Intel Larrabee 5�R�A
Intel Larrabee 4�R�A
http://pc11.2ch.net/test/read.cgi/jisaku/1248799339/
http://pc11.2ch.net/test/read.cgi/jisaku/1248799339/
|
|
|
�ߋ��X��
Intel Larrabee 1�R�A
http://pc11.2ch.net/test/read.cgi/jisaku/1217915128/
Intel Larrabee 2�R�A
http://pc11.2ch.net/test/read.cgi/jisaku/1238152183/
Intel Larrabee 3�R�A
http://pc11.2ch.net/test/read.cgi/jisaku/1245944113/
Intel Larrabee 1�R�A
http://pc11.2ch.net/test/read.cgi/jisaku/1217915128/
Intel Larrabee 2�R�A
http://pc11.2ch.net/test/read.cgi/jisaku/1238152183/
Intel Larrabee 3�R�A
http://pc11.2ch.net/test/read.cgi/jisaku/1245944113/
(�L�E�ցE`)
LalaVoice
�����������ق���
nvidia�͏o��ڏ����Ȃ�Fermi���o���o����`���Ă�̂�
���Ȃ��Ƃ��R�A���Ǝ��g�����킩���...
nvidia�͏o��ڏ����Ȃ�Fermi���o���o����`���Ă�̂�
���Ȃ��Ƃ��R�A���Ǝ��g�����킩���...
�ւ肪�Ȃ��̂͗ǂ��ւ�
>>6
����́A���C�ɑ���o���Ă���B
����́A���C�ɑ���o���Ă���B
�����������\���o�Ȃ���������I���{���ڂ����i752���̗\��
�I���{�ɂł���悤�ȃT�C�Y�Ȃ́H
10 �F,,�E�L�́M�E,,�j��-�������F2009/11/29(��) 21:04:18 ID:1kopwAVM
�ǂ����ɂ���CPU�����O��Ōv�悪�����Ă�
Larrabee����CPU�R�A����Vec���j�b�g1�Ȃ��A
CPU�Ƃ̓����Ƃ����̂́A���ʂ�CPU�R�A��Vec���j�b�g1����������Ƃ������ƂɂȂ�̂��ȁB
CPU�Ƃ̓����Ƃ����̂́A���ʂ�CPU�R�A��Vec���j�b�g1����������Ƃ������ƂɂȂ�̂��ȁB
12 �F,,�E�L�́M�E,,�j��-�������F2009/11/29(��) 22:49:01 ID:1kopwAVM
>>11
http://pc.watch.impress.co.jp/docs/2004/1228/kaigai02l.gif
�݊����Ƃ��Ă����߃Z�b�g���x���Ō݊����Ă��������
���j�b�g�̍\���܂œ����ɂ���K�v�͂Ȃ��ł���B
�C���I�[�_�E�A�E�g�I�u�I�[�_�ł��œK�ȕ��@�͕ς��B
�y���G�H���z
Nehalem, Sandy Bridge
�y�V���v���R�A�H���z
Atom, Keifer, Larrabee
�y�n�C�u���b�h�z
Haswell�H
http://pc.watch.impress.co.jp/docs/2004/1228/kaigai02l.gif
{kind=link}
�݊����Ƃ��Ă����߃Z�b�g���x���Ō݊����Ă��������
���j�b�g�̍\���܂œ����ɂ���K�v�͂Ȃ��ł���B
�C���I�[�_�E�A�E�g�I�u�I�[�_�ł��œK�ȕ��@�͕ς��B
�y���G�H���z
Nehalem, Sandy Bridge
�y�V���v���R�A�H���z
Atom, Keifer, Larrabee
�y�n�C�u���b�h�z
Haswell�H
Automatic Generation of Vectorized Fast Fourier Transform Libraries for
the Larrabee and AVX Instruction Set Extension
http://www.ece.cmu.edu/~franzf/papers/hpec09-lrb.pdf
the Larrabee and AVX Instruction Set Extension
http://www.ece.cmu.edu/~franzf/papers/hpec09-lrb.pdf
Intel�̃X�J��CPU+Larrabee�̃w�e���W�j�A�XCPU�r�W����
http://pc.watch.impress.co.jp/docs/column/kaigai/20091201_332428.html
�L���̖`���̈�ۂŁAIntel�̏���CPU�\�z��Larrabee���g�ݍ��܂�Ă���̂��Ǝv����
�ǂݐi�߂Ă�������A�I�`�ň����̕s�����������킹�Ă�������B�ǂ��Ȃ�낤�B
http://pc.watch.impress.co.jp/docs/column/kaigai/20091201_332428.html
�L���̖`���̈�ۂŁAIntel�̏���CPU�\�z��Larrabee���g�ݍ��܂�Ă���̂��Ǝv����
�ǂݐi�߂Ă�������A�I�`�ň����̕s�����������킹�Ă�������B�ǂ��Ȃ�낤�B
�Q���V���K�[�̐l���Ȃ��Ȃ����̂��s���ޗ��̂悤�ł��Ȃ��B
�v���Z�X�����ƃX�P�[�����āA����Ł[�Ԃ�����{���с[�i�R�A�͂��Ƃނ������ȁ[�j*8��CELL���h�L����Ă���������I�I
�v���Z�X�����ƃX�P�[�����āA����Ł[�Ԃ�����{���с[�i�R�A�͂��Ƃނ������ȁ[�j*8��CELL���h�L����Ă���������I�I
Larrabee�̃v���W�F�N�g���[�_�[��Douglas Carmean
�㓡�͂��̎�̘b��Ɋւ��Ă͌����z�ȉ�����
�㓡�͂��̎�̘b��Ɋւ��Ă͌����z�ȉ�����
>>16
�͂��H�u���i�v�Ə����Ă��邾������
����ɋȉ����邨�O�������z�ȉ�
2008/1111/kaigai475.htm
��Larrabee�̃A�[�L�e�N�`����S������Intel��Doug Carmean��(Larrabee Chief Architect, Intel)�ɂ���
�͂��H�u���i�v�Ə����Ă��邾������
����ɋȉ����邨�O�������z�ȉ�
2008/1111/kaigai475.htm
��Larrabee�̃A�[�L�e�N�`����S������Intel��Doug Carmean��(Larrabee Chief Architect, Intel)�ɂ���
�Q����Larrabee�𐄐i���Ă����H
�̂���Larrabee�̂悤�ȃ��j�[�R�A�����Ă����̂̓��g�i�[
5����11���Ƀh�C�c�Ńv���[�������̂����g�i�[������
���łɌ�����Douglas Carmean���ގЂ�����͂��ĂȂ�
�ǂ����s�����Ȃ̂��Ă���
�̂���Larrabee�̂悤�ȃ��j�[�R�A�����Ă����̂̓��g�i�[
5����11���Ƀh�C�c�Ńv���[�������̂����g�i�[������
���łɌ�����Douglas Carmean���ގЂ�����͂��ĂȂ�
�ǂ����s�����Ȃ̂��Ă���
19 �F,,�E�L�́M�E,,�j��-�������F2009/12/01(��) 01:34:48 ID:ekg7DMWw
> Rattner���̔����ŁA����1�ʔ����̂́A�f�[�^����d���R�A�ɂ����āA16-way�����łȂ��A32-way��SIMD�̎������������Ă���_�B
> ����́AIntel�����݂�LNI��16-way��SIMD���A�ŏI�I�ȉł���Ƃ܂����肵�Ă��Ȃ����Ƃ��������Ă���B
�㓡�̓{�P�Ă�̂��H
AVX��VEX�G���R�[�f�B���O��1024�r�b�g�܂ł�z�肵�������ɂ킽�閽�߃Z�b�g�g���X�L�[��������
�����Ă��낤��
> ����́AIntel�����݂�LNI��16-way��SIMD���A�ŏI�I�ȉł���Ƃ܂����肵�Ă��Ȃ����Ƃ��������Ă���B
�㓡�̓{�P�Ă�̂��H
AVX��VEX�G���R�[�f�B���O��1024�r�b�g�܂ł�z�肵�������ɂ킽�閽�߃Z�b�g�g���X�L�[��������
�����Ă��낤��
>>18
���������d���͒P�Ȃ�X�s�[�J�[���Ƃ����F���Ȃ́H
http://www.4gamer.net/news/history/2007.04/20070420195746detail.html
http://techon.nikkeibp.co.jp/article/NEWS/20080318/149166/
http://journal.mycom.co.jp/articles/2008/08/21/idf03/001.html
Larrabee�̊J����Tera-Scale Research�𗣂�ăq���Y�{����̂ɂȂ�A
�������NJ�����G���v���O���[�v�g�b�v�̍s�����u���i�v�ƌĂԂ̂͐������ł���B
http://pc.watch.impress.co.jp/docs/2008/1217/kaigai481.htm
��Larrabee��3�`�[���̂����A�q���Y�{���n�̐l�ނɂ���ĊJ������Ă���B
���q���Y�{���̃g�b�v�ł���Patrick(Pat) P. Gelsinger(�p�b�g�EP�E�Q���V���K�[)��(Senior Vice President and General Manager, Digital Enterprise Group)
���������d���͒P�Ȃ�X�s�[�J�[���Ƃ����F���Ȃ́H
http://www.4gamer.net/news/history/2007.04/20070420195746detail.html
http://techon.nikkeibp.co.jp/article/NEWS/20080318/149166/
http://journal.mycom.co.jp/articles/2008/08/21/idf03/001.html
Larrabee�̊J����Tera-Scale Research�𗣂�ăq���Y�{����̂ɂȂ�A
�������NJ�����G���v���O���[�v�g�b�v�̍s�����u���i�v�ƌĂԂ̂͐������ł���B
http://pc.watch.impress.co.jp/docs/2008/1217/kaigai481.htm
��Larrabee��3�`�[���̂����A�q���Y�{���n�̐l�ނɂ���ĊJ������Ă���B
���q���Y�{���̃g�b�v�ł���Patrick(Pat) P. Gelsinger(�p�b�g�EP�E�Q���V���K�[)��(Senior Vice President and General Manager, Digital Enterprise Group)
21 �F,,�E�L�́M�E,,�j��-�������F2009/12/01(��) 01:54:17 ID:ekg7DMWw
���U����ƃA�[�L�e�N�g�͕ʃ��m���낤
���ˁB
�A�[�L�e�N�g�͗v�����������ׂ��f�U�C������B
���K�͂ŗ\�Z���������i����̂͏㋉���В��Ƃ��̎d���B
�A�[�L�e�N�g�͗v�����������ׂ��f�U�C������B
���K�͂ŗ\�Z���������i����̂͏㋉���В��Ƃ��̎d���B
23 �F,,�E�L�́M�E,,�j��-�������F2009/12/01(��) 02:19:40 ID:ekg7DMWw
�Q���̑ގЂ̗v����Larrabee�]�X��FUD�̈���o�Ȃ��Ǝv�����B
��{�~���ގЂ���
��{�~���ގЂ���
�ԐV���̕ł���"EMC�̈�������"�������
ttp://www.theregister.co.uk/2009/09/14/emc_gelsinger/
ttp://www.theregister.co.uk/2009/09/14/emc_gelsinger/
�~���ގЂ��ǂ�����EMC��IA�̗p���̕ω��𒍎����Ȃ��Ɖ��Ƃ��B
�g�D�ĕҌ��VCG�̗������n���炷��ƁA
Larrabee�̗\�Z�������邱�Ƃ͂����Ă����邱�Ƃ͂Ȃ�������B
http://pc.watch.impress.co.jp/img/pcw/docs/316/184/genko565.jpg
�g�D�ĕҌ��VCG�̗������n���炷��ƁA
Larrabee�̗\�Z�������邱�Ƃ͂����Ă����邱�Ƃ͂Ȃ�������B
http://pc.watch.impress.co.jp/img/pcw/docs/316/184/genko565.jpg
{kind=link}
������Xbox�̗̍p������AMD�ɔs�ꂽ�̂��������낤
27 �F,,�E�L�́M�E,,�j��-�������F2009/12/01(��) 22:00:18 ID:ekg7DMWw
����Ȃ�őސE����قǔނ̌��т͔����炢����ˁ[���낤��
�㓡���܂�Larrabee�W�̋L�����o���Ă邪�B
�Z�p�I�ȏ������i��ł���Ƃ�����̓I�Ȑ��i���v��ɋ^�╄��悵�Ă���̂�
��ނ̊��G����Larrabee�̐�s�����������݂Ă�̂��ȁB
�Z�p�I�ȏ������i��ł���Ƃ�����̓I�Ȑ��i���v��ɋ^�╄��悵�Ă���̂�
��ނ̊��G����Larrabee�̐�s�����������݂Ă�̂��ȁB
������IDF�̃X�s�[�`�̗\�肪�������Ƃ����_���炵�ĉ~���ގЂ��Ċ����ł͂Ȃ�����
�O���猩�����͉��炩�̈��ӎ��C�Ƃ��v���Ȃ���
�O���猩�����͉��炩�̈��ӎ��C�Ƃ��v���Ȃ���
30 �F,,�E�L�́M�E,,�j��-�������F2009/12/02(��) 00:35:07 ID:4wnVhNuN
http://japan.emc.com/about/emc-at-glance/exec-team/gelsinger.htm
EMC�ł̔ނ̃|�W�V�����݂Ă݂悤��
EMC�ł̔ނ̃|�W�V�����݂Ă݂悤��
31 �F,,�E�L�́M�E,,�j��-�������F2009/12/02(��) 00:39:43 ID:4wnVhNuN
VMWare�̐e��ЂȂ��
�Q���V���K�[���ɂ��ẮAIDF�Ńv���[������\��ɂȂ��Ă���ƌ��\���ꂽ��̑ގЂ�
�~���Ȃ킯�Ȃ��ł���B
���炩�̎Г�����������Ƃ݂�̂����R�B
�~���Ȃ킯�Ȃ��ł���B
���炩�̎Г�����������Ƃ݂�̂����R�B
33 �F,,�E�L�́M�E,,�j��-�������F2009/12/02(��) 01:04:07 ID:4wnVhNuN
�l�b�g��ɗ���Ă��邾���̏���Ēm�������Ԃ���M�ߐ������邯�ǂ�
35 �F,,�E�L�́M�E,,�j��-�������F2009/12/02(��) 01:43:17 ID:4wnVhNuN
�듚��
�㓡�����X��
�㓡�ƕ���������z�E�������v���o��
>>33
�����܂Œf�����Č����Ȃ�㓡���Ԉ���Ă���A���̏ؖ������Ă݂��w
�㓡���Ԉ���Ă��邩�A���O�������l�b�g�ő��l��ے肷�邵���\���Ȃ������̃o�J��
�����̏Z�l�����f���Ă����
�����܂Œf�����Č����Ȃ�㓡���Ԉ���Ă���A���̏ؖ������Ă݂��w
�㓡���Ԉ���Ă��邩�A���O�������l�b�g�ő��l��ے肷�邵���\���Ȃ������̃o�J��
�����̏Z�l�����f���Ă����
�㓡�M�҃����X��
41 �F,,�E�L�́M�E,,�j��-�������F2009/12/02(��) 07:35:41 ID:4wnVhNuN
�Ƃ��������A
AVX��FP1024�r�b�g(32����), Int 512�r�b�g�܂Ŋg���������Č����Ă������2008�N��IDF
����ȉߋ��̘b��ɂȂ�ō��X�����Ă�́H
�����Ō����Ă��듚��
http://pc.watch.impress.co.jp/docs/2008/0407/kaigai434.htm
Cell��1TFLOPS�Ƃ����Ⴂ�����Ƃ������������ǁA�듚����͖{���Ƀu���Ă�B
�듚�̈ӌ���ǂ��Ă����Intel�̈ӌ����R���R���ς���Ă�悤�Ɍ����邪
���͎����т��ĂāA�P�ɋL�������Ă�듚�̉��߂��u���Ă邾���Ƃ����B
���Ƃ���Larrabee��2008�N�́u10�R�A��Core 2 Duo(143mm2)�Ɠ������x�̖ʐρv��
�قڂ��̂܂�܂̎d�l�Ń_�C���o�Ă�����Ƃ����B
�듚�₻�̑�theINQ�`���h�����������Ă邾���Ȃ��
AVX��FP1024�r�b�g(32����), Int 512�r�b�g�܂Ŋg���������Č����Ă������2008�N��IDF
����ȉߋ��̘b��ɂȂ�ō��X�����Ă�́H
�����Ō����Ă��듚��
http://pc.watch.impress.co.jp/docs/2008/0407/kaigai434.htm
Cell��1TFLOPS�Ƃ����Ⴂ�����Ƃ������������ǁA�듚����͖{���Ƀu���Ă�B
�듚�̈ӌ���ǂ��Ă����Intel�̈ӌ����R���R���ς���Ă�悤�Ɍ����邪
���͎����т��ĂāA�P�ɋL�������Ă�듚�̉��߂��u���Ă邾���Ƃ����B
���Ƃ���Larrabee��2008�N�́u10�R�A��Core 2 Duo(143mm2)�Ɠ������x�̖ʐρv��
�قڂ��̂܂�܂̎d�l�Ń_�C���o�Ă�����Ƃ����B
�듚�₻�̑�theINQ�`���h�����������Ă邾���Ȃ��
42 �F,,�E�L�́M�E,,�j��-�������F2009/12/02(��) 07:44:28 ID:4wnVhNuN
http://software.intel.com/en-us/articles/intel-avx-new-frontiers-in-performance-improvements-and-energy-efficiency/
* OS context management rework only needs to be done once.
* Future Vector Integer support to 256 and 512 bits.
* Vector Future FP support to 512 bits and even 1024 bits.
���̂ւ�Ƃ�
* OS context management rework only needs to be done once.
* Future Vector Integer support to 256 and 512 bits.
* Vector Future FP support to 512 bits and even 1024 bits.
���̂ւ�Ƃ�
1024bit�܂Ŋg���ł��邯�ǁA�����܂Ŋg�������R�A������̂��ǂ��̂�
�ǂ���Intel�Г��ł��܂����������Č��������Ǝv������
�ǂ���Intel�Г��ł��܂����������Č��������Ǝv������
44 �F,,�E�L�́M�E,,�j��-�������F2009/12/02(��) 08:17:38 ID:4wnVhNuN
�Ȃɂ��������Ⴂ�܂����B
Ct�m���Ă�H����ŏ�����1024��SIMD�Ȃ撆�ԃR�[�h�iVIP�j���B
��ɂ���ɂ������1024�B
http://www.intel.com/technology/itj/2007/v11i4/7-future-proof/7-implement.htm
> �ǂ���Intel�Г��ł��܂����������Č��������Ǝv������
�����ʂ�듚�������Ă邾���ł����Ƃ�
Ct�m���Ă�H����ŏ�����1024��SIMD�Ȃ撆�ԃR�[�h�iVIP�j���B
��ɂ���ɂ������1024�B
http://www.intel.com/technology/itj/2007/v11i4/7-future-proof/7-implement.htm
> �ǂ���Intel�Г��ł��܂����������Č��������Ǝv������
�����ʂ�듚�������Ă邾���ł����Ƃ�
�c�q���Ȃ��㓡�ɂ����������Ă邩�悭�킩���
�����Ă邱�Ƃ͂قړ������Ǝv������
���m�Ɍ������Ă邩�ǂ������č������邾����
�����Ă邱�Ƃ͂قړ������Ǝv������
���m�Ɍ������Ă邩�ǂ������č������邾����
46 �F,,�E�L�́M�E,,�j��-�������F2009/12/02(��) 08:30:18 ID:4wnVhNuN
1024�r�b�g��SIMD���z���߃Z�b�g�������^�C���ʼn��߂��Ď��s����B
SSE�Ȃ�8��J��Ԃ������BAVX�Ȃ�4��ALarrabee�Ȃ�2��B
�ŏ����1024�r�b�g�ŁA�����Ɍ������ĐL���Ă����`�ƂȂ�B
�t��VIP��64����i2048�r�b�g�j��SIMD���j�b�g�̓J�o�[������Ȃ��B
�����炻��͖��m�ɂ��肦�Ȃ��B
SSE�Ȃ�8��J��Ԃ������BAVX�Ȃ�4��ALarrabee�Ȃ�2��B
�ŏ����1024�r�b�g�ŁA�����Ɍ������ĐL���Ă����`�ƂȂ�B
�t��VIP��64����i2048�r�b�g�j��SIMD���j�b�g�̓J�o�[������Ȃ��B
�����炻��͖��m�ɂ��肦�Ȃ��B
http://www.enterprisenetworksandservers.com/newsflash/art.php?762
http://www.theregister.co.uk/2009/11/17/sc09_rattner_keynote/page2.html
�㓡�ȊO�ɂ�������Ă���C�O�̋L���͂���Ƃ����̂�
>>33�͓�����������
http://www.theregister.co.uk/2009/11/17/sc09_rattner_keynote/page2.html
�㓡�ȊO�ɂ�������Ă���C�O�̋L���͂���Ƃ����̂�
>>33�͓�����������
���߂̃x�N�^�[���Ɖ��Z�R�A�̃x�N�^�[�����������Ă���Ƃ�
���̈����z�̂�肽�����Ƃ͗����ł��Ȃ���
�o�J�͋Z�p�L���ǂ�ŁA2ch�ɏ������ނȂ�
�C���C������,,�E�L�́M�E,,�j��-�������̃o�J�͂�
���̈����z�̂�肽�����Ƃ͗����ł��Ȃ���
�o�J�͋Z�p�L���ǂ�ŁA2ch�ɏ������ނȂ�
�C���C������,,�E�L�́M�E,,�j��-�������̃o�J�͂�
>>48
���Ȃ��Ƃ�Larrabee�͉��Z�R�A�̃x�N�^���ƈ�v���Ă邯��
���Ȃ��Ƃ�Larrabee�͉��Z�R�A�̃x�N�^���ƈ�v���Ă邯��
>>48�͊���I�ɂȂ��Ă�悤����44�̈Ӗ����ǂ߂ĂȂ��ȁB
Ct�Ɋւ��Ă͍����ł��b��ɂ����̂͑匴���炢�������Ȃ��B
�㓡�⓪�̈����㓡�ׂ͉��̂��Ƃ��킩��Ȃ��Ă������͂Ȃ��B
Ct�Ɋւ��Ă͍����ł��b��ɂ����̂͑匴���炢�������Ȃ��B
�㓡�⓪�̈����㓡�ׂ͉��̂��Ƃ��킩��Ȃ��Ă������͂Ȃ��B
51 �FSocket774�F2009/12/02(��) 10:07:05 ID:YlYrw+KL
�������[�X���邩�ǂ߂Ȃ��̂́A�㓡�̓A���e�i������Ȃ��������낤
http://www.brightsideofnews.com/news/2009/11/25/intel-larrabee-to-surprise-with-performance2c-launch-in-1h-2010.aspx
�������Intel�͈Ӑ}�I�Ƀ����[�X�����̖���������Ă���B
http://www.brightsideofnews.com/news/2009/11/25/intel-larrabee-to-surprise-with-performance2c-launch-in-1h-2010.aspx
�������Intel�͈Ӑ}�I�Ƀ����[�X�����̖���������Ă���B
Intel�����������Ă���N�ɂ������[�X���͓ǂ߂Ȃ���Ȃ����H
�m�x�̍������������Ă���l�ŁA�������
�L��ȑO�Ɍ������Ă������l���Ă��Ȃ���Ȃ���
�L��ȑO�Ɍ������Ă������l���Ă��Ȃ���Ȃ���
Intel Larrabee finally hits 1TFLOPS - 2.7x faster than nVidia GT200!
http://www.brightsideofnews.com/news/2009/12/2/intel-larrabee-finally-hits-1tflops---27x-faster-than-nvidia-gt200!.aspx
SGEMM 4K x 4K
1. Intel Larrabee [LRB, 45nm] - 1006 GFLOPS
2. EVGA GeForce GTX 285 FTW - 425 GFLOPS
3. nVidia Tesla C1060 [GT200, 65nm] - 370 GFLOPS
4. AMD FireStream 9270 [RV770, 55nm] - 300 GFLOPS
5. IBM PowerXCell 8i [Cell, 65nm] - 164 GFLOPS
http://www.brightsideofnews.com/news/2009/12/2/intel-larrabee-finally-hits-1tflops---27x-faster-than-nvidia-gt200!.aspx
SGEMM 4K x 4K
1. Intel Larrabee [LRB, 45nm] - 1006 GFLOPS
2. EVGA GeForce GTX 285 FTW - 425 GFLOPS
3. nVidia Tesla C1060 [GT200, 65nm] - 370 GFLOPS
4. AMD FireStream 9270 [RV770, 55nm] - 300 GFLOPS
5. IBM PowerXCell 8i [Cell, 65nm] - 164 GFLOPS
�㓡�̓T�C�g���肾���ŋL���������Ȃ���ă��C�^�[�ƈ����
�����ȂƂ���Ŏ�ނ�����Ă���̂ɃA���e�i������Ȃ��Ă��Ƃ�
���m��N�����̌������Ƃ͈ꖡ�Ⴄ��
�����ȂƂ���Ŏ�ނ�����Ă���̂ɃA���e�i������Ȃ��Ă��Ƃ�
���m��N�����̌������Ƃ͈ꖡ�Ⴄ��
�I������b�����������������B�㓡�N���������ˁ`
57 �F,,�E�L�́M�E,,�j��-�������F2009/12/03(��) 00:22:56 ID:Vx3UacNb
�㓡����͂�����悭�ǂ�ł����悤�ɁB
�Z�p�𐳂����������ĂȂ��̂͋L���������ȑO�̖�肾�B
http://pc12.2ch.net/test/read.cgi/tech/1255256230/552
�Z�p�𐳂����������ĂȂ��̂͋L���������ȑO�̖�肾�B
http://pc12.2ch.net/test/read.cgi/tech/1255256230/552
58 �F,,�E�L�́M�E,,�j��-�������F2009/12/03(��) 00:27:00 ID:Vx3UacNb
SIMD�ŏ���肪�������ǂ������Ă̂́A���͐Ϙa�ȊO�̃��[�h�E�X�g�A�E�]�u�̃X���[�v�b�g��
�Ϙa������邩�ǂ����ɂ������Ă�B
Cell�̓��[�h���X�g�A���]�u�������p�C�v�ɂ����ē������s�o���Ȃ�����l�b�N�ɂȂ�Ɍ��܂��Ă邶��Ȃ����B
Fermi��2�N���X�^�[��1��LSU���L�Ȃ�ł�͂�l�b�N�B
�Ϙa������邩�ǂ����ɂ������Ă�B
Cell�̓��[�h���X�g�A���]�u�������p�C�v�ɂ����ē������s�o���Ȃ�����l�b�N�ɂȂ�Ɍ��܂��Ă邶��Ȃ����B
Fermi��2�N���X�^�[��1��LSU���L�Ȃ�ł�͂�l�b�N�B
�㓡�ɉ����`�������̂Ȃ�A������̕������Ėi���ĂȂ��Ŗ{�l���ҏW���Ƀ��[�������
ttp://pc.watch.impress.co.jp/docs/news/20091203_333078.html
��畺�q�ł�������B
��畺�q�ł�������B
��������
���ǂ̂Ƃ�����с[�͓��ݑ䂾�����́H
�v��ʂ肾�낤
�{����Larrabee���Ƃ����̐̂ɏo�Ă����͂�������������
�{����Larrabee���Ƃ����̐̂ɏo�Ă����͂�������������
���[�[�[�[�[�[�[�[���ڂŌ����炻������
���Ђł�SCC���2����̃��j�C�R�A�v���Z�b�T�Ƃ��Ĉʒu�t���Ă���(��1�����Larrabee)�B
>>60
�����p�v���Z�b�T������A����z���͑啪���Ƃ��낤�ˁB
�����p�v���Z�b�T������A����z���͑啪���Ƃ��낤�ˁB
�㓡���x���̒�i���ȋL�҂��葝���Ă��
>>65
����͂����������̋L�҂̏o�L�ڂ�����
Intel�̌�����1�����Polaris�i65nm 80�R�A)
SCC�͋����Č�����Larrabee�̌Z��
download.intel.com/pressroom/pdf/rockcreek/SCC_Announcement_JustinRattner.pdf
>>65
����͂����������̋L�҂̏o�L�ڂ�����
Intel�̌�����1�����Polaris�i65nm 80�R�A)
SCC�͋����Č�����Larrabee�̌Z��
download.intel.com/pressroom/pdf/rockcreek/SCC_Announcement_JustinRattner.pdf
Larrabee�A�����O�ɐ���x��ŏI�����B
�����A��������Q�҂�
>>68
ID�ʂ�Aho����
ID�ʂ�Aho����
��]����Q���瓦���͓̂��
72 �F,,�E�L�́M�E,,�j��-�������F2009/12/03(��) 23:21:38 ID:Vx3UacNb
����͂Ђǂ��~�X���[�h�L��
Larrabee�͌��z�������̂�
���������C�ˁ[���\����
75 �F,,�E�L�́M�E,,�j��-�������F2009/12/03(��) 23:35:54 ID:Vx3UacNb
�����炱���Keifer����
76 �F,,�E�L�́M�E,,�j��-�������F2009/12/03(��) 23:43:09 ID:Vx3UacNb
http://www.bit-tech.net/news/hardware/2009/12/03/intel-demos-48-core-processor/1
http://news.bbc.co.uk/2/hi/technology/8392392.stm
http://www.pcinpact.com/actu/news/54429-tera-scale-scc-ct-larrabee.htm?vc=1
���{���炢���ȍ������Ⴂ���Ă�̂�
���ꂾ�������݂�IT��i�����
��������
http://news.bbc.co.uk/2/hi/technology/8392392.stm
http://www.pcinpact.com/actu/news/54429-tera-scale-scc-ct-larrabee.htm?vc=1
���{���炢���ȍ������Ⴂ���Ă�̂�
���ꂾ�������݂�IT��i�����
��������
Netburst�Ƃ�i7�Ƃ��Ǝ�������
���s�̃L�[���[�h�Ƃ��ăN���E�h���p�N�������O��
�ύX������
Larrabee�͂�������
���s�̃L�[���[�h�Ƃ��ăN���E�h���p�N�������O��
�ύX������
Larrabee�͂�������
�Ƃ������Ƃɂ���ƁA�����s���������̂ł���? :)
79 �F,,�E�L�́M�E,,�j��-�������F2009/12/04(��) 00:46:50 ID:d2iN0iPh
��������������GeForce��n���ɂ���Ȃ�
http://pc.watch.impress.co.jp/docs/2007/0611/kaigai364_03l.gif
2010�N48core�̓��[�h�}�b�v�ʂ肾���ǐ��i���ł��ĂȂ����Ă��Ƃ���B
�܂��\�z�̌����J�����x���Ȃ̂Ƀ��j�C�R�A�ŕ������C������킯�Ȃ��B
{kind=link}
2010�N48core�̓��[�h�}�b�v�ʂ肾���ǐ��i���ł��ĂȂ����Ă��Ƃ���B
�܂��\�z�̌����J�����x���Ȃ̂Ƀ��j�C�R�A�ŕ������C������킯�Ȃ��B
�Ƃ������Ƃɂ������̂ł��ˁB :)
�����̂�������
���͒c�q�ɔC������
���͒c�q�ɔC������
>>81
����ȊO�Ȃ�����
����ȊO�Ȃ�����
�Ƃ������Ƃɂ������̂ł��ˁB
85 �F,,�E�L�́M�E,,�j��-�������F2009/12/04(��) 01:05:38 ID:d2iN0iPh
�A�z�����邗������
86 �F,,�E�L�́M�E,,�j��-�������F2009/12/04(��) 01:07:55 ID:d2iN0iPh
����45nm�v���Z�X�łȂ��SCC�̂ق�����������
�n���ɂ͗����ł��Ȃ�
�n���ɂ͗����ł��Ȃ�
87 �FSocket774�F2009/12/04(��) 04:23:57 ID:HeTfDNYU
�ŐV��larrabee����ĂR����ڂ������H
�����͂S����ڂ��ȁB
���C�g���[�V���O�ł͂��Ȃ���҂��邪�A�]����Direct3D�Ȃ���Ҕ����ȁB
����̗���͑S�ʓI�Ƀ��C�g���[�V���O�G���W���Ɍ���������������킯�ŁB
�����͂S����ڂ��ȁB
���C�g���[�V���O�ł͂��Ȃ���҂��邪�A�]����Direct3D�Ȃ���Ҕ����ȁB
����̗���͑S�ʓI�Ƀ��C�g���[�V���O�G���W���Ɍ���������������킯�ŁB
�܂�����FUD�M���Ă�n�������̂�
>>87
PC�Ń��A���^�C�����C�g���[�V���O�ł��鐫�\�ɂȂ�̂͑����Ă�5�N�ȏォ���邩��C�ɂ���ȁB
���������ォ���������Windows��DirectX�ł̑Ή����낤�B
�����瓖����DX11�ō�炴������Ȃ��B
�Ƃ肠����1�`�b�v�ł̎����\���P���x5T/�{���x2T�ӂ肪�ڕW���ĂƂ��낶��Ȃ����ˁB
PC�Ń��A���^�C�����C�g���[�V���O�ł��鐫�\�ɂȂ�̂͑����Ă�5�N�ȏォ���邩��C�ɂ���ȁB
���������ォ���������Windows��DirectX�ł̑Ή����낤�B
�����瓖����DX11�ō�炴������Ȃ��B
�Ƃ肠����1�`�b�v�ł̎����\���P���x5T/�{���x2T�ӂ肪�ڕW���ĂƂ��낶��Ȃ����ˁB
���A���^�C���p�̊Ȉ�RT�Ȃ�{���x�͂����B
�S��RT�͂܂��܂���ɂ���DX��GL�Ɉˑ����Ȃ��v���O���}�u��GPU�͕K�v�Ƃ���Ă�B
Unreal Engine��Epic Games����{Larrabee�x�����Ă邩���
�����̃Q�[����DX�ˑ��ł͂Ȃ��ă~�h���E�F�A��Unreal Engine�ˑ��Ȃ��
������Intel�̏��@������B
Fermi���e�N�X�`�����j�b�g��ROP��CUDA Core�ɐ����������邱�Ƃ�
CUDA�����ŃJ�X�^�������_����`����悤�ɂȂ����B
�ނ���DX�����ו��B
�S��RT�͂܂��܂���ɂ���DX��GL�Ɉˑ����Ȃ��v���O���}�u��GPU�͕K�v�Ƃ���Ă�B
Unreal Engine��Epic Games����{Larrabee�x�����Ă邩���
�����̃Q�[����DX�ˑ��ł͂Ȃ��ă~�h���E�F�A��Unreal Engine�ˑ��Ȃ��
������Intel�̏��@������B
Fermi���e�N�X�`�����j�b�g��ROP��CUDA Core�ɐ����������邱�Ƃ�
CUDA�����ŃJ�X�^�������_����`����悤�ɂȂ����B
�ނ���DX�����ו��B
>Fermi���e�N�X�`�����j�b�g��ROP��CUDA Core�ɐ�����������
����ȏ���������H
����ȏ���������H
������ۂ����Ƃ͏����Ă���B
���ƁAGT200�̂Ƃ��ɂ�Shader�ȏ�̖ʐς��߂Ă���ROP��TMU�̃u���b�N����������Ȃ��B
http://www.nvidia.com/content/PDF/fermi_white_papers/NVIDIA_Fermi_Compute_Architecture_Whitepaper.pdf
> Adding a true cache hierarchy for load / store operations presented significant
> challenges. Traditional GPU architectures support a read-only �e�eload�f�f path for texture
> operations and a write-only �e�eexport�f�f path for pixel data output. However, this approach is
> poorly suited to executing general purpose C or C++ thread programs that expect reads and
> writes to be ordered. As one example: spilling a register operand to memory and then reading it
> back creates a read after write hazard; if the read and write paths are separate, it may be
> necessary to explicitly flush the entire write /�e�eexport�f�f path before it is safe to issue
> the read, and any caches on the read path would not be coherent with respect to the write data.
�������ɂ�����Ȃ��Ə����Ă�����
http://www.realtimerendering.com/blog/nvidia-announces-fermi-architecture/
> With this announcement, NVIDIA is focusing firmly on the GPGPU market, rather than on graphics.
> No details of the graphics-specific parts of the chip (such as triangle rasterizers and texture
> units) were even mentioned.
���ƁAGT200�̂Ƃ��ɂ�Shader�ȏ�̖ʐς��߂Ă���ROP��TMU�̃u���b�N����������Ȃ��B
http://www.nvidia.com/content/PDF/fermi_white_papers/NVIDIA_Fermi_Compute_Architecture_Whitepaper.pdf
> Adding a true cache hierarchy for load / store operations presented significant
> challenges. Traditional GPU architectures support a read-only �e�eload�f�f path for texture
> operations and a write-only �e�eexport�f�f path for pixel data output. However, this approach is
> poorly suited to executing general purpose C or C++ thread programs that expect reads and
> writes to be ordered. As one example: spilling a register operand to memory and then reading it
> back creates a read after write hazard; if the read and write paths are separate, it may be
> necessary to explicitly flush the entire write /�e�eexport�f�f path before it is safe to issue
> the read, and any caches on the read path would not be coherent with respect to the write data.
�������ɂ�����Ȃ��Ə����Ă�����
http://www.realtimerendering.com/blog/nvidia-announces-fermi-architecture/
> With this announcement, NVIDIA is focusing firmly on the GPGPU market, rather than on graphics.
> No details of the graphics-specific parts of the chip (such as triangle rasterizers and texture
> units) were even mentioned.
Fermi��HPC�p�̃`�b�v�Ƃ��Ĕ��\����ɂ��ꂽ�̂ŁAROP�Ȃ�GPU�ɕK�v�ȋ@�\�ɂ��ẮA
�܂���o�Ă��ĂȂ�������Ȃ��́H
�܂���o�Ă��ĂȂ�������Ȃ��́H
>>93
���O����̖ڂ͐ߌ��ł����H
���̃_�C�̃��C�A�E�g�łǂ���TMU��ROP��z�u����́H
�e�N�X�`����p�L���b�V���ƃ��X�^�f�[�^��p�X�g�A�o�b�t�@��p����
�����R/W���Ή���L2�L���b�V���ɂ����Ƃ�����|�̂��Ƃ������Ă���B
CUDA Core��TMU�EROP�̋@�\�������ƂɂȂ�B
�Ƃ��������ۂ̂Ƃ���SP���g�����\�t�g�����Ǝv����B
�F�߂����͂Ȃ����낤��GeForce��Larrabee�Ɠ��������ɐi�B
����DirectX�̂悤�ȍd������API���o�R����K�v�͂Ȃ��B
���c���ꂽ�͎̂���Radeon�������ƁB
���O����̖ڂ͐ߌ��ł����H
���̃_�C�̃��C�A�E�g�łǂ���TMU��ROP��z�u����́H
�e�N�X�`����p�L���b�V���ƃ��X�^�f�[�^��p�X�g�A�o�b�t�@��p����
�����R/W���Ή���L2�L���b�V���ɂ����Ƃ�����|�̂��Ƃ������Ă���B
CUDA Core��TMU�EROP�̋@�\�������ƂɂȂ�B
�Ƃ��������ۂ̂Ƃ���SP���g�����\�t�g�����Ǝv����B
�F�߂����͂Ȃ����낤��GeForce��Larrabee�Ɠ��������ɐi�B
����DirectX�̂悤�ȍd������API���o�R����K�v�͂Ȃ��B
���c���ꂽ�͎̂���Radeon�������ƁB
gnZhJ1DD�̒m�b�x�ꂪ�͂�ςȂ�
http://techreport.com/r.x/fermi-gpu/gf100_full_tr.png
L2��ROP������Ƃ����\�������邪
{kind=link}
L2��ROP������Ƃ����\�������邪
98 �FSocket774�F2009/12/04(��) 14:45:28 ID:BVzVsagO
�����~�ɂƂ���DirectX�͂���Ȃɖڂ̏�̂��ԂȂ̂��˂�
99 �FSocket774�F2009/12/04(��) 14:57:34 ID:s7Sazrmv
���̂���DirectX���g��Ȃ��Q�[��������Ă��邩���ȁB
�O���t�B�b�N�����������ɋK�i���ꂽ��܂����ڃn�[�h�������悤�ɂ��邾�낤����
DirectX�͂P�P�`�P�Q�܂ł��낤��
Win95������̎���openGL�Ƃ�DirectX�o��������̊��ɖ߂邾��
DirectX�͂P�P�`�P�Q�܂ł��낤��
Win95������̎���openGL�Ƃ�DirectX�o��������̊��ɖ߂邾��
101 �FSocket774�F2009/12/04(��) 15:10:01 ID:uLgGErR7
DX��������
���X�^���C�U�\���̌��E
���X�^���C�U�\���̌��E
>>80
�����\���ו����͊m���ɂ��Ă����
demo�@����`�ʎY���̖ڏ��`���X�e�b�v�`demo�@����`
�i���ɐ��i�łȂ��C������
�Ȃo�b�p�[�c�Ō��~�����`�̉���݂�������
�����\���ו����͊m���ɂ��Ă����
demo�@����`�ʎY���̖ڏ��`���X�e�b�v�`demo�@����`
�i���ɐ��i�łȂ��C������
�Ȃo�b�p�[�c�Ō��~�����`�̉���݂�������
��������c�q���Ăǂ�ȃX�y�b�N�̂o�b�g���Ă�́H
Xeon�Ƃ��ς�ł���
Xeon�Ƃ��ς�ł���
2015�N�ɂ�11nm��5000sp�A20TFlops��(�د
�Ƃ�����������Ă�������܂�����
�Ƃ�����������Ă�������܂�����
��N�Ŕ{�y�[�X�Ȃ炻��ʂ�����Ȃ����H
09 1T
10 2T
11 4T
12 8T
13 16T
14 32T
15 64T
�v���Z�X������ł��邯��15�N20T�͂������I�ł��������������B
09 1T
10 2T
11 4T
12 8T
13 16T
14 32T
15 64T
�v���Z�X������ł��邯��15�N20T�͂������I�ł��������������B
���̂���NVDIA���̂��r�b�O�o�������ˁH��
>>105
�N���b�N10GHz��f�i�Ƃ������
�N���b�N10GHz��f�i�Ƃ������
���ʏ�
���̃��[�h�}�b�v�ŏ����ɂ������Ƃ��Ă�
21�N 4096TFlops 0.5nm�v���Z�X
������ŃQ�[�g�������q1���ȉ����炢�ɂȂ���
11nm�v���Z�X�ȉ��͇_���Ĉ��Ƃ��̌����Ă���
���̃��[�h�}�b�v�ŏ����ɂ������Ƃ��Ă�
21�N 4096TFlops 0.5nm�v���Z�X
������ŃQ�[�g�������q1���ȉ����炢�ɂȂ���
11nm�v���Z�X�ȉ��͇_���Ĉ��Ƃ��̌����Ă���
>>105
>>108
�M��肪�����ł���A��C�ɉ��������A���܂܂Œ���Ă��������ȁB
�Ⴆ�Ό��z���Z�p�Ƃ��B�ʎq�g�����W�X�^�Ȃǂ̎����Ƃ��B�������g��Ȃ�
�V���R���x�[�X��ReRAM�ȂǁB
���ʎq�R���s���[�^�ł͂Ȃ��ł��B
>>108
�M��肪�����ł���A��C�ɉ��������A���܂܂Œ���Ă��������ȁB
�Ⴆ�Ό��z���Z�p�Ƃ��B�ʎq�g�����W�X�^�Ȃǂ̎����Ƃ��B�������g��Ȃ�
�V���R���x�[�X��ReRAM�ȂǁB
���ʎq�R���s���[�^�ł͂Ȃ��ł��B
>>109
21�N���炢�ɂ͗ʎY�͖����Ƃ��Ă����z���Z�p�͊J��Ă��邱��B
�R�����v���Z�X��A�X�^�b�N�`�̔����̂��Y���ȁB
�����̓����Ɍ��z���������H�̎����IBM�Ȃǂ����łɃf�����Ă���B
�v���Z�b�T�������̒��ߋ����z�������ǂˁB
�����Ƃ����Ă���������Ȃ��B
21�N���炢�ɂ͗ʎY�͖����Ƃ��Ă����z���Z�p�͊J��Ă��邱��B
�R�����v���Z�X��A�X�^�b�N�`�̔����̂��Y���ȁB
�����̓����Ɍ��z���������H�̎����IBM�Ȃǂ����łɃf�����Ă���B
�v���Z�b�T�������̒��ߋ����z�������ǂˁB
�����Ƃ����Ă���������Ȃ��B
112 �F,,�E�L�́M�E,,�j��-�������F2009/12/05(�y) 00:16:30 ID:KKTvEirv
22nm 2012
16nm 2015�H
11nm 2017�H
�Ԃ����Ⴏ����Ȃɐ悪�����ȁB
���[�A�̖@�����~�܂����Ƃ��̂��߂̃��j�[�R�A����
16nm 2015�H
11nm 2017�H
�Ԃ����Ⴏ����Ȃɐ悪�����ȁB
���[�A�̖@�����~�܂����Ƃ��̂��߂̃��j�[�R�A����
113 �F,,�E�L�́M�E,,�j��-�������F2009/12/05(�y) 00:20:37 ID:KKTvEirv
http://www.itmedia.co.jp/news/articles/0906/18/news006.html
�Ă�����Intel�ȊO20nm�O��Ŏ~�܂�\�����邩���ȁB
�Ă�����Intel�ȊO20nm�O��Ŏ~�܂�\�����邩���ȁB
�v���Z�X�Z�p������Intel�͂��ƂP�O�N�킦��I�I�̂��ȁH�H
�����AIA��CELL���o���B���с[�Ƃ̃n�C�u���b�h�ł������B
�����AIA��CELL���o���B���с[�Ƃ̃n�C�u���b�h�ł������B
115 �F,,�E�L�́M�E,,�j��-�������F2009/12/05(�y) 00:27:07 ID:KKTvEirv
http://japan.cnet.com/news/ent/story/0,2000056022,20081030,00.htm
�������o���b�g��
5nm�܂ōs���Ƃ͗�����������
�������o���b�g��
5nm�܂ōs���Ƃ͗�����������
MS�̃o���}�[�I�ȂЂƂ��Ȃ��H�H���{�̃j���[�X�ł͂���܂蕷���Ȃ����O���˂��B
��܂ōs�����l����
�����ސE��������
�����ސE��������
����������������ϑw��͍����Ă邯�ǂ����Ȃ�ƕ��M�̖���1�w������̖��x��������̂��ȁH
119 �FSocket774�F2009/12/05(�y) 07:10:03 ID:eVFai6RT
http://www.semiaccurate.com/2009/12/03/sandra-2010-adds-opencl-gpgpu-benchmarks/
gpgpu���Z�ł�amd���ŋ��ł��邱�Ƃ��A���E�ł����Ƃ��M������Ă���sandra�ŏؖ����ꂽ
�����Alarrabee��fermi�Ȃ�đ҂��Ȃ��Ă�����
����Ȃ烉���[
�N�ɂ͂��ł������ɂ����邩�炗
gpgpu���Z�ł�amd���ŋ��ł��邱�Ƃ��A���E�ł����Ƃ��M������Ă���sandra�ŏؖ����ꂽ
�����Alarrabee��fermi�Ȃ�đ҂��Ȃ��Ă�����
����Ȃ烉���[
�N�ɂ͂��ł������ɂ����邩�炗
http://grape.mtk.nao.ac.jp/pub/people/makino/articles/future_sc/note076.html
�����炭�A Intel �̂��̏ɑ���� Larrabee �ł���A����� NVIDIA ��
HPC �}�[�P�b�g�ւ̖��� Fermi �ł���̂Ɠ��l�Ɏ��s���^���t�����Ă��܂��B
������(GPU �Ƃ��Đ������Ȃ����) HPC �ȊO�Ƀ}�[�P�b�g�������Ȃ����̂ł���A
HPC �}�[�P�b�g�̓v���Z�b�T�ւ̋��z�ȓ���������ł��邾���̃}�[�P�b�g�T�C�Y
�������Ă��Ȃ��ȏ�A�����͂������i�ŃV�X�e������ė��v���グ�邱�Ƃ�
�ɂ߂č������ł��B
�ł́AGPU �Ƃ��Ă͐�������̂��H�Ƃ����ƁA GPU �}�[�P�b�g���̂������`�b�v
�Z�b�g��CPU �Ƃ̓����ɂ���ďk���A���ł�����A���̂��Ǝ��̂� NVIDIA ��
HPC �}�[�P�b�g�ɖ������R�ɂȂ��Ă���̂ł͂Ȃ����Ƒz������܂��B
����� 90�N��O���Ɍ��X�̓O���t�B�b�N���[�N�X�e�[�V�������[�J�[�ł�����
SGI �� HPC �}�[�P�b�g�ɒǂ����܂�A���ɂ� Rackable Systems �ɋz�����ꂽ
�̂Ɠ����^����H�炴��Ȃ��ł��傤�B
�����炭�A Intel �̂��̏ɑ���� Larrabee �ł���A����� NVIDIA ��
HPC �}�[�P�b�g�ւ̖��� Fermi �ł���̂Ɠ��l�Ɏ��s���^���t�����Ă��܂��B
������(GPU �Ƃ��Đ������Ȃ����) HPC �ȊO�Ƀ}�[�P�b�g�������Ȃ����̂ł���A
HPC �}�[�P�b�g�̓v���Z�b�T�ւ̋��z�ȓ���������ł��邾���̃}�[�P�b�g�T�C�Y
�������Ă��Ȃ��ȏ�A�����͂������i�ŃV�X�e������ė��v���グ�邱�Ƃ�
�ɂ߂č������ł��B
�ł́AGPU �Ƃ��Ă͐�������̂��H�Ƃ����ƁA GPU �}�[�P�b�g���̂������`�b�v
�Z�b�g��CPU �Ƃ̓����ɂ���ďk���A���ł�����A���̂��Ǝ��̂� NVIDIA ��
HPC �}�[�P�b�g�ɖ������R�ɂȂ��Ă���̂ł͂Ȃ����Ƒz������܂��B
����� 90�N��O���Ɍ��X�̓O���t�B�b�N���[�N�X�e�[�V�������[�J�[�ł�����
SGI �� HPC �}�[�P�b�g�ɒǂ����܂�A���ɂ� Rackable Systems �ɋz�����ꂽ
�̂Ɠ����^����H�炴��Ȃ��ł��傤�B
�E2009/11/30-12/2 Accelerator-based Computing and Manycore Manycore and
�@Accelerator-based Computing for Physics and Astronomy Applications�ŏI���B
�@�����̃n�C���C�g�� Bill Dally �ł���B
�@A3 �V���R���͓����̂��H�Ƃ����������Ǝv�������ǎ~�߂Ă����B
�E"Double Precision is for entirely scientific computation" --- Bill Dally.
