Intel�̎�����CPU�ɂ��Č�낤 41
���O�X��
Intel�̎�����CPU�ɂ��Č�낤 40
http://pc11.2ch.net/test/read.cgi/jisaku/1246074491/
���֘A�X��
�yPenryn�z�����ヂ�o�C��CPU�G�k�� 4�yNehalem�z
ttp://pc11.2ch.net/test/read.cgi/notepc/1200200003/
Intel uPs Info 4
ttp://pc11.2ch.net/test/read.cgi/mac/1214461149/
���X����>>950�A�Ղ�i�s�̎���>>850�痧�Ă�錾�����A�o���Ȃ����͈��p���w�������B
��>>950�̓��ݓ������������Ă��܂��B�X�����Ă̈ӎv�̖�������>>950���O�̏������݂͍T���Ă��������B
Intel�̎�����CPU�ɂ��Č�낤 40
http://pc11.2ch.net/test/read.cgi/jisaku/1246074491/
���֘A�X��
�yPenryn�z�����ヂ�o�C��CPU�G�k�� 4�yNehalem�z
ttp://pc11.2ch.net/test/read.cgi/notepc/1200200003/
Intel uPs Info 4
ttp://pc11.2ch.net/test/read.cgi/mac/1214461149/
���X����>>950�A�Ղ�i�s�̎���>>850�痧�Ă�錾�����A�o���Ȃ����͈��p���w�������B
��>>950�̓��ݓ������������Ă��܂��B�X�����Ă̈ӎv�̖�������>>950���O�̏������݂͍T���Ă��������B
|
|
|
Radeon XLVIII (Codename:Larrabee) inside™
ð�!�����!
ð�!�����!
1��
�}���`�R�A�Ή��̃Q�[����
i5-6xx�V���[�Y���ǂ��܂Ńp�t�H�[�}���X�ł邩�C�ɂȂ�B
�N���b�N��������A��ʓI�ȃQ�[���Ȃ�R���ł����Ǝv�����ǁA
�}���`�R�A�Ή��̃Q�[���łg�s���ǂꂭ�炢�����낤�E�E
i7�̂W�X���b�h�����ł́A�قƂ�LjӖ����Ȃ��������ǁB
i5-750�Ƃ̈ʒu�W���C�ɂȂ�B
���ƁA�f�o�t�R�A�́A�Q�t�H�Ƃ��ʂɍڂ����ꍇ�ł��A�d�C������ςȂ��H
�}���`�R�A�Ή��̃Q�[����
i5-6xx�V���[�Y���ǂ��܂Ńp�t�H�[�}���X�ł邩�C�ɂȂ�B
�N���b�N��������A��ʓI�ȃQ�[���Ȃ�R���ł����Ǝv�����ǁA
�}���`�R�A�Ή��̃Q�[���łg�s���ǂꂭ�炢�����낤�E�E
i7�̂W�X���b�h�����ł́A�قƂ�LjӖ����Ȃ��������ǁB
i5-750�Ƃ̈ʒu�W���C�ɂȂ�B
���ƁA�f�o�t�R�A�́A�Q�t�H�Ƃ��ʂɍڂ����ꍇ�ł��A�d�C������ςȂ��H
1��
�O�X���̃I�`�ɐ�������
�O�X���̃I�`�ɐ�������
7 �FSocket774�F2009/10/11(��) 02:05:10 ID:e1lJqKvX
sandy�ŃA�[�L�e�N�`�������Ƃ������ɂق����Ă�������������
���ɂ͂킩���B
���������Đ��Ԃł�AVX���������ŃA�[�L�e�N�`��������������ƂɂȂ�́H
�܂��������Ƀf�R�[�_�͕ς�邯�ǁB
���ɂ͂킩���B
���������Đ��Ԃł�AVX���������ŃA�[�L�e�N�`��������������ƂɂȂ�́H
�܂��������Ƀf�R�[�_�͕ς�邯�ǁB
�ӂ�
�ŋ߂̃x���`�}�[�N�ő����Ă����@�R�[�f�b�N�Ƃ��摜�����̃p�t�H�[�}���X�̒�グ�ɂȂ��邩�炶��ˁH
����Ӗ��L�p�ł���Ӗ����Ӗ�
����Ӗ��L�p�ł���Ӗ����Ӗ�
Sandy���R�A�̒�����Ȃ��O�����ς�邾���������ȁB
GPU�t����AVX�Ή����������B
�L���b�V���������Ȃ�����H
GPU�t����AVX�Ή����������B
�L���b�V���������Ȃ�����H
Win7�ł�AVX�Ή����Ȃ��ƌ����Ă邩��12�N�ɏo��Ƃ������Ă�
Win8�ɉ����ăA�v���̑Ή����҂��Ȃ��ƁE�E�E
�Ƃ��l����ƈĊONehalem�͒���������̂�����
Win8�ɉ����ăA�v���̑Ή����҂��Ȃ��ƁE�E�E
�Ƃ��l����ƈĊONehalem�͒���������̂�����
AVX�Ń��W�X�^�����ς�邩��AOS���ŃR���e�N�X�g�X�C�b�`����
���W�X�^�ޔ������AVX�Ή��ɂ��Ă���Ƒʖڂ���ˁH
�^�C�~���O�I�ɂ��蓾��̂�Win7 SP1���Ȃ�
���W�X�^�ޔ������AVX�Ή��ɂ��Ă���Ƒʖڂ���ˁH
�^�C�~���O�I�ɂ��蓾��̂�Win7 SP1���Ȃ�
�A�[�L���啝�ɕύX�����̂�Haswell����
Cell�̂悤�ȃw�e���W�j�A�X�}���`�R�A�ɂȂ�iLarrabee�����j
�����ē����ɔ��M�g�[CPU�APenD�̍ė��i�J�����Ă�̃I���S���`�[�������j
Cell�̂悤�ȃw�e���W�j�A�X�}���`�R�A�ɂȂ�iLarrabee�����j
�����ē����ɔ��M�g�[CPU�APenD�̍ė��i�J�����Ă�̃I���S���`�[�������j
�ŋߏo��Larrabee�̃��A���^�C�����C�g���[�V���O�f�����������ł�
�~�h���n�C�`�G���X�[�W�A�X�g�����f�B�X�N���[�gGPU�s��̃V�F�A��
�D���قǂł͂Ȃ��Ɗ������B
���[�G���h����~�h�����[�ӂ�̃f�B�X�N���[�gGPU�s�ꂪ�����Ȃ�
�\���͂���B
�~�h���n�C�`�G���X�[�W�A�X�g�����f�B�X�N���[�gGPU�s��̃V�F�A��
�D���قǂł͂Ȃ��Ɗ������B
���[�G���h����~�h�����[�ӂ�̃f�B�X�N���[�gGPU�s�ꂪ�����Ȃ�
�\���͂���B
������Ė{����larrabee�œ����Ă�̂��H
>>16
����͂ǂ��������Ƃ����H
����͂ǂ��������Ƃ����H
Geforce�œ���������ł́H
���╁�ʂ�Corei7�ł���Ă���Ȃ��̂�
���̒��x�Ȃ�
���̒��x�Ȃ�
>>18
ttp://www.4gamer.net/games/049/G004963/20090923003/
���̐��J�[�h��GeForce�����Ă��ƁH
Intel�قǂ̑��Ƃ�����ȃy�e�����邩�H
ttp://www.4gamer.net/games/049/G004963/20090923003/
���̐��J�[�h��GeForce�����Ă��ƁH
Intel�قǂ̑��Ƃ�����ȃy�e�����邩�H
�O��Intel��64bitOS���Ɛ��\���ǂ��Ȃ����ĕ������̂ł����A
���ꂩ��o��Corei�V���[�Y�ł͉��P����Ă܂����H
���ꂩ��o��Corei�V���[�Y�ł͉��P����Ă܂����H
>>15
���̃f���ł킩����Đ���ESP�͂���
���̃f���ł킩����Đ���ESP�͂���
>>22
P55�͎~�߂����������A�W���d�l�Ƃ��ĘR��Ȃ��G���b�^���t���Ă���
P55�͎~�߂����������A�W���d�l�Ƃ��ĘR��Ȃ��G���b�^���t���Ă���
>>24
�T���N�X�ł�
���ƃ����R�����ē�������Ă��ł���ˁH
AMD�̂Ɣ�ׂĂ����F�Ȃ��ł��傤���H
�x���`�I�Ȑ��\�����̊���D�悵�����̂ŁB
�T���N�X�ł�
���ƃ����R�����ē�������Ă��ł���ˁH
AMD�̂Ɣ�ׂĂ����F�Ȃ��ł��傤���H
�x���`�I�Ȑ��\�����̊���D�悵�����̂ŁB
���̒��xCorei7�ł��o����i�د
���Ɏg�����ɂ�邾��
�摜���k�Ƃ��d�����A�v���g���Ȃ獂���̔������ق����������A
web�T�[�t�B�����x�Ȃ�l�i�������̑I��ł�����Ȃɕς���
�摜�`��Ƃ��ŕ��ʂ͖��Ȃ��̂�����ւ��̂Ƃ��Ƃ��͕ςɂ��������肵�Ă���Ȃ��c
(C2D+nV88GTS)
�摜���k�Ƃ��d�����A�v���g���Ȃ獂���̔������ق����������A
web�T�[�t�B�����x�Ȃ�l�i�������̑I��ł�����Ȃɕς���
�摜�`��Ƃ��ŕ��ʂ͖��Ȃ��̂�����ւ��̂Ƃ��Ƃ��͕ςɂ��������肵�Ă���Ȃ��c
(C2D+nV88GTS)
�����R�������L�r�L�r�͓s�s�`�������ǁB
Corei�̓����R�����������炢����łȂ��ł��傤���B
Corei�̓����R�����������炢����łȂ��ł��傤���B
>>26
����X������
����X������
�݂Ȃ��肪�Ƃ��������܂��B
����ς܂������ȂƂ��������ł��˂��E�E�E�B
i5-6XX�����肪�C�ɂȂ��ŁA�o���炢�낢�뒲�ׂĂ݂܂��B
>>30
������ƃX���`�Șb��ɂȂ��Ă��݂܂���i���j
����ς܂������ȂƂ��������ł��˂��E�E�E�B
i5-6XX�����肪�C�ɂȂ��ŁA�o���炢�낢�뒲�ׂĂ݂܂��B
>>30
������ƃX���`�Șb��ɂȂ��Ă��݂܂���i���j
>�j31
x64�̐��\��
i7>i5=AMD>Core2����
x64�̐��\��
i7>i5=AMD>Core2����
AMD���ĉ��H�s�s�`���ł���H
64���\�����ɂ��Ă���core2�������߂�Ȃ�Ă��܂���ǂ������Ȃ�w
����ׂł�����A�����Ă��������B
Corei�ł�����
Core2��AMD�ɗ��ƌ������Ƃ͑S���Ȃ�����64bit�ł��BAMD�͕s�v�B
Core2��AMD�ɗ��ƌ������Ƃ͑S���Ȃ�����64bit�ł��BAMD�͕s�v�B
�f�X�N�g�b�v�p�r�ɂ�����x64�̗��_�Ȃ�ă���������������g����Ƃ�����_�����ŏ\������Ȃ��̂��B
���W�X�^�������邩����s���x�オ��Ƃ��ASSE2�K�{������x��x87�g��Ȃ��čςނƂ��F�X���邾��
ASCII�̃l�b�g�L����7��64�̂����邩��݂�Ƃ����B
Core2�ł���AMD�������Ă�v�f���قƂ�ǂȂ��B
Nehalem�ł͂���ɑR��c
Core2�ł���AMD�������Ă�v�f���قƂ�ǂȂ��B
Nehalem�ł͂���ɑR��c
�|�C���^��2�{��8�o�C�g�ɂȂ��đ��E����镪������B
64bit�Ő��\���シ��Ȃ獡��AlphaAXP�̓V���B
64bit�Ő��\���シ��Ȃ獡��AlphaAXP�̓V���B
�����ł܂����́ASandayBrige�A128bitCPU�œo��B
Win8�ȍ~��128bit�ł�����炵���̂ŁB
Win8�ȍ~��128bit�ł�����炵���̂ŁB
������IA-64�n��Ƃ����b�E�E�E
>>18
���b�N�A�b�v�łǂ�����ē������́H
���b�N�A�b�v�łǂ�����ē������́H
45 �FSocket774�F2009/10/13(��) 22:12:19 ID:nn0+1DAh
i11�����肪128bit�ɂȂ��ł˂��́B
>>15
�I���W�i����Quake Wars���ǂ�Ȃ̂��m���Ă�̂��H
�e�N�X�`����f�����O������x��Ȃ̂͂���������肾����d���Ȃ��B
�Â��Q�[���𐅖ʂ�����̎����ň������Ă�̂��f���̈Ӑ}����B
�����Â��Q�[�����ƁA����Ӗ��Ń��C�g���̌��ʂ̂��܂�����������B
�Ԉ���Ă�Crysis�ȂƔ�ׂ�Ȃ�B
�I���W�i����Quake Wars���ǂ�Ȃ̂��m���Ă�̂��H
�e�N�X�`����f�����O������x��Ȃ̂͂���������肾����d���Ȃ��B
�Â��Q�[���𐅖ʂ�����̎����ň������Ă�̂��f���̈Ӑ}����B
�����Â��Q�[�����ƁA����Ӗ��Ń��C�g���̌��ʂ̂��܂�����������B
�Ԉ���Ă�Crysis�ȂƔ�ׂ�Ȃ�B
���������Ȃ����邾�끄�f��
IDF�ł̃f���ɂ�����Larrabee��A6�̃o�O���܂������ł炵������A
�f���ő債�����Ƃł��Ȃ�������Ȃ��́H
�f���ő債�����Ƃł��Ȃ�������Ȃ��́H
���Ⴀ�o�O���Ă���f������H���Ă����B
�ʂɕϐg�c������Ԃœo�ꂵ�Ęb����グ�Ȃ��Ă�������B
�ʂɕϐg�c������Ԃœo�ꂵ�Ęb����グ�Ȃ��Ă�������B
���ł����\��J����Ƃł��H
���w�������܂�
���w�������܂�
A6�܂Ői�߂Ăăo�O���Ȃ��̂��ǂ�����
�Ƃ������v�����Đ��\�łȂ������낤��
Rev.A��Rev.B����ʕ��炵������
�Ƃ������v�����Đ��\�łȂ������낤��
Rev.A��Rev.B����ʕ��炵������
Nehalem�͏�����Bloomfield����C0����Nehalem-EP��D0�Ȃ�
�f���ő������|����p���[����������Ȃ������
�V���{�����ǂ܂��o�O����ł�����S�͂��Ⴀ��܂���A�ȃf���Ȃ�
���Ȃ���������
�V���{�����ǂ܂��o�O����ł�����S�͂��Ⴀ��܂���A�ȃf���Ȃ�
���Ȃ���������
����ڂ�������Ȃ��ŊJ���i��ł邩�^���邩�A
����ڂ��Ă������f���ňꉞ���@����܂�����Č�����ق����������ŁA
Intel�͂���������������Ĕ��f������������Ȃ��́H
����ڂ��Ă������f���ňꉞ���@����܂�����Č�����ق����������ŁA
Intel�͂���������������Ĕ��f������������Ȃ��́H
Intel���I���ɐ��\��r����f��������̂���Opteron�ɒǂ��l�߂��Ă鎞���炢
��{�I�ɂ���n�̃A�s�[���̓}�C���h
��{�I�ɂ���n�̃A�s�[���̓}�C���h
B0��IDF�ɊԂɍ���Ȃ������������B
����IDF���炢�C���ɑ҂Ƃ����B�ǂ݂̂�3�J���ȓ��ɂ͏o�Ȃ����B
����IDF���炢�C���ɑ҂Ƃ����B�ǂ݂̂�3�J���ȓ��ɂ͏o�Ȃ����B
>>46
���ʂ̃Q�[�}�[�Ȃ�Crysis�Ƃ��Ɣ�ׂ�
���ʂ̃Q�[�}�[�Ȃ�Crysis�Ƃ��Ɣ�ׂ�
���ʂ̃Q�[�}�[�i�j����Ȃ��ĊJ���Ҍ����̃C�x���g�ł��̂ŁB
>>12
�����Ăˁ[��
�ǂ��̃o�J���C�^�[����t�J�V�L���ɂ���������
���W�X�^�ޔ��iXSAVE/XRESTOR�j�����T�|�[�g����Ί�{�I�Ɏg���邵�B
Win7�̓f�t�H�Ή��B
�Ȃɂ��̏؋��Ƃ���VS2010/Win7SDK��AVX�̑g�ݍ��݊��w�b�_������
�P�ɓ���DLL��SSE����̒u���������i��łȂ���������
�A�v���Ŏg�����ɂ͉���x��Ȃ��B
�����Ăˁ[��
�ǂ��̃o�J���C�^�[����t�J�V�L���ɂ���������
���W�X�^�ޔ��iXSAVE/XRESTOR�j�����T�|�[�g����Ί�{�I�Ɏg���邵�B
Win7�̓f�t�H�Ή��B
�Ȃɂ��̏؋��Ƃ���VS2010/Win7SDK��AVX�̑g�ݍ��݊��w�b�_������
�P�ɓ���DLL��SSE����̒u���������i��łȂ���������
�A�v���Ŏg�����ɂ͉���x��Ȃ��B
http://msdn.microsoft.com/en-us/library/dd445216.aspx
> XsaveSupport
> A UINT64 value that specifies whether the processor supports the XSAVE feature. The XSAVE feature indication is set in the first bit of the 64-bit AsUINT64 member (0x0000000000000001).
> XsaveoptSupport
> A UINT64 value that specifies whether the processor supports the XSAVE optional feature. The XSAVE optional feature indication is set in the second bit of the 64-bit AsUINT64 member (0x0000000000000002).
> AvxSupport
> A UINT64 value that specifies whether the processor supports the AVX feature. The AVX feature indication is set in the third bit of the 64-bit AsUINT64 member (0x0000000000000004).
> XsaveSupport
> A UINT64 value that specifies whether the processor supports the XSAVE feature. The XSAVE feature indication is set in the first bit of the 64-bit AsUINT64 member (0x0000000000000001).
> XsaveoptSupport
> A UINT64 value that specifies whether the processor supports the XSAVE optional feature. The XSAVE optional feature indication is set in the second bit of the 64-bit AsUINT64 member (0x0000000000000002).
> AvxSupport
> A UINT64 value that specifies whether the processor supports the AVX feature. The AVX feature indication is set in the third bit of the 64-bit AsUINT64 member (0x0000000000000004).
���[�U�[���[�h���x���ł͂��������ȁH
http://msdn.microsoft.com/en-us/library/dd405472%28VS.85%29.aspx
> XSTATE_MASK_GSSE Intel Advanced Vector Extensions (Intel AVX) are enabled.
> (��)
> Minimum supported client Windows 7
> Minimum supported server Windows Server 2008 R2
Windows 7��AVX�Ή��ς�
�����āA�������Ȃ��Ƃ������Ă�L�҂͂�����
http://ascii.jp/elem/000/000/464/464223/index-3.html
http://msdn.microsoft.com/en-us/library/dd405472%28VS.85%29.aspx
> XSTATE_MASK_GSSE Intel Advanced Vector Extensions (Intel AVX) are enabled.
> (��)
> Minimum supported client Windows 7
> Minimum supported server Windows Server 2008 R2
Windows 7��AVX�Ή��ς�
�����āA�������Ȃ��Ƃ������Ă�L�҂͂�����
http://ascii.jp/elem/000/000/464/464223/index-3.html
3Q�̌��Z�B�����߂�
ttp://www.intel.com/pressroom/archive/releases/20091013corp.htm
ttp://www.intel.com/pressroom/archive/releases/20091013corp.htm
�������v
�C���e���A3Q�D���͌i�C�ɋZ�p�v�V���d�v�ł��邱�Ƃ̏ƕ���
���㍂�͑O�N�������������A�A�i���X�g�\���ƑO�l���������鋭��
ttp://www.computerworld.jp/news/trd/164649.html
���㍂�͑O�N�������������A�A�i���X�g�\���ƑO�l���������鋭��
ttp://www.computerworld.jp/news/trd/164649.html
�C�V���̎�����u�j���e���h�[DS�v��HD����⍂�掿�ȃQ�[���ɂ��Ή������uTegra�v���Z�b�T�v�𓋍ڂ�
http://gigazine.net/index.php?/news/comments/20091014_next_ds/
http://gigazine.jp/img/2009/10/14/next_ds/next_ds01.jpg
Zune X�͒P�Ȃ�\���������ǁAAtom��SoC���o�����������?
http://gigazine.net/index.php?/news/comments/20091014_next_ds/
http://gigazine.jp/img/2009/10/14/next_ds/next_ds01.jpg
{kind=link}
Zune X�͒P�Ȃ�\���������ǁAAtom��SoC���o�����������?
67 �F,,�E�L�́M�E,,�j��-�������F2009/10/14(��) 23:00:09 ID:BZHRxyoI
68 �F,,�E�L�́M�E,,�j��-�������F2009/10/14(��) 23:18:29 ID:BZHRxyoI
����ς܂�ǂ���
�C���v���\�ɂ��������A�h
SIGGRAPH ASIA 2009�̓p�V�t�B�R���l��12��
Larrabee��B0(������ȍ~)���J����Ƃ��Ă��̂����肾��
IDF�͏t����
Larrabee��B0(������ȍ~)���J����Ƃ��Ă��̂����肾��
IDF�͏t����
���m�Q���d�g��U��T���Ȃ��ƁA
����ς�ߑa���Ă�Ȃ�
�@�@�@�@�@�@,,,
(�@߄t�)��
�@�@,,�E�L�́M�E,,�j��-������
����ς�ߑa���Ă�Ȃ�
�@�@�@�@�@�@,,,
(�@߄t�)��
�@�@,,�E�L�́M�E,,�j��-������
�����H�c�q�A���~�Ɍ��ܔ������H��
�A���~�ɂ���Ȍ����͂Ȃ��悗
�R�{����NT���ォ��Windows�̏��А��������Ă郉�C�^�[�����B
�Ȃ�ł���Ȕ���L���������낤�B
�Ȃ�ł���Ȕ���L���������낤�B
���͔��Ȃ��Ă��邾�낤��
77 �F,,�E�L�́M�E,,�j��-�������F2009/10/15(��) 22:49:19 ID:I+UKJFoq
�����������B�����ƕ����t����B
���������t��o������
�������������͗p�ӂ��Ă�B�J�ߎE���H���ŁB
���������t��o������
�������������͗p�ӂ��Ă�B�J�ߎE���H���ŁB
78 �FSocket774�F2009/10/16(��) 00:41:32 ID:zYXCtdXf
E7500���Ăǂ���
79 �FSocket774�F2009/10/16(��) 01:30:29 ID:TSfghjNf
Intel to release Core i5 on January 3rd | VR-Zone | Gadgets | PC Enthusiasts
http://vr-zone.com/articles/intel-to-release-core-i5-on-january-3rd/7873.html?doc=7873
Intel is set to release the first 32nm desktop CPUs on 3rd January 2010.
Releasing first are the Clarkdale CPUs - part of the Westmere,
or 32nm Nehalem die shrinks. A total of four models are expected,
Core i5 650, 660 and 670, clocking in at 3.2, 3.33 and 3.46 GHz respectively.
They will be priced at the $176, $196 and $284 respectively.
The other Clarkdale CPUs are the Core i3 530 and 540 covering $123-$150.
The Core i3 CPUs will not feature Turbo mode.
A budget Pentium G6950 is also expected at $84, without turbo, HT and 1MB less L3 cache.
http://vr-zone.com/articles/intel-to-release-core-i5-on-january-3rd/7873.html?doc=7873
Intel is set to release the first 32nm desktop CPUs on 3rd January 2010.
Releasing first are the Clarkdale CPUs - part of the Westmere,
or 32nm Nehalem die shrinks. A total of four models are expected,
Core i5 650, 660 and 670, clocking in at 3.2, 3.33 and 3.46 GHz respectively.
They will be priced at the $176, $196 and $284 respectively.
The other Clarkdale CPUs are the Core i3 530 and 540 covering $123-$150.
The Core i3 CPUs will not feature Turbo mode.
A budget Pentium G6950 is also expected at $84, without turbo, HT and 1MB less L3 cache.
,,�E�L�́M�E,,�j��-������
���ŋ߁A��������悤�ɂȂ���AA�Ȃ��A���ꌩ��ƃ��J�c�N�B
�Ȍ�A��؎g�p�֎~���B���������ȁB
���ŋ߁A��������悤�ɂȂ���AA�Ȃ��A���ꌩ��ƃ��J�c�N�B
�Ȍ�A��؎g�p�֎~���B���������ȁB
82 �F,,�E�L�́M�E,,�j��-������ �F2009/10/16(��) 16:44:12 ID:zE/a6yWW
>>81
�����킩����
�����킩����
Intel�W���X�e�B���E���g�i�[CTO�����
ttp://pc.watch.impress.co.jp/docs/news/20091016_322120.html
ttp://pc.watch.impress.co.jp/docs/news/20091016_322120.html
�e�N�X�`�����j�b�g��ROP�͕ʂƂ��āA���с[�̉��Z�\�͂ɂ�
������Ɗ��҂��Ă�B
������Ɗ��҂��Ă�B
85 �F,,�E�L�́M�E,,�j��-�������F2009/10/17(�y) 00:07:58 ID:6Eq7iFe7
ROP���Č��ǑS���O���[�o���������iVRAM�j�ɓs�x�����߂����B���̕��̃g���t�B�b�N���ʂ����B
�C�R�[���d�̖͂��ʁB���������������S�B
����̒ʂ�ALarrabee�̓\�t�g�E�F�AROP�Ȃ킯�����A�K�v�ȕ������������X�^���C�Y����
�o�b�t�@�ɏ㏑�����邩��A�������Č������ǂ��ʂ�����
Larrabee�̃R�A�͓���FLOPS����GeForce�̃V�F�[�_���j�b�g����ꡂ��ɍ����\�����@�\�ɂȂ��Ă�B
���Z���̂̓X�J���ior �}�X�N�j�ƃx�N�^�̕ϑ�2�������������ɋ��h�����ăI�y���[�V���������҂���B
���ۂ̏��A�Œ�@�\���j�b�g�Ȃ��GPGPU�Ƃ��Ă͖��ʂȃ��j�b�g�Ȃ���r�����ăR�A�����@�\�ɂ����ق��������B
���Ȃ��Ƃ�HPC�ƃ\�t�g�E�F�A�����_���𒌂Ƃ���Larrabee�ɂ͖��ʂ̂Ȃ������B
�C�R�[���d�̖͂��ʁB���������������S�B
����̒ʂ�ALarrabee�̓\�t�g�E�F�AROP�Ȃ킯�����A�K�v�ȕ������������X�^���C�Y����
�o�b�t�@�ɏ㏑�����邩��A�������Č������ǂ��ʂ�����
Larrabee�̃R�A�͓���FLOPS����GeForce�̃V�F�[�_���j�b�g����ꡂ��ɍ����\�����@�\�ɂȂ��Ă�B
���Z���̂̓X�J���ior �}�X�N�j�ƃx�N�^�̕ϑ�2�������������ɋ��h�����ăI�y���[�V���������҂���B
���ۂ̏��A�Œ�@�\���j�b�g�Ȃ��GPGPU�Ƃ��Ă͖��ʂȃ��j�b�g�Ȃ���r�����ăR�A�����@�\�ɂ����ق��������B
���Ȃ��Ƃ�HPC�ƃ\�t�g�E�F�A�����_���𒌂Ƃ���Larrabee�ɂ͖��ʂ̂Ȃ������B
86 �F,,�E�L�́M�E,,�j��-�������F2009/10/17(�y) 00:34:05 ID:6Eq7iFe7
>>83�̕����ǂ�Ŏv��������
�����Intel��Larrabee��CPU�̃_�C��ɓ��������ۂ�L3�L���b�V���o�R��CPU�Ƃ̃f�[�^�̎n�����鎞��
�����̂��Ƃ��l���Ă�ȂƁB
Larrabee�����̎����𖾂����Ȃ��̂͂��̕ӂ̃\�t�g���̐����ł���
�_�C������́iWindows Server 2008�ȍ~�ł����Ƃ���́j�n�C�p�[�o�C�U�w�ɍڂ�����
�Q�X�gOS�Ƃ��āuLarrabee OS�v�i���j���������ƂɂȂ�B
�������f�B�X�N���[�g�ł̏ꍇ�̓Q�X�gOS��VRAM��œ��삷��B
���Ȃ݂ɃQ�X�gOS�̋N���C���[�W�̓h���C�o�̃f�[�^�Ɋ܂܂��
���āA���̂ւ�ɂ��Ƃ�����
�����Intel��Larrabee��CPU�̃_�C��ɓ��������ۂ�L3�L���b�V���o�R��CPU�Ƃ̃f�[�^�̎n�����鎞��
�����̂��Ƃ��l���Ă�ȂƁB
Larrabee�����̎����𖾂����Ȃ��̂͂��̕ӂ̃\�t�g���̐����ł���
�_�C������́iWindows Server 2008�ȍ~�ł����Ƃ���́j�n�C�p�[�o�C�U�w�ɍڂ�����
�Q�X�gOS�Ƃ��āuLarrabee OS�v�i���j���������ƂɂȂ�B
�������f�B�X�N���[�g�ł̏ꍇ�̓Q�X�gOS��VRAM��œ��삷��B
���Ȃ݂ɃQ�X�gOS�̋N���C���[�W�̓h���C�o�̃f�[�^�Ɋ܂܂��
���āA���̂ւ�ɂ��Ƃ�����
>>86
Sandy Bridge��CPU��GPU��L3$�����L����炵�����c�܂����Ȃ�
Sandy Bridge��CPU��GPU��L3$�����L����炵�����c�܂����Ȃ�
Sandy Bridge�̏�S�������Ă��܂����
Intel�͔閧��`�������
ISSCC��HOT CHIPS�̘_���ł��u��`����œ��e�������v�ƍĒ�o�����߂��邱�Ƃ�������
ISSCC��HOT CHIPS�̘_���ł��u��`����œ��e�������v�ƍĒ�o�����߂��邱�Ƃ�������
�����r�[�̏ڍ׃}�_�[�H����I
����t�����
92 �F,,�E�L�́M�E,,�j��-�������F2009/10/17(�y) 12:45:50 ID:6Eq7iFe7
�܂�܂�݂Ă������}�_�[�H�����r�[�̏ڍׁI
�c�q���Ă���Ȃ��Ԕ��L��������������
94 �F,,�E�L�́M�E,,�j��-�������F2009/10/17(�y) 16:37:43 ID:6Eq7iFe7
�d�g�l�^�Ɛ���ƃK�`���قǂ悭�~�b�N�X
�Â����Đh�����ċꂷ����
������CPU��8�R�A�H
Intel Ct�̃v���[���ɂłĂ���悤��16�R�A32�R�A���嗬�ɂȂ�̂͂��̓���
98 �F,,�E�L�́M�E,,�j��-�������F2009/10/17(�y) 18:14:10 ID:6Eq7iFe7
���̋���_�C��1GH���~64�R�A�����o�Ă�悤���ȁB
�{����45nm�Ȃ�17���g�����W�X�^���x�ł��̃_�C�T�C�Y600mm²�͂��蓾��
34���Ȃ�[���B
�{����45nm�Ȃ�17���g�����W�X�^���x�ł��̃_�C�T�C�Y600mm²�͂��蓾��
34���Ȃ�[���B
Bloomfield��263mm��7��3000��
(600/263)*730M=16��7000��
�E�E�E�ʂɕ��ʂȂ悤�ȁH
(600/263)*730M=16��7000��
�E�E�E�ʂɕ��ʂȂ悤�ȁH
100 �F,,�E�L�́M�E,,�j��-�������F2009/10/17(�y) 18:59:15 ID:6Eq7iFe7
����1GHz�Ȃ�g�����W�X�^���x�����ƍ����ł��邾��H
�Ƃ������AIntel�̏o���Ă���_�����ď��1GHz�Ȃ�ˁB
�Ƃ������AIntel�̏o���Ă���_�����ď��1GHz�Ȃ�ˁB
2011�N���Ŏ�����CPU��8�R�A�͂����炮�炢�H
�u�ڋq�̎��_���炷��A45nm�ł́A�ԈႢ�Ȃ�(�N�A�b�h�R�A�̓j�b�`)���B
32nm�ȉ��ł́A����������Ƃ�≺�֍~��Ă��邩������Ȃ��B�������A
���C���X�g���[���͈ˑR�Ƃ��ăf���A���R�A�ɗ��܂邾�낤�B22nm�ɂ��ẮA
�킩��Ȃ��B����́A�n�[�h�E�F�A�����łȂ��A�\�t�g�E�F�A�Ɉˑ����Ă���v(Eden��)�B
32nm�ȉ��ł́A����������Ƃ�≺�֍~��Ă��邩������Ȃ��B�������A
���C���X�g���[���͈ˑR�Ƃ��ăf���A���R�A�ɗ��܂邾�낤�B22nm�ɂ��ẮA
�킩��Ȃ��B����́A�n�[�h�E�F�A�����łȂ��A�\�t�g�E�F�A�Ɉˑ����Ă���v(Eden��)�B
�[�l�����с[�́A�܂��ł����H
westmere����ł�
32nm�v���Z�X����3.8Ghz�̃N�A�b�h�R�A���o�邱�ƂɊ���
32nm�v���Z�X����3.8Ghz�̃N�A�b�h�R�A���o�邱�ƂɊ���
>103
���������̎q�̏W�c���ۂ��C���[�W
C2D�ȂA�o�q�ɂȂ��Ă����ȁH
���������̎q�̏W�c���ۂ��C���[�W
C2D�ȂA�o�q�ɂȂ��Ă����ȁH
106 �FSocket774�F2009/10/18(��) 10:43:56 ID:6GJzUVmG
�f�X�N�g�b�v�����Ӗ��ȂقǃR�A�����₵�Ȃ��琫�\�グ�Ă������A��
�m�[�g���₦�₦�����\�Œ��x�ǂ��Ȃ��Ă�����
�m�[�g���₦�₦�����\�Œ��x�ǂ��Ȃ��Ă�����
���˂����`
���˂����`
2ch��ϼޓ˂����݂���n��(���~)��
���˂����`�A�A�A
���˂����`
2ch��ϼޓ˂����݂���n��(���~)��
���˂����`�A�A�A
>>96
�߂������ɂł�Nehalem-EX�Ȃ�8�R�A�����A�����4�\�P�b�g�T�[�o�����B
45nm�v���Z�X�����Ń_�C�T�C�Y���傫���B
�f�X�N�g�b�v�������ƁA32nm�v���Z�X�Ő��������Gulftown��6�R�A�B
�߂������ɂł�Nehalem-EX�Ȃ�8�R�A�����A�����4�\�P�b�g�T�[�o�����B
45nm�v���Z�X�����Ń_�C�T�C�Y���傫���B
�f�X�N�g�b�v�������ƁA32nm�v���Z�X�Ő��������Gulftown��6�R�A�B
��Ԗʐώ���Ă�̂�24MB��L3�����ǂ�
45nm�łW�R�A���Ă��Ȃ�`�������W���[���ȁB
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@SCENE�@�P
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �@�@�@�@�@�@�@�@/
�@�@(�܁܁T�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ EXPRESS�@��
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@THE�@�@�@(�܁܁T
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@STOP
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@(�܁T
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�Q�Q�Q�Q�Q�Q�Q�Q
�@�@�@�@�@�@�@�@�@�@/�P�P�R�@�@�@�@_�^���j�����j�����j���M�[�\�\�\�\�\
�@�@�@�@�@�@�@�@�@�@| HELP |�@�@,�ځQ�Q�Q�Q�Q�@�@�@�@�@�Q�Q�Q_�@�@ �@ �Q�Q_
�@�@�@�@�@�@�@�@�@�@�R�Q�Q_�T�^�@ __�@�@�@�@ ,�\��@߁R�@ /�@�@�@�@�@ ߁R�@/�@�@�@
�@�@�@�@�@�@�@�@�@�@�@�@ �@ �^�@ ��d��@��M��L��@|�@|�@�@�@�@�@�@�@|�@|�@�@�@
�@�@�@�@�@�@�@�@�@�@�@�@�@/�@�@ �@ ɞH'�@�@�@o'�]=�]�R �m�@�R�@�@�@�@�@ �m�@ �R�@�@�@
�@�@�@�@�@�@�@�@�@�@�@�@�i�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P
�@�@�@�@�@�@�@�@�@�@�@�@�@�T�Q�Q,���\����Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q__
�������������������������������
������������������������������������������������������������
�,��,��,��,��,��,��,��,��,��,��,��,��,��,��,��,��,��,��,��,��,��,��,��,��,��,��,�
�@�@�@�@�@�@�@�@�@�@ ��Q�U�Q,
�@�@�@�@�@�@�@�@�@�@�@�@���e�R)
�@�@�@�@�@�@�@�@�@�@�@OƁ^_�O
�@�@�@�@�@�@�@�@�@�@�@�@ �m�v �R)
ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR
ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �@�@�@�@�@�@�@�@/
�@�@(�܁܁T�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ EXPRESS�@��
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@THE�@�@�@(�܁܁T
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@STOP
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@(�܁T
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�Q�Q�Q�Q�Q�Q�Q�Q
�@�@�@�@�@�@�@�@�@�@/�P�P�R�@�@�@�@_�^���j�����j�����j���M�[�\�\�\�\�\
�@�@�@�@�@�@�@�@�@�@| HELP |�@�@,�ځQ�Q�Q�Q�Q�@�@�@�@�@�Q�Q�Q_�@�@ �@ �Q�Q_
�@�@�@�@�@�@�@�@�@�@�R�Q�Q_�T�^�@ __�@�@�@�@ ,�\��@߁R�@ /�@�@�@�@�@ ߁R�@/�@�@�@
�@�@�@�@�@�@�@�@�@�@�@�@ �@ �^�@ ��d��@��M��L��@|�@|�@�@�@�@�@�@�@|�@|�@�@�@
�@�@�@�@�@�@�@�@�@�@�@�@�@/�@�@ �@ ɞH'�@�@�@o'�]=�]�R �m�@�R�@�@�@�@�@ �m�@ �R�@�@�@
�@�@�@�@�@�@�@�@�@�@�@�@�i�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P
�@�@�@�@�@�@�@�@�@�@�@�@�@�T�Q�Q,���\����Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q__
�������������������������������
������������������������������������������������������������
�,��,��,��,��,��,��,��,��,��,��,��,��,��,��,��,��,��,��,��,��,��,��,��,��,��,��,�
�@�@�@�@�@�@�@�@�@�@ ��Q�U�Q,
�@�@�@�@�@�@�@�@�@�@�@�@���e�R)
�@�@�@�@�@�@�@�@�@�@�@OƁ^_�O
�@�@�@�@�@�@�@�@�@�@�@�@ �m�v �R)
ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR
ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR��ɁR
�����Ȃ藎�����
��×p�A�v���P�[�V�����̃x���`�}�[�N�͂ǂ��Ȃ����H
Larrabee��i7+GTX280�̂��
Larrabee��i7+GTX280�̂��
�{�X���ɂ����
http://www-03.ibm.com/technology/resources/technology_cell_pdf_IBM_Mayo_Demo.pdf
http://www-03.ibm.com/press/us/en/attachment/23251.wss?fileId=ATTACH_FILE2&fileName=cell-reg.pdf
���ꂩ�I���҂��Ă悳��������
http://www-03.ibm.com/press/us/en/attachment/23251.wss?fileId=ATTACH_FILE2&fileName=cell-reg.pdf
���ꂩ�I���҂��Ă悳��������
116 �F,,�E�L�́M�E,,�j��-�������F2009/10/19(��) 00:01:45 ID:lG+f+kn0
> Moriyoshi Ohara, Hiroshi Inoue and Hideaki Komatsu, IBM Tokyo Research Laboratory
���������E�l�|�ł���̂͂���ϓ��{�l�Ȃ�
Intel��AVX�̃R�[�h�T���v���̓I���������������̂ق���ꡂ��ɑ����Ƃ��̃��x������
���������E�l�|�ł���̂͂���ϓ��{�l�Ȃ�
Intel��AVX�̃R�[�h�T���v���̓I���������������̂ق���ꡂ��ɑ����Ƃ��̃��x������
�c�q�̈ӌ���intel�Ƀt�B�[�h�o�b�N
Gulftown�͂���������H
5�������H
5�������H
�V���O������f���A���A�f���A������N�A�b�h��2�{������
�N�A�b�h����w�L�T�͂�������1.5�{�B
�A���_�[���̖@���ɉ����ă������ш�̃{�g���l�b�N��
�R�A�ԒʐM�̃I�[�o�[�w�b�h�Ŏ����ʂ͂���ɒႭ�Ȃ�B
IPC���ォ��}���`�R�A���ɑǂ�������̂́A
���\����̔����������͑������s�����������B
TDP�]���Ă�Ȃ�A�N�A�b�h�̂܂܃N���b�N�グ�������}�V�����B
�N�A�b�h����w�L�T�͂�������1.5�{�B
�A���_�[���̖@���ɉ����ă������ш�̃{�g���l�b�N��
�R�A�ԒʐM�̃I�[�o�[�w�b�h�Ŏ����ʂ͂���ɒႭ�Ȃ�B
IPC���ォ��}���`�R�A���ɑǂ�������̂́A
���\����̔����������͑������s�����������B
TDP�]���Ă�Ȃ�A�N�A�b�h�̂܂܃N���b�N�グ�������}�V�����B
ttp://journal.mycom.co.jp/articles/2009/10/19/powerorg_tokyo2009/001.html
�}���`�R�A���s���l�܂��āA�n�C�u���b�h�ɂȂ�
��p�̃��W���[����K�v�Ȏ��������삳��������ŁA
���\������̏���d�͂����炷�悤�ɂȂ�A��������
�}���`�R�A���s���l�܂��āA�n�C�u���b�h�ɂȂ�
��p�̃��W���[����K�v�Ȏ��������삳��������ŁA
���\������̏���d�͂����炷�悤�ɂȂ�A��������
���ł����g�����W�X�^�����ė]���C������
���̂܂܂��ƁA�n�C�u���b�h���͂�ނ����Ȃ��ˁB
���̂܂܂��ƁA�n�C�u���b�h���͂�ނ����Ȃ��ˁB
http://ascii.jp/elem/000/000/464/464223/index-3.html
�Ȃ����ɏC�����ꂽ�炵��
OS�̃t�b�g�v�����g�ǂ�����B
�J�[�l�����[�h�Ŏg���悤�Ȗ��߂��Ƃł��v���Ă�̂��ˁH
�Ȃ����ɏC�����ꂽ�炵��
OS�̃t�b�g�v�����g�ǂ�����B
�J�[�l�����[�h�Ŏg���悤�Ȗ��߂��Ƃł��v���Ă�̂��ˁH
Linux Kernel Watch
http://www.atmarkit.co.jp/flinux/rensai/watch2008/watch07b.html
�uAVX���ǂ��g�������́H�v�u�g���ׂ�����Ȃ��v
http://www.atmarkit.co.jp/flinux/rensai/watch2008/watch07b.html
�uAVX���ǂ��g�������́H�v�u�g���ׂ�����Ȃ��v
>>123
�u�h���C�o�J���҂́v�@�Ƃ����̂��ȗ������Ⴞ�߂��낤
�u�h���C�o�J���҂́v�@�Ƃ����̂��ȗ������Ⴞ�߂��낤
�ǂ����A�v���J���҂��Ή����Ȃ��Ⴂ���Ȃ��@�\�Ȃ�
�{���I�Ƀv���G���v�e�B�u�ȃ^�X�N�X�P�W���[���ɂ����Ȃ�OS����
���W�X�^�̑ޔ��E���A��������Ă����������Ȃ��A
�������Ⴂ���Ă���B
������������OS���ǂ̃��x����MMX��SSE�Ɂu�Ή��v���Ă�Ǝv���Ă��
�{���I�Ƀv���G���v�e�B�u�ȃ^�X�N�X�P�W���[���ɂ����Ȃ�OS����
���W�X�^�̑ޔ��E���A��������Ă����������Ȃ��A
�������Ⴂ���Ă���B
������������OS���ǂ̃��x����MMX��SSE�Ɂu�Ή��v���Ă�Ǝv���Ă��
Linux����software raid�Ɏg���Ă��C�K�X>MMX/SSE
���ƃJ�[�l����Ԃł�AES�Í�����AES-NI���g��ꂽ�͂�
���͂ǂ����������Ȃ�
���ƃJ�[�l����Ԃł�AES�Í�����AES-NI���g��ꂽ�͂�
���͂ǂ����������Ȃ�
OS�Ɋ܂߂邩���������A�摜�����p�̃��C�u�����A�h���C�o�ł͕��������_�K�v������
AVX������Ɣ����ɑ����Ȃ邩���ȁB
���������_���Z�Ȃ�āA3D�摜�ȊO�Ŏg���Ƃ��날��̂��H
AVX������Ɣ����ɑ����Ȃ邩���ȁB
���������_���Z�Ȃ�āA3D�摜�ȊO�Ŏg���Ƃ��날��̂��H
mpeg2�Ŏg���Ă�
AVX���ăG���e�B�b�N�Ȋ����������o���Ă���c
130 �F,,�E�L�́M�E,,�j��-�������F2009/10/21(��) 01:44:58 ID:pXjOHmBL
WMP��DirectX��OS�W�Ȃ��ɍX�V�ł��邯�ǂ�
7�ȍ~�ł����g���Ȃ��ƕ����ĂȂ�قǂƎv�����Ƃ͂����Ă�
8�܂ő҂��Ȃ��Ƃ����Ȃ��̂����Ă͈̂Ⴄ����
Intel��MS��AVX�Ή��A�v���P�[�V���������Ȃ���鐨���ł���
7�ȍ~�ł����g���Ȃ��ƕ����ĂȂ�قǂƎv�����Ƃ͂����Ă�
8�܂ő҂��Ȃ��Ƃ����Ȃ��̂����Ă͈̂Ⴄ����
Intel��MS��AVX�Ή��A�v���P�[�V���������Ȃ���鐨���ł���
�Ȃ�Œc�q����Ȃǂ��ł������l�^�H�����قljɂȂ�
132 �F,,�E�L�́M�E,,�j��-�������F2009/10/21(��) 07:35:35 ID:pXjOHmBL
�ɂł��Ȃ��B
���ƕ�����������ǁ[�B
���ƕ�����������ǁ[�B
133 �F,,�E�L�́M�E,,�j��-�������F2009/10/21(��) 07:36:54 ID:pXjOHmBL
�����������Ă�Sandy Bridge�����[�X���O��AVX�Ή��A�v���P�[�V�������J�\�肪����E�E�E����
clarkdale�͂�����IGP��CPU���\�ɂ͊�^���Ȃ������ǁA
sandy bridge�ł�IGP�����܂��g���ĕ��������_���Z���\�����߂�́H
sandy bridge�ł�IGP�����܂��g���ĕ��������_���Z���\�����߂�́H
��Teradata�A�g�_�̏�h�Ńf�[�^��͂���uEnterprise Analytics Cloud�v
�N���E�h�헪�𖾂炩��
http://enterprise.watch.impress.co.jp/docs/news/20091021_322904.html
�N���E�h�헪�𖾂炩��
http://enterprise.watch.impress.co.jp/docs/news/20091021_322904.html
���₻����
http://www.computerworld.jp/topics/saasw/114209-2.html
http://www.computerworld.jp/topics/cloud/137491.html
http://www.computerworld.jp/topics/storage/149610.html
http://www.computerworld.jp/topics/cloud/151729-4.html
http://enterprise.watch.impress.co.jp/docs/series/infostand/20090525_169973.html
http://enterprise.watch.impress.co.jp/docs/series/infostand/20091019_322710.html
http://www.computerworld.jp/topics/saasw/114209-2.html
http://www.computerworld.jp/topics/cloud/137491.html
http://www.computerworld.jp/topics/storage/149610.html
http://www.computerworld.jp/topics/cloud/151729-4.html
http://enterprise.watch.impress.co.jp/docs/series/infostand/20090525_169973.html
http://enterprise.watch.impress.co.jp/docs/series/infostand/20091019_322710.html
>>134
����Ȍv��́A���܂̂Ƃ���A�Ȃ��B
����Ȍv��́A���܂̂Ƃ���A�Ȃ��B
>>137
�����Ă��̂�AMD�̕�����
�����Ă��̂�AMD�̕�����
140 �F,,�E�L�́M�E,,�j��-�������F2009/10/21(��) 20:28:00 ID:pXjOHmBL
�\�t�g�����������
���N�A�b�h�R�A�̏�ʐ��i������ijϰ
���N�A�b�h�R�A�̏�ʐ��i������ijϰ
�܂�AMD�ɒx����Ƃ�̂�
Larrabee��Fusion��葁���o��͂��Ȃ���
���̃R�c�𗬗p����Ivy Bridge��Haswell�Ŋ������Ăق���
Larrabee��Fusion��葁���o��͂��Ȃ���
���̃R�c�𗬗p����Ivy Bridge��Haswell�Ŋ������Ăق���
�V�������Ă���Ƃ�
AMD��CPU��GPU������Ƃ������̂�
�̂̐l�͞X�J�Ƃ����܂����B
AMD��CPU��GPU������Ƃ������̂�
�̂̐l�͞X�J�Ƃ����܂����B
�����X
>>134
SandyBridge�ŃI���_�C��������̂ŁA���̎��̒i�K�Ƃ���
����Ɏ��̃A�[�L�e�N�`��"Haswell"�ŋ�����������������̂ł͂Ȃ����A�Ɛ�������Ă���B
�I���S����4�Ԗڂ̐��i�ŁA���e��22nm�̑�2����A�����ɍs����2013�`14�N���[���`�B
���������GPU��GMA�A�[�L���ǂ����͕s���BLarrabee�n���Z����I���R�A��������GPU���G�~�����[�g����\��������B
SandyBridge�ŃI���_�C��������̂ŁA���̎��̒i�K�Ƃ���
����Ɏ��̃A�[�L�e�N�`��"Haswell"�ŋ�����������������̂ł͂Ȃ����A�Ɛ�������Ă���B
�I���S����4�Ԗڂ̐��i�ŁA���e��22nm�̑�2����A�����ɍs����2013�`14�N���[���`�B
���������GPU��GMA�A�[�L���ǂ����͕s���BLarrabee�n���Z����I���R�A��������GPU���G�~�����[�g����\��������B
�c�q�͂ǂ����x���`���[�̐l�������̂��B
>>144
�t��Haswell�����Ƃ��̂���ɃV�������N�ł܂ŐV�A�[�L���Ȃ��\��
�t��Haswell�����Ƃ��̂���ɃV�������N�ł܂ŐV�A�[�L���Ȃ��\��
Haswell�̃V�������N����16nm�ł���H
EUV�I���Ƃ����܂������̂���
���������������
���[�N�d���̖��Ƃ�
���낻�땨�����E���������ȗ\��
EUV�I���Ƃ����܂������̂���
���������������
���[�N�d���̖��Ƃ�
���낻�땨�����E���������ȗ\��
4nm�܂ōs���C���X��intel�l���r�߂Ă�����Ă͍���
4nm����45nm��1/10�ȉ�������
�P����100�{�ȏ�g�����W�X�^���ς߂�킯��w
��������Ƃ����邯�Ǔ��̂��������������
22nm�܂ł�HKMG�ł��̂�������16nm�ł̓g�����W�X�^�ɂ�
���Ȃ������邱�ƂɂȂ�͂�������
�Y�݂̋ꂵ�݂����키�낤��
�P����100�{�ȏ�g�����W�X�^���ς߂�킯��w
��������Ƃ����邯�Ǔ��̂��������������
22nm�܂ł�HKMG�ł��̂�������16nm�ł̓g�����W�X�^�ɂ�
���Ȃ������邱�ƂɂȂ�͂�������
�Y�݂̋ꂵ�݂����키�낤��
http://journal.mycom.co.jp/articles/2009/10/22/asml_euv/index.html
ASML��EUV�撣���Ă�݂�������
�j�R���͂ǂ��Ȃc
ASML��EUV�撣���Ă�݂�������
�j�R���͂ǂ��Ȃc
�~�N���̐��E��
>>151
�i�m�̐��E����
�i�m�̐��E����
>��p�̃��W���[��
�ŁA��̓I�ɉ����̂��Ă���낤���Harm�݂�����Java�̃n�[�h�G�~�����[�^�݂����Ȃ̂Ƃ��H
