AMD�̎�����CPU�ɂ��Č�낤 ��30����
�Q�Q�Q_
�_.�Q�@ | �r�炵�E����E�~�[�͕��u����ԁB
�^|�Q|�@| �ނ�ꂸ�ɃX���[���܂��傤�B
|�Q�^�_! sage�i�s�Ń}�^�[�������܂��傤�B
���O�X��
AMD�̎�����CPU�ɂ��Č�낤 ��29����
http://pc11.2ch.net/test/read.cgi/jisaku/1247396388/
�����AMD�n�X���b�h�ߋ����O�ۑ��T�C�g�l
http://amd.jisakuita.net/
���֘A�X��
Intel�̎�����CPU�ɂ��Č�낤 40
http://pc11.2ch.net/test/read.cgi/jisaku/1246074491/
CPU�A�[�L�e�N�`���ɂ��Č�� 15
http://pc11.2ch.net/test/read.cgi/jisaku/1235699613/
�_.�Q�@ | �r�炵�E����E�~�[�͕��u����ԁB
�^|�Q|�@| �ނ�ꂸ�ɃX���[���܂��傤�B
|�Q�^�_! sage�i�s�Ń}�^�[�������܂��傤�B
���O�X��
AMD�̎�����CPU�ɂ��Č�낤 ��29����
http://pc11.2ch.net/test/read.cgi/jisaku/1247396388/
�����AMD�n�X���b�h�ߋ����O�ۑ��T�C�g�l
http://amd.jisakuita.net/
���֘A�X��
Intel�̎�����CPU�ɂ��Č�낤 40
http://pc11.2ch.net/test/read.cgi/jisaku/1246074491/
CPU�A�[�L�e�N�`���ɂ��Č�� 15
http://pc11.2ch.net/test/read.cgi/jisaku/1235699613/
|
|
|
���ߋ��X���ꗗ
28 ttp://pc11.2ch.net/test/read.cgi/jisaku/1240713914/
27 ttp://pc11.2ch.net/test/read.cgi/jisaku/1236773340/
26 ttp://pc11.2ch.net/test/read.cgi/jisaku/1231688064/
25 ttp://pc11.2ch.net/test/read.cgi/jisaku/1228783643/
24 ttp://pc11.2ch.net/test/read.cgi/jisaku/1226628399/
23 ttp://pc11.2ch.net/test/read.cgi/jisaku/1219751351/
22 ttp://pc11.2ch.net/test/read.cgi/jisaku/1214276833/
21 ttp://pc11.2ch.net/test/read.cgi/jisaku/1209908499/
20 ttp://pc11.2ch.net/test/read.cgi/jisaku/1203947286/
19 ttp://pc11.2ch.net/test/read.cgi/jisaku/1199338832/
18 ttp://pc11.2ch.net/test/read.cgi/jisaku/1197562571/
17 ttp://pc11.2ch.net/test/read.cgi/jisaku/1195270082/
16 ttp://pc11.2ch.net/test/read.cgi/jisaku/1192923006/
15 ttp://pc11.2ch.net/test/read.cgi/jisaku/1190954072/
14 ttp://pc11.2ch.net/test/read.cgi/jisaku/1189440665/
13 ttp://pc11.2ch.net/test/read.cgi/jisaku/1187934610/
12 ttp://pc11.2ch.net/test/read.cgi/jisaku/1183558273/
11 ttp://pc11.2ch.net/test/read.cgi/jisaku/1181563841/
10 ttp://pc11.2ch.net/test/read.cgi/jisaku/1177368830/
09 ttp://pc11.2ch.net/test/read.cgi/jisaku/1172183431/
08 ttp://pc9.2ch.net/test/read.cgi/jisaku/1167003467/
07 ttp://pc7.2ch.net/test/read.cgi/jisaku/1161618220/
06 ttp://pc7.2ch.net/test/read.cgi/jisaku/1157327883/
05 ttp://pc7.2ch.net/test/read.cgi/jisaku/1150393478/
04 ttp://pc7.2ch.net/test/read.cgi/jisaku/1145187468/
03 ttp://pc7.2ch.net/test/read.cgi/jisaku/1138983969/
02 ttp://pc7.2ch.net/test/read.cgi/jisaku/1133374045/
01 ttp://pc7.2ch.net/test/read.cgi/jisaku/1124542812/
28 ttp://pc11.2ch.net/test/read.cgi/jisaku/1240713914/
27 ttp://pc11.2ch.net/test/read.cgi/jisaku/1236773340/
26 ttp://pc11.2ch.net/test/read.cgi/jisaku/1231688064/
25 ttp://pc11.2ch.net/test/read.cgi/jisaku/1228783643/
24 ttp://pc11.2ch.net/test/read.cgi/jisaku/1226628399/
23 ttp://pc11.2ch.net/test/read.cgi/jisaku/1219751351/
22 ttp://pc11.2ch.net/test/read.cgi/jisaku/1214276833/
21 ttp://pc11.2ch.net/test/read.cgi/jisaku/1209908499/
20 ttp://pc11.2ch.net/test/read.cgi/jisaku/1203947286/
19 ttp://pc11.2ch.net/test/read.cgi/jisaku/1199338832/
18 ttp://pc11.2ch.net/test/read.cgi/jisaku/1197562571/
17 ttp://pc11.2ch.net/test/read.cgi/jisaku/1195270082/
16 ttp://pc11.2ch.net/test/read.cgi/jisaku/1192923006/
15 ttp://pc11.2ch.net/test/read.cgi/jisaku/1190954072/
14 ttp://pc11.2ch.net/test/read.cgi/jisaku/1189440665/
13 ttp://pc11.2ch.net/test/read.cgi/jisaku/1187934610/
12 ttp://pc11.2ch.net/test/read.cgi/jisaku/1183558273/
11 ttp://pc11.2ch.net/test/read.cgi/jisaku/1181563841/
10 ttp://pc11.2ch.net/test/read.cgi/jisaku/1177368830/
09 ttp://pc11.2ch.net/test/read.cgi/jisaku/1172183431/
08 ttp://pc9.2ch.net/test/read.cgi/jisaku/1167003467/
07 ttp://pc7.2ch.net/test/read.cgi/jisaku/1161618220/
06 ttp://pc7.2ch.net/test/read.cgi/jisaku/1157327883/
05 ttp://pc7.2ch.net/test/read.cgi/jisaku/1150393478/
04 ttp://pc7.2ch.net/test/read.cgi/jisaku/1145187468/
03 ttp://pc7.2ch.net/test/read.cgi/jisaku/1138983969/
02 ttp://pc7.2ch.net/test/read.cgi/jisaku/1133374045/
01 ttp://pc7.2ch.net/test/read.cgi/jisaku/1124542812/
���1000�ɒB�������ƕ��u�������̂Ō��Ă��B
������̘b��Ȃ�ď���Ȃ�����A�������ĂȂ����ǂ��c�B
�����Ă��낻��ߋ��X���ꗗ�C�������Ȃ��c�B
Phenom�X���ɂ���R�[�h�l�[���ꗗ�ł��u���Ă����������}�V�����B
������̘b��Ȃ�ď���Ȃ�����A�������ĂȂ����ǂ��c�B
�����Ă��낻��ߋ��X���ꗗ�C�������Ȃ��c�B
Phenom�X���ɂ���R�[�h�l�[���ꗗ�ł��u���Ă����������}�V�����B
i9�ɑR���Ă����Ȃ�Athlon10���o��
Athlon4�Ƃ������������肦����
Athlon4�Ƃ������������肦����
944 ���O�FSocket774[sage] ���e���F2009/09/12(�y) 19:04:40 ID:clrVH6Wf
�H�t���s�������B
�V�쎁�̎Ӎߓ��e
P55�`�b�v�Z�b�g�ŁAUSB1.1�̃f�o�C�X���Ȃ��ƁA�f�[�^�[���̕s����N����B
��
�L�[�{�[�h�iUSB1.1�j�ƃA�C�|�b�h�iUSB1.1�j���q���ƁA�A�C�|�b�g�̉����Ƀm�C�Y���̂�B
���Ȃ݂ɁAUSB2.0�̃f�o�C�X�iUSB�@HDD�g�J�j�ɂ͉e���Ȃ��B
�܂��AUSB�|�[�g�ɃO���[�v������炵���A�ʂ̂Ƃ���Ɏh���Ή���ł���ꍇ������炵���B
�Ƃɂ����A�����P55�̕s���PS/2�̃}�E�X�ƃL�[�{�[�ǂ��g���Ă�Ζ��Ȃ������B
�܁[�ڍׂ́APCwatch������ɋL�ڂ����ł��傤�B
947 ���O�FSocket774[sage] ���e���F2009/09/12(�y) 19:10:22 ID:PL5fXyZW
>>944
USB�}�E�X���q�����Ă�X���b�g��360�R���q���ŃQ�[��������360�R�����U�������ςȂ��ɂȂ�����
�����������Ƃ������̂�
�H�t���s�������B
�V�쎁�̎Ӎߓ��e
P55�`�b�v�Z�b�g�ŁAUSB1.1�̃f�o�C�X���Ȃ��ƁA�f�[�^�[���̕s����N����B
��
�L�[�{�[�h�iUSB1.1�j�ƃA�C�|�b�h�iUSB1.1�j���q���ƁA�A�C�|�b�g�̉����Ƀm�C�Y���̂�B
���Ȃ݂ɁAUSB2.0�̃f�o�C�X�iUSB�@HDD�g�J�j�ɂ͉e���Ȃ��B
�܂��AUSB�|�[�g�ɃO���[�v������炵���A�ʂ̂Ƃ���Ɏh���Ή���ł���ꍇ������炵���B
�Ƃɂ����A�����P55�̕s���PS/2�̃}�E�X�ƃL�[�{�[�ǂ��g���Ă�Ζ��Ȃ������B
�܁[�ڍׂ́APCwatch������ɋL�ڂ����ł��傤�B
947 ���O�FSocket774[sage] ���e���F2009/09/12(�y) 19:10:22 ID:PL5fXyZW
>>944
USB�}�E�X���q�����Ă�X���b�g��360�R���q���ŃQ�[��������360�R�����U�������ςȂ��ɂȂ�����
�����������Ƃ������̂�
>>5
�X���`
�X���`
>>3
��
��
>>3�@��
http://www.z-z-z.jp/BLOG/log/eid434.html
��AMD�͑���E���̃~�b�h�E�F�C�C��Ŋ��A
����̓��}�g�߂����z�[�l�b�g��݂�����ɂ��Ĕ��\����s����
AMD����
��AMD�͑���E���̃~�b�h�E�F�C�C��Ŋ��A
����̓��}�g�߂����z�[�l�b�g��݂�����ɂ��Ĕ��\����s����
AMD����
Lynnfield�Ȃ�ă}���Z�[���Ă�̂͒�]�������낗
�u�X���`�v���e���v���E�E�E���ƁE�E�E�H
���̒�]�������Ă���������d���Ȃ�
>>13
�����Ă���Ӗ��������ς�킩���B�u�X���`�v���e���v�����ĉ��H
�����Ă���Ӗ��������ς�킩���B�u�X���`�v���e���v�����ĉ��H
>>15
�X���`
�X���`
17 �FSocket774�F2009/09/14(��) 23:44:21 ID:b8DCihhc
���I�i�j�[�R���g���[����
�I�i�j�[�R���g���[���Ƃ͍��x�ȃI�i�e�N�̈�ł���
��3���Ő��q��MAX�ɂȂ�Ƃ����������ۂ𗘗p�����I�i�j�[�Ǘ��̎��ł���B
���x���̍����I�i�j�X�g�́u�I�i�R���v�܂��́u�Q�����v�ƌĂԎ�������B
�I�i�j�[�R���g���[���͖������q����Ԃʼn����̔����I�i�j�[�𑱂������
�Q�C�R���I�i�ւ��Ȃɉۂ�����̔����I�������I�i�j�[��
�ق����O�҂̉������͂邩�ɗ��킷��Ƃ������ٓI�Ȕ������琶�܂ꂽ�B
�����Ɏ����Ȃ炳��Ă���Ⴍ���m�Ȓj�͉��Y��
��������ۂ������������Ă��邽�ߒZ��������
�I�i�ւ͈ӊO�Ɩӓ_�ɂȂ肪���Ȕ��z�Ȃ̂ł���B
�u�����Ɏx�z�����̂ł͂Ȃ��������x�z����!�v�A�t�]�̔��z���琶�܂ꂽ
�I�i�j�[�R���g���[�����}�X�^�[����Ύ����̃I�i�j�[���C�t��
��ɓ���邱�Ƃ��\���B���������̉\���ցI
�����N����������Let's�I�i�j�[�R���g���[���I
�I�i�j�[�R���g���[���Ƃ͍��x�ȃI�i�e�N�̈�ł���
��3���Ő��q��MAX�ɂȂ�Ƃ����������ۂ𗘗p�����I�i�j�[�Ǘ��̎��ł���B
���x���̍����I�i�j�X�g�́u�I�i�R���v�܂��́u�Q�����v�ƌĂԎ�������B
�I�i�j�[�R���g���[���͖������q����Ԃʼn����̔����I�i�j�[�𑱂������
�Q�C�R���I�i�ւ��Ȃɉۂ�����̔����I�������I�i�j�[��
�ق����O�҂̉������͂邩�ɗ��킷��Ƃ������ٓI�Ȕ������琶�܂ꂽ�B
�����Ɏ����Ȃ炳��Ă���Ⴍ���m�Ȓj�͉��Y��
��������ۂ������������Ă��邽�ߒZ��������
�I�i�ւ͈ӊO�Ɩӓ_�ɂȂ肪���Ȕ��z�Ȃ̂ł���B
�u�����Ɏx�z�����̂ł͂Ȃ��������x�z����!�v�A�t�]�̔��z���琶�܂ꂽ
�I�i�j�[�R���g���[�����}�X�^�[����Ύ����̃I�i�j�[���C�t��
��ɓ���邱�Ƃ��\���B���������̉\���ցI
�����N����������Let's�I�i�j�[�R���g���[���I
L3�Ȃ��̃N�A�b�h���ĒN�������̂�z�肵�Ă�낤
�����N�A�b�h�R�A���~�����l��������Ȃ����ȁH
L3�����Ə���d�͂����Ȃ��������ǁA���������l��45W�ő҂����낤����
L3�����Ə���d�͂����Ȃ��������ǁA���������l��45W�ő҂����낤����
L3�����̃N�A�b�h�R�A�̓Q�[�����Ȃ��Ȃ�A�ǂ��I�������Ǝv��
�l�i���S���Ȃ�f���A���ł�������Ȃ��B�N�A�b�h�łȂ��Əo���Ȃ����Ȃ�ĂȂ�����B
�t�ɃN�A�b�h�̃p�t�H�[�}���X���~�����Ȃ�L3�ȗ��͂��蓾�Ȃ��B
�t�ɃN�A�b�h�̃p�t�H�[�}���X���~�����Ȃ�L3�ȗ��͂��蓾�Ȃ��B
���[�J�[��PC�y�сA�ȓd��PC�B
�ǂ���Athlon II X4���\�ȓd�݂͂��������B
�uDeneb�R�A���������Ă��邩��TDP95W���v��
�M�ߐ����������قǂɁB
�ǂ���Athlon II X4���\�ȓd�݂͂��������B
�uDeneb�R�A���������Ă��邩��TDP95W���v��
�M�ߐ����������قǂɁB
L3�̗L���łǂꂾ���Ⴄ�́H
>>23
AMD���\�ł͊m��10%�̐��\������Ȃ������H
���RL3�����ʓI�Ɍ�������ƌ����Ȃ����삪���邩��A
���ʂ����镪��ł�10%�ȏ�̍����t�����낤���A
���̋t�ł̓N���b�N�������ł���قƂ�Ǎ����Ȃ����낤���A
�ǂ��炪�D�z�Ƃ͌��ߐh���̂�����̋C������B
AMD���\�ł͊m��10%�̐��\������Ȃ������H
���RL3�����ʓI�Ɍ�������ƌ����Ȃ����삪���邩��A
���ʂ����镪��ł�10%�ȏ�̍����t�����낤���A
���̋t�ł̓N���b�N�������ł���قƂ�Ǎ����Ȃ����낤���A
�ǂ��炪�D�z�Ƃ͌��ߐh���̂�����̋C������B
ttp://www.tweaktown.com/reviews/2922/amd_athlon_ii_x4_620_processor_review_quad_core_for_mainstream/index.html
AMD Athlon II X4 620 Processor Review - Quad-Core for Mainstream
AMD Athlon II X4 620 Processor Review - Quad-Core for Mainstream
ttp://pc.watch.impress.co.jp/docs/column/tawada/20090916_315797.html
L3�����̉��������Ԃ����肩�ȁH
L3�����̉��������Ԃ����肩�ȁH
�Ԃ������Ċ����Ȃ�킴�킴�ʃ}�X�N�ɂ��ˁ[��
�u��������L3�����v�ł͂Ȃ��uL3�����̉�����]���ƁE�E�E
�ǂ���ɂ���ʐ^������ADeneb�R�A���Ԃ������Ă��A
Propus�ɂȂ�Ȃ��̂͂킩�肻���Ȃ���B
����Ƃ����͂��͂��p�b�h�ɈӖ����Ȃ��Ƃł��������Ă�̂��H
Propus�ɂȂ�Ȃ��̂͂킩�肻���Ȃ���B
����Ƃ����͂��͂��p�b�h�ɈӖ����Ȃ��Ƃł��������Ă�̂��H
���[�U�[��`�F���\�[�ŕ����I�ɐ�킯����Ȃ����낤���_���I�ɂ͓���������Ă�
���ꂪ�ł��Ȃ��Ȃ烂�W���[�������ĉ����Ă���
���ꂪ�ł��Ȃ��Ȃ烂�W���[�������ĉ����Ă���
�ォ��ڐ��̊�n�X�Œ肪���Ȃ������ŁA
�����Ԃ�}�^�[���X���ɂȂ�Ȃ��E�E�E
�����Ԃ�}�^�[���X���ɂȂ�Ȃ��E�E�E
���W���[�������Ă��邩��A�ʃ}�X�N�ŊȒP�ɑ����낤�ȁB
�L���b�V�������炷�Ƃ������z�������_��
Athlon�͈����낤�����낤�u�����h����Ȃ������͂�
Athlon�͈����낤�����낤�u�����h����Ȃ������͂�
>>33
fab�̉ғ������グ�邽�߂ɂ��L�p
fab�̉ғ������グ�邽�߂ɂ��L�p
�L���b�V���𑝂₷�Ƃ������z���f���炵��
���L���b�V���ݾ
��CoreMA(2�Ai7)�ݾ
���L���b�V���ݾ
��CoreMA(2�Ai7)�ݾ
>>33
Phenom���猩��Έ����낤�����낤��
Phenom���猩��Έ����낤�����낤��
>>33
�����낤�����낤����Ȃ�������Ȃ��ˁH
�����낤�����낤����Ȃ�������Ȃ��ˁH
Pentium�u�����h�݂����Ȃ���
Intel��Pentium4���~�\�t��������Pentium�̖��O���̂Ă�K�v������������
����ɂ��ď���������Athlon���̂Ă�AMD��
�����l���Ă���̂������ς�킩��Ȃ��B
�}�[�P�e�B���O�ɂ��������p��Intel�Ƃ͌��Ⴂ�ɏ������̂�
Intel�Ɠ������x�Ńu�����h�X�V���Ă�������
����҂ɖ��O���Z������͂����Ȃ��B
����ɂ��ď���������Athlon���̂Ă�AMD��
�����l���Ă���̂������ς�킩��Ȃ��B
�}�[�P�e�B���O�ɂ��������p��Intel�Ƃ͌��Ⴂ�ɏ������̂�
Intel�Ɠ������x�Ńu�����h�X�V���Ă�������
����҂ɖ��O���Z������͂����Ȃ��B
�x���`�~����Ȃ���Pen4�̎S��Ȃ�Ēm��Ȃ���
�x���`�~�Ȃ疼�O�ς������ĉ��ł��Ȃ���
�i�x���`�~�͂���������ƍL�`�ł��j
�p���m�C�A��Intel�ɉ��l�ύ��킹��K�v��������
�x���`�~�Ȃ疼�O�ς������ĉ��ł��Ȃ���
�i�x���`�~�͂���������ƍL�`�ł��j
�p���m�C�A��Intel�ɉ��l�ύ��킹��K�v��������
Athlon�܂��̂ĂĂȂ���
�L���b�V�������炵�ĂȂ���
�L���b�V�������炵�ĂȂ���
Radeon HD 5800 new AF mode vs Nvidia GT200
ttp://vr-zone.com/forums/484183/radeon-hd-5800-new-af-mode-vs-nvidia-gt200.html
Cypress(HD5870/HD5850)
ttp://resources.vr-zone.com/image_deposit/up2/12531213210aed5b6739.jpg
GT200
ttp://resources.vr-zone.com/image_deposit/up2/1253121373dc3bae3119.jpg
HD4870
ttp://techreport.com/r.x/radeon-hd-4870/aniso-color-rv770.png
ttp://vr-zone.com/forums/484183/radeon-hd-5800-new-af-mode-vs-nvidia-gt200.html
Cypress(HD5870/HD5850)
ttp://resources.vr-zone.com/image_deposit/up2/12531213210aed5b6739.jpg
{kind=link}
GT200
ttp://resources.vr-zone.com/image_deposit/up2/1253121373dc3bae3119.jpg
{kind=link}
HD4870
ttp://techreport.com/r.x/radeon-hd-4870/aniso-color-rv770.png
{kind=link}
>>41
���Ƃ��Ă�AMD�̃u�����f�B���O�헪�����S�ɖ������Ă�̂͊ԈႢ�Ȃ����ƁB
�܂��A���i��Intel�ɑR�ł���悤�ɂȂ��Ă����������ǂ��B
���Ƃ��Ă�AMD�̃u�����f�B���O�헪�����S�ɖ������Ă�̂͊ԈႢ�Ȃ����ƁB
�܂��A���i��Intel�ɑR�ł���悤�ɂȂ��Ă����������ǂ��B
Core2���o�����_��Athlon���\���~�\�t�����Ǝv������
�܂�AMD����Ԓɂ������̂�65nm�̎��s���Ǝv�����ǂ�
�܂�AMD����Ԓɂ������̂�65nm�̎��s���Ǝv�����ǂ�
Intel��AMD�ȏ�ɖ������Ă��邪��
LGA775/1156/1336�ƌ݊������Ȃ��܂������ʂ̋K�i���������Ă���
���\�������i�тł͓����悤�Ȃ��̂����B
9550��750�A860��920�Ƃ��B
LGA775/1156/1336�ƌ݊������Ȃ��܂������ʂ̋K�i���������Ă���
���\�������i�тł͓����悤�Ȃ��̂����B
9550��750�A860��920�Ƃ��B
���Ƃ��Ă����ĉ��H
���ۂ�Athlon�̐V�^�������������
���ۂ�Athlon�̐V�^�������������
>>45
����ł��܂�Intel�̕����}�V���Ǝv�����BCeleron��Pentium�̉��Ƃ����W���т��Ă�B
Duron�ASempron���Ȃ��Ȃ��ăf�X�N�g�b�v�p�Ƃ��Ă�Athlon����ԉ��ɂȂ���AMD�Ɣ�ׂ�ƁB
����A���i���悯�������B����ǂ����Ă������B
����ł��܂�Intel�̕����}�V���Ǝv�����BCeleron��Pentium�̉��Ƃ����W���т��Ă�B
Duron�ASempron���Ȃ��Ȃ��ăf�X�N�g�b�v�p�Ƃ��Ă�Athlon����ԉ��ɂȂ���AMD�Ɣ�ׂ�ƁB
����A���i���悯�������B����ǂ����Ă������B
���̋���ȓd�g�͈�́E�E�E
intel��Havendale�̊J���Ɏ��s��������ˁB
LG1156�p��45nm�����R�A���Ȃ��Ȃ�������A32nm�Ń��C���i�b�v�S���܂��Ȃ���܂ŁA
Celeron��Pentium�̉���LGA775�ł��̂��K�v������̂ŁA
���N��t�v���b�g�t�H�[���͓��ꉻ�ł��Ȃ��̂ŁA���������ɂȂ��Ă���B
LG1156�p��45nm�����R�A���Ȃ��Ȃ�������A32nm�Ń��C���i�b�v�S���܂��Ȃ���܂ŁA
Celeron��Pentium�̉���LGA775�ł��̂��K�v������̂ŁA
���N��t�v���b�g�t�H�[���͓��ꉻ�ł��Ȃ��̂ŁA���������ɂȂ��Ă���B
Sempron���܂������Ă܂����
Athlon��Phenom�Ɣ�ׂ�ƈꉞL3�������Ƃ��_�ŁA�L���b�V���͌����Ă���B
�u�����h�헪���C�}�C�`�ɂ�������̂́A��ʂ������������Ă��鎖�������Ȃ�B
���ƁADuron��Sempron�ɂȂ���Sempron�͐����Ă���B
�Ă��ADruon��Sempron�ɂȂ����̂���SocketA��SocketS754���ゾ�B
���Ȃ�Â��b����������ł����ȁB���������r�b�N�����B
�u�����h�헪���C�}�C�`�ɂ�������̂́A��ʂ������������Ă��鎖�������Ȃ�B
���ƁADuron��Sempron�ɂȂ���Sempron�͐����Ă���B
�Ă��ADruon��Sempron�ɂȂ����̂���SocketA��SocketS754���ゾ�B
���Ȃ�Â��b����������ł����ȁB���������r�b�N�����B
�X�����Sempron���Ȃ��ȁA�Ǝv���Ă����������Ă݂��烁�[�J�[��PC�ł͂܂�����̂��B
���Ⴂ���Ă��B�X�}���������B
���Ⴂ���Ă��B�X�}���������B
�i���d�g�ɏI�~���Ȃ邩
ttp://ja.wikipedia.org/wiki/Sempron#Socket_AM3.E7.89.88
ttp://ja.wikipedia.org/wiki/Sempron#Socket_AM3.E7.89.88
>>53
�I�~���ł����B�X�}���������B
>>54
�f�X�N�g�b�v�ł͈ꎞ����荷�����܂��Ă�Ǝv�����A
��͈Â����ˁB�I������Ȓ��q�ł́B
�I�~���ł����B�X�}���������B
>>54
�f�X�N�g�b�v�ł͈ꎞ����荷�����܂��Ă�Ǝv�����A
��͈Â����ˁB�I������Ȓ��q�ł́B
�����ƃm�[�g�̕����A�f�X�N�g�b�v��蔄��Ă��邩��A
�f�X�N�g�b�v�ȊO�̃V�F�A�グ�Ȃ��ƃW���n�Ȃ�Ȃ����ȁB
�f�X�N�g�b�v�ȊO�̃V�F�A�グ�Ȃ��ƃW���n�Ȃ�Ȃ����ȁB
�m�[�g�̃V�F�A�͈ꉞ�ێ����Ă邯�ǂ�
AMD�̓v���b�g�t�H�[���S�̂Ō������������
�m�[�g�͈�萔�͊m�ۂł���悤��
AMD�̓v���b�g�t�H�[���S�̂Ō������������
�m�[�g�͈�萔�͊m�ۂł���悤��
L3�͖����ł悢����AL2��1MB��X4����Ă���
Fusion��Ontario��40nm�H
http://blog.livedoor.jp/amd646464/archives/51406641.html
http://blog.livedoor.jp/amd646464/archives/51406641.html
>>59
���N��Analyst Day�ł������v���Z�X�͖��炩�ɂ��ĂȂ���������
���̃N���X��SOI�͎g��Ȃ����낤����40nm�͏\���ɂ��肤��I����
���N��Analyst Day�ł������v���Z�X�͖��炩�ɂ��ĂȂ���������
���̃N���X��SOI�͎g��Ȃ����낤����40nm�͏\���ɂ��肤��I����
>>58
�����BL2�L���b�V���M�ҁI�@����͕ی쓮���o�^���Ă�������B
�����BL2�L���b�V���M�ҁI�@����͕ی쓮���o�^���Ă�������B
������₷���z���Ȃ�
�������ɂȂ����܂���
��������>>62
��������>>62
�ǂ�������炻��Ȃɍ����Ƀ��X�ԊԈႦ����H
CPU���o���N�v���Z�X�ō��킯�Ȃ����낤�B
�����a�c�V��̃j���[�A�C�e���f�f����
TDP 45W�̒����d�̓N�A�b�h�R�A�uAthlon II X4 605e�v
http://pc.watch.impress.co.jp/docs/column/tawada/20090918_316192.html
�����ĂȂ���
TDP 45W�̒����d�̓N�A�b�h�R�A�uAthlon II X4 605e�v
http://pc.watch.impress.co.jp/docs/column/tawada/20090918_316192.html
�����ĂȂ���
�����㔼�p��
�딚
>>64
�����̒m�I��Q�ҁE�E�E
�����̒m�I��Q�ҁE�E�E
���ł���ȉ��������Ă�́H��
Ontario
ttp://www.fudzilla.com/content/view/15534/1/
ttp://northwood.blog60.fc2.com/blog-entry-3140.html
Phenom stepping 3
ttp://www.fudzilla.com/content/view/15557/1/
ttp://northwood.blog60.fc2.com/blog-entry-3138.html
�o������"fudzilla"�l�^���BPhenom�͐V�X�e�b�s���O��"C3"�Ȃ̂��A
���ǂ��ꂽ"stepping3"�Ȃ̂����m���ɋC�ɂȂ�Ƃ���B
"Magny-Cours"�l�^�œd�������Ȃ艺������SS�l�^��A
�u�m�[�g�����ɂ��\�v�Ƃ����_��S���m�肵�čl����ƁA
�P�Ȃ�"C3"�ł͂Ȃ��āA���Ȃ���ǂ������Ă���̂��H
"Ontario"����������������"fudzilla"�����I
ttp://www.fudzilla.com/content/view/15534/1/
ttp://northwood.blog60.fc2.com/blog-entry-3140.html
Phenom stepping 3
ttp://www.fudzilla.com/content/view/15557/1/
ttp://northwood.blog60.fc2.com/blog-entry-3138.html
�o������"fudzilla"�l�^���BPhenom�͐V�X�e�b�s���O��"C3"�Ȃ̂��A
���ǂ��ꂽ"stepping3"�Ȃ̂����m���ɋC�ɂȂ�Ƃ���B
"Magny-Cours"�l�^�œd�������Ȃ艺������SS�l�^��A
�u�m�[�g�����ɂ��\�v�Ƃ����_��S���m�肵�čl����ƁA
�P�Ȃ�"C3"�ł͂Ȃ��āA���Ȃ���ǂ������Ă���̂��H
"Ontario"����������������"fudzilla"�����I
45nm��High-K���I�v�V�����݂����Ȏ������Ă��C���������
���������Ă��ꂾ�����肵�ĂˁB
���������Ă��ꂾ�����肵�ĂˁB
�P��45nm�̉��ǂ��i��ł邾������
AMD�ł͂����̂���
High-K�͎�����Ȃ���Ȃ�Ȃ��͈͂��L���炵�����炻��ȃ��X�N�͂Ƃ�Ȃ����낤
���\�I�ɂ�i7��i5�ɏ��ĂȂ��Ă��Ƃ肠�����ȑO��65nm�ƈ����
���N���b�N���͏����������[�N�ʁX�R��Ƃ�����肪����킯�ł��Ȃ�����
AMD�ł͂����̂���
High-K�͎�����Ȃ���Ȃ�Ȃ��͈͂��L���炵�����炻��ȃ��X�N�͂Ƃ�Ȃ����낤
���\�I�ɂ�i7��i5�ɏ��ĂȂ��Ă��Ƃ肠�����ȑO��65nm�ƈ����
���N���b�N���͏����������[�N�ʁX�R��Ƃ�����肪����킯�ł��Ȃ�����
3.2GHzTDP125W��3.4GHzTDP140W�ŏ����˂��c�c�c
���ʓ��ł����Č�����ˁH
�܂����̑f�ގg���Ă����4GHz�ӂ肪��Ɍ��E�炵������w
���ʓ��ł����Č�����ˁH
�܂����̑f�ގg���Ă����4GHz�ӂ肪��Ɍ��E�炵������w
3.6GHz�ł�140W�炵������P�Ȃ�v���Z�X���ǂƌ��Ă�����Ȃ���
�X�e�b�s���O���ς��̂�High-k�Ƃ͂܂��ʂ̖�肾�낤
�t��High-k�̗p�ł��ꂾ������K�b�J���Ȃ���
�X�e�b�s���O���ς��̂�High-k�Ƃ͂܂��ʂ̖�肾�낤
�t��High-k�̗p�ł��ꂾ������K�b�J���Ȃ���
>>77
High-k�g���Ă悤���V���R���g���Ă����v���Z�X�����낪���4GHz�ӂ肪���E�ł��傤�B
���̕t�߂ɂȂ�ƃ��[�N�o�[�X�g��
�C���e���ł���A�[�L�e�N�`���ς�낪��ɍō��N���b�N��3.5GHz�`3.8GHz�B
Sandy Bridge���ō���3.8GHz�B
���Ƃ͂킩���ȁH
High-k�g���Ă悤���V���R���g���Ă����v���Z�X�����낪���4GHz�ӂ肪���E�ł��傤�B
���̕t�߂ɂȂ�ƃ��[�N�o�[�X�g��
�C���e���ł���A�[�L�e�N�`���ς�낪��ɍō��N���b�N��3.5GHz�`3.8GHz�B
Sandy Bridge���ō���3.8GHz�B
���Ƃ͂킩���ȁH
>>78
AMD�����E���̔�V���R���ޗ��ɂ��x86�v���Z�b�T���J������킯��
AMD�����E���̔�V���R���ޗ��ɂ��x86�v���Z�b�T���J������킯��
���Ƃ͓d�g
POWER6�͖��m�̋Z�p�ō���Ă����̂�
�������x86�O��̘b����B
���Ԕ��ł�Atom��4G�t�߂܂ł���yOC�\
>>78
����(�t��)�����Ȃ����Ă��Ƃ�
����(�t��)�����Ȃ����Ă��Ƃ�
�����R�O�O�h���ȏ�̂������Ȃ�ăj�b�`
����Ȃ�Ē��j�b�`�Ŕ���͂P�O�O�h���O�ゾ��
����͍X�ɉ������ĂU�T�h��
�`�l�c���\�������c���Ă�����@�O���t�B�b�N��������Βm���Ă�l�͂`�l�c�������
����Ȃ�Ē��j�b�`�Ŕ���͂P�O�O�h���O�ゾ��
����͍X�ɉ������ĂU�T�h��
�`�l�c���\�������c���Ă�����@�O���t�B�b�N��������Βm���Ă�l�͂`�l�c�������
���{���
�����l�������Ȃ��X���ʼn������Ă��
�̂�AMD��I�ԗ��R����������
���́u�p�r�ɂ���Ă̓R�X�g�p�t�H�[�}���X�������v���炢����
���R���Ȃ�����Ȃ��B
������̏����o�Ȃ����A�܂Ƃ��Ȑl�͂ǂ�ǂ��Ă���B
���́u�p�r�ɂ���Ă̓R�X�g�p�t�H�[�}���X�������v���炢����
���R���Ȃ�����Ȃ��B
������̏����o�Ȃ����A�܂Ƃ��Ȑl�͂ǂ�ǂ��Ă���B
����������
intel�͐���_�A���Ă����l�X
���쒇�Ԃł��������l���邯�ǁA���낵���قǘb�����݂���Ȃ��č���
intel�͐���_�A���Ă����l�X
���쒇�Ԃł��������l���邯�ǁA���낵���قǘb�����݂���Ȃ��č���
�Ȃ�ƂȂ�AMD�Ȑl���Y���Ȃ�
���m�ȖړI���������肷��ƑI�����ɂ͓���Ȃ����ǂ�
���m�ȖړI���������肷��ƑI�����ɂ͓���Ȃ����ǂ�
> ���m�ȖړI���������肷���
�@����̗��R���Ă�ł����B�������̓u�����h���Ȑl�B
���ʂ̏���҂̓R�X�g�p�t�H�[�}���X����ɍl���܂����ǂˁB
�@����̗��R���Ă�ł����B�������̓u�����h���Ȑl�B
���ʂ̏���҂̓R�X�g�p�t�H�[�}���X����ɍl���܂����ǂˁB
�G���b�^��₾�M�҂�����Ȃɒ�������
�C���e���̃G���b�^�B���͖{���ɍ���
�������͊�ƂƂ������ő��閧����
(�閧�ł��Ȃ�ł��Ȃ�����)
�������͊�ƂƂ������ő��閧����
(�閧�ł��Ȃ�ł��Ȃ�����)
�Ƃ����Windows7�������m���Ȍ��ɂ���
>>94
Mini-ITX�ŏ�����PC�g�ނƂ�����ł���M�Ҕ]���ĕ|����
Mini-ITX�ŏ�����PC�g�ނƂ�����ł���M�Ҕ]���ĕ|����
���������̂�atom�ɂ�������
������I�����ɓ���Ȃ����Č����Ă邶���
�����A��������
Bulldozer��2010�N�I���Ɋ����H
http://blog.livedoor.jp/amd646464/archives/51408934.html
Magny-Cours��Istanbul*2�ł͂Ȃ�Lisbon*2
http://blog.livedoor.jp/amd646464/archives/51408938.html
http://blog.livedoor.jp/amd646464/archives/51408934.html
Magny-Cours��Istanbul*2�ł͂Ȃ�Lisbon*2
http://blog.livedoor.jp/amd646464/archives/51408938.html
�� Magny-Cours��Istanbul*2�ł͂Ȃ�Lisbon*2
�܂�������
�܂�������
>>78
�t�̒��f��p��6GHz�s�����ǂ����̃t�F�m���͉���������
�t�̒��f��p��6GHz�s�����ǂ����̃t�F�m���͉���������
>>102
Fudzilla�c�̗\�z���Ă���܂肠������ˁB
�������������̂�"Istanbul"�ł͂Ȃ��āA
"Lisbon"���Ă͓̂����肻�����ȁB
�m�[�g�������ǂ��I�ɂ������Ă���̂��B
���邢�͎I�p�̉��ǂ��m�[�g�Ɏ����čs���̂��c�ǂ��炾�B
Fudzilla�c�̗\�z���Ă���܂肠������ˁB
�������������̂�"Istanbul"�ł͂Ȃ��āA
"Lisbon"���Ă͓̂����肻�����ȁB
�m�[�g�������ǂ��I�ɂ������Ă���̂��B
���邢�͎I�p�̉��ǂ��m�[�g�Ɏ����čs���̂��c�ǂ��炾�B
Istanbul��Lisbon�������̂Ńv���b�g�t�H�[�����Ⴄ����
Magny-Cours�͌��XDDR3��Lisbon*2�����`�b�v�I�ɂ�Istanbul*2�ł�����B
AMD��G32���G34���ɏo���\��Ŕ�������Magny-Cours��Lisbon��
Lisbon��2010�NQ2�Ƃ����̂����\�ʂ�B
Lisbon��Magny-Cours�Ɗ��Ⴂ���������̃A�z�L�����B
Magny-Cours�͌��XDDR3��Lisbon*2�����`�b�v�I�ɂ�Istanbul*2�ł�����B
AMD��G32���G34���ɏo���\��Ŕ�������Magny-Cours��Lisbon��
Lisbon��2010�NQ2�Ƃ����̂����\�ʂ�B
Lisbon��Magny-Cours�Ɗ��Ⴂ���������̃A�z�L�����B
���Ȃ��Sao Paolo*2�̋L������������
AMD-V 2.0�AAMD-P 2.0�Ȃ���A���RMagny-Cours��Lisbon*2
Fiorano�ɂȂ�AIstanbul��2.0�g����悤�ɂȂ�͂��B
Lisbon�̕����X�e�b�s���O�オ���āA���o�Ă���Istanbul���ȓd�͂ɂȂ��Ă邩������Ȃ����ǁA
�قƂ�Ljꏏ�Ȃ�Ȃ��́H
Lisbon�̕����X�e�b�s���O�オ���āA���o�Ă���Istanbul���ȓd�͂ɂȂ��Ă邩������Ȃ����ǁA
�قƂ�Ljꏏ�Ȃ�Ȃ��́H
111 �FSocket774�F2009/09/21(��) 17:58:50 ID:FRP6VUHl
�N�A�b�h�R�A�͖{���ɑ����̂��H
�}���`�R�A�����i�ލ����A�f���A���R�A�͏펯�ɂȂ���邪
�}���`�R�A����肭�g�����߂ɂ́A�v���O�������}���`�X���b�h�ɑΉ�����
�K�v������B
�T�[�o�[�p�̃v���O�����̓}���`�X���b�h�Ή��͊ȒP�Ȃ̂���
��X��ʐl���g���v���O�����̂قƂ�ǂ̓}���`�X���b�h����
����ł���B
�V���O���R�A�͊��Ƀ��[�G���h�ƂȂ��Ă��܂�������
����A�G���R�[�h�Ȃǂ�����������ꂽ�}���`�X���b�h�Ɍ����Ă�p�r��
�x���`�}�[�N�ȊO�͍��N���b�N�̃f���A���R�A���N�A�b�h�R�A
�Ƃ������Ƃ�������B
�}���`�R�A�����i�ލ����A�f���A���R�A�͏펯�ɂȂ���邪
�}���`�R�A����肭�g�����߂ɂ́A�v���O�������}���`�X���b�h�ɑΉ�����
�K�v������B
�T�[�o�[�p�̃v���O�����̓}���`�X���b�h�Ή��͊ȒP�Ȃ̂���
��X��ʐl���g���v���O�����̂قƂ�ǂ̓}���`�X���b�h����
����ł���B
�V���O���R�A�͊��Ƀ��[�G���h�ƂȂ��Ă��܂�������
����A�G���R�[�h�Ȃǂ�����������ꂽ�}���`�X���b�h�Ɍ����Ă�p�r��
�x���`�}�[�N�ȊO�͍��N���b�N�̃f���A���R�A���N�A�b�h�R�A
�Ƃ������Ƃ�������B
���ʂɃf���A���R�A�ƃN�A�b�h�R�A�g���Ă�A
�N�A�b�h�R�A�������ɉ��K���킩�邯�ǂȁB
�N�A�b�h�R�A�������ɉ��K���킩�邯�ǂȁB
>>111
���͂�A����p�Ńn�C�G���hCPU�g���Ȃ�āA�G���R���Q�[�����낤���ǁA
�O�҂͂��ł�4�R�A�ɑΉ����Ă��邵�A�Q�[�����ŋ߂̂�4�R�A�ɑΉ����Ă��Ă邩��A
����Ȃ�ɐ�������Ă�Ǝv�����ǂȁB
�l�b�g��A���y�������蓮�挩���肷�邮�炢�Ȃ�A2�R�A�ő���邯�ǁB
���͂�A����p�Ńn�C�G���hCPU�g���Ȃ�āA�G���R���Q�[�����낤���ǁA
�O�҂͂��ł�4�R�A�ɑΉ����Ă��邵�A�Q�[�����ŋ߂̂�4�R�A�ɑΉ����Ă��Ă邩��A
����Ȃ�ɐ�������Ă�Ǝv�����ǂȁB
�l�b�g��A���y�������蓮�挩���肷�邮�炢�Ȃ�A2�R�A�ő���邯�ǁB
���Ȃ݂�8800�f�s�łʂ�ʂ�ł���
IBM Develops eDRAM in 32nm SOI Technology
http://en.expreview.com/2009/09/21/ibm-develops-edram-in-32nm-soi-technology.html
The IBM eDRAM in 32nm SOI technology is the fastest embedded memory announced to date,
achieving latency and cycle times of less than 2 nanoseconds.
>>111
�u����v�ł͂Ȃ��B�}���`�R�A�����y���Ă��Ȃ������̂ŁA
�}���`�R�A�Ή��A�v�������y���Ă��Ȃ����������B
Vista���厸�s�������̂ŁAWin7�ӂ肩��悤�₭���y�J�n����Ȃ��H
�u����v�ł͂Ȃ��B�}���`�R�A�����y���Ă��Ȃ������̂ŁA
�}���`�R�A�Ή��A�v�������y���Ă��Ȃ����������B
Vista���厸�s�������̂ŁAWin7�ӂ肩��悤�₭���y�J�n����Ȃ��H
�`���o��A�`�����y����A
�͐��N�O���猾��ꑱ���ĕ����O����
�͐��N�O���猾��ꑱ���ĕ����O����
��͂�u����v�Ȃ�ł���B
�A�v���P�[�V�����̎S�������Ƃ����v����B
�o�J�`�����Ń}���`�X���b�h�Ή��o����d�g�݂��K�v�Ȃ�B
�����AOpenMP�Ȃ��������Ƃ����ƊȒP�Ȏd�g�݂��B
�A�|�[��GCD�łȂ�Ƃ��Ȃ����肹���ւȁH�Ǝv���Ă���ǁc�ǂ��Ȃ�ł���
�A�v���P�[�V�����̎S�������Ƃ����v����B
�o�J�`�����Ń}���`�X���b�h�Ή��o����d�g�݂��K�v�Ȃ�B
�����AOpenMP�Ȃ��������Ƃ����ƊȒP�Ȏd�g�݂��B
�A�|�[��GCD�łȂ�Ƃ��Ȃ����肹���ւȁH�Ǝv���Ă���ǁc�ǂ��Ȃ�ł���
OpenMP����g���Ȃ�����܂Ƃ��ɕ���A�v���̐v�ł���Ƃ͎v���Ȃ��B
���������}���`���f�B�A�ȊO�̃R���X�[�}�A�v���ŕ��̕K�v��������̂��Ăǂ�Ȃ̂�����H
�A�v���P�̂�CPU�̑S�R�A���K�v�ɂȂ�悤�Ȃ��̂��Ďv�����Ȃ����ǁB
���������}���`���f�B�A�ȊO�̃R���X�[�}�A�v���ŕ��̕K�v��������̂��Ăǂ�Ȃ̂�����H
�A�v���P�̂�CPU�̑S�R�A���K�v�ɂȂ�悤�Ȃ��̂��Ďv�����Ȃ����ǁB
����܂�m���Ȃ����ǁA�I�����C���Q�[���Ƃ��ߎS���ۂ���
����v�Z�̕��@�_��1950�`70�N��ɂقƂ�Ǐo�s�����Ă���̂�
�f�l����Ɂu���ꂩ��̓}���`�R�A�̎���I�v�Ɛ�`���Ȃ��Ⴂ���Ȃ��Ή�����ܲ��
�f�l����Ɂu���ꂩ��̓}���`�R�A�̎���I�v�Ɛ�`���Ȃ��Ⴂ���Ȃ��Ή�����ܲ��
�����̉�ЁA�}���`�R�A�ɑΉ����Ă邾���ň�l����������Ȃ�����
�͂��HSMP��CMP����ʂ���悤�ȃR�[�h�����Ă�́H
��ʂ��Ȃ��ŃX�P�[���A�b�v���邩��
���H��ʂ���R�[�h�����Ă�́H
AMD [finally] launches own server platform: Meet Fiorano, Kroner
http://www.brightsideofnews.com/news/2009/9/20/amd-finally-launches-own-server-platform-meet-fiorano2c-kroner.aspx
http://brightsideofnews.com/Data/2009_9_20/AMD-launch-server-platform-Fiorano-Kroner/AMD_Fiorano_Launch_675.jpg
http://www.brightsideofnews.com/news/2009/9/20/amd-finally-launches-own-server-platform-meet-fiorano2c-kroner.aspx
http://brightsideofnews.com/Data/2009_9_20/AMD-launch-server-platform-Fiorano-Kroner/AMD_Fiorano_Launch_675.jpg
{kind=link}
�̂̃X�p�R���̕��ƈ���ăR�A�Ԃ̒ʐM���x�͔���I�ɏ㏸���Ă邾��
�ʐM���x�̐�Βl���Ⴄ����Ŕ�ׂĂ��L�v�Ƃ͎v����B
���Z�\�͂ƒʐM�\�͂̔䂪�d�v�ŁA����͗ǂ��Ȃ��ĂȂ���Ȃ��̂���
�̂��Č��t�����ՂɎg���̂��ǂ����ȁB�R�A�ԒʐM�Ƃ������t��
�p���Ȃ��Ȃ����ォ��X�p�R���͂������킯��
���Z�\�͂ƒʐM�\�͂̔䂪�d�v�ŁA����͗ǂ��Ȃ��ĂȂ���Ȃ��̂���
�̂��Č��t�����ՂɎg���̂��ǂ����ȁB�R�A�ԒʐM�Ƃ������t��
�p���Ȃ��Ȃ����ォ��X�p�R���͂������킯��
�u���ꂩ��̓}���`�R�A�łǂ��ɂ����鎞��I�v�Ȃ���ʂɊԈႢ����Ȃ��悤��
�Г��Ŏg���Ɩ��\�t�g�J���Ɍg����Ă邯��
�}���`�X���b�h�͌����֎~�ɂ��Ă�
�}���`�X���b�h�͌����֎~�ɂ��Ă�
MT������l�Ԃ������d���ŏ����R�A�K�w��
MT�̒m���Ȃ��Ă��N�ł�������r�W�l�X���W�b�N�w��
���܂���������̂��d�v�Ȃ낤�ȁB
�ʂƎ��̗����̃x�N�g�����ɖ������Ȃ����肭���Ȃ��Ƃ����B
MT�̒m���Ȃ��Ă��N�ł�������r�W�l�X���W�b�N�w��
���܂���������̂��d�v�Ȃ낤�ȁB
�ʂƎ��̗����̃x�N�g�����ɖ������Ȃ����肭���Ȃ��Ƃ����B
>>134
����Ⴀ�ԓ��Ɩ��p�\�t�g�Ȃ́A���[�U�[�̑I���̗]�n����������A�����������
�o�N�邭�炢�Ȃ炵�Ȃ������}�V������ȁB
���[�U�[�̖ڂ��������s��Ŕ���ׂ̃\�t�g�Ƃ͈Ⴄ�̂���B
����Ⴀ�ԓ��Ɩ��p�\�t�g�Ȃ́A���[�U�[�̑I���̗]�n����������A�����������
�o�N�邭�炢�Ȃ炵�Ȃ������}�V������ȁB
���[�U�[�̖ڂ��������s��Ŕ���ׂ̃\�t�g�Ƃ͈Ⴄ�̂���B
����͓��R�}���`�X���b�h������O�c�̃N���b�J�[�Ȋ�����ȁB
Netbook�����A�v���X�g�A���F
Intel�Atom�����A�v���J���x���uAtom Developer Program�v�����グ
http://www.itmedia.co.jp/enterprise/articles/0909/24/news066.html
Netbook�����A�v���X�g�A���F
Intel�Atom�����A�v���J���x���uAtom Developer Program�v�����グ
http://www.itmedia.co.jp/enterprise/articles/0909/24/news066.html
138 �FSocket774�F2009/09/24(��) 23:05:40 ID:Hl+xMiCN
�A�X�y���K�[��Q�̓���
�@(01) ������肪����
�@(02) �K���◝�����d��
�@(03) ���
�@(04) �ω�������
�@(05) ��k�C��g�C�ق̂߂����C����Ȃǂ̗������ア�i�}�W�Ŏ��Ȃǁj
�@(06) �Öق̃��[�����킩��Ȃ�
�@(07) �����̍D���Șb��i���������b��j�ɖ߂��Ă���
�@(08) �G�O�ɂƂ���₷���A���Ȃ��Ƃ⍡�s�v�Ȏv�l��r���ł��Ȃ�
�@(09) �L���ُ͂̈�
�@(10) ���ɉߕq
�@(11) ����\�����ւ�
�@(12) �X�g���X���₷���{����ۂ�
�@(13) �����͈͂ł̗D�ꂽ�m��
�@(14) �ƂĂ��_���I�ŗ����n�ɋ������Ƃ�����
�@(15) �Ȗڂœ��ӕs���ӂ̍���������
�@(16) �F���l�C�ϐl�C�{�P�̂ǂꂩ����ꂽ���Ƃ�����
�i17�j�ᛎ����Ŏv���ʂ�ɂȂ�Ȃ��Ƃ����L����
�@(01) ������肪����
�@(02) �K���◝�����d��
�@(03) ���
�@(04) �ω�������
�@(05) ��k�C��g�C�ق̂߂����C����Ȃǂ̗������ア�i�}�W�Ŏ��Ȃǁj
�@(06) �Öق̃��[�����킩��Ȃ�
�@(07) �����̍D���Șb��i���������b��j�ɖ߂��Ă���
�@(08) �G�O�ɂƂ���₷���A���Ȃ��Ƃ⍡�s�v�Ȏv�l��r���ł��Ȃ�
�@(09) �L���ُ͂̈�
�@(10) ���ɉߕq
�@(11) ����\�����ւ�
�@(12) �X�g���X���₷���{����ۂ�
�@(13) �����͈͂ł̗D�ꂽ�m��
�@(14) �ƂĂ��_���I�ŗ����n�ɋ������Ƃ�����
�@(15) �Ȗڂœ��ӕs���ӂ̍���������
�@(16) �F���l�C�ϐl�C�{�P�̂ǂꂩ����ꂽ���Ƃ�����
�i17�j�ᛎ����Ŏv���ʂ�ɂȂ�Ȃ��Ƃ����L����
��138
�@�R�s�y�ɉ������A�S�����ɓ��Ă͂܂��Ă��ċ�������
�@�R�s�y�ɉ������A�S�����ɓ��Ă͂܂��Ă��ċ�������
140 �FSocket774�F2009/09/25(��) 16:26:37 ID:2MJOebE/
���̘b�����������B
���[�U�[�ɂƂ��ẮA�V���O���X���b�h���\�̍����f���A���R�A���������ł���
�Ƃ������������낤�A���Ęb�����Ă���B
�܂Ƃ��Ɂu�}���`�X���b�h�Ή�������y���v�Ƃ����R�[�h�͂������������Ȃ��B������A
�y���Ȃ�Ȃ��Ȃ�u���[�U�[�ɂƂ��āv�R�A��������������͖����B�V���O���X���b�h
���\���������������}�V�B�������͈ꉞ�m���ɑ����Ȃ邵�B
�u�}���`�X���b�h�Ŋy�ɑg�߂܂����v�Ȃ�Ă̂̓��[�U�[�ɂ͂ǂ��ł��������A���
�v���O���X�o�[�Ȃ�āA�I���f�}���h�ŃX���b�h�����グ�Ă��\��Ȃ����x�̕��e��
���U��������B���������ǂ��ł������}���`�X���b�f�B���O�̘b�͂��ĂȂ���B2�R�A
���x�ŗ]�邾�낤���B
�X���b�h�ŏ��ɗ����グ���ςȂ��ɂ��āA�ʐM���Ȃ��番�U�������āA�I�����ɐ�����
�����Ń��\�[�X��������Ă��������ł��A�����܂ł͓�Փx���V���O���X���b�h��
�R�[�h���ꡂ��ɍ����B�������p�t�H�[�}���X�o�����Ƃ���ƍی��Ȃ�����Ȃ�B
������킴�킴����o���z�͏��Ȃ��B
�v���O���X�o�[�̒��ɂ͂�����������̂��S�ē����Ă��邩������Ȃ����A�ʓ|�ȕ���
�͉B������Ă��邩��Ӗ��������B
4�R�A���邯�ǎg���ĂȂ����̓^�[�{���[�h�A���Ă����v������Ӌ`��������Ȃ�
�ł͂Ȃ����A2�R�A�ł����������Ă���炻�����̕�����������A�ƁB
�Ƃ������A4�R�A�i�삵�悤�Ƃ��āA�܂Ƃ��ȃ}���`�X���b�h�̃R�[�h�����������Ƃ�
�����z�������ɔw�L�т��Ă�悤�Ɍ�������ǁB�Ԃ����Ⴏ�B
���[�U�[�ɂƂ��ẮA�V���O���X���b�h���\�̍����f���A���R�A���������ł���
�Ƃ������������낤�A���Ęb�����Ă���B
�܂Ƃ��Ɂu�}���`�X���b�h�Ή�������y���v�Ƃ����R�[�h�͂������������Ȃ��B������A
�y���Ȃ�Ȃ��Ȃ�u���[�U�[�ɂƂ��āv�R�A��������������͖����B�V���O���X���b�h
���\���������������}�V�B�������͈ꉞ�m���ɑ����Ȃ邵�B
�u�}���`�X���b�h�Ŋy�ɑg�߂܂����v�Ȃ�Ă̂̓��[�U�[�ɂ͂ǂ��ł��������A���
�v���O���X�o�[�Ȃ�āA�I���f�}���h�ŃX���b�h�����グ�Ă��\��Ȃ����x�̕��e��
���U��������B���������ǂ��ł������}���`�X���b�f�B���O�̘b�͂��ĂȂ���B2�R�A
���x�ŗ]�邾�낤���B
�X���b�h�ŏ��ɗ����グ���ςȂ��ɂ��āA�ʐM���Ȃ��番�U�������āA�I�����ɐ�����
�����Ń��\�[�X��������Ă��������ł��A�����܂ł͓�Փx���V���O���X���b�h��
�R�[�h���ꡂ��ɍ����B�������p�t�H�[�}���X�o�����Ƃ���ƍی��Ȃ�����Ȃ�B
������킴�킴����o���z�͏��Ȃ��B
�v���O���X�o�[�̒��ɂ͂�����������̂��S�ē����Ă��邩������Ȃ����A�ʓ|�ȕ���
�͉B������Ă��邩��Ӗ��������B
4�R�A���邯�ǎg���ĂȂ����̓^�[�{���[�h�A���Ă����v������Ӌ`��������Ȃ�
�ł͂Ȃ����A2�R�A�ł����������Ă���炻�����̕�����������A�ƁB
�Ƃ������A4�R�A�i�삵�悤�Ƃ��āA�܂Ƃ��ȃ}���`�X���b�h�̃R�[�h�����������Ƃ�
�����z�������ɔw�L�т��Ă�悤�Ɍ�������ǁB�Ԃ����Ⴏ�B
>>140
�^���̋L�������̂܂܉����E���ď����L�����������ȁB
�^���̋L�������̂܂܉����E���ď����L�����������ȁB
(07)�ł�
143 �FSocket774�F2009/09/25(��) 18:24:39 ID:B5TZ0/Au
�P�U�������Ă邩��a�@������
>>140
�������̃A�v���P�[�V���������ɑ����Ă邩����ʂ������Ȃ��́H
�������̃A�v���P�[�V���������ɑ����Ă邩����ʂ������Ȃ��́H
�v���O���X�o�[�N�ł����H�Ђ���Ƃ���
AMD�̎�����CPU���Ăǂ��Ȃ��Ă�́H
Intel��SandyBridge�̎����f��������݂���������
Intel��SandyBridge�̎����f��������݂���������
�V���R�����̂܂��Ȃ���Ȃ��́H
http://www.xbitlabs.com/news/cpu/display/20090925143055_Globalfoundries_Delays_32nm_SOI_Production_AMD_Says_No_Delays_for_Bulldozer.html
���̋L���ɂ��ƁAGF��32nmSOI��AMD����32nmSOI�̌ڋq���Ȃ��̂ŁA
AMD�̃X�P�W���[���ɂ��킹�āArisk production��2010�N��Q1����Q3�ɒx�点��悤�����B
http://www.xbitlabs.com/news/cpu/display/20090925143055_Globalfoundries_Delays_32nm_SOI_Production_AMD_Says_No_Delays_for_Bulldozer.html
���̋L���ɂ��ƁAGF��32nmSOI��AMD����32nmSOI�̌ڋq���Ȃ��̂ŁA
AMD�̃X�P�W���[���ɂ��킹�āArisk production��2010�N��Q1����Q3�ɒx�点��悤�����B
PhenomII��32nm���͖����Ȃ���
�ł�PhenomIII�ł��ˁH���҂����Ă���܂��B
����悩��ATI�̃h���C�o�����A���𑁂���ɂ��Ă���B
������������ˁ[����
����悩��ATI�̃h���C�o�����A���𑁂���ɂ��Ă���B
������������ˁ[����
>>148
���X�ˁ[��B
���X�ˁ[��B
���̌��X�Ȃ����Ă̂����Ȃ��ǂ�
�o�b�N�A�b�v�v��������������������B
65n�̎��̓��[�G���h��Bri�݂̂ŏ���P�̒x���܂܂ɉ����A
1MBx2�ł̃V�������N������Ώ����̓}�V�������B
���x��32n��Bul�ɍ��킹��32n���̕��������A
P2�̃V�������N����Ηǂ������̂ɂ��ďɂȂ肻���Ȃ��B
�o�b�N�A�b�v�v��������������������B
65n�̎��̓��[�G���h��Bri�݂̂ŏ���P�̒x���܂܂ɉ����A
1MBx2�ł̃V�������N������Ώ����̓}�V�������B
���x��32n��Bul�ɍ��킹��32n���̕��������A
P2�̃V�������N����Ηǂ������̂ɂ��ďɂȂ肻���Ȃ��B
GF��AMD�ȊO�̌ڋq�l���̂��߂ɃA�s�[����Q1�̃��[�h�}�b�v��
�����Ă��������ŁABulldozer�͕ʂɒx��Ă��Ȃ���������Ȃ��B
���̋L���ɂ́A40nm�̕���STMicro�̃X�P�W���[���ɍ��킹�Ēx�点����ď����Ă��邵�B
�����Ă��������ŁABulldozer�͕ʂɒx��Ă��Ȃ���������Ȃ��B
���̋L���ɂ́A40nm�̕���STMicro�̃X�P�W���[���ɍ��킹�Ēx�点����ď����Ă��邵�B
>>151
AMD�̃o�b�N�A�b�v�v�����Ȃ�āA����قږ�������B
K9/K10�p�̃o�b�N�A�b�v�v�����́A
K8��n�Ԕn�̔@�����g���ė��������ǁA
�������E�ɒB���Ă��邾�낤�ȁB
����"Bulldozer"�̃o�b�N�A�b�v�v�����͂����o�Ă���B
6�R�A��"Thuban"�����ꂾ��B
AMD�̃o�b�N�A�b�v�v�����Ȃ�āA����قږ�������B
K9/K10�p�̃o�b�N�A�b�v�v�����́A
K8��n�Ԕn�̔@�����g���ė��������ǁA
�������E�ɒB���Ă��邾�낤�ȁB
����"Bulldozer"�̃o�b�N�A�b�v�v�����͂����o�Ă���B
6�R�A��"Thuban"�����ꂾ��B
>147
�L����ǂ��ǁc���ǁu"risk production"�������w�����킩��Ȃ��v���Č����Ă���Ȃ�
AMD�́u�ʂ�"Bulldozer"�͗\��ʂ肾���lj����H�v���Č����Ă���悤�����A
GF�̕��́uAMD�ɂ��킹�ăX�P�W���[����������ƕς�����H�v���Č����Ă��邵��
�L����ǂ��ǁc���ǁu"risk production"�������w�����킩��Ȃ��v���Č����Ă���Ȃ�
AMD�́u�ʂ�"Bulldozer"�͗\��ʂ肾���lj����H�v���Č����Ă���悤�����A
GF�̕��́uAMD�ɂ��킹�ăX�P�W���[����������ƕς�����H�v���Č����Ă��邵��
32nm�v���Z�X�̒����p��PhenomII��32nm�ł��炢�͗p�ӂ��Ă���Ƃ͎v�����A
��������i�����邩��Bulldozer�̏o������ȋC������B
�v���Z�X�ƃR�A���ɐ�ւ���̂̓��X�N���������ǁA
���ꂪ�o����قǏo���������Ƃ������ƂȂ낤���B
��������i�����邩��Bulldozer�̏o������ȋC������B
�v���Z�X�ƃR�A���ɐ�ւ���̂̓��X�N���������ǁA
���ꂪ�o����قǏo���������Ƃ������ƂȂ낤���B
���X�N�����Ă����s���Ȃ���Ȃ��قǒǂ��l�߂��Ă�悤�ɂ��������Ȃ��B
�ł��A���ۂɂ�32nm�V�������N�ŏo�����ƂɂȂ��Ȃ����Ȃ��B
Bulldozer�̉�����F�߂����Ȃ����獡�͌����Ȃ������ŁB
�ł��A���ۂɂ�32nm�V�������N�ŏo�����ƂɂȂ��Ȃ����Ȃ��B
Bulldozer�̉�����F�߂����Ȃ����獡�͌����Ȃ������ŁB
intel��nehalem�������Ă邯��K8��AMD�������Ă��
GF�����ď����͊y�ɂȂ����Ƃ͂����A���݂�AMD�̑䏊������l����ƁA
K10.5��32m�ɃV�������N����悤�Ȑl����������̂�����B
����Ȃ��ƂŖ��ʂɊJ���\�Z�Ɛl���U���邮�炢�Ȃ�A
�l������bulldozer�Ɏg����������������B
�����I�ɏo��\���͂��邪�A�����bulldozer���I��������Ƃ���Ȃ��H
K10.5��32m�ɃV�������N����悤�Ȑl����������̂�����B
����Ȃ��ƂŖ��ʂɊJ���\�Z�Ɛl���U���邮�炢�Ȃ�A
�l������bulldozer�Ɏg����������������B
�����I�ɏo��\���͂��邪�A�����bulldozer���I��������Ƃ���Ȃ��H
Bulldozer����]�������Ƃ��̃o�b�N�A�b�v�v�������낤��32nmK10
Bulldozer�����̗\��ʂ�Ȃ琻�i�Ԃ̍����l�܂肷���邩��V�������N�͘J�̖͂���
Bulldozer�����̗\��ʂ�Ȃ琻�i�Ԃ̍����l�܂肷���邩��V�������N�͘J�̖͂���
Bulldpzer����������AMD�͎��S���邩��o�b�N�A�b�v�v�����Ȃ�ĈӖ����Ȃ���
����AMD�������ł���̂͊F��Bulldozer�Ɋ��҂��Ă��邩�炾�����
����AMD�������ł���̂͊F��Bulldozer�Ɋ��҂��Ă��邩�炾�����
����AMD�������ł���̂͋��������������
���C�o�����x���`��p�����lj��̂�����܂����Ă邾�Ƃ������͕̂ʂɊW����
���C�o�����x���`��p�����lj��̂�����܂����Ă邾�Ƃ������͕̂ʂɊW����
���ŋ����������Ǝv��
���̓W�]���Ȃ��Ԏ���Ƃɂǂ������Ȃo�����
����̃g�����h�ɂȂ�GPGPU�����ɑ��Ђɐ�삯��CPU+GPU��Fusion���v�悵�āA
K10����Ȃ�������R�A��Bulldozer��Radeon�R�A�Ȃ獡���Intel�Ə����o�����������炾��
���̓W�]���Ȃ��Ԏ���Ƃɂǂ������Ȃo�����
����̃g�����h�ɂȂ�GPGPU�����ɑ��Ђɐ�삯��CPU+GPU��Fusion���v�悵�āA
K10����Ȃ�������R�A��Bulldozer��Radeon�R�A�Ȃ獡���Intel�Ə����o�����������炾��
���߂������
>>160
bulldozer���������炳������AMD�����������낤�ȁB
�܂��BK10.5�R�A���̓}�V���낤����A
����ƕς�炸���ޒ��܂Ȃ��ʒu�ŕY�����낤���B
bulldozer��ˑR�L�����Z��������H�@�����B�I������B
bulldozer���������炳������AMD�����������낤�ȁB
�܂��BK10.5�R�A���̓}�V���낤����A
����ƕς�炸���ޒ��܂Ȃ��ʒu�ŕY�����낤���B
bulldozer��ˑR�L�����Z��������H�@�����B�I������B
bulldozer���L�����Z���Ƃ��ɂȂ����犔���ǂ����Ԃ����ꂻ������
Sandy Bridge���K���K�����o���ĘI�o�����Ă��Ă�̂�
Bulldozer�̕��͂Ȃ��̂ԂāA�Ƃ����̂́A����܂肢������Ȃ��ˁB
��x�d�蒼�������ɕێ�����ɐU���Ă��āA�������鏊���Ȃ��̂��낤�B
�܂��ň��Ȃ̂�Sun��Rock�݂����Ɉꔭ�t�]�̊v�V�I�M�~�b�N���ڂ���
�J�������ꂸ�Ƀ|�V���邱�ƂȂ�ŁA����ɔ�ׂ�}�V�Ȃ��ǁB
Bulldozer�̕��͂Ȃ��̂ԂāA�Ƃ����̂́A����܂肢������Ȃ��ˁB
��x�d�蒼�������ɕێ�����ɐU���Ă��āA�������鏊���Ȃ��̂��낤�B
�܂��ň��Ȃ̂�Sun��Rock�݂����Ɉꔭ�t�]�̊v�V�I�M�~�b�N���ڂ���
�J�������ꂸ�Ƀ|�V���邱�ƂȂ�ŁA����ɔ�ׂ�}�V�Ȃ��ǁB
Intel�̃f���D���͖��x�̂��Ɓc�ƌ��������Ƃ��낾���ǁA
���̍�"��IDF"�Ƃ����˂��ȁBAMD�́B
���̍�"��IDF"�Ƃ����˂��ȁBAMD�́B
�_�s�����������ǃu���h�[�U�͂����Ɨ\��ʂ�ɏo���Ăق����B
���͂����ł�i7�������Ă邯�ǁA�{���͂���u���h�[�U�̗\�肾�������B
���͂����ł�i7�������Ă邯�ǁA�{���͂���u���h�[�U�̗\�肾�������B
Bulldozer�͗��N�̍����Ƀf�����o���邩�ǂ������낤���A
�������o����悤�Ȓi�K����Ȃ�����
�Ƃ������A����ɏ��o����Intel�ɑꂽ��ڂ����Ă��Ȃ�
�Ƃ肠����
�E�}���`�X���b�h��
�EL1/L2�r���L���b�V���̔p�~
�EK7���瑝�݂��܂����Č����������Ȃ����R�A�̍Đv
�Ex64�̍����\��
�ʂ͎������ė~������
�������o����悤�Ȓi�K����Ȃ�����
�Ƃ������A����ɏ��o����Intel�ɑꂽ��ڂ����Ă��Ȃ�
�Ƃ肠����
�E�}���`�X���b�h��
�EL1/L2�r���L���b�V���̔p�~
�EK7���瑝�݂��܂����Č����������Ȃ����R�A�̍Đv
�Ex64�̍����\��
�ʂ͎������ė~������
Intel will soon have real reasons to fear ARM
http://www.tgdaily.com/content/view/44102/118/
ARM is likely to strike a strategic deal with GlobalFoundries during the next week or so.
