Intel�̎�����CPU�ɂ��Č�낤 71
Intel�̎�����CPU��A����Ɋ֘A������e�ɂ��ẴX���b�h�ł�
���O�X��
Intel�̎�����CPU�ɂ��Č�낤 70
http://anago.2ch.net/test/read.cgi/jisaku/1385580500/
���O�X��
Intel�̎�����CPU�ɂ��Č�낤 70
http://anago.2ch.net/test/read.cgi/jisaku/1385580500/
|
|
|
>>1tel�A������B
3 �FSocket774�F2013/12/29(��) 01:21:15.60 ID:po11gdFT
�@���@�@>>1 ���@�������O�ɗp�͂Ȃ�
�@��|�j��
�@�@�r�@�@�@�R���m
�P�P7�@�@�w/
�@�@�^�@ �@�m
�@�@| �@�@�@�@ �R�@�@�@�@�@�@�@�@ ���Q
�@�^ �@�@�@�@�@�R�@�@�@�@�@ �@ �m(�Q�@�@�@�@�@�@�@�@�@�@�@�@�_�@ �Q
�@| �@�@�@�@�@�@�@�@�@�@�@�@�@�@�@���@�@�@�@�@�@�@�@�@�@�@�@�@/��l��
�^ �@�@�@�@�@�@�@ �R�@ �@ �^�@�@�@�@�@ �_�@�@�@�@ �^
�@�@�@�@�@�@�@�@�@�@�@�@/�@�@�@�@�@�@�@�@�@�@�@�@/�@�@�@�@�@�@�@�@ �Q_���Q�Q
�@�@�@�@�@�@�@���@ �@�u�@ �@���@�@�@ ���@�@ �u�@�@���@�@�@�@�@ /|�P�P�P�P|
�@�@�@�@�@�@�@�@)�R������/)�@�@�@�@�@)�R������/)�@�@�@ �@�^���@ ���@�@ |
�@�@�@�@�@�@�@�m>�@�@�@�@�@/<�@�@�@�@�m>�@�@�@�@�@/<�@�@�@ ��������������
�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P
�@��|�j��
�@�@�r�@�@�@�R���m
�P�P7�@�@�w/
�@�@�^�@ �@�m
�@�@| �@�@�@�@ �R�@�@�@�@�@�@�@�@ ���Q
�@�^ �@�@�@�@�@�R�@�@�@�@�@ �@ �m(�Q�@�@�@�@�@�@�@�@�@�@�@�@�_�@ �Q
�@| �@�@�@�@�@�@�@�@�@�@�@�@�@�@�@���@�@�@�@�@�@�@�@�@�@�@�@�@/��l��
�^ �@�@�@�@�@�@�@ �R�@ �@ �^�@�@�@�@�@ �_�@�@�@�@ �^
�@�@�@�@�@�@�@�@�@�@�@�@/�@�@�@�@�@�@�@�@�@�@�@�@/�@�@�@�@�@�@�@�@ �Q_���Q�Q
�@�@�@�@�@�@�@���@ �@�u�@ �@���@�@�@ ���@�@ �u�@�@���@�@�@�@�@ /|�P�P�P�P|
�@�@�@�@�@�@�@�@)�R������/)�@�@�@�@�@)�R������/)�@�@�@ �@�^���@ ���@�@ |
�@�@�@�@�@�@�@�m>�@�@�@�@�@/<�@�@�@�@�m>�@�@�@�@�@/<�@�@�@ ��������������
�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P
4 �FSocket774�F2013/12/29(��) 22:29:50.17 ID:e+x+NBFS
Broadwell-K���o���w�i�ɂ�Skylake�̒x��߂邽�߂���
GT4e����Ȃ�ʔ��������Ȃ�
GT4e����Ȃ�ʔ��������Ȃ�
5 �F���|�̍ݓ��E�n���^�u�[�F2013/12/29(��) 22:37:51.97 ID:/8s48jkV
�ݓ�or�A�����N�l�Ȃ�A�l���E���Ă�������鐢�̒��ɂȂ����͗l
�u���{�l�Ȃ牽�l���E�����Ǝv�����v�����ʂ薂�����@�؍��Ђ̒j��s�N�i��
http://blog.livedoor.jp/societynews/archives/1108674.html
�y���A���ώ��z�j���s�Ҏ��A�p�c����q���퍐�Ɛe����W�l�S���s�N�i
http://jacklog.doorblog.jp/archives/35922412.html
������s�N�i�ց@�������̂Ō��@
http://www.nikkei.com/article/DGXNASDG0901P_Z00C13A8CR0000/
���nj������̌������@�͈�@�B����ɂ��̎��@�̂����ŁA���q�F�̌�����ƊJ�n��
�x�ꂽ���Ƃ������ɂȂ������A�ƍ���ŒNjy���ꂽ�B
�i�S���Ȃ������d�E�g�c�������G���C���^�ɂď،��j
�}�X�R�~�́A���̎������قƂ�Ǖ��E�B
�Ǘ����Ă�͓̂��{����Ȃ��A���{�̃}�X�R�~�B
�~�X�E�C���^�[�i�V���i���g���������@�|�\�E�̈ł��������}�X�R�~�َE�����܂ő_����
http://kamonohashi.doorblog.jp/archives/35001601.html
�y�|�\�z�ă��f�B�A�u���{�̒��ق���w�v �g���������ւ̌����点�����X�g�[�J�[�����A�������f�B�A�͉����тŃ_���}��
http://www.entaboo.com/archives/entry-3516.html
�����̒j�́A�n���呲�i�ݓ��H�j�Ƃ������A��
����
�u���{�l�Ȃ牽�l���E�����Ǝv�����v�����ʂ薂�����@�؍��Ђ̒j��s�N�i��
http://blog.livedoor.jp/societynews/archives/1108674.html
�y���A���ώ��z�j���s�Ҏ��A�p�c����q���퍐�Ɛe����W�l�S���s�N�i
http://jacklog.doorblog.jp/archives/35922412.html
������s�N�i�ց@�������̂Ō��@
http://www.nikkei.com/article/DGXNASDG0901P_Z00C13A8CR0000/
���nj������̌������@�͈�@�B����ɂ��̎��@�̂����ŁA���q�F�̌�����ƊJ�n��
�x�ꂽ���Ƃ������ɂȂ������A�ƍ���ŒNjy���ꂽ�B
�i�S���Ȃ������d�E�g�c�������G���C���^�ɂď،��j
�}�X�R�~�́A���̎������قƂ�Ǖ��E�B
�Ǘ����Ă�͓̂��{����Ȃ��A���{�̃}�X�R�~�B
�~�X�E�C���^�[�i�V���i���g���������@�|�\�E�̈ł��������}�X�R�~�َE�����܂ő_����
http://kamonohashi.doorblog.jp/archives/35001601.html
�y�|�\�z�ă��f�B�A�u���{�̒��ق���w�v �g���������ւ̌����点�����X�g�[�J�[�����A�������f�B�A�͉����тŃ_���}��
http://www.entaboo.com/archives/entry-3516.html
�����̒j�́A�n���呲�i�ݓ��H�j�Ƃ������A��
����
eDRAM��PCH�̓����͂�I�I
7 �F���|�̍ݓ��E�n���^�u�[�F2013/12/29(��) 22:39:56.20 ID:/8s48jkV
����
�n�����ݓ����I�E���Ƀ��X��������̂́A�����u�P�Ɓv��������
�y�N��z�����}�u���@�̂����œ���̏@�������U�������Ȃ��v
http://www.log-channel.net/bbs/poverty/1386937136/
�����̃I�E�������U�������Ȃ����̎i�@�ƌ��@�͖��Ǝv���܂��H
�X����ɂ���ւ��Č��@�����ɔ����Ă�n�������}�A���̑����}�̐��̂ƁA
�ݓ��n�X�|���T�[�������郁�f�B�A��������_���ɋC�t�����B
�����P�Ɛ����������A�����������̍Œ�K�v����
�O�@�Ŏ����}�P�ƂQ�^�R ���A
�O�Q���@�Ŏ����P�Ɖߔ���
���������A�����ɂ��A���l�X�p�C���c���Ă�\�����l����ƁA����ɑ����̋c�Ȃ��K�v�B
���݃N���A���Ă�̂́A�O�c�@�ł̒P�Ɖߔ����̂�
�Ȃ��ݓ��Ƒn���̓^�u�[�Ȃ̂��l�@ �P
http://www.youtube.com/watch?v=CxIGOhFT4g8
�Ȃ��ݓ��Ƒn���̓^�u�[�Ȃ̂��l�@�@2
http://www.youtube.com/watch?v=iG_oaqU0pEM
�n�����ݓ����I�E���Ƀ��X��������̂́A�����u�P�Ɓv��������
�y�N��z�����}�u���@�̂����œ���̏@�������U�������Ȃ��v
http://www.log-channel.net/bbs/poverty/1386937136/
�����̃I�E�������U�������Ȃ����̎i�@�ƌ��@�͖��Ǝv���܂��H
�X����ɂ���ւ��Č��@�����ɔ����Ă�n�������}�A���̑����}�̐��̂ƁA
�ݓ��n�X�|���T�[�������郁�f�B�A��������_���ɋC�t�����B
�����P�Ɛ����������A�����������̍Œ�K�v����
�O�@�Ŏ����}�P�ƂQ�^�R ���A
�O�Q���@�Ŏ����P�Ɖߔ���
���������A�����ɂ��A���l�X�p�C���c���Ă�\�����l����ƁA����ɑ����̋c�Ȃ��K�v�B
���݃N���A���Ă�̂́A�O�c�@�ł̒P�Ɖߔ����̂�
�Ȃ��ݓ��Ƒn���̓^�u�[�Ȃ̂��l�@ �P
http://www.youtube.com/watch?v=CxIGOhFT4g8
�Ȃ��ݓ��Ƒn���̓^�u�[�Ȃ̂��l�@�@2
http://www.youtube.com/watch?v=iG_oaqU0pEM
>>4
��̓����ƌ��������ŁASkylake�͒x�����Ȃ��Ƃ������ʂ����o�Ă�
��̓����ƌ��������ŁASkylake�͒x�����Ȃ��Ƃ������ʂ����o�Ă�
����ȏ������?
�\�[�X������Ă��BBroadwell�x���̍ۂɏo�������ŁA�Ⴆ���̂ւ�
> Broadwell's delay won't affect the release of its successor, Skylake, Krzanich said,
> as Skylake will be based on a brand-new architecture.
http://www.computerworld.com/s/article/9243235/Intel_delays_Broadwell_chips_for_PCs_and_hybrids
> Broadwell's delay won't affect the release of its successor, Skylake, Krzanich said,
> as Skylake will be based on a brand-new architecture.
http://www.computerworld.com/s/article/9243235/Intel_delays_Broadwell_chips_for_PCs_and_hybrids
�v���Z�X��������ŁA�V�K�v������`�����悵���Ă��H
����������DDR4���LPDDR4�̂ق����������y����̂���
http://www.fudzilla.com/home/item/33525-4gb-lpddr4-phones-possible-in-2014
http://www.fudzilla.com/home/item/33525-4gb-lpddr4-phones-possible-in-2014
�T���X��������o���o�����\�����ˁH
14 �F �y���g�z �y939�~�z �F2014/01/01(��) 01:00:20.87 ID:CqIWoOLf
Intel�l�������l�ނ̖������J����B��_
�S�l�ނ�Intel�l�̉��ɕ�����Intel�l�����𐒔q��
Intel�l�ɑS�Ă������ׂ��ł���
Intel�l���I�I�I�I�I
�S�l�ނ�Intel�l�̉��ɕ�����Intel�l�����𐒔q��
Intel�l�ɑS�Ă������ׂ��ł���
Intel�l���I�I�I�I�I
��������
����Intel��2013�N�̊�����12��31������ԍ����Ȃ����݂�����
����Intel��2013�N�̊�����12��31������ԍ����Ȃ����݂�����
16 �FSocket774�F2014/01/01(��) 08:23:09.76 ID:fvdiHUD8
�N���X�}�X����A��Amazon�ōł����ꂽ�m�[�gPC�́uChromebook�v��MS�̌��O������
http://rbmen.blogspot.jp/2013/12/amazonpcchromebookms.html
https://www.npd.com/wps/portal/npd/us/news/press-releases/u-s-commercial-channel-computing-device-sales-set-to-end-2013-with-double-digit-growth-according-to-npd/
�N���[���u�b�N�̃V�F�A���������ƂɂȂ��Ă�̂�
http://rbmen.blogspot.jp/2013/12/amazonpcchromebookms.html
https://www.npd.com/wps/portal/npd/us/news/press-releases/u-s-commercial-channel-computing-device-sales-set-to-end-2013-with-double-digit-growth-according-to-npd/
�N���[���u�b�N�̃V�F�A���������ƂɂȂ��Ă�̂�
��������v���[���g�p�ɔ��ꂽ���ǎ��ۂ͎g���Ȃ� or �ԕi�̃p�^�[������ˁ[�́H
�l�b�g���邾���Ȃ�iPad�ł������A���Y���~�����Ȃ�Windows or Mac�I�Ȃ��ق�����������
�l�b�g���邾���Ȃ�iPad�ł������A���Y���~�����Ȃ�Windows or Mac�I�Ȃ��ق�����������
���Ƃ̕��́A�O�X���܂Ƃ�
�EIntel��Fab�߂邾���̎s������o���Ȃ�������A������]��������
�E14nm�ɂȂ�ƑS���Y�L���p�V�e�B�߂��Ȃ��Ȃ�
�E�����炭22nm�ł�Fab�߂��ĂȂ�
�E���i�����藣��
�E�t�@�E���_���r�W�l�X���n�߂�������IP�����肸���o�C���p�J�X�^��SoC�͍��Ȃ�
�E����������O�҂��g����Intel�̔����̋Z�p�ɑΉ������ėpEDA�c�[�����Ȃ�
�EIntel��Fab�߂邾���̎s������o���Ȃ�������A������]��������
�E14nm�ɂȂ�ƑS���Y�L���p�V�e�B�߂��Ȃ��Ȃ�
�E�����炭22nm�ł�Fab�߂��ĂȂ�
�E���i�����藣��
�E�t�@�E���_���r�W�l�X���n�߂�������IP�����肸���o�C���p�J�X�^��SoC�͍��Ȃ�
�E����������O�҂��g����Intel�̔����̋Z�p�ɑΉ������ėpEDA�c�[�����Ȃ�
>>17
��Amazon�ł͔N�Ԃ�ʂ��Ĕ���g�b�v�L�[�v
��Amazon�ł͔N�Ԃ�ʂ��Ĕ���g�b�v�L�[�v
�������̍���&�K�i�X�V���O�ŁA
������CPU������K�R�����Ȃ���ˁ[
������CPU������K�R�����Ȃ���ˁ[
CPU�����ւ��悤�Ǝv����ł���
���̐����Core i7���Ă��o�����ł����H�\�z�ŗǂ��̂ŗǂ�������Ă�������....
���̐����Core i7���Ă��o�����ł����H�\�z�ŗǂ��̂ŗǂ�������Ă�������....
DDR4���Ă���ɍ����Ȃ�̂���
Haswell�̎��̓\�P�b�g�ς��̂��ȁH
���̕ӏ��łĂ�H
���̕ӏ��łĂ�H
http://vr-zone.com/articles/new-details-intels-upcoming-skylake-processor/62999.html
skylake��LGA1151�ɂȂ肻���Ƃ��Ȃ�Ƃ�
�������ЂƂ̃O���b�h�����炢�Ȃ�Ƃ��Ȃ�����
skylake��LGA1151�ɂȂ肻���Ƃ��Ȃ�Ƃ�
�������ЂƂ̃O���b�h�����炢�Ȃ�Ƃ��Ȃ�����
25 �F,,�E�L�́M�E,,�j��-�������F2014/01/01(��) 15:23:40.28 ID:hlV9Oqd6
�����̃e�N�j�J�����C�^�[���o�c�́u���Ɓv�͏Ύ~�B
>>25
�͂��ǂ�
�͂��ǂ�
27 �F,,�E�L�́M�E,,�j��-�������F2014/01/01(��) 15:27:04.23 ID:hlV9Oqd6
�s���{�����������Ό݊�������Ȃ�1155���猸�炵���肵�Ȃ��B
�킴�ƕ����I�ɍ���Ȃ����邽�߂Ƀs�����ς��Ă���B
�킴�ƕ����I�ɍ���Ȃ����邽�߂Ƀs�����ς��Ă���B
>>22
DDR3�ł��疳��������������̂�4�Ƃ��{���ɑ��v�Ȃ́H
DDR3�ł��疳��������������̂�4�Ƃ��{���ɑ��v�Ȃ́H
�������Ƃ�����HBM���Ăǂ��Ȃ��
�������C���^�[�t�F�C�X���ς��̂Ƀ\�P�b�g�̃s�������������ɂ������Ďd���Ȃ��ł���
�L���b�V���ł͂��܂����Ȃ��悤�ȕ��ׂ�CPU�ɋ���ɂ�����悤��
�L���[�A�v���P�[�V����������Ηǂ�������ȁB
�݂��CPU���Â₩���������B
�����������v����͂������烁�����̓��W���[���`���ł͂Ȃ�
�O���t�B�b�N�J�[�h���VRAM�̂悤��CPU�J�[�h��̃��C���������Ƃ���
�X�^�C���̔�������蒅���Ă�����������Ȃ��B
�L���[�A�v���P�[�V����������Ηǂ�������ȁB
�݂��CPU���Â₩���������B
�����������v����͂������烁�����̓��W���[���`���ł͂Ȃ�
�O���t�B�b�N�J�[�h���VRAM�̂悤��CPU�J�[�h��̃��C���������Ƃ���
�X�^�C���̔�������蒅���Ă�����������Ȃ��B
������L4�L���b�V���ł���
33 �F,,�E�L�́M�E,,�j��-�������F2014/01/01(��) 21:06:37.17 ID:hlV9Oqd6
���������p�r�i���̉��Z�Ȃǁj�̂��߂�NEC�̃x�N�g���X�p�R��������B
�w�p�֘A�ȊO�ł����������Z�p�r���V���ɐ��܂��Ƃ���A
�A���S���Y����R�[�f�B���O���Ó��łȂ��ꍇ���قƂ�ǁB
�ނ����ʂ̉��Z���[�N���[�h�ɂ��킹��CPU�A�[�L�e�N�`����
���B���Ă����킯�ŁA�\�t�g�̓n�[�h���Â₩���Ƃ����قNJÂ₩���ĂȂ��B
VB�Ŗ��ʂɃ��[�v�𑽏d�ɉ悤�ȕ��R�[�h�ł���������킸�����킯�ŁB
�w�p�֘A�ȊO�ł����������Z�p�r���V���ɐ��܂��Ƃ���A
�A���S���Y����R�[�f�B���O���Ó��łȂ��ꍇ���قƂ�ǁB
�ނ����ʂ̉��Z���[�N���[�h�ɂ��킹��CPU�A�[�L�e�N�`����
���B���Ă����킯�ŁA�\�t�g�̓n�[�h���Â₩���Ƃ����قNJÂ₩���ĂȂ��B
VB�Ŗ��ʂɃ��[�v�𑽏d�ɉ悤�ȕ��R�[�h�ł���������킸�����킯�ŁB
>33
�ߕی싳��}�}�i����H�j��
�����ł͊Â₩���ĂȂ����܂��ƌ����Ă�悤�ɂ����������Ȃ�
�ߕی싳��}�}�i����H�j��
�����ł͊Â₩���ĂȂ����܂��ƌ����Ă�悤�ɂ����������Ȃ�
�L���b�V���͐ς߂ΐ��\����������Ă���ł��Ȃ�����Ȃ��B
�������̓L���p�V�^�Z�����g���Ă����̓��C�e���V���]����
�]�����x���҂��肵���Ȃ����ǁA����DDR3�̂܂܂ł���B
SRAM�Ń��C���������̓R�X�g�����ˏオ�邵�B
�������̓L���p�V�^�Z�����g���Ă����̓��C�e���V���]����
�]�����x���҂��肵���Ȃ����ǁA����DDR3�̂܂܂ł���B
SRAM�Ń��C���������̓R�X�g�����ˏオ�邵�B
4GB��SRAM�Ƃ����M�œ~�͗ǂ���������
37 �F,,�E�L�́M�E,,�j��-�������F2014/01/01(��) 23:38:22.06 ID:hlV9Oqd6
���Ⴀ���̃������ш惂���X�^�[�d�l�ɂ����Ƃ����
���̉��Z�ȊO�ŗL�p�ȕ�����ĉ��H
�R�X�g�I�Ɍ������́H�m�[�gPC��^�u���b�g�ɐς߂�́H
�ˋ�̎��v���ł���������̂̓o�u���O�̌����H���܂łŏ\���B
���̉��Z�ȊO�ŗL�p�ȕ�����ĉ��H
�R�X�g�I�Ɍ������́H�m�[�gPC��^�u���b�g�ɐς߂�́H
�ˋ�̎��v���ł���������̂̓o�u���O�̌����H���܂łŏ\���B
���ˋ�̎��v���ł�������
ManyCore�̈����͎~�߂�
ManyCore�̈����͎~�߂�
39 �F,,�E�L�́M�E,,�j��-�������F2014/01/01(��) 23:55:15.72 ID:hlV9Oqd6
���j�[�R�A�̓r�b�O�f�[�^��͂Ƃ����g�����h�̒����ɏ���Ă邶���B
����ȉ��Z�@�\�E���\�͂��ׂĂ̐l���K�v�Ƃ��Ă���킯�ł͂Ȃ��B
1�l1��̃p�\�R���Œ��r���[�Ȑ��\�������́A��K�͂ȃN���X�^�[��
�N���E�h��Ɏ����ċ��L�����ق����������B
����ȉ��Z�@�\�E���\�͂��ׂĂ̐l���K�v�Ƃ��Ă���킯�ł͂Ȃ��B
1�l1��̃p�\�R���Œ��r���[�Ȑ��\�������́A��K�͂ȃN���X�^�[��
�N���E�h��Ɏ����ċ��L�����ق����������B
�ш�H����GPU���������ꂽ���Ƃ����A200GB/s���炢�͗~������
eDRAM��PCH�̃_�C�����͂�I�I
���K�v�Ȃ�͑ш�ł����ėe�ʂ���Ȃ�����ȁB
�ш悳������A�L���b�V���g�������Ă����̃T�C�N���őS�����߂�Ƃ��]�T������ȁB
�ш悳������A�L���b�V���g�������Ă����̃T�C�N���őS�����߂�Ƃ��]�T������ȁB
>�Ó��łȂ�
�݂��ɉe����^���邩��A�������݂��N������
����̎�@�������ˏo���ċ����Ȃ��B
�n�[�h�A�\�t�g���݂��ɃT�|�[�g���邩��A
�O��Ă�����̂��Ó��ł͂Ȃ��h������h
�Z�p�⓪�]�̏W�����A���U�ɂ���ăG�l���M�[���Ƃ�����g��������
�W���I�Ɉ������܂�锭�U�̓�����H�Ɏ��Ă���ʂ�����B
�݂��ɉe����^���邩��A�������݂��N������
����̎�@�������ˏo���ċ����Ȃ��B
�n�[�h�A�\�t�g���݂��ɃT�|�[�g���邩��A
�O��Ă�����̂��Ó��ł͂Ȃ��h������h
�Z�p�⓪�]�̏W�����A���U�ɂ���ăG�l���M�[���Ƃ�����g��������
�W���I�Ɉ������܂�锭�U�̓�����H�Ɏ��Ă���ʂ�����B
�t���p�l���Ȃ����U�����Ⴞ�ȁB
�f���͑S�R�ǂ��Ȃ��̂ɁA���݂�����Q�Ŕ��U���Ă��邩��
���ɂ��f�����������̂������Ă����̃s�[�N�ɓ͂��Ȃ�������
�X�^�[�g�ł��Ȃ�
�f���͑S�R�ǂ��Ȃ��̂ɁA���݂�����Q�Ŕ��U���Ă��邩��
���ɂ��f�����������̂������Ă����̃s�[�N�ɓ͂��Ȃ�������
�X�^�[�g�ł��Ȃ�
�Ă��Ƃ̓��j�[�R�A��L4�L���b�V�������y���Ă����Ă��ƁH
�����ɍD��S���������@�Ȃ�Έ������݂͂���قNj����Ȃ���
�o�ό������������݂���������
�o�ό������������݂���������
���C�u������OS�A�\�t�g��AVX2�Ή������킶��i��ł邵�A
Haswell�̎���CPU���o�邱��ɂ́AAVX2�̉��b�����Ȃ���悤�ɂȂ��Ă����Ȃ����ȁH
Haswell�̎���CPU���o�邱��ɂ́AAVX2�̉��b�����Ȃ���悤�ɂȂ��Ă����Ȃ����ȁH
Intel�̐������C�����Ă��܂��Ă��邩�痘�v�����Ⴍ�Ă�������邵���Ȃ��Ă��ꂪL4$�Ƃ����͂��肤��B�ʃ_�C�Ȃ̂ŋ�����̃v���Z�X���g���邵���C���������̑ш�s����Ƃ��ėL���Ȏ�i�ł�����B
Many Core�̓N���C�A���g�p�ł͂ǂ����낤���BTDP�g�����邩��N���b�N�𗎂Ƃ��ăR�A���𑝂₷�̂͌��x������B8C16T�܂���8M16C�܂łł͂Ȃ����B
�������T�[�o�[�����_�C�̕s�ǃR�A���E����GPU�����̃n�C�G���h�͗L�肩�ȂƂ͎v���B
Many Core�̓N���C�A���g�p�ł͂ǂ����낤���BTDP�g�����邩��N���b�N�𗎂Ƃ��ăR�A���𑝂₷�̂͌��x������B8C16T�܂���8M16C�܂łł͂Ȃ����B
�������T�[�o�[�����_�C�̕s�ǃR�A���E����GPU�����̃n�C�G���h�͗L�肩�ȂƂ͎v���B
49 �F,,�E�L�́M�E,,�j��-�������F2014/01/02(��) 07:49:27.37 ID:pSce6GE7
���j�[�R�A�͕K�v�Ȃ̂͊m�������ǁA�{���ɕK�v�Ƃ��Ă�
�G���h���[�U�[�ɂ�130W��TDP�g�Ɏ��܂肫�邭�炢�ł�
����Ȃ��߂����ˁB
���r���[�Ȃ��̂͗v���B
������N���E�h�^�̃T�[�r�X�łł����V�X�e������ĉ��Z���\�[�X��
�V�F�A���悤���A���Ă̂���Ԍ����I�ȕ��@�Ȃ��āB
����Ńl�b�g�ɂȂ�����������[�����痘�p�ł���B
�G���h���[�U�[�ɂ�130W��TDP�g�Ɏ��܂肫�邭�炢�ł�
����Ȃ��߂����ˁB
���r���[�Ȃ��̂͗v���B
������N���E�h�^�̃T�[�r�X�łł����V�X�e������ĉ��Z���\�[�X��
�V�F�A���悤���A���Ă̂���Ԍ����I�ȕ��@�Ȃ��āB
����Ńl�b�g�ɂȂ�����������[�����痘�p�ł���B
50 �F,,�E�L�́M�E,,�j��-�������F2014/01/02(��) 08:01:45.58 ID:pSce6GE7
>>43
���̂��[�@������E�E�E
���Ȃ��̌������Ƃɂ́A��̐��̂�������Ȃ���ˁH
��̓I�ɁA�u�������ш惂���X�^�[�v�v�i���C�e���V�ł͂Ȃ��H�j�ɂ��邱�Ƃ�
�ǂ�ȃA�v���P�[�V�����������Ȃ�́H
���������o�Ă��Ȃ����Ă��Ƃ́A�u�K�v�Ƃ���ĂȂ��v���Ă��Ƃ���B
2D��3D�̃O���t�B�b�N�݂����Ƀs�N�Z�����Ԃ�A���邢�͒��_����
�ȒP�ɕ����ł��܂��I�ȕ���Ȃ�A�ш�ɂ��̂����킹��
�C���^�[���[�u����Ⴂ�����ǁACPU�̏����̎�͕̂����ҏW�ɂ���\�v�Z�ɂ���
�����܂Ń��[�U�[�̓��͂ɑ��ăf�[�^���č\�����\������Ƃ����A���������Ȃ킯�B
�����f�[�^�����̏����ł܂��ė��p���邩��A���C����������葬����
�Z���ԂŃA�N�Z�X�ł���L���b�V�����������������̗v�ɂȂ�B
���̂��[�@������E�E�E
���Ȃ��̌������Ƃɂ́A��̐��̂�������Ȃ���ˁH
��̓I�ɁA�u�������ш惂���X�^�[�v�v�i���C�e���V�ł͂Ȃ��H�j�ɂ��邱�Ƃ�
�ǂ�ȃA�v���P�[�V�����������Ȃ�́H
���������o�Ă��Ȃ����Ă��Ƃ́A�u�K�v�Ƃ���ĂȂ��v���Ă��Ƃ���B
2D��3D�̃O���t�B�b�N�݂����Ƀs�N�Z�����Ԃ�A���邢�͒��_����
�ȒP�ɕ����ł��܂��I�ȕ���Ȃ�A�ш�ɂ��̂����킹��
�C���^�[���[�u����Ⴂ�����ǁACPU�̏����̎�͕̂����ҏW�ɂ���\�v�Z�ɂ���
�����܂Ń��[�U�[�̓��͂ɑ��ăf�[�^���č\�����\������Ƃ����A���������Ȃ킯�B
�����f�[�^�����̏����ł܂��ė��p���邩��A���C����������葬����
�Z���ԂŃA�N�Z�X�ł���L���b�V�����������������̗v�ɂȂ�B
>>49
�l�b�g�ɓ�������d�������̓o�b�`�������������獡��L�т�Ȃ�Ėϑz�����B�l�b�g�Q�[�������ĎI�̓A�J�E���g�Ɖۋ��ƃX�e�[�^�X�A�A�C�e���Ǘ��������ĂȂ��āA���ۂ̓N���C�A���g�œ����Ă���B
�l�b�g�ɓ�������d�������̓o�b�`�������������獡��L�т�Ȃ�Ėϑz�����B�l�b�g�Q�[�������ĎI�̓A�J�E���g�Ɖۋ��ƃX�e�[�^�X�A�A�C�e���Ǘ��������ĂȂ��āA���ۂ̓N���C�A���g�œ����Ă���B
52 �F,,�E�L�́M�E,,�j��-�������F2014/01/02(��) 08:05:09.31 ID:pSce6GE7
�����āA�V��FF14�i�j�݂����ȃ`�[�g�V���ł����H
�T�[�o���̉��Z���ăo���f�[�V�������Ȃ��Ⴂ���Ȃ��Ƃ���܂ŃN���C�A���g�C���ɂ���Ƃ�
�ʖڐv�̓T�^�B
�T�[�o���̉��Z���ăo���f�[�V�������Ȃ��Ⴂ���Ȃ��Ƃ���܂ŃN���C�A���g�C���ɂ���Ƃ�
�ʖڐv�̓T�^�B
>>52
����͂܂Ƃ��ɃX�e�[�^�X��A�C�e�����Ǘ��ł��ĂȂ���������B
�N���C�A���g�ł�������ʂ𒀎��I�ɏグ�ĊǗ����邾���ł���ςȒʐM���ׂȂ̂Ƀ��A���^�C�����̋��߂���GUI�Ƃ��܂ŎI�ł���Ă���܂Ƃ��ɓ������B
����͂܂Ƃ��ɃX�e�[�^�X��A�C�e�����Ǘ��ł��ĂȂ���������B
�N���C�A���g�ł�������ʂ𒀎��I�ɏグ�ĊǗ����邾���ł���ςȒʐM���ׂȂ̂Ƀ��A���^�C�����̋��߂���GUI�Ƃ��܂ŎI�ł���Ă���܂Ƃ��ɓ������B
54 �F,,�E�L�́M�E,,�j��-�������F2014/01/02(��) 08:18:28.17 ID:pSce6GE7
�ʂ�GUI�܂ŃT�[�o��������Ȃ�Č����ĂȂ������B
�T�[�o�ł��N���C�A���g�ł����Z���āu�������킹�v�����悤�ȕ��@�ł����B
�������Z���ʂ��X�e�[�^�X�ɉe������悤�ȃQ�[��������炻�ꂱ��
�T�[�o���ɋ��߂��鉉�Z�\�͂͑����Ȃ��̂�B
�T�[�o�ł��N���C�A���g�ł����Z���āu�������킹�v�����悤�ȕ��@�ł����B
�������Z���ʂ��X�e�[�^�X�ɉe������悤�ȃQ�[��������炻�ꂱ��
�T�[�o���ɋ��߂��鉉�Z�\�͂͑����Ȃ��̂�B
>>50
���ႠeDRAM�Ɋ��҂��ׂ��H
���ႠeDRAM�Ɋ��҂��ׂ��H
>>54
�������Z���I�ł�郁���b�g�������B
�}�N���ȏ�ʂ̕������Z�̓Q�[�����Ɩ��W�Ȏ��Ȗ����ł����Ȃ��B
�~�N���ȏ�ʂł̕������Z�Ȃ�N���C�A���g�ŕ��U���Ă������B
�������Z���I�ł�郁���b�g�������B
�}�N���ȏ�ʂ̕������Z�̓Q�[�����Ɩ��W�Ȏ��Ȗ����ł����Ȃ��B
�~�N���ȏ�ʂł̕������Z�Ȃ�N���C�A���g�ŕ��U���Ă������B
>50
���Ɏx�z�I�ȃG�l���M�[�W�����N�����Ă钆��������l�Ԃ��肾�B
���������l�Ԃ����݂���^�������ݒ��̊�����
�ώ@���悤�Ƃ��Ă����o������̂Ɍ��E������͓̂��R
���Ɏx�z�I�ȃG�l���M�[�W�����N�����Ă钆��������l�Ԃ��肾�B
���������l�Ԃ����݂���^�������ݒ��̊�����
�ώ@���悤�Ƃ��Ă����o������̂Ɍ��E������͓̂��R
58 �F,,�E�L�́M�E,,�j��-�������F2014/01/02(��) 10:24:17.02 ID:pSce6GE7
���ۘ_����ŋ�̐��������ˁB
�ǂ������A�v���P�[�V�����ł����������\���K�v�����Ă������
�Ꭶ���Ȃ��Ɠ`���Ȃ��B
���ꂪ�ł��Ȃ����Ȃ��ɂ����A�v���[���\�͂̌��E�������Ă���B
�ǂ������A�v���P�[�V�����ł����������\���K�v�����Ă������
�Ꭶ���Ȃ��Ɠ`���Ȃ��B
���ꂪ�ł��Ȃ����Ȃ��ɂ����A�v���[���\�͂̌��E�������Ă���B
eDRAM�̐i���Ɋ��҂��邩���Ȃ��́H
60 �F,,�E�L�́M�E,,�j��-�������F2014/01/02(��) 11:05:12.43 ID:pSce6GE7
���Z�R�X�g���f�[�^�̈ړ��R�X�g�̂ق����y���ɑ傫���B
����͕����@���̖��łǂ����悤���Ȃ��B
�K�w�^�L���b�V���\���ȏ�̍œK���͂Ȃ���B
GPU�����ă������ш悠�肫�̐��\�����̌��E�ɂԂ���������
�L���b�V���̍��@�\���E��e�ʉ���i�߂Ă�B
����͕����@���̖��łǂ����悤���Ȃ��B
�K�w�^�L���b�V���\���ȏ�̍œK���͂Ȃ���B
GPU�����ă������ш悠�肫�̐��\�����̌��E�ɂԂ���������
�L���b�V���̍��@�\���E��e�ʉ���i�߂Ă�B
DRAM�͂��킶�퍂�������Ă邯��SRAM�Ƃ�eDRAM���Ăǂ��Ȃ�
SRAM�͂��Ƃ���DRAM��葬�������
eDRAM�́A�������ł�����Ă������A�z���̐����A�z�݂����ɑ����ł���̂�
���ш扻�ł�����Ċ���
eDRAM�́A�������ł�����Ă������A�z���̐����A�z�݂����ɑ����ł���̂�
���ш扻�ł�����Ċ���
���ŁASTT-MRAM�����ʼn��Z�ƋL�����s���R���s���[�e�B���O�E�A�[�L�e�N�`������
http://techon.nikkeibp.co.jp/article/EVENT/20131211/321882/
���������̖ʔ�����������CPU����͊O��邩
�ł����̏ł�CPU���̓������̐i���̕��Ɋ��҂���ׂ��Ȃ̂�������Ȃ���
http://techon.nikkeibp.co.jp/article/EVENT/20131211/321882/
���������̖ʔ�����������CPU����͊O��邩
�ł����̏ł�CPU���̓������̐i���̕��Ɋ��҂���ׂ��Ȃ̂�������Ȃ���
�Ђ�ƁF�r�c�c�̍s���l��
66 �F,,�E�L�́M�E,,�j��-�������F2014/01/02(��) 15:36:39.52 ID:pSce6GE7
>>63
����LUT���Ă����ÓT�I�Ȏ�@��MRAM�̑�e�ʂ��g���Ď������悤�Ƃ����b�ł�����
�ʂɐV�K��������킯����Ȃ���B
�Í����Ƃ��Ɏg�����ɂ�L1�L���b�V���Ɏ��܂�8�r�b�g(256�v�f�j�e�[�u����
�����������ق�����������ˁB
�ւ��Ƀe�[�u���W�J������L1�L���b�V���Ɏ��܂�悤�ɃR�[�h�g�ق���
������ȁB
����LUT���Ă����ÓT�I�Ȏ�@��MRAM�̑�e�ʂ��g���Ď������悤�Ƃ����b�ł�����
�ʂɐV�K��������킯����Ȃ���B
�Í����Ƃ��Ɏg�����ɂ�L1�L���b�V���Ɏ��܂�8�r�b�g(256�v�f�j�e�[�u����
�����������ق�����������ˁB
�ւ��Ƀe�[�u���W�J������L1�L���b�V���Ɏ��܂�悤�ɃR�[�h�g�ق���
������ȁB
>>64
��{�I��SRAM�̑f�q��CPU�R�A���̃��W�b�N�Ɠ����f�q������A
�����v���Z�X�ɂ�鐫�\����ɏ����đ��x�A�b�v����͂��B
��{�I��SRAM�̑f�q��CPU�R�A���̃��W�b�N�Ɠ����f�q������A
�����v���Z�X�ɂ�鐫�\����ɏ����đ��x�A�b�v����͂��B
CPU�̃��W�X�^��SRAM���Ēm��Ȃ��̂���
>>67
DRAM�݂����Ȃ��킶��i�����Ă���Ă��ƁH
DRAM�݂����Ȃ��킶��i�����Ă���Ă��ƁH
SRAM���Ă̂͊�{�I�ɃN���X�J�b�v���̃C���o�[�^�ɃX�C�b�`�t���������̂��̂ł�����
DRAM�̂悤�ɓ���ȃv���Z�X�ō����f�o�C�X�ł͂Ȃ�
������CMOS�v���Z�X���i�������SRAM�������I�ɐi������
�v���Z�X�̐��\�w�W��SRAM�̃Z���T�C�Y�Ƃ��o�^�t���C�J�[�u�Ƃ��悭����ł���
DRAM�̂悤�ɓ���ȃv���Z�X�ō����f�o�C�X�ł͂Ȃ�
������CMOS�v���Z�X���i�������SRAM�������I�ɐi������
�v���Z�X�̐��\�w�W��SRAM�̃Z���T�C�Y�Ƃ��o�^�t���C�J�[�u�Ƃ��悭����ł���
DDR�nSDRAM�Ƌ�����������SRAM�͂���Ȃ̂�����ˁB
http://jp.cypress.com/sync_SRAMs/
���Ƀ����_���A�N�Z�X���\��DRAM���1���͏�Ȋ����B
�������Ȃ���\����i�����v���Z�X�Łj�_�C�T�C�Y��DRAM��4�`6�{������A
PC�p�r�ł̓R�X�g�E���\���l������ƌ��ǂ̂Ƃ���A
��e�ʃ�������DRAM �{ �i���j�����������̓o�X�����L������I���_�CSRAM�i�L���b�V�����j�A
�Ƃ������g�ݍ��킹�Œ����V�[�P���V������e�ʂƁi���j���������_�����e�ʂő��₳������@�������I�ŁA
�P�iSRAM�͔����ȃ|�W�V�����ȂƎv���B
http://jp.cypress.com/sync_SRAMs/
���Ƀ����_���A�N�Z�X���\��DRAM���1���͏�Ȋ����B
�������Ȃ���\����i�����v���Z�X�Łj�_�C�T�C�Y��DRAM��4�`6�{������A
PC�p�r�ł̓R�X�g�E���\���l������ƌ��ǂ̂Ƃ���A
��e�ʃ�������DRAM �{ �i���j�����������̓o�X�����L������I���_�CSRAM�i�L���b�V�����j�A
�Ƃ������g�ݍ��킹�Œ����V�[�P���V������e�ʂƁi���j���������_�����e�ʂő��₳������@�������I�ŁA
�P�iSRAM�͔����ȃ|�W�V�����ȂƎv���B
>58
���𗪂������������ꂽ�̂�������Ȃ����A>57�̑Ώۂ͉�b���Ă���
����̂��O/���O�����ł͂Ȃ���B�������܂߂����𐢑��
�܂������s�⒆���Ȃǂł͂Ȃ��ƌ�����������������
���𗪂������������ꂽ�̂�������Ȃ����A>57�̑Ώۂ͉�b���Ă���
����̂��O/���O�����ł͂Ȃ���B�������܂߂����𐢑��
�܂������s�⒆���Ȃǂł͂Ȃ��ƌ�����������������
74 �F,,�E�L�́M�E,,�j��-�������F2014/01/02(��) 21:47:09.89 ID:pSce6GE7
��肭�ǂ������ŗv�_�����������������Ă�ȁB
�@�@�@�ڂ��̂������������傤�̂���҂�[���Ƃ͈Ⴄ�I
�@�@�@��̂Ȃ��͂܂������Ă�I
���Ă��Ƃ���H
�����牽�Ȃ́H�Ƃ����B
���\�قǍ�������̂��g�����Ȃ��Ȃ�������������ȁB
�p�r����̓I�Ɍ����Ƃ����Ă�̂Ɍ����Ȃ��B
�N�ɔ\�͂��Ȃ����炾��B
�܂��t�����D�ꂽ�i�R�X�g�ʁE���\�ʑo���Łj���̂Ȃ��
���������o�Ă��Ȃ���Ȃ��H
�\�j�[�ƃp�i�\�j�b�N�A�L�@�d�k�J���̒�g������
http://jp.reuters.com/article/topNews/idJPTYE9BO03C20131225
�@�@�@�ڂ��̂������������傤�̂���҂�[���Ƃ͈Ⴄ�I
�@�@�@��̂Ȃ��͂܂������Ă�I
���Ă��Ƃ���H
�����牽�Ȃ́H�Ƃ����B
���\�قǍ�������̂��g�����Ȃ��Ȃ�������������ȁB
�p�r����̓I�Ɍ����Ƃ����Ă�̂Ɍ����Ȃ��B
�N�ɔ\�͂��Ȃ����炾��B
�܂��t�����D�ꂽ�i�R�X�g�ʁE���\�ʑo���Łj���̂Ȃ��
���������o�Ă��Ȃ���Ȃ��H
�\�j�[�ƃp�i�\�j�b�N�A�L�@�d�k�J���̒�g������
http://jp.reuters.com/article/topNews/idJPTYE9BO03C20131225
>>66
������Cell��SPE�ł���
���C����������L1$���݂̗e�ʂ�SRAM�ɂ��邱�ƂŒ����ш�E��x�������āA
���������Ɏ��܂鉉�Z�ł͒�����������
������Cell��SPE�ł���
���C����������L1$���݂̗e�ʂ�SRAM�ɂ��邱�ƂŒ����ш�E��x�������āA
���������Ɏ��܂鉉�Z�ł͒�����������
77 �F,,�E�L�́M�E,,�j��-�������F2014/01/02(��) 23:56:18.53 ID:pSce6GE7
>>77
�\�j�[�̗L�@EL��PVM/BVM���j�^�[
�t���E�u���E���ǁE�v���Y�}���A�����̃f�B�X�v���C���͂邩�ɏ���
����ł͈��|�I�Ȑ��E�ō��掿
�����ǂ���f���X�^�W�I�E�n���E�b�h���ł͂�����������Ă�
�\�j�[�̗L�@EL��PVM/BVM���j�^�[
�t���E�u���E���ǁE�v���Y�}���A�����̃f�B�X�v���C���͂邩�ɏ���
����ł͈��|�I�Ȑ��E�ō��掿
�����ǂ���f���X�^�W�I�E�n���E�b�h���ł͂�����������Ă�
�܂��}�W�Șb�A�掿���Č����Ă��ǂ����w�����ɂ���ĈقȂ���
>>79
�F�悾���Ȃ�OLED��背�[�U�[�o�b�N���C�g�̉t���̂ق������|����
�f���̗ǂ����Ă̂͗ʎY����R�X�g���܂߂��o�����X�ł�������
>>79
�F�悾���Ȃ�OLED��背�[�U�[�o�b�N���C�g�̉t���̂ق������|����
�f���̗ǂ����Ă̂͗ʎY����R�X�g���܂߂��o�����X�ł�������
81 �F,,�E�L�́M�E,,�j��-�������F2014/01/03(��) 00:04:49.04 ID:pSce6GE7
���[����Cell SPE�ŕ����I��LUT�g�����R�[�h�g�Ȃ��E�E�E
���C�e���V6�A����ISA�������ŃA�h���X�����ɗ]���ȃT�C�N�������邩��
L1���͏����x���Ƃ����F�������ǁB
���C�e���V6�A����ISA�������ŃA�h���X�����ɗ]���ȃT�C�N�������邩��
L1���͏����x���Ƃ����F�������ǁB
PVM�ABVM��XEL-1���琔���Ă��܂��O����ڂŁA�f�����ׂ�Ȃ�
�������炢�̓������ݐς������̉t�����Ó��Ȃ͂��B
����A���ڂ͂����炭SHARP LC-10C1-H�APC-9801T model F5
�������炢�̓������ݐς������̉t�����Ó��Ȃ͂��B
����A���ڂ͂����炭SHARP LC-10C1-H�APC-9801T model F5
>>82
���������炢�̓������ݐς������̉t�����Ó��Ȃ͂��B
�S�R�Ó��ł��������A�S���킩���Ė����ˁB
�ʎY�ׂ̈̓����ƌ����J���̓����͕ʕ�
��b���������Ȃ�ԈႢ�Ȃ�OLED�̕������H����
�t���̑�ʐ��Y�����ɂ�OLED�قǂ̋��͕K�v�Ȃ�����
http://www.asahi.com/articles/ASF0TKY201312250490.html
�������N���o�̂ɁA���܂��ɗʎY�̌�����K�v�Ƃ��A�Ȃ�����
���s����悤�ȋZ�p�̑f�����ǂ��ƁH
���������炢�̓������ݐς������̉t�����Ó��Ȃ͂��B
�S�R�Ó��ł��������A�S���킩���Ė����ˁB
�ʎY�ׂ̈̓����ƌ����J���̓����͕ʕ�
��b���������Ȃ�ԈႢ�Ȃ�OLED�̕������H����
�t���̑�ʐ��Y�����ɂ�OLED�قǂ̋��͕K�v�Ȃ�����
http://www.asahi.com/articles/ASF0TKY201312250490.html
�������N���o�̂ɁA���܂��ɗʎY�̌�����K�v�Ƃ��A�Ȃ�����
���s����悤�ȋZ�p�̑f�����ǂ��ƁH
�L�@EL�͂R�����ŏĂ��t�����Ƃ��S�R�����ł���ڏ��������ĂȂ����A��������������ʂ̉摜�ȊO�ł�LED�o�b�N���C�g�̉t�������B
��^�����ł��Ȃ���Ώ��^�̂܂܍����x�����ł��Ȃ��B���O�ŗ��p���邽�߂̋P�x������Ȃ��B
�_���_�������B
��^�����ł��Ȃ���Ώ��^�̂܂܍����x�����ł��Ȃ��B���O�ŗ��p���邽�߂̋P�x������Ȃ��B
�_���_�������B
���掿OLED�͗ʎY���ɓ���邩�炱���A
�\�j�[��50���ȏ�̒l�i�Ŕ����s�N�`���[���j�^�[�E�}�X�^�[���j�^�[����OLED�g���āA
�ӂ��̉ƒ�p�e���r�͉t���ł���Ă��ł��傤��
�\�j�[��50���ȏ�̒l�i�Ŕ����s�N�`���[���j�^�[�E�}�X�^�[���j�^�[����OLED�g���āA
�ӂ��̉ƒ�p�e���r�͉t���ł���Ă��ł��傤��
SED�ɏ��Ă錩���݂��Ȃ��̂�
>74
���̊Ԉ���Ă��Ȃ��݂�悤�A�Ȃ�Ă��̂�����̂��ǂ����m��Ȃ����A
�����Ȃ炻�ꂪ�킩��ȂǂƎv���͂��Ȃ���B
�����A�����������猩�����Ă��������Ȃ����Ƃ�
���Ă���̂�������Ȃ��A�Ƃ����悤�Ȃ��Ƃ�
�����Ԏv�������ׂȂ��͉̂I舂��Ǝv���������B
���̊Ԉ���Ă��Ȃ��݂�悤�A�Ȃ�Ă��̂�����̂��ǂ����m��Ȃ����A
�����Ȃ炻�ꂪ�킩��ȂǂƎv���͂��Ȃ���B
�����A�����������猩�����Ă��������Ȃ����Ƃ�
���Ă���̂�������Ȃ��A�Ƃ����悤�Ȃ��Ƃ�
�����Ԏv�������ׂȂ��͉̂I舂��Ǝv���������B
>>83
������Ƃ����Č��݂̗��҂��r����̂��t�F�A�ł͂Ȃ����낤
������Ƃ����Č��݂̗��҂��r����̂��t�F�A�ł͂Ȃ����낤
L4�L���b�V�����������̂��ēƎ��̃R�[�h�����Ȃ��Ⴂ���Ȃ��́H
����Ƃ����܂܂Œʂ�ł����b����́H
����Ƃ����܂܂Œʂ�ł����b����́H
�L���b�V���Ȃ̂ʼn������Ȃ��Ă������BLLC�Ƃ��Ɠ���
�\�����ʂ��o�邩�̓A�v���P�[�V�����ɂ��
�ꍇ�ɂ���Ă̓R�[�h�̃`���[�j���O�ɂ���Č��ʂ����܂邩������Ȃ�
�\�����ʂ��o�邩�̓A�v���P�[�V�����ɂ��
�ꍇ�ɂ���Ă̓R�[�h�̃`���[�j���O�ɂ���Č��ʂ����܂邩������Ȃ�
�Ȃ�ق�
�ł��{��������ƍ���L4�Ȃ�Ė����Ă�����������ŁA�œK�����Ȃ����Ƃ�L4�����������Ƃ����Ȃ����Ȃ��B
L3�Ƃ�L4���ėv����ɑ�e�ʉ�����ւ��ɃA�\�V�G�C�e�B�u�̋@�\���ȗ������ă��C�e���V��
����������
�����Ē����d�́E�ᔭ�M��
L1��L2�ƃ������Ƃ����w�ɂ�����w���͂�����
����������
�����Ē����d�́E�ᔭ�M��
L1��L2�ƃ������Ƃ����w�ɂ�����w���͂�����
>>88
���O����̂���"�t�F�A"���ĉ��H
�c�q�̎w�E����u�ڂ��̂������������傤�́`�܂������Ă���v��
�����Ă��鎖�������ς��Ȃ��B�����ߔN�ǂꂾ��OLED�ɓ������ꂽ��
���ׂĂ݂ȁB
���O����̂���"�t�F�A"���ĉ��H
�c�q�̎w�E����u�ڂ��̂������������傤�́`�܂������Ă���v��
�����Ă��鎖�������ς��Ȃ��B�����ߔN�ǂꂾ��OLED�ɓ������ꂽ��
���ׂĂ݂ȁB
95 �F,,�E�L�́M�E,,�j��-�������F2014/01/03(��) 15:11:19.68 ID:OosgDtQq
����ł���
�u���y���Ă�Z�p��ے肷�鎩���J�b�R�C�C�v
�I��
�~�x�݂������
�u���y���Ă�Z�p��ے肷�鎩���J�b�R�C�C�v
�I��
�~�x�݂������
Intel X.Org Driver Gets Fixes, Broadwell Acceleration
http://www.phoronix.com/scan.php?page=news_item&px=MTU1NTg
Intel Releases A Boatload Of Haswell Documentation
http://www.phoronix.com/scan.php?page=news_item&px=MTU1NTc
http://www.phoronix.com/scan.php?page=news_item&px=MTU1NTg
Intel Releases A Boatload Of Haswell Documentation
http://www.phoronix.com/scan.php?page=news_item&px=MTU1NTc
�f�[�^�Z���^�[�ɕK�v�Ȃ͓̂d�͌����̂����v���Z�T�ł͂Ȃ��C�^�_���R�̓d�͂ł���
�����Ԃ�傫���o����
�f�[�^�Z���^�[��Ƃ������������킯����
�ŋ߂̌������ă^�_�Ȃ́H
�̂͌��q�͂ɂ��d�C�̓^�_�ɋ߂��ƍl�����Ă������A���������p�͐��ވ��
�č��̌����͌o�ϓI���R�łقڃK�X�ɋ쒀�������
�č��̌����͌o�ϓI���R�łقڃK�X�ɋ쒀�������
>>95
�܂�ARM�ᔻ�J��Ԃ��Ă邨�O�̂��Ƃ����
�܂�ARM�ᔻ�J��Ԃ��Ă邨�O�̂��Ƃ����
�����Ȃ��������炵��[�Ȃ�
�܂������R�����A���Ȃ�ł����ǂˁB
���������͈̂��S����T�{���Ĉ�������ɂ��ėǂ�������ɂ͂Ȃ�Ȃ������
���܂ł��`�[�g�������̂Ō�������������3.11�O�̂悤�ȓd�C��͂�������
���܂ł��`�[�g�������̂Ō�������������3.11�O�̂悤�ȓd�C��͂�������
������̌���I�ɏグ�ă��@�J�����͂�[�ғ����[�ƌ���
�����ȓd�͖͂��͂����A���v��H�����邾���̃G�S�V�X�e���ɂ�
�f���Ɏ^���ł��Ȃ��Ƃ��낪����
�Ƃ���ł����͉��X��?
�����ȓd�͖͂��͂����A���v��H�����邾���̃G�S�V�X�e���ɂ�
�f���Ɏ^���ł��Ȃ��Ƃ��낪����
�Ƃ���ł����͉��X��?
�����o�b�N�G���h�������X��
�������A�ǂ����l�Z�߂Ȃ�����A�d�̓t�@�[���ɂł���������̂ɂȁ[�Ǝv�����ǂˁB
���z�d�r�ƃo�b�e���[�̊J��������ł��́B�����͑����Ă�Ǝv�����ǁB
���z�d�r�ƃo�b�e���[�̊J��������ł��́B�����͑����Ă�Ǝv�����ǁB
���ɂ��Ă��G�l���M�[�����Nj��͕K�v
>108
�����Y�̕āE���Y���E�_�앨�����ʂ��Ă܂����H
�����Y�̕āE���Y���E�_�앨�����ʂ��Ă܂����H
���ʂ͂��Ă邯�ǃr�W�l�X�I�ɂ͋�킵�Ă�����
�����ł���
���?
