と区別するためにLGA1150では出す気が無いだけだよ。
AMDのCPU性能がもっと高ければメインストリームで6コア出したかもしれないがな。
>>206
全く転嫁してないからCPUの性能通り、i3より高くてi5より安い価格に初めからなっているけど??
全く転嫁してないからCPUの性能通り、i3より高くてi5より安い価格に初めからなっているけど??
ダークシリコンの問題とか一般用途だと多コアがあっても有効な
ソフトがほとんどないからだろ
ブル土下座がなんで売れてないか考えればわかる
そのかわり多コアが必要な用途にはちゃんと15コアとか出してるじゃないか
ニコイチとかのチャチなもんじゃなく
ソフトがほとんどないからだろ
ブル土下座がなんで売れてないか考えればわかる
そのかわり多コアが必要な用途にはちゃんと15コアとか出してるじゃないか
ニコイチとかのチャチなもんじゃなく
215 :Socket774:2014/05/10(土) 02:06:22.49 ID:+BNkl2vs
>>212
AMDもそう思っているから一部のユーザーにしか売れないんだよw
大多数のユーザーから見るとCore i3並の性能なのにCore i5に近い価格のCPUであることを認識しないといつまで経っても売れないよ。
>>213
価格を据え置くの意味を調べることから始めたらどうだ?
据え置くというのは変更しないということ。
前モデルと後継モデルの価格(ドルベース)が同じ事を言うんだぞ。
『手頃な価格』であるかとか『ぼったくり価格』であるかとかは全く関係無い。
AMDもそう思っているから一部のユーザーにしか売れないんだよw
大多数のユーザーから見るとCore i3並の性能なのにCore i5に近い価格のCPUであることを認識しないといつまで経っても売れないよ。
>>213
価格を据え置くの意味を調べることから始めたらどうだ?
据え置くというのは変更しないということ。
前モデルと後継モデルの価格(ドルベース)が同じ事を言うんだぞ。
『手頃な価格』であるかとか『ぼったくり価格』であるかとかは全く関係無い。
216 :,,・´∀`・,,)っ-○○○:2014/05/10(土) 02:15:55.97 ID:1jDHUPL0
Intelの歴代アッパーミドルCPU(Core 2以降)
Core 2 Duo E6600($316)
Core 2 Duo E8500/Quad Q9450($316)
Core i7-860($284)
Core i7-2600K($316)
Core i7-3770K($316)
Core i7-4770K($316)
ひとつ上の製品の値段が100ドル以上跳ね上がるのも全世代の特徴
Core 2 Duo E6600($316)
Core 2 Duo E8500/Quad Q9450($316)
Core i7-860($284)
Core i7-2600K($316)
Core i7-3770K($316)
Core i7-4770K($316)
ひとつ上の製品の値段が100ドル以上跳ね上がるのも全世代の特徴
>>208
intelがi3,i5あたりを利用するユーザーの処理能力を2倍にしても
いまの製品に満足するユーザーに売れる訳もなく
同じ製品の延長のpcの役割は終わってるんだよ
鯖でさえcpuではなく、むしろ気にするには足回りだったりする
これから求められるのは、小型化、省電力
その次の時代は、また多機能、大型
繰り返してるだけで、切り替わる時期さね
SDカード並みのPCとか、もうでてるだろ
これらがどんどん我々の生活を豊かにしていく
intelがi3,i5あたりを利用するユーザーの処理能力を2倍にしても
いまの製品に満足するユーザーに売れる訳もなく
同じ製品の延長のpcの役割は終わってるんだよ
鯖でさえcpuではなく、むしろ気にするには足回りだったりする
これから求められるのは、小型化、省電力
その次の時代は、また多機能、大型
繰り返してるだけで、切り替わる時期さね
SDカード並みのPCとか、もうでてるだろ
これらがどんどん我々の生活を豊かにしていく
>>218
それがそのままAPUを示すとは限らないし
AMDに有利に働くとは限らないよ
外部GPUを差さないユーザが、
ますます多くなるのは確実だろうけど
それはそのまま、ゲームがそれでいい作りになり
また、グラボが売れなくなることも意味するのだから
それがそのままAPUを示すとは限らないし
AMDに有利に働くとは限らないよ
外部GPUを差さないユーザが、
ますます多くなるのは確実だろうけど
それはそのまま、ゲームがそれでいい作りになり
また、グラボが売れなくなることも意味するのだから
APUマンよ、お前にはこの貧乏の神が力を貸すぜ!
222 :Socket774:2014/05/10(土) 03:32:56.71 ID:FCP7RXN6
>>218
いや、たぶんIntelのAPUの時代が来る
いや、たぶんIntelのAPUの時代が来る
OSもandroidは軽いしwin8以降は軽くなっていってるしDX12はCPU負荷軽いし、オフィスやブラウザに今以上のCPU性能は意味ないからなあ
逆にグラフィック用途は重くなる一方なんだよな
H265は糞重いしHDから4kで負荷4倍になるし、ゲームは物理演算やポストプロセス使うようになるしな
CPU性能は重要とか言ってるけど、じゃあi5やi7で負荷が50%超えるような処理って何があるんだろうか
GPUは動画やゲーム、マルチ画面やってれば今でも足りないけど
逆にグラフィック用途は重くなる一方なんだよな
H265は糞重いしHDから4kで負荷4倍になるし、ゲームは物理演算やポストプロセス使うようになるしな
CPU性能は重要とか言ってるけど、じゃあi5やi7で負荷が50%超えるような処理って何があるんだろうか
GPUは動画やゲーム、マルチ画面やってれば今でも足りないけど
Sony will sell more than 50 million PlayStation 4 in 2016
http://yournewsticker.com/2014/05/sony-will-sell-50-million-playstation-4-2016.html
大きく出たな
http://yournewsticker.com/2014/05/sony-will-sell-50-million-playstation-4-2016.html
大きく出たな
Windows 9 will get a virtual assistant and integration with cloud services
http://yournewsticker.com/2014/05/windows-9-will-get-virtual-assistant-integration-cloud-services.html
http://yournewsticker.com/2014/05/windows-9-will-get-virtual-assistant-integration-cloud-services.html
量産効果や20/14nmにシュリンクとかで結構低価格化出来そうだし案外5000万台くらい売れるかもね
20nm以降はシュリンクしてもコスト下がらないって言われてるけどね
PS4は売れてるけどコアゲーマーに行き渡ったら売れ行き鈍るんじゃないかな
PS4は売れてるけどコアゲーマーに行き渡ったら売れ行き鈍るんじゃないかな
ARM has disclosed performance data Cortex-A53/A57
http://yournewsticker.com/2014/05/arm-disclosed-performance-data-cortex-a53a57.html
http://yournewsticker.com/2014/05/arm-disclosed-performance-data-cortex-a53a57.html
オーバーヘッドがでかすぎて使い道がない
オーバーヘッド分でcpuでやった方が早いものがほとんど
オーバーヘッド無視するんなら独自中間コードなんてつかわず
既存のソフトをバイナイリトランスレーションしてgpgpuすればいいよ
オーバーヘッド分でcpuでやった方が早いものがほとんど
オーバーヘッド無視するんなら独自中間コードなんてつかわず
既存のソフトをバイナイリトランスレーションしてgpgpuすればいいよ
>>223
4kや120Hz144HzはdGPUの最上位(250〜500W)でも足りないしねぇ、8kなんかとてもとても……
性能飽和が起こらない限りCPUとダイトランジスタ電力帯域諸々取り合うiGPUは
帯に短し襷に流しから抜け出すのは無理だな、dGPUちゃんはまだまだ死なへんでー
4kや120Hz144HzはdGPUの最上位(250〜500W)でも足りないしねぇ、8kなんかとてもとても……
性能飽和が起こらない限りCPUとダイトランジスタ電力帯域諸々取り合うiGPUは
帯に短し襷に流しから抜け出すのは無理だな、dGPUちゃんはまだまだ死なへんでー
http://tech.d-itlab.co.jp/omasutani/2014/05/09/c-amp%e3%81%ae%e5%ae%9f%e5%8a%9b%e3%82%92%e8%a9%a6%e3%81%99/
http://tech.d-itlab.co.jp/omasutani/wp-content/uploads/sites/22/2014/05/image.png
いいね
http://tech.d-itlab.co.jp/omasutani/wp-content/uploads/sites/22/2014/05/image.png
{kind=link}
いいね
232 :,,・´∀`・,,)っ-○○○:2014/05/10(土) 07:33:40.59 ID:MGA8KM9P
> H265は糞重いしHDから4kで負荷4倍になるし、
NUCですら4k再生できてるのにいったい何をやらせたいの?
デコードじゃなくてエンコード?そっちの負荷は4倍どころじゃないが。
まあそれすらこんなサイズに収まってるわけだが
東芝、4K動画の録画もこなす“世界最速”microSDカードをサンプル出荷
http://headlines.yahoo.co.jp/hl?a=20140421-00000056-zdn_n-prod
あんまりGPUを使わせることを目的にしないほうがいい。
NUCですら4k再生できてるのにいったい何をやらせたいの?
デコードじゃなくてエンコード?そっちの負荷は4倍どころじゃないが。
まあそれすらこんなサイズに収まってるわけだが
東芝、4K動画の録画もこなす“世界最速”microSDカードをサンプル出荷
http://headlines.yahoo.co.jp/hl?a=20140421-00000056-zdn_n-prod
あんまりGPUを使わせることを目的にしないほうがいい。
まてw
そのmicroSDは“最低30MB/秒の連続書込みに対応し、4K動画の撮影も可能だ。”ってはなしだww
そのmicroSDは“最低30MB/秒の連続書込みに対応し、4K動画の撮影も可能だ。”ってはなしだww
234 :,,・´∀`・,,)っ-○○○:2014/05/10(土) 07:50:05.56 ID:MGA8KM9P
>>231
ええ?
「いい」の?
> Surface Pro 2(Intel Core i5 4300U) と ショップブランドマシン(AMD Kaveri A10-7850K)を使いました。
~~~~~~~~~~~~~~~~~~~~
↑デュアルコアで1.9GHz駆動のモバイルCPU
グラフを見てみると差がなさすぎるんだが。
サンプルレベルですら、GPU駆使してタブレットPC相手に2倍も差がつかない程度?
これなら安心して今度PC新調する友人にi3+GTX750Tiを勧めるよ。
ええ?
「いい」の?
> Surface Pro 2(Intel Core i5 4300U) と ショップブランドマシン(AMD Kaveri A10-7850K)を使いました。
~~~~~~~~~~~~~~~~~~~~
↑デュアルコアで1.9GHz駆動のモバイルCPU
グラフを見てみると差がなさすぎるんだが。
サンプルレベルですら、GPU駆使してタブレットPC相手に2倍も差がつかない程度?
これなら安心して今度PC新調する友人にi3+GTX750Tiを勧めるよ。
Intel Core i5 4300U 15W
AMD Kaveri A10-7850K 95W
AMD Kaveri A10-7850K 95W
236 :,,・´∀`・,,)っ-○○○:2014/05/10(土) 08:01:44.47 ID:MGA8KM9P
>>233 突っ込まれたか・・・
PCで再生するのに基本CPU処理できないほど重たい処理なら
ハードでやればいいと思ってるけど、ソフトで十分まかなえてるからなぁ
http://www.stereosound.co.jp/review/article/2013/10/01/25117.html
「XJIVEスィングウェブエンジン」とかいってるけど、
ハード自体はHaswellのNUCそのもの
PCで再生するのに基本CPU処理できないほど重たい処理なら
ハードでやればいいと思ってるけど、ソフトで十分まかなえてるからなぁ
http://www.stereosound.co.jp/review/article/2013/10/01/25117.html
「XJIVEスィングウェブエンジン」とかいってるけど、
ハード自体はHaswellのNUCそのもの
ワープする宇宙
元記事読めばとC++ AMPの有用性を指して良いと言ってるってわかるでしょうよ
そこまで読解力無いわけじゃあるまいに
まぁどんだけ良い結果だろうとお前はC++AMP使わないんだから関係無い話だな
microSDカードで4k録画でもしててくれ
そこまで読解力無いわけじゃあるまいに
まぁどんだけ良い結果だろうとお前はC++AMP使わないんだから関係無い話だな
microSDカードで4k録画でもしててくれ
239 :,,・´∀`・,,)っ-○○○:2014/05/10(土) 08:27:01.00 ID:MGA8KM9P
並列化+AVX2/FMAを駆使したコードとの比較までやってくれたら
まだ検討の余地はあったのだがな
(CilkPlusなら楽に書けるのだが、parralel_forじゃSIMD化まではやらないしなー)
まだ検討の余地はあったのだがな
(CilkPlusなら楽に書けるのだが、parralel_forじゃSIMD化まではやらないしなー)
240 :,,・´∀`・,,)っ-○○○:2014/05/10(土) 08:32:21.46 ID:MGA8KM9P
すべてか無か、みたいな変なロジックを押し付けるのはどうなんだろうね
誤:フルで使えなければダメ
正;同じ仕様の中で、より広く高度な処理が出来れば優秀
数学でも現国でも美術でも及第点の取れるメーカ製品次世代を語るスレなんだ
計算だけ異様に早い富豪の子だけ、特別扱いするように職員を全部カネで入れ替えて
そいつらの常識にだけ従うように、徒党で流れ込んで大声で吹聴し続け、日常会話も難しいような環境にするとか
滑稽とかを通り越して醜悪、情報封殺活動になってる
誤:フルで使えなければダメ
正;同じ仕様の中で、より広く高度な処理が出来れば優秀
数学でも現国でも美術でも及第点の取れるメーカ製品次世代を語るスレなんだ
計算だけ異様に早い富豪の子だけ、特別扱いするように職員を全部カネで入れ替えて
そいつらの常識にだけ従うように、徒党で流れ込んで大声で吹聴し続け、日常会話も難しいような環境にするとか
滑稽とかを通り越して醜悪、情報封殺活動になってる
近年では
CPU性能は2年で10パーセントの伸び
GPU性能は2年で50パーセントの伸び
性能差は開く一方
CPU性能は2年で10パーセントの伸び
GPU性能は2年で50パーセントの伸び
性能差は開く一方
245 :,,・´∀`・,,)っ-○○○:2014/05/10(土) 09:16:58.04 ID:MGA8KM9P
> CPU性能は2年で10パーセントの伸び
こっちはスカラの実効性能
> GPU性能は2年で50パーセントの伸び
こっちはSIMDの理論性能
不公平だと思わないのかね?
SIMDの理論性能でいいならCPUはAVXで2倍, AVX2/FMAでさらにその2倍と
GPU以上の性能向上率を達成してるわな
こっちはスカラの実効性能
> GPU性能は2年で50パーセントの伸び
こっちはSIMDの理論性能
不公平だと思わないのかね?
SIMDの理論性能でいいならCPUはAVXで2倍, AVX2/FMAでさらにその2倍と
GPU以上の性能向上率を達成してるわな
246 :,,・´∀`・,,)っ-○○○:2014/05/10(土) 09:19:13.18 ID:MGA8KM9P
あ、AMD限定の話でしたか。たしかに2年で10%しか進化してないな。
>>243
で、でたー!
で、でたー!
irisのGPU性能より
AMDのAPU性能のが上とはっきりした
AMDのAPU性能のが上とはっきりした
>>246
VisheraFX出した時だったと思うが、毎年10%ずつP/W改善していきますって発表してたのに
結局それすら投げちゃったからな、Bulldozerがほんとにもうどうしようもなく素性が悪かった
VisheraFX出した時だったと思うが、毎年10%ずつP/W改善していきますって発表してたのに
結局それすら投げちゃったからな、Bulldozerがほんとにもうどうしようもなく素性が悪かった
250 :,,・´∀`・,,)っ-○○○:2014/05/10(土) 09:30:37.35 ID:MGA8KM9P
【ボボッタ】ほんと、いつもわかりやすいよな【貧乏空想】
東〜、団子丸〜
西〜、鰻銀河〜
はっけよーいボボッタボボッタ!
西〜、鰻銀河〜
はっけよーいボボッタボボッタ!
>>249
大原氏によると10%ずつの改良は果たされているらしい(この後のオチは書かない)
大原氏によると10%ずつの改良は果たされているらしい(この後のオチは書かない)
スパイ対策をしようとする自民党が在日に脅迫されています↓ ↓
秘密保護法の反対派が理由を白状しましたw (※国家公務員限定の準スパイ防止法)
「外務省職員には帰化した在日韓国・朝鮮人が多数、特定秘密保護法案は彼らを切り捨てる人種条項」[12/04]
http://awabi.2ch.net/test/read.cgi/news4plus/1386159045/
↓ ↓ ↓ ↓
秘密保護法反対派に脅迫される自民党議員
http://uni.2ch.net/test/read.cgi/newsplus/1386116831/
「法案に賛成したらあなたのお子様はタダではいられませんよ」 ← ← ←!!!!
「特定秘密保護法案に賛成したならばあなたは、次回の選挙で落選するでしょう」
※おそらく、創価等が選挙協力しないという脅迫。
「一年生議員にさえこれほどの脅迫があるということは幹事長はじめ党役員の方々は
日々どのような目に遭われておられることでしょうか。 」
成立こそしましたが、メディアに猛反対され、公明党や野党に調整されて、
けっきょく、骨抜きフニャフニャ法にされた模様。
秘密保護法の反対派が理由を白状しましたw (※国家公務員限定の準スパイ防止法)
「外務省職員には帰化した在日韓国・朝鮮人が多数、特定秘密保護法案は彼らを切り捨てる人種条項」[12/04]
http://awabi.2ch.net/test/read.cgi/news4plus/1386159045/
↓ ↓ ↓ ↓
秘密保護法反対派に脅迫される自民党議員
http://uni.2ch.net/test/read.cgi/newsplus/1386116831/
「法案に賛成したらあなたのお子様はタダではいられませんよ」 ← ← ←!!!!
「特定秘密保護法案に賛成したならばあなたは、次回の選挙で落選するでしょう」
※おそらく、創価等が選挙協力しないという脅迫。
「一年生議員にさえこれほどの脅迫があるということは幹事長はじめ党役員の方々は
日々どのような目に遭われておられることでしょうか。 」
成立こそしましたが、メディアに猛反対され、公明党や野党に調整されて、
けっきょく、骨抜きフニャフニャ法にされた模様。
さすがに大原さんでも持ち上げきれなくなってきたかw
健気によいしょしてたのにかわいそうだなぁ…
健気によいしょしてたのにかわいそうだなぁ…
韓国と通じてる創価/公明党が与党にいる限り、スパイ対策は骨抜きにされ、
自民党は、在日(カジノ・パチンコ等)や隣国への利益誘導圧力を受け続けます↓
池田大作名誉会長 韓国から特別顕彰牌w
http://hayabusa3.2ch.net/test/read.cgi/news/1394674716/
【政治】河野談話の見直しけん制=公明幹事長 ← 韓国政府と同じスタンス!!
http://uni.2ch.net/test/read.cgi/newsplus/1392962732/
※自民党以外の議員が帰化朝鮮人、またはその影響下にあると考えれば、
現在の創価・在日タブーに説明がつきます。
自公解消=自民単独政権実現の最低必要条件
衆院で自民党単独2/3 か、
衆参両院で自民単独過半数
※ただし、自民にも帰化人スパイが残ってる可能性を考えると、さらに多くの議席が必要。
現在クリアしてるのは、衆議院での単独過半数のみ。
自民党は、在日(カジノ・パチンコ等)や隣国への利益誘導圧力を受け続けます↓
池田大作名誉会長 韓国から特別顕彰牌w
http://hayabusa3.2ch.net/test/read.cgi/news/1394674716/
【政治】河野談話の見直しけん制=公明幹事長 ← 韓国政府と同じスタンス!!
http://uni.2ch.net/test/read.cgi/newsplus/1392962732/
※自民党以外の議員が帰化朝鮮人、またはその影響下にあると考えれば、
現在の創価・在日タブーに説明がつきます。
自公解消=自民単独政権実現の最低必要条件
衆院で自民党単独2/3 か、
衆参両院で自民単独過半数
※ただし、自民にも帰化人スパイが残ってる可能性を考えると、さらに多くの議席が必要。
現在クリアしてるのは、衆議院での単独過半数のみ。
256 :,,・´∀`・,,)っ-○○○:2014/05/10(土) 10:00:09.14 ID:MGA8KM9P
GFの28nmはKaveriといいBeemaといい、めっちゃ調子良いみたいだしな
GF製のRADEONもいくつか出てくると予測してるんだが
GF製のRADEONもいくつか出てくると予測してるんだが
在庫不足って、生産側の問題じゃなく、
どうせ流通・小売りはほとんど売れないだろうって思ってほとんど発注してなかったのが
在庫不足の原因だろ
どうせ流通・小売りはほとんど売れないだろうって思ってほとんど発注してなかったのが
在庫不足の原因だろ
261 :,,・´∀`・,,)っ-○○○:2014/05/10(土) 10:52:49.05 ID:MGA8KM9P
7850Kなら需要一巡して在庫ダブついてるじゃん
発注側の問題ってことか
>歩留まり良すぎてA4とかの下位グレードがそろわない作ると全部A10/A8になってしまうという
これはなんかソースあるの?
歩留まりよくたってA4とかは作れるはずだけど
>歩留まり良すぎてA4とかの下位グレードがそろわない作ると全部A10/A8になってしまうという
これはなんかソースあるの?
歩留まりよくたってA4とかは作れるはずだけど
正常なコアを潰して下位モデルとして売ることは可能
逆は無理だけどね
下位モデルに回す数が取れないってことは歩留まり悪いんでしょ
逆は無理だけどね
下位モデルに回す数が取れないってことは歩留まり悪いんでしょ
>>263
揃わないっていうか、わざわざ販売価格の高い7850kをダウンクロックして安く売るのは損じゃん
揃わないっていうか、わざわざ販売価格の高い7850kをダウンクロックして安く売るのは損じゃん
>>263
ソース:大原先生
ソース:大原先生
A10-7850KとA4-7300てマスク共通なの?
270 :,,・´∀`・,,)っ-○○○:2014/05/10(土) 11:16:34.08 ID:MGA8KM9P
ウナ銀河は機能を削った廉価版を作ることを悪ということにしたがってるけど
WindowsにしろOracleDBにしろソフトウェアでは当たり前にやってることなんだけどな
ま、ソフトはハードと違って化粧箱に入れて販売しない限り在庫を抱えることはないのだが。
WindowsにしろOracleDBにしろソフトウェアでは当たり前にやってることなんだけどな
ま、ソフトはハードと違って化粧箱に入れて販売しない限り在庫を抱えることはないのだが。
そもそも、いまどきのCPUは、型番・クロック周波数・特定機能のオン/オフとか、
特殊なメモリに後で書き込んでるからなぁ
起動時にそのメモリを見て、クロック周波数を変更したり特定機能をオン/オフしたりしてる
http://www.semicon.toshiba.co.jp/product/asic/memory/efuse.html
こんなメモリね
上位モデルと下位モデルはメモリ内容以外はまったく同じダイなのが当たり前
むかしは、特定ピンの電圧で判別したりしてたので、基板上の抵抗をいじったりして
別モデルに化けたりするCPUもあったりしたけどね
特殊なメモリに後で書き込んでるからなぁ
起動時にそのメモリを見て、クロック周波数を変更したり特定機能をオン/オフしたりしてる
http://www.semicon.toshiba.co.jp/product/asic/memory/efuse.html
こんなメモリね
上位モデルと下位モデルはメモリ内容以外はまったく同じダイなのが当たり前
むかしは、特定ピンの電圧で判別したりしてたので、基板上の抵抗をいじったりして
別モデルに化けたりするCPUもあったりしたけどね
A4-7300が出たら245mm^2のダイを6000円くらいで売ることになるの?
AMDが下位モデル出さないのは、下位モデルは需要ないから
Intelとは違い上位しか需要ないのがAMD
Intelとは違い上位しか需要ないのがAMD
>>272
AthlonIIもPhenomIIと同じダイ使ってた時もあったしなー
AthlonIIもPhenomIIと同じダイ使ってた時もあったしなー
275 :,,・´∀`・,,)っ-○○○:2014/05/10(土) 11:34:49.22 ID:MGA8KM9P
BayTrail-DのPentium/Celeronに至っては上位から下位までIntelが売る単価は
まったく同じでベンダーの裁量で価格差つけてるという現実
まったく同じでベンダーの裁量で価格差つけてるという現実
A10しか売ってないのは歩留まり高くてA10が多く取れてるからだし、
A10の受注が多いから性能つぶしの低価格品を作れないだけ
A10の受注が多いから性能つぶしの低価格品を作れないだけ
>>268
ウェハ単位で製造コストがかかってるのに面積あたりの単価下げてどうするのさ
コア無効にするのは可能だけど最初期からやるような事じゃないよ
そんな事するくらいならOEMメーカーにA10安く流した方がなんぼもましでしょ
>>269
1つか2つくらいしかないんじゃない?
APUってKaveriならKaveriでダイ面積全部いっしょじゃないっけ
INTELみたいにマスクが何種類もあったりしないはずだよ
ウェハ単位で製造コストがかかってるのに面積あたりの単価下げてどうするのさ
コア無効にするのは可能だけど最初期からやるような事じゃないよ
そんな事するくらいならOEMメーカーにA10安く流した方がなんぼもましでしょ
>>269
1つか2つくらいしかないんじゃない?
APUってKaveriならKaveriでダイ面積全部いっしょじゃないっけ
INTELみたいにマスクが何種類もあったりしないはずだよ
>>275
サーバ用だけだったかどうだったか失念したけどJaguar系も確かそうだよ
サーバ用だけだったかどうだったか失念したけどJaguar系も確かそうだよ
279 :,,・´∀`・,,)っ-○○○:2014/05/10(土) 12:30:43.28 ID:MGA8KM9P
HSAを駆使して面白ポエムをツイートするウナ銀河ボットを作ろうず
通称ボボッター
通称ボボッター
280 :sage:2014/05/10(土) 12:53:03.35 ID:7Ky58x6+
団子の話は至るところが破綻してるのに気づかないやつは良いようにやられるだけw
半分以上はハッタリ
半分以上はハッタリ
>>280
そのはったりの部分に突っ込んでくれよ
そのはったりの部分に突っ込んでくれよ
まあ本当に歩留まりがいいなら2コアと4コアで別に設計した方が無駄がなくていいと思うが
283 :sage:2014/05/10(土) 13:14:48.28 ID:q48CIcz5
携帯だし今は無理
C++ AMPを推す人が居るが、ちょっとプログラムを書いてみるといい
既存のコードと互換性がないので、かなり大変だぞ?
ただでさえC++プログラマーの確保が大変になってきているのに、
さらに特殊なC++AMPプログラマーを抱え込めるかというと・・・
既存のコードと互換性がないので、かなり大変だぞ?
ただでさえC++プログラマーの確保が大変になってきているのに、
さらに特殊なC++AMPプログラマーを抱え込めるかというと・・・
>>280はハッタリ
突っ込むだけ無駄
相手しないのが一番
相手しないのが一番
C#から使えるようにしたらヒットするんじゃね?
凶箱壱と共通ライブラリーが使えるようにして。
凶箱壱と共通ライブラリーが使えるようにして。
>>287
団子「またCUDAの後追いですかww」
団子「またCUDAの後追いですかww」
NGに登録済み
intelの宣伝マンだからな
intelの宣伝マンだからな
>>284
C++書けるスキルあるならC++ AMPだろうとOpenCLだろうとCUDAだろうとなんだって対応できる
ただそれに習熟する時間を取る価値があるかどうかが問題
PC向けならnvのグラボ積んでないと動かないCUDAで書くより
Windowsなら何処でも動くAMPやOpenCLを選ぶ
ぶっちゃけCUDAはソニーのβに被さって見えるw
C++書けるスキルあるならC++ AMPだろうとOpenCLだろうとCUDAだろうとなんだって対応できる
ただそれに習熟する時間を取る価値があるかどうかが問題
PC向けならnvのグラボ積んでないと動かないCUDAで書くより
Windowsなら何処でも動くAMPやOpenCLを選ぶ
ぶっちゃけCUDAはソニーのβに被さって見えるw
AMD Cafeみたいに毎日海外のPC情報あさって日本語訳してくれるサイトって他にないのか?
もう終わったんだよ
サムチョンAMDになってしまった
在日しか買わない
サムチョンAMDになってしまった
在日しか買わない
>>284
何度も言われてるけど、GPUを活用するうえで最大の障害は
コードの行数なんだよ
それが一番短くて済むのがHSA。
一番長くなってしまうのがOpenCLだが、どのメーカーのGPUでも一応対応できるから
存在価値は確固たるものがある。
C++AMPは中間程度。
http://news.mynavi.jp/column/hotchips25/019/
http://news.mynavi.jp/photo/column/hotchips25/019/images/012l.jpg
何度も言われてるけど、GPUを活用するうえで最大の障害は
コードの行数なんだよ
それが一番短くて済むのがHSA。
一番長くなってしまうのがOpenCLだが、どのメーカーのGPUでも一応対応できるから
存在価値は確固たるものがある。
C++AMPは中間程度。
http://news.mynavi.jp/column/hotchips25/019/
http://news.mynavi.jp/photo/column/hotchips25/019/images/012l.jpg
{kind=link}
>>291
そのC++を書ける人間が減っているという問題で、
C++プログラマーをC++AMPというマイナー技術に割り当てる余裕がない
Streamの頃は、まだ大丈夫だったんだけれどね…
>>295
大半のプログラマーはそれもできなくてな
要素技術を使える者がライブラリを書いて、提供することになる
そのC++を書ける人間が減っているという問題で、
C++プログラマーをC++AMPというマイナー技術に割り当てる余裕がない
Streamの頃は、まだ大丈夫だったんだけれどね…
>>295
大半のプログラマーはそれもできなくてな
要素技術を使える者がライブラリを書いて、提供することになる
Beema買うかSkyBridge買うか迷う
今の言語はCpuのことしか考えられてないからメモリ管理が別のGPGPUで使おうとするとクソ面倒だからな
最初からメモリ管理も統合されたGPGPU前提の汎用的に使える言語が今後は必要になってくる
OpenCLがアルファ版で、メモリ管理が進んだHSAがベータ版、より使いやすくて効率がいいのがその先で出て来るだろうね
まあ、AVXで十分ならそれでいいし、GPGPU使いたいなら使えばいいだけ
ここでGPGPUがクソだのいらないとか喚くのは見当違いだよ
最初からメモリ管理も統合されたGPGPU前提の汎用的に使える言語が今後は必要になってくる
OpenCLがアルファ版で、メモリ管理が進んだHSAがベータ版、より使いやすくて効率がいいのがその先で出て来るだろうね
まあ、AVXで十分ならそれでいいし、GPGPU使いたいなら使えばいいだけ
ここでGPGPUがクソだのいらないとか喚くのは見当違いだよ
5付10日付のandoさんの記事より。
Skybridgeではx86、ARMともにHSAに(完全?)対応。
2016年に投入予定の64bit ARMのアーキテクチャ開発は終わっている。
土木機械系と猫系のプロセサ開発の一本化は継続。
http://www.geocities.jp/andosprocinfo/wadai14/20140510.htm
Skybridgeではx86、ARMともにHSAに(完全?)対応。
2016年に投入予定の64bit ARMのアーキテクチャ開発は終わっている。
土木機械系と猫系のプロセサ開発の一本化は継続。
http://www.geocities.jp/andosprocinfo/wadai14/20140510.htm
・SkybridgeではPuma+推し。
・土木機械系と猫系のプロセサ開発の一本化は継続。
つまり猫系に集約ってことか
・土木機械系と猫系のプロセサ開発の一本化は継続。
つまり猫系に集約ってことか
AMDのロードマップで判ったことは、AMDはx86とARMアーキテクチャの壁を取っ払おうとしている。そして彼らの強力なIPであるGPUを活かした製品で勝負しようとしてる。
そういうことにしたくない人は反論するだろうが、コンピューティングは今、緩やかだが確実な転換点に来ている。
そういうことにしたくない人は反論するだろうが、コンピューティングは今、緩やかだが確実な転換点に来ている。
猫系で土木系に近い性能出せるなら猫系だけでいいからね
しかし、20nmで猫系とA57のAPU、14nmで新ARM 64bitコアか
しかも設計は終わってるらしいしかなり順調そうだな
しかし、20nmで猫系とA57のAPU、14nmで新ARM 64bitコアか
しかも設計は終わってるらしいしかなり順調そうだな
LlanoやTrinityは後から2コア専用のダイを作ったけど(LN2, TN2)、最初は4コアダイのコア無効にして製品化してた。
売れ筋、生産量で専用作るかどうか決めてるンじゃない?
