Intel�̎�����CPU�ɂ��Č�낤 47
|
|
|
�ߔN�H�Ɍ��邵�傤���Ȃ��L�[�m�[�g������
http://download.intel.com/newsroom/kits/idf/2011_fall/pdfs/IDF_Day_1_factsheet.pdf
http://download.intel.com/newsroom/kits/idf/2011_fall/pdfs/IDF_Day_1_factsheet.pdf
���܂�����������������������������������������������������
>> Haswell���ǂ���Sandy�̃}�C�i�[�`�F���W
> �\�[�X��]
�����ŋ߂̃��[�}�[�T�C�g�ł̏��W�߂���AAVX�Q�Ƃ��V���߁ASoC���Ƒ啝�d�͍팸���x�����Ȃ��킯��
�܂肻��ȊO�ɂƂ��Ƀl�^���Ȃ���Sandy�R�A�g���ŏI�n
�����A�ȓd�͉��Ɋւ��Ă͂͂�����ARM�����z�I�ɂ���Ultrabook�𐄐i���Ă����炵���̂�
���҂͂��Ă����݂�����
> �\�[�X��]
�����ŋ߂̃��[�}�[�T�C�g�ł̏��W�߂���AAVX�Q�Ƃ��V���߁ASoC���Ƒ啝�d�͍팸���x�����Ȃ��킯��
�܂肻��ȊO�ɂƂ��Ƀl�^���Ȃ���Sandy�R�A�g���ŏI�n
�����A�ȓd�͉��Ɋւ��Ă͂͂�����ARM�����z�I�ɂ���Ultrabook�𐄐i���Ă����炵���̂�
���҂͂��Ă����݂�����
���ǔ]���\�[�X���悗����
6 �FSocket774�F2011/09/14(��) 07:47:44.28 ID:MOszTd4D
sandyE�̑��w�A�n���L���ڂ���
>>5
http://www.4gamer.net/games/132/G013298/20110904002/
����Ŗ�����
���̋L�����t��������ƁA���C�����͂Ȃɂ��ς�炸AVX�֘A���p���߂��������₳��Ă�
http://www.4gamer.net/games/132/G013298/20110904002/
����Ŗ�����
���̋L�����t��������ƁA���C�����͂Ȃɂ��ς�炸AVX�֘A���p���߂��������₳��Ă�
Ivy Bridge CPU Architecture Details Revealed
http://images.anandtech.com/galleries/1374/IMG_0190_575px.JPG
http://images.anandtech.com/galleries/1374/IMG_0191_575px.JPG
http://images.anandtech.com/galleries/1374/IMG_0192_575px.JPG
http://images.anandtech.com/galleries/1374/IMG_0193_575px.JPG
http://images.anandtech.com/galleries/1374/IMG_0194_575px.JPG
http://images.anandtech.com/galleries/1374/IMG_0195_575px.JPG
http://images.anandtech.com/galleries/1374/IMG_0196_575px.JPG
http://images.anandtech.com/galleries/1374/IMG_0197_575px.JPG
http://images.anandtech.com/galleries/1374/IMG_0198_575px.JPG
http://images.anandtech.com/galleries/1374/IMG_0199_575px.JPG
http://images.anandtech.com/galleries/1374/IMG_0200_575px.JPG
http://images.anandtech.com/galleries/1374/IMG_0190_575px.JPG
{kind=link}
http://images.anandtech.com/galleries/1374/IMG_0191_575px.JPG
{kind=link}
http://images.anandtech.com/galleries/1374/IMG_0192_575px.JPG
{kind=link}
http://images.anandtech.com/galleries/1374/IMG_0193_575px.JPG
{kind=link}
http://images.anandtech.com/galleries/1374/IMG_0194_575px.JPG
{kind=link}
http://images.anandtech.com/galleries/1374/IMG_0195_575px.JPG
{kind=link}
http://images.anandtech.com/galleries/1374/IMG_0196_575px.JPG
{kind=link}
http://images.anandtech.com/galleries/1374/IMG_0197_575px.JPG
{kind=link}
http://images.anandtech.com/galleries/1374/IMG_0198_575px.JPG
{kind=link}
http://images.anandtech.com/galleries/1374/IMG_0199_575px.JPG
{kind=link}
http://images.anandtech.com/galleries/1374/IMG_0200_575px.JPG
{kind=link}
AVX���ĂȂg���Ă邩�H
��ʌ����A�v����AVX�̉��b���悤�Ǝv���Ȃ痈�N��Adobe CS�̐V�^�����҂��邵���Ȃ���
���������̂̓O���t�B�b�N�n�A�v������Ԍ�������
���������̂̓O���t�B�b�N�n�A�v������Ԍ�������
>>5
���_�ł���\�[�X�������ɑ����ȁB���O��AMD�X�����r�炷���m�Q����
�}�C�i�[�`�F���W�ł͂Ȃ��m�M������\�[�X������Ȃ���̃\�[�X������
���_�ł���\�[�X�������ɑ����ȁB���O��AMD�X�����r�炷���m�Q����
�}�C�i�[�`�F���W�ł͂Ȃ��m�M������\�[�X������Ȃ���̃\�[�X������
>>8
rep movsb���ă��K�V�[����Ȃ��̂�
rep movsb���ă��K�V�[����Ȃ��̂�
�Q�[���Ŏg���邩�Ǝv����
�Q�[���ƊE���̂��I����Ă��܂���
�Q�[���ƊE���̂��I����Ă��܂���
AVX��256bit�����悤�ƂƂ���Ɩʓ|������
128bit�����Ȃ�intrinsics�g����C�̃R�[�h�ł���R���p�C�������������Ȃ̂ɂ�
128bit�����Ȃ�intrinsics�g����C�̃R�[�h�ł���R���p�C�������������Ȃ̂ɂ�
16 �FSocket774�F2011/09/14(��) 10:12:22.02 ID:ITSk3vkz
�Q�[���ƊE���Ȃ��A�I���H
AES�ɑ�������������Ƃ�
padlock�������ɂȂ��Ă����ȁA����RSA��SHA��
padlock�������ɂȂ��Ă����ȁA����RSA��SHA��
18 �FSocket774�F2011/09/14(��) 10:32:47.79 ID:z6yOxHKC
�@�u�n�C�G���h�ȃn�[�h�E�F�A�Ńn�C�p�[�X���b�f�B���O��L���ɂ����ꍇ�A�����[�����ۂ��������邱�Ƃ��A
�����̌ڋq���m�F���Ă���BSQL Server�ɍ������ׂ�������ƁACPU�̎g�p�������ɍ����Ȃ�ɂ��ւ��
���ASQL Server�̐��\���ቺ����ꍇ�����邱�ƂɌڋq�͒��ڂ��Ă���v�Ə����Ă���B
�@�����āAOcks�́A���̌��ۂ��Č�����e�X�g�̏ڍׂ��L�ڂ��Ă���B����ɏ]���ăe�X�g����ƁA�f�B�X�N
�L���b�V�����������N���A����V�X�e���X���b�h���A���[�J�[�X���b�h�Ɠ����ɉғ�����B�uIntel�̃n�C�p�[
�X���b�f�B���O�Z�p�ɂ��A�_���v���Z�b�T��L1�����L2�L���b�V�������L����B����ɂ��AL1�����L2
�L���b�V���̓��e���p������邱�Ƃ��l������v�iOcks�j
�@�����̃I���`�b�v�L���b�V���́A�`�b�v�̏������x�����コ���邽�߂ɂ���B�I���`�b�v�L���b�V���ɂ́A
���߂ɃA�N�Z�X���ꂽ�f�[�^�̃R�s�[���ێ������B�I���`�b�v�L���b�V���̃f�[�^�ɃA�N�Z�X��������A
���C���V�X�e���̃������ɃA�N�Z�X����悢�������炾�BCPU���A�n�C�p�[�X���b�f�B���O�Z�p���g���ĕ�����
�X���b�h�삳����ۂɁA�����̋��L���ꂽ�L���b�V���ł͎��X�ɓ����Ă���v���ɑΉ��ł��Ȃ��Ȃ�A
���\�̒ቺ����������Ƃ����̂��AOcks��Ibbotson�ɂ�镪�͌��ʂ��B
�����̌ڋq���m�F���Ă���BSQL Server�ɍ������ׂ�������ƁACPU�̎g�p�������ɍ����Ȃ�ɂ��ւ��
���ASQL Server�̐��\���ቺ����ꍇ�����邱�ƂɌڋq�͒��ڂ��Ă���v�Ə����Ă���B
�@�����āAOcks�́A���̌��ۂ��Č�����e�X�g�̏ڍׂ��L�ڂ��Ă���B����ɏ]���ăe�X�g����ƁA�f�B�X�N
�L���b�V�����������N���A����V�X�e���X���b�h���A���[�J�[�X���b�h�Ɠ����ɉғ�����B�uIntel�̃n�C�p�[
�X���b�f�B���O�Z�p�ɂ��A�_���v���Z�b�T��L1�����L2�L���b�V�������L����B����ɂ��AL1�����L2
�L���b�V���̓��e���p������邱�Ƃ��l������v�iOcks�j
�@�����̃I���`�b�v�L���b�V���́A�`�b�v�̏������x�����コ���邽�߂ɂ���B�I���`�b�v�L���b�V���ɂ́A
���߂ɃA�N�Z�X���ꂽ�f�[�^�̃R�s�[���ێ������B�I���`�b�v�L���b�V���̃f�[�^�ɃA�N�Z�X��������A
���C���V�X�e���̃������ɃA�N�Z�X����悢�������炾�BCPU���A�n�C�p�[�X���b�f�B���O�Z�p���g���ĕ�����
�X���b�h�삳����ۂɁA�����̋��L���ꂽ�L���b�V���ł͎��X�ɓ����Ă���v���ɑΉ��ł��Ȃ��Ȃ�A
���\�̒ቺ����������Ƃ����̂��AOcks��Ibbotson�ɂ�镪�͌��ʂ��B
�@�u�܂��ɔ�����v��Ibbotson�͏q�ׂ�B�uIntel�́A�}���`�X���b�h���T�|�[�g����\�t�g�E�F�A�Ő��\�����シ��ƁA
�n�C�p�[�X���b�f�B���O�Z�p�荞��ł����BSQL Server�́A�}���`�X���b�h���T�|�[�g���Ă��邪�AIntel�̃`�b�v
��ł��̌��ʂ��ł��Ȃ������B�����A�n�C�p�[�X���b�f�B���O�Ή��̃T�[�o�\�t�g�E�F�A�ŁA���\�����サ������
���������Ƃ��Ȃ��BCitrix�Ƃ����̃\�t�g�E�F�A��T�[�o�œ��삳����ꍇ�ɂ́A���Z�p���ɂ��邱�Ƃ�
�ڋq�ɂ͊��߂Ă���v�iIbbotson�j
�@Intel�̍L��S����Scott McLaughlin�͕č�����21���A�قƂ�ǂ̃x���`�}�[�N�ɂ����āA�n�C�p�[�X���b�f�B���O
�Z�p�͗ǂ����ʂ��o���Ă���Əq�ׂ��B�uIntel�ł́A�ǂ̂悤�ȏꍇ�ɓ��Z�p�����ɗ����A�ǂ̂悤�ȏꍇ�ɂ�����
�Ȃ����𖾂炩�Ɏ����Ă����v�iMcLaughlin�j
�n�C�p�[�X���b�f�B���O�Z�p�荞��ł����BSQL Server�́A�}���`�X���b�h���T�|�[�g���Ă��邪�AIntel�̃`�b�v
��ł��̌��ʂ��ł��Ȃ������B�����A�n�C�p�[�X���b�f�B���O�Ή��̃T�[�o�\�t�g�E�F�A�ŁA���\�����サ������
���������Ƃ��Ȃ��BCitrix�Ƃ����̃\�t�g�E�F�A��T�[�o�œ��삳����ꍇ�ɂ́A���Z�p���ɂ��邱�Ƃ�
�ڋq�ɂ͊��߂Ă���v�iIbbotson�j
�@Intel�̍L��S����Scott McLaughlin�͕č�����21���A�قƂ�ǂ̃x���`�}�[�N�ɂ����āA�n�C�p�[�X���b�f�B���O
�Z�p�͗ǂ����ʂ��o���Ă���Əq�ׂ��B�uIntel�ł́A�ǂ̂悤�ȏꍇ�ɓ��Z�p�����ɗ����A�ǂ̂悤�ȏꍇ�ɂ�����
�Ȃ����𖾂炩�Ɏ����Ă����v�iMcLaughlin�j
SQL Server���ǂ����͒m��Ȃ���HTT�Ńp�t�H�[�}���X��������ꍇ�͕��ʂɂ����
�}���`�X���b�h�̍œK���v���O�����������Ȃ�
�^�[�Q�b�g�ɓK�����X���b�h���ƃA�t�B�j�e�B�}�X�N��ݒ肷��̂������Ȃ�
�}���`�X���b�h�̍œK���v���O�����������Ȃ�
�^�[�Q�b�g�ɓK�����X���b�h���ƃA�t�B�j�e�B�}�X�N��ݒ肷��̂������Ȃ�
Intel��Google����g�AAndroid��Atom�v���Z�b�T�ɍœK��
�����Ɍ����� Sandy Bridge �� windows 7 64bit �̑g�ݍ��킹�ł̂�
�����Ȃ�ꍇ��HT-ON�ő��x�͌��シ��B
����ȊO�͂ǂ�ȑg�ݍ��킹�ł����ʂ������薳��������B
�����Ȃ�ꍇ��HT-ON�ő��x�͌��シ��B
����ȊO�͂ǂ�ȑg�ݍ��킹�ł����ʂ������薳��������B
��
�����@���x����Ȃ��ď�����
�����@���x����Ȃ��ď�����
Windows7����HT�ɑ��鏈���̐U�蕪�������܂�����Ă����������H
�Ⴆ��4�X���b�h�������悭�l������2�R�A4�X���b�h�ɐU�蕪����������肷���
���̏ꍇ���R4�R�A4�X���b�h�ł���萫�\�ቺ����B
������Windows7�͂����Ǝ��R�A��HT�ő��������z�̃R�A����ʂ���
���R�A���ȏ�̃X���b�h���K�v�ȂƂ��ȊO��
���z�R�A�ɂ͐U�蕪���Ȃ��悤�ɂ��Ă����E�E�E
�Ƃ�����Ȋ����������H
�Ⴆ��4�X���b�h�������悭�l������2�R�A4�X���b�h�ɐU�蕪����������肷���
���̏ꍇ���R4�R�A4�X���b�h�ł���萫�\�ቺ����B
������Windows7�͂����Ǝ��R�A��HT�ő��������z�̃R�A����ʂ���
���R�A���ȏ�̃X���b�h���K�v�ȂƂ��ȊO��
���z�R�A�ɂ͐U�蕪���Ȃ��悤�ɂ��Ă����E�E�E
�Ƃ�����Ȋ����������H
����U��̍œK���]�X�͂悭�킩��Ȃ�����
Sandy Bridge�ł���Ƃ܂Ƃ��Ȃ̂������ł������Ƃ͎����B
����ȉ��̐���ł͎������x���ł��łɓ�L�ȗL�B
Sandy Bridge�ł���Ƃ܂Ƃ��Ȃ̂������ł������Ƃ͎����B
����ȉ��̐���ł͎������x���ł��łɓ�L�ȗL�B
27 �FSocket774�F2011/09/14(��) 12:19:16.63 ID:ONuyN2d3
�A�v�����̃v���O���~���O�ɂ��Ȃ荶�E�����悤��
�ʂ�Sandy��Nehalem��HT�̎����͕ς���
7��OS�̃X�P�W���[���̋������ς��������
7��OS�̃X�P�W���[���̋������ς��������
http://laptop-computer-planet.com/blog/wp-content/uploads/2011/09/Intel-Ivy-Bridge-release-date.jpg
ivy�̃_�C
GPU�̔䗦���������AGPU��CPU2�R�A��
�f�b�h�X�y�[�X���Ȃ��Ȃ����A�����R�������̃G�b�W�ɂȂ�
{kind=link}
ivy�̃_�C
GPU�̔䗦���������AGPU��CPU2�R�A��
�f�b�h�X�y�[�X���Ȃ��Ȃ����A�����R�������̃G�b�W�ɂȂ�
�X�P�W���[�������Windows7�Ȃ��Linux�̕�������ۂǗD�G�����ǂ���܂芈�p�ł���\�t�g���Ȃ���Ȃ�
x264�Ȃ炠�邯��
x264�Ȃ炠�邯��
>>23
>�����Ȃ�ꍇ��HT-ON�ő��x�͌��シ��B
4C8T�ŏ�ɂW�X���b�h�̕����S�X���b�h���X���[�v�b�g���オ��Ƃ����Ӗ���������
����Ȃ��Ƃ͂Ȃ�
>�����Ȃ�ꍇ��HT-ON�ő��x�͌��シ��B
4C8T�ŏ�ɂW�X���b�h�̕����S�X���b�h���X���[�v�b�g���オ��Ƃ����Ӗ���������
����Ȃ��Ƃ͂Ȃ�
GPU������2�R�A����悤�Ɍ������
>>28
TLB�G���g�����▽�߃E�B���h�E�����L�����Ă���̂��n���Ɍ����Ă���
PRF�Ɉڍs����read port stall���Ȃ��Ȃ����̂����������Ă���
TLB�G���g�����▽�߃E�B���h�E�����L�����Ă���̂��n���Ɍ����Ă���
PRF�Ɉڍs����read port stall���Ȃ��Ȃ����̂����������Ă���
���߂����Y��Ɏ����ł��Ȃ��ǂ���Ȃ�
����ɂ��Ă�Ivy�̃_�C�ʐ^�Y�킾�ȁc
����ɂ��Ă�Ivy�̃_�C�ʐ^�Y�킾�ȁc
�E�G�n�̎ʐ^���ƃ����R�������ɂ���悤�Ɍ�������ǂȂ�
>>30
Linux�̃X�P�W���[���[���D�G�H �ǂ��̂ǂ�����Linux�̎��������Ă�H
Linux�̃X�P�W���[���[���D�G�H �ǂ��̂ǂ�����Linux�̎��������Ă�H
>>20
���C��Nehalem�ɂȂ��Ă���L1�L���b�V���̊��蓖�ă|���V�[���ς���Ă���
>>34
������180nm�v���Z�X�ł͊e�X���b�h�̃��\�[�X���m�ۂȂ�Č�����قǃg�����W�X�^�g���Ȃ�����
�cWillamette�̃_�C�T�C�Y��217mm2�ƍl����Ɗu���̊�������
���C��Nehalem�ɂȂ��Ă���L1�L���b�V���̊��蓖�ă|���V�[���ς���Ă���
>>34
������180nm�v���Z�X�ł͊e�X���b�h�̃��\�[�X���m�ۂȂ�Č�����قǃg�����W�X�^�g���Ȃ�����
�cWillamette�̃_�C�T�C�Y��217mm2�ƍl����Ɗu���̊�������
>>29
PCIe�͂ǂ��ɂ������낤
PCIe�͂ǂ��ɂ������낤
>�C�[�f�����́uHaswell�̓��K�`�F���W(���ɑ傫�ȕύX������)�̐��i�ƂȂ�B
>�}�C�N���A�[�L�e�N�`���A��H�v�A�d������A�قڂ��ׂĂ��ς��ƍl���Ă�����Ă����v
>�Ƃ̌��ʂ��𖾂炩�ɂ����B
http://pc.watch.impress.co.jp/docs/column/ubiq/20110601_449745.html
>Major changes architecturally reportedly include a totally redesigned cache,
>fused multiply add (FMA3) instruction support, and an on-chip vector coprocessor.
http://www.dailytech.com/Intel+Says+Haswell+Coming+in+2013+Will+Rival+Todays+Discrete+Graphics/article22002.htm
����Haswell�̋Z�p�I�ו��ɂ܂œ��ݍ��L���͂قƂ�ǂȂ�
���Ă������A�܂����ݐi�s�`�Őv���̂͂��Ȃ̂ŁA���ɏڂ���������t�ɉ�������
�ł��A���Ȃ�啝�Ɏ������̂͊ԈႢ�Ȃ��Ǝv�����ǂȂ�
>�}�C�N���A�[�L�e�N�`���A��H�v�A�d������A�قڂ��ׂĂ��ς��ƍl���Ă�����Ă����v
>�Ƃ̌��ʂ��𖾂炩�ɂ����B
http://pc.watch.impress.co.jp/docs/column/ubiq/20110601_449745.html
>Major changes architecturally reportedly include a totally redesigned cache,
>fused multiply add (FMA3) instruction support, and an on-chip vector coprocessor.
http://www.dailytech.com/Intel+Says+Haswell+Coming+in+2013+Will+Rival+Todays+Discrete+Graphics/article22002.htm
����Haswell�̋Z�p�I�ו��ɂ܂œ��ݍ��L���͂قƂ�ǂȂ�
���Ă������A�܂����ݐi�s�`�Őv���̂͂��Ȃ̂ŁA���ɏڂ���������t�ɉ�������
�ł��A���Ȃ�啝�Ɏ������̂͊ԈႢ�Ȃ��Ǝv�����ǂȂ�
���n�X�E�F�����^�̏����g��
�I���S���`�[�����C�X���G���̏Ă������Ƃ����Ȃ���ˁA������
Nehalem�����Č��\�ς���Ă����A���̂��炢�̕ω��͂���͂�
Nehalem�����Č��\�ς���Ă����A���̂��炢�̕ω��͂���͂�
>>29�̎ʐ^�͒��ӂɂ���C���^�[�t�F�[�X���͎ʂ��ĂȂ���������ˁH
���ɁA���ۂ̃_�C�T�C�Y�f���ĂȂ��A�Ȃ�ď����Ă��邩��A
�c�������H���Ă��邩���ˁB
�c�������H���Ă��邩���ˁB
������CPU�R�A�Ƃ̑��T�C�Y�ł����ƁA
�ǂ����Ă�GPU����2�{���炢�ɂȂ��Ă���C������
GPU�A�[�L�e�N�`���̃X���C�h
http://www.anandtech.com/Gallery/Album/1375
�ǂ����Ă�GPU����2�{���炢�ɂȂ��Ă���C������
GPU�A�[�L�e�N�`���̃X���C�h
http://www.anandtech.com/Gallery/Album/1375
EU���̂�16�炵��
�傫�ȕύX�_�Ƃ���stream out(GS)�̋���
�n�[�h�E�G�Astream out���Ă����Ă邩��O��ROP����f���Ă��̂���
����ł�GS�̐��\�͌��\����������
���ꂪ���������Ɣėp�v�Z�������ԑ����Ȃ�
�傫�ȕύX�_�Ƃ���stream out(GS)�̋���
�n�[�h�E�G�Astream out���Ă����Ă邩��O��ROP����f���Ă��̂���
����ł�GS�̐��\�͌��\����������
���ꂪ���������Ɣėp�v�Z�������ԑ����Ȃ�
>L3$:
>Less BW need from LL$ = Less Energy spent
���C��L3���lj�����Ă���c�c���Ɓc�c�H
LLC�ւ̃A�N�Z�X�����点��̂ŏ���d�͂��������܂����Ă�
>Less BW need from LL$ = Less Energy spent
���C��L3���lj�����Ă���c�c���Ɓc�c�H
LLC�ւ̃A�N�Z�X�����点��̂ŏ���d�͂��������܂����Ă�
47 �FSocket774�F2011/09/14(��) 19:02:25.50 ID:ONuyN2d3
���K�`�F���W�ŃO�_�O�_�ɂȂ����Ⴊ�ŋ߂���������Ȃ�
Ivy��GPU��OpenCL�I�ɂ��Ȃ���҂��Ă���
����C�e���V�����ɂȂ��Ă��肵�Ȃ�����
�܂������炭�o�Ă݂��炪������Ȃ낤����
����C�e���V�����ɂȂ��Ă��肵�Ȃ�����
�܂������炭�o�Ă݂��炪������Ȃ낤����
���N��14nm��SRAM�E�G�n���o�Ă��Ă����������Ȃ��������ǁA�o�Ă��Ȃ������ˁB
�������ɂ�����ƒx��C���Ȃ̂��낤���B
����Ƃ��A14nm�ł�22nm��Tri-Gate�̂悤�ȉB�����ł�����̂��ȁH
�������ɂ�����ƒx��C���Ȃ̂��낤���B
����Ƃ��A14nm�ł�22nm��Tri-Gate�̂悤�ȉB�����ł�����̂��ȁH
�EIII-V��
�EEUV�I��
�E450mm�E�F�n
14nm��EUV�I���͂��蓾������
450mm�͋ƊE�̏����������ĂȂ��̂Ŗ���
III-V����Intel�̈̂�����2015�N�܂łɂ͓�������Ƃ������Ă����ʂ�����
�EEUV�I��
�E450mm�E�F�n
14nm��EUV�I���͂��蓾������
450mm�͋ƊE�̏����������ĂȂ��̂Ŗ���
III-V����Intel�̈̂�����2015�N�܂łɂ͓�������Ƃ������Ă����ʂ�����
�X�}�[�g�t�H���s��ɍ��x���������z���邩�ǂ�����
���x�Ȃ���Intel�̊J���\�͂͂����[��
���N���������Ă���^�Ђɒ܂̍C�����ȁc�B
�����A����ɂȂ肷�����̂���_�ɂȂ�Ȃ����ƁA
�ߍ��̎s��̗�����݂Ă���ƕ|��
���N���������Ă���^�Ђɒ܂̍C�����ȁc�B
�����A����ɂȂ肷�����̂���_�ɂȂ�Ȃ����ƁA
�ߍ��̎s��̗�����݂Ă���ƕ|��
53 �FSocket774�F2011/09/14(��) 20:06:34.02 ID:ONuyN2d3
atom�ɂ͊��҂ł����
Wichita��arm��windows�̂�̂�҂�����������
Wichita��arm��windows�̂�̂�҂�����������
AMD�ɂ͊��҂ł���
arm�̓h���C�o�����҂ł���
arm�̓h���C�o�����҂ł���
EUV�͌��i�K60��/hr����B���ł��Ȃ��̂ɁA
���Ɠ�N�Ƃ͌����A���肷��Ǝl�d�p�^�[���̕���EUV���R�X�g�I�ɗǂ��B
�e�X�g�̂���14nm���班�ʐ��Y�Ɏg����������Ȃ���
���Ɠ�N�Ƃ͌����A���肷��Ǝl�d�p�^�[���̕���EUV���R�X�g�I�ɗǂ��B
�e�X�g�̂���14nm���班�ʐ��Y�Ɏg����������Ȃ���
�p�C���b�g���C���ɓ�������Ƃ����b���ǂ����œǂ悤��
>>51
���x�������������c
�X�}�[�g�t�H�������Ƀf�U�C�������Atom��22nm��Silvermont�����߂�
���̃��[�h�}�b�v��2009�N���炸���ƕς���ĂȂ�
MID��������������Moorestown���x��ă^�u���b�g�a���ɂ����͖̂�肾������
����Ń`�����h���V�[�J���N�r�Ȃ�������
���x�������������c
�X�}�[�g�t�H�������Ƀf�U�C�������Atom��22nm��Silvermont�����߂�
���̃��[�h�}�b�v��2009�N���炸���ƕς���ĂȂ�
MID��������������Moorestown���x��ă^�u���b�g�a���ɂ����͖̂�肾������
����Ń`�����h���V�[�J���N�r�Ȃ�������
medfield�̃^�u���b�g����arm�Ɣ�ׂĂǂ��Ȃ�
59 �F,,�E�L�́M�E,,�j��-�������F2011/09/14(��) 20:48:37.35 ID:SLf0ZgMZ
�T���v���Ƃ͂����悤�₭���z�d�r�œ��������`�b�vx86����ꂽ���ƂɊ��������B
>>56
http://pc.watch.impress.co.jp/img/pcw/docs/212/014/html/kaigai12.jpg.html
2009�N�̂Ƃ�����AMedfield�����C���X�g���[�������X�}�z�p������A
Medfield�ł��A�ǂ��ɂ��̗p����Ȃ��悤���Ƃ����Ȃ��́H
http://pc.watch.impress.co.jp/img/pcw/docs/212/014/html/kaigai12.jpg.html
{kind=link}
2009�N�̂Ƃ�����AMedfield�����C���X�g���[�������X�}�z�p������A
Medfield�ł��A�ǂ��ɂ��̗p����Ȃ��悤���Ƃ����Ȃ��́H
>>60
�茳�̎����m�F������f�ŊԈ���Ċo���Ă���
Silvermont�AMedfield�AMoorestown�ł͂Ȃ�Medfield�AMoorestown�AMenlow��������
Menlow�Ƃ����ݎ��̖Y��Ă�����
�茳�̎����m�F������f�ŊԈ���Ċo���Ă���
Silvermont�AMedfield�AMoorestown�ł͂Ȃ�Medfield�AMoorestown�AMenlow��������
Menlow�Ƃ����ݎ��̖Y��Ă�����
>>50
����III-V���̓����������ł������ɂȂ��Ă�
�g���C�Q�[�g�̎��݂����ɁA���߂܂Ŕ��\����Ȃ��낤�Ȃ�
Rockwell�ō̗p�ł�����Ռ������c�c
����III-V���̓����������ł������ɂȂ��Ă�
�g���C�Q�[�g�̎��݂����ɁA���߂܂Ŕ��\����Ȃ��낤�Ȃ�
Rockwell�ō̗p�ł�����Ռ������c�c
>>52
�v���Z�X�͊J���\�͂��[����������ł���͋Z����
�v���Z�X�͊J���\�͂��[����������ł���͋Z����
��������
����͂ˁ[��
����͂ˁ[��
http://live.ubergizmo.com/files/ubergizmo_live_260_700.jpg
�K�`�ʼn��̃G�b�W�������R���̃p�b�h�݂�����
�g�����W�X�^��14.8��Tr
{kind=link}
�K�`�ʼn��̃G�b�W�������R���̃p�b�h�݂�����
�g�����W�X�^��14.8��Tr
First Shot of Haswell, Working Demo at IDF
ttp://www.anandtech.com/show/4800/first-shot-of-haswell-working-demo-at-idf
ttp://images.anandtech.com/galleries/1379/IMG_0275_575px.JPG
Sandy��Ivy�Ɠ������ג����_�C
���ꂾ�����Ⴛ�ꂭ�炢�����킩��Ȃ����ǁc
ttp://www.anandtech.com/show/4800/first-shot-of-haswell-working-demo-at-idf
ttp://images.anandtech.com/galleries/1379/IMG_0275_575px.JPG
{kind=link}
Sandy��Ivy�Ɠ������ג����_�C
���ꂾ�����Ⴛ�ꂭ�炢�����킩��Ȃ����ǁc
This is not the actual die image, but it's good enough for this presentation.
���ď����Ă��邩�����σ����R���B���Ă�̂���
�Ȃ�ł���Ȃ��Ƃ���̂��킩��Ȃ�����
���ď����Ă��邩�����σ����R���B���Ă�̂���
�Ȃ�ł���Ȃ��Ƃ���̂��킩��Ȃ�����
���炩��GPU��CPU�̕����͈Ⴄ�ʐ^�̍���������
CPU��GPU�ɂ܂����郁���R�������̓J�b�g�������ĂƂ���
CPU��GPU�ɂ܂����郁���R�������̓J�b�g�������ĂƂ���
Ivy��GPU�����������̂͂���
����ǂ���GPU�h���C�o�����Əo����낤��
�n�[�h���ǂ��Ă����̕�������ԐM�p�o���Ȃ���
����ǂ���GPU�h���C�o�����Əo����낤��
�n�[�h���ǂ��Ă����̕�������ԐM�p�o���Ȃ���
�y���|�[�g�z Hot Chips 23 - Intel�̃~�b�V�����N���e�B�J���T�[�o�p�v���Z�T
http://journal.mycom.co.jp/articles/2011/09/14/hot_chips23_poulson/
http://journal.mycom.co.jp/articles/2011/09/14/hot_chips23_poulson/
544mm2�Ƃ͋v�X�ɃR���p�N�g�BXeonMP�Ƒ卷�Ȃ��Ƃ����͖̂ʔ���
>>69
���S���뉴������͐M�p���Ă��Ȃ�
���S���뉴������͐M�p���Ă��Ȃ�
>>62
�g���C�Q�[�g�����߂܂Ŕ��\����Ȃ����ĂȂ�̒��߁H
�g���C�Q�[�g�����߂܂Ŕ��\����Ȃ����ĂȂ�̒��߁H
Intel�A8way��Knights Ferry�V�X�e�����f��
http://blog.livedoor.jp/amd646464/archives/52217109.html
http://blog.livedoor.jp/amd646464/archives/52217109.html
�悤�₭Knights���\�ɏo�Ă���悤�ɂȂ�����
sandy
http://ascii.jp/elem/000/000/580/580114/SandyBridge_Desktop_Chip2_c_800x562.jpg
ivy
http://www.intel.com/newsroom/kits/idf/2011_fall/gallery/images/idf2011_day2_Mooly-Keynote8_p.jpg
haswell
http://pc.watch.impress.co.jp/img/pcw/docs/477/626/47.jpg
ivy���ō�
http://ascii.jp/elem/000/000/580/580114/SandyBridge_Desktop_Chip2_c_800x562.jpg
{kind=link}
ivy
http://www.intel.com/newsroom/kits/idf/2011_fall/gallery/images/idf2011_day2_Mooly-Keynote8_p.jpg
{kind=link}
haswell
http://pc.watch.impress.co.jp/img/pcw/docs/477/626/47.jpg
{kind=link}
ivy���ō�
sandy�͎��ĂȂ��̂�ivy��haswell���ē����Č�����z���܂Ŏ��Ă��
�܂������b�N����c
�܂������b�N����c
>>72
�N��������͐M�p���Ă��Ȃ���
�N��������͐M�p���Ă��Ȃ���
intel�̒��̐l��Haswell���ƋC�Â��Ȃ��Ŏʐ^�ڂ������ĉ\��������B
Ivy�̃p�b�P�[�W�̎ʐ^���j���[�X�L���ŏo�ĂȂ����B
�_�C�ʐ^�ƃR�[�h�l�[���ԈႦ�܂����������������ƁA
�����͂��������ȏꍇ������Aintel
Ivy�̃p�b�P�[�W�̎ʐ^���j���[�X�L���ŏo�ĂȂ����B
�_�C�ʐ^�ƃR�[�h�l�[���ԈႦ�܂����������������ƁA
�����͂��������ȏꍇ������Aintel
>>76
�S�������Ɍ�����
�S�������Ɍ�����
82 �F,,�E�L�́M�E,,�j��-�������F2011/09/15(��) 18:21:46.88 ID:hvxtR3dd
83 �F,,�E�L�́M�E,,�j��-�������F2011/09/15(��) 18:29:42.75 ID:hvxtR3dd
>>74
> 1.
> AMD Cayman can produce 2.7 TFLOPs of single precision performance
> 2.7 Times 8 = 21.6 TFLOPs
> 2 2 [Posted by: blazzin [Rating 10.17] | Date: 09/14/11 07:02:10 PM]
���������r���݂����Ȃ��ƌ����o���t�@���{�[�C���Đ��E���ǂ��ɂł������
> 1.
> AMD Cayman can produce 2.7 TFLOPs of single precision performance
> 2.7 Times 8 = 21.6 TFLOPs
> 2 2 [Posted by: blazzin [Rating 10.17] | Date: 09/14/11 07:02:10 PM]
���������r���݂����Ȃ��ƌ����o���t�@���{�[�C���Đ��E���ǂ��ɂł������
SGEMM�Ȃ�Cayman�ł����\�o���Ȃ��́H
8�������邩�͒m��Ȃ���
8�������邩�͒m��Ȃ���
��̒����̐l��Cypress��SGEMM�EDGEMM������Ƃ��͌��\�Ȑ������o�Ă����ǂǂ��������c�ƃT�C�g�ɍs������503�Ō���˂��I�I
AMD�̃T�C�g�ɏ���Ă��_����Cayman��DGEMM600GFlops�o���Ă��ŃJ�^���O�l��8�����炢�͂����Ă邵
8�����������h���ł���Ȃ炻���܂Ńg���`�L�Ȑ����Ƃ����킯�ł��Ȃ��悤�ȁA�ł��Ȃ�����
AMD�̃T�C�g�ɏ���Ă��_����Cayman��DGEMM600GFlops�o���Ă��ŃJ�^���O�l��8�����炢�͂����Ă邵
8�����������h���ł���Ȃ炻���܂Ńg���`�L�Ȑ����Ƃ����킯�ł��Ȃ��悤�ȁA�ł��Ȃ�����
Opteron�o�ׂ̃A�i�E���X�����T�Ԃ��x���Xeon E5�̏o�ׂ��A�i�E���X�����B
ttp://www.eweek.com/c/a/IT-Infrastructure/Intel-Ships-Xeon-E5-Server-Chips-for-Cloud-HPC-Environments-792348/
�N���E�h��HPC�̐����ɂ����OEM�̔�������X�炵��SNB-EP��Nehalem�ȏ�̑�q�b�g���\������Ă���B
���������Η��N��Cray�̗̍p�v���Z�b�T��Xeon�ɂȂ�N�B
Poulson�����N���Ƃ��B���̂Ƃ���Tukwila���͏����ɂ����Ă���c�悤�Ɍ�����B
SNB�̏o�א���7500����˔j�B�C���e���j��ł������y�[�X�B
ttp://www.washingtonpost.com/business/technology/1/2011/09/14/gIQAOF4HSK_story.html
���R�[�������̂��́c�Ƃ��������R�[���̂������Ńs�b�`�オ�����H
SNB��L3�L���b�V�������ڂ��ꂸ�AIvy�œ��ڂ��ꂽ���R�B
ttp://www.theregister.co.uk/2011/09/15/ivy_bridge/page2.html
���ɒP���Șb�ŁASNB�ł�L3��ς�ł��債�Đ��\���L�тȂ�����ς܂Ȃ������B
Ivy�ł͎��s���j�b�g����������ă����O�o�X�ւ̕��ׂ����d�͂������ł��Ȃ��Ȃ��Ă����̂�L3��ςB
(�����O�o�X�̏���d�͂������ăo���h���ɂ��]�T���o��̂Ń`�b�v�S�̂̃p�t�H�[�}���X�ɂ���^����B)
Intel�̂��������ƃ��_��(�c�ƌ����Ă����̂��H)�ȁAdata hungry��GPU�ɂȂ��Ă����ƁB
discrete GPU�Ȃ�GDDR�ŗǂ������낤���BGeforce��L3�͐ς�łȂ������͂��B
ttp://www.eweek.com/c/a/IT-Infrastructure/Intel-Ships-Xeon-E5-Server-Chips-for-Cloud-HPC-Environments-792348/
�N���E�h��HPC�̐����ɂ����OEM�̔�������X�炵��SNB-EP��Nehalem�ȏ�̑�q�b�g���\������Ă���B
���������Η��N��Cray�̗̍p�v���Z�b�T��Xeon�ɂȂ�N�B
Poulson�����N���Ƃ��B���̂Ƃ���Tukwila���͏����ɂ����Ă���c�悤�Ɍ�����B
SNB�̏o�א���7500����˔j�B�C���e���j��ł������y�[�X�B
ttp://www.washingtonpost.com/business/technology/1/2011/09/14/gIQAOF4HSK_story.html
���R�[�������̂��́c�Ƃ��������R�[���̂������Ńs�b�`�オ�����H
SNB��L3�L���b�V�������ڂ��ꂸ�AIvy�œ��ڂ��ꂽ���R�B
ttp://www.theregister.co.uk/2011/09/15/ivy_bridge/page2.html
���ɒP���Șb�ŁASNB�ł�L3��ς�ł��債�Đ��\���L�тȂ�����ς܂Ȃ������B
Ivy�ł͎��s���j�b�g����������ă����O�o�X�ւ̕��ׂ����d�͂������ł��Ȃ��Ȃ��Ă����̂�L3��ςB
(�����O�o�X�̏���d�͂������ăo���h���ɂ��]�T���o��̂Ń`�b�v�S�̂̃p�t�H�[�}���X�ɂ���^����B)
Intel�̂��������ƃ��_��(�c�ƌ����Ă����̂��H)�ȁAdata hungry��GPU�ɂȂ��Ă����ƁB
discrete GPU�Ȃ�GDDR�ŗǂ������낤���BGeforce��L3�͐ς�łȂ������͂��B
L2�͂ǂ��H
GPU���ɂ�L3�����̂�
�Ƃ���fermi�̂悤�Ƀe�b�Z���[�^�Ō��ʂł�������
�t���[���o�b�t�@�ɂ͏��������낤����
�����stream out���A���������ʂނ�����
�Ƃ���fermi�̂悤�Ƀe�b�Z���[�^�Ō��ʂł�������
�t���[���o�b�t�@�ɂ͏��������낤����
�����stream out���A���������ʂނ�����
Haswell�Ƃ����Ă�́AIvy�̃_�C�Ȃ�ˁH
�����Knights Corner�Ɋ��҂���������Ȃ�
�����Ƃ��A��ʌ����ɍ~��Ă�����͗���̂���
�����Ƃ��A��ʌ����ɍ~��Ă�����͗���̂���
91 �F,,�E�L�́M�E,,�j��-�������F2011/09/16(��) 00:57:02.27 ID:ZL5xKSsy
>>85
����Tesla��DGEMM�͗��_���\������̎������\��90%�I�[�o�[���o���Ă邯�ǂȁB
�������{���x���������ꂽFermi�ł͎��s���\��͑傫�����������B
�����牉�Z���j�b�g�����ɂ��Ă��������ш�œ��ł��Ȃ�B
http://gpgpu.org/2010/10/12/fast-gemm-cypress#high_1
���������������������āA�S�������ғ��������I�ɖ����ȃJ�^���O�X�y�b�N��
�������\���ꏏ�ɂ���Ȃ��Ă��ƁB
����Tesla��DGEMM�͗��_���\������̎������\��90%�I�[�o�[���o���Ă邯�ǂȁB
�������{���x���������ꂽFermi�ł͎��s���\��͑傫�����������B
�����牉�Z���j�b�g�����ɂ��Ă��������ш�œ��ł��Ȃ�B
http://gpgpu.org/2010/10/12/fast-gemm-cypress#high_1
���������������������āA�S�������ғ��������I�ɖ����ȃJ�^���O�X�y�b�N��
�������\���ꏏ�ɂ���Ȃ��Ă��ƁB
Fermi�̎��s�������łȂ��̂̓��W�X�^�n�R�̂������Ǝv����
�ŁCSM�ɓǂݏ����ɍs���Ƒш摫��Ȃ����C�e���V������
�U�X�Ȗڂɍ���
GEMM�A�N�Z�����[�^�Ƃ��Ă��������AMD��VLIW�̂ق����D��Ă���
�ƌ��킴��Ȃ�
>>74�̃��C�g���͗��x���������Ȃ��ƌ������o�Ȃ�����MIC�Ɍ����Ă邯��
�ŁCSM�ɓǂݏ����ɍs���Ƒш摫��Ȃ����C�e���V������
�U�X�Ȗڂɍ���
GEMM�A�N�Z�����[�^�Ƃ��Ă��������AMD��VLIW�̂ق����D��Ă���
�ƌ��킴��Ȃ�
>>74�̃��C�g���͗��x���������Ȃ��ƌ������o�Ȃ�����MIC�Ɍ����Ă邯��
93 �F,,�E�L�́M�E,,�j��-�������F2011/09/16(��) 01:43:04.30 ID:ZL5xKSsy
AMD������VLIW��߂邯�ǂ�
AMD��VLIW��߂�͖̂{���Ɏc�O��
���C�e���V���Z����Fermi���͂悢�̂�������Ȃ���
DRAM�A�N�Z�X�͂���܂肵�Ȃ��Ń��W�X�^�ɏ悹�Ă��育��v�Z����n����
�P�X���b�h�Ń��W�X�^��R�g�����ق����������ǂ�
�܂�AMD�̓h���C�o���ʖډ߂��Ăǂ݂̂��I�����ɂ������Ȃ�w
���C�e���V���Z����Fermi���͂悢�̂�������Ȃ���
DRAM�A�N�Z�X�͂���܂肵�Ȃ��Ń��W�X�^�ɏ悹�Ă��育��v�Z����n����
�P�X���b�h�Ń��W�X�^��R�g�����ق����������ǂ�
�܂�AMD�̓h���C�o���ʖډ߂��Ăǂ݂̂��I�����ɂ������Ȃ�w
>>65
SandyBridge�̂T���������炢������
�S��GPU�Ɏg�����̂���
CPU�Ńg�����W�X�^�g�������ȉ��ǂ��Ĕ��\����ĂȂ���ˁH
SandyBridge�̂T���������炢������
�S��GPU�Ɏg�����̂���
CPU�Ńg�����W�X�^�g�������ȉ��ǂ��Ĕ��\����ĂȂ���ˁH
DEGIMA�̂��ڂ�b�������Ǝv����
�uGeForce�̃h���C�o���\�����Ē�~�R�}���h��ł��Ă��~�܂�Ȃ��Ȃ����v�Ƃ��A
���낵���Șb�������Ƃ����邪�A
Radeon�͂���ɗւ������č����̂��c�c�H
�uGeForce�̃h���C�o���\�����Ē�~�R�}���h��ł��Ă��~�܂�Ȃ��Ȃ����v�Ƃ��A
���낵���Șb�������Ƃ����邪�A
Radeon�͂���ɗւ������č����̂��c�c�H
97 �F,,�E�L�́M�E,,�j��-�������F2011/09/16(��) 02:23:35.32 ID:ZL5xKSsy
MIC�̓t���v���O���}�u�������烆�[�U�[�����悾�ȁB
Larrabeeeeeeeee!!!