�@GPU �łɂ͔{���x�͂Ȃ��Ƃ�������������悤�ȁH
�E�ł����āA���`�b�v����Ă��炢�Ȃ� Merrimac �� P4 �� xx �{�����Ƃ������Ă��A�A�A
�@NVIDIA �͂��������Z�[���X�g�[�N�ɂЂ����������̂��H
�EDally �搶�̏����r�W�����͖��m�ŁA1�`�b�v�̒��Ɋ������͂ȃR�A�������A
�@�P���ȃR�A���R����Ă���őS�Ă��܂��Ȃ��A�Ƃ������ƂȂ��ǁA
�@���̂�Fermi �͒��r���[�ɋ��͂ȃR�A1�킾���𒆓r���[�Ȑ������A
�@�Ƃ����ʖڂȍ\���ɂȂ��Ă���BDally �搶�̍l���ł͒P���ȃR�A����
�@����Ȃ����ǁAATI �ɔ�ׂăg�����W�X�^���������߂���B
�@Accelerator-based Computing for Physics and Astronomy Applications�ŏI���B
�@�����̃n�C���C�g�� Bill Dally �ł���B
�@A3 �V���R���͓����̂��H�Ƃ����������Ǝv�������ǎ~�߂Ă����B
�E"Double Precision is for entirely scientific computation" --- Bill Dally.
�@GPU �łɂ͔{���x�͂Ȃ��Ƃ�������������悤�ȁH
�E�ł����āA���`�b�v����Ă��炢�Ȃ� Merrimac �� P4 �� xx �{�����Ƃ������Ă��A�A�A
�@NVIDIA �͂��������Z�[���X�g�[�N�ɂЂ����������̂��H
�EDally �搶�̏����r�W�����͖��m�ŁA1�`�b�v�̒��Ɋ������͂ȃR�A�������A
�@�P���ȃR�A���R����Ă���őS�Ă��܂��Ȃ��A�Ƃ������ƂȂ��ǁA
�@���̂�Fermi �͒��r���[�ɋ��͂ȃR�A1�킾���𒆓r���[�Ȑ������A
�@�Ƃ����ʖڂȍ\���ɂȂ��Ă���BDally �搶�̍l���ł͒P���ȃR�A����
�@����Ȃ����ǁAATI �ɔ�ׂăg�����W�X�^���������߂���B
>119
larrabee��fermi�ɒǂ��z���ꂽ��ǂ�����́H
larrabee��fermi�ɒǂ��z���ꂽ��ǂ�����́H
123 �FSocket774�F2009/12/05(�y) 07:21:52 ID:eVFai6RT
http://www.tweak.dk/nyheder2.php?id=22388
AMD and SiSoftware Collaborate on Development of an Industry Benchmark Suite for OpenCL
�܂����肦�Ȃ����炗
amd�ŋ�w
AMD and SiSoftware Collaborate on Development of an Industry Benchmark Suite for OpenCL
�܂����肦�Ȃ����炗
amd�ŋ�w
124 �FSocket774�F2009/12/05(�y) 07:22:54 ID:eVFai6RT
�Ȃ�Ƃ����Ă�1600SP��3tflops�߂���ł����̂�������
AMD��OpenCL�̃x���`�ōœK��������Ƃ͂ˁB
Sandra�͒�Ԃ�����g���邾�낤���AAMD��GPU�̕���OpenCL�͋�������
��ێ��l�͑����������ȁB
Sandra�͒�Ԃ�����g���邾�낤���AAMD��GPU�̕���OpenCL�͋�������
��ێ��l�͑����������ȁB
126 �FSocket774�F2009/12/05(�y) 10:01:39 ID:IFzrHH/f
���J�I�i�j�[�͌��\�ł�
>>122
���������28nm��HD6xxx�Ŕ����Ԃ���������
���������28nm��HD6xxx�Ŕ����Ԃ���������
SemiAccurate :: Intel kills consumer Larrabee, focuses on future variants
http://www.semiaccurate.com/2009/12/04/intel-kills-consumer-larrabee-focuses-future-variants/
http://www.semiaccurate.com/2009/12/04/intel-kills-consumer-larrabee-focuses-future-variants/
���킽
�l�p�ɂ͏o�Ȃ����Ď��H
Intel�Ƃ��Ă�GPGPU�ɑR�o����Ηǂ��̂����琻�i�̌`�ɂ͍S��Ȃ��ł���B
�������CPU�ɓ������Ă��낤���B
�������CPU�ɓ������Ă��낤���B
132 �F,,�E�L�́M�E,,�j��-�������F2009/12/05(�y) 11:47:14 ID:KKTvEirv
Sandra�͑S����ALU���ғ������邾���̉��̈Ӗ��������x���`����Ԃł�
133 �F,,�E�L�́M�E,,�j��-�������F2009/12/05(�y) 11:48:34 ID:KKTvEirv
134 �FSocket774�F2009/12/05(�y) 12:14:06 ID:IFzrHH/f
>Sandra�͑S����ALU���ғ������邾���̉��̈Ӗ��������x���`����Ԃł�
�ɂ�������炸�ASP��DP��2�{���x���������Ȃ�AMD��
�ǂ��X�J�X�J�Ȃ̂��Ƃ�
�A�[�L��5�{���Ȃ���Ȃ�
�ɂ�������炸�ASP��DP��2�{���x���������Ȃ�AMD��
�ǂ��X�J�X�J�Ȃ̂��Ƃ�
�A�[�L��5�{���Ȃ���Ȃ�
�����ɂ��݁H
�P���x�̓f�[�^�������ǂ����Ȃ��A�Ƃ����H
�X�|�[�N�X�}���̐������\���Č����Ă邶���
139 �F,,�E�L�́M�E,,�j��-�������F2009/12/05(�y) 12:55:42 ID:KKTvEirv
Sandra��iSSSE3�̃X���[�v�b�g�̌v�Z���@�Ƃ��o�J�����Đ�����
pmaddubsw��16��̏�Z��8��̉��Z������24�I�y���[�V���������I�Ƃ���
����ł���paddb��16�T�C�N������B
Core 2 Duo���A�z�݂����Ƀp���[�A�b�v���Ă�悤�Ɍ������g���b�N�͂��̂ւ�B
���ۂ͍���Phenom II�Ƃ̍��͂���قǑ傫���Ȃ��B
�Ƃ������A����pmaddubsw�ƌ������߁A���͍��܂ň�x���g�������Ƃ��Ȃ��B
pmaddubsw��16��̏�Z��8��̉��Z������24�I�y���[�V���������I�Ƃ���
����ł���paddb��16�T�C�N������B
Core 2 Duo���A�z�݂����Ƀp���[�A�b�v���Ă�悤�Ɍ������g���b�N�͂��̂ւ�B
���ۂ͍���Phenom II�Ƃ̍��͂���قǑ傫���Ȃ��B
�Ƃ������A����pmaddubsw�ƌ������߁A���͍��܂ň�x���g�������Ƃ��Ȃ��B
140 �FSocket774�F2009/12/05(�y) 12:55:45 ID:YsqC5a9X
>>137
���R�DIntel��Larrabee�O���t�B�b�N�X�`�b�v���L�����Z��
���@�@2009�N12��4����CNET���CIntel ��Larrabee�`�b�v�̃X�^���h�A�����O���t�B�b�N�X�����̏��i�����L�����Z���ƕĂ��܂��B
��Intel�̃X�|�[�N�X�}���̔��\�ƂȂ��Ă���̂ŁC�����ȏ��ƍl�����܂��B
�����R�̓V���R���̊J�����\�t�g�E�F�A�̊J�����x�����Ă���C
�����ʂƂ��ăO���t�B�b�N�X�`�b�v�Ƃ��Ă̏��i���̓L�����Z���������ł��B
�����̑��ƌ����Ă͉��ł����C���N�ɂ́C�Г��C�ЊO�̃\�t�g�E�F�A�̊J���p�L�b�g�Ƃ��ďo�ׂ���Əq�ׂĂ��܂��B
���@�@�O���t�B�b�N�X�̃A�i���X�g��J.Peddy���́C�挎��SC09�̃f����Larrabee��1TFlops���o�������C
��5TFlops�� AMD�̃{�[�h�����S�h���Ŕ�����̂ŁCLarrabee�̐��\�s���͖����Ƃ��Ă��܂��B
���Ȃ��CSC09��Rattner����������f���́C�������܂������C�ʏ�̎g�p��Ԃł�SGEMM��700GFlops���x�ŁC
���u�ԓI��Max��800GFlops�ŁC�I�[�o�N���b�N���ĕ��ϓI��900GFlops�C�u�ԕ�����1TFlops���͂��ɒ�����Ƃ������̂ł����B
�����Ⴀ����������������������������������������������������������
���R�DIntel��Larrabee�O���t�B�b�N�X�`�b�v���L�����Z��
���@�@2009�N12��4����CNET���CIntel ��Larrabee�`�b�v�̃X�^���h�A�����O���t�B�b�N�X�����̏��i�����L�����Z���ƕĂ��܂��B
��Intel�̃X�|�[�N�X�}���̔��\�ƂȂ��Ă���̂ŁC�����ȏ��ƍl�����܂��B
�����R�̓V���R���̊J�����\�t�g�E�F�A�̊J�����x�����Ă���C
�����ʂƂ��ăO���t�B�b�N�X�`�b�v�Ƃ��Ă̏��i���̓L�����Z���������ł��B
�����̑��ƌ����Ă͉��ł����C���N�ɂ́C�Г��C�ЊO�̃\�t�g�E�F�A�̊J���p�L�b�g�Ƃ��ďo�ׂ���Əq�ׂĂ��܂��B
���@�@�O���t�B�b�N�X�̃A�i���X�g��J.Peddy���́C�挎��SC09�̃f����Larrabee��1TFlops���o�������C
��5TFlops�� AMD�̃{�[�h�����S�h���Ŕ�����̂ŁCLarrabee�̐��\�s���͖����Ƃ��Ă��܂��B
���Ȃ��CSC09��Rattner����������f���́C�������܂������C�ʏ�̎g�p��Ԃł�SGEMM��700GFlops���x�ŁC
���u�ԓI��Max��800GFlops�ŁC�I�[�o�N���b�N���ĕ��ϓI��900GFlops�C�u�ԕ�����1TFlops���͂��ɒ�����Ƃ������̂ł����B
�����Ⴀ����������������������������������������������������������
141 �F,,�E�L�́M�E,,�j��-�������F2009/12/05(�y) 12:56:23 ID:KKTvEirv
������ł���paddb��16�I�y���[�V����������B
���ʏ�̎g�p��Ԃł�SGEMM��700GFlops���x�ŁC�u�ԓI��Max��800GFlops�ŁC
���I�[�o�N���b�N���ĕ��ϓI��900GFlops�C�u�ԕ�����1TFlops���͂��ɒ�����
OC���Ȃ��ł����ς�700GFlops���Ă��Ȃ肷������Ȃ́H�{���x�����̔����͊��҂ł�����B
���I�[�o�N���b�N���ĕ��ϓI��900GFlops�C�u�ԕ�����1TFlops���͂��ɒ�����
OC���Ȃ��ł����ς�700GFlops���Ă��Ȃ肷������Ȃ́H�{���x�����̔����͊��҂ł�����B
�㓡�����ŋ߂̃R�����ŋ^�╄�𓊂������Ă������ǎ��O�ɒm���Ă��̂���
>5TFlops�� AMD�̃{�[�h�����S�h���Ŕ�����̂ŁCLarrabee�̐��\�s���͖����Ƃ��Ă��܂��B
���s�Ɨ��_�l���ׂ�Ȃ�
���s�Ɨ��_�l���ׂ�Ȃ�
145 �FSocket774�F2009/12/05(�y) 13:01:13 ID:YsqC5a9X
�܂�����ς�Ƃ������AGelsinger������ɂȂ������_�ŏI����Ă��˂�
146 �F,,�E�L�́M�E,,�j��-�������F2009/12/05(�y) 13:04:17 ID:KKTvEirv
���āAHaswell�܂ŃR�[�h���������߂��Ƃɖ߂邩
147 �FSocket774�F2009/12/05(�y) 13:05:18 ID:IFzrHH/f
fermi�̈�l�����͂��������Ȃ���
148 �F,,�E�L�́M�E,,�j��-�������F2009/12/05(�y) 13:14:46 ID:KKTvEirv
http://www.internetnews.com/hardware/article.php/3851421
But it appears Larrabee just wasn't cutting it after all. "Larrabee silicon and
software development are behind where we hoped to be at this point in the project,"
Intel spokesperson Nick Knupffer told InternetNews.com.
Intel spokesperson Nick Knupffer told InternetNews.com.
"As a result, our first Larrabee product will not be launched as a stand-alone,
discrete graphics product," he added. "Rather it will be used as a software
development platform for internal and external use."
>>145
����
Tim Sweeney��NTR�ꂽ
�Ƃ��H
But it appears Larrabee just wasn't cutting it after all. "Larrabee silicon and
software development are behind where we hoped to be at this point in the project,"
Intel spokesperson Nick Knupffer told InternetNews.com.
Intel spokesperson Nick Knupffer told InternetNews.com.
"As a result, our first Larrabee product will not be launched as a stand-alone,
discrete graphics product," he added. "Rather it will be used as a software
development platform for internal and external use."
>>145
����
Tim Sweeney��NTR�ꂽ
�Ƃ��H
>>144
�˂����ݓ���鎞���炢�͂����ƕϊ����悤��@�@���������s
�˂����ݓ���鎞���炢�͂����ƕϊ����悤��@�@���������s
151 �F,,�E�L�́M�E,,�j��-�������F2009/12/05(�y) 13:23:39 ID:KKTvEirv
���X������Intel Haswell�ł�����ȁH
���܂���I��HPC������p��Larrabee�͂���܂������Ȃ�����H
���܂���I��HPC������p��Larrabee�͂���܂������Ȃ�����H
�X�^���h�A���[���ł͂łȂ��A�J���L�b�g�͏o�����Ă��Ƃ́A
Haswell�̓����ł݂̂��Ă��ƁH
Haswell�̓����ł݂̂��Ă��ƁH
>HPC������p
����Ɖ��̊W���Ȃ�����
����Ɖ��̊W���Ȃ�����
��������Ȃ��ƕʂɎ���PC�Ɖ������Ȃ邩��قƂ�ǔႢ����
���X�����������̃X���g���ʂ����O�ɗ�������
���X�����������̃X���g���ʂ����O�ɗ�������
�܂����I�܂��I�����
156 �F,,�E�L�́M�E,,�j��-�������F2009/12/05(�y) 13:37:12 ID:KKTvEirv
���Ⴀ������n�[�h�E�F�A�Ɉړ����ȁB
��������Itanium�X���i���X�p�R���X���j�ɍ����̕����ŁB
��������Itanium�X���i���X�p�R���X���j�ɍ����̕����ŁB
157 �F,,�E�L�́M�E,,�j��-�������F2009/12/05(�y) 13:40:07 ID:KKTvEirv
�]�������������������A�z
���E���Ă���ˁ[����
6 �FSocket774 [sage] �F2009/11/29(��) 08:00:15 ID:TZPHEo00
�ւ肪�Ȃ��̂͗ǂ��ւ�
23 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/12/01(��) 02:19:40 ID:ekg7DMWw
�Q���̑ގЂ̗v����Larrabee�]�X��FUD�̈���o�Ȃ��Ǝv�����B
��{�~���ގЂ���
33 �F,,�E�L�́M�E,,�j��-������ [] �F2009/12/02(��) 01:04:07 ID:4wnVhNuN
>>28
�����́u�듚�v�搶�ł��������C�����邪�B
��ނ͂����܂�10�������B
���ꂩ��̘b�͔ނ̓n��ł����Ď����ł͂Ȃ��B
40 �FSocket774 [sage] �F2009/12/02(��) 06:42:40 ID:X6SYGH4o
�㓡�M�҃����X��
51 �FSocket774 [] �F2009/12/02(��) 10:07:05 ID:YlYrw+KL
�������[�X���邩�ǂ߂Ȃ��̂́A�㓡�̓A���e�i������Ȃ��������낤
http://www.brightsideofnews.com/news/2009/11/25/intel-larrabee-to-surprise-with-performance2c-launch-in-1h-2010.aspx
�������Intel�͈Ӑ}�I�Ƀ����[�X�����̖���������Ă���B
78 �FSocket774 [sage] �F2009/12/04(��) 00:37:38 ID:iO3Gpznu
�Ƃ������Ƃɂ���ƁA�����s���������̂ł���? :)
���E���Ă���ˁ[����
6 �FSocket774 [sage] �F2009/11/29(��) 08:00:15 ID:TZPHEo00
�ւ肪�Ȃ��̂͗ǂ��ւ�
23 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/12/01(��) 02:19:40 ID:ekg7DMWw
�Q���̑ގЂ̗v����Larrabee�]�X��FUD�̈���o�Ȃ��Ǝv�����B
��{�~���ގЂ���
33 �F,,�E�L�́M�E,,�j��-������ [] �F2009/12/02(��) 01:04:07 ID:4wnVhNuN
>>28
�����́u�듚�v�搶�ł��������C�����邪�B
��ނ͂����܂�10�������B
���ꂩ��̘b�͔ނ̓n��ł����Ď����ł͂Ȃ��B
40 �FSocket774 [sage] �F2009/12/02(��) 06:42:40 ID:X6SYGH4o
�㓡�M�҃����X��
51 �FSocket774 [] �F2009/12/02(��) 10:07:05 ID:YlYrw+KL
�������[�X���邩�ǂ߂Ȃ��̂́A�㓡�̓A���e�i������Ȃ��������낤
http://www.brightsideofnews.com/news/2009/11/25/intel-larrabee-to-surprise-with-performance2c-launch-in-1h-2010.aspx
�������Intel�͈Ӑ}�I�Ƀ����[�X�����̖���������Ă���B
78 �FSocket774 [sage] �F2009/12/04(��) 00:37:38 ID:iO3Gpznu
�Ƃ������Ƃɂ���ƁA�����s���������̂ł���? :)
>>157
���̑O��SNB����Ń��o�C���������o��
���̑O��SNB����Ń��o�C���������o��
������Q�[���@�ɐς܂�邩���Ƃ����b�͂ǂ��Ȃ�̂��ȁ[�B
EPIC���͓���Ă�����2012�N�܂�UE4�͖������B
�����Ń����Ńf�B�X�N���[�gGPU�ɑR�o����̂��ȁH
EPIC���͓���Ă�����2012�N�܂�UE4�͖������B
�����Ń����Ńf�B�X�N���[�gGPU�ɑR�o����̂��ȁH
�����ł����v��x�����Ă���̂ɃQ���V���K�[�ގЂőʖډ���������ȁB
���e�����o�Ȃ������B
���e�����o�Ȃ������B
PS4�ɍڂ邩���E�E�E�Ƃ����Ęb�H
PS3���������������Ă��������H���ĂƂ����
���T�����ŁACell��IBM�Ɏ̂Ă���탉���r�[�͂���Ȃ�ŁASCE�ܖڂ��Ȃ��E�E�E
PS3���������������Ă��������H���ĂƂ����
���T�����ŁACell��IBM�Ɏ̂Ă���탉���r�[�͂���Ȃ�ŁASCE�ܖڂ��Ȃ��E�E�E
eVGA���̃x���_���甭���A������Q�[���@�̗p�A�Ƃ����������[�}�[�ɐϋɓI�ɗ����A
�o�O���������V���R���̃E�G�n���J�A����ڂ����C�g���f�����J�B
���̂ւ�͑ΊO�����Ƃ������A�Г��́A���ɏ�w���ɑ���S�ۂ�ǂ�������
�v���W�F�N�g�Ɍg����Ă�l�����̕K�����������Č����Ă��B
�o�O���������V���R���̃E�G�n���J�A����ڂ����C�g���f�����J�B
���̂ւ�͑ΊO�����Ƃ������A�Г��́A���ɏ�w���ɑ���S�ۂ�ǂ�������
�v���W�F�N�g�Ɍg����Ă�l�����̕K�����������Č����Ă��B
165 �FSocket774�F2009/12/05(�y) 14:33:04 ID:IFzrHH/f
�ȂA����fermi�����
�܂���
������Intel
�܂���
������Intel
Fermi�~���E�U�C��
William (Bill) R. Mark�AMichael Abrash�ATom Forsyth�A
Daniel Pohl�ATim Sweeney�i�ЊO�FEPIC GAMES�j
���̃O���t�B�b�N�X�x���_���痈���l��A�Q�[���G���W������Ă��l�B
���Ƃ����S�u�����Ɍ��܂��Ă낗�v�v���Ă����Ƃ��Ă��A�������ɏo����
�������ς��̃y�[�o�[���������A���������ƍ����x�V�~�����[�^���ɐ����o���B
���̂������Ƀt�@���^�W�[���E�������A�\�Ȍ���1st�V���R����x�点�āA
�������ԋ������炢�A�����̃I�i�j�[�����˂邱�Ƃ��ł����A���̂悤�Ȏd���ł����ˁO�O
�����Ă悵�I
Daniel Pohl�ATim Sweeney�i�ЊO�FEPIC GAMES�j
���̃O���t�B�b�N�X�x���_���痈���l��A�Q�[���G���W������Ă��l�B
���Ƃ����S�u�����Ɍ��܂��Ă낗�v�v���Ă����Ƃ��Ă��A�������ɏo����
�������ς��̃y�[�o�[���������A���������ƍ����x�V�~�����[�^���ɐ����o���B
���̂������Ƀt�@���^�W�[���E�������A�\�Ȍ���1st�V���R����x�点�āA
�������ԋ������炢�A�����̃I�i�j�[�����˂邱�Ƃ��ł����A���̂悤�Ȏd���ł����ˁO�O
�����Ă悵�I
168 �F,,�E�L�́M�E,,�j��-�������F2009/12/05(�y) 15:00:37 ID:KKTvEirv
>>159
�Ȃɂ��ꂻ�̏��m��Ȃ��B
���������A�����B
�Ȃ�̂��߂�Sandy Bridge�œ���GMA��L3�R�q�[�����g�ɂ����Ǝv����H
�K�v�Ȃ�CPU�R�A��GPU�̃V�F�[�_�̌����肳�������Ă������H
AVX���g�����Ƃ�1�R�A��GeForce���Z8SP�����̕����������Z���ł���B�N���b�N���{���x������16SP���B
4�R�A�̂���3�R�A��GPU�����ɉĂ�����Ȃ�ɐ��\���o����B
L3�Ńf�[�^�����ł��镪�APS3�̃\�t�g�E�F�AVertex Shader���͌����������A�v���[�`���B
�m��I�Ɍ���A�m�[�g��TDP�̔��肩��GPU�̊O���������ш悪��������邩��
���̕��L���b�V���������őш�Z�[�u����A�v���[�`�͑��ΓI�ɗL����������Ȃ��B
�������A�Ԃ����Ⴏ2012�N�܂łɃm�[�g�p�̃f�B�X�N���[�g�͂قƂ�lj�ł���Ǝv���B
�Ȃɂ��ꂻ�̏��m��Ȃ��B
���������A�����B
�Ȃ�̂��߂�Sandy Bridge�œ���GMA��L3�R�q�[�����g�ɂ����Ǝv����H
�K�v�Ȃ�CPU�R�A��GPU�̃V�F�[�_�̌����肳�������Ă������H
AVX���g�����Ƃ�1�R�A��GeForce���Z8SP�����̕����������Z���ł���B�N���b�N���{���x������16SP���B
4�R�A�̂���3�R�A��GPU�����ɉĂ�����Ȃ�ɐ��\���o����B
L3�Ńf�[�^�����ł��镪�APS3�̃\�t�g�E�F�AVertex Shader���͌����������A�v���[�`���B
�m��I�Ɍ���A�m�[�g��TDP�̔��肩��GPU�̊O���������ш悪��������邩��
���̕��L���b�V���������őш�Z�[�u����A�v���[�`�͑��ΓI�ɗL����������Ȃ��B
�������A�Ԃ����Ⴏ2012�N�܂łɃm�[�g�p�̃f�B�X�N���[�g�͂قƂ�lj�ł���Ǝv���B
GMA�̌�p=�V�F�A�ő�ŁA���y����̂͊m��Ȃ�
�Ō�̋��菊�́uGMA�̌�p�v���E�E�E
�܂��撣���Đ��N�ԘA�Ă��Â��Ă�������
�܂��撣���Đ��N�ԘA�Ă��Â��Ă�������
GPU�Ƃ��ĕ��y�������Ȃ�����HPC�ł��������Ȃ�̂���
�Ƃ肠����Larrabee�����������Ă��l�͈�����炢�ٓ����Ƃ������Ǝv����
�Ƃ肠����Larrabee�����������Ă��l�͈�����炢�ٓ����Ƃ������Ǝv����
CPU�̔̔�����Ϲ��GPU�̐�
����ٓ����ᐶ����
3�N�Ԓ��ق��Ă������
3�N�Ԓ��ق��Ă������
174 �FSocket774�F2009/12/05(�y) 15:10:34 ID:IFzrHH/f
chrome400/500���K�͉������
Larrbee�ɋ߂��Ȃ�
Larrbee�ɋ߂��Ȃ�
>>170
http://ja.wikipedia.org/wiki/Intel_740#Intel_740.E3.81.AE.E8.A9.95.E4.BE.A1.E3.81.A8.E5.BD.B1.E9.9F.BF
>����i752���x�[�X�Ƃ���IGT�R�A�𓋍ڂ���Intel 810�`�b�v�Z�b�g��
>�s��Ŕ����I�Ȑ��������߁A���ʓI�ɂ�i740���\�����ɗ\�z���ꂽ�悤��
>�����̃O���t�B�b�N�`�b�v�x���_�݂̂Ȃ炸�`�b�v�Z�b�g�x���_�܂�
>�܂߂ē����Ǝs��̍ĕ҂ւƌ��т��Ă������ƂɂȂ�B
���ǁAIntel�̓���=PC�ƊE�̓���
http://ja.wikipedia.org/wiki/Intel_740#Intel_740.E3.81.AE.E8.A9.95.E4.BE.A1.E3.81.A8.E5.BD.B1.E9.9F.BF
>����i752���x�[�X�Ƃ���IGT�R�A�𓋍ڂ���Intel 810�`�b�v�Z�b�g��
>�s��Ŕ����I�Ȑ��������߁A���ʓI�ɂ�i740���\�����ɗ\�z���ꂽ�悤��
>�����̃O���t�B�b�N�`�b�v�x���_�݂̂Ȃ炸�`�b�v�Z�b�g�x���_�܂�
>�܂߂ē����Ǝs��̍ĕ҂ւƌ��т��Ă������ƂɂȂ�B
���ǁAIntel�̓���=PC�ƊE�̓���
176 �F,,�E�L�́M�E,,�j��-�������F2009/12/05(�y) 15:15:06 ID:KKTvEirv
�܂����ۖ��PCIe�̓]�����{�g���l�b�N����
�ėp�R�A�Ƃ̃w�e���W�j�A�X�\���ŃV���O���_�C�ɐڑ����A
�L���b�V�������L���郂�f����GPU���܂߂�������p�r�ł͗��z�^�Ȃ��ǂȁB
NVIDIA�I�ɂ�x86�̓R���g���[���Ƃ��čŒ���̐��\�������������H
TSMC�ɊO�̂��Ă�Atom��GeForce�������Ċ撣���Ă���Ƃ����B
�ėp�R�A�Ƃ̃w�e���W�j�A�X�\���ŃV���O���_�C�ɐڑ����A
�L���b�V�������L���郂�f����GPU���܂߂�������p�r�ł͗��z�^�Ȃ��ǂȁB
NVIDIA�I�ɂ�x86�̓R���g���[���Ƃ��čŒ���̐��\�������������H
TSMC�ɊO�̂��Ă�Atom��GeForce�������Ċ撣���Ă���Ƃ����B
�X�^���t�H�[�h�o�g�҂ƌ�ATI�̃X�p�C��
Intel�̎����i�E���\���h���j�������悤�ɐH�����ɂ��ꂿ�܂����B
Intel�̎����i�E���\���h���j�������悤�ɐH�����ɂ��ꂿ�܂����B
��ԔߎS�Ȃ̂́A�X�^���t�H�[�h��w�̃R���s���[�^����̏d��������Dally��i����NVIDIA�B
Fermi/GT300�H���œ˂��i�ޑI�����������Ȃ��Ƃ����B
Fermi/GT300�H���œ˂��i�ޑI�����������Ȃ��Ƃ����B
Tegra�����邳
�ႦLarrabee������厸�s�ɂȂ��Ă��A���̘H���Ńf�[�^���ƃ��j�[�R�A���Ői�ޕ��j�ȊO�ɁA
intel���Ƃ�ׂ����j���Ă���́H
intel���Ƃ�ׂ����j���Ă���́H
�Ō�̋��菊�̓`�b�v�Z�b�g������GPU�V�F�A�g�b�v��
Intel�}���Z�[����肽�������ƕ�����X�����Ă����
Intel�}���Z�[����肽�������ƕ�����X�����Ă����
�����r�L�����Z���Œc�q���S������������������
184 �F,,�E�L�́M�E,,�j��-�������F2009/12/05(�y) 15:37:31 ID:KKTvEirv
>>180
PCIe���l�b�N���Ƃǂ݂̂��������Ȃ��ł���
Sandy Bridge���ꑫ���GPU�Ƃ�Fusion���ʂ�������A�����̐��ʎ���ŕ��������܂��Ȃ��́H
�v���Z�X���[���̍��V�ɗ������Z�p�v�V�͂���10�N�ȓ��ɒʗp���Ȃ��Ȃ邵�B
PCIe���l�b�N���Ƃǂ݂̂��������Ȃ��ł���
Sandy Bridge���ꑫ���GPU�Ƃ�Fusion���ʂ�������A�����̐��ʎ���ŕ��������܂��Ȃ��́H
�v���Z�X���[���̍��V�ɗ������Z�p�v�V�͂���10�N�ȓ��ɒʗp���Ȃ��Ȃ邵�B
�����܂ł��ǂ蒅���̂ɒ������H�������ȁE�E�E
������Larrbee�͋Z�p�Ҍ����̃w�{����i�ł܂Ƃ��Ɏs��ɏo����悤�ȑ㕨����˂����āA
���x�������Ă��낤���E�E�E���āA���̐�����Ԃ�߂��Ⴄ�̂��B����͂�����ƈӊO�B
���x�������Ă��낤���E�E�E���āA���̐�����Ԃ�߂��Ⴄ�̂��B����͂�����ƈӊO�B
187 �F,,�E�L�́M�E,,�j��-�������F2009/12/05(�y) 15:52:05 ID:KKTvEirv
����x�̍����s�Z������߂Ă����I�ɂ�HPC�p�ł��\��������
����1��100�����炢�ɂ͂Ȃ�낤��
���₳��ׂꂿ�Ⴄ
��߂�����
����1��100�����炢�ɂ͂Ȃ�낤��
���₳��ׂꂿ�Ⴄ
��߂�����
>>181
SCC�̘H�����ƃL���b�V���R�q�[�����V���\�t�g�E�F�A���Ă̂͌݊����Ńl�b�N�ɂȂ�Ȃ��̂��ȁH
���j�[�R�A�����̓����^�C���Œ��ۉ����邩����Ȃ��̂��낤���B
SCC�̘H�����ƃL���b�V���R�q�[�����V���\�t�g�E�F�A���Ă̂͌݊����Ńl�b�N�ɂȂ�Ȃ��̂��ȁH
���j�[�R�A�����̓����^�C���Œ��ۉ����邩����Ȃ��̂��낤���B
189 �F,,�E�L�́M�E,,�j��-�������F2009/12/05(�y) 15:56:08 ID:KKTvEirv
>>188
�L���b�V���R�q�[�����V����
������������Ԃ��R�A�ŋ��L���Ȃ���K�v�Ȃ��̂�
�n�[�h�E�F�A�R�q�[�����g�ȃL���b�V���ɑ��āA�R�q�[�����g�����œǂݏ������閽�߂�p�ӂ����̂�Larrabee
�葱�����@���ς���������Ō��ʓI�ɂ͂�邱�Ƃ͓����B
�L���b�V���R�q�[�����V����
������������Ԃ��R�A�ŋ��L���Ȃ���K�v�Ȃ��̂�
�n�[�h�E�F�A�R�q�[�����g�ȃL���b�V���ɑ��āA�R�q�[�����g�����œǂݏ������閽�߂�p�ӂ����̂�Larrabee
�葱�����@���ς���������Ō��ʓI�ɂ͂�邱�Ƃ͓����B
190 �F,,�E�L�́M�E,,�j��-�������F2009/12/05(�y) 15:59:09 ID:KKTvEirv
�듚�����X�����Ă��x�N�g����1024�r�b�g�]�X�̈Ӗ��͂悭�l���Ă݂���ǂ߂Ă����B
�L���b�V�����C����128byte�ɂ����Ƃ���1��œǂ݂����o����̂Œ��x�����ȁB
�����A����Ō����ǂ����s����ɂ́A���߃Z�b�g���炲�j�Z�ɂ��č�蒼���K�v������B
�L���b�V�����C����128byte�ɂ����Ƃ���1��œǂ݂����o����̂Œ��x�����ȁB
�����A����Ō����ǂ����s����ɂ́A���߃Z�b�g���炲�j�Z�ɂ��č�蒼���K�v������B
Larrabee�g�[���_�E���A
NEC�̃C���^�[�R�l�N�g������V�X�e���ɋ����������A
�R�A�����R�قǕ��ׂĂ��A�o�����X�����āA���ӂȏ����̎�ނ�
���Ȃ�������Ă��Ƃ��ĔF��������A�܂��Ƃ��Ȕ��f��
NEC�̃C���^�[�R�l�N�g������V�X�e���ɋ����������A
�R�A�����R�قǕ��ׂĂ��A�o�����X�����āA���ӂȏ����̎�ނ�
���Ȃ�������Ă��Ƃ��ĔF��������A�܂��Ƃ��Ȕ��f��
192 �F,,�E�L�́M�E,,�j��-�������F2009/12/05(�y) 16:03:24 ID:KKTvEirv
�ŋߋC�Â������ǁA�{���x8Way�{�X�J��1Way���č\���ANEC�X�p�R���Ɏ��Ă���
Itanium�ł�����������Ԃތ���������̂�
HPC�����Ȃ�[�j�b�`��Intel�����i���ł��邩�r���^��
HPC�����Ȃ�[�j�b�`��Intel�����i���ł��邩�r���^��
Intel�̓v���Z�X�J���ɋ���ł������B
�F�C�o���Ċv�V��S�����Ȃ�Ėژ_�ނ��炢�����ʂɏI���B
���Ђ��L�������������e�N�j�b�N���W�߂Ă�������CPU���̂��g��
�F�C�o���Ċv�V��S�����Ȃ�Ėژ_�ނ��炢�����ʂɏI���B
���Ђ��L�������������e�N�j�b�N���W�߂Ă�������CPU���̂��g��
195 �F,,�E�L�́M�E,,�j��-�������F2009/12/05(�y) 16:11:30 ID:KKTvEirv
HPC�͂܂��܂������s�ꂾ��B
����ȏ�ɃN���E�h�i�j�̂ق����L�тĂ邯�ǁB
�Ƃ肠����Google�Ƃ�������̌ڋq��Xeon���x���Ă�̂������ł�����
���������ʂɓW�J����̂͐����������B
�����AGoogle�ȊO�̊�Ƃ��䓪���Ă��邩�ǂ����͉�����
����ȏ�ɃN���E�h�i�j�̂ق����L�тĂ邯�ǁB
�Ƃ肠����Google�Ƃ�������̌ڋq��Xeon���x���Ă�̂������ł�����
���������ʂɓW�J����̂͐����������B
�����AGoogle�ȊO�̊�Ƃ��䓪���Ă��邩�ǂ����͉�����
196 �F,,�E�L�́M�E,,�j��-�������F2009/12/05(�y) 16:13:42 ID:KKTvEirv
��������TOP500�ɓ����Ă�Xeon�N���X�^���čŋ߂�Web���܂Ń����L���O���Ă���
197 �F,,�E�L�́M�E,,�j��-�������F2009/12/05(�y) 16:38:58 ID:KKTvEirv
�����s�ꂾ�낤�������낤��Intel�̋K�͂��炷��Ώ�������
�������x���Ȃ�Ƃ��������ƂƂ��Đ��藧������͓̂������
�������x���Ȃ�Ƃ��������ƂƂ��Đ��藧������͓̂������
199 �F,,�E�L�́M�E,,�j��-�������F2009/12/05(�y) 16:47:28 ID:KKTvEirv
����ϑ傫�������̂��ȁH
�R�A���{�����Ă��������ш�͂قƂ�ǐL�тĂȂ��f�B�X�N���[�g����
�J�b�g�_�E�����Ăł�CPU�Ɠ������A�ʐM�R�X�g��}����L3�L���b�V�������p����
�������ш��}�����ق����ǂ��������B
���⌋�ǂ��ꂪHaswell���B
�R�A���{�����Ă��������ш�͂قƂ�ǐL�тĂȂ��f�B�X�N���[�g����
�J�b�g�_�E�����Ăł�CPU�Ɠ������A�ʐM�R�X�g��}����L3�L���b�V�������p����
�������ш��}�����ق����ǂ��������B
���⌋�ǂ��ꂪHaswell���B
���Ђ̃��C���A�b�v�ŐH�������Ă�̂ɕt�����l�̍����`�b�v��V�K�ɊJ�����Ă̂�
��Փx������ȁB�ׂ����Z�O�����g����������Intel�ɑ��Ďs��͗אڂ��Ă���̂͋ɗ�
���p�����������낤���B
��Փx������ȁB�ׂ����Z�O�����g����������Intel�ɑ��Ďs��͗אڂ��Ă���̂͋ɗ�
���p�����������낤���B
�����Ȃ�Ƃ�����̃��j�[�R�ACPU�̌������\�͑O�t���������ȁ[���Ďv����
�O���{�Ƃ��Ă͂Ƃ��������j�[�R�A���̂͘H���Ƃ��ĊO�����Ƃ͂Ȃ����낤���B
�O���{�Ƃ��Ă͂Ƃ��������j�[�R�A���̂͘H���Ƃ��ĊO�����Ƃ͂Ȃ����낤���B
202 �FSocket774�F2009/12/05(�y) 17:24:10 ID:IFzrHH/f
Larrbee��CPU�ɑg�ݍ��܂�Ă���
Larabee�X���ɗ��Ă݂Ă�c�q������������^�]�����
���Ȃł��Ȃ��̂��ĉ��ȉ����Ǝv����H
���Ȃł��Ȃ��̂��ĉ��ȉ����Ǝv����H
204 �F,,�E�L�́M�E,,�j��-�������F2009/12/05(�y) 18:14:40 ID:KKTvEirv
���₳��͂��邢���̂������̂���
���������CPU-GPU�����`�b�v�����̂������͂����
����Ɋւ��Ă�Intel��AMD�����ɂႢ����d�������B
����Ɋւ��Ă�Intel��AMD�����ɂႢ����d�������B
sandy��Llano�œ������邶���B
����Ƃ��_�C���x������Ȃ��ăA�[�L���x���ł�
���������H
����Ƃ��_�C���x������Ȃ��ăA�[�L���x���ł�
���������H
�������A����ȃ_�C��300W�Ƃ����d�͘g�����E�܂Ŏg����
�X�ɂ�����p�ӂ��ăX�y�b�N���i��o���Ă���n�C�G���hGPU���A
�G���X�[�����ł���������150W���x�܂ł���������Ȃ�CPU�ɓ������ꂽ������GPU�ŋ쒀���鎖��
���������Ȃ��낤���B
������v���Z�X�������Ȃ�A�ŏI�I�ɂ͕���(��H�K��)���������Ȃ�����B
GPU�����ƃO���t�B�b�N�ƊE���e�͒��߂āACPU��GPU�̃����R���ɑ��ݏ�����\�ȋK�i�ł����肷��̂������I�Ȃ�Ȃ��́B
�X�ɂ�����p�ӂ��ăX�y�b�N���i��o���Ă���n�C�G���hGPU���A
�G���X�[�����ł���������150W���x�܂ł���������Ȃ�CPU�ɓ������ꂽ������GPU�ŋ쒀���鎖��
���������Ȃ��낤���B
������v���Z�X�������Ȃ�A�ŏI�I�ɂ͕���(��H�K��)���������Ȃ�����B
GPU�����ƃO���t�B�b�N�ƊE���e�͒��߂āACPU��GPU�̃����R���ɑ��ݏ�����\�ȋK�i�ł����肷��̂������I�Ȃ�Ȃ��́B
��������Lincroft�ł�
���ǂ̂Ƃ���
�EIntel�̊J���͂��Ⴂ
�E���p���ɂ͑�������
�E���������Ԉ���Ă���
�E���C�������Ȃ���
�̂ǂ�Ȃ낤
�������AItanium�̓�̕����Ƃ͂�
�EIntel�̊J���͂��Ⴂ
�E���p���ɂ͑�������
�E���������Ԉ���Ă���
�E���C�������Ȃ���
�̂ǂ�Ȃ낤
�������AItanium�̓�̕����Ƃ͂�
������������������
�����_�C�ɏ�����܂�������Ȃ��ăA�[�L���x���ł̗Z�����Ƃ����b
���ߊg���Ƃ��ł�����x����Ă����ł͂��邯�ǁB
�����_�C�ɏ�����܂�������Ȃ��ăA�[�L���x���ł̗Z�����Ƃ����b
���ߊg���Ƃ��ł�����x����Ă����ł͂��邯�ǁB
�J���͒Ⴗ���Ɉ�[
����GPU�Ɣ�r���ăv���O���}�u���������[��
��������\�t�g�J���̓i�b�V���O���Ă��Ƃ���
Itanium�̎������O�A�i�E���X���X�P�W���[���Œx���
���\�͖��B�Ń\�t�g�T�|�[�g���s���S
�z���g��̕�����
�J���ɎI���[�J������łȂ����瑁�߂Ƀ^�[�Q�b�g��
�k���ł����������čς�ŗǂ������ł���
����GPU�Ɣ�r���ăv���O���}�u���������[��
��������\�t�g�J���̓i�b�V���O���Ă��Ƃ���
Itanium�̎������O�A�i�E���X���X�P�W���[���Œx���
���\�͖��B�Ń\�t�g�T�|�[�g���s���S
�z���g��̕�����
�J���ɎI���[�J������łȂ����瑁�߂Ƀ^�[�Q�b�g��
�k���ł����������čς�ŗǂ������ł���
GPU�����Ƀ`���[�j���O���Ȃ��Ⴂ���Ȃ�����J������q���Ă�
���Ă����Ȃ�GPU���^�[�Q�b�g����O�����炷��Ȃ�o���������ǂ�
GPU�W�Ȃ��J������q���Ă�Ȃ��ςł���
���Ă����Ȃ�GPU���^�[�Q�b�g����O�����炷��Ȃ�o���������ǂ�
GPU�W�Ȃ��J������q���Ă�Ȃ��ςł���
214 �F,,�E�L�́M�E,,�j��-�������F2009/12/05(�y) 19:20:30 ID:KKTvEirv
>>208
�f�B�X�N���[�g��300W�����邾���̎������\��150W�ȓ��Ŏ����o����Ζ��Ȃ��ˁB
�R�A�����{�ɂȂ��Ă��������ш��PCIe�̑ш�͐L�тȂ����ATDP�̑������O���������]���Ɏ����Ă����B
����Ȃ�CPU�ƃ_�C���x���Ŗ����������ق����]���������オ�邵�A�L���b�V���̋��L���Ń������ш���Z�[�u�ł���B
�f�B�X�N���[�g��300W�����邾���̎������\��150W�ȓ��Ŏ����o����Ζ��Ȃ��ˁB
�R�A�����{�ɂȂ��Ă��������ш��PCIe�̑ш�͐L�тȂ����ATDP�̑������O���������]���Ɏ����Ă����B
����Ȃ�CPU�ƃ_�C���x���Ŗ����������ق����]���������オ�邵�A�L���b�V���̋��L���Ń������ш���Z�[�u�ł���B
>>210
Itanium�͐��i�����Ďs��ɏo����Ă�����̕����Ă̂͂�����������
Itanium�͐��i�����Ďs��ɏo����Ă�����̕����Ă̂͂�����������
>>215
�ɂ�x86��u�������悤�Ƃ��Ď��s���Ă�B
�ɂ�x86��u�������悤�Ƃ��Ď��s���Ă�B
Opteron�̃����[�X�ɍ��킹�đR�ɗ�����Itanium���o��������
���̈Ӗ����Ȃ��������
���̈Ӗ����Ȃ��������
�c�q������ƒɁX�������邼
���������������t���Ă邵
���������������t���Ă邵
219 �FSocket774�F2009/12/05(�y) 19:36:39 ID:76DDBxPY
������ƁH���ł����H����́B���v���ȁH�Ǝv���Ă��܂������B
Larrabee��Kikayon�������̂ł����H
���オ���߂Ȃ�A���̑�Ȃ�\�ł���ˁH
�����Ɛ��i�����Ă���������B�K���ł���I
Larrabee��Kikayon�������̂ł����H
���オ���߂Ȃ�A���̑�Ȃ�\�ł���ˁH
�����Ɛ��i�����Ă���������B�K���ł���I
�Q�[���@�ɍ̗p���Ă��炦�Ȃ��������Ă̂������ł́H
222 �F,,�E�L�́M�E,,�j��-�������F2009/12/05(�y) 19:43:07 ID:KKTvEirv
>>216
�ŏ�����R���V���[�}�����͒��߂Ă��悤�ȁB
�łȂ���AMD�Ƃ͕ʂ�64�r�b�g�g����Yamhill�Ȃ�čl���ĂȂ��ł���
x86�ł͐i�o�o���Ȃ��ƍl���Ă����n�C�G���hRISC�s���H���r�炻���Ƃ͍l���Ă�����
���ۂɂ�Xeon�EOpteron�����̂����������ŐH���Ă������B
�ŏ�����R���V���[�}�����͒��߂Ă��悤�ȁB
�łȂ���AMD�Ƃ͕ʂ�64�r�b�g�g����Yamhill�Ȃ�čl���ĂȂ��ł���
x86�ł͐i�o�o���Ȃ��ƍl���Ă����n�C�G���hRISC�s���H���r�炻���Ƃ͍l���Ă�����
���ۂɂ�Xeon�EOpteron�����̂����������ŐH���Ă������B
223 �F,,�E�L�́M�E,,�j��-�������F2009/12/05(�y) 19:43:50 ID:KKTvEirv
>>221
���̃Q�[���@�Ȃ珮�X���o���̂͑���
���̃Q�[���@�Ȃ珮�X���o���̂͑���
�^���b�Ȃ��ANEC�̋Z�p�҂�H���Ă����X�p�R���̋Z�p�ō�ꂽ�肷��낤���H�H�H
225 �F,,�E�L�́M�E,,�j��-�������F2009/12/05(�y) 19:50:46 ID:KKTvEirv
�Ƃ������ASX��Larrabee�̃p�C�v���C���\������ׂăA�z�݂����ɋ��ʓ_�����Đ�����
http://word.smilevision.jp/wikipedia/detail/title/IA-64/
>�C���e����RISC�w�c�̈�Ђł���q���[���b�g�E�p�b�J�[�h (HP)�ƒ�g���A
>HP��VLIW�Z�p�i��ɉ��ǔł�EPIC�A�[�L�e�N�`���j���̗p����IA-64�̋����J���\�����B
>���̍ہA�]����32�r�b�g�܂ł�80x86�A�[�L�e�N�`����IA-32�ƌĂсA�����I�ɂ�IA-64��
>�u����������Ƃ����B�܂�HP��IA-64�����Ђ�PA-RISC�̌�p�ƈʒu�Â����B
64bit���C���̎������������x86�̒u��������O���ɂ��Ă����̂�IA-64�B
�v�悪���\���ꂽ������m���Ă���l�Ȃ�A�R���V���[�}���܂߂��啔����
IA-32��IA-64�̈ڍs���Ӑ}���Ă���Ǝ�����͂��B
�܂����̎v�f��Intel���P���̂���肩�������������ǂȁB
>�C���e����RISC�w�c�̈�Ђł���q���[���b�g�E�p�b�J�[�h (HP)�ƒ�g���A
>HP��VLIW�Z�p�i��ɉ��ǔł�EPIC�A�[�L�e�N�`���j���̗p����IA-64�̋����J���\�����B
>���̍ہA�]����32�r�b�g�܂ł�80x86�A�[�L�e�N�`����IA-32�ƌĂсA�����I�ɂ�IA-64��
>�u����������Ƃ����B�܂�HP��IA-64�����Ђ�PA-RISC�̌�p�ƈʒu�Â����B
64bit���C���̎������������x86�̒u��������O���ɂ��Ă����̂�IA-64�B
�v�悪���\���ꂽ������m���Ă���l�Ȃ�A�R���V���[�}���܂߂��啔����
IA-32��IA-64�̈ڍs���Ӑ}���Ă���Ǝ�����͂��B
�܂����̎v�f��Intel���P���̂���肩�������������ǂȁB
>210
��Intel��x86�v���Z�b�T�̊J���͂�����
�~Intel�̓v���Z�b�T�̊J���͂�����
��Intel��x86�v���Z�b�T�̊J���͂�����
�~Intel�̓v���Z�b�T�̊J���͂�����
229 �F,,�E�L�́M�E,,�j��-�������F2009/12/05(�y) 20:00:53 ID:KKTvEirv
Tim Sweeney�͉��v��
http://software.intel.com/en-us/blogs/2009/08/13/gdc09-vectorization-und-rasterization-with-larrabee/
http://software.intel.com/en-us/blogs/2009/08/13/gdc09-vectorization-und-rasterization-with-larrabee/
230 �F,,�E�L�́M�E,,�j��-�������F2009/12/05(�y) 20:01:34 ID:KKTvEirv
����Larrabee�̋Z�p��Haswell�ȍ~��
�w�e���W�j�A�X�R�A�̒��Ɋ��������Ƃ������ƂȂ́H
�㓡�������Ă��X�J�����\�d��������^�R�A��
�x�N�g�����\�d���̏��^�R�A�̍����͖ʔ�����������
�P�̂�GPU�Ƃ��Ĕ����Ȃ��͎̂c�O�������
�ł��x�ꂽ��ɏo�����Ƃ��Ă�
�x���`�}�[�N�ň��|�ł���킯�ł��Ȃ�
�`�b�v�ʐς��傫������l�i���������邵���Ȃ��ƌ��_��������
���������̒n���Ȑ��\��GPU�ɂȂ�ᔄ��Ȃ����낤��
�C���[�W�I�ɂ��悭�Ȃ����A�������߂�̂���������
�w�e���W�j�A�X�R�A�̒��Ɋ��������Ƃ������ƂȂ́H
�㓡�������Ă��X�J�����\�d��������^�R�A��
�x�N�g�����\�d���̏��^�R�A�̍����͖ʔ�����������
�P�̂�GPU�Ƃ��Ĕ����Ȃ��͎̂c�O�������
�ł��x�ꂽ��ɏo�����Ƃ��Ă�
�x���`�}�[�N�ň��|�ł���킯�ł��Ȃ�
�`�b�v�ʐς��傫������l�i���������邵���Ȃ��ƌ��_��������
���������̒n���Ȑ��\��GPU�ɂȂ�ᔄ��Ȃ����낤��
�C���[�W�I�ɂ��悭�Ȃ����A�������߂�̂���������
�����_�������V���ꂻ���ȍ��ɏo���̂��������낤�B
��O����͒P�̂ŏo����������Ȃ��݂�������
��O����͒P�̂ŏo����������Ȃ��݂�������
233 �FSocket774�F2009/12/05(�y) 20:16:51 ID:76DDBxPY
�������܂��I
�����ǂ�ł�Ԃ���2�`3�N�ȓ��ɂ��鎖�����҂������I
�����ǂ�ł�Ԃ���2�`3�N�ȓ��ɂ��鎖�����҂������I
234 �F,,�E�L�́M�E,,�j��-�������F2009/12/05(�y) 20:23:22 ID:KKTvEirv
�������f���̕���Intel�I�ɂ͓s���ǂ����������ǂˁB
�o�����[�����W�����̃C���e�O���[�gGPU�ł͂��邪�A�A�N�Z�����[�^�Ƃ��Ă��g����B
Haswell�ɍڂ�̂��Ă�������8�R�A�O�ゾ�낤���ǁA����ł�GMA�̒u�������Ƃ���͏\�����낤���B
������ƃ��W���[�������Ă�����CoreMA�I�����[�̍\�����ł��邵�ALarrabee�R�A�ʂ��邱�Ƃ��ł���B
���ꂭ�炢�̃t���L�V�r���e�B���Ȃ���HPC�ŏ\�����v��͓̂���̂ł́B
�o�����[�����W�����̃C���e�O���[�gGPU�ł͂��邪�A�A�N�Z�����[�^�Ƃ��Ă��g����B
Haswell�ɍڂ�̂��Ă�������8�R�A�O�ゾ�낤���ǁA����ł�GMA�̒u�������Ƃ���͏\�����낤���B
������ƃ��W���[�������Ă�����CoreMA�I�����[�̍\�����ł��邵�ALarrabee�R�A�ʂ��邱�Ƃ��ł���B
���ꂭ�炢�̃t���L�V�r���e�B���Ȃ���HPC�ŏ\�����v��͓̂���̂ł́B
�����v�����ł�AMD����s���Ă�킯�Ő^�̓G�͂���ς�AMD��������B
236 �F,,�E�L�́M�E,,�j��-�������F2009/12/05(�y) 20:57:58 ID:KKTvEirv
Llano����H
���ꓝ�����Ă���Ă�����̂��H
L3�L���b�V���o�R�Ńf�[�^���L�Ƃ��H
�Ƃ��v������L3���̂��Ȃ������ł�����B
���������Ӗ��ł�Sandy Bridge�̂ق�����i�I�B
���ꓝ�����Ă���Ă�����̂��H
L3�L���b�V���o�R�Ńf�[�^���L�Ƃ��H
�Ƃ��v������L3���̂��Ȃ������ł�����B
���������Ӗ��ł�Sandy Bridge�̂ق�����i�I�B
����Phenom�̓�̕��ɂȂ�Ȃ����ƂɋF���
>>235
Intel��Pineview/PineTrail��2010Q1�����[�X
Intel��Pineview/PineTrail��2010Q1�����[�X
�[��"Larrabee"���f�B�X�N���[�gGPU�Ƃ��ďo�����Ęb�̏o���͂ǂ��H
>>239
�������̂��H
�o����Intel�Ɍ��܂��Ă邾��B
http://pc.watch.impress.co.jp/img/pcw/docs/317/313/html/22.jpg.html
�������̂��H
�o����Intel�Ɍ��܂��Ă邾��B
http://pc.watch.impress.co.jp/img/pcw/docs/317/313/html/22.jpg.html
{kind=link}
>>239
�yIDF�v���r���[�zIntel�Ђ��O���t�B�b�N�XLSI�Ŗ{���C�uLarrabee�v�͒P�̐��i�Œ�
http://techon.nikkeibp.co.jp/article/NEWS/20080318/149166/
�y���|�[�g�zSIGGRAPH 2008 - Intel��CPU�EGPU�n�C�u���b�h�v���Z�b�T�uLarrabee�v�̐���
http://journal.mycom.co.jp/articles/2008/08/13/siggraph02/
����������GPU�Ƃ͌ĂȂ��i"GPU"�͂��Ƃ���nvidia�ɂ�鑢��Ƃ��čL�܂����o�܂�����j
http://pc.watch.impress.co.jp/docs/news/event/20090924_317313.html
���Ȃ��AIntel�͌�����Larrabee�̂��Ƃ�GPU�Ƃ͌���Ȃ����A
����ʓI�ȗp��ŕ\������Ȃ��͂�GPU�Ƃ����̂������Ƃ��������肭�邾�낤�B
�yIDF�v���r���[�zIntel�Ђ��O���t�B�b�N�XLSI�Ŗ{���C�uLarrabee�v�͒P�̐��i�Œ�
http://techon.nikkeibp.co.jp/article/NEWS/20080318/149166/
�y���|�[�g�zSIGGRAPH 2008 - Intel��CPU�EGPU�n�C�u���b�h�v���Z�b�T�uLarrabee�v�̐���
http://journal.mycom.co.jp/articles/2008/08/13/siggraph02/
����������GPU�Ƃ͌ĂȂ��i"GPU"�͂��Ƃ���nvidia�ɂ�鑢��Ƃ��čL�܂����o�܂�����j
http://pc.watch.impress.co.jp/docs/news/event/20090924_317313.html
���Ȃ��AIntel�͌�����Larrabee�̂��Ƃ�GPU�Ƃ͌���Ȃ����A
����ʓI�ȗp��ŕ\������Ȃ��͂�GPU�Ƃ����̂������Ƃ��������肭�邾�낤�B
242 �F,,�E�L�́M�E,,�j��-�������F2009/12/05(�y) 21:19:19 ID:KKTvEirv
ggrks
http://www.google.co.jp/search?q=Larrabee+Discrete+site:intel.com
for example,
http://www.intel.com/pressroom/archive/releases/20090408corp_a.htm
> The first Larrabee discrete graphics products are due in the late 2009/2010 timeframe.
http://www.google.co.jp/search?q=Larrabee+Discrete+site:intel.com
for example,
http://www.intel.com/pressroom/archive/releases/20090408corp_a.htm
> The first Larrabee discrete graphics products are due in the late 2009/2010 timeframe.
