AMDの次世代APU/CPUについて語ろう第175世代
\._ | 荒らし・煽り・厨房は放置が一番。
/|_| | 釣られずにスルーしましょう。
|_/\! sage進行でマターリいきますお
自作板AMD系スレッド過去ログ保存サイト
ttp://amd.jisakuita.net/
Intelの次世代CPUについて語ろう 69
http://anago.2ch.net/test/read.cgi/jisaku/1383722837/
CPUアーキテクチャについて語れ 24
http://anago.2ch.net/test/read.cgi/jisaku/1377863763/
☆ARMの次世代core, SoCについて語るスレ #002☆
http://anago.2ch.net/test/read.cgi/jisaku/1362032148/
前スレ
AMDの次世代APU/CPUについて語ろう第174世代
http://anago.2ch.net/test/read.cgi/jisaku/1383641486/
/|_| | 釣られずにスルーしましょう。
|_/\! sage進行でマターリいきますお
自作板AMD系スレッド過去ログ保存サイト
ttp://amd.jisakuita.net/
Intelの次世代CPUについて語ろう 69
http://anago.2ch.net/test/read.cgi/jisaku/1383722837/
CPUアーキテクチャについて語れ 24
http://anago.2ch.net/test/read.cgi/jisaku/1377863763/
☆ARMの次世代core, SoCについて語るスレ #002☆
http://anago.2ch.net/test/read.cgi/jisaku/1362032148/
前スレ
AMDの次世代APU/CPUについて語ろう第174世代
http://anago.2ch.net/test/read.cgi/jisaku/1383641486/
|
|
|
>>1
乙!
乙!
ARMって将来的にx86駆逐するの?
http://hayabusa3.2ch.net/test/read.cgi/morningcoffee/1384202732/
http://hayabusa3.2ch.net/test/read.cgi/morningcoffee/1384202732/
洗濯機スレはここですか?
5 :Socket774:2013/11/12(火) 08:54:48.00 ID:qUgqi9e9
おい、11/11に何か発表あるって話どうなったの?
9時から開始。
vts.inxpo.com/scripts/Server.nxp?LASCmd=AI:4;F:QS!10100&ShowKey=16356
こっから登録すればストリーミングで見れるよ
こっから登録すればストリーミングで見れるよ
前みたいに荒らされてる様子はないね
登録制にして正解だったな
登録制にして正解だったな
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w詐欺w
終わった
次は15時間後か
次は15時間後か
KaveriがTA積んでるのは確定
GCN2.0で8CU、GPUの割合は47%
SteamRollerのスライドに書いてあったのは
Expand computation effeciency
Feed the core faster
Improve single-core exection
BF4の海に落ちた車から脱出するシーンのデモあったけど
Kaveriはで30FPSちょい出てたけど”これはMantleバージョンでは無い”と言っていた
4770K+GT630だと同じシーンで10〜15FPS程度だった
GCN2.0で8CU、GPUの割合は47%
SteamRollerのスライドに書いてあったのは
Expand computation effeciency
Feed the core faster
Improve single-core exection
BF4の海に落ちた車から脱出するシーンのデモあったけど
Kaveriはで30FPSちょい出てたけど”これはMantleバージョンでは無い”と言っていた
4770K+GT630だと同じシーンで10〜15FPS程度だった
早、もう記事あがってた
www.pcworld.com/article/2062430/amds-next-gen-kaveri-chip-due-in-january.html
www.pcworld.com/article/2062430/amds-next-gen-kaveri-chip-due-in-january.html
AMD Tips Client, Server Chips for HSA
www.eetimes.com/document.asp?doc_id=1320059&
www.eetimes.com/document.asp?doc_id=1320059&
14 :Socket774:2013/11/12(火) 12:18:59.93 ID:xSvHvNPR
APU13はまだか
15 :Socket774:2013/11/12(火) 12:27:18.09 ID:qUgqi9e9
Your processor's IQ: An Intro to HSA
http://www.youtube.com/watch?v=i6BWzL12KMI
Revolutionizing computing with HSA-enabled APUs
http://www.youtube.com/watch?v=4YV6z6Fgw48
>>1
これテンプレにいれよう
解説がわかりやすい
http://www.youtube.com/watch?v=i6BWzL12KMI
Revolutionizing computing with HSA-enabled APUs
http://www.youtube.com/watch?v=4YV6z6Fgw48
>>1
これテンプレにいれよう
解説がわかりやすい
APU13: AMD "Kaveri" vs Intel Core i7 4770K + NVIDIA GeForce GT630
https://www.youtube.com/watch?v=HjAM2zYNqko
https://www.youtube.com/watch?v=HjAM2zYNqko
下位dGPUになら勝てる( ー`дー´)キリッみたいなのはもういいや
18 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 12:38:50.88 ID:tlodbvu9
> AMD executives also announced the performance of the Kaveri―856 gigaflops.
CPU: 2(FMA) * 4(SIMD) * 2(unit) * 2(Module) * 3.7(GHz) = 118.4GFLOPS
GPU: 512(SP) * 2(FMA) * 0.72(GHz) = 737.28GFLOPS
合計 855.68GFLOPS
【参考】
Core i7 4771(GT2)
CPU: 8(SIMD) * 2(FMA) * 2(unit) * 4(core) * 3.5(GHz) = 448GFLOPS
GPU: 20(EU) * 8(SIMD) * 2(FMA) * 1.2(GHz) = 384GFLOPS
合計 832GFLOPS
Core i7 4770R(GT3e 128MB eDRAM)
CPU: 8(SIMD) * 2(FMA) * 2(unit) * 4(core) * 3.2(GHz) = 409.6GFLOPS
GPU: 20(EU) * 8(SIMD) * 2(FMA) * 1.3(GHz) = 832GFLOPS
合計 1,241.6GFLOPS
これでi7に挑むとか本当に竹槍で飛行機を(ryの世界だな
CPU: 2(FMA) * 4(SIMD) * 2(unit) * 2(Module) * 3.7(GHz) = 118.4GFLOPS
GPU: 512(SP) * 2(FMA) * 0.72(GHz) = 737.28GFLOPS
合計 855.68GFLOPS
【参考】
Core i7 4771(GT2)
CPU: 8(SIMD) * 2(FMA) * 2(unit) * 4(core) * 3.5(GHz) = 448GFLOPS
GPU: 20(EU) * 8(SIMD) * 2(FMA) * 1.2(GHz) = 384GFLOPS
合計 832GFLOPS
Core i7 4770R(GT3e 128MB eDRAM)
CPU: 8(SIMD) * 2(FMA) * 2(unit) * 4(core) * 3.2(GHz) = 409.6GFLOPS
GPU: 20(EU) * 8(SIMD) * 2(FMA) * 1.3(GHz) = 832GFLOPS
合計 1,241.6GFLOPS
これでi7に挑むとか本当に竹槍で飛行機を(ryの世界だな
>>18
価格も書いておいてね
価格も書いておいてね
中位以上のdGPU+CPUのTDPはどれくらいになるんだ?
コスト無視すりゃ作れるだろうが、どうやって冷却すんだよ!ってことにならん?
コスト無視すりゃ作れるだろうが、どうやって冷却すんだよ!ってことにならん?
Iris Proはカタログスペックはいいがドライバの質が・・・
Intelはドライバをまともにする気はないのかな?
Intelはドライバをまともにする気はないのかな?
KaveriでようやくCPUとGPUとARMの合体
比較対象のGT630って、内蔵GPUでオフィスやwebとか使ってる人がマルチモニタ化したいときに買うGPUで、
ゲーム用GPUじゃないじゃん
ゲーム用GPUじゃないじゃん
とりあえずゲフォでも差しとかないと内蔵じゃフルHDで動くかどうかすらあやしいんじゃ
それはそれで見てみたかった気もするが
それはそれで見てみたかった気もするが
25 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 12:55:08.72 ID:tlodbvu9
>>19
ソフトを開発する側にとって大事なのは本体価格が安いことじゃなくて普及台数
いくらGPU性能がよくてもGPGPU対応アプリがないとCPU性能に合算できない
スペックなんだからさ
APUのシェアって10%もないでしょ?
APU専用のGPGPUアプリケーションを作るくらいならIris専用のほうが
よっぽどソフト屋の採算性はよくなると思うよ
(CPUに高い金を払える=ソフト購入率も高いってことになるわけで)
ソフトを開発する側にとって大事なのは本体価格が安いことじゃなくて普及台数
いくらGPU性能がよくてもGPGPU対応アプリがないとCPU性能に合算できない
スペックなんだからさ
APUのシェアって10%もないでしょ?
APU専用のGPGPUアプリケーションを作るくらいならIris専用のほうが
よっぽどソフト屋の採算性はよくなると思うよ
(CPUに高い金を払える=ソフト購入率も高いってことになるわけで)
デスクトップでゴリ押す以上、kaveri+dGPUでどうなのかが気になる
dGPU積んだらiGPUゴミになりますじゃあFXで8コアスチームローラー出せよとしかならん
dGPU積んだらiGPUゴミになりますじゃあFXで8コアスチームローラー出せよとしかならん
GT630とLlanoが大体互角ぐらいの性能だろ
その倍の性能って事だけが分かればいい
Llanoだって32nmSOIだから
その倍の性能って事だけが分かればいい
Llanoだって32nmSOIだから
HSAが花開けばごみにはならんね。
DGは・・・中位以下のCFと同様あんまり・・・
DGは・・・中位以下のCFと同様あんまり・・・
右がKaveri、左は4770k+Gt630
http://pbs.twimg.com/media/BY1KItjCEAEy288.jpg:large?.jpg
http://pbs.twimg.com/media/BY1KItjCEAEy288.jpg:large?.jpg
{kind=link}
自社製品と比較して欲しいなぁ。
7750は無理だろうから7730あたりで。
7750は無理だろうから7730あたりで。
>>25
GT3eってデスクトップでどの程度普及してんのよdGPU積んでねーGPGPUマシンあるかヴォケ
ってのはまあAPUにも言えることなわけだけど
現状のデスクトップのネックをどうにかできるならシェアは増えるでしょ
できないなら、もしくは別のネックが出てくるならIrisと同じゴミ
目くそ鼻くそ笑うにしかなってないよ
GT3eってデスクトップでどの程度普及してんのよdGPU積んでねーGPGPUマシンあるかヴォケ
ってのはまあAPUにも言えることなわけだけど
現状のデスクトップのネックをどうにかできるならシェアは増えるでしょ
できないなら、もしくは別のネックが出てくるならIrisと同じゴミ
目くそ鼻くそ笑うにしかなってないよ
まあ、オレの予想が的中したわけだが
ダイサイズはLlanoと同等かそれより小さいってのが判明してるわけだから
28nmと言われているが
実際の所は22nmと言われていたものだった
そして32nmは失敗プロセスのため、性能が生かせれなかったが
28nmプロセスは成功プロセスのため、性能が飛躍的に伸びる
この予想も的中だわなw
ダイサイズはLlanoと同等かそれより小さいってのが判明してるわけだから
28nmと言われているが
実際の所は22nmと言われていたものだった
そして32nmは失敗プロセスのため、性能が生かせれなかったが
28nmプロセスは成功プロセスのため、性能が飛躍的に伸びる
この予想も的中だわなw
右がKaveri、左は4770k+Gt630
http://pbs.twimg.com/media/BY1KItjCEAEy288.jpg:large?.jpg
Kaveriは12月にデスクトップ版を、ノートPC向けは2014年になると、AMDのリサ・スー副社長
Kaveriは856GFLOPS
http://pbs.twimg.com/media/BY1H1fvCcAEnYiF.jpg:large?.jpg
http://pbs.twimg.com/media/BY1KItjCEAEy288.jpg:large?.jpg
Kaveriは12月にデスクトップ版を、ノートPC向けは2014年になると、AMDのリサ・スー副社長
Kaveriは856GFLOPS
http://pbs.twimg.com/media/BY1H1fvCcAEnYiF.jpg:large?.jpg
{kind=link}
>>25
>APU専用のGPGPUアプリケーションを作るくらいならIris専用のほうが
今だってIris積んでるのはほとんどMacでしょ
じゃあiOSの方でIrisの開発頑張ればいいんじゃん
そもそもなんでAPU専用に作らないといけないわけ?意味不明
GCN向けに作ると自動的にKaveriも恩恵に与れるってだけでしょ
>APU専用のGPGPUアプリケーションを作るくらいならIris専用のほうが
今だってIris積んでるのはほとんどMacでしょ
じゃあiOSの方でIrisの開発頑張ればいいんじゃん
そもそもなんでAPU専用に作らないといけないわけ?意味不明
GCN向けに作ると自動的にKaveriも恩恵に与れるってだけでしょ
36 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 13:10:16.10 ID:tlodbvu9
>>31
とりあえずHaswell世代のGPUではOpenCLをフルサポートしてて
x86ではどのプラットフォームでも気軽に使えるようになったわけで
あとはAMDのAPU限定で積極的に開発したがるソフト屋が
どれだけ現れるかだな
ちなみにAVX*もOpenCLランタイムで透過的に使うことができるので
AVX*よりGPGPUのほうが普及するいうことは絶対にありえないこと。
とりあえずHaswell世代のGPUではOpenCLをフルサポートしてて
x86ではどのプラットフォームでも気軽に使えるようになったわけで
あとはAMDのAPU限定で積極的に開発したがるソフト屋が
どれだけ現れるかだな
ちなみにAVX*もOpenCLランタイムで透過的に使うことができるので
AVX*よりGPGPUのほうが普及するいうことは絶対にありえないこと。
37 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 13:10:50.49 ID:tlodbvu9
>>35
PCでHSA=APU専用だから
PCでHSA=APU専用だから
GPGPUはPS4とかあっちから応用が進むんじゃね
サーバーは別にして、結局複雑な処理が必要な計算ってゲームが殆どなんだし
サーバーは別にして、結局複雑な処理が必要な計算ってゲームが殆どなんだし
絶対とかSIMMていう言葉を使ったりゲハをソースにする人は信用しちゃだめってお婆ちゃんが言ってたよ
>>25
irisのローレベルAPIが普及するといいですねw
もう団子の相手するのやめようぜ
intelとAMDは方向性が全く逆だから比較するのは意味が無い
AMDは異種コアでアドレス統合して処理分散
intelはx86での集中処理、GPUはおまけでドライバが糞
AMDの目的は、異種コアでアドレス統合で、その普及のため最大シェアのARMとかと共同でHSAの策定しているから、
団子やintelには全く関係ない方向に進んでいる
intelはどうでもいいんで、Phiやiris、AVX512、スマフォ進出大いに結構なんで勝手にやってくれ
irisのローレベルAPIが普及するといいですねw
もう団子の相手するのやめようぜ
intelとAMDは方向性が全く逆だから比較するのは意味が無い
AMDは異種コアでアドレス統合して処理分散
intelはx86での集中処理、GPUはおまけでドライバが糞
AMDの目的は、異種コアでアドレス統合で、その普及のため最大シェアのARMとかと共同でHSAの策定しているから、
団子やintelには全く関係ない方向に進んでいる
intelはどうでもいいんで、Phiやiris、AVX512、スマフォ進出大いに結構なんで勝手にやってくれ
>>34
CPUの面積ちっさw
CPUの面積ちっさw
42 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 13:40:52.57 ID:tlodbvu9
たかだかハーフノード分のシュリンクに3年もかかって他社に遅れをとった
GF28nmが成功なわけあるか
(実際PS4/XboxOneに間に合わなかったからTSMC使ってるじゃん)
>>38
単純な処理を大量にやれるのがGPGPUであって
複雑な処理は根本的に向かない
(だからCPUを8コアも積んでるんだけど)
GF28nmが成功なわけあるか
(実際PS4/XboxOneに間に合わなかったからTSMC使ってるじゃん)
>>38
単純な処理を大量にやれるのがGPGPUであって
複雑な処理は根本的に向かない
(だからCPUを8コアも積んでるんだけど)
43 :Socket774:2013/11/12(火) 13:41:19.99 ID:tFfsoQGB
44 :Socket774:2013/11/12(火) 13:41:47.86 ID:reU9LetM
>irisのローレベルAPIが普及するといいですねw
別にいらねじゃん
既にOpenCLは無双状態でcpu側のメモリにもアクセスできるし
ネックになるようなCPU性能ではないし
別にいらねじゃん
既にOpenCLは無双状態でcpu側のメモリにもアクセスできるし
ネックになるようなCPU性能ではないし
しょうがないだろう、今勢いがあるのは確かにAMDの方だから
それが気に食わない人はたくさんいるわけで
余裕があるのはAMDなのだから、きちんと相手をしてやりなよ(´・ω・`)
それが気に食わない人はたくさんいるわけで
余裕があるのはAMDなのだから、きちんと相手をしてやりなよ(´・ω・`)
46 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 13:44:11.32 ID:tlodbvu9
> しょうがないだろう、今勢いがあるのは確かにAMDの方だから
確かに今AMDが一番(シェア下落の)勢いがある
確かに今AMDが一番(シェア下落の)勢いがある
47 :Socket774:2013/11/12(火) 13:47:11.12 ID:xSvHvNPR
あ〜そういえば今日はAPU13の日だったかあ。
団子が来た事で思い出したw
団子が来た事で思い出したw
なんかjavaのデモンストレーションでNBODYのGPGPUデモやってたな
Kaveriの1coreで150くらい、4coreで300くらい、GPGPUで1300くらいだったけど
Kaveriの1coreで150くらい、4coreで300くらい、GPGPUで1300くらいだったけど
IrisってintelのIGPU全般じゃないんだぜ?
50 :Socket774:2013/11/12(火) 13:51:24.18 ID:reU9LetM
>なんかjavaのデモンストレーションでNBODY
結局使い道が無いままなんだなって
結局使い道が無いままなんだなって
なんか北米だとPS4がフライングで届き始めているみたいだね
steamのフレが何人か発狂してる(´・ω・`)
steamのフレが何人か発狂してる(´・ω・`)
届いて発狂? 自分ところに届かなくて発狂?
54 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 13:59:59.54 ID:tlodbvu9
2014年以降のロードマップ
http://blog.livedoor.jp/amd646464/archives/52369286.html
・Opteron 3000/4000シリーズ撤退
・FXシリーズ撤退
うーん、この
>>50
nbodyデモってGeForce8世代でまだソフトなかったころのあれだよなー
ごく単純なループで処理できるし、メモリ帯域も食わないから
簡単にスケールするわけだ。
IntelのAVX512のマニュアル読みながらNBODYのコアループ書いてみたけど
あんなもん10分もかからなかったよ。
つーか、JavaのGPGPUバインドなんてjcudaで既にやってることなんだが
何年遅れてるんだっていう・・・
http://blog.livedoor.jp/amd646464/archives/52369286.html
・Opteron 3000/4000シリーズ撤退
・FXシリーズ撤退
うーん、この
>>50
nbodyデモってGeForce8世代でまだソフトなかったころのあれだよなー
ごく単純なループで処理できるし、メモリ帯域も食わないから
簡単にスケールするわけだ。
IntelのAVX512のマニュアル読みながらNBODYのコアループ書いてみたけど
あんなもん10分もかからなかったよ。
つーか、JavaのGPGPUバインドなんてjcudaで既にやってることなんだが
何年遅れてるんだっていう・・・
Mantleで赤っ恥書いてから団子の書き込みに勢いがあるなw
57 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 14:09:21.17 ID:tlodbvu9
832SPとか妄想してた奴wwww
60 :Socket774:2013/11/12(火) 14:13:55.98 ID:reU9LetM
GT630が96sp(fermi世代)なのか384sp(kepler世代なのか)知らんが
いずれにせよカタログスペック737.28GFLOPSには及ばんよね
96*2*1.4=268.8gflops
96*2*1.62=311.04gflops
384*2*0.902=692.7gflops
いずれにせよカタログスペック737.28GFLOPSには及ばんよね
96*2*1.4=268.8gflops
96*2*1.62=311.04gflops
384*2*0.902=692.7gflops
62 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 14:15:55.06 ID:tlodbvu9
832SPっていったらHaswell+GT3eにギリギリ勝てる数字ですかね
まあそんなもんでしょう。
eDRAMも32MBとか64MBくらいに減らせば低価格版にも載せられる気がしますが。
もちろんIntel社内で作るから安く調達できるわけだけど。
まあそんなもんでしょう。
eDRAMも32MBとか64MBくらいに減らせば低価格版にも載せられる気がしますが。
もちろんIntel社内で作るから安く調達できるわけだけど。
63 :Socket774:2013/11/12(火) 14:17:52.29 ID:tFfsoQGB
なんだかんだでアンチも楽しそうで良かった
ありがとうAMD
ありがとうAMD
4770K使う人がGT630とか使うわけないじゃん…
65 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 14:23:17.59 ID:tlodbvu9
せっかくだからIrisでやってほしかったな
GPGPUも使い方次第だと思うよ。
TegraNoteの疑似筆圧認識技術みたいなのが、GPUコアがKeplerベースに
なったときにどんな化学反応を起こすのかは楽しみかな
あと、あんまり話題にしないけどKinectもGPGPUなわけだろ
GPGPUも使い方次第だと思うよ。
TegraNoteの疑似筆圧認識技術みたいなのが、GPUコアがKeplerベースに
なったときにどんな化学反応を起こすのかは楽しみかな
あと、あんまり話題にしないけどKinectもGPGPUなわけだろ
あ630も別コアあるんか
だったらGT2でやっても良かったのに
それこそ大勝利だったろ
intel固定機能少ないんだから
それこそ大勝利だったろ
intel固定機能少ないんだから
71 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 14:27:02.92 ID:tlodbvu9
別に遠慮すること無いだろAMDの圧倒的パワーを見せ付けるべきときなのに
http://ascii.jp/elem/000/000/471/471862/index-3.html
>将来的にはGPUとCPUコアが密結合し、プログラムからはx86の拡張命令を発行しているように見えるが、実際はGPUコアが動作するようなモデルもありえることを考慮していた。
これ実現できるのかな?
なんかIntelがAVXをねじ込んだせいで駄目になったみたいだけどw
>将来的にはGPUとCPUコアが密結合し、プログラムからはx86の拡張命令を発行しているように見えるが、実際はGPUコアが動作するようなモデルもありえることを考慮していた。
これ実現できるのかな?
なんかIntelがAVXをねじ込んだせいで駄目になったみたいだけどw
あー、あれだVRAMのせいじゃん?
BF4のフルHDってVRAM2GBは無いと7770(の1G)でもきついって聞いたよ
APUはVRAM2Gに設定できるしな
BF4のフルHDってVRAM2GBは無いと7770(の1G)でもきついって聞いたよ
APUはVRAM2Gに設定できるしな
75 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 14:34:46.71 ID:tlodbvu9
>>72
いや?むしろCPUでサポートされるベクトル長を長くしてGPUに近づける必要があるので
Intelのベクトル長拡大路線は都合がいいはずだ。
少なくともCPU側がSSE5のような128ビットSIMD止まりで
その当時の320並列のVLIWに命令発行とか言われても
「ハァ?バカジャネーノ?」としか思わないわけで。
最初から株価対策のハッタリなのは明らかだけど。
いや?むしろCPUでサポートされるベクトル長を長くしてGPUに近づける必要があるので
Intelのベクトル長拡大路線は都合がいいはずだ。
少なくともCPU側がSSE5のような128ビットSIMD止まりで
その当時の320並列のVLIWに命令発行とか言われても
「ハァ?バカジャネーノ?」としか思わないわけで。
最初から株価対策のハッタリなのは明らかだけど。
77 :Socket774:2013/11/12(火) 14:47:06.92 ID:m2FyG93M
AMD APU13レポート - まもなく開幕、ヘテロジニアスをテーマにAMD開発者が集う
米国時間の11月11日より13日にかけて、サンノゼにあるSJCC(San Jose Convention Center)で、AMD Developer Summit 2013(通称APU13)が開催される(Photo01)。
AMDは同時にAPU365と呼ばれるサイトもオープンし、APU13で発表された講演などを随時公開してゆく予定だ。
APU13は一応正式名称が"AMD Developer Summit"なので主催はAMDであるが(Photo02)、
メインとなるテーマはHSA(Heterogeneous System Architecture)であり、
なのでHSA Foundationに加盟しているメーカーからの発表も多く予定されている。
実際基調講演にはARMCTOであるMike Muller氏、OracleでVice President, Java Platoformを務めるNandini Ramani氏、
MediaTek USAのSenior DirectorであるDr. CHein-Ping Lu、ImaginationのExecutive Vice PresidentのTony King-Smith氏などが並んでいる。
ほかにもSCE AmericaのDominic Mallison氏(Vice President, R&D)とかOculus VRのBrendon Iribe氏(CEO)、
DICE/EAのJohan Andresson氏(Technical Director)などHSAを「使う側」の講演も含まれている。
もちろんメインとなるのは基調講演ではなくTechnical Sessionで、126ほどのTechnical Sessionが12のテーマ
(Cloud Computing, Gaming Summit, Heterogeneous Computing, HSA Expo, Innovation Summit, Innovative Client Experiences,
Multimedia Processing, Professional Grapihcs & Visual Computing, Programming Languages and Models, Programming Tools, Security, Web Technologies)
に分かれて展開される。
もっともこうしたセッションが行われるのは11月12・13日の2日で、初日である11月11日はLisa Su氏とPhil Rogers氏の2人の基調講演が16時から行われて終了である。
実はこの原稿を書いているのは、最初に行われるLisa Su氏の講演開始3時間ほど前の段階であり、基調講演そのもののレポートは後追いの形で随時行いたいと思う。
ところで、何でそもそもイベントが16時なんて遅い時間から始まるかであるが、本日11月11日というのは米国ではVeterans Day(復員軍人の日)である。
http://news.mynavi.jp/articles/2013/11/12/apu01/
米国時間の11月11日より13日にかけて、サンノゼにあるSJCC(San Jose Convention Center)で、AMD Developer Summit 2013(通称APU13)が開催される(Photo01)。
AMDは同時にAPU365と呼ばれるサイトもオープンし、APU13で発表された講演などを随時公開してゆく予定だ。
APU13は一応正式名称が"AMD Developer Summit"なので主催はAMDであるが(Photo02)、
メインとなるテーマはHSA(Heterogeneous System Architecture)であり、
なのでHSA Foundationに加盟しているメーカーからの発表も多く予定されている。
実際基調講演にはARMCTOであるMike Muller氏、OracleでVice President, Java Platoformを務めるNandini Ramani氏、
MediaTek USAのSenior DirectorであるDr. CHein-Ping Lu、ImaginationのExecutive Vice PresidentのTony King-Smith氏などが並んでいる。
ほかにもSCE AmericaのDominic Mallison氏(Vice President, R&D)とかOculus VRのBrendon Iribe氏(CEO)、
DICE/EAのJohan Andresson氏(Technical Director)などHSAを「使う側」の講演も含まれている。
もちろんメインとなるのは基調講演ではなくTechnical Sessionで、126ほどのTechnical Sessionが12のテーマ
(Cloud Computing, Gaming Summit, Heterogeneous Computing, HSA Expo, Innovation Summit, Innovative Client Experiences,
Multimedia Processing, Professional Grapihcs & Visual Computing, Programming Languages and Models, Programming Tools, Security, Web Technologies)
に分かれて展開される。
もっともこうしたセッションが行われるのは11月12・13日の2日で、初日である11月11日はLisa Su氏とPhil Rogers氏の2人の基調講演が16時から行われて終了である。
実はこの原稿を書いているのは、最初に行われるLisa Su氏の講演開始3時間ほど前の段階であり、基調講演そのもののレポートは後追いの形で随時行いたいと思う。
ところで、何でそもそもイベントが16時なんて遅い時間から始まるかであるが、本日11月11日というのは米国ではVeterans Day(復員軍人の日)である。
http://news.mynavi.jp/articles/2013/11/12/apu01/
78 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 14:51:47.15 ID:tlodbvu9
79 :Socket774:2013/11/12(火) 14:55:40.60 ID:m2FyG93M
これを休日とみなすかどうか、はケースバイケース(「ビジネスに拠る」のだそうだ)なのだが、実際SJCCの周囲ではVeterans Dayを祝うパレードが今もまさに盛大に行われており(Photo03〜05)、会場の周りの交通がかなり滞っている。
おそらくはこのパレードが終了して交通が平常に戻るのが16時くらいということなのではないかと思う。
んじゃいっそのこと12日からやればいいとも思うのだが、それだと基調講演を全部こなし切れないというあたりではないかと筆者は推察している。
ところでPhoto01のキャプションで妙なことを書いたのは、反対側から見るとこんな光景になっているから(Photo06)。
SJCC(正式名称はSan Jose McEnery Convention Centerだが、McEneryを省いてSJCCで通じることが多い)は2011年の夏からホールの拡張工事を行っており、Photo06で正面に見えるのがこの拡張部分であるSouth Hallとなっている。
従来のSJCCの面積が13,300平方mなのに対し、South Hallは単体で7,400平方mmほどあり、会場全体の面積が50%ほど増えた計算になる。
IT系イベントで多く利用されるSan FranciscoのMoscone Westには及ばない(あちらは1フロアあたり10500平方mの展示エリア+2500平方mの通路エリアがあり、それが三階建てである)が、小規模なイベントには十分対応できるように拡充された事になる。
というわけで、とりあえずまもなくAPU13が開始されるのでお楽しみに。
おそらくはこのパレードが終了して交通が平常に戻るのが16時くらいということなのではないかと思う。
んじゃいっそのこと12日からやればいいとも思うのだが、それだと基調講演を全部こなし切れないというあたりではないかと筆者は推察している。
ところでPhoto01のキャプションで妙なことを書いたのは、反対側から見るとこんな光景になっているから(Photo06)。
SJCC(正式名称はSan Jose McEnery Convention Centerだが、McEneryを省いてSJCCで通じることが多い)は2011年の夏からホールの拡張工事を行っており、Photo06で正面に見えるのがこの拡張部分であるSouth Hallとなっている。
従来のSJCCの面積が13,300平方mなのに対し、South Hallは単体で7,400平方mmほどあり、会場全体の面積が50%ほど増えた計算になる。
IT系イベントで多く利用されるSan FranciscoのMoscone Westには及ばない(あちらは1フロアあたり10500平方mの展示エリア+2500平方mの通路エリアがあり、それが三階建てである)が、小規模なイベントには十分対応できるように拡充された事になる。
というわけで、とりあえずまもなくAPU13が開始されるのでお楽しみに。
HEVCのデコーダくらいはデモしてほしかった
>>18
> Core i7 4770R(GT3e 128MB eDRAM)
> CPU: 8(SIMD) * 2(FMA) * 2(unit) * 4(core) * 3.2(GHz) = 409.6GFLOPS
> GPU: 20(EU) * 8(SIMD) * 2(FMA) * 1.3(GHz) = 832GFLOPS
> 合計 1,241.6GFLOPS
× GPU: 20(EU) * 8(SIMD) * 2(FMA) * 1.3(GHz) = 832GFLOPS
○ GPU: 20(EU) * 8(SIMD) * 2(FMA) * 1.3(GHz) = 416GFLOPS
2をかけ忘れてるのか
> Core i7 4770R(GT3e 128MB eDRAM)
> CPU: 8(SIMD) * 2(FMA) * 2(unit) * 4(core) * 3.2(GHz) = 409.6GFLOPS
> GPU: 20(EU) * 8(SIMD) * 2(FMA) * 1.3(GHz) = 832GFLOPS
> 合計 1,241.6GFLOPS
× GPU: 20(EU) * 8(SIMD) * 2(FMA) * 1.3(GHz) = 832GFLOPS
○ GPU: 20(EU) * 8(SIMD) * 2(FMA) * 1.3(GHz) = 416GFLOPS
2をかけ忘れてるのか
いい感じだな
amdはこればかりやってきたからな
intelだけ使ってる人は、つまらないと思って
無理してるが、興味津々だろう
どちらも使えば正常な判断ができる
amdはこればかりやってきたからな
intelだけ使ってる人は、つまらないと思って
無理してるが、興味津々だろう
どちらも使えば正常な判断ができる
84 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 15:06:05.03 ID:tlodbvu9
GT3eは40EUの間違い。
他で言うところの320SPだね。
他で言うところの320SPだね。
CPUなんて飾りです。ARMもそうでしょ。
>>76
スライドの補足説明にはこう書いてあった、なにか誤解してるのかな、てかこれどういう計算?
Theoretical GFLOPs calculated by AMD as 856 for AMD A10-7850K with AMD Radeon R7 Series Graphics.
GFLOPS = CPU GFLOPS + GPU GFLOPS= CPU Core Freq (3.7 Ghz) x Core count (4) x 8 + GPU Core Freq (720MHz) x Radeon Core (512) x 2
スライドの補足説明にはこう書いてあった、なにか誤解してるのかな、てかこれどういう計算?
Theoretical GFLOPs calculated by AMD as 856 for AMD A10-7850K with AMD Radeon R7 Series Graphics.
GFLOPS = CPU GFLOPS + GPU GFLOPS= CPU Core Freq (3.7 Ghz) x Core count (4) x 8 + GPU Core Freq (720MHz) x Radeon Core (512) x 2
87 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 15:09:36.99 ID:tlodbvu9
もともとARMはコプロセッサを繋げるためのホストチップとして支持されてきたからね
CPU性能が求められるようになったのはスマホの普及でアプリケーション
プラットフォームとしての性能が求められるようになったから。
CPU性能が求められるようになったのはスマホの普及でアプリケーション
プラットフォームとしての性能が求められるようになったから。
88 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 15:13:59.63 ID:tlodbvu9
FMAは乗算+加算で2回の浮動小数点演算という扱い。
Bulldozerと同じ128bit FMAC×2だから1モジュールあたり8FMA。
それが2モジュール。
結局>>18の計算で合ってる(GT3eのEU数以外)
Bulldozerと同じ128bit FMAC×2だから1モジュールあたり8FMA。
それが2モジュール。
結局>>18の計算で合ってる(GT3eのEU数以外)
この団子って呼ばれてるコテはamdをディスりに来てるの?
HSAの話かよ
Mantle知りたかったのに
Mantle知りたかったのに
92 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 15:18:33.24 ID:tlodbvu9
共有ハンドルです。
団子の真価は中身ではなく行動によって示される。
団子の真価は中身ではなく行動によって示される。
>>82
何がいい感じなのかまったくわからない
何がいい感じなのかまったくわからない
団子とか来てるのか?
いつものBotかとおもってたら
いつものBotかとおもってたら
いくつかきになる点がある、まずクロックが低い
これはConfigurableTDPを導入したせいなのか、GPUクロックなぞTrinityより低い
これが容易にあげられるものなら結構化ける
あとGPUコアはBonaire系だというからGPU側にもターボコア積んでるかも
これはConfigurableTDPを導入したせいなのか、GPUクロックなぞTrinityより低い
これが容易にあげられるものなら結構化ける
あとGPUコアはBonaire系だというからGPU側にもターボコア積んでるかも
>>92
その行動の目的はインテルユーザーを増やすことなの?
その行動の目的はインテルユーザーを増やすことなの?
あいつらにとって重要なのはCPUのシングルスレッドベンチの数値とシェアと売上だから、
APUを買うことも使うことも絶対無いな
このスレの住人にとって重要な、異種コアの連携とは完全に相容れない
見えないけど団子はどうせCPU性能だけで十分とか騒いでるんだろうけど、マジどうでもいい
AVXもどうでもいい、対応ソフト持ってないし探しても見当たらない
Trinity購入から1年くらいFMA3対応ソフト待ったけどHaswell登場後も存在すらしないから諦めた
AMDはAPUやHSA普及のために他社を引き込んで色々頑張ってて内容も面白いから応援したくなるけど
intelやNVIDIAの最近のは独善的で押し付け感が大きくてサッパリ興味がわかないな
APUを買うことも使うことも絶対無いな
このスレの住人にとって重要な、異種コアの連携とは完全に相容れない
見えないけど団子はどうせCPU性能だけで十分とか騒いでるんだろうけど、マジどうでもいい
AVXもどうでもいい、対応ソフト持ってないし探しても見当たらない
Trinity購入から1年くらいFMA3対応ソフト待ったけどHaswell登場後も存在すらしないから諦めた
AMDはAPUやHSA普及のために他社を引き込んで色々頑張ってて内容も面白いから応援したくなるけど
intelやNVIDIAの最近のは独善的で押し付け感が大きくてサッパリ興味がわかないな
>>98
いやめちゃくちゃ感じるがI
いやめちゃくちゃ感じるがI
>>95
新プロセスの最初の大型ダイだから歩留まりや成熟度が低いんだろ
新プロセスの最初の大型ダイだから歩留まりや成熟度が低いんだろ
>>98
あんたからは感じるけどなー
あんたからは感じるけどなー
魅力的なら買ってあげて
http://www.msi.com/product/windpad/W20-3M.html
http://www.msi.com/product/windpad/W20-3M.html
感じるとか感じないとか、体感と同じで不毛
106 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 15:38:58.49 ID:tlodbvu9
でもまあよかったんじゃね
コスト的に6コア版i7と同じ枠で語るべきGT3eはおいとくとして
IntelのミッドレンジCPU上位のCore i7 4771の理論性能は
Kaveriでかろうじて超えたわけだし。
単精度64並列の粒度のGCNのほうが並列化アプリケーションの対応が進む
というのはどういう理論なのかわからんが。
> 今後どうやっていくの方向性もない
方向なら示されてるがあんたが興味がないだけだろ
逆にAMDは背水の陣で「それしかない」わけで
コスト的に6コア版i7と同じ枠で語るべきGT3eはおいとくとして
IntelのミッドレンジCPU上位のCore i7 4771の理論性能は
Kaveriでかろうじて超えたわけだし。
単精度64並列の粒度のGCNのほうが並列化アプリケーションの対応が進む
というのはどういう理論なのかわからんが。
> 今後どうやっていくの方向性もない
方向なら示されてるがあんたが興味がないだけだろ
逆にAMDは背水の陣で「それしかない」わけで
なんでや!ハゲは関係ないやろ!