�[���d�͂�ߖ����̂��A���菈�������������������A����ړI�ɂ��Ă�̂����悭�킩���
���������ē�e�_���Ă�́H�u���邼
�ŁA��̓I�ɉ����̂��Ă���낤���Harm�݂�����Java�̃n�[�h�G�~�����[�^�݂����Ȃ̂Ƃ��H
�[���d�͂�ߖ����̂��A���菈�������������������A����ړI�ɂ��Ă�̂����悭�킩���
���������ē�e�_���Ă�́H�u���邼
TDP��D����������A�d�͐��\��̉��P=������
�܂����̃X���I�ȃ|�C���g�́ASPE�ɂ���GPU�ɂ���A�uISA����Ǝ��ɍ\�z����
�f�R�[�_�w����܂���Ɩ��̈�ɍœK�����Ȃ��Ɠd�͌������s������������v
�Ƃ��������Ǝv���B
�ėpISA�����͐l�C��p�ŗ͋Z��x86�ɂ����@�����������A
��p���W���[���̗̈�ł͂����͂����Ȃ����낤�A�ƁB
�����͂��ꂩ��Larrbee�Ŏ������B
�f�R�[�_�w����܂���Ɩ��̈�ɍœK�����Ȃ��Ɠd�͌������s������������v
�Ƃ��������Ǝv���B
�ėpISA�����͐l�C��p�ŗ͋Z��x86�ɂ����@�����������A
��p���W���[���̗̈�ł͂����͂����Ȃ����낤�A�ƁB
�����͂��ꂩ��Larrbee�Ŏ������B
>>155
���̂ւ�̔F�������ɑO���I�I�����B
Cell���܂߂��ÓT�IRISC�̔s���́A�V���v�����������ƁB
�f�R�[�_�̃R�X�g�����őS�̂̌������ς��قǃ}�C�N���A�[�L�e�N�`����
���E�͊Â��Ȃ��B
RISC���V���v�������邱�Ƃ͑傫�Ȍ��_�ɂȂ��Ă���B
����������Ȃ�ĕp�ɂɎg���̂ɃA�h���b�V���O�ɉ��I�y���[�V�����ɉ����߂�
�g���Ċe���߂S�o�C�g���H���͔̂��I����Ȃ����A�Ƃ��B
ARM��MIPS������V�F�A��D�����̂́A�Q�o�C�g���߂̗̍p���r�I���͂�
�A�h���b�V���O���[�h�ȂǁACISC�̗��_���̂肢��Ă邩�炾�B
�T����RISC��IPC���҂��ɂ����B���\�����߂�ɂ̓N���b�N���グ�邵���Ȃ��B
�t��CISC�͂P�R�A�Ɏg����g�����W�X�^�������������A���߃X�g���[����
���s�p�C�v���C���̗��ʂʼn��Z���x�����߂₷���B
x86�s��̒��ł��������Ă�B
�p�C�v���C���t�����g�G���h����x86�f�R�[�_����蕥���A����RISC������
Pentium 4�ƁACISC������I�y���[�V�������x���ŏ����̌�����}����
Pentium M��Athlon�̃A�v���[�`�A�ǂ��������Ɍq�����Ă��邩�H
������GPU�����܂ł�VRAM�Ԃ̃g���t�B�b�N���l�b�N�ɂȂ�A���r���[�Ƀv���O���}�u����
���������œd�͌����͒Ⴍ�Ƃǂ܂��Ă�B���ۓx���Ⴂ���߁A���Y�Ɏ�����
�啝�Ȑv�ύX���ł��Ȃ��Ƃ����W�����}�Ɋׂ��Ă���B���Ă�RISC�Ɠ����\�}���B
GPGPU�����F�͓d�͂������FLOPS���������Ƃ������̖\�͂��s�g���Ă���ɂ����Ȃ��B
�i���_FLOPS��������̌����͓x�O���j
���̓_�ł�GPU�Ƃ��Ă̎��Y�������Ȃ�Larrabee�͑�_�ȃp���_�C���V�t�g��
��Ăł��闧��ɂ���B
�����Ƃ��ŏI�I�ɂ͐��\�W�Ȃ��ɐ��J����GMA����̒u�������Ƃ���
���G�̃J�[�h������킯�����B
���̂ւ�̔F�������ɑO���I�I�����B
Cell���܂߂��ÓT�IRISC�̔s���́A�V���v�����������ƁB
�f�R�[�_�̃R�X�g�����őS�̂̌������ς��قǃ}�C�N���A�[�L�e�N�`����
���E�͊Â��Ȃ��B
RISC���V���v�������邱�Ƃ͑傫�Ȍ��_�ɂȂ��Ă���B
����������Ȃ�ĕp�ɂɎg���̂ɃA�h���b�V���O�ɉ��I�y���[�V�����ɉ����߂�
�g���Ċe���߂S�o�C�g���H���͔̂��I����Ȃ����A�Ƃ��B
ARM��MIPS������V�F�A��D�����̂́A�Q�o�C�g���߂̗̍p���r�I���͂�
�A�h���b�V���O���[�h�ȂǁACISC�̗��_���̂肢��Ă邩�炾�B
�T����RISC��IPC���҂��ɂ����B���\�����߂�ɂ̓N���b�N���グ�邵���Ȃ��B
�t��CISC�͂P�R�A�Ɏg����g�����W�X�^�������������A���߃X�g���[����
���s�p�C�v���C���̗��ʂʼn��Z���x�����߂₷���B
x86�s��̒��ł��������Ă�B
�p�C�v���C���t�����g�G���h����x86�f�R�[�_����蕥���A����RISC������
Pentium 4�ƁACISC������I�y���[�V�������x���ŏ����̌�����}����
Pentium M��Athlon�̃A�v���[�`�A�ǂ��������Ɍq�����Ă��邩�H
������GPU�����܂ł�VRAM�Ԃ̃g���t�B�b�N���l�b�N�ɂȂ�A���r���[�Ƀv���O���}�u����
���������œd�͌����͒Ⴍ�Ƃǂ܂��Ă�B���ۓx���Ⴂ���߁A���Y�Ɏ�����
�啝�Ȑv�ύX���ł��Ȃ��Ƃ����W�����}�Ɋׂ��Ă���B���Ă�RISC�Ɠ����\�}���B
GPGPU�����F�͓d�͂������FLOPS���������Ƃ������̖\�͂��s�g���Ă���ɂ����Ȃ��B
�i���_FLOPS��������̌����͓x�O���j
���̓_�ł�GPU�Ƃ��Ă̎��Y�������Ȃ�Larrabee�͑�_�ȃp���_�C���V�t�g��
��Ăł��闧��ɂ���B
�����Ƃ��ŏI�I�ɂ͐��\�W�Ȃ��ɐ��J����GMA����̒u�������Ƃ���
���G�̃J�[�h������킯�����B
intel��15nm��EUV�͊Ԃɍ���Ȃ���Ȃ����Ƃ������Ă�悤�����ǁB
�ʎY�������������ɂ���intel�̓s��������낤���A����̃v���Z�X��
���܂������Ă��������B
�ʎY�������������ɂ���intel�̓s��������낤���A����̃v���Z�X��
���܂������Ă��������B
�c�q�����Ԕ����[�h�ŏ������ϑz�����̂܂܉L�ۂ݂ɂ���������̂��B
�܂�Larrabee�̎�������Ζڂ��o�߁c�c�Ȃ����낤�ȁB
�܂���ꐢ�ゾ���玟�̐��ォ��Ƃ��Ȃ�Ƃ��B
�܂�Larrabee�̎�������Ζڂ��o�߁c�c�Ȃ����낤�ȁB
�܂���ꐢ�ゾ���玟�̐��ォ��Ƃ��Ȃ�Ƃ��B
>>158
��2����͑�1���ォ��傫���͕ς����B
���[�A�̖@���̏I�������z���Đv����Ă�B
Larrabee���������ǂ��Ƃ͌���Ȃ�������GPGPU�̎������\�������B
�W�Ԃ���s�[�NFLOPS����2�����x�ł��o���CPU��萫�\�o�����
���������Ⴄ����A�����������Ƃ����F�������������B
��2����͑�1���ォ��傫���͕ς����B
���[�A�̖@���̏I�������z���Đv����Ă�B
Larrabee���������ǂ��Ƃ͌���Ȃ�������GPGPU�̎������\�������B
�W�Ԃ���s�[�NFLOPS����2�����x�ł��o���CPU��萫�\�o�����
���������Ⴄ����A�����������Ƃ����F�������������B
>>156
�����������Ƃ͕����邯��
>�T����RISC��IPC���҂��ɂ����B
IPC�́A1�N���b�N������̕��ϖ��ߎ��s���̂��Ƃ���
������ARISC��IPC�ƃN���b�N���҂��₷�����Đ��\�����}�������̂ƌ�����
RISC�̖��_�� >>156 �������Ƃ���ꖽ�ߓ�����̔\�͂��Ⴗ����_����
lea eax, [ebx + ecx * 8 + 24]�@�@�@�@; ���ʊi�[��eax�ȊO�̓��W�X�^�j��
��
mov r4, 24�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@; ���ʊi�[��r1�̑�r4���j��
shl r1, r3, 3
add r1, r2, r1
add r1, r1, r4
������ׂ���O�҂̕����������Ɍ�����ł���
�����������Ƃ͕����邯��
>�T����RISC��IPC���҂��ɂ����B
IPC�́A1�N���b�N������̕��ϖ��ߎ��s���̂��Ƃ���
������ARISC��IPC�ƃN���b�N���҂��₷�����Đ��\�����}�������̂ƌ�����
RISC�̖��_�� >>156 �������Ƃ���ꖽ�ߓ�����̔\�͂��Ⴗ����_����
lea eax, [ebx + ecx * 8 + 24]�@�@�@�@; ���ʊi�[��eax�ȊO�̓��W�X�^�j��
��
mov r4, 24�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@; ���ʊi�[��r1�̑�r4���j��
shl r1, r3, 3
add r1, r2, r1
add r1, r1, r4
������ׂ���O�҂̕����������Ɍ�����ł���
>>161
�������Ɍ�������Ă����ۂɑ������ǂȁB
x86�̖��߃Z�b�g�Ƀ}�b�`�A�h���X���Z�p�̐�p���j�b�g(AGU)�������Ƃ�
�ėpALU�ł����������������������Ă���B
�p�ɂɎg�����Z�ɓ����������߁i���邢�͂��̃��[�h�j�Ɛ�p���j�b�g��
�����Ă̂́A�������Ƃ��Ă͐������B
x86���x�X�g�Ƃ͌���Ȃ����A���ĉh�����ւ���RISC�����ł��Ă������B
POWER7�ł́AARM�̐^�����ă��[�h�E�X�g�A�Ɠ����Ƀx�[�X�|�C���^��
�i�߂閽�߂��������Ă������A�v����ɂ����܂ōs���l���Ă���B
�K���Ȍ��t���v��������Ȃ������̂�IPC���ĕ\���������njꕾ�����邩�ȁB
����Operations Per Clock�Ƃł����悤���B
Core MA�ł̓}�C�N���A�[�L�e�N�`�����x���ł�6�̉��Z���j�b�g��
�����ɃI�y���[�V�����s�ł��邯�ǁAPowerPC�ł͂�������4�B
�������Ɍ�������Ă����ۂɑ������ǂȁB
x86�̖��߃Z�b�g�Ƀ}�b�`�A�h���X���Z�p�̐�p���j�b�g(AGU)�������Ƃ�
�ėpALU�ł����������������������Ă���B
�p�ɂɎg�����Z�ɓ����������߁i���邢�͂��̃��[�h�j�Ɛ�p���j�b�g��
�����Ă̂́A�������Ƃ��Ă͐������B
x86���x�X�g�Ƃ͌���Ȃ����A���ĉh�����ւ���RISC�����ł��Ă������B
POWER7�ł́AARM�̐^�����ă��[�h�E�X�g�A�Ɠ����Ƀx�[�X�|�C���^��
�i�߂閽�߂��������Ă������A�v����ɂ����܂ōs���l���Ă���B
�K���Ȍ��t���v��������Ȃ������̂�IPC���ĕ\���������njꕾ�����邩�ȁB
����Operations Per Clock�Ƃł����悤���B
Core MA�ł̓}�C�N���A�[�L�e�N�`�����x���ł�6�̉��Z���j�b�g��
�����ɃI�y���[�V�����s�ł��邯�ǁAPowerPC�ł͂�������4�B
>>156
RISC�̌��_�ƌ��������v�v�z��64bit�Ή��̍l�����̈Ⴂ�B
MIPS��Power�Ɠ����悤�ȏ���_���ĊJ������Ă�������
����Ȃ������Ⴂ���Ƃ͍l���ĂȂ������B
DS��PSP�Ȃ݂ĂĎv������
ARM�͏��K�͂ȂƂ낱�ł͗D�G�Ȃ��ǂł�����Ɖ�ʂ��傫��
�Ȃ����肵����g���Ȃ��̂ł́B
RISC�̌��_�ƌ��������v�v�z��64bit�Ή��̍l�����̈Ⴂ�B
MIPS��Power�Ɠ����悤�ȏ���_���ĊJ������Ă�������
����Ȃ������Ⴂ���Ƃ͍l���ĂȂ������B
DS��PSP�Ȃ݂ĂĎv������
ARM�͏��K�͂ȂƂ낱�ł͗D�G�Ȃ��ǂł�����Ɖ�ʂ��傫��
�Ȃ����肵����g���Ȃ��̂ł́B
> Core MA�ł̓}�C�N���A�[�L�e�N�`�����x���ł�6�̉��Z���j�b�g��
> �����ɃI�y���[�V�����s�ł��邯��
���Z���j�b�g�ɐڑ�����Ă���|�[�g�́A3�����Ȃ���
> �����ɃI�y���[�V�����s�ł��邯��
���Z���j�b�g�ɐڑ�����Ă���|�[�g�́A3�����Ȃ���
�C�V���ƃ\�j�[�̕��j�̈Ⴂ���A�[�L�e�N�`���̗D��ɒu�������鋭������
�Ȃ��Ȃ��E�E�E
DS��ARM�̒��ł����[�G���h�Ŏ���x��̃A�[�L�e�N�`�����x�[�X�B
ARM���̂��̂�DS���o��O����500MHz�I�[�o�[�̎�����PDA�ɍڂ��Ă����B
���̓_PSP��333MHz����Ȃ��MIPS�ł��n�C�G���h�N���X���낤�B
�Ȃ��Ȃ��E�E�E
DS��ARM�̒��ł����[�G���h�Ŏ���x��̃A�[�L�e�N�`�����x�[�X�B
ARM���̂��̂�DS���o��O����500MHz�I�[�o�[�̎�����PDA�ɍڂ��Ă����B
���̓_PSP��333MHz����Ȃ��MIPS�ł��n�C�G���h�N���X���낤�B
>>167
�����A���W�X�^�Ԑڂ̃f�B�X�v���[�X�����g�t�B�[���h��12�r�b�g�����Ȃ��ˁB
�����I�y�����h�̃f�[�^���Ɉˑ����ăX�P�[�����邩��
�ɒ[�ɏ��Ȃ��Ƃ������Ƃ��Ȃ��B
�����Ƃ���ʏ������ǂ��܂�ARM�̖��߃Z�b�g�ł�邩�Ƃ����̂��^�₾���B
���{�I�ȂƂ��댾�����������Ƃ��댾���o������12��16���낤��
�債�ĕς���悤�Ɍ����邪�B
��Ύw��̑��l���Ƃǂ��Ȃ�H
�y�q���g�z
http://d.hatena.ne.jp/natsutan/20080411/1207920875
�����A���W�X�^�Ԑڂ̃f�B�X�v���[�X�����g�t�B�[���h��12�r�b�g�����Ȃ��ˁB
�����I�y�����h�̃f�[�^���Ɉˑ����ăX�P�[�����邩��
�ɒ[�ɏ��Ȃ��Ƃ������Ƃ��Ȃ��B
�����Ƃ���ʏ������ǂ��܂�ARM�̖��߃Z�b�g�ł�邩�Ƃ����̂��^�₾���B
���{�I�ȂƂ��댾�����������Ƃ��댾���o������12��16���낤��
�債�ĕς���悤�Ɍ����邪�B
��Ύw��̑��l���Ƃǂ��Ȃ�H
�y�q���g�z
http://d.hatena.ne.jp/natsutan/20080411/1207920875
intel�̎����オ�Ȃ��CISC VS RISC�̘b�ɂȂ����
���߃R�[�h���ɑ��閽�ߖ��x�Ɋւ��Ă�RISC�Ƃ������MIPS����������
�P���ɂ�������ok�Ƃ��������ŁA�P���ɂ��������̂ƁA���ߒ������
���������ɂ����̂��s�����낤�ˁB(���l�t�������ȂǁA32bit�ŕs��������̂�32bit������Ȃ����̂͑���)
x86�݂����ȃn�t�}�����k���ꂽ���ۂ����߃Z�b�g�Ƃ����̂����߃f�R�[�_�ŕ��ׂ��d����
�Ȃɂ����̌��_�̓��W�X�^�����薳������
x86-64�Ń��W�X�^�𑝂₵�������Ō��\�X�s�[�h�A�b�v�����̂̓��W�X�^�s���ɂ��
load/store���ׂ����������߂��낤�ˁB
�|�C���^�܂�64bit�ɂȂ����e���ɂ��L���b�V�������ቺ�ő��x�̌���͈�背�x���ɗ��܂��Ă���悤�ł͂��邪�B
���߃R�[�h���ɑ��閽�ߖ��x�Ɋւ��Ă�RISC�Ƃ������MIPS����������
�P���ɂ�������ok�Ƃ��������ŁA�P���ɂ��������̂ƁA���ߒ������
���������ɂ����̂��s�����낤�ˁB(���l�t�������ȂǁA32bit�ŕs��������̂�32bit������Ȃ����̂͑���)
x86�݂����ȃn�t�}�����k���ꂽ���ۂ����߃Z�b�g�Ƃ����̂����߃f�R�[�_�ŕ��ׂ��d����
�Ȃɂ����̌��_�̓��W�X�^�����薳������
x86-64�Ń��W�X�^�𑝂₵�������Ō��\�X�s�[�h�A�b�v�����̂̓��W�X�^�s���ɂ��
load/store���ׂ����������߂��낤�ˁB
�|�C���^�܂�64bit�ɂȂ����e���ɂ��L���b�V�������ቺ�ő��x�̌���͈�背�x���ɗ��܂��Ă���悤�ł͂��邪�B
���̈Ӗ���ARM��32�r�b�g���l�𖽗߃X�g���[���ɒu�����Ƃ�
����8�o�C�g���߂������ł���킯�ŁB
�Ƃ������l�����Ƃ��Ă�ModRM�̌㕔�̊g���t�B�[���h�ƂȂ��ς��Ȃ��B
���������ARM��x86�ɔ��鍂���v�͉\�B�ȓd�͂����]���ɂ�������ǁB
����16�{����Ώ\������Ȃ��́H���l�[�������G�ɂȂ邵�B
����8�o�C�g���߂������ł���킯�ŁB
�Ƃ������l�����Ƃ��Ă�ModRM�̌㕔�̊g���t�B�[���h�ƂȂ��ς��Ȃ��B
���������ARM��x86�ɔ��鍂���v�͉\�B�ȓd�͂����]���ɂ�������ǁB
����16�{����Ώ\������Ȃ��́H���l�[�������G�ɂȂ邵�B
x86�Α�̖��́A�v���Â����ăI�[�o�[�w�b�h�ɂȂ��Ă邱�Ƃł���H
PowerPC�Ƃ�ARM�ɂ���ׂāA���b�g�ӂ菈���\�͂����Ȃ舫���̂͂��ꂪ�����������͂�
PowerPC�Ƃ�ARM�ɂ���ׂāA���b�g�ӂ菈���\�͂����Ȃ舫���̂͂��ꂪ�����������͂�
�v����Ȃ��Ė��߃Z�b�g�̖�肾���ǂ�
173 �F,,�E�L�́M�E,,�j��-�������F2009/10/22(��) 22:00:11 ID:QfHQkvVn
Unisys Corporation Unisys ES7000 Model 7600R, Intel Xeon X7460, 2.66GHz *����d��6KW
Peak 1050 / Base 999
http://www.spec.org/cpu2006/results/res2008q4/cpu2006-20081208-06233.html
IBM Corporation IBM Power 570 ( 4.2 GHz, 32 core, RedHat) *����d��6.3KW
Base 809 / Peak 928
http://spec.org/cpu2006/results/res2008q4/cpu2006-20081003-05500.html
Nehalem-EX����������POWER6�n���Ȃ́H���ʂ́H
Peak 1050 / Base 999
http://www.spec.org/cpu2006/results/res2008q4/cpu2006-20081208-06233.html
IBM Corporation IBM Power 570 ( 4.2 GHz, 32 core, RedHat) *����d��6.3KW
Base 809 / Peak 928
http://spec.org/cpu2006/results/res2008q4/cpu2006-20081003-05500.html
Nehalem-EX����������POWER6�n���Ȃ́H���ʂ́H
174 �F,,�E�L�́M�E,,�j��-�������F2009/10/22(��) 22:08:14 ID:QfHQkvVn
���Ȃ݂�Atom���ȓd�͂�PowerPC�̐��\���Ă�����ς����B
175 �F,,�E�L�́M�E,,�j��-�������F2009/10/22(��) 22:22:59 ID:QfHQkvVn
���Ȃ݂ɁA����ARM����`���Ă�40nm�v���Z�X��A9�Ȃ�Ď��ې��i�ɑg�ݍ��܂��̂�3�`4�N��i���邢�̓|�V����j
���̍��ɂ�Atom�͂����Ɛ��\�ǂ��Ȃ��Ă邩�炠�̕ӂ̃x���`���ʂȂ�Đ^�Ɏ�K�v�Ȃ��B
�g�ݍ��݂̐��i�T�C�N�����Ă���Ȃ��B
���i���o�邱��ɂ͎���x��̐����v���Z�X�ɂȂ��Ă�B�����炱��ARM�͈������B
i.MX515�iCortex-A8�x�[�X��SoC�j�̔��\���č��N�̏��߂��炢�������C�������
Freescale��2���~�ȉ����������Ă��̂ɁA���ۏo�Ă������i(NetWalker)�͎���3���~��B
Atom�l�b�g�u�b�N�ƕς�����B
���̍��ɂ�Atom�͂����Ɛ��\�ǂ��Ȃ��Ă邩�炠�̕ӂ̃x���`���ʂȂ�Đ^�Ɏ�K�v�Ȃ��B
�g�ݍ��݂̐��i�T�C�N�����Ă���Ȃ��B
���i���o�邱��ɂ͎���x��̐����v���Z�X�ɂȂ��Ă�B�����炱��ARM�͈������B
i.MX515�iCortex-A8�x�[�X��SoC�j�̔��\���č��N�̏��߂��炢�������C�������
Freescale��2���~�ȉ����������Ă��̂ɁA���ۏo�Ă������i(NetWalker)�͎���3���~��B
Atom�l�b�g�u�b�N�ƕς�����B
>>173
Xeon�̕���16chip 96core�ƕ���x�������Ă��̐���������A
POWER6�̃V���O���X���b�h���\�̍����������Ă���̂łȂ����ȁB
�Ă�����POWER7���������ȁB
Xeon�̕���16chip 96core�ƕ���x�������Ă��̐���������A
POWER6�̃V���O���X���b�h���\�̍����������Ă���̂łȂ����ȁB
�Ă�����POWER7���������ȁB
177 �F,,�E�L�́M�E,,�j��-�������F2009/10/22(��) 23:49:25 ID:QfHQkvVn
���ǂ̏�����d�͂��Ȃ���̂Ă���̒��x�����Ă���
�����APOWER6�̂ق��̐����Ԉ���Ă邩��ˁB
�{���̐����̓����N��Q�ƁB
�d�͌����̕��ɂ̓G���g���[���炳��ĂȂ��B
�����APOWER6�̂ق��̐����Ԉ���Ă邩��ˁB
�{���̐����̓����N��Q�ƁB
�d�͌����̕��ɂ̓G���g���[���炳��ĂȂ��B
178 �F,,�E�L�́M�E,,�j��-�������F2009/10/22(��) 23:53:19 ID:QfHQkvVn
http://www.spec.org/power_ssj2008/results/power_ssj2008.html
Gainestown�̓d�͌���������������
Gainestown�̓d�͌���������������
���_�����a(���������ǁj�̊댯��
1. �N���Ɍ����点������Ă���Ƃ����B
2. �N���ɑ_��ꂽ��A����ꂽ��A�������ꂽ�肵�Ă���Ƃ����B
3. �d�g�̂悤�Ȃ��̂ł������Ƃ����B
4. �����̍l�����s�v�c�ȗ͂ɂ���ĉ��̐l�����ɓ`����Ă��܂��Ƃ����B�i�e���p�V�[�Ȃǁj
5. ����ɐl�����Ȃ��̂Ɏ�����ӂ߂�悤�Ȑ����������Ă���Ƃ����B
6. �N���������ɂ̂肤���Ă���Ƃ����B
7. �̂̒��ɉ����̋@�B���͂����Ă���Ƃ����B
8. �̂̈ꕔ�i���A�]�Ȃǁj���n������`����������肷��Ƃ����B
9. ���̒����������āA�����l���Ă����̂��킩��Ȃ��Ȃ�Ƃ����B
10. �b�ɂ܂Ƃ܂肪�Ȃ��B�x���ŗ�ʼn��������Ă�̂������ł��Ȃ��B
11. �����̍l���Ă��鎖�����ɂȂ��ĕ������Ă���Ƃ����B
12. �����ƓƂ茾�������Ă���B��l��������B
13. ��{���y�̊���Ȃ��Ȃ��Ă��܂����B
14. ���������肪���ŁA�قƂ�NJO�o���Ȃ��B
15. �ȑO�͌����Ȃ������悤�Ȋ�Ȍ���������B
1. �N���Ɍ����点������Ă���Ƃ����B
2. �N���ɑ_��ꂽ��A����ꂽ��A�������ꂽ�肵�Ă���Ƃ����B
3. �d�g�̂悤�Ȃ��̂ł������Ƃ����B
4. �����̍l�����s�v�c�ȗ͂ɂ���ĉ��̐l�����ɓ`����Ă��܂��Ƃ����B�i�e���p�V�[�Ȃǁj
5. ����ɐl�����Ȃ��̂Ɏ�����ӂ߂�悤�Ȑ����������Ă���Ƃ����B
6. �N���������ɂ̂肤���Ă���Ƃ����B
7. �̂̒��ɉ����̋@�B���͂����Ă���Ƃ����B
8. �̂̈ꕔ�i���A�]�Ȃǁj���n������`����������肷��Ƃ����B
9. ���̒����������āA�����l���Ă����̂��킩��Ȃ��Ȃ�Ƃ����B
10. �b�ɂ܂Ƃ܂肪�Ȃ��B�x���ŗ�ʼn��������Ă�̂������ł��Ȃ��B
11. �����̍l���Ă��鎖�����ɂȂ��ĕ������Ă���Ƃ����B
12. �����ƓƂ茾�������Ă���B��l��������B
13. ��{���y�̊���Ȃ��Ȃ��Ă��܂����B
14. ���������肪���ŁA�قƂ�NJO�o���Ȃ��B
15. �ȑO�͌����Ȃ������悤�Ȋ�Ȍ���������B
180 �F,,�E�L�́M�E,,�j��-�������F2009/10/23(��) 00:01:28 ID:QfHQkvVn
POWER6�Ȃ�Ď���Pentium 4�̌�p�݂����Ȃ����B
�܂��V���O���R�A���\�Ȃ炠�̂܂܋�Nehalem�ɓ˂��i�߂�
�ŋ�����������������
���̂������債���Ӗ��Ȃ�����
�܂��V���O���R�A���\�Ȃ炠�̂܂܋�Nehalem�ɓ˂��i�߂�
�ŋ�����������������
���̂������債���Ӗ��Ȃ�����
Tejas��Pen4�����������Ȃ�
182 �F,,�E�L�́M�E,,�j��-�������F2009/10/23(��) 00:11:00 ID:Ue3qZdbi
�n�C�G���hGPU���ᓖ����O�ɂȂ������A1�R�A200W�I�[�o�[�Ƃ����肦�Ȃ�������B
�ǂ���PowerPC��x86���d�͌����D��Ă��
�ǂ���PowerPC��x86���d�͌����D��Ă��
183 �F,,�E�L�́M�E,,�j��-�������F2009/10/23(��) 00:14:43 ID:Ue3qZdbi
�������Ƃ���B1�\�P�b�g������
�Ƃ������AG4�̓N���b�N������ł�Atom���x��
�Ƃ������AG4�̓N���b�N������ł�Atom���x��
�\�P�b�g������̏���d�͂��C�ɂȂ�Ȃ�
PowerPC 450���g����������Ȃ�
PowerPC 450���g����������Ȃ�
185 �F,,�E�L�́M�E,,�j��-�������F2009/10/23(��) 00:56:02 ID:Ue3qZdbi
> IBM�́APowerPC 970MP�i�R�[�h�l�[���̓A���^���X�j��2005�N�̑�O�l�����Ƀ����[�X�����B
> 970MP�̓f���A���R�A�v���Z�b�T�ŁA1.4GHz����2.5GHz�̊Ԃœ��삵���B�ő����d�͂�
> 1.7GHz�̂Ƃ���37W�A2.5GHz�̎��ɂ�100W�ł������B���ꂼ��̃R�A��L2�L���b�V����
> 970FX��2�{�ƂȂ�1MB�������Ă���A90nmSOI�v���Z�X�Ő������ꂽ�B���R�A�̂����ЂƂ�
> �A�C�h����ԂɂȂ�ƁA���̃R�A��"doze"�i����j���[�h�ɓ����ăX���[�v��ԂɂȂ�B
PPC�͂�������x86�Ɣ�ׂ���悤�ȃp���[�����W�̐��i�݂͂�ȓP�ނ��������
�Ȃ������āA���\����Ή��邾��
> 970MP�̓f���A���R�A�v���Z�b�T�ŁA1.4GHz����2.5GHz�̊Ԃœ��삵���B�ő����d�͂�
> 1.7GHz�̂Ƃ���37W�A2.5GHz�̎��ɂ�100W�ł������B���ꂼ��̃R�A��L2�L���b�V����
> 970FX��2�{�ƂȂ�1MB�������Ă���A90nmSOI�v���Z�X�Ő������ꂽ�B���R�A�̂����ЂƂ�
> �A�C�h����ԂɂȂ�ƁA���̃R�A��"doze"�i����j���[�h�ɓ����ăX���[�v��ԂɂȂ�B
PPC�͂�������x86�Ɣ�ׂ���悤�ȃp���[�����W�̐��i�݂͂�ȓP�ނ��������
�Ȃ������āA���\����Ή��邾��
>>185
����̓T�[�o�����̃p�t�H�[�}���XCPU�Ƃ����s�ꂪ
�J���R�X�g�������R�X�g���ׂ�ڂ��ɂ�����̂ɉ��i�ɓ]�ł��ɂ����A
Intel��ЈȊO�͗{���Ȃ����������s�ꂾ����A�Ƃ����b���ȁB
Intel���g�ł���A���\�}���ă`�b�v�ʐς�����������Atom�ɃV�t�g����
���v�������P������n���B
����Intel�łȂ�x86���D��Ă���̂��c�c�Ƃ����Ȃ�A���ɖ���邷�^�Ђ�
�j�]���O�ɒǂ��l�߂��Ă��܂��͂��͂Ȃ��B
����̓T�[�o�����̃p�t�H�[�}���XCPU�Ƃ����s�ꂪ
�J���R�X�g�������R�X�g���ׂ�ڂ��ɂ�����̂ɉ��i�ɓ]�ł��ɂ����A
Intel��ЈȊO�͗{���Ȃ����������s�ꂾ����A�Ƃ����b���ȁB
Intel���g�ł���A���\�}���ă`�b�v�ʐς�����������Atom�ɃV�t�g����
���v�������P������n���B
����Intel�łȂ�x86���D��Ă���̂��c�c�Ƃ����Ȃ�A���ɖ���邷�^�Ђ�
�j�]���O�ɒǂ��l�߂��Ă��܂��͂��͂Ȃ��B
��ԃp�C�̑傫��PC�s����������ĂāA���s���ɊJ����p�������߂邩�炱���A
x86�͂Ȃ�Ƃ��떂��������Ă�Ƃ�������킯����
�t�ɂ����A������p��PPC�Ȃǂɂ����߂A�����ƃ��b�g�����ɗD�ꂽCPU�͍��邾�낤��
������Apple��Q�[���@�̎��v�ł����薳���̂�������
x86�͂Ȃ�Ƃ��떂��������Ă�Ƃ�������킯����
�t�ɂ����A������p��PPC�Ȃǂɂ����߂A�����ƃ��b�g�����ɗD�ꂽCPU�͍��邾�낤��
������Apple��Q�[���@�̎��v�ł����薳���̂�������
����ɓ���Intel�ł���A�@������x86���߂������Ă�̂������Ȃ킯��
���ꂭ�炢�Ax86�̃I�[�o�[�w�b�h�͔n���ɖ�Ȃ��낤
���ꂭ�炢�Ax86�̃I�[�o�[�w�b�h�͔n���ɖ�Ȃ��낤
>>188
���Ă͂����������������������A����Intel��x86�������������C�͂Ȃ��B
GPU�Ƀt���X�y�b�N��x86�R�A�̗p�Ƃ��A�Ύ����I��x86�ւ̎����ȊO�̉����ł��Ȃ��B
���Ă͂����������������������A����Intel��x86�������������C�͂Ȃ��B
GPU�Ƀt���X�y�b�N��x86�R�A�̗p�Ƃ��A�Ύ����I��x86�ւ̎����ȊO�̉����ł��Ȃ��B
�ŋߒc�q�������Ă邱�Ƃ���
http://pc.watch.impress.co.jp/docs/2004/1130/kaigai136.htm
������ӂł��łɌ���Ă��ˁB
���̐l�͒c�q�Ƃ͌��_���Ⴄ���ǁB
http://pc.watch.impress.co.jp/docs/2004/1130/kaigai136.htm
������ӂł��łɌ���Ă��ˁB
���̐l�͒c�q�Ƃ͌��_���Ⴄ���ǁB
���̂��l����Ƃ����Ӗ��ł�Larrabee�̊J������Fermi�̊J���̕���
�y�������B�r�W�l�X�Ƃ��Ă͂ǂ����킩��Ȃ���
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20091023_323529.html
�y�������B�r�W�l�X�Ƃ��Ă͂ǂ����킩��Ȃ���
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20091023_323529.html
Fermi��̃\�t�g�J������Ȃ���Fermi���J���Ƃ����Ӗ���
193 �F,,�E�L�́M�E,,�j��-�������F2009/10/23(��) 07:33:24 ID:Ue3qZdbi
>>186
�́H
970�n�͐V�K�J���͎��߂����܂������͂��Ă��B
Mac�p�̕ێ�Ƃ��A����PS3�N���X�^�̕�͂Ƃ��E�E�E����I�����Ă邩�B
������������IBM��90nm SOI�ł���Athlon64 X2 4800+�̂ق���970MP������ۂǁE�E�E���ӂӂ�
IBM��Core 2�ȍ~970�n�Ŗ��߂Ă����А��i�����W�͂ق�Xeon, Opteron��
�u��������������ˁB
AMD�͂����P��Fab�̐����L���p�����܂��ĂȂ������B
������t�@�E���h���Ƃ��ēƗ����đ��А��i��낤���Ęb�ɂȂ��Ă�B
x86���Ȃ��̂ɕK����������۽
���ɂ������POWER�Ƃ�Cell�͂Ȃ��킗����
���͂ǂ��N�\���m���Ă��邵
�́H
970�n�͐V�K�J���͎��߂����܂������͂��Ă��B
Mac�p�̕ێ�Ƃ��A����PS3�N���X�^�̕�͂Ƃ��E�E�E����I�����Ă邩�B
������������IBM��90nm SOI�ł���Athlon64 X2 4800+�̂ق���970MP������ۂǁE�E�E���ӂӂ�
IBM��Core 2�ȍ~970�n�Ŗ��߂Ă����А��i�����W�͂ق�Xeon, Opteron��
�u��������������ˁB
AMD�͂����P��Fab�̐����L���p�����܂��ĂȂ������B
������t�@�E���h���Ƃ��ēƗ����đ��А��i��낤���Ęb�ɂȂ��Ă�B
x86���Ȃ��̂ɕK����������۽
���ɂ������POWER�Ƃ�Cell�͂Ȃ��킗����
���͂ǂ��N�\���m���Ă��邵
194 �F,,�E�L�́M�E,,�j��-�������F2009/10/23(��) 07:36:01 ID:Ue3qZdbi
195 �F,,�E�L�́M�E,,�j��-�������F2009/10/23(��) 07:40:50 ID:Ue3qZdbi
PowerISA��x86�ȏ�̊�
���Ƃ������ǁA���l�[����H�̋K�͖͂��ߐ���2��ɔ�Ⴗ��B
Core MA�ɕC�G����6�I�y���[�V�����������s����������ɂ�
PPC�ł�6���߂��f�R�[�h���Ȃ��Ƃ����Ȃ��킯�ŁB
Core MA�F4x4 = 16
Power�i���j�F6x6 = 36
���̑����X�A�]�T�Ō������Ă��B
�}�C�N���A�[�L�e�N�`�����ĉ��[����
���Ƃ������ǁA���l�[����H�̋K�͖͂��ߐ���2��ɔ�Ⴗ��B
Core MA�ɕC�G����6�I�y���[�V�����������s����������ɂ�
PPC�ł�6���߂��f�R�[�h���Ȃ��Ƃ����Ȃ��킯�ŁB
Core MA�F4x4 = 16
Power�i���j�F6x6 = 36
���̑����X�A�]�T�Ō������Ă��B
�}�C�N���A�[�L�e�N�`�����ĉ��[����
http://journal.mycom.co.jp/column/architecture/159/index.html
�ŋ߂����������ʂł���
�ŋ߂����������ʂł���
197 �F,,�E�L�́M�E,,�j��-�������F2009/10/23(��) 08:14:40 ID:Ue3qZdbi
�c�O�ACQ�o�ŎЂ̖^���Ђɂ��ڂ��Ă��ʏ펯
198 �F,,�E�L�́M�E,,�j��-�������F2009/10/23(��) 08:40:25 ID:Ue3qZdbi
> �yRattner���z ���́AISA����ǂɂȂ�Ȃ��Ƃ����ӌ��Ɋ�{�I�ɂ͈٘_�͂Ȃ��B�������A
�̂�����͒��ڂ�
>�@�����ŏd�v�Ȃ̂́A�v���Z�b�T�̃p�t�H�[�}���X�͕��Ϗ���d�͂Ő����̂ł͂Ȃ��A
> �s�[�N���x�Ő���邱�Ƃ��B���̂��߁A�z�b�g�X�|�b�g�ł���f�R�[�_���ACPU�̓�����g����
> ����ɂȂ�B�Ȃ��Ȃ�A���̕����̃W�����N�V�������x������l���Ȃ��悤�ɂ��Ȃ����
> �Ȃ�Ȃ����炾�B���̈Ӗ��ł́AISA�̓[���R�X�g�ł͂Ȃ��B�t���b�h�ƁA������Ƒ��Ⴊ����̂�
> ���̕����ŁA�f�R�[�_�̓d�͌����Ɋւ��ẮA�Œ蒷���߃Z�b�g�A�[�L�e�N�`���̕����ǂ����Ă��L���ɂȂ�B
�����͂��̒ʂ�B���ۏo�Ă���Atom���Ă݂��2GH����������������Ă邯�ǂȁB
>�@����1�̗v�f�̓L���b�V���A�N�Z�X���BIntel�A�[�L�e�N�`���ł́A���L���b�V���C���e���V�u�ɂȂ�B
> ���W�X�^�t�@�C�������Ȃ����߂ŁA���ꂪ�f�[�^�L���b�V���ɕ��S��������B����ɑ��āA(RISC�n
> CPU�̂悤��)���W�X�^�t�@�C�����傫���ƁA�f�[�^�L���b�V���ւ̕��S�͏������Ȃ�B���̕����A
> �d�͏���̖ʂł͗L�����B�����ɂ��g���[�h�I�t������B
�g�ݍ��n��CPU�ō����Ȃ��͔̂ėp���W�X�^16�{�̂��̂��嗬�Ȃ�
���Ƃ͑��l���[�h�����b�`�ȕ�x86�̂ق������W�X�^�{���̊��ɂ̓��[�h�E�X�g�A�����炷���Ƃ��o����͂����B
���[�A�ʂ�ARM�̑��l���[�h�͕n��ł��Ȃ���B
���̋C�ɂȂ��32�r�b�g�Ƃ�64�r�b�g�Ƃ����邩��ˁB��ɐ�������Ă邯�ǁB
�g�ݍ���CPU�ɑ���x86�̋��݂́APC�K�i�����ʉ�����Ă邩�瑦���i�����ł��邪��
���ʓI�Ƀv���Z�X���[���̗D�ʂ����݂ɏo���邱�ƁB
40nm��Cortex-A8���ܘ_�ł�����Ă邪�A�����i�ɂȂ��Ă郌�x���ł͎�����A8��1GH�����������肪�����B
Atom�͂��̂�����ɂ͕����ĂȂ��B
�̂�����͒��ڂ�
>�@�����ŏd�v�Ȃ̂́A�v���Z�b�T�̃p�t�H�[�}���X�͕��Ϗ���d�͂Ő����̂ł͂Ȃ��A
> �s�[�N���x�Ő���邱�Ƃ��B���̂��߁A�z�b�g�X�|�b�g�ł���f�R�[�_���ACPU�̓�����g����
> ����ɂȂ�B�Ȃ��Ȃ�A���̕����̃W�����N�V�������x������l���Ȃ��悤�ɂ��Ȃ����
> �Ȃ�Ȃ����炾�B���̈Ӗ��ł́AISA�̓[���R�X�g�ł͂Ȃ��B�t���b�h�ƁA������Ƒ��Ⴊ����̂�
> ���̕����ŁA�f�R�[�_�̓d�͌����Ɋւ��ẮA�Œ蒷���߃Z�b�g�A�[�L�e�N�`���̕����ǂ����Ă��L���ɂȂ�B
�����͂��̒ʂ�B���ۏo�Ă���Atom���Ă݂��2GH����������������Ă邯�ǂȁB
>�@����1�̗v�f�̓L���b�V���A�N�Z�X���BIntel�A�[�L�e�N�`���ł́A���L���b�V���C���e���V�u�ɂȂ�B
> ���W�X�^�t�@�C�������Ȃ����߂ŁA���ꂪ�f�[�^�L���b�V���ɕ��S��������B����ɑ��āA(RISC�n
> CPU�̂悤��)���W�X�^�t�@�C�����傫���ƁA�f�[�^�L���b�V���ւ̕��S�͏������Ȃ�B���̕����A
> �d�͏���̖ʂł͗L�����B�����ɂ��g���[�h�I�t������B
�g�ݍ��n��CPU�ō����Ȃ��͔̂ėp���W�X�^16�{�̂��̂��嗬�Ȃ�
���Ƃ͑��l���[�h�����b�`�ȕ�x86�̂ق������W�X�^�{���̊��ɂ̓��[�h�E�X�g�A�����炷���Ƃ��o����͂����B
���[�A�ʂ�ARM�̑��l���[�h�͕n��ł��Ȃ���B
���̋C�ɂȂ��32�r�b�g�Ƃ�64�r�b�g�Ƃ����邩��ˁB��ɐ�������Ă邯�ǁB
�g�ݍ���CPU�ɑ���x86�̋��݂́APC�K�i�����ʉ�����Ă邩�瑦���i�����ł��邪��
���ʓI�Ƀv���Z�X���[���̗D�ʂ����݂ɏo���邱�ƁB
40nm��Cortex-A8���ܘ_�ł�����Ă邪�A�����i�ɂȂ��Ă郌�x���ł͎�����A8��1GH�����������肪�����B
Atom�͂��̂�����ɂ͕����ĂȂ��B
199 �F,,�E�L�́M�E,,�j��-�������F2009/10/23(��) 08:41:09 ID:Ue3qZdbi
40nm�̂�A9���������܂�
�ǂ�Ȗ��߂̑g�ݍ��킹�ł������f�R�[�h���Ȃ��Ƃ����Ȃ����ł͂������A
Pentium�݂����ɔ�ΏƂŃy�A�����O�ɐ����̂�������Ȃ炻���܂ŕ��G�ɂ͂Ȃ�Ȃ��B
�����Č����ƁA���������X���b�h����������ƁA���炩�ɓ�����o���\�Ȗ��ߐ�������ɔ�Ⴕ�đ�����B
Pentium�݂����ɔ�ΏƂŃy�A�����O�ɐ����̂�������Ȃ炻���܂ŕ��G�ɂ͂Ȃ�Ȃ��B
�����Č����ƁA���������X���b�h����������ƁA���炩�ɓ�����o���\�Ȗ��ߐ�������ɔ�Ⴕ�đ�����B
�㓡�͌�����Ă邯�NJeSP�N���X�^�͐����ƕ��������̉��Z�̃y�A�����O��
�\������SM������̍ő哯�����ߔ��s����3.25���߂���Ȃ���4���߂��B
�\������SM������̍ő哯�����ߔ��s����3.25���߂���Ȃ���4���߂��B
>>171
�����̐e���͑吳���܂�̂W�R�����A�m���ɌÂ��ĕ��ώ������I�[�o�[�w�b�h���Ă��ȁB
������I�펞�͓��{�C�R���т������炵�����A�ł��Ⴂ���m���̐����c��̈�l���낤�B
�����̐e���͑吳���܂�̂W�R�����A�m���ɌÂ��ĕ��ώ������I�[�o�[�w�b�h���Ă��ȁB
������I�펞�͓��{�C�R���т������炵�����A�ł��Ⴂ���m���̐����c��̈�l���낤�B
���т͉��m������Ȃ�����
204 �F,,�E�L�́M�E,,�j��-�������F2009/10/24(�y) 01:20:00 ID:/pRpwPyp
���m���Ƃ��������̎����[�����R�����������悤�ȁB
�d������B
���������A�ČR�ŏ����܂ł������Ƃ������{���Ђ̂ނ��ނ���
�ЂƂ̋L�������̂܂��������B�}�W���킻��������
���������A�ČR�ŏ����܂ł������Ƃ������{���Ђ̂ނ��ނ���
�ЂƂ̋L�������̂܂��������B�}�W���킻��������
�����̂�������̓g���b�N�̉^�]�肾������
�ˌ����v���I�ɉ��肾����������
�ˌ����v���I�ɉ��肾����������
>206
�����̃g���b�N�^�]����Ď��͌��\�ȋZ�\��������
�A�z�ł��^�]�ł���悤����V�X�e��������Ă��A�����J�ƈ���Ď����Ԃ��z�����ꂾ���������
�܂��u�����ԉ^�]�S���v�����S�ɈÏ��o����悤�ɂȂ�Ȃ��Ǝ����ԂɐG�邱�Ƃ��ł��Ȃ������Ƃ���������ɔn���炵��
�c�����R���������H
�����̃g���b�N�^�]����Ď��͌��\�ȋZ�\��������
�A�z�ł��^�]�ł���悤����V�X�e��������Ă��A�����J�ƈ���Ď����Ԃ��z�����ꂾ���������
�܂��u�����ԉ^�]�S���v�����S�ɈÏ��o����悤�ɂȂ�Ȃ��Ǝ����ԂɐG�邱�Ƃ��ł��Ȃ������Ƃ���������ɔn���炵��
�c�����R���������H
CPU�̖����ł͂Ȃ��Ă�������̉ߋ������X���ɂȂ�܂���
�ǂ�����
�ǂ�����
�ȏ�A�R���o�ϐ��̍s�����^�]�����ꂽ����ł����B
������CPU�֍Ăс�
������CPU�֍Ăс�
�Ǒf�l�����Ǎŋ߂�Intel���ĂȂ茘�������Ŗʔ����Ȃ����
�}���`�R�A�Ƃ�GPU�����Ƃ����ǔn���ɂ��Ă�AMD�̂����Ă�
���Ƃƕς��Ȃ����Ƃ���Ă邾������
AVX�Ƃ���̓I�ɃG���h���[�U�[���x���łǂ�ȓ�������́H
���Əȓd�͂Ƃ�Soc�Ƃ��j�[�Y�ɉ����Ă��낢���낤�Ƃ��Ă邯��
�Ȃ����Ƃ��������Ǝv���Ȃ��ł�
�}���`�R�A�Ƃ�GPU�����Ƃ����ǔn���ɂ��Ă�AMD�̂����Ă�
���Ƃƕς��Ȃ����Ƃ���Ă邾������
AVX�Ƃ���̓I�ɃG���h���[�U�[���x���łǂ�ȓ�������́H
���Əȓd�͂Ƃ�Soc�Ƃ��j�[�Y�ɉ����Ă��낢���낤�Ƃ��Ă邯��
�Ȃ����Ƃ��������Ǝv���Ȃ��ł�
�唼�̃��[�U�͂���Ȃ̂ɖ��łɃn�C�X�y�b�N�Ȃ��̂��K�v���̂悤�ɐ��]����Ă���
���Â�PenM�}�V���ŏ\���Ȏd����i7�}�V���킳�ꂽ��c
���Â�PenM�}�V���ŏ\���Ȏd����i7�}�V���킳�ꂽ��c
>AMD�̂����Ă� ����
���₶�������������Ƃ����₶�I���W�i���̎v�z�������炢���̂ɂȁA�Ƃ����b�ł���?
���₶�������������Ƃ����₶�I���W�i���̎v�z�������炢���̂ɂȁA�Ƃ����b�ł���?
����I���W�i���Ƃ��W�Ȃ��Ă�
���Ǔ����悤�Ȃ��Ƃ����ł��Ȃ����Ăǂ��Ȃ́H
Intel�����ǔ��������\���Ȃ���
�ǂ���������̂�������Ȃ��낤�Ȃ�
�v�����Ⴄ�킯�ł���
�܂���ƂƂ��Ăׂ͖��肳����������Ǝv���Ă�낤����
���Ǔ����悤�Ȃ��Ƃ����ł��Ȃ����Ăǂ��Ȃ́H
Intel�����ǔ��������\���Ȃ���
�ǂ���������̂�������Ȃ��낤�Ȃ�
�v�����Ⴄ�킯�ł���
�܂���ƂƂ��Ăׂ͖��肳����������Ǝv���Ă�낤����
�킩��������D�G�Ȃ��܂����N�Ԕ���376���j�̊�Ƃ̑ǎ������Ă���
216 �F,,�E�L�́M�E,,�j��-�������F2009/10/24(�y) 20:20:30 ID:/pRpwPyp
Larrabee���茘���Ǝv����Ȃ炻��͂���ŁE�E�E
���������\���Ȃ�IDM
KO���邵���\���Ȃ��v���{�N�T�[
��R����\���Ȃ������ԃ��[�J�[
�_��邵���\���Ȃ��t�b�g�{�[���[
KO���邵���\���Ȃ��v���{�N�T�[
��R����\���Ȃ������ԃ��[�J�[
�_��邵���\���Ȃ��t�b�g�{�[���[
��������Ȃ�����
�@�������������\���Ȃ�������
�@�ł����\���Ȃ��x�[�X�{�[���v���[���[
�Ƃ���
�@�������������\���Ȃ�������
�@�ł����\���Ȃ��x�[�X�{�[���v���[���[
�Ƃ���
����������Larrabee����������
�f�l�ڂɂ�����͂���������
�ł��Ȃ��Ȃ��o�Ă��Ȃ��̂��ȁ[
������������I�Ȃ��̍���Ă�
�����^�C�~���O���S�O���Ă邤����
�o���Ȃ��Ȃ��ăL�����Z���Ƃ��ɂȂ肻���ŁE�E�E
�������i���o���Ăق������̂�
�f�l�ڂɂ�����͂���������
�ł��Ȃ��Ȃ��o�Ă��Ȃ��̂��ȁ[
������������I�Ȃ��̍���Ă�
�����^�C�~���O���S�O���Ă邤����
�o���Ȃ��Ȃ��ăL�����Z���Ƃ��ɂȂ肻���ŁE�E�E
�������i���o���Ăق������̂�
�����ԂȂ牽���̃��[�J�[���K�������ς��Ă邾����
�n�C�u���b�h�܂ł͑傫�ȃu���C�N�X���[�Ȃ�������ȁB
���[�J�[�͈���Ă����z�̍����������l��������A
�}�j���A�������ł����\�ȏ�����邩��ȁB
�n�C�u���b�h�܂ł͑傫�ȃu���C�N�X���[�Ȃ�������ȁB
���[�J�[�͈���Ă����z�̍����������l��������A
�}�j���A�������ł����\�ȏ�����邩��ȁB
���ł��鏈���͂��ꂩ������\���シ��B
����ȊO�̉��P�̓\�t�g�E�F�A�̍œK���ňׂ����B
���܃E�F�u�u���E�U��OS�̕��삪�����ł���悤�ɁB
GUI���\�ɂ����悤�Ȍ��I�Ȑ��\����͂����Ȃ����낤�B
����ȊO�̉��P�̓\�t�g�E�F�A�̍œK���ňׂ����B
���܃E�F�u�u���E�U��OS�̕��삪�����ł���悤�ɁB
GUI���\�ɂ����悤�Ȍ��I�Ȑ��\����͂����Ȃ����낤�B
�}�t�͂Ƃ������A��{�I�ȕ��̎�@�͏o�s�����Ă�B
����DLP��Nj���������Ŗ͍����Ă��邪�A�����ɂ͐�p���W�b�N�EASIC�Ƃ̐킢������B
�����ԍ����L�������`��H�킳���̂́i���ɍ����\�E�Ő�[�v���Z�X�𑈂��j�����̉��B
����DLP��Nj���������Ŗ͍����Ă��邪�A�����ɂ͐�p���W�b�N�EASIC�Ƃ̐킢������B
�����ԍ����L�������`��H�킳���̂́i���ɍ����\�E�Ő�[�v���Z�X�𑈂��j�����̉��B
intel���茘���Ȃ������ǂ����͂��ꂾ���ǁAAndo's�̂Ƃ��ŐG��Ă��AInq�̋L���A
http://www.theinquirer.net/inquirer/news/1559651/intel-ceo-bullish-2010-prospects
��Chipzilla has already produced chips using new materials,
��but Otellini declined to give more details. "It's cool. Trust me," he said.
���V���R���ɑ���f�ނƂ��ẮC�J�[�{���i�m�`���[�u��
���O���t�F���Ȃǂ����ɂ������Ă��܂����C���p����10�N�ȏ�
����Ƃ��������ŁCIntel��2017�N�ɗʎY�ƂȂ�Ƒ傫�ȉ����ŁC
�����̃��[�J�[�ɑ��郊�[�h���L�������ł��B
����́A
http://techon.nikkeibp.co.jp/article/COLUMN/20091018/176539/
��III-V�������̂���Ȃ��̂��ȁH
���炩�̃`�b�v������ł����Ƃ��Ă��ANehalem�݂����ȋ���CPU�̗ʎY��
��������낤�ȁB
http://www.theinquirer.net/inquirer/news/1559651/intel-ceo-bullish-2010-prospects
��Chipzilla has already produced chips using new materials,
��but Otellini declined to give more details. "It's cool. Trust me," he said.
���V���R���ɑ���f�ނƂ��ẮC�J�[�{���i�m�`���[�u��
���O���t�F���Ȃǂ����ɂ������Ă��܂����C���p����10�N�ȏ�
����Ƃ��������ŁCIntel��2017�N�ɗʎY�ƂȂ�Ƒ傫�ȉ����ŁC
�����̃��[�J�[�ɑ��郊�[�h���L�������ł��B
����́A
http://techon.nikkeibp.co.jp/article/COLUMN/20091018/176539/
��III-V�������̂���Ȃ��̂��ȁH
���炩�̃`�b�v������ł����Ƃ��Ă��ANehalem�݂����ȋ���CPU�̗ʎY��
��������낤�ȁB
�܁A���ʂɍl�����III-V�����낤��
�Y�f�n�̂͗ʎY���@�m�����ĂȂ��ł���
�Y�f�n�̂͗ʎY���@�m�����ĂȂ��ł���
����100GHz�̎��オ����̂�
227 �F,,�E�L�́M�E,,�j��-�������F2009/10/25(��) 11:57:47 ID:vK8GI5hT
1017�N�ȍ~�����[�A�̖@�������̂�
��Ȫ
��Ȫ
1017�N����������A������w�@(�o�W�A����������)
�ł����� [�ҏW]
�������ʂ��ې��ƂȂ�
�ł����� [�ҏW]
�������ʂ��ې��ƂȂ�
1000�N�߂����[�A�̖@���������Ă����Ƃ�����A1017�N�̃g�����W�X�^�T�C�Y�����낵������B
230 �F,,�E�L�́M�E,,�j��-�������F2009/10/25(��) 12:43:55 ID:vK8GI5hT
�A�z�t�X�C�b�`
�܁A�����̎��̂��A�C�f�A�Ƃ��ďo���ꂽ�̂�1952�N�AIC�̎�����
���ꂽ�̂�1959�N�A���[�A�̖@����1965�N�ALSI�ƌĂ�镨��
����1970�N��ȍ~���ˁB
���Ă݂�ƁA��������50�N�ȂȁA�ŏ���IC����B
���ꂽ�̂�1959�N�A���[�A�̖@����1965�N�ALSI�ƌĂ�镨��
����1970�N��ȍ~���ˁB
���Ă݂�ƁA��������50�N�ȂȁA�ŏ���IC����B
�d�͐��\�䂳�����P�����Ȃ�A�K�����������͕K�v�łȂ��C������B
��������������Z�p����������B
��������������Z�p����������B
���̃C���^�[�`�F���W�͂ǂ��ł����H
���͔��������r���[������CPU���\�����サ�Ȃ���ȁB
�S�`�WGB�̃��������I���_�C�o����APC�̑啝�Ȑ��\�A�b�v���\����B
�S�`�WGB�̃��������I���_�C�o����APC�̑啝�Ȑ��\�A�b�v���\����B
>>234
�o��
�o��
�J�[�{���i�m�`���[�u���p���������O��NEC�̓����ꂿ�Ⴄ��
���쌠�݂����ɓ���������������Ă����A���͋��Ȃ��̂���
238 �F,,�E�L�́M�E,,�j��-�������F2009/10/26(��) 00:57:00 ID:ijmzBkZG
IntelR Architecture Code Analyzer��1.1�ɂ���
Linux�����T�|�[�g
http://software.intel.com/en-us/articles/intel-architecture-code-analyzer/
Linux�����T�|�[�g
http://software.intel.com/en-us/articles/intel-architecture-code-analyzer/
pcmpgtq��vpcmpgtq�Ő��\���Ⴄ�͉̂��ł���?