>>240-242
�����B�HIntel���H�������肵�Ă���悧����
�����B�HIntel���H�������肵�Ă���悧����
>>236
intel�����ăL���b�V���̃R�q�[�����V�Ƃ�Ȃ������ɐU���Ă邵�B
intel�����ăL���b�V���̃R�q�[�����V�Ƃ�Ȃ������ɐU���Ă邵�B
�l�C�Ɏ��i
246 �F,,�E�L�́M�E,,�j��-�������F2009/12/05(�y) 21:33:29 ID:KKTvEirv
>>244
Sandy Bridge��GMA��L3�o�R�Ńf�[�^�����ł���`�ɂȂ��Ă邯��
���C���������o�R�ł����f�[�^�̂��Ƃ肪�o���Ȃ��Ȃ�Ȃ���ăf���A���R�A��Pentium D�ƕς��܂����
Sandy Bridge��GMA��L3�o�R�Ńf�[�^�����ł���`�ɂȂ��Ă邯��
���C���������o�R�ł����f�[�^�̂��Ƃ肪�o���Ȃ��Ȃ�Ȃ���ăf���A���R�A��Pentium D�ƕς��܂����
248 �F,,�E�L�́M�E,,�j��-�������F2009/12/05(�y) 21:58:40 ID:KKTvEirv
L3�o�R�Ńf�[�^�����ł���A�[�L�e�N�`�����f���͌�̃A�[�L�e�N�`���ɂ������p�����B
Shared Virtual Memory���L���b�V����̃A�h���X�Ƀ}�b�s���O������C�����������o�R������
�����Ƀf�[�^�����ł���킯���B
Shared Virtual Memory���L���b�V����̃A�h���X�Ƀ}�b�s���O������C�����������o�R������
�����Ƀf�[�^�����ł���킯���B
>>247
���Ⴀ���ɋ�������
���Ⴀ���ɋ�������
���T�ӂ��nVidia����������A
����intel���J�o�������ȂƎv��
����intel���J�o�������ȂƎv��
���l�[�����@�̃m�E�n�E�ł������̂��H
SandyBridge�����GPU�������ł�̂���
�ᐫ�\GPU��������킹�ɂ���Ă����f�疜
AMD��GPU�͐��\�ɂ����҂ł��邯��
Llano��CPU�R�A��K10��Bulldozer����Ȃ���
�o���ł��낦������������
�ᐫ�\GPU��������킹�ɂ���Ă����f�疜
AMD��GPU�͐��\�ɂ����҂ł��邯��
Llano��CPU�R�A��K10��Bulldozer����Ȃ���
�o���ł��낦������������
>>252
http://pc11.2ch.net/test/read.cgi/jisaku/1255132918/429
> 4�R�ACPU�̏�ʃ��f���ɁA�O���t�B�b�N�X�@�\���Ȃ��A
> ��荂�N���b�N����������������f���̓������v�悵�Ă���悤���B
http://pc11.2ch.net/test/read.cgi/jisaku/1255132918/429
> 4�R�ACPU�̏�ʃ��f���ɁA�O���t�B�b�N�X�@�\���Ȃ��A
> ��荂�N���b�N����������������f���̓������v�悵�Ă���悤���B
LRBni���d�蒼�����ǂ���
775 ���O�F���������ҏW��[sage] ���e���F2009/12/05(�y) 23:27:44 ID:aLWw0DeO
�b�Ԃ������邪Larrabee�J�����~�炵��
���܂߂�GPGPU�ɏ����ł����҂��Ă���}�W�ܖڂ���
776 ���O�F���������ҏW��[sage] ���e���F2009/12/05(�y) 23:32:04 ID:uKJpPkeG
�\�[�X�́H
777 ���O�F���������ҏW��[sage] ���e���F2009/12/05(�y) 23:45:19 ID:aLWw0DeO
�����A���߂�A�͂�Y�ꂽ��
ttp://www.semiaccurate.com/2009/12/04/intel-kills-consumer-larrabee-focuses-future-variants/
ttp://www.geocities.jp/andosprocinfo/wadai09/20091205.htm
ttp://www.internetnews.com/hardware/article.php/3851421
���Ɛ��m�Ɍ����ƊJ�����~����Ȃ��ď��i���̒��~��
�b�Ԃ������邪Larrabee�J�����~�炵��
���܂߂�GPGPU�ɏ����ł����҂��Ă���}�W�ܖڂ���
776 ���O�F���������ҏW��[sage] ���e���F2009/12/05(�y) 23:32:04 ID:uKJpPkeG
�\�[�X�́H
777 ���O�F���������ҏW��[sage] ���e���F2009/12/05(�y) 23:45:19 ID:aLWw0DeO
�����A���߂�A�͂�Y�ꂽ��
ttp://www.semiaccurate.com/2009/12/04/intel-kills-consumer-larrabee-focuses-future-variants/
ttp://www.geocities.jp/andosprocinfo/wadai09/20091205.htm
ttp://www.internetnews.com/hardware/article.php/3851421
���Ɛ��m�Ɍ����ƊJ�����~����Ȃ��ď��i���̒��~��
257 �F,,�E�L�́M�E,,�j��-�������F2009/12/06(��) 00:03:56 ID:nTu8nNRJ
�����̃X���H
�ʂ��Ă���
�ʂ��Ă���
���܂��͑�l�������Ă�
259 �F,,�E�L�́M�E,,�j��-�������F2009/12/06(��) 00:09:40 ID:nTu8nNRJ
�����Ă��₳����
���̃X����
542 �F���������ҏW�� �F2009/11/25(��) 14:39:21 ID:tt7hwAi4
CPU�́A�����R�A�P�ʂŐ��\���グ��̂͌��E�Ȃ킯
���Ƃ́A�@�Q�N���Intel AVX�ɑΉ������邩�}���`�R�A�̂�
�������AIntel AVX�ɑΉ������Ă�SSE�̂Q�{�ɂ����Ȃ�Ȃ�����
��Ԃ̊��ɂ͌��ʂ͔����A��������GPGPU�ɑΉ������������J����/���[�U�ɂƂ��Ă������b�g�������
����ɁA�Q�N�̊��Ԃ������GPU�͂���ɐi�����Ă���
543 �F���������ҏW�� �F2009/11/25(��) 14:53:17 ID:72Gt4sRw
GPGPU�ɖ�������
x264�J���ҒB�̈ӌ���>>537�̒ʂ�
544 �F���������ҏW�� �F2009/11/25(��) 15:04:58 ID:tt7hwAi4
GPGPU�́A������Ȃ��Č����Ȃ��ǂ�
����Ȃ��ƁA�킴�킴�C���e����Larrabee�𓊓�����K�v���Ȃ���
���j�[�R�A�Ƃ��āA�ŏI�I�ɂ�Intel AVX�̌�p�Ƃ���
Larrabee��CPU�ɓ�������v��𗧈Ă��闝�R���Ȃ�
x264�̊J���҂�����̕ω��ɋt�s����悤�ȕϐl�ł��Ȃ����
���R�̐���s���őΉ������
545 �F���������ҏW�� �F2009/11/25(��) 15:07:21 ID:oDNJzApa
NGID:tt7hwAi4
542 �F���������ҏW�� �F2009/11/25(��) 14:39:21 ID:tt7hwAi4
CPU�́A�����R�A�P�ʂŐ��\���グ��̂͌��E�Ȃ킯
���Ƃ́A�@�Q�N���Intel AVX�ɑΉ������邩�}���`�R�A�̂�
�������AIntel AVX�ɑΉ������Ă�SSE�̂Q�{�ɂ����Ȃ�Ȃ�����
��Ԃ̊��ɂ͌��ʂ͔����A��������GPGPU�ɑΉ������������J����/���[�U�ɂƂ��Ă������b�g�������
����ɁA�Q�N�̊��Ԃ������GPU�͂���ɐi�����Ă���
543 �F���������ҏW�� �F2009/11/25(��) 14:53:17 ID:72Gt4sRw
GPGPU�ɖ�������
x264�J���ҒB�̈ӌ���>>537�̒ʂ�
544 �F���������ҏW�� �F2009/11/25(��) 15:04:58 ID:tt7hwAi4
GPGPU�́A������Ȃ��Č����Ȃ��ǂ�
����Ȃ��ƁA�킴�킴�C���e����Larrabee�𓊓�����K�v���Ȃ���
���j�[�R�A�Ƃ��āA�ŏI�I�ɂ�Intel AVX�̌�p�Ƃ���
Larrabee��CPU�ɓ�������v��𗧈Ă��闝�R���Ȃ�
x264�̊J���҂�����̕ω��ɋt�s����悤�ȕϐl�ł��Ȃ����
���R�̐���s���őΉ������
545 �F���������ҏW�� �F2009/11/25(��) 15:07:21 ID:oDNJzApa
NGID:tt7hwAi4
262 �F,,�E�L�́M�E,,�j��-�������F2009/12/06(��) 00:16:53 ID:nTu8nNRJ
Larrabee��h.264�̃G���R�[�h�ɓ��ʌ����Ă�Ƃ͎v���ȁB
�ނ���Sandy Bridge�݂����ȃN���b�N���オ���ăR�A����������SIMD���\2�{�Ƃ���
�f���Ȑi�����Ċ��Ɖ��b�͑傫���Ǝv���B
�ނ���Sandy Bridge�݂����ȃN���b�N���オ���ăR�A����������SIMD���\2�{�Ƃ���
�f���Ȑi�����Ċ��Ɖ��b�͑傫���Ǝv���B
263 �F,,�E�L�́M�E,,�j��-�������F2009/12/06(��) 00:19:35 ID:nTu8nNRJ
��H.264�͂قƂ�ǐ����Ȃ̂�256�r�b�gAVX���̂��̂͂���܂����b����܂���B�������炸
>>236
> Llano����H
> ���ꓝ�����Ă���Ă�����̂��H
> L3�L���b�V���o�R�Ńf�[�^���L�Ƃ��H
> �Ƃ��v������L3���̂��Ȃ������ł�����B
>
> ���������Ӗ��ł�Sandy Bridge�̂ق�����i�I�B
AMD�����Ĕn������Ȃ�����B
L3�ł̋��L�����̂ЂƂ������͂��B
�m��780G��L3�o�R�ŋ��L����\���������Ǝv�����ˁB
L2 1M*4��L2 512k*4+ L3 2M���V�~�����[�V�������Ĕ�r�������ʂ�L2 1M�̗̍p���Ǝv���B
L3���L�́A��葽���̃L���b�V����ς߂�28nm��22nm���ォ��ɂȂ��Ȃ����ȁB
> Llano����H
> ���ꓝ�����Ă���Ă�����̂��H
> L3�L���b�V���o�R�Ńf�[�^���L�Ƃ��H
> �Ƃ��v������L3���̂��Ȃ������ł�����B
>
> ���������Ӗ��ł�Sandy Bridge�̂ق�����i�I�B
AMD�����Ĕn������Ȃ�����B
L3�ł̋��L�����̂ЂƂ������͂��B
�m��780G��L3�o�R�ŋ��L����\���������Ǝv�����ˁB
L2 1M*4��L2 512k*4+ L3 2M���V�~�����[�V�������Ĕ�r�������ʂ�L2 1M�̗̍p���Ǝv���B
L3���L�́A��葽���̃L���b�V����ς߂�28nm��22nm���ォ��ɂȂ��Ȃ����ȁB
���ႠBulldozer��FPU�����L������Ă̂͂������f�Ȃ̂�
266 �F,,�E�L�́M�E,,�j��-�������F2009/12/06(��) 00:29:38 ID:nTu8nNRJ
��Nehalem�܂łȂ炻����L�����������낤�ˁB
Bulldozer8�R�A��Sandy Bridge 4�R�A�Ȃ�s�[�NFP���\�͌݊p�B
Sandy Bridge 6�R�A��������Ƃ��Ă͔����B
Bulldozer8�R�A��Sandy Bridge 4�R�A�Ȃ�s�[�NFP���\�͌݊p�B
Sandy Bridge 6�R�A��������Ƃ��Ă͔����B
268 �FSocket774�F2009/12/06(��) 00:30:46 ID:5sVI7Mg3
PCIe�o�R��l3�����L���ĈӖ�����́H
269 �F,,�E�L�́M�E,,�j��-�������F2009/12/06(��) 00:31:59 ID:nTu8nNRJ
>>256
���{�����l���C�u�����Ƃ����Ă������������x�[�X������˂��B
FPU���̂̓v���O���}���̂��x�����Ƃ�m���Ă邵�A�덷�ł邵�A�����Ă�l���������B
���{�����l���C�u�����Ƃ����Ă������������x�[�X������˂��B
FPU���̂̓v���O���}���̂��x�����Ƃ�m���Ă邵�A�덷�ł邵�A�����Ă�l���������B
271 �F,,�E�L�́M�E,,�j��-�������F2009/12/06(��) 00:36:02 ID:nTu8nNRJ
�ꉞLarrabee�͑��{�����������X�^�[�ł����������ȁB
Westmere��CLMUL�Ƃ����̎�̖��߂͑��₵�ė~����
Westmere��CLMUL�Ƃ����̎�̖��߂͑��₵�ė~����
���A�����҂������Ă�
>>270�̈�����>>265�������B�B�Borz
>>271
�c�q�̐l�I�ɂ͑��{�����Z�̎l�����Z��sqrt�Ƃ��̏������w���ĕ��ł������Ȃ́H
>>270�̈�����>>265�������B�B�Borz
>>271
�c�q�̐l�I�ɂ͑��{�����Z�̎l�����Z��sqrt�Ƃ��̏������w���ĕ��ł������Ȃ́H
273 �F,,�E�L�́M�E,,�j��-�������F2009/12/06(��) 00:44:44 ID:nTu8nNRJ
���ʂɕ��ł���B
���{���x��sqrt�͂��ꂱ��FFT�g���Ηǂ��̂ł́H
���{���x��sqrt�͂��ꂱ��FFT�g���Ηǂ��̂ł́H
>>273
���܂����̓��̂Q���ڈʂ܂ł��������ĂȂ�����ڍׂ͂킩��ǁA�ł�����ē��������炦�Ă��ꂵ����B
���܂����̓��̂Q���ڈʂ܂ł��������ĂȂ�����ڍׂ͂킩��ǁA�ł�����ē��������炦�Ă��ꂵ����B
���A���{�������������A�f�������ň�疜�҂��I�I
�ƁA���S�t���O���ĂĐQ��I���₷��/~
�ƁA���S�t���O���ĂĐQ��I���₷��/~
276 �F,,�E�L�́M�E,,�j��-�������F2009/12/06(��) 00:59:17 ID:nTu8nNRJ
�}�X�N���W�X�^���L�����[�r�b�g�Ƃ��ĕ]�����閽�߂�����B
���ꂪ���������_�ŁAGPU�̔�����Ԃ���HPC�����v���Z�b�T���Ƃ킩�����B
���̕ӂ�Fermi���ǂ����͂킩���GeForce�͊ߋ�݂����ȃ������Ǝv���B
���ꂪ���������_�ŁAGPU�̔�����Ԃ���HPC�����v���Z�b�T���Ƃ킩�����B
���̕ӂ�Fermi���ǂ����͂킩���GeForce�͊ߋ�݂����ȃ������Ǝv���B
278 �F,,�E�L�́M�E,,�j��-�������F2009/12/06(��) 01:46:46 ID:nTu8nNRJ
POWER7�łǂ���
>>266
Bulldozer��GPU���������z���Ă��̃f�U�C���ɂȂ��Ă�͂�������
�s�[�NFP���\�͂���ŏ\������
GPU���\�ł�AMD�̃J�[�h�̕������͂���
Bulldozer��GPU���������z���Ă��̃f�U�C���ɂȂ��Ă�͂�������
�s�[�NFP���\�͂���ŏ\������
GPU���\�ł�AMD�̃J�[�h�̕������͂���
280 �F,,�E�L�́M�E,,�j��-�������F2009/12/06(��) 02:07:01 ID:nTu8nNRJ
FFT�̐��\�����\�ł��Ȃ��悤��FP���\�����H
sse�x�[�X��shader��i����via/s3�����͈�ԕ|��
282 �F,,�E�L�́M�E,,�j��-�������F2009/12/06(��) 02:15:20 ID:nTu8nNRJ
�[���ASandy Bridge�̐��\��r����ƕs�������ĉ�������ł̌��ʘ_���낤�B
AMD��SIMD���j�b�g��256�r�b�g�����邾�����B
�������Intel��256�r�b�gFMA�~2�ɂ��邾�낤���ǂȁB
AMD��SIMD���j�b�g��256�r�b�g�����邾�����B
�������Intel��256�r�b�gFMA�~2�ɂ��邾�낤���ǂȁB
�X�y�b�N�~�������K���Ȃ��Ƃ����Ă�Ȃ�
Larrabee�̌��݂����O������������n����قǂقǂɂ���
�����N�̃R�s�y�}�V�[���ɓO���Ă��
Larrabee�̌��݂����O������������n����قǂقǂɂ���
�����N�̃R�s�y�}�V�[���ɓO���Ă��
Sandy�̒��ړ_�͓���GPU����˂�
���v���H���ق�IGP�����H
���v���H���ق�IGP�����H
���̐��̔����ȏ��intel igp�ŏo���Ă��܂���
>>280
����RADEON�̓O���t�B�b�N�����C���ŁA�ėp���Z�͂Ƃ肠�����Ή����܂������x������ˁB
��{�I�ɃV�F�[�_�[��L���b�V���𑝂₵�������ŁA���x���傫�����Č����������͎̂d���Ȃ��B
����RADEON�̓O���t�B�b�N�����C���ŁA�ėp���Z�͂Ƃ肠�����Ή����܂������x������ˁB
��{�I�ɃV�F�[�_�[��L���b�V���𑝂₵�������ŁA���x���傫�����Č����������͎̂d���Ȃ��B
>>285
CPU�̂��܂��ŕt���Ă��āA����Ȃ�Ɏg���邩��F�d���Ȃ��g���Ă��邾�����ˁB
CPU�̂��܂��ŕt���Ă��āA����Ȃ�Ɏg���邩��F�d���Ȃ��g���Ă��邾�����ˁB
>>287
��������PC��99�����炢�͂���Ŏ������Ǝv���
��������PC��99�����炢�͂���Ŏ������Ǝv���
289 �F,,�E�L�́M�E,,�j��-�������F2009/12/06(��) 11:48:42 ID:nTu8nNRJ
IGP�͑������������������Ƃ��f�B�X�N���[�gGPU�������Ȃ��Ă��\���Ǝv�킹�邾���̐��\����������B
�lj��Ŕ��킹��̂ƐS�����ʂ��܂�ňႤ�B
�lj��Ŕ��킹��̂ƐS�����ʂ��܂�ňႤ�B
�ǂ����S�����ʂ̐��Ƃł�����炵���ł�
����͐S�����ʂ���Ȃ��āA���K�I�A����d�́A�X�y�[�X�I�Ȗ�肾�낗
292 �F,,�E�L�́M�E,,�j��-�������F2009/12/06(��) 12:14:33 ID:nTu8nNRJ
��������GMA���Ċ�ƌ���PC�Ƃ��m�[�gPC���唼�������
�Œ���̉�ʏo�͋@�\���������������
�����ADX10.1���炢�͑Ή����Ăق�����
������Ȃ�CPU�ŃS�������͌������Ȃ���邵
�����ADX10.1���炢�͑Ή����Ăق�����
������Ȃ�CPU�ŃS�������͌������Ȃ���邵
http://www.tgdaily.com/business-and-law-features/36390-unreal-creator-tim-sweeney-qpcs-are-good-for-anything-just-not-games?start=1
Tim Sweeney �uIntel�fs integrated graphics just don't work. I don't think they will ever work.�v
Tim Sweeney �uIntel�fs integrated graphics just don't work. I don't think they will ever work.�v
����T�̂܂Ƃ߁�
Larrabee�̓p�t�H�[�}���X�Ⴗ���ďI�����܂���
Larrabee�̓p�t�H�[�}���X�Ⴗ���ďI�����܂���
gt240,4870,540gtx��gpubench�̌��ʂ��Ă����܂���
ttp://ultraxs.com/image-36B9_4B1B20E6.jpg
�ƐԂ͂����Ɗ撣���Ăق���
ttp://ultraxs.com/image-36B9_4B1B20E6.jpg
{kind=link}
�ƐԂ͂����Ɗ撣���Ăق���
Larrabee���ă��C�g���[�V���O�Ō��͂��\�ɂłĂ���킯�ŁA
�RD�t���{�S�[�O���Ŏg���悤�ȉf���ړI����
Direct3D�ŗ��̉f���݂Ă���яo�Č����Ȃ���B�Ⴂ�����Ă݂�Ζ����B
�ߐڂقǎ��_����̌v�Z���c��ł���̂��RD�v�Z�̊ȗ����ׂ̈��낤�B
�܂��ʂ�艜�̂RD�܂łȂ�Direct3D�͂Ȃ�Ƃ��v�Z�ł��邪
��ʂ����O�̔�яo����̂͂܂Ƃ��Ɍv�Z�ł��Ȃ����Ă��ƁB
�RD�t���{�S�[�O���Ŏg���悤�ȉf���ړI����
Direct3D�ŗ��̉f���݂Ă���яo�Č����Ȃ���B�Ⴂ�����Ă݂�Ζ����B
�ߐڂقǎ��_����̌v�Z���c��ł���̂��RD�v�Z�̊ȗ����ׂ̈��낤�B
�܂��ʂ�艜�̂RD�܂łȂ�Direct3D�͂Ȃ�Ƃ��v�Z�ł��邪
��ʂ����O�̔�яo����̂͂܂Ƃ��Ɍv�Z�ł��Ȃ����Ă��ƁB
298 �F,,�E�L�́M�E,,�j��-�������F2009/12/06(��) 12:44:03 ID:nTu8nNRJ
PS1�̍�����̋Z�@�����
�̂��肵�����̂𗧑̂Ɍ����邽�߂ɑ�U���ڂɘc�܂��Ă�
���Ăނ������p�̐搶�������Ă�
�̂��肵�����̂𗧑̂Ɍ����邽�߂ɑ�U���ڂɘc�܂��Ă�
���Ăނ������p�̐搶�������Ă�
299 �FSocket774�F2009/12/06(��) 13:08:30 ID:NeeeC2YB
Larrabee�͎��s�삾���I
�S�[��Q �Q�@�@�@�@�@�@�@�@�@�@�@�@�@ , '�@�@�_�@�S�@�R�@�@ �@�@�@/�@�@/�@�@
�@ �r�@,�S�L �^�@�@�@�@�@�@�@�@�@�@�@, �L�@�@�@�@�@�_| �_|�@�@�@ �@/�@�@/
�@ |�S' �^�@�@�@�@�@�@�@�@�@�@�@�^�@�@�@�@�@�@�@�@/�_/�_�@�@ /�@�@/
�@/�^�@,'�L�@�P �R�@,,,,,,,,,�@�@/�@�@�@,;;;::::::::::::::::::/:::::/:�_::::�_/::::::/:::::::::::::::::::::
�@�@ �@�n�Ƀ��)ځr:::::::::;;;�@�@�@�@,;;;::::::::::::::::::/:::::/:::::::::�_/::�_/:::��::::::::��:::::::��:::
�@�@�@�m�Ɂ� ߁��:::::::::::::::;;;�@�@�@:::::::::::::::::::::/::::/::::::::::::��:::/��:�_/:���_::::::��::::::::::::
�@�@�@�Mk'_.�r �@�M��:::::::::::::::;;;�@�@�@::::::::::::::::::/::::/:::::::::::::::/��:::::::/�_::::�_��:::��::::::::::::
�@�@�@�@�@���m__/__|;;::::::::::;;;�@�@�@�@ ';;;:::::::::/::::/::::::::::::::/::::::::/::::��:::::�_::::�_:::::::::::::
�@�@�@�@�@ (_ )�@ (�Q"""�@�@�R�@�@�@';;;;:::/::::/::::::::::::::/::::::::/:::::::::::::::::�_::::�_::::::::::::::::
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �_�@�@ /�@/�@�@�@�@/�@�@/�@�@�@�@�@�@�@�_�@ �_
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �M�m. �m�@�@�@�@/�@�@/�@�@�@�@�@�@�@�@�@ �_�@ �_
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�S�Q�Q�Q/�Q /�@�@�@�@�@ �@�@�@�@�@�@�_�@ �_
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ V�Q�m �P�P�P�P�P�P�P�[�\-�_�\�_�\
DX���_���߂��邩�烌�C�g�����C�g���Ɩ����Ă�낤��
Larrabee���ĕʂ�GPU�ɔ�ׂă��C�g�������ӂ��Ė�Ȃ�����
�Ƃ��������ʂ̍��Ń��C�g���ł�������B
Larrabee���ĕʂ�GPU�ɔ�ׂă��C�g�������ӂ��Ė�Ȃ�����
�Ƃ��������ʂ̍��Ń��C�g���ł�������B
301 �F,,�E�L�́M�E,,�j��-�������F2009/12/06(��) 15:18:51 ID:nTu8nNRJ
����GPU�Ƃ͋�̓I�ɂǂ���
302 �F,,�E�L�́M�E,,�j��-�������F2009/12/06(��) 15:31:06 ID:nTu8nNRJ
RTRT�̓g���[�X�f�[�^���i�[���邽�߂ɋ��L���U�^�̃L���b�V�����x�X�g�ŗ��z�̗e�ʂ�16MB���x���Ę_���������Ă��ȁB
���Z���j�b�g������ɂ���L���b�V�������ɍČv�Z�����ق����������Ă��Ƃ����邪
�Čv�Z�ɂ����͒l�^���Ă��ɂ�Ȃ��킯��B
Larrabee�ɑ���ĂȂ����ʂƂ̓L���b�V���������B1�R�A������1MB�����16�R�A�ł�16MB���B
���ꂱ��5Way VLIW�ł̍X��64����ł̑e�����Z���x�ł́u���ʁv�Ȃ�đ��ǂ�����Ă�B
���C�g������Ȃ����Ǖ����G���W����Havok����CPU���x�����B
���Z���j�b�g������ɂ���L���b�V�������ɍČv�Z�����ق����������Ă��Ƃ����邪
�Čv�Z�ɂ����͒l�^���Ă��ɂ�Ȃ��킯��B
Larrabee�ɑ���ĂȂ����ʂƂ̓L���b�V���������B1�R�A������1MB�����16�R�A�ł�16MB���B
���ꂱ��5Way VLIW�ł̍X��64����ł̑e�����Z���x�ł́u���ʁv�Ȃ�đ��ǂ�����Ă�B
���C�g������Ȃ����Ǖ����G���W����Havok����CPU���x�����B
���܂ł������Ă�Ȃ�
�ł���͈͂ō���Ă݂��琫�\���肸�ɐ��i���f�O�̂����`�b�v�����
�ł���͈͂ō���Ă݂��琫�\���肸�ɐ��i���f�O�̂����`�b�v�����
>>297
���C�g�������čL�p�����Y�g���Θc�ނ��AZ�o�b�t�@��D3D�ł�������Y
�݂����ȃ����_�����O�͉\����B���������c�݂����镔���̓��C�g��
��������₷�����Ă��Ƃ͂Ȃ��B
����Ƀ��C�g���ɂ��Ă�Nvidia��mental images�������Ă邵Optix���o���Ă邵�A
���R���ł�����ł��X�C�b�`�ł���̐�����ˁB���C�g������ɂȂ�����
����GPU���[�J�[�͖v������A�݂����Ȍ�������FUD�������Ƃ����B
���C�g�������čL�p�����Y�g���Θc�ނ��AZ�o�b�t�@��D3D�ł�������Y
�݂����ȃ����_�����O�͉\����B���������c�݂����镔���̓��C�g��
��������₷�����Ă��Ƃ͂Ȃ��B
����Ƀ��C�g���ɂ��Ă�Nvidia��mental images�������Ă邵Optix���o���Ă邵�A
���R���ł�����ł��X�C�b�`�ł���̐�����ˁB���C�g������ɂȂ�����
����GPU���[�J�[�͖v������A�݂����Ȍ�������FUD�������Ƃ����B
305 �F,,�E�L�́M�E,,�j��-�������F2009/12/06(��) 15:55:23 ID:nTu8nNRJ
���������f�B�X�N���[�gGPU�Ƃ��Ă̓������̂��s���p�����u�����v�ȊO�̉��ł��Ȃ��C�����邪�ȁB
���C�g���ɑ��{���������Z�@�\���K�v���H
����łȂ��Ƃ��s��ϓ����̖��߃Z�b�g�����B
���Ƒ����i�K�Ō����Ă��Ǝv�����ǂ�GPU�̔�������X�p�R���v���Z�b�T�����āB
�܂�����łȂ��Ƃ�����GPU�̓f�[�^�t���[�ɖ��ʂ��������邩��A���̃X�p�R�������v���Z�b�T�ɂ���
�t�����錄�͂������Ǝv�����킯�����B
���C�g���ɑ��{���������Z�@�\���K�v���H
����łȂ��Ƃ��s��ϓ����̖��߃Z�b�g�����B
���Ƒ����i�K�Ō����Ă��Ǝv�����ǂ�GPU�̔�������X�p�R���v���Z�b�T�����āB
�܂�����łȂ��Ƃ�����GPU�̓f�[�^�t���[�ɖ��ʂ��������邩��A���̃X�p�R�������v���Z�b�T�ɂ���
�t�����錄�͂������Ǝv�����킯�����B
306 �F,,�E�L�́M�E,,�j��-�������F2009/12/06(��) 16:01:21 ID:nTu8nNRJ
���̊��Ғʂ�X�p�R���p�ɂ͖��ʂ̏��Ȃ��v���Z�b�T�ɂ͂Ȃ������A�Z���Ƃ�����2�N���x��
������ɓ���\���������Ȃ��Ă��܂����B
������ɓ���\���������Ȃ��Ă��܂����B
307 �FSocket774�F2009/12/06(��) 16:21:07 ID:lsM8Bz7P
>>296
������āA100m���_���X�g��1.4�g���̃|���V�F������10m�ŋ���������
�l�Ԃ̕����������Č����Ă�悤�Ȃ��̂���Ȃ��̂�
������āA100m���_���X�g��1.4�g���̃|���V�F������10m�ŋ���������
�l�Ԃ̕����������Č����Ă�悤�Ȃ��̂���Ȃ��̂�
�ڂ������Ƃ͕������
a�Ə��Ȃ��Ƃ����܂�n��gpu�k�����������Ȃ͕̂�����
a�Ə��Ȃ��Ƃ����܂�n��gpu�k�����������Ȃ͕̂�����
�������~�ɂȂ�����
i752�H����
i752�H����
Larrabee�̃O���t�B�b�N�H���j���ŃX���̉����̔炪�����ꂽ�Ȃ�
���В@����Intel���őf���炵���M�҃X���ł���
���В@����Intel���őf���炵���M�҃X���ł���
312 �FSocket774�F2009/12/06(��) 18:54:52 ID:lsM8Bz7P
�H
�����Ȃ��̂ɌQ����̂�
�����̍r�炵�Ɣn������
�����Ȃ��̂ɌQ����̂�
�����̍r�炵�Ɣn������
��c�Ɩk�X�͍��̂Ƃ���R���V���[�}�����f�B�X�N���[�gLarrabee���~�̃l�^�����Ă��
����A�R�_�ق͂��̃l�^�����������ڂ���
����A�R�_�ق͂��̃l�^�����������ڂ���
Larrabee�̓R�P�ANVIDIA��Voodoo�̎��������Ă邵�b���O���t�B�b�N�X�s���AMD1�����オ������
amd�̓X�J�X�J�Ȃ��
����fermi��������Ȃ���
����fermi��������Ȃ���
fermi(��)
���̏ŃA���Ɋ��҂���̂���������[
���̏ŃA���Ɋ��҂���̂���������[
>313
�R�_�ق��ď��߂Č������A�����͋@�B�|��̃e�X�g����������Ă�Ƃ��Ȃ́H
�R�_�ق��ď��߂Č������A�����͋@�B�|��̃e�X�g����������Ă�Ƃ��Ȃ́H
318 �F,,�E�L�́M�E,,�j��-�������F2009/12/06(��) 22:51:11 ID:nTu8nNRJ
���f�~�̒��̐l����
���̏ł�amd�͖���
>>315
�����Fermi�͍������ɔ����Ă��܂����H
�����Fermi�͍������ɔ����Ă��܂����H
321 �F,,�E�L�́M�E,,�j��-�������F2009/12/06(��) 23:30:52 ID:nTu8nNRJ
Intel���R���V���[�}�����ɏo���Ȃ��ƌ��������A
�u�v�A�}���YLarrabee�v�Ƃ��Ă�Fermi�͊��҂�����Ȃ��B
�u�v�A�}���YLarrabee�v�Ƃ��Ă�Fermi�͊��҂�����Ȃ��B
���ǒ��̐l��Larrabee�ȂɊ��҂͂��ĂȂ��������Ă��Ƃ��B
>>313
�������́u�l�^�͎�ŏE���Ă�v���Č������Ă邩��ʂɗǂ���ˁH
���X�����r���S����j���[�X�Ǝv���Ă�̂�Intel�M�҂��炢�ŁA�����炷��悤�₭���\���������Ē��x�ł���B
�ŏ��̃u�`�グ����x���ɂ��x���B���X�ɘI�o�������Ă��ă����r���̂̃j���[�X�o�����[���̂����ꂷ���B
SC09��OC���Ė������1T�o���ĎГ��O�����Ɂu���ʁv���������ł���H
�Љ�l�Ȃ画�邾�낤���ǁA����ŃP���������Ǝv���B
�������́u�l�^�͎�ŏE���Ă�v���Č������Ă邩��ʂɗǂ���ˁH
���X�����r���S����j���[�X�Ǝv���Ă�̂�Intel�M�҂��炢�ŁA�����炷��悤�₭���\���������Ē��x�ł���B
�ŏ��̃u�`�グ����x���ɂ��x���B���X�ɘI�o�������Ă��ă����r���̂̃j���[�X�o�����[���̂����ꂷ���B
SC09��OC���Ė������1T�o���ĎГ��O�����Ɂu���ʁv���������ł���H
�Љ�l�Ȃ画�邾�낤���ǁA����ŃP���������Ǝv���B
>>323
�܂����̔��\���āA�uLarrabee����i�I�v�Ƃ��v������́A
�����Ƃ��������ʂ̉�Ћ߂ɂ͌����ĂȂ����A����������n�����B
�M�҂Ƃ������ȑO�ɁA�������]�݂����猇���Ă�낤���A���̂Ԃ̂��̂����܂�悤�w�͂���ƁB
�܂����̔��\���āA�uLarrabee����i�I�v�Ƃ��v������́A
�����Ƃ��������ʂ̉�Ћ߂ɂ͌����ĂȂ����A����������n�����B
�M�҂Ƃ������ȑO�ɁA�������]�݂����猇���Ă�낤���A���̂Ԃ̂��̂����܂�悤�w�͂���ƁB
325 �F,,�E�L�́M�E,,�j��-�������F2009/12/07(��) 00:17:45 ID:3pFyeiTC
���������Q�[���p�r��Epic�̎x�����肫�������
��{�X���Ƃ����ɓ����o���Ă��܂����̂ɍ��XLarrabee3�Ƃ������Ă��Ȃ�
�������������o��i�o����j��H���Ęb����
�R�����W���Ȃ���ł�����܂��ɁB
�R�����W���Ȃ���ł�����܂��ɁB
������ƑO��BSN�ɃI���S���`�[����Larrabee�J���ɓ������Ƃ������L������������
���ۂ�Larrabee�������AVX�̌�p�Ƃ��Ă�LNI���x�ɏk�������
�t��CPU�w���Ɏ�荞�܂ꂽ���Ď��������̂��B
���ۂ�Larrabee�������AVX�̌�p�Ƃ��Ă�LNI���x�ɏk�������
�t��CPU�w���Ɏ�荞�܂ꂽ���Ď��������̂��B
330 �F,,�E�L�́M�E,,�j��-�������F2009/12/07(��) 08:42:32 ID:3pFyeiTC
����ŏ\������Ȃ��H
LRBni�̎����Ɋւ���������������A���������Ӗ��ł͒����v��ɑ傫�Ȍ��т͎c�����B
AMD��AVX���̗p���������_�Ŏ���512bit���܂ޒ����헪�͏\���D�ʂɂ�������B
���z�Ȃ̂͐܊pAMD��DREX�G���R�[�h�̓�����������̂Ɉ�x���g��ꂸ�Ƀ|�V������SSE5����ȁB
LRBni�̎����Ɋւ���������������A���������Ӗ��ł͒����v��ɑ傫�Ȍ��т͎c�����B
AMD��AVX���̗p���������_�Ŏ���512bit���܂ޒ����헪�͏\���D�ʂɂ�������B
���z�Ȃ̂͐܊pAMD��DREX�G���R�[�h�̓�����������̂Ɉ�x���g��ꂸ�Ƀ|�V������SSE5����ȁB
���ɂȂ��ĉߋ��X����ǂނƒc�q�������ɔn���R�e�����������悭�킩���
���삷��ł��ĂȂ����̋Z�p�����͖̂������������Ƃ������ł��傤�B
���ɐ��Y�E�d�́E���M�Ő�����R�X�g�������\�c�_�͋���������(HPC����ł������Ȃ�Ăł��Ȃ�)
���ɐ��Y�E�d�́E���M�Ő�����R�X�g�������\�c�_�͋���������(HPC����ł������Ȃ�Ăł��Ȃ�)
����肷����J����ĂȂ��v���Z�b�T�̐��\�����ς����킯���Ȃ��B
�R�A���L���b�V�������ł̓}���f���u���݂����ɉ��X�Ə��ʃf�[�^��
���˂���v�Z�̐��\�����킩���
�R�A���L���b�V�������ł̓}���f���u���݂����ɉ��X�Ə��ʃf�[�^��
���˂���v�Z�̐��\�����킩���
>>331
�R�e��������ˁ[�@��芪���A����Larrabee�ȊO�̃`�b�v�����ɂ��܂���
�R�e��������ˁ[�@��芪���A����Larrabee�ȊO�̃`�b�v�����ɂ��܂���
GPU�Ƃ��Ċ��҂��Ă���l�ԂȂ�ĂقƂ�ǂ��Ȃ�����o�������̂ɂ��Ďv�����A
���̕����������̗\��قǐ��\�łȂ��������Ă��ƂȂ낤���B
���̕����������̗\��قǐ��\�łȂ��������Ă��ƂȂ낤���B
>>334
�Ƃ�����Tim Sweeney�Ƃ����J���X�}���O�]�������������Ă��������傫���B
�t�Ɍ�����Epic�������ی������炻�̎��_�ŏI����Ă��B
�Ȃ�Ōv�撆�~�����āA����Ε����邾�낤�BUE4��2012�N���B
�Ƃ�����Tim Sweeney�Ƃ����J���X�}���O�]�������������Ă��������傫���B
�t�Ɍ�����Epic�������ی������炻�̎��_�ŏI����Ă��B
�Ȃ�Ōv�撆�~�����āA����Ε����邾�낤�BUE4��2012�N���B
�t�H���[���Ă����ƁA�ʂ�Tim Sweeney��Larrabee��No��@���t�����킯�ł͂Ȃ��B
Sweeney��Larrabee�ł͂Ȃ�Larrabee�ɒǏ]���悤�Ƃ��Ȃ�GPU�w�c�Ɏ��]��
������Unreal Engine�̊J���v�����ނ������B
�e�w�c�������݂Ŕނ̖]�݂ǂ���̃A�[�L�e�N�`���ɒu�������K�v�����������炾�B
�����ALarrabee�������t���J�X�^���G���W���������͏]���ǂ���Ƃ������̂�����Ă��O�̂̎��M�͖��������낤�B
�������ALarrabee���]����DirectX��OpenGL�ł����|�����邾���̐��\��
�����Ă����Ȃ�AIntel, Epic�Ƃ��ɋ��C�̑Ή��͂ł����낤�B
���������Ӗ��ł͂�͂荡�����Larrabee�͏��i���O�Ɏ��s�����B
�����ĕ��������Ԉ���Ă����킯�ł͂Ȃ�������s���߂����B
12/6�̒NjL��ǂ܂ꂽ���B
Larrabee��������Tim Sweeney�̗��z�ʂ�̐v���������킩��B
http://www.brightsideofnews.com/news/2009/12/5/intel-cans-consumer-larrabee2c-compatibility2c-performance-and-nvidia-related-issues.aspx
Sweeney��Larrabee�ł͂Ȃ�Larrabee�ɒǏ]���悤�Ƃ��Ȃ�GPU�w�c�Ɏ��]��
������Unreal Engine�̊J���v�����ނ������B
�e�w�c�������݂Ŕނ̖]�݂ǂ���̃A�[�L�e�N�`���ɒu�������K�v�����������炾�B
�����ALarrabee�������t���J�X�^���G���W���������͏]���ǂ���Ƃ������̂�����Ă��O�̂̎��M�͖��������낤�B
�������ALarrabee���]����DirectX��OpenGL�ł����|�����邾���̐��\��
�����Ă����Ȃ�AIntel, Epic�Ƃ��ɋ��C�̑Ή��͂ł����낤�B
���������Ӗ��ł͂�͂荡�����Larrabee�͏��i���O�Ɏ��s�����B
�����ĕ��������Ԉ���Ă����킯�ł͂Ȃ�������s���߂����B
12/6�̒NjL��ǂ܂ꂽ���B
Larrabee��������Tim Sweeney�̗��z�ʂ�̐v���������킩��B
http://www.brightsideofnews.com/news/2009/12/5/intel-cans-consumer-larrabee2c-compatibility2c-performance-and-nvidia-related-issues.aspx
�Z�p�I�ɗD��Ă��Ă������̗͋Ƃɂ���Đ��\�����������ꋣ���͂������Ȃ��Ă��܂�
�܂�ō��܂�Intel(x86)������Ă������Ƃ̗��Ԃ��̂悤��
�܂�ō��܂�Intel(x86)������Ă������Ƃ̗��Ԃ��̂悤��
�����r�[�͑����������̂ɃC���e���̎Г������Œׂ��ꂽ�̂���i��
Tim�̏]��GPU�ɑ��鎸�]�͂��̂�����B
http://www.tomshardware.com/news/Sweeney-Epic-GPU-GPGPU,8461.html
>>339
�Q���W���K�[�ސw���Visual Computing Group�̗\�Z���Ȃ��ӓI�B
Intel�Г��̓��Q�o����Ȃ��̂��ˁBIntel�Г��ł�x86�R�A��Atom�x�[�X��
���ׂ����Ƃ����ӌ����������Ƃ��ȑO�㓡�������Ă��B
http://www.tomshardware.com/news/Sweeney-Epic-GPU-GPGPU,8461.html
>>339
�Q���W���K�[�ސw���Visual Computing Group�̗\�Z���Ȃ��ӓI�B
Intel�Г��̓��Q�o����Ȃ��̂��ˁBIntel�Г��ł�x86�R�A��Atom�x�[�X��
���ׂ����Ƃ����ӌ����������Ƃ��ȑO�㓡�������Ă��B
����ዣ�����Ђ�r���Ď������D�ʂɗ��Ă�Ȃ�x�������邾�낤��
>>339
�������������A����������L�����Z������ĂȂ���B
�����������Ǝv�����ǂȁB
�c�q�͗͐����Ă���GPU��x86�̈Ӗ��͗L����ȁH
�������������A����������L�����Z������ĂȂ���B
�����������Ǝv�����ǂȁB
�c�q�͗͐����Ă���GPU��x86�̈Ӗ��͗L����ȁH
�G���W������DirectX�͎��ł���ƌ����Ėʔ����Ȃ�Microsoft��
���GPGPU�Ή����x��Ă�ATI���x������̂��������R
���GPGPU�Ή����x��Ă�ATI���x������̂��������R
>>342
1���߂�����̃I�y���[�V���������҂����߂ɏ��Ȃ��Ƃ�CISC�ł���K�v�͂��邪
x86�������z�I�Ȗ��߃Z�b�g������Ȃ炻��ł�������Ȃ��H
Intel�ɂ�x86�łȂ�������Ȃ����R�͕������邵�AAMD�������v��Ƃ���
x86�t�����g�G���h����GPU�Ƀ_�C���N�g�ɃI�y���[�V�����s����\�z��
����Ă���B�t��x86�œs���������̂̓��C�Z���X�������Ă��Ȃ�NVIDIA���ȁH
1���߂�����̃I�y���[�V���������҂����߂ɏ��Ȃ��Ƃ�CISC�ł���K�v�͂��邪
x86�������z�I�Ȗ��߃Z�b�g������Ȃ炻��ł�������Ȃ��H
Intel�ɂ�x86�łȂ�������Ȃ����R�͕������邵�AAMD�������v��Ƃ���
x86�t�����g�G���h����GPU�Ƀ_�C���N�g�ɃI�y���[�V�����s����\�z��
����Ă���B�t��x86�œs���������̂̓��C�Z���X�������Ă��Ȃ�NVIDIA���ȁH
>>338
���������b���o���Ƃ��AIntel fan boy �̊F����̔����͂���
�@�D��Ă��邩�珟�����A�����ɂ��݉���
�Ɨ�𗁂т�����̂������B
Larrabee�͌v�攒���ł��A����ł��D��Ă��Đ�i�I��
�قߑ����Ă������ɂ��݂���Ȃ��炵��
���������b���o���Ƃ��AIntel fan boy �̊F����̔����͂���
�@�D��Ă��邩�珟�����A�����ɂ��݉���
�Ɨ�𗁂т�����̂������B
Larrabee�͌v�攒���ł��A����ł��D��Ă��Đ�i�I��
�قߑ����Ă������ɂ��݂���Ȃ��炵��
http://journal.mycom.co.jp/articles/2007/09/15/barcelona/004.html
> A: �����g�́ASSE��CPU�T�C�h�ł̏�������CPU+GPU�ł̏����ɃX���[�Y��
> �ڍs���邽�߂̖��߃Z�b�g�̕ύX�ƍl���Ă���B�����́Ax86���߂�
> CPU�T�C�h�ŁASSE���߂�GPU�T�C�h�ŏ�������Ă䂭�̂ł͂Ȃ����Ǝv���B
> SSE5�́A������������̒��̑����ł���A������x��(�]���ɔ�ׂ�)
> ���������̂��B����GPGPU�����y���Ă䂭���ŁA�x�N�^���߂��o����
> (GPGPU��)��������Ƃ����p�[�e�B�V���j���O���\�ɂ��邽�߂̂��̂��B
> �ܘ_�v���O���}���猩��Γ���OpCode�ɂȂ邩��A���ꂪ�ǂ���ŏ���
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
> ����邩���ӎ�����K�v�͂Ȃ����B�������n�[�h�E�F�A�Ō���ΈقȂ�
> ���j�b�g���������ƂɂȂ邾�낤
������OpCode���Ă̂�x86��SIMD���߂ł�����GPU���̖��߃Z�b�g�ł͂Ȃ�
> A: �����g�́ASSE��CPU�T�C�h�ł̏�������CPU+GPU�ł̏����ɃX���[�Y��
> �ڍs���邽�߂̖��߃Z�b�g�̕ύX�ƍl���Ă���B�����́Ax86���߂�
> CPU�T�C�h�ŁASSE���߂�GPU�T�C�h�ŏ�������Ă䂭�̂ł͂Ȃ����Ǝv���B
> SSE5�́A������������̒��̑����ł���A������x��(�]���ɔ�ׂ�)
> ���������̂��B����GPGPU�����y���Ă䂭���ŁA�x�N�^���߂��o����
> (GPGPU��)��������Ƃ����p�[�e�B�V���j���O���\�ɂ��邽�߂̂��̂��B
> �ܘ_�v���O���}���猩��Γ���OpCode�ɂȂ邩��A���ꂪ�ǂ���ŏ���
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
> ����邩���ӎ�����K�v�͂Ȃ����B�������n�[�h�E�F�A�Ō���ΈقȂ�
> ���j�b�g���������ƂɂȂ邾�낤
������OpCode���Ă̂�x86��SIMD���߂ł�����GPU���̖��߃Z�b�g�ł͂Ȃ�
������Tim/EPIC�����ƎҁB
�l�l�̋��A���\���h��(�̉�����)�g���ăI�i�j�[���₪���āB
���˂�J�X�B
�l�l�̋��A���\���h��(�̉�����)�g���ăI�i�j�[���₪���āB