売れ筋、生産量で専用作るかどうか決めてるンじゃない?
305 :,,・´∀`・,,)っ-○○○:2014/05/10(土) 16:28:34.27 ID:MGA8KM9P
>>290
歩留まりが良ければ2コアと4コアを別に設計した方がいいって事が理解できないの?
歩留まりが良ければ2コアと4コアを別に設計した方がいいって事が理解できないの?
307 :,,・´∀`・,,)っ-○○○:2014/05/10(土) 16:39:14.75 ID:3TlviFrc
単純な反復処理の内側を記述するような記法しかできない
単純なループだけでプログラムが書けるならここまでCPUの分岐予測は
発達しなかっただろうよ
STLのfor_each関数に相当するものごとにKernelを起こすイメージね
CUDAのようにKernelの中からKernelを起こすみたいな凝ったことが基本的にできない。
その程度の生産性と言われましても。
1.0リリースからしばらく経つけど、その【生産性の高いBolt】はどんな
実用プログラムで使われてるんですか?
単純なループだけでプログラムが書けるならここまでCPUの分岐予測は
発達しなかっただろうよ
STLのfor_each関数に相当するものごとにKernelを起こすイメージね
CUDAのようにKernelの中からKernelを起こすみたいな凝ったことが基本的にできない。
その程度の生産性と言われましても。
1.0リリースからしばらく経つけど、その【生産性の高いBolt】はどんな
実用プログラムで使われてるんですか?
309 :,,・´∀`・,,)っ-○○○:2014/05/10(土) 16:43:35.22 ID:3TlviFrc
2コア用ダイにすればウェハから切り出せる量は増えるが、
数が売れなきゃ逆に損だな
数が売れなきゃ逆に損だな
>>300
Intelで例えるならPentiumMとXscaleの二本立てみたいなものか。
Intelで例えるならPentiumMとXscaleの二本立てみたいなものか。
>>295
それ言い出すと、SSE/AVX(C/C++)なんか使わずに86だけで書いとけば?という話になる
それで事足りるんならそれで頑張ればいい
だけどSSEとかが必要になる分野はGPGPUの方が有利で
じゃ、APIとして何を使うのかっていう話だとおもうのだが
>>296
C++出来る人にどのAPIで開発してもらうかって話で
いま使えるのはCUDA, OpenCL, C++AMP位だけど
確かにC++AMPという選択はないなぁ、とは思う。
ゲーム開発でXboxとWindowsの両方を視野に入れてるなら知らんけど
汎用性求めるならOpenCLになりそう
それ言い出すと、SSE/AVX(C/C++)なんか使わずに86だけで書いとけば?という話になる
それで事足りるんならそれで頑張ればいい
だけどSSEとかが必要になる分野はGPGPUの方が有利で
じゃ、APIとして何を使うのかっていう話だとおもうのだが
>>296
C++出来る人にどのAPIで開発してもらうかって話で
いま使えるのはCUDA, OpenCL, C++AMP位だけど
確かにC++AMPという選択はないなぁ、とは思う。
ゲーム開発でXboxとWindowsの両方を視野に入れてるなら知らんけど
汎用性求めるならOpenCLになりそう
プログラム書いたことの無い奴がAMDの大本営発表を
鵜呑みにして生産性を語る滑稽さ。
HSA総合スレ全くレスついてないぞ
鵜呑みにして生産性を語る滑稽さ。
HSA総合スレ全くレスついてないぞ
製造量少ない28nmは最上位のkaveriだけ、数が必要なミドル以下は32nmのRichlandで使い分けしているんだろう
一応2コアの設計くらいはしてるだろうけど、よほど需要がない限りは4コアの機能制限で対応するだろうね
一応2コアの設計くらいはしてるだろうけど、よほど需要がない限りは4コアの機能制限で対応するだろうね
>>313
だから2コア版を作る必要がないぐらい歩留まりが良かったというのが大原氏の推測。
だから2コア版を作る必要がないぐらい歩留まりが良かったというのが大原氏の推測。
3大オフィスの1つLibreOfficeがHSA対応だからな
6月にはH265対応もアナウンスされる
Java9か10も対応
OpenCL2.0がhUMA対応
団子やインテル使いが何をわめこうが開発環境に組み込まれるし、対応ソフトも存在してるんだよね
20nmや14nmの上位APUだと単精度1Tflops、倍精度500GFlopsいくからGPGPUとしてもかなりの性能出せる
20/14nm APUとHSAやOpenCL2.0の組み合わせは今考えてもすごくワクワクするな
6月にはH265対応もアナウンスされる
Java9か10も対応
OpenCL2.0がhUMA対応
団子やインテル使いが何をわめこうが開発環境に組み込まれるし、対応ソフトも存在してるんだよね
20nmや14nmの上位APUだと単精度1Tflops、倍精度500GFlopsいくからGPGPUとしてもかなりの性能出せる
20/14nm APUとHSAやOpenCL2.0の組み合わせは今考えてもすごくワクワクするな
で?
20nm出せるのいつになるの?
20nm出せるのいつになるの?
三大オフィスはMS(Offfce360含む),Apple iWorks,GoogleDocsだろ
OO系はシェア低下してるよ。スマホやタブ、クラウドに対応してないのが痛い
OO系はシェア低下してるよ。スマホやタブ、クラウドに対応してないのが痛い
>>293
それは検討段階であって確定事項では無いよ。
それは検討段階であって確定事項では無いよ。
SkylakeはCPUだけで単精度900Gいくのに
上位でGPUこみ1Tは低性能すぎるだろ
上位でGPUこみ1Tは低性能すぎるだろ
×3大オフィスの1つLibreOffice
○3大Office互換ソフトの1つLibreOffice
○3大Office互換ソフトの1つLibreOffice
パチモンとはAMDにふさわしいな
>>321
ソース無いじゃん
ソース無いじゃん
>>324
SkylakeじゃAVX-512実装されないと予想してるの?
SkylakeじゃAVX-512実装されないと予想してるの?
されない可能性も結構あるぞ?
価格に転嫁できない上にAVX2ですら発熱や採用率で酷い状態なのに叩かれる原因になるだけだろ?
価格に転嫁できない上にAVX2ですら発熱や採用率で酷い状態なのに叩かれる原因になるだけだろ?
>>325
ここはintelの次世代スレじゃない
ここはintelの次世代スレじゃない
そもそも、AMDのAPUでしか使えないようなものでソフトを作るやつがどれだけいるんだよ
しかも、AMDは自ら立ち上げた規格やらが滑ったら放り出すことの常習犯
たとえすべってもそれなりにケアしてくれるIntelとは異なる
しかも、AMDは自ら立ち上げた規格やらが滑ったら放り出すことの常習犯
たとえすべってもそれなりにケアしてくれるIntelとは異なる
流石Intel単独で誰も真似しないボッチ路線を突き進めているだけあって説得力が違うなw
Haswellの4コアが単精度400GFlopsぐらい。Skylake世代だとたぶん2倍になる
IntelのiGPUは、Haswell世代のGT2(Intel HD4400)が最大400GFlopsぐらい
いわゆるGT3(Iris Pro)だとその2倍で、800GFlopsぐらいが上限
Broadwell世代、Skylake世代でそれぞれアーキテクチャが変わるはずなので、将来はもうちょっと増えるかも
これが事実上のベースラインで、これと比較してどれぐらいになるかが問題
ただいい加減にメモリバンド幅が難しい。DDR4も焼け石に水
IntelのiGPUは、Haswell世代のGT2(Intel HD4400)が最大400GFlopsぐらい
いわゆるGT3(Iris Pro)だとその2倍で、800GFlopsぐらいが上限
Broadwell世代、Skylake世代でそれぞれアーキテクチャが変わるはずなので、将来はもうちょっと増えるかも
これが事実上のベースラインで、これと比較してどれぐらいになるかが問題
ただいい加減にメモリバンド幅が難しい。DDR4も焼け石に水
うんうんすごいすごい。で、お値段いくら?
プロセスでも大きく先行しているんだし、最低でも値段差以上の性能差が出せないなら欠陥製品としか言えないけどね。
プロセスでも大きく先行しているんだし、最低でも値段差以上の性能差が出せないなら欠陥製品としか言えないけどね。
>>332
どうみてもお前が分かって無さ過ぎw
歩留まりっつうのは不良率な
4コアのうち1コアが不良だった場合は廃棄
クロックが出なかったら廃棄
TDP想定外なら廃棄
などの廃棄するような不良品でも
廃棄すれば廃棄する費用が発生するが
2コアでも動作すれば製品として出せるなら費用が廃棄するよりおさえれる
お前の言うように2コア専用の作ってどうすんだ?
2コアのうち1コアが不良だった場合は廃棄
クロックが出なかったら廃棄
TDP想定外なら廃棄
廃棄コストだけ発生でもととれるぐらい売れるのかってw
どうみてもお前が分かって無さ過ぎw
歩留まりっつうのは不良率な
4コアのうち1コアが不良だった場合は廃棄
クロックが出なかったら廃棄
TDP想定外なら廃棄
などの廃棄するような不良品でも
廃棄すれば廃棄する費用が発生するが
2コアでも動作すれば製品として出せるなら費用が廃棄するよりおさえれる
お前の言うように2コア専用の作ってどうすんだ?
2コアのうち1コアが不良だった場合は廃棄
クロックが出なかったら廃棄
TDP想定外なら廃棄
廃棄コストだけ発生でもととれるぐらい売れるのかってw
335 :Socket774:2014/05/10(土) 19:21:26.63 ID:+BNkl2vs
『AMDでしか使えない』機能なら、まだマシだったんだけどね。
『AMDの現行製品の1部でしか使えない』機能だからな。
旧製品どころか、現行製品だけで見ても使える製品の方が少ない上に価格も高いから、対応ハードウェアが普及する見通しすら立たない。
『AMDの現行製品の1部でしか使えない』機能だからな。
旧製品どころか、現行製品だけで見ても使える製品の方が少ない上に価格も高いから、対応ハードウェアが普及する見通しすら立たない。
336 :Socket774:2014/05/10(土) 19:24:15.63 ID:+BNkl2vs
>>332
316は、313が歩留まりを理解していないのを『頭悪すぎ』と言っているだけだな。
316は、313が歩留まりを理解していないのを『頭悪すぎ』と言っているだけだな。
>>337
普及してから言ってくれよ
普及してから言ってくれよ
339 :Socket774:2014/05/10(土) 19:30:56.60 ID:+BNkl2vs
Knights Landingみたいな700mm2?とか力技でどうにかしちゃうところが恐ろしいところだけどねww
汎用コアのアクセラレータって意味では数歩前に進んでるかな。破綻しそうでしてない絶妙なラインなのかも。
汎用系だとまだintelに分があるのはかわら無そうだけど、ワッパは相当悪いだろうし、コスパも悪いだろうね。
逆につけこむ隙が出来るわけだけど、そうなるとNVIDIAのNVLink+IBMが競合になってきそうだけど
この辺はかなり面白そう。
汎用コアのアクセラレータって意味では数歩前に進んでるかな。破綻しそうでしてない絶妙なラインなのかも。
汎用系だとまだintelに分があるのはかわら無そうだけど、ワッパは相当悪いだろうし、コスパも悪いだろうね。
逆につけこむ隙が出来るわけだけど、そうなるとNVIDIAのNVLink+IBMが競合になってきそうだけど
この辺はかなり面白そう。
>>324
>どうみてもお前が分かって無さ過ぎw
>歩留まりっつうのは不良率な
一般的に半導体業界では歩留まりってのは良品率の事だがな
とりあえず辞書みてこいよ
>>326
「ウェハあたりの歩留まり」の意味がわからないのか?
>どうみてもお前が分かって無さ過ぎw
>歩留まりっつうのは不良率な
一般的に半導体業界では歩留まりってのは良品率の事だがな
とりあえず辞書みてこいよ
>>326
「ウェハあたりの歩留まり」の意味がわからないのか?
>>341
残念だが、アップルのシェアすら越えられんだろ
残念だが、アップルのシェアすら越えられんだろ
>>338
全くだスレチのIntel単独規格なんて普及してから話してほしい
全くだスレチのIntel単独規格なんて普及してから話してほしい
HSAはモバイルからだと昔から言われてるけどなにいってんだ?w
ネットの出来る端末の2/3がHSA対応になるといわれてるんだけど。
ネットの出来る端末の2/3がHSA対応になるといわれてるんだけど。
>>342
だから歩留まり率が悪ければ、自然と1M2C品やクロックの低い下位モデルも量産できたけど、ってのがミソ
だから歩留まり率が悪ければ、自然と1M2C品やクロックの低い下位モデルも量産できたけど、ってのがミソ
>>331
何言ってんだか良く分からない
FX7500(384SP)が1450
Haswell iris GT3が1080
Haswell GT2(HD4400)が890
IvyBridge HD4000が658
http://images.anandtech.com/graphs/graph7072/55812.png
http://cdn.wccftech.com/wp-content/uploads/2014/05/AMD-Mobile-Kaveri-APUs-Gaming-Performance.png
何言ってんだか良く分からない
FX7500(384SP)が1450
Haswell iris GT3が1080
Haswell GT2(HD4400)が890
IvyBridge HD4000が658
http://images.anandtech.com/graphs/graph7072/55812.png
http://cdn.wccftech.com/wp-content/uploads/2014/05/AMD-Mobile-Kaveri-APUs-Gaming-Performance.png
>>347
それ演算性能ちゃう
それ演算性能ちゃう
GPU性能はirisよりKaveriの圧勝ですよ
4Cの不良品を2Cとして売るより、最初から2Cダイを作ったほうが低コスト化できる気がするよ
>>351
お前が欲しいのは2コアなのか4コアなのかはっきりして
お前が欲しいのは2コアなのか4コアなのかはっきりして
>>352
どういう理屈何だろう??
どういう理屈何だろう??
2コア欲しがる人は安ければって人じゃね?
4コアの不良品を売るってのは安く売る理由が廃棄するなら廃棄コストがかかるから
安くしてでも売るってだけだからな
1個あたりのコストは同じなんだよ
4コアの不良品を売るってのは安く売る理由が廃棄するなら廃棄コストがかかるから
安くしてでも売るってだけだからな
1個あたりのコストは同じなんだよ
そりゃ普通に半分で作れるからな
歩留まりがよければそのほうがいいに決まってる
昔のAMDも、歩留まり上がったら2コアで新規設計していたし
歩留まりがよければそのほうがいいに決まってる
昔のAMDも、歩留まり上がったら2コアで新規設計していたし
>>337
それもamd限定じゃん
それもamd限定じゃん
おもわないよ
各社対応するんなら自社製品向けのドライバー
コンパイラー、ランタイムを自前で用意しなきゃいけない
各社対応するんなら自社製品向けのドライバー
コンパイラー、ランタイムを自前で用意しなきゃいけない
AMDといえば3コアが有名だな
なぜみんな喧嘩してるの?
素人ですが
アスロンとAM1マザー合計1万のマシンを組みました。
とっても快適です!
素人ですが
アスロンとAM1マザー合計1万のマシンを組みました。
とっても快適です!
APUスレじゃ1モジュール品買うのは止めとけってみんな言うよね
368 :,,・´∀`・,,)っ-○○○:2014/05/10(土) 20:53:12.35 ID:3TlviFrc
AMDがHSAを普及させたいならCPUコアもi7とまではいかなくても
最低限i5と互角以上にやりあえるものを用意してくれないとダメだね。
IntelのCPUを使ってたからAPUの内蔵GPUが使いたいから
マザーボードごと交換する
なんてありえない話じゃん。
GPU性能が欲しいならGDDR5つきでファンレス・ロープロの
ビデオカードならいくらでもあるから増設で事足りる。
ノートPCならExpressCardやThunderbolt接続で外部GPUを使うような
ソリューションも出ている(ニッチだけど)
クラウドを活用したソフトって、離散メモリコンピューティングだけど
業界ではすごく流行ってる。別に共有である必要はないんだよ。
金になりさえすればソフト屋はコストをかける。
AMDはCPU性能でシェアを取り返す努力をするべきだ。
最低限i5と互角以上にやりあえるものを用意してくれないとダメだね。
IntelのCPUを使ってたからAPUの内蔵GPUが使いたいから
マザーボードごと交換する
なんてありえない話じゃん。
GPU性能が欲しいならGDDR5つきでファンレス・ロープロの
ビデオカードならいくらでもあるから増設で事足りる。
ノートPCならExpressCardやThunderbolt接続で外部GPUを使うような
ソリューションも出ている(ニッチだけど)
クラウドを活用したソフトって、離散メモリコンピューティングだけど
業界ではすごく流行ってる。別に共有である必要はないんだよ。
金になりさえすればソフト屋はコストをかける。
AMDはCPU性能でシェアを取り返す努力をするべきだ。
2コアkaveriを新規に起こすくらいなら4コアkabiniを量産した方がいいんでないかな。
>>368
あら、主戦場はラップトップになったんじゃなかったっけ。ならマザー云々は関係ないんじゃない
てかINTELのみで考えたってマザー規格ころころ変えてるじゃん
i5と互角ねぇ、、まぁいい線いってんじゃん
http://wccftech.com/amd-kaveri-mobile-apus-vs-ulv-haswell-benchmarks/
あら、主戦場はラップトップになったんじゃなかったっけ。ならマザー云々は関係ないんじゃない
てかINTELのみで考えたってマザー規格ころころ変えてるじゃん
i5と互角ねぇ、、まぁいい線いってんじゃん
http://wccftech.com/amd-kaveri-mobile-apus-vs-ulv-haswell-benchmarks/
371 :Socket774:2014/05/10(土) 20:58:04.14 ID:+BNkl2vs
>>367
Intelで1コアのCPUはやめておけというのと同じような意味だからね。
Intelで1コアのCPUはやめておけというのと同じような意味だからね。
>>363
ちゃんと動く4コアを2コアで売るよりは2コア版を別に用意したほうがいいというのは当然だよ。
だけど2コア版を設計するのにもコストはかかるし、わざわざ作っても出来るのは4コアモデルより安い物。
だからそのへんのバランスを考えてそのうち判断するでしょ
ちゃんと動く4コアを2コアで売るよりは2コア版を別に用意したほうがいいというのは当然だよ。
だけど2コア版を設計するのにもコストはかかるし、わざわざ作っても出来るのは4コアモデルより安い物。
だからそのへんのバランスを考えてそのうち判断するでしょ
>>365
AMDが2コア出すって発表してるんだが?
やっぱり出すのやめましたとか、今さら言うのか?
AMDはもう2コアモデル出すしかない状況なんだってわかってる?
どうせ2コアモデル作るなら効率よく作った方がいいに決まってるだろ
AMDが2コア出すって発表してるんだが?
やっぱり出すのやめましたとか、今さら言うのか?
AMDはもう2コアモデル出すしかない状況なんだってわかってる?
どうせ2コアモデル作るなら効率よく作った方がいいに決まってるだろ
375 :,,・´∀`・,,)っ-○○○:2014/05/10(土) 21:01:56.33 ID:3TlviFrc
>>370
まあノートが主戦場・・・なんだが、そのノートこそAMD弱いじゃないか
ウルトラブック向けCPUの年間販売数だけでAMDのCPU売上を超えるのも
時間の問題ですね(金額ベースだととっくに超えてる)
まあノートが主戦場・・・なんだが、そのノートこそAMD弱いじゃないか
ウルトラブック向けCPUの年間販売数だけでAMDのCPU売上を超えるのも
時間の問題ですね(金額ベースだととっくに超えてる)
法人のシステム(鯖)ではAMDでしか使かえないもの採用なんてあんまりないだろう
と俺は思うけど、Intelあるのに法人はそんなのをほいほい採用するのか。
>>312
HSA、HSAっていっても、プログラム作らない自作erがすごいと騒いでいるって状態だからね
プログラムスレじゃそんな奴が騒いでもって感じだろう
と俺は思うけど、Intelあるのに法人はそんなのをほいほい採用するのか。
>>312
HSA、HSAっていっても、プログラム作らない自作erがすごいと騒いでいるって状態だからね
プログラムスレじゃそんな奴が騒いでもって感じだろう
OpenCL NBody Simulator Benchmark for Windows Linux Solaris and Macosx
https://www.youtube.com/watch?v=YNj10f-7yTA
http://www.fileswap.com/dl/zaZqomw3bk/
Suitable for VLIW-4(float4), VLIW-5(float4), GCN, SSE(float4), AVX(float8), Xeon-phi(float16) and any opencl-capable Nvidia card.
Score tables for some hardwares(Nvidia ones are multiplied by 1.2 by hand to have a clue of CUDA):
______25600 particles______points________
GTX Titan(1140MHz gpu) = 8518
GTX 780(902/1502) = 6600
GTX670(1450/7600 ) = 5972
HD7950 (1225/1525) = 5425
GTX 670 (1228/7000 Mhz) = 5265
GTX660-TI =4798
HD7870 (1200/1320) =3982
HD5850 (725/1000) =2350
HD6850 (775/1000) =2286
7850K (960/1200) =1670
GT650M (1000/1500) =1371
Intel-HD4000 (1100/800) =482
Xeon-E3-1270-V2 (3500MHz-7 threads compute, 1 thread data move+render, 800MHz ddr3) =268
i7-3770K (4500MHz-7 threads compute, 1 thread data move + render) =207
FX8150 (4300MHz-7 threads compute, 1 thread data move+render, 933MHz ddr3) =142
i7 3610QM (3.1GHz-7 threads) =141
FX8350 (4000MHz, 7 threads compute, 1 thread data move+render) =90
Xeon E3-1240 (3.3GHz-4 threads compute, 4 threads render + data move) =90
i7 3610QM (3.1GHz-4 threads) =73
Xeon E3-1240 (3.3GHz-7 threads compute, 1 thread data move+render) =46
FX8150 (1400MHz-4 threads compute, 4 threads render+data move, 933MHz ddr3) =28
https://www.youtube.com/watch?v=YNj10f-7yTA
http://www.fileswap.com/dl/zaZqomw3bk/
Suitable for VLIW-4(float4), VLIW-5(float4), GCN, SSE(float4), AVX(float8), Xeon-phi(float16) and any opencl-capable Nvidia card.
Score tables for some hardwares(Nvidia ones are multiplied by 1.2 by hand to have a clue of CUDA):
______25600 particles______points________
GTX Titan(1140MHz gpu) = 8518
GTX 780(902/1502) = 6600
GTX670(1450/7600 ) = 5972
HD7950 (1225/1525) = 5425
GTX 670 (1228/7000 Mhz) = 5265
GTX660-TI =4798
HD7870 (1200/1320) =3982
HD5850 (725/1000) =2350
HD6850 (775/1000) =2286
7850K (960/1200) =1670
GT650M (1000/1500) =1371
Intel-HD4000 (1100/800) =482
Xeon-E3-1270-V2 (3500MHz-7 threads compute, 1 thread data move+render, 800MHz ddr3) =268
i7-3770K (4500MHz-7 threads compute, 1 thread data move + render) =207
FX8150 (4300MHz-7 threads compute, 1 thread data move+render, 933MHz ddr3) =142
i7 3610QM (3.1GHz-7 threads) =141
FX8350 (4000MHz, 7 threads compute, 1 thread data move+render) =90
Xeon E3-1240 (3.3GHz-4 threads compute, 4 threads render + data move) =90
i7 3610QM (3.1GHz-4 threads) =73
Xeon E3-1240 (3.3GHz-7 threads compute, 1 thread data move+render) =46
FX8150 (1400MHz-4 threads compute, 4 threads render+data move, 933MHz ddr3) =28
378 :,,・´∀`・,,)っ-○○○:2014/05/10(土) 21:11:51.80 ID:3TlviFrc
先にも書いてるけどノートでもデスクトップ向けディスクリートGPUを
使うソリューションはある。VAIOが先がけだけど。
http://ascii.jp/elem/000/000/662/662080/
外付けGPUボックスみたいなソリューションはむしろGPUメーカーが主導で
やって欲しいものだけどな。
特にAMDはね。
Intel/Appleが認めた製品しか出せないThunderboltよりも
フリーなDockPortのほうが商品展開がしやすいでしょ。
外付けGPUボックスからの発展系として、ARMとかの汎用CPUコアも
ボックス側に載せちゃって、ノートPCと繋げて使うだけでなくてそれ単体でも
独立したコンピュータとして使える、みたいなものもあってもいいと思うけど。
使うソリューションはある。VAIOが先がけだけど。
http://ascii.jp/elem/000/000/662/662080/
外付けGPUボックスみたいなソリューションはむしろGPUメーカーが主導で
やって欲しいものだけどな。
特にAMDはね。
Intel/Appleが認めた製品しか出せないThunderboltよりも
フリーなDockPortのほうが商品展開がしやすいでしょ。
外付けGPUボックスからの発展系として、ARMとかの汎用CPUコアも
ボックス側に載せちゃって、ノートPCと繋げて使うだけでなくてそれ単体でも
独立したコンピュータとして使える、みたいなものもあってもいいと思うけど。
端子数(I/Oパッド数)が制約になって、ダイがこれ以上小さくできないのかもしれないぞ
クロックが高ければ需要もあるだろう
2コアゴミとかいっているけど、Intelのセレって結構売れているみたいだよな
AMDの場合は1Mが1コアだからゴミなんだろ?
AMDの場合は1Mが1コアだからゴミなんだろ?
kabini、Beemaラインがあるの現状では2コアkaveriは無理に作るようなものでもないな
あのダイサイズで4コアで5000円程度なんだし、あっち大量生産した方が儲かるんじゃないか
あのダイサイズで4コアで5000円程度なんだし、あっち大量生産した方が儲かるんじゃないか
>366
俺もボーナス出たら買いたい。マザーはDC電源可の奴が欲しい。
俺もボーナス出たら買いたい。マザーはDC電源可の奴が欲しい。
386 :,,・´∀`・,,)っ-○○○:2014/05/10(土) 21:37:24.91 ID:3TlviFrc
Xeonにも2コアで上限クロックを引き上げた製品あったな
ある用途向けのワークステーションは1スレッドあたりの性能もI/O性能も欲しいから。
最後のデュアルコアXeon
http://ark.intel.com/ja/products/64598/Intel-Xeon-Processor-E5-2637-5M-Cache-3_00-GHz-8_00-GTs-Intel-QPI
IvyBridge世代ではTurboBoostの上限クロックが引き上げられたこともあって
あえて2コアを選ぶ必要がなくなったことから2コアの製品自体がなくなった。
ただし4コアはある。
ある用途向けのワークステーションは1スレッドあたりの性能もI/O性能も欲しいから。
最後のデュアルコアXeon
http://ark.intel.com/ja/products/64598/Intel-Xeon-Processor-E5-2637-5M-Cache-3_00-GHz-8_00-GTs-Intel-QPI
IvyBridge世代ではTurboBoostの上限クロックが引き上げられたこともあって
あえて2コアを選ぶ必要がなくなったことから2コアの製品自体がなくなった。
ただし4コアはある。
まとめるとIntelは歩留りが悪いから検品落ちのゴミが大量に出る
大量のゴミの処分に困るので、2コア品として捨て値で叩き売ったらそれなりに売れた
世の中には使用用途としてゴミでも十分な人が多かった
大量のゴミの処分に困るので、2コア品として捨て値で叩き売ったらそれなりに売れた
世の中には使用用途としてゴミでも十分な人が多かった
389 :,,・´∀`・,,)っ-○○○:2014/05/10(土) 21:57:33.61 ID:3TlviFrc
トリプルコア出したのはAMDくらいですよ?
最近はIntelは2コアは4コアとは別の専用マスクで出してる。
ノートでのメインストリームが2コアだからね。
最近はIntelは2コアは4コアとは別の専用マスクで出してる。
ノートでのメインストリームが2コアだからね。
INTELは各ライン全て専用マスクなんじゃないの、金もラインも余ってるわけだし少なくとも8種類はあるかと
http://cdn3.wccftech.com/wp-content/uploads/2013/09/3.jpg
http://cdn3.wccftech.com/wp-content/uploads/2013/09/3.jpg
{kind=link}
Llanoは2コアの専用ダイが出たんだがそれっきりだな
歩留りが悪かった世代だから別に作る必要はあったのかどうか
歩留りが悪かった世代だから別に作る必要はあったのかどうか
392 :Socket774:2014/05/10(土) 22:08:49.30 ID:HELAz9C+
BobcatベースのAPUが低性能だったからLlanoの2コアが必要だったが
Puma+の4コアだと十分だしな
Puma+の4コアだと十分だしな
kabiniのダイサイズは10.35mm x 10.35mm (107mm^2)だから
低価格路線でceleronに対抗したきゃこれ量産した方がいいね
どうせ来年で猫系もHSAにも対応する事になってるんだし
低価格路線でceleronに対抗したきゃこれ量産した方がいいね
どうせ来年で猫系もHSAにも対応する事になってるんだし
ハイエンド AM3+
ミドルレンジ FM2+
エントリー AM1
ミドルレンジ FM2+
エントリー AM1
>>388
続き、更に悪い事にIntelの歩留まりの悪いFab工場から何とか出した検品通過品も結局は高いだけとマニアにしか売れなくなった
生産過剰になった上に売れても叩き売りのゴミばかりなので、始めからゴミを目的で作る工場に一部した
なんとか工場の閉鎖は免れたかに思ったがそれでも時間稼ぎにしかならないので、結局一部工場を閉鎖したり従業員解雇したり
工場を他社に開放して使ってもらおうとしたりとかなりの末期状態に今あると
まあどうでもいい話だなIntelスレで話してくれ
続き、更に悪い事にIntelの歩留まりの悪いFab工場から何とか出した検品通過品も結局は高いだけとマニアにしか売れなくなった
生産過剰になった上に売れても叩き売りのゴミばかりなので、始めからゴミを目的で作る工場に一部した
なんとか工場の閉鎖は免れたかに思ったがそれでも時間稼ぎにしかならないので、結局一部工場を閉鎖したり従業員解雇したり
工場を他社に開放して使ってもらおうとしたりとかなりの末期状態に今あると
まあどうでもいい話だなIntelスレで話してくれ
397 :,,・´∀`・,,)っ-○○○:2014/05/10(土) 22:19:58.31 ID:3TlviFrc
22nmの稼働率が低いのは需要の過大見積もりのせい。
稼働率のことを言ったらGFはもっと酷い状況だぞ
NYのFab8で何の製品作ってるかおまいら知ってる?
まあAMDと資本関係完全に切れたから知らなくてもいいかもしれんがな
稼働率のことを言ったらGFはもっと酷い状況だぞ
NYのFab8で何の製品作ってるかおまいら知ってる?
まあAMDと資本関係完全に切れたから知らなくてもいいかもしれんがな
>>395
AM3は次はなくなるだろ。だからこそ、ローAPUソケをAMってしたんだよ
AM3は次はなくなるだろ。だからこそ、ローAPUソケをAMってしたんだよ
>>397
あそこは20n未満用のfabだろう。来年、次のAPUががんがん生産されるよ
あそこは20n未満用のfabだろう。来年、次のAPUががんがん生産されるよ
400 :,,・´∀`・,,)っ-○○○:2014/05/10(土) 22:29:07.33 ID:3TlviFrc
あれは本来x86シェア50%を狙う為にIBM 32nmを移植したのだが・・・
それだけのキャパが死蔵状態にあるという由々しき事態。
それだけのキャパが死蔵状態にあるという由々しき事態。
>>397
ST Microが何かやってなかった?