http://semiaccurate.com/2011/09/15/supermicro-shows-off-a-larrabee-box/
http://semiaccurate.com/2011/09/15/supermicro-shows-off-a-larrabee-box/
ttp://www.anandtech.com/show/4818/1
SNB��Ivy��Tr���ɔ��C���BIvy��14.8��14B���ԈႦ���悤��14B���������B
SNB��11.6B�Ƃ���̂���萳�m�Ƃ̂��ƁB���҂̔�r��20.4�p�[�Z���g���Ƃ������ƂɁB
SNB��Ivy��Tr���ɔ��C���BIvy��14.8��14B���ԈႦ���悤��14B���������B
SNB��11.6B�Ƃ���̂���萳�m�Ƃ̂��ƁB���҂̔�r��20.4�p�[�Z���g���Ƃ������ƂɁB
HC23�ɂ�Micron�����\����HMC��Intel�Ƃ̋����J���ł��邱�Ƃ�IDF�Ŗ��炩�ɂ��ꂽ�͗l�B
Intel and Micron Develop Hybrid Memory Cube, Stacked DRAM is Coming
ttp://www.anandtech.com/show/4819/1
�yHot Chips 23���|�[�g�z ���ς��郁�j�[�R�A�����DRAM�A�[�L�e�N�`��
ttp://pc.watch.impress.co.jp/docs/news/event/20110823_472122.html
Intel and Micron Develop Hybrid Memory Cube, Stacked DRAM is Coming
ttp://www.anandtech.com/show/4819/1
�yHot Chips 23���|�[�g�z ���ς��郁�j�[�R�A�����DRAM�A�[�L�e�N�`��
ttp://pc.watch.impress.co.jp/docs/news/event/20110823_472122.html
Intel reveals 'Claremont' Near Threshold Voltage Processor, other conceptual awesomeness at IDF
ttp://www.engadget.com/2011/09/15/intel-reveals-claremont-near-threshold-voltage-processor-othe/
���z�d�r�œ����v���Z�b�T�̃R�[�h�l�[����Clare�umont�v�Ƃ́AIntel�͐����ނ�t�łˁi�E�́E�j
���������c�ނ�ꂿ�Ⴄ�i����
ttp://www.engadget.com/2011/09/15/intel-reveals-claremont-near-threshold-voltage-processor-othe/
���z�d�r�œ����v���Z�b�T�̃R�[�h�l�[����Clare�umont�v�Ƃ́AIntel�͐����ނ�t�łˁi�E�́E�j
���������c�ނ�ꂿ�Ⴄ�i����
103 �F,,�E�L�́M�E,,�j��-�������F2011/09/16(��) 03:08:33.51 ID:ZL5xKSsy
>>99
���܂�C0�X�e�b�s���O�Ȃ̂��B�n���ɉ��ǂ��ĂȁB
���܂�C0�X�e�b�s���O�Ȃ̂��B�n���ɉ��ǂ��ĂȁB
VLIW�̃��C�e���V���݂���������
>>104
Fermi 18cycle
VLIW 8cycle
VLIW�̓o�C�p�X������
ns�ɂ���Ɠ������炢������
���C�e���V�B������̂ɃX���b�h�Ȃ�\�t�g�E�F�A�p�C�v���C�j���O�Ȃ��
���W�X�^�g�����Ⴄ�̂��h��
���C�e���V�ł�����Larrabee�͍ŋ�
DRAM���C�e���V�̓\�t�g�E�F�A�X���b�h�ʼnB������d�l
Fermi 18cycle
VLIW 8cycle
VLIW�̓o�C�p�X������
ns�ɂ���Ɠ������炢������
���C�e���V�B������̂ɃX���b�h�Ȃ�\�t�g�E�F�A�p�C�v���C�j���O�Ȃ��
���W�X�^�g�����Ⴄ�̂��h��
���C�e���V�ł�����Larrabee�͍ŋ�
DRAM���C�e���V�̓\�t�g�E�F�A�X���b�h�ʼnB������d�l
>>101
Micron��HMC����DARPA��Exa�X�P�[����NVIDIA�`�[���ł���Ă�����ˁH
Micron��Intel�`�[���ɂ������Ă�̂���
Micron��HMC����DARPA��Exa�X�P�[����NVIDIA�`�[���ł���Ă�����ˁH
Micron��Intel�`�[���ɂ������Ă�̂���
����I�����͂��o��́HIDF�̃��|�[�g����Ɨ��N���X�ɂ܂��O�|���ɂȂ����̂��H
1.4B (Billion)��1.48���Ǝv���ĊԈ���Ĕ��\�����̂���
�Ђł���
�Ђł���
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20110916_478013.html
���㓡�O��Weekly�C�O�j���[�X��
Intel������CPU�uIvy Bridge�v�́gTick+�h
���㓡�O��Weekly�C�O�j���[�X��
Intel������CPU�uIvy Bridge�v�́gTick+�h
111 �F �E�@���yLv=40,xxxPT�z �F2011/09/16(��) 10:23:51.75 ID:JI+t74xi
2012�N��Thunderbolt���ڂ�Windows�@
IDF 2011: Thunderbolt ab 2012 auch in Windows-Rechnern
http://www.hardwareluxx.de/index.php/news/hardware/mainboards/19911-idf-2011-thunderbolt-ab-2012-auch-in-windows-rechnern.html
IDF 2011: Thunderbolt ab 2012 auch in Windows-Rechnern
http://www.hardwareluxx.de/index.php/news/hardware/mainboards/19911-idf-2011-thunderbolt-ab-2012-auch-in-windows-rechnern.html
112 �F,,�E�L�́M�E,,�j��-�������F2011/09/16(��) 10:46:03.35 ID:ZL5xKSsy
>>105
�p�C�v���C���i���Ɋւ��Ă͒P����Fermi�̂ق������N���b�N�����ɐv����Ă邩��Ȃ��B
�X�J����VLIW���Ȃ�đS���W�Ȃ��B
�p�C�v���C���i���Ɋւ��Ă͒P����Fermi�̂ق������N���b�N�����ɐv����Ă邩��Ȃ��B
�X�J����VLIW���Ȃ�đS���W�Ȃ��B
113 �F �E�@���yLv=40,xxxPT�z �F2011/09/16(��) 10:52:13.21 ID:JI+t74xi
�������[�ɂ��g���C�Q�[�g���p���Ď��H
Intel Hybrid Memory Cube: When Ultra High-Density Meets Ultra High-Speed
http://www.xbitlabs.com/news/memory/display/20110915162718_Intel_Hybrid_Memory_Cube_When_Ultra_High_Density_Meets_Ultra_High_Speed.html
Intel Hybrid Memory Cube: When Ultra High-Density Meets Ultra High-Speed
http://www.xbitlabs.com/news/memory/display/20110915162718_Intel_Hybrid_Memory_Cube_When_Ultra_High_Density_Meets_Ultra_High_Speed.html
�yHot Chips 23���|�[�g�z�@���ς��郁�j�[�R�A�����DRAM�A�[�L�e�N�`��
http://pc.watch.impress.co.jp/docs/news/event/20110823_472122.html
Hot Chips 23 - �������o���h��������I�ɍ��߂�Hybrid Memory Cube
http://journal.mycom.co.jp/articles/2011/09/13/hot_chips23_micron/index.html
������ӓǂ݂܂��傤
http://pc.watch.impress.co.jp/docs/news/event/20110823_472122.html
Hot Chips 23 - �������o���h��������I�ɍ��߂�Hybrid Memory Cube
http://journal.mycom.co.jp/articles/2011/09/13/hot_chips23_micron/index.html
������ӓǂ݂܂��傤
115 �FSocket774�F2011/09/16(��) 18:59:11.85 ID:LdinxqzF
>>108
�N���ɂ̓��[�J�[�ɏo�ׂ����炵�����痈�N���X�ɂł邾�낤
�N���ɂ̓��[�J�[�ɏo�ׂ����炵�����痈�N���X�ɂł邾�낤
�P���ɏo����O�|������Ȃ��ė\��ʂ肾��B�N��������L���o���Ă����Ă��ƂɂȂ�B
�I�t�B�V�����ȃX�P�W���[���ł�
�ȑO����2012 Q1��������H1���ĕ\������Ȃ������H
�����̗��ꂩ�炵��1���Ƃ̗\�z����������������
�ȑO����2012 Q1��������H1���ĕ\������Ȃ������H
�����̗��ꂩ�炵��1���Ƃ̗\�z����������������
118 �FSocket774�F2011/09/16(��) 20:05:34.16 ID:8Z9yK1iy
���x�͂ǂ�Ȓv���I�ȕs�������̂���
����K���Ȃ��ł����Ă邩��A���N�ʒx�炵�Ė��S�ŏo���ׂ����낤
����K���Ȃ��ł����Ă邩��A���N�ʒx�炵�Ė��S�ŏo���ׂ����낤
�s�Ǖi�@�I�ʗ������R�A������肷��AMD������債�ĕς���̂ł�
AMD�Ȃ�B������������
AMD�Ȃ�B������������
>>119
�A�\�R�̓o�J�������BPhenom��TLB�G���b�^���o�J�����Ɍ����Ă��甄��o���Ă�A�z
Intel��C2D E6xx0�ɂ�����TLB�G���b�^���Z�p�����ɂ͏���������ʌ����ɂ͖ق��Ă���
Sandy�̃`�b�v�Z�b�g�̕s�s�����ǂ��l���Ă�����O����m���Ă�������H�@�A���B
�R�A�팸�����ʂɍ�����̂ł͂Ȃ��āA���i�Ƃ��Ĕ���o���Ӗ��̂킩��Ȃ���������
�������܂߂Ĕ���������肷����BCPU�J���̒x�������邪�A����������肭��������Ǝv����
�A�\�R�̓o�J�������BPhenom��TLB�G���b�^���o�J�����Ɍ����Ă��甄��o���Ă�A�z
Intel��C2D E6xx0�ɂ�����TLB�G���b�^���Z�p�����ɂ͏���������ʌ����ɂ͖ق��Ă���
Sandy�̃`�b�v�Z�b�g�̕s�s�����ǂ��l���Ă�����O����m���Ă�������H�@�A���B
�R�A�팸�����ʂɍ�����̂ł͂Ȃ��āA���i�Ƃ��Ĕ���o���Ӗ��̂킩��Ȃ���������
�������܂߂Ĕ���������肷����BCPU�J���̒x�������邪�A����������肭��������Ǝv����
�܂��㏬���{���a�l�����̐^�����Ă���肭������
�o�J�����ł���
�o�J�����ł���
122 �FSocket774�F2011/09/16(��) 22:31:01.60 ID:5K9do3gq
������������B�o����ΉB���Ȃ��ŗ~�����B�\�b�`�̕����o�Ă��������l������Ǝv����B
123 �FSocket774�F2011/09/16(��) 22:54:21.38 ID:x129F4+0
>>120
���̂������ŐM�҂��l�����Ă邶��Ȃ�����
���̂������ŐM�҂��l�����Ă邶��Ȃ�����
IDF Day 2 Recap: Intel's Medfield Mobile CPU, Future of Integrated GPUs
ttp://www.pcworld.com/article/240126/idf_day_2_recap_intels_medfield_mobile_cpu_future_of_integrated_gpus.html
DirectX 10��11�̎�v�ȃA�[�L�e�N�g������David Blythe�͌���Intel��Intel HD Graphics�̃\�t�g�E�F�A�̉��ǂɌg����Ă���悤���B
���݂�DX11��OpenGL�̓f�B�X�N���[�g�O���t�B�b�N�X�ɍœK������Ă���킯�����A
CPU�Ƃ̖��Ȍ�����A���L�������̋����o���h���Ƃ��̃t���b�g���ȂǂƂ���������������
�����^�O���t�B�b�N�X�Ƀt�B�b�g����悤API���g������K�v������Ɣނ͍l���Ă��邻���ȁB
����Medfield��1.9GHz�œ����A���ʂɎg���o�b�e���[��1���ۂ悤�ɂ��Ȃ����Ƃ��B
Medfield�ɂ��Ă͉��̃��[�}�[�L�����ʔ����B
�uCES 2012��HTC��Atom�̗p��Android�g�т\����v�Ƃ����\�����ł܂��Ƃ��₩�ɚ�����Ă��������ȁB
Atom�g�т��}�C�i�[�̘g���甲���o���邩�͂킩��Ȃ����AF-07C�̂悤�ȕϑԈ����͂���ŏI���Ƃ������B
HTC Preparing an Intel Smartphone for CES 2012?
ttp://www.brightsideofnews.com/news/2011/9/15/htc-preparing-an-intel-smartphone-for-ces-2012.aspx
ttp://www.pcworld.com/article/240126/idf_day_2_recap_intels_medfield_mobile_cpu_future_of_integrated_gpus.html
DirectX 10��11�̎�v�ȃA�[�L�e�N�g������David Blythe�͌���Intel��Intel HD Graphics�̃\�t�g�E�F�A�̉��ǂɌg����Ă���悤���B
���݂�DX11��OpenGL�̓f�B�X�N���[�g�O���t�B�b�N�X�ɍœK������Ă���킯�����A
CPU�Ƃ̖��Ȍ�����A���L�������̋����o���h���Ƃ��̃t���b�g���ȂǂƂ���������������
�����^�O���t�B�b�N�X�Ƀt�B�b�g����悤API���g������K�v������Ɣނ͍l���Ă��邻���ȁB
����Medfield��1.9GHz�œ����A���ʂɎg���o�b�e���[��1���ۂ悤�ɂ��Ȃ����Ƃ��B
Medfield�ɂ��Ă͉��̃��[�}�[�L�����ʔ����B
�uCES 2012��HTC��Atom�̗p��Android�g�т\����v�Ƃ����\�����ł܂��Ƃ��₩�ɚ�����Ă��������ȁB
Atom�g�т��}�C�i�[�̘g���甲���o���邩�͂킩��Ȃ����AF-07C�̂悤�ȕϑԈ����͂���ŏI���Ƃ������B
HTC Preparing an Intel Smartphone for CES 2012?
ttp://www.brightsideofnews.com/news/2011/9/15/htc-preparing-an-intel-smartphone-for-ces-2012.aspx
>>124
> CPU�Ƃ̖��Ȍ�����A���L�������̋����o���h���Ƃ��̃t���b�g���ȂǂƂ���������������
> �����^�O���t�B�b�N�X�Ƀt�B�b�g����悤API���g������K�v������Ɣނ͍l���Ă��邻���ȁB
INTEL�Ǝ���GPU API������Ă�Ƃ������Ƃ��H
���̂��߂̔ėp�I�Ȏd�g�݂�MS��C++AMP��OpenCL�Ȃ��A���XGPU�y����INTEL�ł���Ȃ��Ƃ��Ă����Ӗ����Ǝv����
> CPU�Ƃ̖��Ȍ�����A���L�������̋����o���h���Ƃ��̃t���b�g���ȂǂƂ���������������
> �����^�O���t�B�b�N�X�Ƀt�B�b�g����悤API���g������K�v������Ɣނ͍l���Ă��邻���ȁB
INTEL�Ǝ���GPU API������Ă�Ƃ������Ƃ��H
���̂��߂̔ėp�I�Ȏd�g�݂�MS��C++AMP��OpenCL�Ȃ��A���XGPU�y����INTEL�ł���Ȃ��Ƃ��Ă����Ӗ����Ǝv����
>Phenom��TLB�G���b�^���o�J�����Ɍ����Ă��甄��o���Ă�A�z
AMD���ŏ��͖ق��ďo�ׂ��Ă����B
���ƁAC2D�̃G���b�^��Pheneom��TLB�̃G���b�^�͖��̑傫�����Ⴄ�B
�㏬AMD�͑傫�Ȗ�肵�����J���Ă��Ȃ����ǁA�悭�킩���ĂȂ��z���x����Ă��邾���B
Sandy Bridge�̃G���b�^�̓t�@�[����ŏC�����s�\�Ȏ�ނ̂�����m���Ăďo�ׂ��Ă����ǂˁB
AMD���ŏ��͖ق��ďo�ׂ��Ă����B
���ƁAC2D�̃G���b�^��Pheneom��TLB�̃G���b�^�͖��̑傫�����Ⴄ�B
�㏬AMD�͑傫�Ȗ�肵�����J���Ă��Ȃ����ǁA�悭�킩���ĂȂ��z���x����Ă��邾���B
Sandy Bridge�̃G���b�^�̓t�@�[����ŏC�����s�\�Ȏ�ނ̂�����m���Ăďo�ׂ��Ă����ǂˁB
127 �F �E�@���yLv=40,xxxPT�z �F2011/09/17(�y) 04:27:29.41 ID:N2OVJ93F
DirectX 11.1���C�ɂȂ�
>>125
�����MS�ɂ͂��炫�����Ď���DX�ɒ�Ă����Ȃ��́H
����AMD�哱��10.1���ł��Ăقڂ��̂܂�11�Ɋg�����ꂽ��ASM�̊g���ɍ��킹��DX9�ia,
b,c�j���ł����肵����
�����MS�ɂ͂��炫�����Ď���DX�ɒ�Ă����Ȃ��́H
����AMD�哱��10.1���ł��Ăقڂ��̂܂�11�Ɋg�����ꂽ��ASM�̊g���ɍ��킹��DX9�ia,
b,c�j���ł����肵����
�ėp���Z�Ƃ�����Ȃ���
�ш�v�A��iGPU�����ɍœK���������̂��K�v�����ē��e�̂悤�ȋC�������
�ш�v�A��iGPU�����ɍœK���������̂��K�v�����ē��e�̂悤�ȋC�������
�y�x��zWintel���_��������B
ttp://www.infoworld.com/d/microsoft-windows/windows-8-arm-chips-it-was-too-good-be-true-173265
>Late Wednesday, in an earnings call with financial analysts, Sinofsky corrected a questioner on the issue,
> stating unequivocally for the first time that Windows 8 on ARM devices will run only the new Metro widget-style apps, not legacy Windows apps like Office.
ttp://cloud.watch.impress.co.jp/docs/event/20110915_477539.html
���̃t�@�[�X�g�C���v���b�V������ǂ������ƁAIntel���l�b�g�u�b�N����V�t�g�E�F�[�g�����n�C�u���b�h�����\������Ȃ����Ǝv���Ă݂���B
IDF 2011: Intel's Cedar Trail Atom aims for netbook-tablet hybrids
ttp://www.zdnet.com/blog/computers/idf-2011-intels-cedar-trail-atom-aims-for-netbook-tablet-hybrids/6722
Intel's Medfield Gingerbread Smartphone Reference Platform
ttp://www.anandtech.com/show/4788/intels-medfield-gingerbread-smartphone-reference-platform
Atom�g�т̗��N���������Ċe�Ђ͂���ƌ����ɓ����n�߂��̂�������Ȃ��B
���̗v���̈�Ƀm�L�A�Ƃ̓�������(MeeGo�̕���)����������Ƃ����c
ttp://www.infoworld.com/d/microsoft-windows/windows-8-arm-chips-it-was-too-good-be-true-173265
>Late Wednesday, in an earnings call with financial analysts, Sinofsky corrected a questioner on the issue,
> stating unequivocally for the first time that Windows 8 on ARM devices will run only the new Metro widget-style apps, not legacy Windows apps like Office.
ttp://cloud.watch.impress.co.jp/docs/event/20110915_477539.html
���̃t�@�[�X�g�C���v���b�V������ǂ������ƁAIntel���l�b�g�u�b�N����V�t�g�E�F�[�g�����n�C�u���b�h�����\������Ȃ����Ǝv���Ă݂���B
IDF 2011: Intel's Cedar Trail Atom aims for netbook-tablet hybrids
ttp://www.zdnet.com/blog/computers/idf-2011-intels-cedar-trail-atom-aims-for-netbook-tablet-hybrids/6722
Intel's Medfield Gingerbread Smartphone Reference Platform
ttp://www.anandtech.com/show/4788/intels-medfield-gingerbread-smartphone-reference-platform
Atom�g�т̗��N���������Ċe�Ђ͂���ƌ����ɓ����n�߂��̂�������Ȃ��B
���̗v���̈�Ƀm�L�A�Ƃ̓�������(MeeGo�̕���)����������Ƃ����c
131 �FSocket774�F2011/09/17(�y) 23:59:53.70 ID:Uo3bql8A
�^�u���b�g��corei5�̂������
132 �FSocket774�F2011/09/18(��) 00:01:20.04 ID:+igQOMTE
atom�g�т��āA�e�Ђ�F07-C�݂����̂��o���̂��A�����M���Ȃ��
133 �FSocket774�F2011/09/18(��) 00:14:03.00 ID:SZWx5sgU
�L���b�V���ς߂Ȃ��������m�ۂł��Ȃ������IntelCPU�B
���Q�[������
���Q�[������
Ivy�̃_�C�T�C�Y�͂��悻150����mm�Ƃ������Ƃ��낾�낤���B
ttp://images.anandtech.com/doci/4773/DSC_3231_575px.jpg
ttp://www.anandtech.com/show/4830/intels-ivy-bridge-architecture-exposed/2
ttp://images.anandtech.com/doci/4773/DSC_3231_575px.jpg
{kind=link}
ttp://www.anandtech.com/show/4830/intels-ivy-bridge-architecture-exposed/2
150mm��Merom���ł��Ȃ菬�������A�܂��܂����̃T�C�Y�ł͏ォ�牺�܂őS���N�A�b�h�R�A�Ƃ͂����Ȃ����낤��
2�R�A�ł�Penryn-3M���炢�̃T�C�Y�����҂ł��邾�낤��
2�R�A�ł�Penryn-3M���炢�̃T�C�Y�����҂ł��邾�낤��
150mm^2�Ȃ�ׂɏォ�牺�܂�4�R�A�ɂ��Ă����͂Ȃ����x��
�A���ȓd�͂ȕ�����
�A���ȓd�͂ȕ�����
�Z������������2�R�A�ɂȂ邩
������������ƃ^�u���b�g��Cortes-A15�̗p���n�߂���R�A���ŕ����邼
������������ƃ^�u���b�g��Cortes-A15�̗p���n�߂���R�A���ŕ����邼
�@�\��on/off�͕ʂɂ���Sandy�͂�������ă_�C���Ă邩��
�t����i7,i5
2core��遨i5,i3
2core�ALLC��0.5M���AGPU��6EU��遨Pentium,Celeron
Ivy���Ƃ����Ȃ邩��
�t����i7,i5
2core��遨i3
2core�ALLC��0.5M���AGPU��8EU��遨Pentium,Celeron
�t����i7,i5
2core��遨i5,i3
2core�ALLC��0.5M���AGPU��6EU��遨Pentium,Celeron
Ivy���Ƃ����Ȃ邩��
�t����i7,i5
2core��遨i3
2core�ALLC��0.5M���AGPU��8EU��遨Pentium,Celeron
Ivy��2�R�A�A8EU�R���t�B�O�͖��炩�ɒ���d��PC��Celeron��������Ȃ��c
�ԈႦ���A�ԈႦ��
Sandy
�t����i7,i5
2core��遨i5
2core�ALLC��0.5M���AGPU��6EU��遨i3,Pentium,Celeron
Ivy(�\�z)
�t����i7,i5
2core��遨i3
2core�ALLC��0.5M���AGPU��8EU��遨Pentium,Celeron
�m�[�g�͂����ƕ��G������V���l
Sandy
�t����i7,i5
2core��遨i5
2core�ALLC��0.5M���AGPU��6EU��遨i3,Pentium,Celeron
Ivy(�\�z)
�t����i7,i5
2core��遨i3
2core�ALLC��0.5M���AGPU��8EU��遨Pentium,Celeron
�m�[�g�͂����ƕ��G������V���l
���������Ă����ǁAIvy��2�R�A�@�WEU�̃������́ADDR3-1600 1�`�����l���ɂȂ��łȂ��H
�������܂��AIntel���m�[�g�x���_�[�ɁACULV�̗p���Ƀ�����1�`�����l���̂݁A
���Ă̂������đ����E�������̂��v���o�����B
�m���ɏ��^�E�ȓd�͉��������ɁA������1�`�����l��������ƌ����V�i���I�͂��肦��
�������܂��AIntel���m�[�g�x���_�[�ɁACULV�̗p���Ƀ�����1�`�����l���̂݁A
���Ă̂������đ����E�������̂��v���o�����B
�m���ɏ��^�E�ȓd�͉��������ɁA������1�`�����l��������ƌ����V�i���I�͂��肦��
�������ASandy��4�R�A�t���Z�b�g�ŁADDR3�������`�����l����2�`�����l���{1�`�����l�����̋A
���Ċ����ɂ��Ă��L���B
Sandy2�R�A�łŁADDR3������2�`�����l���M���M���B
������CPU�_�C�̂Ȃ��ł��ADRAM��PCI-Express�ȂǁA
�O�ɔz�����q���p�b�h�����͏��^���ł��Ȃ��̂�
�V�������N���Ă������̗]�T�͂Ƃ�Ȃ��Ƃ����Ȃ��B
�Ȃ̂ŁA22nm�ɃV�������N���ꂽIvy�́A4�R�A�Łi�{2�R�A�E���Łj�̂�DDR3-2�`�����l���A
��d���E��R�X�g�p�l�C�e�B�u2�R�A��DDR3-1�`�����l���̂݁A���Ă̂͂���
���Ċ����ɂ��Ă��L���B
Sandy2�R�A�łŁADDR3������2�`�����l���M���M���B
������CPU�_�C�̂Ȃ��ł��ADRAM��PCI-Express�ȂǁA
�O�ɔz�����q���p�b�h�����͏��^���ł��Ȃ��̂�
�V�������N���Ă������̗]�T�͂Ƃ�Ȃ��Ƃ����Ȃ��B
�Ȃ̂ŁA22nm�ɃV�������N���ꂽIvy�́A4�R�A�Łi�{2�R�A�E���Łj�̂�DDR3-2�`�����l���A
��d���E��R�X�g�p�l�C�e�B�u2�R�A��DDR3-1�`�����l���̂݁A���Ă̂͂���
�t����4�R�A
2core��遨Mobile-i7
2core�ALLC��0.5M���AGPU��6EU��遨Desktop-i5,i3 Mobile-i5,i3 Pentium,Celeron
�������͂������Ǝv��
2core��遨Mobile-i7
2core�ALLC��0.5M���AGPU��6EU��遨Desktop-i5,i3 Mobile-i5,i3 Pentium,Celeron
�������͂������Ǝv��
>>143
IDC�݂Ă�ƁAIvy����ł͈�ʃm�[�g���N���b�h�R�A�ɂȂ�݂�������B
���M�E�r�M�Ɋւ��ĉ��P�����A�v���[�`������̂ŁA35W�̃N���b�h�R�A���o����悤�ɂȂ�炵��
IDC�݂Ă�ƁAIvy����ł͈�ʃm�[�g���N���b�h�R�A�ɂȂ�݂�������B
���M�E�r�M�Ɋւ��ĉ��P�����A�v���[�`������̂ŁA35W�̃N���b�h�R�A���o����悤�ɂȂ�炵��
A15�̂Q�R�A�ŃZ�������P�R�A�����x�̏����\�͂��������Ǝv�����B
�����_��A9�R�A�ł���Q�R�A��Atom�P�R�A���x���̂悤�Ɍ����Ă����肷�邵
�����_��A9�R�A�ł���Q�R�A��Atom�P�R�A���x���̂悤�Ɍ����Ă����肷�邵
4core��1core�Ǝv���
IDF���I������킯�����A���o�C���̘b�肪���S�ŃT�[�o�[�̘b��͂قƂ�ǖ��������ˁB
�X�J�E�Q����SNB-EP�̍D���ȗ����オ���\������Poulson�̗��N�o�ׂ����������炢���낤���B
MIC��Knights Corner�Ƃ��̌�p�Ɋւ���A�b�v�f�[�g�͂قڊF���B
���g�i�[��������MIC��Atom�x�[�X�ɂȂ�ƌ��������炢���ȁH
�Z���Z�[�V���i���������̂͂�͂�d�͌�����5�`10�{���P����Ƃ���Near-Threshold Voltage�B
NTV���哱���Ă�̂�OR�Ȃ̂ŁA2017�N��2021�N��"Tick"�ŏo�Ă���Ɨ\�z�B
2018�N��Exascale�ɕK�v�Ƃ����b�������̂Ń^�C�~���O�I�ɍ����Ă�̂�2017�N�B
ISR��uarch���g�����āAOR����H�����ǂ���Ƃ����\�}�������Ă����悤�ȋC������BNHM������Ȋ����������B
�X�J�E�Q����SNB-EP�̍D���ȗ����オ���\������Poulson�̗��N�o�ׂ����������炢���낤���B
MIC��Knights Corner�Ƃ��̌�p�Ɋւ���A�b�v�f�[�g�͂قڊF���B
���g�i�[��������MIC��Atom�x�[�X�ɂȂ�ƌ��������炢���ȁH
�Z���Z�[�V���i���������̂͂�͂�d�͌�����5�`10�{���P����Ƃ���Near-Threshold Voltage�B
NTV���哱���Ă�̂�OR�Ȃ̂ŁA2017�N��2021�N��"Tick"�ŏo�Ă���Ɨ\�z�B
2018�N��Exascale�ɕK�v�Ƃ����b�������̂Ń^�C�~���O�I�ɍ����Ă�̂�2017�N�B
ISR��uarch���g�����āAOR����H�����ǂ���Ƃ����\�}�������Ă����悤�ȋC������BNHM������Ȋ����������B
148 �FSocket774�F2011/09/18(��) 16:28:09.78 ID:+igQOMTE
�uSNB�v���ĉ��Ȃ̂�
�����Ɏg���Ă�́H
�����Ɏg���Ă�́H
����BHSW���g���Ă�BLRB�͎g���Ă�(�ߋ��`)�B����MIC�B
Intel�̓A�N���j�������D���B
Intel�̓A�N���j�������D���B
Atom�̃`�[����1�����Ȃ�����
�A�[�L�e�N�`�����V��5�N�T�C�N���ɂȂ��Ă��邯�ǁA
�������d�͗̈�̋}���ȐL�т��l����ƁA������Ǝ��Ԃ������肷���Ă��銴������
Knights�Ƃ̋��ʉ����N����A�����ƃT�C�N�����Z���Ȃ�낤��
�A�[�L�e�N�`�����V��5�N�T�C�N���ɂȂ��Ă��邯�ǁA
�������d�͗̈�̋}���ȐL�т��l����ƁA������Ǝ��Ԃ������肷���Ă��銴������
Knights�Ƃ̋��ʉ����N����A�����ƃT�C�N�����Z���Ȃ�낤��
�������肨�Ȃ��݂ɂȂ��Ă���uIntel Inside�v���S�����A���T�A�V���ɁuWD Inside�v�̃G���u��
�������ꂽ�B����́A�������Western Digital��HDD���̗p���Ă��邱�Ƃ��������́BCPU�ȊO��
�p�[�c���[�J�[�����̎�̃��S���g�p����̂͒������Ⴞ�B
�uWD Inside�v���S���m�F�����̂́ATSUKUMO eX.�œW������Ă���c�N���u�����h��PC�B
�@�c�N���u�����h�̃V���b�v��i��W�J����Project White�ƁAWestern Digital�̑㗝�X�ł���V
�l�b�N�X�Ƃ̃R���{���[�V�����ɂ����̂ŁA�G���u�����ɏ�����Ă���̂́uHard Drive by WD�v
�Ƃ��������B�uWD Inside�v���̂��̂ł͂Ȃ����A�Ӗ����l���Ă��A�V�l�b�N�X�ł͂�����uWD
Inside�X�e�b�J�[�v�ƌĂ�ł���B
�@�V�l�b�N�X�̐����ɂ��ƁA�c�N���u�����hPC�ueX.computer�v�ɂ�Western Digital��HDD���S��
�I�ɍ̗p����邱�ƂɂȂ�A���i�ɂ����̃G���u������\��t���邱�ƂɂȂ����Ƃ����B�\�t���ς�
PC�̔����J�n��16���i���j�B
�@�Ȃ��A�P�̔z�z�̗\��Ȃǂ͓��ɍ��m����Ă��Ȃ��B
http://akiba-pc.watch.impress.co.jp/hotline/20110917/etc_wd2.html
http://akiba-pc.watch.impress.co.jp/hotline/20110917/image/stwd1.jpg
http://akiba-pc.watch.impress.co.jp/hotline/20110917/image/stwd2.jpg
http://akiba-pc.watch.impress.co.jp/hotline/20110917/image/stwd3.jpg
http://akiba-pc.watch.impress.co.jp/hotline/20110917/image/stwd4.jpg
�������ꂽ�B����́A�������Western Digital��HDD���̗p���Ă��邱�Ƃ��������́BCPU�ȊO��
�p�[�c���[�J�[�����̎�̃��S���g�p����̂͒������Ⴞ�B
�uWD Inside�v���S���m�F�����̂́ATSUKUMO eX.�œW������Ă���c�N���u�����h��PC�B
�@�c�N���u�����h�̃V���b�v��i��W�J����Project White�ƁAWestern Digital�̑㗝�X�ł���V
�l�b�N�X�Ƃ̃R���{���[�V�����ɂ����̂ŁA�G���u�����ɏ�����Ă���̂́uHard Drive by WD�v
�Ƃ��������B�uWD Inside�v���̂��̂ł͂Ȃ����A�Ӗ����l���Ă��A�V�l�b�N�X�ł͂�����uWD
Inside�X�e�b�J�[�v�ƌĂ�ł���B
�@�V�l�b�N�X�̐����ɂ��ƁA�c�N���u�����hPC�ueX.computer�v�ɂ�Western Digital��HDD���S��
�I�ɍ̗p����邱�ƂɂȂ�A���i�ɂ����̃G���u������\��t���邱�ƂɂȂ����Ƃ����B�\�t���ς�
PC�̔����J�n��16���i���j�B
�@�Ȃ��A�P�̔z�z�̗\��Ȃǂ͓��ɍ��m����Ă��Ȃ��B
http://akiba-pc.watch.impress.co.jp/hotline/20110917/etc_wd2.html
http://akiba-pc.watch.impress.co.jp/hotline/20110917/image/stwd1.jpg
{kind=link}
http://akiba-pc.watch.impress.co.jp/hotline/20110917/image/stwd2.jpg
{kind=link}
http://akiba-pc.watch.impress.co.jp/hotline/20110917/image/stwd3.jpg
{kind=link}
http://akiba-pc.watch.impress.co.jp/hotline/20110917/image/stwd4.jpg
{kind=link}
153 �FSocket774�F2011/09/19(��) 16:09:30.16 ID:7zUMAN9/
Atom�Ɋ��҂�����ACorei���ǂ̃T�C�Y�܂ł̂�悤�ɂȂ邩���낤
�yCPU�zIvy Bridge��Tick+�@�@��ȉ��ǂ�GPU�̑啝�����@�@CPU�̐��\�����4�`6����
http://hatsukari.2ch.net/test/read.cgi/news/1316436404/
http://hatsukari.2ch.net/test/read.cgi/news/1316436404/
ttp://pc.watch.impress.co.jp/docs/news/event/20110920_478686.html
�yIDF 2011���|�[�g�z
Justin Rattner���L�[�m�[�g�X�s�[�`
�`���j�C�R�A���オ��������
�yIDF 2011���|�[�g�z
Justin Rattner���L�[�m�[�g�X�s�[�`
�`���j�C�R�A���オ��������
��������A�������ƃ��{��p����Ȃ����蕨�o����
2004�N11��
�� �yQ�z CPU�R�A���́A���㐢�㖈�ɁA8�R�A��16�R�A�ւƑ����čs���̂��B
�� �yRattner���z �����Ȃ邾�낤�B����10�R�A���x�̘b�����Ă��邪�A
�� 5�N��ɂ́A�����A100�R�A�ȏオ����ɓ����Ă��邾�낤�B
�� �������Ĉ����Ă����悤�ȁA��K��SMP�V�X�e���������`�b�v�Ɏ��܂�悤�ɂȂ�B
2011�N9��
�� �u2�R�A����4�R�A�����܂�A4�R�A����8�R�A�����܂�A
�� ���A��X�̓��j�C�R�A����̎n�܂�ɂ���B�����Ƃ����Ƒ����̃R�A����������v
�� ���g�i�[���̓X�s�[�`�̖`���ŁA2006�N����n�܂���Intel�̃}���`�R�A���̗��������B
�� �d�͌��������߂邽�߂ɁACPU���}���ɃR�A���𑝂₵�Ă����ߋ�5�N�Ԃ�U��Ԃ����B
2004�N11��
�� �yQ�z CPU�R�A���́A���㐢�㖈�ɁA8�R�A��16�R�A�ւƑ����čs���̂��B
�� �yRattner���z �����Ȃ邾�낤�B����10�R�A���x�̘b�����Ă��邪�A
�� 5�N��ɂ́A�����A100�R�A�ȏオ����ɓ����Ă��邾�낤�B
�� �������Ĉ����Ă����悤�ȁA��K��SMP�V�X�e���������`�b�v�Ɏ��܂�悤�ɂȂ�B
2011�N9��
�� �u2�R�A����4�R�A�����܂�A4�R�A����8�R�A�����܂�A
�� ���A��X�̓��j�C�R�A����̎n�܂�ɂ���B�����Ƃ����Ƒ����̃R�A����������v
�� ���g�i�[���̓X�s�[�`�̖`���ŁA2006�N����n�܂���Intel�̃}���`�R�A���̗��������B
�� �d�͌��������߂邽�߂ɁACPU���}���ɃR�A���𑝂₵�Ă����ߋ�5�N�Ԃ�U��Ԃ����B
Rattner���́A�X�s�[�`�̒��ŁAKnights Ferry�ł̌o�����������āA
���̃o�[�W������MIC�A�[�L�e�N�`��CPU���A�����Ȑ��i�Ƃ��ďo�ׂ���ƌ�����B
22nm�v���Z�X��50�R�A�ȏ���W�ς���uKnights Corner(�i�C�c�R�[�i�[)�v���A���̐��i�Ń��j�C�R�A�ƂȂ�B
�����Ƃ��AKnights Corner�̃A�i�E���X���̂͂��łɍs�Ȃ��Ă��邽�߁AIDF�ł̔��\�͂��̍Ċm�F�ɉ߂��Ȃ��B
���̃o�[�W������MIC�A�[�L�e�N�`��CPU���A�����Ȑ��i�Ƃ��ďo�ׂ���ƌ�����B
22nm�v���Z�X��50�R�A�ȏ���W�ς���uKnights Corner(�i�C�c�R�[�i�[)�v���A���̐��i�Ń��j�C�R�A�ƂȂ�B
�����Ƃ��AKnights Corner�̃A�i�E���X���̂͂��łɍs�Ȃ��Ă��邽�߁AIDF�ł̔��\�͂��̍Ċm�F�ɉ߂��Ȃ��B
158 �FSocket774�F2011/09/20(��) 14:36:18.16 ID:Z+M5BMx8
>>156
�������炳�����ƂW�R�A�o��
�������炳�����ƂW�R�A�o��
http://www.anandtech.com/show/4830/intels-ivy-bridge-architecture-exposed/2
IvyBride�͂��Ȃ�肪�����Ă�̂�
�O�X���Řb��ɂłĂ�MOV����������炵��
IPC 4-6%��������蓾��b����
�I���S���̓n�[�h���グ���߂�����
IvyBride�͂��Ȃ�肪�����Ă�̂�
�O�X���Řb��ɂłĂ�MOV����������炵��
IPC 4-6%��������蓾��b����
�I���S���̓n�[�h���グ���߂�����
�ǂ����n�C�t�@�̃u���b�V���A�b�v�����o���Ȃ�����C�y����
>>159
HTT�̃��\�[�X�z���̌������Ȃǂ�����炵������A����������Ă�Ȃ���
6���ƌ�����Phenom2����Llano�����̒��x�������ȁB
HTT�̃��\�[�X�z���̌������Ȃǂ�����炵������A����������Ă�Ȃ���
6���ƌ�����Phenom2����Llano�����̒��x�������ȁB
Athlon2���낤
Phenom��L3�̌��ʂ�Llano�Ɠ���������ȏ�
Phenom��L3�̌��ʂ�Llano�Ɠ���������ȏ�
163 �FSocket774�F2011/09/20(��) 20:11:46.18 ID:vMoqM0Bu
>>156
���j�C�R�A�̗���ň�ԑ����������Ă�̂�
Intel����Ȃ��ǁB
�N���b�N�N���b�N�A�X���b�h�X���b�h����
�����܂Ńr�b�O�}�E�X�������H
�i����4�R�AIPC�H����
���X1�R�A���\�ɂ�������ĂĂ���������B
�X�}�z4�R�A�I32�R�A��
���̃��[�J�[�͏���ɐi��ł�����ŁB
���j�C�R�A�̗���ň�ԑ����������Ă�̂�
Intel����Ȃ��ǁB
�N���b�N�N���b�N�A�X���b�h�X���b�h����
�����܂Ńr�b�O�}�E�X�������H
�i����4�R�AIPC�H����
���X1�R�A���\�ɂ�������ĂĂ���������B
�X�}�z4�R�A�I32�R�A��
���̃��[�J�[�͏���ɐi��ł�����ŁB
164 �FSocket774�F2011/09/20(��) 20:23:40.51 ID:s8JUVI3/
����Ŕ����Ηǂ����ǂ�
>>163
������
������
166 �FSocket774�F2011/09/20(��) 20:34:45.40 ID:vMoqM0Bu
���������Ă̂�10G�Ɛ��������
100�R�A�Ƃ��������Ⴄ�l��������B
�z�b�v���X�e�b�v���Ȃ�3�i��сB
������ڍ����āu1�R�A���\�v�ɐ�c������B
��̂���5�N�ɉ�������ė����́H
100�R�A�Ƃ��������Ⴄ�l��������B
�z�b�v���X�e�b�v���Ȃ�3�i��сB
������ڍ����āu1�R�A���\�v�ɐ�c������B
��̂���5�N�ɉ�������ė����́H
bull�͌����ɓڍ������悤����
168 �FSocket774�F2011/09/20(��) 20:38:59.51 ID:vMoqM0Bu
AMD�Ȃǂ��ł�������A�����OS����B
�ނ�ނ�
170 �FSocket774�F2011/09/20(��) 20:43:44.91 ID:axtGtPDa
����قǂ̑ʍ�͖���
����ɂ��Ă��A���̓���100�R�A�Ƃ����̂͂ǂ������Z�p���g���Ď���������肾�����낤���B
Larrabee�n�̃����O�o�X���ƁA64�R�A�܂ł����V�~�����[�V�������ʂłĂ��Ȃ����ǁA
����ς�A���S�R�A�ƂȂ�ƁASCC�n�̃��b�V���ōs���̂��ȁH
Larrabee�n�̃����O�o�X���ƁA64�R�A�܂ł����V�~�����[�V�������ʂłĂ��Ȃ����ǁA
����ς�A���S�R�A�ƂȂ�ƁASCC�n�̃��b�V���ōs���̂��ȁH
172 �FSocket774�F2011/09/20(��) 20:51:51.54 ID:vMoqM0Bu
�n�[�h�ȑO�Ƀ\�t�g�̎������ڒ��������̂�
IA-64��f�i��������Larrabee�́B
�������ׂ����r�[�A�ɂ����Ȃ�u2�R�A�ŏ\���~�v��������������ȁ[�B
������w�E�����R�����g�������k�X�͏������K�������邵
��ĉ�А~�͂ǂ����悤���Ȃ��B
IA-64��f�i��������Larrabee�́B
�������ׂ����r�[�A�ɂ����Ȃ�u2�R�A�ŏ\���~�v��������������ȁ[�B
������w�E�����R�����g�������k�X�͏������K�������邵
��ĉ�А~�͂ǂ����悤���Ȃ��B
�|�����X�H
>>159
C2D�ŏオ��܂������n�[�h���́A���b�g�p�t�H�[�}���X��
���\������d�͂��オ�����Ƃ����ߏ�ȉz�������������B
�T�[�o�[�����Ƀt�H�[�J�X�����ƌ�������A�_���ʂ�Ȃ낤�B
Ultrabook�ɒ��͂���ƌ�������Haswell�͂ǂ��Ȃ邱�Ƃ��B
ARM�́A���\���������đf�����X�^���o�C�Ɉڍs�A���g�����h�̂悤������A
x86�͋t�ɁA�X�^���o�C���̏ȓd�͐��������A�ɒ��͂��Ă�̂��ȁH
C2D�ŏオ��܂������n�[�h���́A���b�g�p�t�H�[�}���X��
���\������d�͂��オ�����Ƃ����ߏ�ȉz�������������B
�T�[�o�[�����Ƀt�H�[�J�X�����ƌ�������A�_���ʂ�Ȃ낤�B
Ultrabook�ɒ��͂���ƌ�������Haswell�͂ǂ��Ȃ邱�Ƃ��B
ARM�́A���\���������đf�����X�^���o�C�Ɉڍs�A���g�����h�̂悤������A
x86�͋t�ɁA�X�^���o�C���̏ȓd�͐��������A�ɒ��͂��Ă�̂��ȁH
>>171
128�R�A�܂ł̃X�P�[���������ƁA���b�V���ȊO�̑I�����͖�������
��NoC�ɂ��ẮC�u�ŋ߂̃}���`�R�A�̃`�b�v�ł̓����O�^��NoC���g���Ă��邪�C
�����j�[�R�A����ɂȂ�Ɠd�͌����Ƃ����_�ł̓��b�V���^���D�ʁv
http://techon.nikkeibp.co.jp/article/NEWS/20110307/190149/?SS=imgview&FD=2138503421
���������S�R�A�Ȃ�Ă����ȒP�ɂ͂��肦��Ǝv���Ă����A
Knights Corner�i2012�N�\��j��50+�R�A�A200+�X���b�h�A
8���ς��400+�R�A������A�Ȃ��������Ȃ��L�ы��
���Ƃ͂��ꂪ�A�����I�ȉ��i�ň�ʌ����ɍ~��Ă��Ă����Ζʔ������c�c
���炭�͖������˂�
128�R�A�܂ł̃X�P�[���������ƁA���b�V���ȊO�̑I�����͖�������
��NoC�ɂ��ẮC�u�ŋ߂̃}���`�R�A�̃`�b�v�ł̓����O�^��NoC���g���Ă��邪�C
�����j�[�R�A����ɂȂ�Ɠd�͌����Ƃ����_�ł̓��b�V���^���D�ʁv
http://techon.nikkeibp.co.jp/article/NEWS/20110307/190149/?SS=imgview&FD=2138503421
���������S�R�A�Ȃ�Ă����ȒP�ɂ͂��肦��Ǝv���Ă����A
Knights Corner�i2012�N�\��j��50+�R�A�A200+�X���b�h�A
8���ς��400+�R�A������A�Ȃ��������Ȃ��L�ы��
���Ƃ͂��ꂪ�A�����I�ȉ��i�ň�ʌ����ɍ~��Ă��Ă����Ζʔ������c�c
���炭�͖������˂�
176 �F,,�E�L�́M�E,,�j��-�������F2011/09/20(��) 21:33:30.73 ID:ly8ypN4o
GPU�Ƃ��Ă�Larrabee�͎���̐���s���߂�����ˁB
NVIDIA��AMD��GPU�������̌Œ�p�C�v���C�����̂Ăăv���O���}�u���p�C�v���C����
�V�t�g���Ȃ����Ƃɂ͂ˁB�s��̃p���_�C�����ς��Ȃ����Ƃɂ�
Intel���R���V���[�}���i�Ƃ��ċ��݂����ɂ����B
�p���_�C�������ς���Ă��܂��A���Ƃ�GMA��50���̃V�F�A�ɂ˂����߂�Intel�̗͂ŁE�E�E
NVIDIA��AMD��GPU�������̌Œ�p�C�v���C�����̂Ăăv���O���}�u���p�C�v���C����
�V�t�g���Ȃ����Ƃɂ͂ˁB�s��̃p���_�C�����ς��Ȃ����Ƃɂ�
Intel���R���V���[�}���i�Ƃ��ċ��݂����ɂ����B
�p���_�C�������ς���Ă��܂��A���Ƃ�GMA��50���̃V�F�A�ɂ˂����߂�Intel�̗͂ŁE�E�E
2,3�N��̘b�Ȃ�܂�����10�N��̘b�͂ȁ[
Ivy��GPU�͂��Ȃ艉�Z�����ɂȂ��Ă�悤������
>>174
>Haswell�͂ǂ��Ȃ邱�Ƃ��B
AVX�ɍœK�������Ȃ���?
FMA3��AVX2�ɍ��킹�ă��[�h�X�g�A�ш��256Bit�����ꂽ�肷��낤�ȁB
�܂��A�n���Ɋ������߂������Ȃ�悤�ȉ��ǂ�����낤�B
���ƁA�E�B�L�y�f�B�A�ɂ�L1��64KB+64KB�ɂȂ���ď����Ă���ȁB
>Haswell�͂ǂ��Ȃ邱�Ƃ��B
AVX�ɍœK�������Ȃ���?