���˂�J�X�B
> Larrabee�͌v�攒���ł��A����ł��D��Ă��Đ�i�I��
�����NVIDIA�w�c�͔F�߂�����Ȃ����낤�������ɂ������낤�B
AMD��CPU-GPU�Z���̑����ƍl���Ă���SSE5��AVX�݊��ɒu�����������_��
�������͌��܂����BAMD��LRBni�݊������Ȃ��������R�͂Ȃ�����ȁB
�x�N�^��4�`8Way���x��SSE��AVX���ጻ���ɂ�GPU�̕���A�[�L�e�N�`����
���̂܂�������ɂ͕���x������Ȃ��߂���B
��胏�C�h�ȉ��Z���j�b�g�\�����Ƃ�K�v������B
���邢��Intel�Ƃ͕ʂ�512�r�b�g�₻��ȏ��SIMD���߃Z�b�g����邩�H
���ꂪAMD�ɏo����Ȃ�SSE5�̓L�����Z�����ĂȂ��B
�����łЂƂA�d�_�������Ă݂�B
Intel��AMD�Ƃ̊ԂɌ��ꂽx86�Ɋւ���V���ȃN���X���C�Z���X�̓��e��
���J����ĂȂ��B������Larrabee�Ɋւ��閧�������Ƃ�����H
Larrabee��AMD�ɂƂ��ĕs�s���Ȃ̂́AIntel��IGP�̈��|�I�ȃV�F�A�ɂ���
���킹��LRBni�����Ђ݂̂ɗD�ʂȌ`�ŕ��y������̂��ڂɌ����Ă��邱�ƁB
�t�ɁAFusion�̌v��̒x������J�o������܂�Larrabee��x�点�Ă��炢�A
Larrabee�݊����߃Z�b�g���֘A�����܂�Intel���^�_���R�Ń��C�Z���X����
�����Ȃ�AMD�Ƃ��Ă����Ȃ�D�s���ƂȂ�B
�����NVIDIA�w�c�͔F�߂�����Ȃ����낤�������ɂ������낤�B
AMD��CPU-GPU�Z���̑����ƍl���Ă���SSE5��AVX�݊��ɒu�����������_��
�������͌��܂����BAMD��LRBni�݊������Ȃ��������R�͂Ȃ�����ȁB
�x�N�^��4�`8Way���x��SSE��AVX���ጻ���ɂ�GPU�̕���A�[�L�e�N�`����
���̂܂�������ɂ͕���x������Ȃ��߂���B
��胏�C�h�ȉ��Z���j�b�g�\�����Ƃ�K�v������B
���邢��Intel�Ƃ͕ʂ�512�r�b�g�₻��ȏ��SIMD���߃Z�b�g����邩�H
���ꂪAMD�ɏo����Ȃ�SSE5�̓L�����Z�����ĂȂ��B
�����łЂƂA�d�_�������Ă݂�B
Intel��AMD�Ƃ̊ԂɌ��ꂽx86�Ɋւ���V���ȃN���X���C�Z���X�̓��e��
���J����ĂȂ��B������Larrabee�Ɋւ��閧�������Ƃ�����H
Larrabee��AMD�ɂƂ��ĕs�s���Ȃ̂́AIntel��IGP�̈��|�I�ȃV�F�A�ɂ���
���킹��LRBni�����Ђ݂̂ɗD�ʂȌ`�ŕ��y������̂��ڂɌ����Ă��邱�ƁB
�t�ɁAFusion�̌v��̒x������J�o������܂�Larrabee��x�点�Ă��炢�A
Larrabee�݊����߃Z�b�g���֘A�����܂�Intel���^�_���R�Ń��C�Z���X����
�����Ȃ�AMD�Ƃ��Ă����Ȃ�D�s���ƂȂ�B
�Ƌ֖@���݂ł킴��AMD�Ƀ��C�Z���X���^�Ƃ��H
>>348
����Ȃ�����t���������ĂȂ����ĕ\������Ă��܂���
����Ȃ�����t���������ĂȂ����ĕ\������Ă��܂���
�܂�Intel��AMD��NVIDIA�Ƀ`�b�v�Z�b�g���C�Z���X��^���Ȃ����Ƃ�
nForce���Ƃ�p�Ƃɒǂ��������Ƃ��Ă�킯��
���̕����NVIDIA�����ʂ̉��z�G�ɂȂ��Ă鎖��������킯�����ȁB
nForce���Ƃ�p�Ƃɒǂ��������Ƃ��Ă�킯��
���̕����NVIDIA�����ʂ̉��z�G�ɂȂ��Ă鎖��������킯�����ȁB
>>300
GPU�ł̓f�[�^�x�[�X�̂悤�ȃI�u�W�F�N�g���Ǘ�����͕̂s�������Ă��Ƃ�B
GPU�ł̓f�[�^�x�[�X�̂悤�ȃI�u�W�F�N�g���Ǘ�����͕̂s�������Ă��Ƃ�B
>>350
���ꎩ���ЂƂ肵�������ĂȂ����낤
���ꎩ���ЂƂ肵�������ĂȂ����낤
�N���N���@Heavendale�Ɏ������s�L������ɂ�
>>350
��̓I�Ɍ��������B
Intel�́A�I���S���ƃn�C�t�@�ŕ��Ƃ���Tick-Tock���f���Ō��݂�
�A�[�L�e�N�`�������V���邱�ƂŁA������Е��̐������g���u���Ă�
���J�o�������₷���悤�ɉ��d�ɂ����X�N������ł��Ă��Ă���B
����Intel���ALarrabee�����Ɍ����Ă͉��̕ی����������ɕ����i��ł���
�Ǝv������ł�̂Ȃ�N�����u�t�Α̍זE�����݂ėt�����݂Ă��Ȃ��v
�̂ł́H
�P�̔ł��������悤�����s���悤���Ō�ɂ�GPU��CPU�_�C�ɓ�������v�悾��
�v����Ƀf�B�X�N���[�gGPU�Ƃ��Ă�Larrabee�̑��ݎ��́AIntel���炷���
�u�����v�ɂ����Ȃ������B
>>354
�|�V�����Ă��҉�ł�����x���ĈӖ��ł͓��ނ��ȁB
�ʔ����̂́A���͂⌋�ʓI�Ƀu���t�ɂȂ��Ă��܂��������͂̑��݂�O���
�Љ^������ׂ������悤�ȋ����͂����̉�Ђ����݂��邱�ƁB
������A�v��̏C���������Ȃ���ԂŁB
��̓I�Ɍ��������B
Intel�́A�I���S���ƃn�C�t�@�ŕ��Ƃ���Tick-Tock���f���Ō��݂�
�A�[�L�e�N�`�������V���邱�ƂŁA������Е��̐������g���u���Ă�
���J�o�������₷���悤�ɉ��d�ɂ����X�N������ł��Ă��Ă���B
����Intel���ALarrabee�����Ɍ����Ă͉��̕ی����������ɕ����i��ł���
�Ǝv������ł�̂Ȃ�N�����u�t�Α̍זE�����݂ėt�����݂Ă��Ȃ��v
�̂ł́H
�P�̔ł��������悤�����s���悤���Ō�ɂ�GPU��CPU�_�C�ɓ�������v�悾��
�v����Ƀf�B�X�N���[�gGPU�Ƃ��Ă�Larrabee�̑��ݎ��́AIntel���炷���
�u�����v�ɂ����Ȃ������B
>>354
�|�V�����Ă��҉�ł�����x���ĈӖ��ł͓��ނ��ȁB
�ʔ����̂́A���͂⌋�ʓI�Ƀu���t�ɂȂ��Ă��܂��������͂̑��݂�O���
�Љ^������ׂ������悤�ȋ����͂����̉�Ђ����݂��邱�ƁB
������A�v��̏C���������Ȃ���ԂŁB
�v����ɉ������������̂��B
357 �FSocket774�F2009/12/07(��) 16:05:15 ID:/6dOwMyJ
F�������ɓ˂��������o������
Larrabee�J����Ɣ�ׂČ�1�������B
Larrabee�J����Ɣ�ׂČ�1�������B
>>357
Tela-Scale Research Group�S�̂���Ȃ��Ă��H
Larrabee�P�̗̂\�Z�Ȃ�Č��\���ꂽ���Ƃ͈�x�������B
Larrabee�́u���܂��v�Ƃ͂���22nm�ȍ~��S��������GMA�����A
���̕ӂ��܂�Larrabee�łȂ��Ă��g���܂킵�̂������̂̌o��܂�
�v�コ��Ă邩�炾��B
�@�@������
�C���e���A�������Z�G���W����Havok����
http://japan.cnet.com/news/ent/story/0,2000056022,20356674,00.htm
�C���e���A�g�ݍ���OS�x���_�̃E�C���h���o�[��
http://monoist.atmarkit.co.jp/fembedded/news/2009/06/05intel.html
�C���e���A�\�t�g�E�F�A���2�Ђ�--����v���O���~���O�̊J���𑣐i��
http://japan.cnet.com/news/ent/story/0,2000056022,20398736,00.htm
�����Đ������Ȃ����ASCC���\��45nm����Larrabee GPU���i���Ȃ�
���̏��Ԃɂ����͈̂Ӗ�������B
Tela-Scale Research Group�S�̂���Ȃ��Ă��H
Larrabee�P�̗̂\�Z�Ȃ�Č��\���ꂽ���Ƃ͈�x�������B
Larrabee�́u���܂��v�Ƃ͂���22nm�ȍ~��S��������GMA�����A
���̕ӂ��܂�Larrabee�łȂ��Ă��g���܂킵�̂������̂̌o��܂�
�v�コ��Ă邩�炾��B
�@�@������
�C���e���A�������Z�G���W����Havok����
http://japan.cnet.com/news/ent/story/0,2000056022,20356674,00.htm
�C���e���A�g�ݍ���OS�x���_�̃E�C���h���o�[��
http://monoist.atmarkit.co.jp/fembedded/news/2009/06/05intel.html
�C���e���A�\�t�g�E�F�A���2�Ђ�--����v���O���~���O�̊J���𑣐i��
http://japan.cnet.com/news/ent/story/0,2000056022,20398736,00.htm
�����Đ������Ȃ����ASCC���\��45nm����Larrabee GPU���i���Ȃ�
���̏��Ԃɂ����͈̂Ӗ�������B
�悭�m��Ȃ����A��v��Č��\���邳�����̂炵����
������p��R&D�Ɍv�シ��K���Ȃ̂��H
������p��R&D�Ɍv�シ��K���Ȃ̂��H
�c�q�������48�R�A���炦��́H
������狌�h�̒�R�ɂ�������i��
���Ԕ��_��U��T��Cell�~�𒎂���̂悤�Ɉ����Ă���
�����M�҂����x�͉��d�g���T���U�炷���ɂȂ�Ƃ́E�E�E�E
���ꂪ���ʉ�����Ă���B
�����M�҂����x�͉��d�g���T���U�炷���ɂȂ�Ƃ́E�E�E�E
���ꂪ���ʉ�����Ă���B
>>347
Tim�̌������Ƃ�^�Ɏ�z�͂ɂ킩����
Tim Sweeney�����\������A21���I�̃��A���^�C���R�c�Z�p�B(1999�N��)
http://bbx.hp.infoseek.co.jp/news.shtml
http://archive.gamespy.com/legacy/interviews/sweeney.shtm
Tim�̌������Ƃ�^�Ɏ�z�͂ɂ킩����
Tim Sweeney�����\������A21���I�̃��A���^�C���R�c�Z�p�B(1999�N��)
http://bbx.hp.infoseek.co.jp/news.shtml
http://archive.gamespy.com/legacy/interviews/sweeney.shtm
�����ɑ��݂��Đ��\���o���Ă�CelL�Ǝ��삷��Ȃ�Larrabee�ł͔�ׂ�̂����炾�낤
��������Cell���I����������H
Intel�ALarrabee�O���t�B�b�N�X�`�b�v�̌v���j���i���C�^�[�j
http://www.itmedia.co.jp/news/articles/0912/07/news041.html
http://www.itmedia.co.jp/news/articles/0912/07/news041.html
>>368
�ӖړI�M�҂��ȁB
����\���̐��ۂ��u���e�v����Ȃ��āu�N�����������v�Ŕ��f����B
�ǂ�ȂɗD�G�ł��A���T�Ȑl�Ԃ͋��Ȃ����B
�ӖړI�M�҂��ȁB
����\���̐��ۂ��u���e�v����Ȃ��āu�N�����������v�Ŕ��f����B
�ǂ�ȂɗD�G�ł��A���T�Ȑl�Ԃ͋��Ȃ����B
Intel ���J������ GPU�wLarrabee�x�A1�e���t���b�v�X��B��
http://japan.internet.com/webtech/20091207/12.html
>Intel �ɂƂ��ăO���t�B�b�N�X �v���Z�b�T ���j�b�g (GPU) �s��Q���Ɍ��������̑�K�͂Ȏ��g�݂ƂȂ�
>�wLarrabee�x(�J���R�[�h��) �́A2009�N9���́wIntel Developer Forum (IDF)�x�ł͑債����ۂ�^�����Ȃ������B
>�����A11���ɊJ�Â��ꂽ�wSC09�x�ł́A���̖��ߍ��킹���ł����悤���B
�����̂��Ԕ������ڂ̋L���́B
http://japan.internet.com/webtech/20091207/12.html
>Intel �ɂƂ��ăO���t�B�b�N�X �v���Z�b�T ���j�b�g (GPU) �s��Q���Ɍ��������̑�K�͂Ȏ��g�݂ƂȂ�
>�wLarrabee�x(�J���R�[�h��) �́A2009�N9���́wIntel Developer Forum (IDF)�x�ł͑債����ۂ�^�����Ȃ������B
>�����A11���ɊJ�Â��ꂽ�wSC09�x�ł́A���̖��ߍ��킹���ł����悤���B
�����̂��Ԕ������ڂ̋L���́B
>>365
������i740���A�����[�X���ꂽ���Ă����_�ł�Larrabee���ォ
������i740���A�����[�X���ꂽ���Ă����_�ł�Larrabee���ォ
�ӖړI�Ȃɂ킩�Q�[�}�[���ȁB
����͗\�z�Ƃ������́u��������ׂ��v�Ƃ����ނ̊�]���낤�B
����Ȕނ̗��z����葽�����������v���b�g�t�H�[���Ő��X�̃q�b�g�삪
���ݏo���ꂽ�Ƃ������т͊m���ɂ���B
���Ƃ���PS3�ł�UE�̎U�X�����E�E�E�AMS��360�Ŕނ̗v�]�����Ă����Đ�����������H
����͗\�z�Ƃ������́u��������ׂ��v�Ƃ����ނ̊�]���낤�B
����Ȕނ̗��z����葽�����������v���b�g�t�H�[���Ő��X�̃q�b�g�삪
���ݏo���ꂽ�Ƃ������т͊m���ɂ���B
���Ƃ���PS3�ł�UE�̎U�X�����E�E�E�AMS��360�Ŕނ̗v�]�����Ă����Đ�����������H
�܂����̑傫���z�[�������o�b�^�[���Ǝv���Ă���������Ȃ�
������ł�����������Ȃ���O�U
������ł�����������Ȃ���O�U
Epic�̊Ŕ삪������Ȃ��������Ƃ��������H
�ŗ�����Ȃ��ēo�����Ⴂ�B
�ŗ�����Ȃ��ēo�����Ⴂ�B
MS�̃��~�b�g���肬��܂�Direct3D10�Ή��ł��Ȃ�����Intel��GPU�Ŋ��҂��邱�Ƃ͉����Ȃ�
���_�̘b����Ȃ��́H
>>372
�����܂ł킩���ĂĐ^�Ɏ�Ȃ��ăR���ɔ��_����̂������ł��Ȃ�
�����܂ł킩���ĂĐ^�Ɏ�Ȃ��ăR���ɔ��_����̂������ł��Ȃ�
����̋�_�Ƃ������ȁB
���X������SCC�Ƀ^�C�g����ς���̂��H
Larrabee(��)�X���Ƃ�
Many-Core�X���ł��������
Many-Core�X���ł��������
�yLarrabee�z Intel GPU Project �yFailed�z
Intel�̎�����CPU�X���Ɣ���Ă邩��ʃX�������ł���B
383 �F,,�E�L�́M�E,,�j��-�������F2009/12/07(��) 23:41:18 ID:3pFyeiTC
�i>336�@>337�j�@�i>353�@>355�j
�������݂̍s���p�^�[�����c�q�Ƃ�������
�������݂̍s���p�^�[�����c�q�Ƃ�������
385 �F,,�E�L�́M�E,,�j��-�������F2009/12/07(��) 23:46:29 ID:3pFyeiTC
�������̉��i��
386 �F,,�E�L�́M�E,,�j��-�������F2009/12/07(��) 23:47:10 ID:3pFyeiTC
�������Ă�́H
387 �F,,�E�L�́M�E,,�j��-�������F2009/12/07(��) 23:59:33 ID:3pFyeiTC
http://northwood.blog60.fc2.com/blog-entry-3339.html
���ꕁ�ʂ� 45nm ���ځ[�� 32nm ���ځ[�� �� 22nm�Q�n ��3���ゾ���
�y�����u���z
�@GMA�́u����܁v�Ɣ������܂�
���ꕁ�ʂ� 45nm ���ځ[�� 32nm ���ځ[�� �� 22nm�Q�n ��3���ゾ���
�y�����u���z
�@GMA�́u����܁v�Ɣ������܂�
388 �FSocket774�F2009/12/08(��) 00:15:09 ID:SJC9DSD8
Geforce��Radeon�͓��ʂ�40nm
Larrabee��32nm�A���������Ђ�GPU���g���o���N�v���Z�X���D�ꂽCPU�����v���Z�X���g�����Ƃ��o�����͂�
����ł��������o���Ȃ��ƌ����̂ł́E�E�E���{�I�Ƀ_�������Ă��Ƃ���
22nm����ɂȂ��Ă����Ђ�GPU�Ƃ̑��ΓI�ȊW�͕ς���Ǝv��
Larrabee��32nm�A���������Ђ�GPU���g���o���N�v���Z�X���D�ꂽCPU�����v���Z�X���g�����Ƃ��o�����͂�
����ł��������o���Ȃ��ƌ����̂ł́E�E�E���{�I�Ƀ_�������Ă��Ƃ���
22nm����ɂȂ��Ă����Ђ�GPU�Ƃ̑��ΓI�ȊW�͕ς���Ǝv��
32nm����Ȃ���45nm�ł���
390 �F,,�E�L�́M�E,,�j��-�������F2009/12/08(��) 00:23:15 ID:lpxlFx1c
Tick-Tock��������������B�܂�32nm�̌���Ƃ��B
�������L���b�V�����������A�z�݂����ɏ��Ȃ��ăR�A�����{�����Ă��������ш悪1.x�{�ɂ��������Ȃ�
�Ƃ����ǂ�l�܂��Ԃ̂܂ܕۂĂ�D�ʂȂ疳������B
����3�N��Intel��CPU�̓��[�A�̖@���ȏ�̑����ŁiSandy Bridge��2�{�AHaswell�ōX��2�{�j
SIMD���Z���\�𑝂₵�Ă����v�悾���瑊�ΓI��GPGPU�̉��l�͂ǂ�ǂ��Ȃ��Ă����B
�������L���b�V�����������A�z�݂����ɏ��Ȃ��ăR�A�����{�����Ă��������ш悪1.x�{�ɂ��������Ȃ�
�Ƃ����ǂ�l�܂��Ԃ̂܂ܕۂĂ�D�ʂȂ疳������B
����3�N��Intel��CPU�̓��[�A�̖@���ȏ�̑����ŁiSandy Bridge��2�{�AHaswell�ōX��2�{�j
SIMD���Z���\�𑝂₵�Ă����v�悾���瑊�ΓI��GPGPU�̉��l�͂ǂ�ǂ��Ȃ��Ă����B
�N���b�N���オ���̂���
�l�I�ɂ̓I�v�\�n�����������̂������Ǝg���Ă����Ɗ��������ǁA�ǂ��Ȃ낤�Ȃ��B
�����Ƃ��A����ȊO�̐��\����̗]�n���������Ȃ�g�����I���������B
�����Ƃ��A����ȊO�̐��\����̗]�n���������Ȃ�g�����I���������B
���̈��Ƃ邪L���уV�p�[�C�錾���Ă�̂ɂ��ւ�炸�A
���̊��ɋy��ŁA���ꂾ����{�����������債������ł��B
���̊��ɋy��ŁA���ꂾ����{�����������債������ł��B
394 �F,,�E�L�́M�E,,�j��-�������F2009/12/08(��) 00:45:01 ID:lpxlFx1c
���A���ꂾ���͊m�����B
Sandy Bridge��Core 2 Duo�ȗ��̌��삾�B
AVX��������Ȃ��ɂ����ƃX�J�����\���]��SSE���\���オ��B
�����ɁA�����B
Sandy Bridge��Core 2 Duo�ȗ��̌��삾�B
AVX��������Ȃ��ɂ����ƃX�J�����\���]��SSE���\���オ��B
�����ɁA�����B
���b�N�A�b�v��NVIDIA�߷ެ����Č����Ă���������������
Sandy Bridge�Ȃ�ďo���1�N���悾��Larrabee�ƊW�Ȃ���
397 �F,,�E�L�́M�E,,�j��-�������F2009/12/08(��) 01:30:28 ID:lpxlFx1c
SSE�ȗ���SIMD���߃Z�b�g�̎d�蒼��������
��s�҂̗���ɂ͍�����R�[�h�����Ă����đ��͂Ȃ��̂�\�t�g���ɂ�
��s�҂̗���ɂ͍�����R�[�h�����Ă����đ��͂Ȃ��̂�\�t�g���ɂ�
398 �F,,�E�L�́M�E,,�j��-�������F2009/12/08(��) 01:58:40 ID:lpxlFx1c
�����Ƃ��{�����B
�����A�嗬�ɂȂ���̂Ȃ牽�ł��ǂ������B
�����A�嗬�ɂȂ���̂Ȃ牽�ł��ǂ������B
AVX��LNI�͌݊���������̂��ˁB
How many cores(0-15)? _
>>371
i740�̔��Ȃ܂��āA�����[�X���Ȃ��Ƃ����I�����o����悤�ɂȂ����Ƃ����i���H������H
i740�̔��Ȃ܂��āA�����[�X���Ȃ��Ƃ����I�����o����悤�ɂȂ����Ƃ����i���H������H
>>400
0
0
�܂�Intel�̃O���t�B�b�N�X�`�b�v�������������܂������킯�Ȃ����펯�I�ɍl����
>>397
�V���s��̂킯�̂킩���C�b�g��Ƃ̊��Ɏ���o���Ă₯�ǂ�����̃Z���t�ƕς���ȁB
�V���s��̂킯�̂킩���C�b�g��Ƃ̊��Ɏ���o���Ă₯�ǂ�����̃Z���t�ƕς���ȁB
Larrabee(��)�AIntel�͍��𓊂��܂����悗
���͓�����ꂽ�I
������ɂ���AGPGPU�s��ւ̏o�x��͌���I�Ȃ��̂ɂȂ��
��c���Ĕ��ł���
Intel������Ă܂�������������
Intel������Ă܂�������������
�������ƃ����[�X���������\�t�g�̑Ή��������Ȃ��Ȃ����ˁB
�����N�\�ł��B
�����ōς߂B
�����N�\�ł��B
�����ōς߂B
410 �F,,�E�L�́M�E,,�j��-�������F2009/12/08(��) 09:05:41 ID:lpxlFx1c
>>407
����Ȏs��͂Ȃ��B����܂Œʂ肽���̃A�N�Z�����[�^�����B
����Ȏs��͂Ȃ��B����܂Œʂ肽���̃A�N�Z�����[�^�����B
>>410
���O�͖{���ɔn������
���O�͖{���ɔn������
IGP�̃V�F�A�g��Ō����Ă����f�B�X�N���[�gGPU�̎��v�k����H���~�߂�̂��ړI�ȁuGPGPU�v��
Intel�����������قǂ̎s�ꐬ�����͂Ȃ��ł���B
HPC��p�v�͍��Ă��X�P�[�������b�g�Ȃ����瓊�����������炢������ȁB
Intel���炷���SSE(AVX)�̐��\���グ��킴�킴�����GPGPU�v���O���~���O�����Ă܂�
�g�����l�͑��ΓI�ɉ�����킯�����玩���̓y�U�Ő���Ă��낵���B
Intel�����������قǂ̎s�ꐬ�����͂Ȃ��ł���B
HPC��p�v�͍��Ă��X�P�[�������b�g�Ȃ����瓊�����������炢������ȁB
Intel���炷���SSE(AVX)�̐��\���グ��킴�킴�����GPGPU�v���O���~���O�����Ă܂�
�g�����l�͑��ΓI�ɉ�����킯�����玩���̓y�U�Ő���Ă��낵���B
���ǃ`�b�v�Z�b�g�̓���GPU��GPGPU�ɑΉ�������x��
����CPU��GPU�̘e�ɒu���ăT�u�`�b�v�ł������
����CPU��GPU�̘e�ɒu���ăT�u�`�b�v�ł������
>>413
��Fusion
��Fusion
>>413
��ƃ��[�U�[�̑唼��CPU���\�͗~�����낤��75W����悤��GPU�Ȃ��
��{�v��Ȃ��킯�����B
�e�ɒu�����ׂ��͂ǂ������͌��܂����悤�Ȃ��́B
��ƃ��[�U�[�̑唼��CPU���\�͗~�����낤��75W����悤��GPU�Ȃ��
��{�v��Ȃ��킯�����B
�e�ɒu�����ׂ��͂ǂ������͌��܂����悤�Ȃ��́B
GPGPU�̃n�b�^����͂܂Ƃ���HPC�ɍ̗p����Ȃ�����������Ζ��炩����
NV�EATI���Ɍ����I�ȃx���`��R�X�g������Ɏ����Ȃ��ȏ�ǂ�����͂�����
���Z��GPU�g���Ă�V��1���̌̏ጴ�����A���ғ��ɂ�郉�f�̌̏�Ƃ���w
NV�EATI���Ɍ����I�ȃx���`��R�X�g������Ɏ����Ȃ��ȏ�ǂ�����͂�����
���Z��GPU�g���Ă�V��1���̌̏ጴ�����A���ғ��ɂ�郉�f�̌̏�Ƃ���w
ECC���Ȃ��������Ȃ���
���������X�p�R���Ɩ��ł㕨�ɂ�����Ŕ����Ă�s�̕i�g�������ǂ������Ă˂���
�M�������m�ۂł��Ă��镨�Ȃ�܂������B
�M�������m�ۂł��Ă��镨�Ȃ�܂������B
���̎s�̕i�ō\���������[�h�����i�[�������\�ɑ���
�ݔ������E�ݒu�ʐρE�̏ᗦ�̒Ⴓ�ƃ����j���O�R�X�g���}�����Ĉ�Ԃ�����Ȃ�
�s�̂�GPU���킴�킴��ɒ��t���Đv���Ȃ����ƓV��1���̌v�悩�炸��邵
GPGPU�N���X�^�̍ő�̖��_�����i�̕i���̒Ⴓ���ˁB
�ݔ������E�ݒu�ʐρE�̏ᗦ�̒Ⴓ�ƃ����j���O�R�X�g���}�����Ĉ�Ԃ�����Ȃ�
�s�̂�GPU���킴�킴��ɒ��t���Đv���Ȃ����ƓV��1���̌v�悩�炸��邵
GPGPU�N���X�^�̍ő�̖��_�����i�̕i���̒Ⴓ���ˁB
loadrunner��IBM��solution�Œ��Ă�Ȃ��̂��B
���������s�̕i�őg�Ȃ�Ęb�͕��������Ƃ��Ȃ����B
���������s�̕i�őg�Ȃ�Ęb�͕��������Ƃ��Ȃ����B
���������X�p�R�����̃X���b�h�ɂ���ȕ��G�ȏ����@�\���ł���CPU�͗v��Ȃ��āA
�P���ȏ�������ʂɎ��s�\��GPGPU���R�X�p�I�ɗD��Ă�����F��ȏ��ō̗p����Ă邵�A
�ŐV��HPC�̂����肾�Ɩw�ǂ�GPGPU�ɑΉ����Ă邾��H
�����r�[���I��������GPGPU�ᔻ�n�߂Ă邯�ǁA���ǂ��O��I�ɂ͂ǂ��Ȃ��Ăق��������́H
�P���ȏ�������ʂɎ��s�\��GPGPU���R�X�p�I�ɗD��Ă�����F��ȏ��ō̗p����Ă邵�A
�ŐV��HPC�̂����肾�Ɩw�ǂ�GPGPU�ɑΉ����Ă邾��H
�����r�[���I��������GPGPU�ᔻ�n�߂Ă邯�ǁA���ǂ��O��I�ɂ͂ǂ��Ȃ��Ăق��������́H
CS�ł͐�ł��Ȃ����C�g����PC�Q�[���̕����I
>>419
RADEON����Ȃ�FirePro��ATI Stream�g���Ƃ������Ƃ�
RADEON����Ȃ�FirePro��ATI Stream�g���Ƃ������Ƃ�
>>429
PS3��Cell����{���x�̐��\����Ȃ������蒼���Ă��Ȃ��̂���
PS3��Cell����{���x�̐��\����Ȃ������蒼���Ă��Ȃ��̂���
>420
BladeCenter QS22��LS21�Ƃ����s�̕i���q��������
Opteron�g�p�̌_����˂����܂�Đ���p�u���[�h�𑫂����c�ȍ\���ɂȂ����B
������PPC��Cell2�Ȃ�V�K�v�Ńu���[�h2���ɗ}����ꂽ����
IBM�H��Opteron�폜���Ɛݒu�ʐ�4�����E����d��3�����E���s����5�`8%up�Ǝ��Z���Ă�
(�Đ��{�̔���������IBM�����傢�������Ȃ�ĂȂ���)
>423
�P�ɒl�i�̖��Ŗ����i���g���Ă�
BladeCenter QS22��LS21�Ƃ����s�̕i���q��������
Opteron�g�p�̌_����˂����܂�Đ���p�u���[�h�𑫂����c�ȍ\���ɂȂ����B
������PPC��Cell2�Ȃ�V�K�v�Ńu���[�h2���ɗ}����ꂽ����
IBM�H��Opteron�폜���Ɛݒu�ʐ�4�����E����d��3�����E���s����5�`8%up�Ǝ��Z���Ă�
(�Đ��{�̔���������IBM�����傢�������Ȃ�ĂȂ���)
>423
�P�ɒl�i�̖��Ŗ����i���g���Ă�
API�ŃT�|�[�g�����悤�Ȃ��̂��A����Ȃ��K�v�Ȃ��ōς܂���͕̂����ɂ��݂ł����Ȃ�
>>425
HPC�p�̍��ϐ��A���M�����̑I�ʕi
HPC�p�̍��ϐ��A���M�����̑I�ʕi
>>426
����API���܂Ƃ��Ȃ��
���ۂɂ�
���\�����o���̂Ɍ��ǃA�Z���u���o�͂����Ȃ���
�g���[�X���Ȃ��Ƃ����Ȃ�������Ƃ��A
�i�v�Ƀx�[�^�ł�������Ƃ��A
��������GPU�ł͓����Ȃ������肾�Ƃ�
����ȗȃ\�t�g�J�����̃T�|�[�g���x���Ŗ����ł���Ȃ�
�N��Intel�Ɋ��҂Ȃ�Ă��ĂȂ��킯����
����API���܂Ƃ��Ȃ��
���ۂɂ�
���\�����o���̂Ɍ��ǃA�Z���u���o�͂����Ȃ���
�g���[�X���Ȃ��Ƃ����Ȃ�������Ƃ��A
�i�v�Ƀx�[�^�ł�������Ƃ��A
��������GPU�ł͓����Ȃ������肾�Ƃ�
����ȗȃ\�t�g�J�����̃T�|�[�g���x���Ŗ����ł���Ȃ�
�N��Intel�Ɋ��҂Ȃ�Ă��ĂȂ��킯����
�܂����E�E�E�܂��I����Ă��Ȃ��E�E�E�b�I
�o�Ă��ǂ���i740�݂����ȃS�~���낗
��������������������������������������������������������������������������
��������������������������������������������������������������������������
��������������������������������������������������������������������������
��������������������������������������������������������������������������
��������������������������������������������������������������������������
��������������������������������������������������������������������������
��������������������������������������������������������������������������
��������������������������������������������������������������������������
��������������������������������������������������������������������������
��������������������������������������������������������������������������
��������������������������������������������������������������������������
��������������������������������������������������������������������������
��������������������������������������������������������������������������
��������������������������������������������������������������������������
��������������������������������������������������������������������������
��������������������������������������������������������������������������
��������������������������������������������������������������������������
��������������������������������������������������������������������������
��������������������������������������������������������������������������
��������������������������������������������������������������������������
��������������������������������������������������������������������������
��������������������������������������������������������������������������
��������������������������������������������������������������������������
��������������������������������������������������������������������������
��������������������������������������������������������������������������
Larrabee Lullaby
�R�s�y�l�^���Ǝv������Lullaby���q��S���Ă킩���Ă�̂��ȁH
���N�C�G���̕��������Ƃł����������̂��H
�C��ł邾���ş����ɂȂ��ĂȂ������B
GPU�v��点��Ƃ����Ă��短���ɂȂ��Ă�Ǝv����
�N���邩�ǂ����͒m��Ȃ����ǂ�
�N���邩�ǂ����͒m��Ȃ����ǂ�
�uCore�n�Ɠ���������{�C�o���v
������A���₷�݃����r�[���ĈӖ��ŏ��������B
���ꂾ�������ʼn��������낤�ˁA�A�z�炵����
440 �F,,�E�L�́M�E,,�j��-�������F2009/12/08(��) 20:51:57 ID:lpxlFx1c
�Ղ�͂܂��I���Ȃ�
�����ƃO�_�O�_�ɂȂ���Ă�
442 �F,,�E�L�́M�E,,�j��-�������F2009/12/08(��) 20:57:57 ID:lpxlFx1c
Ct�̃��v���O�������Ă̂������Ă���
��������Haswell�ɂȂ����瓝�������Ƃ�����
�����Larrabee�R�A�Ȃ̂��ǂ����킩���
�����Larrabee�R�A�Ȃ̂��ǂ����킩���
444 �F,,�E�L�́M�E,,�j��-�������F2009/12/08(��) 21:01:20 ID:lpxlFx1c
Atom��Larrabee NI�����������悤�Ȃ���
����Atom��Core i��Larrabee��GMA���D���Ȃ������ڂ����
��������Ȃ��ł����@�[�[�[�[�b!!!�Ǝv���̂����ǁB
��������Ȃ��ł����@�[�[�[�[�b!!!�Ǝv���̂����ǁB
�g�������v�����Ȃ����Ƃł��Ȃ���
�Ȃ�SCC�̓E�P�����ˁB
���i���\�肪��������ł�
�����邾�������܂��ATilera��Tile processor�̂ق����܂����ȁB
�����O�o�X��gpu��������Ȃ������낤��
texture�ǂݍ��݂����肾��
�`��ł����Z��̂̃��C�g���Ȃ�悩�����낤��
�܁A���A���^�C�����C�g���̓���nv���J������A����܂ő҂��ĂĂ�
texture�ǂݍ��݂����肾��
�`��ł����Z��̂̃��C�g���Ȃ�悩�����낤��
�܁A���A���^�C�����C�g���̓���nv���J������A����܂ő҂��ĂĂ�
�n������
>427
���X�A�����X�������̃��[�h�����i�[�͎s�̕i���u���[�h4��1�Z�b�g�̏W���̂���
��������̂܂ܓ]�p���č\�z�����琫�\�ɑ���R�X�g��������ԂȂ̂͒P�ɗD�ꂽ���i���Ƃ�������
�h���C�u���g�̌o�N�ӊO�łقƂ�ƌ̏Ⴕ�Ȃ�PS3�N���X�^�݂����Ȃ���(�������Ă�)
���X�A�����X�������̃��[�h�����i�[�͎s�̕i���u���[�h4��1�Z�b�g�̏W���̂���
��������̂܂ܓ]�p���č\�z�����琫�\�ɑ���R�X�g��������ԂȂ̂͒P�ɗD�ꂽ���i���Ƃ�������
�h���C�u���g�̌o�N�ӊO�łقƂ�ƌ̏Ⴕ�Ȃ�PS3�N���X�^�݂����Ȃ���(�������Ă�)
AMD�������O�o�X��߂��̂��������R
����AMD��10240bit�̓��C�g���Ɍ����Ȃ�
����AMD��10240bit�̓��C�g���Ɍ����Ȃ�
���A���^�C�����C�g���[�V���O�ŕ`�����Ruby�B�uRuby Verite�v�����O�o�[�W�����̃��[�r�[��Up
http://www.4gamer.net/games/045/G004578/20080930002/
http://www.4gamer.net/games/045/G004578/20080930002/
GPU�Ƃ��Č����ꍇ�ǂꂭ�炢�x�������̂������������˂�
GTX285���Ƃ������Ă����ǎ��ۂ͂����ƍ��������肵�Ă�
GTX285���Ƃ������Ă����ǎ��ۂ͂����ƍ��������肵�Ă�
����Ruby�̂��
�T�[�o�[�ŏ���������𐂂ꗬ���ɂ��Ă邾��
������OTOY�̃T�[�o�[�Ŏg���Ă�̂�
DX9������shader���������e����
�T�[�o�[�ŏ���������𐂂ꗬ���ɂ��Ă邾��
������OTOY�̃T�[�o�[�Ŏg���Ă�̂�
DX9������shader���������e����
GTX285����$500�ȉ��ɂł��������Ȃ�������Ȃ���
AMD(ATI)�ŁAR6xx/R7xx�n�̃������R���g���[���Ɠ����o�X��
�v�����A�[�L�e�N�g��Fritz Kruger���͎��̂悤�Ɍ��B
�uR600�A�[�L�e�N�`���Ń`�b�v���k�����悤�Ƃ������ɁA
�����O�o�X����Ԃ̖��ƂȂ����B�����O�o�X���`�b�v���
�傫�Ȗʐς�����Ă��܂��A�d�͂��H�����߂��B�����ŁA
�����O�o�X�̃g���t�B�b�N�͂����Ƃ���A90%��
�e�N�X�`���̓]�����Ɣ��������BR600�ł́A�e�N�X�`��
�L���b�V���Ԃ̓]���������O�o�X��ʂ��Ă������߂��B
�e�N�X�`���]�����N���X�o�ւƐ�ւ������ƂŁA�����O
�o�X����90%�̃g���t�B�b�N���Ȃ��Ȃ����B�e�N�X�`����
�����A�g���t�B�b�N�͂����������Ƃ��Ȃ������B���̂��߁A
�ŏI�I�Ƀ����O�o�X���̂��s�v�ƂȂ��Ă��܂���(��)�B
���ꂪ�A�����O�o�X����N���X�o�ւƖ߂����^�����B�v
�v�����A�[�L�e�N�g��Fritz Kruger���͎��̂悤�Ɍ��B
�uR600�A�[�L�e�N�`���Ń`�b�v���k�����悤�Ƃ������ɁA
�����O�o�X����Ԃ̖��ƂȂ����B�����O�o�X���`�b�v���
�傫�Ȗʐς�����Ă��܂��A�d�͂��H�����߂��B�����ŁA
�����O�o�X�̃g���t�B�b�N�͂����Ƃ���A90%��
�e�N�X�`���̓]�����Ɣ��������BR600�ł́A�e�N�X�`��
�L���b�V���Ԃ̓]���������O�o�X��ʂ��Ă������߂��B
�e�N�X�`���]�����N���X�o�ւƐ�ւ������ƂŁA�����O
�o�X����90%�̃g���t�B�b�N���Ȃ��Ȃ����B�e�N�X�`����
�����A�g���t�B�b�N�͂����������Ƃ��Ȃ������B���̂��߁A
�ŏI�I�Ƀ����O�o�X���̂��s�v�ƂȂ��Ă��܂���(��)�B
���ꂪ�A�����O�o�X����N���X�o�ւƖ߂����^�����B�v
CES 2009 - �N���E�h�̃��X�g10%��ς���uAMD Fusion Render Cloud�v
http://journal.mycom.co.jp/articles/2009/01/10/ces07/index.html
http://journal.mycom.co.jp/articles/2009/01/10/ces07/index.html
DX11�x�[�X�ɐ����������̃T�[�o�[�����_�����O
�����͌Â����
462 �FSocket774�F2009/12/09(��) 12:57:32 ID:DSp+Ejow
�C���e���ɂ̓O���t�B�b�N�`�b�v�J������Z���X���Z�p�͂����������ǂ��킩����
�C�X���G���`�[����������ȒP�ɖv���������ȋC�͂����
�����C�X���G���`�[�����Aintel��CPU�A�[�L���߂鑤�ɂȂ��Ă邶��Ȃ��B
�I���S���̕����I�p�ɃA�����W���鑤���낤�B
�I���S���̕����I�p�ɃA�����W���鑤���낤�B
���㓡�O��Weekly�C�O�j���[�X��
�d�蒼���ƂȂ���Larrabee�̉�����肾�����̂�
http://pc.watch.impress.co.jp/docs/column/kaigai/20091209_334552.html
�d�蒼���ƂȂ���Larrabee�̉�����肾�����̂�
http://pc.watch.impress.co.jp/docs/column/kaigai/20091209_334552.html
>>465
���@���ہA�R��`������Larrabee�̃O���t�B�b�N�X�n�ł̕]���͂��Ȃ舫�������B
�����ɁA�����̃O���t�B�b�N�X�^�X�N�ł́A�p�t�H�[�}���X�������ɂ߂Ĉ��������Ƃ����B
��DirectX�̂悤�Ȋ����̃O���t�B�b�N�XAPI�x�[�X�ł́A
�����\�̓n�C�G���hGPU�́u�����s�����s���Ȃ����v�Ƃ���ƊE�W�҂͌���Ă����B
���[��A����ς肩�E�E�Ƃ��������H
���@���ہA�R��`������Larrabee�̃O���t�B�b�N�X�n�ł̕]���͂��Ȃ舫�������B
�����ɁA�����̃O���t�B�b�N�X�^�X�N�ł́A�p�t�H�[�}���X�������ɂ߂Ĉ��������Ƃ����B
��DirectX�̂悤�Ȋ����̃O���t�B�b�N�XAPI�x�[�X�ł́A
�����\�̓n�C�G���hGPU�́u�����s�����s���Ȃ����v�Ƃ���ƊE�W�҂͌���Ă����B
���[��A����ς肩�E�E�Ƃ��������H
>>453
���C�g�����x�N�g��������̂͊m���ɓ����������ĂȂ��ƌ����Ă�����
�܂�����ĂȂ������ŁA������N���Ύ��I�Ȑl������Ă��܂����낤�B
�h�x�N�g�������ꂽ�h�A���S���Y���ɑ��Ă͐���Ɏg��Tr��
�ł��邾�����炵�ĉ��Z��Ɋ��蓖�Ă��̕����������悢�B
���̎������ς��Ȃ���A������̂ł������ăx�N�g�������悤�A
�Ƃ������@�͎�����Â���
���C�g�����x�N�g��������̂͊m���ɓ����������ĂȂ��ƌ����Ă�����
�܂�����ĂȂ������ŁA������N���Ύ��I�Ȑl������Ă��܂����낤�B
�h�x�N�g�������ꂽ�h�A���S���Y���ɑ��Ă͐���Ɏg��Tr��
�ł��邾�����炵�ĉ��Z��Ɋ��蓖�Ă��̕����������悢�B
���̎������ς��Ȃ���A������̂ł������ăx�N�g�������悤�A
�Ƃ������@�͎�����Â���
�n�C�G���hGPU��A�Ђ�40nm 300mm^2��N�Ђ�55nm 400mm^2
�Ƃ̔�r���Ƃ���ƁA�����卷�ł̕����B
�Ƃ̔�r���Ƃ���ƁA�����卷�ł̕����B
���\�ōl����Ɣ����͈����Ȃ��Ǝv�������ǁA600mm2���Ƃ������Ƃ��l����ƁA
�g�����W�X�^�����ōl�����1/4���炢�ɂȂ�̂��B
�g�����W�X�^�����ōl�����1/4���炢�ɂȂ�̂��B
���\�������Ă��Ƃ͓���Larrabee��TDP300W����������
���HD5970�Ɠ�������d�͂Ő��\��HD4890���炢���Ă��Ƃ�
�����܂�l����Ɖ��i��$700�ȏ�͊m��
�m���Ɉ�ʌ����̔��͒��߂邵���Ȃ����炢�����ǂ��ꂮ�炢�͑z��͈͓̔���������Ȃ��̂���
GPGPU���ʂŌ��s�J�[�h��������Fermi�ɂ���������Z������������Ȃ��́H
���HD5970�Ɠ�������d�͂Ő��\��HD4890���炢���Ă��Ƃ�
�����܂�l����Ɖ��i��$700�ȏ�͊m��
�m���Ɉ�ʌ����̔��͒��߂邵���Ȃ����炢�����ǂ��ꂮ�炢�͑z��͈͓̔���������Ȃ��̂���
GPGPU���ʂŌ��s�J�[�h��������Fermi�ɂ���������Z������������Ȃ��́H
>>471
�P���ɁA�`�b�v�Z�b�g���ƂɈ��e�����o�邩�玫�߂������ł���B
�����ق�A����̂��A�ŃO���t�B�b�N����̃V�F�ANO.1�Ȗ��B
�P���ɁA�`�b�v�Z�b�g���ƂɈ��e�����o�邩�玫�߂������ł���B
�����ق�A����̂��A�ŃO���t�B�b�N����̃V�F�ANO.1�Ȗ��B
�G���搶���Ă܂������Ă�́H
�ŐV����Ƃ̔�r����Ȃ��O����̃n�C�G���h�@�Ƃ̔�r�ŃO���t�B�N�X���\�������Ď�����
�T���v���z�z���Ă̕]��������A5970�Ȃ��o�Ă���O�̘b����
�T���v���z�z���Ă̕]��������A5970�Ȃ��o�Ă���O�̘b����
http://www.pcgameshardware.com/aid,701071/Larrabee-2-is-still-possible/News/
�ӊO�Ɨ�����葁������
�ӊO�Ɨ�����葁������
����Itanium���a�������ƕ����Ă������ł��܂���
Larrabee�n�܂�O�ɏI�������w
>>465
�����_���S�搶�����_�����Ă�낤�ȁB
�����_���S�搶�����_�����Ă�낤�ȁB
�c�q�ܖ�w
�c�q�͌�������ڂ����炵��
Ct���т�NV�@���ɋ���ǂ��
Ct���т�NV�@���ɋ���ǂ��
AMD Responds to Intel�fs Larrabee Delay
http://en.expreview.com/2009/12/08/amd-responds-to-intels-larrabee-delay/6037.html
�gIt really comes down to design philosophy,�h said Erskine. �gGPUs are hard to design and
�@you can�ft design one with a CPU-centric approach that utilizes existing x86 cores.�h
http://en.expreview.com/2009/12/08/amd-responds-to-intels-larrabee-delay/6037.html
�gIt really comes down to design philosophy,�h said Erskine. �gGPUs are hard to design and
�@you can�ft design one with a CPU-centric approach that utilizes existing x86 cores.�h
���ǃZ���X�̖������o�J�������낤�c
�i���Ă��Ď��싷��Ɋׂ肪���ɂȂ���̂�����ȁj
�i���Ă��Ď��싷��Ɋׂ肪���ɂȂ���̂�����ȁj
