AMD�̎�����APU/CPU�ɂ��Č�낤��180����
�Q�Q�Q_
�_.�Q�@ | �r�炵�E����E�~�[�͕��u����ԁB
�^|�Q|�@| �ނ�ꂸ�ɃX���[���܂��傤�B
|�Q�^�_! sage�i�s�Ń}�^�[�������܂���
�����AMD�n�X���b�h�ߋ����O�ۑ��T�C�g
ttp://amd.jisakuita.net/
Intel�̎�����CPU�ɂ��Č�낤 70
http://anago.2ch.net/test/read.cgi/jisaku/1385580500/
CPU�A�[�L�e�N�`���ɂ��Č�� 24
http://anago.2ch.net/test/read.cgi/jisaku/1377863763/
��ARM�̎�����core, SoC�ɂ��Č��X�� #002��
http://anago.2ch.net/test/read.cgi/jisaku/1362032148/
Your processor's IQ: An Intro to HSA
http://www.youtube.com/watch?v=i6BWzL12KMI
Revolutionizing computing with HSA-enabled APUs
http://www.youtube.com/watch?v=4YV6z6Fgw48
�O�X��
AMD�̎�����APU/CPU�ɂ��Č�낤��179����
http://anago.2ch.net/test/read.cgi/jisaku/1386335737/
�_.�Q�@ | �r�炵�E����E�~�[�͕��u����ԁB
�^|�Q|�@| �ނ�ꂸ�ɃX���[���܂��傤�B
|�Q�^�_! sage�i�s�Ń}�^�[�������܂���
�����AMD�n�X���b�h�ߋ����O�ۑ��T�C�g
ttp://amd.jisakuita.net/
Intel�̎�����CPU�ɂ��Č�낤 70
http://anago.2ch.net/test/read.cgi/jisaku/1385580500/
CPU�A�[�L�e�N�`���ɂ��Č�� 24
http://anago.2ch.net/test/read.cgi/jisaku/1377863763/
��ARM�̎�����core, SoC�ɂ��Č��X�� #002��
http://anago.2ch.net/test/read.cgi/jisaku/1362032148/
Your processor's IQ: An Intro to HSA
http://www.youtube.com/watch?v=i6BWzL12KMI
Revolutionizing computing with HSA-enabled APUs
http://www.youtube.com/watch?v=4YV6z6Fgw48
�O�X��
AMD�̎�����APU/CPU�ɂ��Č�낤��179����
http://anago.2ch.net/test/read.cgi/jisaku/1386335737/
|
|
|
2 �F081 ��081081gg9U �F2013/12/16(��) 18:23:19.95 ID:X7ySjzHR
���܂�������
http://prohardver.hu/teszt/mit_tudhat_a_kaveri_gpu-ja/teszteles.html
����ς�OpenCL���\���̂͌��I�Ȍ���͂Ȃ��ˁi�t���[�����`�I�ȈӖ��Łj
����ς�OpenCL���\���̂͌��I�Ȍ���͂Ȃ��ˁi�t���[�����`�I�ȈӖ��Łj
>>3
7750��DDR3��GDDR5(?)�o�Ă��邯�ǁA�L�ш惁�����ɂ��Ȃ��Ƃق�Ƒʖڂ���
Kaveri��DDR3�������������������邱�ƂɂȂ肻������
APU��iGPU�������\�����Ă�DDR3x4ch��GDDR5M�ɂ��Ȃ��Ɗ��҂����قǎ����\���サ�Ȃ���������Ȃ�
7750��DDR3��GDDR5(?)�o�Ă��邯�ǁA�L�ш惁�����ɂ��Ȃ��Ƃق�Ƒʖڂ���
Kaveri��DDR3�������������������邱�ƂɂȂ肻������
APU��iGPU�������\�����Ă�DDR3x4ch��GDDR5M�ɂ��Ȃ��Ɗ��҂����قǎ����\���サ�Ȃ���������Ȃ�
�@�N���b�N����Ⴂ�ɂ��ւ�炸DDR3��7750���ǂ����ʂ��o�Ă���̂�
hUMA�̌��ʁH�@GCN2.0������H
hUMA�̌��ʁH�@GCN2.0������H
�������N���b�N���Ⴄ���Ƃ�����Ȃ��A7750�iDDR3�j�̂�1600Mhz�Ƃ�����Ȃ�����
������������E����c�c
�͂₢�Ƃ��Ȃ�Ƃ����Ȃ��ƁA�L���b�V���R�����iris�ɒǂ������ꂿ�܂���
�C���e�������Ă��܂ł��q���C���ۖV��̂܂ܕ��u��������킯���Ȃ����낤��
�͂₢�Ƃ��Ȃ�Ƃ����Ȃ��ƁA�L���b�V���R�����iris�ɒǂ������ꂿ�܂���
�C���e�������Ă��܂ł��q���C���ۖV��̂܂ܕ��u��������킯���Ȃ����낤��
���A�ł��N���b�N��Kaveri��GPU�̕���10%�Ⴂ�ȁA�ʂȗ��R�����邩����
>>7
����V�~�����[�g�Ȃ̂����[�N�Ȃ̂��킩���ĂȂ���
����V�~�����[�g�Ȃ̂����[�N�Ȃ̂��킩���ĂȂ���
>>7
iris�͒l�i�I�ɋ������Ȃ����������ǂˁBi7���炢�ɂ����t���Ȃ����낤���B
�����������E�Ȃ͓̂��ӁB
�ȓd�͓I�ɂ�1.2v�쓮��DDR4�Ɋ��ҁB
�n�C�p�t�H�[�}���X��1.5v�쓮��GDDR5M�ɂ͕ʂ̈Ӗ��Ŋ��҂�
iris�͒l�i�I�ɋ������Ȃ����������ǂˁBi7���炢�ɂ����t���Ȃ����낤���B
�����������E�Ȃ͓̂��ӁB
�ȓd�͓I�ɂ�1.2v�쓮��DDR4�Ɋ��ҁB
�n�C�p�t�H�[�}���X��1.5v�쓮��GDDR5M�ɂ͕ʂ̈Ӗ��Ŋ��҂�
dualcpu�o����悤�ɂȂ��4ch�ɂȂ邩�����������
PS4����肭�s�������Ƃ����A�ڐA�̎����l������AMD�͂������Ǝ���GDDR5������(2GB��M/B��ՂɎ���)�ƁAPCIe4.0�ւ̊g��(APU�J�[�h�p�̑ш�m��)��AMD�`�b�v�Z�b�g��M/B������܂��ė~�����B
GDDR5��L3�ł�L4�L���b�V���ɂł�����APU��dGPU��A�g�����ASSD/HDD�̓ǂݏ����̎��������܂Œʂ�DDR3������(������������DDR4�ւ��ڍs)���g���B
GDDR5��L3�ł�L4�L���b�V���ɂł�����APU��dGPU��A�g�����ASSD/HDD�̓ǂݏ����̎��������܂Œʂ�DDR3������(������������DDR4�ւ��ڍs)���g���B
>>4
�t�Ɍ����ƁA���������肪���ǂ��ꂽkaveri���o�Ă���Ƃ���wktk��
�t�Ɍ����ƁA���������肪���ǂ��ꂽkaveri���o�Ă���Ƃ���wktk��
kaveri��1333MHz����������
1600����Ȃ���
Trinity�ł�1866�Ή���������
Rich�ł�2133�`2400���炢�̍����������g����1333���3�`5���قǐ��\�L�т邩��Ȃ�
APU�Ő����c��Ȃ獂���������̑Ή��ƕ��y�����킹�Ċ撣���Ăق�����
APU�Ő����c��Ȃ獂���������̑Ή��ƕ��y�����킹�Ċ撣���Ăق�����
�S�z����ȁBkaveri�̎��̓��C����������4ch��GDDR5M����
4ch�͖����A�s����400�{������
�����������������ăT�C�Y�ȊO�ɂ������܂ł������葵����ׂ����̂Ǝv���Ă�����
�ŋ߂�intel�̂�̓v���t�@�C��������v���Ă���Ηe�ʃo���o���ł�
�ŏ��e�ʕ��܂ł�2ch�Ŏc��̓V���O���`���l���ɂȂ��
AMD�����������Ȃ́H
�ŋ߂�intel�̂�̓v���t�@�C��������v���Ă���Ηe�ʃo���o���ł�
�ŏ��e�ʕ��܂ł�2ch�Ŏc��̓V���O���`���l���ɂȂ��
AMD�����������Ȃ́H
APU��dGPU�̘A�g�Ƃ��������n���͂��ɂȂ����炢�Ȃ��Ȃ�̂�
����Ȃ�AMD���g���ے肵�Ă邩��
http://www.4gamer.net/games/133/G013322/20130420010/
>Caracappa���́C�����Maximus���u�}�[�P�e�B���O�L�[���[�h�Ƃ��Ă͎��ɑf���炵���v�ƕ]�����������ŁC
>���̂悤�ɋ^���悵���B�u�����C���������̘b�Ƃ��āC�Ȃ�2���GPU�p���Ȃ���Ȃ�Ȃ��̂��H�v�B
����Ȃ�AMD���g���ے肵�Ă邩��
http://www.4gamer.net/games/133/G013322/20130420010/
>Caracappa���́C�����Maximus���u�}�[�P�e�B���O�L�[���[�h�Ƃ��Ă͎��ɑf���炵���v�ƕ]�����������ŁC
>���̂悤�ɋ^���悵���B�u�����C���������̘b�Ƃ��āC�Ȃ�2���GPU�p���Ȃ���Ȃ�Ȃ��̂��H�v�B
AMD Graphics Momentum 2013
http://www.youtube.com/watch?v=Ndy1JSwatw8
http://www.youtube.com/watch?v=Ndy1JSwatw8
���Y������D�̉ЂŃ��������i�オ��܂������̂�APU�ɂ͒ɍ����˂�
���{���ƍX�ɉ~����������āc�c
�܂��オ�肻��������Kaveri�͂��Ȃ肫���ł̃f�r���[�ɂȂ肻��
���߂ė\��ʂ荡�N�̑��������ɏo���Ă��
���{���ƍX�ɉ~����������āc�c
�܂��オ�肻��������Kaveri�͂��Ȃ肫���ł̃f�r���[�ɂȂ肻��
���߂ė\��ʂ荡�N�̑��������ɏo���Ă��
Kaveri 4.9GHz �܂���Ă���
http://cdn.overclock.net/8/80/900x900px-LL-809f06c7_1387129105752.jpeg
http://cdn.overclock.net/8/80/900x900px-LL-809f06c7_1387129105752.jpeg
{kind=link}
>>25
�������̂����ɂ���̂͂ǂ����낤?
�������̂����ɂ���̂͂ǂ����낤?
>>21
�O�X����PhysX��p�Ɠ������ȁB
�킴�킴SLI�o�����������̂ɁA�Е����p�Ɛ�̂Ă�Ӗ��������Ƃ���������B
ttp://www.nvidia.co.jp/object/sli-technology-physx-jp.html
�َ�R�A�Ԃ�SLI���邽�߂����̗��R�Â���PhysX��p��GPGPU��p�Ƃ��������ŁA���R�A��SLI�������ʃR�A1�g������������������ˁH���Ă�������B
AMD��CFX�Ȃ�َ�R�A�Ԃł��\�����ADirectX���������ӂƂ��A3D���Z���������ӂƂ��AGPGPU���������ӂƂ��A�����������Ӗ��Ȑ��������ĂȂ����A
����3-way�܂łȂ�ăR�A�A�g�����������������ĂȂ����Ă����̘b����B
�O�X����PhysX��p�Ɠ������ȁB
�킴�킴SLI�o�����������̂ɁA�Е����p�Ɛ�̂Ă�Ӗ��������Ƃ���������B
ttp://www.nvidia.co.jp/object/sli-technology-physx-jp.html
�َ�R�A�Ԃ�SLI���邽�߂����̗��R�Â���PhysX��p��GPGPU��p�Ƃ��������ŁA���R�A��SLI�������ʃR�A1�g������������������ˁH���Ă�������B
AMD��CFX�Ȃ�َ�R�A�Ԃł��\�����ADirectX���������ӂƂ��A3D���Z���������ӂƂ��AGPGPU���������ӂƂ��A�����������Ӗ��Ȑ��������ĂȂ����A
����3-way�܂łȂ�ăR�A�A�g�����������������ĂȂ����Ă����̘b����B
NV�̕������ƍŏ��\���ł�2���K�v�ɂȂ�̂ł�
30 �FSocket774�F2013/12/17(��) 09:39:27.81 ID:x43ylb1+
�ʂɌ��p�ł��g���邪
����i7��HTT�L���ɂȂ��Ă�ł���
�ނ���킦�Ă鐔�l����Ȃ���
A10-7850K @4.9GHz 547cb
http://cdn.overclock.net/8/80/900x900px-LL-809f06c7_1387129105752.jpeg
A10-6800K @5.1GHz 403cb
http://hwbot.org/benchmark/cinebench_r15/rankings?hardwareTypeId=processor_2826#start=0#interval=20
i5-2500k @4.5GHz 585cb
i5-4670k @4.4GHz 649cb
FX-8350 @4.5GHz 725cb
http://forums.pureoverclock.com/video-card-overclocking/22523-post-your-cinebench-r15-scores.html
�����Ă�Ⴄ�H
http://cdn.overclock.net/8/80/900x900px-LL-809f06c7_1387129105752.jpeg
A10-6800K @5.1GHz 403cb
http://hwbot.org/benchmark/cinebench_r15/rankings?hardwareTypeId=processor_2826#start=0#interval=20
i5-2500k @4.5GHz 585cb
i5-4670k @4.4GHz 649cb
FX-8350 @4.5GHz 725cb
http://forums.pureoverclock.com/video-card-overclocking/22523-post-your-cinebench-r15-scores.html
�����Ă�Ⴄ�H
�t����EIZO�A�L�[�{�[�h��Realforce�A�g���b�N�{�[����Kensington�ACPU��AMD�ASSD��Intel
http://engawa.2ch.net/test/read.cgi/poverty/1387241176/9
http://engawa.2ch.net/test/read.cgi/poverty/1387241176/9
�����Ă�̂��Ȃ�
i5����Ƃ����荞�݂��ꕔ�L���Łi�����t���ł��낤���j
���ǐ��N��}���g���Ή��������i�Ƃ��łȂ��ƒ�����\�͂͂łȂ����
i5����Ƃ����荞�݂��ꕔ�L���Łi�����t���ł��낤���j
���ǐ��N��}���g���Ή��������i�Ƃ��łȂ��ƒ�����\�͂͂łȂ����
Mantle�g�����Ă��Ƃ̓Q�[���Ȃ킯��
�Q�[���Ȃ�i5�Ȃ�āA�ŏ�����APU�̑���ɂ��Ȃ��G���ł���
��Ȃ���O�ɓ��b�����
�Q�[���Ȃ�i5�Ȃ�āA�ŏ�����APU�̑���ɂ��Ȃ��G���ł���
��Ȃ���O�ɓ��b�����
dGPU�t���Ȃ���Richland�ɂ���R�ł��Ȃ�Intel���������
>>34
FX�̂ق������������邗
FX�̂ق������������邗
�����A�R�A��2�{�����B
��Google���Icpu���炵�����[
�����܂����wwwww
�����܂����wwwww
�����ɒx������A���Ȃ�google��amazon���肶������ۗ�����
�����܂ł���Ɛ��̔F���K�{�Ȑ��̒��ɂȂ��Ă���Ȃ��̂�
�����܂ł���Ɛ��̔F���K�{�Ȑ��̒��ɂȂ��Ă���Ȃ��̂�
>>34
3�N�O��2���ŏo��CPU�ɂ����ĂȂ��̂�
3�N�O��2���ŏo��CPU�ɂ����ĂȂ��̂�
Mantle���g����CPU�͂���ڂ��Ă������݂�������
Celeron�{290X���ŋ��̃Q�[�~���O�\���ɂȂ�
Celeron�{290X���ŋ��̃Q�[�~���O�\���ɂȂ�
>>21
������ĉ��Z�p�� Tesla �O���t�B�b�N�p�� Quadro ���Ă��� nVidia �̐헪�ɑ���
FirePro �Ȃ���ŏ\���ȃp���[�������Ă�����ăA�s�[�����Ă���Ęb�ł���H
���������āA���̕��������Ƃ肠����̂͂ǂ����Ǝv���B
������ĉ��Z�p�� Tesla �O���t�B�b�N�p�� Quadro ���Ă��� nVidia �̐헪�ɑ���
FirePro �Ȃ���ŏ\���ȃp���[�������Ă�����ăA�s�[�����Ă���Ęb�ł���H
���������āA���̕��������Ƃ肠����̂͂ǂ����Ǝv���B
��������APU������1�`�b�v�ŏ\���ȃp���[�������Ă̂����肾������Ȃ��́H
�r�f�I�J�[�h�}�����炻�̍ő�̃����b�g�������Ȃ�킯�ł�
�r�f�I�J�[�h�}�����炻�̍ő�̃����b�g�������Ȃ�킯�ł�
���ۂɂ�GPU���v���G���v�e�B�u�^�X�N�X�C�b�`�ɖ��Ή��Ȃ̂Ŗ����Ȃ��ǂ�
����API�œ����A�v���œ������Ȃ���
����API�œ����A�v���œ������Ȃ���
>>46
APU��dGPU�̔�Ώ�CF���A�g�̘b�Ƃ͑S�����т��Ȃ���Ȃ���
APU��dGPU�̔�Ώ�CF���A�g�̘b�Ƃ͑S�����т��Ȃ���Ȃ���
50 �FSocket774�F2013/12/17(��) 12:48:56.87 ID:gABAx5z9
APU��iGPU���A�ӂ��Ƀl�b�g�⓮�挩����y���l�g�Q��Flash�Q�[�������I�t�B�X�g�����肷��p�r�Ŏg�������
���x��GPU����
�Q�[������ɂ�dGPU�K�{�����琳��APU/iGPU��GPU���\�Ȃ�Ăǂ��ł�������
���x��GPU����
�Q�[������ɂ�dGPU�K�{�����琳��APU/iGPU��GPU���\�Ȃ�Ăǂ��ł�������
age�͂�������炸���Ȃ���
>>50
���������A�����炱��APU�g���p�J�[�h�Ƃ�APU���m�̘A�g�Ƃ��͍����ė~������ˁB
�G���R�Ƃ�CPU����Ƃ��Ďg���p�r�ɂ�APU���g�����A�Q�[����GPGPU����Ƃ��Ďg���p�r�ɂ�GPU���g���o����悤�ɂȂ�̂����z���ˁB
���������A�����炱��APU�g���p�J�[�h�Ƃ�APU���m�̘A�g�Ƃ��͍����ė~������ˁB
�G���R�Ƃ�CPU����Ƃ��Ďg���p�r�ɂ�APU���g�����A�Q�[����GPGPU����Ƃ��Ďg���p�r�ɂ�GPU���g���o����悤�ɂȂ�̂����z���ˁB
Xeon Phi��PCIe������APU���ł���������
>>48
PS4�ŏo����݂���������Kaveri�ł��o���邩����
PS4�ŏo����݂���������Kaveri�ł��o���邩����
GPU���Q�[���ȊO�Ɏg���Ȃ�����Llano�ATrinity�ERichland���ケ��
GPU�������CPU��1�R�A(1���W���[��)���₵�����f�������݉\�������̂ɂl�n�s�s�`�h�m�`�h���
>>40
�m����Bull�̍��X���[�v�b�g���Ȃ��Ȃ��E�E
GPU�������CPU��1�R�A(1���W���[��)���₵�����f�������݉\�������̂ɂl�n�s�s�`�h�m�`�h���
>>40
�m����Bull�̍��X���[�v�b�g���Ȃ��Ȃ��E�E
FX���X�`�[����������ŋ�����
���ł�10�R�A�����Ăق���
���ł�10�R�A�����Ăق���
CPU���ア����GPU�����p���������OpenCL��HSA
����GPU��������債�����\����Ȃ���Mantle�Ńu�[�X�g��Mantle��dGPU�ƘA�g
���ꂾ���̘b�Ȃ̂ɁA���܂Ōo���Ă����l�Ƀ|�C���g�O����������~
����GPU��������債�����\����Ȃ���Mantle�Ńu�[�X�g��Mantle��dGPU�ƘA�g
���ꂾ���̘b�Ȃ̂ɁA���܂Ōo���Ă����l�Ƀ|�C���g�O����������~
>>23
�t���b�N�X���[�h�̎����͂��������Â��b����
ttp://pc.watch.impress.co.jp/docs/2007/1227/hot522.htm
�����z���S���Ȃ��Ă����Ԃ�o������
�t���b�N�X���[�h�̎����͂��������Â��b����
ttp://pc.watch.impress.co.jp/docs/2007/1227/hot522.htm
�����z���S���Ȃ��Ă����Ԃ�o������
>>54
�ނ�
�ނ�
A99-9999K������
99�R�A9999GHz9999��W�ł��܂��
99�R�A9999GHz9999��W�ł��܂��
62 �FSocket774�F2013/12/17(��) 15:35:13.46 ID:tmAR0uUC
>>61
AMD�ɒ��ڗ��݂ɂ����A�J�X�^��SoC���Ǝn�߂Ă邾��
AMD�ɒ��ڗ��݂ɂ����A�J�X�^��SoC���Ǝn�߂Ă邾��
64 �FSocket774�F2013/12/17(��) 15:51:19.58 ID:tmAR0uUC
32nm SOI��TDP100W��
28nm �o���N��TDP95W�Ƃ��Ɖ��肵���ꍇ
����d�͕ӂ�̐��\���ǂ�قǏオ���Ă邩���l�����ׂ�
SOI��40%���b�g�p�t�H�[�}���X�オ���Ă�킯������
32nm�v���Z�X���������ďꍇ�A�{���Ȃ�28nm�o���N�v���Z�X�ɂ����10%���\��������
�Ƃ��낪���\���{�߂��オ���Ă�ƂȂ��28nm�o���N�ƌ����Ă�����̂�
���ۂ̂Ƃ����22nm�v���Z�X�Ő������Ă�Ƃ݂Ă����Ǝv��
28nm �o���N��TDP95W�Ƃ��Ɖ��肵���ꍇ
����d�͕ӂ�̐��\���ǂ�قǏオ���Ă邩���l�����ׂ�
SOI��40%���b�g�p�t�H�[�}���X�オ���Ă�킯������
32nm�v���Z�X���������ďꍇ�A�{���Ȃ�28nm�o���N�v���Z�X�ɂ����10%���\��������
�Ƃ��낪���\���{�߂��オ���Ă�ƂȂ��28nm�o���N�ƌ����Ă�����̂�
���ۂ̂Ƃ����22nm�v���Z�X�Ő������Ă�Ƃ݂Ă����Ǝv��
APU���{�C�o���̂�OS��GPGPU�����S�T�|�[�g���Ă���
����܂ł̓G�R�p�r��������
����܂ł̓G�R�p�r��������
>>64
�������ɂ��̘_���͐F�X��������
�������ɂ��̘_���͐F�X��������
�{���悩�A�����悩�A���Ęb�����ǂ����Ȃ�ˁB
�܂���AMD���撣����APU�Ƃ����n�[�h�E�F�A������Ă��ꂽ�̂�����A
���x��MS���\�t�g�E�F�A�Ƃ���OS��GPGPU���T�|�[�g����̂͂������A
�\�t�g�E�F�A�J���̕���ł����k�𓀂�Í�������v�Z�����Ȃǂ�
������GPGPU�Ɋ���U���悤�ɂ��ĖႦ��Ɩ{���̈Ӗ���APU�֗̕�����
���̒��ɓ`���悤�ɂȂ�Ǝv�����ǂˁB
�܂���AMD���撣����APU�Ƃ����n�[�h�E�F�A������Ă��ꂽ�̂�����A
���x��MS���\�t�g�E�F�A�Ƃ���OS��GPGPU���T�|�[�g����̂͂������A
�\�t�g�E�F�A�J���̕���ł����k�𓀂�Í�������v�Z�����Ȃǂ�
������GPGPU�Ɋ���U���悤�ɂ��ĖႦ��Ɩ{���̈Ӗ���APU�֗̕�����
���̒��ɓ`���悤�ɂȂ�Ǝv�����ǂˁB
amd���\�t�g���Ȃ���ǂ����g��Ȃ�
�܂�AVX512�Ή��̕����悾�낤�ˁB
>>62
AMD Phenom II X4 955_4.2GHz ���@422
AMD Phenom II x6 1090t_3.9GHz ���@600
AMD A-10 6800k_4.8GHz�@���@376
A10-7850K�̃��t�@�����X�N���b�N��450�炵������A�Ƃ肠����FPU�ɂ��Ă�Llano/Richland�z���͔Z��?
http://www.xtremesystems.org/forums/showthread.php?287414-Cinebench-R15-AMD-results-new-fun-for-next-months
https://docs.google.com/spreadsheet/pub?key=0Avrck3jWivLcdC14MnV4U2JReWpwRExxc0FRZTZEa0E&gid=7
http://blog.livedoor.jp/amd646464/archives/52389985.html
AMD Phenom II X4 955_4.2GHz ���@422
AMD Phenom II x6 1090t_3.9GHz ���@600
AMD A-10 6800k_4.8GHz�@���@376
A10-7850K�̃��t�@�����X�N���b�N��450�炵������A�Ƃ肠����FPU�ɂ��Ă�Llano/Richland�z���͔Z��?
http://www.xtremesystems.org/forums/showthread.php?287414-Cinebench-R15-AMD-results-new-fun-for-next-months
https://docs.google.com/spreadsheet/pub?key=0Avrck3jWivLcdC14MnV4U2JReWpwRExxc0FRZTZEa0E&gid=7
http://blog.livedoor.jp/amd646464/archives/52389985.html
�����Kaveri��CPU���\���ނ���GPU���\���ڋʂȂ̂�
�_�C�T�C�Y�������x��Llano�Ɣ�r�����ꍇ�ɂǂꂾ��GPU���\���オ���Ă邩
�����ł�2�{�̐��\��@���o������SOI�̈Ӗ�������
���̉���ł�32nmSOI��45nmSOI����P����High-K�̗p�������x�̐��\�ŃV�������N�ɂ��{�̐��\������ʂ����������̂ł͖�����
�����l�����̂�40nm�o���N�v���Z�X�̗p��HD5670�Ɠ����x��400SP���̗p����32nmSOI��High-K�̑g�ݍ��킹��Llano��HD5670�Ɣ�r���Đ��\�ł݂��ꍇ��
HD5550���x�̐��\�ł����Ȃ��̂���������
�_�C�T�C�Y�������x��Llano�Ɣ�r�����ꍇ�ɂǂꂾ��GPU���\���オ���Ă邩
�����ł�2�{�̐��\��@���o������SOI�̈Ӗ�������
���̉���ł�32nmSOI��45nmSOI����P����High-K�̗p�������x�̐��\�ŃV�������N�ɂ��{�̐��\������ʂ����������̂ł͖�����
�����l�����̂�40nm�o���N�v���Z�X�̗p��HD5670�Ɠ����x��400SP���̗p����32nmSOI��High-K�̑g�ݍ��킹��Llano��HD5670�Ɣ�r���Đ��\�ł݂��ꍇ��
HD5550���x�̐��\�ł����Ȃ��̂���������
�}���g���Ƃ��I�[�f�B�I�̉��Ƃ������̂����Ă���̂���
��r����̂Ȃ�HD7000�V���[�Y�ȍ~�̂���˂�
��r����̂Ȃ�HD7000�V���[�Y�ȍ~�̂���˂�
>>59
�@3DCG�̉��Z���S��CPU�ɂ�点��GPU�̓t���[���o�b�t�@�Ɏg���́H
�@�Z�b�g�A�b�v�̃��X�ɂ��Ă��v�Z�\�͂ɂ��Ă�hUMA�Ή�iGPU��SIMD��H��
dGPU�̊ԂɈʒu����킯������A����ɉ������g������������������ƁB
�@3DCG�̉��Z���S��CPU�ɂ�点��GPU�̓t���[���o�b�t�@�Ɏg���́H
�@�Z�b�g�A�b�v�̃��X�ɂ��Ă��v�Z�\�͂ɂ��Ă�hUMA�Ή�iGPU��SIMD��H��
dGPU�̊ԂɈʒu����킯������A����ɉ������g������������������ƁB
OC�Ō��\���̂�
�Ă��Ƃ͐�ΐ��\�ɂ����Ă�intel�ɋ߂��Ȃ��Ă����킯����
���b�g�p�t�H�[�}���X�͂ǂ��Ȃ낤
�Ă��Ƃ͐�ΐ��\�ɂ����Ă�intel�ɋ߂��Ȃ��Ă����킯����
���b�g�p�t�H�[�}���X�͂ǂ��Ȃ낤
>>62
Cinebench�Ă݂���H
Cinebench�Ă݂���H
AMD Working With Hynix For Development of High-Bandwidth 3D Stacked Memory
http://wccftech.com/amd-working-hynix-development-highbandwidth-3d-stacked-memory
http://wccftech.com/amd-working-hynix-development-highbandwidth-3d-stacked-memory
�������̖���HBM�ʼn�������������Ă������ˁACarrizo���M���M���Ԃɍ������炢��
GDDR5M�̎���HBM�g�����Ď����͋��N����o�Ă�����
GDDR5M�̎���HBM�g�����Ď����͋��N����o�Ă�����
DDR3�ł��������̂ɁAAMD��p�ɂȂ肻����GDDR5M�͂��������������ɂȂ��
����Ȃ̂�PC���[�J�[�̗p����̂��B�g�[�^����Intel�V�X�e����荂���Ȃ肻���Ȋ���
����Ȃ̂�PC���[�J�[�̗p����̂��B�g�[�^����Intel�V�X�e����荂���Ȃ肻���Ȋ���
�H
GDDR5M�͂�����ɂ�����ŁADDR3��DDR4��TSV�g������ɂ�����Ęb�Ȃ�
GDDR5M�͂�����ɂ�����ŁADDR3��DDR4��TSV�g������ɂ�����Ęb�Ȃ�
82 �FSocket774�F2013/12/17(��) 20:28:42.33 ID:HqRvioOZ
> Carrizo, their APU for 2015 with Excavator core is most likely going to extend DDR3 memory support
> so its successor which is rumored to be codenamed Basilisk will either feature Stacked memory or go with DDR4.
Carrizo�ł�DDR3�ABasilisk�Őϑw��������������DDR4�Ə����Ă���悤�Ɍ������
HBM�̑�ʐ��Y��2014�`2015�N���炢�ŁA�����͍������č����ȃf�o�C�X�ɂ����g���Ȃ����낤����A
2016�N��ڈ��ɂ���̂͂܂��Ó����낤
������HBM�̓\�P�b�g�ɂł��Ȃ�����APU�̃��C���ɓ�����邩�Ƃ����ƁA�Ȃ��Ȃ������ȁc�c
> so its successor which is rumored to be codenamed Basilisk will either feature Stacked memory or go with DDR4.
Carrizo�ł�DDR3�ABasilisk�Őϑw��������������DDR4�Ə����Ă���悤�Ɍ������
HBM�̑�ʐ��Y��2014�`2015�N���炢�ŁA�����͍������č����ȃf�o�C�X�ɂ����g���Ȃ����낤����A
2016�N��ڈ��ɂ���̂͂܂��Ó����낤
������HBM�̓\�P�b�g�ɂł��Ȃ�����APU�̃��C���ɓ�����邩�Ƃ����ƁA�Ȃ��Ȃ������ȁc�c
>>82
���A���߂�HBM�̓O���{�̕��������A�ׂ�3DS���Ă̂����C���������p����
���A���߂�HBM�̓O���{�̕��������A�ׂ�3DS���Ă̂����C���������p����
�V���R���C���^�|�[�U���܂���2.5DTSV��APU��HBM���p�b�P�[�W���O������
>>82
���L���͂����݂����ˁA�ǂ��肶��WCCF�̐��������Ȃ�����Ă���ۂ�����
http://electroiq.com/blog/2013/12/amd-and-hynix-announce-joint-development-of-hbm-memory-stacks/
���L���͂����݂����ˁA�ǂ��肶��WCCF�̐��������Ȃ�����Ă���ۂ�����
http://electroiq.com/blog/2013/12/amd-and-hynix-announce-joint-development-of-hbm-memory-stacks/
Win8�Ń\�P370�����Ȃ��Ȃ����炵������
�\�P370��win7���ꂿ�Ⴄ����
�\�P370��win7���ꂿ�Ⴄ����
20nm or 16nm APU+3DS��5���ȓ��Ȃ�]�T�ő������鎩�M�������
>>81
�ėp�ϑw�������̘b������C���e�����Ή����邱�Ƃ͏o����
�������AAMD�������J�����Ă邩��AAMD����̗̍p�ɂȂ��Ă��܂�
�ϑw�������Ή� APU vs �B�̃������Ή� Intel�ʼnʂ����ď����ɂȂ�̂��͒m��Ȃ�
20nm APU���ƁA32nm Richland���CPU��GPU���{�ȏ�̐��\�ɂȂ��Ă�����
14nm APU����Richland�Ƃ̓A�[�L�e�N�`���������ς�肷���Ăčő��z���ł��Ȃ���
>>81
�ėp�ϑw�������̘b������C���e�����Ή����邱�Ƃ͏o����
�������AAMD�������J�����Ă邩��AAMD����̗̍p�ɂȂ��Ă��܂�
�ϑw�������Ή� APU vs �B�̃������Ή� Intel�ʼnʂ����ď����ɂȂ�̂��͒m��Ȃ�
20nm APU���ƁA32nm Richland���CPU��GPU���{�ȏ�̐��\�ɂȂ��Ă�����
14nm APU����Richland�Ƃ̓A�[�L�e�N�`���������ς�肷���Ăčő��z���ł��Ȃ���
�s����啝�ɑ��₹��ʐς��Ȃ�����A�s�����͕ς��Ȃ������������邭�炢�ɗ}����Ǝv��
�����R�X�g����ǂ��ǂ������ĉ��i�������͂��ێ��o���Ȃ���
>>89
����ōL�ш惁�����ɂł���̂�
�܁ADDR4���W���[���ƌ݊����Ȃ��Ȃ������_�łǂ��Ȃ�����ċC�����邯��
>>90
�ϑw���������Ē�e�ʂ̍L�ш惁�����Ȃ̂�
����ōL�ш惁�����ɂł���̂�
�܁ADDR4���W���[���ƌ݊����Ȃ��Ȃ������_�łǂ��Ȃ�����ċC�����邯��
>>90
�ϑw���������Ē�e�ʂ̍L�ш惁�����Ȃ̂�
���ʂ�DDR3��4�Ƃ͕ʂɁA�n�C�G���h�̑I�����Ƃ��Đϑw�������������낤���A
���i�}����Ȃ畁�ʂ̃�����������������
���̏ꍇ�A���͖��킸�ϑw�������������A�����悤�ɍ����\�Ȃق������������������̂�A10�g����
���i�}����Ȃ畁�ʂ̃�����������������
���̏ꍇ�A���͖��킸�ϑw�������������A�����悤�ɍ����\�Ȃق������������������̂�A10�g����
94 �FSocket774�F2013/12/18(��) 01:35:57.96 ID:InY8+4r2
�������͂悭�m��A3DS���Ă̂́A�m���C���^�t�F�[�X����DDR4�̂܂܃��������X�^�b�N����̂ŁA
�݊������ێ������܂ܑ�e�ʂ���������Z�p�̂͂��Łc�c
���ʂɍl����K�i��ς��Ȃ��܂܂��ƃ������o���h���͐L�тȂ����ǂȂ�
HBM�Ƃ�TSV���g�����L�ш惁�����̓\�P�b�g���g���Ȃ��̂Ɨe�ʂ��l�b�N
�Ȃ�Ƃ�����DDR�Ƒg�ݍ��킹�悤�Ƃ���ƁACrystalwell�݂����Ȉ�H�v���邱�ƂɂȂ�
�݊������ێ������܂ܑ�e�ʂ���������Z�p�̂͂��Łc�c
���ʂɍl����K�i��ς��Ȃ��܂܂��ƃ������o���h���͐L�тȂ����ǂȂ�
HBM�Ƃ�TSV���g�����L�ш惁�����̓\�P�b�g���g���Ȃ��̂Ɨe�ʂ��l�b�N
�Ȃ�Ƃ�����DDR�Ƒg�ݍ��킹�悤�Ƃ���ƁACrystalwell�݂����Ȉ�H�v���邱�ƂɂȂ�
>>92
���N�O�̂Ȃ�ō��Ə���������Ă��邩������Ȃ�������ǂނƏ����͕�����C������
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20130708_606743.html
���N�O�̂Ȃ�ō��Ə���������Ă��邩������Ȃ�������ǂނƏ����͕�����C������
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20130708_606743.html
http://i.imgur.com/hxQCe8N.jpg
http://www.jedec.org/standards-documents/results/jesd235
�̐S�ȂƂ��낪���Ō����Ȃ��c
����͂��Ă���co-developed a special prototype�Ƃ���悤�ɗ��҂����悵�ĊJ�����s���Ă���悤�ł��B
�W�����Ɋւ��Ă͔��\����Ă��܂��AJEDEC�̃����N�ɂ���悤�Ɏ�����m��A�قڊ������Ă��܂��B
���łɍu�������l�ɂ��ƁA�ŏI�I�ȃ^�[�Q�b�g��1024 IOs x 1GHz ��(�`�b�v������H�������ɂ����܂ōs���̂��ȁH)1TB/s�ƂȂ��Ă��܂��B
�u���҂�Bryan Black�͂���Intel��3D stacking�̌������s���Ă��܂������A10�N�O�ɂ��̌������傲�ƕ��A
���̌�AMD�ɈڐЂ�����AMD�Ń_�C�X�^�b�L���O�̌����J�����s���Ă��܂��B
>>94
�\�P�b�g�g���邩�ǂ����Ȃ��TSV�ɊW�����ł����ˁH�Ԃ����Ⴏ�ʏ�\�P�b�g�̃�������r�������
���PCI-E�ƃT�E�X�u���b�W�ƂȂ��镔�������ōςނ킯�ŁA�s�����������Ɍ���Ǝv���܂����B
{kind=link}
http://www.jedec.org/standards-documents/results/jesd235
�̐S�ȂƂ��낪���Ō����Ȃ��c
����͂��Ă���co-developed a special prototype�Ƃ���悤�ɗ��҂����悵�ĊJ�����s���Ă���悤�ł��B
�W�����Ɋւ��Ă͔��\����Ă��܂��AJEDEC�̃����N�ɂ���悤�Ɏ�����m��A�قڊ������Ă��܂��B
���łɍu�������l�ɂ��ƁA�ŏI�I�ȃ^�[�Q�b�g��1024 IOs x 1GHz ��(�`�b�v������H�������ɂ����܂ōs���̂��ȁH)1TB/s�ƂȂ��Ă��܂��B
�u���҂�Bryan Black�͂���Intel��3D stacking�̌������s���Ă��܂������A10�N�O�ɂ��̌������傲�ƕ��A
���̌�AMD�ɈڐЂ�����AMD�Ń_�C�X�^�b�L���O�̌����J�����s���Ă��܂��B
>>94
�\�P�b�g�g���邩�ǂ����Ȃ��TSV�ɊW�����ł����ˁH�Ԃ����Ⴏ�ʏ�\�P�b�g�̃�������r�������
���PCI-E�ƃT�E�X�u���b�W�ƂȂ��镔�������ōςނ킯�ŁA�s�����������Ɍ���Ǝv���܂����B
HBM�̗p�̃n�C�G���hAPU��BGA�݂̂ɂȂ肻������
GT3��GT3e�A2��ނ̃_�C������Intel�叟��
GT3��GT3e�A2��ނ̃_�C������Intel�叟��
AMD��Hynix��GDDR5M�ƌ����Ă邪���̎d�l�͂ق�DDR4��OC
DDR4�ɖт����������x�̃R�X�g�Ŏ����ł����������������Ǝv�킹�č������肽���͗l
DDR4�ɖт����������x�̃R�X�g�Ŏ����ł����������������Ǝv�킹�č������肽���͗l
PS4��xboxone������܂����Ă�݂�������
�X�}�t�H�̃��������t���ŕ��匾����͂��Ȃ�����
APU��Kaveri �ł�������GDDR5�Ɉڍs����悩�����̂ɁB
�����E�f�B�X�N���[�g��킸DDR3�Ɍq������GPU�ȂS�~�B
APU��Kaveri �ł�������GDDR5�Ɉڍs����悩�����̂ɁB
�����E�f�B�X�N���[�g��킸DDR3�Ɍq������GPU�ȂS�~�B
PS4�ɍD����OS��������悤�ɉ������悤
�����p�ɍœK������ĂȂ���Jaguar 8�R�A�͂����B
PS4��������x���y�����GDDR5�̉��i���������Ȃ����Ǝv�����ǂǂ��Ȃ낤
>>104
�N��1000������s���Ȃ�PS4�̎��v����w�Ǖω�������Ȃ����Ȃ��H
PC��o�C���݂�������P�ʁA���Ɠd��Y�ƌ����ɂ��g����悤����Ȃ���
DRAM�݂����X�|�b�g�s�ꂪ�@�\����悤�ɂȂ邩�ۂ����w�W�ɂȂ�Ǝv��
�Q�n����PS4�̗p�ł̗ʎY���ʂ�GDDR5��DDR3�������Ȃ���PS4�叟�����Ă��ƂɂȂ��Ă邯��w
�N��1000������s���Ȃ�PS4�̎��v����w�Ǖω�������Ȃ����Ȃ��H
PC��o�C���݂�������P�ʁA���Ɠd��Y�ƌ����ɂ��g����悤����Ȃ���
DRAM�݂����X�|�b�g�s�ꂪ�@�\����悤�ɂȂ邩�ۂ����w�W�ɂȂ�Ǝv��
�Q�n����PS4�̗p�ł̗ʎY���ʂ�GDDR5��DDR3�������Ȃ���PS4�叟�����Ă��ƂɂȂ��Ă邯��w
>>105
PS4�̔̔��䐔�Ő����Ăǂ�����A�d�v�Ȃ͎̂�������Ă�GDDR5���W���[���̐�
PS4�̔̔��䐔�Ő����Ăǂ�����A�d�v�Ȃ͎̂�������Ă�GDDR5���W���[���̐�
GDDR5�̃��W���[���H
�Ƃ����˂����݂͂��Ă����A�`�b�v���Ŕ�r���Ă���ׂ�ׂ�������
PC��X�}�z������DRAM������g���Ă��Ȃ��킯�ł��Ȃ������
�Ƃ����˂����݂͂��Ă����A�`�b�v���Ŕ�r���Ă���ׂ�ׂ�������
PC��X�}�z������DRAM������g���Ă��Ȃ��킯�ł��Ȃ������
3D/2.5D��TSV��CPU�̃s���������Đ��Ƃ����?