FMA3��AVX2�ɍ��킹�ă��[�h�X�g�A�ш��256Bit�����ꂽ�肷��낤�ȁB
�܂��A�n���Ɋ������߂������Ȃ�悤�ȉ��ǂ�����낤�B
���ƁA�E�B�L�y�f�B�A�ɂ�L1��64KB+64KB�ɂȂ���ď����Ă���ȁB
180 �F,,�E�L�́M�E,,�j��-�������F2011/09/20(��) 22:46:10.90 ID:ly8ypN4o
Wikipedia�͂�����������ȁBSandy Bridge��L2��512K�Ƃ������Ă����nj���256K�ɂȂ������B
�ǂ����̂���݂����ɃX���b�h����32K���Ƃ��������ʔ�������������
�ǂ����̂���݂����ɃX���b�h����32K���Ƃ��������ʔ�������������
>>163
POWER��2�R�A�o��������Athlon 1GHz�Ƃ������Ă���
POWER��2�R�A�o��������Athlon 1GHz�Ƃ������Ă���
���s��HPC����~��Ă�����̂����ȁB
K8�Ƃ�21364�̃p�N�������B
K8�Ƃ�21364�̃p�N�������B
CPU�ƊE�ɂƂ���DEC�̓����S�������[�}�鍑�݂����Ȃ������
�ǂ������������̌���ł��邱�Ƃ��������₪��
�ǂ������������̌���ł��邱�Ƃ��������₪��
184 �F,,�E�L�́M�E,,�j��-�������F2011/09/21(��) 00:12:22.05 ID:yBEzbLlT
��������ȍ~�́u���a�����̖���v�݂����Ȃ���ł����H
�ŋ߂̋^��́AGPGPU�̖{���I�ȗ��_�͉������Ă�������
���ׂĂ��悭������Ȃ���
GPU���v���O���}�u�������ǂ�ǂ����Ă�
�����CPU���}���`�R�A�����ăX���b�h���x�����Ő��\���҂��A�v���[�`��i�߂�̂Ȃ�
CPU�����ăg�����W�X�^���ɔ�Ⴗ��`�Ő��\��L���Ă����͂����Ǝv����
�i����Intel��MIC�𐄐i���Ă���j
CPU�̃��j�[�R�A�H���ɑ��āA
GPGPU�ɂ͂ǂ�ȃA�[�L�e�N�`���I�ȗ��_������̂��H
����Ƃ�VGA�Ƃ��Đ����o�Ă��邩��A
�O���t�B�b�N�����̂��߂̑�ʂ̉��Z��ƁA������GDDR�������ɒł��邱�Ƃ����_�H
���ׂĂ��悭������Ȃ���
GPU���v���O���}�u�������ǂ�ǂ����Ă�
�����CPU���}���`�R�A�����ăX���b�h���x�����Ő��\���҂��A�v���[�`��i�߂�̂Ȃ�
CPU�����ăg�����W�X�^���ɔ�Ⴗ��`�Ő��\��L���Ă����͂����Ǝv����
�i����Intel��MIC�𐄐i���Ă���j
CPU�̃��j�[�R�A�H���ɑ��āA
GPGPU�ɂ͂ǂ�ȃA�[�L�e�N�`���I�ȗ��_������̂��H
����Ƃ�VGA�Ƃ��Đ����o�Ă��邩��A
�O���t�B�b�N�����̂��߂̑�ʂ̉��Z��ƁA������GDDR�������ɒł��邱�Ƃ����_�H
���d���ɂ���ł���
�Ɨ������X���b�h�������ς����邨�d���Ȃ�MIC�Ń��j�A�ɐ��\���オ���
GPU�͕���Ƃ�������ƍl���Ȃ��Ă��ǂ����d������
����s����������߂ɍ��ڂ����
�Ɨ������X���b�h�������ς����邨�d���Ȃ�MIC�Ń��j�A�ɐ��\���オ���
GPU�͕���Ƃ�������ƍl���Ȃ��Ă��ǂ����d������
����s����������߂ɍ��ڂ����
187 �F,,�E�L�́M�E,,�j��-�������F2011/09/21(��) 00:21:59.72 ID:yBEzbLlT
NVIDIA�́uGPU�Ɛv�����L���Ă邩���R�X�g�v���Ď咣����Ă邯�ǂ��Ȃ�������̂��Ǝv�����ǂˁB
Tesla�{�[�h��Fermi�ɂȂ��Ă���GT2xx����Ɣ�ׂĂ����悻�{�ɒl�オ�肵�Ă邵
Tesla�Ɠ����_�C���g���܂킵�Ă�̂���GTX�N���X�����Ȃ��B
2�{�̃R�X�g�ł�2�{�̒l�i�Ŕ������̍���A�\�������ɂȂ�Ǝv�����ǂˁB
Tesla�{�[�h��Fermi�ɂȂ��Ă���GT2xx����Ɣ�ׂĂ����悻�{�ɒl�オ�肵�Ă邵
Tesla�Ɠ����_�C���g���܂킵�Ă�̂���GTX�N���X�����Ȃ��B
2�{�̃R�X�g�ł�2�{�̒l�i�Ŕ������̍���A�\�������ɂȂ�Ǝv�����ǂˁB
>>186
��������Ƃ����ア����ɁA
���������̂̕p�x�����Ȃ��A�P���ȉ��Z���S�̎d���Ȃ�����ǂ����Ȃ�����Ă������Ƃ�
HPC�����̌v�Z�@�̃j���[�X�����Ă��
Tesla���ς�ł��邱�Ƃ������悤�Ɏv���邵�A
�J�^���O�X�y�b�N�ł͗��_�s�[�N���\�̑傫�����x���Ă���悤�Ɍ�����
�Ƃ������Ƃ́AGPGPU��L���Ɏg����^�X�N�͈̔͂�
���Ȃ�L���Ɨ������Ă�����A
GPGPU�������Ȃ����ǂ��AMIC�̂悤�ȃ��j�[�R�A�Ȃ�
�����ǂ�������悤�ȃ^�X�N���Ă̂����\����́H
��������Ƃ����ア����ɁA
���������̂̕p�x�����Ȃ��A�P���ȉ��Z���S�̎d���Ȃ�����ǂ����Ȃ�����Ă������Ƃ�
HPC�����̌v�Z�@�̃j���[�X�����Ă��
Tesla���ς�ł��邱�Ƃ������悤�Ɏv���邵�A
�J�^���O�X�y�b�N�ł͗��_�s�[�N���\�̑傫�����x���Ă���悤�Ɍ�����
�Ƃ������Ƃ́AGPGPU��L���Ɏg����^�X�N�͈̔͂�
���Ȃ�L���Ɨ������Ă�����A
GPGPU�������Ȃ����ǂ��AMIC�̂悤�ȃ��j�[�R�A�Ȃ�
�����ǂ�������悤�ȃ^�X�N���Ă̂����\����́H
189 �F,,�E�L�́M�E,,�j��-�������F2011/09/21(��) 00:53:15.68 ID:yBEzbLlT
�x�N�g�����߂��d�_��������CPU���̂��̂�����ˁB
���Mercury�Ƃ�Fixstars�̏o���Ă��悤��Cell B.E.�J�[�h��PPE�ł�ꂽ���Ƃ�
�قƂ�Ǐo����Ǝv���Ă�����Ȃ��́H
�������S�ẴR�A��SPE����x�N�g�����Z���\�������Ȃ���PPE�����̎��R�x������B
PCIe�����C�[�T�[�l�b�g�Ɍ����Ăăz�X�g��NAS�Ƃ݂Ȃ��ăt�@�C���ɃA�N�Z�X��������ł��邵
���̋C�ɂȂ��Apache��MySQL�����ē�������B
���Mercury�Ƃ�Fixstars�̏o���Ă��悤��Cell B.E.�J�[�h��PPE�ł�ꂽ���Ƃ�
�قƂ�Ǐo����Ǝv���Ă�����Ȃ��́H
�������S�ẴR�A��SPE����x�N�g�����Z���\�������Ȃ���PPE�����̎��R�x������B
PCIe�����C�[�T�[�l�b�g�Ɍ����Ăăz�X�g��NAS�Ƃ݂Ȃ��ăt�@�C���ɃA�N�Z�X��������ł��邵
���̋C�ɂȂ��Apache��MySQL�����ē�������B
Larrabee�̓��X�^���C�U��ROP���Œ�@�\�n�[�h�E�F�A�ɂ���Ό��\������Ǝv�����ǂ�
�͓̂����ł��������Ɍł߂��Ă���������������
���̓��C�Z���X���邵IGP�Ńm�E�n�E�߂Ă邵
���s���j�b�g�����̓d�͌����Ȃ炻���܂ō����Ȃ��Ǝv��
MIC��IGP�̓����V�i���I�͂܂��o�ĂȂ�����
IGP�̎��s���j�b�g��x86���͖ʔ�����
GPGPU�̃L���[�A�v���͉摜�������Ǝv���Ă�
�e�N�X�`���t�B���^��X�^���C�U��CPU���ƌ����o�Ȃ�����GPU�͐�p�n�[�h���邩���
����ɏ�����@�����̐��قǂ��邩��v���O���}�u���ł��邱�Ƃ��d�v
Windows8�⎟����Android�̓W�F�X�`���[�F�������Ă����Ȃ�����
����Ɏv���Ă����ǑS���C�z���Ȃ���ww
>>187
�m�[�gPC����HPC�܂ő����O��͂��邯�Ǔ���A�[�L�e�N�`�����Ă̂������ł��Ȃ������b�g�Ȃ��
GPGPU�������Ă݂�܂ł̃n�[�h�������ɒႢ
MIC��LNI��߂�AVX�ɂ��邭�炢�̊���肪�~����
�͓̂����ł��������Ɍł߂��Ă���������������
���̓��C�Z���X���邵IGP�Ńm�E�n�E�߂Ă邵
���s���j�b�g�����̓d�͌����Ȃ炻���܂ō����Ȃ��Ǝv��
MIC��IGP�̓����V�i���I�͂܂��o�ĂȂ�����
IGP�̎��s���j�b�g��x86���͖ʔ�����
GPGPU�̃L���[�A�v���͉摜�������Ǝv���Ă�
�e�N�X�`���t�B���^��X�^���C�U��CPU���ƌ����o�Ȃ�����GPU�͐�p�n�[�h���邩���
����ɏ�����@�����̐��قǂ��邩��v���O���}�u���ł��邱�Ƃ��d�v
Windows8�⎟����Android�̓W�F�X�`���[�F�������Ă����Ȃ�����
����Ɏv���Ă����ǑS���C�z���Ȃ���ww
>>187
�m�[�gPC����HPC�܂ő����O��͂��邯�Ǔ���A�[�L�e�N�`�����Ă̂������ł��Ȃ������b�g�Ȃ��
GPGPU�������Ă݂�܂ł̃n�[�h�������ɒႢ
MIC��LNI��߂�AVX�ɂ��邭�炢�̊���肪�~����
��������AVX�ł��̂܂ܓ����Ί����v���O�����̗��p�͂��₷���Ȃ邯��
���̂����x�N�g������������256bit�ɂȂ��ăN���b�N������flops�����������c
Pentium�����̒P���ȃX�J���R�A�ɋ��͂ȃx�N�g�����Z�������K�̓R�A����ׂ���Ă���MIC�̃R���Z�v�g�ɂ����������蔽���Ă��
�ǂ݂̂�MIC�͓���HPC�A�N�Z�����[�^�ɗ��܂��ɗ��p���邽�߂ɂ̓A�v���P�[�V�������Ȃ����Ȃ��Ƃ����Ȃ�����
AVX�ɍS��Ӗ��͂���܂�Ȃ��Ǝv����
���̂����x�N�g������������256bit�ɂȂ��ăN���b�N������flops�����������c
Pentium�����̒P���ȃX�J���R�A�ɋ��͂ȃx�N�g�����Z�������K�̓R�A����ׂ���Ă���MIC�̃R���Z�v�g�ɂ����������蔽���Ă��
�ǂ݂̂�MIC�͓���HPC�A�N�Z�����[�^�ɗ��܂��ɗ��p���邽�߂ɂ̓A�v���P�[�V�������Ȃ����Ȃ��Ƃ����Ȃ�����
AVX�ɍS��Ӗ��͂���܂�Ȃ��Ǝv����
�A�v���P�[�V������蒼���Ȃ��Ƃ����Ȃ��Ȃ�x86�łȂ��Ă������悤��
�o�C�i�������Ȃ����C�u������g�ݍ��߂�Ƃ��͎|���̂��ȂƎv���Ă�����
�ăR���p�C���O��Ȃ�
�t���Z�b�g��C���ꂪ�g����x86�ƃo�C�g�I�[�_��MMU���݊��Ȃ牽�ł������C������
x86�̍œK���Z�p�҂������ƌ����Ă�Core�A�[�L�̍œK����������Larrabee�ł͖𗧂�������
���ʂƂ���P5�R�A���I���Ƃ����̂͂��蓾�邯��x86������Ȃ̂��H
�o�C�i�������Ȃ����C�u������g�ݍ��߂�Ƃ��͎|���̂��ȂƎv���Ă�����
�ăR���p�C���O��Ȃ�
�t���Z�b�g��C���ꂪ�g����x86�ƃo�C�g�I�[�_��MMU���݊��Ȃ牽�ł������C������
x86�̍œK���Z�p�҂������ƌ����Ă�Core�A�[�L�̍œK����������Larrabee�ł͖𗧂�������
���ʂƂ���P5�R�A���I���Ƃ����̂͂��蓾�邯��x86������Ȃ̂��H
194 �FSocket774�F2011/09/21(��) 06:58:23.98 ID:DcG/8lz3
x86�̈������悭������Ȃ��B
�U�Xx86���n�u�낤�Ƃ��Ă��̂�
�Ȃ�Ńx�N�g�����Z�Ŏg�����Ƃ���B
�U�Xx86���n�u�낤�Ƃ��Ă��̂�
�Ȃ�Ńx�N�g�����Z�Ŏg�����Ƃ���B
>x86�̍œK���Z�p�҂������ƌ����Ă�Core�A�[�L�̍œK����������Larrabee�ł͖𗧂�������
�C�~�t������
�C�~�t������
196 �FSocket774�F2011/09/21(��) 07:05:16.29 ID:DcG/8lz3
�z�b�v���X�e�b�v���Ȃ�
�����Ȃ��W�����v��炩���Ă�����������̂�Intel�̓`���Ȃ��
���̘b���b��������ȁA������������CPU�ɔ��f����Ȃ����B
�����Ȃ��W�����v��炩���Ă�����������̂�Intel�̓`���Ȃ��
���̘b���b��������ȁA������������CPU�ɔ��f����Ȃ����B
����knights�̃X�J����Atom����
198 �FSocket774�F2011/09/21(��) 07:48:59.25 ID:DcG/8lz3
Atom���̂������ˁB
�l�b�g�u�b�N��E-350�ɒu��������Ă邵
�X�}�z�̓X�i�h��4�R�A�Ō��܂肶��Ȃ����H
�l�b�g�u�b�N��E-350�ɒu��������Ă邵
�X�}�z�̓X�i�h��4�R�A�Ō��܂肶��Ȃ����H
���܂��n������
200 �FSocket774�F2011/09/21(��) 08:23:30.83 ID:DcG/8lz3
�n���ƌ����̂�10G�Ɛ�������� (ry
AVX��LNI���������镨�����ɂԂ������Ă邵
���Ԃ�_���A�[�L��bull�y�����Ƃ��ے肵�܂����Ă邵�B
���̃X���͈�Ԃ̂��Ԕ��ϑ����ł���B
AVX��LNI���������镨�����ɂԂ������Ă邵
���Ԃ�_���A�[�L��bull�y�����Ƃ��ے肵�܂����Ă邵�B
���̃X���͈�Ԃ̂��Ԕ��ϑ����ł���B
>>195
OoO��Core�A�[�L�e�N�`�������̍œK����
�C���I�[�_��P5�R�A�����̍œK���͋��߂���m�����Z�p�����Ȃ�Ⴄ����
���̂܂g����킯�ł͂Ȃ�
P5���Ɩ��߂̃y�A�����O�Ƃ����C�e���V��������Ƃ����d�v�ɂȂ�
���Ȑ��������
OoO��Core�A�[�L�e�N�`�������̍œK����
�C���I�[�_��P5�R�A�����̍œK���͋��߂���m�����Z�p�����Ȃ�Ⴄ����
���̂܂g����킯�ł͂Ȃ�
P5���Ɩ��߂̃y�A�����O�Ƃ����C�e���V��������Ƃ����d�v�ɂȂ�
���Ȑ��������
>DcG/8lz3
����AMD������ł��i���Ă��ȁA�������Ŋ撣��悗
����AMD������ł��i���Ă��ȁA�������Ŋ撣��悗
Bobcat����AMD�I�ɂ�Netbook����̗����m�[�gPC�_���Ȃ̂ɁA
Netbook�����H���ĂȂ�������A�헪���s����Ȃ��́H
Netbook�����H���ĂȂ�������A�헪���s����Ȃ��́H
���܂����A�����A���ď���ɂ����炾�߂��ȁB
���������AMercuryResearch�̒������ʂ��炷��ƁABobcat��Atom����
�ΏۂƂ��Ă���s�ꂪ���܂������ĂȂ����ۂ����ǁB
���������AMercuryResearch�̒������ʂ��炷��ƁABobcat��Atom����
�ΏۂƂ��Ă���s�ꂪ���܂������ĂȂ����ۂ����ǁB
205 �FSocket774�F2011/09/21(��) 11:30:29.21 ID:DcG/8lz3
>>202
AMD�̎�����X������
bull���
sandy����
���ĘA�Ă���X���ł���B
����Ȃ̂ǂ������W��������A
100�R�A��P5��AVX-AVX2���A�z�b�v���X�e�b�v��������
2�R�A�ŏ\��IPC�ݾ���x86�͉ߋ��̎��Y���[���Ă̂�
�ǂ�����Ƃ��܂荇���̂��Ȃ����E��K���Ɏ����グ��̂�
����g���������X���ł��傱��
AMD�̎�����X������
bull���
sandy����
���ĘA�Ă���X���ł���B
����Ȃ̂ǂ������W��������A
100�R�A��P5��AVX-AVX2���A�z�b�v���X�e�b�v��������
2�R�A�ŏ\��IPC�ݾ���x86�͉ߋ��̎��Y���[���Ă̂�
�ǂ�����Ƃ��܂荇���̂��Ȃ����E��K���Ɏ����グ��̂�
����g���������X���ł��傱��
intel��amd�݂����ɘH����������Ȃ���Ȃ�����
�R���V���[�}�����ɂ̓V���O����������
�T�[�o�A���[�N�X�e�[�V�����AHPC�����ɂ�
�j�[�Y�ɉ����āA�V���O���A�}���`�ɓK�������̂�ł���悤�ɂȂ�킯��
�R���V���[�}�����ɂ̓V���O����������
�T�[�o�A���[�N�X�e�[�V�����AHPC�����ɂ�
�j�[�Y�ɉ����āA�V���O���A�}���`�ɓK�������̂�ł���悤�ɂȂ�킯��
�z�b�v���X�e�b�v���Ȃ��ɂƂ������Ă�A�z��ID:DcG/8lz3�ɂ�SCC��Larrabee��
���̑��̃}���`/���j�C�R�A���T�[�`�v���W�F�N�g�͖����������ƂɂȂ����炵����
���������p�r���Ⴄ���̈ꏏ�ɕ��ׂĐ܂荇�������Ȃ��Ƃ��n���Ȃ́H
���̑��̃}���`/���j�C�R�A���T�[�`�v���W�F�N�g�͖����������ƂɂȂ����炵����
���������p�r���Ⴄ���̈ꏏ�ɕ��ׂĐ܂荇�������Ȃ��Ƃ��n���Ȃ́H
ID:DcG/8lz3���炷��ƁA����AMD������X���Ń}���Z�[���镨�����Ȃ��Ȃ����낗
����i���������s��ɏo���̂�AMD�ʂ����
210 �FSocket774�F2011/09/21(��) 13:23:49.83 ID:DcG/8lz3
>>207
Larrabee���u�z�b�v�v�u�X�e�b�v�v�H
����[���������Ԕ��X���͖ʔ������Ƃ��������ɂȂ�www
����8�R�A�������e�[��PC�s��ɏo�����i���Ȃ��̂�
�����Ȃ�100�R�A�ł���w
Larrabee���u�z�b�v�v�u�X�e�b�v�v�H
����[���������Ԕ��X���͖ʔ������Ƃ��������ɂȂ�www
����8�R�A�������e�[��PC�s��ɏo�����i���Ȃ��̂�
�����Ȃ�100�R�A�ł���w
Larrabee�́A�z�b�v�X�e�b�v�o�b�N�h���b�v��������
>>211
�R�P���Ǝv������h�邩��A����������ĎO���i��ł݂�����
Larrabee�n���̃A�[�L�����C���X�g���[���Ɠ��������Ƃ����
Skylake�i2015�N�H�j�ȍ~�炵������
�܂�����܂ł�AVX�Ƃǂ��܂荇�������邩
2004�N���_�̏�����������ɁA�悤�₭�����炸�Ƃ������炸�A���炢��
�E�E�E�E�E����ӊO�ɐ��m�ȗ\�z��������
http://pc.watch.impress.co.jp/docs/2004/1228/kaigai03.jpg
�R�P���Ǝv������h�邩��A����������ĎO���i��ł݂�����
Larrabee�n���̃A�[�L�����C���X�g���[���Ɠ��������Ƃ����
Skylake�i2015�N�H�j�ȍ~�炵������
�܂�����܂ł�AVX�Ƃǂ��܂荇�������邩
2004�N���_�̏�����������ɁA�悤�₭�����炸�Ƃ������炸�A���炢��
�E�E�E�E�E����ӊO�ɐ��m�ȗ\�z��������
http://pc.watch.impress.co.jp/docs/2004/1228/kaigai03.jpg
{kind=link}
213 �FSocket774�F2011/09/21(��) 13:57:03.68 ID:DcG/8lz3
>>212
���̊g�����߂��ux86�����߂�����v�����ɍs���Ă邤����
�܂荇�����ւ���������Ȃ���B
GPGPU�Ƃ��ĐςނȂ�x86�ł���K�v���͂Ȃ���
�����R�A�̊g���Ƃ��Ă̈ڍs�ł������1�R�A���\�����K������
�K�R���ƃX�e�b�v���Ȃ���M�҈ȊO�N�����Ă��Ȃ���B
���̊g�����߂��ux86�����߂�����v�����ɍs���Ă邤����
�܂荇�����ւ���������Ȃ���B
GPGPU�Ƃ��ĐςނȂ�x86�ł���K�v���͂Ȃ���
�����R�A�̊g���Ƃ��Ă̈ڍs�ł������1�R�A���\�����K������
�K�R���ƃX�e�b�v���Ȃ���M�҈ȊO�N�����Ă��Ȃ���B
���j�[�R�A���Č���GPGPU��肩�̓v���O�������₷�����Ă����ŁA
�N���C�A���g�����ɂ͂��܂胁�j�[�R�A�����ɗ��A�v�����Ȃ���Ȃ��́H
�𗧂Ă����ȃA�v����3D�Q�[�������ǁA�������͖{�E��GPU�̕����������ǂ����B
����ň�U�d�蒼���āAHPC�����Ƃ��āA�����̂��߂̑���ł߂Ɏ�肩�����Ă��Ȃ��́H
�N���C�A���g�����ɂ͂��܂胁�j�[�R�A�����ɗ��A�v�����Ȃ���Ȃ��́H
�𗧂Ă����ȃA�v����3D�Q�[�������ǁA�������͖{�E��GPU�̕����������ǂ����B
����ň�U�d�蒼���āAHPC�����Ƃ��āA�����̂��߂̑���ł߂Ɏ�肩�����Ă��Ȃ��́H
Intel�̓n�[�h�E�F�A��������A������������ꂻ���ł����ꂻ���Ȃ��̂��s��ɓK�X�������Ă鑤�ʂ�����B
�������Č���Ɖߋ���IPF��Netburst�ȂǂƂ������`�O�n�O�Ȑ��i��������x�[���ł���B
����ŋƐт��g�債�Ă����o�܂�����킯�ŁB�܂��A���܂�[��(Intel�S�\���H)�l����ƓD���ɛƂ��Ȃ����ƁB
�������Č���Ɖߋ���IPF��Netburst�ȂǂƂ������`�O�n�O�Ȑ��i��������x�[���ł���B
����ŋƐт��g�債�Ă����o�܂�����킯�ŁB�܂��A���܂�[��(Intel�S�\���H)�l����ƓD���ɛƂ��Ȃ����ƁB
�����A�����ǂ�
�y���q�zBulldozer�y����y���{�zpart3
�������
�y���q�zBulldozer�y����y���{�zpart3
�������
���������̂�A�Ђ̎�����X���b�h�ŗ��߂����Ǝv����
���Intel�_�ƌ����ǂ��AIA-64�ŒN���t���Ă��Ȃ��ăR�P��������Ă���B
x86�Ȃ�Ď~�߂������A���������킯�ɂ������Ȃ��̂ŁA
CPU+GPGPU �� �w�e���W�j�A�X�@�Ɛi�߂邽�߂ɁA
�R���p�C���Ȃǂ̊J�����𐮂��悤�Ƃ��Ă��鏊���Ǝv���B
�P�ɁAIntel��x86�Ŕe����������悤�ɁAAMD��Nvidia�ɋ����̂�S�z���Ă邾����������B
x86�Ȃ�Ď~�߂������A���������킯�ɂ������Ȃ��̂ŁA
CPU+GPGPU �� �w�e���W�j�A�X�@�Ɛi�߂邽�߂ɁA
�R���p�C���Ȃǂ̊J�����𐮂��悤�Ƃ��Ă��鏊���Ǝv���B
�P�ɁAIntel��x86�Ŕe����������悤�ɁAAMD��Nvidia�ɋ����̂�S�z���Ă邾����������B
219 �FSocket774�F2011/09/21(��) 16:08:40.03 ID:DcG/8lz3
x86���ǂ��������̂���
����Intel���猩���Ă��Ȃ��̂��Ȃ�Ƃ��B
���̃A�[�L���ƃ��j�[�R�A�Ɉڂ��Ă�TDP90Wover�g��
������4�R�A�ɂ����݂��Ċg�����ߗ���������A
�t��IPC���グ��ׂ����[���b�g�g��x86�ɂ��������4�R�A�A�i�E���X������B
64bit���j�[�R�A������AMD�̌����点�������Ă��Ȃ��B
����Intel���猩���Ă��Ȃ��̂��Ȃ�Ƃ��B
���̃A�[�L���ƃ��j�[�R�A�Ɉڂ��Ă�TDP90Wover�g��
������4�R�A�ɂ����݂��Ċg�����ߗ���������A
�t��IPC���グ��ׂ����[���b�g�g��x86�ɂ��������4�R�A�A�i�E���X������B
64bit���j�[�R�A������AMD�̌����点�������Ă��Ȃ��B
"��������"
intel�ƊW�Ȃ�����ɂ��Ηǂ������
AMD
intel�ƊW�Ȃ�����ɂ��Ηǂ������
AMD
221 �FSocket774�F2011/09/21(��) 17:22:10.51 ID:DcG/8lz3
>>220
������ �̕ϊ��~�X �Ͽ
AMD���ǂ����邩����Ȃ��AAMD���������
���r���[��x86�ɑ���v�������Ȃ�Intel�ɐG�ꂽ����Ȃ��B
AMD���A�N�V�����N�����܂ʼn������Ȃ��̂��H
������ �̕ϊ��~�X �Ͽ
AMD���ǂ����邩����Ȃ��AAMD���������
���r���[��x86�ɑ���v�������Ȃ�Intel�ɐG�ꂽ����Ȃ��B
AMD���A�N�V�����N�����܂ʼn������Ȃ��̂��H
64bit���j�[�R�A����AMD�̌����点���ĉ����Ӗ����Ă�̂��킩��Ȃ������c
>>218
�\�t�g�E�F�A�w������}���`�R�A�ɒǂ��t���ĂȂ�
���R�ȕ�������T�[�o����͑Ή������������ق����Ǝv�����ǁc�c
�܂��ăw�e���W�j�A�X�Ȃ�āA���ꉽ�ł�����Ԃł���
���X�^���t�H�[�h��w�w����John Hennesy�̌��t�����A
���u�R���s���[�^�T�C�G���X�j��ő�̖��ɒ��ʂ��Ă���v
http://www.publickey1.jp/blog/10/50.html
���\�̌���v���͏�ɂ���B�����V�������N�͑����g�����W�X�^�͔{�X�Q�[���Ŏg���邪�A
�d�͏���͑��₹�Ȃ��B�����Ń��b�g�p�t�H�[�}���X�̉��P���K�v����
���̈�}���`�R�A�͒Z���Ԃł̑Ή��͖���
�����������ŁAIntel�̐헪�͗��ʓI�ɂȂ��Ă���̂��낤
�n�[�h�E�F�A���x���̉��ǂŃV���O���X���b�h���\��L���Ď��ԉ҂���������
�}���`�R�A���y�ɗ��p���邽�߂̊��������s����
���C���X�g���[���łȂ��Ƃ͂����AKnights�݂����Ƀ��j�[�R�A����������
�\�t�g�E�F�A�w������}���`�R�A�ɒǂ��t���ĂȂ�
���R�ȕ�������T�[�o����͑Ή������������ق����Ǝv�����ǁc�c
�܂��ăw�e���W�j�A�X�Ȃ�āA���ꉽ�ł�����Ԃł���
���X�^���t�H�[�h��w�w����John Hennesy�̌��t�����A
���u�R���s���[�^�T�C�G���X�j��ő�̖��ɒ��ʂ��Ă���v
http://www.publickey1.jp/blog/10/50.html
���\�̌���v���͏�ɂ���B�����V�������N�͑����g�����W�X�^�͔{�X�Q�[���Ŏg���邪�A
�d�͏���͑��₹�Ȃ��B�����Ń��b�g�p�t�H�[�}���X�̉��P���K�v����
���̈�}���`�R�A�͒Z���Ԃł̑Ή��͖���
�����������ŁAIntel�̐헪�͗��ʓI�ɂȂ��Ă���̂��낤
�n�[�h�E�F�A���x���̉��ǂŃV���O���X���b�h���\��L���Ď��ԉ҂���������
�}���`�R�A���y�ɗ��p���邽�߂̊��������s����
���C���X�g���[���łȂ��Ƃ͂����AKnights�݂����Ƀ��j�[�R�A����������
>>219
TDP90W�z���Ő����c���Ă�CPU����x86�ȊO�̓T�[�o�p�������
���X���b�h�ɍs���͓̂��R
Intel��x86�Ŏx�z�I�ȃV�F�A�������Ă��Ă�����ێ�����K�v������̂�����
�����h�̋q�ɍ��킹�ĕێ�I�ɂȂ�͓̂�����
AMD�̓j�b�`���U�߂�ΐ��ݕ����ł���̂�����悢��łȂ��́H
�t�Ƀn�C�G���hGPU�ł͒���҂�����Intel��LRB�Ŋv�V���悤�Ƃ��Ď��������̂�����
TDP90W�z���Ő����c���Ă�CPU����x86�ȊO�̓T�[�o�p�������
���X���b�h�ɍs���͓̂��R
Intel��x86�Ŏx�z�I�ȃV�F�A�������Ă��Ă�����ێ�����K�v������̂�����
�����h�̋q�ɍ��킹�ĕێ�I�ɂȂ�͓̂�����
AMD�̓j�b�`���U�߂�ΐ��ݕ����ł���̂�����悢��łȂ��́H
�t�Ƀn�C�G���hGPU�ł͒���҂�����Intel��LRB�Ŋv�V���悤�Ƃ��Ď��������̂�����
225 �FSocket774�F2011/09/21(��) 18:12:23.48 ID:DcG/8lz3
>>223
1-2�R�A��100�R�A�I�[�o�[��������\�t�g�̌q���肪�Ȃ�����B
Intel�̎㖡�͂��̌q����̂Ȃ��Z�p�������Ă��ă|�b�L���܂�邱�ƁB
���݂͂�����������ɂ���1�N�Ń��J�o�[�o����`�[���ƍ��͂�����Ă邱�ƁB
1-2�R�A��100�R�A�I�[�o�[��������\�t�g�̌q���肪�Ȃ�����B
Intel�̎㖡�͂��̌q����̂Ȃ��Z�p�������Ă��ă|�b�L���܂�邱�ƁB
���݂͂�����������ɂ���1�N�Ń��J�o�[�o����`�[���ƍ��͂�����Ă邱�ƁB
>>225
Larrabee��32�R�A�ő����悤�Ɍ����邯��
600mm2�̋���_�C������ʐϓ�����R�A���ł݂��45nm��Penryn��Nehalem��3�{���炢
����قNJu�₵�Ă�킯�ł��Ȃ���
�t�ɂ��̒��x�����炠��܂�|�݂��Ȃ��킯����
Larrabee��32�R�A�ő����悤�Ɍ����邯��
600mm2�̋���_�C������ʐϓ�����R�A���ł݂��45nm��Penryn��Nehalem��3�{���炢
����قNJu�₵�Ă�킯�ł��Ȃ���
�t�ɂ��̒��x�����炠��܂�|�݂��Ȃ��킯����
>>225
�v���O�����ɂ��
2�R�A�ɍœK�����ꂽ�v���O������100�R�A�ő����Ȃ�Ƃ͎v���Ȃ���
���I�Ƀf�[�^�������s���t���[�����[�N���g���Ă����肵���ꍇ��
�A���S���Y������ŃX�P�[��������
��̓I�ɂ�Intel TBB���g�����P�[�X�i1�`40�R�A�܂ŁA�قڃ��j�A�ɐ��\���L�тĂ���j
http://software.intel.com/sites/products/web2010/prod-images/PFSSCale.gif
�v���O�����ɂ��
2�R�A�ɍœK�����ꂽ�v���O������100�R�A�ő����Ȃ�Ƃ͎v���Ȃ���
���I�Ƀf�[�^�������s���t���[�����[�N���g���Ă����肵���ꍇ��
�A���S���Y������ŃX�P�[��������
��̓I�ɂ�Intel TBB���g�����P�[�X�i1�`40�R�A�܂ŁA�قڃ��j�A�ɐ��\���L�тĂ���j
http://software.intel.com/sites/products/web2010/prod-images/PFSSCale.gif
{kind=link}
228 �FSocket774�F2011/09/21(��) 18:52:30.75 ID:DcG/8lz3
>>226
���������A32�R�A�ǂ��납�A������16�R�A����
�����Ɏg����N���C�A���g����ł��ĂȂ�����B
bull�y�����ɉB��ĕ\�ɏo�ĂȂ����ǁASandy-E���F�X���ʖ�ɂȂ��Ă�B
IntelCPU�͒�d�̓��j�[�R�A�����A�N���b�N�𑊓����Ƃ��Ȃ��ƂȂ�Ȃ��B
�N���b�N�H���Ɋ�肷���ă}���`�R�A���̃��b�g�p�t�H�[�}���X�̐L�т������B
�I�s���64bit����AVX2��x86���j�[�R�A�̓v�����Ƃ��Ă�������Ǝv���B
���������A32�R�A�ǂ��납�A������16�R�A����
�����Ɏg����N���C�A���g����ł��ĂȂ�����B
bull�y�����ɉB��ĕ\�ɏo�ĂȂ����ǁASandy-E���F�X���ʖ�ɂȂ��Ă�B
IntelCPU�͒�d�̓��j�[�R�A�����A�N���b�N�𑊓����Ƃ��Ȃ��ƂȂ�Ȃ��B
�N���b�N�H���Ɋ�肷���ă}���`�R�A���̃��b�g�p�t�H�[�}���X�̐L�т������B
�I�s���64bit����AVX2��x86���j�[�R�A�̓v�����Ƃ��Ă�������Ǝv���B
�ف[SIMD�̖��߃Z�b�g�ł�x86��������̂�
230 �FSocket774�F2011/09/21(��) 19:44:48.48 ID:DcG/8lz3
x87��AMD64�ŏ���������B
�����A���W�U���߂Ȃ��3DNow���݂Ɏg��˂���
http://www.theregister.co.uk/2011/09/15/intel_rattner_mic_coprocessor/
������MIC��Atom�x�[�X�ɂȂ����A64bit�����̂Ƃ��Ή��Ȃ�Ȃ��́H
������MIC��Atom�x�[�X�ɂȂ����A64bit�����̂Ƃ��Ή��Ȃ�Ȃ��́H
233 �FSocket774�F2011/09/21(��) 20:34:21.62 ID:ZoBOIfDq
>x87��AMD64�ŏ���������B
�����x86���ǂ������W�H
�����x86���ǂ������W�H
�A���~��
SSE2�Ȃ�ď���BAMD��K7����ߏo�����邽�߂�Pen4�ō�����B
�ƁA���N�����ꂵ�����Ă����̂ɁA
�ŋ߂�x87�ے肷�邾�ˁB�i���ɔn���Ȃ̂������Ȃ̂ɋC���t�������ɂȂ��ȁA������w
SSE2�Ȃ�ď���BAMD��K7����ߏo�����邽�߂�Pen4�ō�����B
�ƁA���N�����ꂵ�����Ă����̂ɁA
�ŋ߂�x87�ے肷�邾�ˁB�i���ɔn���Ȃ̂������Ȃ̂ɋC���t�������ɂȂ��ȁA������w
235 �FSocket774�F2011/09/21(��) 20:44:44.96 ID:DcG/8lz3
x86��AVX�łǂ��܂荇�������邩���ĊF�Ō����Ă邻����
>>233�݂����Ȃ̂�AMD�X���r�炷���o�Ŕn�����N���ɂ���ė���B
Intel�̊g�����߂�x86�K�{�������̂��A����͒m��Ȃ�������w
>>233�݂����Ȃ̂�AMD�X���r�炷���o�Ŕn�����N���ɂ���ė���B
Intel�̊g�����߂�x86�K�{�������̂��A����͒m��Ȃ�������w
236 �FSocket774�F2011/09/21(��) 20:47:56.88 ID:DcG/8lz3
Intel�̃X���ł�AMD���C�ɂȂ��Ďd���Ȃ��̂��A�����͐M�҃X������Ȃ�����
Intel�̘b���o���Ȃ��M�҂͑��ɋA���B
Intel�̘b���o���Ȃ��M�҂͑��ɋA���B
237 �FSocket774�F2011/09/21(��) 20:52:53.12 ID:ZoBOIfDq
�F�Łi�j
�����A�����ǂ�
Bulldozer�������p�[�e�B���part2
�������
Bulldozer�������p�[�e�B���part2
�������
239 �FSocket774�F2011/09/21(��) 20:57:57.13 ID:ZoBOIfDq
3�N�O�̌㓡�L���ł��ǂ�ł�����
�_�_���悭������Ȃ���
���j�[�R�A�̘b���Ǝv�����疽�߃Z�b�g�ɔ�Ԃ�
���j�[�R�A�̘b���Ǝv�����疽�߃Z�b�g�ɔ�Ԃ�
241 �F,,�E�L�́M�E,,�j��-�������F2011/09/21(��) 20:59:13.80 ID:yBEzbLlT
4�R�A�ɕ����鎩��8�R�A�Ȃ�Ďs��͕K�v�Ƃ��ĂȂ��B
242 �FSocket774�F2011/09/21(��) 21:00:36.78 ID:DcG/8lz3
>>237
���X�ォ�猩���킩�邪
x86���j�[�R�A�Ȃ�Ė������ݾ����Ԕ��ȓW�J���Ă�̂͒c�q���炢���B
AVX�i�߂�̂��A���j�[�R�A�������ĉ����܂ŃR�A�ς߂��邩
���̒��x�̃��X�N�͕��ʂɍl�����番����A���ʂ͂ȁB
���X�ォ�猩���킩�邪
x86���j�[�R�A�Ȃ�Ė������ݾ����Ԕ��ȓW�J���Ă�̂͒c�q���炢���B
AVX�i�߂�̂��A���j�[�R�A�������ĉ����܂ŃR�A�ς߂��邩
���̒��x�̃��X�N�͕��ʂɍl�����番����A���ʂ͂ȁB
243 �F,,�E�L�́M�E,,�j��-�������F2011/09/21(��) 21:01:29.93 ID:yBEzbLlT
ID:DcG/8lz3�����Ԕ�
244 �FSocket774�F2011/09/21(��) 21:03:44.41 ID:DcG/8lz3
LNI��512bit����SIMD������
�P����bull��2�{��core�ɑ������邩��
�P����bull��2�{��core�ɑ������邩��
246 �F,,�E�L�́M�E,,�j��-�������F2011/09/21(��) 21:10:14.63 ID:yBEzbLlT
�������ア�̂����������Ղ蔭�����Ă�Ȃ�
> 4�R�A�ɕ�����16�R�A�ł����Hw
����Interlagos�̂��Ƃ���ˁH������
4�R�A�͗��ɂȂ���������Ȃ�����SNB-E��6�R�A�ɗ��_���\�ɕ�����̊m�肵�Ă邩��B
����ł�32�R�A�ŒP���x1TFLOPS�I�[�o�[������ˁB
Knights Corner�Ȃ�{���x�ł�1T���炢�o�����Ȃ�������B
> 4�R�A�ɕ�����16�R�A�ł����Hw
����Interlagos�̂��Ƃ���ˁH������
4�R�A�͗��ɂȂ���������Ȃ�����SNB-E��6�R�A�ɗ��_���\�ɕ�����̊m�肵�Ă邩��B
����ł�32�R�A�ŒP���x1TFLOPS�I�[�o�[������ˁB
Knights Corner�Ȃ�{���x�ł�1T���炢�o�����Ȃ�������B
���Abull��SIMD��2core���L������512bit����4core�ɑ�������̂���
248 �FSocket774�F2011/09/21(��) 21:15:00.79 ID:DcG/8lz3
bull�Ȃ�ĒN���Ă�Ńl�[�̂ɂ܂��m�R�m�R��w
Interlagos�̔{�����Ȃ�AXeon�Ŕ�����������w
Interlagos�̔{�����Ȃ�AXeon�Ŕ�����������w
249 �F,,�E�L�́M�E,,�j��-�������F2011/09/21(��) 21:17:33.47 ID:yBEzbLlT
>>247
�^�[�Q�b�g�N���b�N�������悻�������x������2�R�A�����炢�ł�����ˁH
L1D�L���b�V���ш悪��艺��Ƃ�64�o�C�g����������I�ɂ͂���ȏ�ɋ����������ǁB
�^�[�Q�b�g�N���b�N�������悻�������x������2�R�A�����炢�ł�����ˁH
L1D�L���b�V���ш悪��艺��Ƃ�64�o�C�g����������I�ɂ͂���ȏ�ɋ����������ǁB
250 �F,,�E�L�́M�E,,�j��-�������F2011/09/21(��) 21:18:57.15 ID:yBEzbLlT
251 �FSocket774�F2011/09/21(��) 21:22:50.39 ID:DcG/8lz3
AMD�X����Intel�����o���Ȃ��ƋC���ς܂Ȃ��z��
Intel�X���ł�AMD�����o���Ȃ��ƑʖڂȂȁB
Intel�X���ł�AMD�����o���Ȃ��ƑʖڂȂȁB
252 �FSocket774�F2011/09/21(��) 21:25:44.91 ID:ZoBOIfDq
����������
�����̓�
�����̓�
�ȂA���~�����킢�������ȁB
�ŋ߂ɂȂ��Ă悤�₭Bull���ŋ߂ł͂܂�Ɍ���ʍ삾���Ă��Ƃ�
�킩���Ă��āA����ɔ[���ł��Ȃ�����T�����炵�ɂ��Ă���݂����B
�ʂɌÎQ�����̃A�[�L�e�N�`���݂����Ȃ��낤���x���̌��ʂȂ��ǂ�w
�ŋ߂ɂȂ��Ă悤�₭Bull���ŋ߂ł͂܂�Ɍ���ʍ삾���Ă��Ƃ�
�킩���Ă��āA����ɔ[���ł��Ȃ�����T�����炵�ɂ��Ă���݂����B
�ʂɌÎQ�����̃A�[�L�e�N�`���݂����Ȃ��낤���x���̌��ʂȂ��ǂ�w
254 �F,,�E�L�́M�E,,�j��-�������F2011/09/21(��) 21:26:03.68 ID:yBEzbLlT
AMD�́u�R�A�v�̐V��`���Đ����o�b�N�G���h�����Ȃ�H
AMD��NetBurst���o������A�{��ALU�̃N���b�N�i�R�A�̂Q�{������j���i�N���b�N���Č����o���Ǝv���B
�܂�Prescott��OC����5GHz�ȏ�o����10GHz�B�����B
AMD��NetBurst���o������A�{��ALU�̃N���b�N�i�R�A�̂Q�{������j���i�N���b�N���Č����o���Ǝv���B
�܂�Prescott��OC����5GHz�ȏ�o����10GHz�B�����B
255 �F,,�E�L�́M�E,,�j��-�������F2011/09/21(��) 21:30:55.68 ID:yBEzbLlT
256 �FSocket774�F2011/09/21(��) 21:31:08.61 ID:DcG/8lz3
�c�q������ƁA
���������������A�Ƃ������Ȃ���X���Ⴂ�ȃ��X��
���X�ƒP������������ł��̂��p�^�[�������Ă�ȁB
�[������r��Ē��Ԃ̏������݂ƃ��x���Ⴂ�������đ��{��I���O�ɍr�炷���c�݂����B
���������������A�Ƃ������Ȃ���X���Ⴂ�ȃ��X��
���X�ƒP������������ł��̂��p�^�[�������Ă�ȁB
�[������r��Ē��Ԃ̏������݂ƃ��x���Ⴂ�������đ��{��I���O�ɍr�炷���c�݂����B
257 �F,,�E�L�́M�E,,�j��-�������F2011/09/21(��) 21:32:57.21 ID:yBEzbLlT
ID:DcG/8lz3�̔n���������͗���NG�o�^�������C��
258 �FSocket774�F2011/09/21(��) 21:36:37.37 ID:DcG/8lz3
�ォ��m�R�m�R����ė���
�u������NG�ɂ��ĉ������v
NG�ɂȂ�̂͂���ȏ���bull�ްAMD�ް�Ƒ������O�̕����n����
�u������NG�ɂ��ĉ������v
NG�ɂȂ�̂͂���ȏ���bull�ްAMD�ް�Ƒ������O�̕����n����
259 �F,,�E�L�́M�E,,�j��-�������F2011/09/21(��) 21:38:01.50 ID:yBEzbLlT
�Ƃ���ō����͕��������j�[�g
260 �FSocket774�F2011/09/21(��) 21:41:26.84 ID:DcG/8lz3
2ch�Ńj�[�g�F����Ă܂��܂��ݓ����c����w
�����ی���Ȃ��ł��ސ��������Ă邩�Hw
�����ی���Ȃ��ł��ސ��������Ă邩�Hw
261 �F,,�E�L�́M�E,,�j��-�������F2011/09/21(��) 21:43:49.63 ID:yBEzbLlT
���⎩���ł����H
�����o���̂����b�ɂȂ��Ă����ȕ������L��������
�����o���̂����b�ɂȂ��Ă����ȕ������L��������
262 �FSocket774�F2011/09/21(��) 21:52:11.74 ID:DcG/8lz3
bull�ްAMD�ް�̎��̓j�[�g�F�肩��w
�y���Ɩ�Ԃ̍s���p�^�[���Ƃ���
���O�{���ɍݓ������c�̍H����Ȃ�ˁ[�́H
��������A�Ǝ��Ԃɍ��킹��OFF�ɏo�v���邩���
�y���Ɩ�Ԃ̍s���p�^�[���Ƃ���
���O�{���ɍݓ������c�̍H����Ȃ�ˁ[�́H
��������A�Ǝ��Ԃɍ��킹��OFF�ɏo�v���邩���
263 �F,,�E�L�́M�E,,�j��-�������F2011/09/21(��) 21:57:24.50 ID:yBEzbLlT
�ق畉�����͂����H����
�ŋ߂�VIA��x87�@FMA�̓����ɋ����ÁX
>>246
1TFLOPS�������̂̓f���̎������Ń����[�X�ł�Knights Ferry�͒P���x1TFLOPS�����ĂȂ������悤�ȁB
TDP��150W���x�Ɏ��߂邽�߃N���b�N�𗎂Ƃ��Ă邩��B(������900GFLOPS���炢�H)
Knights Corner��2����v���Z�X���i�ފ���50�R�A�ȏ�Ƃ����b�Ńs�[�N���\�̐L�т͉��₩�������ˁB
�_�C�T�C�Y�������������������̂��L���b�V���𑝂₵���������̂��_�����悭�킩��Ȃ�����C�ɂȂ��Ă���B
1TFLOPS�������̂̓f���̎������Ń����[�X�ł�Knights Ferry�͒P���x1TFLOPS�����ĂȂ������悤�ȁB
TDP��150W���x�Ɏ��߂邽�߃N���b�N�𗎂Ƃ��Ă邩��B(������900GFLOPS���炢�H)
Knights Corner��2����v���Z�X���i�ފ���50�R�A�ȏ�Ƃ����b�Ńs�[�N���\�̐L�т͉��₩�������ˁB
�_�C�T�C�Y�������������������̂��L���b�V���𑝂₵���������̂��_�����悭�킩��Ȃ�����C�ɂȂ��Ă���B
266 �FSocket774�F2011/09/21(��) 22:02:50.37 ID:DcG/8lz3
���������Ƃ��j�[�g�F��Ƃ��A�{���Ɍ������̐l�̓��b�e���\�肪�D������w
����ʼn��Z���u�錾�Ƃ�������ǂ����悤w
����ʼn��Z���u�錾�Ƃ�������ǂ����悤w
267 �FSocket774�F2011/09/21(��) 22:10:58.60 ID:DcG/8lz3
>>265
CPU��̉��ڎw���Ȃ琸�X����d�͂�75W�����E���낤����B
���Ƃ�CPU��45W�Ńg�[�^��110W���B
CPU�ɑ���GPGPU�͓d�̓��\�[�X���傪�~�܂�Ȃ���������ˁB
Intel��AMD���d�͔z���ŋ�J����Ǝv���B
CPU��̉��ڎw���Ȃ琸�X����d�͂�75W�����E���낤����B
���Ƃ�CPU��45W�Ńg�[�^��110W���B
CPU�ɑ���GPGPU�͓d�̓��\�[�X���傪�~�܂�Ȃ���������ˁB
Intel��AMD���d�͔z���ŋ�J����Ǝv���B
268 �F,,�E�L�́M�E,,�j��-�������F2011/09/21(��) 22:11:01.30 ID:yBEzbLlT
>>265
> Knights Corner��2����v���Z�X���i�ފ���50�R�A�ȏ�Ƃ����b�Ńs�[�N���\�̐L�т͉��₩�������ˁB
Knights Ferry�͓���GPU�Ƃ��Đv����Ă��̂Ŕ{���x���j�b�g���x���炵���i100GFLOPS������ƒ��x�H)
HPC�������Ă��ƂɂȂ�Ɠ��R�{���x�̋����͕K�v�ɂȂ�B
�{���x�����̃R�X�g��Cell�̏ꍇ�Ŗʐ�2�`3���A�b�v���炢���������ȁB
���Ƃ̓_�C�T�C�Y���ł��������悤�����A500mm²�ȓ��ɂ͗}�������Ƃ���ł���B
> Knights Corner��2����v���Z�X���i�ފ���50�R�A�ȏ�Ƃ����b�Ńs�[�N���\�̐L�т͉��₩�������ˁB
Knights Ferry�͓���GPU�Ƃ��Đv����Ă��̂Ŕ{���x���j�b�g���x���炵���i100GFLOPS������ƒ��x�H)
HPC�������Ă��ƂɂȂ�Ɠ��R�{���x�̋����͕K�v�ɂȂ�B
�{���x�����̃R�X�g��Cell�̏ꍇ�Ŗʐ�2�`3���A�b�v���炢���������ȁB
���Ƃ̓_�C�T�C�Y���ł��������悤�����A500mm²�ȓ��ɂ͗}�������Ƃ���ł���B
��͂�L�`�K�C���������c
http://download.intel.com/newsroom/kits/idf/2011_fall/pdfs/IDF2011_Mooly_Eden_Presentation.pdf
�����Mooly Eden�̃v���[���e�[�V�������A�b�v���ꂽ��
���̂͂����ɃA�b�v���ꂽ�̂Ɉُ�Ɏ��Ԃ��������B
������肪����낤�ȂƎv���Ă�����
haswell�̃`�b�v�ʐ^�������ւ����Ă�
�����Mooly Eden�̃v���[���e�[�V�������A�b�v���ꂽ��
���̂͂����ɃA�b�v���ꂽ�̂Ɉُ�Ɏ��Ԃ��������B
������肪����낤�ȂƎv���Ă�����
haswell�̃`�b�v�ʐ^�������ւ����Ă�
Mark Bohr�̃v���[���e�[�V�����ɏo�Ă���Ivy�̎ʐ^��
Ivy_Bridge Die-mod.jpg�����A���낢�돬�H���Ă�
Ivy_Bridge Die-mod.jpg�����A���낢�돬�H���Ă�
�����炭�\�t�g�E�F�A�̃}���`�X���b�h���́A
�R���p�C����CPU�������I�ɏ����̈ˑ�����c�����āA
�ˑ����������������A�����I�ɕ����̃X���b�h�ɕ�����
�������Ă����d�g�݂����邵���Ȃ��Ǝv���B
�ϐ��i�f�[�^�j���ƂɁA�ǂ��ōX�V�E�Q�Ƃ��Ă��邩�ˑ��W�͂��A
�������ˑ��W�Ńc���[��ɕ��ёւ��āA�o�C�i���[�����B
���s���́A�v�Z����̂ɕK�v�ȃf�[�^�������Ă��鏈������A
���ꂼ��̃X���b�h�Ōv�Z���A�v�Z���I��菇���f�[�^�������A
���s�\�ȏ����������X���b�h�Ŏ��s�B
�ǂ̏������ǂ̃f�[�^�Ɉˑ����Ă��邩���A
CPU���̃������ŊǗ����A�I�[�o�[�w�b�h���ŏ�������B
�܂��X���b�h���鏈���̍������A
�����̃X���b�h�Ń�������Ԃ����L����d�g�݁A
�X���b�h�ԒʐM��b�N�����̍������Ȃǂ��B
���������W�R�A���炢�g�����Ȃ��Ȃ����낤���H
�R���p�C����CPU�������I�ɏ����̈ˑ�����c�����āA
�ˑ����������������A�����I�ɕ����̃X���b�h�ɕ�����
�������Ă����d�g�݂����邵���Ȃ��Ǝv���B
�ϐ��i�f�[�^�j���ƂɁA�ǂ��ōX�V�E�Q�Ƃ��Ă��邩�ˑ��W�͂��A
�������ˑ��W�Ńc���[��ɕ��ёւ��āA�o�C�i���[�����B
���s���́A�v�Z����̂ɕK�v�ȃf�[�^�������Ă��鏈������A
���ꂼ��̃X���b�h�Ōv�Z���A�v�Z���I��菇���f�[�^�������A
���s�\�ȏ����������X���b�h�Ŏ��s�B
�ǂ̏������ǂ̃f�[�^�Ɉˑ����Ă��邩���A
CPU���̃������ŊǗ����A�I�[�o�[�w�b�h���ŏ�������B
�܂��X���b�h���鏈���̍������A
�����̃X���b�h�Ń�������Ԃ����L����d�g�݁A
�X���b�h�ԒʐM��b�N�����̍������Ȃǂ��B
���������W�R�A���炢�g�����Ȃ��Ȃ����낤���H
Itanium�H
>>272
�̂��猤�����x���ł͂��邯�ǖړr�̂����Ȃ����삾���
���Ȃ��Ƃ�C����̃Z�}���e�B�N�X���ƕs�\�ɋ߂�
����������͈ˑ��W�̕��͂��e�ՂȂ̂Ői��ł��邯��
��Ԃ��܂������Ă�̂�Haskell��GHC SMP��
2�R�A�ł��ǂ����H�Ƃ������x��
http://research.microsoft.com/en-us/um/people/simonpj/papers/parallel/multiproc.pdf
����ȂƂ����Erlang�݂�����
�e�����̗��x�����[�U���v����悤�ȐV�����Z�}���e�B�N�X�����邱�Ƃ�
Intel��Cilk�Ƃ��͂��̗���
C���ꂾ����ˑ����̓��[�U���ۏ��Ă��K�v������
�̂��猤�����x���ł͂��邯�ǖړr�̂����Ȃ����삾���
���Ȃ��Ƃ�C����̃Z�}���e�B�N�X���ƕs�\�ɋ߂�
����������͈ˑ��W�̕��͂��e�ՂȂ̂Ői��ł��邯��
��Ԃ��܂������Ă�̂�Haskell��GHC SMP��
2�R�A�ł��ǂ����H�Ƃ������x��
http://research.microsoft.com/en-us/um/people/simonpj/papers/parallel/multiproc.pdf
����ȂƂ����Erlang�݂�����
�e�����̗��x�����[�U���v����悤�ȐV�����Z�}���e�B�N�X�����邱�Ƃ�
Intel��Cilk�Ƃ��͂��̗���
C���ꂾ����ˑ����̓��[�U���ۏ��Ă��K�v������
>>221
�������Ă��镔���ɂ������̂Ƃ���s�ꂪ�Ȃ���AMD�Ƌ��ʂ̌����Ȃ�ł���B
�������Ă��镔���ɂ������̂Ƃ���s�ꂪ�Ȃ���AMD�Ƌ��ʂ̌����Ȃ�ł���B
277 �F,,�E�L�́M�E,,�j��-�������F2011/09/23(��) 00:23:15.43 ID:BI7Yim1q
�������ɓ\���Ă�����
Intel��20�N�Ԃ��CB�i���z50���h���j���s
http://www.bloomberg.co.jp/apps/news?pid=90920012&sid=axf1HVIJrZLA
Intel��20�N�Ԃ��CB�i���z50���h���j���s
http://www.bloomberg.co.jp/apps/news?pid=90920012&sid=axf1HVIJrZLA
�搶�A�������ƂĂ������ł��c
>>270
>>66��>>76��HSW�̎ʐ^�Ƃ���Ă������̂�����Ivy�������\�������܂������ȁB
�k����摜���������Ȃ����R�ł�����낤���BMCM�Ƃ��B
DRAM�͂�����Ɩ������ȁ[�Ǝv�����̂����B
>>270
>>66��>>76��HSW�̎ʐ^�Ƃ���Ă������̂�����Ivy�������\�������܂������ȁB
�k����摜���������Ȃ����R�ł�����낤���BMCM�Ƃ��B
DRAM�͂�����Ɩ������ȁ[�Ǝv�����̂����B
10�N����肪1.77%�Ȃ�
280 �F,,�E�L�́M�E,,�j��-�������F2011/09/23(��) 00:59:31.61 ID:BI7Yim1q
�䂤�����z�a���Ƃǂ������}�V���낤�ȁB
�ނ���10�N��̃h���̉��i���킩���B
�ނ���10�N��̃h���̉��i���킩���B
>>278
���o�C���p��HSW�ŃI���p�b�P�[�W��DRAM�������Ǝv�������R�ɂ��ĕ⑫�B
Exploring DRAM Cache Architectures for CMP Server Platforms
ttp://iccd.et.tudelft.nl/Proceedings/2007/Papers/1.3.2.pdf
DRAM Cache�ɂ��Č�������OR�̘_���B2007�N�̂��̂ŁA�V���v����8�R�A@4GHz��L3-8MB�Ƃ������Ƃ�45nm��32nm��z�肵�Ă����ȕ��͋C�B
�v��Ƃ��ẮA��e�ʂ�LLC�Ƃ���DRAM��p���Ă��܂��ƃ^�O�̔�剻�����ɂȂ�B
256MB(2Gbit)�̃`�b�v���g�����ꍇ�A�x�[�V�b�N��64B�̃L���b�V�����C�����ƃ^�O�T�C�Y��11MB�ɂ��Ȃ��Ă��܂��B
11MB���^�O�Ɋ����Ă��܂��ẮA���̕������I���_�C�̍�����SRAM�L���b�V��������̂ŁA�������Đ��\���ቺ���Ă��܂����낤�B
����Ȃ킯�Ń^�O�܂ŃI�t�_�C�ɂ�����A�^�O���ꕔ��������������ADRAM���Z�N�^�ɕ�������ȂǂƂ�������@���āA�]���B
64MB��DRAM�L���b�V����25�`75�p�[�Z���g���\����Ƃ������_�B
�]���ɗp���Ă���x���`��TPC-C��SAP-SD�Ȃǃ��[�N���[�h�Ƃ��Ă̓T�[�o�[�݂̂����A
"This makes DRAM caches very attractive for future CMP server platforms."�Ƃ������ƂŁA�Ԃ����ႰXeon�����z�肵�ĂȂ���˂��Ă����B
SPEC CPU���ƕ��ʂ�SRAM�L���b�V���ŏ\���Ƃ������A�����DRAM�L���b�V����ςނƑO�q�̗��R�Ő��\���������Ȃ����Ǝv����B
�b��Xeon�Ɍ����40W�̒�d���ł�z�肵�Ă�DRAM�̃_�C��1���ςނ��炢�ł�25�p�[�Z���g(10W)���d�͂��オ��Ƃ͎v���Ȃ��̂œd�͓I�ɂ͔����������B
�����A�̐S��DRAM���ǂ����璲�B���邩���������������Ȗ��Ȃ�Ȃ����Ǝv���Ă݂���B
���o�C���p��HSW�ŃI���p�b�P�[�W��DRAM�������Ǝv�������R�ɂ��ĕ⑫�B
Exploring DRAM Cache Architectures for CMP Server Platforms
ttp://iccd.et.tudelft.nl/Proceedings/2007/Papers/1.3.2.pdf
DRAM Cache�ɂ��Č�������OR�̘_���B2007�N�̂��̂ŁA�V���v����8�R�A@4GHz��L3-8MB�Ƃ������Ƃ�45nm��32nm��z�肵�Ă����ȕ��͋C�B
�v��Ƃ��ẮA��e�ʂ�LLC�Ƃ���DRAM��p���Ă��܂��ƃ^�O�̔�剻�����ɂȂ�B
256MB(2Gbit)�̃`�b�v���g�����ꍇ�A�x�[�V�b�N��64B�̃L���b�V�����C�����ƃ^�O�T�C�Y��11MB�ɂ��Ȃ��Ă��܂��B
11MB���^�O�Ɋ����Ă��܂��ẮA���̕������I���_�C�̍�����SRAM�L���b�V��������̂ŁA�������Đ��\���ቺ���Ă��܂����낤�B
����Ȃ킯�Ń^�O�܂ŃI�t�_�C�ɂ�����A�^�O���ꕔ��������������ADRAM���Z�N�^�ɕ�������ȂǂƂ�������@���āA�]���B
64MB��DRAM�L���b�V����25�`75�p�[�Z���g���\����Ƃ������_�B
�]���ɗp���Ă���x���`��TPC-C��SAP-SD�Ȃǃ��[�N���[�h�Ƃ��Ă̓T�[�o�[�݂̂����A
"This makes DRAM caches very attractive for future CMP server platforms."�Ƃ������ƂŁA�Ԃ����ႰXeon�����z�肵�ĂȂ���˂��Ă����B
SPEC CPU���ƕ��ʂ�SRAM�L���b�V���ŏ\���Ƃ������A�����DRAM�L���b�V����ςނƑO�q�̗��R�Ő��\���������Ȃ����Ǝv����B
�b��Xeon�Ɍ����40W�̒�d���ł�z�肵�Ă�DRAM�̃_�C��1���ςނ��炢�ł�25�p�[�Z���g(10W)���d�͂��オ��Ƃ͎v���Ȃ��̂œd�͓I�ɂ͔����������B
�����A�̐S��DRAM���ǂ����璲�B���邩���������������Ȗ��Ȃ�Ȃ����Ǝv���Ă݂���B
http://semiaccurate.com/2010/12/29/intel-puts-gpu-memory-ivy-bridge/
������Ăǂ��Ȃ����낤
Hyper Memory Cube�̂��Ƃ�������
������Ăǂ��Ȃ����낤
Hyper Memory Cube�̂��Ƃ�������
�ʐ^�ŃC���^�[�t�F�[�X�B���Ă��̂���������
����MCM�ł��肻���Ȃ̂͂��ꂩ�ȁB
ttp://www.anandtech.com/show/1770
ttp://images.anandtech.com/reviews/tradeshows/IDF/2005/Fall/Day3/Keynote/integratedGMCH.jpg
ttp://www.anandtech.com/show/1770
ttp://images.anandtech.com/reviews/tradeshows/IDF/2005/Fall/Day3/Keynote/integratedGMCH.jpg
{kind=link}
>>284
����ɂ͊��҂��Ă����AHaswell�ł��邩��
����ɂ͊��҂��Ă����AHaswell�ł��邩��
>>282
����������GPU�������烌�C�e���V�͌�������
���x��VRAM�����C���������ɂȂ��đш悪�������Ȃ��Ă�̂�
����Ȃ�̗ʂ�GDDR��CPU�p�b�P�[�W�ɓ������ĉ\�Ȃ�H
����������GPU�������烌�C�e���V�͌�������
���x��VRAM�����C���������ɂȂ��đш悪�������Ȃ��Ă�̂�
����Ȃ�̗ʂ�GDDR��CPU�p�b�P�[�W�ɓ������ĉ\�Ȃ�H
CPU�p�b�P�[�W���ɕ��������Ƃ����CPU�̃G�b�W���̕s�������������킯�ł͂Ȃ����A
32bit�`64bit���x�̃o�X�����m�ۂ����1GB�l�߂邩�炻��ŏ\���ł��낤
�ėpCPU�Ō����I�ȃR�X�g���Ńp�b�P�[�W����3��4��DRAM�_�C���悹���邩�͋^�₪���邪�B
32bit�`64bit���x�̃o�X�����m�ۂ����1GB�l�߂邩�炻��ŏ\���ł��낤
�ėpCPU�Ō����I�ȃR�X�g���Ńp�b�P�[�W����3��4��DRAM�_�C���悹���邩�͋^�₪���邪�B
�ϑw�őш�m�ۂ������Ȃ�Ȃ���?