�܂��ɒ��q�̌Ղ�������w
>>484
�s���悪x86�Ȃ�Ες������鎖���ł����Intel�͌��ς������̂�����
�s���悪x86�Ȃ�Ες������鎖���ł����Intel�͌��ς������̂�����
486 �F,,�E�L�́M�E,,�j��-�������F2009/12/09(��) 23:18:49 ID:2I2x2Rba
���ł���O�ɏ��B
x86�����x86�ւ̃\�t�g���Y���o�����~�߂���Ώ\���B
�uHPC�ɂ�������Ȃ�GPGPU���ĉ��̉��l������́H�v�Ƃ����Ƃ���܂ŗU���ł����
����ŏ\���Ȃ̂ł��B
���̏��̖����ł����ASandy Bridge�͂��Ȃ�o���͂悢�炵����
3.2GHz��6�R�A�Ŕ{���x150GFLOPS���x�AGEMM�ł�����130GFLOPS���x���Ƃ�����H
�uLarrabee�Ȃ�ĕK�v�Ȃ��������v�Ƃ��������������Ă������ł��ȁB
�������̐����͂���Ӗ��Ŏ���
x86�����x86�ւ̃\�t�g���Y���o�����~�߂���Ώ\���B
�uHPC�ɂ�������Ȃ�GPGPU���ĉ��̉��l������́H�v�Ƃ����Ƃ���܂ŗU���ł����
����ŏ\���Ȃ̂ł��B
���̏��̖����ł����ASandy Bridge�͂��Ȃ�o���͂悢�炵����
3.2GHz��6�R�A�Ŕ{���x150GFLOPS���x�AGEMM�ł�����130GFLOPS���x���Ƃ�����H
�uLarrabee�Ȃ�ĕK�v�Ȃ��������v�Ƃ��������������Ă������ł��ȁB
�������̐����͂���Ӗ��Ŏ���
Banias�̂悤�Ɏ�����̎�ƂȂ邩�B�B�B
Itanium�̂悤�ɓk�ԂƂȂ邩�B�B�B
Itanium�̂悤�ɓk�ԂƂȂ邩�B�B�B
�����c�q����̌������Ƃ��M�����Ȃ��B
489 �F,,�E�L�́M�E,,�j��-�������F2009/12/09(��) 23:41:20 ID:2I2x2Rba
���Ȃ݂Ɍ�����Bulldozer��FP���\�͗��_�l�ł�8�R�A�œ��N���b�N��Sandy Bridge 4�R�A�Ƃ悤�₭�^�����͂����x�Ȃ̂�
HPC�ł�AMD�̍X�Ȃ�v���͕K���ł��B
HPC�ł�AMD�̍X�Ȃ�v���͕K���ł��B
(�د
491 �F,,�E�L�́M�E,,�j��-�������F2009/12/09(��) 23:51:46 ID:2I2x2Rba
�����A�t�Ɍ�����SIMD���\���������ȊO�͂���ȂɖJ�߂�Ƃ���͂Ȃ���ł���
Sandy Bridge�Ɋւ��ẮB
Sandy Bridge�Ɋւ��ẮB
���N�������r�[�͔����Ȃ�������
�܂���������w
�܂���������w
�����_���S�A���O�Ӗ��s���Ȃ��Ƃ����Ă�˂���
���݂����Ȕn���ɂ��킩��悤�ɍ��ؒ��J�ɖ���������Ă��������B
SIMD�Ƃ����킯�킩���A�������Ă������ł���Ƃ��낪�Ȃ��B
�Ȃ�œd�C�𗬂���CPU�����삷��̂�������
���݂����Ȕn���ɂ��킩��悤�ɍ��ؒ��J�ɖ���������Ă��������B
SIMD�Ƃ����킯�킩���A�������Ă������ł���Ƃ��낪�Ȃ��B
�Ȃ�œd�C�𗬂���CPU�����삷��̂�������
495 �FSocket774�F2009/12/10(��) 00:44:40 ID:HC6NkjgB
�����r�[��
�͂��̂ǂ���
��߂̂���
�͂��̂ǂ���
��߂̂���
,,�E�L�́M�E,,�j��-������
�@�@�@�@�@�@�@�@�@�@������Ȃ�ł����H
�݂�Ȓc�q���Č����Ă邯�ǃE���R�[�Ɍ�����̂ł�߂Ē��������̂ł����B
�@�@�@�@�@�@�@�@�@�@������Ȃ�ł����H
�݂�Ȓc�q���Č����Ă邯�ǃE���R�[�Ɍ�����̂ł�߂Ē��������̂ł����B
>>470
�ł����ꂾ�ƐӔC�҂������p�b�g�E�Q���V���K�[���ގЂ������R��������Ȃ�
�z��͈͓̔���������ACPU�ɑg�ݍ��ނ��߂̉��Ǎ�Ƃ𑱂���K�v�����邩��
�����Ȏ����ɑގЂȂ�Ă��Ȃ��������Ȃ����낤
AMD��Fusion�ł����������ǁA�O���v���Z�b�T����i�K�I�ɓ����A�[�L�e�N�`����
��荞��ł����Ƃ����X�e�b�v�͔������Ȃ��͂�
���̍ŏ��̈�����L�����Z�������Ƃ����̂́A�v���Ă���ȏ�ɃC���e���͖������Ă�������
�ł����ꂾ�ƐӔC�҂������p�b�g�E�Q���V���K�[���ގЂ������R��������Ȃ�
�z��͈͓̔���������ACPU�ɑg�ݍ��ނ��߂̉��Ǎ�Ƃ𑱂���K�v�����邩��
�����Ȏ����ɑގЂȂ�Ă��Ȃ��������Ȃ����낤
AMD��Fusion�ł����������ǁA�O���v���Z�b�T����i�K�I�ɓ����A�[�L�e�N�`����
��荞��ł����Ƃ����X�e�b�v�͔������Ȃ��͂�
���̍ŏ��̈�����L�����Z�������Ƃ����̂́A�v���Ă���ȏ�ɃC���e���͖������Ă�������
�Q������ƃ��C���[�Ŋ�F�����Ό����I
x86�̖����͕a��ł邺�I
�Ƃ��v���Ă�������������
���C���[��CEO�ɏ��l�߂����Q�����r���Ń��^�C�A�Ȃ���Ȃ�
x86�̖����͕a��ł邺�I
�Ƃ��v���Ă�������������
���C���[��CEO�ɏ��l�߂����Q�����r���Ń��^�C�A�Ȃ���Ȃ�
GPU�����H���̍ŏ��̈���͂܂��R�P��Ƃ��납��n�܂�B
501 �F,,�E�L�́M�E,,�j��-�������F2009/12/10(��) 04:43:41 ID:t3OdgNqV
�������Ȏ����ɑގЂȂ�Ă��Ȃ��������Ȃ����낤
����ǂ�ł�����Ǝv���o����
��AMD��Fusion�ł����������ǁA�O���v���Z�b�T����i�K�I�ɓ����A�[�L�e�N�`����
����荞��ł����Ƃ����X�e�b�v�͔������Ȃ��͂�
����Fusion�̍\�z��ł����Ă�CTO��Hester�̓g���Y���ASwift�̓L�����Z���A
Bulldozer���啝�x���̂����ASSE5�L�����Z���Ƃ������ʂɏI����Ă�킯�����B
�����AMD�̎��ƋK�͂��炷��Ύ������Ȏ����͎��s�Ƃ͊Ř��A
���������������i�i�f�B�X�N���[�gGPU�j�Ő������悤�������悤�����܂�Ƃ���̌��܂��Ă���
Larrabee�̒x���͑厸�s�ƘA�Ă������Ƃ����Ȃ��l���ĂȂ�Ȃ낤�H
�u��������128�r�b�g��SIMD���߂łǂ������1�X���b�h320����̉��Z���j�b�g�𑀍삷���A�z���v
���Č����Ă������������Ȃ���������B
Hester�v�����̒ʂ�ACPU����GPU�ɖ��߂𓊂�����ċ�̓I�ɂǂ����邩�H
�P�DGPU���̉��Z���x������������i��128�r�b�g�j
�Q�DCPU����SIMD�f�[�^���𑝂₷�i��5�~2048�r�b�g�H�j
�R�D���̗������i512 or 1024�r�b�g�H�j
�ǂ��Larrabee���D�ꂽ�\�����[�V�����ɂ͂ƂĂ������Ȃ����B
�����̑O��ɂȂ�̂́AGPU�����ɓK��������x������SIMD�g�����߂̕��y����O��ɂȂ�B
Larrabee��j�k�ɂ��ꂽ���ԍ���̂�AMD�ł́H
����ǂ�ł�����Ǝv���o����
��AMD��Fusion�ł����������ǁA�O���v���Z�b�T����i�K�I�ɓ����A�[�L�e�N�`����
����荞��ł����Ƃ����X�e�b�v�͔������Ȃ��͂�
����Fusion�̍\�z��ł����Ă�CTO��Hester�̓g���Y���ASwift�̓L�����Z���A
Bulldozer���啝�x���̂����ASSE5�L�����Z���Ƃ������ʂɏI����Ă�킯�����B
�����AMD�̎��ƋK�͂��炷��Ύ������Ȏ����͎��s�Ƃ͊Ř��A
���������������i�i�f�B�X�N���[�gGPU�j�Ő������悤�������悤�����܂�Ƃ���̌��܂��Ă���
Larrabee�̒x���͑厸�s�ƘA�Ă������Ƃ����Ȃ��l���ĂȂ�Ȃ낤�H
�u��������128�r�b�g��SIMD���߂łǂ������1�X���b�h320����̉��Z���j�b�g�𑀍삷���A�z���v
���Č����Ă������������Ȃ���������B
Hester�v�����̒ʂ�ACPU����GPU�ɖ��߂𓊂�����ċ�̓I�ɂǂ����邩�H
�P�DGPU���̉��Z���x������������i��128�r�b�g�j
�Q�DCPU����SIMD�f�[�^���𑝂₷�i��5�~2048�r�b�g�H�j
�R�D���̗������i512 or 1024�r�b�g�H�j
�ǂ��Larrabee���D�ꂽ�\�����[�V�����ɂ͂ƂĂ������Ȃ����B
�����̑O��ɂȂ�̂́AGPU�����ɓK��������x������SIMD�g�����߂̕��y����O��ɂȂ�B
Larrabee��j�k�ɂ��ꂽ���ԍ���̂�AMD�ł́H
������cpu�g�ݍ��݂����܂��Ă�larrabee�ɂƂ���
���͒P�̏o�ׂȂ�Ă��܂�Ӗ�������
����larrabee�o���Ă��amd�͌݊��H���ɓ��ݍ��߂���
�u���o��܂ł�lni���̂ɕύX����������\�������邽�߁A�������s���Ȃ��Ȃ���
�����Ȃ̂�avx��gpu����邱�Ƃ����A�P�̂ŏo�����Ƃ����
���ǃA�z�ǂ����n���ɂ��Ă�P��larrabee�ƈꏏ�̓�
���͒P�̏o�ׂȂ�Ă��܂�Ӗ�������
����larrabee�o���Ă��amd�͌݊��H���ɓ��ݍ��߂���
�u���o��܂ł�lni���̂ɕύX����������\�������邽�߁A�������s���Ȃ��Ȃ���
�����Ȃ̂�avx��gpu����邱�Ƃ����A�P�̂ŏo�����Ƃ����
���ǃA�z�ǂ����n���ɂ��Ă�P��larrabee�ƈꏏ�̓�
AMD�̎��s�Ȃ�Č��݂̌o�c��Ԃ�����ΒN�̖ڂɂ����炩�ŁA
�����ĘA�Ă���K�v�Ȃ�ĂȂ�����ł���B
�����ĘA�Ă���K�v�Ȃ�ĂȂ�����ł���B
���[��geforce���݂�Ȃ����Ă����̂�
AMD�ɂƂ��Ẵx�X�g�ȏ��
����Ȃ��ƃf�B�X�N���[�gGPU���B�B�B
�w�e���W�j�A�X�}���`�R�A�Ȃ�Ă��Ȃ���
���܂Œʂ��
AMD�ɂƂ��Ẵx�X�g�ȏ��
����Ȃ��ƃf�B�X�N���[�gGPU���B�B�B
�w�e���W�j�A�X�}���`�R�A�Ȃ�Ă��Ȃ���
���܂Œʂ��
>>502
������LNI�̎d�l�ł߂��x���ƁA����AMD64�Ɠ����ɂȂ��Ă��܂�
���߃Z�b�g�̎d�l�͎s��Ɏ��@�����݂���AMD�哱�ōs���A�ŏI�I��
Intel��������ۓۂ݂���Ƃ������ꂾ
��������Larrabee��P��GPU�Ƃ��ēo�ꂳ������肾�����̂́A����������
�s��K�͂ɂ�鎖����̕W���d�l���l������ړI���������͂�
������LNI�̎d�l�ł߂��x���ƁA����AMD64�Ɠ����ɂȂ��Ă��܂�
���߃Z�b�g�̎d�l�͎s��Ɏ��@�����݂���AMD�哱�ōs���A�ŏI�I��
Intel��������ۓۂ݂���Ƃ������ꂾ
��������Larrabee��P��GPU�Ƃ��ēo�ꂳ������肾�����̂́A����������
�s��K�͂ɂ�鎖����̕W���d�l���l������ړI���������͂�
���@�����݂���H
�wLarrbee���łȂ���AMD������x
�܂��ŁH�H�H�H
���Βc�q����A��l�̋y�ʂƂ���ɂ����܂���
�܂��ŁH�H�H�H
���Βc�q����A��l�̋y�ʂƂ���ɂ����܂���
508 �FSocket774�F2009/12/10(��) 06:54:38 ID:nEjbL69E
�ȂɁH
SSE5�i�j����������́H
SSE5�i�j����������́H
�u�����Ȃ�avx�ɂȂ����̂�
AMD��AVX��SSE5�̖��߂��Ǝ��Ɋg�����Ă��邩��ASSE5�����S�Ɏ̂Ă��Ƃ����̂͊ԈႢ
�ނ��낢���Ƃ���肾
�ނ��낢���Ƃ���肾
511 �FSocket774�F2009/12/10(��) 07:27:10 ID:nEjbL69E
���ǎg��ꂸ�I��
Intel�ALarrabee�O���t�B�b�N�X�`�b�v�̌v���j��
�J���̒x�ꂩ��AIntel��Larrabee�O���t�B�b�N�X�`�b�v�����v��𒆎~�����B�i���C�^�[�j
http://www.itmedia.co.jp/news/articles/0912/07/news041.html
�J���̒x�ꂩ��AIntel��Larrabee�O���t�B�b�N�X�`�b�v�����v��𒆎~�����B�i���C�^�[�j
http://www.itmedia.co.jp/news/articles/0912/07/news041.html
513 �FSocket774�F2009/12/10(��) 08:07:20 ID:nEjbL69E
�����ĐX������
SSE4a�͎g���Ă��
�c�q�ܐ@����w
SSE4a��4��4���߂�4�Ȃ�Ȃ�
517 �F,,�E�L�́M�E,,�j��-�������F2009/12/10(��) 09:38:52 ID:t3OdgNqV
128�r�b�g�̕���x�ŏ\���Ȃ킯���Ȃ��B�����ƕ���x���K�v���B
��Intel��AVX���g����256�r�b�g�܂ł͊m�ۂł��邼�B
��AVX�݊��X�L�[���̗p����Ȃ�SSE5�̃G���R�[�f�B���O���[���͖Ӓ��ɂȂ�͂���
��SSE5�͗v��Ȃ���ˁH
�ƁA���̂ւ�܂ł͋��N4�����_�ŗ\�����Ă��B
���p�߂�ǂ���
> ���߃Z�b�g�̎d�l�͎s��Ɏ��@�����݂���AMD�哱�ōs���A
AMD��GPU�͂�����x86�݊����߃Z�g�ɂȂ�����ł����H
��Intel��AVX���g����256�r�b�g�܂ł͊m�ۂł��邼�B
��AVX�݊��X�L�[���̗p����Ȃ�SSE5�̃G���R�[�f�B���O���[���͖Ӓ��ɂȂ�͂���
��SSE5�͗v��Ȃ���ˁH
�ƁA���̂ւ�܂ł͋��N4�����_�ŗ\�����Ă��B
���p�߂�ǂ���
> ���߃Z�b�g�̎d�l�͎s��Ɏ��@�����݂���AMD�哱�ōs���A
AMD��GPU�͂�����x86�݊����߃Z�g�ɂȂ�����ł����H
518 �F,,�E�L�́M�E,,�j��-�������F2009/12/10(��) 09:41:07 ID:t3OdgNqV
519 �FSocket774�F2009/12/10(��) 10:06:13 ID:mHyDzSx3
�c�q��������������Larrabee�͏I�����LNI��CPU�����͌�ށA
Bulldozer�͒x�ꂽ����2011�N�ɏo�邵�ASandy�Ǝ����͂��܂�ς��Ȃ�����\�������ł���B
Llano�͓���GPU�̕Ȃ�DX11�Ή���HD4650�N���X�̉��������\�ʼnƒ������A4�m�[�g�ł͓G�Ȃ��B
�Ƃ������A2011�N��Bulldozer�ALlano�AHD6xxx�̔g��U����Sandy������Intel����������B
��������GPGPU�͏��F�K�p�͈͂̏��Ȃ��x�N�^�[�������A�x�N�^�[���j�b�g���炯��GPU�ł��������悤�Ƃ������x�̑㕨�B
SSE�Ή��\�t�g��DXCS�Ή��ɂȂ���x����Ȃ����ȁH
���Ƀ\�t�g���[�J�[��SSE2/3/4/CUDA/Stream/AVX/LNI/DXCS�ɓ����Ή��Ƃ����˂�B
���̕ӑS��Windows�̕W���Ƃ�������DXCS�ɏW����Ȃ����ȁB
�X�J����AMD64�A�x�N�^�[��CS�A�Q�[����DX�Ƃ�����ɁB
SSE/AVX��CS�Ή����\���ǂ����͒m���A�����Ȃ�\�t�g���[�J�[�͍œK���Ŏ��ɂ������B
Bulldozer�͒x�ꂽ����2011�N�ɏo�邵�ASandy�Ǝ����͂��܂�ς��Ȃ�����\�������ł���B
Llano�͓���GPU�̕Ȃ�DX11�Ή���HD4650�N���X�̉��������\�ʼnƒ������A4�m�[�g�ł͓G�Ȃ��B
�Ƃ������A2011�N��Bulldozer�ALlano�AHD6xxx�̔g��U����Sandy������Intel����������B
��������GPGPU�͏��F�K�p�͈͂̏��Ȃ��x�N�^�[�������A�x�N�^�[���j�b�g���炯��GPU�ł��������悤�Ƃ������x�̑㕨�B
SSE�Ή��\�t�g��DXCS�Ή��ɂȂ���x����Ȃ����ȁH
���Ƀ\�t�g���[�J�[��SSE2/3/4/CUDA/Stream/AVX/LNI/DXCS�ɓ����Ή��Ƃ����˂�B
���̕ӑS��Windows�̕W���Ƃ�������DXCS�ɏW����Ȃ����ȁB
�X�J����AMD64�A�x�N�^�[��CS�A�Q�[����DX�Ƃ�����ɁB
SSE/AVX��CS�Ή����\���ǂ����͒m���A�����Ȃ�\�t�g���[�J�[�͍œK���Ŏ��ɂ������B
521 �FSocket774�F2009/12/10(��) 10:14:41 ID:nEjbL69E
stream,DXCS�i�j
> Bulldozer�͒x�ꂽ����2011�N�ɏo�邵�ASandy�Ǝ����͂��܂�ς��Ȃ�����\�������ł���B
���������_���Z���\��8�R�A��Sandy Bridge�̕��y�Łi4�R�A�{IGP�j��
�����Ȃ̂ɂǂ�������珟���ł���́H
��ɂ����Socket B2�ɑR�ł��鐻�i�s�݁B
�T�[�o�ȏゾ�Ƃ����ƔߎS�Ȃ��ƂɂȂ�B
Socket H2(LGA1155)��6�R�A�ł𓊓�������f�X�N�g�b�v�ł��牺�ʃ����W�B
> Llano�͓���GPU�̕Ȃ�DX11�Ή���HD4650�N���X�̉��������\�ʼnƒ������A4�m�[�g�ł͓G�Ȃ��B
CPU�����sCore i5�ɂ������Ă�悤��Phenom II�̂��̂܂��ł��Ⴈ�b�ɂȂ�Ȃ��B
SSSE3�ɂ���Ή��̋�����A�[�L�e�N�`���B
Atom�Ȃ݂̒ቿ�i�ŏo����Δ��W�r�㍑�s��ł͂���Ȃ肩���ˁB
���������_���Z���\��8�R�A��Sandy Bridge�̕��y�Łi4�R�A�{IGP�j��
�����Ȃ̂ɂǂ�������珟���ł���́H
��ɂ����Socket B2�ɑR�ł��鐻�i�s�݁B
�T�[�o�ȏゾ�Ƃ����ƔߎS�Ȃ��ƂɂȂ�B
Socket H2(LGA1155)��6�R�A�ł𓊓�������f�X�N�g�b�v�ł��牺�ʃ����W�B
> Llano�͓���GPU�̕Ȃ�DX11�Ή���HD4650�N���X�̉��������\�ʼnƒ������A4�m�[�g�ł͓G�Ȃ��B
CPU�����sCore i5�ɂ������Ă�悤��Phenom II�̂��̂܂��ł��Ⴈ�b�ɂȂ�Ȃ��B
SSSE3�ɂ���Ή��̋�����A�[�L�e�N�`���B
Atom�Ȃ݂̒ቿ�i�ŏo����Δ��W�r�㍑�s��ł͂���Ȃ肩���ˁB
523 �FSocket774�F2009/12/10(��) 11:46:35 ID:LmYt9ZVi
���~�ܖڂ����邗����
524 �FSocket774�F2009/12/10(��) 12:06:22 ID:nEjbL69E
HT�Ɏh����GPU������AMD����Ȃ��낤��
Llano��yukon��congo�N���X��u����������x�ł���H
�T�[�o�[�ȏ�̓\�P�b�gG34��16�R�A���\�肳��Ă��邪�H
i5��6�R�A�Ƃ����ɂȂ�Ǝv���Ă�B
�ő�3���ȏ��CPU�̓n�C�G���h�Ƃ��ċ͂��ɂ�������Ȃ��j�b�`�s��Ȃ��B
SSE3/4�Ȃǂ���AVX�ɒu������邵�A��CUDA��Stream�Ή����Ă�Ƃ���DXCS�Ɍ�������B(���邢��OpenCL)
�����Ɏ��p�ɂȂ邩�͋^�₾���ǁAGPGPU�Ή��͍���̑傫�ȃg�����h�ŁA�Ή��ł��Ȃ�Intel�ƑΉ�����AMD�ɂȂ�A
�̗p�������Ă��邾�낤�ˁB
GMA��DX11��DXCS�Ή����Ȃ�����͒u���čs����������Ǝv����B
���i7/i9�������\�ł��AGPGPU�Ή��\�t�g�Ō݊p�ȉ��Ȃ�債�ċ��Ђł��Ȃ��Ȃ邾�낤�B
���ꂪ�|������Larrabee����Ă����̂Ɏ��s��������āB
i5��6�R�A�Ƃ����ɂȂ�Ǝv���Ă�B
�ő�3���ȏ��CPU�̓n�C�G���h�Ƃ��ċ͂��ɂ�������Ȃ��j�b�`�s��Ȃ��B
SSE3/4�Ȃǂ���AVX�ɒu������邵�A��CUDA��Stream�Ή����Ă�Ƃ���DXCS�Ɍ�������B(���邢��OpenCL)
�����Ɏ��p�ɂȂ邩�͋^�₾���ǁAGPGPU�Ή��͍���̑傫�ȃg�����h�ŁA�Ή��ł��Ȃ�Intel�ƑΉ�����AMD�ɂȂ�A
�̗p�������Ă��邾�낤�ˁB
GMA��DX11��DXCS�Ή����Ȃ�����͒u���čs����������Ǝv����B
���i7/i9�������\�ł��AGPGPU�Ή��\�t�g�Ō݊p�ȉ��Ȃ�債�ċ��Ђł��Ȃ��Ȃ邾�낤�B
���ꂪ�|������Larrabee����Ă����̂Ɏ��s��������āB
�c�q����Ȃ��ăE���R���ČĂѕ���蒅�����悤��
Llano��AthlonII�n�̒u�������BPhenomII�̌�p��Zambezi�B
yukon�Ƃ��̔��^�m�[�g������Bobcat�̗p��Ontario�B
yukon�Ƃ��̔��^�m�[�g������Bobcat�̗p��Ontario�B
Larrabee���J���I���ƕ����ċL�O�J�L�R
�v��j�����
AMD�͕��������_���Z��GPU�ɂ�点�Ă��������Ȃ̂̓K�C�V���c
Larrabee�ڍ������̂��B�ŏ����疳��������Ƃ͎v���Ă������A����ł�INTEL�Ȃ�
�v�̂܂��������H�̗D�G���ŃJ�o�[���Ă���Ȃ�̓d�͐��\�������Ă���Ǝv���Ă����B
����ς薳���Ȃ��͖̂����������ˁB
�v�̂܂��������H�̗D�G���ŃJ�o�[���Ă���Ȃ�̓d�͐��\�������Ă���Ǝv���Ă����B
����ς薳���Ȃ��͖̂����������ˁB
> �ő�3���ȏ��CPU�̓n�C�G���h�Ƃ��ċ͂��ɂ�������Ȃ��j�b�`�s��Ȃ��B
���̃j�b�`�s���
> �T�[�o�[�ȏ�̓\�P�b�gG34��16�R�A���\�肳��Ă��邪�H
�ƁASandy Bridge-EX�i12�R�A�j���o����E����邾���̂悤��
CPU���킴�킴MCM�ŃR�X�g�����ē����Ƃ��ǂꂾ���}�]�Ȃ�AMD���āH
����łȂ��Ƃ�8�R�A�܂ł�DP�ɂ���Ă���\�肾��
> SSE3/4�Ȃǂ���AVX�ɒu������邵
Llano��AVX�ȑO��SSSE3�ɂ��Ή����ĂȂ����B
5000�~�Ŕ�����l�ȃJ�[�h��CPU�ɓ������ꂽ������ĉ��̋��Ђɂ��Ȃ���B
��ɂ����GDI�`�悪�������GMA���x�����B
���̃j�b�`�s���
> �T�[�o�[�ȏ�̓\�P�b�gG34��16�R�A���\�肳��Ă��邪�H
�ƁASandy Bridge-EX�i12�R�A�j���o����E����邾���̂悤��
CPU���킴�킴MCM�ŃR�X�g�����ē����Ƃ��ǂꂾ���}�]�Ȃ�AMD���āH
����łȂ��Ƃ�8�R�A�܂ł�DP�ɂ���Ă���\�肾��
> SSE3/4�Ȃǂ���AVX�ɒu������邵
Llano��AVX�ȑO��SSSE3�ɂ��Ή����ĂȂ����B
5000�~�Ŕ�����l�ȃJ�[�h��CPU�ɓ������ꂽ������ĉ��̋��Ђɂ��Ȃ���B
��ɂ����GDI�`�悪�������GMA���x�����B
> AMD�͕��������_���Z��GPU�ɂ�点�Ă��������Ȃ̂̓K�C�V���c
��Nehalem��z�肵�Ă��̂ɏo�x��ċ����͖����Ȃ������̂��k�قȂ̂�
�N�ł��킩��BC/C++����g���Ȃ����j�b�g�Ȃ�Ă��ꂾ���Ŗь��������B
��Nehalem��z�肵�Ă��̂ɏo�x��ċ����͖����Ȃ������̂��k�قȂ̂�
�N�ł��킩��BC/C++����g���Ȃ����j�b�g�Ȃ�Ă��ꂾ���Ŗь��������B
Fusion��CPU��GPU�������ǂ��������邽�߂̍\�z����
CPU��GPU�̏����̐�ւ��A���ł�AMD���f�����I���Ă����
CPU��GPU�̏����̐�ւ��A���ł�AMD���f�����I���Ă����
536 �FSocket774�F2009/12/10(��) 13:02:48 ID:nEjbL69E
CPU��胂�b�T�����삾����
OpenCL HavokFX�̂��Ƃ��H
OpenCL HavokFX�̂��Ƃ��H
537 �FSocket774�F2009/12/10(��) 14:16:17 ID:UYur6OPD
MCM���������Ă͉̂ߋ��̘b
A�N���X�̃R�A�Q��C�N���X�̃R�A�Q
���ꂪ1�`�b�v�������ꍇ�̓`�b�v�̃����N��C�N���X�ɂȂ邪
�ʁX�̃`�b�v�̏ꍇ�͑���A�N���X�̃R�A�Q��MCM�ɂ����A�N���X�̃`�b�v�Ƃ��Ĕ��邱�Ƃ��o����
�����MCM�̃R�X�g�Ȃǂǂ��ł��ǂ��Ȃ�
A�N���X�̃R�A�Q��C�N���X�̃R�A�Q
���ꂪ1�`�b�v�������ꍇ�̓`�b�v�̃����N��C�N���X�ɂȂ邪
�ʁX�̃`�b�v�̏ꍇ�͑���A�N���X�̃R�A�Q��MCM�ɂ����A�N���X�̃`�b�v�Ƃ��Ĕ��邱�Ƃ��o����
�����MCM�̃R�X�g�Ȃǂǂ��ł��ǂ��Ȃ�
Core 2 Quad�܂ł͌����̈����Z�p������AMD���̗p���邩�獇���I�I�i�د
�����C���e���Ƃ��̐M�҂������ǂ�ǂ\��������������悤�ɂȂ��Ă鍡�����̍�
�F�l���������߂����ł���
�F�l���������߂����ł���
���Ȃ��Ƃ�����AMD�̓R�A�Ԑڑ��͏]���Ɠ����N���X�o�[������A
8�R�A��12�R�A��1�`�b�v�ɂ���ƁA�N���X�o�[���������ł��Ȃ�_�C�T�C�Y�H�����Ⴄ��Ȃ��́H
SandyBridge�̃_�C�T�C�Y����r�I�������̂̓N���X�o�[�����Ȃ��Ȃ��Ă�̂����肻�������B
8�R�A��12�R�A��1�`�b�v�ɂ���ƁA�N���X�o�[���������ł��Ȃ�_�C�T�C�Y�H�����Ⴄ��Ȃ��́H
SandyBridge�̃_�C�T�C�Y����r�I�������̂̓N���X�o�[�����Ȃ��Ȃ��Ă�̂����肻�������B
>>539
C2Q��GTX260�łf�o�f�o�t���ėV�тȂ���g���ȓ��X���߂����Ă��܂��B
C2Q��GTX260�łf�o�f�o�t���ėV�тȂ���g���ȓ��X���߂����Ă��܂��B
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20091126_331235.html
>>��X�́A�S�ẴA�v���P�[�V�����̃��[�N���[�h�������B���̌��ʁA�v���Z�b�T�̒��ōł��g���Ă��镔���͐������Z���j�b�g�ł����āA���������_���Z���j�b�g�ł͂Ȃ����Ƃ��킩�����B
>>���������_���Z���j�b�g�́A����99%�̎��Ԃ͎g���Ă��Ȃ��B
>>���ɁAPatla�����S������T�[�o�[�s��̏ꍇ�́A�n�C�p�t�H�[�}���X�R���s���[�e�B���O(HPC)�ȊO�ł͕��������_���Z�͂قƂ�ǎg���Ȃ����낤�B
>>��X�́A�S�ẴA�v���P�[�V�����̃��[�N���[�h�������B���̌��ʁA�v���Z�b�T�̒��ōł��g���Ă��镔���͐������Z���j�b�g�ł����āA���������_���Z���j�b�g�ł͂Ȃ����Ƃ��킩�����B
>>���������_���Z���j�b�g�́A����99%�̎��Ԃ͎g���Ă��Ȃ��B
>>���ɁAPatla�����S������T�[�o�[�s��̏ꍇ�́A�n�C�p�t�H�[�}���X�R���s���[�e�B���O(HPC)�ȊO�ł͕��������_���Z�͂قƂ�ǎg���Ȃ����낤�B
>>542
> >>���������_���Z���j�b�g�́A����99%�̎��Ԃ͎g���Ă��Ȃ��B
���ꂱ��Sandy Bridge�ɑ��鋣���͂��Ȃ����Ƃ���������䂦��
�o�Ă����k�قł����āAGPGPU�̐��ݓI���v�̏��Ȃ�������\�I�����ɓ�����
> >>���ɁAPatla�����S������T�[�o�[�s��̏ꍇ�́A�n�C�p�t�H�[�}���X�R���s���[�e�B���O(HPC)�ȊO�ł͕��������_���Z�͂قƂ�ǎg���Ȃ����낤�B
�K�ɖ�ƁuBulldozer��HPC�ł͋����͂��Ȃ��V�F�A�����炵�����邾�낤�v
> >>���������_���Z���j�b�g�́A����99%�̎��Ԃ͎g���Ă��Ȃ��B
���ꂱ��Sandy Bridge�ɑ��鋣���͂��Ȃ����Ƃ���������䂦��
�o�Ă����k�قł����āAGPGPU�̐��ݓI���v�̏��Ȃ�������\�I�����ɓ�����
> >>���ɁAPatla�����S������T�[�o�[�s��̏ꍇ�́A�n�C�p�t�H�[�}���X�R���s���[�e�B���O(HPC)�ȊO�ł͕��������_���Z�͂قƂ�ǎg���Ȃ����낤�B
�K�ɖ�ƁuBulldozer��HPC�ł͋����͂��Ȃ��V�F�A�����炵�����邾�낤�v
����̒ނ�j�������Ȃ�
Intel�ЁA�e���t���b�v���̃}�C�N���v���Z�b�T�J���̐V�헪�𖾂炩��
ttp://eetimes.jp/news/3552
�����r�[�L�����Z���Ɠ������ɂ���\�����炵������
���Ȃ̂���ALarrabee�Ƃ͎��Ĕ�Ȃ���̂Ȃ́B
ttp://eetimes.jp/news/3552
�����r�[�L�����Z���Ɠ������ɂ���\�����炵������
���Ȃ̂���ALarrabee�Ƃ͎��Ĕ�Ȃ���̂Ȃ́B
546 �FSocket774�F2009/12/10(��) 15:58:43 ID:UYur6OPD
>>538
��ΐ��\�Ȃ�l�C�e�B�u�œ����������������Ɍ��܂��Ă�
�ł��Ǖi�A�܂藘�v�̑傫�����i���o���闦��MCM�̕��������ƍ������Ă����̘b
��ΐ��\�Ȃ�l�C�e�B�u�œ����������������Ɍ��܂��Ă�
�ł��Ǖi�A�܂藘�v�̑傫�����i���o���闦��MCM�̕��������ƍ������Ă����̘b
�Ƃ肠����
�P�D�u���������_���Z���j�b�g�́A����99%�̎��Ԃ͎g���Ă��Ȃ��v
�Q�D�uAMD�͕��������_���Z��GPU�ɂ�点�Ă��������v
���̂Q�̎咣���傫�Ȗ���������Ă���̂͂킩�邾��B
GPGPU�Œu�������ł���̂́ASSE�ł��\�ȉ��Z�̂��������ꕔ��
������x�̍����A��菭�Ȃ��L���b�V���������œ������̂������B
�P�D�u���������_���Z���j�b�g�́A����99%�̎��Ԃ͎g���Ă��Ȃ��v
�Q�D�uAMD�͕��������_���Z��GPU�ɂ�点�Ă��������v
���̂Q�̎咣���傫�Ȗ���������Ă���̂͂킩�邾��B
GPGPU�Œu�������ł���̂́ASSE�ł��\�ȉ��Z�̂��������ꕔ��
������x�̍����A��菭�Ȃ��L���b�V���������œ������̂������B
>>545
��{�I�ɂ͓������́B�������O���t�B�b�N�p�r�Ƃ����̂����߂��B
��{�I�ɂ͓������́B�������O���t�B�b�N�p�r�Ƃ����̂����߂��B
���j�[�R�A���ĂƂ���ȊO���Ȃ�Ⴄ�Ǝv�����B
Larrabee���ƃL���b�V���R�q�[�����V�̓n�[�h�E�F�A�Ő��䂾���ǁASCC�̓\�t�g�E�F�A�����A
�R�A�Ԑڑ��������O�ƃ��b�V���ňႤ�B
�ȑO������80�R�APolaris��IA32�ŁB
Larrabee���ƃL���b�V���R�q�[�����V�̓n�[�h�E�F�A�Ő��䂾���ǁASCC�̓\�t�g�E�F�A�����A
�R�A�Ԑڑ��������O�ƃ��b�V���ňႤ�B
�ȑO������80�R�APolaris��IA32�ŁB
��ʌ����ŕ��������_���Z���s���悤�ȏ�ʂ��ăQ�[���E�E�E�H
SSE4.2��AES�ɑΉ����Ă����Έ�ʂ̃T�[�o�̃��[�N���[�h�ł��L�p�ɂȂ肤��
SIMD�������j�b�g���܂߂ċ��L�ɂ��Ă��܂������Ƃ��˂����݂ǂ���B
SIMD�������j�b�g���܂߂ċ��L�ɂ��Ă��܂������Ƃ��˂����݂ǂ���B
GDI�`��w
�ł��AAMD��GPU�͋��͂����H
�g��Ȃ���̓i�b�V���O
�g��Ȃ���̓i�b�V���O
554 �FSocket774�F2009/12/10(��) 17:06:46 ID:nEjbL69E
�������͂Ȃ�
�uGDI�`��w�v (�د
DirectX�Ƃ�WPF�������w�ǂ�Windows�A�v���P�[�V������GDI�ˑ��ł���
DirectX�Ƃ�WPF�������w�ǂ�Windows�A�v���P�[�V������GDI�ˑ��ł���
����GDI�͒N���`�悷���
���L������������琫�\�������Ⴄ�́H
Larrabee�����s�������̂͊ԈႢ�Ȃ���
����ɂ����CPU�܂�AMD���L���ɂȂ����Ƃ������o���̂�
�������ɓ������Ԕ��ɂȂ��Ă�Ƃ��������Ȃ���
��������Fusion�ɂ��Ă�L��ANO�Ƃ��`�b�v�ʐς��ш���D����������
�n�C�G���h�ɑR�ł��鐫�\�������ł���킯�Ȃ�����
Intel�ȏ�Ƀ\�t�g�J��������ڂ�AMD���ǂ������
CPU��GPU�����܂��g��������낤
����ɂ����CPU�܂�AMD���L���ɂȂ����Ƃ������o���̂�
�������ɓ������Ԕ��ɂȂ��Ă�Ƃ��������Ȃ���
��������Fusion�ɂ��Ă�L��ANO�Ƃ��`�b�v�ʐς��ш���D����������
�n�C�G���h�ɑR�ł��鐫�\�������ł���킯�Ȃ�����
Intel�ȏ�Ƀ\�t�g�J��������ڂ�AMD���ǂ������
CPU��GPU�����܂��g��������낤
Vista��Aero��GDI�A�N�Z�����[�V�����Ȃ����ĕs�]�A
Windows 7�ōQ�Ăĕ����������炢�����AGDI�͕K�v����B
�ǂ�����DirectX11�Ή�GPU�i�د �͎̂Ă���������ǂˁB
����͎��͈��Windows 7�Ɍ����ĂȂ��B
Windows 7�ōQ�Ăĕ����������炢�����AGDI�͕K�v����B
�ǂ�����DirectX11�Ή�GPU�i�د �͎̂Ă���������ǂˁB
����͎��͈��Windows 7�Ɍ����ĂȂ��B
�������ɏ����錾�͂͂₷�����
>>558
OpenCL�Ŋ撣�邵��
MS��AMD�����肵����
�����ĂȂ����Ƃ͂Ȃ��͂���
�����~���ʎY���ꂽ�łɂ́c�c���`�_���ς��_���ς�
>>558
OpenCL�Ŋ撣�邵��
MS��AMD�����肵����
�����ĂȂ����Ƃ͂Ȃ��͂���
�����~���ʎY���ꂽ�łɂ́c�c���`�_���ς��_���ς�
OpenCL�Ȃ�Ă������ɑ̂��낤
larrabee���s��
�܁`�A�I���{�̃O���t�B�b�N������ȂɃw�{�C�̂�
�����������@�Ō��s��GPU�ɏ��Ă�킯�Ȃ��ȁi�O���t�B�b�N�݂̂Ȃ�j
�ǂ����A��ԍŏ��̐��i�͎s��J��̂��߂̎̐��낤��
atom�݂����ɂ�
�_���͂����Ǝv�����ǂ������܂������
PS3��Cell�ł������\�j�[���牽���w��łȂ�
�\�t�g�E�F�A�J���̎x�����Ȃ��ᕁ�y�͂ނ�������
���Ȃ��ƈ��͒��ڂ����\�t�g���o���ׂ����iintel���g���j
�\�t�g�J�������Ăǂ�قǐ����Ă���́H
�u�R���s���[�^�A�\�t�g�Ȃ�������̔��v
�܁`�A�I���{�̃O���t�B�b�N������ȂɃw�{�C�̂�
�����������@�Ō��s��GPU�ɏ��Ă�킯�Ȃ��ȁi�O���t�B�b�N�݂̂Ȃ�j
�ǂ����A��ԍŏ��̐��i�͎s��J��̂��߂̎̐��낤��
atom�݂����ɂ�
�_���͂����Ǝv�����ǂ������܂������
PS3��Cell�ł������\�j�[���牽���w��łȂ�
�\�t�g�E�F�A�J���̎x�����Ȃ��ᕁ�y�͂ނ�������
���Ȃ��ƈ��͒��ڂ����\�t�g���o���ׂ����iintel���g���j
�\�t�g�J�������Ăǂ�قǐ����Ă���́H
�u�R���s���[�^�A�\�t�g�Ȃ�������̔��v
GMA�~���Ă���Ȃ�
564 �FSocket774�F2009/12/10(��) 18:38:42 ID:HC6NkjgB
>>538
C2Q��QPI��HT����������R�A���m���q���Ȃ��̂Ō�������
C2Q��QPI��HT����������R�A���m���q���Ȃ��̂Ō�������
GDI�ŏ����ꂽ�v���O�����͑S��DirectX�Ɉڍs��������i�د
>>564
�R�X�g�̖�肶��Ȃ��̂��H
�R�X�g�̖�肶��Ȃ��̂��H
>>561
���F�uOpenCL Havok���������琫�\���������̂łȂ��������Ƃɂ������v
���F�uOpenCL Havok���������琫�\���������̂łȂ��������Ƃɂ������v
����GDI���ǂ��̂����̂��ĉ������Ă�́H
GDI�n�[�h�E�F�A�A�N�Z�����[�V�����Ή��̃O���{���ǂꂾ�������H
GDI�n�[�h�E�F�A�A�N�Z�����[�V�����Ή��̃O���{���ǂꂾ�������H
�\�t�g�E�F�A�A�N�Z�����[�V�������痘���ĂȂ����ǂȁB
�������ƃ��[�U�[��Radeon�������킯���B
�������ƃ��[�U�[��Radeon�������킯���B
Larrabee����ʼn������̂͂킩�邪AMD�@���������Ď��Ԃ͍D�]���˂�����
AMD���ߋ���Funsion�֘A�Ŕh��ɓ]��ł邩��@���͎s��
�t��Zambezi��Llano���i�C�Â��킯�ł�����܂��B
�i�C�Â��͍̂��N�̃N���X�}�X�ɔޏ������鉴����
�c�q�̓s�G���i�j��
575 �FSocket774�F2009/12/10(��) 19:21:09 ID:nEjbL69E
>������786KB�A�g�����W�X�^�R�X�g�ɂ���3,4�疜�g�����W�X�^
>GF100�S�̂�1�����̃��C�^�u���L���b�V���ʼn����̐��\������ʂ�����Ǝv���Ă���̂��ˁB
���ق���
>GF100�S�̂�1�����̃��C�^�u���L���b�V���ʼn����̐��\������ʂ�����Ǝv���Ă���̂��ˁB
���ق���
�Q�[�����\�ɂ����Ă�Llano�ɂ͏��ĂȂ����
�ϑz���������݂����Ȃ�ŏ����Ă݂���
�ϑz���������݂����Ȃ�ŏ����Ă݂���
���̌��ň�ԑ�������̂͂ǂ��ł��傤���B���͂��̉�Ђ��Ǝv���Ă܂��B
>>576
�v��Ȃ��ȁBGT220�ł��w���������}�V�B
�v��Ȃ��ȁBGT220�ł��w���������}�V�B
���҂Ƀ`�b�v�Z�b�g�ߏo����ăf�B�X�N���[�g�ŏ������邵���Ȃ�NVIDIA�͂炢�̂���
����ION 2(��)�������������ǂꂾ�����\���o�邩�s�������Ȃ�
����ION 2(��)�������������ǂꂾ�����\���o�邩�s�������Ȃ�
GT220���A���Ȃ����ۂ��Ɏv����قǂ������ނ�t�����ˁc
�`�b�v�Z�b�g�r�W�l�X�Ȃ�Ă��Ƃ��ƖԂ���˂������
��ƌ����͖w�ǂ��I���{������ȁB�킴�킴�O���{�������K�v�ȂǂȂ��B
��ƌ�����PC��AMD��CPU�ȂǂقƂ�Ǎ̗p����ĂȂ�����B
�܂�ION�̕������o�Ă邼�B
�܂�ION�̕������o�Ă邼�B
����AGMA�������ς����ˁB
x86�s��ł�intel�ȊO�ׂ͖���Ȃ��d�g�݂ɂȂ��Ă���̂�
��86���́E�E�E����Ђ��x�z���Ă�
��x86���́E�E�E�ʂ̐���Ђ��x�z���Ă�
��x86���́E�E�E�ʂ̐���Ђ��x�z���Ă�
������big blue
HPC�p�Ƃ�����ʏo�͋@�\�����肵�Ă���Ȃ����ȁB
GPU�Ɣ�r����Ă�������ł��邵�B
CG�����̃l�^�ɂ����������E�E�E
GPU�Ɣ�r����Ă�������ł��邵�B
CG�����̃l�^�ɂ����������E�E�E
���i�Ƃ��ďo�ׂł���Cell�����s�Ȃ�
�o�ׂ���ł��Ȃ�����Larrabee�͑厸�s�H�����s�H�����s�H
�o�ׂ���ł��Ȃ�����Larrabee�͑厸�s�H�����s�H�����s�H
590 �F,,�E�L�́M�E,,�j��-�������F2009/12/10(��) 23:10:15 ID:t3OdgNqV
���O��Q�n(GMA)���ɂ���Ȃ�
�O���t�B�b�N�ɛZ�т悤�Ƃ����̂����s�̌������낤��
�L���Z���������������낤��GPU�Ƃ��čL�߂�ɂ�GPU�̐��\���Ȃ��Ƙb�ɂȂ�Ȃ������킯��
�L���Z���������������낤��GPU�Ƃ��čL�߂�ɂ�GPU�̐��\���Ȃ��Ƙb�ɂȂ�Ȃ������킯��
�C���e���I�ɂ͂���܂���C�Ȃ�������łȂ���
���܂��������烉�b�L�[���x�Ƃ��A�����炩���������m��ǂ��B
���܂��������烉�b�L�[���x�Ƃ��A�����炩���������m��ǂ��B
593 �F,,�E�L�́M�E,,�j��-�������F2009/12/10(��) 23:17:20 ID:t3OdgNqV
48�A�������_�e�a�̂ق�����1�R�A������2.5GHz��128�r�b�gFMAC���ȁH
Cell��POWER7���o������m������
595 �F,,�E�L�́M�E,,�j��-�������F2009/12/10(��) 23:18:39 ID:t3OdgNqV
256�r�b�g��1.3GHz����
Each Bulldozer "core" is capable of 2 loads/cycle; each is a 4-way out-of-order machine
Each INT scheduler can issue 4 inst./cycle; the FP scheduler can issue 4 inst./cycle
HPC�ŏ���H
Each INT scheduler can issue 4 inst./cycle; the FP scheduler can issue 4 inst./cycle
HPC�ŏ���H
597 �F,,�E�L�́M�E,,�j��-�������F2009/12/10(��) 23:43:31 ID:t3OdgNqV
FP�N���X�^����128�r�b�gFMAC�~2, FMISC, FSTORE��4���j�b�g
Bulldozer��128�r�b�gFMAC�~2���R�A���Ȃ�HPC�ł��������������A2�R�A�ŋ��L����������B
�uK12�v�܂ł̂Ȃ����Ǝv�����ق��������B
RICC�iNehalem1024�m�[�h�j�Ȃ�LINPACK��FPU�̉ғ���90���I�[�o�[�Ƃ����������B�����Ă�B
���̒��x�܂ōœK�����i��ł邩��A������SIMD���\���ق������Ă��Ƃ͂����Ă�
2�R�A��FPU���\�[�X�����L�Ȃ�čl�����Ƃ���BHT�ł��炩�����Đ��\�ቺ���邭�炢�����B
Bulldozer��128�r�b�gFMAC�~2���R�A���Ȃ�HPC�ł��������������A2�R�A�ŋ��L����������B
�uK12�v�܂ł̂Ȃ����Ǝv�����ق��������B
RICC�iNehalem1024�m�[�h�j�Ȃ�LINPACK��FPU�̉ғ���90���I�[�o�[�Ƃ����������B�����Ă�B
���̒��x�܂ōœK�����i��ł邩��A������SIMD���\���ق������Ă��Ƃ͂����Ă�
2�R�A��FPU���\�[�X�����L�Ȃ�čl�����Ƃ���BHT�ł��炩�����Đ��\�ቺ���邭�炢�����B
�ŏ������GPU�̃R�v���Z�b�T�Ƃ��Ĕ��\���Ƃ��悩�����̂�������Ȃ��E�E�E
�Ȃ���Intel�̔̔���r���^�������Ȃ��Ă����B
�x����Ȃ����ڂ���GPGPU�o���Ă��Ă��������c����̂��H
CPU�ɓ���Ă܂����M���̌�����̂��I�`����Ȃ��̂��B
�x����Ȃ����ڂ���GPGPU�o���Ă��Ă��������c����̂��H
CPU�ɓ���Ă܂����M���̌�����̂��I�`����Ȃ��̂��B
600 �F,,�E�L�́M�E,,�j��-�������F2009/12/11(��) 00:20:31 ID:QYYq4m1S
3��܂łȂ�]�T��
Win7��GDI��GMA�Ƃ��ő��Ӗ��s�����ȁB
Aero��DX10.1�ȍ~��GPU�Ȃ畁�ʂɌ����悭�����`�悳��邵�AGDI�Ƃ��ǂ��ł������B
Intel��Nvidia��Win7�̕W���@�\����ے肵�Ȃ�����Ȃ�Ȃ��đ�ς��ȁB
Intel�v���b�g�t�H�[������ς���ȁA�O���t�B�b�N������GPU�������Ă���Ȃ��āA
�S��CPU�����ɂȂ��āB
���Ȃ݂�IE9��Direct2D�Ή��ō����`�悷��炵�����B�ǂ������GMA�B
���̕�����OFFICE���Ή����������B
Aero��DX10.1�ȍ~��GPU�Ȃ畁�ʂɌ����悭�����`�悳��邵�AGDI�Ƃ��ǂ��ł������B
Intel��Nvidia��Win7�̕W���@�\����ے肵�Ȃ�����Ȃ�Ȃ��đ�ς��ȁB
Intel�v���b�g�t�H�[������ς���ȁA�O���t�B�b�N������GPU�������Ă���Ȃ��āA
�S��CPU�����ɂȂ��āB
���Ȃ݂�IE9��Direct2D�Ή��ō����`�悷��炵�����B�ǂ������GMA�B
���̕�����OFFICE���Ή����������B
602 �F,,�E�L�́M�E,,�j��-�������F2009/12/11(��) 00:59:21 ID:QYYq4m1S
Direct2D�i�j
��Ƃ�IE9�Ƃ��ŐVOffice������͉̂��N�悾�낤
604 �F,,�E�L�́M�E,,�j��-�������F2009/12/11(��) 01:11:00 ID:QYYq4m1S
���܂���XP���݂�����ˁB
WDDM���ǂ��Ƃ����Ă�����
�I�t�B�X�p�r�Ȃ�Windows 7 Enterprise��G31��G41�`�b�v�Z�b�g������ł��y���ɓ����킯����
Aero�͉�ʑS�̍�����GPU�����ɂȂ��������ŃE�B���h�E���Ƃ̃f�o�C�X�R���e�N�X�g�͌��݁B.