���H�i�E�O�H�ł͔��f�ł��Ȃ���
���H�i�E�O�H�ł͔��f�ł��Ȃ���
>>113
���H�ƎҁE�O�H�Ǝҕ��ʂł͎d����̎��ɒl��@�����\���͂���B
���H�ƎҁE�O�H�Ǝҕ��ʂł͎d����̎��ɒl��@�����\���͂���B
�Z�V�E����̂��߂ɁA�R���̖��ɉe���̂���悤�ȃJ���E���T���Ă����肵�đ�ς��ȂƎv���܂����B�i����
>>114
�N�����m���Ă��錾�t���R�s�y���ĉ������������̂�
���O�̓o�J�Ȃ悤������킩��₷���͂����茾���Ă�낤
���i���̐����ɍ��x�Ȑ^�������K�v�Ƃ���OLED�̑f���͈���
����@�ł͒�掿��OLED�ɂȂ�
�N�����m���Ă��錾�t���R�s�y���ĉ������������̂�
���O�̓o�J�Ȃ悤������킩��₷���͂����茾���Ă�낤
���i���̐����ɍ��x�Ȑ^�������K�v�Ƃ���OLED�̑f���͈���
����@�ł͒�掿��OLED�ɂȂ�
118 �FSocket774�F2014/01/04(�y) 16:51:44.44 ID:+RUX8VZ1
��E8500�ŐV������Ă����Broadwell���Ă̑҂Ă�����H
�f�X�N�g�b�v��Haswell �̂܂�܂Ȃ̂ł������Ɣ����ւ��₪��
120 �FSocket774�F2014/01/04(�y) 18:09:49.11 ID:+RUX8VZ1
����ȁ[�[�[�[�[�[�[�[�[
�܂��������ւ���C�ɂȂ����Ȃ�Haswell�ł�����ˁH�Ǝv���B
�ׂ�E8500�ł̐����𑱂��Ă��ǂ��Ƃ͎v�����ǁB
�ׂ�E8500�ł̐����𑱂��Ă��ǂ��Ƃ͎v�����ǁB
Broadwell-K���o�邩�ǂ������C�ɂȂ�
>>115
�����Y������Ƃ������R�Ŕ����@���ꂽ�ꍇ�A���d���獷�z���̕⏞�����Ⴆ��̂ŁA
�����@����Ă��_�Ƃ��炷��P�K�����͂��Ȃ���
�����Y������Ƃ������R�Ŕ����@���ꂽ�ꍇ�A���d���獷�z���̕⏞�����Ⴆ��̂ŁA
�����@����Ă��_�Ƃ��炷��P�K�����͂��Ȃ���
�����當�匾���Ă�����̃����[�X�͑S���O���X�o�[�K�[������
����������I��Ŗ��Ȃ����B
����������I��Ŗ��Ȃ����B
�܂��m����Ivy Bridge����Haswell�ւ̕ύX�͂���ƌ������ڋʂ͂Ȃ�����
����IGP�͑啝�ɃO���[�h�A�b�v���ꂽ���ǂ܂��g��Ȃ����A�����Č�����
AVX2��C6/C7�X�e�[�g�̒lj����H���[�v�\���������ǂ��Ȃ��Ă���x
����IGP�͑啝�ɃO���[�h�A�b�v���ꂽ���ǂ܂��g��Ȃ����A�����Č�����
AVX2��C6/C7�X�e�[�g�̒lj����H���[�v�\���������ǂ��Ȃ��Ă���x
C6/C7��Ivy Bridge�Œlj����ꂽ���ǂ�
ALU Port������₳�ꂽ�̂����\�傫���̂ł́H
ALU Port������₳�ꂽ�̂����\�傫���̂ł́H
Haswell�ł̕ύX�_�̓I���_�CVRM�Ƃ��g�����U�N�V���i���������Ƃ��L���b�V����
�]���ш�g��Ƃ��A������ł̒��ړI�Ȑ��\����ɂ͒������Ȃ�
�����ւ̐�s�����I�Ȃ��̂����������
�]���ш�g��Ƃ��A������ł̒��ړI�Ȑ��\����ɂ͒������Ȃ�
�����ւ̐�s�����I�Ȃ��̂����������
Intel�͗]�����v���Z�X��Nand���������ׂ����ȁB
�ה�������Ǝ�������̂ŋt��Ɏ���čה������Ȃ��v���Z�X�ł���Nand���ׂ����ȁB
�ה����̑���Ƀ��W�b�N�ŏ������Ȃ�悤�ɃC���e���}�W�b�N�łǂ��ɂ��̎Z��銴���ŁB
�ה�������Ǝ�������̂ŋt��Ɏ���čה������Ȃ��v���Z�X�ł���Nand���ׂ����ȁB
�ה����̑���Ƀ��W�b�N�ŏ������Ȃ�悤�ɃC���e���}�W�b�N�łǂ��ɂ��̎Z��銴���ŁB
Intel�AWindows 8.1��Android OS�����쓮�́u�f���A��OS�v�^�u���b�g��CES�Ŕ�I��
http://rbmen.blogspot.jp/2014/01/intelwindows-81android-ososces.html
�X���C�h�A�E���A��]����PC�ɑ���2-in-1�������
�f���A��OS�@��2-in-1�ƌĂ����������藈��悤��
http://rbmen.blogspot.jp/2014/01/intelwindows-81android-ososces.html
�X���C�h�A�E���A��]����PC�ɑ���2-in-1�������
�f���A��OS�@��2-in-1�ƌĂ����������藈��悤��
�����~�߂悤���A���Y�c����Ȃ������בR���o�C����
���o�C��OS�A�X�}�[�g�t�H�� - 2014�N�̃��o�C���ƊE�͂����Ȃ�
http://news.mynavi.jp/articles/2014/01/04/keitai_2014/003.html
�������ƂȂ�̂��ASamsung��g�уL�����A��Tizen�łǂ̂�����̉��i�^�[�Q�b�g��_����
����̂��Ƃ����_���B���Ƃ���Bada�̓X�}�[�g�t�H��OS�Ƃ����Ă�Nokia��Symbian�𓋍ڂ���
�~�b�h�����W�ȉ��̒[���s����^�[�Q�b�g�ɂ������i�������A����p�t�H�[�}���X��"����Ȃ�"���B
�����_�ł̊����x���������A�����̃A�v���̏[���������Ă��Ă���i���s��Ŏ����
�]�n�͂��܂�Ȃ����낤�B���ہAAndroid��iOS�����Ɏ�v�ȃA�v������Ă��镡����
�x���_�[�ɘb�����Ƃ���ATizen�����̃A�v���J���v����f���Ă�����Ƃ����B
���o�C��OS�A�X�}�[�g�t�H�� - 2014�N�̃��o�C���ƊE�͂����Ȃ�
http://news.mynavi.jp/articles/2014/01/04/keitai_2014/003.html
�������ƂȂ�̂��ASamsung��g�уL�����A��Tizen�łǂ̂�����̉��i�^�[�Q�b�g��_����
����̂��Ƃ����_���B���Ƃ���Bada�̓X�}�[�g�t�H��OS�Ƃ����Ă�Nokia��Symbian�𓋍ڂ���
�~�b�h�����W�ȉ��̒[���s����^�[�Q�b�g�ɂ������i�������A����p�t�H�[�}���X��"����Ȃ�"���B
�����_�ł̊����x���������A�����̃A�v���̏[���������Ă��Ă���i���s��Ŏ����
�]�n�͂��܂�Ȃ����낤�B���ہAAndroid��iOS�����Ɏ�v�ȃA�v������Ă��镡����
�x���_�[�ɘb�����Ƃ���ATizen�����̃A�v���J���v����f���Ă�����Ƃ����B
>>129
�{���Ƀo�J�Ȃ�
�ǂ������Ȃ��ΓI�Ȃ��̂Ɍ��܂��Ă邾��[��
LSI�ɔ䂷��Z�p�ŃN���[�����[�����K�v�Ȃ����m���L���
�����������ƂɂȂ邾�낤�������ɂ���Ȃ��̂͂Ȃ�
�{���Ƀo�J�Ȃ�
�ǂ������Ȃ��ΓI�Ȃ��̂Ɍ��܂��Ă邾��[��
LSI�ɔ䂷��Z�p�ŃN���[�����[�����K�v�Ȃ����m���L���
�����������ƂɂȂ邾�낤�������ɂ���Ȃ��̂͂Ȃ�
Tizen�́A���ʂ�Google�̎x�z���Ȃ���Android���ǂ�OS���Ă��������ɂȂ邾��
Google�Ƀv���b�g�z�[���E���v��D��ꂽ���Ȃ��L�����A��[�����[�J�[�ɂƂ��Ă͈Ӗ������邪�A
���p�҂ɂƂ��Ă͍��̂Ƃ��뗘�v������
Google�Ƀv���b�g�z�[���E���v��D��ꂽ���Ȃ��L�����A��[�����[�J�[�ɂƂ��Ă͈Ӗ������邪�A
���p�҂ɂƂ��Ă͍��̂Ƃ��뗘�v������
�L�����A�Ƃ��ẮA���XGoogle��ˑ��ɂ��闘�_���������A���������s�\������
�I���^�i�e�B�u�Ƃ��Ď��у[����Tizen�̗p���郁���b�g�͖�����
���[�X�y�b�N�@�̂��߂̌y��OS�Ƃ����_�ł��A�ŋ߂�Android�͂��Ȃ�}�V�ɂȂ��ė������A
�\�ʂ�MS��WP�̃��C�Z���X�����^�_���R�ɂ��Ċe���[�J�[�ƌ����Ă�Ȃ�A
���[�G���h�Ŕ�Android�̃I���^�i�e�B�u�~�����Ƃ��i����Ȗ����Ǝv�����ǁj�͂������s���ł���
�I���^�i�e�B�u�Ƃ��Ď��у[����Tizen�̗p���郁���b�g�͖�����
���[�X�y�b�N�@�̂��߂̌y��OS�Ƃ����_�ł��A�ŋ߂�Android�͂��Ȃ�}�V�ɂȂ��ė������A
�\�ʂ�MS��WP�̃��C�Z���X�����^�_���R�ɂ��Ċe���[�J�[�ƌ����Ă�Ȃ�A
���[�G���h�Ŕ�Android�̃I���^�i�e�B�u�~�����Ƃ��i����Ȗ����Ǝv�����ǁj�͂������s���ł���
Intel's Knights Landing Xeon Phi Will Target 3TFLOPs, Offer 16GB of RAM
http://hothardware.com/News/Intels-Knights-Landing-Xeon-Phi-Will-Target-3TFLOPs-Offer-16GB-of-RAM/
http://hothardware.com/News/Intels-Knights-Landing-Xeon-Phi-Will-Target-3TFLOPs-Offer-16GB-of-RAM/
eDRAM�ɂ�����e�ʑ傫���悤�ȁB
Haswell�̎��ĉ����̔��H
��ܐ���Ńm�[�gPC����������������
��ܐ���Ńm�[�gPC����������������
Knights Landing Details
http://www.realworldtech.com/knights-landing-details/
����́c�cSkylake-EX�Ƃ̊֘A�̘b�Ƃ��͊��S�ɏ����ȋC������
http://www.realworldtech.com/knights-landing-details/
����́c�cSkylake-EX�Ƃ̊֘A�̘b�Ƃ��͊��S�ɏ����ȋC������
64GB���炢�͗~������
16GB on-package eDRAM + 384GB DDR4���Ă�肷�����낗
eDRAM ���L�ш�ڑ����C������������Ȃ��̂�? �Ƃ����^�������B
�I���p�b�P�[�W�͂���������TSV������
�Ȃ����x�ݒ��̒c�q����r�Ԃ��Ă��w
>>141
DDR4�ł�HPC�ł͑���Ȃ��B
DDR4�ł�HPC�ł͑���Ȃ��B
16G������eDRAM�������Ԓx��6chDDR4��
�������Ă������ǃr�b�g���x�̒ႢeDRAM��16GB���đ�����? �����R�X�g�����Ă�
�^�O���x��eDRAM ���ɍڂ邱�ƂɂȂ邵�A�K�w������DDR4�x�����ő��Ђ��ς��܂���B
��������eDRAM+DDR4��߂�HBM�Ȃ�HMC�Ȃ�����C���������ɂ������������đ�����Ȃ�? �ĂȂ��Ƃ��l�����B
�^�O���x��eDRAM ���ɍڂ邱�ƂɂȂ邵�A�K�w������DDR4�x�����ő��Ђ��ς��܂���B
��������eDRAM+DDR4��߂�HBM�Ȃ�HMC�Ȃ�����C���������ɂ������������đ�����Ȃ�? �ĂȂ��Ƃ��l�����B
���C���`�b�v���̂�700mm2�AeDRAM��1200mm2���Đ��C�Ȃ�H��
22nm��14nm���A���̂܂܍s���Ɛ��Y���C����V�т܂��点�邱�ƂɂȂ邩��A���������K���ł���
��ǂ݂��ē��������瑁���Ȃ�\�肪�t�ɂȂ��Ă��ł���
150 �F,,�E�L�́M�E,,�j��-�������F2014/01/05(��) 21:30:00.85 ID:1/IbjsBG
����AeDRAM��16GB��Knights Corner��6�`8GB���傫����
7000�ԑ�Ɠ�������B
NearMemory��FarMemory���A���������C���������ł����ăL���b�V���ł͂Ȃ��B
�����������͒x�����Ă̂�NUMA�ł͓�����O�̂��ƂȂ̂�
���̂������SMP�\�������̃v���O������g��ł�l�ɂƂ��Ă�
����قǃn�[�h���͍����Ȃ�Ȃ��B
7000�ԑ�Ɠ�������B
NearMemory��FarMemory���A���������C���������ł����ăL���b�V���ł͂Ȃ��B
�����������͒x�����Ă̂�NUMA�ł͓�����O�̂��ƂȂ̂�
���̂������SMP�\�������̃v���O������g��ł�l�ɂƂ��Ă�
����قǃn�[�h���͍����Ȃ�Ȃ��B
>>140
�ނ��뉽����肽���̂�������₷���Ǝv��
�A�N�Z�����[�^�Ƃ��Ă̍������������c�����܂܁A
�]���̃A�N�Z�����[�^�ł͓������������ʂɃ��������K�v�ȏ����ɂ��Ή��ł���
���͂╁�ʂ�CPU�Ȃ킯������A���l�i�͂Ƃ���������ł��邩�������c�c
���Ă�Polaris���Ƃ����������߂Ă����ǁA
72�R�A���炢��������L���b�V���R�q�[�����V�撣���̂��Ȃ�
�ނ��뉽����肽���̂�������₷���Ǝv��
�A�N�Z�����[�^�Ƃ��Ă̍������������c�����܂܁A
�]���̃A�N�Z�����[�^�ł͓������������ʂɃ��������K�v�ȏ����ɂ��Ή��ł���
���͂╁�ʂ�CPU�Ȃ킯������A���l�i�͂Ƃ���������ł��邩�������c�c
���Ă�Polaris���Ƃ����������߂Ă����ǁA
72�R�A���炢��������L���b�V���R�q�[�����V�撣���̂��Ȃ�
L4�L���b�V�����₵�Ăǂ��Ӗ������
iris�̃x���`�}�[�N���Ă��t��L4�L���b�V���Ƀq�b�g���Ȃ��Ƌt�Ƀ��C�e���V���傷��݂�������
iris�̃x���`�}�[�N���Ă��t��L4�L���b�V���Ƀq�b�g���Ȃ��Ƌt�Ƀ��C�e���V���傷��݂�������
POWER8�Ȃ���eDRAM�g����L3�L���b�V���𑝂₵�Ă�
�������̂ق��������悳����
�������̂ق��������悳����
>>131
> 2014�N�̒��ڋZ�p�́uHTML5�v
���̋L�����m���Ȃ�A2008�N��2009�N���炢���疈�N�����ƌ��������Ă�C�����邪�E�E�E
��Firefox OS�AUbuntu Touch�ATizen������́u���@�v��G���
HTML5�ւ̌��z�Ȃǐ�����Ԃ��B5�N��10�N������Ǝv�����ق��������B
> 2014�N�̒��ڋZ�p�́uHTML5�v
���̋L�����m���Ȃ�A2008�N��2009�N���炢���疈�N�����ƌ��������Ă�C�����邪�E�E�E
��Firefox OS�AUbuntu Touch�ATizen������́u���@�v��G���
HTML5�ւ̌��z�Ȃǐ�����Ԃ��B5�N��10�N������Ǝv�����ق��������B
Lisp�}�V���͒x����BGUI�Ȃ�����]�v�d����B
����ł��A�Âɂ��čŋ���Lisp�̓u���b�N�z�[�����B
����͂��ׂ�Lisp�ɕԂ��Ă����B
����Ȃ��̂͂����ЂƂA�A�C�f�B�A���B
����ł��A�Âɂ��čŋ���Lisp�̓u���b�N�z�[�����B
����͂��ׂ�Lisp�ɕԂ��Ă����B
����Ȃ��̂͂����ЂƂA�A�C�f�B�A���B
Knights Landing�̂�LLC�͂����܂�L3�ł�����Crystalwell�̂悤��eDRAM��L4�ł͂Ȃ��̂ł�?
�����Ƃ�Intel�����ł�MC(Memory Cube)DRAM�ƕ\�����Ă�̂ł�����
DK��eDRAM�Ə����Ă鍪�����悭�������
�����Ƃ�Intel�����ł�MC(Memory Cube)DRAM�ƕ\�����Ă�̂ł�����
DK��eDRAM�Ə����Ă鍪�����悭�������
HPC�Ƃ����Ă��������ш�Ɋւ��Ă̓f�}���h�͂��낢��
Crystalwell�̃Z�����x���炵��16GB����������̂�14nm�ł���ς��낤���A
TSV�������ŕ��ʂ�DRAM�Z�����q���Ŏg����Ȃ����Ǝv���BIntel�̃X���C�h�ł�MCDRAM�ƂȂ��Ă�킯������
TSV�������ŕ��ʂ�DRAM�Z�����q���Ŏg����Ȃ����Ǝv���BIntel�̃X���C�h�ł�MCDRAM�ƂȂ��Ă�킯������
>>154
���������AHTML5�́A����̃}�[�P�b�g��ʂ����ɃQ�[���E�A�v����z�M����ۋ�����鋰��̂���Flash��
iPhone����r�����邽�߂̕��ւƂ��ăW���u�X�������ł�����������
���������AHTML5�́A����̃}�[�P�b�g��ʂ����ɃQ�[���E�A�v����z�M����ۋ�����鋰��̂���Flash��
iPhone����r�����邽�߂̕��ւƂ��ăW���u�X�������ł�����������
>>156
"EDRAM"���̗p�����Ƃ�����̂�SC13���������Ō��J����Ă����͂�
�����I���p�b�P�[�W�������Ƃ��������̈Ӗ��Ȃ̂��A
IBM�����ӂȃA���̂��ƂȂ̂��͂悭��������
"EDRAM"���̗p�����Ƃ�����̂�SC13���������Ō��J����Ă����͂�
�����I���p�b�P�[�W�������Ƃ��������̈Ӗ��Ȃ̂��A
IBM�����ӂȃA���̂��ƂȂ̂��͂悭��������
SC13�ŏo���̂�http://regmedia.co.uk/2013/11/19/knights_landing.jpg��
eDRAM�Ƃ͌����ĂȂ��悤��
�����łǂ������������͕������
�܂��Ƃ���������̓L���b�V���ł͂Ȃ��A�摜�ɂ���ʂ�near memory�Ȃ̂ł��傤
{kind=link}
eDRAM�Ƃ͌����ĂȂ��悤��
�����łǂ������������͕������
�܂��Ƃ���������̓L���b�V���ł͂Ȃ��A�摜�ɂ���ʂ�near memory�Ȃ̂ł��傤
162 �F,,�E�L�́M�E,,�j��-�������F2014/01/06(��) 20:00:15.01 ID:ZQqNHXKF
ThinkPad 8�����̂ɔ������������I
�����8�C���`�^�u�̑�{�����������ˁB
http://pc.watch.impress.co.jp/docs/news/event/20140106_629596.html
>>158
�e�ʂ��������Crystalwell��64�{�Ȃ���128�{�����A
�ш�͂�������5�{�ɂ����Ȃ��B
�L���b�V���Ƃ��Ăł͂Ȃ����C���������̈ꕔ�Ƃ��Ďg���̂ł����
�^�O�f�B���N�g���͕K�v�Ȃ����AGDDR*���L�ш�E��C�e���V��
��������Ώ\���Ƃ�����B
512�r�b�g�o�X�ڑ���1�`2GB�̃`�b�v��8����Ɍq���Ηv���͖�������ˁH
���R����Ȃ��͖̂����s��ɂ͖����̂ŁA���O�ō�����ق����ǂ�
�Ƃ������ƂɂȂ�B
DDR4-2400MHz��6ch����115.2GB/s�Ȃ̂ł���Ȃɋɒ[�ɒx��
�Ƃ������Ƃ��Ȃ��B
�ނ���PCIe�o�R�Ńz�X�g�������ɃA�N�Z�X������y���ɑ��x���o��B
�����8�C���`�^�u�̑�{�����������ˁB
http://pc.watch.impress.co.jp/docs/news/event/20140106_629596.html
>>158
�e�ʂ��������Crystalwell��64�{�Ȃ���128�{�����A
�ш�͂�������5�{�ɂ����Ȃ��B
�L���b�V���Ƃ��Ăł͂Ȃ����C���������̈ꕔ�Ƃ��Ďg���̂ł����
�^�O�f�B���N�g���͕K�v�Ȃ����AGDDR*���L�ш�E��C�e���V��
��������Ώ\���Ƃ�����B
512�r�b�g�o�X�ڑ���1�`2GB�̃`�b�v��8����Ɍq���Ηv���͖�������ˁH
���R����Ȃ��͖̂����s��ɂ͖����̂ŁA���O�ō�����ق����ǂ�
�Ƃ������ƂɂȂ�B
DDR4-2400MHz��6ch����115.2GB/s�Ȃ̂ł���Ȃɋɒ[�ɒx��
�Ƃ������Ƃ��Ȃ��B
�ނ���PCIe�o�R�Ńz�X�g�������ɃA�N�Z�X������y���ɑ��x���o��B
Pen4�̂��납��v���t�F�b�`���O����
�y�i���e�B���ł������Č����Ă܂�����
��������ł����H
�y�i���e�B���ł������Č����Ă܂�����
��������ł����H
164 �F,,�E�L�́M�E,,�j��-�������F2014/01/06(��) 20:08:58.97 ID:ZQqNHXKF
����̓f�[�^�L���b�V���~�X����ƃp�C�v���C���ۂ��ƃt���b�V�����邩��x���B
Pentium 4��L2���C�e���V��20�`31����̂́A�L���b�V�����̂��̂�
���C�e���V�ł͂Ȃ��p�C�v���C���i�����̍Ď��s�̃y�i���e�B���������Ă邩��B
Sandy Bridge�ȍ~�̃�OPs�L���b�V����NetBurst�̎��s�g���[�X�L���b�V���͕ʕ�
Pentium 4��L2���C�e���V��20�`31����̂́A�L���b�V�����̂��̂�
���C�e���V�ł͂Ȃ��p�C�v���C���i�����̍Ď��s�̃y�i���e�B���������Ă邩��B
Sandy Bridge�ȍ~�̃�OPs�L���b�V����NetBurst�̎��s�g���[�X�L���b�V���͕ʕ�
���Ⴀ�S�Q�O�O�~�̃Z�������������Ⴄ����
Surface mini��Atom�ŕ��ʂɍ���Ă����Β��h�{���ɂȂ�̂ɂȁ[
RT�Ƃ�Kinect�Ƃ������
RT�Ƃ�Kinect�Ƃ������
������Mac mini��i7���������炢�������Ă݂��
���������Z�L�����e�B�l�����璆����Lenovo���Ď��_�Ŕ����Ȃ̂ɂ��̑傫���̃^�u�Ƃ��ǂ������iPad Air�Ə�������Hwww
Win 7 or Win 8.1�g���Ȃ�}�E�X�ƃL�[�{�[�h�O��Ȃ���Œ�11�C���`�K�v����A�𑜓x�̖�肶��Ȃ�
�}�E�X�ƃL�[�{�[�h�K�v�Ȃ��Ȃ�iPad Air or mini�ɂ͂ǂ�����Ă����Ă��
Win 7 or Win 8.1�g���Ȃ�}�E�X�ƃL�[�{�[�h�O��Ȃ���Œ�11�C���`�K�v����A�𑜓x�̖�肶��Ȃ�
�}�E�X�ƃL�[�{�[�h�K�v�Ȃ��Ȃ�iPad Air or mini�ɂ͂ǂ�����Ă����Ă��
169 �F,,�E�L�́M�E,,�j��-�������F2014/01/06(��) 21:59:59.95 ID:ZQqNHXKF
Lenovo�̃Z�L�����e�B���Ƃ��A�d����������l�����銄���
���ۂɃf�[�^�����o���Ă�Ƃ���̓I�Ɏ����ꂽ��͂Ȃ���ˁB
���ۂɃf�[�^�����o���Ă�Ƃ���̓I�Ɏ����ꂽ��͂Ȃ���ˁB
�Ă̑��_����������������
���̍��Ȃ��邾�낤�Ȉʎv���Ƃ��̂����傤�ǂ���
���̍��Ȃ��邾�낤�Ȉʎv���Ƃ��̂����傤�ǂ���
>>162
128MB��Crystalwell��84mm2�Ȃ킯�ŁA�Z�����x��4�{�ɂȂ����Ƃ���ŁA16�{��32�{�A
���Ӊ�H�̃I�[�o�[�w�b�h���������Ă�1000mm2�Ƃ�2000mm2�̕��ʂ��K�v�ɂȂ�킯�ŁA����͂�����Ȃ�ł������ł��傤�B
�Ȃ̂ŁACMOS�ł͂Ȃ����ʂ�NMOS DRAM���g���ق������R�����ACMOS����Ȃ��Ȃ�Intel�����K�v���������B
�����_�Ŏg������̂͂Ȃ��̂͊m�������Aknights Landing��2015�Ȃ̂�HBM���HMC��炪�\���Ɏ��p������Ă���͂��B
TSMC�̃��[�h�}�b�v�ł������N�̌㔼��HBM���ڐ��i���\�肳��Ă邵�ˁB
128MB��Crystalwell��84mm2�Ȃ킯�ŁA�Z�����x��4�{�ɂȂ����Ƃ���ŁA16�{��32�{�A
���Ӊ�H�̃I�[�o�[�w�b�h���������Ă�1000mm2�Ƃ�2000mm2�̕��ʂ��K�v�ɂȂ�킯�ŁA����͂�����Ȃ�ł������ł��傤�B
�Ȃ̂ŁACMOS�ł͂Ȃ����ʂ�NMOS DRAM���g���ق������R�����ACMOS����Ȃ��Ȃ�Intel�����K�v���������B
�����_�Ŏg������̂͂Ȃ��̂͊m�������Aknights Landing��2015�Ȃ̂�HBM���HMC��炪�\���Ɏ��p������Ă���͂��B
TSMC�̃��[�h�}�b�v�ł������N�̌㔼��HBM���ڐ��i���\�肳��Ă邵�ˁB
207 �FSocket774 �F2013/12/04(��) 02:52:37.07 ID:3aYXbRLp
MCDRAM���ĉ��̗��Ȃ�
209 �FSocket774 �F2013/12/04(��) 05:49:51.55 ID:IWAAL02E
���ׂĂ݂��Ƃ���ǂ����AMulti-Channel DRAM�̗��̖̂͗l
��R�X�g���̔g�ɍR�����Âɐ�ł��������\DRAM�̌n�������˂�
211 �FSocket774 �F2013/12/04(��) 06:26:35.70 ID:IzebVci3
Memory Cube�Ƃ�����Ȃ����Ȃ��BHMC�Ɩ��W�Ƃ͎v���Ȃ�
212 �FSocket774 �F2013/12/04(��) 06:39:38.12 ID:PKhH0hO1
DRAM��M��Memory�����
��̏n��̒��œ����P�����g���͕̂s���R�����
�p�꓾�ӂ���Ȃ�����f��͂ł��Ȃ���
213 �FSocket774 �F2013/12/04(��) 06:40:58.41 ID:IWAAL02E
���ׂ�����ł͂قږ��W
���݂ɁAintel�̋��l����ʂŃq�b�g����w
����NEC�̃X�p�R�������Ƃ��A����}�V���Ƃ�
���̊E�G�ł͈�ʓI�ȗ��������̖͗l
MCDRAM���ĉ��̗��Ȃ�
209 �FSocket774 �F2013/12/04(��) 05:49:51.55 ID:IWAAL02E
���ׂĂ݂��Ƃ���ǂ����AMulti-Channel DRAM�̗��̖̂͗l
��R�X�g���̔g�ɍR�����Âɐ�ł��������\DRAM�̌n�������˂�
211 �FSocket774 �F2013/12/04(��) 06:26:35.70 ID:IzebVci3
Memory Cube�Ƃ�����Ȃ����Ȃ��BHMC�Ɩ��W�Ƃ͎v���Ȃ�
212 �FSocket774 �F2013/12/04(��) 06:39:38.12 ID:PKhH0hO1
DRAM��M��Memory�����
��̏n��̒��œ����P�����g���͕̂s���R�����
�p�꓾�ӂ���Ȃ�����f��͂ł��Ȃ���
213 �FSocket774 �F2013/12/04(��) 06:40:58.41 ID:IWAAL02E
���ׂ�����ł͂قږ��W
���݂ɁAintel�̋��l����ʂŃq�b�g����w
����NEC�̃X�p�R�������Ƃ��A����}�V���Ƃ�
���̊E�G�ł͈�ʓI�ȗ��������̖͗l
MC�̓}���`�`���l���̗�����
����MCDRAM��HMC�ł͂Ȃ����A
HMC��MCDRAM�̈��(16�`���l����)�ɂ͈Ⴂ�Ȃ�
����16�`���l�����x�ł�72�R�A�ɑ��ăo�����X
�������ł͂���
HBM�ɂ̓}���`�`���l���̗v�f������̂��H
����MCDRAM��HMC�ł͂Ȃ����A
HMC��MCDRAM�̈��(16�`���l����)�ɂ͈Ⴂ�Ȃ�
����16�`���l�����x�ł�72�R�A�ɑ��ăo�����X
�������ł͂���
HBM�ɂ̓}���`�`���l���̗v�f������̂��H
>>169
�� baidu
�� baidu
Tegra K1��7-way SuperScalar
128KB + 64KB��L1�L���b�V��
http://pc.watch.impress.co.jp/docs/column/kaigai/20140107_629706.html
128KB + 64KB��L1�L���b�V��
http://pc.watch.impress.co.jp/docs/column/kaigai/20140107_629706.html
179 �F,,�E�L�́M�E,,�j��-�������F2014/01/07(��) 07:39:07.36 ID:PZOPEiR3
>>162
���ꂪ�V����ThinkPad
http://pc.watch.impress.co.jp/img/pcw/docs/629/598/html/02.jpg.html
IBM PC AT��������30�N�ڂ�PC�I���̂��m�点�B
�����l�ł���!
���ꂪ�V����ThinkPad
http://pc.watch.impress.co.jp/img/pcw/docs/629/598/html/02.jpg.html
{kind=link}
IBM PC AT��������30�N�ڂ�PC�I���̂��m�点�B
�����l�ł���!
181 �F,,�E�L�́M�E,,�j��-�������F2014/01/07(��) 08:02:54.35 ID:PZOPEiR3
�����̔��̍ۂɂ́uHHKB Pro�p��Ŕz��v�����ЁE�E�E
>>179
���Ƃ��ƃT���X����n�C�j�N�X�́ADRAM�s���������ɐ������C����Flash�]�����đς��Ă�������
DRAM�I�����[�ʼn�Ђ��Ə������G���s�[�_�Ƃ͈قȂ�
���Ƃ��ƃT���X����n�C�j�N�X�́ADRAM�s���������ɐ������C����Flash�]�����đς��Ă�������
DRAM�I�����[�ʼn�Ђ��Ə������G���s�[�_�Ƃ͈قȂ�
����������FLASH��DRAM�����t�@�E���h�����ĕ����Ȃ���
�������[�n�͐v�Ɛ������s���Ȃ̂�?
�������[�n�͐v�Ɛ������s���Ȃ̂�?
>>183
������������ΐv�͕s�v����B�ǂ����W�������ꂽ�ėp�i��邾�������B
������������ΐv�͕s�v����B�ǂ����W�������ꂽ�ėp�i��邾�������B
Asus announces ZenFone 4,5 and 6: Intel-powered budget handsets
http://www.androidauthority.com/asus-zenfone-331066/
22nm�f���A���R�AQuark
http://images.scribblelive.com/2014/1/7/c133000f-a78b-4b09-af51-d0da4e63a08b.jpg
http://www.androidauthority.com/asus-zenfone-331066/
22nm�f���A���R�AQuark
http://images.scribblelive.com/2014/1/7/c133000f-a78b-4b09-af51-d0da4e63a08b.jpg
{kind=link}
Intel announces Edison, a 22nm dual core PC the size of an SD card
http://www.engadget.com/2014/01/06/intel-edison/
http://www.engadget.com/2014/01/06/intel-edison/
�T���`������8�R�AExynos 5420�̃N���[���u�b�N���o���炵����
����8�R�A�Ŕ��\�������ǁA8�R�A�����ɓ������ƂȂ�������ăc�b�R�~��������������
�����ǂ܂�������Δ��ꂻ����
����8�R�A�Ŕ��\�������ǁA8�R�A�����ɓ������ƂȂ�������ăc�b�R�~��������������
�����ǂ܂�������Δ��ꂻ����
Intel�AMcAfee�u�����h���uIntel Security�v��
http://www.itmedia.co.jp/news/articles/1401/07/news069.html
Intel���A2011�N�ɔ��������Z�L�����e�B���McAfee�̃u�����h���uIntel Security�v�ɍ��V���A
���ݖ�3000�~�Ŕ̔����Ă��郂�o�C�������Z�L�����e�B���i���ɂ���Ɣ��\�����B
ASUS�A�J���t���X�}�z�uZenFone�v�V���[�Y�𐳎����\����99����
http://rbmen.blogspot.jp/2014/01/asuszenfone99.html
http://www.itmedia.co.jp/news/articles/1401/07/news069.html
Intel���A2011�N�ɔ��������Z�L�����e�B���McAfee�̃u�����h���uIntel Security�v�ɍ��V���A
���ݖ�3000�~�Ŕ̔����Ă��郂�o�C�������Z�L�����e�B���i���ɂ���Ɣ��\�����B
ASUS�A�J���t���X�}�z�uZenFone�v�V���[�Y�𐳎����\����99����
http://rbmen.blogspot.jp/2014/01/asuszenfone99.html
ASUS�A���R�����f�W�^�C�U��Bay Trail���ڂ�8�^Win8.1�^�u"VivoTab Note 8"
http://news.mynavi.jp/news/2014/01/07/225/
http://news.mynavi.jp/news/2014/01/07/225/
VivoTab Note 8�A32GB��299�h���ŁA64GB��349�h���炵����
�܂����ꂪ3���~�A3��5��~�Ƃ͂Ȃ�Ȃ��̂͂����̂��Ƃ�
���܍��Ƃ������邯�Ǔ��{���������Ƃ������A�����J���������Ȃ��Ă���C�����Ȃ����Ȃ�
���܍��Ƃ������邯�Ǔ��{���������Ƃ������A�����J���������Ȃ��Ă���C�����Ȃ����Ȃ�
�I�t�B�X�̎d�l���Ⴄ�����
H��S��H��B����$80����������
64GB349�h���Ȃ�+80=429�h����43000�~�Ŕ�������Ă��
�����Ȃ��l�i���Ǝv����
�f��Venue 8 Pro��41,980�~�����炿�傤�ǂ��̂��炢
H��S��H��B����$80����������
64GB349�h���Ȃ�+80=429�h����43000�~�Ŕ�������Ă��
�����Ȃ��l�i���Ǝv����
�f��Venue 8 Pro��41,980�~�����炿�傤�ǂ��̂��炢
Intel�A�w�b�h�Z�b�g�^�[����Quark�x�[�X��SoC�uIntel Edison�v�\
http://www.itmedia.co.jp/enterprise/articles/1401/07/news084.html
http://www.itmedia.co.jp/enterprise/articles/1401/07/news084.html
Intel�A3�����[�x�Z���T��2�����J�����������J�����E���W���[���\
http://news.mynavi.jp/news/2014/01/07/339/
�C���e���A2014�N�����̑S�v���Z�b�T���畴���z����r���\��
http://ggsoku.com/2014/01/intel-2014-non-conflict-mineral/
http://news.mynavi.jp/news/2014/01/07/339/
�C���e���A2014�N�����̑S�v���Z�b�T���畴���z����r���\��
http://ggsoku.com/2014/01/intel-2014-non-conflict-mineral/
195 �F,,�E�L�́M�E,,�j��-�������F2014/01/07(��) 21:05:47.32 ID:PZOPEiR3
�u�R�������G���L�������v�Ƃ��N�����猾���o����������
Kinect�̂������Ő[�x�Z���T�Ƃ���������ɓ���₷���Ȃ����ƌ����邪�A
Intel�����U��ɎQ������̂��B�G�R�V�X�e�����ł���Ƃ������ǂȂ�
Intel�����U��ɎQ������̂��B�G�R�V�X�e�����ł���Ƃ������ǂȂ�
�HIDF�̃L�[�m�[�g��Broadwell����̃f�o�C�X�ɂ�3D�J�������ڂ��I�Č��\�A�s�[�����Ă��̂�����
���̂��L���ł̓X���[����܂����Ă��Ƃ���
���̂��L���ł̓X���[����܂����Ă��Ƃ���
�܂��܂������グ���������烁�f�B�A�̊S�����ΓI�ɒႢ��Ȃ����Ȃ�
���̏ꍇ�AIntel�̗������͒n���ȍ��q���ĂȂ邾�낤���A
�����ɉX�������ʂ͖]�߂Ȃ����낤
Kinect���ꕔ�̃A�[���[�A�_�v�^�Ȑl�B���y�������ɂ������Ă邯��
���ł������ʂ̃J�����̂悤�Ɉ�ʉ����Ă���킯�ł͂Ȃ���
���̏ꍇ�AIntel�̗������͒n���ȍ��q���ĂȂ邾�낤���A
�����ɉX�������ʂ͖]�߂Ȃ����낤
Kinect���ꕔ�̃A�[���[�A�_�v�^�Ȑl�B���y�������ɂ������Ă邯��
���ł������ʂ̃J�����̂悤�Ɉ�ʉ����Ă���킯�ł͂Ȃ���
http://anandtech.com/show/7648/gigabyte-brix-pro/2
GIGABYTE BRIX Pro: A First Look at the Intel i7-4770R with Iris Pro HD 5200
GIGABYTE BRIX Pro: A First Look at the Intel i7-4770R with Iris Pro HD 5200
CES�̓n�[�h���ȓW����Ƃ͂����A�����܂�MS����C�Ȃ̂͒��������Ă�
Intel�A�u�R���s���[�^�͐l����������f�o�C�X�ւƐi������v
�`ASUS�ADell�ALenovo�̎���PC�����J
http://pc.watch.impress.co.jp/docs/news/event/20140108_629925.html
�yIntel��u���zIoT����ɔ����Ă��܂��܂Ȏ��ł�Intel
�`SD�J�[�h���Quark���ڃR���s���[�^�uEdison�v�����J l
http://pc.watch.impress.co.jp/docs/news/event/20140108_629931.html
�`ASUS�ADell�ALenovo�̎���PC�����J
http://pc.watch.impress.co.jp/docs/news/event/20140108_629925.html
�yIntel��u���zIoT����ɔ����Ă��܂��܂Ȏ��ł�Intel
�`SD�J�[�h���Quark���ڃR���s���[�^�uEdison�v�����J l
http://pc.watch.impress.co.jp/docs/news/event/20140108_629931.html
Intel��SteamOS���v�悵�Ă���Valve����g
4����Core�v���Z�b�T�ɓ�������Ă���GPU(Iris Pro)�𓋍ڂ���GIGABYTE����
���^PC��SteamOS���C���X�g�[�������V�X�e�����Љ���B
Intel�́A���Ђ̓���GPU�̐��\���オ��ɂ�āAPC�Q�[�~���O�ւ̑Ή���ϋɓI�ɍs�Ȃ��Ă���A
����Iris Pro�̓��[�G���h��dGPU�𗽉킷�鐫�\�������Ă��邽�߁A�Q�[�~���OPC�őI�����郆�[�U�[����������B
�����Valve�Ƃ̒�g�́A���̐헪�̉�������ɂ��铮�����ƍl���邱�Ƃ��ł��邾�낤�B
4����Core�v���Z�b�T�ɓ�������Ă���GPU(Iris Pro)�𓋍ڂ���GIGABYTE����
���^PC��SteamOS���C���X�g�[�������V�X�e�����Љ���B
Intel�́A���Ђ̓���GPU�̐��\���オ��ɂ�āAPC�Q�[�~���O�ւ̑Ή���ϋɓI�ɍs�Ȃ��Ă���A
����Iris Pro�̓��[�G���h��dGPU�𗽉킷�鐫�\�������Ă��邽�߁A�Q�[�~���OPC�őI�����郆�[�U�[����������B
�����Valve�Ƃ̒�g�́A���̐헪�̉�������ɂ��铮�����ƍl���邱�Ƃ��ł��邾�낤�B
�J�����A�Z���T�[�g�����f��
https://www.youtube.com/watch?v=N32FPn_8PmY
https://www.youtube.com/watch?v=ZGQZjlaCZh4
https://www.youtube.com/watch?v=uzX08iSnlR0
https://www.youtube.com/watch?v=ffW-sdVrp_U
https://www.youtube.com/watch?v=AtdelN_thyE
https://www.youtube.com/watch?v=AZIYO-rD3CY
https://www.youtube.com/watch?v=N32FPn_8PmY
https://www.youtube.com/watch?v=ZGQZjlaCZh4
https://www.youtube.com/watch?v=uzX08iSnlR0
https://www.youtube.com/watch?v=ffW-sdVrp_U
https://www.youtube.com/watch?v=AtdelN_thyE
https://www.youtube.com/watch?v=AZIYO-rD3CY
�⏕���Ђ��헪����
�yCES 2014�zIntel SD�J�[�h�T�C�Y��PC�\�gEdison�h�𖾂炩��
http://northwood.blog60.fc2.com/blog-entry-7308.html
���J���҂ւ̕Ƃ���13���h�������Ƃ����B
Intel CES 2014�ōŐV���i��W��/�^�u���b�g�������i�̃��[�h�}�b�v���X�V
http://northwood.blog60.fc2.com/blog-entry-7294.html
���p�[�g�i�[�ɑ��}�[�P�e�B���O�ɂ�����T�|�[�g�ƕ⏕���̒��s���B
��$99��Android�^�u���b�g�̎�����ڎw���Ƃ����B
�yCES 2014�zIntel SD�J�[�h�T�C�Y��PC�\�gEdison�h�𖾂炩��
http://northwood.blog60.fc2.com/blog-entry-7308.html
���J���҂ւ̕Ƃ���13���h�������Ƃ����B
Intel CES 2014�ōŐV���i��W��/�^�u���b�g�������i�̃��[�h�}�b�v���X�V
http://northwood.blog60.fc2.com/blog-entry-7294.html
���p�[�g�i�[�ɑ��}�[�P�e�B���O�ɂ�����T�|�[�g�ƕ⏕���̒��s���B
��$99��Android�^�u���b�g�̎�����ڎw���Ƃ����B
206 �F,,�E�L�́M�E,,�j��-�������F2014/01/08(��) 18:52:19.78 ID:LHoZZIGp
>>205
Qualcomm��Google�����̊J���҉������Ȃ��ɂł����Ȃ����Ǝv���Ă�́H
Qualcomm��Google�����̊J���҉������Ȃ��ɂł����Ȃ����Ǝv���Ă�́H
13���h�����Đ������c�Ǝv�����猳�L����130���h�������
�ǂ����ǂ����ԈႦ����
�ǂ����ǂ����ԈႦ����
�~���I���ƃr���I�������Ⴆ��Ƃ��c�c
������130���h���Ń������b�g�����ł���Ȃ��������
MS�������������x�������Ȃ���Ȃ�Ȃ��Ǝv�����
����ǂ��납�����Ńn�[�h����ăp�[�g�i�[�����Ăɂ�����Ƃ��E�E�E
����ǂ��납�����Ńn�[�h����ăp�[�g�i�[�����Ăɂ�����Ƃ��E�E�E
Intel����10�N�O���炢�͂����܂�CES�ɗ͓���ĂȂ������C���[�W�������
����AMD���Q�[���K�[�Q�[���K�[�����ĂĖ��ɗ����Ȃ���ȁB
Win�^�u���L�܂�Ȃ�AMD�ɂƂ��Ă��ǂ����Ƃ̂͂��Ȃ̂ɁB
�^�u���b�g����CPU������̂Ȃ�AIntel����ɃQ�[���K�[�����ĂȂ���
iPad��Nexus�����Ă���AMD�^�u���b�g�̂ق����ǂ��I�Ƃ���Ă݂��ƁB
Win�^�u���L�܂�Ȃ�AMD�ɂƂ��Ă��ǂ����Ƃ̂͂��Ȃ̂ɁB
�^�u���b�g����CPU������̂Ȃ�AIntel����ɃQ�[���K�[�����ĂȂ���
iPad��Nexus�����Ă���AMD�^�u���b�g�̂ق����ǂ��I�Ƃ���Ă݂��ƁB
>>212
���{��A�����J�͂Ƃɂ���PC��windows�������Ă邩��Ȃ�
������windows�A�e���[�̓_����!!!!�����������y���悤���c�c
���{��A�����J�͂Ƃɂ���PC��windows�������Ă邩��Ȃ�
������windows�A�e���[�̓_����!!!!�����������y���悤���c�c
MS�ƃC���e����PC�Ŗׂ������ŁA�ƊE����͌����Ă��邾�낤�ȁB
������X�}�z�Ƃ��^�u���b�g�݂����ȐV�����s��ɎQ�����悤�Ƃ���������B
������X�}�z�Ƃ��^�u���b�g�݂����ȐV�����s��ɎQ�����悤�Ƃ���������B
>>212
�����݂�����AMD�X���̕����r�炵�ĂĂ���
�����݂�����AMD�X���̕����r�炵�ĂĂ���
>>212
AMD�͑���HSA�̊J���������Ă�����Ďv���B
AMD�͑���HSA�̊J���������Ă�����Ďv���B
218 �F,,�E�L�́M�E,,�j��-�������F2014/01/09(��) 00:01:50.79 ID:LHoZZIGp
������Lenovo�̐V���i���C���i�b�v�͂����[��
�x�m�ʂ���꒴�����
�x�m�ʂ���꒴�����
>>199
���[��B����ł�i5�̔{���E�E�E�BRadeonHD7750�̔������x���Ȃ��B
Core2�����v���[�X���������ǁA�܂��������B
�X�J�C���[�N�҂����ق����ǂ��������ȁB����ŁA�m�[�}���̃f�X�N�g�b�v��g�ށB
���[��B����ł�i5�̔{���E�E�E�BRadeonHD7750�̔������x���Ȃ��B
Core2�����v���[�X���������ǁA�܂��������B
�X�J�C���[�N�҂����ق����ǂ��������ȁB����ŁA�m�[�}���̃f�X�N�g�b�v��g�ށB
>>199��iGPU����Ȃ���CPU�̏������\���A�b�v���Ă�ƌ���������Ȃ���
>>221
�����A�S�����B
���������������������̂ŐF�X�����T���Ă�B
���傤�ǂ�������������������Ԃ₢�Ă��܂����B
���[���[��[�B
�����A�S�����B
���������������������̂ŐF�X�����T���Ă�B
���傤�ǂ�������������������Ԃ₢�Ă��܂����B
���[���[��[�B
>216
iGPU����MEM�Ƃ��Ă͐�������CPU��L4�Ƃ��Ă͖��ɗ����Ă�̂��ƂĂ��������ˁc4770k�ƕς���
iGPU����MEM�Ƃ��Ă͐�������CPU��L4�Ƃ��Ă͖��ɗ����Ă�̂��ƂĂ��������ˁc4770k�ƕς���
>>223
�܂��AiGPU�ł̗��p���x�z�I���Ƃ��Ă��A�����Ă�Ȃ炤�ꂵ�����B
�܂��AiGPU�ł̗��p���x�z�I���Ƃ��Ă��A�����Ă�Ȃ炤�ꂵ�����B
���̂������̃x���`���Ƃ��Ȃ�����Ă��L�������邯�ǁA
���������P�[�X�͏������낤
���������P�[�X�͏������낤
226 �F,,�E�L�́M�E,,�j��-�������F2014/01/09(��) 21:47:24.18 ID:P13k86Ye
>>233
����܂��ʂ̃��[�N���[�h��������Ȃ�����
����ȃe�[�u����A���ŎQ�Ƃ���悤�ȃA�v�����Ƃ��������ʂ����B
���ƁAAVX-512���L���g����悤�ɂȂ�Ƃ���DDR4 2ch�ł�����Ȃ��Ȃ�Ǝv���B
����܂��ʂ̃��[�N���[�h��������Ȃ�����
����ȃe�[�u����A���ŎQ�Ƃ���悤�ȃA�v�����Ƃ��������ʂ����B
���ƁAAVX-512���L���g����悤�ɂȂ�Ƃ���DDR4 2ch�ł�����Ȃ��Ȃ�Ǝv���B
�����R�͐��\�ւ̃��^�[��������I�Ȃ̂ł��܂����H�w���L�тȂ�
�Ԃ����Ⴏ�����Ɍ�����Intel���g���Z�p�̒~�ς�����ׂ̃e�X�g�v���_�N�g�ł���
�c�q����Ȃ����ǁA�ǂ��݂Ă�AVX-512�Ƃ��̕z�ɂ����݂���
�Ԃ����Ⴏ�����Ɍ�����Intel���g���Z�p�̒~�ς�����ׂ̃e�X�g�v���_�N�g�ł���
�c�q����Ȃ����ǁA�ǂ��݂Ă�AVX-512�Ƃ��̕z�ɂ����݂���
���̂����Z�������ȊO�S���t���悤�ɂȂ邾��
�Ƃ͂�������̘b�ɂȂ�Ƃ�����
�Ƃ͂�������̘b�ɂȂ�Ƃ�����
230 �F,,�E�L�́M�E,,�j��-�������F2014/01/09(��) 23:21:45.84 ID:P13k86Ye
��ʃ��f����GeForce�ڂ��Ă�̂�GT3e���ڂ��Ă���Ă̂�
Apple�̂��������������
Apple�̂��������������
SSD�A��Q�ɋ����̂�Intel�� - ExtremeTech
http://news.mynavi.jp/news/2014/01/09/088/
http://news.mynavi.jp/news/2014/01/09/088/
���Ȃ������[�i�X��intel��SSD����đ����ɂȂ��Ă���
CPU Texture Compositing with InstantAccess
http://software.intel.com/en-us/blogs/2013/03/27/cpu-texture-compositing-with-direct-resource-access
IrisPro��CPU��GPU�e�N�X�`���Ƀ_�C���N�g�ɓǂݏ����ł���@�\������ˁB
GPU����CPU�̗��_�����������ǂ��@�\���Ƃ͎v�����ǁA
�\�[�X�R�[�h���p�ɏ����Ȃ��Ƃ����Ȃ��̂͂��������Ȃ��B
�h���C�o�ʼnB�����Ă��ꂽ�瑼��GPU�p�Ɠ����o�C�i���ōςނ̂ɁB
http://software.intel.com/en-us/blogs/2013/03/27/cpu-texture-compositing-with-direct-resource-access
IrisPro��CPU��GPU�e�N�X�`���Ƀ_�C���N�g�ɓǂݏ����ł���@�\������ˁB
GPU����CPU�̗��_�����������ǂ��@�\���Ƃ͎v�����ǁA
�\�[�X�R�[�h���p�ɏ����Ȃ��Ƃ����Ȃ��̂͂��������Ȃ��B
�h���C�o�ʼnB�����Ă��ꂽ�瑼��GPU�p�Ɠ����o�C�i���ōςނ̂ɁB
�Ȃ��GPU�̃��j�b�g��192���ŏ��\���Ȃ́H
����������Ɗ撣����200�Ƃ��ɂ����炢���̂�
����Ƃ��Ȃɂ��Ӗ�������́H
���w��192�Ƃ����K�悩�ȂŌ�������
����������Ɗ撣����200�Ƃ��ɂ����炢���̂�
����Ƃ��Ȃɂ��Ӗ�������́H
���w��192�Ƃ����K�悩�ȂŌ�������
64*3=192�����炾
>>233
Intel��nVidia���A�������Ă��Ȃ��킯�ł͂Ȃ��āA
2014�N����GPU�̉����������ł��o���Ă���̂�AMD�ɓ����Ȃ�
>>234
10�i���́A��̈��������ł�
Intel��nVidia���A�������Ă��Ȃ��킯�ł͂Ȃ��āA
2014�N����GPU�̉����������ł��o���Ă���̂�AMD�ɓ����Ȃ�
>>234
10�i���́A��̈��������ł�
238 �F,,�E�L�́M�E,,�j��-�������F2014/01/10(��) 08:33:53.84 ID:Qjsbm7RH
�����o�C�i���ōςނ���B
�����DLL�����߂����ŌĂяo���Ȃ��Ƃ����Ȃ����C�u�����Ȃ�A
������g��������DLL�����Ēx�����[�h���Ă��������B
�����DLL�����߂����ŌĂяo���Ȃ��Ƃ����Ȃ����C�u�����Ȃ�A
������g��������DLL�����Ēx�����[�h���Ă��������B
���̍l�����̓������Ŋ��ꂽ
>>236
���̊g����Haswell���炶��Ȃ����������H
Broadwell�̑�8����GPU�ɂ��Ă�
�u�啝�ɕω�����v�ȏ�̏�o�Ă��Ȃ��C������
���̊g����Haswell���炶��Ȃ����������H
Broadwell�̑�8����GPU�ɂ��Ă�
�u�啝�ɕω�����v�ȏ�̏�o�Ă��Ȃ��C������
Intel�ATDP 60W��10�R�A���f���ȂǁuXeon E5-2400 v2�v�V���[�Y
�`1�`2 CPU��������LGA1356�p�b�P�[�W���f��
http://pc.watch.impress.co.jp/docs/news/20140110_630321.html
�`1�`2 CPU��������LGA1356�p�b�P�[�W���f��
http://pc.watch.impress.co.jp/docs/news/20140110_630321.html
4�\�Popteron�̑��̍��͎~�܂�������E5-4000�V���[�Y�͏I����
ASUS�AWindows��Android�������g����n�C�u���b�h�}�V���\
http://wired.jp/2014/01/10/asus-duet-td300/
http://wired.jp/2014/01/10/asus-duet-td300/
Intel��Haswell�ꎮ��Android�h���C�o�������Ă����N�b�\�����ŋ���Android�}�V���ɂȂ�̂ɂȂ��E�E�E
�����̗\�肾��Tizen������Ȋ����ɂ����������t�V�͂����
������������
������������
�Ȃ�قǂˁB�ł��A�ǂ�ȗp�r?