WideIO��2014��ڎw���Ă��邩��
TSV���g���Ȃ瑁���Ă����炢�ɂȂ��łȂ���
Haswell/Broadwell�ɂ͊Ԃɍ���Ȃ�����
Skylake���炩��
������TSV�����������܂��DDR4�����̂ւ�Ƃ����Ă邩��
�����Ȃ������ȃX�P�W���[��
MIC�������{���ɋN����Ȃ�Skylake�����肾�낤����
�ш���v�̑������l���Ă��ǂ��^�C�~���O
Intel��DRAM�͕��y�Z�p���g�킴��Ȃ������
3D�g�����W�X�^�݂����ɐ�[�̋Z�p��^����ɓ����Ƃ����̂͋N����Ȃ�
Micron�Ƃ̃R���{���ǂ̃��x���Ȃ̂��͋C�ɂȂ�Ƃ���
TSV���g���Ȃ瑁���Ă����炢�ɂȂ��łȂ���
Haswell/Broadwell�ɂ͊Ԃɍ���Ȃ�����
Skylake���炩��
������TSV�����������܂��DDR4�����̂ւ�Ƃ����Ă邩��
�����Ȃ������ȃX�P�W���[��
MIC�������{���ɋN����Ȃ�Skylake�����肾�낤����
�ш���v�̑������l���Ă��ǂ��^�C�~���O
Intel��DRAM�͕��y�Z�p���g�킴��Ȃ������
3D�g�����W�X�^�݂����ɐ�[�̋Z�p��^����ɓ����Ƃ����̂͋N����Ȃ�
Micron�Ƃ̃R���{���ǂ̃��x���Ȃ̂��͋C�ɂȂ�Ƃ���
CPU�p�b�P�[�W�ɕ�������DRAM�ł������������ʂɎg���킯�ł��Ȃ���
DIMM�Ƃ��ĕ��L���̔������肷��Ƃ������Ƃ��Ȃ�����A�R���f�B�e�BDRAM�ɂ������K�v���͖�����Ȃ��̂���
���C���������ƃo�X�C���^�[�t�F�[�X�����ʉ�����K�v���͔������낤����
DIMM�Ƃ��ĕ��L���̔������肷��Ƃ������Ƃ��Ȃ�����A�R���f�B�e�BDRAM�ɂ������K�v���͖�����Ȃ��̂���
���C���������ƃo�X�C���^�[�t�F�[�X�����ʉ�����K�v���͔������낤����
http://www.fudzilla.com/processors/item/24170-cedar-trail-loses-directx-10-support
�o���Ȃ�������߂��悤��
Ivy�͂ǂ��Ȃ邩�ˁH
�o���Ȃ�������߂��悤��
Ivy�͂ǂ��Ȃ邩�ˁH
�f����DX11�Q�[���������
Cedarview�ɂ̂��Ă�GPU��PowerVR�B
Ivy�ɂ̂��Ă�̂́Aintel���O��HDGraphics�B
�����APowerVR�̃h���C�o��Imagination�ɍ���Ă��炦�����̂ɁB
Ivy�ɂ̂��Ă�̂́Aintel���O��HDGraphics�B
�����APowerVR�̃h���C�o��Imagination�ɍ���Ă��炦�����̂ɁB
��������I/O�p�b�h�̃X�y�[�X���m�ۂ��邽�߂ɁACPU�ɓ����ł������ȃ��W���[���͉��ł���������
�Ƃ肠�����`�b�v�̃X�y�[�X��100mm�O2�`230mm^2�ɐ���������K�v�ɔ����Ă�Ƃ�
�Ȃ�Ƃ�����ƌ��킴��Ȃ�
�Ƃ肠�����`�b�v�̃X�y�[�X��100mm�O2�`230mm^2�ɐ���������K�v�ɔ����Ă�Ƃ�
�Ȃ�Ƃ�����ƌ��킴��Ȃ�
>>294
�������ă`�b�v�������炷�f�����b�g�͂��܂�Ȃ����獡�̂Ƃ���悢����
����PCH�܂œ�������SOC����B��������ǂ��Ȃ邩����
�Ƃ͂����Ă��܂��`�b�v�O���̔������g���ĂȂ�����
�������炳��ɂP�C�Q����]�T�͂��邯��
�R�A���𑝂₳��������Ȃ��̂�
PARROT�݂����ȃ_�C�T�C�Y���g���Ē����d�͉�IPC���㗼���H����
�������ă`�b�v�������炷�f�����b�g�͂��܂�Ȃ����獡�̂Ƃ���悢����
����PCH�܂œ�������SOC����B��������ǂ��Ȃ邩����
�Ƃ͂����Ă��܂��`�b�v�O���̔������g���ĂȂ�����
�������炳��ɂP�C�Q����]�T�͂��邯��
�R�A���𑝂₳��������Ȃ��̂�
PARROT�݂����ȃ_�C�T�C�Y���g���Ē����d�͉�IPC���㗼���H����
>>290
��p��DRAM�̐�DRAM���[�J�ɍ�点��Ƃ����͍̂l���Â炢���ǂ�
�����ł����X�^�b�N�̓R�X�g���Ȃ̂�
DRAM���[�J�ɐ�p�`�b�v�Ńv���~�A����点��]�T�͂Ȃ���Ȃ����H
Intel�͎��O��DRAM������ĂȂ������
���C���������ƃo�X�C���^�[�t�F�C�X�����ʉ�����K�v���͂Ȃ���
DRAM�`�b�v���̂͋��ʉ����邾�낤
��������WideIO�₽�Ԃ�DDR4��TSV�̋K�i�����̂�����
��p��DRAM�̐�DRAM���[�J�ɍ�点��Ƃ����͍̂l���Â炢���ǂ�
�����ł����X�^�b�N�̓R�X�g���Ȃ̂�
DRAM���[�J�ɐ�p�`�b�v�Ńv���~�A����点��]�T�͂Ȃ���Ȃ����H
Intel�͎��O��DRAM������ĂȂ������
���C���������ƃo�X�C���^�[�t�F�C�X�����ʉ�����K�v���͂Ȃ���
DRAM�`�b�v���̂͋��ʉ����邾�낤
��������WideIO�₽�Ԃ�DDR4��TSV�̋K�i�����̂�����
�̂ƈ���ăL���b�V����������CPU�R�A�AGPU�V�F�[�_�̌��ׂ��łĂ�OFF�ɂ��邾���ł�������A
�R�X�g�I�ɗ]�荂���Ȃ�Ȃ���ˁB�B�B
�R�X�g�I�ɗ]�荂���Ȃ�Ȃ���ˁB�B�B
Wide I/O��DRAM��SoC�`�b�v�̏�ɃX�^�b�N��������݂���������60W��80W�̃v���Z�T�ł�������ɂ͂�قǃR�A�𑝂₵�ēd�͖��x�������Ȃ��������Ǝv���B
HMC�̂悤�ȃx�[�V�b�N��MCM��z�肵���K�i��Intel����o�Ă���Ƃ��납�炵�Ă���Ȉ�ہB(�K�i�ƌ����Ă�HMC�̕W�����͂܂����ꂩ��̘b�̂悤�����ǁB)
HMC�̂悤�ȃx�[�V�b�N��MCM��z�肵���K�i��Intel����o�Ă���Ƃ��납�炵�Ă���Ȉ�ہB(�K�i�ƌ����Ă�HMC�̕W�����͂܂����ꂩ��̘b�̂悤�����ǁB)
http://www.geocities.jp/andosprocinfo/wadai11/20110924.htm
KnightsCorner�̗p�\��̃X�p�R�����܂�������͗l�B
KnightsCorner�̗p�\��̃X�p�R�����܂�������͗l�B
�������̉c�Ɨ͂���
"�g����"���̂Ȃ�~�����ł���
>���̌Â�Pentium�삳���邽��eBay�ŌÂ��}�U�[�{�[�h��T���Ĕ������̂������ł��B
������Ə����B
���Г��ɌÂ���Ƃ��c���ĂȂ��ȁB
������Ə����B
���Г��ɌÂ���Ƃ��c���ĂȂ��ȁB
303 �FSocket774�F2011/09/24(�y) 15:05:02.51 ID:8fdhrRC1
CPU���Ď�ւ�����ł����H
$1950�ɂ���$3900�ɂ���ĊO�����ȁBTesla�Ɠ������炢�̑Ó��Ȓl�i�ɂȂ���
1���Ŕ������獂���̂��������
�����Ŕ�����l�i�ł͂����
1���Ŕ������獂���̂��������
�����Ŕ�����l�i�ł͂����
$2.5M��6400�Ŋ����ďo�Ă���Knights Corner�̒l�i��$3,900�ł͂Ȃ���$390�ł́B
$25M��P����6400�Ŋ����2�\�P�b�g�T�[�o�[1�䂠����̒l�i��$3,900�B
��������42GB�A�f�B�X�N��2TB�A�����InfiniBand�ƃI�[�_�[���C�h�̓d���ƃV���[�V�B
Xeon������2PFLOPS�Ȃ�Ó��Ȓl�i�H
1��$2,000�`$5,000���炢�Ŕ��ꂻ����Knights Corner��$390�Ƒ�����肵�Ă�̂��傫���ˁB
����͍̎Z���C���M���M���̒l�i����Ȃ��낤���B
$25M��P����6400�Ŋ����2�\�P�b�g�T�[�o�[1�䂠����̒l�i��$3,900�B
��������42GB�A�f�B�X�N��2TB�A�����InfiniBand�ƃI�[�_�[���C�h�̓d���ƃV���[�V�B
Xeon������2PFLOPS�Ȃ�Ó��Ȓl�i�H
1��$2,000�`$5,000���炢�Ŕ��ꂻ����Knights Corner��$390�Ƒ�����肵�Ă�̂��傫���ˁB
����͍̎Z���C���M���M���̒l�i����Ȃ��낤���B
>>$2.5M��6400�Ŋ����ďo�Ă���Knights Corner�̒l�i��$3,900�ł͂Ȃ���$390�ł́B
�{����
$390�Ĉُ�ȑ�����肾��
���ɂ����̒l�i�Ŕ����Ă����www
�{����
$390�Ĉُ�ȑ�����肾��
���ɂ����̒l�i�Ŕ����Ă����www
�₷����
�ł�Knights Corner�̔{���x1.25TFLOPS���Č��\�����ˁB
8Flops/Cycle�Ɖ��肵�āA64�`96�R�A��1.6�`2.5GHz���炢�B
8Flops/Cycle�Ɖ��肵�āA64�`96�R�A��1.6�`2.5GHz���炢�B
>>304
50������Ȃ���20��������
50������Ȃ���20��������
�Ȃ�l�Ȃ甃�������Ȃ��l�i
312 �F,,�E�L�́M�E,,�j��-�������F2011/09/24(�y) 21:02:33.53 ID:GRGIU1hL
>>309
Knights Ferry��1.2GHz�~32�R�A�ŗ��_�l1.25TFLOPS�i�P���x�j������A�{���xFLOPS����
�P���x�̔������Ƃ��āA�R�A���E�N���b�N�����{�Ȃ�\���B���\���ƁB
�ĊO32�R�A�ŃJ�[�h2����������Ȃ����ǁi����Ȃ�1�`�b�v�̃_�C�T�C�Y�͍���Sandy Bridge�Ȃ݂ōςށj
Knights Ferry��1.2GHz�~32�R�A�ŗ��_�l1.25TFLOPS�i�P���x�j������A�{���xFLOPS����
�P���x�̔������Ƃ��āA�R�A���E�N���b�N�����{�Ȃ�\���B���\���ƁB
�ĊO32�R�A�ŃJ�[�h2����������Ȃ����ǁi����Ȃ�1�`�b�v�̃_�C�T�C�Y�͍���Sandy Bridge�Ȃ݂ōςށj
HD6990�݂�����32�R�A�̃`�b�v��2��1���̊g���J�[�h�ɍڂ��Ă�Ƃ��H
����Ȃ烁�����`�b�v���͑����邯�Ǒ���ɃR�A�����胁�����ш�Ɨe�ʂ��҂��邵��p���y�ɂȂ�
����Ȃ烁�����`�b�v���͑����邯�Ǒ���ɃR�A�����胁�����ш�Ɨe�ʂ��҂��邵��p���y�ɂȂ�
314 �F,,�E�L�́M�E,,�j��-�������F2011/09/24(�y) 21:28:10.61 ID:GRGIU1hL
GPU�̂悤�ȌŒ�@�\�u���b�N������ĂȂ����A����ȃV���O���_�C�ł�����Ȃ�̕����܂藦�͓������Ȃ����ƁB
�i�s�ǃR�A���ɂ��ďo�ׂ���Ƃ����O��j
�i�s�ǃR�A���ɂ��ďo�ׂ���Ƃ����O��j
�����TMU�Ƃ��͖��������̂���
316 �F,,�E�L�́M�E,,�j��-�������F2011/09/24(�y) 21:43:26.35 ID:GRGIU1hL
TMU���ėv��Ȃ��ł���BTesla�ł����ɋ@�\�����B
ROP�����̓R�A�ɑg�ݍ��܂�Ă�����i������O���Ă���\���͂��邪�E�E�E�j
ROP�����̓R�A�ɑg�ݍ��܂�Ă�����i������O���Ă���\���͂��邪�E�E�E�j
��̑Ό��p�ɂ͓d�C�H���ȌŒ�@�\�͊O���ł��傤��
CPU�R�A�A�L���b�V���������AGPU�V�F�[�_�A�������p�b�h�APCI-Express�p�b�h�A����g�����X�R�[�_
Sandy�͂ǂ���璷���Ƃ��Ă�̂�OFF�ɂ��Ă����i�Ƃ��Đ�������킯��
Sandy-4�R�A�ł́A���̓������p�b�h��3�������āA���̂����P���I�~�b�g���Ă�B
PCI-Express��16���[���̑��ɂ���4���[������̂ŁA����4�_���ł��o�ׂł���
Sandy�͂ǂ���璷���Ƃ��Ă�̂�OFF�ɂ��Ă����i�Ƃ��Đ�������킯��
Sandy-4�R�A�ł́A���̓������p�b�h��3�������āA���̂����P���I�~�b�g���Ă�B
PCI-Express��16���[���̑��ɂ���4���[������̂ŁA����4�_���ł��o�ׂł���
�`���I�ɂ�Intel�̓L���b�V���ɕs�ǃu���b�N�̂���̂��L���b�V���̏��Ȃ����i�Ƃ��ă����[�X���邱�Ƃ����Ă��Ȃ����Ƃ��l����ƁA
�L���b�V���ȊO�ɕs�ǂȋ@�\�u���b�N���Ɛ藣���Đ��i�o�ׂ͂��ĂȂ���Ȃ����Ȃ�
�L���b�V�����̂ɏ璷��������Ƃ��Ȃ��Ƃ��A�N���b�N��d���őI�ʂ��ď�ʐ��i�Ɖ��ʐ��i�ɐU�蕪������Č����̂͂܂��ʂ̘b�Ƃ��āB
�L���b�V���ȊO�ɕs�ǂȋ@�\�u���b�N���Ɛ藣���Đ��i�o�ׂ͂��ĂȂ���Ȃ����Ȃ�
�L���b�V�����̂ɏ璷��������Ƃ��Ȃ��Ƃ��A�N���b�N��d���őI�ʂ��ď�ʐ��i�Ɖ��ʐ��i�ɐU�蕪������Č����̂͂܂��ʂ̘b�Ƃ��āB
�S�������Ȃ��̂́ACore����Ȃ���Pentium��Celeron�ŏo���Ă��Ȃ����ȁH
�����炨�����Ȃ��Ƃ�������Ȃ��r�W�l�X������Core���I�ƌ��������͕�����B
>>319
�������̃��x�����悾����˂��B
�ꍇ�ɂ���Ă͑S�����������i�̋@�\���킴�ƎE���ĉ��ʂƂ��Ă������Ƃ�����킯��
�����炨�����Ȃ��Ƃ�������Ȃ��r�W�l�X������Core���I�ƌ��������͕�����B
>>319
�������̃��x�����悾����˂��B
�ꍇ�ɂ���Ă͑S�����������i�̋@�\���킴�ƎE���ĉ��ʂƂ��Ă������Ƃ�����킯��
Xeon�̏o���a�芴�͐������
>>303
�X�b�|��������Ȃ���ΊȒP����w
�X�b�|��������Ȃ���ΊȒP����w
>>316
CUDA��OpenCL����g����̂͐��`��Ԃ���������Tesla�ł����ʂɎg����ł���
���ɉ摜�����A�v���P�[�V�������ƕK�{�@�\
���`��Ԃ����Ȃ�t�����Z�킪����Ȃ�����ʐϓI�ɂ͏������ł���Ƃ͎v����
CUDA��OpenCL����g����̂͐��`��Ԃ���������Tesla�ł����ʂɎg����ł���
���ɉ摜�����A�v���P�[�V�������ƕK�{�@�\
���`��Ԃ����Ȃ�t�����Z�킪����Ȃ�����ʐϓI�ɂ͏������ł���Ƃ͎v����
�X���Q�U���@�ăC���e���@�p�\�R�����������̂̐�����
Ultrabook�𔖌^�E�ȓd�͉�����Z�p���C���e��������
http://ascii.jp/elem/000/000/637/637307/
http://ascii.jp/elem/000/000/637/637307/
326 �F,,�E�L�́M�E,,�j��-�������F2011/09/26(��) 23:20:35.00 ID:meMe/xrt
�Ȃ�����
Configurable TDP = �����typical TDP
����
329 �F,,�E�L�́M�E,,�j��-�������F2011/09/27(��) 00:01:29.48 ID:CSCB8uWC
������A���ۂ�TDP���ςȂ�B
�Ⴍ�ݒ肷����̘g���Ńp�t�H�[�}���X�𐧌����邵�A
�t�ɗ�p�v�ɗ]�T������Ȃ�TDP�����߂ɐݒ肵�A�ő���̐��\���ł���B
�h�b�L���O�X�e�[�V�����ɑ����������p�\�̓A�b�v��TDP�ݒ�������グ��Ƃ�
���������M�~�b�N���������o�C���[���o�Ă�����ʔ��������B
�Ⴍ�ݒ肷����̘g���Ńp�t�H�[�}���X�𐧌����邵�A
�t�ɗ�p�v�ɗ]�T������Ȃ�TDP�����߂ɐݒ肵�A�ő���̐��\���ł���B
�h�b�L���O�X�e�[�V�����ɑ����������p�\�̓A�b�v��TDP�ݒ�������グ��Ƃ�
���������M�~�b�N���������o�C���[���o�Ă�����ʔ��������B
�����Ȃ�ƒ�i�N���b�N�Ƃ��Ӗ����Ȃ��Ȃ��Ă����
�^�[�{���[�h�Ȃ�Ă̂��o�Ă������_�Œ�i�N���b�N�͈Ӗ��𐬂��ĂȂ������
���Ȑf�f�A���ȓK��
�e���X�P�[���Ō����Ă����������������������𑝂��Ă����Ɗ����鍡�����̍��B
�e���X�P�[���Ō����Ă����������������������𑝂��Ă����Ɗ����鍡�����̍��B
>>329
>�h�b�L���O�X�e�[�V�����ɑ����������p�\�̓A�b�v��TDP�ݒ�������グ��Ƃ�
IBM��Metapad�����c����
�h�b�L���O�X�e�[�V�����Ƀt�@�������Ă�
http://www.research.ibm.com/WearableComputing/MetaPad/metapad.html
���̂���̑�a�͖ʔ������̐F�X����Ă�
>�h�b�L���O�X�e�[�V�����ɑ����������p�\�̓A�b�v��TDP�ݒ�������グ��Ƃ�
IBM��Metapad�����c����
�h�b�L���O�X�e�[�V�����Ƀt�@�������Ă�
http://www.research.ibm.com/WearableComputing/MetaPad/metapad.html
���̂���̑�a�͖ʔ������̐F�X����Ă�
�h�b�L���O�X�e�[�V�����ɑ��������Ƃ���ŃN�[���[���̂��̂����������킯�͂Ȃ����A
���ۂɂǂ�قǂ܂ŗ�p�\�͂������グ���邩�͂�����Ƌ^�₾�Ȃ��B
�h�b�L���O�X�e�[�V�����ɑ����Ƃ������Ƃ͒�ʂ��l���ɐG��Ȃ��Ȃ�ƌ������ƂŁA
TDP��������Ȃ���TA��Tcase�Ȃ��ς�����낤��
���ۂɂǂ�قǂ܂ŗ�p�\�͂������グ���邩�͂�����Ƌ^�₾�Ȃ��B
�h�b�L���O�X�e�[�V�����ɑ����Ƃ������Ƃ͒�ʂ��l���ɐG��Ȃ��Ȃ�ƌ������ƂŁA
TDP��������Ȃ���TA��Tcase�Ȃ��ς�����낤��
������Ԃł͊��S�t�@�����X�Ńh�b�L���O�X�e�[�V�����Ƀu���A��
�Ǝv��������Macbook Air�ł���t�@��������ł��Ă邩���
�Ǝv��������Macbook Air�ł���t�@��������ł��Ă邩���
336 �F,,�E�L�́M�E,,�j��-�������F2011/09/27(��) 01:42:37.06 ID:CSCB8uWC
���^�̃A���~➑̂�➑̎��̂��q�[�g�V���N�̖���������ˁB
��ʂɕ����Ă邾���ł�������x���ʂ����Ȃ��́H
�̎����Ă��m�[�g�ŁAUSB�N�[���[���̃X�^���h���Ďq���x�����Ǝv���g���Ă�����
ACPI�T�[�}�����j�^�ǂ݂ō�������70�x��65�x�ɂȂ���x�ɂ͌��ʂ͂������ׁB
��ʂɕ����Ă邾���ł�������x���ʂ����Ȃ��́H
�̎����Ă��m�[�g�ŁAUSB�N�[���[���̃X�^���h���Ďq���x�����Ǝv���g���Ă�����
ACPI�T�[�}�����j�^�ǂ݂ō�������70�x��65�x�ɂȂ���x�ɂ͌��ʂ͂������ׁB
>>334
���������������낤�B���Ȃ�₦��̂Ńl�^�Ŕ������V���b�v�u�����h�m�[�g���g���Ă����͂����b�ɂȂ����B
ttp://www.ainex.jp/products/np-01a.htm
���������������낤�B���Ȃ�₦��̂Ńl�^�Ŕ������V���b�v�u�����h�m�[�g���g���Ă����͂����b�ɂȂ����B
ttp://www.ainex.jp/products/np-01a.htm
killer whale�̂Ƃ����o���Ă�m�[�gPC�N�[���[�Ȃ悳�������ȁB
339 �F�|���͓��{�̓y�F2011/09/27(��) 04:04:03.73 ID:STH6QlLS
���̂�t(ry
Knights Corner���A�L�o�ň�ʌ����̔�����Ȃ����Ȃ���
4�R�A8�R�A�Ƃ��Ȃ�܂������A�P�̃J�[�h��50�R�A�ȏ���Ă̂�
���N���N����
Tesla�R������������猻���I�ȗ\�Z�Ő���������100�R�A�}�V���Ƃ��ł���������
���ꂮ�炢�Ȃ�����撣�낤�����Ă����C�ɂ��Ȃ邵
4�R�A8�R�A�Ƃ��Ȃ�܂������A�P�̃J�[�h��50�R�A�ȏ���Ă̂�
���N���N����
Tesla�R������������猻���I�ȗ\�Z�Ő���������100�R�A�}�V���Ƃ��ł���������
���ꂮ�炢�Ȃ�����撣�낤�����Ă����C�ɂ��Ȃ邵
Knights Corner��Atom�x�[�X���ĉ\�炵������
�e�|�[�g�ւ̊��蓖�Ă͂ǂ��Ȃ�낤��
Memory read/write��FMA���������s�ł���Ƃ��Ȃ�|���̂�����
�e�|�[�g�ւ̊��蓖�Ă͂ǂ��Ȃ�낤��
Memory read/write��FMA���������s�ł���Ƃ��Ȃ�|���̂�����
Larrabee�̒i�K�Ŋ��ɓ������s�ł����̂�
http://www.stanford.edu/class/ee380/Abstracts/100106-slides.pdf
�����SGEMM��90%�������Ȃ����Ăǂ��������ƂȂ낤
http://www.stanford.edu/class/ee380/Abstracts/100106-slides.pdf
�����SGEMM��90%�������Ȃ����Ăǂ��������ƂȂ낤
�˂�MAC�I�^�́H
MAC�I�^�͂ǂ�������������́H
MAC�I�^�͂ǂ�������������́H
�����C�y�ɏ������߂闧��ł͂Ȃ��Ȃ����낤
Ivy Bridge�̃N���b�N���ĉ\�Řb��ɂȂ������Ƃ����������H
��GHz���炢�ɂȂ�낤
��GHz���炢�ɂȂ�낤
346 �F,,�E�L�́M�E,,�j��-�������F2011/09/27(��) 20:17:32.20 ID:CSCB8uWC
>>341
Larrabee1�̏ꍇ�����ǁA���������ϑ��I��dual issue���\�B
�@V: Load->Permute/TypeCvt->FMA
�@U: Store
Atom�x�[�X���ƃf�R�[�h��ɖ��߂��o�b�t�@�����O���Ă���e�|�[�g�Ƀf�B�X�p�b�`���邩��
P5�p�C�v���C���̂悤�ȃf�R�[�_����i�f�R�[�h���ꂽ���ɘA�Ȃ郆�j�b�g�̂ݎg����j�͂Ȃ��������ǁB
Larrabee1�̏ꍇ�����ǁA���������ϑ��I��dual issue���\�B
�@V: Load->Permute/TypeCvt->FMA
�@U: Store
Atom�x�[�X���ƃf�R�[�h��ɖ��߂��o�b�t�@�����O���Ă���e�|�[�g�Ƀf�B�X�p�b�`���邩��
P5�p�C�v���C���̂悤�ȃf�R�[�_����i�f�R�[�h���ꂽ���ɘA�Ȃ郆�j�b�g�̂ݎg����j�͂Ȃ��������ǁB
347 �F,,�E�L�́M�E,,�j��-�������F2011/09/27(��) 20:29:21.97 ID:CSCB8uWC
>>342
���߂̃y�A�����O���[�����������Ƃ��A�R���p�C���������n�Ƃ����낢��v���͂��肻�������ˁB
����v�Z���Ɗ��Ƃ������������ǁB
�A�[�L���ς��Ȃ�������\�͕ς�肻�������ǁB
���_���\��7�������o�Ȃ��Ȃ�1.4�{�ς߂�������Ȃ��B
�Ă�Venus���ĒP����������H
���߂̃y�A�����O���[�����������Ƃ��A�R���p�C���������n�Ƃ����낢��v���͂��肻�������ˁB
����v�Z���Ɗ��Ƃ������������ǁB
�A�[�L���ς��Ȃ�������\�͕ς�肻�������ǁB
���_���\��7�������o�Ȃ��Ȃ�1.4�{�ς߂�������Ȃ��B
�Ă�Venus���ĒP����������H
348 �F,,�E�L�́M�E,,�j��-�������F2011/09/27(��) 22:44:53.39 ID:CSCB8uWC
�R���V���[�}�����ɒP�̔�������Ƃ�����ϑԃv���O���}�����̊ߋ�Ƃ��Ă͖ʔ�������
�\�t�g���Ȃ����Ƃɂ͂˂��B
�\�t�g���Ȃ����Ƃɂ͂˂��B
��������KC����ʂŔ����w�͌����Ă�
�V���b�v���u���킯�Ȃ���
�ǂ�Ȃ̂����Ă݂�������
�V���b�v���u���킯�Ȃ���
�ǂ�Ȃ̂����Ă݂�������
350 �F,,�E�L�́M�E,,�j��-�������F2011/09/27(��) 23:13:19.93 ID:CSCB8uWC
GPU�Ɣ�ׂĉ��ł��ł��邯�lj��ɂ��\�t�g����������ˁB
�x���`���[��Ƃ��w�ɂƂ肠�����G�点�Ă݂Ė��͓I�Ȑ��i�łĂ�����ۂ��Ɣ����グ��
���Ɖ��A���炢�܂ł����헪�������������Ȃ��B
�Ȃ�ɂ��揤�Ǝs����g�傷��ɂ̓C���X�g�[���x�[�X�𑝂₳�Ȃ��ƂˁB
������uLarrabee��IGP���v���]�܂��킯�����B
�x���`���[��Ƃ��w�ɂƂ肠�����G�点�Ă݂Ė��͓I�Ȑ��i�łĂ�����ۂ��Ɣ����グ��
���Ɖ��A���炢�܂ł����헪�������������Ȃ��B
�Ȃ�ɂ��揤�Ǝs����g�傷��ɂ̓C���X�g�[���x�[�X�𑝂₳�Ȃ��ƂˁB
������uLarrabee��IGP���v���]�܂��킯�����B
�����w��1000�l�����Intel���璼�ڔ�����
>>347
GEMM�̌������グ�邱�Ƃ������܂ŏd�v�Ƃ͎v��Ȃ���
���炩�̃{�g���l�b�N�����邱�Ƃ��������Ă���킯������
������ƐS�z�ł͂���
GEMM�̌������グ�邱�Ƃ������܂ŏd�v�Ƃ͎v��Ȃ���
���炩�̃{�g���l�b�N�����邱�Ƃ��������Ă���킯������
������ƐS�z�ł͂���
353 �F,,�E�L�́M�E,,�j��-�������F2011/09/27(��) 23:25:00.02 ID:CSCB8uWC
>>351
1000���x��Intel������ɂ���킯�Ȃ������
1000���x��Intel������ɂ���킯�Ȃ������
����܂���萫��������Ԃ������A��炢�����̂��o���Ă�tesla�ŊԂɍ����Ă܂��ɂȂ��ė��s��Ȃ��\��
��ʂɗ��s��K�v���Ȃ����A����Ȃ��Ƒ_���ĂȂ���
358 �F,,�E�L�́M�E,,�j��-�������F2011/09/28(��) 20:05:13.93 ID:O+Y4L23T
Fixstars�����肪�㗝�X�ɂȂ��Ă����Ƃ������ǂȁB
���C�g��API�Ƃ��ɑΉ����Ă�������Ȃ�Ɏ��v���邶��Ȃ��ł�����
CG������
CG������
���z�d�r�œ����APentium�x�[�X�̎���CPU
ttp://pc.nikkeibp.co.jp/article/trend/20110928/1037143/
ttp://pc.nikkeibp.co.jp/article/trend/20110928/1037143/
�܂�OpenRL�ɑΉ������ł��ˁI
�m����GPU���͋��݂����邾�낤�Ȃ��B
�m����GPU���͋��݂����邾�낤�Ȃ��B
������Knights�n���̃R�A��Atom�ƍ���������̂Ȃ�
SIMD�̖��߃Z�b�g���ǂ�����̂����C�ɂȂ�
LNI�͎̂Ă�AVX-512�ɂ���̂��ȁH���邢��1024�܂Ŋg�����邩�H
SIMD�̖��߃Z�b�g���ǂ�����̂����C�ɂȂ�
LNI�͎̂Ă�AVX-512�ɂ���̂��ȁH���邢��1024�܂Ŋg�����邩�H
Atom�̂Q�p�C�v����AVX�̓X���[�v�b�g���o�Ȃ����瓝���͓����Ȃ����H
����Ƃ���AVX1024�ɂ��ĉ��Z���512bit�Ƃ�������
���x���r������f�����b�g�͑傫������
�݊����Ƃ����Ӗ��Ȃ�LNI��256bit���[�h�𑝂₵��
�\�t�g�E�F�A�I��AVX�Ƌ��ʂɂ���Ƃ�
����Ƃ���AVX1024�ɂ��ĉ��Z���512bit�Ƃ�������
���x���r������f�����b�g�͑傫������
�݊����Ƃ����Ӗ��Ȃ�LNI��256bit���[�h�𑝂₵��
�\�t�g�E�F�A�I��AVX�Ƌ��ʂɂ���Ƃ�
���z�d�r��10�N���̂�Windows�������ĉ�������Ă����낤
>>364
����Ȃ��Ƃ��O�ȊO�ɒN�������Ă�́H
����Ȃ��Ƃ��O�ȊO�ɒN�������Ă�́H
MeeGo��LiMo�����������V���o�C��OS�v���W�F�N�g�uTizen�v ���n��
http://journal.mycom.co.jp/news/2011/09/29/034/index.html
Intel�͂܂�MeeGo����߂ĂȂ��݂�����
Samsung�Ǝ��g�ޖ͗l
http://journal.mycom.co.jp/news/2011/09/29/034/index.html
Intel�͂܂�MeeGo����߂ĂȂ��݂�����
Samsung�Ǝ��g�ޖ͗l
Android����Google�哱�����Aintel��������x�e���͂���OS���~������Ȃ��́H
�f�t�@�N�g�X�^���_�[�h������
���������������A�����������������m��Ȃ�����
�Ȃ����������H
���������������A�����������������m��Ȃ�����
�Ȃ����������H
MidoriLinux�v���o����
Intel�̒��ŖT���ɒǂ����ꂽ�`�[�����K���Ŋ撣���Ă�̂�����ƐȂ��Ȃ��
Itanium�Ƃ��A�A�A�����������琔�N���MIC��
Itanium�Ƃ��A�A�A�����������琔�N���MIC��
CPU�����j�@�ʍ�ɂ��炸����̂Ă�ꔄ�p XScale
http://ascii.jp/elem/000/000/636/636639/
http://ascii.jp/elem/000/000/636/636639/
������S������ł��Ȃ���������ʍ삾��
�匴���ăA�z�����
�匴���ăA�z�����
PC DOS�iQDOS�j�Ƃ�Internet Explorer�Ƃ��H�@���������A��
Intel�́uHaswell�v�̃_�C�Əȓd�͋Z�p
http://pc.watch.impress.co.jp/docs/column/kaigai/20110930_480539.html
http://pc.watch.impress.co.jp/docs/column/kaigai/20110930_480539.html
375 �F,,�E�L�́M�E,,�j��-�������F2011/09/30(��) 03:25:16.28 ID:2NSjAgDD
>>368
���ʕ��͂�����Linux�f�B�X�g���r���[�V�����Ƀ}�[�W�������疳�ʂł͂Ȃ��ł���B
���ʕ��͂�����Linux�f�B�X�g���r���[�V�����Ƀ}�[�W�������疳�ʂł͂Ȃ��ł���B
Omoikane Linux
�㓡���u�o�J�����v�Ƃ��u���������G���v�Ƃ������L����������ł���
>>374
�m���Ƀ��K�`�F���W���ȁB ����������Ƃ͌����AAMD���ȒP�ɒǏ]�ł�����������
�u�}�C�N���A�[�L�e�N�`���A��H�v�A�d������A�قڂ��ׂĂ��ς��v�Ƃ̎����������ǁA
��H�v�Ɠd�������CPPM�ɓ��Ă͂܂肻�������A�A�[�L���ς��Ă���Ǝv���ėǂ��̂��ȁH
�m���Ƀ��K�`�F���W���ȁB ����������Ƃ͌����AAMD���ȒP�ɒǏ]�ł�����������
�u�}�C�N���A�[�L�e�N�`���A��H�v�A�d������A�قڂ��ׂĂ��ς��v�Ƃ̎����������ǁA
��H�v�Ɠd�������CPPM�ɓ��Ă͂܂肻�������A�A�[�L���ς��Ă���Ǝv���ėǂ��̂��ȁH
379 �F,,�E�L�́M�E,,�j��-�������F2011/09/30(��) 15:37:47.33 ID:2NSjAgDD
����H�������R���g���[���͂ǂ��Ɏ�������Ă�̂�����H
http://ascii.jp/elem/000/000/634/634856/
Interrupt Routing��IvyBridge�Ŏ�������Ă��邯�ǁA
�f�o�C�X��CPPM�ɑΉ�����ł��낤Haswell���ゾ�ƁA
����Ɍ��ʂ��傫���̂��ȁH
Interrupt Routing��IvyBridge�Ŏ�������Ă��邯�ǁA
�f�o�C�X��CPPM�ɑΉ�����ł��낤Haswell���ゾ�ƁA
����Ɍ��ʂ��傫���̂��ȁH
Ivy�ł�CPU�����AHaswell�̓V�X�e���S�̂𐧌䂷��Ƃ������Ƃ�
�ǂ����ɂ���ҋ@����d�͂����炷�����Ȃ�
�ǂ����ɂ���ҋ@����d�͂����炷�����Ȃ�
����Ƀo�b�e���[�����̃J�^���O�X�y�b�N�Ǝ��g�p�̍����J������
����͐ݒ莟��Ȃ�Ȃ���
�Ȃ�Ƃ������m�[�gPC�����@�\�Ă��肾���
Ivy�ɓ��ڂ����DX11 GPU��16SP�܂ŋ����A
���̂����œ����O���t�B�b�N�̌J��Ԃ��\���Ȃ�A
�d�C��H��CPU�E�������ւ̃A�N�Z�X�����ɃO���t�B�b�N�������o���@�\�����炵��
Ivy�ɓ��ڂ����DX11 GPU��16SP�܂ŋ����A
���̂����œ����O���t�B�b�N�̌J��Ԃ��\���Ȃ�A
�d�C��H��CPU�E�������ւ̃A�N�Z�X�����ɃO���t�B�b�N�������o���@�\�����炵��
�t���[���o�b�t�@���������Ƃ�����SRAM�������Ă��Ȃ����x�̗ʂ��K�v�Ȃ͂������A�ǂ��Ȃ�낤
PCH�ɃL���b�V���Ƃ��Đςނ̂��낤��
PCH�ɃL���b�V���Ƃ��Đςނ̂��낤��
�������A�k�����ł̒��̐l�������܂Ō���&�l�g�E���S�J�̎����������Ă�Ƃ͂Ȃ��corz
�����Ȃ�ǂ������H
�ݓ����N�l�u�l�g�E���K�[�v
�ŋ߂̖k�`����͂Ȃ�Ƃ��������������c��������Ȃ����ǂ��[���
�ʂɂǂ������v�z�����Ă悤���l�̏��肾���A
�������p�ɂɈ��ՂȌ��l�^�D����������PC��[��
�i���E�i�i�̕]���ɂ������܂�!w
�������p�ɂɈ��ՂȌ��l�^�D����������PC��[��
�i���E�i�i�̕]���ɂ������܂�!w
�l�u���O�̊Ǘ��l�̘b���l���`�ȊO�Ŏn�߂邨�O�ɕi�i�Ƃ�����ꂽ���Ȃ����낤��
FlashSSD�X����VIP�̎���Wiki���ŃT���`����SSD�̕]�����Ⴂ�Ƃ������ĎU�X�l�K�L�������Ă��z�Ƃ����A
�ŋ߂͂��������̗��s�Ȃ̂��ȁB
�ŋ߂͂��������̗��s�Ȃ̂��ȁB
2ch�Ȃ炻��ł������ǁA
�l�̃T�C�g�ł��������̂���Ă��10�N��Ƃ��ɐl�ԊW���L�����Ă���w�ɂȂ���
������邩���߂Ă������ق���������B�l�b�g���������A���̈ꕔ������ˁB
�ȏ�
�l�̃T�C�g�ł��������̂���Ă��10�N��Ƃ��ɐl�ԊW���L�����Ă���w�ɂȂ���
������邩���߂Ă������ق���������B�l�b�g���������A���̈ꕔ������ˁB
�ȏ�
�}�W���X�����2ch�ł����Ȃ���������
���ہA��肪��������̂͂ǂ�ȏ��i�ł�������ǐM�p���ˁc
���Y����ꂽ��u�^�����������̂��ȁH�v�����ǒ����E�؍����Ȃ�u����ς蒆�ؐ��̓_�����ȁv�ɂȂ�B
���Y����ꂽ��u�^�����������̂��ȁH�v�����ǒ����E�؍����Ȃ�u����ς蒆�ؐ��̓_�����ȁv�ɂȂ�B
396 �FSocket774�F2011/10/01(�y) 00:52:17.57 ID:Hrss7FjI
397 �FSocket774�F2011/10/01(�y) 00:56:05.04 ID:3+772VBN
�܂��A�؍����D�����낤���������낤���A�l�̎��R�������
���l�̚n�D���ߓx�ɂ���ʂ郄�c���������Ȃ��̂�
���l�̚n�D���ߓx�ɂ���ʂ郄�c���������Ȃ��̂�
���������ǂ������Ȃ̂���������Ȃ��B
�؍����Ŏv���o��������LG����Low Grade�̗��炵���ˁB
�����܂ł�PC�n�u���O�̕⊮�ł��݂����Ȑ����ŁA�W�Ȃ����l�^��݂����Ȃ��B
�؍��̌o�ς��ǂ��Ƃ��A����er�ɂ͎��ɂǂ��ł������b�����A
�؍��}�j�A�ł��Ȃ��̂ɋC�����������Ă̂͂���B
�����l�^���Ȃ炻��炵���A�͂�����̌n�I�ɂ���Ă����ׂ����ȁB
PC�Ɗ؍��Z�b�g��߂Ă���w
�؍��̌o�ς��ǂ��Ƃ��A����er�ɂ͎��ɂǂ��ł������b�����A
�؍��}�j�A�ł��Ȃ��̂ɋC�����������Ă̂͂���B
�����l�^���Ȃ炻��炵���A�͂�����̌n�I�ɂ���Ă����ׂ����ȁB
PC�Ɗ؍��Z�b�g��߂Ă���w
�k�X�ɗ���Ȃ�������W�߂��Ȃ��悤�ȓz���̂����ɒ�������l�͊��m�ł��炠��
>>400
>����er�ɂ͎��ɂǂ��ł������b�����A
����Ȃ�C�ɂȂ�Ȃ��������ǁB
�C�ɂ��Ă鎞�_�ŌN�ɂƂ��āu���ɂǂ��ł������b�v�ł͂Ȃ����A
�N�́u����er�v�ł��Ȃ����Ęb�ɂȂ�킯�����B
>����er�ɂ͎��ɂǂ��ł������b�����A
����Ȃ�C�ɂȂ�Ȃ��������ǁB
�C�ɂ��Ă鎞�_�ŌN�ɂƂ��āu���ɂǂ��ł������b�v�ł͂Ȃ����A
�N�́u����er�v�ł��Ȃ����Ęb�ɂȂ�킯�����B
�؍��̘b�����˂ɔ�э���ł���Ɉ�a�������Ȃ��z�̕���������������B
����ȂɊ؍��̍ŐV��厖�Ȃ̂���?w
����ȂɊ؍��̍ŐV��厖�Ȃ̂���?w
>>398
����ȁB
������܂őS�R�C�t���Ȃ��ǂ��납�����Ă��킩���B
�ǂ����R�����g�K�����ꂽ���Ȃł��̕������ł����Ă�Ȃ����B
����ȁB
������܂őS�R�C�t���Ȃ��ǂ��납�����Ă��킩���B
�ǂ����R�����g�K�����ꂽ���Ȃł��̕������ł����Ă�Ȃ����B
�ŁA���̃X���Ɖ��̊W��
�`�l�c�̂���ڂ���F�߂��Ȃ��L�`�s�[(���`�l�c�M�ҕ���)�������̃l�g�E�����֑̌�ϑz�c��܂��ď���ɂ̂��܂��Ă邾���ł���B
�`�l�c�ɐg���S���������܂����z���L�̂т�[������A�т�[���B
�`�l�c�ɐg���S���������܂����z���L�̂т�[������A�т�[���B
>>398
�u���O����Ȃ��Ęb�̓c�C�b�^�[�̂ق��ł��B
�u���O����Ȃ��Ęb�̓c�C�b�^�[�̂ق��ł��B
�������AMD�Ɗ֘A�t����ID:T/fRbC0V��ID:xpkFtKXV�Ɠ����x�����Ǝv���܂�
�������S�R�W�Ȃ�2ch�̃X���ł����������吂���Ƃ��p���������Ȃ��̂��˂�
�t�Ɍ����Ɗ؍����D�����ēz�͓��{�l�Ƃ��Ă�����������
�ǂ��ł��������Ƃ�intel�̎�����ł���n�O��AMD�M�҈ȊO���ˁ[��n�Q�b�K
���₻��͂���ŕʂɂ�������w
�D�����������l�̎��R�B
�Ă����낻��b�߂��Ȃ����B
�D�����������l�̎��R�B
�Ă����낻��b�߂��Ȃ����B
PSR�̂��Ƃł���Ήt���p�l�����̃R���g���[����DRAM���q�����
LPDDR���Ȃ�
LPDDR���Ȃ�
CRT���Ⴀ��܂����t�����̃o�b�t�@�X�V�~�߂�ςށB
�\���̍X�V���Ȃ���APC���̓f�[�^����Ȃ��ŁA
�t�����͎��g�̃R���g���[���[�ɂ���o�b�t�@��\������������Ďd�g�݂̂͂��B
�t�����͎��g�̃R���g���[���[�ɂ���o�b�t�@��\������������Ďd�g�݂̂͂��B
>>401
�k�X�Ȃ��Ȃ������đ��̃T�C�g���邩��ʂɂ�����
�k�X�Ȃ��Ȃ������đ��̃T�C�g���邩��ʂɂ�����
�������獡���k�X���Ȃ��Ⴂ����ˁH
���Ȃ��Ă������悤�Ȗ����l�̏��T�C�g�ɗ���Ȃ��Ƃ����Ȃ�����ȓz�������悤�ȃ��X�͂�߂��
�L���`�������X������
���܂��̑̏L�����?