http://www.tgdaily.com/content/view/44102/118/
ARM is likely to strike a strategic deal with GlobalFoundries during the next week or so.
>>171
�}�W�Ȃ����ڋq�����킟�I
�}�W�Ȃ����ڋq�����킟�I
�R�����g���ł����Ȃ�˂����܂�Ă���ʂ�AARM�͐����Ƀ^�b�`���Ă��Ȃ��̂ŁA
(ARM�����C�Z���X������Ђ���������)
GF�Ɖ������ӂ���Ƃ����̂��悭�킩��Ȃ��B
(ARM�����C�Z���X������Ђ���������)
GF�Ɖ������ӂ���Ƃ����̂��悭�킩��Ȃ��B
GF�̃v���Z�X�ɑΉ������n�[�h�}�N���ł�����ˁH
GF�̃v���Z�X�ɍ��킹��IP���܂�����Ă��Ƃ���
���C�Z���X�̊T�v
http://www.jp.arm.com/products/licensing/index.html
�C���v�������e�[�V�����E���C�Z���X
�������C�Z���X�́AARM�̍ł��l�C�̍������C�Z���X�E���f���ł���A
ARM�v���Z�b�T�𓋍ڂ����W�ω�H��v�A�������邽�߂̑����I�ȏ�����܂��B
�������C�Z���X�́A�v�Ɛ����̐ݔ��������A
�����̐��i��ARM�v���Z�b�T���g�p���悤�ƌv�悵�Ă��锼���̃x���_�ɍœK�ł��B
ARM�́A�e�p�[�g�i�[�̐v�t���[�ɉ����A�n�[�h�E�R�A�܂��̓\�t�g�E�R�A�̃f���o���u������܂��B
�t�@�E���h���E���C�Z���X
ARM�v���Z�b�T�E�t�@�E���h���E�v���O�����́A
�����ݔ��������Ȃ��i�t�@�u���X�j�����̃x���_��@�탁�[�J��ARM�v���Z�b�T���ڐ��i�̊J���Ɣ̔����s���A
���������C�Z���X�̂���t�@�E���h���Ɉϑ����邽�߂̊v�V�I�ȃ��f���ł��B
���̃v���O�����́A2�̓��L�̃��C�Z���X�ō\������܂��B
1�́A�f�U�C���E���C�Z���X�ŁA�t�@�u���X�����̃x���_�܂��͋@�탁�[�J�ɋ��^����܂��B
���̃��C�Z���X�ɁAARM���ڃV�X�e���I���`�b�v��v���邽�߂ɕK�v�Ȃ��ׂĂ̗v�f�ƃr���[���܂܂�܂��B
����1�́A�t�@�E���h���E���C�Z���X�ŁA�����̃t�@�E���h���ɋ��^����܂��B
http://www.jp.arm.com/products/licensing/index.html
�C���v�������e�[�V�����E���C�Z���X
�������C�Z���X�́AARM�̍ł��l�C�̍������C�Z���X�E���f���ł���A
ARM�v���Z�b�T�𓋍ڂ����W�ω�H��v�A�������邽�߂̑����I�ȏ�����܂��B
�������C�Z���X�́A�v�Ɛ����̐ݔ��������A
�����̐��i��ARM�v���Z�b�T���g�p���悤�ƌv�悵�Ă��锼���̃x���_�ɍœK�ł��B
ARM�́A�e�p�[�g�i�[�̐v�t���[�ɉ����A�n�[�h�E�R�A�܂��̓\�t�g�E�R�A�̃f���o���u������܂��B
�t�@�E���h���E���C�Z���X
ARM�v���Z�b�T�E�t�@�E���h���E�v���O�����́A
�����ݔ��������Ȃ��i�t�@�u���X�j�����̃x���_��@�탁�[�J��ARM�v���Z�b�T���ڐ��i�̊J���Ɣ̔����s���A
���������C�Z���X�̂���t�@�E���h���Ɉϑ����邽�߂̊v�V�I�ȃ��f���ł��B
���̃v���O�����́A2�̓��L�̃��C�Z���X�ō\������܂��B
1�́A�f�U�C���E���C�Z���X�ŁA�t�@�u���X�����̃x���_�܂��͋@�탁�[�J�ɋ��^����܂��B
���̃��C�Z���X�ɁAARM���ڃV�X�e���I���`�b�v��v���邽�߂ɕK�v�Ȃ��ׂĂ̗v�f�ƃr���[���܂܂�܂��B
����1�́A�t�@�E���h���E���C�Z���X�ŁA�����̃t�@�E���h���ɋ��^����܂��B
�Ȃ�قǁA�ڋq��GF�̕����B
�`���[�^�[�h�����Ɏ����Ă郉�C�Z���X�̂悤�ȋC�����邪�A�܂������̂��B
�`���[�^�[�h�����Ɏ����Ă郉�C�Z���X�̂悤�ȋC�����邪�A�܂������̂��B
ARM�AIP�����t�@�u���X��ƁA�t�@�u��ƁA3�Ђ��_�Đ��藧���Ă�킯����
ARM�n�̉�Ђ�����d��������悤�ɂȂ����킯���B
���̎�̘b�����x�����Ă���d��肾�Ǝv���ĂȂ�Ȃ��B
�t�@�E���h�������C�Z���X�v��Ȃ�āB
�t�@�E���h�������C�Z���X�v��Ȃ�āB
�t�ɍl����B
�t�@�u���X��Ƃƃt�@�E���_���Ń��C�Z���X��p�S���Ă�ƍl����B
�ނ���u���܂�ARM�������C�Z���X�����Ńt�@�E���_�������Ă����I�v��
�˂����ނׂ����ȋC�����Ă����B
TSMC���ɍŐV�R�A��D�悵�Đ����ł���_��Ȃ�GF�叟�����ȁB
�t�@�u���X��Ƃƃt�@�E���_���Ń��C�Z���X��p�S���Ă�ƍl����B
�ނ���u���܂�ARM�������C�Z���X�����Ńt�@�E���_�������Ă����I�v��
�˂����ނׂ����ȋC�����Ă����B
TSMC���ɍŐV�R�A��D�悵�Đ����ł���_��Ȃ�GF�叟�����ȁB
�l�^���s�����̂��ȁB
������l�^���V�����l�^���o�Ă��Ȃ�����B
184 �F,,�E�L�́M�E,,�j��-�������F2009/10/05(��) 23:20:46 ID:0ajGxjyC
>>169
�����u���b�N�}�o�Ă���ǂȂ���������
http://www.tomshardware.com/forum/265666-28-bulldozer-core-patents-diagram-core-turbo
�f�R�[�_��2�X���b�h��4Way�̃f�R�[�_�����L���Ă�̂�Nehalem�Ɠ����B
�������S�f�R�[�_��Complex Decoder�ɂȂ��Ă�̂Ŗ��ߋ����͑����B
2�̐����N���X�^����L1�L���b�V��������W�X�^��������Ă���A�X���b�h���Ƀ��\�[�X���Œ�z��
���Ă�Ԃ�A2�X���b�h���������Ƃ��̎������\��Sandy Bridge���͍����͂Ȃ肻�������A
���̕��g�����W�X�^���������Ă�킯�ŁA�Ȃ畨���R�A�����₹����ăc�b�R�~�������ł��Ȃ��B
�����N���X�^����ALU+AGU�y�A��3Way����2Way�Ɍ��炳��Ă�B
1�X���b�h�̃X�J���������Z���\�͗�������Ă��ƂȁB
�����̃V���O���X���b�h���\�͂��낢��c�O�Ȃ��ƂɂȂ肻�����B
�܂������������j�b�g�͂���Ȃ�ɍ����\�ɂȂ��Ă�̂ŗ��_���Ȃ��ėǂ��Ǝv���Ǝv�����ǂ�
��ɂ����AVX/XOP�g��Ȃ��Ǝg����Ȃ����ǂȁB
�܂��AAMD�������Ƃ��V�~�����[�^�o�������Ǝv����B
Intel��Sandy Bridge�̂ق��͗ǂ���������Core MA�̐����i���B
�����u���b�N�}�o�Ă���ǂȂ���������
http://www.tomshardware.com/forum/265666-28-bulldozer-core-patents-diagram-core-turbo
�f�R�[�_��2�X���b�h��4Way�̃f�R�[�_�����L���Ă�̂�Nehalem�Ɠ����B
�������S�f�R�[�_��Complex Decoder�ɂȂ��Ă�̂Ŗ��ߋ����͑����B
2�̐����N���X�^����L1�L���b�V��������W�X�^��������Ă���A�X���b�h���Ƀ��\�[�X���Œ�z��
���Ă�Ԃ�A2�X���b�h���������Ƃ��̎������\��Sandy Bridge���͍����͂Ȃ肻�������A
���̕��g�����W�X�^���������Ă�킯�ŁA�Ȃ畨���R�A�����₹����ăc�b�R�~�������ł��Ȃ��B
�����N���X�^����ALU+AGU�y�A��3Way����2Way�Ɍ��炳��Ă�B
1�X���b�h�̃X�J���������Z���\�͗�������Ă��ƂȁB
�����̃V���O���X���b�h���\�͂��낢��c�O�Ȃ��ƂɂȂ肻�����B
�܂������������j�b�g�͂���Ȃ�ɍ����\�ɂȂ��Ă�̂ŗ��_���Ȃ��ėǂ��Ǝv���Ǝv�����ǂ�
��ɂ����AVX/XOP�g��Ȃ��Ǝg����Ȃ����ǂȁB
�܂��AAMD�������Ƃ��V�~�����[�^�o�������Ǝv����B
Intel��Sandy Bridge�̂ق��͗ǂ���������Core MA�̐����i���B
185 �F,,�E�L�́M�E,,�j��-�������F2009/10/05(��) 23:21:49 ID:0ajGxjyC
�������Z������̂��c
����AMD�̂Ă悤����
�������Z��Intel�ƍ����������c
����AMD�̂Ă悤����
�������Z��Intel�ƍ����������c
�Ȃ��������Z���������Ă����Ȃ��̂��낤
189 �F,,�E�L�́M�E,,�j��-�������F2009/10/06(��) 00:35:16 ID:pNgM/YvX
�����̕����ʂ�ł���܂�ɐ����͂��肷���ď������Ȃ�����
�ꉞFADD�{FMAC���ƃs�[�N���\�͓��N���b�N��Sandy Bridge��1.5�{��������A
�����ɂ�AMD�炵���Ȃ��Ďv�����B
�Ȃɂ�萮�����\��1�X���b�h�łȂ�s�[�N���\�͗����邪2�X���b�h���v�Ȃ炩�Ȃ�L�т�ł��傤��B
�m���ɂ���Ȃ�T�[�o�p�r��Nehalem�ɒD��ꂽ�V�F�A�D�҂ł��邩������Ȃ����Ďv����
���[�A���̓V���O���X���b�h���\��
K8 Opteron��3Way ALU+AGU���������ǃX�P�W���[�����n��œ��N���b�N��Pentium M�i2Way ALU�j
�ɕ����P�[�X���炠�����B
3Way�̊���ɂ��܂萫�\�オ��Ȃ������̂́A�ˑ��W�낭�ɒ��ׂ���3�̃p�C�v�Ƀf�B�X�p�b�`���Ă���
�e�p�C�v���œƗ��ɃX�P�W���[�����O���Ă�����Ȃ킯��
2Way�ł��f�B�X�p�b�`�O�Ɉˑ��W��������ƒ��ׂăX�P�W���[�����O����ΗL����x���������͂�����B
����ł��ǂ��Č���ێ������ǂȁB
�ꉞFADD�{FMAC���ƃs�[�N���\�͓��N���b�N��Sandy Bridge��1.5�{��������A
�����ɂ�AMD�炵���Ȃ��Ďv�����B
�Ȃɂ�萮�����\��1�X���b�h�łȂ�s�[�N���\�͗����邪2�X���b�h���v�Ȃ炩�Ȃ�L�т�ł��傤��B
�m���ɂ���Ȃ�T�[�o�p�r��Nehalem�ɒD��ꂽ�V�F�A�D�҂ł��邩������Ȃ����Ďv����
���[�A���̓V���O���X���b�h���\��
K8 Opteron��3Way ALU+AGU���������ǃX�P�W���[�����n��œ��N���b�N��Pentium M�i2Way ALU�j
�ɕ����P�[�X���炠�����B
3Way�̊���ɂ��܂萫�\�オ��Ȃ������̂́A�ˑ��W�낭�ɒ��ׂ���3�̃p�C�v�Ƀf�B�X�p�b�`���Ă���
�e�p�C�v���œƗ��ɃX�P�W���[�����O���Ă�����Ȃ킯��
2Way�ł��f�B�X�p�b�`�O�Ɉˑ��W��������ƒ��ׂăX�P�W���[�����O����ΗL����x���������͂�����B
����ł��ǂ��Č���ێ������ǂȁB
�^�[�{�u�[�X�g�I�ȋ@�\�������Ƃ��ꂱ���x���`�}�[�N�ō����ڂɂ��������Ȃ�
AMD�͂ǂ��l���Ă���̂��낤?
�ׂ��ȓd�̓R���g���[�����꒩��[�Ɏ����ł���Ƃ͎v���Ȃ�����
����̃V���O���X���b�h�\�͂͂���ɂ������Ă����Ȃ̂ʼn��Ƃ��撣���Ăق���
AMD�͂ǂ��l���Ă���̂��낤?
�ׂ��ȓd�̓R���g���[�����꒩��[�Ɏ����ł���Ƃ͎v���Ȃ�����
����̃V���O���X���b�h�\�͂͂���ɂ������Ă����Ȃ̂ʼn��Ƃ��撣���Ăق���
�c�q���}�Ɍ��C�ɂȂ�����
����Ȃ��킳�b���x�̃u���b�N�}�ʼn��𑛂��ł��
�܂��܂�2�N��łȂ�̏����Ȃ����APhenomII���͐��\��������C�ɂ����
���O�̓C���e���̎�����X����Larrabee�ł��}���Z�[���Ă�B
����Ȃ��킳�b���x�̃u���b�N�}�ʼn��𑛂��ł��
�܂��܂�2�N��łȂ�̏����Ȃ����APhenomII���͐��\��������C�ɂ����
���O�̓C���e���̎�����X����Larrabee�ł��}���Z�[���Ă�B
192 �F,,�E�L�́M�E,,�j��-�������F2009/10/06(��) 08:33:27 ID:pNgM/YvX
>>190
Dresdenboy���uPCU�v�̑��݂ɂ��ĐG��Ă��
Dresdenboy���uPCU�v�̑��݂ɂ��ĐG��Ă��
K8�̃X�P�W���[�����ăo�b�t�@�ɋ߂���
Pack�̒i�K�ňˑ��W�ׂĂ��Ȃ���
Pack�̒i�K�ňˑ��W�ׂĂ��Ȃ���
�������Z���������Ă��S�̂̐��\�Ō������Ƀo�����X�������̂ł́H�Ǝv���B
PC�̃p�b�P�[�W�ɗႦ��ƁA�������Z��CPU�ŁA����HDD��������A��������������
bus���x��������Ɓc�B
���������������Z�������Ȃ���Ԃ̃A�v�����Č������Ȃ����H
PC�̃p�b�P�[�W�ɗႦ��ƁA�������Z��CPU�ŁA����HDD��������A��������������
bus���x��������Ɓc�B
���������������Z�������Ȃ���Ԃ̃A�v�����Č������Ȃ����H
�������Z�ăO���t�B�b�N��2D�Ɠ����ō���\���Ȑ��\�������Ă���Ǝv�����B
�{�g���l�b�N�̓�������HDD�Ƃ���IO�W�ł���B
�{�g���l�b�N�̓�������HDD�Ƃ���IO�W�ł���B
IMEC teams up with TSMC
http://www.fudzilla.com/content/view/15845/1/
TSMC maintains 18-inch wafer tape-out in 2012
http://www.digitimes.com/news/a20091002PD208.html
TSMC��Intel�w�c�ɓ����Ă��܂��܂����B
�����̋ƊE���킽�B
http://www.fudzilla.com/content/view/15845/1/
TSMC maintains 18-inch wafer tape-out in 2012
http://www.digitimes.com/news/a20091002PD208.html
TSMC��Intel�w�c�ɓ����Ă��܂��܂����B
�����̋ƊE���킽�B
�������X�c
TSMC��Intel�w�c���Ȃ�đO�X����킩���Ă̂��Ƃ��ȁB
���N�̓��ɂ͊���ATOM�����̘b���o�Ă�����˂����ƁB
���N�̓��ɂ͊���ATOM�����̘b���o�Ă�����˂����ƁB
���ꂭ�炢�œ������Č����Ă���ƊE�S�������w�c����
�f���A��Opteron�̕Е���HyperTransport�Ή�Fermi�ɍ����ւ��čŋ��X�p�R�����v��Ƃ����̂�
�Ȃ��Ȃ����ʂȘb���Ǝv�����B
�Ȃ��Ȃ����ʂȘb���Ǝv�����B
CPU �������x�̖����x�����L���O�@�@1.2finish
�R�X�g�p�[���낤����ǂ���
http://kakaku.com/pc/cpu/ranking_0510/rating/sort=1/
�R�X�g�p�[���낤����ǂ���
http://kakaku.com/pc/cpu/ranking_0510/rating/sort=1/
>>201
����͂Ȃ��Ȃ��ʔ����b���ȁB
"Bulldozer"�ł���ʃR�A��GPU�����ł͂Ȃ�����A
�������������@�Ŕėp��������̂͂������B
����͂Ȃ��Ȃ��ʔ����b���ȁB
"Bulldozer"�ł���ʃR�A��GPU�����ł͂Ȃ�����A
�������������@�Ŕėp��������̂͂������B
ARM announces plans for 28nm SOC
http://www.brightsideofnews.com/news/2009/10/7/arm-announces-plans-for-28nm-soc.aspx
http://www.brightsideofnews.com/news/2009/10/7/arm-announces-plans-for-28nm-soc.aspx
http://www.ne.jp/asahi/comp/tarusan/main214.htm
�`�����`
�ƌ����킯��AMD�̕��j�������Ă����悤�Ɏv���B
�V���O���X���b�h���\�́u�R�̃E�H�[���v�̕ǂ̒��O�܂łɂƂǂ܂�A���ꂪNehalem�Ɣ�ׂċɒ[�ɏオ�邱�Ƃ͂Ȃ��Ɨ\�z����B
�������A�}���`�X���b�h���쎞�̓d�͌����͑傫�����P����Ǝv���B
�_����
�V���O���X���b�h���쎞��Nehalem�̐�ΐ��\���A�}���`�X���b�h���쎞��Atom�̍��������A����`�b�v�ŗ��������邱��
���Ɨ\�z����B
�`�����`
�ƌ����킯��AMD�̕��j�������Ă����悤�Ɏv���B
�V���O���X���b�h���\�́u�R�̃E�H�[���v�̕ǂ̒��O�܂łɂƂǂ܂�A���ꂪNehalem�Ɣ�ׂċɒ[�ɏオ�邱�Ƃ͂Ȃ��Ɨ\�z����B
�������A�}���`�X���b�h���쎞�̓d�͌����͑傫�����P����Ǝv���B
�_����
�V���O���X���b�h���쎞��Nehalem�̐�ΐ��\���A�}���`�X���b�h���쎞��Atom�̍��������A����`�b�v�ŗ��������邱��
���Ɨ\�z����B
���邳��̓}���`�R�A�S�̂�TDP�������N���b�N�A�b�v�ɂ��Ă͑S�R�l�����Ė�����
�^�[�{�u�[�X�g������̃V���O���X���b�h�\�͂����E����Ǝv���
�^�[�{�u�[�X�g������̃V���O���X���b�h�\�͂����E����Ǝv���
���L�Ȃ��Ă��獂�N���b�N�����������Ȃ邾�낤����
���ʂɃw�e���ł��������Ă���
���ʂɃw�e���ł��������Ă���
>>207
�����Ȃ肻���ȋC�����邪�A�Ȃ��Ȗ����\�z�}���ȁB
�����\���́u����������v�������@����܂���A�݂����ȁB�o����͈̖͂����Ȃ낤���ǁB
�����Ȃ肻���ȋC�����邪�A�Ȃ��Ȗ����\�z�}���ȁB
�����\���́u����������v�������@����܂���A�݂����ȁB�o����͈̖͂����Ȃ낤���ǁB
ttp://northwood.blog60.fc2.com/blog-entry-3189.html
ttp://xtreview.com/addcomment-id-10225-view-amd-september-roadmap.html
ttp://www.xtremesystems.org/forums/showthread.php?t=236187
�Ȃ��c�ň��c2011�N��"Bulldozer"�R�A��"K11"�R�A���������L�����c�B
"Scorpius"��"Zambezi"��"AM3r2"�����A"Lynx"��"K10.5"�R�A��"32nm"����B
�l�I�ɂ�"32nm"��"K10"�R�A���o���ꍇ��"K11"�͉������Ǝv���Ă������A
�{�C�ʼn����ɂȂ肻���ȗ\���B
���������悢�\���Ƃ��Ă͂�����������GF��"28nm"������Ȃ�ɑ������������Ȃ̂ŁA
"28nm"�ɕW�������킹�A�ő���2011�N�㔼�B�ň���2012�N�Ƃ��Ȋ�����������Ȃ��B
���Ƃ��������ϑz�Ƃ��Ă�"AVX"�lj�����N�������x�ʼn\�Ƃ͎v���Ȃ�����A
����"K11"��"32nm"��"AVX"�������o�[�W�����𓊓��B���؊������"28nm"��
"AVX"�L���R�A�𓊓�����Ȃ����Ɩϑz���Ă����킯�ł����c�B
����B"Scorpius"�v���b�g�t�H�[����"Zambezi"�R�A��"K11"�̉\��������܂���H
�ł���"Socket"��"AM3r2"���Ă̂��˂��H�@���N�O����"Stepping 3"�R�A�Ȃ镨���C�ɂȂ邵�A
�����Ɏ���"Leo"�v���b�g�t�H�[���ɑΉ��ł���CPU��"AM3r2"�Ȃ̂�������Ȃ��ƍl����Ɓc
�c�����AAMD�D���Ƃ��Ă͉��݂�����ϑz�Ȃ̂Œ����I���B
ttp://xtreview.com/addcomment-id-10225-view-amd-september-roadmap.html
ttp://www.xtremesystems.org/forums/showthread.php?t=236187
�Ȃ��c�ň��c2011�N��"Bulldozer"�R�A��"K11"�R�A���������L�����c�B
"Scorpius"��"Zambezi"��"AM3r2"�����A"Lynx"��"K10.5"�R�A��"32nm"����B
�l�I�ɂ�"32nm"��"K10"�R�A���o���ꍇ��"K11"�͉������Ǝv���Ă������A
�{�C�ʼn����ɂȂ肻���ȗ\���B
���������悢�\���Ƃ��Ă͂�����������GF��"28nm"������Ȃ�ɑ������������Ȃ̂ŁA
"28nm"�ɕW�������킹�A�ő���2011�N�㔼�B�ň���2012�N�Ƃ��Ȋ�����������Ȃ��B
���Ƃ��������ϑz�Ƃ��Ă�"AVX"�lj�����N�������x�ʼn\�Ƃ͎v���Ȃ�����A
����"K11"��"32nm"��"AVX"�������o�[�W�����𓊓��B���؊������"28nm"��
"AVX"�L���R�A�𓊓�����Ȃ����Ɩϑz���Ă����킯�ł����c�B
����B"Scorpius"�v���b�g�t�H�[����"Zambezi"�R�A��"K11"�̉\��������܂���H
�ł���"Socket"��"AM3r2"���Ă̂��˂��H�@���N�O����"Stepping 3"�R�A�Ȃ镨���C�ɂȂ邵�A
�����Ɏ���"Leo"�v���b�g�t�H�[���ɑΉ��ł���CPU��"AM3r2"�Ȃ̂�������Ȃ��ƍl����Ɓc
�c�����AAMD�D���Ƃ��Ă͉��݂�����ϑz�Ȃ̂Œ����I���B
��������DDR3�̂܂܂�����AAM3�̃\�P�b�g�`������̂܂g�����Ă����A
�܂����̃��[�h�}�b�v����͓ǂݎ��Ȃ��Ǝv�����ǁB
�R�[�h�l�[�����ς���Ă���̂��C�ɂȂ邪�A���̂Ƃ��킹�����Ă����̉\��������̂ŁA
Bulldozer���x�ꂽ�Ƃ�����߂�ɂ͂܂������Ƃ悤�ȁB
�܂����̃��[�h�}�b�v����͓ǂݎ��Ȃ��Ǝv�����ǁB
�R�[�h�l�[�����ς���Ă���̂��C�ɂȂ邪�A���̂Ƃ��킹�����Ă����̉\��������̂ŁA
Bulldozer���x�ꂽ�Ƃ�����߂�ɂ͂܂������Ƃ悤�ȁB
Server��Interlagos�������Ȃ���������
�m���ɁA�T�[�o�[���[�h�}�b�v�܂ŃR�[�h�l�[���ς��Ă���Ƃ͎v���Ȃ���
�����������[�N���Ȃ�����
�����������[�N���Ȃ�����
CPU�I���_�CIGP�̍ŏI�o�͂�HT���p�Ń`�b�v�Z�b�g�ɗ����āA��������VGA�o�͂₷���Ƃ͕s�\�ł͂Ȃ��B
�]��IGP�Ń��C����������VRAM�Ƃ���CPU�o�R�ڑ����Ă������Ƃ��l����ƁA�ނ���HT�ш��L���͌���B
"�`�b�v�Z�b�g����VGA�̍ŏI�o�͒i�݂̂�ݒu����AM3��AM3R2"�ƍl����A
�P�ɐV�\�P�b�g(����AM2�n�\�P�b�g�Q�̍ŐV�^)�ƐV�R�A�̐����R�[�h�l�[�������܂������x����Ȃ����H
�ߋ��ɂ�180nm Athron��"Corvette"��"Palomino"�A
180nm Duron��"Spitfire"��"Camaro"��"Morgan"�A
90nm Athron64��"ClawHammer-S"��"Sandiego"�Ƃ������悤�ɁA
�R�[�h�l�[���̕ύX�͐̂��炠��B
Intel�ł�"Tejas-C"��"CedarMill"��"Nehalem-C"��"Westmere"�A
"Gesher"��"Sandy Bridge"�ȂǂȂǁB
�]��IGP�Ń��C����������VRAM�Ƃ���CPU�o�R�ڑ����Ă������Ƃ��l����ƁA�ނ���HT�ш��L���͌���B
"�`�b�v�Z�b�g����VGA�̍ŏI�o�͒i�݂̂�ݒu����AM3��AM3R2"�ƍl����A
�P�ɐV�\�P�b�g(����AM2�n�\�P�b�g�Q�̍ŐV�^)�ƐV�R�A�̐����R�[�h�l�[�������܂������x����Ȃ����H
�ߋ��ɂ�180nm Athron��"Corvette"��"Palomino"�A
180nm Duron��"Spitfire"��"Camaro"��"Morgan"�A
90nm Athron64��"ClawHammer-S"��"Sandiego"�Ƃ������悤�ɁA
�R�[�h�l�[���̕ύX�͐̂��炠��B
Intel�ł�"Tejas-C"��"CedarMill"��"Nehalem-C"��"Westmere"�A
"Gesher"��"Sandy Bridge"�ȂǂȂǁB
�m���ɉߋ��ɃR�[�h�l�[���ύX�͂��邵�A
"Orochi"�������R�[�h�l�[���Ƃ��Ĉَ��������̂͊m�������ǂ��B
�����A"K11"��CPU���ɂǂꂾ���̋@�\���lj������̂�����Ȃ̂ƁA
"K11"������Intel��"Lynnfield"�̂悤��"PCI-e"�Ȃǂ̃m�[�X�@�\��
CPU�ɓ�������Ȃ�i���Ȃ���Ζ��Ȃ��j�A�t��HT�̑ш�͑����邾�낤���A
�����Ȃ��"AM3"�̃s�����ő��v�Ȃ̂��H
���������Ƃ��Ă�"AM3r2"��HT�ш�㏸����\�������邯�ǁc�B
�Ă��A"Zambezi" = "Orochi"�ƂȂ��"Scorpius"�v���b�g�t�H�[����
GPU�����ł͂Ȃ��̂ŁA��ʃR�A������"K11"�̉\���͂���̂��H
"Orochi"�������R�[�h�l�[���Ƃ��Ĉَ��������̂͊m�������ǂ��B
�����A"K11"��CPU���ɂǂꂾ���̋@�\���lj������̂�����Ȃ̂ƁA
"K11"������Intel��"Lynnfield"�̂悤��"PCI-e"�Ȃǂ̃m�[�X�@�\��
CPU�ɓ�������Ȃ�i���Ȃ���Ζ��Ȃ��j�A�t��HT�̑ш�͑����邾�낤���A
�����Ȃ��"AM3"�̃s�����ő��v�Ȃ̂��H
���������Ƃ��Ă�"AM3r2"��HT�ш�㏸����\�������邯�ǁc�B
�Ă��A"Zambezi" = "Orochi"�ƂȂ��"Scorpius"�v���b�g�t�H�[����
GPU�����ł͂Ȃ��̂ŁA��ʃR�A������"K11"�̉\���͂���̂��H
�ŏ�ʂ̓T�[�o�[�Ɠ���CPU�g�����낤����A
PCIe�Ȃ��CPU�ɓ������Ȃ����낤�B
�Ƃ������APCIe�������Ă���̂ɁA�`�b�v�Z�b�g������PCIe�̃o�X�ł�Ȃ��
�ςȍ\�����Ȃ����낤�B
���Ȃ�A�\�P�b�g���̕ύX���āAFusion�Ɠ���CPU����PCIe�̃o�X���o��\�����낤�B
PCIe�Ȃ��CPU�ɓ������Ȃ����낤�B
�Ƃ������APCIe�������Ă���̂ɁA�`�b�v�Z�b�g������PCIe�̃o�X�ł�Ȃ��
�ςȍ\�����Ȃ����낤�B
���Ȃ�A�\�P�b�g���̕ύX���āAFusion�Ɠ���CPU����PCIe�̃o�X���o��\�����낤�B
Bulldozer��IA-128������������ĉ\�͖{���Ȃ̂��ˁH
Windows 8�AWindows 9��128�r�b�g�ł��������Ă���Ƃ�����
http://www.itmedia.co.jp/news/articles/0910/09/news032.html
Windows 8�AWindows 9��128�r�b�g�ł��������Ă���Ƃ�����
http://www.itmedia.co.jp/news/articles/0910/09/news032.html
>>217 �N�Ȃ�K���ɂȂ����100���~�Ŕ����Ă��ꂻ���ȋC�������B
"Bulldozer"��IA-128�Ȃ\�Ȃ����A
AVX��256bit���s���j�b�g��ςނ��Ėϑz�̕����M������B
AVX��256bit���s���j�b�g��ςނ��Ėϑz�̕����M������B
�`�l�c�̐����铹�͂T�O�O�h���łR�c�e�o�r�ł��邇�����������@���������@���@����T�N�T�N��������
������ɂ���Q�[����������n�j�̃O���t�B�b�N�����m�[�g
������ɂ���Q�[����������n�j�̃O���t�B�b�N�����m�[�g
222 �F,,�E�L�́M�E,,�j��-�������F2009/10/10(�y) 02:20:37 ID:4pELrNs/
>>220
�v��2GHz�ȏ�ł������A��l�̎���Ŕ{������������1.6GH���ɗ}���Ă�̂�Atom�B
�iYahoo�f����Pentium M 1.5GHz���N���b�N��������HT�Ή����Ă��萫�\�������Ǝv�����Ⴄ�c�O�ȏ���҂����đ�������j
ARM���̂��̂�Atom��肸���Ɛ��\�Ⴂ�B
N270�ɍŐV�s��Cortex-A9�̃f���A���R�A��L2��MB�ς��2GHz�œ�������
�h�����ď��Ă邩�ǂ����̃��x���B
�V���O���R�A��Atom Z550�ɑR�ł��邭�炢�̐v�ɂ��悤�Ǝv������
4�{�ȏ�̃_�C�T�C�Y�Ə���d�͂��K�v�ɂȂ�BAMDer�A���Ƃ��A���_�[���̖@�����ȁB
�n�C�G���h�ł��̒��x�����炻�����N���b�N�ȁATegra�ɑg�ݍ��킳��Ȃ�đ��ǂ�����Ă�B
GPU�������肫�B
�v��2GHz�ȏ�ł������A��l�̎���Ŕ{������������1.6GH���ɗ}���Ă�̂�Atom�B
�iYahoo�f����Pentium M 1.5GHz���N���b�N��������HT�Ή����Ă��萫�\�������Ǝv�����Ⴄ�c�O�ȏ���҂����đ�������j
ARM���̂��̂�Atom��肸���Ɛ��\�Ⴂ�B
N270�ɍŐV�s��Cortex-A9�̃f���A���R�A��L2��MB�ς��2GHz�œ�������
�h�����ď��Ă邩�ǂ����̃��x���B
�V���O���R�A��Atom Z550�ɑR�ł��邭�炢�̐v�ɂ��悤�Ǝv������
4�{�ȏ�̃_�C�T�C�Y�Ə���d�͂��K�v�ɂȂ�BAMDer�A���Ƃ��A���_�[���̖@�����ȁB
�n�C�G���h�ł��̒��x�����炻�����N���b�N�ȁATegra�ɑg�ݍ��킳��Ȃ�đ��ǂ�����Ă�B
GPU�������肫�B
28nm��Snapdragon�҂�
>>220
MID���Ȃ�Ƃ�����PC�p�r�Ŕ�x86�Ȃ�Č����ɒl���Ȃ��B
���s�̃l�C�e�B�ux86�A�[�L�ł�Atom��Bonnell�R�A���ō������B
MID���Ȃ�Ƃ�����PC�p�r�Ŕ�x86�Ȃ�Č����ɒl���Ȃ��B
���s�̃l�C�e�B�ux86�A�[�L�ł�Atom��Bonnell�R�A���ō������B
�����g�����W�X�^�̌����ł����Đ��\�̌�������Ȃ�����
>>222
�������ɂ��������肫�����g�c������������d�͂Ō���邩�炁������(�v���b�g�t�H�[��)���������ƌ�����Ƒ�l�̎�������a��������
�������ƂĒP�Ƃł͈Ӗ����Ȃ��v���b�g�t�H�[���Ō���Ă����Ӗ��������
����x�������Ⴂ���̂̓d�͂܂ʼn�������Ɨ]�v�ɂ������n�̐i�������Ȃ葬���Ɗ�����
�������ɂ��������肫�����g�c������������d�͂Ō���邩�炁������(�v���b�g�t�H�[��)���������ƌ�����Ƒ�l�̎�������a��������
�������ƂĒP�Ƃł͈Ӗ����Ȃ��v���b�g�t�H�[���Ō���Ă����Ӗ��������
����x�������Ⴂ���̂̓d�͂܂ʼn�������Ɨ]�v�ɂ������n�̐i�������Ȃ葬���Ɗ�����
>>222
��2GHz�ȏ�ł����
�n���̂����ɒ����������Ă�E�E�E
�Ǝv������ō��ł�2G�����Ȃ����f�������邗
ttp://www.ripping.org/database.php?coreidwr=Diamondville
��2GHz�ȏ�ł����
�n���̂����ɒ����������Ă�E�E�E
�Ǝv������ō��ł�2G�����Ȃ����f�������邗
ttp://www.ripping.org/database.php?coreidwr=Diamondville
>>227
�k�m�Q�łQ�E�R�f�������Ă�
�k�m�Q�łQ�E�R�f�������Ă�
229 �F,,�E�L�́M�E,,�j��-�������F2009/10/10(�y) 11:35:29 ID:4pELrNs/
�u�{���v���Ēf���Ă邼
GMA��OC�̑�������������đ�̂���̖��̂悤�ȁB
ION���Ƃǂ�Ȃ���
GMA��OC�̑�������������đ�̂���̖��̂悤�ȁB
ION���Ƃǂ�Ȃ���
�����̂�533/800�Ή���945GC����ASRock��1,333MHz�܂ŏグ���I
����Ȃ���v���Ǝv����Atom�ɓK�p�����珔�N�̈����Ă��ꂽAtom�́AOC��27.53%�`�Ɛ⋩���Ď��I�@�Ȃ����I
����Ȃ���v���Ǝv����Atom�ɓK�p�����珔�N�̈����Ă��ꂽAtom�́AOC��27.53%�`�Ɛ⋩���Ď��I�@�Ȃ����I
231 �F,,�E�L�́M�E,,�j��-�������F2009/10/10(�y) 12:31:04 ID:4pELrNs/
>>226
���Ȃ݂�Sharp�̂����A8�x�[�X��800MH��
����ł�ARM����MID�̒��ł̓g�b�v�N���X�̐��\������������Ȃ�
�g�ݍ��݂̝|�Ƃ��āA�f���ŏo�Ă���悤�ȃX�y�b�N�̐��i�͎��ۂ̐��i�ɑg�ݍ��܂��܂�3�`4�N������B
���邢�͌ڋq�����Ȃ��ă|�V����B
�g�ݍ��݂̏ꍇ�͗ʎY���O����A�\�t�g�����撣���ă`���[�����邱�Ƃ�
�M���M���܂Œ�R�X�g�̐ڂ��邱�ƂŒP�����Ƃ��̂��|�������
�n�C�G���h�Ȃ�Ďg���悤���Ȃ��B
2GH���d�A���R�A�Ȃ�Ē�����
���Ȃ݂�Sharp�̂����A8�x�[�X��800MH��
����ł�ARM����MID�̒��ł̓g�b�v�N���X�̐��\������������Ȃ�
�g�ݍ��݂̝|�Ƃ��āA�f���ŏo�Ă���悤�ȃX�y�b�N�̐��i�͎��ۂ̐��i�ɑg�ݍ��܂��܂�3�`4�N������B
���邢�͌ڋq�����Ȃ��ă|�V����B
�g�ݍ��݂̏ꍇ�͗ʎY���O����A�\�t�g�����撣���ă`���[�����邱�Ƃ�
�M���M���܂Œ�R�X�g�̐ڂ��邱�ƂŒP�����Ƃ��̂��|�������
�n�C�G���h�Ȃ�Ďg���悤���Ȃ��B
2GH���d�A���R�A�Ȃ�Ē�����
232 �F,,�E�L�́M�E,,�j��-�������F2009/10/10(�y) 12:33:01 ID:4pELrNs/
�S�p�p�����w�E����ƉΕa���N�����z�����邯�ǁA
�S�p�p�����w�E�����z�́A���X�ɂ��Ēm���I�ɔ�������ˁB
�S�p�p�����w�E�����z�́A���X�ɂ��Ēm���I�ɔ�������ˁB
234 �F,,�E�L�́M�E,,�j��-�������F2009/10/10(�y) 15:12:05 ID:4pELrNs/
x86�v���Z�b�T�̏ꍇ���ʂ̃n�[�h�E�F�A�E�\�t�g�E�F�A��Ղ����邩�犮���㑦�����[�X�ł��邪
�g�ݍ��݃v���Z�b�T�́ASoC�̃`�b�v���������Ă��炻��ɑΉ������g�ݍ��݃\�t�g�E�F�A�̊J�����n�܂�B
�g�ݍ��킹����A�N�Z�����[�^�̃^�C�~���O����Ƃ��]�X�͎��@��G���Ă���łȂ��Ƃ킩��Ȃ��B
���A���^�C���������߂��邩��PC���V�r�A�B
���ۂ̐��i�Ɏg���Ă�ARM���ăv���Z�X���[�������ԌÂ������肷�邾��B
�����܂ōŏ��̐��i�����܂ł̋N�_�͓����Ȃ�B
���Ƃ�����40nm�Ő������ꂽARM���f������Ă��肷�邪�A���ۑg�ݍ��݂Ƃ��Ďs��ɏo��Ƃ��ɂ�
40nm���̂�������ɂȂ��ĂāAx86�iAtom�܂ށj�Ȃ͍X�ɂ��̐�������Ă��܂��Ă���B
�g�ݍ��݃v���Z�b�T�́ASoC�̃`�b�v���������Ă��炻��ɑΉ������g�ݍ��݃\�t�g�E�F�A�̊J�����n�܂�B
�g�ݍ��킹����A�N�Z�����[�^�̃^�C�~���O����Ƃ��]�X�͎��@��G���Ă���łȂ��Ƃ킩��Ȃ��B
���A���^�C���������߂��邩��PC���V�r�A�B
���ۂ̐��i�Ɏg���Ă�ARM���ăv���Z�X���[�������ԌÂ������肷�邾��B
�����܂ōŏ��̐��i�����܂ł̋N�_�͓����Ȃ�B
���Ƃ�����40nm�Ő������ꂽARM���f������Ă��肷�邪�A���ۑg�ݍ��݂Ƃ��Ďs��ɏo��Ƃ��ɂ�
40nm���̂�������ɂȂ��ĂāAx86�iAtom�܂ށj�Ȃ͍X�ɂ��̐�������Ă��܂��Ă���B
>>210
ttp://northwood.blog60.fc2.com/blog-entry-3192.html
6�R�A��Thuban�����sAM3�Ȃ̂�
�Œ�4�R�A��Zanbezi��AM3Rev.2���g���Ӗ��͖���
Zanbezi��4�R�A�`8�R�A�\�肾����K11�R�A�Ŋm�肾��
ttp://northwood.blog60.fc2.com/blog-entry-3192.html
6�R�A��Thuban�����sAM3�Ȃ̂�
�Œ�4�R�A��Zanbezi��AM3Rev.2���g���Ӗ��͖���
Zanbezi��4�R�A�`8�R�A�\�肾����K11�R�A�Ŋm�肾��
�C�~�t
AM3�����̒����\�P�b�g�ɂȂ肻���Ȃ̂��H
�Œ�2�R�A�ōō�4�R�A��Agena�����sAM2+�Ȃ̂�
�ō�2�R�A�ōŒ�1�R�A��Regor��AM3���g���Ӗ��͖���
Regor��4�R�A�`8�R�A�\�肾����K11�R�A�Ŋm�肾��
�ō�2�R�A�ōŒ�1�R�A��Regor��AM3���g���Ӗ��͖���
Regor��4�R�A�`8�R�A�\�肾����K11�R�A�Ŋm�肾��
AM3Rev.2�͒P����DDR2�̃T�|�[�g������������Ȃ�����
>>238
���̔���ɂ��Ȃ��Ė�����
Regor��DDR3�Ή��Ƃ����V�v�f������������1�R�A�ł�AM3��p�ɂȂ���
4�R�A��Zambezi��AM3Rev2�Ȃ̂�
���s��PhenomII�{HT3.0�Ƃ͈Ⴄ�V�A�[�L�e�N�`��������Ƃ������Ƃɑ��Ȃ�Ȃ�
K8��K10��AM2��AM2+�ōs��ꂽ�����
���̔���ɂ��Ȃ��Ė�����
Regor��DDR3�Ή��Ƃ����V�v�f������������1�R�A�ł�AM3��p�ɂȂ���
4�R�A��Zambezi��AM3Rev2�Ȃ̂�
���s��PhenomII�{HT3.0�Ƃ͈Ⴄ�V�A�[�L�e�N�`��������Ƃ������Ƃɑ��Ȃ�Ȃ�
K8��K10��AM2��AM2+�ōs��ꂽ�����
�I�̃��[�h�}�b�v���o�Ă��āA�]���ǂ���Bulldozer�R�A�̃R�[�h�l�[��������A
Zambezi��Orochi����R�[�h�l�[���ς���������̉\���������Ȃ���B
Zambezi��Orochi����R�[�h�l�[���ς���������̉\���������Ȃ���B
243 �F,,�E�L�́M�E,,�j��-�������F2009/10/10(�y) 17:01:17 ID:4pELrNs/
�\���͂���B
�U���x�W��̐_�͋���Ȏւ������ŁB
�U���x�W��̐_�͋���Ȏւ������ŁB
���̔���ɂ��Ȃ��Ė�����
Lisbon��DDR3�Ή��Ƃ����V�v�f������������4�R�A�ł�C32��p�ɂȂ���
12�R�A��Magny-Cours��G34�Ȃ̂�
���s��PhenomII�{HT3.0�Ƃ͈Ⴄ�V�A�[�L�e�N�`��������Ƃ������Ƃɑ��Ȃ�Ȃ�
HT1��HT2��AM2��AM2+�ōs��ꂽ�����
Lisbon��DDR3�Ή��Ƃ����V�v�f������������4�R�A�ł�C32��p�ɂȂ���
12�R�A��Magny-Cours��G34�Ȃ̂�
���s��PhenomII�{HT3.0�Ƃ͈Ⴄ�V�A�[�L�e�N�`��������Ƃ������Ƃɑ��Ȃ�Ȃ�
HT1��HT2��AM2��AM2+�ōs��ꂽ�����
244
>>234
�����v���������
�ȓd�́A�g�ѐ��A�����ĂȂɂ�����R�X�g�@�v�������������������������̎��Y�����邵
���̂����Q��~����Ȃ��Ƃ������ǂ�
�����v���������
�ȓd�́A�g�ѐ��A�����ĂȂɂ�����R�X�g�@�v�������������������������̎��Y�����邵
���̂����Q��~����Ȃ��Ƃ������ǂ�
>>231
������MIPS�ł���B
�~�b�v�X��CEATEC������ɃZ�~�i�[���J�ÁA�u�Ɠd��Android�Ȃ�MIPS�v�Ǝ咣
http://eetimes.jp/news/3384
�@�����āAAndroid���ŏ��Ƀ^�[�Q�b�g�Ƃ���ARM�A�[�L�e�N�`���Ƃ̐��\��r�̌��ʂ��I���AMIPS�A�[�L�e�N�`��
�������f�W�^���E�z�[���ɓK�����v���Z�b�T�ł���Ƌ��������i�}2�j�B
�}2�@MIPS�A�[�L�e�N�`����ARM�A�[�L�e�N�`���̐��\��r
�����̓V���O���R�A�A�E���̓f���A���R�A�E�v���Z�b�T�ł̔�r���ʁB�V���O���R�A�ł�MIPS32 74K��ARM Cortex-A9
�iOsprey�j�A�f���A���R�A�ł�MIPS32 1004K��Osprey���r���Ă���B�ǂ����MIPS�A�[�L�e�N�`���̕����������\��
�������Ƃ����B
������MIPS�ł���B
�~�b�v�X��CEATEC������ɃZ�~�i�[���J�ÁA�u�Ɠd��Android�Ȃ�MIPS�v�Ǝ咣
http://eetimes.jp/news/3384
�@�����āAAndroid���ŏ��Ƀ^�[�Q�b�g�Ƃ���ARM�A�[�L�e�N�`���Ƃ̐��\��r�̌��ʂ��I���AMIPS�A�[�L�e�N�`��
�������f�W�^���E�z�[���ɓK�����v���Z�b�T�ł���Ƌ��������i�}2�j�B
�}2�@MIPS�A�[�L�e�N�`����ARM�A�[�L�e�N�`���̐��\��r
�����̓V���O���R�A�A�E���̓f���A���R�A�E�v���Z�b�T�ł̔�r���ʁB�V���O���R�A�ł�MIPS32 74K��ARM Cortex-A9
�iOsprey�j�A�f���A���R�A�ł�MIPS32 1004K��Osprey���r���Ă���B�ǂ����MIPS�A�[�L�e�N�`���̕����������\��
�������Ƃ����B
>>244
Socket G34�Ɏg�p�����"Magny-Cours�i12/8�R�A)"�́A
"Lisbon�i6/4�R�A)"��MCM�ł�DDR3��4ch������ŁA
�ϑz���Ă���Ƃ���c�O�����ǁA�o���Ƃ��]���Ɠ����ŁA
K10.5�A�[�L�e�B�N�`���Ȃ킯�����B
����͌���Ȃ����A�ϑz�͂�߂Ƃ��Ƃ����c�B
Socket G34�Ɏg�p�����"Magny-Cours�i12/8�R�A)"�́A
"Lisbon�i6/4�R�A)"��MCM�ł�DDR3��4ch������ŁA
�ϑz���Ă���Ƃ���c�O�����ǁA�o���Ƃ��]���Ɠ����ŁA
K10.5�A�[�L�e�B�N�`���Ȃ킯�����B
����͌���Ȃ����A�ϑz�͂�߂Ƃ��Ƃ����c�B
ID:4pELrNs/��ID:p1odnWsZ
250 �F,,�E�L�́M�E,,�j��-�������F2009/10/11(��) 09:59:49 ID:X3Uk0g//
�悤
��A�
252 �F,,�E�L�́M�E,,�j��-�������F2009/10/11(��) 11:01:36 ID:X3Uk0g//
����1�N�A�[�L���ς��Ȃ����Ă̂��₵�����肾��
SSSE3, SSE4.1���炢�̓��r�W�������ǂœ���Ȃ��̂���
�Ă��ɐ�����
SSSE3, SSE4.1���炢�̓��r�W�������ǂœ���Ȃ��̂���
�Ă��ɐ�����
���T�C�g���u�v���[���ĂȂ��ŏ�߂�
254 �F,,�E�L�́M�E,,�j��-�������F2009/10/11(��) 15:16:09 ID:X3Uk0g//
�V�A�[�L�ł���{�C�o��
�M���Ă����ȁH
�܂��R�e���₷�̂���E�E�E
����͎��S�t���O���Ȃ�
AMD�̂Ȃ�
�N���g�[���j�[�^���Ă���Ȃ��Ĕ߂���
�V�A�[�L�e�N�`���i�v�v�z�j�̃R�e����Ė{�C�o���Ƃ������Č��ǂǂ��������]����˂���
�����߂��Ăǂ����g��������Ȃ��ł�����̊�
�R�X�g�����肷���Ń}�[�W����������CPU���炢�����p�r���Ȃ��B
AMD���g��GPU�Ɏg��Ȃ��Ƃ��납�琄���Ēm��ׂ��B
GF�����O����SOI�v���Z�X�̐��Y�\�͂͗]���Ă�����
SOI���g�����ɂȂ�Ȃ�Ƃ����Ɏg���Ă�B
AMD���g��GPU�Ɏg��Ȃ��Ƃ��납�琄���Ēm��ׂ��B
GF�����O����SOI�v���Z�X�̐��Y�\�͂͗]���Ă�����
SOI���g�����ɂȂ�Ȃ�Ƃ����Ɏg���Ă�B
SOI�v���Z�X�����s��Ȃ���������A�V���R���܂œ����ɂȂ��Ă��邩��ȁB
�ŏ��̖ڂ̕t�����͗ǂ��������A�ς���@����킵�Ă����̂��ɂ������B
�ŏ��̖ڂ̕t�����͗ǂ��������A�ς���@����킵�Ă����̂��ɂ������B
�������I�I
ARM showcases 40% power savings when using SOI
http://www.brightsideofnews.com/news/2009/10/9/arm-showcases-4025-power-savings-when-using-soi.aspx