>>243
ASUS�́Atransormer�Ŗ������߂āA�ϑԂ��~�܂�Ȃ��Ȃ��Ă��܂����ȁB�G�W�\���ł���ɕϑԂ��Ă���邱�Ƃ��y���݂ɂ��Ă���܂��B
ASUS�́Atransormer�Ŗ������߂āA�ϑԂ��~�܂�Ȃ��Ȃ��Ă��܂����ȁB�G�W�\���ł���ɕϑԂ��Ă���邱�Ƃ��y���݂ɂ��Ă���܂��B
248 �F,,�E�L�́M�E,,�j��-�������F2014/01/10(��) 19:08:21.34 ID:Qjsbm7RH
���������ʔ����M�~�b�N�̃n�[�h���Ă��Ƃ���SONY VAIO�̖����������悤��
���{���[�J�[�̖v����������
���{���[�J�[�̖v����������
http://software.intel.com/en-us/forums/topic/499090
>Flexible memory modes for the on package memory include: flat, cache, and hybrid modes
KNL�̃I���p�b�P�[�W�������̓L���b�V���Ƃ��Ă��@�\�����邱�Ƃ��ł��邻���ȁB
�^�O�͂ǂ�����낤
>Flexible memory modes for the on package memory include: flat, cache, and hybrid modes
KNL�̃I���p�b�P�[�W�������̓L���b�V���Ƃ��Ă��@�\�����邱�Ƃ��ł��邻���ȁB
�^�O�͂ǂ�����낤
250 �F,,�E�L�́M�E,,�j��-�������F2014/01/10(��) 20:08:20.61 ID:Qjsbm7RH
RAM�̈ꕔ���^�O�Ƃ��Ďg���\�t�g�E�F�A�L���b�V���̗\��
�p�\�R�����E�o�ׁA13�N10�����@�ߋ��ő�̗�������
http://uni.2ch.net/test/read.cgi/newsplus/1389324599/
http://mw.nikkei.com/content/pic/20140110/96958A9C9381959CE3E2E2E2868DE3E2E2E3E0E2E3E6E2E2E2E2E2E2-DSXBZO6512890010012014I00001-PB1-3.jpg
http://uni.2ch.net/test/read.cgi/newsplus/1389324599/
http://mw.nikkei.com/content/pic/20140110/96958A9C9381959CE3E2E2E2868DE3E2E2E3E0E2E3E6E2E2E2E2E2E2-DSXBZO6512890010012014I00001-PB1-3.jpg
{kind=link}
2014�N��XP�}�V���̔������ł�����Ǝ����������낤���ǁA2015�N�͔����Œn���G�}����
2�N�O�܂ł͏㏸���Ă���
�X�}�z�͂��̂����ƑO���炠��̂�
�X�}�z�͂��̂����ƑO���炠��̂�
Windows
256 �FSocket774�F2014/01/11(�y) 00:39:33.81 ID:kDa1+7ok
>>252
�O���t�B�N�{�[�h��t������}�U�[�{�[�h�Ȃ��
����Windows7�ւ̓���ւ��������h���C�o�[��
�Ή����Ă��邩��{�̂܂ł͕ς��Ȃ���
�O���t�B�N�{�[�h��t������}�U�[�{�[�h�Ȃ��
����Windows7�ւ̓���ւ��������h���C�o�[��
�Ή����Ă��邩��{�̂܂ł͕ς��Ȃ���
���[�J�[�́uXP�}�V���͂����@�B�I�����ɒB���Ă���v�Ɛ�`���Ă�
�������p�\�R��BTO���[�J�[�͂ǂ�����Đ����c�����Ȃ낤�Ȃ��E�E�E
�^�u���b�g��BTO�ł�����H
�������p�\�R��BTO���[�J�[�͂ǂ�����Đ����c�����Ȃ낤�Ȃ��E�E�E
�^�u���b�g��BTO�ł�����H
�ʂ�PC����ł���킯�ł��ˁ[����e���F�X��������ˁH
�����ւ��X�p��������ɐL�т�͎̂������Ǝv�����c�c
�����ւ��X�p��������ɐL�т�͎̂������Ǝv�����c�c
���܂��̓p�\�R��BTO�s�ꂪ�i���ɑ��݂�������Ƃł��v���Ă���̂��H
�͂��B
>>251
Win�^�u���b�g�A�����^2-in-1�����O���ĂȂ�2009�N���x������������Ă�قǂ���Ȃ���
Win�^�u���b�g�A�����^2-in-1�����O���ĂȂ�2009�N���x������������Ă�قǂ���Ȃ���
�m���Ƀp�\�R���s�ꂩ��^�u���b�g�s��ւ̈ڍs�͑n���I�j��ɓ���낤���ǁE�E�E�������Ȃ�
�f�X�N�g�b�v�������Ȃ�����2013��mac�݂����ɂȂ����Ⴄ�낤�Ȃ�
���A�N���E�h�Ƃ������S�~�͂���Ȃ���ŁO�O�G
http://iup.2ch-library.com/i/i1108056-1389373800.png
���A�N���E�h�Ƃ������S�~�͂���Ȃ���ŁO�O�G
http://iup.2ch-library.com/i/i1108056-1389373800.png
{kind=link}
�SPC��NUC������킯��
>>263�@�ז������[����S�����܂��锠��낤��
���������AWindows8/8.1���A�f�X�N�g�b�vPC���[�U�[���炷��ƕ������A
CPU��Sandy�ȍ~���������ւ������Ǝv���قǑ����Ȃ��ĂȂ��̂ŁA
�킴�킴PC�V������Ӗ����������
Win7+Sandy�����Ă�l�͓��ʔ����ւ���K�v�Ȃ�
Win9�{�����\������CPU�̃Z�b�g��PC������
CPU��Sandy�ȍ~���������ւ������Ǝv���قǑ����Ȃ��ĂȂ��̂ŁA
�킴�킴PC�V������Ӗ����������
Win7+Sandy�����Ă�l�͓��ʔ����ւ���K�v�Ȃ�
Win9�{�����\������CPU�̃Z�b�g��PC������
�܂��d���R���f���T�̎����͒����Ă��U�`�V�N������ȁB
XP�}�V���͂Ƃ����Ɏ������낤�B
XP�}�V���͂Ƃ����Ɏ������낤�B
��Ȃ����[�Ȃ�
Intel��SD�J�[�h�^�R���s���[�^�uEdison�v�̏ڍׂ�����
�`512MB�������A2GB�X�g���[�W�A�����@�\�Ȃǂ��l�ߍ���
http://pc.watch.impress.co.jp/docs/news/event/20140111_630478.html
�`512MB�������A2GB�X�g���[�W�A�����@�\�Ȃǂ��l�ߍ���
http://pc.watch.impress.co.jp/docs/news/event/20140111_630478.html
270 �FSocket774�F2014/01/11(�y) 09:46:03.99 ID:gdRblvns
�Ƃ肠�����b�o�t�Ƃu�f�`���ЂƂɂȂ����B
����ǂ�ǂ�W�ω����i�߂�
���}�U�[�{�[�h�ɏ�������Ă郂�m��
�����ꃏ���`�b�v�ɂȂ�B
����ǂ�ǂ�W�ω����i�߂�
���}�U�[�{�[�h�ɏ�������Ă郂�m��
�����ꃏ���`�b�v�ɂȂ�B
IBM��Aptiva�V���[�Y�̃��C���A�b�v����V
http://pc.watch.impress.co.jp/docs/article/960605/aptiva.htm
���\�͂��̃N���X��z�肵�Ă��������̂��낤���
http://pc.watch.impress.co.jp/docs/article/960605/aptiva.htm
���\�͂��̃N���X��z�肵�Ă��������̂��낤���
Intel finishes work on 64-bit Android 4.4 for x86 smartphones
http://www.pcworld.com/article/2086380/intel-finishes-work-on-64bit-android-44-for-x86-smartphones.html
http://www.pcworld.com/article/2086380/intel-finishes-work-on-64bit-android-44-for-x86-smartphones.html
273 �FSocket774�F2014/01/11(�y) 15:15:05.11 ID:kDa1+7ok
4�R�A��BayTrail-D�ς�mini-itx�}�}���͈������80-90�h�����x�炵��
���{�~����13000�~���炢���낤����A�Z������1820��萫�\����������Ȃ畁�ʂɃ}�}����CPU�����ق����ǂ�������
���{�~����13000�~���炢���낤����A�Z������1820��萫�\����������Ȃ畁�ʂɃ}�}����CPU�����ق����ǂ�������
>>272
�������AMD���^�_���ł���́H
�������AMD���^�_���ł���́H
MMX�Ή�CPU����Ȃ��Ɠ������Ȃ������o�[�`������ for Windows
�C���e���l��(��)AMD��������Ɉϑ�����Ƃ��A�ǁ[�Ȃ��Ă�
Intel�A�G���g���[�����x�[�X�o���h�`�b�v��GlobalFoundries�ɐ����ϑ�
http://blog.livedoor.jp/amd646464/archives/52393818.html
Intel�A�G���g���[�����x�[�X�o���h�`�b�v��GlobalFoundries�ɐ����ϑ�
http://blog.livedoor.jp/amd646464/archives/52393818.html
�C���e�������̍H��]���Ă�Ǝv�������A28nm���炢���Ƃ�������Ȃ��̃i�B
���Ѓt�@�u���Ƒ�ʂɉ��X�ƍ�葱���Ȃ��ƃy�C�ł��Ȃ�����
��������Ȃ����i�͈ϑ����邵���Ȃ��̂�
��������Ȃ����i�͈ϑ����邵���Ȃ��̂�
�C���e���̓��W�b�N�v���Z�X�ɓ������Ă邩��A
�����g�����ʐM�����̃A�i���O���ڃ`�b�v�͑��Јϑ��Ȃ�ˁH
���W�b�N�����̃v���Z�X�Ő��Y�\�ȃA�i���O�`�b�v�Ȃ�A�킴�킴���Јϑ����Ȃ�����
�����g�����ʐM�����̃A�i���O���ڃ`�b�v�͑��Јϑ��Ȃ�ˁH
���W�b�N�����̃v���Z�X�Ő��Y�\�ȃA�i���O�`�b�v�Ȃ�A�킴�킴���Јϑ����Ȃ�����
�t�@�u�Ȃ�݂�ȓ������Ǝv���Ă�Ȃ�傫�ȊԈႢ���ȁB
Intel�̓d�q�H��pCPU�{�[�h�uGalileo�v�����A�����^��x86 �VSoC����
Arduino�����̃n�[�h/�\�t�g�����p�\
http://akiba-pc.watch.impress.co.jp/docs/news/news/20140111_630491.html
Arduino�����̃n�[�h/�\�t�g�����p�\
http://akiba-pc.watch.impress.co.jp/docs/news/news/20140111_630491.html
MSX�݂����̂��������炢���Ǝv��
�A�������邩�獡�̉���݂����Ȃ���������
�A�������邩�獡�̉���݂����Ȃ���������
>>286
�i���̃X�s�[�h�̑����o�b�̐��E�ɂ͂l�r�w��ƒ�p�Q�[���@�̂悤��
�n�[�h�E�G�A�Ō݊�������������`�Ԃ͂����������ċ����ɏ��ĂȂ�
���j���ؖ����Ă�
�i���̃X�s�[�h�̑����o�b�̐��E�ɂ͂l�r�w��ƒ�p�Q�[���@�̂悤��
�n�[�h�E�G�A�Ō݊�������������`�Ԃ͂����������ċ����ɏ��ĂȂ�
���j���ؖ����Ă�
�r�W���A���X�^�W�I�͂���Ȃ����S�����g���킯����Ȃ�����
Windows�Ƀx�[�V�b�N�Ƃ�C��������ė~������
Windows�Ƀx�[�V�b�N�Ƃ�C��������ė~������
C����Ȃ�MS�̖����_�E�����[�h�ł����ł����������͑�����
��������GUI�s�v�ȃA�v���Ȃ�Win32�pGCC�ł���Ă�����
��������GUI�s�v�ȃA�v���Ȃ�Win32�pGCC�ł���Ă�����
���ꂪC#�Ƃ��ł��悯���
Vista�ȍ~�Ȃ�.NET Framework��OS�W���ŃC���X�g�[������Ă邩��
csc.exe jsc.exe vbc.exe ������̃R�}���h��
�ŏ����� \Windows\Microsoft.NET\Framework\ �ȉ��ɓ����Ă�
Vista�ȍ~�Ȃ�.NET Framework��OS�W���ŃC���X�g�[������Ă邩��
csc.exe jsc.exe vbc.exe ������̃R�}���h��
�ŏ����� \Windows\Microsoft.NET\Framework\ �ȉ��ɓ����Ă�
>>285
����Galileo���Ă�͕�����������Arduino��IF��������RaspberryPi�̂悤�Ȃ��̂��H
�X�y�b�N�I�ɂ����i�I�ɂ�RaspberryPi�����芷����K�v���������Ȃ��̂����B
�����b�g���ĉ��Ȃ̂��낤�B
����Galileo���Ă�͕�����������Arduino��IF��������RaspberryPi�̂悤�Ȃ��̂��H
�X�y�b�N�I�ɂ����i�I�ɂ�RaspberryPi�����芷����K�v���������Ȃ��̂����B
�����b�g���ĉ��Ȃ̂��낤�B
>>287
PC�̐i��������Ă鍡�͂܂����Ⴄ��������Ȃ�
PC�̐i��������Ă鍡�͂܂����Ⴄ��������Ȃ�
���Y�p�C�ׂ���
ARM�g���Ƃ���NPO�ł���ׂ��ɂ�����Ƃ�
intel�l�����˂���
ARM�g���Ƃ���NPO�ł���ׂ��ɂ�����Ƃ�
intel�l�����˂���
���^SoC�����č�����ċZ�p��`�ƁA�����̈Ӗ�������
�e�탉�C���i�b�v���y�����Ă��Ȃ����Ƃ�搂�������
�u�����h�C���[�W�ւ̐e�ߊ����L�߂ď����̃J�X�^�}�Ɍ�������ۑ����
�e�탉�C���i�b�v���y�����Ă��Ȃ����Ƃ�搂�������
�u�����h�C���[�W�ւ̐e�ߊ����L�߂ď����̃J�X�^�}�Ɍ�������ۑ����
x86�g�ݍ��݂͈ˑR�Ƃ��Ď��v�����邵������d�͂̏��Ȃ����i�̈����������������A
���܂ł͂������������Ď�̏o���₷���J���p�̃{�[�h������܂�Ȃ������̂ŁA�܂����肪����
�ŏI���i�ɂ����g�ݍ���Ŏg���C�͑S�R���Ȃ����낤��
���܂ł͂������������Ď�̏o���₷���J���p�̃{�[�h������܂�Ȃ������̂ŁA�܂����肪����
�ŏI���i�ɂ����g�ݍ���Ŏg���C�͑S�R���Ȃ����낤��
Quark���̋��N�̏HIDF�œ��˂ɏo�Ă�������
(KNF�݂�����)�ꕔ�̌ڋq����ŎT�������Ƃ������W�J����̂��Ǝv��������
���������G���h���[�U�������i���o�Ă����Ƃ������
�VCEO�̃t�@�E���h���J�����j�Ƃ����{�C�ŊJ���_���Ă�̂��ȁH
(KNF�݂�����)�ꕔ�̌ڋq����ŎT�������Ƃ������W�J����̂��Ǝv��������
���������G���h���[�U�������i���o�Ă����Ƃ������
�VCEO�̃t�@�E���h���J�����j�Ƃ����{�C�ŊJ���_���Ă�̂��ȁH
USB�������ƈꏏ�ŁA���܂܂�x86�p�t�H�[�}���X�����ł���Ă�������A�������炢���̂��悭�킩���̂��Ǝv��
>>296
��w�ɂ�܂��Ƃ��w�Z�Ɉ����ɒƂ������Ă����ŁA���䉮����ʎY�w�Z��
�g���Ă��炤�̂��ړI����Ȃ��H���w�Z������ɂ��܂�x86�A�Z���u���g����V�l�����邱�Ƃ���
�q���̊ߋ�ɂ͂��傤�ǂ������i�B
��w�ɂ�܂��Ƃ��w�Z�Ɉ����ɒƂ������Ă����ŁA���䉮����ʎY�w�Z��
�g���Ă��炤�̂��ړI����Ȃ��H���w�Z������ɂ��܂�x86�A�Z���u���g����V�l�����邱�Ƃ���
�q���̊ߋ�ɂ͂��傤�ǂ������i�B
�G�A�R����e���r�Ƃ��̑g�ݍ��݂ɂ��g����悤�ɁAx86�͑g�ݍ������̒ቿ�i�Ȑ��i��IP��ϋɓI�ɍs�������̂�
>>288
Windows��VS�ȊO�Ȃɂ��g�����ɂȂ�̂��t�ɋ���������Hw
������Win�J���҂�OS X�ELinux�EiOS�EAndroid�J����VS���g�����������ӂȂ�www
������Xamarin���M�����A.NET framework��������Ӗ��Ȃ�����Mono Develop��Xamarin Studio�Œ���Ă��
VS�͐��E���IDE���ƌ����Ă��ߌ�����Ȃ�
Windows��VS�ȊO�Ȃɂ��g�����ɂȂ�̂��t�ɋ���������Hw
������Win�J���҂�OS X�ELinux�EiOS�EAndroid�J����VS���g�����������ӂȂ�www
������Xamarin���M�����A.NET framework��������Ӗ��Ȃ�����Mono Develop��Xamarin Studio�Œ���Ă��
VS�͐��E���IDE���ƌ����Ă��ߌ�����Ȃ�
�l�J���Ȃ炻��������
�t����A�E�P���w
��K�͊J����VS�����Ƃ��ǂ��ɑ��݂���̂������Ăق�����w
��K�͊J����VS�����Ƃ��ǂ��ɑ��݂���̂������Ăق�����w
xml�x�[�X�̃v���W�F�N�g�t�@�C���ŕ����l�̕ύX�̃}�[�W���ǂ��X�P�[������̂�
�N�̃`�[���̉����@�������Ă݂Ăق����B
�N�̃`�[���̉����@�������Ă݂Ăق����B
>>303
�����l���ʁX�ɕҏW���ă}�[�W�Ȃ��1980�N�ォ��B
�����l���ʁX�ɕҏW���ă}�[�W�Ȃ��1980�N�ォ��B
>>288
Excel VBA
Excel VBA
Knights Landing�i�������R�A���͌��炷�j��Skylake-EX��QPI�Ƃ��œ�������
2�_�C1�p�b�P�[�W�ɂ��Ă��܂���
2�_�C1�p�b�P�[�W�ɂ��Ă��܂���
>>303
�����Ă�Ӗ����킩��Ȃ�����w
�X�P�[���r���e�B�̈Ӗ��Ō����Ă�Ȃ�X�P�[���A�E�g�Ȃ̂��X�P�[���A�b�v�Ȃ̂��ǂ����Ȃ�w
�ŁASVN��Git�g���Ă�Ȃ牽�����Ȃ̂�����킩��Ȃ�����w
�����Ă�Ӗ����킩��Ȃ�����w
�X�P�[���r���e�B�̈Ӗ��Ō����Ă�Ȃ�X�P�[���A�E�g�Ȃ̂��X�P�[���A�b�v�Ȃ̂��ǂ����Ȃ�w
�ŁASVN��Git�g���Ă�Ȃ牽�����Ȃ̂�����킩��Ȃ�����w
>>272
Intel�AAndroid 4.4�iKitKat�j�̃J�[�l���E�h���C�o��64bit���ς݁A�����X�}�[�g�t�H������Atom SoC?Merrifield�h��64bit�Ή�
http://juggly.cn/archives/104981.html
Intel�AAndroid 4.4�iKitKat�j�̃J�[�l���E�h���C�o��64bit���ς݁A�����X�}�[�g�t�H������Atom SoC?Merrifield�h��64bit�Ή�
http://juggly.cn/archives/104981.html
MIPS���V64bitCPU�o�����A���悢�惂�o�C�����S��64bit����ɓ˓�����
�����Ɠd�̃����R���͍���4bit�݂�������
�����Ɠd�̃����R���͍���4bit�݂�������
�Ⴆ�Ήƒ���̃����R�����X�}�z�ɏW�ꂽ�Ƃ�����
��C��64bit�Ƃ������Ƃ�
��C��64bit�Ƃ������Ƃ�
���u�E�C���X�ŁA�Ɛl���Ƃɕ����߂ăG�A�R���ŏ����Ă��ɂ��邱�Ƃ��ł���̂ł���
Intel��Android�pMcAfee���eOEM������root�ō���Ă��ꂽ�炢���̂�
�ƒ���Ɉ�l�����Z��łȂ���Ε֗��������ȁB
>>312
�������̏��Android�ł��o���\��܂ł͏o�Ă��悤��
�������̏��Android�ł��o���\��܂ł͏o�Ă��悤��
��Ȃ��Ƃ������Ɋe�ƒ��/64��n���Ă��ׂĂ̋@�킪�O���[�o��IP�����悤�ɂȂ��B
�������P�\�@��SSL��HomeGateway�����ތ`�ɂȂ邪�B
���x�v�ƃG�A�R���̏�Ԃ�Trap���邱�Ƃ��ł���悤�ɂȂ�BMIB����������Ȃ��B
�������P�\�@��SSL��HomeGateway�����ތ`�ɂȂ邪�B
���x�v�ƃG�A�R���̏�Ԃ�Trap���邱�Ƃ��ł���悤�ɂȂ�BMIB����������Ȃ��B
���ɉƓd�����ׂăO���[�o���A�h���X���悤�ɂȂ����Ƃ��Ă��A
���[�J�[�͏����ݒ�œ���LAN���̃��[�J���A�h���X���炵���Ď��E������t���Ȃ��悤�ɂ��Ăق������̂�
�\�t�g�E�F�A�Ɏシ������{���[�J�[������Ƀ����[�g���������
�Z�L�����e�B�[�z�[������ă{���{���ɂȂ�̂͌����Ă�
���[�J�[�͏����ݒ�œ���LAN���̃��[�J���A�h���X���炵���Ď��E������t���Ȃ��悤�ɂ��Ăق������̂�
�\�t�g�E�F�A�Ɏシ������{���[�J�[������Ƀ����[�g���������
�Z�L�����e�B�[�z�[������ă{���{���ɂȂ�̂͌����Ă�
�C���^�[�l�b�g�ڑ��̊��S������
�������͐ŋ���
�ؔ[����ΑS�@�\��~
���炵��
�������͐ŋ���
�ؔ[����ΑS�@�\��~
���炵��
�f�B�X�g�s�A�ɂ܂�����߂Â���
�����ł��A�n��
228 Socket774 sage 2014/01/14(��) 19:44:20.45 ID:b/+fsCoW
2�R�A3GHz��Pentium G3220��7780�~���c
4�R�A3GHz��Athlon X4 640��3�N�O�ɓ������炢�̒l�i�������͂������c
2�R�A3GHz��Pentium G3220��7780�~���c
4�R�A3GHz��Athlon X4 640��3�N�O�ɓ������炢�̒l�i�������͂������c
IPC��TDP�B
322 �F,,�E�L�́M�E,,�j��-�������F2014/01/14(��) 19:57:26.71 ID:PBzJA1XS
�~/�h�����[�g����
���\���������炢��
http://www.cpubenchmark.net/cpu.php?cpu=AMD+Athlon+X4+640&id=215
http://www.cpubenchmark.net/cpu.php?cpu=Intel+Pentium+G3220+%40+3.00GHz&id=2020
http://www.cpubenchmark.net/cpu.php?cpu=AMD+Athlon+X4+640&id=215
http://www.cpubenchmark.net/cpu.php?cpu=Intel+Pentium+G3220+%40+3.00GHz&id=2020
324 �F,,�E�L�́M�E,,�j��-�������F2014/01/14(��) 20:32:10.19 ID:PBzJA1XS
Llano��GPU�����ł����������B
���������Ɍ�����̂́A�}�U�[�{�[�h���ɃI���{�[�hGPU���Ȃ���
�f�B�X�N���[�gGPU�K�{���������炻�̕�CPU������������Ȃ������Ƃ���
�}�[�P�e�B���O��̗��R�B
�ǂ����̃X���̕n�R��������Ȃ����ǁA����قǏd�����Q�[���Ƃ����Ȃ��Ȃ�
�lj���GPU�s�v���Ă��Ƃ����������Pentium�ł��\�����i�Ȃ�̉��l�͂��邩�ƁB
���������Ɍ�����̂́A�}�U�[�{�[�h���ɃI���{�[�hGPU���Ȃ���
�f�B�X�N���[�gGPU�K�{���������炻�̕�CPU������������Ȃ������Ƃ���
�}�[�P�e�B���O��̗��R�B
�ǂ����̃X���̕n�R��������Ȃ����ǁA����قǏd�����Q�[���Ƃ����Ȃ��Ȃ�
�lj���GPU�s�v���Ă��Ƃ����������Pentium�ł��\�����i�Ȃ�̉��l�͂��邩�ƁB
���̃��X�������Ă那
Athlon X4 640��Llano����Ȃ��ł����ALlano��3�N�O�͂܂���������Ă܂��A
�}�U�[�{�[�h���ɃI���{GPU���t���Ă܂������ǂ�(880G��890GX��)�B
Athlon X4 640��Llano����Ȃ��ł����ALlano��3�N�O�͂܂���������Ă܂��A
�}�U�[�{�[�h���ɃI���{GPU���t���Ă܂������ǂ�(880G��890GX��)�B
326 �F,,�E�L�́M�E,,�j��-�������F2014/01/14(��) 20:58:01.48 ID:PBzJA1XS
Propus�̂ق����B
�c�q����AHSA���Ė{�i�I�ɂȂ���Ȃ�p�t�H�[�}���X�o�������H
328 �F,,�E�L�́M�E,,�j��-�������F2014/01/14(��) 22:52:16.43 ID:PBzJA1XS
�u��������GPGPU���ĉ��Ɏg����́H�v�Ƃ������{�I�Ȗ�肪����̂�ˁB
����3�N�ԃR�X�g�p�t�H�[�}���X�͕ς���ĂȂ����Ă��Ƃ�
��͂�ꋭ��Ԃ͗ǂ��Ȃ���
PC�̔����������i�܂Ȃ��Ȃ�Č����邯�ǂ��ꂶ�ᔃ��������Ӗ��Ȃ����
��͂�ꋭ��Ԃ͗ǂ��Ȃ���
PC�̔����������i�܂Ȃ��Ȃ�Č����邯�ǂ��ꂶ�ᔃ��������Ӗ��Ȃ����
>>328
����A�����A���ꂪ��ԑ傫����肾�Ǝv����
����A�����A���ꂪ��ԑ傫����肾�Ǝv����
���������ăR�X�g�p�t�H�[�}���X�ƌ����Ă�̂��͒m��ǁA
�������N�Ō����Ȃ�בւ̕ϓ����傫�������̂͂���
�������N�Ō����Ȃ�בւ̕ϓ����傫�������̂͂���
�n�[�h�E�F�A�A�\�t�g�E�F�A(�܃R���p�C����v���O���})�A���p�҂ƁA�ǂꂪ��Ȃ̂���Ȃ̂��B
��Cell-BE�Ɋ��҂��ē������Ďg������ŕ���������
��Cell-BE�Ɋ��҂��ē������Ďg������ŕ���������
333 �F,,�E�L�́M�E,,�j��-�������F2014/01/14(��) 23:27:32.22 ID:PBzJA1XS
CPU��GPU�̕����I�������k�߂邱�ƂŁA������GPGPU�ł͂ł��Ȃ�����
�A�v���P�[�V�����������ł���Ƃ��]�X�����
���������ӌ������сA���x���������ƌ��킹��Ȃ��Ďv���킯��
�u����CPU������SIMD���j�b�g���������ق���������ˁH�v
�A�v���P�[�V�����������ł���Ƃ��]�X�����
���������ӌ������сA���x���������ƌ��킹��Ȃ��Ďv���킯��
�u����CPU������SIMD���j�b�g���������ق���������ˁH�v
SIMD�̓I�[�o�[�w�b�h�[���ǂ��납�A�X�[�p�[���j�A������˂�
�ł��v���O���}�u������Ȃ���
�r�b�O�R�A�ƃX���[���R�A��K���ɕ��ׂ�x86��CELL�}�_�[�H
�x�����Ă���Broadwell���������������Ȃ�Ƃ����b������炵��
�����܂�̉��P�͒x��Ă��Ă��}�s�b�`�Ői��ł����悤������A
�����x����߂�����x�ɂȂ����̂���
���̗��ꂾ��Haswell�Ɠ������A6����COMPUTEX�Ő������\���낤��
Intel May Introduce First �gBroadwell�h Chips in Q3
http://www.xbitlabs.com/news/cpu/display/20140113225621_Intel_May_Introduce_First_Broadwell_Chips_in_Q3_Report.html
�����܂�̉��P�͒x��Ă��Ă��}�s�b�`�Ői��ł����悤������A
�����x����߂�����x�ɂȂ����̂���
���̗��ꂾ��Haswell�Ɠ������A6����COMPUTEX�Ő������\���낤��
Intel May Introduce First �gBroadwell�h Chips in Q3
http://www.xbitlabs.com/news/cpu/display/20140113225621_Intel_May_Introduce_First_Broadwell_Chips_in_Q3_Report.html
>>335
?
?
>>333-334
�ł�GPGPU�͍��ш惁�������g���闘�_�������
�܂�kaveri��iGPU�����烁�����o���h��������SIMD�ł������I�Ȋ���������
�ł�GPGPU�͍��ш惁�������g���闘�_�������
�܂�kaveri��iGPU�����烁�����o���h��������SIMD�ł������I�Ȋ���������
>>333
�u��剻����GPU�����������Ȃ����瑼�̗p�r�ɂ��g�������v���Ă̂����������̓��@�ł���
�u��剻����GPU�����������Ȃ����瑼�̗p�r�ɂ��g�������v���Ă̂����������̓��@�ł���
�ł�iGPU�ŋ���intel�Ȃ���
http://pc.watch.impress.co.jp/docs/column/hothot/20140115_630555.html
http://pc.watch.impress.co.jp/docs/topic/review/20140114_630739.html
�����n��1920x1080
Core i5-4670R�F4140
A10-7850K�F3042
A10-7850K
http://pc.watch.impress.co.jp/docs/column/hothot/20140115_630555.html
http://pc.watch.impress.co.jp/docs/topic/review/20140114_630739.html
�����n��1920x1080
Core i5-4670R�F4140
A10-7850K�F3042
A10-7850K
>>341
FF��Fire Strike��������Ă邼
FF��Fire Strike��������Ă邼
MMX�ł��Ȃ�classic Pentium�ƌ����CPentium 120MHz�}�V�������Ƀv���X�R�̔��M���Ղ肪��������܂����Ă�
2004�N5���܂Ŏg�������Ă��ȡ
���̃��C���}�V���͓̉��͎���10�N�����Č������
2004�N5���܂Ŏg�������Ă��ȡ
���̃��C���}�V���͓̉��͎���10�N�����Č������
GPGPU�́A�V���O���m�[�h�̃x�N�g���^�X�p�R���̑�ւ��ł�����
��{�I�Ƀx�N�g���^�X�p�R���́A�Ƃɂ������C���������𑁂����āA
CPU�̓������ш�����邾���̐��\����������I�ȍl��
�������𑬂����āA�V�F�[�_�[�̓������ш�����邾���̐��\���������GPU�Ƃ�������
���傤�ǃv���O���}�u���V�F�[�_�[�����Ĉȍ~��GPU���A�V���O���m�[�h�̃x�N�g���^�X�p�R����
��R�X�g�ȑ�p�i�ɂȂ邱�Ƃ��킩�����̂ŁA���������ʂ�nvidia���J��
��{�I�Ƀx�N�g���^�X�p�R���́A�Ƃɂ������C���������𑁂����āA
CPU�̓������ш�����邾���̐��\����������I�ȍl��
�������𑬂����āA�V�F�[�_�[�̓������ш�����邾���̐��\���������GPU�Ƃ�������
���傤�ǃv���O���}�u���V�F�[�_�[�����Ĉȍ~��GPU���A�V���O���m�[�h�̃x�N�g���^�X�p�R����
��R�X�g�ȑ�p�i�ɂȂ邱�Ƃ��킩�����̂ŁA���������ʂ�nvidia���J��
346 �FSocket774�F2014/01/15(��) 17:58:12.59 ID:HrzuAIXI
950�����E�E�Eskylake�܂ł����Ă��ꗊ�ށE�E�E
>>345
�C���X�g���N�V�����Z�b�g�������Ɠ��ꂳ��Ă�Έ����p�����邯�ǁA2��ނ̈ӎv�������̂͑�ςł��B
x86�ł�CELL���ǂ��Ɋ��҂��Ă܂��B
�C���X�g���N�V�����Z�b�g�������Ɠ��ꂳ��Ă�Έ����p�����邯�ǁA2��ނ̈ӎv�������̂͑�ςł��B
x86�ł�CELL���ǂ��Ɋ��҂��Ă܂��B
�H
Intel will pay $1.5 billion in Nvidia settlement
http://www.guru3d.com/news_story/intel_will_pay_1_5_billion_in_nvidia_settlement.html
Intel will pay $1.5 billion in Nvidia settlement
http://www.guru3d.com/news_story/intel_will_pay_1_5_billion_in_nvidia_settlement.html
>>348
�����A�����iGPU�����̂��߂̕ی��B�ٔ���Ƃ������E�E�E�B
�����A�����iGPU�����̂��߂̕ی��B�ٔ���Ƃ������E�E�E�B
���N���O�ɂ�����ٔ��̌��ʂ���邩��
�܂�����������Ă��Ƃ���
nvidia�͑��ς�炸x86�Ƀ^�b�`�ł��Ȃ��݂���������
�܂�����������Ă��Ƃ���
nvidia�͑��ς�炸x86�Ƀ^�b�`�ł��Ȃ��݂���������
���������炘86�ɂ͗��Ȃ��ł����������Ċ�����
ARM�݂����Ƀ��C�Z���X��������̂�
�Ȃ�ł������Ȃ�x86��r���I�ɂ��悤�Ƃ����
�Ȃ�ł������Ȃ�x86��r���I�ɂ��悤�Ƃ����
intel��x86�̐v��̗D�ʐ��͉��x����������Ă�����
���i�Ƃ��Ă͐��Y�͂ʼn������ăg�b�v���ێ����Ă���
���C�Z���X����Ȃ�Ď������痘�_���������AMD����VIA����
���邢��ARM��PowerPC�Ɠ������x���ɍ~��Ă������ƂɂȂ�
���i�Ƃ��Ă͐��Y�͂ʼn������ăg�b�v���ێ����Ă���
���C�Z���X����Ȃ�Ď������痘�_���������AMD����VIA����
���邢��ARM��PowerPC�Ɠ������x���ɍ~��Ă������ƂɂȂ�
Quark? �Ӂ[��A�����ˁB���C�Z���X�����Ȃ���? ����A�v��Ȃ��B�����Ă�����IP�ATSMC�p������B
�ĂȂ邩��˂��A����SoC����́BCPU�`�b�v�P�̔��肶��Ȃ��Ɛ������Ȃ��r�W�l�X�����܂ł����������Ă���B
�ĂȂ邩��˂��A����SoC����́BCPU�`�b�v�P�̔��肶��Ȃ��Ɛ������Ȃ��r�W�l�X�����܂ł����������Ă���B
Quark�֘A�ŁA������x86�v���Z�b�T�͂��낻���������Ă��邩��
�I�[�v���������̂ł͂Ƃ����ϑ����������C�͂���
�I�[�v���������̂ł͂Ƃ����ϑ����������C�͂���
356 �F,,�E�L�́M�E,,�j��-�������F2014/01/15(��) 20:05:35.78 ID:eC8fveDT
Renesas��M16C��RX��IP���肶��Ȃ���
Intel�͂ނ���IP���Ă���SoC��v���鑤���낤
����Fab�̐������\�[�X�߂Ȃ��Ⴂ���Ȃ��̂�
�킴�킴���Ѓt�@�E���h���������i�Ɏ���IP�𗬂��Ă��̂�
����͂���Ő헪�Ƃ��Ă͂܂����B
Intel�͂ނ���IP���Ă���SoC��v���鑤���낤
����Fab�̐������\�[�X�߂Ȃ��Ⴂ���Ȃ��̂�
�킴�킴���Ѓt�@�E���h���������i�Ɏ���IP�𗬂��Ă��̂�
����͂���Ő헪�Ƃ��Ă͂܂����B
����Ă�̃X���͕��a����
358 �F,,�E�L�́M�E,,�j��-�������F2014/01/15(��) 20:46:26.64 ID:eC8fveDT
���Galileo����ʔ������ꂽ�Ƃ����̂ɂ��܂���Ƃ�����E�E�E
�܂��������������Ɏg���̂��悭�킩���B
�܂��������������Ɏg���̂��悭�킩���B
�l�I�ɂ�Arduino�Ƃ��̐���オ��͂�����ƕ������̂�
Galileo������܂薣�͓I�Ɋ����Ȃ�
Edison�͂Ƃ肠�����ʔ������B���ꂮ�炢�ɒ[�ɂȂ�ƁA�������p���l���Ă݂����Ȃ�
Galileo������܂薣�͓I�Ɋ����Ȃ�
Edison�͂Ƃ肠�����ʔ������B���ꂮ�炢�ɒ[�ɂȂ�ƁA�������p���l���Ă݂����Ȃ�
>>358
�c�q����A�����S�[�O�������B
�c�q����A�����S�[�O�������B
Intel��TSMC�͐�Atom��SoC���Y�Œ�g���Ă����
�ڋq���t�����Ɉ�N���x�Œׂꂽ�݂���������
�ڋq���t�����Ɉ�N���x�Œׂꂽ�݂���������
Intel����x86 CPU�ł͂ƂĂ��Ȃ����\������ێ����Ă邯�ǁA
����ȊO���āA������������˥����
���AIris Pro�͂�����Ɗ������������B
����ȊO���āA������������˥����
���AIris Pro�͂�����Ɗ������������B
����͌�N�U��Ԃ��Ă݂�Ɠk�Ԃ������ƌ���ꂻ���ȋC�����邯��
>>362
NIC�́H
NIC�́H
365 �F,,�E�L�́M�E,,�j��-�������F2014/01/15(��) 22:06:30.19 ID:eC8fveDT
�Ă̒�LuxMark�Ƃ���CPU+GPU�������\�𑪂��x���`�}�[�N�ł�
Core i3��Kaveri�������Ă�悤�����ǁA�Ԃ����Ⴏ���b�AiGPU�ł�GPGPU���p
���Ă̂́A�ėp�������̐�ΓI�ȑш�s���������ɂ��ĕ₤���ɂ������Ă�킯�ŁB
CPU�Ɠ��������ő�̗��_�́ACPU�̃L���b�V�����߂����ƁB
HD4600��L3�L���b�V���ʼn��Z���ʂ��o�b�t�@�����O���Ă邩�瑬���B
�i���C�g�����ăL���b�V����������ˁj
AMD�͂���������������Ԃ������̂ɂȂ�CPU���̃L���b�V�����g��Ȃ��̃��@�J�Ȃ́H�ƁB
�i�t�ɂȂ������Ă邩���̌������f�l�ڂɂ��킩��ƑΏ����悤������킯�Łj
Core i3��Kaveri�������Ă�悤�����ǁA�Ԃ����Ⴏ���b�AiGPU�ł�GPGPU���p
���Ă̂́A�ėp�������̐�ΓI�ȑш�s���������ɂ��ĕ₤���ɂ������Ă�킯�ŁB
CPU�Ɠ��������ő�̗��_�́ACPU�̃L���b�V�����߂����ƁB
HD4600��L3�L���b�V���ʼn��Z���ʂ��o�b�t�@�����O���Ă邩�瑬���B
�i���C�g�����ăL���b�V����������ˁj
AMD�͂���������������Ԃ������̂ɂȂ�CPU���̃L���b�V�����g��Ȃ��̃��@�J�Ȃ́H�ƁB
�i�t�ɂȂ������Ă邩���̌������f�l�ڂɂ��킩��ƑΏ����悤������킯�Łj
HSA���T�|�[�g�������炵�����炻���ł܂��]������Ηǂ���LuxMark
luxmark�̓J�^���O�X�y�b�N�ɋ߂��f�[�^�o�����
�����s�[�N���\�̍���intel�̕����������
AMD�͈ꕔ��opencl�n�x���`age���Ă�����
�܂��꒷��Z�����������ʔ�������
�����s�[�N���\�̍���intel�̕����������
AMD�͈ꕔ��opencl�n�x���`age���Ă�����
�܂��꒷��Z�����������ʔ�������
368 �F,,�E�L�́M�E,,�j��-�������F2014/01/15(��) 22:35:08.38 ID:eC8fveDT
����AKaveri�������Ă�̂�Iris Pro(GT3e)����Ȃ��ăJ�^���O�X�y�b�N������
HD4600(GT2)�̂ق��B
Kaveri��720MHz�����732GFLOPS�������Ai3������HD4600��
1.15GHz����ŗ��_�l�ł�400GFLOPS���x�ɂ����Ȃ��B
HD4600(GT2)�̂ق��B
Kaveri��720MHz�����732GFLOPS�������Ai3������HD4600��
1.15GHz����ŗ��_�l�ł�400GFLOPS���x�ɂ����Ȃ��B
AMD�̂��L���b�V���g���ĂȂ����ă}�W�H
���ق��Ⴄ����
���ق��Ⴄ����
GT3e�ɏ��Ă�̂�GT750M�ȏゾ��
����rMBP15������������ؖ����Ă���
AMD��CPU/iGPU��Intel�̂���������Ă���Ȃ���Apple���̗p����
Mac Pro��FireGL�̃J�X�^���i�����ȁAApple�͂��̕Ӓ������I�ł�����肪����
����rMBP15������������ؖ����Ă���
AMD��CPU/iGPU��Intel�̂���������Ă���Ȃ���Apple���̗p����
Mac Pro��FireGL�̃J�X�^���i�����ȁAApple�͂��̕Ӓ������I�ł�����肪����
����႟�AHSA�����Ҕ����ȥ���B
AMD�A���ɂᎸ�]�����楥��B
AMD�A���ɂᎸ�]�����楥��B
����͔��������Ȃ�GT3e���f�����撣���ĕ]�����Ă����������
���̂���Intel�Ɏ��]������
�Ȃ�Ŏ�����̂Ă���
���̂���Intel�Ɏ��]������
�Ȃ�Ŏ�����̂Ă���
373 �F,,�E�L�́M�E,,�j��-�������F2014/01/15(��) 22:57:27.59 ID:eC8fveDT
�����烁������Ԃ��_���I�ɂЂƂɂȂ��Ă��L���b�V�������p���Ȃ���
�f�[�^�����Ƃ肷��̂�CPU����������GPU�Ɩ��ʂȃt���[����������
��������ԓ����̃����b�g�]�X���`�����Ȃ̂ł��B
�f�[�^�����Ƃ肷��̂�CPU����������GPU�Ɩ��ʂȃt���[����������
��������ԓ����̃����b�g�]�X���`�����Ȃ̂ł��B
Iris Pro��eDRAM������������ł��Ȃ撣���Ă銴������
375 �F,,�E�L�́M�E,,�j��-�������F2014/01/15(��) 23:25:58.16 ID:eC8fveDT
Intel��GPU�����ɍœK�����Ă邱�Ƃ��������Ă�Q�[����Civ5���炢����
�m��Ȃ����A�ʂ����Ă��ꂩ������Ƒ�����̂��낤��
�m��Ȃ����A�ʂ����Ă��ꂩ������Ƒ�����̂��낤��
Intel�́AAVX2��gather�������Ƃ����Ă����A�����ǂ��ł�������
iGPU��DX11.2�t���Ή��A
PCH��eDRAM�̃_�C�����͂�I�I
PCH��eDRAM�̃_�C�����͂�I�I
>>375
�e�X�g�p�̃n�[�h�E�F�A�Ƃ��ē���m�F����f�x���b�p�͑������Ȃ��낤��
�œK���Ƃ��ȑO�ɁA��������������t�B�[�h�o�b�N������̂͗L�v���Ǝv��
�e�X�g�p�̃n�[�h�E�F�A�Ƃ��ē���m�F����f�x���b�p�͑������Ȃ��낤��
�œK���Ƃ��ȑO�ɁA��������������t�B�[�h�o�b�N������̂͗L�v���Ǝv��
379 �F,,�E�L�́M�E,,�j��-�������F2014/01/16(��) 09:00:00.87 ID:Jrwr+BE3
�v���C�}���Ƃ��Ďg�����ǂ����͂Ƃ������Ƃ���
LGA2011�ȊO�̂��ׂĂ�PC����Intel�v���Z�b�T�Ŏg����Ƃ����Ӗ��͂ł�����ȁB
Windows�^�u���b�g���ƕK�R�I��90%�ȏ�̃V�F�A�ɂȂ邵�B
AMD�̐V�����X�V���ꂽ�œK���}�j���A���ǂ����Ȃ�ނ�����
�iCarrizo����Ŏ��������AVX2������128�r�b�g���������Ƃ������ˁE�E�E�j
LGA2011�ȊO�̂��ׂĂ�PC����Intel�v���Z�b�T�Ŏg����Ƃ����Ӗ��͂ł�����ȁB
Windows�^�u���b�g���ƕK�R�I��90%�ȏ�̃V�F�A�ɂȂ邵�B
AMD�̐V�����X�V���ꂽ�œK���}�j���A���ǂ����Ȃ�ނ�����
�iCarrizo����Ŏ��������AVX2������128�r�b�g���������Ƃ������ˁE�E�E�j
�������Ă邪�A�v���O�����̊J�����̓v�A�ȕ��������B
���̂ق����p�C���f�J�C���炾�B
�J�������x���Ƃ������Ă�z�͏o�ׂ��B
���̂ق����p�C���f�J�C���炾�B
�J�������x���Ƃ������Ă�z�͏o�ׂ��B
381 �FSocket774�F2014/01/16(��) 14:53:43.46 ID:+Ni0Ihul
>>365
�����_�����O�Ȃ�gpgpu�ɂ�点��Cpu�͕ʂ̍�ƂɎg������
Apu�Ȃ�}���`�^�X�N�œ����i�s�ł����
�C���e����Cpu�����_�����O�����牽���o���Ȃ�w
���ł�CF���g���邩���
�����_�����O�Ȃ�Apu���ŋ�����
�����_�����O�Ȃ�gpgpu�ɂ�点��Cpu�͕ʂ̍�ƂɎg������
Apu�Ȃ�}���`�^�X�N�œ����i�s�ł����
�C���e����Cpu�����_�����O�����牽���o���Ȃ�w
���ł�CF���g���邩���
�����_�����O�Ȃ�Apu���ŋ�����
382 �FSocket774�F2014/01/16(��) 14:59:20.91 ID:+Ni0Ihul
>>347
����ISA�ׂ̈�HSA������
����ISA�ׂ̈�HSA������
�c�q��������ɂ��Ă���̂��A�Ƃ����b
�v���O���}�ł���AJava���f����write once�`�̗��z��
�ǂ̒��x�����������m���Ă���͂��ŁA�听���������z��HSA��
�܂����ꂮ�炢���Ǝv������
�v���O���}�ł���AJava���f����write once�`�̗��z��
�ǂ̒��x�����������m���Ă���͂��ŁA�听���������z��HSA��
�܂����ꂮ�炢���Ǝv������
�����ōD���ȃ��[�J�[�̍D���ȃv���W�F�N�g��I�ׂ���ꂢ���̂��낤��
�����͌ق��ŏォ��w�����ꂽ���Ƃ����Ȃ����������A�����Ɏ����̈ӎu�͉�݂��Ȃ���
���z����т͐H����A�����͋�s��������Ȃ̂�
�����͌ق��ŏォ��w�����ꂽ���Ƃ����Ȃ����������A�����Ɏ����̈ӎu�͉�݂��Ȃ���
���z����т͐H����A�����͋�s��������Ȃ̂�
�V�K�ɗ����グ��\�肾����14nm��fab�̈���g��ꂸ�ɕ��u����邱�ƂɂȂ����炵��
����ȂɎ��v�̌��ʂ��������̂���
http://www.reuters.com/article/2014/01/14/us-intel-arizona-idUSBREA0D1F920140114
����ȂɎ��v�̌��ʂ��������̂���
http://www.reuters.com/article/2014/01/14/us-intel-arizona-idUSBREA0D1F920140114
450mm�E�F�n�[���ɂ��É_���������߂܂���
���Y�ʂ�2�{�ɂȂ�����ғ���������܂���
�����t�@�E���h�����Ƃɖ{�������ă��C�����߂Ȃ��ƐԎ����ꗬ����Ԃ�
���Y�ʂ�2�{�ɂȂ�����ғ���������܂���
�����t�@�E���h�����Ƃɖ{�������ă��C�����߂Ȃ��ƐԎ����ꗬ����Ԃ�
450mm���Ńg�����W�X�^�ӂ�̃R�X�g�͉�����̂ŁA
�ғ�����ۂƂ����ϓ_�ł���A�P�ɓ]������t�@�u�����邾�����Ǝv��
�����ƌ����Ƃ��������_�C�T�C�Y�͏k���X���ɂ���̂ɁA
22nm����̓t�@�u������������������
�ғ�����ۂƂ����ϓ_�ł���A�P�ɓ]������t�@�u�����邾�����Ǝv��
�����ƌ����Ƃ��������_�C�T�C�Y�͏k���X���ɂ���̂ɁA
22nm����̓t�@�u������������������
14nm�ɂ��Ă��A���ς�炸���\����̖ڏ��������Ȃ����疳�ʂƔ��f������[��
�Ⴆ14nm�ő����̃R�X�g�_�E�����ł����Ƃ��Ă��A���ꂪ����グ����Ɋ�^����Ƃ͎v����
���\���オ�o���Ȃ�����W���n�ɂȂ�̔������Ȃ��B
�Ⴆ14nm�ő����̃R�X�g�_�E�����ł����Ƃ��Ă��A���ꂪ����グ����Ɋ�^����Ƃ͎v����
���\���オ�o���Ȃ�����W���n�ɂȂ�̔������Ȃ��B
���E���Ŏ����^�]�ԊJ�����n�܂������A
�����\CPU����ʂɕK�v�ɂȂ邩�炢����Ȃ��̂��ˁH
���Y�̎В�������̃_�C�̏��^���Ɋ��҂��Ă���Ƃ��b���Ă��B
�����\CPU����ʂɕK�v�ɂȂ邩�炢����Ȃ��̂��ˁH
���Y�̎В�������̃_�C�̏��^���Ɋ��҂��Ă���Ƃ��b���Ă��B
�����Ԃ̃}�C�R���Ɏg���v���Z�T���Ăǂ�Ȃ���Ȃ�
�����Ԋ֘A�̃V�X�e���J���͒n�����݂�邼
���ƃ}�W��
���ƃ}�W��
�J�[�i�r�͂قƂ��ARM�݂��������ǁA�Ԃ̐���n��ARM�͂���قǂł͂Ȃ�
MIPS�������Ƃ����b�����N���������������
MIPS�������Ƃ����b�����N���������������
�͂�Ă���MIPS����R10000�V���[�Y�Ƃ�����
�p�C�v���C���i�������V���v���Ŏg���₷���̂���
�p�C�v���C���i�������V���v���Ŏg���₷���̂���
�ԍڂ�Power��SH����Ȃ���
����������Ƃ�������������
����n��ARM���ア���ĕ����ȊO�悭�o���ĂȂ���
����n��ARM���ア���ĕ����ȊO�悭�o���ĂȂ���
�X�}�z�o�u�������낻��I��肻�������Ȃ��c
Intel does ARM: Citi 'identifies' another possible customer
Marvell is cited as a likely chip customer for Intel. If the analysis pans out, it would be Intel's third ARM customer.
http://news.cnet.com/8301-1001_3-57617310-92/intel-does-arm-citi-identifies-another-possible-customer/
Marvell is cited as a likely chip customer for Intel. If the analysis pans out, it would be Intel's third ARM customer.
http://news.cnet.com/8301-1001_3-57617310-92/intel-does-arm-citi-identifies-another-possible-customer/
401 �FSocket774�F2014/01/16(��) 23:56:40.90 ID:6j7WYthe
Intel�l�������l�ނ̖������J����B��_
�S�l�ނ�Intel�l�̉��ɕ�����Intel�l�����𐒔q��
Intel�l�ɑS�Ă������ׂ��ł���
Intel�l���I�I�I�I�I
�S�l�ނ�Intel�l�̉��ɕ�����Intel�l�����𐒔q��
Intel�l�ɑS�Ă������ׂ��ł���
Intel�l���I�I�I�I�I
���̐��E��2010�N�͏�Â����邩������Ȃ���
>�Ƃɂ����v���Z�b�T�ƌĂ����̂̎s��͂��ׂĂЂ�����߂�ƁA�T��150����/�N
>���̂���MCU�ɃJ�e�S���������̂�45����
>20��ވȏ�̃A�[�L�e�N�`��������
>ARM�͂������������ɐV����MCU�����̐��i�𓊓����邱�ƂŁA
>����A�[�L�e�N�`���ōL�����p�ł��邱�Ƃ�ژ_��ł���킯�����A
>����A�[�L�e�N�`���ƌ����Ă����ۂɂ�ARM�̃R�A���g�����\��ނ�����
ttp://news.mynavi.jp/articles/2010/09/21/ftfj2010_keynote/002.html
>�Ƃɂ����v���Z�b�T�ƌĂ����̂̎s��͂��ׂĂЂ�����߂�ƁA�T��150����/�N
>���̂���MCU�ɃJ�e�S���������̂�45����
>20��ވȏ�̃A�[�L�e�N�`��������
>ARM�͂������������ɐV����MCU�����̐��i�𓊓����邱�ƂŁA
>����A�[�L�e�N�`���ōL�����p�ł��邱�Ƃ�ژ_��ł���킯�����A
>����A�[�L�e�N�`���ƌ����Ă����ۂɂ�ARM�̃R�A���g�����\��ނ�����
ttp://news.mynavi.jp/articles/2010/09/21/ftfj2010_keynote/002.html
�m�s�s�h�R��:�V�n�r�u�^�C�[���v�X�}�z�����ʌ�����
http://mainichi.jp/select/news/20140117k0000m020010000c.html
http://mainichi.jp/select/news/20140117k0000m020010000c.html
�gBayTrail-D�h���ƁuCeleron J1900�v���ڃ}�U�[�{�[�h������
http://ascii.jp/elem/000/000/858/858375/
3��4680�~���Ęb���Ⴄ����
������Ȃ������́H
http://ascii.jp/elem/000/000/858/858375/
3��4680�~���Ęb���Ⴄ����
������Ȃ������́H
�ǂ����Ă�Supermicro�̃T�[�o�[�O���[�h���i�Ȃ킯��
BayTrail����Ȃ��ă}�U�[������
BayTrail����Ȃ��ă}�U�[������
����͂ǂ����Ă��I�O���[�h����Ȃ���
�����o�Ă邵
akiba-pc.watch.impress.co.jp/docs/news/news/20131112_623292.html
���������i��56,980�~
�����o�Ă邵
akiba-pc.watch.impress.co.jp/docs/news/news/20131112_623292.html
���������i��56,980�~
ATM�⌔���@�ɓ����^�C�v�̐��i�Ɍ�����
���[�v����ɍ����i���Ă��ƁB�Ƃ��������Ɉ������Ă���낤���c�c
�����Ԃ��āA�N���e�B�J���ȕ����Ə��n�͕ʃ`�b�v�g���Ă邵��
�N���e�B�J���ȕ����́AITRON+���l�T�X�̃`�b�v�A
���n��ARM�Ƃ�
ECU�Ƃ��M�A����E�G�A�o�b�O����Ƃ��́AITRON+���l�T�X������������ˁH
���n��ARM�Ƃ�ATOM�Ƃ��AOS��Android�Ƃ�Linux�Ƃ�Windows�Ƃ��������ȗ\��
�N���e�B�J���ȕ����́AITRON+���l�T�X�̃`�b�v�A
���n��ARM�Ƃ�
ECU�Ƃ��M�A����E�G�A�o�b�O����Ƃ��́AITRON+���l�T�X������������ˁH
���n��ARM�Ƃ�ATOM�Ƃ��AOS��Android�Ƃ�Linux�Ƃ�Windows�Ƃ��������ȗ\��
�܂��J�[�i�r�̕��ׂ��d���Ƃ��̓u���[�L�A�V�X�g���x���Ȃ�Ƃ����።����
�g�ݍ��݂͑S��������ǁA
�n�[�h���A���^�C���ȕ�����Atom+VxWorks�Ƃ����蓾��낤��
�n�[�h���A���^�C���ȕ�����Atom+VxWorks�Ƃ����蓾��낤��
>>411
Atom�̃R�A���̂��̂�RAS�v���K�p����Ă��邩�ǂ������낤�ˁB
Renesas�͎����ԉ��̓����d�l�������Ď��ꎩ���ɂȂ����Ƃ��낪����B
�Ƃ������A�g���^����Fub�����ĂȂ����������H���̂Ƃ���IGBT����Ă邾��������
Renesas�����̏��Ǝ��А��Y�����˂Ȃ��B
Atom�̃R�A���̂��̂�RAS�v���K�p����Ă��邩�ǂ������낤�ˁB
Renesas�͎����ԉ��̓����d�l�������Ď��ꎩ���ɂȂ����Ƃ��낪����B
�Ƃ������A�g���^����Fub�����ĂȂ����������H���̂Ƃ���IGBT����Ă邾��������
Renesas�����̏��Ǝ��А��Y�����˂Ȃ��B
���l�T�X�͋��N�������N�̏t�����TSMC�ō��Ƃ������Ă��C�����邪
�l�Ԃ̔]�ɑ�]�Ə��]�ł��ꂼ����������悤�ɁA
���A���^�C�������ƔA���^�C���������P�̃u���b�N�Řd���Ƃ����͓̂���悤�Ɏv���B
���A���^�C�������ƔA���^�C���������P�̃u���b�N�Řd���Ƃ����͓̂���悤�Ɏv���B
http://car.watch.impress.co.jp/docs/event_repo/CES2014/20140109_630162.html
�A�E�f�B�������^�]�p��Tegra K1�𓋍ڂ����Ԃ\
�A�E�f�B�������^�]�p��Tegra K1�𓋍ڂ����Ԃ\
>>409
����ǂ�����?
�v���E�X���n�b�L���O���ꂽ����A
����Í����@�\�����ڂ���Ă�����Ȃ����ȁB
ttp://techon.nikkeibp.co.jp/article/COLUMN/20140114/327061/?rt=nocnt
ttp://jp.reuters.com/article/mostViewedNews/idJPTYE96S04820130729
����ǂ�����?