ivy��LGA1155����Ȃ��́H
1154�炵��
>>417
�t�����̃R���g���[���[�̑Ή����K�v���Ď�����ˁB
�P���Ƀf�[�^�[�̑��M���~�߂�̂��ȁB����Ƃ��f����ێ�����R�}���h�𑗂�̂��ȁB
1234444456���ĉ�ʂ��X�V����Ă������A1234xxxx56�Ƃ���̂��A1234Bxxx56�Ƃ���̂��B
�O�҂��ƁAPC�����ُ�I������No signal�ł��t���͕\���𑱂��Ă��肵������^^;
�t�����̃R���g���[���[�̑Ή����K�v���Ď�����ˁB
�P���Ƀf�[�^�[�̑��M���~�߂�̂��ȁB����Ƃ��f����ێ�����R�}���h�𑗂�̂��ȁB
1234444456���ĉ�ʂ��X�V����Ă������A1234xxxx56�Ƃ���̂��A1234Bxxx56�Ƃ���̂��B
�O�҂��ƁAPC�����ُ�I������No signal�ł��t���͕\���𑱂��Ă��肵������^^;
>>426
IDF�̃f���ŁA�P�[�u�������Ă��A�\�������܂܂��Ă̂���Ă���B
IDF�̃f���ŁA�P�[�u�������Ă��A�\�������܂܂��Ă̂���Ă���B
428 �FSocket774�F2011/10/03(��) 15:21:41.30 ID:wGL55PUT
����ł�
���}�U�[ P5K-E�ɁAi7-2600K���悹�邱�Ƃ͂ł���ł��傤���H
��i7-2600K�̔r�M���Ƃ��āA�~�j�^���[�͏��O���ׂ��ł��傤���H
��낵�����肢���܂��B
���}�U�[ P5K-E�ɁAi7-2600K���悹�邱�Ƃ͂ł���ł��傤���H
��i7-2600K�̔r�M���Ƃ��āA�~�j�^���[�͏��O���ׂ��ł��傤���H
��낵�����肢���܂��B
429 �FSocket774�F2011/10/03(��) 15:41:33.60 ID:RQ0yJ/TC
�����炳�܂ɃX���^�C�ǂ�łȂ����e���炵�Ēނ�
>>428
���̎���̂ЂƂ��m��Ȃ����Ǎ���intel��amd��cpu�̓}�U�[�{�[�h���݊����邩��
�S���ڂ��B
�͕̂ʐ��i���������ǃp�\�R�����v����ɔ����ċ��ʉ����s���Ă��ˁB
���Ɣr�M�����Ȃ��Ǝv����B
���̎���̂ЂƂ��m��Ȃ����Ǎ���intel��amd��cpu�̓}�U�[�{�[�h���݊����邩��
�S���ڂ��B
�͕̂ʐ��i���������ǃp�\�R�����v����ɔ����ċ��ʉ����s���Ă��ˁB
���Ɣr�M�����Ȃ��Ǝv����B
432 �FSocket774�F2011/10/03(��) 17:46:01.17 ID:5VNyBnh8
�X���`�����A����PhenomIIX4 970BE�g���Ă��₯�ǁAIntel��CPU�g���Ă�
�u�����A����ς�Ⴄ�Ȃ��B�v���Ďv��������H�����������̂�PCSX2�����掿��
����Ă鎞�ƃx���`�̓��_���������炢��˂ǁB����ȊO�̂�����Ă���ւ�H
����ς�FPS�����掿�ł��Ƃ��Ȃ͈Ⴄ�H
�u�����A����ς�Ⴄ�Ȃ��B�v���Ďv��������H�����������̂�PCSX2�����掿��
����Ă鎞�ƃx���`�̓��_���������炢��˂ǁB����ȊO�̂�����Ă���ւ�H
����ς�FPS�����掿�ł��Ƃ��Ȃ͈Ⴄ�H
Intel�@CPU����
HD Graphics 3000�@�X�R�A5037
Intel�@���o�C��CPU����
HD Graphics 3000�@�X�R�A3882
cpu������hd3000�Ƀ��o�C���p�Ƃ��̋�ʂ��Ă���́H
���̍�1155�ɂǂꂭ�炢�̈Ⴂ������̂��킩���
HD Graphics 3000�@�X�R�A5037
Intel�@���o�C��CPU����
HD Graphics 3000�@�X�R�A3882
cpu������hd3000�Ƀ��o�C���p�Ƃ��̋�ʂ��Ă���́H
���̍�1155�ɂǂꂭ�炢�̈Ⴂ������̂��킩���
�\�P�b�g�����
���I�\�P�b�g����1155�E�E�E
(Ɂ�`)����
�\�P�b�g���I�H
(-�l-) ����
(-�l-) ����
438 �F,,�E�L�́M�E,,�j��-�������F2011/10/03(��) 22:21:26.22 ID:ldMK2l/W
>>433
������GPU�̃R�A�N���b�N��1.5�{���炢�Ⴄ�悤�ȁB
������GPU�̃R�A�N���b�N��1.5�{���炢�Ⴄ�悤�ȁB
439 �FSocket774�F2011/10/04(��) 00:50:32.10 ID:mKlF6Y1j
Socket7�u�v
�u����intel��amd��cpu�̓}�U�[�{�[�h���݊�����v
�u���̓}�U�[�{�[�h���݊�����v
�u���͌݊�����v
�u���́v
�u���̓}�U�[�{�[�h���݊�����v
�u���͌݊�����v
�u���́v
�l�^�ɕK���Ƀ}�W���X���Ă�A�z�̎q������X�b�h���͂����ł����H
���{�l���̂��A�z�Ȃ���
�܂�����������
�܂�����������
�؍��l���̓}�V�ł���
�o�ϋK�͂��l�������y�����{�ɔ䌨����Ǝv���Ă���悤�Ȗ�������
�o�ϋK�͂��l�������y�����{�ɔ䌨����Ǝv���Ă���悤�Ȗ�������
�؍��W�Ȃ������E�E�E�B
���{�l��2ch�܂ŗ���sage����̂�k���]������������
�A�o�Y�Ƃ͒ʉ݈�����
�E�H�����~���ȍ�
�f�W�^�����i���i�̂悤�Șb�Ɋւ��Ă�
�����͑����I�Ɋ؍������D��Ă���ƌ���ׂ����낤
�E�H�����~���ȍ�
�f�W�^�����i���i�̂悤�Șb�Ɋւ��Ă�
�����͑����I�Ɋ؍������D��Ă���ƌ���ׂ����낤
�o�c�A��{�͒ʉ݈�����������Ƃ����R�~�b�g�����g�̕\�������ׂ����낤
>>447
�D��Ă��邩�ǂ����͕ʖ�肾��
�D��Ă��邩�ǂ����͕ʖ�肾��
�s�тȂ̂ŁA���̕ӂŎ~�߂Ă���
>>447
���{���܂߂����O���ɋ��菟���߂ɕa�I�Ȃ܂łɃE�H������i�߂Ă�������
�ŋ߃f�t�H���g�ڑO�܂ʼn������Ă���i100�E�H����6�~�A�S�N�O�Ɣ�r���ĉ��l�����ȉ��j����
���{���u�E�H������h�����߂ɍ��ۋ������K�v�v���ƃE�H�������~�߂邽�߂Ɏ������b��ł���ƌ����o���n���B
�����Q�����œ��{���Εăh����2.2%�~�����Ă���ԂɁA�؍����Εăh����12%�E�H�����Ȃ���
���i�����������l����T���X����LG�͋�����ˁB���{����ŋ���������Č���������Ă��邵�B
���{���܂߂����O���ɋ��菟���߂ɕa�I�Ȃ܂łɃE�H������i�߂Ă�������
�ŋ߃f�t�H���g�ڑO�܂ʼn������Ă���i100�E�H����6�~�A�S�N�O�Ɣ�r���ĉ��l�����ȉ��j����
���{���u�E�H������h�����߂ɍ��ۋ������K�v�v���ƃE�H�������~�߂邽�߂Ɏ������b��ł���ƌ����o���n���B
�����Q�����œ��{���Εăh����2.2%�~�����Ă���ԂɁA�؍����Εăh����12%�E�H�����Ȃ���
���i�����������l����T���X����LG�͋�����ˁB���{����ŋ���������Č���������Ă��邵�B
�C���t������4-5%���x�Ȃ炤�܂������Ă�ƌ���ׂ��ł͂Ȃ���
�X���`�̋������k�`�͗�O�Ȃ��S�~����
�����͊؍��̂�
456 �F,,�E�L�́M�E,,�j��-�������F2011/10/04(��) 22:11:29.15 ID:6LT3fbzZ
�|���͓��{�̍��y�ł�
457 �F,,�E�L�́M�E,,�j��-�������F2011/10/04(��) 22:15:11.47 ID:6LT3fbzZ
���Ȃ݂ɃE�H���͔j�]���O����
�T���X���ȊO�̊�ƏI����Ă邵
�C�O�u���̋������v����ɍ��O�ɓ����o���������炢���o�C���Ă��ƁB
�A���i�������ݍ����ď����̐����������ň��B
�؍��i�j
�T���X���ȊO�̊�ƏI����Ă邵
�C�O�u���̋������v����ɍ��O�ɓ����o���������炢���o�C���Ă��ƁB
�A���i�������ݍ����ď����̐����������ň��B
�؍��i�j
�X���^�C100��ǂݕԂ���
�b���
http://www.anandtech.com/show/4830/intels-ivy-bridge-architecture-exposed/2
�����ɂ���Ivy��IPC5�����シ��炵�����ǁA���̉��Ǖ������đS�ʓI�Ɍ��ʂ���́H
�E�X���b�h�̃f�[�^�����Ă̌�����
�E�v���t�F�b�`���[�̋K��������
�EFP/integer������̃X���[�v�b�g��2�{��
�EMOV
�炵����
�b���
http://www.anandtech.com/show/4830/intels-ivy-bridge-architecture-exposed/2
�����ɂ���Ivy��IPC5�����シ��炵�����ǁA���̉��Ǖ������đS�ʓI�Ɍ��ʂ���́H
�E�X���b�h�̃f�[�^�����Ă̌�����
�E�v���t�F�b�`���[�̋K��������
�EFP/integer������̃X���[�v�b�g��2�{��
�EMOV
�炵����
459 �F,,�E�L�́M�E,,�j��-�������F2011/10/04(��) 22:19:24.21 ID:6LT3fbzZ
> �EFP/integer������̃X���[�v�b�g��2�{��
���Z��̂��Ƃ��ˁB������ƖĂ���
���Z��̂��Ƃ��ˁB������ƖĂ���
������IMF�Ɠ��{�Ɏ؋���ԍς��Ă��Ȃ�������ɂ͖łȂ���
461 �F,,�E�L�́M�E,,�j��-�������F2011/10/04(��) 22:35:04.30 ID:6LT3fbzZ
�؍����܂������j�]�����璩�N���{�𗧂ĂĊǗ����Ȃ��Ƃ����Ȃ���
�S�ʂɔg�y������ǂȂ�ď��Ȃ����낤�B���[�N���[�h����B
�オ�邱�Ƃ����邵�����邱�Ƃ����邵�ς��Ȃ����Ƃ�����B
�オ�邱�Ƃ����邵�����邱�Ƃ����邵�ς��Ȃ����Ƃ�����B
�����킗����
ttp://images.anandtech.com/reviews/cpu/intel/IvyBridge/IDFarchitecture/isachanges.jpg
> Float16 format conversion instructions
> �EConversion between a 16-bit (compressed) floating point memory format and 32-bit single precision (256-bit AVX and 128-bit SSE versions)
��H����ALNI�ƈႤ���H
ttp://www.4gamer.net/games/049/G004963/20090328006/
ttp://www.4gamer.net/games/049/G004963/20090328006/screenshot.html?num=009
{kind=link}
> Float16 format conversion instructions
> �EConversion between a 16-bit (compressed) floating point memory format and 32-bit single precision (256-bit AVX and 128-bit SSE versions)
��H����ALNI�ƈႤ���H
ttp://www.4gamer.net/games/049/G004963/20090328006/
ttp://www.4gamer.net/games/049/G004963/20090328006/screenshot.html?num=009
466 �F,,�E�L�́M�E,,�j��-�������F2011/10/05(��) 01:04:56.21 ID:ovhXWyS+
M16C��AVX�}�j���A���ɍڂ��Ă邼
467 �F,,�E�L�́M�E,,�j��-�������F2011/10/05(��) 01:05:11.01 ID:ovhXWyS+
���߂�F16C
����ł���ˁ[�悗����
divider�����璼��
����Ȃ�u���z�ҁv���Ǝv����
�킴�킴�Z�p���p��Ƃ��Ė��l�Ԃ��u���Z��i����Z��j�v�ł͂Ȃ��u������v��I�Ȃ痧�h�Ȍ��ł���
�킴�킴�Z�p���p��Ƃ��Ė��l�Ԃ��u���Z��i����Z��j�v�ł͂Ȃ��u������v��I�Ȃ痧�h�Ȍ��ł���
472 �F,,�E�L�́M�E,,�j��-�������F2011/10/05(��) 02:24:04.31 ID:ovhXWyS+
�Z�p�I�ȈӖ��𗝉����Ă�l�ԂȂ�Ԉ�������{����茴���̂ق����킩��
����͂���
http://ejje.weblio.jp/content/divider
�F�X��������
�F�X��������
�����͕�����ł��傤��
>FP/integer������
����ŕ��ʂɏ��Z�킾�ȂƗ����ł������ْ[�Ȃ�?
����ŕ��ʂɏ��Z�킾�ȂƗ����ł������ْ[�Ȃ�?
>>476
��U�p��ɒ����Ă邾��H
�[��2�{�̐��\�Ƃ������Ƃ�Radix256�i8�r�b�g�j���H
AES�����������ł��邾���̂��Ƃ͂���ˁB
��U�p��ɒ����Ă邾��H
�[��2�{�̐��\�Ƃ������Ƃ�Radix256�i8�r�b�g�j���H
AES�����������ł��邾���̂��Ƃ͂���ˁB
�u�C���e�������Ă�v�u�E�B���e���v�̎��́H�@Intel�̃��o�C�����N���E�h�헪
http://techtarget.itmedia.co.jp/tt/news/1110/04/news02.html
�|���E�X�L�[���ɂ��ƁA���Ђ̓v���Z�b�T�ɃA���S���Y����g�ݍ��݁A
��ƕ��ׂ�K�ȃ}�V���ɐU�蕪������悤�ɂ�����g�݂𐄐i���Ƃ����B
����̓v���Z�b�T�A�t�B�j�e�B�i�v���Z�b�T�e�a���j�Ƃ��Ēm����l�������B
�����́A���߃Z�b�g�Ɋւ������m�邱�Ƃ��ł���n�C�p�[�o�C�U�[��
�V�X�e�����x���œ��삳���邱�Ƃ��\�z���Ă���Ƃ����B
�u�Ⴆ�A���̃������͂��̃v���Z�X�ɑ����Ă��邩��A�f�[�^�͂��̃v���Z�X
�����s���Ă���R�A�̋߂��ɒu���Ă������Ƃ���������v�Ɠ����B
�@Red Hat�̏㋉�N���E�h�X�g���e�W�X�g�ł���S�[�h���E�n�t���ɂ��ƁA
���������@�\������A���[�U�[�̓A�N�e�B�u�ł͂Ȃ��R�A���~������
�ߓd������A�s����I������ł���Ƃ����B�u�V�X�e�����x����
�C���e���W�F���X�����߂�̂͗ǂ����Ƃ��v�Ɠ����B
http://techtarget.itmedia.co.jp/tt/news/1110/04/news02.html
�|���E�X�L�[���ɂ��ƁA���Ђ̓v���Z�b�T�ɃA���S���Y����g�ݍ��݁A
��ƕ��ׂ�K�ȃ}�V���ɐU�蕪������悤�ɂ�����g�݂𐄐i���Ƃ����B
����̓v���Z�b�T�A�t�B�j�e�B�i�v���Z�b�T�e�a���j�Ƃ��Ēm����l�������B
�����́A���߃Z�b�g�Ɋւ������m�邱�Ƃ��ł���n�C�p�[�o�C�U�[��
�V�X�e�����x���œ��삳���邱�Ƃ��\�z���Ă���Ƃ����B
�u�Ⴆ�A���̃������͂��̃v���Z�X�ɑ����Ă��邩��A�f�[�^�͂��̃v���Z�X
�����s���Ă���R�A�̋߂��ɒu���Ă������Ƃ���������v�Ɠ����B
�@Red Hat�̏㋉�N���E�h�X�g���e�W�X�g�ł���S�[�h���E�n�t���ɂ��ƁA
���������@�\������A���[�U�[�̓A�N�e�B�u�ł͂Ȃ��R�A���~������
�ߓd������A�s����I������ł���Ƃ����B�u�V�X�e�����x����
�C���e���W�F���X�����߂�̂͗ǂ����Ƃ��v�Ɠ����B
�E�B���e���Ƃ����������Ȃ�����
AMD�Ƃׂ����肶���}�C�N�\
GPU�̋K�i���߂�̂�ATI�ƌ��߂Ă邩��s��������
AMD�Ƃׂ����肶���}�C�N�\
GPU�̋K�i���߂�̂�ATI�ƌ��߂Ă邩��s��������
>>480
Direct3D�̗��j������Ă���
Direct3D�̗��j������Ă���
NV�����Z�ɑ����Ă��܂����̂Ŏ���DX�̍��肪�S���i��łȂ�
�Ă���������̂�
�Ă���������̂�
DX11.1�̍���͐i��ł�炵������GPGPU�W�̃}�C�i�[�`�F���W���S�炵�������͓����悶���
����ł���
Intel�̃��[�h�}�b�v��11.1���ď��߂Č����C������
ttp://msdn.microsoft.com/en-us/library/windows/desktop/hh404562(v=vs.85).aspx
Intel�̃��[�h�}�b�v��11.1���ď��߂Č����C������
ttp://msdn.microsoft.com/en-us/library/windows/desktop/hh404562(v=vs.85).aspx
485 �FSocket774�F2011/10/05(��) 22:39:39.25 ID:SdThZgTy
486 �FSocket774�F2011/10/06(��) 03:25:16.75 ID:zsqh0CeR
>>449
NEC�ƻ���݂��A�قړ����i�Ń^�u���b�g�o�������ׂĂ݂�
NEC�ƻ���݂��A�قړ����i�Ń^�u���b�g�o�������ׂĂ݂�
http://akiba-pc.watch.impress.co.jp/hotline/20080119/etc_wolfdale_amano.html
���̐́A�V�삪�e�w���c�Ɠ���l���ł����ƕ�����ē������͂��炩��������
�N��������x�V��ɂ��O���āA�r���m��̂т��[����i�e�w���c�j�Ȃ�ł����H���Ď��₵�Ă݂�悗��������������������
���̐́A�V�삪�e�w���c�Ɠ���l���ł����ƕ�����ē������͂��炩��������
�N��������x�V��ɂ��O���āA�r���m��̂т��[����i�e�w���c�j�Ȃ�ł����H���Ď��₵�Ă݂�悗��������������������
488 �FSocket774�F2011/10/06(��) 09:42:14.45 ID:XQ+uguMv
���iAMD�X����
�u1�R�A���\���[�v�������ł邭����
Intel�l�̃X���ŕ�������>>432
�N�������Ȃ����Ăǁ[��[���ƁH
1�R�A���\�K�v�Ȃ�ł���A���Ɏg���́H
�u1�R�A���\���[�v�������ł邭����
Intel�l�̃X���ŕ�������>>432
�N�������Ȃ����Ăǁ[��[���ƁH
1�R�A���\�K�v�Ȃ�ł���A���Ɏg���́H
�؍�(�l)���čD���ɂȂ�̂͊W�҂����ł���H��
����ȊW�̂Ȃ��X���Ɂu�����͌������炯�������v�Ƃ���������ŃA�s�[�����Ȃ��Ă��ǂ����炗
�ǂ�Ȃɔ�Q�Җʂ������āA�{���͉��Q�҂����Ă݂̂͂�Ȃ����Ă邩�疳�ʂ����Ă�
�����Ď��Ǝ����Ȃ�H �����̏��������Ă�H
�c�c�������ĂȂ����炱���̍��Ȃ낤�˂�
����ȊW�̂Ȃ��X���Ɂu�����͌������炯�������v�Ƃ���������ŃA�s�[�����Ȃ��Ă��ǂ����炗
�ǂ�Ȃɔ�Q�Җʂ������āA�{���͉��Q�҂����Ă݂̂͂�Ȃ����Ă邩�疳�ʂ����Ă�
�����Ď��Ǝ����Ȃ�H �����̏��������Ă�H
�c�c�������ĂȂ����炱���̍��Ȃ낤�˂�
>>489
�ˑR�ǂ����[�H
�ˑR�ǂ����[�H
491 �FSocket774�F2011/10/06(��) 15:25:29.46 ID:O2g4dqM8
>>488
�Q�[��
�Q�[��
492 �FSocket774�F2011/10/06(��) 16:47:01.72 ID:dIQo3MnF
>>488
�@ �@ �@ �@�@�@�@�@�@�@��P �M�R� �@�@�Q_�Q_�Q_
�@ �@ �@ �@�@�@�@�@�@�@�k -�] '�L �P �M�R- ��@�@�@�r
�@�@�@�@�@�@�@�@�@�@�^ �@ �@ �@�@�@�@�@�@�R�_ /
�@�@�@�@�@�@�@�@�^/ �@/ �@/ �@ �@ �@�R�R�@�R�q
�@ �@�@�@�@�@�@�R���! {�@ �-t ʁ@li � i�@i�@�@}Ĥ
�@�@�@�@�@�@�@�@�@ʂm |�@l�R��l �R���V�R��� j/ l�@!
�@ �@�@�@�@�@�@�@/�. �� �R��=���@,�@r= ��ق��@l�k�v
�@�@�@�@�@�@�@�@�RN�� ���@ �@���]�� �@ �l �l�@l
�@ �@�@�@�@�@�@�@�@�@�R�j�R��@�R_�m �@ �m//ځ�
�@�@�@�@r�V�V�V�V�V�V�V�V�VtɁM ��@r �L�/��
�@�@�@���LƁT �@�@�@�@�@�@�@��|�R �@_/�M�_
�@ �@�q�@�]�@�m���Ă邪�@��āA�@/ �@ �V�T�A
�@ �@�q��.. �@�@�@�@�@�@ �@.���e �u=��"�^ �l.
�@�@�@�g |���O�̑ԓx�� �ƃj�R��^�@�@��
�@�@�@�R.|l�@�@�@�@ �@ �@�@�q�- �@ !�@�M�R. �@ ��
�@ �@ �@ |l�C�ɓ���Ȃ� ���Ƥ_� �@ �@ �S�A!
�@ �@ �@ |l_�Q_�Q_�Q_�Q__��| �@�@�_ �@�@�@�\
�@ �@ �@ �@�@�@�@�@�@�@��P �M�R� �@�@�Q_�Q_�Q_
�@ �@ �@ �@�@�@�@�@�@�@�k -�] '�L �P �M�R- ��@�@�@�r
�@�@�@�@�@�@�@�@�@�@�^ �@ �@ �@�@�@�@�@�@�R�_ /
�@�@�@�@�@�@�@�@�^/ �@/ �@/ �@ �@ �@�R�R�@�R�q
�@ �@�@�@�@�@�@�R���! {�@ �-t ʁ@li � i�@i�@�@}Ĥ
�@�@�@�@�@�@�@�@�@ʂm |�@l�R��l �R���V�R��� j/ l�@!
�@ �@�@�@�@�@�@�@/�. �� �R��=���@,�@r= ��ق��@l�k�v
�@�@�@�@�@�@�@�@�RN�� ���@ �@���]�� �@ �l �l�@l
�@ �@�@�@�@�@�@�@�@�@�R�j�R��@�R_�m �@ �m//ځ�
�@�@�@�@r�V�V�V�V�V�V�V�V�VtɁM ��@r �L�/��
�@�@�@���LƁT �@�@�@�@�@�@�@��|�R �@_/�M�_
�@ �@�q�@�]�@�m���Ă邪�@��āA�@/ �@ �V�T�A
�@ �@�q��.. �@�@�@�@�@�@ �@.���e �u=��"�^ �l.
�@�@�@�g |���O�̑ԓx�� �ƃj�R��^�@�@��
�@�@�@�R.|l�@�@�@�@ �@ �@�@�q�- �@ !�@�M�R. �@ ��
�@ �@ �@ |l�C�ɓ���Ȃ� ���Ƥ_� �@ �@ �S�A!
�@ �@ �@ |l_�Q_�Q_�Q_�Q__��| �@�@�_ �@�@�@�\
�G�~�����āADolphin��Desmume��JPCSP���C���e���̕����������
Haswell��LGA1155�̉\�����Ăǂꂮ�炢����̂���
0
>>494
���j���[����Haswell�X���ɂ������낗��
���s��6�V���[�Y��Ivy��7�V���[�Y�̃}�U�{�ł�99%�g���Ȃ�������S���Ă�����
���j���[����Haswell�X���ɂ������낗��
���s��6�V���[�Y��Ivy��7�V���[�Y�̃}�U�{�ł�99%�g���Ȃ�������S���Ă�����
(1$=139�~�O�㓝���r�j
2600K $317 = \44000
�@8150 $245 = \34000
�u���y����( �L �� ` )�
2600K $317 = \44000
�@8150 $245 = \34000
�u���y����( �L �� ` )�
�����Ɍ����ƁABull�̓R�A�P�̂̐��\���Ⴗ���邨�����ŁA
�}���`�X���b�h�ł������I��Sandy��Ivy�ɗ�郌�x���Ȃ̂ŁA
�����_���������F�����������B
�}���`�X���b�h�ł������I��Sandy��Ivy�ɗ�郌�x���Ȃ̂ŁA
�����_���������F�����������B
�Ȃ�Sandy-E������
������Bull�̑S�Ă��_�����Ă킯�ł͂Ȃ������B�ߋ��`�����B
1�\�P�Ȃ�intel���������A�\�P�����������ꍇ�ɃX�P�[�����ɂ����Ƃ������_���A
Intel�͂����Ǝc���Ă����B
FSB�p�~����i�V���[�Y�ȍ~�ɘa���ꂽ���Asandy�ł܂��l�܂�悤�ɂȂ����B
sandy-e������ȂɎ��Ԃ����������̂́Abull�ɕ����Ă�������ւ�����ǂ��Ă�����B
����sandy-e��sandy����O���t�B�b�N����������̂��̂����̂܂o���Ă���A
2�\�P�ȏ�̎I�����amd�ɕt�������錄���ł��Ă����낤�B
�܂荡�ł͑S���ʖ��G�ɂȂ����킯�����B
1�\�P�Ȃ�intel���������A�\�P�����������ꍇ�ɃX�P�[�����ɂ����Ƃ������_���A
Intel�͂����Ǝc���Ă����B
FSB�p�~����i�V���[�Y�ȍ~�ɘa���ꂽ���Asandy�ł܂��l�܂�悤�ɂȂ����B
sandy-e������ȂɎ��Ԃ����������̂́Abull�ɕ����Ă�������ւ�����ǂ��Ă�����B
����sandy-e��sandy����O���t�B�b�N����������̂��̂����̂܂o���Ă���A
2�\�P�ȏ�̎I�����amd�ɕt�������錄���ł��Ă����낤�B
�܂荡�ł͑S���ʖ��G�ɂȂ����킯�����B
�Ӂ[��E�E�E
����>>500�Ɂw�N�̌����Ă��邱�Ƃ͑S���������Ȃ��BCMA�ȍ~�́AFSB�̍�����Xeon�̕������\���ǂ������B�x�Ƃ��������X���A�C�����������Ă��܂������т�����B
Xeon�̃}���`�\�P�b�g���č��܂Œʂ�QPI�Őڑ�������>>500�̌����Ă邱�Ƃ��ě������ɂ��Ȃ��ĂȂ���
sandy�̕����\�P���Ă܂���������
>>500�͂悭�m���Ă�Ȃ�
>>500�͂悭�m���Ă�Ȃ�
505 �F,,�E�L�́M�E,,�j��-�������F2011/10/08(�y) 20:55:33.65 ID:1y4MqMyQ
Llano��Bobcat���}���`�\�P�b�g�ɑΉ����Ă邩�H�����Ă邱�Ƃ��܂�Ŗ��Ӗ�����B
�}���`�X���b�h���㐶���c��̂�AMD���낤�ȁB
Intel Barcelona Research Center�u����ȁv�B
508 �F,,�E�L�́M�E,,�j��-�������F2011/10/08(�y) 22:57:59.29 ID:1y4MqMyQ
���sXeon��1�m�[�h80�R�A160�X���b�h�܂ō\�z�ł��邯�ǁB
AMD���ă}���`�X���b�h�Ɋւ��ĉ�������Ă�́H
Pallarel Studio�݂����ȊJ���c�[���Ƃ��Ȃo���Ă�́H
AMD���ă}���`�X���b�h�Ɋւ��ĉ�������Ă�́H
Pallarel Studio�݂����ȊJ���c�[���Ƃ��Ȃo���Ă�́H
�J���c�[���H�H
����ȃX���b�h�����ăc�[���K�v�Ȃ́HBIOS�̏��OS�̂���VM����ǂ�����
�ق�Ə����ĕ|����ȁB�c�[�����S�ĂƎv�����ނȂ̕a�C���H
������������o�Ȃ����牽���m��Ȃ��̂��c��
����ȃX���b�h�����ăc�[���K�v�Ȃ́HBIOS�̏��OS�̂���VM����ǂ�����
�ق�Ə����ĕ|����ȁB�c�[�����S�ĂƎv�����ނȂ̕a�C���H
������������o�Ȃ����牽���m��Ȃ��̂��c��
510 �F,,�E�L�́M�E,,�j��-�������F2011/10/08(�y) 23:26:59.75 ID:1y4MqMyQ
�m���Ă�Ȃ狳���Ă�B
�����ӂ[�ɂ킩���B
OJT����(��)
OJT����(��)
512 �FSocket774�F2011/10/08(�y) 23:31:33.46 ID:VEf73SDL
>>509�݂����ȉ��͂Ȃ�ł��m���Ă���I�ȃL�`�K�C�|��
age�~�c�q���q�܂��L�`�K�C�B
514 �F,,�E�L�́M�E,,�j��-�������F2011/10/08(�y) 23:34:42.31 ID:1y4MqMyQ
> OJT
�����A�����́u�ق����炩���v���C����ĉ������ɒu�����������̂���
IT�ŃX�C�[�c�i�j�̂ЂƂB
�����A�����́u�ق����炩���v���C����ĉ������ɒu�����������̂���
IT�ŃX�C�[�c�i�j�̂ЂƂB
�����A���~�������ȐQ���������̂�������Ȃ��Ȃ�
�܂��C���e���X��������
�܂��C���e���X��������
AMD�X���̂悤��age��r���Ǝv���Ă���K�L���S�����Ă��邾������
AMD������X����age�Ă邨���̂��ڂ�����܂��\��Ă���悤�ł����ǁB�ォ�甭���Ŏ����̎��͒I�ł��˕�����܂��B
258 ���O�FSocket774[sage] ���e���F2011/10/08(�y) 22:58:25.46 ID:hkcNhHHG
>>252
���ׂ͊�{�I�Ƀo�J�����烊�e���V�������͂̋K�i�����܂��Ă���̂𗝉��ł��Ȃ���B
�u����N�[���[���t���Ȃ��ʼn���v�Ȃ�A�K�C�h���C���ʂ�ɐ������Ȃ������A
M/B�x���_�[�̐ӔC�����A����L�b�g����������AM3�K�i�Ή���CPU�N�[���[�S�ĂŖ�肪�o��B
�t�ɐ���N�[���[���K�C�h���C���ɉ����Ă��Ȃ���A���������Ӗ��͂Ȃ��A
�N�[���[�����đI�肷�邾���ŁA�ɂ͑S���e�����Ȃ��̂������ł��Ȃ��̂��ƁB
>>253�݂����ȃA�z�q���������킯�����A�m�����̂��F���Ȃ낤�B
258 ���O�FSocket774[sage] ���e���F2011/10/08(�y) 22:58:25.46 ID:hkcNhHHG
>>252
���ׂ͊�{�I�Ƀo�J�����烊�e���V�������͂̋K�i�����܂��Ă���̂𗝉��ł��Ȃ���B
�u����N�[���[���t���Ȃ��ʼn���v�Ȃ�A�K�C�h���C���ʂ�ɐ������Ȃ������A
M/B�x���_�[�̐ӔC�����A����L�b�g����������AM3�K�i�Ή���CPU�N�[���[�S�ĂŖ�肪�o��B
�t�ɐ���N�[���[���K�C�h���C���ɉ����Ă��Ȃ���A���������Ӗ��͂Ȃ��A
�N�[���[�����đI�肷�邾���ŁA�ɂ͑S���e�����Ȃ��̂������ł��Ȃ��̂��ƁB
>>253�݂����ȃA�z�q���������킯�����A�m�����̂��F���Ȃ낤�B
����
�}������DC���v�ɉ����Ă���̂�Xeon�ő�ׂ����Ă���̂�Intel������VM�Ƃ��i���Ă݂Ă���������������
SandyBridge-E�͊��Ɉꕔ�̌ڋq�@���ێ��_�������ŏo�ς݂ŕ]���͏�X
�ނ�͈�������Xeon���w������C���X�Ƃ����b�Ȃ��Opteron�͂���1�N���炢�͔���Ȃ����������낤��
��ID:oVZwbxXc�փ}�W���X���悤���Ǝv�������~�߂Ă�����
�}������DC���v�ɉ����Ă���̂�Xeon�ő�ׂ����Ă���̂�Intel������VM�Ƃ��i���Ă݂Ă���������������
SandyBridge-E�͊��Ɉꕔ�̌ڋq�@���ێ��_�������ŏo�ς݂ŕ]���͏�X
�ނ�͈�������Xeon���w������C���X�Ƃ����b�Ȃ��Opteron�͂���1�N���炢�͔���Ȃ����������낤��
��ID:oVZwbxXc�փ}�W���X���悤���Ǝv�������~�߂Ă�����
>>514
�c�q�͂���Ȗڂɂ������̂��E�E�E�E�B�ق����炩���Ȃ�ĉ��������ȁB
�ł����̌�������@����ɂ͂����肢���Ă��������O�ɋ��������͖����B���Ȓ����������Ă鎖���܂��q�ǂ��B�����Ă��Ӗ����Ȃ��B
�N�����ċ����������ɋ�����������H�@�������ŕԂ��悤�ł͂܂��܂��ʖڂ���B
�c�q�͂���Ȗڂɂ������̂��E�E�E�E�B�ق����炩���Ȃ�ĉ��������ȁB
�ł����̌�������@����ɂ͂����肢���Ă��������O�ɋ��������͖����B���Ȓ����������Ă鎖���܂��q�ǂ��B�����Ă��Ӗ����Ȃ��B
�N�����ċ����������ɋ�����������H�@�������ŕԂ��悤�ł͂܂��܂��ʖڂ���B
OJT���Ăق����炩���̂��Ƃ����Ă̂͏펯
�r�W�l�X�p��͂��������̑��������w
�r�W�l�X�p��͂��������̑��������w
�����ǁ[�ł���������
�Ȃ�Sandy-E������
�Ƃ肠����>>509�݂����ȔF���͂��������Ȃ�
���̃X���b�h�͎�舵����������A�f�o�b�O�͎���Ƃ���������
���炩�̃t���[�����[�N��J�����̎x���������Ă�
�ȒP�Șb�ł͂Ȃ��̂�
���̓_��Intel�͊撣���Ă�����Ǝv�����A�܂��܂������J�����K�v�ȕ���
���̂܂܂Ńw�e���W�j�A�X�A�[�L�e�N�`������ɓ˓������������
�ǂ�����Ⴂ���낤��
���̃X���b�h�͎�舵����������A�f�o�b�O�͎���Ƃ���������
���炩�̃t���[�����[�N��J�����̎x���������Ă�
�ȒP�Șb�ł͂Ȃ��̂�
���̓_��Intel�͊撣���Ă�����Ǝv�����A�܂��܂������J�����K�v�ȕ���
���̂܂܂Ńw�e���W�j�A�X�A�[�L�e�N�`������ɓ˓������������
�ǂ�����Ⴂ���낤��
(1$=139�~�O�㓝���r�j
2600K $317 = \44000
�@8150 $245 = \34000
�u���y����( �L �� ` )�
2600K $317 = \44000
�@8150 $245 = \34000
�u���y����( �L �� ` )�
�n�i�s�Ƃ����u�ق����炩���v
ttp://japan.zdnet.com/blog/netcommerce/2010/04/10/entry_27038966/
���u�킪�Ђ́A�n�i�s�ł���Ă���v
�����u�킪�Ђ́A�l����Ă���g�݂�������Ă��܂��B�����łł���l�Ԃ������c���Ă����A����ł����v
�����u�Ў�ԋ���v
ttp://japan.zdnet.com/blog/netcommerce/2010/04/10/entry_27038966/
���u�킪�Ђ́A�n�i�s�ł���Ă���v
�����u�킪�Ђ́A�l����Ă���g�݂�������Ă��܂��B�����łł���l�Ԃ������c���Ă����A����ł����v
�����u�Ў�ԋ���v
��C����ID:oVZwbxXc�������낵�������A����������ĂĔ��ɒɁX�����I�b�T�����ƌ����̂͂悭�킩�����B
��523
���O�F�n�[�h�E�F�A���x���̕����Ώ̐��͂��̐�����܂�ӎ����Ȃ��Ă�����B�i�{���F���ЂƂ͂������Ⴄ��ł������j
���O�F���̂����A�v���̕��́A�}�������g���čő���Ɉ����o���ĂˁB�i�{���F����ێ�����I�����͏���Ȃ��|�C���c�ˁI�I�j
���O�F���̂���`�������邽�߂Ƀ��C�u�����ƃf�o�b�K����������B�i�{���F��{�͌���ێ������Ǒ��Ђ��̓}�V�Ȃ͂���ˁB�j
���O�F�E�`�͂��ꂩ��MIC�Ƃ�HSW�Ƃ����̌�p���i�Ƃ��p���t���ȃn�[�h�����o����B�i�{���F���������Ď����Đ��E��̔�������Ȃ�������c�j
���O�F���̂����Ƀp�������ȃR�[�h�������Ă������R���p�C������^�C���ł��̂܂܍����������B�i�{���F���ЂƂ͂������Ⴄ��ł������j
���O�F�v����ɏ��ǂ��Ȃ邱�Ƃ͂Ȃ����Lj������Ȃ�Ȃ����ʂ���B�i�{���F������蓪��Y�܂��čs���ĂˁI�������Ă������I�I�j
�@�@�@�@�@�@ .�ȁ@��
�@�@�@�@�@�@In�L�܁M�� ���
�@�@�@�@�@./i�@��Ɂj)�j�r�@�����c
�@�@�@�@ / /�!��.� �����/�P�P�P�P/�@ ���肷���ӂ������[�F�D�L���œK����f�o�b�O�����Ȃ���Ȃ�Ȃ����Ƃ�����B�i�{���F�����͔��ł���B�j
�@�@�@�@ �Ɂj��PD��/Centrino / �@�@�@�@�@�@
�P�P�P�P�P�@ �_/�Q�Q�Q�Q/�@�P�P
���O�F�n�[�h�E�F�A���x���̕����Ώ̐��͂��̐�����܂�ӎ����Ȃ��Ă�����B�i�{���F���ЂƂ͂������Ⴄ��ł������j
���O�F���̂����A�v���̕��́A�}�������g���čő���Ɉ����o���ĂˁB�i�{���F����ێ�����I�����͏���Ȃ��|�C���c�ˁI�I�j
���O�F���̂���`�������邽�߂Ƀ��C�u�����ƃf�o�b�K����������B�i�{���F��{�͌���ێ������Ǒ��Ђ��̓}�V�Ȃ͂���ˁB�j
���O�F�E�`�͂��ꂩ��MIC�Ƃ�HSW�Ƃ����̌�p���i�Ƃ��p���t���ȃn�[�h�����o����B�i�{���F���������Ď����Đ��E��̔�������Ȃ�������c�j
���O�F���̂����Ƀp�������ȃR�[�h�������Ă������R���p�C������^�C���ł��̂܂܍����������B�i�{���F���ЂƂ͂������Ⴄ��ł������j
���O�F�v����ɏ��ǂ��Ȃ邱�Ƃ͂Ȃ����Lj������Ȃ�Ȃ����ʂ���B�i�{���F������蓪��Y�܂��čs���ĂˁI�������Ă������I�I�j
�@�@�@�@�@�@ .�ȁ@��
�@�@�@�@�@�@In�L�܁M�� ���
�@�@�@�@�@./i�@��Ɂj)�j�r�@�����c
�@�@�@�@ / /�!��.� �����/�P�P�P�P/�@ ���肷���ӂ������[�F�D�L���œK����f�o�b�O�����Ȃ���Ȃ�Ȃ����Ƃ�����B�i�{���F�����͔��ł���B�j
�@�@�@�@ �Ɂj��PD��/Centrino / �@�@�@�@�@�@
�P�P�P�P�P�@ �_/�Q�Q�Q�Q/�@�P�P
���XOJT���đ�H�݂����ɋZ�p�͌��ē���
�݂����Ȃ��̂�����Ԉ���ĂȂ�
�݂����Ȃ��̂�����Ԉ���ĂȂ�
>>525
����T�[�r�X�Ǝ҂��A��X�ɋ����o�����ɏ���ɎЈ����炷��Ȃ��ċ������Ă����B
����T�[�r�X�Ǝ҂��A��X�ɋ����o�����ɏ���ɎЈ����炷��Ȃ��ċ������Ă����B
530 �F,,�E�L�́M�E,,�j��-�������F2011/10/09(��) 12:30:59.07 ID:ZbiUNwkk
AMD�̊J���c�[�������C�Ȃ�������̂�OJT�ł���Ȃ�����
�Ȃ�Ŏ��������ϓI�ɂ������Ȃ����̂�
���R���Ȃ������o�Ă��Ăق����Ȃ낤�˂��B
���������ďH�t����2�����n�̃V���b�v�s�����肵�Ă�낤�ɁB
�����͑��l�ɑz���͓����������Ďv����B
���R���Ȃ������o�Ă��Ăق����Ȃ낤�˂��B
���������ďH�t����2�����n�̃V���b�v�s�����肵�Ă�낤�ɁB
�����͑��l�ɑz���͓����������Ďv����B
AMD���ċZ�p��H���ăC���[�W�����Ȃ���
�悻�l�̋Z�p�ɏ�������āA�s���悭�����ڂ�ɗa���낤�Ƃ��Ă�悤�ɂ��������Ȃ�
�悻�l�̋Z�p�ɏ�������āA�s���悭�����ڂ�ɗa���낤�Ƃ��Ă�悤�ɂ��������Ȃ�
����͂����̕Ό���
���\�[�X�S���n�[�h�̊J���̕��ɓ˂�����ł邩��\�t�g����̗]�͂��˂���
>>532
����Intel��(x86)CPU��AMD64�݊�CPU�����Ȃ�
����Intel��(x86)CPU��AMD64�݊�CPU�����Ȃ�
536 �F,,�E�L�́M�E,,�j��-�������F2011/10/09(��) 16:16:48.10 ID:ZbiUNwkk
����AMD64���̂�Intel����ΓI����������x86���߃Z�b�g�̏�ɊԎ肵���g�����߃Z�b�g�����ǂȁB
��肩��h�������e�R���h�[���؍��N���Ƃ����悤�Ȃ��B
��肩��h�������e�R���h�[���؍��N���Ƃ����悤�Ȃ��B
�Ȃ�Sandy-E������
nexgen
dec
ati
pentium4(andy glew)
dec
ati
pentium4(andy glew)
�`�l�c�ׂ̊Ď��p�˂���
>��肩��h�������e�R���h�[���؍��N��
�����^
�����^
�܂��N���j�_���Ă����Ă�̂�AMD�Ђł͂Ȃ��āA
���_�����̃A���~��������B
���_�����̃A���~��������B
>532
�������Ȃ�
SSE5���L�����Z������AVX�ʂɎ��ꂿ������Ƃ��̃u�[�������̎h������̓}�W�����
�������Ȃ�
SSE5���L�����Z������AVX�ʂɎ��ꂿ������Ƃ��̃u�[�������̎h������̓}�W�����
���߂�
>535
�ł���
>535
�ł���
������RISC�S���̎��ォ�炱�̋ƊE�ǂ������Ă������ǁA
�A���`Intel��肽������A�I���W�i���e�B�̂�������Ȃ����ɂ����
AMD�ЂȂɂ������Ă���̂��Е��ɂ���ˁB
�܂����j��m��Ȃ����炻���Ȃ��Ă��܂����낤���ǁA
Intel�x�z�̑R�n�Ƃ���ARM�̘b�肪�Ђ�����Ȃ��ɂȂ��Ă����
�A���~�̃A�C�f���e�B�e�B�̕�����Ղ肪�ŋߊy�����B
�A���`Intel��肽������A�I���W�i���e�B�̂�������Ȃ����ɂ����
AMD�ЂȂɂ������Ă���̂��Е��ɂ���ˁB
�܂����j��m��Ȃ����炻���Ȃ��Ă��܂����낤���ǁA
Intel�x�z�̑R�n�Ƃ���ARM�̘b�肪�Ђ�����Ȃ��ɂȂ��Ă����
�A���~�̃A�C�f���e�B�e�B�̕�����Ղ肪�ŋߊy�����B
�g�����߂ł͑��ς�炸Intel�Ɍ��茠�������Ă邩���
Intel�ɂ��Ă�Pentium4 Prescott�����������ɂȂ�����Ȃ���
������Intel�Ƃ͂����A�_����CPU����蔄�낤�Ƃ��Ă�������
������Intel�Ƃ͂����A�_����CPU����蔄�낤�Ƃ��Ă�������
��������Ȃ��ăv���Z�b�T�v�̏펯�̐ߖڂɂ������������B
���̐ߖڂɌÂ��펯�̂܂܃W�����v���悤�Ƃ��đ傫���Ԃ����������̂�Prescott�B
���̐ߖڂɌÂ��펯�̂܂܃W�����v���悤�Ƃ��đ傫���Ԃ����������̂�Prescott�B
�����@���͌������������
IBM��Y����Ă͍���B
�C���`����intel�����˂̒n�Ǝv�����ގn���ǂ��Ȃ邱�Ƃ��......
>>523
�C���e���݂����ɃV���O���X���b�h���ɂ߂Ă����Ƃ�"�X���b�h"���悗���̂Ȃ���̃v���Z�X�̊ԈႢ����g��(*�Po�P)���h������
���̓_AMD�̓R�A�𑝂₵�ăX���b�h���ɂ߂Ă���B���܂��ɃX���b�h�̓�������H��Ȃ�����F�}���Z�[���낤��B�L���b�V���̎g������AMD����͌����I�����ȁI
�C���`����intel�����˂̒n�Ǝv�����ގn���ǂ��Ȃ邱�Ƃ��......