ST Microが何かやってなかった?
Carrizoは28nmなんですが…
20nmのAPUはPuma+の改良版で性能面は期待できないし
1xnmまでは高性能のAPUはお預けの可能性大だよ
20nmのAPUはPuma+の改良版で性能面は期待できないし
1xnmまでは高性能のAPUはお預けの可能性大だよ
Puma+の段階でワッパがJaguarの倍なんだから
Puma+改はHSA対応してシュリンクで面積小さくなって単価下がるだけでもいいよ
まぁGF20nmの歩留まりが良いと決まったわけでもないし
Puma+改はHSA対応してシュリンクで面積小さくなって単価下がるだけでもいいよ
まぁGF20nmの歩留まりが良いと決まったわけでもないし
404 :,,・´∀`・,,)っ-○○○:2014/05/10(土) 23:15:10.06 ID:3TlviFrc
リソース共有じゃない独立したコアでSMTサポートなら2コアでも売れるよ
(Bulldozerモジュール換算で4コア相当の性能ってことだけど)
いまどきシングルコア級を押しても需要もないんじゃねーの?
(Bulldozerモジュール換算で4コア相当の性能ってことだけど)
いまどきシングルコア級を押しても需要もないんじゃねーの?
2コアSMTでBullに勝てるかな?
理屈ならシングル性能あげられる訳だし、マルチ性能を同等くらいまで
に抑えれば大成功だろうね。 Excavator比で。
に抑えれば大成功だろうね。 Excavator比で。
407 :,,・´∀`・,,)っ-○○○:2014/05/10(土) 23:25:17.84 ID:3TlviFrc
AMDはSMTを実装した実績がないからAMDがやってどうなるかはわからんが
とりあえずこういう結果は出てる。
http://www.tomshardware.com/reviews/fx-4170-core-i3-3220-benchmarks,3314.html
とりあえずこういう結果は出てる。
http://www.tomshardware.com/reviews/fx-4170-core-i3-3220-benchmarks,3314.html
{kind=link}
intelのロードマップ
本当だったら今年には10nm出してるんだが
もうこう言ういい加減なロードマップは勘弁して欲しいな本当
http://blog-imgs-56.fc2.com/k/e/s/kesemoi/141075nm.png
本当だったら今年には10nm出してるんだが
もうこう言ういい加減なロードマップは勘弁して欲しいな本当
http://blog-imgs-56.fc2.com/k/e/s/kesemoi/141075nm.png
{kind=link}
なんだぁ、まぁ、こういってはなんだが
自分の好みと世間の好みは別だぞ、理解不能だ
2コアのCPUとか糞だが
officeじゃなく、ゲームpcのこと細かい収集している
steamでさえ、2コアの割合が48%でそれがまた増加傾向
4コアは減らしている
今持っているpcは、夢見せて買い換え促さないと
悲しいひどく長持ちするよ
自分の好みと世間の好みは別だぞ、理解不能だ
2コアのCPUとか糞だが
officeじゃなく、ゲームpcのこと細かい収集している
steamでさえ、2コアの割合が48%でそれがまた増加傾向
4コアは減らしている
今持っているpcは、夢見せて買い換え促さないと
悲しいひどく長持ちするよ
対話型PCくらいでてこないとデスクの買い替えはもはや無理ってくらい縮小してくね。
windows9でコルタナ使えるそうじゃないか
Windows 9 will get a virtual assistant and integration with cloud services
http://yournewsticker.com/2014/05/windows-9-will-get-virtual-assistant-integration-cloud-services.html
Windows 9 will get a virtual assistant and integration with cloud services
http://yournewsticker.com/2014/05/windows-9-will-get-virtual-assistant-integration-cloud-services.html
>ういい加減なロードマップ
それはGFに言ってやれw
http://www.4gamer.net/games/100/G010000/20101224018/TN/003.jpg
http://techon.nikkeibp.co.jp/article/NEWS/20130207/264872/global1.jpg
それはGFに言ってやれw
http://www.4gamer.net/games/100/G010000/20101224018/TN/003.jpg
{kind=link}
http://techon.nikkeibp.co.jp/article/NEWS/20130207/264872/global1.jpg
{kind=link}
付け足しで、Carrizoのチップセットも現状のままなのかよ
インテルもGFもその他ファウンドリは技術的な面とコスト的な面で遅れてるだけだが
AMDの場合それ以前に行き当たりばったりでころころ変わるから問題
5年後くらいにHSAがきれいさっぱりなくなってても驚かないぞ
AMDの場合それ以前に行き当たりばったりでころころ変わるから問題
5年後くらいにHSAがきれいさっぱりなくなってても驚かないぞ
まあなんか見間違ってるんでしょ
予定では14nmの量産が2013Q4狙いのはずだから
とりあえずロードマップからのズレは数ヶ月ぐらい
予定では14nmの量産が2013Q4狙いのはずだから
とりあえずロードマップからのズレは数ヶ月ぐらい
>>421
>>409はR&Dのロードマップ出して生産のロードマップでは
10nは今年生産(出す)って言うだからな。2013Q4(予定)の14nの後、1年後に10nの生産って
すごい生産ロードマップをIntelは出していたのかな
>>409はR&Dのロードマップ出して生産のロードマップでは
10nは今年生産(出す)って言うだからな。2013Q4(予定)の14nの後、1年後に10nの生産って
すごい生産ロードマップをIntelは出していたのかな
ネ実でPCに詳しい人に聞いてみたらA10 7850Kはゲーム用途には向かないと言われました
i3にHD7550をのせた程度にしか動かず最新のゲームはパワー不足というのは事実ですか?
i3にHD7550をのせた程度にしか動かず最新のゲームはパワー不足というのは事実ですか?
{kind=link}
425 :Socket774:2014/05/11(日) 01:21:07.17 ID:kvJLEGQZ
>>423
重い3Dゲームに向かないなら事実。
ドラクエとかなら十分快適に遊べる性能はある。
全てのゲームが高い性能を必要とするわけでは無いので、Kaveriの性能だけを見ればラインナップの1つとしては有りなんだけど・・・
コストパフォーマンスが悪いから、もっと安く無ければいらね・・・というところだ。
重い3Dゲームに向かないなら事実。
ドラクエとかなら十分快適に遊べる性能はある。
全てのゲームが高い性能を必要とするわけでは無いので、Kaveriの性能だけを見ればラインナップの1つとしては有りなんだけど・・・
コストパフォーマンスが悪いから、もっと安く無ければいらね・・・というところだ。
>>416
1年前くらいには20nmと14nmのサンプルできてたね
http://semiaccurate.com/2013/01/10/global-foundries-shows-off-20nm-and-14nm-wafers/
CadenceとGF、20/14nmノードにおいてDFMサインオフ改善のため協業
http://news.mynavi.jp/news/2013/05/01/064/index.html
1年前くらいには20nmと14nmのサンプルできてたね
http://semiaccurate.com/2013/01/10/global-foundries-shows-off-20nm-and-14nm-wafers/
CadenceとGF、20/14nmノードにおいてDFMサインオフ改善のため協業
http://news.mynavi.jp/news/2013/05/01/064/index.html
>>423
あえて答えよう
グラボを補助電源なしで差そうとすると
とたんに見えてくるはずだ
実際7859kのバランスを超えるのは、なかなか難しい
290xで、mantleで足を引っ張ることはない
むしろ、内蔵も利用でき幸せになれる
でもゲームタイトル少ない
directXは、12待ちでmantleと同等
それまで?
今あるゲームも、GPU指せば問題なく遊べるでしょう
でも、宗教的理由で煽られるから、
聞くぐらいならintel買っておきな
あえて答えよう
グラボを補助電源なしで差そうとすると
とたんに見えてくるはずだ
実際7859kのバランスを超えるのは、なかなか難しい
290xで、mantleで足を引っ張ることはない
むしろ、内蔵も利用でき幸せになれる
でもゲームタイトル少ない
directXは、12待ちでmantleと同等
それまで?
今あるゲームも、GPU指せば問題なく遊べるでしょう
でも、宗教的理由で煽られるから、
聞くぐらいならintel買っておきな
>>423
高画質でガチゲームするにはむかんでしょ。
i3程度のCPU性能とHD7730(DDR3)レベルでも
満足できる人が買うものだよ
高画質でガチにやりたい人はi7・i5・FXにdGPU
『mantleに対応してるゲーム限定』ではAPU+dGPUでもいいかもね
A10-7850k
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_a10_7850k.png
i3-4330
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_i3_4330.png
PentiumG3220
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_g3220.png
高画質でガチゲームするにはむかんでしょ。
i3程度のCPU性能とHD7730(DDR3)レベルでも
満足できる人が買うものだよ
高画質でガチにやりたい人はi7・i5・FXにdGPU
『mantleに対応してるゲーム限定』ではAPU+dGPUでもいいかもね
A10-7850k
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_a10_7850k.png
{kind=link}
i3-4330
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_i3_4330.png
{kind=link}
PentiumG3220
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_g3220.png
{kind=link}
430 :,,・´∀`・,,)っ-○○○:2014/05/11(日) 01:44:33.09 ID:MM3JOBtq
マジレス優しいな。
いつもみたいにHSAが使われるようになれば〜とか
APUのすばらしさを説くのかと思ってた
いつもみたいにHSAが使われるようになれば〜とか
APUのすばらしさを説くのかと思ってた
AMD次世代スレでAMD次世代技術を説いて
なんで難癖クズに何がしか言われなきゃならんのか
スレタイすら読めんなら百万年消えろよ
少なくとも半年後まで建設的な話題の邪魔すんな
なんで難癖クズに何がしか言われなきゃならんのか
スレタイすら読めんなら百万年消えろよ
少なくとも半年後まで建設的な話題の邪魔すんな
AMDの次世代に対する難癖ならいいんじゃないの
AMDの次世代をマンセーするスレとかじゃないんだし
AMDの次世代をマンセーするスレとかじゃないんだし
433 :,,・´∀`・,,)っ-○○○:2014/05/11(日) 02:00:53.68 ID:MM3JOBtq
現状を理解すれば無理だとわかる願望を書き連ねるのを建設的とは言わない
ただの現実逃避だ。
未来ってのは今の積み重ねなんだよ?
HSAの将来のために何か考えたいなら、プログラム1行でもかいてごらんよ。
ただの現実逃避だ。
未来ってのは今の積み重ねなんだよ?
HSAの将来のために何か考えたいなら、プログラム1行でもかいてごらんよ。
434 :Socket774:2014/05/11(日) 02:02:59.71 ID:kvJLEGQZ
間違った事を言っている人を正すのも良いこと。
ただ、正しい事を言っている人に「珍しく正しい事言っているな」みたいな発言は控えた方が良いかとは思う。
ただ、正しい事を言っている人に「珍しく正しい事言っているな」みたいな発言は控えた方が良いかとは思う。
スレタイ次世代への建設的指摘や難癖なら良いだろうね
他社品の話にすり替えることばかりだから指摘してる
AMDの次世代を主題にしないどころか、意図的に感情を
害させるとまで宣言してるんだからどうしようもない
他社品の話にすり替えることばかりだから指摘してる
AMDの次世代を主題にしないどころか、意図的に感情を
害させるとまで宣言してるんだからどうしようもない
#123
”これは火病を起こさせるのが楽しいからあえて言う”
”これは火病を起こさせるのが楽しいからあえて言う”
437 :,,・´∀`・,,)っ-○○○:2014/05/11(日) 02:09:38.96 ID:MM3JOBtq
>>72のTrinityへの期待みたいなのは今見て建設的な意見だと思うの?
スレの趣旨に則った上で、擁護があるなら、
論理立ててどうぞ>ID:kvJLEGQZ ID:8LiJ+8Vg
論理立ててどうぞ>ID:kvJLEGQZ ID:8LiJ+8Vg
建設合体! ブルドタイガー
いい加減、HSAがプログラム言語じゃないことぐらい理解しろよ
AMDにしてみれば、シングル性能を必要としなくなった時点で
x86自体重要じゃないんだよ
Intelと競合してた時代はとっくに終わってることに気付け
AMDにしてみれば、シングル性能を必要としなくなった時点で
x86自体重要じゃないんだよ
Intelと競合してた時代はとっくに終わってることに気付け
まずは申し開きをすべきだと指摘しておく
トリニティを、次世代製品 と読み替えた上で、据置ゲーム機に採用された現状を踏まえるなら、
大きく外れているとまでは言えないだろうよ
むしろゲーム機を現実にドライブできているという単純な事実すら、スレチ企業の技術賛美でスレッドごと貶してはお門違いの結論を書き散らしてきた謝罪なりすべきじゃないのかね
トリニティを、次世代製品 と読み替えた上で、据置ゲーム機に採用された現状を踏まえるなら、
大きく外れているとまでは言えないだろうよ
むしろゲーム機を現実にドライブできているという単純な事実すら、スレチ企業の技術賛美でスレッドごと貶してはお門違いの結論を書き散らしてきた謝罪なりすべきじゃないのかね
442 :,,・´∀`・,,)っ-○○○:2014/05/11(日) 02:20:16.49 ID:MM3JOBtq
> HSAがプログラム言語じゃない
え?
そんなこと理解してない人間なんているの?
で、HSA専用の開発用ライブラリであるBoltだけど
「生産性が優れてる」って、大方プログラム書いたことのないやつが
AMD大本営のプレゼンの受け売りで言ってるのしか見たことないんだが
その生産性を証明する何かしらはあるのかな?
SourceForgeやGitHubでBoltを使った有望な開発プロジェクトやってる
ところがあるなら教えて欲しいのだが。
え?
そんなこと理解してない人間なんているの?
で、HSA専用の開発用ライブラリであるBoltだけど
「生産性が優れてる」って、大方プログラム書いたことのないやつが
AMD大本営のプレゼンの受け売りで言ってるのしか見たことないんだが
その生産性を証明する何かしらはあるのかな?
SourceForgeやGitHubでBoltを使った有望な開発プロジェクトやってる
ところがあるなら教えて欲しいのだが。
443 :Socket774:2014/05/11(日) 02:21:55.15 ID:kvJLEGQZ
>>440
Windowsソフトを動かすためにx86は重要だろ。
WindowsRTの惨状を見れば『ARMがあるからx86いらね』なんてとても思えないよ。
x86互換CPUメーカーだからこそAMDに期待するのであって、ARMだけしか作らないメーカーなら多数有るARM系メーカーの1つとしか見ないよ。
Windowsソフトを動かすためにx86は重要だろ。
WindowsRTの惨状を見れば『ARMがあるからx86いらね』なんてとても思えないよ。
x86互換CPUメーカーだからこそAMDに期待するのであって、ARMだけしか作らないメーカーなら多数有るARM系メーカーの1つとしか見ないよ。
Haswellリフレッシュがゴミすぎたからな、最新CPUなのに全く話題に上らない
奴らの希望はブロードウェル通り越してAVX512対応するSkylakeだけなんだ
次世代ネタがなさすぎて、話題豊富なAMDスレ荒らすしか出来ないのが現状
後2年はこの状況が続くと見ていいな
まあ、2年後と言ったらCPU負荷軽いDX12や、hUMA対応OpenCL2.0、HSA対応JAVAなんかが登場している時期だし、
20/14nm x64/ARM APUが登場して、Radeonも単精度10T Flopsとか化け物みたいな性能だろうから、
正直、ネタが多すぎて俺らはIntelなんか気にする余裕ないし、インテル使いは話題の多さについていけなくて右往左往してそうだ
奴らの希望はブロードウェル通り越してAVX512対応するSkylakeだけなんだ
次世代ネタがなさすぎて、話題豊富なAMDスレ荒らすしか出来ないのが現状
後2年はこの状況が続くと見ていいな
まあ、2年後と言ったらCPU負荷軽いDX12や、hUMA対応OpenCL2.0、HSA対応JAVAなんかが登場している時期だし、
20/14nm x64/ARM APUが登場して、Radeonも単精度10T Flopsとか化け物みたいな性能だろうから、
正直、ネタが多すぎて俺らはIntelなんか気にする余裕ないし、インテル使いは話題の多さについていけなくて右往左往してそうだ
動く動かないのレベルの話なら、
ベンチ咬ませてグラフの優劣とか、
開発市場を数とカネで押さえてるのを承知の上で「現行の実例を出せ」とか
そういう、二値化した極端な論旨・展開で異論を封じるような持っていき様はあんまりじゃないのかな
CPUの生産技術を力で押さえているから性能を誇る
GPU技術に優れているからその技術を高速化に用いる
なぜ潰し合う以外に結論が無い様なお話にするのか、そうしないといけないのか、
誰か説明してくれないかな
私の知る限り、これまでからそうした一方的独占的支配を好む企業はあって、
まるでその企業がメディアやネットの論調をコントロールしているかのように、
比較批評ばかりが成され続けているのだけれどね
ベンチ咬ませてグラフの優劣とか、
開発市場を数とカネで押さえてるのを承知の上で「現行の実例を出せ」とか
そういう、二値化した極端な論旨・展開で異論を封じるような持っていき様はあんまりじゃないのかな
CPUの生産技術を力で押さえているから性能を誇る
GPU技術に優れているからその技術を高速化に用いる
なぜ潰し合う以外に結論が無い様なお話にするのか、そうしないといけないのか、
誰か説明してくれないかな
私の知る限り、これまでからそうした一方的独占的支配を好む企業はあって、
まるでその企業がメディアやネットの論調をコントロールしているかのように、
比較批評ばかりが成され続けているのだけれどね
447 :,,・´∀`・,,)っ-○○○:2014/05/11(日) 02:35:18.68 ID:MM3JOBtq
先駆者ならともかく、我田引水な開発言語・ライブラリってのは普及しない
「SSEplus」の滑りっぷりを見ればわかる。
NVIDIAが子会社したPGIが推進してるOpenACCってあるじゃん。
CUDAデバイスだけじゃなくてXeon Phiのコードも生成してるよ
自社製品に都合がいいだけでなく、他社製品向けで使っても
メリットがあるものを用意する。
これは自身のパラダイムを広げるためには必要なことなんだ。
ソフトウェアを作るのには開発期間が必要だ。
いま開発が動いてないHSA開発プロジェクトは
いつになったら始動するのだろうか?
もうBoltは使えるんだよ?
「SSEplus」の滑りっぷりを見ればわかる。
NVIDIAが子会社したPGIが推進してるOpenACCってあるじゃん。
CUDAデバイスだけじゃなくてXeon Phiのコードも生成してるよ
自社製品に都合がいいだけでなく、他社製品向けで使っても
メリットがあるものを用意する。
これは自身のパラダイムを広げるためには必要なことなんだ。
ソフトウェアを作るのには開発期間が必要だ。
いま開発が動いてないHSA開発プロジェクトは
いつになったら始動するのだろうか?
もうBoltは使えるんだよ?
>>442
Boltは超高脳でないと使いこなせない。
だから、HSAプログラムプログラムソースはなかなか見かけない。
誰でも使いこなせるものなら、自作PCして、そしてレベル低いプログラム趣味の奴が
HSAはすごいぞっって自慢しているだろ。
Boltは超高脳でないと使いこなせない。
だから、HSAプログラムプログラムソースはなかなか見かけない。
誰でも使いこなせるものなら、自作PCして、そしてレベル低いプログラム趣味の奴が
HSAはすごいぞっって自慢しているだろ。
449 :,,・´∀`・,,)っ-○○○:2014/05/11(日) 02:39:12.87 ID:MM3JOBtq
マルチスレッドは必要だよ。
ただし、C++のソースコードのコンパイル中に何も仕事してくれないGPUコアなんて
俺の仕事にはいくらあっても無駄。
ただし、C++のソースコードのコンパイル中に何も仕事してくれないGPUコアなんて
俺の仕事にはいくらあっても無駄。
BoltやHSAILなんかはゲームエンジンやコンパイラ作れるような一部の天才たちのためのツールだろ
一般のプログラマはC++やOpenCLやらで今までどおりプログラミングすればいい
GPGPU対応やhUMA対応なんかはHSA対応のコンパイラとかが勝手にやってくれる
hUMA対応したOpenCL2.0ならHSAに近い事ができるし、もはや標準言語だから普通に使われるだろうね
一般のプログラマはC++やOpenCLやらで今までどおりプログラミングすればいい
GPGPU対応やhUMA対応なんかはHSA対応のコンパイラとかが勝手にやってくれる
hUMA対応したOpenCL2.0ならHSAに近い事ができるし、もはや標準言語だから普通に使われるだろうね
452 :,,・´∀`・,,)っ-○○○:2014/05/11(日) 02:55:12.40 ID:MM3JOBtq
BoltってOpenCL以上の生産性の高さが売りじゃなかったの?
ぶっちゃけOpenCL2.0がhUMA対応した時点でAMDの勝ちは決まったようなもんだ
万が一HSAが潰れても、OpenCLのバージョンが上がれば自然とHSAの方向に進むし
当のIntelやNvidiaですら対応しているから、廃れることもありえないからね
今後HSAとOpenCLがどういう風に進化するのか、関係性はどうなるのかは気になるけど
どちらもCPU+iGPUの活用で開発されていくから、AMDの不利益になるようなことはまず無いだろうね
万が一HSAが潰れても、OpenCLのバージョンが上がれば自然とHSAの方向に進むし
当のIntelやNvidiaですら対応しているから、廃れることもありえないからね
今後HSAとOpenCLがどういう風に進化するのか、関係性はどうなるのかは気になるけど
どちらもCPU+iGPUの活用で開発されていくから、AMDの不利益になるようなことはまず無いだろうね
>>446
この世界でのお話だね
まずはシングル性能だけの環境が姿を消した
性能を削られた廉価販売品ですら、数世代前から複数コアまたは複数スレッドで出荷されている
”みんなもっと高いシングル性能を必要としている” は言い過ぎだ
”日本では廉価版のCPUが売れる”
業界一の企業の副社長様が、大昔にそう言いきってるんだから
>ttp://pc.watch.impress.co.jp/docs/2004/0911/hot338.htm
>(前略)Siu副社長は声を大にして不満を述べた。それは、成熟市場を抱える先進国中、
>日本だけが突出してCeleronの比率が高い、ということで(後略)
場面としてはユーモアを交えたものだった様だけれど、根拠とする数字や状況までもがユーモアの対象だとはとても思えない
この世界でのお話だね
まずはシングル性能だけの環境が姿を消した
性能を削られた廉価販売品ですら、数世代前から複数コアまたは複数スレッドで出荷されている
”みんなもっと高いシングル性能を必要としている” は言い過ぎだ
”日本では廉価版のCPUが売れる”
業界一の企業の副社長様が、大昔にそう言いきってるんだから
>ttp://pc.watch.impress.co.jp/docs/2004/0911/hot338.htm
>(前略)Siu副社長は声を大にして不満を述べた。それは、成熟市場を抱える先進国中、
>日本だけが突出してCeleronの比率が高い、ということで(後略)
場面としてはユーモアを交えたものだった様だけれど、根拠とする数字や状況までもがユーモアの対象だとはとても思えない
455 :,,・´∀`・,,)っ-○○○:2014/05/11(日) 03:00:10.19 ID:MM3JOBtq
> AMDのopenclコンパイラはGPUを使って超速でコンパイルするように当然しているだろ
> 強力GPUを搭載しているのにわざわざ非力なCPUでコンパイルするってアホすぎ
だよなーAMDの技術の結晶だもんなー
その点、Microsoftって無能だぜ?
C++ AMPのコードをコンパイルするときすらGPU使ってくれないんだぜ。
つまり、コンパイラ作ったやつらはGPGPUが使いこなせてないんだぜ。
C++AMPを使ったGPGPUでは、コンパイラ作れない欠陥処理系だと
認めてるようなものだ。やっぱりMicrosoftは無能だぜ。
↑棒読み
> 強力GPUを搭載しているのにわざわざ非力なCPUでコンパイルするってアホすぎ
だよなーAMDの技術の結晶だもんなー
その点、Microsoftって無能だぜ?
C++ AMPのコードをコンパイルするときすらGPU使ってくれないんだぜ。
つまり、コンパイラ作ったやつらはGPGPUが使いこなせてないんだぜ。
C++AMPを使ったGPGPUでは、コンパイラ作れない欠陥処理系だと
認めてるようなものだ。やっぱりMicrosoftは無能だぜ。
↑棒読み
>>452
超高脳はそうだろう。でも、それ以外の奴には生産性よくなってるのかって?だよ
超高脳はそうだろう。でも、それ以外の奴には生産性よくなってるのかって?だよ
>>429
FXにdGPUよりKaveriにdGPUの方がPCIexpressのバージョンが上なんじゃないか。
FXにdGPUよりKaveriにdGPUの方がPCIexpressのバージョンが上なんじゃないか。
458 :,,・´∀`・,,)っ-○○○:2014/05/11(日) 03:03:12.22 ID:MM3JOBtq
失敗するハードウェアの特徴だな
460 :,,・´∀`・,,)っ-○○○:2014/05/11(日) 03:10:18.38 ID:MM3JOBtq
>>459
それは間違いだと直に気づくはずだ
AMDのシェアは確かに20%をきってる。
でもAMDを使ってるユーザーは選ばれた金持ち集団だから
収益性が高いはずだよ。
彼らには1ライセンス100万円くらい要求しても喜んでソフトを買ってくれるよ。
HSAはそのくらいの価値を生み出せるんだ。
それは間違いだと直に気づくはずだ
AMDのシェアは確かに20%をきってる。
でもAMDを使ってるユーザーは選ばれた金持ち集団だから
収益性が高いはずだよ。
彼らには1ライセンス100万円くらい要求しても喜んでソフトを買ってくれるよ。
HSAはそのくらいの価値を生み出せるんだ。
まだろくに公開されてないHSAのバージョンはせいぜい0.1か0.2というところだろ
一応バージョンが1.2に上がって使いやすくなってるOpenCLに色んな面で勝てるわけはないな
OpenCL3.0、HSA2.0とかで追いつき追い越すくらいだろうな
団子やインテル使い共はIntelに文句言えよ、
OpenCLなんかやめてiGPU強化もやめてCPUコア満載してAVXに専念しろってね
一応バージョンが1.2に上がって使いやすくなってるOpenCLに色んな面で勝てるわけはないな
OpenCL3.0、HSA2.0とかで追いつき追い越すくらいだろうな
団子やインテル使い共はIntelに文句言えよ、
OpenCLなんかやめてiGPU強化もやめてCPUコア満載してAVXに専念しろってね
463 :,,・´∀`・,,)っ-○○○:2014/05/11(日) 03:18:02.41 ID:MM3JOBtq
きっとそうだ!
HSAは完成したら最高のコンピューティング環境を提供するよね!
それがわかってるソフトメーカーはみんな、HSA Foundationの
メンバーに名前を連ね、多額の活動資金を提供しているはずだ!
HSAの将来性に期待してないGoogleやAppleなんて所詮三流企業だよ!
HSAは完成したら最高のコンピューティング環境を提供するよね!
それがわかってるソフトメーカーはみんな、HSA Foundationの
メンバーに名前を連ね、多額の活動資金を提供しているはずだ!
HSAの将来性に期待してないGoogleやAppleなんて所詮三流企業だよ!
>>455
すっとぼけか?C++ AMPのCompilerってAMDが作ってるんじゃないのか
http://blogs.msdn.com/b/nativeconcurrency/archive/2013/11/13/c-amp-to-target-khronos-spir-and-hsail.aspx
すっとぼけか?C++ AMPのCompilerってAMDが作ってるんじゃないのか
http://blogs.msdn.com/b/nativeconcurrency/archive/2013/11/13/c-amp-to-target-khronos-spir-and-hsail.aspx
AMDはもう旧世代の規格には見切りをつけて、
次世代規格のHSA、Mantle、DX12、Sumatra、OpenCL2.0、OpenGL4.4、x265に向けてプロセッサの開発を進めているな
HSAとMantleは抜きにしても、それ以外の一般規格の最新バージョンで果たしてIntelがどれほどの性能を出せるのか見ものだな
まさかその時になってすらパイ焼きやcinebenchで喚いてるんだろうかね
次世代規格のHSA、Mantle、DX12、Sumatra、OpenCL2.0、OpenGL4.4、x265に向けてプロセッサの開発を進めているな
HSAとMantleは抜きにしても、それ以外の一般規格の最新バージョンで果たしてIntelがどれほどの性能を出せるのか見ものだな
まさかその時になってすらパイ焼きやcinebenchで喚いてるんだろうかね
>>464
それってこれの事じゃないの?
ttp://www.hsafoundation.com/bringing-camp-beyond-windows-via-clang-llvm/
ttps://bitbucket.org/multicoreware/cppamp-driver-ng/wiki/Home
それってこれの事じゃないの?
ttp://www.hsafoundation.com/bringing-camp-beyond-windows-via-clang-llvm/
ttps://bitbucket.org/multicoreware/cppamp-driver-ng/wiki/Home
まあ実際の物が出てくるまでが楽しいんだけどね。
実物が出てくる頃には次の話で盛り上がってる訳だし
過去の遺物に興味は無いからその出来とかどうでもいいし。
実物が出てくる頃には次の話で盛り上がってる訳だし
過去の遺物に興味は無いからその出来とかどうでもいいし。
469 :,,・´∀`・,,)っ-○○○:2014/05/11(日) 03:36:57.31 ID:MM3JOBtq
http://jp.investing.com/equities/adv-micro-device-income-statement
たいへんだ!
研究開発費が2012→2013年に$1,354Mから$1,199Mに削減されてる!
でも賢いAMDユーザーがすごいAPUを研究開発してくれるから平気だよね
たいへんだ!
研究開発費が2012→2013年に$1,354Mから$1,199Mに削減されてる!
でも賢いAMDユーザーがすごいAPUを研究開発してくれるから平気だよね
>>467
オクラポートなんだ・・・garlic、onionときてokraなのか?!
オクラポートなんだ・・・garlic、onionときてokraなのか?!
>>462
OpenCLもLLVM介して色々やろうとしてるから、向かう先は.NETやHSAのようなフレームワークだと思ってる
OSより下のハイパーバイザというかコードモーフィングみたいにネイティブに近いところで動くような感じだな
http://pc.watch.impress.co.jp/img/pcw/docs/620/789/html/03.png.html
が、こうなる
http://pc.watch.impress.co.jp/img/pcw/docs/620/789/html/04.png.html
HSAの資料だけど、GPGPU向けのOpenCLやその他の言語も効率を追求したら同じ方向に進むだろう
hUMAとhQでとりあえずハード的には準備ができて、次にソフト環境を整え始める段階になったのが今
OpenCLもLLVM介して色々やろうとしてるから、向かう先は.NETやHSAのようなフレームワークだと思ってる
OSより下のハイパーバイザというかコードモーフィングみたいにネイティブに近いところで動くような感じだな
http://pc.watch.impress.co.jp/img/pcw/docs/620/789/html/03.png.html
{kind=link}
が、こうなる
http://pc.watch.impress.co.jp/img/pcw/docs/620/789/html/04.png.html
{kind=link}
HSAの資料だけど、GPGPU向けのOpenCLやその他の言語も効率を追求したら同じ方向に進むだろう
hUMAとhQでとりあえずハード的には準備ができて、次にソフト環境を整え始める段階になったのが今
472 :,,・´∀`・,,)っ-○○○:2014/05/11(日) 03:47:55.50 ID:MM3JOBtq
研究開発費が減ってるけど社員が無償労働してソフト環境整えてるから平気だよね!
473 :,,・´∀`・,,)っ-○○○:2014/05/11(日) 03:52:22.55 ID:MM3JOBtq
今見たらすごいレスついてるじゃん。
この活発さならフリーソフトにも期待できるね!
HSA総合スレ【part 2】
http://toro.2ch.net/test/read.cgi/tech/1399310364/
この活発さならフリーソフトにも期待できるね!