http://www.brightsideofnews.com/news/2009/10/9/arm-showcases-4025-power-savings-when-using-soi.aspx
�������i�ނɏ]���ĐF��ȃR�X�g�������邩��
���ΓI��SOI�̃R�X�g�͉������Ă���͂������ǂ˂�
���ΓI��SOI�̃R�X�g�͉������Ă���͂������ǂ˂�
�������i�ނɏ]���ĐF��ȃR�X�g�������邩���p�Ό��ʂ̔���SOI�C���l���Ęb�ɂȂ�
270 �F,,�E�L�́M�E,,�j��-�������F2009/10/13(��) 02:46:04 ID:2Fv1JsD6
����������ARM��SOI�g���āA�ʂ����ė��v�ɂȂ邩�ǂ����E�E�E
http://books.google.co.jp/books?id=nEUYFzMc2ZsC&pg=PA494&source=web&ots=aV3o6FTdxT&sig=L-T1HRWmEUHBsu5nNvW2dAPF9_w&hl=ja&sa=X&oi=book_result&resnum=1&ct=result#PPA494,M1
http://books.google.co.jp/books?id=nEUYFzMc2ZsC&pg=PA494&sa=X&oi=book_result&resnum=1&ct=result#PPA494,M1
http://books.google.co.jp/books?id=nEUYFzMc2ZsC&pg=PA494&ct=result#PPA494,M1
���݂�SIMOX�̉��i�͉������Ă����Ƃ����A�܂�6���Ŋ�V���R����
10�`12�{���x�A�\�荇�킹SOI�ł�5�`7�{�ł���A�ʎY�����͍l���ɂ����B
�i�V���R���̉Ȋw 1996�N�j
http://www.din.or.jp/~kwat/ih75.html
�ʏ��Si�E�F�[�n�ɑ�����܂ł�SIMOX��13�{���������A
IMT�Ђ̐��@�ł͂R�{���x�ɗ}����ꂻ���ł���B
�i���o�}�C�N���f�o�C�X 1998/3�����j
http://www.denda-a.com/column04.html
�m���ɁC��ʂ̃V���R���E�E�G�n�Ɣ�ׂČ����
�T�t�@�C�A�E�E�G�n�̉��i�͖�2�{�����܂��B
�i���oBP BizTec�� 2001�N�j
http://www.electronicjournal.co.jp/news/2005/01/25.html
�ʏ�10�`15���R�X�g���ƂȂ�SOI�E�F�[�n
�i2005�N1��25���́uZ-RAM�v�j���[�X�L���j
http://books.google.co.jp/books?id=nEUYFzMc2ZsC&pg=PA494&sa=X&oi=book_result&resnum=1&ct=result#PPA494,M1
http://books.google.co.jp/books?id=nEUYFzMc2ZsC&pg=PA494&ct=result#PPA494,M1
���݂�SIMOX�̉��i�͉������Ă����Ƃ����A�܂�6���Ŋ�V���R����
10�`12�{���x�A�\�荇�킹SOI�ł�5�`7�{�ł���A�ʎY�����͍l���ɂ����B
�i�V���R���̉Ȋw 1996�N�j
http://www.din.or.jp/~kwat/ih75.html
�ʏ��Si�E�F�[�n�ɑ�����܂ł�SIMOX��13�{���������A
IMT�Ђ̐��@�ł͂R�{���x�ɗ}����ꂻ���ł���B
�i���o�}�C�N���f�o�C�X 1998/3�����j
http://www.denda-a.com/column04.html
�m���ɁC��ʂ̃V���R���E�E�G�n�Ɣ�ׂČ����
�T�t�@�C�A�E�E�G�n�̉��i�͖�2�{�����܂��B
�i���oBP BizTec�� 2001�N�j
http://www.electronicjournal.co.jp/news/2005/01/25.html
�ʏ�10�`15���R�X�g���ƂȂ�SOI�E�F�[�n
�i2005�N1��25���́uZ-RAM�v�j���[�X�L���j
SOI�����ɂ�菊�L�R�X�g���ő�40���팸�\�ASemico�̕���
http://www.sijapan.com/breaking/0605/26soi_semico-research060525.html
����ɑ���Semico��COO�͂��A�u��A�̐����R�X�g���݂�ƁA
10�`15���Ƃ���SOI�֘ACOO����S�̂�c�����邱�Ƃ͂ł��Ȃ��v
(Semico�����S���}�l�[�W���O�f�B���N�^��Joanne Itow��)�Ƃ����B
�u�����̐����v���Z�X�̐�i�݁A�E�F�[�n�̎�����_�C�V���O�A
�Ǖi�_�C�̕��~��Ƃ܂�SOI�̃R�X�g�ׂ�ƁASOI��COO�͑S����
�R�X�g���킸��4�`6�����₷�����ōςނ��Ƃ����������v(Itow��)
�V���R���E�G�n�̉��i
http://soudan1.biglobe.ne.jp/qa1506115.html
SOI�E�F�[�n�s��A2012�N�܂ł�11���ăh���ɒB����Ƃ̗\��
http://www.ednjapan.com/content/l_news/2008/u0o686000000ky63.html
2007�N�ɂ�����V���R���E�F�[�n�s��S�̂ł�SOI�E�F�[�n
�̊�����ʐσx�[�X�Ō���ƁA1.4���قǂł������Ƃ����B
�����2002�N�ɂ����鐔���Ɣ�r�����3�{�߂��L�тĂ���B
VLSI Research�Ђ�2008�N��SOI�E�F�[�n�̎s��\���ɂ��āA
�u2007�N�Ɣ�ׂĎ��������ƌ����邪�A2009�N�ȍ~��45nm
�v���Z�X�ւ̈ڍs�Ȃǂɂ��2�������������܂��v�Ɨ\�����Ă���B
http://www.sijapan.com/breaking/0605/26soi_semico-research060525.html
����ɑ���Semico��COO�͂��A�u��A�̐����R�X�g���݂�ƁA
10�`15���Ƃ���SOI�֘ACOO����S�̂�c�����邱�Ƃ͂ł��Ȃ��v
(Semico�����S���}�l�[�W���O�f�B���N�^��Joanne Itow��)�Ƃ����B
�u�����̐����v���Z�X�̐�i�݁A�E�F�[�n�̎�����_�C�V���O�A
�Ǖi�_�C�̕��~��Ƃ܂�SOI�̃R�X�g�ׂ�ƁASOI��COO�͑S����
�R�X�g���킸��4�`6�����₷�����ōςނ��Ƃ����������v(Itow��)
�V���R���E�G�n�̉��i
http://soudan1.biglobe.ne.jp/qa1506115.html
SOI�E�F�[�n�s��A2012�N�܂ł�11���ăh���ɒB����Ƃ̗\��
http://www.ednjapan.com/content/l_news/2008/u0o686000000ky63.html
2007�N�ɂ�����V���R���E�F�[�n�s��S�̂ł�SOI�E�F�[�n
�̊�����ʐσx�[�X�Ō���ƁA1.4���قǂł������Ƃ����B
�����2002�N�ɂ����鐔���Ɣ�r�����3�{�߂��L�тĂ���B
VLSI Research�Ђ�2008�N��SOI�E�F�[�n�̎s��\���ɂ��āA
�u2007�N�Ɣ�ׂĎ��������ƌ����邪�A2009�N�ȍ~��45nm
�v���Z�X�ւ̈ڍs�Ȃǂɂ��2�������������܂��v�Ɨ\�����Ă���B
273 �FSocket774�F2009/10/13(��) 05:04:57 ID:M+Kea34U
SOI���Ĕ������i�ޒ����ʔ�����Ȃ���������
SOI�̓`�b�v�̖ʐς����点�邩��Ȃ�
>>261
���O��ID��SOI������
���O��ID��SOI������
SOI���ISOI���I
����ɂ͔������i�ނ�SOI�̌��ʂ��������Ă����b���L�����Ă���
�Ȃ�ł���
SOI�̓L���p�V�^���X��eDRAM�����p�I�ɂȂ肻���ȂƂ���������b�g�����
TSV�̗p���ɂ�eDRAM���g�����Ęb�����邵
�Ȃ�ł���
SOI�̓L���p�V�^���X��eDRAM�����p�I�ɂȂ肻���ȂƂ���������b�g�����
TSV�̗p���ɂ�eDRAM���g�����Ęb�����邵
�ђʓd�Ɏg����Ȃ�
�{����DRAM���q����������Ȃ��B
CPU�́A��[�v���Z�X�̋M�d�ȃV���R����eDRAM�ɂ�(bit������̃R�X�g��
��������)�g���Ȃ��A�Ƃ������ƂŌ��_�o�Ă�悤�Ɍ����邯�ǂȁB
POWER7�͎g���Ă邯�ǁA�����ȈӖ��ŏ펯�O��̃����X�^�[�`�b�v������
�\�Ȃ̂ł͂Ȃ����B
�{����DRAM���q����������Ȃ��B
CPU�́A��[�v���Z�X�̋M�d�ȃV���R����eDRAM�ɂ�(bit������̃R�X�g��
��������)�g���Ȃ��A�Ƃ������ƂŌ��_�o�Ă�悤�Ɍ����邯�ǂȁB
POWER7�͎g���Ă邯�ǁA�����ȈӖ��ŏ펯�O��̃����X�^�[�`�b�v������
�\�Ȃ̂ł͂Ȃ����B
�V���ȃx���`�T�C�g���a�����Ă���
ttp://www.toei-anim.co.jp/tv/fresh_precure/
ttp://www.toei-anim.co.jp/tv/fresh_precure/
���[�A�d���B
�߂�ǂ������T�C�g���ȁB
�߂�ǂ������T�C�g���ȁB
iida�ƃv���L���A�Ɩh�q�Ȃ��x���`�T�C�g
Prime�̑���Ɏg���������ȁB
283 �F,,�E�L�́M�E,,�j��-�������F2009/10/14(��) 00:21:31 ID:BZHRxyoI
��������炱���܂�CPU���[�^�[�オ���
�����������
�܂������\�[�X�����Ă݂�����
�v���L���A�A�����̃{��PC�ł��������Ɠ����Ă邩��ŐV�̃��c�Ȃ�X�g���X�Ȃ��̂��ȁA�Ǝv���Ă����ǁA
�V���߂�PC�ł��x�������肷��́H
�V���߂�PC�ł��x�������肷��́H
287 �F,,�E�L�́M�E,,�j��-�������F2009/10/14(��) 00:31:08 ID:BZHRxyoI
�ǂ����Flash���ŃL���L���̕`���CPU�ł���Ă���ۂ�
�y�[�W�����ɃX�N���[���������C�ɕ������������������
�y�[�W�����ɃX�N���[���������C�ɕ������������������
���f��Web�S���͂ǂ��PC�Ńu���E�U�e�X�g���Ă�낤��
���}�ȃA�C�f�A�ł���
�@PV�ŃC���Z���e�B�u���t���悤�Ȍ_�������
�@�S������T�C�g�ɂ킴�ƕ��d���t���b�V����u��
�@2ch�e���ɂ��炷
�@�h�ό��h�r�W�^�[��PV���҂�
�@�ϰ
�@PV�ŃC���Z���e�B�u���t���悤�Ȍ_�������
�@�S������T�C�g�ɂ킴�ƕ��d���t���b�V����u��
�@2ch�e���ɂ��炷
�@�h�ό��h�r�W�^�[��PV���҂�
�@�ϰ
��AMD�̊J�����\�[�X���Ăǂ�Ȋ�����
�U�蕪�����Ă邩������H
�U�蕪�����Ă邩������H
>>291
CPU����͊m��2�`�[������3�`�[������Ȃ������H
CPU����͊m��2�`�[������3�`�[������Ȃ������H
>>291
����Ȃ���AMD�{�Ђ̂ƂĂ��̂��l�ȊO�N����������B
����Ȃ���AMD�{�Ђ̂ƂĂ��̂��l�ȊO�N����������B
�v���L���A�T�C�g�K�₵����Ȃ������������̂��������ׂ��������Ă���
�z���g���������y���Ȃ��Ă��
�g�p���͕ς���̂ɉ��Ȃ낤��
�g�p���͕ς���̂ɉ��Ȃ낤��
296 �F,,�E�L�́M�E,,�j��-�������F2009/10/14(��) 23:20:19 ID:BZHRxyoI
�g�p����������
�c�q����A�����Ƃ��Ԕ��S�J����Ȃ��ƁA
�X���L�тȂ��悗����
�@�@�@�@�@�@,,,
(�@߄t�)��
�@�@,,�E�L�́M�E,,�j��-������
�X���L�тȂ��悗����
�@�@�@�@�@�@,,,
(�@߄t�)��
�@�@,,�E�L�́M�E,,�j��-������
298 �F,,�E�L�́M�E,,�j��-�������F2009/10/15(��) 22:47:55 ID:I+UKJFoq
���₳��
,,�E�L�́M�E,,�j��-������
���ŋ߁A��������悤�ɂȂ���AA�Ȃ��A���ꌩ��ƃ��J�c�N�B
�Ȍ�A��؎g�p�֎~���B���������ȁB
���ŋ߁A��������悤�ɂȂ���AA�Ȃ��A���ꌩ��ƃ��J�c�N�B
�Ȍ�A��؎g�p�֎~���B���������ȁB
�c�q�~�ܖڂ�������
�C�V���������snapdragon�`�b�N�ɂȂ��łȂ��́H
ARM��(��)ATI�̑g�ݍ��킹�Ŗ���ɑI�Ԃ�
GF��������ꂽ��~���N���ł����A�\���������Ƃ͌����Ȃ��[�A����
ARM�̃��C�Z���X���Q�b�g����������
�d��������Ƃ����ł���
ARM��(��)ATI�̑g�ݍ��킹�Ŗ���ɑI�Ԃ�
GF��������ꂽ��~���N���ł����A�\���������Ƃ͌����Ȃ��[�A����
ARM�̃��C�Z���X���Q�b�g����������
�d��������Ƃ����ł���
�Ȃ��́u����̂���������F�肢�����܂��v�I�ȕs�̗p�̒ʒm
�~����300�����̌v�Z���ԃ����L���O
http://h2np.net/pi/pi_record.html
�}���`�X���b�h����
http://h2np.net/pi/pi_thread.html
�v�Z��@
http://h2np.net/pi/
���ʂ̍l�@
http://h2np.net/pi/amd_vs_intel.html
AMD����
�}���`�X���b�h���������ɏG��
http://h2np.net/pi/pi_record.html
�}���`�X���b�h����
http://h2np.net/pi/pi_thread.html
�v�Z��@
http://h2np.net/pi/
���ʂ̍l�@
http://h2np.net/pi/amd_vs_intel.html
AMD����
�}���`�X���b�h���������ɏG��
308 �F,,�E�L�́M�E,,�j��-�������F2009/10/17(�y) 22:55:11 ID:6Eq7iFe7
�������I�[�o�[�N���b�N
Intel Pentium 4 Prescott�́A���܂�ɂ��������������v���Z�b�T�� ����B�ėp�ȃ\�t�g�E�F�A�ɂ́A�ƂĂ�����Ȃ����g���Ȃ��B
Intel Core 2�́A���߃��x���ł͐��\���ǂ��B�Ȃ̂Ȃ��悭�ł����v ���Z�b�T�ł���B�������������ƃv���Z�b�T�Ԃ̃������o���h�����l�b�N�ɂ� ��悤�ȃv���O�����ɂ͌����Ȃ��B
Athlon 64�����߃��x���ł͑��Intel Core 2�ƌ݊p�B�܂�adc���߂� ��������GMP�ł͗L���ɍ�p���Ă���B�������o���h�����K�v�ȃv���O�����ł� Intel Core 2 �����L���ł���B
�n�C�p�t�H�[�}���X�R���s���[�e�B���O�ł́A�������o���h���Ƃ����͔̂�� �ɃN���e�B�J���ȕ����ł���̂ŁA�����ł�Athlon 64�n��CPU���g�����Ƃ� �Ȃ邾�낤�B
�������f�X�N�g�b�v�Ŏ�������������悤�ȃ��x���ł����Core 2�n��Athlon 64�n�̃p�t�H�[�}���X�̍����c�_����͈̂Ӗ����Ȃ��悤�Ɏv ����B
�܂�Web �T�[�o�̂悤�Ȃ��̃������o���h���͂��܂�W�Ȃ��̂œ� �l�ł���B
Intel Core 2�́A���߃��x���ł͐��\���ǂ��B�Ȃ̂Ȃ��悭�ł����v ���Z�b�T�ł���B�������������ƃv���Z�b�T�Ԃ̃������o���h�����l�b�N�ɂ� ��悤�ȃv���O�����ɂ͌����Ȃ��B
Athlon 64�����߃��x���ł͑��Intel Core 2�ƌ݊p�B�܂�adc���߂� ��������GMP�ł͗L���ɍ�p���Ă���B�������o���h�����K�v�ȃv���O�����ł� Intel Core 2 �����L���ł���B
�n�C�p�t�H�[�}���X�R���s���[�e�B���O�ł́A�������o���h���Ƃ����͔̂�� �ɃN���e�B�J���ȕ����ł���̂ŁA�����ł�Athlon 64�n��CPU���g�����Ƃ� �Ȃ邾�낤�B
�������f�X�N�g�b�v�Ŏ�������������悤�ȃ��x���ł����Core 2�n��Athlon 64�n�̃p�t�H�[�}���X�̍����c�_����͈̂Ӗ����Ȃ��悤�Ɏv ����B
�܂�Web �T�[�o�̂悤�Ȃ��̃������o���h���͂��܂�W�Ȃ��̂œ� �l�ł���B
���N�O�̘_�l��������c
���N�o���Ă��i���Ȃ�
�̂̌��������፡����10����Ƃ��œ���CPU���o�Ă��͂��Ȃ̂ɁB
�����������痈�N�˔@�Ƃ��ău���C�N�X���[���N���������I�I�I
http://journal.mycom.co.jp/news/2003/02/21/30_17.jpg
http://journal.mycom.co.jp/news/2003/02/21/30_17.jpg
{kind=link}
������CPU��GPU��Fusion���Ă�͂��Ȃ̂ɁA�Ƃ�
315 �F,,�E�L�́M�E,,�j��-�������F2009/10/18(��) 02:25:44 ID:ug3wQg4J
SSE5�Ή���Bulldozer���č��N��������ˁA�Ƃ�
40nm��Ontario�����S�V�K�̏��
��MH������̒����I�Ȏ��_�őΐ��I�Ɍ����
10GH����3.6GH���ii7 870 TB�j���Ă���Ȃɉ����Ȃ��C�����Ȃ��ł��Ȃ�
10GH����3.6GH���ii7 870 TB�j���Ă���Ȃɉ����Ȃ��C�����Ȃ��ł��Ȃ�
�����ƁAAMD�̃X���b�h������3.4GHz�iX4 965�j�Ə����Ȃ����
Core2��������̌�����̃z�[���X�e�C��Œm�荇�����h�C�c�l(�݃C�X���G��)�Z�p�҂�
�̘b�Ő���オ�������łɃ_�����ŕ����Ă݂���A�������苳���Ă��ꂽ�B
Core2�́AL1�`L2(XEON�ł�L3���܂�)�ƃp�C�v���C�����̖��ߑS�Ă��L�����Z������d�g��
���L���āA�n�[�h�I�� non maskable interrupt �܂�A�\�t�g�I�ȋ��ۂ��s�\��
���荞�ݐM�������p�ӂ���Ă���炵���B
�{���́A�T�[�o�@�p�Ƀf�b�h���b�N�������̍ŏI�����i�Ƃ��ėp�ӂ���Ă���炵��
�̂�����ǂ��A���ʂ̃p�\�R���ł������ȃ}�U�[�̏ꍇ�A���G�Ȕz����BIOS�\�����ȗ���
�����i�Ƃ��āAHDD�A�N�Z�X�̒���ȂǂɁA���̊��荞�ݐM�����g���ă������ƃL���b�V��
����v����悤�Ɉ�UL1�`L2�ƃp�C�v���C���̑S�Ă��N���A���Ă��܂����������炵���B
�܂�A�蔲�����B
��������ƁA���̊��荞�ݏ��������Ă�Ԃ́A���̊��荞�݂��֎~�����̂ŁA�v�`�t����
�������肪�������Ă��܂��ƌ������Ȃ��āB
�W�w�ȏ�̊���g�����}�U�[�Ȃ���v�ȉ\���������炵�����ǁA���P�T�O�ȉ���
�����ɏo����Ă���}�U�[�̏ꍇ�́A�܂��A���ꂪ�����ň����|�銴�G����(�܂�
�v�`�t�����������̎�)�ɂȂ�����ȁB
����Ȏ��A���\�ł��Ȃ����낤���A�\�[�X�͗F�l����̌��`��������A
�M���Ȃ��Ă����R����ˁB
�S���P������Ȃ���ŁA�R�͌����ĂȂ��Ǝv�����ǁA�s�s�`�����x����
�l���������������B
�R��͂W�w�ȏ�̂R���`�̕�őg�ݒ����Ă݂邩�A����Ƃ�X2�ɏ�芷��
�邩�Ŗ����Ă�B
�̘b�Ő���オ�������łɃ_�����ŕ����Ă݂���A�������苳���Ă��ꂽ�B
Core2�́AL1�`L2(XEON�ł�L3���܂�)�ƃp�C�v���C�����̖��ߑS�Ă��L�����Z������d�g��
���L���āA�n�[�h�I�� non maskable interrupt �܂�A�\�t�g�I�ȋ��ۂ��s�\��
���荞�ݐM�������p�ӂ���Ă���炵���B
�{���́A�T�[�o�@�p�Ƀf�b�h���b�N�������̍ŏI�����i�Ƃ��ėp�ӂ���Ă���炵��
�̂�����ǂ��A���ʂ̃p�\�R���ł������ȃ}�U�[�̏ꍇ�A���G�Ȕz����BIOS�\�����ȗ���
�����i�Ƃ��āAHDD�A�N�Z�X�̒���ȂǂɁA���̊��荞�ݐM�����g���ă������ƃL���b�V��
����v����悤�Ɉ�UL1�`L2�ƃp�C�v���C���̑S�Ă��N���A���Ă��܂����������炵���B
�܂�A�蔲�����B
��������ƁA���̊��荞�ݏ��������Ă�Ԃ́A���̊��荞�݂��֎~�����̂ŁA�v�`�t����
�������肪�������Ă��܂��ƌ������Ȃ��āB
�W�w�ȏ�̊���g�����}�U�[�Ȃ���v�ȉ\���������炵�����ǁA���P�T�O�ȉ���
�����ɏo����Ă���}�U�[�̏ꍇ�́A�܂��A���ꂪ�����ň����|�銴�G����(�܂�
�v�`�t�����������̎�)�ɂȂ�����ȁB
����Ȏ��A���\�ł��Ȃ����낤���A�\�[�X�͗F�l����̌��`��������A
�M���Ȃ��Ă����R����ˁB
�S���P������Ȃ���ŁA�R�͌����ĂȂ��Ǝv�����ǁA�s�s�`�����x����
�l���������������B
�R��͂W�w�ȏ�̂R���`�̕�őg�ݒ����Ă݂邩�A����Ƃ�X2�ɏ�芷��
�邩�Ŗ����Ă�B
>>320
����
����
�܂Ƃ�
�Ƃ������ƂŐ��\�x���`�}�[�N�҂��炾���ԋĂ��܂������A������͕҂����͂��ł����B
�Ƃ肠����Phenom II�́APhenom�ōő�̖�肾��������d�͂̑������A�v���Z�X�̉��P�ɂ��������邱�Ƃ��o���Ă���A6�R�A���i�����̂܂ܖ��Ȃ��J���ł��邾���̃w�b�h���[���������Ă��邱�Ƃ͊m�F�ł����B
���̈���ACore i7�ɑ���ő�̃l�b�N��L2/L3/Memory��Bandwidth�̒Ⴓ�ł���BCPU�R�A���̂��̂�L1�L���b�V���ɂ͏\���ȑш悪����A��������g������邾���̍\���ɂȂ��Ă��邪�A���̐悪����Ƃ������Ƃ���B
�Ⴆ��Ȃ�A3���b�^�[�N���X�̃p���t���ȃG���W���Ɍy�����Ԃ̃^�C������Ă�悤�Ȃ��̂��B
���͖��m�����A�R�A�Ɏ������K�v�͂Ȃ�����ACPU�̃p�C�v���C����ύX����قǓ����Ƃł͂Ȃ��Ƃ͎v�����A������Ƃ����Ă�����Ƃ���Revision Up�ʼn�������قNJȒP�Ȗ��ł��Ȃ����낤�B
���̂�����̉��P��Ƃ�Istanbul�ɊԂɍ������ǂ����B���ꂪ�Ԃɍ�����Core i7�ɕ����Ȃ����\���ł��邾�낤���A�Ԃɍ���Ȃ��ƈˑR�Ƃ���Core i7�ɑ傫�ȃr�n�C���h�������邾�낤�B
���ɃT�[�o��HPC�̕���ł��̐��\���͒v���I�Ȃ��̂�����킯�ŁA���̂܂܂��Ɛ܊p����܂Ŋl�����Ă����T�[�o����̃V�F�A���������˂Ȃ��l�ɕM�҂ɂ͊�������B����̓W�J���C�ɂȂ�Ƃ��낾�B
http://journal.mycom.co.jp/special/2009/deneb02/022.html
�Ƃ������ƂŐ��\�x���`�}�[�N�҂��炾���ԋĂ��܂������A������͕҂����͂��ł����B
�Ƃ肠����Phenom II�́APhenom�ōő�̖�肾��������d�͂̑������A�v���Z�X�̉��P�ɂ��������邱�Ƃ��o���Ă���A6�R�A���i�����̂܂ܖ��Ȃ��J���ł��邾���̃w�b�h���[���������Ă��邱�Ƃ͊m�F�ł����B
���̈���ACore i7�ɑ���ő�̃l�b�N��L2/L3/Memory��Bandwidth�̒Ⴓ�ł���BCPU�R�A���̂��̂�L1�L���b�V���ɂ͏\���ȑш悪����A��������g������邾���̍\���ɂȂ��Ă��邪�A���̐悪����Ƃ������Ƃ���B
�Ⴆ��Ȃ�A3���b�^�[�N���X�̃p���t���ȃG���W���Ɍy�����Ԃ̃^�C������Ă�悤�Ȃ��̂��B
���͖��m�����A�R�A�Ɏ������K�v�͂Ȃ�����ACPU�̃p�C�v���C����ύX����قǓ����Ƃł͂Ȃ��Ƃ͎v�����A������Ƃ����Ă�����Ƃ���Revision Up�ʼn�������قNJȒP�Ȗ��ł��Ȃ����낤�B
���̂�����̉��P��Ƃ�Istanbul�ɊԂɍ������ǂ����B���ꂪ�Ԃɍ�����Core i7�ɕ����Ȃ����\���ł��邾�낤���A�Ԃɍ���Ȃ��ƈˑR�Ƃ���Core i7�ɑ傫�ȃr�n�C���h�������邾�낤�B
���ɃT�[�o��HPC�̕���ł��̐��\���͒v���I�Ȃ��̂�����킯�ŁA���̂܂܂��Ɛ܊p����܂Ŋl�����Ă����T�[�o����̃V�F�A���������˂Ȃ��l�ɕM�҂ɂ͊�������B����̓W�J���C�ɂȂ�Ƃ��낾�B
http://journal.mycom.co.jp/special/2009/deneb02/022.html
>>319
�g�s�b�N�܂Ƃ�
Thuban:
�ETurboBoost�����̋Z�p�𓋍�
Zambezi:
�EBulldozer�R�A
�E8�R�A
�E8MB L3$
�EAM3r�Q
Liano:
�EPhenom�U�Ɠ����R�A
�E1MB/�R�A��L2$�ADDR3-1600�ɋ���(L3�͊C�O�L���ɂ���4MB)
�E�\�P�b�g��FM1
�E2~4�R�A�œW�J
�E�f�X�N�g�b�v�̎嗬�`�m�[�g�̃n�C�G���h�p
Ontario:
�E40nm�̒ቿ�i�m�[�g����(AthlonNeo�̌�p�H)
8x0Gx:
�E785��OC�ł�55nm�̂܂�
�E890FX�̓p�b�P�[�W�����剻(�T�[�o�[�p�Ƌ��L?)
�EDirectX11�Ή�,40nm�����O���t�B�b�N��Liano�܂ł��a�����H
�E���Ԃ�Bulldozer�ALiano�ɒ��͂��邽�߂ɐV���i�����Ȃ̂��낤
SB8x0:
�ESATA 3.0,USB3.0�Ή�
�E�n����NB�ASB�Ԃ̑ш�{��
�g�s�b�N�܂Ƃ�
Thuban:
�ETurboBoost�����̋Z�p�𓋍�
Zambezi:
�EBulldozer�R�A
�E8�R�A
�E8MB L3$
�EAM3r�Q
Liano:
�EPhenom�U�Ɠ����R�A
�E1MB/�R�A��L2$�ADDR3-1600�ɋ���(L3�͊C�O�L���ɂ���4MB)
�E�\�P�b�g��FM1
�E2~4�R�A�œW�J
�E�f�X�N�g�b�v�̎嗬�`�m�[�g�̃n�C�G���h�p
Ontario:
�E40nm�̒ቿ�i�m�[�g����(AthlonNeo�̌�p�H)
8x0Gx:
�E785��OC�ł�55nm�̂܂�
�E890FX�̓p�b�P�[�W�����剻(�T�[�o�[�p�Ƌ��L?)
�EDirectX11�Ή�,40nm�����O���t�B�b�N��Liano�܂ł��a�����H
�E���Ԃ�Bulldozer�ALiano�ɒ��͂��邽�߂ɐV���i�����Ȃ̂��낤
SB8x0:
�ESATA 3.0,USB3.0�Ή�
�E�n����NB�ASB�Ԃ̑ш�{��
>>323
�U���x�W�͍��܂Œʂ�r���L���b�V�����ȁB
���ꂾ�ƌ���̂܂�intel�̓������菭���g�[�^���L���b�V�����������炢���B
�U���x�W�͍��܂Œʂ�r���L���b�V�����ȁB
���ꂾ�ƌ���̂܂�intel�̓������菭���g�[�^���L���b�V�����������炢���B
�V�������[�h�}�b�v�̔��\���������̂��Ƃ���������
�V�K���̐}�\�͑S��copyright bun ...
IOMMU����m��Ȃ����C�^�[�̖ϑz����Ȃ���
�V�K���̐}�\�͑S��copyright bun ...
IOMMU����m��Ȃ����C�^�[�̖ϑz����Ȃ���
���ƈꃖ�����AnalystDay
�������[�h�}�b�v���X�V����邾�낤
�������[�h�}�b�v���X�V����邾�낤
328 �FSocket774�F2009/10/18(��) 11:52:38 ID:dpnz9F+h
4�T����
>>328
�u�L���v�̈Ӗ����킩���Ă��Ȃ��z���B
�u�L���v�̈Ӗ����킩���Ă��Ȃ��z���B
>>319
"Thuban"��낽���@����Ȃ��Ǝv��������"Turbo Boost"����Ă�������
�������A"Zambezi"="Bulldozer�A�[�L�e�B�N�`��"�Ȃ̂��Ȃ��B
�uAM3r2�v�������ł�܂őΉ����Ă���邩�킩�疳�����ǁA
�i������ł́jRD8x0�ȏ�ł͂Ȃ��Ɩ������ۂ��C������B
"Thuban"��낽���@����Ȃ��Ǝv��������"Turbo Boost"����Ă�������
�������A"Zambezi"="Bulldozer�A�[�L�e�B�N�`��"�Ȃ̂��Ȃ��B
�uAM3r2�v�������ł�܂őΉ����Ă���邩�킩�疳�����ǁA
�i������ł́jRD8x0�ȏ�ł͂Ȃ��Ɩ������ۂ��C������B
>>328�͑��a�c�̃O���t���ۈ�����߂Ă��珑�����ނׂ�
�̖{���̈Ӗ���������
�̖{���̈Ӗ���������
334 �FSocket774�F2009/10/18(��) 15:02:18 ID:dpnz9F+h
�ǂ���ɂ���u�L���v����˂��ȁB
336 �FSocket774�F2009/10/18(��) 15:20:27 ID:dpnz9F+h
�m���ɁA�ǂ����悢���債�Ă��ł������̂Łu�v���ĕ\���͐������Ȃ������B
�����́A�\�z�������B�i���n�ƈꏏ���H�j
>>333
���a�c����̃x���`�́A���܂ɂȂ��Ⴂ���Ę_�_������Ă鎞�����邯��
�܂��A���Ȃ�����ȕ����Ǝv����B
�{���ɂЂǂ��̂́A�}�C�R�~�B
�G���̕��͂������ĕ��ʂ����ǂ������Ă��邯�ǁA�T�C�g�̕��͂����
���S�ȔS����n�O������Ă�Ƃ����v����B
�����́A�\�z�������B�i���n�ƈꏏ���H�j
>>333
���a�c����̃x���`�́A���܂ɂȂ��Ⴂ���Ę_�_������Ă鎞�����邯��
�܂��A���Ȃ�����ȕ����Ǝv����B
�{���ɂЂǂ��̂́A�}�C�R�~�B
�G���̕��͂������ĕ��ʂ����ǂ������Ă��邯�ǁA�T�C�g�̕��͂����
���S�ȔS����n�O������Ă�Ƃ����v����B
>>336
���[�h�}�b�v�L�����u�v�ƌ�������A
CPU���[�h�}�b�v���ڂ����S�Ă̋L����
AMD�ł��낤��Intel�ł��낤�Ɓu�L���v���ȁB
����ɑ��a�c�L���̑唼������Ȃ��Ǝv���̂́A
�������Ԕ��ł�����Ȃ��̂ł��傤���H
���_�B�uID:dpnz9F+h�v�͕K����age�čr�����Ƃ��Ă������ǁA
���̊ɂ�����ڕW��B���ł��܂���ł����Ƃ��B
���[�h�}�b�v�L�����u�v�ƌ�������A
CPU���[�h�}�b�v���ڂ����S�Ă̋L����
AMD�ł��낤��Intel�ł��낤�Ɓu�L���v���ȁB
����ɑ��a�c�L���̑唼������Ȃ��Ǝv���̂́A
�������Ԕ��ł�����Ȃ��̂ł��傤���H
���_�B�uID:dpnz9F+h�v�͕K����age�čr�����Ƃ��Ă������ǁA
���̊ɂ�����ڕW��B���ł��܂���ł����Ƃ��B
338 �FSocket774�F2009/10/18(��) 15:59:46 ID:dpnz9F+h
337<<���[�h�}�b�v�L�����u�v�ƌ�������`
���߁A��E�\�E�z���Ē������������B
�������[�h�}�b�v�Ȃ�ł��Ȃ�ł��Ȃ����A�N������l�^�����ɏ����Ă�
�̂Ȃ炻��́A�ł��낤�������낤���A������Ƃ������|�[�g�����ǁA
�W�߂̏����Ȃ����Ƃ���ŁA�����̗\�z�ɂ����Ȃ��ł���B
���a�c����̌��́A�ꌾ�����ᖳ���Ƃ͌����ĂȂ����낤�H
���߁A��E�\�E�z���Ē������������B
�������[�h�}�b�v�Ȃ�ł��Ȃ�ł��Ȃ����A�N������l�^�����ɏ����Ă�
�̂Ȃ炻��́A�ł��낤�������낤���A������Ƃ������|�[�g�����ǁA
�W�߂̏����Ȃ����Ƃ���ŁA�����̗\�z�ɂ����Ȃ��ł���B
���a�c����̌��́A�ꌾ�����ᖳ���Ƃ͌����ĂȂ����낤�H
939��AM2�̂悤�ȉ��ʂ���ʂ��݊����Ȃ��悤�ȕύX�͓�����ł����H
�u�{�ԕ��v�̋L���Ȃ�āA�b�̃l�^�ɂȂ�ǂȁB
�����̋L����99.9%�͖ϑz�ŏo���Ă��邵�B
�����̋L����99.9%�͖ϑz�ŏo���Ă��邵�B
>>341
�o�܂���B
�o�܂���B
>>343
4gamer�̋L�����̐}�͊Ԉ���Ă�́H
4gamer�̋L�����̐}�͊Ԉ���Ă�́H
Regor��1�R�A�팸�ł̗\��͂���ȁB
������DDR3�Ή���L2��1MB�B
������DDR3�Ή���L2��1MB�B
SocketAM3Revision2��CPU���ĂȂE�E�E
���sAM3�ɂ����ʌ݊��ł̂�����E�E��ȁE�E�E�H
���sAM3�ɂ����ʌ݊��ł̂�����E�E��ȁE�E�E�H
>>346
���ʌ݊����Ȃ��Ȃ�A�������O�͎g��Ȃ��ł���B
���ʌ݊����Ȃ��Ȃ�A�������O�͎g��Ȃ��ł���B
348 �F�A���~ ��Fh2IQtNvbw �F2009/10/18(��) 18:38:44 ID:rNfbTKGQ
�����̑�����炾�B�b��ɂ��Ă��炦�邾���ł����ӂ���(�E�L��`�E)
>>319
���̃y�[�X����m�[�g�s��̓C���e������肾�ȁc�c
���̃y�[�X����m�[�g�s��̓C���e������肾�ȁc�c
352 �F,,�E�L�́M�E,,�j��-�������F2009/10/19(��) 01:42:13 ID:lG+f+kn0
�܂��`���[���[�f�}�������B
�܂�TSMC��32nm�v���Z�X���]��o�����ǂ��Ȃ��i28nm����{�C�o���j����
�悭�����Ă����ǂ�
�܂�TSMC��32nm�v���Z�X���]��o�����ǂ��Ȃ��i28nm����{�C�o���j����
�悭�����Ă����ǂ�
>C State Performance Boost
����������Ɖ��Ƃ��Ȃ�Ȃ������̂��A���O
����������Ɖ��Ƃ��Ȃ�Ȃ������̂��A���O
���O���炵��Turbo Boost�Ă�����IDA���ȁ`
�܂�PCU��PowerGate����������2010�N�ɂ͏o���Ȃ����
�܂�PCU��PowerGate����������2010�N�ɂ͏o���Ȃ����
Atom�����łȂ�ARM�̐����ɂ��g�������A�v���Z�X�Z�p�̋��^�͂��蓾�Ȃ��Ǝv�����ǁB
356 �F,,�E�L�́M�E,,�j��-�������F2009/10/19(��) 02:12:29 ID:lG+f+kn0
������INVIDIA���n�C�G�i�̂悤�ɂ�����̂�������I
AMD��i9�ɑR�ł����ł��傤��
amd�̃l�[�~���O�Z���X�ɜ��R
>>319�̖{�ԕ��̋L����M����Ƃ��B���ƂŒɂ��ڂɑ������H
>C1E���C���̃R�A�̃N���b�N�A�b�v�v��
AMD��`��C1e:�S�R�AHalt & �R�A���Ӊ�H(xbar��L3��)�̏���d�͍팸���
�S�R�A�Ƃ܂��Ă�̂ɉ����N���b�N�A�b�v����̂��Ə��ꎞ��
C5����������́uC�X�e�[�g�p�t�H�[�}���X�̉��P�v�����Ⴂ������łˁ[�́H
AMD��`��C1e:�S�R�AHalt & �R�A���Ӊ�H(xbar��L3��)�̏���d�͍팸���
�S�R�A�Ƃ܂��Ă�̂ɉ����N���b�N�A�b�v����̂��Ə��ꎞ��
C5����������́uC�X�e�[�g�p�t�H�[�}���X�̉��P�v�����Ⴂ������łˁ[�́H
AMD��hp��acer�ɂǂꂾ���̗p���Ă��炦�邩���������낤
�̗p���Ă����Ƃ���܂Œl��������A���̏����Ȃ畉���͂Ȃ���
HP�Ƃ��Ă�(�����̃C���Z���e�B�u�Ȃ��Ȃ�)Intel��Јˑ��͂������Ȃ��킯�����B
������{���̏����́u�V�F�A2���̍Œ���ɂǂꂾ����ς݂ł��邩�v
�u�l�������������B���ł��邩�v���Ǝv�����B
HP�Ƃ��Ă�(�����̃C���Z���e�B�u�Ȃ��Ȃ�)Intel��Јˑ��͂������Ȃ��킯�����B
������{���̏����́u�V�F�A2���̍Œ���ɂǂꂾ����ς݂ł��邩�v
�u�l�������������B���ł��邩�v���Ǝv�����B
�l���������́AGF��STMicro�����܂Ŗ����Ȃ�Ȃ��́H
AMD�{�͍̂����ŁA�������傪��Ԏ��ȏ�Ԃ����B
AMD�{�͍̂����ŁA�������傪��Ԏ��ȏ�Ԃ����B
ttp://www.xbitlabs.com/news/cpu/display/20091015173531_AMD_s_First_Fusion_Processors_to_Be_Made_Using_32nm_SOI_Process_Technology_CEO.html
URL���Ȃ����c���B2011�N�ɂȂ�"Llano"��SOI�݂������ȁB
GPU�R�A��32nm�ɒ����Ƃ���ς��������c�B
URL���Ȃ����c���B2011�N�ɂȂ�"Llano"��SOI�݂������ȁB
GPU�R�A��32nm�ɒ����Ƃ���ς��������c�B
����hp��acer�̂��������Ƃ����Ƃ��Ă��܂���17��
�ł��m�[�g���S�̓��łƂ�lenovo��athlon NEO�͔��荞�߂����ɂȂ�
���K�̓��[�J�[�����Ƃ��Ƃ�BTO�Ǝ���������炢�����Ȃ����ǁA����������AMD���撣��Ȃ��Ǝd���Ȃ����������
�ł��m�[�g���S�̓��łƂ�lenovo��athlon NEO�͔��荞�߂����ɂȂ�
���K�̓��[�J�[�����Ƃ��Ƃ�BTO�Ǝ���������炢�����Ȃ����ǁA����������AMD���撣��Ȃ��Ǝd���Ȃ����������
>>365
Phenom�U��Athlon�U��Turion�U���ؗ�ɃX���[����Ȃ�
Phenom�U��Athlon�U��Turion�U���ؗ�ɃX���[����Ȃ�
���_�����a(���������ǁj�̊댯��
1. �N���Ɍ����点������Ă���Ƃ����B
2. �N���ɑ_��ꂽ��A����ꂽ��A�������ꂽ�肵�Ă���Ƃ����B
3. �d�g�̂悤�Ȃ��̂ł������Ƃ����B
4. �����̍l�����s�v�c�ȗ͂ɂ���ĉ��̐l�����ɓ`����Ă��܂��Ƃ����B�i�e���p�V�[�Ȃǁj
5. ����ɐl�����Ȃ��̂Ɏ�����ӂ߂�悤�Ȑ����������Ă���Ƃ����B
6. �N���������ɂ̂肤���Ă���Ƃ����B
7. �̂̒��ɉ����̋@�B���͂����Ă���Ƃ����B
8. �̂̈ꕔ�i���A�]�Ȃǁj���n������`����������肷��Ƃ����B
9. ���̒����������āA�����l���Ă����̂��킩��Ȃ��Ȃ�Ƃ����B
10. �b�ɂ܂Ƃ܂肪�Ȃ��B�x���ŗ�ʼn��������Ă�̂������ł��Ȃ��B
11. �����̍l���Ă��鎖�����ɂȂ��ĕ������Ă���Ƃ����B
12. �����ƓƂ茾�������Ă���B��l��������B
13. ��{���y�̊���Ȃ��Ȃ��Ă��܂����B
14. ���������肪���ŁA�قƂ�NJO�o���Ȃ��B
15. �ȑO�͌����Ȃ������悤�Ȋ�Ȍ���������B
1. �N���Ɍ����点������Ă���Ƃ����B
2. �N���ɑ_��ꂽ��A����ꂽ��A�������ꂽ�肵�Ă���Ƃ����B
3. �d�g�̂悤�Ȃ��̂ł������Ƃ����B
4. �����̍l�����s�v�c�ȗ͂ɂ���ĉ��̐l�����ɓ`����Ă��܂��Ƃ����B�i�e���p�V�[�Ȃǁj
5. ����ɐl�����Ȃ��̂Ɏ�����ӂ߂�悤�Ȑ����������Ă���Ƃ����B
6. �N���������ɂ̂肤���Ă���Ƃ����B
7. �̂̒��ɉ����̋@�B���͂����Ă���Ƃ����B
8. �̂̈ꕔ�i���A�]�Ȃǁj���n������`����������肷��Ƃ����B
9. ���̒����������āA�����l���Ă����̂��킩��Ȃ��Ȃ�Ƃ����B
10. �b�ɂ܂Ƃ܂肪�Ȃ��B�x���ŗ�ʼn��������Ă�̂������ł��Ȃ��B
11. �����̍l���Ă��鎖�����ɂȂ��ĕ������Ă���Ƃ����B
12. �����ƓƂ茾�������Ă���B��l��������B
13. ��{���y�̊���Ȃ��Ȃ��Ă��܂����B
14. ���������肪���ŁA�قƂ�NJO�o���Ȃ��B
15. �ȑO�͌����Ȃ������悤�Ȋ�Ȍ���������B
�ŋ߂�AMD�͂������ȁB
���_�Ӓ�܂ł���̂��B
���_�Ӓ�܂ł���̂��B
���̃X����AMD�̒ł����肵�Ă��܂�
�Ȑ��E������܂�
�Ȑ��E������܂�
1. �}�C�N���\�t�g�Ɍ����点������Ă���Ƃ����B
2. Intel�ɑ_��ꂽ��A����ꂽ��A�������ꂽ�肵�Ă���Ƃ����B
3. HyperTransport�̂悤�Ȃ��̂ł������Ƃ����B
4. �����̍l�����C���^�[�l�b�g�ɂ���ĉ��̐l�����ɓ`����Ă��܂��Ƃ����B�i�e���p�V�[�Ȃǁj
5. �����HDD���Ȃ��̂Ƀw�b�h���V�[�N����悤�ȉ����������Ă���Ƃ����B
6. �Q�C�c�������ɂ̂肤���Ă���Ƃ����B
7. �̂̒���Intel��CPU���͂����Ă���Ƃ����B
8. M/B�̈ꕔ�i�R�l�N�^�A�L���p�V�^�Ȃǁj���n������`����������肷��Ƃ����B
9. �L���b�V���̒����������āA�����������Ă����̂��킩��Ȃ��Ȃ�Ƃ����B
10. ���[�h�}�b�v�ɂ܂Ƃ܂肪�Ȃ��B�x���ŗ�ʼn��������Ă�̂������ł��Ȃ��B
2. Intel�ɑ_��ꂽ��A����ꂽ��A�������ꂽ�肵�Ă���Ƃ����B
3. HyperTransport�̂悤�Ȃ��̂ł������Ƃ����B
4. �����̍l�����C���^�[�l�b�g�ɂ���ĉ��̐l�����ɓ`����Ă��܂��Ƃ����B�i�e���p�V�[�Ȃǁj
5. �����HDD���Ȃ��̂Ƀw�b�h���V�[�N����悤�ȉ����������Ă���Ƃ����B
6. �Q�C�c�������ɂ̂肤���Ă���Ƃ����B
7. �̂̒���Intel��CPU���͂����Ă���Ƃ����B
8. M/B�̈ꕔ�i�R�l�N�^�A�L���p�V�^�Ȃǁj���n������`����������肷��Ƃ����B
9. �L���b�V���̒����������āA�����������Ă����̂��킩��Ȃ��Ȃ�Ƃ����B
10. ���[�h�}�b�v�ɂ܂Ƃ܂肪�Ȃ��B�x���ŗ�ʼn��������Ă�̂������ł��Ȃ��B
���������^
11. ��Ђ̍l���Ă���\�肪�����ɂȂ��ĕ������Ă���Ƃ����B
12. �����ƓƂ葊�o���Ƃ��Ă���B��l�����錾������B
13. �n�C�G���h���[�G���h�̋�ʂ��Ȃ��Ȃ��Ă��܂����B
14. �V�F�A�����������肪���ŁA�قƂ�Ǐ㏸���Ȃ��B
15. �ȑO�͌����Ȃ������悤�Ȋ�ȃv���Z�b�T��������
12. �����ƓƂ葊�o���Ƃ��Ă���B��l�����錾������B
13. �n�C�G���h���[�G���h�̋�ʂ��Ȃ��Ȃ��Ă��܂����B
14. �V�F�A�����������肪���ŁA�قƂ�Ǐ㏸���Ȃ��B
15. �ȑO�͌����Ȃ������悤�Ȋ�ȃv���Z�b�T��������
>7. �̂̒���Intel��CPU���͂����Ă���Ƃ����B
x86�̃��C�Z���X�̎����c
x86�̃��C�Z���X�̎����c
�[���ȁB
�v���̔ƍs���B
�v���̔ƍs���B
����GF�͎q��Ђ�x86���C�Z���X�ᔽ�ł͂Ȃ�
�t�@�E���_�������Ń��C�g�A�Z�b�g�]�X�͖ό��������A�ŏI���Ȃ̂�
�t�@�E���_�������Ń��C�g�A�Z�b�g�]�X�͖ό��������A�ŏI���Ȃ̂�
�����������Intel�̓��ӋZ
����A����Ȍ������z������ŊO�ɓf���o���Ȃ��������傪�藣���Ă��Ȃ��̂�
�{�̂̒v�����Ɍq������c�c
�{�̂̒v�����Ɍq������c�c
Intel�ɐ������Ă��炦�Ηǂ��ˁH
������؋����މ�ₔ��o�Ƃ������̂���
>>376
�㏞��AVX�̗̍p�������肵�āB
�㏞��AVX�̗̍p�������肵�āB
382 �F,,�E�L�́M�E,,�j��-�������F2009/10/24(�y) 21:07:57 ID:/pRpwPyp
Sandy Bridge��Gesher���ČĂ�Ă����ɂ�MS�͊���Windows 7/Server 2008 R2��
�V�������W�X�^�ւ̑Ή��i�߂Ă���ōR���������ʂ�����
�V�������W�X�^�ւ̑Ή��i�߂Ă���ōR���������ʂ�����
>>381
��������ʔ����ˁB�g�����߂̕��U��������Intel�Ƃ��Ă��ǂ���������Ȃ����B
��������ʔ����ˁB�g�����߂̕��U��������Intel�Ƃ��Ă��ǂ���������Ȃ����B
�o�C�i�������S�ɕ������64bit�Ή��ƈ����
OS��AVX�Ή���SSE5�Ή��͔r������Ȃ�����A
OS�̑��͌����ΑΉ����Ă��ꂽ���낤�B
��߂��̂͐��\�����b�g�̂Ȃ�AMD�Ǝ��g���Ƀ��[�U�[�̎��v���Ȃ�����B
OS��AVX�Ή���SSE5�Ή��͔r������Ȃ�����A
OS�̑��͌����ΑΉ����Ă��ꂽ���낤�B
��߂��̂͐��\�����b�g�̂Ȃ�AMD�Ǝ��g���Ƀ��[�U�[�̎��v���Ȃ�����B
SSE5��SSE�̓Ǝ��g���ł���悤��
XOP/FMA4��AVX�̓Ǝ��g���Ȃ̂�����
�g�����߂̕��U�Ƃ����_�ł͉����ς���Ă��Ȃ�
AVX���g���镪����AMD�������Ă��邾���Ȃ�
�ǂ���Intel�̃����b�g�������
XOP/FMA4��AVX�̓Ǝ��g���Ȃ̂�����
�g�����߂̕��U�Ƃ����_�ł͉����ς���Ă��Ȃ�
AVX���g���镪����AMD�������Ă��邾���Ȃ�
�ǂ���Intel�̃����b�g�������
AVX�̕��y���i
��������intel�̋Z�p���݊��œ��ڂ������
AMD�͂���Ȃ�̋]�����Ă��Ȃ���?