IRISがどうとかPhiがどうしたとかはINTEL次世代スレでやればいいだろうというね
>>99
そう感じるのはもともと無理にAMD側に振ったレスが飛び交うから結果的にそれの否定になる構図なわけでね
そう感じるのはもともと無理にAMD側に振ったレスが飛び交うから結果的にそれの否定になる構図なわけでね
HEVCのデコーダーってのは開発楽にできるのかな
アナゴ・・・じゃなくてだんごさん
アナゴ・・・じゃなくてだんごさん
111 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 15:40:50.22 ID:tlodbvu9
ぶるるぁ〜
アップル、GLOBALFOUNDRIESにチップ製造委託を検討か
japan.cnet.com/news/service/35039782/
まじかよー
japan.cnet.com/news/service/35039782/
まじかよー
intelと淫厨の基本思想はAMD憎しだから何言っても無駄
CPUが全てでiGPUはオマケ以下でしか無い
CPUとGPUの高度な連携を押し進めるAMDとARMが邪魔で憎くてたまらないだけ
そのくせRADEONと組み合わせてゲーム性能は上とか言ってくるから頭おかしい
intel vs AMDやりたいなら、FX9590+R9 290x vs i7 4770でいいじゃない?なんならiris搭載機でもいいけど
ゲフォやラデ使わないでインテルだけでかかってくればいい
CPUが全てでiGPUはオマケ以下でしか無い
CPUとGPUの高度な連携を押し進めるAMDとARMが邪魔で憎くてたまらないだけ
そのくせRADEONと組み合わせてゲーム性能は上とか言ってくるから頭おかしい
intel vs AMDやりたいなら、FX9590+R9 290x vs i7 4770でいいじゃない?なんならiris搭載機でもいいけど
ゲフォやラデ使わないでインテルだけでかかってくればいい
114 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 15:46:09.63 ID:tlodbvu9
HEVCといえばこんなニュースがマイコンで・・いや舞い込んできましたよ
http://av.watch.impress.co.jp/docs/news/20131112_623146.html
http://av.watch.impress.co.jp/docs/news/20131112_623146.html
>>108
NGいれればいいじゃん。大抵共有NGでも消えてるよ
コメントにたいしてレスのなさが読まれてない証拠
レスがない=意見が賛同されている
じゃないんだぜ
そうだな、とレスついた少数が成る程と思っただけで
NGいれればいいじゃん。大抵共有NGでも消えてるよ
コメントにたいしてレスのなさが読まれてない証拠
レスがない=意見が賛同されている
じゃないんだぜ
そうだな、とレスついた少数が成る程と思っただけで
H.265 HEVC トランスコードのスライドは出てたけど
まぁ今日は1時間しかなかったしそういう話する日じゃないしな
まぁ今日は1時間しかなかったしそういう話する日じゃないしな
>>113
「オマケ以下」のiGPUに追いつかれてるからヤバイと思う・・
「オマケ以下」のiGPUに追いつかれてるからヤバイと思う・・
>>112
日本語訳: ちょっと値引き足りないんじゃないですかねえTSMCさん
日本語訳: ちょっと値引き足りないんじゃないですかねえTSMCさん
単体GPUの付加価値ってのは高解像度、高画質(高負荷)なゲームを動かすことだろうけど
それもゲーム側の飽和が近いから何ともなぁ
それこそiGPUで構わない範囲が広がっていくだけだし
それもゲーム側の飽和が近いから何ともなぁ
それこそiGPUで構わない範囲が広がっていくだけだし
>>98
すまないがおまいには聞いてないんだなあ
すまないがおまいには聞いてないんだなあ
AMD、856GFLOPSのAPU「Kaveri」を2014年1月より投入
http://pc.watch.impress.co.jp/docs/news/event/20131112_623164.html
http://pc.watch.impress.co.jp/docs/news/event/20131112_623164.html
>>113
どうしても理解出来ん、AMDの駄目な所を指摘すると、
なぜアンチになるのか・・・。そういう目でしか物事見れなくなってるだけじゃね?
で、あげくに
>intel vs AMDやりたいなら、FX9590+R9 290x vs i7 4770でいいじゃない?なんならiris搭載機でもいいけど
>ゲフォやラデ使わないでインテルだけでかかってくればいい
完全に、AMD以外の否定しかしてない、単なる自己中だろ。
どうしても理解出来ん、AMDの駄目な所を指摘すると、
なぜアンチになるのか・・・。そういう目でしか物事見れなくなってるだけじゃね?
で、あげくに
>intel vs AMDやりたいなら、FX9590+R9 290x vs i7 4770でいいじゃない?なんならiris搭載機でもいいけど
>ゲフォやラデ使わないでインテルだけでかかってくればいい
完全に、AMD以外の否定しかしてない、単なる自己中だろ。
>>122
スレタイ嫁よな
スレタイ嫁よな
>>122
ここ vsするところじゃないと思うけど
ここ vsするところじゃないと思うけど
125 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 15:56:06.18 ID:tlodbvu9
てか、GPU使ったからって汎用の整数演算性能伸びるわけじゃないんだけどな
http://www.guru3d.com/articles_pages/amd_a10_6800k_review_apu,12.html
AVX2が普及してないからGPGPU勝つる!という意味不明な論理を
(OpenCL使ったらAVX2/FMAのコードも生成できるんですが)
誰かわかりやすく説明してくれませんかね
http://www.guru3d.com/articles_pages/amd_a10_6800k_review_apu,12.html
AVX2が普及してないからGPGPU勝つる!という意味不明な論理を
(OpenCL使ったらAVX2/FMAのコードも生成できるんですが)
誰かわかりやすく説明してくれませんかね
FX9590+R9 290x vs i7 4770じゃ色々あんまりなんで市販されてるもので値段合わせてみた
i7 4770k 3万円
vs
A10 6800k or FX 8320 1.5万円 + HD7790 1.5万円
CPUとGPUで3万円なら結構色んな組み合わせができそうだ
i7 4770k 3万円
vs
A10 6800k or FX 8320 1.5万円 + HD7790 1.5万円
CPUとGPUで3万円なら結構色んな組み合わせができそうだ
128 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 16:04:38.69 ID:tlodbvu9
あとHEVCは浮動小数点演算を使いません。
1.x86にほとんど入ってるavxすら普及していないのにhsaなる新規のgpgpu環境が広まる理屈を簡単に述べよ
2.gpgpuが広まったとしてどういう用途があるのか簡単に述べよ
2.gpgpuが広まったとしてどういう用途があるのか簡単に述べよ
言語の肝はランタイムとかコンパイラだな
>>122
> >>113
> どうしても理解出来ん、AMDの駄目な所を指摘すると、
> なぜアンチになるのか・・・。そういう目でしか物事見れなくなってるだけじゃね?
ダメなところだけ言ってるのが本当にダメ
じゃあAMDの良い所言ってみな
> で、あげくに
> >intel vs AMDやりたいなら、FX9590+R9 290x vs i7 4770でいいじゃない?なんならiris搭載機でもいいけど
> >ゲフォやラデ使わないでインテルだけでかかってくればいい
> 完全に、AMD以外の否定しかしてない、単なる自己中だろ。
>intel vs AMDやりたいなら、
コレ読める?日本語分かりますか?
AMDとintel以外は全く関係ないよ、ホント淫厨は自己中しかいないな
> >>113
> どうしても理解出来ん、AMDの駄目な所を指摘すると、
> なぜアンチになるのか・・・。そういう目でしか物事見れなくなってるだけじゃね?
ダメなところだけ言ってるのが本当にダメ
じゃあAMDの良い所言ってみな
> で、あげくに
> >intel vs AMDやりたいなら、FX9590+R9 290x vs i7 4770でいいじゃない?なんならiris搭載機でもいいけど
> >ゲフォやラデ使わないでインテルだけでかかってくればいい
> 完全に、AMD以外の否定しかしてない、単なる自己中だろ。
>intel vs AMDやりたいなら、
コレ読める?日本語分かりますか?
AMDとintel以外は全く関係ないよ、ホント淫厨は自己中しかいないな
>>130
AMDのアキレス腱じゃないですかそれ
AMDのアキレス腱じゃないですかそれ
スマフォでGPUを汎用の演算に簡易に使えるところまで整備できれば
使われるんじゃないかね、HSA。
困難は多いが、頑張ると言ってるのを別に止めるものでもあるまい。
使われるんじゃないかね、HSA。
困難は多いが、頑張ると言ってるのを別に止めるものでもあるまい。
134 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 16:13:15.43 ID:tlodbvu9
AMDのHSAの根幹ってさ
「GPGPUが普及しないのはCPUとGPUの距離が遠いからだ!」
だよね?
一因ではあるけどそれは全てではないんだよな。
少なくともBolt(笑)みたいなのが生産性向上のためのツールなら
誰もコード書きたがらないよ。
それならArray Building Blocksのほうがよっぽどわかりやすい。
「GPGPUが普及しないのはCPUとGPUの距離が遠いからだ!」
だよね?
一因ではあるけどそれは全てではないんだよな。
少なくともBolt(笑)みたいなのが生産性向上のためのツールなら
誰もコード書きたがらないよ。
それならArray Building Blocksのほうがよっぽどわかりやすい。
>>129
HSAの中心はx86じゃなくてARMだから。
HSAの中心はx86じゃなくてARMだから。
ちなみに、俺intelの良い所言えるよ
売上凄い
シェア凄い
営業力凄い
プロセス開発力凄い
シングルスレッド凄い
ARMに喧嘩売るのが凄い
売上凄い
シェア凄い
営業力凄い
プロセス開発力凄い
シングルスレッド凄い
ARMに喧嘩売るのが凄い
>>134
ちがいます。
GPGPUがメインストリームのプログラマに広がっていかない理由
(1)プロセッサの演算能力に余剰が発生している
(2)メモリ空間がそれぞれ別に存在していること
(3)一般のプログラマにはOpenCLなどがややハードルが高いこと
(4)新しいプログラミングツールやライブラリに投資が必要であること
ちがいます。
GPGPUがメインストリームのプログラマに広がっていかない理由
(1)プロセッサの演算能力に余剰が発生している
(2)メモリ空間がそれぞれ別に存在していること
(3)一般のプログラマにはOpenCLなどがややハードルが高いこと
(4)新しいプログラミングツールやライブラリに投資が必要であること
BF4のフルHDミディアムだと〜30fpsくらいか
HD5870だと50fps後半くらいなのでだいたい半分くらいの性能ってところか
Mantleでどれだけ伸びるか楽しみ
HD5870だと50fps後半くらいなのでだいたい半分くらいの性能ってところか
Mantleでどれだけ伸びるか楽しみ
ID:reU9LetM
AMDの良い所言ってみな
3つくらいは出るだろ流石に
出来なきゃ淫厨、ゲフォ厨で確定
AMDの良い所言ってみな
3つくらいは出るだろ流石に
出来なきゃ淫厨、ゲフォ厨で確定
140 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 16:18:39.65 ID:tlodbvu9
>>133
> (1)プロセッサの演算能力に余剰が発生している
Core i7上位(4コアではなく6コア)を使っているユーザーを満足させられるだけの
CPUをリリースできていないAMDが言うことかこれは
AMDのハイエンドでカバーできない演算性能に需要があるのは
不足が発生しているからに他ならない。
> (1)プロセッサの演算能力に余剰が発生している
Core i7上位(4コアではなく6コア)を使っているユーザーを満足させられるだけの
CPUをリリースできていないAMDが言うことかこれは
AMDのハイエンドでカバーできない演算性能に需要があるのは
不足が発生しているからに他ならない。
団子なんて言ってる事も支離滅裂の嘘だらけのキチなんだから
NG入れて放置が推奨
もしくは雑音並みに叩いて追い出すか
NG入れて放置が推奨
もしくは雑音並みに叩いて追い出すか
なにかあるのか
逆に聞くけどVIAのいいところって何さw
逆に聞くけどVIAのいいところって何さw
>(1)プロセッサの演算能力に余剰が発生している
ならGPGPUなんて要らないじゃん
ならGPGPUなんて要らないじゃん
>>137
アーキテクチャが複数あり、ハードウェア非依存かつ高効率に書くのは困難で、つまり費用対効果が悪い。
アーキテクチャが複数あり、ハードウェア非依存かつ高効率に書くのは困難で、つまり費用対効果が悪い。
検索した結果初出であることが判明したVIAの話題が
今の会話の流れにどんな重要性を発揮するのか簡潔に述べよ
今の会話の流れにどんな重要性を発揮するのか簡潔に述べよ
んーPS4以下じゃん...
>(2)メモリ空間がそれぞれ別に存在していること
>(3)一般のプログラマにはOpenCLなどがややハードルが高いこと
>(4)新しいプログラミングツールやライブラリに投資が必要であること
フレームワーク上でメモリアドレスが仮想化、統合されてればプログラマは楽なわけだ
すでにそういうものは存在してるわけだけど、HPC以外では一向に広まらない
>(3)一般のプログラマにはOpenCLなどがややハードルが高いこと
>(4)新しいプログラミングツールやライブラリに投資が必要であること
フレームワーク上でメモリアドレスが仮想化、統合されてればプログラマは楽なわけだ
すでにそういうものは存在してるわけだけど、HPC以外では一向に広まらない
>>141
仕方ないのでNGしたよ
仕方ないのでNGしたよ
っていうかkaveri詳細はもう明日におあずけなの?
>>152
明日か明後日かCESか
明日か明後日かCESか
154 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 16:26:38.27 ID:tlodbvu9
> 実際ほとんどの人がi7の性能を持て余してるでしょうが
持て余してるならなおさらGPGPUを必要としてない
持て余してるならなおさらGPGPUを必要としてない
>>154
GPUはそれ以上に持て余してるって話だよ
GPUはそれ以上に持て余してるって話だよ
156 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 16:28:12.74 ID:tlodbvu9
>GPUはそれ以上に持て余してるって話だよ
じゃあ削れ。なくせ。
じゃあ削れ。なくせ。
え>>121が詳細なんじゃないの
CPUもGPUも持て余してるなら新しいフレームワークなんていらないじゃん
この子は何が言いたいの
この子は何が言いたいの
>>156
まずHaswellから削れば?w GPU強化でTDPアップとかバカバカしい
まずHaswellから削れば?w GPU強化でTDPアップとかバカバカしい
160 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 16:31:30.05 ID:tlodbvu9
>>159
持て余してると主張してるのはお前のほうなんだが何逆切れしてんだ
持て余してると主張してるのはお前のほうなんだが何逆切れしてんだ
>>160
はぁ?俺の主張ではないが
はぁ?俺の主張ではないが
団子除け撒いとこう
525 ,,・´∀`・,,)っ-○○○[sage] 2013/10/14(月) 17:14:21.75 ID:Ae2cnZVE
Mantleなんてもの眼中にねーっす。
先進性どころか前世紀のGlide(あるいはDOS時代のゲーム)に回帰しようとしてるだけ。
なんのためにハードウェアを抽象化してるのか。
近年でいえばNVIDIAがCUDA/PhysXでやろうとしてコケたことを再現するだけになりそうかな。
特定ベンダーのハードごとに専用の最適化ってのはコスト要因なんだよ
開発者のコストが増してスマホ向けやFlashゲーに鞍替えするデベロッパーが
ますます増えそうだな。
AMD空気読めなさ杉
544 :,,・´∀`・,,)っ-○○○ : 2013/10/14(月) 17:30:22.87 ID:Ae2cnZVE
インパクトとしてはアンリアルトーナメントのCUDA PhysX対応程度かそれ以下だな
出直しておいで
563 :,,・´∀`・,,)っ-○○○ : 2013/10/14(月) 17:52:56.23 ID:Ae2cnZVE
ローレベルAPIなら既にBrook+/CAL/ILの前科があるので
「ぼくらの考えたさいきょうのBulldozer」程度の薔薇色の未来しか想像できないな
525 ,,・´∀`・,,)っ-○○○[sage] 2013/10/14(月) 17:14:21.75 ID:Ae2cnZVE
Mantleなんてもの眼中にねーっす。
先進性どころか前世紀のGlide(あるいはDOS時代のゲーム)に回帰しようとしてるだけ。
なんのためにハードウェアを抽象化してるのか。
近年でいえばNVIDIAがCUDA/PhysXでやろうとしてコケたことを再現するだけになりそうかな。
特定ベンダーのハードごとに専用の最適化ってのはコスト要因なんだよ
開発者のコストが増してスマホ向けやFlashゲーに鞍替えするデベロッパーが
ますます増えそうだな。
AMD空気読めなさ杉
544 :,,・´∀`・,,)っ-○○○ : 2013/10/14(月) 17:30:22.87 ID:Ae2cnZVE
インパクトとしてはアンリアルトーナメントのCUDA PhysX対応程度かそれ以下だな
出直しておいで
563 :,,・´∀`・,,)っ-○○○ : 2013/10/14(月) 17:52:56.23 ID:Ae2cnZVE
ローレベルAPIなら既にBrook+/CAL/ILの前科があるので
「ぼくらの考えたさいきょうのBulldozer」程度の薔薇色の未来しか想像できないな
164 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 16:34:18.54 ID:tlodbvu9
誰の主張なのか引用元を示せ。1〜4までお前がソースにしか思えん
AMDイジメはそこまでだ
ゲハの妄想がソース(キリッ
を素でやっちゃった称号を持ってる奴はスルーしとけ
を素でやっちゃった称号を持ってる奴はスルーしとけ
168 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 16:42:19.82 ID:tlodbvu9
とりあえず「持て余してるなら尚更GPGPUいらねーだろ」の反論はお前自身の言葉だろ
おそらくゲームしないときGPUは御暇してるのでという前程が必要
GPGPUが普及しないのって開発に金が掛かるからでしょ。
開発ツールなんかより人件費的なものが。
それだけ投資しても十分なリターンが得られる分野なんて高が知れてるから大半のアプリでは使用されず普及していないように見える。
JavaかC#で普通に書いたらコンパイラが勝手に変換してくれるようにならないと普及なんてしないよ。
開発ツールなんかより人件費的なものが。
それだけ投資しても十分なリターンが得られる分野なんて高が知れてるから大半のアプリでは使用されず普及していないように見える。
JavaかC#で普通に書いたらコンパイラが勝手に変換してくれるようにならないと普及なんてしないよ。
並列化範囲指定するだけのものはあるんだけどね
172 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 16:48:18.31 ID:tlodbvu9
スパコンでGPGPUが使われてるのは演算性能が1FLOPSでも稼ぎたいから。
持て余してるところにはGPGPUの需要は発生し得ない。
ある問題を高速に解きたいというニーズがあってCPUで精一杯努力して
どうしても足りない。
だからTeslaは売れてるわけ。
自らCPUコア数削って性能不足にさせてよりプログラミングが面倒なGPU
使って補いましょうなんてのは所詮マッチポンプでしかない。
持て余してるところにはGPGPUの需要は発生し得ない。
ある問題を高速に解きたいというニーズがあってCPUで精一杯努力して
どうしても足りない。
だからTeslaは売れてるわけ。
自らCPUコア数削って性能不足にさせてよりプログラミングが面倒なGPU
使って補いましょうなんてのは所詮マッチポンプでしかない。
ヘテロジニアスもGPGPUもアドレス統合も全くインテルには関係ないから全力で否定するのも分かる
ただし、残念なことにintel以外の全ての企業がHSAか類似の技術を開発している
今のAPUは単体GPUと単体CPUをくっつけて、既存の規格上でアレコレしてるだけ
HSAもそれを動かすためにクソややこしいことをしている
その為、Kaveriと今のHSAは非効率極まりないのは皆承知している
だからこそ、新しい規格、仕組みづくりのために多数の企業と研究しているのが現在
HSA前提の効率のいい規格、HSAに最適化したAPUってのはずっと先の話だね
来年がHSA元年、毎年改善されて洗練もされていき、5年後くらいに理想的なHSAとAPUが出てくるとは思う
それまでは進捗を楽しむことにしている
此処の住人は大体そうじゃないのかな
ただし、残念なことにintel以外の全ての企業がHSAか類似の技術を開発している
今のAPUは単体GPUと単体CPUをくっつけて、既存の規格上でアレコレしてるだけ
HSAもそれを動かすためにクソややこしいことをしている
その為、Kaveriと今のHSAは非効率極まりないのは皆承知している
だからこそ、新しい規格、仕組みづくりのために多数の企業と研究しているのが現在
HSA前提の効率のいい規格、HSAに最適化したAPUってのはずっと先の話だね
来年がHSA元年、毎年改善されて洗練もされていき、5年後くらいに理想的なHSAとAPUが出てくるとは思う
それまでは進捗を楽しむことにしている
此処の住人は大体そうじゃないのかな
何気にxeon+phiが完成形な気がするんだが
>>170
> GPGPUが普及しないのって開発に金が掛かるからでしょ。
> 開発ツールなんかより人件費的なものが。
> それだけ投資しても十分なリターンが得られる分野なんて高が知れてるから大半のアプリでは使用されず普及していないように見える。
> JavaかC#で普通に書いたらコンパイラが勝手に変換してくれるようにならないと普及なんてしないよ。
CPUとはメモリ管理が別なのが最大要因
だから、開発が難しいし環境も構築しにくいし金かかる上に性能も出ない
HSAとhUMAはここを解消するための規格
HSAがとりあえず完成したら、こぞってどこも対応してくるよ、intelとNV以外は
> GPGPUが普及しないのって開発に金が掛かるからでしょ。
> 開発ツールなんかより人件費的なものが。
> それだけ投資しても十分なリターンが得られる分野なんて高が知れてるから大半のアプリでは使用されず普及していないように見える。
> JavaかC#で普通に書いたらコンパイラが勝手に変換してくれるようにならないと普及なんてしないよ。
CPUとはメモリ管理が別なのが最大要因
だから、開発が難しいし環境も構築しにくいし金かかる上に性能も出ない
HSAとhUMAはここを解消するための規格
HSAがとりあえず完成したら、こぞってどこも対応してくるよ、intelとNV以外は
>>173
2020年に8Kを容易に扱えるAPUが出てくるのを楽しみにしているよ。
日本以外だと8Kがどれだけ普及するのか知らないけど、日本だとその頃から8KのPC環境も揃ってくるだろうからね。
後7年もあればHMDやAR技術、立体映像の技術も成熟してくるだろうし、その時にその処理にAPUが真価を発揮してくれると思っている。
2020年に8Kを容易に扱えるAPUが出てくるのを楽しみにしているよ。
日本以外だと8Kがどれだけ普及するのか知らないけど、日本だとその頃から8KのPC環境も揃ってくるだろうからね。
後7年もあればHMDやAR技術、立体映像の技術も成熟してくるだろうし、その時にその処理にAPUが真価を発揮してくれると思っている。
PCでGPGPUが使われるのはゲーム用途だろうな
>>172
スパコンはもうずっとPhiでもCUDA使ってなさいよ
なんでHSAでARMが主になってるのかわかんないのかね
ARMをスパコンに使うためか?違うよな
ARMはIoT市場に注力すると宣言してたろ
向いてる方向が違うんだから理解できるわけはないわ
スパコンはもうずっとPhiでもCUDA使ってなさいよ
なんでHSAでARMが主になってるのかわかんないのかね
ARMをスパコンに使うためか?違うよな
ARMはIoT市場に注力すると宣言してたろ
向いてる方向が違うんだから理解できるわけはないわ
IoTでもGPGPUは使わんけどね
180 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 16:58:16.58 ID:tlodbvu9
現状でも3K解像度のディスプレイ搭載のハイエンドノートPCは
Intel CPUしか採用が無い状況なんだが・・・
1366x768どまり低解像度でしか使われないAMDに何で必要なんだ
Intel CPUしか採用が無い状況なんだが・・・
1366x768どまり低解像度でしか使われないAMDに何で必要なんだ
なおさら使い道がない
182 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 16:59:59.23 ID:tlodbvu9
> ARMはIoT市場に注力すると宣言してたろ
> 向いてる方向が違うんだから理解できるわけはないわ
インテルがIoT部門を設立、主力は「Quark」
http://eetimes.jp/ee/articles/1311/08/news062.html
AMDこそこのレンジのチップ持ってないじゃないかww
> 向いてる方向が違うんだから理解できるわけはないわ
インテルがIoT部門を設立、主力は「Quark」
http://eetimes.jp/ee/articles/1311/08/news062.html
AMDこそこのレンジのチップ持ってないじゃないかww
185 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 17:03:37.00 ID:tlodbvu9
ARMの言ってるIoTに組み込むデバイスの主力はCortex AじゃなくてCortex-R/Mだよ。
AMDはGeode売っちまったじゃん。
今更組み込み業界に頭下げて使ってくださいって頼み込むの?
売る石も無いのに?
AMDはGeode売っちまったじゃん。
今更組み込み業界に頭下げて使ってくださいって頼み込むの?
売る石も無いのに?
>183
じゃ使い道教えてよ
じゃ使い道教えてよ
X86だけで頑張るintelが、異種コアで連携して頑張るAMDやARMと仲良く出来るわけもない
はっきり言って邪魔だし憎い存在だろう
AVX512以外なんか面白そうな計画あったっけintelって
正直話題が少なくてどうでもいい
はっきり言って邪魔だし憎い存在だろう
AVX512以外なんか面白そうな計画あったっけintelって
正直話題が少なくてどうでもいい
188 :Socket774:2013/11/12(火) 17:05:20.61 ID:zjtSJm+A
シャープのIGZOがdpiが非常に高く消費電力が低い
これ出せてるのが今はシャープだけだから今は高い
来年から4月からはクアルコムやらサムスンやら中国のCECパンダから出るから価格も安くなる
そしたらAMDへの採用も自然と流れる
まさにこの時期にKaveriのノートPC向けのAPUを出すだろう
これ出せてるのが今はシャープだけだから今は高い
来年から4月からはクアルコムやらサムスンやら中国のCECパンダから出るから価格も安くなる
そしたらAMDへの採用も自然と流れる
まさにこの時期にKaveriのノートPC向けのAPUを出すだろう
celeron+7750の牙城を救世主カヴェリが崩すからな
みとけよお前ら
みとけよお前ら
191 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 17:07:44.94 ID:tlodbvu9
Intelの14nmプロセスとARM「Cortex-A53」を採用、Alteraの「Stratix 10 SoC」
http://eetimes.jp/ee/articles/1310/30/news007.html
AlteraはQPIでXeonと繋いでヘテロジニアスコンピューティングやるって言ってますよ
HyperTransport対応製品はどこに行ったのか知らないけど
http://eetimes.jp/ee/articles/1310/30/news007.html
AlteraはQPIでXeonと繋いでヘテロジニアスコンピューティングやるって言ってますよ
HyperTransport対応製品はどこに行ったのか知らないけど
>>175
その考えが、お花畑なんだよな。
MMX/SSEですら、今でもコンパイラまかせじゃ、性能出し切れないんだぜ?
それよりもっとピーキーだと思われるHASが、
コンパイラが対応するだけで使われるようになるとか、
いくらなんでも、おかしくね?
その考えが、お花畑なんだよな。
MMX/SSEですら、今でもコンパイラまかせじゃ、性能出し切れないんだぜ?
それよりもっとピーキーだと思われるHASが、
コンパイラが対応するだけで使われるようになるとか、
いくらなんでも、おかしくね?
193 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 17:09:08.57 ID:tlodbvu9
>>189
じゃあAMDだけがIoTの方向向いてないわけだね
じゃあAMDだけがIoTの方向向いてないわけだね
>>186
1000の言葉で綴っても聞く耳持たないものには届かない
それは、ここにいるものにも言える
intelの素晴らしさを語って届くだろうか
信じるというのは大切なこと
技術者に必要なのは直感だよ
そして最後まで貫くこと
1000の言葉で綴っても聞く耳持たないものには届かない
それは、ここにいるものにも言える
intelの素晴らしさを語って届くだろうか
信じるというのは大切なこと
技術者に必要なのは直感だよ
そして最後まで貫くこと
>>194
は?
は?
197 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 17:12:01.64 ID:tlodbvu9
じゃあいつやるの?
縮小する市場で自分の切った尻尾を食べるトカゲに成り下がってたら
ジリ貧ですよ。
戦わなきゃ勝利も得られない。
縮小する市場で自分の切った尻尾を食べるトカゲに成り下がってたら
ジリ貧ですよ。
戦わなきゃ勝利も得られない。
ARMが助けてくれるってか
>>197
ARMがいるのにAMDがしゃしゃりでる必要無いだろ?
それこそハイリスク・ローリターンだわ
APUとHSAに全力を注いでるんだから余計なこと考えてる暇も余裕なんてない
と、俺は思うがね。実際はどうだかしらないよ
ARMがいるのにAMDがしゃしゃりでる必要無いだろ?
それこそハイリスク・ローリターンだわ
APUとHSAに全力を注いでるんだから余計なこと考えてる暇も余裕なんてない
と、俺は思うがね。実際はどうだかしらないよ
ARMがAMDのグループ会社かなんかだと思ってるのか
201 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 17:18:50.39 ID:tlodbvu9
Xeon Phiが世界一のスパコンに載ったし
タブレットではBayTrailがCortex A15を下してる
「〜には勝てない」と決め付けて勝負を諦めていたら得られない成果だ
そのくせHSAという伝家の宝刀の力にはすがるんだね
タブレットではBayTrailがCortex A15を下してる
「〜には勝てない」と決め付けて勝負を諦めていたら得られない成果だ
そのくせHSAという伝家の宝刀の力にはすがるんだね
本業が軌道に乗ってないのに横道にそれるとろくな事にならんぜ
それで倒産するパターンはいくつも見たからな
>>200
アライアンスの形をとってる以上、互いに不可侵な部分は存在するはずだろう
協調路線をとろうとしている相手の市場領域に土足で踏み込むのを良しとするか?
そういうのはINTELとnVIDIAだけに任せておけばいいわ
それで倒産するパターンはいくつも見たからな
>>200
アライアンスの形をとってる以上、互いに不可侵な部分は存在するはずだろう
協調路線をとろうとしている相手の市場領域に土足で踏み込むのを良しとするか?
そういうのはINTELとnVIDIAだけに任せておけばいいわ
203 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 17:22:12.87 ID:tlodbvu9
> 協調路線をとろうとしている相手の市場領域に土足で踏み込むのを良しとするか?
MSとIntelが育ててたネットブック市場破壊したのどこのメーカーだったかな
MSとIntelが育ててたネットブック市場破壊したのどこのメーカーだったかな
協調路線w
言っとくけど今後PC向けの製品なんて成長しないよ
つまり、AMD本業が軌道に乗ることなんてこの先無い
言っとくけど今後PC向けの製品なんて成長しないよ
つまり、AMD本業が軌道に乗ることなんてこの先無い
>>192
別に出しきる必要はないな
とりあえず対応してくれればいい
最適化とかは技術があってお金があるとこがやればいい
ノウハウとか環境やスキルの向上とか直ぐ出来るものじゃないし、
俺は5年後くらいに芽が出ると思ってるから、直近で広まらないとか気にしてない
別に出しきる必要はないな
とりあえず対応してくれればいい
最適化とかは技術があってお金があるとこがやればいい
ノウハウとか環境やスキルの向上とか直ぐ出来るものじゃないし、
俺は5年後くらいに芽が出ると思ってるから、直近で広まらないとか気にしてない
今後成長が見込めるのはクラウドサーバーや
それを利用する端末であるモバイル製品
それを利用する端末であるモバイル製品
>>175
今時大半のアプリにおいてメモリ管理なんてのはランタイムが勝手にやってくれるものだからHSAなんか無くたってプログラムは変わらないよ。単にHSAでちょっと早くなって少ないメモリで動くようになるだけ。
そんなことより超並列動作が可能なプログラムが難しい。
スレッド4つくらいなら大きな機能ブロック単位で切り分けるだけで済むけど、数百以上となると時間軸を除いて2D/3D的に広がる大量のデータに対して同じ処理を行う用途、例えば物理シミュレーションや画像処理以外では根本から考え方を変えないと対応できない。
いやそれも難しいだろう。電力効率が重要になった今となってはマルチスレッドの有力な用途となる投機実行が使えないからだ。
音声がGPGPUと相性が悪いのも時間軸を除くと0次元になるから。フーリエ変換しても1次元で要素数は二桁だから。
今時大半のアプリにおいてメモリ管理なんてのはランタイムが勝手にやってくれるものだからHSAなんか無くたってプログラムは変わらないよ。単にHSAでちょっと早くなって少ないメモリで動くようになるだけ。
そんなことより超並列動作が可能なプログラムが難しい。
スレッド4つくらいなら大きな機能ブロック単位で切り分けるだけで済むけど、数百以上となると時間軸を除いて2D/3D的に広がる大量のデータに対して同じ処理を行う用途、例えば物理シミュレーションや画像処理以外では根本から考え方を変えないと対応できない。
いやそれも難しいだろう。電力効率が重要になった今となってはマルチスレッドの有力な用途となる投機実行が使えないからだ。
音声がGPGPUと相性が悪いのも時間軸を除くと0次元になるから。フーリエ変換しても1次元で要素数は二桁だから。
IoTって10年も前にソニコン社長(当時)の久夛良木が言ってた
Cellコンピューティング構想そっくりそのままなんだよな
眉唾というか…その…
つーか、これからはIoTの時代(ドヤッ
とか言って当のAMDは参戦しませんとか苦しすぎるだろ
Cellコンピューティング構想そっくりそのままなんだよな
眉唾というか…その…
つーか、これからはIoTの時代(ドヤッ
とか言って当のAMDは参戦しませんとか苦しすぎるだろ
>>207 そうやってAMD以下のゴミクズ押し付けるのやめてくれませんかねえ?
googleの回し者かよクソが
googleの回し者かよクソが
ゲーム機採用で大儲け、利益V字回復って喜んでたけど
つれーわー売上も利益も大幅に落ち込んでマジつれーわー
なNVの半分以下とかだから、どっか開拓せんとまたジリ貧やで
つれーわー売上も利益も大幅に落ち込んでマジつれーわー
なNVの半分以下とかだから、どっか開拓せんとまたジリ貧やで
>>211
ウルブとwin8でV字回復とか言ってた企業があってだな
ウルブとwin8でV字回復とか言ってた企業があってだな
http://jp.techcrunch.com/2013/10/22/20131021tablets-vs-pcs/
2013年のタブレット出荷台数は42.7%成長の見込み。従来型PCは11.2%の減少か
http://news.mynavi.jp/news/2013/10/11/104/
世界PC市場は6Q連続マイナス成長 - タブレット端末による打撃が鮮明に
2013年のタブレット出荷台数は42.7%成長の見込み。従来型PCは11.2%の減少か
http://news.mynavi.jp/news/2013/10/11/104/
世界PC市場は6Q連続マイナス成長 - タブレット端末による打撃が鮮明に
nVidiaてビデオカードしか作ってないでしょ。
そんなに売れてるのか。
そんなに売れてるのか。
昔より売れなくなってきてるから
モバイル向けのtegraやHPC,データセンター向けtesla等に力を入れてる
モバイル向けのtegraやHPC,データセンター向けtesla等に力を入れてる
217 :Socket774:2013/11/12(火) 18:17:49.79 ID:xSvHvNPR
ビデオカードしか作ってないというのはかなり昔の話だよ>NV
むしろAMDこそだ。
むしろAMDこそだ。
だからさあ、自作板なのにモバイルの話で荒らすヴァカはなんなの?死ぬの?