HSA総合スレ【part 2】
http://toro.2ch.net/test/read.cgi/tech/1399310364/
ついには研究開発費とか持ち出してくる団子が哀れすぎて泣ける
まあ、開発範囲が広すぎて個々の予算が不足しまくりなのはわかるけど
まあ、開発範囲が広すぎて個々の予算が不足しまくりなのはわかるけど
>>471
フレームワークという意味ではそうだね。
後、気になるのはHSAILとSPIRの役割が被ってきている事。
個人的にはHSAのアイデアをOpenCLに盛り込んでSPIRに一本化するのがいいと思うけど
実際どうなるだろうね。
フレームワークという意味ではそうだね。
後、気になるのはHSAILとSPIRの役割が被ってきている事。
個人的にはHSAのアイデアをOpenCLに盛り込んでSPIRに一本化するのがいいと思うけど
実際どうなるだろうね。
476 :,,・´∀`・,,)っ-○○○:2014/05/11(日) 04:09:24.68 ID:MM3JOBtq
Tizenアプリ作成
http://toro.2ch.net/test/read.cgi/tech/1379472106/
↑このスレなんて不満だらけじゃん
HSAスレは愚痴が全くかかれてない。
HSAの完成度が高く、業務プロジェクトが円滑に進んでいる証拠といえるのだよ!
>>474
そうだよね!
独自ARMも立ち上げるから研究開発費はそっちにつかってるよね!
しわよせとしあわせは似ているよね!
http://toro.2ch.net/test/read.cgi/tech/1379472106/
↑このスレなんて不満だらけじゃん
HSAスレは愚痴が全くかかれてない。
HSAの完成度が高く、業務プロジェクトが円滑に進んでいる証拠といえるのだよ!
>>474
そうだよね!
独自ARMも立ち上げるから研究開発費はそっちにつかってるよね!
しわよせとしあわせは似ているよね!
>>475
比較表があるけど、多少の違いはあるから当面は別々に進化して、そのうち両方のイイトコどりの規格に一本化するんじゃないかな
http://pc.watch.impress.co.jp/img/pcw/docs/612/591/html/09.jpg.html
まあOpenCLはここまでの効率化を想定はしてないだろうからどこかで無理が生じるだろうし、
いずれはHSAに吸収統合されていくと思う
比較表があるけど、多少の違いはあるから当面は別々に進化して、そのうち両方のイイトコどりの規格に一本化するんじゃないかな
http://pc.watch.impress.co.jp/img/pcw/docs/612/591/html/09.jpg.html
{kind=link}
まあOpenCLはここまでの効率化を想定はしてないだろうからどこかで無理が生じるだろうし、
いずれはHSAに吸収統合されていくと思う
478 :,,・´∀`・,,)っ-○○○:2014/05/11(日) 04:28:08.84 ID:MM3JOBtq
> まあOpenCLはここまでの効率化を想定はしてないだろうからどこかで無理が生じるだろうし、
> いずれはHSAに吸収統合されていくと思う
wwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwww
> いずれはHSAに吸収統合されていくと思う
wwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwww
ARMのCCN-508はHSAをサポートしない模様。
> One major question was whether or not the CCN-508 would support AMD's HSA,
> given that the chip isn't expected for several years and ARM is a member of the
> HSA Foundation. The answer to that question is "No" -- while CCN-508 does
> support fully coherent accelerators (including GPUs) and can be used for OpenCL
> and GPU offloading, it does not implement the HSA specification. In fact, one point
> ARM made to us at the event is that the HSA spec hasn't even been fully defined
> yet -- implementing it in hardware is basically impossible at this point in time.
http://hothardware.com/Reviews/ARMs-Race-Company-Details-Attack-Plan-in-Server-Mobile-/
もうグダグダだな。
X-Geneは4IPCの独自ARMコアで2.4GHzなのにAMDのSeattleは
Cortex-A57そのまんま。ARMサーバ市場ですら売れないゴミ確定。
> One major question was whether or not the CCN-508 would support AMD's HSA,
> given that the chip isn't expected for several years and ARM is a member of the
> HSA Foundation. The answer to that question is "No" -- while CCN-508 does
> support fully coherent accelerators (including GPUs) and can be used for OpenCL
> and GPU offloading, it does not implement the HSA specification. In fact, one point
> ARM made to us at the event is that the HSA spec hasn't even been fully defined
> yet -- implementing it in hardware is basically impossible at this point in time.
http://hothardware.com/Reviews/ARMs-Race-Company-Details-Attack-Plan-in-Server-Mobile-/
もうグダグダだな。
X-Geneは4IPCの独自ARMコアで2.4GHzなのにAMDのSeattleは
Cortex-A57そのまんま。ARMサーバ市場ですら売れないゴミ確定。
>>477
OpenCLは対応を表明している企業が多いし、HSAランタイムが出来上がっていない現状を考えるとSPIRに統合した方がいい。
HSA Foundationとしては実現さえすればいいのだから、HSAILに拘る必要も無いしね。
OpenCLは対応を表明している企業が多いし、HSAランタイムが出来上がっていない現状を考えるとSPIRに統合した方がいい。
HSA Foundationとしては実現さえすればいいのだから、HSAILに拘る必要も無いしね。
HSA Foundationって事実上AMDオンリーの組織だよ
ARMはIPライセンスをAMDに買わせることを条件に参加しただけで
本気でやる気なんてない
Boltはごらんのとおりのゴミライブラリ
Aparapiの開発も停滞中(去年5月以降、コードの大半がほとんど改変されていない)
HSA Foundationのページは半年も更新なし
もう独自ツール作るのは匙投げてるよ
ARMはIPライセンスをAMDに買わせることを条件に参加しただけで
本気でやる気なんてない
Boltはごらんのとおりのゴミライブラリ
Aparapiの開発も停滞中(去年5月以降、コードの大半がほとんど改変されていない)
HSA Foundationのページは半年も更新なし
もう独自ツール作るのは匙投げてるよ
HSAライフをエンジョイしたい?
ならばメンバーにジョインしてマニーを貢ぐことだな!
HAHAHA
ならばメンバーにジョインしてマニーを貢ぐことだな!
HAHAHA
団子はなんでそんなに必死なの?
ここまで必死だとファンボーイを弄って遊んでいるようにはとても見えない。
ここまで必死だとファンボーイを弄って遊んでいるようにはとても見えない。
LarrabeeがソフトウェアでグダってコケたからHSAにもコケてもらわないと困るのさ
え?
phiがいつこけたの
phiがいつこけたの
486 :ボボッタに選ばれし銀河鰻(^0^):2014/05/11(日) 06:28:46.02 ID:UTM8Qtp7
(年度) 2010 2011 2012 2013
NVIDIA 848.83 1002.61 1147.28 1335.83
AMD 1405 1453 1354 1199 (単位:百万ドル)
http://jp.investing.com/equities/adv-micro-device-income-statement
http://jp.investing.com/equities/nvidia-corp-income-statement
:::::::::::.: .:. . ∧_∧ . . . .: ::::::::
:::::::: :.: . . /彡ミ゛ヽ;)ヽ、. ::: : :: x86, ARM, GPU作ってるAMDの研究開発費が
::::::: :.: . . / :::/:: ヽ、ヽ、i . .:: :.: ::: GPUとARMだけ作ってる会社に負けた・・・だと?
 ̄ ̄ ̄(_,ノ  ̄ ̄ヽ、_ノ ̄
NVIDIA 848.83 1002.61 1147.28 1335.83
AMD 1405 1453 1354 1199 (単位:百万ドル)
http://jp.investing.com/equities/adv-micro-device-income-statement
http://jp.investing.com/equities/nvidia-corp-income-statement
:::::::::::.: .:. . ∧_∧ . . . .: ::::::::
:::::::: :.: . . /彡ミ゛ヽ;)ヽ、. ::: : :: x86, ARM, GPU作ってるAMDの研究開発費が
::::::: :.: . . / :::/:: ヽ、ヽ、i . .:: :.: ::: GPUとARMだけ作ってる会社に負けた・・・だと?
 ̄ ̄ ̄(_,ノ  ̄ ̄ヽ、_ノ ̄
フリー「2012年はずっと状況がよくなると思っている。
我々は良い製品を手中にしており、これはインテルに対して
非常に強い状況にある。
インテルはサーバー向けでは『Sandy Bridge-EP』でBulldozerに
対抗してくると思われるが、難しいだろう」
http://ascii.jp/elem/000/000/656/656905/index-4.html
このおっさん元気かな
我々は良い製品を手中にしており、これはインテルに対して
非常に強い状況にある。
インテルはサーバー向けでは『Sandy Bridge-EP』でBulldozerに
対抗してくると思われるが、難しいだろう」
http://ascii.jp/elem/000/000/656/656905/index-4.html
このおっさん元気かな
AMDはx86とGPU両方持ってるからって手広くやりすぎなんだよな
身の丈を考えろと、Intelの市場&NVIDIAの市場で競争+ARM参戦でR&D大幅減とか
何考えてんの、ただでさえ足りねーものを減らした上に更に分散する愚行
そら全方位で後退するっての
身の丈を考えろと、Intelの市場&NVIDIAの市場で競争+ARM参戦でR&D大幅減とか
何考えてんの、ただでさえ足りねーものを減らした上に更に分散する愚行
そら全方位で後退するっての
AMD to Introduce New High-Performance Micro-Architecture in 2015 ? Report.
http://www.xbitlabs.com/news/cpu/display/20140510165441_AMD_to_Introduce_New_High_Performance_Micro_Architecture_in_2015_Report.html
http://www.xbitlabs.com/news/cpu/display/20140510165441_AMD_to_Introduce_New_High_Performance_Micro_Architecture_in_2015_Report.html
>>489
BulldozerはCore i7 960より50%高速らしいからな
BulldozerはCore i7 960より50%高速らしいからな
>>487
>このおっさん元気かな
だれもいなくなった↓
AMD Loses Chief Engineer Michael Goddard to Samsung.
Other high profile executives that departed AMD include
CFO Thomas Seifert,
CMO Nigel Dessau,
COO Bob Rivet,
CSO Emilio Ghilardi,
graphics CTO Eric Demers,
SVP Marty Seyer,
corporate VP David Wang,
chief engineer Jim Mergard,
corporate VP Pat Moorhead,
GM Rick Bergman, and
GM Chris Cloran.
Media reports suggest that Goddard was not fired,
but left AMD voluntarily to accept the position with Samsung,
which will compete with AMD in the ARM server SoC market.
ttp://www.tomshardware.com/news/amd-business-Michael-Goddard-engineer-departure,20050.html
先を争うように逃げ出すAMDのトップマネジメント、エグゼクティブ、エンジニアの数々。
ダメだコリア\(^o^)/
Mike Houston. ← NEW!
AMD Senior System Architect → nVidia
>このおっさん元気かな
だれもいなくなった↓
AMD Loses Chief Engineer Michael Goddard to Samsung.
Other high profile executives that departed AMD include
CFO Thomas Seifert,
CMO Nigel Dessau,
COO Bob Rivet,
CSO Emilio Ghilardi,
graphics CTO Eric Demers,
SVP Marty Seyer,
corporate VP David Wang,
chief engineer Jim Mergard,
corporate VP Pat Moorhead,
GM Rick Bergman, and
GM Chris Cloran.
Media reports suggest that Goddard was not fired,
but left AMD voluntarily to accept the position with Samsung,
which will compete with AMD in the ARM server SoC market.
ttp://www.tomshardware.com/news/amd-business-Michael-Goddard-engineer-departure,20050.html
先を争うように逃げ出すAMDのトップマネジメント、エグゼクティブ、エンジニアの数々。
ダメだコリア\(^o^)/
Mike Houston. ← NEW!
AMD Senior System Architect → nVidia
>>496
北森瓦版は誤字脱字は結構あるから、規制されたのはプロバイダ規制に巻き込まれただけじゃないの
そうじゃなかったら『HASって書いてあるから注意した』っていうのが一般常識からかけ離れていたのかもな
北森瓦版は誤字脱字は結構あるから、規制されたのはプロバイダ規制に巻き込まれただけじゃないの
そうじゃなかったら『HASって書いてあるから注意した』っていうのが一般常識からかけ離れていたのかもな
143585
HASじゃなくてHSAな
2014/04/30(Wed) 12:12 | URL | LGA774 #-[ 編集]
http://northwood.blog60.fc2.com/blog-entry-7512.html
これか?
HASじゃなくてHSAな
2014/04/30(Wed) 12:12 | URL | LGA774 #-[ 編集]
http://northwood.blog60.fc2.com/blog-entry-7512.html
これか?
Bulldozerが大失敗だったから、裏であらたなマイクロアーキテクチャ開発しながら
Bulldozer系改良CPU出し続けてるんだろうけど、
その新たな改良マイクロアーキテクチャが出てくるまではAMDはどうにもならないだろうな
Bulldozer系改良CPU出し続けてるんだろうけど、
その新たな改良マイクロアーキテクチャが出てくるまではAMDはどうにもならないだろうな
intelのソケットが変わる度に「変えすぎ、互換性が無い」云々言うのがいるが、
AMDのソケット乱立状態なのには全く言及しないのが笑える
AMDのソケット乱立状態なのには全く言及しないのが笑える
そりゃAMDのやることは何でも正義だからな
>>499
昔、低消費電力用にPentiumMと言うのがあってだな
その頃の大失敗がPentium4なのな
その後どうなったかっつうとCore2 Duoに一本化された
Jagaurがその流れに乗っかるんじゃないか?
製造プロセスが不利な状況下でダイサイズがほぼ同じでGPU性能3倍差ある中でクロックが2割も低い状況下で圧勝してる
AMD Athlon 5350 quad-core, 2.0 GHz GPU 600MHz 28nmプロセス ダイサイズ107mm2前後
Intel Celeron J1900, quad-core, 2.42 GHz GPU 854MHz 22nmプロセス ダイサイズ107mm2前後
Higer is betterの項目
PCMark 8
http://media.bestofmicro.com/B/9/430677/original/pcmark.png
Sandra Arithmetic
http://media.bestofmicro.com/B/E/430682/original/sandra-arith.png
GPGPU Processor Cryptography
http://media.bestofmicro.com/C/H/430721/original/sandra-GPGPU-crypt.png
3DMark2013
http://media.bestofmicro.com/B/1/430669/original/3dmark.png
Peacekeeper
http://media.bestofmicro.com/B/B/430679/original/peacekeeper.png
Dota 2
http://media.bestofmicro.com/C/K/430724/original/Dota2.png
Grid 2
http://media.bestofmicro.com/B/5/430673/original/Grid2.png
Lower is betterの項目
Adobi Acrobat XI
http://media.bestofmicro.com/B/0/430668/original/acrobat.png
ABBYY FineReader
http://media.bestofmicro.com/B/2/430670/original/abbyy.png
JPEG Dedoder
http://media.bestofmicro.com/B/7/430675/original/JPEG-decoder.png
iTunes x64
http://media.bestofmicro.com/B/6/430674/original/iTunes.png
Lame MP3
http://media.bestofmicro.com/B/8/430676/original/lame.png
HandBrake CLI
http://media.bestofmicro.com/B/A/430678/original/handbrake.png
TotalCodeStudio
http://media.bestofmicro.com/B/I/430686/original/totalcode.png
Zip 9.28
http://media.bestofmicro.com/B/3/430671/original/7zip.png
WinRAR 5.10
http://media.bestofmicro.com/B/J/430687/original/winRAR.png
Processor Temperature
http://media.bestofmicro.com/B/H/430685/original/temp.png
昔、低消費電力用にPentiumMと言うのがあってだな
その頃の大失敗がPentium4なのな
その後どうなったかっつうとCore2 Duoに一本化された
Jagaurがその流れに乗っかるんじゃないか?
製造プロセスが不利な状況下でダイサイズがほぼ同じでGPU性能3倍差ある中でクロックが2割も低い状況下で圧勝してる
AMD Athlon 5350 quad-core, 2.0 GHz GPU 600MHz 28nmプロセス ダイサイズ107mm2前後
Intel Celeron J1900, quad-core, 2.42 GHz GPU 854MHz 22nmプロセス ダイサイズ107mm2前後
Higer is betterの項目
PCMark 8
http://media.bestofmicro.com/B/9/430677/original/pcmark.png
Sandra Arithmetic
http://media.bestofmicro.com/B/E/430682/original/sandra-arith.png
GPGPU Processor Cryptography
http://media.bestofmicro.com/C/H/430721/original/sandra-GPGPU-crypt.png
3DMark2013
http://media.bestofmicro.com/B/1/430669/original/3dmark.png
Peacekeeper
http://media.bestofmicro.com/B/B/430679/original/peacekeeper.png
Dota 2
http://media.bestofmicro.com/C/K/430724/original/Dota2.png
Grid 2
http://media.bestofmicro.com/B/5/430673/original/Grid2.png
Lower is betterの項目
Adobi Acrobat XI
http://media.bestofmicro.com/B/0/430668/original/acrobat.png
ABBYY FineReader
http://media.bestofmicro.com/B/2/430670/original/abbyy.png
JPEG Dedoder
http://media.bestofmicro.com/B/7/430675/original/JPEG-decoder.png
iTunes x64
http://media.bestofmicro.com/B/6/430674/original/iTunes.png
Lame MP3
http://media.bestofmicro.com/B/8/430676/original/lame.png
HandBrake CLI
http://media.bestofmicro.com/B/A/430678/original/handbrake.png
TotalCodeStudio
http://media.bestofmicro.com/B/I/430686/original/totalcode.png
Zip 9.28
http://media.bestofmicro.com/B/3/430671/original/7zip.png
WinRAR 5.10
http://media.bestofmicro.com/B/J/430687/original/winRAR.png
Processor Temperature
http://media.bestofmicro.com/B/H/430685/original/temp.png
最近AMD系の板ってマッチポンプくさいパターン化した話題そらし&荒れる話題流しな書き込みいぱーいだね。
>>500
乱立してないからねぇ
乱立してないからねぇ
来月開催のこんぷてっくすでノート用KaveriとHSAのドライバの発表かな
いやFM1は最初から短命なの分かってたじゃん、754みたいなもん
長く使う次世代も載るって言ってたのに反故にしたFM2が新939
長く使う次世代も載るって言ってたのに反故にしたFM2が新939
A10-6800Kがあるじゃん
>>381
まだ言ってるのか?
お前はさっきから2コアをプッシュしてるようにしか見えん
こっちは2コアなんかいらないから4コア
>>383
intelのセレロンもゴミだろ
i7発表と同時にセレロンも発表したか?
i7の廃棄用ダイをセレロンとして二次的にあとから追加したに過ぎんだろ
まだ言ってるのか?
お前はさっきから2コアをプッシュしてるようにしか見えん
こっちは2コアなんかいらないから4コア
>>383
intelのセレロンもゴミだろ
i7発表と同時にセレロンも発表したか?
i7の廃棄用ダイをセレロンとして二次的にあとから追加したに過ぎんだろ
コードネームだけ変えて次世代コア"ということにした"最悪のパターンな
>>502
今後モバイルベースの設計が加速するようであれば、Bullアーキの系譜は消えるだろうな
用途によっては鯖系でもARM載せる今だし、ワッパも重視しなければならずだし
ただBullアーキの失敗は、なんか当初の目論見通りにしてこなかったのが原因とも思える
あれはモジュール単位でコアを増やしやすいようにコアを簡素な設計にしていたが
結局今(Kaveri)になってもコアは4コアどまり、OSも当初はスレッドの割り当て問題でどんくさかった
AMDはそれで周りと調整してから事を進めることを学習したのか知らんが
HSAはちゃんと仲間集めはしているな
今後モバイルベースの設計が加速するようであれば、Bullアーキの系譜は消えるだろうな
用途によっては鯖系でもARM載せる今だし、ワッパも重視しなければならずだし
ただBullアーキの失敗は、なんか当初の目論見通りにしてこなかったのが原因とも思える
あれはモジュール単位でコアを増やしやすいようにコアを簡素な設計にしていたが
結局今(Kaveri)になってもコアは4コアどまり、OSも当初はスレッドの割り当て問題でどんくさかった
AMDはそれで周りと調整してから事を進めることを学習したのか知らんが
HSAはちゃんと仲間集めはしているな
>>521
2コア専用ダイって言うのは想像だろ
2コア専用ダイって言うのは想像だろ
>>519
ggrks
ggrks
ブロードウェルは延期だろ
リフレッシュは前倒しw
リフレッシュは前倒しw
525 :,,・´∀`・,,)っ-○○○:2014/05/11(日) 11:25:35.86 ID:FOZtCqCQ
>>522
目が腐ってるの?現実を見ないことにしてるの?
http://www.theregister.co.uk/2013/06/04/intel_silvermont_bay_trail_and_haswell_hopes/
目が腐ってるの?現実を見ないことにしてるの?
http://www.theregister.co.uk/2013/06/04/intel_silvermont_bay_trail_and_haswell_hopes/
Intelの宣伝マンがHaswellRefreshやBroadwellの宣伝を始めたな
527 :,,・´∀`・,,)っ-○○○:2014/05/11(日) 11:29:15.44 ID:FOZtCqCQ
2コア+GT3と4コア+GT2だね
>>525
セレロンのことを言ってると思うんだが
セレロンのことを言ってると思うんだが
>>521
歩留まりが分かってないのはお前だw
ダイサイズが半分になって倍になるのはウエハ上に生成されるパターンの数(歩留まりの分母)
良品数(分子)が倍になっても歩留まりは同じにしかならないし、むしろ専用ダイにして冗長性を失ったことで
良品数は倍未満になって歩留まりは下がる
お前の超理論だと元の歩留まりが50%以上ならダイサイズ半減させると100%を超えることになるんだがおかしいと思わなかったのか?
だからお前は頭が悪いんだよ
歩留まりが分かってないのはお前だw
ダイサイズが半分になって倍になるのはウエハ上に生成されるパターンの数(歩留まりの分母)
良品数(分子)が倍になっても歩留まりは同じにしかならないし、むしろ専用ダイにして冗長性を失ったことで
良品数は倍未満になって歩留まりは下がる
お前の超理論だと元の歩留まりが50%以上ならダイサイズ半減させると100%を超えることになるんだがおかしいと思わなかったのか?
だからお前は頭が悪いんだよ
>>528
妄想じゃなければソース出せばいいだけだな
妄想じゃなければソース出せばいいだけだな
Intel対抗にAPUを作りこんだらチップセットやプラットフォームも世代ごとに強化するから互換性維持は難しいんだよな
特に省電力機能が毎回シビアだから性能競争で勝つには一新することになる
特に省電力機能が毎回シビアだから性能競争で勝つには一新することになる
>>529
まだ歩留まりの意味がわかってなかったのか
歩留まりって言葉には良品率のほかにも意味があるんだよ
加工する場合の、使用原料に対する製品の出来高の比率って意味がな
ウェハあたりの歩留まりって言葉はこっちの意味だって普通わかるだろ
とりあえず辞書を見てこいよ
まだ歩留まりの意味がわかってなかったのか
歩留まりって言葉には良品率のほかにも意味があるんだよ
加工する場合の、使用原料に対する製品の出来高の比率って意味がな
ウェハあたりの歩留まりって言葉はこっちの意味だって普通わかるだろ
とりあえず辞書を見てこいよ
Haswell Refreshって、いわばTrinityに対するRichlandでしょ
ちょっと高クロック、ちょっと消費電力削減。その程度のもの。
ちょっと高クロック、ちょっと消費電力削減。その程度のもの。
534 :,,・´∀`・,,)っ-○○○:2014/05/11(日) 11:56:04.23 ID:FOZtCqCQ
>>528
2コアのほうが面積は小さいんだし、ノートPC向けに大量に作ってるから
Celeronも2コア版使ったほうがコスト的には有利だって理窟はわかるよね
とりあえずG1820のヒートスプレッダはがしてみれば疑問は解決するんじゃね?
俺はそこまでやらないけど。
2コアのほうが面積は小さいんだし、ノートPC向けに大量に作ってるから
Celeronも2コア版使ったほうがコスト的には有利だって理窟はわかるよね
とりあえずG1820のヒートスプレッダはがしてみれば疑問は解決するんじゃね?
俺はそこまでやらないけど。
intelの宣伝するな
>>533
・・すごくね?
・・すごくね?
すごいのはBeemaだろ
ちょっとどころじゃねえぞ
ちょっとどころじゃねえぞ
539 :,,・´∀`・,,)っ-○○○:2014/05/11(日) 12:26:41.47 ID:FOZtCqCQ
Haswellがそもそもなんであんな長方形のダイになってるかって
エッジにメモリインターフェイスとかQPI/DMIとかのインターフェースが
必要だからで
コアを削れば小さくできるかというとそういう単純な話ではない
4コア+GT3e、2コア+GT3、4コア+GT2以外のダイのバリエーションは
ないんじゃないの
メモリ1chなら削れるだろうけど。
エッジにメモリインターフェイスとかQPI/DMIとかのインターフェースが
必要だからで
コアを削れば小さくできるかというとそういう単純な話ではない
4コア+GT3e、2コア+GT3、4コア+GT2以外のダイのバリエーションは
ないんじゃないの
メモリ1chなら削れるだろうけど。
すごいならIntelスレで盛り上がってるしここでも自慢しまくるよ
それが全くないからつまりは微妙なんだよ
それが全くないからつまりは微妙なんだよ
>>443
スマホタブ世代にはRTもいいけどね。
コケタのは、Tegra3がカスだったのもあるが、日本では発売が遅すぎたし、移行が急だった。
Atomの8タブ使って、ストアアプリに慣れたあとだと、すんなり移行できる。
なのでSurfaceは2から本気。MSは初代に全力しちゃったけどね。
スマホタブ世代にはRTもいいけどね。
コケタのは、Tegra3がカスだったのもあるが、日本では発売が遅すぎたし、移行が急だった。
Atomの8タブ使って、ストアアプリに慣れたあとだと、すんなり移行できる。
なのでSurfaceは2から本気。MSは初代に全力しちゃったけどね。
エプダイのTemashタブ、A10-Microに載せ替えたのないかな。
動画再生はAMDが綺麗だよね。
使い比べるとそう思う。
動画再生はAMDが綺麗だよね。
使い比べるとそう思う。
544 :Socket774:2014/05/11(日) 12:56:37.94 ID:UP+EyOK7
3DMark11
intel
Haswell iris GT3が1080
Haswell GT2(HD4400)が890
IvyBridge HD4000が658
AMD
A8-3850M(400SP)が810で Llano
A8-5545M(384SP)が1100 Richland
FX-7500が(384SP)1450 Kaveri
intel
Haswell iris GT3が1080
Haswell GT2(HD4400)が890
IvyBridge HD4000が658
AMD
A8-3850M(400SP)が810で Llano
A8-5545M(384SP)が1100 Richland
FX-7500が(384SP)1450 Kaveri
Kaveriのスライドの3Dmarkは数値的にGPU Scoreの方っぽい
A10-7300≧Iris 5100くらいに見た方がいいかな
A10-7300≧Iris 5100くらいに見た方がいいかな
546 :,,・´∀`・,,)っ-○○○:2014/05/11(日) 13:05:40.92 ID:FOZtCqCQ
>>543
え?
Core 2 Duoのときにクロック上げたバージョン出してP965→P35への
リフレッシュやってるけど?
あれはFSBの定格クロックを上げてクロック倍率を下げたから
OCerには概ね不評だった。
え?
Core 2 Duoのときにクロック上げたバージョン出してP965→P35への
リフレッシュやってるけど?
あれはFSBの定格クロックを上げてクロック倍率を下げたから
OCerには概ね不評だった。
547 :Socket774:2014/05/11(日) 13:13:07.46 ID:lqBZiEuj
>>518
どれがノート用だ?言ってみろ
どれがノート用だ?言ってみろ
548 :,,・´∀`・,,)っ-○○○:2014/05/11(日) 13:14:25.62 ID:FOZtCqCQ
ただクロック上げただけじゃなくて、たとえばキャッシュの読み書きが高速化されてる
http://www.tweaktown.com/articles/6319/intel-core-i7-4790-haswell-refresh-cpu-and-z97-performance-preview/index3.html
http://imagescdn.tweaktown.com/content/6/3/6319_32_intel_core_i7_4790_haswell_refresh_cpu_and_z97_performance_preview.png
http://imagescdn.tweaktown.com/content/6/3/6319_33_intel_core_i7_4790_haswell_refresh_cpu_and_z97_performance_preview.png
しかし8150おっせーなwww
http://www.tweaktown.com/articles/6319/intel-core-i7-4790-haswell-refresh-cpu-and-z97-performance-preview/index3.html
http://imagescdn.tweaktown.com/content/6/3/6319_32_intel_core_i7_4790_haswell_refresh_cpu_and_z97_performance_preview.png
{kind=link}
http://imagescdn.tweaktown.com/content/6/3/6319_33_intel_core_i7_4790_haswell_refresh_cpu_and_z97_performance_preview.png
{kind=link}
しかし8150おっせーなwww
>>543
ステッピング変わってないでしょ?
ステッピング変わってないでしょ?
>>548
値段が違うだろバカかこいつ
値段が違うだろバカかこいつ
551 :,,・´∀`・,,)っ-○○○:2014/05/11(日) 13:35:11.34 ID:FOZtCqCQ
じゃあ同じ値段でi7に勝てるもの作ってくださいよー
勝てないから値下げしたのを「価格あたりの性能に優れてる」なんて見苦しい
言い訳は聞きたくない。
仕事でVisual Studio使うからi5未満の性能なんてありえないのですよ。
APU?俺がリフレッシュルームでくつろいでる時間を倍にしたいんですか?
勝てないから値下げしたのを「価格あたりの性能に優れてる」なんて見苦しい
言い訳は聞きたくない。
仕事でVisual Studio使うからi5未満の性能なんてありえないのですよ。
APU?俺がリフレッシュルームでくつろいでる時間を倍にしたいんですか?
ダイサイズのはるかに大きいチップを安売りしてくれるAMDさんマジ優良企業
利益は悪
利益は悪
553 :,,・´∀`・,,)っ-○○○:2014/05/11(日) 13:40:43.50 ID:FOZtCqCQ
cl.exeをHSA対応したらコンパイルがBA☆KU☆SO☆KUですよね?
なんで対応しないんですか?
HSAはなんでも高速化できる魔法の処理系なんでしょ?
なんで対応しないんですか?
HSAはなんでも高速化できる魔法の処理系なんでしょ?
ゼクス 「私のブールーはじゅうぶん速いさ!」
ちょっと昔、Athlon XPで一番性能の良いコンパイラーがIntel製だった頃を思い出す
今でもそうなのかな?
今でもそうなのかな?