�v���E�X���n�b�L���O���ꂽ����A
����Í����@�\�����ڂ���Ă�����Ȃ����ȁB
ttp://techon.nikkeibp.co.jp/article/COLUMN/20140114/327061/?rt=nocnt
ttp://jp.reuters.com/article/mostViewedNews/idJPTYE96S04820130729
�����^�]�̎��ォ
�Ԍɓ���ƁA�c�ԂƂ�����ɂ���Ă�����Ȃ�
���̊ԃh���C�o�͉ƂƂ��X�ɍs���Ă��������
�Ԍɓ���ƁA�c�ԂƂ�����ɂ���Ă�����Ȃ�
���̊ԃh���C�o�͉ƂƂ��X�ɍs���Ă��������
���Z�͂��������\�z�ʂ肾�����̂��ȁH
>>412
�d�͗p�����̂ƃ��W�b�N�`�b�v�͕ʕ�����
�d�͗p�����̂ƃ��W�b�N�`�b�v�͕ʕ�����
�����I�ɎГ��Ő��q���Ⴛ��������邾�낤�ȂƎv������낤��
Intel�A���o�C���ƃf�[�^�Z���^�[�������D����2�N�Ԃ�̑��v
http://www.itmedia.co.jp/news/articles/1401/17/news042.html
http://www.itmedia.co.jp/news/articles/1401/17/news042.html
>>420
�ŋ߂̉ƒ�p�Q�[���@�Ƃ��A���Ƃɕ�������Ď��R�ɂ������Ă��n�b�L���O�ł��Ȃ��悤�ɂȂ��Ă邶���
�����Ԃ����Ȃ��悤�ɂȂ��ˁH
�������A�����Ȃ�����ꕔ�̋Ǝ҂�����Ă�ECU�J�X�^�����EECU�����Ƃ���
�ł��Ȃ��Ȃ肻��
�ŋ߂̉ƒ�p�Q�[���@�Ƃ��A���Ƃɕ�������Ď��R�ɂ������Ă��n�b�L���O�ł��Ȃ��悤�ɂȂ��Ă邶���
�����Ԃ����Ȃ��悤�ɂȂ��ˁH
�������A�����Ȃ�����ꕔ�̋Ǝ҂�����Ă�ECU�J�X�^�����EECU�����Ƃ���
�ł��Ȃ��Ȃ肻��
�C���e���AIoT��14nm�ڍs�Ȃ�2014�N�̃r�W�l�X�ڕW���Љ�
�`�uPC�s��͑ΑO�N��Ő������A���艻�̒����v
http://pc.watch.impress.co.jp/docs/news/20140117_631188.html
�`�uPC�s��͑ΑO�N��Ő������A���艻�̒����v
http://pc.watch.impress.co.jp/docs/news/20140117_631188.html
424 �FSocket774�F2014/01/17(��) 15:06:06.16 ID:tv6iKjgn
�y���|�[�g�zTizen�̓��{�����ʉ������\�A�h�R���ɉ����������̂��H
http://news.mynavi.jp/articles/2014/01/16/tizenos/
�h�R���A�V�n�r�X�}�z�̔��\�ĉ����@�u�^�C�[���v�w�c�A�h��鎖�Ɖ�
http://www.sankeibiz.jp/business/news/140116/bsj1401160503000-n1.htm
���u�V���ȁg���ו��h�͕������Ȃ��v�i�m�s�s�O���[�v�����j
���������R�̂n�r�A�h�R���u�^�C�[���v�����̐^��
http://www.nikkei.com/article/DGXBZO65399160W4A110C1000000/
������C�O���[�J�[�W�Ҋ����́u�^�C�[���͕����g�̏W�܂�B(����) ���̃I�[�����Y���Ă���v�Ɛ�̂Ă�B
http://news.mynavi.jp/articles/2014/01/16/tizenos/
�h�R���A�V�n�r�X�}�z�̔��\�ĉ����@�u�^�C�[���v�w�c�A�h��鎖�Ɖ�
http://www.sankeibiz.jp/business/news/140116/bsj1401160503000-n1.htm
���u�V���ȁg���ו��h�͕������Ȃ��v�i�m�s�s�O���[�v�����j
���������R�̂n�r�A�h�R���u�^�C�[���v�����̐^��
http://www.nikkei.com/article/DGXBZO65399160W4A110C1000000/
������C�O���[�J�[�W�Ҋ����́u�^�C�[���͕����g�̏W�܂�B(����) ���̃I�[�����Y���Ă���v�Ɛ�̂Ă�B
TIZEN���܂Ƃ��ɂȂ��Ă���[���̗p������������
Android1.x�A2.x�݂����ȕs�ւ�OS��悤�Ȃ��Ƃ��Ȃ��Ă�������
Android1.x�A2.x�݂����ȕs�ւ�OS��悤�Ȃ��Ƃ��Ȃ��Ă�������
docomo ���̗p���ċ��o���Ȃ���i���ɂ܂Ƃ��ɂȂ���B�܂��o���Ă��Ȃ��̂����B
tizen�̖ڕW�͒Eandroid �݂̂Ȃ̂��ˁB
����Ƃ�����android�Ƃ͈قȂ�x�N�g��������̂�
����Ƃ�����android�Ƃ͈قȂ�x�N�g��������̂�
��Ɍ`�ɂȂ�Tizen�͎ԍڌ���������
Intel�I�ɂ�Atom�������Ȃ當��Ȃ��낤����A
�����O�ɔ��\��������Android�ł������̂�������Ȃ���
Intel�I�ɂ�Atom�������Ȃ當��Ȃ��낤����A
�����O�ɔ��\��������Android�ł������̂�������Ȃ���
���܂ɂ�TRON�̂��Ƃ��v���o���ĉ�����(�L�E�ցE�M)
>>424
��������E�B���h�E�Y�t�H���o����
��������E�B���h�E�Y�t�H���o����
431 �FSocket774�F2014/01/17(��) 19:59:06.84 ID:Vt0XwSYW
Tizen IVI�͂����n�V�S���O���Ȃ��Ƃ���܂ŗ��Ă���悤�ȋC�����邪�ATizen Mobile�����ɑ̂ȏ�
iOS in the Car��OAA(Android)�Ƌ�����u���ATizen IVI�ɒ��͂��Â���Ӗ��͂���̂��낤��
�˂��A�g���^����H
iOS in the Car��OAA(Android)�Ƌ�����u���ATizen IVI�ɒ��͂��Â���Ӗ��͂���̂��낤��
�˂��A�g���^����H
�ǂꂾ����₵�Ă������m�����܂ł̘J�͂Ɠ������l�������Ȃ��̂�����
�g���^�̋K�͂Ȃ瑼���̗p���Ȃ��Ă��S�������ł��s����ƍl���Ă�̂����m��Ȃ�
�܂��͓��{�l�����ӂ̐摗�肩���m���
���������JustInTime�ł��o�c���f�͂�������Ȃ������
�g���^�̋K�͂Ȃ瑼���̗p���Ȃ��Ă��S�������ł��s����ƍl���Ă�̂����m��Ȃ�
�܂��͓��{�l�����ӂ̐摗�肩���m���
���������JustInTime�ł��o�c���f�͂�������Ȃ������
���������o�c���f���ĐӔC���Ȃ��Ƃ����Ȃ�����N�ł��������ˁA�K�v�Ȃ��Ƃ�����
�ς���ς����Ď��s�̘A�������܂��ƍ���NEC�݂����ɂȂ����܂�
�ς���ς����Ď��s�̘A�������܂��ƍ���NEC�݂����ɂȂ����܂�
���𑱂��ĉ����~�߂邩�A�����҂ɂ͈ӊO�Ɏ����ł͂Ȃ���B����Ă�Œ��́B
�ォ��A�O���猩��ƈ�ڗđR�����ǁB
�ォ��A�O���猩��ƈ�ڗđR�����ǁB
�g���^�͎��s�������
Intel�X���I�ɂ͊��}���ׂ��W�J�Ȃ̂�������Ȃ�����
Intel�X���I�ɂ͊��}���ׂ��W�J�Ȃ̂�������Ȃ�����
>>434
����͂܂��Ɍ�m�b�Ƃ�����ł�����
����͂܂��Ɍ�m�b�Ƃ�����ł�����
437 �FSocket774�F2014/01/17(��) 20:48:49.69 ID:Vt0XwSYW
EETimes��2014�N�ԍڌ����s���\�z����L���Ŋ��S���������Tizen����
�A�g�i�ރX�}�z�ƎԍڃV�X�e���AAndroid�A�v����iOS�A�v���̐킢��
http://eetimes.jp/ee/articles/1312/25/news029.html
Tizen Association�ɎQ�����Ă���p�i�\�j�b�N�ł���Tizen IVI�̑��݂͎��O���Ă��邲�l�q
�p�i�\�j�b�N�AMozilla�ƒ�g����Firefox OS���ڂ̃X�}�[�gTV�J����
http://m.jp.techcrunch.com/2014/01/07/20140106panasonic-ffos-tvs/
�u�X�}�z�Ŏԑ���v�p�i�\�j�b�N���Z�p�J���@�P�U�N�ɂ����p��
http://www.sankeibiz.jp/smp/business/news/140106/bsa1401060502000-s.htm
���V�Z�p�́A�ăA�b�v���̃X�}�z�u���o���������v�A�ăO�[�O���̊�{�\�t�g�u�A���h���C�h�v���ڂ�
���X�}�z�ɑΉ�������B���łɎ����ԉ�Ђ̃e�X�g�R�[�X�Ȃǂ����p���Č����ɓ����Ă���B
�A�g�i�ރX�}�z�ƎԍڃV�X�e���AAndroid�A�v����iOS�A�v���̐킢��
http://eetimes.jp/ee/articles/1312/25/news029.html
Tizen Association�ɎQ�����Ă���p�i�\�j�b�N�ł���Tizen IVI�̑��݂͎��O���Ă��邲�l�q
�p�i�\�j�b�N�AMozilla�ƒ�g����Firefox OS���ڂ̃X�}�[�gTV�J����
http://m.jp.techcrunch.com/2014/01/07/20140106panasonic-ffos-tvs/
�u�X�}�z�Ŏԑ���v�p�i�\�j�b�N���Z�p�J���@�P�U�N�ɂ����p��
http://www.sankeibiz.jp/smp/business/news/140106/bsa1401060502000-s.htm
���V�Z�p�́A�ăA�b�v���̃X�}�z�u���o���������v�A�ăO�[�O���̊�{�\�t�g�u�A���h���C�h�v���ڂ�
���X�}�z�ɑΉ�������B���łɎ����ԉ�Ђ̃e�X�g�R�[�X�Ȃǂ����p���Č����ɓ����Ă���B
���s�������A��������TIZEN IVI�͌����_�ŋ�̓I�ȍ̗p�v���
���������킯��
�����n�����܂��Ă���ł��ǂ��Ƃł��Ȃ邶���
���N������������̂��̂Ɣ�r����Ӗ�������Ƃ��v����
������N�\�n�}��������A�b�v���̎ԍڂƂ��W���[�N�H
���������킯��
�����n�����܂��Ă���ł��ǂ��Ƃł��Ȃ邶���
���N������������̂��̂Ɣ�r����Ӗ�������Ƃ��v����
������N�\�n�}��������A�b�v���̎ԍڂƂ��W���[�N�H
439 �F,,�E�L�́M�E,,�j��-�������F2014/01/17(��) 23:26:31.74 ID:lNYi6oxZ
>>438
> ���s�������A��������TIZEN IVI�͌����_�ŋ�̓I�ȍ̗p�v���
> ���������킯��
�S�g���^�O���[�v��������
Atom�̗p���Č����Ă�����Ȃ��ł����I
�܂�x86�Ȃ�Windows Embedded�ł��ق��̑g�ݍ���Linux�ł�������킯�����ǁB
> ���s�������A��������TIZEN IVI�͌����_�ŋ�̓I�ȍ̗p�v���
> ���������킯��
�S�g���^�O���[�v��������
Atom�̗p���Č����Ă�����Ȃ��ł����I
�܂�x86�Ȃ�Windows Embedded�ł��ق��̑g�ݍ���Linux�ł�������킯�����ǁB
>>439
�܁A�m����Tizen IVI�̃f���ɂ͍̗p���ꂽ��˂�����
Tizen�ԍڋ@����̗p�m�肵���Ԏ���������ǂ�������
�Ԃ����Ⴏ�AOAA���܂�������������̉�݂���
�Z�p�����A��l�ɔF�߂����鎖�̂ق�����Փx��
�����̂ł͖�������
eetimes�Ŏ�����Ă����C���p�l��UI������ɕς���l��
���m���A�A������������ƔF�߂�Ƃ͓���v����
�܁A�m����Tizen IVI�̃f���ɂ͍̗p���ꂽ��˂�����
Tizen�ԍڋ@����̗p�m�肵���Ԏ���������ǂ�������
�Ԃ����Ⴏ�AOAA���܂�������������̉�݂���
�Z�p�����A��l�ɔF�߂����鎖�̂ق�����Փx��
�����̂ł͖�������
eetimes�Ŏ�����Ă����C���p�l��UI������ɕς���l��
���m���A�A������������ƔF�߂�Ƃ͓���v����
apple,google����������
���{�ԃ��[�J�����̂��ς�̓Ǝ��F�o�����߂�tizen�Ċ��������
���{�ԃ��[�J�����̂��ς�̓Ǝ��F�o�����߂�tizen�Ċ��������
���O�Ŏ����ĂȂ���AppleGoogle�̌����Ȃ�ɂȂ邵���Ȃ�����ˁB���̂��ς�ɂ͈Ӗ�������̂��B
443 �FSocket774�F2014/01/18(�y) 09:38:28.90 ID:r5HEL/EK
�����܂ł��C���e���ɂƂ��Ắu���O�v���낗
�g���^��Tizen IVI�ƐS�����鐨���œ˂�����̂͗���������̂������
http://www.ceatec.com/news/ja-webmagazine/j098
���C���e��������ԍڏ��@������v���b�g�t�H�[���uTizen IVI�v
http://www.turbolinux.com/products/tizen/
���T���X���d�q��C���e���Ђ��哱���Ă��܂��B
http://prtimes.jp/main/html/rd/p/000000004.000003830.html
��Tizen �́A�T���X���d�q��C���e���Ђ��哱����
http://diamond.jp/articles/-/47093?page=3
���C���e�������͂���C���t�H�e�C�������g�n�e���}�e�B�N�X��OS�uTizen IVI�v�B
���g���^�����p���Ɍ����ĐϋɓI�B
�g���^��Tizen IVI�ƐS�����鐨���œ˂�����̂͗���������̂������
http://www.ceatec.com/news/ja-webmagazine/j098
���C���e��������ԍڏ��@������v���b�g�t�H�[���uTizen IVI�v
http://www.turbolinux.com/products/tizen/
���T���X���d�q��C���e���Ђ��哱���Ă��܂��B
http://prtimes.jp/main/html/rd/p/000000004.000003830.html
��Tizen �́A�T���X���d�q��C���e���Ђ��哱����
http://diamond.jp/articles/-/47093?page=3
���C���e�������͂���C���t�H�e�C�������g�n�e���}�e�B�N�X��OS�uTizen IVI�v�B
���g���^�����p���Ɍ����ĐϋɓI�B
444 �FSocket774�F2014/01/18(�y) 09:50:06.38 ID:r5HEL/EK
�g���^����A
���X�N�}�l�W�����g�͂������肵�܂��傤�ˁI �i���^
http://www.oesf-global.com/jp/linux-foundation-��automotive-grade-linux-���[�L���O�O���[�v�̐ݗ��\/
��MeeGo�J�������ɓ���ƁAGE�ABMW�A�v�W���[�AIntel�Ȃǂ̑��Ƃ�
��������GENIVI Alliance��ݗ��AMeeGo��IvI�̊J���v���b�g�t�H�[���Ƃ����B
�������̎����ԃ��[�J�[Hawtai��2010�N�̔N����Intel��
��Atom�v���Z�b�T���g�p����MeeGo IVI�V�X�e���������ꂽ�V�Ԏ�AB11�\�����B
http://eetimes.jp/ee/spv/1110/26/news062.html
��Intel��2011�N9�����ɁALinux�x�[�X�̃��o�C���@�����OS
���uMeeGo�v�̊J������P�ނ��邱�Ƃ�\�������B����ɂ��A
���J�[�G���N�g���j�N�X�֘A�̐v����|����3�Ђ̃v���W�F�N�g�ɉe�����o�Ă���B
��Intel���P�ނ\�����Ƃ��AMeeGo���x�[�X�Ƃ����ԍڃC���t�H�e�C�������g
���iIVI�FIn-Vehicle Infotainment�j�V�X�e�����J�����Ă��郁�[�J�[���A���Ȃ��Ƃ�2�Ђ������B
http://gihyo.jp/news/report/2013/01/3001
��Tizen�̐��������ɂ��āA���ۂɂ�MeeGo����̗���ɂ���Tizen�ƁC
��SLP�iSamsung Linux Platform�j�̗���ɂ���TIzen������C
������2�͖��m�ɋ�ʂ���ׂ����i�ł���Ǝw�E���܂����B
���O�҂́uTizen IVI�v�Ƃ�����Ɏԍڌ����Ƃ��Ă̊J�����i�߂��Ă�����̂ŁC
����҂��uTizen Mobile�v�ƌĂ�Ă��܂��B
���X�N�}�l�W�����g�͂������肵�܂��傤�ˁI �i���^
http://www.oesf-global.com/jp/linux-foundation-��automotive-grade-linux-���[�L���O�O���[�v�̐ݗ��\/
��MeeGo�J�������ɓ���ƁAGE�ABMW�A�v�W���[�AIntel�Ȃǂ̑��Ƃ�
��������GENIVI Alliance��ݗ��AMeeGo��IvI�̊J���v���b�g�t�H�[���Ƃ����B
�������̎����ԃ��[�J�[Hawtai��2010�N�̔N����Intel��
��Atom�v���Z�b�T���g�p����MeeGo IVI�V�X�e���������ꂽ�V�Ԏ�AB11�\�����B
http://eetimes.jp/ee/spv/1110/26/news062.html
��Intel��2011�N9�����ɁALinux�x�[�X�̃��o�C���@�����OS
���uMeeGo�v�̊J������P�ނ��邱�Ƃ�\�������B����ɂ��A
���J�[�G���N�g���j�N�X�֘A�̐v����|����3�Ђ̃v���W�F�N�g�ɉe�����o�Ă���B
��Intel���P�ނ\�����Ƃ��AMeeGo���x�[�X�Ƃ����ԍڃC���t�H�e�C�������g
���iIVI�FIn-Vehicle Infotainment�j�V�X�e�����J�����Ă��郁�[�J�[���A���Ȃ��Ƃ�2�Ђ������B
http://gihyo.jp/news/report/2013/01/3001
��Tizen�̐��������ɂ��āA���ۂɂ�MeeGo����̗���ɂ���Tizen�ƁC
��SLP�iSamsung Linux Platform�j�̗���ɂ���TIzen������C
������2�͖��m�ɋ�ʂ���ׂ����i�ł���Ǝw�E���܂����B
���O�҂́uTizen IVI�v�Ƃ�����Ɏԍڌ����Ƃ��Ă̊J�����i�߂��Ă�����̂ŁC
����҂��uTizen Mobile�v�ƌĂ�Ă��܂��B
>>257
Duron1GHz������512M�̃}�V���Ȃ�ă}�W�ŋ@�B�I�����Ȃ�ő����ς��ĉ������B
Duron1GHz������512M�̃}�V���Ȃ�ă}�W�ŋ@�B�I�����Ȃ�ő����ς��ĉ������B
>>445
ID��HIS
ID��HIS
http://techreport.com/news/25936/intel-reports-2013-financials-plans-5-cut-to-workforce
Intel reports 2013 financials, plans 5% cut to workforce
Intel reports 2013 financials, plans 5% cut to workforce
�����Ԏ��ɂȂ���ė\�z�����邩��A���߂ɐl���J�b�g���Ď��łƂ��������Ȃ̂���
Intel�̃��X�g���͊��ƒ���I�ȃC���[�W������
����グ����������������ƁB�������Ԏ��H
����グ����������������ƁB�������Ԏ��H
448�̎�M�d�g��������������
451 �FSocket774�F2014/01/18(�y) 19:35:41.00 ID:aoSwwo7v
�R�DIntel��Fab42�̌��݂𓀌��C5%�̐l�����팸
�A���]�i��Fab42��3�N�O�Ɍ��݂����߂��̂ł����C�����̎��v�\���ɔ�ׂāC
PC�����̃`�b�v�̎��v����������ł��Ă���C14nm����́C���ɂ���Fab��
���Y���܂��Ȃ���ɂȂ��Ă���Ƃ̂��ƂŁCFab42�͌��������݂����Ƃ���œ������C
�������u�͐ݒu���Ȃ��ŋĒu���C�����C���p����\�����c���Ēu���Ƃ̂��Ƃł��B
http://www.geocities.jp/andosprocinfo/wadai14/20140118.htm
�A���]�i��Fab42��3�N�O�Ɍ��݂����߂��̂ł����C�����̎��v�\���ɔ�ׂāC
PC�����̃`�b�v�̎��v����������ł��Ă���C14nm����́C���ɂ���Fab��
���Y���܂��Ȃ���ɂȂ��Ă���Ƃ̂��ƂŁCFab42�͌��������݂����Ƃ���œ������C
�������u�͐ݒu���Ȃ��ŋĒu���C�����C���p����\�����c���Ēu���Ƃ̂��Ƃł��B
http://www.geocities.jp/andosprocinfo/wadai14/20140118.htm
���i�����Ȃ������̍H��́A���z�Ԏ������@�ł����Ȃ�����
���v�ɂ��킹�Č��炷�͓̂��R����
�������A���]�i�����̎��A�e�ɂ��Ă����A���u�̃��[�J��
����ǂ����낤�Ȃ�
���v�ɂ��킹�Č��炷�͓̂��R����
�������A���]�i�����̎��A�e�ɂ��Ă����A���u�̃��[�J��
����ǂ����낤�Ȃ�
�܂��[�����Ȃ��ł������H�O�������H�͖Ⴆ�邾�낤���炢����˓I�ȁB
PC�̐��E�o���̂��O�N��10%������ǂ��ɂ��Ȃ���ȁB
���N�̗\�z���F�X�o�Ă邪�A�ǂ��������������B
�ǂ��Ȃ���B
���N�̗\�z���F�X�o�Ă邪�A�ǂ��������������B
�ǂ��Ȃ���B
Fab42�ȊO�̂Ƃ����14nm�p�̐ݔ����������A�[���̖��͂Ȃ��̂ł́B
14nm����S�̂̑䐔�͌��邾�낤���A�����[�����͍ŏ����Ȃ�łȂ��B
14nm����S�̂̑䐔�͌��邾�낤���A�����[�����͍ŏ����Ȃ�łȂ��B
>>455
>�����[����
�������������u�̕��[���Ă���ܕ��������Ɩ���
�V�K�����ł̃R���^�~�Ƃ������ł̖����ׂ������
�Ƃ��������R��
�����̏ꍇ�́A���Ƃ��Ɨ\���ŋĂ��錚���̏ꏊ��
�p���ɐV�݂���̂��퓅�ł͂Ȃ��낤��
>�����[����
�������������u�̕��[���Ă���ܕ��������Ɩ���
�V�K�����ł̃R���^�~�Ƃ������ł̖����ׂ������
�Ƃ��������R��
�����̏ꍇ�́A���Ƃ��Ɨ\���ŋĂ��錚���̏ꏊ��
�p���ɐV�݂���̂��퓅�ł͂Ȃ��낤��
>>456
���[�ł͂Ȃ��ł����A5���C����2���C���ɏk���Ƃ��͂悭����܂�
450mm�Ή����C�������炷�Ƃ��A��́A�[����1�N�x�点��Ƃ�
���[�ł͂Ȃ��ł����A5���C����2���C���ɏk���Ƃ��͂悭����܂�
450mm�Ή����C�������炷�Ƃ��A��́A�[����1�N�x�点��Ƃ�
14nm�k����
�����m�[�h���������A
�M�Ÿ�۸�グ���Ȃ���
�����b�g�Ȃ���Ȃ�
�߂����ʎq�R���s���[�^w
�����m�[�h���������A
�M�Ÿ�۸�グ���Ȃ���
�����b�g�Ȃ���Ȃ�
�߂����ʎq�R���s���[�^w
>>458
Google���ʎq�R���s���[�^�uD-Wave Two�v�̃X�s�[�h�e�X�g�����{
ttp://gigazine.net/news/20140117-google-quantum-computer/
>���\�e�X�g�ɂ�D-Wave Two�ƒʏ��PC���p�����A��r�p�̍œK���A���S���Y����o���ő��点�Ĕ�r���s���܂����B
>���̌��ʁAD-Wave Two�V�X�e���͗ʎq�R���s���[�e�B���O�Z�p�̗��_�������A�ʏ�̃R���s���[�^�[�Ƃ��قǕς��Ȃ����ʂ����o���Ȃ������Ƃ̂��ƁB
Google���ʎq�R���s���[�^�uD-Wave Two�v�̃X�s�[�h�e�X�g�����{
ttp://gigazine.net/news/20140117-google-quantum-computer/
>���\�e�X�g�ɂ�D-Wave Two�ƒʏ��PC���p�����A��r�p�̍œK���A���S���Y����o���ő��点�Ĕ�r���s���܂����B
>���̌��ʁAD-Wave Two�V�X�e���͗ʎq�R���s���[�e�B���O�Z�p�̗��_�������A�ʏ�̃R���s���[�^�[�Ƃ��قǕς��Ȃ����ʂ����o���Ȃ������Ƃ̂��ƁB
���i�̕i�����N�X�オ���Ă邨�����őϗp�N���͒�����
���Ă邯��PC���̂��̂̎��v�͉���������������ȁB
�|�[�^�u���f�o�C�X����I�t�B�X�Ɩ��Ȃł��Ȃ����B
���Ă邯��PC���̂��̂̎��v�͉���������������ȁB
�|�[�^�u���f�o�C�X����I�t�B�X�Ɩ��Ȃł��Ȃ����B
IBM PC�Ȃ�ăI���`���ł���
>>458
�ǂ��Ǝv�����ǂ�
�I�̓N���b�N�グ���ɓd�͌����̈�Ԃ����o���h�Ŏg������
�����ĎI��CPU�P���͍�����intel�̍������Z�ł����v���L�тĂ�
�ǂ��Ǝv�����ǂ�
�I�̓N���b�N�グ���ɓd�͌����̈�Ԃ����o���h�Ŏg������
�����ĎI��CPU�P���͍�����intel�̍������Z�ł����v���L�тĂ�
�ނ���Xeon����r�I�R�A�������Ȃ��č��N���b�N�u����WS������
�R�A�������T�[�o�����ɕ�����Ă��āA
���������P���Ԃɍ����ĂȂ�����TDP�������グ�ĉ��Ƃ���������Ȃ̂ŁA
�ˑR�Ƃ��ē�����g���͏d�v�Ƃ�����
������embarrassingly parallel�Ȗ��ł����Xeon Phi�Ƃ�Tesla���g���邾�낤���ǁA
HPC�ȊO�ł͂����ȒP�ɂ͂����Ȃ����낤�c�c
�R�A�������T�[�o�����ɕ�����Ă��āA
���������P���Ԃɍ����ĂȂ�����TDP�������グ�ĉ��Ƃ���������Ȃ̂ŁA
�ˑR�Ƃ��ē�����g���͏d�v�Ƃ�����
������embarrassingly parallel�Ȗ��ł����Xeon Phi�Ƃ�Tesla���g���邾�낤���ǁA
HPC�ȊO�ł͂����ȒP�ɂ͂����Ȃ����낤�c�c
>>459
����͈�ʂɌ����Ă�ʎq�R���s���[�^�Ƃ͂�����ƈႤ���̂�����E�E�E
����͈�ʂɌ����Ă�ʎq�R���s���[�^�Ƃ͂�����ƈႤ���̂�����E�E�E
465 �FSocket774�F2014/01/19(��) 05:07:07.18 ID:1SCGcQX5
Apple A�V���[�Y�̐������J�n����̂͂܂��܂��܂��܂���ȂȁH
���y�}���z�ł��A���̓����ƌ�����������������A���炩��Apple�����̐�����������Ȃ��Ďv���܂���ˁB
���y�}���z�ł��A���̓����ƌ�����������������A���炩��Apple�����̐�����������Ȃ��Ďv���܂���ˁB
466 �FSocket774�F2014/01/19(��) 05:41:34.50 ID:1SCGcQX5
XP�@�X�V���ʂ��ꂽ���PC�ƊE�̂��Ƃ��l����ƁA���X�g����A�����鎖�ԂւƊׂ�O��
�������܋������Ă���6550���~�ł������グ����McAfee����������M&A�Ɋ��҂������Ƃ���
�������܋������Ă���6550���~�ł������グ����McAfee����������M&A�Ɋ��҂������Ƃ���
���݂̗ʎq�R���s���[�^�[��x�����Ă�������āA
���Ƃ���Ȃ�i4004���]���^�R���s���[�^���x�����Ă����Ă�悤�Ȃ���
���Ƃ���Ȃ�i4004���]���^�R���s���[�^���x�����Ă����Ă�悤�Ȃ���
�I�́A�����d�͌������K�v�ȃ��[�U�[�ƁA���Ƃ��d�͌������]���ɂ��Ă�
�����p�t�H�[�}���X���K�v�ȃ��[�U�[�������
���Ƒ����̃��[�U�[�́A�A�C�h�����E�y�����ɂ͒����d�́A
�������ɍ��p�t�H�[�}���X�����߂�Ǝv��
���ƁA�R�A���ۋ��̏��p�\�t�g���g���ꍇ�́A�����R�A���\���������R�A�̂ق���
���C�Z���X���I�ɗL��
�ᐫ�\���R�A�H���ɑǂ����bulldozer�ȍ~��opetron��
�T�[�o�s��łǂ��Ȃ��������l����˂�
�����p�t�H�[�}���X���K�v�ȃ��[�U�[�������
���Ƒ����̃��[�U�[�́A�A�C�h�����E�y�����ɂ͒����d�́A
�������ɍ��p�t�H�[�}���X�����߂�Ǝv��
���ƁA�R�A���ۋ��̏��p�\�t�g���g���ꍇ�́A�����R�A���\���������R�A�̂ق���
���C�Z���X���I�ɗL��
�ᐫ�\���R�A�H���ɑǂ����bulldozer�ȍ~��opetron��
�T�[�o�s��łǂ��Ȃ��������l����˂�
�d�͌����͂܂��オ�肻�������ǂȁ[
�����\�����߂郆�[�U�[���A�l�b�N�͓d�͋����Ɣ��M�������肷��킯�����B
�����\�����߂郆�[�U�[���A�l�b�N�͓d�͋����Ɣ��M�������肷��킯�����B
http://pc.watch.impress.co.jp/docs/column/ubiq/20121221_579666.html
> Intel�̌v��͂����Ɩ�S�I�ŁA������\�[�X�ɂ���U�v���Z�b�T�����Y�v���Z�b�T�̊�����
> 2013�N���܂ł�50%�A2014�N���̎��_�ł�80%���^�[�Q�b�g�ɂ��Ă���̂��Ƃ����B�܂�A
> U��Y�v���Z�b�T���̂�銄�����AHaswell�ł�50%�ABroadwell�ł�80%�ɂȂ�悤�A
> ��H�v����Z�p�̒������s�Ȃ��邱�Ƃ��B�t�Ɍ����A�ŏI�I��H��M�v���Z�b�T��
> ���p�ł���_�C��20%���炢�����̂�Ȃ����ƂɂȂ�B
�N���b�N���オ��ɂ������R�͂��������Ƃ��낾���
> Intel�̌v��͂����Ɩ�S�I�ŁA������\�[�X�ɂ���U�v���Z�b�T�����Y�v���Z�b�T�̊�����
> 2013�N���܂ł�50%�A2014�N���̎��_�ł�80%���^�[�Q�b�g�ɂ��Ă���̂��Ƃ����B�܂�A
> U��Y�v���Z�b�T���̂�銄�����AHaswell�ł�50%�ABroadwell�ł�80%�ɂȂ�悤�A
> ��H�v����Z�p�̒������s�Ȃ��邱�Ƃ��B�t�Ɍ����A�ŏI�I��H��M�v���Z�b�T��
> ���p�ł���_�C��20%���炢�����̂�Ȃ����ƂɂȂ�B
�N���b�N���オ��ɂ������R�͂��������Ƃ��낾���
�R�X�g���n�[�h2���A�\�t�g8���݂����ȕ���́A
�X�J�X�J���C�A�E�g�ŔM���x����{���ꂽ���N���b�NCPU����������
���������ł��I�Ԃ�Ȃ����B�����ɍ���Ă���Ȃ�����
�X�J�X�J���C�A�E�g�ŔM���x����{���ꂽ���N���b�NCPU����������
���������ł��I�Ԃ�Ȃ����B�����ɍ���Ă���Ȃ�����
>>471
������\�[�X�̌����ʂ��2013�N����U+Y�̊���50%�s������
������\�[�X�̌����ʂ��2013�N����U+Y�̊���50%�s������
���������N���b�N�オ��Ȃ����Ă͈̂�̂ǂ�����o�����Ȃ́H
14nm�ɂ��Ă͂قƂ�lj����������ĂȂ��͂�����
�����\�ŏ���d��3�����Ƃ����R�Ƃ����b����
14nm�ɂ��Ă͂قƂ�lj����������ĂȂ��͂�����
�����\�ŏ���d��3�����Ƃ����R�Ƃ����b����
476 �FSocket774�F2014/01/19(��) 12:59:48.77 ID:foDZpCRi
�v���Z�X���[���ƍő哮����g�����v���b�g�����
http://ascii.jp/elem/000/000/711/711003/img.html
http://ascii.jp/elem/000/000/711/711003/img.html
>>476
NetBurst����肷����
NetBurst����肷����
�ǂ��炩�ƌ����ƁA����
>>471
U Y���ĂȂɁH
U Y���ĂȂɁH
Y�͖Y�ꂽ����U��15W�Ƃ�17W�Ƃ����̂ւ�̂ł���B
Sandy�͂����Ԃ�U�i�͂Ȃ���������17W��M�j�Ƀv���~�A���i���t���Ă�����
���������ǎ��ۂǂ̂��炢�̊����Ő��ڂ��Ă����낤�B
Sandy�͂����Ԃ�U�i�͂Ȃ���������17W��M�j�Ƀv���~�A���i���t���Ă�����
���������ǎ��ۂǂ̂��炢�̊����Ő��ڂ��Ă����낤�B
NetbBurst�̓I�[�p�[�c�������̂��c
�p�C�v���C���̃X�e�[�W��[������1�X�e�[�W�ł�邱�Ƃ����Ȃ�����A
����ł������ƃN���b�N�͏オ��ł���H
�����ɃX�e�[�W��[��������N���b�N���グ���ɍ���������ق��ɓ����Ă邩��A
�����Ȃ�Ȃ�������
�������A4GHz������œ��ł��Ȃ̂͂���������Ȃ�Ƃ����Ăق�����
����ł������ƃN���b�N�͏オ��ł���H
�����ɃX�e�[�W��[��������N���b�N���グ���ɍ���������ق��ɓ����Ă邩��A
�����Ȃ�Ȃ�������
�������A4GHz������œ��ł��Ȃ̂͂���������Ȃ�Ƃ����Ăق�����
�N���M�͊w���@�����āB
�ʎq�h�b�g�g���ĔM�����Ƃ��ĕ��o
����d�C�Ƃ��čė��p�݂����Șb�������Ƃ����邯�ǂǂ��Ȃ��Ă�낤��
����d�C�Ƃ��čė��p�݂����Șb�������Ƃ����邯�ǂǂ��Ȃ��Ă�낤��
���[�N�d�������Ă悵
>>482
���g����+10�`20%�A����d�͂�+5�`10%�A���\��-5%�`+5%
�ɂȂ邯�ǂ����H
�܂��A��������Pentium4�̓�̕��ɂ͂Ȃ�ɂ����Ƃ͎v�����E�E�E
���̂����3GHz�O�オ���E�������̂ɁA
���g�����グ�邽�߂Ƀp�C�v���C���̃X�e�[�W�𑽂����������̂��������������B
���g����+10�`20%�A����d�͂�+5�`10%�A���\��-5%�`+5%
�ɂȂ邯�ǂ����H
�܂��A��������Pentium4�̓�̕��ɂ͂Ȃ�ɂ����Ƃ͎v�����E�E�E
���̂����3GHz�O�オ���E�������̂ɁA
���g�����グ�邽�߂Ƀp�C�v���C���̃X�e�[�W�𑽂����������̂��������������B
Pentium4�̎���20�i�������炵���B
http://ja.wikipedia.org/wiki/%E3%82%B9%E3%83%BC%E3%83%91%E3%83%BC%E3%83%91%E3%82%A4%E3%83%97%E3%83%A9%E3%82%A4%E3%83%B3#.E8.A4.87.E9.9B.91.E5.8C.96
http://ja.wikipedia.org/wiki/%E3%82%B9%E3%83%BC%E3%83%91%E3%83%BC%E3%83%91%E3%82%A4%E3%83%97%E3%83%A9%E3%82%A4%E3%83%B3#.E8.A4.87.E9.9B.91.E5.8C.96
���i�p�C�v���C�����N���b�N�w�����āA
�l�Ԃ���闬���ƂŌ����A
1�l����̍�Ɠ��e�����Ȃ���������̕��n�C�e���|�ō�Ƃ��i�߂�����Ă�����ǁA
���ʂ̓e���|�͏オ�������ǁA
����ɍ�Əꏊ�̑�����ƑΏۂ̎�n���H���̑���������āA
����Ƃ��̂��̂͂��قǑ����Ȃ������ƁB
�l�Ԃ���闬���ƂŌ����A
1�l����̍�Ɠ��e�����Ȃ���������̕��n�C�e���|�ō�Ƃ��i�߂�����Ă�����ǁA
���ʂ̓e���|�͏オ�������ǁA
����ɍ�Əꏊ�̑�����ƑΏۂ̎�n���H���̑���������āA
����Ƃ��̂��̂͂��قǑ����Ȃ������ƁB
�m��Pen4�v���X�R�ȍ~�̌���ł�30�i�ɂ܂ő��傳���Ă��ȁB
��������GHz���ł͏�ʂ̐��т��o���Ă�悤�����B
��������GHz���ł͏�ʂ̐��т��o���Ă�悤�����B
�O�H���ł̌�肪������ƁA��H������蒼���ɂȂ�Ƃ����B
�����������͔{�N���b�N������A8GHz�ߕӂœ��삵�Ă������Ƃ�
�{�N���b�N���c�c
�����
�����Ƃ��Ă͍�������������
�`���I�ȃV�������N�������Ă�����܂��i�̂��낤
�`���I�ȃV�������N�������Ă�����܂��i�̂��낤
��{�I��90�N�㔼�ɐv���n�܂����킯����
�܂���2000�N��ɓ����Ă���Ȃ��ƂɂȂ�Ƃ͖��ɂ��v��Ȃ������̂��낤
�܂���2000�N��ɓ����Ă���Ȃ��ƂɂȂ�Ƃ͖��ɂ��v��Ȃ������̂��낤
PenD�����C���������Ƃ��̓I�[���d���Z��łȂ��̂�
����ȏ�̓d�C�ゾ����
�������ғ����Ăď��Ƃ�ł��Ȃ������d�C���������Ă���
����ȏ�̓d�C�ゾ����
�������ғ����Ăď��Ƃ�ł��Ȃ������d�C���������Ă���
�k�X����C2D�ɕς�����d�C�オ�ڂɌ����ĉ���������
�����ق�24����PC�N�����Ă�����
�����ق�24����PC�N�����Ă�����
Core2Duo��Atom�ɕς��邾���œd�C�オ�ڂɌ����ĉ����邾��
�y�ߕ�z�C���e�����܂��ŃI���R�����ۂ���
http://hayabusa3.2ch.net/test/read.cgi/morningcoffee/1390125528/
http://hayabusa3.2ch.net/test/read.cgi/morningcoffee/1390125528/
�Ȃ������͂��ʖ邾�ȁA�Ȃl�^�Ȃ��́H
���N��1���͂��傤�ǃl�^���Ȃ�����
����CES�ŃE�F�A���u���̘b��Ƃ����������ǁA
���܂�Ƀv���g�^�C�v�����Ĕ����ɍ���
����2����MWC���Ȃ��BMerrifield���������\�ɂȂ�͂�
����CES�ŃE�F�A���u���̘b��Ƃ����������ǁA
���܂�Ƀv���g�^�C�v�����Ĕ����ɍ���
����2����MWC���Ȃ��BMerrifield���������\�ɂȂ�͂�
�������AIntel��dGPU���t�@�u�����p���Ղ��Ȃ�i��āj
�n�C�G���h�͂ǂ��Ȃ�́H
�G�N�X�g���[���ȃO���t�B�b�N�̓_�C�T�C�Y��L�ʐς��L�����M�ʂ����[�Ȃ��̂�
CPU�Ɉ�̂őg�ݍ��ނ��Ƃ͔M���x�I�ɓ�����珟���̓y�U�ɂ���オ��Ȃ�
�G���g�����璆�ʂ̃O���t�B�b�N�X��ɂ���헪�Ȃ̂ł��[��
���łɓƋ֖@�ɂ���G���Ȃ������I���ʂ�����̂��[
CPU�Ɉ�̂őg�ݍ��ނ��Ƃ͔M���x�I�ɓ�����珟���̓y�U�ɂ���オ��Ȃ�
�G���g�����璆�ʂ̃O���t�B�b�N�X��ɂ���헪�Ȃ̂ł��[��
���łɓƋ֖@�ɂ���G���Ȃ������I���ʂ�����̂��[
�C���e���̒�������Ԃ���ĂȂ�Ȃ�(�L�E�ցE�M)
PC�ŕ��ׂ�����d�����ĂȂ���(�L�E�ցE�M)
�����Ƒ����}�V���~������(�L�G�ցG�M)
PC�ŕ��ׂ�����d�����ĂȂ���(�L�E�ցE�M)
�����Ƒ����}�V���~������(�L�G�ցG�M)
508 �FSocket774�F2014/01/20(��) 10:55:34.40 ID:0lAuULMA
�C���e���Ƃ��������Ȃ��Ȃ��Ă�������
arm���邩�炢���
arm���邩�炢���
Intel�A�N���b�N�A�b�v�������o�C����Core i7/i5/Celeron��ʃ��f��
�`Extreme Edition����Celeron�܂Ōv10���f��
http://pc.watch.impress.co.jp/docs/news/20140120_631375.html
�`Extreme Edition����Celeron�܂Ōv10���f��
http://pc.watch.impress.co.jp/docs/news/20140120_631375.html
Windows XP���g����ATM��95�������݂��A�X�V���Ԃɍ���Ȃ�������
http://gigazine.net/news/20140120-atm-upgrade-windows-xp/
IBM�Ax86�T�[�o��6����--���C���������ɍő�12.8TB�̃t���b�V���X�g���[�W
http://japan.zdnet.com/datacenter/analysis/35042743/
http://gigazine.net/news/20140120-atm-upgrade-windows-xp/
IBM�Ax86�T�[�o��6����--���C���������ɍő�12.8TB�̃t���b�V���X�g���[�W
http://japan.zdnet.com/datacenter/analysis/35042743/
511 �FSocket774�F2014/01/20(��) 12:20:14.12 ID:VnaM8sCe
�ǂ����悤���Ȃ���I�I
Windows XP�̉ғ����A2015�N3�����ł�25���O��̌�����
http://www.itmedia.co.jp/enterprise/articles/1311/21/news064.html
Windows XP���p�����p�����Ƃ��A���H�g�������Ƃ𒆐S�ɑ������Ƃ����������B
���Ђł�2015�N3�������_�ʼnғ���������25���O��ɂȂ�Ƃ݂Ă���B
XP�ڍs�̑O�ɗ����͂�����傫�ȕ�
http://www.itmedia.co.jp/enterprise/articles/1312/05/news013.html
�J�X�^���A�v���P�[�V�����́A�J������10�N�ȏオ�o���A�J�����̂𐿂�������
��Ђ����݂��Ȃ�������A�J�����̃\�[�X�R�[�h��h�L�������g���U�킵���肵�āA
�u���b�N�{�b�N�X�����Ă��܂��A�V����OS�ֈڍs���悤�ɂ��A�u�ǂ����悤�������c�c�v�Ƃ������Ƃ������B
Windows XP�̉ғ����A2015�N3�����ł�25���O��̌�����
http://www.itmedia.co.jp/enterprise/articles/1311/21/news064.html
Windows XP���p�����p�����Ƃ��A���H�g�������Ƃ𒆐S�ɑ������Ƃ����������B
���Ђł�2015�N3�������_�ʼnғ���������25���O��ɂȂ�Ƃ݂Ă���B
XP�ڍs�̑O�ɗ����͂�����傫�ȕ�
http://www.itmedia.co.jp/enterprise/articles/1312/05/news013.html
�J�X�^���A�v���P�[�V�����́A�J������10�N�ȏオ�o���A�J�����̂𐿂�������
��Ђ����݂��Ȃ�������A�J�����̃\�[�X�R�[�h��h�L�������g���U�킵���肵�āA
�u���b�N�{�b�N�X�����Ă��܂��A�V����OS�ֈڍs���悤�ɂ��A�u�ǂ����悤�������c�c�v�Ƃ������Ƃ������B
512 �FSocket774�F2014/01/20(��) 12:25:33.06 ID:VnaM8sCe
�s��Ȃ��g���Ă�����̂�ς���͔̂n���I�I
Windows XP�̈ڍs�������IT�S���҂��������ׂ�3�̎���
http://www.itmedia.co.jp/enterprise/articles/1311/29/news040.html
���鐻���Ƃ̌ږ�����Ă��ċC���t�������Ƃ��������B
���̊�Ƃł̓��{�b�g����Ɋւ���p�����[�^�̐ݒ�ƁA���̂��߂̃t���b�s�[�f�B�X�N��
�쐬���s�����߂�1���PC���Ћ��œ����Ă����B�Ȃ�ƁANEC��PC-98�ł���B
�����E���Ƃł͂��Ȃ�̋K�͂�Windows 3.1��95�A98�A������XP�������Ŋ��Ă���B
�T���Ώ���Ƃ̒��ɂ�DOS�̂܂g���Ă��镔�����܂�������B���ꂪ�������B
�o�c�҂̍l���͊ȒP�E���Ăł���B�u�Ȃ��s����Ȃ��A�������g������̂ɑ���
�킴�킴���������̂��i����o�c�҂́w�P���~�ȏ�͑S�č��z�x�Ƙb���Ă����j�B
����Ȃ��Ƃ����ă��X�N�����߂�͔̂n���������Ȃ��v
Windows XP�̈ڍs�������IT�S���҂��������ׂ�3�̎���
http://www.itmedia.co.jp/enterprise/articles/1311/29/news040.html
���鐻���Ƃ̌ږ�����Ă��ċC���t�������Ƃ��������B
���̊�Ƃł̓��{�b�g����Ɋւ���p�����[�^�̐ݒ�ƁA���̂��߂̃t���b�s�[�f�B�X�N��
�쐬���s�����߂�1���PC���Ћ��œ����Ă����B�Ȃ�ƁANEC��PC-98�ł���B
�����E���Ƃł͂��Ȃ�̋K�͂�Windows 3.1��95�A98�A������XP�������Ŋ��Ă���B
�T���Ώ���Ƃ̒��ɂ�DOS�̂܂g���Ă��镔�����܂�������B���ꂪ�������B
�o�c�҂̍l���͊ȒP�E���Ăł���B�u�Ȃ��s����Ȃ��A�������g������̂ɑ���
�킴�킴���������̂��i����o�c�҂́w�P���~�ȏ�͑S�č��z�x�Ƙb���Ă����j�B
����Ȃ��Ƃ����ă��X�N�����߂�͔̂n���������Ȃ��v
MS��������OS�ς�������Windows�ȊO�ɂ����o���郊�X�N�������
�L����XP�̃T�|�[�g����������v�����p�ӂ���I���͖����̂���
�L����XP�̃T�|�[�g����������v�����p�ӂ���I���͖����̂���
�@�l�����͂����Ƒ����i�K�ŏ�����p��A�b�v�f�[�g��������
������p�����N�Ԕ�p�^�Ɉڍs�����Ă����悩�����̂�
������p�����N�Ԕ�p�^�Ɉڍs�����Ă����悩�����̂�
����CPU�I���{�Ƃ��\���邯�ǃ}�U�{�ƊE�I�����
MS������WinXP�����Ă��l�̂�����芄���͎��߂Ă�
���XWin7/8�ƕ��s���ă����e���[�Ă����Ȃ��ςȂ�ˁ[�́H
Linux�ł�Kernel 2.4�Ƃ����ł�������ƃ����e����Ă�̂��ȁH
���XWin7/8�ƕ��s���ă����e���[�Ă����Ȃ��ςȂ�ˁ[�́H
Linux�ł�Kernel 2.4�Ƃ����ł�������ƃ����e����Ă�̂��ȁH
MS���̂͂��Ƃ���OS��10�N�P�ʂŕێ炷��悤�Ȃ�������Ƃ����A
��������������Ƃ̎���́A��������OS�̃A�b�v�f�[�g�������ł����
���Ƃ��Ȃ�悤�Șb�ł͂Ȃ��̂�
��������������Ƃ̎���́A��������OS�̃A�b�v�f�[�g�������ł����
���Ƃ��Ȃ�悤�Șb�ł͂Ȃ��̂�
MS���Z�L�����e�B�T�|�[�g��闝�R�́A��OS���T�|�[�g���Ă�
�x�o������Ŏ������Ȃ�����ł͂Ȃ��̂��B
����������������悤�Ȍ_��ɂȂ��Ă���T�|�[�g��
�炸�ɑ�������̂ł͂Ȃ����Ǝv�����̂���
�x�o������Ŏ������Ȃ�����ł͂Ȃ��̂��B
����������������悤�Ȍ_��ɂȂ��Ă���T�|�[�g��
�炸�ɑ�������̂ł͂Ȃ����Ǝv�����̂���
�T�|�[�g�̓����O�e�[���Ƃ������A�ʃT�[�r�X�̂悤�Ȃ��̂�����ׂ����̂ł���B�T�|�[�g�Ńr��������ł���H������MS�͂�߂Ă��܂��B
>514�@�̔N�Ԕ�p�̓T�|�[�g�̔�p�ł͂Ȃ�
Vista�����܂�ɂ����������̂�XP�̃T�|�[�g�����邸�鉄�������Ă��܂����̂�
�����̍����ŁA�{����7�ɋ����Ɉڍs������ׂ���������ł���B
���ƁALonglifeSupport�łƒʏ�T�|�[�g�ł𗼗������Ă����ׂ��������B
�����̍����ŁA�{����7�ɋ����Ɉڍs������ׂ���������ł���B
���ƁALonglifeSupport�łƒʏ�T�|�[�g�ł𗼗������Ă����ׂ��������B
�ŐV��OS���̔�p���Ă�����XP�̉����T�|�[�g�𑱂��Ă�����������ǂ��Ƃ������v�͏��Ȃ��Ȃ��Ǝv�����ǂ�
523 �FSocket774�F2014/01/20(��) 15:08:27.43 ID:K5r8Xs+7
Galileo��Raspberry Pi�Ɠ���3000�~���x�Ȃ�
��������Ƃ��Ĕ����Ă݂������ǂ�
��������Ƃ��Ĕ����Ă݂������ǂ�
�����͂̂��郆�[�U�ł���XP����ڍs�������Ȃ��A�Ƃ����͖̂����͂Ȃ��������ł͂Ȃ����ȁB
��p�Ƃ������Ƃ��ȑO�ɁA�̐S�̌Â�OS��\�t�g����̃T�|�[�g�o����l�Ԃ����Ȃ����
XP�Ȃ�܂��Ȃ�Ƃ��Ȃ邾�낤���ǁA2000�ȑO�͒��߂���������
����ʼn��ďI���ȃV�X�e�����Ƃׂ͒�Ă�����
�V�����V�X�e���ō\�z�ł���V������Ƃ��o�Ă��邾��
XP�Ȃ�܂��Ȃ�Ƃ��Ȃ邾�낤���ǁA2000�ȑO�͒��߂���������
����ʼn��ďI���ȃV�X�e�����Ƃׂ͒�Ă�����
�V�����V�X�e���ō\�z�ł���V������Ƃ��o�Ă��邾��
�u�l�r�鍑�v��������ʃA�b�v���@���ߎ茇���Ɩ��\�t�g������
http://www.nikkei.com/article/DGXNASFK0301A_X10C14A1000000/?dg=1
http://www.nikkei.com/article/DGXNASFK0301A_X10C14A1000000/?dg=1
�A�b�v����10�N������CPU�A�[�L�e�N�`�����ς�邩���
��Ƃ͂���ȋ@�B�|���Ďg���Ȃ�����
��Ƃ͂���ȋ@�B�|���Ďg���Ȃ�����
Chromebook�����ɓ��{�㗤��
�`Acer C720 Chromebook���g�ߓ������h
http://pc.watch.impress.co.jp/docs/news/20140120_631434.html
�`Acer C720 Chromebook���g�ߓ������h
http://pc.watch.impress.co.jp/docs/news/20140120_631434.html
Apple�͍ŐVOS�ȊO�͒�����������
���W���[�o�[�W�����A�b�v�̓x�ɊGUI API�̑�ʕύX�ŐVOS�����ɏ����ꂽ�\�t�g����OS�œ��삵�Ȃ��Ȃ�
����ł���OS�����Ƀ����^�C�����C�u�����̍X�V�Ȃǂ͒������Ƃ��Ȃ�
�VOS�ŋ�OS�݊��̃\�t�g���J�����悤�Ƃ���Ƃ�₱�����菇�ŋ�OS�����̃R���p�C����SDK�����Ȃ���Ȃ炸
OS�Ԃ̌݊������J���҂Ɉێ�������C���Ȃ� (�����10.6���炢�܂ł͂����ł͂Ȃ�������)
����ȃN�\�ȏŃr�W�l�X�s���MS���R�U�炷�Ȃ�Ė����ł��傤
���W���[�o�[�W�����A�b�v�̓x�ɊGUI API�̑�ʕύX�ŐVOS�����ɏ����ꂽ�\�t�g����OS�œ��삵�Ȃ��Ȃ�
����ł���OS�����Ƀ����^�C�����C�u�����̍X�V�Ȃǂ͒������Ƃ��Ȃ�
�VOS�ŋ�OS�݊��̃\�t�g���J�����悤�Ƃ���Ƃ�₱�����菇�ŋ�OS�����̃R���p�C����SDK�����Ȃ���Ȃ炸
OS�Ԃ̌݊������J���҂Ɉێ�������C���Ȃ� (�����10.6���炢�܂ł͂����ł͂Ȃ�������)
����ȃN�\�ȏŃr�W�l�X�s���MS���R�U�炷�Ȃ�Ė����ł��傤
�y�V��FFXIV�x���`�L������ 1280x720 �f�X�N�W���z
���ᕉ��
A10-7850K �� 6,320
G1610 + HD7750 �� 11,171
���������i�G���R�Ȃ���j
A10-7850K �� 4,774
G1610 + HD7750 �� 9,029
���������̃X�R�A�������ݗ�
A10-7850K �� 24.4%
G1610 + HD7750 �� 19.1%
������d��
A10-7850K �� 143W�ȏ�
G1610 + HD7750 �� 87W
�����i
A10-7850K �� 21,980�~
G1610 + HD7750 �� 12,670�~
���؋�����
G1610 + HD7750 �� 11,171
http://youtu.be/wMXUbmb_LxA
G1610 + HD7750 �� 9,029
http://youtu.be/uPj5dkTdskU
(߄t�) A10-7850K���Z�������ɎS�s���܂���
(߄t�) ���ɒɂ��͍̂����׃e�X�g��2�R�A�̃Z�������ɎS�s�������ł�
(߄t�) ���C����������VRAM�����L���Ă���7850K�́A�������Ƀ��������p���N����4�R�A�������ꂸ�����\�͂��K�^�������܂�
�R(߄t�)� �����
���ᕉ��
A10-7850K �� 6,320
G1610 + HD7750 �� 11,171
���������i�G���R�Ȃ���j
A10-7850K �� 4,774
G1610 + HD7750 �� 9,029
���������̃X�R�A�������ݗ�
A10-7850K �� 24.4%
G1610 + HD7750 �� 19.1%
������d��
A10-7850K �� 143W�ȏ�
G1610 + HD7750 �� 87W
�����i
A10-7850K �� 21,980�~
G1610 + HD7750 �� 12,670�~
���؋�����
G1610 + HD7750 �� 11,171
http://youtu.be/wMXUbmb_LxA
G1610 + HD7750 �� 9,029
http://youtu.be/uPj5dkTdskU
(߄t�) A10-7850K���Z�������ɎS�s���܂���
(߄t�) ���ɒɂ��͍̂����׃e�X�g��2�R�A�̃Z�������ɎS�s�������ł�
(߄t�) ���C����������VRAM�����L���Ă���7850K�́A�������Ƀ��������p���N����4�R�A�������ꂸ�����\�͂��K�^�������܂�
�R(߄t�)� �����
���Z�������֘A����
SF4�x���` 1080p 176fps
http://youtu.be/-W98b6WYWDQ
SF4��DQ10�x���`���Ȃ���FF14�x���` 7,389
http://youtu.be/fD2J0_fmuiI
�R(߄t�)� ���������
SF4�x���` 1080p 176fps
http://youtu.be/-W98b6WYWDQ
SF4��DQ10�x���`���Ȃ���FF14�x���` 7,389
http://youtu.be/fD2J0_fmuiI
�R(߄t�)� ���������
>>527
PPC��x86��AMD64�̃y�[�X��10�N�����Ȃ�ă��x������Ȃ�
PPC��x86��AMD64�̃y�[�X��10�N�����Ȃ�ă��x������Ȃ�
�yPC�z Nexus 7�V���f���A�C���e��Bay Trail���ڂ�
http://www.emsodm.com/html/2014/01/20/1390193353468.html
http://www.emsodm.com/html/2014/01/20/1390193353468.html
534 �F,,�E�L�́M�E,,�j��-�������F2014/01/20(��) 19:22:09.55 ID:9NoCp0WJ
>>532
Apple��64�r�b�g��Intel64�����ł����āuAMD64�v����Ȃ��ł���B
AMD64�Ɍ������Ă閽�߂��J�[�l���ɑg�ݍ���ł���B
#UD���g���b�v��������H
�J�[�l����Ԃŗ�O�Ȃ�Ĕ��N���E���Ă��Ă�����ł����H
Apple��64�r�b�g��Intel64�����ł����āuAMD64�v����Ȃ��ł���B
AMD64�Ɍ������Ă閽�߂��J�[�l���ɑg�ݍ���ł���B
#UD���g���b�v��������H
�J�[�l����Ԃŗ�O�Ȃ�Ĕ��N���E���Ă��Ă�����ł����H
�J�[�l�����������������������Ă����̂��P���^�b�L�[
536 �F,,�E�L�́M�E,,�j��-�������F2014/01/20(��) 19:43:58.79 ID:9NoCp0WJ
�T���_�[�X�卲�̓t���[�f��
>>507
�Ԃ����Ⴏ�A�p���s�[��Bay Trail�ŏ[��w
>>512
> ����Ȃ��Ƃ����ă��X�N�����߂�͔̂n���������Ȃ�
�܂�AM$���i���w�������o�c�҂��o�J���Ă��Ƃł���w
�Ԃ����Ⴏ�A�p���s�[��Bay Trail�ŏ[��w
>>512
> ����Ȃ��Ƃ����ă��X�N�����߂�͔̂n���������Ȃ�
�܂�AM$���i���w�������o�c�҂��o�J���Ă��Ƃł���w
538 �F,,�E�L�́M�E,,�j��-�������F2014/01/20(��) 21:10:19.04 ID:9NoCp0WJ
�V�`�W�N�O���炢�ɊJ����������Ă��V�X�e����NT4.0�Ƃ��g���Ă���
������Ń��X�N�Ǘ��ł���Ȃ炻��ł�����Ȃ���
������Ń��X�N�Ǘ��ł���Ȃ炻��ł�����Ȃ���
>>533
�Ȃ�ł�����x86�o�����̂��Ǝv�������ǁA64bit�����łɏ�����Ă邩����Ă��Ƃ��ȁBARM��64bit��nexus�ɂ���ɂ͂܂��������邾�낤���B
�Ȃ�ł�����x86�o�����̂��Ǝv�������ǁA64bit�����łɏ�����Ă邩����Ă��Ƃ��ȁBARM��64bit��nexus�ɂ���ɂ͂܂��������邾�낤���B