ARMの手柄がなぜかAMDの手柄になってて笑った
米AMD、ヘテロジニアス・コンピューティング開発者向けのSDKを発表
新SDKにはAMDとしては初となるMedia SDKのv1.0βが含まれており、
これにより開発者は、GPUアクセラレートされたビデオ前処理/後処理ライブラリに加え、
低遅延なビデオ・エンコーディングのためのライブラリを使うことで他社と異なるAMD独自のマルチメディア機能を利用できるという。
news.mynavi.jp/news/2013/11/12/295/index.html
新SDKにはAMDとしては初となるMedia SDKのv1.0βが含まれており、
これにより開発者は、GPUアクセラレートされたビデオ前処理/後処理ライブラリに加え、
低遅延なビデオ・エンコーディングのためのライブラリを使うことで他社と異なるAMD独自のマルチメディア機能を利用できるという。
news.mynavi.jp/news/2013/11/12/295/index.html
あえて、モバイルの話をすればnexus 7が転機で
あれでnvidiaは、評価のすこぶる悪かったtegra3をさばき
さらにMSは Surfaceの値段で負けずっこけ瀕死
ひとつの失敗がいかに大きいか振り替えるに十分な
できごとだよ
あれでnvidiaは、評価のすこぶる悪かったtegra3をさばき
さらにMSは Surfaceの値段で負けずっこけ瀕死
ひとつの失敗がいかに大きいか振り替えるに十分な
できごとだよ
でもnexus7(2013)が欠陥品だったので(2012)の方が高評価という
>>222
SurfaceもTegraだけどね
SurfaceもTegraだけどね
intelはさ、iGPUとかSandyレベルで十分だからその分コア数増やせばいいのに
淫厨がほしいのはGT3eじゃなく8コアや12コアのCPUだろ
全くintelは自分のユーザーを全く見てないな
淫厨はこんなトコで油売ってないでインテル本社にメールでもすれば?
iGPUいらないから8コア3万円で出せってさ
淫厨がほしいのはGT3eじゃなく8コアや12コアのCPUだろ
全くintelは自分のユーザーを全く見てないな
淫厨はこんなトコで油売ってないでインテル本社にメールでもすれば?
iGPUいらないから8コア3万円で出せってさ
「Kaveriは非常に高い性能を持っているため、まずはゲーミングユーザーなどがターゲットになるデスクトップPC向けバージョンを先行させる。」
???
???
>>225
それXeonじゃん
それXeonじゃん
なにげにsurface2は良い感じなんだ
ただGPSが無いんだよなぁ
ただGPSが無いんだよなぁ
メモリ空間の統合なんてHaswellではとっくにやってて
IrisではeDRAMでデータ交換できるようになってんだが…
肝心のメモリ帯域不足にはなんの解決策もなしじゃ、GPGPUの難しさを
舐めてるとしかいいようがない。
コストかけていいからi7を倒せる最強APU作ってみてくれよ。
IrisではeDRAMでデータ交換できるようになってんだが…
肝心のメモリ帯域不足にはなんの解決策もなしじゃ、GPGPUの難しさを
舐めてるとしかいいようがない。
コストかけていいからi7を倒せる最強APU作ってみてくれよ。
まじか、PS4とoneの次世代はIris搭載確定やな
それよりKaveri環境はWIN7で動くのかな?
動くだろ
233 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 19:24:31.06 ID:tlodbvu9
メモリ帯域据え置きでGPUダイをニコイチにしたカードがHPC向けでは
皆無なことを考えればメモリ帯域を上げずにFLOPS数だけ引き上げても
汎用演算では使い物にならないことは確定的に明らか。
HPC業界ですら求めてないものがコンシューマ向けのGPGPU用途で
花開くなんてそんな馬鹿な話はあるわけがない。
そんなわけでeDRAMでもGDDR5でもいいからメモリ帯域問題を解決した
ハイエンドAPUぜひとも作ってみて欲しいけどな。
i7上位だって売れてるわけだし、良い物を求める客は本当に良い物には
金を出すんだから。Athlon 64 X2だって10万越えてたろ?
皆無なことを考えればメモリ帯域を上げずにFLOPS数だけ引き上げても
汎用演算では使い物にならないことは確定的に明らか。
HPC業界ですら求めてないものがコンシューマ向けのGPGPU用途で
花開くなんてそんな馬鹿な話はあるわけがない。
そんなわけでeDRAMでもGDDR5でもいいからメモリ帯域問題を解決した
ハイエンドAPUぜひとも作ってみて欲しいけどな。
i7上位だって売れてるわけだし、良い物を求める客は本当に良い物には
金を出すんだから。Athlon 64 X2だって10万越えてたろ?
実際KaveriはHaswellRefresh(GT3でeDRAM無)と勝負やな
IPCはLlanoと同じぐらいに改善されてると嬉しいのう
IPCはLlanoと同じぐらいに改善されてると嬉しいのう
236 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 19:40:16.06 ID:tlodbvu9
AMDのCPUだとスコアが上がる新しいN-benchを作ればいいんじゃないの?
つかMcAfeeまじうぜーIntelの子会社だけどまじうぜー
つかMcAfeeまじうぜーIntelの子会社だけどまじうぜー
>>236
うざいのはお前だけどな(´・ω・`)
うざいのはお前だけどな(´・ω・`)
コスパしかとりえのないAMDにとってARMは最大の脅威なんだが
なんでAMDの子分みたいな扱いになってるんだろうな
なんでAMDの子分みたいな扱いになってるんだろうな
少なくともメインメモリがボトルネックになる処理に関しては、
SSE/AVXでやっても、APU/iGPU+OpenCLでやっても、
速度はかわらんのちゃう?
SSE/AVXでやっても、APU/iGPU+OpenCLでやっても、
速度はかわらんのちゃう?
240 :Socket774:2013/11/12(火) 19:54:14.50 ID:73W0UmI6
R9 270が補助電源1本なのか2本なのかで評価が真っ二つに分かれるんだが
>>230
FFキャラが全員丸坊主かよちょっと興味ある
FFキャラが全員丸坊主かよちょっと興味ある
団子に振り回されすぎだろここww
ほっとけよ団子とか
ほっとけよ団子とか
団子もインテルももうつまらんよ
で、今日の発表3行でまとめてくれ!
今日のは偽団子だろ
専門的な話が少ないし無駄にレス数多いし
専門的な話が少ないし無駄にレス数多いし
250 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 20:09:05.44 ID:tlodbvu9
ところでOpenCVって元はIntelの作った画像処理ライブラリだよな
Cellとか組み込みMIPSに移植されてるから本当に出来がいいんだろうな
CPUオンリーだけどAMDの作ったライブラリってこんなのがあったけどな
まったく保守されてないけど
http://framewave.sourceforge.net/
>>239
HaswellみたいにCPUだけで400GFLOPS以上あると
ものによってはメモリ帯域飽和してしまう可能性はありますね。
でもA10 6k/7kみたいにCPU合計で単精度100GFLOPS程度だと
CPUだけではDDR3の余剰帯域を使い切れない可能性があるから
そこを埋めるためにGPUを使う余地がある。
むしろCPU側のほうがキャッシュメモリを取ってる分
メモリ帯域あたりの実効FLOPS数は稼ぎやすい構造になっている筈で
実際にものが無い以上は「HSAで勝つる」は幻想。
Cellとか組み込みMIPSに移植されてるから本当に出来がいいんだろうな
CPUオンリーだけどAMDの作ったライブラリってこんなのがあったけどな
まったく保守されてないけど
http://framewave.sourceforge.net/
>>239
HaswellみたいにCPUだけで400GFLOPS以上あると
ものによってはメモリ帯域飽和してしまう可能性はありますね。
でもA10 6k/7kみたいにCPU合計で単精度100GFLOPS程度だと
CPUだけではDDR3の余剰帯域を使い切れない可能性があるから
そこを埋めるためにGPUを使う余地がある。
むしろCPU側のほうがキャッシュメモリを取ってる分
メモリ帯域あたりの実効FLOPS数は稼ぎやすい構造になっている筈で
実際にものが無い以上は「HSAで勝つる」は幻想。
団子41レスもしてるwwwwwwwwwww
なんでそんなにヒマなんやろ
>>247
PS4ってHSAに対応しないんじゃなかったっけ?
PS4からの移植で使うことはあるかもしれないが
>>250
intrinsicsとかであまり考えずにAVX使うと、
32Kくらいで性能がSSE並に落ち込むのは、
キャッシュからあふれているせいでしょうしね
PS4ってHSAに対応しないんじゃなかったっけ?
PS4からの移植で使うことはあるかもしれないが
>>250
intrinsicsとかであまり考えずにAVX使うと、
32Kくらいで性能がSSE並に落ち込むのは、
キャッシュからあふれているせいでしょうしね
>>248今日のまとめ
・AMD等が立ち上げたAPU推進の業界団体「HSA Foundation」には全半導体メーカーの3分の2が参加。大手で不参加はIntelとNVIDIAのみ。>>121
・KaveriはデスクトップPC版を2014年1月14日に正式発表。年明けにはHSA対応ソフトウェアを開発する環境が整う。
・Oracleは2015年までにJAVAのHSA対応を明言。>>13
・AMD等が立ち上げたAPU推進の業界団体「HSA Foundation」には全半導体メーカーの3分の2が参加。大手で不参加はIntelとNVIDIAのみ。>>121
・KaveriはデスクトップPC版を2014年1月14日に正式発表。年明けにはHSA対応ソフトウェアを開発する環境が整う。
・Oracleは2015年までにJAVAのHSA対応を明言。>>13
PS4はHSA非対応
意味ないし
意味ないし
少なくとも、GPUとGPGPUの同時実行が不要な非ゲームに関しては、
Intel・AMD・nvidiaともにOpenCLに対応したので、
これからはOpenCL化していくよ
すでにOpenCL対応アプリがかなり増えてる
Intel・AMD・nvidiaともにOpenCLに対応したので、
これからはOpenCL化していくよ
すでにOpenCL対応アプリがかなり増えてる
259 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 20:18:51.97 ID:tlodbvu9
別に使ってもいいけどかえって面倒だぜ?
単精度使って24bitずつしか使えないなら32bit整数でやったほうが速いし
単精度使って24bitずつしか使えないなら32bit整数でやったほうが速いし
>>258
OpenCLする場合の開発環境ってどこの使うんだ?
OpenCLする場合の開発環境ってどこの使うんだ?
3日目にSCEアメリカの副社長が講演する事になってるでしょ
HSAはどうだかしらないけどAPUの後押しにはなるんじゃない
HSAはどうだかしらないけどAPUの後押しにはなるんじゃない
どうせCPU性能なんてもう要らんし
GPUなんてゲームと高解像度ディスプレイにしか使わんのやろ?
重要なのは省エネとメモリの進歩
1chのkabiniじゃ4k液晶のハンドリングは不安
GPUなんてゲームと高解像度ディスプレイにしか使わんのやろ?
重要なのは省エネとメモリの進歩
1chのkabiniじゃ4k液晶のハンドリングは不安
4K液晶が安くなったら起こして
266 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 20:38:28.94 ID:tlodbvu9
結局GPGPU開発ツールって開発ツール各社任せになってるから
マルチプラットフォーム開発が面倒なんだよな。
MSもOpenCL不支持だから(HSAは言わずもがな)
VC++で対応してないし。
マルチプラットフォーム開発が面倒なんだよな。
MSもOpenCL不支持だから(HSAは言わずもがな)
VC++で対応してないし。
SEIKIの50インチ4k2kなら1500ドルで買えるぜ
僕も買ったよ!いまいちだったけど(´・ω・`)
僕も買ったよ!いまいちだったけど(´・ω・`)
javaアクセラレートは何気に凄い事だな
269 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 20:43:41.46 ID:tlodbvu9
スマトラはあくまでJavaのOpenCLバインドであって
既存のJavaコードそのものが高速化されるわけじゃない
既存のJavaコードそのものが高速化されるわけじゃない
明日はどんな発表あるんかね?
>>266
そうなのか。
>結局GPGPU開発ツールって開発ツール各社任せ
Intel用、AMD用、Nv用でやらないと駄目って、ソフト開発する奴は大変だな。
同一コードで各社のを全て対応できるのかな。
MSがサポートしないとなるとWinではメジャーにはなれないだろうな
そうなのか。
>結局GPGPU開発ツールって開発ツール各社任せ
Intel用、AMD用、Nv用でやらないと駄目って、ソフト開発する奴は大変だな。
同一コードで各社のを全て対応できるのかな。
MSがサポートしないとなるとWinではメジャーにはなれないだろうな
どんだけスレの勢いあるんだよw
>>結局GPGPU開発ツールって開発ツール各社任せ
>Intel用、AMD用、Nv用でやらないと駄目って、ソフト開発する奴は大変だな。
じゃじゃーん!そんなあなたにDirectCompute!
パフォーマンスを追求するなら結局は特化した環境を使うなり
特化したチューニングをするなりすることになるんだろうけどね。
>Intel用、AMD用、Nv用でやらないと駄目って、ソフト開発する奴は大変だな。
じゃじゃーん!そんなあなたにDirectCompute!
パフォーマンスを追求するなら結局は特化した環境を使うなり
特化したチューニングをするなりすることになるんだろうけどね。
>>271
GPGPUに限って言えば将来的にはシェアはAMD+HSA加盟企業>Nv>intelだろう
openCLに関してはリンゴが作ったぽいからMSは乗ってこないのは見えてた、逆に
リンゴが乗ってこないのが不思議なとこだけど。
winは対応らしいけどリンゴはどうなんだろ?
GPGPUに限って言えば将来的にはシェアはAMD+HSA加盟企業>Nv>intelだろう
openCLに関してはリンゴが作ったぽいからMSは乗ってこないのは見えてた、逆に
リンゴが乗ってこないのが不思議なとこだけど。
winは対応らしいけどリンゴはどうなんだろ?
結局、kaveriはライトなPCゲーマー向きの代物で、dGPU積むような層はお呼びじゃない感じ?
gt630みたいなゴミと比べてるからゴミしか作れねーんだよ。
せめてgt650超えてくれないと土俵にも上がらんよ。
最新のcodで1080p60fps出せるようになってから出てこい話はそれからだ。
せめてgt650超えてくれないと土俵にも上がらんよ。
最新のcodで1080p60fps出せるようになってから出てこい話はそれからだ。
kaveriはFMでのフラグシップなだけでAMDのフラグシップはFX9590ってのはしばらく
続きそう
続きそう
279 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 21:09:42.20 ID:tlodbvu9
Compute Shaderはゲーム(DirectXパイプライン)に特化しすぎてて
汎用性が低い
結局(x86に限れば)IntrinsicなりASMなりでAVX叩くのが一番効果的に
並列化アプリケーションを記述できる。
AVX2/FMAでカリカリにチューンしたらメモリ帯域使い切って
IGPまで動かしてる余裕なくなることのほうが多い
HaswellのCPUだけ使っても既にKeplerの帯域あたりFLOPS数を上回ってるから
そこで更にGPUを動かそうとしたところで頭を打ってしまうことのほうが多い
(そんなわけでIntelのOpenCL SDKは事実上Irisのためだけにあるといってもいい)
汎用性が低い
結局(x86に限れば)IntrinsicなりASMなりでAVX叩くのが一番効果的に
並列化アプリケーションを記述できる。
AVX2/FMAでカリカリにチューンしたらメモリ帯域使い切って
IGPまで動かしてる余裕なくなることのほうが多い
HaswellのCPUだけ使っても既にKeplerの帯域あたりFLOPS数を上回ってるから
そこで更にGPUを動かそうとしたところで頭を打ってしまうことのほうが多い
(そんなわけでIntelのOpenCL SDKは事実上Irisのためだけにあるといってもいい)
HSAに追加参加する企業ってどこだろ?アポーは無いか。
282 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 21:16:36.38 ID:tlodbvu9
ジョブズはiOSをAtomに移行させ全x86化を検討してたが
社員に止められたんだよ
それはともかく、iOSはAppleが独占供給してることで対応端末が限られるから
バリデーションコストがかからず、それで既にソフト開発者の負担を減らす
要因になり得てるわけで、わざわざAndroidの多機種とマルチ環境を
作ったところでAppleにはまったくうまみが無いわけ。
実際パズドラなんかもiOS先行開発ですし。
社員に止められたんだよ
それはともかく、iOSはAppleが独占供給してることで対応端末が限られるから
バリデーションコストがかからず、それで既にソフト開発者の負担を減らす
要因になり得てるわけで、わざわざAndroidの多機種とマルチ環境を
作ったところでAppleにはまったくうまみが無いわけ。
実際パズドラなんかもiOS先行開発ですし。
団子のいってることは、一昔前にFX8コア対応してるソフトがでれば性能が出せる
と言ってた人と同じ理由だな、一番売れてるセレロンでAVXって対応してるのか?
シェアとれないCPUに最適化するソフトのが少ない。鯖やらHPC用は別だろうけどな。
結局理想論で裏付ける根拠が乏しすぎる。
と言ってた人と同じ理由だな、一番売れてるセレロンでAVXって対応してるのか?
シェアとれないCPUに最適化するソフトのが少ない。鯖やらHPC用は別だろうけどな。
結局理想論で裏付ける根拠が乏しすぎる。
284 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 21:26:05.16 ID:tlodbvu9
> 一番売れてるセレロンでAVXって対応してるのか?
【今は】してないよ。
PenrynセレロンのときはSSE4が非対応だった。でも今はしてる。
どのみち非対応の古いCPU向けに分岐パスは書かないといけないんだから
全部のプロセッサが対応してないから使ってはいけないなんてことを言ったら
それこそAMDがIntelを潰してシェア100%取らない限りHSAの対応が
進まないことになってしまうよ?
【今は】してないよ。
PenrynセレロンのときはSSE4が非対応だった。でも今はしてる。
どのみち非対応の古いCPU向けに分岐パスは書かないといけないんだから
全部のプロセッサが対応してないから使ってはいけないなんてことを言ったら
それこそAMDがIntelを潰してシェア100%取らない限りHSAの対応が
進まないことになってしまうよ?
iOSアプリは課金システムだけ発展して行くなあ。
つかHSAがcpuのSIMD演算機に取って代わるわけじゃないし、
演算機の密度で考えたらgpuに圧倒的に分があるんだから、棲み分けるだろ。
avxavxうるせーぞ糞団子
演算機の密度で考えたらgpuに圧倒的に分があるんだから、棲み分けるだろ。
avxavxうるせーぞ糞団子
287 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 21:30:45.14 ID:tlodbvu9
Celeronが多いのは事実だけども
AVXに対応してるi3, i5, i7, Xeonだけでも年間2億台は出荷してたと記憶してたが。
AVXに対応してるi3, i5, i7, Xeonだけでも年間2億台は出荷してたと記憶してたが。
セレロンにはないしモバイル向けすら搭載してないってことはインテル自体いらないと思ってるんだろうしな
実際対応してるものはほとんどないし
実際対応してるものはほとんどないし
289 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 21:33:19.37 ID:tlodbvu9
> 演算機の密度で考えたらgpuに圧倒的に分があるんだから、棲み分けるだろ。
演算機があったところで汎用演算にはキャッシュメモリが圧倒的に少ない。
参照するメインメモリはCPUと同じ。
GPU使ったからってメモリ帯域が広がるわけじゃなくて
CPUで使える分をとってしまうだけ。
CPUだけで性能頭打ちになるならわざわざGPGPUを使う意味は無い。
演算機があったところで汎用演算にはキャッシュメモリが圧倒的に少ない。
参照するメインメモリはCPUと同じ。
GPU使ったからってメモリ帯域が広がるわけじゃなくて
CPUで使える分をとってしまうだけ。
CPUだけで性能頭打ちになるならわざわざGPGPUを使う意味は無い。
用は採算の話だろ、100%とか極論だしてもアフォか?って話だ
それにHSAのメインはARMのモバイル端末、PCとは買い替え周期も
違う訳だし、モバイル端末に関してはかなりのシェアが取れると言える。
PCの方に関してはその後の話になるだろうけど、開発が止まることは無い
だろう。
それにHSAのメインはARMのモバイル端末、PCとは買い替え周期も
違う訳だし、モバイル端末に関してはかなりのシェアが取れると言える。
PCの方に関してはその後の話になるだろうけど、開発が止まることは無い
だろう。
291 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 21:34:43.35 ID:tlodbvu9
正直Celeron層にSIMDはいらんと思う
普遍的な必要性があるなら専用回路とかになっちゃうことも多いし
オーディオ系はIntelのAtomでもDSPが使われているようだ
普遍的な必要性があるなら専用回路とかになっちゃうことも多いし
オーディオ系はIntelのAtomでもDSPが使われているようだ
293 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 21:37:25.57 ID:tlodbvu9
で、結局AMDはゲーム業界でのAVXの普及に協力してくれてるんだろ?
さすがにAVXよりはGPUのほうが将来性あるだろう
296 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 21:39:59.05 ID:tlodbvu9
どのアーキテクチャが?
IGP・dGPU合計でもRadeonの売上げは右肩下がりですよ
IGP・dGPU合計でもRadeonの売上げは右肩下がりですよ
>>290
ARMでシェア取ったってその餅を食うのはQualcommやサムチョンやMediatekだぜ
ARMでシェア取ったってその餅を食うのはQualcommやサムチョンやMediatekだぜ
TrueAudioも載ってるんだな
使われるか使われないかは分からないが面白い
使われるか使われないかは分からないが面白い
Intelがララビー構想を実現させてたらよかったのにね
300 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 21:45:20.32 ID:tlodbvu9
Creativeはサンブラのブランド力が残ってるうちにどこかしらのチップにIPを
ライセンスしないかねー
ライセンスしないかねー
>>297
AMDとしてはモバイルで加盟企業がうまうまできたあとには
PC市場でいくばくかの見返りあると思ってるだろうし、ARM
でもモバイル端末狙ってるし、損ばかりじゃない。
ある程度土台ができちゃえばAMD的には成功でしょHSAは。
AMDとしてはモバイルで加盟企業がうまうまできたあとには
PC市場でいくばくかの見返りあると思ってるだろうし、ARM
でもモバイル端末狙ってるし、損ばかりじゃない。
ある程度土台ができちゃえばAMD的には成功でしょHSAは。
302 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 21:47:19.56 ID:tlodbvu9
NVIDIAですらサポートガーなんて言われる魔窟でAMDが何すんの?www
HSAはCPU、SIMD、GPGPU、DSP混在の環境向けソフトを、統一メモリアドレスで楽に開発するための規格
AVXも当然適用内で、多分殆んどロスゼロで透過的に活用可能
AVXも当然適用内で、多分殆んどロスゼロで透過的に活用可能
お前らアホかw
スレ勢いw
どんだけ〜
スレ勢いw
どんだけ〜
307 :Socket774:2013/11/12(火) 22:02:17.38 ID:uK/5F3CO
先生助けて!HSA陣営が息してないの!
http://pc.watch.impress.co.jp/img/pcw/docs/623/201/html/m.02.png.html
1位:iPhone 5s 32GB (NTT docomo)
2位:iPhone 5c 16GB (SoftBank)
3位:iPhone 5s 64GB (SoftBank)
4位:iPhone 5s 32GB (SoftBank)
5位:iPhone 5s 32GB (au)
6位:iPhone 5s 16GB (SoftBank)
7位:iPhone 5s 16GB (au)
8位:iPhone 5c 16GB (au)
9位:iPhone 5s 16GB (NTT docomo)
10位:iPhone 5s 64GB (au)
http://pc.watch.impress.co.jp/img/pcw/docs/623/201/html/m.02.png.html
{kind=link}
1位:iPhone 5s 32GB (NTT docomo)
2位:iPhone 5c 16GB (SoftBank)
3位:iPhone 5s 64GB (SoftBank)
4位:iPhone 5s 32GB (SoftBank)
5位:iPhone 5s 32GB (au)
6位:iPhone 5s 16GB (SoftBank)
7位:iPhone 5s 16GB (au)
8位:iPhone 5c 16GB (au)
9位:iPhone 5s 16GB (NTT docomo)
10位:iPhone 5s 64GB (au)
どっかのライターがHSAのことを至宝だと言ってたが、
たぶん届かないけど理想は高く掲げる、
という意味で非常に的確な形容だとは思った
ああいうのを本当にそのまま真に受けると大変なことになる
ちょっと割り引かないと
たぶん届かないけど理想は高く掲げる、
という意味で非常に的確な形容だとは思った
ああいうのを本当にそのまま真に受けると大変なことになる
ちょっと割り引かないと
聖杯とでも言えばいいのか
あーそうそう聖杯
311 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 22:07:18.91 ID:tlodbvu9
既に公開されてるラッパーライブラリのBolt(笑)のやばさで気づけというレベル
まぁ、でてきていきなり画期的なアプリやソフトがでてくる訳もないし
過度な期待はしてないけど、継続的に成長できる環境が大切なわけだし。
どんどん進めてほしい事業だな
過度な期待はしてないけど、継続的に成長できる環境が大切なわけだし。
どんどん進めてほしい事業だな
313 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 22:15:32.91 ID:tlodbvu9
5年前の「SSE5をGPUでダイレクトに実行」よりは実現の可能性がまだあるだけ
マシなレベルでは
マシなレベルでは
HSAだってまだ未完成なんだし
気楽にいこうぜ
気楽にいこうぜ
315 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 22:20:14.37 ID:tlodbvu9
じゃあ完成品が出るまで不買でいいね
何よりもまずハードウェアとソフトウェアスタック一式を出せとしか言えない
317 :Socket774:2013/11/12(火) 22:30:46.55 ID:/8hYBRTG
A10-7850K すごい楽しみだ!
初代のA8-3850から載せ替えるから期待してる。
ASUSもはやくFM2+だしてくれよ!
初代のA8-3850から載せ替えるから期待してる。
ASUSもはやくFM2+だしてくれよ!
さっき知ったけど、R9 290Xって仮想メモリでメモリ管理してるんだな
なんでもhUMAやHSA対応のために搭載してるってさ
新ラデがPCIeだけでCF出来るようになったし、メモリ管理の改善でCFの効率が良くなってくれるといいな
多分Kaveri以降としか連携できなさそうだけど、MantleやTrue AUDIOと合わせてうまく囲い込んでいってるよねAMD
Mantleってメモリ管理にも踏み込めそうだし、そしたらHSA想定の仮想メモリの活用につながって、
Kaveriと組み合わせた時にフル活用とかになりそう
インテルと組合せた時にどう動くのかは知らない
なんでもhUMAやHSA対応のために搭載してるってさ
新ラデがPCIeだけでCF出来るようになったし、メモリ管理の改善でCFの効率が良くなってくれるといいな
多分Kaveri以降としか連携できなさそうだけど、MantleやTrue AUDIOと合わせてうまく囲い込んでいってるよねAMD
Mantleってメモリ管理にも踏み込めそうだし、そしたらHSA想定の仮想メモリの活用につながって、
Kaveriと組み合わせた時にフル活用とかになりそう
インテルと組合せた時にどう動くのかは知らない
319 :,,・´∀`・,,)っ-○○○:2013/11/12(火) 22:35:09.29 ID:tlodbvu9
むしろ仮想化まだやってなかったのか
http://www.itmedia.co.jp/pcuser/articles/1207/26/news043.html
http://www.itmedia.co.jp/pcuser/articles/1207/26/news043.html
A10-7850Kで思い出したけど
HD 7850の改良版が
13日に発表あるって話
GTX660を上回る性能で
HD 7850の改良版が
13日に発表あるって話
GTX660を上回る性能で
>>318 ちゃんとdGPUとの連携も考えてるってことかね
APUとdGPUがうまく連携できるなら面白そうだけど、具体的な話が分からないとなあ
APUとdGPUがうまく連携できるなら面白そうだけど、具体的な話が分からないとなあ
iPhoneのCPUもGPUもIP提供元がHSAに参加しているよね。
最近OBRちゃんのリークがないよなー。
そろそろESのKaveri入手できないんか?
そろそろESのKaveri入手できないんか?
>>321
7850って事はPS4ベースなのか
7850って事はPS4ベースなのか
>>324
普通に切られたんじゃないの
普通に切られたんじゃないの
DGについてなんか発表あった?
DGより、iGPUは物理演算等に、dGPUは画面表示にと
適した用途で両方活用出来たら面白いんだけどね。
適した用途で両方活用出来たら面白いんだけどね。
LibreOfficeのCalcでOpenCLのサポートだって
http://www.phoronix.com/scan.php?page=news_item&px=MTQ5OTA
ちなみにAMDは陣頭指揮を執ってる
つまり同等のMS EXCELでもGPGPUが有効そうだ
そのうちEXCELもGPGPU化しないかな
intelが邪魔か文句言うから無理か
ついでにOpenGLにも対応らしい
http://www.phoronix.com/scan.php?page=news_item&px=MTQ3OTU
世の中GPU活用に色々進んでいってるね
団子が否定していることばかりだ
http://www.phoronix.com/scan.php?page=news_item&px=MTQ5OTA
ちなみにAMDは陣頭指揮を執ってる
つまり同等のMS EXCELでもGPGPUが有効そうだ
そのうちEXCELもGPGPU化しないかな
intelが邪魔か文句言うから無理か
ついでにOpenGLにも対応らしい
http://www.phoronix.com/scan.php?page=news_item&px=MTQ3OTU
世の中GPU活用に色々進んでいってるね
団子が否定していることばかりだ
AMDが囲い込んでる物理エンジンなんかあったっけ
5870のCFでHavok使ってまともな速度で動かなかったろ
(あのときはIntelのせいにしてた奴も居たが)
5870のCFでHavok使ってまともな速度で動かなかったろ
(あのときはIntelのせいにしてた奴も居たが)
> intelが邪魔か文句言うから無理か
どんだけ陰謀論が渦巻いてるんだこのうすら馬鹿の脳内にはwww
どんだけ陰謀論が渦巻いてるんだこのうすら馬鹿の脳内にはwww
スラドあたりにまとめてトピック作ってくれませんかね
>>328
はいはい
http://www.4gamer.net/games/133/G013322/20130420010/
「だが,そもそもの話として,なぜ2基のGPUを併用しなければならないのか?」
氏によれば,FirePro W8000であれば,描画も演算も同時に行えるとのこと。
はいはい
http://www.4gamer.net/games/133/G013322/20130420010/
「だが,そもそもの話として,なぜ2基のGPUを併用しなければならないのか?」
氏によれば,FirePro W8000であれば,描画も演算も同時に行えるとのこと。
>>331
Bullet Physics
Bullet Physics
libreoffice 4.2で一部の関数でopencl入れるから
待ってろよゴラ。でも来年のことだから知らね
まで読んだ
待ってろよゴラ。でも来年のことだから知らね
まで読んだ
明日はHSA Foundationメンバー中心の講演か
ハイパーすごいアーキテクチャ
5870CFでHavokClothってハゲの人形3体をものすごいガクガクで表示させてたあれか
あれCPUのほうが速いとか笑うしかなかったなwww
つーか、いまどきのPCで物理演算をGPUでやる必要を見出せないな
これはHavokなどの物理エンジンを使わずIntel社員がフルスクラッチで書いたデモアプリ。
http://www.youtube.com/watch?v=NANx8vPYW2c
ここからサンプルをDLできる
http://software.intel.com/en-us/articles/soa-cloth-simulation-with-256-bit-intel-advanced-vector-extensions-intel-avx
AMDのオープンソースチームにはここまでのコード書けないだろうな
あれCPUのほうが速いとか笑うしかなかったなwww
つーか、いまどきのPCで物理演算をGPUでやる必要を見出せないな
これはHavokなどの物理エンジンを使わずIntel社員がフルスクラッチで書いたデモアプリ。
http://www.youtube.com/watch?v=NANx8vPYW2c
ここからサンプルをDLできる
http://software.intel.com/en-us/articles/soa-cloth-simulation-with-256-bit-intel-advanced-vector-extensions-intel-avx
AMDのオープンソースチームにはここまでのコード書けないだろうな
なんか懐かしいなその話題…
CPUとの距離が違うから尚の事ありえないんだよ
既にビデオカードを挿してるなら1枚も2枚も大して違わないけど
ビデオカードが0枚と1枚の間には大きな隔たりが存在する
そもそもの話として、ビデオカードを挿さなくて済むようにIGPを強化したんだし
既にビデオカードを挿してるなら1枚も2枚も大して違わないけど
ビデオカードが0枚と1枚の間には大きな隔たりが存在する
そもそもの話として、ビデオカードを挿さなくて済むようにIGPを強化したんだし
rubyちゃん最近どうよ
HSAだのhUMAだのhqだのでちょっとは可愛くなった?
HSAだのhUMAだのhqだのでちょっとは可愛くなった?
海外だと活用されるのはゲームなんだろうけど、
日本だとミクさんのスカートの物理演算とかなんだろうな。
日本だとミクさんのスカートの物理演算とかなんだろうな。
その話題知らんけど
データコピーが必要な従来のGPGPUの限界だろ
hUMAになればそういう制約はなくなって大域物理演算が可能になる
データコピーが必要な従来のGPGPUの限界だろ
hUMAになればそういう制約はなくなって大域物理演算が可能になる
3体が限界ってググっても全く出てこないんだけど
業務用VGAではAMDのFireProが圧倒的なシェアなのに、業務PCはだめってのがな
Nvはおかげで業務用VGAはスパーコンピューティングに活路を見出せざる得なかったし
>>342 ソフトが糞でラデではCF人形3体が限界だったんだろ
Nvはおかげで業務用VGAはスパーコンピューティングに活路を見出せざる得なかったし
>>342 ソフトが糞でラデではCF人形3体が限界だったんだろ
> メモリ空間をCPUとGPUで共有する「hUMA」
ひ、飛雄馬・・・
ひ、飛雄馬・・・
三体が限界だ!って主張してる人がいたのは覚えてる。
結論は知らない。
結論は知らない。
なぜ3体が限界なのか?それを検証した者はいない。
そっち系も割とオワコンに向かってるからそんなに需要ないんじゃないかねぇ
http://www.nicozon.net/watch/sm6968676
正確には3体表示できたのはCPU処理のときで、
GPU処理のときは1体だけしか表示させてない(しかも動きがガクガクになってフレームが飛んでる)
AMDが技術者を送り込んで協力関係のもと最適化してこのざまだったんだし
これがRadeonの限界だろ
正確には3体表示できたのはCPU処理のときで、
GPU処理のときは1体だけしか表示させてない(しかも動きがガクガクになってフレームが飛んでる)
AMDが技術者を送り込んで協力関係のもと最適化してこのざまだったんだし
これがRadeonの限界だろ
2009年のか
OpenCLの名前が出てきて1年も経ってない頃のだな
OpenCLの名前が出てきて1年も経ってない頃のだな
Intel傘下だしなHavok
シングルGPUで重いグラフィック処理と物理演算を同時に両立できるものなのか?
と昔から疑問に思ってる。
と昔から疑問に思ってる。
>>357
APUのiGPUなら余裕で出来るから、CPU性能たいしてイラネなんだよ
APUのiGPUなら余裕で出来るから、CPU性能たいしてイラネなんだよ
>>357
CPU処理が終わるまでGPUが動けなかったりして
GPUが遊んでる時間があったりなかったり。
とはいえ、PS4みたいなコンソールならハードウェア固定だから資源を100%使うように最適化しても割にあうけど、
PCでは労多くして益なしなので、やらない。
CPU処理が終わるまでGPUが動けなかったりして
GPUが遊んでる時間があったりなかったり。
とはいえ、PS4みたいなコンソールならハードウェア固定だから資源を100%使うように最適化しても割にあうけど、
PCでは労多くして益なしなので、やらない。
HavokはIntelが製品を採用してないコンシューマゲーム機やAndroidやiOSにも
エンジンを提供してるし親会社だからって口出しはしないでしょ。
IntelもTBBのプロプライエタリ版を360の開発者に無償で使えるようにライセンスしたり
他社プラットフォームへの技術供与はむしろ積極的に行ってる。
いずれにしてもAMDが無能なだけでしょ。
GPU版PhysXが専用ハード(PPU)以上の性能を発揮してた頃に
こんな醜態を晒してたという一例。
AMDがBulletで挽回したという話は寡聞にして聞かないが。
エンジンを提供してるし親会社だからって口出しはしないでしょ。
IntelもTBBのプロプライエタリ版を360の開発者に無償で使えるようにライセンスしたり
他社プラットフォームへの技術供与はむしろ積極的に行ってる。
いずれにしてもAMDが無能なだけでしょ。
GPU版PhysXが専用ハード(PPU)以上の性能を発揮してた頃に
こんな醜態を晒してたという一例。
AMDがBulletで挽回したという話は寡聞にして聞かないが。
女装した男なんて1体で十分だろ
http://www.youtube.com/watch?v=7MJr_8aldSE
聞かないのは耳塞いでるからだろ
http://www.youtube.com/watch?v=5gtPByI5wQY
ついでにPS4のHavok
聞かないのは耳塞いでるからだろ
http://www.youtube.com/watch?v=5gtPByI5wQY
ついでにPS4のHavok
> http://www.youtube.com/watch?v=7MJr_8aldSE
> 聞かないのは耳塞いでるからだろ
棒人間と積み木がどうかしたの?ドレス着たマネキンよりしょぼくなってるけど?