数年ぐらい前に聞いた話だけども、AMD環境で最速のコンパイラはICCってIntelが言ってた
まあ今でも変わらんとは思う
まあ今でも変わらんとは思う
557 :,,・´∀`・,,)っ-○○○:2014/05/11(日) 14:38:25.54 ID:FOZtCqCQ
いちおうOpen64 CompilerのAMD謹製ビルドがAMD推奨コンパイラということには
なってる。Linuxでは、の話だけど。
FXがなかったからOpteron 3380のスコア探してきた。
AMD Opteron 3380(2.6GHz)
https://www.spec.org/cpu2006/results/res2012q4/cpu2006-20121203-25238.html
403.gcc 106/93
※MSI (Test Sponsor: Advanced Micro Devices)
同じくらいのクロックのIntel CPUだとこんな感じ
Xeon E3 1260L v3(2.5GHz)
https://www.spec.org/cpu2006/results/res2013q4/cpu2006-20131007-26596.html
403.gcc 147
Kaveri/Berlinの4コアだと同クロックで単純計算50くらいしかでず、
Haswell4コアより3倍コンパイル時間がかかる計算になるんだが
少なくとも俺みたいにコンパイル終わるまでリフレッシュルーム、みたいな
使い方だと時間給が無駄に食いつぶされることは間違いない。
コンパイルしつつDirectXやOpenGLで3D描画みたいな使い方ならかろうじて
Kaveri/Berlinはいい線いくかもしれないが、そんなことやらなきゃ
いけない業務が思い浮かばない。
なってる。Linuxでは、の話だけど。
FXがなかったからOpteron 3380のスコア探してきた。
AMD Opteron 3380(2.6GHz)
https://www.spec.org/cpu2006/results/res2012q4/cpu2006-20121203-25238.html
403.gcc 106/93
※MSI (Test Sponsor: Advanced Micro Devices)
同じくらいのクロックのIntel CPUだとこんな感じ
Xeon E3 1260L v3(2.5GHz)
https://www.spec.org/cpu2006/results/res2013q4/cpu2006-20131007-26596.html
403.gcc 147
Kaveri/Berlinの4コアだと同クロックで単純計算50くらいしかでず、
Haswell4コアより3倍コンパイル時間がかかる計算になるんだが
少なくとも俺みたいにコンパイル終わるまでリフレッシュルーム、みたいな
使い方だと時間給が無駄に食いつぶされることは間違いない。
コンパイルしつつDirectXやOpenGLで3D描画みたいな使い方ならかろうじて
Kaveri/Berlinはいい線いくかもしれないが、そんなことやらなきゃ
いけない業務が思い浮かばない。
コンパイル速度はFX-8xx0ならそこそこいいんだけどね。
ttp://openbenchmarking.org/prospect/1401165-PL-A107850K704/d20626f048caad8d0d880fea92c9e439149a3b0d
ttp://www.behardware.com/articles/880-8/amd-fx-8350-review-is-amd-back.html
HSAで高速化できるのなら是非やって欲しい所。
ttp://openbenchmarking.org/prospect/1401165-PL-A107850K704/d20626f048caad8d0d880fea92c9e439149a3b0d
ttp://www.behardware.com/articles/880-8/amd-fx-8350-review-is-amd-back.html
HSAで高速化できるのなら是非やって欲しい所。
gpuでコンパイル?w
>>532
お前しつけえなあ
このラインナップに2コアなんてどこにある?
1個だけだろが
赤字で売るけど廃棄するよりマシって数しかねえっつってんだろが
KaveriノートAPU
FX-7600P(35W):..4コア 2.7-3.6GHz/512SP 600-686MHz DDR3-2133x2
A10-7400P(35W):4コア 2.5-3.4GHz/384SP 576-654MHz DDR3-1866x2
A8-7200P(35W):..4コア 2.4-3.3GHz/256SP 553-626MHz DDR3-1866x2
FX-7500(19W):.....4コア 2.1-3.3GHz/384SP 496-553MHz DDR3-1600x2
A10-7300(19W):..4コア 1.9-3.2GHz/384SP 464-553MHz DDR3-1600x2
A8-7100(19W):.....4コア 1.8-3.0GHz/256SP 450-514MHz DDR3-1600x2
A6-7000(17W):.....2コア 2.2-3.0GHz/192SP 494-533MHz DDR3-1600x2
http://pan.baidu.com/share/link?shareid=1332838846&uk=3859845275
お前しつけえなあ
このラインナップに2コアなんてどこにある?
1個だけだろが
赤字で売るけど廃棄するよりマシって数しかねえっつってんだろが
KaveriノートAPU
FX-7600P(35W):..4コア 2.7-3.6GHz/512SP 600-686MHz DDR3-2133x2
A10-7400P(35W):4コア 2.5-3.4GHz/384SP 576-654MHz DDR3-1866x2
A8-7200P(35W):..4コア 2.4-3.3GHz/256SP 553-626MHz DDR3-1866x2
FX-7500(19W):.....4コア 2.1-3.3GHz/384SP 496-553MHz DDR3-1600x2
A10-7300(19W):..4コア 1.9-3.2GHz/384SP 464-553MHz DDR3-1600x2
A8-7100(19W):.....4コア 1.8-3.0GHz/256SP 450-514MHz DDR3-1600x2
A6-7000(17W):.....2コア 2.2-3.0GHz/192SP 494-533MHz DDR3-1600x2
http://pan.baidu.com/share/link?shareid=1332838846&uk=3859845275
561 :,,・´∀`・,,)っ-○○○:2014/05/11(日) 15:45:53.73 ID:FOZtCqCQ
いっぺんgcc自身を-ftree-vectorizeで最適化ビルドかけてみればわかるけど
SIMDで並列化できるコードがほぼ皆無
SIMDで並列化できるコードがほぼ皆無
562 :Socket774:2014/05/11(日) 15:47:59.01 ID:kvJLEGQZ
2コアKaveriなんてどうでも良いが、A8-7600はいつになったら出るんだとは言いたい。
コンパイルにはSMTが効くんだよね
gccやVCのマルチスレッドビルドで、
IntelのHTTですら、40%以上の高効率
gccやVCのマルチスレッドビルドで、
IntelのHTTですら、40%以上の高効率
>>551
あまり性能が上がると、コンパイル中に休憩ができなくなって困るじゃん
あまり性能が上がると、コンパイル中に休憩ができなくなって困るじゃん
>>532
なにすっ呆けたこと言ってるのかと思ったら、お前国語辞典で意味調べたのかよ
使用原料に対する製品の出来高の比率ってそんなん単位が重量とか体積の製品でしか使わねーよボケw
CPUはいつから量り売りするようになったんだよwwwwwwwwwww
じゃあ聞くけど、ウエハ1枚から良品80個と不良品20個が取れたときお前はどう歩留まりを計算するんだ?
80/1で8000%か?こりゃ傑作だなオイwwwwww
なにすっ呆けたこと言ってるのかと思ったら、お前国語辞典で意味調べたのかよ
使用原料に対する製品の出来高の比率ってそんなん単位が重量とか体積の製品でしか使わねーよボケw
CPUはいつから量り売りするようになったんだよwwwwwwwwwww
じゃあ聞くけど、ウエハ1枚から良品80個と不良品20個が取れたときお前はどう歩留まりを計算するんだ?
80/1で8000%か?こりゃ傑作だなオイwwwwww
チップ面積が 1/2 になると、歩留まりは向上するんだが、
半導体メーカー勤務の俺が使わない定義を ID:IvIvCyT3 はどこから?
半導体メーカー勤務の俺が使わない定義を ID:IvIvCyT3 はどこから?
通常、チップ面積が減るほど歩留まりは向上する
ただし極端な例として、通常のチップ100個相当を並べて冗長性を持たせた超巨大チップの場合、
100個のブロックのうちどれか1個でも動けば良いから歩留まりはほぼ100%だろうな
ウェハあたり1個しか取れないだろうけど
ただし極端な例として、通常のチップ100個相当を並べて冗長性を持たせた超巨大チップの場合、
100個のブロックのうちどれか1個でも動けば良いから歩留まりはほぼ100%だろうな
ウェハあたり1個しか取れないだろうけど
>>560
しつこいもなにも、intelの2コアに4コアの不良品が使われてると勘違いしてる馬鹿や
歩留まりの意味を知らない馬鹿が絡んできたから相手しただけなんだがな
文句言うなら>>514と>>529に言ってくれ
しつこいもなにも、intelの2コアに4コアの不良品が使われてると勘違いしてる馬鹿や
歩留まりの意味を知らない馬鹿が絡んできたから相手しただけなんだがな
文句言うなら>>514と>>529に言ってくれ
×歩留まりの意味を知らない馬鹿が絡んできた
○歩留まりの意味を知らない馬鹿だから絡まれた
○歩留まりの意味を知らない馬鹿だから絡まれた
>>565
歩留まりって言葉には%では表せない意味もあるって事だよ
例えば1トンの原料でマンホールの蓋が50個を鋳造できるなら、1トンあたり50個の歩留まり
これを強度計算やり直して新設計で60個できた場合は旧製品に比べて歩留まりが120%になる
マンホールの蓋が計り売りじゃない事はわかるだろ?
>>566
工業関連で使われる定義だ
歩留まりって言葉には%では表せない意味もあるって事だよ
例えば1トンの原料でマンホールの蓋が50個を鋳造できるなら、1トンあたり50個の歩留まり
これを強度計算やり直して新設計で60個できた場合は旧製品に比べて歩留まりが120%になる
マンホールの蓋が計り売りじゃない事はわかるだろ?
>>566
工業関連で使われる定義だ
>>570-571
> 例えば1トンの原料でマンホールの蓋が50個を鋳造できるなら
それ製品一個当たりの標準材料消費量が20kgって言ってるだけなんだけど?
1トン(50個分)の材料投入して仕損等々がなくて良品50個作れたら歩留まり100%、40個なら80%というだけの話
設計変えた?標準材料消費量が変わるだけで歩留まり関係ないんだけど?
> >>566-567に否定されたわけだが
お前がなw
>>566と>>567の前半で言ってるのは冗長性抜きにした一般論の話だ
>>567の後半をよく読めよ
> 例えば1トンの原料でマンホールの蓋が50個を鋳造できるなら
それ製品一個当たりの標準材料消費量が20kgって言ってるだけなんだけど?
1トン(50個分)の材料投入して仕損等々がなくて良品50個作れたら歩留まり100%、40個なら80%というだけの話
設計変えた?標準材料消費量が変わるだけで歩留まり関係ないんだけど?
> >>566-567に否定されたわけだが
お前がなw
>>566と>>567の前半で言ってるのは冗長性抜きにした一般論の話だ
>>567の後半をよく読めよ
>>573
極端な例の方が分かり易いからだろ?
特にお前みたいな馬鹿には
じゃあ聞くけど、100コア中の99コア潰す場合と2モジュール中の1モジュール潰すのはどう違うんだ?
前者は歩留まりが上がるのに後者は下がるのか?
なるほどね〜、PS3のCellが8基あるSPEのうち1つを潰したりしてたけど、あれって歩留まりを下げるだけの無意味な行為だったんだへ〜
極端な例の方が分かり易いからだろ?
特にお前みたいな馬鹿には
じゃあ聞くけど、100コア中の99コア潰す場合と2モジュール中の1モジュール潰すのはどう違うんだ?
前者は歩留まりが上がるのに後者は下がるのか?
なるほどね〜、PS3のCellが8基あるSPEのうち1つを潰したりしてたけど、あれって歩留まりを下げるだけの無意味な行為だったんだへ〜
AMDは昔はウェファー購入で今は良品チップ購入だろ
GFからウェファー購入のときは、ウェファーの駄目チップを下位の2コアに回せたが
良品チップ購入の場合はコアを強制無効にしないと駄目でコスト的に採算合わんだろ。
チップ購入になったおかげでAPUの値段上がったよな。
GFからウェファー購入のときは、ウェファーの駄目チップを下位の2コアに回せたが
良品チップ購入の場合はコアを強制無効にしないと駄目でコスト的に採算合わんだろ。
チップ購入になったおかげでAPUの値段上がったよな。
あー、あとなかなかフルスペックのが出なかったFermiなんかもいい例だな
しかし冗長性の為にダイサイズを増やしても歩留まりが下がるとは知らなかったなぁ
これが事実なら半導体業界に激震が走るねwwww
しかし冗長性の為にダイサイズを増やしても歩留まりが下がるとは知らなかったなぁ
これが事実なら半導体業界に激震が走るねwwww
>>573
現実であり得ない話ではなく極端な例の方がわかりやすいからさ
欠陥のある4コアの中には2コアとしてなら動かせるものが含まれているって事
これが4コアの持つ冗長性の要素、対して2コアの不良は廃棄するしかない
例えばウェハ1枚が4コアマスクなら2個取れる、2コアマスクなら4個とれる面積を有するものとする
ウェハ上には欠陥が一箇所必ずできるものとしよう、ウェハ1枚のコストは4万としようか
4コアマスクなら完璧な4コアが1個、欠陥のある4コアなら1個 → 4コアを4万で売らないと採算とれない
2コアマスクなら完璧な2コアが3個、欠陥のある2コアが1個取れる → 2コアを1.34万で売らないと採算とれない
この段階で歩留まりを判定すると4コアの歩留まりは50%、2コアの歩留まりは75%で2コアのが歩留まりは良い
しかし、ここに冗長性の要素を加味する(4コアの中には2コアで動くものがある)とどうなるかというと
4コアマスクの歩留まりは4コアが1個に2コアが1個取れウェハあたりの製品歩留まりは100%になる
これに先の価格設定を当てはめると4コアを4万、2コアを1.34万で売る事になるので利益は増える
あるいは逆にウェハコスト4万ベースに価格設定するなら4コアと2コアの単価をもっと下げてもいいことになる
実際にはこんな単純な話ではないが、こんな感じで冗長性を加味するか否かで話が変わるって事さ
現実であり得ない話ではなく極端な例の方がわかりやすいからさ
欠陥のある4コアの中には2コアとしてなら動かせるものが含まれているって事
これが4コアの持つ冗長性の要素、対して2コアの不良は廃棄するしかない
例えばウェハ1枚が4コアマスクなら2個取れる、2コアマスクなら4個とれる面積を有するものとする
ウェハ上には欠陥が一箇所必ずできるものとしよう、ウェハ1枚のコストは4万としようか
4コアマスクなら完璧な4コアが1個、欠陥のある4コアなら1個 → 4コアを4万で売らないと採算とれない
2コアマスクなら完璧な2コアが3個、欠陥のある2コアが1個取れる → 2コアを1.34万で売らないと採算とれない
この段階で歩留まりを判定すると4コアの歩留まりは50%、2コアの歩留まりは75%で2コアのが歩留まりは良い
しかし、ここに冗長性の要素を加味する(4コアの中には2コアで動くものがある)とどうなるかというと
4コアマスクの歩留まりは4コアが1個に2コアが1個取れウェハあたりの製品歩留まりは100%になる
これに先の価格設定を当てはめると4コアを4万、2コアを1.34万で売る事になるので利益は増える
あるいは逆にウェハコスト4万ベースに価格設定するなら4コアと2コアの単価をもっと下げてもいいことになる
実際にはこんな単純な話ではないが、こんな感じで冗長性を加味するか否かで話が変わるって事さ
とりあえず落ち着いて、後藤氏の解説図でも見よう
ttp://pc.watch.impress.co.jp/img/pcw/docs/359/288/html/kaigai-04.jpg.html
ttp://pc.watch.impress.co.jp/img/pcw/docs/359/288/html/kaigai-04.jpg.html
{kind=link}
これウェファーに突っ込んだら負けなんだろうか
ウェファーの方が正しい表記だと思ったが
相変わらずこのスレだけは賑わっているな。
新製品が出てもスレが過疎のままで鳴かず飛ばずの他社と違って常に良い製品を創り続けているという証拠だな。
逆に過疎スレな他社は何をどう取り繕っても魅力ある製品を創る力が無い事の証左でしかない。
新製品が出てもスレが過疎のままで鳴かず飛ばずの他社と違って常に良い製品を創り続けているという証拠だな。
逆に過疎スレな他社は何をどう取り繕っても魅力ある製品を創る力が無い事の証左でしかない。
>>572
繰り返しになるが、歩留まりって言葉には良品率とは別の意味もあるんだよ
原料消費量が変わっても製品として同等の機能が認められるなら、それは同じ製品なんだよ
この場合の歩留まりの意味は1トンの原料あたり何個のマンホールの蓋ができるかって事なんだ
4コアの機能制限で2コアを出そうが専用ダイで出そうが、同等性能なら同じ製品と言えるけど
ウェハあたりの取れるチップの数は違ってくるだろ
これで理解できないならもう知らん
繰り返しになるが、歩留まりって言葉には良品率とは別の意味もあるんだよ
原料消費量が変わっても製品として同等の機能が認められるなら、それは同じ製品なんだよ
この場合の歩留まりの意味は1トンの原料あたり何個のマンホールの蓋ができるかって事なんだ
4コアの機能制限で2コアを出そうが専用ダイで出そうが、同等性能なら同じ製品と言えるけど
ウェハあたりの取れるチップの数は違ってくるだろ
これで理解できないならもう知らん
583 :Socket774:2014/05/11(日) 20:28:31.14 ID:kvJLEGQZ
>>574
567はおまえの発言を否定している側なんだが、何故味方を得たかのような発言をしているんだ?
567はおまえの発言を否定している側なんだが、何故味方を得たかのような発言をしているんだ?
たしかにあいかわらず異様な熱気だな
良い製品を作ることと
売れる製品を作ることと
夢を与えて市場活性化させること
活気のない自作PCは、もう一回ぐらい化けて欲しいな
良い製品を作ることと
売れる製品を作ることと
夢を与えて市場活性化させること
活気のない自作PCは、もう一回ぐらい化けて欲しいな
>>587
だよね
だよね
589 :,,・´∀`・,,)っ-○○○:2014/05/11(日) 20:35:45.18 ID:FOZtCqCQ
Haswellの2コア+GT2には
4コア+GT2の2コア無効版と2コア+GT3のGPU半分無効版の
2通りが存在する。それだけの話でしょ。
4コア+GT2の2コア無効版と2コア+GT3のGPU半分無効版の
2通りが存在する。それだけの話でしょ。
>>589
それは本当なのか。そう、Intelはいっているのか?
それは本当なのか。そう、Intelはいっているのか?
語源はお菓子のウェファーでしょ
味覇「呼んだ?」
595 :,,・´∀`・,,)っ-○○○:2014/05/11(日) 21:51:20.08 ID:FOZtCqCQ
<丶`∀´><ウェハ(ry
>>584
猿でも分かるように話してやる
ウエハの面積が200、2モジュールのダイサイズが2、1モジュールが1、
それぞれのモジュールに不良が発生する確率を1/2とするだろ?
1基潰すの前提で2モジュールのダイを作る場合
・ダイが100個作れる
・1モジュール以上動く製品は(確率上)75個作れる
・歩留まりは75/100で75%
1モジュールの専用ダイを作る場合
・ダイが200個作れる
・1モジュールが動作する製品は(確率上)100個作れる
・歩留まりは100/200で50%
歩留まりの単位が「個」じゃなくて「%」だということをよく考えろ
「%で表せない」とか言い出すのは場外ホームラン級の馬鹿だ
猿でも分かるように話してやる
ウエハの面積が200、2モジュールのダイサイズが2、1モジュールが1、
それぞれのモジュールに不良が発生する確率を1/2とするだろ?
1基潰すの前提で2モジュールのダイを作る場合
・ダイが100個作れる
・1モジュール以上動く製品は(確率上)75個作れる
・歩留まりは75/100で75%
1モジュールの専用ダイを作る場合
・ダイが200個作れる
・1モジュールが動作する製品は(確率上)100個作れる
・歩留まりは100/200で50%
歩留まりの単位が「個」じゃなくて「%」だということをよく考えろ
「%で表せない」とか言い出すのは場外ホームラン級の馬鹿だ
>>596
>歩留まりの単位が「個」じゃなくて「%」だということをよく考えろ
それ歩留まり率のことじゃね?
1tあたり何個とか、ウェハ1枚あたり何個ってのも比率じゃん
歩留まりの単位が「%」限定ってそんな決まりあるの?
>歩留まりの単位が「個」じゃなくて「%」だということをよく考えろ
それ歩留まり率のことじゃね?
1tあたり何個とか、ウェハ1枚あたり何個ってのも比率じゃん
歩留まりの単位が「%」限定ってそんな決まりあるの?
600 :Socket774:2014/05/11(日) 22:44:30.91 ID:kvJLEGQZ
>>596
何故不良ダイが発生するかの理由を全く理解していない恥ずかしいヤツだなw
Fermiの話にしても、GF100のフルスペックは512CUDAコアに対してGeForceGTX480が480CUDAコアなのは、『480で計画していたけど、冗長性を持たせるために512でダイを作成した』のでは無い。
『最上位は512で、不良があるダイの一部を殺して下位モデルで計画していたけど、歩留まりが悪すぎて最上位でも480にせざるを得なかった』が正解だね。
何故不良ダイが発生するかの理由を全く理解していない恥ずかしいヤツだなw
Fermiの話にしても、GF100のフルスペックは512CUDAコアに対してGeForceGTX480が480CUDAコアなのは、『480で計画していたけど、冗長性を持たせるために512でダイを作成した』のでは無い。
『最上位は512で、不良があるダイの一部を殺して下位モデルで計画していたけど、歩留まりが悪すぎて最上位でも480にせざるを得なかった』が正解だね。
歩留まりの歩ってのが割合、比率を意味することばだってことを理解してないのがいるようだな。
>>598
めんどくせーからウィキペから引用な
> 歩留まりあるいは歩止まり(ぶどまり)とは、製造など生産全般において、「原料(素材)の投入量から
> 期待される生産量に対して、実際に得られた製品生産数(量)比率」のことである
~~~~~~~~~~~~~~~~~~
ダイサイズが半分になったら、期待される生産量はどうなる?
めんどくせーからウィキペから引用な
> 歩留まりあるいは歩止まり(ぶどまり)とは、製造など生産全般において、「原料(素材)の投入量から
> 期待される生産量に対して、実際に得られた製品生産数(量)比率」のことである
~~~~~~~~~~~~~~~~~~
ダイサイズが半分になったら、期待される生産量はどうなる?
AMD Could Feature Next Generation HBM Memory on Volcanic Islands 2.0 Graphics Cards - Allegedly Launching in 2H 2014
http://wccftech.com/amd-feature-generation-hbm-memory-volcanic-islands-20-graphics-cards-allegedly-launching-2h-2014
2H 2014にHBM採用RADEONだってよ、隠し球が山ほどあるな
http://wccftech.com/amd-feature-generation-hbm-memory-volcanic-islands-20-graphics-cards-allegedly-launching-2h-2014
2H 2014にHBM採用RADEONだってよ、隠し球が山ほどあるな
>>600
確かに最初からその為にデザインしたわけではないが、一部潰した物を完成品と
決めた時点で冗長性を持たせたことになるでしょ
冗長性が無駄ならGF100なんて即廃棄してGTX480専用のCUDAコアx480のダイを作るべきだったよなぁ
実際はしなかったけどw
確かに最初からその為にデザインしたわけではないが、一部潰した物を完成品と
決めた時点で冗長性を持たせたことになるでしょ
冗長性が無駄ならGF100なんて即廃棄してGTX480専用のCUDAコアx480のダイを作るべきだったよなぁ
実際はしなかったけどw
>>602
wikiソースでドヤ顔とかないわー
wikiソースでドヤ顔とかないわー
>>603
それ、後藤の記事が正しいとしたらWide I/Oのことだな、モバイル用?でも劇的進化には変わりないかな。
http://pc.watch.impress.co.jp/docs/column/kaigai/20130412_595546.html
それ、後藤の記事が正しいとしたらWide I/Oのことだな、モバイル用?でも劇的進化には変わりないかな。
http://pc.watch.impress.co.jp/docs/column/kaigai/20130412_595546.html
>>596の計算だとダイサイズ半分なら25個も多く出来るけどそれはいいの?
609 :Socket774:2014/05/11(日) 23:21:31.64 ID:kvJLEGQZ
>>602
1モジュールが正常動作するチップが欲しい時に、2モジュール製品を作って1モジュール殺していたら、
どれだけ歩留まり上げでも『期待される生産量』の半分以下しかチップが取れないじゃ無いですかー。
1モジュールが正常動作するチップが欲しい時に、2モジュール製品を作って1モジュール殺していたら、
どれだけ歩留まり上げでも『期待される生産量』の半分以下しかチップが取れないじゃ無いですかー。
>>605
ではお好みのソースをどうぞ
http://kotobank.jp/word/歩留まり
http://e-words.jp/w/E6ADA9E79599E381BEE3828A.html
http://www.sophia-it.com/content/yield+rate
>>608
だから割合だって何度も言ってるじゃん
>>609
そこは否定しないよ
そもそも俺は>>313の2行目に噛み付いただけだからな
ではお好みのソースをどうぞ
http://kotobank.jp/word/歩留まり
http://e-words.jp/w/E6ADA9E79599E381BEE3828A.html
http://www.sophia-it.com/content/yield+rate
>>608
だから割合だって何度も言ってるじゃん
>>609
そこは否定しないよ
そもそも俺は>>313の2行目に噛み付いただけだからな
ある程度作って、出来損ないをまとめて安く売るのは上等手段だろ。
4コアで20000円として2コアで6000円なら4コア作ったほうが利益率高い。
4コア動いても20000円で在庫になるなら6000円で売ったほうが売り上げになる。
2コアで専用設計するとしたらまとまった受注が確保されてないとありえない。
4コアで20000円として2コアで6000円なら4コア作ったほうが利益率高い。
4コア動いても20000円で在庫になるなら6000円で売ったほうが売り上げになる。
2コアで専用設計するとしたらまとまった受注が確保されてないとありえない。
>>603
APUに乗せたいのう
APUに乗せたいのう
>>610
ソースの持ち込みはありですか?
http://dictionary.goo.ne.jp/leaf/jn2/194167/m0u/%E6%AD%A9%E7%95%99%E3%81%BE%E3%82%8A/
ソースの持ち込みはありですか?
http://dictionary.goo.ne.jp/leaf/jn2/194167/m0u/%E6%AD%A9%E7%95%99%E3%81%BE%E3%82%8A/
そもそも1モジュールのチップなんて欲しくて作ってるわけじゃないからな
歩留まりの関係上半分つぶさないといけないものが大量に出ると言うだけで
2コア4コアにGT3,3、3eの組み合わせ自由なインテルとは需要も生産数も違うんだ
全部乗ったでかいチップでまともに動くものを欲しい分用意する間に下にまわした物は必要以上の数になってしまうと言うだけ
歩留まりの関係上半分つぶさないといけないものが大量に出ると言うだけで
2コア4コアにGT3,3、3eの組み合わせ自由なインテルとは需要も生産数も違うんだ
全部乗ったでかいチップでまともに動くものを欲しい分用意する間に下にまわした物は必要以上の数になってしまうと言うだけ
>>607
その安価先の記事を上から下まで読んだ?
その安価先の記事を上から下まで読んだ?
デスクトップは4コアA10ばかり、モバイルも2コア品は一種しかない状態を鑑みるにGF28nmの歩留まりは良いと推測される
そーゆう意味ではモジュール構造だと採算合わないと判断したんだろうな、
辞めるってことは。性能面での改善もあるだろうけど、8コアしか売れないしな・・・
辞めるってことは。性能面での改善もあるだろうけど、8コアしか売れないしな・・・
>>616
なんの話?間違えてた?
なんの話?間違えてた?
せっかくだから
>1tあたり何個とか、ウェハ1枚あたり何個ってのも比率じゃん
こっちにも突っ込んどくか
ウエハ1枚辺りって何?100mmも300mmも450mmも同じ1枚?
良品数をそれで割って何が分かるの?
>1tあたり何個とか、ウェハ1枚あたり何個ってのも比率じゃん
こっちにも突っ込んどくか
ウエハ1枚辺りって何?100mmも300mmも450mmも同じ1枚?
良品数をそれで割って何が分かるの?
hUMAを一番歓迎しているのは、AMDのiGPUのドライバ部隊だろうよ。
メモリー・メモリ間コピーがなくなるだけで、コードが単純になるからな。
将来的にはCPU側とiGPU側の演算器が共有化できるかもな。
ブルドーザのコンセプトの発展形だな。
結局、CPUとGPUは同時に使わないことが多いのだから、共有化できればトランジスタを節約できるよな。
メモリー・メモリ間コピーがなくなるだけで、コードが単純になるからな。
将来的にはCPU側とiGPU側の演算器が共有化できるかもな。
ブルドーザのコンセプトの発展形だな。
結局、CPUとGPUは同時に使わないことが多いのだから、共有化できればトランジスタを節約できるよな。
日本語は学校でならえよwww
626 :,,・´∀`・,,)っ-○○○:2014/05/11(日) 23:55:26.77 ID:FOZtCqCQ
歩留まり議論のせいでホルホル老害くんが息をしていない
上は用語が統一できていないから混乱している気がする
>ウエファ上に作られた良品チップの個数を歩留りと呼び、ウエファ上の全チップに対する比率を歩留り率と呼ぶ。
マイクロプロセサの実装コスト - チップの値段はどのようにして決まるのか
http://news.mynavi.jp/column/architecture/024/
>ウエファ上に作られた良品チップの個数を歩留りと呼び、ウエファ上の全チップに対する比率を歩留り率と呼ぶ。
マイクロプロセサの実装コスト - チップの値段はどのようにして決まるのか
http://news.mynavi.jp/column/architecture/024/
>>627
やっぱり歩留まりの意味がわかってなかったのはID:zYrqdXQ5じゃないか
やっぱり歩留まりの意味がわかってなかったのはID:zYrqdXQ5じゃないか
>>624
数字までしか見てないw
数字までしか見てないw
団子も暇そーだなww
631 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 00:09:19.74 ID:N3oQTwZC
とりあえず8〜14コア中1〜2コア死んでても数1000ドルの上位製品として
出せるXeonは異常に儲かる
出せるXeonは異常に儲かる
そんだけ儲かるのにリストラってことは大所帯を食わすほど儲かってないってことだろ。
633 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 00:20:12.36 ID:N3oQTwZC
2012年に25%以上も従業員切ってまだ赤字が出てる上、長期社債が20億ドルも
残ってるAMDと比べたら健全じゃないかね
赤字を出さないのは大前提、不採算事業を切って利益の最大化をしないと
株主が納得しないからね
残ってるAMDと比べたら健全じゃないかね
赤字を出さないのは大前提、不採算事業を切って利益の最大化をしないと
株主が納得しないからね
数が出ない高級品では固定費は出ないよ。
量産品があってはじめて減価償却費や人件費が出る。
量産品があってはじめて減価償却費や人件費が出る。
インテルの人員整理は、2年おきくらいの定例行事だよな
事業を買い付けてきて、駄目なら見切りを付ける
というサイクルがそこそこ回っているという点で、資金力はうらやましい
事業を買い付けてきて、駄目なら見切りを付ける
というサイクルがそこそこ回っているという点で、資金力はうらやましい
赤字があっても倒産しなきゃある意味あり。不採算だろうが前に進んでる内は
金だしてくれるところがあると思うぞ。
金だしてくれるところがあると思うぞ。
2年は言い過ぎだが、4〜5年ぐらいごとにやっているはず
なんか景気の波に合わせてるかのようだが……
そういえば以前の人員整理はリーマンショックを受けてだった気がする
なんか景気の波に合わせてるかのようだが……
そういえば以前の人員整理はリーマンショックを受けてだった気がする
639 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 00:28:42.20 ID:N3oQTwZC
Seattleって200mm^2以上のダイになるようだけど数が出る見込みはあるのかね?