�u�W�v�ǂ���
PC�ɕK�v�Ƃ���郁�����ʂ�32GB�Ƃ�64GB�ł���
�g���݂Ƃ͂�͂�Ⴄ�
�g���݂Ƃ͂�͂�Ⴄ�
http://japan.zdnet.com/cio/analysis/35040668/
�\�[�V�����Q�[���Ɠd�q���Ўs�ꂪ�g���--2018�N�\��
����A�Q�[����p�[���s��́ASCE�� �uPlayStation4�v�Ȃǎ�����@�̓o��ɂ��A
�ꎞ�I�Ɏs��̊����������҂���邪�A2013�N��2504���~�A2014�N��2103���~�A2018�N��1252���~�A
CAGR�}�C�i�X12.9���ƒ������I�ɂ͎s��K�͂��k������Ƃ����B
�\�[�V�����Q�[���Ɠd�q���Ўs�ꂪ�g���--2018�N�\��
����A�Q�[����p�[���s��́ASCE�� �uPlayStation4�v�Ȃǎ�����@�̓o��ɂ��A
�ꎞ�I�Ɏs��̊����������҂���邪�A2013�N��2504���~�A2014�N��2103���~�A2018�N��1252���~�A
CAGR�}�C�i�X12.9���ƒ������I�ɂ͎s��K�͂��k������Ƃ����B
113 �FSocket774�F2013/12/18(��) 16:07:01.50 ID:/iBxWWpv
>>73
����PS3��Cell����낤�Ƃ��������
�V�F�[�_�[�R�A��CPU�ł���āAROP��GPU�ł�낤�Ƃ��Ă��݂�������
���ǂ��܂������Ȃ���������
����PS3��Cell����낤�Ƃ��������
�V�F�[�_�[�R�A��CPU�ł���āAROP��GPU�ł�낤�Ƃ��Ă��݂�������
���ǂ��܂������Ȃ���������
Cell gpu�̓��X�^���C�Y��ROP��cell����
�{��Mantle�f�����J��
Oxide Games AMD Mantle Presentation and Demo
http://www.youtube.com/watch?v=QIWyf8Hyjbg
Oxide Games AMD Mantle Presentation and Demo
http://www.youtube.com/watch?v=QIWyf8Hyjbg
Cell��GPU��Cell�x�[�X��������PS3�̓n�[�h�I�ɖʔ����������A
CPU��GPU��SOC�����\�������͂�
�Ȃ�����ȃS�~���x���ꂽ�v��ǖ�E�E�E�E
�����ƃo�u���ŃJ�l���������i�C��������Cell�œ��{��
���E��������ł��������Ȃ�
CPU��GPU��SOC�����\�������͂�
�Ȃ�����ȃS�~���x���ꂽ�v��ǖ�E�E�E�E
�����ƃo�u���ŃJ�l���������i�C��������Cell�œ��{��
���E��������ł��������Ȃ�
Mantle�f����26:00�����肩��
>>116
Cell��POWER������A���{���N���j�_�I�Ƃ͍s���Ȃ�����
Cell��POWER������A���{���N���j�_�I�Ƃ͍s���Ȃ�����
>>116�@TV�Ƃ�PS�R�Ƃ��̐�p�@�����ɂ͈ꎞ�������������y���Ă��݂���������
�ėp�@�����͂��Ȃ���ɓI���������˂�
�Ȃ�ł�����ł���p�K�i�ɂ���������{��Ƃ�����ł鎞�_�ŁA���Ȃ��Ƃ�PC���ᕁ�y���Ȃ�����
�ėp�@�����͂��Ȃ���ɓI���������˂�
�Ȃ�ł�����ł���p�K�i�ɂ���������{��Ƃ�����ł鎞�_�ŁA���Ȃ��Ƃ�PC���ᕁ�y���Ȃ�����
120 �FSocket774�F2013/12/18(��) 19:50:01.11 ID:p8emAlS4
��������CPU�Ń����_�����O���s���Ă�������������Ă������Ȃ�
CPU�ɂ�CPU�̖����������ŁA�S�~���x���ꂽ�v��ǖ͂���܂ł������ƌ�����
CPU�ɂ�CPU�̖����������ŁA�S�~���x���ꂽ�v��ǖ͂���܂ł������ƌ�����
�������_�Ńc�[�������C�u�������������Ńm�E�n�E��������������
�T�[�h�����t����ɂ̓k�r�g�������Ȃ�������
�J����̍��������ɂȂ�n�߂�����������т̖����n�[�h�ɂ͏��ɓI���낤��
���C�o����MS��PC�Ƃ̈ڐA����ɂ��Ă�����T�[�h���S�����ꂽ�\�������Ă���
�T�[�h�����t����ɂ̓k�r�g�������Ȃ�������
�J����̍��������ɂȂ�n�߂�����������т̖����n�[�h�ɂ͏��ɓI���낤��
���C�o����MS��PC�Ƃ̈ڐA����ɂ��Ă�����T�[�h���S�����ꂽ�\�������Ă���
>>121
�ǂ�ȕϑԎd�l�̃n�[�h�ł��APS2���݂ɕ��y����T�[�h�͂��Ă����
�ǂ�ȕϑԎd�l�̃n�[�h�ł��APS2���݂ɕ��y����T�[�h�͂��Ă����
123 �FSocket774�F2013/12/18(��) 21:55:50.97 ID:j2xLHO9D
�C���e�����ƒ�p�Q�[���@�ɍ̗p�����̂͂����ɂ�H��
Intel��CPU�R�A+nvidia��GPU�R�A���g����SoC�������`��80�h���Œ�
(�n�[�h���������`����ɂ͂����ƈ����Ȃ錩���݂�����)�Ȃ�A
�̗p���[�J�[�o�Ă����ˁH
(�n�[�h���������`����ɂ͂����ƈ����Ȃ錩���݂�����)�Ȃ�A
�̗p���[�J�[�o�Ă����ˁH
>>116
�ŏ��͂��̂��肾��������
���ۂɍ������nVidia/ATI��GPU�ɑS�������ł��ł��Ȃ��Čv�悪�L�����Z�����ꂽ���
�ǂ���������nVidia/ATI�̒P���n�[�h���W�b�N�ɂ��A�N�Z�����[�^�Z�p��
Sony�̑z����͂邩�ɒ����Ă��܂������
���͂܂���������GPU��Cell���ۂ��A�[�L�e�N�`���ɂȂ���邯��
����ɂ�2013�N�̃e�N�m���W�[���K�v���������
�ŏ��͂��̂��肾��������
���ۂɍ������nVidia/ATI��GPU�ɑS�������ł��ł��Ȃ��Čv�悪�L�����Z�����ꂽ���
�ǂ���������nVidia/ATI�̒P���n�[�h���W�b�N�ɂ��A�N�Z�����[�^�Z�p��
Sony�̑z����͂邩�ɒ����Ă��܂������
���͂܂���������GPU��Cell���ۂ��A�[�L�e�N�`���ɂȂ���邯��
����ɂ�2013�N�̃e�N�m���W�[���K�v���������
>>124
MS�u����X���Œ��肽��[�v
MS�u����X���Œ��肽��[�v
>>116
�V�F�[�_�������b�`�ő����a���ŁAGPGPU�͂Ƃ������A
�O���ł͐��\�łȂ��Ƃ����邩��ȁB
�V�F�[�_�����������njŒ�@�\�����Ƃ��A���Ă݂Ȃ�B
PS3��Cell�ŃV�F�[�_�������肵�Ă邪�A���͎g���Ă�B
CellGPU�����܂������Ȃ������̂����������̂��������낤�B
�V�F�[�_�������b�`�ő����a���ŁAGPGPU�͂Ƃ������A
�O���ł͐��\�łȂ��Ƃ����邩��ȁB
�V�F�[�_�����������njŒ�@�\�����Ƃ��A���Ă݂Ȃ�B
PS3��Cell�ŃV�F�[�_�������肵�Ă邪�A���͎g���Ă�B
CellGPU�����܂������Ȃ������̂����������̂��������낤�B
kaveri���X���P�������ėǂ�����
���ǃ��[�G���h������A�ȓd�͐���intel�ɒǂ����Ă���Ȃ��Ɩ����͖����Ȃ�
�~�h�������W�����̃`�b�v����Ă���Ȃ����ȁB
dualAPU�Ƃ��ł�����w
���ǃ��[�G���h������A�ȓd�͐���intel�ɒǂ����Ă���Ȃ��Ɩ����͖����Ȃ�
�~�h�������W�����̃`�b�v����Ă���Ȃ����ȁB
dualAPU�Ƃ��ł�����w
�ꉞ�M���M���~�h�������W���낗�ߏ��]�����߂�
�ȓd�͐��͂ǂ����~���Ă������悤���Ȃ��̂������
����������"Intel�ȊO�̍��W�ϔ�����"�S���Ɍ����邯�ǂ�
�����ċ��炭�����Ǎ��͊J������A�A���K���Ƃ��Č��E���x���߂��̂ł����Ɋ|���邵���Ȃ�
���łŃA�[�L��������Ă����A��肭�������ΐ��N�ȓ��ɑ��肪�R�P�邳
����������"Intel�ȊO�̍��W�ϔ�����"�S���Ɍ����邯�ǂ�
�����ċ��炭�����Ǎ��͊J������A�A���K���Ƃ��Č��E���x���߂��̂ł����Ɋ|���邵���Ȃ�
���łŃA�[�L��������Ă����A��肭�������ΐ��N�ȓ��ɑ��肪�R�P�邳
�ȓd�͐���
�m���ǂ����ŁATrinity��Richland��Ivy��Haswell���A�C�h���d�͒Ⴉ�����O���t�����C������
�m���ǂ����ŁATrinity��Richland��Ivy��Haswell���A�C�h���d�͒Ⴉ�����O���t�����C������
�Ⴂ��������1�A2���b�g���炢����
���̓��[�h����
���̓��[�h����
5W���炢���邩��
>>123
�قڌ��܂��Ă�AMD����D�������Ƃ����邾�낤��
�قڌ��܂��Ă�AMD����D�������Ƃ����邾�낤��
�ł��ȓd�͂o�b�X����MAD�̃f�X�N�g�b�v����CPU���ł̓��e���w�Ǐo�Ă��Ȃ����H
�V�F�A�̍��ɂ�闝�R���傫���Ǝv�����ǁB
�V�F�A�̍��ɂ�闝�R���傫���Ǝv�����ǁB
137 �F,,�E�L�́M�E,,�j��-�������F2013/12/19(��) 01:32:48.88 ID:5cXMqucJ
�ȓd�̓f�X�N�g�b�v�������i���قڊF��������d���Ȃ�����
1�`�b�v�̂������ŃA�C�h�����͏ȃG�l�����Ǖ��ׂ�����Ɠr�[�ɏ���d�͒��ˏオ��̂��Ȃ�
�ʃ`�b�v���L���Ȃ�Ȃ��́H
���M���W������̂Ȃ�킩�邯��
���M���W������̂Ȃ�킩�邯��
�����ԃG���R�ł����Ȃ�����ғ����̖w�ǂ��A�C�h����Ԃ�����A�A�C�h���Ō݊p�ȏ�Ȃ�S�����Ȃ���
�ō����\��������Ƃ������ň�u�����ׂɂȂ�ȊO�́A����G���R���x���`���炢������������A�����ǂ��ł�����
�ō����\��������Ƃ������ň�u�����ׂɂȂ�ȊO�́A����G���R���x���`���炢������������A�����ǂ��ł�����
���������A�C�h���d�͂��݊p�ȏ���Ă̂������Ȃ̂��Ǝv���B
>>136
�ȓd�̓X������ǂ��o����ĕʃX�����Ă�ꂽ��ˁ[��
�ȓd�̓X������ǂ��o����ĕʃX�����Ă�ꂽ��ˁ[��
>>123
����Xbox��������ƂȂ��������Ƃɂ��邩
����Xbox��������ƂȂ��������Ƃɂ��邩
�{���ɃA�C�h�������Ȃ炢����������B
�����A���ۂ̉^�p�ł́A��ΐ��\�����������A�C�h���ł����鎞�Ԃ������̂ŏȓd�́B
�����A���ۂ̉^�p�ł́A��ΐ��\�����������A�C�h���ł����鎞�Ԃ������̂ŏȓd�́B
���C���Ŏg���Ȃ�Intel�A�T�u�Ŏg���Ȃ�AMD
�̂��炱�ꂾ��
�̂��炱�ꂾ��
�����͋t�ɕ��i�g����AMD�ŃT�u(�G���R�ƃQ�[��)��Intel�ɂȂ��Ă��
���ʂ̗p�r���Ⴛ��Ȃ�CPU�p���[�v�����̂ȁ[
���ʂ̗p�r���Ⴛ��Ȃ�CPU�p���[�v�����̂ȁ[
����Ȃ��Ə��߂Ă����f���o���������畷���Ă���
SAPPHIRE��R�X�Q�V�O��BF4���f�����Ă���Ƃ������g�ݏI����Ă�
����BF4���_�E�����[�h���ĐQ�悤�Ǝv���ăV���A���������Ă���J�[�h�̃V�[����������V���A���R�[�h���Ɣ����ꂿ�������
����T�|�[�g�͈͂ɓ����Ă邩�Ȗ����d�b���Ă݂悤�Ƃ͎v�����ǔ߂�������
SAPPHIRE��R�X�Q�V�O��BF4���f�����Ă���Ƃ������g�ݏI����Ă�
����BF4���_�E�����[�h���ĐQ�悤�Ǝv���ăV���A���������Ă���J�[�h�̃V�[����������V���A���R�[�h���Ɣ����ꂿ�������
����T�|�[�g�͈͂ɓ����Ă邩�Ȗ����d�b���Ă݂悤�Ƃ͎v�����ǔ߂�������
>>148
���܂Ȃ����肪�Ƃ�
���܂Ȃ����肪�Ƃ�
���ʂ̗p�r����Ȃ�����GPU�p���[����낗
�C���e���̃_����������m��Ȃ��炵����
�W���̊������鐫�\���C�����Ă̂͂����
�W���̊������鐫�\���C�����Ă̂͂����
�`�b�v�Z�b�g�����O���t�B�b�N�X����Ȃ�Ƃ������A
���݂�Intel HD�ŕ`��s��Ƃ��͂قƂ�ǂȂ��āA
�ނ���Q�[���Ƃ������܂������Ȃ��ꍇ�́A�P���Ȑ��\�s���̂��Ƃ������Ǝv�����ǂȂ�
����ł���Web�u���E�W���O���x�̃^�X�N�ɑ��Ă͐��\�ߏ�ƌ����ׂ���
���݂�Intel HD�ŕ`��s��Ƃ��͂قƂ�ǂȂ��āA
�ނ���Q�[���Ƃ������܂������Ȃ��ꍇ�́A�P���Ȑ��\�s���̂��Ƃ������Ǝv�����ǂȂ�
����ł���Web�u���E�W���O���x�̃^�X�N�ɑ��Ă͐��\�ߏ�ƌ����ׂ���
���{�̏��Y��PS4��FX8350����Ԃ�����ŏՌ���^���Ăق���
>>152
�u�قƂ�ǁv�Ƃ��������Ȃ��������ɒv����������ȁB
Windows�̕`�悪�S���o���Ȃ����Ƃ����������_�Œv�����߂���B
��ʂ��S���������ɖ��������ł���X�L���̂���l���ǂꂾ������̂��ƁB
�u�قƂ�ǁv�Ƃ��������Ȃ��������ɒv����������ȁB
Windows�̕`�悪�S���o���Ȃ����Ƃ����������_�Œv�����߂���B
��ʂ��S���������ɖ��������ł���X�L���̂���l���ǂꂾ������̂��ƁB
FM2��CPU������l�����肷��̂��l�オ�肷��̂�
>Windows�̕`�悪�S���o���Ȃ����Ƃ����������_�Œv�����߂���B
�悭�m�����͂Ȃʂ̌�������ˁH
�悭�m�����͂Ȃʂ̌�������ˁH
���������Ƃ͂Ȃ��ǏȁB
158 �FSocket774�F2013/12/19(��) 11:13:30.16 ID:tmKCzsvC
���܂ɃQ�[���⓮��݂邯�ǁAApu��f���g������C���e���O���t�B�b�N�őË��Ƃ���Ζ���
�y���Q�[���⓮�悷�猩�Ȃ��z�̓C���e���ɉ������߂Ă���̂���
�y���Q�[���⓮�悷�猩�Ȃ��z�̓C���e���ɉ������߂Ă���̂���
���芴�ƃu�����h����Ȃ��́H
�r�f�I�J�[�h�����ˁH
APUAPU������A����
Radeon �Ȃ��ł���Q�[���ɑς�����̂�?
Radeon �Ȃ��ł���Q�[���ɑς�����̂�?
�Ȃɂ킯�킩��Ȃ����ƌ����Ă�
RADEON�Ȃ�APU�̒��ɓ����Ă邾��
RADEON�Ȃ�APU�̒��ɓ����Ă邾��
���Ⴀ�u�f�B�X�N���[�g�́vRadeon ���Ă��������������B
��������イ�Q�[�����邯�ǁASLI�g������CFX�őË��Ƃ���Ζ���
����Ȃ́A�Q�[���ɂ����
>>164
IntelCPU�ƈ���āARichland�ŕ��ʂɃQ�[���o���Ă邩��Ȃ�
IntelCPU�ƈ���āARichland�ŕ��ʂɃQ�[���o���Ă邩��Ȃ�
dgpu�ł�6450�݂����ȃ��[�G���h����Richland�̂���������
169 �FSocket774�F2013/12/19(��) 13:54:35.43 ID:GqmdDKYk
kaveri�͐�Δ����
���i.com�Ŕ��グ1�ʎ���
���i.com�Ŕ��グ1�ʎ���
SLI��CFX�̘b������l�́A����ނ̃Q�[�����i���Ƀv���C���邱�Ƃ�O��ɂ��Ă��邩���
�Ƃ������Ђ������Q�[�������Ă���ƁA���Ή��Q�[�����قƂ�ǂȂ̂��ƋC�Â��͂���
�Ƃ������Ђ������Q�[�������Ă���ƁA���Ή��Q�[�����قƂ�ǂȂ̂��ƋC�Â��͂���
171 �FSocket774�F2013/12/19(��) 15:04:21.15 ID:tmKCzsvC
>>162
�ς����Ȃ��Ȃ�lj��ŕt���邾��
�܂��ō��ݒ�ɂ��Ȃ��Ȃ��̕��ʂɃQ�[���o�����
6800k�Ȃ�280X�Ƒg�ݍ��킹�Ă��ނ荇��������Ȃ�
�ς����Ȃ��Ȃ�lj��ŕt���邾��
�܂��ō��ݒ�ɂ��Ȃ��Ȃ��̕��ʂɃQ�[���o�����
6800k�Ȃ�280X�Ƒg�ݍ��킹�Ă��ނ荇��������Ȃ�
172 �FSocket774�F2013/12/19(��) 15:05:23.71 ID:tmKCzsvC
>>164
���O�͗������Ă��Ȃ����炢����������
���O�͗������Ă��Ȃ����炢����������
>>155
�グ�������낤���グ��ׂ��Ǝv����ADIY�s��ŃV�F�A�L�тĂ邯�Lj����肵�Ă邹����
�S�R�ׂ���Ȃ����āA���ꂶ��s��Ă邾���A�T���`��������
�グ�������낤���グ��ׂ��Ǝv����ADIY�s��ŃV�F�A�L�тĂ邯�Lj����肵�Ă邹����
�S�R�ׂ���Ȃ����āA���ꂶ��s��Ă邾���A�T���`��������
>>170
���Ή��Q�[�����ĉ�������H
���Ή��Q�[�����ĉ�������H
>>170
�Ƃ������Ђ��������Ă���A���̒��d���Q�[����������Ȃ����Ƃ�
�C�Â������Ȃ����ǂȁB
�p�b�P�[�W����ēX���̔�����Ă邾����PC�Q�[������Ȃ���
�Ƃ������Ђ��������Ă���A���̒��d���Q�[����������Ȃ����Ƃ�
�C�Â������Ȃ����ǂȁB
�p�b�P�[�W����ēX���̔�����Ă邾����PC�Q�[������Ȃ���
����er���Ăق�ƃQ�[���I�^�������
������������PC���p�X�^�C����I��������̃X�^���_�[�h���Ǝv�����������B
�Œ�60fps����Ȃ���N�Y�A�݂����Ȏv�z�̐l�������ˁB
�A�N�V�����Q�[������Ȃ����ɂ܂ŁB
�A�N�V�����Q�[������Ȃ����ɂ܂ŁB
>>177
�Q�[�����邽�߂Ɏ��삷����Đl���������炩�ȁH�m���ɑ����Ǝv���B
�Q�[�����邽�߂Ɏ��삷����Đl���������炩�ȁH�m���ɑ����Ǝv���B
�Q�[���@�ɕ�����悤�ȃX�y�b�N��PC�Q�[��V�т����͂Ȃ�
�Ȃ�ł�����ł��������������������Ă���͂��q����܂܂łɂ��Ƃ��܂��傤�I
>>181
�܂��A�Q�[�}�[���Q�[���@�ɗ���邾�낤����A���N�͒��r���[�ȃQ�[���p�f�X�NPC�͗������ނƎv����
�܂��A�Q�[�}�[���Q�[���@�ɗ���邾�낤����A���N�͒��r���[�ȃQ�[���p�f�X�NPC�͗������ނƎv����
184 �FSocket774�F2013/12/19(��) 20:40:56.49 ID:K7NVi+OK
APU�Q�[�}�[��FX��Radeon���z�`����������
�N������|��ł����l����H
�����Ă邱�Ƃ͕����邪�A���̕����łȂ�������������̂����s��
>>184
�Ȃɂ�OK����{�P�I
�Ȃɂ�OK����{�P�I
�N������|��ł����l����H
>>177
���ł�����ŃQ�[���ƌ�������A���̎��_�ň�ԏd���Q�[���̎��������
���ł�����ŃQ�[���ƌ�������A���̎��_�ň�ԏd���Q�[���̎��������
�܂菫�����H
������Řb��ɏオ��̂���FF�x���`�Ƃ��A�����O�̓X�J�C�����A����BF4
�����̓Q�[���Ȃ��Ȃ����ǁA�b��ɂȂ��Ă邩�炿����Ƃ���Ă݂邩���Ċ�������
�~�[�n�[������
�����̓Q�[���Ȃ��Ȃ����ǁA�b��ɂȂ��Ă邩�炿����Ƃ���Ă݂邩���Ċ�������
�~�[�n�[������
�P���ɂ���炪�����قƂ�ǂ̃Q�[���Ŗ��Ȃ��������Ă����ł���
�K�v�X�y�b�N�J�c�J�c�œ������ǂ����r�N�r�N���Ȃ���Q�[�������̂Ȃ�������
�K�v�X�y�b�N�J�c�J�c�œ������ǂ����r�N�r�N���Ȃ���Q�[�������̂Ȃ�������
>>192
�����ł��Ȃ��̂��Q�[���Ƃ������̂̕|���Ƃ���
9c����̂Ȃ�ē����͖��Ȃ������̂ɍ��̊����ƋN������܂܂Ȃ�Ȃ������肷����̂�����
Wot�ō��ݒ�Ȃ͂��̃O���t�B�b�N��BF4�Ə����o�������Ȓ��d��
���Ƃ�������PSO2�Ƃ����̂������Llano�̒������x���ł��ō��ݒ�ŊT�˃v���C�A�u���Ƃ�
�����ł��Ȃ��̂��Q�[���Ƃ������̂̕|���Ƃ���
9c����̂Ȃ�ē����͖��Ȃ������̂ɍ��̊����ƋN������܂܂Ȃ�Ȃ������肷����̂�����
Wot�ō��ݒ�Ȃ͂��̃O���t�B�b�N��BF4�Ə����o�������Ȓ��d��
���Ƃ�������PSO2�Ƃ����̂������Llano�̒������x���ł��ō��ݒ�ŊT�˃v���C�A�u���Ƃ�
>>193
�����P���ɊY���Q�[����DirectX�̃o�[�W������GPU���n�[�h�E�F�A�őΉ����Ă��邩�A�\�t�g�E�F�A�ŃG�~�����[�g���Ă��邩�̈Ⴂ����H
�����P���ɊY���Q�[����DirectX�̃o�[�W������GPU���n�[�h�E�F�A�őΉ����Ă��邩�A�\�t�g�E�F�A�ŃG�~�����[�g���Ă��邩�̈Ⴂ����H
BF4�݂����ȕ��Q�[�͂ǂ��ł�������
G-sync�̌��ʂ��[���I�ɑ̌��ł���y�[�W
http://www.testufo.com/#demo=tearing&foreground=00C000&test=stutter&background=000000&max=12&pps=720
http://www.blurbusters.com/gsync/preview/
http://www.testufo.com/#demo=tearing&foreground=00C000&test=stutter&background=000000&max=12&pps=720
http://www.blurbusters.com/gsync/preview/
�f�B�X�v���C�����ւ��K�{��G-Sync�Ƃ��A�}�W�ǂ��ł�������
�D�ʐ�����ł��nVidia�M�҂����ł���
�D�ʐ�����ł��nVidia�M�҂����ł���
�z���f�I����Tearing & Bad Stuttering���\���Ȃ��������
�Ă��劽�}��fraps���\��
�Ă��劽�}��fraps���\��
���A������������Ă܂���ł�
���l�ł��Ȃ�
���ΐ��育��J�l�B
���l�ł��Ȃ�
���ΐ��育��J�l�B
201 �FSocket774�F2013/12/20(��) 10:43:58.40 ID:Z2iTt8sV
(����I���j
��������nv�Ɏw�E����Ȃ���������炩���������낤��
G-Sync�̂��Ƃ�fraps���\���Č���Ȃ��̂�
�s���̂������Ƃ����劽�}
�s���̂������Ƃ����劽�}
G-Sync����60Hz�Ƃ��̃��[�G���h���f������Ȃ��ƌ��ʖ�����
G-sync�͌����������̃t���[�����[�g��x���`�X�R�A���オ��킯����Ȃ������
�Ă��A�hG-Sync�̂��Ƃ�fraps���\���Č���Ȃ��̂ȁh�Ȃ�Č����Ă���Ă��Ƃ�
�ǂ��������̂Ȃ̂��������ĂȂ��낤��
�Ă��A�hG-Sync�̂��Ƃ�fraps���\���Č���Ȃ��̂ȁh�Ȃ�Č����Ă���Ă��Ƃ�
�ǂ��������̂Ȃ̂��������ĂȂ��낤��
�n�C�G���h�ł�60fps�邭�炢���グ����Q�[��������ł����邵��
�܂�EIZO�̃��j�^�ɐς܂ꂽ��l���Ă���
>>205
V-sync�ɒǂ����Ȃ�������ē����������Ƀr�f�I�J�[�h�ɍ��킹��̂�
V-sync�ɒǂ����Ȃ�������ē����������Ƀr�f�I�J�[�h�ɍ��킹��̂�
G-Sync�݂����Ȏd�g�݂́A�t�������y���n�߂����ɋƊE�̕W���Ƃ��č��ꂽ��悩���������ˁB
�������Ђ��撣���Ă��x���Ǝv���B
�������Ђ��撣���Ă��x���Ǝv���B
�܂��Q�[�~���O�m�[�g�ł͍̗p����邩������Ȃ�
���z�͍D�������ǁA�n�[�h�E�F�A�Ƃ��������O��Ȃ̂̓}�C�i�X����Ȃ�
�Q�[���ȊO������ɗ����Ȃ�����ȁcintel�������Ȃ�܂�����nv1�Ђ̃V�F�A�@���ł͌��������낤
����Ƀf�B�X�v���C���̕`�ʃG���W���܂�SoC�Ɋ܂߂Ĉ͂����݂������Ă�����
������ɂ���t���[�����[�g������Ȃ��ꍇ�̍��{�I�ȉ����ł͂Ȃ�����
�Q�[���̂��߂ɋK�i�����悤�Ƃ����Ƃ���ő��Ђ��ǂ��܂Ő^�ʖڂɕt�������̂�
����Ƀf�B�X�v���C���̕`�ʃG���W���܂�SoC�Ɋ܂߂Ĉ͂����݂������Ă�����
������ɂ���t���[�����[�g������Ȃ��ꍇ�̍��{�I�ȉ����ł͂Ȃ�����
�Q�[���̂��߂ɋK�i�����悤�Ƃ����Ƃ���ő��Ђ��ǂ��܂Ő^�ʖڂɕt�������̂�
�L���b
�ܖډ�
�܂��z���f�I���̓J�N�J�N���׃t���[���Ŋy����łĂ�
G-Sync�Ή��f�B�X�v���C���o���Ƃ���Radeon���Ή����Ă����Ⴆ�[��B
�E���g������C�g�j���O�v���Y�}����킩��悤�ɁE�E��
�S�~�V���N�[����
CS�@���e�ƃ}���g���ő叟���I���ꂩ��̃Q�[������Ȃ烉�f�I�������ׂ�
�Ή��n�[�h��������G-sync�̓_��
�Ή��n�[�h��������G-sync�̓_��
�Ȃ惉�C�g�j���O�v���Y�}����
G-Sync��3D Vision�Ƃ��Ɠ���������ނƎv��
�n�[�h����̂����P�̂ł͐��藧���Ȃ��A�]�ސl��������Ƃ��������_��
�n�[�h����̂����P�̂ł͐��藧���Ȃ��A�]�ސl��������Ƃ��������_��
>>220
���������m�̋Z����ˁ[�́H
���������m�̋Z����ˁ[�́H
���[�Ǝ��q���̂��ꂾ�����A������
�Z���A�g�~�b�N�T���_�[�{���g
INTEL�������炯��2014�N�AAMD�͎���PC�߂����ይ���H��
AMD aims to hike global DIY market share; updates 2014 roadmap
http://www.digitimes.com/news/a20131218PD214.html
AMD aims to hike global DIY market share; updates 2014 roadmap
http://www.digitimes.com/news/a20131218PD214.html
(����)
>>225
>In 2015, AMD will release Carrizo and Nolan APU series to replace Kaveri and Beema, respectively, both adopting Heterogeneous System Architecture (HSA) designs.
>The Carrizo will support Socket FM2 and feature AMD's Excavator CPU architecture and pair with A88x/A78 chipsets, the sources added.
����2015�N���傢�Ɋ��ҏo���������ȁB
>In 2015, AMD will release Carrizo and Nolan APU series to replace Kaveri and Beema, respectively, both adopting Heterogeneous System Architecture (HSA) designs.
>The Carrizo will support Socket FM2 and feature AMD's Excavator CPU architecture and pair with A88x/A78 chipsets, the sources added.
����2015�N���傢�Ɋ��ҏo���������ȁB
�W���K�[(��)����8�R�A�ł�Snapdragon800��Tegra4��萫�\�Ⴂ�����ɁB
AMD�͕��ᐫ�\CPU����₪����
AMD�͕��ᐫ�\CPU����₪����
�͂������ł���
����o���Ă����܂����炨�厖�Ɂ`
����o���Ă����܂����炨�厖�Ɂ`
230 �FSocket774�F2013/12/20(��) 16:52:36.48 ID:K7cInM0F
2015�N�ɂȂ��Ă�PS4��APU������̂͏o�Ȃ��̂ˁc
PhysX��Mantle�̔�r�����������ƌ���ꂽ�玟��G-SYNC�����o������
�Ȃ�ł���r���ď���������ȃQ�t�H�~��
�Ȃ�ł���r���ď���������ȃQ�t�H�~��
�܂��A�Q�t�H�����炩������Ȃ�
mantle��
PhysX��Mantle���r���邱�Ǝ��̂�������
�����X�^�[���[���h�ƍ������l�̖`�������r����悤�Ȃ���A�f���ĈႤ���̂�
�����X�^�[���[���h�ƍ������l�̖`�������r����悤�Ȃ���A�f���ĈႤ���̂�
�N���g��Ȃ�
H.265�֘A�ŃO�O���Ă���2014�N�̑���������OpenCL�Ή����邩��
AMD��HSA�ʼn��b�����A�Ƃ����悤�ȓ��e�̃T�C�g���������A
Beema�Ɋւ��Ă�HSA�Ή��ł��������H
�Ή��Ə�����Ă�T�C�g�Ɣ�Ή��Ə�����Ă�T�C�g�������Ă悭�킩��Ȃ��B
�܂������d�͂ŃG���R�̓i���Z���X�Ȃ̂�������Ȃ����B
AMD��HSA�ʼn��b�����A�Ƃ����悤�ȓ��e�̃T�C�g���������A
Beema�Ɋւ��Ă�HSA�Ή��ł��������H
�Ή��Ə�����Ă�T�C�g�Ɣ�Ή��Ə�����Ă�T�C�g�������Ă悭�킩��Ȃ��B
�܂������d�͂ŃG���R�̓i���Z���X�Ȃ̂�������Ȃ����B
SPECviewperf12��Quadro��Firepro�ɂ��炢�������Ă��
http://www.pcper.com/news/General-Tech/Some-Strong-AMD-FirePro-Results-SPECviewperf-12
�e�Ђ�openCL�̑Ή����i��ł�݂��������A���̊�������Firepro�̓W�J�������ɍs����������
http://www.fireprographics.com/ws/tech/opencl/index.asp
http://www.fortmilltimes.com/2013/12/18/3172814/spec-releases-all-new-version.html
http://www.pcper.com/news/General-Tech/Some-Strong-AMD-FirePro-Results-SPECviewperf-12
�e�Ђ�openCL�̑Ή����i��ł�݂��������A���̊�������Firepro�̓W�J�������ɍs����������
http://www.fireprographics.com/ws/tech/opencl/index.asp
http://www.fortmilltimes.com/2013/12/18/3172814/spec-releases-all-new-version.html
�ނ肗
���������Ȃ炻�ꂱ���T�N�ȏ�O����Fire�̕����ǂ������̂ɁA����̔̔����ʂȂ�B
���\�������ᔄ��Ȃ����Ă��Ƃ��܂��������ĂȂ��Ƃ����猵�����ˁB
���\�������ᔄ��Ȃ����Ă��Ƃ��܂��������ĂȂ��Ƃ����猵�����ˁB
http://cpplover.blogspot.jp/2013/07/amdlibreofficelibreoffice-41.html
Blender��GPGPU���g�����R�̂���\�t�g�E�F�A�ł���BBlender��GPGPU���g����Cycles�����_���[�́A
AMD��GPU�ł͓����Ȃ��B
�����Blender�̂����ł͂Ȃ��AAMD�̕s���R�ȃh���C�o�[��OpenCL�������ɂ߂ĕn��Ȃ��߂ł���B
AMD�̕s���R�ȃh���C�o�[��OpenCL�����͋K�i�ɑΉ����Ă���Ɛ�`���Ă��邪�AAMD�̃R���p�C���[�́A
������Ƃł��傫�ȁA�܂茻���I�ȃR�[�h���R���p�C���������邾���ŁA�������s���̃G���[�������ăN���b�V�����邻�����B
���s�ȑO�̖��ł���B
nVidia�̕s���R��CUDA�́A�l�I�ɂƂĂ��c�O�Ȃ��ƂɁA�ƂĂ��g���₷�������ŁA�c�O�Ȃ��ƂɍL���g���Ă���B
�܂�nVidia�̕s���R�ȃh���C�o�[��OpenCL�������AAMD�̕s���R�ȃh���C�o�[���܂Ƃ����������B
�Ƃ͂����A����ł�OpenCL�͂ǂ������������n���������B
���ǁAnVidia��CUDA�̂悤��nVidia��GPU�ł��������Ȃ��Ǝ��̃v���v���C�G�^���Ȏ������g���Ă���B
�Ⴆ�ABlender��Cycles�����_���[���A�f�t�H���g�̎�����CUDA���B
OpenCL����������AnVidia�̕s���R�ȃh���C�o�[���Ȃ�A�ꉞ�͓����������B
�����AOpenCL�̎����͂ǂ������n�Ȃ̂ŁA����CUDA�̂悤�ȓƎ��X�^�b�N�Ɉ͂����܂��B
���������Ƃ��B
Blender��GPGPU���g�����R�̂���\�t�g�E�F�A�ł���BBlender��GPGPU���g����Cycles�����_���[�́A
AMD��GPU�ł͓����Ȃ��B
�����Blender�̂����ł͂Ȃ��AAMD�̕s���R�ȃh���C�o�[��OpenCL�������ɂ߂ĕn��Ȃ��߂ł���B
AMD�̕s���R�ȃh���C�o�[��OpenCL�����͋K�i�ɑΉ����Ă���Ɛ�`���Ă��邪�AAMD�̃R���p�C���[�́A
������Ƃł��傫�ȁA�܂茻���I�ȃR�[�h���R���p�C���������邾���ŁA�������s���̃G���[�������ăN���b�V�����邻�����B
���s�ȑO�̖��ł���B
nVidia�̕s���R��CUDA�́A�l�I�ɂƂĂ��c�O�Ȃ��ƂɁA�ƂĂ��g���₷�������ŁA�c�O�Ȃ��ƂɍL���g���Ă���B
�܂�nVidia�̕s���R�ȃh���C�o�[��OpenCL�������AAMD�̕s���R�ȃh���C�o�[���܂Ƃ����������B
�Ƃ͂����A����ł�OpenCL�͂ǂ������������n���������B
���ǁAnVidia��CUDA�̂悤��nVidia��GPU�ł��������Ȃ��Ǝ��̃v���v���C�G�^���Ȏ������g���Ă���B
�Ⴆ�ABlender��Cycles�����_���[���A�f�t�H���g�̎�����CUDA���B
OpenCL����������AnVidia�̕s���R�ȃh���C�o�[���Ȃ�A�ꉞ�͓����������B
�����AOpenCL�̎����͂ǂ������n�Ȃ̂ŁA����CUDA�̂悤�ȓƎ��X�^�b�N�Ɉ͂����܂��B
���������Ƃ��B
>>241
Blender�̘b������Ă��Ȃ��BSPECviewperf12�ɂ͊܂܂�ĂȂ���
�܂��c�q�����������Ȃ炻���Ȃ�Ȃ���
�E catia-04 - basiert auf CATIA V6 R2012 von DassaultSystemes
�E creo-01 - basiert auf Creo2 von PTC
�E Energy-01 - Geopysikalische Simulation
�E Maya-04 - basiert auf Maya 2013 von Autodesk
�E Medical-01 - Medizinische Simulation
�E Showcase-01 - basiert auf Showcase 2013 von Autodesk
�E SNX-02 - basiert auf NX 8.0 von Siemens PLM
�E SW-03 - basiert auf SolidWorks 2013 SP1 von DassaultSystemes
Blender�̘b������Ă��Ȃ��BSPECviewperf12�ɂ͊܂܂�ĂȂ���
�܂��c�q�����������Ȃ炻���Ȃ�Ȃ���
�E catia-04 - basiert auf CATIA V6 R2012 von DassaultSystemes
�E creo-01 - basiert auf Creo2 von PTC
�E Energy-01 - Geopysikalische Simulation
�E Maya-04 - basiert auf Maya 2013 von Autodesk
�E Medical-01 - Medizinische Simulation
�E Showcase-01 - basiert auf Showcase 2013 von Autodesk
�E SNX-02 - basiert auf NX 8.0 von Siemens PLM
�E SW-03 - basiert auf SolidWorks 2013 SP1 von DassaultSystemes
��s�ǂ��납��P��ő��l����葱���Ă��l���ˑR�����̃R�s�y��\���
�������̐l�������͏����邾���̒m�����Ȃ��Ȃ����Ĉ�ۂ�^���邩��
���Ȃ��ق���������B
�������̐l�������͏����邾���̒m�����Ȃ��Ȃ����Ĉ�ۂ�^���邩��
���Ȃ��ق���������B
>>240
���\�̗ǂ�FX������Ȃ��̂Ɠ�������
���\�̗ǂ�FX������Ȃ��̂Ɠ�������
Blender��Cycles��nVidia�J�[�h�ł������Ȃ����������w
>>244
����Ȃɓd�͍����邩�H
����Ȃɓd�͍����邩�H
>>238
���x�o��S�~����MacPro��GPU�̓f���A��FirePro���̗p���ꂽ����
���x�o��S�~����MacPro��GPU�̓f���A��FirePro���̗p���ꂽ����
�o�[�W�����A�b�v���ꂽ�t�@�C�i���J�b�g�v�����f���A��GPU�Ή��ɂȂ����Ə����Ă�����
��̓I�ɂǂ��Ȃ�ƌ����Ă��m���
��̓I�ɂǂ��Ȃ�ƌ����Ă��m���
FirePro�͐VMac Pro�ňȑO�Ƃ͔�r�ɂȂ�Ȃ��قǂ̐����o��邩��A
OpenCL��Mac�����őΉ����i�ނ��낤�ˁB
OpenCL��Mac�����őΉ����i�ނ��낤�ˁB
����FX��APU���Đ��\���ǂꂭ�炢����́H
�{
���܂����Z�C����
APU�̕������Ȃ́H
8�R�AFX����4�R�A�Ƃ��ς���ĕς���GPU���ꂽ�̂�APU
�����ł͂܂��܂������ˁB
Kaveri��6xxx�ɋ߂����\�@��������Ȃ��́H
�����ƌ����������ƃp�C����5�R�A���炢�A����Ȃ̖�������
>>254
����AFX��trinity��rich��CPU�͓���������A6/8�R�AFX�Ɣ�ׂ��猩��肷��B
����AFX��trinity��rich��CPU�͓���������A6/8�R�AFX�Ɣ�ׂ��猩��肷��B
PS4��APU���ǂ��ɂ������ɂ�����WindowsPC�ɏo���Ȃ����̂��c
261 �FSocket774�F2013/12/20(��) 22:33:08.28 ID:/wBsShhH
Llano�o��̋łɂ�
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ� �� new�I
�������߂Ȍ���
http://www.cpubenchmark.net/market_share.html
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ� �� new�I
�������߂Ȍ���
http://www.cpubenchmark.net/market_share.html
�Ȃ�قǁA�T���N�X�ł��B
���`�����APU�ȊO���Ȃ������Ă邵�ȁ`
intel�͂Ȃ�ׂ��Ȃ甃�������Ȃ���
�����AAPU��FX���Ԃ������Ă���Ȃ����ȁ`�Ǝv������
���`�����APU�ȊO���Ȃ������Ă邵�ȁ`
intel�͂Ȃ�ׂ��Ȃ甃�������Ȃ���
�����AAPU��FX���Ԃ������Ă���Ȃ����ȁ`�Ǝv������
�@������HSA��Mantle�Ɋ��҂Ƃ������ƂŁB�����̏ꍇ���A�V��ɏd��
�p�r�̓G���R�ƃQ�[���ʂ����B
�p�r�̓G���R�ƃQ�[���ʂ����B
�u������ς�����̂�AMD�����v�\�\�A�L�o��Radeon R�V���[�Y�X���C�x���g
http://www.itmedia.co.jp/pcuser/articles/1312/20/news153.html
http://www.itmedia.co.jp/pcuser/articles/1312/20/news153.html
>>262
�����炻��f�}
�����炻��f�}
>>260
�v����ȁ[
�v����ȁ[
267 �FSocket774�F2013/12/20(��) 23:56:07.15 ID:PXJAo8/J
���ꂪWindows���c�̑��ӂł��邩
���ɂ���
Intel��HaswellReflesh�Ŗʔ��݂��Ȃ�����
Kaveri�ɂ͋�������
���߂�Steamroller��IPC������Llano��K10�Ȃ݂ɒǂ�����
Intel��HaswellReflesh�Ŗʔ��݂��Ȃ�����
Kaveri�ɂ͋�������
���߂�Steamroller��IPC������Llano��K10�Ȃ݂ɒǂ�����
���̖��ɗ��̂��T�b�p���s���ȃV���O���X���b�h�x���`��IPC�Ƃ��C�ɂ��Ă����傤���Ȃ�
Llano����Trinity�Ɍ��������猋�\���K�ɂȂ�������AWin7�ȍ~�̍ŋ߂̃\�t�g���g���Ȃ�A
IPC�Ƃ��V���O���X���b�h�ȂC�ɂ��邾������
Llano����Trinity�Ɍ��������猋�\���K�ɂȂ�������AWin7�ȍ~�̍ŋ߂̃\�t�g���g���Ȃ�A
IPC�Ƃ��V���O���X���b�h�ȂC�ɂ��邾������
IPC���グ�悤�Ƃ��Ă�AMD�Ɍ����Ă���Ă�������
�X���b�h����������I�[�o�[�w�b�h�������邩��ȁ[
�@GPU���܂߂�APU�S�̂̏����\�͌���̈�Ƃ��āACPU����IPC����
�ɂ��Ӗ����������Ƃ͂Ȃ��ł���B���́A���̂��߂ɔ�₵���g�����W�X�^
�Ƃ̍������������ǁc�c�B
�ɂ��Ӗ����������Ƃ͂Ȃ��ł���B���́A���̂��߂ɔ�₵���g�����W�X�^
�Ƃ̍������������ǁc�c�B
>>272
FPU��iGPU�ɃI�t���[�h����E�E�E!
FPU��iGPU�ɃI�t���[�h����E�E�E!