>>239
�o�O����L��
�o�O����L��
241 �F,,�E�L�́M�E,,�j��-�������F2009/10/26(��) 22:10:45 ID:ijmzBkZG
���肪�������Ƃ�Nehalem��Westmere�̃V�~�����[�^�܂ŕt���Ă�B
Core 2 Duo�ő�������ƌ������肾�B
Core 2 Duo�ő�������ƌ������肾�B
���{�̃x���`���[��ƁB
Intel
�VIntel
Shindel
�VIntel
Shindel
244 �F,,�E�L�́M�E,,�j��-�������F2009/10/27(��) 21:01:44 ID:f5xox4cV
�E�m��́u�C���`�����v����Ȃ��āu�ɂ���v
�EJR������g��w�̃z�[���ŃR�u�N��
�E�����I�������{���\���Ă˂�
�E��(�����)�w�@
�E���{�n���q
�EJR������g��w�̃z�[���ŃR�u�N��
�E�����I�������{���\���Ă˂�
�E��(�����)�w�@
�E���{�n���q
245 �F,,�E�L�́M�E,,�j��-�������F2009/10/27(��) 23:13:01 ID:p0qmGqi2
246 �F,,�E�L�́M�E,,�j��-�������F2009/10/27(��) 23:24:20 ID:p0qmGqi2
�ŁA�V�~�����[�^����@����Ƃ���AWestmere��Nehalem�́E�E�E�E�قړ���
��DLL�̃T�C�Y���S���������_�ŁE�E�E
����ł�AES���߂̃T�|�[�g�́A�Ή����Ă�\�t�g����ł͌��ʂ͑傫����������Ȃ��B
��DLL�̃T�C�Y���S���������_�ŁE�E�E
����ł�AES���߂̃T�|�[�g�́A�Ή����Ă�\�t�g����ł͌��ʂ͑傫����������Ȃ��B
New company promises 100 core CPUs by next year
http://www.gadgetell.com/tech/comment/new-company-promises-100-core-cpus-by-next-year/
�����r�[���wwww
http://www.gadgetell.com/tech/comment/new-company-promises-100-core-cpus-by-next-year/
�����r�[���wwww
248 �F,,�E�L�́M�E,,�j��-�������F2009/10/27(��) 23:47:05 ID:p0qmGqi2
�܂�TILELA���B��ɂ���Ď������W�܂炸�ɐ��i�������ɏI���낤�ȁB
1025�R�A�Ȃ�Ă̂�����܂����B
http://slashdot.jp/mobile/06/04/05/1315213.shtml
���̊Ԃɂ����[�h�}�b�v�ǂ��납��Ђ��̂��̂������Ȃ��Ă����ȁB
1025�R�A�Ȃ�Ă̂�����܂����B
http://slashdot.jp/mobile/06/04/05/1315213.shtml
���̊Ԃɂ����[�h�}�b�v�ǂ��납��Ђ��̂��̂������Ȃ��Ă����ȁB
��
�����i�������ɏI���낤�ȁB
2�N�O
��TILE64���I������]�X�̂ق��������ł���B
747 �F�E�́E�j��-������ [sage] �F2007/08/22(��) 00:24:00 ID:InXaTzlV0
>>744
�����B
�S�R�A�������[�N�X�e�[�V�����pCell�ŃE���\��������ȁB
751 �F�E�́E�j��-������ [sage] �F2007/08/22(��) 00:37:27 ID:InXaTzlV0
�u�Q�[�����Y�v�Ȃ�Ă��ꂱ��HPC��n�C�G���h�g�ݍ��@��ɂƂ�����
�����ɓ��������B
����͊w�p�������ʂ̐��i���ł����āAMIT�ł�ASIC���Linux�Ȃ�
���ۓ����Ă�낤���A���ۂ����ɏo���郌�x�����Ǝv�����B
757 �F�E�́E�j��-������ [sage] �F2007/08/22(��) 00:44:31 ID:InXaTzlV0
���ڔ�r����ɂ͂����Ă��̂������ɂ��邶��Ȃ���
http://www.tilera.com/products/boards.php
���i�͖����J�����A�`�b�v�Z�b�g���s�v�������Ȃ�����Ȃ�\���B
����I�ɂ͂����Cell�A�N�Z�����[�^�{�[�h�ƂԂ���ˁB
788 �F�E�́E�j��-������ [sage] �F2007/08/22(��) 02:53:24 ID:InXaTzlV0
TILE�͕ʂ�H.264�ɓ������ꂽ�n�[�h�Ȃ킯����Ȃ��������܂Ő��\��\����Ⴖ���B
Linux�������Ȃ炠��Apache�Ƃ���������Web�T�[�o�ɋ����ɂ��Ȃ肤���ˁB
MIT���ǂ��܂ŊJ������Ă�̂��m��ǁB
�Ƃ肠����ISA�ɋ���������̂�kernel.org�ł��T���Ă��邩�B
794 �F�E�́E�j��-������ [sage] �F2007/08/22(��) 03:30:05 ID:InXaTzlV0
�Ƃ肠����10���ȉ��Ȃ甃�����M������B
�ł�PCIe��x16�Ȃ�ĂȂ��BG33�̃}�U�[�ɂł����邩�B
827 �F�E�́E�j��-������ [sage] �F2007/08/23(��) 07:01:53 ID:Z2uxU27o0
�Ƃ肠�����t��HD�̃G���r�ʎY����Ώ��@�͂���
838 �F�E�́E�j��-������ [sage] �F2007/08/24(��) 00:27:24 ID:mmwHiBC80
CUDA�������ɑΉ����ĂȂ�Windows Vista�ɑΉ�������Ă����̂Ȃ�ʔ������ƂɂȂ��Ȃ��́H
�܂��j�b�`�s��̒��̃j�b�`�s�ꂾ���ǁB
GeForce8�͂���܂萮�����\�����Ȃ���ŁA���������ʂł͌��\���҂ł���B
7 �F�E�́E�j��-������ [sage] �F2007/08/26(��) 22:34:07 ID:3bG/XKKR0
>>5
�������BTILE64���I������]�X�̂ق��������ł���B
�����i�������ɏI���낤�ȁB
2�N�O
��TILE64���I������]�X�̂ق��������ł���B
747 �F�E�́E�j��-������ [sage] �F2007/08/22(��) 00:24:00 ID:InXaTzlV0
>>744
�����B
�S�R�A�������[�N�X�e�[�V�����pCell�ŃE���\��������ȁB
751 �F�E�́E�j��-������ [sage] �F2007/08/22(��) 00:37:27 ID:InXaTzlV0
�u�Q�[�����Y�v�Ȃ�Ă��ꂱ��HPC��n�C�G���h�g�ݍ��@��ɂƂ�����
�����ɓ��������B
����͊w�p�������ʂ̐��i���ł����āAMIT�ł�ASIC���Linux�Ȃ�
���ۓ����Ă�낤���A���ۂ����ɏo���郌�x�����Ǝv�����B
757 �F�E�́E�j��-������ [sage] �F2007/08/22(��) 00:44:31 ID:InXaTzlV0
���ڔ�r����ɂ͂����Ă��̂������ɂ��邶��Ȃ���
http://www.tilera.com/products/boards.php
���i�͖����J�����A�`�b�v�Z�b�g���s�v�������Ȃ�����Ȃ�\���B
����I�ɂ͂����Cell�A�N�Z�����[�^�{�[�h�ƂԂ���ˁB
788 �F�E�́E�j��-������ [sage] �F2007/08/22(��) 02:53:24 ID:InXaTzlV0
TILE�͕ʂ�H.264�ɓ������ꂽ�n�[�h�Ȃ킯����Ȃ��������܂Ő��\��\����Ⴖ���B
Linux�������Ȃ炠��Apache�Ƃ���������Web�T�[�o�ɋ����ɂ��Ȃ肤���ˁB
MIT���ǂ��܂ŊJ������Ă�̂��m��ǁB
�Ƃ肠����ISA�ɋ���������̂�kernel.org�ł��T���Ă��邩�B
794 �F�E�́E�j��-������ [sage] �F2007/08/22(��) 03:30:05 ID:InXaTzlV0
�Ƃ肠����10���ȉ��Ȃ甃�����M������B
�ł�PCIe��x16�Ȃ�ĂȂ��BG33�̃}�U�[�ɂł����邩�B
827 �F�E�́E�j��-������ [sage] �F2007/08/23(��) 07:01:53 ID:Z2uxU27o0
�Ƃ肠�����t��HD�̃G���r�ʎY����Ώ��@�͂���
838 �F�E�́E�j��-������ [sage] �F2007/08/24(��) 00:27:24 ID:mmwHiBC80
CUDA�������ɑΉ����ĂȂ�Windows Vista�ɑΉ�������Ă����̂Ȃ�ʔ������ƂɂȂ��Ȃ��́H
�܂��j�b�`�s��̒��̃j�b�`�s�ꂾ���ǁB
GeForce8�͂���܂萮�����\�����Ȃ���ŁA���������ʂł͌��\���҂ł���B
7 �F�E�́E�j��-������ [sage] �F2007/08/26(��) 22:34:07 ID:3bG/XKKR0
>>5
�������BTILE64���I������]�X�̂ق��������ł���B
�c�q�̐����̋L�^���ǂ߂�̂�2�����˂邾���I
251 �F,,�E�L�́M�E,,�j��-�������F2009/10/28(��) 00:07:45 ID:y5ysAT1N
DAPDNA�̃A�C�s�[�t���b�N�X���|�Y����
DSP���}���`�R�A�������悤�ȃ\�����[�V�������Č��E�Ȃ�ˁH
�����������蕶����Ĕ����t���O�Ȃ��
http://tamuchi.net/2007/08/xeon1064cputile64.html
���₱���̏ꍇ�l�b�g���[�N�v���Z�b�T�Ƃ��Ă͏\���D�G���Ǝv����
�\���ȃX�P�[�������b�g�̖ʂł��Ȃ�����B
�T���ă}�[�P�e�B���O�i�c�Ɛ헪�j������Ȃ�ȁB
DSP���}���`�R�A�������悤�ȃ\�����[�V�������Č��E�Ȃ�ˁH
�����������蕶����Ĕ����t���O�Ȃ��
http://tamuchi.net/2007/08/xeon1064cputile64.html
���₱���̏ꍇ�l�b�g���[�N�v���Z�b�T�Ƃ��Ă͏\���D�G���Ǝv����
�\���ȃX�P�[�������b�g�̖ʂł��Ȃ�����B
�T���ă}�[�P�e�B���O�i�c�Ɛ헪�j������Ȃ�ȁB
���̐���͉����������Y�ꂽ
�E16�R�A@1GHz��GTX 280��蕽��1.5�{�����A�V���O���R�A��Harpertown��10�{�����B
�E32�R�A��64�R�A�ł�CPU�Ƃ̊Ԃł̃f�[�^�]�����{�g���l�b�N�ɂȂ�B
�@�����A���̃f�[�^�]���̃R�X�g��0�Ȃ��32�R�A�ł�(CPU��)24�{�����Ȃ�A64�R�A�ł�42�{�����Ȃ�B
�E16�R�A@1GHz��GTX 280��蕽��1.5�{�����A�V���O���R�A��Harpertown��10�{�����B
�E32�R�A��64�R�A�ł�CPU�Ƃ̊Ԃł̃f�[�^�]�����{�g���l�b�N�ɂȂ�B
�@�����A���̃f�[�^�]���̃R�X�g��0�Ȃ��32�R�A�ł�(CPU��)24�{�����Ȃ�A64�R�A�ł�42�{�����Ȃ�B
253 �F,,�E�L�́M�E,,�j��-�������F2009/10/28(��) 00:12:55 ID:y5ysAT1N
http://journal.mycom.co.jp/news/2009/10/27/011/?rt=na
26MB��L3�L���b�V��������
Itatatatatanium�Ȃ�Ėڂ���ˁ[��
�����Fermi����ɏo���炠��Ӗ�NVIDIA���S
26MB��L3�L���b�V��������
Itatatatatanium�Ȃ�Ėڂ���ˁ[��
�����Fermi����ɏo���炠��Ӗ�NVIDIA���S
254 �F,,�E�L�́M�E,,�j��-�������F2009/10/28(��) 00:16:51 ID:y5ysAT1N
���̕��ʂ��ƁAL2�L���b�V���U���L�L���b�V���Ƃ��Ďg����100�R�A����26MB�Ȃ�Ȃ�����
Larrabee�ł͂����܂ő��̃R�A�̎��f�Ђ��܂߂�L2���ČĂ�ł邯��
Larrabee�ł͂����܂ő��̃R�A�̎��f�Ђ��܂߂�L2���ČĂ�ł邯��
255 �F,,�E�L�́M�E,,�j��-�������F2009/10/28(��) 00:27:08 ID:y5ysAT1N
http://up3.viploader.net/pc/src/vlpc000927.jpg
Dunnington(45nm)�̏ꍇ�B
�Ŋ�����������L2&L3�L���b�V���B���v25MB
�����503mm²�Ȃ��
�m����Fermi���ł����B
�ʖڂ����̉�ЁA���C����Ȃ��B
{kind=link}
Dunnington(45nm)�̏ꍇ�B
�Ŋ�����������L2&L3�L���b�V���B���v25MB
�����503mm²�Ȃ��
�m����Fermi���ł����B
�ʖڂ����̉�ЁA���C����Ȃ��B
100�R�A���đf�G���H
257 �F,,�E�L�́M�E,,�j��-�������F2009/10/28(��) 00:45:55 ID:y5ysAT1N
> �T���v���̏o������TILE-Gx36��2010�N��4�l������\�肵�Ă���A
> �c��3���i���������甼�N�ȓ��Ƀ��[���A�E�g�����\��
�Ƃ܂��A������ɂ��Ă������ɍ̗p�悪���܂��Ă����ۑg�ݍ����i���o��̂�
������̘b���ȁi����2012�N�ȍ~�j
���̍��ɂ�40nm�v���Z�X�̕����܂���P���������荠�ɂȂ��Ă邾�낤
> �c��3���i���������甼�N�ȓ��Ƀ��[���A�E�g�����\��
�Ƃ܂��A������ɂ��Ă������ɍ̗p�悪���܂��Ă����ۑg�ݍ����i���o��̂�
������̘b���ȁi����2012�N�ȍ~�j
���̍��ɂ�40nm�v���Z�X�̕����܂���P���������荠�ɂȂ��Ă邾�낤
�ǂ��ł�������
http://resource.renesas.com/lib/jpn/edge/13/special02.html
32�r�b�g�}�C�N���v���Z�b�T�iMPU�j�Ɣ�r�����Ƃ���A100�{���̐��\��������
http://www.artcompsci.org/~makino/talks/tentairikigaku20050311.pdf
Intel�Ƃ��̃v���Z�b�T���1000�{����
http://monoist.atmarkit.co.jp/fembedded/07ipflex/ipflex01.html
���\��Pentium 4��50�{�ȏ�
http://www-03.ibm.com/technology/resources/technology_cell_pdf_IBM_Mayo_Demo.pdf
���\��Pentium 4��3GHz��60�{�ȏ�
http://itpro.nikkeibp.co.jp/article/NEWS/20070821/279976/
�f���A���R�A��Xeon�ɔ�������x��10�{�C����d�͓�����̏������x��30�{
http://www.asyura.com/0601/it09/msg/472.html
�P�ʏ���d�͓�����̉��Z���\��50�{�ȏ�
http://resource.renesas.com/lib/jpn/edge/13/special02.html
32�r�b�g�}�C�N���v���Z�b�T�iMPU�j�Ɣ�r�����Ƃ���A100�{���̐��\��������
http://www.artcompsci.org/~makino/talks/tentairikigaku20050311.pdf
Intel�Ƃ��̃v���Z�b�T���1000�{����
http://monoist.atmarkit.co.jp/fembedded/07ipflex/ipflex01.html
���\��Pentium 4��50�{�ȏ�
http://www-03.ibm.com/technology/resources/technology_cell_pdf_IBM_Mayo_Demo.pdf
���\��Pentium 4��3GHz��60�{�ȏ�
http://itpro.nikkeibp.co.jp/article/NEWS/20070821/279976/
�f���A���R�A��Xeon�ɔ�������x��10�{�C����d�͓�����̏������x��30�{
http://www.asyura.com/0601/it09/msg/472.html
�P�ʏ���d�͓�����̉��Z���\��50�{�ȏ�
259 �F,,�E�L�́M�E,,�j��-�������F2009/10/28(��) 00:52:15 ID:y5ysAT1N
���������ƂɑS��URL�����ɂȂ��Ă�
�f�X�N�g�b�v�ɓ��ڂ���Ă��H
�����`�b�v�E�g�����X�s���[�^���˂��B25�N���B
�҂イ���˂��B
Intel��Numonyx�APCM�A���C��ϑw���P��̃v���Z�b�T�[�E�_�C��ɏW�ς���Z�p���J��
http://it.nikkei.co.jp/business/news/release.aspx?i=235140
http://it.nikkei.co.jp/business/news/release.aspx?i=235140
�^�C�g��������ƌ�����Ă��܂���PCM���_�C�X�^�b�L���O��CPU�̃L���b�V���Ƃ��Ďg���Ƃ����b�ł͂Ȃ���
265 �F,,�E�L�́M�E,,�j��-�������F2009/10/29(��) 22:35:49 ID:uFX20jKt
�ϋv���ǂ��Ȃ�
�o�Ԃ͂܂��������ɂȂ����ǂˁB
(NAND���y���ɑ����Ƃ͂���)���������Ɍ��x�����郁������
DRAM��ւŃ��C���������Ƃ��Ďg���Z�p�����������
PRAM��ReRAM�͉�����̂����B
(NAND���y���ɑ����Ƃ͂���)���������Ɍ��x�����郁������
DRAM��ւŃ��C���������Ƃ��Ďg���Z�p�����������
PRAM��ReRAM�͉�����̂����B
����ADRAM�Ȃ��X�^�b�N���ă��C�e���V�ጸ�ƃo�X�ш摝�₷�ق����Ӗ������肻��
SRAM�Ƃ������C�e���V�̒Ⴂ�������͊��ɂ���̂ɁA
��������C���������Ɏg���V�X�e�����قƂ�ǂȂ��̂�
��͂胁�C���������̃��C�e���V�팸�ɔ���ȋ��������Ă���p�Ό��ʂ���������H
��������C���������Ɏg���V�X�e�����قƂ�ǂȂ��̂�
��͂胁�C���������̃��C�e���V�팸�ɔ���ȋ��������Ă���p�Ό��ʂ���������H
�e�ʂ�������1�ɂȂ�
270 �FSocket774�F2009/10/31(�y) 21:54:49 ID:YZ/qI7n5
����d�͂��Ȃ�
�e�ʂɂ��ẮA�p�r�ɂ���Ă͎g���邾�낤����
�e�ʂɂ��ẮA�p�r�ɂ���Ă͎g���邾�낤����
271 �F,,�E�L�́M�E,,�j��-�������F2009/10/31(�y) 22:01:53 ID:i+EhVJVU
Larrabee��VRAM�̃g���t�B�b�N��}����̂ɗL����x�̑傫����SRAM�����p�����������
�ł��o���Ă邯�ǂˁB
Sandy Bridge��vmulps/pd�̃��C�e���V��4�Ɍ������̂ˁB
���Ȃ�g���₷���Ȃ����B
�ł��o���Ă邯�ǂˁB
Sandy Bridge��vmulps/pd�̃��C�e���V��4�Ɍ������̂ˁB
���Ȃ�g���₷���Ȃ����B
272 �F,,�E�L�́M�E,,�j��-�������F2009/11/01(��) 01:54:48 ID:mtXW/RVq
�����_���A�N�Z�X�������Ȃ�SRAM�����ǁA
��J���Ɍł܂����傫���f�[�^���o�[�X�g�]������Ȃ�
DRAM�ł����\�ɖ�肪�Ȃ��B
������L���b�V����SRAM�A��e�ʂ�DRAM���g���Ă�B
�P����r�͏o���Ȃ�����SRAM��6�g�����W�X�^�A
DRAM��1�g�����W�X�^�{1�L���p�V�^�Ȃ�ŃT�C�Y���Ⴄ�B
�ȓd�͉��Ȃ玟���チ�������Ă��Ƃ�SRAM�ɂ͂Ȃ�Ȃ��B
��J���Ɍł܂����傫���f�[�^���o�[�X�g�]������Ȃ�
DRAM�ł����\�ɖ�肪�Ȃ��B
������L���b�V����SRAM�A��e�ʂ�DRAM���g���Ă�B
�P����r�͏o���Ȃ�����SRAM��6�g�����W�X�^�A
DRAM��1�g�����W�X�^�{1�L���p�V�^�Ȃ�ŃT�C�Y���Ⴄ�B
�ȓd�͉��Ȃ玟���チ�������Ă��Ƃ�SRAM�ɂ͂Ȃ�Ȃ��B
�������}�g���N�X����̓ǂݏo���ƁA��������V���A���`������X�s�[�h�l����Ǝ����悤�Ȃ���
���t���b�V�����ׂ�����قǂł͂Ȃ����A�z���e�ʂւ̃`���[�W������d�͂ɂ��Ă�
�x�z�I�v�f�ɂȂ���������l�����DRAM�ŏ\����
����ł��d���ϓ����̑��Ɋւ������x���܂߂��l�����SRAM�ɂ������b�g�͂���̂�����
���������C�e���V���ǂ����������Ă��A�����ȃ������ɂ���ɂ�SRAM�������ɃT�C�Y�̑傫�Ȃ��̂ɂ��Ȃ���
�����ɏo���Ȃ��Ȃ�
���t���b�V�����ׂ�����قǂł͂Ȃ����A�z���e�ʂւ̃`���[�W������d�͂ɂ��Ă�
�x�z�I�v�f�ɂȂ���������l�����DRAM�ŏ\����
����ł��d���ϓ����̑��Ɋւ������x���܂߂��l�����SRAM�ɂ������b�g�͂���̂�����
���������C�e���V���ǂ����������Ă��A�����ȃ������ɂ���ɂ�SRAM�������ɃT�C�Y�̑傫�Ȃ��̂ɂ��Ȃ���
�����ɏo���Ȃ��Ȃ�
LTE���A�s�[������G���N�\�����AWiMAX������
http://k-tai.impress.co.jp/docs/news/20091027_324627.html
> 2014�N���̒ʐM�����ʂ̃V�F�A�\�����Љ�BLTE�͐��E��90�����߁A
> �����ʘb���S��CDMA��10���A���o�C��WiMAX��1�����x�ɂȂ�Ƃ����B
KDDI�^���́uWiMAX�v�s�U
http://zasshi.news.yahoo.co.jp/article?a=20091104-00000000-facta-bus_all
http://k-tai.impress.co.jp/docs/news/20091027_324627.html
> 2014�N���̒ʐM�����ʂ̃V�F�A�\�����Љ�BLTE�͐��E��90�����߁A
> �����ʘb���S��CDMA��10���A���o�C��WiMAX��1�����x�ɂȂ�Ƃ����B
KDDI�^���́uWiMAX�v�s�U
http://zasshi.news.yahoo.co.jp/article?a=20091104-00000000-facta-bus_all
Centorino�̘b���S���o�Ă��Ȃ����_�ł����ʖ�
�z���z����������
5 �FSocket774 [sage] �F2008/12/05(��) 00:29:49 ID:CXZX8xIb
���o�C��WiMAX ���
�v���l�`�w�̂��Ă��O�ꂽ�j�c�c�h
http://it.nikkei.co.jp/mobile/news/index.aspx?n=MMIT0f000004042008&cp=2
��
KDDI�ALTE�̗̍p�𐳎����\
http://plusd.itmedia.co.jp/mobile/articles/0811/07/news131.html
KDDI�ALTE�̗p��\���@�������R�A�l�b�g���[�N�@��x���_�[��
http://www.itmedia.co.jp/news/articles/0812/04/news013.html
6 �F,,�E�L�́M�E,,�j��-������ [sage] �F2008/12/05(��) 06:12:15 ID:NDLqSqDC
Intel�͎�����Centrino�}�V���Ƀ��o�C��WiMAX�ʐM���W���[�����ڂ��������Ă鎖���͂��邪
����͌g�ѓd�b���̂��̂�Atom���ڂ��悤�Ȃ�čl���Ă�킯����Ȃ��̂ŕʂ�
�y���{�́z���g�ѓd�b�L�����A�R�Ђ����o�C��WiMAX���̗p���Ȃ������Ƃ��đ傫�ȉe���͂Ȃ��B
32 �F,,�E�L�́M�E,,�j��-������ [sage] �F2008/12/05(��) 21:56:06 ID:NDLqSqDC
LTE�������w�̋Z�p�͂قƂ�Ǔ����Ȃ̂ɂˁBWiMAX���ʖڂȂ�LTE���ʖڂ��낊��
121 �F,,�E�L�́M�E,,�j��-������ [sage] �F2008/12/06(�y) 04:15:19 ID:r7a/Stqo
���o�C��WiMAX�ő��s���Ɏ���1M�o����Ă���ۂǗD�G�����ǂȁB
�ǂ������Ƃ�����JR�������p���Ɍ����Ď�������Ă邱�Ƃ̂ق����E�F�C�g�傫�����ǁB
�R��E���l���k��������Ŏg����悤�ɂȂ�Ύ�s���ł̕��y�͌��܂����悤�ȃ�������Ȃ���
367 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/03/23(��) 05:06:58 ID:ZZtaNKG2
������ɂ��Ă�LTE�����̋K�i���Ă̂͂ˁ[��B
�_�C�A���A�b�v���K�v�Ȏ��_�ŃR�X�g�ʂőg�ݍ��݂ɂ͕s������
368 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/03/23(��) 05:18:12 ID:ZZtaNKG2
���Ȃ݂�LTE�̎������\�������b�g��
http://ascii.jp/elem/000/000/208/208796/
369 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/03/23(��) 05:46:05 ID:ZZtaNKG2
1.5GH��/1.7GHz��LTE���̗p����͓̂��{���炢�����Ȃ�
���X�P�[�������b�g�ʂŔ���
LTE��4�L�����A���ꂼ��10MH�����̊��������Ȃ��̂�HPSA+�ɑ��鐫�\�ʂł̃����b�g�����Ȃ�
������2014�N�n��
�I����Ă�Ƃ��킴��y�I���Ȃ��z
5 �FSocket774 [sage] �F2008/12/05(��) 00:29:49 ID:CXZX8xIb
���o�C��WiMAX ���
�v���l�`�w�̂��Ă��O�ꂽ�j�c�c�h
http://it.nikkei.co.jp/mobile/news/index.aspx?n=MMIT0f000004042008&cp=2
��
KDDI�ALTE�̗̍p�𐳎����\
http://plusd.itmedia.co.jp/mobile/articles/0811/07/news131.html
KDDI�ALTE�̗p��\���@�������R�A�l�b�g���[�N�@��x���_�[��
http://www.itmedia.co.jp/news/articles/0812/04/news013.html
6 �F,,�E�L�́M�E,,�j��-������ [sage] �F2008/12/05(��) 06:12:15 ID:NDLqSqDC
Intel�͎�����Centrino�}�V���Ƀ��o�C��WiMAX�ʐM���W���[�����ڂ��������Ă鎖���͂��邪
����͌g�ѓd�b���̂��̂�Atom���ڂ��悤�Ȃ�čl���Ă�킯����Ȃ��̂ŕʂ�
�y���{�́z���g�ѓd�b�L�����A�R�Ђ����o�C��WiMAX���̗p���Ȃ������Ƃ��đ傫�ȉe���͂Ȃ��B
32 �F,,�E�L�́M�E,,�j��-������ [sage] �F2008/12/05(��) 21:56:06 ID:NDLqSqDC
LTE�������w�̋Z�p�͂قƂ�Ǔ����Ȃ̂ɂˁBWiMAX���ʖڂȂ�LTE���ʖڂ��낊��
121 �F,,�E�L�́M�E,,�j��-������ [sage] �F2008/12/06(�y) 04:15:19 ID:r7a/Stqo
���o�C��WiMAX�ő��s���Ɏ���1M�o����Ă���ۂǗD�G�����ǂȁB
�ǂ������Ƃ�����JR�������p���Ɍ����Ď�������Ă邱�Ƃ̂ق����E�F�C�g�傫�����ǁB
�R��E���l���k��������Ŏg����悤�ɂȂ�Ύ�s���ł̕��y�͌��܂����悤�ȃ�������Ȃ���
367 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/03/23(��) 05:06:58 ID:ZZtaNKG2
������ɂ��Ă�LTE�����̋K�i���Ă̂͂ˁ[��B
�_�C�A���A�b�v���K�v�Ȏ��_�ŃR�X�g�ʂőg�ݍ��݂ɂ͕s������
368 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/03/23(��) 05:18:12 ID:ZZtaNKG2
���Ȃ݂�LTE�̎������\�������b�g��
http://ascii.jp/elem/000/000/208/208796/
369 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/03/23(��) 05:46:05 ID:ZZtaNKG2
1.5GH��/1.7GHz��LTE���̗p����͓̂��{���炢�����Ȃ�
���X�P�[�������b�g�ʂŔ���
LTE��4�L�����A���ꂼ��10MH�����̊��������Ȃ��̂�HPSA+�ɑ��鐫�\�ʂł̃����b�g�����Ȃ�
������2014�N�n��
�I����Ă�Ƃ��킴��y�I���Ȃ��z
>>277
10MHz���Ċ������蓖�ĂƂ͕ʂ̐V�K�lj����Ȃ̂ɂ����̓A�t�H�`���Ȃ�
���܂ꂽ�̎v���������B
docomo��au�͊���+�V�K�̏d�w���Ȃ̂ɊԔ������c
���Ƃ�2�Ђ̓_�u���L���X�g����̈ڍs������DC�Ŋ��ɒǂ��t�����n���B
10MHz���Ċ������蓖�ĂƂ͕ʂ̐V�K�lj����Ȃ̂ɂ����̓A�t�H�`���Ȃ�
���܂ꂽ�̎v���������B
docomo��au�͊���+�V�K�̏d�w���Ȃ̂ɊԔ������c
���Ƃ�2�Ђ̓_�u���L���X�g����̈ڍs������DC�Ŋ��ɒǂ��t�����n���B
WiMAX�̖��͂�2�N���肪�Ȃ�
�[���������A�����ȃ��C�����X�Ƃ����Ƃ���
�t�ɂ����A�����I�ɂ����ɐ�����
�N������˂�
�[���������A�����ȃ��C�����X�Ƃ����Ƃ���
�t�ɂ����A�����I�ɂ����ɐ�����
�N������˂�
�o�������烆�[�U�[�̂����]�����������Ă��Ȃ������̂͒ɂ�
���uMVNO�i���z�ړ��̒ʐM���Ǝҁj��[�����[�J�[�ɃC���t������闧��ɓO����v
���i�Љ����В��j�ƌ������邪�A���̃C���t���ɂ��Ă����������B
��
��2.5GHz�Ƃ��������g���т́A�d�g�̒��i���������A�G���A���ł����Ă��r���A�ȂǁA
��������Ƃ���Ɂg���h���ł���B�u�R������̉��O�ł��r�ꂽ�肵�ĕs����ɂȂ�v
���u�����痣�ꂽ�����̉����ƂȂ���Ȃ��v�Ȃǂƕ]���͖F�����Ȃ��B
��
���}�[�P�e�B���O���_�ł́u�q�b�g���i�̃J�M������v�Ƃ����A�[���[�A�_�v�^�[��������
���u�Ȃ���Ȃ�WiMAX�v�Ƃ������]�́A�l�b�g��ʂ��ďu���ԂɍL����A�w���ӗ~���ނ������Ă���B
���uMVNO�i���z�ړ��̒ʐM���Ǝҁj��[�����[�J�[�ɃC���t������闧��ɓO����v
���i�Љ����В��j�ƌ������邪�A���̃C���t���ɂ��Ă����������B
��
��2.5GHz�Ƃ��������g���т́A�d�g�̒��i���������A�G���A���ł����Ă��r���A�ȂǁA
��������Ƃ���Ɂg���h���ł���B�u�R������̉��O�ł��r�ꂽ�肵�ĕs����ɂȂ�v
���u�����痣�ꂽ�����̉����ƂȂ���Ȃ��v�Ȃǂƕ]���͖F�����Ȃ��B
��
���}�[�P�e�B���O���_�ł́u�q�b�g���i�̃J�M������v�Ƃ����A�[���[�A�_�v�^�[��������
���u�Ȃ���Ȃ�WiMAX�v�Ƃ������]�́A�l�b�g��ʂ��ďu���ԂɍL����A�w���ӗ~���ނ������Ă���B
281 �F,,�E�L�́M�E,,�j��-�������F2009/11/04(��) 23:38:30 ID:4Ohrun5l
���{�̓s�s���قǍ��w�r�������W�������͐��E�ł��������Ȃ��킯��
�����������v�����u�K���p�S�X���v�̈�[��S���Ă�Ɓi�د
�����������v�����u�K���p�S�X���v�̈�[��S���Ă�Ɓi�د
���o�C���ʐM�̂��łɋ��Z����iBurst�͂ǂ��Ȃ����I
>>275
���o�C��WiMAX��5%�����Ȃ��͖̂��炩�Ƃ��Ă��A
LTE��2014�N��90%���Ă̂��|�W�V�����g�[�N���߂����Ȃ��́H
�命���̃L�����A������ȃy�[�X�ňڍs�ł�����̂Ȃ́A���ہH
���o�C��WiMAX��5%�����Ȃ��͖̂��炩�Ƃ��Ă��A
LTE��2014�N��90%���Ă̂��|�W�V�����g�[�N���߂����Ȃ��́H
�命���̃L�����A������ȃy�[�X�ňڍs�ł�����̂Ȃ́A���ہH
90���Ɋւ��Ă͘b������
���ʐM�V�X�e���x���_�[�e�Ђ����L���ʐM�����փV�X�e�����������钆�A
���G���N�\���́AW-CDMA������LTE�ɂ̂݃V�X�e�����������Ă���B
���ʐM�V�X�e���x���_�[�e�Ђ����L���ʐM�����փV�X�e�����������钆�A
���G���N�\���́AW-CDMA������LTE�ɂ̂݃V�X�e�����������Ă���B
285 �F,,�E�L�́M�E,,�j��-�������F2009/11/05(��) 00:47:49 ID:B/8/aVsq
>>282
�r�㍑�����ł͂���Ȃ�ɁB
��WiMAX�̓��o�C���ʐM����Ȃ���Wi-Fi�̒������łȂ��B
���Ⴂ���������Ă邪�T�[�r�X�Z�O�����g���܂������Ⴄ�B
���ɒʘb�����̃C���t������Ȃ��B
2.5GHz�т����_����͓̂�����O�ł�������m��docomo���A�b�J�A�����������グ�Ă��킯��
���[���`���s��KDDI�̓����R����UQ�̉c�Ɛ헪�~�X����
�܂��C���Z���e�B�u�헪�̗L�p���r�߂��Ⴂ����B
�����̂�扄�����邾���ƌ���ꂽ�炻����������Ȃ���
���ꌾ���������ҋ��Z�Ȃ�ė��s��Ȃ��킯��
�r�㍑�����ł͂���Ȃ�ɁB
��WiMAX�̓��o�C���ʐM����Ȃ���Wi-Fi�̒������łȂ��B
���Ⴂ���������Ă邪�T�[�r�X�Z�O�����g���܂������Ⴄ�B
���ɒʘb�����̃C���t������Ȃ��B
2.5GHz�т����_����͓̂�����O�ł�������m��docomo���A�b�J�A�����������グ�Ă��킯��
���[���`���s��KDDI�̓����R����UQ�̉c�Ɛ헪�~�X����
�܂��C���Z���e�B�u�헪�̗L�p���r�߂��Ⴂ����B
�����̂�扄�����邾���ƌ���ꂽ�炻����������Ȃ���
���ꌾ���������ҋ��Z�Ȃ�ė��s��Ȃ��킯��
286 �F,,�E�L�́M�E,,�j��-�������F2009/11/05(��) 00:53:55 ID:B/8/aVsq
���R�Ȃ���A�u�g�ѓd�b�v��PC�s���j��Ƃ����y�ϓI�ȗ\���̉��ł�90���ł���B
287 �F,,�E�L�́M�E,,�j��-�������F2009/11/05(��) 01:37:16 ID:B/8/aVsq
���������G���N�\���݂����Ȍg�тŐ��藧���Ă�悤�Ȏ��Ǝ҂��A���������̐��Ƃ�
�s���̈����\���Ȃ�Č����܂����H
���Ƃ������A�g�уQ�[���@��Wi-Fi�̉����Ŕ�r�I��R�X�g��WiMAX�A�_�v�^��
�������邱�Ƃ͂��邩������Ȃ����ASIM�J�[�h�Ǘ��Œʘb���ۋ���
�Z�����[�t�H���C���t���ɃA�N�Z�X������Ă��ƂɂȂ�ƌ����I�ł͂Ȃ��Ȃ�B
�C�V���͎�����Wi-Fi�R�l�N�V�����̂��߂ɁiGBA�̈ꌬ�܂߁j�u�g�ѓd�b�v���̗p���Ȃ����R��
�\���ɂ��邵�A���s�邩�ǂ����͕ʂɂ���mWiMAX�̂ق�����ǂ͒Ⴂ�B
���́A�����������r�W����������Ȃ��ق�UQ���E�B���R���������Ă邱�Ƃ��B
���̎�̃C�m�x�[�V�����͊C�O�ɔC���邵���Ȃ��ˁB
�s���̈����\���Ȃ�Č����܂����H
���Ƃ������A�g�уQ�[���@��Wi-Fi�̉����Ŕ�r�I��R�X�g��WiMAX�A�_�v�^��
�������邱�Ƃ͂��邩������Ȃ����ASIM�J�[�h�Ǘ��Œʘb���ۋ���
�Z�����[�t�H���C���t���ɃA�N�Z�X������Ă��ƂɂȂ�ƌ����I�ł͂Ȃ��Ȃ�B
�C�V���͎�����Wi-Fi�R�l�N�V�����̂��߂ɁiGBA�̈ꌬ�܂߁j�u�g�ѓd�b�v���̗p���Ȃ����R��
�\���ɂ��邵�A���s�邩�ǂ����͕ʂɂ���mWiMAX�̂ق�����ǂ͒Ⴂ�B
���́A�����������r�W����������Ȃ��ق�UQ���E�B���R���������Ă邱�Ƃ��B
���̎�̃C�m�x�[�V�����͊C�O�ɔC���邵���Ȃ��ˁB
�@������[�H
�G���N�\���ƃT���X���A���E����LTE���݉^�p�����ɐ���(2009�N10��29��)
http://www.ericsson.com/jp/ericsson/pr/2009/10/20091029_samsung.shtml
�G���N�\���ƃT���X���A���E����LTE���݉^�p�����ɐ���(2009�N10��29��)
http://www.ericsson.com/jp/ericsson/pr/2009/10/20091029_samsung.shtml
�������̉��i�����������ȁB
�����Ƃ��W�Ȃ��ɓr���̂��p������̂����Ȃ��C�~�t�Ȍ�����B
W-CDMA�n�Ɠ����i���ɂ���̂Ɋ�n�ǂ�3�{������Ď��_�ŏI����Ă�B
M(obile)�WiMAX�Ɩ�����Ă����Wi�Fi�̉����Ȃ�Č�����o���Ȃ��B
�n���Ɋ��蓖�Ă�ꂽ�Œ�WiMAX�̌������Mobile�WiMAX�Ɠ��`�ɂ���A�t�H�`����
�Q�[���@�ɓ��ɂȂ���̂�Pocket WiFi�݂����̂ŏ\���B
�����Ƃ��W�Ȃ��ɓr���̂��p������̂����Ȃ��C�~�t�Ȍ�����B
W-CDMA�n�Ɠ����i���ɂ���̂Ɋ�n�ǂ�3�{������Ď��_�ŏI����Ă�B
M(obile)�WiMAX�Ɩ�����Ă����Wi�Fi�̉����Ȃ�Č�����o���Ȃ��B
�n���Ɋ��蓖�Ă�ꂽ�Œ�WiMAX�̌������Mobile�WiMAX�Ɠ��`�ɂ���A�t�H�`����
�Q�[���@�ɓ��ɂȂ���̂�Pocket WiFi�݂����̂ŏ\���B
�`���������[
������]���L�b�g��������Ă���Ƃ����c�q�搶�I����͂ǂ��ł����H
NVIDIA��x86 CPU���J�����Ă���Ƃ����\�`�Ă�
http://northwood.blog60.fc2.com/blog-entry-3264.html
��NVIDIA�͂���x86 CPU���J�����Ă���Transmeta�̐l�ނ��ق��Ă���B
NVIDIA��x86 CPU���J�����Ă���Ƃ����\�`�Ă�
http://northwood.blog60.fc2.com/blog-entry-3264.html
��NVIDIA�͂���x86 CPU���J�����Ă���Transmeta�̐l�ނ��ق��Ă���B
��n�ǐݒu���x�グ�邭�炢�Ȃ瑢��Ȃ���
http://www.rbbtoday.com/news/20080211/48601.html
�v���l�`�w�̍��ۃ��[�~���O�ɐ������ăN���A���C���ƃG�C�Z���g�k�a�v�l
http://money.biglobe.ne.jp/kabu/news/economy/CN28Y675.html
���o�C��WiMAX�A���ۃ��[�~���O���\��
http://headlines.yahoo.co.jp/hl?a=20091026-00000033-yonh-kr
�O���[���p�P�b�g�A�V���K�|�[���̒ʐM���ƖƋ����擾
http://www.asiax.biz/news/2009/10/26-113059.php
���̃X���I�ɂ͂��ꂩ
�y�C���h�o�ρz�C���e���AWiMAX�p���g�����D�ŃC���h�ʐM���Ƌ�����
http://news.indochannel.jp/news/nws0001662.html
http://www.rbbtoday.com/news/20080211/48601.html
�v���l�`�w�̍��ۃ��[�~���O�ɐ������ăN���A���C���ƃG�C�Z���g�k�a�v�l
http://money.biglobe.ne.jp/kabu/news/economy/CN28Y675.html
���o�C��WiMAX�A���ۃ��[�~���O���\��
http://headlines.yahoo.co.jp/hl?a=20091026-00000033-yonh-kr
�O���[���p�P�b�g�A�V���K�|�[���̒ʐM���ƖƋ����擾
http://www.asiax.biz/news/2009/10/26-113059.php
���̃X���I�ɂ͂��ꂩ
�y�C���h�o�ρz�C���e���AWiMAX�p���g�����D�ŃC���h�ʐM���Ƌ�����
http://news.indochannel.jp/news/nws0001662.html
Nvidia crushes MSI's Lucid based board
ttp://www.semiaccurate.com./2009/11/04/nvidia-crushes-msis-lucid-based-board/
Hydra 200�����߂ē��ڂ��邱�ƂŒ��ڂ��ꂽMSI Big Bang�̃X�C�b�`�`�b�v��NF200�ɍ����ւ���ꂽ���ɂ��Ă����A
Hydra 200�̃h���C�o��`�b�v�ɖ�肪�������킯�ł͂Ȃ��ASLI�̃��C�Z���X���Ŗׂ�����NV�����͂��������A�A�A�Ƃ����X���L���B
���N�̑��l�����ɓ��������ꍞ�炵�����A����͑�O��VGA�J�[�h�̓o�ꎞ�����Î����Ă������ȁB
ttp://www.semiaccurate.com./2009/11/04/nvidia-crushes-msis-lucid-based-board/
Hydra 200�����߂ē��ڂ��邱�ƂŒ��ڂ��ꂽMSI Big Bang�̃X�C�b�`�`�b�v��NF200�ɍ����ւ���ꂽ���ɂ��Ă����A
Hydra 200�̃h���C�o��`�b�v�ɖ�肪�������킯�ł͂Ȃ��ASLI�̃��C�Z���X���Ŗׂ�����NV�����͂��������A�A�A�Ƃ����X���L���B
���N�̑��l�����ɓ��������ꍞ�炵�����A����͑�O��VGA�J�[�h�̓o�ꎞ�����Î����Ă������ȁB
����i�j
����I�Ƀ��o�C������o�����Ă����n�O
�g�т̂Ȃ��̂�ł����Ⴄ��́H��
>>296
�A���ʼn����ȏЉ�ĂA�t�H�`��
����Ƃ��ɂ������g���Ă邵��
Pocket WiFi��2�3���O�ɔ��\�������炽�܂��o���������ŁA
����docomo�����\�����p�P�z�_�u���̂܂܂�128k�܂�PC����Ƃ������邵�Q�[���O�ł��ĂȂ�g�ьn�ŏ\������ƒ�N������������B
�O�������o���z�̓L�����Ȃ��c��
�A���ʼn����ȏЉ�ĂA�t�H�`��
����Ƃ��ɂ������g���Ă邵��
Pocket WiFi��2�3���O�ɔ��\�������炽�܂��o���������ŁA
����docomo�����\�����p�P�z�_�u���̂܂܂�128k�܂�PC����Ƃ������邵�Q�[���O�ł��ĂȂ�g�ьn�ŏ\������ƒ�N������������B
�O�������o���z�̓L�����Ȃ��c��
�u���MAX�v������͊m���ɃL����
�@������[�H
�`���������[
����i�j
��n�O
��
�������Ȃ݂Ȃ��n����
�`���������[
����i�j
��n�O
��
�������Ȃ݂Ȃ��n����
�Ђ���Ƃ��ē��ӂ̊؍��N�����H
����LTE�[���͊؍����ŏ����B���ꂾ���͔F�߂Ă��B
����LTE�[���͊؍����ŏ����B���ꂾ���͔F�߂Ă��B
�T���X���͈��H�����ǖ\�H�Ȃ�����̂��v���I�Ȍ��_����
LTE�܂ň���i�j�ʼn䖝�Ȃ�
2�N����撣���đς����
2�N����撣���đς����
���������O���Ɠ����o���n����
�ڂɂ́u�n���v
���ꂪ�������̐���t�̒�R
���ꂪ�������̐���t�̒�R
�ƎO�����\���Ă܂���
�u�O���v�i�j
�����̃��X�����p���Ď��Ȃ��Ȃ݂Ă��ł��ˁB
�������ł��i���j
�������ł��i���j
�n���ɓ������J��Ԃ��������B
2���t�@�r���ɉ��x�����Ă����ʂ������ˁB
2���t�@�r���ɉ��x�����Ă����ʂ������ˁB
�~�n����
���n����
���{���������������
���n����
���{���������������
���܂���܂Ƃ߂ăj�_�[�A��
���{�͑����Ȏw���̉��A�S�L�����ALTE�ɒ��́B����͌��莖���B
http://blog-imgs-41-origin.fc2.com/x/e/n/xenonews/2009-06-10_211330.jpg
���Ȃ̂�LTE�J�n�������悻2013�N��KDDI�B
���Ђ�HSUPA�AHSPA+�`DC-HSDPA�ALTE����Ă�ԁA
1xEV-DO�i��UQ ���o�C��WiMAX�j�Ő키���ƂɂȂ�B
http://blog-imgs-41-origin.fc2.com/x/e/n/xenonews/2009-06-10_211330.jpg
{kind=link}
���Ȃ̂�LTE�J�n�������悻2013�N��KDDI�B
���Ђ�HSUPA�AHSPA+�`DC-HSDPA�ALTE����Ă�ԁA
1xEV-DO�i��UQ ���o�C��WiMAX�j�Ő키���ƂɂȂ�B
�ꃆ�[�U�[�Ƃ��Ă͂ǂ��������Ƃ����@���ł��ǂ����āA���R�X�g/�p�t�H�[�}���X��
�D���ق����g�����Ă����̘b������ȁB�����_�ň�������Ɍ����ꂷ�闝�R���ǂ��킩���B
�����_�ł�WiMax�̕��y�����ċ��A�����̗\�����炩������Ă���Ƃ�������������
�ǂ��킩�邪�B
���Ȃ݂ɗ�������Ă�m�L�A�W�[�����X��2007�N�ł̔�r�͂���Ȋ����B
http://www.ew2007.org/Documents/Comparison_LTE_WiMax_BALL_EW2007.pdf
����A���[�h�^�C����S���������Ă��Ȃ�WiMAX�́A�ꂵ���Ƃ��������悤���Ȃ����ƁB
�D���ق����g�����Ă����̘b������ȁB�����_�ň�������Ɍ����ꂷ�闝�R���ǂ��킩���B
�����_�ł�WiMax�̕��y�����ċ��A�����̗\�����炩������Ă���Ƃ�������������
�ǂ��킩�邪�B
���Ȃ݂ɗ�������Ă�m�L�A�W�[�����X��2007�N�ł̔�r�͂���Ȋ����B
http://www.ew2007.org/Documents/Comparison_LTE_WiMax_BALL_EW2007.pdf
����A���[�h�^�C����S���������Ă��Ȃ�WiMAX�́A�ꂵ���Ƃ��������悤���Ȃ����ƁB
315 �F,,�E�L�́M�E,,�j��-�������F2009/11/05(��) 22:50:35 ID:B/8/aVsq
>>291
��̂��̘b�����Ă�B
�܂�NVIDIA�����炩�̕��@��x86�݊����͎̂����ō��X�������Ƃł��Ȃ��̂���
Transmeta�̎c�}�ɉ����ł��邩�Ȃ�Ċ��҂���Ƃ����������������B
���[�i�X�����`�Ŗ\���Ă�Ƃ���A�\�t�g���������Ȃ������W�c���B
�n�[�h�v�͑S�ăV�~�����[�^�ł���Ă������ȁB
���c��x86�G�~���̂��߂ɉ�����������Ă݂�Ɩʔ����B
x86�̃A�h���b�V���O���[�h���̂��̂��������邽�߂�AGU������������
MMX���ڂ����肵���B
CISC���߂������I�ɏ����ł���̂�CISC�}�C�N���A�[�L�e�N�`�������������̂�
�o�����ŏؖ�����Ă���A�܂���낤�Ƃ��Ă��Ƃ����邱�Ƃɋ����B
����ȓ������������肷����ǂˁB
http://www.freepatentsonline.com/20090204785.pdf
��̂��̘b�����Ă�B
�܂�NVIDIA�����炩�̕��@��x86�݊����͎̂����ō��X�������Ƃł��Ȃ��̂���
Transmeta�̎c�}�ɉ����ł��邩�Ȃ�Ċ��҂���Ƃ����������������B
���[�i�X�����`�Ŗ\���Ă�Ƃ���A�\�t�g���������Ȃ������W�c���B
�n�[�h�v�͑S�ăV�~�����[�^�ł���Ă������ȁB
���c��x86�G�~���̂��߂ɉ�����������Ă݂�Ɩʔ����B
x86�̃A�h���b�V���O���[�h���̂��̂��������邽�߂�AGU������������
MMX���ڂ����肵���B
CISC���߂������I�ɏ����ł���̂�CISC�}�C�N���A�[�L�e�N�`�������������̂�
�o�����ŏؖ�����Ă���A�܂���낤�Ƃ��Ă��Ƃ����邱�Ƃɋ����B
����ȓ������������肷����ǂˁB
http://www.freepatentsonline.com/20090204785.pdf
���܂�NVIDIA�����炩�̕��@��x86�݊����͎̂�����
Vertex86�̃��C�Z���X����Ƃ����ˁB
Vertex86�̃��C�Z���X����Ƃ����ˁB
�����ł܂�����mP6�𓊓��ł���
SiS�����������l�b�g���[�N�@��Ɏg���Ă���ăj���[�X���Ȃ�����������RiSE���Ă܂�����̂��H
�������Ă��i���Z�Ƃ������o�Ă��Ȃ��ł���
SiS�����������l�b�g���[�N�@��Ɏg���Ă���ăj���[�X���Ȃ�����������RiSE���Ă܂�����̂��H
�������Ă��i���Z�Ƃ������o�Ă��Ȃ��ł���
x86�ɎQ�����Ă������͂Ȃ��͎̂���������A����Ǝv�����ǂ˂��B
ARM�ɒlj�����x86�G�~�����[�V�����̃A�N�Z�����[�^�A�Ƃ��Ȃ�
���蓾�邾�낤���B
MS���R�~�b�g���Ȃ�����͗p�r�����������B
ARM�ɒlj�����x86�G�~�����[�V�����̃A�N�Z�����[�^�A�Ƃ��Ȃ�
���蓾�邾�낤���B
MS���R�~�b�g���Ȃ�����͗p�r�����������B
nVidia�������Bx86�s��Ɏ�o����AMD�ƈꏏ�ɑ�Ώ��������R�͉����Ȃ��ȁB
>>320
�ڐ�̂��Ƃ������ĂȂ��������낗
�ڐ�̂��Ƃ������ĂȂ��������낗
322 �F,,�E�L�́M�E,,�j��-�������F2009/11/07(�y) 12:55:09 ID:l1trHeV7
������̖����Ȃ��Ă��玟�̏��ޒT���Ă��Ȃ��Ȃ����܂������Ȃ��̂ł���
>>321
�C�m�x�[�V�����̃W�����}���炢�m���Ă�w
�C�m�x�[�V�����̃W�����}���炢�m���Ă�w
325 �F,,�E�L�́M�E,,�j��-�������F2009/11/07(�y) 12:57:43 ID:l1trHeV7
PS3���������ȁB
�܂��C�V���̕����V�܂����B
�܂��C�V���̕����V�܂����B
nVidia��Fermi�ŏ\���߂��邭�炢�C�m�x�[�V�����̊댯�ȋ���n���Ă�r�����낤�B
x86�̗����ʒu��Tegra�ɑn���I�ɔj��鑤����B
���ꂪ�ژ_���ʂ肢�����͒m��A������x86���|�[�g�t�H���I�ɉ�����̂͑S���̉���B
Atom�ɏ��ĂȂ��`�b�v������Ă��d���Ȃ��B
x86�̗����ʒu��Tegra�ɑn���I�ɔj��鑤����B
���ꂪ�ژ_���ʂ肢�����͒m��A������x86���|�[�g�t�H���I�ɉ�����̂͑S���̉���B
Atom�ɏ��ĂȂ��`�b�v������Ă��d���Ȃ��B
�����X�N�w�b�W
328 �F,,�E�L�́M�E,,�j��-�������F2009/11/07(�y) 14:47:32 ID:l1trHeV7
Tegra�i�j���˂�
329 �F,,�E�L�́M�E,,�j��-�������F2009/11/07(�y) 15:01:46 ID:l1trHeV7
Fermi�̃C�m�x�[�V�������ĂȂ�Ȃ̂�B
Linpack�����X���[�v�b�g50�����x�i�����܂ʼn��\�z�j�Ŕėp�R���s���[�e�B���O�s�����Ƃł��v���Ă��ł����H
CUDA�Ȃ�OpenCL�Ȃ�Ǝ����ꂪ�K�v�Ȏ��_��PG�P���I�ɕs���B
GPGPU�͋l��ł��B
Linpack�����X���[�v�b�g50�����x�i�����܂ʼn��\�z�j�Ŕėp�R���s���[�e�B���O�s�����Ƃł��v���Ă��ł����H
CUDA�Ȃ�OpenCL�Ȃ�Ǝ����ꂪ�K�v�Ȏ��_��PG�P���I�ɕs���B
GPGPU�͋l��ł��B
>>329
GT200��Fermi�ő啪HPC�I�ɂ��Ȃ�Ă�������_���ς��Ă����ȁB
GPGPU���l��ł�͓̂��ӁBCPU������ȏ�ɂǂ�l�܂�łȂ���A
�܂����̓����S�čǂ���Ă���̂łȂ���ΑI�тÂ炢�A�v���[�`���낤�B
GT200��Fermi�ő啪HPC�I�ɂ��Ȃ�Ă�������_���ς��Ă����ȁB
GPGPU���l��ł�͓̂��ӁBCPU������ȏ�ɂǂ�l�܂�łȂ���A
�܂����̓����S�čǂ���Ă���̂łȂ���ΑI�тÂ炢�A�v���[�`���낤�B
331 �F,,�E�L�́M�E,,�j��-�������F2009/11/07(�y) 15:30:28 ID:l1trHeV7
���Ȃ�Ăˁ[��B
FMA���j�b�g�ɑ���LSU�̃X���[�v�b�g��Larrabee��1/4���x�����Ȃ��悤�Ȃ��̂�
�ǂ��������������\�ŏ�����ł����H
���FGPGPU�ȂǐϘa�Z���j�b�g��ʓ��ڂ̐��̖\�͂ɂ�����B�������\�Ȃ�ē�̎��B
Larrabee��16x16�s��P�ʂł������X���[�v�b�g8���o����̂�
FMA���j�b�g�ɑ���LSU�̃X���[�v�b�g��Larrabee��1/4���x�����Ȃ��悤�Ȃ��̂�
�ǂ��������������\�ŏ�����ł����H
���FGPGPU�ȂǐϘa�Z���j�b�g��ʓ��ڂ̐��̖\�͂ɂ�����B�������\�Ȃ�ē�̎��B
Larrabee��16x16�s��P�ʂł������X���[�v�b�g8���o����̂�
332 �F,,�E�L�́M�E,,�j��-�������F2009/11/07(�y) 16:06:07 ID:l1trHeV7
http://pc11.2ch.net/test/read.cgi/jisaku/1248799339/696
�Ŏw�E���Ă邯�ǁA����CUDA�͂����炳�܂ɃX�N���b�`�p�b�h�������ɑ���
Load/Store�̃X���[�v�b�g�ŗ��������B
���W�X�^����ʂɂ���O���b�h�T�C�Y��傫�߂Ɏ�邱�Ƃ�LSU�̔��s�����点�邪
�X���b�h������16�{���x�Ŕr�����p����Ӗ����Ȃ��B
�����������Z�Ɠ����ɂǂꂾ���f�[�^�̃Z�b�g�A�b�v����s���čs���邩����������B
GPU�̏ꍇ�AFLOPS���́u���_�l�v�����������s��ς̂悤�ȒP���Ȗ��ł���
�o���̂��u���_�I�ɖ����Ȓl�v�őS���Ӗ����Ȃ��B
�Ŏw�E���Ă邯�ǁA����CUDA�͂����炳�܂ɃX�N���b�`�p�b�h�������ɑ���
Load/Store�̃X���[�v�b�g�ŗ��������B
���W�X�^����ʂɂ���O���b�h�T�C�Y��傫�߂Ɏ�邱�Ƃ�LSU�̔��s�����点�邪
�X���b�h������16�{���x�Ŕr�����p����Ӗ����Ȃ��B
�����������Z�Ɠ����ɂǂꂾ���f�[�^�̃Z�b�g�A�b�v����s���čs���邩����������B
GPU�̏ꍇ�AFLOPS���́u���_�l�v�����������s��ς̂悤�ȒP���Ȗ��ł���
�o���̂��u���_�I�ɖ����Ȓl�v�őS���Ӗ����Ȃ��B
Larrabee�̓L���b�V���q�b�g�����牼����n�߂Ȃ��ƌ����͉]�X�o���Ȃ��悤��
�����͉��łƂ��
�����͉��łƂ��
����
335 �F,,�E�L�́M�E,,�j��-�������F2009/11/08(��) 00:54:31 ID:g0j+SMPB
�s�Z�͓����f�[�^�̍ė��p�p�x��������A�x�N�g�����Z�̗��Ńv���t�F�b�`���s�����肵�Ă�ǂ��ɂł��Ȃ�B
��ł����ĒP�ꕂ�������_�l�̃��[�h����u���[�h�L���X�g�E�Ϙa�Z�̑g�ݍ��킹��1���߂ōςށB
SIMD���W�X�^24�{���炢�g����16(or�{���x�~8)��~24�s�̍s��܂킵�Ă��576�i�{���j�T�C�N����
1�X���b�h�ł�VRAM���C�e���V���炢���܂�B
�ĂȂ킯��Larrabee��LINPACK�����X�^�[���B�O���t�B�b�N�p�r�Ȃ�Ă������ɔ�ׂ������݂����ȃ����ł��B
����ł���Ӗ��������̂����ǁB
��ł����ĒP�ꕂ�������_�l�̃��[�h����u���[�h�L���X�g�E�Ϙa�Z�̑g�ݍ��킹��1���߂ōςށB
SIMD���W�X�^24�{���炢�g����16(or�{���x�~8)��~24�s�̍s��܂킵�Ă��576�i�{���j�T�C�N����
1�X���b�h�ł�VRAM���C�e���V���炢���܂�B
�ĂȂ킯��Larrabee��LINPACK�����X�^�[���B�O���t�B�b�N�p�r�Ȃ�Ă������ɔ�ׂ������݂����ȃ����ł��B
����ł���Ӗ��������̂����ǁB
DGEMM�����X�^�[�����
337 �F,,�E�L�́M�E,,�j��-�������F2009/11/08(��) 01:02:13 ID:g0j+SMPB
16�~N�̍s��ς͂����܂�SGEMM�̂ق������ǁH
DGEMM�̌����͌��킸������
�܂��{���x����8����Ȃ�ŁA����Ӗ��ł͕����y�Ȃ�
���Ȃ݂�CUDA�̏ꍇ�Adouble�̕����I�ȃ��W�X�^��ł̕\����
double��ʁ~32��double���ʁ~32������������
kwsk�m���Ă�z������˂�����ł���
DGEMM�̌����͌��킸������
�܂��{���x����8����Ȃ�ŁA����Ӗ��ł͕����y�Ȃ�
���Ȃ݂�CUDA�̏ꍇ�Adouble�̕����I�ȃ��W�X�^��ł̕\����
double��ʁ~32��double���ʁ~32������������
kwsk�m���Ă�z������˂�����ł���
�� �ĂȂ킯��Larrabee��LINPACK�����X�^�[��
�Ȃ������K�b�J���Ȍ��_�Ɂc�c
�L���b�V���ɏ��Ȃ����ʂ̃A�v���P�[�V�����͂ǂ������
�Ȃ������K�b�J���Ȍ��_�Ɂc�c
�L���b�V���ɏ��Ȃ����ʂ̃A�v���P�[�V�����͂ǂ������
339 �F,,�E�L�́M�E,,�j��-�������F2009/11/08(��) 15:17:33 ID:g0j+SMPB
Sandy Bridge�E�E�E
���������ʂ��s�Z�̐��\�����߂���ǂ��Ă�B
�EYMM���W�X�^8�{�g����8x8�s��̃f�X�e�B�l�[�V�������i�[
�ELoad Unit�ŃX�J���l�����[�h����
�E256�r�b�gShuffle���j�b�g�Ńu���[�h�L���X�g����
�E256�r�b�gMul��256�r�b�gAdd�ŐϘa�����s
Haswell��FMA��256bit-MAD�~2�Ƃ��ɂȂ�ƃu���[�h�L���X�g���߂�
���s�ł��鉉�Z�|�[�g�������P�{�K�v�ɂȂ�Ǝv���B
�s��T�C�Y��傫�����������邪����ɂ̓��W�X�^��Ԃ�����������B
�܂���������[�h���j�b�g�ɑg�ݍ���ł��܂��Ă��ǂ��Ǝv�����B
Larrabee�̖��߃Z�b�g�͂����ȃM�~�b�N�����邩��
�ӊO�Ȗ��߂����ɗ����������ˁB
���������ʂ��s�Z�̐��\�����߂���ǂ��Ă�B
�EYMM���W�X�^8�{�g����8x8�s��̃f�X�e�B�l�[�V�������i�[
�ELoad Unit�ŃX�J���l�����[�h����
�E256�r�b�gShuffle���j�b�g�Ńu���[�h�L���X�g����
�E256�r�b�gMul��256�r�b�gAdd�ŐϘa�����s
Haswell��FMA��256bit-MAD�~2�Ƃ��ɂȂ�ƃu���[�h�L���X�g���߂�
���s�ł��鉉�Z�|�[�g�������P�{�K�v�ɂȂ�Ǝv���B
�s��T�C�Y��傫�����������邪����ɂ̓��W�X�^��Ԃ�����������B
�܂���������[�h���j�b�g�ɑg�ݍ���ł��܂��Ă��ǂ��Ǝv�����B
Larrabee�̖��߃Z�b�g�͂����ȃM�~�b�N�����邩��
�ӊO�Ȗ��߂����ɗ����������ˁB
340 �FSocket774�F2009/11/08(��) 18:05:04 ID:9akTCoYX
��CPU�Ƃ������o�Ȃ�����
���낻��u���C�N�X���[���N���Ăق���
���낻��u���C�N�X���[���N���Ăق���
�����ł܂�����VIA����CPU���J�����I���Ă���
�q�[�g�|���v�������PC���嗬�ɂȂ�̂܂��[?