>>523
�C���e���݂����ɃV���O���X���b�h���ɂ߂Ă����Ƃ�"�X���b�h"���悗���̂Ȃ���̃v���Z�X�̊ԈႢ����g��(*�Po�P)���h������
���̓_AMD�̓R�A�𑝂₵�ăX���b�h���ɂ߂Ă���B���܂��ɃX���b�h�̓�������H��Ȃ�����F�}���Z�[���낤��B�L���b�V���̎g������AMD����͌����I�����ȁI
�ǂ�Ȃɂ������̍���Ă��\�t�g������ɑΉ����Ȃ���˂�
���̑Ή��̃R�X�g��啝�ɉ�����̂��J���c�[���̒Ȃ̂�
���̑Ή��̃R�X�g��啝�ɉ�����̂��J���c�[���̒Ȃ̂�
�X���^�C�ʂ�AIvyBridge,Haswell,Broadwell,Skylake �ӂ�ɂ��Č�荇���ĉ������B
Intel��AMD���ǂ��ł������ł���
Intel��AMD���ǂ��ł������ł���
553 �FSocket774�F2011/10/09(��) 18:54:19.87 ID:SVAuzwMg
�܂�11nm�܂ł�Intel�Ƒ����낤���Ȃ�
Haswell�̓A���R�A���ǂ����C���Ȋ���������
CPU�R�A�������u���Ȃ�IPC�オ��Ɗ��҂��Ă����̂���
CPU�R�A�������u���Ȃ�IPC�オ��Ɗ��҂��Ă����̂���
555 �F,,�E�L�́M�E,,�j��-�������F2011/10/09(��) 19:05:01.07 ID:ZbiUNwkk
�ő��̃u���E�U�����̂���Chrome�̓E�B���h�E���ƂɃv���Z�X�𗧂��グ���ˁB
IE��8�Ƃ�9�����肩�炻���Ȃ�����Ȃ����������H
1�v���Z�X������̃��\�[�X���������邵�s�������ƑS�v���O���������ʂ���
�@�\���ƂɃv���Z�X�ɂ킯��COM�ł��Ƃ肷��̂��}���`�v���O���~���O�̃Z�I���[�̂悤�ȁB
IE��8�Ƃ�9�����肩�炻���Ȃ�����Ȃ����������H
1�v���Z�X������̃��\�[�X���������邵�s�������ƑS�v���O���������ʂ���
�@�\���ƂɃv���Z�X�ɂ킯��COM�ł��Ƃ肷��̂��}���`�v���O���~���O�̃Z�I���[�̂悤�ȁB
>>555
�ꉞIE��Vista+IE7�̎��_�Ń}���`�v���Z�X�B
�^�u������O���I�v�V�����ŃE�C���h�E���ƂɃv���Z�X���邱�Ƃ��o�����悤�ȁH
�ꉞIE��Vista+IE7�̎��_�Ń}���`�v���Z�X�B
�^�u������O���I�v�V�����ŃE�C���h�E���ƂɃv���Z�X���邱�Ƃ��o�����悤�ȁH
>>555
�u���E�U�ł����ʗp����b�Ȃ��ǂ˂����������u���E�U�ɂ�����CPU���ׂ͛��̛�
�l�b�g�u�b�N�͂Ȃ�Ńl�b�g�u�b�N���Ă����Ǝv���H����̓u���E�U�N��Atom or�@Zacate�ł��ʂ�ʂ铮�����x�̕��ׂ����炳
�u���E�U�ɕK�v�Ȃ̂̓}���`�X���b�h���\�悩������x�̕����Ǝv������
�u���E�U�ł����ʗp����b�Ȃ��ǂ˂����������u���E�U�ɂ�����CPU���ׂ͛��̛�
�l�b�g�u�b�N�͂Ȃ�Ńl�b�g�u�b�N���Ă����Ǝv���H����̓u���E�U�N��Atom or�@Zacate�ł��ʂ�ʂ铮�����x�̕��ׂ����炳
�u���E�U�ɕK�v�Ȃ̂̓}���`�X���b�h���\�悩������x�̕����Ǝv������
558 �F,,�E�L�́M�E,,�j��-�������F2011/10/09(��) 20:04:24.08 ID:ZbiUNwkk
���̐lHTML5���Ēm��Ȃ��̂��ȁH�i˿˿
559 �F,,�E�L�́M�E,,�j��-�������F2011/10/09(��) 20:27:42.87 ID:ZbiUNwkk
����v���Z�X���ŕ����^�X�N�i�X���b�h�j�����ꍇ�̐����ƃf�����b�g�𐳂��������ł��Ă��
�}���`�v���Z�X�̃v���O�����������Ă鎖��͗����ł���͂������ǂˁB
UNIX�̃R�}���h���C���c�[���̑����������̃V���v���ȃv���O�����̕W�����o�͂��p�C�v����
���G�ȋ@�\����������v�v�z�����A����Ӗ��ł͌��_��A�I�ȂƂ����������ǁB
���Ȃ��Ƃ��v���Z�X���X���b�h�̂ق����������H��Ȃ��Ƃ��̌�������
�n�������ĕ����悶��邩���߂Ă��ꂗ����
�}���`�v���Z�X�̃v���O�����������Ă鎖��͗����ł���͂������ǂˁB
UNIX�̃R�}���h���C���c�[���̑����������̃V���v���ȃv���O�����̕W�����o�͂��p�C�v����
���G�ȋ@�\����������v�v�z�����A����Ӗ��ł͌��_��A�I�ȂƂ����������ǁB
���Ȃ��Ƃ��v���Z�X���X���b�h�̂ق����������H��Ȃ��Ƃ��̌�������
�n�������ĕ����悶��邩���߂Ă��ꂗ����
>>
AVX���Č��ǂȂ����́HIvy����Sandy-E���̌���Ă銄�ɂ͑S������オ��Ȃ�AVX
�uAMD��2007�N�ɐϘa���Z���܂�SSE5�\�A�x���Intel����N(2008�N)�t��AVX�ƐϘa���Z��FMA�\�����B�v
�Ɛ̂̌㓡�O��Weekly�C�O�j���[�X�ɏ�����Ă���B
���\�O����AVX���o�܂��I�Ȃ�Č����Ă�����(�C���e�������ӂ̊J���c�[���H�H)�S���𗧂����B�c�O��I�I�I
AVX���Č��ǂȂ����́HIvy����Sandy-E���̌���Ă銄�ɂ͑S������オ��Ȃ�AVX
�uAMD��2007�N�ɐϘa���Z���܂�SSE5�\�A�x���Intel����N(2008�N)�t��AVX�ƐϘa���Z��FMA�\�����B�v
�Ɛ̂̌㓡�O��Weekly�C�O�j���[�X�ɏ�����Ă���B
���\�O����AVX���o�܂��I�Ȃ�Č����Ă�����(�C���e�������ӂ̊J���c�[���H�H)�S���𗧂����B�c�O��I�I�I
����ς�AMD��AVX�ɑΉ�����̂��\�t�g�����҂��Ă��邩�炾�ˁB�C���e�����哱���H�H�ǂ��̃z�����悖��������
�Ȃ�Sandy-E������
563 �F,,�E�L�́M�E,,�j��-�������F2011/10/09(��) 20:36:33.94 ID:ZbiUNwkk
�N�����̃A���J�[���悗������
���Ƃ���UI��WPF��WinForms�ŏ����ăo�b�N�O���E���h�v���O�������l�C�e�B�u�ŏ����Ȃ�ďꍇ�ɂ�RPC�͎g���B
.NET���炶��CPU�l�C�e�B�u�̖��߂ڒ@���Ȃ����ˁB
���Ƃ���UI��WPF��WinForms�ŏ����ăo�b�N�O���E���h�v���O�������l�C�e�B�u�ŏ����Ȃ�ďꍇ�ɂ�RPC�͎g���B
.NET���炶��CPU�l�C�e�B�u�̖��߂ڒ@���Ȃ����ˁB
Adobe��Photoshop�@CS6�������AVX�Ή����Ă���Ȃ��Ɖ��b���Ȃ�
�����Ď���Adobe CS6�͗��N4���c
�����Ď���Adobe CS6�͗��N4���c
AMD�哱�Ȃ�SSE5(��)�������̂ɂ�
�����Ƃ͏������
AMD������X���Ə������݃p�^�[���������ł����킩��
AMD������X���Ə������݃p�^�[���������ł����킩��
567 �FSocket774�F2011/10/09(��) 22:51:39.89 ID:sPP8rdxV
��������BIOS�A�b�v�ړI�̃��[�J�[��������
�u���Õi���[�v���đ������Ⴄ�o�J�ł�����B
�܂�Intel�͂��q�l�ɒ��Õi��n�������Ȃ�����
���׃`�b�v�}�U�[�o����������肵����ł����˂��B
�u���Õi���[�v���đ������Ⴄ�o�J�ł�����B
�܂�Intel�͂��q�l�ɒ��Õi��n�������Ȃ�����
���׃`�b�v�}�U�[�o����������肵����ł����˂��B
�u�������Ĕ��Â�������A�X�����ł������Ď����ł����Ă���������(�L�_�`)
AMD�̎�����CPU���ӂ����Ȃ�����intel�̎�����CPU��
�J�������݂������ˁB
�J�������݂������ˁB
���[�h�}�b�v�ʂ�ł���
Haswell�͔��\�����A���y���i�тł��f�t�H���g8�R�A���������ǂ�
�R�A���₷������d�͌��炷�������d�v�ɂȂ��Ă����̂�
�Ȃ�Sandy-E������
574 �FSocket774�F2011/10/10(��) 02:06:31.28 ID:XQWcbHD1
���o�Ă郍�[�h�}�b�v����
Haswell��Broadwell�̓��C���X�g���[�������o�Ȃ����
Haswell��Broadwell�̓��C���X�g���[�������o�Ȃ����
�Ȃ����\���Ă��Ȃ������̂ŁB>>278,281�ӂ�Ɋ֘A����b��
Intel�̃��������[�h�}�b�v��DDR4���Ȃ����R
http://pc.watch.impress.co.jp/docs/column/kaigai/20111005_481542.html
��Intel�́A���C���X�g���[��PC������Haswell�̍ŏ�ʍ\���ł́A
���I���p�b�P�[�W�܂��̓I���_�C�̂ǂ��炩��eDRAM�`�b�v���ڂ���v�������������Ă���ƌ����Ă���B
�������炭�AGPU�R�A�̃������o�b�t�@�Ƃ��Ďg���ƌ�����B
�ш������ɘa���邽�߂ɃL���b�V�����g���̂͐����I�Ȏ�@���Ǝv����
�E�Ⴆ��32�`64MB���炢��eDRAM�������Ƃ��āA�ǂ̒��x���ʂ�����̂��H
�@�Q�[����GPGPU�͂悭�������Ă��Ȃ����A�ŋ߂�dGPU��GDDR��
�@GB�P�ʂȏ�������ƁA�e�N�X�`���f�[�^���Ă������傫����
�@�Ƃ�����CPU�̂悤�Ƀf�[�^�ɋ����Ǐ����͊��҂ł���́H
�E�������o���h���s����Llano�Ŋ��Ɍ�������AMD�͂ǂ�������@���Ƃ�̂��H
�@Intel��������ɐ؎��Ȃ͂�����
���̕ӂ��C�ɂȂ鏊
Intel�̃��������[�h�}�b�v��DDR4���Ȃ����R
http://pc.watch.impress.co.jp/docs/column/kaigai/20111005_481542.html
��Intel�́A���C���X�g���[��PC������Haswell�̍ŏ�ʍ\���ł́A
���I���p�b�P�[�W�܂��̓I���_�C�̂ǂ��炩��eDRAM�`�b�v���ڂ���v�������������Ă���ƌ����Ă���B
�������炭�AGPU�R�A�̃������o�b�t�@�Ƃ��Ďg���ƌ�����B
�ш������ɘa���邽�߂ɃL���b�V�����g���̂͐����I�Ȏ�@���Ǝv����
�E�Ⴆ��32�`64MB���炢��eDRAM�������Ƃ��āA�ǂ̒��x���ʂ�����̂��H
�@�Q�[����GPGPU�͂悭�������Ă��Ȃ����A�ŋ߂�dGPU��GDDR��
�@GB�P�ʂȏ�������ƁA�e�N�X�`���f�[�^���Ă������傫����
�@�Ƃ�����CPU�̂悤�Ƀf�[�^�ɋ����Ǐ����͊��҂ł���́H
�E�������o���h���s����Llano�Ŋ��Ɍ�������AMD�͂ǂ�������@���Ƃ�̂��H
�@Intel��������ɐ؎��Ȃ͂�����
���̕ӂ��C�ɂȂ鏊
�ŋ߂�GPU����ʂ�VRAM��v������̂́A�e�ʂ��̂��̂��K�v�Ƃ������]���ш�
�m�ۂ̂��߂Ƀo�X���L����ƃ������̃O���j�������e�B�����ɂ��K�v�ȏ�̃�������
���ڂ�����Ȃ����Ė�肪�����ɂ���B
eDRAM���ƃO���j�������e�B�������ɘa������Ŕ�r�I���e�ʂł����ʂ͂���͂��B
�m�ۂ̂��߂Ƀo�X���L����ƃ������̃O���j�������e�B�����ɂ��K�v�ȏ�̃�������
���ڂ�����Ȃ����Ė�肪�����ɂ���B
eDRAM���ƃO���j�������e�B�������ɘa������Ŕ�r�I���e�ʂł����ʂ͂���͂��B
�������ш���o�J�H������͓̂��ɉ𑜓x�����������荂�i����AA���g�����肷��ꍇ����
eDRAM���g���A�L���b�V���Ɏ��܂�͈͓��Ȃ�قƂ�ǃt���[�����[�g�𗎂Ƃ����ɂ���
�e�N�X�`���Ƃ��͂���܂��e���Ȃ��Ǝv���B�����k�ȃt�H�[�}�b�g�̊J��������Ă�悤����
AMD�̕���eDRAM�Ƃ��l���Ă��Ȃ����ȁH���ƃ������ш�̎g�p��������VLIW����߂�݂�������
�Q�[�����[�J�[�Ƌ��͂��ă������ш���Ȃ�ׂ��H��Ȃ��悤�ɍœK�������Ă������낤
eDRAM���g���A�L���b�V���Ɏ��܂�͈͓��Ȃ�قƂ�ǃt���[�����[�g�𗎂Ƃ����ɂ���
�e�N�X�`���Ƃ��͂���܂��e���Ȃ��Ǝv���B�����k�ȃt�H�[�}�b�g�̊J��������Ă�悤����
AMD�̕���eDRAM�Ƃ��l���Ă��Ȃ����ȁH���ƃ������ш�̎g�p��������VLIW����߂�݂�������
�Q�[�����[�J�[�Ƌ��͂��ă������ш���Ȃ�ׂ��H��Ȃ��悤�ɍœK�������Ă������낤
���ł�eDRAM��28nm�m�[�h�����y�����512MB�Ƃ����l�߂��B
�Ƃ��������l�T�X�Ȃ���CPU L3 Cache�Ƃ��čڂ�̂�512MB�`1GB���Ɨ\�z���Ă��肷��B
�Ƃ��������l�T�X�Ȃ���CPU L3 Cache�Ƃ��čڂ�̂�512MB�`1GB���Ɨ\�z���Ă��肷��B
GPU�őш���g���̂̓t���[���o�b�t�@������
eDRAM���\MB����Α����
XBox360�݂�����ROP��eDRAM���ɐς߂�eDRAM�`�b�v-GPU�Ԃ̑ш���ߖ�ł���
Llano�̉��i�т��ƃR�X�g���ɂȂ�eDRAM�͂��蓾�Ȃ��C������
�ǂꂭ�炢�R�X�g���Ȃ̂����킩���
�{�i�I�ɑш悪�s��������PowerVR��Larrabee�݂����Ƀ^�C���A�[�L�e�N�`���ɂ�������
���ɂȂ邩������Ȃ�
>>577
VLIW��߂�̂̓������ш�Ƃ͊W�Ȃ��Ȃ����H
>>578
��e�ʃL���b�V�����g���Ȃ�^�O�̖�肪������čŋߒN�������ĂȂ���������
eDRAM���\MB����Α����
XBox360�݂�����ROP��eDRAM���ɐς߂�eDRAM�`�b�v-GPU�Ԃ̑ш���ߖ�ł���
Llano�̉��i�т��ƃR�X�g���ɂȂ�eDRAM�͂��蓾�Ȃ��C������
�ǂꂭ�炢�R�X�g���Ȃ̂����킩���
�{�i�I�ɑш悪�s��������PowerVR��Larrabee�݂����Ƀ^�C���A�[�L�e�N�`���ɂ�������
���ɂȂ邩������Ȃ�
>>577
VLIW��߂�̂̓������ш�Ƃ͊W�Ȃ��Ȃ����H
>>578
��e�ʃL���b�V�����g���Ȃ�^�O�̖�肪������čŋߒN�������ĂȂ���������
�L���b�V���ɂ��Ȃ���(GPU��p�̃��[�J���������ɂ���)�Ηǂ��̂ł́B
���̂���NoC��Clustered Ring�Ƃ��ɂȂ肻���ȁc
���̂���NoC��Clustered Ring�Ƃ��ɂȂ肻���ȁc
���̂����SGB�܂ł�DRAM����������悤�ɂȂ��łȂ��̂��ȁ[��
582 �F,,�E�L�́M�E,,�j��-�������F2011/10/10(��) 09:36:52.65 ID:BVhhtGh9
���C���������ł��Ȃ����̂�OS����ǂ�������̂��˂��H
RAMDISK�H
RAMDISK�H
�n�r���ǂ��\�����邩�̖��ł���
���ʂɃ��C����������������������������
���ʂɃ��C����������������������������
���SMB��GB�ڂ���Ƃ�����Ȃ��āA���\MB���炢�Ȃ�L���b�V���ɂ�������Ă�
���v�Ȃ�Ȃ��́H
���v�Ȃ�Ȃ��́H
�Ǘ����@��ς�������Ǝv���@����e�ʃL���b�V���ɂ�����^�O�̖��
�K���ɂ�intel�ɂ�SSD��HDD�̃L���b�V���Ƃ��ė��p����Z�p���������
��������ǂ���eDRAM��SDRAM�̃L���b�V���Ƃ��ė��p������@���J����������ƁH
���ꂱ��1�y�[�W4KB�P�ʂŃL���b�V���Ƃ�����������B
���������HDD�i���z�������j�̃L���b�V���ł���SDRAM�̃L���b�V���ł���eDRAM�ɃJ�^�`�ňꌳ���͕ۂĂ����B
�K���ɂ�intel�ɂ�SSD��HDD�̃L���b�V���Ƃ��ė��p����Z�p���������
��������ǂ���eDRAM��SDRAM�̃L���b�V���Ƃ��ė��p������@���J����������ƁH
���ꂱ��1�y�[�W4KB�P�ʂŃL���b�V���Ƃ�����������B
���������HDD�i���z�������j�̃L���b�V���ł���SDRAM�̃L���b�V���ł���eDRAM�ɃJ�^�`�ňꌳ���͕ۂĂ����B
�gBulldozer�h�O��Ձ\�e�����FX-8150�̃x���`�}�[�N�X�R�A�����[�N
http://northwood.blog60.fc2.com/blog-entry-5340.html
����d�� FX-8150 129.72W�A2600K 93.12W
2600K��60%�̐��\�Ȃ̂ɓd�C�o�J�H��
http://northwood.blog60.fc2.com/blog-entry-5340.html
����d�� FX-8150 129.72W�A2600K 93.12W
2600K��60%�̐��\�Ȃ̂ɓd�C�o�J�H��
�������������ɂ�����
�v�Z�����ɂ����ق������ʂ̃L���b�V����
�������ʂ�����̂���
�v�Z�����ɂ����ق������ʂ̃L���b�V����
�������ʂ�����̂���
���G�����̓L���b�V���̌��ʂ�������Ȃ�������?
�Ȃ�Sandy-E������
590 �F �E�@���yLv=1,xxxP�z �F2011/10/10(��) 22:28:20.50 ID:37rPRmdX
�}���ŏڂ������
All About Ivy Bridge
http://www.bit-tech.net/hardware/cpus/2011/10/10/all-about-ivy-bridge/1
All About Ivy Bridge
http://www.bit-tech.net/hardware/cpus/2011/10/10/all-about-ivy-bridge/1
�yCPU�zSandy Bridge-E�ɂ͏����̐���N�[���[���t���I�@(�摜����)
http://hatsukari.2ch.net/test/read.cgi/news/1318265447/
http://www.xbitlabs.com/images/news/2011-10/intel_coolers.jpg
Intel�̐���N�[���[
http://kakaku.com/item/K0000225999/
AMD�̐���N�[���[
http://kakaku.com/item/K0000249123/
http://hatsukari.2ch.net/test/read.cgi/news/1318265447/
http://www.xbitlabs.com/images/news/2011-10/intel_coolers.jpg
{kind=link}
Intel�̐���N�[���[
http://kakaku.com/item/K0000225999/
AMD�̐���N�[���[
http://kakaku.com/item/K0000249123/
>>590
�{����������̂͂�������63�{���Ă����̂����r���[����Ȃ����Ȃ��E�E�E
�{����������̂͂�������63�{���Ă����̂����r���[����Ȃ����Ȃ��E�E�E
593 �FSocket774�F2011/10/11(��) 09:15:38.92 ID:/r32yTBG
���NQ2�ɏo����e�͗ǐɂȂ肻���ȗ\��
i7-3940K�ȊO�R�A��������ɂȂ��Ă���
������������i7-3830�͔{���Œ�AHTT�����ŏ��߂Ă�300$���6�R�A
������i7-3970X��22nm8�R�A�̉\�������� �@
i7-3940K�ȊO�R�A��������ɂȂ��Ă���
������������i7-3830�͔{���Œ�AHTT�����ŏ��߂Ă�300$���6�R�A
������i7-3970X��22nm8�R�A�̉\�������� �@
�Ȃ�Sandy-E������
>>593
SMT���I�t�Ȃ킯�Ȃ����AIvy E�͗��N�㔼����
SMT���I�t�Ȃ킯�Ȃ����AIvy E�͗��N�㔼����
597 �FSocket774�F2011/10/11(��) 14:13:07.88 ID:/r32yTBG
>>596
980X�̑O�Ⴊ����
980X�̑O�Ⴊ����
>>597
�����H980X�͗\��ʂ肾��
�����H980X�͗\��ʂ肾��
599 �FSocket774�F2011/10/11(��) 18:15:17.62 ID:+petq2eX
>>590
�����̗\��ʂ�1���ɏo����Č�������
���̍��ɂ͒l�����肵�Ă���ł��낤�u��������
���̓��ɔ������Ǝv���Ă��̂ɁA���ǒx���̂���
3,4������x�����邼��٧
Haswell�͂�����2013�N1�����{�ɏo����
�����̗\��ʂ�1���ɏo����Č�������
���̍��ɂ͒l�����肵�Ă���ł��낤�u��������
���̓��ɔ������Ǝv���Ă��̂ɁA���ǒx���̂���
3,4������x�����邼��٧
Haswell�͂�����2013�N1�����{�ɏo����
intel�͂��܂�4GHz�ȏ���Ƃ��Ƃ�����Ȃ�
TB��2700K�Ƃ�3960X��3.9GHz����������
Ivy��3970X�Œ����Ă���邩�ȁH
3.95GHz�Ƃ��Ȃ����
TB��2700K�Ƃ�3960X��3.9GHz����������
Ivy��3970X�Œ����Ă���邩�ȁH
3.95GHz�Ƃ��Ȃ����
��Xeon X5698
602 �FSocket774�F2011/10/11(��) 21:20:16.12 ID:SHwqg2uq
�����Ȃ肾���A����PhenomIIX4 970BE�g���Ă��₯�ǁAIntel��CPU�g���Ă�
�u�����A����ς�Ⴄ�Ȃ��B�v���Ďv��������H�����������̂�PCSX2�����掿��
����Ă鎞�ƃx���`�̓��_���������炢��˂ǁB����ȊO�̂�����Ă���ւ�H
����ς�FPS�����掿�ł��Ƃ��Ȃ͈Ⴄ�H
�u�����A����ς�Ⴄ�Ȃ��B�v���Ďv��������H�����������̂�PCSX2�����掿��
����Ă鎞�ƃx���`�̓��_���������炢��˂ǁB����ȊO�̂�����Ă���ւ�H
����ς�FPS�����掿�ł��Ƃ��Ȃ͈Ⴄ�H
�����ł�
�Ȃ�Sandy-E������
>>602
���̃R�s�y���O������
���̃R�s�y���O������
606 �FSocket774�F2011/10/12(��) 10:10:12.74 ID:Xcb/I5Nw
�R�s�y�H�l�^����Ȃ��Ȃ瓚������͂������B
�P��1�R�A���\���Ă̂�AMD�X���r�炷�����̃l�^�ɂ����Ȃ��ĂȂ����������B
ARM�Ɉ���������Atom4�R�A�Ȃ�ă��C�����o��̂������Ⴞ��B
�P��1�R�A���\���Ă̂�AMD�X���r�炷�����̃l�^�ɂ����Ȃ��ĂȂ����������B
ARM�Ɉ���������Atom4�R�A�Ȃ�ă��C�����o��̂������Ⴞ��B
���Ȃ�ăS�~�������ĂȂ�����
>>606
���̃X���ł��S���������e������������R�s�y���}���`�̂ǂ������ł���
�ǂ����ɂ���}�g���ɂƂ肠�����l�̂Ȃ����e
���̃X���ł��S���������e������������R�s�y���}���`�̂ǂ������ł���
�ǂ����ɂ���}�g���ɂƂ肠�����l�̂Ȃ����e
>>606
�������_�Ȃ̂������B
�������_�Ȃ̂������B
610 �FSocket774�F2011/10/12(��) 10:29:33.12 ID:Xcb/I5Nw
�Ȃ��Ǔ������Ȃ����B
AMD�X���r�炷�ȏ�̈Ӗ��Ȃ��ȁB
AMD�X���r�炷�ȏ�̈Ӗ��Ȃ��ȁB
����Ⴛ�����BDQN��AMD�n�X�����r�炷���߂ɃR�s�y������
FPGA�̃R���p�C������Ƃ��͂P�X���b�h���\�͂�����ł��~�������ǂ�
�}���`�X���b�h�͑啪�O����Ή����Ă邯�ǑS�R�X�P�[�����Ȃ�����
�����p�r�͖�����Yonah�g���Ă邯�ǂ���܂荢���ĂȂ�
�R���s���[�e�B���O�p���[��������ł��~�����ꕔ�̐l�B��
��ʌ����p�r�̎��v�Ƀ^�_���ł�������͏I������Ƃ͎v����
Intel�̒����d�͎u�������̗���Ȃ낤
�}���`�X���b�h�͑啪�O����Ή����Ă邯�ǑS�R�X�P�[�����Ȃ�����
�����p�r�͖�����Yonah�g���Ă邯�ǂ���܂荢���ĂȂ�
�R���s���[�e�B���O�p���[��������ł��~�����ꕔ�̐l�B��
��ʌ����p�r�̎��v�Ƀ^�_���ł�������͏I������Ƃ͎v����
Intel�̒����d�͎u�������̗���Ȃ낤
613 �FSocket774�F2011/10/12(��) 12:39:48.83 ID:qrc7KYyO
�`�l�c�ׂ̔�Q�ϑz���ĕ|��m9(^�D^)�߷ެ�
�A���_�[���̒�`������Ă�����B
��10�N���̂ɂ`�l�c�̘H���̓o�J����邱�Ƃ����Ĕے肵�Ă邩���B
�A���_�[���̒�`������Ă�����B
��10�N���̂ɂ`�l�c�̘H���̓o�J����邱�Ƃ����Ĕے肵�Ă邩���B
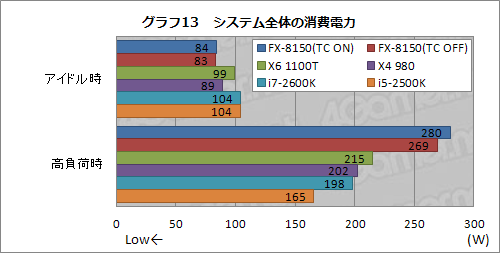{kind=link}
�Ȃ�Sandy-E������
����Ł[E�A�o�Ȃ��̂��c
2600k�ł������Ă�������( �L-�M)
2600k�ł������Ă�������( �L-�M)
8150�̑��������Ȃ�2500K�ŗ]�T�@���Ɉꕔ�Q�[���̓x���`�ň������Ă邵
�������ďo���K�v�͂Ȃ��������Ď���
>>614
�ߔN�̃v���Z�b�T�͗�p�V�X�e���̌��E�܂Ńu�[�X�g����悤�ɂȂ��Ă��邩��A���낻��s�[�N���̏���d�͂����Ō��̂͂悵�������c�Ǝv���B
IvyBridge�ł͒�TDP�̃��f������TDP�̃��f���Ɠ������x���܂Ńs�[�N���̏���d�͂͏オ�邾�낤����s�[�N��������Ƃ킯���킩��Ȃ��Ȃ肻���B
ttp://ascii.jp/elem/000/000/637/637314/slide5_c_800x600.jpg (>>325)
SPECpower��Average Active Power�݂����Ȃ̂��o����Ηǂ��̂��낤���ǎ�ԂƋ@�ނ��ȁc
�ߔN�̃v���Z�b�T�͗�p�V�X�e���̌��E�܂Ńu�[�X�g����悤�ɂȂ��Ă��邩��A���낻��s�[�N���̏���d�͂����Ō��̂͂悵�������c�Ǝv���B
IvyBridge�ł͒�TDP�̃��f������TDP�̃��f���Ɠ������x���܂Ńs�[�N���̏���d�͂͏オ�邾�낤����s�[�N��������Ƃ킯���킩��Ȃ��Ȃ肻���B
ttp://ascii.jp/elem/000/000/637/637314/slide5_c_800x600.jpg (>>325)
{kind=link}
SPECpower��Average Active Power�݂����Ȃ̂��o����Ηǂ��̂��낤���ǎ�ԂƋ@�ނ��ȁc
>>620
�����܂ł��Ȃ��Ɛ��\������Ȃ��̂�Bulldozer
�^�[�{�͂�����TDP�܂łɉ������Ă�̂ɐ��\�������̂�Sandy
Sandy�������d�͔����������Ȃ̂�Ivy
�����܂ł��Ȃ��Ɛ��\������Ȃ��̂�Bulldozer
�^�[�{�͂�����TDP�܂łɉ������Ă�̂ɐ��\�������̂�Sandy
Sandy�������d�͔����������Ȃ̂�Ivy
�Ȃ�Sandy-E������
���ȂɃR�C�c�H
�܂ڂ낵
bot
626 �FSocket774�F2011/10/12(��) 20:50:31.35 ID:+ToUWs5Z
>>623
�j�[�g
�j�[�g
�܂�Sandy-E������
���ȂɃR�C�c�H
629 �FSocket774�F2011/10/12(��) 21:59:59.69 ID:Ot8VvQvx
���I�ɂ�2600K��Llano��GPU�����ڂ����ō��Ȃ��B
ivy��Llano������̂��Ȃ��HGPU���\�ŁB
ivy��Llano������̂��Ȃ��HGPU���\�ŁB
CPU������ǁAGPU�����ǂ���Sandy��22nm�ō�������̂�Ivy
�V�������N�łɂ��Ă͊��Ǝ肪�����Ă邩�猋�\�����Ǝv��
�V�������N�łɂ��Ă͊��Ǝ肪�����Ă邩�猋�\�����Ǝv��
5����������
����d�͂ɂ��Ă�TECH REPORT���撣���Ă���Ă����B
ttp://techreport.com/articles.x/21813/16
ttp://techreport.com/r.x/amd-fx/cine-power-comparo.gif
ttp://techreport.com/r.x/amd-fx/cine-power-total.gif
ttp://techreport.com/r.x/amd-fx/cine-power-task-energy.gif
ttp://techreport.com/r.x/amd-fx/cinebench.gif
2600K��40�p�[�Z���g���Ȃ��d�͂�Cinebench�����s�o���邪�X�R�A��15�p�[�Z���g�����Ȃ�A�ƁB
2600K�͓d�͓�����̐��\��FX-8150���93�p�[�Z���g�����Ƃ�������B
��[�E�E�E�E����͂Ȃ��Ȃ��ɃX�L�����_���X�Ȍ��ʂ��o���ȁB
ttp://techreport.com/articles.x/21813/16
ttp://techreport.com/r.x/amd-fx/cine-power-comparo.gif
{kind=link}
ttp://techreport.com/r.x/amd-fx/cine-power-total.gif
{kind=link}
ttp://techreport.com/r.x/amd-fx/cine-power-task-energy.gif
{kind=link}
ttp://techreport.com/r.x/amd-fx/cinebench.gif
{kind=link}
2600K��40�p�[�Z���g���Ȃ��d�͂�Cinebench�����s�o���邪�X�R�A��15�p�[�Z���g�����Ȃ�A�ƁB
2600K�͓d�͓�����̐��\��FX-8150���93�p�[�Z���g�����Ƃ�������B
��[�E�E�E�E����͂Ȃ��Ȃ��ɃX�L�����_���X�Ȍ��ʂ��o���ȁB
K10��胏�b�g�p�t�H�[�}���X�������Ăǂ�����̂��Ęb�����
����45nm�ł͂Ȃ�32nm�ɔ�������Ă�Ƃ����̂�
����45nm�ł͂Ȃ�32nm�ɔ�������Ă�Ƃ����̂�
�g�����W�X�^�̑��₵��������
�����ƃR���p�N�g�ɍ��Ȃ���
�����ƃR���p�N�g�ɍ��Ȃ���
�x�A�x���`��Bull�Ɍ����ĂȂ���I
�����ƃ}���`�X���b�h�����Ă�����I�I
�����ƃ}���`�X���b�h�����Ă�����I�I
�܂���e�ʃL���b�V���������悤�ȃx���`�������Ă����
���ΓI�ɂ����X�R�A���o���Ȃ��́c�c�I�����x���`�Ƃ�
�i����܂葽���Ȃ����ǁATPC-C�݂����Ȃ̂������H�j
�{���]�|���͂��邪�A�ނ���ǂ������x���`��
�ǂ����ʂɂȂ�̂��t�ɋC�ɂȂ�
���ΓI�ɂ����X�R�A���o���Ȃ��́c�c�I�����x���`�Ƃ�
�i����܂葽���Ȃ����ǁATPC-C�݂����Ȃ̂������H�j
�{���]�|���͂��邪�A�ނ���ǂ������x���`��
�ǂ����ʂɂȂ�̂��t�ɋC�ɂȂ�
�r�f�I�J�[�h����������Acpu��GPU�́A
�ʂ̋@�\�ɂȂ�Ƃ��Acpu�ɑg�ݍ��܂��cpu�������ɂȂ�Ƃ��A
���������̂Ȃ��́H�H�H
�ʂ̋@�\�ɂȂ�Ƃ��Acpu�ɑg�ݍ��܂��cpu�������ɂȂ�Ƃ��A
���������̂Ȃ��́H�H�H
>>cpu�ɑg�ݍ��܂��cpu�������ɂȂ�
���ꂪ�o�����GPGPU�Ƃ�OpenCL�Ƃ��s�v�ɂȂ�Ȃ�
�܁AIntel�Ȃ�ŐV�}�U�{�ŃG���R��p�`�b�v�ɂ�����O��GPU�̕⏕������ł���B
AMD�ł������CrossFire�Ƃ��ĊO���i���[�G���h�jRADEON�̕⏕������悤�ɂȂ�B
���ꂪ�o�����GPGPU�Ƃ�OpenCL�Ƃ��s�v�ɂȂ�Ȃ�
�܁AIntel�Ȃ�ŐV�}�U�{�ŃG���R��p�`�b�v�ɂ�����O��GPU�̕⏕������ł���B
AMD�ł������CrossFire�Ƃ��ĊO���i���[�G���h�jRADEON�̕⏕������悤�ɂȂ�B
Bull���Y����
AMD�撣��敳��
AMD�撣��敳��
Bull���b��ivy���l���m�肾��
����͌����E�E�E(�L�E�ցE`)
���C���X�g���[���̐��Y��22nm�Ɉڂ��ċ�32nm���C���͉��Ɏg���H
Sandy-E���HATOM���H
Sandy-E���HATOM���H
Atom��LGA2011�p����
���ƃ��[�G���h��Sandy����
���ƃ��[�G���h��Sandy����
�����A�Z�����������Y���邩
645 �FSocket774�F2011/10/13(��) 11:41:00.36 ID:/LsDF7NY
AMD�ɂ��撣���Ă����Ȃ���Intel�����~�܂肵�Ă��܂��E�E�E�E
���������Ӗ��ł�AMD��{�C�ʼn�������OہO�G
���������Ӗ��ł�AMD��{�C�ʼn�������OہO�G
646 �FSocket774�F2011/10/13(��) 11:53:38.37 ID:ANZJ+Adn
�u��8�R�A�����N9500�~���炢�Ȃ�u���ɂ͏��i���l������B
���i�ݒ肿���Ƃ����AAMD
���i�ݒ肿���Ƃ����AAMD
647 �FSocket774�F2011/10/13(��) 12:01:18.81 ID:/LsDF7NY
�܂�\13000�ʂȂ狖����B����Intel��5���Ƃ��ŏo���Ă������₵�B
�₽��Sandy-E�ɔS�����Ă�z���邯�ǂԂ����Ⴏ�ǂ��ł������Ǝv���Ă�z��������
�ǂ��������Ă�n���L�����{����Ivy����
�ǂ��������Ă�n���L�����{����Ivy����
��ɔ����������̂�b�̃l�^�ɂ���͓̂��R�ł���
�����̂�Ivy���Ƃ��Ă�
�����̂�Ivy���Ƃ��Ă�
�܂�Sandy-E������
Bull�������Ă���ۂlj�����������
�����Ƌ@�B�݂����ɋ���łĂ�����
�����Ƌ@�B�݂����ɋ���łĂ�����
>>651
��http://hissi.org/read.php/jisaku/20111012/dFhZckV0OEU.html
�Ƃ����ɋ@�B���ς܂��Ă��邲�l�q�ł���E�E�E
��http://hissi.org/read.php/jisaku/20111012/dFhZckV0OEU.html
�Ƃ����ɋ@�B���ς܂��Ă��邲�l�q�ł���E�E�E
653 �FSocket774�F2011/10/13(��) 23:46:52.22 ID:VF4MQHqa
>>652
�S�������������݂��Ǝv�����炽�܂ɈႤ���Ə�������ł��w
�S�������������݂��Ǝv�����炽�܂ɈႤ���Ə�������ł��w
>>653
�q���g Bull�Ɏ��ă|���R�c������
�q���g Bull�Ɏ��ă|���R�c������
�q���g(�د
���܂킵�ɏ����Ȃ��ƃq���g�ɂȂ�˂����낤���n����
����ƃX���^�C100�ǂ��Ď���
����ƃX���^�C100�ǂ��Ď���
�܂��߂�Bulldozer���������
����Ȃ��Trinity���v�Ȃ̂���
Intel���t�ɍ����Ă��Ȃ��̂�
����Ȃ��Trinity���v�Ȃ̂���
Intel���t�ɍ����Ă��Ȃ��̂�
����Ȕp�����ɃA�C�h���̏���d�͉�����ăJ�`���Ƃ��Ă�Ǝv��
�ނ���Bull��Sandy���A�C�h���������r���[���قƂ�ǂ���
���r���[����
���r���[����
�A�C�h���̏���d�͂̓V�X�e���̍����傫������Ⴄ�v���b�g�z�[�����Ɣ�r�͓��
sandy��Bull���p���[�Q�[�g����Ă邩��A��������Ɍ��܂ŒႢ���낤
�ނ��뒍�ڂ���Ƃ���̓A�C�h���ƃs�[�N�̍�����
sandy��Bull���p���[�Q�[�g����Ă邩��A��������Ɍ��܂ŒႢ���낤
�ނ��뒍�ڂ���Ƃ���̓A�C�h���ƃs�[�N�̍�����
>>652
������Ⴄ�������݂Ń����^
������Ⴄ�������݂Ń����^
22nm�������Ă����炭��Sandy-E���n�C�G���h�����ɋ�����̂�
�ł����`�b�v���͕̂����܂�̗ǂ����v���Z�X�ł��Ċ����H
�ł����`�b�v���͕̂����܂�̗ǂ����v���Z�X�ł��Ċ����H
>>661
��Ђ�CPU�Ń`�b�v�Z�b�g�������ł����Ȃ�����V�X�e���S�̂ł̔�r�ɈӖ��͂����
�C���e���̓E���g���u�b�N�Ɍ����ăV�X�e���S�̂ł̏���d�͂����炷���j������
AMD�̃}�U�[�{�[�h�̃`�b�v�̏���d�͂��Ⴂ�������A�Ȃ�Č����Ă��Ȃ�
��Ђ�CPU�Ń`�b�v�Z�b�g�������ł����Ȃ�����V�X�e���S�̂ł̔�r�ɈӖ��͂����
�C���e���̓E���g���u�b�N�Ɍ����ăV�X�e���S�̂ł̏���d�͂����炷���j������
AMD�̃}�U�[�{�[�h�̃`�b�v�̏���d�͂��Ⴂ�������A�Ȃ�Č����Ă��Ȃ�
���������̂̓`�b�v�Z�b�g�ɂ��e���Ƃ������}�U�[�Ǝ��̎d�l�ɂ��e�����傫����H
�����`�b�v�Z�b�g�ڂ��ĂĂ��}�U�[�ɂ���Č��\����d�͈�����肷�邶���B
�����`�b�v�Z�b�g�ڂ��ĂĂ��}�U�[�ɂ���Č��\����d�͈�����肷�邶���B
�ŏ��d�l�̃V���v���ƃI���{�@�\���ڂ̃n�C�G���h��
��҂̊g���`�b�v���L���̂܂܃A�C�h���d�͑�����Ď�@�̒����݂��邱�Ƃ͊m�����B
��҂̊g���`�b�v���L���̂܂܃A�C�h���d�͑�����Ď�@�̒����݂��邱�Ƃ͊m�����B
>>663
���Ȃ�Ă���A�[�L�e�N�`���ƃv���Z�X�ƂŁA���܂Œʂ薳��ɍ�������Ƃ������Ƃł���B
���Ȃ�Ă���A�[�L�e�N�`���ƃv���Z�X�ƂŁA���܂Œʂ薳��ɍ�������Ƃ������Ƃł���B
�A�C�h���̏���d�́H�d���Ȃ�����܂Ƃ߂Ă���i��������
���`��AMD
�� ttp://ascii.jp/elem/000/000/641/641562/g017_454x217.jpg ��
ttp://cdn5.tweaktown.com/content/4/3/x4348_42_amd_fx_8150_am3_3_6ghz_bulldozer_cpu_review.png.pagespeed.ic.FCIiwu-uef.png
ttp://journal.mycom.co.jp/special/2011/zambezi/images/graph34.jpg
ttp://www.4gamer.net/games/100/G010000/20111012001/TN/033.gif
ttp://i.neoseeker.com/a/amd_fx-8150/power.png
ttp://limages.vr-zone.net/body/13694/shocking.jpg.jpeg
ttp://www.bit-tech.net/hardware/cpus/2011/10/12/amd-fx-8150-review/10
ttp://www.hwupgrade.it/articoli/cpu/2997/consumo_idle.png
Intel�̉A�d
ttp://images.anandtech.com/graphs/graph4955/41714.png
ttp://pc.watch.impress.co.jp/img/pcw/docs/483/000/graph26.gif
ttp://www.hardwareheaven.com/reviews/1285/pg15/1.html
ttp://images.hardwarecanucks.com/image/mac/reviews/AMD/Bulldozer/AMD_FX-8150-194.jpg
ttp://img.hexus.net/v2/cpu/amd/Dozerbull1/FX8150/PowerI.png
ttp://hothardware.com/articleimages/Item1742/power.png
ttp://www.overclockers.com/amd-fx-8150-bulldozer-processor-review
ttp://static.techspot.com/articles-info/452/bench/Power.png
ttp://www.tomshardware.com/reviews/fx-8150-zambezi-bulldozer-990fx,3043-22.html
ttp://www.legitreviews.com/images/reviews/1741/power-consumption.jpg
ttp://www.sweclockers.com/image/diagram/2490?k=2d4f2e21c019f275f4eaf5b727fbfae3
ttp://www.pcper.com/files/imagecache/article_max_width/review/2011-10-10/power-idle_0.jpg
ttp://nl.hardware.info/reviews/2382/28/1
ttp://www.hardwareluxx.de/index.php/artikel/hardware/prozessoren/20127-bulldozer-amd-fx-8150.html?start=9
ttp://wd.ch-img.com/1217969-conso.png
ttp://www.pcgameshardware.de/screenshots/original/2011/10/FX-8150-Power.png
���`��AMD
�� ttp://ascii.jp/elem/000/000/641/641562/g017_454x217.jpg ��
{kind=link}
ttp://cdn5.tweaktown.com/content/4/3/x4348_42_amd_fx_8150_am3_3_6ghz_bulldozer_cpu_review.png.pagespeed.ic.FCIiwu-uef.png
{kind=link}
ttp://journal.mycom.co.jp/special/2011/zambezi/images/graph34.jpg
{kind=link}
ttp://www.4gamer.net/games/100/G010000/20111012001/TN/033.gif
ttp://i.neoseeker.com/a/amd_fx-8150/power.png
{kind=link}
ttp://limages.vr-zone.net/body/13694/shocking.jpg.jpeg
{kind=link}
ttp://www.bit-tech.net/hardware/cpus/2011/10/12/amd-fx-8150-review/10
ttp://www.hwupgrade.it/articoli/cpu/2997/consumo_idle.png
{kind=link}
Intel�̉A�d
ttp://images.anandtech.com/graphs/graph4955/41714.png
{kind=link}
ttp://pc.watch.impress.co.jp/img/pcw/docs/483/000/graph26.gif
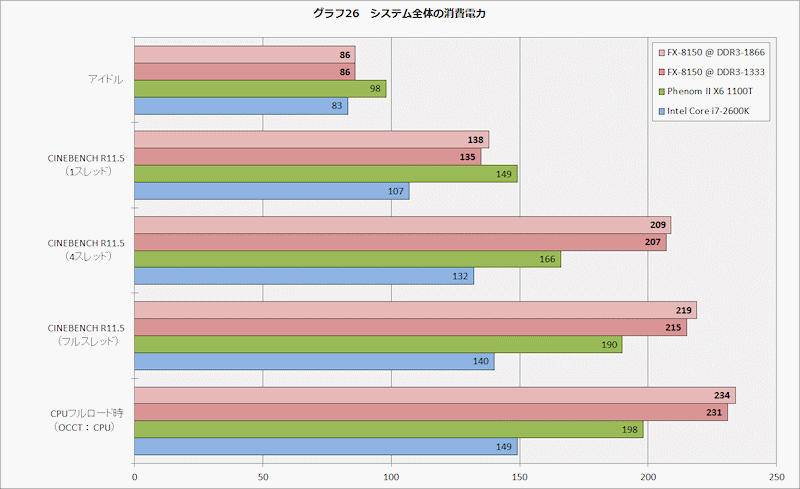{kind=link}
ttp://www.hardwareheaven.com/reviews/1285/pg15/1.html
ttp://images.hardwarecanucks.com/image/mac/reviews/AMD/Bulldozer/AMD_FX-8150-194.jpg
{kind=link}
ttp://img.hexus.net/v2/cpu/amd/Dozerbull1/FX8150/PowerI.png
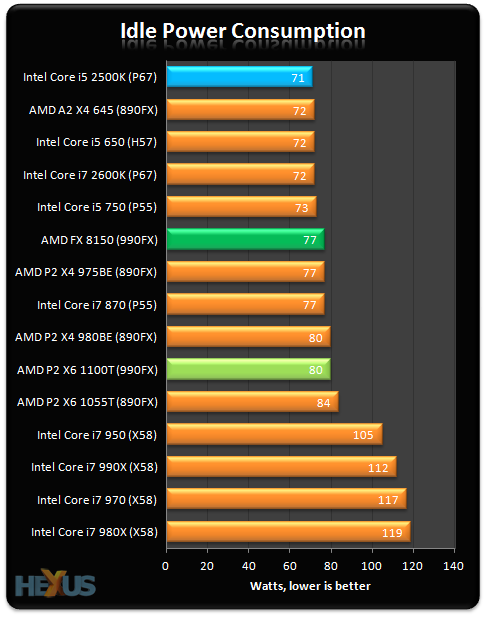{kind=link}
ttp://hothardware.com/articleimages/Item1742/power.png
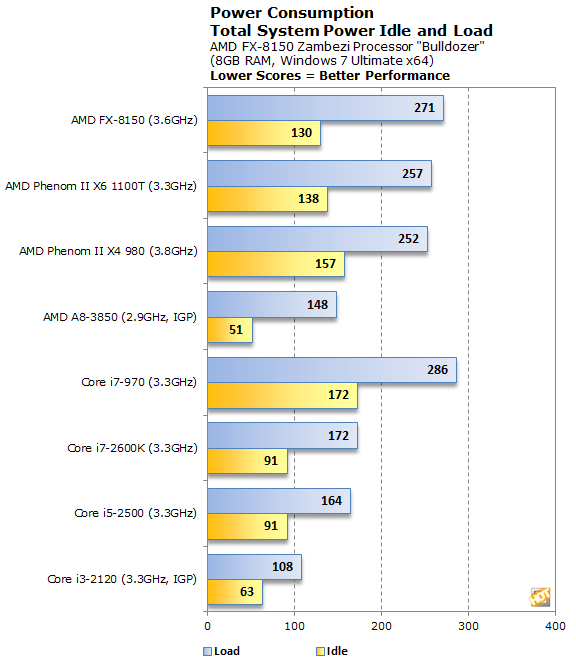{kind=link}
ttp://www.overclockers.com/amd-fx-8150-bulldozer-processor-review
ttp://static.techspot.com/articles-info/452/bench/Power.png
{kind=link}
ttp://www.tomshardware.com/reviews/fx-8150-zambezi-bulldozer-990fx,3043-22.html
ttp://www.legitreviews.com/images/reviews/1741/power-consumption.jpg
{kind=link}
ttp://www.sweclockers.com/image/diagram/2490?k=2d4f2e21c019f275f4eaf5b727fbfae3
ttp://www.pcper.com/files/imagecache/article_max_width/review/2011-10-10/power-idle_0.jpg
{kind=link}
ttp://nl.hardware.info/reviews/2382/28/1
ttp://www.hardwareluxx.de/index.php/artikel/hardware/prozessoren/20127-bulldozer-amd-fx-8150.html?start=9
ttp://wd.ch-img.com/1217969-conso.png
{kind=link}
ttp://www.pcgameshardware.de/screenshots/original/2011/10/FX-8150-Power.png
{kind=link}
�A�d������AMD������Ɏ��������������
�܂Ƃ߂��ĂȂ������i�L�E�ցE�M�j
���EIntel�̉A�d
ttp://pc.nikkeibp.co.jp/article/news/20111013/1037603/ph24_px400.jpg
ttp://plusd.itmedia.co.jp/pcuser/articles/1110/12/news041_2.html
���EIntel�̉A�d
ttp://pc.nikkeibp.co.jp/article/news/20111013/1037603/ph24_px400.jpg
{kind=link}
ttp://plusd.itmedia.co.jp/pcuser/articles/1110/12/news041_2.html
�܂�Sandy-E������
Intel�A�uDigital Home Group�v���ƕ���p�~���A�e���r�������i�̊J���𒆎~
>>668
�����}�U�[�œ����ʂ�CPU���o�����ƂŁAPhenom2�͏��Ȃ��Ƃ��A�C�h������20W �ȏ㏊��d�͂�H���Ă�̂��킩������
�����}�U�[�œ����ʂ�CPU���o�����ƂŁAPhenom2�͏��Ȃ��Ƃ��A�C�h������20W �ȏ㏊��d�͂�H���Ă�̂��킩������
>>667
�Ⴆ��Clarkdale��
CPU��32nm��81mm2
GMCH��45nm��114mm2
�_�C�T�C�Y�ł����Ό^�����v���Z�X�̃`�b�v�Z�b�g�̕����傫��
Sandy����͏]����GMCH�܂ł��[�v���Z�X�ō�邱�ƂɂȂ邩��
�P����O�̃v���Z�X�̃��C����ʂɗL�����p����K�v������
�Ⴆ��Clarkdale��
CPU��32nm��81mm2
GMCH��45nm��114mm2
�_�C�T�C�Y�ł����Ό^�����v���Z�X�̃`�b�v�Z�b�g�̕����傫��
Sandy����͏]����GMCH�܂ł��[�v���Z�X�ō�邱�ƂɂȂ邩��
�P����O�̃v���Z�X�̃��C����ʂɗL�����p����K�v������
�܂�Sandy-E������
677 �FSocket774�F2011/10/15(�y) 06:22:44.88 ID:rfrqDyZ9
�������ˁA�u���h�[�U�[��������
���ۂ̓��C�o���s�݂�intel���l�グ���ĉ��炪�����ɂȂ�킯����
�ŏ�ʂ�$999�ł��̎���$500���炢�Ń��C���X�g���[����$300���x�Ƃ������̉��i�g������Ƃ͍l���ɂ������E�E�E
���܂ł��V���i�̃����[�X�������̐��i�̒l���������Ȃ��Ƃ������Ƃ͂���ɂ���
���܂ł��V���i�̃����[�X�������̐��i�̒l���������Ȃ��Ƃ������Ƃ͂���ɂ���
>>675
�ꐢ��O�̃��C���̓t�@�E���_����AMD��CPU��������Ƃ�w
�ꐢ��O�̃��C���̓t�@�E���_����AMD��CPU��������Ƃ�w
���������C���e���͂����l�i�ς��Ă��Ȃ����
�ł�2500K��2600K���������
2600K��1100T�����|�I���\���ʼn��i���������������ׂ̃L���b�v
�������������K�v��������
>>680
AMD���ׂꂻ���ɂȂ�����AFTC�ӂ肪�ނ��Ⴍ����ȗ��R����
�v��������������
�݂��ɃX�Q�[���ɂ�����������
�������������K�v��������
>>680
AMD���ׂꂻ���ɂȂ�����AFTC�ӂ肪�ނ��Ⴍ����ȗ��R����
�v��������������
�݂��ɃX�Q�[���ɂ�����������
����ς��̐��\�����̒l�i�Ƃ����̂͑����������Ă���
2600k�͔���Δ���قǐԎ��ł����6�R�A�ȏ��Xeon�̔���グ�ŃJ�o�[�Ƃ��������ɂȂ��ĂȂ���������ǁE�E�E
2600k�͔���Δ���قǐԎ��ł����6�R�A�ȏ��Xeon�̔���グ�ŃJ�o�[�Ƃ��������ɂȂ��ĂȂ���������ǁE�E�E
>>525
�u���C�v���Č����قǖ��ɗ�����ł��Ȃ����낗����
�����Ă邱�Ƃ��A���ۓI�ȉ�������ʼn��������������킩���
���̈����ۏo��
�u���C�v���Č����قǖ��ɗ�����ł��Ȃ����낗����
�����Ă邱�Ƃ��A���ۓI�ȉ�������ʼn��������������킩���
���̈����ۏo��
����A�S�R
�_�C�T�C�Y�I�Ƀ��C���X�g���[�����x�Ɏ��܂��Ă���
GPU���݂�����A�ނ���ASP�͏オ�����Ƃ����b���������͂�
�_�C�T�C�Y�I�Ƀ��C���X�g���[�����x�Ɏ��܂��Ă���
GPU���݂�����A�ނ���ASP�͏オ�����Ƃ����b���������͂�
>>684
�����ł��Ȃ���
2600K�̓_�C�T�C�Y����t�Z�����
�������x���łP�����傢���x�Ƃ����\�z���o�Ă��͂�
��́A�_���s���O�Ȃ�Ă����炻�ꂱ�����B�ψ����FTC��
�I�̑��ɂ���Ă��܂���
�����ł��Ȃ���
2600K�̓_�C�T�C�Y����t�Z�����
�������x���łP�����傢���x�Ƃ����\�z���o�Ă��͂�
��́A�_���s���O�Ȃ�Ă����炻�ꂱ�����B�ψ����FTC��
�I�̑��ɂ���Ă��܂���
688 �FSocket774�F2011/10/15(�y) 10:11:26.45 ID:E2U6ejjB
���������A�������G�Aintel�g���������Ă�̂���B
�`�l�c�׃^�`���[�ȁB
�`�l�c�׃^�`���[�ȁB
����Δ���قǐԎ��ɂȂ�̂�bull�ł���
20���g�����W�X�^300mm2�����̃_�C�T�C�Y
2500K�ȉ��̐��\
�܂�������i��2500K�ȉ��ɂ��Ȃ��Ɣ���Ȃ�
20���g�����W�X�^300mm2�����̃_�C�T�C�Y
2500K�ȉ��̐��\
�܂�������i��2500K�ȉ��ɂ��Ȃ��Ɣ���Ȃ�
>>689
�����甄��Ȃ���Ȃ����B���{��������o��500�A����Ƃ�����B
�����甄��Ȃ���Ȃ����B���{��������o��500�A����Ƃ�����B
2600K�͓��{���ƈ��������邯�Ǖ��ʂ�$315������
�t��Intel�����{��Intel�Ŏ��Ȃ��ُ͈̂�
�܁A�R�P�Ă��㗝�X�ŃK���悹��AMD�͍X�ɋ����Ă邯�ǂ�
�܁A�R�P�Ă��㗝�X�ŃK���悹��AMD�͍X�ɋ����Ă邯�ǂ�
�N���b�N�グ���Ȃ���2M4C��Trinity�͂���ɔߎS�Ȍ��ʂɂȂ肻�����ȁB
Llano > Trinity�Ƃ���
Llano > Trinity�Ƃ���
694 �FSocket774�F2011/10/15(�y) 11:08:52.37 ID:a4TPGFBs
�u�}���ŏo���K�v���Ȃ��Ȃ����킯�����v�i10/14�j
http://www.gdm.or.jp/voices_html/201110/14a.html
>�\���͖�28,000�O��Ƃ̂��ƁB
����320�`350�������A���s2600K�̒u����������
2600K���l���������̂��ި��݂ɂȂ̂��͖���
http://www.gdm.or.jp/voices_html/201110/14a.html
>�\���͖�28,000�O��Ƃ̂��ƁB
����320�`350�������A���s2600K�̒u����������
2600K���l���������̂��ި��݂ɂȂ̂��͖���
2600K�ł�3.5GHz�Ȃ�ė]�T������̂�
�o���K�v�Ȃ�Ă���낤��
�o���K�v�Ȃ�Ă���낤��
���\��2600K+100MHz������
�����l�i���܂�ς�����
�����l�i���܂�ς�����
�N���b�N�ϐ��̍����I�ʕi�Ƃ�����Ȃ���?