NET��WinForms�ł��疢����GDI/GDI+�ˑ������B
�t��ATI�`�b�v�Z�b�g��Pentium DC�@�͂Ƃ낭�������ă��������݂��Ă��J�N�J�N�B
���≽���x�����āAUSB���x����ˁBUSB�ڑ��̃}���`�f�B�X�v���C�̓]�������h��B
GMA�͓e���p���̂ւ���Intel�͎d���܂Ƃ����B
WDDM���ǂ��Ƃ����Ă�����
�I�t�B�X�p�r�Ȃ�Windows 7 Enterprise��G31��G41�`�b�v�Z�b�g������ł��y���ɓ����킯����
Aero�͉�ʑS�̍�����GPU�����ɂȂ��������ŃE�B���h�E���Ƃ̃f�o�C�X�R���e�N�X�g�͌��݁B.
NET��WinForms�ł��疢����GDI/GDI+�ˑ������B
�t��ATI�`�b�v�Z�b�g��Pentium DC�@�͂Ƃ낭�������ă��������݂��Ă��J�N�J�N�B
���≽���x�����āAUSB���x����ˁBUSB�ڑ��̃}���`�f�B�X�v���C�̓]�������h��B
GMA�͓e���p���̂ւ���Intel�͎d���܂Ƃ����B
Tim Sweeney�͉������������Ă�H
606 �F,,�E�L�́M�E,,�j��-�������F2009/12/11(��) 01:24:26 ID:QYYq4m1S
���ɉ����B���ނ�UE4��x�点���̂������̌�������ˁH
�Œ�I�ŏ_��ɖR����DX11��API�̏�œ������ɂ͗D�ʐ��Ȃ��͉̂���������Ƃ����B
�Œ�I�ŏ_��ɖR����DX11��API�̏�œ������ɂ͗D�ʐ��Ȃ��͉̂���������Ƃ����B
��������Ȃ��ăL�����Z���ł���
����Ȉ�l�Ɉˑ��������X�N�w�b�W�̂Ȃ��v���W�F�N�g�ɑ���˂����̂��B
�ǂ����悤���Ȃ��Ȃ����B
�ǂ����悤���Ȃ��Ȃ����B
���܂�XP�V���Ȃ낤�˂�
610 �F,,�E�L�́M�E,,�j��-�������F2009/12/11(��) 01:32:37 ID:QYYq4m1S
Larrabee�̌v�悻�̂��̂�Sandy Bridge�ɑ��郊�X�N�w�b�W���Ǝv���Ă����B
�R�P����Westmere�ő������˂Ȃ�Ȃ��Ȃ�A2�{�ɂȂ�\�肾����FLOPS������ΓI�ɕs������B
�Ȃ���Unreal Engine�̓g�b�v�V�F�A�����炱���̎x����������Ώ����͊m�肷��B
�R�P����Westmere�ő������˂Ȃ�Ȃ��Ȃ�A2�{�ɂȂ�\�肾����FLOPS������ΓI�ɕs������B
�Ȃ���Unreal Engine�̓g�b�v�V�F�A�����炱���̎x����������Ώ����͊m�肷��B
611 �F,,�E�L�́M�E,,�j��-�������F2009/12/11(��) 01:34:02 ID:QYYq4m1S
>>609
MS�ɕ�����B
Windows 7���XP���[�h�͊���Ɖ��K�����B
����Ȃ��̂�p�ӂ��Ȃ��Ƃ����Ȃ��̂͂��ꂾ���\�t�g�E�F�A�����Ă��ĂȂ����Ă��ƁB
MS�ɕ�����B
Windows 7���XP���[�h�͊���Ɖ��K�����B
����Ȃ��̂�p�ӂ��Ȃ��Ƃ����Ȃ��̂͂��ꂾ���\�t�g�E�F�A�����Ă��ĂȂ����Ă��ƁB
���v�V�I�Ȍv��̕������X�N�w�b�W�Ă��Ƃ���
���X�N�Ǘ����Ȃ��ĂȂ�����
���X�N�Ǘ����Ȃ��ĂȂ�����
613 �F,,�E�L�́M�E,,�j��-�������F2009/12/11(��) 01:44:03 ID:QYYq4m1S
HPC�����̃A�N�Z�����[�^�Ƃ��ď\���Ɏg����悤�ɐv���Ă��邩�炾��B
�t��GPU�炵���@�\�͖w�ǔ�����ĂȂ��B
���X��Tera-Scale Research�̃��j�[�R�A�̎��������̂ЂƂ���B
����Ŏs������Ĕ����Ζׂ����̂��������Ő������邩�ǂ����͖{������Ȃ��B
���s���Ă�������GMA�Ɍ����Ă̌��������˂Ă邩��A�ʂɗ��v���o�����Ƃ͋��߂��ĂȂ��B
��ŁAIntel�������}�K��VMWare�ɂ��Č�肾���܂����B
�Q���W���K�[�̈ڐЂ�����Ђ̃A���ˁB
�t��GPU�炵���@�\�͖w�ǔ�����ĂȂ��B
���X��Tera-Scale Research�̃��j�[�R�A�̎��������̂ЂƂ���B
����Ŏs������Ĕ����Ζׂ����̂��������Ő������邩�ǂ����͖{������Ȃ��B
���s���Ă�������GMA�Ɍ����Ă̌��������˂Ă邩��A�ʂɗ��v���o�����Ƃ͋��߂��ĂȂ��B
��ŁAIntel�������}�K��VMWare�ɂ��Č�肾���܂����B
�Q���W���K�[�̈ڐЂ�����Ђ̃A���ˁB
614 �F,,�E�L�́M�E,,�j��-�������F2009/12/11(��) 01:48:03 ID:QYYq4m1S
������GMA�A�Ƃ������A�w�e���W�j�A�X�̏��������̃R�A���Č����������ǂ���
>>603
Larrabee�̃X���Ŋ�Ɖ]�X�����Ă����̌�����ɂ��Ȃ�Ȃ�����
Larrabee�̃X���Ŋ�Ɖ]�X�����Ă����̌�����ɂ��Ȃ�Ȃ�����
616 �F,,�E�L�́M�E,,�j��-�������F2009/12/11(��) 02:11:00 ID:QYYq4m1S
Sandy Bridge�������ł��邱�ƂŁAIntel�S�̂Ƃ��Ă͖�������Larrabee�𓊓�����K�v���Ȃ��Ȃ����B
���������AVX��LNI�Ƃ���2�̐V���߂������ɍ��݂��邱�Ƃ�
�����ɍ������������͑z���ɓ�Ȃ��B
����Sandy Bridge���]���Ă��玟��Ivy Bridge��������B
�I���S���`�[����Westmere�̂܂ܑ�������Haswell�܂Ōq�����ƂɂȂ�B
���̍ۂɕK�v�ɂȂ�̂�SIMD�A�N�Z�����[�^��Larrabee��FP���\��⊮������Ă��Ƃ��B
���̓I���S���C�X���G���Ȃ�ł���B
���Ƃ���Haswell��FMA�ɂ�����vfmadd231ps�݂����ȉ����I�y�����h���ߏ����Ɩ����K����Larrabee�̂���R���B
���������AVX��LNI�Ƃ���2�̐V���߂������ɍ��݂��邱�Ƃ�
�����ɍ������������͑z���ɓ�Ȃ��B
����Sandy Bridge���]���Ă��玟��Ivy Bridge��������B
�I���S���`�[����Westmere�̂܂ܑ�������Haswell�܂Ōq�����ƂɂȂ�B
���̍ۂɕK�v�ɂȂ�̂�SIMD�A�N�Z�����[�^��Larrabee��FP���\��⊮������Ă��Ƃ��B
���̓I���S���C�X���G���Ȃ�ł���B
���Ƃ���Haswell��FMA�ɂ�����vfmadd231ps�݂����ȉ����I�y�����h���ߏ����Ɩ����K����Larrabee�̂���R���B
>>614
��80%�ȏ�̃��[�U�[�́uGMA�ł�����v���Ďv���Ă���đO�����Ă���ˁH
���̏�ԂŁA������GMA�����̉����łȂ�LRBni������x86�ɂ���Ӗ����ĉ��H
��80%�ȏ�̃��[�U�[�́uGMA�ł�����v���Ďv���Ă���đO�����Ă���ˁH
���̏�ԂŁA������GMA�����̉����łȂ�LRBni������x86�ɂ���Ӗ����ĉ��H
618 �F,,�E�L�́M�E,,�j��-�������F2009/12/11(��) 02:16:16 ID:QYYq4m1S
>>617
Celeron�Ƃ��đ�ʂɏĂ��R�A�����̂܂�SIMD�����̓����̃R�A�ɂ��Ȃ���Ă��ƁB
���ƁAOS�̃}�C�N���J�[�l�������i�ނƁA��ʂ̏������v���O������������
�������R�A����ʂɂ���\�����L���ɂȂ�Bx86�̃X�J�����Z�@�\�������Ő����Ă���B
���[�G���h�@��GPU����G���v����HPC�����Ȃ��閜�\�`�b�v��ڎw���Ă�̂ł��B
Celeron�Ƃ��đ�ʂɏĂ��R�A�����̂܂�SIMD�����̓����̃R�A�ɂ��Ȃ���Ă��ƁB
���ƁAOS�̃}�C�N���J�[�l�������i�ނƁA��ʂ̏������v���O������������
�������R�A����ʂɂ���\�����L���ɂȂ�Bx86�̃X�J�����Z�@�\�������Ő����Ă���B
���[�G���h�@��GPU����G���v����HPC�����Ȃ��閜�\�`�b�v��ڎw���Ă�̂ł��B
����Windows7�܂Ŕے肵�Ȃ��ƌ�����ł��Ȃ��Ȃ��Ă�w
�����Ⴂ�Ȃ��Ƃ������Ă�̂��j���j������̂��ʔ����ł��B
��ƌ����Ȃ�CPU��Atom��Z�������AAthlonX2�AGPU��GMA��780G�ŕK�v�\���Ȃ͕̂�����B
�Ƃ������A������������������̐���̍Œᐫ�\�̏����s��݂����Ȃ���B
���������A�Z�������ŏ\���Ȋ�ƌ�����O��ɂ�����Ƃ����̐̂ɐ��\����ȂӖ����Ȃ��Ȃ��Ă���B
�c�q���ǂ�Ȃɑf���炵�������Z�p��z�����Ă��A
�����I�ɃC���e���͂��������ł��Ȃ��������A����������������낤�ȁB
Sandy����͔���邾�낤���ǁAGMA�͎ז��҈����ŊFRADEON�ςނ��A
9500GT�������x��MMO��Q�[����Llano�P�̂ŏ\���B
Bulldozer��AM3�ɍڂ�\���������APhenomIIX6�̐��\���邩��A�b�v�O���[�h�Ŕ����B
(965/955BE�����Ă�z�͒l�i����Œ����ɍw����������)
���ǒc�q�̗��z�ƃC���e���̌����͕ʂŁA�����Z�p�̉�����AMD�ɔ����邾�낤�ȁB
�Ƃ������A������������������̐���̍Œᐫ�\�̏����s��݂����Ȃ���B
���������A�Z�������ŏ\���Ȋ�ƌ�����O��ɂ�����Ƃ����̐̂ɐ��\����ȂӖ����Ȃ��Ȃ��Ă���B
�c�q���ǂ�Ȃɑf���炵�������Z�p��z�����Ă��A
�����I�ɃC���e���͂��������ł��Ȃ��������A����������������낤�ȁB
Sandy����͔���邾�낤���ǁAGMA�͎ז��҈����ŊFRADEON�ςނ��A
9500GT�������x��MMO��Q�[����Llano�P�̂ŏ\���B
Bulldozer��AM3�ɍڂ�\���������APhenomIIX6�̐��\���邩��A�b�v�O���[�h�Ŕ����B
(965/955BE�����Ă�z�͒l�i����Œ����ɍw����������)
���ǒc�q�̗��z�ƃC���e���̌����͕ʂŁA�����Z�p�̉�����AMD�ɔ����邾�낤�ȁB
�㓡�͖ѐF�̈Ⴄ�R�A�̃w�e���Ƃ������Ă����A
���float�̂��߂� �A�N�Z�����[�^�����̓��C���ɂȂ郊�b�`�ȃR�A��
�R�v���Z�b�T�I�Ȃ��̂ł�����Ȃ��̂�
�A�N�Z�����[�^�R�A���̂��A���b�`�ȃR�A�Ɠ����悤�ɂ���P�Ƃ�
�X���b�h���s���\�ȃR�A�ł���K�v������̂���
���float�̂��߂� �A�N�Z�����[�^�����̓��C���ɂȂ郊�b�`�ȃR�A��
�R�v���Z�b�T�I�Ȃ��̂ł�����Ȃ��̂�
�A�N�Z�����[�^�R�A���̂��A���b�`�ȃR�A�Ɠ����悤�ɂ���P�Ƃ�
�X���b�h���s���\�ȃR�A�ł���K�v������̂���
�c�q��������������c
���S�����
���S�����
GPU�̕��������_���Z�\�͂��Ăǂ�Ȃ���Ȃ́H
625 �FSocket774�F2009/12/11(��) 08:17:48 ID:mFK+3hTB
Larrabee�̃R�A��x86�łȂ�ARM�������獡����������Ă����낤�Ǝv�����A�ANV��������낤���H
>>625
Tegra�̂��Ƃ�
Tegra�̂��Ƃ�
�����A�I�������B
GPU�Ƃ��Ẵg�����W�X�^���������Ђ�1/4
��GMA�Ɣ�ׂĂ��������x
AMD��NVIDIA�͓��S�u�����~�jLRB�������Ă���v�v���Ă���
��GMA�Ɣ�ׂĂ��������x
AMD��NVIDIA�͓��S�u�����~�jLRB�������Ă���v�v���Ă���
GMA�̐��\�ł�������Ă��Ƃ́AGMA�̑����Larrabee�n�̃R�A�������āA
3D�`�搫�\���������Ă��s���������Ȃ��w��������Ă��Ƃ���Ȃ��́H
3D�`�搫�\���������Ă��s���������Ȃ��w��������Ă��Ƃ���Ȃ��́H
630 �F,,�E�L�́M�E,,�j��-�������F2009/12/11(��) 09:10:03 ID:QYYq4m1S
> ��ƌ����Ȃ�CPU��Atom��Z�������AAthlonX2�AGPU��GMA��780G�ŕK�v�\���Ȃ͕̂�����B
�n��������E�E�E
���z�����T�|�[�g���ĂȂ����̂��H
�N�A�E�Ȃ�����H
�n��������E�E�E
���z�����T�|�[�g���ĂȂ����̂��H
�N�A�E�Ȃ�����H
631 �F,,�E�L�́M�E,,�j��-�������F2009/12/11(��) 09:18:30 ID:QYYq4m1S
�I���{�[�h�ŏ\������CPU�͂��낢��ȗv�f�������ƑʖځB
AthlonX2�͂Ȃ��ȁBAMD���Ă��������łǂ��̊�Ƃ������B
AthlonX2�͂Ȃ��ȁBAMD���Ă��������łǂ��̊�Ƃ������B
AMD-V�Ȃ�قƂ�ǂ�AMD�v���Z�b�T�ɓ��ڂ���Ă邺
>>630
Atom��Z�������͒m���Athlon�n�͑S�����z���ɑΉ����Ă��邾��B
����Ƃ�AMD-V�ȊO�̂��Ƃ������Ă���̂��H
>>631
���ꂽ���̍D�������Ȃ����ł́B
���܂�Intel���x�z���Ă�������AMD���̗p���ɂ����͕̂����邪�A
�I�����Ƃ��Ă�����x���݂���A���ԂƂƂ��ɕ��y���Ă����Ǝv�����B
����ɖw�ǂ���ʎ����p�r���낤���烍�[�G���h�i�ł����Ȃ��B
���������Z��������C2D���ő�V�F�A�̊�ƌ����ɍ��x�ȋ@�\�Ȃ債�ĈӖ��Ȃ�������B
Atom��Z�������͒m���Athlon�n�͑S�����z���ɑΉ����Ă��邾��B
����Ƃ�AMD-V�ȊO�̂��Ƃ������Ă���̂��H
>>631
���ꂽ���̍D�������Ȃ����ł́B
���܂�Intel���x�z���Ă�������AMD���̗p���ɂ����͕̂����邪�A
�I�����Ƃ��Ă�����x���݂���A���ԂƂƂ��ɕ��y���Ă����Ǝv�����B
����ɖw�ǂ���ʎ����p�r���낤���烍�[�G���h�i�ł����Ȃ��B
���������Z��������C2D���ő�V�F�A�̊�ƌ����ɍ��x�ȋ@�\�Ȃ債�ĈӖ��Ȃ�������B
���E���
�C���e����w���ɂ�ZYa/lFPS�݂����Ȃ��Ԕ��������낤�Ȃ�
>>625
ARM���ߑ�]�����Ă�悤�����A����̓d�͌����̍�����Atom���X��
�f�[�^�o�X�̑ш悪�������ƁB
��������イ�p�C�v���C�����Ƃ܂邵�A���X�f�[�^���������
�v�ł͂Ȃ��̂ŁAGPU�Ȃ�č�낤�Ǝv������10�N�͂�����B
>>633
vPro�݂����Ȋ�ƌ����Z�L�����e�B�Z�p����́H
http://plusd.itmedia.co.jp/pcuser/articles/0911/12/news093.html
AMD�ɂ͈�ԍ�����Ⴂ���Ȃ��L����`��������Ă��Ȃ�����M�����Ȃ��ē��R�B
�����ɓd�ʂɛZ�т�����
ARM���ߑ�]�����Ă�悤�����A����̓d�͌����̍�����Atom���X��
�f�[�^�o�X�̑ш悪�������ƁB
��������イ�p�C�v���C�����Ƃ܂邵�A���X�f�[�^���������
�v�ł͂Ȃ��̂ŁAGPU�Ȃ�č�낤�Ǝv������10�N�͂�����B
>>633
vPro�݂����Ȋ�ƌ����Z�L�����e�B�Z�p����́H
http://plusd.itmedia.co.jp/pcuser/articles/0911/12/news093.html
AMD�ɂ͈�ԍ�����Ⴂ���Ȃ��L����`��������Ă��Ȃ�����M�����Ȃ��ē��R�B
�����ɓd�ʂɛZ�т�����
637 �FSocket774�F2009/12/11(��) 10:22:32 ID:NInrPGUH
>AMD���Ă��������łǂ��̊�Ƃ�����
�Г���IT���̕���������悤�ȑ��Ƃ̔䗦�Ȃ��0.6��
1��������
��ʓI�Ȋ�ƂɂƂ��Ă�PC�̗���́A�d�C�␅���A���|�ȂǂƓ��l�ɃC���t���̈�Ƃ��ĊO���Ɉϑ����Ă����܂�
���[�X�����ʂŁAPC�̒��g�Ȃ�Č��Ȃ�
�ƌ������AIT�Ƃ����̂�PC�̂ق��ɓd�C�H���i�R���Z���g��P�[�u���̔z���E�ݒ�etc�j������H���i�ѓd�h�~��etc�j�ȂǂƃZ�b�g�Ő������镨
�S�Ă��Ђ�����߂Ă���n�̉�ЂɈϑ����Ă��܂������Ȃ��̂�����
�Г���IT���̕���������悤�ȑ��Ƃ̔䗦�Ȃ��0.6��
1��������
��ʓI�Ȋ�ƂɂƂ��Ă�PC�̗���́A�d�C�␅���A���|�ȂǂƓ��l�ɃC���t���̈�Ƃ��ĊO���Ɉϑ����Ă����܂�
���[�X�����ʂŁAPC�̒��g�Ȃ�Č��Ȃ�
�ƌ������AIT�Ƃ����̂�PC�̂ق��ɓd�C�H���i�R���Z���g��P�[�u���̔z���E�ݒ�etc�j������H���i�ѓd�h�~��etc�j�ȂǂƃZ�b�g�Ő������镨
�S�Ă��Ђ�����߂Ă���n�̉�ЂɈϑ����Ă��܂������Ȃ��̂�����
>>636
> >>633
> vPro�݂����Ȋ�ƌ����Z�L�����e�B�Z�p����́H
���傢�ƒ��ׂĂ݂���A�uDASH�v�Ƃ����ƊE�W���炵���Z�L�����e�B�E�Ǘ��@�\�ɑΉ�����݂������B
K10.5��HD4xxx�ȍ~��GPU�őΉ�����݂������ˁB
ttp://sites.amd.com/jp/microsoft/windows-7/Pages/commercial.aspx
> AMD�ɂ͈�ԍ�����Ⴂ���Ȃ��L����`��������Ă��Ȃ�����M�����Ȃ��ē��R�B
���̕ӂ͎d���Ȃ��ȁA�������͐G��Ȃ����B
�Z�L�����e�B��Ǘ��@�\�ɂ��Ή��ł��鐻�i�͂��邩��A���i��������Ύ��Ԃ��������Ă���邾��B
> >>633
> vPro�݂����Ȋ�ƌ����Z�L�����e�B�Z�p����́H
���傢�ƒ��ׂĂ݂���A�uDASH�v�Ƃ����ƊE�W���炵���Z�L�����e�B�E�Ǘ��@�\�ɑΉ�����݂������B
K10.5��HD4xxx�ȍ~��GPU�őΉ�����݂������ˁB
ttp://sites.amd.com/jp/microsoft/windows-7/Pages/commercial.aspx
> AMD�ɂ͈�ԍ�����Ⴂ���Ȃ��L����`��������Ă��Ȃ�����M�����Ȃ��ē��R�B
���̕ӂ͎d���Ȃ��ȁA�������͐G��Ȃ����B
�Z�L�����e�B��Ǘ��@�\�ɂ��Ή��ł��鐻�i�͂��邩��A���i��������Ύ��Ԃ��������Ă���邾��B
�d���Ȃ�����Ȃ��Ă����Ɛ�`���Ȃ��ƁB���A2ch�łƂ�����Ȃ��ĂˁB
>>630-631
���l�Ȏ�������w
���l�Ȏ�������w
>>639
��`�������Ƃ����������A���������Ă�Intel�Ɏז������A�ז�����Ȃ��Ă��S���҂����m�B
���z����ׂ��ǂ͊�����邩���ςȂ�B
AMD�̃V�F�A5%�ȉ���Intel��Nvidia�̎x�z���̓��{�s����Â�����ȁB
��`�������Ƃ����������A���������Ă�Intel�Ɏז������A�ז�����Ȃ��Ă��S���҂����m�B
���z����ׂ��ǂ͊�����邩���ςȂ�B
AMD�̃V�F�A5%�ȉ���Intel��Nvidia�̎x�z���̓��{�s����Â�����ȁB
Larrabee�̐��i���̎p�������Ă��Ȃ��̂Ɠ��l��2����ڈȍ~��AMD Fusion�̎p�������Ă��Ȃ��킯�ł�
>>641
�����Ȃ�ɂ����Ȃ����`��̔P�o���炢�ł���ł���B
��`���C���e���Ɏז��������ĉ���H
�S���҂����m���āc�m�炵�߂�ׂɐ�`�����ł���[���B
�����Ȃ�ɂ����Ȃ����`��̔P�o���炢�ł���ł���B
��`���C���e���Ɏז��������ĉ���H
�S���҂����m���āc�m�炵�߂�ׂɐ�`�����ł���[���B
i740�̔ߌ��Ăтƕ����Ĕ��ł��܂���
�܂��I���{�ōׁX�Ƃ��낤����
�ŏ�����I���{�p�Ŕ��\����Ηǂ������̂�
�܂��I���{�ōׁX�Ƃ��낤����
�ŏ�����I���{�p�Ŕ��\����Ηǂ������̂�
���H���{��5%�H
���E�V�F�A�Ƃ̘�������Ђǂ����邗��
���E�V�F�A�Ƃ̘�������Ђǂ����邗��
>>621
> Bulldozer��AM3�ɍڂ�\��������
������č�������́HBulldozer��AM3r2���Ęb�������悤��
����AM3�ƌ݊������������Ƃ��Ă�
Bulldozer��K10�Ɣ�ׂĐ����ς���Ă邩��
������ɂ���}�U�[�ς��Ȃ����ᓮ���Ȃ��Ǝv����
> Bulldozer��AM3�ɍڂ�\��������
������č�������́HBulldozer��AM3r2���Ęb�������悤��
����AM3�ƌ݊������������Ƃ��Ă�
Bulldozer��K10�Ɣ�ׂĐ����ς���Ă邩��
������ɂ���}�U�[�ς��Ȃ����ᓮ���Ȃ��Ǝv����
647 �FSocket774�F2009/12/11(��) 12:07:08 ID:q0cPHQem
���E�ł�20%����
NEC��x�m�ʂ̊�ƃ��f����AMD�Ȃ�Ė������瓖�R
http://www.necdirect.jp/desktop/mate/ma/
http://www.fujitsu-webmart.com/pc/webmart/ui6004.jsp
http://www.necdirect.jp/desktop/mate/ma/
http://www.fujitsu-webmart.com/pc/webmart/ui6004.jsp
649 �FSocket774�F2009/12/11(��) 12:12:24 ID:q0cPHQem
���������ς�낤��
�\�P�b�g�ɉe������̂̓������ƃo�X(HT)
�\�P�b�g�ɉe������̂̓������ƃo�X(HT)
�}�U�[�{�[�h�Ȃ�Ĕ�����������������
CPU�����A�b�v�O���[�h�Ƃ��ǂ��n�R�Ȃ́H
CPU�����A�b�v�O���[�h�Ƃ��ǂ��n�R�Ȃ́H
��������Bulldozer�̐��\���ǂ��ꈫ����A�����_��AM3�Ȃ��AMD�M�҈ȊO�������l�Ȃ�����
LGA1366��1156�Ɏh����́H
LGA1366��1156�Ɏh����́H
AM3�}�U�[�̐�ΐ����o�ĂȂ����A�b�v�O���[�h���v�Ȃ�Ă������������ɓ������B
http://ranking.rakuten.co.jp/rnk/navi/g211607/?scid=s_kwa
http://ranking.rakuten.co.jp/rnk/navi/g211607/?scid=s_kwa
�y�V�̃����L���O�����Ă��Č���������
�A���_�[���炷��Ώ���Phenom���R�P���̂�Intel�̖W�Q�̂����ɂȂ�낤��
��Q�ϑz���ĕ|���˂�
> Sandy����͔���邾�낤���ǁAGMA�͎ז��҈����ŊFRADEON�ςނ��A
�����������̑O�炵�Ă��������B
GMA�ł��̎����Windows�Ǝ�v�ȃf�X�N�g�b�v�A�v���A�u���E�U�AYouTube
���ł�HD����z�M�����ʂɎg������RADEON���낤��GeForce���낤��
�����l�Ȃ�Ă����͂��̃X�y�b�N�I�^���Q�[�}�[�݂̂ɂȂ��Ă��܂����A
Sandy Bridge����Ȃ瑽�������Ȃ�B
�����������̑O�炵�Ă��������B
GMA�ł��̎����Windows�Ǝ�v�ȃf�X�N�g�b�v�A�v���A�u���E�U�AYouTube
���ł�HD����z�M�����ʂɎg������RADEON���낤��GeForce���낤��
�����l�Ȃ�Ă����͂��̃X�y�b�N�I�^���Q�[�}�[�݂̂ɂȂ��Ă��܂����A
Sandy Bridge����Ȃ瑽�������Ȃ�B
>>654
�Ȃ����Ɠs���̈����f�[�^�����Ă��Ăق����́H
�������Ȃ�19�ʂ��������B
AMD�S�̂ł�Atom�ȉ��̃j�[�Y���Ăǂ��v���H
http://www.coneco.net/masterranking/01504010.html
�Ȃ����Ɠs���̈����f�[�^�����Ă��Ăق����́H
�������Ȃ�19�ʂ��������B
AMD�S�̂ł�Atom�ȉ��̃j�[�Y���Ăǂ��v���H
http://www.coneco.net/masterranking/01504010.html
2011�N�̃A�b�v�O���[�h���v�ɂ��猩�����ꂽAMD(��)
661 �FSocket774�F2009/12/11(��) 12:57:36 ID:W1DlvZd7
�����r����������r����
Intel�͋������Ă邩����҂��Ă����ǂȂ��B�B�B
AMD�̃A����Radeon���������邾���ɏI��肻�������B�B
AMD�̃A����Radeon���������邾���ɏI��肻�������B�B
Fermi�͒x��Ă邾���ŃL�����Z������Ȃ��̂ɁA
��Larrabee�����錾�����Ė\��܂��肻����nVidia�~�̓ˌ������Ȃ��ȁB
����ˌ����ė����ƌ����Ă��Ȃ�����ȁI
�^�ʖڂȘb�ALarrabee�����Ɩ{�C�Ŏv���Ă��悤�Ȑl�Ԃ́A
Fermi������Ȃ�ɗǂ����̂ł���Ȃ�Ɉ����A�x���Ƃ�2Q2010�ɂ�����
�o�Ă��Ȃ��Ƌt�ɍ����łȂ��H
��Larrabee�����錾�����Ė\��܂��肻����nVidia�~�̓ˌ������Ȃ��ȁB
����ˌ����ė����ƌ����Ă��Ȃ�����ȁI
�^�ʖڂȘb�ALarrabee�����Ɩ{�C�Ŏv���Ă��悤�Ȑl�Ԃ́A
Fermi������Ȃ�ɗǂ����̂ł���Ȃ�Ɉ����A�x���Ƃ�2Q2010�ɂ�����
�o�Ă��Ȃ��Ƌt�ɍ����łȂ��H
> AMD�̃A����Radeon���������邾���ɏI��肻�������B�B
�������̕����܂����҂ł����w
�������̕����܂����҂ł����w
�ʂё��̑唼��Fermi���b�N�A�b�v�ƃ��l�[��300�V���[�Y�����Ŏ��ɐ₦����
�����͂��̐�����AMD�X���ɂȂ��Ă��܂����ˁB
���A���Љ�ł�intel�T�C�R�[�Ȏ��ゾ����A
�Q�����ł����i�����Ȃ��A���~�͕��u�����ŁO�O
�Q�����ł����i�����Ȃ��A���~�͕��u�����ŁO�O
AMD�X���ŏ펞��������i�̋t���ꎞ�I�ɂ����Ŕ������Ă邾����
Larrabee�v�撆�~�Ő���オ��uIntel��NVIDIA�����v��
http://www.itmedia.co.jp/news/articles/0912/11/news029.html
http://www.itmedia.co.jp/news/articles/0912/11/news029.html
5%�āc���܂���ǂ����ٍD���Ȃ̂�
�Ƃ����������lj�����َg��
�X��AMD�@�u���ĂȂ�����ȁ`
�Ƃ����������lj�����َg��
�X��AMD�@�u���ĂȂ�����ȁ`
672 �FSocket774�F2009/12/11(��) 17:09:50 ID:q0cPHQem
>�����͂��̐�����AMD�X���ɂȂ��Ă��܂����ˁB
�����āA���傹���AMD�M�҂Ȃ��
��ǂ���߂Ȃ��Q�O�ɂ����Ȃ�����
�����āA���傹���AMD�M�҂Ȃ��
��ǂ���߂Ȃ��Q�O�ɂ����Ȃ�����
�ق��A���̑�ǂƂ����̂́H
��ǂ�ǂ߂Ȃ�����Intel�l��Larrabee���L�����Z�����܂����B
675 �FSocket774�F2009/12/11(��) 20:13:40 ID:DgEyzoZd
��S�I�����Ēx���Ƃ͎v���Ă���������Ƃ͂�
��͂�ėp�͐�p�ɂ��Ȃ�Ȃ����Ă��Ƃ���
��͂�ėp�͐�p�ɂ��Ȃ�Ȃ����Ă��Ƃ���
�������킯�Ȃ��I
���݂�Larrabee�́�
�т́I�Ȃ��IAMD�ɂ���āI
��储���������������傭����Ă��܂�������������������
���݂�Larrabee�́�
�т́I�Ȃ��IAMD�ɂ���āI
��储���������������傭����Ă��܂�������������������
�Ă��Alarrabee�̓����͋K��H��
��S�I�E�E�E���`��H
x86���ׂ܂������Ă̂͏����߂̓D�L������������H���̋ɒv��
���z�̒Nj��ȂǑS���D�悳��Ă��Ȃ��悤�ɂ��������Ȃ�
�G���K���g�Ƃ��X�}�[�g�Ƃ��������ĂȂ�ӂ肩�܂킸�����ɍs�����̂ɕ����������
�܂��ɕ����̒��̕����@�@�@����Ȃ��̂��H
x86���ׂ܂������Ă̂͏����߂̓D�L������������H���̋ɒv��
���z�̒Nj��ȂǑS���D�悳��Ă��Ȃ��悤�ɂ��������Ȃ�
�G���K���g�Ƃ��X�}�[�g�Ƃ��������ĂȂ�ӂ肩�܂킸�����ɍs�����̂ɕ����������
�܂��ɕ����̒��̕����@�@�@����Ȃ��̂��H
�����r�[��x86���������ނ̂͂���Ӗ�Intel�̌����点����
x64�Ȃ�ăo�J�ȋK�i��AMD�����Ȃ���A����Ȃ��Ƃɂ͂Ȃ�Ȃ��������낤��
x64�Ȃ�ăo�J�ȋK�i��AMD�����Ȃ���A����Ȃ��Ƃɂ͂Ȃ�Ȃ��������낤��
CPU��GPU��������O���t�B�b�N���\�͉����邾��
���ʂ̃��[�U�[�ɂ�GPU�������̕K�v�Ȃ�����ΐ��\�������邩��Q�[�}�[�ɂ����}����Ȃ�
���Ⴀ�N�������̂����Ęb����
���ʂ̃��[�U�[�ɂ�GPU�������̕K�v�Ȃ�����ΐ��\�������邩��Q�[�}�[�ɂ����}����Ȃ�
���Ⴀ�N�������̂����Ęb����
684 �FSocket774�F2009/12/11(��) 22:25:28 ID:q0cPHQem
�ɒ[�Șb�f��Ηǂ���
�`��p�t�H�[�}���X�Ȃ��
�`��p�t�H�[�}���X�Ȃ��
GMA�̃V�F�[�_��Westmere�ł�12SP���x�B
Larrabee�Ȃ�1�R�A�ł�16SP����������GMA�̒u�������Ƃ��Ă͏\���B
Larrabee�Ȃ�1�R�A�ł�16SP����������GMA�̒u�������Ƃ��Ă͏\���B
�\���Ȃ�A����GMA�Ȃ�ď����ĂȂ��Ȃ��Ă��Ȃ��Ⴈ�������B
GMA�ł��\��������Ɍ��܂��Ă邾��
���ႠGMA�Ŗ������Ă����larrabee�̓����Ȃ�ĕK�v�Ȃ����
689 �FSocket774�F2009/12/11(��) 22:44:08 ID:q0cPHQem
�ׂɂ��������͂Ȃ�ł����܂��
GPU�ȊO�̕t�����l���K�v�ɂȂ邩��B
������Ȃ��Ă��ˁB
������Ȃ��Ă��ˁB
>>690
Clarkdale Gets GPGPU Support
http://news.softpedia.com/news/Clarkdale-Gets-GPGPU-Support-128936.shtml
Clarkdale Gets GPGPU Support
http://news.softpedia.com/news/Clarkdale-Gets-GPGPU-Support-128936.shtml
���݂�I�ɂ�gpgpu�Ȃ�Ă�����Ă�A�ǂ���ꏏ�̌����Ǝv�������
���ʂɂ����ڂ������Ȃ����
���ʂɂ����ڂ������Ȃ����
gpgpu�ʼn�������̂�
���q�ԗ͂̌v�Z�Ƃ�����
����Ȃ�Ŕ���邩��
���ႠFermi�͔���Ȃ���
957 �F�s���ȃf�o�C�X����F2009/10/16(��) 07:51:25 ID:yq54j+T5
tesla�Ƃ�fermi���Ă��������Ėׂ���Ǝv���ďo���Ă�킯�H
960 �F�s���ȃf�o�C�X����F2009/10/16(��) 21:33:28 ID:nKaM2KJ/
>>957
���A�w�C���o��
961 �F�s���ȃf�o�C�X����F2009/10/16(��) 22:19:10 ID:tEjYpzUq
�����͂����邩�ǂ������悾��
Larrabee�̌����������Ȃ�HPC�s��ɂ�����Intel�̉�������邾�낤
������Ȃ�E�E�E
962 �F�s���ȃf�o�C�X����F2009/10/17(�y) 12:03:41 ID:IdMHkVqK
���v���̈Ⴂ�͂Ƃ������A���ʃx�[�X99.99���%��GPU�s����y�������炨���B
HP�ADell�AApple�����͌�����Radeon�̗p���𑝂₵�Ă���B
963 �F�s���ȃf�o�C�X����F2009/10/17(�y) 14:34:15 ID:/z1CEwIT
Intel�l������O�Ƀ��[�U�[�͂����߂���
tesla��fermi�ւ̒��ړx���₽�獂�����̂����Ȃ��x����Ă���邩�������
��Ȃ菬�Ȃ�A�C���t���i�Ƃ����̂��낤���j����U���܂�Ǝv�l��~���Ă����ɂ͈ڂ��
964 �F�s���ȃf�o�C�X����F2009/10/17(�y) 15:40:48 ID:7swNV+bu
http://www.4gamer.net/games/085/G008506/20091008061/images/04.jpg
tesla�Ƃ�fermi���Ă��������Ėׂ���Ǝv���ďo���Ă�킯�H
960 �F�s���ȃf�o�C�X����F2009/10/16(��) 21:33:28 ID:nKaM2KJ/
>>957
���A�w�C���o��
961 �F�s���ȃf�o�C�X����F2009/10/16(��) 22:19:10 ID:tEjYpzUq
�����͂����邩�ǂ������悾��
Larrabee�̌����������Ȃ�HPC�s��ɂ�����Intel�̉�������邾�낤
������Ȃ�E�E�E
962 �F�s���ȃf�o�C�X����F2009/10/17(�y) 12:03:41 ID:IdMHkVqK
���v���̈Ⴂ�͂Ƃ������A���ʃx�[�X99.99���%��GPU�s����y�������炨���B
HP�ADell�AApple�����͌�����Radeon�̗p���𑝂₵�Ă���B
963 �F�s���ȃf�o�C�X����F2009/10/17(�y) 14:34:15 ID:/z1CEwIT
Intel�l������O�Ƀ��[�U�[�͂����߂���
tesla��fermi�ւ̒��ړx���₽�獂�����̂����Ȃ��x����Ă���邩�������
��Ȃ菬�Ȃ�A�C���t���i�Ƃ����̂��낤���j����U���܂�Ǝv�l��~���Ă����ɂ͈ڂ��
964 �F�s���ȃf�o�C�X����F2009/10/17(�y) 15:40:48 ID:7swNV+bu
http://www.4gamer.net/games/085/G008506/20091008061/images/04.jpg
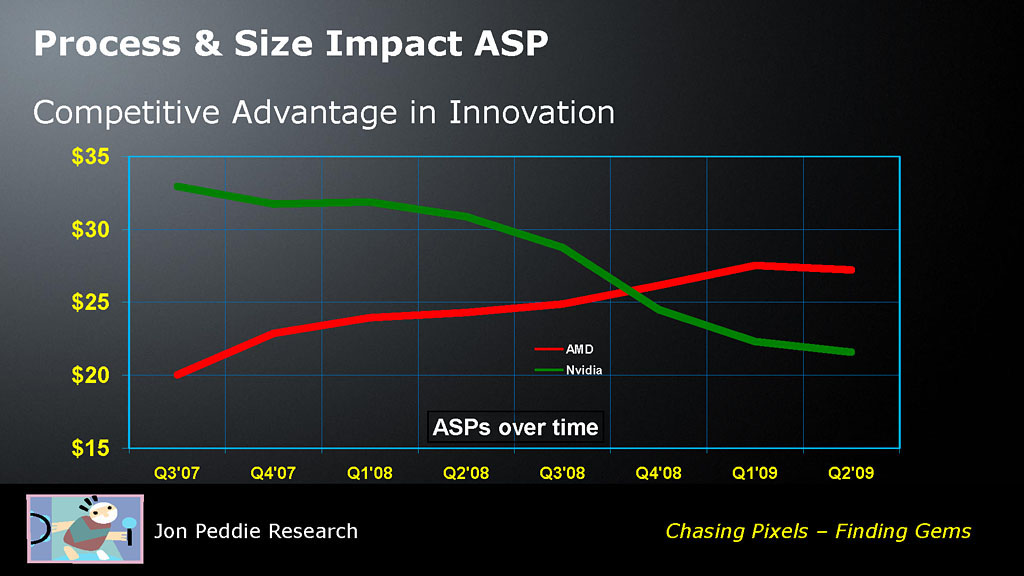{kind=link}
Fermi�̎����Ă�ėp�����Q�[���̃O���t�B�N�X��i��������悤�Ȃ��̂łȂ��Ȃ�
���R����Ȃ����낤
���R����Ȃ����낤
��2������Ɏ����̏������݂��R�s�y����錻��ɗ�����̂��܂��悭���邱�ƁB
���C�o���B�̎��ł����܂���RADEON�叟��
701 �FSocket774�F2009/12/11(��) 23:08:52 ID:q0cPHQem
�叟���i�j
RADEON�ŃQ�[���̃O���t�B�N�X���i�������Ȃ炢������
�ʂɂ��ĂȂ������
�ʂɂ��ĂȂ������
http://akiba-pc.watch.impress.co.jp/hotline/20091017/etc_shopwatch.html
http://akiba-pc.watch.impress.co.jp/hotline/20091212/etc_shopwatch.html
http://akiba-pc.watch.impress.co.jp/hotline/20091212/etc_shopwatch.html
����GPGPU�u�[���ɂǂꂾ���̐l���x���邩
���ɂ͂��������ĂĂ�GPU�\�����[�V���������[���Ɣ��ꑱ����Ƃ͎v���Ă��Ȃ��ł��傤
���ɂ͂��������ĂĂ�GPU�\�����[�V���������[���Ɣ��ꑱ����Ƃ͎v���Ă��Ȃ��ł��傤
705 �FSocket774�F2009/12/11(��) 23:14:29 ID:q0cPHQem
�x���`�D������
�Ă�larrabee��gpgpu����Ȃ�����
GPGPU�������č����ȕ��Z���������Ȃ�o�J�ł���GPU��}������
CPU�Ɠ����������Đ�ΐ��\���łȂ���j�b�`�Ȏs��ł�����Ȃ���
CPU�Ɠ����������Đ�ΐ��\���łȂ���j�b�`�Ȏs��ł�����Ȃ���
�Ȃ�ō��X����Șb���Ă�́H
he- w
�����r�[���|�ꂽ��CPU��GPU�̓������̂������ꂾ���Ęb�����Ă�������������Ȃ����Ȃ���
amd�͂�
���ʂɂ��̂��킹�����X�^���C�Y�x�[�X�̕`�悪���̐�������̂Ȃ�CPU�֓����͓����
CPU��GPU�̓����v��͑�������[
���̓��������NV�́E�E�E
���̓��������NV�́E�E�E
amd�̂悤�ɂ����̂��G�`���`�b�v�Ɠ������Ă��Ӗ��͂Ȃ���
�ނ���sse�x�[�X��s3/via�̕����A�����ɂ͈�ԋ߂���
�ނ���sse�x�[�X��s3/via�̕����A�����ɂ͈�ԋ߂���
����ΐ��\���łȂ���
�������ˁB�f�B�X�N���[�g��PCIe�̃l�b�N�����Ƃ����Ȃ���Ȃ�Ȃ��ˁB
�������ˁB�f�B�X�N���[�g��PCIe�̃l�b�N�����Ƃ����Ȃ���Ȃ�Ȃ��ˁB
>>710
���̒���8�`9���̏���҂ɂƂ��ẮA������PC�̂Ȃ���GPU�Ȃ���̂�
�ǂ�Ȏ���������Ăĉ����g���Ă��邩�Ȃ�Ăǂ��ł������b�Ȃ̂ŁA
�S�̂̕��i�_�������Ȃ��Ȃ��ăR�X�g�팸�ɂȂ�ȏ�A�ǂ��l���Ă�
���C���X�g���[����CPU��GPU�����Ɍ������ȊO���肦��B
���̏ŁA�ߖ����̔����̋Z�p��Larrabee���[�G���h�ł�����CPU�ɓ����ł���
���̐��\�ŕ��ʂ�Web/Office/HD����ӏ܂ɖ�肪�����̂ł���A
CPU+SIMD���j�b�g�̊J���ȊO�AGMA�V���[�Y�̊J�����\�[�X����Ȃ��Ȃ������B
�����I�ɍl����������Larrabee�R�A�����̂��̂�CPU�ɓ�������͖̂��炩�B
2012�N�ɂ��ꂪ���邩2015�N�ʂ܂ł����邩�͍��\�z���Ă��d���Ȃ������ŁB
���̒���8�`9���̏���҂ɂƂ��ẮA������PC�̂Ȃ���GPU�Ȃ���̂�
�ǂ�Ȏ���������Ăĉ����g���Ă��邩�Ȃ�Ăǂ��ł������b�Ȃ̂ŁA
�S�̂̕��i�_�������Ȃ��Ȃ��ăR�X�g�팸�ɂȂ�ȏ�A�ǂ��l���Ă�
���C���X�g���[����CPU��GPU�����Ɍ������ȊO���肦��B
���̏ŁA�ߖ����̔����̋Z�p��Larrabee���[�G���h�ł�����CPU�ɓ����ł���
���̐��\�ŕ��ʂ�Web/Office/HD����ӏ܂ɖ�肪�����̂ł���A
CPU+SIMD���j�b�g�̊J���ȊO�AGMA�V���[�Y�̊J�����\�[�X����Ȃ��Ȃ������B
�����I�ɍl����������Larrabee�R�A�����̂��̂�CPU�ɓ�������͖̂��炩�B
2012�N�ɂ��ꂪ���邩2015�N�ʂ܂ł����邩�͍��\�z���Ă��d���Ȃ������ŁB
717 �F,,�E�L�́M�E,,�j��-�������F2009/12/11(��) 23:45:56 ID:QYYq4m1S
>>663
�m���PVIDIA�̉c�Ƃ����PTX2.0�̃h�L�������g�������ƌ��J���Ȃ���
���čÑ������Ƃ��n�܂邨�B
�Ƃ����SP��Int��FP�̓������s�ɂȂ���������ĕЕ������g�����ɂ͂���܂�L���݂Ȃ����
����FP���ł��������Z�ł���Ƃ��̑f�G�Ȏd�l���ڂ�
�m���PVIDIA�̉c�Ƃ����PTX2.0�̃h�L�������g�������ƌ��J���Ȃ���
���čÑ������Ƃ��n�܂邨�B
�Ƃ����SP��Int��FP�̓������s�ɂȂ���������ĕЕ������g�����ɂ͂���܂�L���݂Ȃ����
����FP���ł��������Z�ł���Ƃ��̑f�G�Ȏd�l���ڂ�
�I���{��GPU�݂����Ȃ���ɂł��K�v�ɂȂ���͓̂������������
���[�G���h�����r�[�Ȃ������ĒN���������
�킴�킴�d�͌������������i���������āu�I���{�Ɠ������炢��GPU���\������܂��v���ĒN���[�����˂��悻��Șb
���[�G���h�����r�[�Ȃ������ĒN���������
�킴�킴�d�͌������������i���������āu�I���{�Ɠ������炢��GPU���\������܂��v���ĒN���[�����˂��悻��Șb
719 �F,,�E�L�́M�E,,�j��-�������F2009/12/11(��) 23:49:21 ID:QYYq4m1S
���vGMA�͂����ƈ�������
Intel��GPU����CPU�܂ł���30��
�EAtom N450(1�R�A/1.66GHz/667MHz/L2 512KB/7W/2010�N1��10��)
�EAtom D410(1�R�A/1.66GHz/667MHz/L2 512KB/2010�NQ1)
�EAtom D510(2�R�A/1.66GHz/667MHz/L2 512KB*2/2010�NQ1)
3chip��2chip�Ńt�b�g�v�����g�Ə���d�͂�팸
http://www.dos-v.biz/images/stories/cpu/2009/03270dd2-7820-43c9-a0b3-415dd7b3deb4.png
�EAtom N450(1�R�A/1.66GHz/667MHz/L2 512KB/7W/2010�N1��10��)
�EAtom D410(1�R�A/1.66GHz/667MHz/L2 512KB/2010�NQ1)
�EAtom D510(2�R�A/1.66GHz/667MHz/L2 512KB*2/2010�NQ1)
3chip��2chip�Ńt�b�g�v�����g�Ə���d�͂�팸
http://www.dos-v.biz/images/stories/cpu/2009/03270dd2-7820-43c9-a0b3-415dd7b3deb4.png
{kind=link}
�ނ�Radeon��GeForce���������肻�̂܂�CPU�ɓ����̂��C���[�W���Ă�̂��ȁH
���Ƃ����炠�܂�ɂ����n��������
���Ƃ����炠�܂�ɂ����n��������
��VIA��AMD�ȏ�ɏ�����������ˁH
Atom�Ƀ��C�[�v����Ă邵
Atom�Ƀ��C�[�v����Ă邵
724 �F,,�E�L�́M�E,,�j��-�������F2009/12/11(��) 23:56:22 ID:QYYq4m1S
GMA�̐��\���m�Ɍ���z�͂��Ȃ�����
���Ƃ���G41�̓���GPU�͉�GFLOPS���H
����A��MFLOPS���H
���Ƃ���G41�̓���GPU�͉�GFLOPS���H
����A��MFLOPS���H
725 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 00:04:25 ID:LfwDXAhP
GMA������GPU�̔������g�����W�X�^�������������Ă�Ǝv�����炻���GMA�ɑ���ߑ�]���Ƃ������̂�
Apple�̑Ή����Ă�킩�邪�A���ۖ��G45��GeForce 9100M�̐��\�ɂ���B�i����
Apple�̑Ή����Ă�킩�邪�A���ۖ��G45��GeForce 9100M�̐��\�ɂ���B�i����
���ʂ̐l�ɂƂ�����GPU�Ȃ�Ă�����ʂ��f�����������Ȃ�ł���������
727 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 00:10:29 ID:LfwDXAhP
�Ԃ����ႯVertex Shader�Ȃ�CPU�������������������炢���ȁB
Sandy Bridge��L3�L���b�V��������CPU��GPU�ŋ��L�����Ă�����
�E
�E
�E
���āA�������̘b���O����
Sandy Bridge��L3�L���b�V��������CPU��GPU�ŋ��L�����Ă�����
�E
�E
�E
���āA�������̘b���O����
vantage�Ń`�[�g�����C���e����GPU���\�����҂�������Ȃ�[
�c�q�搶���̘b�O�ɕ����܂����[
GeForce 9400 vs G45
http://materialistica.livedoor.biz/archives/51409995.html
G45 vs Clarkdale vs GeForce 9400
http://www.hkepc.com/3878/page/6#view
http://materialistica.livedoor.biz/archives/51409995.html
G45 vs Clarkdale vs GeForce 9400
http://www.hkepc.com/3878/page/6#view
732 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 00:19:20 ID:LfwDXAhP
�`�[�g�Ă��Ƃ͗]�T���Ȃ��Ȃ�
Westmere�̂��Ƃ���
�N���b�N���{�Ȃ̂�Turbo Boost�������悤�ɂȂ������ƁA���Ɠ���QPI�ڑ��ł̑��������
�A���͕��ʂɂ��蓾�鐔������
Intel�̒��̐l��GMA�̃p�t�H�[�}���X�A�i���C�U���ꂽ��B
�ɒB�ɐl�ޕ����ĂȂ���B
Westmere�̂��Ƃ���
�N���b�N���{�Ȃ̂�Turbo Boost�������悤�ɂȂ������ƁA���Ɠ���QPI�ڑ��ł̑��������
�A���͕��ʂɂ��蓾�鐔������
Intel�̒��̐l��GMA�̃p�t�H�[�}���X�A�i���C�U���ꂽ��B