>http://www.youtube.com/watch?v=5gtPByI5wQY
> ついでにPS4のHavok
それCPU処理なのかGPU処理なのかどっち?
> 聞かないのは耳塞いでるからだろ
棒人間と積み木がどうかしたの?ドレス着たマネキンよりしょぼくなってるけど?
>http://www.youtube.com/watch?v=5gtPByI5wQY
> ついでにPS4のHavok
それCPU処理なのかGPU処理なのかどっち?
>棒人間と積み木がどうかしたの?
えっ?有名所のソフトで使えるようになってるんだけど
寡聞にして聞かない(キリッ ってアホ過ぎる発言だよね?
えっ?有名所のソフトで使えるようになってるんだけど
寡聞にして聞かない(キリッ ってアホ過ぎる発言だよね?
IntelがHavok買収してからもAMDとの開発契約を継続して数年がかりで
出してきた成果がこれ
PhysX買収から短期間でPPU版を越えてきたNVIDIAの開発力と比べてどうよ?
この体制じゃ他社より優位性を見せることは難しいんじゃないの。
ただでさえCPUの製造技術で2世代も差がついてるのに。
出してきた成果がこれ
PhysX買収から短期間でPPU版を越えてきたNVIDIAの開発力と比べてどうよ?
この体制じゃ他社より優位性を見せることは難しいんじゃないの。
ただでさえCPUの製造技術で2世代も差がついてるのに。
intel 22nm
AMD 28nm
AMD 28nm
371 :Socket774:2013/11/13(水) 00:57:42.69 ID:LnNc+/b4
>>365
GPGPU以外でこんなの出来るとでも思ってるのかよ
GPGPU以外でこんなの出来るとでも思ってるのかよ
>>357
Mantle対応なら高設定でもGPUに余裕できるから物理演算も出来るだろ
Mantle対応なら高設定でもGPUに余裕できるから物理演算も出来るだろ
つまりPS4でIntelも儲かる算段ってことか。
結局はHavokも懐の深いIntel資本に入ってよかったんじゃないの。
NVIDIAはPhysX GPUの囲い込みのためにわざとCPU処理をSIMD使わなかったり
Radeon刺さってると無効になるようにしたり、そういうことをやってPhysXを腐らせてしまった。
結局はHavokも懐の深いIntel資本に入ってよかったんじゃないの。
NVIDIAはPhysX GPUの囲い込みのためにわざとCPU処理をSIMD使わなかったり
Radeon刺さってると無効になるようにしたり、そういうことをやってPhysXを腐らせてしまった。
来年?出てもないのと比べてたの?
7750クラスが積んであるから
まともにDGできればdGPUがモデル1つ上ぐらいの性能になるのか?
まともにDGできればdGPUがモデル1つ上ぐらいの性能になるのか?
>>377
DGで78xxクラスになるんじゃない
DGで78xxクラスになるんじゃない
もう4コアから増えないんでしょうか
増やしても意味ないとかなんですかね
増やしても意味ないとかなんですかね
381 :Socket774:2013/11/13(水) 01:16:49.28 ID:LnNc+/b4
2010年 Llano(32nm)
2011年 Bulldozer(32nm)
2014年 Kaveri(28nm)
たかだかハーフノード分の刷新に4年かかるってGFが駄目すぎるのか
AMDの論理設計が腐ってるのかどっちだろうな
2011年 Bulldozer(32nm)
2014年 Kaveri(28nm)
たかだかハーフノード分の刷新に4年かかるってGFが駄目すぎるのか
AMDの論理設計が腐ってるのかどっちだろうな
>>382
GF駄目なのもあるのもあるけど、28nはもうTSMCに行っていて、
急ぎの顧客は駄目AMD程度だしでノンビリで良いやって感じじゃないか。
ただし、次プロセスからはTSMCからARM陣営を奪うために奮闘、でもAMDは後回し
GF駄目なのもあるのもあるけど、28nはもうTSMCに行っていて、
急ぎの顧客は駄目AMD程度だしでノンビリで良いやって感じじゃないか。
ただし、次プロセスからはTSMCからARM陣営を奪うために奮闘、でもAMDは後回し
そういう過去も含めて
どんなにわめいても
mantleで統一だろ
飯うまだな
どんなにわめいても
mantleで統一だろ
飯うまだな
intelがいくら微細化で先行してCPUを強化しても、
ラデやゲフォと組み合わせないと何も出来ないのは変わらないからな
ラデはHSA前提になるし、ゲフォも内蔵ARMとの連携に走るのは規定路線だし
GPUと高度な連携ができないintelはどうするんだろうな
もう一回ララビー作りなおすのかな
ラデやゲフォと組み合わせないと何も出来ないのは変わらないからな
ラデはHSA前提になるし、ゲフォも内蔵ARMとの連携に走るのは規定路線だし
GPUと高度な連携ができないintelはどうするんだろうな
もう一回ララビー作りなおすのかな
HaswellにCPU+GPU合計のFLOPS数でも勝ててない時点でKaveriの訴求力は弱い
SkyLakeはCPUだけで900GFLOPSいく
結局誰もAPU専用のソフトなんて書かない
周回遅れになった時点で価値が無い
さよなら
SkyLakeはCPUだけで900GFLOPSいく
結局誰もAPU専用のソフトなんて書かない
周回遅れになった時点で価値が無い
さよなら
GPU関係のパテントはNVとAMDに固められて厳しいでしょ
ハードに限らずソフトよりの部分もな
ララビーがGPU用途としてパフォーマンスが出なかった一因は
そこにもあるのは間違いない
IntelはNVを買うのが一番手っ取り早いと思う
ハードに限らずソフトよりの部分もな
ララビーがGPU用途としてパフォーマンスが出なかった一因は
そこにもあるのは間違いない
IntelはNVを買うのが一番手っ取り早いと思う
Skylekeの9世代目でたぶんEUがLalabeeを元にしたコアに置き換わるはず
それにしてもKaveriはA10-7850kはターボで4Ghzはいってほしかったな
それにしてもKaveriはA10-7850kはターボで4Ghzはいってほしかったな
Skylakeからは512ビット命令になるんだけな
Mantleって排他的な技術なの?
普及したとしてIntelやNVIDIAには恩恵なし?
CUDAでもMantleでもいいから排他的じゃない技術が普及して欲しい
普及したとしてIntelやNVIDIAには恩恵なし?
CUDAでもMantleでもいいから排他的じゃない技術が普及して欲しい
Skylekeの9世代目って何?
たぶんスペルミスだと思うけど9世代目の部分がよくわからない
たぶんスペルミスだと思うけど9世代目の部分がよくわからない
intelのGPUにまだ期待している奴がいるのか
そりゃ楽しみだろうな、毎年倍々で増えるからな
あれがドライバが糞な張子の虎だって知ってる大多数からすれば哀れでしか無い
>>391
>排他的じゃない技術が普及して欲しい
DirectXとOpenGLがあるじゃないか
そりゃ楽しみだろうな、毎年倍々で増えるからな
あれがドライバが糞な張子の虎だって知ってる大多数からすれば哀れでしか無い
>>391
>排他的じゃない技術が普及して欲しい
DirectXとOpenGLがあるじゃないか
デュアルコアが出始めた頃の
Cellの8コア!200GFLOPS!に比べるとAPUってインパクト弱いんだよな
今回のKaveriだって同じ4コアのCPU同士では依然負けたままだし
GPU単純加算しても理論FLOPS値で勝ててないという・・・
なんだかんだでGPUはGPUであること以上のキラーコンテンツはないと思う。
GPGPUでCPU性能をブーストするなんて同じCPUコア並べて
「ReverseHT」やる以上に困難な問題だ。
Cellの8コア!200GFLOPS!に比べるとAPUってインパクト弱いんだよな
今回のKaveriだって同じ4コアのCPU同士では依然負けたままだし
GPU単純加算しても理論FLOPS値で勝ててないという・・・
なんだかんだでGPUはGPUであること以上のキラーコンテンツはないと思う。
GPGPUでCPU性能をブーストするなんて同じCPUコア並べて
「ReverseHT」やる以上に困難な問題だ。
むしろ○○が出ればAMD大勝利!Intelもうオワタ
毎年こういってる奴のほうが哀れ
kaveriもどうせ爆死で残念でした
毎年こういってる奴のほうが哀れ
kaveriもどうせ爆死で残念でした
OpenCLでは
Haswell/GT3e>>同GT3>同GT2>Kaveri
くらいじゃないの
汎用演算ではDirectXのドライバ関係ないからな
どうやってもGPUは理論値あたりの実効性能比がCPUに比べて大幅に低下するから
同じ800GFLOPS強ならCPU側が強いHaswellのほうが速いだろう
Haswell/GT3e>>同GT3>同GT2>Kaveri
くらいじゃないの
汎用演算ではDirectXのドライバ関係ないからな
どうやってもGPUは理論値あたりの実効性能比がCPUに比べて大幅に低下するから
同じ800GFLOPS強ならCPU側が強いHaswellのほうが速いだろう
PS4はMantle非対応ですが。
HSAにNVIDIA参加!Mantleもサポートします!
AMDもCUDAサポートします!みたいな斜め上の展開ないかな
AMDもCUDAサポートします!みたいな斜め上の展開ないかな
アーキテクチャ越えて使えたら
それは低レベルAPIじゃないからね。
それは低レベルAPIじゃないからね。
うんだからアーキテクチャをある部分まで統一してほしいなと
ただの妄想、願望、おとぎ話だけど
ただの妄想、願望、おとぎ話だけど
一応今のCUDAはオープンだが
CUDAの言語処理系の仕様にに手を入れて他のプロセッサでも
使えるようにしようということは試みられてるわけで、
それがOpenCLだったりするわけで
CUDAそのものをサポートしたがるチップは出てきようがない
CUDAの言語処理系の仕様にに手を入れて他のプロセッサでも
使えるようにしようということは試みられてるわけで、
それがOpenCLだったりするわけで
CUDAそのものをサポートしたがるチップは出てきようがない
つまりPS4とMantleはAPI互換
ppp
> AMD Mantle Not Meant for Xbox One and PlayStation 4
http://www.tomshardware.com/news/amd-mantle-api-xbox-one-directx-11.2,24691.html
ppp
> AMD Mantle Not Meant for Xbox One and PlayStation 4
http://www.tomshardware.com/news/amd-mantle-api-xbox-one-directx-11.2,24691.html
>>392
今までの例から順当に推測すれば、Skylakeで採用されるIntel HD/Irisは
第9世代のものになるっていう話のことでしょ
もっとも、Broadwellの第8世代すらよく分かっていない状況で
そういう話をするのはちょっと早いと思うけど
今までの例から順当に推測すれば、Skylakeで採用されるIntel HD/Irisは
第9世代のものになるっていう話のことでしょ
もっとも、Broadwellの第8世代すらよく分かっていない状況で
そういう話をするのはちょっと早いと思うけど
そりゃハードウェアと一対一だろうから大きく違うものにはなりようがないけれども。
>>400
NVIDIAとintelに言ってくれ
絶対無理だけどな
>>402
PS4と箱1とRADEONで統一してるだろ
intelとNVIDIAがGCNのライセンス受けるなら考えなくもないだろうけど
絶対ありえない
NVIDIAとintelに言ってくれ
絶対無理だけどな
>>402
PS4と箱1とRADEONで統一してるだろ
intelとNVIDIAがGCNのライセンス受けるなら考えなくもないだろうけど
絶対ありえない
>>403
じゃあもうOpenCLでいいかもね
じゃあもうOpenCLでいいかもね
>>406
GPUが9世代目ってことかありがとう
GPUが9世代目ってことかありがとう
PS4、Xboxoneがamdになった時点で
もう排他的もなにもないと
ゲーム作る側は、Pc含めて
どのプラットフォームも同じなのを見越して
修正あまり要らないのを最初から作るだろうね
もう排他的もなにもないと
ゲーム作る側は、Pc含めて
どのプラットフォームも同じなのを見越して
修正あまり要らないのを最初から作るだろうね
>>405
こういう馬鹿がインテルやゲフォを買うんだな
日本語訳の一文
Xbox Oneのハードウェアは、Direct3D 11.2の機能のスーパーセットを提供しています
このようなOpenGLとAMDのマントルなどの他のグラフィックスAPIは、Xbox Oneでは使用できません。
箱1はDirectxしか使わせてない、OpenGLですらダメだとさ
同社はまた、マントルを使用する利点の一つは、次世代ゲーム機からPC、および新しいレンダリング技術を最適化作業を活用されることが示された。
したがって、すべてのGPUの機能に直接アクセスでき、開発者は、GCNベースのGPUでコンソールとゲームのリグでより高いグラフィックス性能のロックを解除できます。
こういう馬鹿がインテルやゲフォを買うんだな
日本語訳の一文
Xbox Oneのハードウェアは、Direct3D 11.2の機能のスーパーセットを提供しています
このようなOpenGLとAMDのマントルなどの他のグラフィックスAPIは、Xbox Oneでは使用できません。
箱1はDirectxしか使わせてない、OpenGLですらダメだとさ
同社はまた、マントルを使用する利点の一つは、次世代ゲーム機からPC、および新しいレンダリング技術を最適化作業を活用されることが示された。
したがって、すべてのGPUの機能に直接アクセスでき、開発者は、GCNベースのGPUでコンソールとゲームのリグでより高いグラフィックス性能のロックを解除できます。
>>411
短期的に見たらAMD選んどけば間違いないってことなんだろうけど
長い目で見たら競争が起きたほうがいいよね
でも競争した結果、排他的な規格が乱立してたら結局メリット無い
それが嫌だなあと思いました
短期的に見たらAMD選んどけば間違いないってことなんだろうけど
長い目で見たら競争が起きたほうがいいよね
でも競争した結果、排他的な規格が乱立してたら結局メリット無い
それが嫌だなあと思いました
とりあえずあと
3日後にPS4
10日後にXbox One
3日後にPS4
10日後にXbox One
低消費電力では競争力ないかも。
EAはmantleがスマホで使えるようになると
思ってるよな
これって、HSAがらみなきも
思ってるよな
これって、HSAがらみなきも
ローレベルAPIが受け入れられる土壌が出来たら
NVも参戦するってだけじゃね
類似するインタフェースにしないと見向きもされないだろうけど
NVも参戦するってだけじゃね
類似するインタフェースにしないと見向きもされないだろうけど
ソフト売上でいえは普通にCS機(AMD)に最適化するだろう
GTAとかその辺が露骨だけど
GTAとかその辺が露骨だけど
CS機のローレベルAPIをPCで実現するのがMantelなんじゃねぇの?
そりゃCS機にはないだろうよ
そりゃCS機にはないだろうよ
>>409
問題はCUDA/OpenCLのコードの書き方が特殊すぎて
従来のCやFORTRANの記法に慣れてる人になかなか広がらないこと
IntelのOpenMP拡張とかNVIDIAらが推進してるOpenACCは
CやFORTRANのコードをちょっと書き足すだけで異種混合の
並列化コードが書けるようにするもの。
実効性能は専用に書いたコードよりやや落ちるが
少ない記述で簡単にCUDAやPhiのリソースにアクセスすることができる。
まずここでNVIDIA,IntelとAMDのやり方の違いが出てる。
そしてヘテロの抱えるパフォーマンス問題の解決策も異なってる。
Xeon Phiの個々のユニット自体が自立動作する汎用のCPUコアで
ホスト側があれこれ指示しなくてもコプロ側のプロセスだけで
独立して動作できる自由度がある。
NVIDIAも同様に、段階的に自立動作の機能を高めていってる。
プログラムの独立性を高めれば必然的にホストとの間の通信も必要性が減る。
だからHSAのようなアプローチが最初から不要。
AMDとIntel,NVIDIAにはこういう立場の違いがあるから
「AMDに従わないなんてけしからん!」なんてことを言っても
堂々巡りにしかならないわけで。
問題はCUDA/OpenCLのコードの書き方が特殊すぎて
従来のCやFORTRANの記法に慣れてる人になかなか広がらないこと
IntelのOpenMP拡張とかNVIDIAらが推進してるOpenACCは
CやFORTRANのコードをちょっと書き足すだけで異種混合の
並列化コードが書けるようにするもの。
実効性能は専用に書いたコードよりやや落ちるが
少ない記述で簡単にCUDAやPhiのリソースにアクセスすることができる。
まずここでNVIDIA,IntelとAMDのやり方の違いが出てる。
そしてヘテロの抱えるパフォーマンス問題の解決策も異なってる。
Xeon Phiの個々のユニット自体が自立動作する汎用のCPUコアで
ホスト側があれこれ指示しなくてもコプロ側のプロセスだけで
独立して動作できる自由度がある。
NVIDIAも同様に、段階的に自立動作の機能を高めていってる。
プログラムの独立性を高めれば必然的にホストとの間の通信も必要性が減る。
だからHSAのようなアプローチが最初から不要。
AMDとIntel,NVIDIAにはこういう立場の違いがあるから
「AMDに従わないなんてけしからん!」なんてことを言っても
堂々巡りにしかならないわけで。
アーキが近いというよりもそのものでしょ
同じGCNなんだから
APIも全く同じはないだろうけど
AMDが情報出さん限りPS4独自のAPIも作りようがない
同じGCNなんだから
APIも全く同じはないだろうけど
AMDが情報出さん限りPS4独自のAPIも作りようがない
AMDはGPU側の構造を大きく変えたくないから
別の切り口での効率化の方法を模索してるわけ。
hUMAやhQはたしかにGPGPUのオーバーヘッドを軽減する技術だけど
それはあくまで内蔵GPUに限った話で
ディスクリートのRadeonはどうするのか?という戦略的矛盾をはらんでる。
シェア8割以上を握るIntelのユーザーが使えてこそRadeonは
PCゲームのデベロッパーに支持されてるわけで、AMD専用GPUに
成り下がったらとたんに袋小路だからね。
別の切り口での効率化の方法を模索してるわけ。
hUMAやhQはたしかにGPGPUのオーバーヘッドを軽減する技術だけど
それはあくまで内蔵GPUに限った話で
ディスクリートのRadeonはどうするのか?という戦略的矛盾をはらんでる。
シェア8割以上を握るIntelのユーザーが使えてこそRadeonは
PCゲームのデベロッパーに支持されてるわけで、AMD専用GPUに
成り下がったらとたんに袋小路だからね。
>>415
ARM勢はHSAに対応したGPUを開発しているから別にいらんだろ
後はHSA市場の中で競争して良いのが残っていくだけ
>>419
>MantleはPCオンリー、コンソール機にはないと言い切ってんのに。
よくわかってるじゃないかw
コンソール機にはない、絶対無い、ありえないし馬鹿げてる
PS4のゲームをPCに移植するためのAPIだからな
ARM勢はHSAに対応したGPUを開発しているから別にいらんだろ
後はHSA市場の中で競争して良いのが残っていくだけ
>>419
>MantleはPCオンリー、コンソール機にはないと言い切ってんのに。
よくわかってるじゃないかw
コンソール機にはない、絶対無い、ありえないし馬鹿げてる
PS4のゲームをPCに移植するためのAPIだからな
>>427
> ディスクリートのRadeonはどうするのか?という戦略的矛盾をはらんでる。
仮想メモリに対応してるから、メインメモリとグラフィックメモリを統一的に扱えるようになってる
>AMD専用GPUに成り下がったらとたんに袋小路だからね。
intelでも使える、単にHSA向けの機能が使えないだけ
> ディスクリートのRadeonはどうするのか?という戦略的矛盾をはらんでる。
仮想メモリに対応してるから、メインメモリとグラフィックメモリを統一的に扱えるようになってる
>AMD専用GPUに成り下がったらとたんに袋小路だからね。
intelでも使える、単にHSA向けの機能が使えないだけ
>>426
> MantleはGCN以外では動きませんじゃ困るわけで
誰が困るの?EAは困ってないし、対応表明してるいくつかのゲームエンジン作ってるとこも困ってないよ
intelとNVIDIAならどうでもいい
> MantleはGCN以外では動きませんじゃ困るわけで
誰が困るの?EAは困ってないし、対応表明してるいくつかのゲームエンジン作ってるとこも困ってないよ
intelとNVIDIAならどうでもいい
Oracle joins the HSA Foundation
Broadcom
Canonical Limited
Electronics and Telecommunications Research Institute (ETRI)
Huawei
Industrial Technology Res. Institute
Kishonti
Lawrence Livermore National Laboratory
Linaro
Oak Ridge National Laboratory
Oracle
Synopsys
TEI of Crete
UChicago Argonne, LLC, operator of Argonne National Laboratory
VIA Technologies
がHSA陣営か
VIAに目が行くw
Canonical Limited
Electronics and Telecommunications Research Institute (ETRI)
Huawei
Industrial Technology Res. Institute
Kishonti
Lawrence Livermore National Laboratory
Linaro
Oak Ridge National Laboratory
Oracle
Synopsys
TEI of Crete
UChicago Argonne, LLC, operator of Argonne National Laboratory
VIA Technologies
がHSA陣営か
VIAに目が行くw
>>413
XboxOneは低レベル層を触らせるのを嫌がってるとどこかで読んだ。
将来のハードでたとえばGeForceを選んだ場合、下位互換性をとるのが難しくなる
というのもあるのではないかな?
MSとしては戦略の自由度を失うことは避けたいだろう。
それでなくとも中長期的にGCNのアーキテクチャがずっと続く保障はどこにもない。
CUDAはある程度の抽象度を保ってるので初期の8800GTX向けに書いたコードが
アーキの変わったKeplerでもそのまま動くというコードの互換性が保たれてる。
低レベルマンセーも考え物だね。
XboxOneは低レベル層を触らせるのを嫌がってるとどこかで読んだ。
将来のハードでたとえばGeForceを選んだ場合、下位互換性をとるのが難しくなる
というのもあるのではないかな?
MSとしては戦略の自由度を失うことは避けたいだろう。
それでなくとも中長期的にGCNのアーキテクチャがずっと続く保障はどこにもない。
CUDAはある程度の抽象度を保ってるので初期の8800GTX向けに書いたコードが
アーキの変わったKeplerでもそのまま動くというコードの互換性が保たれてる。
低レベルマンセーも考え物だね。
>>435
HD4000シリーズを出したときにはAMDは「ビッグダイの時代は終わった」と言ってたよ
CUDAに対抗するためのBrook+/CALなどのGPGPU開発ツールを整備しつつあったし
アーキは変更しないものだと思ったら次の世代ではあっさり切り捨ててきた。
つまり、そんな発言は根拠にならない。
HD4000シリーズを出したときにはAMDは「ビッグダイの時代は終わった」と言ってたよ
CUDAに対抗するためのBrook+/CALなどのGPGPU開発ツールを整備しつつあったし
アーキは変更しないものだと思ったら次の世代ではあっさり切り捨ててきた。
つまり、そんな発言は根拠にならない。
Mantleと互換性についてDICEがいうには
ゲームエンジンにMantleを組み込んだ形なので
他のグラボのDirectX準拠のものも問題ない
とのことだが
逆に言えばエンジンの形じゃないとMantle使うの難しいよな
ゲームエンジンにMantleを組み込んだ形なので
他のグラボのDirectX準拠のものも問題ない
とのことだが
逆に言えばエンジンの形じゃないとMantle使うの難しいよな
20nm16nmと立て続けにくるからPSやXBOXはすぐ性能遅れになるよ
思い込みが根拠ってあんた・・・
将来を見据えたフレキシブルなアーキテクチャでGeForce8から一貫して
同じ言語処理系の互換性を貫いてきたCUDAのブレのなさを
コロコロアーキも開発言語も切り捨ててきたAMD Streamに対しても
期待するのは間違ってるとしか
将来を見据えたフレキシブルなアーキテクチャでGeForce8から一貫して
同じ言語処理系の互換性を貫いてきたCUDAのブレのなさを
コロコロアーキも開発言語も切り捨ててきたAMD Streamに対しても
期待するのは間違ってるとしか
>>438
まずロードマップ通りすんなりプロセス微細化できるか
できたところで今までのように
トランジスタの集積度を高めて
飛躍的に性能アップ可能なのか、はおいといて
それでも記録的な売上のGTA5のようにハイクォリティにできるPC無視して
時代遅れのCS機のみに敢えて開発を絞るビッグタイトルもある
結局ビッグタイトルはどれだけ儲かるかだな
まずロードマップ通りすんなりプロセス微細化できるか
できたところで今までのように
トランジスタの集積度を高めて
飛躍的に性能アップ可能なのか、はおいといて
それでも記録的な売上のGTA5のようにハイクォリティにできるPC無視して
時代遅れのCS機のみに敢えて開発を絞るビッグタイトルもある
結局ビッグタイトルはどれだけ儲かるかだな
少なくとも今回はARM勢を取り込めるだけの抽象化はしているわけで、
それは今後のAMD製GPUの進化への対応にも通じるんでない?
それは今後のAMD製GPUの進化への対応にも通じるんでない?
同じにしか見えない
CUDAアーキテクチャはプログラミングインターフェースの互換を
保ったままマイクロアーキテクチャを変化させることができたし
これからも続ける
GCNはFermiの側だけ真似たデッドコピーだが骨組みとなる概念がない
そして採用した言語・ライブラリをずっと保守するという信念が無い
せめてBrook+を保守してみろよ
CUDAアーキテクチャはプログラミングインターフェースの互換を
保ったままマイクロアーキテクチャを変化させることができたし
これからも続ける
GCNはFermiの側だけ真似たデッドコピーだが骨組みとなる概念がない
そして採用した言語・ライブラリをずっと保守するという信念が無い
せめてBrook+を保守してみろよ
PS4と凶箱1のハードウェアが類似したものになったといってもOSは違う訳で当然APIも違う。
ただしGPUが同じならグラフィックAPIも類似するはずなので一枚被せると共通ソースで両対応のゲームが作れる。
ここでPCにもMantleという似たAPIがあるならついでにそれにも対応しとくか。
で目出度くゲームコンソール用アプリがGCN専用アプリとして出回る。これでAPUで勝つる。
果たしてそうかな。
1.CPU性能はゲームコンソールに合わせて設定される。すなわちAPUでは性能不足すぎて動作対象外になってしまう。極論すれば動作対象は一部のCore i7/i5とOpteron/FXのみとなってしまう。
2.GCNとゲフォのGPUの機能はそんなに違わない。どうせシェーダ言語もPS4と凶箱1で違うのを共通化するレイヤー(マクロにすれば実行時のペナルティは無い)を噛ませるならついでにゲフォにも対応させることができるし、その方が販路が広がっていい。
PC版はCPUやメモリ容量に余裕があるので変換レイヤーを被せてGPUメーカー不問で作られるのではないか。
3.MSは凶箱とWindowsの移植性を重視しておりMantleなどなくても次期DirectXで凶箱1用アプリをPCに移植できるようになる。となるとMantleなど誰も使わないのではないか。
ただしGPUが同じならグラフィックAPIも類似するはずなので一枚被せると共通ソースで両対応のゲームが作れる。
ここでPCにもMantleという似たAPIがあるならついでにそれにも対応しとくか。
で目出度くゲームコンソール用アプリがGCN専用アプリとして出回る。これでAPUで勝つる。
果たしてそうかな。
1.CPU性能はゲームコンソールに合わせて設定される。すなわちAPUでは性能不足すぎて動作対象外になってしまう。極論すれば動作対象は一部のCore i7/i5とOpteron/FXのみとなってしまう。
2.GCNとゲフォのGPUの機能はそんなに違わない。どうせシェーダ言語もPS4と凶箱1で違うのを共通化するレイヤー(マクロにすれば実行時のペナルティは無い)を噛ませるならついでにゲフォにも対応させることができるし、その方が販路が広がっていい。
PC版はCPUやメモリ容量に余裕があるので変換レイヤーを被せてGPUメーカー不問で作られるのではないか。
3.MSは凶箱とWindowsの移植性を重視しておりMantleなどなくても次期DirectXで凶箱1用アプリをPCに移植できるようになる。となるとMantleなど誰も使わないのではないか。
448 :Socket774:2013/11/13(水) 04:54:36.63 ID:bskRf7Oi
PCの買い換えサイクルは長期化の傾向 - IDC Japan調査
IDC Japanは12日、国内家庭市場におけるPC/タブレット/スマートフォン所有者の利用実態調査の結果を発表した。
これによるとPCの買い換え期間は現在の4.5年から今後は4.8年と長期化の傾向を示している。
タブレット所有/非所有でPCの買い換え期間を調査
調査結果をユーザー別に見ると、PCの買い換え期間について
現在すでにタブレットを所有しているユーザーでは4.2年から4.6年に、
一方タブレットを所有してないユーザーでは5.1年から5.2年へと、
いずれのユーザーも買い換え期間が長期化する傾向が示された。
http://news.mynavi.jp/news/2013/11/12/323/index.html
IDC Japanは12日、国内家庭市場におけるPC/タブレット/スマートフォン所有者の利用実態調査の結果を発表した。
これによるとPCの買い換え期間は現在の4.5年から今後は4.8年と長期化の傾向を示している。
タブレット所有/非所有でPCの買い換え期間を調査
調査結果をユーザー別に見ると、PCの買い換え期間について
現在すでにタブレットを所有しているユーザーでは4.2年から4.6年に、
一方タブレットを所有してないユーザーでは5.1年から5.2年へと、
いずれのユーザーも買い換え期間が長期化する傾向が示された。
http://news.mynavi.jp/news/2013/11/12/323/index.html
1に関してはMantle関係なくね
>>446
なんでコテハンつけたりはずしたりするの?
なんでコテハンつけたりはずしたりするの?
つーか別にGCNはMantleじゃなきゃ戦えないってもんでもないし
Mantleを使わない理由をいくら考えたて意味ないけどな、現に使ってるんだから
採用するとこが増えることはあっても減ることはないよ、一度組み込んだら外す意味は無いから
採用するとこが増えることはあっても減ることはないよ、一度組み込んだら外す意味は無いから
CUDAより低レベルなAPIなんてあるか?ねーよ
まずそもそもDirectXがあるのに
Mantleなんて大それたものが出ることになった背景を知らんと
AMDの副社長Roy Taylorが「DX12が出ることはないだろう」
と明言しているように、DirectXの旗振り役がMSから抜けて
開発がほぼ止まっているのは公然の事実
メジャーバージョンアップの気配はない
http://news.mynavi.jp/articles/2013/10/02/amd/001.html
Mantleなんて大それたものが出ることになった背景を知らんと
AMDの副社長Roy Taylorが「DX12が出ることはないだろう」
と明言しているように、DirectXの旗振り役がMSから抜けて
開発がほぼ止まっているのは公然の事実
メジャーバージョンアップの気配はない
http://news.mynavi.jp/articles/2013/10/02/amd/001.html
次期DirectXでMantleと同じようなこと出来るようにするならAMDもそれに従っただろうけどね
AMDの行動を考えるとそんなものはないと考えるのが正解かな
AMDの行動を考えるとそんなものはないと考えるのが正解かな
Tress FX 2.0 to take on Grass and Fur
With all of Amd's innovations lately, they are really making a strong case that they ARE the the gaming company.
Originally Tress FX 1.0 was able to give Miss Croft a more realistic appearance by allowing 1000s of hair strands at once in Tomb Raider.
Tress FX 2.0 will take that technology to a new level by rendering two of the most difficult textures, grass and fur.
Already Tress Fx 2.0 has support as EIDOS montreal has announced support for this, as well as every other technology
Amd seems to come up with including Mantle and True Audio in their upcoming title Thief.
These will be very good times for gaming indeed.
TressFXが髪の毛だけから草と毛皮までに拡張、早速Thiefで採用
wccftech.com/tress-fx-20-coming-revolutionize-grass-fur-visuals-hair/
With all of Amd's innovations lately, they are really making a strong case that they ARE the the gaming company.
Originally Tress FX 1.0 was able to give Miss Croft a more realistic appearance by allowing 1000s of hair strands at once in Tomb Raider.
Tress FX 2.0 will take that technology to a new level by rendering two of the most difficult textures, grass and fur.
Already Tress Fx 2.0 has support as EIDOS montreal has announced support for this, as well as every other technology
Amd seems to come up with including Mantle and True Audio in their upcoming title Thief.
These will be very good times for gaming indeed.
TressFXが髪の毛だけから草と毛皮までに拡張、早速Thiefで採用
wccftech.com/tress-fx-20-coming-revolutionize-grass-fur-visuals-hair/
>>334
ハードウェア的にできても、それがソフトウェア・開発環境的にできないとダメじゃん
ハードウェア的にできても、それがソフトウェア・開発環境的にできないとダメじゃん
ねずみっくすがさらにモコモコになるのか
Oracleの基調演説でSumatraのデモやってたけど
全文検索?みたいなのでCPU処理で44秒かかってたのがGPU処理で9秒になってたな
全文検索?みたいなのでCPU処理で44秒かかってたのがGPU処理で9秒になってたな
>>448
買い替えが長期化してるのは
パソコンが壊れにくくなったから
パソコンが安定してるから
パソコンの性能に満足してるから
パソコンの利用頻度が低下し他に使うから
様々あるわけだが
例にあるように5.2年前なら
2008年春モデル
Windows Vista、CPUはCore 2 QuadQ6600 2.4GHz、メモリー2GB、Geforce8800GTX
Phenom x4 9600 2.4GHz、Radeon HD2900XT
この辺りだろ。その人らが性能なるべく落とさずに消費電力下げたいと考えたら
もしくは、当時のハイスペックに手が出せないミドルスペックを持ってる人からしたら
アイドル時の消費電力が150Wでピーク時が300Wの世界
Kaveriならアイドル時30Wでピーク時が100Wの世界
買い替えが長期化してるのは
パソコンが壊れにくくなったから
パソコンが安定してるから
パソコンの性能に満足してるから
パソコンの利用頻度が低下し他に使うから
様々あるわけだが
例にあるように5.2年前なら
2008年春モデル
Windows Vista、CPUはCore 2 QuadQ6600 2.4GHz、メモリー2GB、Geforce8800GTX
Phenom x4 9600 2.4GHz、Radeon HD2900XT
この辺りだろ。その人らが性能なるべく落とさずに消費電力下げたいと考えたら
もしくは、当時のハイスペックに手が出せないミドルスペックを持ってる人からしたら
アイドル時の消費電力が150Wでピーク時が300Wの世界
Kaveriならアイドル時30Wでピーク時が100Wの世界
AMDが次期APU「Kaveri」の概要を発表
http://pc.watch.impress.co.jp/docs/column/kaigai/20131113_623198.html
http://pc.watch.impress.co.jp/docs/column/kaigai/20131113_623198.html
目標の1TFlopsに届かなかったのは残念だね
ただ、1TFlopsに届いたところでメモリ帯域どうしようにもないのでそこまで上げる必要性もないのだけど
ただ、1TFlopsに届いたところでメモリ帯域どうしようにもないのでそこまで上げる必要性もないのだけど
1Tであったとしても、実感としてどのくらいになるかは別だしな。
>>365
jaguarみたいな非力なCPUでできるんだ?w
jaguarみたいな非力なCPUでできるんだ?w
Jaguarは非力ってことになってるようだけど、PS4やXbox OneはJaguar8コア。
合計102Gflops
Kaveriは 3.7Ghz * 4コア x 8=118Gflops
両者は実際は大差ないんだよ。
合計102Gflops
Kaveriは 3.7Ghz * 4コア x 8=118Gflops
両者は実際は大差ないんだよ。
>>465
Bonaireコアならクロック1Ghzくらいまでいけると思うんですけどね
720Mhzまで下げたのはTDPとの兼ね合いか、GFがへぼいかのどちらかだろうな
無理に定格で1TFlops狙わないでTDP優先したのなら評価できる
Bonaireコアならクロック1Ghzくらいまでいけると思うんですけどね
720Mhzまで下げたのはTDPとの兼ね合いか、GFがへぼいかのどちらかだろうな
無理に定格で1TFlops狙わないでTDP優先したのなら評価できる
TDPと言うよりメモリー帯域のが先だろ
Richlandでさえキツキツなのに
FM2+と言えど
Richlandでさえキツキツなのに
FM2+と言えど
確かに単純に1TFlops以上のAPUなら
今月時点で数百万単位で出荷されてるからな(PS4とXbox oneで)
今月時点で数百万単位で出荷されてるからな(PS4とXbox oneで)
やっぱりCPUを自動?で作らせたのは間違いだったな
ようやくPhenom級まで戻ってきたか?
ようやくPhenom級まで戻ってきたか?
>>470
通常のGPUとしての用途でも、hUMAでメモリ帯域の節約が出来るんでないの?