�_��̓��e�͒m��Ȃ����ǁA�^�_�Ŏg���Ă������Ƃ͂����Ȃ���c
AMD�͂���Ȃ�̋]�����Ă��Ȃ���?
�_��̓��e�͒m��Ȃ����ǁA�^�_�Ŏg���Ă������Ƃ͂����Ȃ���c
AMD�͖���SSE�̎������^�R�Ȃ̂�AVX������܊��҂ł��Ȃ��Ȃ�
389 �F,,�E�L�́M�E,,�j��-�������F2009/10/25(��) 12:18:29 ID:vK8GI5hT
Shanghai�n�A�[�L�e�N�`���𗈔N���������Ȃ��Ƃ����Ȃ��Ƃ����̂͑傫�ȑ㏞���Ǝv����
���X�̌v��ł�Bulldozer��45nm���������B
���X�̌v��ł�Bulldozer��45nm���������B
AVX�����̂������ŊJ������N���тĂ��邵�ȁB
�������ASSE�̎������^�R���Č����z�B�ق�100%�Ń\�[�X������ȁB
�������ASSE�̎������^�R���Č����z�B�ق�100%�Ń\�[�X������ȁB
�^�R������^�R�Ȃ낤
�܂��B�u�^�R�͂ٓ��ށv�Ƃ����z�͖ő��ɂ��Ȃ����낤���ǂȁB
�ł��A�����̎���̓\�[�X�����ł��M����z�������Ă��邩��A
�u�^�R�͂ٓ��ށv�ƌ����Ă��M����z���o�Ă������Ȃ̂��ʂ���B
�ł��A�����̎���̓\�[�X�����ł��M����z�������Ă��邩��A
�u�^�R�͂ٓ��ށv�ƌ����Ă��M����z���o�Ă������Ȃ̂��ʂ���B
���c�͚M���ނȂ̂��H
>>390
�J������N���т�����AVX�̎������܂߂���悤�ɂȂ����A�ł́B
SSE5�Ƃ����R�\�͂��ꉞ�����Ă���V�`�b�v���A
���ꂩ��s��Ƀo�C�i�����o�ꂷ��AVX�̎����̂��߂Ɉ�N�x�点��̂�
�����I�Ȕ��f�Ƃ͑S���v���Ȃ��B
�傫������45nm����ڂ肫��Ȃ��̂�������������32nm�҂��Ƃɂ��܂����A
�Ƃ����̂Ȃ�悭�킩��B
�J������N���т�����AVX�̎������܂߂���悤�ɂȂ����A�ł́B
SSE5�Ƃ����R�\�͂��ꉞ�����Ă���V�`�b�v���A
���ꂩ��s��Ƀo�C�i�����o�ꂷ��AVX�̎����̂��߂Ɉ�N�x�点��̂�
�����I�Ȕ��f�Ƃ͑S���v���Ȃ��B
�傫������45nm����ڂ肫��Ȃ��̂�������������32nm�҂��Ƃɂ��܂����A
�Ƃ����̂Ȃ�悭�킩��B
http://pc.watch.impress.co.jp/docs/column/kaigai/20090518_168661.html
> �@AVX�̃T�|�[�g�́ASSE5����������\�肾����2011�N�̎�����CPU Bulldozer
> �A�[�L�e�N�`���̊J���ɃC���p�N�g��^�����B����AMD�W�҂́A2008�N�t��
> Bulldozer�̌v�悪2010�N����2011�N�ւƌ�ނ���������AAVX���\����
> ���߃Z�b�g�̍Č����ɂ���Ǝ��������B
> �@AVX�̃T�|�[�g�́ASSE5����������\�肾����2011�N�̎�����CPU Bulldozer
> �A�[�L�e�N�`���̊J���ɃC���p�N�g��^�����B����AMD�W�҂́A2008�N�t��
> Bulldozer�̌v�悪2010�N����2011�N�ւƌ�ނ���������AAVX���\����
> ���߃Z�b�g�̍Č����ɂ���Ǝ��������B
�����u������Ԃɍ���Ȃ����ۂ��������璚�x�ǂ������v�Ȃ�ăo��������
�Ԃ����Ⴏ�����ł��傤�B�܂Ƃ��ȉ�ЂȂ�^�������炩�ɂȂ�͂��͂Ȃ��B
3D Now!�̗��j����V�F�A2����AMD�Ǝ��g����������ς��͎̂����B
�ł�����̓j���[�g�����ȏ���ґ��̎��_������ł����āA
���AMD���͕ʂ̘_���œ����Ă���B
SSE5�o����Intel�����ē����͓̂��R�\��������ŃV�i���I�������͂�������A
SSE5��Bulldozer���X�P�W���[���ʂ�o���Ă��Ȃ�AAVX�����Ă�
�X�P�W���[���ʂ�o���Ă��A�ƍl����̂������I�ł��傤�B
AVX��AMD�̑z���y���ɏ��鋣���͂œo�ꂵ���A�Ȃ�Ă��Ƃ�
���ۂȂ���������B
�Ԃ����Ⴏ�����ł��傤�B�܂Ƃ��ȉ�ЂȂ�^�������炩�ɂȂ�͂��͂Ȃ��B
3D Now!�̗��j����V�F�A2����AMD�Ǝ��g����������ς��͎̂����B
�ł�����̓j���[�g�����ȏ���ґ��̎��_������ł����āA
���AMD���͕ʂ̘_���œ����Ă���B
SSE5�o����Intel�����ē����͓̂��R�\��������ŃV�i���I�������͂�������A
SSE5��Bulldozer���X�P�W���[���ʂ�o���Ă��Ȃ�AAVX�����Ă�
�X�P�W���[���ʂ�o���Ă��A�ƍl����̂������I�ł��傤�B
AVX��AMD�̑z���y���ɏ��鋣���͂œo�ꂵ���A�Ȃ�Ă��Ƃ�
���ۂȂ���������B
�܂����̃A�[�L�܂�AVX�������Ă�
�f�R�[�h�������Ⴄ��256bit���W�X�^�ɂ��Ή����Ȃ��Ƃ����Ȃ�AVX��
���X�̒x��̂��łŎ����ł���Ƃ�AMD�̐v�����������ȁB
���X�̒x��̂��łŎ����ł���Ƃ�AMD�̐v�����������ȁB
�v�����Bulldozer�͌��X�x��Ă����A�ƌ������肽���낤���ǁA
�k�ق܂݂�̒��������Ă܂Ŏ咣����Ӗ����킩���B
�k�ق܂݂�̒��������Ă܂Ŏ咣����Ӗ����킩���B
400 �F,,�E�L�́M�E,,�j��-�������F2009/10/25(��) 16:31:57 ID:vK8GI5hT
���W�X�^�{���Ɋւ��Ă͖��Ȃ����낤�B
���Ƃ��Ƙ_�����W�X�^�̐��{�̋K�͂̕������W�X�^�ɑ����I�ɃA���P�[�g������������B
K7���Ȃ��ŒZ���Ԃ�SSE�ɑΉ����Ă邩��ȁ[�B
�ǂ����Ńo�b�N�A�b�v�v���������������̂ł́H
���Ƃ��Ƙ_�����W�X�^�̐��{�̋K�͂̕������W�X�^�ɑ����I�ɃA���P�[�g������������B
K7���Ȃ��ŒZ���Ԃ�SSE�ɑΉ����Ă邩��ȁ[�B
�ǂ����Ńo�b�N�A�b�v�v���������������̂ł́H
402 �F,,�E�L�́M�E,,�j��-�������F2009/10/25(��) 16:52:42 ID:vK8GI5hT
Fusion�i�j��Radeon��R600�A�[�L�e�N�`�����_�C���N�g�Ɏ��s����悤�ȋ@�\��낤�Ƃ��Ă�̂�AMD���B
����GPU�̉��Z���x���̂܂�g���Ȃ�10240�r�b�g�i�j�����B
�t�J�V�ɂ��Ă��ʔ�������B
����GPU�̉��Z���x���̂܂�g���Ȃ�10240�r�b�g�i�j�����B
�t�J�V�ɂ��Ă��ʔ�������B
AMD�̏ꍇR600�n���̂܂ܓ��������Intel�ł���Sandy Bridge�I�Ȃ��̂ɂ����Ȃ��
�܁A�����_���Ă��Ȃ炢������
���Z�]�X�͏o�����Ă����ł��Ċ���
����Ƃ�R900�n���ł��p�ӂ���́H
�A�[�L�e�N�g���Ȃ��̂�
�����悤�Ŏ��͈�ԋ߂��Ƃ���ɂ���̂�VIA�Ȃ�������
�܁A�����_���Ă��Ȃ炢������
���Z�]�X�͏o�����Ă����ł��Ċ���
����Ƃ�R900�n���ł��p�ӂ���́H
�A�[�L�e�N�g���Ȃ��̂�
�����悤�Ŏ��͈�ԋ߂��Ƃ���ɂ���̂�VIA�Ȃ�������
>>403
��������̂�"Evergreen"����BHD5x00�����Mobile�ł��ۂ��ˁB
�ꉞDirectX11�܂ł͑Ή����Ă���݂�����B
���̎��̐����VGA�͗��Ɏ����I�ɖ�������Ȃ��́H
���Fusion�ł͓������Ă��邾�낤���ǂ��B
��������̂�"Evergreen"����BHD5x00�����Mobile�ł��ۂ��ˁB
�ꉞDirectX11�܂ł͑Ή����Ă���݂�����B
���̎��̐����VGA�͗��Ɏ����I�ɖ�������Ȃ��́H
���Fusion�ł͓������Ă��邾�낤���ǂ��B
������Evergreen=R600����Ȃ�
�����G����������ĂĐV����GPU�����͂�����AMD�ɂ���̂��ˁH
Haswell�ȍ~�ǂ��R���Ă����낤���H
Haswell�ȍ~�ǂ��R���Ă����낤���H
�܂��҂��Ȃ����A���肪�]�ԉ\���������?
�]�ڂ����]�Ԃ܂����A���|�I�ȃV�F�A�̍��̑O�ɂ͊W�Ȃ�
409 �F,,�E�L�́M�E,,�j��-�������F2009/10/25(��) 18:11:31 ID:vK8GI5hT
�܂����������Ĕėp�R���s���[�e�B���O�ɂ͌����ĂȂ�R600�̉����Ōo�c�����������Ƃ��Ă����
����ȃ��������
����ȃ��������
>>405
���̒ʂ肾���A�����ȁB���낢��ȈӖ��ŁB
���̒ʂ肾���A�����ȁB���낢��ȈӖ��ŁB
R600�̉��ǔł�NV���X�������Ă܂���
>>409
���[�U�[�����߂Ă�����̂́u�R�X�g�����ɂ����ꂽGPU�v���Ă��ƂȂ�ȁE�E�E�B
���[�U�[�����߂Ă�����̂́u�R�X�g�����ɂ����ꂽGPU�v���Ă��ƂȂ�ȁE�E�E�B
��������Fusion�̑��݈Ӌ`��ے肷��Ȃ�
(��)�������f�R����Y
NVIDIA�̂��A��AMD���������т�Intel������ɑR����CPU�J���̎���ɂ߂Ȃ����猋�\�Ȃ��Ƃ�
>>416
���݂��킩���B
���݂��킩���B
418 �F,,�E�L�́M�E,,�j��-�������F2009/10/26(��) 00:49:16 ID:ijmzBkZG
PATCH: Add LWP support for upcoming AMD Orochi processor.
http://archives.free.net.ph/message/20091001.040623.932ef21f.ja.html
LWP��kwsk
http://support.amd.com/us/Processor_TechDocs/43724.pdf
http://archives.free.net.ph/message/20091001.040623.932ef21f.ja.html
LWP��kwsk
http://support.amd.com/us/Processor_TechDocs/43724.pdf
�m�I��Q�҂����Ă�
>R600�̉��ǔł�NV���X�������Ă܂���
�����v���Ă�̂͂��O�炾������
����RV870�̍\������G80�ɂ���͂��ĂȂ�
�����v���Ă�̂͂��O�炾������
����RV870�̍\������G80�ɂ���͂��ĂȂ�
>���[�U�[�����߂Ă�����̂́u�R�X�g�����ɂ����ꂽGPU�v���Ă��ƂȂ�ȁE�E�E�B
��ΐ��\��������i��1/10�ł����H
�Ȃ琔����O�̎̂Ēl�Ŕ����Ă钆�ẪO���{���ė����A�ł���肻���b����
��ΐ��\��������i��1/10�ł����H
�Ȃ琔����O�̎̂Ēl�Ŕ����Ă钆�ẪO���{���ė����A�ł���肻���b����
�m�[�g��l�b�g�u�b�N����܂����Ƃ邵
����Ȑ��\�����v���̂�
����Ȑ��\�����v���̂�
enable�ɂ��邾����LWP�g��Ȃ��Ă��R���e�L�X�g�X�C�b�`�̃I�[�o�[�w�b�h��
������A�Ƃ����̂͋��e?
������A�Ƃ����̂͋��e?
>>420
���ƓI�Șb�ɐv�I�ȃc�b�R�~���ăA�z���H
���ƓI�Șb�ɐv�I�ȃc�b�R�~���ăA�z���H
�ǂ����˂����ނȂ�u�ӂ���킩�߁v�̂ق���
RV870�̍\����G80�ɂ��͂��Ȃ����āA��s���s����GPGPU����̘b���낤��
�Q�[����FPS�⓮��g�����X�R�[�h�̃��b�g�p�t�H�[�}���X��GT300�ł�RV870�̑����ɋy�Ȃ�
�Q�[����FPS�⓮��g�����X�R�[�h�̃��b�g�p�t�H�[�}���X��GT300�ł�RV870�̑����ɋy�Ȃ�
>>421
���܂�Intel GPU���ڃm�[�g��PC�ɓ������Ƃ������̂��H
���܂�Intel GPU���ڃm�[�g��PC�ɓ������Ƃ������̂��H
428 �F,,�E�L�́M�E,,�j��-�������F2009/10/26(��) 22:09:09 ID:ijmzBkZG
��ΐ��\�ł���5870�D������ˁ[�̂��H
>>426
�܂��o�ĂȂ����Ƃ͔�ׂ��Ȃ�����
�܂��o�ĂȂ����Ƃ͔�ׂ��Ȃ�����
430 �F,,�E�L�́M�E,,�j��-�������F2009/10/26(��) 22:29:48 ID:ijmzBkZG
�o�ĂȂ����_�Ńr�W�l�X�I�ɕ����Ă�B
�������Larrabee���܂߂Ă����ǁB
�������Larrabee���܂߂Ă����ǁB
�܂�GPGPU�Ɋւ��ẮAFireStream�͐��\�]�X�̑O��
�܂��X�^�[�g���C���ɗ��̂��悾�Ǝv�����ǁB
�܂��X�^�[�g���C���ɗ��̂��悾�Ǝv�����ǁB
�S���\���畷���Ȃ����FireStream
GPGPU��OpenCL�Ή���搂��Ă��邩��AHPC�������p�ӂ��Ă���͂��Ȃ̂ɁB
����������Radeon��D�悵��Stream�͌�Ȃ̂��ȁB
GPGPU��OpenCL�Ή���搂��Ă��邩��AHPC�������p�ӂ��Ă���͂��Ȃ̂ɁB
����������Radeon��D�悵��Stream�͌�Ȃ̂��ȁB
��ނƍ���t����̂�߂��������
�@�\��\�ł̍����Ȃ����������B
HPC�����ɂ͐��\�Ɠ������炢�i���Ƃ��T�|�[�g���d�v�B
���͊���h���C�o��DirectX>>OpenCL������ARADEON�ւ̃��\�[�X�𑽂����Ă���낤�B
HPC�����ɂ͐��\�Ɠ������炢�i���Ƃ��T�|�[�g���d�v�B
���͊���h���C�o��DirectX>>OpenCL������ARADEON�ւ̃��\�[�X�𑽂����Ă���낤�B
ECC���Ȃ��J�[�h��HPC�Ŏ��p���肤�邩�Ƃ�����������B
HPC�p�Ƃ��Ă�Tesla�̐��\�����艿�i���ُ�Ɉ����̂�ECC��
�Ή����ĂȂ�����Ƃ����ʂ�����B
�������GPU��Ȃ�{�b�^�N��
HPC�p�Ƃ��Ă�Tesla�̐��\�����艿�i���ُ�Ɉ����̂�ECC��
�Ή����ĂȂ�����Ƃ����ʂ�����B
�������GPU��Ȃ�{�b�^�N��
���̕ӂ܂����Fermi�őΉ����Ă�������AHPC�p�r��GPGPU��
FireStream��������એ�ɂ̂邱�Ƃ͂Ȃ��ł���B
���������ړI�̃`�b�v����Ȃ����B
FireStream��������એ�ɂ̂邱�Ƃ͂Ȃ��ł���B
���������ړI�̃`�b�v����Ȃ����B
HPC��^�ʖڂɂ��l�i��w�Ƃ��������Ƃ��j������
�����Ƃ���GPGPU�J�[�h��Fermi�ɂ���Ă��̂������ł��傤�ȁB
�ǂ����s�ꋷ������nV�Ǝ�荇���Ėׂ���قǂłȂ����A
���ۂ̐�͂��ǂ�قǂ��͕s���Ȃ���A�߂�����
���Larrabee�ɑS�ł�������\�������邵�B
�����Ƃ���GPGPU�J�[�h��Fermi�ɂ���Ă��̂������ł��傤�ȁB
�ǂ����s�ꋷ������nV�Ǝ�荇���Ėׂ���قǂłȂ����A
���ۂ̐�͂��ǂ�قǂ��͕s���Ȃ���A�߂�����
���Larrabee�ɑS�ł�������\�������邵�B
GPGPU���ł��邯�ǃ��C���̓O���t�B�b�N����H���ōs���Ă����O���t�B�b�N�̓��f�A
GPGPU�{�[�h��Larrabee�Ƃ������̃^�b�O�}�b�`�̊����ł���iFermi�Ȃ�1���łǂ������ł���Ƃ����˂����݂͎t���Ȃ��j
GPGPU�{�[�h��Larrabee�Ƃ������̃^�b�O�}�b�`�̊����ł���iFermi�Ȃ�1���łǂ������ł���Ƃ����˂����݂͎t���Ȃ��j
�ǂ����R���V���[�}������GPGPU�Ȃ��DX Compute Shader��
�Q�[���̕������Z�ƃG�t�F�N�g�A����g���X�R�ӂ�ɂ����g���̂�����A
ECC�t������{���x���Z���u����������t�����肵��
HPC����̐��Ɗ���邾���̍������̂ɂ��Ă����傤���Ȃ��B
�Q�[���̕������Z�ƃG�t�F�N�g�A����g���X�R�ӂ�ɂ����g���̂�����A
ECC�t������{���x���Z���u����������t�����肵��
HPC����̐��Ɗ���邾���̍������̂ɂ��Ă����傤���Ȃ��B
�uAMD�̌�CEO�w�N�^�[�E���C�Y���A�C���T�C�_�[����Ɋ֗^�v�̕�
http://www.itmedia.co.jp/news/articles/0910/28/news048.html
http://www.itmedia.co.jp/news/articles/0910/28/news048.html
AMD���ւ���Ă����c
��������w�N�^�[�E���C�Y����CEO�ނ��Ă��牽����Ă��H
��������w�N�^�[�E���C�Y����CEO�ނ��Ă��牽����Ă��H
GF�̉
MAC�I�^�����Ńl�^�ɂ������Șb��Ȃ̂ɍŋߌ��Ȃ���
Intel�̍����S�������̌��Ŏ�˂�����ł������H
Intel�̍����S�������̌��Ŏ�˂�����ł������H
MAC�I�^�͖������ŏ�������ł邩�C���t���G���U�Ő�������
�m��R�e�Ȃ炱�̑O�������肶���
>>440
���������z�͂������Ə���������B
���������z�͂������Ə���������B
�܂��A����ȃE���R�o�c�҂���o�c�����Ȃ��ē��R���Ă��Ƃ��c
�����@�O���ɂȂ�ł��킩��Ȃ����ǁA���C�X�E�K���V�A���Q�炢�����������̂�
�@�@�@�@�o�Ă��Ȃ���������A�����ĂȂ������̂��ȂƁB���ꂪ�o�Ă��猈��I�ȃ`�����X���������A
�@�@�@�@���炦��`�����X���ĂƂ���ł��炦�Ȃ��āA�����̃`�����X������Ă���ŁA���\����ˁB
����\��10�� 31�̃x�e����
����\��20�� 23�̎��
�{�c�@�p�X�����Ȃ��Ƃ����̂����̎��́B����ł����͏���������
�@�@�@�@�o�Ă��Ȃ���������A�����ĂȂ������̂��ȂƁB���ꂪ�o�Ă��猈��I�ȃ`�����X���������A
�@�@�@�@���炦��`�����X���ĂƂ���ł��炦�Ȃ��āA�����̃`�����X������Ă���ŁA���\����ˁB
����\��10�� 31�̃x�e����
����\��20�� 23�̎��
�{�c�@�p�X�����Ȃ��Ƃ����̂����̎��́B����ł����͏���������
�����̎咣
�E�����ɂ��Ė��S����Ȃ�
�E���C�X�K���V�A���p�X�����Ȃ�
�E��\���R�l���x�̎G���`�[������Z�p�ŗ��
�E�ウ��ꂽ�̂͊ē������S�z��������ŏo���͊W�Ȃ��A���ɂ�
�����̂�炩���Ă���_
�E�v���I��ʼn����������ɂ���l�͑����炢
�E���C�X�K���V�A�̓X�y�C��(EURO2008���e ���[���h�J�b�v�D�����M��)�ő�\�N���X�A����EU���O�̏����l(�N��2��)
�E���f�B�A�̕]�����`�[���Œ�̑I�肪�`�[�����[�g�̋Z�p��ᔻ
�E�����O�͉������v�ƌ����Ȃ���A��p�t�H�[�}���X�͉���̂���
�E�����ɂ��Ė��S����Ȃ�
�E���C�X�K���V�A���p�X�����Ȃ�
�E��\���R�l���x�̎G���`�[������Z�p�ŗ��
�E�ウ��ꂽ�̂͊ē������S�z��������ŏo���͊W�Ȃ��A���ɂ�
�����̂�炩���Ă���_
�E�v���I��ʼn����������ɂ���l�͑����炢
�E���C�X�K���V�A�̓X�y�C��(EURO2008���e ���[���h�J�b�v�D�����M��)�ő�\�N���X�A����EU���O�̏����l(�N��2��)
�E���f�B�A�̕]�����`�[���Œ�̑I�肪�`�[�����[�g�̋Z�p��ᔻ
�E�����O�͉������v�ƌ����Ȃ���A��p�t�H�[�}���X�͉���̂���
450 �FSocket774�F2009/11/01(��) 15:38:24 ID:cflGvpE5
�������[�h���Ȃ������B
ttp://image.itmedia.co.jp/pcuser/articles/0911/01/l_og_akibad_032.jpg
�قډ\�ʂ�B�A
ttp://image.itmedia.co.jp/pcuser/articles/0911/01/l_og_akibad_032.jpg
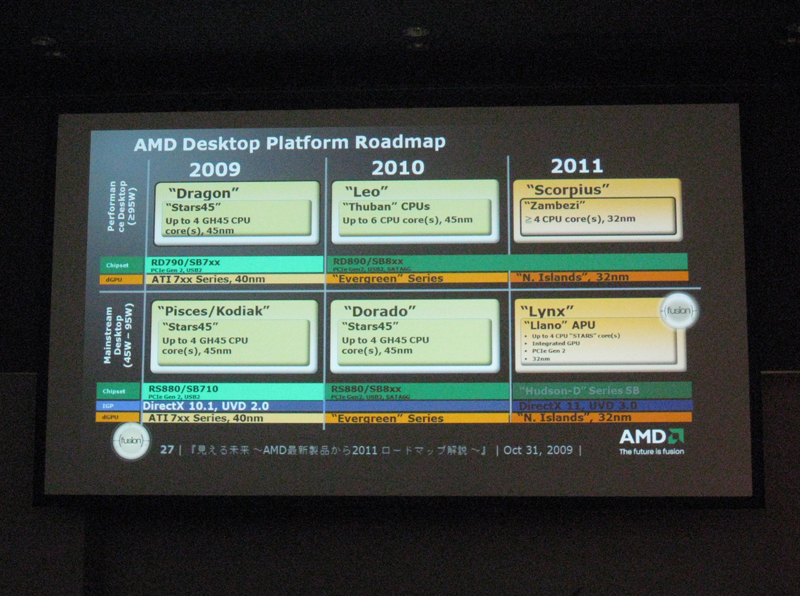{kind=link}
�قډ\�ʂ�B�A
451 �F,,�E�L�́M�E,,�j��-�������F2009/11/01(��) 15:39:18 ID:mtXW/RVq
��������߂�����̂�
Intel�ɂ��DDR3���y��ƂɁA������x���y�����Ƃ������v����āA
AMD�̓l�C�e�B�u8�R�A���o���āAIntel�̂Ȃ����8�R�A�ii7�j�Ə����I
�܂������ɗ��N������AATOM�ɑR���ďȓd��CPU�����ޏo������
AMD�̓l�C�e�B�u8�R�A���o���āAIntel�̂Ȃ����8�R�A�ii7�j�Ə����I
�܂������ɗ��N������AATOM�ɑR���ďȓd��CPU�����ޏo������
453 �F,,�E�L�́M�E,,�j��-�������F2009/11/01(��) 21:05:15 ID:mtXW/RVq
�Ƃ��낪�ǂ�����
���N�o��Core i9�̓l�C�e�B�u6�R�A12�X���b�h�Ȃ�ł�
���N�o��Core i9�̓l�C�e�B�u6�R�A12�X���b�h�Ȃ�ł�
>>452
���������ȊO�ɉ����ł��Ȃ��B
�����R�����g���悤���Ȃ����e���ȁB
�I���Ȃ�Βp���������ăl�^�ł������Ȃ��B
�����ăR�����g����Ȃ�Ζϑz�̓`���V�̗��ɂƂ����B
���������ȊO�ɉ����ł��Ȃ��B
�����R�����g���悤���Ȃ����e���ȁB
�I���Ȃ�Βp���������ăl�^�ł������Ȃ��B
�����ăR�����g����Ȃ�Ζϑz�̓`���V�̗��ɂƂ����B
i7��HT�L���ɂ���BOINC�Ă邪�j�R������Ɣ����ɃJ�N�c�N
BOINC�~�߂�Ƒ��v�Ȃ��ǂ�
905e����BOINC�Ȃ���j�R�����Ă����v
�����HT�����ق��������Ȃ�
������J�N�c�L�����Ȃ邩�ǂ����m�F�͂��ĂȂ���
BOINC�~�߂�Ƒ��v�Ȃ��ǂ�
905e����BOINC�Ȃ���j�R�����Ă����v
�����HT�����ق��������Ȃ�
������J�N�c�L�����Ȃ邩�ǂ����m�F�͂��ĂȂ���
456 �FSocket774�F2009/11/01(��) 21:09:38 ID:oGAV8xce
>453
�Ȃ�A�l�C�e�B�u12�R�A�ŏ����I
>454
(�E�ÁE)�s���s��
�Ȃ�A�l�C�e�B�u12�R�A�ŏ����I
>454
(�E�ÁE)�s���s��
457 �F,,�E�L�́M�E,,�j��-�������F2009/11/01(��) 21:18:21 ID:mtXW/RVq
���ꂩ�H���ꂪ�u�l�C�e�B�u�v���H
458 �F,,�E�L�́M�E,,�j��-�������F2009/11/01(��) 22:00:36 ID:mtXW/RVq
459 �F,,�E�L�́M�E,,�j��-�������F2009/11/01(��) 22:26:22 ID:mtXW/RVq
�܂�Magny-Cours�������͂Ȃ����A�R�A�K�p�v��0.5�ȉ�����Ȃ���Oracle���[�U�[�ɂ͂����Ǝv����
��N���b�N�Ȃ̂�1�\�P�b�g6���C�Z���X�����Ă����B
http://www.oracle.com/lang/jp/corporate/pricing/mcpu.html
http://www.oracle.com/lang/jp/corporate/pricing/doc/Processor_Core_Factor_Table_jp.pdf
�W���グ���Ȃ����x�ɃN���b�N�グ�ăX���b�h���҂������L�����Ă��ƂɂȂ��ȁB
��N���b�N�Ȃ̂�1�\�P�b�g6���C�Z���X�����Ă����B
http://www.oracle.com/lang/jp/corporate/pricing/mcpu.html
http://www.oracle.com/lang/jp/corporate/pricing/doc/Processor_Core_Factor_Table_jp.pdf
�W���グ���Ȃ����x�ɃN���b�N�グ�ăX���b�h���҂������L�����Ă��ƂɂȂ��ȁB
�R�A�K�p�v���ĂȂ�c�q
������̂߂�ǂ������狳����c�q
������̂߂�ǂ������狳����c�q
�L���������J�X
���肪�Ƃ��S�~
POWER6�Ȃ�ŃR�A�W��1.0�Ȃ̂�?
SPARC T1��1.2GHz��0.25��1.4GHz��0.5�Ƃ��Ӗ��s��
�������x���`�X�R�A��1�|�C���g������ʼn��i���߂��ႦYO!
SPARC T1��1.2GHz��0.25��1.4GHz��0.5�Ƃ��Ӗ��s��
�������x���`�X�R�A��1�|�C���g������ʼn��i���߂��ႦYO!
ID:mtXW/RVq���\��邽�߂̗\�����삪ID:oGAV8xce
�Ɩϑz����A���~�ł�����
�X�ɕʂ̃R�e���܂Ŗ��Ӗ��Ɏ����o��
�^�ɋC���������G��
�^�ɋC���������G��
���̈������E�܂��Ȃ��Ȃ�
PC�Ńx���l�b�^�łˁ[���ȁ[
HD5870�Ńk���k���V�т���
HD5870�Ńk���k���V�т���
>>468
PS3�ł̗�����
PS3�ł̗�����
�Q�n�ɋA��
>>469
�������o�����ȏ�A�J���Ɛ����������ł�肽���A�Ƃ����̂�
�^�����Șb�����A���ۂɏo���邩�ǂ����͖��m�����ȁB
��������u�A���u��Ɖ��v�����ƔF�������A�ڋq�Ɛl�ޗ��o�Ŗ��S�Ȃ��ƂɂȂ肻�����B
�������o�����ȏ�A�J���Ɛ����������ł�肽���A�Ƃ����̂�
�^�����Șb�����A���ۂɏo���邩�ǂ����͖��m�����ȁB
��������u�A���u��Ɖ��v�����ƔF�������A�ڋq�Ɛl�ޗ��o�Ŗ��S�Ȃ��ƂɂȂ肻�����B
AMD�I��������������
���̏�ԂŏI���Ȃ�
3�N�O�ɂ��łɏI����Ă܂����ǂ˂�
3�N�O�ɂ��łɏI����Ă܂����ǂ˂�
�������̒ʉ݂͎����A�o�̂����ō����Ȃ肪�������琻���Ƃɕs���B
�����Ȃ�����o���邾���Ζ���������{�b��������TSMC�Ƃ��ɓ�������������������B
�����Ȃ�����o���邾���Ζ���������{�b��������TSMC�Ƃ��ɓ�������������������B
>>475
���Ⴂ���Ă���B
�Ζ��������Ζ����Ȃ��Ȃ������̂��߂Ɂ�GF�Ɂ����������Ă����B
AMD�{�̂ւ̓����̓I�}�P�B�{���͂ǂ��݂Ă�GF�̔����̐����{�݁B
AMD���ׂ�Ă�CPU�n�̋Z�p�͒����ɂ͗����Ȃ����A����Ȃ��̂ŁA
�����҂Ƃ��Ă�AMD�ׂ͒�Ȃ���Βׂ�Ȃ��ł������炢�̋C�������ƁB
���Ⴂ���Ă���B
�Ζ��������Ζ����Ȃ��Ȃ������̂��߂Ɂ�GF�Ɂ����������Ă����B
AMD�{�̂ւ̓����̓I�}�P�B�{���͂ǂ��݂Ă�GF�̔����̐����{�݁B
AMD���ׂ�Ă�CPU�n�̋Z�p�͒����ɂ͗����Ȃ����A����Ȃ��̂ŁA
�����҂Ƃ��Ă�AMD�ׂ͒�Ȃ���Βׂ�Ȃ��ł������炢�̋C�������ƁB
477 �F,,�E�L�́M�E,,�j��-�������F2009/11/05(��) 00:26:19 ID:B/8/aVsq
�O���G���x�[�^�ɂł��o�����Ă���B
Hector Ruiz��GlobalFoundries�̉�����E
http://blog.livedoor.jp/amd646464/archives/51447166.html
http://blog.livedoor.jp/amd646464/archives/51447166.html
���Intel(��@�s�ד�����O���)�̂ق��͋x�E����
AMD�̈�@�s�ׂ��Y��Ȉ�@�s��
Intel�̓A�}�A�}���˂�
�܂��^����ƂƔ�ׂ�Ζڂ����@�����ł���
�܂��^����ƂƔ�ׂ�Ζڂ����@�����ł���
��͂܂�������
���_�����E���᎕�~�߂��Ȃɂ��˂�
���_�����E���᎕�~�߂��Ȃɂ��˂�
�g�b�v�̉��E�Ƃ����W���̃X�L�����_�����ؗ�ɃX���[����Intel�ᔻ�Ƃׂ͖̊ӂł���
�v���o�����悤�ɗN���ďo�Ă��Đ������킗
�w�N�^�[�E���C�Y��AMD�ɍv���������Ƃ������H
�Q�ɂ����Ȃ��ĂȂ�����̐l
�Q�ɂ����Ȃ��ĂȂ�����̐l
�ȏ�N�Y�ׂ̕����ɂ��݂ł���
tst
Intel���ƌW�����炢�ɂȂ�Ȃ��ƑސE���Ȃ��čς݂���
�Ƃ������ƁuAMD�̌W�����Y��ȌW���I�I�I�v�Ƃ��������Ԕ����X���Ԃ��Ă���������
�Ƃ������ƁuAMD�̌W�����Y��ȌW���I�I�I�v�Ƃ��������Ԕ����X���Ԃ��Ă���������
AMD�̌W�����Y��ȌW���I�I�I
���E�ɗ���Łu�x�E�ł��ށv�̂���肾��ȁB
Chartered voters approve takeover by GlobalFoundries owner
http://www.brightsideofnews.com/news/2009/11/6/chartered-voters-approve-takeover-by-globalfoundries-owner.aspx
Dresden, Germany: Fab 1 Module 1 and Module 2, expandable with Module 3
Saratoga, United States: Fab 2 Module 1, expandable with Module 2 and 3
Singapore, Singapore: Fab 3 Module 1 to Module 6 [former 2, 3, 3E, 5/SMP, 6CSP, 7]
2010 - GlobalFoundries Inc. completely merges with Chartered Semiconductor Manufacturing Ltd.
2010 - Chartered facility is renamed into Fab 3 with associated modules [Module 1-7]
2010 - AMD announces the foundation of AMD Design Center in UAE, financed by ATIC
2010/2011 - ATIC announces strategic acquisition of two more companies
2011 - 65nm equipment is transitioned from Singapore to Abu Dhabi for learning phase
2012 - Fab 2 Module 1 in Saratoga officially opens
2015 - ATIC announces the building of Module 2 in Fab 2, Saratoga NY
By 2015 - ATIC announces the building of Fab 4 in Abu Dhabi
ATIC������UAE�Ƀt�@�u�ƃf�U�C���Z���^�[
http://www.brightsideofnews.com/news/2009/11/6/chartered-voters-approve-takeover-by-globalfoundries-owner.aspx
Dresden, Germany: Fab 1 Module 1 and Module 2, expandable with Module 3
Saratoga, United States: Fab 2 Module 1, expandable with Module 2 and 3
Singapore, Singapore: Fab 3 Module 1 to Module 6 [former 2, 3, 3E, 5/SMP, 6CSP, 7]
2010 - GlobalFoundries Inc. completely merges with Chartered Semiconductor Manufacturing Ltd.
2010 - Chartered facility is renamed into Fab 3 with associated modules [Module 1-7]
2010 - AMD announces the foundation of AMD Design Center in UAE, financed by ATIC
2010/2011 - ATIC announces strategic acquisition of two more companies
2011 - 65nm equipment is transitioned from Singapore to Abu Dhabi for learning phase
2012 - Fab 2 Module 1 in Saratoga officially opens
2015 - ATIC announces the building of Module 2 in Fab 2, Saratoga NY
By 2015 - ATIC announces the building of Fab 4 in Abu Dhabi
ATIC������UAE�Ƀt�@�u�ƃf�U�C���Z���^�[
>>491
UAE�Ɂc�˂��H�@�C���h�⒆���Ɍ��Ă������l�ނ̈Ӗ��Ō����I�̂悤�ȁc�B
UAE�Ɂc�˂��H�@�C���h�⒆���Ɍ��Ă������l�ނ̈Ӗ��Ō����I�̂悤�ȁc�B
�����C���h�ł̓X�|���T�[�ɂƂ��ĈӖ����Ȃ��B
�ł����Ƃ������C���h�ł������̊J���𐬌�������͓̂���悤�ȁB
�������o���Ȃ�Ƃ��Ȃ�̂��B
�ł����Ƃ������C���h�ł������̊J���𐬌�������͓̂���悤�ȁB
�������o���Ȃ�Ƃ��Ȃ�̂��B
�s�a�r�@�p�i�\�j�b�N�h���}�w���̂��̓��x�@�@�@�@2009�N11��23�������@
�@�@http://www.tbs.co.jp/inochinoshima/
���o����
�_��߂��݁F�i�씎��
�@�@��
����܂ǂ��F�R�����I
�V���g�I���F�r���s��
�q���R�����F���{�@��
������F�с@���j
���c�@�E�F�����Ƃ��̂�
�@�@��
���J�쎡�F�����V
���q���q�F�ݖ{�����q
�@�@http://www.tbs.co.jp/inochinoshima/
���o����
�_��߂��݁F�i�씎��
�@�@��
����܂ǂ��F�R�����I
�V���g�I���F�r���s��
�q���R�����F���{�@��
������F�с@���j
���c�@�E�F�����Ƃ��̂�
�@�@��
���J�쎡�F�����V
���q���q�F�ݖ{�����q
�ӊO�Ɛ��w�҂Ƃ��Z�p�҂��������炩���W�߂�ΐv�͂ł����Ȃ����B
���c�͈ӊO�Ƃ����ł����ۂ��B���Y��ST�ۓ����Ƃ��Đv�łǂꂾ���ւ���Ă�̂��킩��ǁB
���c�͈ӊO�Ƃ����ł����ۂ��B���Y��ST�ۓ����Ƃ��Đv�łǂꂾ���ւ���Ă�̂��킩��ǁB
���肠������肽����ΊY���X��������B
�A�~�͂ǂ����ċ�C���ǂ߂Ȃ��̂��B
�A�~�͂ǂ����ċ�C���ǂ߂Ȃ��̂��B
�����̂��O�������ȃ��X�ł���
499 �FSocket774�F2009/11/07(�y) 21:53:50 ID:ohFZ3R1V
>>455�M�d�ȏ�肪�Ƃ��B
>455
BOINC�̃v���C�I���e�B�ύX�ōςޘb����?
BOINC�̃v���C�I���e�B�ύX�ōςޘb����?
>455�����̃v���W�F�N�g����Ă邩�m��ǂ��܂ɗD��x���A�C�h������Ȃ����s���j�b�g�������Ŋm�F���Ă݂�
���܂ɍœK���łƂ��ŗD��x���ʏ�ɂȂ��Ă�̂�����
���܂ɍœK���łƂ��ŗD��x���ʏ�ɂȂ��Ă�̂�����
Analyst Day�ʼn����ʔ�����o��Ƃ������B�B�B
0
ARABIC GLOBALFOUNDRIES FACTORY IN FOUR YEARS
http://xtreview.com/addcomment-id-10555-view-Arabic-Globalfoundries-factory-in-four-years.html
http://xtreview.com/addcomment-id-10555-view-Arabic-Globalfoundries-factory-in-four-years.html
AnalystDay�݂������ǒ������c
���ǐQ�Ă����`
Llano�̃_�C�ʐ^���ۂ��̂��o�Ă�
�R�A�͊�����K10.5���ۂ�
L2��1MB x4��L3�͂Ȃ����Ɍ����邪�ʂ����āH
������Bulldozer
�R�A���̃u���b�N�_�C���O�������o�Ă�
�ڂ����͉摜��
http://u9.getuploader.com/sh/download/1/Bulldozer.png
��������4issue�Ȃ̂��ȁH
����͂������낢
Llano�̃_�C�ʐ^���ۂ��̂��o�Ă�
�R�A�͊�����K10.5���ۂ�
L2��1MB x4��L3�͂Ȃ����Ɍ����邪�ʂ����āH
������Bulldozer
�R�A���̃u���b�N�_�C���O�������o�Ă�
�ڂ����͉摜��
http://u9.getuploader.com/sh/download/1/Bulldozer.png
{kind=link}
��������4issue�Ȃ̂��ȁH
����͂������낢
Bobcat����������
http://u9.getuploader.com/sh/download/2/Bobcat.png
���̏������ł�����Bulldozer�̃p�C�v���C���̂������Load/Store�Ƃ��H
�܂����ˁc
���̑��̎���
http://phx.corporate-ir.net/phoenix.zhtml?c=74093&p=irol-analystday
http://u9.getuploader.com/sh/download/2/Bobcat.png
{kind=link}
���̏������ł�����Bulldozer�̃p�C�v���C���̂������Load/Store�Ƃ��H
�܂����ˁc
���̑��̎���
http://phx.corporate-ir.net/phoenix.zhtml?c=74093&p=irol-analystday
AMD uncovers Bulldozer, Bobcat and Fusion
http://www.semiaccurate.com/2009/11/11/amd-uncovers-bulldozer-bobcat-and-fusion/
http://www.semiaccurate.com/static/uploads/2009/11_november/Bobcat_core_small.png
http://www.semiaccurate.com/static/uploads/2009/11_november/Bulldozer_core_small.png
http://www.semiaccurate.com/static/uploads/2009/11_november/Fusion_controller_small.png
http://www.semiaccurate.com/2009/11/11/amd-uncovers-bulldozer-bobcat-and-fusion/
http://www.semiaccurate.com/static/uploads/2009/11_november/Bobcat_core_small.png
{kind=link}
http://www.semiaccurate.com/static/uploads/2009/11_november/Bulldozer_core_small.png
{kind=link}
http://www.semiaccurate.com/static/uploads/2009/11_november/Fusion_controller_small.png
{kind=link}
First Die Shot of AMD Fusion Processors
http://resources.vr-zone.com/image_deposit/up2/125796576923456c889b.jpg
http://resources.vr-zone.com/image_deposit/up2/125796576923456c889b.jpg
{kind=link}
�����X�g�c���Ɓc
Chekib Akrout, General Manager, Technology Group��pdf��
> Two tightly linked cores share resources to increase efficiency
�Ə����Ă��邯��
Bulldozer�̃R�A���������u���b�N�̐��Ȃ̂���?
> Two tightly linked cores share resources to increase efficiency
�Ə����Ă��邯��
Bulldozer�̃R�A���������u���b�N�̐��Ȃ̂���?