�ɒB�ɐl�ޕ����ĂȂ���B
ION�������킯�����
>>722
VIA�̓A���h�ȏ�ɑ̗͂����
VIA�̓A���h�ȏ�ɑ̗͂����
Larrabee�̎���GMA�������グ��d�����n�܂邨
chrome��540�ł�35gflops,igp��520�ł�20gflops���x�����i���̒l�j
���p�t�H�[�}���X�͂��Ȃ�̂���
�܁Acpu�ʼn��Z�������͑����̂��낤��
���p�t�H�[�}���X�͂��Ȃ�̂���
�܁Acpu�ʼn��Z�������͑����̂��낤��
GPGPU���g�p������ɐl�́A�Œ�ł�CPU+GPU+GPGPU�݂����ȍ\���ɂȂ��ŁE�E�E
���ł������j�b�`�ȊO�t��GPU�s��Łu�����ꖇ�����ĉ������I�v�Ƃ��ˁ[��
���ł������j�b�`�ȊO�t��GPU�s��Łu�����ꖇ�����ĉ������I�v�Ƃ��ˁ[��
GMA(��)
�c�q�A�I�������Larrabee��
�c�q�A�I�������Larrabee��
GPGPU���g����Ȃ�Ėc��ȉ��Z�𑁂��I��点����������Ȃ���
CPU�̋��X�y�[�X���ɗL�����p����GPU�łȂ���
�������Z�o����{����GPU����Ȃ��Ɣ���Ȃ�����
CPU�̋��X�y�[�X���ɗL�����p����GPU�łȂ���
�������Z�o����{����GPU����Ȃ��Ɣ���Ȃ�����
740 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 09:19:57 ID:LfwDXAhP
>>738
���ꌾ������Fusion��Bulldozer���I����Ă܂���
���ꌾ������Fusion��Bulldozer���I����Ă܂���
741 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 09:22:23 ID:LfwDXAhP
�uLarrabee�͏I�������v
��������ꂽ�͓̂�N�O�ł���
��������ꂽ�͓̂�N�O�ł���
743 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 09:23:42 ID:LfwDXAhP
�g���������ꂽ�E�E�E
���₵���E�E�E����
���₵���E�E�E����
745 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 09:28:01 ID:LfwDXAhP
���p�̑`����āu���p�v�H
�e���X�P�[���̐��ʂ�GPU�Ő��i�����悤�Ƃ���Larrabee�̂��Ƃ��끄�����ɗL�����p
���������������玸�s���܂���
���������������玸�s���܂���
�����ɗL�����p�E�E�E�������L�������p�ɂ������Ă������{��Ƃ���OK����
748 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 10:26:39 ID:LfwDXAhP
�܂��Ȃ��A��Ԃ��Q��܂�
���F�������̌��ɂ������肭������
���F�������̌��ɂ������肭������
Intel�ɂ͒c�q�̗��z����������J���͂������̂����낻�뗝�������ق��������B
IA-64���A�����ɂ͂܂��J�����Ȃ����H
�������E����PC���[�U����ڂ��������������ǂԂɎ̂Ă�o�J�������ȃC���e������͂�
�������E����PC���[�U����ڂ��������������ǂԂɎ̂Ă�o�J�������ȃC���e������͂�
IPF�͑���ƂƐܔ����Ă邩��A�ɂ݂͂���قǂł��E�E�E����ϐ�Ίz�Ō���Βɂ����B
�@ �@ �@�@�@�Q�Q�Q_
�@ �@�@�@�^�@�@ �@ �@�_
�@�@�@�^�@ _�m �@�R�_�@ �_
�@ �^ �@o߁܁@�@�@���o�@ �_ �@�܂�������Intel�̉��������
�@ |�@�@�@�@ �i__�l__�j�@�@�@�@|�@�@���C�V������d�����n�܂�����
�@ �_�@�@ �@ �M �܁L �@ �@ �^
�@ �@�@�@�^�@�@ �@ �@�_
�@�@�@�^�@ _�m �@�R�_�@ �_
�@ �^ �@o߁܁@�@�@���o�@ �_ �@�܂�������Intel�̉��������
�@ |�@�@�@�@ �i__�l__�j�@�@�@�@|�@�@���C�V������d�����n�܂�����
�@ �_�@�@ �@ �M �܁L �@ �@ �^
753 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 11:58:12 ID:LfwDXAhP
>>749
Fermi�Ły�䖝���Ă��z�ƌ����Ă邾��
Fermi�Ły�䖝���Ă��z�ƌ����Ă邾��
�W���J�����盛������������
755 �FSocket774�F2009/12/12(�y) 12:11:39 ID:5rkUpHyv
AMD�͑I�����ɓ�������Ȃ�
756 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 12:15:50 ID:LfwDXAhP
�����ȁB
�����Ɍ�����������ĂȂ����_�Ő����Ēm��ׂ��B
�����Ɍ�����������ĂȂ����_�Ő����Ēm��ׂ��B
�������Ƃ����ǂ��炵�Ă�Ɠ��S���₩����Ȃ��Ȃ����ȁ`
�c�q��A�����~�łق�Ƃɉ䖝�ł���̂��H
�c�q��A�����~�łق�Ƃɉ䖝�ł���̂��H
�������Ă��ꂩ
������������l�R�o�o��������������
������������l�R�o�o��������������
�����������R�A���ăp���s�[�ł����b����p�r����H
����܂���
Larrabee�̖��O������Ɍ��߂邩
Intel Molecule Processor
Intel Molecule Processor
762 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 12:42:31 ID:LfwDXAhP
�f�B�X�N���[�g�ł����ꔭ���炢�����ւ̂�
�f�B�X�N���[�g��GMA�ł���
604 ���O�F,,�E�L�́M�E,,�j��-������[sage] ���e���F2009/12/06(��) 11:42:58 ID:nTu8nNRJ
���͍���̃f�B�X�N���[�gGPU�v�悻�̂��̂��u���t�ŁANVIDIA��ATI�ɁuLarrabee��v�������邱�Ƃ��ړI�������A�Ƃ��H
����Ă����͍̂��̏�NVIDIA����������
�c�q������ɂ����ׂė\��ʂ�炵���ł���
���͍���̃f�B�X�N���[�gGPU�v�悻�̂��̂��u���t�ŁANVIDIA��ATI�ɁuLarrabee��v�������邱�Ƃ��ړI�������A�Ƃ��H
����Ă����͍̂��̏�NVIDIA����������
�c�q������ɂ����ׂė\��ʂ�炵���ł���
�����[GMA�āE�E�EGMA�āE�E�EGMA�ς}�V���͉�Ђł����g��Ȃ�����
���ۂǂ̂��炢�̃p���[������̂��悭�m��Ȃ������肷��
���ۂǂ̂��炢�̃p���[������̂��悭�m��Ȃ������肷��
�A�d�_�ɓ������������
�c�q�K������w
���̂��т̎v���������Ȃ����Г�ł����������Q���̂��ƂƎv���܂��B
�S���炨����ݐ\���グ�܂��B
�����₩�Ȃ��琶�O�Ɍ̐l������������Ђ�������Ă����D���̗p�ӂ����Ă������܂��̂ŁA
�̐l�����̂Ԃ��b�̏�̂��������Ƃ��Ă������オ�肭�������B
�@�@�@�@ �ȁQ�� �@�@�@�@ �ȁQ��
�@�@ (�R�i�@�@�@�@�j�m) (�R�i�@�@�@�@�j�m)
�@�@�@�R�P �� �P_�^ �@ �R�P �� �P_�^
�@�@�@�@|�@.�@. �@|�� �@�@ |�@.�@. �@|��
�@�@�@ (___�l__�@�j �@ �@ (___�l__�@�j
�@�@�@�@| ��i::i�� , �@�@�@�@| ��i:i�� ,
- -�@.-��'-.i::i- - - - --.U |:::|
"�@�@�@�@�@ �j::�j�@�@�@�@�@�@.. ):;;)
�@�@�@�@�@�i:;;;;;;;)�@"�@.�@"�@�i;:�i
�@�@�@�@�@�@�@�@�@�@�@�@"�@�@`�i�@
�@�@�@�@�@�@*�@o�@�F��:.:�@:�@.::�@::�� o�@*
�@�@�@�@�@�@ +o ��:::..�@�@�l�@�@ ..:::�� o +
�@�@�@�@�@�@*�@o ��::.�@�i�Q_�j�@ .:: �� o�@*
�@�@�@�@�@*�@o ��::..�@�i�Q____�j�@ .:: �� o�@*
�@�@�@�@�@�@ o �F:::..:�@�i�Q�Q�Q�j .:: ��+
�@�@�@�@�@�@�@*�@o�@��.::.�F��..::.:�� o
�S���炨����ݐ\���グ�܂��B
�����₩�Ȃ��琶�O�Ɍ̐l������������Ђ�������Ă����D���̗p�ӂ����Ă������܂��̂ŁA
�̐l�����̂Ԃ��b�̏�̂��������Ƃ��Ă������オ�肭�������B
�@�@�@�@ �ȁQ�� �@�@�@�@ �ȁQ��
�@�@ (�R�i�@�@�@�@�j�m) (�R�i�@�@�@�@�j�m)
�@�@�@�R�P �� �P_�^ �@ �R�P �� �P_�^
�@�@�@�@|�@.�@. �@|�� �@�@ |�@.�@. �@|��
�@�@�@ (___�l__�@�j �@ �@ (___�l__�@�j
�@�@�@�@| ��i::i�� , �@�@�@�@| ��i:i�� ,
- -�@.-��'-.i::i- - - - --.U |:::|
"�@�@�@�@�@ �j::�j�@�@�@�@�@�@.. ):;;)
�@�@�@�@�@�i:;;;;;;;)�@"�@.�@"�@�i;:�i
�@�@�@�@�@�@�@�@�@�@�@�@"�@�@`�i�@
�@�@�@�@�@�@*�@o�@�F��:.:�@:�@.::�@::�� o�@*
�@�@�@�@�@�@ +o ��:::..�@�@�l�@�@ ..:::�� o +
�@�@�@�@�@�@*�@o ��::.�@�i�Q_�j�@ .:: �� o�@*
�@�@�@�@�@*�@o ��::..�@�i�Q____�j�@ .:: �� o�@*
�@�@�@�@�@�@ o �F:::..:�@�i�Q�Q�Q�j .:: ��+
�@�@�@�@�@�@�@*�@o�@��.::.�F��..::.:�� o
������̌�������������AAMDer�̓R�s�y�r�炵�ɐ����o���̂͐̂���ς��Ȃ������Ȃ������̈��
���㐷��オ�肷����
774 �FSocket774�F2009/12/12(�y) 15:09:44 ID:5rkUpHyv
�S���̔ڂ���������Ă��
�f���Ɏ���F�߂��Ȃ����������܂��䂦
�F���|�߂ɎQ��d���Ă��邾���ł���܂���
�F���|�߂ɎQ��d���Ă��邾���ł���܂���
�P�̐��i����������Ŏd�蒼�����uLarrabee�v�BHPC�p�v���Z�b�T�������^�O���t�B�b�N�X�@�\�ւ�2������
http://www.4gamer.net/games/049/G004963/20091212001/
http://www.4gamer.net/games/049/G004963/20091212001/
777 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 15:47:57 ID:LfwDXAhP
GMA�ɂĂ����ꂵ�čœK�����邭�炢�Ȃ�A�N�A�b�h�R�A�̂���2�R�A���炢�ɉ揈���̎�`���������ق����}�V
778 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 15:54:46 ID:LfwDXAhP
��������炸4�T�̋L���͂Ђǂ���
780 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 15:58:04 ID:LfwDXAhP
���������݂�
>>776
��Intel�̓A�[�L�e�N�`���̊g�����{�����uLarrabee3�v�i�J���R�[�h�l�[���j�̊J�����i�߂Ă���C�u���̌v��ɕύX�͂Ȃ��ƕ����Ă���v�i���W�ҁj�Ƃ̂��ƁB
�L�^�[�[�[
��Intel�̓A�[�L�e�N�`���̊g�����{�����uLarrabee3�v�i�J���R�[�h�l�[���j�̊J�����i�߂Ă���C�u���̌v��ɕύX�͂Ȃ��ƕ����Ă���v�i���W�ҁj�Ƃ̂��ƁB
�L�^�[�[�[
�T���v���z������ɕ]���̂��߂̘J�͂��������đS�L�����Z���f�X��������
���㓯�����Ƃ�낤�Ƃ��Ă��܂Ƃ��ɑ��肵�Ă���Ȃ��Ȃ邩��
���㓯�����Ƃ�낤�Ƃ��Ă��܂Ƃ��ɑ��肵�Ă���Ȃ��Ȃ邩��
783 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 16:18:59 ID:LfwDXAhP
�����A�����GCC��Visual Studio��AMD XOP�̑Ή��x��Ă�̂��B
SSE5��J���đΉ������ăL�����Z�������S�{�̍����ł�����ȁB
SSE5��J���đΉ������ăL�����Z�������S�{�̍����ł�����ȁB
���S���S�m�F
>>783
���̂������Ґ����˂���
Yamhill�L�����Z��������AMD64�ɓ��ꂳ����MS�Ȃ�
SSE5������AVX�Ɨ�����������
�L�����Z����������������L������
���̂������Ґ����˂���
Yamhill�L�����Z��������AMD64�ɓ��ꂳ����MS�Ȃ�
SSE5������AVX�Ɨ�����������
�L�����Z����������������L������
786 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 16:37:42 ID:LfwDXAhP
GCC4.4�ł�AVX�Ή��͊������Ă邯��4.5�͐����ł��猩���Ă��Ȃ�
�����[�X�܂łɏo��̂�����H
���AAVX�����̑Ή�����Ϙa���߂��T�|�[�g���Ȃ�����ABulldozer�o�����Ƃ����FP���\�͔������������ł��Ȃ�
�����[�X�܂łɏo��̂�����H
���AAVX�����̑Ή�����Ϙa���߂��T�|�[�g���Ȃ�����ABulldozer�o�����Ƃ����FP���\�͔������������ł��Ȃ�
>>773
Larrabee�Ő���オ���Ă��郏�P����Ȃ���
��q�O���ꂽ�̂ɏ@��l�ɂ����邱�Ƃ��ł�����
�X���𗬂����Ƃ��Ă��邾�������ǂ�
���̃X�����炴���Ƃ݂Ă݂�Ɩʔ�������
���ɖ`���̕��̋}�W�J��
Larrabee�Ő���オ���Ă��郏�P����Ȃ���
��q�O���ꂽ�̂ɏ@��l�ɂ����邱�Ƃ��ł�����
�X���𗬂����Ƃ��Ă��邾�������ǂ�
���̃X�����炴���Ƃ݂Ă݂�Ɩʔ�������
���ɖ`���̕��̋}�W�J��
788 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 17:20:00 ID:LfwDXAhP
>>785
�ʂɁH������
�]��SSE�ɑ��ă��W�X�^���₵�ĂȂ�����SSE5��������Ă����Ȃ���B
AMD�͌����Ă���BOS���̑Ή����K�v�̂Ȃ��g�����ƁB
�i3DNow!�̂Ƃ��̔��蕶��Ɠ������j
�������������Ă邱�Ƃ��k�ى߂��đ���ɂ���̂��n���n������
�ʂɁH������
�]��SSE�ɑ��ă��W�X�^���₵�ĂȂ�����SSE5��������Ă����Ȃ���B
AMD�͌����Ă���BOS���̑Ή����K�v�̂Ȃ��g�����ƁB
�i3DNow!�̂Ƃ��̔��蕶��Ɠ������j
�������������Ă邱�Ƃ��k�ى߂��đ���ɂ���̂��n���n������
�ƌ����K���Ń��X���ĕ��Â����߂����Ƃ���c�q�ł�����
790 �FSocket774�F2009/12/12(�y) 19:20:52 ID:ICISDpjc
Larrabee����ł���̒c�q�̉����Ղ肪�ُ킗
��̏��������I�悵����
��̏��������I�悵����
��������Sandy Bridge�Ƃ��������グ���Ƃɖ߂��
>�O�X��231
> �uGelsinger���ƂƂ��ɁC��v�G���W�j�A��Intel���������v�Ƃ�����������B
http://hak.wablog.com/80.html ��twitter
Larrabee �L�����Z���̊��B�m�l�����X�]�E���n�߂������肩������������B
10:45 AM Dec 5th web��
> �uGelsinger���ƂƂ��ɁC��v�G���W�j�A��Intel���������v�Ƃ�����������B
http://hak.wablog.com/80.html ��twitter
Larrabee �L�����Z���̊��B�m�l�����X�]�E���n�߂������肩������������B
10:45 AM Dec 5th web��
�ǂ��ɓ]�E������
�Q������ɂ��čs����?
795 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 20:39:25 ID:LfwDXAhP
IntermediateBuffer��256K�A512K�̃A�[�L�e�N�`���ł͏�肭�����Ȃ����Ƃ����ɂ킩���Ă���̂ŁA16MB���炢IntermediateBuffer����������ǂ����H
2:14 PM Dec 3rd web��
�������s����₤���߂̃f�[�^�쓮���f�����Ă̂́A���X��肭�����Ȃ��B�o�X�⓯���R�X�g�����Ȃ肩����̂ŁA��K�̓f�[�^�łȂ��ƍ̎Z����Ȃ����A��������ƃX�g���[�W����������K�v�ɂȂ邵�A�őO�j�]�B
2:11 PM Dec 3rd web��
CacheCoherency������������̂͐��X�����Ă������ǁA���ڂ̏��Ȃ��ƊO���o�X�̑��ΓI�ȍׂ����Ȃ��Ȃ���ς���
2:08 PM Dec 3rd web��
Intel SCC: DualCorex24�W�ρBDDR3x4�R���g���[���AOnMemory386KB���Ă̂͂����ɂ����Ȃ��B http://news.zdnet.co.uk/hardware/0,1000000091,39918721,00.htm
2:04 PM Dec 3rd web��
�ق�
2:14 PM Dec 3rd web��
�������s����₤���߂̃f�[�^�쓮���f�����Ă̂́A���X��肭�����Ȃ��B�o�X�⓯���R�X�g�����Ȃ肩����̂ŁA��K�̓f�[�^�łȂ��ƍ̎Z����Ȃ����A��������ƃX�g���[�W����������K�v�ɂȂ邵�A�őO�j�]�B
2:11 PM Dec 3rd web��
CacheCoherency������������̂͐��X�����Ă������ǁA���ڂ̏��Ȃ��ƊO���o�X�̑��ΓI�ȍׂ����Ȃ��Ȃ���ς���
2:08 PM Dec 3rd web��
Intel SCC: DualCorex24�W�ρBDDR3x4�R���g���[���AOnMemory386KB���Ă̂͂����ɂ����Ȃ��B http://news.zdnet.co.uk/hardware/0,1000000091,39918721,00.htm
2:04 PM Dec 3rd web��
�ق�
796 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 20:46:22 ID:LfwDXAhP
�ь�₳��̎Ј����˂��̐l
�ǂ������Ă����
�����r�[�ȂC���e�������̋C�ɂȂ��[���[�ŕ��y�ł����
GMA���D�����Ēl�i���������ꔭ����
90nm��GMA�̕s�o���Ə������Ղ���l����ᖾ�炩����
�`�b�v�Z�b�g�����ߏo�����݂����Ȃ�Ƃ��Ȃ�S�����������[����
�₾�˂�
GMA���D�����Ēl�i���������ꔭ����
90nm��GMA�̕s�o���Ə������Ղ���l����ᖾ�炩����
�`�b�v�Z�b�g�����ߏo�����݂����Ȃ�Ƃ��Ȃ�S�����������[����
�₾�˂�
799 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 21:09:40 ID:LfwDXAhP
TSMC��40nm�̕����܂肪����ō������K�v���Ȃ��Ȃ����̂��^������
���őf���Ɏ��s��F�߂��Ȃ��́H
801 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 21:20:34 ID:LfwDXAhP
���Ⴀ�����������H
CoreMA�̈�_�̂�
���̒c�q�͗�����F�̒��̐l���ǂ������Ȃ��p�[�v����
>>788
�����k�قȂ�N�͎x���ŗ�
Larrabee�L�����Z���ȍ~Intel�M�Ҋۏo���Ȃ̂͗ǂ�����
���邱�ƂȂ����Ƃ݂�Ȑ����͎����Ă邩��
�����k�قȂ�N�͎x���ŗ�
Larrabee�L�����Z���ȍ~Intel�M�Ҋۏo���Ȃ̂͗ǂ�����
���邱�ƂȂ����Ƃ݂�Ȑ����͎����Ă邩��
805 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 21:31:06 ID:LfwDXAhP
���҂�1�̐��i�����Ń��m�̑P�������f����
AMD�̕����p�^�[���ɂ͂܂����̂͂������ȁB
>>802
���Ƃ���Core MA��SSE���\
�O��Pentium III, Pentium 4���Ȃ���Ή��̃R�[�h���Y�����������킯��
�i�K�܂Ȃ������ȂǂȂ��̂���B
AMD�̕����p�^�[���ɂ͂܂����̂͂������ȁB
>>802
���Ƃ���Core MA��SSE���\
�O��Pentium III, Pentium 4���Ȃ���Ή��̃R�[�h���Y�����������킯��
�i�K�܂Ȃ������ȂǂȂ��̂���B
>>805
�X���^�C�ǂ߂邩�H
�X���^�C�ǂ߂邩�H
807 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 21:32:16 ID:LfwDXAhP
808 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 21:32:57 ID:LfwDXAhP
>>806
�͂��͂��A�B�ꖪ���K�v�ł����B
�͂��͂��A�B�ꖪ���K�v�ł����B
809 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 21:35:44 ID:LfwDXAhP
���Ƃ��Ɖ����v�b�V�����Ă��̂�SIMD���߃Z�b�g�̂ق���
�}�C�N���A�[�L�e�N�`���͎��̂����ǂ��ł��ǂ�
�}�C�N���A�[�L�e�N�`���͎��̂����ǂ��ł��ǂ�
SIMD�AMIMD�A�x�N�g�����Ɋւ���X���ł����ĂĂ����ł��
811 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 21:50:10 ID:LfwDXAhP
SSSE3��Tejas�ɍڂ�\�肾������
�c�q���C���e����J�ߎE������X���ɂȂ��ė����ȁB
����O���炻����...
����O���炻����...
�����̓����r�[�̃��N�C�G���X���ɂȂ�܂����B
Intel�ɂ̓}�C�N���\�t�g�قǂ̔S�荘�͂Ȃ������
���������S�荘������̂Ȃ�Larrabee�̌��������`����̂��ʔ�������
Windows��3���O��1�A2�͍�����������
IE��Netscepe���t�]�����̂�Ver����������
���������S�荘������̂Ȃ�Larrabee�̌��������`����̂��ʔ�������
Windows��3���O��1�A2�͍�����������
IE��Netscepe���t�]�����̂�Ver����������
815 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 22:08:26 ID:LfwDXAhP
Win95��OEM���f���̋N����ʂŊ��Ɂuwith Internet Explorer�v���o�Ă��C�����邪
����ł�IE4����Ȃ��́H
�V�F��������OS��IE�̃R���|�[�l���g��g�ݍ��̂ő��ΓI��Netscape���N���������Ȃ����B
�Z�p�I�ɒ������̂�5.0���炢���Ǝv�����B
�ނ���l�X�P���N�\�߂����B
����ł�IE4����Ȃ��́H
�V�F��������OS��IE�̃R���|�[�l���g��g�ݍ��̂ő��ΓI��Netscape���N���������Ȃ����B
�Z�p�I�ɒ������̂�5.0���炢���Ǝv�����B
�ނ���l�X�P���N�\�߂����B
>>814
NN4�̂��ƁANetscape���S�Ă��ꂩ���蒼�����Ƃ��Ď��������B
NN4�̂��ƁANetscape���S�Ă��ꂩ���蒼�����Ƃ��Ď��������B
817 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 22:13:20 ID:LfwDXAhP
Netscape���珤�p�R���|�[�l���g����蕥����5.0�̓L�����Z���B
Mozilla Milestone���x�[�X��6.0������UI���N�\�d�������������B
Mozilla Milestone���x�[�X��6.0������UI���N�\�d�������������B
���ǍL�����y����������GPU�@�\���Ĕ��肽����������
���y�ł��Ȃ��قǂ̂���ڂ����\�����o���Ȃ�������ł���
���y�ł��Ȃ��قǂ̂���ڂ����\�����o���Ȃ�������ł���
>>771
�{�P�V�l�͎��������^���Ă����āu�N�����������́I�v�Ƌ��Ԃ��
�{�P�V�l�͎��������^���Ă����āu�N�����������́I�v�Ƌ��Ԃ��
820 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 22:42:28 ID:LfwDXAhP
http://developer.amd.com/CPU/LIBRARIES/SSEPLUS/Pages/default.aspx
���̃S�~�ǂ�����́H
���̃S�~�ǂ�����́H
>>801
GPU�Ƃ��Đ�`�A�̔���ڎw�������̂͂܂�����Ȃ������Larrabee
���ꂪ�K��̐��\����ѐ�����̊J���Ɏ��s�������ɂ��A�\�肳��Ă������i���̂��L�����Z�����ꂽ
��������s�Ƃ��킸�Ȃ�Ƃ����H���H�c�q�I�H
GPU�Ƃ��Đ�`�A�̔���ڎw�������̂͂܂�����Ȃ������Larrabee
���ꂪ�K��̐��\����ѐ�����̊J���Ɏ��s�������ɂ��A�\�肳��Ă������i���̂��L�����Z�����ꂽ
��������s�Ƃ��킸�Ȃ�Ƃ����H���H�c�q�I�H
822 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 22:55:45 ID:LfwDXAhP
���ႠAMD��ATI�̍��������s����
823 �F,,�E�L�́M�E,,�j�@�E�E�E���@-�������F2009/12/12(�y) 23:00:09 ID:LfwDXAhP
��������s�Ƃ��킸�Ȃ�Ƃ����H���H�c�q�I�H�i�د
>>822
�͂��A�F�߂Ă����錾���������܂�����
�͂��A�F�߂Ă����錾���������܂�����
825 �F,,�E�L�́M�E,,�j�@�E�E�E���@-�������F2009/12/12(�y) 23:06:12 ID:LfwDXAhP
���O��ǂ����Ă����P���ȂH
Larrabee��SCC��Intel�̒��Ō����͑���
�ǂ���̌������ʂ�������CPU�̖��ɗ���
���ꂾ���̘b����
Larrabee��SCC��Intel�̒��Ō����͑���
�ǂ���̌������ʂ�������CPU�̖��ɗ���
���ꂾ���̘b����
827 �F,,�E�L�́M�E,,�j�@�E�E�E���@-�������F2009/12/12(�y) 23:10:27 ID:LfwDXAhP
Intel��LPIA�͉��Z�N���X�^�P�ʂŃ��W���[��������Ă�̂Ŋ���Ǝg���܂킵�͂����B
Larrabee��VPU�͑�������ڐA�������邱�Ƃ������Ă܂����B
Larrabee��VPU�͑�������ڐA�������邱�Ƃ������Ă܂����B
������40mm�̕����܂肪��������Larrabee�𓊓�����K�v�͖����Ȃ���
�Ƃ����Ԕ������邾��
���y��ژ_�ނȂ�ނ���`�����X�Ȃ̂�
���ׂė\��ʂ�(�د
�Ƃ����ĂĈ���ɂȂ��Ă���
�Ƃ����Ԕ������邾��
���y��ژ_�ނȂ�ނ���`�����X�Ȃ̂�
���ׂė\��ʂ�(�د
�Ƃ����ĂĈ���ɂȂ��Ă���
829 �F,,�E�L�́M�E,,�j�@�E�E�E���@-�������F2009/12/12(�y) 23:11:51 ID:LfwDXAhP
>>826
�M��AMD���A���s������̂Ă邵���������̂������Ă邩�炻���������̂����ł�������Ȃ���ł���B
���߂Ă͐؎̂Ă����Ɗ���
�M��AMD���A���s������̂Ă邵���������̂������Ă邩�炻���������̂����ł�������Ȃ���ł���B
���߂Ă͐؎̂Ă����Ɗ���
830 �FSocket774�F2009/12/12(�y) 23:12:05 ID:z+e/x6tF
�܂��C���e���͖������[�h�˓��Ƃ������ŁE�E�E
�̂��炯�������������Ă��
�������Ȃ��̂͐����I���͂̍s�g���炢�̂����
�������Ȃ��̂͐����I���͂̍s�g���炢�̂����
833 �F,,�E�L�́M�E,,�j�@�E�E�E���@-�������F2009/12/12(�y) 23:15:29 ID:LfwDXAhP
>>828
> ���y��ژ_�ނȂ�ނ���`�����X�Ȃ̂�
Intel�ɂ͖{���I��GPGPU�͕K�v�Ȃ��B
�X�^���X�͂����܂Łu�A���`GPGPU�v
�����y�U�ɂ����炸�ɏ]��CPU���i�̉���������HPC�ւ̐i�U��j�~�ł���Ȃ�
����ɉz�������Ƃ͖����B
�N�͂��������L������Ō����ق��������B
> ���y��ژ_�ނȂ�ނ���`�����X�Ȃ̂�
Intel�ɂ͖{���I��GPGPU�͕K�v�Ȃ��B
�X�^���X�͂����܂Łu�A���`GPGPU�v
�����y�U�ɂ����炸�ɏ]��CPU���i�̉���������HPC�ւ̐i�U��j�~�ł���Ȃ�
����ɉz�������Ƃ͖����B
�N�͂��������L������Ō����ق��������B
>>833
����HPC�����̐��i�͂���ɓ���̂��
GPGPU�͂���Ȃ��ƌ�����GPU�@�\�̂��߂ɊJ����q���Ă�ᐢ�b�Ȃ���
��������ŏ�����HPC�����ɑ_�����i���Ă����悩�����̂�
CPU�ɓ������Ďg���������邩�͒m���
����HPC�����̐��i�͂���ɓ���̂��
GPGPU�͂���Ȃ��ƌ�����GPU�@�\�̂��߂ɊJ����q���Ă�ᐢ�b�Ȃ���
��������ŏ�����HPC�����ɑ_�����i���Ă����悩�����̂�
CPU�ɓ������Ďg���������邩�͒m���
835 �F,,�E�L�́M�E,,�j�@�E�E�E���@-�������F2009/12/12(�y) 23:22:01 ID:LfwDXAhP
�Ԃ����ႯGPU�s��͔��������Ȃ��B���z�x�[�X���傫���Ȃ����B
�Ȃ�GPU�����������āACPU��FLOPS�P���̔j����������炾�B
Intel���炷��Α��̗��ɂ������т̔ї��݂����Ȃ���B
�Ƃ��Ă��H���Ȃ��B
�����܂�CPU�̉��l���ێ�����ɂ͂ǂ�����̂������̂��B
�Ȃ�GPU�����������āACPU��FLOPS�P���̔j����������炾�B
Intel���炷��Α��̗��ɂ������т̔ї��݂����Ȃ���B
�Ƃ��Ă��H���Ȃ��B
�����܂�CPU�̉��l���ێ�����ɂ͂ǂ�����̂������̂��B
836 �F,,�E�L�́M�E,,�j�@�E�E�E���@-�������F2009/12/12(�y) 23:23:11 ID:LfwDXAhP
> ����HPC�����̐��i�͂���ɓ���̂��
Xeon�����������ǁH
���݂͓lj�͂�������
Xeon�����������ǁH
���݂͓lj�͂�������
837 �F,,�E�L�́M�E,,�j�@�E�E�E���@-�������F2009/12/12(�y) 23:25:51 ID:LfwDXAhP
GMA�̓V�F�A�g�債�Ă���B
����͂܂�GPU�̎s��K�͂͏k�����Ă���Ă��Ƃ��B
GPGPU�H���ꂱ��GPU�ł���K�v���Ȃ��B
����͂܂�GPU�̎s��K�͂͏k�����Ă���Ă��Ƃ��B
GPGPU�H���ꂱ��GPU�ł���K�v���Ȃ��B
�Ȃ�CPU�̉��l�̈ێ�����
�������ȓd�͂ɂȂ�����Ȃ�ȊO�̓��ȂȂ�����
�������ȓd�͂ɂȂ�����Ȃ�ȊO�̓��ȂȂ�����
839 �F,,�E�L�́M�E,,�j�@�E�E�E���@-�������F2009/12/12(�y) 23:27:17 ID:LfwDXAhP
> �������ȓd�͂ɂȂ�����Ȃ�ȊO�̓��ȂȂ�����
GPU����
GPU����
�c�q��Intel��LNI���y�헪�������Ă�����悩�����̂ɂ�
GPU�Ȃ�Ă���Ȃ��IHPC������������I
����
���i���\����������܂������������ɁA
�uGPU�̓y�U�ɏ��K�v�͂Ȃ����琻�i���L�����Z���͗��ɂ��Ȃ��Ă�v
�Ƃ������Ă��߂��������
GPU�Ȃ�Ă���Ȃ��IHPC������������I
����
���i���\����������܂������������ɁA
�uGPU�̓y�U�ɏ��K�v�͂Ȃ����琻�i���L�����Z���͗��ɂ��Ȃ��Ă�v
�Ƃ������Ă��߂��������
����\�肳�ꂽ���͎��s�ɏI������A�Ƃ��������͕ς��Ȃ����ǂ�
842 �F,,�E�L�́M�E,,�j�@�E�E�E���@-�������F2009/12/12(�y) 23:29:05 ID:LfwDXAhP
���x�������Ă��邪CPU�̓���SIMD���j�b�g�̕���x��2�{�ɂȂ��GPGPU�̉��l�͔�������B
GPU�ɂ͍Ő�[�Q�[�������g��������
CPU�̓R�A������̐��\�͏オ�炸�R�A�𑝂₵�Ă��p�r���Ȃ����S�Ȏ�l�܂肾
�������Ȃ�̂�CPU�ł�
CPU�̓R�A������̐��\�͏オ�炸�R�A�𑝂₵�Ă��p�r���Ȃ����S�Ȏ�l�܂肾
�������Ȃ�̂�CPU�ł�
�܂�HPC�p�r�Ƃ�
�債�Ėׂ���Ȃ����
����Ȍ����J����͂ǂ��������̂���
����Ƃ�CPU�����ł������ɐK�@��������̂��˂�
�܂��M�҂����z�{�����Ă��������͌������邩���m���
�����������Ȃ������炨�����Ƃ��Ȃ�
�o�c�w�̐ӔC���ɂȂ�킗
�債�Ėׂ���Ȃ����
����Ȍ����J����͂ǂ��������̂���
����Ƃ�CPU�����ł������ɐK�@��������̂��˂�
�܂��M�҂����z�{�����Ă��������͌������邩���m���
�����������Ȃ������炨�����Ƃ��Ȃ�
�o�c�w�̐ӔC���ɂȂ�킗
845 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 23:31:37 ID:LfwDXAhP
��GPU�ɂ͍Ő�[�Q�[�������g��������
�Ő�[�͊��ɃR���V���[�}����ŁAPC�����͂������肵�����炦�Ȃ��Ȃ��Ă܂����B
�Ő�[�͊��ɃR���V���[�}����ŁAPC�����͂������肵�����炦�Ȃ��Ȃ��Ă܂����B
>�R�A�𑝂₵�Ă��p�r���Ȃ�
�A�z��
�A�z��
���Ő�[�͊��ɃR���V���[�}�����
�������Ă�̂��̎q�H
�������Ă�̂��̎q�H
848 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 23:35:09 ID:LfwDXAhP
�\�t�g�E�F�A�������Ă����ĂȂ����Ă��ƁB
http://www.bravenewgamer.com/2009/12/bngs-2009-game-of-the-year-awards/
Best Innovation�Ƃ����Ă݂Ȃ�����
Best Innovation�Ƃ����Ă݂Ȃ�����
850 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 23:39:07 ID:LfwDXAhP
PC�͕s���R�s�[����Ŗׂ���Ȃ����Ď̂đ䎌�f����Crytek�̍ŐV��
�uCrysis 2�v��PS3��360�Ŕ����ȂȁB
NVIDIA�̓G���X�[�W�A�j�X�g��1�l��2��3���r�f�I�J�[�h�킹�邱�ƂŔ��グ���ێ����Ă邪
�\�t�g�̔��グ�͔N�X�������B
���^�m�[�g�̃I���{�[�hVGA�ŏo����悤�ȃQ�[�����肪�L�тĂ�Ƃ��B
����Ȃ�PC���C����3D�Q�[������Ă���ǂ��̉�Ђ�������B
�uCrysis 2�v��PS3��360�Ŕ����ȂȁB
NVIDIA�̓G���X�[�W�A�j�X�g��1�l��2��3���r�f�I�J�[�h�킹�邱�ƂŔ��グ���ێ����Ă邪
�\�t�g�̔��グ�͔N�X�������B
���^�m�[�g�̃I���{�[�hVGA�ŏo����悤�ȃQ�[�����肪�L�тĂ�Ƃ��B
����Ȃ�PC���C����3D�Q�[������Ă���ǂ��̉�Ђ�������B
�Ȃ��ꂗ
>>820
>>820
HPC�̐��E�͒m���GPU�łȂ܂�������l�������H
����������Ă��ƂŃ}�l����l�����ς��o�Ă��邾�낤�ˁB
Larrabee�͂����������Ƃ��N����̂�j�~���Ȃ��Ⴂ���Ȃ��`�b�v������
�͂������ǁA�t�ɍ���̂��Ƃ�Intel��҂��Ă��l��GPU�ɗ�����ˁB
�ق�Ƃ��ꂩ��ǁ[����B
����������Ă��ƂŃ}�l����l�����ς��o�Ă��邾�낤�ˁB
Larrabee�͂����������Ƃ��N����̂�j�~���Ȃ��Ⴂ���Ȃ��`�b�v������
�͂������ǁA�t�ɍ���̂��Ƃ�Intel��҂��Ă��l��GPU�ɗ�����ˁB
�ق�Ƃ��ꂩ��ǁ[����B
���G�`����p�`�b�v�Ȃ�Ă����v��Ȃ�
���ǃL���C�L���C�����Ă�Q�[����SCE���ȊOPC�ł����o�Ă�킯��
�����PC�Ɍ����Ă͕t�����l�Ƃ���PhysX�ɑΉ������Ă��邱�Ƃ�������
dirt2������PC�ł̂ق������|�I�ɃL���C
�ׂ���Ȃ��̂�150���{�����Ă������ɏo���Ȃ��悤�ȃ^�C�g���������cryteck�������Ƃ��������悤������
��̉��{����C�������H�ǂ����G���W���r�W�l�X�ړI�������̂�UE3�Ɋ��s��������O�_�O�_�����Ă��
�����PC�Ɍ����Ă͕t�����l�Ƃ���PhysX�ɑΉ������Ă��邱�Ƃ�������
dirt2������PC�ł̂ق������|�I�ɃL���C
�ׂ���Ȃ��̂�150���{�����Ă������ɏo���Ȃ��悤�ȃ^�C�g���������cryteck�������Ƃ��������悤������
��̉��{����C�������H�ǂ����G���W���r�W�l�X�ړI�������̂�UE3�Ɋ��s��������O�_�O�_�����Ă��
855 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 23:42:35 ID:LfwDXAhP
>>852
�����̃X�p�R���Ɋւ�����l�Ȃ�AVX�x�������Č����Ă���B
�����̃X�p�R���Ɋւ�����l�Ȃ�AVX�x�������Č����Ă���B
���܂��O�Ɏ��S���ė��Y�ł����H
���Y����v���Z�b�T���ĉ���I����Ȃ��ł����H
����I�����ēx�̂Ƌ��ʔ����ꂿ�Ⴂ�܂�����B
���ꂾ���ł��ނɂ͑��݈Ӌ`���������̂Ȃ��̂ł��傤���H
���͂Ƃ�����S���炨����ݐ\���グ�܂��B
�@�@�@�@�@�@�@�@�@ �Q�Q�Q�Q�Q
�@�@�@ �@ �@ �@ �^Ɂ@�@�@�@�@ �R �_�@�@�@�@
�@�@�@�@�@�@�^�@�^�E�_�@�@�^�E�_�@�_�@�@�@
�@�@�@�@�@ |�@�@�@�P�P�@�@�@�P�P�@�@ |
�@�@�@�@�@ |�@�@�@�@�i�Q�l�Q�j� �@�@�@ |
�@�@�@�@�@ |�@�@�@�@�@�_�@�@�@|�@�@�@�@ |
�@ �@ �@ �@ �_�@�@�@�@�@�_�Q|�@�@�@ �^
���Y����v���Z�b�T���ĉ���I����Ȃ��ł����H
����I�����ēx�̂Ƌ��ʔ����ꂿ�Ⴂ�܂�����B
���ꂾ���ł��ނɂ͑��݈Ӌ`���������̂Ȃ��̂ł��傤���H
���͂Ƃ�����S���炨����ݐ\���グ�܂��B
�@�@�@�@�@�@�@�@�@ �Q�Q�Q�Q�Q
�@�@�@ �@ �@ �@ �^Ɂ@�@�@�@�@ �R �_�@�@�@�@
�@�@�@�@�@�@�^�@�^�E�_�@�@�^�E�_�@�_�@�@�@
�@�@�@�@�@ |�@�@�@�P�P�@�@�@�P�P�@�@ |
�@�@�@�@�@ |�@�@�@�@�i�Q�l�Q�j� �@�@�@ |
�@�@�@�@�@ |�@�@�@�@�@�_�@�@�@|�@�@�@�@ |
�@ �@ �@ �@ �_�@�@�@�@�@�_�Q|�@�@�@ �^
>>850
EA�ACrytek���wCrysis 2�x�\�IPS3�AXbox360�APC�Ŕ����ցI
http://www.ps3-fan.net/2009/06/eacrytekcrysis_2ps3xbox360pc.html
�H�H�H
EA�ACrytek���wCrysis 2�x�\�IPS3�AXbox360�APC�Ŕ����ցI
http://www.ps3-fan.net/2009/06/eacrytekcrysis_2ps3xbox360pc.html
�H�H�H
>>852
> GPU�ɗ�����ˁB
����āA��]����l����ʂɌ����̂�2010�N�Ǝv����B�{���ɁB
���ܑ嗬�s������A�K����CUDA�̕����Ă�z�����ς����邾�낤���A
���ۂ�GPGPU�ɐ������̂߂肱��ł݂Ȃ�
����Ă݂�Δ���B
> GPU�ɗ�����ˁB
����āA��]����l����ʂɌ����̂�2010�N�Ǝv����B�{���ɁB
���ܑ嗬�s������A�K����CUDA�̕����Ă�z�����ς����邾�낤���A
���ۂ�GPGPU�ɐ������̂߂肱��ł݂Ȃ�
����Ă݂�Δ���B
859 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 23:47:05 ID:LfwDXAhP
Xeon��HPC����ɂ����镐���Xeon5xxx�ȉ��̈�������
Xeon�ł�7xxx�͊�����HPC�ւ̗̍p�͏��Ȃ��B
Nehalem-EX��5xxx�̉��i�т���Ȃ����疢�������Ă��Ȃ��B
Nealem-EX�͂����Ă�POWER7�N���X�ɑR�ł���`�b�v�͂Ȃ�
Xeon�ł�7xxx�͊�����HPC�ւ̗̍p�͏��Ȃ��B
Nehalem-EX��5xxx�̉��i�т���Ȃ����疢�������Ă��Ȃ��B
Nealem-EX�͂����Ă�POWER7�N���X�ɑR�ł���`�b�v�͂Ȃ�
>>859
�R���V���[�}�ŏo������PC�œƐ�ɂ��鉿�l������قǍ���GPU���Z�p�I�Ɉ����͂Ȃ��ĂȂ����Ă�������
�𑜓x�Ƃ��t���[�����[�g�ɂ��������PC�ł�(���ꂩ������Ȃ���)�~�����邵
�R���V���[�}�̐���͓����ς��Ȃ����炻�̂����R���V���[�}�ƃ}���`�o���Ȃ����炢�̍����J����
�R���V���[�}�ŏo������PC�œƐ�ɂ��鉿�l������قǍ���GPU���Z�p�I�Ɉ����͂Ȃ��ĂȂ����Ă�������
�𑜓x�Ƃ��t���[�����[�g�ɂ��������PC�ł�(���ꂩ������Ȃ���)�~�����邵
�R���V���[�}�̐���͓����ς��Ȃ����炻�̂����R���V���[�}�ƃ}���`�o���Ȃ����炢�̍����J����
�R���V���[�}����^�C�g�����قƂ�ǂȂ��Ȃ����������l���Ȃ��Ⴞ�߂Ȃ�Ȃ���
863 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 23:55:26 ID:LfwDXAhP
��PC�ł�(���ꂩ������Ȃ���)�~�����邵
���ꂪPC�Q�[���s�U�̗��R����
�Œᐫ�\���ۏ���ĂāA�s���R�s�[����Ȃ��v���b�g�t�H�[�����K�v��
NVIDIA��AMD���Q�[���J������́H�J������̂̓\�t�g�����B
�L�̓X�^�W�I���ǂ�ǂ�������Ă钆�ŁAPC���C���ł�낤���Ċ�Ƃ͏o�Ă��悤���Ȃ��B
���ꂪPC�Q�[���s�U�̗��R����
�Œᐫ�\���ۏ���ĂāA�s���R�s�[����Ȃ��v���b�g�t�H�[�����K�v��
NVIDIA��AMD���Q�[���J������́H�J������̂̓\�t�g�����B
�L�̓X�^�W�I���ǂ�ǂ�������Ă钆�ŁAPC���C���ł�낤���Ċ�Ƃ͏o�Ă��悤���Ȃ��B
>>863
����������������Ɛ�ō���ĉ���o����悤�Ȏs���PC�Q�[���̐��E�ɂ͍��܂ł����ꂩ����Ȃ���
�����Z�p�I�ɍŐ�[�ɋ������邽�߂ɃQ�[����Ђ�PC�Q�[���ɓ����������Ȃ��Ⴂ���Ȃ���
����������������Ɛ�ō���ĉ���o����悤�Ȏs���PC�Q�[���̐��E�ɂ͍��܂ł����ꂩ����Ȃ���
�����Z�p�I�ɍŐ�[�ɋ������邽�߂ɃQ�[����Ђ�PC�Q�[���ɓ����������Ȃ��Ⴂ���Ȃ���
865 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 23:57:14 ID:LfwDXAhP
>>862
FIFA 10�͂���PC�ŏo���Ȃ����Ă��B
FIFA 10�͂���PC�ŏo���Ȃ����Ă��B
866 �F,,�E�L�́M�E,,�j��-�������F2009/12/13(��) 00:01:37 ID:Gw3F5ZKy
> �����Z�p�I�ɍŐ�[�ɋ������邽�߂ɃQ�[����Ђ�PC�Q�[���ɓ����������Ȃ��Ⴂ���Ȃ���
PC�Q�[���Ɋ֗^�������Ƃ��Ȃ���Ђ����E�g�b�v�ȏ��l����Ɠ��ł������ɂ���������B
���ɂǂ�l�܂芴���邯�ǂˁBVRAM�̑ш��傫�������グ��m�M�I�ȋZ�p���Ȃ����B
PC�Q�[���Ɋ֗^�������Ƃ��Ȃ���Ђ����E�g�b�v�ȏ��l����Ɠ��ł������ɂ���������B
���ɂǂ�l�܂芴���邯�ǂˁBVRAM�̑ш��傫�������グ��m�M�I�ȋZ�p���Ȃ����B
867 �F,,�E�L�́M�E,,�j��-�������F2009/12/13(��) 00:02:23 ID:LfwDXAhP
�v�V�I�A��
dirt2
�����A����dx9��dx11�ŁA�قƂ�nj������̂��Ȃ����c�l
�����A����dx9��dx11�ŁA�قƂ�nj������̂��Ȃ����c�l
>>866
�C�V���Ɋւ��Ă͂�������
���{�̕��ʂ̃��[�J�[��PC�Q�[������ĂȂ��������
�Z�p�I�ɊC�O���[�J�[�ɑS�����Ă����Ȃ��Ȃ���
�܂������̕������ǂ�l�܂����烊�A���^�C�����C�g���Ȃ�Ȃ�炩�̃\�t�g�E�F�A�����_���������ɓ������悤�ɂ���Ȃ�
���낢����Ⴀ����
�C�V���Ɋւ��Ă͂�������
���{�̕��ʂ̃��[�J�[��PC�Q�[������ĂȂ��������
�Z�p�I�ɊC�O���[�J�[�ɑS�����Ă����Ȃ��Ȃ���
�܂������̕������ǂ�l�܂����烊�A���^�C�����C�g���Ȃ�Ȃ�炩�̃\�t�g�E�F�A�����_���������ɓ������悤�ɂ���Ȃ�
���낢����Ⴀ����
PS3��360��PC�Q�[���̋Z�p�ō���Ă邩���
����GPU��
�����R���V���[�}����^�C�g��������
�Ă�����PC�x�[�X��PC�APS3�A360�Ή��Ŕ���o���̂�
��ԃp�C���傫���킯������݂�Ȃ������ɍs�����
����GPU��
�����R���V���[�}����^�C�g��������
�Ă�����PC�x�[�X��PC�APS3�A360�Ή��Ŕ���o���̂�
��ԃp�C���傫���킯������݂�Ȃ������ɍs�����
�c�q�͂��ALarrabee�����s���Ă��̌㉄�X��GMA��牽������Ă邯��
�����Ă��̂�SIMD���߃Z�b�g�Ȃ�ALarrabee���̂͂ǂ��ł�������H
��������A�������s�������̃X���ɂ���K�v�͂Ȃ��������
����Ƃ��B�̃J�}�b�e�����Ȃ����Ȃ̂��Ȃ�
�����Ă��̂�SIMD���߃Z�b�g�Ȃ�ALarrabee���̂͂ǂ��ł�������H
��������A�������s�������̃X���ɂ���K�v�͂Ȃ��������
����Ƃ��B�̃J�}�b�e�����Ȃ����Ȃ̂��Ȃ�
ID:LfwDXAhP�͂ق�Ɖ����m��Ȃ���
http://features.metacritic.com/features/2009/the-best-games-of-2009/
HD�@�Ȃ�����ۂǃQ�[���o�Ă���Č����̂�
�X�ɂ����ƁAFIFA10�͏o�Ȃ��Ă�FIFA manager10��PC�ɂ����o���Ȃ����
EA�ɂ��Ă͂܂Ƃ��Ȕ��f��
http://features.metacritic.com/features/2009/the-best-games-of-2009/
HD�@�Ȃ�����ۂǃQ�[���o�Ă���Č����̂�
�X�ɂ����ƁAFIFA10�͏o�Ȃ��Ă�FIFA manager10��PC�ɂ����o���Ȃ����
EA�ɂ��Ă͂܂Ƃ��Ȕ��f��
�}���`�Ȃ̂́A�������Ȃ��ƊJ��������ł��Ȃ����炾��
XBOX360��PC or PC��XBOX�̈ڐA�͊y��
�t��PS3��ry
�t��PS3��ry
875 �F,,�E�L�́M�E,,�j��-�������F2009/12/13(��) 00:21:38 ID:Gw3F5ZKy
>>875
�A��
�A��
���ꂾ���匾�s��ő��̃v���Z�b�T��n���ɂ����������J��Ԃ����������
Larrabee���~���Ă����ł��A���Ȃ̂ɁA���ς�炸���Ȃł��Ȃ����i���M����
���Ȑ����������ݎx���ŗ�Ȕ����̐��X�B���͂�l�^�R�e�B
Larrabee���~���Ă����ł��A���Ȃ̂ɁA���ς�炸���Ȃł��Ȃ����i���M����
���Ȑ����������ݎx���ŗ�Ȕ����̐��X�B���͂�l�^�R�e�B
878 �F,,�E�L�́M�E,,�j��-�������F2009/12/13(��) 00:59:30 ID:Gw3F5ZKy
CUDA�ŕs��������ł��B
�g�����ǁB
�ȏ�B
�g�����ǁB
�ȏ�B
�f�B�X�N���[�gGPU�̗��_���Ă��̔n���ł���VRAM�ш悾��B�t�ɂ��������g�ɂ��Ȃ��Ă邪�B
880 �F,,�E�L�́M�E,,�j��-�������F2009/12/13(��) 01:24:53 ID:Gw3F5ZKy
�ш�͑������ǃL���b�V�����v���I�ɏ��Ȃ��B
4870��5870�Ń��j�b�g����2�{�ɂȂ�������VRAM�ш��1.2�{������ȁB
4870��5870�Ń��j�b�g����2�{�ɂȂ�������VRAM�ш��1.2�{������ȁB
Larrabee�̑ш悪�������������킩��Ȃ����A1�R�A������̃I�t�`�b�v
�ш悪POWER7���Ɋm�ۂ���Ă��Ȃ������̂͊ԈႢ�Ȃ����낤��
�ш悪POWER7���Ɋm�ۂ���Ă��Ȃ������̂͊ԈႢ�Ȃ����낤��
�ł��O���t�B�N�X�őS�R���������Ȃ��Ƃ���
�c�Ȃ�ł���ȂɃ��X�Ԕ��ł�
884 �F,,�E�L�́M�E,,�j��-�������F2009/12/13(��) 01:40:26 ID:Gw3F5ZKy
�Q�[���������̂��������[���ƒʗp����Ƃ͎v���Ă͂��Ȃ����낤��
886 �F,,�E�L�́M�E,,�j��-�������F2009/12/13(��) 01:51:06 ID:Gw3F5ZKy
�Q�[�����ĊG���Y�큁�ʔ�������Ȃ������
���炭�����u�������`�������č��ł���DS������o������
�g�ѓd�b�̑��@�\����PC�s�ꂪ���o�C�ȏ��PC���܂߂����u�Q�[�������o�C�C������B
���炭�����u�������`�������č��ł���DS������o������
�g�ѓd�b�̑��@�\����PC�s�ꂪ���o�C�ȏ��PC���܂߂����u�Q�[�������o�C�C������B
�����قǂ����ł��Ȃ��݂��������ǂ�
��͂�n�C�G���h�Ɉ���������Ɛ��\�V���{�C�@��ł̊J���͂߂�ǂ������Ȃ��
��͂�n�C�G���h�Ɉ���������Ɛ��\�V���{�C�@��ł̊J���͂߂�ǂ������Ȃ��
PC�p�r�ł�GPU�̏o�א���CPU�̏o�א���葽��
889 �F,,�E�L�́M�E,,�j��-�������F2009/12/13(��) 02:10:05 ID:Gw3F5ZKy
CPU�������������i�������
�܁[�A�f�B�X�N���[�gGPU�̕��ʘH���͎�����2�`3����ځA���̎��͌����������m��Ȃ��B
����܂łɃQ�[���O���t�B�b�N�X�̃^�[�j���O�|�C���g���K���ł��傤�ȁB
����܂łɃQ�[���O���t�B�b�N�X�̃^�[�j���O�|�C���g���K���ł��傤�ȁB
891 �F,,�E�L�́M�E,,�j��-�������F2009/12/13(��) 02:11:45 ID:Gw3F5ZKy
>>887
�J������ŐԎ��Ԃ��Ă�\�t�g�n�E�X�ׂ̒��O�̌��t����
�J������ŐԎ��Ԃ��Ă�\�t�g�n�E�X�ׂ̒��O�̌��t����
�܂��܂��O���t�B�b�N�\�͑����Ƃ������A�����X�ɐ�̉f���ɓ˂�������ɂ�5870��10�{�����Ă�������
�Ȃ������ш悷��d�l�����܂��ĂȂ��̂���B
�܂��O���t�B�b�N���i�Ƃ��Ă�Larrabee�͎����
HPC��p�̃`�b�v�ɂȂ邩IGP�Ɏ��[����ē����̑z��Ƃ͔�ׂ��̂ɂȂ�Ȃ��قǂ���ڂ��Ȃ邩������Ȃ�����
HPC��p�̃`�b�v�ɂȂ邩IGP�Ɏ��[����ē����̑z��Ƃ͔�ׂ��̂ɂȂ�Ȃ��قǂ���ڂ��Ȃ邩������Ȃ�����
�d������������A�����r�[�̕ς��ɂȂ���̍l���悤���B
�E�`���R���[�g
�E���X
�E�|�b�L�[
�E
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�j
�@�@�@�@�@�@�@�@�@�@�@�@�@�i
�@�@�@ �@�@�@�@�@,,�@�@�@�@�@�@�@�@�j�@�@�@�@�@�@�j
�@�@�@�@ �@�@�@�@��;;;;;,_�@�@�@�@�@�@�@�@�@�@�@�i
�@�@�@�@ �@�@�@�@�@�~;;;;;;;;�;:..,,.,,,,,
�@�@�@�@�@�@�@�@�@�@i;i;i;i; '',',;^��..�R
�@�@�@�@�@�@�@�@�@�@ށUy��;:..��j�@�@�p
�@�@�@�@�@�@�@�@�@�@�@.�N.�,_,,�_,,r_,�m��
�@�@�@�@ �@�@�@�@/;:;":;.:;";i; '',',;;;_~;;;��.�R
�@�@�@�@�@�@�@�@�{y��;:...:,:.:.�;:..:,:.:.�@._�@�@��p
�@�@�@�@�@�@�@�@".�N�=v ''�] .:v�,,�_,r_,�m��
�@�@�@�@�@�@�@/;i;i; '',',;;;_~�܁N;;;;;;;;�S.�ށL�^��..�R�@
�@�@�@�@�@�@ �{y��;:...:,:.:.�;�;:.:,:.:.�@._�@�@.��j�@�@��p
�@�@�@�@�@�@�@".�N�=v ''�] .:v��q_._ .�,_,,�_,,r_,�m��
�@�@�@�@�@�@/i;i; '',',;;;_~�ҁ܁N;;;;;;;;�S.�ށL�^��.�.�R
�@�@�@�@�@�@�{y��;:..�U.:,:.:.�;:.�.:,:.:.�@._���o,,'.��j�@�@��p
�@�@�@�@�@�@�S,,..;::;;;::,;,::;):;:;:; .:v��q_._ .�,_,,�_,,r_,�m��
�E�`���R���[�g
�E���X
�E�|�b�L�[
�E
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�j
�@�@�@�@�@�@�@�@�@�@�@�@�@�i
�@�@�@ �@�@�@�@�@,,�@�@�@�@�@�@�@�@�j�@�@�@�@�@�@�j
�@�@�@�@ �@�@�@�@��;;;;;,_�@�@�@�@�@�@�@�@�@�@�@�i
�@�@�@�@ �@�@�@�@�@�~;;;;;;;;�;:..,,.,,,,,
�@�@�@�@�@�@�@�@�@�@i;i;i;i; '',',;^��..�R
�@�@�@�@�@�@�@�@�@�@ށUy��;:..��j�@�@�p
�@�@�@�@�@�@�@�@�@�@�@.�N.�,_,,�_,,r_,�m��
�@�@�@�@ �@�@�@�@/;:;":;.:;";i; '',',;;;_~;;;��.�R
�@�@�@�@�@�@�@�@�{y��;:...:,:.:.�;:..:,:.:.�@._�@�@��p
�@�@�@�@�@�@�@�@".�N�=v ''�] .:v�,,�_,r_,�m��
�@�@�@�@�@�@�@/;i;i; '',',;;;_~�܁N;;;;;;;;�S.�ށL�^��..�R�@
�@�@�@�@�@�@ �{y��;:...:,:.:.�;�;:.:,:.:.�@._�@�@.��j�@�@��p
�@�@�@�@�@�@�@".�N�=v ''�] .:v��q_._ .�,_,,�_,,r_,�m��
�@�@�@�@�@�@/i;i; '',',;;;_~�ҁ܁N;;;;;;;;�S.�ށL�^��.�.�R
�@�@�@�@�@�@�{y��;:..�U.:,:.:.�;:.�.:,:.:.�@._���o,,'.��j�@�@��p
�@�@�@�@�@�@�S,,..;::;;;::,;,::;):;:;:; .:v��q_._ .�,_,,�_,,r_,�m��
���ʓI��NV�̓Q�[���ƊE�̊��ƂȂ��Ă��܂�����
���̌��ɍ��YGPU����l�T�X�I
SH�ł����H
����Larrabee3�̃A�[�L�e�N�`���ł��\�z���悤���B
���N���ė��N������Q�[�����\���ӎ��������̂ɂȂ邾�낤�ˁB
�����O�o�X�̓Q�[�����\�ɕs���Ȃ͎̂��m�̎���������A�ʕ����ɂ��邾�낤�ˁB
RADEON�̓����R�����N���X�o�[�Ōq�������ǁA�R�A���m�̐ڑ��ɂ͑������Ė������낤�ȁB
����̃^�C���o�X�H��SCC���Q�[���p�r�ɓ��Ă͂܂肻���ȋC������B
���͂��̑O��SCC��Larraee3���̂��̂��A�v���g�^�C�v�H
���N���ė��N������Q�[�����\���ӎ��������̂ɂȂ邾�낤�ˁB
�����O�o�X�̓Q�[�����\�ɕs���Ȃ͎̂��m�̎���������A�ʕ����ɂ��邾�낤�ˁB
RADEON�̓����R�����N���X�o�[�Ōq�������ǁA�R�A���m�̐ڑ��ɂ͑������Ė������낤�ȁB
����̃^�C���o�X�H��SCC���Q�[���p�r�ɓ��Ă͂܂肻���ȋC������B
���͂��̑O��SCC��Larraee3���̂��̂��A�v���g�^�C�v�H
�ʓ|������CPU�R�A������ČŒ�@�\���ڂ��Ă����肵�āB
�ȂA�ȑO iAPX432��i860���l�ALarrabee���厸�s�ɏI�����
���̌������ʂ������]�p����邾��������Ďw�E������A�c�q��
�n�c�ʓ���Ŕے肵�܂����Ă����ǁA���nj������ʂ�ɂȂ�����
���̌������ʂ������]�p����邾��������Ďw�E������A�c�q��
�n�c�ʓ���Ŕے肵�܂����Ă����ǁA���nj������ʂ�ɂȂ�����
>>894
�O�X���ɓ\���Ă�����theo�L�����
> �u�����\�������R���g���[����v����̂ɂ������l�X�́A�p�C�v���C�������Ɋւ���
> ��{�T�O�𗝉����Ă������܂���A�����āA�ނ�̓������d�l��ǂޕ��@�𗝉����Ă��܂���v�B
�O�X���ɓ\���Ă�����theo�L�����
> �u�����\�������R���g���[����v����̂ɂ������l�X�́A�p�C�v���C�������Ɋւ���
> ��{�T�O�𗝉����Ă������܂���A�����āA�ނ�̓������d�l��ǂޕ��@�𗝉����Ă��܂���v�B
>901
shader�̗��_�l��amd��1/5�ŏ\��
shader�̗��_�l��amd��1/5�ŏ\��
905 �F,,�E�L�́M�E,,�j��-�������F2009/12/13(��) 14:36:56 ID:Gw3F5ZKy
N-Body���Ƃ���ȂɃ������ш�H��Ȃ�����̂Ēl�ŏo���Ζq��搶���сE�E�E�ɂ͂Ȃ�Ȃ���
�}�L�m�搶�ɉ��蕨��H�킹����c�q�����
907 �F,,�E�L�́M�E,,�j��-�������F2009/12/13(��) 14:50:58 ID:Gw3F5ZKy
����Larrabee�p�̃R�[�h�����삵�Ă݂����ǃJ�[�l���R�[�h��1���[�v��������16���߂ōς�B
�܂����C�e���V������̂ł�����|���B�����Ȃ��Ƃ����Ȃ����ǂˁB
i, j�̐���������Ώ\���B���ł���Ǝv����������
�l�I�ɂ�Atom�{VPU�������Ȃ��C�����Ă���B
�v���f�R�[�h�o�b�t�@�Ɏ��܂郋�[�v�Ȃ�\��1�N���b�N��2���ߋ����ł��邵�B
�܂����C�e���V������̂ł�����|���B�����Ȃ��Ƃ����Ȃ����ǂˁB
i, j�̐���������Ώ\���B���ł���Ǝv����������
�l�I�ɂ�Atom�{VPU�������Ȃ��C�����Ă���B
�v���f�R�[�h�o�b�t�@�Ɏ��܂郋�[�v�Ȃ�\��1�N���b�N��2���ߋ����ł��邵�B
�c�q��NVIDIA�Ɍ����ꂵ�Đ��E��ς��Ă݂悤��
�������낻��Intel�Ɉ����n���Ă��
�������낻��Intel�Ɉ����n���Ă��
909 �F,,�E�L�́M�E,,�j��-�������F2009/12/13(��) 14:53:55 ID:Gw3F5ZKy
�悵�A����Fermi�p�́uN-BODIA�v������Ă��
CUDA�ł���ȃA�v�����Ă݂�����ł��ƃv���[������A
�c�q�݂����Ƀr�f�I�J�[�h���炦��̂��ȁB
�c�q�݂����Ƀr�f�I�J�[�h���炦��̂��ȁB
�c�q�����������ɏo���Ă��Q�[���̐l�������Ă��̂��āA�C���ł̖��Ȃǂ�������
�u�Q�[����PC����Q�[���@�Ɉڍs����v
�ł͂Ȃ���
�u�Q�[���̌`�Ԃ̓p�b�P�[�W���肩��I�����C���`���Ɉڍs����v
���Ęb����Ȃ��������H
�u�Q�[����PC����Q�[���@�Ɉڍs����v
�ł͂Ȃ���
�u�Q�[���̌`�Ԃ̓p�b�P�[�W���肩��I�����C���`���Ɉڍs����v
���Ęb����Ȃ��������H
�����̃I�����C���Q�[�����ő�s��ɂȂ�̂�
�����m����ۂ�����A���{�ɓ����Ă���Q�[���͒��������I�����C���Q�[����
�����������Ȃ�ďɂȂ肻���B
�t�ɂ��ꂪ�ł��Ȃ����{�̃Q�[����Ђ͍��̃K���p�S�X�g�т݂����ɁA
���X�ɔ敾���Ă����āA�������x����Ȃ��Ȃ�A���̂�����������邾�낤�B
���N��FF,DQ�̐V��ADS,PSP�̐V�^���b�V�����āA�Ō�̑ł��グ�ԉ����
�����m����ۂ�����A���{�ɓ����Ă���Q�[���͒��������I�����C���Q�[����
�����������Ȃ�ďɂȂ肻���B
�t�ɂ��ꂪ�ł��Ȃ����{�̃Q�[����Ђ͍��̃K���p�S�X�g�т݂����ɁA
���X�ɔ敾���Ă����āA�������x����Ȃ��Ȃ�A���̂�����������邾�낤�B
���N��FF,DQ�̐V��ADS,PSP�̐V�^���b�V�����āA�Ō�̑ł��グ�ԉ����
�c�q����GPU�g�����g���b�v�����\�t�g�ɂڂ땉���������\�t�g������G���ł���H
�Ȃ�ł���ȂɈ̂����Ȃ́H
�Ȃ�ł���ȂɈ̂����Ȃ́H
�����l�b�g�Ŗi���鎖���炢�����������炶���
�Ⴄ�Ȃ�A�R�̃\�t�g����Č��J���Ă锤����
�Ⴄ�Ȃ�A�R�̃\�t�g����Č��J���Ă锤����
���傾���炳
�I�����C���Q�[������Ȃ��ăQ�[���̃I�����C���z�M�Ȃ�
���ꍪ��̂��߂ɂ�׳���߭�èݸނ͕K�v�s��
918 �FSocket774�F2009/12/15(��) 10:02:24 ID:cCvgrZeN
��������
919 �FSocket774�F2009/12/15(��) 10:15:24 ID:mU1hOewP
�K�������H
���X���͂���Ȃ���
�c�q���ă��i�V�e�B�ɂ����A�����̐e������݂����B
�����c�q��BAN�ł����ꂽ�̂���
923 �FSocket774�F2009/12/15(��) 20:35:45 ID:cCvgrZeN
���ۂ�
10240bit�̉��Z���x�̂܂ܓ������Ăǂ����邗
CPU�Ƃ̖��߃Z�b�g�̓����͂ǂ�����́H
���b�T��VLIW�̂܂܂��H
�L�蓾�Ȃ��Ȃ��炗
���A���G������p������ǂ��̂�
�X�}����
10240bit�̉��Z���x�̂܂ܓ������Ăǂ����邗
CPU�Ƃ̖��߃Z�b�g�̓����͂ǂ�����́H
���b�T��VLIW�̂܂܂��H
�L�蓾�Ȃ��Ȃ��炗
���A���G������p������ǂ��̂�
�X�}����
924 �FSocket774�F2009/12/15(��) 20:39:12 ID:cCvgrZeN
�S�o�N
Fusion���X�P�[���_�E�������̂͂����Ȃ��
926 �FSocket774�F2009/12/15(��) 21:20:22 ID:crwa+Mmm
�@�@�@�@�@�@,,,
(�@߄t�)��
(�@߄t�)��
�@�@�@�@�@�@,,,�@,,,
(�@߄t�)����
(�@߄t�)����
928 �F,,�E�L�́M�E,,�j��-�������F2009/12/16(��) 01:14:28 ID:TBS43rg6
�@�@�@�@�@�@,,,�@,,,
(�@߄t�)����
(�@߄t�)����
929 �FSocket774�F2009/12/16(��) 03:05:10 ID:5mJJeWAA
�@�@�@�@�@�@�@�@�@�@�@,,
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@���Q�Q
�@�@�@�@�@�@�@�@�@�@�@�@�@ �^�P�@L�@�_
�@�@�@�@�@�` ���@�@�@�@�@|�@�@�@a�@�@:::|
�@�@�@�@�@�@ �@ ~ �@ �@ �@ |�@�@�@r�@�@::::|
�@�@�@�@�@�@�@�@�@�@�@ �@ |�@�@�@ r �@::::::|
�@�@�@�@�@�@�@�@�@�@�@�@ |�@�@�@�@b�@ ::::::|
�@�@�@�@�@�@�@�@�@�@�@�@ |�@�@ �@ e�@�@:::::|
�@�@�@�@�@�@�@�@�@�@�@�@ |�@�@�@�@e�@�@:::::::|
�@�@�@�@�@�@ �@ �@ �@ �@ |�@�@�@�@�́@�@:::::::|
�@�@�@�@�@�@ �@ �@ �@ �@ |�@�@�@�@��@�@:::::::::|
�@�@�@�@�@�@�@ �@ �@ �@ |�@ ��@�@�@ �@ ��:::|�@���ݤ��
�@�@�@�@ �@ �@ �@ �@ �@ |�@�@ii�@,,����� :ii :::::|
�@�@�@�@�@�@�@ �@ �@ _ |�@�@�U�a===�a�U::::::| _
�@�@�@�@-W-----������������--ff---\--
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@���Q�Q
�@�@�@�@�@�@�@�@�@�@�@�@�@ �^�P�@L�@�_
�@�@�@�@�@�` ���@�@�@�@�@|�@�@�@a�@�@:::|
�@�@�@�@�@�@ �@ ~ �@ �@ �@ |�@�@�@r�@�@::::|
�@�@�@�@�@�@�@�@�@�@�@ �@ |�@�@�@ r �@::::::|
�@�@�@�@�@�@�@�@�@�@�@�@ |�@�@�@�@b�@ ::::::|
�@�@�@�@�@�@�@�@�@�@�@�@ |�@�@ �@ e�@�@:::::|
�@�@�@�@�@�@�@�@�@�@�@�@ |�@�@�@�@e�@�@:::::::|
�@�@�@�@�@�@ �@ �@ �@ �@ |�@�@�@�@�́@�@:::::::|
�@�@�@�@�@�@ �@ �@ �@ �@ |�@�@�@�@��@�@:::::::::|
�@�@�@�@�@�@�@ �@ �@ �@ |�@ ��@�@�@ �@ ��:::|�@���ݤ��
�@�@�@�@ �@ �@ �@ �@ �@ |�@�@ii�@,,����� :ii :::::|
�@�@�@�@�@�@�@ �@ �@ _ |�@�@�U�a===�a�U::::::| _
�@�@�@�@-W-----������������--ff---\--
�c�q�����̂���w
���������ɂł��Ȃ�����ˁHw
������������
�ڐ�̋Z�p�_�ɂ͋������A
���������ʂ��͂͂Ȃ��B
�e�_�ɋ��������_�ɂ͎ア�B
��]���n�̓T�^���ȕ��c�q��������������
���������ʂ��͂͂Ȃ��B
�e�_�ɋ��������_�ɂ͎ア�B
��]���n�̓T�^���ȕ��c�q��������������
28 �FSocket774�F2009/12/02(��) 00:24:46 ID:gmDZrfQ/
�㓡���܂�Larrabee�W�̋L�����o���Ă邪�B
�Z�p�I�ȏ������i��ł���Ƃ�����̓I�Ȑ��i���v��ɋ^�╄��悵�Ă���̂�
��ނ̊��G����Larrabee�̐�s�����������݂Ă�̂��ȁB
33 �F,,�E�L�́M�E,,�j��-�������F2009/12/02(��) 01:04:07 ID:4wnVhNuN
>>28
�����́u�듚�v�搶�ł��������C�����邪�B
��ނ͂����܂�10�������B
���ꂩ��̘b�͔ނ̓n��ł����Ď����ł͂Ȃ��B
38 �FSocket774�F2009/12/02(��) 03:32:18 ID:jm5HKRHT
>>33
�����܂Œf�����Č����Ȃ�㓡���Ԉ���Ă���A���̏ؖ������Ă݂��w
�㓡���Ԉ���Ă��邩�A���O�������l�b�g�ő��l��ے肷�邵���\���Ȃ������̃o�J��
�����̏Z�l�����f���Ă����
57 �F,,�E�L�́M�E,,�j��-�������F2009/12/03(��) 00:22:56 ID:Vx3UacNb
�㓡����͂�����悭�ǂ�ł����悤�ɁB
�Z�p�𐳂����������ĂȂ��̂͋L���������ȑO�̖�肾�B
http://pc12.2ch.net/test/read.cgi/tech/1255256230/552
�㓡���܂�Larrabee�W�̋L�����o���Ă邪�B
�Z�p�I�ȏ������i��ł���Ƃ�����̓I�Ȑ��i���v��ɋ^�╄��悵�Ă���̂�
��ނ̊��G����Larrabee�̐�s�����������݂Ă�̂��ȁB
33 �F,,�E�L�́M�E,,�j��-�������F2009/12/02(��) 01:04:07 ID:4wnVhNuN
>>28
�����́u�듚�v�搶�ł��������C�����邪�B
��ނ͂����܂�10�������B
���ꂩ��̘b�͔ނ̓n��ł����Ď����ł͂Ȃ��B
38 �FSocket774�F2009/12/02(��) 03:32:18 ID:jm5HKRHT
>>33
�����܂Œf�����Č����Ȃ�㓡���Ԉ���Ă���A���̏ؖ������Ă݂��w
�㓡���Ԉ���Ă��邩�A���O�������l�b�g�ő��l��ے肷�邵���\���Ȃ������̃o�J��
�����̏Z�l�����f���Ă����
57 �F,,�E�L�́M�E,,�j��-�������F2009/12/03(��) 00:22:56 ID:Vx3UacNb
�㓡����͂�����悭�ǂ�ł����悤�ɁB
�Z�p�𐳂����������ĂȂ��̂͋L���������ȑO�̖�肾�B
http://pc12.2ch.net/test/read.cgi/tech/1255256230/552
�c�q�������グ��̂͂��Ƃ��Ƃ����s�������ȋC������B
���Ȃ݂ɍ��̓z��Fermi�Ɋ��҂��Ă���B
���Ȃ݂ɍ��̓z��Fermi�Ɋ��҂��Ă���B
�悭���邱��
���Ƃ��Ƃ������g�n�[�h���蔃���z���Ă����Ȃ�
�����A��肽���Q�[���������g����ɂ�����Ă����̂��������Șb�ŁA
���������������R�Ńn�[�h��I��łȂ������낤��
�����A��肽���Q�[���������g����ɂ�����Ă����̂��������Șb�ŁA
���������������R�Ńn�[�h��I��łȂ������낤��
>>934
�܂���o���Ƃ͂����A������ɂ͌㓡�����
�����Ă����悤�Ȏ����ƊE�W�҂͐����ƑO����
�F�v���Ă������Ă̂����X�Əo�ė�������ȁB
�c�q�͋ƊE�W�҂ۂ��������悭�����Ă邪
�����̔炪�����ꂽ�Ƃ������A�]���W�҂͑�ς��Ƃ�����...
�܂���o���Ƃ͂����A������ɂ͌㓡�����
�����Ă����悤�Ȏ����ƊE�W�҂͐����ƑO����
�F�v���Ă������Ă̂����X�Əo�ė�������ȁB
�c�q�͋ƊE�W�҂ۂ��������悭�����Ă邪
�����̔炪�����ꂽ�Ƃ������A�]���W�҂͑�ς��Ƃ�����...
CUDA�R�~���j�e�C�ł��r�f�I�J�[�h������������b�������ċ����Ă���������w
�T�^�I�Ȓ���a�ł�w
�T�^�I�Ȓ���a�ł�w
940 �F,,�E�L�́M�E,,�j��-�������F2009/12/16(��) 23:54:24 ID:TBS43rg6
>>935
���邹�[Radeon�J�ߍ�����
���邹�[Radeon�J�ߍ�����
Larrabee��1TFLOPS��100W�I�I�Ɨ\�z���Ă����c�q����Ȃ��ł���
>>940
���Џ����J�߂Ă����āB
���Џ����J�߂Ă����āB
Fermi���X�p�R���̗p���~�Ŏ����B
�c�q�̖@���͋��낵���ȁB
�c�q�̖@���͋��낵���ȁB
>>940
�ėp���Z�����Ȃ݂̂͂�Ȓm���Ă��邩��A�ʂ̕����ŖJ�ߎE���𗊂ށB
�ėp���Z�����Ȃ݂̂͂�Ȓm���Ă��邩��A�ʂ̕����ŖJ�ߎE���𗊂ށB
NVIDIA�͒c�q�ɂ��Ε�ł�������
AMD��J�߂Ă��炤�ׂ�����w
AMD��J�߂Ă��炤�ׂ�����w
�c�q����������w
�c�q���Ȃ߂��
���̂��炢����w�R�^�����
���̂��炢����w�R�^�����
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ,r'::::::::::::::::::::;::r;:r l::::::::::::::::::l!
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ 'i::::::::i:::;:::;r'�L'�L �@ `�S:::::::::::::l!
�@�@�@�@�@�@�@r�]��@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ 'i;i::::::l_,,,_�@�@�@�@__,,,_ �S::::::::::l!
�@�@�@�@�@�@ �l�@�T,,_�@�@,,_,,,��@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@'i;:::,,i�L�P�l�]'i�L�P�Mi!�_l::::::::;;;l!
�@ �@ �@ �@ �i���j�P�@�P i�]�-l��@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �@ �@ �@ !i`'�]''�l _`�]-�]'� �@ `;�L!;;;l!
�@�@�@�@�@�@�@�M`'�]��i�@�]`-'__ )�j�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �@ �@ �l�@�@�@�@�@�@ ,�@�@�,/;l!''
�@�@�@�@�@�@�@�@�@�@l�@l!�@`-' ,r'i {_,,,_�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@l�@ -===�''�@�@ �`'l!
�@�@�@�@�@�@�@�@�@�@ l�@l!�@�P l!�@/,_�@�j�@�@�@�@�@�@ �@ �@ �@ �@ �@ �@ �@ �@ l!�@�@�L �@�@�@ / :l''
�@�@�@�@�@ �@ �@ �@ �^l�@l!/�,=-,(��)��,,_�@�@�@�@�@_,,r�]�]--�]�[�]--�@,,__,,,r}�T__,,, ��@ -'�@ l�
�@�@ �@ �@ �@ �@ �@ l�__l :l!__,(_�\�P�j l;;;;;;�P�P�P;;;;;;;;;;;;;;;;;;;;;;;;;�R;;;;;;;l;;;;;;;�R_�P�M`''�]- � , -�]}
�@�@�@�@�@�@�@ �@ �@ }�@�R-~__,,,' -�]i/�t;;;;;;;;;;;;;;;;;;;�R;;;;;;;;;;;;;;;;;;;;;;;;;�R;;;;l;;;;;;;;;;;�R�P`''�]- �l!/�^{`�]-�
�@�@�@�@�@�@�@�@�@�@ l!�@�@�Q__,,, -�]{ l l;;;;;;;;;;;;;;;;;;;;;l;;;;;;;;;;;;;;;;;;;;;;;;;;;;l;;;;;;`''=�]-�@�_�]-�'�L�@', ' ,�R;;;;�R�__
�@�@�@�@�@�@�@�@�@ �@ `- ,,�Q_,,,�@�]'l./ l;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;l;;;;;;;;;`'�] �;;;;;;;;;;;>'�@�@�@',�@' ,�R��;;;;;;�P`'�]�
�@�@�@�@�@�@�@�@�@�@�@�@ l! �R`�]-��^ /;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;l;;;;;;;;;;;;;;;;;;;;;`'�] /�@�@�@�@ , �@ '�@�R/;;;;;;;;;;;;;;;;;�R
�c�q�͖łтʁA���x�ł��S�邳�I�I
Fermi�̗͂����l�ނ̖������炾�I�I
����Fermi���I�I�삯�I�I���������I�IIntel��������߂��I�I
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ 'i::::::::i:::;:::;r'�L'�L �@ `�S:::::::::::::l!
�@�@�@�@�@�@�@r�]��@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ 'i;i::::::l_,,,_�@�@�@�@__,,,_ �S::::::::::l!
�@�@�@�@�@�@ �l�@�T,,_�@�@,,_,,,��@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@'i;:::,,i�L�P�l�]'i�L�P�Mi!�_l::::::::;;;l!
�@ �@ �@ �@ �i���j�P�@�P i�]�-l��@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �@ �@ �@ !i`'�]''�l _`�]-�]'� �@ `;�L!;;;l!
�@�@�@�@�@�@�@�M`'�]��i�@�]`-'__ )�j�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �@ �@ �l�@�@�@�@�@�@ ,�@�@�,/;l!''
�@�@�@�@�@�@�@�@�@�@l�@l!�@`-' ,r'i {_,,,_�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@l�@ -===�''�@�@ �`'l!
�@�@�@�@�@�@�@�@�@�@ l�@l!�@�P l!�@/,_�@�j�@�@�@�@�@�@ �@ �@ �@ �@ �@ �@ �@ �@ l!�@�@�L �@�@�@ / :l''
�@�@�@�@�@ �@ �@ �@ �^l�@l!/�,=-,(��)��,,_�@�@�@�@�@_,,r�]�]--�]�[�]--�@,,__,,,r}�T__,,, ��@ -'�@ l�
�@�@ �@ �@ �@ �@ �@ l�__l :l!__,(_�\�P�j l;;;;;;�P�P�P;;;;;;;;;;;;;;;;;;;;;;;;;�R;;;;;;;l;;;;;;;�R_�P�M`''�]- � , -�]}
�@�@�@�@�@�@�@ �@ �@ }�@�R-~__,,,' -�]i/�t;;;;;;;;;;;;;;;;;;;�R;;;;;;;;;;;;;;;;;;;;;;;;;�R;;;;l;;;;;;;;;;;�R�P`''�]- �l!/�^{`�]-�
�@�@�@�@�@�@�@�@�@�@ l!�@�@�Q__,,, -�]{ l l;;;;;;;;;;;;;;;;;;;;;l;;;;;;;;;;;;;;;;;;;;;;;;;;;;l;;;;;;`''=�]-�@�_�]-�'�L�@', ' ,�R;;;;�R�__
�@�@�@�@�@�@�@�@�@ �@ `- ,,�Q_,,,�@�]'l./ l;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;l;;;;;;;;;`'�] �;;;;;;;;;;;>'�@�@�@',�@' ,�R��;;;;;;�P`'�]�
�@�@�@�@�@�@�@�@�@�@�@�@ l! �R`�]-��^ /;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;l;;;;;;;;;;;;;;;;;;;;;`'�] /�@�@�@�@ , �@ '�@�R/;;;;;;;;;;;;;;;;;�R
�c�q�͖łтʁA���x�ł��S�邳�I�I
Fermi�̗͂����l�ނ̖������炾�I�I
����Fermi���I�I�삯�I�I���������I�IIntel��������߂��I�I
http://www.semiaccurate.com/2009/12/16/oak-ridge-cans-nvidia-based-fermi-supercomputer/
�iORNL��Nvidia�ɂ��Felmi�̃X�[�p�[�R���s���[�^�[���L�����Z�����܂�
�M���Ēx�ꂷ��������Fermi�̃X�p�R�����L�����Z�������āB
���̕����ᑼ�̃L�����Z�����������낤�ȁB
�������[�J�X�t�B�����̓z���_�����낤�ˁB
�iORNL��Nvidia�ɂ��Felmi�̃X�[�p�[�R���s���[�^�[���L�����Z�����܂�
�M���Ēx�ꂷ��������Fermi�̃X�p�R�����L�����Z�������āB
���̕����ᑼ�̃L�����Z�����������낤�ȁB
�������[�J�X�t�B�����̓z���_�����낤�ˁB
�c�q�����������������
���E�����ڂ��Ă܂�
���E�����ڂ��Ă܂�
����̓�������
Fermi���U�x���`���o��邠���胄�o������ˁB
����ɂ��Ă����i�c�q�̐l���ǂꂾ����������Ă��邩�A��������
�ɂȂ�ƕ�������ɂȂ��Ă���Ȃ��B
����ɂ��Ă����i�c�q�̐l���ǂꂾ����������Ă��邩�A��������
�ɂȂ�ƕ�������ɂȂ��Ă���Ȃ��B
�c�q�ƋƊE�̊W
Larrabee�ō������s�A��������
����Fermi���ȁ��s��A�����A�X�p�R���L�����Z��
���f�͌�����HD58xx�̑O�|���A��l�C�A���N1���Ń��C���i�b�v�����A���NRV9xx�\��ALlano����480SP
Larrabee�ō������s�A��������
����Fermi���ȁ��s��A�����A�X�p�R���L�����Z��
���f�͌�����HD58xx�̑O�|���A��l�C�A���N1���Ń��C���i�b�v�����A���NRV9xx�\��ALlano����480SP
���o�C��WiMAX�ɂ������ꂵ�ĂȂ����������H
955 �F,,�E�L�́M�E,,�j��-�������F2009/12/18(��) 01:50:00 ID:ZyHdS8Sd
Radeon�ō�
Radeon�}���Z�[
Radeon�}���Z�[
�c�q����B��߂Ă���AAMD�܂ŋN�i����Ă��܂��B
957 �F,,�E�L�́M�E,,�j��-�������F2009/12/18(��) 02:14:09 ID:ZyHdS8Sd
Bulldozer�叟���I
Llano�̓��[�G���h�s��𐧂���I
Llano�̓��[�G���h�s��𐧂���I
959 �F,,�E�L�́M�E,,�j��-�������F2009/12/18(��) 06:58:29 ID:ZyHdS8Sd
960 �F,,�E�L�́M�E,,�j��-�������F2009/12/18(��) 07:01:24 ID:ZyHdS8Sd
Fermi����̓I�ɖJ�߂����ƂȂ�Ă��������H
��̓I�Ɍ����ȗ��R�Ȃ猾���Ă邪
��̓I�Ɍ����ȗ��R�Ȃ猾���Ă邪
961 �F,,�E�L�́M�E,,�j��-�������F2009/12/18(��) 07:12:07 ID:ZyHdS8Sd
5�E�F�C��64�����10240�r�b�g���̉��Z���\������Cell��80�{�����I
��Llano����480SP
�Ȃ�Chrome400/500��32SP�ȉ����E�E
�Ȃ�Chrome400/500��32SP�ȉ����E�E
�Œ�@�\���ǂ�قǂ̂��Ă邩���Ȋ̐S�Ȃ̂�
����961
�T�^�[���I�I��64bit���I�I
�T�^�[���I�I��64bit���I�I
965 �F,,�E�L�́M�E,,�j��-�������F2009/12/18(��) 07:30:45 ID:ZyHdS8Sd
>>963
Llano��Windows 7��BitLocker�ɑΉ�����AES���߂��T�|�[�g���Ȃ����ƂŁA��R�X�g�������I
��ƌ����Ƃ͍��ʉ����邱�ƂŒቿ�i�w�ւ̃A�s�[���������I
��AES�ǂ��납SSSE3, SSE4.1, SSE4.2���T�|�[�g���܂���
Llano��Windows 7��BitLocker�ɑΉ�����AES���߂��T�|�[�g���Ȃ����ƂŁA��R�X�g�������I
��ƌ����Ƃ͍��ʉ����邱�ƂŒቿ�i�w�ւ̃A�s�[���������I
��AES�ǂ��납SSSE3, SSE4.1, SSE4.2���T�|�[�g���܂���
>963
���̂��߂ɓ�������́H
���̂��߂ɓ�������́H
Intel�Ɠ������R����jk
Why the FTC lawsuit against Intel has substance
http://www.brightsideofnews.com/news/2009/12/17/why-the-ftc-lawsuit-against-intel-has-substance.aspx
�����̔炪�|���|���|���|����
http://www.brightsideofnews.com/news/2009/12/17/why-the-ftc-lawsuit-against-intel-has-substance.aspx
�����̔炪�|���|���|���|����
AMD�̏ꍇSSE�͎g���Ƃ������Ēx���Ȃ�
Intel C/C++�̏��H�Ɉ����������Ă��Ȃ��āH
Intel�Ɠ������R���ĂȂɁH
��č팸�A���\up�̉\���̖͍�
����ȂƂ���ł���
NV�́c�c�c�c
����ȂƂ���ł���
NV�́c�c�c�c
>>965
����AMD��AES�Ή����Ȃ��̂��͕s�������ǁA
��Ƃ͈�ʎ����ł�Windows7 Ultimate��Windows server�̗p����Ƃ��������ł��ˁB
ttp://www.microsoft.com/japan/athome/umall/win7/function/05.aspx
BitLocker�ABitLocker To Go �� Windows 7 Ultimate �ł݂̂��g�����������܂��B
XP�̃V�X�e�����x���ł�AES�Ή��͒m������������낤�B
����AMD��AES�Ή����Ȃ��̂��͕s�������ǁA
��Ƃ͈�ʎ����ł�Windows7 Ultimate��Windows server�̗p����Ƃ��������ł��ˁB
ttp://www.microsoft.com/japan/athome/umall/win7/function/05.aspx
BitLocker�ABitLocker To Go �� Windows 7 Ultimate �ł݂̂��g�����������܂��B
XP�̃V�X�e�����x���ł�AES�Ή��͒m������������낤�B
��Ƃ̃N���C�A���gPC�Ƃ��AXP�ł�Home�̗p�����������̂ɁA
7��Ultimate�ȂR�X�g�ʂŋp������B
��{�I�ȔF���������Ă�B
7��Ultimate�ȂR�X�g�ʂŋp������B
��{�I�ȔF���������Ă�B
��Ƃ�BitLocker���K�v��������Enterprise�̃��C�Z���X��������Ȃ��́H
��ʎ����̓h���C���ɎQ�����Ȃ���
�l�b�g�ɂ��q����Ȃ����Ă�
�l�b�g�ɂ��q����Ȃ����Ă�
�܂�o��팸�Ńl�b�g�u�b�N���̗p����Ƃ����Win7 Ultimate�̗p��������̂�Intel�́B
���O��ǂ������ȁA��Ђ�Ultimate�g���āB
����Business��Home��������g���ˁ[���Č����ĕς��Ă��炦��B
���O��ǂ������ȁA��Ђ�Ultimate�g���āB
����Business��Home��������g���ˁ[���Č����ĕς��Ă��炦��B
Business�Ȃ�ĂȂ����H
PRO�ł����H
Ultimate�Ƃ̉��i������1000�~�������������H
PRO�ł����H
Ultimate�Ƃ̉��i������1000�~�������������H
>>978
Vista�ƍ������Ă����B
�A�}�]������
Ulti���K�ŁF35990�~
Pro���K�F34980�~
home�F22990�~
����1000�~�����Ǎ��{�I�ɍ�������ww
home��1���~�ȏ�����B
�A�b�v�O���[�h����
Uli�F24690�~
Pro�G18719�~(�D�Ҕ�)
home�F13100(�D�Ҕ�)
���������킹���Ȃ����ǁA���݂�6000�~�̍��B
home�Ƃ�1���~�ȏ�B
��ƌ����͂ǂ��Ȃ낤���B
Vista�ƍ������Ă����B
�A�}�]������
Ulti���K�ŁF35990�~
Pro���K�F34980�~
home�F22990�~
����1000�~�����Ǎ��{�I�ɍ�������ww
home��1���~�ȏ�����B
�A�b�v�O���[�h����
Uli�F24690�~
Pro�G18719�~(�D�Ҕ�)
home�F13100(�D�Ҕ�)
���������킹���Ȃ����ǁA���݂�6000�~�̍��B
home�Ƃ�1���~�ȏ�B
��ƌ����͂ǂ��Ȃ낤���B
��ƂȂ�G���v���ł�VL�Ŕ����̂��₷��
10���C�Z���X�ł�DSP�ł������Ȃ�̂�VL��
��Ƃł�OS�����PC������Ȃ��̂��ȁH
OS���{�����[�����C�Z���X�Ŕ����悤�ȂƂ����
OS�Ȃ��̋@�ނ��w�������ł��傤���H
OS���{�����[�����C�Z���X�Ŕ����悤�ȂƂ����
OS�Ȃ��̋@�ނ��w�������ł��傤���H
L
>>982
�m��ǁA����PC�[�J�[�����炩����VL���܂�ł���Ă��Ƃ���Ȃ��́H
���炪�\�j�[��VAIO����Windows���g���̂́A
���炪�\�j�[�ƌ_��Windows���g���Ă�Ȃ���
����̓Q�C�c�ƌ_��Windows���g���Ă��ł���H
�\�j�[�̓Q�C�c�ɗ����Windows���ڂ������Ă��������Ă��H
�����牴��ƃQ�C�c�̌_��Ƀ\�j�[�͊W�Ȃ��킯����H
�ł��o���o���ɕ����͖̂ʓ|������A���炩���߃\�j�[���Q�C�c�_��̑�����܂߂�VAIO���Ă��ˁB
�@�@�@�@�Q�C�c
����@�@�@�@�@�@�\�j�[
�O�p�W
�m��ǁA����PC�[�J�[�����炩����VL���܂�ł���Ă��Ƃ���Ȃ��́H
���炪�\�j�[��VAIO����Windows���g���̂́A
���炪�\�j�[�ƌ_��Windows���g���Ă�Ȃ���
����̓Q�C�c�ƌ_��Windows���g���Ă��ł���H
�\�j�[�̓Q�C�c�ɗ����Windows���ڂ������Ă��������Ă��H
�����牴��ƃQ�C�c�̌_��Ƀ\�j�[�͊W�Ȃ��킯����H
�ł��o���o���ɕ����͖̂ʓ|������A���炩���߃\�j�[���Q�C�c�_��̑�����܂߂�VAIO���Ă��ˁB
�@�@�@�@�Q�C�c
����@�@�@�@�@�@�\�j�[
�O�p�W
�Ƃ��邤����ՂƂł܂����Ă܂�
��������������ǂ����������ʂ��ł������傤�Ԃł�
��������������ǂ����������ʂ��ł������傤�Ԃł