通常のGPUとしての用途でも、hUMAでメモリ帯域の節約が出来るんでないの?
想定してたプランはGDDR5M採用
それがキャンセルされた影響だよ
それがキャンセルされた影響だよ
>>475
あれは元からBerlin用だよ
あれは元からBerlin用だよ
HP’s Moonshot now supports AMD’s Opteron X-Series APUs
http://semiaccurate.com/2013/11/12/hps-moonshot-now-supports-amd-opteron-x-series-apus/
http://semiaccurate.com/2013/11/12/hps-moonshot-now-supports-amd-opteron-x-series-apus/
GPU部分が10%未満の実質FX2的なCPU作ってくれ
半分もゴミGPUに持ってかれるのは勘弁
半分もゴミGPUに持ってかれるのは勘弁
482 :Socket774:2013/11/13(水) 08:22:11.09 ID:bskRf7Oi
AppleがGlobal Foundriesに製造委託
http://www.macrumors.com/2013/11/11/apple-to-begin-a-series-chip-production-at-globalfoundries-facility-in-new-york/
http://www.macrumors.com/2013/11/11/apple-to-begin-a-series-chip-production-at-globalfoundries-facility-in-new-york/
スレチ
https://twitter.com/AMDHSA/status/400383080587730945
公式TwiterではなぜかGFlopsと打ち間違いしてるが
来年投入というPirate Islands世代では演算性能が20-30TFlopsになるとか
スッゲーナ
公式TwiterではなぜかGFlopsと打ち間違いしてるが
来年投入というPirate Islands世代では演算性能が20-30TFlopsになるとか
スッゲーナ
エロサイト開きまくるんだけど、何がおすすめですか?
今はavastです。
セキュリティソフト安いなら、買いたかったな。。
今はavastです。
セキュリティソフト安いなら、買いたかったな。。
>>468
JaguarはFMAではないのでFADD+FMULでの合算値。
Jaguar向けに書いたコードをKaveriでそのまま動かしても
ピーク59GFLOPSしか出ない。
それでなくとも加算と乗算の命令が常に融合できるわけではないので
同じ理論値なら平均ではKaveriのほうが下回ることになる。
JaguarはFMAではないのでFADD+FMULでの合算値。
Jaguar向けに書いたコードをKaveriでそのまま動かしても
ピーク59GFLOPSしか出ない。
それでなくとも加算と乗算の命令が常に融合できるわけではないので
同じ理論値なら平均ではKaveriのほうが下回ることになる。
今日の何時にR9 270発表よ?
>>489
現地時間じゃないの?
現地時間じゃないの?
> フロントエンドはK7時代と同レベル
バックエンドの間違いだろ
バックエンドの間違いだろ
デコーダ3基×2になったけど32byteを2スレッドでシェアしてるのは変わらないし
ALUはBulldozerから据え置きの2ALU+2AGU。
未だL1D 16KってPrescottかと。Smithfieldかと。
シンプルALUとAGUの機能を併せ持つ「AGLU」なんてものが
最適化マニュアルに記述されてたが未だそんなものが実装された形跡なし。
CPU側には期待するなよ。
ALUはBulldozerから据え置きの2ALU+2AGU。
未だL1D 16KってPrescottかと。Smithfieldかと。
シンプルALUとAGUの機能を併せ持つ「AGLU」なんてものが
最適化マニュアルに記述されてたが未だそんなものが実装された形跡なし。
CPU側には期待するなよ。
493 :Socket774:2013/11/13(水) 11:17:43.55 ID:LnNc+/b4
>>462
DirectXは全然ローレベルじゃないぞ。
DirectXは全然ローレベルじゃないぞ。
>>493
ローレベル拡張するんだよ。でないとただでさえPS4にハードウェアスペックで劣るのにどうすんのよ。Mantleの中から特に性能に効果のあるものを選んで皮被せるだけでいい。
ローレベル拡張するんだよ。でないとただでさえPS4にハードウェアスペックで劣るのにどうすんのよ。Mantleの中から特に性能に効果のあるものを選んで皮被せるだけでいい。
>>496
理解してないくせによく泣けるな
理解してないくせによく泣けるな
FXとマスクを共用しているOpteron 3300番台(Piledriver 8コア)が
同クロック帯で投入されたAtom C2750(Avoton 8コア)に性能で
追いつかれたのは何故なのか思考実験してみた。
実はSilvermont世代のAtomでもフェッチ・デコードは8バイト/clkで
最大2命令デコードでしかなく、かなり貧弱。
Bulldozerの32byteで4命令でフェッチ・デコードだから命令供給には
見た目上ネックは無いように思える。
1コアあたりの演算ユニットもAtomよりむしろリッチだ。
ではデータ供給は?
PiledriverはL2・L3の容量は大きい(2MB×4および8MB)
Avotonは1コア毎に512KBのL2キャッシュがあるのみ(×8コア)
じゃあ劣る部分は?
・L1Dが小さい&Way数少ない
・L2が遅い(レイテンシが大きい)上に2コア分をクロスバーで共有
→L1でフェッチ・リタイヤ連発されると詰まる可能性がある?
L1Dのサイズ・Way数の改善とL2の高速化が今後のパフォーマンス
改善の鍵になると見た。
同クロック帯で投入されたAtom C2750(Avoton 8コア)に性能で
追いつかれたのは何故なのか思考実験してみた。
実はSilvermont世代のAtomでもフェッチ・デコードは8バイト/clkで
最大2命令デコードでしかなく、かなり貧弱。
Bulldozerの32byteで4命令でフェッチ・デコードだから命令供給には
見た目上ネックは無いように思える。
1コアあたりの演算ユニットもAtomよりむしろリッチだ。
ではデータ供給は?
PiledriverはL2・L3の容量は大きい(2MB×4および8MB)
Avotonは1コア毎に512KBのL2キャッシュがあるのみ(×8コア)
じゃあ劣る部分は?
・L1Dが小さい&Way数少ない
・L2が遅い(レイテンシが大きい)上に2コア分をクロスバーで共有
→L1でフェッチ・リタイヤ連発されると詰まる可能性がある?
L1Dのサイズ・Way数の改善とL2の高速化が今後のパフォーマンス
改善の鍵になると見た。
五年くらい前のAMDは過渡期とかいってる場合じゃなかったが
いまは「うん!自分のペースで頑張ろう!やればできる!ファイト!」って感じだな。
いまは「うん!自分のペースで頑張ろう!やればできる!ファイト!」って感じだな。
>>481
ブルの同時命令発行数はHaswellより多いんだけど
ブルの同時命令発行数はHaswellより多いんだけど
>>498
http://www.servethehome.com/wp-content/uploads/2013/10/Intel-Atom-C2750-UnixBench-crafty-chess-benchmark.jpg
http://www.servethehome.com/wp-content/uploads/2013/10/Intel-Atom-C2750-pts-stream-7-zip-openssl-pybench-benchmarks.jpg
これで追いつかれてるっていうのか?
http://www.servethehome.com/wp-content/uploads/2013/10/Intel-Atom-C2750-UnixBench-crafty-chess-benchmark.jpg
{kind=link}
http://www.servethehome.com/wp-content/uploads/2013/10/Intel-Atom-C2750-pts-stream-7-zip-openssl-pybench-benchmarks.jpg
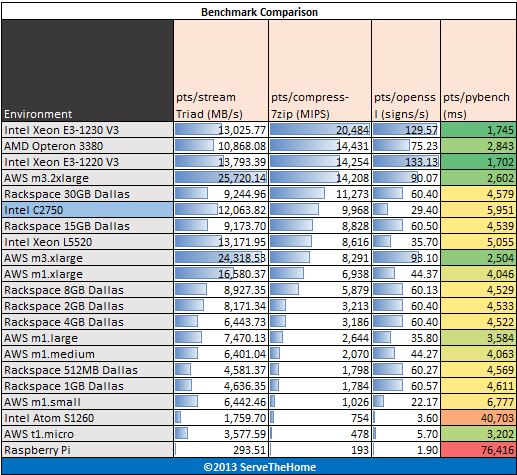{kind=link}
これで追いつかれてるっていうのか?
Battlefield 4 Running on AMD A10 Kaveri APU and Image Decoder HSA Acceleration
http://www.youtube.com/watch?v=O07YOk4nLyo
http://www.youtube.com/watch?v=O07YOk4nLyo
FXの後継はロードマップから消滅した状態になってるから
1Bulldozerモジュール(2コア)で1コアに勝てばいい、という論理は
既に通用しないんだけどな。
局面は既に、4コア(2モジュール)対4コア(4〜8スレッド)
ちなみにALUの数ならHaswellでALU4基に拡張されてるから
Sandy/Ivyのときに「2コアで合計2ALUだからSandyの3ALUより速い!」
というのも既に通用してない。
全ALU使うような最適化をするようなチューンが求められるシーンでは
ではそれこそスカラを使うのではなくSSE/AVX整数の並列演算に置き換えるだろ
そうするとFP/SIMD共有構造はむしろ仇になる。
1Bulldozerモジュール(2コア)で1コアに勝てばいい、という論理は
既に通用しないんだけどな。
局面は既に、4コア(2モジュール)対4コア(4〜8スレッド)
ちなみにALUの数ならHaswellでALU4基に拡張されてるから
Sandy/Ivyのときに「2コアで合計2ALUだからSandyの3ALUより速い!」
というのも既に通用してない。
全ALU使うような最適化をするようなチューンが求められるシーンでは
ではそれこそスカラを使うのではなくSSE/AVX整数の並列演算に置き換えるだろ
そうするとFP/SIMD共有構造はむしろ仇になる。
AMDのプロセッサの仮想敵は既にCore i3/Pentium/Celeron (+ dGPU)になりました
AMD開発部に修三さんを送り込まないと。
1月はよ
510 :Socket774:2013/11/13(水) 13:38:10.79 ID:igN7Ktva
今日は淫厨がいつもより必死だな
どんだけ追いつめられたんだインテルは
所詮グラフィックがウンコだから先がないのは仕方ない
どんだけ追いつめられたんだインテルは
所詮グラフィックがウンコだから先がないのは仕方ない
>>506
"CrossFire Unleashed" 開放されたクロスファイア
"Asymmetric configuration" 非対称な構成
http://www.hardware.fr/medias/photos_news/00/43/IMG0043438_1.jpg
APUとdGPUの性能が非対称な構成連でもCFが発動すると書いてある
よな?
"CrossFire Unleashed" 開放されたクロスファイア
"Asymmetric configuration" 非対称な構成
http://www.hardware.fr/medias/photos_news/00/43/IMG0043438_1.jpg
{kind=link}
APUとdGPUの性能が非対称な構成連でもCFが発動すると書いてある
よな?
>>485
これまじなの?
これまじなの?
516 :Socket774:2013/11/13(水) 13:53:26.62 ID:h27l2eiI
>>513
おお、これでAPUよりもっと高性能なGPU挿しても無駄にはならないんだな!
おお、これでAPUよりもっと高性能なGPU挿しても無駄にはならないんだな!
481 名前:Socket774[sage] 投稿日:2013/11/13(水) 13:47:15.50 ID:iIxbYI9E
AFRの先へゆうてるな
micro-stutteringがなくなるならCFしてやってもよいぞw
482 名前:Socket774[sage] 投稿日:2013/11/13(水) 13:53:51.09 ID:AVoH1yI0 [2/2]
>>480
Mantle噛ませば今までのDG,CFの様な決まった組合せじゃなく、どんな組み合わせでもDG,CFが可能なのか。
その際のAFRモードはきっちりと一枚置きの交互レンダリング以外にも
リンクGPUの性能に合わせ複数枚置きの交互レンダリングにも対応できると。
MantleAPIが各GPUの状態を考慮しつつ命令の割り振りをするといった感じか
片方にはGPGPUだけに専念してもいいと書いてあるね
AFRの先へゆうてるな
micro-stutteringがなくなるならCFしてやってもよいぞw
482 名前:Socket774[sage] 投稿日:2013/11/13(水) 13:53:51.09 ID:AVoH1yI0 [2/2]
>>480
Mantle噛ませば今までのDG,CFの様な決まった組合せじゃなく、どんな組み合わせでもDG,CFが可能なのか。
その際のAFRモードはきっちりと一枚置きの交互レンダリング以外にも
リンクGPUの性能に合わせ複数枚置きの交互レンダリングにも対応できると。
MantleAPIが各GPUの状態を考慮しつつ命令の割り振りをするといった感じか
片方にはGPGPUだけに専念してもいいと書いてあるね
AFRはきついな
タイル分割ででないの
タイル分割ででないの
519 :Socket774:2013/11/13(水) 14:04:28.32 ID:lOGYpsqJ
AMD、1,280SPの「Radeon R9 270」
米AMDは13日(現地時間)、デスクトップ用GPU「Radeon R9 270」を発表した。
米国での実売価格は179ドル。
主な仕様は、SP数が1,280基、コアクロックが925MHzで、256bit接続5.6GHz駆動のGDDR5を2GB搭載する。
演算性能は2.37TFLOPS。ボード消費電力は150Wで、電源コネクタは6ピン。
DirectX 11.2、OpenGL 4.3のほか、同社独自のゲーム用API「Mantle」に対応する。
GeForce GTX 660との性能比較
http://pc.watch.impress.co.jp/img/pcw/docs/623/355/02.jpg
http://pc.watch.impress.co.jp/docs/news/20131113_623355.html
米AMDは13日(現地時間)、デスクトップ用GPU「Radeon R9 270」を発表した。
米国での実売価格は179ドル。
主な仕様は、SP数が1,280基、コアクロックが925MHzで、256bit接続5.6GHz駆動のGDDR5を2GB搭載する。
演算性能は2.37TFLOPS。ボード消費電力は150Wで、電源コネクタは6ピン。
DirectX 11.2、OpenGL 4.3のほか、同社独自のゲーム用API「Mantle」に対応する。
GeForce GTX 660との性能比較
http://pc.watch.impress.co.jp/img/pcw/docs/623/355/02.jpg
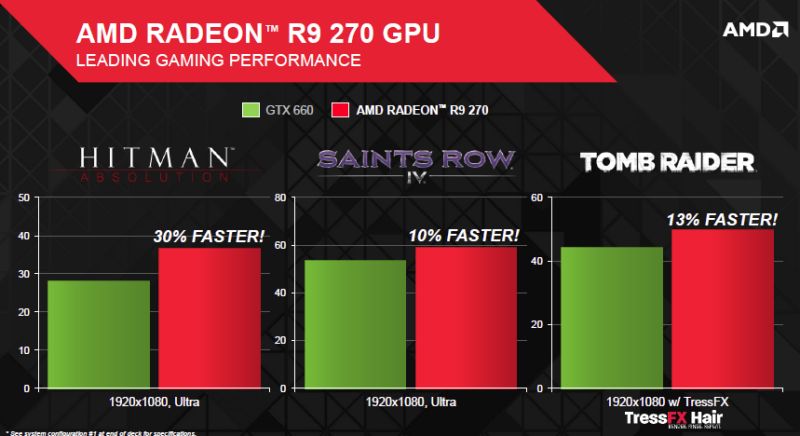{kind=link}
http://pc.watch.impress.co.jp/docs/news/20131113_623355.html
BF4のミドルセッテイングが1080Pで普通に動くのか
これで6800k/tくらいの値段ならアホなブランド好き長いものに巻かれろ的
日本人以外にはかなり売れるだろうな
これで6800k/tくらいの値段ならアホなブランド好き長いものに巻かれろ的
日本人以外にはかなり売れるだろうな
>>521
しかもMantle使わずにな
しかもMantle使わずにな
「Pirate Islands TFlops」で英語系のニュース検索してもでてこない
打ち間違いじゃなくて普通にGFlopsなのでは
打ち間違いじゃなくて普通にGFlopsなのでは
AMD APU13レポート - AMD、"Kaveri"ことA10-7850Kの概略を発表
http://news.mynavi.jp/articles/2013/11/13/apu02/
http://news.mynavi.jp/articles/2013/11/13/apu02/
FX後継は作らなくても、
APUでも、GPU部分の性能軽視で、CPU部分の性能重視してコア数増やしたVerをちゃんと作ってほしい
APUでも、GPU部分の性能軽視で、CPU部分の性能重視してコア数増やしたVerをちゃんと作ってほしい
>>433
VIAたん?(^ω^)?
VIAたん?(^ω^)?
かなり売れるだろうな
だってさ
だってさ
529 :Socket774:2013/11/13(水) 14:48:57.27 ID:LnNc+/b4
>>494
ますますAMDの思う壺w
ますますAMDの思う壺w
投資家の反応は冷ややかだな。
コンシューマ向けGPUなんて所詮既存の縮小市場のパイの奪い合いで
しかないから大きな期待もされてない。
10月中旬以降株価は下落傾向
http://seekingalpha.com/article/1815202-is-amds-newfound-strength-in-graphics-and-servers-enough-to-offset-pc-misfortunes
3300シリーズの路線を辞めてKaveri流用のBerlinで置き換えるから
同じマスクのFXは出せない。
当然従来8コアサーバ使ってたところにL3なしの4コアとGPUを
渡されたところで使い物になるわけがないから
既存市場を捨てて内蔵GPUが生かせる用途に特化するわけだが
どれだけニーズがあるのかは未知数だな。
当たれば競合の追従を許さないアドバンテージになるだろうが
当たらなければ・・・
コンシューマ向けGPUなんて所詮既存の縮小市場のパイの奪い合いで
しかないから大きな期待もされてない。
10月中旬以降株価は下落傾向
http://seekingalpha.com/article/1815202-is-amds-newfound-strength-in-graphics-and-servers-enough-to-offset-pc-misfortunes
3300シリーズの路線を辞めてKaveri流用のBerlinで置き換えるから
同じマスクのFXは出せない。
当然従来8コアサーバ使ってたところにL3なしの4コアとGPUを
渡されたところで使い物になるわけがないから
既存市場を捨てて内蔵GPUが生かせる用途に特化するわけだが
どれだけニーズがあるのかは未知数だな。
当たれば競合の追従を許さないアドバンテージになるだろうが
当たらなければ・・・
来年の今頃にはCarrizo(20nm)が出荷開始な予定だから
それまで様子見なんだろ
それまで様子見なんだろ
532 :Socket774:2013/11/13(水) 15:43:12.20 ID:LnNc+/b4
>>530
当期純利益だけを指針にしてる奴も多いって事だろ。
当期純利益だけを指針にしてる奴も多いって事だろ。
AMDのプロセッサは発売までが全盛期
534 :Socket774:2013/11/13(水) 16:02:49.02 ID:6+/acxE8
金持ち相手の商売ができなきゃどんどん先細る
社訓 「悪かろう安かろう」
もともと、安いのが売りなんだから
もともと、安いのが売りなんだから
あんまりCeleronの悪口言うなよ
>>534
その辺はAMDとNVIDIAで露骨に出てるよな
AMD Q3 4800万
NVIDIA Q3 1億1870万
とか売上自体はAMDの方が1.5倍近いんだけど、どうにも不安定であまり儲からない
NVIDIAの方は何だかんだで今年も売上40億純利4億は行きそうで堅調
その辺はAMDとNVIDIAで露骨に出てるよな
AMD Q3 4800万
NVIDIA Q3 1億1870万
とか売上自体はAMDの方が1.5倍近いんだけど、どうにも不安定であまり儲からない
NVIDIAの方は何だかんだで今年も売上40億純利4億は行きそうで堅調
業務向けに強いか否かで違うのね
高く売れるからな(´・ω・`)
高く売れるからな(´・ω・`)
539 :Socket774:2013/11/13(水) 16:22:49.24 ID:6+/acxE8
Intelはダイハツからレクサスまでやってるトヨタみたいに幅広くやればええねん
「これからは軽トラックの時代だ」!といって普通乗用車から撤退しかけてるのがAMD
「これからは軽トラックの時代だ」!といって普通乗用車から撤退しかけてるのがAMD
軽トラはダイハツがいいらしいな
>>537
業界の囲い込みの為に数年かけてやっているんだから今の時点でそれだけあれば十分じゃね?
Amazonと同じ手法だろ。
利益は全部投資に廻して完全な囲い込みが完成してからゆっくり旨味は吸い取れば良いという経営判断。
後最低5年はこの流れで行くつもりじゃないか?
そして5年後のnVIDIAとの立ち位置次第でその後の舵をきる腹積もり。
業界の囲い込みの為に数年かけてやっているんだから今の時点でそれだけあれば十分じゃね?
Amazonと同じ手法だろ。
利益は全部投資に廻して完全な囲い込みが完成してからゆっくり旨味は吸い取れば良いという経営判断。
後最低5年はこの流れで行くつもりじゃないか?
そして5年後のnVIDIAとの立ち位置次第でその後の舵をきる腹積もり。
今駄目なのは、HASが使えると利用者がどうなるかって事を、
全く示せてないことだな。
動くサンプルは当然あるんだろ?ゲーム以外に
HAS使った何かを示せば良いのに、それが出来ない。
ま、万が一それをやって、HSAの効果がばれると、
それはそれで困る事になるのかもしれんが。
x264にHSA対応でもして、5割速くなりましたって言えれば、良い宣伝になるのに。
HSAってそんくらいすごいんだろ?
全く示せてないことだな。
動くサンプルは当然あるんだろ?ゲーム以外に
HAS使った何かを示せば良いのに、それが出来ない。
ま、万が一それをやって、HSAの効果がばれると、
それはそれで困る事になるのかもしれんが。
x264にHSA対応でもして、5割速くなりましたって言えれば、良い宣伝になるのに。
HSAってそんくらいすごいんだろ?
従来のCPU+GPUではコピーがオーバーヘッドで性能が出ないなりにも
「動く」というものがあって、それがどれだけ速くなったを示すことができれば
HSAのアプローチは成功なのだけど。
需要が無いところに架空のニーズを作り出して問題を解決しました
といっても乗ってくる人は少ない。
dGPUだろうがiGPUだろうがGPGPU活用に本当に一番必要なのはより広い
メモリ帯域であって、hQだのhUMAだの実は優先順位はそれほど高くない。
奇しくもGPGPU活用に一番乗り気じゃなかったIntelがもっとも理想に近い
ヘテロジニアスコンピューティングアーキテクチャをIris Proで実現してるのは
皮肉なところ。
「動く」というものがあって、それがどれだけ速くなったを示すことができれば
HSAのアプローチは成功なのだけど。
需要が無いところに架空のニーズを作り出して問題を解決しました
といっても乗ってくる人は少ない。
dGPUだろうがiGPUだろうがGPGPU活用に本当に一番必要なのはより広い
メモリ帯域であって、hQだのhUMAだの実は優先順位はそれほど高くない。
奇しくもGPGPU活用に一番乗り気じゃなかったIntelがもっとも理想に近い
ヘテロジニアスコンピューティングアーキテクチャをIris Proで実現してるのは
皮肉なところ。
>>544
その時にはルネサスのH.265ハードウェアエンコ搭載製品が出てるんじゃないか。
めちゃくちゃ重い代わりにかなり高画質らしいからプロファイル決め打ちでも
高速に処理できるのはメリットがある。
その時にはルネサスのH.265ハードウェアエンコ搭載製品が出てるんじゃないか。
めちゃくちゃ重い代わりにかなり高画質らしいからプロファイル決め打ちでも
高速に処理できるのはメリットがある。
R270はメモリ帯域がライバルより広いのが効いてるのかな?
nvidiaは一部のハイエンド以外メモリ帯域けちりすぎな気がするよ
nvidiaは一部のハイエンド以外メモリ帯域けちりすぎな気がするよ
AMD派はスバルやマツダのオタクがおおそうだね
>>546
Iris Proのどのあたりがヘテロジニアスなの?
Iris Proのどのあたりがヘテロジニアスなの?
ヘタレの間違いだろ
>>550
逆に、お前の認識するヘテロジニアスの定義を3行で説明してみて
逆に、お前の認識するヘテロジニアスの定義を3行で説明してみて
なにこの命令口調
何様なんだろうね
何様なんだろうね
270とKaveriかって非対称CF組んでMantleで貧乏BF4環境ってのも楽しそうだな
・CPU+GPUで最大1.2TFLOPS(単精度)の演算能力
・128MBの広帯域eDRAMによりCPU-GPU間のデータを高速かつ大量にやり取りできる
・並列化が利かない処理もCore i7による高いシングルスレッド性能でカバー
全部Kaveriには無い要素
・128MBの広帯域eDRAMによりCPU-GPU間のデータを高速かつ大量にやり取りできる
・並列化が利かない処理もCore i7による高いシングルスレッド性能でカバー
全部Kaveriには無い要素
hUMAよりもメモリ帯域の方が重要だ!とか何が言いたいのかわからん
GPUとCPUのやり取りってLLCでできるんじゃなかったっけ
>>557
そもそもhUMA相当のことはHaswell/GT2で既にできてる
そもそもhUMA相当のことはHaswell/GT2で既にできてる
Irisすごいね〜hUMAすごいね〜はどうでもいいよ
intelにしろAMDにしろiGPUばっかでCPU疎かになってるんだから
dGPU積む層にとっても解りやすい利点示せって話
それがない限りどっちもゴミなんだよ
intelにしろAMDにしろiGPUばっかでCPU疎かになってるんだから
dGPU積む層にとっても解りやすい利点示せって話
それがない限りどっちもゴミなんだよ
Irisは置くとして、2.5Dが現実的になってきた時にhUMAはどうなるのだろう
という疑問は無きにしもあらず。
という疑問は無きにしもあらず。
>>560
Iris proに限定したのはお前だろ?w
その前提ならIris proだけには限定されないどころかsandy以降全部じゃん
Iris proだけに限定したのはなにか特別な意味があるのかって問いなんだけど
Iris proに限定したのはお前だろ?w
その前提ならIris proだけには限定されないどころかsandy以降全部じゃん
Iris proだけに限定したのはなにか特別な意味があるのかって問いなんだけど
> ID:j9NNjT6D
1.2TFLOPSなんていうふうにGPUの理論値を盛る前に
早く端折りの無いグラフィックドライバ作ってね
1.2TFLOPSなんていうふうにGPUの理論値を盛る前に
早く端折りの無いグラフィックドライバ作ってね
まぁ言わなくてもIris proに限定しとかないと
後から突っ込まれた時に勝ちの構図が作り出せないから前もって限定したのはわかってるけどさ
後から突っ込まれた時に勝ちの構図が作り出せないから前もって限定したのはわかってるけどさ
>>556
>並列化が利かない処理もCore i7による高いシングルスレッド性能でカバー
カバー出来てるか?
Battlefield 4 1,920×1,080 Medium
Core i7-4770K+GeForce GT 630 : 10〜15fps程度
Kaveri A10 APU : 25〜30fps前後
>並列化が利かない処理もCore i7による高いシングルスレッド性能でカバー
カバー出来てるか?
Battlefield 4 1,920×1,080 Medium
Core i7-4770K+GeForce GT 630 : 10〜15fps程度
Kaveri A10 APU : 25〜30fps前後
AMDのいらぬハッタリに釘を刺すためなんだからGT3コアがGPGPUとして
活用できなくても別に誰も困らないんだよ。
CPUコアの性能では圧倒しているし、eDRAMはCPU側からもL4キャッシュとして
使えて数値計算に活用できる。
>>566
それのどこが並列化のきかない処理なの?
活用できなくても別に誰も困らないんだよ。
CPUコアの性能では圧倒しているし、eDRAMはCPU側からもL4キャッシュとして
使えて数値計算に活用できる。
>>566
それのどこが並列化のきかない処理なの?
>>566
ワザワザfermi版630使って頭打ちにしてるだけじゃないんですか
ワザワザfermi版630使って頭打ちにしてるだけじゃないんですか
mantleじゃないGPUになんの意味があるのか
GPGPUのためだけにiGPUを入れるとか
好きにすればだよ
GPGPUのためだけにiGPUを入れるとか
好きにすればだよ
>>559
hUMA相当の機能が使えるライブラリはよ
hUMA相当の機能が使えるライブラリはよ
GPUで同程度の能力をもつnvidiaのコメント苦しいと言うのに
intelはお花畑か
良いもんだな
intelはお花畑か
良いもんだな
IntelHDだと描写端折られまくりでショボいしな
わざわざVRAM2GB以上必要と書いてるのにIGPでやりたがる池沼はいないよ
dGPUを使ってはいけない頭の病気の人なの?
ちなみにSandy Bridgeの内蔵グラフィックはOpenCL SDKには非対応。
dGPUを使ってはいけない頭の病気の人なの?
ちなみにSandy Bridgeの内蔵グラフィックはOpenCL SDKには非対応。
576 :Socket774:2013/11/13(水) 18:09:44.70 ID:pKCy16iR
LuxMark2.0
http://images.anandtech.com/graphs/graph7503/59858.png
Sony Vegas Pro 12 Video Render
http://images.anandtech.com/graphs/graph7503/59859.png
CLBenchmark 1.1fluid simulation
http://images.anandtech.com/graphs/graph7503/59860.png
CLBenchmark 1.1 computer vision
http://images.anandtech.com/graphs/graph7503/59861.png
Folding @ Home
http://images.anandtech.com/graphs/graph7503/59862.png
DirectCompute is the compute backend for C++ AMP on Windows, so this forms our other DirectCompute test.
http://images.anandtech.com/graphs/graph7503/59864.png
GPGPU関連のベンチいくつか拾ったけど
http://images.anandtech.com/graphs/graph7503/59858.png
{kind=link}
Sony Vegas Pro 12 Video Render
http://images.anandtech.com/graphs/graph7503/59859.png
{kind=link}
CLBenchmark 1.1fluid simulation
http://images.anandtech.com/graphs/graph7503/59860.png
{kind=link}
CLBenchmark 1.1 computer vision
http://images.anandtech.com/graphs/graph7503/59861.png
{kind=link}
Folding @ Home
http://images.anandtech.com/graphs/graph7503/59862.png
{kind=link}
DirectCompute is the compute backend for C++ AMP on Windows, so this forms our other DirectCompute test.
http://images.anandtech.com/graphs/graph7503/59864.png
{kind=link}
GPGPU関連のベンチいくつか拾ったけど
>>567
ああ、悪い、一番最後の行だけコピペした。
上にiGPUやeDRAMのこと書いてるからさ、
んで最後に「並列化が利かない処理も」と書いてたら、
並列処理が高速だ。並列化が利かない処理「も」高速だと理解したのよ。
それが、dGPUのそれもローエンドの力借りてこのざまということが言いたかったのよ。
それともこれはCore i7-4770K単体のが性能良かったんだろうか?
ああ、悪い、一番最後の行だけコピペした。
上にiGPUやeDRAMのこと書いてるからさ、
んで最後に「並列化が利かない処理も」と書いてたら、
並列処理が高速だ。並列化が利かない処理「も」高速だと理解したのよ。
それが、dGPUのそれもローエンドの力借りてこのざまということが言いたかったのよ。
それともこれはCore i7-4770K単体のが性能良かったんだろうか?
575 :Socket774:2013/11/13(水) 18:08:11.94 ID:j9NNjT6D
わざわざVRAM2GB以上必要と書いてるのにIGPでやりたがる池沼はいないよ
dGPUを使ってはいけない頭の病気の人なの?
わざわざVRAM2GB以上必要と書いてるのにIGPでやりたがる池沼はいないよ
dGPUを使ってはいけない頭の病気の人なの?
自信があるならGTX 650 Ti当り使えばよかったと思うよw
Haswellじゃなくて前世代のものだが、Core i7-3770kとA10-5800kの
CPU+GPGPU性能の比較が載ってる
http://semiaccurate.com/2013/04/29/a-look-at-intels-opencl-performance/
Kaveriは理論性能の時点でHaswell+GT2にも勝ててないだろ
CPU+GPGPU性能の比較が載ってる
http://semiaccurate.com/2013/04/29/a-look-at-intels-opencl-performance/
Kaveriは理論性能の時点でHaswell+GT2にも勝ててないだろ
582 :Socket774:2013/11/13(水) 18:18:26.99 ID:dxGK0faG
IrisってhUMAなの?
>>582
違うよ、キャッシュ共有しただけの前世代的な構造
違うよ、キャッシュ共有しただけの前世代的な構造
>>580
ダブルスコアじゃないとカッコ悪いっしょ
ダブルスコアじゃないとカッコ悪いっしょ
未だにIntel IGPは最大1696MBじゃなかったっけ?
APUは専用に割り当てられたメモリの他に
DirectX専用とはいえ専用のVRAMの他に
仮想記憶的な共有システムメモリを透過的に使えるので
全体のVRAM総容量は2GBを超える
APUは専用に割り当てられたメモリの他に
DirectX専用とはいえ専用のVRAMの他に
仮想記憶的な共有システムメモリを透過的に使えるので
全体のVRAM総容量は2GBを超える
まず足下を見てみろ
ほぼ確定の未来で
1年後はmantle動かないGPU=ゲーム動かないGPUだぞ
今でさえnvidiaのGPUの評価がガッツリ落ちてるのに
ゲームに利用しないGPUはどこいくの?
ほぼ確定の未来で
1年後はmantle動かないGPU=ゲーム動かないGPUだぞ
今でさえnvidiaのGPUの評価がガッツリ落ちてるのに
ゲームに利用しないGPUはどこいくの?
クロック低めの512SPでDDR3じゃUMAのオーバヘッドを考えると
GT640DDR3相当の性能が出れば奇跡だろうな
GT640DDR3相当の性能が出れば奇跡だろうな
セミアキュにはKaveriが出たときに改めて>>581同じベンチで比較して欲しいな
AMDが心血を注いだHSAが全く意味をなさなかったことが白日の下に晒されるだろう
AMDが心血を注いだHSAが全く意味をなさなかったことが白日の下に晒されるだろう
DDR3-2400とかが使えるならGT640越えも出来るだろうけどコストパフォーマンスを考えると非現実的だろうし
市場に出回っているメモリの大半はIntelに合わせてDDR3-1600という現実
市場に出回っているメモリの大半はIntelに合わせてDDR3-1600という現実
ぷあまんずAPU
Mantle非対応のGPUはもはや旧時代の遺物にすぎんだろうな
お前らこんな弱小企業に振り回されすぎだろ・・・
>>594の詳細
http://software.intel.com/en-us/blogs/2013/06/03/tiling-format-for-intel-iris-graphics-extension-for-instant-access
http://software.intel.com/en-us/blogs/2013/06/03/tiling-format-for-intel-iris-graphics-extension-for-instant-access
>>594
それ一方通行でインタラクティブじゃないって事?
それ一方通行でインタラクティブじゃないって事?
>>595
OpenCLランタイムが?なにを寝ぼけたことを
OpenCLランタイムが?なにを寝ぼけたことを
Intel iGPUは既にhUMAと同等の機能を持っているんだよね?
それでこの差なのか・・・
それでこの差なのか・・・
偉そうにくっちゃべってんならお前らがAMD超えるintelのカウンターつくればいいんじゃね
気持ち悪いわカスどもが
気持ち悪いわカスどもが
>>563
L4キャッシュを共有してるからでしょ
L4キャッシュを共有してるからでしょ
一切コピー不要といったら語弊はあるかな
GPU側メモリから取ってきたデータを参照するときに(v)movntdqaで
64byteずつとってきてCPU側のメモリ空間(L1上)にコピーしてから使うし。
hUMAではGPUに割り当てられてる領域をCPUから参照したとき
Write-Combine扱いにはなったりしないの?
CPUとGPU間のキャッシュの調停はMESIプロトコル互換?
誰か教えて欲しいな
GPU側メモリから取ってきたデータを参照するときに(v)movntdqaで
64byteずつとってきてCPU側のメモリ空間(L1上)にコピーしてから使うし。
hUMAではGPUに割り当てられてる領域をCPUから参照したとき
Write-Combine扱いにはなったりしないの?
CPUとGPU間のキャッシュの調停はMESIプロトコル互換?
誰か教えて欲しいな
それはintelのランタイム次第じゃないの
kaveriにtrueaudio載ってるから290にこだわらなくてもいいな
kaveriは最近のゲームに使えそうな性能ないじゃん
二人乗れるから彼女を乗せてデートにも行けるしな(棒
しかし軽自動車=ARMの牙城を崩すことも出来ないという
>>613
そんなギリギリ「動かせてる」のレベルで満足なの?
CPU性能高めのマシンにしておけば60fps以上出せて
もっと重たいゲーム出てもグラボ買い替えで済むのに。
そもそも推奨動作環境はCPUは6コア以上(AMDの場合)だし
おかねないひとかわいそう。
そんなギリギリ「動かせてる」のレベルで満足なの?