513 �F,,�E�L�́M�E,,�j��-�������F2009/11/12(��) 09:13:33 ID:gjkqx3Og
>>508
����op reg., reg/mem�`���͂���܂Œʂ�fused�ň�����悤�ɂ����łȂ��H�X�g�A�͓Ɨ����낤���ǁB
>>512
���A�ق���Intel�̔{���R�A��ς߂��߂�悤�Ȗ��@�̎�͌�������Ȃ��B
�������܂��AIntel�ȏ�̃Y�R�[�d�l�Ȃ킯�����B
����op reg., reg/mem�`���͂���܂Œʂ�fused�ň�����悤�ɂ����łȂ��H�X�g�A�͓Ɨ����낤���ǁB
>>512
���A�ق���Intel�̔{���R�A��ς߂��߂�悤�Ȗ��@�̎�͌�������Ȃ��B
�������܂��AIntel�ȏ�̃Y�R�[�d�l�Ȃ킯�����B
AMD2009 Analyst Day_Server Platforms.pdf��17�y�[�W�������L3$��Bulldozer�hmodule���ɓƗ��Ȃ�
515 �F,,�E�L�́M�E,,�j��-�������F2009/11/12(��) 09:21:38 ID:gjkqx3Og
Intel�F
�@256�r�b�g��AVX���g��Ȃ��ƃt�����\���ł��Ȃ�
AMD�F
�@FMA4���g��Ȃ��ƃt�����\���ł��Ȃ��i������128�r�b�g�łł����߂���j
�@256�r�b�g��AVX���g��Ȃ��ƃt�����\���ł��Ȃ�
AMD�F
�@FMA4���g��Ȃ��ƃt�����\���ł��Ȃ��i������128�r�b�g�łł����߂���j
�悭�킩���4�s�ł܂Ƃ߂Ă���
PDF�ǂ�
>>517�@>508�̉�
519 �FSocket774�F2009/11/12(��) 11:42:57 ID:p6k7otTn
�ǂ��ł������^�₾���ǐ���Ƃ��Ă�K10�Ȃ̂���
���̃V�F�A�����\���ŃV���O���X���b�h�ƃ}���`�X���b�h���ꂼ���
�ǂꂭ�炢�̃s�[�N�l��@���o���邩�����[���Ƃ���
�����I�ɂ�SandyBridge�Ƃ̒��ڑΌ��ɂȂ邯��
�����ŃL���b�`�A�b�v�ł��Ȃ��ƍ�����ꂵ�����Ȃ�
���̃V�F�A�����\���ŃV���O���X���b�h�ƃ}���`�X���b�h���ꂼ���
�ǂꂭ�炢�̃s�[�N�l��@���o���邩�����[���Ƃ���
�����I�ɂ�SandyBridge�Ƃ̒��ڑΌ��ɂȂ邯��
�����ŃL���b�`�A�b�v�ł��Ȃ��ƍ�����ꂵ�����Ȃ�
�J�X�߂������^
>>519
��������K11�ł���B
SIMD���\�ɂ��Ă���
���j�b�g�\����������AIntel AVX�̃R�[�h�̓y�U�ł͍ő�2�{��
���������ĕs���Ƃ����̂͊m�����ȁB
���Z���j�b�g��256�r�b�g������ĂȂ����A�Ϙa���j�b�g����Z�̂�or���Z�݂̂ł͎�������B
AMD�Ǝ���XOP, CVT16, FMA4���g���ď��߂ď����Ɏ������߂�B
�Ƃ肠�����R���p�C�����ǂ��ɂ����Ȃ��ƂȁB
���ƃV���b�t�����j�b�g�͂ǂ��ɏ������H
FMAC�Ɠ������s�ł��Ȃ��Ǝ������\�͊��҂ł��Ȃ��B
��������K11�ł���B
SIMD���\�ɂ��Ă���
���j�b�g�\����������AIntel AVX�̃R�[�h�̓y�U�ł͍ő�2�{��
���������ĕs���Ƃ����̂͊m�����ȁB
���Z���j�b�g��256�r�b�g������ĂȂ����A�Ϙa���j�b�g����Z�̂�or���Z�݂̂ł͎�������B
AMD�Ǝ���XOP, CVT16, FMA4���g���ď��߂ď����Ɏ������߂�B
�Ƃ肠�����R���p�C�����ǂ��ɂ����Ȃ��ƂȁB
���ƃV���b�t�����j�b�g�͂ǂ��ɏ������H
FMAC�Ɠ������s�ł��Ȃ��Ǝ������\�͊��҂ł��Ȃ��B
decode���\�ƁAint�p�C�v�����ł̃��[�v���ł��邩�ۂ�
�������|�C���g�ɂȂ肻�����ȁ[
����ۂł́u�ȓd�͂͑_���邩����������͊��҂ł��Ȃ��v����
�������|�C���g�ɂȂ肻�����ȁ[
����ۂł́u�ȓd�͂͑_���邩����������͊��҂ł��Ȃ��v����
�C�O�ł�Niagara/Rock�Ƃ������Ă�
�f�X�N�g�b�v&���o�C����K10��������
�f�X�N�g�b�v&���o�C����K10��������
L2��L3�����ꂼ��R�A(?)���L�ɂȂ����̂�
Exclusive�𑱂���̂��A�~�߂�̂�
�ȑO�̑匴����̉�́E����ł�L2/L3�̒x����
K8�̃{�g���l�b�N�����������Ȃ̂ʼn������Ă�̂��ǂ���
http://journal.mycom.co.jp/special/2009/deneb02/index.html
http://journal.mycom.co.jp/special/2009/deneb02/004.html
http://journal.mycom.co.jp/special/2009/deneb02/005.html
http://journal.mycom.co.jp/special/2009/deneb02/006.html
http://journal.mycom.co.jp/special/2009/deneb02/022.html
Exclusive�𑱂���̂��A�~�߂�̂�
�ȑO�̑匴����̉�́E����ł�L2/L3�̒x����
K8�̃{�g���l�b�N�����������Ȃ̂ʼn������Ă�̂��ǂ���
http://journal.mycom.co.jp/special/2009/deneb02/index.html
http://journal.mycom.co.jp/special/2009/deneb02/004.html
http://journal.mycom.co.jp/special/2009/deneb02/005.html
http://journal.mycom.co.jp/special/2009/deneb02/006.html
http://journal.mycom.co.jp/special/2009/deneb02/022.html
6�R�A35W�Ȃ�ď����Ă���y�[�W�����邩�珈���\/�d�͂͑_���Ă�������
��ΐ��\�͊��҂����Ⴂ���Ȃ�����
���b�g�p�t�H�[�}���X�ɂ͊��҂��Ă�������Ă��Ƃ�
���b�g�p�t�H�[�}���X�ɂ͊��҂��Ă�������Ă��Ƃ�
���[35W��Linsbon����ŏo���b���������
pdf�͑S����Bulldozer����̘b����Ȃ�����
pdf�͑S����Bulldozer����̘b����Ȃ�����
���C��SocketC32�̊T�v�͍����߂āH�����
�ƌ����Ă��ȓd�͊W��DDR3�ȊO�O����ƕς�����Ƃ��떳�����ǂ�
�ƌ����Ă��ȓd�͊W��DDR3�ȊO�O����ƕς�����Ƃ��떳�����ǂ�
>521
APU��pdf 5�y�[�W�Ƃ��݂�ƁABulldozer����̎����ɂ̓X���[�v�b�g
�R���s���[�e�B���O�̏d����͂܂�GPU�ł��Ǝv���Ă邭������AMD��
APU��pdf 5�y�[�W�Ƃ��݂�ƁABulldozer����̎����ɂ̓X���[�v�b�g
�R���s���[�e�B���O�̏d����͂܂�GPU�ł��Ǝv���Ă邭������AMD��
semiaccurate�̃t�H�[��������i���̐l�����j
�E�R�A�i�����W�����[�j�̃J�E���g�ƌĂѕ���p�ӂ��Ă���
�E�iSun��Niagara�݂����ɁjCMT�Ƃ͌ĂȂ��ŗ~����
�EInterlagos��8���W���[���A�v16integer�R�A
�E�T���}�͋ɂ߂đ�܂��Ŏ��ۂ͂����Ə��������v�f�������
�E�}�[�P�e�B���O���̘A�������̃X���C�h������낤��
�E�����������̗v�f�������Ă�ˁi�j
�EBulldozer�ɂ͂��y���݂���t�����A�Ƃ��������Ȃ���
�E��R�̊v�V�I�v�f�����邯�ǎ��Ԃ��o�ĂΖ��炩�ɂȂ��
�E�R�A�i�����W�����[�j�̃J�E���g�ƌĂѕ���p�ӂ��Ă���
�E�iSun��Niagara�݂����ɁjCMT�Ƃ͌ĂȂ��ŗ~����
�EInterlagos��8���W���[���A�v16integer�R�A
�E�T���}�͋ɂ߂đ�܂��Ŏ��ۂ͂����Ə��������v�f�������
�E�}�[�P�e�B���O���̘A�������̃X���C�h������낤��
�E�����������̗v�f�������Ă�ˁi�j
�EBulldozer�ɂ͂��y���݂���t�����A�Ƃ��������Ȃ���
�E��R�̊v�V�I�v�f�����邯�ǎ��Ԃ��o�ĂΖ��炩�ɂȂ��
>521 >530
�ŁA����ɑ���Intel�́A�Ɨ�����GPU�͎����ĂȂ������R������
���������ɃX���[�v�b�g�R���s���[�e�B���O�������̓y�U��
�������荞�ނ��߂�AVX���Larrabee�𐄐i���A�Ƃ������ƂȂ낤��
�ŁA����ɑ���Intel�́A�Ɨ�����GPU�͎����ĂȂ������R������
���������ɃX���[�v�b�g�R���s���[�e�B���O�������̓y�U��
�������荞�ނ��߂�AVX���Larrabee�𐄐i���A�Ƃ������ƂȂ낤��
> �E�T���}�͋ɂ߂đ�܂��Ŏ��ۂ͂����Ə��������v�f�������
> �E�}�[�P�e�B���O���̘A�������̃X���C�h������낤��
> �E�����������̗v�f�������Ă�ˁi�j
������Ƃ������S�B256�r�b�g���͒u���Ƃ��Ă��AFMAD�Ƃ͓Ɨ�����
�V���b�t�����j�b�g����������HPC�ł̏����͌������B
�Ȃ�ɂ���256�r�b�g��AVX�͂��炭�x���̂͊m��
22nm�܂ł�SIMD���j�b�g�̔{����3�I�y��FMA�Ή��ł����
��Haswell�ŗD�ʂɎ������ނ��Ƃ��ł��邩������Ȃ��B
����͂����ƃN���X�^����GPU�Ɖ��Z���j�b�g���p���邽�߂̕z��
��������Fusion�ʼn�����炩�������m���ˁB
���̂Ƃ��ɂ�GPU�R�A��VLIW�A���C����Ȃ��Ȃ肻�������B
> �E�}�[�P�e�B���O���̘A�������̃X���C�h������낤��
> �E�����������̗v�f�������Ă�ˁi�j
������Ƃ������S�B256�r�b�g���͒u���Ƃ��Ă��AFMAD�Ƃ͓Ɨ�����
�V���b�t�����j�b�g����������HPC�ł̏����͌������B
�Ȃ�ɂ���256�r�b�g��AVX�͂��炭�x���̂͊m��
22nm�܂ł�SIMD���j�b�g�̔{����3�I�y��FMA�Ή��ł����
��Haswell�ŗD�ʂɎ������ނ��Ƃ��ł��邩������Ȃ��B
����͂����ƃN���X�^����GPU�Ɖ��Z���j�b�g���p���邽�߂̕z��
��������Fusion�ʼn�����炩�������m���ˁB
���̂Ƃ��ɂ�GPU�R�A��VLIW�A���C����Ȃ��Ȃ肻�������B
>>534
AVX�̎����̓C���e����������128bit�~2�Ŏ��s�������͂��Ȃ̂ŁA
�����͕ʂɖ��Ȃ��͂��B���s���j�b�g�̐��\�͂킩��Ȃ����B
���Ƃ͐F�X�Ə�łĂ��Ȃ��Ƃ킩��Ȃ��B
L3���e�R�A���Ƃ���ƁA�C���e���̂悤�ɁA
�L���b�V���������O�o�X�݂����Ȃ̂Ōq���̂��H
�����c�{���ɍ���Ă����ȁc�B�悩�����B
AVX�̎����̓C���e����������128bit�~2�Ŏ��s�������͂��Ȃ̂ŁA
�����͕ʂɖ��Ȃ��͂��B���s���j�b�g�̐��\�͂킩��Ȃ����B
���Ƃ͐F�X�Ə�łĂ��Ȃ��Ƃ킩��Ȃ��B
L3���e�R�A���Ƃ���ƁA�C���e���̂悤�ɁA
�L���b�V���������O�o�X�݂����Ȃ̂Ōq���̂��H
�����c�{���ɍ���Ă����ȁc�B�悩�����B
>>535
�݂�Ȃ����v���Ă���
�C�X���G���`�[���͗e�͂Ȃ�����
http://software.intel.com/en-us/forums/intel-avx-and-cpu-instructions/topic/68554/reply/96175/
�݂�Ȃ����v���Ă���
�C�X���G���`�[���͗e�͂Ȃ�����
http://software.intel.com/en-us/forums/intel-avx-and-cpu-instructions/topic/68554/reply/96175/
�c�C�X���G���̖��p�����炵�傤���Ȃ��B
����ʂ肾���ꉞ���{��L���Ƃ������Ƃ�
AMD�ABulldozer�A�[�L�e�N�`�������J
http://pc.watch.impress.co.jp/docs/news/20091112_328379.html
AMD�A2011�N�܂ł̃N���C�A���g���[�h�}�b�v�����J �`Fusion CPU�ɂ��Ă����y
http://pc.watch.impress.co.jp/docs/news/20091112_328384.html
���Ƃ͌㓡����E�匴����E����������̋L���҂�����
AMD�ABulldozer�A�[�L�e�N�`�������J
http://pc.watch.impress.co.jp/docs/news/20091112_328379.html
AMD�A2011�N�܂ł̃N���C�A���g���[�h�}�b�v�����J �`Fusion CPU�ɂ��Ă����y
http://pc.watch.impress.co.jp/docs/news/20091112_328384.html
���Ƃ͌㓡����E�匴����E����������̋L���҂�����
Dresdenboy�����ȁAAMD�̓������甼�N�ȏ���O��
���������u���b�N�_�C�A�O����������̔��\�Ƃقڈꏏ��
Dresdenboy
http://data5.blog.de/media/291/3428291_45cdf95bfa_l.png
AMD
http://pc.watch.impress.co.jp/img/pcw/docs/328/384/amd-08.jpg
�X�ɎO�����O�Ɏd�グ���ڍׂȐ���u���b�N�_�C�A�O����
http://info.nuje.de/Bulldozer_Core_uArch_0.5b.png
����͂����Ă������Ȉ�ہE�E�E
Pentium4��Trace Cache�Ƃقړ��l��Nehalem��Loop Cache��
SandyBridge�ł͋��������炵���iTrace Cache���̗e�ʂɖ߂�j
���l��AMD��Bulldozer��Redirect Recovery Cache�i�����擾�ς݁j��
����Ɠ��l�̎d�g�݂�����������̂Ɛ��������͗l
�_�����ܘ_�ꏏ�Ńf�R�[�_�̕��S�y���i�Ƃ���ɂ�����d�͒ቺ�j
���������u���b�N�_�C�A�O����������̔��\�Ƃقڈꏏ��
Dresdenboy
http://data5.blog.de/media/291/3428291_45cdf95bfa_l.png
{kind=link}
AMD
http://pc.watch.impress.co.jp/img/pcw/docs/328/384/amd-08.jpg
{kind=link}
�X�ɎO�����O�Ɏd�グ���ڍׂȐ���u���b�N�_�C�A�O����
http://info.nuje.de/Bulldozer_Core_uArch_0.5b.png
{kind=link}
����͂����Ă������Ȉ�ہE�E�E
Pentium4��Trace Cache�Ƃقړ��l��Nehalem��Loop Cache��
SandyBridge�ł͋��������炵���iTrace Cache���̗e�ʂɖ߂�j
���l��AMD��Bulldozer��Redirect Recovery Cache�i�����擾�ς݁j��
����Ɠ��l�̎d�g�݂�����������̂Ɛ��������͗l
�_�����ܘ_�ꏏ�Ńf�R�[�_�̕��S�y���i�Ƃ���ɂ�����d�͒ቺ�j
�͂������[
�㓡�����̑�����
�y�㓡�O��Weekly�C�O�j���[�X�z
AMD�������A�[�L�e�N�`���uBulldozer�v�ƁuBobcat�v�̊T�v�𖾂炩��
http://pc.watch.impress.co.jp/docs/column/kaigai/20091112_328392.html
�㓡�����̑�����
�y�㓡�O��Weekly�C�O�j���[�X�z
AMD�������A�[�L�e�N�`���uBulldozer�v�ƁuBobcat�v�̊T�v�𖾂炩��
http://pc.watch.impress.co.jp/docs/column/kaigai/20091112_328392.html
2010�N���ɃJ�X�^�}�[�ɃT���v���o���ƌ����Ă邩��
�o���2011�N�O���ł����邩��
�o���f�[�V�����Ƃ��\��ʂ�ɐi�߂���
�o���2011�N�O���ł����邩��
�o���f�[�V�����Ƃ��\��ʂ�ɐi�߂���
���⍡�̃X�P�W���[�����ƌ㔼�炵����
GF�̃v���Z�X�I�ɂ͊J���������ƏI��点����Ă��炢�]�T���邩��
�ǂ�AMD���撣��邩����
�ǂ�AMD���撣��邩����
�܂�Bulldozer���\����x���
2012�N�ȍ~�ɓo��Ȃ�Ď��ԂɂȂ���������l�݂���
2012�N�ȍ~�ɓo��Ȃ�Ď��ԂɂȂ���������l�݂���
Opteron�̂ق��͂Ƃ�����Zambezi�Ȃ�ďo�����
�ł�Bulldozer�o���AMD��������ˁH
Intel�ɂ���𗽂������̐��\���o�����Ȏ�����v�悠��́H
�N���X�^���������������Ă邩��܂˂�Ȃ����������B
Intel�ɂ���𗽂������̐��\���o�����Ȏ�����v�悠��́H
�N���X�^���������������Ă邩��܂˂�Ȃ����������B
���₢��A�Ƃ肠�����x���`�Ƃ��Ă݂Ƃɂ́E�E�E
AMD�ɂ��ƃN���X�^����50%�̃��\�[�X����80%�̃X���[�v�b�g����B
intel�H��HTT��5%�قǂ̃��\�[�X����15�`30%�̐��\����B
�N���X�^���̕���HTT�������������ǂ��Ƃ����킯�ł͂Ȃ������B
intel�H��HTT��5%�قǂ̃��\�[�X����15�`30%�̐��\����B
�N���X�^���̕���HTT�������������ǂ��Ƃ����킯�ł͂Ȃ������B
550 �F,,�E�L�́M�E,,�j��-�������F2009/11/12(��) 23:11:31 ID:gjkqx3Og
>>547
����͍ŏ���SSE5�v�����ō��N���ɏo���ꍇ�Ȃ炻��������������
�����_�̏��ł�
Sandy Bridge�@256bit FADD+FMUL / cluster
Bulldozer 128�r�b�gFMA�~2 / core
�ŁA�N���b�N������̃s�[�N�����������Z���\�͂ǂ����������B
���\�]���������Ȃ�ASandy Bridge�̊ȈՃT�C�N���V�~�����[�^��Intel�̃T�C�g���痎�Ƃ����B
�N���X�^�ƌ����Ă��f�R�[�h�t�����g�G���h�͋��L�Ȃ̂ŁA������2�X���b�h�̍��v���\�͓��ł��ɂȂ�B
���v4issue���Ƃ����炻�ꂱ��Sandy Bridge�����������A�����Ȃ�ƃs�[�N���\�ō��ʉ�����͓̂���B
����AMD�Ǝ����ߔ�����AVX�̓y�U����AMD�͌������Ǝv���B
�ǂ������Ƃ�����L1�f�[�^�L���b�V�����X���b�h���ɓƗ����Ă�̂ŃL���b�V������荇�킸�ɍςނƂ�
���[�X�g�P�[�X�ł̐��\�ቺ��h���v�����傫����Ȃ����Ǝv�����A���̕ӂ͂ǂ��Ƃ�������B
SMT�ɂ�CMT�ɂ����ꂼ�ꗘ�_�͂���B
����͍ŏ���SSE5�v�����ō��N���ɏo���ꍇ�Ȃ炻��������������
�����_�̏��ł�
Sandy Bridge�@256bit FADD+FMUL / cluster
Bulldozer 128�r�b�gFMA�~2 / core
�ŁA�N���b�N������̃s�[�N�����������Z���\�͂ǂ����������B
���\�]���������Ȃ�ASandy Bridge�̊ȈՃT�C�N���V�~�����[�^��Intel�̃T�C�g���痎�Ƃ����B
�N���X�^�ƌ����Ă��f�R�[�h�t�����g�G���h�͋��L�Ȃ̂ŁA������2�X���b�h�̍��v���\�͓��ł��ɂȂ�B
���v4issue���Ƃ����炻�ꂱ��Sandy Bridge�����������A�����Ȃ�ƃs�[�N���\�ō��ʉ�����͓̂���B
����AMD�Ǝ����ߔ�����AVX�̓y�U����AMD�͌������Ǝv���B
�ǂ������Ƃ�����L1�f�[�^�L���b�V�����X���b�h���ɓƗ����Ă�̂ŃL���b�V������荇�킸�ɍςނƂ�
���[�X�g�P�[�X�ł̐��\�ቺ��h���v�����傫����Ȃ����Ǝv�����A���̕ӂ͂ǂ��Ƃ�������B
SMT�ɂ�CMT�ɂ����ꂼ�ꗘ�_�͂���B
551 �F,,�E�L�́M�E,,�j��-�������F2009/11/12(��) 23:12:11 ID:gjkqx3Og
�t��
Sandy Bridge�@256bit FADD+FMUL / core
Bulldozer 128�r�b�gFMA�~2 / cluster
Sandy Bridge�@256bit FADD+FMUL / core
Bulldozer 128�r�b�gFMA�~2 / cluster
�����Ȃ�SandyBridge�L���b�`�A�b�v�o������{���ɋO�Ղ���
Pentium4����core2�ʂ̏Ռ���������
��͓d�͂���
Pentium4����core2�ʂ̏Ռ���������
��͓d�͂���
554 �F,,�E�L�́M�E,,�j��-�������F2009/11/12(��) 23:46:27 ID:gjkqx3Og
Intel��Haswell�܂łɂ�����FMA�������AAMD��MAD��256�r�b�g����
�����������j�b�g�̎����̈Ⴂ�͂�����x���܂邩�Ǝv��
�����������j�b�g�̎����̈Ⴂ�͂�����x���܂邩�Ǝv��
AMD and Intel reach antitrust, IP settlement
http://www.fudzilla.com/content/view/16409/1/
Intel to pay AMD $1.25 billion
http://www.fudzilla.com/content/view/16409/1/
Intel to pay AMD $1.25 billion
�R�A���傫���Ȃ��āA���\�[�X���L�ŕ��G�����āA
�N���b�N���g�����]���ɂȂ�C��������ǞX�J������B
�f�X�N�g�b�v�͂����s��͍L����Ȃ��Ƃ݂Ă�����߂��̂��ȁB
�����T�[�o�ɂ��Ă��A�f�R�[�_���L��80%�X���[�v�b�g���シ��̂��ȁH
�N���b�N���g�����]���ɂȂ�C��������ǞX�J������B
�f�X�N�g�b�v�͂����s��͍L����Ȃ��Ƃ݂Ă�����߂��̂��ȁB
�����T�[�o�ɂ��Ă��A�f�R�[�_���L��80%�X���[�v�b�g���シ��̂��ȁH
557 �FSocket774�F2009/11/13(��) 01:29:59 ID:EQWfLDgj
Bulldozer��1�N�����o���Intel�ɏ��Ă���B
12.5���h�������Bulldozer���o��܂ł͉����ł��邩��
2�X���b�h�������s�Ƃ���Ƃ� >>549 �̌����Ƃ���ɁAAMD�̂ق����ʐς͋���
���\���ǂ��AIntel HT�͖ʐς͋��Ȃ����ǐ��\�͂��܂�L�тȂ��A
�Ƃ����_��������P�������čl����ƁA�����ʐς̃`�b�v�ł͓��R�AAMD�̂ق���
�������s�X���b�h�͏��Ȃ����Ǎő啉���ɃX���b�h������̃p�t�H�[�}���X�͏�A
Intel�̓X���b�h���������Ǎő啉���̃X���b�h������̃p�t�H�[�}���X�͉�
�Ƃ����g���[�h�I�t�ɂȂ�B
Intel������HT�̂����ł��̂܂ܐi�ނ��͕s�������ǁA���Ђ�2011�N�ȍ~��PC�p
�v���Z�b�T�œ������s�X���b�h���ƃX���b�h������̐��\�̂ǂ�����D�悵�Ă���
���̈Ⴂ�ƒP���Ɍ��邱�Ƃ��o���邩���B
���\���ǂ��AIntel HT�͖ʐς͋��Ȃ����ǐ��\�͂��܂�L�тȂ��A
�Ƃ����_��������P�������čl����ƁA�����ʐς̃`�b�v�ł͓��R�AAMD�̂ق���
�������s�X���b�h�͏��Ȃ����Ǎő啉���ɃX���b�h������̃p�t�H�[�}���X�͏�A
Intel�̓X���b�h���������Ǎő啉���̃X���b�h������̃p�t�H�[�}���X�͉�
�Ƃ����g���[�h�I�t�ɂȂ�B
Intel������HT�̂����ł��̂܂ܐi�ނ��͕s�������ǁA���Ђ�2011�N�ȍ~��PC�p
�v���Z�b�T�œ������s�X���b�h���ƃX���b�h������̐��\�̂ǂ�����D�悵�Ă���
���̈Ⴂ�ƒP���Ɍ��邱�Ƃ��o���邩���B
560 �FSocket774�F2009/11/13(��) 02:01:46 ID:Cbg6mSdh
1���W���[�����Q�R�A�Ɛ�����̂��E�E�E�E�B����Ƃ��A�P���W���[����1�R�A��
�����邩�ő����l�������ς���Ă���悤�ȋC�����邯�ǁB
�����邩�ő����l�������ς���Ă���悤�ȋC�����邯�ǁB
�ǂ��l���Ă�1���W���[���������̊T�O�ł�1�R�A����
1���W���[������2�X���b�h�𑖂点�邱�Ƃ��o����
1���W���[������2�X���b�h�𑖂点�邱�Ƃ��o����
���W�����[�Ɋ��蓖�Ă���d����1�X���b�h�̎��͂Q�R�A���̃��\�[�X���L�ł���
2�X���b�h�̎��͏_��Ƀ��\�[�X�z���邱�Ƃ��\���Ă��Ƃ��H
1�X���b�h������ɗp�ӂł��郊�\�[�X���ӂ���Ȃ�V���O���X���b�h���\�������肻������
�[������̓��W�����[�P�ʂŃX�P�W���[�����O������Ă��ƂɂȂ�̂���
���܂܂ł̓\�P�b�g-�R�A-�X���b�h����������
����̓\�P�b�g-���W�����[-�R�A-�X���b�h���Ă��ƂɂȂ�̂��ȁH
2�X���b�h�̎��͏_��Ƀ��\�[�X�z���邱�Ƃ��\���Ă��Ƃ��H
1�X���b�h������ɗp�ӂł��郊�\�[�X���ӂ���Ȃ�V���O���X���b�h���\�������肻������
�[������̓��W�����[�P�ʂŃX�P�W���[�����O������Ă��ƂɂȂ�̂���
���܂܂ł̓\�P�b�g-�R�A-�X���b�h����������
����̓\�P�b�g-���W�����[-�R�A-�X���b�h���Ă��ƂɂȂ�̂��ȁH
�ȑO�̐��\�\���Ɣ�ׂ�ƁAMagny-Cours�͎���サ�Ă��邪�A
Interlagos�͎�ቺ���Ă���悤�Ɍ�����̂͋C�̂������ȁB
http://pc.watch.impress.co.jp/img/pcw/docs/167/815/html/kaigai_16.jpg.html
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=3673&p=5
Interlagos�͎�ቺ���Ă���悤�Ɍ�����̂͋C�̂������ȁB
http://pc.watch.impress.co.jp/img/pcw/docs/167/815/html/kaigai_16.jpg.html
{kind=link}
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=3673&p=5
564 �FSocket774�F2009/11/13(��) 03:11:04 ID:Cbg6mSdh
�㓡���H���A�P���W���[����2�R�A�ƃJ�E���g���邻�[�ȁB
���Ƃ���ƁA�ǂ����֍l����ƁA�ނ��Ⴍ��������̗ǂ��f���A���R�A���Ď����ȁB
�������������ƁA�Q�R�A�̗l�ɂ����삷��P�R�A���A�Q�R�A�Ƃ��Ĕ�����Ď��ɂȂ�B
�ǂ����݂��A�Ȃ܂��d�|�������肻�������ǁB
���Ƃ���ƁA�ǂ����֍l����ƁA�ނ��Ⴍ��������̗ǂ��f���A���R�A���Ď����ȁB
�������������ƁA�Q�R�A�̗l�ɂ����삷��P�R�A���A�Q�R�A�Ƃ��Ĕ�����Ď��ɂȂ�B
�ǂ����݂��A�Ȃ܂��d�|�������肻�������ǁB
�Ȃ�Ƃ�Mhz�����Ƃ��̂���������
�������Č��Ȃ�ˁB�ȂE�E�E�B
���̕��l�i������ݒ肷�������B
�������Č��Ȃ�ˁB�ȂE�E�E�B
���̕��l�i������ݒ肷�������B
>>562
> ���W�����[�Ɋ��蓖�Ă���d����1�X���b�h�̎��͂Q�R�A���̃��\�[�X���L�ł���
> 2�X���b�h�̎��͏_��Ƀ��\�[�X�z���邱�Ƃ��\���Ă��Ƃ��H
�}���������f�R�[�h��FP unit���������p�A�t�Ɍ����ƁA1�X���b�h/���W�����[��
���͕Е���Integer�p�C�v�͗V�܂܁B����2�X���b�h����Integer�p�C�v�S��
�A�E�g�I�u�I�[�_��1�X���b�h���s���Ă̂́A�����ꒃ��ςȊ��Ɍ��ʏo�Ȃ��ł��傤�B
FP�p�C�v�̃X�P�W���[�����O�̏ڍׂ͂܂��悭����Ȃ����ǁB
>>564
2�l�ŕ�炷�̂Ɏ�H�̕Ă�H���̂ɕK�v�Ȕ��ƒ��q������2�g�p�ӂ��邯�ǁA
���H�g���킯�ł��Ȃ��t�H�[�N��X�v�[����1�l�������p�ӂ��Ȃ��Ƃ�������
> ���W�����[�Ɋ��蓖�Ă���d����1�X���b�h�̎��͂Q�R�A���̃��\�[�X���L�ł���
> 2�X���b�h�̎��͏_��Ƀ��\�[�X�z���邱�Ƃ��\���Ă��Ƃ��H
�}���������f�R�[�h��FP unit���������p�A�t�Ɍ����ƁA1�X���b�h/���W�����[��
���͕Е���Integer�p�C�v�͗V�܂܁B����2�X���b�h����Integer�p�C�v�S��
�A�E�g�I�u�I�[�_��1�X���b�h���s���Ă̂́A�����ꒃ��ςȊ��Ɍ��ʏo�Ȃ��ł��傤�B
FP�p�C�v�̃X�P�W���[�����O�̏ڍׂ͂܂��悭����Ȃ����ǁB
>>564
2�l�ŕ�炷�̂Ɏ�H�̕Ă�H���̂ɕK�v�Ȕ��ƒ��q������2�g�p�ӂ��邯�ǁA
���H�g���킯�ł��Ȃ��t�H�[�N��X�v�[����1�l�������p�ӂ��Ȃ��Ƃ�������
���ƂȂ��}�ɂ��Ă݂��B�����������Ƃō����Ă�H
ttp://sukima.vip2ch.com/up/sukima015376.jpg
ttp://sukima.vip2ch.com/up/sukima015376.jpg
{kind=link}
��������GPU�̐��\�ł͈��������������B
1���W���[����1�R�A�Ɛ�����Ɠ����R�A���̃C���e���𐮐����Z�łԂ������邪
2�R�A�Ɛ�����Ɠ����R�A���̃C���e���ɕ��������_���Z�łԂ���������
�l�i�t���̖������邩��Y�܂�����1�R�A�Ɛ����ė~����������
2�R�A�Ɛ�����Ɠ����R�A���̃C���e���ɕ��������_���Z�łԂ���������
�l�i�t���̖������邩��Y�܂�����1�R�A�Ɛ����ė~����������
�x�N�^���Z�̓x�N�^�R�A�łł���
>>547
�u���_�C������舳������v�f���������c
�u���_�C������舳������v�f���������c
572 �FSocket774�F2009/11/13(��) 08:44:47 ID:aa2/JaLQ
�ꕔ�����L�������f���A���R�A���ȁB
�ꕔ����ł��痼�����ʁB
�����܂舫���B
������R�A�����ɐ����Ĕ����B
�Z�R�C��������Ȃ��ŗ~�����B
�ꕔ����ł��痼�����ʁB
�����܂舫���B
������R�A�����ɐ����Ĕ����B
�Z�R�C��������Ȃ��ŗ~�����B
573 �F,,�E�L�́M�E,,�j��-�������F2009/11/13(��) 08:53:24 ID:TwafIZZ/
>>567
�ɂ����BSandy Bridge��
256�r�b�gFP MUL�~�P
256�r�b�gFP ADD�~�P
���ƁA�h���[���Ȃ炱�����E�߁B
http://cacoo.com/
�ɂ����BSandy Bridge��
256�r�b�gFP MUL�~�P
256�r�b�gFP ADD�~�P
���ƁA�h���[���Ȃ炱�����E�߁B
http://cacoo.com/
���_�l�ł͕������������Ă邯��
�����l�ł͂���Ȏ��Ȃ���(�د
�����l�ł͂���Ȏ��Ȃ���(�د
575 �F,,�E�L�́M�E,,�j��-�������F2009/11/13(��) 09:21:56 ID:TwafIZZ/
�o�b�N�G���h��������������Sandy Bridge�̎��s���j�b�g�\����
�V�~�����[�^�����͂�����ŏ����Ƃ�
https://cacoo.com/diagrams/q3shnziz0wXnUW24
���͂قƂ�ǂ����iNehalem�j�̐����i���`
http://pc.watch.impress.co.jp/docs/2008/0424/kaigai_02l.gif
�V�~�����[�^�����͂�����ŏ����Ƃ�
https://cacoo.com/diagrams/q3shnziz0wXnUW24
���͂قƂ�ǂ����iNehalem�j�̐����i���`
http://pc.watch.impress.co.jp/docs/2008/0424/kaigai_02l.gif
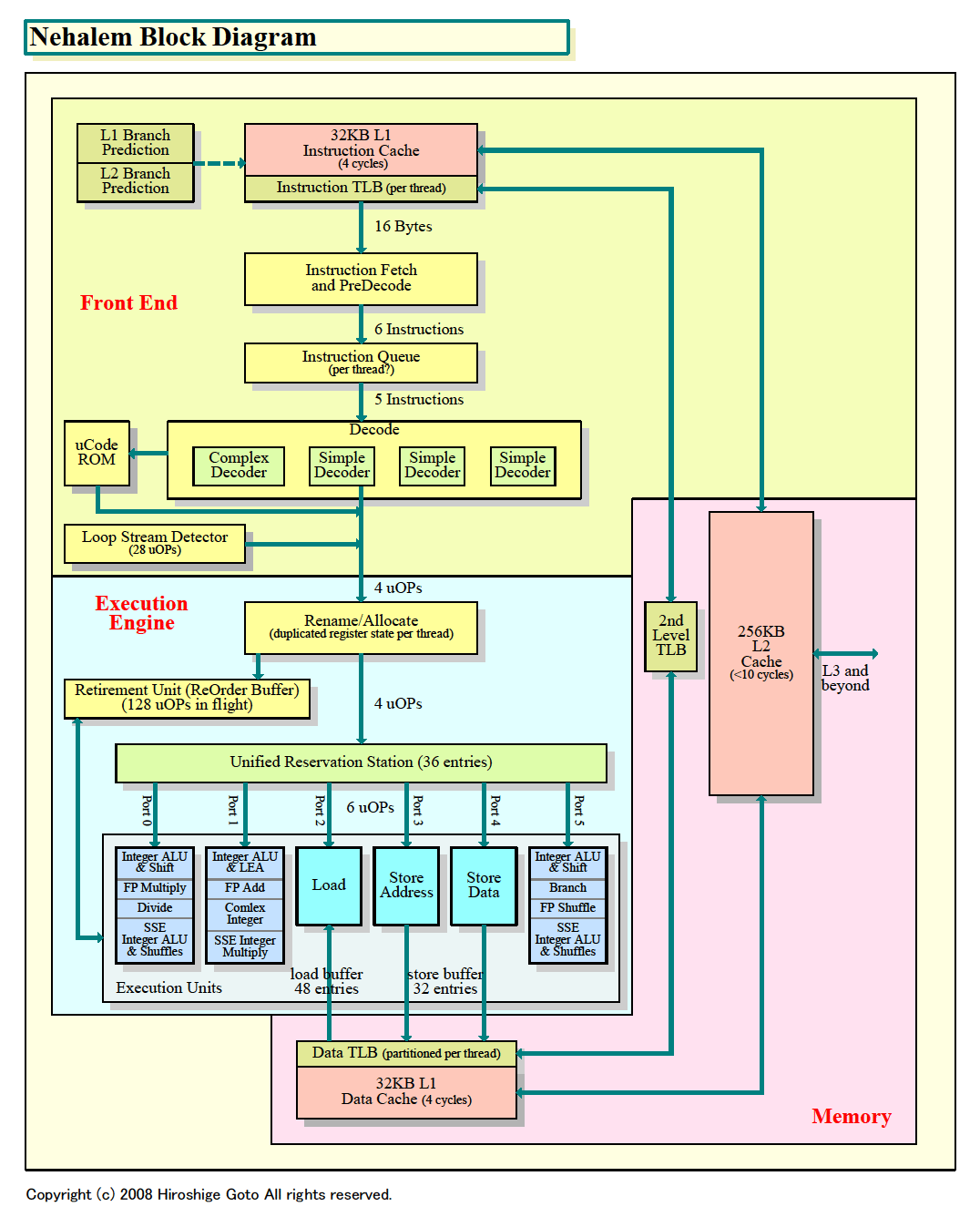{kind=link}
��]�̑����������������Ă��܂�
577 �FSocket774�F2009/11/13(��) 09:54:57 ID:aa2/JaLQ
�X���b�h���\�͂قƂ�Ǐオ��Ȃ��ȁB
�ʐ�5�����Ő��\8�����B
�ʐό���2�����B
HT�Ƒ卷�����B
�Ȃ̂�1�P�ʂ��傫���Ȃ�A�����܂肪�Ⴂ�B
�ŒႪ2�R�A�ɂȂ�A�}���`�X���b�h�����i�ށB
�����ɑ����̃R�A�A�����N���b�N���v�_�Ȃ͕̂ς���ĂȂ��B
�����āA�ʐό����ȏ�ɓd�͌������K�v�ɂȂ邾�낤�B
�u���h�[�U���������������Ȃ̂��́A������Ȃ��B
�ʐ�5�����Ő��\8�����B
�ʐό���2�����B
HT�Ƒ卷�����B
�Ȃ̂�1�P�ʂ��傫���Ȃ�A�����܂肪�Ⴂ�B
�ŒႪ2�R�A�ɂȂ�A�}���`�X���b�h�����i�ށB
�����ɑ����̃R�A�A�����N���b�N���v�_�Ȃ͕̂ς���ĂȂ��B
�����āA�ʐό����ȏ�ɓd�͌������K�v�ɂȂ邾�낤�B
�u���h�[�U���������������Ȃ̂��́A������Ȃ��B
�����ł������G��x86�̃t�F�b�`/�f�R�[�h��
2�X���b�h�ŋ��L����͍̂����I�łȂ��Ǝv�����B
�������Ċȑf�����āu50%�̃g�����W�X�^��80%�̌����v��B������A
�g�����W�X�^�𑝂₳���Ɍ������グ����Ƃ���Ȃ̂ł͂Ȃ���?
2�X���b�h�ŋ��L����͍̂����I�łȂ��Ǝv�����B
�������Ċȑf�����āu50%�̃g�����W�X�^��80%�̌����v��B������A
�g�����W�X�^�𑝂₳���Ɍ������グ����Ƃ���Ȃ̂ł͂Ȃ���?
AMD�̓f���A��CPU���f���A���R�A�ɂ������ǁA
���x�̓f���A���R�A���X�ɗZ��������1���W���[���ɂ�����Ă��Ƃ���ˁB
�_�C�T�C�Y50�����Ńp�t�H�[�}���X80%�A�b�v�Ƃ����Ȃ�A
�_�C�T�C�Y100%���Ńp�t�H�[�}���X100%�A�b�v�������f���A���R�A�����������������
�����1���W���[���̒���2�X���b�h�͓���L2L3�L���b�V�����Q�Ƃ��邩��
���܂ł�AMD CPU�Ŏ�_�������R�A�Ԃ̃L���b�V���q�b�g�����シ��B
���x�̓f���A���R�A���X�ɗZ��������1���W���[���ɂ�����Ă��Ƃ���ˁB
�_�C�T�C�Y50�����Ńp�t�H�[�}���X80%�A�b�v�Ƃ����Ȃ�A
�_�C�T�C�Y100%���Ńp�t�H�[�}���X100%�A�b�v�������f���A���R�A�����������������
�����1���W���[���̒���2�X���b�h�͓���L2L3�L���b�V�����Q�Ƃ��邩��
���܂ł�AMD CPU�Ŏ�_�������R�A�Ԃ̃L���b�V���q�b�g�����シ��B
1���ŔN�������l�X�V�Ƃ����
http://jp.moneycentral.msn.com/investor/charts/chartdl.aspx?symbol=US%3aAMD&CP=0&PT=6
http://jp.moneycentral.msn.com/investor/charts/chartdl.aspx?symbol=US%3aAMD&CP=0&PT=6
���������_���Z��2�X���b�h�ŋ��L�Ȃ̂͊m���Ɏ�_������
������Ă��̍��ɂ�GPU�����S�����Ƒ����Ȃ肻���������薳����K�X
������Ă��̍��ɂ�GPU�����S�����Ƒ����Ȃ肻���������薳����K�X
>>579
�f���A���R�A���̓V���O���X���b�h���\�𗎂Ƃ��Ȃ���
���W���[�����ł͊ԈႢ�Ȃ�������B
���\�ቺ���ǂ̒��x���ɂ���ă`�b�v�Ƃ��Ă̕]���͕ς�邪�A
�l�I�ɂ�(���x�̑召�Ɋւ�炸)�����B
�f���A���R�A���̓V���O���X���b�h���\�𗎂Ƃ��Ȃ���
���W���[�����ł͊ԈႢ�Ȃ�������B
���\�ቺ���ǂ̒��x���ɂ���ă`�b�v�Ƃ��Ă̕]���͕ς�邪�A
�l�I�ɂ�(���x�̑召�Ɋւ�炸)�����B
�u�n�C�p�[�X���b�f�B���O��80%���\��������v�ł����H
>>582
���W���[��������ƃV���O���X���b�h���\��������Ƃ����̂��Ӗ��s���Ȃ���
�f���A���R�A��1���W���[���ł́A
�����_�C�T�C�Y�Ȃ�Ό�҂̂ق������ʂɐ��\��ł���
��������1�X���b�h�������点�Ȃ��Ƃ����O��Ȃ��
�f���A��CPU���낤���f���A���R�A���낤��SMT���낤�����N���b�N�Ő��\�������B
���W���[��������ƃV���O���X���b�h���\��������Ƃ����̂��Ӗ��s���Ȃ���
�f���A���R�A��1���W���[���ł́A
�����_�C�T�C�Y�Ȃ�Ό�҂̂ق������ʂɐ��\��ł���
��������1�X���b�h�������点�Ȃ��Ƃ����O��Ȃ��
�f���A��CPU���낤���f���A���R�A���낤��SMT���낤�����N���b�N�Ő��\�������B
>>584
1�̃t�F�b�`/�f�R�[�h�ł́A2�X���b�h���ꂼ��ɖ��߂��]���Ɠ�������
�t�B�[�h���邱�Ƃ͂ł��Ȃ��B
���ۂ�1�X���b�h������̐������Z�R�A�͏k������Ă���B
http://pc.watch.impress.co.jp/docs/column/kaigai/20091112_328392.html
> ALU��AGU�̃y�A��2���Ƃ���ƁA���݂̃R�A��2/3�̋K�͂ƂȂ�B
�����������Z�R�A���t�Ɋg������Ă���Ƃ�����A����͂���ł������Ȃ��Ƃ��B
�{�g���l�b�N�̓t�F�b�`�E�f�R�[�h�̕����[�����낤�B
1�̃t�F�b�`/�f�R�[�h�ł́A2�X���b�h���ꂼ��ɖ��߂��]���Ɠ�������
�t�B�[�h���邱�Ƃ͂ł��Ȃ��B
���ۂ�1�X���b�h������̐������Z�R�A�͏k������Ă���B
http://pc.watch.impress.co.jp/docs/column/kaigai/20091112_328392.html
> ALU��AGU�̃y�A��2���Ƃ���ƁA���݂̃R�A��2/3�̋K�͂ƂȂ�B
�����������Z�R�A���t�Ɋg������Ă���Ƃ�����A����͂���ł������Ȃ��Ƃ��B
�{�g���l�b�N�̓t�F�b�`�E�f�R�[�h�̕����[�����낤�B
�܂��A�ꌾ�Ō�����AMD's Rock�Ȃ̂���B
�X���[�v�b�g�R���s���[�e�B���O�ɐU���ċ��lIntel�Ƃ̐��ݕ�����}��̂�
�Ԉ���Ă��Ȃ��B���炤�ǂ��̎��ゾ���ȁB
�킴�킴�u�l�I�Ɂv�����Ə������̂͂��������Ӗ��B
�X���[�v�b�g�R���s���[�e�B���O�ɐU���ċ��lIntel�Ƃ̐��ݕ�����}��̂�
�Ԉ���Ă��Ȃ��B���炤�ǂ��̎��ゾ���ȁB
�킴�킴�u�l�I�Ɂv�����Ə������̂͂��������Ӗ��B
�悭�l����ƁASMT�͓���Ă��Ȃ�������A�X���[�v�b�g�ɐU�����킯�ł�
�Ȃ��ȁB����ς胂�m���݂Ȃ��ƁA���҂Ȃ��悭�킩��Ȃ��ȁB
�{���ɂ�肽�������̂́A(���������_���Z�Ɠ��l��)�����̐������Z�p�C�v����ׂāA
1�X���b�h�Ő�L��2�X���b�h�ŋ��L���ł���d�g�݂������Ǝv���B
�V���O���X���b�h���\���]���ɂ��邱�ƂȂ��X���[�v�b�g������ł��āA
�f�l�ڂɒf�R�J�b�R�C�C�B�ł�����Ă݂������č��܂����낤�Ȃ��B
�Ȃ��ȁB����ς胂�m���݂Ȃ��ƁA���҂Ȃ��悭�킩��Ȃ��ȁB
�{���ɂ�肽�������̂́A(���������_���Z�Ɠ��l��)�����̐������Z�p�C�v����ׂāA
1�X���b�h�Ő�L��2�X���b�h�ŋ��L���ł���d�g�݂������Ǝv���B
�V���O���X���b�h���\���]���ɂ��邱�ƂȂ��X���[�v�b�g������ł��āA
�f�l�ڂɒf�R�J�b�R�C�C�B�ł�����Ă݂������č��܂����낤�Ȃ��B
589 �FSocket774�F2009/11/13(��) 11:25:37 ID:aa2/JaLQ
FPU���g���̂͌Â��\�t�g�ŁA�Â��\�t�g�̓V���O���X���b�h�v���O�����B
�Ă��ƂŁA�����Ȃ����̂��ȁB
�Œ�4�R�A���ゾ��4�R�A���W���[���ɂ���B
���\����̖ړI����Ȃ��ȁB
�Ă��ƂŁA�����Ȃ����̂��ȁB
�Œ�4�R�A���ゾ��4�R�A���W���[���ɂ���B
���\����̖ړI����Ȃ��ȁB
���p����128bit��FPU���āA���܂łǂ���SSE��AVX�����s����낤����A
�Â��\�t�g�ȊO�ɂ��W����Ǝv�����ǁB
�Â��\�t�g�ȊO�ɂ��W����Ǝv�����ǁB
>>585
CMT�̈Ӗ��������Ă�̂�
INT���k�������Ɖ��߂���̂͊ԈႢ
���Ƃ����̔���������������Ȃ���
�����̕��͂ɂ�������Ɩڂ�ʂ�����
CMT�̈Ӗ��������Ă�̂�
INT���k�������Ɖ��߂���̂͊ԈႢ
���Ƃ����̔���������������Ȃ���
�����̕��͂ɂ�������Ɩڂ�ʂ�����
���̑O�̃��X����ڒʂ��킩�邯�ǁA585�̓V���O���X���b�h���\�̘b����B
�����͂����܂ł����W���[���P�ʂŌ���ׂ��ł�����
�����I�ȃu���b�N�Ō��Ă��܂������ł����v����낤��
Intel��HT�����ނ���H/W���\�[�X��INT�Ɋ����Ă�\���������
HT�ŃV���O���X���b�h���\��������ƌ����Ă邭�炢�ɂ�����������
�����I�ȃu���b�N�Ō��Ă��܂������ł����v����낤��
Intel��HT�����ނ���H/W���\�[�X��INT�Ɋ����Ă�\���������
HT�ŃV���O���X���b�h���\��������ƌ����Ă邭�炢�ɂ�����������
Bob�L��R�ςނ̂���Ԑ��\�オ�肻���ȋC������B
> �����͂����܂ł����W���[���P�ʂŌ���ׂ��ł�����
������2�X���b�h���s���s���O��B
�F�߂����Ȃ��̂͂킩�邯�ǁA
Bulldozer�̃A�v���[�`���Ɓu�V���O���X���b�h���\�́v�������B
Hyper-Threading�Ƃ͈Ⴄ�B
�X���[�v�b�g�̓p�t�H�[�}���X�Ƃ̃g���[�h�I�t�Ȃ���A���傤���Ȃ��B
������2�X���b�h���s���s���O��B
�F�߂����Ȃ��̂͂킩�邯�ǁA
Bulldozer�̃A�v���[�`���Ɓu�V���O���X���b�h���\�́v�������B
Hyper-Threading�Ƃ͈Ⴄ�B
�X���[�v�b�g�̓p�t�H�[�}���X�Ƃ̃g���[�h�I�t�Ȃ���A���傤���Ȃ��B
>>588
�ˑR���̈ʒu�܂Ŕ��͖����ł���H
������ȍ~�ł͂����Ȃ�̂ł́H
���ƁA�V���O�����\�͗����邾�낤���ǁA
�����I�ɂ͍S��Ȃ��Ă����������ˁc�B
�ˑR���̈ʒu�܂Ŕ��͖����ł���H
������ȍ~�ł͂����Ȃ�̂ł́H
���ƁA�V���O�����\�͗����邾�낤���ǁA
�����I�ɂ͍S��Ȃ��Ă����������ˁc�B
Bobcat��Bulldozer��肳��ɂ悭�킩��Ȃ��ȁB
50%�̃_�C�T�C�Y��90%�̃p�t�H�[�}���X����������Z�p�͂Ȃ낤��?
���ꂪ�{���Ȃ�Bobcat����ׂ��180%�ŁABulldozer�Ȃ�ėv��Ȃ�(��)�B
�L���b�V���ȗ��A�f�R�[�_�����Z����ǂ��g�����߂ɂ��킹�Ċȑf���E�E�E
90%�͎��͌�������������Ȃ�Ȃ����Ǝv���邵�A
�_�C�T�C�Y�����ł́A�R�X�g������d�͂����܂艺����Ȃ��Ȃ��悤�ɂ��v����B
���m���Ȃ��Ƃ����ς肾�B
50%�̃_�C�T�C�Y��90%�̃p�t�H�[�}���X����������Z�p�͂Ȃ낤��?
���ꂪ�{���Ȃ�Bobcat����ׂ��180%�ŁABulldozer�Ȃ�ėv��Ȃ�(��)�B
�L���b�V���ȗ��A�f�R�[�_�����Z����ǂ��g�����߂ɂ��킹�Ċȑf���E�E�E
90%�͎��͌�������������Ȃ�Ȃ����Ǝv���邵�A
�_�C�T�C�Y�����ł́A�R�X�g������d�͂����܂艺����Ȃ��Ȃ��悤�ɂ��v����B
���m���Ȃ��Ƃ����ς肾�B
��{�c���\��^���ɍl�����Ⴄ�l���āc�B
�s�[�N���\�������̂�intel
���s���\�������̂�AMD
1w�P�ʂ̐��\�������̂�intel
1\�P�ʂ̐��\�������̂�AMD
���s���\�������̂�AMD
1w�P�ʂ̐��\�������̂�intel
1\�P�ʂ̐��\�������̂�AMD
SSE��128-bit AVX���\���ƎBulldozer�L���B
2��MAD��mulps�~2�݂̂��邢��addps�~2�݂̂Ƃ��Ďg���邩��B
256-bit AVX���\���ƒf�RIntel�L���B
256-bit vmulps��vaddps��1�T�C�N���ɓ������s�ł��邩��B
AMD�Ǝ���XOP/FMA4������łȂ�Ƃ�������ׂ邱�Ƃ��ł���
256-bit vmulps��vaddps�ɑ��A128-bit��vmaddps�~2���邢��256-bit�Ł~1��
���荇�����Ƃ��ł��邩��B
> 1\�P�ʂ̐��\�������̂�AMD
����ւ邱�Ƃ���Ȃ����ǂȁB
�����R�X�g���Ⴂ�Ȃ�܂������A��������Ȃ����B
���l���������̌���͒P�Ɏs�ꋣ���͂��Ȃ������B
2��MAD��mulps�~2�݂̂��邢��addps�~2�݂̂Ƃ��Ďg���邩��B
256-bit AVX���\���ƒf�RIntel�L���B
256-bit vmulps��vaddps��1�T�C�N���ɓ������s�ł��邩��B
AMD�Ǝ���XOP/FMA4������łȂ�Ƃ�������ׂ邱�Ƃ��ł���
256-bit vmulps��vaddps�ɑ��A128-bit��vmaddps�~2���邢��256-bit�Ł~1��
���荇�����Ƃ��ł��邩��B
> 1\�P�ʂ̐��\�������̂�AMD
����ւ邱�Ƃ���Ȃ����ǂȁB
�����R�X�g���Ⴂ�Ȃ�܂������A��������Ȃ����B
���l���������̌���͒P�Ɏs�ꋣ���͂��Ȃ������B
���������ATurboBoost�I�ȉ����̓��ڂ͔��\�Ȃ������̂��ȁH
�p�C�v�����Ă�̂ɗ����Ȃ��͂����Ȃ�����
Hyper-Threading������On�ɂ���V���O���X���b�h�̐��\�͗�������
�܂��p�b�ƌ�
�f�R�[�_�[������������Ɠ]�������ȃA�[�L���ȁB
�t�����g�G���h�̋��L�����Č��\�o�N�`�Ȃ悤�ȋC������B
�f�R�[�_�[������������Ɠ]�������ȃA�[�L���ȁB
�t�����g�G���h�̋��L�����Č��\�o�N�`�Ȃ悤�ȋC������B
>>602
APM Boost�Ƃ����ގ��Z�p�͓��ڂ����͗l
>>604
HyperThreading�Ɣ�ׂ�ƃX���b�h�̋����N���Ȃ�����
���̕��L���ɂȂ�Ȃ��̂��ȁH�P���ɃV���O���X���b�h������
������Ƃ����v�Z�����ȋC�����邯��ǂ�
APM Boost�Ƃ����ގ��Z�p�͓��ڂ����͗l
>>604
HyperThreading�Ɣ�ׂ�ƃX���b�h�̋����N���Ȃ�����
���̕��L���ɂȂ�Ȃ��̂��ȁH�P���ɃV���O���X���b�h������
������Ƃ����v�Z�����ȋC�����邯��ǂ�
HyperThreading�Ɣ�r����Ӗ����킩���B
>>585
�܂����f�R�[�_�[��1�Ƃ��l���Ă�́H
>>597
�V���O���X���b�h���\�������邩�炵���l���悤����������
Atom���}���`�R�A�ɂ�����Nehalem�Ȃ�ėv��Ȃ�(��)�B�����H
�܂����f�R�[�_�[��1�Ƃ��l���Ă�́H
>>597
�V���O���X���b�h���\�������邩�炵���l���悤����������
Atom���}���`�R�A�ɂ�����Nehalem�Ȃ�ėv��Ȃ�(��)�B�����H
������]������
ttp://www.ne.jp/asahi/comp/tarusan/main147.htm
��x86�ł�LOAD�ASTORE�n�̖��߂��p�ɂɎg�p�����
���f�R�[�h�\�͂��\���������Ƃ��Ă�ALU�̏����\�͂őS�̂̔\�͂����܂�
�u��ʓI�Ȉˑ��W�̂��鐮�����Z�ł̖��ߓ������s�i���Ԃ�����̂ɕ���H�j�v�Ƃ��l�I�ɉ��Z�����ɂ͂悭��������邯��
�Ƃ肠����Bull�̃A�[�L�̓}���`�X���b�h�œ�����O�ȎI�ł̌����ɍ��킹���v�����Ă�Ȃ����Ǝv��
��x86�ł�LOAD�ASTORE�n�̖��߂��p�ɂɎg�p�����
���f�R�[�h�\�͂��\���������Ƃ��Ă�ALU�̏����\�͂őS�̂̔\�͂����܂�
�u��ʓI�Ȉˑ��W�̂��鐮�����Z�ł̖��ߓ������s�i���Ԃ�����̂ɕ���H�j�v�Ƃ��l�I�ɉ��Z�����ɂ͂悭��������邯��
�Ƃ肠����Bull�̃A�[�L�̓}���`�X���b�h�œ�����O�ȎI�ł̌����ɍ��킹���v�����Ă�Ȃ����Ǝv��
ttp://pc.watch.impress.co.jp/docs/2008/0523/kaigai441.htm
>�z�b�g�X�|�b�g�ł���f�R�[�_���ACPU�̓�����g���̎�����̐���ƂȂ�
�einteger core��2�̐������Z���s���j�b�g�������Ă��Ƃ��Ă��f�R�[�_��4���ߓ������s�ŁA���Ȃ蕡�G
���ꂩ��N���b�N��Nj�����Power6�I�v���Z�b�T�łȂ����Ƃ�������
�X���b�h���������߂�Ȃ�A���ꂱ��Bobcat����ׂ��ق����V���v���ȃR�A�ŃN���b�N�������ł��āA
(�����o�X�Ƃ��������ш�Ƃ��̖��������ł���Ȃ�)�`�b�v�P�ʂł̃p�t�H�[�}���X�������Ȃ�
�����@�I��IPC�����߂Ă���ƍl�����邯�ǁA
ttp://pc.watch.impress.co.jp/docs/2008/0428/kaigai438.htm
>Intel���A�������ȃv���t�B�b�N�X���Ȃ��g�m�[�}������(Normal Instruction)�h���A3����4���߂��f�R�[�h���邱�Ƃ�O��Ƃ��Ă���͂���
>����(�m�[�}������)�ȊO�̃P�[�X��(3�`4���߂̓����f�R�[�h��)�g�����悤�Ƃ���ƁA�f�R�[�_���ɒ[�ɕ��G�ɂȂ��Ă��܂����낤
�einteger core��3�ȏ�̐������Z���s���j�b�g�������Ă���A�f�R�[�_��6�ȏ㓯���ɖ��ߔ��s�ł��Ȃ��Ⴂ���Ȃ�
����͔��I
�Ƃ����>>531�́u������Ă��Ȃ����̗v�f�v��
�@�V���O���X���b�h���n�[�h�œ��I��2�X���b�h�ɐU�蕪����@�\
�A2��integer core���P�̃��\�[�X�Ƃ��Ĉ����@�\
�̂ǂ��炩������A�ƍl������B�ǂ����ɘ_���̔�邩�ȁH
>�z�b�g�X�|�b�g�ł���f�R�[�_���ACPU�̓�����g���̎�����̐���ƂȂ�
�einteger core��2�̐������Z���s���j�b�g�������Ă��Ƃ��Ă��f�R�[�_��4���ߓ������s�ŁA���Ȃ蕡�G
���ꂩ��N���b�N��Nj�����Power6�I�v���Z�b�T�łȂ����Ƃ�������
�X���b�h���������߂�Ȃ�A���ꂱ��Bobcat����ׂ��ق����V���v���ȃR�A�ŃN���b�N�������ł��āA
(�����o�X�Ƃ��������ш�Ƃ��̖��������ł���Ȃ�)�`�b�v�P�ʂł̃p�t�H�[�}���X�������Ȃ�
�����@�I��IPC�����߂Ă���ƍl�����邯�ǁA
ttp://pc.watch.impress.co.jp/docs/2008/0428/kaigai438.htm
>Intel���A�������ȃv���t�B�b�N�X���Ȃ��g�m�[�}������(Normal Instruction)�h���A3����4���߂��f�R�[�h���邱�Ƃ�O��Ƃ��Ă���͂���
>����(�m�[�}������)�ȊO�̃P�[�X��(3�`4���߂̓����f�R�[�h��)�g�����悤�Ƃ���ƁA�f�R�[�_���ɒ[�ɕ��G�ɂȂ��Ă��܂����낤
�einteger core��3�ȏ�̐������Z���s���j�b�g�������Ă���A�f�R�[�_��6�ȏ㓯���ɖ��ߔ��s�ł��Ȃ��Ⴂ���Ȃ�
����͔��I
�Ƃ����>>531�́u������Ă��Ȃ����̗v�f�v��
�@�V���O���X���b�h���n�[�h�œ��I��2�X���b�h�ɐU�蕪����@�\
�A2��integer core���P�̃��\�[�X�Ƃ��Ĉ����@�\
�̂ǂ��炩������A�ƍl������B�ǂ����ɘ_���̔�邩�ȁH
���������l�������ǁA
�R�A���ɑ��ăf�R�[�_�[��1/2�ɂȂ��ȁH
���̂Ԃ�M�e�ʕ�������N���b�N�A�b�v�ɂ܂킷�Ƃ��E�E�E�E�E�E�Ȃ��H
�Ȃ������ĂS�R�A�ȏ�̓\�t�g���Ή����ĂĂ��قƂ�ǔ�p�Ό��ʂ�邢���A
�N���b�N�A�b�v���������̂Ƃ���t���[�����`�I�ɐ��\����������B��̎�i�Ȃ���A
�R�A�������̂܂܂ɂ���1�X���b�h������ɗp�ӂ���Ă�����s���\�[�X�����炳�Ȃ���
�ꕔ���\�[�X���R�A�Ԃŋ��L�����Đߖ�cpu�S�̂ŔM�ʂ����ăN���b�N��������Ȃ�A
���肦�Ȃ��I�����ł͂Ȃ��Ǝv�����B
���̓N���X�^�[�h�A�[�L�e�N�`���̃I�[�o�w�b�h�ƁABulldozer�ȑO�Ɣ�ׂ��V���O���E�}���`�X���b�h�̎��s�����ŁA
���̗ǂ������ɂ��N���b�N�A�b�v���̐��\�������邩���ʂ��̂ǂ������ɂȂ��ȁB
���ƁA�L���b�V�����̂��ǂ��ɂ����Ȃ��Ɖi���̓�Ԏ�ɂ����܂����܂�
�R�A���ɑ��ăf�R�[�_�[��1/2�ɂȂ��ȁH
���̂Ԃ�M�e�ʕ�������N���b�N�A�b�v�ɂ܂킷�Ƃ��E�E�E�E�E�E�Ȃ��H
�Ȃ������ĂS�R�A�ȏ�̓\�t�g���Ή����ĂĂ��قƂ�ǔ�p�Ό��ʂ�邢���A
�N���b�N�A�b�v���������̂Ƃ���t���[�����`�I�ɐ��\����������B��̎�i�Ȃ���A
�R�A�������̂܂܂ɂ���1�X���b�h������ɗp�ӂ���Ă�����s���\�[�X�����炳�Ȃ���
�ꕔ���\�[�X���R�A�Ԃŋ��L�����Đߖ�cpu�S�̂ŔM�ʂ����ăN���b�N��������Ȃ�A
���肦�Ȃ��I�����ł͂Ȃ��Ǝv�����B
���̓N���X�^�[�h�A�[�L�e�N�`���̃I�[�o�w�b�h�ƁABulldozer�ȑO�Ɣ�ׂ��V���O���E�}���`�X���b�h�̎��s�����ŁA
���̗ǂ������ɂ��N���b�N�A�b�v���̐��\�������邩���ʂ��̂ǂ������ɂȂ��ȁB
���ƁA�L���b�V�����̂��ǂ��ɂ����Ȃ��Ɖi���̓�Ԏ�ɂ����܂����܂�
>>612
2011�N�܂ő҂�������炻�̂ǂ��炩�ʂ̂��Ƃ͂���ė~������
2011�N�܂ő҂�������炻�̂ǂ��炩�ʂ̂��Ƃ͂���ė~������
HT����5�N�キ�炢�ɂ��̐������Z�@�\��CPU���o�Ă�����Ȃ��E�E�E
>>611
>�f�R�[�h�\�͂��\���������Ƃ��Ă�ALU�̏����\�͂őS�̂̔\�͂����܂�
����f�R�[�_�[�ƃo�b�N�G���h���P�P�̏ꍇ�̘b�ȁB
�撣���ăf�R�[�_�[�����ߑ��荞��ł�
���s���j�b�g����Ȃ���Ӗ���������Ęb�B
Bulldozer�͊�{1�Q������o�b�N�G���h�͑���Ă��B
������t��
ALU�̏����\�͂��\���������Ƃ��ăf�R�[�h�\�͂őS�̂̔\�͂����܂� �B
Bulldozer�̏ꍇ�́B
>�f�R�[�h�\�͂��\���������Ƃ��Ă�ALU�̏����\�͂őS�̂̔\�͂����܂�
����f�R�[�_�[�ƃo�b�N�G���h���P�P�̏ꍇ�̘b�ȁB
�撣���ăf�R�[�_�[�����ߑ��荞��ł�
���s���j�b�g����Ȃ���Ӗ���������Ęb�B
Bulldozer�͊�{1�Q������o�b�N�G���h�͑���Ă��B
������t��
ALU�̏����\�͂��\���������Ƃ��ăf�R�[�h�\�͂őS�̂̔\�͂����܂� �B
Bulldozer�̏ꍇ�́B
>>612��
���einteger core��3�ȏ�̐������Z���s���j�b�g�������Ă���A
���f�R�[�_��6�ȏ㓯���ɖ��ߔ��s�ł��Ȃ��Ⴂ���Ȃ�
������InegerCore�̉��Z�킪�S���������̂Ȃ�đz�肵�ĂȂ���Ȃ��́H