�ǐΕۏ�Ƃł�������
�ǐΕۏ�Ƃł�������
�����l�グ
Intel�͐e���ȃC���[�W�����ǂȁBAMD�͔�����Ƃ��
���������̌������ł���Ă�
�܂�Sandy-E������
�������[������
����intel�͔�Ώ̃}���`�X���b�f�B���O�͂�߂��̂���
�R�A���͂�����x�O�a��Ԃ�����Haswell�Ƃ�Rockwell������Ŏ��������炢���̂�
������GPU�ɂǂ�ǂ\�[�X�������Ă����肩��
�R�A���͂�����x�O�a��Ԃ�����Haswell�Ƃ�Rockwell������Ŏ��������炢���̂�
������GPU�ɂǂ�ǂ\�[�X�������Ă����肩��
�X�p�R���͖��K�͂��R�A���ɔ�Ⴗ��ア�X�P�[�����O�������߂��Ȃ�
�����K�̖͂��𐔕S�{�̑��x�ʼn�������͂ł��Ȃ�
���S�R�A�g���Ȃ牽�S�{�̋K�̖͂������炢�̎��Ԃʼn����ăE�}�[�Ă���
�p�[�\�i�����[�X�ł͍��̂Ƃ��낻��Ȃ��Ƃ��Ă��ꂵ���A�v���P�[�V�������قƂ�ǂȂ�
�����K�̖͂��𐔕S�{�̑��x�ʼn�������͂ł��Ȃ�
���S�R�A�g���Ȃ牽�S�{�̋K�̖͂������炢�̎��Ԃʼn����ăE�}�[�Ă���
�p�[�\�i�����[�X�ł͍��̂Ƃ��낻��Ȃ��Ƃ��Ă��ꂵ���A�v���P�[�V�������قƂ�ǂȂ�
�R�A���𑝂₳���Ɏ���̃`�b�v�����ݍ���ł鎞�_�ł����O�a���Ă邾��
�X�p�R����PC����A�v���P�[�V�����̐������Ⴂ�����Ĕ�r�ɂȂ�Ȃ�
>>705
���X�P�[�����O���d�v�Ȗ��������
Anton�Ȃ��̂��߂ɐ�p�J�����ꂽ�킯��
�X�p�R����PC����A�v���P�[�V�����̐������Ⴂ�����Ĕ�r�ɂȂ�Ȃ�
>>705
���X�P�[�����O���d�v�Ȗ��������
Anton�Ȃ��̂��߂ɐ�p�J�����ꂽ�킯��
�Q�[���̂��G����������ɂ̓������ш悪�l�b�N�ɂȂ�
GPU����������Ƃ����Ă�Intel�̏ꍇ�͉��Z����
GPU����������Ƃ����Ă�Intel�̏ꍇ�͉��Z����
�yIntel�z������gIvy Bridge�h�V���[�Y�A�f�X�N�g�b�v����4�R�A���f����TDP��20%����77W��
http://hatsukari.2ch.net/test/read.cgi/news/1318686470/
http://hatsukari.2ch.net/test/read.cgi/news/1318686470/
95W�͍����Ȃ��Ǝv�����A65W���炢���������ǁA�ł�77W�Ȃ狖����Ƃ��H��
P77 Extreme4
711 �F,,�E�L�́M�E,,�j��-�������F2011/10/16(��) 02:01:37.11 ID:arCmCIWG
��p�\�͂ɗ]�T�������TDP�I�[�o�[��Turbo�����ł����
���\��D�悷��l�ɕs�s���͖����Ǝv�����ǂˁB
�ǂ�������er�̑唼��K����������H
S��50W���炢�ɂȂ肻�����B
���\��D�悷��l�ɕs�s���͖����Ǝv�����ǂˁB
�ǂ�������er�̑唼��K����������H
S��50W���炢�ɂȂ肻�����B
>>709
�X�����P�[�X�Ȃ炻��Ȋ����ȋC������
�X�����P�[�X�Ȃ炻��Ȋ����ȋC������
����CPU���ނ���i�~�h�������W�ȏ�́jGPU�̔��M�̕�����肾��
GPU�̔��M�����Ȃ̂�NVIDIA���肾��B
715 �FSocket774�F2011/10/16(��) 08:15:35.51 ID:dwtS7NTR
DTP��77W�Ȃ�m�[�gPC�ɂ��g���܂��B
�܂�Sandy-E������
����i3 530 �Ȃ�APU�ɂ��悤�������Ă�
������Ȃ���ς�����������̂��Ƃ���
GPU�ŔY��ł�Ȃ�APU�I��
CPU�ŔY��ł�Ȃ�i3�ł�������
CPU�ŔY��ł�Ȃ�i3�ł�������
�r�f�I�J�[�h�������������̂��Ƃ���
�J�[�h�h���Ȃ��ꍇ�͂ǂ������
�}�U�[�{�[�h�ƃP�[�X��������������̂��Ƃ���
�}�U�{�ƃP�[�X�ς�����Ȃ�̂��߂�i3������Ȃ��Ȃ邾��
����������
����������
724 �F,,�E�L�́M�E,,�j��-�������F2011/10/16(��) 11:58:21.31 ID:arCmCIWG
Mini-ITX���Ȃ��H
���́A�K�v�Ƃ������������Ή����ǂ��g�ނ������]�n���Ȃ���������Ȃ���
�܂�Ȃ����ǂ�
�܂�Ȃ����ǂ�
�G�Aintel�g���͂����[�Ȃ�
LGA1366�͂ǂ��Ȃ�́H
��p�\�P�b�g�ł�́H
2011�ɂƂ��ĕς����́H
��p�\�P�b�g�ł�́H
2011�ɂƂ��ĕς����́H
LGA2011����p
77W���ĉR���ۂ���22nm�������Ȃ̂��ˁH
�A�v���𐧂�����̂��A�[�L�e�N�`���𐧂��B(Haswell�\�z����2.)
http://www.ne.jp/asahi/comp/tarusan/main240.htm
http://www.ne.jp/asahi/comp/tarusan/main240.htm
{kind=link}
intel�͂������N���_�����Ă��
�ł��������x���x�V�����Z�p�������Ȃ���
�y�[�X���ێ��ł��Ȃ��Ǝv���Ƃ��̐悪�s������
�ł��������x���x�V�����Z�p�������Ȃ���
�y�[�X���ێ��ł��Ȃ��Ǝv���Ƃ��̐悪�s������
��Ƀg�b�v�����i�[�����畨���@���̗��Ƃ����ɂ܂��Ƃ��Ă��܂�����������?
����T���Ă�AMD�ƕ��Ԓ��x�ɂȂ邾����������Ȃ���
����T���Ă�AMD�ƕ��Ԓ��x�ɂȂ邾����������Ȃ���
���[�A�̐M�҂Ȃ�B
>>733
3�炢�T���Ȃ��Ɩ����ł́B
���Ƃ���Bulldozer�͍���N��10 15%�̐��\�����3�N�ԑ�����Ƃ��Ă��邪�A
���ɂ��ꂪ��ՓI�ɑS�����������Ƃ��Đςݏオ�����ł���ƁA
����1�ΐ^�߂�Sandy Bridge�Ƃ���������������x�B
2�ɂȂ��Ƃ���Gulftown�̐K����q�߂Ȃ��B
Intel�͍���3�N�ԐQ�ĂĂ�������������B
3�炢�T���Ȃ��Ɩ����ł́B
���Ƃ���Bulldozer�͍���N��10 15%�̐��\�����3�N�ԑ�����Ƃ��Ă��邪�A
���ɂ��ꂪ��ՓI�ɑS�����������Ƃ��Đςݏオ�����ł���ƁA
����1�ΐ^�߂�Sandy Bridge�Ƃ���������������x�B
2�ɂȂ��Ƃ���Gulftown�̐K����q�߂Ȃ��B
Intel�͍���3�N�ԐQ�ĂĂ�������������B
>>732
�����ɂ����Ă邾���Ȃ��
�����ɂ����Ă邾���Ȃ��
�ۑ�͎R�ς݂����A�����Intel���g���悭�������Ă���
������邱�Ƃ��s���邱�Ƃ͂Ȃ�
������邱�Ƃ��s���邱�Ƃ͂Ȃ�
>>735
10�`15%�͐��\����Ȃ��ă��b�p����Ȃ����������H
10�`15%�͐��\����Ȃ��ă��b�p����Ȃ����������H
TDP�g���g�����Ȃ��Ȃ瓯�����Ƃł́B
>>738
http://semiaccurate.com/assets/uploads/2011/10/Bulldozer_Excavator1.jpg
| HIGH PERFORMANCE CORE ROADMAP
| �E 10-15% increses in performance each year
�m���ɏc����performance per watt�����Ahigh performance core�ɂ����Ă͌���
TDP�͐v����ɓ\��t�����܂܂ʼn�����Ӗ����Ȃ�����Aper watt�̌����
performance�̌���Ɠ������B
>>739
�Ƃ������Ƃ��ˁB
���́A���P�œ���ꂽ�g��TDP�̈��������Ɏg�����Aperformance�̈����グ��
�g�����̑I�����B�����Bulldozer�ɂ͔߂����قǂɑI���̗]�n���Ȃ��̂�����ǂ��B
http://semiaccurate.com/assets/uploads/2011/10/Bulldozer_Excavator1.jpg
{kind=link}
| HIGH PERFORMANCE CORE ROADMAP
| �E 10-15% increses in performance each year
�m���ɏc����performance per watt�����Ahigh performance core�ɂ����Ă͌���
TDP�͐v����ɓ\��t�����܂܂ʼn�����Ӗ����Ȃ�����Aper watt�̌����
performance�̌���Ɠ������B
>>739
�Ƃ������Ƃ��ˁB
���́A���P�œ���ꂽ�g��TDP�̈��������Ɏg�����Aperformance�̈����グ��
�g�����̑I�����B�����Bulldozer�ɂ͔߂����قǂɑI���̗]�n���Ȃ��̂�����ǂ��B
�����܂ł��R�A���\�������
�A���R�A�����ǂ̗]�n�͂��肻�������琻�i�ɂ���Ă͂����Ɨǂ��Ȃ邩������Ȃ�
�A���R�A�����ǂ̗]�n�͂��肻�������琻�i�ɂ���Ă͂����Ɨǂ��Ȃ邩������Ȃ�
��Intel�͐e���ȃC���[�W�����ǂȁBAMD�͔�����Ƃ��
��̓I�ȍ������L��Ȃ烈��
�P�Ȃ�ϑz�Ȃ�X���[��
��̓I�ȍ������L��Ȃ烈��
�P�Ȃ�ϑz�Ȃ�X���[��
743 �F,,�E�L�́M�E,,�j��-�������F2011/10/18(��) 22:59:59.12 ID:/+ySCO9L
�ǂ��ւ̃��X�H
���Ɏ��Ə������Ă邵�A���{�l�𑽐��ٗp���Ă���ĈӖ��ł͍v���x�͑傫���Ǝv�����ǂˁB
http://www.nikkei.com/tech/trend/article/g=96958A9C93819499E0EBE2E2828DE0EBE2E5E0E2E3E3E2E2E2E2E2E2;p=9694E0E7E2E6E0E2E3E2E2E0E2E0
���Ɏ��Ə������Ă邵�A���{�l�𑽐��ٗp���Ă���ĈӖ��ł͍v���x�͑傫���Ǝv�����ǂˁB
http://www.nikkei.com/tech/trend/article/g=96958A9C93819499E0EBE2E2828DE0EBE2E5E0E2E3E3E2E2E2E2E2E2;p=9694E0E7E2E6E0E2E3E2E2E0E2E0
�������o�J�̖ϑz�d�g�������A�����ׂ�����������ꂻ���ł���
745 �FSocket774�F2011/10/19(��) 01:59:58.30 ID:5cwNRgYL
���������u���v�Ƃ͌����Ǝv�Ӊ��B
�݂�Ȏ������킯�ŁA����Ƃ���v���
������t���Ȃ��ق������������݂����ȕ����ɂȂ����炻�̕����|�����ǂ�
������t���Ȃ��ق������������݂����ȕ����ɂȂ����炻�̕����|�����ǂ�
���ӁB
�����������������̂��F�߂�B
�����������������̂��F�߂�B
�܂������͊�t���ꂽintel����̐��i���܂�����B2600k
�{����Haswell�܂�E6600�Ŋ撣����肾�������ǂ�
�{����Haswell�܂�E6600�Ŋ撣����肾�������ǂ�
�����҂̃Q�C�c�͎��P�������܂��肾���M�҂ɐ��߂��܂����Ă�W���u�Y��1�y�j�[����t�����Ɏ���
4�R�}����ɂȂ��Ă邵�ӊO�ƈ�����Ă�悤�Ȃ�
�X�e�B�[�u�������悤��4�R�}�ɂ�����A�{�l�͂Ƃ��������肪�\��܂���˂����Ƃ�
�X�e�B�[�u�������悤��4�R�}�ɂ�����A�{�l�͂Ƃ��������肪�\��܂���˂����Ƃ�
������ɂ��Ȃ��
���܂������͊�t���ꂽintel����̐��i���܂�����B
���퐶�����x����܂���Ȃ낤��
�܂����������̂����Ȃ��ƌo�ω��Ȃ����炠�肪�������݂�
���퐶�����x����܂���Ȃ낤��
�܂����������̂����Ȃ��ƌo�ω��Ȃ����炠�肪�������݂�
Intel����t���Č����͉̂R�������̂��H
2011Q3�AIntel�ߋ��ō��̔���
http://techreport.com/discussions.x/21851?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+techreport%2Farticles+%28The+Tech+Report%3A+Articles%29
http://techreport.com/discussions.x/21851?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+techreport%2Farticles+%28The+Tech+Report%3A+Articles%29
�N�Y�������ꎸ�s����
���ꂵ���Ԕ�����
���ꂵ���Ԕ�����
757 �FSocket774�F2011/10/19(��) 19:01:37.46 ID:N5HtQkSZ
758 �F �E�@���yLv=8,xxxP�z �F2011/10/19(��) 20:43:59.65 ID:tB6sWCK3
�J���X�P�W���[���ɉe�����邩�ȁH
Tape Out of Multi-Core 20nm ARM Design Revealed
http://www.tomsguide.com/us/Cortex-A15-Tape-Out-TSMC-ARM-20-nm,news-12910.html
Tape Out of Multi-Core 20nm ARM Design Revealed
http://www.tomsguide.com/us/Cortex-A15-Tape-Out-TSMC-ARM-20-nm,news-12910.html
TSMC�Ȃ��32/28nm�ł���gdgd�Ȃ̂�
����ŋ߂�Intel�̗l�q�����Ă�����14nm����Ȃ��ڍs�ł�����
>>757
���ꂵ���o�J��
���ꂵ���o�J��
intel�̃��C�o���͂��̐���intel���g��E�E�E
�����J���������݂��ɐ������������̂�����肠���A���ǂ����i�����B
������Z�p�I�u���C�N�X���[�̐G�}�Ƃ��āA������AMD�͂܂�������^���Ă��Ȃ�����
�Ƃ��Ƃƒׂ�Ă�����B
�����J���������݂��ɐ������������̂�����肠���A���ǂ����i�����B
������Z�p�I�u���C�N�X���[�̐G�}�Ƃ��āA������AMD�͂܂�������^���Ă��Ȃ�����
�Ƃ��Ƃƒׂ�Ă�����B
2500k��2600k�Ŗ����Ă��ł����A
������CPU���Ă���Ȃɔ����I�Ȑi���Ȃ������Ȃ��
2600k�̕���������ł�����
������CPU���Ă���Ȃɔ����I�Ȑi���Ȃ������Ȃ��
2600k�̕���������ł�����
���������
�����A�x��PC�ŃC���C�����Ă�Ȃ獡��������������
�����A�x��PC�ŃC���C�����Ă�Ȃ獡��������������
��4���䖝�����2700K�������邩�炻���
Intel�AIvyBridge��ʎY�J�n
http://blog.livedoor.jp/amd646464/archives/52225648.html
http://blog.livedoor.jp/amd646464/archives/52225648.html
�`�b�N�^�b�N�헪���Ă��܂���������
Ivy��Haswell�����̂܂������y���݂ɂȂ�
Ivy��Haswell�����̂܂������y���݂ɂȂ�
IvyBridge�̏o�ׂ�2011�NQ4��
���������A���N��SCC�݂����ȃ��T�[�`�`�b�v��
���Ȃ��̂��ȁH
���Ȃ��̂��ȁH
����܂ł̃��T�[�`�`�b�v�̌��ʂ�KnightCorner�ɔ��f�������炻�����փ��\�[�X���W�����Ă��Ȃ��́H
�R�A��P5�x�[�X����Atom�x�[�X�̂ɕς�鎟������MIC�����łɊJ���n�܂��ĂȂ��Ƃ���������
�R�A��P5�x�[�X����Atom�x�[�X�̂ɕς�鎟������MIC�����łɊJ���n�܂��ĂȂ��Ƃ���������
771 �FSocket774�F2011/10/20(��) 22:38:54.87 ID:ksnlALLL
>>768
�\��ʂ肾��
�\��ʂ肾��
>>766
Bulldozer��BSoD�̔�������o�O���C�O�̃��r���A�[�ɂ���Ĕ������ꂽ�悤����
�N���̗����グ�͎��s����IvyBridge�ƂԂ��肻���ȏ
Barcelona��TLB�̃o�O�Œx���Penryn�ƂԂ��������݂����ɂȂ��Ă�����
Bulldozer��BSoD�̔�������o�O���C�O�̃��r���A�[�ɂ���Ĕ������ꂽ�悤����
�N���̗����グ�͎��s����IvyBridge�ƂԂ��肻���ȏ
Barcelona��TLB�̃o�O�Œx���Penryn�ƂԂ��������݂����ɂȂ��Ă�����
AMD��90nm��65nm��45nm��32nm��
���݂ɏ����������蒲�q�����Ȃ����肷��݂����Șb����������
�}�W�ł���Ȋ����ɂȂ��Ă����ȁE�E�E
���݂ɏ����������蒲�q�����Ȃ����肷��݂����Șb����������
�}�W�ł���Ȋ����ɂȂ��Ă����ȁE�E�E
���R�ł���BGF��������Ȃ���TSMC����킵�Ă���l�q
�ǂ�ǂ�����̓�x���オ���Ă���Ƃ���������Ȃ��̂���
Intel�̓g���C�Q�[�g�̗����グ�ɐ��������22nm�͉��Ƃ��Ȃ肻�������A
����10nm��ł̓���������A20nm��̃v���Z�X�ł�
����ɍ������͖̂ڂɌ����Ă�
�ǂ�ǂ�����̓�x���オ���Ă���Ƃ���������Ȃ��̂���
Intel�̓g���C�Q�[�g�̗����グ�ɐ��������22nm�͉��Ƃ��Ȃ肻�������A
����10nm��ł̓���������A20nm��̃v���Z�X�ł�
����ɍ������͖̂ڂɌ����Ă�
TSMC��45/40nm�̍�����O�_�O�_������
�A�����J��Intel�Ȃ̂ɓ��{�̓G�N�T�X�P�[��������ȂƂ���ɐ����ϑ�����̂��c
�A�����J��Intel�Ȃ̂ɓ��{�̓G�N�T�X�P�[��������ȂƂ���ɐ����ϑ�����̂��c
Intel�̎���SRAM
�@�@�@�@�Z���T�C�Y�@�@����SRAM�`�b�v
90nm�@1.0um2�@�@�@ [52Mbit, 109mm2]
65nm�@0.57um2�@�@�@[70Mbit, 110mm2]
45nm�@0.346um2�@�@[153Mbit, 119mm2]
32nm�@0.171um2�@�@[291Mbit, ???]
22nm�@0.092um2�@�@[364Mbit, ???]
SRAM�Z���T�C�Y�̏k���͏������ۂ�����22nm�ł͎���`�b�v�̏W�ϗ��͉������Ă�
�P�ɏ����Ȏ���`�b�v�Ƃ����������A����Ƃ�SRAM�ȊO�̉�H�̏k�������������̂���
�@�@�@�@�Z���T�C�Y�@�@����SRAM�`�b�v
90nm�@1.0um2�@�@�@ [52Mbit, 109mm2]
65nm�@0.57um2�@�@�@[70Mbit, 110mm2]
45nm�@0.346um2�@�@[153Mbit, 119mm2]
32nm�@0.171um2�@�@[291Mbit, ???]
22nm�@0.092um2�@�@[364Mbit, ???]
SRAM�Z���T�C�Y�̏k���͏������ۂ�����22nm�ł͎���`�b�v�̏W�ϗ��͉������Ă�
�P�ɏ����Ȏ���`�b�v�Ƃ����������A����Ƃ�SRAM�ȊO�̉�H�̏k�������������̂���
777 �F,,�E�L�́M�E,,�j��-�������F2011/10/21(��) 02:03:56.80 ID:5JsqQk3/
Intel��SRAM�͏ȓd�͏d���ŏW�ϗ��͑��ΓI�ɒ�߂���
>>776
���������ǂ��4����������A�������ĂȂ���Ȃ��H
���������ǂ��4����������A�������ĂȂ���Ȃ��H
>>778,779
�Z���T�C�Y�̏k��������Ȃ��Ď���SRAM�`�b�v�̗e�ʂ̑������̂���
32nm��22nm��291Mbit��364Mbit��25%���������ĂȂ�
�`�b�v�T�C�Y�������Ȃ̂��͕�����ǁc
�Ƃ����ŋC�t�����̂����A32nm�̃`�b�v��19���g�����W�X�^�A
22nm�̃`�b�v��29���g�����W�X�^��SRAM�e�ʂ̑�������葽��
�ǂ���22nm�ł̓��W�b�N���ɂ����Ȃ�g�����W�X�^�������Ă��邹����
SRAM�e�ʂ̑��������������Ȃ����݂�����
���ʂ̓��W�b�N����SRAM�A���C�Ƃ͕ʂɍ��͂��Ȃ̂ʼn��̈ꏏ�ɍ�����̂��͓�
45nm��22nm�̃V���g���e�X�g�`�b�v
http://pc.watch.impress.co.jp/docs/2006/0126/intel.htm
http://techreport.com/discussions.x/17632
SRAM�A���C�ƃ��W�b�N���͕ʁX�ɂȂ��Ă�(���Ƃ��͈ꏏ�����nj�Ő藣��)
�����22nm�ł�SRAM�A���C�̃T�C�h�ɂ����W�b�N���H�������ς�
�Z���T�C�Y�̏k��������Ȃ��Ď���SRAM�`�b�v�̗e�ʂ̑������̂���
32nm��22nm��291Mbit��364Mbit��25%���������ĂȂ�
�`�b�v�T�C�Y�������Ȃ̂��͕�����ǁc
�Ƃ����ŋC�t�����̂����A32nm�̃`�b�v��19���g�����W�X�^�A
22nm�̃`�b�v��29���g�����W�X�^��SRAM�e�ʂ̑�������葽��
�ǂ���22nm�ł̓��W�b�N���ɂ����Ȃ�g�����W�X�^�������Ă��邹����
SRAM�e�ʂ̑��������������Ȃ����݂�����
���ʂ̓��W�b�N����SRAM�A���C�Ƃ͕ʂɍ��͂��Ȃ̂ʼn��̈ꏏ�ɍ�����̂��͓�
45nm��22nm�̃V���g���e�X�g�`�b�v
http://pc.watch.impress.co.jp/docs/2006/0126/intel.htm
http://techreport.com/discussions.x/17632
SRAM�A���C�ƃ��W�b�N���͕ʁX�ɂȂ��Ă�(���Ƃ��͈ꏏ�����nj�Ő藣��)
�����22nm�ł�SRAM�A���C�̃T�C�h�ɂ����W�b�N���H�������ς�
�\�t�g�G���[��Ŗʐϋ���Ă���
>>775
�����A���{�͋Z�p����Ȃ�����O���Ɉϑ����Ȃ��Ƃ����Ȃ�����
�����A���{�͋Z�p����Ȃ�����O���Ɉϑ����Ȃ��Ƃ����Ȃ�����
���{�͋Z�p���Ȃ�����A�̃~�X
784 �F,,�E�L�́M�E,,�j��-�������F2011/10/21(��) 20:33:41.05 ID:5JsqQk3/
�ʂɖ����킯����Ȃ����B���Z���������G���N�g���������E�Ɍւ�ׂ������̊֘A��Ƃ��B
�����t�@�E���h���̖��_�́A�~���������邱�ƁB
�C�O�̐l����̈����ɂ͏��ĂȂ��B
�����t�@�E���h���̖��_�́A�~���������邱�ƁB
�C�O�̐l����̈����ɂ͏��ĂȂ��B
�I�����p�X��剤�����̎��������Ă�ƁA���{�̌o�c�ґw�̃������̒Ⴓ�A�l�i�I�Ȗ�肪���{�̌o�ς̑����v��������Ђ��ς��Ă�
���̑���܂Ƃ��̔n���o�c�҂�K�������Ďx���鉺�w�����d�J���̋ꂵ�݂ƕn���ɂ������ł���̂��킩��B
���Ȃ̂́A���̂���o�c�w�𗧔h�Ȑl�i�҂ŁA���m�ȘJ���҂��w�͂�����Ȃ��ȂǂƂ��ĐӔC�]�ł����܂���}�X�S�~�ɂ����]�����B
����ɂ���Ă܂��܂����Ԃ������̈�r�����ǂ�B
���̑���܂Ƃ��̔n���o�c�҂�K�������Ďx���鉺�w�����d�J���̋ꂵ�݂ƕn���ɂ������ł���̂��킩��B
���Ȃ̂́A���̂���o�c�w�𗧔h�Ȑl�i�҂ŁA���m�ȘJ���҂��w�͂�����Ȃ��ȂǂƂ��ĐӔC�]�ł����܂���}�X�S�~�ɂ����]�����B
����ɂ���Ă܂��܂����Ԃ������̈�r�����ǂ�B
�t���̘b�����ǁA���{���̍Ő�[�I�����u��
�������̂��������D��I�Ɏg����݂���
http://jbpress.ismedia.jp/articles/-/23069?page=2
http://jbpress.ismedia.jp/articles/-/23671
�������̂��������D��I�Ɏg����݂���
http://jbpress.ismedia.jp/articles/-/23069?page=2
http://jbpress.ismedia.jp/articles/-/23671
>>784
TEL����?
�s��o���܂���₪����...
���{�̋Z�p�́A����������Ȃ��̂��ő�̖�肾��
����������}�l�[�W�����g�̕s�݁B
�g���u���t�H���[���}�l�[�W�����g���Ǝv���Ă₪��
�������ɐi�߂��A�R�X�g�������A
�����Č㑱�ɔ������
TEL����?
�s��o���܂���₪����...
���{�̋Z�p�́A����������Ȃ��̂��ő�̖�肾��
����������}�l�[�W�����g�̕s�݁B
�g���u���t�H���[���}�l�[�W�����g���Ǝv���Ă₪��
�������ɐi�߂��A�R�X�g�������A
�����Č㑱�ɔ������
��n�O�̓T�^�����X�Ŏ��Ȑ�`������
>>782
�Z�p���Ȃ����A�������ł��Ȃ���������
��Z�p����������Ȃ�Ɏ����Ă��邪�A
����ɋ��������ď������邱�Ƃ��ł��Ȃ�
���S�ɓ��{�l�̎����̖��
�Z�p���Ȃ����A�������ł��Ȃ���������
��Z�p����������Ȃ�Ɏ����Ă��邪�A
����ɋ��������ď������邱�Ƃ��ł��Ȃ�
���S�ɓ��{�l�̎����̖��
>>784
�~���ȑO������{�̃t�@�E���h���Ȃ�Č���e���Ȃ�����B
�~���ȑO������{�̃t�@�E���h���Ȃ�Č���e���Ȃ�����B
791 �F,,�E�L�́M�E,,�j��-�������F2011/10/21(��) 23:40:25.73 ID:5JsqQk3/
�G���s�[�_�E�E�E
792 �FSocket774�F2011/10/22(�y) 00:30:01.39 ID:fYRrTc9U
�`�������������
>>792
�����̋Z�p�͓��{���N���j�_�I
�����̋Z�p�͓��{���N���j�_�I
>>791
�G���s�[�_�����͑�p�֗�����Ȃ���
�G���s�[�_�����͑�p�֗�����Ȃ���
���̐ŋ��������ꂽ�̂ɊO���ړ]���@�ŋ��D�_��
�ׂ��ƌ����̂�
>>796
�V���[�v�����������ĎO�d�����ǂ�������i�ׂ���Ă�
�V���[�v�����������ĎO�d�����ǂ�������i�ׂ���Ă�
���ꂾ��
�O�d���͂P�Q���A�V���[�v�q�U�V�T�R�r����N�A�T�R�H��i�O�d���T�R�s�j�̉t���p�l����
�Y�ݔ��𒆍���Ƃɔ��p����_��������Ƃ��A���⏕�������p���Ď擾����
�@�B�ݔ��Ȃǂɑ���⏕�������z��U���S�Q�O�O���~�𐿋����邱�Ƃ𖾂炩�ɂ����B
���̂������N�x�͍������ɔ[���ʒm���𑗕t���A���łɌ�t�����⏕���ɉ�������R
���W�O�O�O���~�̔[�t�����߂�B
�m�����ʐM�Ёn
�O�d���͂P�Q���A�V���[�v�q�U�V�T�R�r����N�A�T�R�H��i�O�d���T�R�s�j�̉t���p�l����
�Y�ݔ��𒆍���Ƃɔ��p����_��������Ƃ��A���⏕�������p���Ď擾����
�@�B�ݔ��Ȃǂɑ���⏕�������z��U���S�Q�O�O���~�𐿋����邱�Ƃ𖾂炩�ɂ����B
���̂������N�x�͍������ɔ[���ʒm���𑗕t���A���łɌ�t�����⏕���ɉ�������R
���W�O�O�O���~�̔[�t�����߂�B
�m�����ʐM�Ёn
�d�����i�͓��{���N���j�_
���[�N�d�����ēd�q�X�s���ɂ����̂Ȃ�Ȃ��́H
http://journal.mycom.co.jp/news/2010/10/01/090/index.html
http://journal.mycom.co.jp/news/2010/10/01/090/index.html
���̑ONHK�̔ԑg�Ń[�[�x�b�N���ʂ��g�������d�f�q�ɂ��O��̎g���Ă����Ȃł����q�[�g�V���N�������ăt�@�����Ă���
2700k���Đ��\�ǂ�Ȃ���Ȃ́H
2600k����ʏ펞100MHz����TC�ő�100MHz����
806 �F,,�E�L�́M�E,,�j��-�������F2011/10/23(��) 13:33:12.34 ID:ASBFHzOT
2600K�f�B�X�R���Ȃ�����I�ɂ͒l�グ���ˁB
Z68/P67�Ŏg�������i�{���Ȃ�Ď��ȐӔC�ōD���ɐݒ�ł��邵�B
Ivy Bridge�����[���`���猋�\����ɏo��肻�������������Ĕ�������ł��Ȃ��Ǝv���B
Z68/P67�Ŏg�������i�{���Ȃ�Ď��ȐӔC�ōD���ɐݒ�ł��邵�B
Ivy Bridge�����[���`���猋�\����ɏo��肻�������������Ĕ�������ł��Ȃ��Ǝv���B
�ăh���̓C���t���������߂�����
�������i�͂���ܕς�����
�������i�͂���ܕς�����
Ivy ��AVX�g������邩�ǂ����A
�������o�������H
�������o�������H
�g���͂����͂�
������AVX2�ł͂Ȃ���
������AVX2�ł͂Ȃ���
i5-2600k�̗\��͂Ȃ��̂��H
>>810
�����͔�炳�Ȃ�����
�����͔�炳�Ȃ�����
E6300�݂����ɕ���킵���Ȃ�̂͌���
2400��2500�A2500��2600
3���ڂ̐������\���̂́A�R�A�̎d�l�Ȃ̂��N���b�N�Ȃ̂��͂����肵�Ăق���
����HT��L���ɂ���2500K���o���ꍇ�ǂ����Â�����낤�H
3���ڂ̐������\���̂́A�R�A�̎d�l�Ȃ̂��N���b�N�Ȃ̂��͂����肵�Ăق���
����HT��L���ɂ���2500K���o���ꍇ�ǂ����Â�����낤�H
intel�̃i���o�����O�͍s������������芴�����Ȃ苭��
�Ƃ��ɍ��ʉ�����Ƃ��낪������Core2�ȍ~��
�Ƃ��ɍ��ʉ�����Ƃ��낪������Core2�ȍ~��
i5�ɖ�����i7�ɗL��t�����l�̈�Ƃ���HT������킯������
��������i5��HT��L���ɂ������i��
Intel�I�ɍl���O�̂悤�ȋC������
��������i5��HT��L���ɂ������i��
Intel�I�ɍl���O�̂悤�ȋC������
���ʉ��̂��߂ɖ����ɂ����@�\�Ƃ��L���b�V���e�ʂ͂��̂܂܂�
�N���b�N�����オ�����̂��u�������čs���`�ɂȂ邾�낤�ˁB
�W�Ȃ�����Pentium��E5000�n��E6000�n�͍ŏI�I�ɂ₽�獂�N���b�N�ɂȂ��Ă��ȁB
�N���b�N�����オ�����̂��u�������čs���`�ɂȂ邾�낤�ˁB
�W�Ȃ�����Pentium��E5000�n��E6000�n�͍ŏI�I�ɂ₽�獂�N���b�N�ɂȂ��Ă��ȁB
>>813
������Ă�����i7�̃N���b�N�_�E���ł���ˁH
���ʂ�i7-2500K�Ƃ��Ai5-2500K�Ɣ��̂����Ȃ�i7-2400K�Ƃ��ł�����Ȃ��́H
������Ă�����i7�̃N���b�N�_�E���ł���ˁH
���ʂ�i7-2500K�Ƃ��Ai5-2500K�Ɣ��̂����Ȃ�i7-2400K�Ƃ��ł�����Ȃ��́H
���i�̐��Y�����͈�N�����Ȃ���ׂ������Ƃ͂�����
9���G�N�X�g���[���A5���p�t�H�[�}���X�A1���o�����[
7�Ƃ�3�͒��ԁA�����͂���ɒ���
9���G�N�X�g���[���A5���p�t�H�[�}���X�A1���o�����[
7�Ƃ�3�͒��ԁA�����͂���ɒ���
819 �FSocket774�F2011/10/24(��) 16:34:52.47 ID:Cn3UXNmG
3960X����11/15���\�A11/20�����ł����H
2500k �����Ȃ��ĂˁH
����Șb�����邪
ttp://www.brightsideofnews.com/news/2011/10/20/intel-retailers-jack-up-core-i5i7-prices-after-bulldozer-launch.aspx
ttp://www.brightsideofnews.com/news/2011/10/20/intel-retailers-jack-up-core-i5i7-prices-after-bulldozer-launch.aspx
����32nm�v���Z�X�̐����ݔ��̂���D1D��D1C��22nm�v���Z�X�ɓ]�����ėʎY���n�߂Ă�킯��
���ꂩ�琶�Y�ʂ������čɂ͌��������낤����ŏI�I�ɂ�3���I�[�o�[�Ƃ����邩����
���ꂩ�琶�Y�ʂ������čɂ͌��������낤����ŏI�I�ɂ�3���I�[�o�[�Ƃ����邩����
Intel�͊�{�I�ɒl�����Ȃ��Ń��C���i�b�v��ւ��邩��Ivy���o��O�オ��l�Ȃ�Ă��Ƃ͂Ȃ�
�������낻��`�b�v�Z�b�g��USB3.0������Ȃǂ��l����ƁA
����ς�V�����ق��������ꍇ���H
����ς�V�����ق��������ꍇ���H
QSV�̋����͂���낤��
�Ȃ�Sandy-E������
�Ԃ�ǁ[���[���킢����(�L�G�ցG`)
�@ �@ �@�@�@�Q�Q�Q_
�@ �@�@�@�^�@�@ �@ �@�_
�@�@�@�^�@ _�m �@�R�_�@ �_
�@ �^ �@o߁܁@�@�@���o�@ �_ �@�܂��R�s�y��\��d������������Ȃ��������c
�@ |�@�@�@�@ �i__�l__�j�@�@�@�@|
�@ �_�@�@ �@ �M �܁L �@ �@ �^
http://hissi.org/read.php/jisaku/20111025/Mk5SWmhoaHE.html
http://hissi.org/read.php/jisaku/20111016/L0lpVlJtdFg.html
http://hissi.org/read.php/jisaku/20111015/MXUvNTlsdys.html
http://hissi.org/read.php/jisaku/20111014/dlZEV1Z2dlM.html
http://hissi.org/read.php/jisaku/20111012/dFhZckV0OEU.html
http://hissi.org/read.php/jisaku/20111010/cjRaNnNVT0g.html
�@ �@�@�@�^�@�@ �@ �@�_
�@�@�@�^�@ _�m �@�R�_�@ �_
�@ �^ �@o߁܁@�@�@���o�@ �_ �@�܂��R�s�y��\��d������������Ȃ��������c
�@ |�@�@�@�@ �i__�l__�j�@�@�@�@|
�@ �_�@�@ �@ �M �܁L �@ �@ �^
http://hissi.org/read.php/jisaku/20111025/Mk5SWmhoaHE.html
http://hissi.org/read.php/jisaku/20111016/L0lpVlJtdFg.html
http://hissi.org/read.php/jisaku/20111015/MXUvNTlsdys.html
http://hissi.org/read.php/jisaku/20111014/dlZEV1Z2dlM.html
http://hissi.org/read.php/jisaku/20111012/dFhZckV0OEU.html
http://hissi.org/read.php/jisaku/20111010/cjRaNnNVT0g.html
831 �FSocket774�F2011/10/25(��) 16:56:16.57 ID:AMZoNcLS
Ivy���ē����̗\��ʂ�12���o�J�n��1�������H
Intel��22nm CPU�uIvy Bridge�v�A2012�N3���ɏo�J�n��
http://eetimes.jp/ee/articles/1110/25/news046.html
OEM���[�J�[�ւ̏o�J�n�͍��l������������ŁA���ڂ��ꂽ���i��2012�N�t�ɂȂ�Ƃ̂��ƁB
http://www.tomshardware.com/news/ivy-bridge-processor-release-22nm-3d-transistor,13753.html
http://eetimes.jp/ee/articles/1110/25/news046.html
OEM���[�J�[�ւ̏o�J�n�͍��l������������ŁA���ڂ��ꂽ���i��2012�N�t�ɂȂ�Ƃ̂��ƁB
http://www.tomshardware.com/news/ivy-bridge-processor-release-22nm-3d-transistor,13753.html
�Ȃ�Sandy-E������
Method and resultant structure for floating body memory on bulk wafer
ttp://www.patents.com/us-7851862.html
Intel�̓�������BFinFET�Ȃ�o���N�v���Z�X�ł�1T-SRAM(eDRAM)�������Ƃ������e�B
1T-SRAM��SOI�̃q�X�g�����ʂ𗘗p������̂Ȃ̂ŁA���Ɏ_���V���R���̐≏�����K�v�ɂȂ邪�A
�o���N�v���Z�X�ŗp������E�F�n�ɂ͂������ȋC�̗��������͖����B
����Ȃ�Ή��Ƃ����ă`���l���̉��Ɏ_���V���R���̐≏����݂��悤�Ƃ������ƂŁA���ɂ܂�SiGe�̑w�����A���̏�ɍX��Si�̑w�����B
SiGe�̑w�͑I��I��etch(Si�̑w���c���ď���)�ł���̂ŁA�����ɐ≏����݂���Ηǂ��Ƃ����̂���{�I�ȃA�C�f�B�A�B
�����P���ɍl����ƁA�܂����Si���ז���SiGe�̑w�͏����ł��Ȃ����A���ɏ����ł���Ƃ��Ă����ɕ�����Si�̑w�͗������Ă��܂��B
���̂܂܂ŗ���������Ȃ�x�����������Ȃ��Ƃ������ƂŁA�܂�Si�̏�Ɍ�������SiN�̑w��݂��A
���ꂩ��Q�[�g�����\��̒n�_�����ݍ��ނ悤���s�ɏc�����@���č\���ނ��[�U���A�X��SiN�̑w�������Ă��܂��B
�\���ނ͌䊘�̊W���t���܂ɂ����l�Ȍ`(����)�ɂȂ�A����ɂ�����SiN�̋��x�Ƒ��܂���SiGe������������ɏo����M���b�v���ێ����邱�Ƃ��o����B
��������SiGe���������邽�߃`���l���̑��ʂ�I�o�����ASiGe���������Đ≏�������A
Si�̏��SiN���������ĘI�o������ʂƑ��ʂ�HK/MG���쐬����FBC�������A�Ƃ����̂���܂��ȗ���B
�ŋߘb��ɂȂ���HMC�ȊO�ɂ�22nm�ȍ~�͂��̂悤�ȑI����������ƁB
1T-SRAM�Ȃ̂ŁA�g���[�h�I�t��I�[�o�[�w�b�h�����čl�����LLC��6�{�̗e�ʂɂȂ�v�Z�B
ttp://www.patents.com/us-7851862.html
Intel�̓�������BFinFET�Ȃ�o���N�v���Z�X�ł�1T-SRAM(eDRAM)�������Ƃ������e�B
1T-SRAM��SOI�̃q�X�g�����ʂ𗘗p������̂Ȃ̂ŁA���Ɏ_���V���R���̐≏�����K�v�ɂȂ邪�A
�o���N�v���Z�X�ŗp������E�F�n�ɂ͂������ȋC�̗��������͖����B
����Ȃ�Ή��Ƃ����ă`���l���̉��Ɏ_���V���R���̐≏����݂��悤�Ƃ������ƂŁA���ɂ܂�SiGe�̑w�����A���̏�ɍX��Si�̑w�����B
SiGe�̑w�͑I��I��etch(Si�̑w���c���ď���)�ł���̂ŁA�����ɐ≏����݂���Ηǂ��Ƃ����̂���{�I�ȃA�C�f�B�A�B
�����P���ɍl����ƁA�܂����Si���ז���SiGe�̑w�͏����ł��Ȃ����A���ɏ����ł���Ƃ��Ă����ɕ�����Si�̑w�͗������Ă��܂��B
���̂܂܂ŗ���������Ȃ�x�����������Ȃ��Ƃ������ƂŁA�܂�Si�̏�Ɍ�������SiN�̑w��݂��A
���ꂩ��Q�[�g�����\��̒n�_�����ݍ��ނ悤���s�ɏc�����@���č\���ނ��[�U���A�X��SiN�̑w�������Ă��܂��B
�\���ނ͌䊘�̊W���t���܂ɂ����l�Ȍ`(����)�ɂȂ�A����ɂ�����SiN�̋��x�Ƒ��܂���SiGe������������ɏo����M���b�v���ێ����邱�Ƃ��o����B
��������SiGe���������邽�߃`���l���̑��ʂ�I�o�����ASiGe���������Đ≏�������A
Si�̏��SiN���������ĘI�o������ʂƑ��ʂ�HK/MG���쐬����FBC�������A�Ƃ����̂���܂��ȗ���B
�ŋߘb��ɂȂ���HMC�ȊO�ɂ�22nm�ȍ~�͂��̂悤�ȑI����������ƁB
1T-SRAM�Ȃ̂ŁA�g���[�h�I�t��I�[�o�[�w�b�h�����čl�����LLC��6�{�̗e�ʂɂȂ�v�Z�B
8�R�A, LLC32MB, 12��, 567mm^2@45nm
ttp://j.mycom.jp/news/2010/02/09/051/images/002l.jpg
8�R�A, LLC32MB, 31��, 544mm^2@32nm
ttp://j.mycom.jp/articles/2011/09/14/hot_chips23_poulson/images/002l.jpg
���[�h�}�b�v��̐��i�ō̗p�����\���������̂�Kittson�AIVB-EX�AKnights Corner�ӂ肾�낤���B
IVB��GPU�ɐ�p��L3���t�������ǁAHSW�ȍ~��IGP��LLC����1T-SRAM���Ƃ����肤��̂��ȁH
ttp://j.mycom.jp/news/2010/02/09/051/images/002l.jpg
{kind=link}
8�R�A, LLC32MB, 31��, 544mm^2@32nm
ttp://j.mycom.jp/articles/2011/09/14/hot_chips23_poulson/images/002l.jpg
{kind=link}
���[�h�}�b�v��̐��i�ō̗p�����\���������̂�Kittson�AIVB-EX�AKnights Corner�ӂ肾�낤���B
IVB��GPU�ɐ�p��L3���t�������ǁAHSW�ȍ~��IGP��LLC����1T-SRAM���Ƃ����肤��̂��ȁH
1T-SRAM��GC�ɍ̗p���ꂽ���납�炢���肪�o�邾�낤�ƂЂ����Ɋ��҂��Ă�
Haswell��1���ɔ�������
http://bit.ly/o24W0U
http://bit.ly/o24W0U
�Q�[���@��1T-SRAM����Ȃ��Ă�����Z-RAM�̎�����Ȃ��́H
Haswell��CPU���ǂ����ǂ����̂��y����
>����������
�܂œǂ�
�܂œǂ�
�^�J���t�@�����X�ɍs���Ă݂���
AMD���ł�ICC���ő����Ƃ�
�����ŕ��ʂɐ�`���Ă�̂�
Intel�͑��ЂƂ̔�r������܂���Ȃ�
��ۂ����������班��������
AMD���ł�ICC���ő����Ƃ�
�����ŕ��ʂɐ�`���Ă�̂�
Intel�͑��ЂƂ̔�r������܂���Ȃ�
��ۂ����������班��������
����?