�t�̒��f����jk
����Ƃ��������Ə��i�����Ăق������̂��B
���d���X�C�b�`/100�{�����ďȃG�l�I���d���X�C�b�`�Ƃ́H
http://www.keyman.or.jp/3w/prd/47/30002447/
>��������̍����d�C�M�����������������d���X�C�b�`�ƁA��舵�����e�ՂȗⓀ�@�Ƃ��A�W����19 �C���`���b�N�ɑg�ݍ��ނ��Ƃɐ���
>SFQ��H�̓p���X�_����H�ŁA�_���U����1mV�ȉ��ł��邱�Ƃ���A100GHz���钴�������\�ŁA���̂Ƃ�1�Q�[�g������̏���d�͂������̂ɔ�ׂ�6�P�^���������B
>�������A��p�̂��߂̓d�͂��K�v�ɂȂ邱�Ƃ�����ۂɂ�3�P�^�ɂƂǂ܂邪�A����ł�1000����1�ōςށB�܂��ASFQ �͒��d���z�����������ɋ߂��X�s�[�h�Ō����Ȃ��ɓ`��邱�Ƃ��ł���B
���d���X�C�b�`/100�{�����ďȃG�l�I���d���X�C�b�`�Ƃ́H
http://www.keyman.or.jp/3w/prd/47/30002447/
>��������̍����d�C�M�����������������d���X�C�b�`�ƁA��舵�����e�ՂȗⓀ�@�Ƃ��A�W����19 �C���`���b�N�ɑg�ݍ��ނ��Ƃɐ���
>SFQ��H�̓p���X�_����H�ŁA�_���U����1mV�ȉ��ł��邱�Ƃ���A100GHz���钴�������\�ŁA���̂Ƃ�1�Q�[�g������̏���d�͂������̂ɔ�ׂ�6�P�^���������B
>�������A��p�̂��߂̓d�͂��K�v�ɂȂ邱�Ƃ�����ۂɂ�3�P�^�ɂƂǂ܂邪�A����ł�1000����1�ōςށB�܂��ASFQ �͒��d���z�����������ɋ߂��X�s�[�h�Ō����Ȃ��ɓ`��邱�Ƃ��ł���B
�ǂ��݂Ă��̏ᗦ���ς˂��㕨�ł�
�g���郌�x���ɂȂ�܂ł��Ɖ��N��������
�g���郌�x���ɂȂ�܂ł��Ɖ��N��������
�X�P�[���A�b�v����X�P�[���A�E�g�̎���ɂȂ������������A�����Ȃ�Ȃ��ƑS���g���Ȃ����낤���Ȃ��B
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20091109_327607.html
>�����āA�O���t�B�b�N�X�f�x���b�p�́A��X�ɁA������GPU�p�C�v���C���͔��ɐ���I�ŁA
>�ނ炪�]�ރA���S���Y���𑖂点�邱�Ƃ��ł��Ȃ��Ƒi�����B
>�����ŁA��X��MIMD�����邱�Ƃł���ɉ����邱�Ƃɂ����B
>�����āA�O���t�B�b�N�X�f�x���b�p�́A��X�ɁA������GPU�p�C�v���C���͔��ɐ���I�ŁA
>�ނ炪�]�ރA���S���Y���𑖂点�邱�Ƃ��ł��Ȃ��Ƒi�����B
>�����ŁA��X��MIMD�����邱�Ƃł���ɉ����邱�Ƃɂ����B
ISA�����������f����x86���̂܂�܁A�Ƃ����͕̂ʂɖ]�܂�Ă͂��Ȃ������悤�ȁB
�m�[�R�X�g�Ȃ�Ƃ������B
�m�[�R�X�g�Ȃ�Ƃ������B
�A�z��
>>348
CPU�ɑg�ݍ��ނ̂��O���炻��͐�Ώ����Ȃ̂���
CPU�ɑg�ݍ��ނ̂��O���炻��͐�Ώ����Ȃ̂���
�G�C�T�[�����A�u��荂���ȃC���e����CULV�`�b�v�v�̓o�������
ttp://www.computerworld.jp/news/plf/166850.html
>�@���̂����ŁAAcer�����̓p�t�H�[�}���X�����������锖�^�y�ʃm�[�gPC�̐V���i�𗈔N��1�l�����ɔ��\����ƌ����A
>���̒��ŁA����PC�ɂ�Intel���̐V�����`�b�v�����ڂ���邱�Ƃ𖾂炩�ɂ����B�u���x�͊��Ғʂ�̂��̂ɂȂ�͂����v�i�������j�B
>
>�@�č�Mercury Research�̎�ȃA�i���X�g�A�f�B�[���E�}�b�J�����iDean McCarron�j���́AAcer��������������Intel�̐V�`�b�v�Ƃ́A
>�����A�[�L�e�N�`���uWestmere�v���̗p�����`�b�v�̂��Ƃ��Ɛ�������B
ttp://www.computerworld.jp/news/plf/166850.html
>�@���̂����ŁAAcer�����̓p�t�H�[�}���X�����������锖�^�y�ʃm�[�gPC�̐V���i�𗈔N��1�l�����ɔ��\����ƌ����A
>���̒��ŁA����PC�ɂ�Intel���̐V�����`�b�v�����ڂ���邱�Ƃ𖾂炩�ɂ����B�u���x�͊��Ғʂ�̂��̂ɂȂ�͂����v�i�������j�B
>
>�@�č�Mercury Research�̎�ȃA�i���X�g�A�f�B�[���E�}�b�J�����iDean McCarron�j���́AAcer��������������Intel�̐V�`�b�v�Ƃ́A
>�����A�[�L�e�N�`���uWestmere�v���̗p�����`�b�v�̂��Ƃ��Ɛ�������B
352 �F,,�E�L�́M�E,,�j��-�������F2009/11/09(��) 21:43:00 ID:Q5DSOVTc
>>348
Itanium�M�҂̕��ł����H
�X�J�����Z��낤�Ƃ�����32�v�f�S���œ������o�͒l�̐������Z�����o��
����ȃA�z�݂����Ȃ��Ƃ���Ă�GPU��I�ɏグ��x86�͔�������Ƃ������o��
NVIDIA�̎咣�Ȃ�Đ^�Ɏ�K�v�͖����B
Itanium�M�҂̕��ł����H
�X�J�����Z��낤�Ƃ�����32�v�f�S���œ������o�͒l�̐������Z�����o��
����ȃA�z�݂����Ȃ��Ƃ���Ă�GPU��I�ɏグ��x86�͔�������Ƃ������o��
NVIDIA�̎咣�Ȃ�Đ^�Ɏ�K�v�͖����B
2010�N�̐ݔ�������70�����|Apple�̎��́g�傫�Ȃ��Ɓh
ttp://enterprise.watch.impress.co.jp/docs/series/infostand/20091109_327612.html
ttp://enterprise.watch.impress.co.jp/docs/series/infostand/20091109_327612.html
>>353
���@Cihra���͐ݔ������̓��e�ɂ��āA�u�iApple�́j���Y�E�����v���Z�X�@��̍w���Ɍ��y���Ă���B
���!
�A�|�[���Ƃ��Ƃ��t�@�u���̂��`
���@Cihra���͐ݔ������̓��e�ɂ��āA�u�iApple�́j���Y�E�����v���Z�X�@��̍w���Ɍ��y���Ă���B
���!
�A�|�[���Ƃ��Ƃ��t�@�u���̂��`
�����̂́A�Ƃ͏����ĂȂ�����
�����S��������撣���Ă��
357 �F,,�E�L�́M�E,,�j��-�������F2009/11/10(��) 01:07:02 ID:cPyPK127
�������͎O���d�@������Ƃ̃p�[�g�i�[��������Ƃ��]�X
���(��)
�G���R�[�h�����Ȃ�d���t�B���^�g���Ă��\�[�X�̎��ԂƓ������ԂŏI��邭�炢�ɂȂ�������܂��l��
MAC���^���Ȃ����ǂǂ�����������́H
�����Ă��܂�ꂽ�́H
�����Ă��܂�ꂽ�́H
����ȃQ�n���R�̗L��l���ᗈ�Ȃ��̂����ʂ���
362 �F,,�E�L�́M�E,,�j��-�������F2009/11/12(��) 00:18:12 ID:gjkqx3Og
http://software.intel.com/en-us/articles/intel-architecture-code-analyzer/
> Release Notes for 1.1.1
> The following features were added for 1.1.1
>
> Fixed IntelR AVX zero idiom instructions wrong identification
> Fixed empty code blocks (containing only zero idiom instructions / not supported instructions) crashing the analyzer
> Fixed Analyzer narch nehalem option to treat AES and PCLMUL instructions as illegal.
> these aren't supported on Intel(R) microArchitecture - codename Nehalem. ���������ځI
> Changed analyzer marks to abort if the binary is executed. To deactivate the marks
> when building for execution #define IACA_MARKS_OFF or use -DIACA_MARKS_OFF option
> in the compiler command line. Binaries with active marks should be used for analysis only.
�Ȃ��Nehalem��Westmere��DLL���S�������T�C�Y���� ���Ďv�����炻���������Ƃł���
> Release Notes for 1.1.1
> The following features were added for 1.1.1
>
> Fixed IntelR AVX zero idiom instructions wrong identification
> Fixed empty code blocks (containing only zero idiom instructions / not supported instructions) crashing the analyzer
> Fixed Analyzer narch nehalem option to treat AES and PCLMUL instructions as illegal.
> these aren't supported on Intel(R) microArchitecture - codename Nehalem. ���������ځI
> Changed analyzer marks to abort if the binary is executed. To deactivate the marks
> when building for execution #define IACA_MARKS_OFF or use -DIACA_MARKS_OFF option
> in the compiler command line. Binaries with active marks should be used for analysis only.
�Ȃ��Nehalem��Westmere��DLL���S�������T�C�Y���� ���Ďv�����炻���������Ƃł���
363 �F,,�E�L�́M�E,,�j��-�������F2009/11/12(��) 01:42:37 ID:gjkqx3Og
Atom���T�|�[�g���ė~������
Six Charged in Vast Insider-Trading Ring
http://online.wsj.com/article/SB125570373292090093.html
http://online.wsj.com/article/SB125570373292090093.html
32nm��i7�͏o�Ȃ��́H
20�N�푈�Ƀs���I�h
http://www.nikkei.co.jp/news/kaigai/media/djDDX1593.html
http://www.nikkei.co.jp/news/kaigai/media/djDDX1594.html
http://www.nikkei.co.jp/news/kaigai/media/djDDX1593.html
http://www.nikkei.co.jp/news/kaigai/media/djDDX1594.html
SSD�̉��i���ׂ悤�Ƃ��Č������Ă���intel��l�C�����
CPU�Ƃ͒��ڊW�Ȃ����ǁA�ӊO�ȃ}�[�P�b�g��ɓ���Ă���
CPU�Ƃ͒��ڊW�Ȃ����ǁA�ӊO�ȃ}�[�P�b�g��ɓ���Ă���
CPU�̃v���Z�X���i�ނƁA��Ƃ��A2�O�̃v���Z�X�̍H��ł�
�����ʂ̐��i�Ŗׂ��Ȃ���Ȃ�Ȃ��B
�`�b�v�Z�b�g�AGPU�A�t���V���Ǝ���o�������ASSD�͑�ʂ�NAND���g���̂ŃE�}�[�B
�����ʂ̐��i�Ŗׂ��Ȃ���Ȃ�Ȃ��B
�`�b�v�Z�b�g�AGPU�A�t���V���Ǝ���o�������ASSD�͑�ʂ�NAND���g���̂ŃE�}�[�B
NAND�̃v���Z�X�ƃ��W�b�N�̃v���Z�X�͕ʂ���
���������������SSD��34nm��CPU���i��ł邵
���������������SSD��34nm��CPU���i��ł邵
130nm��CPU�A90nm��DRAM�A34nm��SSD
�������ׂ�ƍ��g���Ă邱��PC�͎��ɕϑ�
�������ׂ�ƍ��g���Ă邱��PC�͎��ɕϑ�
�ŐV��CPU��ǂ�����������A�������������������̊����D���̂�
�����̗p�r�ł����邱�Ƃ����A������Nj�����Ǝ��R�ƕϑԓ��֓������킯��
�����̗p�r�ł����邱�Ƃ����A������Nj�����Ǝ��R�ƕϑԓ��֓������킯��
�m�[�g�Ȃ�ʂɕϑԂ���Ȃ��
�������Ƀm�[�g�ł�Banias�����SSD�ڂ���O�ɔ�����������Ă���
����A����X40�������Ȃ̂�
����A����X40�������Ȃ̂�
>>374
�E�T�M�ƃC�k�ƃ{�m�{����
�E�T�M�ƃC�k�ƃ{�m�{����
�Ɠd����SoC�̗̍p���x�X�Ƃ��Đi�܂Ȃ��̂�
ONKYO�ɖ������点�܂�
ONKYO�ɖ������点�܂�
�C���e���E�C�X���G���@�܂[
2009�N11��17���i�j07:00���o�r�W�l�X
�C�X���G���@�����̌[���@�Z�p�卑�C�X���G���̔閧�@
���{��180�x�قȂ�u��ƕ��y�v�A�g���^���ł̓C�m�x�[�V�����N����
http://news.goo.ne.jp/article/nbonline/business/nbonline-209585-01.html
�C�X���G����1990�N�㔼����A�n�C�e�N�u�[�����N�����B
�Z�L�����e�B�[�\�t�g�u�t�@�C�A�E�I�[���v�Ő��E�g�b�v��ƂƂȂ���
�`�F�b�N�E�|�C���g�E�\�t�g�E�G�A�E�e�N�m���W�[�Y�ȂǐV����Ƃ��H�������B
���݂��ăi�X�_�b�N�s��ł̓C�X���G����Ƃ�140�Ћ߂�����B���{�̃x���`���[��Ƃ̏��͂قڃ[�����B
�l��730���l�̏����ŁA�Ȃ����E���������x���`���[��Ƃ��������o�Ă���̂��B
�E�E�E
�C�X���G���͐��E�o�ς̉e������^����ɔ����o������B
���Ă̓�����s�Ȃǂ̗\�z�ɂ��A
�C�X���G���̗��N��GDP�i���������Y�j�͑ΑO�N���2.5�`3�����ɂȂ�Ƃ����B
7������̓C�X���G���o�ς̂�������ł���n�C�e�N����̗A�o���}���Ă��邱�Ƃ��傫���B
�C�X���G����GDP��2008�N���M�݊��Z��18���~���炢�B
���̂����A�o��4��5000���~���ł���A�n�C�e�N�����4������߂Ă���B
�C�X���G���o�ς�2001�N��IT�o�u���̕����p���X�`�i������ł̕����ȂǂŁA�������ɒǂ����܂�Ă����B
�����A2004�N����}���ɉ��A2007�N�܂ł�4�N�Ԃ�5�����鐬���𑱂����B
���̍ő�̌����͔N1000�В��x�̃y�[�X�Ńx���`���[��Ƃ����܂�A���ꂪ�o�ϐ����̒S����ƂȂ������Ƃ��傫���B
2009�N11��17���i�j07:00���o�r�W�l�X
�C�X���G���@�����̌[���@�Z�p�卑�C�X���G���̔閧�@
���{��180�x�قȂ�u��ƕ��y�v�A�g���^���ł̓C�m�x�[�V�����N����
http://news.goo.ne.jp/article/nbonline/business/nbonline-209585-01.html
�C�X���G����1990�N�㔼����A�n�C�e�N�u�[�����N�����B
�Z�L�����e�B�[�\�t�g�u�t�@�C�A�E�I�[���v�Ő��E�g�b�v��ƂƂȂ���
�`�F�b�N�E�|�C���g�E�\�t�g�E�G�A�E�e�N�m���W�[�Y�ȂǐV����Ƃ��H�������B
���݂��ăi�X�_�b�N�s��ł̓C�X���G����Ƃ�140�Ћ߂�����B���{�̃x���`���[��Ƃ̏��͂قڃ[�����B
�l��730���l�̏����ŁA�Ȃ����E���������x���`���[��Ƃ��������o�Ă���̂��B
�E�E�E
�C�X���G���͐��E�o�ς̉e������^����ɔ����o������B
���Ă̓�����s�Ȃǂ̗\�z�ɂ��A
�C�X���G���̗��N��GDP�i���������Y�j�͑ΑO�N���2.5�`3�����ɂȂ�Ƃ����B
7������̓C�X���G���o�ς̂�������ł���n�C�e�N����̗A�o���}���Ă��邱�Ƃ��傫���B
�C�X���G����GDP��2008�N���M�݊��Z��18���~���炢�B
���̂����A�o��4��5000���~���ł���A�n�C�e�N�����4������߂Ă���B
�C�X���G���o�ς�2001�N��IT�o�u���̕����p���X�`�i������ł̕����ȂǂŁA�������ɒǂ����܂�Ă����B
�����A2004�N����}���ɉ��A2007�N�܂ł�4�N�Ԃ�5�����鐬���𑱂����B
���̍ő�̌����͔N1000�В��x�̃y�[�X�Ńx���`���[��Ƃ����܂�A���ꂪ�o�ϐ����̒S����ƂȂ������Ƃ��傫���B
�ނ���A���̃j���[�X�̓C�X���G����GDP��18���~�����Ȃ����Ƃɋ��������B
�l��730���l�ő��ʂ̃g���^�̔���グ��菬�������Ă����B
�l��730���l�ő��ʂ̃g���^�̔���グ��菬�������Ă����B
��l������240�}�����炢����
�S�l�Ƒ��Ƃ��āA�Ƒ�������1000�}�����x�c
�S�l�Ƒ��Ƃ��āA�Ƒ�������1000�}�����x�c
�C�X���G���͒��̐l�̋C�����ł����Ă��鍑�B
����̃A���u�̍��Ɣ�ׂĂ��A�l�������Ȃ����A
�����R�����B
����̃A���u�̍��Ɣ�ׂĂ��A�l�������Ȃ����A
�����R�����B
Arrandale����14�C���`���o�C���m�[�g�́AThinkPad T410s�����[�N����Ă����A
�r�C�������Ȃ�傫���Ȃ��Ă�炵��
http://bbs.tt315.cn/thread-105058-1-1.html
Turbo Boost���펞�ێ����邽�߂ɂ͂��ꂭ�炢�̔r�C��������̂�
�r�C�������Ȃ�傫���Ȃ��Ă�炵��
http://bbs.tt315.cn/thread-105058-1-1.html
Turbo Boost���펞�ێ����邽�߂ɂ͂��ꂭ�炢�̔r�C��������̂�
�A�����J�̕x�T�w�Ƀ��_���n�������āA
���ꂪ�A�����J�����܂߂ăC�X���G���Ɏ����������Ă邩��ł́B
���ꂪ�A�����J�����܂߂ăC�X���G���Ɏ����������Ă邩��ł́B
����ς����G�Ɉ͂܂�Ă��鍑����
�A�j���������Ɉ͂܂�Ă��鍑���ł�
���̂��ƕ�����������Ă��邩�ƁB
�����Z�݂������͈��|�I�Ɍ�҂ł����B������O���B
�A�j���������Ɉ͂܂�Ă��鍑���ł�
���̂��ƕ�����������Ă��邩�ƁB
�����Z�݂������͈��|�I�Ɍ�҂ł����B������O���B
�ꏏ�ɂ��Ȃ��ł���c
�yPDC09��u�����|�[�g�z�N���C�A���g�����Ă����̃N���E�h
http://pc.watch.impress.co.jp/docs/news/event/20091120_330198.html
http://pc.watch.impress.co.jp/docs/news/event/20091120_330198.html
���┄���~���X�̎�����
�}�W�ō��������邩���ʂ��̐��ˍۂ���
�}�W�ō��������邩���ʂ��̐��ˍۂ���
�y�����z���{�̎�����^�}�ɂ��Č�낤41�y����z
�X���́A�����ł����H
�X���́A�����ł����H
���{�@�����Ă�o�J���͉��Ȃ́H
���݂̏𗝉��������y�ώ����Ă�̂�n���Ƃ����B
�Z�p�����ƌ����Ȃ���A�Z�p�ɂ���ē���ꂽ�L���ȕ�炵���������āA
�Z�p���x����l�����d����Ȃ��悤�ł͒���œ��R�B
���܂���ł��Ă����ʃ��x���ɂ����Ȃ��A������x�ꂾ��B
�Z�p�����ƌ����Ȃ���A�Z�p�ɂ���ē���ꂽ�L���ȕ�炵���������āA
�Z�p���x����l�����d����Ȃ��悤�ł͒���œ��R�B
���܂���ł��Ă����ʃ��x���ɂ����Ȃ��A������x�ꂾ��B
���ꌩ��Ɠ��{���������͂ŕs������E�o�ł�����Ă�
http://www.nicovideo.jp/watch/sm8873625
http://www.youtube.com/watch?v=VMMA0oA10Do
�A�����J������Intel�͂ǂ�����낤��
http://www.nicovideo.jp/watch/sm8873625
http://www.youtube.com/watch?v=VMMA0oA10Do
�A�����J������Intel�͂ǂ�����낤��
394 �F,,�E�L�́M�E,,�j��-�������F2009/11/24(��) 01:12:43 ID:hPX1Nh9Y
�X�J�C�l�b�g������Đl�ނ��x�z����A�Ƃ��H
>>392
�l�b�g�ŗ������˂��莩���Ŏ蓮���������������̂�
�l�b�g�ŗ������˂��莩���Ŏ蓮���������������̂�
45nm��Nehalem�͒n�����ۂ�����
Westmere�Ɋ���
Westmere�Ɋ���
��x���x��Ƃ��A�����ɂ��^�����l�A�݁��̈�ۑ��삩�l�K�L�����݂������ȁB
Ath64-3500+(2.2GHz)@sok939 + RadeHD3850@AGP
3D�Q�[�����C���ł��낻�����Ȃ��Ă����̂Ŕ������������̂���
Intel�̃g�����h���c���ł��ĂȂ��AGPU��nVidia GTX285�\��
Core2DuoE8600(3.3GHz)���ǂ��̂ł́H�Ǝv���̂���
LGA775�͂��������I����Ă��܂��H
LGA1366�iCorei7�j���Ă����ׂ��H
LGA1156�Ȃ�Ă��̂�����̂���A�݊��������̂���H
3D�Q�[�����C���ł��낻�����Ȃ��Ă����̂Ŕ������������̂���
Intel�̃g�����h���c���ł��ĂȂ��AGPU��nVidia GTX285�\��
Core2DuoE8600(3.3GHz)���ǂ��̂ł́H�Ǝv���̂���
LGA775�͂��������I����Ă��܂��H
LGA1366�iCorei7�j���Ă����ׂ��H
LGA1156�Ȃ�Ă��̂�����̂���A�݊��������̂���H
���쑊�k�X���ł��
>>399
����ނ���y�Ϙ_�Ŏv�l��~�����悤�Ƃ��Ă���z��̕���
�����l���ۂ���B�Ⴆ�ΌN�Ƃ��ˁB
�L�\�Ȑl�Ԃ����v���Ƃ����̂Ȃ炢�����A
�ǂ��ł��������\�����{�}���Z�[���ĂĂ��o�J���܂��܂��w�͂��Ȃ��Ȃ邾������B
����ނ���y�Ϙ_�Ŏv�l��~�����悤�Ƃ��Ă���z��̕���
�����l���ۂ���B�Ⴆ�ΌN�Ƃ��ˁB
�L�\�Ȑl�Ԃ����v���Ƃ����̂Ȃ炢�����A
�ǂ��ł��������\�����{�}���Z�[���ĂĂ��o�J���܂��܂��w�͂��Ȃ��Ȃ邾������B
�Ђ߂�����߂��肷��̂�
����������ē˂������̂͑S�R�Ⴄ
����������ē˂������̂͑S�R�Ⴄ
�ȂɃl�b�g���傽��R�~���̏�ɂȂ����Љ�s�K���҂��������m��A
�����ʂ�ɂ������t�̈Ӗ��������Ȃ��o�J���������ǁA
�o�J�N�́A
���{�͂������߂��[�Ƃ�������Ђł����Ă���������
�����͔����l�������̂��Ƃ��M���n�߂�̂���?
�t�Ɋ؍��l���؍��͎O�����ƂɂȂ����܂���[���Ă�������A
�����͊؍��ȊO�̃X�p�C���Ǝv���̂���?
�����������߂����o���Ȃ��R�~���\�͂̌��@�����o�J���Љ�I�ɐ����o����Ƃ͎v���Ȃ��̂����B
�ɂ����˂�Ƃ͂����A���̒�ӂ������Ă���X������Ȃ�����������������g���ĕ��ӓǂ�����B
�����ʂ�ɂ������t�̈Ӗ��������Ȃ��o�J���������ǁA
�o�J�N�́A
���{�͂������߂��[�Ƃ�������Ђł����Ă���������
�����͔����l�������̂��Ƃ��M���n�߂�̂���?
�t�Ɋ؍��l���؍��͎O�����ƂɂȂ����܂���[���Ă�������A
�����͊؍��ȊO�̃X�p�C���Ǝv���̂���?
�����������߂����o���Ȃ��R�~���\�͂̌��@�����o�J���Љ�I�ɐ����o����Ƃ͎v���Ȃ��̂����B
�ɂ����˂�Ƃ͂����A���̒�ӂ������Ă���X������Ȃ�����������������g���ĕ��ӓǂ�����B
�}�����ꂽ������ă��L�ɂȂ�Ȃ悗
�݂��Ƃ��Ȃ���ID:RYUwrwye
�݂��Ƃ��Ȃ���ID:RYUwrwye
SAMSUNG�ɂ���ď��Ă錩���݂��Ȃ��̂Ɋy�ώ��ł���Ȃ�Ăǂ������Ă�B
�����̍��ƃu�����h�������オ���Ă�����A�����Ɗ댯�ɂȂ�̂ɂˁB
�����̍��ƃu�����h�������オ���Ă�����A�����Ɗ댯�ɂȂ�̂ɂˁB
407 �F,,�E�L�́M�E,,�j��-�������F2009/11/24(��) 22:31:02 ID:hPX1Nh9Y
�������ǂ��Ƃ������Ă邪
�A�����J�l�͂��āu�s�퍑�v�̍��x�o�ϐ������ڂŌ��Ă��낤�ȂƎv���B
�A�����J�͂܂��L��ȍ��y�ő�_�Ƃ��邩��}�V����
���{�͋Z�p�ŊO�݉҂������Ȃ��B
�Ƃ肠�����L���ɔ����ĐH�����������悤���B���̕����͔|���悤���B
�A�����J�l�͂��āu�s�퍑�v�̍��x�o�ϐ������ڂŌ��Ă��낤�ȂƎv���B
�A�����J�͂܂��L��ȍ��y�ő�_�Ƃ��邩��}�V����
���{�͋Z�p�ŊO�݉҂������Ȃ��B
�Ƃ肠�����L���ɔ����ĐH�����������悤���B���̕����͔|���悤���B
���̕����ĉ����H
409 �F,,�E�L�́M�E,,�j��-�������F2009/11/24(��) 22:37:38 ID:hPX1Nh9Y
�ĕ�
�\���̖͂R�����A�s�Ԃ��g�����Ȃ��Ȃ��l�Ԃق�
�ǂݎ��Ȃ����ɐӔC�������t����
�ǂݎ��Ȃ����ɐӔC�������t����
411 �F,,�E�L�́M�E,,�j��-�������F2009/11/24(��) 23:16:31 ID:hPX1Nh9Y
�܂�����
�����Ń��P�b�g�ł��グ��悤�Ȑ~����ODA�͂����B
�����͂�����Ǝd��������d����
�����Ń��P�b�g�ł��グ��悤�Ȑ~����ODA�͂����B
�����͂�����Ǝd��������d����
>>393
�X���`�����ʔ����ԑg���ȁB���{�͗ǂ��Ӗ��ŕϑԂ�����c
�X���`�����ʔ����ԑg���ȁB���{�͗ǂ��Ӗ��ŕϑԂ�����c
�������Ă��Ƃ��Ƃ��������̑嗤��ǂ��Ă���Ă����l�Ԃłł���������Ȃ��̂��B
>>413
����ǂ��̂��Ă̍��̂��b�ł���
����ǂ��̂��Ă̍��̂��b�ł���
�ǂ��������Č����ƕ����߂�ꂽ��Ȃ�
�~���������̑嗤��ǂ��Ă���Ă����l�Ԃłł�����
����O�ɂ������̔�����ǂ��Ă���Ă����l�Ԃ��A�炸�ɋ������Ă鍑
����O�ɂ������̔�����ǂ��Ă���Ă����l�Ԃ��A�炸�ɋ������Ă鍑
{kind=link}
ID:1T1zydgw, ID:1T1zydgw
�������ǂ�����������>>392�Ƃ͕ʐl�Ȃ��B
�l�b�g�ȊO�ł̃R�~���s�������炷���ɑ��l���^���Ȃ����Ă�悤���B
�C��������������w
�������ǂ�����������>>392�Ƃ͕ʐl�Ȃ��B
�l�b�g�ȊO�ł̃R�~���s�������炷���ɑ��l���^���Ȃ����Ă�悤���B
�C��������������w
�K�������������
�Ƃ��ɁASAndyBridge��CPU�R�A����Westmere����卷�Ȃ����Ė{������
�ȂA�_�C�ʐ^�ňڂ��Ă�R�A�̑傫���Əc���䂪ClarkDale�Ƃ����Ȃ��Ƃ�
�ȂA�_�C�ʐ^�ňڂ��Ă�R�A�̑傫���Əc���䂪ClarkDale�Ƃ����Ȃ��Ƃ�
>>392�͂��������ςɌ����A���{�͋Z�p�����̂����ɋZ�p�҂̈���������
�Ə����Ă邾�����낤?�lj��ȑO�̑z���̖͂��Ȃ�B
���ꂪ�킩��Ȃ��Ƃ����l�́A�������Љ�ł܂Ƃ��ɐ����ĂȂ��낤?
�����قȂ�n�����A�������ē����悤�ȃA�t�H�ȃ��X���Ă�ቴ���K���ɂȂ邳�B
�Ə����Ă邾�����낤?�lj��ȑO�̑z���̖͂��Ȃ�B
���ꂪ�킩��Ȃ��Ƃ����l�́A�������Љ�ł܂Ƃ��ɐ����ĂȂ��낤?
�����قȂ�n�����A�������ē����悤�ȃA�t�H�ȃ��X���Ă�ቴ���K���ɂȂ邳�B
>>422
AVX���卷�����Ǝv����l�ɂ͑卷�Ȃ��Ƃ����邵�A
AVX���傫�ȍ����Ǝv����l�ɂ͑卷������Ƃ�����B
����Ȋ����B�c����͂��܂�d�v����Ȃ��B
AVX���卷�����Ǝv����l�ɂ͑卷�Ȃ��Ƃ����邵�A
AVX���傫�ȍ����Ǝv����l�ɂ͑卷������Ƃ�����B
����Ȋ����B�c����͂��܂�d�v����Ȃ��B
�R�e�܂ł��ăX���Ⴂ�Șb��
>>392 >>406 �����������ǁA
��x����ď������̂́A���͂������Ǖ����Ă͂��Ȃ�
�����Ǎ���̐l�ވ琬���o���Ă�̂����Ă��ƁB
�e����������Ă�����悭�����邯�ǁA�قƂ�ǂ̋�����
�Z�p��m������������Ȃ�����PC����g���Ȃ��B
�Z�p�҂̓w�͂����Ő��藧���ĂĎЉ�V�X�e���Ƃ��ċZ�p�҂�
�琬���悤�Ƃ��Ă��Ȃ��B����ł̓_������B
��x����ď������̂́A���͂������Ǖ����Ă͂��Ȃ�
�����Ǎ���̐l�ވ琬���o���Ă�̂����Ă��ƁB
�e����������Ă�����悭�����邯�ǁA�قƂ�ǂ̋�����
�Z�p��m������������Ȃ�����PC����g���Ȃ��B
�Z�p�҂̓w�͂����Ő��藧���ĂĎЉ�V�X�e���Ƃ��ċZ�p�҂�
�琬���悤�Ƃ��Ă��Ȃ��B����ł̓_������B
427 �F,,�E�L�́M�E,,�j��-�������F2009/11/25(��) 23:54:58 ID:XnXiDy9n
�ǂ�Ȃɕn�����Ă�
�l�������łɉƓd�����A����ȌÂ��悫���{��Ƃɖ߂��Ă�������
�l�������łɉƓd�����A����ȌÂ��悫���{��Ƃɖ߂��Ă�������
>>426
�������������ۂ������ɒ��ڊW����Ƃ͎v���Ȃ��̂����A
���̒��x�̓w�͂��炵�Ă��Ȃ��䂪���A�ƍl����Ƃ���������Ɖ��Ƃ��Ȃ����̂��Ǝv���B
�������������ۂ������ɒ��ڊW����Ƃ͎v���Ȃ��̂����A
���̒��x�̓w�͂��炵�Ă��Ȃ��䂪���A�ƍl����Ƃ���������Ɖ��Ƃ��Ȃ����̂��Ǝv���B
�ق�
2009�@Gulftown
2010 Sandy Bridge B2
��H
2010 Sandy Bridge B2
��H
�ڐV�����̂�DMI�̑ш�2�{��L3��1.5MB���ĂƂ����炢��
>>431
1�N����Ă�˂�
sandy�ň�ԋC�ɂȂ�̂̓N���b�N�Ə���d�͂�Lynn�Ɣ�ׂĂǂ��Ȃ邩���Ȃ��`�B
����d�͂͂悳�����B�ǂꂪ�ǂ�̒l���悭������Ȃ����ǂ�
�O���@�\������S�R�A�̍��N���b�N���Ă̂��C�ɂȂ�B
�ʏ�̂ƃ��C�A�E�g����Ⴄ��ł��傤���ˁH
1�N����Ă�˂�
sandy�ň�ԋC�ɂȂ�̂̓N���b�N�Ə���d�͂�Lynn�Ɣ�ׂĂǂ��Ȃ邩���Ȃ��`�B
����d�͂͂悳�����B�ǂꂪ�ǂ�̒l���悭������Ȃ����ǂ�
�O���@�\������S�R�A�̍��N���b�N���Ă̂��C�ɂȂ�B
�ʏ�̂ƃ��C�A�E�g����Ⴄ��ł��傤���ˁH
Bloomfield��Gulftown�̌�p�Ƃ������JasperForest�̌�p���Ċ������ȁB
XeonDP����CPU�Ԑڑ��p��QPI�����̂��A�\�P�b�g���̕ʂȂ̂��낤���B
XeonDP����CPU�Ԑڑ��p��QPI�����̂��A�\�P�b�g���̕ʂȂ̂��낤���B
>>431
http://www.expertspc.com/images/37/EXPC_Intel_CPU2009Nov.png
���炩��1�N����Ă��ˁB
Clarkdale�̗����グ��2009�����ɂȂ��Ă邵�B
http://www.expertspc.com/images/37/EXPC_Intel_CPU2009Nov.png
{kind=link}
���炩��1�N����Ă��ˁB
Clarkdale�̗����グ��2009�����ɂȂ��Ă邵�B
436 �F,,�E�L�́M�E,,�j��-�������F2009/11/26(��) 01:03:07 ID:Y7m0S63w
GMA����Ȃ�����L���b�V���{�ɂ���Ƃ�
�t�H�g�V���}�V����E8400����930�{12GB�{SSD�ɂ���
�����_�����O�}�V����Q9650�ōė��N�܂őς��邩�Ȃ�
�����_�����O�}�V����Q9650�ōė��N�܂őς��邩�Ȃ�
�ԈႦ��>>435�̉摜�̂���
441 �FSocket774�F2009/11/26(��) 04:57:49 ID:rwYszIE1
>>424
�c���䂪�����������R�A�̎g���܂킵�A
���Ă��ƂȂ�Ȃ��̂���
�����l����ƁA�����������AVX��������Westmrere�R�A�̎��_�œ����Ă�̂�������Ȃ��i�e�X�g�p�f�B�Z�[�u������Ă�Ɓj
�c���䂪�����������R�A�̎g���܂킵�A
���Ă��ƂȂ�Ȃ��̂���
�����l����ƁA�����������AVX��������Westmrere�R�A�̎��_�œ����Ă�̂�������Ȃ��i�e�X�g�p�f�B�Z�[�u������Ă�Ɓj
Core2�̎��ɔ�ׂ�Sandy�̓C�X���G������n���ȉ��ǂ��ˁB
AVX�͂Ƃ������AAMD�ɊT�˒ǂ��t�����̂ł́B
AVX�͂Ƃ������AAMD�ɊT�˒ǂ��t�����̂ł́B
�S�قǓd�͐��\�䂪�オ���Ă��炳�����C�X���G���`�[�����ƊS�͂��邪
�ǂ������������͂Ȃ�
�ǂ������������͂Ȃ�
>>442
�ǂ��������������������܂�܂�����ȁB
http://pc.watch.impress.co.jp/docs/column/kaigai/20091126_331235.html
> ���r�W�[�Ȃ̂͐������j�b�g�ŕ��������_���j�b�g�͉�
AMD�͂����̌��_�ɂ��ǂ蒅���܂ł��x�������B
������ƑO�܂�AMD��Integer ALU��FPU�Ńp�C�v���C����������Ă�
�����ғ�����̂����肾�����B
�ł����͂��Ă݂��畂���������Ă�����������ȂɎg���ĂȂ��B
�t�ɕ����������o���o���g���V�[���iHPC�╨�����Z�j�ł͎��͐�����
����قǎg���Ȃ��i���[�v�J�E���g�ƃA�h���X�v�Z�̂݁j
�\���N��Intel���g���Ă�P6�p�C�v���C���i�����X�P�W���[���ŊǗ���
Integer ALU��FPU���������s�|�[�g�ɂԂ牺�����Ă�j�̍�������F�߂�
�ʂ̐v�v�z�Ō������グ�Ă����Ă̂�Bulldozer�̗��Ƃ��ǂ���B
�ǂ��������������������܂�܂�����ȁB
http://pc.watch.impress.co.jp/docs/column/kaigai/20091126_331235.html
> ���r�W�[�Ȃ̂͐������j�b�g�ŕ��������_���j�b�g�͉�
AMD�͂����̌��_�ɂ��ǂ蒅���܂ł��x�������B
������ƑO�܂�AMD��Integer ALU��FPU�Ńp�C�v���C����������Ă�
�����ғ�����̂����肾�����B
�ł����͂��Ă݂��畂���������Ă�����������ȂɎg���ĂȂ��B
�t�ɕ����������o���o���g���V�[���iHPC�╨�����Z�j�ł͎��͐�����
����قǎg���Ȃ��i���[�v�J�E���g�ƃA�h���X�v�Z�̂݁j
�\���N��Intel���g���Ă�P6�p�C�v���C���i�����X�P�W���[���ŊǗ���
Integer ALU��FPU���������s�|�[�g�ɂԂ牺�����Ă�j�̍�������F�߂�
�ʂ̐v�v�z�Ō������グ�Ă����Ă̂�Bulldozer�̗��Ƃ��ǂ���B
���������_�̓_�𗪂��Ȃ�@�C��������
>>435
�C�������ˁB
�C�������ˁB
>>444
K6�̍��ɁA�������Z�͗ǂ����Ǖ��������_���Z��Intel���x���A�Ƃ����]����
���@����ׂ�K7�Ŋ撣�����������L�邯�ǂˁB
�����Ȑ��\����������]���ׁ̈A���ĂƂ��낪�~�\�B
K6�̍��ɁA�������Z�͗ǂ����Ǖ��������_���Z��Intel���x���A�Ƃ����]����
���@����ׂ�K7�Ŋ撣�����������L�邯�ǂˁB
�����Ȑ��\����������]���ׁ̈A���ĂƂ��낪�~�\�B
1156�͌���4�R�A�܂ł�
449 �F,,�E�L�́M�E,,�j��-�������F2009/11/26(��) 22:22:22 ID:Y7m0S63w
GMA����Ȃ�����L���b�V���Ԃ��Ă恄��
450 �F,,�E�L�́M�E,,�j��-�������F2009/11/26(��) 22:23:03 ID:Y7m0S63w
�厖�Ȃ��ƂȂ̂�2���܂���
�L���b�V�����Č����̂��Ƃ��c�B
�ނ��덡��̏���LGA1155�̕��������ɂȂ����ȁB
Lynnfield/Clarkdale �� LGA136x Sandy Bridge
�̃R�[�X������Ƃ��Ă͖��͂Ɏv���Ă����킯�����B
Lynnfield/Clarkdale �� LGA136x Sandy Bridge
�̃R�[�X������Ƃ��Ă͖��͂Ɏv���Ă����킯�����B
453 �F,,�E�L�́M�E,,�j��-�������F2009/11/26(��) 22:31:26 ID:Y7m0S63w
4�R�A��8MB�Ȃ��ƃ��_�A�Ƃ�
�\�P�b�g�ύX�����ˁH
����Ȃ���H
�l/�a���[�J�[����̈��́H
����Ȃ���H
�l/�a���[�J�[����̈��́H
�c�q���ăA�[�L�e�N�`���E�̎d�����l�݂��������
�L���b�V���T�C�Y���������̂́A�A�N�Z�X���x����̂��߂Ƃ��H
457 �F,,�E�L�́M�E,,�j��-�������F2009/11/26(��) 23:29:08 ID:Y7m0S63w
2�̙p�悶��Ȃ����B
�Ƃ����Socket B2��B����Broomfield��B����ˁBH�̂ق��́i���jHavendale����
�����LGA1365�Ƃ��������肷��́H
�Ƃ����Socket B2��B����Broomfield��B����ˁBH�̂ق��́i���jHavendale����
�����LGA1365�Ƃ��������肷��́H
�_�C�T�C�Y�P�`��ׂ���
Xeon�͂Ă���̗\��
Xeon�͂Ă���̗\��
459 �F,,�E�L�́M�E,,�j��-�������F2009/11/26(��) 23:32:19 ID:Y7m0S63w
����ɂ��Ă��ϑ��W�R�A��_�����悤�Ȓ����`�����
�t�ɂ����������Ă��傤���Ȃ��B
�t�ɂ����������Ă��傤���Ȃ��B
�܂�����̏���C���i�b�v�̑S�Ăł͂Ȃ����낤�ȁB
���C���X�R���[����_���������R�X�g�팸�̂��߂��Ȗ���ɁB
�[���A�\�P�b�g�Ȃ�ăK���K���ς��ė~�����B
���C���X�R���[����_���������R�X�g�팸�̂��߂��Ȗ���ɁB
�[���A�\�P�b�g�Ȃ�ăK���K���ς��ė~�����B
http://www.isscc.org/isscc/2010/ISSCCAP2010.pdf
ISSCC2010�̃v���O�������������B
intel�̔��\�͐F�X����悤�����ǁA48��IA32�R�A��4ch��DDR3�����b�V���łȂ������̂�
45nm�ō�����`�b�v�̔��\���\�肳��Ă���B
���炭�̓R�A�Ԑڑ��̓����O�o�X�ɂȂ肻�������ǁA����ɑ����̃R�A���ڂ���Ƃ���
���b�V���̕����L�͂ƍl���Ă���̂��낤���B
ISSCC2010�̃v���O�������������B
intel�̔��\�͐F�X����悤�����ǁA48��IA32�R�A��4ch��DDR3�����b�V���łȂ������̂�
45nm�ō�����`�b�v�̔��\���\�肳��Ă���B
���炭�̓R�A�Ԑڑ��̓����O�o�X�ɂȂ肻�������ǁA����ɑ����̃R�A���ڂ���Ƃ���
���b�V���̕����L�͂ƍl���Ă���̂��낤���B
462 �F,,�E�L�́M�E,,�j��-�������F2009/11/27(��) 00:54:37 ID:XBEF90Op
>>461
Keifer�܂�����łȂ�������
Keifer�܂�����łȂ�������
�܂��k�ɐ��ɑ�������i���cIntel���]�肷������
���{�͋�����邩���Ȃ����ŝ��߂Ă郌�x���Ȃ̂�
���{�͋�����邩���Ȃ����ŝ��߂Ă郌�x���Ȃ̂�
Nehalem-EX�ł̓����O�o�X�̑ш悪1.2TB/s�ɂȂ�Ƃ������Ă����
�o�X��256bit��ring��4�Ȃ̂�9.6GT/s��
LRB�������l�Ȏd�l�ɂȂ肻��
�[��Nehalem-EX�̓n�h�\���̃f�U�C���Ȃ̂�
Poulson��2012�N�炵��������Itanium����Ă�̂̓t�H�[�g�R�����Y��300�l��������
���Ƃ���ς�S�̓I�ɃI���S���̘_���������ł���
�o�X��256bit��ring��4�Ȃ̂�9.6GT/s��
LRB�������l�Ȏd�l�ɂȂ肻��
�[��Nehalem-EX�̓n�h�\���̃f�U�C���Ȃ̂�
Poulson��2012�N�炵��������Itanium����Ă�̂̓t�H�[�g�R�����Y��300�l��������
���Ƃ���ς�S�̓I�ɃI���S���̘_���������ł���
Itanium�Ȃ�āu�����オ����v���ċq�Ɏv�킹�邽�߂����ɊJ�����Ă�悤�Ȃ���
�@�@�@�@�@�@�@�@SandyBridge H2�@�@�@�@SandyBridge B2
Sokcet�@�@�@�@�@�@LGA1155�@�@�@�@�@�@LGA1366��p(��1)
�R�A���@�@�@�@�@�@2�܂���4�@�@�@�@�@�@�@�@6�܂���8
�@�@�@�@�@�@�@�@�i6core�����邩���j
L3�e�ʁ@�@�@�@1.5MB x �R�A���@�@�@�@ 2.5MB x �R�A��
GPU�R�A�@�@�@�@�@�@�@���@�@�@�@�@�@�@�@�@�@�@�@�~
�Ή������� �@�@�@DDR3-1333 �@�@�@�@�@�@DDR3-1600
�@�@�@�@�@�@�@�@�@ Dual-channel�@�@�@�@ Triple-channel
PCI-Ex���[���@�@ 2.0�F16�@�@�@�@�@�@�@�@�@�@3.0�F24
�`�b�v�Z�b�g�@�@Couger Point�@�@�@�@�@�@�@Patsburg
S-ATA�@�@�@�@�@6.0Gbps�F2�@�@�@�@�@�@�@�@6.0Gbps�F2
�@�@�@�@�@�@�@�@�@ 3.0Gbps�F4�@�@�@�@�@�@�@�@3.0Gbps�F4
USB�@�@�@�@�@�@ USB 2.0�F14�@�@�@�@�@�@�@USB 2.0�F14
TDP�@�@�@�@�@ 4-core�F95 or 45W
�@�@�@�@�@�@�@�@2-core�F65 or 20W
(��1)���sCPU�Ƃ̌݊������ۂ����\���͒Ⴂ
USB3.0�́A2012�N�ɓ����\��́gIvy Bridge�h�Ή��`�b�v�Z�b�g�܂Ő摗�肳���
QPI���ĂȂ�肠������
>>466
H2�ɂ�GPU����������A
����Lynnfield�̌�p32nm�ł݂����̂������B
Westmere�̖��ߍ��킹�p�ɂ��ꂪ�B�����݊��������肻�������ǂȁB
H2�ɂ�GPU����������A
����Lynnfield�̌�p32nm�ł݂����̂������B
Westmere�̖��ߍ��킹�p�ɂ��ꂪ�B�����݊��������肻�������ǂȁB
Lynnfield�������ł�QPI�Őڑ�����ĂȂ���������
�m�[�X�����������ĂȂ�X58�ł�QPI�g�����Ƃ��������ŁA�m�[�X���������ꍇ��
CPU�����Ńm�[�X��QPI�ڑ�����Ă��Ȃ��H
�悭�킩��ǖϑz���Ă݂�
�m�[�X�����������ĂȂ�X58�ł�QPI�g�����Ƃ��������ŁA�m�[�X���������ꍇ��
CPU�����Ńm�[�X��QPI�ڑ�����Ă��Ȃ��H
�悭�킩��ǖϑz���Ă݂�
�`�b�v����QPI�łȂ��Ӗ����킩���
���m�ɂ́uQPI�݊��̃I���_�C�p�o�X�v�Ȃ낤��
�S���ʕ��̕������g���̂͐v�R�X�g���ܑ̖���
�z�����Z���������d�͓��X��QPI�W�����啝�Ɉ����������Ă�͂�
�S���ʕ��̕������g���̂͐v�R�X�g���ܑ̖���
�z�����Z���������d�͓��X��QPI�W�����啝�Ɉ����������Ă�͂�
Jasper Forest�������Lynn��QPI�͉��Ȃ̂����������������l�H
QPI���̂�����PCIE
ttp://journal.mycom.co.jp/photo/special/2009/lynnfield/images/Photo06l.jpg
���ʂ�QPI���邯�lj��Ɏg���Ă�̂��낤�H
���̖ڂ̍��o���낤��
{kind=link}
���ʂ�QPI���邯�lj��Ɏg���Ă�̂��낤�H
���̖ڂ̍��o���낤��
Nehalem�̃_�C�ʐ^�Ȃ���QPI������͓̂�����O
�v���X�e�̊g���[�q�݂����Ȃ��̂�
>>447
�����ĕ]���C���t�F�[�Y�͊����Ƃ����킯��
�����ĕ]���C���t�F�[�Y�͊����Ƃ����킯��
478 �F,,�E�L�́M�E,,�j��-�������F2009/11/28(�y) 13:24:04 ID:q4aoUrmv
���W���[�ȏ��p�r�f�I�G���R�[�_��Q�[����AVX�Ή��͍ς܂��Ă��邾�낤����
���炭�����������x���Ƃ����]�������܂Ƃ���������
���炭�����������x���Ƃ����]�������܂Ƃ���������
���������_�̓_�𗪂��Ȃ�@�C��������
480 �F,,�E�L�́M�E,,�j��-�������F2009/11/28(�y) 13:43:19 ID:q4aoUrmv
�Ȃ猾�������������_���̐��𗪂��Ȃ�
���������_���Z�Ȃ��琔�͂���˂�����H���̏ꍇ
>>445�Ŏn�߂āA�����ԃl�^�ɂ������Ȃ낤�B
���_���������B
���_���������B
483 �F,,�E�L�́M�E,,�j��-�������F2009/11/28(�y) 13:49:54 ID:q4aoUrmv
�킩������A��������Ȃ���
�����ċC�����������炵�傤���Ȃ�������[
�����ċC�����������炵�傤���Ȃ�������[
������
�����_���������邩�� floating-point �Ȃ̂ɂȂ�
>>485
���߂�悤�@��������Ȃ��悤
���߂�悤�@��������Ȃ��悤
�ȂA��ԃl�^�ɂȂ�����牴�����̃X���Ƃ��ŃR�s�y�Ƃ����悤�Ǝv���Ă��̂ɁB
>>488
�L�~�̂���莟��
�L�~�̂���莟��
���Ⴀ
�u���������_���̓_���𗪂��Ȃ�@�C���������v
�ɂ��Ƃ��H
����Ƃ�
�u�Ȃ猾�������������_���̐��𗪂��Ȃ�v
�܂ō��킹��1�̃l�^�ɂ���H
�u���������_���̓_���𗪂��Ȃ�@�C���������v
�ɂ��Ƃ��H
����Ƃ�
�u�Ȃ猾�������������_���̐��𗪂��Ȃ�v
�܂ō��킹��1�̃l�^�ɂ���H
���݂܂���A���q�ɏ��܂���
�ق�Ƃ���ŏ����܂�
�ق�Ƃ���ŏ����܂�
����Ȃ��Ƃ��Sandy bridge�̘b���悤���H
493 �F,,�E�L�́M�E,,�j��-�������F2009/11/28(�y) 17:37:35 ID:q4aoUrmv
http://www.tomshardware.com/reviews/project-keifer-32-core,1280.html
>>461�̂́AKeifer��32�R�A����48�R�A�ɂȂ��ė\��ʂ�o�ꂵ���悤�Ɍ�����
>>461�̂́AKeifer��32�R�A����48�R�A�ɂȂ��ė\��ʂ�o�ꂵ���悤�Ɍ�����
Sandy Bridge
http://maps.google.co.jp/maps/place?cid=8866593860667882326&q=Sandy+Bridge,+Rowley,+Massachusetts&gl=jp&hl=ja&cd=1&cad=src:pplink,view:map&ei=e-AQS8_1IZXyuwP8u4WJDQ
����ƌ������ό���o�Ă��܂������̂悤�ł�
http://maps.google.co.jp/maps/place?cid=8866593860667882326&q=Sandy+Bridge,+Rowley,+Massachusetts&gl=jp&hl=ja&cd=1&cad=src:pplink,view:map&ei=e-AQS8_1IZXyuwP8u4WJDQ
����ƌ������ό���o�Ă��܂������̂悤�ł�
������Ȃ���
�V���݂����Ȃ����
�Ȃ�ق�
http://maps.google.co.jp/maps?ie=UTF8&view=map&cid=8866593860667882326&ved=0CA8QpQY&hnear=&t=h&brcurrent=3,0x0:0x0,0&ll=42.734531,-70.856162&spn=0.003014,0.00442&z=18&iwloc=A
http://maps.google.co.jp/maps?ie=UTF8&sll=35.665416,139.759494&sspn=0.003334,0.00442&brcurrent=3,0x60188bea19971e1b:0x50c5e400d9b07e1a,0&ll=35.665272,139.759467&spn=0.003334,0.00442&z=18
http://maps.google.co.jp/maps?ie=UTF8&sll=35.665416,139.759494&sspn=0.003334,0.00442&brcurrent=3,0x60188bea19971e1b:0x50c5e400d9b07e1a,0&ll=35.665272,139.759467&spn=0.003334,0.00442&z=18
499 �F,,�E�L�́M�E,,�j��-�������F2009/11/28(�y) 20:56:40 ID:q4aoUrmv
�c�ɂ��Ȃ�
Sandy Brdige���Ė{���ɕ����������̂�?
���˂�����Ă���ƕ������i����
502 �F,,�E�L�́M�E,,�j��-�������F2009/11/28(�y) 22:49:41 ID:q4aoUrmv
�������Ȃ��Ȃ�@��������肢
�[���Ȃ��Ȃ�@��������肢
�V�X�����Ă܂���
���ǂ��g���Ă�
Intel Larrabee 5�R�A
http://pc11.2ch.net/test/read.cgi/jisaku/1259422247/
���ǂ��g���Ă�
Intel Larrabee 5�R�A
http://pc11.2ch.net/test/read.cgi/jisaku/1259422247/
������128bitSSE���߂̃X���[�v�b�g��2�{�ɂȂ��Ă�����͂��Ȃ��̂���?