Tizen OS�𓋍ڂ����uZTE Geek�v��2������MWC2014�ŏo�W��
http://rbmen.blogspot.jp/2014/01/tizen-oszte-geek2mwc2014.html
http://rbmen.blogspot.jp/2014/01/tizen-oszte-geek2mwc2014.html
541 �F,,�E�L�́M�E,,�j��-�������F2014/01/21(��) 00:45:10.75 ID:g9d+mgAX
��������Ƃ������R���p�C�������C�u���������蓮��̎��т��܂��Ȃ��ł�
ARMv7A�l�C�e�B�u�ŏ����Ă��R�[�h��v8�i64�r�b�g�j�����ɃR���p�C������
��Ԃ��������邩��A���ł�����x86�Ή������Ă��܂����Ƃ����x���_�[��
�o�Ă����ȁB
ARMv7A�l�C�e�B�u�ŏ����Ă��R�[�h��v8�i64�r�b�g�j�����ɃR���p�C������
��Ԃ��������邩��A���ł�����x86�Ή������Ă��܂����Ƃ����x���_�[��
�o�Ă����ȁB
x86�ł�64�r�b�g�Ή����܂߂�Intel�����\�[�X�������Ԋ����Ă���悤������
�\���炵�ď��Ȃ��Ƃ�Nexus�Ɏg���邩���ˁA���Ă������x�ɂ͂Ȃ��Ă���̂��낤
Google�I�ɂ͖��߃Z�b�g�����ł����Ă�����Ȃ��̂��낤���c�c
Imagination���撣���MIPS��Nexus�Ƃ��o����낤����
�\���炵�ď��Ȃ��Ƃ�Nexus�Ɏg���邩���ˁA���Ă������x�ɂ͂Ȃ��Ă���̂��낤
Google�I�ɂ͖��߃Z�b�g�����ł����Ă�����Ȃ��̂��낤���c�c
Imagination���撣���MIPS��Nexus�Ƃ��o����낤����
543 �FSocket774�F2014/01/21(��) 02:59:55.79 ID:NGwpkBht
>>519
�}�C�N���\�t�g�͂��ꂾ�����v�����Ă���30�N���炢�T�|�[�g�����ł��̂�������O
�}�C�N���\�t�g�͂��ꂾ�����v�����Ă���30�N���炢�T�|�[�g�����ł��̂�������O
>>534
����Apple��AMD�g���Ȃ�A
AMD�ɂ����ɔ[�i����CPU�ɂ͑S���������ߓ����Ƃ��A
���Ƃ�OSX��AMD�œ����悤�ɏC�������������
����Apple��AMD�g���Ȃ�A
AMD�ɂ����ɔ[�i����CPU�ɂ͑S���������ߓ����Ƃ��A
���Ƃ�OSX��AMD�œ����悤�ɏC�������������
���������A�T�|�[�g�����邤���ł��A�g�ݍ���WinXP�g���Ă�悤�Ȍڋq�̑�����
����WindowsUpdate�Ȃ�ē��ĂĂȂ��킯�����A�ׂɃT�|�[�g���Ȃ��Ȃ��Ă��債�ĕς��Ȃ���
����WindowsUpdate�Ȃ�ē��ĂĂȂ��킯�����A�ׂɃT�|�[�g���Ȃ��Ȃ��Ă��債�ĕς��Ȃ���
���������m�[�K�[�h�ŏ\�����Č����̂�
PC�̃E�B���X����C����������Č����̂�
����ɂ�����Ċ�������
PC�̃E�B���X����C����������Č����̂�
����ɂ�����Ċ�������
�A�b�v�f�[�g���K�v�Ȃ̂́A�ʏ�̃N���C�A���gPC�Ƃ��Ďg������A
�C���^�[�l�b�g�T�[�o�Ƃ��Ďg�����肷��ꍇ�̘b�ł����āA
�g�ݍ��݃V�X�e���̑����̓A�b�v�f�[�g���Ȃ��Ă������悤�Ȋ��Ŏg���Ă�
�C���^�[�l�b�g�T�[�o�Ƃ��Ďg�����肷��ꍇ�̘b�ł����āA
�g�ݍ��݃V�X�e���̑����̓A�b�v�f�[�g���Ȃ��Ă������悤�Ȋ��Ŏg���Ă�
�������f�͋֕���
http://28byteslater.com/2009/10/29/ocr-injection/
http://28byteslater.com/2009/10/29/ocr-injection/
>>548
�v���ɓK�ɔz������Ă��Ȃ��ꍇ�A�{���ɃA�b�v�f�[�g�s�v���ǂ����V�X�e�����č�����̂��܂�����͂���c�c
�v���ɓK�ɔz������Ă��Ȃ��ꍇ�A�{���ɃA�b�v�f�[�g�s�v���ǂ����V�X�e�����č�����̂��܂�����͂���c�c
>>549
����QR�R�[�h�ɂ����p�ł���������
���Ƃ��AQR�R�[�h�ɂ����ȃ��R�[�h����ĊǗ��ɗ��p���Ă�Ƃ���͑������A
���̃��R�[�h��SQL�C���W�F�N�V�����n���[�h�����Ă����A
�ǂݎ������DB�Ԃ�����ł��邩��
����QR�R�[�h�ɂ����p�ł���������
���Ƃ��AQR�R�[�h�ɂ����ȃ��R�[�h����ĊǗ��ɗ��p���Ă�Ƃ���͑������A
���̃��R�[�h��SQL�C���W�F�N�V�����n���[�h�����Ă����A
�ǂݎ������DB�Ԃ�����ł��邩��
552 �FSocket774�F2014/01/21(��) 12:53:50.07 ID:z/KmGWMP
���������̓���ڋq��������Ȃ��A�S���ʊO���̃t�@�E���h���r�W�l�X���C�ɂȂ��Ă����̂�
http://www.itmedia.co.jp/pcuser/spv/1312/05/news062_2.html
Intel�̔����̐����Z�p�ɑΉ����������̐v�c�[�����Ȃ�
��
http://cloud.watch.impress.co.jp/docs/column/virtual/20140117_631074.html
���܂ł̃v���Z�b�T�v�A�����Ŕ|���Ă����e��̃c�[���Ȃǂ����p�ł���
http://www.itmedia.co.jp/pcuser/spv/1312/05/news062_2.html
Intel�̔����̐����Z�p�ɑΉ����������̐v�c�[�����Ȃ�
��
http://cloud.watch.impress.co.jp/docs/column/virtual/20140117_631074.html
���܂ł̃v���Z�b�T�v�A�����Ŕ|���Ă����e��̃c�[���Ȃǂ����p�ł���
�uBay Trail�v���ڂ́uAndroid�v�^�u���b�g�A��2�l�����ɓo���
http://japan.cnet.com/news/service/35042789/
����ASUS���uNAS�v�ɐi�o�IASUS�O���[�v�̐V��NAS���[�J�[�uASUSTOR�v�̎��M�̂قǂ́H
http://akiba-pc.watch.impress.co.jp/docs/sp/20140121_630424.html
http://japan.cnet.com/news/service/35042789/
����ASUS���uNAS�v�ɐi�o�IASUS�O���[�v�̐V��NAS���[�J�[�uASUSTOR�v�̎��M�̂قǂ́H
http://akiba-pc.watch.impress.co.jp/docs/sp/20140121_630424.html
�V���i�̏��`�F�b�N���Ă�킩�邱�Ƃ���
���̋L���͂ǂ������˗��ŏ����ꂽ�̂��j���j�����ĉ{�����Ă����グ��ׂ�����
ttp://akiba-pc.watch.impress.co.jp/hotline/20121215/ni_cas602t.html
�v�����قǔ���ĂȂ�����CM�L�����������킯�ł���
���̋L���͂ǂ������˗��ŏ����ꂽ�̂��j���j�����ĉ{�����Ă����グ��ׂ�����
ttp://akiba-pc.watch.impress.co.jp/hotline/20121215/ni_cas602t.html
�v�����قǔ���ĂȂ�����CM�L�����������킯�ł���
����邩�ǂ����͂���Ȃ�����
���������Ȃ�܂���Ƃ̃C���^�r���[�L���͂ǂ���j���j�����ĉ{�����Ă����グ��ׂ����̂��Ă��ƂɂȂ��
>>554�̂�͊�ƌ����ł��������l�i������������553�̋L����
���@�u���[�G���h��NAS��ARM�v�Ƃ������[�J�[���������A��Ђł͑S��Intel�v���b�g�t�H�[�����̗p���Ă��܂����A�E�E
�̕�����������ƒ��ړ_���Ǝv���ē\�������ǂ�
���ƑO��Intel��CedarTrail���܂����肳���C���Ƃ����b���o�Ă����ǁA�^�[�Q�b�g��NAS���ȂƂ����C������
Ark�ɍڂ��ĂȂ�AtomD2701�Ƃ������̂��ڂ���NAS���o�Ă��Ă�����
���������Ȃ�܂���Ƃ̃C���^�r���[�L���͂ǂ���j���j�����ĉ{�����Ă����グ��ׂ����̂��Ă��ƂɂȂ��
>>554�̂�͊�ƌ����ł��������l�i������������553�̋L����
���@�u���[�G���h��NAS��ARM�v�Ƃ������[�J�[���������A��Ђł͑S��Intel�v���b�g�t�H�[�����̗p���Ă��܂����A�E�E
�̕�����������ƒ��ړ_���Ǝv���ē\�������ǂ�
���ƑO��Intel��CedarTrail���܂����肳���C���Ƃ����b���o�Ă����ǁA�^�[�Q�b�g��NAS���ȂƂ����C������
Ark�ɍڂ��ĂȂ�AtomD2701�Ƃ������̂��ڂ���NAS���o�Ă��Ă�����
�o�b�t�@����NAS���āA������Ƃł͂ӂ��ɓ������Ă�Ƃ��낪�����Ăт����肵��
��ɑ��ƌ���SI�݂����Ȃ��Ƃ�������ĂȂ��l�������猋�\�s���R�Ȋ���������
��ɑ��ƌ���SI�݂����Ȃ��Ƃ�������ĂȂ��l�������猋�\�s���R�Ȋ���������
4K��������K�ɕҏW�ł���PC���l����X��
http://anago.2ch.net/test/read.cgi/jisaku/1390301181/
http://anago.2ch.net/test/read.cgi/jisaku/1390301181/
SB�N���G�C�e�B�u�A�����X�����f�W�^���T�C�l�[�W - �C���e���Ƌ���
http://news.mynavi.jp/news/2014/01/21/453/index.html
Google���uNexus 8�v��2014�N���ɓ�������Digitimes��
http://rbmen.blogspot.jp/2014/01/googlenexus-82014digitimes.html
http://news.mynavi.jp/news/2014/01/21/453/index.html
Google���uNexus 8�v��2014�N���ɓ�������Digitimes��
http://rbmen.blogspot.jp/2014/01/googlenexus-82014digitimes.html
���N�̍������炨�����߂�MAC������
�n�b�L���g�b�V���ł͖����ł���������������
�n�b�L���g�b�V���ł͖����ł���������������
�q��ŊJ�����Ă��CPU���SSD���@���ɏd�v���ǂ��킩��
���Ƃ�i7��4�R�A�ł�HDD���Ă����ł����_���A��ƌ����K�^����
VS�ŃX�N���[��������������10���t���[�Y�Ƃ��C�~�t�������
���Ƃ�i7��4�R�A�ł�HDD���Ă����ł����_���A��ƌ����K�^����
VS�ŃX�N���[��������������10���t���[�Y�Ƃ��C�~�t�������
�t���[�Y�Ƃ͈��
�����HDD�̂�������Ȃ�
�V�X�e���J������ɂ́A
�V�X�e���h���C�u�A����ъJ���E�R���p�C���p�f�B�X�N��SSD�A��������16G�A
CPU��Sandy�ȍ~��core i7���炢�~������
�V�X�e���h���C�u�A����ъJ���E�R���p�C���p�f�B�X�N��SSD�A��������16G�A
CPU��Sandy�ȍ~��core i7���炢�~������
�v���O�����̏ꍇ�͋t���ȁB
�Ȃ�ׂ����̈����p�\�R���ō�����ق��������B
�Ȃ�ׂ����̈����p�\�R���ō�����ق��������B
�H�H�H
HDD�̘b��ɂȂ�ƶض���������
�R���p�C�����邲�ƂɁA�R�[�q�[����A�����z�����肷��z�F
568 �F,,�E�L�́M�E,,�j��-�������F2014/01/22(��) 00:57:32.62 ID:f/+10yLV
Haswell�͓d���v�������o�����X�ݒ�ɂ��Ă����ƃA�C�h�����ɗ]�T��1GHz����܂�
�N���b�N���Ƃ�����ȁB
�������A�悭�����ȂƎv���B
�N���b�N���Ƃ�����ȁB
�������A�悭�����ȂƎv���B
AMD���Ɛ̂���800MHz�܂ŗ����Ă�
>>556
�����ɂ͂����A����Ƀo�b�N�A�b�v����@�\���֗��B
�����ɂ͂����A����Ƀo�b�N�A�b�v����@�\���֗��B
>>568
�ł��A���̏ȓd�͋@�\�����������āA���A���^�C���������K�v��
���Ӌ@��̃h���C�o���N���b�V��������s������������肷����
�ꕔ�̎��Ӌ@��́AOS��BIOS�ŏȓd�͌n�@�\��OFF�ɂ��Ȃ��Ƃ��܂��������Ȃ������肷��
�ł��A���̏ȓd�͋@�\�����������āA���A���^�C���������K�v��
���Ӌ@��̃h���C�o���N���b�V��������s������������肷����
�ꕔ�̎��Ӌ@��́AOS��BIOS�ŏȓd�͌n�@�\��OFF�ɂ��Ȃ��Ƃ��܂��������Ȃ������肷��
>>556
��/��/�����w�Z��ۈ�/�c�t���Ȃɂ��[�����Ă��B
��/��/�����w�Z��ۈ�/�c�t���Ȃɂ��[�����Ă��B
Intel�AIPTV���Ƃ�Verizon�ɔ��p
ttp://pc.watch.impress.co.jp/docs/news/20140122_631771.html
>Intel�����p����̂́AOnCue�ƌĂ��IPTV�v���b�g�t�H�[���̒m�I���Y������т��̑��̎��Y�B
>�܂��A��350�l����Intel Media���ƕ��̏]�ƈ����قڑS�āA�č��̒ʐM���Ǝ҂ł���Verizon�ւƓ]�Ђ���B
>���p�͓��ǂ̏��F���o�āA2014�N��1�l���������Ɋ�������\��B
ttp://pc.watch.impress.co.jp/docs/news/20140122_631771.html
>Intel�����p����̂́AOnCue�ƌĂ��IPTV�v���b�g�t�H�[���̒m�I���Y������т��̑��̎��Y�B
>�܂��A��350�l����Intel Media���ƕ��̏]�ƈ����قڑS�āA�č��̒ʐM���Ǝ҂ł���Verizon�ւƓ]�Ђ���B
>���p�͓��ǂ̏��F���o�āA2014�N��1�l���������Ɋ�������\��B
�ǂ���ZTE��Tizen�X�}�z��Intel�����Ă���ۂ�
http://www.digitaltrends.com/mobile/tizen-powered-zte-geek-smartphone-on-display-at-mwc-2014/
http://www.androidauthority.com/zte-geek-tizen-mwc-337780/
http://www.digitaltrends.com/mobile/tizen-powered-zte-geek-smartphone-on-display-at-mwc-2014/
http://www.androidauthority.com/zte-geek-tizen-mwc-337780/
�쐬�}�V���͂���ł������C�ŏI���i��MMX Pentium��K6���x�̃}�V���ł��y�X�����A�v���ɂ��ė~�����
Broadwell�܂��H
�V����Classmate PC 2���
http://thejournal.com/articles/2014/01/22/intel-reveals-android-powered-education-tablet-new-classmate-pc-reference-designs.aspx
http://thejournal.com/articles/2014/01/22/intel-reveals-android-powered-education-tablet-new-classmate-pc-reference-designs.aspx
Broadwell�͂ǂꂭ�炢���\�グ�Ă��邩���������
���N���ɂł��甃������
Has-E�͑O�|�����ė~������
���N���ɂł��甃������
Has-E�͑O�|�����ė~������
�f�X�N�g�b�v�p�ɓW�J���Ȃ��Ƃ��납�炨�@����������
Broadwell��GT4e�̑��݂̗L�����C�ɂȂ��
Skyleke��Gen.9��EU�̃R�A��Lalabee�̂悤��x86�R�A�ɒu�������̂����C�ɂȂ�
�������AeDRAM�̗L���ł������܂Ō��I�ɐ��\���オ��̂̓X�Q�[��
Skyleke��Gen.9��EU�̃R�A��Lalabee�̂悤��x86�R�A�ɒu�������̂����C�ɂȂ�
�������AeDRAM�̗L���ł������܂Ō��I�ɐ��\���オ��̂̓X�Q�[��
581 �FSocket774�F2014/01/23(��) 00:19:57.28 ID:yKnjw/FA
Skylake��������
GT4e�Ƃ������Ă�̂��O��������ˁH
��������2.5D TSV�����̂ɂȂ�Ȃ��B
>>579
Broadwell-K�ǂ��Ȃ��������H
Broadwell-K�ǂ��Ȃ��������H
GT4e�ق����B
GT5 Prologue�͂�
�v�����[�O���@�����
Intel�̓v�����[�O����J���@
�@�\�u�b�N�����߂čڂ�������ł�disable
enable �ɂȂ�͎̂��̐���
�@�\�u�b�N�����߂čڂ�������ł�disable
enable �ɂȂ�͎̂��̐���
���̂����������̘b������
�A�����J�ŃC���e���̊�u����O�ɍs�������ǁA����CPU�͂܂��Γd�͌�������������
���ʂ̉Ɠd�ɔ�ׂĂ�95%�ȏ㉺����Ă��āA�܂��܂��ȓd�͉��A�����\�����\
���Ƃ���300w���x�̃J�[�{���q�[�^�[�������g������A��߂Â���ƔM���Ă₯�ǂ���
�Ƃ��낪�f�X�N�g�b�v��600w����800w���̎g���Ă���̂ɁA�P�[�X�t�@���Ƃ��ő���Ă��܂��A�{����600w�g������P�[�X���M�ŗn���邭�炢�M���Ȃ��A150w�ł��₯�ǂ��邭�炢�ɔM���o��
�����������Ɗ��d�r�ł����A�X�`���[�����x�Ȃ�Ă���������邾��A���w�Z�̎����Ȃ��������H
������Ivy��20w���x�ł���u�����������v�Ƃ����̂��G���W�j�A�̍l���B
�ȓd�͂ɂ���Ɣ��M���}�����āA�N���b�N�����Ȃ��̂ڂ�ɂȂ�B
2020�N���͍�����n�C�G���h��10�{�ȏ�̐��\��10w���A��p���K�v�Ȃ��Ȃ鎞�オ������Č����Ă��A3.5�C���`��2.5�C���`��HDD�͂Ȃ��Ȃ��āA1�C���`�ȉ��̃V���R���h���C�u���嗬�ɂȂ�Ƃ��B
�X�}�z���x�̑傫����4770k��10�{+�X�g���[�W��20TB�ȏ�AGT690�̐��{��ł�����d�͂�1w���x�ɂȂ�B
�m�[�g�Ȃ�2�T�Ԉȏ�[�d�Ȃ��Ŏg���郂�f�����o����A�t�����܂��܂��ȓd�͂��i�ށALED�̎��̐��オ�T���Ă�����Ă��B
PC�͊e�p�[�c1w�����ō����\�����\�����Ă��A�o�b�e���[�����`�E���̎����㌤���i��ł���B
�A�����J�ŃC���e���̊�u����O�ɍs�������ǁA����CPU�͂܂��Γd�͌�������������
���ʂ̉Ɠd�ɔ�ׂĂ�95%�ȏ㉺����Ă��āA�܂��܂��ȓd�͉��A�����\�����\
���Ƃ���300w���x�̃J�[�{���q�[�^�[�������g������A��߂Â���ƔM���Ă₯�ǂ���
�Ƃ��낪�f�X�N�g�b�v��600w����800w���̎g���Ă���̂ɁA�P�[�X�t�@���Ƃ��ő���Ă��܂��A�{����600w�g������P�[�X���M�ŗn���邭�炢�M���Ȃ��A150w�ł��₯�ǂ��邭�炢�ɔM���o��
�����������Ɗ��d�r�ł����A�X�`���[�����x�Ȃ�Ă���������邾��A���w�Z�̎����Ȃ��������H
������Ivy��20w���x�ł���u�����������v�Ƃ����̂��G���W�j�A�̍l���B
�ȓd�͂ɂ���Ɣ��M���}�����āA�N���b�N�����Ȃ��̂ڂ�ɂȂ�B
2020�N���͍�����n�C�G���h��10�{�ȏ�̐��\��10w���A��p���K�v�Ȃ��Ȃ鎞�オ������Č����Ă��A3.5�C���`��2.5�C���`��HDD�͂Ȃ��Ȃ��āA1�C���`�ȉ��̃V���R���h���C�u���嗬�ɂȂ�Ƃ��B
�X�}�z���x�̑傫����4770k��10�{+�X�g���[�W��20TB�ȏ�AGT690�̐��{��ł�����d�͂�1w���x�ɂȂ�B
�m�[�g�Ȃ�2�T�Ԉȏ�[�d�Ȃ��Ŏg���郂�f�����o����A�t�����܂��܂��ȓd�͂��i�ށALED�̎��̐��オ�T���Ă�����Ă��B
PC�͊e�p�[�c1w�����ō����\�����\�����Ă��A�o�b�e���[�����`�E���̎����㌤���i��ł���B
590 �F,,�E�L�́M�E,,�j��-�������F2014/01/23(��) 02:59:05.40 ID:FSs5i7Bq
�Ȃ�̃G���W�j�A����
>>589
���̘_�����ƃl�g�o�������������Ď��ɂȂ��
���̘_�����ƃl�g�o�������������Ď��ɂȂ��
��p�K�v�Ȃ��p�\�R���Ȃ�ăp�\�R������Ȃ�
�������G�Ђ�����ɍi��ƁB
>>589
���Ⴀ����2020�N�ɂ����Ȃ�Ȃ������炠�Ȃ��͉����Ă���܂����H
10�N�O�ɂ�2010�N�ɂ�100�R�A��CPU�ɂȂ��Ă�Ƃ�
1THz�ɂȂ��Ă�Ƃ���CPU�����S�{�����ň����Ƃ�
�R�t���ɎU�X�U���Ă��肾��
���Ⴀ����2020�N�ɂ����Ȃ�Ȃ������炠�Ȃ��͉����Ă���܂����H
10�N�O�ɂ�2010�N�ɂ�100�R�A��CPU�ɂȂ��Ă�Ƃ�
1THz�ɂȂ��Ă�Ƃ���CPU�����S�{�����ň����Ƃ�
�R�t���ɎU�X�U���Ă��肾��
�M����ق����ǂ������Ă���
���m�̂����ɂł�����
589���z�������̐��S�~�ł��鎖�͂ЂƖڌ���Ε����邾�낤
6�N�ザ��������E����K��ĂȂ���
�ǂ�ȂɊ撣���Ă�2�N�Ő��\��2�{�������Ă����ď���d�͂�2�{�������Ă������x�����x
�ޗ���ς���K�v�����o�Ă���������E�����ĂȂ����V���R�����g���Ă���ȏセ��ȏ�̌���͖���
���m�̂����ɂł�����
589���z�������̐��S�~�ł��鎖�͂ЂƖڌ���Ε����邾�낤
6�N�ザ��������E����K��ĂȂ���
�ǂ�ȂɊ撣���Ă�2�N�Ő��\��2�{�������Ă����ď���d�͂�2�{�������Ă������x�����x
�ޗ���ς���K�v�����o�Ă���������E�����ĂȂ����V���R�����g���Ă���ȏセ��ȏ�̌���͖���
Intel�A�V�����������10" Android�^�u���b�g���J - 12���Ԃ̒����ԋ쓮
http://news.mynavi.jp/news/2014/01/23/047/
���h�o�V�ƃ\�t�}�b�v��ASUS�uVivoTab Note 8�v���\���t���A24������
�`���R���f�W�^�C�U���ڂ�8�^Windows 8.1�^�u���b�g
http://pc.watch.impress.co.jp/docs/news/20140123_632019.html
http://news.mynavi.jp/news/2014/01/23/047/
���h�o�V�ƃ\�t�}�b�v��ASUS�uVivoTab Note 8�v���\���t���A24������
�`���R���f�W�^�C�U���ڂ�8�^Windows 8.1�^�u���b�g
http://pc.watch.impress.co.jp/docs/news/20140123_632019.html
>>589
�d�C�G�l���M�[��100%�M�G�l���M�[�ɕϊ������鎖�Ɏ��S�̃G���W�j�A���Ȃ�
���M��łȂ����m�̔��M�͎����ԃG���W���̔��M�Ɠ��l�ɒP�Ȃ�G�l���M�[�����ʂ����H
���������f�X�N�g�b�v��600W����800W���̂��ē��ړd���̍ő�o�͂̎������E�E�E
�d�C�G�l���M�[��100%�M�G�l���M�[�ɕϊ������鎖�Ɏ��S�̃G���W�j�A���Ȃ�
���M��łȂ����m�̔��M�͎����ԃG���W���̔��M�Ɠ��l�ɒP�Ȃ�G�l���M�[�����ʂ����H
���������f�X�N�g�b�v��600W����800W���̂��ē��ړd���̍ő�o�͂̎������E�E�E
>>595
���������B
10�N���炢��������High-K��g���C�Q�[�g�ⓝ���d�����M�����[�^�ȂǑS�ďo�����������ʂ��R�����B
�������̐�����ʂ���قNJv�V�I�ɂȂ肻���ȋZ�p�Ȃ�ĕ��������Ȃ����B
���\�͔������i����10%���\�オ���ăA�[�L���ς�鎞��5%���\�オ�邩���Ċ�������B
GPU���\�͂��̐�܂��オ��Ǝv���B�܂����s������������������ȁB
���������B
10�N���炢��������High-K��g���C�Q�[�g�ⓝ���d�����M�����[�^�ȂǑS�ďo�����������ʂ��R�����B
�������̐�����ʂ���قNJv�V�I�ɂȂ肻���ȋZ�p�Ȃ�ĕ��������Ȃ����B
���\�͔������i����10%���\�オ���ăA�[�L���ς�鎞��5%���\�オ�邩���Ċ�������B
GPU���\�͂��̐�܂��オ��Ǝv���B�܂����s������������������ȁB
�v���O���}�����낤
�g���C�Q�[�g�ɂ͂������肵��
���m�Ȓm�������n�������Ⴂ���Ă�悤�����A���O�̌����Ă�CPU�̐����Ȃ�Č�����2�N��2�{�ɂȂȂ��ĂȂ�����
����������AVX�Ή�����Ƃ��ŃX�y�b�N��ł͈ꉞ2�{�ɋ߂����\�ɂ͂Ȃ��Ă�悤������
CPU�ł����������͂��O�������Ă���悤�ɂ��s�����������Ȃ�����܂��܂��オ��͂�
�܂����X�i�ǂ�ȂɊ撣���Ă��j���Ă����Ⴆ�b�ł͂��邪�ȁA���������Ⴂ����Ȃ�
2010�N�܂ł��}���`�R�A�Ȃ�2020�N�܂ł͕s���������������L�ш惁�����̐��\���サ���Ȃ����낤
GPU�������������Ń��������]�v�ɑ��������肷���Ă�
��CPU�Ȃ��2030�N�ł�����������
�d�C�ɕϊ�����̂����ʂɂȂ邩��S�����ŏ���������Ɩ��p�Ȃ炠�肦�邾�낤����
��ʗp�r�Ȃ�CPU����H���S���s�������̕������p�I
����������AVX�Ή�����Ƃ��ŃX�y�b�N��ł͈ꉞ2�{�ɋ߂����\�ɂ͂Ȃ��Ă�悤������
CPU�ł����������͂��O�������Ă���悤�ɂ��s�����������Ȃ�����܂��܂��オ��͂�
�܂����X�i�ǂ�ȂɊ撣���Ă��j���Ă����Ⴆ�b�ł͂��邪�ȁA���������Ⴂ����Ȃ�
2010�N�܂ł��}���`�R�A�Ȃ�2020�N�܂ł͕s���������������L�ш惁�����̐��\���サ���Ȃ����낤
GPU�������������Ń��������]�v�ɑ��������肷���Ă�
��CPU�Ȃ��2030�N�ł�����������
�d�C�ɕϊ�����̂����ʂɂȂ邩��S�����ŏ���������Ɩ��p�Ȃ炠�肦�邾�낤����
��ʗp�r�Ȃ�CPU����H���S���s�������̕������p�I
MRAM�����p������ADRAM���݂̉��i�E���x��SRAM�ɋ߂����x�ɂȂ�
MRAM�́A�s�������ĕ����ɒ��ڂ���Ă邯�ǁA
�ނ���SRAM�ɋ߂����x���Ă����Ƃ���𗘗p����܂��܂��������\����ˁH
MRAM�́A�s�������ĕ����ɒ��ڂ���Ă邯�ǁA
�ނ���SRAM�ɋ߂����x���Ă����Ƃ���𗘗p����܂��܂��������\����ˁH
604 �F,,�E�L�́M�E,,�j��-�������F2014/01/23(��) 19:22:53.63 ID:FSs5i7Bq
���������M���邱�Ƃ����p�̔��c���Ăƈꏏ�ɂ���Ă�����킯����
605 �F,,�E�L�́M�E,,�j��-�������F2014/01/23(��) 19:27:25.80 ID:FSs5i7Bq
>>602
SRAM�ɏ����鑬�x�Ƃ����Ă������܂őg�ݍ��݃`�b�v�ł̐��\��ł�����
�f�X�N�g�b�v��GH���I�[�_�[�œ����Ă�L���b�V���������̑�ւɂȂ邩�Ƃ�����
���̂������������Ǝv���B
�g���ĂȂ��Ƃ��͑����ɃX���[�v�������X�}�z�E�^�u���b�g�Ƃ��A
���邢�̓T�[�o��memcached�݂����ȃA�v���������Ƃ���
�g���ɂ͂������ǁA�f�X�N�g�b�v�N���X�̃A�v���Ɏg����Ƃ�
�ƂĂ��v���Ȃ�
SRAM�ɏ����鑬�x�Ƃ����Ă������܂őg�ݍ��݃`�b�v�ł̐��\��ł�����
�f�X�N�g�b�v��GH���I�[�_�[�œ����Ă�L���b�V���������̑�ւɂȂ邩�Ƃ�����
���̂������������Ǝv���B
�g���ĂȂ��Ƃ��͑����ɃX���[�v�������X�}�z�E�^�u���b�g�Ƃ��A
���邢�̓T�[�o��memcached�݂����ȃA�v���������Ƃ���
�g���ɂ͂������ǁA�f�X�N�g�b�v�N���X�̃A�v���Ɏg����Ƃ�
�ƂĂ��v���Ȃ�
PC�œd�͂��M�ȊO�ɉ��ɂȂ�Ƃ����̂�ww
�M�ȊO���ăt�@���̉^���G�l���M�[��LED�����v���炢����B
�������A�������Ō�͔M�ɂȂ�킯�����B
�M�ȊO���ăt�@���̉^���G�l���M�[��LED�����v���炢����B
�������A�������Ō�͔M�ɂȂ�킯�����B
�ш�̃{�g���l�b�N�������Ă���̂̓������f�q�̓����ł͂Ȃ��ʐM�Ȃ̂�
MRAM�����p������Ă��ڑ����@�����ƕς��Ȃ��̂Ȃ�Αш�͂��܂���サ�Ȃ��ł��傤��
MRAM�����p������Ă��ڑ����@�����ƕς��Ȃ��̂Ȃ�Αш�͂��܂���サ�Ȃ��ł��傤��
���E�ō��̋Z�p���ւ�T���X���ł���\�[���[�^�u���b�g�͎����ł��Ă��Ȃ���
Broadwell�܂��H
�����ɂ͍�����n�C�G���h��10�{�ȏ�̐��\��10w���A
��p���K�v�Ȃ��Ȃ鎞�オ������ĒN���������Ă��B
3.5�C���`��2.5�C���`��HDD�͂Ȃ��Ȃ��āA1�C���`�ȉ��̃V���R���h���C�u���嗬�ɂȂ�Ƃ��B
�X�}�z���x�̑傫����4770k��10�{+�X�g���[�W��20TB�ȏ�AGT690�̐��{��ł�����d�͂�1w���x�ɂȂ�Ƃ��B
��p���K�v�Ȃ��Ȃ鎞�オ������ĒN���������Ă��B
3.5�C���`��2.5�C���`��HDD�͂Ȃ��Ȃ��āA1�C���`�ȉ��̃V���R���h���C�u���嗬�ɂȂ�Ƃ��B
�X�}�z���x�̑傫����4770k��10�{+�X�g���[�W��20TB�ȏ�AGT690�̐��{��ł�����d�͂�1w���x�ɂȂ�Ƃ��B
MRAM�̓R�X�g�I�ɂ܂����y���Ȃ��Ƃǂ��ɂ��Ȃ��
�ł�DRAM�̔��������E�ɋ߂�����s�������̃����b�g���l���ɓ����Ώ��^�[���ł̑����̕��y�͊m��
�L�ш惁�����������̂��̂Ɣ�ׂ�ƃR�X�g������
�ǂ��������\���N�����Ă��Ď��v�̍����X�}�z���x���Ȃ�p�r�ɉ�����3�N��ȍ~�ɍ̗p���ꂻ������
�e�ʂ��傫���f�X�N�g�b�v�ɍ~��Ă���͍̂L�ш惁�����ł�6�N�͗]�T�ł����邾�낤��
�f�X�N�g�b�v�͎��v���Ȃ����݊�����R�X�g�d���ŃM���M���܂ŕ��ʂ�DDR4�ň������葱������
�������X�}�z�̍L�ш扻�̓f�X�N�g�b�v��葬��
DDR3��2ch��20G�A4ch��40G�Ȃ̂ɃX�}�z��50G�N���X���̗p���悤�Ƃ��Ă���
GPU���������̂����œ��ł��ɂȂ��Ă��Ă邵���������ǂ��ɂ����Ȃ��ƕ�������2�{��������
�X�}�z��GPU�Ȃ烁�����̓���ւ����Ȃ����݊��������܂�C�ɂ��Ȃ��Ă������琻�i����6�N������Ȃ����낤
�ł�DRAM�̔��������E�ɋ߂�����s�������̃����b�g���l���ɓ����Ώ��^�[���ł̑����̕��y�͊m��
�L�ш惁�����������̂��̂Ɣ�ׂ�ƃR�X�g������
�ǂ��������\���N�����Ă��Ď��v�̍����X�}�z���x���Ȃ�p�r�ɉ�����3�N��ȍ~�ɍ̗p���ꂻ������
�e�ʂ��傫���f�X�N�g�b�v�ɍ~��Ă���͍̂L�ш惁�����ł�6�N�͗]�T�ł����邾�낤��
�f�X�N�g�b�v�͎��v���Ȃ����݊�����R�X�g�d���ŃM���M���܂ŕ��ʂ�DDR4�ň������葱������
�������X�}�z�̍L�ш扻�̓f�X�N�g�b�v��葬��
DDR3��2ch��20G�A4ch��40G�Ȃ̂ɃX�}�z��50G�N���X���̗p���悤�Ƃ��Ă���
GPU���������̂����œ��ł��ɂȂ��Ă��Ă邵���������ǂ��ɂ����Ȃ��ƕ�������2�{��������
�X�}�z��GPU�Ȃ烁�����̓���ւ����Ȃ����݊��������܂�C�ɂ��Ȃ��Ă������琻�i����6�N������Ȃ����낤
�����Ȃɂ����I�ȕω�������Ƃ�����f�ނ��ς�邭�炢�̂��Ƃ��Ȃ��ƌ������̂���
CNT�z���͉��\�N�ゾ�H
�X�}�z�̓�������CPU/GPU�����Ȃ��p�b�P�[�W���ɓ����Ă邩��
���_�I�ɑш敝�͏グ�₷��
PC�́ACPU�̓\�P�b�g���A���������\�P�b�g�����Ă������������邩��A
�ǂ�����Ă����܂�ш���グ��Ȃ�
�������@�Ƃ��ẮAPS4�݂����Ƀ�������CPU���͂t������Ƃ��A
�������́ACPU�Ƃ��Ȃ��p�b�P�[�W�ɋ���L4$�Ȃ�����Ƃ�
���_�I�ɑш敝�͏グ�₷��
PC�́ACPU�̓\�P�b�g���A���������\�P�b�g�����Ă������������邩��A
�ǂ�����Ă����܂�ш���グ��Ȃ�
�������@�Ƃ��ẮAPS4�݂����Ƀ�������CPU���͂t������Ƃ��A
�������́ACPU�Ƃ��Ȃ��p�b�P�[�W�ɋ���L4$�Ȃ�����Ƃ�
>>607
�ʐM���ă������ш�Ƃ��̂��ƁH
�ł��Ȃ�őш���Ă������Ƃ����i�����Ȃ��낤
�Ⴆ��DDR3���GDDR5�̂ق������炩�ɑ���
�Z�p�I�ɂ�GDDR5�����̑ш�͉\�Ȃ͂�����ˁH
�Ȃ�ł������Ɛi�����Ȃ��낤
SSD�̑��x�Ƃ��ɂ������邯�ǂ�
�n���Ȃ��Ǝ��₵�Ă��炲�߂��
�ʐM���ă������ш�Ƃ��̂��ƁH
�ł��Ȃ�őш���Ă������Ƃ����i�����Ȃ��낤
�Ⴆ��DDR3���GDDR5�̂ق������炩�ɑ���
�Z�p�I�ɂ�GDDR5�����̑ш�͉\�Ȃ͂�����ˁH
�Ȃ�ł������Ɛi�����Ȃ��낤
SSD�̑��x�Ƃ��ɂ������邯�ǂ�
�n���Ȃ��Ǝ��₵�Ă��炲�߂��
GPU����CPU�ŃO���t�B�b�N�̃v���O�������Ă邪�A
����ς胁�����ш悪�l�b�N���ȁB
���Z�͑������₵�Ă�fps�قƂ�Ǖς��Ȃ����A�o�b�t�@�A�N�Z�X���������r�[�K�N���Ɨ�����B
HMC�ł����s��႟�A���Ȃ���P�����Ȃ����ȁB
����ς胁�����ш悪�l�b�N���ȁB
���Z�͑������₵�Ă�fps�قƂ�Ǖς��Ȃ����A�o�b�t�@�A�N�Z�X���������r�[�K�N���Ɨ�����B
HMC�ł����s��႟�A���Ȃ���P�����Ȃ����ȁB
>>615
�\�P�b�g�̂Ă�Α����ł����
CPU������������ɒ��t������Α����ł���
���C���i�b�v�̏_��Ƃ���������D�悵�Ă邩�獡�̂悤�ɂȂ��Ă邾��
�\�P�b�g�̂Ă�Α����ł����
CPU������������ɒ��t������Α����ł���
���C���i�b�v�̏_��Ƃ���������D�悵�Ă邩�獡�̂悤�ɂȂ��Ă邾��
�����I�Ȏ���Ȃ̂łȂ�Ƃ�
�]������������Ȃ�Ȃ�Ƃ��Ȃ肻���Ȃ��������I�Ȗ��͂��ێ������Ă̂ɓ��
�ŏI�I�ɂ͔����ɒ��˕Ԃ��Ĕ���Ȃ�
�]������������Ȃ�Ȃ�Ƃ��Ȃ肻���Ȃ��������I�Ȗ��͂��ێ������Ă̂ɓ��
�ŏI�I�ɂ͔����ɒ��˕Ԃ��Ĕ���Ȃ�
����͌݊����ƃR�X�g�̈ꌾ�ŕЕt����
�R�X�g�����Ă����\���オ�̊����ɂ��������͌���낤
SSD��NAND�̐��\���Ⴂ��������
���x�̂��߂ɕ�����Ə���d�͂��オ������Ȃǐ������Ȃ�
ReRAM���o�Ă����1�e���N���X�Ń��[�h�����C�g��1000M�ȏ�ɂȂ��Ă����������Ȃ�
�������݂���40M��400M�ʂ̍�������
SRAM�͐��i�m�b�AMRAM��10�i�m�b�ȏ�
CPU�L���b�V������Ɛ��\�ቺ��������
L4�L���b�V���̑�e�ʃ������Ȃ�s����������
�R�X�g�����Ă����\���オ�̊����ɂ��������͌���낤
SSD��NAND�̐��\���Ⴂ��������
���x�̂��߂ɕ�����Ə���d�͂��オ������Ȃǐ������Ȃ�
ReRAM���o�Ă����1�e���N���X�Ń��[�h�����C�g��1000M�ȏ�ɂȂ��Ă����������Ȃ�
�������݂���40M��400M�ʂ̍�������
SRAM�͐��i�m�b�AMRAM��10�i�m�b�ȏ�
CPU�L���b�V������Ɛ��\�ቺ��������
L4�L���b�V���̑�e�ʃ������Ȃ�s����������
DDR�n�͗e�ʏd�������A������TSV�ڑ��̔�r�I���e�ʁE�L�ш惁���������������`��
�e�ʂƑш�̃o�����X�����͂�
�����L���b�V���Ƃ��ē�������Crystalwell�̎��_�Ń^�O�̎����R�X�g���o�J�ɂȂ�Ȃ��l�q������
�ǂ������`�Ԃɂ܂Ƃ߂�̂���
���������Ӗ��ł�Knights Landing���q���g�ɂȂ��Ă���͂������c�c�\�t�g�E�F�A�L���b�V���Ƃ��H
�e�ʂƑш�̃o�����X�����͂�
�����L���b�V���Ƃ��ē�������Crystalwell�̎��_�Ń^�O�̎����R�X�g���o�J�ɂȂ�Ȃ��l�q������
�ǂ������`�Ԃɂ܂Ƃ߂�̂���
���������Ӗ��ł�Knights Landing���q���g�ɂȂ��Ă���͂������c�c�\�t�g�E�F�A�L���b�V���Ƃ��H
>>621
�ł�SSD�̓W���W���Ɛi�����Ă邶���
��̑O�̃��������炢�̑��x�ɂ͂Ȃ��Ă�
�ł��Ȃ�Ői�����x���낤�H���Ă̂��C�ɂȂ�
CPU��������M�������Ă킩�邯��SSD�͉��������Ȃ낤
�ł�SSD�̓W���W���Ɛi�����Ă邶���
��̑O�̃��������炢�̑��x�ɂ͂Ȃ��Ă�
�ł��Ȃ�Ői�����x���낤�H���Ă̂��C�ɂȂ�
CPU��������M�������Ă킩�邯��SSD�͉��������Ȃ낤
>>614
> CPU�Ƃ��Ȃ��p�b�P�[�W�ɋ���L4$�Ȃ�����Ƃ�
(߄t�) ����L���b�V�����^�p����I�[�o�[�w�b�h���l���Ȃ���
(߄t�) �ǂ�ŗ����������̓��e���������L���b�V���ɏ�������ŁA����L���b�V���ɓ����̓��e�����邩�m�F�����Ԃ����āA�Ȃ��������̔ߎS������
(߄t�) ����L���b�V���Ȃ�Đς�ł��I�[�o�[�w�b�h�������ނ�
(߄t�) �L���b�V�����������̂������C�e���V�ɂȂ邩��q�b�g���Ă��債�đ����Ȃ�Ȃ���
(߄t�) �L���b�V���I�[�o�[�w�b�h�y���Z�p�������ɐi�������Ă��Ȃ��ƁA�����e�ʂ������₵�Ă������͂Ȃ�Ȃ���
> CPU�Ƃ��Ȃ��p�b�P�[�W�ɋ���L4$�Ȃ�����Ƃ�
(߄t�) ����L���b�V�����^�p����I�[�o�[�w�b�h���l���Ȃ���
(߄t�) �ǂ�ŗ����������̓��e���������L���b�V���ɏ�������ŁA����L���b�V���ɓ����̓��e�����邩�m�F�����Ԃ����āA�Ȃ��������̔ߎS������
(߄t�) ����L���b�V���Ȃ�Đς�ł��I�[�o�[�w�b�h�������ނ�
(߄t�) �L���b�V�����������̂������C�e���V�ɂȂ邩��q�b�g���Ă��債�đ����Ȃ�Ȃ���
(߄t�) �L���b�V���I�[�o�[�w�b�h�y���Z�p�������ɐi�������Ă��Ȃ��ƁA�����e�ʂ������₵�Ă������͂Ȃ�Ȃ���
625 �F,,�E�L�́M�E,,�j��-�������F2014/01/23(��) 22:30:54.33 ID:FSs5i7Bq
�\�t�g�E�F�A�L���b�V���́A�L���b�V���Ƃ��Ďg���ȏ�͂ނ���
�n�[�h�E�F�A�����̃^�O�f�B���N�g���ETLB�������\�����邼
�n�[�h�E�F�A�����̃^�O�f�B���N�g���ETLB�������\�����邼
NAND��DRAM�ȏ�ɔ������E���߂��̂ł��̃W���W������ł������E���߂�
�������ݒx���������ɑf�q�͉��邵����d�͂������A��������x�ɐ��\���郌�x��
�����͋Z�p�ŃJ�o�[���Ăč��͂��ꂵ���Ȃ�����g���Ă��邾��
2015�N��16G���Ƃ���Ȃ�P���v�Z��10�����160�A17��320�A19��640�A2021��1280G
��ւƂ��Ďg����ReRAM�ł��܂Ƃ��Ɏg����悤�ɂȂ�܂ŐF�X�������Ă�6�N������
�Ȃ�ɂ���ŏI�I�ɂ̓R�X�g���S��
�������ݒx���������ɑf�q�͉��邵����d�͂������A��������x�ɐ��\���郌�x��
�����͋Z�p�ŃJ�o�[���Ăč��͂��ꂵ���Ȃ�����g���Ă��邾��
2015�N��16G���Ƃ���Ȃ�P���v�Z��10�����160�A17��320�A19��640�A2021��1280G
��ւƂ��Ďg����ReRAM�ł��܂Ƃ��Ɏg����悤�ɂȂ�܂ŐF�X�������Ă�6�N������
�Ȃ�ɂ���ŏI�I�ɂ̓R�X�g���S��
���Z�p�ŃJ�o�[���Ă�
��̓I�ɂǂ������ӂ��ɃJ�o�[���Ă�́H
��̓I�ɂǂ������ӂ��ɃJ�o�[���Ă�́H
628 �F,,�E�L�́M�E,,�j��-�������F2014/01/23(��) 22:45:26.09 ID:FSs5i7Bq
���������Ԃ�A�Z���̎����������Ă��A��e�ʉ���1�Z���������
�������������Ȃ��Ȃ邩�獷�������I�b�P�[�I��
���R�����������ϓ��ɂȂ�悤�ɊǗ����Ă��K�v������B
�������������Ȃ��Ȃ邩�獷�������I�b�P�[�I��
���R�����������ϓ��ɂȂ�悤�ɊǗ����Ă��K�v������B
�������݂͕��ƃR���g���[���̉��ǁA�f�q�̓E�F�A���x�����O�A����d�͔͂����łȂ�Ƃ��Ή����Ă邾��
�]������̂ɂ킴�킴�f�[�^�����k������Ƃ�����ڂ������̋Z�p�g�����肷�鍓���L�l
�����Ȃ�Ďg���Ă邾���Ńt���[�Y���郌�x��������
�]������̂ɂ킴�킴�f�[�^�����k������Ƃ�����ڂ������̋Z�p�g�����肷�鍓���L�l
�����Ȃ�Ďg���Ă邾���Ńt���[�Y���郌�x��������
>>623
���������Ȃ肫�������
SLC�ő��₹�Ȃ�����MLC
����ł�����Ȃ�����TLC
����QLC�Ƃ�����̂���
�E�F�A�����O�������炤�܂��Ȃ��Ă����E�͂��邾�낤��
���������Ȃ肫�������
SLC�ő��₹�Ȃ�����MLC
����ł�����Ȃ�����TLC
����QLC�Ƃ�����̂���
�E�F�A�����O�������炤�܂��Ȃ��Ă����E�͂��邾�낤��
DRAM��STT-RAM��
NAND��ReRAM��
���ꂪ���ꂾ
NAND��ReRAM��
���ꂪ���ꂾ
DDR3��1G���ڂ����肵�Đ��\���ێ��A�����̉e�����ɂ����悤�ɂ��Ă��邯��
�������������̗e�ʂ𑝂₹�Α��₷�قǓd���̏u�f�Ɏキ�Ȃ邵����d�͂������Ȃ�
�Ƃ肠����DDR3�̑���Ƃ���ReRAM���̗p���ăR�X�g��������x�ɗe�ʂ��グ�Ă�������
�ŏI�I��NAND�͏����čs��
�������������̗e�ʂ𑝂₹�Α��₷�قǓd���̏u�f�Ɏキ�Ȃ邵����d�͂������Ȃ�
�Ƃ肠����DDR3�̑���Ƃ���ReRAM���̗p���ăR�X�g��������x�ɗe�ʂ��グ�Ă�������
�ŏI�I��NAND�͏����čs��
������ɂ��Ă��A�����̃������C���^�[�t�F�[�X�̃V���A������W���Ă���̂�
Rambus����B���������܂Ƃ��ȃ��C�Z���X���o���Γ`���H��SerDes���͈�C�ɐi�ނ�B
�������C���^�[�t�F�[�X�������Ƀp�������Ȃ̂�Rambus�̂������Ƃ������Ƃ͊o���Ă��������������B
Rambus����B���������܂Ƃ��ȃ��C�Z���X���o���Γ`���H��SerDes���͈�C�ɐi�ނ�B
�������C���^�[�t�F�[�X�������Ƀp�������Ȃ̂�Rambus�̂������Ƃ������Ƃ͊o���Ă��������������B
2013�N12����PC�����o�ב䐔���ߋ��ō���
http://blog.livedoor.jp/amd646464/archives/52395992.html
http://blog.livedoor.jp/amd646464/archives/52395992.html
>>632
�o�b�t�@���[��SSD�̓����L���b�V����MRAM�𓋍ڂ������i�𗈔N�����\��
http://buffalomemory.jp/news/131118a.html
�o�b�t�@���[��SSD�̓����L���b�V����MRAM�𓋍ڂ������i�𗈔N�����\��
http://buffalomemory.jp/news/131118a.html
�P�Ȃ钘�쌠�S����Rambus�ɂ���ȗ͂�����悤�ɂ͌����Ȃ�����
�ז����Ă�̂��������邾�낤���P���ɋZ�p�ƃR�X�g�̖�肾�낤
CPU�݂̂Ȃ炻���܂œ��ꍞ�ނقǂ̑ш悪�K�v����Ȃ�
�_�C���傫���Ȃ��Ă��������獂��������Ȃ�ăl�b�g�o�[�X�g�݂�������
�V���A�����x�̃����b�g�ň�C�ɐi�ނȂǂƂ������Ƃ����肦�Ȃ�����RDRAM���ؖ����Ă���
��C�ɐi�ނɂ͍����ȕs���������x���̖ڂɌ����ĕ�����v�����K�v
>>635
�������Ȃ��ƃR�X�g��������Ȃ�
�ϑw���ŗe�ʂ�\�オ�邪�R�X�g�́H�ɂȂ肻������
>>637
MRAM�̗e�ʂ�2015�N��1G�����璚�x�����낤��
�ז����Ă�̂��������邾�낤���P���ɋZ�p�ƃR�X�g�̖�肾�낤
CPU�݂̂Ȃ炻���܂œ��ꍞ�ނقǂ̑ш悪�K�v����Ȃ�
�_�C���傫���Ȃ��Ă��������獂��������Ȃ�ăl�b�g�o�[�X�g�݂�������
�V���A�����x�̃����b�g�ň�C�ɐi�ނȂǂƂ������Ƃ����肦�Ȃ�����RDRAM���ؖ����Ă���
��C�ɐi�ނɂ͍����ȕs���������x���̖ڂɌ����ĕ�����v�����K�v
>>635
�������Ȃ��ƃR�X�g��������Ȃ�
�ϑw���ŗe�ʂ�\�オ�邪�R�X�g�́H�ɂȂ肻������
>>637
MRAM�̗e�ʂ�2015�N��1G�����璚�x�����낤��
���߂ē������ƒ��쌠
�p�e���g��ƂƃT�u�}���������S���̋�ʂ��炢���悤�ɂȂ��Ă��畨������ׂ�
R&D�������ɓ������n�ʂ���N���Ă���Ƃł��v���Ă�̂�
�p�e���g��ƂƃT�u�}���������S���̋�ʂ��炢���悤�ɂȂ��Ă��畨������ׂ�
R&D�������ɓ������n�ʂ���N���Ă���Ƃł��v���Ă�̂�
>>636
�܂���Crystalwell�ł́B�����Ƃ��A���ǃ^�ORAM�������Ȃ��Ƃ����Ȃ�����
L4���Ȃ��ꍇ��葽�����C�e���V�͈���������Ęb�͂�����
�T�^�I�ȃA�v���P�[�V�����Ń������K�w�S�̂ł̕��σ��C�e���V�͂ǂ��Ȃ�̂��˂�
�����Ƃ�Crystalwell��L4$�̓��C�e���V���P�Ƃ������A
�������o���h���̕⋭�ƌ���ق����������C�͂��邪
�܂���Crystalwell�ł́B�����Ƃ��A���ǃ^�ORAM�������Ȃ��Ƃ����Ȃ�����
L4���Ȃ��ꍇ��葽�����C�e���V�͈���������Ęb�͂�����
�T�^�I�ȃA�v���P�[�V�����Ń������K�w�S�̂ł̕��σ��C�e���V�͂ǂ��Ȃ�̂��˂�
�����Ƃ�Crystalwell��L4$�̓��C�e���V���P�Ƃ������A
�������o���h���̕⋭�ƌ���ق����������C�͂��邪
>>634
AMD���̊ԂɁc�Ǝv������kakaku�m�[�gPC����؏��20�̓�
18�� HP Pavilion TouchSmart 10-e003AU \34,860
1�䂾������A�킯���킩���
AMD���̊ԂɁc�Ǝv������kakaku�m�[�gPC����؏��20�̓�
18�� HP Pavilion TouchSmart 10-e003AU \34,860
1�䂾������A�킯���킩���
���������N�Ŋ��Ⴂ�����AAMD����Ȃ�����PC�̘b��
���C���������ш�̏㏸���x���͎̂��v���Ⴗ���邩�炾�B
�X�p�R���ł���Byte/FLOP���d�������V�X�e����
LINPACK FLOPS/$ ���d�������V�X�e���ɋ�a���Ȃ߂������ė����B
�����⏑�ւ⎖�����ɂ����Ă���
�X�p�R���ł���Byte/FLOP���d�������V�X�e����
LINPACK FLOPS/$ ���d�������V�X�e���ɋ�a���Ȃ߂������ė����B
�����⏑�ւ⎖�����ɂ����Ă���
644 �FSocket774�F2014/01/24(��) 02:45:47.71 ID:PNbjULqC
IBM����A�Ƃ��Ƃ��I���R����x86����
�yPC�z���m�{�iLenovo�j�A��IBM�̒ቿ�i�T�[�o�[����(X86�T�[�o�[)��23���h���Ŕ�����[14/01/23]
http://anago.2ch.net/test/read.cgi/bizplus/1390483959/
�yPC�z���m�{�iLenovo�j�A��IBM�̒ቿ�i�T�[�o�[����(X86�T�[�o�[)��23���h���Ŕ�����[14/01/23]
http://anago.2ch.net/test/read.cgi/bizplus/1390483959/
���H��̏����搶�́A�Z�O�����g�S�̂�
���ꂵ�����߃Z�b�g���ێ��ł��Ȃ��Ȃ���IBM�̒E���Ɖ��߂��Ă���
���ꂵ�����߃Z�b�g���ێ��ł��Ȃ��Ȃ���IBM�̒E���Ɖ��߂��Ă���
646 �F,,�E�L�́M�E,,�j��-�������F2014/01/24(��) 04:18:20.30 ID:rAd6RwLn
>>636
Crystalwell(Haswell+GT3e)�̃X�y�b�N���ĂāA�Ȃ�L3�̗e�ʂ�2MB�����Ă�̂�
�����Ƌ^�₾�����������������Ƃ���
Crystalwell(Haswell+GT3e)�̃X�y�b�N���ĂāA�Ȃ�L3�̗e�ʂ�2MB�����Ă�̂�
�����Ƌ^�₾�����������������Ƃ���
Intel �gBroadwell�h�̐��Y���1�l�������ɊJ�n
http://northwood.blog60.fc2.com/blog-entry-7350.html
FinFET yields caused Intel to mothball Fab42
http://www.newelectronics.co.uk/electronics-blogs/finfet-yields-caused-intel-to-mothball-fab42/59037/
http://northwood.blog60.fc2.com/blog-entry-7350.html
FinFET yields caused Intel to mothball Fab42
http://www.newelectronics.co.uk/electronics-blogs/finfet-yields-caused-intel-to-mothball-fab42/59037/
�����������TDP1000W��������鐢�E�ɏ����ނƂ͂�
�ق�Ƃ��ǂ����킩��Ȃ����ljp���Wikipedia�ɂ���Skylake�ł͊e�L���b�V���̃��C�e���V���팸����݂���������
�l�I�ɂ�L4�AL5�Ƃ��ނ�݂₽��ɃL���b�V���K�w���₵�Ă����̂̓}�[�P�e�B���O��̐헪�Ŗ{���Ɍ��������l������̂��^��B�������̑ш�s���Ƃ����_�ɂ����Ă͕K�v��������Ȃ����A���C�e���V���K���K�������Ă����̂͂Ȃ�
�l�I�ɂ�L4�AL5�Ƃ��ނ�݂₽��ɃL���b�V���K�w���₵�Ă����̂̓}�[�P�e�B���O��̐헪�Ŗ{���Ɍ��������l������̂��^��B�������̑ш�s���Ƃ����_�ɂ����Ă͕K�v��������Ȃ����A���C�e���V���K���K�������Ă����̂͂Ȃ�
���C�e���V�����ă��C���������ɋߕt��=�L���݂������Ȃ�̂�
�e�ʂł�������R�X�g�͔{�X�ő�����B
�L���b�V���K�w���₷�̂͒n���ւ̓����ȁB
�e�ʂł�������R�X�g�͔{�X�ő�����B
�L���b�V���K�w���₷�̂͒n���ւ̓����ȁB
�L���b�V���̊K�w���₷���Ęb�͂ǂ�����N������
L4�͓���GPU�̃������ш�m�ۂ̂��߂Ɨ������Ă邪�A�}�[�P�e�B���O�]�X�����ł��\�������I���Ǝv������
L4�͓���GPU�̃������ш�m�ۂ̂��߂Ɨ������Ă邪�A�}�[�P�e�B���O�]�X�����ł��\�������I���Ǝv������
�L���b�V���ɂ��邽�߂ɂƂ�ł��Ȃ��傫��TAG��ς�ł�̂����ʂȂ�B
Intel��Haswell GT3e��L4�^�O�̃T�C�Y��2-4MB�Ɛ������Ă��邪�Ƃ�ł��Ȃ��傫�����ˁH
4�R�A+L3 8MB��4�R�A+L3 6MB+L4�^�O 2-4MB�Ƃ��Ă�킯�ł���
4�R�A+L3 8MB��4�R�A+L3 6MB+L4�^�O 2-4MB�Ƃ��Ă�킯�ł���
IRIS�̂悤�ȕʃ`�b�v�L���b�V�������W���[�ɂȂꂸ�ɏ����Ă����^���Ȃ̂͗��j���ؖ����Ă���Ǝv��
�����I�Ƃ͂����Ȃ�
�����I�Ƃ͂����Ȃ�
�����Ă������Ă��_�C��������Ă邩��
IRIS���ĕʃ`�b�v�Ȃ́H
eDRAM����
�`�b�v�ƃ_�C���ē����Ӗ��H
1��CPU�̒���eDRAM�������łȂ��́H
1��CPU�̒���eDRAM�������łȂ��́H
�ʃ_�C�I���p�b�P�[�W�̑�e��L4$�ς��̃p�t�H�[�}���X�ቺ���Œ���ɂ��邽�߂ɁA
L4$�̃^�O�̈��L4$�_�C��ɍ�炸�ɁA���C���_�C��SRAM��ɍ��A
�f�[�^�����ʃ_�C�I���p�b�P�[�W��DRAM��ɒu�����肷����
L4$�̃^�O�̈��L4$�_�C��ɍ�炸�ɁA���C���_�C��SRAM��ɍ��A
�f�[�^�����ʃ_�C�I���p�b�P�[�W��DRAM��ɒu�����肷����
�`�b�v���Ɠ����p�b�P�[�W�A���ɕʂ�Ă����Ă��I���`�b�v�Ƃ������������Ȃ�
�I���_�C�Ȃ�P��_�C��
http://media.pcgamer.com/files/2013/06/Iris-Pro.jpg
�I���_�C�Ȃ�P��_�C��
http://media.pcgamer.com/files/2013/06/Iris-Pro.jpg
{kind=link}
�p�b�P�[�W���Ȃ�PentiumPro��PII�������������B
CPU�p�b�P�[�W�̊O���ADRAM�Ƃ͕ʂ̃L���b�V���Ƃ����̂�
�����ƃ}�C�i�[�ȑ��݁BPentium�pMB�̈ꕔ��
alpha ��POWER�ł͎g���Ă�����
CPU�p�b�P�[�W�̊O���ADRAM�Ƃ͕ʂ̃L���b�V���Ƃ����̂�
�����ƃ}�C�i�[�ȑ��݁BPentium�pMB�̈ꕔ��
alpha ��POWER�ł͎g���Ă�����
�}�U�[��ɂ���������pipeline burst sram
IBM�͓͗���Ă����u���[�h�T�[�o�����ۂɂ͔M�̋Ǐ�����������
�f�[�^�Z���^�ɂ�������Ȃ���������ȁB
�����̌ڋq�͋��d�b�����@�̃X�y�[�X��19�C���`��ї�������
1U����荞�̂ŗD�ʐ����m�ۂł��Ȃ��Ȃ����B
����ȂƂ���͎��Аv�܂ł��Ă邩��ȁB
�܂��ASystem i��System Z�ASystem�@p�����肪LPAR�ʼn��z�}�V�����RAS�܂߂�Ǝ��͎v�����قǍ����Ȃ���ˁA
�Ƃ����K�V�[�Ƌ����ł���ˁA�Ƃ����̂��킩������ł������Ɍo�c�������W���������B
�f�[�^�Z���^�ɂ�������Ȃ���������ȁB
�����̌ڋq�͋��d�b�����@�̃X�y�[�X��19�C���`��ї�������
1U����荞�̂ŗD�ʐ����m�ۂł��Ȃ��Ȃ����B
����ȂƂ���͎��Аv�܂ł��Ă邩��ȁB