まあ、A57のIPは買って来たものだから自前設計するよりは安く済んでるのかも
しれないが。
まあ、A57のIPは買って来たものだから自前設計するよりは安く済んでるのかも
しれないが。
Denvertonと殴り合う展開になるとまあダメなので、
ARMであることを利用してどう差別化するか、みたいな話になるんだろう >Seattle
ARMであることを利用してどう差別化するか、みたいな話になるんだろう >Seattle
とりあえず、作ってみました的な感じはするけど、Group Hug仕様ぽいし注目はされるんじゃね。
次世代もARMだし、売れれば何でも良い感はあるけど、なりふり構ってらんねーんだよきっとw
次世代もARMだし、売れれば何でも良い感はあるけど、なりふり構ってらんねーんだよきっとw
いい加減歩留まり論議やめろお前らw
次世代じゃない話題で埋めるんじゃない
そんなもんは雑談スレでやれ
せっかくの新しいネタが流れたじゃないか
AMD Could Feature Next Generation HBM Memory on Volcanic Islands 2.0 Graphics Cards - Allegedly Launching in 2H 2014
http://wccftech.com/amd-feature-generation-hbm-memory-volcanic-islands-20-graphics-cards-allegedly-launching-2h-2014
次世代メモリの本命HBM搭載のRADEONが後数ヶ月で出てくるらしいぞ
次世代じゃない話題で埋めるんじゃない
そんなもんは雑談スレでやれ
せっかくの新しいネタが流れたじゃないか
AMD Could Feature Next Generation HBM Memory on Volcanic Islands 2.0 Graphics Cards - Allegedly Launching in 2H 2014
http://wccftech.com/amd-feature-generation-hbm-memory-volcanic-islands-20-graphics-cards-allegedly-launching-2h-2014
次世代メモリの本命HBM搭載のRADEONが後数ヶ月で出てくるらしいぞ
やっぱGFでRADEON作るようだな
AMD 2014-2016 GPU roadmap
http://videocardz.com/50472/amd-launch-new-flagship-radeon-graphics-card-summer
28nm TSMC 1H 2014 : Hawaii, VI 1.0
28nm GlobalFoundries 2H 2014 : Iceland & Tonga, VI 2.0
28nm GlobalFoundries 1H 2015 : Maui, VI 2.0
20nm GlobalFoundries 2H 2015 : Fiji and Treasure, PI 1.0
20nm GlobalFoundries 1H 2016 : Bermuda, PI 1.0
14nm GlobalFoundries 2H 2016 : Mid-GPU and Low-GPU, PI 2.0
14nm GlobalFoundries 1H 2017 : High-GPU, PI 2.0
AMD 2014-2016 GPU roadmap
http://videocardz.com/50472/amd-launch-new-flagship-radeon-graphics-card-summer
28nm TSMC 1H 2014 : Hawaii, VI 1.0
28nm GlobalFoundries 2H 2014 : Iceland & Tonga, VI 2.0
28nm GlobalFoundries 1H 2015 : Maui, VI 2.0
20nm GlobalFoundries 2H 2015 : Fiji and Treasure, PI 1.0
20nm GlobalFoundries 1H 2016 : Bermuda, PI 1.0
14nm GlobalFoundries 2H 2016 : Mid-GPU and Low-GPU, PI 2.0
14nm GlobalFoundries 1H 2017 : High-GPU, PI 2.0
28nmの性能はTSMCよりGFの方がかなり良かったし、製造ラインもAMD専用だからね
しかし、TSMCの方ではもう作らないのかね
28nmはともかく20/14nmはTSMCも使わないと製造量が全く足りない気がするんだけど
しかし、TSMCの方ではもう作らないのかね
28nmはともかく20/14nmはTSMCも使わないと製造量が全く足りない気がするんだけど
28nmはGFの方が性能良いからそっちで作ったほうがいいんだろうけどその先はどうだろうね
でも両方で作ったところでみんなGF産しか買わなくなっちゃったりするんでない
kabiniとbeemaの差を見た後なら尚更
でも両方で作ったところでみんなGF産しか買わなくなっちゃったりするんでない
kabiniとbeemaの差を見た後なら尚更
ああ、直接比較できないものならいいのか
モバイル向けはTSMCで作る、あるいはその逆とかはやりそうだね
モバイル向けはTSMCで作る、あるいはその逆とかはやりそうだね
650 :Socket774:2014/05/12(月) 02:17:22.72 ID:4y4ui9jG
団子の殺害って合法化できないのかね?
今日掃除してたら雷鳥でてきた。
あまりの懐かしさに・・・捨てた。
あまりの懐かしさに・・・捨てた。
Spitfireなら飾ってあるけどな
ついこないだのConference Callで、GPUの出荷は既に開始しているとの言があった。
Kabiniに関しては、GFとTSMCの双方でほぼ同じものを作っている。(AM1がGF、BGAがTSMC)
少なくともこの数年で、二つのファウンダウリにまたがって複数の製品を、時期はともかく製造しえる、という能力を整備しつつある。
コンソールの製造を請け負っている以上は必要とされる能力ではある。ただこれをAPU/GPUにどう適応するかはあまり読めない。
GFの20nmはあまり芳しいとは言いがたいから、TSMCに行きそうな気もする。とはいえいったんは消えた28nmSHPを開発していたGFであったから
裏で何かやっているかもしれない。
Kabiniに関しては、GFとTSMCの双方でほぼ同じものを作っている。(AM1がGF、BGAがTSMC)
少なくともこの数年で、二つのファウンダウリにまたがって複数の製品を、時期はともかく製造しえる、という能力を整備しつつある。
コンソールの製造を請け負っている以上は必要とされる能力ではある。ただこれをAPU/GPUにどう適応するかはあまり読めない。
GFの20nmはあまり芳しいとは言いがたいから、TSMCに行きそうな気もする。とはいえいったんは消えた28nmSHPを開発していたGFであったから
裏で何かやっているかもしれない。
Tongaはこないだリークしてたね
AMD Radeon R9 200 Series
https://compubench.com/device-environment.jsp?config=20101996
Tonga 32CU-800MHz 2GB
AMD Radeon R9 200 Series
https://compubench.com/device-environment.jsp?config=20101996
Tonga 32CU-800MHz 2GB
Icelandが270X後継でTongaが280X後継っぽいね
HBMは来年以降だと思ってたらもうすぐ実装製品が出るのか
APUでも対応するとかいう話があったような気がするけどどうなったんだろうか
APUでも対応するとかいう話があったような気がするけどどうなったんだろうか
658 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 07:03:47.89 ID:N3oQTwZC
>>636
> 不採算だろうが前に進んでる内は
R&D費まで削減して交代してるからもうダメだってことじゃねーかwwww
HSA Foundationも会員が集まらないし大変だな
http://deliciousstat.com/domain/hsafoundation.com
2chまとめブログ未満の価値って・・・
> 不採算だろうが前に進んでる内は
R&D費まで削減して交代してるからもうダメだってことじゃねーかwwww
HSA Foundationも会員が集まらないし大変だな
http://deliciousstat.com/domain/hsafoundation.com
2chまとめブログ未満の価値って・・・
おわた
ウェハーの欠陥はランダムではなく局所的に分布しているそうな
しかもほとんど欠陥のないウェハーと欠陥が多いウェハーに二極化している
http://pc.watch.impress.co.jp/docs/news/event/20130425_597463.html
しかもほとんど欠陥のないウェハーと欠陥が多いウェハーに二極化している
http://pc.watch.impress.co.jp/docs/news/event/20130425_597463.html
>>658
サイトのアクセス解析してどうしようってんだお前は・・・
お前が気づいてないだけで最近Supportersにstreamcomputingとmobicaが追加されたしAcademicにも2校増えてる
サイトの更新が滞ってようが中の人らは動いてるってこった。サイトも近いうちにWordPressベースからSharePointベースに変わるかもしれんなぁ
http://streamcomputing.eu/
http://streamcomputing.eu/blog/2014-02-05/heterogeneous-systems-architecture-hsa-the-tldr/
http://www.mobica.com/
streamcomputingはなかなか面白そうなところだな
”We have helped several R&D and product-development departments get up-to-speed and get things done with OpenCL and HPC.”
サイトのアクセス解析してどうしようってんだお前は・・・
お前が気づいてないだけで最近Supportersにstreamcomputingとmobicaが追加されたしAcademicにも2校増えてる
サイトの更新が滞ってようが中の人らは動いてるってこった。サイトも近いうちにWordPressベースからSharePointベースに変わるかもしれんなぁ
http://streamcomputing.eu/
http://streamcomputing.eu/blog/2014-02-05/heterogeneous-systems-architecture-hsa-the-tldr/
http://www.mobica.com/
streamcomputingはなかなか面白そうなところだな
”We have helped several R&D and product-development departments get up-to-speed and get things done with OpenCL and HPC.”
662 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 07:59:39.83 ID:N3oQTwZC
28nm世代のGPUでHBMはまだ早い気がする
まだ7GbpsのGDDR5使えば粘れると思うんだがな
まだ7GbpsのGDDR5使えば粘れると思うんだがな
>>662
お前はずーっと明後日の方向ばかり見ている。見るべきところを見ていない
OpenCL + Java Acceleration on Mobile Promises 8x speedup with 3x Less Power
http://techenablement.com/opencl-acceleration-on-mobile-promises-8x-speedup-with-3x-less-power/
お前はずーっと明後日の方向ばかり見ている。見るべきところを見ていない
OpenCL + Java Acceleration on Mobile Promises 8x speedup with 3x Less Power
http://techenablement.com/opencl-acceleration-on-mobile-promises-8x-speedup-with-3x-less-power/
665 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 08:03:02.79 ID:N3oQTwZC
AndroidもiOSもJavaVMの実行が許可されてないよ?
Androidのあれ?JavaじゃなくてDarvikです
Androidのあれ?JavaじゃなくてDarvikです
ACML 6 is the first version of ACML that attempts to assign work between host-side native compute devices (i.e. traditional x86 cores) and OpenCL compute devices.
http://developer.amd.com/community/blog/2014/05/06/acmlscript/
http://developer.amd.com/community/blog/2014/05/06/acmlscript/
667 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 08:07:13.35 ID:N3oQTwZC
これならまだわかるんだ。
車載コンピュータの標準化団体だけでこれだけの会員が集まるわけで
NVIDIAがCUDAを使った空間認識やろうとしてるのもこの団体の活動の一環
http://www.genivi.org/genivi-members
より守備範囲が広くて会員数少ないってどういうことなんだよHSAF
車載コンピュータの標準化団体だけでこれだけの会員が集まるわけで
NVIDIAがCUDAを使った空間認識やろうとしてるのもこの団体の活動の一環
http://www.genivi.org/genivi-members
より守備範囲が広くて会員数少ないってどういうことなんだよHSAF
>プログラマ1〜2人月分しか雇えない程度の年会費でいったい何ができるの
そりゃ個人屋は役立たずだっていう自虐か?
そりゃ個人屋は役立たずだっていう自虐か?
669 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 08:12:36.76 ID:N3oQTwZC
ACMLの利用率なんてHPC業界では1割にも満たないでしょ
Intel MKLのほうがドキュメントも多いし
AMDローカルの最適化ライブラリなんて誰も使わない
本当に広く使われたいなら現行AMDプロセッサでは未対応の
AVX2やAVX-512にも対応しないとね。
我田引水はもう流行らない。
Intel MKLのほうがドキュメントも多いし
AMDローカルの最適化ライブラリなんて誰も使わない
本当に広く使われたいなら現行AMDプロセッサでは未対応の
AVX2やAVX-512にも対応しないとね。
我田引水はもう流行らない。
670 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 08:15:39.21 ID:N3oQTwZC
>>668
HSAはそれだけソフトウェア産業から見限られてるってこと
少ない会費でもいろんな数百の企業が金を出し合えば100人月、200人月分くらいは
確保できるだろ?
HSAを使いやすくなることにメリットを感じる企業がほとんどいないんだから当然だ。
今じゃない。
未来が期待されていない。
HSAはそれだけソフトウェア産業から見限られてるってこと
少ない会費でもいろんな数百の企業が金を出し合えば100人月、200人月分くらいは
確保できるだろ?
HSAを使いやすくなることにメリットを感じる企業がほとんどいないんだから当然だ。
今じゃない。
未来が期待されていない。
671 :Socket774:2014/05/12(月) 08:23:05.88 ID:D7qwKRr2
672 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 08:23:16.26 ID:N3oQTwZC
http://pc.watch.impress.co.jp/docs/column/kaigai/20140417_644632.html
> Huang氏はマシンラーニングでのCUDAが浸透しつつあることを下のスライドで
> 紹介した。このスライドで日本にとってのポイントは、自動車電装機器メーカーの
> デンソーが加わっていることだ。デンソーはGTCで、歩行者認識などをディープ
> ニューラルネットワークで行なう研究結果を発表している。
GENIVI Allianceに参加してないAMD, HSA Foundation
その結果がカーナビ大手のデンソーはHSA Foundationに参加せず
NVIDIA CUDAを支持という結末
> Huang氏はマシンラーニングでのCUDAが浸透しつつあることを下のスライドで
> 紹介した。このスライドで日本にとってのポイントは、自動車電装機器メーカーの
> デンソーが加わっていることだ。デンソーはGTCで、歩行者認識などをディープ
> ニューラルネットワークで行なう研究結果を発表している。
GENIVI Allianceに参加してないAMD, HSA Foundation
その結果がカーナビ大手のデンソーはHSA Foundationに参加せず
NVIDIA CUDAを支持という結末
>>667
AMDはそう言う団体に加入して、少しでも自動車分野開拓をしたほうが良いって思うんだよな
AMDはそう言う団体に加入して、少しでも自動車分野開拓をしたほうが良いって思うんだよな
現在測量分野で車載のレーザースキャンってのがあるけど
http://www.nais21.co.jp/modules/pico0/?content_id=77
デンソーやアウディなんかの画像認識データをクラウド側で集約して
ストリートビュー的なマップを(障害物情報入り)作成してやると
自動運転コースが簡単に出来上がりそう
信号や対人なんかのリアルタイム性の高いものはクライアント側でやるだろうけど
http://www.nais21.co.jp/modules/pico0/?content_id=77
デンソーやアウディなんかの画像認識データをクラウド側で集約して
ストリートビュー的なマップを(障害物情報入り)作成してやると
自動運転コースが簡単に出来上がりそう
信号や対人なんかのリアルタイム性の高いものはクライアント側でやるだろうけど
675 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 08:40:34.52 ID:N3oQTwZC
しかもちゃっかりARMをはじめ、TI、Samsung、Qualcomm、Marvell、
FreescaleなどのARM関連主力企業もこぞってGENIVI Allianceに加盟してるし
これらの企業はいろんな方面にとりあえず出資してるから
HSAがコケても痛くもないわけだ。
AMDが参加してない団体のもとで、ヘテロジニアスコンピューティングの
産業活用の成果が次々とあがっていく。
AMDはThrustやjcudaの物真似ライブラリ作ってるだけじゃなくて
GPGPU活用が期待できる産業の研究をもう少ししたほうがいいと
思うんだけどね
FreescaleなどのARM関連主力企業もこぞってGENIVI Allianceに加盟してるし
これらの企業はいろんな方面にとりあえず出資してるから
HSAがコケても痛くもないわけだ。
AMDが参加してない団体のもとで、ヘテロジニアスコンピューティングの
産業活用の成果が次々とあがっていく。
AMDはThrustやjcudaの物真似ライブラリ作ってるだけじゃなくて
GPGPU活用が期待できる産業の研究をもう少ししたほうがいいと
思うんだけどね
>>669
悪いけど1割もあったら充分だぞ、今のAMDにはな。
streamcomputingはHPC関係らしいな、いろいろ書いてるわ
Building a 150 TFLOPS cluster with Accelerators in 2014
http://streamcomputing.eu/blog/2014-04-08/accelerators-hpc-2014/
I have been astonished by the FUD around OpenCL;but that, at least, says they are afraid of the open standard.
”openCLに対してのFUDがひどい、彼らはそれがオープンスタンダードになることを恐れている。”だと
確かに身近にそんな奴がいるような気がするなぁ
悪いけど1割もあったら充分だぞ、今のAMDにはな。
streamcomputingはHPC関係らしいな、いろいろ書いてるわ
Building a 150 TFLOPS cluster with Accelerators in 2014
http://streamcomputing.eu/blog/2014-04-08/accelerators-hpc-2014/
I have been astonished by the FUD around OpenCL;but that, at least, says they are afraid of the open standard.
”openCLに対してのFUDがひどい、彼らはそれがオープンスタンダードになることを恐れている。”だと
確かに身近にそんな奴がいるような気がするなぁ
677 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 08:58:01.86 ID:N3oQTwZC
車は「走るIoT端末」になるだろうね。
車が収集したデータはクラウドに蓄積され渋滞予測や交通事故のリスク分析など
さまざまな方面に活用されることになる。
世界的ですからね
乗るしかない、このビッグデータに
車が収集したデータはクラウドに蓄積され渋滞予測や交通事故のリスク分析など
さまざまな方面に活用されることになる。
世界的ですからね
乗るしかない、このビッグデータに
678 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 09:02:07.72 ID:N3oQTwZC
StreamComputingってAMDに傾倒してるわけでもないようだけど?
https://twitter.com/StreamComputing/status/436114702666829824
EU圏ならHPCベンダーのBullとか、研究機関直属のCERN OpenLabなどの
大御所があるわけで、彼らがどんなアーキテクチャを選んでるのか
調べてみたらいいよ。
https://twitter.com/StreamComputing/status/436114702666829824
EU圏ならHPCベンダーのBullとか、研究機関直属のCERN OpenLabなどの
大御所があるわけで、彼らがどんなアーキテクチャを選んでるのか
調べてみたらいいよ。
cudaと言うかnvidiaは2006年に出してから
手広く利用機会を与え支援も行い
7年6ヶ月かけてGPGPUを使える業界を探って現在にいたる
ほとんど手探りの状態からはじめて
CUDAを継続しているから手を上げる業界も見つけられた
手広く利用機会を与え支援も行い
7年6ヶ月かけてGPGPUを使える業界を探って現在にいたる
ほとんど手探りの状態からはじめて
CUDAを継続しているから手を上げる業界も見つけられた
680 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 09:04:40.75 ID:N3oQTwZC
NVIDIAは去年、社債を発行して13億ドルの資金調達やってる
AMDが借金漬けで身動き取れない間にパイを総取りにいくのだろうな。
AMDが借金漬けで身動き取れない間にパイを総取りにいくのだろうな。
スレが伸びてるから何かと思ったら
歩留まりの意味を知らないID:zYrqdXQ5が知ったかぶりで恥をさらしていただけだった
歩留まりの意味を知らないID:zYrqdXQ5が知ったかぶりで恥をさらしていただけだった
>>678
傾倒してないよ、極めて中庸だ。だから言ってることに耳を傾ける価値がある
傾倒してないよ、極めて中庸だ。だから言ってることに耳を傾ける価値がある
http://www.toshiba.be/nl/laptops/satellite/satellite-l50-b/satellite-l50d-b-131/
A8-6410
4C 2.0GHz-2.4GHz
まだ未発表のBeema A8(25W?)っぽい
A8-6410
4C 2.0GHz-2.4GHz
まだ未発表のBeema A8(25W?)っぽい
団子の主張をまとめると
スパコンではPhiが競争に勝つだろう
エンドユーザー向けデバイスではOpenCLなどのGPUも重要だろう
ってことなのかな?
なんとなくだけど個人的に真逆な気がする
並列度の高いスパコンではGPUが競争に勝ちそう
エンドユーザー向けデバイスでは既存のコード使えるCPUが有利でGPUは淘汰されそう
スパコンではPhiが競争に勝つだろう
エンドユーザー向けデバイスではOpenCLなどのGPUも重要だろう
ってことなのかな?
なんとなくだけど個人的に真逆な気がする
並列度の高いスパコンではGPUが競争に勝ちそう
エンドユーザー向けデバイスでは既存のコード使えるCPUが有利でGPUは淘汰されそう
クライアント向けではオーバヘッドを含みで効果がある用途(計算量)が殆ど無いので使われない
計算量の多いHPC向けではオーバーヘッドを含んでも許容できる物がある
計算量の多いHPC向けではオーバーヘッドを含んでも許容できる物がある
>>685
何が使われないの?主語がわからん
何が使われないの?主語がわからん
GPGPU
まぁGPUでやれるところでは生き残るだろうが、そのうちGPUという垣根がなくなるだろうから
結局CPU(あるいは、内蔵ベクタプロセッサ)に収束する流れになるだろうねぇ…
今までもそうだったし、きっとこれからもそうだよ
結局CPU(あるいは、内蔵ベクタプロセッサ)に収束する流れになるだろうねぇ…
今までもそうだったし、きっとこれからもそうだよ
どうでもいいくだらない話題で流そうとしてるし
団子はAMDがHBMを採用したRADEONを出すのが気に入らないようだな
団子はAMDがHBMを採用したRADEONを出すのが気に入らないようだな
>>688
AtomはAVX非対応、AVX2は殆ど使われてない状況だから、GPUをCPUに収束とかは当分ありえないんじゃないかな
AVX512? AVX2以上に空気になるだけ
クライアント向けGPGPUは、ARM、Qualcomm、イマジネーションが揃って強化しているから使い道があるんだろ
AtomはAVX非対応、AVX2は殆ど使われてない状況だから、GPUをCPUに収束とかは当分ありえないんじゃないかな
AVX512? AVX2以上に空気になるだけ
クライアント向けGPGPUは、ARM、Qualcomm、イマジネーションが揃って強化しているから使い道があるんだろ
693 :Socket774:2014/05/12(月) 11:34:45.35 ID:Y9GCeU9V
「Haswell Refresh」の「Core i7-4790」を動かしてみた。体感速度はHaswellと変わらず,消費電力はやや増加
http://www.4gamer.net/games/132/G013298/20140511001/
発売前の予想情報はめちゃくちゃパワーアップしてたが出てきたブツは性能下がって消費電力だけ増えたブツか
http://www.4gamer.net/games/132/G013298/20140511001/
発売前の予想情報はめちゃくちゃパワーアップしてたが出てきたブツは性能下がって消費電力だけ増えたブツか
googleは、交渉としてintelから離れるというより
AMDふがいなからintelから完全に離れて、
ibm育てるようだな
AMDふがいなからintelから完全に離れて、
ibm育てるようだな
流石anandって言わんばかりの見る価値のない記事だな
intelはHPC飽きたのか、投資家が冷ややかに
技術的に不利な資料があるのではと語るほど
展示にも力をいれていない
技術的に不利な資料があるのではと語るほど
展示にも力をいれていない
ロードマップでわかる!当世プロセッサー事情 ― 第252回
半導体プロセスまるわかり EUVは微細化の救世主となるか?
http://ascii.jp/elem/000/000/892/892582/
半導体プロセスまるわかり EUVは微細化の救世主となるか?
http://ascii.jp/elem/000/000/892/892582/
クロック+3%でスコア+10%って、anandさんちょっと盛りすぎじゃないですかね
違いがクロックだけなら良かったんだけどね
4gamer見れ
Linuxのkernel 3.11の暗号化モジュールにAVX2対応モジュール入ってるし
gnu libcもstringやメモリ操作関数の大多数が対応してるんだが
AVX2が使われてないってどこの異次元の話なんだろう?
carrizoもAVX2対応するのにそれすら否定するとか
ブーメランを頭に突き刺す作業に精が出ますなあ
gnu libcもstringやメモリ操作関数の大多数が対応してるんだが
AVX2が使われてないってどこの異次元の話なんだろう?
carrizoもAVX2対応するのにそれすら否定するとか
ブーメランを頭に突き刺す作業に精が出ますなあ
703 :Socket774:2014/05/12(月) 12:47:36.47 ID:D9oQS4it
>>690
AVX2はHaswellから搭載だから、1年前に出荷開始されたPCでしか使えない機能。
PCは1年で買い換える人なんてほとんどいないから、世界中で稼働しているPCの内1年以内に購入したPCの割合はたいしたことない。
つまり、AVX2というのはまだ普及率の低い機能でしかないから、AVX2を使用したソフトはそれほど多くない。
しかし、市場で圧倒的シェアを持つIntelがCPUに搭載した機能は、5年後にはほとんどのPCが搭載している機能になる。
SSEもPentium3登場直後は対応したソフトが少なかったという事を忘れてはいけない。
AVX2はHaswellから搭載だから、1年前に出荷開始されたPCでしか使えない機能。
PCは1年で買い換える人なんてほとんどいないから、世界中で稼働しているPCの内1年以内に購入したPCの割合はたいしたことない。
つまり、AVX2というのはまだ普及率の低い機能でしかないから、AVX2を使用したソフトはそれほど多くない。
しかし、市場で圧倒的シェアを持つIntelがCPUに搭載した機能は、5年後にはほとんどのPCが搭載している機能になる。
SSEもPentium3登場直後は対応したソフトが少なかったという事を忘れてはいけない。
>>692
じゃあGPU無くせってことなのか
じゃあGPU無くせってことなのか
http://www.4gamer.net/games/132/G013298/20140511001/SS/021.jpg
http://www.4gamer.net/games/132/G013298/20140511001/SS/022.jpg
やっぱ変わってねーじゃねーか
anandェ・・・
{kind=link}
http://www.4gamer.net/games/132/G013298/20140511001/SS/022.jpg
{kind=link}
やっぱ変わってねーじゃねーか
anandェ・・・
都合の悪い記事は信じないいつものパターン
ワークステーション用のハイエンドなの出してくれればいいんだけど
>>703
今年Haswell-EPが出るんだが。
PCや1Pサーバに一年速く先行投入のおかげでソフトの足回りの整備が進み
LinuxのサーバアプリのほとんどがすぐにAVX2の機能の恩恵に預かることができる。
いっぽうAMDのメインストリームサーバ向けは来年もPiledriverコアのまま。
FireProも事実上Xeon専用だから、AMD自らOpteron離れを加速させる自滅路線。
今年Haswell-EPが出るんだが。
PCや1Pサーバに一年速く先行投入のおかげでソフトの足回りの整備が進み
LinuxのサーバアプリのほとんどがすぐにAVX2の機能の恩恵に預かることができる。
いっぽうAMDのメインストリームサーバ向けは来年もPiledriverコアのまま。
FireProも事実上Xeon専用だから、AMD自らOpteron離れを加速させる自滅路線。
NVIDIAの特許
http://microboy.seesaa.net/article/396786737.html
最も肝心な部分を先に言えば、この特許で説明に使われているprocessing systemは、
hardwareによるbinary変換と、softwareによるbinary変換の両刀の方式です。このことは、かつてのTransmeta製品とは異なっています。
softwareのみの動的binary変換は、stream処理のように単調で反復回数が多い処理では変換のoverheadがpayするので有効ですが、
system処理のように雑多で反復回数が少ない処理ではoverheadがかさんで、性能や電力効率の面で不利になることが想像されます。
この特許で述べられている構成では、非nativeなcodeが初めhardware decoderで、例えばcounterで指定される回数のみ実行され、
後々、最適化されたtranslationの実行へ切り替わる方式になっています。
つまり、反復回数が少ない処理ではhardware decoderによる変換が主体になり、
反復回数が多い処理ではsoftwareによって変換されたtranslationの実行が主体になるわけです。
これにより広い範囲の応用で、binary変換の短所が現れにくく、そのことがhardware/software両刀方式の狙いのように思われます。
http://microboy.seesaa.net/article/396786737.html
最も肝心な部分を先に言えば、この特許で説明に使われているprocessing systemは、
hardwareによるbinary変換と、softwareによるbinary変換の両刀の方式です。このことは、かつてのTransmeta製品とは異なっています。
softwareのみの動的binary変換は、stream処理のように単調で反復回数が多い処理では変換のoverheadがpayするので有効ですが、
system処理のように雑多で反復回数が少ない処理ではoverheadがかさんで、性能や電力効率の面で不利になることが想像されます。
この特許で述べられている構成では、非nativeなcodeが初めhardware decoderで、例えばcounterで指定される回数のみ実行され、
後々、最適化されたtranslationの実行へ切り替わる方式になっています。
つまり、反復回数が少ない処理ではhardware decoderによる変換が主体になり、
反復回数が多い処理ではsoftwareによって変換されたtranslationの実行が主体になるわけです。
これにより広い範囲の応用で、binary変換の短所が現れにくく、そのことがhardware/software両刀方式の狙いのように思われます。
LinuxカーネルもglibcもすでにずいぶんAVX2対応が進んでるからなぁ
アプリはそのままでも、ライブラリやOSが勝手にAVX2対応CPUの場合AVX2使ってくれる
アプリはそのままでも、ライブラリやOSが勝手にAVX2対応CPUの場合AVX2使ってくれる
割と出ると思うよ
http://www.google.com/patents/USD702684
http://patentimages.storage.googleapis.com/USD702684S1/USD0702684-20140415-D00000.png
http://pc.watch.impress.co.jp/docs/column/kaigai/20140212_634557.html
問題は、どうやって多くの命令を発行できるようにするかという点にある。
この問題を解決する方法の1つは、当然だが、非常に複雑な(命令スケジューリング)ハードウェアを搭載することだ。
だが、そうすると、IBMのPowerアーキテクチャのように、CPUが複雑で大きくなってしまうため、モバイル向けでこの方法は採ることが難しい。
それではハードウェアを複雑にしないで済む、その解決法は何かということになる。
我々もほかのCPU設計会社も、みな同じ物理の法則の枠の中で戦っている。
同じ物理ならテクニックを工夫するしかない。
そして、我々は、いくつかの新しいテクニックが、この問題を解決する助けになると考えている。
ただし、その詳細の発表はしばらく先にさせて欲しい。
非常に画期的で、楽しみな発表になることは確かで、おそらく驚かれると思う。
新しいテクニックを開発したからこそ、我々はDenverの開発に5年もかかったのだ」。
http://www.google.com/patents/USD702684
http://patentimages.storage.googleapis.com/USD702684S1/USD0702684-20140415-D00000.png
{kind=link}
http://pc.watch.impress.co.jp/docs/column/kaigai/20140212_634557.html
問題は、どうやって多くの命令を発行できるようにするかという点にある。
この問題を解決する方法の1つは、当然だが、非常に複雑な(命令スケジューリング)ハードウェアを搭載することだ。
だが、そうすると、IBMのPowerアーキテクチャのように、CPUが複雑で大きくなってしまうため、モバイル向けでこの方法は採ることが難しい。
それではハードウェアを複雑にしないで済む、その解決法は何かということになる。
我々もほかのCPU設計会社も、みな同じ物理の法則の枠の中で戦っている。
同じ物理ならテクニックを工夫するしかない。
そして、我々は、いくつかの新しいテクニックが、この問題を解決する助けになると考えている。
ただし、その詳細の発表はしばらく先にさせて欲しい。
非常に画期的で、楽しみな発表になることは確かで、おそらく驚かれると思う。
新しいテクニックを開発したからこそ、我々はDenverの開発に5年もかかったのだ」。
715 :Socket774:2014/05/12(月) 15:42:12.34 ID:tjStACnE
うざいな
ヌビ次世代スレ作れよカス共
ヌビ次世代スレ作れよカス共
UbuntuのLTSは2年おきにしか出ないからPC向けCPUで1年先行で新命令を実装しておいて
同コアのDP Xeonが出たらですぐに使えるようになってる状況ってベストなんだよね。
Ubuntu14.04LTSもカーネル&#8226;ライブラリともにAVX2対応
先に足を踏み入れることを恐れていては永遠に道筋はつくれない。
もちろんHSA対応LibOもLTSに入ってる。
LibOをサーバやWSで使うのかという問題はあるが…
同コアのDP Xeonが出たらですぐに使えるようになってる状況ってベストなんだよね。
Ubuntu14.04LTSもカーネル&#8226;ライブラリともにAVX2対応
先に足を踏み入れることを恐れていては永遠に道筋はつくれない。
もちろんHSA対応LibOもLTSに入ってる。
LibOをサーバやWSで使うのかという問題はあるが…
Kernel3.12.13使ってるけどAVX2の項目なかった
>>703
>SSEもPentium3登場直後は対応したソフトが少なかったという事を忘れてはいけない。
そうでもない。性能がガクンと上がる、という理由からSSEが出てすぐ辺りから
午後のこーだ等といったmp3エンコードのソフトをはじめとしてフリーでの盛り上げ運動が盛んだった。
現在のAVX2対応のフリー系もあることはあるんだけど・・・
>SSEもPentium3登場直後は対応したソフトが少なかったという事を忘れてはいけない。
そうでもない。性能がガクンと上がる、という理由からSSEが出てすぐ辺りから
午後のこーだ等といったmp3エンコードのソフトをはじめとしてフリーでの盛り上げ運動が盛んだった。
現在のAVX2対応のフリー系もあることはあるんだけど・・・
>>707
A8-3000Mより遅いA8-6000とな
A8-3000Mより遅いA8-6000とな
721 :Socket774:2014/05/12(月) 18:25:52.62 ID:D9oQS4it
>>719
いや、その程度で少なくないとか言われても困るんですが。
その程度の例を挙げれば良いなら、AVX2対応ソフトもx264/TMPGEnc/Power Directorとか現状でもいくつもあるよ。
いや、その程度で少なくないとか言われても困るんですが。
その程度の例を挙げれば良いなら、AVX2対応ソフトもx264/TMPGEnc/Power Directorとか現状でもいくつもあるよ。
話題性って奴ですか。そういう意味では当時かなり盛り上がってたんですよ。
MMXの時はバーチャロンを代名詞に、SSEの時はセガラリー2だったかを代名詞にして
雑誌に飾られてましたし。
AVX2も性能的にはどこぞビデオコーデックのプログラマもチートみたいな性能だとか褒めてたが
ニュース系統ではトップニュースに置かれる程の話題にはなっていない。そんな違いです。
MMXの時はバーチャロンを代名詞に、SSEの時はセガラリー2だったかを代名詞にして
雑誌に飾られてましたし。
AVX2も性能的にはどこぞビデオコーデックのプログラマもチートみたいな性能だとか褒めてたが
ニュース系統ではトップニュースに置かれる程の話題にはなっていない。そんな違いです。
A10だけ見て右側の数字見なかったわ。安すぎるとは思った
ずいぶん前からエコって単語は主流になってるはずなんだけどな・・・
サーバーの電気代もしかり、経費の削減=黒字の確保になるし、すぐに実行できる意味では
どこの会社も興味がある分野。
http://jp.techcrunch.com/2014/01/29/20140128facebook-open-compute/
電気食って演算性能あげても喜ぶところはスパコン関係くらいか?