507 �F,,�E�L�́M�E,,�j��-�������F2009/11/29(��) 05:42:37 ID:1kopwAVM
����Ɋւ��Ă�AMD���Ȃ��B
�ł�����Ȃ̊W�˂�
�@�@�mʃn�w
�@�^�V�V�S �_
`/�Q�Q�Q�Q_�@��
(/�@�@�@�@ �r |
|�߁��@���߁R_|
|�S���r ��� |6)
|�@_�R_ɁQ�@ �
��((Ĵ���)) /
`�����jƁV�^�܁R
�@ �_�Q_�^ | �b �_
�@ (��)�b|`| �b_�m��
�@ (�O��m | />-����
�@�@���@�@<L_)�@| �b
�@�@�@�@�@| Ɂ@ ���b
�@�@�@�@���Q)�@ (nm)
�@�@�mʃn�w
�@�^�V�V�S �_
`/�Q�Q�Q�Q_�@��
(/�@�@�@�@ �r |
|�߁��@���߁R_|
|�S���r ��� |6)
|�@_�R_ɁQ�@ �
��((Ĵ���)) /
`�����jƁV�^�܁R
�@ �_�Q_�^ | �b �_
�@ (��)�b|`| �b_�m��
�@ (�O��m | />-����
�@�@���@�@<L_)�@| �b
�@�@�@�@�@| Ɂ@ ���b
�@�@�@�@���Q)�@ (nm)
510 �F,,�E�L�́M�E,,�j��-�������F2009/11/29(��) 14:45:08 ID:1kopwAVM
>>509
software.intel.com�̃t�H�[�����Œ��̐l�������Ă�B
���Z���j�b�g�̃��C�e���V�E�X���[�v�b�g�͗�̃T�C�N���V�~�����[�^(IACA)���قڎ��@�Ɠ������Ƃ̂��ƁB
Nehalem, Westmere�̃V�~�����[�^���lj�����Ă��ꂪ�قڎ��@�̃T�C�N�����ƈ�v���Ă邩��
�قڊԈႢ�Ȃ��B�L���b�V���~�X�Ƃ����߃t�F�b�`�ш�̃{�g���l�b�N�Ƃ��͍Č��ł��Ȃ����
���̕ӂ̃`���[�j���O�͎蓮�ł��Ȃ��Ƃ����Ȃ��B
��ŁA�Ԃ����ႯGCC 4.4�̂͂��Ȃ�ǂ�64bit�����R�[�h��f���B
Intel Compiler����Ȃ��Ȃ邼������
software.intel.com�̃t�H�[�����Œ��̐l�������Ă�B
���Z���j�b�g�̃��C�e���V�E�X���[�v�b�g�͗�̃T�C�N���V�~�����[�^(IACA)���قڎ��@�Ɠ������Ƃ̂��ƁB
Nehalem, Westmere�̃V�~�����[�^���lj�����Ă��ꂪ�قڎ��@�̃T�C�N�����ƈ�v���Ă邩��
�قڊԈႢ�Ȃ��B�L���b�V���~�X�Ƃ����߃t�F�b�`�ш�̃{�g���l�b�N�Ƃ��͍Č��ł��Ȃ����
���̕ӂ̃`���[�j���O�͎蓮�ł��Ȃ��Ƃ����Ȃ��B
��ŁA�Ԃ����ႯGCC 4.4�̂͂��Ȃ�ǂ�64bit�����R�[�h��f���B
Intel Compiler����Ȃ��Ȃ邼������
>>510
gcc�̂��ǂ��ǂ��̂��ڂ���
gcc�̂��ǂ��ǂ��̂��ڂ���
512 �F,,�E�L�́M�E,,�j��-�������F2009/11/29(��) 16:40:32 ID:1kopwAVM
���Ƃ���vbroadcastss��128�r�b�g�ł�256�r�b�g�łŔ��s�|�[�g������Ⴄ����
������ƌ������ă��C�e���V���B���悤�ɖ��߃X�P�W���[�����O���Ă�B
�Ԃ����Ⴏ���Intrinsics�ŏ������R�[�h��ׂĂ݂���Intel Compiler����GCC�̂ق���
�V�~�����[�^�ʂ����ꍇ�ɃT�C�N�����Z���R�[�h��f����
������ƌ������ă��C�e���V���B���悤�ɖ��߃X�P�W���[�����O���Ă�B
�Ԃ����Ⴏ���Intrinsics�ŏ������R�[�h��ׂĂ݂���Intel Compiler����GCC�̂ق���
�V�~�����[�^�ʂ����ꍇ�ɃT�C�N�����Z���R�[�h��f����
513 �F,,�E�L�́M�E,,�j��-�������F2009/11/29(��) 16:42:14 ID:1kopwAVM
���A���Ȃ݂ɍs��ςŃT�C�N�������v���ˁB
�Ȃ�قǁA���肪�Ƃ��c�q����B
Intel�R���p�C�����Ĉ��|�I�ɐ��\�ǂ��C���[�W����������ӊO����B
Intel�R���p�C�����Ĉ��|�I�ɐ��\�ǂ��C���[�W����������ӊO����B
�C���e���R���p�C�����āA����p�r�̃x���`���p�B�A
�v����ɃC���e�����i�̃v�����[�V�����p����Ȃ��̂��B
�v����ɃC���e�����i�̃v�����[�V�����p����Ȃ��̂��B
517 �F,,�E�L�́M�E,,�j��-�������F2009/11/29(��) 19:15:03 ID:1kopwAVM
L1�L���b�V���̃o���h���͏��32byte/clk�{����16byte/clk����B
�����������t���ŁB
prefetchnta���Ȃɂ��ɏd�v�ɂȂ肻���B
�i����Ȃ̖������J����Ă�V�~�����[�^���ᐄ���ʂ�Ȃ��j
�����������t���ŁB
prefetchnta���Ȃɂ��ɏd�v�ɂȂ肻���B
�i����Ȃ̖������J����Ă�V�~�����[�^���ᐄ���ʂ�Ȃ��j
518 �F,,�E�L�́M�E,,�j��-�������F2009/11/30(��) 00:52:58 ID:/FO+CjDb
���A���������ꉞ������SSE�ł��A���I�Ƃ͂����Ȃ��܂ł����\�オ��v���͂����B���Ȃ�n���ɁB
���̕ӂ͂�����x�����Ă���Ǝv��
�E���[�h���߂�1�T�C�N����2���s�o����B
�Emulps�̃��C�e���V��5�T�C�N������4�T�C�N���ɍ팸
���ƃX�J���̕������\���オ��M�~�b�N���p�ӂ���Ă�B
���̕ӂ͂�����x�����Ă���Ǝv��
�E���[�h���߂�1�T�C�N����2���s�o����B
�Emulps�̃��C�e���V��5�T�C�N������4�T�C�N���ɍ팸
���ƃX�J���̕������\���オ��M�~�b�N���p�ӂ���Ă�B
4�T�C�N���ɂȂ�̂�mulpd����ˁH
520 �F,,�E�L�́M�E,,�j��-�������F2009/11/30(��) 01:14:22 ID:/FO+CjDb
����A�m����mulps��Nehalem�ł�4����
521 �F,,�E�L�́M�E,,�j��-�������F2009/11/30(��) 01:20:53 ID:/FO+CjDb
mulps 4��4
mulpd 5��5
vmulps na��4
vmulpd na��4
���_�FAVX�g��
mulpd 5��5
vmulps na��4
vmulpd na��4
���_�FAVX�g��
�Ƃ����Sandybridge�X�������̂܂ɂ������Ă�ˁB
���s���݂�1366�͂Ȃ���1156�̂����������Ƃ������Ă��̂�
���̐���͂Ȃ��nj݊����Ȃ��݂�����
�ǂ������ł���ꂻ�����Ȃ�
�`bridge����̓������X���b�g6�܂őΉ�����_��
1366��B2�I��ǂ��������K���ɂȂꂻ������
���s���݂�1366�͂Ȃ���1156�̂����������Ƃ������Ă��̂�
���̐���͂Ȃ��nj݊����Ȃ��݂�����
�ǂ������ł���ꂻ�����Ȃ�
�`bridge����̓������X���b�g6�܂őΉ�����_��
1366��B2�I��ǂ��������K���ɂȂꂻ������
Socket H1 (LGA1156) = DMI Gen.1
Socket H2 (LGA1155) = DMI Gen.2
Socket B1 (LGA1366) = QPI
Socket B2 (LGAxxxx) = DMI Gen.2
DMI�������I��PCI-Express 2.0 x4�x�[�X��
PCI-Ex��Gen.1��Gen.2�����̂܂g���Ȃ�
Socket H1 (LGA1156)��Socket H2 (LGA1155)��
�݊��̉\���͍����ƍl����̂����R
���QPI��DMI�͑ш敝�ȂLjقȂ�v�f�������̂�
Socket B1 (LGA1366)��Socket B2 (LGAxxxx)��
�݊��̉\���͂��Ȃ�Ⴂ��Ȃ��ł��傤��
����QPI���̂�2way�ȏ��Xeon�ł����炭��������
�Ȃ�ق� 1156�͂��ł�DMI�������̂�
�d��
��������775�����g���ĂȂ��̂Ń[������V�K�őg�ނ���
B2��
�E��q�̃g���v���`�����l��������
�E4�`8�R�A�܂ŗ\��
�EIvy bridge��B2���������Ă����炵��
�}�U�[1��Haswell�܂Ŏg���|��������
�������������牴��B2�̕���I�Ԃ���
�d��
��������775�����g���ĂȂ��̂Ń[������V�K�őg�ނ���
B2��
�E��q�̃g���v���`�����l��������
�E4�`8�R�A�܂ŗ\��
�EIvy bridge��B2���������Ă����炵��
�}�U�[1��Haswell�܂Ŏg���|��������
�������������牴��B2�̕���I�Ԃ���
Intel�Ƃ��Ă̓\�P�b�g���ꂵ�������낤����Socket B2��
����Bulldozer���ǂ������ꍇ�̂ւ̃o�b�N�A�b�v���낤
������邾���]�v�ȃR�X�g�����邵�{�C�ł��Ȃ�
LGA1366�iQPI&3ch-DDR3)���p��/���W����ς�
Socket H2�ƃo�X���݊��ɂȂ�`�b�v�Z�b�g��
���ʂ̂��̂��g���܂킹�邩�炻�̕ӂ��l�����Ă邩��
����Bulldozer���ǂ������ꍇ�̂ւ̃o�b�N�A�b�v���낤
������邾���]�v�ȃR�X�g�����邵�{�C�ł��Ȃ�
LGA1366�iQPI&3ch-DDR3)���p��/���W����ς�
Socket H2�ƃo�X���݊��ɂȂ�`�b�v�Z�b�g��
���ʂ̂��̂��g���܂킹�邩�炻�̕ӂ��l�����Ă邩��
XeonDP�̃v���b�g�t�H�[�����ANehalem-EP����Ȃ��āA
JasperForest�̕��ɓ����������Ă��Ƃ���Ȃ��́H
CPU�{IOH�{ICH�̍\���Ȃ̂́ANehalem����܂łŁA
���Ƃ͊�{�I��CPU�{PCH�\���ɂȂ�낤�B
JasperForest�̕��ɓ����������Ă��Ƃ���Ȃ��́H
CPU�{IOH�{ICH�̍\���Ȃ̂́ANehalem����܂łŁA
���Ƃ͊�{�I��CPU�{PCH�\���ɂȂ�낤�B
Intel�I��2�`�b�v�\�����[�V�����͂��͂�ߋ��̈╨
>Intel�Ƃ��Ă̓\�P�b�g���ꂵ�������낤����
�Ȃ���
�ŏ��5�p�[�Z���g���\�P�b�g�ʂ�Ă����ĉ��̖����Ȃ���
�Ȃ���
�ŏ��5�p�[�Z���g���\�P�b�g�ʂ�Ă����ĉ��̖����Ȃ���
UP-Xeon���������Ă�̂������̂��Ƃ����ȁB
Intel�̃X�J��CPU+Larrabee�̃w�e���W�j�A�XCPU�r�W����
http://pc.watch.impress.co.jp/docs/column/kaigai/20091201_332428.html
http://pc.watch.impress.co.jp/docs/column/kaigai/20091201_332428.html
Intel�uLarrabee��CPU����������{�C�o���v
532 �F,,�E�L�́M�E,,�j��-�������F2009/12/01(��) 02:00:03 ID:ekg7DMWw
�ŏ����猾���Ă���B
PCIe���l�b�N���ኈ�p�̕������������B
PCIe���l�b�N���ኈ�p�̕������������B
LNI��SSE���݂ɕ��ʂɂȂ�����AMD�ǂ������?
AVX�݂����ɂ�������ƃT�|�[�g����?
AVX�݂����ɂ�������ƃT�|�[�g����?
534 �F,,�E�L�́M�E,,�j��-�������F2009/12/01(��) 02:49:18 ID:ekg7DMWw
1024�r�b�g�܂ł�AVX�̉�������ɂ���B
�T�|�[�g���Ȃ��Ȃ�Ă��Ƃ͂��蓾��ł���B
AMD�͂킴�킴VEX�Ƃ͕ʌɐ��疽�ߊm�ۂł���VEX�̃t�H�[�}�b�g�݊��̃X�L�[����
�p�ӂ��Ă���炳�B
�������uLNI Now!�v�I�Ȃ��̂��p�ӂ��Ă���ł���B
�T�|�[�g���Ȃ��Ȃ�Ă��Ƃ͂��蓾��ł���B
AMD�͂킴�킴VEX�Ƃ͕ʌɐ��疽�ߊm�ۂł���VEX�̃t�H�[�}�b�g�݊��̃X�L�[����
�p�ӂ��Ă���炳�B
�������uLNI Now!�v�I�Ȃ��̂��p�ӂ��Ă���ł���B
LNI Now!�A�����^
128bit�Ă�����Ή�������
Sandybridge����H
Sandybridge����H
�������Haswell�͂܂����ˁH
����x86�A�[�L�e�N�`���ɂ�LNI�ڐA�ł������Ă��Ƃ�����
Larrabee�����LNI����肭�g�����!�A�I��
�����p�t�H�[�}���X�̕ǂ��������肵�Ȃ��̂��낤��?
Larrabee�����LNI����肭�g�����!�A�I��
�����p�t�H�[�}���X�̕ǂ��������肵�Ȃ��̂��낤��?
GPU�Ȃ����ꕔ�̓���ȗp�r�łȂ����
256bitSIMD�ł����x���r�����Ď��ė]����Ȃ�?
���Ⴀ���ʂ̃R�A��512bit���ڂ�����GPU�̑��肪�ł��邩�Ƃ����ƁA����Ȃ��Ƃ��Ȃ�
(�X�J�����̃g�����W�X�^�����ʂɂȂ��ăR�A�����₹�Ȃ��̂ŁAGPU���ɂ͑���Ȃ�)�B
LNI�ڂ��悤�Ǝv���ڂ����邯�Ǘ\��͂Ȃ���A�Ƃ����̂͂��������Ӗ��B
256bitSIMD�ł����x���r�����Ď��ė]����Ȃ�?
���Ⴀ���ʂ̃R�A��512bit���ڂ�����GPU�̑��肪�ł��邩�Ƃ����ƁA����Ȃ��Ƃ��Ȃ�
(�X�J�����̃g�����W�X�^�����ʂɂȂ��ăR�A�����₹�Ȃ��̂ŁAGPU���ɂ͑���Ȃ�)�B
LNI�ڂ��悤�Ǝv���ڂ����邯�Ǘ\��͂Ȃ���A�Ƃ����̂͂��������Ӗ��B
540 �F,,�E�L�́M�E,,�j��-�������F2009/12/01(��) 22:01:12 ID:ekg7DMWw
�����ALarrabee�̖��߃Z�b�g���ł������ǂ���������̂�Intel�̓����͔����Ēʂ�Ȃ������
541 �F,,�E�L�́M�E,,�j��-�������F2009/12/01(��) 22:18:21 ID:ekg7DMWw
>>539
�N�͖{���Ƀo�J����
Larrabee�̖��߃Z�b�g��4x4�̍s�Z�������I�ɏ����ł���悤�ɐv����Ă�B
float x16�ł͂Ȃ�float 4x4���B
�Q�[���Ȃ̊ȈՕ����Ŏg����]�s��Ȃ���ʂɏ����ł���B
�N�͖{���Ƀo�J����
Larrabee�̖��߃Z�b�g��4x4�̍s�Z�������I�ɏ����ł���悤�ɐv����Ă�B
float x16�ł͂Ȃ�float 4x4���B
�Q�[���Ȃ̊ȈՕ����Ŏg����]�s��Ȃ���ʂɏ����ł���B
542 �F,,�E�L�́M�E,,�j��-�������F2009/12/01(��) 22:28:00 ID:ekg7DMWw
> ���Ⴀ���ʂ̃R�A��512bit���ڂ�����GPU�̑��肪�ł��邩�Ƃ����ƁA����Ȃ��Ƃ��Ȃ�
�Ƃ������GeForce�̃V�F�[�_���j�b�g��256�r�b�g��SIMD���j�b�g��4��ʂ��d�l����
> (�X�J�����̃g�����W�X�^�����ʂɂȂ��ăR�A�����₹�Ȃ��̂ŁAGPU���ɂ͑���Ȃ�)�B
1�̃f�[�^��16�v�f�Ƀu���[�h�L���X�g����̂Ɋe�v�f���ɓ������͒l�̐������Z��
�A�h���X�Z�o����d�l��GPU����B
�o�J�����ď������Ȃ��B
�A�h���X�v�Z�̓X�J�����j�b�g�̕��������I���B
�Ƃ������GeForce�̃V�F�[�_���j�b�g��256�r�b�g��SIMD���j�b�g��4��ʂ��d�l����
> (�X�J�����̃g�����W�X�^�����ʂɂȂ��ăR�A�����₹�Ȃ��̂ŁAGPU���ɂ͑���Ȃ�)�B
1�̃f�[�^��16�v�f�Ƀu���[�h�L���X�g����̂Ɋe�v�f���ɓ������͒l�̐������Z��
�A�h���X�Z�o����d�l��GPU����B
�o�J�����ď������Ȃ��B
�A�h���X�v�Z�̓X�J�����j�b�g�̕��������I���B
543 �F,,�E�L�́M�E,,�j��-�������F2009/12/01(��) 22:32:05 ID:ekg7DMWw
�z��A�̑�100�v�f�����[�h����
���S����SIMD�̗v�f�ŃA�h���X�v�Z������B
����ȓd�͌����̈������Ƃ���Ă������GPU��x86���������邱�ƂɂȂ�B
���S����SIMD�̗v�f�ŃA�h���X�v�Z������B
����ȓd�͌����̈������Ƃ���Ă������GPU��x86���������邱�ƂɂȂ�B
Sandy bridge�܂ő҂������
Larrabee�̐�D�u�V�F�A�[�h�o�[�`�����������v
http://pc.watch.impress.co.jp/docs/column/kaigai/20091202_332618.html
http://pc.watch.impress.co.jp/docs/column/kaigai/20091202_332618.html
>>545
����͂�����ς�
����͂�����ς�
�͂��͂�MMUMMU
�Ƃ����L��
���ۃ�������ԍl����Ƃ�������̂������I�Ȃ낤����
�Ƃ����L��
���ۃ�������ԍl����Ƃ�������̂������I�Ȃ낤����
548 �F,,�E�L�́M�E,,�j��-�������F2009/12/02(��) 02:03:52 ID:4wnVhNuN
����Ȃ��Ƃ��STM�͂ǂ��Ȃ���
�������H
550 �F,,�E�L�́M�E,,�j��-�������F2009/12/02(��) 07:11:05 ID:4wnVhNuN
�\�t�g�E�F�A�E�g�����U�N�V���i��������
GPU�ɂ͗v��Ȃ����AGPU�̎��̃t�F�[�Y�͖������猋�Ǘv��Ȃ���B
ttp://itpro.nikkeibp.co.jp/article/NEWS/20091203/341438/
ISSCC�̑O��48�R�A�̎���`�b�v�����\���ꂽ�B
����̃`�b�v�͊O���̊�ƁE��w�ɂ��z��悤���B
ISSCC�̑O��48�R�A�̎���`�b�v�����\���ꂽ�B
����̃`�b�v�͊O���̊�ƁE��w�ɂ��z��悤���B
��1��F�N���E�h�E�T�[�r�X���㓞���A�^�p���ς��
http://thinkit.jp/article/1084/1/
http://thinkit.jp/article/1084/1/
����d�͈ȊO�ɐ��\��\�����l��������炩�ɂ��Ȃ��̂̓C���b�Ƃ���
555 �FSocket774�F2009/12/03(��) 15:02:01 ID:BIjw8p6n
556 �FSocket774�F2009/12/03(��) 15:39:02 ID:BIjw8p6n
> A 567mm2 processor in 45nm CMOS integrates 48 IA-32 cores and 4 DDR3
> channels in a 6�~4 2D-mesh network. Cores communicate through message
> passing using 384KB of on-die shared memory. Fine grain power management
> takes advantage of 8 voltage and 28 frequency islands to allow independent
> DVFS of cores and mesh. As performance scales, the processor dissipates
> between 25W and 125W.
>>554
�C���C����������
> channels in a 6�~4 2D-mesh network. Cores communicate through message
> passing using 384KB of on-die shared memory. Fine grain power management
> takes advantage of 8 voltage and 28 frequency islands to allow independent
> DVFS of cores and mesh. As performance scales, the processor dissipates
> between 25W and 125W.
>>554
�C���C����������
567mm2 �@���@��
CELL�݂����Ƀ_���ȃR�A�������������Ă�OK�ł���A
���\�Ǖi����ꂻ���ł͂��邪�A��ł��s�ǂƂȂ�Ƃ��Ȃ茵������
�ǂꂮ�炢�g�����ɂȂ邩�͖��m�����ȁc
CELL�݂����Ƀ_���ȃR�A�������������Ă�OK�ł���A
���\�Ǖi����ꂻ���ł͂��邪�A��ł��s�ǂƂȂ�Ƃ��Ȃ茵������
�ǂꂮ�炢�g�����ɂȂ邩�͖��m�����ȁc
48Core 24Router�A2D mesh 256GB/s bisection bandwidth
ttp://download.intel.com/pressroom/pdf/rockcreek/SCC_Announcement_JustinRattner.pdf
"experimental many core cpu"
Larrabee �Ƃ͂ǂ��ɂ������ĂȂ�
ttp://download.intel.com/pressroom/pdf/rockcreek/SCC_Announcement_JustinRattner.pdf
"experimental many core cpu"
Larrabee �Ƃ͂ǂ��ɂ������ĂȂ�
������Larrabee����Ȃ����c
560 �FSocket774�F2009/12/03(��) 17:40:26 ID:BIjw8p6n
>>557
Youtube�̉���������u���b�N�P�ʂŃ_�C�i�~�b�N�ɃR�A��
�f�B�[�[�u���ɂ��ďȓd�͉�����d�g�݂����邩��A
�s�ǃR�A�̂���u���b�N����ɖ����ɂ���̂��\�ł́H
>>558-559
�ǂ������Ƃ����Ɣp�~�̉\��������Keifer����
Youtube�̉���������u���b�N�P�ʂŃ_�C�i�~�b�N�ɃR�A��
�f�B�[�[�u���ɂ��ďȓd�͉�����d�g�݂����邩��A
�s�ǃR�A�̂���u���b�N����ɖ����ɂ���̂��\�ł́H
>>558-559
�ǂ������Ƃ����Ɣp�~�̉\��������Keifer����
Keifer�ł��Ȃ����c
�����r�[�̎�������Ĉʒu�Â��݂������ȁB
GPU�Ƃ��Ďg�������ɖ�����������]���������Ęb�ł���B
Intel�A48�R�A��IA�v���Z�b�T���J��
http://pc.watch.impress.co.jp/docs/news/20091203_333078.html
�@���Ђł�SCC���2����̃��j�C�R�A�v���Z�b�T�Ƃ��Ĉʒu�t���Ă���(��1�����Larrabee)�B
GPU�Ƃ��Ďg�������ɖ�����������]���������Ęb�ł���B
Intel�A48�R�A��IA�v���Z�b�T���J��
http://pc.watch.impress.co.jp/docs/news/20091203_333078.html
�@���Ђł�SCC���2����̃��j�C�R�A�v���Z�b�T�Ƃ��Ĉʒu�t���Ă���(��1�����Larrabee)�B
GPU�Ƃ�����Ȏ����̘b����Ȃ�������
�^�C���̂ق��������O��莟���ゾ�Ƃł��H
�g�����U�N�V���������ɂ̓^�C���^���b�V���l�b�g���[�N
GPU��HPC�̂悤�ȃX�g���[�������ɂ̓����O�^3D�g�[���X
1�R�A�̑傫�������Larrabee��Atom������SCC
�g�����U�N�V���������ɂ̓^�C���^���b�V���l�b�g���[�N
GPU��HPC�̂悤�ȃX�g���[�������ɂ̓����O�^3D�g�[���X
1�R�A�̑傫�������Larrabee��Atom������SCC
��������Intel�̔��\�����ł͑�ꐢ��͗��FMAC������80�R�A�iPolaris�j
�ł�����Larrabee�������Ă̂͋L�҂̊��Ⴂ�ȊO�̂Ȃ�ł��Ȃ��B
�ł�����Larrabee�������Ă̂͋L�҂̊��Ⴂ�ȊO�̂Ȃ�ł��Ȃ��B
566 �F,,�E�L�́M�E,,�j��-�������F2009/12/03(��) 23:37:50 ID:Vx3UacNb
�����炱��Keifer�����B
2010�N�ɏo�����Č����Ă����B
������_�C�T�C�Y��1�R�A������ɂ����Larrabee��Atom�̖��Ȃ��
2010�N�ɏo�����Č����Ă����B
������_�C�T�C�Y��1�R�A������ɂ����Larrabee��Atom�̖��Ȃ��
Keifer�͂Ƃ����̐̂ɃL�����Z������܂���
568 �F,,�E�L�́M�E,,�j��-�������F2009/12/03(��) 23:52:04 ID:Vx3UacNb
���Ⴀ�����̃R�[�h�l�[���Ȃ�
569 �F,,�E�L�́M�E,,�j��-�������F2009/12/03(��) 23:54:06 ID:Vx3UacNb
��������Keifer���L�����Z���ɂȂ����Ȃ�ĉ����̏��
sutherland
�ň��
�ň��
���ʂ�SCC����Ȃ���
LRB�Ƃ�HSW�Ƃ�������ƑO����O�������s���Ă邵
LRB�Ƃ�HSW�Ƃ�������ƑO����O�������s���Ă邵
572 �F,,�E�L�́M�E,,�j��-�������F2009/12/04(��) 00:00:47 ID:Vx3UacNb
���̊Ԃɂ����j�[�R�A�`�[����������̐��ɂȂ����ȁB
�܂��ALarrabee�݂����ȃO���t�B�b�N�EHPC�ɓ��������v���Z�b�T������
���j�[�R�A�̎��v����Ȃ��킯�����B
�܂��ALarrabee�݂����ȃO���t�B�b�N�EHPC�ɓ��������v���Z�b�T������
���j�[�R�A�̎��v����Ȃ��킯�����B
Bangalore�͒��X�Ǝ��ѐς�ł���
���̓�Tick-Tock��Tick-Tack-Tock�ɂł��Ȃ�납
Larrabee��Atom��Tick-Tock���n�܂��Ă��ʔ�����
���̓�Tick-Tock��Tick-Tack-Tock�ɂł��Ȃ�납
Larrabee��Atom��Tick-Tock���n�܂��Ă��ʔ�����
>>573
����������Keifer���ă����O�o�X���Ęb�������ȁB
���̋L�����āAKeifer�ɂ��ċ�Tukwila���݂����Ȉ�ۂ������̎v���o�����B
����������Keifer���ă����O�o�X���Ęb�������ȁB
���̋L�����āAKeifer�ɂ��ċ�Tukwila���݂����Ȉ�ۂ������̎v���o�����B
576 �F,,�E�L�́M�E,,�j��-�������F2009/12/04(��) 00:20:54 ID:d2iN0iPh
IA�R�A�̎����͎����悤�Ȃ�����
Keifer�̑���Kevet�Ȃ�Ă̂���������
�ǂ�Ȃm���
�ǂ�Ȃm���
��������n�[�h�E�F�A�̃������R�q�[�����V��������߂Ă���̂ɋ������B
Larrabee�ł������͂�������Ă���̂ɁB
���炤�ǂ������炢���̂��ȁB
Larrabee�ł������͂�������Ă���̂ɁB
���炤�ǂ������炢���̂��ȁB
���������A�N���E�h�̃X�����Ė����ȁB
���ꂱ�����Ԃ̖��������̊T�O������H
�������A�ǂ����N���E�h�N���E�h���Ă��邹����ȁB
���ꂱ�����Ԃ̖��������̊T�O������H
�������A�ǂ����N���E�h�N���E�h���Ă��邹����ȁB
>>579
���Ȃ��Ƃ����̎���PC�̔��e�ł͂Ȃ����ˁB
Google App Engine��Amazon S3��WebProg�A
Amazon EC2�͑O�̓����^���I�ɂ����������͖����݂����B
Windows Azure�X���͌���Windows�܂߂ǂ����Ȃ��̂�
�ǂ����ɗ��Ă悤���Ƃ��v�����ǁA�ǂ��ɗ��ĂĂ��ςȘA����
�������r�炳�ꂻ�������Ȃ��B
���Ȃ��Ƃ����̎���PC�̔��e�ł͂Ȃ����ˁB
Google App Engine��Amazon S3��WebProg�A
Amazon EC2�͑O�̓����^���I�ɂ����������͖����݂����B
Windows Azure�X���͌���Windows�܂߂ǂ����Ȃ��̂�
�ǂ����ɗ��Ă悤���Ƃ��v�����ǁA�ǂ��ɗ��ĂĂ��ςȘA����
�������r�炳�ꂻ�������Ȃ��B
DDR3�~4ch��48�R�A�ŋ��L���ďo����������ĂȂ낤
PHP(��)
MVC(��)
MVC(��)
583 �F,,�E�L�́M�E,,�j��-�������F2009/12/04(��) 23:06:50 ID:d2iN0iPh
�܂������ŋ߂�Web�n�V����ƂƂ�����
MovableType�ŃT�C�g�\�z�Ƃ����l���Ă��
�E�E�����ƒN�������悤��
MovableType�ŃT�C�g�\�z�Ƃ����l���Ă��
�E�E�����ƒN�������悤��
�얳
�O���t�B�b�N�{�[�h�ƊE�Q�����Ȃ����ۂ������Ĕ��ł��܂���
586 �F,,�E�L�́M�E,,�j��-�������F2009/12/06(��) 01:24:41 ID:nTu8nNRJ
�ނ��날���炳�܂�HPC�����@�\���R����Ȃ̂�GPU���ƌ��������������������B
�����������������ŊJ����q���Ă��琢�b������
�r�W�l�X�Ƃ��Ă͎��s����������
�Q���V���K�[����������
�Q���V���K�[����������
589 �F,,�E�L�́M�E,,�j��-�������F2009/12/06(��) 01:49:17 ID:nTu8nNRJ
�܂��A����Ӗ��ł͑��g�͎�ꂽ�B
>>588
�r�W�l�X�Ƃ��Ă͐������Ȃ��悤�Ȃ��̂�1000���ȏ�𓊂��ăX�p�R����낤�Ƃ��Ă�o�J�ȍ��������ł���
>>588
�r�W�l�X�Ƃ��Ă͐������Ȃ��悤�Ȃ��̂�1000���ȏ�𓊂��ăX�p�R����낤�Ƃ��Ă�o�J�ȍ��������ł���
���������_�Ō��܂��Ă����̂�������Ȃ��ȁ@�L��͍����낾������
�O���t�B�b�N�Ƃ��đ�ʏo�ׂ����`�b�v�P���͈����Ȃ����̂�
592 �F,,�E�L�́M�E,,�j��-�������F2009/12/06(��) 04:30:53 ID:nTu8nNRJ
>>591
���ႠXeon MP���R���V���[�}�����ɏo���Έ����ł����ł����H
�ʂɕς���ł���B
32�R�A��Larrabee��8�R�A��Nehalem-EX�Ɠ����x�̃_�C�T�C�Y
�o�חʓI�ɂ�XeonMP�͂���Ȃɑ����Ȃ��B
�ނ������������Ȃ����Ƃɂ���Intel�̐^�ӂ����肻�����B
���ႠXeon MP���R���V���[�}�����ɏo���Έ����ł����ł����H
�ʂɕς���ł���B
32�R�A��Larrabee��8�R�A��Nehalem-EX�Ɠ����x�̃_�C�T�C�Y
�o�חʓI�ɂ�XeonMP�͂���Ȃɑ����Ȃ��B
�ނ������������Ȃ����Ƃɂ���Intel�̐^�ӂ����肻�����B
593 �F,,�E�L�́M�E,,�j��-�������F2009/12/06(��) 04:39:29 ID:nTu8nNRJ
Xeon MP��6�R�A�ŃN���b�N�グ��HPC�ł����ƌ����Ă�����H
XeonMP�̋��݂�QPI�̖{���BDP�ł�2�{�ɑ���MP��4�{�B
���Ƃ��A4�v���Z�b�T����ڑ����Ă�1�\�P�b�g������2�{��QPI�����N���c��킯��
������A�N�Z�����[�^�̐ڑ��Ɏg����킯���B
XeonMP�̋��݂�QPI�̖{���BDP�ł�2�{�ɑ���MP��4�{�B
���Ƃ��A4�v���Z�b�T����ڑ����Ă�1�\�P�b�g������2�{��QPI�����N���c��킯��
������A�N�Z�����[�^�̐ڑ��Ɏg����킯���B
XeonMP�̓R�A���̂̓R���V���[�}�Ƌ��ʂȂ���J����̕��S�͏��Ȃ�
����Larrabee��HPC�s��ł��ׂĂ�������Ȃ���Ȃ�Ȃ�
����Larrabee��HPC�s��ł��ׂĂ�������Ȃ���Ȃ�Ȃ�
595 �F,,�E�L�́M�E,,�j��-�������F2009/12/06(��) 05:19:04 ID:nTu8nNRJ
>>594
Xeon MP���݂̃_�C�T�C�Y�̂��̂𐔖��~�̃r�f�I�J�[�h�ɂ��Ĕ���̂�����ł����H
����45nm�ł������Ɩʐς����艿�i�̂������i���邾��B
PCIe�ڑ��̂��̂͑ш�l�b�N�ɂȂ肪���Ƃ͂���N-Body�݂����ȃl�b�N�ɂȂ�ɂ������ł�
�댯�Ȑ��\���낤�B���̃A���݂����Ȃ̂�����킯�����B
GPU��Larrabee���uSIMD���Z�̑�������x86�v�Ƃ��Ďg����悤�ɂȂ��Ă��̕�Xeon������Ȃ��Ȃ�����
�����q���Ȃ��B�Ƃ������������������͓��R�\�z�����B
�Ӑ}�I�Ɉ��������Ȃ�����K�v������킯����B
�Ȃɂ�蓖��Intel CPU�ɂƂ��Ă̓_�C�T�C�Y������FLOPS��啝�Ɉ����グ��Z�p��
Larrabee�ł͂Ȃ�AVX, FMA���B
���オ�ǂ����ĂȂ�����AGPU�Ƃ��ėv��ʈ��]���t�����͖{����HPC�ɓ��������ق���
�����_�ł͂܂��Ȃ̂ł́H
�t��HPC���������ɂ͔��肽�����R�B
�P�D��������������
�Q�DHPC�ł͂��܂�̗p���̏��Ȃ�Xeon MP��QPI���������Ĕ��荞�ލD�@
�R�D�X�p�R���̓R���s���[�^�ƊE��F1�ł���
Xeon MP���݂̃_�C�T�C�Y�̂��̂𐔖��~�̃r�f�I�J�[�h�ɂ��Ĕ���̂�����ł����H
����45nm�ł������Ɩʐς����艿�i�̂������i���邾��B
PCIe�ڑ��̂��̂͑ш�l�b�N�ɂȂ肪���Ƃ͂���N-Body�݂����ȃl�b�N�ɂȂ�ɂ������ł�
�댯�Ȑ��\���낤�B���̃A���݂����Ȃ̂�����킯�����B
GPU��Larrabee���uSIMD���Z�̑�������x86�v�Ƃ��Ďg����悤�ɂȂ��Ă��̕�Xeon������Ȃ��Ȃ�����
�����q���Ȃ��B�Ƃ������������������͓��R�\�z�����B
�Ӑ}�I�Ɉ��������Ȃ�����K�v������킯����B
�Ȃɂ�蓖��Intel CPU�ɂƂ��Ă̓_�C�T�C�Y������FLOPS��啝�Ɉ����グ��Z�p��
Larrabee�ł͂Ȃ�AVX, FMA���B
���オ�ǂ����ĂȂ�����AGPU�Ƃ��ėv��ʈ��]���t�����͖{����HPC�ɓ��������ق���
�����_�ł͂܂��Ȃ̂ł́H
�t��HPC���������ɂ͔��肽�����R�B
�P�D��������������
�Q�DHPC�ł͂��܂�̗p���̏��Ȃ�Xeon MP��QPI���������Ĕ��荞�ލD�@
�R�D�X�p�R���̓R���s���[�^�ƊE��F1�ł���
XeonMP M/B�ɐ�p�\�P�b�g(?)�lj���QPI�ڑ���Larrabee����
���ꂱ���A�m�[�h������̃R�X�g��HPC�����ɂ��Ă����������Ȃ��H
����QPI Larrabee���Ƃ��Ă�(QPI 2ch XeonDP + Larrabee)/node
�ʂ���Ȃ��́H
�����ȂƂ���AQPI Larrabee�Ƃ��{���ɔ��\����ɂ��Ă��A
(Opteron + HyperTransport3 Fermi HPC�A�N�Z�����[�^) �Ƃ����̂�
���E�̃X�p�R���ŗ��s��\����������Ƃł��o�Ă�����A���̎��_��
���\�������Č������܂���Ƃ������x�ŁA�X�p�R���̎��{����
����܂ł̓J�^���O�ɏ����Ă��������ȋC������B
���ꂱ���A�m�[�h������̃R�X�g��HPC�����ɂ��Ă����������Ȃ��H
����QPI Larrabee���Ƃ��Ă�(QPI 2ch XeonDP + Larrabee)/node
�ʂ���Ȃ��́H
�����ȂƂ���AQPI Larrabee�Ƃ��{���ɔ��\����ɂ��Ă��A
(Opteron + HyperTransport3 Fermi HPC�A�N�Z�����[�^) �Ƃ����̂�
���E�̃X�p�R���ŗ��s��\����������Ƃł��o�Ă�����A���̎��_��
���\�������Č������܂���Ƃ������x�ŁA�X�p�R���̎��{����
����܂ł̓J�^���O�ɏ����Ă��������ȋC������B
����AGMA�̑����Larrabee���ڂ��Ă���{�C������Ȃ�������
�c�q�����ڂ���߂���
�c�q�����ڂ���߂���
�{�������Ƃ�����
�킩��₷����
�킩��₷����
QPI�g���Ȃ�AHPC�pXeonMP��QPI�̂����A1�{��I/O�p�A�c��3�{��Larrabee�Ɏg�����������悭�Ȃ��H
>>595
> >>594
> Xeon MP���݂̃_�C�T�C�Y�̂��̂𐔖��~�̃r�f�I�J�[�h�ɂ��Ĕ���̂�����ł����H
AMD�͕����肪�����ŐV��40nm��330mm2�̃T�C�Y��RV870���ŏ�ʂ�$400�Ƃ��Ŕ����Ă����v���o�Ă���悤�ł����ˁB
200mm2���RV840�Ȃ�$200�ł���B
�܂�����Ă����������Ή���͏o���܂��ˁB
XEON MP���Ԏ�����Ȃ��}0�łȂ�10���~�������Ȃ��ł��傤�B
���������̗��v�ł����Ȃ�10���~�ł������̂ł́B
�v��HPC�̓{�b�^�N���ׂ̎s��Ƃ������ƂŁA����͂ǂ��ł������ł��傤�B
PC�s�ꂾ���ŏ\������ł��Ă��܂�����ˁB
> GPU��Larrabee���uSIMD���Z�̑�������x86�v�Ƃ��Ďg����悤�ɂȂ��Ă��̕�Xeon������Ȃ��Ȃ�����
> �����q���Ȃ��B�Ƃ������������������͓��R�\�z�����B
> �Ӑ}�I�Ɉ��������Ȃ�����K�v������킯����B
���RPC������HPC�����͕ʃu�����h�ɂ��āA���i�������Ĕ̔�����ł���B
CPU��i7/i5��Xeon�ANvidia��Geforce��tesla�݂����ɁB
�ǂ�����������炢�����i�ō����v�ɂȂ邩��Intel�Ƃ��Ă͂ǂ��炪����Ă����Ȃ��ł��ˁB
> �t��HPC���������ɂ͔��肽�����R�B
> �P�D��������������
> �Q�DHPC�ł͂��܂�̗p���̏��Ȃ�Xeon MP��QPI���������Ĕ��荞�ލD�@
> �R�D�X�p�R���̓R���s���[�^�ƊE��F1�ł���
�S�DPC�������ᐫ�\��������Intel�̃u�����h�������ᔄ��Ȃ�
�T�DAMD��Nvidia�ւ̌����点���炢�ɂ͖��ɗ���
����锄��Ȃ��͂ǂ��ł��悳�����B
> >>594
> Xeon MP���݂̃_�C�T�C�Y�̂��̂𐔖��~�̃r�f�I�J�[�h�ɂ��Ĕ���̂�����ł����H
AMD�͕����肪�����ŐV��40nm��330mm2�̃T�C�Y��RV870���ŏ�ʂ�$400�Ƃ��Ŕ����Ă����v���o�Ă���悤�ł����ˁB
200mm2���RV840�Ȃ�$200�ł���B
�܂�����Ă����������Ή���͏o���܂��ˁB
XEON MP���Ԏ�����Ȃ��}0�łȂ�10���~�������Ȃ��ł��傤�B
���������̗��v�ł����Ȃ�10���~�ł������̂ł́B
�v��HPC�̓{�b�^�N���ׂ̎s��Ƃ������ƂŁA����͂ǂ��ł������ł��傤�B
PC�s�ꂾ���ŏ\������ł��Ă��܂�����ˁB
> GPU��Larrabee���uSIMD���Z�̑�������x86�v�Ƃ��Ďg����悤�ɂȂ��Ă��̕�Xeon������Ȃ��Ȃ�����
> �����q���Ȃ��B�Ƃ������������������͓��R�\�z�����B
> �Ӑ}�I�Ɉ��������Ȃ�����K�v������킯����B
���RPC������HPC�����͕ʃu�����h�ɂ��āA���i�������Ĕ̔�����ł���B
CPU��i7/i5��Xeon�ANvidia��Geforce��tesla�݂����ɁB
�ǂ�����������炢�����i�ō����v�ɂȂ邩��Intel�Ƃ��Ă͂ǂ��炪����Ă����Ȃ��ł��ˁB
> �t��HPC���������ɂ͔��肽�����R�B
> �P�D��������������
> �Q�DHPC�ł͂��܂�̗p���̏��Ȃ�Xeon MP��QPI���������Ĕ��荞�ލD�@
> �R�D�X�p�R���̓R���s���[�^�ƊE��F1�ł���
�S�DPC�������ᐫ�\��������Intel�̃u�����h�������ᔄ��Ȃ�
�T�DAMD��Nvidia�ւ̌����点���炢�ɂ͖��ɗ���
����锄��Ȃ��͂ǂ��ł��悳�����B
�t��Power�Ƀv���b�V���[���������Ƃ����̂͂Ȃ����ˁB
��IBM���S�����EPower�P�ނȂ�Ă��Ƃ͂��肦�Ȃ��ɂ��Ă��A
IBM��Power�̊J�����\�[�X�������\�i�Ƀt�H�[�J�X�����Ă��Ă����A
PC�̃Z�O�����g�ɑ��Ă̋��Ђ͒ቺ����B
���Ƃ͑�ARM���Ă����B
��IBM���S�����EPower�P�ނȂ�Ă��Ƃ͂��肦�Ȃ��ɂ��Ă��A
IBM��Power�̊J�����\�[�X�������\�i�Ƀt�H�[�J�X�����Ă��Ă����A
PC�̃Z�O�����g�ɑ��Ă̋��Ђ͒ቺ����B
���Ƃ͑�ARM���Ă����B
Power�̓Q�[���@��ʐM�@��(�[������Ȃ���n�Ǒ�)�Ƃ��ɂ����Ȃ�̗p����Ă���ˁB
603 �F,,�E�L�́M�E,,�j��-�������F2009/12/06(��) 11:39:06 ID:nTu8nNRJ
>>600
> AMD�͕����肪�����ŐV��40nm��330mm2�̃T�C�Y��RV870���ŏ�ʂ�$400�Ƃ��Ŕ����Ă����v���o�Ă���悤�ł����ˁB
> 200mm2���RV840�Ȃ�$200�ł���B
> �܂�����Ă����������Ή���͏o���܂��ˁB
AMD�͖{����5870�ŗ��v���o�Ă�́HRadeon�̔��グ���オ���������ō������Ƃ͌����ĂȂ��͂��B
�܂�CPU�������傪���N�Ԏ��̎�v���Ȃ̂͂��Ă����B
32 core��Larrabee��600mm²�I�[�o�[�ł��B�O�㖢���ł��B
�����������o��Ηǂ��Ƃ����̂͂��肦�Ȃ��ł���B����͗��v�̍ő剻��v�����Ă���B
�Ƃ͌����Ă݂����{���͂����ł���
�EGPU�Ƃ��Ĕ���ɂ͂܂��܂��n�[�h�E�\�t�g���Ƀ`���[�j���O�s��
�EGPGPU��ւ����҂��Ă��z�r�[�v���O���}�͍��͗v���
�@��AVX�֘A�͐ϋɓI�ɏ����J����T��LRBni�͏�����܂���B��������Ӑ}������Ǝv����B
����͕̂ʂ�32nm�ňȍ~�̃R���V���[�}�E�f�B�X�N���[�gGPU�̉\����ے肵���킯����Ȃ�
> AMD�͕����肪�����ŐV��40nm��330mm2�̃T�C�Y��RV870���ŏ�ʂ�$400�Ƃ��Ŕ����Ă����v���o�Ă���悤�ł����ˁB
> 200mm2���RV840�Ȃ�$200�ł���B
> �܂�����Ă����������Ή���͏o���܂��ˁB
AMD�͖{����5870�ŗ��v���o�Ă�́HRadeon�̔��グ���オ���������ō������Ƃ͌����ĂȂ��͂��B
�܂�CPU�������傪���N�Ԏ��̎�v���Ȃ̂͂��Ă����B
32 core��Larrabee��600mm²�I�[�o�[�ł��B�O�㖢���ł��B
�����������o��Ηǂ��Ƃ����̂͂��肦�Ȃ��ł���B����͗��v�̍ő剻��v�����Ă���B
�Ƃ͌����Ă݂����{���͂����ł���
�EGPU�Ƃ��Ĕ���ɂ͂܂��܂��n�[�h�E�\�t�g���Ƀ`���[�j���O�s��
�EGPGPU��ւ����҂��Ă��z�r�[�v���O���}�͍��͗v���
�@��AVX�֘A�͐ϋɓI�ɏ����J����T��LRBni�͏�����܂���B��������Ӑ}������Ǝv����B
����͕̂ʂ�32nm�ňȍ~�̃R���V���[�}�E�f�B�X�N���[�gGPU�̉\����ے肵���킯����Ȃ�
604 �F,,�E�L�́M�E,,�j��-�������F2009/12/06(��) 11:42:58 ID:nTu8nNRJ
���͍���̃f�B�X�N���[�gGPU�v�悻�̂��̂��u���t�ŁANVIDIA��ATI�ɁuLarrabee��v�������邱�Ƃ��ړI�������A�Ƃ��H
����Ă����͍̂��̏�NVIDIA����������
����Ă����͍̂��̏�NVIDIA����������
606 �F,,�E�L�́M�E,,�j��-�������F2009/12/06(��) 12:11:28 ID:nTu8nNRJ
����Ȃ炻��Ōi�C��ƌ����k�ق͓P�ꂽ���B
�y���o���}�L��߂���A�n���͎��ʂ�B
�o���}�L���ł��Ȃ��Ȃ�����߂����ǂ�
609 �F,,�E�L�́M�E,,�j��-�������F2009/12/06(��) 12:27:02 ID:nTu8nNRJ
���łɓy���ł���K�v���Ȃ�
�q���蓖�ă}���Z�[�̃~���X�}���ł���
611 �F,,�E�L�́M�E,,�j��-�������F2009/12/06(��) 12:33:34 ID:nTu8nNRJ
�y�����蓖�Ă��̓}�V����
613 �F,,�E�L�́M�E,,�j��-�������F2009/12/06(��) 12:40:27 ID:nTu8nNRJ
���ꂪ�M������
>>603
> >>600
> AMD�͖{����5870�ŗ��v���o�Ă�́HRadeon�̔��グ���オ���������ō������Ƃ͌����ĂȂ��͂��B
> �܂�CPU�������傪���N�Ԏ��̎�v���Ȃ̂͂��Ă����B
GPU����Ƃ��ė��v���o��Ƃ肠�������͂Ȃ��ł���B
AMD�S�̂������ɂȂ�ɂ́ACPU��GF�������ɂȂ�K�v�����邩��ǂ����悤���Ȃ��B
> 32 core��Larrabee��600mm²�I�[�o�[�ł��B�O�㖢���ł��B
> �����������o��Ηǂ��Ƃ����̂͂��肦�Ȃ��ł���B����͗��v�̍ő剻��v�����Ă���B
45nm�̘b�ŁA���i��32nm�ł̓o��̗\�肾��������A400mm2�ʂ̃T�C�Y�ɂȂ��Ȃ����������B
���Ȃ݂�570mm2��GTX280��8���~�ł����B
> �Ƃ͌����Ă݂����{���͂����ł���
>
> �EGPU�Ƃ��Ĕ���ɂ͂܂��܂��n�[�h�E�\�t�g���Ƀ`���[�j���O�s��
�P�Ƀ^�C�~���O���ԈႦ�������ł���B
�܂��܂��Œ�@�\���x�z�I��DX11�ɌŒ�@�\�T���߂Ƃ����\�o��킯�Ȃ��B
> �EGPGPU��ւ����҂��Ă��z�r�[�v���O���}�͍��͗v���
GPGPU���̂��܂��܂����y���߂̒i�K�ŁA�K�p�͈͂����Ȃ苷���㕨������ˁB
�z�r�[�v���O���}�ɕW���K�i��DX11��OpenCL�ȊO�����߂�͍̂����Ǝv���B
> �@��AVX�֘A�͐ϋɓI�ɏ����J����T��LRBni�͏�����܂���B��������Ӑ}������Ǝv����B
Larrabee�̌v�悪��ނ���̂��m��ŁA�]�v�ȃ��\�[�X�̂�T�����~�߂��������Ǝv���B
���y���������Ȃ瓝������K�v�͂Ȃ�����ˁB
> ����͕̂ʂ�32nm�ňȍ~�̃R���V���[�}�E�f�B�X�N���[�gGPU�̉\����ے肵���킯����Ȃ�
�ėp���Z���\���d�v�ȃ��C�g�����Q�[�����x���ł����p������鎞���ɍē������l���Ă����������ǁA
�Œ�@�\�D���DX11����ɂ͂����f�B�X�N���[�gGPU�̓����̌v��͂Ȃ����낤�ˁB
> >>600
> AMD�͖{����5870�ŗ��v���o�Ă�́HRadeon�̔��グ���オ���������ō������Ƃ͌����ĂȂ��͂��B
> �܂�CPU�������傪���N�Ԏ��̎�v���Ȃ̂͂��Ă����B
GPU����Ƃ��ė��v���o��Ƃ肠�������͂Ȃ��ł���B
AMD�S�̂������ɂȂ�ɂ́ACPU��GF�������ɂȂ�K�v�����邩��ǂ����悤���Ȃ��B
> 32 core��Larrabee��600mm²�I�[�o�[�ł��B�O�㖢���ł��B
> �����������o��Ηǂ��Ƃ����̂͂��肦�Ȃ��ł���B����͗��v�̍ő剻��v�����Ă���B
45nm�̘b�ŁA���i��32nm�ł̓o��̗\�肾��������A400mm2�ʂ̃T�C�Y�ɂȂ��Ȃ����������B
���Ȃ݂�570mm2��GTX280��8���~�ł����B
> �Ƃ͌����Ă݂����{���͂����ł���
>
> �EGPU�Ƃ��Ĕ���ɂ͂܂��܂��n�[�h�E�\�t�g���Ƀ`���[�j���O�s��
�P�Ƀ^�C�~���O���ԈႦ�������ł���B
�܂��܂��Œ�@�\���x�z�I��DX11�ɌŒ�@�\�T���߂Ƃ����\�o��킯�Ȃ��B
> �EGPGPU��ւ����҂��Ă��z�r�[�v���O���}�͍��͗v���
GPGPU���̂��܂��܂����y���߂̒i�K�ŁA�K�p�͈͂����Ȃ苷���㕨������ˁB
�z�r�[�v���O���}�ɕW���K�i��DX11��OpenCL�ȊO�����߂�͍̂����Ǝv���B
> �@��AVX�֘A�͐ϋɓI�ɏ����J����T��LRBni�͏�����܂���B��������Ӑ}������Ǝv����B
Larrabee�̌v�悪��ނ���̂��m��ŁA�]�v�ȃ��\�[�X�̂�T�����~�߂��������Ǝv���B
���y���������Ȃ瓝������K�v�͂Ȃ�����ˁB
> ����͕̂ʂ�32nm�ňȍ~�̃R���V���[�}�E�f�B�X�N���[�gGPU�̉\����ے肵���킯����Ȃ�
�ėp���Z���\���d�v�ȃ��C�g�����Q�[�����x���ł����p������鎞���ɍē������l���Ă����������ǁA
�Œ�@�\�D���DX11����ɂ͂����f�B�X�N���[�gGPU�̓����̌v��͂Ȃ����낤�ˁB
615 �F,,�E�L�́M�E,,�j��-�������F2009/12/06(��) 13:04:23 ID:nTu8nNRJ
��������Windows XP�ɂ̓h���C�o���Ȃ��Ƃ������ĂȂ����������B
>>614
AMD��CPU�����Q3����7600���h���̍����Ȃ̂ɁBGPU�����800���h����葽����B
AMD��CPU�����Q3����7600���h���̍����Ȃ̂ɁBGPU�����800���h����葽����B
>>616
�� AMD��CPU�����Q3����7600���h���̍���
�����̐Ԏ���GF�ɔ���Ă̍���������A�������ʂ�Ă�GPU�̍����ƒ��ڂɔ�r�͏o���Ȃ����ƁB
�� AMD��CPU�����Q3����7600���h���̍���
�����̐Ԏ���GF�ɔ���Ă̍���������A�������ʂ�Ă�GPU�̍����ƒ��ڂɔ�r�͏o���Ȃ����ƁB
Clarkdale Gets GPGPU Support
http://news.softpedia.com/news/Clarkdale-Gets-GPGPU-Support-128936.shtml
> Intel recently announced that its next-generation graphics circuits,
> which will be part of the Clarkdale CPU, would include support for
> GPGPU on video transcoding.
>
> Intel announced that the Clarkdale would be capable of video encoding
> through a driver update that would allow it to distribute the computing
> tasks among 10 graphics processing engines.
http://news.softpedia.com/news/Clarkdale-Gets-GPGPU-Support-128936.shtml
> Intel recently announced that its next-generation graphics circuits,
> which will be part of the Clarkdale CPU, would include support for
> GPGPU on video transcoding.
>
> Intel announced that the Clarkdale would be capable of video encoding
> through a driver update that would allow it to distribute the computing
> tasks among 10 graphics processing engines.
619 �F,,�E�L�́M�E,,�j��-�������F2009/12/06(��) 18:39:24 ID:nTu8nNRJ
�C�X���G���`�[��ktkr!
>>605
������ƌ����đ�����4�{���������鐳�����͌�������Ȃ���
�r�c�M�v�Z���Z�C�����Ă܂��B
�_�j���Ă݂Ă��������B
������ƌ����đ�����4�{���������鐳�����͌�������Ȃ���
�r�c�M�v�Z���Z�C�����Ă܂��B
�_�j���Ă݂Ă��������B
�X���Ⴂ�����ǁA�y�n���������œ��H���TSUBAME��10����Ă̂��Ȃ�Ƃ��c
NEC�EIntel�ɋ��o���������Ǝv���B
�C���^�[�R�l�N�g��NEC�̕��������Ɛi��ł���B
���̋����͂ǂ��l���Ă���鉿�l�̂Ȃ��v���W�F�N�g�B
NEC�EIntel�ɋ��o���������Ǝv���B
�C���^�[�R�l�N�g��NEC�̕��������Ɛi��ł���B
���̋����͂ǂ��l���Ă���鉿�l�̂Ȃ��v���W�F�N�g�B
http://www.mext.go.jp/b_menu/shingi/gijyutu/gijyutu2/006/shiryo/07061518/004.pdf
�č��قǃX�p�R���ɋ�������ł鍑�͂Ȃ�����B
���\����Ă�ȊO�ɌR����i�ڍה���\�j������x���{�[�ȋ����X�p�R���ɓ����B
�[���A�����J�͂Ȃ�ł�����ł��R���Y�ƈ������č��̋�����Ƃɗ����B
���{�Ȃǂ���������Ƃɓ�������Ɛ��{�J��������������100�����̑��E�ł��ۂ������ɂ��B
NEC��SX������������������̂����ŃA�����J�ɂ͔���Ȃ������i���Cray�o�R�Ŕ̔��j�B
�č��قǃX�p�R���ɋ�������ł鍑�͂Ȃ�����B
���\����Ă�ȊO�ɌR����i�ڍה���\�j������x���{�[�ȋ����X�p�R���ɓ����B
�[���A�����J�͂Ȃ�ł�����ł��R���Y�ƈ������č��̋�����Ƃɗ����B
���{�Ȃǂ���������Ƃɓ�������Ɛ��{�J��������������100�����̑��E�ł��ۂ������ɂ��B
NEC��SX������������������̂����ŃA�����J�ɂ͔���Ȃ������i���Cray�o�R�Ŕ̔��j�B
���{���X�p�R���̐����̋���˂�����ł�����������
����̗\�Z�Ȃ�10�Z�b�g�ł��邾�낤�ȁB
���߂�5�Z�b�g�B
����̗\�Z�Ȃ�10�Z�b�g�ł��邾�낤�ȁB
���߂�5�Z�b�g�B
http://anchorage.2ch.net/test/read.cgi/bizplus/1259160517/643
http://anchorage.2ch.net/test/read.cgi/bizplus/1259160517/667
http://anchorage.2ch.net/test/read.cgi/bizplus/1259484786/293
http://anchorage.2ch.net/test/read.cgi/bizplus/1259484786/418
http://anchorage.2ch.net/test/read.cgi/bizplus/1259484786/424
http://anchorage.2ch.net/test/read.cgi/bizplus/1259756970/224
http://anchorage.2ch.net/test/read.cgi/bizplus/1259160517/667
http://anchorage.2ch.net/test/read.cgi/bizplus/1259484786/293
http://anchorage.2ch.net/test/read.cgi/bizplus/1259484786/418
http://anchorage.2ch.net/test/read.cgi/bizplus/1259484786/424
http://anchorage.2ch.net/test/read.cgi/bizplus/1259756970/224
���ʌ���(�V�����l�ɑ��z�̕�V�Ƃ�)���~�߂����܂��傤�Ƃ����b�������̂�
���Ⴀ�v�掩�̂�߂��Ⴂ�܂�?�I�ȏ������L�`�K�C���݂Ă邾����
�f�B�X�N���[�g����CPU�ɍ��ڂ��鎞��Ɍ����ĊJ�����Ă�낤����
�t��LNI�����L�p�������肷��ƊO�t���œ��肷��p���Ȃ�AMD��
LNI now!�I�ȉ����𓋍ڂ���܂ŒZ���I��(#^��^)�Ȋ����ɂȂ��Ȃ���?
���Ⴀ�v�掩�̂�߂��Ⴂ�܂�?�I�ȏ������L�`�K�C���݂Ă邾����
�f�B�X�N���[�g����CPU�ɍ��ڂ��鎞��Ɍ����ĊJ�����Ă�낤����
�t��LNI�����L�p�������肷��ƊO�t���œ��肷��p���Ȃ�AMD��
LNI now!�I�ȉ����𓋍ڂ���܂ŒZ���I��(#^��^)�Ȋ����ɂȂ��Ȃ���?