AMD�͕s���ɂȂ�悤�ɍ���Ă��Ȃ�������?
�ǂ�����fanboy�I�ɂ͂�
AMD�͕s���ɂȂ�悤�ɍ���Ă��Ȃ�������?
�ǂ�����fanboy�I�ɂ͂�
�u���ł��炢���ς������ς��̃t�@���{�[�C�����ɔ߂���������m�点�Ȃ����߂ɖق��Ă�������E�E�E�B
Intel��������`���Ă����������͊F������E�E�E��O�҂��x���`��r����Ȃ�Ƃ�����
>>842
ICC�Ɋւ��Ă͐̂��瑼�Ђ̃R���p�C���Ɣ�r���ăA�s�[�����Ă�
ICC�Ɋւ��Ă͐̂��瑼�Ђ̃R���p�C���Ɣ�r���ăA�s�[�����Ă�
>>845
��O�҂̒�����Ђ̌��ʂ����p����`�Ŕ��\���Ă���
��O�҂̒�����Ђ̌��ʂ����p����`�Ŕ��\���Ă���
�܂�fanboy�I�ɂ͑�O�҂̒����@�ւ�intel�ɗ��Ŕ�������Ă邩����Ȃ����
Windows��Linux�����^�p��p�������Ƃ�����O�ҋ@�ւł̒������ʂƈꏏ�����
�A���̂ǂ����y�H�������̂��c�c�H
Intel�̍��͂̈�[�������C�����邗
Intel�̍��͂̈�[�������C�����邗
4Gamer.net �\ �����̌v������X�y�b�N���傫���ቺ����X79�`�b�v�Z�b�g�BIntel��PCI Express 3.0�Ή��v��������I��
http://www.4gamer.net/games/132/G013252/20111027090/
PCIe 3.0�̑Ή���Ivy Bridge-E�܂Ō�������\��������
�͂��E�E
http://www.4gamer.net/games/132/G013252/20111027090/
PCIe 3.0�̑Ή���Ivy Bridge-E�܂Ō�������\��������
�͂��E�E
i7��ECC�������g���Ȃ��̂�8�X���b�g�Ή�����Ӗ����Ă����
�|���Ďg���Ȃ������l
�|���Ďg���Ȃ������l
�n�C�G���h�f�X�N�g�b�v�����Ƃ������Ƃ��l����Ȃ�
���̂Ƃ���3.0�͕K�v�Ȃ��ƌ�����A�܂��m���ɂ������������
GPU�̑ш悪�O�a����C�z�͂Ȃ���
�Ƃ͂���Xeon�͖����ƕs�������A�������ɑΉ��\����ۂ���
���̂Ƃ���3.0�͕K�v�Ȃ��ƌ�����A�܂��m���ɂ������������
GPU�̑ш悪�O�a����C�z�͂Ȃ���
�Ƃ͂���Xeon�͖����ƕs�������A�������ɑΉ��\����ۂ���
>>852
4�X���܂łȂ�Ӗ�����́H
4�X���܂łȂ�Ӗ�����́H
>>854
4�ł͂Ȃ�6���B
4�ł͂Ȃ�6���B
�u���̎��Ԃł͐[��̔��͂ł��܂���ˁv�i10/28�j ---�^�V���b�v�X���k
http://www.gdm.or.jp/voices_html/201110/28a.html
�J���R�[�h�l�[���uSandy Bridge-E�v����LGA2011�Ή��v���b�g�t�H�[���̍������֎��Ԃ�11��14��17��01���ƂȂ�悤���B
�����ɔ����ƂȂ�CPU�͈ȉ���2���f���B�����ł̗\�������킹�ċL�ڂ���B
Core i7-3960X Extreme Edition ��90,000�~�O��
Core i7-3930K ��48,000�~�O��
Core i7-3820 ��24,800�~�O��i����������
http://www.gdm.or.jp/voices_html/201110/28a.html
�J���R�[�h�l�[���uSandy Bridge-E�v����LGA2011�Ή��v���b�g�t�H�[���̍������֎��Ԃ�11��14��17��01���ƂȂ�悤���B
�����ɔ����ƂȂ�CPU�͈ȉ���2���f���B�����ł̗\�������킹�ċL�ڂ���B
Core i7-3960X Extreme Edition ��90,000�~�O��
Core i7-3930K ��48,000�~�O��
Core i7-3820 ��24,800�~�O��i����������
>>850
�u�y�H�����p�ӂ��܂����B�v���ă��c���H�u�e�i�ł���...�v�Ɠ������A�Ќ�����Ȃ̂ł́B�ǂ�������ȃ��m�B�z���g�Ɍy�H�o���Ă���Ƃ����...�@���Ă���B
�u�y�H�����p�ӂ��܂����B�v���ă��c���H�u�e�i�ł���...�v�Ɠ������A�Ќ�����Ȃ̂ł́B�ǂ�������ȃ��m�B�z���g�Ɍy�H�o���Ă���Ƃ����...�@���Ă���B
>>850
���A���̂ǂ����y�H�������̂��c�c�H
��Intel�̍��͂̈�[�������C�����邗
Intel�̃C�x���g�͂��y�Y���J�l�������Ă�Ȃ��A�Ƃ����v��
�A���h�̃C�x���g�Ȃ��ЍL������̃V���{���N���A�t�@�C���Ƃ����邪
���A���̂ǂ����y�H�������̂��c�c�H
��Intel�̍��͂̈�[�������C�����邗
Intel�̃C�x���g�͂��y�Y���J�l�������Ă�Ȃ��A�Ƃ����v��
�A���h�̃C�x���g�Ȃ��ЍL������̃V���{���N���A�t�@�C���Ƃ����邪
>>837
���ŁH
���ŁH
>>851
��Kingston Technology��IDF 2011 SF�Ō��J�����uX79�{8 DIMM�\���v�̓���f���B
�����Ђ̒S���҂́u�f���ɂ͕Жʎ����������𗘗p���Ă���B���ʎ����^�C�v��8DIMM�\������������͓̂���v�Ɛ������Ă���
����
��Kingston Technology��IDF 2011 SF�Ō��J�����uX79�{8 DIMM�\���v�̓���f���B
�����Ђ̒S���҂́u�f���ɂ͕Жʎ����������𗘗p���Ă���B���ʎ����^�C�v��8DIMM�\������������͓̂���v�Ɛ������Ă���
����
Haswell�̃_�C�X�^�b�L���O�ɂ���ă������ш悪���P������
���ʓI��GPU�̋����ɂȂ�̂��ȁH
���ʓI��GPU�̋����ɂȂ�̂��ȁH
����GPU�Ȃ烁�����ш悪�L���Ȃ�Ό��ʂƂ��ċ����Ɍq�����Ȃ����H
>>859
�V����̎n�܂������C�x���g������B
�V����̎n�܂������C�x���g������B
haswell�͓d�͂̎��ȊO�S��������Ȃ����c
ivy-e��sandy-e�̉��nj^�����番����₷��
ivy-e��sandy-e�̉��nj^�����番����₷��
�������͑������ʂ���Ǝv����
�}���`�X���b�h�Ń������A�N�Z�X��������ƑS�R�X�P�[�����Ȃ��Ȃ����
�}���`�X���b�h�Ń������A�N�Z�X��������ƑS�R�X�P�[�����Ȃ��Ȃ����
>>861
DDR4�ɂȂ邩���
�����ADDR4�ڍs���\�z�ȏ�ɂ������ɂȂ�炵������
���肷��ƁA�I����DDR4�ŁA�f�X�N�g�b�v��DDR3�̂܂܂̉\��������
DDR4�ɂȂ邩���
�����ADDR4�ڍs���\�z�ȏ�ɂ������ɂȂ�炵������
���肷��ƁA�I����DDR4�ŁA�f�X�N�g�b�v��DDR3�̂܂܂̉\��������
���X���ꂽ�����肪�Ƃ��������܂��B
Ivy���������Ǝv�������ǁAHaswell���l���Ȃ��Ƃ�����ȁc
Ivy���������Ǝv�������ǁAHaswell���l���Ȃ��Ƃ�����ȁc
868 �FSocket774�F2011/10/30(��) 18:24:11.01 ID:1IdhgQ4Z
�m�[�gPC�Ȃ�n�X�E�F���҂��ł�������Ȃ�
Intel���E���g���u�b�N�̓n�X�E�F���Ŋ�������݂����ɂ����Ă邵
Intel���E���g���u�b�N�̓n�X�E�F���Ŋ�������݂����ɂ����Ă邵
Ultrabook����CPU�����͖����H
��Ultrabook�����ė��Nivy�A�ė��Nhaswell�Ɋ����ł����炢���̂�
��Ultrabook�����ė��Nivy�A�ė��Nhaswell�Ɋ����ł����炢���̂�
�ł����Ƃ��Ă��ȓd�͖ړ��ĂłȂ�m�[�g�ۂ��Ƒւ����ق�����������
CPPM�ɑΉ��������Ӌ@��Ƌ������ď���d�͉�����̂�Haswell�̐^�����݂�������
CPPM�ɑΉ��������Ӌ@��Ƌ������ď���d�͉�����̂�Haswell�̐^�����݂�������
ivy��haswell��100%����
������99���������Ǝv����
�����ł����Ƃ��Ă�Haswell�v���b�g�t�H�[���̓V�X�e���S�̂ŒB���ł�����̂�����
CPU�����������Ă��債�ĈӖ��͂Ȃ���
�����ł����Ƃ��Ă�Haswell�v���b�g�t�H�[���̓V�X�e���S�̂ŒB���ł�����̂�����
CPU�����������Ă��債�ĈӖ��͂Ȃ���
>>861
�ނ���GPU���C���������Ă����B���ꂩ�琔�N�͏ȓd��+GPU�������Ă����H���Ȃ̂��ȁB
ttp://www.newslogplus.com/2011/10/intel2013haswellgpu.html
�ނ���GPU���C���������Ă����B���ꂩ�琔�N�͏ȓd��+GPU�������Ă����H���Ȃ̂��ȁB
ttp://www.newslogplus.com/2011/10/intel2013haswellgpu.html
GPU�͐��\�グ�₷���Ƃ���ł͂��邩��ԈႢ����Ȃ�����
���Ƃ��Ă�CPU�����ǂ��ė~�����Ȃ��iIPC�Ƃ���
���Ƃ��Ă�CPU�����ǂ��ė~�����Ȃ��iIPC�Ƃ���
�������Ƃ���Haswell�ŃI���S�������W���[������i�߂āA
Skylake��CPU+GPU+Larrabee�n�A�N�Z�����[�^+���̑���
�_��ȑg�ݍ��킹�Œł���悤�ɂ��闬���ϑz��
Haswell��PARROT�Ƃ�4way-SMT�Ƃ������̖ڂ�����Ζʔ�������
Skylake��CPU+GPU+Larrabee�n�A�N�Z�����[�^+���̑���
�_��ȑg�ݍ��킹�Œł���悤�ɂ��闬���ϑz��
Haswell��PARROT�Ƃ�4way-SMT�Ƃ������̖ڂ�����Ζʔ�������
877 �FSocket774�F2011/10/31(��) 03:28:29.54 ID:WDpqluzl
>>873
���C���X�g���[����4�R�A�̂܂܁A�v���Z�X�X�V�̉��b����GPU�ɒ�������
�v���Z�X�X�V���݉������Ƃ���ŁA�f�X�N�g�b�v�n�C�G���h���I���R���ɂȂ���
���C���X�g���[���ɂU�R�A�A�W�R�A�lj����ė��ꂩ��
���C���X�g���[����4�R�A�̂܂܁A�v���Z�X�X�V�̉��b����GPU�ɒ�������
�v���Z�X�X�V���݉������Ƃ���ŁA�f�X�N�g�b�v�n�C�G���h���I���R���ɂȂ���
���C���X�g���[���ɂU�R�A�A�W�R�A�lj����ė��ꂩ��
�����̃A�v���̐��\�𗎂Ƃ��킯�ɂ͍s���Ȃ��̂�
���C���X�g���[���ł�4�R�A���ێ������܂�
���鎞�_����MIC�R�A���Ă����`����Ȃ��낤��
�����̌v�悾��Larrabee��GPU�ɂ��g�����肾�����̂��낤����
GPU�]�p���؈����Ɣ��f����Ă���́A
Intel HD�����p����`��CPU�ɓ�������Ă����̂��Ȃ�
���C���X�g���[���ł�4�R�A���ێ������܂�
���鎞�_����MIC�R�A���Ă����`����Ȃ��낤��
�����̌v�悾��Larrabee��GPU�ɂ��g�����肾�����̂��낤����
GPU�]�p���؈����Ɣ��f����Ă���́A
Intel HD�����p����`��CPU�ɓ�������Ă����̂��Ȃ�
879 �FSocket774�F2011/11/03(��) 02:19:07.37 ID:W3Sh9JdU
�ǂ���IvyE���f�X�N�g�b�v�n�C�G���h�̍ŏI�ɂȂ肻���ȋC�z����
>>879
���������ɂ��̂悤�Ȃ��Ƃ��̂��܂��B
���������ɂ��̂悤�Ȃ��Ƃ��̂��܂��B
�]�������Ȃ��낤>>879��
����
�I�ł̓V���O��������ێ��ŏ\���ɂȂ���邩��ȁB
�I�p�ɍœK�����i���̂�����N���b�N�����ďo�����Ƃ���ŁA
�E�g������Ȃ����X���b�h�̂��߂ɍ����M
�E1�`4�X���b�h�̈�ʌ����A�v���ł͍ő��ł͈�ʌ����ŏ�ʂɏ��ĂȂ�
�E��ʌ����@�\���Ȃ�
�ł͎��v�͐�ׂ������B
�I�p�ɍœK�����i���̂�����N���b�N�����ďo�����Ƃ���ŁA
�E�g������Ȃ����X���b�h�̂��߂ɍ����M
�E1�`4�X���b�h�̈�ʌ����A�v���ł͍ő��ł͈�ʌ����ŏ�ʂɏ��ĂȂ�
�E��ʌ����@�\���Ȃ�
�ł͎��v�͐�ׂ������B
�Ӗ���������A����Ȃ�f�X�N�g�b�v�n�C�G���h��
�T�[�o�[����CPU�̃Z�O�����g���������邾���Ȃ�Ȃ��́H
�T�[�o�[����CPU�̃Z�O�����g���������邾���Ȃ�Ȃ��́H
885 �FSocket774�F2011/11/03(��) 17:31:56.08 ID:W3Sh9JdU
>>880
Haswell�ȍ~�̓f�X�N�g�b�v�n�C�G���h���^�C���e�[�u���ɂ̂��ĂȂ�
>>884
���R�A�{���N���b�N�Ƃ����̂����Ƀj�b�`�ȏ��i�ɂȂ��Ă���
�킴�킴���̂��߂̃v���b�g�t�H�[����Intel���ێ��������邩�Ƃ������
>>881
���ˁA�J�X
Haswell�ȍ~�̓f�X�N�g�b�v�n�C�G���h���^�C���e�[�u���ɂ̂��ĂȂ�
>>884
���R�A�{���N���b�N�Ƃ����̂����Ƀj�b�`�ȏ��i�ɂȂ��Ă���
�킴�킴���̂��߂̃v���b�g�t�H�[����Intel���ێ��������邩�Ƃ������
>>881
���ˁA�J�X
�����ƈ����Ȃ��̂�
����1155��Haswell��������OC���o�Ȃ牽������Ȃ�
i7 920�����肩�炠��܂�i�����Ė����l�Ɋ�����
�������I�ȕω����N����Ȃ����ȁ[
�������I�ȕω����N����Ȃ����ȁ[
889 �FSocket774�F2011/11/03(��) 20:15:02.29 ID:Jy211MZz
x86�̏I��������Ă�����
�N�b�\�����^����������������
���A���܂�딚
Sandy-E���܂�Ȃ������ł�
Ivy�͓������邩�炾������
�C��������������B
���܂ł̓p�t�H�[�}���X�d������������
���x�͏ȓd�͏d���ɂ��悤�Ǝv���Ă�B
Ivy�͓������邩�炾������
�C��������������B
���܂ł̓p�t�H�[�}���X�d������������
���x�͏ȓd�͏d���ɂ��悤�Ǝv���Ă�B
893 �FSocket774�F2011/11/03(��) 23:39:57.78 ID:W3Sh9JdU
�唼�̃Q�[����SandyE���Ivy�̕����X�R�A�������낤����
ivy��cpu�̐��\�t�o�����łf�o�t�̂ݐ��\����Ƃ��ӂ������}�l���Ă�̂�
����σu���g�|�U�[���I���R�������������Ȃ̂��H�c
����σu���g�|�U�[���I���R�������������Ȃ̂��H�c
�啪�O���炻�������Ă�����
�v�Ȃ���ȃz�C�z�C�ς����Ȃ���
�v�Ȃ���ȃz�C�z�C�ς����Ȃ���
>>894
�ނ���������i�ރ^�[���ł���قǎ������������ٗ�
������Intel�������Tick-Tock���f����Tick����Ȃ�Tick+�ƌ����Ă�
�ނ���������i�ރ^�[���ł���قǎ������������ٗ�
������Intel�������Tick-Tock���f����Tick����Ȃ�Tick+�ƌ����Ă�
CPU���̂̐��\�������オ��ƌ����Ă���͂�����
1�`2�����x�́B�ǂ��炩�ƌ����ƃV�������N�̌��ʂ�
TDP������������ɐU���Ă���ۂ����ǂ�
1�`2�����x�́B�ǂ��炩�ƌ����ƃV�������N�̌��ʂ�
TDP������������ɐU���Ă���ۂ����ǂ�
�݂�Ȃ��������}���Ȃ�
CPU�����Ȃ������Ăǂ����G�����悩�A�j���Đ��ɂ����g��Ȃ���H
CPU�����Ȃ������Ăǂ����G�����悩�A�j���Đ��ɂ����g��Ȃ���H
��Ȏg�p�ړI : 2ch
��Ȏg�p�ړI2�F�x���`
�\�[�X�R�[�h�̃r���h�Ƃ�FPGA�̍����Ƃ���
������CPU���\�[�X�������Ă�����Ȃ����炢
������������͂����ς�����Ǝv�����ǂ�
������CPU���\�[�X�������Ă�����Ȃ����炢
������������͂����ς�����Ǝv�����ǂ�
http://semiaccurate.com/2011/11/01/intel-8-core-server-atom-gets-a-name-and-date/
2-way OoOE��8�R�AAtom "Avadon (Abadon?)" ��64bit ARM�R�œo��?
2-way OoOE��8�R�AAtom "Avadon (Abadon?)" ��64bit ARM�R�œo��?
�o�ꂵ���Ƃ���ŁA���Nj����̂�x86 64bit�v���Z�b�T�ɂȂ邾������
��������d�͎��悾��
�ł�HP��ARM�I���J������Ɣ��\��������Atom���ڔł��\�肵�Ă���ƌ����Ă邵
����Niagara�̑R���i�Ƃ���LPIA��32�R�A�W�ς����`�b�v��Intel�̃��[�h�}�b�v��ɂ������B
��������̔̔����т���Niagara�ɂ͂����ċ����͂��������ƂȂ����Ƃ��킩���ăL�����Z�����ꂽ�B
����Niagara(��APL)�͒������Sun�̋Ɛт��ł�����Oracle�g���肷�邱�ƂɂȂ�킯�����c
���x��LPIA�ŃT�[�o�[�`�b�v�͓��̖ڂ�����̂��ˁB
��������̔̔����т���Niagara�ɂ͂����ċ����͂��������ƂȂ����Ƃ��킩���ăL�����Z�����ꂽ�B
����Niagara(��APL)�͒������Sun�̋Ɛт��ł�����Oracle�g���肷�邱�ƂɂȂ�킯�����c
���x��LPIA�ŃT�[�o�[�`�b�v�͓��̖ڂ�����̂��ˁB
SeaMicro�̍����xAtom�T�[�o�͔���Ă�̂��Ȃ��H
>>907
���x�����f���`�F���W����3D�g���X�ڑ�������W�ϓx�グ���肵�Ă�ӂ肻��Ȃ�ɔ���Ă�Ȃ���
���x�����f���`�F���W����3D�g���X�ڑ�������W�ϓx�グ���肵�Ă�ӂ肻��Ȃ�ɔ���Ă�Ȃ���
>>898
�g�c�c�X���ŁAHDD���l�オ�肵������G���R�ň��k���������ǃG���R�̑��x���x���Ċ���ɂ���Ȃ����Ă݂�Ȍ����Ă��
16�R�A�Ƃ�32�R�A�������o��G���R�������Ǝ��p�I�ɂȂ�̂ɂ�
�g�c�c�X���ŁAHDD���l�オ�肵������G���R�ň��k���������ǃG���R�̑��x���x���Ċ���ɂ���Ȃ����Ă݂�Ȍ����Ă��
16�R�A�Ƃ�32�R�A�������o��G���R�������Ǝ��p�I�ɂȂ�̂ɂ�
�G���R�̃\�t�g�E�F�A���ă}���`�m�[�h�ɑΉ����ĂȂ����̂Ȃ́H
��d���ł̂S�R�A�̃m�[�h����ׂ����������������d�͂���Ȃ��H
SMP�ɂ��������R���킩��Ȃ�
��d���ł̂S�R�A�̃m�[�h����ׂ����������������d�͂���Ȃ��H
SMP�ɂ��������R���킩��Ȃ�
�����͂ł��Ă����[�r�[�P�ʂł����G���R�[�h�ł��Ȃ��̂��قƂ�ǂ���Ȃ����B
�o���o���ɃG���R���Č�ł����t����Ⴂ�����������
�\�t�g�őΉ����闝�R���Ȃ�
�\�t�g�őΉ����闝�R���Ȃ�
ivy��GPU�����ŃG���R���x�͏オ��H
���₻��͂Ȃ�����
917 �FSocket774�F2011/11/04(��) 19:17:24.09 ID:uoHyBrI9
920��OC���Ȃ��Ƃ����������b�T���������
i7-920��Turbo���|�����Ă���������2.93GHz�Ȃ̂�3.2GHz��E8600�ɕ����邱�Ƃ����邾�낤
������ƒf������قǂł��Ȃ����낤���B
������ƒf������قǂł��Ȃ����낤���B
919 �FSocket774�F2011/11/04(��) 19:35:14.60 ID:uoHyBrI9
Bloom��Sandy�݂���BC�Œ肾������A���̒l�i�ł͔���ĂȂ����낤��
>>914
ivy��QSV�����������
16EU�ł�sandy��2�{��or�����ƍ��掿�ɏo�������
http://www.anandtech.com/show/4763/ivy-bridge-gpu-performance-up-to-60-faster-than-snb-better-quicksync
ivy��QSV�����������
16EU�ł�sandy��2�{��or�����ƍ��掿�ɏo�������
http://www.anandtech.com/show/4763/ivy-bridge-gpu-performance-up-to-60-faster-than-snb-better-quicksync
�������VT-d�����ȥ��
�����Ƃ��p�������������߂�
�͓��Ƃ��L�ӂ�͒蒅���Ă��C�����邯��Sandy Bridge �� ���� �͒N���g���ĂȂ���
���j��
�V�����������Ƃ���
�P�ɕ������������ǂ������Ǝv��
bulldozer�̓u�����ČĂ�ł邶���
bulldozer�̓u�����ČĂ�ł邶���
>>920
Llano�Ɣ�ׂ�1�A2���葝���̃x���`�}�[�N��
���C�g�����RD�Q�[���̍Œ������グ���ꂻ���E�E�E
����~�h�������W�Ƃ͂����ŏ�ʃN���XCPU�̓���GPU����^�[�Q�b�g�ɂ͂ł��Ȃ���
Llano�Ɣ�ׂ�1�A2���葝���̃x���`�}�[�N��
���C�g�����RD�Q�[���̍Œ������グ���ꂻ���E�E�E
����~�h�������W�Ƃ͂����ŏ�ʃN���XCPU�̓���GPU����^�[�Q�b�g�ɂ͂ł��Ȃ���
Sandy��GPU�V�F�A���Ȃ�D���Ă�̂ɁAIvy�ł���ɐ��\���シ��ƂȂ��GPU��Intel�ꋭ��
���\���オ��Ƃ����Ă��f�B�X�N���[�gGPU��������قǂł͂Ȃ����낤�B
GPU�V�F�A�ł͂��łɃg�b�v������A�Œᐫ�\�̌���Ƃ����Ӗ��ŏd�v�����B
GPU�V�F�A�ł͂��łɃg�b�v������A�Œᐫ�\�̌���Ƃ����Ӗ��ŏd�v�����B
����Ńh���C�o�����{�C�o���Ă����Ό������ƂȂ���
��������v���Z�X���[���̐������E���Ăǂꂭ�炢�Ȃ낤��
�����I�ɂ�12nm�v���Z�X�Ƃ����L�蓾��̂���
�����I�ɂ�12nm�v���Z�X�Ƃ����L�蓾��̂���
936 �FSocket774�F2011/11/05(�y) 16:36:08.59 ID:0BwIq4Uq
TSMC���킭7nm�܂ł͏\�N��������炵��
����ȍ~�͒m���
����ȍ~�͒m���
938 �FSocket774�F2011/11/06(��) 00:29:32.11 ID:FplYRsoB
�܂����A���c
32��16
�@ 22��11
�݂����ȗ���Ƃ͈Ⴄ�́H
32��16
�@ 22��11
�݂����ȗ���Ƃ͈Ⴄ�́H
������ƑO�܂�12nm�ɂł����ǂ�������
������Ȃ�Ƃ�����Z�p����������Ă���5�N�قǂ����o���ĂȂ�
��ʂɗ��ʂ������邮�炢�ɂ܂ŃR�X�g�}����̂ɂ܂��܂���Ԏ���Ă͂���Ǝv��
������Ȃ�Ƃ�����Z�p����������Ă���5�N�قǂ����o���ĂȂ�
��ʂɗ��ʂ������邮�炢�ɂ܂ŃR�X�g�}����̂ɂ܂��܂���Ԏ���Ă͂���Ǝv��
940 �FSocket774�F2011/11/06(��) 00:49:25.24 ID:NYE+Xqvh
>>938
�Ȃ���934�������悤��22�̌��14�A11�炵���AIntel�I��
�Ȃ���934�������悤��22�̌��14�A11�炵���AIntel�I��
EUV�����Ȃ茵�����悤������S�z�B
http://www.semicon-news.co.jp/news/htm/sn1960-j.htm
http://www.ushio.co.jp/jp/NEWS/products/20111027.html
http://www.semicon-news.co.jp/news/htm/sn1960-j.htm
http://www.ushio.co.jp/jp/NEWS/products/20111027.html
942 �FSocket774�F2011/11/06(��) 01:39:11.50 ID:NYE+Xqvh
>>939
>>941
broadwell�ȍ~�P�T�C�N���R�N�Ƀy�[�X�_�E������ƌ����Ă�
���������A10nm�̎�O�ł��Ȃ��q����\���A���ƌ���
���̎�O��14nm�܂�Broadwell�ň�C�ɐi�߂Ă������Ƃ������j��������Ȃ�
>>941
broadwell�ȍ~�P�T�C�N���R�N�Ƀy�[�X�_�E������ƌ����Ă�
���������A10nm�̎�O�ł��Ȃ��q����\���A���ƌ���
���̎�O��14nm�܂�Broadwell�ň�C�ɐi�߂Ă������Ƃ������j��������Ȃ�
�Ă��g�����W�X�^�����E�܂ŏk�߂����Ƃ�
�ǂ�����č����������@�\�����Ă����낤
�܂��������ŃR���s���[�^�̐i���I��肶��Ȃ�����E�E�E�H
�ǂ�����č����������@�\�����Ă����낤
�܂��������ŃR���s���[�^�̐i���I��肶��Ȃ�����E�E�E�H
�ϑw���_�C�T�C�Y
���炭�͐ϑw��2.5D�Ńg�����W�X�^�𑝂₷��Ȃ��́H
�����Ȃ�Ɣ��M���ǂɂȂ邩��NTV��Intel�̐�D�ɂȂ�
������R�X�g�̕ǂ����邩�炻���͎����Ȃ����낤��
�����̂̋}���Ȕ��W�͓��R�X�g�Ȃ̂ɍ����\���Ă����X�P�[�����O���ɋ����ˑ����Ă�������
�i���͊�{�I�ɏI��肾�낤
�����Ԃ̐��\���キ�炢�̂������Ƃ����y�[�X�ɂȂ�
�Ƃ肠�����̓v���Z�X�ւ̓��������������������Intel���������ǂ��Ɍ����邩
�Ƃ����̂����ǂ���Ȃ̂���
�����Ȃ�Ɣ��M���ǂɂȂ邩��NTV��Intel�̐�D�ɂȂ�
������R�X�g�̕ǂ����邩�炻���͎����Ȃ����낤��
�����̂̋}���Ȕ��W�͓��R�X�g�Ȃ̂ɍ����\���Ă����X�P�[�����O���ɋ����ˑ����Ă�������
�i���͊�{�I�ɏI��肾�낤
�����Ԃ̐��\���キ�炢�̂������Ƃ����y�[�X�ɂȂ�
�Ƃ肠�����̓v���Z�X�ւ̓��������������������Intel���������ǂ��Ɍ����邩
�Ƃ����̂����ǂ���Ȃ̂���
�f�X�N�g�b�v�͂����������̃j�[�Y���Ȃ����炢����ˁH
���\�K�v�ȕ���͐�p��H�g�ݍ��J�X�^���`�b�v�̕�����
���\�K�v�ȕ���͐�p��H�g�ݍ��J�X�^���`�b�v�̕�����
�[���X�[�p�[�R���s���[�^�[�̐��\�������intel��CPU���i�����Ȃ��Ƃǂ��ɂ��Ȃ��̂���Ȃ��́H
IBM��Z�������
>>947
�C���e���Ȃ�ĉᒠ�̊O����
�C���e���Ȃ�ĉᒠ�̊O����
�ᒠ�̊O���āA���N�o��MICKnightsCorner�̗p�\��̃X�p�R�����������邵�A
Tesla�̑R�̍ŗL�͌�₾���B
Tesla�̑R�̍ŗL�͌�₾���B
>>949
HPC�����L���O�̂قƂ�ǂ�x86��Xeon���炯�̏ʼnᒠ�̊O�Ƃ��A�z����
HPC�����L���O�̂قƂ�ǂ�x86��Xeon���炯�̏ʼnᒠ�̊O�Ƃ��A�z����
���Z�̃��C����tesla�����ĈӖ��ł�
>>940
14��2�{��28��GPU�ł͎g�����ȁB
14��2�{��28��GPU�ł͎g�����ȁB
���Ă��g�����W�X�^�����E�܂ŏk�߂����Ƃ́A�ǂ�����č����������@�\�����Ă����낤
�V���R���ȊO�̍ގ��ɍs����łȂ����������H�i��b�������x��
�V���R���ȊO�̍ގ��ɍs����łȂ����������H�i��b�������x��
http://vr-zone.com/articles/mainstream-desktop-cpus-future-evolution--more-performance-or-just-more-integration-/13880.html
Haswell�̏�F�X��
�N���v�_���ӏ������ɂ��Ă���
Haswell�̏�F�X��
�N���v�_���ӏ������ɂ��Ă���
��
��
��
��
��
http://kishinkannet.blog.fc2.com/blog-entry-469.html
�u���N3���ɓo�ꂷ��Ɨ\�z�����22nm Ivy Bridge�̃p�t�H�[�}���X�́ASandy Bridge�ɔ�ׁA�傫����Ă��܂���B
�����v���Z�X�͏k������܂����A���ꂪ�@�\�����Ɍ��т��Ă��Ȃ����߂ŁALGA1155�݊����\�ɂȂ����̂��A���ꂪ���R�ł��B
IPC���P�ƃN���b�N�̌���ŁA�p�t�H�[�}���X��Sandy Bridge��20%�߂��܂Łi����ł��傫�����邩���H�j�オ��ł��傤�B
�������A�O���t�B�b�N�X�p�t�H�[�}���X�͊m����2�{���锤�ł��B
�����āA����d�͂̉��P���}���܂��B
2013�N�O���Ɨ\�z�����Haswell�́A22nm�Ȃ���A��]�A�������i�����܂��B
�\�P�b�g���f�X�N�g�b�v�pLGA1150�A���o�C���prPGA947��BGA1364�ɕύX����܂��B
�p�t�H�[�}���X��Ivy Bridge���20%���シ��ƌ����܂�܂��B
�����āA8MB��L3�L���b�V���ƁA�f���A���`�����l��DDR3-1600���T�|�[�g�����ł��傤�B
�܂��A�d�����M�����[�^�A�f�B�X�v���C�|�[�g�́ACPU�ɓ�������܂��B
���������i���́A���傫�ȏ���d�͉��P�Ɍ��ѕt�����܂��B�v
�u���N3���ɓo�ꂷ��Ɨ\�z�����22nm Ivy Bridge�̃p�t�H�[�}���X�́ASandy Bridge�ɔ�ׁA�傫����Ă��܂���B
�����v���Z�X�͏k������܂����A���ꂪ�@�\�����Ɍ��т��Ă��Ȃ����߂ŁALGA1155�݊����\�ɂȂ����̂��A���ꂪ���R�ł��B
IPC���P�ƃN���b�N�̌���ŁA�p�t�H�[�}���X��Sandy Bridge��20%�߂��܂Łi����ł��傫�����邩���H�j�オ��ł��傤�B
�������A�O���t�B�b�N�X�p�t�H�[�}���X�͊m����2�{���锤�ł��B
�����āA����d�͂̉��P���}���܂��B
2013�N�O���Ɨ\�z�����Haswell�́A22nm�Ȃ���A��]�A�������i�����܂��B
�\�P�b�g���f�X�N�g�b�v�pLGA1150�A���o�C���prPGA947��BGA1364�ɕύX����܂��B
�p�t�H�[�}���X��Ivy Bridge���20%���シ��ƌ����܂�܂��B
�����āA8MB��L3�L���b�V���ƁA�f���A���`�����l��DDR3-1600���T�|�[�g�����ł��傤�B
�܂��A�d�����M�����[�^�A�f�B�X�v���C�|�[�g�́ACPU�ɓ�������܂��B
���������i���́A���傫�ȏ���d�͉��P�Ɍ��ѕt�����܂��B�v
>>959
�w���e�R�ȉ�������A������Љ��̂��l���w���e�R���B
IP�ƃv���Z�X���ɑ傫���ς��Ȃ����Ƃ��Z�I���[�����炾��B
�w���e�R�ȉ�������A������Љ��̂��l���w���e�R���B
IP�ƃv���Z�X���ɑ傫���ς��Ȃ����Ƃ��Z�I���[�����炾��B
����B�Ԉ���Ă��炲�߂�Ȃ���
�EIvyBridge�ł́i�R�A������j20%�ȏ��CPU���\�̉��P������
�@�@�EIPC�̉��P�Ǝ��g���̌���ɂ��
�@�@�E���l�ɃO���t�B�b�N�X���\�͏��Ȃ��Ƃ�2�{�ɂȂ�
�@�@�E�\�P�b�g�݊��iLGA1155����j�̑��݂����ǂ̐����
�EHaswell��2013�N�����ɓo��
�@�@�E�\�P�b�g�̕ύX����i�f�X�N�g�b�v�FLGA1150�@���o�C���FrPGA947 & BGA1364�j
�@�@�E�\�P�b�g�ύX�ɂ��I���_�C�ւ̓���������ɐi�߂���
�@�@�E���̎��_�ł��AIntel��AMD��CPU�ɑ��Đ��\�D�ʂ�ۂ��낤
�@�@�@�@���ł́A�ǂ��Ƀ��\�[�X�𓊂��邩�H
�EHaswell�̉��ǂɏ��ʂ�t����Ȃ�
�@�@�E���\�iPerformance�j��蓝���iIntegration�j�ɁA����������d�́iPower�j�̉��P�ɒ���
�E���\�̉���
�@�@�E���߃��x�����̑����ɂ��X���b�h���\�̉��P
�@�@�@�@�E�V�������s�|�[�g�inew execution ports�j
�@�@�@�@�E�v���t�F�b�`�ƕ���n���h�����O�̉��P�ibetter prefetching & branch handling�j
�@�@�@�@�EAVX2��FMA(��Ɍ��ʂ�����킯�ł͂Ȃ�)
�@�@�@�@�E�L���b�V���ш悪�{�Ɂidoubled cache bandwidth�j
�@�@�E�Ƃ����킯��Haswell�ł͓��N���b�N��20%�قǂ̐��\���P
�@�@�EL3�L���b�V����8MB�A��������(DDR3-1600+)
�E�����Ƃ����_�ł̉���
�@�@�E�{���e�[�W���M�����[�^�[��CPU�ւ̊��S�ȓ���
�@�@�@�@�E�d�͐v�ipower design�j��啝�ɉ��P
�@�@�@�@�E�V�X�e���v�ɍD�e��
�@�@�E�f�B�X�v���C�|�[�g��CPU�ɓ���
�@�@�E�_�C�ɂ�USB3�ESATA3�EEthernet�Ȃǂ�����G���A���c��
�@�@�@�@�E�C���^�t�F�[�X�����Ⴂ�R�X�g�œ����ł���
�E�d�͂̉���
�@�@�E���IDF�ŏq�ׂ�ꂽ�ʂ�
�@�@�EUltrabook��^�u���b�g�����ɖ𗧂Z�p�ł͂Ȃ�
�EAVX���߂̊g��
�@�@�ERISC�̂悤��3�A�h���X���߃t�H�[�}�b�g���
�EIvyBridge�ł́i�R�A������j20%�ȏ��CPU���\�̉��P������
�@�@�EIPC�̉��P�Ǝ��g���̌���ɂ��
�@�@�E���l�ɃO���t�B�b�N�X���\�͏��Ȃ��Ƃ�2�{�ɂȂ�
�@�@�E�\�P�b�g�݊��iLGA1155����j�̑��݂����ǂ̐����
�EHaswell��2013�N�����ɓo��
�@�@�E�\�P�b�g�̕ύX����i�f�X�N�g�b�v�FLGA1150�@���o�C���FrPGA947 & BGA1364�j
�@�@�E�\�P�b�g�ύX�ɂ��I���_�C�ւ̓���������ɐi�߂���
�@�@�E���̎��_�ł��AIntel��AMD��CPU�ɑ��Đ��\�D�ʂ�ۂ��낤
�@�@�@�@���ł́A�ǂ��Ƀ��\�[�X�𓊂��邩�H
�EHaswell�̉��ǂɏ��ʂ�t����Ȃ�
�@�@�E���\�iPerformance�j��蓝���iIntegration�j�ɁA����������d�́iPower�j�̉��P�ɒ���
�E���\�̉���
�@�@�E���߃��x�����̑����ɂ��X���b�h���\�̉��P
�@�@�@�@�E�V�������s�|�[�g�inew execution ports�j
�@�@�@�@�E�v���t�F�b�`�ƕ���n���h�����O�̉��P�ibetter prefetching & branch handling�j
�@�@�@�@�EAVX2��FMA(��Ɍ��ʂ�����킯�ł͂Ȃ�)
�@�@�@�@�E�L���b�V���ш悪�{�Ɂidoubled cache bandwidth�j
�@�@�E�Ƃ����킯��Haswell�ł͓��N���b�N��20%�قǂ̐��\���P
�@�@�EL3�L���b�V����8MB�A��������(DDR3-1600+)
�E�����Ƃ����_�ł̉���
�@�@�E�{���e�[�W���M�����[�^�[��CPU�ւ̊��S�ȓ���
�@�@�@�@�E�d�͐v�ipower design�j��啝�ɉ��P
�@�@�@�@�E�V�X�e���v�ɍD�e��
�@�@�E�f�B�X�v���C�|�[�g��CPU�ɓ���
�@�@�E�_�C�ɂ�USB3�ESATA3�EEthernet�Ȃǂ�����G���A���c��
�@�@�@�@�E�C���^�t�F�[�X�����Ⴂ�R�X�g�œ����ł���
�E�d�͂̉���
�@�@�E���IDF�ŏq�ׂ�ꂽ�ʂ�
�@�@�EUltrabook��^�u���b�g�����ɖ𗧂Z�p�ł͂Ȃ�
�EAVX���߂̊g��
�@�@�ERISC�̂悤��3�A�h���X���߃t�H�[�}�b�g���
>>961
�����A�߂��Ⴍ����킩��₷��
�����A�߂��Ⴍ����킩��₷��
�v���t�F�b�`�̉��P�Ƃ��܂����邱�Ƃ���̂�
�킴�Ə��o���ɂ��Ă�낤��
�킴�Ə��o���ɂ��Ă�낤��
����������O�H
�L�������������ɏ�����Ă�̂��������ȁB
�|�[�g��������Ƃ����[�N����Ă�����
�|�[�g��������Ƃ����[�N����Ă�����
>>965
�ǂ�ňӖ��𗝉��ł��Ȃ����O�ł́A���₵�Ă������ł��Ȃ�����
����ɖ��ʎ�Ԃ��g�킹�ĕs�����ɂ����邱�Ƃ������O�ɂ͖�������B
�w�̓e�X�g�Ő��т����サ���Ƃ���B
����́A���Ɋw�m�������܂ŏo���ɂ��݂��ē_����Ⴍ���Ă��Ă�������Ȃ̂��H
�ǂ�ňӖ��𗝉��ł��Ȃ����O�ł́A���₵�Ă������ł��Ȃ�����
����ɖ��ʎ�Ԃ��g�킹�ĕs�����ɂ����邱�Ƃ������O�ɂ͖�������B
�w�̓e�X�g�Ő��т����サ���Ƃ���B
����́A���Ɋw�m�������܂ŏo���ɂ��݂��ē_����Ⴍ���Ă��Ă�������Ȃ̂��H
���ꂪ�A�X�y�Ƃ����z���E�E�E
�S���ϑz�ŏ������Ƃ�����t�ɂ����[��
�ڂ����l�ɕ��������������Ƃ��날�����H
�ڂ����l�ɕ��������������Ƃ��날�����H
�W�҂Ƃ��m�荇���������疼�O�t���̋L����NDA�ᔽ�Ƃ����肦��
���������Ƃ������A�\�[�X���m�肽�������B
���������Ƃ������A�\�[�X���m�肽�������B
972 �FSocket774�F2011/11/07(��) 02:18:01.11 ID:Je4ZF7tV
�������h�����̃N���b�N�͂ǂ��܂ŏグ����̂���
�N���b�N��łT�����ゾ�Ƃ���ƂQ�O�����\���₻���Ƃ���Β�i�S�D�O�s�a�S�D�S���炢�K�v����
�N���b�N��łT�����ゾ�Ƃ���ƂQ�O�����\���₻���Ƃ���Β�i�S�D�O�s�a�S�D�S���炢�K�v����
+20%�͂������Ƀ��b�g�p�t�H�[�}���X����Ȃ��́H
TDP95W��77W�ɉ����邩��2700�̌�p�͂���ȂɃN���b�N�オ��Ȃ����낤
TDP95W��77W�ɉ����邩��2700�̌�p�͂���ȂɃN���b�N�オ��Ȃ����낤
�V�������s�|�[�g���āA�������s�ł��閽�ߐ�����������Ă��Ƃ��ȁH
���ꂾ������AHTT�ɂ��}���`�X���b�h���\����ŁA
1�R�A�ӂ�̐��\��20%�����Ă��ƂȂ炠�邩���H
���ꂾ������AHTT�ɂ��}���`�X���b�h���\����ŁA
1�R�A�ӂ�̐��\��20%�����Ă��ƂȂ炠�邩���H
>>973
�ނ���TDP95W�̂܂܂ł��������i�N���b�N���グ�ė~�����Ǝv���Ă鉴�͏����h�Ȃˁ[
TB������Ȃ��Ċ��S�ɒ�i�̕��̃N���b�N��4GHz�����鎞����ė���납
�ނ���TDP95W�̂܂܂ł��������i�N���b�N���グ�ė~�����Ǝv���Ă鉴�͏����h�Ȃˁ[
TB������Ȃ��Ċ��S�ɒ�i�̕��̃N���b�N��4GHz�����鎞����ė���납
>>975
��Xeon X5698 4.4GHz
��Xeon X5698 4.4GHz
>>976
�����ԑO�ɉ\�ł͕��������Ƃ��������Ǐo�ׂ���Ă��̂�
�ł�������ăf���A���R�A�Ȃ��(�L��֥�M)
���Ƃ����C���X�g���[���т̃N�A�b�h�ȏ��CPU��4GHz�������鎞��ɂȂ��Ăق�������
�����ԑO�ɉ\�ł͕��������Ƃ��������Ǐo�ׂ���Ă��̂�
�ł�������ăf���A���R�A�Ȃ��(�L��֥�M)
���Ƃ����C���X�g���[���т̃N�A�b�h�ȏ��CPU��4GHz�������鎞��ɂȂ��Ăق�������
���̃I���S���̃^�[��(Haswell)�ł��V�X�e�������Əȓd�͂�����ȁ[
�ǂ����ƂȂ��ǐ�������܃��N���N���Ȃ�
��i4GHz������Broadwell�����肩�ȁH
����Ȃ��ƌ����Ă����傤���Ȃ����ǁA���̋Z�p(HK/MG,22nmtri-gate)��
��������Tejas����Ă���Ȃ����ȂƂ��v�����Ⴄ���
�ǂ����ƂȂ��ǐ�������܃��N���N���Ȃ�
��i4GHz������Broadwell�����肩�ȁH
����Ȃ��ƌ����Ă����傤���Ȃ����ǁA���̋Z�p(HK/MG,22nmtri-gate)��
��������Tejas����Ă���Ȃ����ȂƂ��v�����Ⴄ���
���\���オ�T���߂ƌ����Ă�>>957�ɂ���
Sandy��Haswell�́ANehalem��Sandy���炢�͐��\���シ��݂�������
���̓I���S�������\��邶���Ǝv������
Sandy��Haswell�́ANehalem��Sandy���炢�͐��\���シ��݂�������
���̓I���S�������\��邶���Ǝv������
AMD���O�_�O�_�����琫�\�����u���Ń_�C�T�C�Y�k���Əȓd�͉��Ɍ������Ă��
Bulldozer�̎S�킩��O����AHaswell�̐v�͎n�܂��Ă����A
AMD�W�Ȃ��ɁA�ȓd�͉���簐i���Ă��邾������Ȃ��́H
VR�����Ȃ�āA���N���O���猤�����Ă�����B
AMD�W�Ȃ��ɁA�ȓd�͉���簐i���Ă��邾������Ȃ��́H
VR�����Ȃ�āA���N���O���猤�����Ă�����B
Intel��AMD��S�R�C�ɂ��Ȃ��̂�AMD�͋C�ɂ���邽���Ă��ꂽ���Ă��悤���Ȃ��Ȃ�
���킢����
���킢����
�Ƃ�����AMD�̐��\���ǂ��ł���Intel�͂ǂ�ǂ�i���������Ȃ��Ƃ����Ȃ���
Intel�̍ő�̓G�͎��Ђ̑O���㐻�i
Intel�̍ő�̓G�͎��Ђ̑O���㐻�i
������x�i�����Ȃ��ƐV���i�����Ă��炦�Ȃ����A�i�����߂���Ǝ����̎������k�ނ���ς���
�݂�Ȃ͂ǂ����̃^�C�~���O��CPU�����Ă�H
�v���Z�X�Z�p���v�V(Tick)
�}�C�N���A�[�L�e�N�`�������V(Tock)
�v���Z�X�Z�p���v�V(Tick)
�}�C�N���A�[�L�e�N�`�������V(Tock)
�O�҂��ȁB�ƌ������V�A�[�L�e�N�`���̗l�q�������ėǂ������Ȃ瓯�A�[�L�e�N�`���̑��ڂ����Ƃɂ��Ă�B
���̗��ꂩ��s���āAIntel��肨�O��̂ق���AMD���C�ɂ��Ă�̂͊m��
AMD�M�҂́A�Ⴂ�����ƃz����������z����I�Ԑl�킾�����
���o�b�������Ƃ����g�������Ȃ̂ɃC���e�����`�l�c�̕�����������`�l�c�̂o�b���������ǁH
���̐S�́u����������Ɩ��@�����ɐ���Ȃ�����v��������
>>985
�傫�ȃW�����v���Ɗ�������ǂ���ł��B
�ǂ������ɌŒ肷��K�v�͖�������B
���Ƃ́A�ɂȎ��Ƃ����������t����B
���͖Z���߂��āA������W�����v�̂��傫���Ă����Ȃ��B
�傫�ȃW�����v���Ɗ�������ǂ���ł��B
�ǂ������ɌŒ肷��K�v�͖�������B
���Ƃ́A�ɂȎ��Ƃ����������t����B
���͖Z���߂��āA������W�����v�̂��傫���Ă����Ȃ��B
���ʂ̓X�y�b�N����Ȃ��Ǝv�������ɔ���������̂�����
���X�����
>>989
FX�������グ���肪�Ƃ��������܂�
FX�������グ���肪�Ƃ��������܂�
���߂Ă�AMD���ĂȂ������ȁ[
K6-III���������������XP��������
K6-III���������������XP��������
���e���v����
Ivy Bridge�֘A
http://pc.watch.impress.co.jp/docs/column/kaigai/20110916_478013.html
http://www.anandtech.com/show/4830/intels-ivy-bridge-architecture-exposed
http://www.bit-tech.net/hardware/cpus/2011/10/10/all-about-ivy-bridge/1
Haswell�֘A
http://pc.watch.impress.co.jp/docs/column/kaigai/20110915_477478.html
http://pc.watch.impress.co.jp/docs/column/kaigai/20110930_480539.html
http://www.4gamer.net/games/132/G013298/20110904002/
http://vr-zone.com/articles/mainstream-desktop-cpus-future-evolution--more-performance-or-just-more-integration-/13880.html
Ivy Bridge�֘A
http://pc.watch.impress.co.jp/docs/column/kaigai/20110916_478013.html
http://www.anandtech.com/show/4830/intels-ivy-bridge-architecture-exposed
http://www.bit-tech.net/hardware/cpus/2011/10/10/all-about-ivy-bridge/1
Haswell�֘A
http://pc.watch.impress.co.jp/docs/column/kaigai/20110915_477478.html
http://pc.watch.impress.co.jp/docs/column/kaigai/20110930_480539.html
http://www.4gamer.net/games/132/G013298/20110904002/
http://vr-zone.com/articles/mainstream-desktop-cpus-future-evolution--more-performance-or-just-more-integration-/13880.html
>>997
������
������
1000
1001 �F�P�O�O�P�F
1��̃}�V�����g�ݏオ��܂����B�B�B
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://hibari.2ch.net/jisaku/
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://hibari.2ch.net/jisaku/