CPU性能高めのマシンにしておけば60fps以上出せて
もっと重たいゲーム出てもグラボ買い替えで済むのに。
そもそも推奨動作環境はCPUは6コア以上(AMDの場合)だし
おかねないひとかわいそう。
仏作ってTemash入れず。
×Kabini耳あり障子に目あり。
○Kaveri耳あり障子に目あり。
×Kabini耳あり障子に目あり。
○Kaveri耳あり障子に目あり。
宗教上グラボ使えないんだろw
>そもそも推奨動作環境はCPUは6コア以上(AMDの場合)だし
これってあくまで現行FXのことなんだからkaveriならOC込でギリいけるんじゃね?
>そもそも推奨動作環境はCPUは6コア以上(AMDの場合)だし
これってあくまで現行FXのことなんだからkaveriならOC込でギリいけるんじゃね?
CPU性能的にきつんじゃないの?
最近のゲームはPS4やXBOXOneのマルチ前提で作られてるから
実行できるスレッド数が少ないと話にならないと思う
特にAVX命令だとFPUが1/4で
動作クロックを配慮すると1/2だし
次世代機の半分程度の性能しか出ないだろ
最近のゲームはPS4やXBOXOneのマルチ前提で作られてるから
実行できるスレッド数が少ないと話にならないと思う
特にAVX命令だとFPUが1/4で
動作クロックを配慮すると1/2だし
次世代機の半分程度の性能しか出ないだろ
>>618
それを言ったらintelもキツイ気がするけど……なんちゃって8スレッドだしさ
kaveriのOC耐性が気になるな、殻割りしないとhaswellは4.2前後が常用域だし
4,5くらいまで引っ張れれば結構いい線いくと思うんだけどどうだろう?
それを言ったらintelもキツイ気がするけど……なんちゃって8スレッドだしさ
kaveriのOC耐性が気になるな、殻割りしないとhaswellは4.2前後が常用域だし
4,5くらいまで引っ張れれば結構いい線いくと思うんだけどどうだろう?
621 :Socket774:2013/11/13(水) 19:39:32.12 ID:dnpYGcVu
>>615
そもそもターゲットゾーンが違うだろ?
そもそもターゲットゾーンが違うだろ?
ライトな人なら安価なKaveriで試してゲームによって性能に満足できなければ
GCNグラボ足せばCF駆動するから無駄になりません
これはIntelもNVも不可能
GCNグラボ足せばCF駆動するから無駄になりません
これはIntelもNVも不可能
>>619
クロックも倍あるから問題ないのでは?
そもそも実機からPCに移植するんじゃなくて、PCで作ったプロトタイプを
そのまま流用して出すだけでしょ。
もちろんそのプロトタイプを作るマシンもRadeonが使われる可能性が高いけどね。
CPUプラットフォームとしてPCIe3.0が使えて8スレッド以上動かせるマシンとなると
Intelしか選択肢がなくなる。
クロックも倍あるから問題ないのでは?
そもそも実機からPCに移植するんじゃなくて、PCで作ったプロトタイプを
そのまま流用して出すだけでしょ。
もちろんそのプロトタイプを作るマシンもRadeonが使われる可能性が高いけどね。
CPUプラットフォームとしてPCIe3.0が使えて8スレッド以上動かせるマシンとなると
Intelしか選択肢がなくなる。
kaveriはdGPU組み合わせないと最近のゲームはまともに楽しめないってことか
AMD,Kaveriに向けてGPUコンピューティング用の統合SDKを刷新
http://www.4gamer.net/games/147/G014731/20131113015/
http://www.4gamer.net/games/147/G014731/20131113015/
グラボ挿したらそれこそCPUの低性能が足引っ張るだけだろ
http://techreport.com/review/24879/intel-core-i7-4770k-and-4950hq-haswell-processors-reviewed/9
http://techreport.com/review/24879/intel-core-i7-4770k-and-4950hq-haswell-processors-reviewed/9
intelのHTはあれこれ叩かれてるが
そんな性能で大丈夫か
そんな性能で大丈夫か
HybridCrossFireってまさにベンチマークのためだけの技術だよね
Kaveriがグラボ必須の最新のゲームでCore i*シリーズに勝つためには
IntelのCPUを検出するとグラボに速度リミッターをかける細工でも
Mantleに施すしかないね。
IntelのCPUを検出するとグラボに速度リミッターをかける細工でも
Mantleに施すしかないね。
>>624
そんなことないよ
十分に楽しめる
FPSでフレームレートの少しの遅れも許せないようなゲーマーは
そもそも既にハイエンド構成だしKaveriの対象じゃない
むしろそっちの方がAMDとして利益率の高い上客だが
Kaveriでハイエンドが賄えるのならdGPUなんて必要ないでしょ
そんなことないよ
十分に楽しめる
FPSでフレームレートの少しの遅れも許せないようなゲーマーは
そもそも既にハイエンド構成だしKaveriの対象じゃない
むしろそっちの方がAMDとして利益率の高い上客だが
Kaveriでハイエンドが賄えるのならdGPUなんて必要ないでしょ
>>630
まあそうだね。
ゲーム機では1コアあたりの性能が低いから8スレッドで並列処理しなきゃ性能が出ないが
i5以上ならクロック・IPCともに高いからOSのオーバーヘッド考慮しても問題ないはずだな。
あんまり意味の無い比較だけど256bitFMAを使った理論FLOPS値だけなら
i3の1コアだけでもJaguar 8コアと同等なわけだし。
まあそうだね。
ゲーム機では1コアあたりの性能が低いから8スレッドで並列処理しなきゃ性能が出ないが
i5以上ならクロック・IPCともに高いからOSのオーバーヘッド考慮しても問題ないはずだな。
あんまり意味の無い比較だけど256bitFMAを使った理論FLOPS値だけなら
i3の1コアだけでもJaguar 8コアと同等なわけだし。
ゲームベンダーがオワコンのPC市場に本気になるわけ無いし
PS4とXBOX1が出たら嫌でもGPGPUを使うようなソフトが増えてくるよ
PS4とXBOX1が出たら嫌でもGPGPUを使うようなソフトが増えてくるよ
>>633
ゲームでGPGPUに使っても結局絵描きに使うだけだけでそいつらは元々
描画性能のためにグラボを買う連中だからそれ以上のひろがりはないでしょ
むしろゲームをやらないユーザーにより高性能なGPUを使ってもらって
販路を拡大したいたがめに、非ゲーム用途でのGPGPUの展開を求めてるわけで。
ゲームでGPGPUに使っても結局絵描きに使うだけだけでそいつらは元々
描画性能のためにグラボを買う連中だからそれ以上のひろがりはないでしょ
むしろゲームをやらないユーザーにより高性能なGPUを使ってもらって
販路を拡大したいたがめに、非ゲーム用途でのGPGPUの展開を求めてるわけで。
>>631 ハイエンド帯は元々GPU一つでいいなんて考えがないだろ
仮にiGPUがTITANクラスになってもTITAN倍プッシュするよ奴らは
仮にiGPUがTITANクラスになってもTITAN倍プッシュするよ奴らは
http://youtu.be/O07YOk4nLyo?t=1m10s
HSAを使ったJPEGデコードデモ
HSAを使ったJPEGデコードデモ
JPEGってデコーダの実装方法によって品質に差が出るから
特に演算粒度の荒いGPUでデコードするは品質には期待できないな
ブロックノイズとか酷くなりそう
というかJPEGのデコードなんて今更CPUのネックじゃねーwww
コプロに処理投げてたのなんてプレステ1とかの時代だぞ
ARMですらCPUで処理してるわ
HEVCエンコードはよ
特に演算粒度の荒いGPUでデコードするは品質には期待できないな
ブロックノイズとか酷くなりそう
というかJPEGのデコードなんて今更CPUのネックじゃねーwww
コプロに処理投げてたのなんてプレステ1とかの時代だぞ
ARMですらCPUで処理してるわ
HEVCエンコードはよ
扱うのはデジカメとかの20MBくらいのjpegじゃないのか?
ARM SoCみたく素直に専用のJPEGデコーダ・エンコーダをつめばいいだけの気もする
つかGPGPUを使ってJPEGをデコードって既にあるような・・・
http://sourceforge.net/projects/cudajpegdecoder/
つかGPGPUを使ってJPEGをデコードって既にあるような・・・
http://sourceforge.net/projects/cudajpegdecoder/
MozillaあたりがHSA参加すれば大きいんだろうけどね
ライブラリとして提供しますからゲームに使うと速くて便利ですよ
BF4では使っていますっているデモなだけだろう
BF4では使っていますっているデモなだけだろう
>>638
デジカメでそんな巨大なJPEG吐く機種は見たことないわ。
というかそんな超高解像度の絵を撮るならJPEGじゃなくてRAW形式にして
PCで現像する。
やるならImageMagickをGPGPUで高速化してくれ
あれは腐りすぎててCPUの最適化すらろくにできてない
デジカメでそんな巨大なJPEG吐く機種は見たことないわ。
というかそんな超高解像度の絵を撮るならJPEGじゃなくてRAW形式にして
PCで現像する。
やるならImageMagickをGPGPUで高速化してくれ
あれは腐りすぎててCPUの最適化すらろくにできてない
IE11はGPGPUによるJPEGデコードが出来るんだっけか
あんまし早くなってる実感がない・・・
ネットサーフ程度じゃローエンドクラスのCPUじゃないと差がわかんないかな
あんまし早くなってる実感がない・・・
ネットサーフ程度じゃローエンドクラスのCPUじゃないと差がわかんないかな
http://www.gdm.or.jp/pressrelease/2013/0702/35909
APU最適化されたWEBブラウザなら既にあったような
まあ中華製だから一部の表示がどうやっても
中華フォントになる難点があるので使う気にならないけど
APU最適化されたWEBブラウザなら既にあったような
まあ中華製だから一部の表示がどうやっても
中華フォントになる難点があるので使う気にならないけど
デカいテクスチャーをどんどん展開して貼り付けてるとちりも積もればになるかもしれない
これがあるからどうだっていうものでもないだろうがムキになって否定するようなものでもない
これがあるからどうだっていうものでもないだろうがムキになって否定するようなものでもない
JPEGファイル表示はデコードよりもむしろストレージのアクセスのほうがネックな気がする
既にあるしな
>>643
普通に考えて大半の環境でネックになるのは
ネットワークIOのはずだから、そりゃそうなのでは
消費電力とかはどうかなあ
理想的なHSAファイナライザがあれば
専用ハードがもしあればマップしてくれるんだろうか
普通に考えて大半の環境でネックになるのは
ネットワークIOのはずだから、そりゃそうなのでは
消費電力とかはどうかなあ
理想的なHSAファイナライザがあれば
専用ハードがもしあればマップしてくれるんだろうか
JPEGデコードが2倍ってのもあくまで当社比なわけで
BulldozerはそもそもFP/SIMDユニットを共有の128ビットにしてるから遅いだけで
Core i3でAVX*使ったらその3〜4倍高速でした、とかつまらない落ちはないよね?
CPU側で遅いコードを使って「○○倍」とかNVIDIAも初期のころはよくやってたから
この手のは話半分にしといたほうが。
BulldozerはそもそもFP/SIMDユニットを共有の128ビットにしてるから遅いだけで
Core i3でAVX*使ったらその3〜4倍高速でした、とかつまらない落ちはないよね?
CPU側で遅いコードを使って「○○倍」とかNVIDIAも初期のころはよくやってたから
この手のは話半分にしといたほうが。
JPEGデコードは、手抜きすぎると普通に一目で分かる差が出るからな
結局この問題は、h.264みたいに実数精度を排除するしか対応方法は無い
JPEGなら実数精度を頑張るしか無いから、綺麗にデコードしようとすればCPU演算だし、普通のPCで
Webブラウジングしてる時のCPUなんて大抵は暇だから、そもそも大した負荷でもないJPEGデコードを
GPUに投げる意味あんのかな、とは思う
結局この問題は、h.264みたいに実数精度を排除するしか対応方法は無い
JPEGなら実数精度を頑張るしか無いから、綺麗にデコードしようとすればCPU演算だし、普通のPCで
Webブラウジングしてる時のCPUなんて大抵は暇だから、そもそも大した負荷でもないJPEGデコードを
GPUに投げる意味あんのかな、とは思う
Jpegデコードできるってことは、
動画にも対応できるってアピールしてるだけ
ノートに動画支援チップ載せるより、お手軽でしょ
動画にも対応できるってアピールしてるだけ
ノートに動画支援チップ載せるより、お手軽でしょ
いや、支援回路の方が楽
DCTで256ビットAVX使えば128ビットの2倍のスループットは出るから
i3にやらせてもKaveriの2倍のCPUデコード性能は出せるんじゃないの。
i3にやらせてもKaveriの2倍のCPUデコード性能は出せるんじゃないの。
>>652
JPEGは実数使うけどAVCやHEVCは整数だし
JPEGは実数使うけどAVCやHEVCは整数だし
firefoxはマルチスレッドで対応してるけどgpuに投げてくれたほうが有難いね
jpegよりHEVCの画像版に早く対応してくれりゃもっといいけど
jpegよりHEVCの画像版に早く対応してくれりゃもっといいけど
ちなみにKaveriはCPU:110GFLOPS + GPU:720GFLOPSです
GPU使ってたったの2倍にしかならないなら
GPGPUの実効性能の低さをアピールしただけの予感
これならAVXの256ビット化して共有構造をやめたほうが
グラボ使わずに30fps程度で3Dゲームがやりたい人以外にとっては
メリットがあるはず。
> HEVCの画像版
なにそれ?詳しく
GPU使ってたったの2倍にしかならないなら
GPGPUの実効性能の低さをアピールしただけの予感
これならAVXの256ビット化して共有構造をやめたほうが
グラボ使わずに30fps程度で3Dゲームがやりたい人以外にとっては
メリットがあるはず。
> HEVCの画像版
なにそれ?詳しく
HEVC-MSP
http://people.mozilla.org/~josh/lossy_compressed_image_study_october_2013/
webpあたりもCPUでデコードするには解像度が上がると割ともたつくので
軽いjpegよきゃこういうのデモすりゃいいのに。
http://people.mozilla.org/~josh/lossy_compressed_image_study_october_2013/
webpあたりもCPUでデコードするには解像度が上がると割ともたつくので
軽いjpegよきゃこういうのデモすりゃいいのに。
PNGでいい
PNGはさすがに圧縮率悪すぎるだろ・・・
HEVCだと画像ですら変換に時間かかりすぎるだろうけど
HEVCだと画像ですら変換に時間かかりすぎるだろうけど
intelがここにひっきりなしに工作員送るのも
すでに決したからだよ
mantleでおおくの意味ががらりと変わる
intelが崩れる日も案外近い
すでに決したからだよ
mantleでおおくの意味ががらりと変わる
intelが崩れる日も案外近い
動画は縦×横ピクセル×時間軸で差分をとって圧縮するわけで
HEVCの1フレーム分を静止画として使っても
変換速度に見合う圧縮効率が得られなさそうな気がする
HEVCの1フレーム分を静止画として使っても
変換速度に見合う圧縮効率が得られなさそうな気がする
整数で実装しなけりゃなんとかなりそうな気はするけども。
GPUじゃなくてもよくなるけどさ
GPUじゃなくてもよくなるけどさ
なにはともあれ漸くKaveriが来たと実感する
TryもRichもゴミだったしコレが本命
スー博士は純粋にiGPU性能で4770KのHD4600と比較すりゃええもんを
GT630とか話にもなんねーようなdGPUをもってくるのか?
あえて価格帯でお高いGT3e版のモデルと比較しなかったのは当然だな
TryもRichもゴミだったしコレが本命
スー博士は純粋にiGPU性能で4770KのHD4600と比較すりゃええもんを
GT630とか話にもなんねーようなdGPUをもってくるのか?
あえて価格帯でお高いGT3e版のモデルと比較しなかったのは当然だな
666 :Socket774:2013/11/13(水) 22:13:54.58 ID:h27l2eiI
俺みたいなスコア重視のFPSプレイヤーだと高いCPUやGPU買ったところで
視覚効果とか無駄なもん切っちゃうから正直Kaveriに毛が生えた程度で問題ない
その上MantleやらHSAやらTrueAudioやら面白そうな話が転がってるとなれば
こりゃ買わないわけにはいかんな!
Intel先輩はどこで動かしても大安定だけど、AMDはまだ俺本気出してない感が残ってるのが面白い
視覚効果とか無駄なもん切っちゃうから正直Kaveriに毛が生えた程度で問題ない
その上MantleやらHSAやらTrueAudioやら面白そうな話が転がってるとなれば
こりゃ買わないわけにはいかんな!
Intel先輩はどこで動かしても大安定だけど、AMDはまだ俺本気出してない感が残ってるのが面白い
一般人が選ぶようなノートだとほぼIntelしかないからなぁ
ぶっちゃけなんでデスクトップを優先したんだろ
単純に現行リビジョンだと問題があって省電力化がうまくいってないとか?
あとクロックが4GHzを超えないのは単純にプロセスの特性の問題なのかもしれないが
ぶっちゃけなんでデスクトップを優先したんだろ
単純に現行リビジョンだと問題があって省電力化がうまくいってないとか?
あとクロックが4GHzを超えないのは単純にプロセスの特性の問題なのかもしれないが
32nmSOIから28nmバルクじゃ、消費電力が減る要素はまるでないので。
普通は単価の高いノートを優先するはずだよな
グラボ増設が当たり前でメリットの小さいデスクトップで優先する理由があるとしたら
ノートのTDP枠内に収まる石がまだ十分にとれてないからだろう
SOIやめた分リーク電流増えてるんじゃね?
グラボ増設が当たり前でメリットの小さいデスクトップで優先する理由があるとしたら
ノートのTDP枠内に収まる石がまだ十分にとれてないからだろう
SOIやめた分リーク電流増えてるんじゃね?
単価はリテール品の方が高くね
ボリュームも考えるとやっぱりモバイルなんだけど
ボリュームも考えるとやっぱりモバイルなんだけど
>>667
デスクトップは電圧特盛で出してしまえるけどノートでは無理だからね
デスクトップは電圧特盛で出してしまえるけどノートでは無理だからね
モバイルはTSMCに振ってるしプロセス変わらないから性能上がらないんじゃね
4k8k時代になればどっちにしろ次世代規格いりそうだしCPUだけじゃどうにもならなさそうだな
4kすら未だ普及してないのに何を言う
ノートでやっと2560x1440とかが出回り始めた程度だぞ?
ノートでやっと2560x1440とかが出回り始めた程度だぞ?
ハイエンドウルトラブックの存在がゲームやる気なしのIntelもIGPを強化する
動機付けのひとつになってる。
Haswell世代から一気に増えたよな3200x1800みたいな化け物解像度のが。
スマホより低い解像度が許せないという価値観のユーザーが増えたことも
パソコンのハイエンド志向の一因としてあるわけで、スマホ様様だったり
動機付けのひとつになってる。
Haswell世代から一気に増えたよな3200x1800みたいな化け物解像度のが。
スマホより低い解像度が許せないという価値観のユーザーが増えたことも
パソコンのハイエンド志向の一因としてあるわけで、スマホ様様だったり
絵餅しか語らないスレなうえにインテルCPUの話はもっと先の話までしてるだろうに・・・
ハイエンド思考ではなく単によくあるメーカーの一方的な高付加価値押し戦略だと思うよ
需要はないし当然売れてもいない
需要はないし当然売れてもいない
MBPもRetinaモデルが売れてるのに?
あまり高DPIになっても、OS自体がそれに対応した作りじゃないから
物凄く目がいい人以外、現時点ではあんまり意味ない気がするけどねぇ。
物凄く目がいい人以外、現時点ではあんまり意味ない気がするけどねぇ。
あれはブランドみたいなもんだしな
ブランド志向ってまさに高級志向だ
それよりMR-IOV対応を早くしてくれよ。
OSが悪いのかもしれんけど悲しい争いだな・・・
ブランド力なんて無いWindowsノートじゃ売れないというおはなし
実用性のほうも>>682の言うとおりで
結局はMSが何とかしない限り普及することはなさそうだ
何とかするのも古いもの全部捨てるくらいしないと無理だからできるはずも無く
実用性のほうも>>682の言うとおりで
結局はMSが何とかしない限り普及することはなさそうだ
何とかするのも古いもの全部捨てるくらいしないと無理だからできるはずも無く
一応Windows8,1から200%拡大時は96dpi用のアプリがボケなくなったりとか改善はされてるんだけどね
まあ200%拡大だと最低でも2560x1600は無いときついと言う問題があるけど
まあ200%拡大だと最低でも2560x1600は無いときついと言う問題があるけど
>>681
最近買ったけど、Retinaが欲しくて買ったんじゃなくてMacbookProが欲しいから買ったんだ。
最近買ったけど、Retinaが欲しくて買ったんじゃなくてMacbookProが欲しいから買ったんだ。
Appleはドットバイドットで描画しなきゃいけないという考え方そのものがない。
Retina Macでデスクトップサイズを最大にしても1920x1200を倍角描画してスケーリングしたものになるし。
液晶の高解像度化が進めば、ドットの概念自体がなくなってブラウン管みたいに
好きな描画解像度でぼやけのない全画面表示ができるようになる、みたいなことを
割と本気で考えている。
Retina Macでデスクトップサイズを最大にしても1920x1200を倍角描画してスケーリングしたものになるし。
液晶の高解像度化が進めば、ドットの概念自体がなくなってブラウン管みたいに
好きな描画解像度でぼやけのない全画面表示ができるようになる、みたいなことを
割と本気で考えている。
Macはよくわかってると思うな
上位は2880x1800で下位は2560x1600で
縦1440で200%表示だと縦720みたいな馬鹿仕様とは違う
http://www.apple.com/jp/macbook-pro/features-retina/
上位は2880x1800で下位は2560x1600で
縦1440で200%表示だと縦720みたいな馬鹿仕様とは違う
http://www.apple.com/jp/macbook-pro/features-retina/
iPhoneのretinaもPSVitaも前世代の4倍の解像度だからな
中途半端に150%拡大とかしてぼやけるというのは最悪といっていい
中途半端に150%拡大とかしてぼやけるというのは最悪といっていい
Retinaってivyがショボ過ぎてまともに描写すら出来なかったやつだよね
わざわざゲフォと切り替えて描写してたりしてた
わざわざゲフォと切り替えて描写してたりしてた
確かにMacOSでRetinaは画面が印刷物みたいに綺麗で見やすいし
あれ見ちゃうとMacに戻ろうかなって気がしてくるw
Windowsでは…コンデジとかデジイチで撮った写真の確認に便利かもしれないね(棒
あれ見ちゃうとMacに戻ろうかなって気がしてくるw
Windowsでは…コンデジとかデジイチで撮った写真の確認に便利かもしれないね(棒
ID:gth54D8e (12/12)
↑こいつすげぇwwwwAMDスレには引き篭もりの低脳しかいないのか
↑こいつすげぇwwwwAMDスレには引き篭もりの低脳しかいないのか
引きこもりって団子に言ってやれよ
↑ニート乙
もう叩けりゃなんでもいいって感じだな
ID:gth54D8e
涙拭けよwww
涙拭けよwww
つーか金のかかる趣味の板では、ニートや引きこもりって勝ち組に対する言葉だわ。
道楽につぎ込みつつも働かなくていいだけの資産があるんだろ。羨ましいわ。
道楽につぎ込みつつも働かなくていいだけの資産があるんだろ。羨ましいわ。
働かないで自作やっていけるなら俺だって働きたくねぇ。
このスレにニートジサカーがいるなら憧れる。
このスレにニートジサカーがいるなら憧れる。
やっぱ300dpi以上は欲しいね。出来れば450dpi
むしろ朝から晩まで働いて、なけなしの自由時間を他人を叩くために費やしてる
アホのほうがよっぽど哀れだわww
アホのほうがよっぽど哀れだわww
団子の事ですね判ります
richland値下げ来たら買う
Kaveriの型番が7850Kが最上位のままとは思えん
多分少し遅れて1TFLOPSの7870Kが出てくるだろうね
多分少し遅れて1TFLOPSの7870Kが出てくるだろうね
熱に問題があるんじゃ?ターボも考慮に入れてないっぽいし
ハイエンドクーラーや水冷化でどこまで引っ張れるか楽しみ
スッポンとOCはもうAMDじゃなくちゃ楽しめないからな
ハイエンドクーラーや水冷化でどこまで引っ張れるか楽しみ
スッポンとOCはもうAMDじゃなくちゃ楽しめないからな
100Wいっぱい使ってクロック上げるのかと思ったらTDP95Wなのはなんなんだろうね。
どうせ実測じゃ大して変わらないとはいえ。
どうせ実測じゃ大して変わらないとはいえ。
TDPはSandyのi7/i5を意識してたりってことはないか
95Wだろうが100Wだろうがこの辺が(発熱的に)限度だと思うんだが
7870Kなんて出るのかねえ……
95Wだろうが100Wだろうがこの辺が(発熱的に)限度だと思うんだが
7870Kなんて出るのかねえ……
大手メーカーだと100Wの大台を超えるのは受けがわるかったんじゃないの?
APUは65W(HP) FXは95W(Acer)位しか積んでないし
APUは65W(HP) FXは95W(Acer)位しか積んでないし
713 :Socket774:2013/11/14(木) 02:46:56.94 ID:oH48ETFM
やっぱマカーはアホだな
65W以下の製品も出してくれるとうれしいな
もちろん4コアで
もちろん4コアで
>>707
GFバルクのYieldが悪いんじゃない?普通は良品がある程度溜まって発表出荷なんだろうけど
とりあえずイベント前に出しとけ、みたいな感じかな。
リーク電流が低い奴とかクロック上げやすいものは作り貯めて後日発売になるかと。
SOIだとリーク電流が低く出来るので、高クロック低TDPが原理的には作りやすいんだが
しかし、GFのスパイラル開発はうまくいってるんだろうか。FD-SOITriGateHKMGは早くて来年だそうで
GFバルクのYieldが悪いんじゃない?普通は良品がある程度溜まって発表出荷なんだろうけど
とりあえずイベント前に出しとけ、みたいな感じかな。
リーク電流が低い奴とかクロック上げやすいものは作り貯めて後日発売になるかと。
SOIだとリーク電流が低く出来るので、高クロック低TDPが原理的には作りやすいんだが
しかし、GFのスパイラル開発はうまくいってるんだろうか。FD-SOITriGateHKMGは早くて来年だそうで
新プロセスの初っぱなだから歩留まりが低いのは仕方ないな
32nmのLlanoも最初は3850が最上位で、後から3870kが出てきたしね
32nmのLlanoも最初は3850が最上位で、後から3870kが出てきたしね
やっぱりGFの技術力の問題?
片や1.8TflopsのAPUが載ったハードが
ホリデーシーズンに向けて大量に出回るというのに
片や1.8TflopsのAPUが載ったハードが
ホリデーシーズンに向けて大量に出回るというのに
28nm がようやく始まるというのは
自分達が公言してきたスケジュールに照らしてどうなんだろう
自分達が公言してきたスケジュールに照らしてどうなんだろう
まあいいんじゃない?無理にシュリンクしてもintelの二の舞だし
プロセス進んでもコスト上がって、トランジスタコスト変わらないし、
シュリンクの利点って多少の省電力化しか無いから最早どうでもいい
シュリンクの利点って多少の省電力化しか無いから最早どうでもいい
GF32nmはプロセスルール相当の性能じゃない気がする
>>720
むしろIntelぐらいにコントロールできたら万々歳だと言うべきで
2014H2に20nmを出せるのか、
というかSamsungは14nmへスキップとかいう噂も出てた気がするが
なんかゴタゴタっぽいけど大丈夫なのか、謎は多い
むしろIntelぐらいにコントロールできたら万々歳だと言うべきで
2014H2に20nmを出せるのか、
というかSamsungは14nmへスキップとかいう噂も出てた気がするが
なんかゴタゴタっぽいけど大丈夫なのか、謎は多い
AMDがAPU推せば推すほど今までなんとかPhenomII/FXで耐えてきた
ハイパフォーマンスCPUを求めるユーザーが諦めてIntelに流れていってしまうという…
ハイパフォーマンスCPUを求めるユーザーが諦めてIntelに流れていってしまうという…
PS4にTrueAudioが搭載されていることが確定
https://twitter.com/AMDGaming/status/400668118998978560
>Dominic Mallinson: The audio chip on the PS4 has TrueAudio technology #APU13
http://developer.amd.com/apu/home/keynotes/
>Dominic Mallinson: Vice President, Research & Development Sony Computer Entertainment America
https://twitter.com/AMDGaming/status/400668118998978560
>Dominic Mallinson: The audio chip on the PS4 has TrueAudio technology #APU13
http://developer.amd.com/apu/home/keynotes/
>Dominic Mallinson: Vice President, Research & Development Sony Computer Entertainment America
二の舞?
AMD Publishes Bdver4 (Excavator) GCC Compiler Patch
http://www.phoronix.com/scan.php?page=news_item&px=MTUxMzE
The bdver4 / Excavator scheduling is similar to bdver3 and there's also still three pipelined FP units and two integer units.
The CPU instruction extension supersets in full for "bdver4" include BMI, BMI2, TBM, F16C, FMA, AVX, AVX2, XOP, LWP, AES,
PCL_MUL, CX16, MOVBE, MMX, SSE, SSE2, SSE3, SSE4A, SSSE3, SSE4.1, SSE4.2, ABM.
http://www.phoronix.com/scan.php?page=news_item&px=MTUxMzE
The bdver4 / Excavator scheduling is similar to bdver3 and there's also still three pipelined FP units and two integer units.
The CPU instruction extension supersets in full for "bdver4" include BMI, BMI2, TBM, F16C, FMA, AVX, AVX2, XOP, LWP, AES,
PCL_MUL, CX16, MOVBE, MMX, SSE, SSE2, SSE3, SSE4A, SSSE3, SSE4.1, SSE4.2, ABM.
>>725
TrueAudioがはたして活用されるか懸念していたが、PS4に採用されているなら問題ないな。
TrueAudioがはたして活用されるか懸念していたが、PS4に採用されているなら問題ないな。
http://www.neogaf.com/forum/showthread.php?t=714178
http://i4.minus.com/iMpQPnd0sxZ8u.png
・CPUでの並列処理化
http://i7.minus.com/ibkyJ6T4GpTiTQ.png
・AFRの活用例:4〜8基のGPUでレンダリング(1台のワークステーションで20〜40TFlops)
・AFRの活用例:低レイテンシのVR向けレンダリング
http://i4.minus.com/iMpQPnd0sxZ8u.png
{kind=link}
・CPUでの並列処理化
http://i7.minus.com/ibkyJ6T4GpTiTQ.png
{kind=link}
・AFRの活用例:4〜8基のGPUでレンダリング(1台のワークステーションで20〜40TFlops)
・AFRの活用例:低レイテンシのVR向けレンダリング
BeemaとMullinsの話出たわ、InstantGOとTrustZzone対応だとさ
Impress記事はえーな、今話終わったばっかなのに
事前に用意してたか
AMD、Kabini/Temashの後継「Beema/Mullins」を2014年前半に投入へ
http://pc.watch.impress.co.jp/docs/news/event/20131114_623498.html
事前に用意してたか
AMD、Kabini/Temashの後継「Beema/Mullins」を2014年前半に投入へ
http://pc.watch.impress.co.jp/docs/news/event/20131114_623498.html
732 :Socket774:2013/11/14(木) 07:29:48.48 ID:jME65ub+
AMD、Kabini/Temashの後継「Beema/Mullins」を2014年前半に投入へ
〜クアッドコア、GCN、ARM TrustZone、Instant Go対応でSDP 2W以下
わくてか
〜クアッドコア、GCN、ARM TrustZone、Instant Go対応でSDP 2W以下
わくてか
32nmはほんとひどかった。
逆にIntelが失敗なくあそこまで微細化できるのはなぜだろうか。
専門家でもないのに。
逆にIntelが失敗なくあそこまで微細化できるのはなぜだろうか。
専門家でもないのに。
専門家だろ。
2年おそい今更AMD採用なんて何処もしねぇよ
グラヴニング氏は、Beema/Mullinsの性能に関しても、少しだけだが明らかにした。
判明したのは電力あたりの性能データで、TemashとMullinsの比較では、3DMark11、PCMark8という2つのベンチマークで電力効率が倍以上に、
KabiniとBeemaの比較でもBeemaがちょうど倍になるという結果が示された。
http://pc.watch.impress.co.jp/img/pcw/docs/623/498/html/06.jpg.html
PumaのワッパはJaguarの倍と
微細化してないのに不思議、また謎の技術使ったのか
判明したのは電力あたりの性能データで、TemashとMullinsの比較では、3DMark11、PCMark8という2つのベンチマークで電力効率が倍以上に、
KabiniとBeemaの比較でもBeemaがちょうど倍になるという結果が示された。
http://pc.watch.impress.co.jp/img/pcw/docs/623/498/html/06.jpg.html
{kind=link}
PumaのワッパはJaguarの倍と
微細化してないのに不思議、また謎の技術使ったのか
まだインテルの威を借る身の程知らずが
五流大学でアーキテクチャかじった程度のチンカスが粘着してんのか
失せろ
五流大学でアーキテクチャかじった程度のチンカスが粘着してんのか
失せろ
アムド信者は自分では使いもしないモバイル向けチップで
wktkする振りをするのがほんとうに上手だなw
wktkする振りをするのがほんとうに上手だなw
効率なんだからスコアを倍にすればいいんだろ
メモリー帯域が倍になったか?
KabiniはTDPで15〜25W→Beemaは10〜25W
TemashはSDPで4W以下→MullinsはSDPで2W以下
これで微細化使わず3Dmark11とPcmark8のスコアでワッパ倍にするのはどうすりゃいいんだ?
ワッパ倍ってことはBeemaはTDPそのままでスコア倍、MullinsはスコアはそのままSDP半減って感じと思うが
メモリ周りか?
TemashはSDPで4W以下→MullinsはSDPで2W以下
これで微細化使わず3Dmark11とPcmark8のスコアでワッパ倍にするのはどうすりゃいいんだ?
ワッパ倍ってことはBeemaはTDPそのままでスコア倍、MullinsはスコアはそのままSDP半減って感じと思うが
メモリ周りか?
もともとJaguarは結構電圧盛ってるようなもんだし
早いとこDDR4出て欲しいな
要はHaswellのラインナップみたいに低電圧特化の物理設計で
上の性能向上はソコソコに超低電圧ラインナップの拡充?
今一番求められてる部分はそれだろうし
上の性能向上はソコソコに超低電圧ラインナップの拡充?
今一番求められてる部分はそれだろうし
ワッパ二倍が本当ならSoC最強になる
http://www.cpu-world.com/CPUs/Jaguar/AMD-A4-Series%20A4-1200.html
MSIのあれに乗ってたものがA4 1200
2coreの1GHzで4W
え?
2倍になったところで何と競合するの
MSIのあれに乗ってたものがA4 1200
2coreの1GHzで4W
え?
2倍になったところで何と競合するの
Mantle Not tied to GCN really, but designed with that in mind.
MantleはGCNを念頭に置いて設計されているが、それに縛られるわけではないと
ARMのGPUにも転用可能ってことかな、もちろんINTELとNVのにも
MantleはGCNを念頭に置いて設計されているが、それに縛られるわけではないと
ARMのGPUにも転用可能ってことかな、もちろんINTELとNVのにも
>>747
Dxの代わりを目的としてるなら他のGPUにもある程度動作可能にさせるのはあるだろうね
Dxの代わりを目的としてるなら他のGPUにもある程度動作可能にさせるのはあるだろうね
はやくもブレブレですね
beema でメモリ 2ch化を希望
Mantle対応グラフィックドライバなんてAMD以外作らんし作らせないだろ
重要なのはAMDはGCNに縛られないってこと
重要なのはAMDはGCNに縛られないってこと
"More focus on the APU performance with this game."
http://cdnmo.coveritlive.com/media/image/201311/phposqvnsp1010527.jpg
http://cdnmo.coveritlive.com/media/image/201311/phposqvnsp1010527.jpg
{kind=link}
団子はブーメラン刺さりまくりじゃん
http://cdnmo.coveritlive.com/media/image/201311/phpkdko94p1010521.jpg
want to see mantle on linux and mac!
↓
would enable support for our full engine and rendering.
significantly easier to do efficient renderer with mantle than with openGL.
ほらやっぱりopenGL対応じゃん。これでパラダイムシフト起こらないと思ってる方がどうかしてる
{kind=link}
want to see mantle on linux and mac!
↓
would enable support for our full engine and rendering.
significantly easier to do efficient renderer with mantle than with openGL.
ほらやっぱりopenGL対応じゃん。これでパラダイムシフト起こらないと思ってる方がどうかしてる
significantly easier to do efficient renderer with mantle than with openGL.
これでopengl対応とか読める頭が面白いよ
これでopengl対応とか読める頭が面白いよ
steamOSとmantleの組み合わせはパネェwwwwwみたいなこと書いてあるけどなにかタイトルつくってるのか?