�����ɕ֏悵�Đ_�˂ɓ��H���b���������킯�����}�X�S�~�ƃ~���X�͖ܘ_���y����������
>>620
���������Ȃ��̂ł���A�m�b���o�������𗬂������Ȃ��낤�B
���̒r�c�M�v�Z���Z�C�̓X�p�R���̂��߂ɒm�b���o���Ă����̂��ˁB���𗬂��Ă����̂��ˁB
����͎��肾���̃q���[�����Ƃ���B�����������Ⴕ�₵�Ȃ��B
���������Ȃ��̂ł���A�m�b���o�������𗬂������Ȃ��낤�B
���̒r�c�M�v�Z���Z�C�̓X�p�R���̂��߂ɒm�b���o���Ă����̂��ˁB���𗬂��Ă����̂��ˁB
����͎��肾���̃q���[�����Ƃ���B�����������Ⴕ�₵�Ȃ��B
628 �F,,�E�L�́M�E,,�j��-�������F2009/12/07(��) 02:08:07 ID:3pFyeiTC
RICC�̋���ł���ʖڂȂ́H
>>627
�����Ɏ������Đl�i�ᔻ�����ȁB
������P��o���Ă݂��B
���̋�������Ȃ���ǂ����Ă��ʖڂƂ������R��
�uSPARC��RAS���ǂ����Ă��K�p�Ȃ�ł����v
���炢�����Ȃ��Ǝv�����c�B
�����Ɏ������Đl�i�ᔻ�����ȁB
������P��o���Ă݂��B
���̋�������Ȃ���ǂ����Ă��ʖڂƂ������R��
�uSPARC��RAS���ǂ����Ă��K�p�Ȃ�ł����v
���炢�����Ȃ��Ǝv�����c�B
>>629
���ےr�c�͕ʒi�D�ꂽ�ΈĂ���ĂȂ�����B�����������c�͕]�_�Ƃ���B
Venus����Ȃ��Ă������A�Ƃ����O��ɗ����Č����A�]�_�Ƃ��������]�_�Ƃ����d���������Ƃ��������B
���ےr�c�͕ʒi�D�ꂽ�ΈĂ���ĂȂ�����B�����������c�͕]�_�Ƃ���B
Venus����Ȃ��Ă������A�Ƃ����O��ɗ����Č����A�]�_�Ƃ��������]�_�Ƃ����d���������Ƃ��������B
631 �F,,�E�L�́M�E,,�j��-�������F2009/12/07(��) 08:33:25 ID:3pFyeiTC
���Ⴀ������Ă��Ă��
RICC������1��A2��[�i��
RICC������1��A2��[�i��
Venus���g�����R�HCPU�ɂ͉��Z�Ɠ����̂��߂�HPC�����̃J�X�^�����K�v�����炾��B
Intel��AMD�ɂ�����˂����߂�z�͓��{�ɂ�(���E�ɂ�)���Ȃ����낤�B
�uIA��CPU�ƃ}�U�[�H�t���Ŕ����Ă��ă��b�N�ɓ���Čq���X�p�R���ɂȂ�v
�Ǝv���Ă���Ȃ�A�����v���Ă�z�������ɒ�Ă�������B
�Ⴂ�l�������Ɗ撣���āA�����Ƃ������̂�����Ă��ꂽ��A���ꂪ��ԗL��B
�����ɋ����o���K�v�������Ԃ̗��R�́A��������B
Intel��AMD�ɂ�����˂����߂�z�͓��{�ɂ�(���E�ɂ�)���Ȃ����낤�B
�uIA��CPU�ƃ}�U�[�H�t���Ŕ����Ă��ă��b�N�ɓ���Čq���X�p�R���ɂȂ�v
�Ǝv���Ă���Ȃ�A�����v���Ă�z�������ɒ�Ă�������B
�Ⴂ�l�������Ɗ撣���āA�����Ƃ������̂�����Ă��ꂽ��A���ꂪ��ԗL��B
�����ɋ����o���K�v�������Ԃ̗��R�́A��������B
>>631
�������̕��@�����
2�ƌ��킸�A128���炢�h�[���Ɓc�c
���������������ƌ�����
���܂������Ƃ͌���Ŋ撣���Ă�z��ɔC���悤�����Ď��ł�
����͉���̌�����撣�낤��
���̕�����Ώ�肭����
�������̕��@�����
2�ƌ��킸�A128���炢�h�[���Ɓc�c
���������������ƌ�����
���܂������Ƃ͌���Ŋ撣���Ă�z��ɔC���悤�����Ď��ł�
����͉���̌�����撣�낤��
���̕�����Ώ�肭����
������Ȃ��H
�����āA�A�����āA�X�p�R���Ƃ����������̐�����Ђ����������Ă�b�B
�o�b�N�v���[����HW�ASW�̐v�����͊e�Ђ���Z�p�҂��o�����āA
�ʉ�ЂŊJ�����Ă����ǁE�E�E�E�{���J�X�������B
�ǂ������Ȃ�A�g�p�Ҏ哱�ł������Ǝv���ȁB
Intel/AMD�̔ėp�X�J��CPU���g�p�A�@�o�b�N�v���[����HW/SW�ɒ��́B
���̕����A����̃l�b�g���[�N�u���̂��b���ɏ���Ǝv���B
�����āA�A�����āA�X�p�R���Ƃ����������̐�����Ђ����������Ă�b�B
�o�b�N�v���[����HW�ASW�̐v�����͊e�Ђ���Z�p�҂��o�����āA
�ʉ�ЂŊJ�����Ă����ǁE�E�E�E�{���J�X�������B
�ǂ������Ȃ�A�g�p�Ҏ哱�ł������Ǝv���ȁB
Intel/AMD�̔ėp�X�J��CPU���g�p�A�@�o�b�N�v���[����HW/SW�ɒ��́B
���̕����A����̃l�b�g���[�N�u���̂��b���ɏ���Ǝv���B
30�{�����ă��C�e���V1/10��Infiniband�������Ă��Ƃł��ˁB
>>632
��CPU�ɂ͉��Z�Ɠ����̂��߂�HPC�����̃J�X�^�����K�v�����炾��B
������Ƃ��ڂ���������āB
�[������Ή����������i�h�ɂȂ邩������Ȃ�����B
NEC�̃C���^�[�R�l�N�g�Ƃ��������p���Č�̓R���f�B�e�B���Ė�ɂ͂�����̂��H
������Ƃ��A�����Ƃ��������������C��������B
��CPU�ɂ͉��Z�Ɠ����̂��߂�HPC�����̃J�X�^�����K�v�����炾��B
������Ƃ��ڂ���������āB
�[������Ή����������i�h�ɂȂ邩������Ȃ�����B
NEC�̃C���^�[�R�l�N�g�Ƃ��������p���Č�̓R���f�B�e�B���Ė�ɂ͂�����̂��H
������Ƃ��A�����Ƃ��������������C��������B
>>637
�C���^�[�R�l�N�g���āA��������SCPU�ŋ��L���Ă��Ȃ��̂�
CPU�ԂŒʐM������d�g�݂ŁA10Gbps���̑��x�̂�B
MPI�Ȃǂ̃\�t�g�E�F�A�́A���ꂪ����O�낤�B
�SCPU�Ń����������L�����́A�R���f�B�e�B�Ƃ����킯�ł͂Ȃ��B
ATI Stream��CUDA���ƁA�u���b�N���Ń��������L�Ȃ̂�
�����炩�R���f�B�e�B��������̂��ȁH
�C���^�[�R�l�N�g���āA��������SCPU�ŋ��L���Ă��Ȃ��̂�
CPU�ԂŒʐM������d�g�݂ŁA10Gbps���̑��x�̂�B
MPI�Ȃǂ̃\�t�g�E�F�A�́A���ꂪ����O�낤�B
�SCPU�Ń����������L�����́A�R���f�B�e�B�Ƃ����킯�ł͂Ȃ��B
ATI Stream��CUDA���ƁA�u���b�N���Ń��������L�Ȃ̂�
�����炩�R���f�B�e�B��������̂��ȁH
�x�N�g���^���Ă���ȏ�i�W���肦�Ȃ��́H
���{�g�͂��ׂĒE�p���Ă��邯�ǁc
�p�������]�����V���A���]���݂����Ȉꔭ�t�]�I�݂����ȋZ�p�Ȃ��H
���{�g�͂��ׂĒE�p���Ă��邯�ǁc
�p�������]�����V���A���]���݂����Ȉꔭ�t�]�I�݂����ȋZ�p�Ȃ��H
�X�J���[�^�łȂ���A�x�N�g���^�Ƃ����킯�łȂ�
���Ԃɂ��낢��Ȍ`�Ԃ�����Ǝv���̂����B
http://en.wikipedia.org/wiki/Flynn%27s_taxonomy
���܂́AFlynn�̕��ނ��ʗp����ȁH
���Ԃɂ��낢��Ȍ`�Ԃ�����Ǝv���̂����B
http://en.wikipedia.org/wiki/Flynn%27s_taxonomy
���܂́AFlynn�̕��ނ��ʗp����ȁH
�P��̒��X�p�R�������A�����̃X�p�R���̂ق����֗����Ǝv�����ǁB
���[�J�[������Ȃ�ɏ����ɂȂ�Ȃ�A�ڑ��䐔�������₹���ł�
���X�p�R���ɂȂ�x�[�X�}�V��������̂ł́B
���[�J�[������Ȃ�ɏ����ɂȂ�Ȃ�A�ڑ��䐔�������₹���ł�
���X�p�R���ɂȂ�x�[�X�}�V��������̂ł́B
SX����
>>639
Larrabee�̓X�J���{�{���x8Way�x�N�g���Ȃ�ŁASX�Ȃ݂ɂ̓x�N�g���@����Ă邯�ǂȁB
���[�ʖڂȃp�^�[��������������B
����łȂ��Ƃ�SSE�ȍ~��x86�͊��Ɛ^�ʖڂɃx�N�g�����i��ł�Ǝv�����B
Larrabee�̓X�J���{�{���x8Way�x�N�g���Ȃ�ŁASX�Ȃ݂ɂ̓x�N�g���@����Ă邯�ǂȁB
���[�ʖڂȃp�^�[��������������B
����łȂ��Ƃ�SSE�ȍ~��x86�͊��Ɛ^�ʖڂɃx�N�g�����i��ł�Ǝv�����B
>>634
�t�ɉ��͂��̖��ɋ������Ȃ��B
�f�l���l�����፬���ɂ��ċc�_���Ă錻�̂��ʔ�������B
���l���猩��Αf�l�ɂ����Ⴒ���ጾ���Ă��܂�������Ȃ����낤���B
�t�ɉ��͂��̖��ɋ������Ȃ��B
�f�l���l�����፬���ɂ��ċc�_���Ă錻�̂��ʔ�������B
���l���猩��Αf�l�ɂ����Ⴒ���ጾ���Ă��܂�������Ȃ����낤���B
�ŋ��ł����Ă��Ƃ͑f�l�ɂ����Ⴒ���ጾ����̂��ÎȂ���Ȃ����Ă��Ƃ�����
�^�ꂳ��͂킩���ĂȂ���ȁB
�^�ꂳ��͂킩���ĂȂ���ȁB
>>638
���[��ƁAQPI�g�������m�[�h��NEC�̃C���^�[�R�l�N�g����ʖڂȂ́H���ĈӖ��Ō��������B
SPARC�ł�����256�R�A���Ƀm�[�h�ɕ������H
���[��ƁAQPI�g�������m�[�h��NEC�̃C���^�[�R�l�N�g����ʖڂȂ́H���ĈӖ��Ō��������B
SPARC�ł�����256�R�A���Ƀm�[�h�ɕ������H
256�R�A�H
>>639
�p�������]���͗��_�̕ǂɂԂ��������ăV���A���]���Ɉڂ��
���x�͕����I�ȕǂɂԂ��������ăp�������ɋt�߂肷��̂�
�J��Ԃ��Ă���ǂ�
�����Ă���ȕ֗��ȋZ�p����Ȃ���
�p�������]���͗��_�̕ǂɂԂ��������ăV���A���]���Ɉڂ��
���x�͕����I�ȕǂɂԂ��������ăp�������ɋt�߂肷��̂�
�J��Ԃ��Ă���ǂ�
�����Ă���ȕ֗��ȋZ�p����Ȃ���
649 �F,,�E�L�́M�E,,�j��-�������F2009/12/07(��) 23:40:20 ID:3pFyeiTC
�����ċ����p������
���̃X������Ȃ��d������GB��܊֘A�̃X�������A
SPARC�Ɣ�ׂ�̂�Nehe EX�������o���Ă����Ȃ���
�Öق̂�����Xeon 5xxx���݂̃R�X�g��O��Ɍ��������B
EX��Xeon 7xxx���݂̃R�X�g���낤�̂�
SPARC�Ɣ�ׂ�̂�Nehe EX�������o���Ă����Ȃ���
�Öق̂�����Xeon 5xxx���݂̃R�X�g��O��Ɍ��������B
EX��Xeon 7xxx���݂̃R�X�g���낤�̂�
651 �F,,�E�L�́M�E,,�j��-�������F2009/12/08(��) 00:46:40 ID:lpxlFx1c
SPARC����TOP500�ɂǂ������Ă�̂�H
�̗p��������Xeon MP���DP�̂ق������������
�̗p��������Xeon MP���DP�̂ق������������
MP���āA�}���`�v���Z�b�T���f���̂��߂̃L���b�V���R�q�[�����V�@�\�Ƃ��������Ă���Ď�����
DP�ł������Ă��邩������Ȃ����A�L���b�V���R�q�[�����V�m�ۂ̂��߂�CPU�Ԃ̒ʐM�������Ȃ�����
�����̃������R���g���[���Ƀf�[�^����ƃp�t�H�[�}���X������̂ŏo���邾���g��Ȃ������ɂ�����ˁH
DP�ł������Ă��邩������Ȃ����A�L���b�V���R�q�[�����V�m�ۂ̂��߂�CPU�Ԃ̒ʐM�������Ȃ�����
�����̃������R���g���[���Ƀf�[�^����ƃp�t�H�[�}���X������̂ŏo���邾���g��Ȃ������ɂ�����ˁH
Intel�ALarrabee�O���t�B�b�N�X�`�b�v�̌v���j��
http://www.itmedia.co.jp/news/articles/0912/07/news041.html
��Intel���A�uLarrabee�v�v����ՂƂ������x�ȃO���t�B�b�N�X�`�b�v��
�����グ��v���j�������B�v���W�F�N�g�̒x��ɂ��A�����͂�
�����邽�߂Ƃ����B���Ђ̍L��S���҂�12��6���ɖ��炩�ɂ����B
���̌���́A���݃O���t�B�b�N�X�s��ŗD����NVIDIA��AMD��
�R����Intel�̌v�����ނ�������̂��B
Intel���v��̔j�������߂��̂́ALarrabee�̃V���R���`�b�v��
�\�t�g�̊J�����A�����_�Ŋ��҂��Ă����i�K�ɒB���Ă��Ȃ�����
���ƍL��S���̃j�b�N�E�N�k�t�@�[���͌��B
http://www.itmedia.co.jp/news/articles/0912/07/news041.html
��Intel���A�uLarrabee�v�v����ՂƂ������x�ȃO���t�B�b�N�X�`�b�v��
�����グ��v���j�������B�v���W�F�N�g�̒x��ɂ��A�����͂�
�����邽�߂Ƃ����B���Ђ̍L��S���҂�12��6���ɖ��炩�ɂ����B
���̌���́A���݃O���t�B�b�N�X�s��ŗD����NVIDIA��AMD��
�R����Intel�̌v�����ނ�������̂��B
Intel���v��̔j�������߂��̂́ALarrabee�̃V���R���`�b�v��
�\�t�g�̊J�����A�����_�Ŋ��҂��Ă����i�K�ɒB���Ă��Ȃ�����
���ƍL��S���̃j�b�N�E�N�k�t�@�[���͌��B
���ł��c�B
�ނ�L�����o�����Ȃ�
�{���ǂ߂Ή��邪���i�����ꐢ��摗�肷��Ƃ��������ĂȂ�
����Ɠ������e
�{���ǂ߂Ή��邪���i�����ꐢ��摗�肷��Ƃ��������ĂȂ�
����Ɠ������e
�A���y�Z����̍H��ł����B
�����܂Ő^����`���邽�߂���Ȃ����d���ł�����
�v�悻�̂��̂����ŁH
�c�q���S����������������������������������������
�c�q���S����������������������������������������
�܂�قȂ�A�[�L�e�N�`���̃��j�[�R�A���J�����Đ��N��ɍĒ��킷��Ƃ������Ƃ���
��ʂɂ͔���Ȃ����AGPU�Ƃ��Ă͋����ɏ��ĂȂ��B
���Ă��ƂŁAweb�p�Ƃ��ɓ����������Ⴆ�B
���O���ς��悤!
48�R�A�̑�ꐢ��i���́@Larrabee 3�j
�u�V���O���`�b�v�N���E�h�R���s���[�^�v�@
�������肵�ĂˁB
���Ă��ƂŁAweb�p�Ƃ��ɓ����������Ⴆ�B
���O���ς��悤!
48�R�A�̑�ꐢ��i���́@Larrabee 3�j
�u�V���O���`�b�v�N���E�h�R���s���[�^�v�@
�������肵�ĂˁB
661 �F,,�E�L�́M�E,,�j��-�������F2009/12/08(��) 20:51:09 ID:lpxlFx1c
�悤���܂���
ISSCC�҂��ł�
��ł�Larrabee��GPU�i�P�̃J�[�h�`���j��
�o�����Ƃ���Ŕ����B�~�߂Đ����B
�o�����Ƃ���Ŕ����B�~�߂Đ����B
Intel�l�́uPCIExpress���{�g���l�b�N���I�v�ƋC�Â�����V�K�i����邾���Ȃ̂�
�P�̃J�[�h�ł��Ȃ�̖����Ȃ��B
�P�̃J�[�h�ł��Ȃ�̖����Ȃ��B
�}�b�L�[�m��Itanic���������
666 �F,,�E�L�́M�E,,�j��-�������F2009/12/08(��) 23:23:05 ID:lpxlFx1c
667 �F,,�E�L�́M�E,,�j��-�������F2009/12/08(��) 23:36:08 ID:lpxlFx1c
��ł����āACPU�ƃA�N�Z�����[�^�����̋@�\���������v���Z�b�T���W���[����QPI�̂悤�Ȃ��̂�
�ڑ����邱�ƂŐ��\�X�P�[���A���ȁB
�ڑ����邱�ƂŐ��\�X�P�[���A���ȁB
�������E�H�[���ɂ͂ǂ�����đΏ�����́H
>>665
�}�L�m�̓A�z���ȁ`
Itanium��2��ڂ̃}�b�L�����������ƃq�b�g������
���̌㉺�ɂȂ����̂�Intel���u����ς�x86����ˁv����Xeon�ɐ�ւ�������
�}�L�m�̓A�z���ȁ`
Itanium��2��ڂ̃}�b�L�����������ƃq�b�g������
���̌㉺�ɂȂ����̂�Intel���u����ς�x86����ˁv����Xeon�ɐ�ւ�������
Intel/HP�ɂƂ��ẮAItanium�͈ꉞ�͐����Ȃ�ˁH
���iTukwila�j���o��̂́AFY2010-1Q�i2009�N11���`2010�N2���j�@
DDR3���T�|�[�g����炵���B�@�@
HP/NEC��Superdome�́A2000��/�N���炢���ȁH
Intel�F
�@�t�H���g�g�������gCPU��know-how�̊l��
�@HP��CPU�A�[�L�e�N�g�̊l��
�@�iDEC Alpha MIPS��HP�Ɏc���Ă����̂��j
�@�Â������H���L�����p�ł���iShrink-65nm���������Ɓj
HP�F
�@�����̐����iCPU�����j�ACPU�v����P�ނł���
�@�e��\�t�g�E�F�A��HP PA-RISC�����|�[�e�B���O�R�X�g���J�b�g�ł���
���iTukwila�j���o��̂́AFY2010-1Q�i2009�N11���`2010�N2���j�@
DDR3���T�|�[�g����炵���B�@�@
HP/NEC��Superdome�́A2000��/�N���炢���ȁH
Intel�F
�@�t�H���g�g�������gCPU��know-how�̊l��
�@HP��CPU�A�[�L�e�N�g�̊l��
�@�iDEC Alpha MIPS��HP�Ɏc���Ă����̂��j
�@�Â������H���L�����p�ł���iShrink-65nm���������Ɓj
HP�F
�@�����̐����iCPU�����j�ACPU�v����P�ނł���
�@�e��\�t�g�E�F�A��HP PA-RISC�����|�[�e�B���O�R�X�g���J�b�g�ł���
VLIW�Ƃ����낢���������ǐ��\�o�Ȃ���������A�������낤
Itanium���Ă܂��J�������Ă�́H
>>135 >>386 >>553
�j���[�X�L����URL�\��͕̂ʂɂ�������
�^�C�g���Ɂu�N���E�h�v���Ă��������l�Ȍ��t���܂܂�Ă���ƁA
���������N����ŁA�L����ǂ�ŁA���ʂȎ��Ԃ�Q���
�\���������Ȃ�̂Łi�������炷�����PV�҂����[�h���j�A
����ƂȂ鏤�i�E�T�[�r�X�����Ȃ̂��킩��悤�Ȉ��p��������Ȃ�A
�^�C�g���C�����{���ĂȂ肭��B�@���C����
�ăx���`���[2�ЁA10GbE 4�y�A�̃Q�X�g�ԃ����N�œ`�����x18.5Gbps��B��
http://enterprise.watch.impress.co.jp/docs/news/20091208_334056.html
�j���[�X�L����URL�\��͕̂ʂɂ�������
�^�C�g���Ɂu�N���E�h�v���Ă��������l�Ȍ��t���܂܂�Ă���ƁA
���������N����ŁA�L����ǂ�ŁA���ʂȎ��Ԃ�Q���
�\���������Ȃ�̂Łi�������炷�����PV�҂����[�h���j�A
����ƂȂ鏤�i�E�T�[�r�X�����Ȃ̂��킩��悤�Ȉ��p��������Ȃ�A
�^�C�g���C�����{���ĂȂ肭��B�@���C����
�ăx���`���[2�ЁA10GbE 4�y�A�̃Q�X�g�ԃ����N�œ`�����x18.5Gbps��B��
http://enterprise.watch.impress.co.jp/docs/news/20091208_334056.html
IEDM��ꂩ�綷�
���傤��intel�̔��\�n�܂���
�����ԑO����킩���Ă������Ƃł͂��邪32nm�̃I���d���͂�ς˂�
�������\�X���C�h�e���v���ǂ������ĂȂ��Ƃ���ɂ�����Ƃ���
���傤��intel�̔��\�n�܂���
�����ԑO����킩���Ă������Ƃł͂��邪32nm�̃I���d���͂�ς˂�
�������\�X���C�h�e���v���ǂ������ĂȂ��Ƃ���ɂ�����Ƃ���
�d�蒼���ƂȂ���Larrabee�̉�����肾�����̂�
http://pc.watch.impress.co.jp/docs/column/kaigai/20091209_334552.html
Intel��Larrabee�v��ƃA�[�L�e�N�`�����ǂ��ς���̂�
http://pc.watch.impress.co.jp/docs/column/kaigai/20091210_334671.html
http://pc.watch.impress.co.jp/docs/column/kaigai/20091209_334552.html
Intel��Larrabee�v��ƃA�[�L�e�N�`�����ǂ��ς���̂�
http://pc.watch.impress.co.jp/docs/column/kaigai/20091210_334671.html
IEDM��ꂩ��̃��X���ď�����ˁH
>>672
���[�h�}�b�v�Ŗ��O�͏o�Ă�BTukwila�APoulson�AKittson�B
Poulso�ȍ~�̊J�����Ԃ͕s���B�����������瑶�݂��Ă�͖̂��O�������������B
>>669-670
�r�W�l�X�Ƃ��Ď��s���Ǝv�����ǁA�g�������Ƃ����q�͈�萔�����ˁB
���̎����㔄���V�X�e�� arrowhead �𗈔N��1��4������{�ԉғ�
http://www.nminoru.jp/~nminoru/diary/2009/12.html
���[�h�}�b�v�Ŗ��O�͏o�Ă�BTukwila�APoulson�AKittson�B
Poulso�ȍ~�̊J�����Ԃ͕s���B�����������瑶�݂��Ă�͖̂��O�������������B
>>669-670
�r�W�l�X�Ƃ��Ď��s���Ǝv�����ǁA�g�������Ƃ����q�͈�萔�����ˁB
���̎����㔄���V�X�e�� arrowhead �𗈔N��1��4������{�ԉғ�
http://www.nminoru.jp/~nminoru/diary/2009/12.html
�Ƃ肠����2�����Ă���
abstract�قڂȂ����Ă��������������炠��܂�ʔ����͂Ȃ�����
32nm�Ɍ����đ�4����SiGe S/D�ɂ�鈳�k�c�݂Ƒ�2�����HK/MG���̗p���Ă���Ƃ��̂�
��҂̐����������������A���Ԃ��������c�݂̉��ǂ̂��߂̐V���ゾ�Ǝv��
�ړ��x�̂��������n��p�����܂łƔ�ׂđ傫������
��������炸�|��Si��ɂ߂Ƃ��Č�łق������ă��^���l�ߍ���ł�͗l
�Ƃ肠�������݂̕����܂肪CPU��SoC���������炢�Ƃ̂��ƁB
�O���t����ǂނƌ��i�K��90nm����̐��n���Ɠ������炢�̕����܂�ɂȂ��Ă����ǂ��Ȃ낤
���ƍŌ�Ƀf���A���R�A��Westmere�̃`�b�v�ʐ^���o�Ă����ǂ���͊��o���ȁH�悤�킩���
abstract�قڂȂ����Ă��������������炠��܂�ʔ����͂Ȃ�����
32nm�Ɍ����đ�4����SiGe S/D�ɂ�鈳�k�c�݂Ƒ�2�����HK/MG���̗p���Ă���Ƃ��̂�
��҂̐����������������A���Ԃ��������c�݂̉��ǂ̂��߂̐V���ゾ�Ǝv��
�ړ��x�̂��������n��p�����܂łƔ�ׂđ傫������
��������炸�|��Si��ɂ߂Ƃ��Č�łق������ă��^���l�ߍ���ł�͗l
�Ƃ肠�������݂̕����܂肪CPU��SoC���������炢�Ƃ̂��ƁB
�O���t����ǂނƌ��i�K��90nm����̐��n���Ɠ������炢�̕����܂�ɂȂ��Ă����ǂ��Ȃ낤
���ƍŌ�Ƀf���A���R�A��Westmere�̃`�b�v�ʐ^���o�Ă����ǂ���͊��o���ȁH�悤�킩���
��������Tukwila���Ă܂��o�ĂȂ�������
�M�����Ƃ���
�M�����Ƃ���
>>679
��
TSMC��Intel�Ɠ�����Gate-last�����ǂ������̕��������ȁ[
�M��������Ɛ��\�������邩��Gate-last���Ęb���ȑOIntel�����Ă���
����Ƃ��t��IBM�͔M�������Ă����v�ȕ��@������������Gate-first�Ȃ̂��H
��
TSMC��Intel�Ɠ�����Gate-last�����ǂ������̕��������ȁ[
�M��������Ɛ��\�������邩��Gate-last���Ęb���ȑOIntel�����Ă���
����Ƃ��t��IBM�͔M�������Ă����v�ȕ��@������������Gate-first�Ȃ̂��H
Itanium�͂��߂ē����̌v��+1�N���炢�̃f�B���C�Ń��[�h�}�b�v��
���s���Ă���APOWER�Ƒ��F�Ȃ��킢���o�����Ǝv�����AMontecito
�ȍ~�̒x������������B
���s���Ă���APOWER�Ƒ��F�Ȃ��킢���o�����Ǝv�����AMontecito
�ȍ~�̒x������������B
>>681
�Ƃ������E�ʂɉe�����邩��Gate-last�Ƃ����ʌ�����Ǝv���Ă��������ł��Ȃ��̂�
�V���R���͐�傶��Ȃ�����ǂ��Ȃ̂��悭�m���
Gate-last�Ȃ̂ɂ������ꂢ�ɂł��Ă�̂��s�v�c
�Ƃ������E�ʂɉe�����邩��Gate-last�Ƃ����ʌ�����Ǝv���Ă��������ł��Ȃ��̂�
�V���R���͐�傶��Ȃ�����ǂ��Ȃ̂��悭�m���
Gate-last�Ȃ̂ɂ������ꂢ�ɂł��Ă�̂��s�v�c
�Ō�ɂ����ЂƂ�
���͕��������Ă����ǁA�ŐV��S/D��SiGe��Ge�Z�x��40%�܂ő����Ă�炵��
�O��30%�ł��݂�Ȃтт��Ă��̂�40%���āE�E�E
���͕��������Ă����ǁA�ŐV��S/D��SiGe��Ge�Z�x��40%�܂ő����Ă�炵��
�O��30%�ł��݂�Ȃтт��Ă��̂�40%���āE�E�E
32nm�������߂��ă����X��
>>684
�G�s�o����Ȃ���Ȃɑ��₵�Ă��B
�G�s�o����Ȃ���Ȃɑ��₵�Ă��B
>>682
Intel�ɂ��C���Ȃ��҂��
Intel�ɂ��C���Ȃ��҂��
Itanium�͒N������Ă�����
690 �F,,�E�L�́M�E,,�j��-�������F2009/12/11(��) 02:42:51 ID:QYYq4m1S
http://journal.mycom.co.jp/articles/2009/12/10/sc09_algore/
���X�����Lj��������SC09�L��
���X�����Lj��������SC09�L��
�����D�q�H
>>692
�Ӗ��s��
HP�͔����̍H��̓����ɑς����Ȃ������B
����Itanium�ł́AHP����Intel�Ɉڂ����Z�p�ґ���
����Itanium�v���ɂ́A������HP��CPU�v�Ґw��
�܂�܂�Intel�ɏo��
�ŁA���݂�Itanium������B
�Ӗ��s��
HP�͔����̍H��̓����ɑς����Ȃ������B
����Itanium�ł́AHP����Intel�Ɉڂ����Z�p�ґ���
����Itanium�v���ɂ́A������HP��CPU�v�Ґw��
�܂�܂�Intel�ɏo��
�ŁA���݂�Itanium������B
PA-RISC��Alpha�𑫎�܂Ƃ��������Đ�̂Ă��̂��S�Ă̊ԈႢ�̂���
Intel�̓`�b�v��������Ă��������������ڂ������Ȃ�������C������
HP�͂��C������Intel�̍�����`�b�v�Ŕ�����Ē�Ă���
�s�K�Ȍ����Ƃ��������l������
Intel�̓`�b�v��������Ă��������������ڂ������Ȃ�������C������
HP�͂��C������Intel�̍�����`�b�v�Ŕ�����Ē�Ă���
�s�K�Ȍ����Ƃ��������l������
64bit���K�v�ȕ��삩��ǂ�ǂ�IA-64�ɐ�ւ���āA�ŏI�I�ɃN���C�A���g��IA-64�Œu�����������
��Z�p��������Ȃ��́H
���������A���f�B�J����Tukwila�v������R��ꂽintel���̌��A���t�@�g����
�������Ă���낤�B
��Z�p��������Ȃ��́H
���������A���f�B�J����Tukwila�v������R��ꂽintel���̌��A���t�@�g����
�������Ă���낤�B
�N���b�N��ILP���オ�葱����Ɩ��C�ɍl�����Ă�������̈╨�Ȃ�Ȃ����ȁB
���̃R�A�̑傫���͓��ɁB
����out of order�����B
���̃R�A�̑傫���͓��ɁB
����out of order�����B
Itanium�́A����ς茳Takuwila�Ői�߂Ƃ����ق����ǂ������B
>>695
Bannon�����PA Semi�ŊJ�����Ă����ǁAApple�ɔ����čs��
��������݂����Ȃ悤�ȁB
>>695
out of order�́A695�̌����R��ꂽ�Ƃ�����
>>695
Bannon�����PA Semi�ŊJ�����Ă����ǁAApple�ɔ����čs��
��������݂����Ȃ悤�ȁB
>>695
out of order�́A695�̌����R��ꂽ�Ƃ�����
Tukwila����Ȃ���Takuwila�Ȃ̂�
Tanglewood�ƍ���������ł��˂킩��܂�
Tanglewood�ƍ���������ł��˂킩��܂�
�����Ԉ����....
���X�ATanglewood��2006�N�ɏo���\�肾������ˁB
tangle�u�����A��������v�Ƃ������P��͌��Ȋ���������
�R�[�h�l�[���ς����̂��낤���H
����tangle�Ȃ܂�...
���X�ATanglewood��2006�N�ɏo���\�肾������ˁB
tangle�u�����A��������v�Ƃ������P��͌��Ȋ���������
�R�[�h�l�[���ς����̂��낤���H
����tangle�Ȃ܂�...
>>695
���Ԃ�A����̓K�Z�l�^�ł́H
�Ƃ������A��̃N���E�h�pCPU�Ƃ��ʂ̃v���W�F�N�g�̏��Ƃ�������ɂȂ��ďo�������ł́H
Alpha�`�[���̃f�U�C�����̗p���Ă��Ƃ̓R���p�C���̍œK�����ꂩ������Ă��ƁB
HP�͂���Ȃ��̂ɂ͋��i�J����p�j�͏o���Ȃ����낤���A
3P�AVAR�͗���Ă��܂��\��������
FT�̗̈�ł��A���������|�����M�������A�y�䂩��쐬�������Ȃ����Ȃ��B
���Ԃ�A����̓K�Z�l�^�ł́H
�Ƃ������A��̃N���E�h�pCPU�Ƃ��ʂ̃v���W�F�N�g�̏��Ƃ�������ɂȂ��ďo�������ł́H
Alpha�`�[���̃f�U�C�����̗p���Ă��Ƃ̓R���p�C���̍œK�����ꂩ������Ă��ƁB
HP�͂���Ȃ��̂ɂ͋��i�J����p�j�͏o���Ȃ����낤���A
3P�AVAR�͗���Ă��܂��\��������
FT�̗̈�ł��A���������|�����M�������A�y�䂩��쐬�������Ȃ����Ȃ��B
���Ⴂ�͂��ĂȂ���B
��Tukwila���Ă̂������āA��Alpha�`�[�����v�V�I�ȃf�U�C��
���v���|�[�Y�����B�@
�@���Ă��Ƃ��K�Z�Ƃ������A���̃v���W�F�N�g�ƍ��������`��
�O�ɂɏ��Ƃ��ďo�Ă�����Ȃ��́H�@���Ă���
��Tukwila���Ă̂������āA��Alpha�`�[�����v�V�I�ȃf�U�C��
���v���|�[�Y�����B�@
�@���Ă��Ƃ��K�Z�Ƃ������A���̃v���W�F�N�g�ƍ��������`��
�O�ɂɏ��Ƃ��ďo�Ă�����Ȃ��́H�@���Ă���
�Ȃ�قǁA�킴�킴�]���̍œK���Ӗ��ɂ���悤�Ȓ�Ă��A���t�@�`�[����������Ă��Ǝ��̂��A
������������A�����˂�����Ȃ������Ă��Ƃ��B
����OOO�̗p��������Itanium�̐��\���L�т���Ę_����intel���o���Ă��邵�A
intel���͏��C���������ǁAhp��������Ȃ����Ă��Ƃł��j�Z�ɂȂ������ĉ\�����\�������Ȃ����ȁB
������������A�����˂�����Ȃ������Ă��Ƃ��B
����OOO�̗p��������Itanium�̐��\���L�т���Ę_����intel���o���Ă��邵�A
intel���͏��C���������ǁAhp��������Ȃ����Ă��Ƃł��j�Z�ɂȂ������ĉ\�����\�������Ȃ����ȁB
>>695
ISSCC��SCC�̘_���̓C���e��@�n�h�\������o�Ă�
���̓e���X�P�[���R���s���[�e�B���O�̕���Ŏd�����Ă���
Alpha�̂Ƃ���͐�s�I���ăC���[�W�ō��v���Ă邵��
ISSCC��SCC�̘_���̓C���e��@�n�h�\������o�Ă�
���̓e���X�P�[���R���s���[�e�B���O�̕���Ŏd�����Ă���
Alpha�̂Ƃ���͐�s�I���ăC���[�W�ō��v���Ă邵��
Larrabee/VCG�͓x�d�Ȃ��Ɣ����Ɛl�ވ��������ŁA�S�ē����ɕ����Ă��܂����B
�����Џo���Ȃ��肭�������H�������ϖ������B���~�̌��f�����ɂ����Ȃ镛��p�����邵�B
http://www.itmedia.co.jp/enterprise/articles/0412/17/news013.html
��Hewlett-Packard�́AItanium 2�v���Z�b�T���ڃT�[�o�uHP Integrity�v
�̋�����ڎw���A������3�N�Ԃ�30���h���𓊎�����v��\�����B
http://japan.cnet.com/news/ent/story/0,2000056022,20099350,00.htm
�V�v���W�F�N�g�ł́A2010�N�܂ł�Itanium�Z�p�Ǝs��̔��W�̂��߂�
100���h������������\��ł���B���̂���������HP���狒�o�����B
http://itpro.nikkeibp.co.jp/free/ITPro/USNEWS/20010312/4/
�\�j�[�E�R���s���[�^ �G���^�e�C�������g�iSCEI)�ƕ�IBM�C���ł�������
�}�C�N���v���Z�T�E�A�[�L�e�N�`���̌����J�����s���J���Z���^�[���J�݂���B
Cell�v���Z�T��v���邽�߂ɁC3�Ђ͍���5�N�Ԃ�4���h���𓊂���B
http://game.watch.impress.co.jp/docs/20040202/sce.htm
���ł́A�V���ɑ��ă\�j�[�O���[�v�Ɠ��z�̖�310���~�𓊎�����\��B
�����Џo���Ȃ��肭�������H�������ϖ������B���~�̌��f�����ɂ����Ȃ镛��p�����邵�B
http://www.itmedia.co.jp/enterprise/articles/0412/17/news013.html
��Hewlett-Packard�́AItanium 2�v���Z�b�T���ڃT�[�o�uHP Integrity�v
�̋�����ڎw���A������3�N�Ԃ�30���h���𓊎�����v��\�����B
http://japan.cnet.com/news/ent/story/0,2000056022,20099350,00.htm
�V�v���W�F�N�g�ł́A2010�N�܂ł�Itanium�Z�p�Ǝs��̔��W�̂��߂�
100���h������������\��ł���B���̂���������HP���狒�o�����B
http://itpro.nikkeibp.co.jp/free/ITPro/USNEWS/20010312/4/
�\�j�[�E�R���s���[�^ �G���^�e�C�������g�iSCEI)�ƕ�IBM�C���ł�������
�}�C�N���v���Z�T�E�A�[�L�e�N�`���̌����J�����s���J���Z���^�[���J�݂���B
Cell�v���Z�T��v���邽�߂ɁC3�Ђ͍���5�N�Ԃ�4���h���𓊂���B
http://game.watch.impress.co.jp/docs/20040202/sce.htm
���ł́A�V���ɑ��ă\�j�[�O���[�v�Ɠ��z�̖�310���~�𓊎�����\��B
706 �F,,�E�L�́M�E,,�j��-�������F2009/12/11(��) 23:48:21 ID:QYYq4m1S
�܂��������܂���GMA�p�̃p�t�H�[�}���X�A�i���C�U�������J�Ƃ����l���Ă��
�\�t�g�ł�����撣���Ă���ΓI�ȗ��_���\�͂�����킯����Ȃ���
�\�t�g�ł�����撣���Ă���ΓI�ȗ��_���\�͂�����킯����Ȃ���
�Q�[���ɉ��̐��\���K�v���E�E�E
��������肽����
��������肽����
708 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 00:32:46 ID:LfwDXAhP
�A�z�݂����Ƀ\�t�g�x���`���[�����������Ă邩���
709 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 01:03:46 ID:LfwDXAhP
���������琫�\���Ⴉ�낤�Ɠw�͂��邻�̐S�����Ƃ��Ă͗ǂ��B
���̂�����������Larrabee��3�`4�R�A�ł�ς�ł���B
Celeron��HPC��鎞��̓������B
���̂�����������Larrabee��3�`4�R�A�ł�ς�ł���B
Celeron��HPC��鎞��̓������B
�� Larrabee��3�`4�R�A��
�N���������̂�
�N���������̂�
711 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 09:55:58 ID:LfwDXAhP
1.5GHz���炢�œ����Ă�����1�R�A������48GFLOPS�i�P���x�j�Ȃ�ł�������̃��[�G���hGPU��CUDA�����̓}�V����
4�R�A��PS3��Cell�ɕC�G���ȁB
45nm�ł�100mm²�Ɏ��܂�̂ł́H
�I���{�[�h�Ō���Ȃ������l�ɋ߂�200GFLOPS�ɔ��鐫�\��������Ƃ������Ȃ��GPGPU�Ƃ��Ă�
���p�̂������͂���̂��ȂƁB
�����Ƃ��A22nm��Haswell��6�`8�R�A���Ă̂������I�ȂƂ��낶��Ȃ����ƁB
4�R�A��PS3��Cell�ɕC�G���ȁB
45nm�ł�100mm²�Ɏ��܂�̂ł́H
�I���{�[�h�Ō���Ȃ������l�ɋ߂�200GFLOPS�ɔ��鐫�\��������Ƃ������Ȃ��GPGPU�Ƃ��Ă�
���p�̂������͂���̂��ȂƁB
�����Ƃ��A22nm��Haswell��6�`8�R�A���Ă̂������I�ȂƂ��낶��Ȃ����ƁB
712 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 09:58:44 ID:LfwDXAhP
���Ȃ��Ƃ�
�u���Z���j�b�g�������ׂ܂���
�S�������ɐϘa�Z�ł��邱�Ƃ͂��蓾�܂���TFLOPS�ł��v
���͍D�������ǂˉ���
�u���Z���j�b�g�������ׂ܂���
�S�������ɐϘa�Z�ł��邱�Ƃ͂��蓾�܂���TFLOPS�ł��v
���͍D�������ǂˉ���
Larrabee�̓O���t�B�b�N�ɛZ�т��Ɍv�Z��p�̃}�C�i�[�R�A�Ń����C�N���Ă��Ƃł�����
714 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 10:11:28 ID:LfwDXAhP
GMA�̃V�F�[�_���j�b�g��Westmere�����30GFLOPS���x�Ȃ��
���Ȃ��Ƃ�Larrabee���͖��炩�ɁA�����ʐς̊��ɐ��\�Ⴂ�ł�����
�Ȃ�ŁA�Œ�@�\���j�b�g���̂܂c���ăV�F�[�_����Larrabee�ɒu���������炢����Ȃ��H
���Ȃ��Ƃ�Larrabee���͖��炩�ɁA�����ʐς̊��ɐ��\�Ⴂ�ł�����
�Ȃ�ŁA�Œ�@�\���j�b�g���̂܂c���ăV�F�[�_����Larrabee�ɒu���������炢����Ȃ��H
>>713
�Z�т��Ƃ�����
�u����r�f�I�Ƃ��āh���h�g�����ˁH�v�Ƃ����b��
�ǂ�������o�Ă���
�����ɂ���Ă݂����ǃ|�V����܂������Ă����B
�v���̂̓O���t�B�b�N�ȂɈ�؛Z�тĂ܂��B
�Z�т��Ƃ�����
�u����r�f�I�Ƃ��āh���h�g�����ˁH�v�Ƃ����b��
�ǂ�������o�Ă���
�����ɂ���Ă݂����ǃ|�V����܂������Ă����B
�v���̂̓O���t�B�b�N�ȂɈ�؛Z�тĂ܂��B
>>711
�I���{���Ƃǂ�����ă������ш�m�ۂ���́H
�I���{���Ƃǂ�����ă������ш�m�ۂ���́H
�������ш��������PS3��30GB/s�������炵���Ȃ���Ȃ��������H
�����ɂ���Ă݂����ɂ́A�₽�玑�����C�������������Ă�悤�Ɋ����邪�B
���r�W�����d�˂܂����āA�}�X�N�ゾ���ł������Ȃ��낤���B
Tom Forsyth�̃o�b�N�O�����h�̓\�t�g�E�F�A�����_�����O�A��3Dlabs
http://s08.idav.ucdavis.edu/forsyth-larrabee-graphics-architecture.pdf
http://www.sgi.co.jp/company_info/press_releases/archives/20080820.html
http://pc.watch.impress.co.jp/docs/2008/0822/kaigai461.htm
Larrabee�̃O���t�B�b�N�X�T�C�h�̃A�[�L�e�N�g�ł���Larry Seiler���͌�ATI Technologies�B
�܂��A�r�W���A���R���s���[�e�B���O�ɂ��ẮuChalk Talk�v�ɂ́ANVIDIA�ŃV�F�[�f�B���O
����uCg�v�������William(Bill) R. Mark�����o�ꂵ���BMark����NVIDIA��Ƀe�L�T�X
��w�I�[�X�e�B���Z�Ɉڂ������A���݂�Intel�̃��T�[�`�Z���^�[�ɏ������Ă���Ƃ����B
�g�v���Z�b�T�p���[�ɂ��Ȃ������ς��h�̐��ɑ���̓��C�g���[�V���O
http://www.itmedia.co.jp/news/articles/0402/20/news047_2.html
Pixomatic��2005�N�̏I����Intel�ɂ���Ĕ�������܂���
http://www.radgametools.com/jp/pixomain.htm
Intel��Neoptica�ƌ�����Ђ������Ƃ����b
http://masafumi.cocolog-nifty.com/masafumis_diary/2007/11/post_ebc6.html
Intel�C�Q�[���f�x���b�p��Offset Software��
http://www.4gamer.net/games/021/G002195/20080221047/
Intel�Ђ��O���t�B�b�N�XLSI�Ŗ{���C�uLarrabee�v�͒P�̐��i�Œ�
http://techon.nikkeibp.co.jp/article/NEWS/20080318/149166/
Intel�A�r�W���A���R���s���[�e�B���O�����@�ւ��h�C�c�ɐݗ�
http://www.itmedia.co.jp/enterprise/articles/0905/13/news027.html
Intel��1200���h���𓊎����ăh�C�c�̃U�[�������g��w����Visual Computing
Institute��ݗ������BGPU�����^�}���`�R�A�v���Z�b�T�Z�p�J���̋��_�Ƃ���B
Intel���g�D�ĕҌv��\�C��v���i���Ƃ�����V�����ݗ�
http://techon.nikkeibp.co.jp/article/NEWS/20090915/175259/
http://pc.watch.impress.co.jp/img/pcw/docs/316/184/genko565.jpg
���r�W�����d�˂܂����āA�}�X�N�ゾ���ł������Ȃ��낤���B
Tom Forsyth�̃o�b�N�O�����h�̓\�t�g�E�F�A�����_�����O�A��3Dlabs
http://s08.idav.ucdavis.edu/forsyth-larrabee-graphics-architecture.pdf
http://www.sgi.co.jp/company_info/press_releases/archives/20080820.html
http://pc.watch.impress.co.jp/docs/2008/0822/kaigai461.htm
Larrabee�̃O���t�B�b�N�X�T�C�h�̃A�[�L�e�N�g�ł���Larry Seiler���͌�ATI Technologies�B
�܂��A�r�W���A���R���s���[�e�B���O�ɂ��ẮuChalk Talk�v�ɂ́ANVIDIA�ŃV�F�[�f�B���O
����uCg�v�������William(Bill) R. Mark�����o�ꂵ���BMark����NVIDIA��Ƀe�L�T�X
��w�I�[�X�e�B���Z�Ɉڂ������A���݂�Intel�̃��T�[�`�Z���^�[�ɏ������Ă���Ƃ����B
�g�v���Z�b�T�p���[�ɂ��Ȃ������ς��h�̐��ɑ���̓��C�g���[�V���O
http://www.itmedia.co.jp/news/articles/0402/20/news047_2.html
Pixomatic��2005�N�̏I����Intel�ɂ���Ĕ�������܂���
http://www.radgametools.com/jp/pixomain.htm
Intel��Neoptica�ƌ�����Ђ������Ƃ����b
http://masafumi.cocolog-nifty.com/masafumis_diary/2007/11/post_ebc6.html
Intel�C�Q�[���f�x���b�p��Offset Software��
http://www.4gamer.net/games/021/G002195/20080221047/
Intel�Ђ��O���t�B�b�N�XLSI�Ŗ{���C�uLarrabee�v�͒P�̐��i�Œ�
http://techon.nikkeibp.co.jp/article/NEWS/20080318/149166/
Intel�A�r�W���A���R���s���[�e�B���O�����@�ւ��h�C�c�ɐݗ�
http://www.itmedia.co.jp/enterprise/articles/0905/13/news027.html
Intel��1200���h���𓊎����ăh�C�c�̃U�[�������g��w����Visual Computing
Institute��ݗ������BGPU�����^�}���`�R�A�v���Z�b�T�Z�p�J���̋��_�Ƃ���B
Intel���g�D�ĕҌv��\�C��v���i���Ƃ�����V�����ݗ�
http://techon.nikkeibp.co.jp/article/NEWS/20090915/175259/
http://pc.watch.impress.co.jp/img/pcw/docs/316/184/genko565.jpg
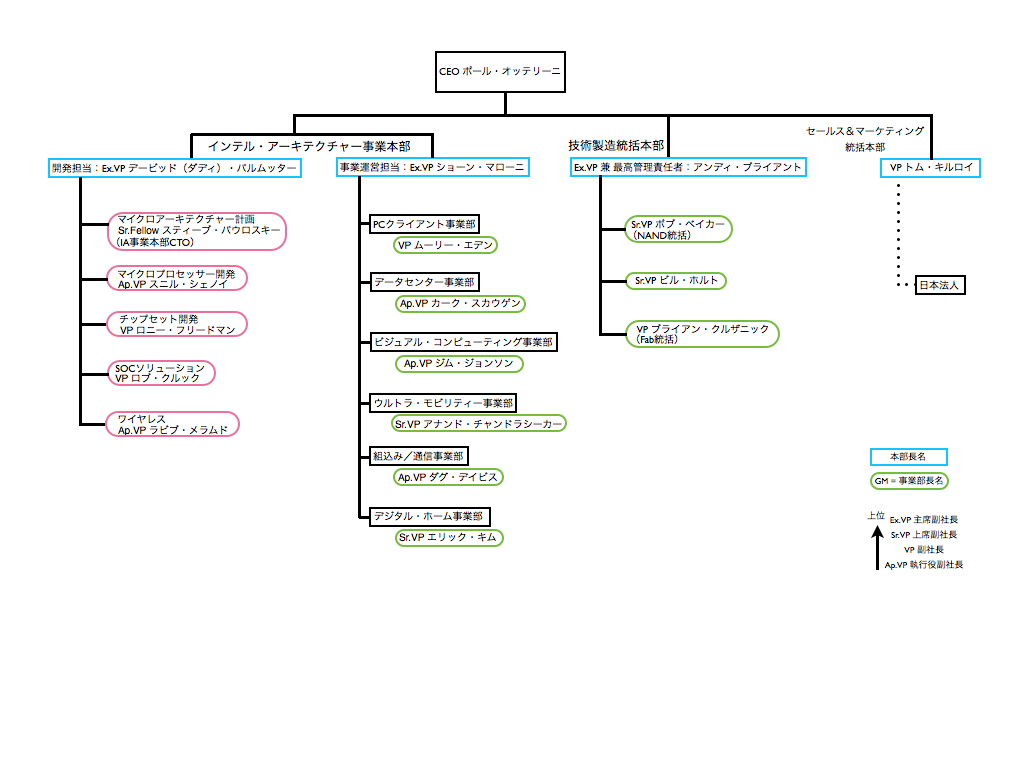{kind=link}
����p�̃{�[�h���ׂ�Ă��ɂ������䂭���Ȃ����Ď�����ˁH
720 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 11:54:20 ID:LfwDXAhP
>>716
���Ƃ���32�R�A��120GB/s���x�̑ш悪�K�v�ł��A4�R�A���x�Ȃ�15GB/s���x�ɂȂ邶���B
���ʂ�DDR3�����L���Ă�����邵�A���ۂɂ̓L���b�V���őш�Z�[�u�ł���̂�
�����ƕK�v�ш�͌��邩������Ȃ��B
���ƁANehalem����L3�̑ш�͎���140GB/s�͂����ŁAPCI Express�o�R������f�[�^������
���C�e���V�E�X���[�v�b�g�Ƃ��ɒf�R�����͂��B���Ƃ��ƃf�B�X�N���[�g���͓����`�b�v�̂ق��������Ă�B
�f�B�X�N���[�gGPU���g���l�ɂ��ALarrabee�R�A��Havok�A�N�Z�����[�V������ƂŎg���Ƃ������ق���
���p���l�͂����肻���B
���Ƃ���32�R�A��120GB/s���x�̑ш悪�K�v�ł��A4�R�A���x�Ȃ�15GB/s���x�ɂȂ邶���B
���ʂ�DDR3�����L���Ă�����邵�A���ۂɂ̓L���b�V���őш�Z�[�u�ł���̂�
�����ƕK�v�ш�͌��邩������Ȃ��B
���ƁANehalem����L3�̑ш�͎���140GB/s�͂����ŁAPCI Express�o�R������f�[�^������
���C�e���V�E�X���[�v�b�g�Ƃ��ɒf�R�����͂��B���Ƃ��ƃf�B�X�N���[�g���͓����`�b�v�̂ق��������Ă�B
�f�B�X�N���[�gGPU���g���l�ɂ��ALarrabee�R�A��Havok�A�N�Z�����[�V������ƂŎg���Ƃ������ق���
���p���l�͂����肻���B
721 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 12:14:07 ID:LfwDXAhP
����GPU�ł́A��юU�����K���X�̔j�Ђ̊G�I�ɕ\�����邱�Ƃ͂ł��邩������Ȃ���
���̔j�Ђɑ���CPU�����œ����蔻�����肽���ꍇ�APCIe�ڑ��̃f�B�X�N���[�gGPU����
CPU�ɒ���t�B�[�h�o�b�N����ۂ̃R�X�g�������肷����B
�f�B�X�N���[�g�ł����@�Ƃ���CPU�����̈ꕔ��GPU���Ɏ������Ă��ƌ����������B
���̂ւo����̂�x86�x�[�X��Larrabee�Ȃ�ł͂̎肶��ˁH
���̔j�Ђɑ���CPU�����œ����蔻�����肽���ꍇ�APCIe�ڑ��̃f�B�X�N���[�gGPU����
CPU�ɒ���t�B�[�h�o�b�N����ۂ̃R�X�g�������肷����B
�f�B�X�N���[�g�ł����@�Ƃ���CPU�����̈ꕔ��GPU���Ɏ������Ă��ƌ����������B
���̂ւo����̂�x86�x�[�X��Larrabee�Ȃ�ł͂̎肶��ˁH
10GHz��10GbE����HD�f�R�[�_�[����80�R�A���̐��i�������Ȃ��`�b�v�����삵�܂����Ă�Intel�l�ɏ펯�͒ʗp���܂���
���̂�����̎���͊T�O���؋@�Ƃ���b�����ɂ�������̂Ő��i�����Ȃ��̂��펯����ˁH
�ނ���A����i�����悤�Ƃ���Ǝ��s���邩�A���邢�͈ꂩ���蒼�������������悤�Ȃ��ƂɂȂ�悤�Ɏv�����B
�ނ���A����i�����悤�Ƃ���Ǝ��s���邩�A���邢�͈ꂩ���蒼�������������悤�Ȃ��ƂɂȂ�悤�Ɏv�����B
GPU��CPU�ɓ���������ł���Ƃ����\�z��
�����̏W�ϓx�̏㏸�̃y�[�X >>> �Q�[���̗v�����\�̏㏸�̃y�[�X
����������鎖����O��
�����̏W�ϓx�̏㏸�̃y�[�X >>> �Q�[���̗v�����\�̏㏸�̃y�[�X
����������鎖����O��
�����̃Q������ROP������������Ε`�搫�\���シ�邩���
GPU��CPU�����H�����{�i������̓����_���̃\�t�g�����i��ł���ł���
GPU��CPU�����H�����{�i������̓����_���̃\�t�g�����i��ł���ł���
726 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 15:36:32 ID:LfwDXAhP
VRAM�̏������݃l�b�N�����炱����ROP�l�b�N���Ɖ��̋C�Â���
727 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 15:43:19 ID:LfwDXAhP
>>724
�f�B�X�N���[�g�J�[�h���K�{��3D�Q�[���̎s�ꐊ�ނł�����
�f�B�X�N���[�g�J�[�h���K�{��3D�Q�[���̎s�ꐊ�ނł�����
Larrabee�̓��������s�����f�B�X�N���[�gGPU���������Q�[���܂ő������Ă�
729 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 17:37:10 ID:LfwDXAhP
�����Ȃ�Č����Ăˁ[��
�����i�Ȑ��i�̎��v���L�тȂ��Ȃ烂�W���[���̓��p�����i�ށB
�T�E���h�J�[�h��������������H
�j�[�Y�Ƃ��Ă�>>721�݂����ȗ�o���Ă邶��Ȃ���
�����i�Ȑ��i�̎��v���L�тȂ��Ȃ烂�W���[���̓��p�����i�ށB
�T�E���h�J�[�h��������������H
�j�[�Y�Ƃ��Ă�>>721�݂����ȗ�o���Ă邶��Ȃ���
Larrabee���āA���X�́ACPU�̓d�͌����A�b�v�F���E�ł��B
�}���`�R�A�F�����₵�Ă��A���\�A�b�v�����ł��i4�R�A���S�{�ł͖����j
���������_�v�Z��ʂɂ�����ǂ��H�@
����AGPU�Ɏg�����ˁH�@�@�@GPU�ɂ��g���Ă݂邩�ȁH�@
���Ă̂肾�������̂ł́H
���݂̎p�̕����^�����Ɍ�����B
�}���`�R�A�F�����₵�Ă��A���\�A�b�v�����ł��i4�R�A���S�{�ł͖����j
���������_�v�Z��ʂɂ�����ǂ��H�@
����AGPU�Ɏg�����ˁH�@�@�@GPU�ɂ��g���Ă݂邩�ȁH�@
���Ă̂肾�������̂ł́H
���݂̎p�̕����^�����Ɍ�����B
�^�����ȏ�Ԃɂ����Ă����̂�3�N�̃��X
733 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 21:38:17 ID:LfwDXAhP
�V�K�̃A�[�L�e�N�`�����d�グ��̂�5�N�ȏォ����̂�CPU�̏펯�ł����H
P6�A�[�L�e�N�`�����{�i���y�����̂�2��ڂ��炾��B
P6�A�[�L�e�N�`�����{�i���y�����̂�2��ڂ��炾��B
735 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 21:42:21 ID:LfwDXAhP
G80��5�N�����肾���Ē��̐l�������Ă邼
5�N5�N�ƘA�Ă��Ă��AWEB��Ɍf�ڂ���Ă��܂����L����
Larrabee�̃����[�X�\��X�P�W���[���̋L�ڂ͏��������Ȃ���B
Larrabee�̃����[�X�\��X�P�W���[���̋L�ڂ͏��������Ȃ���B
737 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 21:57:30 ID:LfwDXAhP
�����ς��낤�ȁB
Core 2 Duo��SSSE3��Tejas New Instruction�����������B
�}�C�N���A�[�L�e�N�`���Ɩ��߃Z�b�g�͐藣����Ă�̂�
������ł��O���C���͂����B
���̓_��Bulldozer�ƐVBulldozer�͖��߃Z�b�g�������ւ��ă}�C�N���A�[�L�e�N�`���ɂ�
�w�ǎ����ꂸ�iAVX�ɍœK�ȍ\���ɂȂ��ĂȂ��j�Ȃ̂͑ΏƓI
Core 2 Duo��SSSE3��Tejas New Instruction�����������B
�}�C�N���A�[�L�e�N�`���Ɩ��߃Z�b�g�͐藣����Ă�̂�
������ł��O���C���͂����B
���̓_��Bulldozer�ƐVBulldozer�͖��߃Z�b�g�������ւ��ă}�C�N���A�[�L�e�N�`���ɂ�
�w�ǎ����ꂸ�iAVX�ɍœK�ȍ\���ɂȂ��ĂȂ��j�Ȃ̂͑ΏƓI
LNI���̂��̂ɂ��܂��������ǁA����������Larrabee1, 2�L�����Z����
�����_�ł̌��J���e����傫�ȏC���͂������ˁB
4�I�y�����h�Ϙa�Ƃ����Ȃ����Ȃ��B
�����_�ł̌��J���e����傫�ȏC���͂������ˁB
4�I�y�����h�Ϙa�Ƃ����Ȃ����Ȃ��B
739 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 22:33:37 ID:LfwDXAhP
Larrabee Prototype Library�͂قږ��߃Z�b�g���̂܂�܂Ȃ�ŁA�A�����ύX����Ȃ�����͂Ȃ��ł��傤�B
�ނ���128/256�r�b�gAVX�̂ق��ǂ��ɂ������
���Ƃ���vextractf128�̍Ō�̑��l�t�B�[���h�v��Ȃ��ˁH
����128�r�b�g�̓]���Ȃ�vmovaps��128�r�b�g�łł����̂ŏ��128�r�b�g�̂Ƃ�������{�I�Ɏg��Ȃ��B
�ނ���128/256�r�b�gAVX�̂ق��ǂ��ɂ������
���Ƃ���vextractf128�̍Ō�̑��l�t�B�[���h�v��Ȃ��ˁH
����128�r�b�g�̓]���Ȃ�vmovaps��128�r�b�g�łł����̂ŏ��128�r�b�g�̂Ƃ�������{�I�Ɏg��Ȃ��B
740 �F,,�E�L�́M�E,,�j��-�������F2009/12/12(�y) 22:54:48 ID:LfwDXAhP
���Aaddsubps�n�̃I�y���[�V�����͗~���������BFFT�Ȃł悭�g�����ǂȂ��������̂́B
��������GPU�ł����AVX�̂ق����d�͌������ǂ��C�����ĂȂ��B
��������GPU�ł����AVX�̂ق����d�͌������ǂ��C�����ĂȂ��B
�Ă�VEX�t�H�[�}�b�g�I��imm8�����������������t�����Ƃ��������ȋC�����Ȃ��ł��Ȃ��B
>>724
�قƂ�ǂ̃Q�[�}�[���~�h�������W��GPU���g���Ă��邱�Ƃ��l�����
���N�ł��̏����͖��������悤�ɂȂ��
���Ȃ��Ƃ��AFusion�TGPU�͂قƂ�ǂ̃Q�[�����[�U�[�ɂ͏\���Ȑ��\�̂͂�
�ꕔ�x���`�~�����̐��i���Q�[�}�[�̕��ϓI�Ȑ��i���Ǝv���Ă͂����Ȃ�
�قƂ�ǂ̃Q�[�}�[���~�h�������W��GPU���g���Ă��邱�Ƃ��l�����
���N�ł��̏����͖��������悤�ɂȂ��
���Ȃ��Ƃ��AFusion�TGPU�͂قƂ�ǂ̃Q�[�����[�U�[�ɂ͏\���Ȑ��\�̂͂�
�ꕔ�x���`�~�����̐��i���Q�[�}�[�̕��ϓI�Ȑ��i���Ǝv���Ă͂����Ȃ�
�f�B�X�N���[�gGPU�s�Ř_�҂�VRAM�ш�H���ȍ��𑜓x�e�N�X�`���y�^�y�^�Q�[�������܂ł������Ǝv���Ă邩���
�ꎞ���Ɣ�ׂ��GPU��ASP�͉����X���ł͂��邯��
�̂������i���ꂩ����j�Q�[�}�[�̑唼�̓~�h�������W�̃f�B�X�N���[�gGPU��I�����Ƃ�
�̂������i���ꂩ����j�Q�[�}�[�̑唼�̓~�h�������W�̃f�B�X�N���[�gGPU��I�����Ƃ�
GPU��́�GPU/CPU�n�C�u���b�h��CPU���
�\�t�g�����v�܂߂�12�`13�N���x�̎��Ԃ������ā��̂悤�ȑJ�ڂ������ł͂Ȃ����ƌ��Ă���
�\�t�g�����v�܂߂�12�`13�N���x�̎��Ԃ������ā��̂悤�ȑJ�ڂ������ł͂Ȃ����ƌ��Ă���
>>742
���{��MMO�̃R�[���Z���^�[�ɗ���₢���킹�ň�ԑ����̂��g������PC�œ����Ȃ����ǁi�����\�s���j�h
�C�O�ł͂��̎�̑��k�͂܂������A���{�ŗL�̌���
���E�I�ȌX���Ƃ��āA���ʂ̐l��PC�̃n�[�h�ɑ���~���͂����ƃA�O���b�V�u����
���{��MMO�̃R�[���Z���^�[�ɗ���₢���킹�ň�ԑ����̂��g������PC�œ����Ȃ����ǁi�����\�s���j�h
�C�O�ł͂��̎�̑��k�͂܂������A���{�ŗL�̌���
���E�I�ȌX���Ƃ��āA���ʂ̐l��PC�̃n�[�h�ɑ���~���͂����ƃA�O���b�V�u����
PC�ŃQ�[����邱�Ǝ��̂����}�C�i�[����B
����Ԕ���Ă�CPU��Atom�����A��Ԕ���Ă�GPU�̓`�b�v�Z�b�g�����B
����Ԕ���Ă�CPU��Atom�����A��Ԕ���Ă�GPU�̓`�b�v�Z�b�g�����B
http://sylphys.ddo.jp/upld2nd/pc3/src/1260716857431.png
light gray line �F standalone graphics
dark gray line �F integrated graphics
{kind=link}
light gray line �F standalone graphics
dark gray line �F integrated graphics
750 �F,,�E�L�́M�E,,�j��-�������F2009/12/14(��) 00:31:57 ID:kgBSmHff
�؍��͓��{�̃Q�[�����}�W�R���ŗV�Ԃ̂�������O�ȕ���������R���V���[�}�@�Q�[���͔���Ȃ��ł���
����Ƀl�g�Q��ʯ�݂�������
����Ƀl�g�Q��ʯ�݂�������
>>749
�؍��Ɛ��͍s�������Ƃ��邪�A����͍s�������ƂȂ��B
�d�C���̎��@��������B �����ł��l�b�g�u�b�N�����Ă����ǂˁB
�؍��Ɛ��͍s�������Ƃ��邪�A����͍s�������ƂȂ��B
�d�C���̎��@��������B �����ł��l�b�g�u�b�N�����Ă����ǂˁB
���{��MMO�v���C���[��240���`�Ɨ\������Ă���
�ƂȂ��PC�ŃQ�[������l�̔䗦��500���`1000�����ĂƂ�����
�m���ɃQ�[���@�̏��L�Ґ��Ɣ�ׂ�Ə��Ȃ���
���Ȃ݂�2009�N��PC����CPU�̏o�א���3����GPU��4����
���ݎ�������̂����ꕔ�̃`�b�v�Z�b�g������GPU�����`�b�v�Z�b�g���f�t�H���g������
CPU�o�א�������GPU�o�א��i�܂�3���j
����ăf�B�X�N���[�gGPU��1����
�ƂȂ��PC�ŃQ�[������l�̔䗦��500���`1000�����ĂƂ�����
�m���ɃQ�[���@�̏��L�Ґ��Ɣ�ׂ�Ə��Ȃ���
���Ȃ݂�2009�N��PC����CPU�̏o�א���3����GPU��4����
���ݎ�������̂����ꕔ�̃`�b�v�Z�b�g������GPU�����`�b�v�Z�b�g���f�t�H���g������
CPU�o�א�������GPU�o�א��i�܂�3���j
����ăf�B�X�N���[�gGPU��1����
753 �F,,�E�L�́M�E,,�j��-�������F2009/12/14(��) 01:16:13 ID:kgBSmHff
���ɓI�ɂ�CPU����FLOPS���������Ă�����GPU�̐��\�̎��v�͂Ȃ��Ȃ�Ǝv���Ă���B
2011�N�̃~�b�h�����W��CPU��200GFLOPS��GeForce�͏�ʂł�1TFLOPS���x�B
2011�N�̃~�b�h�����W��CPU��200GFLOPS��GeForce�͏�ʂł�1TFLOPS���x�B
>>751
������āA�؍��̕����������ɓ����Ă���`���B
PC�[�Ƃ����A�؍����̃Q�[����p�̃l�b�g�J�t�F����e���Ă��B
�؍������A�Ⴂ�l�����̓q������ۂ��āA������ƕ|���B
�f�X�N�g�b�v�^�ŁAIntelQ33+ICH8DO�ɁAnVidia�̃{�[�h��
����Ă����̂��A�����Ō��������B�I���{�[�h��3D���u�������̑����B
���ƒ����́ASiS672+SiS968�Ƃ���M/B���A���{��葽���C������B
���Ȃ݂ɁAnVidia�Ƃ̍��ٍH�ꂪ�A����̋߂��ɂ���炵���B
������āA�؍��̕����������ɓ����Ă���`���B
PC�[�Ƃ����A�؍����̃Q�[����p�̃l�b�g�J�t�F����e���Ă��B
�؍������A�Ⴂ�l�����̓q������ۂ��āA������ƕ|���B
�f�X�N�g�b�v�^�ŁAIntelQ33+ICH8DO�ɁAnVidia�̃{�[�h��
����Ă����̂��A�����Ō��������B�I���{�[�h��3D���u�������̑����B
���ƒ����́ASiS672+SiS968�Ƃ���M/B���A���{��葽���C������B
���Ȃ݂ɁAnVidia�Ƃ̍��ٍH�ꂪ�A����̋߂��ɂ���炵���B
>>752
�m�[�g�����āA�@�l���������ƁA�܂�R���V���[�}�����f�X�N�g�b�v��
�����Ȋ����ŒP�̃f�B�X�N���[�gGPU�ς�ł���Ă��Ƃ����
�m�[�g�����āA�@�l���������ƁA�܂�R���V���[�}�����f�X�N�g�b�v��
�����Ȋ����ŒP�̃f�B�X�N���[�gGPU�ς�ł���Ă��Ƃ����
756 �F,,�E�L�́M�E,,�j��-�������F2009/12/14(��) 01:30:02 ID:kgBSmHff
Sandy Bridge 3.2GHz�~6�R�A(12�X���b�h)�@300GFLOPS
Sandy Bridge 3.5GHz�~4�R�A(8�X���b�h)�@220GFLOPS
Zambezi 3.5GHz�~8�R�A�@220GFLOPS
�����A���̃����W��AMD�ɏ��@����悤�Ɍ�����B
Sandy Bridge 3.5GHz�~4�R�A(8�X���b�h)�@220GFLOPS
Zambezi 3.5GHz�~8�R�A�@220GFLOPS
�����A���̃����W��AMD�ɏ��@����悤�Ɍ�����B
���_�l�H
�Ȃ炱������
Radeon HD 6000�@5000GFLOPS�`
�Ȃ炱������
Radeon HD 6000�@5000GFLOPS�`
�x���X������
>>687
SiGe�G�s����Ȃ���Si���Ge�@������ō���Ă��Ȃ���������
�����Ⴎ���Ⴞ���ǘc�݂��������ł����݂����ȃX�^���X�������悤��
>>687
SiGe�G�s����Ȃ���Si���Ge�@������ō���Ă��Ȃ���������
�����Ⴎ���Ⴞ���ǘc�݂��������ł����݂����ȃX�^���X�������悤��
759 �F,,�E�L�́M�E,,�j��-�������F2009/12/14(��) 03:20:29 ID:kgBSmHff
>>757
LOAD+FMUL+FADD+STORE���䗦�Ŏ��s������ǂ��Ȃ邩�����Ă݁H
LOAD+FMUL+FADD+STORE���䗦�Ŏ��s������ǂ��Ȃ邩�����Ă݁H
Radeon HD 6000�@Single 2.2TFLOPS / Double 1.15TFLOPS
�A�[�L�X�V����炵��������ȂƂ��������
�A�[�L�X�V����炵��������ȂƂ��������
761 �F,,�E�L�́M�E,,�j��-�������F2009/12/14(��) 03:26:28 ID:kgBSmHff
Load/Store�Ń������Ԃ̃f�[�^���z�����Ȃ��玝���\��FLOPS���łȂ���Η��_�l�ȑO�̖��B
762 �F,,�E�L�́M�E,,�j��-�������F2009/12/14(��) 03:27:10 ID:kgBSmHff
>>760
�Ȃ�Ŕ{���x���P���x�̔������Ă܂����H
�Ȃ�Ŕ{���x���P���x�̔������Ă܂����H
�ԈႦ��1.1��
�����̂Ă�ꂽ���Ǝv���Ă����C���W�E���K���E����f�B�����Ă��̂��B
Intel ��荂���ȃX�C�b�`���O���\�Ƃ���g�����W�X�^���J��
http://northwood.blog60.fc2.com/blog-entry-3358.html
254 �F���̖��ݒ�F2006/12/11(��) 20:15:21 ID:NOCNNER40
���������I�I
MIT�A�V���R���ɑ���g�����W�X�^�Z�p�\��
http://japan.cnet.com/news/biz/story/0,2000056020,20338249,00.htm
Intel ��荂���ȃX�C�b�`���O���\�Ƃ���g�����W�X�^���J��
http://northwood.blog60.fc2.com/blog-entry-3358.html
254 �F���̖��ݒ�F2006/12/11(��) 20:15:21 ID:NOCNNER40
���������I�I
MIT�A�V���R���ɑ���g�����W�X�^�Z�p�\��
http://japan.cnet.com/news/biz/story/0,2000056020,20338249,00.htm
III-V�������̂�Si�ɕς��L�͌��ł���
�̂͗ʎq��˂ɂȂ�قNjɒ[�ɔ����Ȃ�������
�����Ă�łȂ��������ǁA�d�q�𔖂��w�ɕ����߂�
����������ăA�C�f�A�͓��{�l�̃A�C�f�A�ł���
�����Ă�łȂ��������ǁA�d�q�𔖂��w�ɕ����߂�
����������ăA�C�f�A�͓��{�l�̃A�C�f�A�ł���
���̐�InSb�Ƃ��g�������Ȃ�ʎq��˂ɂ��ăT�u�o���h�҂��Ȃ���BTBT�ł��炢���ƂɂȂ邩���
UTSOI�̎���ETSOI�Ƃ������Ăі����o�Ă�����
>>764�̋L�����ǂ̔��\�̎������Ă�̂�������Ȃ�
�Ƃ肠�������X�������Ă�������
Intel�̂�3-5��Ge����������ڂ����������o�ĂȂ������悤�ȁ@����Ge
UTSOI�̎���ETSOI�Ƃ������Ăі����o�Ă�����
>>764�̋L�����ǂ̔��\�̎������Ă�̂�������Ȃ�
�Ƃ肠�������X�������Ă�������
Intel�̂�3-5��Ge����������ڂ����������o�ĂȂ������悤�ȁ@����Ge
�c�q�����������Ă����\�ȑO��Intel���܂Ƃ���DirectX�h���C�o������킯��������A
CPU��GPU����Ɏg���͖̂����B
���ƁA4�R�A8�X���b�h�ƁA8�R�A��Ɉ����̂��ǂ����Ǝv�����B
2�R�A��2�X���b�h�������ɂȂ�p�^�[���Ȃ�Ėw�ǖ����B
�����̃x���`���ʂς���A8�X���b�h��6�R�A�����A12�X���b�h��9�R�A�����ɗ����������낤����A
����Sandybridge��Zambezgi�ɍ��͏o�Ă��Ȃ����낤�B
CPU��GPU����Ɏg���͖̂����B
���ƁA4�R�A8�X���b�h�ƁA8�R�A��Ɉ����̂��ǂ����Ǝv�����B
2�R�A��2�X���b�h�������ɂȂ�p�^�[���Ȃ�Ėw�ǖ����B
�����̃x���`���ʂς���A8�X���b�h��6�R�A�����A12�X���b�h��9�R�A�����ɗ����������낤����A
����Sandybridge��Zambezgi�ɍ��͏o�Ă��Ȃ����낤�B
�R�A�����̂ɒǂ����ĂȂ��̂����Ȃ�Ȃ��́H
770 �F,,�E�L�́M�E,,�j��-�������F2009/12/14(��) 08:44:25 ID:kgBSmHff
�v���O���}��AMD�I�����[�̖��߂͂��������Ή����Ȃ��Ƃ���
AVX�����̑Ή�����FLOPS���͔��������o���Ȃ���ȁB
Sandy Bridge 3.2GHz�~6�R�A(12�X���b�h)�@300GFLOPS
Sandy Bridge 3.5GHz�~4�R�A(8�X���b�h)�@220GFLOPS
Zambezi 3.5GHz�~8�R�A�@110GFLOPS��220GFLOPS
�������Z���Ӑ}���Ă����ǂ�
AVX�����̑Ή�����FLOPS���͔��������o���Ȃ���ȁB
Sandy Bridge 3.2GHz�~6�R�A(12�X���b�h)�@300GFLOPS
Sandy Bridge 3.5GHz�~4�R�A(8�X���b�h)�@220GFLOPS
Zambezi 3.5GHz�~8�R�A�@110GFLOPS��220GFLOPS
�������Z���Ӑ}���Ă����ǂ�
Bulldozer��GPU������������H
>DirectX�h���C�o
����Ȃ̂�߂��Ⴂ�܂��傤��I����Ɍ������J���������͂��ł́c
����Ȃ̂�߂��Ⴂ�܂��傤��I����Ɍ������J���������͂��ł́c
CPU��GPU�̋@�\����������Ƃ��āE�E�E
�@�ėp���̍��������r�[�̂悤�Ȃ��̂̓���
�AGPU�I�Ȃ��̂̓���
�@�Ȃ牽�ɂł����p�ł��_��͍������AGPU�Ƃ��ċ@�\����Ƃ���
�A�ɑ��ă��b�g�p�t�H�[�}���X���d�͌����ŗ��
�������d�͘g�Ȃ�GPU�Ƃ��Ă͗�鎖�ɂȂ�
�܂��A�P��GPU�Ƃ��Ẵ����r�[�����������A�Q�[����Geforce��Radeon�Ƀ}�b�`���������ɐi�����邵���Ȃ�
�܂�ACPU�Ƀ����r�[������Ƃ��Ă��A���̃����r�[�ɓK�����Q�[���͖���
�Ԃ����Ⴏ�AIntel��GPU�����^CPU�A���Ƀ~�h���`���[�����̕��ɂ�GMA�����������ǂ��Ȃ�Ď��Ԃ��\���L�蓾��
�@�ėp���̍��������r�[�̂悤�Ȃ��̂̓���
�AGPU�I�Ȃ��̂̓���
�@�Ȃ牽�ɂł����p�ł��_��͍������AGPU�Ƃ��ċ@�\����Ƃ���
�A�ɑ��ă��b�g�p�t�H�[�}���X���d�͌����ŗ��
�������d�͘g�Ȃ�GPU�Ƃ��Ă͗�鎖�ɂȂ�
�܂��A�P��GPU�Ƃ��Ẵ����r�[�����������A�Q�[����Geforce��Radeon�Ƀ}�b�`���������ɐi�����邵���Ȃ�
�܂�ACPU�Ƀ����r�[������Ƃ��Ă��A���̃����r�[�ɓK�����Q�[���͖���
�Ԃ����Ⴏ�AIntel��GPU�����^CPU�A���Ƀ~�h���`���[�����̕��ɂ�GMA�����������ǂ��Ȃ�Ď��Ԃ��\���L�蓾��
>>770
>�v���O���}��AMD�I�����[�̖��߂͂��������Ή����Ȃ��Ƃ���
������3D Now�Ή��\�t�g���o�邩��A���ǑΉ������B
> �������Z���Ӑ}���Ă����ǂ�
�������Z��GPU�R�A�ł�邩��Ӗ��������ȁB
�Q�[���p�̕������Z���x�Ȃ�100GFlops������Ώ\���B
(9600GT��HD4650���x)
����IGP���ᖳ�����낤���ǃ��[�G���hGPU�Ȃ�\���\������CPU�ŏ������邱�Ƃ������B
AVX�ŕ������Z������̂ƁAHavok��Bullet��DXCS�Ή��̂ǂ��炪�x���邾�낤���B
�Q�[������Ȃ�HPC�Ƃ��̉Ȋw�Z�p�n�̕������Z��Tesla��ATI stream����GPGPU�����ӂ��������B
>����Ȃ̂�߂��Ⴂ�܂��傤��I����Ɍ������J��
Larrabee�����s�������瓖�����߂��ق��������B
LNI��CPU�ɓ��ڂ���āA�Ή��Q�[�����o��܂ʼn��N�����邱�Ƃ��B
>�v���O���}��AMD�I�����[�̖��߂͂��������Ή����Ȃ��Ƃ���
������3D Now�Ή��\�t�g���o�邩��A���ǑΉ������B
> �������Z���Ӑ}���Ă����ǂ�
�������Z��GPU�R�A�ł�邩��Ӗ��������ȁB
�Q�[���p�̕������Z���x�Ȃ�100GFlops������Ώ\���B
(9600GT��HD4650���x)
����IGP���ᖳ�����낤���ǃ��[�G���hGPU�Ȃ�\���\������CPU�ŏ������邱�Ƃ������B
AVX�ŕ������Z������̂ƁAHavok��Bullet��DXCS�Ή��̂ǂ��炪�x���邾�낤���B
�Q�[������Ȃ�HPC�Ƃ��̉Ȋw�Z�p�n�̕������Z��Tesla��ATI stream����GPGPU�����ӂ��������B
>����Ȃ̂�߂��Ⴂ�܂��傤��I����Ɍ������J��
Larrabee�����s�������瓖�����߂��ق��������B
LNI��CPU�ɓ��ڂ���āA�Ή��Q�[�����o��܂ʼn��N�����邱�Ƃ��B
>Larrabee�����s����
Larrabee�̃f�B�X�N���[�g�͎~�߂܂����Ęb��������?
���ǖ����̃Q�[����AMD��NV�̃f�B�X�N���[�g���K�v�Ȃ낤��
intel�̖ړI�����Ђ̃f�B�X�N���[�g�s���D��������Ȃ��͖̂����Ȃ킯��
LNI��CPU���ڂŏ�肢��GPU(�ƌĂԂł��낤��)�Ƌ����H���Ŋ撣���Ăق�����
Larrabee�̃f�B�X�N���[�g�͎~�߂܂����Ęb��������?
���ǖ����̃Q�[����AMD��NV�̃f�B�X�N���[�g���K�v�Ȃ낤��
intel�̖ړI�����Ђ̃f�B�X�N���[�g�s���D��������Ȃ��͖̂����Ȃ킯��
LNI��CPU���ڂŏ�肢��GPU(�ƌĂԂł��낤��)�Ƌ����H���Ŋ撣���Ăق�����
������AVX�������Ȃ�256�r�b�g�ꊇ�ł���Ƃ͂ˁB
�u���h�[�U��128��2��őz�肵�Đv���Ă���Ȃ��̂��B
�u���h�[�U��128��2��őz�肵�Đv���Ă���Ȃ��̂��B
��AVX�ŕ������Z������̂ƁAHavok��Bullet��DXCS�Ή��̂ǂ��炪�x���邾�낤���B
Havok�̎��_�Ŋ���CPU�iSSE�j�����̂ق���Radeon��葬�����������
Havok�̎��_�Ŋ���CPU�iSSE�j�����̂ق���Radeon��葬�����������
>>776
> Larrabee�����s����
> Larrabee�̃f�B�X�N���[�g�͎~�߂܂����Ęb��������?
�~�߂�=���s����B
> ���ǖ����̃Q�[����AMD��NV�̃f�B�X�N���[�g���K�v�Ȃ낤��
> intel�̖ړI�����Ђ̃f�B�X�N���[�g�s���D��������Ȃ��͖̂����Ȃ킯��
���炩�ɒD�����Ƃ��ړI�������ˁB
�D���鐫�\���o���h���C�o����q��������~�߂������B
�D�����肪�����Ȃ�A�Œ���̈��萫���m�ۂ��ďo�ׂ���悩��������B
> LNI��CPU���ڂŏ�肢��GPU(�ƌĂԂł��낤��)�Ƌ����H���Ŋ撣���Ăق�����
�����͂��肦�Ȃ��ˁBGPU���Ƃ̐����c����������D���̟r�Ő�ɂȂ邾�낤�ȁB
> Larrabee�����s����
> Larrabee�̃f�B�X�N���[�g�͎~�߂܂����Ęb��������?
�~�߂�=���s����B
> ���ǖ����̃Q�[����AMD��NV�̃f�B�X�N���[�g���K�v�Ȃ낤��
> intel�̖ړI�����Ђ̃f�B�X�N���[�g�s���D��������Ȃ��͖̂����Ȃ킯��
���炩�ɒD�����Ƃ��ړI�������ˁB
�D���鐫�\���o���h���C�o����q��������~�߂������B
�D�����肪�����Ȃ�A�Œ���̈��萫���m�ۂ��ďo�ׂ���悩��������B
> LNI��CPU���ڂŏ�肢��GPU(�ƌĂԂł��낤��)�Ƌ����H���Ŋ撣���Ăق�����
�����͂��肦�Ȃ��ˁBGPU���Ƃ̐����c����������D���̟r�Ő�ɂȂ邾�낤�ȁB
>>778
�\�[�X�́H
�\�[�X�́H
>>778 ggrks
http://www.google.co.jp/search?q=%22CPU%E3%81%98%E3%82%833%E4%BD%93%E3%81%A7GPU%E3%81%A7%E3%81%AF%E3%81%9F%E3%81%A3%E3%81%9F%E3%81%AE1%E4%BD%93%E3%81%97%E3%81%8B%E5%8B%95%E3%81%8B%E3%81%95%E3%81%AA%E3%81%8B%E3%81%A3%E3%81%9F%E3%82%93%E3%81%A0%E3%81%9C%22
���̐l�̌��ꂵ��������F
�u�Q�[���Ȃǂł�GPU�̕��ׂ������A�ނ���CPU�̕������ׂ��Ⴂ�ꍇ������B���̂悤�Ȏ���CPU�ŕ������Z���s���������ǂ��̂ł͂Ȃ����v
http://journal.mycom.co.jp/articles/2009/04/30/amd/001.html
http://www.google.co.jp/search?q=%22CPU%E3%81%98%E3%82%833%E4%BD%93%E3%81%A7GPU%E3%81%A7%E3%81%AF%E3%81%9F%E3%81%A3%E3%81%9F%E3%81%AE1%E4%BD%93%E3%81%97%E3%81%8B%E5%8B%95%E3%81%8B%E3%81%95%E3%81%AA%E3%81%8B%E3%81%A3%E3%81%9F%E3%82%93%E3%81%A0%E3%81%9C%22
���̐l�̌��ꂵ��������F
�u�Q�[���Ȃǂł�GPU�̕��ׂ������A�ނ���CPU�̕������ׂ��Ⴂ�ꍇ������B���̂悤�Ȏ���CPU�ŕ������Z���s���������ǂ��̂ł͂Ȃ����v
http://journal.mycom.co.jp/articles/2009/04/30/amd/001.html
>>779
�ʂɂ��ꂪLarrabee�v��̑S�Ă��Ⴀ��܂����K�����Ȃ��c
�ʂɂ��ꂪLarrabee�v��̑S�Ă��Ⴀ��܂����K�����Ȃ��c
>>778
�\�[�X�́H
�\�[�X�́H
http://www.nicovideo.jp/watch/sm6968676
GPU�iRadeon�j��1�̂��������Ȃ��l�`��CPU��3�̓�����
GPU��Havok���Ӗ��Ȃ�
GPU�iRadeon�j��1�̂��������Ȃ��l�`��CPU��3�̓�����
GPU��Havok���Ӗ��Ȃ�
���₾����\�[�X�́H
���̗Ⴖ��{�g���l�b�N��CPU��GPU�������
��������OpenCL�̓�����CPU��GPU�̋�������A���邢�͂⏈�����V�[�����X�Ɏn���鎖�ɂ���
���̃f���͂���������Ă��邾���ŁA����ȏ�̉����͓`����Ă��Ȃ����H
�E�E�E�Ƃ����܂ŏ����Ă����ĂȂ��ꌾ
������GPU�A�����OpenCL���l������Ă��Ȃ������GPU��OpenCL���������������������낤����
���̗Ⴖ��{�g���l�b�N��CPU��GPU�������
��������OpenCL�̓�����CPU��GPU�̋�������A���邢�͂⏈�����V�[�����X�Ɏn���鎖�ɂ���
���̃f���͂���������Ă��邾���ŁA����ȏ�̉����͓`����Ă��Ȃ����H
�E�E�E�Ƃ����܂ŏ����Ă����ĂȂ��ꌾ
������GPU�A�����OpenCL���l������Ă��Ȃ������GPU��OpenCL���������������������낤����
> ������GPU�A�����OpenCL���l������Ă��Ȃ������GPU��
CPU�������ŕ������Z�ł��邵���̂ق�����������GPU�v��Ȃ����Ă���
CPU�������ŕ������Z�ł��邵���̂ق�����������GPU�v��Ȃ����Ă���
http://www.youtube.com/watch?v=xfrM973spw0
������GPU������3�̓������Ƃ����Ȃ�炵���B
������GPU������3�̓������Ƃ����Ȃ�炵���B
���߂�������Ă�����
�~GPU�����͒x��
��Radeon�͒x��
�~GPU�����͒x��
��Radeon�͒x��
790 �FSocket774�F2009/12/14(��) 15:58:44 ID:7ZztMKkz
CPU�̏ꍇ��3D�̕`���GPU�ł���Ă邩��y�����������
���̃f������GPU�̕��ׂ���������CPU�ɕ������Z���S�����邱�ƂŃp�t�H�[�}���X�o����Ƃ�����|����
�����ł��Ă�H
���̃f������GPU�̕��ׂ���������CPU�ɕ������Z���S�����邱�ƂŃp�t�H�[�}���X�o����Ƃ�����|����
�����ł��Ă�H
OpenCL��CPU�AGPU�̏����̐U�蕪�����s�����߂ɕK�v�Ȃ�(���Ԃ�)
�����Fusion�̂��߂̕z�Ȃ�
�����Fusion�̂��߂̕z�Ȃ�
��CPU�̏ꍇ��3D�̕`���GPU�ł���Ă邩��y�����������
�����̃f������GPU�̕��ׂ���������CPU�ɕ������Z���S�����邱�ƂŃp�t�H�[�}���X�o����Ƃ�����|����
�v����ɂ��̒��x�̂̂���ڂ��Ó��̐l�����f���ɍr�����ʃe�N�X�`����
�`�悷��̂���A�b�v�A�b�v�ȂقǃV���{�C�̂��B
�Ȃ�����Radeon�͎g���Ȃ��ȁB
���Ⴀ�}���`GPU�Ȃ炢����̂��H��������H
�ǂ݂̂��I�u�W�F�N�g�̐���������Ή��Z���ʂ�CPU�Ƀt�B�[�h�o�b�N����̂�
�ш�����C�e���V���l�b�N�ɂȂ��Ăǂ�l�܂�ȏ����͖ڂɌ����Ă����
GPU�͂��G�����ɓO���Ă�������B�݂͖݉��B
�����̃f������GPU�̕��ׂ���������CPU�ɕ������Z���S�����邱�ƂŃp�t�H�[�}���X�o����Ƃ�����|����
�v����ɂ��̒��x�̂̂���ڂ��Ó��̐l�����f���ɍr�����ʃe�N�X�`����
�`�悷��̂���A�b�v�A�b�v�ȂقǃV���{�C�̂��B
�Ȃ�����Radeon�͎g���Ȃ��ȁB
���Ⴀ�}���`GPU�Ȃ炢����̂��H��������H
�ǂ݂̂��I�u�W�F�N�g�̐���������Ή��Z���ʂ�CPU�Ƀt�B�[�h�o�b�N����̂�
�ш�����C�e���V���l�b�N�ɂȂ��Ăǂ�l�܂�ȏ����͖ڂɌ����Ă����
GPU�͂��G�����ɓO���Ă�������B�݂͖݉��B
>>788
��dunlrock (8 �����O)
���ԐM NVIDIA = nSHITia!!!! Fucking nGREEDia nvIDIOTs!!!
����@����͎g�킹�Ă��炤��
��dunlrock (8 �����O)
���ԐM NVIDIA = nSHITia!!!! Fucking nGREEDia nvIDIOTs!!!
����@����͎g�킹�Ă��炤��
�[���������Ȃ��̂͒P���ɕ��ʔC���Ƀ`�b�v���\�グ�Ă����ă������o���h���H���Ԃ���GPU�̕�����H
�O���t�B�b�N�������̎��̋K�i���Ȃ��Ȃ�����Ȃ��̂�����ƁA����͕��ʔC���̕����͌������B
�����Ȃ�ƁA�߂������������]�������d���ɓ]�����鎖�ɂȂ邪�A���̎���CPU�ɑ傫�ȃA�h�o���e�[�W�����邾�낤���B�Ȃ��Ǝv���ˁB
�O���t�B�b�N�������̎��̋K�i���Ȃ��Ȃ�����Ȃ��̂�����ƁA����͕��ʔC���̕����͌������B
�����Ȃ�ƁA�߂������������]�������d���ɓ]�����鎖�ɂȂ邪�A���̎���CPU�ɑ傫�ȃA�h�o���e�[�W�����邾�낤���B�Ȃ��Ǝv���ˁB
DXCS����OpenCL��������Ȃ�����Ȃ����̂ɖ������������B
CPU�����ŃR�[�h���������ɉz�������Ƃ͂Ȃ��B
�����猾��������悤�Ƃ킴�킴C++�ȊO�̎���o���̂͋�ɂł����Ȃ��B
CPU�����ŃR�[�h���������ɉz�������Ƃ͂Ȃ��B
�����猾��������悤�Ƃ킴�킴C++�ȊO�̎���o���̂͋�ɂł����Ȃ��B
�ł�Larrbee�ڍ����������Ő����͊F������
���ށB
�v���Z�b�T�̐��\����݉��ɋƂ��ς₵�������ҒB�́AGPGPU�Ƃ������킯�̂킩��Ȃ����̂Ɏ���o���n�߂�n���B
�n���O���[�Ȍ����ҒB����ł�GPGPU�͎��ԉ҂����x�ɂ����Ȃ�Ȃ��B
CPU�̃x�N�g�����\����ƊJ�����������}�����ȁB
�v���Z�b�T�̐��\����݉��ɋƂ��ς₵�������ҒB�́AGPGPU�Ƃ������킯�̂킩��Ȃ����̂Ɏ���o���n�߂�n���B
�n���O���[�Ȍ����ҒB����ł�GPGPU�͎��ԉ҂����x�ɂ����Ȃ�Ȃ��B
CPU�̃x�N�g�����\����ƊJ�����������}�����ȁB
>>796
�f�B�X�N���[�gLarrabee���s�́AGPGPU�ɖ������Ȃ������ؖ������܂�����B
�f�B�X�N���[�gLarrabee���s�́AGPGPU�ɖ������Ȃ������ؖ������܂�����B
http://www.itmedia.co.jp/news/articles/0502/17/news011.html
������Ăǂ��Ȃ�����
������Ăǂ��Ȃ�����
���N��Radeon��GPGPU�Ɋ��҂Ȃǂ����Ⴂ�Ȃ�
AMD���g���͂����Ă���Ƃ͎v���A���O��CPU������ȏセ�̕K�v�����Ȃ�
�����NVIDIA��GPGPU�ɂ������邽���̓��Ĕn
�����ɂ��đ��Ђ�OpenCL�������o���Ē����̂����ꂾ���̎�
AMD���g���͂����Ă���Ƃ͎v���A���O��CPU������ȏセ�̕K�v�����Ȃ�
�����NVIDIA��GPGPU�ɂ������邽���̓��Ĕn
�����ɂ��đ��Ђ�OpenCL�������o���Ē����̂����ꂾ���̎�
Larrabee�L�����Z���Ō��ʓI��NV(GPU�w�c)�͈ꎞ�I�ɏ����������߂�
GPGPU�̖����ƌ����������͉��т��A�����NV�͎��Ȃ��ɂ���
�ʂɎ���ł�����Ă��ǂ����ǂ�
GPGPU�̖����ƌ����������͉��т��A�����NV�͎��Ȃ��ɂ���
�ʂɎ���ł�����Ă��ǂ����ǂ�
����͋������lj^�ǂ����v������̂�����`�b�v�ō������Ƃ����Ӗ��ł�Radeon����������GPGPU�����ˁB
���������nvidia�͔ėp���Ɍ������Ĉ꒼���ŁAlarrabee�ɂƂ��ăO���t�B�b�N�͕Ў�Ԃ������킯������B
���������nvidia�͔ėp���Ɍ������Ĉ꒼���ŁAlarrabee�ɂƂ��ăO���t�B�b�N�͕Ў�Ԃ������킯������B
>>800
���ႠBulldozer��FP���\����߂�������͂���ς肽�����k�ق�������
���ႠBulldozer��FP���\����߂�������͂���ς肽�����k�ق�������
HPC�͓����
Larrabee�ł���������NehalemEX�������Ă���Intel
POWER7��SPARCVIIIfx�ŒP���ł�Xeon5�������ƈقȂ鉿�i�т�
�@�V�X�e�����x���ł͏��낤�Ƃ��Ă�IBM��F��
Fermi��s���s������NVIDIA
Bulldozer��float�y����AMD��HPC���̂�����߂Ă�̂�����Ƃ�
�����l��������̂��B�Ƃ肠����HD6000�̃f�U�C������������܂Ŕ���ۗ�
Larrabee�ł���������NehalemEX�������Ă���Intel
POWER7��SPARCVIIIfx�ŒP���ł�Xeon5�������ƈقȂ鉿�i�т�
�@�V�X�e�����x���ł͏��낤�Ƃ��Ă�IBM��F��
Fermi��s���s������NVIDIA
Bulldozer��float�y����AMD��HPC���̂�����߂Ă�̂�����Ƃ�
�����l��������̂��B�Ƃ肠����HD6000�̃f�U�C������������܂Ŕ���ۗ�
�F�Y��Ă���݂�������
GPGPU��GPU�ł̔ėp�����ł���A�O���t�B�b�N��Q�[�������C���ŁA
�x�N�g���v���Z�b�T�ۂ�������łɔėp�����������Ⴂ�܂��傤�Ƃ������Ƃł���B
���ꂼ�꓾�ӕ��삪�Ⴄ����A�ɍ��킹�Ďg��������Ε֗����낤�ȂƂ������Ƃ�
GPGPU���L�܂낤�Ƃ��Ă���킯����B
Larrabee�̎��s�͒P��Intel�̋Z�p�͂�����Ȃ����������B����ȏ�ł��ȉ��ł������B
GPGPU��GPU�ł̔ėp�����ł���A�O���t�B�b�N��Q�[�������C���ŁA
�x�N�g���v���Z�b�T�ۂ�������łɔėp�����������Ⴂ�܂��傤�Ƃ������Ƃł���B
���ꂼ�꓾�ӕ��삪�Ⴄ����A�ɍ��킹�Ďg��������Ε֗����낤�ȂƂ������Ƃ�
GPGPU���L�܂낤�Ƃ��Ă���킯����B
Larrabee�̎��s�͒P��Intel�̋Z�p�͂�����Ȃ����������B����ȏ�ł��ȉ��ł������B
>>804
> Bulldozer��float�y����AMD��HPC���̂�����߂Ă�̂�����Ƃ�
> �����l��������̂��B�Ƃ肠����HD6000�̃f�U�C������������܂Ŕ���ۗ�
������������B
���̂��߂�Llano��GPU�R�A��������Ă���Ǝv���B
> Bulldozer��float�y����AMD��HPC���̂�����߂Ă�̂�����Ƃ�
> �����l��������̂��B�Ƃ肠����HD6000�̃f�U�C������������܂Ŕ���ۗ�
������������B
���̂��߂�Llano��GPU�R�A��������Ă���Ǝv���B
> ������������B
> ���̂��߂�Llano��GPU�R�A��������Ă���Ǝv���B
�����������낤�B
GPU�R�A�̓������L���Ȃ�Ȃ�Zambezi�ɓ��ڂ��Ȃ��H
> ���̂��߂�Llano��GPU�R�A��������Ă���Ǝv���B
�����������낤�B
GPU�R�A�̓������L���Ȃ�Ȃ�Zambezi�ɓ��ڂ��Ȃ��H
��Intel�̋Z�p�͂�����Ȃ����������B����ȏ�ł��ȉ��ł������B
Swift�ł�����AMD�͐l�̎������Ȃ���
Swift�ł�����AMD�͐l�̎������Ȃ���
HPC�ƃT�[�o�[
�s��̃p�C�͈��|�I�ɃT�[�o�[�̕����ł���
Bulldozer�́A���������Z�p�Ƃ��������Ȃ�Intel��CPU�����R�A��ς߁A�T�[�o�[�ł̐��\�͏����
�����̂̃T�C�Y�ɂ͐���������̂�����A�����𑝂₹�Ή����͎̂Ă邵���Ȃ�
�����āACPU�̂Ƃ����ƊE��
�����o�����R�X�g�p�t�H�[�}���X�������グ�遨���\�ŏ��鍂���\�ȃ��C�o�����R�X�g�p�t�H�[�}���X�ɂ���đł��j��
�Ƃ����������Ő������Ă����ƊE
2�Ԏ�ł���AMD�ɂƂ��Ă�Bulldozer�͐������I��������
�J���ɐ������邩�ǂ����͕ʂ̘b����
���Ȃ݂ɖʐό����ɗD��邱�̌`�Ԃ́ACPU�̏��^����A���̋@�\�̃R�A������̂ɂ��s�����ǂ���Ȃ��H
�s��̃p�C�͈��|�I�ɃT�[�o�[�̕����ł���
Bulldozer�́A���������Z�p�Ƃ��������Ȃ�Intel��CPU�����R�A��ς߁A�T�[�o�[�ł̐��\�͏����
�����̂̃T�C�Y�ɂ͐���������̂�����A�����𑝂₹�Ή����͎̂Ă邵���Ȃ�
�����āACPU�̂Ƃ����ƊE��
�����o�����R�X�g�p�t�H�[�}���X�������グ�遨���\�ŏ��鍂���\�ȃ��C�o�����R�X�g�p�t�H�[�}���X�ɂ���đł��j��
�Ƃ����������Ő������Ă����ƊE
2�Ԏ�ł���AMD�ɂƂ��Ă�Bulldozer�͐������I��������
�J���ɐ������邩�ǂ����͕ʂ̘b����
���Ȃ݂ɖʐό����ɗD��邱�̌`�Ԃ́ACPU�̏��^����A���̋@�\�̃R�A������̂ɂ��s�����ǂ���Ȃ��H
Larrbee�L�����Z���Ͳ��ق̋Z�p�̖͂�����\�������������
�����������Ƃɂ���AMD��NV�ɂ���O�͂Ȃ���
���肵������PS3�̓�̕����ɂȂ�Ȃ������}�V��
�����������Ƃɂ���AMD��NV�ɂ���O�͂Ȃ���
���肵������PS3�̓�̕����ɂȂ�Ȃ������}�V��
�Ƃ͌����Ă������Z�p�̍����L�肷���邩��A�������Ԏ��Ȃ���Intel�̕��������̃R�A������Ă�Ǝv�����ǂ˂�
������FPU�Ɏ����Ă͔{�ȏ��
������FPU�Ɏ����Ă͔{�ȏ��
Fusion���n�C�G���h�R�A�ɍ̗p���Ȃ��̂�
���]�Ȑ܂����Ĕ��\�����̂悤�ȃw�e���R�A�\�z�����~�߂ɂ���
���[�G���h�����̒P���ȃO���t�B�b�N�`�b�v�����ɓ]���������Ă��Ƃ�
���]�Ȑ܂����Ĕ��\�����̂悤�ȃw�e���R�A�\�z�����~�߂ɂ���
���[�G���h�����̒P���ȃO���t�B�b�N�`�b�v�����ɓ]���������Ă��Ƃ�
���������A�������̐��E�ł͐i���_�͎嗬����Ȃ�
�����_����
�����͂Ƃɂ������������A�����Ă��̒�����K�҂����������c��Ƃ�����
���s���悤���Ƃɂ��������̑I������������Ƃ��낪
��荂���m���Ŏ�����֑����������������Ă����
�����_����
�����͂Ƃɂ������������A�����Ă��̒�����K�҂����������c��Ƃ�����
���s���悤���Ƃɂ��������̑I������������Ƃ��낪
��荂���m���Ŏ�����֑����������������Ă����
816 �F,,�E�L�́M�E,,�j��-�������F2009/12/15(��) 00:40:00 ID:7VClrwiG
SPECint��Shanghai 2�\�P�b�g��Broomfield 1�\�P�b�g�ŏ������肵�Ă��̂����ۂ̏��B
���\�[�X���L��8�R�A��Nehalem�̐�����p��6�R�A12�X���b�h���L�����ǂ����͑����ɋ^�₾�ȁB
���Ƃ���͗]�k�܂łɁB
FADD�{FMUL�����ꂼ��x�N�g�����ɂ��邩�AFMA�~2�ɂ��邩�A�ǂ������������\����ɗL�����Ǝv���H
�O�҂̓f�[�^����x���\���ɂ���X���[�v�b�g2�{�͑_����B
��҂͏�Z�Ɖ����Z�������ł���ꍇ�ɂ���2�{�ɂȂ�Ȃ��B
FMA�ɂ����ق������_���\������̉�H���������Ȃ��Ă��̕��R�A�����ς߂邩��g�[�^���ł�
FLOPS���͉҂���Ƃ����P�[�X������
�������AAMD��FPU�W�ϓx���҂��ɂ͂���߂ĕs���ȃA�v���[�`���Ƃ����B
���\�[�X���L��8�R�A��Nehalem�̐�����p��6�R�A12�X���b�h���L�����ǂ����͑����ɋ^�₾�ȁB
���Ƃ���͗]�k�܂łɁB
FADD�{FMUL�����ꂼ��x�N�g�����ɂ��邩�AFMA�~2�ɂ��邩�A�ǂ������������\����ɗL�����Ǝv���H
�O�҂̓f�[�^����x���\���ɂ���X���[�v�b�g2�{�͑_����B
��҂͏�Z�Ɖ����Z�������ł���ꍇ�ɂ���2�{�ɂȂ�Ȃ��B
FMA�ɂ����ق������_���\������̉�H���������Ȃ��Ă��̕��R�A�����ς߂邩��g�[�^���ł�
FLOPS���͉҂���Ƃ����P�[�X������
�������AAMD��FPU�W�ϓx���҂��ɂ͂���߂ĕs���ȃA�v���[�`���Ƃ����B
BD��FP Unit�͋��L������FADD��FMUL������z�u�Ȃ�ĈĂ͍̂�ɂ���������ˁH
���Z���Z�������������烆�j�b�g�̎�荇���ɂȂ邵�B
������ӂ��l���Ẵg���[�h�I�t���Ǝv�����ǂȁB
���Z���Z�������������烆�j�b�g�̎�荇���ɂȂ邵�B
������ӂ��l���Ẵg���[�h�I�t���Ǝv�����ǂȁB
SPEC�̓��j�b�g�\����胁�����ш�̉e���̂ق����f�J�C����
819 �F,,�E�L�́M�E,,�j��-�������F2009/12/15(��) 01:48:35 ID:7VClrwiG
�ł�DDR3 3ch����2ch�~2�̂ق�������������H
�Ԃ������
FMA + FADD
FMA + FADD
AMD�̐헪�͑���FPU��CPU����GPU�Ɉڂ��Ċ��S�Ȑ������j�b�g�̃N���X�^���ƁA
GPU��FPU��SSE�@�\��g�ݍ���ł�FP�̃N���X�^���ŕ����邱�Ƃ���Ȃ����ȁB
�ׂ�������͕�����A�N���X�^���ɓƗ�����L2�L���b�V���������AL3�����L�Ƃ��B
��͎s��ɉ����Đ����N���X�^�̔䗦�𑽂�������AFP�N���X�^�𑽂�������A�Q�[���p�ɌŒ�@�\�lj�������Ƃ��ł������B
(PC�����͐���2�FFP1�AHPC�����͐���1�FFP2�Ƃ�)
GPU��FPU��SSE�@�\��g�ݍ���ł�FP�̃N���X�^���ŕ����邱�Ƃ���Ȃ����ȁB
�ׂ�������͕�����A�N���X�^���ɓƗ�����L2�L���b�V���������AL3�����L�Ƃ��B
��͎s��ɉ����Đ����N���X�^�̔䗦�𑽂�������AFP�N���X�^�𑽂�������A�Q�[���p�ɌŒ�@�\�lj�������Ƃ��ł������B
(PC�����͐���2�FFP1�AHPC�����͐���1�FFP2�Ƃ�)
DDR2*2ch���DDR3*3ch�̂��͂₢�A���[�[�ł�
��Xeon���VXeon
4�����^��8��
DDR2*2��DDR3*3
���\�{�̐���
4�����^��8��
DDR2*2��DDR3*3
���\�{�̐���
>>819
���̃X�y�b�N�͒m��Ȃ����ǁA�\�P�b�g�Ԃ�HT�̑ш掟��ł͕Б��ɃA�N�Z�X��������Ƃ��S�R���\�łȂ���B
�u���[���̃l�C�e�B�u3ch DDR3�̕����[��4ch DDR2�Ȃ��t���ׂɋ����B
HT�����������v�ш�ł�DDR2 800 4ch�ł����DDR3 1066 3ch�ɏ��Ă���x�����B
���̃X�y�b�N�͒m��Ȃ����ǁA�\�P�b�g�Ԃ�HT�̑ш掟��ł͕Б��ɃA�N�Z�X��������Ƃ��S�R���\�łȂ���B
�u���[���̃l�C�e�B�u3ch DDR3�̕����[��4ch DDR2�Ȃ��t���ׂɋ����B
HT�����������v�ш�ł�DDR2 800 4ch�ł����DDR3 1066 3ch�ɏ��Ă���x�����B
i7 860 �� i7 920 ��������ǂ��������\�ǂ��́H
>>824
SPEC CPU��rate�̎����m��Ȃ��Ȃ�ق��Ă�
SPEC CPU��rate�̎����m��Ȃ��Ȃ�ق��Ă�
�c�q�Ƃ������N�\�R�e���Ă܂������Ă���
829 �F,,�E�L�́M�E,,�j��-�������F2009/12/16(��) 01:08:02 ID:TBS43rg6
�@
TokyoBakaStation��
831 �FSocket774�F2009/12/16(��) 03:23:43 ID:ln93umgu
note PC �p��capella�͂��낻�납�Ǝv���Ă����A
���N�ł����H
���N�ł����H
>>821
Fusion�\�z����I���ꂽ�Ƃ��ɁA�����悤�Ȃ��ƌ�������@���ꂽ���Ƃ��v���o����
Fusion�\�z����I���ꂽ�Ƃ��ɁA�����悤�Ȃ��ƌ�������@���ꂽ���Ƃ��v���o����
���̃X���ŁH
��{�c���f��������
>>832
�n����
�n����
Fusion�Ƃ������͓I��CPU���o����C���e���ɂ͑R�����i����]�I��
�Ȃ������Ă��܂������킯�����AAMD�̎��㓞������
�Ȃ������Ă��܂������킯�����AAMD�̎��㓞������
�������ȁAAMD�̎��㓞�����ȁB
���͂��ꂪ�����̘b����Ȃ����Ă��Ƃ��ȁB
���͂��ꂪ�����̘b����Ȃ����Ă��Ƃ��ȁB
838 �F,,�E�L�́M�E,,�j��-�������F2009/12/17(��) 00:13:07 ID:c1dBcMXj
TBS�̈Ӗ��悤�₭������
����AMD����͂������
���|�I�Ȃ��芷����
�����v���Z�X���ǂ����Ȃ��Ƃ�����g�����W�X�^�ʐς̌����グ�Ă��h����
>821
���s���j�b�g(�N���X�^)�̏璷��?�݂����ȃe�N�j�b�N���g�����Ď�?
���|�I�Ȃ��芷����
�����v���Z�X���ǂ����Ȃ��Ƃ�����g�����W�X�^�ʐς̌����グ�Ă��h����
>821
���s���j�b�g(�N���X�^)�̏璷��?�݂����ȃe�N�j�b�N���g�����Ď�?
����AMD���ȓd�͂ɖ{�������邱�Ƃ�
>>839
> ����AMD����͂������
> ���|�I�Ȃ��芷����
> �����v���Z�X���ǂ����Ȃ��Ƃ�����g�����W�X�^�ʐς̌����グ�Ă��h����
���ɂ��Ĉ��|�I���ɂ���
�O���t�B�b�N��GPGPU���\�͈��|�I���낤�B
�ق��͑������B
������Ƃ̌݊��������Ȃ荂��
> >821
> ���s���j�b�g(�N���X�^)�̏璷��?�݂����ȃe�N�j�b�N���g�����Ď�?
�P���ɐ����ƕ����������j�b�g��ʁX�ɃN���X�^�����A�Z�O�����g���ƂɊ�����������Ƃ������ƁB
���Ȃ�̂�CPU��FPU���ʂ������B
�����̂�CPU��FPU����������B(CPU=����+����)
�ŋ߂�CPU�R�A���ς�ł���B(CPU=(����+����)*X)
Bulldozer��CPU=(����*2)+(128bit����*2)��������CPU�R�A(���W���[��)��
AMD�̏����\�z�́ACPU=(����*X)+(����*Y)�ɂȂ�Ǝv���B
> ����AMD����͂������
> ���|�I�Ȃ��芷����
> �����v���Z�X���ǂ����Ȃ��Ƃ�����g�����W�X�^�ʐς̌����グ�Ă��h����
���ɂ��Ĉ��|�I���ɂ���
�O���t�B�b�N��GPGPU���\�͈��|�I���낤�B
�ق��͑������B
������Ƃ̌݊��������Ȃ荂��
> >821
> ���s���j�b�g(�N���X�^)�̏璷��?�݂����ȃe�N�j�b�N���g�����Ď�?
�P���ɐ����ƕ����������j�b�g��ʁX�ɃN���X�^�����A�Z�O�����g���ƂɊ�����������Ƃ������ƁB
���Ȃ�̂�CPU��FPU���ʂ������B
�����̂�CPU��FPU����������B(CPU=����+����)
�ŋ߂�CPU�R�A���ς�ł���B(CPU=(����+����)*X)
Bulldozer��CPU=(����*2)+(128bit����*2)��������CPU�R�A(���W���[��)��
AMD�̏����\�z�́ACPU=(����*X)+(����*Y)�ɂȂ�Ǝv���B
���_�FFusion�ɑR�ł��鐻�i���C���e���͏o���Ȃ�
�@�@�@���������āA�C���e���̏������̓[��
�@�@�@���������āA�C���e���̏������̓[��
�ŁA�Ȃ����Fusion��Llano����Ȃ��Đ^��Fusion���i�͂��o��́H
2012�N��2013�N�ɂ�Bulldozer4�`8�R�A+HD6670���o�Ă���Ǝv����B
Intel��Sandy�̎��̓z+GMA���낤���ǂȁB
������GMA���t���Ă���Ƃ��������Ȃ����H
�܂��A���܂���͂ǂ�������GMA�Ȃ��Ђ��g��Ȃ���H
��������RADEON����AMD�̍������ɍv�����Ă���B
�������n�C�G���h�u���̂��O��̂��ƁA5���~�ʂ�HD6870��8���~��HD6970���w�����Ă����ƐM���Ă���B
CPU�͂ǂ���OC���邩��3���~���炢�̈����z��������B
���O���2011�N�̍\����
Sandy ��3���ʂ�4�R�A�̈������c�𐅗��5GHz
2�����炢�̈���1155�}�U�[
5�����炢��HD6870
���낤�ȁB
Intel��Sandy�̎��̓z+GMA���낤���ǂȁB
������GMA���t���Ă���Ƃ��������Ȃ����H
�܂��A���܂���͂ǂ�������GMA�Ȃ��Ђ��g��Ȃ���H
��������RADEON����AMD�̍������ɍv�����Ă���B
�������n�C�G���h�u���̂��O��̂��ƁA5���~�ʂ�HD6870��8���~��HD6970���w�����Ă����ƐM���Ă���B
CPU�͂ǂ���OC���邩��3���~���炢�̈����z��������B
���O���2011�N�̍\����
Sandy ��3���ʂ�4�R�A�̈������c�𐅗��5GHz
2�����炢�̈���1155�}�U�[
5�����炢��HD6870
���낤�ȁB
Intel�����\�O���t�B�b�N�`�b�v��Ђ����Ă����悤�ȋC�����邯�ǂ˂��B
>>845
���̌��ʂ�����GMA�ł���A���s����Larrabee�B
Larrabee�͓��Ƀh���C�o�����������炵���B
DX10�Ή����疞���ɂł��Ȃ������Ƃ��B
���̌��ʂ�����GMA�ł���A���s����Larrabee�B
Larrabee�͓��Ƀh���C�o�����������炵���B
DX10�Ή����疞���ɂł��Ȃ������Ƃ��B
GMA��Imagination Technologies����̃��C�Z���X����
>>845
���낢�딃���Ă����ǁA�����ɕ����ė����ڂɂȂ����Ƃ����Ă�����A
intel�̓���GPU�̐��\��AMD�ANVIDIA�ɔ�ׂĂ��܂����Ȃ܂܂���Ȃ��́H
>>847
�����PowerVR���g���Ă���g�ݍ��ݗp��Atom�����B
����GMA��intel�̎��O�B
���낢�딃���Ă����ǁA�����ɕ����ė����ڂɂȂ����Ƃ����Ă�����A
intel�̓���GPU�̐��\��AMD�ANVIDIA�ɔ�ׂĂ��܂����Ȃ܂܂���Ȃ��́H
>>847
�����PowerVR���g���Ă���g�ݍ��ݗp��Atom�����B
����GMA��intel�̎��O�B
http://www.4gamer.net/games/032/G003263/20091217105/
���@PC�p�f�o�C�X�Ƃ��ẮC���łɖY����ċv�����̂����C���ɂ̓m�[�gPC��
���W�����������B�m���ɍŋ߂ł́CIntel��Atom�p�`�b�v�Z�b�g�i������PineView�j
���ɂ��O���t�B�b�N�X�p�R�A�Ƃ���IP���̗p����Ă���B�b���Ă݂�ƁCIntel����
���h���C�o�ł̓R�A�̐��\���܂����������ł��Ă��Ȃ��Ƃ����B�h���C�o�W�̍œK
�����Łu���\�{�͑����Ȃ�v�Ƃ̂��ƁB
Imagination Technologies���h���C�o�J���ɋ��͂��Ă�炵�����炻�̂���Core���Atom�̕���GPU���\�オ�����肵��
���@PC�p�f�o�C�X�Ƃ��ẮC���łɖY����ċv�����̂����C���ɂ̓m�[�gPC��
���W�����������B�m���ɍŋ߂ł́CIntel��Atom�p�`�b�v�Z�b�g�i������PineView�j
���ɂ��O���t�B�b�N�X�p�R�A�Ƃ���IP���̗p����Ă���B�b���Ă݂�ƁCIntel����
���h���C�o�ł̓R�A�̐��\���܂����������ł��Ă��Ȃ��Ƃ����B�h���C�o�W�̍œK
�����Łu���\�{�͑����Ȃ�v�Ƃ̂��ƁB
Imagination Technologies���h���C�o�J���ɋ��͂��Ă�炵�����炻�̂���Core���Atom�̕���GPU���\�オ�����肵��
>Larrabee�͓��Ƀh���C�o�����������炵���B
>DX10�Ή����疞���ɂł��Ȃ������Ƃ��B
������plz
>DX10�Ή����疞���ɂł��Ȃ������Ƃ��B
������plz
>>849
���̋L�������Ă�L�ҁAPineview��PowerVR�̗p����Ă���Ɗ��Ⴂ���Ă�ȁB
Pineview��GMA3150�Ə]������g���Ă���intel��GPU�R�A�̔h���B
�������AH.264�̍Đ��x���ɂ͑Ή����Ă��Ȃ��B
���̋L�������Ă�L�ҁAPineview��PowerVR�̗p����Ă���Ɗ��Ⴂ���Ă�ȁB
Pineview��GMA3150�Ə]������g���Ă���intel��GPU�R�A�̔h���B
�������AH.264�̍Đ��x���ɂ͑Ή����Ă��Ȃ��B
>>850
ttp://www.4gamer.net/games/049/G004963/20091212001/
���́C���̖��߃Z�b�g���������\�t�g�E�F�A���̐������x�ꂽ���ƂɈ��������āC
DirectX���͂��߂Ƃ���O���t�B�b�N�XAPI�ւ̑Ή����啝�ɒx��Ă��܂����_�ɂ���B
�Ƃ���Q�[���f�x���b�p�W�҂ɂ��CLarrabee�́CDirectX 10�ւ̍œK������C
�\���Ƃ͂����Ȃ���Ԃ������悤���B
ttp://www.4gamer.net/games/049/G004963/20091212001/
���́C���̖��߃Z�b�g���������\�t�g�E�F�A���̐������x�ꂽ���ƂɈ��������āC
DirectX���͂��߂Ƃ���O���t�B�b�N�XAPI�ւ̑Ή����啝�ɒx��Ă��܂����_�ɂ���B
�Ƃ���Q�[���f�x���b�p�W�҂ɂ��CLarrabee�́CDirectX 10�ւ̍œK������C
�\���Ƃ͂����Ȃ���Ԃ������悤���B
Larrabee�Ɍ��炸�C���e����GPU�͂���
�\�t�g�E�F�A���肪�l�b�N�ɂȂ��Ă�
�\�t�g�E�F�A���肪�l�b�N�ɂȂ��Ă�
DirectX10�ɑΉ��o���Ȃ��Ȃ�Windows�̃��S�����Ȃ������
���ꂶ�Ⴀ�������Ă����[�J�[���̗p�ł��Ȃ���
�������~��ނȂ�
���ꂶ�Ⴀ�������Ă����[�J�[���̗p�ł��Ȃ���
�������~��ނȂ�
>>851
D410��D510��Intel�ŁAN450��PowerVR�Ƃ������Ƃ��ȁB
D410��D510��Intel�ŁAN450��PowerVR�Ƃ������Ƃ��ȁB
�����r�[�̓Q�[���@�̃r�W�l�X���f���݂����ɁA�����@�̒i�K�ł̓R�X�g����̐Ԏ��ŏo�ׂ��A
�Ƃɂ����\�t�g�𑵂���������肾�����������A���ꂷ����o���Ȃ��������Ď�������A
�ǂ����悤���Ȃ����������ˁB
�Ƃɂ����\�t�g�𑵂���������肾�����������A���ꂷ����o���Ȃ��������Ď�������A
�ǂ����悤���Ȃ����������ˁB
Westmere����Ŕ�IGP��Xeon�������B
Xeon�u�[���ɂȂ肻���ȋC�z�B
Xeon�u�[���ɂȂ肻���ȋC�z�B
�����Ȃ�����AUP-Xeon����
>>857
4�R�A��IGP���ɂȂ�́H
4�R�A��IGP���ɂȂ�́H
>>856
Larrabee���O���t�B�b�N�����œP���̂�FTC�̒�i���݂�
�`���I�ȏ����K�ɂ��̔��T�|�[�g���ł��Ȃ��Ȃ邩�炾�����肵��
���ꂪ�Ȃ������琫�\�ŗ���Ă��悤��������˂�����ł���
Larrabee���O���t�B�b�N�����œP���̂�FTC�̒�i���݂�
�`���I�ȏ����K�ɂ��̔��T�|�[�g���ł��Ȃ��Ȃ邩�炾�����肵��
���ꂪ�Ȃ������琫�\�ŗ���Ă��悤��������˂�����ł���
861 �F,,�E�L�́M�E,,�j��-�������F2009/12/19(�y) 00:25:09 ID:3i+jMY02
�ǂ݂̂��f�B�X�N���[�g���C���e�O���[�g��������ˁH
�uIntel CPU�ɘR��Ȃ������v�̂ق������y����Ǝv�����ǂ�
�uIntel CPU�ɘR��Ȃ������v�̂ق������y����Ǝv�����ǂ�
�f�B�X�N���[�g�ɂ��ĎЊO�ŗL���ȃA�v���J�����Ă��炨���Ƃ����猩���Ă�̂�
���̂܂܃C���e�O���[�g���Ă��f�b�h�X�y�[�X���ł��邾����������
Intel���͂���L���[�A�v���J���ł��Ȃ��ł���
���̂܂܃C���e�O���[�g���Ă��f�b�h�X�y�[�X���ł��邾����������
Intel���͂���L���[�A�v���J���ł��Ȃ��ł���
�����������邩��A�Ƃ肠�����f�B�X�N���[�g�őΉ����Ă��炨���Ƃ������Ƃ������ł���H
������ςȂ����T�����珫���������Ȃ��Ǝv�����B
��������AVX��256bit�Ή��A�v������o�ꂪ�������̂ɁA
LNI��512/1024bit�Ή��������ł���Ƃ͎v����B
�c�q��AVX��LNI�Ή��������ǂ�Ȃӂ��ɐi�ނƎv���Ă�H
�܂����A2011�N��Sandy�o�ꂪ���[�G���h�܂ň�C�ɓo��A������AVX�Ή��\�t�g�����y�A
2014�N����LNI�Ή�CPU����C�ɓo��A�Ή��\�t�g�������ɕ��y�Ƃł��v���Ă�̂��B
������ςȂ����T�����珫���������Ȃ��Ǝv�����B
��������AVX��256bit�Ή��A�v������o�ꂪ�������̂ɁA
LNI��512/1024bit�Ή��������ł���Ƃ͎v����B
�c�q��AVX��LNI�Ή��������ǂ�Ȃӂ��ɐi�ނƎv���Ă�H
�܂����A2011�N��Sandy�o�ꂪ���[�G���h�܂ň�C�ɓo��A������AVX�Ή��\�t�g�����y�A
2014�N����LNI�Ή�CPU����C�ɓo��A�Ή��\�t�g�������ɕ��y�Ƃł��v���Ă�̂��B
�c�q�����Ă���Ȃɑ������y����Ƃ͎v���ĂȂ�����A�������V�ׂ���Ă�����
����P3��SSE���o�Ă���܂Ƃ��Ɏg����悤�ɂȂ����̂�P4�̎���ɂȂ��Ă��炶���
x64�������5�N���炢�����ǂ�������32bit���C������
����P3��SSE���o�Ă���܂Ƃ��Ɏg����悤�ɂȂ����̂�P4�̎���ɂȂ��Ă��炶���
x64�������5�N���炢�����ǂ�������32bit���C������
�����V�Ԃ̘b�����Ȃ畁�y���ǂ��Ƃ������������ƌ��킸��
�O���t�B�b�N�������~��Intel�`�L���Ƃ�
�f�B�X�N���[�g�J�[�h�ł������Ɣ������ė~�����Ƃ�
�����Ƃ����Ęb
�O���t�B�b�N�������~��Intel�`�L���Ƃ�
�f�B�X�N���[�g�J�[�h�ł������Ɣ������ė~�����Ƃ�
�����Ƃ����Ęb
866 �F,,�E�L�́M�E,,�j��-�������F2009/12/19(�y) 11:57:39 ID:3i+jMY02
867 �F,,�E�L�́M�E,,�j��-�������F2009/12/19(�y) 11:59:08 ID:3i+jMY02
>>865
�ǂ��ł������悤�邳���J�[�h��������
�ǂ��ł������悤�邳���J�[�h��������
NEC���X�p�R���̃A�N�Z�����[�^�Ƃ��Ĕ����Ă�����Ȃ��́H
�X�p�R���̊̂͂������Z�@�����f�[�^�p�X
SX�������Ȃ̂��v���Z�b�T������̂�������Ȃ�
Larrabee������ƌ����Ă����ꂵ���Ȃ����낤
SX�������Ȃ̂��v���Z�b�T������̂�������Ȃ�
Larrabee������ƌ����Ă����ꂵ���Ȃ����낤
����ł��X�̉��Z�@�̌������悭�Ȃ����菬�^���ł����
1�m�[�h�̂�������߂���m�[�h�Ԕz�����Z���Ȃ�����
�������͂���
1�m�[�h�̂�������߂���m�[�h�Ԕz�����Z���Ȃ�����
�������͂���
>>866
>>852�Ń\�t�g�����x��Ă���Ƃ����b������ACt���x��Ă�낤�ˁB
SSE��AVX�����܂��Ȃ�ALNI���܂ꂻ�����ȁB
�Ԃ����Ⴏ�c�q��LNI CPU�̃��[�G���h���o�āA�Ή��\�t�g�������Ă���̂͂����炾�Ɨ\�z���Ă���H
>>852�Ń\�t�g�����x��Ă���Ƃ����b������ACt���x��Ă�낤�ˁB
SSE��AVX�����܂��Ȃ�ALNI���܂ꂻ�����ȁB
�Ԃ����Ⴏ�c�q��LNI CPU�̃��[�G���h���o�āA�Ή��\�t�g�������Ă���̂͂����炾�Ɨ\�z���Ă���H
�����܂��߂ɍœK�����HPC�����v���O�����Ƃ���������Ƃ���l�ԂȂ�
�x�N�g�������L�тĂ��L���ȃA�v���P�[�V�����Ȃ�Ă���Ȃɑ�����킯����
�Ȃ����Ƃ��炢�����肻���Ȃ��̂Ȃ̂�
�x�N�g�����𑝂₷���A64bit���������_���Z���j�b�g�𑽂��ςݍ���߂�
�x�N�g�������L�тĂ��L���ȃA�v���P�[�V�����Ȃ�Ă���Ȃɑ�����킯����
�Ȃ����Ƃ��炢�����肻���Ȃ��̂Ȃ̂�
�x�N�g�����𑝂₷���A64bit���������_���Z���j�b�g�𑽂��ςݍ���߂�
�Ⴆ�������炢�悹���炢���Ǝv���H
���������_���Z�̓��C�e���V����������
���Z��𑝂₵�Ă����\�͏オ���
���Z��𑝂₵�Ă����\�͏オ���
���Z�푝�₷�����ł̓_���ŁA
�X���b�h���₵��TLP���w�����邩�A
�x�N�^�����₵��DLP���B
������ɂ���A���S���Y�����̂ɕ���������l�ށB
�X���b�h���₵��TLP���w�����邩�A
�x�N�^�����₵��DLP���B
������ɂ���A���S���Y�����̂ɕ���������l�ށB
Sandy Bridge��CPU���Ė{����Westmare�̂܂܂Ȃ̂��ˁH
�ǂ����炻���������z���o�Ă����̂��s�v�c�����A
Sandy Bridge��Westmere�����ʂȂ͓̂���32nm�v���Z�X�Ƃ������Ƃ��炢���B
Sandy Bridge��Westmere�����ʂȂ͓̂���32nm�v���Z�X�Ƃ������Ƃ��炢���B
878 �F,,�E�L�́M�E,,�j��-�������F2009/12/20(��) 02:34:20 ID:Zm+GEAOX
GPU���̂ق�����
Sandy=Nehalem+AVX+GMA����Ȃ��̂��H
Sandy Bridge�̓C�X���G���`�[���B
Core MA�̖{�Ƃ��A�I���S���������Core MA�̔h�����ł���Nehalem��
�������K�v�͂���܂��B
Core MA�̖{�Ƃ��A�I���S���������Core MA�̔h�����ł���Nehalem��
�������K�v�͂���܂��B
881 �F,,�E�L�́M�E,,�j��-�������F2009/12/20(��) 04:46:29 ID:Zm+GEAOX
AVX�ȊO��Nehalem���̂��̂̐����i������
�C�X���G���~�̔n���͂�������������
ttp://www.intel.com/en_UK/CannonBells/index.htm
�C���e��UK��
�C���e��UK��
884 �F,,�E�L�́M�E,,�j��-�������F2009/12/20(��) 11:48:34 ID:Zm+GEAOX
>>883
�o������Ȫ
�o������Ȫ
885 �F,,�E�L�́M�E,,�j��-�������F2009/12/20(��) 14:17:03 ID:Zm+GEAOX
>>871
�\�t�g���o�Ă��邩�͂��Ă����ALarrabee�����v���Z�b�T���o���ŏ��ōŌ�̋@���
��ɂ���ɂ�Haswell����ˁ[�̂��ȁB
3����ڂ���s����ƌ����Ă邩��45nm��1����Ƃ��Ē��x22nm����
Sandy Bridge�ł�GMA�����iL3�t���A�N�Z�X�j�͂��̕z�ł���B
�Ƃ������A�\�t�g�����Ή����Ȃ��ƃ��\�[�X�����ė]�����ĈӖ��ł�AMD�������Ȃ̂�
�����Ă��炤�����ŁB
�����Ƃ��Ă݂͂�ȓ�������ˁH
���̒��x�̕���x����g�����Ȃ��Ȃ��Ȃ�GPGPU�Ȃ����Ɩ��������B
�\�t�g���o�Ă��邩�͂��Ă����ALarrabee�����v���Z�b�T���o���ŏ��ōŌ�̋@���
��ɂ���ɂ�Haswell����ˁ[�̂��ȁB
3����ڂ���s����ƌ����Ă邩��45nm��1����Ƃ��Ē��x22nm����
Sandy Bridge�ł�GMA�����iL3�t���A�N�Z�X�j�͂��̕z�ł���B
�Ƃ������A�\�t�g�����Ή����Ȃ��ƃ��\�[�X�����ė]�����ĈӖ��ł�AMD�������Ȃ̂�
�����Ă��炤�����ŁB
�����Ƃ��Ă݂͂�ȓ�������ˁH
���̒��x�̕���x����g�����Ȃ��Ȃ��Ȃ�GPGPU�Ȃ����Ɩ��������B
AMD��GPU��Intel�ƈ���Ă܂Ƃ��Ȑ��\�������Ă邩��
��芸�������ʂɃO���t�B�b�N�����Ŏg���Ă��炦�Ηǂ�����
��芸�������ʂɃO���t�B�b�N�����Ŏg���Ă��炦�Ηǂ�����
>>885
AMD��GPU�͓����ł�DX11�Ή��ł���Ȃ�̐��\�ƃh���C�o�̊����x�������̂͊m���B
����GPGPU���y���ڍ���x�����Ă��Đ��x���͓��R�Ƃ��āA��̂̃Q�[�����������邵�A�}���`��ʂȂǂ̕t�����l������B
�t��Intel��Widows�\���ȊO�ɂ܂Ƃ��Ɏg���Ȃ��͕̂ς��Ȃ����낤����ǂ����悤���Ȃ��B
AMD��GPU�͓����ł�DX11�Ή��ł���Ȃ�̐��\�ƃh���C�o�̊����x�������̂͊m���B
����GPGPU���y���ڍ���x�����Ă��Đ��x���͓��R�Ƃ��āA��̂̃Q�[�����������邵�A�}���`��ʂȂǂ̕t�����l������B
�t��Intel��Widows�\���ȊO�ɂ܂Ƃ��Ɏg���Ȃ��͕̂ς��Ȃ����낤����ǂ����悤���Ȃ��B
888 �F,,�E�L�́M�E,,�j��-�������F2009/12/20(��) 15:46:23 ID:Zm+GEAOX
GMA�̃V�F�[�_���j�b�g��Sandy Bridge����ł�12�`16SP���x�B
GeForce 9400M�ɏ��Ă邩�ǂ����̃��x���Ȃ̂�GPGPU�ȑO�̖��B
�Ƃ�����CPU 1�R�A�̕��������B
Sandy Bridge����łƂ�ׂ��p�t�H�[�}���X�헪�́A���_�V�F�[�f�B���O��GMA�ɂ�点�Ȃ����Ƃ��B
�h���C�o���x���ʼn��z������ǂ����œ����Ă邩�̓A�v������͋�ʂ���K�v�͂Ȃ��B
�W�Ȃ����ǃ��C�g�j���O����̓G����
GeForce 9400M�ɏ��Ă邩�ǂ����̃��x���Ȃ̂�GPGPU�ȑO�̖��B
�Ƃ�����CPU 1�R�A�̕��������B
Sandy Bridge����łƂ�ׂ��p�t�H�[�}���X�헪�́A���_�V�F�[�f�B���O��GMA�ɂ�点�Ȃ����Ƃ��B
�h���C�o���x���ʼn��z������ǂ����œ����Ă邩�̓A�v������͋�ʂ���K�v�͂Ȃ��B
�W�Ȃ����ǃ��C�g�j���O����̓G����
>>888
> GMA�̃V�F�[�_���j�b�g��Sandy Bridge����ł�12�`16SP���x�B
> GeForce 9400M�ɏ��Ă邩�ǂ����̃��x���Ȃ̂�GPGPU�ȑO�̖��B
> �Ƃ�����CPU 1�R�A�̕��������B
>
> Sandy Bridge����łƂ�ׂ��p�t�H�[�}���X�헪�́A���_�V�F�[�f�B���O��GMA�ɂ�点�Ȃ����Ƃ��B
> �h���C�o���x���ʼn��z������ǂ����œ����Ă邩�̓A�v������͋�ʂ���K�v�͂Ȃ��B
Larrabee���s�̎�v�����h���C�o�̕����Ȃ��A����ł�Intel�̃h���C�o�Ɋ��҂���́H
���łɕ����������A6�R�A12�X���b�h��Gulftown�ƁA4�R�A8�X���b�h��Sandybridge�͂ǂ��炪�����������Ǝv���H
> GMA�̃V�F�[�_���j�b�g��Sandy Bridge����ł�12�`16SP���x�B
> GeForce 9400M�ɏ��Ă邩�ǂ����̃��x���Ȃ̂�GPGPU�ȑO�̖��B
> �Ƃ�����CPU 1�R�A�̕��������B
>
> Sandy Bridge����łƂ�ׂ��p�t�H�[�}���X�헪�́A���_�V�F�[�f�B���O��GMA�ɂ�点�Ȃ����Ƃ��B
> �h���C�o���x���ʼn��z������ǂ����œ����Ă邩�̓A�v������͋�ʂ���K�v�͂Ȃ��B
Larrabee���s�̎�v�����h���C�o�̕����Ȃ��A����ł�Intel�̃h���C�o�Ɋ��҂���́H
���łɕ����������A6�R�A12�X���b�h��Gulftown�ƁA4�R�A8�X���b�h��Sandybridge�͂ǂ��炪�����������Ǝv���H
890 �F,,�E�L�́M�E,,�j��-�������F2009/12/20(��) 22:29:23 ID:Zm+GEAOX
6�R�A12�X���b�h��Sandybridge���Ηǂ������B
DDR3 3ch�~��������H
DDR3 3ch�~��������H
891 �F,,�E�L�́M�E,,�j��-�������F2009/12/20(��) 22:56:45 ID:Zm+GEAOX
��Larrabee���s�̎�v�����h���C�o�̕����Ȃ��A
���̂���������H
�\�t�g���ǂꂾ���撣�낤���n�[�h�E�F�A�̓����͕ς���B
�w���Ƀv���O���}�u���ɂ�����Œ�@�\�ς��������Ƃ����]��GPU�̃p���_�C����
����Ȃ��������̂̂��ƁB
���̂���������H
�\�t�g���ǂꂾ���撣�낤���n�[�h�E�F�A�̓����͕ς���B
�w���Ƀv���O���}�u���ɂ�����Œ�@�\�ς��������Ƃ����]��GPU�̃p���_�C����
����Ȃ��������̂̂��ƁB
��Larrabee���s�̎�v�����h���C�o�̕����Ȃ��A
�Œ�@�\�̖w�ǂ��\�t�g����������Ƃ�
���̂ǂ̉�Ђ�����ĂȂ��悤��
�������������t�����Ă�̂�
����Ȍ��������ĂȂ�
�Œ�@�\�̖w�ǂ��\�t�g����������Ƃ�
���̂ǂ̉�Ђ�����ĂȂ��悤��
�������������t�����Ă�̂�
����Ȍ��������ĂȂ�
893 �F,,�E�L�́M�E,,�j��-�������F2009/12/20(��) 23:04:58 ID:Zm+GEAOX
�ėp�X���[�v�b�g�R���s���[�e�B���O����肽���l�͕ʂɃQ�[������肽���킯����Ȃ��B
����intel��GPU�̋@�\�̈ꕔ��CPU�œ������悤�Ƀh���C�o�X�V���ĂȂ������H
�����3DMark�ł���Ă͂����Ȃ��œK��������Ă���ĊC�O�̋L�����������悤�ȁB
�����3DMark�ł���Ă͂����Ȃ��œK��������Ă���ĊC�O�̋L�����������悤�ȁB
>>892
�N�������t�����悗
�N�������t�����悗
896 �F,,�E�L�́M�E,,�j��-�������F2009/12/20(��) 23:40:57 ID:Zm+GEAOX
�ق�Epic Games
>>891
> ��Larrabee���s�̎�v�����h���C�o�̕����Ȃ��A
>
> ���̂���������H
> �\�t�g���ǂꂾ���撣�낤���n�[�h�E�F�A�̓����͕ς���B
> �w���Ƀv���O���}�u���ɂ�����Œ�@�\�ς��������Ƃ����]��GPU�̃p���_�C����
> ����Ȃ��������̂̂��ƁB
Larrabee�͊m��DX11�Ɋ��S�Ή�����Ƃ����b��������ˁH
�܂��������Ȃ背�C�g���[�V���O�����y������AHPC�����ɓW�J�ł���Ǝv���Ă����킯����Ȃ��ł���B
�����獡�o���Ȃ�DX11�Ή��͍Œ�ł��K�v�������B
�Q�[���Ή��͔����ł�DXCS��GPGPU�x���`������ō����\�������珫���ɂȂ��邩��ˁB
�Ƃ��낪�����́ADX11�ǂ��납DX10�ɂ��疞���ɑΉ��o���Ȃ������킯�ŁB
�m��Larrabee�̃h���C�o�̓{���N��GMA�`�[������Ȃ��A�I�肷����̃X�^�b�t���J�����Ă���ƕ������B
����ł����̗l�������킯���B
�c�q�͂��낻��A�c�q�̗��z������Intel�͋Z�p�͕s�������A
Intel�̋����Ȑ헪�Ɏ���̃\�t�g�x���_�͂��čs���Ȃ����ƂɋC�Â������������B
> ��Larrabee���s�̎�v�����h���C�o�̕����Ȃ��A
>
> ���̂���������H
> �\�t�g���ǂꂾ���撣�낤���n�[�h�E�F�A�̓����͕ς���B
> �w���Ƀv���O���}�u���ɂ�����Œ�@�\�ς��������Ƃ����]��GPU�̃p���_�C����
> ����Ȃ��������̂̂��ƁB
Larrabee�͊m��DX11�Ɋ��S�Ή�����Ƃ����b��������ˁH
�܂��������Ȃ背�C�g���[�V���O�����y������AHPC�����ɓW�J�ł���Ǝv���Ă����킯����Ȃ��ł���B
�����獡�o���Ȃ�DX11�Ή��͍Œ�ł��K�v�������B
�Q�[���Ή��͔����ł�DXCS��GPGPU�x���`������ō����\�������珫���ɂȂ��邩��ˁB
�Ƃ��낪�����́ADX11�ǂ��납DX10�ɂ��疞���ɑΉ��o���Ȃ������킯�ŁB
�m��Larrabee�̃h���C�o�̓{���N��GMA�`�[������Ȃ��A�I�肷����̃X�^�b�t���J�����Ă���ƕ������B
����ł����̗l�������킯���B
�c�q�͂��낻��A�c�q�̗��z������Intel�͋Z�p�͕s�������A
Intel�̋����Ȑ헪�Ɏ���̃\�t�g�x���_�͂��čs���Ȃ����ƂɋC�Â������������B
HPC�����Ƃ����Ă�PCI-E�ڑ��ł́��݂����ȃV�X�e���Ƃ͏����ɂȂ�Ȃ�����
�܂����i�т��Ⴄ���낤����
ttp://cheerhpc.wordpress.com/2009/11/18/%E2%97%8Fblue-waters%E7%94%A8power7/
1TFLOPS(64bit)�̃v���Z�b�T���W���[���ɑ���1.1TB/s��
�ʐM���W���[�������蓖�Ă���Ƃ����R���f�B�e�BPC�Ƃ͕ʐ��E
�܂����i�т��Ⴄ���낤����
ttp://cheerhpc.wordpress.com/2009/11/18/%E2%97%8Fblue-waters%E7%94%A8power7/
1TFLOPS(64bit)�̃v���Z�b�T���W���[���ɑ���1.1TB/s��
�ʐM���W���[�������蓖�Ă���Ƃ����R���f�B�e�BPC�Ƃ͕ʐ��E
899 �F,,�E�L�́M�E,,�j��-�������F2009/12/21(��) 00:35:27 ID:zko0DQ24
�����炱����QPI���낤
900 �F,,�E�L�́M�E,,�j��-�������F2009/12/21(��) 00:36:37 ID:zko0DQ24
���܂��������Ȃ背�C�g���[�V���O�����y������A
��DX�����C�g���[�V���O�ł����E�E�E�������������ł��������
��HPC�����ɓW�J�ł���Ǝv���Ă����킯����Ȃ��ł���B
�W�J�o����ł���QPI�ڑ��Ȃ�
��DX�����C�g���[�V���O�ł����E�E�E�������������ł��������
��HPC�����ɓW�J�ł���Ǝv���Ă����킯����Ȃ��ł���B
�W�J�o����ł���QPI�ڑ��Ȃ�
��1.1TB/s
���ꎩ�̂�PCIe3.0x16�ŃN���A
�ł����̐��Infiniband��QDR�ł�160Gbps�Ȃ̂Łc
�[���ŁANEC�EIntel�͌��C���^�[�R�l�N�g���������ƍ�鎖
���ꎩ�̂�PCIe3.0x16�ŃN���A
�ł����̐��Infiniband��QDR�ł�160Gbps�Ȃ̂Łc
�[���ŁANEC�EIntel�͌��C���^�[�R�l�N�g���������ƍ�鎖
Intel�̃O���t�B�b�N�����h���C�o�̊J���\�͂��Ⴂ�͎̂���
�{�C�Ń��\�[�X��������łȂ����炩�������
�{�C�Ń��\�[�X��������łȂ����炩�������
����GPU�͐�p�o�X�ڑ��ɉ�A����̂��E�E�E�H
>>897
�ϑz��
�ϑz��
>>897
����
����
>>900
> ���܂��������Ȃ背�C�g���[�V���O�����y������A
> ��DX�����C�g���[�V���O�ł����E�E�E�������������ł��������
�L�������ł̒����ɗ��s�肻���Ȕ�DX�ȊO�̃Q�[������_�����O��@�������Ă���B
> ��HPC�����ɓW�J�ł���Ǝv���Ă����킯����Ȃ��ł���B
> �W�J�o����ł���QPI�ڑ��Ȃ�
�L�����Z������Larrabee����QPI�o�X�ɑΉ����Ă��������H
����Ƃ����ɓ�������z�̂��Ƃ��H
> ���܂��������Ȃ背�C�g���[�V���O�����y������A
> ��DX�����C�g���[�V���O�ł����E�E�E�������������ł��������
�L�������ł̒����ɗ��s�肻���Ȕ�DX�ȊO�̃Q�[������_�����O��@�������Ă���B
> ��HPC�����ɓW�J�ł���Ǝv���Ă����킯����Ȃ��ł���B
> �W�J�o����ł���QPI�ڑ��Ȃ�
�L�����Z������Larrabee����QPI�o�X�ɑΉ����Ă��������H
����Ƃ����ɓ�������z�̂��Ƃ��H
907 �F,,�E�L�́M�E,,�j��-�������F2009/12/21(��) 02:14:17 ID:zko0DQ24
> �c�q�͂��낻��A�c�q�̗��z������Intel�͋Z�p�͕s�������A
> Intel�̋����Ȑ헪�Ɏ���̃\�t�g�x���_�͂��čs���Ȃ����ƂɋC�Â������������B
�ǂ��Ȃ痝�z�����ł���ƁH
Intel�̏o���Ă�t���[�����[�N����g�����Ȃ��Ȃ��\�t�g�x���_���낭�ȃ��m����Ƃ͎v���ȁB
���ЂŃR���p�C���C���t�������Ȃ�AMD�Ɋ��҂��Ă����傤���Ȃ���
�i���ꂪ����Ă�̂�GCC��LLVM�Ȃǂ̃I�[�v���\�[�X�c�[���̃J�X�^�}�C�Y�����j
NVIDIA�̓A���ŃA������
����GPU���g���Ȃ��Ȃ�CPU�I�����[�ł�邾������B
�g���Ȃ����m�o����Ă��g���Ȃ��Ȃ�K�v�Ȃ����B
> Intel�̋����Ȑ헪�Ɏ���̃\�t�g�x���_�͂��čs���Ȃ����ƂɋC�Â������������B
�ǂ��Ȃ痝�z�����ł���ƁH
Intel�̏o���Ă�t���[�����[�N����g�����Ȃ��Ȃ��\�t�g�x���_���낭�ȃ��m����Ƃ͎v���ȁB
���ЂŃR���p�C���C���t�������Ȃ�AMD�Ɋ��҂��Ă����傤���Ȃ���
�i���ꂪ����Ă�̂�GCC��LLVM�Ȃǂ̃I�[�v���\�[�X�c�[���̃J�X�^�}�C�Y�����j
NVIDIA�̓A���ŃA������
����GPU���g���Ȃ��Ȃ�CPU�I�����[�ł�邾������B
�g���Ȃ����m�o����Ă��g���Ȃ��Ȃ�K�v�Ȃ����B
908 �F,,�E�L�́M�E,,�j��-�������F2009/12/21(��) 02:24:16 ID:zko0DQ24
���L�������ł̒����ɗ��s�肻���Ȕ�DX�ȊO�̃Q�[������_�����O��@�������Ă���B
�ŏ�������Intel�������Ă郁�\�b�h�����邾��B
Irregular Z-Buffer�ŃO�O��B����A-Buffer�A�X�Ɍ�����
http://www.4gamer.net/games/032/G003263/20080912053/screenshot.html?num=028
���L�����Z������Larrabee����QPI�o�X�ɑΉ����Ă��������H
HPC������QPI�ŏo�����Ƃ�11���̃��g�i�[�̔��\�Ō��y���Ă���B
�ŏ�������Intel�������Ă郁�\�b�h�����邾��B
Irregular Z-Buffer�ŃO�O��B����A-Buffer�A�X�Ɍ�����
http://www.4gamer.net/games/032/G003263/20080912053/screenshot.html?num=028
���L�����Z������Larrabee����QPI�o�X�ɑΉ����Ă��������H
HPC������QPI�ŏo�����Ƃ�11���̃��g�i�[�̔��\�Ō��y���Ă���B
Cell�~��낵���\�t�g�x���_�ᔻ��
910 �F,,�E�L�́M�E,,�j��-�������F2009/12/21(��) 02:28:03 ID:zko0DQ24
VTune��VB.NET��Python�̃{�g���l�b�N���͂܂őΉ����Ă���ǂ�
CUDA����ATI Stream�͂܂�VB��Python���瓮���Ȃ�����
CUDA����ATI Stream�͂܂�VB��Python���瓮���Ȃ�����
Intel�͎s�ꂩ���@�ɂ����߂����z�̋��ŐF�X�c�[���ނ�����Ă���ˁB
���Q����ĐԎ���AMD���ᖞ���Ƀc�[�������Ȃ�����A�܂������肾�B
CUDA�͒m��AAMD��CPU�������Ă��邩��A���ł�����ł�ATI Stream�őΉ��͂��Ȃ��Ǝv����B
���Ȃ��Ƃ�����\�[�X�I��C++��Brook+�ADX11CS��OpenCL�Ő���t���낤�ˁB
�܂�VB�͑債�ĕ��ł��Ȃ����������APython�Ƃ����߂ĕ���������m���B
���Q����ĐԎ���AMD���ᖞ���Ƀc�[�������Ȃ�����A�܂������肾�B
CUDA�͒m��AAMD��CPU�������Ă��邩��A���ł�����ł�ATI Stream�őΉ��͂��Ȃ��Ǝv����B
���Ȃ��Ƃ�����\�[�X�I��C++��Brook+�ADX11CS��OpenCL�Ő���t���낤�ˁB
�܂�VB�͑債�ĕ��ł��Ȃ����������APython�Ƃ����߂ĕ���������m���B
912 �F,,�E�L�́M�E,,�j��-�������F2009/12/21(��) 07:08:39 ID:zko0DQ24
�ى��͌��\�B
�͂��͂��B
http://developer.amd.com/cpu/simnow/Pages/default.aspx
AMD���i���g���Ă�\�t�g�J���҈ȊO��AMD�����̃R�[�h�����炳���Ă��炦�܂��B
�v��Ȃ�����B
���ꂶ��Intel C++ Compiler��ᔻ�ł��Ȃ���B
�͂��͂��B
http://developer.amd.com/cpu/simnow/Pages/default.aspx
AMD���i���g���Ă�\�t�g�J���҈ȊO��AMD�����̃R�[�h�����炳���Ă��炦�܂��B
�v��Ȃ�����B
���ꂶ��Intel C++ Compiler��ᔻ�ł��Ȃ���B
ATI Stream�Ȃ�Đ�̂Ċm�肾�낤��
914 �F,,�E�L�́M�E,,�j��-�������F2009/12/21(��) 07:21:01 ID:zko0DQ24
���Ȃ݂ɉ��̃R�[�h�`�F�b�N�p�}�V�����Ă�����������ڂ����B
Atom�@��x64 OS�ڂ��Ă���B
Bulldozer�̐V���߂��R�[�h�`�F�b�N����̂ɁA���s��AMD��CPU���ڂ����ς��傱����g���Ƃ�
����Ȕn���Șb�����邩���āB
�s����܂�1�N�`���C��Ȃ̂�XOP�Ή��̃R���p�C���͐��������[�X����ĂȂ��Ƃ������������ꂾ��
�킴�킴GCC 4.5��snapshot������Ă��ăR���p�C�����Ă����R�[�h���������Ƃ��Ă݂��͂�������
����m�F�ł��܂���Ƃ��ǂ��H
�t�@���{�[�C�ɂ�������C���Ȃ��Ƃ����v���Ȃ���ł����B
Apple��낵���A�̈ӂɃj�b�`����Ă��ˁ[�́H
Atom�@��x64 OS�ڂ��Ă���B
Bulldozer�̐V���߂��R�[�h�`�F�b�N����̂ɁA���s��AMD��CPU���ڂ����ς��傱����g���Ƃ�
����Ȕn���Șb�����邩���āB
�s����܂�1�N�`���C��Ȃ̂�XOP�Ή��̃R���p�C���͐��������[�X����ĂȂ��Ƃ������������ꂾ��
�킴�킴GCC 4.5��snapshot������Ă��ăR���p�C�����Ă����R�[�h���������Ƃ��Ă݂��͂�������
����m�F�ł��܂���Ƃ��ǂ��H
�t�@���{�[�C�ɂ�������C���Ȃ��Ƃ����v���Ȃ���ł����B
Apple��낵���A�̈ӂɃj�b�`����Ă��ˁ[�́H
AMD��@���Ă�Intel�̋Z�p�͕s���͒���Ȃ���
���̊�ƂƔ�r���Ăǂ������̖��ł͂Ȃ�
Intel����낤�Ƃ��Ă�����c�q�̖ϑz������������
Intel�̋Z�p�͂͑���ĂȂ��Ƃ������Ƃ���
���̊�ƂƔ�r���Ăǂ������̖��ł͂Ȃ�
Intel����낤�Ƃ��Ă�����c�q�̖ϑz������������
Intel�̋Z�p�͂͑���ĂȂ��Ƃ������Ƃ���
916 �F,,�E�L�́M�E,,�j��-�������F2009/12/21(��) 07:26:52 ID:zko0DQ24
Sandy Bridge / Bulldozer���Ή��̃A�v����낤�Ƃ��Ă�̂�
Intel��Atom�@�ł������悤�ȑf�G�c�[�����A�Ђ�AMD��CPU�ł��������Ȃ��Ƃ�������
����ȏ�Intel�̋Z�p�s���Ƃ�ʧ�H���Ċ����Ȃ�ł����B
Intel��Atom�@�ł������悤�ȑf�G�c�[�����A�Ђ�AMD��CPU�ł��������Ȃ��Ƃ�������
����ȏ�Intel�̋Z�p�s���Ƃ�ʧ�H���Ċ����Ȃ�ł����B
> CUDA����ATI Stream�͂܂�VB��Python���瓮���Ȃ�����
�ق�
��PyCUDA
��? �܂���CUDA��ŃX�N���v�g������������̂�?
���̔��z�͂Ȃ������B
�ق�
��PyCUDA
��? �܂���CUDA��ŃX�N���v�g������������̂�?
���̔��z�͂Ȃ������B
918 �F,,�E�L�́M�E,,�j��-�������F2009/12/21(��) 07:29:01 ID:zko0DQ24
���̗]�n�̂�����Larrabee�͎c�O�Ȃ��ƂɁc�c
920 �F,,�E�L�́M�E,,�j��-�������F2009/12/21(��) 07:36:29 ID:zko0DQ24
�]�n���Ȃ��Ȃ牴�I�Ɏ���ł�����R�B
�X�N���v�g���ꂷ�瓮�����Ȃ���AI�Ȃ�č���Ă��Ȃ�����
�X�N���v�g���ꂷ�瓮�����Ȃ���AI�Ȃ�č���Ă��Ȃ�����
�u�J���������А��i��ł��������Ȃ��v
����͔ᔻ�̑ΏۂɂȂ��ł���B���z���@�\�g���Ă��ł���?
Intel�`�b�v�܂ŃT�|�[�g�����疳�p�ȊJ���R�X�g��������B
�m���ɊԌ����������Ă͂��邪�A�t�Ɏ��А��i�̔̑��ł�����A
��p�Ό��ʂ��l������~�ނȂ��B
����͔ᔻ�̑ΏۂɂȂ��ł���B���z���@�\�g���Ă��ł���?
Intel�`�b�v�܂ŃT�|�[�g�����疳�p�ȊJ���R�X�g��������B
�m���ɊԌ����������Ă͂��邪�A�t�Ɏ��А��i�̔̑��ł�����A
��p�Ό��ʂ��l������~�ނȂ��B
�X�N���v�g����͖{���I�ɐ������Z�ƕ���̘A�������ǁA
AI�͕��������_���Z��ɗ��Ƃ����߂郂�f���������Ȃ���?
(�悭�m��Ȃ����ǁA�j���[�����̃V�i�v�X�ڑ��̃V�~�����[�g�I�ȈӖ���)
GPU�Ɏg��Ȃ��Ȃ�A
�Ƃ肠������̃V���O���`�b�v�E���炤�ǂ��E�R���s���[�^�[ �ł�������Ȃ��B
�L���b�V���R�q�[�����V�̓I�~�b�g���ꂿ��������ǁB
AI�͕��������_���Z��ɗ��Ƃ����߂郂�f���������Ȃ���?
(�悭�m��Ȃ����ǁA�j���[�����̃V�i�v�X�ڑ��̃V�~�����[�g�I�ȈӖ���)
GPU�Ɏg��Ȃ��Ȃ�A
�Ƃ肠������̃V���O���`�b�v�E���炤�ǂ��E�R���s���[�^�[ �ł�������Ȃ��B
�L���b�V���R�q�[�����V�̓I�~�b�g���ꂿ��������ǁB
>>921
�ǂ����ŕ������䎌���B����ICC�͖�����
�ǂ����ŕ������䎌���B����ICC�͖�����
>>923
�����B
�������銄�Ƀ\�t�g�E�F�A�J�����肾�ȁA�Ƃ��A�Z�R�C�ȁA�Ƃ͎v�����ǁA
�p���m�C�A�̂�邱�Ƃ͉�X�̏펯�ł͗ʂ�Ȃ��B
�����B
�������銄�Ƀ\�t�g�E�F�A�J�����肾�ȁA�Ƃ��A�Z�R�C�ȁA�Ƃ͎v�����ǁA
�p���m�C�A�̂�邱�Ƃ͉�X�̏펯�ł͗ʂ�Ȃ��B
�������Ў�����X��fanboy�̌������ɂ����������������̂����邪
�����icc�̌���
intel�������̋���(��r�Ƃ��Ă͖��炩�ɔڋ���)��`���Ă�̂�
�����̂��œK�������R�[�h�Ŕ�r����Ƃ�
���ɃE�W�������Ă�Ƃ����v����
�����icc�̌���
intel�������̋���(��r�Ƃ��Ă͖��炩�ɔڋ���)��`���Ă�̂�
�����̂��œK�������R�[�h�Ŕ�r����Ƃ�
���ɃE�W�������Ă�Ƃ����v����
AMD�͐F�X�Ή����Ȃ���Ȃ��āA�Ή��o���Ȃ����B
�g���邨����Intel�Ɣ�ׂ�Ɛ��̗܂����畝�L���T�|�[�g���A
���l�ȃc�[���J���������Ȃ�B>>916
>>916
�܂�Intel�l��AMD�v���b�g�t�H�[���ł��œK�ȊJ������o����̂��B
�g���邨����Intel�Ɣ�ׂ�Ɛ��̗܂����畝�L���T�|�[�g���A
���l�ȃc�[���J���������Ȃ�B>>916
>>916
�܂�Intel�l��AMD�v���b�g�t�H�[���ł��œK�ȊJ������o����̂��B
>>928
Phenom�g���̉��ł��Ȃ�̐������Ȃ��g���āA
���炩�̃A�N�V�f���g��s��������Ă����ؒ��J�ɃT�|�[�g���Ă����̂��Ƃ������ƁB
Phenom�g���̉��ł��Ȃ�̐������Ȃ��g���āA
���炩�̃A�N�V�f���g��s��������Ă����ؒ��J�ɃT�|�[�g���Ă����̂��Ƃ������ƁB
�b�Ԃ��������Ă��܂����A�V���O����f���A���Ή��̃A�v����
���ׂẴR�A�̗͂𒍂���悤��CPU�͏o�Ă���́H
���ׂẴR�A�̗͂𒍂���悤��CPU�͏o�Ă���́H
����ł�Turbo Boost(TDP�g���N���b�N�A�b�v)�őΉ�
�����I�ɂ͓��@�I�}���`�X���b�f�B���O���̗p���邩������Ȃ���
�d�͌����I�ɃA���Ȃ̂œ������
�����I�ɂ͓��@�I�}���`�X���b�f�B���O���̗p���邩������Ȃ���
�d�͌����I�ɃA���Ȃ̂œ������
�bIntelNewsJ
�b�v���X�����[�X�Ȃ��B�u�C���e�� ������̃C���e�� Atom �v���b�g�t�H�[���\�v
�b���͂��ꂪ�A�C���e������CPU�ɃO���t�B�b�N�X�ƃ������[�E�R���g���[���[���������̂������肷��B
�b12/21 14:33
Timna��Canmore�͍����j�����ł��ˁB�킩��܂��B
http://pc.watch.impress.co.jp/docs/2007/1005/kaigai07.jpg
http://pc.watch.impress.co.jp/docs/2008/0310/kaigai04l.gif
�b�v���X�����[�X�Ȃ��B�u�C���e�� ������̃C���e�� Atom �v���b�g�t�H�[���\�v
�b���͂��ꂪ�A�C���e������CPU�ɃO���t�B�b�N�X�ƃ������[�E�R���g���[���[���������̂������肷��B
�b12/21 14:33
Timna��Canmore�͍����j�����ł��ˁB�킩��܂��B
http://pc.watch.impress.co.jp/docs/2007/1005/kaigai07.jpg
{kind=link}
http://pc.watch.impress.co.jp/docs/2008/0310/kaigai04l.gif
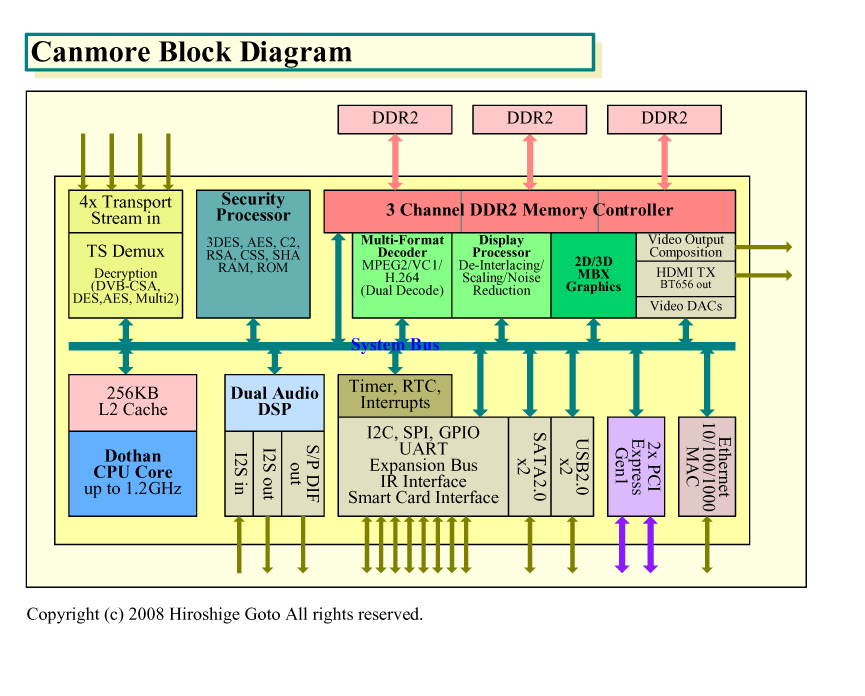{kind=link}
ID:fbkt1P8u�͂����̖��m��AMDfanboy�Ȃ̂Ŗ������Ă���Ă�������
Larrabee��2014�N�Ƀ��C��CPU�ɓ�������܂ł�Intel�̐헪
http://pc.watch.impress.co.jp/docs/column/kaigai/20091222_338322.html
http://pc.watch.impress.co.jp/docs/column/kaigai/20091222_338322.html
���P���ɁA�s��ŏ��Ă邩�ǂ����Ƃ����}�[�P�e�B���O�T�C�h�̔��f�����œ������Ă�
�Ȃ��������玸�s������܂����B
�Ȃ��������玸�s������܂����B
>>932
Cyrix��MediaGX���牽�N�o�����E�E�E���܂�Ă���̑���������
Cyrix��MediaGX���牽�N�o�����E�E�E���܂�Ă���̑���������
���тQ
�R���V���[�}�ł͔��������Ɩ��p�ŏo�����炢����Ȃ����ȁ[��
�R���V���[�}�ł͔��������Ɩ��p�ŏo�����炢����Ȃ����ȁ[��
�A�[�P�[�h�p or �����_���p�A�ǂ����̈Ӗ��ŋƖ��p���Ă�
�����̌v��ʂ胂�o�C���p�ŏo���̂����
�d�͊Ǘ���������Centrino�ɑg�ݍ��߂ΊԈႢ�Ȃ��V�F�A���邵�p�C���傫��
�d�͊Ǘ���������Centrino�ɑg�ݍ��߂ΊԈႢ�Ȃ��V�F�A���邵�p�C���傫��
�yIT�Ɠd�z���E���A�C���e���v���Z�b�T�[��Win XP Embedded��g�ݍ��e���r�wROBRO-TV�x [12/22]
http://anchorage.2ch.net/test/read.cgi/bizplus/1261412035/
http://anchorage.2ch.net/test/read.cgi/bizplus/1261412035/
TV��Wintel��
����Ă݂����x��
32nm��LGA1366��LGA1156��Core i7/i5�������Ă��������̂�
GPU��32nm����Ȃ����������H
�C�~�t�̘A���c
�C�V���̎�����Q�[���@�ɁuLarrabee�v�荞��Intel
http://pc.watch.impress.co.jp/docs/column/kaigai/20091225_339345.html
http://pc.watch.impress.co.jp/docs/column/kaigai/20091225_339345.html
947 �F,,�E�L�́M�E,,�j��-�������F2009/12/25(��) 00:21:44 ID:4VT3uHXD
�C�V���ɔ��荞��ł��͍̂��X�ȃl�^���ȁB
�I�b�e���[�j������������B
TFLOPS���̉��Z�p���[�ŕ������Z������č��x�ȑ̊��^�Q�[�������āB
�I�b�e���[�j������������B
TFLOPS���̉��Z�p���[�ŕ������Z������č��x�ȑ̊��^�Q�[�������āB
Intel��CPU���ʂł͂킭�킭����l�Șb�肪�Ȃ��Ȃ���������ȁE�E�E
SSD�Ƃ��͊y���݂���
SSD�Ƃ��͊y���݂���
949 �F,,�E�L�́M�E,,�j��-�������F2009/12/25(��) 00:23:32 ID:4VT3uHXD
SIMD���Z���\�����͒�R�X�g�X�p�R������݂̐l�͂₽����҂��Ă���ǂ�
SIMD���Z���\�����̓R�A���̔{���Ǝ����悤�Șb��
���I�ω��Ƃ������͗ʓI�ω��̕��������
����͂���ŗǂ����Ƃ����ǁE�E�E
���I�ω��Ƃ������͗ʓI�ω��̕��������
����͂���ŗǂ����Ƃ����ǁE�E�E
�������H
���R�A�ɂȂ�قǂ��������ɂȂ�A�v�����A�݂�Ȃ��~�����~�����ȓW�J�ɂȂ�悤��
�l���܂��傤
�l���܂��傤
Oracle����
���C�g���[�V���O��Nj��������Ƃ����̂̓R�A����������g�������Ƃ���
intel�̗~�����Q�[���ɋ��߂����ʂȂ̂���
�Q�[�����Ȃ��Ƃ�x86�Ƃ������ł܂���Ɩ��ʂɂ͂Ȃ�Ȃ���
�Q�[���̊J���̃g�����h��ς�����Έ�Γ����
intel�̗~�����Q�[���ɋ��߂����ʂȂ̂���
�Q�[�����Ȃ��Ƃ�x86�Ƃ������ł܂���Ɩ��ʂɂ͂Ȃ�Ȃ���
�Q�[���̊J���̃g�����h��ς�����Έ�Γ����
>>953
Oracle�������߂�ǂ������
Oracle�������߂�ǂ������
ttp://www.geocities.jp/andosprocinfo/
> 12��20���ŁC�^F�Ђ����߃t���[�����X�̃e�N�j�J�����C�^�[�i���́j�ɂȂ�܂����B
> �q���蓖�Ȃ������Ƃ��Ă��C�����J�b�g��X�g�����ꂽ��C�ǂ��ɂ��Ȃ�܂����ˁB
Ando�^���c�c��ߥ(ɄD`)�ߥ�
> 12��20���ŁC�^F�Ђ����߃t���[�����X�̃e�N�j�J�����C�^�[�i���́j�ɂȂ�܂����B
> �q���蓖�Ȃ������Ƃ��Ă��C�����J�b�g��X�g�����ꂽ��C�ǂ��ɂ��Ȃ�܂����ˁB
Ando�^���c�c��ߥ(ɄD`)�ߥ�
957 �F,,�E�L�́M�E,,�j��-�������F2009/12/26(�y) 23:03:05 ID:aHgAtyjb
�d�ʑ傩
958 �F,,�E�L�́M�E,,�j��-�������F2009/12/26(�y) 23:07:37 ID:aHgAtyjb
Fermi����E�E�E
���E�ł���?�A���߂����
������ƂȂ����R���������낤����
������ƂȂ����R���������낤����
Fermi������Larrabee�Ɠ������݂̋ꂵ�݂ł�����
�t���O�V�b�v�ȉ�Ђɂ͔������X�N����
�o�ϓI�ɋꂵ���Ȃ��intel�������₷���Ȃ邩����?
�t���O�V�b�v�ȉ�Ђɂ͔������X�N����
�o�ϓI�ɋꂵ���Ȃ��intel�������₷���Ȃ邩����?
���₲�Ƃ����������Ƃ����N��
>>959
���ʂɒ�N���Ǝv������
���ʂɒ�N���Ǝv������
���o�̈Ⴂ��
��N���ƑސE�����ʂ��ȂƎv����
��N���ƑސE�����ʂ��ȂƎv����
964 �F,,�E�L�́M�E,,�j��-�������F2009/12/27(��) 01:06:26 ID:XnI3Fvgw
��N���ĕ���3���ސE����Ȃ��́H
����Ƃ��L�����H
����Ƃ��L�����H
966 �F,,�E�L�́M�E,,�j��-�������F2009/12/27(��) 02:02:59 ID:XnI3Fvgw
���܂�A����������Ȃ�������
��������̏ꍇ�A��E��N�̌�Ɍٗp�������x�ŋ߂Ă�����
���ʂ̒�N�Ƃ͈Ⴄ������
���ʂ̒�N�Ƃ͈Ⴄ������
�������炷���
F�Ђɋ����J�b�g���ꂽ�̂��s���Ŏ��߂��悤�ɂ����ǂ߂�̂����c�c
F�Ђɋ����J�b�g���ꂽ�̂��s���Ŏ��߂��悤�ɂ����ǂ߂�̂����c�c
����̃C�x���g�Ő_�l���uLarrabee�͍�����l�X�Ɗ撣���Ă����܂��v������
Intel���̋K�͂��ƕ����̊J���v�����������ɐi�s��
���̂�����������[�h���[�X�ł����Ƃ���̃G�[�X�ɂ��A�V�X�g�ɂ��Ȃ肦��
���̂����̈�l���g�b�v�ŃS�[�������Intel�̏����ƂȂ�
���Ђ̂悤�ɖ{�������œ˂����镪������Ȃ��̂ł�
���̂�����������[�h���[�X�ł����Ƃ���̃G�[�X�ɂ��A�V�X�g�ɂ��Ȃ肦��
���̂����̈�l���g�b�v�ŃS�[�������Intel�̏����ƂȂ�
���Ђ̂悤�ɖ{�������œ˂����镪������Ȃ��̂ł�
971 �F,,�E�L�́M�E,,�j��-�������F2009/12/27(��) 11:36:19 ID:XnI3Fvgw
NVIDIA�݂����Ƀt���O�V�b�v�̌����������Ⴄ�Ƃǂ����悤���Ȃ�
�����ǂ��Ďז�������Ȃ��R���^�h�[����
�A�[���X�g�����O�݂����Ȃ���
�A�[���X�g�����O�݂����Ȃ���
�A�[���X�g�����O�͐V�`�[�����݂�������
�ʕ{�̖��O���������Ă邯�ǁA�X�L���V�}�m�Ƃ̐܂荇�����C�ɂȂ�
�ʕ{�̖��O���������Ă邯�ǁA�X�L���V�}�m�Ƃ̐܂荇�����C�ɂȂ�
�E�E�E�����r�E�E�E
�͂����H
�����Ŏ��]�ԃl�^�o����Ă��������͂����ˁ[����
StrongARM���Ǝv����
�^�C���[�X�o�[�O�̋t�P������Ɛ_�l�͌�������
����ǂ��������Ȃ́H
�V�`�b�v�Z�b�g���ł���Ă��Ƃ��H
����ǂ��������Ȃ́H
�V�`�b�v�Z�b�g���ł���Ă��Ƃ��H
Xeon�ł�32nm���C���i�b�v����C�ɏo������Ƃ������Ƃ炵��
32nm Westmere�n�R�A��Socket 1366��Xeon����������āA
����Tylersburg (5520) M/B�Ŏg����Ƃ������ƂȂ�A
DP��WS���T�[�o�̘b���ȁH
�ނ���AWestmere 4�R�AGPU������Lynnfield�u�������ƁA
P55�G���b�^�C�����r�W�������������Əo���ė~�������B
����Tylersburg (5520) M/B�Ŏg����Ƃ������ƂȂ�A
DP��WS���T�[�o�̘b���ȁH
�ނ���AWestmere 4�R�AGPU������Lynnfield�u�������ƁA
P55�G���b�^�C�����r�W�������������Əo���ė~�������B
P55��B3�X�e�b�v��H55�Ɠ������炢�ɂȂ�Ƃ̂���
���v������͂���Westmere 4�R�AGPU�����͘b���q���g���S���Ȃ������B
Gulftown���Ẵ{�[�i�X�O�ɏo����2011�N��Sandy Bridge�Ɍq���Ă���
�Ƃ����b�����B���Ȃ݂�i9�Ȃ�Ė��O�ɂ͂Ȃ�Ȃ��ƔO�������Ă��B
���v������͂���Westmere 4�R�AGPU�����͘b���q���g���S���Ȃ������B
Gulftown���Ẵ{�[�i�X�O�ɏo����2011�N��Sandy Bridge�Ɍq���Ă���
�Ƃ����b�����B���Ȃ݂�i9�Ȃ�Ė��O�ɂ͂Ȃ�Ȃ��ƔO�������Ă��B
>>981
tnx
�Ƃ肠�����͂������J������Lynnfield + P55 B3�X�e�b�v��
�f�B�X�N���[�gGPU�D���Ȃ̕t����̂������ȋC������̂����ǁA
������Ƃ����������̂�32nm core�Œlj����ꂽ AES-NI ��
�g���Ȃ����Ƃ��B
Bitlocker�Ƃ������ł͎g���̂ŋC���̖�肾����
tnx
�Ƃ肠�����͂������J������Lynnfield + P55 B3�X�e�b�v��
�f�B�X�N���[�gGPU�D���Ȃ̕t����̂������ȋC������̂����ǁA
������Ƃ����������̂�32nm core�Œlj����ꂽ AES-NI ��
�g���Ȃ����Ƃ��B
Bitlocker�Ƃ������ł͎g���̂ŋC���̖�肾����
�Ƃ������Ƃ́AH55�ɂ�USB�G���b�^�����̂��B
�������ɏC�����Ă��邾��
����ŐV���r�W�����܂ŃG���b�^�L�Ƃ�����ꂽ��
�u�`�M���ł���
����ŐV���r�W�����܂ŃG���b�^�L�Ƃ�����ꂽ��
�u�`�M���ł���