てか団子、お前自分でスキル低い主とか言ってるサイトをソースにしてるたぁ、どういう了見だよww
サーバーの電気代もしかり、経費の削減=黒字の確保になるし、すぐに実行できる意味では
どこの会社も興味がある分野。
http://jp.techcrunch.com/2014/01/29/20140128facebook-open-compute/
電気食って演算性能あげても喜ぶところはスパコン関係くらいか?
てか団子、お前自分でスキル低い主とか言ってるサイトをソースにしてるたぁ、どういう了見だよww
>>725
日本でもいわゆる「ホワイトボックスサーバ」が大流行だよ
だれでも知ってるようなネット企業でも大々的に入ってる
そこの経費の削減の多くはサーバ代なんじゃないの?
IBMとかDELLとかの本格サーバに比べて、ハードウェア代がすごく安く済むって感じで
日本でもいわゆる「ホワイトボックスサーバ」が大流行だよ
だれでも知ってるようなネット企業でも大々的に入ってる
そこの経費の削減の多くはサーバ代なんじゃないの?
IBMとかDELLとかの本格サーバに比べて、ハードウェア代がすごく安く済むって感じで
>>704
http://www.tweaktown.com/articles/6319/intel-core-i7-4790-haswell-refresh-cpu-and-z97-performance-preview/index3.html
キャッシュの読み書きも高速化されてる
http://www.tweaktown.com/articles/6319/intel-core-i7-4790-haswell-refresh-cpu-and-z97-performance-preview/index3.html
キャッシュの読み書きも高速化されてる
Haswell Refreshは、いまivy/haswell使ってる人が乗り換えるようなCPUではないでしょ?
新規にPC買う/作るときに選ぶCPUで
Devil's Canyonは、K型番のSandy/Ivy/hasell使ってる人なら乗り換える価値ありそうだけど
新規にPC買う/作るときに選ぶCPUで
Devil's Canyonは、K型番のSandy/Ivy/hasell使ってる人なら乗り換える価値ありそうだけど
熱対策が全く解決してないからどれも御免だろw
夏場に余裕で75℃超え当たり前のCPUなんてゴミ以外の何物でもないw
夏場に余裕で75℃超え当たり前のCPUなんてゴミ以外の何物でもないw
732 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 20:07:17.86 ID:N3oQTwZC
>>722
あの当時はVertex Shader相当をCPU側でやってたから
MMXや3DNow!の有無で性能に差がついた。
今は重たい演算を雲の向こう側のサーバ側に押し付ける時代になったから
意識してないだけでは?
昔ほどパソコン自体を話題にしなくなっただろ?
>>691
スパコンに関していえば、大規模なスパコンほど、1点特化じゃなくて
いろんな演算に使える汎用性が求められるんだよ。
GPUが得意とするような、ほとんど行列積だけしかやらないような演算の
ニーズってのは、無いわけじゃないんだが、おまいらが期待ほど多くはない。
それがFireProが採用されない最大の原因。
GPUはピーク性能は高いが、得意じゃない演算との落差が激しい。
CPUのSIMD性能が貧弱だったから力技で勝ててたが
SandyBridge-EP以降、勝てない分野が増えてきた。
だからGPUの採用が減少してる。
FireProはピークを伸ばすよりは不得意を克服しないと
大規模演算用途での採用は難しいと思うよ。
あの当時はVertex Shader相当をCPU側でやってたから
MMXや3DNow!の有無で性能に差がついた。
今は重たい演算を雲の向こう側のサーバ側に押し付ける時代になったから
意識してないだけでは?
昔ほどパソコン自体を話題にしなくなっただろ?
>>691
スパコンに関していえば、大規模なスパコンほど、1点特化じゃなくて
いろんな演算に使える汎用性が求められるんだよ。
GPUが得意とするような、ほとんど行列積だけしかやらないような演算の
ニーズってのは、無いわけじゃないんだが、おまいらが期待ほど多くはない。
それがFireProが採用されない最大の原因。
GPUはピーク性能は高いが、得意じゃない演算との落差が激しい。
CPUのSIMD性能が貧弱だったから力技で勝ててたが
SandyBridge-EP以降、勝てない分野が増えてきた。
だからGPUの採用が減少してる。
FireProはピークを伸ばすよりは不得意を克服しないと
大規模演算用途での採用は難しいと思うよ。
>>733
リテールクーラーなんか使うなよ・・・
リテールクーラーなんか使うなよ・・・
735 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 20:21:22.67 ID:N3oQTwZC
皮肉ワロタ
まあ馬鹿は無視して、IntelCPUで75℃超えずに済む空冷CPUクーラーがあるなら教えて欲しいね。
1万台のCPUクーラーが5個ほど試して全滅とか異常過ぎるwww
APUだったらOCで1.4V超えさせても60℃程度で済むというのに…
1万台のCPUクーラーが5個ほど試して全滅とか異常過ぎるwww
APUだったらOCで1.4V超えさせても60℃程度で済むというのに…
738 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 20:27:04.42 ID:N3oQTwZC
>>736
そういやA1100デモ機の脇にOpen Computeのパネルが置いてあったね
http://cdn.pcper.com/files/imagecache/article_max_width/news/2014-05-07/AMD%20Seattle%20Development%20Platform%20Opteron%20A1100.jpg
そういやA1100デモ機の脇にOpen Computeのパネルが置いてあったね
http://cdn.pcper.com/files/imagecache/article_max_width/news/2014-05-07/AMD%20Seattle%20Development%20Platform%20Opteron%20A1100.jpg
{kind=link}
>>737
http://img.kakaku.com/images/magazinem/org/kakaku/i20130601/pcser37_graph15l.jpg
500円くらいのリテールクーラーでも84度だと言うのに
1万台ってウォンか?
http://img.kakaku.com/images/magazinem/org/kakaku/i20130601/pcser37_graph15l.jpg
{kind=link}
500円くらいのリテールクーラーでも84度だと言うのに
1万台ってウォンか?
だからAMDはARMを使ったHPCに需要があると睨んでるんじゃねーの?
Llano はリテールだと冬でも80度に達するんだよな
もう捨てるしかないのかのお
もう捨てるしかないのかのお
Open Compute はデータセンタを武装(ARM)する
http://www.sdncentral.com/japanese/ocp-%E7%B7%8F%E6%8B%AC-open-compute-%E3%81%AF%E3%83%87%E3%83%BC%E3%82%BF%E3%82%BB%E3%83%B3%E3%82%BF%E3%82%92%E6%AD%A6%E8%A3%85arm%E3%81%99%E3%82%8B/2014/01/
http://www.sdncentral.com/japanese/ocp-%E7%B7%8F%E6%8B%AC-open-compute-%E3%81%AF%E3%83%87%E3%83%BC%E3%82%BF%E3%82%BB%E3%83%B3%E3%82%BF%E3%82%92%E6%AD%A6%E8%A3%85arm%E3%81%99%E3%82%8B/2014/01/
744 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 20:36:25.22 ID:N3oQTwZC
> intelもocp加盟してるようだけど、ワッパではA1100には勝てないと予想。
SPECint_rate2006 消費電力
Atom C2750 106 28W(システム全体;メモリ16GB+HDD)
Opteron A1100 80 25W(CPUのみ)
ソースは
https://intel.activeevents.com/sf13/connect/fileDownload/session/C60AC5C04526F97557133399B12DA73D/SF13_SPCS005_101.pdf
http://www.anandtech.com/show/7724/it-begins-amd-announces-its-first-arm-based-server-soc-64bit8core-opteron-a1100
SPECint_rate2006 消費電力
Atom C2750 106 28W(システム全体;メモリ16GB+HDD)
Opteron A1100 80 25W(CPUのみ)
ソースは
https://intel.activeevents.com/sf13/connect/fileDownload/session/C60AC5C04526F97557133399B12DA73D/SF13_SPCS005_101.pdf
http://www.anandtech.com/show/7724/it-begins-amd-announces-its-first-arm-based-server-soc-64bit8core-opteron-a1100
748 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 20:43:37.68 ID:N3oQTwZC
A1100のワッパはAvoton/Denvertonに勝てないというより
同じTDP25WのXeon E3-1230Lv3に勝てないと思う。
> A1100ってHSAもサポートしてるはずだし。
> A1100ってHSAもサポートしてるはずだし。
> A1100ってHSAもサポートしてるはずだし。
> A1100ってHSAもサポートしてるはずだし。
> A1100ってHSAもサポートしてるはずだし。
> A1100ってHSAもサポートしてるはずだし。
あのーGPU載ってないんですが・・・・
老害くんは面白発言が多すぎますね
同じTDP25WのXeon E3-1230Lv3に勝てないと思う。
> A1100ってHSAもサポートしてるはずだし。
> A1100ってHSAもサポートしてるはずだし。
> A1100ってHSAもサポートしてるはずだし。
> A1100ってHSAもサポートしてるはずだし。
> A1100ってHSAもサポートしてるはずだし。
> A1100ってHSAもサポートしてるはずだし。
あのーGPU載ってないんですが・・・・
老害くんは面白発言が多すぎますね
HSA対応GPUを載せると、システムレベルでは対応するんだろ(笑)
750 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 20:45:36.76 ID:N3oQTwZC
そもそも80ってのはAMD自ら主張してる推定値だ。
SPECintでGPGPU云々とかマジ受けるんですが
SPECintでGPGPU云々とかマジ受けるんですが
あら、HSA対応じゃねーのかw
してると思ってたわw
してると思ってたわw
752 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 20:54:49.53 ID:N3oQTwZC
AnandTechはあくまでAMDの主張したことをそのまま表にしてるだけだぞ
他のニュースサイトもAMDの発表と同時期に同じ数字を報じてる。
> Update: AMD is claiming a SpecInt_Rate score of ~80 for the 8-core Seattle
> at a 25W TDP, compared to a SpecInt score of 28.1 for the quad-core X2150.
> An Intel Avoton (top SKU) has a SpecInt score of 106 and a TDP of 20W.
http://hothardware.com/News/AMD-Announces-Sampling-of-New-EightCore-ARM-SoC-At-Facebooks-Open-Compute-Summit/
CPU1チップだけでSPECint_rate2006スコアを比較すると
・A1100 80/25W
・C2750 106/20W
さすがはA57だな
電力効率悪す!
他のニュースサイトもAMDの発表と同時期に同じ数字を報じてる。
> Update: AMD is claiming a SpecInt_Rate score of ~80 for the 8-core Seattle
> at a 25W TDP, compared to a SpecInt score of 28.1 for the quad-core X2150.
> An Intel Avoton (top SKU) has a SpecInt score of 106 and a TDP of 20W.
http://hothardware.com/News/AMD-Announces-Sampling-of-New-EightCore-ARM-SoC-At-Facebooks-Open-Compute-Summit/
CPU1チップだけでSPECint_rate2006スコアを比較すると
・A1100 80/25W
・C2750 106/20W
さすがはA57だな
電力効率悪す!
>>746
虎徹でおk
虎徹でおk
効率悪いから作り直そうと決心したんかのw
A tool which profiles OpenCL devices to find their peak capacities
https://github.com/krrishnarraj/clpeak
https://github.com/krrishnarraj/clpeak
759 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 21:15:09.13 ID:N3oQTwZC
>>755
効率を重視するとこはみんな独自に作ってるじゃん。
A57/A53で突貫SoCを作ったQualcommは64ビット乗り遅れたと見られる。
これはマジで没落するかもな!
これはAMDにとってもチャンスだから歓迎するべきだが。
効率を重視するとこはみんな独自に作ってるじゃん。
A57/A53で突貫SoCを作ったQualcommは64ビット乗り遅れたと見られる。
これはマジで没落するかもな!
これはAMDにとってもチャンスだから歓迎するべきだが。
OpenCL papers up 31% in 2013, OpenMP up 6%, MPI flat, CUDA down 6% but still most popular (Google Scholar)
https://twitter.com/simonmcs/status/433345668602556416/photo/1/large
https://twitter.com/simonmcs/status/433345668602556416/photo/1/large
764 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 21:25:20.21 ID:N3oQTwZC
>>760
OpenCLを使ってる論文で、使ってるデバイスの内訳も調べて欲しいところだな
OpenCLを使ってる論文で、使ってるデバイスの内訳も調べて欲しいところだな
来年なら20nか、コアのてこ入れもするだろうし、armでいい勝負するんじゃね。
鯖分野で既存のARM勢にやられたらAMDも面目ないなw
鯖分野で既存のARM勢にやられたらAMDも面目ないなw
>>759
Qualcommの場合、CPUで売れてたんじゃなく、
無線系の機能がワンストップで提供されてるから売れてるんでしょう
急造64bitはカスタマイズしてるAppleみたいに効率は良くないが、
無線系の優位点があるからなぁ
Qualcommの場合、CPUで売れてたんじゃなく、
無線系の機能がワンストップで提供されてるから売れてるんでしょう
急造64bitはカスタマイズしてるAppleみたいに効率は良くないが、
無線系の優位点があるからなぁ
Opteron A1100
28nmHKMG(TSMC、GF)60〜70万円/ウェハー1枚
Cortex A57
SATA III 8
10GbE 2
DDR3 対応
DDR4 対応
メモリ 最大128GB
PCIe 3.0 対応
Atom C2750
22nmHKMG+FinFET(インテル)100万円超/ウェハー1枚
Atom
SATA III 2
10GbE なし
DDR3 対応
DDR4 なし
メモリ 最大64GB
PCIe 3.0 なし
28nmHKMG(TSMC、GF)60〜70万円/ウェハー1枚
Cortex A57
SATA III 8
10GbE 2
DDR3 対応
DDR4 対応
メモリ 最大128GB
PCIe 3.0 対応
Atom C2750
22nmHKMG+FinFET(インテル)100万円超/ウェハー1枚
Atom
SATA III 2
10GbE なし
DDR3 対応
DDR4 なし
メモリ 最大64GB
PCIe 3.0 なし
>>719
>午後のこーだ等といったmp3エンコードのソフトをはじめとしてフリーでの盛り上げ運動が盛んだった。
HSAもフリーソフトで盛り上げ運動が盛んで、もうそろそろHSA対応フリーソフト色々出るんじゃないか
フリーソフト作者ならHSAすげーでHSAの自作PC・BTOを導入してソフト開発くれるだろう。
>午後のこーだ等といったmp3エンコードのソフトをはじめとしてフリーでの盛り上げ運動が盛んだった。
HSAもフリーソフトで盛り上げ運動が盛んで、もうそろそろHSA対応フリーソフト色々出るんじゃないか
フリーソフト作者ならHSAすげーでHSAの自作PC・BTOを導入してソフト開発くれるだろう。
Prime95 27.9てAVX対応してるんじゃね?
AVXってAVX2じゃなくてホントにAVXの話で来たか…w
まあIntelにとってAVX2なんてその程度のって事なんだろうなwww
まあIntelにとってAVX2なんてその程度のって事なんだろうなwww
777 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 21:53:28.06 ID:I6oLdPF4
>>770
A1100はL3 8MBも盛ってるから200mm^2は軽く超えるよ
っていうか、そのスペックをもってしてSPECint_rateが80なんだけど。
コアが貧弱すぎるのかな
Atomよりもう少しIOが強力なほうがいいっていうならこんなのがある。
Xeon E3-1230Lv3(TDP25W)がSPECint_rateで 168
https://www.spec.org/cpu2006/results/res2013q4/cpu2006-20131104-27170.html
A1100はL3 8MBも盛ってるから200mm^2は軽く超えるよ
っていうか、そのスペックをもってしてSPECint_rateが80なんだけど。
コアが貧弱すぎるのかな
Atomよりもう少しIOが強力なほうがいいっていうならこんなのがある。
Xeon E3-1230Lv3(TDP25W)がSPECint_rateで 168
https://www.spec.org/cpu2006/results/res2013q4/cpu2006-20131104-27170.html
AVX対応のソフトなんてほとんどないって言ったり
AVX使わないと意味が無いとか言ったり
アムドユーザーってホントわけわかんないね
AVX使わないと意味が無いとか言ったり
アムドユーザーってホントわけわかんないね
XOP、CVT16でフカカケテ
>>774
日本で市販ソフトでAMDものの盛り上げは無理。
日本ではHSA PCなんて自作・BTOでぐらいでしか入手できないから、まず開発機導入にハードルある。
そして、なにより、AMD PCは一般向けに普及はしないから金にならないHSA ソフトやらないだろ
海外ならメーカーのHSA PCたくさん出ている(?)から盛り上がるかも知れないが、日本人は
ロシア語・中国語のHSAのソフトなんて使わないよな。
日本で市販ソフトでAMDものの盛り上げは無理。
日本ではHSA PCなんて自作・BTOでぐらいでしか入手できないから、まず開発機導入にハードルある。
そして、なにより、AMD PCは一般向けに普及はしないから金にならないHSA ソフトやらないだろ
海外ならメーカーのHSA PCたくさん出ている(?)から盛り上がるかも知れないが、日本人は
ロシア語・中国語のHSAのソフトなんて使わないよな。
>>769
温度が80℃いったくらいでゴミと断定するお前がおかしいだけ
温度が80℃いったくらいでゴミと断定するお前がおかしいだけ
>>729
こっちにはクロック以上の差は無いって書いてあるけど
http://pc.watch.impress.co.jp/docs/topic/review/20140511_647746.html
こっちにはクロック以上の差は無いって書いてあるけど
http://pc.watch.impress.co.jp/docs/topic/review/20140511_647746.html
>>776
AMDはHSA、HSAって必死にエンドユーザーにアピールしているけど、
IntelはAVXをそんなにアピールしていないよな。
AVXを強くアピールしても、売り上げに大きく貢献するものじゃないし。
ソフトが大してないHSAを必死にアピールしても、一般ユーザーがAMDに飛びつくとは思えないけど。
AMDはHSA、HSAって必死にエンドユーザーにアピールしているけど、
IntelはAVXをそんなにアピールしていないよな。
AVXを強くアピールしても、売り上げに大きく貢献するものじゃないし。
ソフトが大してないHSAを必死にアピールしても、一般ユーザーがAMDに飛びつくとは思えないけど。
785 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 22:05:43.04 ID:I6oLdPF4
>>781
まあ、戦略に一貫性がないのは嫌いだな。
HSAが共有メモリですばらしいなんて御託を並べる一方で
離散メモリのFireProは見掛け倒しのピークFLOPS一辺倒
おなじGPUアーキテクチャだから開発ツールくらい共通化できるだろ?
共有メモリを使って云々やるなら、CUDA6みたいに仮想共有メモリでも
物理共有メモリでも同じプログラマビリティを提供するべきだ。
まあ、戦略に一貫性がないのは嫌いだな。
HSAが共有メモリですばらしいなんて御託を並べる一方で
離散メモリのFireProは見掛け倒しのピークFLOPS一辺倒
おなじGPUアーキテクチャだから開発ツールくらい共通化できるだろ?
共有メモリを使って云々やるなら、CUDA6みたいに仮想共有メモリでも
物理共有メモリでも同じプログラマビリティを提供するべきだ。
>>783
>CPUの動作クロックが向上したことを除き、従来のHaswellアーキテクチャCPUと目立った違いは見られない。
この部分を言ってるなら目立った違いはない=目立ってない違いはあるってことだよ
>CPUの動作クロックが向上したことを除き、従来のHaswellアーキテクチャCPUと目立った違いは見られない。
この部分を言ってるなら目立った違いはない=目立ってない違いはあるってことだよ
788 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 22:15:17.87 ID:I6oLdPF4
Load/Storeが256ビットになったぶん浮動小数点ではAVX2/FMAを使わずとも
AVX1でも十分性能向上してるよ
AVX1でも十分性能向上してるよ
789 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 22:16:05.39 ID:I6oLdPF4
> 嘘じゃないんだけど、体感しにくい数字マジック
Kaveriの850GFLOPSはきれいなマジック入りました
Kaveriの850GFLOPSはきれいなマジック入りました
790 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 22:18:30.80 ID:I6oLdPF4
Cinebench R11.5もSSE3くらいまでしか対応してないだろ確か
それでもきっちりHaswellでスコア上げてるんだからたいしたものだよ
それでもきっちりHaswellでスコア上げてるんだからたいしたものだよ
>>786
型番と値段が違うんだよな
型番と値段が違うんだよな
GT3eって何かと思って調べて見たら
TDP47Wの奴か・・・
FX7500はTDP19Wなんだわ・・・
FX7600Pだと512SP積んで35Wだし
全く競合してないな
TDP47Wの奴か・・・
FX7500はTDP19Wなんだわ・・・
FX7600Pだと512SP積んで35Wだし
全く競合してないな
それを言ったらインテルもやべーぞww
Intel Iris Pro 832 GFLOPS
Intel Iris Pro 832 GFLOPS
795 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 22:32:30.60 ID:I6oLdPF4
Intelは表立ってGPUのFLOPS数アピールしたことなんてないだろ?
796 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 22:35:04.58 ID:I6oLdPF4
>>793
4コア8スレッドと、2コア4スレッド未満の4コアじゃそもそも競合し得ない
4コア8スレッドと、2コア4スレッド未満の4コアじゃそもそも競合し得ない
>>793
するわけないCPU性能が違いすぎる
するわけないCPU性能が違いすぎる
現実に使えない機能を実装し、理論値だけ誇るゴミンテルwwww
HSA対応といってもGPUはGPU
GPUとして使える
GPUとしても使えるCPUのLarrabeeは・・・
GPUとして使える
GPUとしても使えるCPUのLarrabeeは・・・
>>795
HPCならともかく、一般向けにFLOPSをアピールしてもって感じだし。
それより、Intelはベンチマークのほうが重要アピールポイントって分かっているだろう。
HSAやGFLOPSを気合を入れてアピールすることでデスクトップAPUが売れるって思っているから
アピールなんだろうが、俺的にはAMDってアピールする点がずれているじゃと思うことがある。
HPCならともかく、一般向けにFLOPSをアピールしてもって感じだし。
それより、Intelはベンチマークのほうが重要アピールポイントって分かっているだろう。
HSAやGFLOPSを気合を入れてアピールすることでデスクトップAPUが売れるって思っているから
アピールなんだろうが、俺的にはAMDってアピールする点がずれているじゃと思うことがある。
801 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 22:42:35.47 ID:I6oLdPF4
少なくともIntelはiHD/Irisで使えるOpenCLサンプルを出してる
ExcavatorがTDP45WでA10-5800K並のCPU性能持ってるから
ワットパフォーマンスはクソ高くなる
GPU性能はGTX285クラス
ワットパフォーマンスはクソ高くなる
GPU性能はGTX285クラス
803 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 22:45:10.82 ID:I6oLdPF4
外付けGPUと本質的に同じものをCPUダイに内蔵してあたかもそれが
CPUの性能みたいに言うのは詐欺以外の何でもないわな
消費者庁に通報されるレベル
CPUの性能みたいに言うのは詐欺以外の何でもないわな
消費者庁に通報されるレベル
804 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 22:47:27.46 ID:I6oLdPF4
806 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 22:49:43.05 ID:I6oLdPF4
黒歴史に触れてやるなよ
808 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 22:52:30.06 ID:I6oLdPF4
へるみ先生もすっかりサーバサイドのエンジニアになっちゃったしなあ
>詐欺以外の何でもないわな
それを言うならAVXに対応してるソフトなら4倍と修正すべきだな、
まず、インテルがww
AVXなしなら56FLOPSくらいで Nehalemから5FLOPSあがりましたと。
騙されてる奴は必ずいるはずww
それを言うならAVXに対応してるソフトなら4倍と修正すべきだな、
まず、インテルがww
AVXなしなら56FLOPSくらいで Nehalemから5FLOPSあがりましたと。
騙されてる奴は必ずいるはずww
812 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 23:02:19.90 ID:I6oLdPF4
詐欺ってのは
xop,fma4で56倍ですよね
xop,fma4で56倍ですよね
814 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 23:05:00.37 ID:I6oLdPF4
Intel Developer Forumはエンドユーザー向けのイベントじゃないぞ
レガシーアプリが4倍になるなんて勘違いしたお前がアホなだけ
レガシーアプリが4倍になるなんて勘違いしたお前がアホなだけ
815 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 23:07:29.49 ID:I6oLdPF4
256ビットFlexFP(笑)とかAGLU(笑)とかの詐欺プレゼンもあったな
開発者ドキュメント見たら全然違うこと書いてあるの
開発者ドキュメント見たら全然違うこと書いてあるの
その中がAVX全盛期になったら本気出す by Intel
817 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 23:10:23.68 ID:I6oLdPF4
SSE5をキャンセルしてAVX互換にしたときも
AVXって名前使うのが嫌で「VPX」って独自名称使おうとした事実は
あんまり語られていない
AVXって名前使うのが嫌で「VPX」って独自名称使おうとした事実は
あんまり語られていない
>ソフト技術者向けのプレゼンならそれは正しいだろ。
一般向けで条件が付くFLOPS表示そのものが詐欺になるだろっといいたいだけ。
詐欺発言をしだしたのは団子だぞ。
一般向けで条件が付くFLOPS表示そのものが詐欺になるだろっといいたいだけ。
詐欺発言をしだしたのは団子だぞ。
819 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 23:12:57.80 ID:I6oLdPF4
> 一般向けで条件が付くFLOPS表示そのものが詐欺になるだろっといいたいだけ。
> 詐欺発言をしだしたのは団子だぞ。
GPUなんて1/10もでないこともザラなのによくこんな詭弁をいえたものだ
> 詐欺発言をしだしたのは団子だぞ。
GPUなんて1/10もでないこともザラなのによくこんな詭弁をいえたものだ
12 COMPUTE CORES (4CPU + 8GPU)とかはどーなの?
821 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 23:16:49.91 ID:I6oLdPF4
俺はNBODYやSGEMM実行して実際に性能が4倍になることを確認してるからなー
間違いじゃない。
HSAがどうだのプログラム組めないバカがビッグマウスこいてると思えば
こんなときだけエンドユーザー視点とかごみすぐる
間違いじゃない。
HSAがどうだのプログラム組めないバカがビッグマウスこいてると思えば
こんなときだけエンドユーザー視点とかごみすぐる
>GPUなんて1/10もでないこともザラなのによくこんな詭弁をいえたものだ
それはインテルも同じだろうがww
それはインテルも同じだろうがww
>>820
openclに限れば正しい
openclに限れば正しい
824 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 23:20:23.51 ID:I6oLdPF4
世の中がAVX全盛期になっても発熱の問題で当社のCPUはAVXを使えませんので有からず by Intel
Haswell4コア@3.5GHzが56FLOPSくらいとしたら
Phenom II4コア@3.7GHzで59.2FLOPSだし、AVXつかわなきゃAMDでも充分ww
FLOPSだけ見ればね、インテルがシングル性能とかのベンチだしたくないんだろうけどなw
最近は特にwww
Phenom II4コア@3.7GHzで59.2FLOPSだし、AVXつかわなきゃAMDでも充分ww
FLOPSだけ見ればね、インテルがシングル性能とかのベンチだしたくないんだろうけどなw
最近は特にwww
827 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 23:30:00.11 ID:I6oLdPF4
AMDのSSEplus/FramewaveもIntelのCPUで極端に遅くなるような
細工が仕掛けてあったしなー
本来分岐いらずに1サイクルで処理できる命令がswitch文でジャンプするようになって
平均10サイクルもかかるみたいなくそラッパー。
Bulldozerの56倍もおそらくAMDの中では事実なんだろうな。
56倍遅くなるようなデチューンをやってたんだろ
細工が仕掛けてあったしなー
本来分岐いらずに1サイクルで処理できる命令がswitch文でジャンプするようになって
平均10サイクルもかかるみたいなくそラッパー。
Bulldozerの56倍もおそらくAMDの中では事実なんだろうな。
56倍遅くなるようなデチューンをやってたんだろ
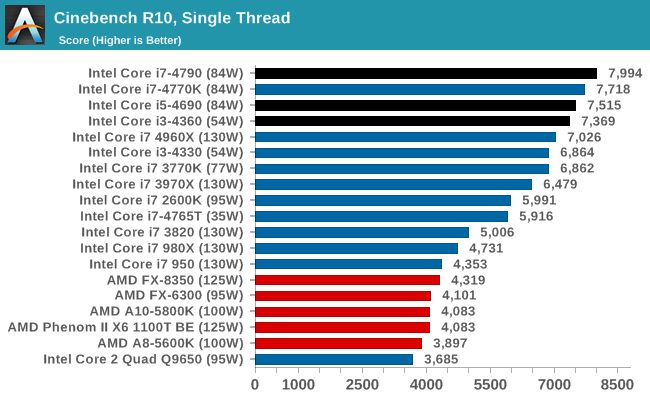{kind=link}
829 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 23:34:32.88 ID:I6oLdPF4
> Haswell4コア@3.5GHzが56FLOPSくらいとしたら
> Phenom II4コア@3.7GHzで59.2FLOPSだし
16ビット時代の一桁GHzの8087コプロでもここまで遅くはない
ブーメラン頭に刺すの好きなんだな。
脳みそすっからかんって楽しそう
> Phenom II4コア@3.7GHzで59.2FLOPSだし
16ビット時代の一桁GHzの8087コプロでもここまで遅くはない
ブーメラン頭に刺すの好きなんだな。
脳みそすっからかんって楽しそう
あれ?59.2FLOPS相手なら初代Pentium@60MHzで100万倍だせるんじゃね?
>>826
PowerPC 7400 500MHzですら3.6ギガフロップスなのにお前らときたら単位まちがえすぎ
PowerPC 7400 500MHzですら3.6ギガフロップスなのにお前らときたら単位まちがえすぎ
832 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 23:38:17.81 ID:I6oLdPF4
電子工学実験で適当にトランジスタ素子並べただけのFPUでも100FLOPSくらいは出せると思う。
クロックジェネレータ次第だけど。
クロックジェネレータ次第だけど。
あ、ちなみに倍精度ねw
834 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 23:41:17.67 ID:I6oLdPF4
ファミコンでもソフト実行で60FLOPSくらい出せるんじゃない?
スーパーマリオのジャンプって半円(x^2 + y^2 = r^2)で近似計算してたそうだし
スーパーマリオのジャンプって半円(x^2 + y^2 = r^2)で近似計算してたそうだし
Gも抜けてたw
836 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 23:42:35.85 ID:I6oLdPF4
http://en.wikipedia.org/wiki/Intel_8087
> The 8087 could perform about 50,000 FLOPS using around 2.4 watts.
> The 8087 could perform about 50,000 FLOPS using around 2.4 watts.
以外にこまけーなw
838 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 23:44:26.35 ID:I6oLdPF4
火病ると地頭の悪さが出ちゃうね、労害君w
打ち忘れただけだろうが、うっせーよw
841 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 23:46:58.76 ID:I6oLdPF4
打ち間違えたんじゃない。
ググったテキストを頭で消化しないまま書いてるから
まったく知識として身についてないだけ
見てください、これがバカがバカたるゆえんですよ
ググったテキストを頭で消化しないまま書いてるから
まったく知識として身についてないだけ
見てください、これがバカがバカたるゆえんですよ
シュリンクして10%ってとこだろう。それをあたかも倍の数字だしてるのは詐欺じゃねーのか?
って話だよ。まだ続くのか?w
って話だよ。まだ続くのか?w
嵐風情に釣られすぎだろ。
釣るならともかく。
釣るならともかく。
団子もうるせーなwお前は間違いがねーとはいわせねーぞw
http://images.anandtech.com/graphs/graph7963/63176.png
エーブイエックスナシノシングルナラナニ?
エーブイエックスナシノシングルナラナニ?
846 :,,・´∀`・,,)っ-○○○:2014/05/12(月) 23:54:20.44 ID:I6oLdPF4
56とか59の数字の根拠が不明だな
AVXを使わない場合なんだろうけどなぜか理論ピーク性能を持ち出してる
わけがわからないよ
現実のプログラムではたいがい大抵FADDだけ・FMULだけとかに偏るから
FMULとFADDが常に1クロックに1命令ずつ欠かすことなく発行できる
状況なんてありえないよ
AVXを使わない場合なんだろうけどなぜか理論ピーク性能を持ち出してる
わけがわからないよ
現実のプログラムではたいがい大抵FADDだけ・FMULだけとかに偏るから
FMULとFADDが常に1クロックに1命令ずつ欠かすことなく発行できる
状況なんてありえないよ
Intelがプロセス差未満の性能差しか出せないゴミって宣伝して楽しいのかな?w
ブバチュウボルケーノ
FLOPSの発表はどこも理論値じゃねーのか?
実測値だして公開すれば?
実測値だして公開すれば?
KaveriでchinebenchR10試してみたけどこれシングルだとコア100%張り付かないな
60-80%程度でうろうろしてる
60-80%程度でうろうろしてる
851 :,,・´∀`・,,)っ-○○○:2014/05/13(火) 00:00:03.80 ID:I6oLdPF4
Haswellの2個のFMAはFMUL+FMUL(or FADD)としても使えるから
レガシーコード動かす場合でもFADD+FMULよりは実効性能出るよ
理屈考えればわかる。
あとFADDのレイテンシも3だから、4のPhenomよりストールしにくい
リザベーションステーションのエントリも多いしリオーダバッファも深い。
ボボッタ
ファビョッタ
ウナギンガ!!!
レガシーコード動かす場合でもFADD+FMULよりは実効性能出るよ
理屈考えればわかる。
あとFADDのレイテンシも3だから、4のPhenomよりストールしにくい
リザベーションステーションのエントリも多いしリオーダバッファも深い。
ボボッタ
ファビョッタ
ウナギンガ!!!
852 :Socket774:2014/05/13(火) 00:01:44.41 ID:D9oQS4it
どういう条件下での数値かは俺も気になるね。
その数値だとPhenomIIはSSEを使って、HaswellはSSEすら使っていないんじゃね?
その数値だとPhenomIIはSSEを使って、HaswellはSSEすら使っていないんじゃね?
AMDはなぜかキャッシュ速度半分くらいまで下げてるからね。省エネの為らしいが
下げなければどうなるのか?興味はある。
下げなければどうなるのか?興味はある。
りみったーとかすきですよね
855 :,,・´∀`・,,)っ-○○○:2014/05/13(火) 00:08:39.37 ID:x8f8yMCX
> 下げなければどうなるのか?興味はある。
無理にゲートピッチ詰めてるから電圧かけたらリーク電流ダダ漏れで爆熱化だろ
IntelがSRAMのゲートピッチを広めに取ってる意味いい加減わかれよ
無理にゲートピッチ詰めてるから電圧かけたらリーク電流ダダ漏れで爆熱化だろ
IntelがSRAMのゲートピッチを広めに取ってる意味いい加減わかれよ
856 :Socket774:2014/05/13(火) 00:15:40.10 ID:FAvGQ24r
あれ?わざと間違えた疑問を入れたのに、突っ込みが無いぞ。
やはり何も判らずにコピペしていただけのようだな。
やはり何も判らずにコピペしていただけのようだな。
857 :,,・´∀`・,,)っ-○○○:2014/05/13(火) 00:17:15.36 ID:x8f8yMCX
はい、後出しじゃんけんのごとく言い訳を始めました。
これが無能の見本。
これが無能の見本。
858 :Socket774:2014/05/13(火) 00:18:20.14 ID:FAvGQ24r
お前ら団子好きだなぁ
まともなことも書くが、実際は、ただのあらしだぞw
I6oLdPF4 29レス
N3oQTwZC 24レス
合わせて本日も一位だ。
AMDの次世代APU/CPUについて語ろう
お前ら、タイトルを読んでみろ
タイトルは、団子と遊ぼうじゃねえぞ?
まともなことも書くが、実際は、ただのあらしだぞw
I6oLdPF4 29レス
N3oQTwZC 24レス
合わせて本日も一位だ。
AMDの次世代APU/CPUについて語ろう
お前ら、タイトルを読んでみろ
タイトルは、団子と遊ぼうじゃねえぞ?
860 :,,・´∀`・,,)っ-○○○:2014/05/13(火) 00:21:35.74 ID:x8f8yMCX
あー、まあ言いたいことはわかるけどねー
Phenom系はStore命令が異常にスループット悪いのも
Intelに実パフォーマンスで差をつけられてる要因。
Phenom系はStore命令が異常にスループット悪いのも
Intelに実パフォーマンスで差をつけられてる要因。
さむちょんで作るかも?って14nもゲートピッチはアグレッシブらしいなwwww
この辺はクロック上げる技術とにてるんじゃねーの?5GhzのCPUが作れるなら
4GHzまで落とせばキャッシュ下げなくていいとかできそーなもんに見えるが?。。。
この辺はクロック上げる技術とにてるんじゃねーの?5GhzのCPUが作れるなら
4GHzまで落とせばキャッシュ下げなくていいとかできそーなもんに見えるが?。。。
chinebenchR10メーカーを見てそれに合わしているんだよ
ベンチではIntelは最新の強力命令、そして、AMDは枯れたレガシー命令を使うって常識
実際のシングル性能はAMDのほうが上なのよ
ベンチではIntelは最新の強力命令、そして、AMDは枯れたレガシー命令を使うって常識
実際のシングル性能はAMDのほうが上なのよ
863 :,,・´∀`・,,)っ-○○○:2014/05/13(火) 00:29:13.76 ID:x8f8yMCX
Bulldozerについていえることは
L2+L3で16MBみたいな無駄に巨大な構成にするくらいなら、SRAMのゲートピッチ
あけてリーク電流対策した上でクロック上げろ
L2+L3で16MBみたいな無駄に巨大な構成にするくらいなら、SRAMのゲートピッチ
あけてリーク電流対策した上でクロック上げろ
864 :,,・´∀`・,,)っ-○○○:2014/05/13(火) 00:30:29.43 ID:x8f8yMCX
>>862
デバッガでトラップしてみたけどそんな分岐コード見つからなかったけど?
デバッガでトラップしてみたけどそんな分岐コード見つからなかったけど?
865 :Socket774:2014/05/13(火) 00:41:21.98 ID:VRPiu41e
A10-7850Kを使ってたけど、今回はイライラするから売ってきます!
期待外れだったな。
期待外れだったな。
>>859
自演だろ、まともな人間ならとっくにNG済
自演だろ、まともな人間ならとっくにNG済
結局理論値性能の発表も嘘?ってことなんか?w
868 :,,・´∀`・,,)っ-○○○:2014/05/13(火) 00:44:21.49 ID:x8f8yMCX
Llanoの1TFLOPSがな
869 :,,・´∀`・,,)っ-○○○:2014/05/13(火) 00:49:26.54 ID:x8f8yMCX
{kind=link}
実行値計るソフトつくれや。っていっても無理かw
871 :,,・´∀`・,,)っ-○○○:2014/05/13(火) 00:52:25.33 ID:x8f8yMCX
Whetstoneを自分でコンパイルすればー?
872 :,,・´∀`・,,)っ-○○○:2014/05/13(火) 00:57:27.27 ID:x8f8yMCX
HSAなら簡単にソフト作れるんだろ?
ソーナンダロ?
ソーナンダロ?
ミッドdGPUつけると1TFlops超の強力PC実現できるってことでAPUは人気ない
CPUは1コアでiGPUはミッドdGPU以上にして高Flopsを実現するAPUにしないと売れない
こんなAPUが理想だろ
CPUは1コアでiGPUはミッドdGPU以上にして高Flopsを実現するAPUにしないと売れない
こんなAPUが理想だろ
874 :,,・´∀`・,,)っ-○○○:2014/05/13(火) 00:59:49.92 ID:x8f8yMCX
APUのアプローチが正しいと思うなら全ディスクリートGPUに汎用CPUコア
内蔵してくだしあ
それでとりあえず俺のやりたいことはできる。
内蔵してくだしあ
それでとりあえず俺のやりたいことはできる。
>>869
時代は高flopsですよ。低flops性能のCPUは1コアで十分
時代は高flopsですよ。低flops性能のCPUは1コアで十分
>>874
何をやりたいんだ? Flopsを見て俺のPCつえーってしたいのか
何をやりたいんだ? Flopsを見て俺のPCつえーってしたいのか
877 :,,・´∀`・,,)っ-○○○:2014/05/13(火) 01:07:25.20 ID:x8f8yMCX
110GFLOPSってAVX+FMA使った上での4コア合計の理論値な。
Haswellなら1コアで十分だけど生まれつきFPUがよわい袈辺痢ちゃんは
4コアでこれがせいいっぱい そしてせいぐっばい
Haswellなら1コアで十分だけど生まれつきFPUがよわい袈辺痢ちゃんは
4コアでこれがせいいっぱい そしてせいぐっばい
878 :,,・´∀`・,,)っ-○○○:2014/05/13(火) 01:08:49.38 ID:x8f8yMCX
PCI Expressのカード上でScientific Linuxが動く「Opteron Phi」的なものを頼む
AVXとかいう旧世代の話ばっかりしてるんじゃねーよ日本語読めないインテル使い共
そもそもBaytrailが非対応な時点で糞だろ
jaguarは対応してるけどな、命令の互換取るために
バカどもに流されたから貼り直しとくよ
AMD Could Feature Next Generation HBM Memory on Volcanic Islands 2.0 Graphics Cards - Allegedly Launching in 2H 2014
http://wccftech.com/amd-feature-generation-hbm-memory-volcanic-islands-20-graphics-cards-allegedly-launching-2h-2014
HBM一番乗りはIntelでもNvidiaでもなくAMDだった
年末くらいに出るらしいからお前らちゃんと金貯めとけよ
そもそもBaytrailが非対応な時点で糞だろ
jaguarは対応してるけどな、命令の互換取るために
バカどもに流されたから貼り直しとくよ
AMD Could Feature Next Generation HBM Memory on Volcanic Islands 2.0 Graphics Cards - Allegedly Launching in 2H 2014
http://wccftech.com/amd-feature-generation-hbm-memory-volcanic-islands-20-graphics-cards-allegedly-launching-2h-2014
HBM一番乗りはIntelでもNvidiaでもなくAMDだった
年末くらいに出るらしいからお前らちゃんと金貯めとけよ
>>879
あくまでVolcanic Islandsの2.0ってことはメモリがHBMに対応しただけで
GPUコア設計自体は既存のマイナーアップデートなんだろうな
Denverコアを搭載して更に効率が上がるであろう
2nd gen世代のMaxwellと比べるとどうなのかが見ものだな
あくまでVolcanic Islandsの2.0ってことはメモリがHBMに対応しただけで
GPUコア設計自体は既存のマイナーアップデートなんだろうな
Denverコアを搭載して更に効率が上がるであろう
2nd gen世代のMaxwellと比べるとどうなのかが見ものだな
881 :,,・´∀`・,,)っ-○○○:2014/05/13(火) 01:59:18.55 ID:x8f8yMCX
> そもそもBaytrailが非対応な時点で糞だろ
> jaguarは対応してるけどな、命令の互換取るために
128bitなのに見栄張って256ビット命令サポートするほうが糞やん
案の定2サイクル以上かかって遅いし
iccの最適化オプションで-QaxAVX -QaxSSE4で両対応コード生成できるんだから
何も手間かかんないよ?
AtomやCeleronが対応してないからって、
どのみち古いCPUを使ってるPCでも動作を保障しないといけないから
AVX非対応CPU向けのコードパスは入れるんだよ
普段CPUチェックして細工しただの言う割りに
こういう理窟を理解できないのな?
頭の悪さなおせないの?病院いったらなおるの?
> jaguarは対応してるけどな、命令の互換取るために
128bitなのに見栄張って256ビット命令サポートするほうが糞やん
案の定2サイクル以上かかって遅いし
iccの最適化オプションで-QaxAVX -QaxSSE4で両対応コード生成できるんだから
何も手間かかんないよ?
AtomやCeleronが対応してないからって、
どのみち古いCPUを使ってるPCでも動作を保障しないといけないから
AVX非対応CPU向けのコードパスは入れるんだよ
普段CPUチェックして細工しただの言う割りに
こういう理窟を理解できないのな?
頭の悪さなおせないの?病院いったらなおるの?
それを言ったらBulldozerなんてFMA命令を使わないと128Bitx2のFPが有効に使われないんじゃなかったか?
SSE/AVXだと128BitのSMT実行だからクロック当たりだとjaguar系にすら劣る始末
SSE/AVXだと128BitのSMT実行だからクロック当たりだとjaguar系にすら劣る始末
> Denverコアを搭載して更に効率が上がるであろう
> 2nd gen世代のMaxwellと比べるとどうなのかが見ものだな
いつ出るかも分からないそんなもんどうでもいいよ
邪魔だからNvidia次世代スレでも作ってそこで語ってろ
> 2nd gen世代のMaxwellと比べるとどうなのかが見ものだな
いつ出るかも分からないそんなもんどうでもいいよ
邪魔だからNvidia次世代スレでも作ってそこで語ってろ
>>490完全スルーワロタ
>>882
GPUのシェーダーがFMA演算の塊だから、Bull系のAVXもそれに合わせてFMAベースで作られている
そうしとけば、AVXとGPGPUでの連携やソフトの移植もしやすいからね
FMAは一時期はAVX命令の本命扱いだったけど、最近は全く話題にも登らないんだよな
FMA3の普及がGPGPU普及に繋がるから、IntelがFMA3の普及どころか妨害に走ってると思うくらい全く採用されないな
GPUのシェーダーがFMA演算の塊だから、Bull系のAVXもそれに合わせてFMAベースで作られている
そうしとけば、AVXとGPGPUでの連携やソフトの移植もしやすいからね
FMAは一時期はAVX命令の本命扱いだったけど、最近は全く話題にも登らないんだよな
FMA3の普及がGPGPU普及に繋がるから、IntelがFMA3の普及どころか妨害に走ってると思うくらい全く採用されないな
886 :,,・´∀`・,,)っ-○○○:2014/05/13(火) 02:12:38.60 ID:x8f8yMCX
> All the latest instruction-set extensions to the x86 architecture
> will probably be supported by the new micro-architecture.
> Expect AVX 3.2 512-bit extensions among many others.
AVX-512を貶してた先見性のないバカ共には特大のブーメラン
> will probably be supported by the new micro-architecture.
> Expect AVX 3.2 512-bit extensions among many others.
AVX-512を貶してた先見性のないバカ共には特大のブーメラン
887 :,,・´∀`・,,)っ-○○○:2014/05/13(火) 02:15:54.11 ID:x8f8yMCX
>>885
言ってることが妄想だらけでちゃんちゃらおかしい
言ってることが妄想だらけでちゃんちゃらおかしい
888 :,,・´∀`・,,)っ-○○○:2014/05/13(火) 02:35:37.03 ID:x8f8yMCX
ということで、2009年の予言どおりになりました
しかも普及前のサポート表明www
> 533:Socket774[sage] 2009/12/01(火) 02:44:09 ID:mS4YUKgW (1/1)
> LNIがSSE並みに普通になったらAMDどうするの?
> AVXみたいにあっさりとサポートする?
> 534:,,・´∀`・,,)っ-○○○[sage] 2009/12/01(火) 02:49:18 ID:ekg7DMWw (2/6)
> 1024ビットまではAVXの延長線上にある。
> サポートしないなんてことはあり得んでしょ。
>
> AMDはわざわざVEXとは別個に数千命令確保できるVEXのフォーマット互換のスキームを
> 用意してるんだからさ。
> もちろん「LNI Now!」的なものも用意してくるでしょ。
x86-64でAMD独自のTFPのプランを破棄してPentium 4のSSE2互換に
舵をきったJim Kellerなら、腐れたプライドよりも協調路線を歩むよな。
普通そうだよな。
独自命令を入れるとすればLNI Now!改めXOP-512といったところかな?
しかも普及前のサポート表明www
> 533:Socket774[sage] 2009/12/01(火) 02:44:09 ID:mS4YUKgW (1/1)
> LNIがSSE並みに普通になったらAMDどうするの?
> AVXみたいにあっさりとサポートする?
> 534:,,・´∀`・,,)っ-○○○[sage] 2009/12/01(火) 02:49:18 ID:ekg7DMWw (2/6)
> 1024ビットまではAVXの延長線上にある。
> サポートしないなんてことはあり得んでしょ。
>
> AMDはわざわざVEXとは別個に数千命令確保できるVEXのフォーマット互換のスキームを
> 用意してるんだからさ。
> もちろん「LNI Now!」的なものも用意してくるでしょ。
x86-64でAMD独自のTFPのプランを破棄してPentium 4のSSE2互換に
舵をきったJim Kellerなら、腐れたプライドよりも協調路線を歩むよな。
普通そうだよな。
独自命令を入れるとすればLNI Now!改めXOP-512といったところかな?
あぼーん解いて団子のレス見たら案の定アンチとIntelマンセーしかなくて気持ち悪くなった
日本人毛嫌いしてる韓国人と同じだな、マジ気持ち悪い
Intel+ゲフォでないとAMDと戦えないくせに
AVX2ですらロクに使われてないのにAVX512とか出されてもドコもすぐには対応出来んよ
どっかの誰かが言ってたけど、AVX2は出て1年しか経ってないから普及するはずがないとか
まあ、どうせ差別化とかでpentiumやセロリは非対応だろうし、Atomには乗ることさえ無いだろうね
日本人毛嫌いしてる韓国人と同じだな、マジ気持ち悪い
Intel+ゲフォでないとAMDと戦えないくせに
AVX2ですらロクに使われてないのにAVX512とか出されてもドコもすぐには対応出来んよ
どっかの誰かが言ってたけど、AVX2は出て1年しか経ってないから普及するはずがないとか
まあ、どうせ差別化とかでpentiumやセロリは非対応だろうし、Atomには乗ることさえ無いだろうね
890 :,,・´∀`・,,)っ-○○○:2014/05/13(火) 02:55:39.09 ID:x8f8yMCX
まだ言ってる。そんな腐れたプライドなんてもう意味ないのに。
891 :,,・´∀`・,,)っ-○○○:2014/05/13(火) 02:59:29.06 ID:x8f8yMCX
> Atomには乗ることさえ無いだろうね
AVX-512を最初に実装するKnights LandingがAtomベースだから
むしろAtomまで全部AVX-512対応のほうが設計コストが浮くのでは?
AVX-512を最初に実装するKnights LandingがAtomベースだから
むしろAtomまで全部AVX-512対応のほうが設計コストが浮くのでは?
892 :Socket774:2014/05/13(火) 03:09:14.17 ID:FAvGQ24r
>>889
AVX2は『まだ』普及率は高く無いだな。
HSAと違って、普及が約束されている機能だ。
何しろ、圧倒的シェアをもつIntelだけでなく、AMDもExcavatorで対応するんだからな。
ところで、Intelは独力でAMDより高いCPUシェアとGPUシェアだが、何故NVIDIAと組まなければAMDと戦えないと思うのかね?
AVX2は『まだ』普及率は高く無いだな。
HSAと違って、普及が約束されている機能だ。
何しろ、圧倒的シェアをもつIntelだけでなく、AMDもExcavatorで対応するんだからな。
ところで、Intelは独力でAMDより高いCPUシェアとGPUシェアだが、何故NVIDIAと組まなければAMDと戦えないと思うのかね?
893 :,,・´∀`・,,)っ-○○○:2014/05/13(火) 03:13:08.77 ID:x8f8yMCX
> Intel+ゲフォでないとAMDと戦えないくせに
Xeon+FireProでないとNVIDIA Quadro/Teslaと戦えないAMDにブーメラン突き刺すなよ
Xeon+FireProでないとNVIDIA Quadro/Teslaと戦えないAMDにブーメラン突き刺すなよ
894 :,,・´∀`・,,)っ-○○○:2014/05/13(火) 03:17:38.38 ID:x8f8yMCX
「うちはRadeonを持っているからAPUを作ればシェアを拡大できる」
そんなAMDの目論見に反してシェアは年々低下し続けた
AMDがプライドかなぐり捨ててIntel互換路線をすすめてるのに
何故毛嫌いしてるのか理解できないのだが
どうやらAVX2/-512が普及するとHSA構想が破綻するという
認識があるらしい
逆に考えるんだ、破綻してもいい程度のものだったと考えるんだ。
そんなAMDの目論見に反してシェアは年々低下し続けた
AMDがプライドかなぐり捨ててIntel互換路線をすすめてるのに
何故毛嫌いしてるのか理解できないのだが
どうやらAVX2/-512が普及するとHSA構想が破綻するという
認識があるらしい
逆に考えるんだ、破綻してもいい程度のものだったと考えるんだ。
intelGPUはゴミ性能だからな、性能低過ぎて戦いにならない
896 :,,・´∀`・,,)っ-○○○:2014/05/13(火) 03:20:16.65 ID:x8f8yMCX
すでにgccやLLVMのソースコードツリーにAVX-512のコードが
マージされてるんだからいまさら流行らないでくれーとか
願っても遅いんだよ
マージされてるんだからいまさら流行らないでくれーとか
願っても遅いんだよ
ADAPTIVE-SYNC ADDED TO VESA DISPLAYPORT 1.2A STANDARD
http://www.brightsideofnews.com/2014/05/12/vesa-adds-adaptive-sync-displayport-1-2-standard/
http://www.brightsideofnews.com/2014/05/12/vesa-adds-adaptive-sync-displayport-1-2-standard/
Intel+ゲフォが強いだけで、Intel単体に存在価値は欠片もないよ
少なくともAPUになぶり殺される程度の存在でしか無い
少なくともAPUになぶり殺される程度の存在でしか無い
899 :,,・´∀`・,,)っ-○○○:2014/05/13(火) 03:37:13.51 ID:x8f8yMCX
Llanoを出して以降、AMDはシェア低下を続けてます
AMD 780GとG45のときは5倍以上性能差があったが、年々差は埋まってるしなぁ
内蔵GPUだけで勝つる!なんて当のAMDすら思ってないわな
結果が出てないもの
AMD 780GとG45のときは5倍以上性能差があったが、年々差は埋まってるしなぁ
内蔵GPUだけで勝つる!なんて当のAMDすら思ってないわな
結果が出てないもの
>>884
英語わかんないからスルーしてたが北森で知った
英語わかんないからスルーしてたが北森で知った
>>897
対応グラボ:R9 290X / R9 290 / R7 260X / R7 260
対応APU:Kabini、Temash、Beema、Mullins
対応モニタ:6〜12ヶ月以内に登場予定
Kaveriが入ってないのが気になるな
対応グラボ:R9 290X / R9 290 / R7 260X / R7 260
対応APU:Kabini、Temash、Beema、Mullins
対応モニタ:6〜12ヶ月以内に登場予定
Kaveriが入ってないのが気になるな
マザー側で対応とか必要ならめんどくさそうだな
>>884 >>901
AMD幹部の発言から、Bulldozerが大失敗したので、Bulldozerを捨てて新たなマイクロアーキテクチャ開発してるのは
ほぼ確実でしょう
ただし、新マイクロアーキテクチャ開発には数年かかり、それまではBulldozerを売っていかないといけないので、
直近まで公表せずに開発すると思われる
AMD幹部の発言から、Bulldozerが大失敗したので、Bulldozerを捨てて新たなマイクロアーキテクチャ開発してるのは
ほぼ確実でしょう
ただし、新マイクロアーキテクチャ開発には数年かかり、それまではBulldozerを売っていかないといけないので、
直近まで公表せずに開発すると思われる
FPUの値段はタダ同然だし、コア数も頭打ちだし、GPGPUでFLOPSを稼げるようになったし
もうクラスタードアーキテクチャにこだわる理由もないか
もうクラスタードアーキテクチャにこだわる理由もないか
906 :Socket774:2014/05/13(火) 10:18:34.31 ID:plpmeP/i
まあそれまでのHSAは気休めだわな。
適用できるプログラムは限定されてるし。
APU限定の時点でソフト屋にはかかる工数に見合わない。
AVX512にも言及してるのは当然といえば当然だが、GPUでCPUのSIMD性能を
補うことの限界を認めたことになる。
いずれにせよものが出るまでは既存製品を騙し騙しでも売るしかないから
こういうことは大っぴらには言わないだろう。
carrizoのAVX2/VT対応みたいにひっそりと情報公開するに留めると。
2015年ターゲットってのがかなり苦し紛れな気がするが
いっこうに減らない20億ドル以上の長期社債をまずはどうにかしないとな
(毎年1億ドルずつ金利の支払いで消えてる)
適用できるプログラムは限定されてるし。
APU限定の時点でソフト屋にはかかる工数に見合わない。
AVX512にも言及してるのは当然といえば当然だが、GPUでCPUのSIMD性能を
補うことの限界を認めたことになる。
いずれにせよものが出るまでは既存製品を騙し騙しでも売るしかないから
こういうことは大っぴらには言わないだろう。
carrizoのAVX2/VT対応みたいにひっそりと情報公開するに留めると。
2015年ターゲットってのがかなり苦し紛れな気がするが
いっこうに減らない20億ドル以上の長期社債をまずはどうにかしないとな
(毎年1億ドルずつ金利の支払いで消えてる)
ソケットFM2+のマザーボードで現在日本で買えるメーカーって
最近はそんなに多くないんだね ATXマザーを探しているんだけど
Asrock、ASUS、Gigabyte、MSIの4択くらいなの?
最近はそんなに多くないんだね ATXマザーを探しているんだけど
Asrock、ASUS、Gigabyte、MSIの4択くらいなの?
>>906
> AVX512にも言及してるのは当然といえば当然だが、GPUでCPUのSIMD性能を
> 補うことの限界を認めたことになる。
認めてないよ、単に対応してないと売れないだけ
どうせi7しか性能でないし、セレロンとかじゃ対応もしないから限界もクソもないw
> AVX512にも言及してるのは当然といえば当然だが、GPUでCPUのSIMD性能を
> 補うことの限界を認めたことになる。
認めてないよ、単に対応してないと売れないだけ
どうせi7しか性能でないし、セレロンとかじゃ対応もしないから限界もクソもないw
910 :Socket774:2014/05/13(火) 11:26:49.87 ID:KOBgc7Db
HSAってサードパーティソフト不在のマーキテクチャ以外のなんでもないだろ
最初の理念はともかく。
他社の最新の命令取り入れないと売れないというのは
要するにマーケティングで完全に負けたということ。
最初の理念はともかく。
他社の最新の命令取り入れないと売れないというのは
要するにマーケティングで完全に負けたということ。
>>910
実のところ、3Dnowから何も成長してないよなw
実のところ、3Dnowから何も成長してないよなw
しつこいなこいつも
既知の技術の応用で新規性の全くないものに勝手な名前を付けて、さも新発明であるかのように宣伝する。
他社から同種の技術のより洗練された実装が登場し、それが業界標準になりそうなると手のひらを返してそちらに切り替え、過去のものはなかったことにする。
マーケティングの基本だよ。
他社から同種の技術のより洗練された実装が登場し、それが業界標準になりそうなると手のひらを返してそちらに切り替え、過去のものはなかったことにする。
マーケティングの基本だよ。
ここまでシツコイのはAVX考えた人とかなんだろなw
AMDが2015年に向けて高性能x86 CPUの新アーキテクチャを開発中らしい
http://northwood.blog60.fc2.com/blog-entry-7531.html
http://northwood.blog60.fc2.com/blog-entry-7531.html
ところでJimさんはk12の開発担当課と思ったけどx86も担当するのか?
人材が(略)。
人材が(略)。
917 :Socket774:2014/05/13(火) 11:59:25.12 ID:UC2rlbcE
919 :Socket774:2014/05/13(火) 12:17:16.35 ID:QpU3hAOM
AMDに明日がくるかどうかはJPモルガン次第じゃないの?
http://m.japan.cnet.com/#story,35024404
いずれにしても2015年までに社員を切るなり資産を売るなりして
社債償還のために5億ドルの現金を用意しないといけないからな。
資産を売却してしまうと債券発行時に担保にするものがなくなるから、
なんでも売れば済む話ではない罠。
研究開発予算も減ってるのにx86もARMも新規設計なんて
無理がある話にみえる。
http://m.japan.cnet.com/#story,35024404
いずれにしても2015年までに社員を切るなり資産を売るなりして
社債償還のために5億ドルの現金を用意しないといけないからな。
資産を売却してしまうと債券発行時に担保にするものがなくなるから、
なんでも売れば済む話ではない罠。
研究開発予算も減ってるのにx86もARMも新規設計なんて
無理がある話にみえる。
VESA,AMDの「FreeSync」を「Adaptive-Sync」として標準化。DisplayPort接続でカク付き・遅延・テアリングフリーの表示を実現
http://www.4gamer.net/games/999/G999902/20140513002/
http://www.4gamer.net/games/999/G999902/20140513002/
>>920
GPUとディスプレイを自動同期する機能がDisplayPortに実装
〜テアリングを解消し、消費電力も削減
http://pc.watch.impress.co.jp/docs/news/20140513_648010.html
同じ内容の記事でもこっちはAMDを出さずにNVIDIAを出しやがった
GPUとディスプレイを自動同期する機能がDisplayPortに実装
〜テアリングを解消し、消費電力も削減
http://pc.watch.impress.co.jp/docs/news/20140513_648010.html
同じ内容の記事でもこっちはAMDを出さずにNVIDIAを出しやがった
借金は借金して返せばいいんだよ
借金を手持ちの現金で返す必要は無い
借金を手持ちの現金で返す必要は無い
PCwatchは悪意あるとしか言いようが無い
> Adaptive-Syncは、ノートPCなどで採用されるeDP(embedded
DisplayPort)には2009年の規格化の時点で組み込まれており、
DisplayPort)には2009年の規格化の時点で組み込まれており、
標準規格化されれば、べつにAMDじゃなくてもnvidiaでも使えるんだから、
そのうち、nvidia・intelのGPUもそのAdaptive-Syncに対応してくるんじゃないの?
そのうち、nvidia・intelのGPUもそのAdaptive-Syncに対応してくるんじゃないの?
現行ビデオカードとAdaptive-Sync対応ディスプレイでAdaptive-Syncは出来んのかな?
HBM対応GPUって外部DRAM無くなるの?
>>903
モニタ側がVariable VBLANKに対応してれば既存のPCで使えるってのがFreeSyncの売りだから
Adaptive-Syncもドライバの対応だけでいいはず
http://www.anandtech.com/show/7641/amd-demonstrates-freesync-free-gsync-alternative-at-ces-2014
>>922
PC WatchではFreesyncは存在しないことになってるみたいだね
http://pc.watch.impress.co.jp/extra/pcw/search/?q="g-sync"
http://pc.watch.impress.co.jp/extra/pcw/search/?q=free+sync
モニタ側がVariable VBLANKに対応してれば既存のPCで使えるってのがFreeSyncの売りだから
Adaptive-Syncもドライバの対応だけでいいはず
http://www.anandtech.com/show/7641/amd-demonstrates-freesync-free-gsync-alternative-at-ces-2014
>>922
PC WatchではFreesyncは存在しないことになってるみたいだね
http://pc.watch.impress.co.jp/extra/pcw/search/?q="g-sync"
http://pc.watch.impress.co.jp/extra/pcw/search/?q=free+sync
GDDR5の代替がhbm
VESAと仲いいな
こういう規格が標準化されてどこでも使えるようになるのは良い事よ
こういう規格が標準化されてどこでも使えるようになるのは良い事よ