>>756
BF4はLinux版作ってるらしいからそれじゃないの?
BF4はLinux版作ってるらしいからそれじゃないの?
マントルの使用によりOpenGLを使うよりも簡単に効率的な描画が可能
バカ:OpenGL対応!
www
バカ:OpenGL対応!
www
Jaguarが進化していくのに合わせて、ゲーム機もスマホみたいに小刻みに性能アップしていくモデルになったりしてね。
二年ぐらいで PS4 → PS4S → PS5 とか
二年ぐらいで PS4 → PS4S → PS5 とか
AMDのGPUでしか使えない技術なんてたいして普及しないだろーなっておもってたけど、
MantleもTrueAudioもコンシューマで使ったのを使いまわせるようにするっていう技でくるとはね
数が出るコンシューマ向けにPS4のローレベルAPI(Mantleに近い?)と、TrueAudioで開発して、
それをちょっと手直しすればPCで動きますよって感じだろうね
MantleもTrueAudioもコンシューマで使ったのを使いまわせるようにするっていう技でくるとはね
数が出るコンシューマ向けにPS4のローレベルAPI(Mantleに近い?)と、TrueAudioで開発して、
それをちょっと手直しすればPCで動きますよって感じだろうね
本当の馬鹿だな
失敗作Kabini/Temashの後継は来年前半か
5月頃かな
次こそタブレットに採用されるといいね笑
5月頃かな
次こそタブレットに採用されるといいね笑
SteamOSはWindowsゲームのプレイはリモートで対応、だろ。
OpenGL(笑)
OpenGL(笑)
ならWindowsでやれよ
いやstream playもできるが
メインはローカルでのプレイだよ
メインはローカルでのプレイだよ
TrueAudioチップがPS4に積まれてても対応予定ゲームってthiefひとつだけなんだよな
現状じゃWindowsタブレットはBayTrail一択だからな
ファンレスタブに載せるならeMMCやLPDDR3対応のオプションは欲しい
ところでAVX2で256ビット整数命令が使えるようになるんだが
256ビット版のXOP2(?)は用意しないわけ?
XOPは128ビット専用の拡張命令のまま?
ファンレスタブに載せるならeMMCやLPDDR3対応のオプションは欲しい
ところでAVX2で256ビット整数命令が使えるようになるんだが
256ビット版のXOP2(?)は用意しないわけ?
XOPは128ビット専用の拡張命令のまま?
>>763
去年のうちに出てたら、Windows8に便乗してもうちょっと採用されたかもねぇ…ジャガーノートではなくクリシュナタブとして。
いまのところは、エプソンダイレクトから一月頃に出るらしいタブが本命。
10万くらいでも買ったるわ。
去年のうちに出てたら、Windows8に便乗してもうちょっと採用されたかもねぇ…ジャガーノートではなくクリシュナタブとして。
いまのところは、エプソンダイレクトから一月頃に出るらしいタブが本命。
10万くらいでも買ったるわ。
>>741
普通に微細化してるんじゃないの
普通に微細化してるんじゃないの
ジャガーノートって言葉カッコよすぎてワロタ
http://ja.wikipedia.org/wiki/%E3%82%B8%E3%83%A3%E3%82%AC%E3%83%BC%E3%83%8E%E3%83%BC%E3%83%88
http://ja.wikipedia.org/wiki/%E3%82%B8%E3%83%A3%E3%82%AC%E3%83%BC%E3%83%8E%E3%83%BC%E3%83%88
ジャガープラス言われてたのがプーマになったと言うこと?
MacOS X 10.2がJaguarで10.1がPumaだからむしろ退化してるなww
>>736
TDPとACPに続いてSDPっていう第三の単位ができちゃったのね
TDPとACPに続いてSDPっていう第三の単位ができちゃったのね
AMD 2014 Mobile APU Update: Beema and Mullins
http://www.anandtech.com/show/7514/amd-2014-mobile-apu-update-beema-and-mullins
http://www.anandtech.com/show/7514/amd-2014-mobile-apu-update-beema-and-mullins
778 :Socket774:2013/11/14(木) 10:58:30.98 ID:u5wbPisR
779 :Socket774:2013/11/14(木) 11:04:35.46 ID:u5wbPisR
780 :Socket774:2013/11/14(木) 11:09:37.84 ID:u5wbPisR
>>758
べつの記事でopenGLの拡張にマントルの技術使うとか何とかという話もあるから、あながち間違いでもない
べつの記事でopenGLの拡張にマントルの技術使うとか何とかという話もあるから、あながち間違いでもない
>774
てかアプリケーションの使うミドルウェアの方で対応を実装しないとなんともならんのじゃないかな
てかアプリケーションの使うミドルウェアの方で対応を実装しないとなんともならんのじゃないかな
>>776
Intelが使い出したからAMDも、って感じでしょ。
もともとARMタブなんかで使われてる熱設計基準をx86に適用したものだけど。
(タブレットは最大負荷で長時間動作させるケースがまず無いという前提だから甘くなってる)
Intelが使い出したからAMDも、って感じでしょ。
もともとARMタブなんかで使われてる熱設計基準をx86に適用したものだけど。
(タブレットは最大負荷で長時間動作させるケースがまず無いという前提だから甘くなってる)
783 :Socket774:2013/11/14(木) 11:18:59.64 ID:u5wbPisR
しかし、インテルとヌビが死ぬような発表ばかりだな
弱点だった根回しやソフトサポートが完璧過ぎる
弱点だった根回しやソフトサポートが完璧過ぎる
intelがAMDの戦略如何でグラつくとは思えんが、nvidiaは将来の雲行きが随分怪しくなってきたね
多分また意味不明な打開企画を打ち出してきて滅亡を早めると思うわ
多分また意味不明な打開企画を打ち出してきて滅亡を早めると思うわ
HSAは打倒Intel連合みたいなもんだからNvidiaはあっさり参加するかも
ジェンスンの言葉を要約するにNVIDIAはIntelのFabを使いたがってるらしいから・・・
IntelにとってNVIDIAと手を組むメリットが希薄だからな。
Phiと競合するTesla, Atomと競合するTegraとか。
IntelにとってNVIDIAと手を組むメリットが希薄だからな。
Phiと競合するTesla, Atomと競合するTegraとか。
Intel 一社でファブが埋まらないなら、どこかと手を組む必要がある。
Fab貸しではないけど、IntelはIntelで業界団体作って囲い込みやってるよ。
HSAはCPUとGPUくっつけてこれから何をするのか考える段階だけど
こっちはソリューションを定めて基盤づくりをやってる。
http://www.genivi.org/genivi-members
これは自動車向け情報機器の例。
立ち上げ時にIntelを含め18社だったメンバーが今は100社を超えてる。
HSAはCPUとGPUくっつけてこれから何をするのか考える段階だけど
こっちはソリューションを定めて基盤づくりをやってる。
http://www.genivi.org/genivi-members
これは自動車向け情報機器の例。
立ち上げ時にIntelを含め18社だったメンバーが今は100社を超えてる。
789 :Socket774:2013/11/14(木) 11:54:16.57 ID:u5wbPisR
>>784
当面は流石に無理
今回は、対応ハード普及やOSや開発環境やゲームエンジンとかのインフラ整備がメイン
対応ソフトは徐々に増えていくだけ
まずはゲーム機とゲームエンジンはマントルとTrue Audioで制覇した
次はARM勢の大半がHSA対応SoCになる
インフラ整備が済めば、後は勝手に対応ソフトが増えていく
当面は流石に無理
今回は、対応ハード普及やOSや開発環境やゲームエンジンとかのインフラ整備がメイン
対応ソフトは徐々に増えていくだけ
まずはゲーム機とゲームエンジンはマントルとTrue Audioで制覇した
次はARM勢の大半がHSA対応SoCになる
インフラ整備が済めば、後は勝手に対応ソフトが増えていく
一瞬お花畑のCellスレにタイムスリップしたのかと思った
791 :Socket774:2013/11/14(木) 12:06:14.68 ID:u5wbPisR
>>788
インテルのソリューションは所詮x86で色々やろうぜでしかない
HSAはX86、ARM、Gpuとか色々使って色々やろうぜだから、インテルのソリューションは後追いできる
インテルはX86を軽視しているからHSAの後追いはできない
スマホやタブの省電力化にメモリコピーをなくせるHSAは必須で、クアルコムとメディアテックとサムソンの最大手が対応するから時間の問題でしかないな
インテルのソリューションは所詮x86で色々やろうぜでしかない
HSAはX86、ARM、Gpuとか色々使って色々やろうぜだから、インテルのソリューションは後追いできる
インテルはX86を軽視しているからHSAの後追いはできない
スマホやタブの省電力化にメモリコピーをなくせるHSAは必須で、クアルコムとメディアテックとサムソンの最大手が対応するから時間の問題でしかないな
TizenIVIプラットフォームのメインチップセット供給はIntelがほぼ独占してる
https://wiki.tizen.org/wiki/IVI/IVI_Platforms
トヨタは既にTizen開発参加を表明。
http://monoist.atmarkit.co.jp/mn/articles/1305/27/news137.html
既報どおりだけどトヨタ車のほぼ全ての車載ナビにIntelチップが採用されるのは
決定的になった
https://wiki.tizen.org/wiki/IVI/IVI_Platforms
トヨタは既にTizen開発参加を表明。
http://monoist.atmarkit.co.jp/mn/articles/1305/27/news137.html
既報どおりだけどトヨタ車のほぼ全ての車載ナビにIntelチップが採用されるのは
決定的になった
793 :Socket774:2013/11/14(木) 12:10:05.16 ID:u5wbPisR
794 :Socket774:2013/11/14(木) 12:15:37.48 ID:u5wbPisR
で、MantleがPowerVRやMaliで動作するのか?
796 :Socket774:2013/11/14(木) 12:20:08.66 ID:u5wbPisR
毎度毎度まだ勝ってもいないのに勝ち誇るの好きだなこのスレ、そんなんだから反感買って
お客さん増えるというのに、毎度の尻すぼみにも懲りずよくやるわ
お客さん増えるというのに、毎度の尻すぼみにも懲りずよくやるわ
>>785
NvidiaのPhysXがPS4に提供されるぐらいだからHSAにも参加するかもな
NvidiaのPhysXがPS4に提供されるぐらいだからHSAにも参加するかもな
来年だか再来年にAMDが出すARM版APUではMantleが動くかもしれないが
汎用のCortex-A57採用の時点でカスタムARMに劣るし
既にシェアを持ってるSnapdragonやApple A7の餌食になるだけだろう
こっち方面に進出するには無線チップのIPを持たないと話にならない。
汎用のCortex-A57採用の時点でカスタムARMに劣るし
既にシェアを持ってるSnapdragonやApple A7の餌食になるだけだろう
こっち方面に進出するには無線チップのIPを持たないと話にならない。
800 :Socket774:2013/11/14(木) 12:23:27.26 ID:u5wbPisR
801 :Socket774:2013/11/14(木) 12:25:06.16 ID:u5wbPisR
>>798
それを言ったらIntelのHavokも全プラットフォームに提供されてるが
それを言ったらIntelのHavokも全プラットフォームに提供されてるが
803 :Socket774:2013/11/14(木) 12:29:49.46 ID:u5wbPisR
>>802
HavokはIntelによる買収以後もAMD最適化だからPhysXほど驚くことではない
HavokはIntelによる買収以後もAMD最適化だからPhysXほど驚くことではない
805 :Socket774:2013/11/14(木) 12:31:20.75 ID:u5wbPisR
>>798
Gpgpu化してないから、あれは苦し紛れの最後のあがき
Gpgpu化してないから、あれは苦し紛れの最後のあがき
807 :Socket774:2013/11/14(木) 12:37:29.68 ID:u5wbPisR
>>799
ARMのカスタムとかAMDは余裕だろ
単に早くApu化したいからしないだけ
一旦Apu化したらアホみたいにカスタム化するよ
ちなみに安定期で安売りしかなく旨味が欠片もないスマホは全く眼中なさげ
ARMのカスタムとかAMDは余裕だろ
単に早くApu化したいからしないだけ
一旦Apu化したらアホみたいにカスタム化するよ
ちなみに安定期で安売りしかなく旨味が欠片もないスマホは全く眼中なさげ
■ CPU Hierarchy Chart 2013
AMD悲惨すぐる笑
まるで勝負になってない笑
5年前の石にすら負けてる笑
何周回遅れなんだか笑
http://www.tomshardware.com/reviews/gaming-cpu-review-overclock,3106-5.html
AMD悲惨すぐる笑
まるで勝負になってない笑
5年前の石にすら負けてる笑
何周回遅れなんだか笑
http://www.tomshardware.com/reviews/gaming-cpu-review-overclock,3106-5.html
段階的な長期進化計画が、じゃあ進化し終わるまでまっとくか、になっちゃってるよな
これでMantleのパフォーマンスが肩透かしだったらAMD潰れるだろうな
これでMantleのパフォーマンスが肩透かしだったらAMD潰れるだろうな
QualcommやAppleが何故Cortex-を使わなくなったのか考えればわかるよな
特定半導体プロセスに最適化されてないASICで提供されてるから
カスタムチップより圧倒的に性能で不利なんだよ。
NVIDIAもCortex採用は来年のTegra5まででそれ以降は
独自設計のDenverに移行する。
ExynosやTegraがBayTrailに軒並み負けてるのをみれば
同様にCortexそのままなARM版OpteronがAtomC(Avoton)の相手になるわけがないし
ただでさえ64ビットARMにはソフトがないから、自分が育成にかかわったx64コード資産に
逆に殺される未来しか見えない。
特定半導体プロセスに最適化されてないASICで提供されてるから
カスタムチップより圧倒的に性能で不利なんだよ。
NVIDIAもCortex採用は来年のTegra5まででそれ以降は
独自設計のDenverに移行する。
ExynosやTegraがBayTrailに軒並み負けてるのをみれば
同様にCortexそのままなARM版OpteronがAtomC(Avoton)の相手になるわけがないし
ただでさえ64ビットARMにはソフトがないから、自分が育成にかかわったx64コード資産に
逆に殺される未来しか見えない。
ASICじゃないし、カスタムチップじゃない
ここまで熱くバラ色の未来を語られちゃうと
新APUに興味津々の自分でさえ
団子の褒め殺しの仕込みなんじゃねーかって気がしてくるw
新APUに興味津々の自分でさえ
団子の褒め殺しの仕込みなんじゃねーかって気がしてくるw
ドル箱だったサーバ事業がやばすぎるのは確かだな。
Radeonが好調な時期でさえ、GPU事業が黒字に貢献したことはほとんどない。
(ウェハあたりの売値がCPUより圧倒的に安いから)
8P向けはMagny-Coursのときに撤退して復活の予定なし。
1Pの8コアも今年限りで終わり。
残るは2-4P向けだが既にIvy Bridge-EXに差をつけられ虫の息。
最大14コアまで対応しDDR4を先行採用するHaswell-EXで詰む。
ARMサーバとAPUサーバのニッチ用途に逃げこもうとしてるが
そこは天国か地獄か・・・
Radeonが好調な時期でさえ、GPU事業が黒字に貢献したことはほとんどない。
(ウェハあたりの売値がCPUより圧倒的に安いから)
8P向けはMagny-Coursのときに撤退して復活の予定なし。
1Pの8コアも今年限りで終わり。
残るは2-4P向けだが既にIvy Bridge-EXに差をつけられ虫の息。
最大14コアまで対応しDDR4を先行採用するHaswell-EXで詰む。
ARMサーバとAPUサーバのニッチ用途に逃げこもうとしてるが
そこは天国か地獄か・・・
お客さんは ID:u5wbPisR だろ。
APUに限らずプレステに搭載されたものはこんな持ち上げ方をしまくるからな。
すべてのソフトウェアエンジニアがCellに特化したコード書くようになるから
x86滅亡wwwとか言ってた頃と何も変わらない。
APUに限らずプレステに搭載されたものはこんな持ち上げ方をしまくるからな。
すべてのソフトウェアエンジニアがCellに特化したコード書くようになるから
x86滅亡wwwとか言ってた頃と何も変わらない。
-EPはともかく、もともとIvyBridge-EXが使われるハイエンドサーバ領域で
シェアなんてほぼ無かった気がする
とはいえサーバはやる気ない。プッシュしてるといえるのはOpteronXなのだろうか
シェアなんてほぼ無かった気がする
とはいえサーバはやる気ない。プッシュしてるといえるのはOpteronXなのだろうか
>>815
Sandy Bridge世代で-EXはE5ブランドにおりてきて(8Pサポートなし)
AMDの16コア×4Pにぶつけてきた。
Xeon E7の穴埋めとして従来のWestmere-EXの後継となるIvyBridge-EXAが出る。
Sandy Bridge世代で-EXはE5ブランドにおりてきて(8Pサポートなし)
AMDの16コア×4Pにぶつけてきた。
Xeon E7の穴埋めとして従来のWestmere-EXの後継となるIvyBridge-EXAが出る。
>>507
> 競合はRichlandのときと同じく、Core i5のハイエンド(多分Core i5-4670Kの方で、Core i5-4670Rではないと思われる)という話であり、
> 価格は当然これを意識したもの(Core i5-4670KはBOXが243.00米ドル)になる模様だ。
> おそらく200米ドル近辺での価格付けになると想像される。
ttp://news.mynavi.jp/articles/2013/11/14/apu03/index.html
> 競合はRichlandのときと同じく、Core i5のハイエンド(多分Core i5-4670Kの方で、Core i5-4670Rではないと思われる)という話であり、
> 価格は当然これを意識したもの(Core i5-4670KはBOXが243.00米ドル)になる模様だ。
> おそらく200米ドル近辺での価格付けになると想像される。
ttp://news.mynavi.jp/articles/2013/11/14/apu03/index.html
>>817
その仮想敵設定はいくらなんでも無茶だろwww
i5でゲームやる人は最初からグラボ刺すし
刺さない人ならなおさら内蔵GPUの性能に興味が無い。
「HSA使えば勝つる!」とかいう以前にCPUの理論FLOPSが4倍も離れてる。
その仮想敵設定はいくらなんでも無茶だろwww
i5でゲームやる人は最初からグラボ刺すし
刺さない人ならなおさら内蔵GPUの性能に興味が無い。
「HSA使えば勝つる!」とかいう以前にCPUの理論FLOPSが4倍も離れてる。
Richlandの時と同じなら$150程度だろ
どうやったら$200行くんだよ
どうやったら$200行くんだよ
>>819
Ivy→Haswellでi5の価格の方が上がったんじゃないの
Ivy→Haswellでi5の価格の方が上がったんじゃないの
非対称CF対応タイトルとその具体的な効果は?
いつでも市場の評価はAMD希望価格の半分以下
>>822
非対称CF対応タイトル→Mantle対応タイトル全部
Mantleの資料
http://www.hardware.fr/news/13445/apu13-amd-mantle-premiers-details.html
Mantle使うとGCN同士ならHD7750+290Xみたいな非対称構成でもクロスファイア可能、APU+GPUでも非対称可
http://www.hardware.fr/medias/photos_news/00/43/IMG0043438_1.jpg
しかも片方をGPGPU、もう片方でレンダリングなんていう仕事の振り分けもできる
http://www.hardware.fr/medias/photos_news/00/43/IMG0043437_1.jpg
別な資料
http://www.neogaf.com/forum/showthread.php?t=714178
http://i4.minus.com/iMpQPnd0sxZ8u.png
・CPUでの並列処理化
http://i7.minus.com/ibkyJ6T4GpTiTQ.png
・AFRの活用例:4〜8基のGPUでレンダリング(1台のワークステーションで20〜40TFlops)
・AFRの活用例:低レイテンシのVR向けレンダリング
非対称CF対応タイトル→Mantle対応タイトル全部
Mantleの資料
http://www.hardware.fr/news/13445/apu13-amd-mantle-premiers-details.html
Mantle使うとGCN同士ならHD7750+290Xみたいな非対称構成でもクロスファイア可能、APU+GPUでも非対称可
http://www.hardware.fr/medias/photos_news/00/43/IMG0043438_1.jpg
しかも片方をGPGPU、もう片方でレンダリングなんていう仕事の振り分けもできる
http://www.hardware.fr/medias/photos_news/00/43/IMG0043437_1.jpg
{kind=link}
別な資料
http://www.neogaf.com/forum/showthread.php?t=714178
http://i4.minus.com/iMpQPnd0sxZ8u.png
・CPUでの並列処理化
http://i7.minus.com/ibkyJ6T4GpTiTQ.png
・AFRの活用例:4〜8基のGPUでレンダリング(1台のワークステーションで20〜40TFlops)
・AFRの活用例:低レイテンシのVR向けレンダリング
DDR3に繋いだGPUなんてゴミだということを一番良くわかってるAMDが
なんでいつまでもAPUにこだわるのかわからないな。
なんでいつまでもAPUにこだわるのかわからないな。
なんというか、理論FLOPSの割りに実測がしょぼいのがAMDの問題なので、
良くも悪くも理論値での競合比較はあてにならない。
良くも悪くも理論値での競合比較はあてにならない。
ここはひとつ、
「hUMA対応だから理論性能の2倍の1.7TFLOPS級!」
みたいなおめでたいウォーズマン理論を。
>>824
MantleはAMDのCPUだけの特権じゃないんだし
いくらDDR3側のGPUの性能を加算したところでCPU性能で生じた差を
埋められるかははなはだ疑問だな
http://www.eteknix.com/amd-a10-6800-a10-6700-richland-apu-review/5/
「hUMA対応だから理論性能の2倍の1.7TFLOPS級!」
みたいなおめでたいウォーズマン理論を。
>>824
MantleはAMDのCPUだけの特権じゃないんだし
いくらDDR3側のGPUの性能を加算したところでCPU性能で生じた差を
埋められるかははなはだ疑問だな
http://www.eteknix.com/amd-a10-6800-a10-6700-richland-apu-review/5/
今はノート型のが売れてるんだから、グラボ買ってPCでゲームやる人は少数派だよ
PS4やXBOX1が出たら、PCでゲームやってた層も流れてくるし
そのうちグラボが売れない日も来るだろ
そうなってから動いてももう遅い
PS4やXBOX1が出たら、PCでゲームやってた層も流れてくるし
そのうちグラボが売れない日も来るだろ
そうなってから動いてももう遅い
> 今はノート型のが売れてるんだから
移行してるのはゲームをやらないか、やってもブラウザゲーや古い
MMORPG程度の層でしょ
移行してるのはゲームをやらないか、やってもブラウザゲーや古い
MMORPG程度の層でしょ
>>828
いや単純に非対称CFでグラボにAPU分の512sp足せるんならグラフィック性能で優位でしょ
↓これ見る限りMantle使うとCPU側の処理もだいぶ変わるみたいだし、出てみないとわからんね
http://i4.minus.com/iMpQPnd0sxZ8u.png
いや単純に非対称CFでグラボにAPU分の512sp足せるんならグラフィック性能で優位でしょ
↓これ見る限りMantle使うとCPU側の処理もだいぶ変わるみたいだし、出てみないとわからんね
http://i4.minus.com/iMpQPnd0sxZ8u.png
>>832
http://www.eteknix.com/amd-a10-6800-a10-6700-richland-apu-review/5/
ありえない仮定だけど、FX4300+HD 7970とA10-6800Kの
「Performance」のスコアを単純加算してもi5-3570+HD7970のそれに届いてない
Mantleでは謎のウォーズマン理論でも発動するの?
http://www.eteknix.com/amd-a10-6800-a10-6700-richland-apu-review/5/
ありえない仮定だけど、FX4300+HD 7970とA10-6800Kの
「Performance」のスコアを単純加算してもi5-3570+HD7970のそれに届いてない
Mantleでは謎のウォーズマン理論でも発動するの?
足かせを外すのがMantleで
今は本来の力を発揮できてないって言ってるだろ?
今は本来の力を発揮できてないって言ってるだろ?
>>833
発動するんじゃないの?
発動するんじゃないの?
APUに積まれるCPU側の性能が低すぎて、なけなしのGPGPU対応ソフトでの
効果もあくまで「当社比」にしかなってないところが問題だな
ノート向けはお察しの状況だし、低クロックで出てきたら
べいとれ4コアのPentium/CeleronのCPU性能に負けることもありうるわけだが
効果もあくまで「当社比」にしかなってないところが問題だな
ノート向けはお察しの状況だし、低クロックで出てきたら
べいとれ4コアのPentium/CeleronのCPU性能に負けることもありうるわけだが
明日PS4が発売される
アメリカでな
アメリカでな
mantleは実際にどんな挙動になるのか楽しみだけどね。
>>835
Mantleを使うとCPUがi5より速くなるの?
Mantleのドライバにi5に速度リミッタをかけるコードを仕込むくらいしか
方法が思い浮かばないよ。
ちなみにCPU側の本来の力はというと
Kaveriは4コアでAVX/FMAを駆使して110GFLOPS
Haswell i5は430GFLOPS
Mantleを使うとCPUがi5より速くなるの?
Mantleのドライバにi5に速度リミッタをかけるコードを仕込むくらいしか
方法が思い浮かばないよ。
ちなみにCPU側の本来の力はというと
Kaveriは4コアでAVX/FMAを駆使して110GFLOPS
Haswell i5は430GFLOPS
>>840
http://linustechtips.com/main/topic/76008-mantle-demo-amd-cpu-performance/
So Oxide Games had a demo of their new game engine running with Mantle and AMD's PR Manager was live tweeting it.
A lot of it was technical jargon which I can hardly understand but there were quite a few really interesting tweets which
make Mantle look pretty awesome! And I haven't seen anyone report this in the forums so here they are:
And this is the part that's really interesting! an under-clocked to 2GHz FX-8350 is not being a bottleneck to an R9 290X during the demo!!
and with Mantle it is equal if not faster than a 4770K! So it turns out AMD has been a company with a plan all along. Impressive.
理由はわからんがウォーズマン理論が発動してるんだろうな
あ、添付画像はユーザー登録しないと見れません、あしからず
http://linustechtips.com/main/topic/76008-mantle-demo-amd-cpu-performance/
So Oxide Games had a demo of their new game engine running with Mantle and AMD's PR Manager was live tweeting it.
A lot of it was technical jargon which I can hardly understand but there were quite a few really interesting tweets which
make Mantle look pretty awesome! And I haven't seen anyone report this in the forums so here they are:
And this is the part that's really interesting! an under-clocked to 2GHz FX-8350 is not being a bottleneck to an R9 290X during the demo!!
and with Mantle it is equal if not faster than a 4770K! So it turns out AMD has been a company with a plan all along. Impressive.
理由はわからんがウォーズマン理論が発動してるんだろうな
あ、添付画像はユーザー登録しないと見れません、あしからず
>>840
CPU側SIMDユニットのスループット理論値は捨てて浮いた面積をGPUに
回し、演算もGPUに回すのがAPUの設計思想だから、そこを直接比較しても
意味が無い。
この際問題になるのは、Steamrollerで「整数側が」どこまで改善されたか。
CPU側SIMDユニットのスループット理論値は捨てて浮いた面積をGPUに
回し、演算もGPUに回すのがAPUの設計思想だから、そこを直接比較しても
意味が無い。
この際問題になるのは、Steamrollerで「整数側が」どこまで改善されたか。
一次ソースはAPU13参加者↓のツイッタです
https://twitter.com/cavemanjim
https://twitter.com/cavemanjim
>>831
Intelみたいに15万のハイエンドスリムノートPCに+2万つめば
GPU性能が劇的に良くなるというソリューションは通用しうる。
でも4〜5万の安ノートに+2万は無理。
要するに高価格帯で売れるものが出せるかどうか次第。
高価格帯向け製品が出せないとやりたいことを実現できないし
コストダウンも進まない。
Intelみたいに15万のハイエンドスリムノートPCに+2万つめば
GPU性能が劇的に良くなるというソリューションは通用しうる。
でも4〜5万の安ノートに+2万は無理。
要するに高価格帯で売れるものが出せるかどうか次第。
高価格帯向け製品が出せないとやりたいことを実現できないし
コストダウンも進まない。
なんというか・・・
Mantleのような低レベルAPI自体は
パフォーマンスを引き出すのに良いことは確実だろ
あれだけDXによるCPUのオーバーヘッドが開発者からも文句でてるのに
だからこそEAも早速エンジンに組み込んだんだし
それをAMDだからと性能へのメリットも疑問視するとか見苦しすぎ
AMD以外のハードへの互換性でMantleの批判するならわかる
Mantleなんてどれだけ広まるんだ?と疑問視するならわかる
Mantleのような低レベルAPI自体は
パフォーマンスを引き出すのに良いことは確実だろ
あれだけDXによるCPUのオーバーヘッドが開発者からも文句でてるのに
だからこそEAも早速エンジンに組み込んだんだし
それをAMDだからと性能へのメリットも疑問視するとか見苦しすぎ
AMD以外のハードへの互換性でMantleの批判するならわかる
Mantleなんてどれだけ広まるんだ?と疑問視するならわかる
>>843
http://wccftech.com/amd-kaveri-steamroller-performance-revealed-integor-point-results-show-viable-competition-haswell/
さすがにこれでHaswell 4コア対抗は無理だろ。
Core 2 Quadでも怪しいレベル。
Near Production SampleでUpload帯域が謎の低下してるのも気になる。
ブロック図でも整数は2ALUのままで
4ALU(実際使えるのは3?)のHaswellに対抗できてるとは言いがたい?
http://wccftech.com/amd-kaveri-steamroller-performance-revealed-integor-point-results-show-viable-competition-haswell/
さすがにこれでHaswell 4コア対抗は無理だろ。
Core 2 Quadでも怪しいレベル。
Near Production SampleでUpload帯域が謎の低下してるのも気になる。
ブロック図でも整数は2ALUのままで
4ALU(実際使えるのは3?)のHaswellに対抗できてるとは言いがたい?
849 :Socket774:2013/11/14(木) 14:55:38.95 ID:oH48ETFM
業界がAMDに傾きつつある現実を認めなくないんだろw
面白いことにMantleの基調演説をしたのはDICEなんだけど、
その後一時間にわたりMantleのプレゼンやってたのはEidosなんだよなー
その後一時間にわたりMantleのプレゼンやってたのはEidosなんだよなー
別にAMDCPUが謎の高速化をしたわけじゃなくて
無駄を省いてより効率的に動くようにしたってだけのことを何故理解できないのか
無駄を省いてより効率的に動くようにしたってだけのことを何故理解できないのか
>>847
> GPUの力を発揮できるCPU性能があればいい
AMDのCPUがRadeonの性能にどれだけリミッタかけてると思ってるんだ
同じGPU使ってて真の8コア(笑)のFX8kがi5に及ばす、4kがi3に及ばずとかそんなんだよ
GPU本来の性能を発揮するためにはAMDのCPUを避ける。
自作板では常識だろ。
> GPUの力を発揮できるCPU性能があればいい
AMDのCPUがRadeonの性能にどれだけリミッタかけてると思ってるんだ
同じGPU使ってて真の8コア(笑)のFX8kがi5に及ばす、4kがi3に及ばずとかそんなんだよ
GPU本来の性能を発揮するためにはAMDのCPUを避ける。
自作板では常識だろ。
>>849
Opteron事業縮小でAMDの経営が傾きつつあるけどな
Opteron事業縮小でAMDの経営が傾きつつあるけどな
C2Qの話題はAMD信者がファビョーンするからやめておいたほうがいい
>>852
Mantleだとたった2GhzのFX8350でも290Xのボトルネックにはならず、かつ4770kより速いと書いてあるじゃないか
Mantleだとたった2GhzのFX8350でも290Xのボトルネックにはならず、かつ4770kより速いと書いてあるじゃないか
まぁそうなのーって感じで話半分だけどもね
実際見るまではね
実際見るまではね
う〜ん残念。
ようやく各記事見終わったけど、最後の最後に落ちが付いちゃったね。
ttp://pc.watch.impress.co.jp/img/pcw/docs/623/498/html/02.jpg.html
来年出る"Kaveri"は非SoC、"Beema""Mullins"は非HSAか。
デスクトップ型の"Kaveri"にAMD Security processorが無いのも用途的にそれほど気にならない。
逆にノート用やタブレット用の"Beema""Mullins"にAMD TrueAudioを内蔵するにはまだ非力なのも仕方が無い。
しかし、HSAとSoCの両立はまだ難しいという事か〜。
2014年に全部入りして2015年にそれをより最適化(というかIntelが先行している部分を詰める)をして本当の完成かと思ったが、
2016年以降に持越しっぽいなこれは。
まあ2006年のATI買収から始まる10年計画と考えれば2016年までかかるのは仕方が無いし、個人的には2020年が日本人としては
区切りの年だと思っているので、それまではゆっくり成熟を待つとしよう。
PS3〜PS4の間隔から言っても次々世代ゲーム機達もその頃発売だろうし、2006年から7年経った今に囲い込み開始を宣言しただけで、
全てを一新させるにはやはり助走期間も含めて全完了にはもう7年かかると見た方が良さそうだな。
まあ今まで同様気長に待つよ。
ようやく各記事見終わったけど、最後の最後に落ちが付いちゃったね。
ttp://pc.watch.impress.co.jp/img/pcw/docs/623/498/html/02.jpg.html
{kind=link}
来年出る"Kaveri"は非SoC、"Beema""Mullins"は非HSAか。
デスクトップ型の"Kaveri"にAMD Security processorが無いのも用途的にそれほど気にならない。
逆にノート用やタブレット用の"Beema""Mullins"にAMD TrueAudioを内蔵するにはまだ非力なのも仕方が無い。
しかし、HSAとSoCの両立はまだ難しいという事か〜。
2014年に全部入りして2015年にそれをより最適化(というかIntelが先行している部分を詰める)をして本当の完成かと思ったが、
2016年以降に持越しっぽいなこれは。
まあ2006年のATI買収から始まる10年計画と考えれば2016年までかかるのは仕方が無いし、個人的には2020年が日本人としては
区切りの年だと思っているので、それまではゆっくり成熟を待つとしよう。
PS3〜PS4の間隔から言っても次々世代ゲーム機達もその頃発売だろうし、2006年から7年経った今に囲い込み開始を宣言しただけで、
全てを一新させるにはやはり助走期間も含めて全完了にはもう7年かかると見た方が良さそうだな。
まあ今まで同様気長に待つよ。
というか事前リークが正しければNehalem以上sandy未満のIPCって話だし
OC耐性も含めれば十分な性能なんじゃないの?ここでやたら神格化されてる
haswellなんてOC耐性ないに等しいし、skylakeなんてAVX512抜きなら下手したら
今より性能下がるわけで
OC耐性も含めれば十分な性能なんじゃないの?ここでやたら神格化されてる
haswellなんてOC耐性ないに等しいし、skylakeなんてAVX512抜きなら下手したら
今より性能下がるわけで
> というか事前リークが正しければNehalem以上sandy未満のIPCって話だし
それは1モジュールでなのか1コアでの話なのか
1コアならFX撤退する必要なかったしLGA2011のi7に対抗できるじゃん。やったね!
それは1モジュールでなのか1コアでの話なのか
1コアならFX撤退する必要なかったしLGA2011のi7に対抗できるじゃん。やったね!
モジュールでIPC合算はずるいなあ。
たしか1コアの話だったような
FX撤退はHSA普及させるためじゃないの?
suteamrollerの8コアFX出るなら俺もそっち買っちゃうだろうしなあ
FX撤退はHSA普及させるためじゃないの?
suteamrollerの8コアFX出るなら俺もそっち買っちゃうだろうしなあ
863 :Socket774:2013/11/14(木) 15:33:39.31 ID:uPqjyKlW
結局HSAを本当の意味で完了させるためには、I/Oが要らなくなるからな。
そしてそれをソフト&ハードで完成させるためにはやっぱり時間掛かるだろ。
そしてそれをソフト&ハードで完成させるためにはやっぱり時間掛かるだろ。
865 :Socket774:2013/11/14(木) 15:40:36.16 ID:u5wbPisR
Ipcはシングルスレッド性能
866 :Socket774:2013/11/14(木) 15:53:08.36 ID:u5wbPisR
マントルはIntelユーザーだってGCNなグラボ刺してれば
(下手すりゃAMD-CPU以上に)恩恵があるんだから
何がなんでも否定したがってるのはnVidiaファンボーイでしょw
上手いことマントルが流行ったらi3やi5の下の方+ラデの
安いノートPCでもバリバリゲームできるようになるかもしれないし
流行るかどうかは別として、面白そうな取り組みやないですか
(下手すりゃAMD-CPU以上に)恩恵があるんだから
何がなんでも否定したがってるのはnVidiaファンボーイでしょw
上手いことマントルが流行ったらi3やi5の下の方+ラデの
安いノートPCでもバリバリゲームできるようになるかもしれないし
流行るかどうかは別として、面白そうな取り組みやないですか
intelCPU+GCNグラボでmantle使えばベストなんかね
APU要らないじゃん...