��������\�z���Ă���T�C�g�݂����ɁA
�f�R�[�_�[��4���ߔ��s�ŁA�f�R�[�h��̃�ops���L���b�V�����čė��p���邱�Ƃɂ���āA
�f�R�[�_�[�̕��S�����炷��Ȃ����낤���B
���einteger core��3�ȏ�̐������Z���s���j�b�g�������Ă���A
���f�R�[�_��6�ȏ㓯���ɖ��ߔ��s�ł��Ȃ��Ⴂ���Ȃ�
������InegerCore�̉��Z�킪�S���������̂Ȃ�đz�肵�ĂȂ���Ȃ��́H
��������\�z���Ă���T�C�g�݂����ɁA
�f�R�[�_�[��4���ߔ��s�ŁA�f�R�[�h��̃�ops���L���b�V�����čė��p���邱�Ƃɂ���āA
�f�R�[�_�[�̕��S�����炷��Ȃ����낤���B
���낻��f�R�[�h�Ȃ��Ȃ��ŁA�R���p�C�����Ă�����s�������������ˁH
RISC����ł������ɂ���͂Ȃ�
ttp://pc.watch.impress.co.jp/img/pcw/docs/328/392/html/kaigai6.jpg.html
���̐}��int�̃X�P�W���[������FP�̃X�P�W���[���ɖ��Ă邯��
int�̃X�P�W���[�����m�ł��Ƃ�͏o���Ȃ��낤��
�o�����Ȃ�u���������v���Ƃ�����Ȃ��Ƃ������ꍇ�ɕ��ω��o���Ă����Ƃ�����
L1�f�[�^�L���b�V����1�R�A��2���ꂽ�\�����Ă��ƂɂȂ�Ƃ�����
{kind=link}
���̐}��int�̃X�P�W���[������FP�̃X�P�W���[���ɖ��Ă邯��
int�̃X�P�W���[�����m�ł��Ƃ�͏o���Ȃ��낤��
�o�����Ȃ�u���������v���Ƃ�����Ȃ��Ƃ������ꍇ�ɕ��ω��o���Ă����Ƃ�����
L1�f�[�^�L���b�V����1�R�A��2���ꂽ�\�����Ă��ƂɂȂ�Ƃ�����
>>617
�ł��������K8�EK10�́u�Œᑬ�𑬂�����v�A�v���[�`�Ƃ͐^�t����ˁB
�Ώۂȃf�R�[�_�EALU�EAGU�~3�Ń��[�X�g�P�[�X�ɔ�����悤�ȁB
�f�R�[�_�͑Ώ�4way��integer core��2�{2�ɂȂ���Ċ����̕����AAMD�炵���C������
�ł��������K8�EK10�́u�Œᑬ�𑬂�����v�A�v���[�`�Ƃ͐^�t����ˁB
�Ώۂȃf�R�[�_�EALU�EAGU�~3�Ń��[�X�g�P�[�X�ɔ�����悤�ȁB
�f�R�[�_�͑Ώ�4way��integer core��2�{2�ɂȂ���Ċ����̕����AAMD�炵���C������
> �Ώۂȃf�R�[�_�EALU�EAGU�~3�Ń��[�X�g�P�[�X�ɔ�����悤�ȁB
�����܂ōl�����v����Ȃ��B
����͂����P���ɃX�P�W���[���̎������y������B
�ǂ��ɓ˂�����ł�ALU�̋@�\���ψꂾ����X�P�W���[�����T�{���B
LSU��2�{�����Ȃ��̂�AGU��3�����Ă����_���\��Ӗ��Ȃ��B
�����܂ōl�����v����Ȃ��B
����͂����P���ɃX�P�W���[���̎������y������B
�ǂ��ɓ˂�����ł�ALU�̋@�\���ψꂾ����X�P�W���[�����T�{���B
LSU��2�{�����Ȃ��̂�AGU��3�����Ă����_���\��Ӗ��Ȃ��B
�f�R�[�_1�ƌ����Ă����g�͂ق�2����
FP scheduler�ɑ��镔���ŏ�L+�œK�����Ă��邾������ˁB
fetch���ɂ����1:1��2:0�ɕς�邭�炢�ŁB
FP scheduler�ɑ��镔���ŏ�L+�œK�����Ă��邾������ˁB
fetch���ɂ����1:1��2:0�ɕς�邭�炢�ŁB
�匴����̃��|����
AMD�����[�h�}�b�v���J - 2011�N��Fusion�����ABulldozer/Bobcat�R�A�̊T�v��
http://journal.mycom.co.jp/articles/2009/11/13/amd/index.html
3�y�[�W��
��Photo13: �����ł�128bit FMAC��2�Ƃ���Ă��邪�A���ۂɂ͂����������G�ȍ\���ɂȂ�Ǝv����B
�����炭x86��FPU���߂���������͕̂Е��݂̂ŁA�����Е���SSE3��AVX�Ȃǂ�128/256bit���Z�݂̂�
���������Ă���̂ł͂Ȃ����Ǝv����B����ƁA����Integer��4Pipeline�ɂȂ����̂͒��ڂɒl����B
�����炭ALU+AGU�̃Z�b�g��4�g�A�Ƃ����\���ł��낤�B
���̕ӂ͏���Ȃ����Ƃ������Č������������悤�ł���
AMD�����[�h�}�b�v���J - 2011�N��Fusion�����ABulldozer/Bobcat�R�A�̊T�v��
http://journal.mycom.co.jp/articles/2009/11/13/amd/index.html
3�y�[�W��
��Photo13: �����ł�128bit FMAC��2�Ƃ���Ă��邪�A���ۂɂ͂����������G�ȍ\���ɂȂ�Ǝv����B
�����炭x86��FPU���߂���������͕̂Е��݂̂ŁA�����Е���SSE3��AVX�Ȃǂ�128/256bit���Z�݂̂�
���������Ă���̂ł͂Ȃ����Ǝv����B����ƁA����Integer��4Pipeline�ɂȂ����̂͒��ڂɒl����B
�����炭ALU+AGU�̃Z�b�g��4�g�A�Ƃ����\���ł��낤�B
���̕ӂ͏���Ȃ����Ƃ������Č������������悤�ł���
���v4�g���ƃ��\�[�X50%�X���[�v�b�g80%�������Ȃ��ˁH
627 �F,,�E�L�́M�E,,�j��-�������F2009/11/13(��) 21:36:57 ID:TwafIZZ/
>>626
���N�̍����ASPECint��Nehalem 4�R�A(8�X���b�h)��Shanghai��2�\�P�b�g���X���[�v�b�g�������Ȃ��
�ǂ�����MAC�I�^�����삵�Ă�����
���O�œK������̒�^�I�ȃx���`�ł��炻���Ȃ���
�v�����HPC����Ȃ���ʓI�ȃT�[�o�̃��[�N���[�h�ɂ�����Opteron�͕���2IPC�͊m���ɉ�����Ă�킯����ȁB
�Ȃ�A2�X���b�h���v4IPC�ɂȂ�Ȃ�A80�p�[�Z���g�͒B���o�����Ȃ��́H
�܂�����̓f�R�[�_��4Way�ŏ\���ȍ����ɂ͂Ȃ邪
ALU��AGU��ʃp�C�v���C���ɂ���1�X���b�h�Ő��\���o�邩�ǂ����͕ʂ����
���N�̍����ASPECint��Nehalem 4�R�A(8�X���b�h)��Shanghai��2�\�P�b�g���X���[�v�b�g�������Ȃ��
�ǂ�����MAC�I�^�����삵�Ă�����
���O�œK������̒�^�I�ȃx���`�ł��炻���Ȃ���
�v�����HPC����Ȃ���ʓI�ȃT�[�o�̃��[�N���[�h�ɂ�����Opteron�͕���2IPC�͊m���ɉ�����Ă�킯����ȁB
�Ȃ�A2�X���b�h���v4IPC�ɂȂ�Ȃ�A80�p�[�Z���g�͒B���o�����Ȃ��́H
�܂�����̓f�R�[�_��4Way�ŏ\���ȍ����ɂ͂Ȃ邪
ALU��AGU��ʃp�C�v���C���ɂ���1�X���b�h�Ő��\���o�邩�ǂ����͕ʂ����
���A�C����������
�Q�R�A���P���W���[���ɂ��邱�ƂŃ��\�[�X��1/4�ߖ�(�t�Ɍ����P�R�A����P���W���[���ɃA�b�v�O���[�h����̂ɂP�R�A����50%�̒lj����\�[�X���K�v)�A
����ɂƂ��Ȃ����\�ቺ��2�R�A���v��1/10�ɂ����߂܂����i�t�Ɍ�����2�R�A����ɂ��邱�Ƃ�80%�̐��\���オ�����߂܂��j
���Ď��Ȃ�ˁH
HTT�Ɣ�r����Ƃ��������ɓI�Ȉʒu�W�ɂȂ��Ă�˂���
�Q�R�A���P���W���[���ɂ��邱�ƂŃ��\�[�X��1/4�ߖ�(�t�Ɍ����P�R�A����P���W���[���ɃA�b�v�O���[�h����̂ɂP�R�A����50%�̒lj����\�[�X���K�v)�A
����ɂƂ��Ȃ����\�ቺ��2�R�A���v��1/10�ɂ����߂܂����i�t�Ɍ�����2�R�A����ɂ��邱�Ƃ�80%�̐��\���オ�����߂܂��j
���Ď��Ȃ�ˁH
HTT�Ɣ�r����Ƃ��������ɓI�Ȉʒu�W�ɂȂ��Ă�˂���
���W�X�^�����ꂼ���ALU�̋߂��Ɋ��S�ɕ��U���Ď��Ă邩��
HT�Ƃ͈Ⴄ��łȂ��B
HT�Ƃ͈Ⴄ��łȂ��B
>>617
>������InegerCore�̉��Z�킪
>�S���������̂Ȃ�đz�肵�ĂȂ���Ȃ��́H
�����v���B
���ۂɂ͕Б��S�S���V��ł�������邾�낤�ȁB
>������InegerCore�̉��Z�킪
>�S���������̂Ȃ�đz�肵�ĂȂ���Ȃ��́H
�����v���B
���ۂɂ͕Б��S�S���V��ł�������邾�낤�ȁB
�悭�킩��AC2D���ۂ���C���G���W���ɂȂ�̂��B
�f�X�N�g�b�v������4�R�A8�X���b�h�Ȃ̂��ȁH
�f�X�N�g�b�v������4�R�A8�X���b�h�Ȃ̂��ȁH
�L���҂̕��X�ɂ��q�˂������B
������\���ꂽ���e��
�`�D Bulldozer���|�V����\��
�a�D Bobcat���|�V����\��
�b�D Fusion/APU���|�V����\��
����̓I�����Ŏ����Ă��������܂����B
������\���ꂽ���e��
�`�D Bulldozer���|�V����\��
�a�D Bobcat���|�V����\��
�b�D Fusion/APU���|�V����\��
����̓I�����Ŏ����Ă��������܂����B
�܂��u�|�V�����v�̒�`�������Ă���
A 12�l
B 24�l
C 38�l
B 24�l
C 38�l
Q�FBulldozer���|�V����\��
A�F0
Q�FBobcat���|�V����\��
A�F0
Q�FFusion/APU���|�V����\��
A�F0
Q�F���ꂼ�ꂪ�x���\��
A�F�Ⴍ�Ȃ�
A�F0
Q�FBobcat���|�V����\��
A�F0
Q�FFusion/APU���|�V����\��
A�F0
Q�F���ꂼ�ꂪ�x���\��
A�F�Ⴍ�Ȃ�
�Ȃ��Ȍ������̂��������ł݂�
�ʂɍ��邱�Ƃł��Ȃ����낤��
A,�킩���
B,�킩���
C,�킩���
���ꂽ���g�[�V���[�̈ӌ��������Ă��Ӗ������Ǝv����
�ʂɍ��邱�Ƃł��Ȃ����낤��
A,�킩���
B,�킩���
C,�킩���
���ꂽ���g�[�V���[�̈ӌ��������Ă��Ӗ������Ǝv����
>>633
���~�A�������̓f�U�C���ύX
���~�A�������̓f�U�C���ύX
�����璆�~���ύX���Ȃ�����B
����AMD���|�Y���Ă�IBM�������p����ˁH
����AMD���|�Y���Ă�IBM�������p����ˁH
639 �F,,�@�L�́M�@,,�j��-�������F2009/11/13(��) 23:24:28 ID:TwafIZZ/
>>633
�e�����Ȃ�
�e�����Ȃ�
A. ����܂����]�Ȑ܂����ăA�[�L�e�N�`���[���J������A���~�E�f�U�C���ύX�̉\���͒Ⴂ�Ǝv���B
B. �_�C�ʐ^�̌��J���Ă邵�A���~�E�f�U�C���ύX�̉\���͒Ⴂ�Ǝv���B
C.���~�E�f�[�C���ύX�̉\���� ���قǒႭ�Ȃ��Ǝv���B
�v�����قǐ��\���o�Ȃ��Ƃ��A�������x���Ƃ��A�v���Z�X�̕����܂肪���サ�Ȃ��Ƃ��͂��肪�������B
B. �_�C�ʐ^�̌��J���Ă邵�A���~�E�f�U�C���ύX�̉\���͒Ⴂ�Ǝv���B
C.���~�E�f�[�C���ύX�̉\���� ���قǒႭ�Ȃ��Ǝv���B
�v�����قǐ��\���o�Ȃ��Ƃ��A�������x���Ƃ��A�v���Z�X�̕����܂肪���サ�Ȃ��Ƃ��͂��肪�������B
���҂̊F�l
�M�d�Ȃ��ӌ����肪�Ƃ��������܂���<�i�Q�j>
�M�d�Ȃ��ӌ����肪�Ƃ��������܂���<�i�Q�j>
���҂���Ȃ����A�������܂Ŏ��Ԃƃ��\�[�X�������ĊJ�����Ă����̂�����
�u���h�[�U�[���s�������Ȃ��Ƃ�����AMD�����̑O�ɒׂꂽ�ꍇ�������낤�ȁB
�u���h�[�U�[���s�������Ȃ��Ƃ�����AMD�����̑O�ɒׂꂽ�ꍇ�������낤�ȁB
�������Z���j�b�g��4�p�C�vx1�g����Ȃ���
2�p�C�vx2�g�ɂ��郁���b�g���đ傫���̂��ȁH
����d�͂̒ቺ�ɂ͊�^������������
���\�ʂł̍v�������҂ł���̂��ǂ���
���ɃV���O���X���b�h�d���̗p�r�Ɍ����
�s���ɂȂ肻���Ɏv���邯�ǂ����ł��Ȃ��̂���
2�p�C�vx2�g�ɂ��郁���b�g���đ傫���̂��ȁH
����d�͂̒ቺ�ɂ͊�^������������
���\�ʂł̍v�������҂ł���̂��ǂ���
���ɃV���O���X���b�h�d���̗p�r�Ɍ����
�s���ɂȂ肻���Ɏv���邯�ǂ����ł��Ȃ��̂���
644 �F,,�E�L�́M�E,,�j��-�������F2009/11/14(�y) 00:36:50 ID:8rfW0ww8
3�p�C�v�{�X�g�A�̗\��
645 �F,,�E�L�́M�E,,�j��-�������F2009/11/14(�y) 00:40:10 ID:8rfW0ww8
��������AMD�̎����ł�4�p�C�v������Ă�킯�Ȃ��
AGU��ALU�ƃy�A�ɂ���ׂ���LSU�Ƃ��ׂ����͋c�_�̗]�n�͂��邪
Fused ��OPs�`�������߂�Ƃ��Ԃ����Ⴏ��������B
�f�R�[�_�̃h���C������������B
�܁A256�r�b�g AVX��2�h���C���Ȃ�ł��������ʂł͕s���m���
AGU��ALU�ƃy�A�ɂ���ׂ���LSU�Ƃ��ׂ����͋c�_�̗]�n�͂��邪
Fused ��OPs�`�������߂�Ƃ��Ԃ����Ⴏ��������B
�f�R�[�_�̃h���C������������B
�܁A256�r�b�g AVX��2�h���C���Ȃ�ł��������ʂł͕s���m���
���\�\�����ƃR�A�̑����ɔ�ׂāAInteger���\�̑������������̂ŁA
�������Z���j�b�g�����������b�`�ɂȂ�Ƃ͎v���Ȃ��B
�uALU+AGU�̃Z�b�g��4�g�v�͂��肦�Ȃ��Ǝv���B
�������Z���j�b�g�����������b�`�ɂȂ�Ƃ͎v���Ȃ��B
�uALU+AGU�̃Z�b�g��4�g�v�͂��肦�Ȃ��Ǝv���B
>>644�ł���Ƃ������ꂽ
>������InegerCore�̉��Z�킪
>�S���������̂Ȃ�đz�肵�ĂȂ���Ȃ��́H
�������ł����C������B
4����/�T�C�N���̖��߂��einteger core�ɕK������2:2�ŐU�蕪������킯����Ȃ��B
���ꂱ��4:0����0:4�܂ŏɉ����ĕς��B
�X���b�h�������Ȃ��Ƃ��̃V���O���X���b�h���\�́AK10����f�R�[�_�̐��\���㕪�オ�邵
�X���b�h���������Ƃ��́AK10���̓V���O���X���b�h���\���Ⴂ�R�A�~2�Ƃ��Ĉ�����B
���Ă��Ƃł����H
>������InegerCore�̉��Z�킪
>�S���������̂Ȃ�đz�肵�ĂȂ���Ȃ��́H
�������ł����C������B
4����/�T�C�N���̖��߂��einteger core�ɕK������2:2�ŐU�蕪������킯����Ȃ��B
���ꂱ��4:0����0:4�܂ŏɉ����ĕς��B
�X���b�h�������Ȃ��Ƃ��̃V���O���X���b�h���\�́AK10����f�R�[�_�̐��\���㕪�オ�邵
�X���b�h���������Ƃ��́AK10���̓V���O���X���b�h���\���Ⴂ�R�A�~2�Ƃ��Ĉ�����B
���Ă��Ƃł����H
http://journal.mycom.co.jp/articles/2009/11/13/amd/002.html
Photo11: 128-bit FMAC
Photo12: 128-bit FAMC
Photo13: 128-bit FAMC
Photo11: 128-bit FMAC
Photo12: 128-bit FAMC
Photo13: 128-bit FAMC
649 �F,,�E�L�́M�E,,�j��-�������F2009/11/14(�y) 10:54:57 ID:8rfW0ww8
iMac�A����Ȃ���IMAC�@�\��2��FMAC���j�b�g�����Ŏg����C�������
IMAC���L���Ɏg����P�[�X�ł�SIMD�����Z�p���Z�̃X���[�v�b�g�͍ő�2�{���Ă��ƂɂȂ���
PMUL* �� PADD* ��A�����Ďg�������ꍇ�ɗL������
�܁A�����ŐϘa�g���Ă����������P�[�X���Ȃ����ǂ�
IMAC���L���Ɏg����P�[�X�ł�SIMD�����Z�p���Z�̃X���[�v�b�g�͍ő�2�{���Ă��ƂɂȂ���
PMUL* �� PADD* ��A�����Ďg�������ꍇ�ɗL������
�܁A�����ŐϘa�g���Ă����������P�[�X���Ȃ����ǂ�
�摜���������A�Q�R�A�W�����Q�����������S�̂łP�R�A�Ȃ̂��A
���ꂪ�S�R�A�Ƃ������W�J�����̂��悭�킩��Ȃ��ȁB
L3�܂ŏ����Ă�����Ă��Ƃ́A���ꂪCPU�S�̂̏����\���ɂȂ�
�悤�ɓǂ߂���B
���ꂪ�S�R�A�Ƃ������W�J�����̂��悭�킩��Ȃ��ȁB
L3�܂ŏ����Ă�����Ă��Ƃ́A���ꂪCPU�S�̂̏����\���ɂȂ�
�悤�ɓǂ߂���B
651 �F,,�E�L�́M�E,,�j��-�������F2009/11/14(�y) 14:48:08 ID:8rfW0ww8
�R�A�̍l�������B���ɂȂ��
652 �FSocket774�F2009/11/14(�y) 15:03:08 ID:M3LDRNq8
�I���N���̃��C�Z���X�ŝ��߂�������w
�ے�I�Ȃ��Ƃ������AFPU�̃R�A�ԋ��L�̓g�����W�X�^�𑝂₳����
�������̃R�A���𑝂₷(�������Z��D�悷��)�ߓn���̃A�v���[�`�B
�����ŗ]�T���o���鎟�̐���ł�1:1�Ŏ��悤�ɂȂ�͂��BNiagara�Ƃ�����ƁB
�X���b�h�����˂�s�[�N�͂����̂ŁA2�R�A�Ƃ��킸4�R�A�E8�R�A���W��
���\�[�X��z���ł���Η��z�I�����A�����ȃ`�b�v�͂��������ӂ��ɍ��Ȃ��悤���B
���ƁA�}���`�R�A�S���Ɏ��������R�̈���u��������1�R�A�����Ƃ̓R�s�y�ł�k�v
�Ƃ����_�ł���A��Ԃ�������2�R�A��Z��������̂��A1�R�A������
�������p�Ό��ʂł݂ėL���Ȃ̂��ǂ����͂܂��킩��Ȃ��B
�������̃R�A���𑝂₷(�������Z��D�悷��)�ߓn���̃A�v���[�`�B
�����ŗ]�T���o���鎟�̐���ł�1:1�Ŏ��悤�ɂȂ�͂��BNiagara�Ƃ�����ƁB
�X���b�h�����˂�s�[�N�͂����̂ŁA2�R�A�Ƃ��킸4�R�A�E8�R�A���W��
���\�[�X��z���ł���Η��z�I�����A�����ȃ`�b�v�͂��������ӂ��ɍ��Ȃ��悤���B
���ƁA�}���`�R�A�S���Ɏ��������R�̈���u��������1�R�A�����Ƃ̓R�s�y�ł�k�v
�Ƃ����_�ł���A��Ԃ�������2�R�A��Z��������̂��A1�R�A������
�������p�Ό��ʂł݂ėL���Ȃ̂��ǂ����͂܂��킩��Ȃ��B
�m��I�Ɍ����AIntel�̌�ǂ��ł͂Ȃ����Ƃm�ɃA�s�[���o�����̂�
�؋������ăA���u�̓����Ƃ̂��@�����f��Ȃ�������Ȃ�AMD�ɂƂ���
�傫�ȈӋ`������A���ȁB
Atom�R�Ƃ����ʒu�t��������Bobcat���AAtom�Ƃ͈Ⴄ���t�����l�H���������B
Intel��Atom�ŗ��v���グ�Ă��邱�Ƃ��l����AAtom�N���[����
����Ă��悳�����Ȃ��̂���(�h���i�����₷���̂����̃Z�O�����g���낤)�A
���i�������Ă������ڂ͂Ȃ��Ƃ����^�����Ȕ��f���������̂��낤���B
�؋������ăA���u�̓����Ƃ̂��@�����f��Ȃ�������Ȃ�AMD�ɂƂ���
�傫�ȈӋ`������A���ȁB
Atom�R�Ƃ����ʒu�t��������Bobcat���AAtom�Ƃ͈Ⴄ���t�����l�H���������B
Intel��Atom�ŗ��v���グ�Ă��邱�Ƃ��l����AAtom�N���[����
����Ă��悳�����Ȃ��̂���(�h���i�����₷���̂����̃Z�O�����g���낤)�A
���i�������Ă������ڂ͂Ȃ��Ƃ����^�����Ȕ��f���������̂��낤���B
655 �F,,�E�L�́M�E,,�j��-�������F2009/11/14(�y) 15:53:47 ID:8rfW0ww8
Llano��Sandy Bridge�̃R�A�T�C�Y����Ɗ���Sandy Bridge��1�R�A��Llano��1.5�{���炢
GPU�����͂قړ��T�C�Y�Ȃ�
GPU�����͂قړ��T�C�Y�Ȃ�
>>653
�قړ����_�C�T�C�Y�Ȃ̂ɐ������Z�̃X���[�v�b�g��2�{�ȏ�̍������邩���
ttp://www.spec.org/cpu2006/results/res2008q4/cpu2006-20081024-05712.html
ttp://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090608-07756.html
Niagara��CoolThreads�I�ȁA�ʐς�����̐��\�Ƀt�H�[�J�X����͎̂��R
�قړ����_�C�T�C�Y�Ȃ̂ɐ������Z�̃X���[�v�b�g��2�{�ȏ�̍������邩���
ttp://www.spec.org/cpu2006/results/res2008q4/cpu2006-20081024-05712.html
ttp://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090608-07756.html
Niagara��CoolThreads�I�ȁA�ʐς�����̐��\�Ƀt�H�[�J�X����͎̂��R
���邳��̗\�z��������
������|��
660 �F,,�E�L�́M�E,,�j��-�������F2009/11/14(�y) 16:18:47 ID:8rfW0ww8
�܂����ɂ���t�����g�G���h��FPU�����p����ȏ�A
HT�Ɠ��l�Ƀ^�X�N�̐U�蕪�����Ő��\���ς��Ȃ�Ă��Ƃ�����킯��
OS���̑Ή�����ς�
HT�Ɠ��l�Ƀ^�X�N�̐U�蕪�����Ő��\���ς��Ȃ�Ă��Ƃ�����킯��
OS���̑Ή�����ς�
SMT������ăX���[�v�b�g��������������Ɩʔ�����������
�����Ɣ���Ȃ�����
�����Ɣ���Ȃ�����
����4pipe���Ɨ��X���b�h�Ƃ��Ă���������
1�R�A��4*2=8�X���b�h�A4�R�A�Ȃ�32�X���b�h�œ����Ƃ�
�G���R������͊�Ԃ����ȁ[
1�R�A��4*2=8�X���b�h�A4�R�A�Ȃ�32�X���b�h�œ����Ƃ�
�G���R������͊�Ԃ����ȁ[
663 �F,,�E�L�́M�E,,�j��-�������F2009/11/14(�y) 16:40:34 ID:8rfW0ww8
����������SMT���Ȃ��Ȃ�Ĉꌾ�������ĂȂ����
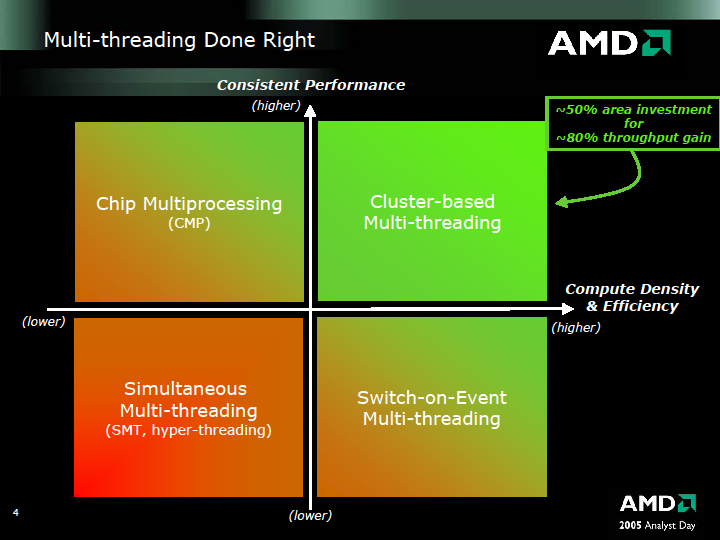{kind=link}
���O��1���W���[�����ŕ��������Č����ĂȂ���������
�������j�b�g2�ς�ł�̂����ꂾ�Ǝv��������
�������j�b�g2�ς�ł�̂����ꂾ�Ǝv��������
Bulldozer���W���[������4�X���b�h�����点����FPU�p���N�����Ⴄ��
�Ƃ����FPU����L2�ɂ����q�����ĂȂ��́H
������L1D�Ɍq�����Ă���ď��������Ă�l�����邯��
�Ƃ����FPU����L2�ɂ����q�����ĂȂ��́H
������L1D�Ɍq�����Ă���ď��������Ă�l�����邯��
667 �F,,�E�L�́M�E,,�j��-�������F2009/11/14(�y) 17:23:26 ID:8rfW0ww8
��������Load���j�b�g�œǂ�œ����f�[�^�o�X�ŋ����ł���B���܂łƓ������ƁB
668 �F,,�E�L�́M�E,,�j��-�������F2009/11/14(�y) 17:32:41 ID:8rfW0ww8
���Ƃ���
addps xmm0, [rax]
���Č������߂͐����p�C�v�ƕ��������p�C�v�̗����ɃI�y���[�V���������s�����B
��������AGU���g���ăA�h���X���Z�o�A�i�[��̂P�Q�W�r�b�g�f�[�^��ǂ��
FPU�̃V���h�E���W�X�^�Ɋi�[�������������j�b�g�ł��̃f�[�^��xmm0�ɉ��Z
�݂����ȁB
Bulldozer�̏ꍇ�̓V���h�E���܂߂����W�X�^�Z�b�g���X���b�h���Ɏ����Ă��ꂼ���
�����R�A�ɐڑ���������B
addps xmm0, [rax]
���Č������߂͐����p�C�v�ƕ��������p�C�v�̗����ɃI�y���[�V���������s�����B
��������AGU���g���ăA�h���X���Z�o�A�i�[��̂P�Q�W�r�b�g�f�[�^��ǂ��
FPU�̃V���h�E���W�X�^�Ɋi�[�������������j�b�g�ł��̃f�[�^��xmm0�ɉ��Z
�݂����ȁB
Bulldozer�̏ꍇ�̓V���h�E���܂߂����W�X�^�Z�b�g���X���b�h���Ɏ����Ă��ꂼ���
�����R�A�ɐڑ���������B
�����߂�
�}�N��Fusion��x86�̎��s��������ɂ��Ȃ���ʓI�݂������ȁB
AMD��RISC�ϊ��͂��Ă邯�ǁA�C���e���̓����Z�p�Ɠ����悤��
��@�͂Ƃ�Ȃ��Ǝv�����AAMD�̍������Ɍ������A�v���[�`��
���̓����҂��Ă������ȋC������B
AMD��RISC�ϊ��͂��Ă邯�ǁA�C���e���̓����Z�p�Ɠ����悤��
��@�͂Ƃ�Ȃ��Ǝv�����AAMD�̍������Ɍ������A�v���[�`��
���̓����҂��Ă������ȋC������B
>>670
�O�������Ă邼�H�������Ă��
�O�������Ă邼�H�������Ă��
AMD���g���Ȃ��C���e���̓����Z�p����x86�̂��Ƃł���
673 �F,,�E�L�́M�E,,�j��-�������F2009/11/14(�y) 20:39:26 ID:8rfW0ww8
���N�ʂ���Intel��������Larrabee�֘A�Ƃ�
>>672
���������Ă���́H
���������Ă���́H
4�̃p�C�v���C�����̂��낤���Ǔ䂪������
ALU+AGU�̃y�A��4�Ƃ����͓̂��������
���Ƃ����ăy�A��2���Ɛ��\�����Ă��܂����
���[��E�E�E
ALU+AGU�̃y�A��4�Ƃ����͓̂��������
���Ƃ����ăy�A��2���Ɛ��\�����Ă��܂����
���[��E�E�E
677 �F,,�E�L�́M�E,,�j��-�������F2009/11/15(��) 00:05:30 ID:GwkMRAwb
LSU�͐����R�A����128bit�~2��Ȃ̂��ȁH
2�X���b�h���v��64KB/clk�̃��[�h�ш�ɂȂ�Ȃ�ASandy Bridge�ɑ���D�ʐ��Ƃ��Ă͏\������
2�X���b�h���v��64KB/clk�̃��[�h�ш�ɂȂ�Ȃ�ASandy Bridge�ɑ���D�ʐ��Ƃ��Ă͏\������
678 �F,,�E�L�́M�E,,�j��-�������F2009/11/15(��) 00:11:44 ID:GwkMRAwb
64byte/clk orz
1�X���b�h�����蕽��2���ߔ��s������2�y�A�A����
+50%��1�R�A�����̏ȃX�y�[�X�����E���Ȃ���
���b�`�Ȃ킯���Ȃ�
+50%��1�R�A�����̏ȃX�y�[�X�����E���Ȃ���
���b�`�Ȃ킯���Ȃ�
�gBulldozer�h�̃T���v����2010�N�����ɓo�ꂷ��
http://northwood.blog60.fc2.com/blog-entry-3287.html
http://northwood.blog60.fc2.com/blog-entry-3287.html
683 �F,,�E�L�́M�E,,�j��-�������F2009/11/15(��) 02:28:55 ID:GwkMRAwb
������AGU�����iLoad or �X�g�A��p�j
684 �F,,�E�L�́M�E,,�j��-�������F2009/11/15(��) 02:46:15 ID:GwkMRAwb
http://www.chip-architect.com/news/K8L_floorplan.jpg
�������j�b�g���ăT�C�Y����ȂɐH���ĂȂ��ˁH
L2�L���b�V�����݂łȂ�1.5�{�͏\���\���Ǝv�����ǁB
{kind=link}
�������j�b�g���ăT�C�Y����ȂɐH���ĂȂ��ˁH
L2�L���b�V�����݂łȂ�1.5�{�͏\���\���Ǝv�����ǁB
����
�������Z���b�`�ɂ���]�T����Ȃ�t�F�b�`�E�f�R�[�h����������Ǝv�����ǁB
�v��Rock�Ɠ�����FPU�̂��L�B�V���͂Ȃ����m���B
2�X���b�h���̃��b�`�Ȑ������Z�p�C�v�ɏ[���Ȗ��߂s�ł���
�X�[�p�[���b�`�ȋ��L�^�t�F�b�`&�f�R�[�_��������~���N���߂���B
�v��Rock�Ɠ�����FPU�̂��L�B�V���͂Ȃ����m���B
2�X���b�h���̃��b�`�Ȑ������Z�p�C�v�ɏ[���Ȗ��߂s�ł���
�X�[�p�[���b�`�ȋ��L�^�t�F�b�`&�f�R�[�_��������~���N���߂���B
OS�̃X�P�W���[���̓X���b�h����256bitAVX�g�p�̗L���ɉ�����
�R�A�ւ̊��蓖�Ă�z�����Ȃ��Ⴂ���Ȃ��̂�����B
�o���Ȃ��͂Ȃ����낤���ǁA�ʓ|�����ˁB
�R�A�ւ̊��蓖�Ă�z�����Ȃ��Ⴂ���Ȃ��̂�����B
�o���Ȃ��͂Ȃ����낤���ǁA�ʓ|�����ˁB
1�X�P�W���[���ɂ�1�X���b�h�Ȃ́H
1�t�F�b�`���f�R�[�h�ɂ�1�X���b�h�Ȃ́H
��҂Ȃ�Bull�̓f�[�^L1�ƃX�P�W���[����2�ɂȂ���������
�u2�R�A��1���W���[���v�Ƃ�����܊W�����悤�ȋC������
1�t�F�b�`���f�R�[�h�ɂ�1�X���b�h�Ȃ́H
��҂Ȃ�Bull�̓f�[�^L1�ƃX�P�W���[����2�ɂȂ���������
�u2�R�A��1���W���[���v�Ƃ�����܊W�����悤�ȋC������
��[����Ɂu�������Z�̓C���e����苭���v�Ƃ���鎞�オ�܂�����Ă���̂��B
������4�p�C�v��
�uALUx2�A���[�hx1�A�X�g�Ax1�v���Ă��Ƃ͂Ȃ��̂��H
Bobcat��AGU�����Ă���Ȋ���������
�uALUx2�A���[�hx1�A�X�g�Ax1�v���Ă��Ƃ͂Ȃ��̂��H
Bobcat��AGU�����Ă���Ȋ���������
GPGPU�́u����܂�CPU�ł͏o���Ȃ��������Ɓv����邽�߂̂��̂�
����GPGPU�����y���Ă��ACPU�̕��������_���Z���v�͌�����
����GPGPU�����y���Ă��ACPU�̕��������_���Z���v�͌�����
693 �F,,�E�L�́M�E,,�j��-�������F2009/11/15(��) 12:48:47 ID:GwkMRAwb
>>689
�܂��A�������\����Ȃ��Ǝv�����ǂ˂��B�U�蕪�����I���Ȃ��ƌ��ǃ��j�b�g���V�ԁB
>>690
���[�h�Ɛ������Z������ƃ�OPs�̃h���C�����������邾��BMacro fusion�����߂�킯���Ȃ��B
���߂��Ƃ���Ńf�R�[�_�̃|�[�g�������ăX�P�W���[������ςɂȂ邩�A�X���[�v�b�g��������B
�܂�Bobcat�͊O��2�`3 issue�̓���4issue���낤���炻��ł�����B
>>691
�����炻���Sandy Bridge�̃X�y�b�N������܂ł̘b���낤�B
SSE5�i��FMA4�j���g�����Ƃŕ����������Z���\��2�{�ŁA
���N�ɓo�ꂵNehalem���Ԃ�������\�肾�����B
�܂��A�������\����Ȃ��Ǝv�����ǂ˂��B�U�蕪�����I���Ȃ��ƌ��ǃ��j�b�g���V�ԁB
>>690
���[�h�Ɛ������Z������ƃ�OPs�̃h���C�����������邾��BMacro fusion�����߂�킯���Ȃ��B
���߂��Ƃ���Ńf�R�[�_�̃|�[�g�������ăX�P�W���[������ςɂȂ邩�A�X���[�v�b�g��������B
�܂�Bobcat�͊O��2�`3 issue�̓���4issue���낤���炻��ł�����B
>>691
�����炻���Sandy Bridge�̃X�y�b�N������܂ł̘b���낤�B
SSE5�i��FMA4�j���g�����Ƃŕ����������Z���\��2�{�ŁA
���N�ɓo�ꂵNehalem���Ԃ�������\�肾�����B
>>692
�͂ł����H
�͂ł����H
695 �F,,�E�L�́M�E,,�j��-�������F2009/11/15(��) 13:06:09 ID:GwkMRAwb
Penryn��Nehalem���Ėw�ǃp�C�v���C���\��������HT�����������炢�Ȃ�
����Ő��\������̂͗v����ɂ��ꂾ���X�J�X�J���������Ă��ƂŁB
��̂�x86�݂����ȃ��W�X�^�{�������Ȃ��Ĉˑ��W�̑������߃Z�b�g����
�������Z���j�b�g���₵�����������\��������悤�Ȃ���Ȃ�����B
�����R�A�ɍX��2�X���b�h�����\���Ƃ��Ȃ炠�肾�낤���B
����Ő��\������̂͗v����ɂ��ꂾ���X�J�X�J���������Ă��ƂŁB
��̂�x86�݂����ȃ��W�X�^�{�������Ȃ��Ĉˑ��W�̑������߃Z�b�g����
�������Z���j�b�g���₵�����������\��������悤�Ȃ���Ȃ�����B
�����R�A�ɍX��2�X���b�h�����\���Ƃ��Ȃ炠�肾�낤���B
>>695
�͂ł����H
�͂ł����H
>>692
����A����I�Ɍ����Ă��ł����c�c�G���R��GPU�ł���̂͑傫���B
GPU���u�g����v�悤�ɂȂ��Ă����ȏ�A�Ƃ���AMD�݂����ȓ���GPU�������ꍇ�A
���Z�\�͂�CPU�P�̂ōl������A����GPU���݂ōl����������������ɂȂ��Ă����B
�����ăO���{�lj��ŃG���R�Ȃǂ̔\�̓A�b�v�ƁB
�@�@�@�@�@�@�@,.� , - �.�Q�@�@ �@ �A
.�@�@�@ �@ ,�/ l/�@�@�@ �@ �P�P�M�R!__
�@�@ �@ �/ |'�@{�@�@�@�@�@�@�@ �@ �@ �@ �M�R.�@�@�@�@�@�@�@�@�@�@�@ ,�
�@ �@ �m�� �R. `�@�@�@�@ �@ �@ �@ �@ �@ �@ �R�@�@ �@ �@ �@ /�R�@/�@ ��
�@�@ N.�R.�R�A�@ �@ �@ �@ �@ �@ ,�@�@�@ �@ �@ }�@�@�@�@l�_/�@�@`��
.�@�@�R�R.�_�@�@�@�@ �@ �@ ,.��ʁ@�@�@�@ �@ |�@�@ �Q|
�@�@ �S�j��@__�@_�@-=_�c�� u_�_�R�A �@ |�@�@�_
.�@�@ �@ �P�r=<�]�Ф�r;��=�;���_�U-=7�L�R�@�@�@>�@�܂�R�v���Z�b�T���݂̎��オ�߂��Ă�����I
.�@�@�@�@ �@ l �@ �P[h �M ��]�]'�@l�]''�L�q)'./�@��__
�@�@�@�@�@�@ �i�- �'__�@�R�..�Q__�m�@�@ �r�]'�@�@�@�@/
�@�@�@�@�@�@�@l�@�@ `�Q__,.�A �@ �@�@�@./���@�@�@�@/�Q
.�@�@�@�@�@ �@ �R.�@ }z�]r--|�@�@ �@ �^�@ �,�@�@�@ �@ �@ |�@ ,�A
����A����I�Ɍ����Ă��ł����c�c�G���R��GPU�ł���̂͑傫���B
GPU���u�g����v�悤�ɂȂ��Ă����ȏ�A�Ƃ���AMD�݂����ȓ���GPU�������ꍇ�A
���Z�\�͂�CPU�P�̂ōl������A����GPU���݂ōl����������������ɂȂ��Ă����B
�����ăO���{�lj��ŃG���R�Ȃǂ̔\�̓A�b�v�ƁB
�@�@�@�@�@�@�@,.� , - �.�Q�@�@ �@ �A
.�@�@�@ �@ ,�/ l/�@�@�@ �@ �P�P�M�R!__
�@�@ �@ �/ |'�@{�@�@�@�@�@�@�@ �@ �@ �@ �M�R.�@�@�@�@�@�@�@�@�@�@�@ ,�
�@ �@ �m�� �R. `�@�@�@�@ �@ �@ �@ �@ �@ �@ �R�@�@ �@ �@ �@ /�R�@/�@ ��
�@�@ N.�R.�R�A�@ �@ �@ �@ �@ �@ ,�@�@�@ �@ �@ }�@�@�@�@l�_/�@�@`��
.�@�@�R�R.�_�@�@�@�@ �@ �@ ,.��ʁ@�@�@�@ �@ |�@�@ �Q|
�@�@ �S�j��@__�@_�@-=_�c�� u_�_�R�A �@ |�@�@�_
.�@�@ �@ �P�r=<�]�Ф�r;��=�;���_�U-=7�L�R�@�@�@>�@�܂�R�v���Z�b�T���݂̎��オ�߂��Ă�����I
.�@�@�@�@ �@ l �@ �P[h �M ��]�]'�@l�]''�L�q)'./�@��__
�@�@�@�@�@�@ �i�- �'__�@�R�..�Q__�m�@�@ �r�]'�@�@�@�@/
�@�@�@�@�@�@�@l�@�@ `�Q__,.�A �@ �@�@�@./���@�@�@�@/�Q
.�@�@�@�@�@ �@ �R.�@ }z�]r--|�@�@ �@ �^�@ �,�@�@�@ �@ �@ |�@ ,�A
>692�͂܂�1�s�ڂɓ˂����ނׂ����Ǝv�����E�E�E
1�s�ڂ����̂܂܂Ȃ�2�s�ڂƂ̖����͖��������
�u����܂�CPU�ł͏o���Ȃ��������Ɓv����PC���Ō�����HDD���LAN���d�����̋@�\�̂ǂꂩ���ĂƂ�����
����Ȃ��Ƃ�GPGPU�ɏo�����ł���
�������E��GPU�́u���Z�Ȃ牽�ł������v��CPU�̋@�\����łł���
1�s�ڂ����̂܂܂Ȃ�2�s�ڂƂ̖����͖��������
�u����܂�CPU�ł͏o���Ȃ��������Ɓv����PC���Ō�����HDD���LAN���d�����̋@�\�̂ǂꂩ���ĂƂ�����
����Ȃ��Ƃ�GPGPU�ɏo�����ł���
�������E��GPU�́u���Z�Ȃ牽�ł������v��CPU�̋@�\����łł���
����Ƃ�����������
DOS/V�}�V����CPU��GPU��ʃp�[�c�ɕ������悤��
�u����H�����������Z�ƕ��������_�E�x�N�g�����Z������Ӗ������ˁH�v
�ƋC�t���Ă��܂����̂�����
�u����H�����������Z�ƕ��������_�E�x�N�g�����Z������Ӗ������ˁH�v
�ƋC�t���Ă��܂����̂�����
�݂�GPGPU�ɂ���ʊ��҂������������B
�c�q�͂����ƃv���p�K���_�撣��Ȃ��ƁB
GPGPU�̓o�Y�[�J�������V�������c�F�l�b�K�[�݂����Ȃ��B
���̗l�q����ς�����j��́B
�ł�����ς�}�V���K�����v���B
�c�q�͂����ƃv���p�K���_�撣��Ȃ��ƁB
GPGPU�̓o�Y�[�J�������V�������c�F�l�b�K�[�݂����Ȃ��B
���̗l�q����ς�����j��́B
�ł�����ς�}�V���K�����v���B
FPU��CPU�Ɏ�荞�܂ꂽ���A
GPU��CPU�ɐH����Ǝv�����E�E�E
GPU��CPU�ɐH����Ǝv�����E�E�E
703 �F,,�E�L�́M�E,,�j��-�������F2009/11/15(��) 14:48:52 ID:GwkMRAwb
>>701
���N�̃V���������̓{�f�B�[�r���_�[������A�E�^�[�}�b�X���͗��h����
�C���i�[�}�b�X���͑��ΓI�Ɏア�B
�e����ɕK�v�Ȃ̂͏u���͂��낤
���N�̃V���������̓{�f�B�[�r���_�[������A�E�^�[�}�b�X���͗��h����
�C���i�[�}�b�X���͑��ΓI�Ɏア�B
�e����ɕK�v�Ȃ̂͏u���͂��낤
�������������݁ACPU�ŕ��������_���Z�g����ʂ��Ă���́H
�E��Ŏg����t�@�C���̃G�N�Z�����炢����Ȃ��̂��B
���^�b�`��L���h����ł͂���GPU�ɂǂ�ǂ�ڍs���Ă邵
3D�`���Q�[���͑S��GPU�Ō��܂邵�A
�G���R������GPU�ɂǂ�ǂ�ڍs���Ă�B
CPU�̕��������_�����̂͂܂����\�����A����ێ����x�ɂ���Ƃ����̂�
�j�[�Y���炢���Ă����Ɍ����I�ȉ����Ǝv�����B
�~�����̂͂���ς萮�����Z�ł��傤�B
�E��Ŏg����t�@�C���̃G�N�Z�����炢����Ȃ��̂��B
���^�b�`��L���h����ł͂���GPU�ɂǂ�ǂ�ڍs���Ă邵
3D�`���Q�[���͑S��GPU�Ō��܂邵�A
�G���R������GPU�ɂǂ�ǂ�ڍs���Ă�B
CPU�̕��������_�����̂͂܂����\�����A����ێ����x�ɂ���Ƃ����̂�
�j�[�Y���炢���Ă����Ɍ����I�ȉ����Ǝv�����B
�~�����̂͂���ς萮�����Z�ł��傤�B
>>702
�T�N�ȏ��ɂ͂Ȃ�
�T�N�ȏ��ɂ͂Ȃ�
706 �F,,�E�L�́M�E,,�j��-�������F2009/11/15(��) 14:56:35 ID:GwkMRAwb
DTM�̓��C�e���V����������GPGPU�Ƃ�����
CPU���݂̃��C�e���V��GPU���g����APU�������I�ɖ]�܂��
CPU���݂̃��C�e���V��GPU���g����APU�������I�ɖ]�܂��
709 �F,,�E�L�́M�E,,�j��-�������F2009/11/15(��) 15:19:07 ID:GwkMRAwb
�Ă�GMA����Sandy Bridge�̑R�͓���K10.5��Llano����
Bulldozer�͎I�ƃG���X�[������
Bulldozer�͎I�ƃG���X�[������
����Ȃ�Fermi�ւ̊��ғx�������Ƃ͐����������B
Fermi�����?
Fermi�����?
711 �F,,�E�L�́M�E,,�j��-�������F2009/11/15(��) 15:24:06 ID:GwkMRAwb
Fermi��GPU�Ƃ��Ă͒P�̃J�[�h��GTX295�����邩����
GPU��������APU���ĂȂ�
���ʂɁA�T�E���h�J�[�h�̃`�b�v�Ƃ��R�[�f�b�N��
�S�ă\�t�g�E�F�A������CPU�Ɏ�荞�܂��A���������肶���B
���ʂɁA�T�E���h�J�[�h�̃`�b�v�Ƃ��R�[�f�b�N��
�S�ă\�t�g�E�F�A������CPU�Ɏ�荞�܂��A���������肶���B
>>683>>690>>693
K8�́A�Ƃ�����AMD��3����/cycle�N�w���炵��
��������2(ALU+AGU)�͖�����Ȃ��́H
���l�ɃX�g�A�����������Ẳ�������a�����邵
�����Ȑi���Ƃ���4(ALU+AGU)�ɂȂ��̂���
K8�́A�Ƃ�����AMD��3����/cycle�N�w���炵��
��������2(ALU+AGU)�͖�����Ȃ��́H
���l�ɃX�g�A�����������Ẳ�������a�����邵
�����Ȑi���Ƃ���4(ALU+AGU)�ɂȂ��̂���
Chekib Akrout��pdf��5�y�[�W�ځASingle-Core Era�̍����C�ɂȂ�
���̐�V���O���X���b�h���\���オ�邩�����邩�H���ď����������Ȃ�
�ȑO�ǂ����̋L���ŃV���O���X���b�h���\�͗��Ƃ��Ȃ���AMD�̐l�������Ă��C�������
���̐�V���O���X���b�h���\���オ�邩�����邩�H���ď����������Ȃ�
�ȑO�ǂ����̋L���ŃV���O���X���b�h���\�͗��Ƃ��Ȃ���AMD�̐l�������Ă��C�������
715 �F,,�E�L�́M�E,,�j��-�������F2009/11/15(��) 15:50:13 ID:GwkMRAwb
>>713
�ނ���X�g�A���Ċ�{�I�ɐ������Z�ƃy�A�ɂł��Ȃ���ˁB
add [eax], ecx ����load��add��store�ɂȂ邯�ǂ�
load+add �� store�ŏ\��������Ă��B
�ނ���X�g�A���Ċ�{�I�ɐ������Z�ƃy�A�ɂł��Ȃ���ˁB
add [eax], ecx ����load��add��store�ɂȂ邯�ǂ�
load+add �� store�ŏ\��������Ă��B
716 �F,,�E�L�́M�E,,�j��-�������F2009/11/15(��) 16:06:32 ID:GwkMRAwb
�X�g�A�A�h���X���m�肷��܂Ń��[�h���o���Ȃ����Ƃ��l����ƃX�g�A��p�p�C�v��p�ӂ���
��p�̃X�P�W���[�����O������Ӗ��͂���̂��ȂƁB
�A�h���X�l�\�����ē��@�I�Ƀ��[�h����e�N�j�b�N�iMemory Disambiguation�j�͂ǂ����̓����ɒ�G���邵�B
��p�̃X�P�W���[�����O������Ӗ��͂���̂��ȂƁB
�A�h���X�l�\�����ē��@�I�Ƀ��[�h����e�N�j�b�N�iMemory Disambiguation�j�͂ǂ����̓����ɒ�G���邵�B
��]������
718 �F,,�E�L�́M�E,,�j��-�������F2009/11/15(��) 16:21:23 ID:GwkMRAwb
�t�Ɍ����ƃX�g�A�A�h���X���m�肷��܂ŃX�g�A�ł��Ȃ�����������ȏ�
ALU�{AGU�̃y�A�������瑝�₵�Ă����ł�
ALU�{AGU�̃y�A�������瑝�₵�Ă����ł�
719 �F,,�E�L�́M�E,,�j��-�������F2009/11/15(��) 16:22:24 ID:GwkMRAwb
���t�Ɍ����ƃX�g�A�A�h���X���m�肷��܂ŃX�g�A�̌��̃��[�h���߂��s���s�ł��Ȃ�����������ȏ�
�������f�B�X�A���r�O�G�[�V�������v���t�F�b�`���t�F�b�`�͂ǂ��̓����ɐG��܂����H
721 �F,,�E�L�́M�E,,�j��-�������F2009/11/15(��) 16:33:28 ID:GwkMRAwb
US Patent 6591342
722 �F,,�E�L�́M�E,,�j��-�������F2009/11/15(��) 16:36:54 ID:GwkMRAwb
�Ƃ�����Intel�̓����͂���
7590825 Counter-based memory disambiguation techniques for selectively predicting load/store conflicts
http://www.patentgenius.com/patent/7590825.html
7590825 Counter-based memory disambiguation techniques for selectively predicting load/store conflicts
http://www.patentgenius.com/patent/7590825.html
723 �F,,�E�L�́M�E,,�j��-�������F2009/11/15(��) 16:57:59 ID:GwkMRAwb
�v���t�F�b�`�N�w��
�����Ƀ������f�B�X�A���r�O�G�[�V�������v���t�F�b�`���t�F�b�`�ƐM���Ă�Ƃ͋���
725 �F,,�E�L�́M�E,,�j��-�������F2009/11/15(��) 17:27:35 ID:GwkMRAwb
�v���t�F�b�`�N���͂悤
726 �F,,�E�L�́M�E,,�j��-�������F2009/11/15(��) 17:32:20 ID:GwkMRAwb
�v���t�F�b�`�N�iID:67+W7s0j�j�̒p�����������X�������X���͂��̃X������
727 �F,,�E�L�́M�E,,�j��-�������F2009/11/15(��) 17:37:09 ID:GwkMRAwb
�˂��˂��v���v���t�F�t�F�t�F�b�`����♥
L2�̑��x�ЂƂŐ��\2�A3���Ƃ��]�T�ŕς����
�R�A���������̃��j�b�g�\�������Ő��\�\�����Ă�
�w�Ǔ�����ǂȁB
�R�A���������̃��j�b�g�\�������Ő��\�\�����Ă�
�w�Ǔ�����ǂȁB
729 �F,,�E�L�́M�E,,�j��-�������F2009/11/15(��) 18:44:49 ID:GwkMRAwb
�܂��p�t�H�[�}���X�v����L1��2���邱�Ƃ��Ǝv���B
1��L1�̑ш�E�|�[�g���𑝂₷�̂͑�ς����A�N���X�^������X�P�[������B
���ʓI�ɕ����������j�b�g��2�{�̃X���[�v�b�g�Ńf�[�^�������ł���悤�ɂȂ�B
1��L1�̑ш�E�|�[�g���𑝂₷�̂͑�ς����A�N���X�^������X�P�[������B
���ʓI�ɕ����������j�b�g��2�{�̃X���[�v�b�g�Ńf�[�^�������ł���悤�ɂȂ�B
Memory Disambiguation�ŃE�B�X�R���V����w�ɑi�����Ă����͘a�������ȁB
Wisconsin Alumni Research Foundation settles suit against Intel
http://www.jsonline.com/business/63534417.html
Wisconsin Alumni Research Foundation settles suit against Intel
http://www.jsonline.com/business/63534417.html
>>597
���������ɋC�ɂȂ����������B
�N���X�^�[�h���̗p����Ƃ����ĂȂ��Ɩ����ȋC�����邪�A�����܂Ŗʓ|�Ȏ���
���Ă�̂��ȁH
�܂�������ɂ��Ă��N���X�^�[�h�͂����Ȃ��B
Intel��HT��^�[�{boost�Ȃō�������ꂽ�C���[�W���L�������A��C��
���߂��������������B
���������ɋC�ɂȂ����������B
�N���X�^�[�h���̗p����Ƃ����ĂȂ��Ɩ����ȋC�����邪�A�����܂Ŗʓ|�Ȏ���
���Ă�̂��ȁH
�܂�������ɂ��Ă��N���X�^�[�h�͂����Ȃ��B
Intel��HT��^�[�{boost�Ȃō�������ꂽ�C���[�W���L�������A��C��
���߂��������������B
3�N�x��Ă��邯�ǂ�
2011�N�̈���3�N�������Ă�̂��E�E�E
�Ȃ��AMD�������オ�܂�����������
��������X���̎���t�@�r���点��Ƃ͂����[���Ȃ��Ȃ��̂����
�ł��AAMD�̂͂܂��R�X�g�オ�肻���B
����AMD�̐́A�Ԃ����Ⴏ�l�i�������Ė����Intel�ƃ^���\���Ă�悤�ȏ�����
����Ō���I�ȍ����o���Ȃ�������A�F�X������Ȃ����E�E�E�B
�����łȂ��Ă��A��������SOI�Ƃ�Intel�ɔ�ׂăR�X�g�̂�����̎g���Ă��ł���H
����AMD�̐́A�Ԃ����Ⴏ�l�i�������Ė����Intel�ƃ^���\���Ă�悤�ȏ�����
����Ō���I�ȍ����o���Ȃ�������A�F�X������Ȃ����E�E�E�B
�����łȂ��Ă��A��������SOI�Ƃ�Intel�ɔ�ׂăR�X�g�̂�����̎g���Ă��ł���H
SOI�̉��i�Ɋւ��Ă͊m���Ɋ����ł͂��邯�ǁA�Z�p�̏o�n�߂�
�����ł͉��i�����I�ɉ�����̂��H�Ɛ��i�̏펯�B
�ڂ������i���͖��炩�ɂȂ��ĂȂ��̂ʼn��Ƃ������Ȃ��Ƃ���ł�
������ǂˁB
�l�I�Ȉ�ۂƂ��Ă�AMD�͉��̉��x�͉�����ɂ��������ɁA
OC���Ă����܂艷�x���オ��ɂ����A�C���e���͂��̋t�Ƃ�������
������B
�����ł͉��i�����I�ɉ�����̂��H�Ɛ��i�̏펯�B
�ڂ������i���͖��炩�ɂȂ��ĂȂ��̂ʼn��Ƃ������Ȃ��Ƃ���ł�
������ǂˁB
�l�I�Ȉ�ۂƂ��Ă�AMD�͉��̉��x�͉�����ɂ��������ɁA
OC���Ă����܂艷�x���オ��ɂ����A�C���e���͂��̋t�Ƃ�������
������B
������R�X�g�Ɍ��������Ԃ肪���邩�炱��������SOI���̗p���Ă��ł���
�E�F�n����������SOI�͍��R�X�g�Ȃ�Č����Ă��Ӗ��Ȃ���
����ɔ������i��ł����ȃe�N�j�b�N���K�{�ɂȂ��Ă��Ă邩��
���ΓI�ɃE�F�n�R�X�g�̉e���͏������Ȃ邵
�E�F�n����������SOI�͍��R�X�g�Ȃ�Č����Ă��Ӗ��Ȃ���
����ɔ������i��ł����ȃe�N�j�b�N���K�{�ɂȂ��Ă��Ă邩��
���ΓI�ɃE�F�n�R�X�g�̉e���͏������Ȃ邵
739 �FSocket774�F2009/11/16(��) 01:30:41 ID:BLwecK3L
�H�Ɛ��i�A���ɔėp�i�ŃR�X�g�p�t�H�[�}���X�ȏ�ɏd�v�Ȃ��̂Ȃ�ĂȂ�
>>739
���Ⴀ�C���e���ň����ȁB
���Ⴀ�C���e���ň����ȁB
>>716
�����X�g�A��p�Ƀp�C�v�𑫂����Ƃ��Ă�
����ALU+AGU�̃y�A�܂߂�����ʓ|����Ȃ��́H
�ʂ����Đ��\�ʂł���ȂɊ�^����̂��낤��
�����X�g�A��p�Ƀp�C�v�𑫂����Ƃ��Ă�
����ALU+AGU�̃y�A�܂߂�����ʓ|����Ȃ��́H
�ʂ����Đ��\�ʂł���ȂɊ�^����̂��낤��
AMD��SOI�̗p���Ă�̂͑��ɕ��@����������ȊO�ɂȂ��ł��傤
�ŏ���SOI���������Ƃ��͉����������ĂȂ�Intel�ɂ���ŏ������B
Intel��SOI�̓���������High-k�������������A
�ގ���z���Ȃǂ�Ǝ��������ĒN�����������������̂ł���
�����܂Ŏ����ĂȂ�AMD��SOI�ɗ��邵���Ȃ����Ɏ���B
AMD�������2010�N����High-k�����B
�ŏ���SOI���������Ƃ��͉����������ĂȂ�Intel�ɂ���ŏ������B
Intel��SOI�̓���������High-k�������������A
�ގ���z���Ȃǂ�Ǝ��������ĒN�����������������̂ł���
�����܂Ŏ����ĂȂ�AMD��SOI�ɗ��邵���Ȃ����Ɏ���B
AMD�������2010�N����High-k�����B
�̗p���͂����A�C�f�B�A��������ASOI�B
�N���X�^������������Ȋ����ɂȂ鈫���B
�N���X�^������������Ȋ����ɂȂ鈫���B
�����R�A�ł�FPU���L�͈����A�C�f�B�A�ł͂Ȃ��Ǝv���B
�����������i�߂ăR�A���̂�s���Ɉ�̉�����̂́A
�����I�ɂ̓����b�g���f�����b�g�̕��������Ǝv���B
�����������i�߂ăR�A���̂�s���Ɉ�̉�����̂́A
�����I�ɂ̓����b�g���f�����b�g�̕��������Ǝv���B
�悭�l����ƁA�J���̒x��ƌ����`�ŁA
�Z���I�ɂ����ɃN���X�^���̃f�����b�g�͘I�o���Ă���̂������B
���ɃN���X�^���̃A�v���[�`���������Ă��ABulldozer�̎��̐����
�����4�R�A1���W���[���ɐi�߂�̂͌����I�łȂ����A
�t�ɃN���X�^���}�Y�[�Ƃ킩���Ă��߂�Ȃ����A
����͕��̈����q�����B
�Z���I�ɂ����ɃN���X�^���̃f�����b�g�͘I�o���Ă���̂������B
���ɃN���X�^���̃A�v���[�`���������Ă��ABulldozer�̎��̐����
�����4�R�A1���W���[���ɐi�߂�̂͌����I�łȂ����A
�t�ɃN���X�^���}�Y�[�Ƃ킩���Ă��߂�Ȃ����A
����͕��̈����q�����B
�V���O���R�A�Ȃ�ɂ��낤�Ɖ����낤�Ɗe�@�\����ʂ�z�u����ĂȂ���
�����Ȃ����A�}���`�R�A�Ȃ�ɂ����ɂ��Ă�@�\�u���b�N�͋��L�����Ă��܂�
�i�Z�������ȂƂ��낾�����d�������A�ł������j
�܂�A�ǂ����Z�����Ȃ邱�Ƃ�ڎw�����A�Ƃ������Ƃ��Ǝv���Ă����̂���
�����Ȃ����A�}���`�R�A�Ȃ�ɂ����ɂ��Ă�@�\�u���b�N�͋��L�����Ă��܂�
�i�Z�������ȂƂ��낾�����d�������A�ł������j
�܂�A�ǂ����Z�����Ȃ邱�Ƃ�ڎw�����A�Ƃ������Ƃ��Ǝv���Ă����̂���
�f�[�^L1��1�R�A��2�ς�ł���
>>746
FPU�͂Ƃ������t�F�b�`�E�f�R�[�h�i���ɂȂ̂��A�Ƃ����ƁA���܂肻���
���ɂ͎v���Ȃ����ǁA�l�����Ƃ��Ă͂����������B
Bulldozer��Sandy Bridge�����m���ɓ������s�X���b�h���������Ȃ�A
�}���`�X���b�h�����ꂽ�A�v���P�[�V�����Ȃ�ΐ������Z�\�͂�
����A256bit AVX�𑽗p����A�v���P�[�V�����łȂ���Ε��������_���Z�ł�
�����̔\�͂�����B
>>747
1�R�A�ł͂Ȃ�1���W���[����2�B
1���W���[��=2�R�A�ƍl����Ȃ�A�ӂ��B
FPU�͂Ƃ������t�F�b�`�E�f�R�[�h�i���ɂȂ̂��A�Ƃ����ƁA���܂肻���
���ɂ͎v���Ȃ����ǁA�l�����Ƃ��Ă͂����������B
Bulldozer��Sandy Bridge�����m���ɓ������s�X���b�h���������Ȃ�A
�}���`�X���b�h�����ꂽ�A�v���P�[�V�����Ȃ�ΐ������Z�\�͂�
����A256bit AVX�𑽗p����A�v���P�[�V�����łȂ���Ε��������_���Z�ł�
�����̔\�͂�����B
>>747
1�R�A�ł͂Ȃ�1���W���[����2�B
1���W���[��=2�R�A�ƍl����Ȃ�A�ӂ��B
������f�[�^L1��1�R�A��2�ς̂����W���[�������Ă�ł���
1�R�A=1���W���[���Ƃ�����������AMD�����ĂȂ��Ǝv�����A
���ɂ����������_�ɗ��ƁABulldozer�͂ƂĂ��ł����R�A�Ƃ������ƂɂȂ�B
(2�{�܂ł͂����Ȃ���)
���ۂ��̂��߂ɊJ���x�ꂽ��45nm�ɍڂ�Ȃ���������A
�������������ł����̂�������Ȃ��Ȃ��B
�ŁA1�n�[�h�E�F�A�X���b�h������1�̃f�[�^L1������A�ӂ��B
���ɂ����������_�ɗ��ƁABulldozer�͂ƂĂ��ł����R�A�Ƃ������ƂɂȂ�B
(2�{�܂ł͂����Ȃ���)
���ۂ��̂��߂ɊJ���x�ꂽ��45nm�ɍڂ�Ȃ���������A
�������������ł����̂�������Ȃ��Ȃ��B
�ŁA1�n�[�h�E�F�A�X���b�h������1�̃f�[�^L1������A�ӂ��B
���ۂɑ厖�Ȃ̂͐��\������
AMD��������ĂȂ������Ȃ�̏��i�Ɏd�オ���Ă���?
������core2�̌ゾ���Ȃ��炱��őʖڂ�������{���ɂԂ��
AMD��������ĂȂ������Ȃ�̏��i�Ɏd�オ���Ă���?
������core2�̌ゾ���Ȃ��炱��őʖڂ�������{���ɂԂ��
���\�ƈ���Ɍ����Ă���邪�A��l��l�݂ȈႤ���\�����߂Ă���̂����̎���B
L1���ʂ�L2��2�R�A�ŋ��L�ABulldozer�̍\����C2D�̉��ǔłɌ�����
���core i7��phenom�ގ��̍\���ɂȂ��Ă邵�A
�ׂ̒�͐�������̂���
���core i7��phenom�ގ��̍\���ɂȂ��Ă邵�A
�ׂ̒�͐�������̂���
�ǂ��������ĂȂ��Ǝv������
���������̃A�v���[�`���C�ɂȂ�
Intel�́ACPU�ƃ������̑��x�̈Ⴂ���z�����邽�߂�
�Ԃɑ��i�K�̃L���b�V��������ɗp�ӂ��Ă邵�A
�������`�����l�������n�C�G���h��3�`�����l���ɂ��Ă�B
AMD�͓`���I�ɏ��e�ʃL���b�V�������AIntel�������R���������Ă��܂������A
Phenom2��L3�̒x���Ɨe�ʂ̏��Ȃ������ɖ��ɂȂ郌�x���B
1���W���[������2�n�[�h�E�F�A�X���b�h��������L2�����p�ƂȂ��
����Ȃ�̑�e��L2�AL3����Ȃ��ƈӖ��Ȃ��Ǝv�����
Intel�́ACPU�ƃ������̑��x�̈Ⴂ���z�����邽�߂�
�Ԃɑ��i�K�̃L���b�V��������ɗp�ӂ��Ă邵�A
�������`�����l�������n�C�G���h��3�`�����l���ɂ��Ă�B
AMD�͓`���I�ɏ��e�ʃL���b�V�������AIntel�������R���������Ă��܂������A
Phenom2��L3�̒x���Ɨe�ʂ̏��Ȃ������ɖ��ɂȂ郌�x���B
1���W���[������2�n�[�h�E�F�A�X���b�h��������L2�����p�ƂȂ��
����Ȃ�̑�e��L2�AL3����Ȃ��ƈӖ��Ȃ��Ǝv�����
�������X�^�b�L���O
���ɂȂ��čl�����Phenom�ł͂��ߏ�Ɏv����ق�
L1�̕���32bytes�ɋ��������̂�Bulldozer�ւ̕z�������̂���
L1�̕���32bytes�ɋ��������̂�Bulldozer�ւ̕z�������̂���
�����������ƌ��ǂ͑̊����x�ɂǂꂭ�炢�e�����Ă��邩���낤
Z-RAM
���[��A�C�O�̃T�C�g���Ă�Ɛ�����4�p�C�v��
2ALU&2AGU���Ă̂͂܂����蓾�낤�Ƃ����_�����x�z�I��
�������ꂾ�Ɖ��̂��߂�Bobcat������ĂȂ����Ⴄ����
���Ⴀ��̓I�ȍ\���́H�ƂȂ�Ƃ܂���܂��ĂȂ����E�E�E
2ALU&2AGU���Ă̂͂܂����蓾�낤�Ƃ����_�����x�z�I��
�������ꂾ�Ɖ��̂��߂�Bobcat������ĂȂ����Ⴄ����
���Ⴀ��̓I�ȍ\���́H�ƂȂ�Ƃ܂���܂��ĂȂ����E�E�E
����CMT���Ă�Andy Glew�炵���E�E�E��
�ǂ���Chuck Moore���̃R�����g�ʂ�Ȃ�
���ꂼ��̐������Z���j�b�g��4����/cycle�ł���͗l
�ɂ킩�ɂ͐M����������
���ꂼ��̐������Z���j�b�g��4����/cycle�ł���͗l
�ɂ킩�ɂ͐M����������
�����������4����?
764 �F,,�E�L�́M�E,,�j��-�������F2009/11/17(��) 00:09:20 ID:ouelv6RY
http://www.ospn.jp/osc2009-shimane/amd.pdf
Bulldozer�̐��\�͂��̕ӂŐG��Ă�
>>762
�Е��̃X���b�h���m����Ȃ��́H
Bulldozer�̐��\�͂��̕ӂŐG��Ă�
>>762
�Е��̃X���b�h���m����Ȃ��́H
765 �F,,�E�L�́M�E,,�j��-�������F2009/11/17(��) 00:10:00 ID:ouelv6RY
���Е��̃X���b�h�����ɖ��ߋ��������ꍇ��������Ȃ��́H
AMD�旊�ށI
Bulldozer��AM3�őΉ����Ă��ꗊ�ށI
Bulldozer��AM3�őΉ����Ă��ꗊ�ށI
>>764
Each Bulldozer "core" is capable of 2 loads/cycle; each is a 4-way out-of-order machine
Each INT scheduler can issue 4 inst./cycle; the FP scheduler can issue 4 inst./cycle
�炵����
Each Bulldozer "core" is capable of 2 loads/cycle; each is a 4-way out-of-order machine
Each INT scheduler can issue 4 inst./cycle; the FP scheduler can issue 4 inst./cycle
�炵����
768 �F,,�E�L�́M�E,,�j��-�������F2009/11/17(��) 00:37:49 ID:ouelv6RY
FP����݂č��v4load/cycle���ȁB
HPC���\���_�����Ȃ��́H����B
HPC���\���_�����Ȃ��́H����B
769 �FSocket774�F2009/11/17(��) 01:01:02 ID:HWM8g8Qc
>>768
HPC�����ɐv���Ă邾��
HPC�����ɐv���Ă邾��
���������ł���̂͂������Ƃ�
771 �FSocket774�F2009/11/17(��) 01:17:28 ID:V8eHzwsO
�Ȃ�Ă��Ƃ͂Ȃ�
��{�I�ɂ�CoreDuo�Ɠ�����
��̃R�A��Z��������L2�͋��L�A�������{���W���[���ɂ��Ă邾��
���W���[���ӂ���4�R�ACPU�����̃f�X�N�g�b�v�����_�C
���W���[��4��8�R�ACPU�����̃T�[�o�[�����_�C
��{�I�ɂ�CoreDuo�Ɠ�����
��̃R�A��Z��������L2�͋��L�A�������{���W���[���ɂ��Ă邾��
���W���[���ӂ���4�R�ACPU�����̃f�X�N�g�b�v�����_�C
���W���[��4��8�R�ACPU�����̃T�[�o�[�����_�C
�@�@�@�@�@�@�@�@�@�@ �@ �@ �@ �@ �@ �@ �@ �@ �@ |
�@�@�@�@�@�@�@�@�@�@ �@ �@ �@ �@ �@ �@ �@ �@ �@ |
�@�@�@�@�@ ���Q�Q�Q���@�@�@�@�@�@ �@ �@ �@ |
�@�@�@�@�@ | �m�@ _,�@�@,_ �R�@�@�@�@ �@ �@�i�i�@ |�@������
�@�@�@�@ /�@�@���@�@�@�� |�@�@�@�@�@�@�@�@�@(=)
�@�@�@�@ |�@�@�@�@( _��_)�@ �~�@�Q�@(��)�@ �@J�@�@�j�j
�@�@�@�@�c��@�@�@|��|�@ �m
���܁R�@/�@�@�@ �R�m�@ �R /�܂�
�@ �_�@�R�@ /�@�@ �@ �@ �@ �R�@/
�@�@�@�__,,�m�@�@�@�@�@�@|��Q�m
�@�@�@�@�@�@�@�@�@�@ �@ �@ �@ �@ �@ �@ �@ �@ �@ |
�@�@�@�@�@ ���Q�Q�Q���@�@�@�@�@�@ �@ �@ �@ |
�@�@�@�@�@ | �m�@ _,�@�@,_ �R�@�@�@�@ �@ �@�i�i�@ |�@������
�@�@�@�@ /�@�@���@�@�@�� |�@�@�@�@�@�@�@�@�@(=)
�@�@�@�@ |�@�@�@�@( _��_)�@ �~�@�Q�@(��)�@ �@J�@�@�j�j
�@�@�@�@�c��@�@�@|��|�@ �m
���܁R�@/�@�@�@ �R�m�@ �R /�܂�
�@ �_�@�R�@ /�@�@ �@ �@ �@ �R�@/
�@�@�@�__,,�m�@�@�@�@�@�@|��Q�m
>>764
Float��Int����Int��Float�ɕς�����̂��H
Float��Int����Int��Float�ɕς�����̂��H
Opteron���X�p�R�������L���O�g�b�v���������
5�ʂɂ�HD4870���g���������̃X�p�R�����������N�C��
AMD����
5�ʂɂ�HD4870���g���������̃X�p�R�����������N�C��
AMD����
�܂�����4 ALU + 4 AGU�Ȃ̂�
���邢��ALU��AGU�̑Ώ̍\����
�����������ɂȂ�̂��E�E�E�H
���邢��ALU��AGU�̑Ώ̍\����
�����������ɂȂ�̂��E�E�E�H
776 �FSocket774�F2009/11/17(��) 01:43:35 ID:HWM8g8Qc
ALU���������j�b�g��AGU���ĂȂH
Bulldozer�̃R�A�����傫���X�P�[������Ȃ�Fermi�L���[�ɂ��Ȃ邩����
�Ƃ����Ă��A�����������P�N�Ⴄ�����r���ׂ��ł͂Ȃ���
�Ƃ����Ă��A�����������P�N�Ⴄ�����r���ׂ��ł͂Ȃ���
�����ɘb������Ă�Ȃ�
�ł�ORNL�̐V�^��Opetron+Fermi�̓����i�Ƃ����\
ALU�@=�@Arithmetic Logic Unit
AGU�@=�@Address Generation Unit
�̂͂�
Load/Store�S���ł��B���Ԃ�
AGU�@=�@Address Generation Unit
�̂͂�
Load/Store�S���ł��B���Ԃ�
783 �F,,�E�L�́M�E,,�j��-�������F2009/11/17(��) 02:42:26 ID:ouelv6RY
���m�ɂ̓��[�h�E�X�g�A�̃A�h���X������̂ƁA���j�b�g�Ɏw�߂𓊂����ڂȁB
AGU�������ăA�h���X���Z�o
�����[�h���j�b�g�Ɂ����Ԓn�Ă�ł����Ƃ����w�߂s
���ǂl��ALU�ŗ��p
�������R���{
AGU�������ăA�h���X���Z�o
�����[�h���j�b�g�Ɂ����Ԓn�Ă�ł����Ƃ����w�߂s
���ǂl��ALU�ŗ��p
�������R���{
784 �FSocket774�F2009/11/17(��) 03:06:46 ID:HWM8g8Qc
>>781
�ǂ݂̂��I�v�e�����g���Ă����
�������\�X�y�b�N�̃t�F���~(�P���x2T�A�{���x1T�A220W��)�ł̌v�悾����A���̑g�����̓L�����Z���ɂȂ邾�낤�ˁB
����CPU�\�P�b�g�ɑ}���ׂɂ�130W�ȉ��ɗ}����K�v������A�{���x��200G���x�ɗ����邱�ƂɂȂ�B
����Ȃ�550mm�ō��R�X�g������������t�F���~���A180mm��HD5770�g�����ق���������ʂɐς߂��B
�ǂ݂̂��I�v�e�����g���Ă����
�������\�X�y�b�N�̃t�F���~(�P���x2T�A�{���x1T�A220W��)�ł̌v�悾����A���̑g�����̓L�����Z���ɂȂ邾�낤�ˁB
����CPU�\�P�b�g�ɑ}���ׂɂ�130W�ȉ��ɗ}����K�v������A�{���x��200G���x�ɗ����邱�ƂɂȂ�B
����Ȃ�550mm�ō��R�X�g������������t�F���~���A180mm��HD5770�g�����ق���������ʂɐς߂��B
785 �F,,�E�L�́M�E,,�j��-�������F2009/11/17(��) 03:14:29 ID:ouelv6RY
> �������\�X�y�b�N�̃t�F���~(�P���x2T�A�{���x1T�A220W��)
���ꎩ�̂��Ȃɂ��ɍ��\����B
���̃X�y�b�N��1.26GHz����̒P���x1.26T, �{���x0.63T, 225W
���ꎩ�̂��Ȃɂ��ɍ��\����B
���̃X�y�b�N��1.26GHz����̒P���x1.26T, �{���x0.63T, 225W
Tsubame��V�̗͂��_�Ǝ����̘����������Ƃ��肦�Ȃ����������
Dresdenboy���\�z���Ă���悤�ɁA
ALU�ŃA�h���X�v�Z�ł���悤�ɂ�����Ă��Ƃ��ȁB
ALU�ŃA�h���X�v�Z�ł���悤�ɂ�����Ă��Ƃ��ȁB
�œ_�͂�����B
�Ă�i7���ċA��炯�邩�ۂ��B
���ꂵ�������Ȃ��B
�������t�]�𐬂��������邱�Ƃ��ł���Ȃ�������p���[���[�X�pPC�������邾�낤�B
�Ă�i7���ċA��炯�邩�ۂ��B
���ꂵ�������Ȃ��B
�������t�]�𐬂��������邱�Ƃ��ł���Ȃ�������p���[���[�X�pPC�������邾�낤�B
There was one AMD patent about an AGU, which recycles intermediate results for more complex address calculations.
While I'm not sure, if this patent could be related to Bulldozer (but to Bobcat or Geode or something else instead),
it offers the possibility to use a regular ALU for address calculations with only little modifications.
���ꂩ
While I'm not sure, if this patent could be related to Bulldozer (but to Bobcat or Geode or something else instead),
it offers the possibility to use a regular ALU for address calculations with only little modifications.
���ꂩ
Fermi���Ď����l����ƕ�����
�ʐςƓd�͐H���߂��Ď��p�I�łȂ���
�ʐςƓd�͐H���߂��Ď��p�I�łȂ���
�Ăт`�l�c������Ԃ��������ȁ@��������
�ł���Ԃ̖��́A�ȓd�͂��ǂ����ɂ������Ă���̂ł́H
�������\��Intel���ǂ������Ƃ��Ă��ATDP��130W�Ƃ��Ŕ��M��PhenomII���
���Ȃ葝���Ă��܂��ẮATDP��GPU���݂�85W��Sandy Bridge�ɔ̔��ł͍���
�t������\��������B
http://en.hardspell.com/doc/enshowcont.asp?id=6470
���X���{�l�͏ȓd�͎u�������琫�\���悭�Ă��Ai7�̗l�ɔ����ɂȂ�\����
���\����Ǝv���B
�������\��Intel���ǂ������Ƃ��Ă��ATDP��130W�Ƃ��Ŕ��M��PhenomII���
���Ȃ葝���Ă��܂��ẮATDP��GPU���݂�85W��Sandy Bridge�ɔ̔��ł͍���
�t������\��������B
http://en.hardspell.com/doc/enshowcont.asp?id=6470
���X���{�l�͏ȓd�͎u�������琫�\���悭�Ă��Ai7�̗l�ɔ����ɂȂ�\����
���\����Ǝv���B
793 �FSocket774�F2009/11/17(��) 12:19:53 ID:HWM8g8Qc
�T���f�B�R�̓����m�ɂȂ肻�����B
AVX�̃T���f�BvsDX11CS�̃����m�B
AVX�̃T���f�BvsDX11CS�̃����m�B
Sandy��12SP��GPU�A�[�L�̃��W���[�A�b�v��������
L3���L���̌��ʂ��y�ϓI�Ɍ��Ă�G45(10SP)��2�{���ĂƂ��낾�낤�B
���Ȃ�CPU�Ώd�Ȑ��\�o�����X���Ǝv����B
�����LIano GPU��480SP�A���C�e���V���������l�����Ă�4650�ȉ��͖������낤�B
95W�g��CPU����3GHz�㔼�`4GHz�O���ɂł����LIano���L�����H
�c��������������čl���Ă݂��GMA�A�[�L�̃_�C�����̈�����GT200�̔䂶��Ȃ��ȁB
L3���L���̌��ʂ��y�ϓI�Ɍ��Ă�G45(10SP)��2�{���ĂƂ��낾�낤�B
���Ȃ�CPU�Ώd�Ȑ��\�o�����X���Ǝv����B
�����LIano GPU��480SP�A���C�e���V���������l�����Ă�4650�ȉ��͖������낤�B
95W�g��CPU����3GHz�㔼�`4GHz�O���ɂł����LIano���L�����H
�c��������������čl���Ă݂��GMA�A�[�L�̃_�C�����̈�����GT200�̔䂶��Ȃ��ȁB
CPU��GPU��1�p�b�P�ɂ���ƂȂ�ƁA�Ƃ����Intel��GPU�����̂܂�����
��������ɂȂ��Ă����
��������ɂȂ��Ă����
>Sandy��12SP��GPU�A�[�L�̃��W���[�A�b�v��������
�����Iron Lake�ł͂Ȃ��̂��HSandy��GPU��45nm��Iron Lake�ƃT�C�Y
�����ʂ����牽������̋����͂���Ă���Ǝv�����ǁB
intel���\�ɂ���3DmarkVantage��Iron Lake��G45��1.5�{�炵������
��G�c�ɍl���ăV�������N��2�{�A���g�����ő��2�{�ŁA�A�[�L�e�N�`��
���ς���ĂȂ��Ȃ�G45��ōő��6�{�ɂȂ�v�Z�B
http://pc.nikkeibp.co.jp/article/news/20081015/1008845/?SS=imgview&FD=1013704592
�܂����ꂪ6�{�ɂȂ����Ƃ���łǂ����悤���������ǂȁB
�����Iron Lake�ł͂Ȃ��̂��HSandy��GPU��45nm��Iron Lake�ƃT�C�Y
�����ʂ����牽������̋����͂���Ă���Ǝv�����ǁB
intel���\�ɂ���3DmarkVantage��Iron Lake��G45��1.5�{�炵������
��G�c�ɍl���ăV�������N��2�{�A���g�����ő��2�{�ŁA�A�[�L�e�N�`��
���ς���ĂȂ��Ȃ�G45��ōő��6�{�ɂȂ�v�Z�B
http://pc.nikkeibp.co.jp/article/news/20081015/1008845/?SS=imgview&FD=1013704592
�܂����ꂪ6�{�ɂȂ����Ƃ���łǂ����悤���������ǂȁB
Intel graphics drivers employ questionable 3DMark Vantage optimizations
3DMurk all over again?
http://techreport.com/articles.x/17732
����Ȃ��Ƃ����邩��ˁALIano�Ƃ̔�r�̂Ƃ��͍H���Ă���������
3DMurk all over again?
http://techreport.com/articles.x/17732
����Ȃ��Ƃ����邩��ˁALIano�Ƃ̔�r�̂Ƃ��͍H���Ă���������
again? ���Ă����Ƃ��낪�~�\�B
3DMark Vantage �͑�����������ǁA���͂���Ȃɑ��������܂���B ���Ă����Ƃ�����~�\�B
���Ƃ���ƁAcrap(ry
3DMark Vantage �͑�����������ǁA���͂���Ȃɑ��������܂���B ���Ă����Ƃ�����~�\�B
���Ƃ���ƁAcrap(ry
Opteron�̃Z�[���X�|�C���g�̈�� �������ш�/���_flops ��Xeon����
�傫�����ŁAHPC�ō̗p����闝�R�̈���Ǝv�����AIntel�̂���
http://pc.watch.impress.co.jp/docs/news/20091117_329468.html
http://www.nec.co.jp/press/ja/0911/1701.html
���L���������o���h���A�����C���^�[�R�l�N�g�ڑ��Z�p�Ȃǂ�
���x�N�g�������V�X�e���̊J���ɂ�����L�x�Ȍo���́A
���C���e���E�A�[�L�e�N�`���[��V���Ȏs��ւ���ɑO�i�����邱�Ƃ��ł��܂��B
�����ʂ��o������Opteron�ꂵ���Ȃ肻���BOpteron��������Ȃ���
Power7��SparcVIII������
�傫�����ŁAHPC�ō̗p����闝�R�̈���Ǝv�����AIntel�̂���
http://pc.watch.impress.co.jp/docs/news/20091117_329468.html
http://www.nec.co.jp/press/ja/0911/1701.html
���L���������o���h���A�����C���^�[�R�l�N�g�ڑ��Z�p�Ȃǂ�
���x�N�g�������V�X�e���̊J���ɂ�����L�x�Ȍo���́A
���C���e���E�A�[�L�e�N�`���[��V���Ȏs��ւ���ɑO�i�����邱�Ƃ��ł��܂��B
�����ʂ��o������Opteron�ꂵ���Ȃ肻���BOpteron��������Ȃ���
Power7��SparcVIII������
>>797
�H�Ƃ������AGMA���x���Ȃ�CPU���g����������Ȃ��A�Ƃ����{���]�|��킾��B
GMA���s�N�Z���A�o�[�e�b�N�X�����ŖO�a�����Ȃ�A�W�I���g���[������CPU�������肷��B
DirectX9�̂Ƃ��̐v��10�ɂ��Ή��ł���悤�ɂ������ǁA���\���S������Ȃ��̂ŁA
GMA950�ȑO�̂悤�ɁA�܂�CPU����ɂȂ��Ă���낤�B
�H�Ƃ������AGMA���x���Ȃ�CPU���g����������Ȃ��A�Ƃ����{���]�|��킾��B
GMA���s�N�Z���A�o�[�e�b�N�X�����ŖO�a�����Ȃ�A�W�I���g���[������CPU�������肷��B
DirectX9�̂Ƃ��̐v��10�ɂ��Ή��ł���悤�ɂ������ǁA���\���S������Ȃ��̂ŁA
GMA950�ȑO�̂悤�ɁA�܂�CPU����ɂȂ��Ă���낤�B
GPU���m�Ȃ�t���[���Ȃ胉�C���Ȃ�u���b�N�Ȃ��
�ȒP�ɕ��ו��U�ł�����ǂ˥��
�ȒP�ɕ��ו��U�ł�����ǂ˥��
intel��NVIDIA������ƌ����B
����͂Ȃ�
���₻���ł��Ȃ�
AMD��ATI���������͂邩�ɓ���B
Intel���g���S�Ă�NVIDIA���݂̊�Ƃ�Ɨ����Ă�����NVIDIA���������y�B
Intel���g���S�Ă�NVIDIA���݂̊�Ƃ�Ɨ����Ă�����NVIDIA���������y�B
���ꂱ���Ȃ�
����Intel���猩��NVIDIA�ɗ~�������̂��Ă���́H
�Ȃ�
809 �FSocket774�F2009/11/17(��) 21:03:51 ID:HWM8g8Qc
�ǂ݂̂�DX11�Ή���HD4650�ȏ�̐��\������LIano�ɑR����p�́A�C���e���͂��납�k�r�Ƃ������n����̂ǂ̊�Ƃ������ĂȂ��Ȃ��B
Propus�Ɠ����x�̃T�C�Y�Ə���d�͂�CPU��4�R�AL2 1M��PhenomIIx4�N���X�AGPU��DX11�Ή�����480SP��HD4650�N���X�B
�������I���_�C������CPU-GPU�ԒʐM��������GPGPU�����ҏo����B
�����T���f�B���R�o����C�����Ȃ��B
���炩�Ɋ����x�̎������Ⴄ�B
Propus�Ɠ����x�̃T�C�Y�Ə���d�͂�CPU��4�R�AL2 1M��PhenomIIx4�N���X�AGPU��DX11�Ή�����480SP��HD4650�N���X�B
�������I���_�C������CPU-GPU�ԒʐM��������GPGPU�����ҏo����B
�����T���f�B���R�o����C�����Ȃ��B
���炩�Ɋ����x�̎������Ⴄ�B
NVIDIA����Z�p�҂������������������葁��
2011�N��K10�R�A�Ȃ���A�m���Ɏ������Ⴄ��ȁB
"LLANO"����Ȃ��́H�@"LIANO"�Ȃ́H
LLANO����Ȃ����ȁB�㓡���͂�����Llano�����A�{�ԕ���Liano�Ə����Ă����ǁA
���Llano�̒������Ă����B
���Llano�̒������Ă����B
Intel+NV �́AAMD���`�b�v���傫���Ȃ肻���ˁB�c�O�B
Llano��HD4650�������߂�CPU�ƈ�ɂȂ�̂���c��ׁ[
816 �FSocket774�F2009/11/17(��) 21:57:10 ID:gLyEgX+s
480sp������`�b�v�Ƃ��Ă�4650����
�ł��������ш旎���邩��4650���炢�̐��\�ł́H�Ƃ������Ƃ���
780G�݂�����GPU��p������������Ȃ�ς���Ă��邾�낤����
�ł��������ш旎���邩��4650���炢�̐��\�ł́H�Ƃ������Ƃ���
780G�݂�����GPU��p������������Ȃ�ς���Ă��邾�낤����
>>812
LlANO
LlANO
818 �FSocket774�F2009/11/17(��) 22:50:23 ID:HWM8g8Qc
>>811
����R�A��Propus�̗B��̎�_�̃L���b�V����1M�ɔ{���ƁA�T�C�Y�p�t�H�[�}���X�����ɗD�ꂽHD5000�R�A�̗Z��������ˁB
�^�[�{���ǂ����������ڂ��邾�낤�B
����bulldozer�����s���Ă��C�ɂ��Ȃ��Ă����ʂ̃n�C�X�y�b�N���낤�B
���Ȃ��Ƃ��f�X�N�g�b�v��n�C�G���h�m�[�g�ɓG�͂��Ȃ��B
����R�A��Propus�̗B��̎�_�̃L���b�V����1M�ɔ{���ƁA�T�C�Y�p�t�H�[�}���X�����ɗD�ꂽHD5000�R�A�̗Z��������ˁB
�^�[�{���ǂ����������ڂ��邾�낤�B
����bulldozer�����s���Ă��C�ɂ��Ȃ��Ă����ʂ̃n�C�X�y�b�N���낤�B
���Ȃ��Ƃ��f�X�N�g�b�v��n�C�G���h�m�[�g�ɓG�͂��Ȃ��B
�Ƃ����Llano����AVX�Ƃ�XOP�ɑΉ����Ă�́H
>>809
�ł����f�͂��Ȃ����������Ǝv����A�C�X���G���`�[���̓I���S���`�[���ƈ����
�閧��`�œ��������Ă���`�[���Ȃ̂ŁACore2�̎��̂悤�ȉB���ʂ�����\����
���\���肻���A�܂��S�e�����S�ɖ��炩�ɂȂ����킯�ł͂Ȃ����B
�ł����f�͂��Ȃ����������Ǝv����A�C�X���G���`�[���̓I���S���`�[���ƈ����
�閧��`�œ��������Ă���`�[���Ȃ̂ŁACore2�̎��̂悤�ȉB���ʂ�����\����
���\���肻���A�܂��S�e�����S�ɖ��炩�ɂȂ����킯�ł͂Ȃ����B
�B���ʁ��x���`��
K10.5
Llano��Wii�̎�����@�ɏ�肻��
�܂��ŁH
SP���Ȃ�ڂ����Ă��AROP���e��Œ胆�j�b�g���������ш�Ƃ̃o�����X��
���ĂȂ��Ɓi�Q�[���Ƃ��Ắj���\�͏o�Ȃ�
�{�g���l�b�N������CPU�ɂ��G�~�����[�g��������`�����Ď肪���邭�炢Fusion���Ă�Ɨǂ��̂���
���ĂȂ��Ɓi�Q�[���Ƃ��Ắj���\�͏o�Ȃ�
�{�g���l�b�N������CPU�ɂ��G�~�����[�g��������`�����Ď肪���邭�炢Fusion���Ă�Ɨǂ��̂���
826 �F,,�E�L�́M�E,,�j��-�������F2009/11/17(��) 23:38:23 ID:ouelv6RY
827 �F,,�E�L�́M�E,,�j��-�������F2009/11/17(��) 23:55:35 ID:ouelv6RY
�Ƃ������AGMA�����|�I�ȃV�F�A��̂ɐ��\�����݂ɂȂ������Ƃ͈�x����Ƃ������킯�ŁB
�I�t�B�X�p�r�ɂ�G41���x���ł���I�[�o�[�X�y�b�N�߂��邪�A
����Ő��̒��ɂ̓A�z�݂�����CPU�X�y�b�N�v������Ɩ��A�v��������킯���B
�ǂ݂̂��O���t�B�b�N���\���K�v�Ȑl��GMA�Ŗ�������킯�Ȃ��킯�ŁA
���ꂱ���f�B�X�N���[�gGPU�݂�����Ęb�ɂȂ�㩁B
CPU�����L���b�V���e�ʂ�SIMD���\�������́uK10.5��L3�폜�Łv�ɗ��Ƃ��Ă܂�
Llano�̓���GPU���g�������l�͑����ς��҂��Ǝv�����B
�I�t�B�X�p�r�ɂ�G41���x���ł���I�[�o�[�X�y�b�N�߂��邪�A
����Ő��̒��ɂ̓A�z�݂�����CPU�X�y�b�N�v������Ɩ��A�v��������킯���B
�ǂ݂̂��O���t�B�b�N���\���K�v�Ȑl��GMA�Ŗ�������킯�Ȃ��킯�ŁA
���ꂱ���f�B�X�N���[�gGPU�݂�����Ęb�ɂȂ�㩁B
CPU�����L���b�V���e�ʂ�SIMD���\�������́uK10.5��L3�폜�Łv�ɗ��Ƃ��Ă܂�
Llano�̓���GPU���g�������l�͑����ς��҂��Ǝv�����B
256�r�b�gAVX
�ʂ����Ăǂꂭ�炢���p�����̂��Ȃ�
�ʂ����Ăǂꂭ�炢���p�����̂��Ȃ�
�@�����̐l�͂����ڒ����Ȃ��Ƃ������Ă邯�ǂ킴�ƂȂ�H
��������ĐV���W�X�^���n�݂���邽�тɁA�^�X�N�X�C�b�`�̃R�X�g���ǂ�ǂ�傫���Ȃ��Ă���
��������ׂĂق���
��������ׂĂق���
>>827
�m�[�g���������ĂȂ��l�ŃQ�[������肽���l�́A���ݓG�ɑ����Ȑ��ɏ��邾�낤
�Q�[�����ł��č���l�͂����l���Ȃ��Ǝv���@�@�@
�m�[�g���������ĂȂ��l�ŃQ�[������肽���l�́A���ݓG�ɑ����Ȑ��ɏ��邾�낤
�Q�[�����ł��č���l�͂����l���Ȃ��Ǝv���@�@�@
832 �F,,�E�L�́M�E,,�j��-�������F2009/11/18(��) 00:12:20 ID:r93Gw0lQ
>>831
�m�[�g���f�B�X�N���[�g�ł��������B
�Q�[�����n��ȃm�[�g�łł���悤�ȃ��[�G���h���̂ق��������L�����Ă�
�܂����Ƃ͎v����Athlon64 X2��Core 2 Duo��SIMD���j�b�g�̃X���[�v�b�g���������Ɍ��ꂽ�̖Y��ĂȂ���ȁH
�܂���Llano���m�[�g�ɍڂ�Ƃ��v���ĂȂ���ȁH
�m�[�g�̃v���b�g�t�H�[����Denube����H�������肵���B
�m�[�g���f�B�X�N���[�g�ł��������B
�Q�[�����n��ȃm�[�g�łł���悤�ȃ��[�G���h���̂ق��������L�����Ă�
�܂����Ƃ͎v����Athlon64 X2��Core 2 Duo��SIMD���j�b�g�̃X���[�v�b�g���������Ɍ��ꂽ�̖Y��ĂȂ���ȁH
�܂���Llano���m�[�g�ɍڂ�Ƃ��v���ĂȂ���ȁH
�m�[�g�̃v���b�g�t�H�[����Denube����H�������肵���B
833 �F,,�E�L�́M�E,,�j��-�������F2009/11/18(��) 00:17:18 ID:r93Gw0lQ
���[�h�}�b�v�������B
�ڂ�̂ˁB���߂�B
�f�X�N�g�b�v����m�[�g�܂œ����悤�ɃA�[�L���V����̂Ƀm�[�g�͎���x��Ȃ̂ˁB
�ڂ�̂ˁB���߂�B
�f�X�N�g�b�v����m�[�g�܂œ����悤�ɃA�[�L���V����̂Ƀm�[�g�͎���x��Ȃ̂ˁB
�A���~�Εa������������
�f�B�X�N���[�gGPU���ƁA�ȓd�͋@�\���ׂ����쓮�����邱�Ƃ�����Ȃ�
CPU��GPU��Idle��ԊĎ����ɁA�����������ōs�������킯��
CPU��GPU��Idle��ԊĎ����ɁA�����������ōs�������킯��
>>767
�������Z��4����/�T�C�N���z�肾�Ƃ����
�܂��܂��p�C�v���C���̍\�����������ȁE�E�E
Llano��K10�R�A�Ȃ̂�ALU��AGU��3���Ώ̂���
Bobcat��ALU2�ɑ����[�h1�A�X�g�A1�ƕ������Ă���
�Ƃ��낪Bulldozer�����킴�킴���\���Ȃ������Ƃ������Ƃ�
�����Ƃ͂܂�������\�����̗p���Ă���\����������
�������Z��4����/�T�C�N���z�肾�Ƃ����
�܂��܂��p�C�v���C���̍\�����������ȁE�E�E
Llano��K10�R�A�Ȃ̂�ALU��AGU��3���Ώ̂���
Bobcat��ALU2�ɑ����[�h1�A�X�g�A1�ƕ������Ă���
�Ƃ��낪Bulldozer�����킴�킴���\���Ȃ������Ƃ������Ƃ�
�����Ƃ͂܂�������\�����̗p���Ă���\����������
838 �F,,�E�L�́M�E,,�j��-�������F2009/11/18(��) 00:32:13 ID:r93Gw0lQ
PC�Q�[���̓|�X�gCrysis���̃w�r�[�H���Ɗ؍��YMMO�݂����ȃJ�W���A���H���œ�ɉ����Ă邩��
�m�[�g�ŃQ�[����낤���Đl�͂��ꂱ���f�B�X�N���[�g���ADX9�N���X�ŏ\�����̂ǂ��������Ǝv���B
���Ȃ݂Ƀl�b�g�u�b�N�ł��o����N���X�̃��[�G���h�Q�[������Ԕ��グ�L�тĂ邻�����B
>>835
�o�b�e���[��3D�l�g�Q���́H
�d���ɉ����ē����ƃf�B�X�N���[�g���ւ���@�\�t����Ώ\���ł���B
�m�[�g�ŃQ�[����낤���Đl�͂��ꂱ���f�B�X�N���[�g���ADX9�N���X�ŏ\�����̂ǂ��������Ǝv���B
���Ȃ݂Ƀl�b�g�u�b�N�ł��o����N���X�̃��[�G���h�Q�[������Ԕ��グ�L�тĂ邻�����B
>>835
�o�b�e���[��3D�l�g�Q���́H
�d���ɉ����ē����ƃf�B�X�N���[�g���ւ���@�\�t����Ώ\���ł���B
>>838
>PC�Q�[���̓|�X�gCrysis���̃w�r�[�H���Ɗ؍��YMMO�݂����ȃJ�W���A���H���œ�ɉ����Ă邩��
>�m�[�g�ŃQ�[����낤���Đl�͂��ꂱ���f�B�X�N���[�g���ADX9�N���X�ŏ\�����̂ǂ��������Ǝv���B
�܂�A�uIntel�̏\���N���X�̃Q�[���}�V��(GeForce�̍ʼn��ʃ��f���Ƃ��t���Ă�����)���
�����Ƒ����Q�[���}�V������������6,7���ŁI�v�Ƃ����ăA�s�[���ł���킯�ŁB
�ꍇ�ɂ���ẮA�����ƃ`�b�v�T�C�Y�̏����� Llano�̂ق���
�u�v���~�A�����i�v�Ƃ��č�������邩������Ȃ��B
����ɁAPC�Q�[�ōŋ��̔���A���v���ւ��Ă���̂�WoW����B
>PC�Q�[���̓|�X�gCrysis���̃w�r�[�H���Ɗ؍��YMMO�݂����ȃJ�W���A���H���œ�ɉ����Ă邩��
>�m�[�g�ŃQ�[����낤���Đl�͂��ꂱ���f�B�X�N���[�g���ADX9�N���X�ŏ\�����̂ǂ��������Ǝv���B
�܂�A�uIntel�̏\���N���X�̃Q�[���}�V��(GeForce�̍ʼn��ʃ��f���Ƃ��t���Ă�����)���
�����Ƒ����Q�[���}�V������������6,7���ŁI�v�Ƃ����ăA�s�[���ł���킯�ŁB
�ꍇ�ɂ���ẮA�����ƃ`�b�v�T�C�Y�̏����� Llano�̂ق���
�u�v���~�A�����i�v�Ƃ��č�������邩������Ȃ��B
����ɁAPC�Q�[�ōŋ��̔���A���v���ւ��Ă���̂�WoW����B
840 �F,,�E�L�́M�E,,�j��-�������F2009/11/18(��) 00:43:12 ID:r93Gw0lQ
�[���ASandy Bridge�̓���GMA�̐��\�ɑ��Ė����v�Ŋ��ҊO�Ȃ̂ȁB
�N���b�N�͔{�ȏ�ɂȂ邵�g�����W�X�^����������AL3�ɃA�N�Z�X�o����
�Ȃɂ��C�X���G���`�[�����������̂ő匊���炢�ɂ��Ƃ�����B
�N���b�N�͔{�ȏ�ɂȂ邵�g�����W�X�^����������AL3�ɃA�N�Z�X�o����
�Ȃɂ��C�X���G���`�[�����������̂ő匊���炢�ɂ��Ƃ�����B
�����r������������������GMA�ɂ����҂���
842 �F,,�E�L�́M�E,,�j��-�������F2009/11/18(��) 00:48:41 ID:r93Gw0lQ
> Intel�̏\���N���X�̃Q�[���}�V��(GeForce�̍ʼn��ʃ��f���Ƃ��t���Ă�����)���
> �����Ƒ����Q�[���}�V��
Phenom II�̃L���b�V���e�ʂ��ɂ����Nehalem��萢��̐i��Sandy Bridge��葬���Ȃ�
�����������ĉ�������
> �����Ƒ����Q�[���}�V��
Phenom II�̃L���b�V���e�ʂ��ɂ����Nehalem��萢��̐i��Sandy Bridge��葬���Ȃ�
�����������ĉ�������
>>842
�������Q�[�����\�I�ȈӖ��ł���B
�������āA�f�X�N�g�b�v��Œ��V���{�CGPU��
�ڂ������i�ɂ������v���~�A�����i���t���Ă邶���B
���������̂��ł��邩����A���āB
�������Q�[�����\�I�ȈӖ��ł���B
�������āA�f�X�N�g�b�v��Œ��V���{�CGPU��
�ڂ������i�ɂ������v���~�A�����i���t���Ă邶���B
���������̂��ł��邩����A���āB
��ʂ����𑜓x�����Ă��Ă邩��GPU�̐��\�͍�������������
845 �F,,�E�L�́M�E,,�j��-�������F2009/11/18(��) 00:56:46 ID:r93Gw0lQ
�܂��ASandy Bridge��Llano��GPU�͓����x�̖ʐς����A
32nm�͖ʐϓ�����g�����W�X�^����Intel�̂ق����������A
����GMA��1GHz�ȏ�쓮���Ƃ��������A�Ȃ�Ƃ������܂ւ�ȁB
32nm�͖ʐϓ�����g�����W�X�^����Intel�̂ق����������A
����GMA��1GHz�ȏ�쓮���Ƃ��������A�Ȃ�Ƃ������܂ւ�ȁB
�f�B�X�N���[�g�Ȃ�ė]���ȋ��K�������邶���
�������i�Ŕ{�ȏ�̃Q�[�����\�@�J�W���A���Q�[�}�[�Ȃ�\��
�������i�Ŕ{�ȏ�̃Q�[�����\�@�J�W���A���Q�[�}�[�Ȃ�\��
>>845
32nm���m����IBM�O���[�v�̕���SRAM�ʐϏ��������ǂ�
32nm���m����IBM�O���[�v�̕���SRAM�ʐϏ��������ǂ�
848 �FSocket774�F2009/11/18(��) 01:09:51 ID:anBjiZBy
Llano��Propus�Ɠ����x�̃T�C�Y������160mm2�O��A�T���f�B�̓l�n�����Ɠ��T�C�Y��240mm2�O��ŃR�X�g���{�ȏ�Ⴄ�B
CPU�x���`�̍ō����\�͏�����邯�ǁA�����x���`�͌݊��ȏゾ�낤�ˁB
CPU�x���`�̍ō����\�͏�����邯�ǁA�����x���`�͌݊��ȏゾ�낤�ˁB
849 �F,,�E�L�́M�E,,�j��-�������F2009/11/18(��) 01:12:25 ID:r93Gw0lQ
http://pc.watch.impress.co.jp/img/pcw/docs/328/392/html/kaigai13.jpg.html
�����
Sandy Bridge��4�R�A��PS3��Cell����P���x�����������Z���\���킯����
���xL3���L�Ȃ���\�t�g�E�F�AVertex Shader�Ȃ���Ă��悳������
�ǂ�ȃM�~�b�N������̂��͂܂��܂��䂾��
>>846
���������i�Ŕ{�ȏ�̃Q�[�����\
�ǂ�����o�Ă��������ł����H
{kind=link}
�����
Sandy Bridge��4�R�A��PS3��Cell����P���x�����������Z���\���킯����
���xL3���L�Ȃ���\�t�g�E�F�AVertex Shader�Ȃ���Ă��悳������
�ǂ�ȃM�~�b�N������̂��͂܂��܂��䂾��
>>846
���������i�Ŕ{�ȏ�̃Q�[�����\
�ǂ�����o�Ă��������ł����H
850 �FSocket774�F2009/11/18(��) 01:14:33 ID:anBjiZBy
851 �F,,�E�L�́M�E,,�j��-�������F2009/11/18(��) 01:16:04 ID:r93Gw0lQ
CPU���̃L���b�V��������Ă镪�������ш�������Ǝv���B
�܂��āA�Ȃ��Ȃ���L2�L���b�V�����g����GPU���̑ш���Z�[�u�ł���킯�ł�����
�ǂ�ȃ}�W�b�N�Ŕ{�̐��\���o����̂��t�Ɋ��҂��Ă��܂��܂���B
>>848
���Ԃ�Llano�̓��Ĕn��2�R�A4�X���b�h�{GMA���Ǝv���B
�܂��āA�Ȃ��Ȃ���L2�L���b�V�����g����GPU���̑ш���Z�[�u�ł���킯�ł�����
�ǂ�ȃ}�W�b�N�Ŕ{�̐��\���o����̂��t�Ɋ��҂��Ă��܂��܂���B
>>848
���Ԃ�Llano�̓��Ĕn��2�R�A4�X���b�h�{GMA���Ǝv���B
852 �F,,�E�L�́M�E,,�j��-�������F2009/11/18(��) 01:16:59 ID:r93Gw0lQ
>>850
��N���b�N�Ȃ���GPU�̃g�����W�X�^���x�������͓̂�����O�����B
��N���b�N�Ȃ���GPU�̃g�����W�X�^���x�������͓̂�����O�����B
853 �FSocket774�F2009/11/18(��) 01:24:26 ID:anBjiZBy
>>849
�����m��2���~�ȉ��A�T���f�B��3���~�ȏゾ����l�i���d�Ȃ邱�Ƃ͂Ȃ����낤�B
����ƍ��̃C���e���I���{��2�{��HD4650����{�ȏ�̐��\���������B
����ȑO��DX11���Ή��Ńh���C�o���C�}�C�`�����瑊��ɂȂ�Ȃ��B
�����m��2���~�ȉ��A�T���f�B��3���~�ȏゾ����l�i���d�Ȃ邱�Ƃ͂Ȃ����낤�B
����ƍ��̃C���e���I���{��2�{��HD4650����{�ȏ�̐��\���������B
����ȑO��DX11���Ή��Ńh���C�o���C�}�C�`�����瑊��ɂȂ�Ȃ��B
�m�[�g�����̃Q�[�����\�Ȃ�Ă������Ō��܂��Ă��܂����낤
�������i�Ŕ�ׂ�Ə��X
���V�m�[�g�Ȃ�Ĕ����w�͓�������Ȃɂ��Ȃ�����@
�Q�O���߂������ˁH�@�@�@
�������i�Ŕ�ׂ�Ə��X
���V�m�[�g�Ȃ�Ĕ����w�͓�������Ȃɂ��Ȃ�����@
�Q�O���߂������ˁH�@�@�@
���V�m�[�g�Ȃ�ďo�n�߂P�N���炢�́A���̃N���b�hcpu�m�[�g�݂����Ȉʒu�Â�����
���y����܂Ō��\�������ˁH
���y����܂Ō��\�������ˁH
856 �F,,�E�L�́M�E,,�j��-�������F2009/11/18(��) 01:32:33 ID:r93Gw0lQ
http://pc.watch.impress.co.jp/docs/column/ubiq/20090925_317554.html
�Ƃ肠����GMA�̐��\�̒@����͂��̕ӂ��B
��������C�X���G�����ǂ�������邩����ʼn��������B
CPU�R�A��AVX�Ƃǂ��A�g�����邩�A�ɂȂ肻�������B
�Ƃ肠����GMA�̐��\�̒@����͂��̕ӂ��B
��������C�X���G�����ǂ�������邩����ʼn��������B
CPU�R�A��AVX�Ƃǂ��A�g�����邩�A�ɂȂ肻�������B
857 �F,,�E�L�́M�E,,�j��-�������F2009/11/18(��) 01:36:54 ID:r93Gw0lQ
���m�[�gPC�Ȃ�AES�A�N�Z�����[�^�̂ق������ݑ傫���Ǝv�����ǂȁB
GPU����ǂ��ɂ��Ȃ��B128�r�b�g���������Ă����قǕ���x�����Ȃ����B
���A�Ȃ�Ńm�[�g���ui7�v�ɂȂ��Ă�H
�������C���X�g���[����2�R�A�i4�X���b�h�j����
GPU����ǂ��ɂ��Ȃ��B128�r�b�g���������Ă����قǕ���x�����Ȃ����B
���A�Ȃ�Ńm�[�g���ui7�v�ɂȂ��Ă�H
�������C���X�g���[����2�R�A�i4�X���b�h�j����
�C���e���̃I���{�������Ȃ킯�ł͂Ȃ����A���\�������̂�
�ǂ��ɂ������Ȃ��B�I���{��7600GT���炢�̐��\����������A
���������Ȃ����ǂȂ��B
�ǂ��ɂ������Ȃ��B�I���{��7600GT���炢�̐��\����������A
���������Ȃ����ǂȂ��B
�m�[�g�p��2�R�A�ł�i7
���l�[�����@�����锄���
���l�[�����@�����锄���
860 �F,,�E�L�́M�E,,�j��-�������F2009/11/18(��) 01:40:54 ID:r93Gw0lQ
����i740�̌n�����p���Ƃ����\
�EVertex Shader���\�t�g�iCPU�j����
�E�Ȃ�����FSB�o�R�Ńf�[�^���Ƃ�
���邢��CPU�Ƃ������b�オ����B
�EVertex Shader���\�t�g�iCPU�j����
�E�Ȃ�����FSB�o�R�Ńf�[�^���Ƃ�
���邢��CPU�Ƃ������b�オ����B
��n�O���S�����ĕ��X���ɂȂ���������ȃR�R�E�E
1�N��
�P�O���̃m�[�g�łȂ�Ƃ����̃Q�[���V�ׂ܂����@(�`�l�c)
�P�T���~�m�[�g�ł��A�S�����̃Q�[���������オ��܂���@(����������)�@�@����
�P�O���̃m�[�g�łȂ�Ƃ����̃Q�[���V�ׂ܂����@(�`�l�c)
�P�T���~�m�[�g�ł��A�S�����̃Q�[���������オ��܂���@(����������)�@�@����
863 �F,,�E�L�́M�E,,�j��-�������F2009/11/18(��) 01:52:10 ID:r93Gw0lQ
Westmere�x�[�X��CULV�Œቿ�i�т��ł߂�Intel�Ɍ��͖�������
864 �F,,�E�L�́M�E,,�j��-�������F2009/11/18(��) 01:54:49 ID:r93Gw0lQ
��������Celeron����Ȃ�Intel�̂Â���R�A�ς�A4�m�[�g�Ȃ�č��ł���6�����x�Ŕ�����̂�
10���������ĉ�����́H
10���������ĉ�����́H
ID:1G6YN+hd��Intel��@����AMD���D�ʂɂȂ�Ƃł��v���Ă�̂��ˁH
866 �F,,�E�L�́M�E,,�j��-�������F2009/11/18(��) 02:01:08 ID:r93Gw0lQ
�u�L���b�V��������Phenom II X4��Sandy Bridge�̐��\2�{�I�v�i�د
�L���b�V�����ĂȂ�ł���ȂɃ_�C�T�C�Y����z���g
Power7��eDRAM�Z�p������AMD
Power7��eDRAM�Z�p������AMD
868 �FSocket774�F2009/11/18(��) 02:25:17 ID:anBjiZBy
�Q�t�H�̑I�������Ȃ��Ȃ闈�N�ȍ~�̃C���e���̓��f�I���̏d�v�Ȍ䓾�ӗl�B
���Ƀm�[�g��AVX�Ȃ����ɑΉ����Ȃ�����DX11���f�͐��\��}�[�P�e�B���O��d���B
���Ƀm�[�g��AVX�Ȃ����ɑΉ����Ȃ�����DX11���f�͐��\��}�[�P�e�B���O��d���B
869 �F,,�E�L�́M�E,,�j��-�������F2009/11/18(��) 02:32:48 ID:r93Gw0lQ
GMA�h���C�o�̃\�t�g�E�F�AVertex Shader���ł��g�߂ȍŏ���AVX�A�v���P�[�V�����ɂȂ肻�������ǂ�
Llano��Propus����̐��\����̗v����
�EL2�{��
�E�X�e�b�s���O�ύX�ɂ��œK��
�E32nm���ɂ��N���b�N�A�b�v
�EGPGPU
���炢����?
CPU�͐����uSandy Bridge�����]�I�ȍ��͂����Ȃ��v���x�����Ǝv��
GPU�͋t�ɁuSandy Bridge�ɂ��Ȃ�̍���������v���x��
�v����ɍ��Ƃ���܂�ς�炸���̃Z�O�����g�ŃV�F�A���}�L���邱�Ƃ��Ȃ��A���Ă̂������I���Ǝv��
�EL2�{��
�E�X�e�b�s���O�ύX�ɂ��œK��
�E32nm���ɂ��N���b�N�A�b�v
�EGPGPU
���炢����?
CPU�͐����uSandy Bridge�����]�I�ȍ��͂����Ȃ��v���x�����Ǝv��
GPU�͋t�ɁuSandy Bridge�ɂ��Ȃ�̍���������v���x��
�v����ɍ��Ƃ���܂�ς�炸���̃Z�O�����g�ŃV�F�A���}�L���邱�Ƃ��Ȃ��A���Ă̂������I���Ǝv��
871 �FSocket774�F2009/11/18(��) 02:34:56 ID:anBjiZBy
���Ȃ݂Ƀ\�t�g��AVX��DXCS�͂ǂ��炪�i�ނ��낤���B
�n�C�G���h�̂ݑΉ���AVX�A�I���{����Ή�����DXCS�ŁA�V�F�A�I�ɂ�DXCS���D�ʂۂ����ǁB
�n�C�G���h�̂ݑΉ���AVX�A�I���{����Ή�����DXCS�ŁA�V�F�A�I�ɂ�DXCS���D�ʂۂ����ǁB
APU�������ăm�[�g�Ƃ����[�G���hPC�ɂ������܂݂��Ȃ�����
����܂苻���Ȃ���ȁB
����܂苻���Ȃ���ȁB
���W�X�^��256bit�Ɋg��������A�]����128bit��SIMD���Z��1/2�T�C�N���Ƃ�
1/4�T�C�N���Ƃ��Ŏ��s���ăX���[�v�b�g�����Ȃ�����Ȃ́H
Pen4��ALU�݂����Ȃ�
1/4�T�C�N���Ƃ��Ŏ��s���ăX���[�v�b�g�����Ȃ�����Ȃ́H
Pen4��ALU�݂����Ȃ�
874 �F,,�E�L�́M�E,,�j��-�������F2009/11/18(��) 02:42:30 ID:r93Gw0lQ
�Ƃ�����DX11��GMA�ł���Ή����܂����E�E�E
�i�Ƃ������CPU�����̔�d���グ��C������j
�q���g�F�I���{���x�̐��\�ł����Ȃ�Compute Shader��CPU�����ł��\��
AVX�͓��ߓI�Ɏg����
Pentium 4����Core 2�ɂ��Ă���GMA�̐��\���オ�����Ǝv������
���ꂪ�\�t�g�E�F�AVertex Shader�ł�
�i�Ƃ������CPU�����̔�d���グ��C������j
�q���g�F�I���{���x�̐��\�ł����Ȃ�Compute Shader��CPU�����ł��\��
AVX�͓��ߓI�Ɏg����
Pentium 4����Core 2�ɂ��Ă���GMA�̐��\���オ�����Ǝv������
���ꂪ�\�t�g�E�F�AVertex Shader�ł�
875 �F,,�E�L�́M�E,,�j��-�������F2009/11/18(��) 02:45:52 ID:r93Gw0lQ
�I���{���x�̐��\�ł����Ȃ�Ƃ������Ă�
���̃I���{GPU�̐��\�����܂ł�����I�ɏオ�����B
���̃I���{GPU�̐��\�����܂ł�����I�ɏオ�����B
877 �F,,�E�L�́M�E,,�j��-�������F2009/11/18(��) 02:55:53 ID:r93Gw0lQ
�L���b�V�������ɍ��ꂽPhenom II��DDR3�������������̑ш��荇�����Ƃł̐��\������u���v�Ƃ����̂Ȃ�
����͎��͘_���̔��Ɖ��߂���
����͎��͘_���̔��Ɖ��߂���
878 �FSocket774�F2009/11/18(��) 03:03:48 ID:anBjiZBy
�܂�A�����m��DX11�l�C�e�B�u�Ή���CS�ƁA�T���f�B��AVX�ɂ��\�t�gDXCS�̔�r�ɂȂ�̂��ȁB
�܂����i�т����Ȃ�Ⴄ���璼�ڔ�r�o���Ȃ����ǁB
���ɉ��i��3���~�����d��95W�œ��ꂵ����ǂ��Ȃ邾�낤���B�����m��3G+HD4650�A�T���f�B��2.6G+G45�̔{�ʂɂȂ邩�ȁB
�܂����i�т����Ȃ�Ⴄ���璼�ڔ�r�o���Ȃ����ǁB
���ɉ��i��3���~�����d��95W�œ��ꂵ����ǂ��Ȃ邾�낤���B�����m��3G+HD4650�A�T���f�B��2.6G+G45�̔{�ʂɂȂ邩�ȁB
�L���b�V�����{�ɂȂ���AthlonII�ƍl����I
Sandy�͂����ƍ��N���b�N�ŏo��Ǝv����
881 �FSocket774�F2009/11/18(��) 03:11:24 ID:anBjiZBy
GPU�ɒ�����64bitGDDR5��128M��LFB��t����Ƃ��o������ō��Ȃ��ȁB
��i2.8G����3.4G�A�^�[�{���[�h��3.8����4Ghz
http://en.hardspell.com/doc/enshowcont.asp?id=6470
http://en.hardspell.com/doc/enshowcont.asp?id=6470
Sandy�̃R�A��r�����Ă����ł́A�ʐςł�Westmere�Ƃ���Ȃɕς��Ȃ���Ȃ�
�����琫�\����͍l���ɂ���
�A���R�A���ł̐��\���オ�ǂ��܂łȂ̂��킩��Ȃ����ǂ�
�����琫�\����͍l���ɂ���
�A���R�A���ł̐��\���オ�ǂ��܂łȂ̂��킩��Ȃ����ǂ�
884 �F,,�E�L�́M�E,,�j��-�������F2009/11/18(��) 03:37:30 ID:r93Gw0lQ
>>881
�����ċt�ɍl���Ăق����B
�������\�ǂ��������ʐ��i�iBulldozer�j�Ȃ�Ĕ���Ȃ��ł���B
���݂��ɑш��荇���Đ��\�E���������炢�����x�����A�Ƃ�����
�ւ�Ƀ{�g���l�b�N�������悤�Ƃ�����R�X�g�����Ȃ肷����̂ł́H
�m�[�g�����Ő��\�����o���ɂ�DDR3 SO-DIMM��1600MHz 2�����K�v���Ď��_�ʼn��i�I�ɂ͕s�m��v�f�����B
>>883
GPU���͂���ȂɘM�邱�Ɩ����̂ł́H
AVX����ł͕����������Z�\�͂�4�R�A�ł�Cell�ɕC�G�������
Cell��낵���\�t�g�E�F�AVertex Shader�̎g���b��͂���Ǝv�����ǂˁB
CPU��L3�L���b�V���o�R�Ńf�[�^�����ł���悤�ɂ������g��Ȃ���͖����B
���������Ζʔ������B
Intel C++ Compiler�ł�CVT16�����A�A���Ȃ킿half float�̕ϊ����s���g�ݍ��݊���
�\�t�g�I�ɒ���Ă���B
�����ʓI�ɂ̓O���t�B�b�N��������ˁB
���̂ւ��GMA���g���~�h���E�F�A�̊J���Ҍ������ȂƎv�������B
�Ȃ��̂ւ��Larrabee�Ƃ͕ʂ�GPU�v�����������B�ꂷ��B
�iLarrabee��GPU�Ɍ��������ăX�p�R���v���Z�b�T�����j
�����ċt�ɍl���Ăق����B
�������\�ǂ��������ʐ��i�iBulldozer�j�Ȃ�Ĕ���Ȃ��ł���B
���݂��ɑш��荇���Đ��\�E���������炢�����x�����A�Ƃ�����
�ւ�Ƀ{�g���l�b�N�������悤�Ƃ�����R�X�g�����Ȃ肷����̂ł́H
�m�[�g�����Ő��\�����o���ɂ�DDR3 SO-DIMM��1600MHz 2�����K�v���Ď��_�ʼn��i�I�ɂ͕s�m��v�f�����B
>>883
GPU���͂���ȂɘM�邱�Ɩ����̂ł́H
AVX����ł͕����������Z�\�͂�4�R�A�ł�Cell�ɕC�G�������
Cell��낵���\�t�g�E�F�AVertex Shader�̎g���b��͂���Ǝv�����ǂˁB
CPU��L3�L���b�V���o�R�Ńf�[�^�����ł���悤�ɂ������g��Ȃ���͖����B
���������Ζʔ������B
Intel C++ Compiler�ł�CVT16�����A�A���Ȃ킿half float�̕ϊ����s���g�ݍ��݊���
�\�t�g�I�ɒ���Ă���B
�����ʓI�ɂ̓O���t�B�b�N��������ˁB
���̂ւ��GMA���g���~�h���E�F�A�̊J���Ҍ������ȂƎv�������B
�Ȃ��̂ւ��Larrabee�Ƃ͕ʂ�GPU�v�����������B�ꂷ��B
�iLarrabee��GPU�Ɍ��������ăX�p�R���v���Z�b�T�����j
>>865
�P�N��U�������łR���Q�[���ł���`�l�c�ƂR���Q�[���ł��Ȃ������������Ȃ�`�l�c���D�ʂɂȂ�Ǝv����
�I���Ȉ�@����������h���Ȃ邾�낤��
�P�N��U�������łR���Q�[���ł���`�l�c�ƂR���Q�[���ł��Ȃ������������Ȃ�`�l�c���D�ʂɂȂ�Ǝv����
�I���Ȉ�@����������h���Ȃ邾�낤��
886 �F,,�E�L�́M�E,,�j��-�������F2009/11/18(��) 03:43:51 ID:r93Gw0lQ
�Q�[���i�j
��ƃ��[�U�[�Ȃ�AES�A�N�Z�����[�^�ʼn��K�Ƀ\�t�gVPN�ł���ق���I�Ԃ���
��ƃ��[�U�[�Ȃ�AES�A�N�Z�����[�^�ʼn��K�Ƀ\�t�gVPN�ł���ق���I�Ԃ���
�ǂ����Q�[�~���O�m�[�g�Ȃ�f�o�t�ʂɐςނ���h�������� CPU�������ސς̔����Ηǂ�����ˁ[���߂�ǂ�����
889 �F,,�E�L�́M�E,,�j��-�������F2009/11/18(��) 03:55:19 ID:r93Gw0lQ
����A�W�A�i�j
AVX�̃v���O���~���O�}�j���A����
�v���Z�b�T�ɂ���Ă�AVX���T�|�[�g���Ă邪AES���T�|�[�g���Ȃ��ꍇ������̂ŗ������Ă�
�I�Ȃ��Ə����Ă��邪�A����ǂ����Ă�Bulldozer�̂��Ƃ����
BitLocker�Ȃ�AES�A�N�Z�����[�V�����͏��Ȃ��Ƃ�����3�N��AMD�v���b�g�t�H�[���ł͎g���Ȃ��E�E������
AVX�̃v���O���~���O�}�j���A����
�v���Z�b�T�ɂ���Ă�AVX���T�|�[�g���Ă邪AES���T�|�[�g���Ȃ��ꍇ������̂ŗ������Ă�
�I�Ȃ��Ə����Ă��邪�A����ǂ����Ă�Bulldozer�̂��Ƃ����
BitLocker�Ȃ�AES�A�N�Z�����[�V�����͏��Ȃ��Ƃ�����3�N��AMD�v���b�g�t�H�[���ł͎g���Ȃ��E�E������
�a�q�h�b�r�S�̂œ��{�̂P�O�{�̂��������͂�������
891 �F,,�E�L�́M�E,,�j��-�������F2009/11/18(��) 04:28:01 ID:r93Gw0lQ
Netbook���ȁB
Atom�Ȃ�ł���Ȉُ�Ɉ�������́H��
��H���ǂ�����ăR�X�g�����Ă�
��H���ǂ�����ăR�X�g�����Ă�
�ȑO�v������H�̍ė��p�B
�i�C���e���ɂƂ��āj����Ȃ���������菜�����ɂ��T�C�Y�̏k���B
��������H�Ȃ̂ŁA1�E�F�n�ӂ�ɑ�ʂ̃`�b�v�̌����ł���B
��������
�i�C���e���ɂƂ��āj����Ȃ���������菜�����ɂ��T�C�Y�̏k���B
��������H�Ȃ̂ŁA1�E�F�n�ӂ�ɑ�ʂ̃`�b�v�̌����ł���B
��������
����A���������ǔ����ł͂Ȃ������͂��ł���
����Ɉ��ȉ��̃_�C�T�C�Y�Ȃ�_�C�P�����p�b�P�[�W���O�����ΓI�ɍ������̂ł͂Ȃ�����
����Ɉ��ȉ��̃_�C�T�C�Y�Ȃ�_�C�P�����p�b�P�[�W���O�����ΓI�ɍ������̂ł͂Ȃ�����
23���X��������
�c�q�����������������Ƃ́A�J�W���A���Q�[����Llano���K���Ă��
adobe��AMD�ɍœK��������
�����`�b�v�ɂ��GPGPU���\�ɂ����҂����Ă��
���Ă��Ƃ���
adobe��AMD�ɍœK��������
�����`�b�v�ɂ��GPGPU���\�ɂ����҂����Ă��
���Ă��Ƃ���
atom�Ƃ��ቿ�i�m�[�g��������Ă��Ƃ͐��\�Ȃ�Ă��܂�d�v������ĂȂ����Ă��Ƃ����
Atom�̒����d�͂͐��\�̔��e�ɓ��邩�ƁB
���Ƃ͏��_�C�Ɛ�[�v���Z�X�̑g�ݍ��킹�ɂ��j��I�ȉ��i�ƁAIntel�Ƃ����u�����h�B
Bobcat��Llano�����߂�w�͊m���ɂ��邾�낤��
Atom�̂悤�ɐV�����w���J�ăq�b�g���i�ݏo���悤��
�C���p�N�g�͊����Ȃ��B
���Ƃ͏��_�C�Ɛ�[�v���Z�X�̑g�ݍ��킹�ɂ��j��I�ȉ��i�ƁAIntel�Ƃ����u�����h�B
Bobcat��Llano�����߂�w�͊m���ɂ��邾�낤��
Atom�̂悤�ɐV�����w���J�ăq�b�g���i�ݏo���悤��
�C���p�N�g�͊����Ȃ��B
Atom�����߂�w��Bobcat�APineview�AION(2)
Llano��HP��dv2�̂悤�Ȃ��̂����߂�w�H
Llano��HP��dv2�̂悤�Ȃ��̂����߂�w�H
����ɂ���2011�N�̘b�ł����܂Ŗϑz�ł���n���ɂ͒E�X
Atom���AthlonNeo�̂ق���������
��RISC�̂ق����ȓd�͂���
�l�b�g���x�̉^�p��Windows�v��̂���
Intel���i����Ȃ���j�b�`�ɂ����Ȃ�Ȃ��Ƃ����v���Ȃ�Atom
����ɑ��������Ă̂�Bob
��RISC�̂ق����ȓd�͂���
�l�b�g���x�̉^�p��Windows�v��̂���
Intel���i����Ȃ���j�b�`�ɂ����Ȃ�Ȃ��Ƃ����v���Ȃ�Atom
����ɑ��������Ă̂�Bob
ARM�ŋ��ł��˂킩��܂�
�N��40���͊m���ɍŋ�
���i�Əȓd�͂��u�����v��������̂��̂ł����āA
����������Ă�TDP15W��Athlon Neo��Athlon�̃��l�[���i�E���؏����i�Ƃ��Ă�
�����������Ȃ��킯�ł��B
����������Ă�TDP15W��Athlon Neo��Athlon�̃��l�[���i�E���؏����i�Ƃ��Ă�
�����������Ȃ��킯�ł��B
��ʐl�̓��l�[�����ǂ��Ƃ��Ȃ�Ă킩��܂���
Intel������̂���ł�
atom���ȓd�͂Ńp�t�H�[�}���X�ʂł��D�G�Ƃ����̂͂������A
���̗D�G��CPU���g�����߂ɂ�CPU���i�i�ɑ����d�͂Ŕ��M���ł����`�b�v�Z�b�g���K�v�Ƃ����̂͂ǂ���H
��k�ɂ��Ȃ�Ȃ���
���̗D�G��CPU���g�����߂ɂ�CPU���i�i�ɑ����d�͂Ŕ��M���ł����`�b�v�Z�b�g���K�v�Ƃ����̂͂ǂ���H
��k�ɂ��Ȃ�Ȃ���
Atom�̏ȓd�͂�ɂ��Ă���̂�Z�V���[�Y�B
Netbook��Nettop�ō̗p����Ă���N�△��͂������������������肪�Ȃ��B
����Atom��NorthBridge��CPU�ɓ������ꂿ�Ⴄ���瑽���}�V�ɂȂ邯�ǁB
Netbook��Nettop�ō̗p����Ă���N�△��͂������������������肪�Ȃ��B
����Atom��NorthBridge��CPU�ɓ������ꂿ�Ⴄ���瑽���}�V�ɂȂ邯�ǁB
Sandy Bridge��4�R�A�����Ȃ����@���b���i��ł�ȁc
Tegra + Windows Embedded CE 6.0 �̒��~�j�m�[�g�����z�B���������{���ᔄ���ĂȂ��B
���~�j���Č����Ă��邯��ǁA�V�O�}���I���ʂ��҂�����ˁB
Atom ���������ԉғ��ł��邵�BARM���ǂ�CPU����B
���~�j���Č����Ă��邯��ǁA�V�O�}���I���ʂ��҂�����ˁB
Atom ���������ԉғ��ł��邵�BARM���ǂ�CPU����B
>>907
atom�̏��p�t�H�[�}���X�m�����眱�R�Ƃ����@
���߂��Ă��@�@�@�����������M�Ҍ�p�B�̃��ƂP�O�SM�@�X�O�b�䂗�@
�j�V�ɂ��]�T�ŏ��ĂȂ���
atom�̏��p�t�H�[�}���X�m�����眱�R�Ƃ����@
���߂��Ă��@�@�@�����������M�Ҍ�p�B�̃��ƂP�O�SM�@�X�O�b�䂗�@
�j�V�ɂ��]�T�ŏ��ĂȂ���
Atom �̗��_�͒����d��CPU�ŁA�������{�f�B��PC���� x86 �A�v���P�[�V�������g����B
�Ƃ����̂����_������ǁA����ȏ�ł�����ȉ��ł��Ȃ��B
�N������CPU�ƌ����ĂȂ���
�N�����̃`�b�v�������d�͂��Č����ĂȂ���
�����ĈĂ̒葬��CPU�o�����Ǝv���Ə���d�͂������B����ŃX�}�[�g�t�H���Ƃ��Ɠd�Ƃ��i�o���悤�Ƃ��Ă邵�B
����ȈӖ��ł��܂��˂��B
�Ƃ����̂����_������ǁA����ȏ�ł�����ȉ��ł��Ȃ��B
�N������CPU�ƌ����ĂȂ���
�N�����̃`�b�v�������d�͂��Č����ĂȂ���
�����ĈĂ̒葬��CPU�o�����Ǝv���Ə���d�͂������B����ŃX�}�[�g�t�H���Ƃ��Ɠd�Ƃ��i�o���悤�Ƃ��Ă邵�B
����ȈӖ��ł��܂��˂��B
>>912
�Ɠd�̓o�b�e���[�쓮�ł��Ȃ����A����قǏ���d�͂ɑ���v���������Ȃ���Ȃ��H
����ɍ��͂ǂ������m��Ȃ����A�I���W�i����Fusion�\�z�ł�Bobcat��
(Atom�Ɠ����l��)�e���r�E�g�ы@����^�[�Q�b�g�ɂ��Ă��B
AMD��D���Ȃ͕̂����邪�AAtom���Ȃ߂錾�t�͂��̂܂�Bobcat�ɕԂ��Ă���킯�ŁB
�܂�A���i���o�ĂȂ����������������Ă����傤���Ȃ��B
�Ɠd�̓o�b�e���[�쓮�ł��Ȃ����A����قǏ���d�͂ɑ���v���������Ȃ���Ȃ��H
����ɍ��͂ǂ������m��Ȃ����A�I���W�i����Fusion�\�z�ł�Bobcat��
(Atom�Ɠ����l��)�e���r�E�g�ы@����^�[�Q�b�g�ɂ��Ă��B
AMD��D���Ȃ͕̂����邪�AAtom���Ȃ߂錾�t�͂��̂܂�Bobcat�ɕԂ��Ă���킯�ŁB
�܂�A���i���o�ĂȂ����������������Ă����傤���Ȃ��B
���m���Ȃ��̂����������ǁABobcat�͂ǂ�ȋZ�p��(������)1W�ȉ���B������̂�
�܂��悭�킩���̂�ˁB
�܂��悭�킩���̂�ˁB
Bobcat��1W�ȉ����\���ăX���C�h�ɏ����Ă���������A
�X�}�[�g�t�H���ڎw���Ă���Z��Atom�n�قǂ���Ȃ��Ă��A
����Ȃ�ɏ���d�͂��Ⴂ�̂��o���Ȃ��́H
�X�}�[�g�t�H���ڎw���Ă���Z��Atom�n�قǂ���Ȃ��Ă��A
����Ȃ�ɏ���d�͂��Ⴂ�̂��o���Ȃ��́H
�@�x�ꂽ���AAtom�̎s��ł̕]�������ɂ߂���ł̌����I�Ȏd�l��
�o�������Ă��Ƃ��ˁB
�o�������Ă��Ƃ��ˁB
��2����/cyc�̃A�E�g�I�u�I�[�_�[������
����d�͂�Atom��荂���Ȃ邵������낤
SMT�������̂�������Ƃ���ǂ�
����d�͂�Atom��荂���Ȃ邵������낤
SMT�������̂�������Ƃ���ǂ�
�X�S�����Ǝv�������B
>>918���J�����Ĕ���o���Α�ׂ��ł���ˁH
Bobcat�͌��sAtom��CULV�̊ԑ_���Ă�낤���ǁA
2011�N�ɂ�Atom��Saltwell�R�A�ɂȂ邵�A���ǎ����悤�ȃ����W�Ɏ��܂�C������
�V���O���X���b�h�̐������Z��Bobcat�̕����������낤����
>>918���J�����Ĕ���o���Α�ׂ��ł���ˁH
Bobcat�͌��sAtom��CULV�̊ԑ_���Ă�낤���ǁA
2011�N�ɂ�Atom��Saltwell�R�A�ɂȂ邵�A���ǎ����悤�ȃ����W�Ɏ��܂�C������
�V���O���X���b�h�̐������Z��Bobcat�̕����������낤����
�� 1w�ł���������荂���\�Ȃ��W�U
����́AOoO�Œ�N���b�N��d���ȕ����̃`�b�v�v�ɂ���Ίm���ɉ\�ł͂��낤
�������AOoO�ɂ���ă_�C�T�C�Y���傫���Ȃ�Ƃ����R�X�g�A�b�v�̃g���[�h�I�t��w�������ɂȂ�
Intel�̔��f���Ȃ�Penryn-L�ł͂Ȃ�Atom�Ȃ̂��A��
����́AOoO�Œ�N���b�N��d���ȕ����̃`�b�v�v�ɂ���Ίm���ɉ\�ł͂��낤
�������AOoO�ɂ���ă_�C�T�C�Y���傫���Ȃ�Ƃ����R�X�g�A�b�v�̃g���[�h�I�t��w�������ɂȂ�
Intel�̔��f���Ȃ�Penryn-L�ł͂Ȃ�Atom�Ȃ̂��A��
�ςȂ��̂�V�����J����������������
intel��Atom��AMD��Bobcat�ő_���Ă���s�ꂪ�Ⴄ��Ȃ��́H
intel�͖{�C�ŃX�}�[�g�t�H����x86����ꂽ���Ǝv���Ă��邯�ǁA
AMD�͂����܂ŏ������@��́A���Ȃ��Ƃ����̂Ƃ���_���Ă��Ȃ���Ȃ����낤���B
intel�͖{�C�ŃX�}�[�g�t�H����x86����ꂽ���Ǝv���Ă��邯�ǁA
AMD�͂����܂ŏ������@��́A���Ȃ��Ƃ����̂Ƃ���_���Ă��Ȃ���Ȃ����낤���B
>>911
�v�����Bobcat���O��K7�x�[�X��GeodeGX������Ă�����Atom�Ƀf�J�C�炳��鎖�͂Ȃ��������Ă��Ƃ��ˁB
�v�����Bobcat���O��K7�x�[�X��GeodeGX������Ă�����Atom�Ƀf�J�C�炳��鎖�͂Ȃ��������Ă��Ƃ��ˁB
����K7�R�A��4W�Ȃ�1W�Ȃ���Ă���TDP�g�ŁA��V�ʼn��N���b�N����ł��������̂ɓ����Ă����Ȃ��Ƃ�
AthlonXP��45nm�ō�蒼������A�l�b�g�u�b�N�p��
����CPU�ɂȂ�Ǝv�����ǂˁB
����CPU�ɂȂ�Ǝv�����ǂˁB
����Power now���፡�̃l�b�g�u�b�N�ł͗���Ă�����낤�B
���\�ł�����d�͂ł��Ȃ����̕ӂ����ł͂Ȃ����ˁB�f���͂悭�Ă����_������Ȃ��B
��Ԃ̗��R�́uAMD�ɂ���ȗ]�T�͂Ȃ������v���Ď����낤���B
���\�ł�����d�͂ł��Ȃ����̕ӂ����ł͂Ȃ����ˁB�f���͂悭�Ă����_������Ȃ��B
��Ԃ̗��R�́uAMD�ɂ���ȗ]�T�͂Ȃ������v���Ď����낤���B
SocketA�Ή���PhenomX4���o������A�n������m��
939�ł�����
939�ł�����
>>920
�m���Ƀ_�C�͑����邾�낤���A�����atom�ł����_�C�͗]���Ă���B���̂��߂�GPU���ڂł�����B
�_�C�ʐς́AI/O�̂��߂̐ڑ������ł�����x�ȏ�ɂ͏��������Ă����ʂ������B
����Ȃ�C���I�[�_�[����Ȃ��A�E�g�I�u�I�[�_�[�ɂ����ق����悢�B
�ނ��GPU�����ڂ���Ȃ�PineView���傫���Ȃ邩������Ȃ�����ǁA
���\�̂悢GPU�����ڂł���AMD�̋��݂�����A�m�[�X�u���b�W��T�E�X�܂œ�������1�`�b�v�����ւƐi�߂A
�m�[�X��T�E�X�����Ȃ��Ă悭�Ȃ�킯������A�������C���͂ނ���]�T���o�Ă��邾�낤�B
Intel��SoC��_���Ă���̂Ő�ΐ��\���������Ă��邱�Ƃ͂���܂�l����ꂸ�A
���������N���b�N�A�b�v����Atom�ɂȂ邭�炢���낤����A
Bobcat�̓l�b�g�u�b�N��V�����������v�ł͂��Ȃ苣���͂��������̂ɂȂ�̂ł͂Ȃ����Ɨ\�z
�m���Ƀ_�C�͑����邾�낤���A�����atom�ł����_�C�͗]���Ă���B���̂��߂�GPU���ڂł�����B
�_�C�ʐς́AI/O�̂��߂̐ڑ������ł�����x�ȏ�ɂ͏��������Ă����ʂ������B
����Ȃ�C���I�[�_�[����Ȃ��A�E�g�I�u�I�[�_�[�ɂ����ق����悢�B
�ނ��GPU�����ڂ���Ȃ�PineView���傫���Ȃ邩������Ȃ�����ǁA
���\�̂悢GPU�����ڂł���AMD�̋��݂�����A�m�[�X�u���b�W��T�E�X�܂œ�������1�`�b�v�����ւƐi�߂A
�m�[�X��T�E�X�����Ȃ��Ă悭�Ȃ�킯������A�������C���͂ނ���]�T���o�Ă��邾�낤�B
Intel��SoC��_���Ă���̂Ő�ΐ��\���������Ă��邱�Ƃ͂���܂�l����ꂸ�A
���������N���b�N�A�b�v����Atom�ɂȂ邭�炢���낤����A
Bobcat�̓l�b�g�u�b�N��V�����������v�ł͂��Ȃ苣���͂��������̂ɂȂ�̂ł͂Ȃ����Ɨ\�z
�_�C�����܂��Ă邩��A�E�g�I�u�I�[�_�ɂ���Ƃ�����
�f�R�[�_�����M���Ȃ��ĔM�v�I�ɂ߂�ǂ���������C���I�[�_�ɂ�����Ȃ��̂���Atom
�f�R�[�_�����M���Ȃ��ĔM�v�I�ɂ߂�ǂ���������C���I�[�_�ɂ�����Ȃ��̂���Atom
>>929
���[�Ȃ�قǂȂ�
��������x86CPU���f�R�[�_�[�ɗ���܂���Ȃ킯���˂�
atom�̏ꍇ�A���ƓI�ȗ��R�ŃN���b�N�͍T���߂��B
�i�����̂̓t�@�����X��2.4Ghz�œd���f�t�H�ň��肵�ē����Ă��邵�j
�����A�E�g�I�u�I�[�_�[��������T�O�����N���b�N�A�b�v�͂ł��Ȃ������낤�ˁB
���Ƀt�@�����X����B�f�R�[�_�[���z�b�g�X�|�b�g�ɂȂ��āB
����bobcat�̃f�R�[�_�[�͂���Ȃ�IPC�������Ȃ������x�ȍœK�������Ȃ�
�Ɨ\�z���Ă݂�B
���������v�Z�ʁA���Ȃ킿�Q�[�g�̗ʁA���Ȃ킿���M�Ƃ�����������̂ł͂Ȃ��낤���B
�������قǍ��x�ȃf�R�[�h���s��Ȃ��Ă��A����ł��C���I�[�_�[���͂��\���������낤�Ƃ��v���B
��ʓI�Ȑ��l�͑f�l������킩��Ȃ����B
�v���Z�X�Z�p�AAMD��High-K������̂ȁB
High-K���������炤�܂�������₦�邾�낤�Ȃ������ƁB
���[�Ȃ�قǂȂ�
��������x86CPU���f�R�[�_�[�ɗ���܂���Ȃ킯���˂�
atom�̏ꍇ�A���ƓI�ȗ��R�ŃN���b�N�͍T���߂��B
�i�����̂̓t�@�����X��2.4Ghz�œd���f�t�H�ň��肵�ē����Ă��邵�j
�����A�E�g�I�u�I�[�_�[��������T�O�����N���b�N�A�b�v�͂ł��Ȃ������낤�ˁB
���Ƀt�@�����X����B�f�R�[�_�[���z�b�g�X�|�b�g�ɂȂ��āB
����bobcat�̃f�R�[�_�[�͂���Ȃ�IPC�������Ȃ������x�ȍœK�������Ȃ�
�Ɨ\�z���Ă݂�B
���������v�Z�ʁA���Ȃ킿�Q�[�g�̗ʁA���Ȃ킿���M�Ƃ�����������̂ł͂Ȃ��낤���B
�������قǍ��x�ȃf�R�[�h���s��Ȃ��Ă��A����ł��C���I�[�_�[���͂��\���������낤�Ƃ��v���B
��ʓI�Ȑ��l�͑f�l������킩��Ȃ����B
�v���Z�X�Z�p�AAMD��High-K������̂ȁB
High-K���������炤�܂�������₦�邾�낤�Ȃ������ƁB
IPC����Ȃ���ILP�̂܂����������˂��T�[�Z����
http://pc.watch.impress.co.jp/docs/column/kaigai/20091112_328392.html
>>Bobcat�́A2���ߔ��s2���߃��^�C��/�T�C�N����Out-of-Order���s�R�A�ŁA�p�t�H�[�}���X�͑��ΓI�ɓ��N���b�N��Atom��荂���Ɛ��肳���B
�����݂�ƁA2���ߔ���(2 issue)���Ă���B
�A�E�g�I�u�I�[�_�[���́A���Z��̃��\�[�X��L�����p����d�g�݂ł�����̂ŁA
Atom��SMT�̖ڎw���Ƃ���ƁA���ʂ͎��Ă�������᎗�Ă���B
Atom�̏ꍇOS����2�R�A�Ƃ��Č�������Ă��Ƃ�2���߂�OS����������킯�����B
OS�Ƃ������v���O���������̕ӂ��œK������n�j��Atom�͂܂��ɑg�ݍ��݂ł͌������悭�Ȃ낤�B
���bobcat��OoO��2���ߓ������s����̂ŁAOS�A�v���O�����͕��ʂɖ��߂��Ă����A2���ߓ����ɂł��邾�����s���Ă����Ɓc
�Ȃ�OoO�łȂ�����SMT�Ȃ�Ă��Ƃ�����A���ꂱ�����������G�������ȁB
�u���b�N�}������Ɛ����̃��j�b�g�͂S�i2�Z�b�g�j�����ĕ��������͂Q�i1�Z�b�g�j����悤���B
3���߂Ƃ�4���߂Ƃ����������Ȃ��ėǂ����A����ς�f�R�[�_�[�͂���ȕ��G�ł͂Ȃ��̂��낤�Ǝv�������A�ڂ����l����ȁB
>>Bobcat�́A2���ߔ��s2���߃��^�C��/�T�C�N����Out-of-Order���s�R�A�ŁA�p�t�H�[�}���X�͑��ΓI�ɓ��N���b�N��Atom��荂���Ɛ��肳���B
�����݂�ƁA2���ߔ���(2 issue)���Ă���B
�A�E�g�I�u�I�[�_�[���́A���Z��̃��\�[�X��L�����p����d�g�݂ł�����̂ŁA
Atom��SMT�̖ڎw���Ƃ���ƁA���ʂ͎��Ă�������᎗�Ă���B
Atom�̏ꍇOS����2�R�A�Ƃ��Č�������Ă��Ƃ�2���߂�OS����������킯�����B
OS�Ƃ������v���O���������̕ӂ��œK������n�j��Atom�͂܂��ɑg�ݍ��݂ł͌������悭�Ȃ낤�B
���bobcat��OoO��2���ߓ������s����̂ŁAOS�A�v���O�����͕��ʂɖ��߂��Ă����A2���ߓ����ɂł��邾�����s���Ă����Ɓc
�Ȃ�OoO�łȂ�����SMT�Ȃ�Ă��Ƃ�����A���ꂱ�����������G�������ȁB
�u���b�N�}������Ɛ����̃��j�b�g�͂S�i2�Z�b�g�j�����ĕ��������͂Q�i1�Z�b�g�j����悤���B
3���߂Ƃ�4���߂Ƃ����������Ȃ��ėǂ����A����ς�f�R�[�_�[�͂���ȕ��G�ł͂Ȃ��̂��낤�Ǝv�������A�ڂ����l����ȁB
LIano�̓V�������N��high-k��5Ghz�ʂŏo���Ă��������B
���ł�3.4G�ŏo���Ă������1.5�{���x�]�T���낤�B
����ł�sandy�R�͌��������낤���B
���ł�3.4G�ŏo���Ă������1.5�{���x�]�T���낤�B
����ł�sandy�R�͌��������낤���B
���낻��DRAM2GB���炢�ڂ�Ȃ��ł��傤���H
>>933
���[�N�o�[�X�g���ǂ�����̂��������[���Ƃ��낾�Ǝv���B
���[�N�o�[�X�g���ǂ�����̂��������[���Ƃ��낾�Ǝv���B
>>933
�����ŃN���b�N�オ����Ă��̎��ォ��̃^�C���g���x���[���Ə��ꎞ��
�����ŃN���b�N�オ����Ă��̎��ォ��̃^�C���g���x���[���Ə��ꎞ��
�����܂�Sandy�R�̖{����Bulldozer����
Llano��Nehalem�̃O���[�h�ł���i5�����̑R��
��{65w������𒆐S�ɓW�J������
�܂�Sandy�̃p�t�H�[�}���X���������낤����
939 �F,,�E�L�́M�E,,�j��-�������F2009/11/19(��) 20:46:02 ID:0wzQGDSa
4�R�A�Ȃ̂ɃL���b�V��4MB�����Ȃ�CPU�������Ƃ��̂ЂƂ���
4MB����Phenom�N���V�b�N�Ɠ���������A�ߓx�Ȋ��҂͏o���Ȃ����
�N���V�b�NPhenom��HD4650�����������Ǝv�������̂�
�ŁA��������UMA
Bulldozer�͂ǂ������4���߂�B���������Ȃ낤��
���U�@�ł���������d�͂ƔM���Ƃ�ł��Ȃ����ƂɂȂ肻������
���U�@�ł���������d�͂ƔM���Ƃ�ł��Ȃ����ƂɂȂ肻������
�f�R�[�_���猩����4way��2�X���b�h�Ŗ��߂邩��
����ق�ILP�Nj����Ȃ��Ă����Ƃ�����ˁH
�ł��V���O���X���b�h�̎��͂ǂ�����낤��
����ق�ILP�Nj����Ȃ��Ă����Ƃ�����ˁH
�ł��V���O���X���b�h�̎��͂ǂ�����낤��
AMD�̎�����CPU�uBulldozer�v�̃N���X�^�x�[�X�}���`�X���b�f�B���O
http://pc.watch.impress.co.jp/docs/column/kaigai/20091120_330076.html
http://pc.watch.impress.co.jp/docs/column/kaigai/20091120_330076.html
4way�~2�X���b�h���Ƃ����b�̂悤�ȁB
��ɂ͐M�����������ǁB
�f�R�[�_�����łȂ��������Z�p�C�v��2�X���b�h�ŋ��L���āA
�ʏ�P�[�X��2�`3way�~2�X���b�h�A
�x�X�g�P�[�X��4way/�X���b�h��
(���̂Ƃ��͑����X���b�h�͋]���ɂȂ�)�Ƃ����Ȃ�
�g�����W�X�^�𑝂₳���ɃV���O���X���b�h���\���ő剻����
�}���`�X���b�h���̃X���[�v�b�g���Nj�����
���z�I�ȃN���X�^���A�[�L�e�N�`�����Ǝv������
���������킯�ł��Ȃ��悤�����B
��ɂ͐M�����������ǁB
�f�R�[�_�����łȂ��������Z�p�C�v��2�X���b�h�ŋ��L���āA
�ʏ�P�[�X��2�`3way�~2�X���b�h�A
�x�X�g�P�[�X��4way/�X���b�h��
(���̂Ƃ��͑����X���b�h�͋]���ɂȂ�)�Ƃ����Ȃ�
�g�����W�X�^�𑝂₳���ɃV���O���X���b�h���\���ő剻����
�}���`�X���b�h���̃X���[�v�b�g���Nj�����
���z�I�ȃN���X�^���A�[�L�e�N�`�����Ǝv������
���������킯�ł��Ȃ��悤�����B
L1�ʂȂ̂�2�X���b�h�Ő����p�C�v���L�Ȃ�����ނ��됫�\������
�ނ��땪����A���Ă̂��ő�̓�������
����4way�̓���͉�������H�v���邾�낤��
���܂ł̂悤��ALU��AGU�Ώ̂��ᖳ������
����4way�̓���͉�������H�v���邾�낤��
���܂ł̂悤��ALU��AGU�Ώ̂��ᖳ������
�[���Ƃ�4way2�X���b�h���P�R�A�ŁA���ꂪ�f���A���Ƃ�
�N�A�b�h�œW�J�����ƌ��Ă����̂��ȁH
�N�A�b�h�œW�J�����ƌ��Ă����̂��ȁH
L1L2L3�L���b�V���Ƃ��邯�ǁAL0.5�L���b�V�����ĂȂ��̂�
���W�X�^�Ɠ���̐��\������1KB�L���b�V��
���W�X�^�Ɠ���̐��\������1KB�L���b�V��
951 �F,,�E�L�́M�E,,�j��-�������F2009/11/20(��) 01:52:49 ID:OfG4YBQO
�X�g�A�o�b�t�@
952 �F,,�E�L�́M�E,,�j��-�������F2009/11/20(��) 01:55:51 ID:OfG4YBQO
��萳�m�Ɍ����ƃX�g�A���t�H���[�h�o�b�t�@
�����W�X�^�E�B���h�E
�ߋ��ɂ͐��\����ɍv�����������������
���͂������߂͂��Ȃ�
�ߋ��ɂ͐��\����ɍv�����������������
���͂������߂͂��Ȃ�
954 �F,,�E�L�́M�E,,�j��-�������F2009/11/20(��) 02:09:25 ID:OfG4YBQO
����x86�̃X�g�A���t�H���[�h�o�b�t�@����
���W�X�^�ǂ��납L1�L���b�V�����݂̃_�C�ʐϐH���Ă邼
�܂��g�����W�X�^���x���傫���Ⴄ�̂ŗe�ʂ͂���Ȃɖ�����
���W�X�^�ǂ��납L1�L���b�V�����݂̃_�C�ʐϐH���Ă邼
�܂��g�����W�X�^���x���傫���Ⴄ�̂ŗe�ʂ͂���Ȃɖ�����
�ӂނ��ALSU�̃l�b�N�ق��Ƃ��킯�ˁ[���A�Ȃ�ق�
�cx64���āA64bit�g���������ă��W�X�^�lj�����ł��ǂ�������ˁ[���Ȃ�
�cx64���āA64bit�g���������ă��W�X�^�lj�����ł��ǂ�������ˁ[���Ȃ�
REX�v���t�B�N�X�̐���͂Ƃ������Ƃ��āA
8�{�͖��炩�ɑ���Ȃ�
8�{�͖��炩�ɑ���Ȃ�
�A�h���b�V���O�̕K�v������EIP��ESP/EBP��64bit��
������Ȃ��B�܂��A�A�h���X���Z�̕K�v��������
�̂Ő������W�X�^��64bit�ɂ�����Ȃ��B
���ǃA�h���X��64bit�ɂ����烌�W�X�^���S��64bit�ɂ���
�K�v������B
������Ȃ��B�܂��A�A�h���X���Z�̕K�v��������
�̂Ő������W�X�^��64bit�ɂ�����Ȃ��B
���ǃA�h���X��64bit�ɂ����烌�W�X�^���S��64bit�ɂ���
�K�v������B
958 �F,,�E�L�́M�E,,�j��-�������F2009/11/20(��) 02:42:07 ID:OfG4YBQO
XMM���W�X�^�̓��W�X�^���l�[�������邩��_��8�{�ł�����Ȃɍ��邱�Ƃ͂Ȃ����A
�������A�N�Z�X�p�Ƀ|�C���^�{�Y���p�ϐ��͊��Ɨ~�����B
r8�`r15�g���Ƒ������z��̃A�N�Z�X�������Ԋy�ɂȂ�B
�s��ςƂ����Ȃ�SIMD���W�X�^�����Ɨ~������B
���[�h�E�X�g�A�����ă[���R�X�g����Ȃ���
�������A�N�Z�X�p�Ƀ|�C���^�{�Y���p�ϐ��͊��Ɨ~�����B
r8�`r15�g���Ƒ������z��̃A�N�Z�X�������Ԋy�ɂȂ�B
�s��ςƂ����Ȃ�SIMD���W�X�^�����Ɨ~������B
���[�h�E�X�g�A�����ă[���R�X�g����Ȃ���
����
960 �FSocket774�F2009/11/20(��) 09:26:05 ID:+0yZyYPF
>>940
K10��L2 1M��L2 512k+L3 6M�ɕC�G����̂�AthlonII���ؖ������B
����Ɉ�ʃA�v���Ȃ�512k�A�Q�[���ł�1M�ŏ[����������Ȃ��B
���������I������}���`�v���Z�b�T�͍l�����Ă��Ȃ�����ᐫ�\�ȋ��LL3�͂���Ȃ��B
K10��L2 1M��L2 512k+L3 6M�ɕC�G����̂�AthlonII���ؖ������B
����Ɉ�ʃA�v���Ȃ�512k�A�Q�[���ł�1M�ŏ[����������Ȃ��B
���������I������}���`�v���Z�b�T�͍l�����Ă��Ȃ�����ᐫ�\�ȋ��LL3�͂���Ȃ��B
AMD�̎�����CPU�uBulldozer�v�̃N���X�^�x�[�X�}���`�X���b�f�B���O
http://pc.watch.impress.co.jp/docs/column/kaigai/20091120_330076.html
http://pc.watch.impress.co.jp/docs/column/kaigai/20091120_330076.html
���������Ӗ�����N�A�b�h���v��Ȃ����
963 �FSocket774�F2009/11/20(��) 11:47:21 ID:+0yZyYPF
����A�N�A�b�h�R�A�Ƃ�����4�X���b�h�܂ł͑̊��o�����ʂ������Ȃ��Ă�������K�v�B
8�X���b�h�͊��p�o����̂��G���R�ƃ����_�����O���������瓖������Ȃ��B
8�X���b�h�͊��p�o����̂��G���R�ƃ����_�����O���������瓖������Ȃ��B
�����������o���邩�͂Ƃ������Ƃ��āA
�N�A�b�h�����ǖʂ�����l�́AL3�L���b�V�����P�`��ׂ��ł͂Ȃ��Ǝv���B
�N�A�b�h�����ǖʂ�����l�́AL3�L���b�V�����P�`��ׂ��ł͂Ȃ��Ǝv���B
>>923
Geode���āA���o�C��AthlonXP-M��NX���������ō����\��LX900�ł��A��������O��
130nm�v���Z�X�ō���Ă�Ȃ��c
�f�l�l�������A�����65nm�ӂ�̃v���Z�X�ŁA�f���A���R�A�o����悤�ɍĐv����
�O���t�B�b�N��ATI���炻�������̐��\�̓K���R�A��E�܂�ŗ��ď悹�Ƃ���
atom����ɂȂ�A���������s�������ȋC��������ǁA
����ȊȒP�Ȃ���Ȃ��낤�ȁB���b�p��c
���AGeode�̊J���`�[�����āA���A������Ă�́H
Geode���āA���o�C��AthlonXP-M��NX���������ō����\��LX900�ł��A��������O��
130nm�v���Z�X�ō���Ă�Ȃ��c
�f�l�l�������A�����65nm�ӂ�̃v���Z�X�ŁA�f���A���R�A�o����悤�ɍĐv����
�O���t�B�b�N��ATI���炻�������̐��\�̓K���R�A��E�܂�ŗ��ď悹�Ƃ���
atom����ɂȂ�A���������s�������ȋC��������ǁA
����ȊȒP�Ȃ���Ȃ��낤�ȁB���b�p��c
���AGeode�̊J���`�[�����āA���A������Ă�́H
�[���AWindows�̃^�X�N�}�l�[�W���[����v���Z�X�����
���ꂾ�������̃v���O�����������N������Ă�Ȃ�A
�R�A���Ȃ�āA������邾���g����Ȃ��́H�Ǝv�����E�E�E
���ꂾ�������̃v���O�����������N������Ă�Ȃ�A
�R�A���Ȃ�āA������邾���g����Ȃ��́H�Ǝv�����E�E�E
�唼��CPU�ɂ���Ȃ�ɕ��ׂ����ē����ɓ����ĂȂ�����ł́H
��̂�1�R�A��1%���炢�����g��Ȃ��v���Z�X�Ȃ�B
�G���v���Z�X�p�ɏ������R�A���l�ߍ��ނƂ��c
���삵�Ă��鎞�Ԃ̂قƂ�ǂ�Idle������Ƃ����āA
���̃v���Z�X�ł͏������x���K�v�Ȃ����Ď��ɂ͂Ȃ��H��
���̃v���Z�X�ł͏������x���K�v�Ȃ����Ď��ɂ͂Ȃ��H��
>>971
�����X���b�h���u�����ɁvRUN��ԂɂȂ邱�Ƃ͈ӊO�ɏ��Ȃ��A�Ƃ�����
�l�Ԃ��猩�ē��쒆�̂͂��̃X���b�h����A
����I/O�҂�(CPU�ɔ�ׂ�ƃX�g���[�W�͂ƂĂ��Ȃ��x��)��
�r���̂��߂̃��b�N�҂��ŃX�J�X�J�������肷��B
�����X���b�h���u�����ɁvRUN��ԂɂȂ邱�Ƃ͈ӊO�ɏ��Ȃ��A�Ƃ�����
�l�Ԃ��猩�ē��쒆�̂͂��̃X���b�h����A
����I/O�҂�(CPU�ɔ�ׂ�ƃX�g���[�W�͂ƂĂ��Ȃ��x��)��
�r���̂��߂̃��b�N�҂��ŃX�J�X�J�������肷��B
�����ŋx�߂ƌ������Ƃ��ˁH
>>966
�}���`�R�A���̖ړI��CPU�g�p���������邱�Ƃ���Ȃ�
�}���`�R�A���̖ړI��CPU�g�p���������邱�Ƃ���Ȃ�
�A�x���[�W�ƃs�[�N�̗���
�o����̂��H
�o����̂��H
�Ƃɂ����V���O���X���b�h���\��K�v�Ƃ���1�{�̃X���b�h�ƁA
���̑��吨���Ă������APC���Ԃ̑唼���߂Ă���
�c���ǁA�œK���̓^�[�{�u�[�X�g�ɍs�������Ă��܂�
���̑��吨���Ă������APC���Ԃ̑唼���߂Ă���
�c���ǁA�œK���̓^�[�{�u�[�X�g�ɍs�������Ă��܂�
>>974
�uCyrix ��Athlon XP�iK7) �� K8 �� K10�v�ł��ˁB�킩��܂��B
�uCyrix ��Athlon XP�iK7) �� K8 �� K10�v�ł��ˁB�킩��܂��B
Intel ��C3 �� C7 �� Nano(Isaiah) �Ƃ������Ȃ�ꂭ�Ƃ��ǂ��Ȃ�
�f�X�N�g�b�v��m�[�gPC�ł́A�p�t�H�[�}���X�R�A��1-2��
Atom�̂悤�ȏ����ȃR�A���ڂ����Ώ̃}���`�R�A��
�g�����W�X�^��d�͌������猩�čœK�Ȃ悤�Ɏv����B
OS�̑Ή����K�v�ɂȂ��Ă��܂���ɁA�}���`�R�A��O��Ƃ����A�v���P�[�V����
�łȂ��ƈӖ����Ȃ��A�T�[�o�����ł��Ȃ��Ƃ���A�N�����Ȃ��̂������͂Ȃ����B
Atom�̂悤�ȏ����ȃR�A���ڂ����Ώ̃}���`�R�A��
�g�����W�X�^��d�͌������猩�čœK�Ȃ悤�Ɏv����B
OS�̑Ή����K�v�ɂȂ��Ă��܂���ɁA�}���`�R�A��O��Ƃ����A�v���P�[�V����
�łȂ��ƈӖ����Ȃ��A�T�[�o�����ł��Ȃ��Ƃ���A�N�����Ȃ��̂������͂Ȃ����B
�s��̒��S�̓T�[�o��g�ы@��Ɉڂ�A
�f�X�N�g�b�vPC�����p�t�H�[�}���XCPU���i���̐擪����O��Ă��܂����A
�Ƃ����\�}������ɂ���̂��B
�f�X�N�g�b�vPC�����p�t�H�[�}���XCPU���i���̐擪����O��Ă��܂����A
�Ƃ����\�}������ɂ���̂��B
PC�������i���̐擪�������̂��Ăǂ�̂��Ƃ�
�d��p4004���瑱���}�C�N���v���Z�b�T�̌n������B
8088��IBM PC�ɍ̗p����A�ߋ�ƌ����Ȃ����80486�Ń��[�N�X�e�[�V�����ɒǂ����A
�i���𐋂�����ɃT�[�o�ɂ܂Ŏg�p�����悤�ɂȂ����c�c�̂͂������A
�����Ɏ傽��p�r��PC����T�[�o�����Ɉڂ��Ă��܂����B
Nehalem��Bulldozer���T�[�o��̃v���O�������ǂ����܂����s���邩��
�v�̎�Ⴊ�u����Ă���B�l�pPC�̐��\����͂��̂����ڂ�ɉ߂��Ȃ��B
8088��IBM PC�ɍ̗p����A�ߋ�ƌ����Ȃ����80486�Ń��[�N�X�e�[�V�����ɒǂ����A
�i���𐋂�����ɃT�[�o�ɂ܂Ŏg�p�����悤�ɂȂ����c�c�̂͂������A
�����Ɏ傽��p�r��PC����T�[�o�����Ɉڂ��Ă��܂����B
Nehalem��Bulldozer���T�[�o��̃v���O�������ǂ����܂����s���邩��
�v�̎�Ⴊ�u����Ă���B�l�pPC�̐��\����͂��̂����ڂ�ɉ߂��Ȃ��B
���ƓI�ȃ��W���[���Ƃ��R�X�g�p�t�H�[�}���X�Ƃ���
�h�i���h�̐擪�Ƃ͈Ⴄ����
CPU��i�������������̃A�C�f�A�̂����A���̃A�[�L�e�N�`����
���x86�ɍ̗p���ꂽ�A�C�f�A�����������
�h�i���h�̐擪�Ƃ͈Ⴄ����
CPU��i�������������̃A�C�f�A�̂����A���̃A�[�L�e�N�`����
���x86�ɍ̗p���ꂽ�A�C�f�A�����������
985 �FSocket774�F2009/11/21(�y) 18:05:20 ID:aaPHx07G
bulldozer�͂������H
���ǂ�X86�ɔ�����^������
�Ƃ����
�uBobcat�̓J�X�^����H���g�킸�ɁA�ė��p���₷���悤�ɍ����x������ŏ�����Ă���B�v
���Ăǂ������Ӗ��H
�uBobcat�̓J�X�^����H���g�킸�ɁA�ė��p���₷���悤�ɍ����x������ŏ�����Ă���B�v
���Ăǂ������Ӗ��H
�ŋ߂̓n�[�h�̐v�ɂ��A�܂�C���g����������Ƃ����g���ċ������L�q����B
��������RTL�������v�ƍs�����ǁA���ʂ�CPU�̓R���s���[�^�̃c�[���Ƃ��g�킸�A�l�̎�Ńo���o���̍œK��������B
����Bobcat�͒P�̂�CPU��������Ȃ��āA���̎��Ӊ�H��SoC�ɂ��������Ȏ�ނ̃`�b�v�����C������A
�o���o���̍œK�������Ă�Ƃނ���g���Â炢
���Ă��Ƃ��Ǝv��
��������RTL�������v�ƍs�����ǁA���ʂ�CPU�̓R���s���[�^�̃c�[���Ƃ��g�킸�A�l�̎�Ńo���o���̍œK��������B
����Bobcat�͒P�̂�CPU��������Ȃ��āA���̎��Ӊ�H��SoC�ɂ��������Ȏ�ނ̃`�b�v�����C������A
�o���o���̍œK�������Ă�Ƃނ���g���Â炢
���Ă��Ƃ��Ǝv��
�\�t�g�R�A�̃����b�g�́A�����v���Z�X�ɔ����Ȃ��Ƃ������Ƃ���Ȃ�����?
�܂�SOI�ƃo���N�̗����ɓW�J�ł���悤�ɂ��Ă���ƁB
���邢��TSMC�ł̐�����������Ȃ����ǁB
�܂�SOI�ƃo���N�̗����ɓW�J�ł���悤�ɂ��Ă���ƁB
���邢��TSMC�ł̐�����������Ȃ����ǁB
Bobcat����65nm�A45nm�A32nm�̂ǂ�ł��Ȃ��F�œh���Ă����ˁA���[�h�}�b�v���ƁB
�\�ɂ������ʂ�40nm�o���N�ō����̂��낤���B
�\�ɂ������ʂ�40nm�o���N�ō����̂��낤���B
�����z�ɂ���28nm��������
�Z�M�̃v���[������40nm�ɂȂ��Ă����ǂ�
�Z�M�̃v���[������40nm�ɂȂ��Ă����ǂ�
>>980
�R�A�̕��т����z���A�A�N�e�B�u���Ԃ̒����X���b�h�����o���āA
�ł����đ�������CPU0�Ɋ��蓖�Ă�c���Ă����̂��n�[�h�E�F�A�������łł��Ȃ����낤��
�R�A�̕��т����z���A�A�N�e�B�u���Ԃ̒����X���b�h�����o���āA
�ł����đ�������CPU0�Ɋ��蓖�Ă�c���Ă����̂��n�[�h�E�F�A�������łł��Ȃ����낤��
�n�[�h�E�F�A�͘_���X���b�h���킩��Ȃ��B�����Ă���X���b�h�̃R�A���蓖�Ă�
��ւ���̂́AL1�L���b�V���̑�����ւ����܂߂ƂĂ��R�X�g�������B
�R�A���蓖�Ă͂����܂�kernel�̎d���B
��ւ���̂́AL1�L���b�V���̑�����ւ����܂߂ƂĂ��R�X�g�������B
�R�A���蓖�Ă͂����܂�kernel�̎d���B
Bulldozer��FPU��2�R�A�����L����̂ŃX���b�h�̊��蓖�Ăɂ͔z�����K�v�ɂȂ�
�͂������A�Z�p���̌��J��OS�̑Ή��͂ǂ̃^�C�~���O�ɂȂ�낤���B
���߂łȂ���(Linux�Ȃ�e�f�B�X�g���r���[�V�����̃��W���[�����[�X�A
Windows�Ȃ�SP�ɊԂɍ��킹�Ȃ���)���\���o����o�Ȃ�������̂�₱�������ƂɂȂ肻�����B
�͂������A�Z�p���̌��J��OS�̑Ή��͂ǂ̃^�C�~���O�ɂȂ�낤���B
���߂łȂ���(Linux�Ȃ�e�f�B�X�g���r���[�V�����̃��W���[�����[�X�A
Windows�Ȃ�SP�ɊԂɍ��킹�Ȃ���)���\���o����o�Ȃ�������̂�₱�������ƂɂȂ肻�����B
�����ȂȂ��c�Ⴆ�A�R���e�L�X�g�X�C�b�`�����i���荞���o�j����
�v���O�����J�E���^�l���L�����Ă����āA���A���������A�o�E�g�ł��킩���Ă�A
�A�N�e�B�u���Ԃ̗\�����ł��Ȃ����납
��ŁA���炩�ɂ��̃X���b�h�����r�W�[���A�����Ă���Ȃ�CPU0�ɓ�����
���zCPU�݂̑��o����halt���߂���̕��A�A�ԋp��halt���ߎ���
�v���O�����J�E���^�l���L�����Ă����āA���A���������A�o�E�g�ł��킩���Ă�A
�A�N�e�B�u���Ԃ̗\�����ł��Ȃ����납
��ŁA���炩�ɂ��̃X���b�h�����r�W�[���A�����Ă���Ȃ�CPU0�ɓ�����
���zCPU�݂̑��o����halt���߂���̕��A�A�ԋp��halt���ߎ���
��������FPU���Ă���ȂɃr�W�[�ɂ��������邱�Ƃ��o���郂���Ȃ̂��ȁB
MMX�Ƒ����œo�ꂵ�����炢�����ˁ�FPU
�m�����肦�Ȃ������ŌĂяo�������c
�m�����肦�Ȃ������ŌĂяo�������c
���L�Ƃ����Ă�128bitx2����H
���ʂ�sse�Ȃ�o�b�e�B���O�����������Ȃ���E�E�E
���ʂ�sse�Ȃ�o�b�e�B���O�����������Ȃ���E�E�E
�f�l�̈ӌ����ƁA�قڂ��ׂċ��L����SMT�̂ق���
�������������ȋC��
�������������ȋC��
�f�l�̍l���ł��A����͂Ȃ�����B�ނ�����s�R�A�܂ŋ��L���Ă悭�����̃X���b�h���������A�Ƃ����v���B
�d�g�݂͂킩�邯�ǁA���쒆�͂������������ƂɂȂ��Ă�낤�ȂƎv��
�d�g�݂͂킩�邯�ǁA���쒆�͂������������ƂɂȂ��Ă�낤�ȂƎv��
1001 �F�P�O�O�P�F
1��̃}�V�����g�ݏオ��܂����B�B�B
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://pc11.2ch.net/jisaku/
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://pc11.2ch.net/jisaku/