>>273
�@HSA�͂܂��ɂ����������Ƃł���BCPU��SIMD���L��iGPU�ւ̃I�t���[�h��
SIMD�̏[�U���������邱�Ƃ����z���Ă̑I�����낤���B
�@HSA�͂܂��ɂ����������Ƃł���BCPU��SIMD���L��iGPU�ւ̃I�t���[�h��
SIMD�̏[�U���������邱�Ƃ����z���Ă̑I�����낤���B
Bulldozer Module�͐����N���X�^���R�A�ƌ��������Ă邩�番����ɂ��������ŁA
���Ƃ��Ƃ͐��������������Ƃ����̂��R���Z�v�g�̂͂���
�Ƃ������A�{�C��SIMD�n�̃^�X�N��GPU�ɑS�������C�������̂Ȃ�
�c��͕̂��̌����Â炢�X�J���n�ɂȂ�
�ł���ނ���IPC��������͂����Ȃ��Ƃ���
���Ƃ��Ƃ͐��������������Ƃ����̂��R���Z�v�g�̂͂���
�Ƃ������A�{�C��SIMD�n�̃^�X�N��GPU�ɑS�������C�������̂Ȃ�
�c��͕̂��̌����Â炢�X�J���n�ɂȂ�
�ł���ނ���IPC��������͂����Ȃ��Ƃ���
>>275
�@����̓g�����W�X�^���Ƃ̃o�����X�ł���BIPC�������Ă��N���b�N�Ńt�H���[
����Ηǂ��Ƃ������z���v���Z�X�̕s�o���Ƃ���ɂ��X�P�W���[���x���
����Ĕj�]���������ŁB
�@����̓g�����W�X�^���Ƃ̃o�����X�ł���BIPC�������Ă��N���b�N�Ńt�H���[
����Ηǂ��Ƃ������z���v���Z�X�̕s�o���Ƃ���ɂ��X�P�W���[���x���
����Ĕj�]���������ŁB
Bulldozer��IPC�͓d�͌����ƃg�����W�X�^�����ɗD���X�C�[�g�X�|�b�g��_�����߂ɒ��������킯����
�����v���Z�X���S�~���������߂Ɏ��s������
�����v���Z�X���S�~���������߂Ɏ��s������
>>276
�V���O���X���b�h���\��������̂͋K�莖���������킯�ŁA
�u���Z�X�̂����ɂ���͈̂��ʊW���t
�N���b�N���グ�鎞�_�œd�͂����萫�\�͈�������̂�����������b
�V���O���X���b�h���\��������̂͋K�莖���������킯�ŁA
�u���Z�X�̂����ɂ���͈̂��ʊW���t
�N���b�N���グ�鎞�_�œd�͂����萫�\�͈�������̂�����������b
�t�c�[�ɍl����IPC�����ăN���b�N�グ���d�͌����ƃg�����W�X�^�������グ���邾��B�����v���Z�X���܂Ƃ��Ȃ��
>>278
�@�����A�g�����W�X�^������ăR�A�𑝂₵����iGPU�ɉ��肷�邱�Ƃ�
�����I�ȏ����\�͂����߂�Ƃ������肪�����Ă̒���I�Ȏ��g�݂�����
�킯�����A���s����̉ߒ��ł͂����H�@�x�X�g�������Ƃ͌���Ȃ��B
�@�v���Z�X�̐i�����v�Z�ɓ���Ă��āA�������������������Ƃ���������
���낤�Ǝv�����ǁA���ۂ�Steamroller�ł̓v���Z�X���ς������Ńf�R�[�_
���L���~�߂Ă���킯������A�܂肻���������ƂȂ�ł���B
�@�����A�g�����W�X�^������ăR�A�𑝂₵����iGPU�ɉ��肷�邱�Ƃ�
�����I�ȏ����\�͂����߂�Ƃ������肪�����Ă̒���I�Ȏ��g�݂�����
�킯�����A���s����̉ߒ��ł͂����H�@�x�X�g�������Ƃ͌���Ȃ��B
�@�v���Z�X�̐i�����v�Z�ɓ���Ă��āA�������������������Ƃ���������
���낤�Ǝv�����ǁA���ۂ�Steamroller�ł̓v���Z�X���ς������Ńf�R�[�_
���L���~�߂Ă���킯������A�܂肻���������ƂȂ�ł���B
>>279
����͂ǂ��̐��E�̃t�c�[���낤���H
�N���b�N�グ��ׂɃp�C�v���C���i���𑝂₹��
�v�Z�ɒ��ڊW�̖������b�`��������ׁA�d�͌����͈�������
����͂ǂ��̐��E�̃t�c�[���낤���H
�N���b�N�グ��ׂɃp�C�v���C���i���𑝂₹��
�v�Z�ɒ��ڊW�̖������b�`��������ׁA�d�͌����͈�������
�m����>>279�̓t�c�[�ł͂Ȃ����A������������I�������̂�AMD���낤�B
�t�ɁA���������I�������Ƃ�Ȃ������Ƃ�����AMD�͕���\�����X�P�W���[����
����ȊJ���R�X�g����������Intel�Ƌ������ɂȂ��Ă����킯�ŁA���Ǖ����Ă����B
�t�ɁA���������I�������Ƃ�Ȃ������Ƃ�����AMD�͕���\�����X�P�W���[����
����ȊJ���R�X�g����������Intel�Ƌ������ɂȂ��Ă����킯�ŁA���Ǖ����Ă����B
fab��藣�������ǂǂ������܂��s���Ă��Ȃ�
���C���e�������v���Z�X�����g���Ȃ�
�����Ȃ��g�����W�X�^�Ő키�����Ȃ�
�������g�����W�X�^������Nj�
��IPC�̒Ⴂ�R�A�𑽐����ׂ�+SIMD��GPU�ɗ���
��APU����
���ł�����ς萫�\������Ȃ������@
���N���b�N���グ�邵���Ȃ�
�����a�A�M��APU�o��
�ɂ߂ăV���v������Ȃ���
���C���e�������v���Z�X�����g���Ȃ�
�����Ȃ��g�����W�X�^�Ő키�����Ȃ�
�������g�����W�X�^������Nj�
��IPC�̒Ⴂ�R�A�𑽐����ׂ�+SIMD��GPU�ɗ���
��APU����
���ł�����ς萫�\������Ȃ������@
���N���b�N���グ�邵���Ȃ�
�����a�A�M��APU�o��
�ɂ߂ăV���v������Ȃ���
�C���e���̓C���e���Ŏg����g�����W�X�^�͑��������ǔM���x���オ��߂��邩��L���b�V�����葝�₷�����Ȃ��āA������h���Ȃ�������GPU�傫������CODEC���ڂ��܂������Ă̂������B
�@����ł��Ax264�Ƃ�������������d�͂ɂ����ڂ��Ԃ�����܂ŋ�
�������m�ł��Ȃ��悤�Ɍ����邯�ǁB���肪���邱�Ƃ�����A�X�P�W���[����
�x��ƃv���Z�X�̕s�o��������ς�ˁc�c�B
�@APU�Ɋւ��ẮAhUMA���Ή��̒i�K�ł�CPU�{dGPU�̗ł�������
�킯�ŁA�������̈������d���Ȃ����ȁA�Ƃ����C�͂���B
�������m�ł��Ȃ��悤�Ɍ����邯�ǁB���肪���邱�Ƃ�����A�X�P�W���[����
�x��ƃv���Z�X�̕s�o��������ς�ˁc�c�B
�@APU�Ɋւ��ẮAhUMA���Ή��̒i�K�ł�CPU�{dGPU�̗ł�������
�킯�ŁA�������̈������d���Ȃ����ȁA�Ƃ����C�͂���B
>>285
�Ƃ���������d�͂����M�ɂȂ����Ă���ŗ\��قǃN���b�N�L�тȂ��̂�����
���̕ӂ͓������낤�B
�v���Z�X�������̂��v�������̂��͒m���B
�Ƃ���������d�͂����M�ɂȂ����Ă���ŗ\��قǃN���b�N�L�тȂ��̂�����
���̕ӂ͓������낤�B
�v���Z�X�������̂��v�������̂��͒m���B
�v�������Ɍ��܂��Ă邾��B
IPC�����ăN���b�N���Œ��K���킷�ɂ��Ă����ʓI�Ɍ���͑����Ă����܂��ǂ���H
APU��iGPU���\�Ɋւ����Ꮗ���ɐL�ё����Ă邵�A�ׂ��ȕ��������P���i��ł邵
����Kaveri/SteamRollerd�ł͂ǂ���������Ԃ�A�S���ʂŌ�����ʂ������������܂��y���݂���
Intel���ǂ��������������ɒP���ɐ��\�L�������܂�ʔ����Ȃ������ɐi��ł��̂ɑ���
�`�������W���[��AMD�͎���er�S���y���܂��Ă����
APU��iGPU���\�Ɋւ����Ꮗ���ɐL�ё����Ă邵�A�ׂ��ȕ��������P���i��ł邵
����Kaveri/SteamRollerd�ł͂ǂ���������Ԃ�A�S���ʂŌ�����ʂ������������܂��y���݂���
Intel���ǂ��������������ɒP���ɐ��\�L�������܂�ʔ����Ȃ������ɐi��ł��̂ɑ���
�`�������W���[��AMD�͎���er�S���y���܂��Ă����
>>288
IPC�����ăN���b�N���Œ��K�����킹��̂ǂ͂Ȃ��B�R�A���Œ��K�����킹��small many core���{���̌`���BPS4�ł͂��ꂪ�������Ă���B
�܂萴���h�ł͏��ĂȂ��̂�SM�̏�����ڎw�����̂����A���͂�����Ȃ������̂ŋq�P�����������Ă��܂��A�d���Ȃ�����h�[�s���O���ċq�̉�]���グ�ė����ł���B
IPC�����ăN���b�N���Œ��K�����킹��̂ǂ͂Ȃ��B�R�A���Œ��K�����킹��small many core���{���̌`���BPS4�ł͂��ꂪ�������Ă���B
�܂萴���h�ł͏��ĂȂ��̂�SM�̏�����ڎw�����̂����A���͂�����Ȃ������̂ŋq�P�����������Ă��܂��A�d���Ȃ�����h�[�s���O���ċq�̉�]���グ�ė����ł���B
>>289
���~�͔��z������
���~�͔��z������
PS4�ł͂��ꂪ�����H
PS4��CPU�p���[�͒Ⴂ�܂܂���Ȃ����B
�N��CPU�p���[�J�߂Ė������H
�^����Ă�̂�APU�ɂ��Ă͋��͂�GPU�p���[�ƁAGDDR5���̗p�����_�ł�����
CPU�͂��������d�͒�_�C�T�C�Y�ł������B�ł���R�A���Q�Z�b�g���ׂ�������
PS4��CPU�p���[�͒Ⴂ�܂܂���Ȃ����B
�N��CPU�p���[�J�߂Ė������H
�^����Ă�̂�APU�ɂ��Ă͋��͂�GPU�p���[�ƁAGDDR5���̗p�����_�ł�����
CPU�͂��������d�͒�_�C�T�C�Y�ł������B�ł���R�A���Q�Z�b�g���ׂ�������
>>289
�����I�Ȑ�������AMD����������Ă��邩�Ƃ����̂́A���ۂ̂Ƃ��납�Ȃ�Y���Ă���̂ŁA
Jaguar�����������X���[�����j�[�R�A�̂悤�ɍ̗p�ł���PS4�͗�O�Ȃ̂��Ǝv��
�Q�[���R���\�[���ł���Α����������ł���
�����I�Ȑ�������AMD����������Ă��邩�Ƃ����̂́A���ۂ̂Ƃ��납�Ȃ�Y���Ă���̂ŁA
Jaguar�����������X���[�����j�[�R�A�̂悤�ɍ̗p�ł���PS4�͗�O�Ȃ̂��Ǝv��
�Q�[���R���\�[���ł���Α����������ł���
�����@�ł��ꂵ���c��Ȃ��������������ǂ�
http://pc.watch.impress.co.jp/docs/topic/review/20131221_628428.html
Atom�̐��\�͓��N���b�N��Bulldozer���݂�
Atom�̐��\�͓��N���b�N��Bulldozer���݂�
>>294
atom�����Ȃǂ�Ȃ��Ȃ�
atom�����Ȃǂ�Ȃ��Ȃ�
>>294
�O�X���H��Sunspider��r���Ă����ǁA
�Ó��ȃX�R�A�Ƃ������AARMCortexA15��Pile��8-9���͂���̂�ˁB
Jaguar�����N���X�����ǁA���o�C�����ƃN���b�N������قǒႢ�̂���_�B
Tegra��1.7-1.9GHz�AAtom��1.8-2.4GHz�Ȃ̂ɁA�e�}�V��1-1.4GHz�B
�O�X���H��Sunspider��r���Ă����ǁA
�Ó��ȃX�R�A�Ƃ������AARMCortexA15��Pile��8-9���͂���̂�ˁB
Jaguar�����N���X�����ǁA���o�C�����ƃN���b�N������قǒႢ�̂���_�B
Tegra��1.7-1.9GHz�AAtom��1.8-2.4GHz�Ȃ̂ɁA�e�}�V��1-1.4GHz�B
>>286
�܂��v�v�z����������
�����Ď��ۂ̐v������
��������̖�������
�������̂�g�ݍ��킹�čs�����珇���Ɉ������̂��ł����������Ƃ������R�Ȃ��b��
�܂��v�v�z����������
�����Ď��ۂ̐v������
��������̖�������
�������̂�g�ݍ��킹�čs�����珇���Ɉ������̂��ł����������Ƃ������R�Ȃ��b��
http://tabkul.com/?p=47722
��̒���WPDang�ɂ��ƁA�wSurface Mini�x�͉�ʃT�C�Y8�C���`�ʼn𑜓x��
�t��HD�i1920��1080�j�^1080P�ŁAIntel Bay Trail�v���Z�b�T�𓋍ځB
��F��Kinect�i�L�l�N�g�j�̂悤�ȃW�F�X�`���[����ɑΉ����A
��ڐG�ɂ��R���g���[���@�\�𓋍ڂ���\��������Ƃ̂��ƁB
-----------
����H��
GPGPU�@��
��̒���WPDang�ɂ��ƁA�wSurface Mini�x�͉�ʃT�C�Y8�C���`�ʼn𑜓x��
�t��HD�i1920��1080�j�^1080P�ŁAIntel Bay Trail�v���Z�b�T�𓋍ځB
��F��Kinect�i�L�l�N�g�j�̂悤�ȃW�F�X�`���[����ɑΉ����A
��ڐG�ɂ��R���g���[���@�\�𓋍ڂ���\��������Ƃ̂��ƁB
-----------
����H��
GPGPU�@��
>>297
����d�͂ɑ傫�ȈႢ�����鐻�i��P���ɔ�r����̂��ǂ����ȁH
����d�͂��Ⴂ���i�́A�N���b�N���Ⴍ�Ă��R�A��Ηǂ������̂悤�ȋC������B
�ܘ_OC�Ƃ���������邯�ǁA�R�A�������������b�p�͗ǂ���Ȃ����ȁH
����d�͂ɑ傫�ȈႢ�����鐻�i��P���ɔ�r����̂��ǂ����ȁH
����d�͂��Ⴂ���i�́A�N���b�N���Ⴍ�Ă��R�A��Ηǂ������̂悤�ȋC������B
�ܘ_OC�Ƃ���������邯�ǁA�R�A�������������b�p�͗ǂ���Ȃ����ȁH
����Intel Bay Trail���x��gpu�ł����Ȃ��킯��
CPU�����Ȃ�gpgpu�Ȃ�Ă��������g��Ȃ��Ă�����
CPU�����Ȃ�gpgpu�Ȃ�Ă��������g��Ȃ��Ă�����
kaveri ���o�C���̓f�X�N�p���x��Ă��܂��̂�
�{�Ԃ̓��o�C���pkaveri������悤�ɂȂ��Ă��炾���A��������S�͂ł���Ă��炢�����Ƃ���
�f�X�N�pkaveri�Ȃ�ăW�T�J�[�ł�����AMD�}�j�A���炢������Ȃ����A���ꂶ�ᔄ��グ�Ɋ�^���Ȃ��킯��
�b�萫�͂���̂ŁA�����Ő�����C�Ȃ�Ė����낤����
�f�X�N�pkaveri�Ȃ�ăW�T�J�[�ł�����AMD�}�j�A���炢������Ȃ����A���ꂶ�ᔄ��グ�Ɋ�^���Ȃ��킯��
�b�萫�͂���̂ŁA�����Ő�����C�Ȃ�Ė����낤����
>>302
���̓R�X�g���A�L�l�N�g�̂悤�ȓ���ȕ���J�����Ȃ̂����ʂ̒P��J�����Ȃ̂�
APU�͓̂���ȃJ������K�v�Ƃ����lj��n�[�h�������_������Ȃ�
http://www.youtube.com/watch?v=7psqRc3OA2I
���̓R�X�g���A�L�l�N�g�̂悤�ȓ���ȕ���J�����Ȃ̂����ʂ̒P��J�����Ȃ̂�
APU�͓̂���ȃJ������K�v�Ƃ����lj��n�[�h�������_������Ȃ�
http://www.youtube.com/watch?v=7psqRc3OA2I
>>291
����ႠWindows�ŊY��APU���������A�ڍׂȎd�l�����J����Ė��������r�̂��悤���Ȃ���������B
�抸����Jaguar8�R�A��Steamroller4�R�A�̐��\�炵���̂ŁAKaveri���o���PS4��CPU���\�������ʂ�鎖�ɂȂ�B
�ł�PS4�̃N���b�N�������Ȃ̂��Ƃ��A���̏ꍇ�̏���d�͂͂Ƃ��AGDDR5�ɂ�鐫�\�ω������邩�牯���̈���o�Ȃ����ǂȁB
����ႠWindows�ŊY��APU���������A�ڍׂȎd�l�����J����Ė��������r�̂��悤���Ȃ���������B
�抸����Jaguar8�R�A��Steamroller4�R�A�̐��\�炵���̂ŁAKaveri���o���PS4��CPU���\�������ʂ�鎖�ɂȂ�B
�ł�PS4�̃N���b�N�������Ȃ̂��Ƃ��A���̏ꍇ�̏���d�͂͂Ƃ��AGDDR5�ɂ�鐫�\�ω������邩�牯���̈���o�Ȃ����ǂȁB
>>306
��`�̃V�[�g�g���ċ����ƈʒu���Œ肵�Ă邶���
��`�̃V�[�g�g���ċ����ƈʒu���Œ肵�Ă邶���
>>307
����APS4��CPU��1.8GHz�Ƃ킩���Ă��ŁA
���ʂ�(Jaguar 1.8GHzx4)x2�̐��\����B
SCE��CPU�����Ɏ�����ĂȂ�����A���ʂ�Jaguar�̐��\����v�Z�ł���B
����APS4��CPU��1.8GHz�Ƃ킩���Ă��ŁA
���ʂ�(Jaguar 1.8GHzx4)x2�̐��\����B
SCE��CPU�����Ɏ�����ĂȂ�����A���ʂ�Jaguar�̐��\����v�Z�ł���B
>>306
kinect�̏ꍇ�͋����𑪂�Ȃ��Ƃ��������J��������
���̒��x�͉̂f��̂��\�ߎw�ƕ������Ă�̂ł���ȂɃp���[���v��Ȃ���
��F��������ʐ^�ł��p�X�ł��Ă��܂�
kinect�̏ꍇ�͋����𑪂�Ȃ��Ƃ��������J��������
���̒��x�͉̂f��̂��\�ߎw�ƕ������Ă�̂ł���ȂɃp���[���v��Ȃ���
��F��������ʐ^�ł��p�X�ł��Ă��܂�
>>309
������������\�Ȃ��̂���Ȃ��ĉ�������Ȃ����������H
������������\�Ȃ��̂���Ȃ��ĉ�������Ȃ����������H
>>300
�R�A�������ł����B
���Ɣ�r�����̂̓��o�C��3��ŁA�ǂ��IPC��Pile�Ɏ�����x�����A���ׂ�ƃe�}�V�̒�N���b�N���ۗ����ĂƂ��B
A10APU�͒�i�ʼn��ɂ͂�����d�C���܂��B�N���b�N���̎d���͂��Ă���܂����疞�����Ă܂���B
�R�A�������ł����B
���Ɣ�r�����̂̓��o�C��3��ŁA�ǂ��IPC��Pile�Ɏ�����x�����A���ׂ�ƃe�}�V�̒�N���b�N���ۗ����ĂƂ��B
A10APU�͒�i�ʼn��ɂ͂�����d�C���܂��B�N���b�N���̎d���͂��Ă���܂����疞�����Ă܂���B
INTEL��Leep Motion�őO�Ȃ����邩���
�܂���MS��Surface�Ƃ����Ȃ�L�l�N�g�J���������̂܂ܓ��ڂ��Ă��Ă����������Ȃ�
http://itlifehack.jp/archives/8110520.html
�܂���MS��Surface�Ƃ����Ȃ�L�l�N�g�J���������̂܂ܓ��ڂ��Ă��Ă����������Ȃ�
http://itlifehack.jp/archives/8110520.html
Baytrail�Ɣw��ׂ��郌�x����Mullins��8�C���`����Ă��V�K�����Ȃ��B
�����MS���̗p���邩�^�₾�B
�����MS���̗p���邩�^�₾�B
intel��Leep Motion�ɉ��̊W���H
�x�m�ʂ��P��J�����ŃW�F�X�`������Ă邪gpgpu ?w
>>315
Leep Motion�J������Omek��INTEL�͔���������
http://www.theverge.com/2013/7/16/4527622/intel-acquires-omek-interactive-gesture-recognition
Leep Motion�J������Omek��INTEL�͔���������
http://www.theverge.com/2013/7/16/4527622/intel-acquires-omek-interactive-gesture-recognition
google��flutter���ăW�F�X�`���J�����Ă�Ƃ�����������
>>318
�����A���O�c�q��
�����A���O�c�q��
MS��Intel��nvidia������ɐ�`���Ă��Ă����̑̂��炭��Surface��
MS�͂��܂ő�����C�Ȃ̂��킩���
MS�͂��܂ő�����C�Ȃ̂��킩���
>>319
����Ⴄ����
����Ⴄ����
�c�q�݂͂�Ȃ���������
���͎O�l�ڂ̒c�q��
�Ă��A����ɂ���Ȕ\�͂͂Ȃ���
664 �F,,�E�L�́M�E,,�j��-������ [��] �F2013/12/17(��) 19:39:00.14 ID:81LQ1yxQ (2/2)
���X�����ǁAAVX2��strlen����������ւ�ݐ搶��SSE2/SSE4.2������
1.4�{���炢�����Ȃ�����
�Ă��A����ɂ���Ȕ\�͂͂Ȃ���
664 �F,,�E�L�́M�E,,�j��-������ [��] �F2013/12/17(��) 19:39:00.14 ID:81LQ1yxQ (2/2)
���X�����ǁAAVX2��strlen����������ւ�ݐ搶��SSE2/SSE4.2������
1.4�{���炢�����Ȃ�����
���O��"�c�q"���Ȃɂ��w���̒P��Ȃ̂�m���Ă�
INTEL������X���ɏo���肵�Ă�l�Ԃ����Ă̂��킩�����ł�����
INTEL������X���ɏo���肵�Ă�l�Ԃ����Ă̂��킩�����ł�����
���A�c�q�ȂH
�T�N����NG���ƁB
�T�N����NG���ƁB
�c�q�͓���̐l�����w���̂ł͂Ȃ��̂��悿�݂��I
�c�q�̃I���W�i���͂��Ȃ�n�[�h���̃A�Z���u�����������C�����邪
���Ȃ��Ƃ�strlen�Ȃ˂����Ă͂��Ȃ��C���[�W
���Ȃ��Ƃ�strlen�Ȃ˂����Ă͂��Ȃ��C���[�W
�c�q�Ƃ�
�ϑz�Ɍ�����˂������w
�ϑz�Ɍ�����˂������w
>>316
general purpose�ł͂Ȃ���pGPU�`�b�v���ڂ��Ă���
general purpose�ł͂Ȃ���pGPU�`�b�v���ڂ��Ă���
>>328
�ϑz�����U�c�q�����������Ƃ����͌������낤
�ϑz�����U�c�q�����������Ƃ����͌������낤
�x�m�ʂ�pointgrab�Ȃ�ňႤ��Ȃ�����
http://techon.nikkeibp.co.jp/article/SEMINAR/20110808/194911/?P=2
�����āA�����摜�Z���T�̂悤�Ȑ�p�n�[�h�E�G�A���g�킸�ɃW�F�X�`���[���͂��\�ɂ���
�摜�F���Z�p�ɂ��ču������̂��A�C�X���G����PointGrab�Ђł��B
���Ђ̋Z�p�́A�p�\�R����e���r�ɓ��ڂ����Web�J�����ƃv���Z�T���g���A
��̓��������ő���ł���̂������ł��B
http://www.fmworld.net/cs/azbyclub/qanavi/jsp/qacontents.jsp?PID=0509-3531
http://techon.nikkeibp.co.jp/article/SEMINAR/20110808/194911/?P=2
�����āA�����摜�Z���T�̂悤�Ȑ�p�n�[�h�E�G�A���g�킸�ɃW�F�X�`���[���͂��\�ɂ���
�摜�F���Z�p�ɂ��ču������̂��A�C�X���G����PointGrab�Ђł��B
���Ђ̋Z�p�́A�p�\�R����e���r�ɓ��ڂ����Web�J�����ƃv���Z�T���g���A
��̓��������ő���ł���̂������ł��B
http://www.fmworld.net/cs/azbyclub/qanavi/jsp/qacontents.jsp?PID=0509-3531
>>331
�R���f�W�̘b���Ǝv������
����������I�ɂ������قǒᐫ�\�ȃv���Z�b�T�ł������͗e�ՂɂȂ��Ă������炱�ꎩ�͕̂s�v�c�Șb����Ȃ�
���͂��̐�̍��t�����l�ȃv���O��������邱�Ƃ��ł��Ȃ����Ă��Ƃ��낤
�R���f�W�̘b���Ǝv������
����������I�ɂ������قǒᐫ�\�ȃv���Z�b�T�ł������͗e�ՂɂȂ��Ă������炱�ꎩ�͕̂s�v�c�Șb����Ȃ�
���͂��̐�̍��t�����l�ȃv���O��������邱�Ƃ��ł��Ȃ����Ă��Ƃ��낤
http://tokyoeoi.sakura.ne.jp/IsraeliInterbeeInJapanese_fnl.pdf
eyesight������gpu�g���悤���Ȃ�
eyesight������gpu�g���悤���Ȃ�
GPGPU�͍��̂Ƃ������I�Ȏg���������Ȃ��킯��
�Ɩ������Ŏg���Ă�Ƃ��F�X���邯�ǁA����Ȃʂ̐l���炵����ǂ��ł������b����
�ɒ[�Șb�A�g��Ȃ��Ă��������낤
�Ɩ������Ŏg���Ă�Ƃ��F�X���邯�ǁA����Ȃʂ̐l���炵����ǂ��ł������b����
�ɒ[�Șb�A�g��Ȃ��Ă��������낤
>>333
APU�ʼn�͑��x��20�{�ɂȂ������ď����Ă�����
http://eyesight-tech.com/upcoming-amd-apus-feature-built-in-gesture-control-powered-by-eyesight/
APU�ʼn�͑��x��20�{�ɂȂ������ď����Ă�����
http://eyesight-tech.com/upcoming-amd-apus-feature-built-in-gesture-control-powered-by-eyesight/
>>333
�[�X�`�����炢�Ȃ獡�Ȃ�X�}�z�ł��ǂ��ɂ��Ȃ�
�������Ƃ���������������ɑ��ă��A���^�C���ł�邱�Ƃ��ł��邩�ƌ�������ł��Ȃ�
ttp://potter0517.files.wordpress.com/2012/11/target1.jpg
�[�X�`�����炢�Ȃ獡�Ȃ�X�}�z�ł��ǂ��ɂ��Ȃ�
�������Ƃ���������������ɑ��ă��A���^�C���ł�邱�Ƃ��ł��邩�ƌ�������ł��Ȃ�
ttp://potter0517.files.wordpress.com/2012/11/target1.jpg
{kind=link}
>>334
�p�X���[�h��Í����̉�ǂ�GPGPU���g���ėv��ȏ�A����ɍ��킹�Ėh�䑤����苭�łȈÍ��������߂���킯�ŁA
��������ǂ��������ĈÍ�/�������∳�k/�𓀂ɂ����郌�X�|���X�̖���GPGPU�͖h�䑤�ɂ��K�v�ɂȂ�B
�p�X���[�h��Í����̉�ǂ�GPGPU���g���ėv��ȏ�A����ɍ��킹�Ėh�䑤����苭�łȈÍ��������߂���킯�ŁA
��������ǂ��������ĈÍ�/�������∳�k/�𓀂ɂ����郌�X�|���X�̖���GPGPU�͖h�䑤�ɂ��K�v�ɂȂ�B
�v���O������GPGPU����������g����悤�ɂȂ�A�����Đ��\�����������シ�邩��A
AMD��CPU���GPU����������APU�ɗ͂����Ă�������
AMD��CPU���GPU����������APU�ɗ͂����Ă�������
�ŁA���b�`�����h�i�H�j�̃��b�`�ȃW�F�X�`�����Ă͂��H��
>>337
���̓x�[�X�̃p�X���[�h�ɕs����������悤�Ȃ����������
�����̃p�X���[�h�Ǘ�����̂��ʓ|�������̔F�ňꌳ�Ǘ�������
���̓x�[�X�̃p�X���[�h�ɕs����������悤�Ȃ����������
�����̃p�X���[�h�Ǘ�����̂��ʓ|�������̔F�ňꌳ�Ǘ�������
>>340
Rich�͎�b�����A���^�C���ʖĂ���邶��Ȃ���
Rich�͎�b�����A���^�C���ʖĂ���邶��Ȃ���
�����Ă͂��H
>>338
����ł������o�b�e���[�������Ă�������d���Ȃ�����
����ł������o�b�e���[�������Ă�������d���Ȃ�����
>>343
���������X�����H�o
���������X�����H�o
>>344
GPGPU�Ȃg������Ȃ�����Ȃ���
GPGPU�Ȃg������Ȃ�����Ȃ���
>>338
���Ԃ�摜�⓮��̏�ɍ������Ă邾��������GPGPU�g�����F���Ƃ͈Ⴄ��Ȃ��H
���Ԃ�摜�⓮��̏�ɍ������Ă邾��������GPGPU�g�����F���Ƃ͈Ⴄ��Ȃ��H
���N�O�����F����Ί�ŃV���b�^��@�\�͂���킯��
��̌����ŊG�������ƂȂ�
��̌����ŊG�������ƂȂ�
APU�̎d�l���悭�킩��Ȃ��̂ł����A������ăO���t�B�b�N�{�[�h�����������GPU�����͎g���Ȃ��Ȃ���̂ł����H
���ARADEON��7700�n���g���Ă��āAFF14����̂ɓ����̂����ꖇ��4�R�A��CPU�ɋ������悤���Ǝv���Ă���̂ł����A
�}�U�[�{�[�h��AM/FM�̂ǂ���ɂ��悤�������Ă܂��B
���ARADEON��7700�n���g���Ă��āAFF14����̂ɓ����̂����ꖇ��4�R�A��CPU�ɋ������悤���Ǝv���Ă���̂ł����A
�}�U�[�{�[�h��AM/FM�̂ǂ���ɂ��悤�������Ă܂��B
���邩��
>>350
VGA�t���ăQ�[���������Ȃ�A4�R�A����Ȃ�FX��8350��7700�nx2�ɂ���
VGA�t���ăQ�[���������Ȃ�A4�R�A����Ȃ�FX��8350��7700�nx2�ɂ���
>>350
�f�B�X�v���C��1���Ȃ�g���Ȃ��ABIOS�Ŗ����I�ɖ����ɂ��邱�Ƃ��\
2���ȏ�Ȃ�����ƊO�t���ŕ����ė�������o�͂��鎖���\
7700�n�Ȃ�4�R�A�ł�������
�f�B�X�v���C��1���Ȃ�g���Ȃ��ABIOS�Ŗ����I�ɖ����ɂ��邱�Ƃ��\
2���ȏ�Ȃ�����ƊO�t���ŕ����ė�������o�͂��鎖���\
7700�n�Ȃ�4�R�A�ł�������
Z1�g���Ď����Ă݂����Nj@�\�g���Ƃ��ɗ\�ߒn�ʂ�ݒ肷��K�v������݂���
AR(�g������)�̖͗l�̑����o�^���銴��
����͂Ȃ��Ȃ��X���[�Y
AR(�g������)�̖͗l�̑����o�^���銴��
����͂Ȃ��Ȃ��X���[�Y
>>294
�ʔ����f�[�^�T���N�X
��͂�Pile�̓S�~�ASteamroller��Llano��K10����IPC�ɋ߂Â��邩�y���݂���
Silvermont�͈ӊO�ƕ�����
Jaguire�������悤�Ȑ��\���Ƃ���Ƃ܂��܂�����
�ʔ����f�[�^�T���N�X
��͂�Pile�̓S�~�ASteamroller��Llano��K10����IPC�ɋ߂Â��邩�y���݂���
Silvermont�͈ӊO�ƕ�����
Jaguire�������悤�Ȑ��\���Ƃ���Ƃ܂��܂�����
357 �F,,�E�L�́M�E,,�j��-�������F2013/12/21(�y) 19:19:11.74 ID:ZbPj4SDW
Silvermont���ł���q�Ȃ̂͑O����\���Ă���
http://www.servethehome.com/Server-detail/intel-atom-c2750-8-core-avoton-rangeley-benchmarks-fast-power/
Jaguar�͔��������ˁHOpteron-X(Kyoto)��GPU�Ȃ��ł�X1150��4�R�A��
�ő�2GHz��17W�B
�������������[��DDR3�V���O���`���l���ł���B
Atom C2750�Ɠ���8�R�A��2.4GHz�œ��������Ǝv������40W���y�������Ă��܂����낤
TSMC16nm(FinFET)���͂₭�̗p�ł���Ƃ����ˁB
http://www.servethehome.com/Server-detail/intel-atom-c2750-8-core-avoton-rangeley-benchmarks-fast-power/
Jaguar�͔��������ˁHOpteron-X(Kyoto)��GPU�Ȃ��ł�X1150��4�R�A��
�ő�2GHz��17W�B
�������������[��DDR3�V���O���`���l���ł���B
Atom C2750�Ɠ���8�R�A��2.4GHz�œ��������Ǝv������40W���y�������Ă��܂����낤
TSMC16nm(FinFET)���͂₭�̗p�ł���Ƃ����ˁB
>>357
Mullins�ł���d�͂�M�̖��͂�����x�ɘa�����B�����܂ł�����x�́B
����AMD�̓V���O���`�����l�������p�ӂ��Ȃ����낤�ȁB
��҂ł��邪�̂ɏ���肪�����Ȃ��Ƃ������̃X�p�C�����ɓ����Ă�B
Mullins�ł���d�͂�M�̖��͂�����x�ɘa�����B�����܂ł�����x�́B
����AMD�̓V���O���`�����l�������p�ӂ��Ȃ����낤�ȁB
��҂ł��邪�̂ɏ���肪�����Ȃ��Ƃ������̃X�p�C�����ɓ����Ă�B
359 �F,,�E�L�́M�E,,�j��-�������F2013/12/21(�y) 19:57:13.85 ID:ZbPj4SDW
�A�[�L�e�N�`�����̂��uPuma�v�����ǁA�������TurionX2�̂Ƃ���
���o�C���v���b�g�t�H�[���Ɠ������O����ȁB
���M�łԂ���ꂽ�Ƃ������b���������Ȃ��B
Mullins�͍ő�2�{�d�͌��������P����Ƃ������Ă邯�ǃ^�u���b�g�ʼnߏ�Ȑ��\��
���j�b�g�̃N���b�N��}����Ƃ��A�f�`���[�����݂ł̒����ɂȂ肻���ȁB
�T�[�o�ŁiKyoto�j�̌�p�͑��݂��Ȃ��悤�����B
���������A�����S�����W�ʼn��̃f�����b�g���Ȃ��d�͌�����2�{�ɉ��P�ł���Ȃ�
ARM��Opteron�Ȃv���B
���o�C���v���b�g�t�H�[���Ɠ������O����ȁB
���M�łԂ���ꂽ�Ƃ������b���������Ȃ��B
Mullins�͍ő�2�{�d�͌��������P����Ƃ������Ă邯�ǃ^�u���b�g�ʼnߏ�Ȑ��\��
���j�b�g�̃N���b�N��}����Ƃ��A�f�`���[�����݂ł̒����ɂȂ肻���ȁB
�T�[�o�ŁiKyoto�j�̌�p�͑��݂��Ȃ��悤�����B
���������A�����S�����W�ʼn��̃f�����b�g���Ȃ��d�͌�����2�{�ɉ��P�ł���Ȃ�
ARM��Opteron�Ȃv���B
���A�`�����킪�n�܂�\��
>>352
8�R�A�̂�ł��ˁB
����d�͂����������������Ȃ��݂����Ȃ̂ňӊO�ł������A8�R�A���ƁA�����I�[�o�[�X�y�b�N���Ȃƍl���Ă��܂��B
�ł��AAM�n�Ȃ炱�ꂪ�ǂ������ł��B
>>353
����ρA���ʂɂȂ��ł��ˁB
�����Ȃ�ƁAAM�n�̕��������̂��Ȃ�
�ł��AFM2+�̂̂т���Ƃǂ����Ƃ邩�Y�܂����ł��B
��p�ʂ��������Č����������Ǝv���܂��B
���肪�Ƃ��������܂����B
8�R�A�̂�ł��ˁB
����d�͂����������������Ȃ��݂����Ȃ̂ňӊO�ł������A8�R�A���ƁA�����I�[�o�[�X�y�b�N���Ȃƍl���Ă��܂��B
�ł��AAM�n�Ȃ炱�ꂪ�ǂ������ł��B
>>353
����ρA���ʂɂȂ��ł��ˁB
�����Ȃ�ƁAAM�n�̕��������̂��Ȃ�
�ł��AFM2+�̂̂т���Ƃǂ����Ƃ邩�Y�܂����ł��B
��p�ʂ��������Č����������Ǝv���܂��B
���肪�Ƃ��������܂����B
>>359
�N���b�N�œK���ŏ���d�͂�甭�M��������͕̂��ʂ̎��B
����ɂ��Ă��d�͌���2�{�͐����Ă邾�낤���ǁB
AMD�͏ȓd�̓R�A���t�F�[�h�A�E�g���A�Œ���܂ʼn������������Ȃ�Ȃ����B
�ȑO�̃��[�h�}�b�v�ł�Excavator����ŋ��ʉ�������悤�ȏ��������������B
Kyoto�̌�p��Kaveri�x�[�X��Berlin�ɂȂ��Ă�B
�N���b�N�œK���ŏ���d�͂�甭�M��������͕̂��ʂ̎��B
����ɂ��Ă��d�͌���2�{�͐����Ă邾�낤���ǁB
AMD�͏ȓd�̓R�A���t�F�[�h�A�E�g���A�Œ���܂ʼn������������Ȃ�Ȃ����B
�ȑO�̃��[�h�}�b�v�ł�Excavator����ŋ��ʉ�������悤�ȏ��������������B
Kyoto�̌�p��Kaveri�x�[�X��Berlin�ɂȂ��Ă�B
>>350
�����̉ł�FX8300�g����FFXIV��
����̒��X�J�X�J�������āA
���͂��甼�`�[�g��������Ƃ邼
VGA�͋��^��5870������
���̃R�A�̑����ق���E�߂�
��������8G�`�Ȃ���v�݂�����
�����̉ł�FX8300�g����FFXIV��
����̒��X�J�X�J�������āA
���͂��甼�`�[�g��������Ƃ邼
VGA�͋��^��5870������
���̃R�A�̑����ق���E�߂�
��������8G�`�Ȃ���v�݂�����
>>364
�����������̍����Ǝv��
�����������̍����Ǝv��
�T�u�@��Phenom955(4�R�A)���g�킹�Ă邪�A����������
���ʂ݂����Ȃ�
14�����グ�̂Ƃ��\���C�Ηp��5870��2�����������A
�����܂ł͗v��Ȃ������]�蕨���p
���ʂ݂����Ȃ�
14�����グ�̂Ƃ��\���C�Ηp��5870��2�����������A
�����܂ł͗v��Ȃ������]�蕨���p
>>363
Medfield�AClover Trail�AClover Trail+�Ő����Ƃ����̂͏���d�͂̏��Ȃ�����
���\����Ȃ��Ď��ې�������
�����͏���Atom�̃R�A�����珈���\�͎��̂̓R�A���Ƃ��N���b�N�̍������t���Ȃ�
�����22nm����2��ڃR�A�ɂȂ��ď��߂�IPC�����サ��
Medfield�AClover Trail�AClover Trail+�Ő����Ƃ����̂͏���d�͂̏��Ȃ�����
���\����Ȃ��Ď��ې�������
�����͏���Atom�̃R�A�����珈���\�͎��̂̓R�A���Ƃ��N���b�N�̍������t���Ȃ�
�����22nm����2��ڃR�A�ɂȂ��ď��߂�IPC�����サ��
����ς�v���Z�X�S�������͋���
Kaveri�͖��߃f�R�[�_���L��߂���
1���W���[���Œ�TDP��APU���o���Ȃ����ȁH
Celeron�݂�����5000�~�ȉ��̓z���~������
1���W���[���Œ�TDP��APU���o���Ȃ����ȁH
Celeron�݂�����5000�~�ȉ��̓z���~������
kaveri�̓��o�C���p���ǂ̃^�C�~���O�ŏo���邩���d�v��
�^�C�~���O����Ȃ����A�����ɑ�����
�^�C�~���O����Ȃ����A�����ɑ�����
�f�R�[�_�[���L�~�߂���Ȃ����₵��
>>346
�����̖�肾
CPU�ł�������ɂ�SIMD�ɗ��邵���Ȃ������p��H��ςނ����Ȃ�
����͍ŋ߂̒����d��CPU�ŗǂ�����Ă������
�K���ɂȂ�ɂ��Ă��A���ł����ߎ���I�Ȃ̂���
�����̖�肾
CPU�ł�������ɂ�SIMD�ɗ��邵���Ȃ������p��H��ςނ����Ȃ�
����͍ŋ߂̒����d��CPU�ŗǂ�����Ă������
�K���ɂȂ�ɂ��Ă��A���ł����ߎ���I�Ȃ̂���
���AAMD��Silvermont�R��chip�������?
>>369
AMD�̓o���G�[�V�������Ȃ������
����Ȃ�����o���G�[�V�������₵�����Ȃ��̂��낤��
>>369
AMD�̓o���G�[�V�������Ȃ������
����Ȃ�����o���G�[�V�������₵�����Ȃ��̂��낤��
>>373
OpteronX
OpteronX
>>374
����Ȃ̂���̂��B����t��ITX�}�U�[���Ă���̂���
����Ȃ̂���̂��B����t��ITX�}�U�[���Ă���̂���
Intel�ɏ��ĂȂ�����BAMD�����B
Intel�̓Ɛ��Ԃ͌��������ǁAx86�ł͑���AMD�������Ȃ��̂͂Ȃ����Ȃ��B
�͉̂��\�Ƃ��������̂ɁAIntel�ȊO�ł�AMD�Ǝ�̔�ꖇ�ȊO��VIA�ȊO�A���S�Ɏ��ɐ₦�Ă��܂����B
Intel�̓Ɛ��Ԃ͌��������ǁAx86�ł͑���AMD�������Ȃ��̂͂Ȃ����Ȃ��B
�͉̂��\�Ƃ��������̂ɁAIntel�ȊO�ł�AMD�Ǝ�̔�ꖇ�ȊO��VIA�ȊO�A���S�Ɏ��ɐ₦�Ă��܂����B
AMD�͐l�X��PC�ւ̖��S���Ɛ���Ă��
�l�X��PC�ɉ�A������ɂ̓l�b�g�Ƀo�[�`�����_�C�u�ł���f���@�C�X���J�����邵���Ȃ�
>>378
���������Ă�ˁACES���y���݂ɂ��Ƃ������Ǝv����
���������Ă�ˁACES���y���݂ɂ��Ƃ������Ǝv����
381 �F,,�E�L�́M�E,,�j��-�������F2013/12/21(�y) 23:43:23.68 ID:ZbPj4SDW
>>374
AMD�����ܔ����Ă��̂͂��̑O�̐����Atom S1200�V���[�Y�̂ق��ł���B
�f�X�N�g�b�v�p�r�łȂ�ABayTrail�x�[�X��Pentium/Celeron�u�����h��������̂����邺
http://ark.intel.com/products/78867/
http://ark.intel.com/products/76529/
TSMC/GF��28nm/20nm�v���Z�X��Intel��22nm/14nm��Atom�ɑR�����i�Ƃ���
�p�ӂ��Ă�͍̂��x�o��8�`16�R�A��ARM��Opteron(Seattle)�B
x86�����炱��Intel�̐H���c�����p�C�ɂ������킯�ŁA�����̏������s���
������̂͂���ȂɊ��S�ł��Ȃ��B
�{����ARM�T�[�o�������s�ꂾ�Ƃ���A���Ӄ`�b�v��IP�𑽐������Ă�
TI��Marvell���p�C�������Ă��Ă��܂���������Ȃ��ˁB
�܂�GPU���[�J�[�̗��ꂩ�炷��Γ�����GPU������NVIDIA���������Ă����K�v��
����̂��낤���ǁB
AMD�����ܔ����Ă��̂͂��̑O�̐����Atom S1200�V���[�Y�̂ق��ł���B
�f�X�N�g�b�v�p�r�łȂ�ABayTrail�x�[�X��Pentium/Celeron�u�����h��������̂����邺
http://ark.intel.com/products/78867/
http://ark.intel.com/products/76529/
TSMC/GF��28nm/20nm�v���Z�X��Intel��22nm/14nm��Atom�ɑR�����i�Ƃ���
�p�ӂ��Ă�͍̂��x�o��8�`16�R�A��ARM��Opteron(Seattle)�B
x86�����炱��Intel�̐H���c�����p�C�ɂ������킯�ŁA�����̏������s���
������̂͂���ȂɊ��S�ł��Ȃ��B
�{����ARM�T�[�o�������s�ꂾ�Ƃ���A���Ӄ`�b�v��IP�𑽐������Ă�
TI��Marvell���p�C�������Ă��Ă��܂���������Ȃ��ˁB
�܂�GPU���[�J�[�̗��ꂩ�炷��Γ�����GPU������NVIDIA���������Ă����K�v��
����̂��낤���ǁB
>>380
wii�f�o�C�X�͕K�v�Ȃ��B�W�F�X�`���[�@�\�̊g���Ń��[�V�����ǂ߂�
wii�f�o�C�X�͕K�v�Ȃ��B�W�F�X�`���[�@�\�̊g���Ń��[�V�����ǂ߂�
384 �F,,�E�L�́M�E,,�j��-�������F2013/12/22(��) 01:14:20.46 ID:XxGJcBDs
Windows RT�[����BayTrail + Windows 8.1�ɋ쒀����܂���
����d�͂�CloverTrail�̎��_�ł����\�����Ȃ���B���͉��i��4G LTE�Ή��B
Lenovo K900��LTE�����Ή����Ă�Δ��������Ǝv�����l�͂����悤���B
����d�͂�CloverTrail�̎��_�ł����\�����Ȃ���B���͉��i��4G LTE�Ή��B
Lenovo K900��LTE�����Ή����Ă�Δ��������Ǝv�����l�͂����悤���B
CES�͒ቿ�i��HMD�������W��������������
�Q�[���@�p�����N�������o��݂��������A���𑜓x�̂��̂��o�Ă����炿����Ɨ~������
�Q�[���@�p�����N�������o��݂��������A���𑜓x�̂��̂��o�Ă����炿����Ɨ~������
Windows RT�[�����쒀����Ă邶��Ȃ���
�D�^�u�ł݂悤��
�D�^�u�ł݂悤��
Oculus Rift�͔����\��
3���̊J���L�b�g�����Ă��ǂ��������V�^�̕����R���p�N�g�ɂȂ�݂�������
3���̊J���L�b�g�����Ă��ǂ��������V�^�̕����R���p�N�g�ɂȂ�݂�������
388 �F,,�E�L�́M�E,,�j��-�������F2013/12/22(��) 01:25:34.81 ID:XxGJcBDs
Lenovo��Merrifield + XMM7260���ڂ�5.5�C���`�t��HD��
K5�Ƃ����t�@�u���b�g���J�����Ă���B
�����s��̃n�C�G���h�u���͂������Ȃ��Ǝv���B
K5�Ƃ����t�@�u���b�g���J�����Ă���B
�����s��̃n�C�G���h�u���͂������Ȃ��Ǝv���B
>>383
�͂��HRazri�͎o���@��Qualcomm��RazrM���o�b�e������
http://images.anandtech.com/graphs/graph6330/50476.png
CloverTrail���S�R�����Ȃ�
http://images.anandtech.com/reviews/SoC/Intel/CTvKrait/sunspider-krait-cpu.png
http://images.anandtech.com/reviews/SoC/Intel/CTvKrait/kraken-krait-cpu.png
http://images.anandtech.com/reviews/SoC/Intel/CTvKrait/riabench-krait-cpu.png
http://images.anandtech.com/reviews/SoC/Intel/CTvKrait/webxprt-krait-cpu.png
http://images.anandtech.com/reviews/SoC/Intel/CTvKrait/touchxprt1-krait-cpu.png
http://images.anandtech.com/reviews/SoC/Intel/CTvKrait/touchxprt2-krait-cpu.png
http://images.anandtech.com/reviews/SoC/Intel/CTvKrait/touchxprt3-krait-cpu.png
http://images.anandtech.com/reviews/SoC/Intel/CTvKrait/touchxprt4-krait-cpu.png
����ɂ����Ȃ菉��ŃX�}�z��Ȋ�����Ȃ�Ă���������ĂȂ�����
�͂��HRazri�͎o���@��Qualcomm��RazrM���o�b�e������
http://images.anandtech.com/graphs/graph6330/50476.png
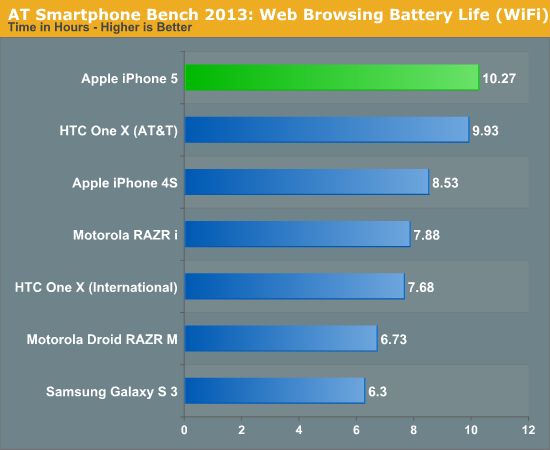{kind=link}
CloverTrail���S�R�����Ȃ�
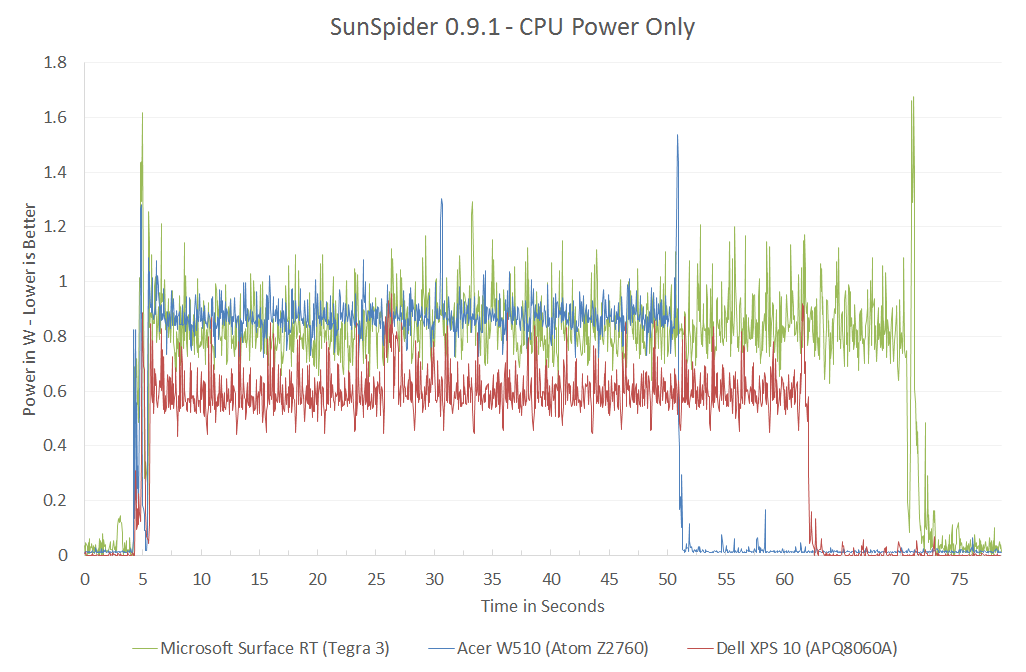
http://images.anandtech.com/reviews/SoC/Intel/CTvKrait/sunspider-krait-cpu.png
{kind=link}
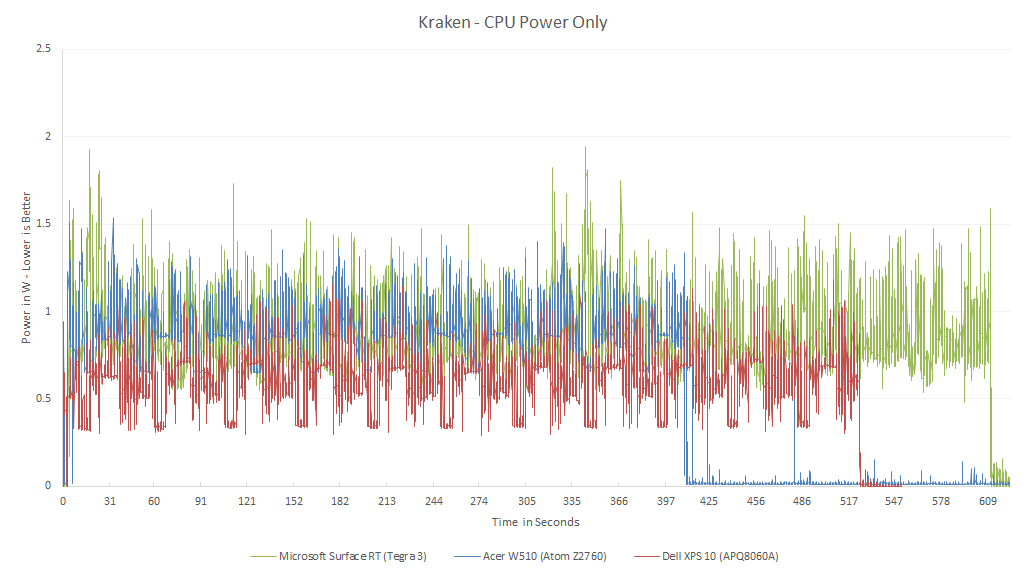
http://images.anandtech.com/reviews/SoC/Intel/CTvKrait/kraken-krait-cpu.png
{kind=link}
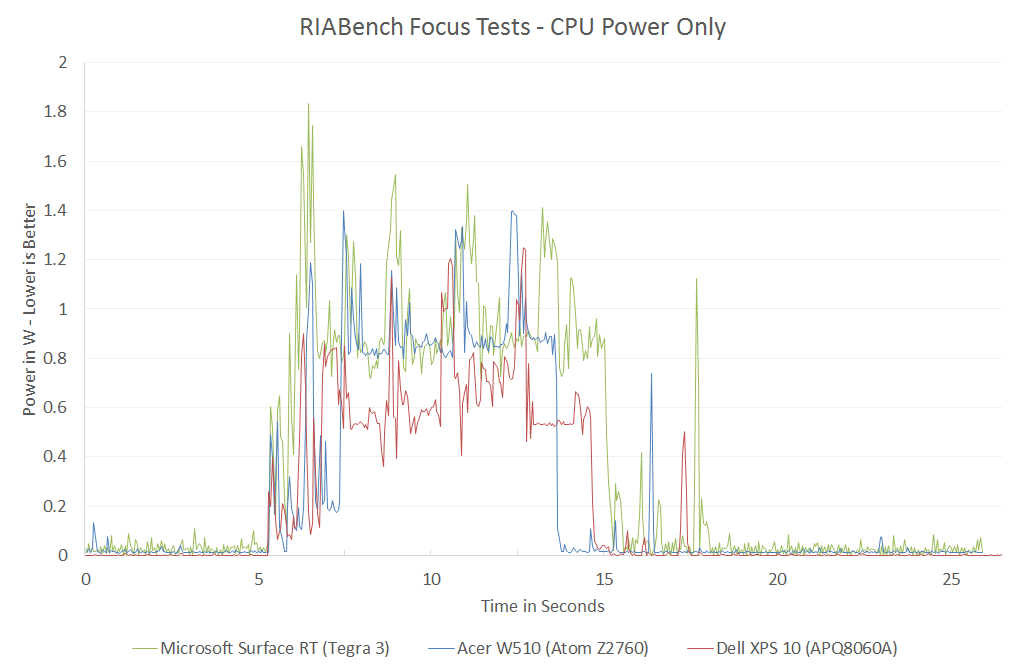
http://images.anandtech.com/reviews/SoC/Intel/CTvKrait/riabench-krait-cpu.png
{kind=link}
http://images.anandtech.com/reviews/SoC/Intel/CTvKrait/webxprt-krait-cpu.png
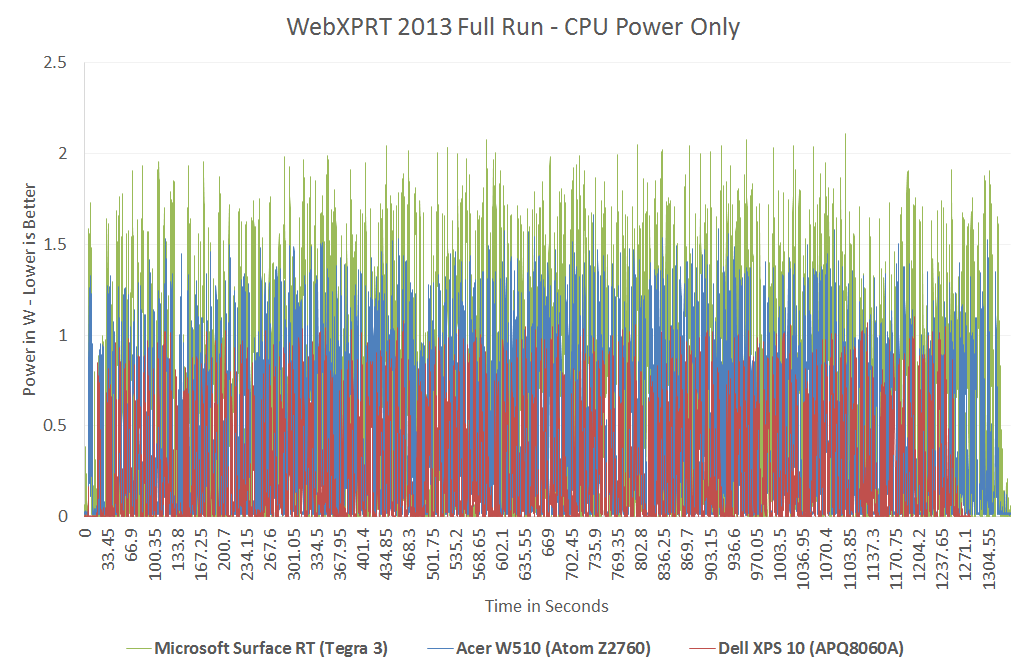{kind=link}
http://images.anandtech.com/reviews/SoC/Intel/CTvKrait/touchxprt1-krait-cpu.png
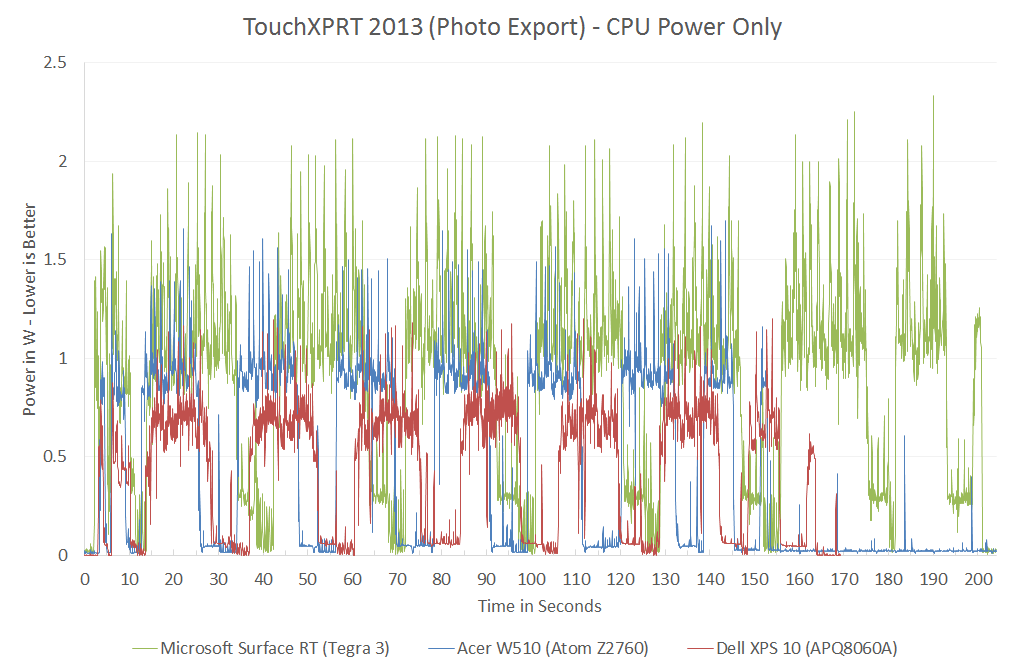
{kind=link}
http://images.anandtech.com/reviews/SoC/Intel/CTvKrait/touchxprt2-krait-cpu.png
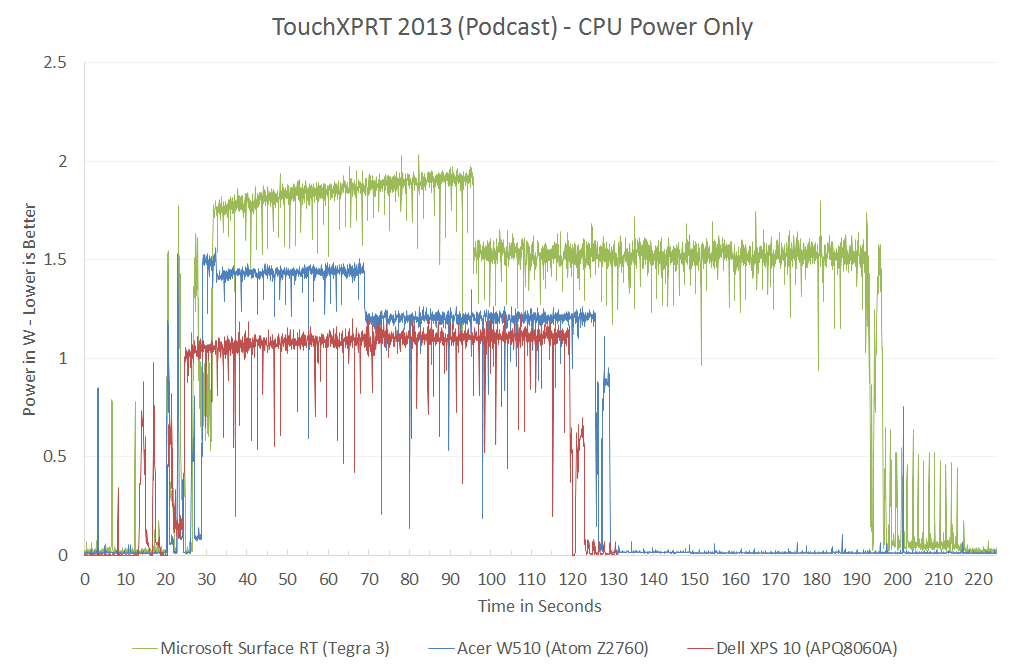
{kind=link}
http://images.anandtech.com/reviews/SoC/Intel/CTvKrait/touchxprt3-krait-cpu.png
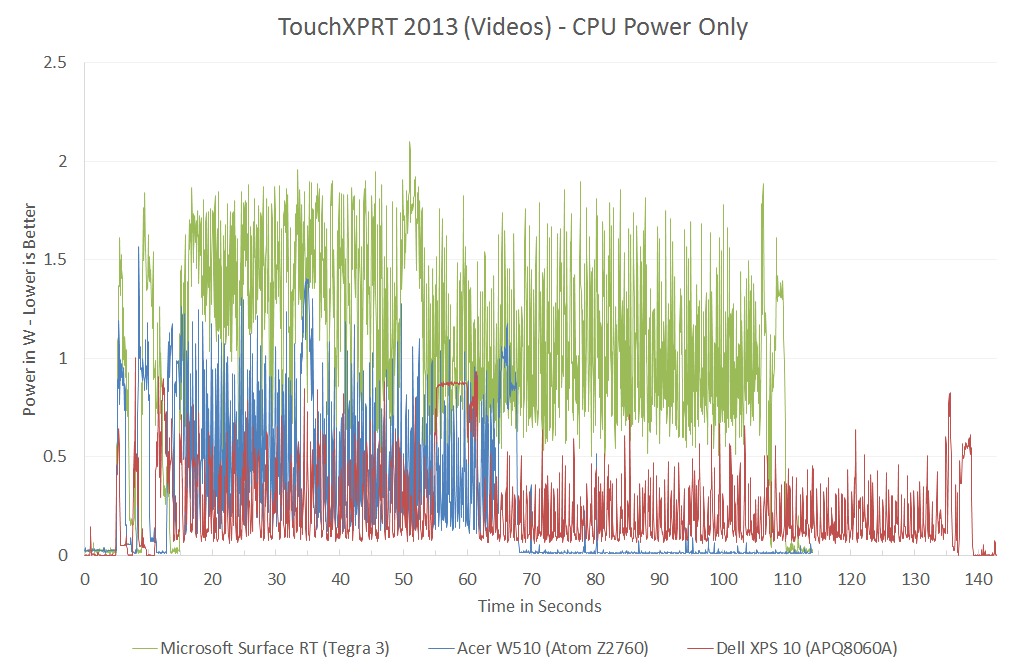
{kind=link}
http://images.anandtech.com/reviews/SoC/Intel/CTvKrait/touchxprt4-krait-cpu.png
{kind=link}
����ɂ����Ȃ菉��ŃX�}�z��Ȋ�����Ȃ�Ă���������ĂȂ�����
�X�}�z�̘b�͑����ł��
>>389
���ꂪ�����Ă�c�q�Ƃ����L�`�R�e��������
���ꂪ�����Ă�c�q�Ƃ����L�`�R�e��������
392 �F,,�E�L�́M�E,,�j��-�������F2013/12/22(��) 03:29:06.37 ID:XxGJcBDs
�ꌾ�������Ăˁ[��
�{���Ɍ������̂Ȃ烍�O�c���Ă邾��H�����Ă݁H
�{���Ɍ������̂Ȃ烍�O�c���Ă邾��H�����Ă݁H
393 �F,,�E�L�́M�E,,�j��-�������F2013/12/22(��) 03:31:04.27 ID:XxGJcBDs
LTE Advanced�Ή���Qualcomm�ɐ�s����Ώ��@�͂���E�E�E��������Ȃ���
���Ɋ؍��ł�LTE Advanced�T�[�r�X�C�����ĂāA
����ɑΉ����Ă�GALAXY S4 LTE-A�͍��h��800�ڂ����Ă�B
�h�R����LTE Advanced���p�T�[�r�X�J�n��2014�N�`2015�N�J�n�\�肾���ǁA
�����ݓ��{�̃L�����A�����Ă�X�}�z��o�C�����[�^�[�ɂ�
LTE Advanced�Ή��̍��h��800��MDM9225��������O�̂悤�ɍڂ��Ă���B
�Ƃ肠�������{�Ɋւ��ẮA�ʐM���Ǝ҂���B�ɑ�D�]��Q�Ђ̃`�b�v�Z�b�g/���f����
LTE Advanced�T�[�r�X�C�����鍠�ɑ��Ђ̕��Ɏ���ĕς��\���͒Ⴂ�̂ł͂܂����H
����ɑΉ����Ă�GALAXY S4 LTE-A�͍��h��800�ڂ����Ă�B
�h�R����LTE Advanced���p�T�[�r�X�J�n��2014�N�`2015�N�J�n�\�肾���ǁA
�����ݓ��{�̃L�����A�����Ă�X�}�z��o�C�����[�^�[�ɂ�
LTE Advanced�Ή��̍��h��800��MDM9225��������O�̂悤�ɍڂ��Ă���B
�Ƃ肠�������{�Ɋւ��ẮA�ʐM���Ǝ҂���B�ɑ�D�]��Q�Ђ̃`�b�v�Z�b�g/���f����
LTE Advanced�T�[�r�X�C�����鍠�ɑ��Ђ̕��Ɏ���ĕς��\���͒Ⴂ�̂ł͂܂����H
395 �FSocket774�F2013/12/22(��) 09:56:46.65 ID:ukAAIWbJ
�����ɂ���l�B��CPU��点����ǂ��̂���ꂻ���ȋC������B
AMD�̐l�����Ă邩�ȁB
AMD�̐l�����Ă邩�ȁB
����킯�ˁ[����
AMD�̐v�`�[��������킯���Q�l�ɂ���킯���ˁ[
�Q���͐Q�Č���
AMD�̐v�`�[��������킯���Q�l�ɂ���킯���ˁ[
�Q���͐Q�Č���
�����痝�n�̒��G���[�g����
����ȂƂ��ł����܂��Ă�A���ƈꏏ�ɂ���Ȃ�
����ȂƂ��ł����܂��Ă�A���ƈꏏ�ɂ���Ȃ�
398 �FSocket774�F2013/12/22(��) 10:26:01.60 ID:XofjccUx
SPECviewperf12���ꎞ�t�H���_�ɏ���Ƀ_�E�����[�h�����
���̂܂����Ă��܂��݂����Ȃ̂ł����A�F����͂ǂ��������ɗ��Ƃ��Ă���̂ł����H
�ꎞ�t�H���_�̗e�ʂ�1G���ڈ�t�݂��������B�B�B
3��ځB�B�����C���[�[
���̂܂����Ă��܂��݂����Ȃ̂ł����A�F����͂ǂ��������ɗ��Ƃ��Ă���̂ł����H
�ꎞ�t�H���_�̗e�ʂ�1G���ڈ�t�݂��������B�B�B
3��ځB�B�����C���[�[
sage�Y��B�B
>>381
������͎��ӂ��낢�뎝���Ă邩�烂�o�C�����ŋ����킯�ŁA
CPU��IO�Əȓd�͂����̃T�[�o�Ɋ����ď�荞�ވӖ��͂Ȃ��ł���B
>>389
����������Atom�Ȃ̂ɁA�o��̂�Android����ŁA
Windows8Phone(WindowsPhone8�ł͂Ȃ�)���o�Ȃ�����Ȃ��B
�x�m�ʂ�Windows7Phone�݂����ȃj�R�C�`����Ȃ��̂��~�����B
������͎��ӂ��낢�뎝���Ă邩�烂�o�C�����ŋ����킯�ŁA
CPU��IO�Əȓd�͂����̃T�[�o�Ɋ����ď�荞�ވӖ��͂Ȃ��ł���B
>>389
����������Atom�Ȃ̂ɁA�o��̂�Android����ŁA
Windows8Phone(WindowsPhone8�ł͂Ȃ�)���o�Ȃ�����Ȃ��B
�x�m�ʂ�Windows7Phone�݂����ȃj�R�C�`����Ȃ��̂��~�����B
>>394
�N�A���R���̐��i�͂��낢������āu�����Ɠ����v���Č����̂�
�ŋ��Ȃ킯�ŁB
�ꌩ������O�̂悤�Ɍ����邪�A���ꂪ�o���郁�[�J�[���N�A���R��
�ȊO�ɖw�ǖ����̂�����B
���̃X�y�b�N�ɏo�Ă��Ȃ������͒N���C�ɂ��Ȃ����A�������ŋ��ɏd�v�B
�N�A���R���̐��i�͂��낢������āu�����Ɠ����v���Č����̂�
�ŋ��Ȃ킯�ŁB
�ꌩ������O�̂悤�Ɍ����邪�A���ꂪ�o���郁�[�J�[���N�A���R��
�ȊO�ɖw�ǖ����̂�����B
���̃X�y�b�N�ɏo�Ă��Ȃ������͒N���C�ɂ��Ȃ����A�������ŋ��ɏd�v�B
http://homepage2.nifty.com/winfaq/c/trouble.html
������ʼn������܂����B�����������܂����B�B
������ʼn������܂����B�����������܂����B�B
403 �F,,�E�L�́M�E,,�j��-�������F2013/12/22(��) 12:12:28.99 ID:XxGJcBDs
TI��Marvell���Ă��܃X�}�z�����`�b�v����ĂȂ���B
ARMv7�x�[�X�����nj�����}�C�N���T�[�o�����`�b�v����Ă邶���B
���Ȃ݂�Marvell�͂��������T�[�o�ɍ̗p����Ă�B
http://eetimes.jp/ee/articles/1206/07/news039.html
ARMv7�x�[�X�����nj�����}�C�N���T�[�o�����`�b�v����Ă邶���B
���Ȃ݂�Marvell�͂��������T�[�o�ɍ̗p����Ă�B
http://eetimes.jp/ee/articles/1206/07/news039.html
404 �FSocket774�F2013/12/22(��) 12:26:02.92 ID:ukAAIWbJ
>>404
���F��Google�搶�Y�̃R�s�y�l�^�ł��[�����[���ƌ����Ă邾���ł���
���F��Google�搶�Y�̃R�s�y�l�^�ł��[�����[���ƌ����Ă邾���ł���
����ȊO�̔���l���W�߂č�点���ق��������Ǝv��
�l�^�Ȃ̂��������킢�����Ȑl�Ȃ̂��A����������Ƃ킩��₷�����Ăق������B
���ς�炸�ȂɌ��������̂��킩��Ȃ��K�����Ղ肾�Ȓc�q��
>>404
PC������ĕ������͗ǂ����A�����n�[�h�A�\�t�g������Ȃ��A
�N�������V���Ă�������g�ݗ��āA�����āA����ŃQ�[���A�G���R����ɂ��������B
��{�I�ɂ����������Ƃ̂Ȃ��z�����������B
PC������ĕ������͗ǂ����A�����n�[�h�A�\�t�g������Ȃ��A
�N�������V���Ă�������g�ݗ��āA�����āA����ŃQ�[���A�G���R����ɂ��������B
��{�I�ɂ����������Ƃ̂Ȃ��z�����������B
�����̃��[�J�[�ɂ��Ă��A���S�ƂȂ�v�҂͐����ł���
>>409
����o�b��H�Śg����Ȃ�A
�o�������̂��y���p�b�N�ɋl�߂Ă��ٓ���郌�x�������ȁB
�f�ނ⒲���ɂ��đS���̖��m�ł��o������e�B
����o�b��H�Śg����Ȃ�A
�o�������̂��y���p�b�N�ɋl�߂Ă��ٓ���郌�x�������ȁB
�f�ނ⒲���ɂ��đS���̖��m�ł��o������e�B
�Q�n�L�`�����Ȑ�����玩��PC�@���ɗ�����
�����A�����Ŗ������ł��Ȃ��Ƒ��l�̂����ɂ���^�C�v�̂��Ƃ�
�܂��m���ɋl�߂邾��������w
�����H�����킹�ƃJ�����[�E�h�{�o�����X���l����]�n���ꉞ����̂ŁA
�u���l�߂�����ȁ[�v�ƍ��z�̒��g���Ȃ���y�����I�ԃ��m�Ȃ�ˁB
�����H�����킹�ƃJ�����[�E�h�{�o�����X���l����]�n���ꉞ����̂ŁA
�u���l�߂�����ȁ[�v�ƍ��z�̒��g���Ȃ���y�����I�ԃ��m�Ȃ�ˁB
>>411
�ł��A�q���T�O�╨�������̊�b��m��Ȃ���
���������Ȃ��ٓ��ɂȂ�����A�H�������ŕ�����
�����
����ȃ��x������
�ł��A�q���T�O�╨�������̊�b��m��Ȃ���
���������Ȃ��ٓ��ɂȂ�����A�H�������ŕ�����
�����
����ȃ��x������
�ٓ���60���ȏ��������10���ȉ��ŕۑ�����Β����������
���r���[�ɂ������������x���댯
���r���[�ɂ������������x���댯
����PC�͂����Ȃ炴��Ȃ�����
�������X������
�{���Ɏ��삷��Ȃ甼���̍H��������Ȃ���Ȃ�Ȃ��Ȃ邾��A�z��
�������X������
�{���Ɏ��삷��Ȃ甼���̍H��������Ȃ���Ȃ�Ȃ��Ȃ邾��A�z��
����͉��̎��_�Ȃ���
����̖{�̓m�[�g����ɂȂ��Č|�p�ɋ߂Â��Ă����Ǝv��
�V�̃f�U�C���Ȃǂɑn�쐫��������
�t�@�b�V�����ƗZ����������ɂȂ�
����̖{�̓m�[�g����ɂȂ��Č|�p�ɋ߂Â��Ă����Ǝv��
�V�̃f�U�C���Ȃǂɑn�쐫��������
�t�@�b�V�����ƗZ����������ɂȂ�
�{�C�Ŏ�ɂ��Ă��Ȃ�o�C�N���炢�Ȃ玩���őg�ݗ��Ăł�����̂���
���̉��\�N���Ńt�@�b�V�����ƗZ�������X�N�[�^�[�͏��Ȃ��Ƃ��{�Ƃ͍l�����Ă��Ȃ�
���̉��\�N���Ńt�@�b�V�����ƗZ�������X�N�[�^�[�͏��Ȃ��Ƃ��{�Ƃ͍l�����Ă��Ȃ�
���H�t�Ŏ���Ƃ�����3D�v�����^�ʼn��p�t�B�M���A�쐬
>>419
�X�}�t�H�̍ŐV�@��������т炩�������ɂ��肪���Ȍ��ۂ�
�����Ƒn��������������Ƃ���Ɠ��R�����Ȃ��Ă��邩��
�X�}�[�g�u�b�N��M.2��SoDDR4�ƃf�U�C���I�ԂƂ�
�X�}�t�H�̍ŐV�@��������т炩�������ɂ��肪���Ȍ��ۂ�
�����Ƒn��������������Ƃ���Ɠ��R�����Ȃ��Ă��邩��
�X�}�[�g�u�b�N��M.2��SoDDR4�ƃf�U�C���I�ԂƂ�
>>66
�����ǂ����������̂��E�E�E�B
45nm��32nm�̐i���͐����Ȑi���Ő��\�{�ɂȂ����Ƃł��H
������̐��ł�45��32�t�ɐ��\�������Ă邪
32��28nm�Ŕ{�̐��\�Ȃ��Ă�킯����
�����ǂ����������̂��E�E�E�B
45nm��32nm�̐i���͐����Ȑi���Ő��\�{�ɂȂ����Ƃł��H
������̐��ł�45��32�t�ɐ��\�������Ă邪
32��28nm�Ŕ{�̐��\�Ȃ��Ă�킯����
>>420
�o�A�o�C�N�͍��������������Ȃ����i�k�����j
�o�A�o�C�N�͍��������������Ȃ����i�k�����j
425 �F,,�E�L�́M�E,,�j��-�������F2013/12/22(��) 20:47:06.56 ID:XxGJcBDs
�������������ȃV�������N����Ȃ��ăo���N�ɍœK�����ꂽ�v���Z�X�����
�����Piledriver�����̂܂�28nm�Ɉڍs�ł��ĂȂ����Ƃ�������炩
�����Piledriver�����̂܂�28nm�Ɉڍs�ł��ĂȂ����Ƃ�������炩
����ȂɃC���e�������Ȃ�
�����w��点�C���e���Ȃ�3�b�Œׂ�����H
�����w��点�C���e���Ȃ�3�b�Œׂ�����H
>>424
�� ���W�R���~�j�`���A�o�C�N����
�� ���W�R���~�j�`���A�o�C�N����
�͂�点
�l�b�g�ő��l�Ƀx���`���ʂ������т炩���ȊO�Ɏ���ɂ��b����������Ȃ��l�Ƃ����̂�
���Ȍ����~�����܂����I�ł��Ă��Ȃ���Ԃ����������Ă�킯��
����͋��h���Ƃ݂�ȋC�Â��������C�Ɏ��삪�p�ꂽ
���������l�B�����Ȍ����~�����A���̐l�ԂɌ����邽�߂ɂ�
��͂�5�C���`���x�̃X�}�[�g�u�b�N���J�X�^�����Ēm�荇���Ɍ����т炩�����Ƃ�����
���Ȍ����~�����܂����I�ł��Ă��Ȃ���Ԃ����������Ă�킯��
����͋��h���Ƃ݂�ȋC�Â��������C�Ɏ��삪�p�ꂽ
���������l�B�����Ȍ����~�����A���̐l�ԂɌ����邽�߂ɂ�
��͂�5�C���`���x�̃X�}�[�g�u�b�N���J�X�^�����Ēm�荇���Ɍ����т炩�����Ƃ�����
>>420
�o�C�N��������Ă������J�X�^�������̂��Ė��炩�ɃZ���X���������̂��肾���ǂ�
�o�C�N��������Ă������J�X�^�������̂��Ė��炩�ɃZ���X���������̂��肾���ǂ�
�n���ɍ������Ƃ������Ă����
http://www.gdm.or.jp/crew/2013/1221/55326/attachment/1221_01_akiba_1024x768_30
>RADEON R�V���[�Y���ΏہBGCN�A�[�L�e�N�`���[���ڂ�RADEON HD7xxxx�ɂ��Ă͖���
http://www.gdm.or.jp/crew/2013/1221/55326/attachment/1221_01_akiba_1024x768_30
>RADEON R�V���[�Y���ΏہBGCN�A�[�L�e�N�`���[���ڂ�RADEON HD7xxxx�ɂ��Ă͖���
>>431
�����T�C�g���Ȃ�����
http://www.amd.com/us/products/technologies/mantle/Pages/mantle.aspx
Mantle is the harmony of three essential ingredients
A driver within the AMD Catalyst software suite that allows applications to speak directly to the Graphics Core Next architecture
A Graphics Core Next GPU, like the AMD Radeon R9 Series, R7 Series or HD 7000 Series GPUs
An application or game engine written to use the Mantle SDK
�����T�C�g���Ȃ�����
http://www.amd.com/us/products/technologies/mantle/Pages/mantle.aspx
Mantle is the harmony of three essential ingredients
A driver within the AMD Catalyst software suite that allows applications to speak directly to the Graphics Core Next architecture
A Graphics Core Next GPU, like the AMD Radeon R9 Series, R7 Series or HD 7000 Series GPUs
An application or game engine written to use the Mantle SDK
�����i5��菟����āH
http://i.imgur.com/J2sYWsA.jpg
http://i.imgur.com/J2sYWsA.jpg
{kind=link}
PcMark8+win8.1���Ƃ����Ȃ�݂�����
�����獑�����f�B�A��PCMark8���g��������Ȃ��ł�����PCMark7�g���Ă�
�����獑�����f�B�A��PCMark8���g��������Ȃ��ł�����PCMark7�g���Ă�
���N��BF4��mantle�p�b�`��������
�ǂ��l���Ă����������
>>434
�Ȃɂ��ǂ������炻���Ȃ��
�Ȃɂ��ǂ������炻���Ȃ��
439 �FSocket774�F2013/12/22(��) 23:42:58.64 ID:A7BIIrKE
Intel�̂����̃��c����
>>438
PcMark8+win8.1�œ�������������
�V�����x���`�قǃ}���`�R�A��GPU�̔�d���傫���Ȃ���Intel�ɂ͓s���������Ȃ��Ă���
������C���e���g���͉����܂ł����Ă��V���O���V���O�����������Ă���
PcMark8+win8.1�œ�������������
�V�����x���`�قǃ}���`�R�A��GPU�̔�d���傫���Ȃ���Intel�ɂ͓s���������Ȃ��Ă���
������C���e���g���͉����܂ł����Ă��V���O���V���O�����������Ă���
�Q�[����AMD��CPU�����͖̂��������Ȃ�
>>431
���l�[���O��GPU�Ƃ̍��ʉ��̂��߂̃}�[�P�e�B���O�̂��߂̐�����d���Ȃ���
HD7xxx��������DX11.2�ɑΉ��ł��Ȃ��̂Ɠ��l�̘b
���l�[���O��GPU�Ƃ̍��ʉ��̂��߂̃}�[�P�e�B���O�̂��߂̐�����d���Ȃ���
HD7xxx��������DX11.2�ɑΉ��ł��Ȃ��̂Ɠ��l�̘b
443 �F,,�E�L�́M�E,,�j��-�������F2013/12/23(��) 00:25:57.72 ID:RkfXxEXv
����GPU�ŃQ�[���i�L���b
�Ƃ����ꂽ���ƌ����Ă邩��̗p����Ȃ���
�Ƃ����ꂽ���ƌ����Ă邩��̗p����Ȃ���
�f�B�X�N���[�gGPU�����Ă郁�[�J�[�������������
�s�����Ȉ�ۂ���
�s�����Ȉ�ۂ���
>>434
������Ȃ���z�O�ɂ���������ł��Ȃ�
���O�m�[�g�ɂ��N���Ă����낗
AMD�ɓs���������Ƃ����A�d�K�[�Ƃ������o���A�z
������Ȃ���z�O�ɂ���������ł��Ȃ�
���O�m�[�g�ɂ��N���Ă����낗
AMD�ɓs���������Ƃ����A�d�K�[�Ƃ������o���A�z
>>445
���o�C���͉�����Ȃ����A�N�����A�d�_�҂���Ȃ��̂��H�A���_�[�K�[���H
��Ȃ���Ȃ��Ď����B7��8������e���܂������ʕ��Ȃ̂ɂȂ������Ȃ�
3Dmark�͌Â��̂���ŐV�̂܂őS�ăx���`����̂ɑ���
PCmark�͊�Ȃ�7�g�������A�ŐV��8���g��Ȃ����R�͂ȂH
�g��Ȃ����R�ɐ��� �a�v�͂��������Ă���
�uPCMark�͊���Windows 8.1�ɂ��Ή�����PCMark8��������̂́A
�X�R�A�̌݊������������߁A���ʂ�7�̂܂ܗl�q���݂����B�v
�X�R�A�̌݊�������������Ȃ��ĂH���R�ɂȂ邩����
�g��Ȃ��ł����炢�܂ł����Ă��X�R�A�̌݊����Ȃ�Ăł��₵�Ȃ��A�������Ă邾��
�P��7��8�̗����ő�����������̎����낤�A3DMark�̎��͕����̃V���[�Y�ő����Ă����
�o�n�߂�8������PCmark8���g���Ă����̂����������A��������鎞������p�^���Ǝ~��
���ʂ͐V�����o�[�W�����̃x���`�̕������Ԍo�߂Ƌ��ɑ����Ă������̂����A�Ȃ��͌���Ƃ����䌻��
Baytrail�̃��r���[��PCMark8 Home�x���`�g�����̂�����Ȃ炿����Ɠ\���Ă݂�
���Ȃ݂ɃA�X�L�[�̒O���t���Ƃ����Ȃ��Ă�
http://ascii.jp/elem/000/000/817/817374/PCMark8_240x.jpg
���͂�l�����A�����Ƃ����������悤���Ȃ���
���o�C���͉�����Ȃ����A�N�����A�d�_�҂���Ȃ��̂��H�A���_�[�K�[���H
��Ȃ���Ȃ��Ď����B7��8������e���܂������ʕ��Ȃ̂ɂȂ������Ȃ�
3Dmark�͌Â��̂���ŐV�̂܂őS�ăx���`����̂ɑ���
PCmark�͊�Ȃ�7�g�������A�ŐV��8���g��Ȃ����R�͂ȂH
�g��Ȃ����R�ɐ��� �a�v�͂��������Ă���
�uPCMark�͊���Windows 8.1�ɂ��Ή�����PCMark8��������̂́A
�X�R�A�̌݊������������߁A���ʂ�7�̂܂ܗl�q���݂����B�v
�X�R�A�̌݊�������������Ȃ��ĂH���R�ɂȂ邩����
�g��Ȃ��ł����炢�܂ł����Ă��X�R�A�̌݊����Ȃ�Ăł��₵�Ȃ��A�������Ă邾��
�P��7��8�̗����ő�����������̎����낤�A3DMark�̎��͕����̃V���[�Y�ő����Ă����
�o�n�߂�8������PCmark8���g���Ă����̂����������A��������鎞������p�^���Ǝ~��
���ʂ͐V�����o�[�W�����̃x���`�̕������Ԍo�߂Ƌ��ɑ����Ă������̂����A�Ȃ��͌���Ƃ����䌻��
Baytrail�̃��r���[��PCMark8 Home�x���`�g�����̂�����Ȃ炿����Ɠ\���Ă݂�
���Ȃ݂ɃA�X�L�[�̒O���t���Ƃ����Ȃ��Ă�
http://ascii.jp/elem/000/000/817/817374/PCMark8_240x.jpg
{kind=link}
���͂�l�����A�����Ƃ����������悤���Ȃ���
�C�O�̂��\���Ă�����
http://www.hardwareheaven.com/reviewimages/amd-richland-apu-review/swf/jpg/pcmark8.jpg
http://legitreviews.com/images/reviews/2209/pcmark8.jpg
����ƂȁA����͊C�O�ł������Ȃ��A
PCMark8�g�����x���`���ƁA�Ȃ���INTEL vs AMD�̐}���̂��̂��ɒ[�ɏ��Ȃ�������
�قƂ��INTEL vs INTEL��AMD vs AMD�Ƃ���������Ђ̐��i���m�̔�r�ł����g���ĂȂ�
����Ȃ̂��Ă��邩�H
����INTEL���������ނ��Ă�Ƃ������Ă��Ȃ���
�L�������Ă�z���h�����܂����h�Ǝv���Ĕ����Ă���}�炸�����̋L�҂̐S��Ƃ������N���Ă��܂���
�S�̂̌X���Ƃ��Č���Ă��܂��Ă����Ȃ��̂����Ď����w�E���Ă��
http://www.hardwareheaven.com/reviewimages/amd-richland-apu-review/swf/jpg/pcmark8.jpg
{kind=link}
http://legitreviews.com/images/reviews/2209/pcmark8.jpg
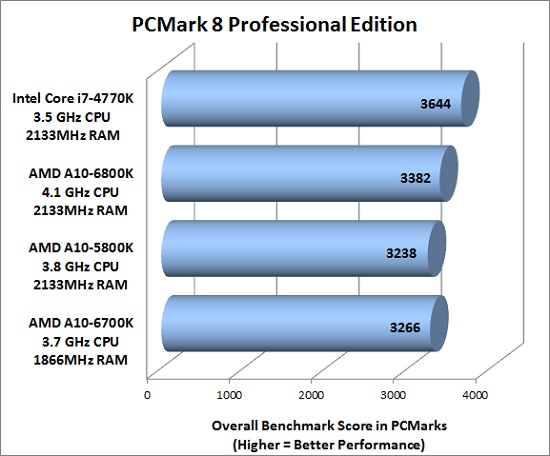{kind=link}
����ƂȁA����͊C�O�ł������Ȃ��A
PCMark8�g�����x���`���ƁA�Ȃ���INTEL vs AMD�̐}���̂��̂��ɒ[�ɏ��Ȃ�������
�قƂ��INTEL vs INTEL��AMD vs AMD�Ƃ���������Ђ̐��i���m�̔�r�ł����g���ĂȂ�
����Ȃ̂��Ă��邩�H
����INTEL���������ނ��Ă�Ƃ������Ă��Ȃ���
�L�������Ă�z���h�����܂����h�Ǝv���Ĕ����Ă���}�炸�����̋L�҂̐S��Ƃ������N���Ă��܂���
�S�̂̌X���Ƃ��Č���Ă��܂��Ă����Ȃ��̂����Ď����w�E���Ă��
�Ȃ�قǁB
PCMark8���ƁA���炩��APU��Haswell�Ƃ����������Ă�
�ނ��뉿�i���l������叟���ƌ����Ă�����
�����Intel��Intel�M�҂̋L�҂��s���������
PCMark8���ƁA���炩��APU��Haswell�Ƃ����������Ă�
�ނ��뉿�i���l������叟���ƌ����Ă�����
�����Intel��Intel�M�҂̋L�҂��s���������
�~Intel�M�҂�
��Intel�ɉa�t�����ꂽ
��Intel�ɉa�t�����ꂽ
450 �FSocket774�F2013/12/23(��) 01:50:20.50 ID:rK5sZiqG
�܂�Ń��N�U�Ƃ����a���S�l��̂Ɠ�����@���ȁB
���ƃ\�t�g�o���N�Ƃ��B
���ƃ\�t�g�o���N�Ƃ��B
451 �F,,�E�L�́M�E,,�j��-�������F2013/12/23(��) 01:54:35.49 ID:RkfXxEXv
�x���`�}�[�N��APU�ɍœK���i�j����Ă����[�U�[�̗��p�V�[����
PCMark7�Ɣ�ׂĕς��킯����Ȃ�����
PCMark7�Ɣ�ׂĕς��킯����Ȃ�����
>>451
PCMark8��office��Adobe�̎��A�v���g���Čv�����Ă�̒m��Ȃ��̂��H
PCMark8��office��Adobe�̎��A�v���g���Čv�����Ă�̒m��Ȃ��̂��H
453 �F,,�E�L�́M�E,,�j��-�������F2013/12/23(��) 02:00:53.08 ID:RkfXxEXv
���A�v���H���ۂ�Word��Excel��Photoshop����������Ă�Ƃł��H
����͌��삾�Ȃ�
����͌��삾�Ȃ�
>>451
���O��Ƃ݂����Ȃ������˂������ςݏオ�������Â�������
���Ӗ��ɑ���ʂɂ������j�^�[��2ch�̃^�u���ɊJ���̂ɓK���Ă�̂�Intel�Ȃ̂͂킩���Ă邩��
���O��Ƃ݂����Ȃ������˂������ςݏオ�������Â�������
���Ӗ��ɑ���ʂɂ������j�^�[��2ch�̃^�u���ɊJ���̂ɓK���Ă�̂�Intel�Ȃ̂͂킩���Ă邩��
455 �F,,�E�L�́M�E,,�j��-�������F2013/12/23(��) 02:05:09.07 ID:RkfXxEXv
���ۂ�Word��Excel���g���Ƃ��������o��킯�ł���
http://us.hardware.info/reviews/4761/15/intel-core-i7-4960x---4930k--4820k-ivy-bridge-e-review-22nm-powerhouse-benchmarks-microsoft-word-2013
http://us.hardware.info/reviews/4761/14/intel-core-i7-4960x---4930k--4820k-ivy-bridge-e-review-22nm-powerhouse-benchmarks-microsoft-excel-2013
http://us.hardware.info/reviews/4761/15/intel-core-i7-4960x---4930k--4820k-ivy-bridge-e-review-22nm-powerhouse-benchmarks-microsoft-word-2013
http://us.hardware.info/reviews/4761/14/intel-core-i7-4960x---4930k--4820k-ivy-bridge-e-review-22nm-powerhouse-benchmarks-microsoft-excel-2013
456 �F,,�E�L�́M�E,,�j��-�������F2013/12/23(��) 02:07:28.95 ID:RkfXxEXv
> �������˂������ςݏオ�������Â�������
���������̑z���ł��Ȃ��Ȃ�
�����̕���������������ł���
���������̑z���ł��Ȃ��Ȃ�
�����̕���������������ł���
>>455
�݂��Ƃ��Ȃ��^������Ȃ�
���[�N���[�h�ɕK�v�ȕ������������Ă�̂��A�O������ǂݍ���ł�̂�����Ȃ����A���A�v���̂��̂��g���Ă鎖�ɂ͂����Ȃ�
http://s3.amazonaws.com/futuremark-static/downloads/PCMark_8_Technical_Guide.pdf
PCMark 8�̓f�X�N�g�b�vPC����^�u���b�g�[���܂ŁC������PC�ł̐��\�v�����\�Ƃ���悤�ɐv���ꂽ�x���`�}�[�N�A�v���P�[�V�������B
�m�[�gPC�����̃o�b�e���[�쓮���Ԍv���e�X�g�uBattery life testing�v��CSSD��HDD�C�n�C�u���b�h�X�g���[�W�̐��\���v������X�g���[�W�e�X�g�ȂǁC
PC�̍\���v�f���ꂼ��ɑ���e�X�g�ƁCAdobe Systems�́uAdobe Photoshop�v��uAdobe InDesign�v�CMicrosoft�́uMicrosoft Word/Excel/PowerPoint�v�Ƃ������C
��v�ȃA�v���P�[�V������p���āC���g�p���ł̐��\���v��e�X�g���Ƃ��ɓ������Ă���̂������ƂȂ��Ă���B
http://www.4gamer.net/games/216/G021685/20131021077/
�݂��Ƃ��Ȃ��^������Ȃ�
���[�N���[�h�ɕK�v�ȕ������������Ă�̂��A�O������ǂݍ���ł�̂�����Ȃ����A���A�v���̂��̂��g���Ă鎖�ɂ͂����Ȃ�
http://s3.amazonaws.com/futuremark-static/downloads/PCMark_8_Technical_Guide.pdf
PCMark 8�̓f�X�N�g�b�vPC����^�u���b�g�[���܂ŁC������PC�ł̐��\�v�����\�Ƃ���悤�ɐv���ꂽ�x���`�}�[�N�A�v���P�[�V�������B
�m�[�gPC�����̃o�b�e���[�쓮���Ԍv���e�X�g�uBattery life testing�v��CSSD��HDD�C�n�C�u���b�h�X�g���[�W�̐��\���v������X�g���[�W�e�X�g�ȂǁC
PC�̍\���v�f���ꂼ��ɑ���e�X�g�ƁCAdobe Systems�́uAdobe Photoshop�v��uAdobe InDesign�v�CMicrosoft�́uMicrosoft Word/Excel/PowerPoint�v�Ƃ������C
��v�ȃA�v���P�[�V������p���āC���g�p���ł̐��\���v��e�X�g���Ƃ��ɓ������Ă���̂������ƂȂ��Ă���B
http://www.4gamer.net/games/216/G021685/20131021077/
>>453
����AMD�̔�r����f���̒i�K�ŁAOffice�̏�����IntelCPU�ƌ݊p�������Ă��ł���
Richland�����O���AMD��Youtube���悠��ł���
���ꂪ���ۂ̗��p�V�[������Ȃ��ĉ��Ȃ̂�
����AMD�̔�r����f���̒i�K�ŁAOffice�̏�����IntelCPU�ƌ݊p�������Ă��ł���
Richland�����O���AMD��Youtube���悠��ł���
���ꂪ���ۂ̗��p�V�[������Ȃ��ĉ��Ȃ̂�
PCMark8�̓V�X�e���S�̂̑������\������x���`�}�[�N�ɂȂ��Ă��邩��
CPU��r�ɂ͂Ȃ��Ă��Ȃ����A���������g�����͓K�łȂ�
IO���\�Ƃ��ł��X�R�A���啝�ɕς��
>>453
�ꕔ�̃x���`���ڂ͖{���ɃC���X�g�[���ς݂̎��A�v���𐧌䂷��`�������悤��
����͂���ň�̃A�v���[�`�ł͂��邪�c�c
CPU��r�ɂ͂Ȃ��Ă��Ȃ����A���������g�����͓K�łȂ�
IO���\�Ƃ��ł��X�R�A���啝�ɕς��
>>453
�ꕔ�̃x���`���ڂ͖{���ɃC���X�g�[���ς݂̎��A�v���𐧌䂷��`�������悤��
����͂���ň�̃A�v���[�`�ł͂��邪�c�c
Application Test�̓���: �����Advanced Edition�ȏ�ŗ��p�ł���@�\�ƂȂ��Ă��邪�A
Adobe��Creative Suite 6�ȍ~��������Adobe Creative Cloud���g����Adobe Creative Suite test�A
�y��Microsoft Office 2010/2013���g����Microsoft Office test���p�ӂ��ꂽ�B
���̃e�X�g�ɓ������ẮA�ʓrAdobe Creative Suite/Cloud�A��������Office 2010/2013���C���X�g�[������K�v������
(������PCMark 8�ɂ͊܂܂�Ȃ�)���A���̎��A�v���P�[�V�������g���Ẵe�X�g���T�|�[�g���ꂽ�B
http://news.mynavi.jp/special/2013/pcmark8/001.html
�C���X�g�[���K�v�Ƃ��邩��O���ǂݍ��݂���
���ꂪ���A�v������Ȃ���Ȃ�ȂH
Adobe��Creative Suite 6�ȍ~��������Adobe Creative Cloud���g����Adobe Creative Suite test�A
�y��Microsoft Office 2010/2013���g����Microsoft Office test���p�ӂ��ꂽ�B
���̃e�X�g�ɓ������ẮA�ʓrAdobe Creative Suite/Cloud�A��������Office 2010/2013���C���X�g�[������K�v������
(������PCMark 8�ɂ͊܂܂�Ȃ�)���A���̎��A�v���P�[�V�������g���Ẵe�X�g���T�|�[�g���ꂽ�B
http://news.mynavi.jp/special/2013/pcmark8/001.html
�C���X�g�[���K�v�Ƃ��邩��O���ǂݍ��݂���
���ꂪ���A�v������Ȃ���Ȃ�ȂH
���������A��ŏグ���Ă�̂�HOME�̃X�R�A������
Office��Adobe�̃e�X�g�͊܂܂�Ă��Ȃ�
http://news.mynavi.jp/special/2013/pcmark8/001.html
Office��Adobe�̃e�X�g�͊܂܂�Ă��Ȃ�
http://news.mynavi.jp/special/2013/pcmark8/001.html
462 �F,,�E�L�́M�E,,�j��-�������F2013/12/23(��) 02:16:12.27 ID:RkfXxEXv
PDF�̓��e�������Ė�������B�p��ǂ߂Ȃ��Ȃ疳������Ȃ���
PCMark8�ŕ]�����Ă�̂͂����܂�Word�ł�Excel�ł�Photoshop�ł��Ȃ��u�ˋ�̃A�v���v��
���ۂɂ�Word��Excel�ŐV�ł�2013�APhotoshop�ŐV�ł�CS6�̎��ۂ̃A�v�����g�������ʂ�
�ق炱�̂Ƃ���A�Ƃ������ƁB
PCMark8�ŕ]�����Ă�̂͂����܂�Word�ł�Excel�ł�Photoshop�ł��Ȃ��u�ˋ�̃A�v���v��
���ۂɂ�Word��Excel�ŐV�ł�2013�APhotoshop�ŐV�ł�CS6�̎��ۂ̃A�v�����g�������ʂ�
�ق炱�̂Ƃ���A�Ƃ������ƁB
�܂��c�q�̔s�k��
�A���������ςȂ��ł悭�����Ă����
�A���������ςȂ��ł悭�����Ă����
464 �F,,�E�L�́M�E,,�j��-�������F2013/12/23(��) 02:18:44.50 ID:RkfXxEXv
�������ł��Ȃ����@�J���Ă����]���ő叟�����Ă�Ȃ�
>>459
���̘b��>>433�̏������݂ɋN�����邯�ǁACPU�̐��\���͂�����̂��Ƃ͂���������Ă��Ȃ��ł���
PCMark8�̃X�R�A����i5�ɏ���A�P�ɂ��ꂾ���̘b����
���������ł����ƁA�����������������̂��̂𖭂ɓ˂�������z������킯��
���̘b��>>433�̏������݂ɋN�����邯�ǁACPU�̐��\���͂�����̂��Ƃ͂���������Ă��Ȃ��ł���
PCMark8�̃X�R�A����i5�ɏ���A�P�ɂ��ꂾ���̘b����
���������ł����ƁA�����������������̂��̂𖭂ɓ˂�������z������킯��
>>458
��{�I��AMD���L��p�ɏo�������Ƃ������f���͍������̂���������M�p�ł��Ȃ��ł���
OpenCL��56�{�������H
���\�O�ɕ��ʂ͂��������Ǝv���͂��̂��̂����R�Əo�Ă���
��{�I��AMD���L��p�ɏo�������Ƃ������f���͍������̂���������M�p�ł��Ȃ��ł���
OpenCL��56�{�������H
���\�O�ɕ��ʂ͂��������Ǝv���͂��̂��̂����R�Əo�Ă���
467 �F,,�E�L�́M�E,,�j��-�������F2013/12/23(��) 02:20:39.07 ID:RkfXxEXv
�f�p�ȋ^�₾��APU�i�j�̐��\���֎����邽�߂́u����GPU����x���`�v��
����GPU�������ĂȂ�FX���i7-49xx�V���[�Y���ǁ[����ĕ]������̂��낤���H
����GPU�������ĂȂ�FX���i7-49xx�V���[�Y���ǁ[����ĕ]������̂��낤���H
���Ԕ��̐l�͒u���Ă����Ƃ���
>>455
����@����ɁAPC Mark08 Application Test�̃X�R�A��
�傫��������\���������BHOME�̃X�R�A�����o����
�����錾����Ӗ����킩��Ȃ�
>>455
����@����ɁAPC Mark08 Application Test�̃X�R�A��
�傫��������\���������BHOME�̃X�R�A�����o����
�����錾����Ӗ����킩��Ȃ�
469 �F,,�E�L�́M�E,,�j��-�������F2013/12/23(��) 02:22:54.30 ID:RkfXxEXv
> Workload�ڍ� - Writing
>
> �����.NET Framework 4.5���g�����e�L�X�g�G�f�B�^(Photo17)���g���A
> 2�̃h�L�������g���J���ăR�s�[/�J�b�g�A���h�y�[�X�g/�e�L�X�g�}��/
> �摜�}��/�ۑ��Ƃ������������L�[�����͂��Ď��{����B�e�X�g�́A
> �e�X�̏���(���v11���)�ɗv�������v���Ԃ𑪒�A�������畽�ς�
> �������Ԃ𑊏敽�ςŎZ�o����B
���ꂪ�ˋ�̃A�v���łȂ��ĂȂ�Ȃ�
>
> �����.NET Framework 4.5���g�����e�L�X�g�G�f�B�^(Photo17)���g���A
> 2�̃h�L�������g���J���ăR�s�[/�J�b�g�A���h�y�[�X�g/�e�L�X�g�}��/
> �摜�}��/�ۑ��Ƃ������������L�[�����͂��Ď��{����B�e�X�g�́A
> �e�X�̏���(���v11���)�ɗv�������v���Ԃ𑪒�A�������畽�ς�
> �������Ԃ𑊏敽�ςŎZ�o����B
���ꂪ�ˋ�̃A�v���łȂ��ĂȂ�Ȃ�
>>465
i5�Ƃ����̂́A���Ԃ�CPU�̃u�����h���̂��Ƃ��Ǝv���̂����c�c
i5�Ƃ����̂́A���Ԃ�CPU�̃u�����h���̂��Ƃ��Ǝv���̂����c�c
{kind=link}
�����錾�Ƃ����@�N��͒N���Ɛ���Ă�́H
����AMD�ɋ�������l�Ɛ��Ԙb�����Ă����Ȃ�
����AMD�ɋ�������l�Ɛ��Ԙb�����Ă����Ȃ�
475 �F,,�E�L�́M�E,,�j��-�������F2013/12/23(��) 02:28:36.33 ID:RkfXxEXv
�߂�ǂ����A���L���\���Ƃ���
http://cpu.zol.com.cn/383/3834644_all.html
Home����g����̂�Home�����낤����INTEL�ɗL�������炾��
http://cpu.zol.com.cn/383/3834644_all.html
Home����g����̂�Home�����낤����INTEL�ɗL�������炾��
478 �F,,�E�L�́M�E,,�j��-�������F2013/12/23(��) 02:32:02.42 ID:RkfXxEXv
http://us.hardware.info/reviews/4761/8/intel-core-i7-4960x---4930k--4820k-ivy-bridge-e-review-22nm-powerhouse-benchmarks-adobe-photoshop-cs6
Photoshop���P�̎��s������i3�ɂ������Ă邼�A6800K
Photoshop���P�̎��s������i3�ɂ������Ă邼�A6800K
���ႠPCMark8�̃X�R�A�ɂ͈٘_�����Ȃ킯��
����PCMark8�̘b�ɓ�Ȃ����A�z���������珑�����܂�
���͕ʂɂǂ��ł�������Ai3��6800k�ɏ����Ă悩���������A�����ς������Ƃ�����
����PCMark8�̘b�ɓ�Ȃ����A�z���������珑�����܂�
���͕ʂɂǂ��ł�������Ai3��6800k�ɏ����Ă悩���������A�����ς������Ƃ�����
>>478
HWI OpenCL Bench���Ă̂������Ă���
HWI OpenCL Bench���Ă̂������Ă���
>>479
�ǂ����f���邩�͐l���ꂼ��A�N�͂�������Ă��ς˂Ă����
����PCMark8���g���Ȃ��̂ɂ͂��ꑊ���̗��R������Ƃ������Ƃ������ł����炻��Ŗ���
�ǂ����f���邩�͐l���ꂼ��A�N�͂�������Ă��ς˂Ă����
����PCMark8���g���Ȃ��̂ɂ͂��ꑊ���̗��R������Ƃ������Ƃ������ł����炻��Ŗ���
483 �F,,�E�L�́M�E,,�j��-�������F2013/12/23(��) 02:39:52.61 ID:RkfXxEXv
.NET 4.5����GPU�̃h���[�A�N�Z�����[�V���������Ă邩���
�ł�PCMark8���g���Ă�.NET 4.5�͂܂������܂ŕ��y���ĂȂ��E�E�E�Ƃ�����
�̐S��MS Office�ł���l�C�e�B�u�����Ȃ��i�������̂ق����������j
.NET 4.5���Ă�����VS2012���炾��
�ł�PCMark8���g���Ă�.NET 4.5�͂܂������܂ŕ��y���ĂȂ��E�E�E�Ƃ�����
�̐S��MS Office�ł���l�C�e�B�u�����Ȃ��i�������̂ق����������j
.NET 4.5���Ă�����VS2012���炾��
>>482
�l�̋^��ɂ������ȗᎦ����������A���̒��߂�����͖����킠
�l�̋^��ɂ������ȗᎦ����������A���̒��߂�����͖����킠
485 �F,,�E�L�́M�E,,�j��-�������F2013/12/23(��) 02:56:33.89 ID:RkfXxEXv
���ۂ�Office��Adobe Photoshop�̍ŐV�ł��g���ăx���`�}�[�N������
���i�ǂ���̐��\�ɂȂ����B
���ꂪ�܂��Ɂu�����̗��R�v����Ȃ�����
������GPU�A�N�Z�����[�V�������������Ƃ����Ă�.NET���̂�
x86/x64�l�C�e�B�u���x���ł���
���i�ǂ���̐��\�ɂȂ����B
���ꂪ�܂��Ɂu�����̗��R�v����Ȃ�����
������GPU�A�N�Z�����[�V�������������Ƃ����Ă�.NET���̂�
x86/x64�l�C�e�B�u���x���ł���
AMD�����X���C�h��PCMark8��4670k��Win8����8.1�ł��炢�X�R�A���Ⴍ�Ȃ��Ă���ŁA
�����̉\���͂���ǁA������ƐM�p�ł��Ȃ����Ȃƌ����C������
�����̉\���͂���ǁA������ƐM�p�ł��Ȃ����Ȃƌ����C������
AMD���낤��intel���낤����{�c�̔��\�͐M�p�ł��Ȃ���i�E�́E�j
488 �F,,�E�L�́M�E,,�j��-�������F2013/12/23(��) 03:19:46.74 ID:RkfXxEXv
�܂�Photoshop��AVX2�Ή����Ă邩��i3�ɕ����ē��R�����
AMD�͎v�z�������ɍs�������Ă��Ȃ�
FX�ɂ��Ă�APU�ɂ��Ă����̑O�̒��ԉ��݂����Ȑ��i���o���ׂ��Ȃ̂������ꂪ�ł��Ȃ����甄��Ȃ�����
FX�ɂ��Ă�APU�ɂ��Ă����̑O�̒��ԉ��݂����Ȑ��i���o���ׂ��Ȃ̂������ꂪ�ł��Ȃ����甄��Ȃ�����
>>483
.NET4.5��.NET4���C���v���[�X�ɒu�������邩��VS2010�̂��ΏۂɂȂ�
.NET4.5��.NET4���C���v���[�X�ɒu�������邩��VS2010�̂��ΏۂɂȂ�
PCMark8.1�ł�Intel�̃X�R�A��������悤��AMD�����͂����������Ƃ͕�������
492 �F,,�E�L�́M�E,,�j��-�������F2013/12/23(��) 07:07:12.90 ID:RkfXxEXv
�l�C�e�B�u�A�v��
����܂�.NET�̈Ӗ����Ȃ����
Java�قǃ}���`�v���b�g�t�H�[���œ����킯�ł��Ȃ����
�l�C�e�B�ux86/x64�̐��\�ɋy�Ԃ킯�ł��Ȃ��B
�}���`�v���b�g�t�H�[����肽����Web�x�[�X�ł����Ċ��������B
�iOffice365�Ƃ�GoogleApps�Ȃ�������j
�悭������GPU�ς�łȂ�FX�����Ȃ荂�X�R�A�ɂȂ��Ă邪�A�����炭
�Ȃɂ�����̈ˑ��W�`�F�C����������ILP���Ⴍ�Ē�IPC�ł����N���b�N��
�ق����L���ɂȂ��Ă邾������ˁH
����A�������ɍ��N���b�N�łԂ��AMD�ɂ͑��ΓI�ɗL����������Ȃ�����
����l�C�e�B�u���x������A�������E�E�E
����܂�.NET�̈Ӗ����Ȃ����
Java�قǃ}���`�v���b�g�t�H�[���œ����킯�ł��Ȃ����
�l�C�e�B�ux86/x64�̐��\�ɋy�Ԃ킯�ł��Ȃ��B
�}���`�v���b�g�t�H�[����肽����Web�x�[�X�ł����Ċ��������B
�iOffice365�Ƃ�GoogleApps�Ȃ�������j
�悭������GPU�ς�łȂ�FX�����Ȃ荂�X�R�A�ɂȂ��Ă邪�A�����炭
�Ȃɂ�����̈ˑ��W�`�F�C����������ILP���Ⴍ�Ē�IPC�ł����N���b�N��
�ق����L���ɂȂ��Ă邾������ˁH
����A�������ɍ��N���b�N�łԂ��AMD�ɂ͑��ΓI�ɗL����������Ȃ�����
����l�C�e�B�u���x������A�������E�E�E
PCMark���ď\���N�O�ɂ�Ver.UP�ŃX�R�A�t�]���ĂȂ����������H
���̎���AMD�����f���i���o�[������������AMD��Intel�ɕς�����悤��
���̎���AMD�����f���i���o�[������������AMD��Intel�ɕς�����悤��
���ꂾ��
�O���t�̓��e�ɕ�������͎����ł����Ƃ���pcmark8�̃O���t�T���Ă��ē\��Ηǂ���
�O���t�̓��e�ɕ�������͎����ł����Ƃ���pcmark8�̃O���t�T���Ă��ē\��Ηǂ���
�T����Ȃ��Ď����̎莝����PC�̌��ʂ�UP���悤�悗
�Q�[���̃x���`���ʂ��\���Ă�
497 �F,,�E�L�́M�E,,�j��-�������F2013/12/23(��) 11:36:52.43 ID:RkfXxEXv
ID:Q5CVtl7l �I�ɂ�.NET�̃p�t�H�[�}���X���d�v�Ȃ�H
���ۂ̂Ƃ���N���C�A���g�A�v����.NET���ϋɓI�ɍ̗p����Ă�̂�
�����̂��p�t�H�[�}���X������Ȃ����������p�A�v�����炢�ł���B
AMD�͂��������ʂ̉c�Ɨ͎ア�ł���B
Celeron�Ɖ��i��������́H
C++�l�C�e�B�u���x���Ȃ��Ă���������J���H������肽������.NET�Ȃ킯��
�Ɩ��Ɏx�Ⴊ�o��قǏd���Ȃ�Ȃ���Ȃ�ł������킯�B
�����x�Ⴊ�o��قǏd�����Ȃ�CPU��ς�����܂��A�z�ȃv���O���}��
�������R�[�h�����������ق����������x���B
�Ԃ����Ⴏ������������ɂ́uAPU�v�Ƃ�����Ă͎�����Ȃ��ł��傤�ȁB
�l�C�e�B�u��@����SSE��AVX���g���Ă��܂����\���s�����镪��ɂ���GPGPU�Ƃ���
��Ă���������킯�ŁA�v�����O�a���Ă���Ƃ���Ɏ��v�͐��܂�Ȃ��B
���ۂ̂Ƃ���N���C�A���g�A�v����.NET���ϋɓI�ɍ̗p����Ă�̂�
�����̂��p�t�H�[�}���X������Ȃ����������p�A�v�����炢�ł���B
AMD�͂��������ʂ̉c�Ɨ͎ア�ł���B
Celeron�Ɖ��i��������́H
C++�l�C�e�B�u���x���Ȃ��Ă���������J���H������肽������.NET�Ȃ킯��
�Ɩ��Ɏx�Ⴊ�o��قǏd���Ȃ�Ȃ���Ȃ�ł������킯�B
�����x�Ⴊ�o��قǏd�����Ȃ�CPU��ς�����܂��A�z�ȃv���O���}��
�������R�[�h�����������ق����������x���B
�Ԃ����Ⴏ������������ɂ́uAPU�v�Ƃ�����Ă͎�����Ȃ��ł��傤�ȁB
�l�C�e�B�u��@����SSE��AVX���g���Ă��܂����\���s�����镪��ɂ���GPGPU�Ƃ���
��Ă���������킯�ŁA�v�����O�a���Ă���Ƃ���Ɏ��v�͐��܂�Ȃ��B
CPU���\�͏\���ƌ�����GPU�����Ƃ�HSA�Ɋ��҂��邱�̃X���̖���
�����̕��U���ŁA�R�X�g������̌������グ��BOS�̃g�����h�ɍ��킹��B
���{���s���R�Ȑl���g���������āA�����̓I�͂���Ȍ���������o�J���ł��ˁB
���{���s���R�Ȑl���g���������āA�����̓I�͂���Ȍ���������o�J���ł��ˁB
>>498
�@���ƂȂ��ẮA�l�p�r�Ő��\���V��ŕK�v�Ȃ̂̓Q�[���ƃ��f�B�A
�W�ʂȂ킯�ŁA�����ėp��������Ăł��������������C/P�ǂ����\��
�L����Ȃ�A�ėp���S�U���CPU�ŃS������������ǂ��ł���B
�@���ƂȂ��ẮA�l�p�r�Ő��\���V��ŕK�v�Ȃ̂̓Q�[���ƃ��f�B�A
�W�ʂȂ킯�ŁA�����ėp��������Ăł��������������C/P�ǂ����\��
�L����Ȃ�A�ėp���S�U���CPU�ŃS������������ǂ��ł���B
502 �FSocket774�F2013/12/23(��) 12:41:04.09 ID:Jb+cbX4z
Cpu�̔ėp���\���[����������AGpu�̃��f�B�A���\�����p���悤�Ƃ����̂�AMD�̊�{�헪�ł���HSA�Ȃ��
�܂��A�ėp���\�ŗ��C���e���ɂ͖����Ȑ헪����
�����ƈӖ����ő��Ȃ��ɓ������V���O���X���b�h���\�������߂Ă��������
�܂��A�ėp���\�ŗ��C���e���ɂ͖����Ȑ헪����
�����ƈӖ����ő��Ȃ��ɓ������V���O���X���b�h���\�������߂Ă��������
�ݸ�ٽگ�ް���Č����Ă�������s�k��
�x���`�ł��畉�������i5�ɑ��݉��l������
�x���`�ł��畉�������i5�ɑ��݉��l������
ttp://en.wikipedia.org/wiki/AMD_Fusion
Architectural Integration - 2014 Kaveri APU
�EUnified Address Space for CPU and GPU �F CPU and GPU now access the memory with the same address space. Pointers can now be freely passed between CPU and GPU.
�EFully coherent memory between CPU & GPU �F GPU can now access and cache data from coherent memory regions in the system memory, and also reference the data from CPU's cache. Cache coherency is maintained.
�EGPU uses pageable system memory via CPU pointers �FGPU can take advantage of the shared virtual memory between CPU and GPU, and pageable system memory can now be referenced directly by the GPU, instead of being copied or pinned before accessing.
System Integration - 2015 Carizzo APU
�EGPU compute context switch �F Compute tasks on GPU can be context switched, allowing a multi-tasking environment and also faster interpretation between applications, compute and graphics.
�EGPU graphics pre-emption �F Long-running graphics tasks can be pre-empted so processes have low latency access to the GPU.
�EQuality of Service �F In addition to context switch and pre-emption, hardware resources can be either equalized or prioritized among multiple users and applications.
Architectural Integration - 2014 Kaveri APU
�EUnified Address Space for CPU and GPU �F CPU and GPU now access the memory with the same address space. Pointers can now be freely passed between CPU and GPU.
�EFully coherent memory between CPU & GPU �F GPU can now access and cache data from coherent memory regions in the system memory, and also reference the data from CPU's cache. Cache coherency is maintained.
�EGPU uses pageable system memory via CPU pointers �FGPU can take advantage of the shared virtual memory between CPU and GPU, and pageable system memory can now be referenced directly by the GPU, instead of being copied or pinned before accessing.
System Integration - 2015 Carizzo APU
�EGPU compute context switch �F Compute tasks on GPU can be context switched, allowing a multi-tasking environment and also faster interpretation between applications, compute and graphics.
�EGPU graphics pre-emption �F Long-running graphics tasks can be pre-empted so processes have low latency access to the GPU.
�EQuality of Service �F In addition to context switch and pre-emption, hardware resources can be either equalized or prioritized among multiple users and applications.
>>497
�܂����́H.NET�H����I�O��
����PCMark8�̃X�R�A�̘b�������ĂȂ�
�hwin8.1+PCMark8����A10�̃X�R�A��i5�̃X�R�A���ǂ��Ȃ�݂����ˁh���Ă��������ꂾ���̘b
CPU���\��A10��i5���D���Ȃ�ď����Ă��������v���Ă����Ȃ�
�Ȃ̂ɏ���ɂ����咣���Ă�Ɗ��Ⴂ���Ęb������Ă�����
���������x���`�}�[�N�l�̗D��Ȃ�ċC�ɂ����Ⴂ�Ȃ���
�����C�ɂ��Ă�̂́h�Ȃ���Ȃ�PCMark8�������̂��h���Ď��Ȃ�
�������[�U�[�̗��ꂩ�猾���A�킯�킩���PCMark7�̃x���`���
Home�ACreative���A���ۂ̗��p�V�[����z�肵������PCMark8�̕����킩��₷����
Microsoft��Abbode���x���`�}�[�N����ŋ��͂��Ă���Ă��H
�Ȃ�������g��Ȃ��A�ǂ����������ċL���������Ă�
������������
�Ȃ̂ɂ��O��PCMark8�̗L�p����₢����A���[�N���[�h�����Ԃɑ����ĂȂ��Ǝ咣������
����͒P�Ƀx���`�}�[�N�S�ʂ̔ے�ɂ����Ȃ��ĂȂ��A����̉ʂĂɂ�.NET�HCeleron�H
�����x���`�}�[�N�ے�h������ے肵�����Ꮯ��ɂǂ����Ƃ���������
�܂����́H.NET�H����I�O��
����PCMark8�̃X�R�A�̘b�������ĂȂ�
�hwin8.1+PCMark8����A10�̃X�R�A��i5�̃X�R�A���ǂ��Ȃ�݂����ˁh���Ă��������ꂾ���̘b
CPU���\��A10��i5���D���Ȃ�ď����Ă��������v���Ă����Ȃ�
�Ȃ̂ɏ���ɂ����咣���Ă�Ɗ��Ⴂ���Ęb������Ă�����
���������x���`�}�[�N�l�̗D��Ȃ�ċC�ɂ����Ⴂ�Ȃ���
�����C�ɂ��Ă�̂́h�Ȃ���Ȃ�PCMark8�������̂��h���Ď��Ȃ�
�������[�U�[�̗��ꂩ�猾���A�킯�킩���PCMark7�̃x���`���
Home�ACreative���A���ۂ̗��p�V�[����z�肵������PCMark8�̕����킩��₷����
Microsoft��Abbode���x���`�}�[�N����ŋ��͂��Ă���Ă��H
�Ȃ�������g��Ȃ��A�ǂ����������ċL���������Ă�
������������
�Ȃ̂ɂ��O��PCMark8�̗L�p����₢����A���[�N���[�h�����Ԃɑ����ĂȂ��Ǝ咣������
����͒P�Ƀx���`�}�[�N�S�ʂ̔ے�ɂ����Ȃ��ĂȂ��A����̉ʂĂɂ�.NET�HCeleron�H
�����x���`�}�[�N�ے�h������ے肵�����Ꮯ��ɂǂ����Ƃ���������
506 �FSocket774�F2013/12/23(��) 13:14:31.09 ID:Jb+cbX4z
�c�q�͎��p�I���͊W�Ȃ��A�C���e�����x���`�ŏ��ĂȂ��̂̓x���`�����������ƌ����Ă��邾��
�C���e���̏����ȊO�͐�ΔF�߂Ȃ�����b����������
�������������̏Z�l�̓x���`�Ƃ��ǂ��ł�����
�J�x����}���g���AHSA�̋Z�p�⏫������wktk���Ă�����
��{�I�Ɉ��~�̓X���^�C�ǂ߂Ȃ��n�����肾���瑊�肷�邾������
�C���e���̏����ȊO�͐�ΔF�߂Ȃ�����b����������
�������������̏Z�l�̓x���`�Ƃ��ǂ��ł�����
�J�x����}���g���AHSA�̋Z�p�⏫������wktk���Ă�����
��{�I�Ɉ��~�̓X���^�C�ǂ߂Ȃ��n�����肾���瑊�肷�邾������
HSA���Ď��p�I�Ȃ́H
���A�v���̃x���`�o��܂ł킩��Ȃ��悤�ȋC���������
���A�v���̃x���`�o��܂ł킩��Ȃ��悤�ȋC���������
�F
���_�F�c�q�͌��Q
�F
�Ȃ�ق�
���_�F�c�q�͌��Q
�F
�Ȃ�ق�
�x���`�ŏ��ĂȂ��̂̓x���`�������������ĂȂ�www
509
�ǂ����̖������������͖�����
�Ԃ�10�E15���[�h�R��Ƃ�������GDP�Ƃ�
���ĂɂȂ�Ȃ������֎�i�������ق����ǂ����Č�����w�W�͂�����ł������Ȃ�����
�ǂ����̖������������͖�����
�Ԃ�10�E15���[�h�R��Ƃ�������GDP�Ƃ�
���ĂɂȂ�Ȃ������֎�i�������ق����ǂ����Č�����w�W�͂�����ł������Ȃ�����
http://www.itmedia.co.jp/pcuser/articles/1312/20/news153.html
���̂ق��A�VA�V���[�YAPU�iRichland�j���h���C�o�̃A�b�v�f�[�g�ɂ�萫�\�����サ�Ă������Ƃɂ��ĐG��A
�uA10�͂ǂ�Core i5�������\�������A���i�������BA8�͂ǂ�Core i3�����n�C�p�t�H�[�}���X�ň����v�Ƌ����B
�u�N���ɐV����PC��g�����ƍl���Ă���l��AMD��I�Ԃׂ��v�ƒ��߂��������B
���̂ق��A�VA�V���[�YAPU�iRichland�j���h���C�o�̃A�b�v�f�[�g�ɂ�萫�\�����サ�Ă������Ƃɂ��ĐG��A
�uA10�͂ǂ�Core i5�������\�������A���i�������BA8�͂ǂ�Core i3�����n�C�p�t�H�[�}���X�ň����v�Ƌ����B
�u�N���ɐV����PC��g�����ƍl���Ă���l��AMD��I�Ԃׂ��v�ƒ��߂��������B
�u�N���ɐV����PC��g�����ƍl���Ă���l�ŁARADEON R���h�����Ƃ͍l���Ă��Ȃ��l�́v����Ȃ��B
HSA�ŃQ�[�����ǂ��ς��́H
HSA�͊W�Ȃ���Ȃ�
>>512�@���Ȃ��Ƃ��V���Ă������}�V���x�ł͂����Ȃ��H
�ǂ���iGPU�ςނȂ炄GPU����ł��Ȃ����Ƃ���Ă����Ȃ��ƁA�P���ȃp���[����t�������Ă�
��GPU�ɂ͑����ł��ł��Ȃ�����
�V���O�����\�͎��Ԃ����ď��������ǂ��Ă������Ȃ����A�]���Ă�X�y�[�X�ŃR�A�����₷��
iGPU��ėp���Z�Ɏg�������đI�����Ȃ��҂̕������͌����I���Ǝv�����ǂ�
�ǂ���iGPU�ςނȂ炄GPU����ł��Ȃ����Ƃ���Ă����Ȃ��ƁA�P���ȃp���[����t�������Ă�
��GPU�ɂ͑����ł��ł��Ȃ�����
�V���O�����\�͎��Ԃ����ď��������ǂ��Ă������Ȃ����A�]���Ă�X�y�[�X�ŃR�A�����₷��
iGPU��ėp���Z�Ɏg�������đI�����Ȃ��҂̕������͌����I���Ǝv�����ǂ�
�������I��GPU�I�t���[�h���ׂ���ACPU�̏����������đ҂����Ԃ����Ȃ��Ȃ�A�������o�X�̕��ׂ������āA�����̕��U������B
�ƃQ�̐V�n�[�h�Ŏ��H����Ă���̂��A����͑����ɂ����b������Ă������ƂɁA���̕s�����Ȃ��͂�����
�e�Ɋp�A������ے肵�āA�������낷�l�^���ق����l�ɂ́A�����������ʂȘb����ȁB
�ƃQ�̐V�n�[�h�Ŏ��H����Ă���̂��A����͑����ɂ����b������Ă������ƂɁA���̕s�����Ȃ��͂�����
�e�Ɋp�A������ے肵�āA�������낷�l�^���ق����l�ɂ́A�����������ʂȘb����ȁB
520 �F,,�E�L�́M�E,,�j��-�������F2013/12/23(��) 16:08:35.98 ID:RkfXxEXv
> ���ۂ̗��p�V�[����z�肵�����
�l�p�ł͂قƂ�ǎg���ĂȂ�.NET Framework 4.5�őg�܂ꂽ�A�v�����g����
�u���p�V�[���v�Ȃ�đz�����ł��Ȃ��Ȃ��B���e�������ĂȂ��ł��傗
�l�p�ł͂قƂ�ǎg���ĂȂ�.NET Framework 4.5�őg�܂ꂽ�A�v�����g����
�u���p�V�[���v�Ȃ�đz�����ł��Ȃ��Ȃ��B���e�������ĂȂ��ł��傗
������AMD���V���{����Ђ��Ɣl���낤�Ƃ�
�l�����z���߂��Ђ�AMD���傫���Ȃ邱�Ƃ͂قږ����낤���ǂ�
�l�����z���߂��Ђ�AMD���傫���Ȃ邱�Ƃ͂قږ����낤���ǂ�
522 �F,,�E�L�́M�E,,�j��-�������F2013/12/23(��) 16:10:57.58 ID:RkfXxEXv
>>512
�����͋@�B��Ńn�[�h�E�F�A�ڎ��s�ł���B
OS�₻�̏�̃~�h���E�F�A�̏�Ŗ|�Ď��s���Ă��Ȃ��Ƃ����Ȃ�HSAIL
�Ȃ������̋@�B��Ɠ��������ʒu�ł���͂��͂Ȃ��B
�����͋@�B��Ńn�[�h�E�F�A�ڎ��s�ł���B
OS�₻�̏�̃~�h���E�F�A�̏�Ŗ|�Ď��s���Ă��Ȃ��Ƃ����Ȃ�HSAIL
�Ȃ������̋@�B��Ɠ��������ʒu�ł���͂��͂Ȃ��B
�����ϑz����
Intel�̎Ј����l���Ă����肷�邩����
�ł��܂���������Intel�Ј�������ȏ��Ŗ������Ă����Ȃ���Ȃ�
�ł��܂���������Intel�Ј�������ȏ��Ŗ������Ă����Ȃ���Ȃ�
HSA��>>517�̊֘A�����悭�킩��Ȃ���
HSA�Ȃ��Ă��ʂɂł���悤�ȋC������
HSA�Ȃ��Ă��ʂɂł���悤�ȋC������
���N�n�̍r�炵���̉���������
527 �F,,�E�L�́M�E,,�j��-�������F2013/12/23(��) 16:16:40.96 ID:RkfXxEXv
PCMark8��MS-Office��Adobe���i���Ăяo���@�\���lj����ꂽ�̂́A�t���I�ɂ�
�����̐��i�̓���p�t�H�[�}���X�𐄂��ʂ邽�߂̘������������Ƃ������Ƃ���
.NET Framework 4.5�œ��삷��A�v���̐��\��r�ɂ͏\���L���B
����Ȃ��̐��̒��ɂǂꂾ�����邩�m��Ȃ����ǂˁB
�G�ۂƂ�TextPad�Ƃ���Ԃ̃l�C�e�B�u�A�v��������̂�
.NET�őg�܂ꂽ�e�L�X�g�G�f�B�^�Ȃ�Ă킴�킴�l���g���̂��H
���ꂪ�������������ł���Ȃ牽���ے肵�Ă����邱�Ƃ͂Ȃ���B
�����̐��i�̓���p�t�H�[�}���X�𐄂��ʂ邽�߂̘������������Ƃ������Ƃ���
.NET Framework 4.5�œ��삷��A�v���̐��\��r�ɂ͏\���L���B
����Ȃ��̐��̒��ɂǂꂾ�����邩�m��Ȃ����ǂˁB
�G�ۂƂ�TextPad�Ƃ���Ԃ̃l�C�e�B�u�A�v��������̂�
.NET�őg�܂ꂽ�e�L�X�g�G�f�B�^�Ȃ�Ă킴�킴�l���g���̂��H
���ꂪ�������������ł���Ȃ牽���ے肵�Ă����邱�Ƃ͂Ȃ���B
>>527
�G�ۂ�1�b�̏�����0.1�b�ɍ��������ĉ��b������̂��ˁH
�G�ۂ�1�b�̏�����0.1�b�ɍ��������ĉ��b������̂��ˁH
>>525
���ۏo����Ǝv����
�L��]���CPU�̔\�͎������}�V�����g�������r��GPGPU�v���O���}��
�Q�[��������
HSA���ƈ����ĊȒP�ɍ�����Ă�����
���ۏo����Ǝv����
�L��]���CPU�̔\�͎������}�V�����g�������r��GPGPU�v���O���}��
�Q�[��������
HSA���ƈ����ĊȒP�ɍ�����Ă�����
shadowplay��twich�֔z�M�݂����Ȃ���H
HSA�����Ă��ł��Ă邶���cPS4�̘^���youtube���e�͉掿���߂��Ę_�O����
HSA�����Ă��ł��Ă邶���cPS4�̘^���youtube���e�͉掿���߂��Ę_�O����
>>529
FX+dGPU���Ƃ�����x�������\���K�v�������
kaveri����7850K�ōςނ��ĔF����OK�H
�ǂ̂��炢��FX��dGPU�̑g�ݍ��킹��APU�Ƒ�ւł���̂��˂�
FX+dGPU���Ƃ�����x�������\���K�v�������
kaveri����7850K�ōςނ��ĔF����OK�H
�ǂ̂��炢��FX��dGPU�̑g�ݍ��킹��APU�Ƒ�ւł���̂��˂�
532 �F,,�E�L�́M�E,,�j��-�������F2013/12/23(��) 16:25:33.03 ID:RkfXxEXv
>>528
1�b��0.1�b�ɒZ�k�ł��鏈�����}�N���ő�ʂɂ��Ȃ�A�\���Ӗ�������B
���Ⴀ�A.NET�őg�܂ꂽ�A�v���̃X�R�A��3100����3112�ɂȂ�܂����A�ɂ͉��b����́H
����v���덷�̔��e����ˁH
�����Ă���ɖ@�l�����ł͂قƂ�nj������Ȃ�AMD��CPU���킴�킴���B���Ă���
�����̉��l������́H
1�b��0.1�b�ɒZ�k�ł��鏈�����}�N���ő�ʂɂ��Ȃ�A�\���Ӗ�������B
���Ⴀ�A.NET�őg�܂ꂽ�A�v���̃X�R�A��3100����3112�ɂȂ�܂����A�ɂ͉��b����́H
����v���덷�̔��e����ˁH
�����Ă���ɖ@�l�����ł͂قƂ�nj������Ȃ�AMD��CPU���킴�킴���B���Ă���
�����̉��l������́H
>>531
FX��990FX��GCN�Ȃ�HSA�g���邩��ʂɖ��Ȃ����
FX��990FX��GCN�Ȃ�HSA�g���邩��ʂɖ��Ȃ����
534 �F,,�E�L�́M�E,,�j��-�������F2013/12/23(��) 16:31:18.46 ID:RkfXxEXv
�x���`�}�[�N�X�C�[�g�͕�������̂����炻�ꂼ��̖ړI�ɂ��킹�čœK��
���̂�I�ׂ����B
�d������������\�����߂邨�q�l�ɂ�.NET�őg�܂ꂽ�A�v���͂����߂��Ȃ����ǂˁB
����C++��������B
���̂�I�ׂ����B
�d������������\�����߂邨�q�l�ɂ�.NET�őg�܂ꂽ�A�v���͂����߂��Ȃ����ǂˁB
����C++��������B
>>532
1�b��0.1�b�ɒZ�k�ł��鏈�����}�N���ő�ʂɂ��l�Ԃ��ǂꂾ������́H
���̑��݂͌덷�̔��e����ˁH
����Ȃ��̂��.NET�őg�܂ꂽ�A�v���������������ق������b���邾��
1�b��0.1�b�ɒZ�k�ł��鏈�����}�N���ő�ʂɂ��l�Ԃ��ǂꂾ������́H
���̑��݂͌덷�̔��e����ˁH
����Ȃ��̂��.NET�őg�܂ꂽ�A�v���������������ق������b���邾��
>>533
HSA�̗L�閳���łǂ��ς�邩�����Ă����
dGPU��HSA���Ȃ���̘b����
HSA������HSA�����Ȃ��HSA�̗L���̔�r�ɂȂ��ł���
HSA�̗L�閳���łǂ��ς�邩�����Ă����
dGPU��HSA���Ȃ���̘b����
HSA������HSA�����Ȃ��HSA�̗L���̔�r�ɂȂ��ł���
537 �F,,�E�L�́M�E,,�j��-�������F2013/12/23(��) 16:32:57.01 ID:RkfXxEXv
���Ⴀ.NET�őg�܂ꂽ��ԃA�v����10���炢���Ă݂悤��
539 �F,,�E�L�́M�E,,�j��-�������F2013/12/23(��) 16:38:56.53 ID:RkfXxEXv
�����g���d���ŋq��v���[���p��C#.�g�����Ƃ��邩�炳
�p�t�H�[�}���X�͓x�O�����Ă���y�Ƀ^�u���b�g�A�v�����̂ɂ�
�œK�ȃc�[�����Ǝv���Ă�B
�ł������Łu���삪�x���I�v�Ȃ�ĕs�����q�悩��o���Ƃ��ɁACPU��
�܂��O�C�̃v���O���}���������R�[�h�����������Č������ǂˁB
���q�l����D����Celeron����Core i7�ɕς����Ƃ����3�{��4�{���悭�Ȃ�Ȃ�����ˁB
�p�t�H�[�}���X�͓x�O�����Ă���y�Ƀ^�u���b�g�A�v�����̂ɂ�
�œK�ȃc�[�����Ǝv���Ă�B
�ł������Łu���삪�x���I�v�Ȃ�ĕs�����q�悩��o���Ƃ��ɁACPU��
�܂��O�C�̃v���O���}���������R�[�h�����������Č������ǂˁB
���q�l����D����Celeron����Core i7�ɕς����Ƃ����3�{��4�{���悭�Ȃ�Ȃ�����ˁB
540 �F,,�E�L�́M�E,,�j��-�������F2013/12/23(��) 16:40:37.04 ID:RkfXxEXv
�c�q�Εa��߂�����
Intel�ސ��x���`�ł���APU�ɓ͂��Ȃ�i5�Ńł��Ă��ĉx�ɓ����Ă��
Intel�ސ��x���`�ł���APU�ɓ͂��Ȃ�i5�Ńł��Ă��ĉx�ɓ����Ă��
>>540
�����Ɋւ��Ă͕��x��Xeon�ʼnĂ���̂�GPGPU�ō������ł��镔���͂���
���������_�͑命���̗��p�҂��ǂ��܂Ŏ��Ԃ�Z�k�ł��邩����
PCMark8�ɂ͂��ꂪ���f����Ă���Ƃ������Ƃ�
�����Ɋւ��Ă͕��x��Xeon�ʼnĂ���̂�GPGPU�ō������ł��镔���͂���
���������_�͑命���̗��p�҂��ǂ��܂Ŏ��Ԃ�Z�k�ł��邩����
PCMark8�ɂ͂��ꂪ���f����Ă���Ƃ������Ƃ�
543 �F,,�E�L�́M�E,,�j��-�������F2013/12/23(��) 16:54:05.59 ID:RkfXxEXv
.NET�őg�܂ꂽ�A�v�����x���A�ƂȂ����ꍇ�ɂ�
�u�l�C�e�B�u�ŏ��������܂��H�v�Ƃ�����Ă�����B
�\�t�g�E�F�A�̕ύX�ł��ނȂ�����n�[�h�����ł��ނ���ˁB
�������S���͏��������Ȃ��B
�{�g���l�b�N�ɂȂ��Ă镔���͂���P/Invoke�l�C�e�B�uDLL������B
.NET�̃p�t�H�[�}���X��AMD��APU�Ƀ��v���[�X������0.3%���シ�邩��
����Ȃ����ǂ�Excel�}�N���̎��s���x�������ȉ��ɂȂ��Ă��������Ƃ�����
�����Ă����͂Ȃ�Ȃ��i�������̂ق����悭�g������˂��q����́j
�u�l�C�e�B�u�ŏ��������܂��H�v�Ƃ�����Ă�����B
�\�t�g�E�F�A�̕ύX�ł��ނȂ�����n�[�h�����ł��ނ���ˁB
�������S���͏��������Ȃ��B
�{�g���l�b�N�ɂȂ��Ă镔���͂���P/Invoke�l�C�e�B�uDLL������B
.NET�̃p�t�H�[�}���X��AMD��APU�Ƀ��v���[�X������0.3%���シ�邩��
����Ȃ����ǂ�Excel�}�N���̎��s���x�������ȉ��ɂȂ��Ă��������Ƃ�����
�����Ă����͂Ȃ�Ȃ��i�������̂ق����悭�g������˂��q����́j
544 �F,,�E�L�́M�E,,�j��-�������F2013/12/23(��) 17:00:02.40 ID:RkfXxEXv
> �����Ɋւ��Ă͕��x��Xeon�ʼnĂ���̂�GPGPU�ō������ł��镔���͂���
�u�������ł���v�ƒf�肷��̂͂����ƒ��������Ă��q����ɃT���v�������
�v���[���ł���i�K�ɂȂ��Ă��猾�����Ƃ���B
GPGPU�g���Ȃ�ď�ʂɏo���킵�����Ƃ͖����Ȃ��B
.NET�őg�܂ꂽ�A�v�����x���Ȃ�Ă̂́A����ȑO�̖�肾����B
�u�������ł���v�ƒf�肷��̂͂����ƒ��������Ă��q����ɃT���v�������
�v���[���ł���i�K�ɂȂ��Ă��猾�����Ƃ���B
GPGPU�g���Ȃ�ď�ʂɏo���킵�����Ƃ͖����Ȃ��B
.NET�őg�܂ꂽ�A�v�����x���Ȃ�Ă̂́A����ȑO�̖�肾����B
545 �FSocket774�F2013/12/23(��) 17:08:23.63 ID:qjDOKB33
����Ȃ��Ƃ��Kaveri��A10-7850k�̃t���Q�x���`�܂�����
546 �FSocket774�F2013/12/23(��) 17:13:29.39 ID:1pyQSxXl
A10�Ƃ�A8�Ƃ�����Ȃ���
Athlon�Ƃ����O�~�����ȁB
����ƁAA10��3���W���[��6�R�A�~������ˁB�������߂Ȃ��̂��ȁB
Athlon�Ƃ����O�~�����ȁB
����ƁAA10��3���W���[��6�R�A�~������ˁB�������߂Ȃ��̂��ȁB
�X���Ⴂ�����ǁA�Ȃ���Intel��AMD����
OS�Ō����Ȃ�@Win��Linux�݂����Ȋ�������ȁB
AMD�͕��D���p�Ń��[�J�[���قƂ�Ǎ̗p���Ȃ����ď�Ԃ���
AMD��D�����[�U�[��HSA���g�����\�t�g��HSA�\�t�g�̍��������J����AMD�̎菕�����炢����!
OS�Ō����Ȃ�@Win��Linux�݂����Ȋ�������ȁB
AMD�͕��D���p�Ń��[�J�[���قƂ�Ǎ̗p���Ȃ����ď�Ԃ���
AMD��D�����[�U�[��HSA���g�����\�t�g��HSA�\�t�g�̍��������J����AMD�̎菕�����炢����!
�܂���6�R�A�o�Ăق�����
����PCIEendpoint�Ńf���A��CPU�o����}�}����
����PCIEendpoint�Ńf���A��CPU�o����}�}����
549 �F,,�E�L�́M�E,,�j��-�������F2013/12/23(��) 17:19:23.07 ID:RkfXxEXv
Athlon�͉��ʃu�����h�Ƃ��Ċ��ɂ���B
�P����A�V���[�Y��GPU�����ł�����f�B�X�N���[�gGPU�K�{�����ǁB
�P����A�V���[�Y��GPU�����ł�����f�B�X�N���[�gGPU�K�{�����ǁB
550 �FSocket774�F2013/12/23(��) 17:22:43.01 ID:1pyQSxXl
>>548
�N���b�N��ς��邾���́A�����̈Ⴂ����Ȃ���
A6 1���W���[��
A8�@2���W���[��
A10�@3���W���[��
����ȕ��ɋ�ʂ��Ăق�����B
�N���b�N��ς��邾���́A�����̈Ⴂ����Ȃ���
A6 1���W���[��
A8�@2���W���[��
A10�@3���W���[��
����ȕ��ɋ�ʂ��Ăق�����B
551 �FSocket774�F2013/12/23(��) 17:25:36.07 ID:1pyQSxXl
>>549
�����B
�悭�킩��Ȃ���B
����������ĂĂ����u�����h��
���������Ƃ���Ɏg���̂́I�ܑ̖����B
�Z���v�����Ƃ������Ǝv����ˁB
Intel�̃y���e�B�A���̎g���������l�B
�����B
�悭�킩��Ȃ���B
����������ĂĂ����u�����h��
���������Ƃ���Ɏg���̂́I�ܑ̖����B
�Z���v�����Ƃ������Ǝv����ˁB
Intel�̃y���e�B�A���̎g���������l�B
>>551
AMD�������
���i�̃u�����h�W�J������AMD�͑ʖڂ���
Phenom�ɂȂ�����FX�ɂȂ�����....�s�������������Ċ����������
AMD�������
���i�̃u�����h�W�J������AMD�͑ʖڂ���
Phenom�ɂȂ�����FX�ɂȂ�����....�s�������������Ċ����������
�u�����f�B���O�ɑ�������̂�A�Ƃ�E����Ȃ���APU�ƌ����ׂ��Ȃ̂��낤
�Ȃ���Ȃ̂ł��܂��s���̂��Ȃ��Ƃ��������͖������Ȃ�����
Pentium�͊��S�ɖ����Ȃ�͂����A�r�㍑�Ƃ��Œm���x�����������̂�
���ʃu�����h�Ƃ��Ďc���ꂽ�ƌ����Ă���
���������o�܂�Athlon�ɂ�����̂�������Ȃ����A���������Ƃ͂Ȃ��C������
�Ȃ���Ȃ̂ł��܂��s���̂��Ȃ��Ƃ��������͖������Ȃ�����
Pentium�͊��S�ɖ����Ȃ�͂����A�r�㍑�Ƃ��Œm���x�����������̂�
���ʃu�����h�Ƃ��Ďc���ꂽ�ƌ����Ă���
���������o�܂�Athlon�ɂ�����̂�������Ȃ����A���������Ƃ͂Ȃ��C������
>>551
Athlon/Sempron��Fs1B�ł�kabini�ŕ�������炵��
http://prohardver.hu/dl/cnt/2013-11/103588/slide6.png
Athlon/Sempron��Fs1B�ł�kabini�ŕ�������炵��
http://prohardver.hu/dl/cnt/2013-11/103588/slide6.png
{kind=link}
>>553
>�r�㍑�Ƃ��Œm���x����������
���i�̃u�����h�����m���Ă�����ďd�v�Ȃ��Ƃ������
���W�r�㍑�ł�Pentium�̓n�C�N���X�ŃZ���͕��N���X�ɂȂ�̂���
>�r�㍑�Ƃ��Œm���x����������
���i�̃u�����h�����m���Ă�����ďd�v�Ȃ��Ƃ������
���W�r�㍑�ł�Pentium�̓n�C�N���X�ŃZ���͕��N���X�ɂȂ�̂���
556 �FSocket774�F2013/12/23(��) 18:10:32.35 ID:1pyQSxXl
���ẮA(�A���t�@�x�b�g+����)���āA�����Ԃ̃l�[�~���O�ɂ��g���Ă��邯�ǁA���{�ɂ͓���܂Ȃ��ˁB
557 �FSocket774�F2013/12/23(��) 18:18:02.15 ID:1pyQSxXl
>>555
�X���`�����ǂ��B
2�R�A�̓Z�������ɂ��Ă����āA
i3 i5 i7�̓��� Pentium��������̂ɂɂ�
Pentium i3
Pentium i5
Pentium i7
�݂����ɂ�����A���W�r�㍑�̐l���X�e�b�v�A�b�v���Ĕ����Ă����Ǝv�����ǂˁB
core�u�����h���Z�������������ł��ˁB
�X���`����!
�X���`�����ǂ��B
2�R�A�̓Z�������ɂ��Ă����āA
i3 i5 i7�̓��� Pentium��������̂ɂɂ�
Pentium i3
Pentium i5
Pentium i7
�݂����ɂ�����A���W�r�㍑�̐l���X�e�b�v�A�b�v���Ĕ����Ă����Ǝv�����ǂˁB
core�u�����h���Z�������������ł��ˁB
�X���`����!
A10��Richland
A8��Richland
A6��Richland�AKabini�ATemash
A4��Richland�AKabini�ATemash
E2��Kabini
E1��Kabini
Athlon��Richland�AKabini
Sempron��Richland�AKabini
Corei7��Haswell
Corei5��Haswell
Corei3��Haswell
Pentium��Haswell�AAtomBayTrail
Celeron��Haswell�AAtomBayTrail
Atom
A8��Richland
A6��Richland�AKabini�ATemash
A4��Richland�AKabini�ATemash
E2��Kabini
E1��Kabini
Athlon��Richland�AKabini
Sempron��Richland�AKabini
Corei7��Haswell
Corei5��Haswell
Corei3��Haswell
Pentium��Haswell�AAtomBayTrail
Celeron��Haswell�AAtomBayTrail
Atom
560 �FSocket774�F2013/12/23(��) 18:43:19.08 ID:1pyQSxXl
>>558
����ς�GPU�̓����͂����̂��ȁB
�݂�ȓ���c�_���Ă邯�ǁB
CPU���čs�����������Ǝv�����ǁB
�x���`�̐��l�͗ǂ��āA���̂����������\��GPU�t����APU�Ƃ������Ƃ����ǁA����̓t���Ɏg���Ȃ��ł���?
�g��Ȃ�
�g���ɂ���
�g���Ȃ�
����ȋ@�\�ɂ����͕����Ȃ���ˁB
����ς�GPU�̓����͂����̂��ȁB
�݂�ȓ���c�_���Ă邯�ǁB
CPU���čs�����������Ǝv�����ǁB
�x���`�̐��l�͗ǂ��āA���̂����������\��GPU�t����APU�Ƃ������Ƃ����ǁA����̓t���Ɏg���Ȃ��ł���?
�g��Ȃ�
�g���ɂ���
�g���Ȃ�
����ȋ@�\�ɂ����͕����Ȃ���ˁB
561 �F,,�E�L�́M�E,,�j��-�������F2013/12/23(��) 18:44:12.83 ID:RkfXxEXv
����A��������.NET��K�v�Ƃ���q��AMD�̐����i�߂�GPGPU�Ƃ�
�܂������������Ƃ����b�����Ă���B
���\������ĂȂ�����ł���GPGPU�͕K�v�Ƃ����B
�������������Ȃ����炱��.NET�Ȃ킯�ŁB
�q�̋��߂Ă���̂Ƒ�������B
������.NET�̃N���C�A���g�A�v����VB6�ƃh�b�R�C�̃��x���i�������v���O���}�̃��x�����j
�V���{�����ɓ��{�ꖼ�̃V���{���g���悤�Ȕ�펯�I�ȃR�[�h�ł��ʂ��Ă��܂��̂�
C#��VB.NET������ȁB
�܂������������Ƃ����b�����Ă���B
���\������ĂȂ�����ł���GPGPU�͕K�v�Ƃ����B
�������������Ȃ����炱��.NET�Ȃ킯�ŁB
�q�̋��߂Ă���̂Ƒ�������B
������.NET�̃N���C�A���g�A�v����VB6�ƃh�b�R�C�̃��x���i�������v���O���}�̃��x�����j
�V���{�����ɓ��{�ꖼ�̃V���{���g���悤�Ȕ�펯�I�ȃR�[�h�ł��ʂ��Ă��܂��̂�
C#��VB.NET������ȁB
i5�ɏ��Ă�Ƃ��Ȃ�Ƃ������Ă邯��i7��i5���ăN���b�N�ȊO�͂���Ȃɕς��Ȃ��ˁH
�Q�[���Ƃ���HTT�I���ɂ���Ƌt�ɐ��\�������C��
�Q�[���Ƃ���HTT�I���ɂ���Ƌt�ɐ��\�������C��
�L���b�V���T�C�Y�̈Ⴂ������Ȃ�Ɍ���
���GPGPU���Ă邯�nj��sAPU��OpenCL�̃��b�g�p�t�H�[�}���X��Radeon280/290���̂���Ă���H
Intel+Radeon280/290���APU+Radeon280/290�̂ق������b�p�ǂ��Ȃ�A�ڍs���悤�Ǝv����...
566 �F,,�E�L�́M�E,,�j��-�������F2013/12/23(��) 19:50:05.43 ID:RkfXxEXv
>>562
��������i5�Ƃ����Ă��g��GPU�ɂ���ăX�R�A�ς���Ă邩��ȁ[
http://www.3dnews.ru/764587/page-2.html
�uWork�v��6800K��Pentium G2130�ɕ����Ă邯��AMDer���F�̐��`�̃x���`�}�[�N�ł�
��������i5�Ƃ����Ă��g��GPU�ɂ���ăX�R�A�ς���Ă邩��ȁ[
http://www.3dnews.ru/764587/page-2.html
�uWork�v��6800K��Pentium G2130�ɕ����Ă邯��AMDer���F�̐��`�̃x���`�}�[�N�ł�
567 �F,,�E�L�́M�E,,�j��-�������F2013/12/23(��) 20:25:35.30 ID:RkfXxEXv
>>564-565��1���Ԃ����u����Ăċ������B
���̃X����AMDer���Ă��̒��x�̎���ɂ��������Ȃ��o�J������ȂȁB
������点�邩�ɂ���邩���T�Ɍ����Ȃ���
�����̑唼���I�����W�X�^�ŏ����ł�����e�łȂ��Ɠ���GPU��GPGPU���
�����b�g�͂Ȃ��B�f�B�X�N���[�gGPU�Ɣ�ׂĂ����|�I�Ƀ������ш悪��������ˁB
128MB�̃L���b�V���Ɏ��܂�͈͂̏����Ȃ炻�ꂱ��Iris Pro�̂ق���
������������Ȃ��ˁi�{���x���g�������Ȃ�ւ��ȃf�B�X�N���[�gGPU��葬���j
���N��������ɂ��x�A�{�[�������������Core i5 4670R��������I������
����Ă݂ẮH
����Haswell�g���Ă�Ȃ�Broadwell-K��҂̂��肾���ǁB
���̃X����AMDer���Ă��̒��x�̎���ɂ��������Ȃ��o�J������ȂȁB
������点�邩�ɂ���邩���T�Ɍ����Ȃ���
�����̑唼���I�����W�X�^�ŏ����ł�����e�łȂ��Ɠ���GPU��GPGPU���
�����b�g�͂Ȃ��B�f�B�X�N���[�gGPU�Ɣ�ׂĂ����|�I�Ƀ������ш悪��������ˁB
128MB�̃L���b�V���Ɏ��܂�͈͂̏����Ȃ炻�ꂱ��Iris Pro�̂ق���
������������Ȃ��ˁi�{���x���g�������Ȃ�ւ��ȃf�B�X�N���[�gGPU��葬���j
���N��������ɂ��x�A�{�[�������������Core i5 4670R��������I������
����Ă݂ẮH
����Haswell�g���Ă�Ȃ�Broadwell-K��҂̂��肾���ǁB
���������A���`�������̂����̃X���̓��������A������̐��i�̖ϑz�ɐZ��X�����낱��
���s��APU�Ȃ�APU�X���ŕ����̂��B
�ŃX���[����Ă�B
���s��APU�Ȃ�APU�X���ŕ����̂��B
�ŃX���[����Ă�B
������ƃC���e�����i���������肷��c�q��������
��肪�Ƃ��I����Ă邱�Ƃ͈Í��W�ŒP���x�ŏ\���Ȃ��ǃ������ш悪�l�b�N�ɂȂ肻���B�{���x���K�v����Radeon��VGPR�A�N�Z�X����������̂ő����[�J�[�s���������ǂ������ł���
>>567
>���N��������ɂ��x�A�{�[�������������Core i5 4670R��������I������
Core����GPU�̓S�~�Ƃ���������
GPU�Ƃ��Ă͎g���Ȃ�GPGPU�Ƃ��Ă��g���Ȃ�����Ȃ�
>���N��������ɂ��x�A�{�[�������������Core i5 4670R��������I������
Core����GPU�̓S�~�Ƃ���������
GPU�Ƃ��Ă͎g���Ȃ�GPGPU�Ƃ��Ă��g���Ȃ�����Ȃ�
572 �FSocket774�F2013/12/23(��) 21:12:54.15 ID:YVV7zT0l
Substance Engine Increases PS4 & Xbox One Texture Generation Speed To 14 MB/s & 12 MB/s Respectively
http://gamingbolt.com/substance-engine-increases-ps4-xbox-one-texture-generation-speed-to-14-mbs-12-mbs-respectively
http://gamingbolt.com/wp-content/uploads/2013/12/Substance-Engine_Texture-Generation.jpg
http://gamingbolt.com/substance-engine-increases-ps4-xbox-one-texture-generation-speed-to-14-mbs-12-mbs-respectively
http://gamingbolt.com/wp-content/uploads/2013/12/Substance-Engine_Texture-Generation.jpg
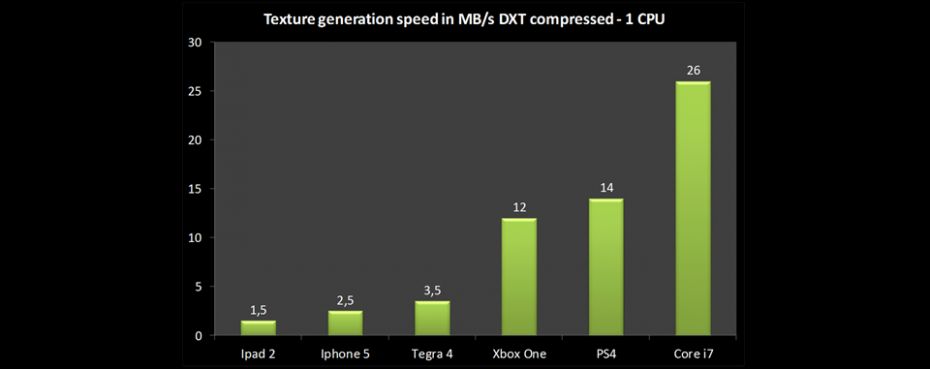{kind=link}
�o�J�Ȃ͔̂ے肵�Ȃ����ǁA���̂��炢�̃X���Ȃ�ꎞ�Ԃ��炢�����Ȃ��͕̂��ʂ���B
�ߑO���������߂�asahi-net���K������Ƃ�c
�ߑO���������߂�asahi-net���K������Ƃ�c
���RAMD��NET��HSA�Ή������͂ɐi�߂Ă��邾��
���N��HSA NET���ł邾�낤
���N����͐F�X�Ȍ���(perl, python�Ȃ�)��HSA�Ή�����悤�ɂȂ邾�낤��
AMD���[�U�[�͂������y���݂���
>>567
����AMDer�̑����͉�GPGPU�����������Ă��邨�B
�����Ńv���O��������悤�ȓz����������̂�AMD����er�B
�ł��A���͒�]�Ŏ�Ńv��GPGPU���ĂȂ����ǁ����B��������AMD�ȂAorz
��������AMD���ēz�͒������h���낤�B
���N��HSA NET���ł邾�낤
���N����͐F�X�Ȍ���(perl, python�Ȃ�)��HSA�Ή�����悤�ɂȂ邾�낤��
AMD���[�U�[�͂������y���݂���
>>567
����AMDer�̑����͉�GPGPU�����������Ă��邨�B
�����Ńv���O��������悤�ȓz����������̂�AMD����er�B
�ł��A���͒�]�Ŏ�Ńv��GPGPU���ĂȂ����ǁ����B��������AMD�ȂAorz
��������AMD���ēz�͒������h���낤�B
�J�x���A����������
��ު��Č�����A�����ゾ
�J�x���I
578 �F,,�E�L�́M�E,,�j��-�������F2013/12/23(��) 21:28:59.17 ID:RkfXxEXv
> GPGPU�Ƃ��Ă��g���Ȃ�����Ȃ�
eDRAM�Ȃ�EU������GT2�ɂ������Ă�6800K�̈����ɂȂ邩��
���������ɂ��Ƃ����ق����悭�ˁH
http://www.nordichardware.se/Processorer-Recensioner/amd-richland-vi-testar-a10-6800k-och-a10-6700/IGP-Luxmark.html
DDR3�Ŏ����\�Ȏ������\�Ȃ�đ��ǂ�����Ă���Ă��Ƃ���B
eDRAM�Ȃ�EU������GT2�ɂ������Ă�6800K�̈����ɂȂ邩��
���������ɂ��Ƃ����ق����悭�ˁH
http://www.nordichardware.se/Processorer-Recensioner/amd-richland-vi-testar-a10-6800k-och-a10-6700/IGP-Luxmark.html
DDR3�Ŏ����\�Ȏ������\�Ȃ�đ��ǂ�����Ă���Ă��Ƃ���B
�L�����F���B�A����������
580 �FSocket774�F2013/12/23(��) 22:06:54.04 ID:qVW2yTXf
�����
������
����
������
����
581 �FSocket774�F2013/12/23(��) 22:17:54.59 ID:qVW2yTXf
>>580
���������v��
���������v��
�������쎩���������悤�ȋC������B
�ǂ����Ă��ނ�A�}���`�L�����X�Ȃ�ŁA����Ń��b�p�Ƃ������Ă鎞�_�œ����A�{���R�e���l���u����B
�ǂ����Ă��ނ�A�}���`�L�����X�Ȃ�ŁA����Ń��b�p�Ƃ������Ă鎞�_�œ����A�{���R�e���l���u����B
�@Kaveri�ɑ��Ă��A�c�q���Intel�T�C�g��炪�]���^GPGPU�^�X�N��
�����������Ȃ߂闬�ꂪ�ڂɕ����Ԃ悤���B
�����������Ȃ߂闬�ꂪ�ڂɕ����Ԃ悤���B
584 �F,,�E�L�́M�E,,�j��-�������F2013/12/23(��) 22:33:39.45 ID:RkfXxEXv
�R�X�g������̌����i�j���グ�����Ȃ�Celeron��I��ł����ΊԈႢ�Ȃ��ł���
���\�l�`���S�l�K�͂̉�Ђ̃J�X�^���Ɩ��A�v����GPGPU�Ȃ�Ďg������
�R�X�g���ˏオ�肷���邵
���\�l�`���S�l�K�͂̉�Ђ̃J�X�^���Ɩ��A�v����GPGPU�Ȃ�Ďg������
�R�X�g���ˏオ�肷���邵
Kaveri iGPU vs Iris Pro 5200
�v���Z�b�V���O �x���`�}�[�N(OpenCL)
Kaveri�F329.7Mpix/�b
http://www.sisoftware.eu/rank2011d/show_run.php?q=c2ffcdf4d2b3d2efddeedce9dcebcdbf82b294f194a999bfccf1c9&l=jp
Iris Pro 5200�F251.6Mpix/�b
http://www.sisoftware.eu/rank2011d/show_run.php?q=c2ffcdf4d2b3d2efddefdeefd8eaccbe83b395f095a898becdf0c0&l=jp
�Í����̃p�t�H�[�}���X(���Z�L�����e�B)
Kaveri�F5.2GB/�b
http://www.sisoftware.eu/rank2011d/show_run.php?q=c2ffccfddbbadbe6d1e2d5e3d7f183be8ea8cda895a583f0cdf5&l=jp
Iris Pro 5200�F2.8GB/�b
http://www.sisoftware.eu/rank2011d/show_run.php?q=c2ffccfddbbadbe6d2eadbe9ddfb89b484a2c7a29faf89fac7f7&l=jp
�������� �i�ʏ�̐����j
Kaveri�F190.4kOPT/�b
http://www.sisoftware.eu/rank2011d/show_run.php?q=c2ffc9fcdabbdae7d4e2d7e2c4b68bbb9df89da090b6c5f8c0&l=jp
Iris Pro 5200�F101.5kOPT/�b
http://www.sisoftware.eu/rank2011d/show_run.php?q=c2ffc9fcdabbdae7d3e1d3e1c7b588b89efb9ea393b5c6fbcb&l=jp
���������N���b�N vs eDRAM����Ȃ̂ŏ����ȃV�F�[�_���\�̔�r�͓���Ǝv�����Ljꉞ
�v���Z�b�V���O �x���`�}�[�N(OpenCL)
Kaveri�F329.7Mpix/�b
http://www.sisoftware.eu/rank2011d/show_run.php?q=c2ffcdf4d2b3d2efddeedce9dcebcdbf82b294f194a999bfccf1c9&l=jp
Iris Pro 5200�F251.6Mpix/�b
http://www.sisoftware.eu/rank2011d/show_run.php?q=c2ffcdf4d2b3d2efddefdeefd8eaccbe83b395f095a898becdf0c0&l=jp
�Í����̃p�t�H�[�}���X(���Z�L�����e�B)
Kaveri�F5.2GB/�b
http://www.sisoftware.eu/rank2011d/show_run.php?q=c2ffccfddbbadbe6d1e2d5e3d7f183be8ea8cda895a583f0cdf5&l=jp
Iris Pro 5200�F2.8GB/�b
http://www.sisoftware.eu/rank2011d/show_run.php?q=c2ffccfddbbadbe6d2eadbe9ddfb89b484a2c7a29faf89fac7f7&l=jp
�������� �i�ʏ�̐����j
Kaveri�F190.4kOPT/�b
http://www.sisoftware.eu/rank2011d/show_run.php?q=c2ffc9fcdabbdae7d4e2d7e2c4b68bbb9df89da090b6c5f8c0&l=jp
Iris Pro 5200�F101.5kOPT/�b
http://www.sisoftware.eu/rank2011d/show_run.php?q=c2ffc9fcdabbdae7d3e1d3e1c7b588b89efb9ea393b5c6fbcb&l=jp
���������N���b�N vs eDRAM����Ȃ̂ŏ����ȃV�F�[�_���\�̔�r�͓���Ǝv�����Ljꉞ
APU��FX���g���ĂȂ�����]�����Ă���E���W�߂Ė�m���
587 �F,,�E�L�́M�E,,�j��-�������F2013/12/23(��) 22:41:45.24 ID:RkfXxEXv
> �v���Z�b�V���O �x���`�}�[�N(OpenCL)
> Kaveri�F329.7Mpix/�b
�Ղ�
> 261.4Mpix/�b (193.1Mpix/�b - 329.7Mpix/�b)
http://www.sisoftware.eu/rank2011d/show_run.php?q=c2ffcdf4d2b3d2efddecdbe2dbeaccbe83b395f095a898becdf0c8&l=jp
�ǂ�������炱��ȍ����o��낤��
> Kaveri�F329.7Mpix/�b
�Ղ�
> 261.4Mpix/�b (193.1Mpix/�b - 329.7Mpix/�b)
http://www.sisoftware.eu/rank2011d/show_run.php?q=c2ffcdf4d2b3d2efddecdbe2dbeaccbe83b395f095a898becdf0c8&l=jp
�ǂ�������炱��ȍ����o��낤��
>>587
> �v���Z�b�V���O �x���`�}�[�N(OpenCL)
> Iris Pro 5200�F251.6Mpix/�b
�Ղ�
> 223.6Mpix/�b (139.0Mpix/�b - 308.2Mpix/�b)
http://www.sisoftware.eu/rank2011d/show_run.php?q=c2ffcdf4d2b3d2efddecdbe2dbeaccbe83b395f095a898becdf0c8&l=jp
�ǂ�������炱��ȍ����o��낤��
> �v���Z�b�V���O �x���`�}�[�N(OpenCL)
> Iris Pro 5200�F251.6Mpix/�b
�Ղ�
> 223.6Mpix/�b (139.0Mpix/�b - 308.2Mpix/�b)
http://www.sisoftware.eu/rank2011d/show_run.php?q=c2ffcdf4d2b3d2efddecdbe2dbeaccbe83b395f095a898becdf0c8&l=jp
�ǂ�������炱��ȍ����o��낤��
���قȂ��ƕ�������
OpenCL����openCL���T�|�[�g���Ă��Ȃ��悤�Ȑ̂�CPU/chipsetVGA�Ƃ����ǂ��Ȃ�H
����ł�����͂���悤�Ȃ��̂Ȃ̂�
OpenCL����openCL���T�|�[�g���Ă��Ȃ��悤�Ȑ̂�CPU/chipsetVGA�Ƃ����ǂ��Ȃ�H
����ł�����͂���悤�Ȃ��̂Ȃ̂�
��Fhttp://www.sisoftware.eu/rank2011d/show_run.php?q=c2ffcdf4d2b3d2efddecdbe2dbeaccbe83b395f095a898becdf0c8&l=jp
���Fhttp://www.sisoftware.eu/rank2011d/show_run.php?q=c2ffcdf4d2b3d2efddefdeefd8eaccbe83b395f095a898becdf0c0&l=jp
���Fhttp://www.sisoftware.eu/rank2011d/show_run.php?q=c2ffcdf4d2b3d2efddefdeefd8eaccbe83b395f095a898becdf0c0&l=jp
591 �F,,�E�L�́M�E,,�j��-�������F2013/12/23(��) 23:01:08.52 ID:RkfXxEXv
GPU�Ɍ��炸CPU�����������ǁASandra���ă������ш�W�Ȃ���
�قڗ��_�l�ǂ���̐��\�o�邩���
GPGPU�ňÍ����Ȃ�Ď��p��g�����B
AES�ł�EBC�Ȃǂ̃u���b�N�Ԃ̈ˑ��W���Ȃ��`�����������I�Ɏg���Ȃ������
�g����̂�Brute Force�ŃN���b�N����Ƃ������������������p�r�B
LuxMark��LuxRenderer�Ƃ������p�����ꂽ�A�v���̃G���W�����̂܂g���Ă邩��
���p�����ꂽ�Ƃ��̐��\�𐄂��ʂ�ɂ̓A���ł���
�قڗ��_�l�ǂ���̐��\�o�邩���
GPGPU�ňÍ����Ȃ�Ď��p��g�����B
AES�ł�EBC�Ȃǂ̃u���b�N�Ԃ̈ˑ��W���Ȃ��`�����������I�Ɏg���Ȃ������
�g����̂�Brute Force�ŃN���b�N����Ƃ������������������p�r�B
LuxMark��LuxRenderer�Ƃ������p�����ꂽ�A�v���̃G���W�����̂܂g���Ă邩��
���p�����ꂽ�Ƃ��̐��\�𐄂��ʂ�ɂ̓A���ł���
592 �F,,�E�L�́M�E,,�j��-�������F2013/12/23(��) 23:04:37.22 ID:RkfXxEXv
>>589
GPU�̏ꍇ�͓����Ȃ���ˁH
CPU�̏ꍇ���ƁAIntel�̏ꍇSSE4.1�Ή��ȍ~��CPU�̂݃T�|�[�g���Ă�B
�v���f�B�P�[�V�����Ƃ��v�f�P�ʂ̒��o�E�}����������K�{������ˁB
�I�[�v���d�l�����瓮������悤�Ƀ����^�C�������O�Ŏ������Ă�������
���Ԃ�]���ȃ��[�h�E�X�g�A���삪�����Ăނ���X�J�����x���Ȃ邾�낤�B
GPU�̏ꍇ�͓����Ȃ���ˁH
CPU�̏ꍇ���ƁAIntel�̏ꍇSSE4.1�Ή��ȍ~��CPU�̂݃T�|�[�g���Ă�B
�v���f�B�P�[�V�����Ƃ��v�f�P�ʂ̒��o�E�}����������K�{������ˁB
�I�[�v���d�l�����瓮������悤�Ƀ����^�C�������O�Ŏ������Ă�������
���Ԃ�]���ȃ��[�h�E�X�g�A���삪�����Ăނ���X�J�����x���Ȃ邾�낤�B
�����c�_���������ɂ���邯�ǁA�����\��������Sandra�͂���܂�c�c
>>589
�����I�ɂ͒��Ƀ\�[�X�R�[�h�������Ă��Ď��s���ɃR���p�C���Ȃ̂�
�����^�C�����ǂ��܂ŃT�|�[�g���邩�Ɉˑ�����
���ۏ�͊��ƍŋ߂̃v���Z�b�T�łȂ��ƃ_���Ȃ͂�
>>589
�����I�ɂ͒��Ƀ\�[�X�R�[�h�������Ă��Ď��s���ɃR���p�C���Ȃ̂�
�����^�C�����ǂ��܂ŃT�|�[�g���邩�Ɉˑ�����
���ۏ�͊��ƍŋ߂̃v���Z�b�T�łȂ��ƃ_���Ȃ͂�
>>592-593
openCL�ł͑Ή����Ă��Ȃ�CPU�EGPU�Ȃ�A�����I�ɃT�|�[�g���Ă���CPU/GPU���߂ł��悤��
�R���p�C���Ƃ����Ă���Ȃ��̂��H
���肷���openCL�Ή��Ɣ�openCL�p��2�̃\�[�X���������Ă߂�ǂ��������Ƃ����Ȃ��Ƃ����Ȃ��Ȃ��Ȃ��̂�
����ȂႠ��܂�openCL�g���Ă���Ȃ�����
openCL�ł͑Ή����Ă��Ȃ�CPU�EGPU�Ȃ�A�����I�ɃT�|�[�g���Ă���CPU/GPU���߂ł��悤��
�R���p�C���Ƃ����Ă���Ȃ��̂��H
���肷���openCL�Ή��Ɣ�openCL�p��2�̃\�[�X���������Ă߂�ǂ��������Ƃ����Ȃ��Ƃ����Ȃ��Ȃ��Ȃ��̂�
����ȂႠ��܂�openCL�g���Ă���Ȃ�����
OpenCL���Â�CPU/GPU�œ������Ӌ`���ĕ��p���炢�����Ȃ��Ǝv�����B
�Â�PC�ł������Ƀp�t�H�[�}���X������\�t�g�Ȃ疳����opencl�g��Ȃ��ł�����Ȃ��H
�Â�PC�ɍ��킹�Ă��A�������ǂ��Ƃ����낤�����̂Ă����ȁB
����ōŐV��Intel/AMD/nVIDIA���e���[�J�[�ɖ��x���킹�悤�Ƃ��Ă���}�W���Ԃ������炠���Ă�����Ȃ��قǎ��X�V�����̂��o�Ă���B
���������Ӗ��Ŗʓ|�Ǝv���͎̂d���������B
�ł��A�D�揇�ʓI�ɂ�AMD > nVIDIA > Intel�̏��Ԃő��x���{�X�ȏ�ɏo��̂ŁA���̏��ɑΉ����Ă����ΊԈႢ�͂Ȃ��B
����ōŐV��Intel/AMD/nVIDIA���e���[�J�[�ɖ��x���킹�悤�Ƃ��Ă���}�W���Ԃ������炠���Ă�����Ȃ��قǎ��X�V�����̂��o�Ă���B
���������Ӗ��Ŗʓ|�Ǝv���͎̂d���������B
�ł��A�D�揇�ʓI�ɂ�AMD > nVIDIA > Intel�̏��Ԃő��x���{�X�ȏ�ɏo��̂ŁA���̏��ɑΉ����Ă����ΊԈႢ�͂Ȃ��B
AMD APP SDK��������������OpenCL�Ȃ�Netburst��K8�݂����ȃN�\CPU�ł�OpenCL���g���邯�ǂ�
>>599
���ʂ͂������Ȃ��Ƃ��߂���B
��Ƃł͌Â�IntelCPU+chisetVGA�̂����܂��ɑ�������ȁB
�Â��̂ł͓����Ȃ�����A�Â�CPU�EVGA�p�R�[�h�������Ă˂��ᕁ�y������C�Ȃ������
�����HSA�ł����l����ȁB��HSA�p�ɕʓr�\�[�X�R�[�h�p�ӂ��Ȃ��Ƃ����Ȃ��悤����ǂ����悤���Ȃ��B
���ʂ͂������Ȃ��Ƃ��߂���B
��Ƃł͌Â�IntelCPU+chisetVGA�̂����܂��ɑ�������ȁB
�Â��̂ł͓����Ȃ�����A�Â�CPU�EVGA�p�R�[�h�������Ă˂��ᕁ�y������C�Ȃ������
�����HSA�ł����l����ȁB��HSA�p�ɕʓr�\�[�X�R�[�h�p�ӂ��Ȃ��Ƃ����Ȃ��悤����ǂ����悤���Ȃ��B
>>589
X86�ŏ�������邾������
OpenCL�ɂ����Ή����Ȃ������͊�{�I�ɑ��݂��Ȃ�
x86��AMD64�ł����X�����āAOpenCL�Ή���GPGPU�ł��o����悤�ɂȂ邾��
X86�ŏ�������邾������
OpenCL�ɂ����Ή����Ȃ������͊�{�I�ɑ��݂��Ȃ�
x86��AMD64�ł����X�����āAOpenCL�Ή���GPGPU�ł��o����悤�ɂȂ邾��
OpenCL�p�r���ĕ��ʐ��\���K�v��������d�͂��C�ɂȂ邩��Â������pPC�œ������Ƃ��Ă��o�ϓI�����b�g�Ȃ��Ǝv����
>>600
HSA�͍���o�Ă���hUMA�⓯���Z�p�ɑΉ������VCPU��p�̊�����
���N�ȑO��SOC�Ȃ��Ђ��z�肵�ĂȂ����Â��V�X�e�������R���S������
�����炱���V�����Z�p��d�g�݂��Ă���ō̗p���Ă���
>>�����HSA�ł����l����ȁB��HSA�p�ɕʓr�\�[�X�R�[�h�p�ӂ��Ȃ��Ƃ����Ȃ��悤����ǂ����悤���Ȃ��B
�t��
HSA�p�ɕʓr��p�R�[�h��p�ӂ��邱�ƂɂȂ�
DirectX��Mantle�̊W�����̂��̃Y�o������
�J�����̍\�z�ɍŏ��̓R�X�g�������邯�ǁA��x�g�ݍ����͖w��ǎ�Ԃ��|�����ɊJ���ł���悤�ɂȂ�
���ʂ͂��̍��ɗ͂����邱�ƂɂȂ��
�܂��AAMD64��Mantle�̌o�����������邩��A���͂Ȃ����낤���ǂ�
HSA�͍���o�Ă���hUMA�⓯���Z�p�ɑΉ������VCPU��p�̊�����
���N�ȑO��SOC�Ȃ��Ђ��z�肵�ĂȂ����Â��V�X�e�������R���S������
�����炱���V�����Z�p��d�g�݂��Ă���ō̗p���Ă���
>>�����HSA�ł����l����ȁB��HSA�p�ɕʓr�\�[�X�R�[�h�p�ӂ��Ȃ��Ƃ����Ȃ��悤����ǂ����悤���Ȃ��B
�t��
HSA�p�ɕʓr��p�R�[�h��p�ӂ��邱�ƂɂȂ�
DirectX��Mantle�̊W�����̂��̃Y�o������
�J�����̍\�z�ɍŏ��̓R�X�g�������邯�ǁA��x�g�ݍ����͖w��ǎ�Ԃ��|�����ɊJ���ł���悤�ɂȂ�
���ʂ͂��̍��ɗ͂����邱�ƂɂȂ��
�܂��AAMD64��Mantle�̌o�����������邩��A���͂Ȃ����낤���ǂ�
APU��dGPU���̐��\�ɂȂ�̂͂����ł��傤���H
���z������2�{�̑傫���ɂȂ鍠�ł��I(�M�E�ցE�L)
���������x����{�ɂȂ邱��ł�
����͑啪��ł���><
���C���������ȊO�ɏ��ʍ����������ڂ����ɂ͂����Ȃ���ł��傤���H���ꂾ������f����dGPU�̕��������H
���C���������ȊO�ɏ��ʍ����������ڂ����ɂ͂����Ȃ���ł��傤���H���ꂾ������f����dGPU�̕��������H
>>603
�g��ꂾ�����͎��͂���������ő����Ă��������
�g��ꂾ�����͎��͂���������ő����Ă��������
api�Ƃ��Ă�HSA��HSA�������ǂ��쓮�ł���n�[�h�E�F�A����������ɂȂ��ĂˁH
��������2���~�ȉ��̉��i�Ŕ��邱�Ƃ��������Ă錻���APU���Ⴛ�̎�̍����������͎g���Ȃ���Ȃ����ȁH
���T�[�o�[�pCPU��3���~�Ƃ��̏�ʂ�Corei7�Ƃ��ꕔ�̗̍p�ɂƂǂ܂�Ɨ\�z
���T�[�o�[�pCPU��3���~�Ƃ��̏�ʂ�Corei7�Ƃ��ꕔ�̗̍p�ɂƂǂ܂�Ɨ\�z
>>607
�@dGPU���ĉ����́H
�@x86�R�A�ɖʐς��������������\�P�b�g�t������ȏ�A�O���t�B�b�N�^�X�N��
�X���[�v�b�g���_�l�ł͂ǂ��܂ōs���Ă��������dGPU���ɂ͂Ȃ�Ȃ���B
�@hUMA��hQ�ɂ����dGPU�ɂ͎��ĂȂ����_����ɓ��ꂽAMD��iGPU�́A
�����̌���GPGPU������̕ʂ̃f�o�C�X�Ƃ��ĕ]�����ׂ��ł����āB
�@dGPU���ĉ����́H
�@x86�R�A�ɖʐς��������������\�P�b�g�t������ȏ�A�O���t�B�b�N�^�X�N��
�X���[�v�b�g���_�l�ł͂ǂ��܂ōs���Ă��������dGPU���ɂ͂Ȃ�Ȃ���B
�@hUMA��hQ�ɂ����dGPU�ɂ͎��ĂȂ����_����ɓ��ꂽAMD��iGPU�́A
�����̌���GPGPU������̕ʂ̃f�o�C�X�Ƃ��ĕ]�����ׂ��ł����āB
Hybrid Memory Cube�𓋍ڂ��悤�ɂ�MCM�Ƃ��Ŗʐς�H���W��
�ň���p�_�C�ɕʃp�b�P�[�W����Ƃ��ɂȂ邾�낤����
���Ȃ��Ƃ��f�X�N�g�b�v���ƍ��Ō���FX�|�W�V������APU�ɂ̂ݍ̗p����邾�낤
�ň���p�_�C�ɕʃp�b�P�[�W����Ƃ��ɂȂ邾�낤����
���Ȃ��Ƃ��f�X�N�g�b�v���ƍ��Ō���FX�|�W�V������APU�ɂ̂ݍ̗p����邾�낤
>610-611
HSA�̊J�����Ƃ��Ẵ����b�g�͂킩���ł����A���\�I�ɂǂ��Ȃ̂��ȂƎv���܂��āB
dGPU�Ƃ͕ʂ̃����b�g�������̂ŁA�߂�����dGPU���s�v�ɂȂ�킯�ł͂Ȃ���ł���
HSA�̊J�����Ƃ��Ẵ����b�g�͂킩���ł����A���\�I�ɂǂ��Ȃ̂��ȂƎv���܂��āB
dGPU�Ƃ͕ʂ̃����b�g�������̂ŁA�߂�����dGPU���s�v�ɂȂ�킯�ł͂Ȃ���ł���
�܂��Ή������������x���y���Ă���łȂ��ƑΉ��\�t�g�͏o�Ă��Ȃ�����Mantle��HSA�����������낤�ˁB
���߂�Intel CPU+Radeon�Ō��I�Ȍ��ʂ�����Θb���ς���Ă���낤���ǁB
���߂�Intel CPU+Radeon�Ō��I�Ȍ��ʂ�����Θb���ς���Ă���낤���ǁB
Kaveri��ES�i��6���̒i�K�Łh�܂��Ȃ��\�t�g�E�F�A�J���n�ɓn���h�Ƃ��Ȃ�Ƃ������ĂȂ��������H
>>615
�@�Ƃ肠�����œK���}�j�A������������G���R����ƁAAPU�ȊO�ł�(Intel��
CPU�{Radeon���ł�)����������Mantle�͊��҂��ėǂ���Ȃ��H
�@�Ƃ肠�����œK���}�j�A������������G���R����ƁAAPU�ȊO�ł�(Intel��
CPU�{Radeon���ł�)����������Mantle�͊��҂��ėǂ���Ȃ��H
ApacheSoftwareFoundation�Ȃɂ͊��ɓn���Ă邾�낤��
�łȂ����Hadoop�ɑΉ����Č����o���Ȃ����낤��
�łȂ����Hadoop�ɑΉ����Č����o���Ȃ����낤��
620 �F,,�E�L�́M�E,,�j��-�������F2013/12/24(��) 01:05:02.37 ID:g+rgk+AI
> ApacheSoftwareFoundation�Ȃɂ͊��ɓn���Ă邾�낤��
�Ђ���Ƃ���Apache���\�t�g�J����Ђ��Ȃ��Ɗ��Ⴂ���Ă�̂��H
�R�[�h�͉����Ƃ��R�~�b�g�����
�Ђ���Ƃ���Apache���\�t�g�J����Ђ��Ȃ��Ɗ��Ⴂ���Ă�̂��H
�R�[�h�͉����Ƃ��R�~�b�g�����
>>614
APU�͍ő�250mm2��CPU��GPU�Őܔ�
dGPU�͍ő�500mm2��GPU�Ő�L
�v�͎���ɊW�Ȃ��ő含�\�͑S���ǂ����Ȃ�
HSA�̗��_�́AGPU�܂߂��v���O������J���̊ȈՉ������C���Ő��\�͓�̎�����
�A�h���X�����Ń������Ǘ����V���v���ɂȂ邩���
�R�A�̈Ⴂ�����ۉ��ŋC�ɂ��Ȃ��Ă�������A���\���]��K�v����Ȃ��\�t�g�Ƃ��̓}���`�������₷���Ȃ�
�����[�X���ꂽ�����͕��������ۉ��ƌ������������o�X�����琫�\�ɂ͂��܂���ҏo���Ȃ����낤��
�������A���P��͂�����ł����邩��A���\���P�͋}�s�b�`�Ői�ނ��낤��
APU�͍ő�250mm2��CPU��GPU�Őܔ�
dGPU�͍ő�500mm2��GPU�Ő�L
�v�͎���ɊW�Ȃ��ő含�\�͑S���ǂ����Ȃ�
HSA�̗��_�́AGPU�܂߂��v���O������J���̊ȈՉ������C���Ő��\�͓�̎�����
�A�h���X�����Ń������Ǘ����V���v���ɂȂ邩���
�R�A�̈Ⴂ�����ۉ��ŋC�ɂ��Ȃ��Ă�������A���\���]��K�v����Ȃ��\�t�g�Ƃ��̓}���`�������₷���Ȃ�
�����[�X���ꂽ�����͕��������ۉ��ƌ������������o�X�����琫�\�ɂ͂��܂���ҏo���Ȃ����낤��
�������A���P��͂�����ł����邩��A���\���P�͋}�s�b�`�Ői�ނ��낤��
�J�x������7750���炢�Ȃ́H
�x���`�o������
�x���`�o������
PS4�Ō����Ƃ���̊J���҂ɂƂ��Ẵp�Y����dGPU�Ȃ�Ȃ�
�����������������邩��7730���炢�����
625 �F,,�E�L�́M�E,,�j��-�������F2013/12/24(��) 02:17:46.86 ID:QDla65f/
>>611
> �����̌���GPGPU������̕ʂ̃f�o�C�X�Ƃ��ĕ]�����ׂ��ł����āB
����GPU�̏����Ȃ�Ă��傹��CPU�R�A�ɓ������ꂽSIMD���j�b�g�ɋy��
�Ƃ���ł͂Ȃ���B
LuxMark������4�R�A��400GFLOPS�ɂ���Haswell(+GT2)�ɕ����Ă邶���B
GPU�̗��_���\������̎��������̈�����₦�������́A
CPU�Ƃ̕����I�����ł͂Ȃ��������ш�B
�u�����v����������GPU�Ȃ�ł͂̃\�t�g�E�F�A�Ȃ�đ��݂���H
�Œ�@�\�Ƃ̑g�ݍ��킹�ɂ͂Ȃ邯�ǁAIntel HDG��QuickSyncVideo���炢����
�v�������Ȃ���B����͋t�ɖړI���͂����肵�Ă邩�炱���Œ�@�\���ł���B
> �����̌���GPGPU������̕ʂ̃f�o�C�X�Ƃ��ĕ]�����ׂ��ł����āB
����GPU�̏����Ȃ�Ă��傹��CPU�R�A�ɓ������ꂽSIMD���j�b�g�ɋy��
�Ƃ���ł͂Ȃ���B
LuxMark������4�R�A��400GFLOPS�ɂ���Haswell(+GT2)�ɕ����Ă邶���B
GPU�̗��_���\������̎��������̈�����₦�������́A
CPU�Ƃ̕����I�����ł͂Ȃ��������ш�B
�u�����v����������GPU�Ȃ�ł͂̃\�t�g�E�F�A�Ȃ�đ��݂���H
�Œ�@�\�Ƃ̑g�ݍ��킹�ɂ͂Ȃ邯�ǁAIntel HDG��QuickSyncVideo���炢����
�v�������Ȃ���B����͋t�ɖړI���͂����肵�Ă邩�炱���Œ�@�\���ł���B
>>625�@��UMA�Ή�APU����܂��o�ĂȂ��̂ɋC�������悗
���ʂɂȂ��Ă����GPU�̎g�����Ƃ��Ĉ����͂Ȃ���Ȃ��́H
���������CPU�J���a���ɂ��Ă�������ł��Ȃ����ǁA��������AVX�Q�ς����Ƃ�����
IPC���P���悤�Ƃ�����A����x��Ȃ�Ɋ撣���Ă��Ȃ��H
��Ԃ����̂�iGPU�ȂS�~���Ɏ̂ĂĂW�R�Asteamroller�o���Ă���邱�Ƃ����ǁAintel�̃n�C�G���h�ȊO��
����iGPU�t�������Ȃ��Ȃ����Ⴄ�킯��
���ʂɂȂ��Ă����GPU�̎g�����Ƃ��Ĉ����͂Ȃ���Ȃ��́H
���������CPU�J���a���ɂ��Ă�������ł��Ȃ����ǁA��������AVX�Q�ς����Ƃ�����
IPC���P���悤�Ƃ�����A����x��Ȃ�Ɋ撣���Ă��Ȃ��H
��Ԃ����̂�iGPU�ȂS�~���Ɏ̂ĂĂW�R�Asteamroller�o���Ă���邱�Ƃ����ǁAintel�̃n�C�G���h�ȊO��
����iGPU�t�������Ȃ��Ȃ����Ⴄ�킯��
627 �F,,�E�L�́M�E,,�j��-�������F2013/12/24(��) 02:33:59.97 ID:QDla65f/
> ��UMA�Ή�APU����܂��o�ĂȂ��̂ɋC�������悗
����͉��̖��_�̉����ɂȂ�Ȃ����Ƃ�m�邾������B
������GPU���ɑ�e�ʃL���b�V�����ڂ��Ă��܂��Ƃ��ˁB
����GPU�ɓ��������\�t�g�����ȑO�ɁA�܂�����GPU�ɓ��������n�[�h����Ȃ����
�f�B�X�N���[�gGPU�̏k���ł��ڂ��Ă����A�ėpCPU�\�P�b�g��
�����������ш�ɓ��������n�[�h�ɂ͂Ȃ�Ȃ����A����ɓ��������\�t�g��
�o�Ă��悤���Ȃ��B
����͉��̖��_�̉����ɂȂ�Ȃ����Ƃ�m�邾������B
������GPU���ɑ�e�ʃL���b�V�����ڂ��Ă��܂��Ƃ��ˁB
����GPU�ɓ��������\�t�g�����ȑO�ɁA�܂�����GPU�ɓ��������n�[�h����Ȃ����
�f�B�X�N���[�gGPU�̏k���ł��ڂ��Ă����A�ėpCPU�\�P�b�g��
�����������ш�ɓ��������n�[�h�ɂ͂Ȃ�Ȃ����A����ɓ��������\�t�g��
�o�Ă��悤���Ȃ��B
>>627�@�ʂɓ���GPU�ɓ�������K�v�͂Ȃ���Ȃ��́H���������g�����Ȃ�
��VIDIA�݂�����GPU��CPU�ς��������Ǝv������
�����܂�CPU�����C����HSA�̓I�}�P���x�ɂ��Ă���Ȃ��ƁA�݊��������h�C����
����������p�K�i�����͊g���{�[�h�ł���ė~�����Ǝv������
��VIDIA�݂�����GPU��CPU�ς��������Ǝv������
�����܂�CPU�����C����HSA�̓I�}�P���x�ɂ��Ă���Ȃ��ƁA�݊��������h�C����
����������p�K�i�����͊g���{�[�h�ł���ė~�����Ǝv������
629 �FSocket774�F2013/12/24(��) 02:55:32.90 ID:pt5Ttgh3
�������ш���܂߂�Ə������\�͂����܂łłȂ����ǂˁB
����ł�APU�������܂ŗ������Ǝv���Ɗ��S�[���B
����ł�APU�������܂ŗ������Ǝv���Ɗ��S�[���B
���ڂ炯�łт����肾��
������-������������t���������
�\�P�b�g�̂Ă�܂�
APU �͗v��Ȃ��q�̂܂܁c�c
APU �͗v��Ȃ��q�̂܂܁c�c
APU�͖����㋌�\�P�b�g��̂ĂĂ邯�ǂ�
hsa��dGPU�ΏۊO��
http://pc.watch.impress.co.jp/docs/column/kaigai/20130502_598132.html
����ƁA�`���̃V�X�e������(System Integration)�̍��ڂł́A1�v�f�������Ă��邱�ƂɋC�����B
��̃X���C�h�ɂ������uExtend to Discrete GPU�v�Ƃ��������������Ă���B
�ȑO�̂悤�ɁA�f�B�X�N���[�gGPU�ɂ��AAPU�Ɠ����v���O���~���O���f�����g�����āA
HSA�̘g�g�݂ɓ���ɑg�ݍ������Ƃ����p���ł͂Ȃ��Ȃ��Ă���B
http://pc.watch.impress.co.jp/docs/column/kaigai/20130502_598132.html
����ƁA�`���̃V�X�e������(System Integration)�̍��ڂł́A1�v�f�������Ă��邱�ƂɋC�����B
��̃X���C�h�ɂ������uExtend to Discrete GPU�v�Ƃ��������������Ă���B
�ȑO�̂悤�ɁA�f�B�X�N���[�gGPU�ɂ��AAPU�Ɠ����v���O���~���O���f�����g�����āA
HSA�̘g�g�݂ɓ���ɑg�ݍ������Ƃ����p���ł͂Ȃ��Ȃ��Ă���B
kaveri�P�̂�G1630+7750�łǂ������Q�[�����K�Ȃ�
Kaveri�͂܂������o�ĂȂ���Ő��\�s���Ă����A�Q�[���^�C�g����ݒ�ɂ���肯�肾�낤����
�{����A10-7000�V���[�Y��iGPU��HD7750�ɂ����邭�炢�̑㕨�Ȃ��
4�R�ACPU�̋��݂ł�葽���̏�ʂŃZ�����������K���낤
�{����A10-7000�V���[�Y��iGPU��HD7750�ɂ����邭�炢�̑㕨�Ȃ��
4�R�ACPU�̋��݂ł�葽���̏�ʂŃZ�����������K���낤
>>635
���ڂ̈Ⴂ�͗���̈Ⴂ�[��
�Г��v���W�F�N�g�Ƒ��Ћ����v���W�F�N�g�̈Ⴂ�𗝉����Ă���Ƃ���
�t���[�����X�ɂ͂킩�����̂Ȃ̂���
���ڂ̈Ⴂ�͗���̈Ⴂ�[��
�Г��v���W�F�N�g�Ƒ��Ћ����v���W�F�N�g�̈Ⴂ�𗝉����Ă���Ƃ���
�t���[�����X�ɂ͂킩�����̂Ȃ̂���
��Aamd�ȊO��dGPU�����HSA���g�����͂O�Ƃ����̂͊m�肾
>>637
Mantle�͎g���܂��B����������Mantle��HSA�̈Ⴂ���o���悤
Mantle�͎g���܂��B����������Mantle��HSA�̈Ⴂ���o���悤
HSA ver1��dGPU�͑ΏۊO���I�}�P����
HSA ver2�Ń}���`�v���Z�b�T��dGPU�Ή�
����ȂƂ�����ǂ���
�n�[�h�E�F�A�I�ɂ�FX + HD7000�ȍ~��HSA�Ή��͎�肠�����o����
���Ȃ݂ɁAKaveri�������I�ɂ�PCIE�o�X�o�R��CPU��GPU���q���Ă���
�܂�A�\���I�ɂ�dGPU���]�T�őΉ��ł���
�P�ɓ����ɔ�ׂĊO���o�X�͐F�X�ʓ|�������Ȃ���
�܂��A���`�ɂ͗����ł��Ȃ����낤��
HSA ver2�Ń}���`�v���Z�b�T��dGPU�Ή�
����ȂƂ�����ǂ���
�n�[�h�E�F�A�I�ɂ�FX + HD7000�ȍ~��HSA�Ή��͎�肠�����o����
���Ȃ݂ɁAKaveri�������I�ɂ�PCIE�o�X�o�R��CPU��GPU���q���Ă���
�܂�A�\���I�ɂ�dGPU���]�T�őΉ��ł���
�P�ɓ����ɔ�ׂĊO���o�X�͐F�X�ʓ|�������Ȃ���
�܂��A���`�ɂ͗����ł��Ȃ����낤��
��������PCI�o�R�ŃA�h���X���L����
CPU�������ɂ�����A�N�Z�X����悤�ȃE���R���ƊO�t���̈Ӗ����܂�łȂ�����˂�
CPU�������ɂ�����A�N�Z�X����悤�ȃE���R���ƊO�t���̈Ӗ����܂�łȂ�����˂�
�����Ɍ㓡�̌듚�����đΏۊO�Ƃ������z����̂�
�������̃R�q�[�����g�͂ǂ������
��GPGPU�̎��������C���������ɃA�N�Z�X����
���x���Ȃ�
���x���Ȃ�
�}�W�ň������Ĕn���Ȃ�
�}���`�v���Z�b�T��T�[�o�[���ǂ�����ă������A�N�Z�X���Ă�̂��m��Ȃ���
�A�h���X���L���Ă����[�J���������D��ŏ�������Ɍ��܂��Ă邾��w
�}���`�v���Z�b�T��T�[�o�[���ǂ�����ă������A�N�Z�X���Ă�̂��m��Ȃ���
�A�h���X���L���Ă����[�J���������D��ŏ�������Ɍ��܂��Ă邾��w
649 �FSocket774�F2013/12/24(��) 13:42:52.92 ID:UxbmFf1z
���܂���͑��@�\�h���C���[���ق����̂��H
dual cpu�ŁA�������R���e�X�����Ă�ƃ������͕Б����������
652 �FSocket774�F2013/12/24(��) 14:03:30.01 ID:u7eDKDUa
>>649
�C���e����Q�z�͂���Ȃ���
�C���e����Q�z�͂���Ȃ���
��������GPGPU�ł�낤���Ĕėp�v�Z�̃f�[�^��CPU�������ɂ���킯��
�Q�[�������K�Ȃق���I�Ԃ�AMD���I�ׂȂ�
����ł̓Z�������ʼn��K�ȃQ�[�����C�t���I
NVIDIA��Voodoo�̎��|�����Ȃ�AMD�����������܂ł�
�Q�[�������nvidia�ɂ��������B
�G�����������l�̓��`����amd���B
�G�����������l�̓��`����amd���B
658 �FSocket774�F2013/12/24(��) 16:00:28.76 ID:u7eDKDUa
���N����̓Q�[�������f������Q�z�͂���Ȃ���
>>ID:PKcY7bnt
dGPU��@���Ƃ���GPGPU�̒x����@��
iGPU��@���Ƃ��͖{���̕`��\�͂̒Ⴓ��@�����Ă킯�ł���
dGPU��@���Ƃ���GPGPU�̒x����@��
iGPU��@���Ƃ��͖{���̕`��\�͂̒Ⴓ��@�����Ă킯�ł���
HSA��dGPU�̏ꍇ��HSA���C���[�����邩�獡�̒�GPGPU���x���Ȃ��
dGPU�̏ꍇ�́A���̒�GPGPU���}���g���ŁAHSA��DirectX�I�Ɉ������Ċ����ɂȂ��
dGPU�̏ꍇ�́A���̒�GPGPU���}���g���ŁAHSA��DirectX�I�Ɉ������Ċ����ɂȂ��
mantle�̃Q�[��������́H
����[�����Ƃ���[
PhenomII����̔����ւ�����Ė�����H�H�H
�ǂ���������H
�ǂ���������H
Vishera�ł��������A���X���`
>>663
X4�ȉ��Ȃ牽�ł��悭�ˁH
X4�ȉ��Ȃ牽�ł��悭�ˁH
>>664
�S�~�X�y�b�N�Ȃ̂�2�������邶���
�S�~�X�y�b�N�Ȃ̂�2�������邶���
>>664
�����͎�����X���Ȃ��猻�sCPU���邱�Ƃ��X���`�Ȃ�˂ƃ}�W���X
�����͎�����X���Ȃ��猻�sCPU���邱�Ƃ��X���`�Ȃ�˂ƃ}�W���X
�y�X�[�p�[��104�����z
Phenom X4 9950 BE�i2008�N7���j�@���@30�b
�@�@�@�@��
�@�킸����N�Ő��\���o������
�@�@�@�@��
Phenom II X4 965 BE�i2009�N8���j�@���@20�b
�@�@�@�@��
�@�����Ċo������4�N�̍Ό������ꂽ�A�A�A
�@�@�@�@��
A10-6800K�i2013�N6���j�@���@22�b
(�@߄t�)�@�@�@�@�@�@22�b
(�t��)��
(�G߄t�)�@�@�@�@�@�@22�b
(�t��)��
�@�@_, ._
�i�G� �D߁j�I�H�@�@22�b
Phenom X4 9950 BE�i2008�N7���j�@���@30�b
�@�@�@�@��
�@�킸����N�Ő��\���o������
�@�@�@�@��
Phenom II X4 965 BE�i2009�N8���j�@���@20�b
�@�@�@�@��
�@�����Ċo������4�N�̍Ό������ꂽ�A�A�A
�@�@�@�@��
A10-6800K�i2013�N6���j�@���@22�b
(�@߄t�)�@�@�@�@�@�@22�b
(�t��)��
(�G߄t�)�@�@�@�@�@�@22�b
(�t��)��
�@�@_, ._
�i�G� �D߁j�I�H�@�@22�b
�@�@�@�@�@�@ �@�,,�
�@�@�@�@�@�@ �i ߃�� �j�@�ǂ����Ă����Ȃ����I�H
�@�߮݁@�@�@( O��O)
�@�@�߮݁@�@ ��-||-J
�@�@�@�@�@�@�@������
�@�@ �@�@�@�@�@�@��
�@�܁R�V�܁R�V
�@�@�@�@�@�@ �i ߃�� �j�@�ǂ����Ă����Ȃ����I�H
�@�߮݁@�@�@( O��O)
�@�@�߮݁@�@ ��-||-J
�@�@�@�@�@�@�@������
�@�@ �@�@�@�@�@�@��
�@�܁R�V�܁R�V
>>670
��������A�D���Ȃ����p�C���~���Ă�
��������A�D���Ȃ����p�C���~���Ă�
�̂�20�b�ƍ���22�b���፡�̕���������������Ȃ�
AMD�ł��p�C�͏Ă��邯��Intel����BF4�����Ȃ������
�o�C�N��4�A�L���u�����݂����Ȋ����ł���
PhenomII�Ɏc���Ă����l������ƈڍs�������ł������Ȃ̂�Kaveri����Ȃ����ȁBX6�͒m���B
��Intel�֏�芷���͂��Ȃ��Ƃ�������ł�
��Intel�֏�芷���͂��Ȃ��Ƃ�������ł�
�X�[�p�[�͎����㕂�������_���Z�x���`������
Phenom�܂ł̃l�C�e�B�u�ŃR�A���ƂɁA�����A���������_���Z���j�b�g������̂�
Bulldozer�APiledriver�̃��W���[�����Ƃɐ���2��A���������_���Z1��Ƃł�
���R��҂��s��
�����Ǖ��������_���Z���j�b�g��4���Phenom II X4��20�b��
��2���A10-6800K��22�b�Ƃ�����r�Ȃ��
���j�b�g�P�ʂł̉��Z��A10-6800K���قڔ{�̔\�͂������ƂɂȂ�
Phenom�܂ł̃l�C�e�B�u�ŃR�A���ƂɁA�����A���������_���Z���j�b�g������̂�
Bulldozer�APiledriver�̃��W���[�����Ƃɐ���2��A���������_���Z1��Ƃł�
���R��҂��s��
�����Ǖ��������_���Z���j�b�g��4���Phenom II X4��20�b��
��2���A10-6800K��22�b�Ƃ�����r�Ȃ��
���j�b�g�P�ʂł̉��Z��A10-6800K���قڔ{�̔\�͂������ƂɂȂ�
�܂����������������Ă���
APU���ƃ��������_�����ƒx���Ȃ�i
APU���ƃ��������_�����ƒx���Ȃ�i
>>676
�Ђ���Ƃ��āA4�X�������p�C������Ƃ����ԍ������̂���
�Ђ���Ƃ��āA4�X�������p�C������Ƃ����ԍ������̂���
679 �FSocket774�F2013/12/24(��) 22:06:24.02 ID:pt5Ttgh3
�X���`�����ǂ��B
AMD�D�������ǂ��B
����ς�A�R�c�R�c�ƃV���O���X���b�h�̐��\��Intel���̂��̂��Ȃ����Ďv���悤�ɂȂ��Ă����B
>>675
�t�F�m�����炾�ƃJ���F���Ȃ̂��Ȃ��B
����܂萫�\�̐L�т������Ȃ��ȁB
���Â����ǂ�LGA1156��i7���}�U�{�[�h�Ƒg�ݍ��킹�Ă�1.5���Ŕ������Ⴄ��ˁB
�R�X�p���������ǂ������B
AMD�D�������ǂ��B
����ς�A�R�c�R�c�ƃV���O���X���b�h�̐��\��Intel���̂��̂��Ȃ����Ďv���悤�ɂȂ��Ă����B
>>675
�t�F�m�����炾�ƃJ���F���Ȃ̂��Ȃ��B
����܂萫�\�̐L�т������Ȃ��ȁB
���Â����ǂ�LGA1156��i7���}�U�{�[�h�Ƒg�ݍ��킹�Ă�1.5���Ŕ������Ⴄ��ˁB
�R�X�p���������ǂ������B
��4���FX-8350�ł͂ǂ��Ȃ�܂����I�H
Phenom2 955BE����7700k�ɍs�����Ǝv���Ă�
GPU��HD4550������啝���\�A�b�v�ɂȂ��
GPU��HD4550������啝���\�A�b�v�ɂȂ��
GPU���\��HD7750�����Ȃ��HD4870�ȏ�ɂȂ���
683 �F,,�E�L�́M�E,,�j��-�������F2013/12/24(��) 22:38:33.71 ID:u1KsJ95Y
100������SuperPI�͕��������_�x���`���Ă��������͂�L���b�V����Write-Allocate���\�𑪂�x���`����
�܂��A������V���O���X���b�h����̓X���ɒ���t���Ă��̂��B
�p�̂Ȃ��Ƃ���ɋ������āA�i�v���[�v���Ċy�����H
�p�̂Ȃ��Ƃ���ɋ������āA�i�v���[�v���Ċy�����H
> 100������SuperPI�͕��������_�x���`���Ă��������͂�L���b�V����Write-Allocate���\�𑪂�x���`
(߄t�) �����́H�Όv�Z�ɂ����������ԂƁAWA�x���`�̃X�R�A����Ⴕ�Ă�\�[�X�͂��邩���H
(߄t�) �����́H�Όv�Z�ɂ����������ԂƁAWA�x���`�̃X�R�A����Ⴕ�Ă�\�[�X�͂��邩���H
686 �F,,�E�L�́M�E,,�j��-�������F2013/12/24(��) 23:07:16.33 ID:u1KsJ95Y
���������_���Z���\����Ⴕ�Ă�\�[�X���Ȃ����ǂ�
687 �F,,�E�L�́M�E,,�j��-�������F2013/12/24(��) 23:09:35.78 ID:u1KsJ95Y
RMMA�ŃL���b�V���̃��C�e���V�E�X���[�v�b�g���Ă݂�Έ��̑����͓���ꂻ������
�~�����v�Z
��
�C�Ӑ��x���Z
��
��Z
��
FFT
��
�o�^�t���C���Z
��
�L���b�V�����d�v
�킩��悤�Ȃ킩��Ȃ��悤��
��
�C�Ӑ��x���Z
��
��Z
��
FFT
��
�o�^�t���C���Z
��
�L���b�V�����d�v
�킩��悤�Ȃ킩��Ȃ��悤��
(߄t�) �\�[�X���Ȃ���ł��˗����ł�
(߄t�) �ł́A��������Ε��������_���Z���\���Όv�Z�ɋy�ڂ��e�����AWA���\�̋y�ڂ��e���̕��������Ƃ����\�[�X������Ώo���ĉ�����
(߄t�) �Ȃ���Θb�͏I���ł�
(߄t�) �ł́A��������Ε��������_���Z���\���Όv�Z�ɋy�ڂ��e�����AWA���\�̋y�ڂ��e���̕��������Ƃ����\�[�X������Ώo���ĉ�����
(߄t�) �Ȃ���Θb�͏I���ł�
(߄t�) �����A����̓Όv�Z���x��WA���\�ɔ�Ⴗ��Ƃ�������O��Ƃ����ꍇ�Ɂi�\�[�X�Ȃ��ł��j�K�v�ɂȂ�\�[�X�ł����ǂ�
691 �F,,�E�L�́M�E,,�j��-�������F2013/12/24(��) 23:19:42.71 ID:u1KsJ95Y
�̂�K6����Athlon������Write Allocate���L���ɂȂ�p�b�`���Ă���
SuperPI�̐��\�����I�ɉ��P�����Ƃ��Ȃ��������ȁB
�L���b�V���̃��C�e���V�����������Ƃ���Intel�EAMD�W�Ȃ��ɉ������Ă�
SuperPI�̐��\�����I�ɉ��P�����Ƃ��Ȃ��������ȁB
�L���b�V���̃��C�e���V�����������Ƃ���Intel�EAMD�W�Ȃ��ɉ������Ă�
692 �F,,�E�L�́M�E,,�j��-�������F2013/12/24(��) 23:25:08.36 ID:u1KsJ95Y
��SuperPI�̓����ɂ��ĉ�����Ă�T�C�g�Ȃ�ĂȂ�����
�����̎G����Write Allocate�̃p�t�H�[�}���X�̉e�����₷�����Ƃ�
������Ă��̂͊m������B
�����������̐��\���v�����Ă�̂��킯���킩�炸��SuperPI�̐��\���ǂ��Ƃ�
�����Ă�̂͊��m�ł����Ȃ����B
��
http://homepage1.nifty.com/~hamar/hitorigoto/hito9902.html
�����̎G����Write Allocate�̃p�t�H�[�}���X�̉e�����₷�����Ƃ�
������Ă��̂͊m������B
�����������̐��\���v�����Ă�̂��킯���킩�炸��SuperPI�̐��\���ǂ��Ƃ�
�����Ă�̂͊��m�ł����Ȃ����B
��
http://homepage1.nifty.com/~hamar/hitorigoto/hito9902.html
����(߄t�)��WA�������킩���Ă�̂��H
����104�������ĉ��o�C�g���낤���H
����104�������ĉ��o�C�g���낤���H
694 �F,,�E�L�́M�E,,�j��-�������F2013/12/24(��) 23:27:49.83 ID:u1KsJ95Y
���̂��̂���̉�������ꂾ��
http://www.geocities.co.jp/SiliconValley-Bay/9439/negoto/ngt006.htm
http://www.geocities.co.jp/SiliconValley-Bay/9439/negoto/ngt006.htm
X87�̉��Z�Ƃ�Intel�ȊO�N���g��Ȃ�����p�C�Ă��Ƃ��ǂ��ł�����
(߄t�) �����Ƀ������A�N�Z�X���ő�̃{���g�l�b�N�ł�����A�L���b�V�����\�̉e����啝�ɎĂ��Ă��s�v�c�͂���܂���
(߄t�) �������������_���Z�̕��ׂ����\�Ȃ��̂ł����AWA���\�𑪂�x���`�Ƃ����̂͌����߂����Ǝv�����̂Ń\�[�X������Ό������Ǝv���܂���
(߄t�) �\�[�X������Ζ����Ŕ[���ł�
(߄t�) �������������_���Z�̕��ׂ����\�Ȃ��̂ł����AWA���\�𑪂�x���`�Ƃ����̂͌����߂����Ǝv�����̂Ń\�[�X������Ό������Ǝv���܂���
(߄t�) �\�[�X������Ζ����Ŕ[���ł�
697 �F,,�E�L�́M�E,,�j��-�������F2013/12/24(��) 23:32:58.30 ID:u1KsJ95Y
�����������{�I�Ȗ��Ƃ���SuperPI�̃X�R�A�̏㉺�ɉ��̈Ӗ�������̂��ˁH
���͂�~���������߂���@�Ƃ��Ă��玞�����̃A���S���Y���Ȃ�
�Â�����g���Ă邩��ϐM�I�ɂ������̂��Ǝv������ł邾������Ȃ��́H
���͂�~���������߂���@�Ƃ��Ă��玞�����̃A���S���Y���Ȃ�
�Â�����g���Ă邩��ϐM�I�ɂ������̂��Ǝv������ł邾������Ȃ��́H
(߄t�) �Όv�Z�ɈӖ������邩�Ȃ����Ȃ�čŏ�����ǂ��ł��ǂ���ł����ǂ˖l��
(߄t�) �������Ȃ���
> 100������SuperPI�͕��������_�x���`���Ă��������͂�L���b�V����Write-Allocate���\�𑪂�x���`
(߄t�) �ƌ������̂Ń\�[�X�͂���܂����H�ƕ����āA�����킯�ł�����A���̘b�͂����ŏI���Ȃ̂ł����A�A�A
(߄t�) �������Ȃ���
> 100������SuperPI�͕��������_�x���`���Ă��������͂�L���b�V����Write-Allocate���\�𑪂�x���`
(߄t�) �ƌ������̂Ń\�[�X�͂���܂����H�ƕ����āA�����킯�ł�����A���̘b�͂����ŏI���Ȃ̂ł����A�A�A
�c�q�I�ɂ͍����̃A�[�L�ɍ�����PI����Ă݂���ċC�͂Ȃ��H
�������ʔ����������ǎ����ł͖���������߂���B(���Ⴂ)
�������ʔ����������ǎ����ł͖���������߂���B(���Ⴂ)
700 �F,,�E�L�́M�E,,�j��-�������F2013/12/24(��) 23:38:49.42 ID:u1KsJ95Y
FFT�̐��\���������̂Ȃ�SSE��AVX���g���ă����e�i���X������Ă�
FFTSS�Ȃ�GMP�Ȃ�̃��C�u����������킯�ł����ǁA
x87�܂ł����g���ĂȂ��v���O�����̉����L�Ӌ`�Ȃ́H
SuperPI�̃X�R�A��\�����̂͌N����Ȃ��̂��ˁH
�����������_���ȃA�v���̃p�t�H�[�}���X�ɉe�������Ȃ���Ύ�������
���K�V�[�A�v���̑��x���x���Ȃ��Ă����͂Ȃ��킯�ł��B
FFTSS�Ȃ�GMP�Ȃ�̃��C�u����������킯�ł����ǁA
x87�܂ł����g���ĂȂ��v���O�����̉����L�Ӌ`�Ȃ́H
SuperPI�̃X�R�A��\�����̂͌N����Ȃ��̂��ˁH
�����������_���ȃA�v���̃p�t�H�[�}���X�ɉe�������Ȃ���Ύ�������
���K�V�[�A�v���̑��x���x���Ȃ��Ă����͂Ȃ��킯�ł��B
�k�ق̃e���v�����Ă�H
>>699
�����[�ł���H��������ˁi �L,_�T�M�j�߯
�����[�ł���H��������ˁi �L,_�T�M�j�߯
703 �F,,�E�L�́M�E,,�j��-�������F2013/12/24(��) 23:47:00.90 ID:u1KsJ95Y
>>699
���܍ő��̕��@����SSD����ʂɕK�v�ɂȂ����肷�邠��ł���
�����i�E��SIMD���߂Ȃ��g����FFT���FHT�����������邾���Ȃ�
�ԗւ̍Ĕ����ɂ����Ȃ���B
���܍ő��̕��@����SSD����ʂɕK�v�ɂȂ����肷�邠��ł���
�����i�E��SIMD���߂Ȃ��g����FFT���FHT�����������邾���Ȃ�
�ԗւ̍Ĕ����ɂ����Ȃ���B
> ����͉������Ă��ƁH
�i�O�ցO�j �������Ⴂ�܂�
�i�O�ցO�j �������Ⴂ�܂�
�y�X�[�p�[��104�����z
A10-6800K �� 22�b
G1610 �� 15�b
�@�@�@�@�@�@ �@�,,�
�@�@�@�@�@�@ �i ߃�� �j�@�ǂ����Ă����Ȃ����I�H
�@�߮݁@�@�@( O��O)
�@�@�߮݁@�@ ��-||-J
�@�@�@�@�@�@�@������
�@�@ �@�@�@�@�@�@��
�@�܁R�V�܁R�V
A10-6800K �� 22�b
G1610 �� 15�b
�@�@�@�@�@�@ �@�,,�
�@�@�@�@�@�@ �i ߃�� �j�@�ǂ����Ă����Ȃ����I�H
�@�߮݁@�@�@( O��O)
�@�@�߮݁@�@ ��-||-J
�@�@�@�@�@�@�@������
�@�@ �@�@�@�@�@�@��
�@�܁R�V�܁R�V
http://www.numberworld.org/y-cruncher/
����������_���Ȃ̂��H
����������_���Ȃ̂��H
>>707
[email protected]�ň�����V���O���E�ŏ����ʼn��Z����29.77�b
SuperPI104@15�b���ă����L���O�T���ƌy��������O���x���Ȃ�
�܂��t�ɂ悭����ȗv��Ȃ�����Ԃ牺���Ă��Ȃ��E�E�E
[email protected]�ň�����V���O���E�ŏ����ʼn��Z����29.77�b
SuperPI104@15�b���ă����L���O�T���ƌy��������O���x���Ȃ�
�܂��t�ɂ悭����ȗv��Ȃ�����Ԃ牺���Ă��Ȃ��E�E�E
709 �F,,�E�L�́M�E,,�j��-�������F2013/12/25(��) 00:08:57.38 ID:UOgu0WYm
FFT�͉��p�͈͂��L�����Z�����瑬���Ȃ邱�Ƃ͈Ӌ`������A���Ă̂�
SuperPI���x�����ꂽ���R�B
����SSE�ɂ���Ή����ĂȂ����R�[�h�̏������\���v������Ӗ��͂܂������Ȃ��B
�摜�Ƃ������̕�������FFT�g���Ă邩��e��G���R�[�_���̂��̂�
�������Ԃ��v�����������Ȃ��́H
���p�I�ł����Ă����̃x���`�}�[�N�ł����B
SuperPI���x�����ꂽ���R�B
����SSE�ɂ���Ή����ĂȂ����R�[�h�̏������\���v������Ӗ��͂܂������Ȃ��B
�摜�Ƃ������̕�������FFT�g���Ă邩��e��G���R�[�_���̂��̂�
�������Ԃ��v�����������Ȃ��́H
���p�I�ł����Ă����̃x���`�}�[�N�ł����B
�@ �@�@�@�Q�Q�Q_
�@�@�@�^�@�@ �@ �@�_
�@ �^�@�@���@ �@ ���_�@
�^ �@�@ �i���j �@�i���j �_�@�悭�l����ƃX�[�p�[���čō�����
|�@ �@�@ �@ �i__�l__�j�@ �@ |�@�@������CPU�̐��\�S�������邵
/�@�@�@�@ ���m ���@�@�^
(�@ �_�@�^ �Q�m�@|�@ |
.�_�@�g�@�@�^�Q�Q|�@ | �@
�@�@�_ �^�Q�Q�Q �^
�@�@�@�^�@�@ �@ �@�_
�@ �^�@�@���@ �@ ���_�@
�^ �@�@ �i���j �@�i���j �_�@�悭�l����ƃX�[�p�[���čō�����
|�@ �@�@ �@ �i__�l__�j�@ �@ |�@�@������CPU�̐��\�S�������邵
/�@�@�@�@ ���m ���@�@�^
(�@ �_�@�^ �Q�m�@|�@ |
.�_�@�g�@�@�^�Q�Q|�@ | �@
�@�@�_ �^�Q�Q�Q �^
711 �F,,�E�L�́M�E,,�j��-�������F2013/12/25(��) 00:10:57.42 ID:UOgu0WYm
104�������x�Ȃ�6�N�O��Core 2 Duo�ł�PiFast��3�b��������Ȃ��������B
�x���n�[�h�E�F�A��I�т����Ȃ��̂Ɠ����悤�ɒx���\�t�g�E�F�A�ɌŎ�����̂�
�����̃o�J�B
�x���n�[�h�E�F�A��I�т����Ȃ��̂Ɠ����悤�ɒx���\�t�g�E�F�A�ɌŎ�����̂�
�����̃o�J�B
�X�[�p�[�́A�x���`�Ƃ�����背�[�X���ȁB
���͂�x���`�Ƃ��Ẳ��l�͂Ȃ����ǁA���E�L�^�𑈂��l�B������B
���͂�x���`�Ƃ��Ẳ��l�͂Ȃ����ǁA���E�L�^�𑈂��l�B������B
SuperPI�͋ɗ�G�N�X�g���[���`�������W��p�B�x���`����
����ȊO�ɈӋ`����́H
����ȊO�ɈӋ`����́H
�x���`�ŕ�����Ƃ����A
< �M�́L>�x���`���J�X�I
< �M�́L>�J�X�x���`�Ӗ��ˁ[�I
�Ƃ������ăn�[�h�̐��\���Ⴂ�̂��\�t�g�̂����ɂ��܂�
(߄t�)�ϯ�����
< �M�́L>�x���`���J�X�I
< �M�́L>�J�X�x���`�Ӗ��ˁ[�I
�Ƃ������ăn�[�h�̐��\���Ⴂ�̂��\�t�g�̂����ɂ��܂�
(߄t�)�ϯ�����
715 �F,,�E�L�́M�E,,�j��-�������F2013/12/25(��) 00:14:09.06 ID:UOgu0WYm
���[�X���ĈӖ��ł͎O�֎ԃ��[�X����
���G�������[�X������ł�
(߄t�) �O�֎ԃ��[�X�ŕ������
(߄t�) �����O�֎Ԃ��R����Ă��₵����܂�
(߄t�)�ϯ�����
(߄t�) �����O�֎Ԃ��R����Ă��₵����܂�
(߄t�)�ϯ�����
�p�C�Ă��Ɍ��炸�A���ǂ��̃}���`�R�A�A�}���`�X���b�h�AGPGPU�Ƃ��ɑΉ������\�t�g�������A
���ʂ�APU��FX�̗D�G�����o���邩��A�C���e���L���ɂ��悤�Ǝv�����猋�ǃV���O���X���b�h�����ō�邱�ƂɂȂ�
���ʂ�APU��FX�̗D�G�����o���邩��A�C���e���L���ɂ��悤�Ǝv�����猋�ǃV���O���X���b�h�����ō�邱�ƂɂȂ�
����ʼ���
>>719
�t�Ɍ����ƃV���O���X���b�h�ł������Ȃ��v���O���}�̃��x���ɍ��킹��
Intel�͌����ƌ�����
���ꂪ�\�t�g�J���̑������������Ă���ǂ�
�t�Ɍ����ƃV���O���X���b�h�ł������Ȃ��v���O���}�̃��x���ɍ��킹��
Intel�͌����ƌ�����
���ꂪ�\�t�g�J���̑������������Ă���ǂ�
104����15�b������������2500�������b�������ł����˂�
>>708��29.77�b�Ȃ���
>>708��29.77�b�Ȃ���
723 �F,,�E�L�́M�E,,�j��-�������F2013/12/25(��) 00:24:01.55 ID:UOgu0WYm
���̒���8�������̃v���O���}�̏����R�[�h��SIMD���g���Ƃ�
�}���`�X���b�h�ɂ���Ƃ�����ȑO�̖��ł���B
��҂�ٌ�m�ɂȂ�悤�ȓ��̂����l�ނ��\�t�g�J���҂ɂȂ�Ȃ����Ƃ�
�������Ǝv���Ă�B
�}���`�X���b�h�ɂ���Ƃ�����ȑO�̖��ł���B
��҂�ٌ�m�ɂȂ�悤�ȓ��̂����l�ނ��\�t�g�J���҂ɂȂ�Ȃ����Ƃ�
�������Ǝv���Ă�B
> ���̒���8�������̃v���O���}�̏����R�[�h��SIMD���g���Ƃ�
> �}���`�X���b�h�ɂ���Ƃ�����ȑO�̖��ł���B
(߄t�) 8���Ƃ������l�̃\�[�X�́H�܂��ϑz����Ȃ���ˁH
> �}���`�X���b�h�ɂ���Ƃ�����ȑO�̖��ł���B
(߄t�) 8���Ƃ������l�̃\�[�X�́H�܂��ϑz����Ȃ���ˁH
725 �F,,�E�L�́M�E,,�j��-�������F2013/12/25(��) 00:30:29.64 ID:UOgu0WYm
> �^ �@�@ �i���j �@�i���j �_�@�悭�l����ƃX�[�p�[���čō�����
> |�@ �@�@ �@ �i__�l__�j�@ �@ |�@�@������CPU�̐��\�S�������邵
����̃\�[�X�́H
> |�@ �@�@ �@ �i__�l__�j�@ �@ |�@�@������CPU�̐��\�S�������邵
����̃\�[�X�́H
�@ /�_�Q�Q_�^�_
�^�@�^�@�@ �@�R ::: �_
|�@�i���j,�@�A�i���j�A�@| �@�@ �^�P�P�P�P�P�P�P�P�P�P
|�@�@,,�m(�A_, )�R�A,, �@ | �@���@�܁`���ϑz���`
|�@�@�@,;�]���]�R �@ .:::::| �@�@ �_�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q
�_�@�@�M�j�j�L�@ .:::�^
�^�M�[�]--�]�]�\�L�L�_
�^�@�^�@�@ �@�R ::: �_
|�@�i���j,�@�A�i���j�A�@| �@�@ �^�P�P�P�P�P�P�P�P�P�P
|�@�@,,�m(�A_, )�R�A,, �@ | �@���@�܁`���ϑz���`
|�@�@�@,;�]���]�R �@ .:::::| �@�@ �_�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q
�_�@�@�M�j�j�L�@ .:::�^
�^�M�[�]--�]�]�\�L�L�_
����SIMD�Ƃ��d���ňӎ��������ƂȂ��ȁB��ł����c�B
8���ł��T���߂��Ǝv���B
8���ł��T���߂��Ǝv���B
-����������A�ϑz����T�ɂ��ĉ�������
�@�,,�
�i ߃�� )���@���ް
.�@�@�@�@�@.��
�@�,,�
�i ߃�� )���@���ް
.�@�@�@�@�@.��
�X�[�p�[�ȂӖ����Ȃ����Ă��Ƃ��
�V���O����SSE���g��Ȃ��x���`�ɉ��̈Ӗ��������
�V���O����SSE���g��Ȃ��x���`�ɉ��̈Ӗ��������
�Ȃ���Intel�̃X�[�p�[�̑����͐����Ƃ͎v�����ǂˁB
�@ /�_�Q�Q_�^�_
�^�@�^�@�@ �@�R ::: �_
|�@�i���j,�@�A�i���j�A�@| �@�@ �^�P�P�P�P�P�P�P�P�P�P
|�@�@,,�m(�A_, )�R�A,, �@ | �@���@�܁`���A�������\�t�g�̂����ɂ��Ă��`
|�@�@�@,;�]���]�R �@ .:::::| �@�@ �_�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q
�_�@�@�M�j�j�L�@ .:::�^
�^�M�[�]--�]�]�\�L�L�_
�^�@�^�@�@ �@�R ::: �_
|�@�i���j,�@�A�i���j�A�@| �@�@ �^�P�P�P�P�P�P�P�P�P�P
|�@�@,,�m(�A_, )�R�A,, �@ | �@���@�܁`���A�������\�t�g�̂����ɂ��Ă��`
|�@�@�@,;�]���]�R �@ .:::::| �@�@ �_�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q
�_�@�@�M�j�j�L�@ .:::�^
�^�M�[�]--�]�]�\�L�L�_
733 �F,,�E�L�́M�E,,�j��-�������F2013/12/25(��) 00:42:04.81 ID:UOgu0WYm
�g�[�^�����\�������グ���猋�ʓI��SuperPI�������Ȃ��Ă邾����
�ʂ�SuperPI�Ƀ`���[�����Ă�킯����Ȃ�����
AVX�̃��t�@�����X���ł��o�����Ƃ���x87��SSE�R�[�h��i�K�I�ɔp�~����
�����I�ɃG�~�����[�V�����Ŏ���������@����Ă����B
�܂��A���͂��Ȃ����ǁA���̒��x�ɖӒ����Ƃ������Ƃ��B
�ʂ�SuperPI�Ƀ`���[�����Ă�킯����Ȃ�����
AVX�̃��t�@�����X���ł��o�����Ƃ���x87��SSE�R�[�h��i�K�I�ɔp�~����
�����I�ɃG�~�����[�V�����Ŏ���������@����Ă����B
�܂��A���͂��Ȃ����ǁA���̒��x�ɖӒ����Ƃ������Ƃ��B
(߄t�) �Ӗ����Ȃ��낤�ƁA�\�t�g���Â��낤�ƁA�O�֎Ԃł��낤�ƕ����͕���
�R(߄t�)� Ϲ�Ϲ��@�R(߄t�)� Ϲ�Ϲ�
�R(߄t�)� Ϲ�Ϲ��@�R(߄t�)� Ϲ�Ϲ�
�R(߄t�)� Ϲ�Ϲ��@�R(߄t�)� Ϲ�Ϲ�
�R(߄t�)� Ϲ�Ϲ��@�R(߄t�)� Ϲ�Ϲ�
>>721
���̃V���O���X���b�h���x�Ȃ�APU�ł��]�T�ŏ����ł����
�������A������Ȃ����Đ��l��������Ƒ̊��ł��Ȃ����x����Intel�̕����L���ɂȂ�
100�̐��\�ŏ\�������ǁAAMD��200�AIntel��300�Ƃ��ɂȂ��āA200�̐��\��AMD�͒ᐫ�\�̕��ƌ�����
���̃V���O���X���b�h���x�Ȃ�APU�ł��]�T�ŏ����ł����
�������A������Ȃ����Đ��l��������Ƒ̊��ł��Ȃ����x����Intel�̕����L���ɂȂ�
100�̐��\�ŏ\�������ǁAAMD��200�AIntel��300�Ƃ��ɂȂ��āA200�̐��\��AMD�͒ᐫ�\�̕��ƌ�����
>>734
�����͂��͂��Ax87�ł͕�������`
Alpha�ł���8350��AVX���g���悤�ɂȂ��Ă邪�����SSE4.1�Ɣ�r���Ď�x���ȁB
SR�A�[�L�͂��̂�����̓����͎�ς���Ă������ł��˂��B
�����͂��͂��Ax87�ł͕�������`
Alpha�ł���8350��AVX���g���悤�ɂȂ��Ă邪�����SSE4.1�Ɣ�r���Ď�x���ȁB
SR�A�[�L�͂��̂�����̓����͎�ς���Ă������ł��˂��B
���Ȃ��ɂ�������B�ƃp�C�ɂ��Č��X���B
> 8350��AVX���g���悤�ɂȂ��Ă邪�����SSE4.1�Ɣ�r���Ď�x����
(߄t�) �����AMD��AVX��256bit��128bit2��ŏ�������炵���ł�����A���x�I�ȃA�h�o���e�[�W�͏��Ȃ��͂��ł���
�ł͎��͂���Ŏ��炵�܂��A�܂��X�[�p�[�ŏ������܂��傤
�@�,,�
�i ߃�� )���@���ް
.�@�@�@�@�@.��
(߄t�) �����AMD��AVX��256bit��128bit2��ŏ�������炵���ł�����A���x�I�ȃA�h�o���e�[�W�͏��Ȃ��͂��ł���
�ł͎��͂���Ŏ��炵�܂��A�܂��X�[�p�[�ŏ������܂��傤
�@�,,�
�i ߃�� )���@���ް
.�@�@�@�@�@.��
(���D��)
���Ȃ��ǂ��납�J�눫�����Ă�Ƃ��������Ɩ{���ɂ����P�ɓ�T�����邾���݂������Ȃ��B
�R������H�I�ɒP�������Ęb����������FPU�֘A�͂���ȍ~�͉��������~���̈�r���ȁH
�R���p�`�ׂ̈ɕt�����悤��AVX���Ȃ��A�܂��킩���Ă����ǁB
���ĐQ�邩�A����Ƃ��C���t�����ɂ͗L���Ė����悤�Ȃ����B�B�B
�R������H�I�ɒP�������Ęb����������FPU�֘A�͂���ȍ~�͉��������~���̈�r���ȁH
�R���p�`�ׂ̈ɕt�����悤��AVX���Ȃ��A�܂��킩���Ă����ǁB
���ĐQ�邩�A����Ƃ��C���t�����ɂ͗L���Ė����悤�Ȃ����B�B�B
Kaveri��GPU��R7 250�͓������炢�̐��\�ł����ˁH
�ǂ��ł��傤�ˁH
743 �FSocket774�F2013/12/25(��) 01:50:47.19 ID:VdUyc2IR
Phenom2x4 980BE��200MHzOC����HD4890
�����̐��\�ɂ������̍ŐV����̖��߃Z�b�g�ɑΉ�����������
����TDP95W�ɉ������߂��ƌ�����
�X�S�C�͓̂����̃n�C�X�y�b�N�@��l���ȉ��i�ŏ���d�͂�Kaveri�̃s�[�N���Ɠ����̍\���̃A�C�h�����Ɠ������炢�ɂ������Ă�
���݂�OS��VIsta��7���͂邩�Ɍy���Ȃ��Ă邽�ߎ��p����Ȃ����\�Ɏ����Ă��Ă邩�甃���ƌ�����
�����̐��\�ɂ������̍ŐV����̖��߃Z�b�g�ɑΉ�����������
����TDP95W�ɉ������߂��ƌ�����
�X�S�C�͓̂����̃n�C�X�y�b�N�@��l���ȉ��i�ŏ���d�͂�Kaveri�̃s�[�N���Ɠ����̍\���̃A�C�h�����Ɠ������炢�ɂ������Ă�
���݂�OS��VIsta��7���͂邩�Ɍy���Ȃ��Ă邽�ߎ��p����Ȃ����\�Ɏ����Ă��Ă邩�甃���ƌ�����
>>725
�����i����ŐV�s�܂ő���CPU�̃f�[�^�������Ƃ����Ӗ��ōō��̃x���`�}�[�N����
�����i����ŐV�s�܂ő���CPU�̃f�[�^�������Ƃ����Ӗ��ōō��̃x���`�}�[�N����
�����Super�̋c�_�ʼn߂������O��Ɋ���
AMD�L�`�K�C��Intel���L���ȕ���ł�100�̐��\�ŏ\���ƌ���
AMD���L���ȕ���ł�100�̐��\�ł͕s���ƌ�������x���ŗ�
AMD���L���ȕ���ł�100�̐��\�ł͕s���ƌ�������x���ŗ�
�V�R�V�R���肾�ƒc�q�̕����i��Ȋ���������
����N�G���Ⴄ����ȁB
�E�Ή��\�t�g�������Ȃ��͍̂�点�Ȃ�Intel�ƍ��Ȃ��v���O���}������
����Ȕn���Ȃ��ƌ����Ă邩��AMD�͍œK�����Ă��炦�Ȃ����Ƃ��炢�C�Â�
����Ȕn���Ȃ��ƌ����Ă邩��AMD�͍œK�����Ă��炦�Ȃ����Ƃ��炢�C�Â�
AMD�̃}�C�N���A�[�L�e�N�`���[�͕Ȃ��������ĉ���ɍœK������Ǝ��Œv���I�ɒx���Ȃ邩��ȁBIntel�̓}�C�N���A�[�L�e�N�`���[��ˑ��Ōy���œK�������R�[�h�������Ɏ��s�ł��邾�������B
��ԕȂ����Ȃ������̂�K8�ł���͉�����点�Ă������������������A�Ƃ�������_�����������B
��ԕȂ����Ȃ������̂�K8�ł���͉�����点�Ă������������������A�Ƃ�������_�����������B
�܂͂��ƂT���ł���́H��
���S���ʓy����FX
ttp://www.agner.org/optimize/blog/read.php?i=187
�E�ȓd�͋@�\���ߏ�ɃN���b�N��}������
�EBull�̃R�A�����\�[�X�����L���Ă��邱�Ƃ�m�炸��OS���^�X�N������U��\��������
�E2�R�A�ɕ��ׂ�������ƃt�F�b�`�ш悪�R�A������16B/clk�ɗ�����
�E2�R�A�ɕ��ׂ�������ƃf�R�[�h�ш悪�R�A������2����/clk�ɗ�����
�ED$�̃o���N�R���t���N�g���p�ɂɋN����
�EI$��2-way��2�X���b�h�������s����ɂ͕s��
�E�����p�C�v���C���ŕ���\���~�X���̃y�i���e�B���傫��
�E�p�C�v���C�����̂�4����/clk��������ALU��2�����Ȃ����ė]���C��
�E����SIMD���j�b�g�Ŏ��s�����fp SIMD���߂�����f�[�^�����ɗ]�v�ȃ��C�e���V��������
�_(^o^)�^
ttp://www.agner.org/optimize/blog/read.php?i=187
�E�ȓd�͋@�\���ߏ�ɃN���b�N��}������
�EBull�̃R�A�����\�[�X�����L���Ă��邱�Ƃ�m�炸��OS���^�X�N������U��\��������
�E2�R�A�ɕ��ׂ�������ƃt�F�b�`�ш悪�R�A������16B/clk�ɗ�����
�E2�R�A�ɕ��ׂ�������ƃf�R�[�h�ш悪�R�A������2����/clk�ɗ�����
�ED$�̃o���N�R���t���N�g���p�ɂɋN����
�EI$��2-way��2�X���b�h�������s����ɂ͕s��
�E�����p�C�v���C���ŕ���\���~�X���̃y�i���e�B���傫��
�E�p�C�v���C�����̂�4����/clk��������ALU��2�����Ȃ����ė]���C��
�E����SIMD���j�b�g�Ŏ��s�����fp SIMD���߂�����f�[�^�����ɗ]�v�ȃ��C�e���V��������
�_(^o^)�^
Bulldozer��Windows8.1�ɂ��鎖�Ő��\��15%�L�т�
754 �F,,�E�L�́M�E,,�j��-�������F2013/12/25(��) 08:28:26.33 ID:UOgu0WYm
>>750
> �Ȃ��������ĉ���ɍœK������Ǝ��Œv���I�ɒx���Ȃ邩��ȁB
Pentium4���낻��́B
����Pentium4�̃A�[�L�e�N�g��������̂�����AMD�A�[�L�����ǂ�
> �Ȃ��������ĉ���ɍœK������Ǝ��Œv���I�ɒx���Ȃ邩��ȁB
Pentium4���낻��́B
����Pentium4�̃A�[�L�e�N�g��������̂�����AMD�A�[�L�����ǂ�
Pen4�A�k�X�ȍ~�͈����Ȃ���(�L�_�`)
���̂�(�m)�Ƃ��Ђǂ�CPU����������
�k�X�ȑO�A�ł�?
758 �FSocket774�F2013/12/25(��) 10:00:18.21 ID:COxn1CU2
�ǂ��l����A���������̂̓v���X�R�������H
�o�b��2013�N�̐��E�o�ב䐔��10.1����-�h�c�b���\�z�����C��
http://www.bloomberg.co.jp/news/123-MX7DI36KLVRX01.html
http://www.bloomberg.co.jp/news/123-MX7DI36KLVRX01.html
�y��4�͈���������Ȃ��āA����������ł���
����ȏ�͖��������獪�{����d�l��ς��܂��傤���Ă��Ƃ�
�}�C�N���\�t�g�ƂȂ���ĂȂ������H
��������C����߂Ȃ�AMD���]�v�Ȃ��Ƃ��ĂƂ�
����ȏ�͖��������獪�{����d�l��ς��܂��傤���Ă��Ƃ�
�}�C�N���\�t�g�ƂȂ���ĂȂ������H
��������C����߂Ȃ�AMD���]�v�Ȃ��Ƃ��ĂƂ�
�����̏́A���邽�߂ɃN���b�N�������āA�p�r���i���������Ȏd�l�ɂ�����
���l�i���A���ۂɏo�Ă������́A�����̃��[�J�[PC�ۂ��ƃ_���߂���I�`�ɂȂ��������ł���B
�ǂ��������AMD�K�[�ɂȂ��w
���l�i���A���ۂɏo�Ă������́A�����̃��[�J�[PC�ۂ��ƃ_���߂���I�`�ɂȂ��������ł���B
�ǂ��������AMD�K�[�ɂȂ��w
762 �FSocket774�F2013/12/25(��) 11:01:39.32 ID:LDjsie3q
�C���e���g���͔n���������
���ɂ��Ďv���v���X�R�t�@�C���[��Intel90nm�v���Z�X���n�Y��������������܂Ƃ��ɐH����Ă��܂����Ƃ����C�̓łȏ�������B
���̃p�C�v���C���i���ł��A�g�����W�X�^���z��ʂ�Ȃ�@�\�����̂��ˁB
���[�N�d���������̌����ݒʂ�10%���x�Ŏ��܂��Ă����Ȃ�A4GHz��60W���x�Ŏ����ł��Ă����͂��ł�����
�uNVIDIA GNG: Glide New Generation�v
�őR���ė~������
�őR���ė~������
���������ŋ߃J�[�{���i�m�`���[�u��CPU���Ƃ������b����Ȃ��Ȃ�����
�܂��܂��Z�p������Ȃ��̂�
�܂��܂��Z�p������Ȃ��̂�
�R�X�g�̖�肶��Ȃ���
>>747
�S�V�S�V���Ăǂ����̋L���̃R�s���N���̔����̎��肵���ł��Ȃ����ǁA
���̎���l�^���̉��������c�q�̔��������ȁB
�S�V�S�V���Ăǂ����̋L���̃R�s���N���̔����̎��肵���ł��Ȃ����ǁA
���̎���l�^���̉��������c�q�̔��������ȁB
>>759
���N�͂���Ɉ������鎖������Ă�悤�Ȃ�����~����������
���N�͂���Ɉ������鎖������Ă�悤�Ȃ�����~����������
���������������玩�삷���
����HDD������������B
����HDD������������B
http://www.nikkei.com/article/DGXNASFL250QV_V21C13A2000000/?dg=1
���@�d�q���Z�p�Y�Ƌ���i�i�d�h�s�`�j��25�����\����11���̃p�\�R���o�ב䐔�́A
���O�N������24.4������89��2000�䂾�����B�Q�J���A���őO�N���������B
���@�d�q���Z�p�Y�Ƌ���i�i�d�h�s�`�j��25�����\����11���̃p�\�R���o�ב䐔�́A
���O�N������24.4������89��2000�䂾�����B�Q�J���A���őO�N���������B
773 �FSocket774�F2013/12/25(��) 15:40:46.83 ID:LDjsie3q
Apu���ڋ@�͍���400����ʔ���Ă��
�Q�[���@������
���ʂ͏o���Δ�����Ԃ��������A�J�x�������Ȃ�l�C�����邩��A���N�͌��\���邻������
�Q�[���@������
���ʂ͏o���Δ�����Ԃ��������A�J�x�������Ȃ�l�C�����邩��A���N�͌��\���邻������
kaveri���Q�[���@��蔄��関�����z���ł���
�}���g���͏�X�Ȋ���o�������AHSA�͂ǂ��Ȃ邱�Ƃ��ȁB
����PC���Q�[���@���\�t�g������ĂƂ����낤���ǁB
����PC���Q�[���@���\�t�g������ĂƂ����낤���ǁB
�y�Z�p�z�P�w�J�[�{���i�m�`���[�u�̗ʎY�Z�p���J��/�Y����
http://anago.2ch.net/test/read.cgi/scienceplus/1387933908/
���ꌩ�Ďv���o�������
http://anago.2ch.net/test/read.cgi/scienceplus/1387933908/
���ꌩ�Ďv���o�������
�J�[�{���̔z���Ȃ�AthlonXP�̍��ɂ����
����`���[�g����������������
�`���[�g����˂����I
�V���[�g������I
�V���[�g������I
������Ƃ����V���[�g������������̗����Ƃ�����
���M�����������
���������Ȃ�
���r�[�̎w�ւ��v���o����
���������Ȃ�
���r�[�̎w�ւ��v���o����
�����������
���������V�ׂ�Ƃ��낪�����Ȃ����̂́A���̎���PC�ɔM�C�������Ȃ����v���̈���낤�ˁB
���������V�ׂ�Ƃ��낪�����Ȃ����̂́A���̎���PC�ɔM�C�������Ȃ����v���̈���낤�ˁB
783 �FSocket774�F2013/12/25(��) 17:30:33.22 ID:VdUyc2IR
7850�ƌ�����AMD���[�U�[�Ȃ�^����ɖ��@
Athlon x2 7850���v�������ׂ邗
Athlon x2 7850���v�������ׂ邗
784 �FSocket774�F2013/12/25(��) 18:10:25.59 ID:UORD5yxt
>>783
Phenom GS-6000����f�B�X���Ă�̂��H
Phenom GS-6000����f�B�X���Ă�̂��H
��X�Ȋ���o�����Ă܂����������ǂ����킩��Ȃ�����
�N���Ƀp�b�`�o���Ȃ�������D���Ȃ��������Ă���
�N���Ƀp�b�`�o���Ȃ�������D���Ȃ��������Ă���
>>783
����KUMA�H
����KUMA�H
Llano�o��̋łɂ͑叟��
Trinity�o��̋łɂ͑叟��
Richland�o��̋łɂ͑叟��
Kaveri�o��̋łɂ͑叟�� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
Trinity�o��̋łɂ͑叟��
Richland�o��̋łɂ͑叟��
Kaveri�o��̋łɂ͑叟�� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
��łǂ����Ă����Ȃ����Ƃ��v���Ń`���[�g�݂����Ȃ��Ƃ���Ă�l��������
�Ȃ��APU�ł͎O�����Ȃ��Ȃ����낤�H
�Ȃ��APU�ł͎O�����Ȃ��Ȃ����낤�H
��R�X�g�̈����ɎO���L���b�V���Ȃ�ēo�ڂł��܂ւ�(�L�_�`)
APU��FX�ƍ��ʉ���}��Ȃ��Ƃ����낤
�ᑬ��3���L���b�V�����́A4�R�A���x����v��Ȃ�����A1���A2���̍œK����f�R�[�_�[���ǂȂ�ł���B
��Ƀ��[�����g�b�s���O�S���X�H���悤��PC�I�т��āA�ቿ�i��APU��������Ȃ���ȁB
��Ƀ��[�����g�b�s���O�S���X�H���悤��PC�I�т��āA�ቿ�i��APU��������Ȃ���ȁB
PS4�̂悤�ȃA�v���[�`��Xbox one���B�����I�ɂ͂ǂ����ɐi�ނ̂�H
���႟phenom��L3�ڂ��Ă�AMD��gmkz���Ă��ƁH
�I�ł��邩��ڂ��Ă�����
>>792
�����̂����Ƃ���肷�������Ȃ����ȁB
�����̂����Ƃ���肷�������Ȃ����ȁB
>>792
�g�݂����V�X�e���ɂ���ĕς�邩��
PS4�̓J�X�^���`�b�v�ŁAOS��BG������⏕
X1��STB�Ƃ��Ă̐��i��A�z�[����ʂ̌Ăяo�����x�ɍS���đ�e��eRAM��I�B
�ǂ������v��Ȃ��ėpPC����A����APU����z�肳��闘�p�V�[���͑債�ĕς��Ȃ��ł���B
�g�݂����V�X�e���ɂ���ĕς�邩��
PS4�̓J�X�^���`�b�v�ŁAOS��BG������⏕
X1��STB�Ƃ��Ă̐��i��A�z�[����ʂ̌Ăяo�����x�ɍS���đ�e��eRAM��I�B
�ǂ������v��Ȃ��ėpPC����A����APU����z�肳��闘�p�V�[���͑債�ĕς��Ȃ��ł���B
>>791
�Ȃ�قǂƂȂ�ƂR�`�S�N�O��X4����apu�̓p���[�����\������
�Ȃ�قǂƂȂ�ƂR�`�S�N�O��X4����apu�̓p���[�����\������
>>793
L3�L���b�V�������ڂ������̂��Ȃ�����
L3�L���b�V�������ڂ������̂��Ȃ�����
Phenom��Athlon�Ńp�t�H�[�}���X���������AL3�����X���ʂł��Ȃ��B
PhenomII��L2���R�A������512k����������AL3���������ʂ����������ǁA
Bull�n��L2��1M�����邩����ʂ͖w��ǂȂ�
�����I�ɂ�CPU�R�A���犮�S�ɐ藣����Ă��邵�A���S�Ƀ}���`�v���Z�b�T�p�ɂȂ��Ă���
�����ACPU��GPU�Ԃł��Ƃ肷��̂ɂ͌��ʂ��肻�������珫����APU�ɂ����ڂ���邩��
Bull�n��L2��1M�����邩����ʂ͖w��ǂȂ�
�����I�ɂ�CPU�R�A���犮�S�ɐ藣����Ă��邵�A���S�Ƀ}���`�v���Z�b�T�p�ɂȂ��Ă���
�����ACPU��GPU�Ԃł��Ƃ肷��̂ɂ͌��ʂ��肻�������珫����APU�ɂ����ڂ���邩��
amd�킵�����Ă���ł��̈�N�͏������Ȏ���amd
�n��in�~wasinimo���Ăւ�
������Intel��LLC�݂�����GPU���L���b�V���g����悤�ɂȂ�������
APU�ł�L3����ƃx���`�Ȃ͌����ݏオ�邾�낤��
APU�ł�L3����ƃx���`�Ȃ͌����ݏオ�邾�낤��
��������Haswell�̈ꕔ�ł���Ă�eDRAM���Ăǂ��Ȃ́H
����Ɠ������Ƃ�APU�ł�����炮�[��Ɛ��\�オ�����肵�Ȃ����ˁB
����Ɠ������Ƃ�APU�ł�����炮�[��Ɛ��\�オ�����肵�Ȃ����ˁB
TDP��_�C�T�C�Y�̊W��L3�ςނ̂͌���������
�Ȃ��ɁA���M�Ə���d�͂Ȃm�������Ƃł͂Ȃ��Ƃ����̂���{���j�Ȃ�����Ȃ�
�_�C�T�C�Y�����܂ł̂悤�Ɍ��̗܂𗬂���������
�_�C�T�C�Y�����܂ł̂悤�Ɍ��̗܂𗬂���������
>>805
��1�����������\������
��1�����������\������
���܂�BF4�܂�����
�������⍡�����Ȃ����A�������˂��ƔN���������܂���
811 �FSocket774�F2013/12/26(��) 15:07:47.58 ID:jPB4mLU1
�����
������
�J�r����
������
�J�r����
�Ή��\���BF4�̂ق��ɂ�mantle�Ή��\��̃Q�[�����Ė����ˁc
frostbite3�Ȃ�Ȃ�ł�mantle�ō���邩�Ǝv���Ă��̂�
frostbite3�Ȃ�Ȃ�ł�mantle�ō���邩�Ǝv���Ă��̂�
���j�v���O���}�[��Mantle������悤�ɂ͂Ȃ�Ȃ��̂��˂��B
814 �FSocket774�F2013/12/26(��) 17:14:02.18 ID:lYvyNeMi
BF4�͂��Ȃ́H
�N���X�}�X�z���f�[���ċx�ނ̂���
BF4�̓}���g���Ή��̑O�ɂ���ׂ����Ƃ����邾�낤��
�܂��m���Ƀo�O���������ă}���g���ǂ��낶��Ȃ��C������
819 �FSocket774�F2013/12/27(��) 01:29:42.51 ID:ZddCnDIn
�Ȃ�Mantle�ߎS�ȏɂȂ��Ă�Ȃ�
����11����Mantle�Ή�BF4�o�����Č����Ă��̂ɁA12�����܂�(���N��)�ɏo���ɉ�������
����c��ȃo�O�Ǝv���悤�ɏオ��Ȃ����\����E�E�����Ȃ������[�X���E�E���N���͖����炵���Ȃ�
FX�͉����ɉ������d��2�N�x�ꂽ����ȁA�܂�2�N���2015�N�ɏo��Ζ��X���낗
AMD��Mantle�v��͏I������ȁA�Q�[�}�[�͂���BF4�̎��ɋC�����ڂ��Ă邵�o��̂��x����
����11����Mantle�Ή�BF4�o�����Č����Ă��̂ɁA12�����܂�(���N��)�ɏo���ɉ�������
����c��ȃo�O�Ǝv���悤�ɏオ��Ȃ����\����E�E�����Ȃ������[�X���E�E���N���͖����炵���Ȃ�
FX�͉����ɉ������d��2�N�x�ꂽ����ȁA�܂�2�N���2015�N�ɏo��Ζ��X���낗
AMD��Mantle�v��͏I������ȁA�Q�[�}�[�͂���BF4�̎��ɋC�����ڂ��Ă邵�o��̂��x����
820 �FSocket774�F2013/12/27(��) 05:50:23.24 ID:T0EsHTRR
AMD����������Ă�悤�ɁA�P���Ƀ}�[�P�e�B���O�I�ȋZ�p�ŁA�����������݂��Ȃ���Ȃ����H��
Kaveri�����O��nvidia�M�҂��ǂ����ݒ@���ɑ����Ă�Ȃ�
���O�炪�������Ƃ����Mantle�͂����ꗈ�邵�AKaveri�͔�����ɂ͔�����
���O�炪�������Ƃ����Mantle�͂����ꗈ�邵�AKaveri�͔�����ɂ͔�����
BF4���ߎS�ȏȂ̂͂킩����
���낻��}���g���t�B�[���h4�ł��H
2tflops�Ɖ\��gt4��
Intel HD & Iris Graphics Version 15.36.0.3353 Alpha
http://www.station-drivers.com/index.php/articles/713-intel-hd-iris-graphics-version-15-36-0-3353
505 ���O�FSocket774[sage] ���e���F2013/12/26(��) 11:53:50.22 ID:orp5wnNG [2/2]
; BDW Simulation
iBDWGD0 = "Intel Broadwell HD Graphics HAS"
iBDWGT0 = "Intel Broadwell HD Graphics HAS GT0"
iBDWGT1 = "Intel Broadwell HD Graphics HAS GT1"
iBDWGT2 = "Intel Broadwell HD Graphics HAS GT2"
iBDWGT3 = "Intel Broadwell HD Graphics HAS GT3"
iBDWGT4 = "Intel Broadwell HD Graphics HAS GT4"
; BDW HW
iBDWMULTGT1 = "Intel Broadwell HD Graphics M ULT GT1"
iBDWULXGT1 = "Intel Broadwell HD Graphics ULX GT1"
iBDWMULTGT2 = "Intel Broadwell HD Graphics M ULT GT2"
iBDWULXGT2 = "Intel Broadwell HD Graphics ULX GT2"
iBWDHALOGT1 = "Intel Broadwell HD Graphics Halo GT1"
iBWDHALOGT2 = "Intel Broadwell HD Graphics Halo GT2"
iBWDHALOGT3 = "Intel Broadwell HD Graphics Halo GT3"
Intel HD & Iris Graphics Version 15.36.0.3353 Alpha
http://www.station-drivers.com/index.php/articles/713-intel-hd-iris-graphics-version-15-36-0-3353
505 ���O�FSocket774[sage] ���e���F2013/12/26(��) 11:53:50.22 ID:orp5wnNG [2/2]
; BDW Simulation
iBDWGD0 = "Intel Broadwell HD Graphics HAS"
iBDWGT0 = "Intel Broadwell HD Graphics HAS GT0"
iBDWGT1 = "Intel Broadwell HD Graphics HAS GT1"
iBDWGT2 = "Intel Broadwell HD Graphics HAS GT2"
iBDWGT3 = "Intel Broadwell HD Graphics HAS GT3"
iBDWGT4 = "Intel Broadwell HD Graphics HAS GT4"
; BDW HW
iBDWMULTGT1 = "Intel Broadwell HD Graphics M ULT GT1"
iBDWULXGT1 = "Intel Broadwell HD Graphics ULX GT1"
iBDWMULTGT2 = "Intel Broadwell HD Graphics M ULT GT2"
iBDWULXGT2 = "Intel Broadwell HD Graphics ULX GT2"
iBWDHALOGT1 = "Intel Broadwell HD Graphics Halo GT1"
iBWDHALOGT2 = "Intel Broadwell HD Graphics Halo GT2"
iBWDHALOGT3 = "Intel Broadwell HD Graphics Halo GT3"
���̍\���ōl�����125EU(500SP����)
�X���^�C�̓ǂ߂Ȃ���n�O�q��������
�C���e�O���͓��܂ł����̂�
�C���e�O���͓��܂ł����̂�
4770K+TITAN������iGPU���g�������ƂȂ���
�ǂ����Q���~�����������炵��
bf���}�X�G�t�F�N�g�͂�B�h���S���G�C�W�͂ǂ��Ȃ낤
AMD�̃G�L�X�p�[�g�̂��O��ɕ���������
�\�P�b�gAM2�́@�A�X����X2�@2.9G�iTDP65���j����A-10-6700�ɂ�����
CPU���̂̏������x�͉��{���炢�オ��܂����H
�\�P�b�gAM2�́@�A�X����X2�@2.9G�iTDP65���j����A-10-6700�ɂ�����
CPU���̂̏������x�͉��{���炢�オ��܂����H
������邩�ɂ���邯���ǁA�G���R�Ȃ�5�{���炢����Ȃ���
2015�N�܂ł�Opteron�̃��[�h�}�b�v�����炩��
ttp://northwood.blog60.fc2.com/blog-entry-7288.html
ttp://northwood.blog60.fc2.com/blog-entry-7288.html
>>832
�gBerlin�h��CPU�ł�����Ƃ������Ƃ�FX�����ł͂Ȃ��H
�gBerlin�h��CPU�ł�����Ƃ������Ƃ�FX�����ł͂Ȃ��H
�g�����g�����ȁ[
1P�����ɑS�͓��������ۃl
�t�Ɍ����ƁA�I����x86�͂����~�߂ăX���[���IARM��S�͂ł�銴����
�������͂悭�킩����
�t�Ɍ����ƁA�I����x86�͂����~�߂ăX���[���IARM��S�͂ł�銴����
�������͂悭�킩����
PS4�ɏ��Ă�̂ǂ�H
>>833
�Ȃ�œ����N���b�N�ɂ��Ĕ�ׂ��H
�Ȃ�œ����N���b�N�ɂ��Ĕ�ׂ��H
�^�Ԏw�肾���A���N���b�N�ł̔�r�͊m���ɂ���Ȃ�������
AMD A10-7850K APU AD785KXBJABOX Price:$173.99
ttp://www.amazon.com/AMD-AD785KXBJABOX-A10-7850K-APU/dp/B00H7Z7YMI
AMD A10-7700K APU AD770KXBJABOX Price:$153.99
ttp://www.amazon.com/AMD-AD770KXBJABOX-A10-7700K-APU/dp/B00H7Z7XA6
ttp://www.amazon.com/AMD-AD785KXBJABOX-A10-7850K-APU/dp/B00H7Z7YMI
AMD A10-7700K APU AD770KXBJABOX Price:$153.99
ttp://www.amazon.com/AMD-AD770KXBJABOX-A10-7700K-APU/dp/B00H7Z7XA6
���{���͂�
7850�� 19800�~
7700�� 16800�~
����Ȋ������ȁA�Ȃ�ƂȂ������ƍ����C�����Ȃ��ł��Ȃ���
7700�� 16800�~
����Ȋ������ȁA�Ȃ�ƂȂ������ƍ����C�����Ȃ��ł��Ȃ���
�܂������ɂ��ĉ~�����i��ł邩��Ȃ��E�E�E
�Ȃ�Ƃ�2���͐��Ăق���
�Ȃ�Ƃ�2���͐��Ăق���
�h��105�~�Ƃ���18200�~
�V�g�̎�蕪��1��������Ƃ��傤��2�����炢��
�V�g�̎�蕪��1��������Ƃ��傤��2�����炢��
>>839
�������r����Ƃ��͏����𑵂�����ė��ȂŏK���ł���H
�������r����Ƃ��͏����𑵂�����ė��ȂŏK���ł���H
�A�X2�����640 99�h������llano��120�h����@����������145�h���t��
����170�h���O��HFX������ł邩��Ƃ����Ċ����̒u�������łȂ���悹�Œi�X��ʂ̉��i���オ���Ă���
20nm�̍��ɂ�200�h���������肵�ĉ��i�グ��Ȃ�6�R�A�����Ă����������肢���܂�
����170�h���O��HFX������ł邩��Ƃ����Ċ����̒u�������łȂ���悹�Œi�X��ʂ̉��i���オ���Ă���
20nm�̍��ɂ�200�h���������肵�ĉ��i�グ��Ȃ�6�R�A�����Ă����������肢���܂�
�C���e����iGPU��GT3��i3�ł��������Ȃ�����l�i�͉�����낤��
���ƍ��N4�������Ȃ�����BF4��mantle�����H
AMD���ʓ|����~�h���E�F�A�ɂȂ��҂����
>>849
GT3�Ȃ��eDRAM�ς܂Ȃ����Richland�ɂ��畉����̂ɖ������Ă̂���K�v�L��̂��H
GT3�Ȃ��eDRAM�ς܂Ȃ����Richland�ɂ��畉����̂ɖ������Ă̂���K�v�L��̂��H
>>847
���w�Z�T�N�̑ΏƎ�����������x���K���Ă݂悤
�Љ�l�݂͂�ȖZ���߂��ċ`������̓��e��Y�����̂�
����ł��Ȃ�Ƃ��Љ�l���܂��Ă��܂��̂����{��Ƃ̎Е���
�N��������Ȃ���
������������
���w�Z�T�N�̑ΏƎ�����������x���K���Ă݂悤
�Љ�l�݂͂�ȖZ���߂��ċ`������̓��e��Y�����̂�
����ł��Ȃ�Ƃ��Љ�l���܂��Ă��܂��̂����{��Ƃ̎Е���
�N��������Ȃ���
������������
>>847
���O�̓������߂��ď������Ȃ���
���N���b�N�ł̐��\��r���������A���Ƃ̓N���b�N��ƃR�A���Ő��\�T�Z�ł���ł���
�}�W�ŏ��w�Z�����蒼��
���O�̓������߂��ď������Ȃ���
���N���b�N�ł̐��\��r���������A���Ƃ̓N���b�N��ƃR�A���Ő��\�T�Z�ł���ł���
�}�W�ŏ��w�Z�����蒼��
��i�ł̈Ⴂ���킩�����ق����͂₢�Ƃ͎v��Ȃ������̂�
�ǂ�Ȍ`�ł���A�����͓�������
���肪�Ƃ��������܂����Ɗ��ӂ��ďI��鎖�āB
���肪�Ƃ��������܂����Ɗ��ӂ��ďI��鎖�āB
>>850
�����N���X�}�X�x�ɓ����Ă��ˁH
�����N���X�}�X�x�ɓ����Ă��ˁH
Athlonx2��2.9G����5200+�H
�܂�6700�Ƌ�̓I�Ɍ����Ă�̂ɂ����ē��N���b�N�Ŕ�r����Ӗ��͂ˁ[���
�܂�6700�Ƌ�̓I�Ɍ����Ă�̂ɂ����ē��N���b�N�Ŕ�r����Ӗ��͂ˁ[���
859 �FSocket774�F2013/12/27(��) 19:32:45.98 ID:Ql3D4wD8
>>848
2.5�����x��CPU�������Ȃ��z�͒��
�yAM3+�zAMD FX���� 39��ځyZambezi Vishera�z
http://anago.2ch.net/test/read.cgi/jisaku/1381059661/
526 ���O:Socket774 [sage] :2013/10/10(��) 19:27:33.45 ID:XzEg8wac
��������25���̐��甃���Ȃ���ӂ͍D���Ɋ����Ă������������
����Ȃ���ߋ�̒l�i�Ƃ��Ă͑Ó�����
2.5�����x��CPU�������Ȃ��z�͒��
�yAM3+�zAMD FX���� 39��ځyZambezi Vishera�z
http://anago.2ch.net/test/read.cgi/jisaku/1381059661/
526 ���O:Socket774 [sage] :2013/10/10(��) 19:27:33.45 ID:XzEg8wac
��������25���̐��甃���Ȃ���ӂ͍D���Ɋ����Ă������������
����Ȃ���ߋ�̒l�i�Ƃ��Ă͑Ó�����
�\�ʂ�Ȃ痈����Epson��Temash�^�u��Kaveri���������A�y���݂��B
�܂�10������ᑫ��邾�낤�B
�܂�10������ᑫ��邾�낤�B
>>846
����̎��_��65W���m�𑵂�����r�ɂȂ��Ă���A
����������Ă܂ŃN���b�N���킹�Ȃ��Ă�����Ȃ����ȁB
�N���b�N��R�A���Ɛ��\���Y��ɔ�Ⴗ��킯����Ȃ�����A
���^�p�ł̐��\��͌��ǂ͂����肵�Ȃ����B
����̎��_��65W���m�𑵂�����r�ɂȂ��Ă���A
����������Ă܂ŃN���b�N���킹�Ȃ��Ă�����Ȃ����ȁB
�N���b�N��R�A���Ɛ��\���Y��ɔ�Ⴗ��킯����Ȃ�����A
���^�p�ł̐��\��͌��ǂ͂����肵�Ȃ����B
����TDP65W������Athlon II�̕�����
>>863
����65W����Ȃ�����
����65W����Ȃ�����
AM2�Ə����Ă邩��A���Ԃ�5600+��Brisbane����
AM2��M/B�ł�AthlonII 245���ڂ��Ă��܂�����f��͏o���Ȃ�����
AM2��M/B�ł�AthlonII 245���ڂ��Ă��܂�����f��͏o���Ȃ�����
K8��2�R�A���烊�b�`4�R�A���Ƒ����オ�肻������
�v���O�����ɂ���Ă�10�{�ʂɂȂ肻��
�v���O�����ɂ���Ă�10�{�ʂɂȂ肻��
�m�[�g�����łȂ��^�u���b�g��X�}�z�C�ʂĂ͌g�ѓd�b�ɂ܂�x86���ڂ��Ă��
�ƌ����Ă����̂͂Ȃ����낤��
�ƌ����Ă����̂͂Ȃ����낤��
x86�����ׂĂɂƂ͌����������А��i��S�ĂɂƂ͌����Ă��Ȃ�
���ʓI�ɉR�͂��ĂȂ��ȁA���А��i����Ȃ�����������w
���܂����́H
�����O�摜���v���o���Ă����Ă�
Kaveri��GPU���\��HD7750�Ɠ����x���Ė{���ł����H
���̎��≽�x�����Ă�C�����邯�ǃ�������������Γ���������ȏザ��Ȃ���������
�}���g���t�B�[���h4�����o���H
875 �FSocket774�F2013/12/28(�y) 12:16:16.04 ID:pFRBGeIZ
���\�͏�A�������������ʂ���������
http://pc.watch.impress.co.jp/docs/topic/feature/20131228_629501.html
�������_�Ƃ��āAMicrosoft��Sony Computer Entertainment�ɍ̗p���Ă��炤���Ƃ��ł��Ȃ������B
�܂�(Mantle��������)�AXbox��PlayStation��OpenGL��DirectX�Ƃ���API�̍����ɗւ�������������B
�J���҂��炷��ƁA�n���̂悤�ȏ�B
�������AMantle�͂�������ŁA������`����ĂȂ��B
�Q�[���@��API�Ǝ��Ă͂��邯�nj݊�����Ȃ��B
�������_�Ƃ��āAMicrosoft��Sony Computer Entertainment�ɍ̗p���Ă��炤���Ƃ��ł��Ȃ������B
�܂�(Mantle��������)�AXbox��PlayStation��OpenGL��DirectX�Ƃ���API�̍����ɗւ�������������B
�J���҂��炷��ƁA�n���̂悤�ȏ�B
�������AMantle�͂�������ŁA������`����ĂȂ��B
�Q�[���@��API�Ǝ��Ă͂��邯�nj݊�����Ȃ��B
877 �FSocket774�F2013/12/28(�y) 13:02:54.04 ID:pFRBGeIZ
���mantle�ʼn�%fps�オ��́H
BF4�̔N���̑Ή��p�b�`�{���ɗ���́H
DirectX������mantle��p��PC�ɈڐA�����Q�[�����o�Ă���\�������H
BF4�̔N���̑Ή��p�b�`�{���ɗ���́H
DirectX������mantle��p��PC�ɈڐA�����Q�[�����o�Ă���\�������H
�ǂ������{�͂��܍����炯�ł낭��PC�Ŕ�������Ȃ�����}���g���Ȃ�ĊW�Ȃ���
>>877
�ˁ[�悗
�ˁ[�悗
�܂��A�㓡�̊��z�����L�ۂ݂ɂ��Ă�̂�w
�V�[���h�Ŋy�������ɗV�Ԍ㓡���G��
ttp://pc.watch.impress.co.jp/img/pcw/docs/629/062/05.jpg
ttp://pc.watch.impress.co.jp/img/pcw/docs/629/062/05.jpg
{kind=link}
mantle�͎��ۖ��A����������͂��o��悤�`���[�j���O�����S�ɏI���܂Ő������ق��Ƃ��Ă��ǂ��������ȁB
Bitcoin�o�u���̂�����AMD��GPU������ɔ���܂����Ă邵�AAMD���ق��Ă����Ă����[�U�[�͏���Ɍ@���Ă����Ă���Ă���B
Bitcoin�o�u���̂�����AMD��GPU������ɔ���܂����Ă邵�AAMD���ق��Ă����Ă����[�U�[�͏���Ɍ@���Ă����Ă���Ă���B
NV���炢���������Ă���̂�����Ȃ����A
SHEILD�Ȃ�ē��{�Ŕ���Ȃ������łȂ���
�C�O�ł�����Ă�b�Ȃ�đS�������Ȃ���
SHEILD�Ȃ�ē��{�Ŕ���Ȃ������łȂ���
�C�O�ł�����Ă�b�Ȃ�đS�������Ȃ���
�����Ŕ̔��䐔���ׂĂ݂悤�Ƃ�������Ƃł��w�͂�����H
http://www.nicovideo.jp/watch/sm22538580
��
6�R�ACPU�Ƀ��f�I���O���{����Ă�̂ɒ�掿�ɂ��Ȃ��ƃJ�N�J�N�Ń����^
�����^�c
��
6�R�ACPU�Ƀ��f�I���O���{����Ă�̂ɒ�掿�ɂ��Ȃ��ƃJ�N�J�N�Ń����^
�����^�c
>>885
�킴�킴���ׂ�܂ł��Ȃ��ASHEILD������Ă�ΊC�O�̃j���[�X�ł��b��ɂȂ�ł���
�����̓Q�[���@��PS4��XBOX ONE���肪����Ă���j���[�X�͂��邪�A
SHEILD�Ȃ��NV�̍L����Ń��r���[���o�����炢�ł͂Ȃ���
�킴�킴���ׂ�܂ł��Ȃ��ASHEILD������Ă�ΊC�O�̃j���[�X�ł��b��ɂȂ�ł���
�����̓Q�[���@��PS4��XBOX ONE���肪����Ă���j���[�X�͂��邪�A
SHEILD�Ȃ��NV�̍L����Ń��r���[���o�����炢�ł͂Ȃ���
>>886
�Ȃ�₱��i3 M330�ł݂����Ǐd����
�Ȃ�₱��i3 M330�ł݂����Ǐd����
>>886
A-8�@3850APU�ŕ��ʂɍĐ��ł��Ă邯�ǁE�E�E
A-8�@3850APU�ŕ��ʂɍĐ��ł��Ă邯�ǁE�E�E
�n�[�h�E�F�A�A�N�Z�烌�[�V����ON�ɂ���ʂ�ʂ�ʂȂ�͂�
�ł�RADEON���Ɠ���Ńo�O���o�邩������낤
�ł�RADEON���Ɠ���Ńo�O���o�邩������낤
Radeon�ł�����̓o�O��ˁ[��
Chrome��Flash Player���Ǝ��̂��̂����炻���ɉ�������g���u���Ă�
Intel iGPU�ł��x���Đ������Ȃ����
Chrome��Flash Player���Ǝ��̂��̂����炻���ɉ�������g���u���Ă�
Intel iGPU�ł��x���Đ������Ȃ����
tsukumo��a10cpu�������烁�����Ⴆ��Ƃ�����Ă邩�甃���Ă��悤����
RADEON���Ɠ���ɗΐF���Ƃ���ʕ���Ƃ������
�Ώ��@���́[�ǂ����߂�ǂ������Ȃ�鎖
�Ώ��@���́[�ǂ����߂�ǂ������Ȃ�鎖
FullHD60fps�ł��x�������Ă�H�������ǂ��傭���傭1.4G�܂ŗ������B
898 �FSocket774�F2013/12/28(�y) 18:52:22.05 ID:n3ikjkXU
>>876
����͎�����DirectX�ŃQ�[����������Ă��Ȃ����H
����͎�����DirectX�ŃQ�[����������Ă��Ȃ����H
API�Ƃ��Ă�DX�����AeSRAM�����p���悤�Ƃ���Ə����̍\����PC�Ƃ̓K���b�ƕς���Ă��܂��Ǝv����
>>886
Chrome�̏ꍇ��FlashPlayer���u���E�U�̃T���h�{�b�N�X��œ����̂ŁA
���܂�n�[�h�E�F�A�A�N�Z�����[�V�����������Ȃ��B
IE��Firefox�Ȃ�AGINZAwatch�̐ݒ�̃p�t�H�[�}���X���ڍׂ̒��ɂ���
�u�\�Ȃ�n�[�h�E�F�A�A�N�Z�����[�V�������g�p����v
��L���ɂ���Η]�T�łʂ�ʂ邾�B
Chrome�̏ꍇ��FlashPlayer���u���E�U�̃T���h�{�b�N�X��œ����̂ŁA
���܂�n�[�h�E�F�A�A�N�Z�����[�V�����������Ȃ��B
IE��Firefox�Ȃ�AGINZAwatch�̐ݒ�̃p�t�H�[�}���X���ڍׂ̒��ɂ���
�u�\�Ȃ�n�[�h�E�F�A�A�N�Z�����[�V�������g�p����v
��L���ɂ���Η]�T�łʂ�ʂ邾�B
�j�R�j�R����ł悭�n�[�h�E�F�A�A�N�Z�����[�V���������ď����Ă���̂́ASandyBridge�܂ł�Intel GPU�Ńo�O�邱�Ƃ������������߁B
Ivy���ォ��͂قډ��������B
Ivy���ォ��͂قډ��������B
�Â߂�radeon����60fps�̓���͎x������ł��܂��Đ��ł��Ȃ������L����
����A�j�R����up���铮��̎��R�x����������A
�n�[�h�E�F�A���Đ��x���ł���K�i����O��Ă铮������\����B
���������̂�CPU�Đ�����邩�A�o�O��B
�n�[�h�E�F�A���Đ��x���ł���K�i����O��Ă铮������\����B
���������̂�CPU�Đ�����邩�A�o�O��B
��ԑ��������Q�ƃt���[������Sandy�܂ł�Intel�̂�������B
�܂��A����ȊO�ɂ��K�i�O�̃G���R�[�h���ĂĂ߂��Ⴍ����ɂȂ铮��͏��Ȃ��Ȃ����ǁB
�܂��A����ȊO�ɂ��K�i�O�̃G���R�[�h���ĂĂ߂��Ⴍ����ɂȂ铮��͏��Ȃ��Ȃ����ǁB
�G�R�m�~�[����Ȃ����ԑтɎ����Ă݂�
�y3920x2940 90fps�z���̎��x���`�}�[�N�@�ŏI��y�����߂�z
http://www.nicovideo.jp/watch/sm8919099
�y3920x2940 90fps�z���̎��x���`�}�[�N�@�ŏI��y�����߂�z
http://www.nicovideo.jp/watch/sm8919099
�����ׂ݂����Ɍ����ŃG���R���ă��o�C���ł��Đ��ł���悤�ɂ��Ă��炢������
�K�i�O�Ƃ��ǂ��ł��������E�E�E
�K�i�O�Ƃ��ǂ��ł��������E�E�E
��������A�ׂ�4k�������GPU�x�������������H
60fps��TAS����Ƃ������̂܂グ����̂͂���͂���Ń����b�g�ł͂��邯�ǂˁB
��X�y�b�N�[���ł̓f�����b�g���傫���B
��X�y�b�N�[���ł̓f�����b�g���傫���B
>>902
phenom�U 720BE�{RADEONHD4670��
�Ή�ʔ������Ă���
�Â�GPU�͎g���Ȃ����Ď��Ȃ炢����
����AMD���Ӗ�������
������������
phenom�U 720BE�{RADEONHD4670��
�Ή�ʔ������Ă���
�Â�GPU�͎g���Ȃ����Ď��Ȃ炢����
����AMD���Ӗ�������
������������
120fps�ŃL���v���Ă݂������HD7970�ł�GPU�Đ��͖�������
Ivy���ォ�炵���܂Ƃ��ɂȂ��ĂȂ��C���e���͂ǂ�����E�E�E
��������4xxx�n�͌Â�����
��������4xxx�n�͌Â�����
>>900���āA
�ւ��[����Ȃ̂��������Ďv�������瑁�������Ă݂�����ׂ��Ȃ���B
4K2K����ŕ��ׂ�90%�z�����Ă��̂�65%�`75%���x�܂ʼn��������B
�����č��܂ł��ׂ������ĂȂ�����GPU��50%�ȏ�܂ʼn��悤�ɂȂ����B
�R�����g�������Ă������܂Ōy������Ȃ������̂ɁE�E�E
���Ȃ݂�>>886�̓����cpu�݂̂Ō���50%�`60%�������̂�30%�`40%����
�ւ��[����Ȃ̂��������Ďv�������瑁�������Ă݂�����ׂ��Ȃ���B
4K2K����ŕ��ׂ�90%�z�����Ă��̂�65%�`75%���x�܂ʼn��������B
�����č��܂ł��ׂ������ĂȂ�����GPU��50%�ȏ�܂ʼn��悤�ɂȂ����B
�R�����g�������Ă������܂Ōy������Ȃ������̂ɁE�E�E
���Ȃ݂�>>886�̓����cpu�݂̂Ō���50%�`60%�������̂�30%�`40%����
�ׂ͉𑜓x�ɑ��ăr�b�g���[�g��߂�4k�ł��掿�����Ƃ͌����Ȃ�����j�R���̎d�l�̂�����
��X�y�b�N�E���o�C���̓G�R�m�~�[�őΉ�������������
�Đ��x�������Ȃ��K�i�O�͂������ɂǂ����Ǝv�����ǂ�
��X�y�b�N�E���o�C���̓G�R�m�~�[�őΉ�������������
�Đ��x�������Ȃ��K�i�O�͂������ɂǂ����Ǝv�����ǂ�
>>913
�u���E�U�́H
�u���E�U�́H
IE11 6800K 4.1Ghz�łʂ�ʂ��
�A�Ȓ�������A10�������Ȃ��̂��c�O�����A
>>886��Tegra4�AIE11�ł��]�T�ˁB
CPU��30%���炢�B0.7-0.8GHz�ʼn���Ă�B
>>905��CPU��10%���g��Ȃ����A���ɐ��̓������m�C�W�[�ȊG���o�Č��ꂽ���̂ł͂Ȃ��B
Tegra�̌��E���B
�b�͕ς�邪�^�[�{���Ăǂꂭ�炢�������́H
������A10�5700(3.4�`4GHz)�͊�{�I��CPU50%(2�R�A��)�܂ł���3.64GHz�ʼn���āA
CPU75%�ʂ܂Ŏg�p�����オ���3.57-3.6GHz�ɗ����銴���B�Ă��~���X���͕ς��Ȃ��B
>>886��Tegra4�AIE11�ł��]�T�ˁB
CPU��30%���炢�B0.7-0.8GHz�ʼn���Ă�B
>>905��CPU��10%���g��Ȃ����A���ɐ��̓������m�C�W�[�ȊG���o�Č��ꂽ���̂ł͂Ȃ��B
Tegra�̌��E���B
�b�͕ς�邪�^�[�{���Ăǂꂭ�炢�������́H
������A10�5700(3.4�`4GHz)�͊�{�I��CPU50%(2�R�A��)�܂ł���3.64GHz�ʼn���āA
CPU75%�ʂ܂Ŏg�p�����オ���3.57-3.6GHz�ɗ����銴���B�Ă��~���X���͕ς��Ȃ��B
>>886
6�R�A���Ă��Ƃ�Phenom�Ux6���ȁH
�����ɂ�1090T�͍~�낵���������Ŏ����Ȃ����ǁAFX8300�ł͕��ʂɌ��ꂽ��
�v���~�A������A�u���E�U�[FireFox���̑�Flash�ŐV�A�O���{HD7750�ɂ�
CPU�g�p���͂���4�R�A�g����10�`20��
>>905
�������̓����90���ȏ�ō��~�܂�
����ł�����������Ƃ������Ȃ����x�����A�d����
6�R�A���Ă��Ƃ�Phenom�Ux6���ȁH
�����ɂ�1090T�͍~�낵���������Ŏ����Ȃ����ǁAFX8300�ł͕��ʂɌ��ꂽ��
�v���~�A������A�u���E�U�[FireFox���̑�Flash�ŐV�A�O���{HD7750�ɂ�
CPU�g�p���͂���4�R�A�g����10�`20��
>>905
�������̓����90���ȏ�ō��~�܂�
����ł�����������Ƃ������Ȃ����x�����A�d����
���܂���E����������
APU�����ɂ�
�E���C�g�Q�[�}�[ DirectX
�E�f�o�t���g�����Ȋw�v�Z��摜���� OpenCL
�E�����ɐ������ăr�W�l�X�p�r
�E�ȓd�͂Ń^�u���b�g
�����
�E���C�g�Q�[�}�[ DirectX
�E�f�o�t���g�����Ȋw�v�Z��摜���� OpenCL
�E�����ɐ������ăr�W�l�X�p�r
�E�ȓd�͂Ń^�u���b�g
�����
APU�͎�i�̂P�ł����ĖړI�ł͖���
APU*2�ŁACrossfire���ۂ����Ƃł���悤�ɂȂ�����͂₻���Ȃ��ǂȁB
��̑O�̃f���A���v���Z�b�T���āA�Ȃ�łȂ��Ȃ����̂������ȁB
�Ȃ�肠�����悤�Șb�͂������L�����Ȃ����ǁB
��̑O�̃f���A���v���Z�b�T���āA�Ȃ�łȂ��Ȃ����̂������ȁB
�Ȃ�肠�����悤�Șb�͂������L�����Ȃ����ǁB
>>920
���ڂ���n�߂Ă��鉼�z�ʉ݂̃}�C�j���O�ׂ̈̔ėp���Ƃ��Ă͌���R�X�p���܂߂��AMD�ő����邵���I�����������B
���Ȃ菫���I�Ȃ��̂ɂȂ邩�������ǁASF�ł悭���闧�̉f���⎺������\���I�ȃz���O�����Ŗ͗l�ւ�����̂�x86�n�Ŋ��𑵂���\������ԍ����̂�AMD�B
���ڂ���n�߂Ă��鉼�z�ʉ݂̃}�C�j���O�ׂ̈̔ėp���Ƃ��Ă͌���R�X�p���܂߂��AMD�ő����邵���I�����������B
���Ȃ菫���I�Ȃ��̂ɂȂ邩�������ǁASF�ł悭���闧�̉f���⎺������\���I�ȃz���O�����Ŗ͗l�ւ�����̂�x86�n�Ŋ��𑵂���\������ԍ����̂�AMD�B
�y�Q�[���z�������{�A�o�g���t�B�[���h4���u�֎~�v�Ɂc�����̃R���e���c��S�č폜�A���{���J�n[12/28]
http://uni.2ch.net/test/read.cgi/newsplus/1388226647/
http://uni.2ch.net/test/read.cgi/newsplus/1388226647/
>>922
��ʋq�����MPen4���������Ȃ������
�ꕔ�̐挩�̖�������W�T�J�[�̓T�[�o�[�p�}�U�[���ăf���A��Pen3�Ō�������Ă�����͂�����
�����������Core2Duo�̓o��Ŏ���̗D�ʐ��͔��ꂽ
�����SSD���y�ȑO��RAM�f�B�X�N��g��ł��W�T�J�[�ɂ��Ă������邱�Ƃ�
��ʋq�����MPen4���������Ȃ������
�ꕔ�̐挩�̖�������W�T�J�[�̓T�[�o�[�p�}�U�[���ăf���A��Pen3�Ō�������Ă�����͂�����
�����������Core2Duo�̓o��Ŏ���̗D�ʐ��͔��ꂽ
�����SSD���y�ȑO��RAM�f�B�X�N��g��ł��W�T�J�[�ɂ��Ă������邱�Ƃ�
���f�I����VLIW�����GPU�h���C�o�̓o�O�o�O�̂܂ܕ��u����Ă�̂ŁA
�n�[�h�E�F�A�x�����I�t�ɂ��Ȃ��Ƃ悭��肪������
������������Ƃ���Ă����nvidia�Ƃ͈Ⴄ
�n�[�h�E�F�A�x�����I�t�ɂ��Ȃ��Ƃ悭��肪������
������������Ƃ���Ă����nvidia�Ƃ͈Ⴄ
3���ȓ���Mantle���o��AMD���叟�����邩���
�N���ɏo���c�c�o����
���� ���̎��Əꏊ�܂ł͎w�肵�Ă��Ȃ��c�c�I
���̋C�ɂȂ��10�N��A20�N��Ƃ������Ƃ��\�c�c�I
���� ���̎��Əꏊ�܂ł͎w�肵�Ă��Ȃ��c�c�I
���̋C�ɂȂ��10�N��A20�N��Ƃ������Ƃ��\�c�c�I
����̊T�O�����̂��c�I
2013�N�̎���PC�p�[�c��U��Ԃ�
http://uni.2ch.net/test/read.cgi/newsplus/1388237434/
http://uni.2ch.net/test/read.cgi/newsplus/1388237434/
���ς�炸�P���X���\�~�̍�Ɗ撣���Ă�ȁB
>>927
ASIC���Ή����Ă�����̂���Bitcoin���������H
���̖����ɂ��鉼�z�ʉ݂�GPU�ō̌@���邵���Ȃ��B
���Ƀ��A���}�l�[�Ƃ܂������o���Ȃ��}�C�i�[�R�C�������̂����Ɍ@���Ă����̂�R9�V���[�Y���Œ��ꒃ����Ăǂ����i���ԁB
ASIC���Ή����Ă�����̂���Bitcoin���������H
���̖����ɂ��鉼�z�ʉ݂�GPU�ō̌@���邵���Ȃ��B
���Ƀ��A���}�l�[�Ƃ܂������o���Ȃ��}�C�i�[�R�C�������̂����Ɍ@���Ă����̂�R9�V���[�Y���Œ��ꒃ����Ăǂ����i���ԁB
���������^�C�v�̉��Z��FPGA�ł�����
>>936
���Ⴀ����Ĕ����Ă���B
ASIC���l�A���̐��{�̒l�i�Ń��t�I�N�Ŕ���Ă���B
������FPGA������Ĕ�����Ȃ畨�����҂��邼��
���Ⴀ����Ĕ����Ă���B
ASIC���l�A���̐��{�̒l�i�Ń��t�I�N�Ŕ���Ă���B
������FPGA������Ĕ�����Ȃ畨�����҂��邼��
���t�I�N��ASIC? �l�A��?
�C���k�r�~�͒����Ă���3���̖��������
Mantle�ɐk���Ă��邪����
Mantle�ɐk���Ă��邪����
���̐��キ�炢�ɂȂ���mantle�̗L���̍��͖��������R�ł���
�����Intel+nVidia���Ր���
http://it.slashdot.jp/story/13/12/28/215241/
�ăW���[�W�A�H�ȑ�w�̌����҂炪�ANVIDIA�Ƌ�����GPU�ɂ��f�[�^�x�[�X�̃N�G�������̍��������������Ă��邻����(�_���A�u�X�g���N�g�A �{��/.)�B
�_���ł�LogiQL�������������p�f�[�^�x�[�XLogicBlox 4.0���g���AGPU�ɂ�鍂���������݂Ă���B
GPU�𗘗p���邱�ƂŁA����N�G��������Xeon E5-2670�~2(16�R�A�A32�X���b�h)��Amazon EC2�m�[�h��6.48�{�A
PCIe�̓]�����Ԃ��������v�Z���Ԃ݂̂Ŕ�r�����7.86�{�����Ƃ������ʂ��o�Ă���B
�܂��A�����N�G�������̏ꍇ�A12GB�̃������[�𓋍ڂ���Core i7-920�}�V����65.92�{�A�v�Z���Ԃ݂̂ł�79.94�{�����Ƃ������ʂɂȂ����Ƃ̂��ƁB
http://it.slashdot.jp/story/13/12/28/215241/
�ăW���[�W�A�H�ȑ�w�̌����҂炪�ANVIDIA�Ƌ�����GPU�ɂ��f�[�^�x�[�X�̃N�G�������̍��������������Ă��邻����(�_���A�u�X�g���N�g�A �{��/.)�B
�_���ł�LogiQL�������������p�f�[�^�x�[�XLogicBlox 4.0���g���AGPU�ɂ�鍂���������݂Ă���B
GPU�𗘗p���邱�ƂŁA����N�G��������Xeon E5-2670�~2(16�R�A�A32�X���b�h)��Amazon EC2�m�[�h��6.48�{�A
PCIe�̓]�����Ԃ��������v�Z���Ԃ݂̂Ŕ�r�����7.86�{�����Ƃ������ʂ��o�Ă���B
�܂��A�����N�G�������̏ꍇ�A12GB�̃������[�𓋍ڂ���Core i7-920�}�V����65.92�{�A�v�Z���Ԃ݂̂ł�79.94�{�����Ƃ������ʂɂȂ����Ƃ̂��ƁB
������A�p�t�H�[�}���X��nvidia�ɂ���Ă��B
AMD�͂��������̖ڎw���ĂȂ�����B
AMD�͂��������̖ڎw���ĂȂ�����B
�킴�킴���̃X���ŃA�s�[�����Ȃ��ƂȂ�Ȃ��قǗ����Ԃ�Ă���̂���
steam����̃_�C�ʐ^�Ƃ��}�_�H
���������Z�p��nVidia����Z�p�Ȃ킯�Ȃ��ł���
APU��HSA�ŃR���s���[�e�B���O��ς���AMD
http://cloud.watch.impress.co.jp/docs/column/virtual/20131227_629232.html
http://cloud.watch.impress.co.jp/docs/column/virtual/20131227_629232.html
��ŃQ�[���͋�̓I�ɂǂ��ς���H
>>946
�����d�v
�h����́AHSA���A1�̃v���O�������R���p�C���[�������I��CPU��GPU�ɖ��߂�U�蕪���āA
�����悭���s�ł���悤�ɂ���A�[�L�e�N�`���ƂȂ��Ă��邱�ƂƁAARM�w�c���܂߂��f�t�@�N�g�X�^���_�[�h�ɂ��悤�Ƃ����v�f�����邽�߂��B �h
�����d�v
�h����́AHSA���A1�̃v���O�������R���p�C���[�������I��CPU��GPU�ɖ��߂�U�蕪���āA
�����悭���s�ł���悤�ɂ���A�[�L�e�N�`���ƂȂ��Ă��邱�ƂƁAARM�w�c���܂߂��f�t�@�N�g�X�^���_�[�h�ɂ��悤�Ƃ����v�f�����邽�߂��B �h
AMD���܂Ƃ��ȃR���p�C���Ƃ�����Ǝv�����
��̉��N��̘b�ɂȂ�̂��
��̉��N��̘b�ɂȂ�̂��
����͂����ʖڂ����킩����
Radeon R9(Hawaii)
Radeon R9 290X
�y�㓡�z����̓v���Z�X���[����28nm�̂܂܂ŁA�A�[�L�e�N�`����ύX�����傫�ȃ`�b�v�ł��B�����ɂ�20nm�v���Z�X��O�ɂ����ꂵ�����悭�����Ă�B
�Ȃ��A�A�[�L�e�N�`�����ς��Ȃ��������Ƃ����ƁA�傫�Șg�ƂȂ�A�[�L�e�N�`��������āA������������g�����Ă����v���Z�X�ɓ���������B
NVIDIA�������BGPU�̃A�[�L�e�N�`����2�N���ɕς��邱�Ƃ́A�������\�[�X�I�ɖ����ɂȂ��Ă�B
�@����1�傫�ȃ|�C���g��Mantle�B���̃|�C���g�̓R���\�[���I�ȊJ���X�^�C����PC�Ɏ����Ă��邱�ƁB
�������_�Ƃ��āAMicrosoft��Sony Computer Entertainment�ɍ̗p���Ă��炤���Ƃ��ł��Ȃ������B
�܂�(Mantle��������)�AXbox��PlayStation��OpenGL��DirectX�Ƃ���API�̍����ɗւ�������������B
�J���҂��炷��ƁA�n���̂悤�ȏ�B
�J���҂��炷��ƁA�n���̂悤�ȏ�B
�J���҂��炷��ƁA�n���̂悤�ȏ�B
�J���҂��炷��ƁA�n���̂悤�ȏ�B
�J���҂��炷��ƁA�n���̂悤�ȏ�B
�������AMantle�͂�������ŁA������`����ĂȂ��B�Q�[���@��API�Ǝ��Ă͂��邯�nj݊�����Ȃ��B
Radeon R9(Hawaii)
Radeon R9 290X
�y�㓡�z����̓v���Z�X���[����28nm�̂܂܂ŁA�A�[�L�e�N�`����ύX�����傫�ȃ`�b�v�ł��B�����ɂ�20nm�v���Z�X��O�ɂ����ꂵ�����悭�����Ă�B
�Ȃ��A�A�[�L�e�N�`�����ς��Ȃ��������Ƃ����ƁA�傫�Șg�ƂȂ�A�[�L�e�N�`��������āA������������g�����Ă����v���Z�X�ɓ���������B
NVIDIA�������BGPU�̃A�[�L�e�N�`����2�N���ɕς��邱�Ƃ́A�������\�[�X�I�ɖ����ɂȂ��Ă�B
�@����1�傫�ȃ|�C���g��Mantle�B���̃|�C���g�̓R���\�[���I�ȊJ���X�^�C����PC�Ɏ����Ă��邱�ƁB
�������_�Ƃ��āAMicrosoft��Sony Computer Entertainment�ɍ̗p���Ă��炤���Ƃ��ł��Ȃ������B
�܂�(Mantle��������)�AXbox��PlayStation��OpenGL��DirectX�Ƃ���API�̍����ɗւ�������������B
�J���҂��炷��ƁA�n���̂悤�ȏ�B
�J���҂��炷��ƁA�n���̂悤�ȏ�B
�J���҂��炷��ƁA�n���̂悤�ȏ�B
�J���҂��炷��ƁA�n���̂悤�ȏ�B
�J���҂��炷��ƁA�n���̂悤�ȏ�B
�������AMantle�͂�������ŁA������`����ĂȂ��B�Q�[���@��API�Ǝ��Ă͂��邯�nj݊�����Ȃ��B
�J���҂��炷��A�����b�g�������Ȃ��Ȃ�̗p���Ȃ�������b�ł͂Ȃ����H
AMD�̊J���҂ɂƂ��Ă͒n����������Ȃ����B
AMD�̊J���҂ɂƂ��Ă͒n����������Ȃ����B
953 �FSocket774�F2013/12/29(��) 17:16:23.63 ID:82Y8pktQ
�܂����`�l�c�������n�����ȂǂƎv���ĂȂ����낤�ȁH
�����b�g�Ă̂́A���̂��Ƃ������
AMD�����o���Ă����̂Ȃ�A����͊J���҂ɂƂ��ă����b�g�Ȃ̂�
AMD�����o���Ă����̂Ȃ�A����͊J���҂ɂƂ��ă����b�g�Ȃ̂�
�J���҂���Ȃ�����n�����ƌ����Ă�̂����|�C���g
���k���SHIELD�ŗV�юn�߂��m�̘b���L�ۂ݂ɂ���Ɛ\����邩
>>956
���̌�m�ɂ���f�B�X��ꂽTegra Note7���Ă��������E�E�E
���̌�m�ɂ���f�B�X��ꂽTegra Note7���Ă��������E�E�E
>>909
HD6850�ł��c�O�Ȃ���N���Ă܂���
HD6850�ł��c�O�Ȃ���N���Ă܂���
���̊E�G�̘b���������̒���8.1�͂������ɂ����܂ł����Ƃ͎v��B
>>932�̐�肪����ɋ߂����B
�O�Ɍ����C�O�̃X���C�h�̂ق��M���邪BF4�Ή��Ɏ��Ԃ������Ă͂��邩��y�ł͂Ȃ��낤��
���p���͂��܂�Ȃ���VP8���G���R�f�R�Ƃ�opencl�����Ă邵x264���opencl�����Ă�Ƃ���������Ă�悤��
x265hsa�����m�͊��ɏo�Ă������
�}���g����HSA�Ńn�C�p�t�H�[�}���X�т͂����������͂łĂ�����
>>932�̐�肪����ɋ߂����B
�O�Ɍ����C�O�̃X���C�h�̂ق��M���邪BF4�Ή��Ɏ��Ԃ������Ă͂��邩��y�ł͂Ȃ��낤��
���p���͂��܂�Ȃ���VP8���G���R�f�R�Ƃ�opencl�����Ă邵x264���opencl�����Ă�Ƃ���������Ă�悤��
x265hsa�����m�͊��ɏo�Ă������
�}���g����HSA�Ńn�C�p�t�H�[�}���X�т͂����������͂łĂ�����
��J����̂̓Q�[���J���҂���Ȃ��Q�[���G���W���̊J���҂�����
��U�G���W���ɑg�ݍ���ł��܂�����͑債����Ԃ���Ȃ����낤��
��U�G���W���ɑg�ݍ���ł��܂�����͑債����Ԃ���Ȃ����낤��
�j�R�j�R����ʼnč��ɑ������Ă����Ή�ʂ̓T�[�o�[���̖��Ȃ̂ŁAGPU�W�Ȃ�����ˁB
>>907
kepler�����GeForce��IvyBridge��HDG�Ȃ炢����͂�
�Ƃ��������s���i�Ȃ�Youtube��4k�Đ��o���Ȃ��̂�Atom��APU�ʂł���
kepler�����GeForce��IvyBridge��HDG�Ȃ炢����͂�
�Ƃ��������s���i�Ȃ�Youtube��4k�Đ��o���Ȃ��̂�Atom��APU�ʂł���
windows�ō��𑜓x�Ȃ�Ē��k��ł��O���ے肵�Ă��̂ɂ˂�
�g���Ă��Ȃ�Ăقڂ��Ȃ����낤�����p�������HEVC����ł��傤��
�g���Ă��Ȃ�Ăقڂ��Ȃ����낤�����p�������HEVC����ł��傤��
>>959
���A�����܂ň����͂Ȃ��Ǝv����<win8.1
���̌��͌l�I�ɂ͓����ŁA�z�C�[���N���b�N�ŃX�^�[�g��ʂ��畡���A���N���o������
�X�^�[�g���j���[�Ȃ�Ĉłɑ����Ǝv��
���A�����܂ň����͂Ȃ��Ǝv����<win8.1
���̌��͌l�I�ɂ͓����ŁA�z�C�[���N���b�N�ŃX�^�[�g��ʂ��畡���A���N���o������
�X�^�[�g���j���[�Ȃ�Ĉłɑ����Ǝv��
�e�O���m�[�g�������Ĉ����Ȃ��o�����Ǝv���̂�ˁA�ނ���ǂ��o���Ă���
�{���Ɏ��������������ȁA����1�N�����o����ƁA���łɂ����ƈ�������(�L�E�ցE`)
�{���Ɏ��������������ȁA����1�N�����o����ƁA���łɂ����ƈ�������(�L�E�ցE`)
����1�N���������ł���悤�ȊJ���͂Ȃ��NVIDIA�ɂ��Ȃ�����
��𑜓x�p�l������Ȃ��ƃo�b�e���[�������Ȃ������̂��낤����
Qualcomm�Ɣ�ׂČ���肵�Ĕ���ĂȂ��̂����B
��𑜓x�p�l������Ȃ��ƃo�b�e���[�������Ȃ������̂��낤����
Qualcomm�Ɣ�ׂČ���肵�Ĕ���ĂȂ��̂����B
�N�A���R����GPU�͂����ƂЂǂ��Ǝv����
Mantle���ď��i�Ƃ��Ă�Mantle�ł�Windows�ł��o���肷��ˁH
����Ƃ�Mantle�ł̂݁H�����c�͂Ȃ����B
>>964
�i�C�X�A�C�f�B�A
�l�I�ɂ́u�v���O�����̋N���v�Ƃ����A�N�V������p�ɂɂ���킯�ł��Ȃ��̂�
���قlj��b�͂Ȃ����ǁB�������R�ŃX�^�[�g���j���[���Ȃ��Ă������ĂȂ��B
����Ƃ�Mantle�ł̂݁H�����c�͂Ȃ����B
>>964
�i�C�X�A�C�f�B�A
�l�I�ɂ́u�v���O�����̋N���v�Ƃ����A�N�V������p�ɂɂ���킯�ł��Ȃ��̂�
���قlj��b�͂Ȃ����ǁB�������R�ŃX�^�[�g���j���[���Ȃ��Ă������ĂȂ��B
��p�łł���킯�˂�
�Ή��p�b�`�o�����������낤
�Ή��p�b�`�o�����������낤
�����A�Ȃ�MantleAPI��SteamOS��ł̂ݓ����A�ƐF�X���Ⴂ���Ă��c���炵�܂���
>>970
�Ή��p�b�`�Ƃ������̃Q�[���{�̂��̂��̂��낤��
DirectX��OpenGL�ʂɂ͈Ⴂ�����邩��A�v���O���������͑����ւ��ɂȂ邩��
�Ή��p�b�`�Ƃ������̃Q�[���{�̂��̂��̂��낤��
DirectX��OpenGL�ʂɂ͈Ⴂ�����邩��A�v���O���������͑����ւ��ɂȂ邩��
>>972
�@�Q�[���{�̂܂邲�Ƃ܂ł͍s���Ȃ���B�G���W�����������ł����B
�@�Q�[���{�̂܂邲�Ƃ܂ł͍s���Ȃ���B�G���W�����������ł����B
�u���҂ƕs�������X�ł��ˁv�i12/30�j �E�E�E�^�V���b�v�X�����W�Ғk
ttp://www.gdm.or.jp/voices/2013/1230/56219
> AMD�̎�����APU�uKaveri�v�ɂ��āB���{�����ł̔̔����֓���2014�N1��14���i�j�̂悤���B
>���������̂́uA10-7850K�v�i�x�[�X�N���b�N3.7GHz�ATB��4.0GHz�ATDP95W�AOPN��AD785KXBI44JA�j��
>�uA10-7700K�v�i�x�[�X�N���b�N3.5GHz�ATB��3.8GHz�ATDP95W�AOPN��AD770KXBI44JA�j��2���f���B
>���łɕ����V���b�v�ւ̓��ׂ��n�܂��Ă���B
>�Ȃ��A�̔����i�́uA10-7850K�v����20,000�~�O��A�uA10-7700K�v����18,000�~�O��̗\��B
> ���Ȃ݂ɁA�����́uBattlefield 4�v�Ƃ̃o���h���̔����\�肳��Ă����uKaveri�v�B
>Mantle��BF4�̃����[�X���x��Ă��邽�߂��A���̂Ƃ���o���h���̔��̘b���i��ł��Ȃ��悤���B
ttp://www.gdm.or.jp/voices/2013/1230/56219
> AMD�̎�����APU�uKaveri�v�ɂ��āB���{�����ł̔̔����֓���2014�N1��14���i�j�̂悤���B
>���������̂́uA10-7850K�v�i�x�[�X�N���b�N3.7GHz�ATB��4.0GHz�ATDP95W�AOPN��AD785KXBI44JA�j��
>�uA10-7700K�v�i�x�[�X�N���b�N3.5GHz�ATB��3.8GHz�ATDP95W�AOPN��AD770KXBI44JA�j��2���f���B
>���łɕ����V���b�v�ւ̓��ׂ��n�܂��Ă���B
>�Ȃ��A�̔����i�́uA10-7850K�v����20,000�~�O��A�uA10-7700K�v����18,000�~�O��̗\��B
> ���Ȃ݂ɁA�����́uBattlefield 4�v�Ƃ̃o���h���̔����\�肳��Ă����uKaveri�v�B
>Mantle��BF4�̃����[�X���x��Ă��邽�߂��A���̂Ƃ���o���h���̔��̘b���i��ł��Ȃ��悤���B
�x���킯��������A���ꂾ������f�B�A�͐M�p�Ȃ��
��2����AMD���叟������Ƃ����̂͊m�肵������
��2����AMD���叟������Ƃ����̂͊m�肵������
�}�b�`�|���v�͊y������?
BF4��mantle��������������́H�{���ɁH
2013�N13�����ɂȂ�Ƃ��c
�ꉞ�o���オ���Ă͂���݂�����
http://www.youtube.com/watch?v=mHaYjVJaQqE
http://www.youtube.com/watch?v=mHaYjVJaQqE
�ƁA�v�������ǃt�F�C�N����
�����t�F�C�N�ł���
BF4 Mantle coming in dec.......... '2015'?
�Ė{���H
�Ė{���H
�����58�b�ӂ��CCC�ŋ�����B
�ł��{����On/Off�Ǘ����d�l�ő��݂���Ȃ�F�X�Ɩʔ������ƂɂȂ邩���B
�ł��{����On/Off�Ǘ����d�l�ő��݂���Ȃ�F�X�Ɩʔ������ƂɂȂ邩���B
��������flaps��mantle�ɑΉ����Ă�C�����Ȃ���
>>984
fraps���������E���Ă�̂��͒m��Amantle�ŕ`��֘A�͊��S�ɐ藣��邩�炻�̂܂܂���g���Ȃ����낤�ˁB
�ł��܂������Ή��������ȋC�͂���B
fraps���������E���Ă�̂��͒m��Amantle�ŕ`��֘A�͊��S�ɐ藣��邩�炻�̂܂܂���g���Ȃ����낤�ˁB
�ł��܂������Ή��������ȋC�͂���B
986 �FSocket774�F2013/12/30(��) 11:22:19.48 ID:VHjswCHj
�����@
�J�x���͔����
��
�ꍇ�ɂ���Ă�
3��7750�̂ق������\�ǂ��Ƃ����\��������E�E�E�Ƃ�������
�J�x���͔����
��
�ꍇ�ɂ���Ă�
3��7750�̂ق������\�ǂ��Ƃ����\��������E�E�E�Ƃ�������
3930k����4930k���Ă���ȈႤ�H
8�R�A�o����
FX������������
���܂܂�?
��������͂��I
�x��ɒx��ė��N��3�����ɂȂ�Ǝv����
�������1���ɏo���Ă��o�O���炯�ł܂Ƃ��ɃQ�[���ɂȂ�Ȃ��㕨�������猙����
������AMD�͐M�p�ł��Ȃ��A�R����
�������1���ɏo���Ă��o�O���炯�ł܂Ƃ��ɃQ�[���ɂȂ�Ȃ��㕨�������猙����
������AMD�͐M�p�ł��Ȃ��A�R����
BF4�łȂ��Ă��AAMD���g��DX�Ƃ̈Ⴂ��������Demo��������Ǝv����
AMD��mantle�����Ă��Ȃ�w
AMD��mantle�����Ă��Ȃ�w
��������ŋ߁Anvidia��AMD�����A���^�C���f���V���z�z���Ȃ��Ȃ������
ruby���炭���ĂȂ���
ruby���炭���ĂȂ���
�N���z���̂Ɠ�����Mantle�Ŕz�M���Ă����ɂ��_���Ă��܂����Ƃ������͂�߂Ăق���
>>992
������AMD�̓Q�[�����ɂȂ����́H�n���Ȃ́H���ʂ́H
������AMD�̓Q�[�����ɂȂ����́H�n���Ȃ́H���ʂ́H
>>996
�ق��Ƃ��n�������邼
�ق��Ƃ��n�������邼
>>974
����A���肰�Ȃ�CINEBEHCN R15�̌��ʂ��ڂ��Ă邪�A�X�R�A311���ĒႢ�悤�ȁE�E
����A���肰�Ȃ�CINEBEHCN R15�̌��ʂ��ڂ��Ă邪�A�X�R�A311���ĒႢ�悤�ȁE�E
R15����
5800K�i3.8/4.1GHz�j��300�O��
6800K�i4.1/4.4GHz�j��320�O��
7850K (3.7/4.0GHz) ��310�O��
�Ⴍ�͖������A4.9Ghz�̃��[�N�Ƃ͐����������Ȃ������H�v�Z���ĂȂ�����
http://cdn.overclock.net/8/80/809f06c7_1387129105752.jpeg
5800K�i3.8/4.1GHz�j��300�O��
6800K�i4.1/4.4GHz�j��320�O��
7850K (3.7/4.0GHz) ��310�O��
�Ⴍ�͖������A4.9Ghz�̃��[�N�Ƃ͐����������Ȃ������H�v�Z���ĂȂ�����
http://cdn.overclock.net/8/80/809f06c7_1387129105752.jpeg
{kind=link}
1001 �F�P�O�O�P�F
1��̃}�V�����g�ݏオ��܂����B�B�B
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://anago.2ch.net/jisaku/
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://anago.2ch.net/jisaku/