�܂��ASystem i��System Z�ASystem�@p�����肪LPAR�ʼn��z�}�V�����RAS�܂߂�Ǝ��͎v�����قǍ����Ȃ���ˁA
�Ƃ����K�V�[�Ƌ����ł���ˁA�Ƃ����̂��킩������ł������Ɍo�c�������W���������B
RAMBUS�͓����S��������ȁ[�B
�����҂��ė~����
Rambus�Ƀz�C�z�C������Ɛ肳��Ă��܂����̉�Ђ�����肪����̂ł͂Ȃ���
Rambus�Ƀz�C�z�C������Ɛ肳��Ă��܂����̉�Ђ�����肪����̂ł͂Ȃ���
RIMM�ƃZ�b�g�̔��͎��s�������
�������̃V���A������gdgd�Ȃ�����DDR4�ȍ~�̓W�]�������Ȃ����ǂ�
�܂�IBM�͐̃e���r���①�ɂ�����Ă�GE�̌�ǂ�������Ă�낤�ˁB�В����R���T���o�g�ɂȂ�����
GE�̏ꍇ���{���i�ɑ����ł��ł��Ȃ��Ȃ��Ă�����A�Ɠd�͂����~�߂�Ƃ͐�Ɍ���Ȃ���������
�^�C�~���O�����Ĕ����ς���Ă������ċ��Z�ƕĐ��{�����̌R���A�d�d����ŐH���Ă�����ЂɂȂ����킯��
�č����G�N�Z�����g�J���p�j�[�̋��ȏ��ʂ肾��
GE�̏ꍇ���{���i�ɑ����ł��ł��Ȃ��Ȃ��Ă�����A�Ɠd�͂����~�߂�Ƃ͐�Ɍ���Ȃ���������
�^�C�~���O�����Ĕ����ς���Ă������ċ��Z�ƕĐ��{�����̌R���A�d�d����ŐH���Ă�����ЂɂȂ����킯��
�č����G�N�Z�����g�J���p�j�[�̋��ȏ��ʂ肾��
�ނ��뎞��͒��p������
Rambus�͓����g���Ă����Ȃ��Ƌ������ė��Ȃ����ǂ�
����Rambus�̃������g���Ă鐻�i���āAPS3�����H
PS3�͂���Ȃ�ɗʂ��o�邩��APS3�̂��߂�����Rambus��DRAM�������邱�Ƃ��ł��邪�A
���̏��i��Rambus�g�����Ƃ���ƁAPS3�p�������Ɠ����̂��g�������Ȃ��A
PS3�̐��Y���~���ꂽ�����s�ɂȂ��H
����Rambus�̃������g���Ă鐻�i���āAPS3�����H
PS3�͂���Ȃ�ɗʂ��o�邩��APS3�̂��߂�����Rambus��DRAM�������邱�Ƃ��ł��邪�A
���̏��i��Rambus�g�����Ƃ���ƁAPS3�p�������Ɠ����̂��g�������Ȃ��A
PS3�̐��Y���~���ꂽ�����s�ɂȂ��H
>>668
���{�̉Ɠd���[�J�[�́A��ʌ����@�킵������ĂȂ���Ђ����������
�d�d�E�C���t��������Ă듌�ŎO�H�����͂����������C���A
���Ƃ��ƉƓd��������ĂȂ���Ђ��ꂵ��ł�
���{�̉Ɠd���[�J�[�́A��ʌ����@�킵������ĂȂ���Ђ����������
�d�d�E�C���t��������Ă듌�ŎO�H�����͂����������C���A
���Ƃ��ƉƓd��������ĂȂ���Ђ��ꂵ��ł�
>>475
������ăN���b�N�オ��Ȃ����Ă��Ƃ����
������ăN���b�N�オ��Ȃ����Ă��Ƃ����
����IBM�͈�ʌ����ǂ��납���ʂ̊�ƌ���H/W����GE�ɂƂ��ẲƓd�̂悤�Ȑ�̂ĂĂ������ƂȂ낤��
power���P�i�T�[�o�Ƃ��Ă͍ŏI�I�ɐ�̂Ă��ˁH�ėp�@�Ƃ��X�p�R���Ƃ��͐��{��d�������ƌ����ɂ���Ă����낤����
�t�ɂ�������������ȊO�̏��������Ă����Ƃ͎v���ˁB���{�͖@�l���Ɛ�̂Ăđ���s�����葊��͖{�����璼�ڂ��Ƃ��T�|�[�g�͑㗝�X�o�R�ɂ���Ƃ�
power���P�i�T�[�o�Ƃ��Ă͍ŏI�I�ɐ�̂Ă��ˁH�ėp�@�Ƃ��X�p�R���Ƃ��͐��{��d�������ƌ����ɂ���Ă����낤����
�t�ɂ�������������ȊO�̏��������Ă����Ƃ͎v���ˁB���{�͖@�l���Ɛ�̂Ăđ���s�����葊��͖{�����璼�ڂ��Ƃ��T�|�[�g�͑㗝�X�o�R�ɂ���Ƃ�
�����������ł�xp�ȑO���g���Ă�Ƃ���͕ʂɃT�|�[�g�ȂK�v�Ȃ���������g���Ă��ˁH
675 �F,,�E�L�́M�E,,�j��-�������F2014/01/24(��) 21:01:07.22 ID:Py4iRBvs
>>671
����3�Ђ́u�k���O�Z��v���Ĕ�������ւ��̂���������
����3�Ђ́u�k���O�Z��v���Ĕ�������ւ��̂���������
�ł������`�b�v�ɑS�Ă̋@�\���l�ߍ��܂Ȃ��ƃX�}�z�ɓ��ڂł��Ȃ��W����
�Q���V���K�[�̐�����������2013�N��VMware
http://cloud.watch.impress.co.jp/docs/column/virtual/20140124_631922.html
��������o�c�ґR�Ƃ�������ɂȂ����Ȃ���
1999�N http://pc.watch.impress.co.jp/docs/article/990922/gel.jpg
2004�N http://pc.watch.impress.co.jp/docs/2004/1112/kaigai01.jpg
2008�N http://pc.watch.impress.co.jp/docs/2008/1006/kaigai_4.jpg
2013�N http://cloud.watch.impress.co.jp/img/clw/docs/631/922/17.jpg
http://cloud.watch.impress.co.jp/docs/column/virtual/20140124_631922.html
��������o�c�ґR�Ƃ�������ɂȂ����Ȃ���
1999�N http://pc.watch.impress.co.jp/docs/article/990922/gel.jpg
{kind=link}
2004�N http://pc.watch.impress.co.jp/docs/2004/1112/kaigai01.jpg
{kind=link}
2008�N http://pc.watch.impress.co.jp/docs/2008/1006/kaigai_4.jpg
{kind=link}
2013�N http://cloud.watch.impress.co.jp/img/clw/docs/631/922/17.jpg
{kind=link}
678 �F,,�E�L�́M�E,,�j��-�������F2014/01/24(��) 22:33:27.47 ID:Py4iRBvs
�����搶������Xeon Phi�ɂ��ċL�������܂�����
http://news.mynavi.jp/column/architecture/298/
http://news.mynavi.jp/column/architecture/298/
�r���A���S�ɕʐl����B
>>673
PC����ACPU���OS����p�[�c����Ă��Ђ��������v�グ�Ă����A
�ނ��냁�C���t���[����AIX�́A���̍����v�ȕ��������Ђō�����A
�����ȒP�ɂ͎̂ĂȂ���H
�������A�܂����C���t���[�����K�v�Ȍڋq�͑���
�R�Ƃ����Z�@�ւƂ�
PC����ACPU���OS����p�[�c����Ă��Ђ��������v�グ�Ă����A
�ނ��냁�C���t���[����AIX�́A���̍����v�ȕ��������Ђō�����A
�����ȒP�ɂ͎̂ĂȂ���H
�������A�܂����C���t���[�����K�v�Ȍڋq�͑���
�R�Ƃ����Z�@�ւƂ�
>>670
HDTV�Ƃ��Ŏg���Ă�݂�������B
�������[�̓V���A��������ƃ��C�e���V�[�傫���Ȃ邩��Ȃ��BBW�����Ȃ瑽�`�����l���V���A�������A�������B
HDTV�Ƃ��Ŏg���Ă�݂�������B
�������[�̓V���A��������ƃ��C�e���V�[�傫���Ȃ邩��Ȃ��BBW�����Ȃ瑽�`�����l���V���A�������A�������B
�Q���V���K�[����386�̐v�҂������B
���v���Ɛ挩�̖����������ȁB
���v���Ɛ挩�̖����������ȁB
Intel and Berkeley announce nano-cooling breakthrough
http://www.bit-tech.net/news/hardware/2014/01/24/intel-berkeley-nanotubes/1
�u���{���A���E���v�\�\Bay Trail�{Windows Embedded 8.1���ڂ̋Ɩ��p�^�u���b�g�[���o��!!
http://monoist.atmarkit.co.jp/mn/articles/1401/24/news131.html
http://www.bit-tech.net/news/hardware/2014/01/24/intel-berkeley-nanotubes/1
�u���{���A���E���v�\�\Bay Trail�{Windows Embedded 8.1���ڂ̋Ɩ��p�^�u���b�g�[���o��!!
http://monoist.atmarkit.co.jp/mn/articles/1401/24/news131.html
�^�u���b�g���ĕ����Ƃ���ȃC���[�W�����Ȃ�
���ʂɃ^�b�`�p�l�����p�\�R���ɗ��������̂�
���ʂɃ^�b�`�p�l�����p�\�R���ɗ��������̂�
�^�u���b�g���ĕ����ƒP���̓S�������v���o���Ȃ�
>>675
���႟�A�c�q����͒k�����˂�
���႟�A�c�q����͒k�����˂�
> 2.5�C���`�x�C�������Intel��Haswell����NUC�x�A�{�[���L�b�g�uD54250WYKH�v�ƁuD34010WYKH�v�A
> �uDN2820FYKH�v��3���f�������A�����������\�肳��Ă���1������2���ɉ������ꂽ�Ƃ̂��ƁB
>
> �Ȃ��A���i�́uD54250WYKH�v����50,000�~�O��A�uD34010WYKH�v����40,000�~�O��A
> �uDN2820FYKH�v����18,000�~�O��ɂȂ�悤���B
http://www.gdm.or.jp/voices/2014/0125/58448
�d�q�Łu��q�蒠�v�W�����ցAMS�ƃC���e�������́@Windows�^�u���b�g��Azure���p
�C���e���ƃ}�C�N���\�t�g�́A��q�蒠�d�q�ł̕W�����ɋ��́BAtom�x�[�X��Windows�^�u���b�g�����p�������،����ȂǂɎ��g�ށB
http://www.itmedia.co.jp/news/articles/1401/24/news135.html
> �uDN2820FYKH�v��3���f�������A�����������\�肳��Ă���1������2���ɉ������ꂽ�Ƃ̂��ƁB
>
> �Ȃ��A���i�́uD54250WYKH�v����50,000�~�O��A�uD34010WYKH�v����40,000�~�O��A
> �uDN2820FYKH�v����18,000�~�O��ɂȂ�悤���B
http://www.gdm.or.jp/voices/2014/0125/58448
�d�q�Łu��q�蒠�v�W�����ցAMS�ƃC���e�������́@Windows�^�u���b�g��Azure���p
�C���e���ƃ}�C�N���\�t�g�́A��q�蒠�d�q�ł̕W�����ɋ��́BAtom�x�[�X��Windows�^�u���b�g�����p�������،����ȂǂɎ��g�ށB
http://www.itmedia.co.jp/news/articles/1401/24/news135.html
http://japan.cnet.com/sp/allaboutms/35043016/
> Windows�̓���ɕK�v�ȃ���������уf�B�X�N�̗e�ʂ�����ɏ��Ȃ����邽�߂�
> Microsoft�������ɐi�߂Ă�����g�݂̈ꕔ���AUpdate 1�Ŏ�������邩������Ȃ��B
> ���ꂪ��������AWindows 8.1 Update 1�������������ȏ��^�^�u���b�g�ɓ��ڂł���B
��͂�v���O���}������̂�������
���܂ŎU�X�n�[�h�̃X�y�b�N����ɊÂ��Ă�����
�W�����v������|�P�b�g����D�������ڂꗎ���郌�x��
> Windows�̓���ɕK�v�ȃ���������уf�B�X�N�̗e�ʂ�����ɏ��Ȃ����邽�߂�
> Microsoft�������ɐi�߂Ă�����g�݂̈ꕔ���AUpdate 1�Ŏ�������邩������Ȃ��B
> ���ꂪ��������AWindows 8.1 Update 1�������������ȏ��^�^�u���b�g�ɓ��ڂł���B
��͂�v���O���}������̂�������
���܂ŎU�X�n�[�h�̃X�y�b�N����ɊÂ��Ă�����
�W�����v������|�P�b�g����D�������ڂꗎ���郌�x��
���C���������̏���ʎ��̂͊m���Ɍ����Ă邪Win8�ȍ~��OS����GPU�Ƃ�����VRAM�����\�g���悤�ɂȂ����̂�
UMA�\�����Ƃ����܂�RAM�S�̂̏���ʂ͌����Ă�Ƃ͂����Ȃ���Ȃ�
UMA�\�����Ƃ����܂�RAM�S�̂̏���ʂ͌����Ă�Ƃ͂����Ȃ���Ȃ�
�̊����x�͉��P���Ă邩�牱
���͏ȓd�͉��ɔ����f�U�C���̃`�[�v����
���g��UI�̂��艟��
�e�w�c�����тŖڐV�������Ȃ��^�C���x�[�X�ɖ������������Ȃ��A�N���悱��Ȃ����f�U�C�����荞���
���͏ȓd�͉��ɔ����f�U�C���̃`�[�v����
���g��UI�̂��艟��
�e�w�c�����тŖڐV�������Ȃ��^�C���x�[�X�ɖ������������Ȃ��A�N���悱��Ȃ����f�U�C�����荞���
Windows �N���V�b�N���D�]�Ŋ�����
693 �F,,�E�L�́M�E,,�j��-�������F2014/01/25(�y) 14:37:55.31 ID:zpqv726y
iPhone�Ŏg���Ă�Puffin��Metro�̃p�N���݂����ȃf�U�C���Ō������B
Intel��14nm��ARM����20nm���Ăǂ�������H
Intel��ARM�Ƃ��͔�����
Intel��ARM�Ƃ��͔�����
�ǂ��������l�������ɗʎY�J�n
ARM 20nm�͍��N���ɃR���V���[�}�f�o�C�X�����̐��i���o�Ă��邩���������ǂ�
Cortex-A12��28nm, Tegra K1��28nm, Snapdragon S805��28nm...
Cortex-A12��28nm, Tegra K1��28nm, Snapdragon S805��28nm...
�t��Intel ��14nm�́A�`�b�v���o�Ă��Ă�������g�������i�ɂ�������̂��Ȃ��Ƃ����P�ꌻ�ہB
>>697
����͋q�ϓI�����ł͂Ȃ�
����͋q�ϓI�����ł͂Ȃ�
699 �F,,�E�L�́M�E,,�j��-�������F2014/01/25(�y) 15:30:09.89 ID:zpqv726y
Knights Landing�x�[�X�ň�ʐl�Ɏ肪�͂����i���o�Ă���Ɩʔ����̂����ǂ�
Avoton�̌�p�|�W�V������8�`16�R�A�ɃJ�b�g�_�E�����AAVX-512�����̂܂g����
�݂�����
Avoton�̌�p�|�W�V������8�`16�R�A�ɃJ�b�g�_�E�����AAVX-512�����̂܂g����
�݂�����
ARM���Ă܂�28nm���ŐV�v���Z�X�Ȃ��
���̂ɂ������45nm�Ƃ��g���Ă��
���̂ɂ������45nm�Ƃ��g���Ă��
Product roadmap: New Intel Bay Trail chips for tablets on the way
http://liliputing.com/2014/01/product-roadmap-new-intel-bay-trail-chips-for-tablets-on-the-way.html
http://cdn.liliputing.com/wp-content/uploads/2014/01/bay-trail-new.jpg
http://liliputing.com/2014/01/product-roadmap-new-intel-bay-trail-chips-for-tablets-on-the-way.html
http://cdn.liliputing.com/wp-content/uploads/2014/01/bay-trail-new.jpg
{kind=link}
�C���e���ł�AMD�ł��������ǁC�ŐV���߂�S�Ĕ������ɂ߂Ēᐫ�\�̃v���Z�T��PG�{���}�V���p�ɏo���ė~������
�N���b�N��10MHz���x�š
�N���b�N��10MHz���x�š
�N���b�N���Ƃ����������
704 �F,,�E�L�́M�E,,�j��-�������F2014/01/25(�y) 16:56:51.90 ID:zpqv726y
�ނ���G�~���ł�������
���߃Z�b�g�͌��J����Ă邩�炻�̋C�ɂȂ�Όl�ł����邵
���߃Z�b�g�͌��J����Ă邩�炻�̋C�ɂȂ�Όl�ł����邵
>>699
������A�~������
AVX2�͐������Z�������āA�ӊO�Ɖ��ł��g������
intrinsics�������ƑΉ����Ă������ꂵ����
������A�~������
AVX2�͐������Z�������āA�ӊO�Ɖ��ł��g������
intrinsics�������ƑΉ����Ă������ꂵ����
14nm�f�X�N�g�b�v��Skylake���{��
���ꂪ��������Í�����˓�
���ꂪ��������Í�����˓�
Skylake�͐V�K�i�Ă���ɂȂ�\��Ȃ̂�
�����遁�ڍs���s������Z�p�I�ɂ����W���Ȃ��Ȃ肻���ŕ|��
�����遁�ڍs���s������Z�p�I�ɂ����W���Ȃ��Ȃ肻���ŕ|��
>>702
FPGA�ł�����Č݊�CPU�������邵���Ȃ���
FPGA�ł�����Č݊�CPU�������邵���Ȃ���
14nm�̗����グ��22nm�̂Ƃ���肸���Ə��K�͂���n�߂��ł���B
Skylake�A������f�X�N�g�b�v�����͂��ɂȂ���B
Skylake�A������f�X�N�g�b�v�����͂��ɂȂ���B
>>709
Skylake��14nm��2��ڂ���
Skylake��14nm��2��ڂ���
���\�����܂�L�тȂ��@�����ւ��T�C�N�������Ȃ�@PC����Ȃ��@����Ȃ����烉�C���k��
���C�o�����Ȃ��Ȃ��Ē�X�p�C�����ɓ�����
���C�o�����Ȃ��Ȃ��Ē�X�p�C�����ɓ�����
�y�X�[�p�[��104�����z
A10-7850K �� 19�b
G1820 �� 14�b
�y���i�z
A10-7850K �� 21,980�~
G1820 �� 4,580�~
G1820 �� 14�b
http://youtu.be/H7YN7Nk16w4
�@ �B�@�B
�@/�@�^ �߰݁I
(�@�D )
�@�@�@�@�@�ۺۺہc
(�@�D )�@ .._�B.._�B
A10-7850K �� 19�b
G1820 �� 14�b
�y���i�z
A10-7850K �� 21,980�~
G1820 �� 4,580�~
G1820 �� 14�b
http://youtu.be/H7YN7Nk16w4
�@ �B�@�B
�@/�@�^ �߰݁I
(�@�D )
�@�@�@�@�@�ۺۺہc
(�@�D )�@ .._�B.._�B
�N�̖ڂɂ����炩�����
���̒��x�̐��\���قȂ�A����܂Ŕ����ւ��悤�Ƃ��v��Ȃ�
�T�{���Ă��ł��Ȃ��낤����A���Ɍ��E��������ł���
�����ɂ����E�͂��邩��ȁB
�莝����i5�A20�N�ȏ�g���Ă鉴�̐���@���l�@���i���g���Ă���B
���̒��x�̐��\���قȂ�A����܂Ŕ����ւ��悤�Ƃ��v��Ȃ�
�T�{���Ă��ł��Ȃ��낤����A���Ɍ��E��������ł���
�����ɂ����E�͂��邩��ȁB
�莝����i5�A20�N�ȏ�g���Ă鉴�̐���@���l�@���i���g���Ă���B
Mac30���N���A����ϗD�ꂽ�v���_�N�g�͗��j��������
PC��Windows������Ȃ��Č��v�AIBM�̓T�[�o�[�܂Ŏ������
�Ƃ��낪Mac�͔N�X����グ���L�тāAXP�̔����ւ����v��Mac�ɗ���Ă�
����PC����Mac�ɑS�ڍs�������A����̃g�����h�̓��[���E�E�F�u������Chrome Book�������E�n���Mac�����Ċ������낤
�l���S�~�݂�����Windows�����X�����K�v���܂������Ȃ������
C#��VS�Ȃ����Windows�̓}�W�ʼn��l�[������
PC��Windows������Ȃ��Č��v�AIBM�̓T�[�o�[�܂Ŏ������
�Ƃ��낪Mac�͔N�X����グ���L�тāAXP�̔����ւ����v��Mac�ɗ���Ă�
����PC����Mac�ɑS�ڍs�������A����̃g�����h�̓��[���E�E�F�u������Chrome Book�������E�n���Mac�����Ċ������낤
�l���S�~�݂�����Windows�����X�����K�v���܂������Ȃ������
C#��VS�Ȃ����Windows�̓}�W�ʼn��l�[������
716 �F,,�E�L�́M�E,,�j��-�������F2014/01/25(�y) 22:37:24.18 ID:zpqv726y
�����i�̃T�|�[�g�Ɋւ��Ă�Mac�͍Œ�̑I�������ǂ�
�Â�PPC Mac��Linux�}�V���Ƃ��Ďg���Ă�
�Â�PPC Mac��Linux�}�V���Ƃ��Ďg���Ă�
���̐lIBM���T�[�o�[��������Ӗ��������Ƌȉ����Ă���
�܁AIBM�͉�v�̉�Ђ�����ȁB
����ɗD�ǃJ���p�j�[�ƕ]������邽�߂Ȃ牽�ł��^�u�[�Ȃ��蔄�肷��B�̔����l�̂��邤����
�����̂��߂Ȃ炢�ł��蔄��ł���悤������d�g�݂�LOB�P�ʂɂȂ��Ă邾��H
����ɗD�ǃJ���p�j�[�ƕ]������邽�߂Ȃ牽�ł��^�u�[�Ȃ��蔄�肷��B�̔����l�̂��邤����
�����̂��߂Ȃ炢�ł��蔄��ł���悤������d�g�݂�LOB�P�ʂɂȂ��Ă邾��H
719 �F,,�E�L�́M�E,,�j��-�������F2014/01/25(�y) 23:02:09.50 ID:zpqv726y
Fab������ĉ\���������ǂȂ��Ȃ�����Ȃ����
>>715
Windows���Ă���̂�Mac���[�U�[��������?
���ʂ�PC���[�U�[�͍ŏ�����C���X�g�[������Ƃ�B
���A������Mac���[�U�[�͊���Windows���g���Ă��邩��A����Ȃ��ȁB
Windows���Ă���̂�Mac���[�U�[��������?
���ʂ�PC���[�U�[�͍ŏ�����C���X�g�[������Ƃ�B
���A������Mac���[�U�[�͊���Windows���g���Ă��邩��A����Ȃ��ȁB
����͒p���������Ⴂ
PPC�ɂ��Č������������W���u�Y��IBM�̂��ł���w���Řb�������Ȃ�����
���R�̐���s�����낤�ˁB�C���e���ɔ�ׂĐ��\���L�єY��ł������炢�낢��v�����ꂽ�낤����
�܂Ƃ��ȉ������L����ꂽ�낤
���R�̐���s�����낤�ˁB�C���e���ɔ�ׂĐ��\���L�єY��ł������炢�낢��v�����ꂽ�낤����
�܂Ƃ��ȉ������L����ꂽ�낤
>>702
VS���M���M���������炢�̐��\�̃}�V���ق�����B���߃Z�b�g���ŐV�̂�B
VS���M���M���������炢�̐��\�̃}�V���ق�����B���߃Z�b�g���ŐV�̂�B
G5�Ȃ�ĔM�����ăm�[�g�ɍڂ����Ȃ�����
���̂����mac�̗�p�@�\�͖ʔ���������
30�N�Ƃ���������ƌ��s�͈Ⴂ�����邾�낤�B
���ʓ_�̕������Ȃ��̂ł�
���ʓ_�̕������Ȃ��̂ł�
�g���Ă������̂��h����ȂƂ��͋���
���܂�22nm�v���Z�XCPU���ĉ������炢���[�N�d���Ŗ��ʂȏ���d�͏o���Ă�́H
Atom��3~4�����ĕ���������
Atom��3~4�����ĕ���������
PowerMac���̂Ă��W���u�Y�͐�ɒn���̋ƉŏĂ���锱���Ă���͂��
����CPU��邩�炨�O��̕����˂������
��̂Ă�ꂽ�͎̂��͗ь�̕��������肷��
��̂Ă�ꂽ�͎̂��͗ь�̕��������肷��
731 �F,,�E�L�́M�E,,�j��-�������F2014/01/26(��) 10:14:26.16 ID:+A4sB4VY
������Mac�͌���3GHz��B���ł��Ȃ�������Ƃ��F�X�Ђǂ������B
�����̂ЂƂƂ���AltiVec�������̔����̃v���Z�X���[���ɂ̓I�[�o�[�X�y�b�N
�������������Đ�������ˁB
����G4�ɑ���G3�AG5(PPC970)�ɑ���POWER4�͍��N���b�N��B�����Ă���B
�����̂ЂƂƂ���AltiVec�������̔����̃v���Z�X���[���ɂ̓I�[�o�[�X�y�b�N
�������������Đ�������ˁB
����G4�ɑ���G3�AG5(PPC970)�ɑ���POWER4�͍��N���b�N��B�����Ă���B
AltiVec�͗ǂ��@�\������
�A���`apple���������AAltiVec�̂��߂����Ɉ����Ȃ���Mac mini��������
�A���`apple���������AAltiVec�̂��߂����Ɉ����Ȃ���Mac mini��������
>>702
���������̂���ARM�ɂ������낤��
���������̂���ARM�ɂ������낤��
734 �F,,�E�L�́M�E,,�j��-�������F2014/01/26(��) 15:01:23.72 ID:+A4sB4VY
�����R�[�h���������邱�Ƃ����ǐ��̍����R�[�h����������ق����厖���Ǝv�����ǂ�
�`�[�����̑S�����œK�����ł���K�v�͖����B
�`�[�����̑S�����œK�����ł���K�v�͖����B
>>734
�c�q�������Ɛ����͂�����B
�c�q�������Ɛ����͂�����B
736 �F,,�E�L�́M�E,,�j��-�������F2014/01/26(��) 16:11:21.94 ID:uU9Tvpeu
�E�ςɃ`���[�����Ă���R�[�h�͉ǐ������Ȃ�X��������
�E���̃A�[�L�e�N�`���̍œK����@��������ʗp����Ƃ͌���Ȃ�
�E���܂ǂ��̃R���p�C����OpenMP�Ŏ����x�N�g�����ł���
���Ƃ���10�N20�N�O�̐l�Ԃ̏���������memcpy�Ȃ�ĂقƂ�ǖ��ɗ����Ȃ��Ȃ��Ă�B
�E���̃A�[�L�e�N�`���̍œK����@��������ʗp����Ƃ͌���Ȃ�
�E���܂ǂ��̃R���p�C����OpenMP�Ŏ����x�N�g�����ł���
���Ƃ���10�N20�N�O�̐l�Ԃ̏���������memcpy�Ȃ�ĂقƂ�ǖ��ɗ����Ȃ��Ȃ��Ă�B
�Ȃ��������ڒ��������ˁB
�������ł��Ȃ�����̕Ƃ݂ȂˁB
�������ł��Ȃ�����̕Ƃ݂ȂˁB
738 �F,,�E�L�́M�E,,�j��-�������F2014/01/26(��) 16:26:21.29 ID:uU9Tvpeu
�Ӗ�F�u�����œK������Ƃ��ɋ�J�����œǂ݂ɂ����R�[�h�����Ȃ��ł��������v
�c�q���ĉ�������ȂH
��{�I�ɁA�{�g���l�b�N�ƂȂ镔�������J���J���Ƀ`���[�������R�[�h�����āA
����ȊO�̕����͕�����₷���R�[�h�������ق���������
�������́A�ǐ������R�[�h�ō���āA���{�g���l�b�N�ƂȂ镔���̃A�Z���u���ł�����āA
#IFDEF�łǂ����g���p�ɂ��ł���Ƃ���
����ȊO�̕����͕�����₷���R�[�h�������ق���������
�������́A�ǐ������R�[�h�ō���āA���{�g���l�b�N�ƂȂ镔���̃A�Z���u���ł�����āA
#IFDEF�łǂ����g���p�ɂ��ł���Ƃ���
�R�[�e�B���O�O����
�E�܂��œK�������
�E�Ō�܂ōœK�������
�E�Ō�̍Ō�܂ōœK���͂����
�E�܂��œK�������
�E�Ō�܂ōœK�������
�E�Ō�̍Ō�܂ōœK���͂����
742 �F,,�E�L�́M�E,,�j��-�������F2014/01/26(��) 17:19:30.64 ID:uU9Tvpeu
�p�t�H�[�}���X���j�^���g���Ċ��P�ʂłǂ����l�b�N�ɂȂ��Ă邩����肷���Ƃ��܂����B
���s����1%�����̃R�[�h��SIMD�œK�����܂����Ƃ�����Ă�����Ȃ̈Ӗ������ł���B
���s����1%�����̃R�[�h��SIMD�œK�����܂����Ƃ�����Ă�����Ȃ̈Ӗ������ł���B
���S�҂���B
744 �F,,�E�L�́M�E,,�j��-�������F2014/01/26(��) 17:31:49.95 ID:uU9Tvpeu
�ϴ��Ű
Pentium 4�Ř_���V�t�g�͉��Z��8�{�x����������ɗ͉��Z���g���ď�������悤�ɂ��Ă���
����ɍ��킹�ď������R�[�h�͍��̃A�[�L�e�N�`���ł͂���ȑO�̃R�[�h���x���Ȃ��Ă��
Pentium 4�Ř_���V�t�g�͉��Z��8�{�x����������ɗ͉��Z���g���ď�������悤�ɂ��Ă���
����ɍ��킹�ď������R�[�h�͍��̃A�[�L�e�N�`���ł͂���ȑO�̃R�[�h���x���Ȃ��Ă��
����Ȃ̂��Ƃ��ƃS�~����B
746 �F,,�E�L�́M�E,,�j��-�������F2014/01/26(��) 17:49:23.47 ID:uU9Tvpeu
ID:duSt28/u���m���ɃS�~����
�|�[�g�\�����ς���đO��葬�x�ቺ�����R�[�h�Ȃ�Ă���ɂ��邪�B
Core 2��Nehalem�iSIMD��int-fp�Ԃ̃y�i���e�B����j
Ivy Bridge��Haswell�iShuffle�|�[�g�����j
���̂��тɏ��������Ă邯�ǁA�S���̃R�[�h�̃����e�ł���킯����Ȃ�����ȁB
�R���p�C���C���ɂł���Ƃ���͂�����ق��������B
�u�R���p�C�����œK�����₷���R�[�h�������v
����͂قƂ�lj���������Ȃ��R�[�h�ɋ߂��Ȃ��ȁB
�|�[�g�\�����ς���đO��葬�x�ቺ�����R�[�h�Ȃ�Ă���ɂ��邪�B
Core 2��Nehalem�iSIMD��int-fp�Ԃ̃y�i���e�B����j
Ivy Bridge��Haswell�iShuffle�|�[�g�����j
���̂��тɏ��������Ă邯�ǁA�S���̃R�[�h�̃����e�ł���킯����Ȃ�����ȁB
�R���p�C���C���ɂł���Ƃ���͂�����ق��������B
�u�R���p�C�����œK�����₷���R�[�h�������v
����͂قƂ�lj���������Ȃ��R�[�h�ɋ߂��Ȃ��ȁB
�_���V�t�g���l�b�N�ɂȂ�v���O�����Ȃ�Ă���̂���w
���������̂ʂȓw�͂��Č�����B
���������̂ʂȓw�͂��Č�����B
748 �F,,�E�L�́M�E,,�j��-�������F2014/01/26(��) 17:53:11.51 ID:uU9Tvpeu
����Ȃ̂��m��Ȃ��̂���B���������̂ʂȐl�����Ă�����B
���ȏЉ�B
750 �F,,�E�L�́M�E,,�j��-�������F2014/01/26(��) 17:59:18.22 ID:uU9Tvpeu
�Ȃ������{�����Z�������������Ƃ̖���DQN�ł�����
�Ɩ��n�V�X�e���̏ꍇ�A�����̏ꍇ�V�X�e���R�[�����DB�A�N�Z�X���{�g���l�b�N�ɂȂ�ꍇ���������C�������
���̏ꍇ�́A�����ɃV�X�e���R�[���̉����炷���A�Ƃ��A�������������Ƃ����S�ɂȂ�
���������d�l���������������肷��̂ŁA�d�l��ς��čŒ���̃V�X�e���R�[���œ����悤�ɂ��邩�A
DB�������I�ɗ��p����悤�ɂ���Ƃ���
���̏ꍇ�́A�����ɃV�X�e���R�[���̉����炷���A�Ƃ��A�������������Ƃ����S�ɂȂ�
���������d�l���������������肷��̂ŁA�d�l��ς��čŒ���̃V�X�e���R�[���œ����悤�ɂ��邩�A
DB�������I�ɗ��p����悤�ɂ���Ƃ���
���������ƑO����PG�ɂ͂ł��邾���v���O�����������ȂƎw�����Ă���B
���ʂȏ����������Ȃ��A�ԗւ̍Ĕ��������Ȃ��A�P�������ȃ��W�b�N���g���A���ꂾ���ōœK���Ȃǂ��Ȃ��Ă������Ȃ�B
���������Y���ێ琫�����܂�i�������܂�Ƃ������Ƃ����߂��B
�œK���͏����n�A�t���[�����[�N�ɕK�v�Ȃ��܂��Ȃ����������Ă����������������I�ɂ���Ă����̂ł���ȏ�͋��߂Ȃ��B
����Ő��\������Ȃ��ꍇ�̓n�[�h�E�F�A�X�y�b�N���������e���s�K��������v���猩���������������B
�O���t�B�b�N�����Ȃ�GPU��ς��邩�ߏ�ȉ摜�i���𗎂Ƃ��ׂ��B
���ʂȏ����������Ȃ��A�ԗւ̍Ĕ��������Ȃ��A�P�������ȃ��W�b�N���g���A���ꂾ���ōœK���Ȃǂ��Ȃ��Ă������Ȃ�B
���������Y���ێ琫�����܂�i�������܂�Ƃ������Ƃ����߂��B
�œK���͏����n�A�t���[�����[�N�ɕK�v�Ȃ��܂��Ȃ����������Ă����������������I�ɂ���Ă����̂ł���ȏ�͋��߂Ȃ��B
����Ő��\������Ȃ��ꍇ�̓n�[�h�E�F�A�X�y�b�N���������e���s�K��������v���猩���������������B
�O���t�B�b�N�����Ȃ�GPU��ς��邩�ߏ�ȉ摜�i���𗎂Ƃ��ׂ��B
>>750
Pen4��SSE���g�킸�ɑ��{���̍������Ƃ�www
Pen4��SSE���g�킸�ɑ��{���̍������Ƃ�www
754 �F,,�E�L�́M�E,,�j��-�������F2014/01/26(��) 18:22:45.69 ID:uU9Tvpeu
Pen4�͔ėpALU�͔{��SSE�͔������������Ƃ��m��Ȃ��n���ł��������ł���
������`�F�X�̃r�b�g�{�[�h�@�ł��V�t�g�͂��̂��������p����̂���
������`�F�X�̃r�b�g�{�[�h�@�ł��V�t�g�͂��̂��������p����̂���
�g�ݍ��n�ŁA�ŋߍœK���Ɍg��������ǁA�����ł̃l�b�N�͕�����������
�̂́A�v�Z�Ƃ��A�ʐM���x���������A
���X���̕���ɋ����̂��W�܂��Ă����̂ŁA�������͏\���������ł��Ă��炵��
�̂́A�v�Z�Ƃ��A�ʐM���x���������A
���X���̕���ɋ����̂��W�܂��Ă����̂ŁA�������͏\���������ł��Ă��炵��
756 �F,,�E�L�́M�E,,�j��-�������F2014/01/26(��) 18:25:19.31 ID:uU9Tvpeu
���Ȃ݂�Pen4��SSE�ł�paddd�̓��C�e���V2�Aps{ll,rl,ra}*�̃��C�e���V��6��
�����ċC�y�Ɏg��������Ȃ������ł���
�����ċC�y�Ɏg��������Ȃ������ł���
>>753
����SSE�X���ŁA�c�q�ƌ�i��j��Ȃ���
����SSE�X���ŁA�c�q�ƌ�i��j��Ȃ���
758 �F,,�E�L�́M�E,,�j��-�������F2014/01/26(��) 18:39:31.57 ID:uU9Tvpeu
2�N������SIMD�̃x�N�g����2�{�Ƃ������Ə���������̂�����ǂ��ł���
������撣����Haswell�ōő��̃R�[�h�Ȃ�ď����Ă�SkyLake�ł͉��̈Ӗ��������Ȃ��̂ł�
�A�z�̎q��VC�ł��悤�₭�����x�N�g�����̃R���p�C���I�v�V����������
���ꂩ��͂����ɃR���p�C���ɂ�点�邩���l���Ȃ��Ƒʖڂ�
������J����@���ς�낤�Ɓu�蔲���̂��߂̓w�͂�����v�Ƃ����i���͂Ȃ��ς��܂���B
������撣����Haswell�ōő��̃R�[�h�Ȃ�ď����Ă�SkyLake�ł͉��̈Ӗ��������Ȃ��̂ł�
�A�z�̎q��VC�ł��悤�₭�����x�N�g�����̃R���p�C���I�v�V����������
���ꂩ��͂����ɃR���p�C���ɂ�点�邩���l���Ȃ��Ƒʖڂ�
������J����@���ς�낤�Ɓu�蔲���̂��߂̓w�͂�����v�Ƃ����i���͂Ȃ��ς��܂���B
>>759
(߄t�) �S���瓯�ӂ������A�ӂ[�̂��̍��̂��d���́A�ӂ[�̃\�t�g��Ђ��A�ӂ[�ɂ��ǂ蒅���A�ӂ[�̉��œ��Ȉ�H
�@�@�@�@�Q�Q�Q
�@�@ �^�@�@�@�@ �_
�@�^�@�܁@�@�܁@�R�@�@�@�@�@�@ �Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q
/�@ �i���j�@ �i���j�@|�@�@�@�@ �^
| ::: �܁i__�l__�j��:: |�@�@�@���@�@�܁A�ӂ[��������ł����ǂˁ[
| �@�@ �@ |r��|�@�@�@i�@�@�@�@�@�_�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q
�_�@�@�@ ��\' �Q�^.�@�@�@| | �@ �@ �@ �@�@ �@ |
�@�@�܁R�@�R�m�@�R �@�@�@�@| | �@ �@ �@ �@�@ �@ |
/�@�@�@�m::::::::::::::::::���_.�@ �@| | �@ �@ �@ �@�@ �@ |
�R�@�@`�[�\ �ܤ�R�@�@�@�@|_|�Q�Q�Q�Q�Q�Q|
�@�@�[�\�\��Q�S�܁R�`�����@| |�@�@|
(߄t�) �S���瓯�ӂ������A�ӂ[�̂��̍��̂��d���́A�ӂ[�̃\�t�g��Ђ��A�ӂ[�ɂ��ǂ蒅���A�ӂ[�̉��œ��Ȉ�H
�@�@�@�@�Q�Q�Q
�@�@ �^�@�@�@�@ �_
�@�^�@�܁@�@�܁@�R�@�@�@�@�@�@ �Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q
/�@ �i���j�@ �i���j�@|�@�@�@�@ �^
| ::: �܁i__�l__�j��:: |�@�@�@���@�@�܁A�ӂ[��������ł����ǂˁ[
| �@�@ �@ |r��|�@�@�@i�@�@�@�@�@�_�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q
�_�@�@�@ ��\' �Q�^.�@�@�@| | �@ �@ �@ �@�@ �@ |
�@�@�܁R�@�R�m�@�R �@�@�@�@| | �@ �@ �@ �@�@ �@ |
/�@�@�@�m::::::::::::::::::���_.�@ �@| | �@ �@ �@ �@�@ �@ |
�R�@�@`�[�\ �ܤ�R�@�@�@�@|_|�Q�Q�Q�Q�Q�Q|
�@�@�[�\�\��Q�S�܁R�`�����@| |�@�@|
Haswell�@�́@�h�����@�ƕς��Ȃ����
�ӂ��̃V�X�e���ł͂ł��邾���v���O�����������Ȃ����Ƃ����߂��邪�A
����͌��ǂ��ꂩ���������v���O�����𗘗p���邱�ƂɂȂ�
�ŁA���̃v���O�����������Ă�l���Ă����̂���{�S���A�����J��IT��Ƃ��s���āA
�A�����J��Ƃ�����IT�C���t���Ŕ��ɍ������v���グ�Ă�
����͌��ǂ��ꂩ���������v���O�����𗘗p���邱�ƂɂȂ�
�ŁA���̃v���O�����������Ă�l���Ă����̂���{�S���A�����J��IT��Ƃ��s���āA
�A�����J��Ƃ�����IT�C���t���Ŕ��ɍ������v���グ�Ă�
��Ȃ����[�Ȃ�
���{�����i�Ŗׂ��Ă�悤�Ȃ���
765 �F,,�E�L�́M�E,,�j��-�������F2014/01/26(��) 20:41:12.71 ID:uU9Tvpeu
�n�[�h�E�F�A�̐������t�@�[���E�F�A��f�o�C�X�h���C�o�����v���O���}������B
�@�@�@�@�@�@�@�@�@�Q�Q�Q
�@�@�@�@�@�@�@�^�@�@�@�@�@�_�@�د
�@�@�@�@�@ �^�@�@ �_ ,�@, �^�_
�@�@�@�@�^�@ �@ �i���j�@ �i���j �_�@�@�����I�\�[�g�̓o�u�������g���Ȃ�I
�@�@ �@ |�@�@ �@ �@ �i__�l__�j�@�@�@|�@�@�P�������ȃ��W�b�N��������I
�@ �@ �@ �_�@ �@ �@ ` �� �L�@�@,�^�@
.�@�@�@ �@ /�܁`"�P,�P�P�Y��,Ƃ�
�@�@�@ �@ |�@�@,�Q_�QށQ__�r�S����
�@�@�@�@�@| �@ �@ �@ �@ �@ �@�Ml�P
.�@�@�@ �@ |�@�@�@�@�@�@�@�@�@ |
�@�@ �^�P�P�_
�@�^�@�@ _�m�@�@�_�@�@�@���όv�Z�ʉ����{����
�@|�@�@�@ �i ���j�i���j�@�@�N�C�b�N�\�[�g���炢�g�킹���
.�@|�@�@�@�@ �i__�l__�j
�@ |�@�@�@�@�@�M �܁L�
.�@ |�@�@�@�@�@�@ �@ }�@�@�~�@�@�@�@�@�@�@�@�ߺ�
.�@ �R�@�@�@�@�@ �@ }�@�~�@ �^�_�@�@,���Q�Q__
�@�@ �R�@�@�@�@�@�m�@�@�@�@�_�@ �_ �^�@�@ �@�@�_
�@�@�@/�@�@�@ ���@�@�_.�@�@�^�_�^�@���@ �@ ���@�_
�@�@�@|�@�@�@�@�@`�[���)�@ �^ �@ �i���j �@�i���j�@ �_
�@ �@ |�@�@�@�@i�L�P�P�P �_ |�@ �@ �@ �i__�l__�j�@�@ �@ |
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�_�Q�@�@ �M �܁L�@ �@�@�^
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�^�@�@�@ �@�@�@�@�@�@�_
�@�@�@�@�@�@�@�^�@�@�@�@�@�_�@�د
�@�@�@�@�@ �^�@�@ �_ ,�@, �^�_
�@�@�@�@�^�@ �@ �i���j�@ �i���j �_�@�@�����I�\�[�g�̓o�u�������g���Ȃ�I
�@�@ �@ |�@�@ �@ �@ �i__�l__�j�@�@�@|�@�@�P�������ȃ��W�b�N��������I
�@ �@ �@ �_�@ �@ �@ ` �� �L�@�@,�^�@
.�@�@�@ �@ /�܁`"�P,�P�P�Y��,Ƃ�
�@�@�@ �@ |�@�@,�Q_�QށQ__�r�S����
�@�@�@�@�@| �@ �@ �@ �@ �@ �@�Ml�P
.�@�@�@ �@ |�@�@�@�@�@�@�@�@�@ |
�@�@ �^�P�P�_
�@�^�@�@ _�m�@�@�_�@�@�@���όv�Z�ʉ����{����
�@|�@�@�@ �i ���j�i���j�@�@�N�C�b�N�\�[�g���炢�g�킹���
.�@|�@�@�@�@ �i__�l__�j
�@ |�@�@�@�@�@�M �܁L�
.�@ |�@�@�@�@�@�@ �@ }�@�@�~�@�@�@�@�@�@�@�@�ߺ�
.�@ �R�@�@�@�@�@ �@ }�@�~�@ �^�_�@�@,���Q�Q__
�@�@ �R�@�@�@�@�@�m�@�@�@�@�_�@ �_ �^�@�@ �@�@�_
�@�@�@/�@�@�@ ���@�@�_.�@�@�^�_�^�@���@ �@ ���@�_
�@�@�@|�@�@�@�@�@`�[���)�@ �^ �@ �i���j �@�i���j�@ �_
�@ �@ |�@�@�@�@i�L�P�P�P �_ |�@ �@ �@ �i__�l__�j�@�@ �@ |
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�_�Q�@�@ �M �܁L�@ �@�@�^
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�^�@�@�@ �@�@�@�@�@�@�_
767 �F,,�E�L�́M�E,,�j��-�������F2014/01/26(��) 20:51:18.45 ID:uU9Tvpeu
qsort���炢�W�����C�u�����ɓ����Ă��ł����ǂˁB
�����Ŏ��������̂Ȃ�Ċ�{���Z�p�҂̃e�L�X�g�ǂ�ł��Ƃ����炢���B
����������ʂɂ���Ȃ�u����v���ő����ȁB�ق�O(n)�ŏI���B
�����Ŏ��������̂Ȃ�Ċ�{���Z�p�҂̃e�L�X�g�ǂ�ł��Ƃ����炢���B
����������ʂɂ���Ȃ�u����v���ő����ȁB�ق�O(n)�ŏI���B
���������āA�����ɂ���Ă߂�����Ԃ�������肷����
�ނ����Asolaris�ɕW���ł��Ă��郉�C�u�����g�����琔�����������������A
���l�̏�����GNU�̃��C�u�����g�������u(1�b�ȉ�)�ł�����Ăт����肵�����Ƃ������
�ނ����Asolaris�ɕW���ł��Ă��郉�C�u�����g�����琔�����������������A
���l�̏�����GNU�̃��C�u�����g�������u(1�b�ȉ�)�ł�����Ăт����肵�����Ƃ������
>>767
(߄t�) ����͗v�f���̑���������Ƃ������̃\�[�g�ɂ͎g���Ȃ���
(߄t�) �����ŏ����Ȃ��ƁAqsort()�g��������o���Ȃ���
(߄t�) ����͗v�f���̑���������Ƃ������̃\�[�g�ɂ͎g���Ȃ���
(߄t�) �����ŏ����Ȃ��ƁAqsort()�g��������o���Ȃ���
770 �F,,�E�L�́M�E,,�j��-�������F2014/01/26(��) 21:01:17.07 ID:uU9Tvpeu
���H�X���b�h���Ԃ���������qsort���ĕ����z����}�[�W�\�[�g�ł���B
�X���b�h�N�����̈ȊO�ASTL�����ōςނ��B
�X���b�h�N�����̈ȊO�ASTL�����ōςނ��B
>>770
(߄t�) qsort()�̓K�`�Œx����
(߄t�) C�Ńe�L�g�[�ɏ������}�[�W�ɃV���O���ł��{������������
(߄t�) �}�[�W��qsort()����������Ȃ�A�S���}�[�W�ł���������S�R����
(߄t�) qsort()�̓K�`�Œx����
(߄t�) C�Ńe�L�g�[�ɏ������}�[�W�ɃV���O���ł��{������������
(߄t�) �}�[�W��qsort()����������Ȃ�A�S���}�[�W�ł���������S�R����
772 �F,,�E�L�́M�E,,�j��-�������F2014/01/26(��) 21:08:50.76 ID:uU9Tvpeu
std::sort()
(߄t�) ���₻���X�^���_�[�h��������Ȃ͕̂����邯��
(߄t�) >>766�͂����̃l�^�����炳
(߄t�) �܂��A���Ԃ����\�[�g�̃T���v���o�����ǁA����ɏ���ă\�[�g�ŗV��ł݂Ȃ������H
(߄t�) >>766�͂����̃l�^�����炳
(߄t�) �܂��A���Ԃ����\�[�g�̃T���v���o�����ǁA����ɏ���ă\�[�g�ŗV��ł݂Ȃ������H
774 �F,,�E�L�́M�E,,�j��-�������F2014/01/26(��) 21:25:42.21 ID:uU9Tvpeu
����������苐��ȃf�[�^�������ĕ��בւ���̂�HDD�ɓs�x�X���b�v���Ȃ��Ⴂ���Ȃ��Ƃ�
����������肾�����玩�삷��Ӗ������邾�낤�����ʂ�STL�ōςނ�
���\�����̃��|�[�g�r���[�̕��בւ�����stable_sort�ł��܂��Ă��
����������肾�����玩�삷��Ӗ������邾�낤�����ʂ�STL�ōςނ�
���\�����̃��|�[�g�r���[�̕��בւ�����stable_sort�ł��܂��Ă��
>>774
(�O�t�O) ������l�^�ł����āA�ӂ[��������I
> ���\�����̃��|�[�g�r���[�̕��בւ�
(�O�t�O) ���\���Ƃ͐������炵���\�[�g�ł���
(�O�t�O) �����O�̘b�ł����A�l�̓\�[�g�̃e�X�g���T�疜���ł���Ă܂������ǂˏ�
(�O�t�O) �ł����ꕷ���Ėʔ������ȗV�т��v��������
(�O�t�O) �X���݂̂�Ȃ��\�[�g�ŗV�т܂��傤
(�O�t�O) ���[�ł��A�l�͂����̋������̃o�C�g�ł��̂ŁA����_�炩�ɏ�
(�O�t�O) ������l�^�ł����āA�ӂ[��������I
> ���\�����̃��|�[�g�r���[�̕��בւ�
(�O�t�O) ���\���Ƃ͐������炵���\�[�g�ł���
(�O�t�O) �����O�̘b�ł����A�l�̓\�[�g�̃e�X�g���T�疜���ł���Ă܂������ǂˏ�
(�O�t�O) �ł����ꕷ���Ėʔ������ȗV�т��v��������
(�O�t�O) �X���݂̂�Ȃ��\�[�g�ŗV�т܂��傤
(�O�t�O) ���[�ł��A�l�͂����̋������̃o�C�g�ł��̂ŁA����_�炩�ɏ�
(�O�t�O) �Ⴆ�e�L�X�g�t�@�C�����當�����ǂݍ���Ń\�[�g���ă��|�[�g�r���[�ŕ\������
(�O�t�O) �ϗ��o����悤�ɂȂ�܂ł̑��x�������Ƃ��ǂ��H
(�O�t�O) ��{���̊�{�Ŗʔ�����
(�O�t�O) �ϗ��o����悤�ɂȂ�܂ł̑��x�������Ƃ��ǂ��H
(�O�t�O) ��{���̊�{�Ŗʔ�����
(�O�t�O) �ł��������r��SSE4�g��ꂿ�Ⴄ�Ɩʔ����Ȃ�����i��������������ˁH�j
(�O�t�O) ������͎��R���Ń\�[�g����Ƃ��ǂ��H
(�O�t�O) ������͎��R���Ń\�[�g����Ƃ��ǂ��H
ocr
>>644
�X�p�R���@top500
�@IBM�@total�@164/500
�@IBM�@POWER7�APoerwPC�@37/500�A�ŏ��3�ʁA��ʃV�F�A19/100
�@IBM�@�@�@�@�@x86�@�@�@�@�@�@ 127/500�A�ŏ��10�ʁA��ʃV�F�A11/100
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@���@Lenovo�i�M�����咆�����{�@�ցj��
HP 197/500�ACray 35/500�ASGI 14/500�AAppro 13/500�ABull 13/500
�X�p�R���@top500
�@IBM�@total�@164/500
�@IBM�@POWER7�APoerwPC�@37/500�A�ŏ��3�ʁA��ʃV�F�A19/100
�@IBM�@�@�@�@�@x86�@�@�@�@�@�@ 127/500�A�ŏ��10�ʁA��ʃV�F�A11/100
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@���@Lenovo�i�M�����咆�����{�@�ցj��
HP 197/500�ACray 35/500�ASGI 14/500�AAppro 13/500�ABull 13/500
�@�@�@�@�@�@�@�@�@�@�@�Q�Q�Q_
�@�@�@�@�@�@�@�@�@ �^�@�@�@ �@ �_
�@�@�@�@�@�@�@�@�^�@ �@ �\�@�@�\�_�@�@�@���[���A�܂��F�ŃX���[����
�@�@�@�@�@�@ �^�@�@�@�i ���j�@ �i���j �_�@�@�ʂɏ����Ƃ�����Ȃ��Čy���V�т̂���Ō����������Ȃ��ǂ�
�@�@�@�@�@�@ |�@�@�@�@�@�@�i__�l__�j�@�@�@|�@�@�@���ăR�s�y�ł����ɍs����
�@�@�@�@�@�@ �_�@�@�@ �@ �@�M�� �L�@�@�^
�@�@�@�@�@�@�@�@/�L�܁M�P �P�@�M ��'
�@�@�@�@�@�@ �@ |�@ �@ �@�@�QށQ ��@�@�_
�@�@�@�@�@�@�@�@�R�@�C�L�P /�@�@�R�� �@ �r
�@�@�@�@�@�@�@ �@ l �@�@�@ /�@�@�� �@�R�c'
�@�@�@�@�@�@�@�@�@�R �@�@/�@ �@ ,�R�@�@�R�@�@ �@ �@�@�@ _-�]�
�@�@�@�@�@�@�@�@ ,�B�R �@�@�@�@ /�@ �x �@ �T�]-� �����L�@ ��
�@�@�@�@�@�@r_-�B__�_�R��Q�QɁQ_�u�Q�Q�Q�__�Q_�Q�Q�v
�@�@�@�@�@�@�@�@�@ �^�@�@�@ �@ �_
�@�@�@�@�@�@�@�@�^�@ �@ �\�@�@�\�_�@�@�@���[���A�܂��F�ŃX���[����
�@�@�@�@�@�@ �^�@�@�@�i ���j�@ �i���j �_�@�@�ʂɏ����Ƃ�����Ȃ��Čy���V�т̂���Ō����������Ȃ��ǂ�
�@�@�@�@�@�@ |�@�@�@�@�@�@�i__�l__�j�@�@�@|�@�@�@���ăR�s�y�ł����ɍs����
�@�@�@�@�@�@ �_�@�@�@ �@ �@�M�� �L�@�@�^
�@�@�@�@�@�@�@�@/�L�܁M�P �P�@�M ��'
�@�@�@�@�@�@ �@ |�@ �@ �@�@�QށQ ��@�@�_
�@�@�@�@�@�@�@�@�R�@�C�L�P /�@�@�R�� �@ �r
�@�@�@�@�@�@�@ �@ l �@�@�@ /�@�@�� �@�R�c'
�@�@�@�@�@�@�@�@�@�R �@�@/�@ �@ ,�R�@�@�R�@�@ �@ �@�@�@ _-�]�
�@�@�@�@�@�@�@�@ ,�B�R �@�@�@�@ /�@ �x �@ �T�]-� �����L�@ ��
�@�@�@�@�@�@r_-�B__�_�R��Q�QɁQ_�u�Q�Q�Q�__�Q_�Q�Q�v
�@�@�@/�@�@�@ ���@�@�_.�@�@�^�_�^�@���@ �@ ���@�_
�@�@�@|�@�@�@�@�@`�[���)�@ �^ �@ �i���j �@�i���j�@ �_
�@ �@ |�@�@�@�@i�L�P�P�P �_ |�@ �@ �@ �i__�l__�j�@�@ �@ |
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�_�Q�@�@ �M �܁L�@ �@�@�^
�@�@�@|�@�@�@�@�@`�[���)�@ �^ �@ �i���j �@�i���j�@ �_
�@ �@ |�@�@�@�@i�L�P�P�P �_ |�@ �@ �@ �i__�l__�j�@�@ �@ |
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�_�Q�@�@ �M �܁L�@ �@�@�^
�V�b�^�J�����悤�Ƃ��Č����Ɏ��s���Ă�� ID:uU9Tvpeu
�R( ߄t�)Ɂ@�\�[�g�ŏ������I
�@�@ �b
�@�@ ��
(߄t�) ���̃X���ɂ̓v���O�����D���Ȑl�������悤�Ȃ̂ŗ]���Ƃ��ď�����݂��鎖�ɂ��܂���
(߄t�) �����̓v���O�����̊�{���̊�{�A�\�[�g�ōs���܂�
(߄t�) 1000�����ʂ̕�������\�[�g���ă��X�g�R���g���[���Ŋϗ��o����v���O��������肻�̑��x�������܂�
(߄t�) �������A���ʂ̕������r�ł͖ʔ����Ȃ��̂ŁA�������r�͎��R���ő召������ʂȂ��iPHP��natcasesort()�����̂��́j�Ƃ��܂�
m9(�O�t�O) �ׂ������[���͂܂��l���邩��A�݂�ȃv���W�F�N�g�ʍ���ď������Ƃ���
�@�@ �b
�@�@ ��
(߄t�) ���̃X���ɂ̓v���O�����D���Ȑl�������悤�Ȃ̂ŗ]���Ƃ��ď�����݂��鎖�ɂ��܂���
(߄t�) �����̓v���O�����̊�{���̊�{�A�\�[�g�ōs���܂�
(߄t�) 1000�����ʂ̕�������\�[�g���ă��X�g�R���g���[���Ŋϗ��o����v���O��������肻�̑��x�������܂�
(߄t�) �������A���ʂ̕������r�ł͖ʔ����Ȃ��̂ŁA�������r�͎��R���ő召������ʂȂ��iPHP��natcasesort()�����̂��́j�Ƃ��܂�
m9(�O�t�O) �ׂ������[���͂܂��l���邩��A�݂�ȃv���W�F�N�g�ʍ���ď������Ƃ���
�������ɓ���Ȃ��ăf�B�X�N�ɂ���f�[�^���f�B�X�N�g���ă\�[�g����ꍇ�AGNU��sort�����\�D�G����
786 �F,,�E�L�́M�E,,�j��-�������F2014/01/27(��) 08:02:50.31 ID:JD19Y3m4
STL��Boost���Ă悭�g���邩��R���p�C������Ă郁�[�J�[��
�悭�������Ă��B
�\���̂̃������A���C�������g�������Ă�ꍇ�A�f�[�^�̈ړ���
�œK���I�v�V������SSE/AVX���g���Ă��ꂽ��Ƃ����B
�A�Z���u���������ƌ�y�ɑE�߂�͎̂����ŏ������߂���Ȃ�
�ǂނ��߂�
�悭�������Ă��B
�\���̂̃������A���C�������g�������Ă�ꍇ�A�f�[�^�̈ړ���
�œK���I�v�V������SSE/AVX���g���Ă��ꂽ��Ƃ����B
�A�Z���u���������ƌ�y�ɑE�߂�͎̂����ŏ������߂���Ȃ�
�ǂނ��߂�
�Ƃ͂������ǂ͎������ǂ݂����Ǝv��Ȃ��Ɠǂ܂Ȃ����ǂ߂Ȃ��Ƃ���
�Ȃ�Ń��t�@�����X��PHP�o�Ă����
789 �F,,�E�L�́M�E,,�j��-�������F2014/01/27(��) 08:23:10.30 ID:JD19Y3m4
80:20���[�����Ă��邶���B�S�̂̃R�[�h��2���قǂ���
���̂ɂ���Ă�90:10���炢���ȁB
�R�[�h�̗����ǂ݂₷�����ꂢ�ȃR�[�h����������
���Ƃ���œK�����𓊓������ق��������I���B
�����̏ꍇ�AASM���ǂ߂���Ă����Ɛ^����ɓ��������̂́u�f�o�b�O�����v
���̂ɂ���Ă�90:10���炢���ȁB
�R�[�h�̗����ǂ݂₷�����ꂢ�ȃR�[�h����������
���Ƃ���œK�����𓊓������ق��������I���B
�����̏ꍇ�AASM���ǂ߂���Ă����Ɛ^����ɓ��������̂́u�f�o�b�O�����v
�O�l�̃R�[�h�Ƃ����ƁA
�R�[�h���͓̂ǂ݂₷��C����ō������A
CPU��586/686�Ƃ����ƁA#ifdef�ŕ��ăA�Z���u���ō��ꂽ�œK���R�[�h�ɍs�����肷��
�R�[�h���͓̂ǂ݂₷��C����ō������A
CPU��586/686�Ƃ����ƁA#ifdef�ŕ��ăA�Z���u���ō��ꂽ�œK���R�[�h�ɍs�����肷��
791 �F,,�E�L�́M�E,,�j��-�������F2014/01/27(��) 09:00:18.52 ID:JD19Y3m4
��̓I�Șb�AFixstars��C/C++�̍œK������Ă����1�l��200�����炢���������ˁB
���ʂ̃v���O���}�Ȃ甼�z�ȉ��ł��ނ����B
���ʂ̃v���O���}�Ȃ甼�z�ȉ��ł��ނ����B
�������ŖړI���B������Ȃ炻��ł�����Ȃ��H
XP�����{��! ���ʂ������O�̐����ɕ���PC�ƊE
1�`3���̖@�l����PC���v�͉ߋ��ō���!?
http://pc.watch.impress.co.jp/docs/column/gyokai/20140127_632511.html
1�`3���̖@�l����PC���v�͉ߋ��ō���!?
http://pc.watch.impress.co.jp/docs/column/gyokai/20140127_632511.html
�V�lPG������Ă̂̓\�[�g�������őg�߂Ȃ��A�z�ƃ\�[�g�������ŏ����Ă�����Ƒ����Ȃ����Ɖx�ɓ���o�J�Ɏd���Ƃ͉��Ȃ̂��������Ȃ���Ȃ�Ȃ������ς���B
�\�[�g�̐V�A���S���Y�����l���Ď�������悤�ȓz���A�����J��IT��Ƃœ����āA
����������IT��Ƃ����{��IT��ƂɃn�[�h�EOS�E�~�h���E�F�A�E�J��������IT�C���t�����āA
���l���������\�[�g�𗘗p����悤�ȓz�����{��IT��Ƃœ����Ă�
����������IT��Ƃ����{��IT��ƂɃn�[�h�EOS�E�~�h���E�F�A�E�J��������IT�C���t�����āA
���l���������\�[�g�𗘗p����悤�ȓz�����{��IT��Ƃœ����Ă�
�������c�����̐V�c�ƒ[���`3�����Windows 8�^�u���b�g�����̑_��
Windows 8�^�u���b�g��������
http://cloud.watch.impress.co.jp/docs/case/20140127_627359.html
Windows 8�^�u���b�g��������
http://cloud.watch.impress.co.jp/docs/case/20140127_627359.html
�y�ȒP�ȏ����̃��[���z
�E �Ƃ肠����Windows��œ����悤�ɂ܂Ƃ߂鎖
�E �g�p���錾���GUI�͉����g���Ă����R
�@�i���X�g�R���g���[���͑S�ẴA�C�e�����ϗ��\�ŏ����ƍ~����芷������悤�ɂ��鎖�j
�E 32bit�ł�64bit�v���O�����ł�OK�A�g�����߂̎g�p�����R�A���X���b�h�g���v���O�����ł�OK�A������GPU�̎g�p��NG
�E �����Ɏg��1000�����̕�����f�[�^�͖l���e�L�g�[�ɗp�ӂ���A�ꌏ10�����ʂ̃��C�h������200M�ʂ̃T�C�Y�Ƃ�
�E �p�ӂ���e�L�X�g�t�@�C���ȊO�ɁA���̃t�@�C����n���Ă�������ƃ\�[�g���ϗ����o����悤�ɂ��鎖
m9(�O�t�O) �ׂ������͂܂����߂邨�A���₠��Ύt���邨
>>794
m9(�O�t�O) �d������2ch�ŗV��ł邨��������Q�����邨�A�l������o������G�����Ȃ炷������ł���
>>795
�݂�Ȃōő��\�[�g����ăA�����J�l���߷ެ����Ă�낤�[���[�A�N���Q�����Ă���
�@�@�ȁQ��
�@ (�@^�D^)��9m��9m
�@ (m9�@��m9��m9
�@ /�@�@�@) �@�߷ެ�߷ެ�߷ެ�߷ެ�
�@ ( /�P��
�E �Ƃ肠����Windows��œ����悤�ɂ܂Ƃ߂鎖
�E �g�p���錾���GUI�͉����g���Ă����R
�@�i���X�g�R���g���[���͑S�ẴA�C�e�����ϗ��\�ŏ����ƍ~����芷������悤�ɂ��鎖�j
�E 32bit�ł�64bit�v���O�����ł�OK�A�g�����߂̎g�p�����R�A���X���b�h�g���v���O�����ł�OK�A������GPU�̎g�p��NG
�E �����Ɏg��1000�����̕�����f�[�^�͖l���e�L�g�[�ɗp�ӂ���A�ꌏ10�����ʂ̃��C�h������200M�ʂ̃T�C�Y�Ƃ�
�E �p�ӂ���e�L�X�g�t�@�C���ȊO�ɁA���̃t�@�C����n���Ă�������ƃ\�[�g���ϗ����o����悤�ɂ��鎖
m9(�O�t�O) �ׂ������͂܂����߂邨�A���₠��Ύt���邨
>>794
m9(�O�t�O) �d������2ch�ŗV��ł邨��������Q�����邨�A�l������o������G�����Ȃ炷������ł���
>>795
�݂�Ȃōő��\�[�g����ăA�����J�l���߷ެ����Ă�낤�[���[�A�N���Q�����Ă���
�@�@�ȁQ��
�@ (�@^�D^)��9m��9m
�@ (m9�@��m9��m9
�@ /�@�@�@) �@�߷ެ�߷ެ�߷ެ�߷ެ�
�@ ( /�P��
>>791
m9(�O�t�O) �����ƁA����������Q�����Ă���A�ǂ����������ꗣ��ĉɂȂ�ł���H
>>788
m9(�O�t�O) ���[��A�Ƃ肠�����N�͂�����A�w���킦�Č��Ăĉ�����
m9(�O�t�O) �����ƁA����������Q�����Ă���A�ǂ����������ꗣ��ĉɂȂ�ł���H
>>788
m9(�O�t�O) ���[��A�Ƃ肠�����N�͂�����A�w���킦�Č��Ăĉ�����
���ł��
800 �F,,�E�L�́M�E,,�j��-�������F2014/01/27(��) 19:08:16.68 ID:bLnPbPlE
>>795
���̉�Ђ��ĂЂ���Ƃ��đ劔�傪�u�S�����m�X�E�|���T�[�v�Ƃ��u������� ���Ɂv�Ƃ�����Ȃ��́H
�\�[�g�A���S���Y�����Ƃ��ŗ��v���Â��Ă�悤�ȉˋ�̉�Ђ�]���ɍ��̎~�߂悤��
���̉�Ђ��ĂЂ���Ƃ��đ劔�傪�u�S�����m�X�E�|���T�[�v�Ƃ��u������� ���Ɂv�Ƃ�����Ȃ��́H
�\�[�g�A���S���Y�����Ƃ��ŗ��v���Â��Ă�悤�ȉˋ�̉�Ђ�]���ɍ��̎~�߂悤��
>>797
�\�[�g���Ă͓̂��͂���f�[�^�Ǝg���郊�\�[�X�ɂ���čœK�ȃA���S���Y�����Ⴄ���B
�f�[�^�ɂ���Ă̓������ɓW�J���鎞�_�ŏ��������܂��Ă��܂��B
�\�[�g���Ă͓̂��͂���f�[�^�Ǝg���郊�\�[�X�ɂ���čœK�ȃA���S���Y�����Ⴄ���B
�f�[�^�ɂ���Ă̓������ɓW�J���鎞�_�ŏ��������܂��Ă��܂��B
802 �F,,�E�L�́M�E,,�j��-�������F2014/01/27(��) 19:16:04.82 ID:bLnPbPlE
4chan��sleep sort���Ă������n���ȃA���S���Y���������Ă���
�����I�ȋǖʂł͐F�X�A
�Ɍ��ł�Radix sort�A���Č������Ă邩��ȁB
�Ɍ��ł�Radix sort�A���Č������Ă邩��ȁB
804 �F,,�E�L�́M�E,,�j��-�������F2014/01/27(��) 19:19:59.18 ID:bLnPbPlE
���[���╶����̑召��r���Ƃ�������big endian�̂ق����L�������
>>801
(߄t�) �V�т����Ƃ肠�������x�����̏����ɂ��������烁�����͍D���Ȃ����g���Ă����ł���
(߄t�) ���������m�ۏo���Ȃ����̃e�L�X�g�t�@�C�������ꍇ�́ANG��������Ă��܂��܂���
(߄t�) �ǂ������������p�ӂ��邩�͂܂����߂Ă܂��A�������낤�ƂȂ낤�ƁA�ǂ�������ނ̕������Ă������悤�ɂ��Ă�
(߄t�) �e�L�X�g�f�[�^�͊F������ɂ�����ł��p�ӂ��Ă��������A����A�s���肪�o�Ă�������
(߄t�) ������\�[�g�ɔėp�I�Ɏg����ŋ��\�[�g�݂����Ȃ̍���ĉ�����
(߄t�) �V�т����Ƃ肠�������x�����̏����ɂ��������烁�����͍D���Ȃ����g���Ă����ł���
(߄t�) ���������m�ۏo���Ȃ����̃e�L�X�g�t�@�C�������ꍇ�́ANG��������Ă��܂��܂���
(߄t�) �ǂ������������p�ӂ��邩�͂܂����߂Ă܂��A�������낤�ƂȂ낤�ƁA�ǂ�������ނ̕������Ă������悤�ɂ��Ă�
(߄t�) �e�L�X�g�f�[�^�͊F������ɂ�����ł��p�ӂ��Ă��������A����A�s���肪�o�Ă�������
(߄t�) ������\�[�g�ɔėp�I�Ɏg����ŋ��\�[�g�݂����Ȃ̍���ĉ�����
806 �F,,�E�L�́M�E,,�j��-�������F2014/01/27(��) 19:28:24.91 ID:bLnPbPlE
�~�v���O���������ďA�E�����������Ȃ�CodeIQ�̖��ł������Ă������
������������Ȃ̂�������
ttp://sacsis.hpcc.jp/2007/cell-challenge/
ttp://sacsis.hpcc.jp/2008/cell/
ttp://sacsis.hpcc.jp/2009/cell/
ttp://sacsis.hpcc.jp/2007/cell-challenge/
ttp://sacsis.hpcc.jp/2008/cell/
ttp://sacsis.hpcc.jp/2009/cell/
809 �F,,�E�L�́M�E,,�j��-�������F2014/01/27(��) 19:50:02.76 ID:bLnPbPlE
�}�����Ǝ��v�̐�H���͋�ʂ��Ȃ��Ƃ�
�ł͊F����A���Z�����ł��傤�������\�[�g������炱��Ȋ����݂����Ȃ̊��҂��Ă܂��̂ł�낵�����肢���܂�
�������ꂩ����n�߂܂��̂ŁA����Ŏ��炵�܂�
�@�,,�
�i ߃�� )���@���ް
.�@�@�@�@�@.��
�������ꂩ����n�߂܂��̂ŁA����Ŏ��炵�܂�
�@�,,�
�i ߃�� )���@���ް
.�@�@�@�@�@.��
811 �F,,�E�L�́M�E,,�j��-�������F2014/01/27(��) 19:56:53.78 ID:bLnPbPlE
�ԗւ̍Ĕ������Č��t���o����Ƃ�����
>>811
�R(`�D�L)� �ǂ��������тȂ��������Ă��͂₭�Ă��Ȃ�ł���������Ƃ��ƂƂ���[
�R(`�D�L)� �ǂ��������тȂ��������Ă��͂₭�Ă��Ȃ�ł���������Ƃ��ƂƂ���[
�Ȃ���Ⴂ�̘b�葽����
815 �F,,�E�L�́M�E,,�j��-�������F2014/01/27(��) 20:08:27.70 ID:bLnPbPlE
>>812
�_�|�͂�������Ȃ���
�A�����J�̉�Ђ��肪���C�u��������ē��{�̃\�t�g���[�J�[�̓��C�u������@��������
�v���O�����������Ȃ��A�Ǝv���Ă邻��͑傢�Ȃ銨�Ⴂ�B
���Ƃ���FlexGrid����Ă��Ђ��Ăǂ����m���Ă�H
�_�|�͂�������Ȃ���
�A�����J�̉�Ђ��肪���C�u��������ē��{�̃\�t�g���[�J�[�̓��C�u������@��������
�v���O�����������Ȃ��A�Ǝv���Ă邻��͑傢�Ȃ銨�Ⴂ�B
���Ƃ���FlexGrid����Ă��Ђ��Ăǂ����m���Ă�H
���\�[�X�����Ɩʔ����Ȃ��ȁB
20�N�ȏ�O��DOS�}�V����100MB�̃\�[�g���������EMS�g���ăe���|�����t�@�C������ĂƂ��낢�����Ċy���������B
�\�[�g����͈͂����s�ڂ��牽�s�ڂ܂ŁA�L�[�ɂȂ镶������������ڂ��牽�����ڂ܂łƎw��ł���悤�ɂ��ă��O�̉�͂Ɏg�������A�I�[��C����ŃA�Z���u���Ƃ��g��Ȃ��������ǃf�B�X�N�̂������傫�ȃt�@�C�����\�[�g�ł������A�X�s�[�h������������B
���Ȃ�I���������ōs���ăZ�O�����g���������܂�Ȃ���ˁB
�H�v�ł���̂̓}���`�R�A�Ή����炢���ȁB
20�N�ȏ�O��DOS�}�V����100MB�̃\�[�g���������EMS�g���ăe���|�����t�@�C������ĂƂ��낢�����Ċy���������B
�\�[�g����͈͂����s�ڂ��牽�s�ڂ܂ŁA�L�[�ɂȂ镶������������ڂ��牽�����ڂ܂łƎw��ł���悤�ɂ��ă��O�̉�͂Ɏg�������A�I�[��C����ŃA�Z���u���Ƃ��g��Ȃ��������ǃf�B�X�N�̂������傫�ȃt�@�C�����\�[�g�ł������A�X�s�[�h������������B
���Ȃ�I���������ōs���ăZ�O�����g���������܂�Ȃ���ˁB
�H�v�ł���̂̓}���`�R�A�Ή����炢���ȁB
>>800���u�����͑��݂��Ȃ���i�]���ɂ����j�v
>>815���u�����������v
815�̂��ꂪ�_�|�Ȃ̂ɁA800�݂����ȕ\���ɂ�����ł����B
��������795����́����̑��݂ɂ��ĉ��������ĂȂ��̂ɁB
>>815���u�����������v
815�̂��ꂪ�_�|�Ȃ̂ɁA800�݂����ȕ\���ɂ�����ł����B
��������795����́����̑��݂ɂ��ĉ��������ĂȂ��̂ɁB
818 �F,,�E�L�́M�E,,�j��-�������F2014/01/27(��) 20:19:29.49 ID:bLnPbPlE
����͂����̛�����
>>816
(߄t�) 20�N�ȏ�̌o��������Ƃ́A���Ȃ��͕K�v�Ȑl�ނł��A���Ђ��Q��������
(߄t�) ���R����r�����炻�̕ӂ����肱�ފy����������Ǝv���܂�
(߄t�) �}���`�X���b�h���f�o�b�O���G�O�����ɂȂ��ĂȂ��Ȃ������ł�
(߄t�) �ꏏ�ɗV�т܂��傤
(߄t�) 20�N�ȏ�̌o��������Ƃ́A���Ȃ��͕K�v�Ȑl�ނł��A���Ђ��Q��������
(߄t�) ���R����r�����炻�̕ӂ����肱�ފy����������Ǝv���܂�
(߄t�) �}���`�X���b�h���f�o�b�O���G�O�����ɂȂ��ĂȂ��Ȃ������ł�
(߄t�) �ꏏ�ɗV�т܂��傤
����������R�����Ă��`���[�j���O����ɂ͏����ȃL���b�V���ƌ�������Ȃ��Ƃ����Ȃ����A
����CPU�ł̓p�C�v���C���̋��������G�����Ă��邩��A����ȂɒP���Șb�ł��Ȃ��悤��
�]���͋���s����g�����������������A���S���Y����
���SGB�ςT�[�o���r�I����������悤�ɂȂ��Ă���I�����Ƃ��Č����I�ɂȂ�����ƁA
�V�X�e�����x���ł���肪���l�����Ă��ē��
���܂���Tesla���Xeon Phi���iGPU���l���n�߂�Ƃ����Ƒ��
����CPU�ł̓p�C�v���C���̋��������G�����Ă��邩��A����ȂɒP���Șb�ł��Ȃ��悤��
�]���͋���s����g�����������������A���S���Y����
���SGB�ςT�[�o���r�I����������悤�ɂȂ��Ă���I�����Ƃ��Č����I�ɂȂ�����ƁA
�V�X�e�����x���ł���肪���l�����Ă��ē��
���܂���Tesla���Xeon Phi���iGPU���l���n�߂�Ƃ����Ƒ��
817�ɂ͛������Ƃ������b�e����t����END��OK�ł��B
>>795�ɑ���>>800�̓C�`�������ł���ƃ��b�e����t���Ă�������END�Ƃ������ƂŁB
>>795�ɑ���>>800�̓C�`�������ł���ƃ��b�e����t���Ă�������END�Ƃ������ƂŁB
��cinebenchR11.5 �V���O��CPU
�C���e��(7�N��60%����)
2013 Haswell 1.76/3.9=0.451
2012 Ivy 1.66/3.9=0.425
2011 Sandy 1.55/3.8=0.407
2010 Arrandale 0.8/2.39=0.334
2009 Lynn 1/2.94=0.340
2008 Penryn 0.93/3=0.310
2006 Conroe 0.86/3=0.286
�A���h(7�N�Ԃ�20%�������ス����)
2013 FX 1.1/4=0.275
2006 939 Opteron 0.68/3=0.226
�C���e��(7�N��60%����)
2013 Haswell 1.76/3.9=0.451
2012 Ivy 1.66/3.9=0.425
2011 Sandy 1.55/3.8=0.407
2010 Arrandale 0.8/2.39=0.334
2009 Lynn 1/2.94=0.340
2008 Penryn 0.93/3=0.310
2006 Conroe 0.86/3=0.286
�A���h(7�N�Ԃ�20%�������ス����)
2013 FX 1.1/4=0.275
2006 939 Opteron 0.68/3=0.226
intel�͂������ƃR�A�����₹��
���C���X�g���[���Ȃ��C2Q����4�R�A�̂܂܂���ˁ[��
���C���X�g���[���Ȃ��C2Q����4�R�A�̂܂܂���ˁ[��
����������Q9550���o�����͂��ƌܔN�������12�R�A���炢�ɂȂ��Ă�̂��ȂƂ��z��������
825 �F,,�E�L�́M�E,,�j��-�������F2014/01/27(��) 20:40:25.90 ID:bLnPbPlE
������2ch�̂܂�6�R�A�Ƃ��o����Ă�����͂���Ŏg����
4�R�A���ێ����Ă��錻��̃y�[�X�ł�
2�N���Ƃɗ��_Flops/core��2�{�̃y�[�X�ʼn��P���Ă邩��c�c
�N���C�A���g�T�C�h�Ő��\���K�v�Ȃ�SIMD�߂�w�͂�����������Ȃ�
�f�B�X�v���C�̍��𑜓x���̗��ꂪ����̂ŁA
Skylake����ł����Ԃ�GPU�Ƀ_�C���H���闬��͕ς��Ȃ����낤
�����T�[�o�͂ǂ�ǂ�R�A���ςݑ������l�q������A
��R�R�A���K�v�ȃ��[�U��Xeon�����ƂɂȂ�̂��Ȃ�
2�N���Ƃɗ��_Flops/core��2�{�̃y�[�X�ʼn��P���Ă邩��c�c
�N���C�A���g�T�C�h�Ő��\���K�v�Ȃ�SIMD�߂�w�͂�����������Ȃ�
�f�B�X�v���C�̍��𑜓x���̗��ꂪ����̂ŁA
Skylake����ł����Ԃ�GPU�Ƀ_�C���H���闬��͕ς��Ȃ����낤
�����T�[�o�͂ǂ�ǂ�R�A���ςݑ������l�q������A
��R�R�A���K�v�ȃ��[�U��Xeon�����ƂɂȂ�̂��Ȃ�
>>825
�قڃL���b�V������
�قڃL���b�V������
828 �F,,�E�L�́M�E,,�j��-�������F2014/01/27(��) 21:01:06.31 ID:bLnPbPlE
OpenCL�ł����Ƃ���́u�X���b�h�v�������葁�����₷�̂ɂ�SIMD�{�X�̂ق���
�y�ł��傤��
�������W�X�^�����ɂ�������X�P�W���[�������G�����邱�Ƃ͂��܂�Ȃ���
�y�ł��傤��
�������W�X�^�����ɂ�������X�P�W���[�������G�����邱�Ƃ͂��܂�Ȃ���
Sandy���炢�͒B���Ă�Ɣ��R�Ǝv���Ă���
>>822
Conroe�@��邶���www
Conroe�@��邶���www
�V���O����Sandy������������4960X��2�{�߂����\�łĂ邵
833 �F,,�E�L�́M�E,,�j��-�������F2014/01/27(��) 21:38:33.70 ID:bLnPbPlE
���F��SMT�ɖт����������̂Ȃ̂ŕK�����������͂Ȃ�Ȃ��B
FP���Z�l�b�N�����B
FP���Z�l�b�N�����B
�������Ƀ��ł��ơ
�v���O���}�[
http://kohada.2ch.net/prog/
�v���O����
http://toro.2ch.net/tech/
�v���O���}�[�̓A�j�����݂悤! 7�N�[��
http://kohada.2ch.net/test/read.cgi/prog/1378818940/
�v���O���}�[
http://kohada.2ch.net/prog/
�v���O����
http://toro.2ch.net/tech/
�v���O���}�[�̓A�j�����݂悤! 7�N�[��
http://kohada.2ch.net/test/read.cgi/prog/1378818940/
�ӂƒ��ׂĂĎv�������A
Broadwell��OpenCL2.0�Ή�������炵�����Ă��Ƃ�
Shared Virtual Memory�Ή��Ƃ���������Ă��ƂȂ̂�
Gen8�ł̓A�[�L�e�N�`�����啝�ɕω����āA������������ς�����ĉ\���o�Ă����ǁA
���������Ȃ�A�ǂ�ǂ��̓x���������܂��Ă����Ȃ��c�c
Broadwell��OpenCL2.0�Ή�������炵�����Ă��Ƃ�
Shared Virtual Memory�Ή��Ƃ���������Ă��ƂȂ̂�
Gen8�ł̓A�[�L�e�N�`�����啝�ɕω����āA������������ς�����ĉ\���o�Ă����ǁA
���������Ȃ�A�ǂ�ǂ��̓x���������܂��Ă����Ȃ��c�c
>>834
�������Ƀ��ł���
�P�P�ɁP�P�P�P�P�P
�@�@(��)�@�@�@�@��
�^�P�P|�@�@�@�@�@�@�@�@ �,,�
|�@||.�@�@|�@�@ �@ �����i ߃�߁@�j�@�@���f�肵�܂�
�_�Q�Q|�@�@�@�@========�@ �_
�@|�@�@�@|�@�@�@�^���������U�,_�j
����PC�Ŏ���v���O�����ł����A�\�t�g�����猩��Intel������CPU�����̂���|�̃C�x���g�ł�����
�Ȃ��X���Ⴂ�ł͂Ȃ��Ƃ������������m����������
�@�,,�
�i ߃�� )���@���ް
.�@�@�@�@�@.��
�������Ƀ��ł���
�P�P�ɁP�P�P�P�P�P
�@�@(��)�@�@�@�@��
�^�P�P|�@�@�@�@�@�@�@�@ �,,�
|�@||.�@�@|�@�@ �@ �����i ߃�߁@�j�@�@���f�肵�܂�
�_�Q�Q|�@�@�@�@========�@ �_
�@|�@�@�@|�@�@�@�^���������U�,_�j
����PC�Ŏ���v���O�����ł����A�\�t�g�����猩��Intel������CPU�����̂���|�̃C�x���g�ł�����
�Ȃ��X���Ⴂ�ł͂Ȃ��Ƃ������������m����������
�@�,,�
�i ߃�� )���@���ް
.�@�@�@�@�@.��
�ǂ���������Ȃ�
��u�_���ɓǂ߂Ă��܂�����
�������ɂች�������ꂽ����Ȃ���
�������ɂች�������ꂽ����Ȃ���
>>837
�@�@�@�@�@�@�@�@�@�@�@ �^�j
�@�@�@�@�@�@�@�@�@�@�@�^�^�^�j
�@�@�@�@�@�@�@�@�@ �^,.=�''"�^
�@�@�@�^�@�@�@�@ i f�@,.r='"-�]'�Q�Q�Q_�@�@�@�@�@���܂���������������I�I
�@�@/�@�@�@�@�@ /�@�@�@_,.-�]'~�^�܁@�@�܁_
�@�@�@�@�^�@ �@,i�@�@�@,��Ɓ��i ���j.�@�i���j�_
�@�@�@/�@ �@�@Ɂ@�@�@ ilރt::::::�܁i__�l__�j��::::: �_
�@�@�@�@�@�@,��Ĥ�@�@,!,!|�@�@�@�@�@|r��-|�@�@�@�@�@|
�@�@�@�@�@/�@iāS�R_/�"�_ �@�@ �@ `�['�L �@ �@ �^
�@�@�@�@�@�@�@�@�@�@�@ �^�j
�@�@�@�@�@�@�@�@�@�@�@�^�^�^�j
�@�@�@�@�@�@�@�@�@ �^,.=�''"�^
�@�@�@�^�@�@�@�@ i f�@,.r='"-�]'�Q�Q�Q_�@�@�@�@�@���܂���������������I�I
�@�@/�@�@�@�@�@ /�@�@�@_,.-�]'~�^�܁@�@�܁_
�@�@�@�@�^�@ �@,i�@�@�@,��Ɓ��i ���j.�@�i���j�_
�@�@�@/�@ �@�@Ɂ@�@�@ ilރt::::::�܁i__�l__�j��::::: �_
�@�@�@�@�@�@,��Ĥ�@�@,!,!|�@�@�@�@�@|r��-|�@�@�@�@�@|
�@�@�@�@�@/�@iāS�R_/�"�_ �@�@ �@ `�['�L �@ �@ �^
�v���t�F�b�V���i��������Premiere Pro��After Effects�ł���
24�R�A�̃��[�N�X�e�[�V�������ŐV�����4�R�A�𓋍ڂ����m�[�g�@�����������ł���Ƃ�������
http://shuffle.genkosha.com/products/hp/zseries/8556.html
24�R�A�̃��[�N�X�e�[�V�������ŐV�����4�R�A�𓋍ڂ����m�[�g�@�����������ł���Ƃ�������
http://shuffle.genkosha.com/products/hp/zseries/8556.html
>>808
���܂�PC�́A���i�͑S���O���̊O�����[�J�[�ŁA
�����H��͂����g�ݗ��Ă邾���ŁA
�Ј����₵�Ă܂ő��Y���ĂȂ��̂Łi���Ԃ�c�ƁE�x���o�E�h�����őΉ����Ă�j
������A���v�}�����Ă��Ƃ��ɉe�����ł���H
���܂�PC�́A���i�͑S���O���̊O�����[�J�[�ŁA
�����H��͂����g�ݗ��Ă邾���ŁA
�Ј����₵�Ă܂ő��Y���ĂȂ��̂Łi���Ԃ�c�ƁE�x���o�E�h�����őΉ����Ă�j
������A���v�}�����Ă��Ƃ��ɉe�����ł���H
>>823-824
�A�[�L�e�N�`���J�����哱���Ă��������̃C�X���G���g�̊�����
�u���C���X�g���[����4�R�A�ŏ\���A��������IPC����ɒ��͂���v
���ČJ��Ԃ������Ă������B
�܁[���̍��̓��j�[�R�A�o�u���E����Larrabee���z�Ȃ̍Œ���
���̎�̃l�^��������X���œ\���Ă����܂葊��ɂ���Ȃ��������B
�A�[�L�e�N�`���J�����哱���Ă��������̃C�X���G���g�̊�����
�u���C���X�g���[����4�R�A�ŏ\���A��������IPC����ɒ��͂���v
���ČJ��Ԃ������Ă������B
�܁[���̍��̓��j�[�R�A�o�u���E����Larrabee���z�Ȃ̍Œ���
���̎�̃l�^��������X���œ\���Ă����܂葊��ɂ���Ȃ��������B
�œK������ʂ���c�_����ƌ��ǁuA+D=P�v�ł��邱�Ƃ��m�F��������ȡ
�g���^�����ԁu���`�E�����D�ꂽ�d�r�����߂Ă���v
Intel�u���`�E�����D�ꂽ�d�r�����߂Ă���v
ARM�u���`�E�����D�ꂽ�d�r�H����Ȃ���w�v
�g���^�����ԁu���`�E�����D�ꂽ�d�r�����߂Ă���v
Intel�u���`�E�����D�ꂽ�d�r�����߂Ă���v
ARM�u���`�E�����D�ꂽ�d�r�H����Ȃ���w�v
�܂�ARM�́u���`�E�����D�ꂽ�d�r�����߂Ă���v���ꂾ���ǂ�
�uA+D=P�v���ĂȂ�
���`�E�����D�ꂽ�d�r���o�ăX�}�z�Ɏg����悤�ɂȂ�A
ATOM���L���ɂȂ肻�������ǂ�
ATOM���L���ɂȂ肻�������ǂ�
����Ȃ��Ȃ��Ƀ}�O�l�V�E���d�r�B�悭�m��˂�����
ARM������ᐫ�\�Ƃ����킯�ł��A�����d�͂Ƃ����킯�ł��Ȃ�
ARM���]�X�Ƃ����c�_�͊�{�I�ɔj�]���Ă�
ARM���]�X�Ƃ����c�_�͊�{�I�ɔj�]���Ă�
�X�}�z�̓d�r�e�ʂ́A�S�R�����Ȃ���
850 �F,,�E�L�́M�E,,�j��-�������F2014/01/28(��) 00:01:10.50 ID:bLnPbPlE
>>846
���̓d�r��Atom�������g����킯����Ȃ�����
���̓d�r��Atom�������g����킯����Ȃ�����
�uA+D=P�v���ĂȂ�
�O�O���Ă����̋L�������łĂ��Ȃ���
http://anond.hatelabo.jp/20070912013027
���̋L���ł���������ĂȂ���
�Ȃ������ꂿ�������
�O�O���Ă����̋L�������łĂ��Ȃ���
http://anond.hatelabo.jp/20070912013027
���̋L���ł���������ĂȂ���
�Ȃ������ꂿ�������
�L�����ƃq�b�g���ɂ������� A plus D equal P �ŃO�O���Ă�����炵�����̂͂łĂ��Ȃ�
�����������
�A���S���Y���{�f�[�^�\�����v���O�����H
���������̏ȗ��͌������Ƃ��Ȃ��c�c�Ђǂ���
�A���S���Y���{�f�[�^�\�����v���O�����H
���������̏ȗ��͌������Ƃ��Ȃ��c�c�Ђǂ���
���Ƃ�����ȗp�Ⴊ����Ƃ�������[�����Ă��炦�邩��?
A+D=P��m��Ȃ��q������ - �͂Ăȓ����_�C�A���[:
http://anond.hatelabo.jp/touch/20070912013027
A+D=P��m��Ȃ��q������ - �͂Ăȓ����_�C�A���[:
http://anond.hatelabo.jp/touch/20070912013027
�悤����ɔ��ʂ̒m���������Ă��ƁH
�ǂ��{����������ǂ݂܂��傤�A���Ă��Ƃ��B
857 �F,,�E�L�́M�E,,�j��-�������F2014/01/28(��) 01:00:38.12 ID:fdPvnZIS
�����̂͂Ăȃ_�C�A���[�̂�������̑��ꂾ��
���[�g���ۏo��
���܂ǂ��̃A�v���P�[�V�����̍\���v�f��Model + View + Control����
���ꂷ�牽�\�N���O�ɐ��������T�O������������
���[�g���ۏo��
���܂ǂ��̃A�v���P�[�V�����̍\���v�f��Model + View + Control����
���ꂷ�牽�\�N���O�ɐ��������T�O������������
>>855
���ʂȂ̂��͒m��A���Ȃ��Ƃ���ʓI�ȏȗ����Ƃ͎v���Ȃ�
�����������ۉ���i�߂�Ǝ��ۂ̃A���S���Y�����ǂ��ł��悭�Ȃ�����A
�A���S���Y���ƃf�[�^�\���̋�ʂ��Ȃ��Ȃ����肷��̂�
���ۉ��Ƃ���������A+D=P�Ȃ�咣�����������o���Ӗ����悭�������Ƃ�����
���ʂȂ̂��͒m��A���Ȃ��Ƃ���ʓI�ȏȗ����Ƃ͎v���Ȃ�
�����������ۉ���i�߂�Ǝ��ۂ̃A���S���Y�����ǂ��ł��悭�Ȃ�����A
�A���S���Y���ƃf�[�^�\���̋�ʂ��Ȃ��Ȃ����肷��̂�
���ۉ��Ƃ���������A+D=P�Ȃ�咣�����������o���Ӗ����悭�������Ƃ�����
����̓I�u�W�F�N�g�w��������\�����v���O���~���O�s�v�݂����Șb����
860 �F,,�E�L�́M�E,,�j��-�������F2014/01/28(��) 01:07:55.32 ID:fdPvnZIS
�f�[�^�\����Model�A�A���S���Y����Control�������
�I�b�T����GUI�v���O�����������Ȃ��A�ƁB
�I�b�T����GUI�v���O�����������Ȃ��A�ƁB
�p�����̂�Ŏ��₵�����肾��������
���̌������̂��}�C�i�[�������̂�
���̌������̂��}�C�i�[�������̂�
862 �F,,�E�L�́M�E,,�j��-�������F2014/01/28(��) 01:22:08.79 ID:fdPvnZIS
���̑��c�ɏ����Ă邨������́A�I�u�W�F�N�g�w�����킩���ĂȂ�����
Ruby��JavaScript�������ł��Ȃ���B
SICP�݂����ȌÕ��Ȗ{�ǂނ��̓f�U�p�^�{����
���s��Rails��Zend�Ȃ��f�U�C���p�^�[���Ɋ�Â��č\�z����Ă�B
Ruby��JavaScript�������ł��Ȃ���B
SICP�݂����ȌÕ��Ȗ{�ǂނ��̓f�U�p�^�{����
���s��Rails��Zend�Ȃ��f�U�C���p�^�[���Ɋ�Â��č\�z����Ă�B
�����X�ǂ������肪�Ƃ��I
Broadwell�̃f�X�N�g�b�v�ł͔�����Ƃ��E�E�E
TSMC�Ƃ��̃t�@�E���_���͓����v���Z�X�ł����o�C�������Ƃ�
�p�t�H�[�}���X�����Ƃ����邯��Intel�ł��������̕����Ȃ���
�ϑz�����Ǎ��܂�Intel�̓f�X�N�g�b�v�����Ńv���Z�X�J������
���o�C���ɗ��p���Ă�����14nm�̓��o�C�������Ƀt�H�[�J�X����
�J�����Ă邩��f�X�N�g�b�v���ƃp�t�H�[�}���X���o�Ȃ����Ă��Ƃ���
�p�t�H�[�}���X�����Ƃ����邯��Intel�ł��������̕����Ȃ���
�ϑz�����Ǎ��܂�Intel�̓f�X�N�g�b�v�����Ńv���Z�X�J������
���o�C���ɗ��p���Ă�����14nm�̓��o�C�������Ƀt�H�[�J�X����
�J�����Ă邩��f�X�N�g�b�v���ƃp�t�H�[�}���X���o�Ȃ����Ă��Ƃ���
{kind=link}
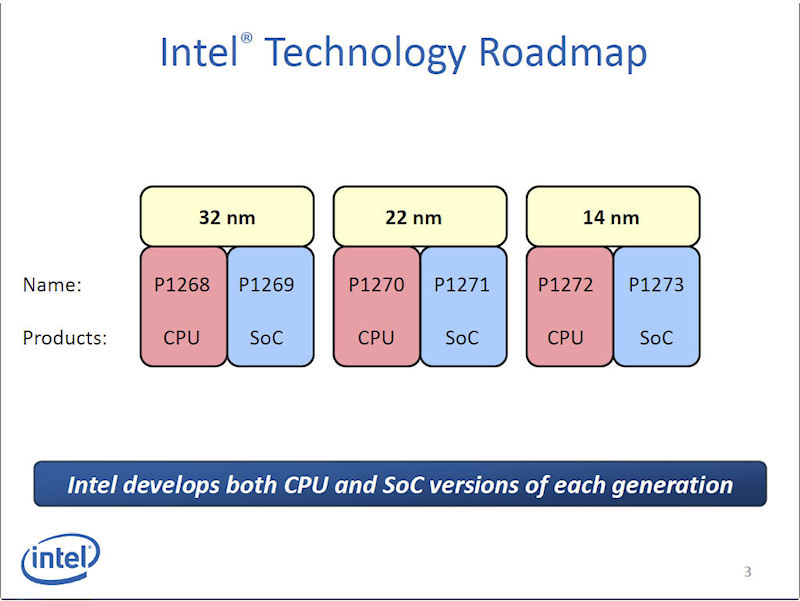{kind=link}
>>865
�C���e���������������̂����邪�A���L���t�@�u���Ƃ���|���Ă�킯����Ȃ��̂�
�����������̂͑��݂��Ă��킴�킴���J���ĂȂ������ł���H
���L���t�@�u���Ǝ�|����悤�ɂȂ�AIntel������J���邩�A
���ꂩ���[�N���ł��낢��o�Ă���ł��傤
�C���e���������������̂����邪�A���L���t�@�u���Ƃ���|���Ă�킯����Ȃ��̂�
�����������̂͑��݂��Ă��킴�킴���J���ĂȂ������ł���H
���L���t�@�u���Ǝ�|����悤�ɂȂ�AIntel������J���邩�A
���ꂩ���[�N���ł��낢��o�Ă���ł��傤
SoC�����v���Z�X�̓��W�b�N�p�̃g�����W�X�^�����Ő���ނ���Ɩ�������Ă邵�A
FPGA�����͂܂��ʂɒ����������Ă�炵���A�Ⴄ�����R�[�h���U���Ă�悤����
�\�����ǂ����P1270�œ������ƌ�����IvyBridge��Haswell�ł����͉��ǂ������Ă�炵����
���Ԃ�O���ɖ������K�v���Ȃ�����\�ɏo���ĂȂ�����
�t�@�E���h�����Ƃ��{�i������ƕ\�ɏo�Ă�������������Ȃ����Ȃ�
FPGA�����͂܂��ʂɒ����������Ă�炵���A�Ⴄ�����R�[�h���U���Ă�悤����
�\�����ǂ����P1270�œ������ƌ�����IvyBridge��Haswell�ł����͉��ǂ������Ă�炵����
���Ԃ�O���ɖ������K�v���Ȃ�����\�ɏo���ĂȂ�����
�t�@�E���h�����Ƃ��{�i������ƕ\�ɏo�Ă�������������Ȃ����Ȃ�
Broadwell�̃f�X�N�g�b�v�����͓o�ꂵ�Ȃ��I�H
�@�@�@�@�@Haswell Refresh �� 2014�N�p�Q�ɓo��\��I
http://tomoji2.blog11.fc2.com/blog-entry-9968.html
�@�@�@�@�@Haswell Refresh �� 2014�N�p�Q�ɓo��\��I
http://tomoji2.blog11.fc2.com/blog-entry-9968.html
Broadwell ���f�X�N�g�b�v�œ������Ȃ��̂�
�@�@�@�@�@�@�ᑬ�E�����d�͂̃��o�C����D�悷�邽��
http://ascii.jp/elem/000/000/799/799634/index-2.html
�@�@�@�@�@�@�ᑬ�E�����d�͂̃��o�C����D�悷�邽��
http://ascii.jp/elem/000/000/799/799634/index-2.html
�T�[�o�pbroadwell�͏o�邩��xeon���p��i7�ŏ�ʃ��f��������broadwell�ɂȂ邩������Ȃ���
Broadwell ��Xeon E3���o��Ƃ��Ă�ultra low power �݂̂Ɉ�[
>>744
�x���X������(�L�E�́E�M)Ͱ
C++ Coding Standards�ɍœK���͂���Ȃ܂�����Ȃ����܂ł���ȂƂ���������
�������������s��ł��ȁ[�@���ɂȂ�
�x���X������(�L�E�́E�M)Ͱ
C++ Coding Standards�ɍœK���͂���Ȃ܂�����Ȃ����܂ł���ȂƂ���������
�������������s��ł��ȁ[�@���ɂȂ�
875 �F,,�E�L�́M�E,,�j��-�������F2014/01/28(��) 19:16:23.81 ID:z35k1DxD
Broadwell-K�͏o�����Č����Ă�W����
�ǂ������p�ł���
�ނ���Xeon E3�̈ꕔ�𗬗p����Broadwell-K���o���̂���
���Ԃ�E3�ŏ�ʂ�800�h���Ƃ����̂ւ�
�ǂ������p�ł���
�ނ���Xeon E3�̈ꕔ�𗬗p����Broadwell-K���o���̂���
���Ԃ�E3�ŏ�ʂ�800�h���Ƃ����̂ւ�
876 �F,,�E�L�́M�E,,�j��-�������F2014/01/28(��) 19:17:57.81 ID:z35k1DxD
>>874
������I�Z���W�̃u���O�����Ă�Ɩ�����
�uadd eax 3���inc eax��3�������ق��������v
�݂�����Pen4����̒m�������������Ă�l������
������I�Z���W�̃u���O�����Ă�Ɩ�����
�uadd eax 3���inc eax��3�������ق��������v
�݂�����Pen4����̒m�������������Ă�l������
�R( ߄t�)� �X���݂̂�ȃ\�[�g���͐i��ł邩���H
�@�@ �b
�@�@ ��
(�O�t�O) �l�͂Ƃ肠�������n�߂���
(߄t�) ����8.1pro32bit��VS2012pro��VC�AGUI��MFC�g��
(߄t�) �����C����32bit�g���Ă邯�ǁAC++�ł��炩���������64�C���X�R���Ă���PC�Ɋ����āA���x�o������������x64�ɏ��������č������Ɏ��g�ޗ\��
(߄t�) x86�͐�̂Ă܂��A�����W�X�^���Ȃ����}�W�Ń��J���A���ق��ė~����
(߄t�) ���[���\���Ԃ����肻���ł�
�@�@�@�@�@�@ �@�,,�
�@�@�@�@�@�@ �i ߃�� �j�@�����������撣��[
�@�߮݁@�@�@( O��O)
�@�@�߮݁@�@ ��-||-J
�@�@�@�@�@�@�@������
�@�@ �@�@�@�@�@�@��
�@�܁R�V�܁R�V
�@�@ �b
�@�@ ��
(�O�t�O) �l�͂Ƃ肠�������n�߂���
(߄t�) ����8.1pro32bit��VS2012pro��VC�AGUI��MFC�g��
(߄t�) �����C����32bit�g���Ă邯�ǁAC++�ł��炩���������64�C���X�R���Ă���PC�Ɋ����āA���x�o������������x64�ɏ��������č������Ɏ��g�ޗ\��
(߄t�) x86�͐�̂Ă܂��A�����W�X�^���Ȃ����}�W�Ń��J���A���ق��ė~����
(߄t�) ���[���\���Ԃ����肻���ł�
�@�@�@�@�@�@ �@�,,�
�@�@�@�@�@�@ �i ߃�� �j�@�����������撣��[
�@�߮݁@�@�@( O��O)
�@�@�߮݁@�@ ��-||-J
�@�@�@�@�@�@�@������
�@�@ �@�@�@�@�@�@��
�@�܁R�V�܁R�V
iGPU���č������������Ă��̂��ȁH
����ȏ�̋����ɂ�eDRAM���K�v����
eDRAM������̂̓R�X�g��������
���b�`��iGPU�̐��i��iGPU�͌���ێ��̐��i�̓�ɉ�����̂���
����ȏ�̋����ɂ�eDRAM���K�v����
eDRAM������̂̓R�X�g��������
���b�`��iGPU�̐��i��iGPU�͌���ێ��̐��i�̓�ɉ�����̂���
�ʂɍ��X22nm��eDRAM��MCM������x����債���R�X�g�͂������̂ł�
880 �F,,�E�L�́M�E,,�j��-�������F2014/01/28(��) 19:27:32.75 ID:z35k1DxD
�����Ȃ������l�ł��
eDRAM���A���C����������GDDR5����������
CPU�����������}�U�[�{�[�h�ɂ͂t�����Ĕ̔�
�������̓\�P�b�g���Ȃ�A8ch DDR4�������g����
GDDR5���݂̑��x�ɂȂ�ł��傤
CPU�����������}�U�[�{�[�h�ɂ͂t�����Ĕ̔�
�������̓\�P�b�g���Ȃ�A8ch DDR4�������g����
GDDR5���݂̑��x�ɂȂ�ł��傤
882 �F,,�E�L�́M�E,,�j��-�������F2014/01/28(��) 19:30:39.53 ID:z35k1DxD
�m�[�gPC�ŏȓd�͉�������Ȃ�̂ł�߂Ă���
LPGDDR�𓊓����I
�܂��l�I�ɂ�IGPU�͂ǂ��ł��悭��
L4�L���b�V�����W���ɂȂ��Ă��̂�
���邢�͑��̌`�̃������ɏ�芷����̂����C�ɂȂ�
L4�L���b�V�����W���ɂȂ��Ă��̂�
���邢�͑��̌`�̃������ɏ�芷����̂����C�ɂȂ�
>>880
m9(�O�t�O) ������̂��[
(�O�t�O) ���C�u�������Ȃ���Βl�̕��בւ����o���Ȃ��́H
(�O�t�O) �\�[�g������ō��Ȃ��G����������CPU��������Ⴄ�́H
�@�@�@�@�@�@�@�@�@�Q�Q�Q_
�@�@�@�@�@�@�@�@�^�@�@ �@ �@�_
�@�@�@�@�@ �@�^�@�@���@ �@ ���_
�@�@�@�@�@�^�@�@�@�@�܁@�@�܁@�@�_ �@�@�@�n�n�b �����X
�@�@�@�@�@|�@ �@�@ �@ ,�(�_, )�R�@ �@ |
�@�@ �@�@ �_�@�@ �@�@ Ī����@ �@�^
�@�@ �@ �@ �^�@�@�@_�@�R�j�,�@ ��
m9(�O�t�O) ������̂��[
(�O�t�O) ���C�u�������Ȃ���Βl�̕��בւ����o���Ȃ��́H
(�O�t�O) �\�[�g������ō��Ȃ��G����������CPU��������Ⴄ�́H
�@�@�@�@�@�@�@�@�@�Q�Q�Q_
�@�@�@�@�@�@�@�@�^�@�@ �@ �@�_
�@�@�@�@�@ �@�^�@�@���@ �@ ���_
�@�@�@�@�@�^�@�@�@�@�܁@�@�܁@�@�_ �@�@�@�n�n�b �����X
�@�@�@�@�@|�@ �@�@ �@ ,�(�_, )�R�@ �@ |
�@�@ �@�@ �_�@�@ �@�@ Ī����@ �@�^
�@�@ �@ �@ �^�@�@�@_�@�R�j�,�@ ��
886 �F,,�E�L�́M�E,,�j��-�������F2014/01/28(��) 19:45:28.12 ID:z35k1DxD
�����������Ȃ�s�폟�ł�������A���Ă�����
���O�̋����ɋ������Ȃ�
���O�̋����ɋ������Ȃ�
887 �F,,�E�L�́M�E,,�j��-�������F2014/01/28(��) 19:48:24.87 ID:z35k1DxD
>>884
�ǂ��l���Ă�22nm�̃��\�[�X������ɂ��邩��ł����\�����[�V�����ł���
�������̓������悶��Ȃ��́B
���͂܂Ƃ��Ɏg����W���K�i���Ȃ��āA���O�ō�����ق����������炻�������B
512bit�o�X�Ƃ����̂��|�V������Wide IO�Ȃ��ɂ��̂Ǝv���邵�B
�ǂ��l���Ă�22nm�̃��\�[�X������ɂ��邩��ł����\�����[�V�����ł���
�������̓������悶��Ȃ��́B
���͂܂Ƃ��Ɏg����W���K�i���Ȃ��āA���O�ō�����ق����������炻�������B
512bit�o�X�Ƃ����̂��|�V������Wide IO�Ȃ��ɂ��̂Ǝv���邵�B
�@�@�@�@�@�@�@�@�@�@�@�@ (�
�@�@�@�@�V�V�� �@_, ,_ �Ɂ@���� ��Ȱ ��Ȱ ��Ȱ ��Ȱ ��Ȱ !!
�@�@�@�@�@���܁i#`�D�L�jilli�@�@�@�� ������̂��|��������ē�����̂��[ !!
�@�@�@�@�@�@ �M�R_�܁R(�) �i �@�@�@ �s�폟�ł����Ƃ� ��Ȱ ��Ȱ !!
�@�@�@�@�@�@�@�@�@�@�@ ��Y�܁@������
�@�@�@�@�V�V�� �@_, ,_ �Ɂ@���� ��Ȱ ��Ȱ ��Ȱ ��Ȱ ��Ȱ !!
�@�@�@�@�@���܁i#`�D�L�jilli�@�@�@�� ������̂��|��������ē�����̂��[ !!
�@�@�@�@�@�@ �M�R_�܁R(�) �i �@�@�@ �s�폟�ł����Ƃ� ��Ȱ ��Ȱ !!
�@�@�@�@�@�@�@�@�@�@�@ ��Y�܁@������
�@�@�@�@�@�@�@��
�@�@�@�@�@����(�@�@_, ,_�j�@
�@�@�@�@�@�@ �M�R_�� ���m�@�@zzz�c
�@�@�@�@�@����(�@�@_, ,_�j�@
�@�@�@�@�@�@ �M�R_�� ���m�@�@zzz�c
890 �F,,�E�L�́M�E,,�j��-�������F2014/01/28(��) 19:52:48.15 ID:z35k1DxD
�@�@�w(�@`�D)Ɂ@�@��������¸���ٶ�Ű
�߁@�i�@���m�@�@�@�@���۰
:�B;�@ �^
�߁@�i�@���m�@�@�@�@���۰
:�B;�@ �^
���オ�s���������獡�����͎̂�������������
> �N���ǂ܂Ȃ��R�[�h
�@�@�@�@��__��
�@�@�@ �i�M��֥�j�@�@�����َ̐҂��ǂނł�����I
�@�@�@.�m^�@y�R�A�@�@�R�[�h�̓A�[�g���I
�@�@�@�R,,�==l �
�@�@�@�@/ �@l |
"""~""""""~"""~"""~"
�R(߄t�)� ����Ҳ���
�@�@�@�@��__��
�@�@�@ �i�M��֥�j�@�@�����َ̐҂��ǂނł�����I
�@�@�@.�m^�@y�R�A�@�@�R�[�h�̓A�[�g���I
�@�@�@�R,,�==l �
�@�@�@�@/ �@l |
"""~""""""~"""~"""~"
�R(߄t�)� ����Ҳ���
CPU��10���Ƃ���������Ȃ甃���������d�v���������A
���܂���4770K�݂����ȃn�C�G���h�ł���������A
����ȋC�ɂ����ɔ�����������
���܂���4770K�݂����ȃn�C�G���h�ł���������A
����ȋC�ɂ����ɔ�����������
895 �F,,�E�L�́M�E,,�j��-�������F2014/01/28(��) 20:22:17.95 ID:z35k1DxD
Broadwell����Ńf�X�N�g�b�v��i7���o�Ȃ������Xeon E3�����Ǝv���Ă�l��
�����Ȃ��́H
�ł����ꍂ�����B
�T�[�o�p�r����128MB�̃L���b�V��������ƍ������ł���p�r�Ȃ�Ă���ɂ��肻���ȋC���B
�i�Ȃ�ƂȂ�Node.js�Ƃ��������̂ɂ�����Ȃ����Ƃ����C�����Ă�j
�O�����Ă�strlen/memchr��AVX2�ł̃R�[�h�ł��N���Ă�������
�ւ�ݐ搶�̃R�[�h�̍ő�2�{�͑����B����Ȃ̈Ӗ��Ȃ����ǂȁB
http://pastie.org/pastes/8674992/text
AVX-512�o����Ӗ��Ȃ��Ȃ邾����āH
�ł�512����vpcmpeqb���g���Ȃ���B
�����Ȃ��́H
�ł����ꍂ�����B
�T�[�o�p�r����128MB�̃L���b�V��������ƍ������ł���p�r�Ȃ�Ă���ɂ��肻���ȋC���B
�i�Ȃ�ƂȂ�Node.js�Ƃ��������̂ɂ�����Ȃ����Ƃ����C�����Ă�j
�O�����Ă�strlen/memchr��AVX2�ł̃R�[�h�ł��N���Ă�������
�ւ�ݐ搶�̃R�[�h�̍ő�2�{�͑����B����Ȃ̈Ӗ��Ȃ����ǂȁB
http://pastie.org/pastes/8674992/text
AVX-512�o����Ӗ��Ȃ��Ȃ邾����āH
�ł�512����vpcmpeqb���g���Ȃ���B
-mavx2
�ɑΉ����ĂȂ�����
gcc�̃o�[�W�����A�b�v���邩
�ɑΉ����ĂȂ�����
gcc�̃o�[�W�����A�b�v���邩
MVC���f�����B
898 �F,,�E�L�́M�E,,�j��-�������F2014/01/28(��) 21:15:02.57 ID:z35k1DxD
_mm_prefetch�܂������Ӗ��Ȃ������͓̂���
8�R�A3.4GHz 23���~
6�R�A3.7GH�� 12���~
�̂̃T�[�o�[�px86�̓}���`�\�P�b�g�ƃL���b�V�����炢�����f�X�N�g�b�v��
���Ȃ���������A�����đI�ԗ��R�͌����Ă������A
���̓R�A���Ƃ��������o���h���Ƃ��i��������������
�f�X�N�g�b�v�������n�C�G���h�ƌĂׂȂ��p�r���������B
6�R�A3.7GH�� 12���~
�̂̃T�[�o�[�px86�̓}���`�\�P�b�g�ƃL���b�V�����炢�����f�X�N�g�b�v��
���Ȃ���������A�����đI�ԗ��R�͌����Ă������A
���̓R�A���Ƃ��������o���h���Ƃ��i��������������
�f�X�N�g�b�v�������n�C�G���h�ƌĂׂȂ��p�r���������B
HMC�͂�
IrisPro�݂��������n�C�G���h�m�[�g�����SKU��
�}���`�v���Z�b�T�����̗��p�݂̗̂̍p�ɂȂ肻���ȗ\��������
�}���`�v���Z�b�T�����̗��p�݂̗̂̍p�ɂȂ肻���ȗ\��������
902 �F,,�E�L�́M�E,,�j��-�������F2014/01/28(��) 22:24:05.39 ID:z35k1DxD
ARM���悶��Ȃ��́HAtom��HMC�g���Ȃ�Celeron�ȏ���A���ĂȂ�킯�ŁB
>>895
����͂������̂�
�Ӗ��́A����܂���
1�~���b�ł������������Ƃ���
����Ȏd�����܂��܂�������
��U�g�ݍ��ނƁA���N�Ԃ̓n�[�h�������ł��Ȃ�
�����āA�������I�������A�V����̃n�[�h�Ɍ�������
���������Ƃ��́A���̎��X�ōō��̐��i�����Ȃ��ƂȂ炸�A
���̂ق�̂킸���̎�ԉɂ��A���P�ʂ̍��ɂȂ��ĕԂ��Ă���
����͂������̂�
�Ӗ��́A����܂���
1�~���b�ł������������Ƃ���
����Ȏd�����܂��܂�������
��U�g�ݍ��ނƁA���N�Ԃ̓n�[�h�������ł��Ȃ�
�����āA�������I�������A�V����̃n�[�h�Ɍ�������
���������Ƃ��́A���̎��X�ōō��̐��i�����Ȃ��ƂȂ炸�A
���̂ق�̂킸���̎�ԉɂ��A���P�ʂ̍��ɂȂ��ĕԂ��Ă���
904 �FSocket774�F2014/01/29(��) 01:39:32.21 ID:2r2Or7go
Intel�l�������l�ނ̖������J����B��_
�S�l�ނ�Intel�l�̉��ɕ�����Intel�l�����𐒔q��
Intel�l��Intel�l�ɂ��Intel�l�̂��߂̐��E�̍\�z�ɑS�͂𒍂��ׂ��ł���
Intel�l���I�I�I�I�I
�S�l�ނ�Intel�l�̉��ɕ�����Intel�l�����𐒔q��
Intel�l��Intel�l�ɂ��Intel�l�̂��߂̐��E�̍\�z�ɑS�͂𒍂��ׂ��ł���
Intel�l���I�I�I�I�I
905 �F,,�E�L�́M�E,,�j��-�������F2014/01/29(��) 09:05:34.73 ID:peQ/svSn
GNU��LIBC�͊���AVX2�Ή����Ă܂���
�i�N������CPUID�ŋ@�\���ʂ��Ċ��|�C���^���Z�b�g�j
�v����ɂ��������̂��u�ԗւ̍Ĕ����v�Ƃ����̂ł��B
�܂�Windows��MSVCRT�͂��܂��ɕێ�I�ȕ��@�ł���Ă܂����ǂˁB
������USC4�ł��g���Ȃ�AVX-512���g�������b�g�͂��邩�ȁE�E�E�݂����Ȋ����ł��ˁB
�i�N������CPUID�ŋ@�\���ʂ��Ċ��|�C���^���Z�b�g�j
�v����ɂ��������̂��u�ԗւ̍Ĕ����v�Ƃ����̂ł��B
�܂�Windows��MSVCRT�͂��܂��ɕێ�I�ȕ��@�ł���Ă܂����ǂˁB
������USC4�ł��g���Ȃ�AVX-512���g�������b�g�͂��邩�ȁE�E�E�݂����Ȋ����ł��ˁB
�VCPU���o�邽�тɁA�J�[�l��/gcc/glibc���ŐV�ɂ��čœK�����Ă�l�͌����Ă�킯��
����XSAVE�Ή��̃J�[�l���ɍX�V���ĂȂ�������A�E�g�ȃp�^�[�������
�� CPU Hierarchy Chart 2014
AMD�ߎS�������
�܂�ŏ����ɂȂ��ĂȂ���
5�N�O�̐ɂ��畉���Ă��
������x��Ȃ���
http://www.tomshardware.com/reviews/gaming-cpu-review-overclock,3106-5.html
AMD�ߎS�������
�܂�ŏ����ɂȂ��ĂȂ���
5�N�O�̐ɂ��畉���Ă��
������x��Ȃ���
http://www.tomshardware.com/reviews/gaming-cpu-review-overclock,3106-5.html
Intel's Ivy Bridge-EX Could Cut IBM's POWER
http://www.dailyfinance.com/2014/01/27/intels-ivy-bridge-ex-could-cut-ibms-power/
http://www.dailyfinance.com/2014/01/27/intels-ivy-bridge-ex-could-cut-ibms-power/
POWER���Ė���_�̔@���I�[����Z���č~�Ղ��邯�ǐ��\��XEON�Ɠ������炢�����
�l��������Ă���͂����납Pentium�ɒǂ��z���ꂽ��
����܂ł͈��|�I����������
����܂ł͈��|�I����������
>>910
POWER���Ė����Ƀp�C�v���C������Ă�Ȃ������\���Ȃ̂�
POWER���Ė����Ƀp�C�v���C������Ă�Ȃ������\���Ȃ̂�
PPC��Pentium�Ƃ�����蕨�Ƃ��Ă�Xeon���낤�ȁc�l�i�I�ɂ�
POWER�̋����͂��Ƃ��ƍ������Ɏ��s����Itanium������
��x86�̐��\�ȏ�ɋ@�\�Ƃ�RAS�ɉ��l��u���Ă���C�����邪
EX���Ƃ�����݊p�������肷��̂���
POWER�̋����͂��Ƃ��ƍ������Ɏ��s����Itanium������
��x86�̐��\�ȏ�ɋ@�\�Ƃ�RAS�ɉ��l��u���Ă���C�����邪
EX���Ƃ�����݊p�������肷��̂���
�V����CPU�̐V�@�\���y�����g��������A
�\�t�g�E�F�A�����V�������܂��傤�Ƃ����͕̂ʂ���ق�
�\�t�g�E�F�A�����V�������܂��傤�Ƃ����͕̂ʂ���ق�
�g�ݍ��݂łȂ����wchar_t ��32bit����BWindows �͈Ⴄ�̂�? �A�v���P�[�V�������x���ŃT���Q�[�g�y�A�ł̏����Ȃ�Ă܂Ƃ��ɂ͏o���Ȃ��Ǝv�����B
�ăN�A���R�������v�Q�����@�ቿ�i�X�}�z���y���d��10�`12��
http://www.nikkei.com/article/DGXNASGN30011_Q4A130C1000000/
http://www.nikkei.com/article/DGXNASGN30011_Q4A130C1000000/
32�r�b�g�����R�[�h��char32_t�A16�r�b�g�����R�[�h��char16_t��wchar_t���Ǝv�����ǁB
������܂�������UTF8��char�����ǁAuchar�ɂ��Ȃ���128�`255�ɑ��{���Ń}�b�v����Ă�悤�ȕ����������Ȃ��Ə�������˂����܂�Ă邻�����B
������܂�������UTF8��char�����ǁAuchar�ɂ��Ȃ���128�`255�ɑ��{���Ń}�b�v����Ă�悤�ȕ����������Ȃ��Ə�������˂����܂�Ă邻�����B
G4�͐_������
G5�͒N�����F�߂�S�~������
���C�o����Pen4�������̂��B��̋~��
G5�͒N�����F�߂�S�~������
���C�o����Pen4�������̂��B��̋~��
WS�Ƃ��Ă�G5��FSB���A�z�݂����ɑ����ėǂ�������
922 �F,,�E�L�́M�E,,�j��-�������F2014/01/31(��) 08:56:39.27 ID:lRYstHby
Linux��wchar_t��4�o�C�g���ȁBUCS4�g���Ă邩��ˁB
�܂�Windows�Ń��C�h�����Ƃ�������16�r�b�g����
SSE4.2(STTNI)�̕������r���߂�32�r�b�gwchar_t�͑z�肵�ĂȂ��B
Windows���^�[�Q�b�g�ł��邱�Ƃ͊m��I�ɖ��炩�B
�܂�Windows�Ń��C�h�����Ƃ�������16�r�b�g����
SSE4.2(STTNI)�̕������r���߂�32�r�b�gwchar_t�͑z�肵�ĂȂ��B
Windows���^�[�Q�b�g�ł��邱�Ƃ͊m��I�ɖ��炩�B
Quark�𓋍ڂ���Intel�̊J���{�[�h�uGalileo�v������(�O��)
http://pc.watch.impress.co.jp/docs/topic/review/20140131_633020.html
http://pc.watch.impress.co.jp/docs/topic/review/20140131_633020.html
�����n�ɂ���ăr�b�g�����Ⴄ�ϐ��^�́A
���܂ɗ\�z�����Ȃ��o�O�����܂�邱�Ƃ������
�t�ɁA�Ȃ����Ȃ��Ƃ����Ȃ��Ǝv���Ă���\�z�O�ɂ��̂܂ܒʂ�����
���܂ɗ\�z�����Ȃ��o�O�����܂�邱�Ƃ������
�t�ɁA�Ȃ����Ȃ��Ƃ����Ȃ��Ǝv���Ă���\�z�O�ɂ��̂܂ܒʂ�����
�W����typedef�p�ӂ���Ă����g������B
926 �F,,�E�L�́M�E,,�j��-�������F2014/01/31(��) 20:10:31.42 ID:VlRdufib
�ꉞgcc�ł�wchar�̃T�C�Y��ύX�\�ɂȂ��Ă邪
������g�����������ASM�őg�܂ꂽ���C�u��������wcslen�̏�����
2�o�C�g�ɂȂ�����4�o�C�g�ɂȂ����肷��킯����Ȃ������
UTF-8�̕������J�E���g���ĈӊO��SSE/AVX���̂܂g�����
2�o�C�g�ȏ�̕������2�o�C�g�ڈȍ~���K�� 10xxxxxxxB �ɂȂ邩��
�t��SJIS�͔��肪�ʓ|
������g�����������ASM�őg�܂ꂽ���C�u��������wcslen�̏�����
2�o�C�g�ɂȂ�����4�o�C�g�ɂȂ����肷��킯����Ȃ������
UTF-8�̕������J�E���g���ĈӊO��SSE/AVX���̂܂g�����
2�o�C�g�ȏ�̕������2�o�C�g�ڈȍ~���K�� 10xxxxxxxB �ɂȂ邩��
�t��SJIS�͔��肪�ʓ|
����Z�������őg���ǂr�r�c���ꂽ�̂ŐÂ������J�i���n���C���o�C
RAID0�̑��݊����Ă��悢��Ȃ��Ȃ��Ă�����
SSD�͎����I��➑̓���RAID0������Ă���ƌ�����̂���
�����SDHC�J�[�h��������RAID0�\���̋[��SSD�Ȃ�ď��i���o�Ă����炢�ł����c
�܂�Win���[�U�[�͖�����SATA6Gbps���肾�����
Mac��PCIe 1TB SSD�g����������߂�Ȃ�
Mac��PCIe 1TB SSD�g����������߂�Ȃ�
Bay Trail-M���ڂ̊i��NUC�������A�ň�15,980�~
Bay Trail-M�ł͌��ݍň��A2.5"�x�C������
http://akiba-pc.watch.impress.co.jp/docs/news/news/20140131_633273.html
Bay Trail-M�ł͌��ݍň��A2.5"�x�C������
http://akiba-pc.watch.impress.co.jp/docs/news/news/20140131_633273.html
>>929
HDD�����ăv���b�^�����������Ă邵�����I��RAID0����Ă�悤�Ȃ���
HDD�����ăv���b�^�����������Ă邵�����I��RAID0����Ă�悤�Ȃ���
���̗��_�ł͂���ł����B500GB�v���b�^1����500GBHDD����
500GB�v���b�^2����1TBHDD�̂ق����L�ӂɑ��������肷��̂ł����B
����Ƃ��̏ᗦ�̂ق��ł����B����Ȃ�܂��c
500GB�v���b�^2����1TBHDD�̂ق����L�ӂɑ��������肷��̂ł����B
����Ƃ��̏ᗦ�̂ق��ł����B����Ȃ�܂��c
GIGABYTE �}�U�[�{�[�h Intel Bay Trail Celeron J1800���� Mini ITX GA-J1800N-D2H
http://www.gigabyte.jp/products/product-page.aspx?pid=4881#sp
�� 9,979
http://www.amazon.co.jp/dp/B00I39OWHC/
http://www.gigabyte.jp/products/product-page.aspx?pid=4881#sp
�� 9,979
http://www.amazon.co.jp/dp/B00I39OWHC/
����Ԃ������Ă��܂�
�A�N�e�B�u�R�A����1�ȊO�̂Ƃ��̃^�[�{�{���̈ꗗ���Ăǂ����ɂȂ�����
specfinder�ɂ��f�[�^�V�[�g�ɂ��ڂ��ĂȂ�����
�A�N�e�B�u�R�A����1�ȊO�̂Ƃ��̃^�[�{�{���̈ꗗ���Ăǂ����ɂȂ�����
specfinder�ɂ��f�[�^�V�[�g�ɂ��ڂ��ĂȂ�����
>>936
i5
http://www.intel.com/jp/support/processors/corei5/sb/CS-032278.htm
i7
http://www.intel.com/jp/support/processors/corei7/sb/CS-032279.htm
i7 EX
http://www.intel.com/jp/support/processors/corei7ee/sb/CS-032277.htm
���o�C���̂͂Ȃ����ۂ�
i5
http://www.intel.com/jp/support/processors/corei5/sb/CS-032278.htm
i7
http://www.intel.com/jp/support/processors/corei7/sb/CS-032279.htm
i7 EX
http://www.intel.com/jp/support/processors/corei7ee/sb/CS-032277.htm
���o�C���̂͂Ȃ����ۂ�
wchar_t����C��C++�̋K�i�ł�char�Ɠ���������ȏ�Ƃ��������ĂȂ����
�i��{�����^�̂����ꂩ�ƈ�v���Ȃ���Ȃ�Ȃ����ł�������char�ŗǂ��j
char��1�o�C�g��1������\���ł���悢�̂ōŏ���0~127�܂ň�����Ώ\���Ƃ���
���ǂ̂Ƃ������7bit����K�i�����@8bit�ł���K�v����Ȃ�
�i���Ȃ݂�1�o�C�g�����r�b�g�ł��邩�̋K����Ȃ������r�b�g�ł��ǂ��j
�ǂ��O�l���A���t�@�x�b�g�ȊO�͌��ꂶ��˂����Ďv���Ă邩�킩�낤�Ƃ�������
�i��{�����^�̂����ꂩ�ƈ�v���Ȃ���Ȃ�Ȃ����ł�������char�ŗǂ��j
char��1�o�C�g��1������\���ł���悢�̂ōŏ���0~127�܂ň�����Ώ\���Ƃ���
���ǂ̂Ƃ������7bit����K�i�����@8bit�ł���K�v����Ȃ�
�i���Ȃ݂�1�o�C�g�����r�b�g�ł��邩�̋K����Ȃ������r�b�g�ł��ǂ��j
�ǂ��O�l���A���t�@�x�b�g�ȊO�͌��ꂶ��˂����Ďv���Ă邩�킩�낤�Ƃ�������
�܂��C�����͉����ł��Ȃ���
�e�L�X�g�E�t�@�C����������A wchar_t=16bit �łقڔ����A wchar_t=32bit�Ȃ�7�������@"0x00" �Ŗ��܂�����
���ʂł���ƌ��������͔ے�ł��Ȃ��B
�e�L�X�g�E�t�@�C����������A wchar_t=16bit �łقڔ����A wchar_t=32bit�Ȃ�7�������@"0x00" �Ŗ��܂�����
���ʂł���ƌ��������͔ے�ł��Ȃ��B
���ۖ��ʂȂ̂ŁAUTF-8�Ƃ����G���R�[�h���嗬��
������i18n�̘b��W�J����Ǝ��܂��
943 �F,,�E�L�́M�E,,�j��-�������F2014/02/01(�y) 09:51:29.91 ID:DMW8wwwb
UTF-8�ł�����BSJIS�̓R���p�C�����s��N�������Ƃ��ƂƖłԂׂ�
944 �F,,�E�L�́M�E,,�j��-�������F2014/02/01(�y) 09:53:07.29 ID:DMW8wwwb
�Ƃ���őS�p�A���t�@�x�b�g���ē��{�ȊO�Ŏg���́H
JIS X 0208/0213�Ƃ̌݊��p�r�ȊO�Ŏg�����Ƃ͂Ȃ�
����AKS�ɂ�GB�ɂ����ꂼ���d�������邩�c�c����܂�ӎ��������ƂȂ��������B
947 �FSocket774�F2014/02/01(�y) 10:27:14.69 ID:P9D+XqFA
�p�\�R���̓I���R�����ˁc
�yPC�z�\�j�[�A�p�\�R�����ƂŒ���lenovo(���m�{)�ƒ�g����--�wVAIO�x�u�����h�͈ێ�������j [02/01]
http://anago.2ch.net/test/read.cgi/bizplus/1391208928/
�yPC�z�\�j�[�A�p�\�R�����ƂŒ���lenovo(���m�{)�ƒ�g����--�wVAIO�x�u�����h�͈ێ�������j [02/01]
http://anago.2ch.net/test/read.cgi/bizplus/1391208928/
�X�}�z�̓R���R�����˥��
�O�[�O���A���g���[���E���r���e�B�����m�{�ɔ��p��--29.1���h��
http://japan.cnet.com/news/business/35043211/
�O�[�O���A���g���[���E���r���e�B�����m�{�ɔ��p��--29.1���h��
http://japan.cnet.com/news/business/35043211/
����Ȃ�Ă������A�R���R���ɂȂ��Ƃ�
950 �FSocket774�F2014/02/01(�y) 11:33:43.97 ID:K2AN2saa
�R���R��???
�P�ɃR���T����Ƃ̏o�����f�[�^�ɂ�鏫���̎s�ꐬ���������l���āA
���X�������̍������Ƃ�����Ďs�ꐬ�����̃}�C�i�X�̋Ǝ����Ă�����Ђ����邯�ǁA
���̏k���s��ł��A���ɑ�ւ��ȒP�ɕ����Ȃ����̂Ȃ�
�c���җ��v�������������肷��
PC�Ȃ�āA��p�[�c���\�t�g����ЂƁA�����̐�����Ƃ͎c���җ��v����܂�����Ȃ����ȁH
���X�������̍������Ƃ�����Ďs�ꐬ�����̃}�C�i�X�̋Ǝ����Ă�����Ђ����邯�ǁA
���̏k���s��ł��A���ɑ�ւ��ȒP�ɕ����Ȃ����̂Ȃ�
�c���җ��v�������������肷��
PC�Ȃ�āA��p�[�c���\�t�g����ЂƁA�����̐�����Ƃ͎c���җ��v����܂�����Ȃ����ȁH
�o���s��A��I���ꍞ�݊F���Ŏg�����Ȃ�����E��
�{�^��7�܂łƂ�����������炵���B
�t���L�[�{�[�h�̃p�\�R�����z�[���ɔ���Ă������̕���
�ُ펖�Ԃ������̂�������Ȃ��B
�{�^��7�܂łƂ�����������炵���B
�t���L�[�{�[�h�̃p�\�R�����z�[���ɔ���Ă������̕���
�ُ펖�Ԃ������̂�������Ȃ��B
�\���L�[�ƃ{�^��4�ŃI�[�o�[���Ă��܂���
954 �F,,�E�L�́M�E,,�j��-�������F2014/02/01(�y) 12:56:05.60 ID:DMW8wwwb
�͂���Ȃ�Ďc���җ��v�_���̃j�b�`�Q�[�����ƍŏ��͎v���Ă���
Flash�Q�[�s�ꂻ�̂��̂��������Ă��܂��������
�Q�[���̂��߂Ƀn�[�h���Ƃ������ۂ܂ŋN�����i�̓^�u�j
Flash�Q�[�s�ꂻ�̂��̂��������Ă��܂��������
�Q�[���̂��߂Ƀn�[�h���Ƃ������ۂ܂ŋN�����i�̓^�u�j
�����_�ŃI�t�B�X���[�J�[�ɂƂ���PC�������I�ȃR���s���[�^�͌������ĂȂ��̂ŁA
���Ƃ��l������PC���ꂵ�悤�Ƃ��APC�͑����čs���đ����̉�Ђ�PC�Ŏ��v���グ������ł���H
���Ƃ��l������PC���ꂵ�悤�Ƃ��APC�͑����čs���đ����̉�Ђ�PC�Ŏ��v���グ������ł���H
�@�l�p�r�����C���Ȃ炻��͂���Personal Computer����Ȃ���ˁB�I�t�R�����B
�p�\�R���ƃI�t�R������K�͂��Ⴄ
�Ⴆ�@�l�p�ł��\�����~���x�Ŕ�����Ȃ�p�\�R����
�Ⴆ�@�l�p�ł��\�����~���x�Ŕ�����Ȃ�p�\�R����
�o���E�����S���҂��Ђ����琔���ł����萔�����Ă����ł̓I�t�R���̂܂܂ŏ\���������Ǝv����
�I�t�R������́A��Ђ̒��ő�ʂ̒��[�E����̂������������Ă�l�E�������R���s���[�^������������Ȃ�
�I�t�R������́A��Ђ̒��ő�ʂ̒��[�E����̂������������Ă�l�E�������R���s���[�^������������Ȃ�
�O�N�O�Ɏ��삵�Ĉȗ��A���ɐG��ĂȂ������̂�
�ŐV��CPU����ɉY����Ԃ���B
CPU�̐��\���{�ȏ�ɂȂ��Ă�̂Ȃ�V�����悤�Ǝv���̂����ǁA
Core i7 930�ƍŐV�̃~�h���A�b�p�[�N���X���Đ��\���ǂ�Ȃ���ł��傤�B
�ŐV��CPU����ɉY����Ԃ���B
CPU�̐��\���{�ȏ�ɂȂ��Ă�̂Ȃ�V�����悤�Ǝv���̂����ǁA
Core i7 930�ƍŐV�̃~�h���A�b�p�[�N���X���Đ��\���ǂ�Ȃ���ł��傤�B
1.5�{���x�オ������ق�����Ȃ��́H
���ɔ{�ȏ�̐��\�����߂�Ȃ�6�R�A���f����I�ق�������
���ɔ{�ȏ�̐��\�����߂�Ȃ�6�R�A���f����I�ق�������
�͂���Ƃ����{�̃L���I�^��������ĂȂ�����w
���������I�^�N���^�[�Q�b�g�ɂ����Q�[���ƌĂׂȂ��Q�[���������Ȃ�����ǂ�ǂ�s�ꂪ�k�������
���āE���B�͍��ł�PC�Q�[�s��͊g�債�Ă��ASteam���L�тĂ邱�Ƃ��m���̂�
�c�q���Č��\�m���������ȁ[�A�������Ă����߂�˂Ƃ��ōς܂��������}�W�ɂ킩����w
���������I�^�N���^�[�Q�b�g�ɂ����Q�[���ƌĂׂȂ��Q�[���������Ȃ�����ǂ�ǂ�s�ꂪ�k�������
���āE���B�͍��ł�PC�Q�[�s��͊g�債�Ă��ASteam���L�тĂ邱�Ƃ��m���̂�
�c�q���Č��\�m���������ȁ[�A�������Ă����߂�˂Ƃ��ōς܂��������}�W�ɂ킩����w
2014�N�̐��E�^�u���b�g�s��AWindows�̃V�F�A���㏸��Android/iOS�͔����AIDC�\��
http://itpro.nikkeibp.co.jp/article/IDG/20140123/531729/?ST=cio-consumerit&P=1
http://itpro.nikkeibp.co.jp/article/IDG/20140123/531729/?ST=cio-consumerit&P=1
�^�u���b�g�Ŏ嗬�Ȃ̂́A
ARM+Android
ARM+iOS
ARM+WindowsRT
ATOM+Android
ATOM+Windows8
�Ȃ����邪�AATOM+Windows8�����Ȃ藬�s���Ă邩��Ȃ�
ARM+WindowsRT�͌��\�������f�����邵
ARM+Android
ARM+iOS
ARM+WindowsRT
ATOM+Android
ATOM+Windows8
�Ȃ����邪�AATOM+Windows8�����Ȃ藬�s���Ă邩��Ȃ�
ARM+WindowsRT�͌��\�������f�����邵
964 �F,,�E�L�́M�E,,�j��-�������F2014/02/01(�y) 16:35:48.16 ID:DMW8wwwb
> �͂���Ƃ����{�̃L���I�^��������ĂȂ�����w
���ꂪ�����ł��Ȃ��B�C�O�̃I�^�N���Ă����[�ȁB
http://kancolle-news.com/archives/35777458.html
�͂���͂Ƃ������Ƃ���iOS��Flash���v���C�ł���Puffin�Ƃ����u���E�U��
AppStore�̃����L���O��1�ʂɂȂ�����AFlash�x�[�X��Web�Q�[���s���
�܂��܂��������ݓI���v���߂Ă���悤���B
�]��Flash��T�|�[�g�������S��ʔ�IE���AWindowsRT�ł��܂߃T�|�[�g��
������������B
�v���O�C���t���[�Ȃnj��z�������B
���ꂪ�����ł��Ȃ��B�C�O�̃I�^�N���Ă����[�ȁB
http://kancolle-news.com/archives/35777458.html
�͂���͂Ƃ������Ƃ���iOS��Flash���v���C�ł���Puffin�Ƃ����u���E�U��
AppStore�̃����L���O��1�ʂɂȂ�����AFlash�x�[�X��Web�Q�[���s���
�܂��܂��������ݓI���v���߂Ă���悤���B
�]��Flash��T�|�[�g�������S��ʔ�IE���AWindowsRT�ł��܂߃T�|�[�g��
������������B
�v���O�C���t���[�Ȃnj��z�������B
965 �F,,�E�L�́M�E,,�j��-�������F2014/02/01(�y) 16:41:57.97 ID:DMW8wwwb
> ARM+WindowsRT�͌��\�������f�����邵
Surface 1������ˁ[��������
�C�O�ł�Nokia������[���o�Ă邯�ǂ��̉�Ђ������܂�MS�̎q��Ђ������
NEC��Lenovo, Dell�͂Ƃ����ɓP�ނ��Ă邵
MS���l���������ŒI�����Y9���h����������Ƃ�������
Surface 1������ˁ[��������
�C�O�ł�Nokia������[���o�Ă邯�ǂ��̉�Ђ������܂�MS�̎q��Ђ������
NEC��Lenovo, Dell�͂Ƃ����ɓP�ނ��Ă邵
MS���l���������ŒI�����Y9���h����������Ƃ�������
�͂���̃��[�U�[���e�ʂ��A�Ƃ肠�����T�[�o�[���̎���œ��ł��ɂȂ��Ă�Ƃ����̂�
�����[����ˁB���ۂɃT�[�o�[�̐��\�E�e�ʓI�ȏ���ɂ������Ă�̂��A
�}�[�P�e�B���O�I�ȗv���Ő������Ă���̂��m��Ȃ����ǁB
Flash�Q�[������A�Ȃ���߂Č��E���������Ƃ������Ƃɂ��Ȃ�B
�����[����ˁB���ۂɃT�[�o�[�̐��\�E�e�ʓI�ȏ���ɂ������Ă�̂��A
�}�[�P�e�B���O�I�ȗv���Ő������Ă���̂��m��Ȃ����ǁB
Flash�Q�[������A�Ȃ���߂Č��E���������Ƃ������Ƃɂ��Ȃ�B
967 �F,,�E�L�́M�E,,�j��-�������F2014/02/01(�y) 16:53:47.19 ID:DMW8wwwb
�Ȃ�ƂȂ��i�����@�ɋ߂����̂͊����邯�ǂ�
�X�}�z���֎~�ɂ��Ă�̂̓L���b�V���̌����������ăg���t�B�b�N�����傷�邩��
�Ȃ�Ęb�����邵
�X�}�z���֎~�ɂ��Ă�̂̓L���b�V���̌����������ăg���t�B�b�N�����傷�邩��
�Ȃ�Ęb�����邵
�g���t�B�b�N�݂̂Ȃ�A�Œ�R���e���c���O���̔z�M�Ǝ҂ɏo���Ή������邪
�g���t�B�b�N�R�X�g�͂�����悤�ɂȂ�
�g���t�B�b�N�R�X�g�͂�����悤�ɂȂ�
Flash�Ɋւ��ẮAApple��Google��ʂ����ɃA�v����Q�[������鋰�ꂪ����̂ŁA
���܂�Apple��Google�������C�͂��Ȃ����낤��
�ǂ������A�v��������A���Ђ̌��σT�[�r�X��ʂ��Ȃ��ۋ��ւ̗U�����K�����Ă�
���܂�Apple��Google�������C�͂��Ȃ����낤��
�ǂ������A�v��������A���Ђ̌��σT�[�r�X��ʂ��Ȃ��ۋ��ւ̗U�����K�����Ă�
>>964
������H�C�O�̃L���I�^����Hw
Flash���ēx�r���𗁂т�Ƃ��Ȃ�����w
���o�Q�[�E�O���[�A�p�Y�h���Ƃ��Ċ͂�����Ă̂��L���I�^���ł̂����̈�ߐ��̃g�����h����
�L���I�^����ɏ����������Ďs�ꂪ�k��������Ă܂��C�Â��Ȃ��̂��ˁA������͏������Ȃ��ċ��g���Ƃ��낪������ˁ[���炽���×~�ɃR���e���c��H�������邾������
�C�O�ł�PC�̃C���f�B�[�Y�����������ł��Ȃ����x���܂ł��Ă邩��PS4��One���C���f�B�[�Y�l���ɕK���Ȃ�
���{�ł��������̂��Y�܂�Ȃ��͕̂��݂����ȓ��l�����肪������L���I�^�̐ӔC����ˁ[��
������H�C�O�̃L���I�^����Hw
Flash���ēx�r���𗁂т�Ƃ��Ȃ�����w
���o�Q�[�E�O���[�A�p�Y�h���Ƃ��Ċ͂�����Ă̂��L���I�^���ł̂����̈�ߐ��̃g�����h����
�L���I�^����ɏ����������Ďs�ꂪ�k��������Ă܂��C�Â��Ȃ��̂��ˁA������͏������Ȃ��ċ��g���Ƃ��낪������ˁ[���炽���×~�ɃR���e���c��H�������邾������
�C�O�ł�PC�̃C���f�B�[�Y�����������ł��Ȃ����x���܂ł��Ă邩��PS4��One���C���f�B�[�Y�l���ɕK���Ȃ�
���{�ł��������̂��Y�܂�Ȃ��͕̂��݂����ȓ��l�����肪������L���I�^�̐ӔC����ˁ[��
971 �FSocket774�F2014/02/01(�y) 19:21:21.39 ID:9hGXrx+2
>>970
���{�ŃQ�[���ƊE�����ł��Ȃ̂́A�g���^���n�߂��J�C�[���Ɠ�������S�Ă̋ƊE������Ă��邩�炾��H
���������Ԃ��ďゾ�����ׂ���
�ɓł��ꂽ���m��������C���f�B�[�Y�͐����c��Ȃ�
���{�ŃQ�[���ƊE�����ł��Ȃ̂́A�g���^���n�߂��J�C�[���Ɠ�������S�Ă̋ƊE������Ă��邩�炾��H
���������Ԃ��ďゾ�����ׂ���
�ɓł��ꂽ���m��������C���f�B�[�Y�͐����c��Ȃ�
���l�̌������ς�����C���f�B�[�Y
973 �F,,�E�L�́M�E,,�j��-�������F2014/02/01(�y) 19:33:31.02 ID:DMW8wwwb
> FPS�Q�[�}�[�̓L���I�^�̎��o�̂Ȃ��L���I�^
�܂œǂ�
�܂œǂ�
974 �F,,�E�L�́M�E,,�j��-�������F2014/02/01(�y) 19:34:20.13 ID:DMW8wwwb
>>972
�Â��Ӗ��̓��l���ăC���f�B�[�Y�Ɠ����Ӗ�����
�Â��Ӗ��̓��l���ăC���f�B�[�Y�Ɠ����Ӗ�����
>>967
�Ƃ�������q�b�g��z�肵�Ă��Ȃ���
�X�P�[���A�E�g��O��ɂ����v�ɂȂ��Ă��Ȃ���������
�D�ꎮ�Ƃ������c�c
�X���I�ɂ́A�T�[�o�A�[�L�e�N�`����̖���
CPU�ʼn����ł��Ȃ��Ƃ����b�ɂȂ�낤����
�Ƃ�������q�b�g��z�肵�Ă��Ȃ���
�X�P�[���A�E�g��O��ɂ����v�ɂȂ��Ă��Ȃ���������
�D�ꎮ�Ƃ������c�c
�X���I�ɂ́A�T�[�o�A�[�L�e�N�`����̖���
CPU�ʼn����ł��Ȃ��Ƃ����b�ɂȂ�낤����
976 �F,,�E�L�́M�E,,�j��-�������F2014/02/01(�y) 19:57:16.97 ID:DMW8wwwb
�ʂ�Flash�̑�\�I�R���e���c�͊͂���łȂ��Ƃ��uAngry Birds�v�ł��������ǂ�
Facebook�Ƃ�������v���b�g�t�H�[���ɂ����āA�u���E�U��ʂł��̂܂�
��������Ӗ��͂ł�����B
Facebook�Ƃ�������v���b�g�t�H�[���ɂ����āA�u���E�U��ʂł��̂܂�
��������Ӗ��͂ł�����B
>>973
�͂���݂����ȃL���I�^�Q�[�Ɋ��ŋ��˂�����ł�z���������Ă������͂Ȃ��܂œǂ�
�͂���݂����ȃL���I�^�Q�[�Ɋ��ŋ��˂�����ł�z���������Ă������͂Ȃ��܂œǂ�
978 �F,,�E�L�́M�E,,�j��-�������F2014/02/01(�y) 20:00:51.33 ID:DMW8wwwb
�ʂɂ����������Ȃ�����
ID:1IBQWV7q ������DQN�Ȃ̂͂킩����
ID:1IBQWV7q ������DQN�Ȃ̂͂킩����
�L���I�^�����������Ă������͂Ȃ���Hw
981 �F,,�E�L�́M�E,,�j��-�������F2014/02/01(�y) 20:05:42.55 ID:DMW8wwwb
> ���������Ă������͂Ȃ�
�m����
�m����
�R(߄t�)� ���X�����Ă܂���
Intel�̎�����CPU�ɂ��Č�낤 72
http://anago.2ch.net/test/read.cgi/jisaku/1391253936/
Intel�̎�����CPU�ɂ��Č�낤 72
http://anago.2ch.net/test/read.cgi/jisaku/1391253936/
�R(߄t�)� �X���݂̂�ȃ\�[�g���͐i��ł邩���H
(߄t�) �l�͂Ƃ肠�����\�[�g��������C++�ō������A�������r�͂܂�
(߄t�) �\�[�g�A���S���Y���͊����̕������ǂ�����ƍH�v���Ď������܂���
(߄t�) �����\�[�g�ƈ���ĕ�����\�[�g�͒l�̔�r�Ɏ��Ԃ������邩��
(߄t�) �\�[�g�����̑������v�Z�ʂ����Ȃ��Ȃ����D�悵�܂���
(߄t�) �����\�[�g�Ɏg�����ꍇ�̑��x�͕������ǁA�����R���\�[�g�Ƒg�ݍ��킹��Ƒ����Ȃ�n�Y
(߄t�) �\�[�g�͍ő�16�X���b�h�œ��삷��悤�ɍ�������ǁA�����\�[�g�Ȃ�Œ�30�����ʂ̗ʂ��Ȃ��ƃ}���`�X���b�h�̃I�[�o�[�w�b�h�ő��x��������
(߄t�) x64�l�C�e�B�u���ɋ�J�������ł����A���͂̂�GUI����Ă܂�
�R(߄t�)� ���ĺ�ޭ�����ް
(߄t�) �l�͂Ƃ肠�����\�[�g��������C++�ō������A�������r�͂܂�
(߄t�) �\�[�g�A���S���Y���͊����̕������ǂ�����ƍH�v���Ď������܂���
(߄t�) �����\�[�g�ƈ���ĕ�����\�[�g�͒l�̔�r�Ɏ��Ԃ������邩��
(߄t�) �\�[�g�����̑������v�Z�ʂ����Ȃ��Ȃ����D�悵�܂���
(߄t�) �����\�[�g�Ɏg�����ꍇ�̑��x�͕������ǁA�����R���\�[�g�Ƒg�ݍ��킹��Ƒ����Ȃ�n�Y
(߄t�) �\�[�g�͍ő�16�X���b�h�œ��삷��悤�ɍ�������ǁA�����\�[�g�Ȃ�Œ�30�����ʂ̗ʂ��Ȃ��ƃ}���`�X���b�h�̃I�[�o�[�w�b�h�ő��x��������
(߄t�) x64�l�C�e�B�u���ɋ�J�������ł����A���͂̂�GUI����Ă܂�
�R(߄t�)� ���ĺ�ޭ�����ް
steam�ł��܍��Ƃ����P���m��������
���̂����鏤�i�����{�ł͓��ʂɍ����̂͂��������F�l��n�s�퍑������ł���?
���̂����鏤�i�����{�ł͓��ʂɍ����̂͂��������F�l��n�s�퍑������ł���?
985 �F,,�E�L�́M�E,,�j��-�������F2014/02/01(�y) 20:42:43.89 ID:DMW8wwwb
>>984
��C�̃X�^�o�����E�ꍂ�����ǒ����͔s�퍑���Ǝv���́H
��C�̃X�^�o�����E�ꍂ�����ǒ����͔s�퍑���Ǝv���́H
�R(߄t�)� �Ƃ���Ŗl�ɒ��킷��Ҏ҂͂���̂����H
(߄t�) �Ƃ肠����,,�E�L�́M�E,,�j��-�������̂������l�ɒ��킵�����炵���ł���
�@�@�@�@�@�@�@�@�@�@ �^�_�@�@�@�@�@�@�@�@�@��
�@�@�@�@�@ �@ �@ ..�^�@ .�^|�@�@�@�@�@�@��
�@�@�@�@�@�@�@ ���_�^.�^�@-��
�@�@�@�@ �@�@�@߁� |�^
�@�@ (�,,�E�L�́M�E,,�jɁ@�@�����ő����낶���[���[�I
�@�@/�@�@�@�@�@/
�m(�G߄t�)�m ��¹�� !! ��ݺ������� !!
�R(߄t�)� ���ɂ������猾���Ă��ꂨ�A�����珟���ׂ̈̉p�m��~���Ă�������
(߄t�) �Ƃ肠����,,�E�L�́M�E,,�j��-�������̂������l�ɒ��킵�����炵���ł���
�@�@�@�@�@�@�@�@�@�@ �^�_�@�@�@�@�@�@�@�@�@��
�@�@�@�@�@ �@ �@ ..�^�@ .�^|�@�@�@�@�@�@��
�@�@�@�@�@�@�@ ���_�^.�^�@-��
�@�@�@�@ �@�@�@߁� |�^
�@�@ (�,,�E�L�́M�E,,�jɁ@�@�����ő����낶���[���[�I
�@�@/�@�@�@�@�@/
�m(�G߄t�)�m ��¹�� !! ��ݺ������� !!
�R(߄t�)� ���ɂ������猾���Ă��ꂨ�A�����珟���ׂ̈̉p�m��~���Ă�������
987 �F,,�E�L�́M�E,,�j��-�������F2014/02/01(�y) 20:56:31.82 ID:DMW8wwwb
�\�[�g�P�̂ō���Ă��g���Ȃ�����
SQL���ŔC�ӂ̃f�[�^��ǂݏ����ł���悤�ɂ��Ă�
���ꂪ�ł��Ȃ��Ⴝ���̎��p���̂Ȃ��I�i�j�[��
SQL���ŔC�ӂ̃f�[�^��ǂݏ����ł���悤�ɂ��Ă�
���ꂪ�ł��Ȃ��Ⴝ���̎��p���̂Ȃ��I�i�j�[��
(߄t�) �Ƃ肠��������͎�����������p���͍��͂Ȃ��Ă�������
> SQL���ŔC�ӂ̃f�[�^��ǂݏ����ł���悤�ɂ��Ă�
(�G߄t�) �Ȉ�DBS�̍쐬���A��{������SQL�ő���ł���悤�ɂƂȂ�Ɩʓ|���A�A�A
> SQL���ŔC�ӂ̃f�[�^��ǂݏ����ł���悤�ɂ��Ă�
(�G߄t�) �Ȉ�DBS�̍쐬���A��{������SQL�ő���ł���悤�ɂƂȂ�Ɩʓ|���A�A�A
989 �F,,�E�L�́M�E,,�j��-�������F2014/02/01(�y) 21:08:57.97 ID:DMW8wwwb
���p�����������͍̂���
990 �F,,�E�L�́M�E,,�j��-�������F2014/02/01(�y) 21:09:50.41 ID:DMW8wwwb
�Ƃ�����2n+1���̉�@�v���O�������������Ƃ�����������
��[
�I�i�j�[�Ȃ���p�I�Ȃ�Ȃ�����
�I�i�j�[�Ȃ���p�I�Ȃ�Ȃ�����
>>989
�@�@�@�ȁ�
�@�@ /�܁R) ��ܶ��
�@�@i�O�@��
�@���O�@|�@�@������γ���Ƹ��
�@�@(/~��
�@�@�O�O
�@�O�O
�O�O�O
�@�@�@�ȁ�
�@�@ /�܁R) ��ܶ��
�@�@i�O�@��
�@���O�@|�@�@������γ���Ƹ��
�@�@(/~��
�@�@�O�O
�@�O�O
�O�O�O
994 �F,,�E�L�́M�E,,�j��-�������F2014/02/01(�y) 21:29:15.12 ID:DMW8wwwb
>>992
���������A�C�e���ۋ��ɂ�����������ɂ͂��邩��g���g�����x�ɂ͂Ȃ��Ă�炵���B
�ق���DMM�̃Q�[���Ɣ�ׂ�Ɣ��������ǁADMM�ɂƂ��Ă��o�^�������
���₷���������ɂȂ��Ă邩�瑽���̑�����DMM���ŕ��S���Ă�̂�������Ȃ��B
�����A�p��n�̎G���Ƃ��t�@�~���[�}�b�g�̃^�C�A�b�v�œƐ�I�Ɏg���邩��
���f�B�A�~�b�N�X�W�J�ł̎��v����_���Ă�݂���
���������A�C�e���ۋ��ɂ�����������ɂ͂��邩��g���g�����x�ɂ͂Ȃ��Ă�炵���B
�ق���DMM�̃Q�[���Ɣ�ׂ�Ɣ��������ǁADMM�ɂƂ��Ă��o�^�������
���₷���������ɂȂ��Ă邩�瑽���̑�����DMM���ŕ��S���Ă�̂�������Ȃ��B
�����A�p��n�̎G���Ƃ��t�@�~���[�}�b�g�̃^�C�A�b�v�œƐ�I�Ɏg���邩��
���f�B�A�~�b�N�X�W�J�ł̎��v����_���Ă�݂���
>>994
DMM���ăG������z�M�T�C�g����
�������Ă���ŋ߂͈Ⴄ�ȁc
�m��Ȃ�������
�O�b�Y��R���e���c�̔��ųϳςȂ�
��p�ʔP�o�ł���������
DMM���ăG������z�M�T�C�g����
�������Ă���ŋ߂͈Ⴄ�ȁc
�m��Ȃ�������
�O�b�Y��R���e���c�̔��ųϳςȂ�
��p�ʔP�o�ł���������
Intel�̎�����CPU�ɂ��Č�낤 71
http://anago.2ch.net/test/read.cgi/jisaku/1388229742/
http://anago.2ch.net/test/read.cgi/jisaku/1388229742/
�u�����͂����Ȃ�v�I�ȋL���͂����Ă��o�b�N�ɃX�|���T�[�����Ă�
�����Ȃ��Ăق����A�����Ȃ��Ă����Ȃ��ƍ�����Ă������v�U��������ȁB
�����Ȃ��Ăق����A�����Ȃ��Ă����Ȃ��ƍ�����Ă������v�U��������ȁB
Intel�̎�����CPU�ɂ��Č�낤 72
http://anago.2ch.net/test/read.cgi/jisaku/1391253936/
http://anago.2ch.net/test/read.cgi/jisaku/1391253936/
����
1000 �FSocket774�F2014/02/01(�y) 22:57:22.17 ID:rnr8N/Xr
Intel�̎�����CPU�ɂ��Č�낤 72
http://anago.2ch.net/test/read.cgi/jisaku/1391253936/
http://anago.2ch.net/test/read.cgi/jisaku/1391253936/
1001 �F�P�O�O�P�F
1��̃}�V�����g�ݏオ��܂����B�B�B
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://anago.2ch.net/jisaku/
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://anago.2ch.net/jisaku/