APU要らないじゃん...
>>867
それどころかIntelは6コア、8コアを積極的にメインCPU市場におろしてくる動機になる。
もちろんXeonDPの片手間で作ってるLGA2011版i7でなくてグラフィック統合版のほうね。
既にBayTrailセレロンが4コアに達してるんだし4コアは最低スペックでいい。
それどころかIntelは6コア、8コアを積極的にメインCPU市場におろしてくる動機になる。
もちろんXeonDPの片手間で作ってるLGA2011版i7でなくてグラフィック統合版のほうね。
既にBayTrailセレロンが4コアに達してるんだし4コアは最低スペックでいい。
871 :Socket774:2013/11/14(木) 16:13:19.12 ID:u5wbPisR
仮にそうなった場合
普及しないだろうな
普及しないだろうな
>>870
amdGPUを使うのを前提として作るとは思えんけどなぁ…
amdGPUを使うのを前提として作るとは思えんけどなぁ…
レンダリング負荷が分散されるって話だから
Mantleではコア数が重要になるんじゃないの
i3辺りのデュアルコアでは恩恵が薄いかと
i7のHTはある程度有効だろうけど、
処理内容からして実コアのほうが断然有利だろうね
Mantleではコア数が重要になるんじゃないの
i3辺りのデュアルコアでは恩恵が薄いかと
i7のHTはある程度有効だろうけど、
処理内容からして実コアのほうが断然有利だろうね
875 :Socket774:2013/11/14(木) 16:17:59.61 ID:u5wbPisR
>>868 IPC向上しててもOC込の性能はむしろsandyから下がってるじゃんw
当たり石を殻割りしてOCすりゃそれなりに回るけど、リスクやハズレ石も考慮に入れると
素直にivy−E買うかhaswell-E待った方がいいしで、メインストリームのCPUとしては完全にハズレだよ
まあ、ここでkaveriはグリスです!とかアフォなことしちゃったらintel大勝利だろうけどさ
当たり石を殻割りしてOCすりゃそれなりに回るけど、リスクやハズレ石も考慮に入れると
素直にivy−E買うかhaswell-E待った方がいいしで、メインストリームのCPUとしては完全にハズレだよ
まあ、ここでkaveriはグリスです!とかアフォなことしちゃったらintel大勝利だろうけどさ
877 :Socket774:2013/11/14(木) 16:21:43.25 ID:u5wbPisR
普通にあるだろ
普通にDirectXで良いって話になるだけ
880 :Socket774:2013/11/14(木) 16:23:32.24 ID:u5wbPisR
インテルのためにゲームをしているわけじゃない
ゲーム最強がインテルだっただけ
AMD最強なら乗り換えるだけ
ゲーム最強がインテルだっただけ
AMD最強なら乗り換えるだけ
>>873
別にNVIDIAのGPUでもいいんじゃね。
デベロッパーがDirectXの柵から離れられて一番困るのはMSだから
もっとCPU/GPUをスケーラブルに使える改良を施してくるだろう。
今は撤退してるけどIntel純正マザボでCrossfireやSLIを使えるようにしてきたIntelですよ
マルチスレッド対応が進まなくてほかに増やすもん無いからGPUブロック増やしてたわけで
サーバのようにコア数増やすだけで性能スケールするようになるなら
その手に乗らない理由は無い
別にNVIDIAのGPUでもいいんじゃね。
デベロッパーがDirectXの柵から離れられて一番困るのはMSだから
もっとCPU/GPUをスケーラブルに使える改良を施してくるだろう。
今は撤退してるけどIntel純正マザボでCrossfireやSLIを使えるようにしてきたIntelですよ
マルチスレッド対応が進まなくてほかに増やすもん無いからGPUブロック増やしてたわけで
サーバのようにコア数増やすだけで性能スケールするようになるなら
その手に乗らない理由は無い
>>876
OC込みで比べなくてもハズレルで淫厨大好きスーパーπ遅くなってる罠
OC込みで比べなくてもハズレルで淫厨大好きスーパーπ遅くなってる罠
883 :Socket774:2013/11/14(木) 16:27:56.45 ID:oYcBHf3g
最強になるかどうかはわからないけど
Mantleが普及すればPCのゲーム人口増加には役に立つんじゃないの
スペック不足だった人もターゲットになるんだから
Mantleが普及すればPCのゲーム人口増加には役に立つんじゃないの
スペック不足だった人もターゲットになるんだから
{kind=link}
>>884
なんでsandyだけ1333挿してるの、sandyって1333が定格なの?
なんでsandyだけ1333挿してるの、sandyって1333が定格なの?
>>885
そうだよ。Ivyから1600対応。
そうだよ。Ivyから1600対応。
>>886
そうなのかー、じゃあベンチは定格メモリ同士で比較してるか注意して見ないといけないんだな
そうなのかー、じゃあベンチは定格メモリ同士で比較してるか注意して見ないといけないんだな
>>884 これってクロック揃えて?それともまさか定格じゃないよね?
>>889
定格クロックなら4770K(3.4-3.9GHz)<3770K(3.5-3.9GHz)だが
定格クロックなら4770K(3.4-3.9GHz)<3770K(3.5-3.9GHz)だが
すまん、ぐぐったら自己解決、2700kなら定格で条件ほぼ同じだね
つか神格化するほどsandy→haswellで性能upしてるか?ベンチ厨以外気づかない程度の差だろこれ
つか神格化するほどsandy→haswellで性能upしてるか?ベンチ厨以外気づかない程度の差だろこれ
HaswellのES品リークが出た頃、なぜかSuperPIは遅くなっていたことがあった
その後Intelの測定部隊の人が遅くなるわけねーよと否定していたが、
その辺りから脳内情報を更新してないんだろうなあと
その後Intelの測定部隊の人が遅くなるわけねーよと否定していたが、
その辺りから脳内情報を更新してないんだろうなあと
むしろ神格化って何
894 :Socket774:2013/11/14(木) 16:57:16.50 ID:uPqjyKlW
>>875
>マントルはインテルにはあまり恩恵ありませんw
電力効率のいいCPUをとにかく並べればいいわけだから、インテルには嫌だろうな。
Jaguar8コアのコンシューマー機がインテルi7に匹敵とか言われる理由はここにあるんだろうな。
>マントルはインテルにはあまり恩恵ありませんw
電力効率のいいCPUをとにかく並べればいいわけだから、インテルには嫌だろうな。
Jaguar8コアのコンシューマー機がインテルi7に匹敵とか言われる理由はここにあるんだろうな。
あほらし
>>891
新命令対応に多くのリソースを割いたにもかかわらず
FPにx87命令しか使ってなくて保守もされてないソフトでも
ちゃんと改良の効果がスコアに反映されてるんだが。
別に前世代同クラスに比べて値段も高くなってないのになぜ叩く必要があるの?
Haswellを執拗に叩くのはIntelの次世代のほうで話題になってた
某BTOスレでi5>i7とか力説してるマジ基地と同じ臭いを感じるよ。
新命令対応に多くのリソースを割いたにもかかわらず
FPにx87命令しか使ってなくて保守もされてないソフトでも
ちゃんと改良の効果がスコアに反映されてるんだが。
別に前世代同クラスに比べて値段も高くなってないのになぜ叩く必要があるの?
Haswellを執拗に叩くのはIntelの次世代のほうで話題になってた
某BTOスレでi5>i7とか力説してるマジ基地と同じ臭いを感じるよ。
http://www.cpu-world.com/news_2013/2013050801_New_benchmarks_of_Core_i5-4570_and_i7-4770K_CPUs_posted.html
やっぱπ遅くなってるじゃん
やっぱπ遅くなってるじゃん
いやもうパイの話はよそう、すごくどうでもいい気がする
> Wednesday May 8, 2013 15:24
この頃はまだ市場に出てませんが・・・
この頃はまだ市場に出てませんが・・・
BeemaやMullinsにしたって、多分自作には何の関係もないぜこれ
あっても組み込み向けのママンが流れてくるとかその程度だろう
あっても組み込み向けのママンが流れてくるとかその程度だろう
>>896 別に叩いてるつもりはないよ、ただsandyごときの追いついてもまだhaswellが〜
みたいな意見に対してそんな差あるか?って話でさ
みたいな意見に対してそんな差あるか?って話でさ
i7が2GHzのFXに負けるとか言ってる人いたけどそれって両方mantleに対応させてやった比較?
>>903
And this is the part that's really interesting! an under-clocked to 2GHz FX-8350 is not being a bottleneck to an R9 290X during the demo!!
and with Mantle it is equal if not faster than a 4770K! So it turns out AMD has been a company with a plan all along. Impressive.
どう解釈したらいいかな
And this is the part that's really interesting! an under-clocked to 2GHz FX-8350 is not being a bottleneck to an R9 290X during the demo!!
and with Mantle it is equal if not faster than a 4770K! So it turns out AMD has been a company with a plan all along. Impressive.
どう解釈したらいいかな
>>903
http://linustechtips.com/main/topic/76008-mantle-demo-amd-cpu-performance/
そのソースはこれのようだ
ただ、鵜呑みにする様な話でもまだない
真偽はいずれわかる
http://linustechtips.com/main/topic/76008-mantle-demo-amd-cpu-performance/
そのソースはこれのようだ
ただ、鵜呑みにする様な話でもまだない
真偽はいずれわかる
まぁ話半分だね、実際見てないから
>>904
>>905
thx
http://www.hardware.fr/news/13450/apu13-oxide-fait-exploser-limite-cpu-avec-mantle.html
この記事とかみるかぎりintelCPUでも十分恩恵ありそうだし、無理にFX買う必要はなさそうだな
>>905
thx
http://www.hardware.fr/news/13450/apu13-oxide-fait-exploser-limite-cpu-avec-mantle.html
この記事とかみるかぎりintelCPUでも十分恩恵ありそうだし、無理にFX買う必要はなさそうだな
ダウンクロックしたFXでGPUを使い切れているので、
i7でもボトルネックにはならないと
同様にi7だから速くなるわけでもない
そもそもMantleで負荷が下がりますという文脈だろうし、
設定環境は擬似的なJaguar8コアを意識したのかな
こういうデモの解釈はかなりぼんやり
i7でもボトルネックにはならないと
同様にi7だから速くなるわけでもない
そもそもMantleで負荷が下がりますという文脈だろうし、
設定環境は擬似的なJaguar8コアを意識したのかな
こういうデモの解釈はかなりぼんやり
2GhzのFX8350でいいなら4GhzのA10-6800Kでもいいのではないのかと
"not faster than"(=同等)がなんで4770Kより速いになるんだ
英語力大丈夫か?
英語力大丈夫か?
>>907
このあたり見る限りi7使ってれば問題ないようだな
http://www.hardware.fr/medias/photos_news/00/43/IMG0043519_1.jpg
http://www.hardware.fr/medias/photos_news/00/43/IMG0043520_1.jpg
このあたり見る限りi7使ってれば問題ないようだな
http://www.hardware.fr/medias/photos_news/00/43/IMG0043519_1.jpg
{kind=link}
http://www.hardware.fr/medias/photos_news/00/43/IMG0043520_1.jpg
{kind=link}
結局、Mantle対応タイトルを、core i7+R290Xでプレイするのが最強ってことで
そもそもHSAはGPUをCPUと同列に扱えるようにするためのものなんだし、
そこまでいかなくても、GCN世代のGPUを普通につかえるようになれば、
コンピュートとグラフィックの同時実行が可能になるわけで、
そうなれば、物理とかAIもGPU側でやれば済むはなしで、
速いCPUへの依存なんてなくなるだろうに。
【AMDのIntel対抗策】
マルチコア・メニーコア化 > Intelのがプロセス技術で先行してるので勝てなかった。
ヘテロジニアス・コンピューティング > 自社でGPUをもってる利点がある。 (今ココね)
そこまでいかなくても、GCN世代のGPUを普通につかえるようになれば、
コンピュートとグラフィックの同時実行が可能になるわけで、
そうなれば、物理とかAIもGPU側でやれば済むはなしで、
速いCPUへの依存なんてなくなるだろうに。
【AMDのIntel対抗策】
マルチコア・メニーコア化 > Intelのがプロセス技術で先行してるので勝てなかった。
ヘテロジニアス・コンピューティング > 自社でGPUをもってる利点がある。 (今ココね)
Oxide's presentation & Mantle demo at #APU13 is awesome,
100k draw calls in their space test game. Great work guys!
デモってこれみたいね、StarSwarmかな。10万draw callってすごいの?
https://twitter.com/repi/status/400803254147485696/photo/1
100k draw calls in their space test game. Great work guys!
デモってこれみたいね、StarSwarmかな。10万draw callってすごいの?
https://twitter.com/repi/status/400803254147485696/photo/1
要するに、Mantleでは今までよりCPUパワーの大小は
グラフィックパフォーマンスに影響しないってことでしょ。
今まではIntelの高速CPUを搭載しないと、ハイエンドGPUを生かしきれなかったが
Mantleゲームならもっと低速なCPUでもパフォーマンスを出せると。
これは高速CPUを持っていないAMDにとって大きなメリットだし、
CPUパワーが制限されてしまうAPUでも大いに利点となりうる
グラフィックパフォーマンスに影響しないってことでしょ。
今まではIntelの高速CPUを搭載しないと、ハイエンドGPUを生かしきれなかったが
Mantleゲームならもっと低速なCPUでもパフォーマンスを出せると。
これは高速CPUを持っていないAMDにとって大きなメリットだし、
CPUパワーが制限されてしまうAPUでも大いに利点となりうる
ところがどっこい
CPUに余裕ができればそのCPUをガッツリ使ってくるのがゲーム屋ですよ
グラフの緑色の部分はCPUの空き時間じゃなくて
エンジンの利用者であるプログラマーが使えるCPU時間を意味している。
まあ、ゲームの進行に影響を与えない物理演算が豪華になるとか
そういう使い道にはなるかもしれないけどね
CPUに余裕ができればそのCPUをガッツリ使ってくるのがゲーム屋ですよ
グラフの緑色の部分はCPUの空き時間じゃなくて
エンジンの利用者であるプログラマーが使えるCPU時間を意味している。
まあ、ゲームの進行に影響を与えない物理演算が豪華になるとか
そういう使い道にはなるかもしれないけどね
KaveriはIPCがLlanoのK10と同等なら文句ないな
GPUは4770R越えのGT3eレベルまで行けるかな?
OCするわけじゃないし、初代Llanoとと同様にAPUの完成度が高ければよい
TryとRich(中身はPoor)は高クロックだけど遅い最悪な出来だった
GPUは4770R越えのGT3eレベルまで行けるかな?
OCするわけじゃないし、初代Llanoとと同様にAPUの完成度が高ければよい
TryとRich(中身はPoor)は高クロックだけど遅い最悪な出来だった
そもそも、グラフィック性脳にこだわるような人が、AMDのAPU買うとはおもえん
常識的に考えてdGPU買うだろ
HD7850/GT660あたりの安いGPUでも、APUよりはるかに速いんだから
常識的に考えてdGPU買うだろ
HD7850/GT660あたりの安いGPUでも、APUよりはるかに速いんだから
>>918
ホント毎回こういう周回遅れ意見が出るのが不思議でしょうがないわ
ホント毎回こういう周回遅れ意見が出るのが不思議でしょうがないわ
なにがあったか三行でオナシャス
>>913
なぜ物理(演算?)とかAIをマルチコア化で解決できなかったの?
なぜ物理(演算?)とかAIをマルチコア化で解決できなかったの?
>>918
APUを選ぶのは手段ではなく目的だから
APUを選ぶのは手段ではなく目的だから
>>921
・マルチコアCPUが少ない
現実のPCでは1コア2コアのPCも考慮せねばならず、平均的なコア数は意外と少ない
最近まで4コアまでしかスケールしないゲームばかり
・物理演算は浮動小数点演算負荷が高いが、CPUではパワー不足
そのうえnVidiaが嫌がらせで、長らくPhysXのCPU対応をシングルコアに縛っている
・GPUを使ったAIが開発されてきたのは最近
AIはCPUを酷使するものだったが、最近ようやくGPUを活用するものが出てきた
それもこれもGPU側のGPGPU向け改良と、ソフトウェア側の努力の賜物
それをより推進するのがHSA
・マルチコアCPUが少ない
現実のPCでは1コア2コアのPCも考慮せねばならず、平均的なコア数は意外と少ない
最近まで4コアまでしかスケールしないゲームばかり
・物理演算は浮動小数点演算負荷が高いが、CPUではパワー不足
そのうえnVidiaが嫌がらせで、長らくPhysXのCPU対応をシングルコアに縛っている
・GPUを使ったAIが開発されてきたのは最近
AIはCPUを酷使するものだったが、最近ようやくGPUを活用するものが出てきた
それもこれもGPU側のGPGPU向け改良と、ソフトウェア側の努力の賜物
それをより推進するのがHSA
>>921
Intelがやってたじゃん、Larrabee(笑)で
Intelがやってたじゃん、Larrabee(笑)で
まあ
CPU処理が軽くなってGPUのタスク充填率をあげられる
→GPU側空き時間をGPGPUで埋める必要なくなる
→じゃあ空いてるほうのCPUでは何やろう?
まあ物理やAIは描画にかかわるものでなければCPU処理したほうがいいでしょ。
ダメージ判定とかCPUでやらないといけないのにGPUでやると遠いし。
CPU処理が軽くなってGPUのタスク充填率をあげられる
→GPU側空き時間をGPGPUで埋める必要なくなる
→じゃあ空いてるほうのCPUでは何やろう?
まあ物理やAIは描画にかかわるものでなければCPU処理したほうがいいでしょ。
ダメージ判定とかCPUでやらないといけないのにGPUでやると遠いし。
今どき、AMDはコスパ良いよね♪って言ってAPU買うヤツはただの情弱だろ。
俺たちはAMD好きだからAPU買ってるだけで、APUに優位性が無い事など百も承知。
俺たちはAMD好きだからAPU買ってるだけで、APUに優位性が無い事など百も承知。
927 :Socket774:2013/11/14(木) 19:00:10.23 ID:HSt3wENY
2013/11/14 17:29ニュース
GTX 780 Tiカードが発火問題でリコール? NVIDIAに問い合わせた結果報告編集部:佐々山薫郁
数日前から,中国のメディアや掲示板で,「『GeForce GTX 780 Ti』搭載カードの基板が燃える」という話が挙がっているのをご存じだろうか。
現地のニュースサイトによれば,実際にGALAXY Microsystems(以下,GALAXY)が55枚のリコールを行ったという話も出てきており,
果たして日本国内で流通しているカードに問題はないのか,不安を感じている読者もいるのではないかと思う。
そこで4Gamerでは,「中国で話題になってるリコールの話はいったい何ですか」と,NVIDIAに直球で問い合わせてみた。
今回,以下のとおりお伝えするのは,その回答の和訳である。
なお,和訳内の( )は筆者による補足。筆者は英文和訳の専門家でも何でもないので,つたない訳文になるところはご容赦を。
GTX 780 Tiカード全般に関わる問題だとされる(中国市場におけるリコールの)報道はNVIDIAのリファレンスデザインに対して許可されていない変更をGALAXYが行ったため,
55枚のカードにおいて問題が生じたのです。
【原文】
The reports about widespread issues with GTX 780 Ti are false. An issue was found with 55 cards from Galaxy which resulted from an unauthorized modification to NVIDIA’s reference design.
This issue has since been corrected by Galaxy, and the originating Facebook post by Centralfield that was referenced in the Chinese articles has already been retracted too.
http://www.4gamer.net/games/216/G021677/20131114061/
,,,
( ゚д゚)つ┃GTX780Tiへ
GTX 780 Tiカードが発火問題でリコール? NVIDIAに問い合わせた結果報告編集部:佐々山薫郁
数日前から,中国のメディアや掲示板で,「『GeForce GTX 780 Ti』搭載カードの基板が燃える」という話が挙がっているのをご存じだろうか。
現地のニュースサイトによれば,実際にGALAXY Microsystems(以下,GALAXY)が55枚のリコールを行ったという話も出てきており,
果たして日本国内で流通しているカードに問題はないのか,不安を感じている読者もいるのではないかと思う。
そこで4Gamerでは,「中国で話題になってるリコールの話はいったい何ですか」と,NVIDIAに直球で問い合わせてみた。
今回,以下のとおりお伝えするのは,その回答の和訳である。
なお,和訳内の( )は筆者による補足。筆者は英文和訳の専門家でも何でもないので,つたない訳文になるところはご容赦を。
GTX 780 Tiカード全般に関わる問題だとされる(中国市場におけるリコールの)報道はNVIDIAのリファレンスデザインに対して許可されていない変更をGALAXYが行ったため,
55枚のカードにおいて問題が生じたのです。
【原文】
The reports about widespread issues with GTX 780 Ti are false. An issue was found with 55 cards from Galaxy which resulted from an unauthorized modification to NVIDIA’s reference design.
This issue has since been corrected by Galaxy, and the originating Facebook post by Centralfield that was referenced in the Chinese articles has already been retracted too.
http://www.4gamer.net/games/216/G021677/20131114061/
,,,
( ゚д゚)つ┃GTX780Tiへ
MS、SCE「AMDはコスパ良いよね♪」
>>926
俺”たち”って君とだれの事?
俺”たち”って君とだれの事?
>>923
CPUを使ったAIはすでにあるならマルチコアで解決できたんじゃね?
物理演算だってNVIDIAが足引っぱたってAMDがコアをもっと増やせば移行せざるをえないだろうし
HSAなんてまだ始まってすら無いものを頼りにしてどうすんだろう
CPUを使ったAIはすでにあるならマルチコアで解決できたんじゃね?
物理演算だってNVIDIAが足引っぱたってAMDがコアをもっと増やせば移行せざるをえないだろうし
HSAなんてまだ始まってすら無いものを頼りにしてどうすんだろう
結局ホモジニアスマルチコア(ララビー)と
ヘテロジニアスマルチコア(APU)の対決で
ゲームに関してはララビーが性能出なかったということだろ
同種のみのホモジニアスは理想論として設計が美しいし
異種混合のヘテロジニアスは設計が煩雑
ただ実際問題として専門の処理は機構をある程度分けて分業して
どちらも可能な処理では効率化良い方にバランシングするのが
パフォーマンス的に現実解だった
ヘテロジニアスマルチコア(APU)の対決で
ゲームに関してはララビーが性能出なかったということだろ
同種のみのホモジニアスは理想論として設計が美しいし
異種混合のヘテロジニアスは設計が煩雑
ただ実際問題として専門の処理は機構をある程度分けて分業して
どちらも可能な処理では効率化良い方にバランシングするのが
パフォーマンス的に現実解だった
始めようとしなきゃ始まらない。
問題はユーザーに対していかにデメリットなく浸透させるか。
APUの本来の目的はちょっと昔のゲームが快適にできればいいや
という層にグラボ不要で安いチップを提供しようというもので
別にCPUのマルチコア活用を阻害しようとかいうものではないから
目くじら立てる必要も無い。
HSAだのは「使えればいいな」というおまけ要素と割り切るべし。
問題はユーザーに対していかにデメリットなく浸透させるか。
APUの本来の目的はちょっと昔のゲームが快適にできればいいや
という層にグラボ不要で安いチップを提供しようというもので
別にCPUのマルチコア活用を阻害しようとかいうものではないから
目くじら立てる必要も無い。
HSAだのは「使えればいいな」というおまけ要素と割り切るべし。
FXスレ眺めてるつもりでいたら間違っててなんか凄まじく奇妙な感覚だったw
こういう人達もいるんだなぁ、とちょっと笑えたw
こういう人達もいるんだなぁ、とちょっと笑えたw
Larrabee GPUも、Cell GPUも、汎用コアでシェーダーやらせても、
グラフィック専門に作ったシェーダーコアにくらべて全然性能が出なかったからキャンセルされたんでしょう
Cellは後に頂点処理等前処理をやったりポストプロセスAA等の後処理に活用され、
LarrabeeはXeon PhiとしてHPC専用になった
グラフィック専門に作ったシェーダーコアにくらべて全然性能が出なかったからキャンセルされたんでしょう
Cellは後に頂点処理等前処理をやったりポストプロセスAA等の後処理に活用され、
LarrabeeはXeon PhiとしてHPC専用になった
単に固定機能が少ないだけ
>>932
ちょうど64bit化の時と同じ流れだな
ちょうど64bit化の時と同じ流れだな
物理演算も専用回路にしたほうが合理的かもね
PhysX PPUの復活ですか
940 :Socket774:2013/11/14(木) 19:38:47.00 ID:uPqjyKlW
DSPだと柔軟性が無いだろ
CPUでもGPUでも動かせるようにしておいて負荷バランスに応じて
切り替えられるようにすればいいんじゃないの。
というかHavokがそうやってるけど。
PC版PhysXみたいに「なにがなんでもGPUで処理する!」はそれでそれで
柔軟性に欠ける。
切り替えられるようにすればいいんじゃないの。
というかHavokがそうやってるけど。
PC版PhysXみたいに「なにがなんでもGPUで処理する!」はそれでそれで
柔軟性に欠ける。
>>937
64bit化は、4G以上のメモリが使えるっていうわかりやすい利点があるじゃん
64bit化は、4G以上のメモリが使えるっていうわかりやすい利点があるじゃん
ゲームの進行に影響を与えるような範囲で物理演算が広く使われるようになると
ネットゲームではサーバサイドでステータスの一環性を保つため
物理演算も大量にそつなくこなせるサーバプロセッサが必要になる。
Havokは親会社と競合関係にあるメーカープラットフォームだろうと
積極的に物理エンジンを提供してる。
結果的にはその分だけXeon/Xeon Phiを売る市場が拡大するからね。
NVIDIAもTeslaが活用できるかもしれない。
ネットゲームではサーバサイドでステータスの一環性を保つため
物理演算も大量にそつなくこなせるサーバプロセッサが必要になる。
Havokは親会社と競合関係にあるメーカープラットフォームだろうと
積極的に物理エンジンを提供してる。
結果的にはその分だけXeon/Xeon Phiを売る市場が拡大するからね。
NVIDIAもTeslaが活用できるかもしれない。
944 :Socket774:2013/11/14(木) 20:09:44.20 ID:uPqjyKlW
だからHAVOKを買収したのは単にララビを売りたかっただけだってば。
>>942
当時256MBが主流だった時代だぞ
当時256MBが主流だった時代だぞ
>>944
必要なくなったのなら手放すか飼い殺しにしてもいいよね。
実際には、AMDのGPUもだけどほぼ全てのゲーム機やスマホに
エンジンの提供を続けてる。
SoftbankモバイルなんてAtom搭載のスマホを出す予定なんて微塵も無い。
でもIntelはMcAfeeを提供してる。
何故か?サーバサイドで稼げるからだよ。
必要なくなったのなら手放すか飼い殺しにしてもいいよね。
実際には、AMDのGPUもだけどほぼ全てのゲーム機やスマホに
エンジンの提供を続けてる。
SoftbankモバイルなんてAtom搭載のスマホを出す予定なんて微塵も無い。
でもIntelはMcAfeeを提供してる。
何故か?サーバサイドで稼げるからだよ。
947 :Socket774:2013/11/14(木) 20:30:04.59 ID:3x54Tegc
Apple,AチップをGlobalFoundriesに製造委託?
http://blog.livedoor.jp/amd646464/archives/52384822.html
http://blog.livedoor.jp/amd646464/archives/52384822.html
3D積層チップ競争で、GFが頭ひとつ抜けたって噂になってますな(´・ω・`)
だって去年から「実はいつでもリリースできる」なんて噂がありましたからね
おっと、TSMCの20nmチップの製造が来年2月から始まるのは
言っちゃいけない話だぞ!
AMDとはとっくに資本関係切れてるからGFが有利だろうと
不利だろうと知ったことじゃないんですけどね。
言っちゃいけない話だぞ!
AMDとはとっくに資本関係切れてるからGFが有利だろうと
不利だろうと知ったことじゃないんですけどね。
3Dチップ開発、メーカーの動きは? (1/2)
3次元積層技術を用いたチップ(3Dチップ)の開発動向に注目が集まっている。
こう着状態にも見える3Dチップの開発だが、メーカーは着実に前進しているようだ。
http://eetimes.jp/ee/articles/1311/14/news063.html
3次元積層技術を用いたチップ(3Dチップ)の開発動向に注目が集まっている。
こう着状態にも見える3Dチップの開発だが、メーカーは着実に前進しているようだ。
http://eetimes.jp/ee/articles/1311/14/news063.html
kaveriもfxもGFだから関係あるだろ
953 :Socket774:2013/11/14(木) 20:52:25.65 ID:uPqjyKlW
954 :Socket774:2013/11/14(木) 20:55:54.66 ID:uPqjyKlW
http://eetimes.jp/ee/articles/1311/14/news063_2.html
>メモリは、この簡素なボードの反対側に搭載されていることが分かった。
アップルは基盤の反対側にチップくっつけたのかな?
>メモリは、この簡素なボードの反対側に搭載されていることが分かった。
アップルは基盤の反対側にチップくっつけたのかな?
オンラインに接続するゲームで物理演算が当たり前に使われるようになると
サーバサイドで大量の物理演算が必要になるからIntelが儲かる
APU版Opteronも袋小路に迷い込んだように見えて実はいい線を
いってる可能性もある
サーバサイドで大量の物理演算が必要になるからIntelが儲かる
APU版Opteronも袋小路に迷い込んだように見えて実はいい線を
いってる可能性もある
956 :Socket774:2013/11/14(木) 21:15:11.74 ID:uPqjyKlW
MantleとPSSLは類似したAPIらしく親和性は高いらしい
http://gearnuke.com/dice-mantle-playstation-4-will-drive-frostbite-development-going-forward/
http://gearnuke.com/dice-mantle-playstation-4-will-drive-frostbite-development-going-forward/
もちろんクライアントでも処理するのだけど
その端末でしか表示されない視覚効果だけじゃなくて
同じサーバに接続してる全員に影響を与える物理演算効果は
サーバで処理するしかない
その端末でしか表示されない視覚効果だけじゃなくて
同じサーバに接続してる全員に影響を与える物理演算効果は
サーバで処理するしかない
実際ソニーはPS3のゲームのオンを実装する際に
大量のPS3実機そのものをクラスタリングして物理演算サーバを作ってた
大量のPS3実機そのものをクラスタリングして物理演算サーバを作ってた
>>950
AMDの来年のメインは28nだからな。
TSMCより遅れているプロセスでIntelと戦うんだから勝負にならないよな。
来年のIntelは、PCのメインストリームのノート用を14nにするんだろ
ノート用のスチームAPUって爆熱、供給問題で碌に採用されないかもしれないな
だからこそ、デスクトップでゲームをがんばるのかもな
AMDの来年のメインは28nだからな。
TSMCより遅れているプロセスでIntelと戦うんだから勝負にならないよな。
来年のIntelは、PCのメインストリームのノート用を14nにするんだろ
ノート用のスチームAPUって爆熱、供給問題で碌に採用されないかもしれないな
だからこそ、デスクトップでゲームをがんばるのかもな
PS4の初期不良が多すぎて海外で大炎上!物売るレベルじゃない。|| ^^ |秒刊SUNDAY
http://www.yukawanet.com/archives/4572062.html
>こちらのユーザは起動後一時間も使わないうちにフリーズが発生。
>PS4のGPUが致命的な問題を起こしていると非難している。
http://www.yukawanet.com/archives/4572062.html
>こちらのユーザは起動後一時間も使わないうちにフリーズが発生。
>PS4のGPUが致命的な問題を起こしていると非難している。
>>961
Sonyって、まぁ韓国企業みたいなものだからそんなのを平然と出す
Sonyって、まぁ韓国企業みたいなものだからそんなのを平然と出す
さてこれはどこの責任となるのかな
ソニーの初期ロットなんて毎度こんなもんだろ。
買う方もわかって買ってる。
買う方もわかって買ってる。
クソニー信者基地外が多いな
ステマなどで工作して他社を攻撃するだけあるわ怖い
ステマなどで工作して他社を攻撃するだけあるわ怖い
勝手にフラゲして保障しろとかまるで韓国人wwwwww
ハード的な問題なのかソフト的な問題なのか
sonyの初期型は買うな
有料で購入者にテストさせるようなもの、サポート含めsonyは良くないから待て
有料で購入者にテストさせるようなもの、サポート含めsonyは良くないから待て
秒刊サンデーってなかなか香ばしいアフィブログだね
問題は1、2件の初期不良を「多すぎ」みたいに捏造してる"日本の"糞ブログ共だよ
アフィブログはアクセス稼いでナンボだしな
PS4そんな状態なのか、どのみち発売されるんだろうけど、ステマなのか
リアルなのかはっきりするんじゃない。
リアルなのかはっきりするんじゃない。
973 :Socket774:2013/11/14(木) 21:57:05.37 ID:uPqjyKlW
>>970
neogafって日本だっけ?w
neogafって日本だっけ?w
毎回アクセス稼ぐためだけにやってるからなぁ興味ないわ
ああいうのはアホなソニー信者がほいほい釣れて金儲けになるからなあ
ARMって将来的にx86駆逐するの?
http://hayabusa3.2ch.net/test/read.cgi/morningcoffee/1384202732/
http://hayabusa3.2ch.net/test/read.cgi/morningcoffee/1384202732/
これも必死のマルチだな
秒間Sunday見てみた。
日本では未発売だけどOuyaなんてゲーム機があるんだな。
Tegra3搭載のスマホをそのまま据え置きスペックにしたようなもの
しかもスクエニがFF3を出してるとか。
なんだ、NVIDIA一応家庭用ゲーム機出してるじゃん(棒
日本では未発売だけどOuyaなんてゲーム機があるんだな。
Tegra3搭載のスマホをそのまま据え置きスペックにしたようなもの
しかもスクエニがFF3を出してるとか。
なんだ、NVIDIA一応家庭用ゲーム機出してるじゃん(棒
プロセッサの歴史上、これまで何度も強力なライバルが登場し、
その都度、x86はもう終わりだと囁かれながら、無慈悲に返り討ちにしてきた歴史が、
また繰り返されるだけだろ。
その都度、x86はもう終わりだと囁かれながら、無慈悲に返り討ちにしてきた歴史が、
また繰り返されるだけだろ。
大胆予測だが
mantleが動いた後
intelのiGPUにamdが載るだろう
mantleが動いた後
intelのiGPUにamdが載るだろう
>>979
x86の繁栄はwindowsと共にあった、なら衰退も同期するのではないか
x86の繁栄はwindowsと共にあった、なら衰退も同期するのではないか
mantleはXeon E5-2000系持ってる人たちが喜びそうな感じだなw
インテルのハイエンドユーザーも喜ぶしAMDユーザーも喜ぶしで良いじゃないかw
インテルのハイエンドユーザーも喜ぶしAMDユーザーも喜ぶしで良いじゃないかw
>>980
ねぇよ
ねぇよ
ついでに予想だが、intelCPUにamdがのった時
amdのcpuはフェードアウトしている
armのcpuを供給しているだろう
amdのcpuはフェードアウトしている
armのcpuを供給しているだろう
>>979
返り討ちっていうかIntelの時価総額ってすでにQualcommの下なんだけど。
返り討ちっていうかIntelの時価総額ってすでにQualcommの下なんだけど。
株価なんてそんなもんだろw
別に株価で使うCPU決めてるわけじゃないし本気でどうでもいい
ARMコア使ってるOS用のソフト開発って結局Windowsとか使ってるよねえ、
ってところでARMとx86の戦いってなんか違和感ある。
デスクトップ用OSじゃないし、売れた個数とかの意味では勿論戦いは成立してるんだけど、
なんかx86に首根っこつかまれてる感がある。
ってところでARMとx86の戦いってなんか違和感ある。
デスクトップ用OSじゃないし、売れた個数とかの意味では勿論戦いは成立してるんだけど、
なんかx86に首根っこつかまれてる感がある。
{kind=link}
シャットダウンじゃなくて冷えるまでスリープなのか?
だとしたら少しだけ親切だなw
だとしたら少しだけ親切だなw
発熱対策のためにR9 290Xみたいな爆音ファン積まれるのも困り物だがな
PS4で使われているSoCのTDPは100Wを軽く超えているだろうから、
CPUでいうとハイエンド級で、そりゃ熱いだろうなと
もっとも程度問題な気はするけど
CPUでいうとハイエンド級で、そりゃ熱いだろうなと
もっとも程度問題な気はするけど
どうせちっちゃいからって熱の篭るような空間に置いてるとか
暖房器具の熱気当ててるとかでしょ
暖房器具の熱気当ててるとかでしょ
PCをテレビの台に入れて置いてたら、
と同じかもな
案外やりそう
と同じかもな
案外やりそう
1000ならAMD爆死
1001 :1001: