Intel Larrabee 4�R�A
Intel Larrabee 1�R�A
http://pc11.2ch.net/test/read.cgi/jisaku/1217915128/
Intel Larrabee 2�R�A
http://pc11.2ch.net/test/read.cgi/jisaku/1238152183/
Intel Larrabee 3�R�A
http://pc11.2ch.net/test/read.cgi/jisaku/1245944113/
Larrabee�͂₭���Ă���[�[�[�[�[�[�[�[�����I�I
http://pc11.2ch.net/test/read.cgi/jisaku/1217915128/
Intel Larrabee 2�R�A
http://pc11.2ch.net/test/read.cgi/jisaku/1238152183/
Intel Larrabee 3�R�A
http://pc11.2ch.net/test/read.cgi/jisaku/1245944113/
Larrabee�͂₭���Ă���[�[�[�[�[�[�[�[�����I�I
|
|
|
�����
3 �FSocket774�F2009/07/30(��) 05:07:18 ID:P3uQTmXv
���X���グ
���X������ˁ[��B
�ŁA���܂��H
�ŁA���܂��H
�Ȃ�ŕ��X������Ȃ����Ă킩��́H
�@
7 �FSocket774�F2009/07/31(��) 13:44:10 ID:a4Ui7vT4
�y���݂����ǁA�O�X����11���X�ŗ���������݂�ȑ҂��ĂȂ��̂��Ȃ�
�� �� �� �� �� �� �� �� ��
��݂�ȁI���҂ɉ����đ�������I�I
(�L�E�ցE`)(�L�E�ցE`)(�L�E�ցE`)(�L�E�ցE`)(�L�E�ցE`)(�L�E�ցE`)(�L�E�ցE`)(�L�E�ցE`)
(�L�E�ցE`)�Ȃ�đ��B����Ƃ��v�����́H
(�L�E�ցE`)���R
(�L�E�ցE`)(�L�E�ցE`)(�L�E�ցE`)(�L�E�ցE`)(�L�E�ցE`)(�L�E�ցE`)(�L�E�ցE`)(�L�E�ցE`)
(�L�E�ցE`)�Ȃ�đ��B����Ƃ��v�����́H
(�L�E�ցE`)���R
(�L�E�ցE`)�������X�����˂�
(�L��֥`)�N�T�b�I���̃X��Ƶ�ְ
(�L�E�ցE`)�V���{���k�鍑in����PC�ƕ����Ĕ��ł��܂���
(�L�E�ցE`)������
(�L�E�ցE`)���R
(�L�E�ցE`)���R
�ܲ�( �L�E�ցE)�
(�L�E�ցE`)�͂��߂܂���
(�L�E�ցE`)�����@�܂�Ȃ��E���R�ł����ǂ���
(�L�E�ցE`)�����@�܂�Ȃ��E���R�ł����ǂ���
(�L�E�ցE`)�c
(�L�E�ցE`)�ꎞ�Ԉȓ��ɃK�b����Ȃ�������_�ɂȂ��
(�L�E�ցE`)�ꎞ�Ԉȓ��ɃK�b����Ȃ�������_�ɂȂ��
�@�@�@�@�@�@�@�~�@�Q�Q�Q�Q
�@�@�@�@�@�@�@�~/�_�@�@�@�@ �_
�@ �@ �@ �@ �@ /�@�@ �_�Q�Q�Q�_
�@�@�@�@ �@�@/�@�@�@�@/�@�@�@�@�@/�@ �ޯ
�@ �ȁQ��/�@�@�@�@/�@�@�l �@/
�@(�L�E�ցE`)�_�@�@/�@�@<�@ >�Q�ȁ�
�@�i�@�@�@�m .�_/�Q�Q_�u�@�M�D�L)/
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@/>>16
�@�@�@�@�@�@�@�~/�_�@�@�@�@ �_
�@ �@ �@ �@ �@ /�@�@ �_�Q�Q�Q�_
�@�@�@�@ �@�@/�@�@�@�@/�@�@�@�@�@/�@ �ޯ
�@ �ȁQ��/�@�@�@�@/�@�@�l �@/
�@(�L�E�ցE`)�_�@�@/�@�@<�@ >�Q�ȁ�
�@�i�@�@�@�m .�_/�Q�Q_�u�@�M�D�L)/
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@/>>16
(�L�E�ցE`)�ʂ�ہI�I�I
(�L�E�ցE`)�ʂ��
(�L�E�ցE`)�I���I���I�ʂ�ہI�I�I�ʂ�ۂʂ�ۂʂ�ʂ���ʂ�ۂʂ�ۂ��ہ[�[�I�I
(�L�E�ցE`)�ʂ��
(�L�E�ցE`)�܂��܂��ʂ��
(�L�E�ցE`)�E�F�[�n�b�n�b�n�I�K�b���Ă݂₪��N�\�ǂ��I
(�L�E�ցE`)�ʂ���ہ`��
(�L�E�ցE`)�ʂ���ہ`��
(�L�E�ցE`)�ʂ�`��ʂ�����ۂ��ہ`��
(�L�E�ցE`)�{���ɃK�b����Ȃ��˂�
(�L�E�ցE`)���������Ȃ��\���I
(�L�E�ցE`)�ʂ�ہI�I
(�L�E�ցE`)���������Ȃ��\���I
(�L�E�ցE`)�ʂ�ہI�I
(�L��֥`)�ʂ��
27 �FSocket774�F2009/08/09(��) 20:44:22 ID:lOoQGexw
(�L��֥�M)�H
(�@�L��֥�M)�����͂ǂ������H
(�L�E�ցE`)�悤�����Ԃ���ʃX����
(�L��֥�M)���
(�L��֥�M)���
(�L��֥�M)��L
(�L��֥�M)
�@��L��
�@��L��
(�L�E�ցE`)����L�ł�
(�L�E�ցE`)�����ςȃI�W�T���ł�
(�L�E�ցE`)���Ⴀ���͕ςȃK���_����
(�L��֥�M)�����c���́c�ςȃ[���ł��c
(�L��֥�M)���̓t���`����
(�L��֥�M)����͂���́E�E�E
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ,===,====�A
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ _.||�Q__|_____||_
..�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �^�@ �@�^||�Q�Q�Q|^ l�@�@�@�@
..�@�@ �@�@�@�@�@�@�@�@�@�@�@(*�e�ցe *)�^�^||�@�@�@|��| |�ցe *)�@�@ �ۂ�������
.�@�@�@�@�@�@�@�@�@�@�@�@�@.�^(^(^ .�^�^||...||�@�@�@|��| |�� �@�j�@�@�@�@
...�@ �@ �@ �@ �@ �@ �@ �@�^�@�@�@�^�^�@ ||...||�@�@�@|��| ||��
.......�@�@�@�@�@�@�@(*�e�ցe *) �^�^....�@�@||...||�@�@�@|��| ||
�@�@ �@�@�@�@�@�@�^(^(^�@�^�^ �@....�@�@.||...||�@�@�@|��| ||
�@"" �@�@�@:::''�@|�^�@ �@|�^�@''�@"�@�@:::�@�@�܁@ :: �܁܁� ::�@""�@�@`
�@::�@,,�@:::::�@,,�@;�P�P�P�@�@"��@:::: "�@,, ,�@:::�@�@ "�@::�@"�@::::�@�@"
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ _.||�Q__|_____||_
..�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �^�@ �@�^||�Q�Q�Q|^ l�@�@�@�@
..�@�@ �@�@�@�@�@�@�@�@�@�@�@(*�e�ցe *)�^�^||�@�@�@|��| |�ցe *)�@�@ �ۂ�������
.�@�@�@�@�@�@�@�@�@�@�@�@�@.�^(^(^ .�^�^||...||�@�@�@|��| |�� �@�j�@�@�@�@
...�@ �@ �@ �@ �@ �@ �@ �@�^�@�@�@�^�^�@ ||...||�@�@�@|��| ||��
.......�@�@�@�@�@�@�@(*�e�ցe *) �^�^....�@�@||...||�@�@�@|��| ||
�@�@ �@�@�@�@�@�@�^(^(^�@�^�^ �@....�@�@.||...||�@�@�@|��| ||
�@"" �@�@�@:::''�@|�^�@ �@|�^�@''�@"�@�@:::�@�@�܁@ :: �܁܁� ::�@""�@�@`
�@::�@,,�@:::::�@,,�@;�P�P�P�@�@"��@:::: "�@,, ,�@:::�@�@ "�@::�@"�@::::�@�@"
(�L��֥�M)���낻��܂����
�@�@�@�@�@�@����ۂ���
�@�@�@ �ȁ@�ȁ@�@�@�@�@�@�@�@�@�@�ڂ��[�[����I
�@(>=���e�ցe *) �@�@(�L��(�L��;;
�@ /_./ �r ��_�m�M�@�@(�L��(�L�߁߁�(�L��;;;�߁߁߁�;;
�@�q/ �j/__�m,Ё@�߁߁�(�L��;;;�߁߁�
�@�i_/^�L�@�@(�L��(�L��;;
�@�@�@ �ȁ@�ȁ@�@�@�@�@�@�@�@�@�@�ڂ��[�[����I
�@(>=���e�ցe *) �@�@(�L��(�L��;;
�@ /_./ �r ��_�m�M�@�@(�L��(�L�߁߁�(�L��;;;�߁߁߁�;;
�@�q/ �j/__�m,Ё@�߁߁�(�L��;;;�߁߁�
�@�i_/^�L�@�@(�L��(�L��;;
���ǃv���O�����g�ނ̂�GPGPU��蕳��ς�
GPU���i��ł�GPGPU�̓����ɍ��킹�邵���Ȃ���������
PS4�Ƃ��Ɏg���������
GPU���i��ł�GPGPU�̓����ɍ��킹�邵���Ȃ���������
PS4�Ƃ��Ɏg���������
44 �FSocket774�F2009/08/18(��) 05:40:57 ID:RoY7i9uV
�I�}�G�o�J�i�m
���N���J���i�C�P�h�I���n�o�J�_��
(�L�E�ցE`)���邹�[�n�Q
>>44
���ʂ�CPU���R�݂����Ɏg����Ƃ��v���Ă�́H
���ʂ�CPU���R�݂����Ɏg����Ƃ��v���Ă�́H
48 �FSocket774�F2009/08/19(��) 21:06:40 ID:8CIehTnA
���Ȃ��Ƃ��A����2������GPU����
�A���`�̍H�삤����
������������
http://www.intel.co.jp/jp/intel/pr/press/jointhp.htm
����Pentium�x�[�X�̍ŏ��̃��j�[�R�A�A�[�L�e�N�`���v���Z�b�T
�uLarrabee(TM)�v�́A�C���e���ɂ���Đv�A�����A�̔������\��ŁA
�ʎY�o�ׂ�2009�N�ɂȂ錩���݂ł��B
http://www.intel.co.jp/jp/intel/pr/press98/980601.htm
�C���e�� �R�[�|���[�V�����i�{�ЁF�č��J���t�H���j�A�B�T���^�N�����j
�́A�{���A�uLarrabee(TM) �v���Z�b�T�v�̐��Y�X�P�W���[���̕ύX��
�ڋq�ɘA�������Ɣ��\���܂����B�A�����ꂽ�ŐV�̐��Y�X�P�W���[��
�ɂ��ƁA���v���Z�b�T�̃T���v���o�ׂ�2009�N�ɁA�܂��A����
2009�N�ɗ\�肳��Ă����ʎY�o�ׂ́A2010�N���ɗ\�肳��Ă��܂��B
http://techon.nikkeibp.co.jp/article/NEWS/20080118/145725/
��Intel�Ђ́C�uLarrabee(�����r)�v�𓋍ڂ������@���g����
3�����O���t�B�b�N�X�f���������J�����B2009�N9��22������
�č��T���t�����V�X�R�ŊJ�Ò��́uIDF Fall 2009�v�̊�u���ŁC
�В���CEO��Paul Otellini�����炪�C�f�����I�����B
Larrabee�́C���łɓ��胁�[�J�����̃T���v���o�ׂ��n�܂��Ă���B
������������
http://www.intel.co.jp/jp/intel/pr/press/jointhp.htm
����Pentium�x�[�X�̍ŏ��̃��j�[�R�A�A�[�L�e�N�`���v���Z�b�T
�uLarrabee(TM)�v�́A�C���e���ɂ���Đv�A�����A�̔������\��ŁA
�ʎY�o�ׂ�2009�N�ɂȂ錩���݂ł��B
http://www.intel.co.jp/jp/intel/pr/press98/980601.htm
�C���e�� �R�[�|���[�V�����i�{�ЁF�č��J���t�H���j�A�B�T���^�N�����j
�́A�{���A�uLarrabee(TM) �v���Z�b�T�v�̐��Y�X�P�W���[���̕ύX��
�ڋq�ɘA�������Ɣ��\���܂����B�A�����ꂽ�ŐV�̐��Y�X�P�W���[��
�ɂ��ƁA���v���Z�b�T�̃T���v���o�ׂ�2009�N�ɁA�܂��A����
2009�N�ɗ\�肳��Ă����ʎY�o�ׂ́A2010�N���ɗ\�肳��Ă��܂��B
http://techon.nikkeibp.co.jp/article/NEWS/20080118/145725/
��Intel�Ђ́C�uLarrabee(�����r)�v�𓋍ڂ������@���g����
3�����O���t�B�b�N�X�f���������J�����B2009�N9��22������
�č��T���t�����V�X�R�ŊJ�Ò��́uIDF Fall 2009�v�̊�u���ŁC
�В���CEO��Paul Otellini�����炪�C�f�����I�����B
Larrabee�́C���łɓ��胁�[�J�����̃T���v���o�ׂ��n�܂��Ă���B
51 �FSocket774�F2009/08/21(��) 07:58:29 ID:UZyhN9oP
http://northwood.blog60.fc2.com/blog-entry-3071.html
���gLarrabee�h�͑�3����Ȃ̂��H
Larrabee is Intel�fs third attempt�iFudzilla�j
http://www.fudzilla.com/content/view/15098/34/
Silicon Valley���̏��ɂ��ƁA����Intel�������gLarrabee�h��3����ڂɂȂ�Ƃ����B
�ŏ���2����͑傫���M�������B�Ȃ̂ŁAIntel�̍l���Ă������̂Ƃ͍��v�����A���s�ƂȂ����B�����đ�3�����2010�N�̒��Ղɂ���I�ڂ����B
�\�ł́gLarrabee 3�h�͂�͂�傫����������A���\�ʂł͌��s�����GeForce GTX 295��Radeon HD 4870X2������Ƃ����B
�������ANVIDIA��AMD-ATi��GPU�̃��t���b�V�����v�悵�Ă���A�gLarrabee 3�h���[���`���_�ł�Intel��NVIDIA��AMD-ATi�ɒǂ������Ƃ͏o�������ɂȂ��B
���ŏ���2����͑傫���M�������B�Ȃ̂ŁAIntel�̍l���Ă������̂Ƃ͍��v�����A���s�ƂȂ����B
���ŏ���2����͑傫���M�������B�Ȃ̂ŁAIntel�̍l���Ă������̂Ƃ͍��v�����A���s�ƂȂ����B
���ŏ���2����͑傫���M�������B�Ȃ̂ŁAIntel�̍l���Ă������̂Ƃ͍��v�����A���s�ƂȂ����B
��Larrabee 3�h���[���`���_�ł�Intel��NVIDIA��AMD-ATi�ɒǂ������Ƃ͏o�������ɂȂ��B
��Larrabee 3�h���[���`���_�ł�Intel��NVIDIA��AMD-ATi�ɒǂ������Ƃ͏o�������ɂȂ��B
��Larrabee 3�h���[���`���_�ł�Intel��NVIDIA��AMD-ATi�ɒǂ������Ƃ͏o�������ɂȂ��B
�v�Q��������������������������������������������������������
���gLarrabee�h�͑�3����Ȃ̂��H
Larrabee is Intel�fs third attempt�iFudzilla�j
http://www.fudzilla.com/content/view/15098/34/
Silicon Valley���̏��ɂ��ƁA����Intel�������gLarrabee�h��3����ڂɂȂ�Ƃ����B
�ŏ���2����͑傫���M�������B�Ȃ̂ŁAIntel�̍l���Ă������̂Ƃ͍��v�����A���s�ƂȂ����B�����đ�3�����2010�N�̒��Ղɂ���I�ڂ����B
�\�ł́gLarrabee 3�h�͂�͂�傫����������A���\�ʂł͌��s�����GeForce GTX 295��Radeon HD 4870X2������Ƃ����B
�������ANVIDIA��AMD-ATi��GPU�̃��t���b�V�����v�悵�Ă���A�gLarrabee 3�h���[���`���_�ł�Intel��NVIDIA��AMD-ATi�ɒǂ������Ƃ͏o�������ɂȂ��B
���ŏ���2����͑傫���M�������B�Ȃ̂ŁAIntel�̍l���Ă������̂Ƃ͍��v�����A���s�ƂȂ����B
���ŏ���2����͑傫���M�������B�Ȃ̂ŁAIntel�̍l���Ă������̂Ƃ͍��v�����A���s�ƂȂ����B
���ŏ���2����͑傫���M�������B�Ȃ̂ŁAIntel�̍l���Ă������̂Ƃ͍��v�����A���s�ƂȂ����B
��Larrabee 3�h���[���`���_�ł�Intel��NVIDIA��AMD-ATi�ɒǂ������Ƃ͏o�������ɂȂ��B
��Larrabee 3�h���[���`���_�ł�Intel��NVIDIA��AMD-ATi�ɒǂ������Ƃ͏o�������ɂȂ��B
��Larrabee 3�h���[���`���_�ł�Intel��NVIDIA��AMD-ATi�ɒǂ������Ƃ͏o�������ɂȂ��B
�v�Q��������������������������������������������������������
�ǂ�Ȃɉ���I�ȂƊ��҂��Ă���
���Ђ�GPU�Ƃ������ĕς��Ȃ��̂��B
���Ђ�GPU�Ƃ������ĕς��Ȃ��̂��B
�啪�O��������L�����Ă����ǂ�…
�l�I�ɂ�Larrabee�܂�GMA�Ŋ撣����ĕ����I����Ă�
�l�I�ɂ�Larrabee�܂�GMA�Ŋ撣����ĕ����I����Ă�
������nVidia�����ł���B
���\���悭�Ȃ������Ŏc�O�ȋ�C�ɂȂ�Ƃ́B
Larrabee�̓v���O���~���O�p�̂�������Ƃ��Ďg�����̂��Ǝv���Ă��B
Larrabee�̓v���O���~���O�p�̂�������Ƃ��Ďg�����̂��Ǝv���Ă��B
�o���@�@�@�@�@�@�@�o���o���o���J�� �o���o��
�o���i���e�ցe *)�@�@�o���o���o���o���J��
�@�Q/_�~��/�P�P�P/
�@�@�@ �_/�Q�Q�Q/�P
�@�@�@�@ �^�@�@�@�@�@ �^|
�@ �@ �@ |�P�P�P�P |�@ |
�@ �@ �@ |[]:: �@ �@ �@ |�@ |
�@ �@ �@ |�������� |�@ |
�@ �@ �@ |[]:: �@ �@ �@ |�@ |�@
�@ �@ �@ |�Q�Q�Q�Q_|�@ |
��ׯ�@ |�Q�Q�Q�Q_|�@�@| �@ �@�ߑa���ˁH
.�@ �c�^(�E�ցE�@�j �^|�@ |�@�@
�@�@�@|�P�P�P�P|�@ |�^�@�@�@�@
�@�@�@|�Q�Q�Q�Q|�^
�@ �@ �@ |�P�P�P�P |�@ |
�@ �@ �@ |[]:: �@ �@ �@ |�@ |
�@ �@ �@ |�������� |�@ |
�@ �@ �@ |[]:: �@ �@ �@ |�@ |�@
�@ �@ �@ |�Q�Q�Q�Q_|�@ |
��ׯ�@ |�Q�Q�Q�Q_|�@�@| �@ �@�ߑa���ˁH
.�@ �c�^(�E�ցE�@�j �^|�@ |�@�@
�@�@�@|�P�P�P�P|�@ |�^�@�@�@�@
�@�@�@|�Q�Q�Q�Q|�^
58 �FSocket774�F2009/08/26(��) 04:06:51 ID:YbgQRfFD
�n�[�h�E�F�A�Œ�@�\�𓋍ڂ���GPU�ɏ��Ă�̂��H
�\�t�g�E�F�A�ɂ��_��͐��\�Ƃ̃g���[�h�I�t
�P��CPU�Ƃ��Ă݂�̓^�_��Pentium����
GPU�Ƃ��Ă݂Ă��A�Œ�@�\���\�t�g�E�F�A�Ŏ������Ă��Ȃ���
�����Ȃ������h�N�T�C����
Cell�̂悤�Ɂu�v���O���~���O������ăA�v���P�[�V���������܂���I�v
�ƂȂ�m���ɑ�
�I�[�v���\�[�X�́u���j�[�R�ACPU�pGPU�G�~�����[�V�������C�u�����v���o���Ȃ��Ɩ���
�\�t�g�E�F�A�ɂ��_��͐��\�Ƃ̃g���[�h�I�t
�P��CPU�Ƃ��Ă݂�̓^�_��Pentium����
GPU�Ƃ��Ă݂Ă��A�Œ�@�\���\�t�g�E�F�A�Ŏ������Ă��Ȃ���
�����Ȃ������h�N�T�C����
Cell�̂悤�Ɂu�v���O���~���O������ăA�v���P�[�V���������܂���I�v
�ƂȂ�m���ɑ�
�I�[�v���\�[�X�́u���j�[�R�ACPU�pGPU�G�~�����[�V�������C�u�����v���o���Ȃ��Ɩ���
CPU��GPU�̍\�����P�������Đ��\����Ɍq�������炢������
DX10�̎��_��DX9�ȑO�̌Œ�@�\�͖Ӓ�
texture unit�͎c�邾�낤���ǂ�
texture unit�͎c�邾�낤���ǂ�
Linux�ł�OpenGL, OpenCL������Ɋւ��Č����ALarrabee���o�邱��ɂ�
Gallum3D��Larrabee Driver�����ΑΉ��o����悤�ɂȂ��Ă���͂��B
Gallum3D��Larrabee Driver�����ΑΉ��o����悤�ɂȂ��Ă���͂��B
�Ō��ǁA���p���͂���H
��芷���郁���b�g�ˁ[�Ȃ炢���
�ǁ[�Ȃ̂�
��芷���郁���b�g�ˁ[�Ȃ炢���
�ǁ[�Ȃ̂�
Larrabee�̃}���`�X���b�h�v���O���~���O����POSIX��pthread�݂����ɂł���̂��ȁH
�ł���v���O�����̈ڐA���y�ɂȂ���c
�ł���v���O�����̈ڐA���y�ɂȂ���c
���ŃS�������̕��y�����悤�Ƃ��Ă��ACell�݂����Ƀ��[�J���Ȋ����ɂȂ�낤��
�����Ƒ����邽�߂ɂ�Larrabee2�Ƃ��o���Ȃ��Ƃ����Ȃ���
����R���s���[�e�B���O�̃V�F�A��CUDA�ɒD��ꂽ���������낤���ǁALarrabee�ɂ��郁���b�g������
�\�t�g�J���̗�����A������Larrabee�����ɂ��邩�����
�o�ׂ���Ă��Ή��\�t�g�������āA���[�G���h��GPU�Ƃ��Ďg�������Ȃ���H
�����Ƒ����邽�߂ɂ�Larrabee2�Ƃ��o���Ȃ��Ƃ����Ȃ���
����R���s���[�e�B���O�̃V�F�A��CUDA�ɒD��ꂽ���������낤���ǁALarrabee�ɂ��郁���b�g������
�\�t�g�J���̗�����A������Larrabee�����ɂ��邩�����
�o�ׂ���Ă��Ή��\�t�g�������āA���[�G���h��GPU�Ƃ��Ďg�������Ȃ���H
65 �FSocket774�F2009/09/03(��) 18:04:05 ID:oFeoXptx
http://www.4gamer.net/games/032/G003263/20090903008/
�}�C�N���\�t�g���S������Z�p�Z�b�V�����ł͂�����݂́u��v�ł���B
�������̕��������Ǝv�����C�쐼�������ӂƂ���̂̓O���t�B�b�N�X�B
���̂��߁C���̃Z�b�V�������u���̃^�C�g���́C�wLarrabee�x�i�����r�[�C�J���R�[�h�l�[���j�̏��������悤�C
������̏��������悤�Ƃ����m���v�ɂ��悤���ƍl���Ă����������B
�}�C�N���\�t�g���S������Z�p�Z�b�V�����ł͂�����݂́u��v�ł���B
�������̕��������Ǝv�����C�쐼�������ӂƂ���̂̓O���t�B�b�N�X�B
���̂��߁C���̃Z�b�V�������u���̃^�C�g���́C�wLarrabee�x�i�����r�[�C�J���R�[�h�l�[���j�̏��������悤�C
������̏��������悤�Ƃ����m���v�ɂ��悤���ƍl���Ă����������B
���̎ʐ^�̵�ϖ�Y���c�q���Ă킯��
67 �FSocket774�F2009/09/03(��) 19:03:28 ID:IdWZrO4K
�܂�DX9�ŏ\���������
Crytec�����łɎ������@�Ɉڂ��Ă邯��
���s�@�͌��E������������O���t�B�b�N�����߂�Ƃ����Ȃ��炂�A���⎟���サ���I�����͂Ȃ����
�����܂ŃO���t�B�b�N�N�I���e�B���߂Ăˁ[��Ƃ����Ȃ�DX9�ŏ\��
�����Ɣ������O���t�B�b�N�ŃQ�[�����������Ă����Ȃ�
Crytec�����łɎ������@�Ɉڂ��Ă邯��
���s�@�͌��E������������O���t�B�b�N�����߂�Ƃ����Ȃ��炂�A���⎟���サ���I�����͂Ȃ����
�����܂ŃO���t�B�b�N�N�I���e�B���߂Ăˁ[��Ƃ����Ȃ�DX9�ŏ\��
�����Ɣ������O���t�B�b�N�ŃQ�[�����������Ă����Ȃ�
MS(DX)���ǂ��i�����Ƃ��Ă邩�͖��炩���
>Microsoft�̓��{�@�l�ł���}�C�N���\�t�g�Ńv���b�g�t�H�[�� �G�o���W�F���X�g�߂�쐼�T�K�����B
>�}�C�N���\�t�g���S������Z�p�Z�b�V�����ł͂�����݂́u��v�ł���B
>�������̕��������Ǝv�����C�쐼�������ӂƂ���̂̓O���t�B�b�N�X�B
http://blogs.msdn.com/hiroyuk/default.aspx
�쐼 �T�K�̃u���O
Windows Graphics & Presentaiton Technologies for Developers
>Microsoft�̓��{�@�l�ł���}�C�N���\�t�g�Ńv���b�g�t�H�[�� �G�o���W�F���X�g�߂�쐼�T�K�����B
>�}�C�N���\�t�g���S������Z�p�Z�b�V�����ł͂�����݂́u��v�ł���B
>�������̕��������Ǝv�����C�쐼�������ӂƂ���̂̓O���t�B�b�N�X�B
http://blogs.msdn.com/hiroyuk/default.aspx
�쐼 �T�K�̃u���O
Windows Graphics & Presentaiton Technologies for Developers
Nehalem EX��L3��24MB�t���b�g����Ȃ���3MB�ÂŃ����O�o�X��
�q�����Ă�Ƃ��B�L���b�V���������O�o�X�ł��Ă̂�Larrabee��
�Ԃ����{�Ԃ���Ȃ��ȁB
Larrabee�ł�
�������̃����O��Ԃɕʂ̃f�[�^���ڂ��邱�Ƃ��ł���B
���ĂȂ��Ă�낤��
http://journal.mycom.co.jp/articles/2009/09/03/hot_chips21_server/002.html
�q�����Ă�Ƃ��B�L���b�V���������O�o�X�ł��Ă̂�Larrabee��
�Ԃ����{�Ԃ���Ȃ��ȁB
Larrabee�ł�
�������̃����O��Ԃɕʂ̃f�[�^���ڂ��邱�Ƃ��ł���B
���ĂȂ��Ă�낤��
http://journal.mycom.co.jp/articles/2009/09/03/hot_chips21_server/002.html
�o�����ɂ͎���x��Ƃ��A�C���e���͏킵�Ă�����
>>69
Sandy Bridge��L3��IGP��Ring�B
Sandy Bridge��L3��IGP��Ring�B
72 �F,,�E�L�́M�E,,�j��-�������F2009/09/10(��) 22:56:13 ID:NYMGAvzW
����Ȃ��߂���킢
�ς����Ɠr�₦�����
�ʂɁw����ς܂����������x���Ă������\�����Ă��S�R�����Ȃ���
�ʂɁw����ς܂����������x���Ă������\�����Ă��S�R�����Ȃ���
4���Ɍ��J�����~�Ղ͊G�ɕ`�����݂�FA�H
�����A������
76 �F,,�E�L�́M�E,,�j��-�������F2009/09/10(��) 23:15:07 ID:NYMGAvzW
���ꂪ�uLarrabee 3�v����
�m�����Larrabee�̎d�l��2��ύX����Ă邩��B
���o���Ă̂���SIMD��SSE�݊��������B
�m�����Larrabee�̎d�l��2��ύX����Ă邩��B
���o���Ă̂���SIMD��SSE�݊��������B
78 �F,,�E�L�́M�E,,�j��-�������F2009/09/10(��) 23:22:32 ID:NYMGAvzW
���܂�Ă��Ȃ��q�̍��������Ă�����[�Ȃ����Ă̂����̐l�̌�����
�������Ƃ�
�������Ƃ�
�l�^�͂Ȃ����A����X�������A�������낻��Q�悤���B
601 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/02/06(��) 07:50:39 ID:36Q+eCpY
����Larrabee�̃T���v����Dreamworks�ŕ]������Ă�悤����
601 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/02/06(��) 07:50:39 ID:36Q+eCpY
����Larrabee�̃T���v����Dreamworks�ŕ]������Ă�悤����
80 �F,,�E�L�́M�E,,�j��-�������F2009/09/10(��) 23:28:52 ID:NYMGAvzW
���̎茳�ɂ���V�~�����[�^���ĉ����낤��
���������ȁA����ˁ[����
50 �FSocket774 [sage] �F2009/03/30(��) 23:05:49 ID:RNqRpRRq
�V�~�����[�^���T���v����������Ȃ�đO�㖢���I
�������c�q����
�[��
62 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/03/31(��) 00:00:02 ID:YbyWNvCs
> TheINQ��Charlie "Groo" Demerjian��Larrabee�̃T���v�������N�̏H�ɂ�
> �J���Ҍ����ɔz�z�����Ɠ`���Ă��邷
�����ł̊J���҂��y�\�t�g�́z�J���҂̂��Ƃ��w���Ă邱�ƂɋC�Â��Ăق����B
�n�[�h�J���҂�Intel�������B
�����āu�T���v���v�Ƃ͈�ʊJ���Ҍ����ɂ�protorype primitive�̂��ƁB
�m���ɂ���̌��J�͔ނ̌������Ƃ���N�x��̍��N3���ɂȂ����B
�n�[�h���Ǝv���Ĉ���J���Ă��̂͂��܂��炾������
63 �FMAC�I�^���c�q ���� [sage] �F2009/03/31(��) 00:09:28 ID:3FaCOFUY
>>62
"silicon"���ď����Ă���̂ł����H
http://www.realworldtech.com/forums/index.cfm?action=detail&id=96437&threadid=96378&roomid=2
�@�@---------------------
�@�@the Taiwanese were expecting silicon in January.
�@�@---------------------
Intel�̓`�b�v�̊J�����[�J�[�ł����āA�r�f�I�J�[�h��}�U�[�{�[�h�̊J�����[�J�[�͕ʓr���܂���B
64 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/03/31(��) 00:11:09 ID:YbyWNvCs
�܂��F������d�g�ł��E������ł���B
�Ȃނ�Penryn�ɂ�HyperThreading����������Ă���B
66 �FSocket774 [sage] �F2009/03/31(��) 00:17:43 ID:PgS7bnB4
http://www.xbitlabs.com/news/video/display/20080117222433_Intel_Promises_to_Sample_Larrabee_Processors_in_Late_2008.html
> �gLarrabee first silicon should be late this year in terms of samples
> and we�fll start playing with it and sampling it to developers and I
> still think we are on track for a product in late �f09, 2010 timeframe,�h
> said Paul Otellini, chief executive officer of Intel.
������F������̓d�g���������
50 �FSocket774 [sage] �F2009/03/30(��) 23:05:49 ID:RNqRpRRq
�V�~�����[�^���T���v����������Ȃ�đO�㖢���I
�������c�q����
�[��
62 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/03/31(��) 00:00:02 ID:YbyWNvCs
> TheINQ��Charlie "Groo" Demerjian��Larrabee�̃T���v�������N�̏H�ɂ�
> �J���Ҍ����ɔz�z�����Ɠ`���Ă��邷
�����ł̊J���҂��y�\�t�g�́z�J���҂̂��Ƃ��w���Ă邱�ƂɋC�Â��Ăق����B
�n�[�h�J���҂�Intel�������B
�����āu�T���v���v�Ƃ͈�ʊJ���Ҍ����ɂ�protorype primitive�̂��ƁB
�m���ɂ���̌��J�͔ނ̌������Ƃ���N�x��̍��N3���ɂȂ����B
�n�[�h���Ǝv���Ĉ���J���Ă��̂͂��܂��炾������
63 �FMAC�I�^���c�q ���� [sage] �F2009/03/31(��) 00:09:28 ID:3FaCOFUY
>>62
"silicon"���ď����Ă���̂ł����H
http://www.realworldtech.com/forums/index.cfm?action=detail&id=96437&threadid=96378&roomid=2
�@�@---------------------
�@�@the Taiwanese were expecting silicon in January.
�@�@---------------------
Intel�̓`�b�v�̊J�����[�J�[�ł����āA�r�f�I�J�[�h��}�U�[�{�[�h�̊J�����[�J�[�͕ʓr���܂���B
64 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/03/31(��) 00:11:09 ID:YbyWNvCs
�܂��F������d�g�ł��E������ł���B
�Ȃނ�Penryn�ɂ�HyperThreading����������Ă���B
66 �FSocket774 [sage] �F2009/03/31(��) 00:17:43 ID:PgS7bnB4
http://www.xbitlabs.com/news/video/display/20080117222433_Intel_Promises_to_Sample_Larrabee_Processors_in_Late_2008.html
> �gLarrabee first silicon should be late this year in terms of samples
> and we�fll start playing with it and sampling it to developers and I
> still think we are on track for a product in late �f09, 2010 timeframe,�h
> said Paul Otellini, chief executive officer of Intel.
������F������̓d�g���������
82 �F,,�E�L�́M�E,,�j��-�������F2009/09/10(��) 23:35:45 ID:NYMGAvzW
Penryn��Hyper Threading�����ڂ���Ă�Demakasejan����ĊJ�H
����͕������B�Q��B
601 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/02/06(��) 07:50:39 ID:36Q+eCpY
����Larrabee�̃T���v����Dreamworks�ŕ]������Ă�悤����
601 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/02/06(��) 07:50:39 ID:36Q+eCpY
����Larrabee�̃T���v����Dreamworks�ŕ]������Ă�悤����
84 �F,,�E�L�́M�E,,�j��-�������F2009/09/10(��) 23:39:34 ID:NYMGAvzW
�V���R��IDF�ŏo�Ă��̂ɂ܂������Ă�̂��B
�N�̉�Ђł�Westmere�̃T���v���ɂ͐G��@��������ˁH
���Ȃ݂�Sandy Bridge��Load/Store�|�[�g�̔ԍ����炢�܂ł͉��̒��ł͊��o���
�N�̉�Ђł�Westmere�̃T���v���ɂ͐G��@��������ˁH
���Ȃ݂�Sandy Bridge��Load/Store�|�[�g�̔ԍ����炢�܂ł͉��̒��ł͊��o���
85 �F,,�E�L�́M�E,,�j��-�������F2009/09/10(��) 23:45:10 ID:NYMGAvzW
���Ȃ݂�Larrabee��Load/Store�̓}���`�|�[�g�ɂȂ��Ă�1�R�A������64�o�C�g/clk
L1�L���b�V����GPU�̃��W�X�^�t�@�C���̂悤�Ɏg������Ă̂͂��Ȃ����R����Ȃ�
L1�L���b�V����GPU�̃��W�X�^�t�@�C���̂悤�Ɏg������Ă̂͂��Ȃ����R����Ȃ�
�v�X�ɒc�q�����������…
���Ȃ��悤�ɂ��Ă��̂�…
���������…
���Ȃ��悤�ɂ��Ă��̂�…
���������…
87 �F,,�E�L�́M�E,,�j��-�������F2009/09/10(��) 23:47:51 ID:NYMGAvzW
>>86
�@�@�@�@�@�@�@�@�@�@�@�@�@ �^�P�_
�@�@�@�@�@�@�@�@�@�@�@�@�@|�@�@�@�@ |
�@�@�@�@�@�@�@�@ �@�@�@�@�@�_�Q�^
�@�@�@�@�@�@�@�@�@�@�@�@�@ �^�P�_
�@�@�@�@�@�@�@�@�@�@�@�@�@|�@�@�@�@ |
�@�@�@�@�@�@�@�@ �@�@�@�@�@�_�Q�^
�@�@�@�@�@�@�@�@�@�@�@�@�@ �^�P�_
�@�@�@�@�@�@�@�@�@�@�@�@�@|�@�@�@�@ |
�@�@�@�@�@�@�@�@ �@�@�@�@�@�_�Q�^
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@|
�@�@�@�@�@�@�@�@�@�@ �@�^ �P �P�@�_
�@�@�@�@�@�@�@�@�@�@�^�@�@�_�@�^�@�@�_
�@�@�@�@�@�@�@�@ �^�@�@ �܁@�@�@�� �@�@�_�@�@�@�@�@�@�悭�����̃X�����J���Ă��ꂽ
�@�@�@�@�@�@�@�@ |�@�@�@�@�i__�l__�j�@�@ �@�@|�@�@�@�@�@�@�J���Ƃ��Ēc�q�����������
�@�@�@�@�@�@�@�@ �_�@�@�@ �M �܁L�@�@�@�@�^�@�@�@��
�@�@�@�@�@�@�@�@�@/�R�--�[��Q�Q,-�]�L �_���^
�@�@�@�@�@�@�@ �^�@> �@�@�R������<�_�@�@||��.
�@�@�@�@�@�@ / �R��@�@�@�_ i�@|�|�@|/�@ �R�@(�j��M�R.
�@�@�@�@�@�@.l�@�@�@�R �@�@�@ l�@|�|�@| ��-�y�@�MƁ@ � �_
�@�@�@�@�@�@l�@�@�@�@_|�Q�Q_|�[�� | �P l �@�@�M~�R�Q�m
�@�@�@�@�@�@�@�@�@�@�@�@�@ �^�P�_
�@�@�@�@�@�@�@�@�@�@�@�@�@|�@�@�@�@ |
�@�@�@�@�@�@�@�@ �@�@�@�@�@�_�Q�^
�@�@�@�@�@�@�@�@�@�@�@�@�@ �^�P�_
�@�@�@�@�@�@�@�@�@�@�@�@�@|�@�@�@�@ |
�@�@�@�@�@�@�@�@ �@�@�@�@�@�_�Q�^
�@�@�@�@�@�@�@�@�@�@�@�@�@ �^�P�_
�@�@�@�@�@�@�@�@�@�@�@�@�@|�@�@�@�@ |
�@�@�@�@�@�@�@�@ �@�@�@�@�@�_�Q�^
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@|
�@�@�@�@�@�@�@�@�@�@ �@�^ �P �P�@�_
�@�@�@�@�@�@�@�@�@�@�^�@�@�_�@�^�@�@�_
�@�@�@�@�@�@�@�@ �^�@�@ �܁@�@�@�� �@�@�_�@�@�@�@�@�@�悭�����̃X�����J���Ă��ꂽ
�@�@�@�@�@�@�@�@ |�@�@�@�@�i__�l__�j�@�@ �@�@|�@�@�@�@�@�@�J���Ƃ��Ēc�q�����������
�@�@�@�@�@�@�@�@ �_�@�@�@ �M �܁L�@�@�@�@�^�@�@�@��
�@�@�@�@�@�@�@�@�@/�R�--�[��Q�Q,-�]�L �_���^
�@�@�@�@�@�@�@ �^�@> �@�@�R������<�_�@�@||��.
�@�@�@�@�@�@ / �R��@�@�@�_ i�@|�|�@|/�@ �R�@(�j��M�R.
�@�@�@�@�@�@.l�@�@�@�R �@�@�@ l�@|�|�@| ��-�y�@�MƁ@ � �_
�@�@�@�@�@�@l�@�@�@�@_|�Q�Q_|�[�� | �P l �@�@�M~�R�Q�m
�����Ȃ������_������Ă邪�A����Ƃ��ɂ͂��ׁ[�̃T���v�����Ȃ����B
�C�\�������ˁI�I�I
601 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/02/06(��) 07:50:39 ID:36Q+eCpY
����Larrabee�̃T���v����Dreamworks�ŕ]������Ă�悤����
�C�\�������ˁI�I�I
601 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/02/06(��) 07:50:39 ID:36Q+eCpY
����Larrabee�̃T���v����Dreamworks�ŕ]������Ă�悤����
89 �F,,�E�L�́M�E,,�j��-�������F2009/09/10(��) 23:57:11 ID:NYMGAvzW
�Ƃ����Opcode 64 67 90���Ēm��Ȃ��H
�ЂŁ[��ȁB���J���Ȃ̂ɁA�uLarrabee�v�ŃO�O���Ă��o�Ă��Ȃ����B
�ЂŁ[��ȁB���J���Ȃ̂ɁA�uLarrabee�v�ŃO�O���Ă��o�Ă��Ȃ����B
�悭�킩��Ȃ����ǁ���\��Ɖ����䗘�v�ł�����́H
601 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/02/06(��) 07:50:39 ID:36Q+eCpY
����Larrabee�̃T���v����Dreamworks�ŕ]������Ă�悤����
601 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/02/06(��) 07:50:39 ID:36Q+eCpY
����Larrabee�̃T���v����Dreamworks�ŕ]������Ă�悤����
91 �F,,�E�L�́M�E,,�j��-�������F2009/09/11(��) 00:00:45 ID:NYMGAvzW
FS LCP NOP
92 �F,,�E�L�́M�E,,�j��-�������F2009/09/11(��) 00:01:25 ID:gMJd18aF
>>90
�����ˁH
601 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/02/06(��) 07:50:39 ID:36Q+eCpY
����Larrabee�̃T���v����Dreamworks�ŕ]������Ă�悤����
�����ˁH
601 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/02/06(��) 07:50:39 ID:36Q+eCpY
����Larrabee�̃T���v����Dreamworks�ŕ]������Ă�悤����
����\��Ƌ��n�ő哖���肷��炵����
601 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/02/06(��) 07:50:39 ID:36Q+eCpY
����Larrabee��(silicon)�T���v����Dreamworks�ŕ]������Ă�悤����
601 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/02/06(��) 07:50:39 ID:36Q+eCpY
����Larrabee��(silicon)�T���v����Dreamworks�ŕ]������Ă�悤����
94 �F,,�E�L�́M�E,,�j��-�������F2009/09/11(��) 00:10:58 ID:gMJd18aF
�n���C�̃p�`���R����������������
601 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/02/06(��) 07:50:39 ID:36Q+eCpY
����Larrabee��(silicon)�T���v����Dreamworks�ŕ]������Ă�悤����
601 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/02/06(��) 07:50:39 ID:36Q+eCpY
����Larrabee��(silicon)�T���v����Dreamworks�ŕ]������Ă�悤����
�ŁA���o��̂��H
HD5870�`�b�v�T�C�Y338mm2��2.6Tflops�炵�����ǁALarrabee�ǂ��Ȃ��Ă�́H
601 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/02/06(��) 07:50:39 ID:36Q+eCpY
����Larrabee��(silicon)�T���v����Dreamworks�ŕ]������Ă�悤����
601 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/02/06(��) 07:50:39 ID:36Q+eCpY
����Larrabee��(silicon)�T���v����Dreamworks�ŕ]������Ă�悤����
>>96
500mm^2�`600mm^2��2Tflops�H�H
601 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/02/06(��) 07:50:39 ID:36Q+eCpY
����Larrabee��(silicon)�T���v����Dreamworks�ŕ]������Ă�悤����
500mm^2�`600mm^2��2Tflops�H�H
601 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/02/06(��) 07:50:39 ID:36Q+eCpY
����Larrabee��(silicon)�T���v����Dreamworks�ŕ]������Ă�悤����
���ALNI�̃o�C�g�R�[�h���Č��J���ꂽ�́H
(�L��֥`)�ʂ��
�� �� �� �� �� �� �� �� ��
���_���S
IDF�ł̃f����J�܂ł��ƂP�O���I
103 �FSocket774�F2009/09/14(��) 18:51:34 ID:Rnj1CaHV
Intel�A9��22���`24���ɊJ�×\���IDF�̓��e��\��
�`32nm���i��Jasper Forest�Ȃǂ̏ڍׂ����炩��
http://pc.watch.impress.co.jp/docs/news/20090914_315467.html
����ɂ͕���R���s���[�e�B���O����������uLarrabee�v�Ȃǂɂ��Ă̐����Ȃǂɂ��Ă��s�Ȃ��Ƃ����B
�`32nm���i��Jasper Forest�Ȃǂ̏ڍׂ����炩��
http://pc.watch.impress.co.jp/docs/news/20090914_315467.html
����ɂ͕���R���s���[�e�B���O����������uLarrabee�v�Ȃǂɂ��Ă̐����Ȃǂɂ��Ă��s�Ȃ��Ƃ����B
���悢�擮��Larrabee�������̂��I�I
��H
���uLarrabee�v�Ȃǂɂ��Ă̐����Ȃǂɂ��Ă��s�Ȃ��Ƃ����B
��bee�v�Ȃǂɂ��Ă̐����Ȃǂɂ���
���@�@�@�@�@���@�@��
�i ߄t� �j
��H
���uLarrabee�v�Ȃǂɂ��Ă̐����Ȃǂɂ��Ă��s�Ȃ��Ƃ����B
��bee�v�Ȃǂɂ��Ă̐����Ȃǂɂ���
���@�@�@�@�@���@�@��
�i ߄t� �j
(�L�E�ցE`)�X���[�N�`�[�Y�͂��邩���H
���������ă��[���`���������ɂ͂����J�������[�����Ă���A�݂�����
��Ԃ�ڎw���Ă���̂��ȁB���Ȃ�T�d�ɂ��Ƃ�i�߂Ă���悤�Ɍ�����
��Ԃ�ڎw���Ă���̂��ȁB���Ȃ�T�d�ɂ��Ƃ�i�߂Ă���悤�Ɍ�����
�v���W�F�N�g���s�̐ӔC����炳���`��
�Q�����N�r���ăz���g�H
�Q�����N�r���ăz���g�H
108 �F,,�E�L�́M�E,,�j��-�������F2009/09/15(��) 22:19:18 ID:CtE/fxwg
>>106
����͂������B�n�[�h�����o���ă\�t�g�J���҂Ɋۓ�������Cell�ƂȂɂ��ς���
�n�[�h�o���@����킵�����Ă�̂��m������
�ǂ������J�����̐����Ɏ�Ԏ���Ă�̂��m������
C++�Ɍ����Threading Building Blocks�݂����Ȑ��ʕ��͏o�Ă��Ă͂��邪
�{����Ct�͂܂������B
�����ۓ�����AMD�Ȃ���ꡂ��Ƀ}�V�Ƃ͂�����
����͂������B�n�[�h�����o���ă\�t�g�J���҂Ɋۓ�������Cell�ƂȂɂ��ς���
�n�[�h�o���@����킵�����Ă�̂��m������
�ǂ������J�����̐����Ɏ�Ԏ���Ă�̂��m������
C++�Ɍ����Threading Building Blocks�݂����Ȑ��ʕ��͏o�Ă��Ă͂��邪
�{����Ct�͂܂������B
�����ۓ�����AMD�Ȃ���ꡂ��Ƀ}�V�Ƃ͂�����
{kind=link}
�܂�C���e���͖{�C����Ȃ��Ƃ������ł���
���_���S
�� �� �� �� �� �� �� �� ��
GT300�̕����܂肪2%�ȉ��炵����
����͂܂�AMD�Ƀ��C�o�������Ȃ��Ȃ����Ǝv���Ă���
����͂܂�AMD�Ƀ��C�o�������Ȃ��Ȃ����Ǝv���Ă���
GPU�s��̘X�C�̉�������
���̂ق�̈�u�̋P���ɉ߂���
���̂ق�̈�u�̋P���ɉ߂���
�������Ɂ@����ŋ����������Ȃ邱�Ƃɂ�鐫�\up�̊��҂͔��ꂽ��
AMD�ꋭ�ɂȂ�\����
AMD�ꋭ�ɂȂ�\����
�P�Ȃ邨�G�������M���
�x���`�����p���������Ă��Ƃ�
�x���`�����p���������Ă��Ƃ�
������DX10����DX11�K�{�Ȏ����ɉ����ɂȂ���
���̑Ή������ׂă\�t�g�������s������ǂ�Ȃ���ςȂ납�ƁB
�n�[�h��������Ă�AtiNv�̃h���C�o�J�����������Đ��S�l�K�͂Ȃ̂ɥ��
���̑Ή������ׂă\�t�g�������s������ǂ�Ȃ���ςȂ납�ƁB
�n�[�h��������Ă�AtiNv�̃h���C�o�J�����������Đ��S�l�K�͂Ȃ̂ɥ��
�n�[�h�����Ƃ������Ⴂ�܂���
DX10�ȍ~�A�قƂ�ǂ�shader�Œu����������
�܂�́ADX9�ȑO�̂���ӂꂽ�@�\�ł����Ă�
�v���O���}�������ɂ�Ȃ���
DX10�ȍ~�A�قƂ�ǂ�shader�Œu����������
�܂�́ADX9�ȑO�̂���ӂꂽ�@�\�ł����Ă�
�v���O���}�������ɂ�Ȃ���
>>118
�e�b�Z���[�^�[��ROP�̓n�[�h�E�F�A��������H
���ꂷ����\�t�g�E�F�A�ŏ����˂Ȃ�Ȃ�Larrabee��
GPU�ɏ����߂ɂ͐����v���Z�X��1������������
�_�C�T�C�Y��傫�����āA�ł�����艉�Z���j�b�g��
�g�����W�X�^�����������̂ǂ��炩�����Ȃ�
3DCG�ȊO�̔ėp�����Ȃ�Larrabee���g�������b�g��
���邾�낤���A�O���t�B�b�N�Ɍ����Ă�����Larrabee��
GPU�ɏ��Ă錩���݂͂Ȃ����낤
�e�b�Z���[�^�[��ROP�̓n�[�h�E�F�A��������H
���ꂷ����\�t�g�E�F�A�ŏ����˂Ȃ�Ȃ�Larrabee��
GPU�ɏ����߂ɂ͐����v���Z�X��1������������
�_�C�T�C�Y��傫�����āA�ł�����艉�Z���j�b�g��
�g�����W�X�^�����������̂ǂ��炩�����Ȃ�
3DCG�ȊO�̔ėp�����Ȃ�Larrabee���g�������b�g��
���邾�낤���A�O���t�B�b�N�Ɍ����Ă�����Larrabee��
GPU�ɏ��Ă錩���݂͂Ȃ����낤
���K�v����������
ATI,nv�͏��F�x���`��p
ATI,nv�͏��F�x���`��p
122 �F,,�E�L�́M�E,,�j��-�������F2009/09/17(��) 07:26:57 ID:ZP1RrD/W
HW�����̃e�b�Z���[�^���ĕK�v�Ȃ́H
�\�t�g�������Ƃǂ̂��炢�̐��\��̃R�X�g�ɂȂ�Ƃ���ʓI�Ȕ�r���ł��Ȃ����Ƃɂ�
�ǂ��Ƃ������Ȃ�
���삢�킭MS�I�ɂ͂��Ƃ��ƃ\�t�g�ł̎�����z�肵�Ă����̂炵����
�\�t�g�������Ƃǂ̂��炢�̐��\��̃R�X�g�ɂȂ�Ƃ���ʓI�Ȕ�r���ł��Ȃ����Ƃɂ�
�ǂ��Ƃ������Ȃ�
���삢�킭MS�I�ɂ͂��Ƃ��ƃ\�t�g�ł̎�����z�肵�Ă����̂炵����
POWER7�͑ш惂���X�^�[�炵���B
Larrabee�͉��Ƃǂ�ȑ����Ōq�����邩�킩��Ȃ����Ƃɂ�
���Ɏg����̂����f�ł��Ȃ�
Larrabee�͉��Ƃǂ�ȑ����Ōq�����邩�킩��Ȃ����Ƃɂ�
���Ɏg����̂����f�ł��Ȃ�
�܂������c�c�q�͉R�����茾������
�����炠��Ȋ�ɂȂ����肷���
�����炠��Ȋ�ɂȂ����肷���
125 �FSocket774�F2009/09/17(��) 18:53:45 ID:YkoJn40H
New Larrabee silicon taped out weeks ago
http://www.semiaccurate.com/2009/09/16/new-larrabee-silicon-taped-out-weeks-ago/
http://www.semiaccurate.com/2009/09/16/new-larrabee-silicon-taped-out-weeks-ago/
Larrabee has a host of bugs which prevented public showings of the Ax silicon.
That said, almost all problems are said to be fixed in the move from Ax to B0 silicon.
����
http://pc11.2ch.net/test/read.cgi/jisaku/1245944113/2
2 �FSocket774�F2009/06/26(��) 00:46:41 ID:K0n9bRUo
FUDzillla���\�t�g�E�F�A�T�|�[�g��h���C�o�̒x���Ă邯�ǁA
����͐^�����B�����߂̌����[�N���ŁA
���ۂ̓t�@�[�X�g�V���R�����܂Ƃ��ɓ��삹���A�J���`�[���͉̎ԏ�ԁB
That said, almost all problems are said to be fixed in the move from Ax to B0 silicon.
����
http://pc11.2ch.net/test/read.cgi/jisaku/1245944113/2
2 �FSocket774�F2009/06/26(��) 00:46:41 ID:K0n9bRUo
FUDzillla���\�t�g�E�F�A�T�|�[�g��h���C�o�̒x���Ă邯�ǁA
����͐^�����B�����߂̌����[�N���ŁA
���ۂ̓t�@�[�X�g�V���R�����܂Ƃ��ɓ��삹���A�J���`�[���͉̎ԏ�ԁB
�e�b�Z���[�^��DX10GPU�ƃ\�t�g�G�~���̃f����1fps�ȉ��̃X�s�[�h���o���Ă��̂�
�\�t�g�G�~���ł�����Ȃ��̂�
�\�t�g�G�~���ł�����Ȃ��̂�
601 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/02/06(��) 07:50:39 ID:36Q+eCpY
����Larrabee�̃T���v����Dreamworks�ŕ]������Ă�悤����
����Larrabee�̃T���v����Dreamworks�ŕ]������Ă�悤����
�o�O���炯�ł܂Ƃ��ɓ����Ȃ�Ax�V���R�����A
Dreamworks�͂��������ǂ�����ĕ]�����Ă����̂��낤�B
Dreamworks�͂��������ǂ�����ĕ]�����Ă����̂��낤�B
�k���肵�ăL���L�����Ă��Y�킾�ȁ`�`�Ƃ�
���������\�t�g���ɂƂ��Ă͐�Ƀ\�t�g�̃T�C�N���A�L�����[�g�ȃV�~�����[�^�����p�ӂ��Ă��炦��Ή��Ƃł��Ȃ��B
�t�ɂ����������\�t�g�J���c�[�����Ȃ��ƃG���W���J�������悤���Ȃ���
��Ƀ`�b�v�����n����Ăǂ��ɂ��Ȃ�킯�ł��Ȃ�
�G���W�j�A�����O�T���v�����K�v�Ȃ̂̓n�[�h�v���B
�t�ɂ����������\�t�g�J���c�[�����Ȃ��ƃG���W���J�������悤���Ȃ���
��Ƀ`�b�v�����n����Ăǂ��ɂ��Ȃ�킯�ł��Ȃ�
�G���W�j�A�����O�T���v�����K�v�Ȃ̂̓n�[�h�v���B
>>128
�������A�c�q�̓o�O���ŗV��ł��̂�
601 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/02/06(��) 07:50:39 ID:36Q+eCpY
����Larrabee�̃T���v����Dreamworks�ŕ]������Ă�悤����
�������A�c�q�̓o�O���ŗV��ł��̂�
601 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/02/06(��) 07:50:39 ID:36Q+eCpY
����Larrabee�̃T���v����Dreamworks�ŕ]������Ă�悤����
�@�@�@�@�@�f�P�f�P�@�@�@�@�@�@|�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@|
�@�@�@�@�@�@�@�@�h�R�h�R�@�@ ���@�ۂ���������������������
�@�@�@���@�@�@�@�@�@�h���h���@|�Q�@�Q�@ �Q�@�Q�@�Q�@�Q|
�@�@�@�@�@�@�@ ���@�@�@�_�_�_�_! �Ɂ@ �Ɂ@�Ɂ@�Ɂ@�Ɂ@��
�@�@�h�V���[��!�@�@�R�@�@�@�@�@�@�@�@�@�I���I���b!!�@�@�@ ��
�@�@�@�@�@�@�@�@�@���߁��@�ȁQ�ȁ@�@�@�@�@��
�@�@�@�@�@�@�� �@�@�^�@�V(*�e�ցe *)�@�@�@�@/�@�V�����V����
�@�@�@�@��@�@�@�Y �@���_�Ɓ_��.�S���߁��U
�@�@�@�@�@�@�@�@�@|| �@�� �܁R�R�R �m�@�@||
�@�@�@�@�@�@�@�@�@||�@���� �@.|:::|���� �@||�@�@�@��
�@�@�@�@�@�@�@ .�^|�_�l �Q.�m�m _||_.�@�^|�_
�@�@�@�@�@�@�@�@�@�h�`�h�`!
134 �FSocket774�F2009/09/20(��) 16:26:19 ID:99plnXPo
ttp://wlog.flatlib.jp/item/1392
Mobile GPU
>�d�͂��ʐς������Ă��郂�o�C������ GPU �ɂƂ��ăo�X�ш�͑傫�Ȗ��ł��B
>�^�C���x�[�X�Ő[�x����̂ݐ�s���A�ŏ����̃t���O�����g�̂݃����_�����O����
>PowerVR �Ɠ����悤�ɁAAMD ���`�b�v���̏��ʂ������� RAM ��p�����^�C���x�[�X
>�����_�����O���s���Ă���悤�ł��B���̕ӂ̍H�v�����ɋ����[���Ƃ���ł��B
Mobile GPU
>�d�͂��ʐς������Ă��郂�o�C������ GPU �ɂƂ��ăo�X�ш�͑傫�Ȗ��ł��B
>�^�C���x�[�X�Ő[�x����̂ݐ�s���A�ŏ����̃t���O�����g�̂݃����_�����O����
>PowerVR �Ɠ����悤�ɁAAMD ���`�b�v���̏��ʂ������� RAM ��p�����^�C���x�[�X
>�����_�����O���s���Ă���悤�ł��B���̕ӂ̍H�v�����ɋ����[���Ƃ���ł��B
Larrabee�|����������������鍂���\�ƒ����d�́AGeForce GTX 285�𗽉�
http://pc.watch.impress.co.jp/docs/column/tawada/20090923_317271.html
http://pc.watch.impress.co.jp/docs/column/tawada/20090923_317271.html
>>136
�ǁ[���[�H�H�H�H�H
�ǁ[���[�H�H�H�H�H
Intel�CIDF 2009�ŁuLarrabee�v�̎��@�f�����I�B2010�N�ȍ~�C�n�C�G���h�s������ɃO���t�B�b�N�X�J�[�h�𓊓���
ttp://www.4gamer.net/games/049/G004963/20090923003/
ttp://www.4gamer.net/games/049/G004963/20090923003/
�Ȃf���̃t���[�����[�g�߂��Ⴍ����Ⴍ�˂�?
����i�K�Ƃ́A����I�ڂŎ����̃��C�g�������̒��x
�Ȃ�����̃��X�^���C�[�[�V�����ł́AHD5xxx��GTX3xx�ɂ͏��ĂȂ�
Larrabee���āA�Ȃɂ�ɂ���́H
�Ȃ�����̃��X�^���C�[�[�V�����ł́AHD5xxx��GTX3xx�ɂ͏��ĂȂ�
Larrabee���āA�Ȃɂ�ɂ���́H
���{���
90MHz��FPGA��SaarCOR�ł��������ƃX���[�Y�ɓ����Ă����悤�ȁc
���C�L���X�g���炢�n�[�h�Ŏ�������Ⴂ���̂�
���C�L���X�g���炢�n�[�h�Ŏ�������Ⴂ���̂�
���A���^�C�����C�g���[�V���O�͋Z�p�҂̖�����
���̒��x�̉掿����N���H�����Ȃ����
���߂�V-ray���̃t�H�g���A���\���ł��Ȃ���
ttp://v-ray.jp/envyspot2008_june.shtml
Cell+RSX�̂悤�ɁAGPU��CPU������Larrabee�ɂ�鋦�Ƃ�͍����Ă�̂��H
���̒��x�̉掿����N���H�����Ȃ����
���߂�V-ray���̃t�H�g���A���\���ł��Ȃ���
ttp://v-ray.jp/envyspot2008_june.shtml
Cell+RSX�̂悤�ɁAGPU��CPU������Larrabee�ɂ�鋦�Ƃ�͍����Ă�̂��H
�s��ɏo�ĂȂ�CPU�����Ă��ĉ��ʗ����Ă�̂ɂ��ꂩ
�l�^��
ttp://www.youtube.com/watch?v=mtHDSG2wNho
Quake Wars: Ray Traced
�����intel�f��
ttp://www.youtube.com/watch?v=G-FKBMct21g
Sean Maloney's IDF 2009 Larrabee graphics demo
ttp://www.youtube.com/watch?v=mtHDSG2wNho
Quake Wars: Ray Traced
�����intel�f��
ttp://www.youtube.com/watch?v=G-FKBMct21g
Sean Maloney's IDF 2009 Larrabee graphics demo
N�~�̉Εa����Ղ肪�ʔ�����
OpenCL���J���̑���CUDA�A�X�y�b�N������Ȃ������r�[�A�ᒠ�̊O��AMD
�yIDF 2009���|�[�g�z�V���[���E�}���[�j����u�����|�[�g
�`Larrabee�̃f���������J
http://pc.watch.impress.co.jp/docs/news/event/20090924_317313.html
�`Larrabee�̃f���������J
http://pc.watch.impress.co.jp/docs/news/event/20090924_317313.html
Ct�Ȃ�CT�Ȃ�Ȃ�Ƃ����Ă����E�E�E�B
�c�q����̓Q�[���p�O���t�B�b�N�X�v���Z�b�T�Ƃ��Ă͋����Ȃ������H
���≴���Ȃ�����
���≴���Ȃ�����
151 �FSocket774�F2009/09/24(��) 00:47:31 ID:w49PsoMK
1600�R�A�̎���ɂ�������4�R�A����8�R�A���̂����Ă�CPU������Ă�ꍇ��
�ꍇ����B
Lynn�̓����[�X����āA���̐V�͔N����Clarkdale/Arrandale������ȁB
���̎��͗��NH1��Westmere-EP�B
Lynn�̓����[�X����āA���̐V�͔N����Clarkdale/Arrandale������ȁB
���̎��͗��NH1��Westmere-EP�B
>>151
1600�R�A�̔ėp�v���Z�b�T����B
1600�R�A�̔ėp�v���Z�b�T����B
Software developement systems shipping now ���ċ�̓I�ɉ��Ȃ낤
ttp://www.4gamer.net/games/049/G004963/20090923003/
ttp://www.4gamer.net/games/049/G004963/20090923003/
Ct�̃x�[�^�e�X�g����
156 �FSocket774�F2009/09/24(��) 10:37:55 ID:miQ0oZWI
>>151
1600�R�A���ĉ��̖ϑz���悗
1600�R�A���ĉ��̖ϑz���悗
>>148
>�ŏ��̃f���ɂ��Ă͂����Ԃ�ƒn���ȃf���������悤�ȋC�����Ȃ����Ȃ�
�Ƃ�PCWatch�̒��̐l������������Ă邮�炢�������Ȃ������ȁ[
>�ŏ��̃f���ɂ��Ă͂����Ԃ�ƒn���ȃf���������悤�ȋC�����Ȃ����Ȃ�
�Ƃ�PCWatch�̒��̐l������������Ă邮�炢�������Ȃ������ȁ[
159 �F,,�E�L�́M�E,,�j��-�������F2009/09/24(��) 22:17:00 ID:Jgvf5I8y
>>156
SIMD���Z��̃G�������g������Ȃ��́H
���̌v�Z�ōs����Core i7��4Way(128�r�b�g)SIMD���Z��~3������48�R�A�ȁB
SIMD���Z��̃G�������g������Ȃ��́H
���̌v�Z�ōs����Core i7��4Way(128�r�b�g)SIMD���Z��~3������48�R�A�ȁB
>>157
CG����
�d���Ō��z�p�[�X�Ƃ�����Ă邪�A�{���Ɏ��ʕ��݂̏o�͂�������B
��������A���^�C���`��ł���Ȃ�ALarrabee���g���Ӗ��͂��邪
���Ȃ����̃f�����������ł�11nm����ɂȂ�܂Ŗ�����������
CG����
�d���Ō��z�p�[�X�Ƃ�����Ă邪�A�{���Ɏ��ʕ��݂̏o�͂�������B
��������A���^�C���`��ł���Ȃ�ALarrabee���g���Ӗ��͂��邪
���Ȃ����̃f�����������ł�11nm����ɂȂ�܂Ŗ�����������
1600�R�A��HD5870��SP���̂��Ƃł���B
CPU�͔ėp�����ړI�i���S�u���O���}�u���j
GPU�͌Œ菈���ړI�i�ꕔ�v���O���}�u���j
��ׂ邱�Ǝ��̃i���Z���X
CPU�͔ėp�����ړI�i���S�u���O���}�u���j
GPU�͌Œ菈���ړI�i�ꕔ�v���O���}�u���j
��ׂ邱�Ǝ��̃i���Z���X
SP���1�R�A�Ƃ�Nvidia���z���g�Ɍ����Ă����
>143�@>>157
�������f��ł��A���@��[�U�[�r�[���݂����ȓ�����ʂ�
�K�v�Ȃ��V�[���ł��A�Z�b�g������胍�P�ɍs������CG�̕���������
���ς���ꂽ��CG�ō���Ă��܂�
�������f��ł��A���@��[�U�[�r�[���݂����ȓ�����ʂ�
�K�v�Ȃ��V�[���ł��A�Z�b�g������胍�P�ɍs������CG�̕���������
���ς���ꂽ��CG�ō���Ă��܂�
������3DCG���������ƌ��ς���ꂽ��}�b�g�y�C���g�̈ꖇ�G�{AE�����ō�����Ⴄ
�Q�[���Ɏg���Ƃ������Ă邪���ʂɖ������낤
���������ΐV�^PS3�����[�N�����j���[�X�ɗ��NPS4���o��݂����Ȃ��Ə����Ă������C�����邪
�܂����ϑԃn�[�h�D���̃\�j�[���V�n�[�h�ɐςނ�˂����낤��
���������ΐV�^PS3�����[�N�����j���[�X�ɗ��NPS4���o��݂����Ȃ��Ə����Ă������C�����邪
�܂����ϑԃn�[�h�D���̃\�j�[���V�n�[�h�ɐςނ�˂����낤��
>>165
Cell�̓�����PS3,PS4,PS5�̕�������ʼn�����邽�߂�
�X�P�[���u���A�[�L�e�N�`�����̗p�����̂�����
Cell�g���ňȊO�g���C�Ȃ��ł���
22nm����ɂȂ�����PS4�o����Ȃ��H
�T�[�h�݂͂�ȔC�V����HD�@�ɗ��ꂻ���ȗ\�������邯��
Cell�̓�����PS3,PS4,PS5�̕�������ʼn�����邽�߂�
�X�P�[���u���A�[�L�e�N�`�����̗p�����̂�����
Cell�g���ňȊO�g���C�Ȃ��ł���
22nm����ɂȂ�����PS4�o����Ȃ��H
�T�[�h�݂͂�ȔC�V����HD�@�ɗ��ꂻ���ȗ\�������邯��
����PS4��Sandy Bridge + Larrabee�݂����Ȃ���ł�����B
���ꂾ��Windows�������邯�ǁAOtherOS�̃C���X�g�[����
�ł��Ȃ��Ȃ�CPU�ɉ���I��ł����[�U�[�ɂ͑卷�Ȃ��ˁB
�ł��Ȃ��Ȃ�CPU�ɉ���I��ł����[�U�[�ɂ͑卷�Ȃ��ˁB
171 �F,,�E�L�́M�E,,�j��-�������F2009/09/27(��) 20:18:33 ID:wZhgRL9c
>>167
PS3�ȊO�̓W�J����Ă�͓̂��ł��炢�Ȃ��E�E�E
�P��LRBni�ŗV�т����Ȃ�AHaswell����Ń~�b�h�����W�ȉ��ɓ��������킯��
PS3�ȊO�̓W�J����Ă�͓̂��ł��炢�Ȃ��E�E�E
�P��LRBni�ŗV�т����Ȃ�AHaswell����Ń~�b�h�����W�ȉ��ɓ��������킯��
�k�X��techreport�̃R�����g�����Ă��I�탂�[�h����
�����_���|
�����_���|
173 �F,,�E�L�́M�E,,�j��-�������F2009/09/27(��) 21:04:15 ID:wZhgRL9c
���[���A����x�������ł��Ȃ��������������Ȃ�128�r�b�gSIMD��p�R�A��
�R�A�������u�X�P�[���v���Ă����܂�|���͂Ȃ��Ǝv�����B
�v���t�@�[�h�X���b�g�݂̂��g������X�J�����Z�̐��\�͐��鈫�����B
�{���̃X�J�����Z���ł���64�r�b�g�A�h���b�V���O���ł��A
���C�h�����_���SIMD�g��������Larrabee�ɔ�ׂĉ����L���Ȃ�H
4PPE+32SPE�ŒP���x1TFLOPS�i�s�[�N�j�ɂȂ�悤�����A45nm��400�`500mm²���x�̃_�C�T�C�Y�����B
���ɃX�P�[���r���e�B�̗D�ʐ����Ȃ��B
�[���ACell�̃X�P�[���r���e�B�̍������āASPE�̓��[�J���������`���ŃO���[�o���������Ƃ̃A�N�Z�X��DMA������
�R�q�[�����g���䂪�Ȃ��킯�����B
������đ����̃f�����b�g���s��ł�킯�ŁB�R�q�[�����g����Ȃ��œǂݏ������邾���Ȃ�LRBni�ł��S�Ă�SIMD���߂Ŏg���邵�B
�R�A�������u�X�P�[���v���Ă����܂�|���͂Ȃ��Ǝv�����B
�v���t�@�[�h�X���b�g�݂̂��g������X�J�����Z�̐��\�͐��鈫�����B
�{���̃X�J�����Z���ł���64�r�b�g�A�h���b�V���O���ł��A
���C�h�����_���SIMD�g��������Larrabee�ɔ�ׂĉ����L���Ȃ�H
4PPE+32SPE�ŒP���x1TFLOPS�i�s�[�N�j�ɂȂ�悤�����A45nm��400�`500mm²���x�̃_�C�T�C�Y�����B
���ɃX�P�[���r���e�B�̗D�ʐ����Ȃ��B
�[���ACell�̃X�P�[���r���e�B�̍������āASPE�̓��[�J���������`���ŃO���[�o���������Ƃ̃A�N�Z�X��DMA������
�R�q�[�����g���䂪�Ȃ��킯�����B
������đ����̃f�����b�g���s��ł�킯�ŁB�R�q�[�����g����Ȃ��œǂݏ������邾���Ȃ�LRBni�ł��S�Ă�SIMD���߂Ŏg���邵�B
�Ƃ肠�����A�Ȃ��Ⴂ���Ă郉�f�I�\�M�҂��T������
175 �F,,�E�L�́M�E,,�j��-�������F2009/09/27(��) 21:18:21 ID:wZhgRL9c
�܂�Prototype Library������ǂ�Larrabee�̖{���킩��Ǝv�����B
���߃Z�b�g���x���ő��{�������⍂�x�ȃ}�g���N�X���Z�Ƀt�H�[�J�X���Ă�B
Intel��TOP500�̃V�F�A90%�I�[�o�[��ڎw���Ȃ��ƋC���ς܂Ȃ��悤��
GPU�Ƃ��Ċ��ҊO��Ō��\����B
���������X�p�R���p�r�̃j�[�Y�Ƃ��čŒ���K�v�ȏ_����̂ĂĂ܂�GPU�i�j��Nj�����K�v���Ȃ��B
���߃Z�b�g���x���ő��{�������⍂�x�ȃ}�g���N�X���Z�Ƀt�H�[�J�X���Ă�B
Intel��TOP500�̃V�F�A90%�I�[�o�[��ڎw���Ȃ��ƋC���ς܂Ȃ��悤��
GPU�Ƃ��Ċ��ҊO��Ō��\����B
���������X�p�R���p�r�̃j�[�Y�Ƃ��čŒ���K�v�ȏ_����̂ĂĂ܂�GPU�i�j��Nj�����K�v���Ȃ��B
��4PPE+32SPE�ŒP���x1TFLOPS�i�s�[�N�j�ɂȂ�悤�����A45nm��400�`500mm�HxB2;���x�̃_�C�T�C�Y�����B
�}�W���E�E�E90nmCell��1PPE+8SPE��235mm^2�����点������300mm^2���Ǝv���Ă�
�}�W���E�E�E90nmCell��1PPE+8SPE��235mm^2�����点������300mm^2���Ǝv���Ă�
178 �F,,�E�L�́M�E,,�j��-�������F2009/09/27(��) 22:05:42 ID:wZhgRL9c
>>177
http://pc.watch.impress.co.jp/docs/2008/0206/kaigai416.htm
45nm��1PPE+8SPE��115.46mm²
HPC�����͔̂{���x���j�b�g�����������_�C�T�C�Y���傫���Ȃ邩��A�����4�{�{�����x�̃_�C�T�C�Y�ɂȂ�Ǝv��
�[���A���̋���Cell�́A2009�N�o��\�肾�����̂������ɏo�ĂȂ����B
TOP500�̍ŏ�ʃN���X��IBM�̏o������ɂȂ�C������B
����Cell�ɍS����TOP500��1�ʂ�]���Ɏ����悤�Ȃ��ƂɂȂ�A���{����̔��������Ȃ��Ȃ邩��ˁB
��ł�����IBM���\�����[�V�������Ƃ���Larrabee��I������ΑS�Ă��I����K�X�B
http://pc.watch.impress.co.jp/docs/2008/0206/kaigai416.htm
45nm��1PPE+8SPE��115.46mm²
HPC�����͔̂{���x���j�b�g�����������_�C�T�C�Y���傫���Ȃ邩��A�����4�{�{�����x�̃_�C�T�C�Y�ɂȂ�Ǝv��
�[���A���̋���Cell�́A2009�N�o��\�肾�����̂������ɏo�ĂȂ����B
TOP500�̍ŏ�ʃN���X��IBM�̏o������ɂȂ�C������B
����Cell�ɍS����TOP500��1�ʂ�]���Ɏ����悤�Ȃ��ƂɂȂ�A���{����̔��������Ȃ��Ȃ邩��ˁB
��ł�����IBM���\�����[�V�������Ƃ���Larrabee��I������ΑS�Ă��I����K�X�B
>>178
�Ȃ悻��ȑS���œK������ĂȂ����Ԃ��炯�̃_�C�������������̂���B
���[���A���̋���Cell�́A2009�N�o��\�肾�����̂������ɏo�ĂȂ����B
2010�N�㔼����H
http://img411.imageshack.us/img411/9205/roadmap1kh0.png
�Ȃ悻��ȑS���œK������ĂȂ����Ԃ��炯�̃_�C�������������̂���B
���[���A���̋���Cell�́A2009�N�o��\�肾�����̂������ɏo�ĂȂ����B
2010�N�㔼����H
http://img411.imageshack.us/img411/9205/roadmap1kh0.png
{kind=link}
180 �F,,�E�L�́M�E,,�j��-�������F2009/09/27(��) 22:31:32 ID:wZhgRL9c
���������APS3�̂�����A�{���x�����ł���Ȃ����H
�����O�Ԃ̃C���^�[�R�l�N�g��H���p�ӂ��Ȃ��Ƃ����Ȃ���
����v����葝����v���̕���������
�����O�Ԃ̃C���^�[�R�l�N�g��H���p�ӂ��Ȃ��Ƃ����Ȃ���
����v����葝����v���̕���������
���Ԃ��炯�Ƃ����Ă��A�œK������2�����炢�������Ȃ����Ƃ��Ă��A400mm2���炢�B
300mm2�ɂ���ɂ́A�œK��������3���ȏ㏬�������Ȃ��Ƃ����Ȃ�����A
�������ɂ���͂Ȃ����낤�B
300mm2�ɂ���ɂ́A�œK��������3���ȏ㏬�������Ȃ��Ƃ����Ȃ�����A
�������ɂ���͂Ȃ����낤�B
>>181
�ŁA����͔ėp�I�ɂ�����̂��ˁH
�ŁA����͔ėp�I�ɂ�����̂��ˁH
184 �F,,�E�L�́M�E,,�j��-�������F2009/09/27(��) 22:38:14 ID:wZhgRL9c
> ���[���A���̋���Cell�́A2009�N�o��\�肾�����̂������ɏo�ĂȂ����B
> 2010�N�㔼����H
�����ɂȂ����̂��B
1���W���[��������̉��i��1 PPE + 8 eSPE�Łi8000�h���O��j�̍X�ɔ{�ȏ�ɂȂ�̂͊m�����낤��
Larrabee���Ȃ��Ă�Sandy Bridge���o�邩��FLOPS�����艿�i�͍X�ɉ������邵
> 2010�N�㔼����H
�����ɂȂ����̂��B
1���W���[��������̉��i��1 PPE + 8 eSPE�Łi8000�h���O��j�̍X�ɔ{�ȏ�ɂȂ�̂͊m�����낤��
Larrabee���Ȃ��Ă�Sandy Bridge���o�邩��FLOPS�����艿�i�͍X�ɉ������邵
185 �FSocket774�F2009/09/27(��) 22:39:23 ID:WToZSfyw
>>183
�Q�[���ɂ����Ă�Cell���͂�ق�
�Q�[���ɂ����Ă�Cell���͂�ق�
186 �F,,�E�L�́M�E,,�j��-�������F2009/09/27(��) 22:39:57 ID:wZhgRL9c
>>183
1�G�������g5Way VLIW�̂���3D�����ł�����3Way���x���������ĂȂ��B
2D��������2Way������ȉ��B
�s�[�NFLOPS���Ǝ���FLOPS���̘������������B
�X�p�R���ȂɎg����킯���Ȃ��B
1�G�������g5Way VLIW�̂���3D�����ł�����3Way���x���������ĂȂ��B
2D��������2Way������ȉ��B
�s�[�NFLOPS���Ǝ���FLOPS���̘������������B
�X�p�R���ȂɎg����킯���Ȃ��B
>>185
�A�N�Z�����[�^�����炻��Ȃ���ȁB
�A�N�Z�����[�^�����炻��Ȃ���ȁB
188 �F,,�E�L�́M�E,,�j��-�������F2009/09/27(��) 22:49:25 ID:wZhgRL9c
Havok Cloth��l�`1�̓������̂ł���q�C�q�C�����Ă���x�̂�
�A�[�L�̉��ǂ��Ȃ��܂܃R�A���{���������x�łǂ��ɂ��Ȃ�킯���Ȃ��B
���ɔ�GPU������点����Cell��32�R�A�̂ق����������\�͏ゾ�낤
�A�[�L�̉��ǂ��Ȃ��܂܃R�A���{���������x�łǂ��ɂ��Ȃ�킯���Ȃ��B
���ɔ�GPU������点����Cell��32�R�A�̂ق����������\�͏ゾ�낤
GPGPU���\�ł͂������łɒǂ����Ȃ����x���ɂȂ����܂����ȁE�E�E
190 �FSocket774�F2009/09/28(��) 06:57:22 ID:E1AFoXSi
�������ˁAATI�͂����邵���Ȃ��Ȃ�
�f���n������
Transcript�ǂ��R�[�h�Z�������������Ӑ}�����邾�낱��
GPU�ŏ�����120�s������LRB�Ȃ�C++���g���邩�炽������25�s�Ȃ��H
�܂��f�G�I
���Ăǂ��̒ʔ̔ԑg��
GPU�ŏ�����120�s������LRB�Ȃ�C++���g���邩�炽������25�s�Ȃ��H
�܂��f�G�I
���Ăǂ��̒ʔ̔ԑg��
193 �FSocket774�F2009/09/28(��) 07:24:51 ID:wXQW5x+U
�ʔ����ʔ���
���ҊO��
Larrabee�͊��ҊO��������Ƃ���
�c�q�A������
�c�q�A������
196 �F,,�E�L�́M�E,,�j��-�������F2009/09/28(��) 23:04:27 ID:L7aVFlKw
�Ȃɂ��u���ҁv���Ă��H
������҂���Ȃ��āu���Ⴂ�v����
������҂���Ȃ��āu���Ⴂ�v����
GT300���Ȃ��Ȃ��o�Ă��Ȃ��ăC���C������C�����͂킩��
198 �F,,�E�L�́M�E,,�j��-�������F2009/09/28(��) 23:05:53 ID:L7aVFlKw
Sandy Bridge�̃T�C�N���A�L�����[�g�V�~�����[�^�ʔ�������B
>>197
��������o�Ȃ������ˁB
��������o�Ȃ������ˁB
>199
HD4���̎�ATI�������Ђ��B���ɂ����悤��nV��GT300�ʼnB�������Ă�Ǝv��
������Y�͎����ŏ���ɏo���̂͗��N���ΈʂȂ�Ȃ�����
�������킵�����i�ɂȂ肻��
HD4���̎�ATI�������Ђ��B���ɂ����悤��nV��GT300�ʼnB�������Ă�Ǝv��
������Y�͎����ŏ���ɏo���̂͗��N���ΈʂȂ�Ȃ�����
�������킵�����i�ɂȂ肻��
GT 212�݂����Ȑ��q�����ɏo�Ă邵�ȁB
202 �FSocket774�F2009/10/01(��) 05:33:45 ID:CkkrzygI
http://pc.watch.impress.co.jp/img/pcw/docs/318/463/kaigai1.jpg
��͂莟����v���Z�b�T�Ɉڂ���
{kind=link}
��͂莟����v���Z�b�T�Ɉڂ���
����Ⴘ���Ԃ�ς��Ă����ˁB�����܂���v���H
���܂Ń����r�[��n���ɂ��Ă����Q�t�H�~�̓}���Z�[�ɈƑւ����܂���
�����GPU�Ƃ��Ĕ����Ȃ�ATI���ɂȂ���
>>205
���́ACPU�A�N�Z�����[�^�Ƃ��Ă��с[���������Ă�B
�~�h���̂��с[���҂��������B
����ȉ���GPU�͂ꂡ�ł�����4670���[�ځB
���́ACPU�A�N�Z�����[�^�Ƃ��Ă��с[���������Ă�B
�~�h���̂��с[���҂��������B
����ȉ���GPU�͂ꂡ�ł�����4670���[�ځB
�����͂���Ȃ�����20�����悱��
>>207
���̐l���̉��ł����B�B�B
���̐l���̉��ł����B�B�B
�n���������Z��2���炢
Pat Gelsinger left Intel because of Larrabee fiasco?
http://www.brightsideofnews.com/news/2009/9/18/pat-gelsinger-left-intel-because-of-larrabee-fiasco.aspx
http://www.brightsideofnews.com/news/2009/9/18/pat-gelsinger-left-intel-because-of-larrabee-fiasco.aspx
�Q������͈����Ȃ��B�ނ����Q�ҁB
�������蔪����Larry Seiler��Tom Forsyth���x���ꂽ�����B
�������蔪����Larry Seiler��Tom Forsyth���x���ꂽ�����B
212 �FSocket774�F2009/10/03(�y) 15:51:37 ID:K9RcF7Or
�����ALarrabee���Č��Ǒ厸�s�ɏI������̂�
���������ĂȂ����̂����s�ƕ]���邨�������B�����A
�o�O�݂�Ax�V���R������ł���A6�܂Ń��r�W�����d�˂Ă邩��A
�}�X�N�R�X�g�܂߂Ăǂ��������Ă�̂Ƃ͎v���B
���Ђ̋��������Ă�IA64�Ƃ͈Ⴂ100��Intel�̎����o�����낤���B
�������挎�̑g�D�ĕ҂ŕ���Ƃ��Ă̊i�͏オ���Ă���B
http://ja.wikipedia.org/wiki/Larrabee
> Larrabee�̋Z�p�x�[�X�ƂȂ��Ă���̂́AIntel�����z�̎����𓊓�
> ���Ă���Z�p�����v���W�F�N�g�u�e���X�P�[���E���T�[�`�v�ł���B
> ���Ȃ݂ɁA���Ђ͍��N��2�l���������Œ����E�J����p��
> 14��7,000���h���𓊎��������A���̋��z�̓��C�o���ł���AMD�́A
> ���l�����ɂ����锄�㍂���������Ă���B
�o�O�݂�Ax�V���R������ł���A6�܂Ń��r�W�����d�˂Ă邩��A
�}�X�N�R�X�g�܂߂Ăǂ��������Ă�̂Ƃ͎v���B
���Ђ̋��������Ă�IA64�Ƃ͈Ⴂ100��Intel�̎����o�����낤���B
�������挎�̑g�D�ĕ҂ŕ���Ƃ��Ă̊i�͏オ���Ă���B
http://ja.wikipedia.org/wiki/Larrabee
> Larrabee�̋Z�p�x�[�X�ƂȂ��Ă���̂́AIntel�����z�̎����𓊓�
> ���Ă���Z�p�����v���W�F�N�g�u�e���X�P�[���E���T�[�`�v�ł���B
> ���Ȃ݂ɁA���Ђ͍��N��2�l���������Œ����E�J����p��
> 14��7,000���h���𓊎��������A���̋��z�̓��C�o���ł���AMD�́A
> ���l�����ɂ����锄�㍂���������Ă���B
>>214
�C���e���K�����Ȃ�
�C���e���K�����Ȃ�
����Wikipedia�̏��������ƁA�e���X�P�[���E���T�[�`��14��7000���h���˂�����ł���悤��
������������˂Ȃ����͂��ȁB
14��7000���h�����āA���̎l������R&D�̑S�z�B
���l����AMD�̔�����݂̊z��R&D�ɓ˂�����ł���B
������������˂Ȃ����͂��ȁB
14��7000���h�����āA���̎l������R&D�̑S�z�B
���l����AMD�̔�����݂̊z��R&D�ɓ˂�����ł���B
�������������������Ƃ��炢�X�����ɂȂ��Ă�������Ȃ��̂���intel��
>>210
�܂������ϑz�ł������̂������͂�������
�v���C�I���e�B��Xeon(Nehalem-EP) ������ Larrabee����
ttp://www.geocities.jp/andosprocinfo/wadai09/20090919.htm
>�@�@Gelsinger�����C���̂Ƃ���Nehalem�������ŗǂ��ʒu�ɕt���Ă���Ǝv��ꂽ�̂ł����C�i9��24�������IDF�ŃL�[�m�[�g�邱�ƂɂȂ��Ă����̂ł����j�ˑR�̑ގЂł��B
>�^���͕s���ł����CIntel�ł�Ottelini�����C�܂��܂��撣�肻���ł���CMaloney���̕��������悳�����ŁC�Ȃ��Ȃ�CEO�ɂ͂Ȃꂻ���ɂȂ��B
>����CEMC�ł�Tucci CEO��2012�N�܂ł͊撣��Ƃ����\���������Ƃ������Ƃ́C���Ԃ��Ƃ����Ŏ��߂�Ƃ������Ƃł���C2012�N��CEO�̍ŗL�͌��̃|�W�V�����̕������͂��������Ƃ������Ƃł��傤���B
��
EMC�A�C���e���́g�~�X�^�[x86�h�Q���V���K�[������������
ttp://www.computerworld.jp/news/trd/162249.html
�܂������ϑz�ł������̂������͂�������
�v���C�I���e�B��Xeon(Nehalem-EP) ������ Larrabee����
ttp://www.geocities.jp/andosprocinfo/wadai09/20090919.htm
>�@�@Gelsinger�����C���̂Ƃ���Nehalem�������ŗǂ��ʒu�ɕt���Ă���Ǝv��ꂽ�̂ł����C�i9��24�������IDF�ŃL�[�m�[�g�邱�ƂɂȂ��Ă����̂ł����j�ˑR�̑ގЂł��B
>�^���͕s���ł����CIntel�ł�Ottelini�����C�܂��܂��撣�肻���ł���CMaloney���̕��������悳�����ŁC�Ȃ��Ȃ�CEO�ɂ͂Ȃꂻ���ɂȂ��B
>����CEMC�ł�Tucci CEO��2012�N�܂ł͊撣��Ƃ����\���������Ƃ������Ƃ́C���Ԃ��Ƃ����Ŏ��߂�Ƃ������Ƃł���C2012�N��CEO�̍ŗL�͌��̃|�W�V�����̕������͂��������Ƃ������Ƃł��傤���B
��
EMC�A�C���e���́g�~�X�^�[x86�h�Q���V���K�[������������
ttp://www.computerworld.jp/news/trd/162249.html
Larrabee�Ȃ�Ăǂ����o���o�����\�ł���
�o���o�����\�Ƃ͖͌^�\���邱�Ƃł���
Larrabee�̓O���t�B�b�N���\�t�g�E�F�A�ŏ�������̂Ȃ�
GPU�ł͂Ȃ��O���t�B�b�N�A�N�Z�����[�^�ƌĂق��������̂ł́H
GPU�ł͂Ȃ��O���t�B�b�N�A�N�Z�����[�^�ƌĂق��������̂ł́H
�́A�O���t�B�b�N�A�N�Z�����[�^���Č��t�͂ނ���n�[�h���C���[�h���w���Ă���
CPU�̃������ǂݏ������g�킸��VRAM�ɏ������ރn�[�h�E�F�A�������Ăꂽ
CPU�̃������ǂݏ������g�킸��VRAM�ɏ������ރn�[�h�E�F�A�������Ăꂽ
224 �F,,�E�L�́M�E,,�j��-�������F2009/10/04(��) 22:57:43 ID:TL0QkM36
CPU�Ńt���[���o�b�t�@�ǂݏ������Ă�����ւ̉�A����
Windows�Ƃ�Linux��GPU�A�N�Z�����[�^�������ĂȂ���Ԃ��ƑS����ʕ`���CPU�ł��킯����
���́uCPU�`��v�ɓ��������̂�Larrabee
���\�Ɍ����Ă��܂���
Windows�Ƃ�Linux��GPU�A�N�Z�����[�^�������ĂȂ���Ԃ��ƑS����ʕ`���CPU�ł��킯����
���́uCPU�`��v�ɓ��������̂�Larrabee
���\�Ɍ����Ă��܂���
Larrabee�̏ꍇ�A1�R�A�����A1�V�F�[�_�[�N���X�^�����݂����Ȋ����ł����̂��ȁH
�ł��邱�Ƃ̏_��͑S�R�Ⴄ���낤����
�ł��邱�Ƃ̏_��͑S�R�Ⴄ���낤����
226 �FSocket774�F2009/10/05(��) 11:38:08 ID:Mi7FxhjD
{kind=link}
>>226
�����^��
�����^��
�����ATi�����̏������n�߂Ă�Ǝ���Ă����̂��H
���ق����\�O�Ɍ����Ă������
�u���̵��ނ��C�ɓ���Ȃ���������ނł����Ă�v����
�u���̵��ނ��C�ɓ���Ȃ���������ނł����Ă�v����
�����f���S���҂ɖG����������
231 �FSocket774�F2009/10/08(��) 13:12:46 ID:6ixaHlGr
�����Ă���Sandy Bridge�ƁC�����Ă��Ȃ�Larrabee�BIntel�̃v���Z�b�T���[�h�}�b�v�A�b�v�f�[�g
http://www.4gamer.net/games/098/G009883/20091007054/
> �@�������̈���C�u�W���O���t�B�b�N�X�C���^�t�F�[�X�Ƃ��Ă�DirectX��OpenGL�C
> OpenCL���T�|�[�g����v�Ƃ͌���ꂽ���̂́C
> ���̃p�t�H�[�}���X�͍Ō�܂Ō��J����Ȃ������B
> Larrabee�̕]�����J�n���Ă���x���_�[�̊W�҂ɂ��C
> �u�����_�ł͈�ʓI��GPU�Ƃ��ĕ]���ł���i�K�ɂȂ��v�������B
> �@�܂��CSean Maloney�i�V���[���E�}���[�j�j�㋉���В����C
> �����I��Larrabee�R�A��CPU�֓�������v��ɕς��͂Ȃ��Ƃ����C
> ���C�ǂ̎s��֓������邷�邩�ɂ��Ắu���܂͌��Ȃ��v�̈�_����ł���B
>
> �@�t��������Ȃ�CLarrabee�v��̊���Ƃ�������
> Patrick P. Gelsinger�i�p�b�g�E�Q���V���K�[�j�㋉���В����C
> IDF 2009�̒��O��Intel��ސE����Ƃ����g�����h�����������C
> ����Ɗ֘A���Ă��C���̐������C�ƊE���ɂ�Larrabee�ɂ��āC
> �������ȏ��ь����Ă���B
> �Ȃ��ɂ́uIntel��Larrabee�v��𒆎~����v�Ƃ��������̂܂Ŋ܂܂�Ă����قǁB
> �uLarrabee�́CTSMC��40nm �v���Z�X�Ő��i������錩�ʂ��v
> �Ƃ��������̋ƊE�̏���C
> �uGelsinger���ƂƂ��ɁC��v�G���W�j�A��Intel���������v�Ƃ�����������B
���H
http://www.4gamer.net/games/098/G009883/20091007054/
> �@�������̈���C�u�W���O���t�B�b�N�X�C���^�t�F�[�X�Ƃ��Ă�DirectX��OpenGL�C
> OpenCL���T�|�[�g����v�Ƃ͌���ꂽ���̂́C
> ���̃p�t�H�[�}���X�͍Ō�܂Ō��J����Ȃ������B
> Larrabee�̕]�����J�n���Ă���x���_�[�̊W�҂ɂ��C
> �u�����_�ł͈�ʓI��GPU�Ƃ��ĕ]���ł���i�K�ɂȂ��v�������B
> �@�܂��CSean Maloney�i�V���[���E�}���[�j�j�㋉���В����C
> �����I��Larrabee�R�A��CPU�֓�������v��ɕς��͂Ȃ��Ƃ����C
> ���C�ǂ̎s��֓������邷�邩�ɂ��Ắu���܂͌��Ȃ��v�̈�_����ł���B
>
> �@�t��������Ȃ�CLarrabee�v��̊���Ƃ�������
> Patrick P. Gelsinger�i�p�b�g�E�Q���V���K�[�j�㋉���В����C
> IDF 2009�̒��O��Intel��ސE����Ƃ����g�����h�����������C
> ����Ɗ֘A���Ă��C���̐������C�ƊE���ɂ�Larrabee�ɂ��āC
> �������ȏ��ь����Ă���B
> �Ȃ��ɂ́uIntel��Larrabee�v��𒆎~����v�Ƃ��������̂܂Ŋ܂܂�Ă����قǁB
> �uLarrabee�́CTSMC��40nm �v���Z�X�Ő��i������錩�ʂ��v
> �Ƃ��������̋ƊE�̏���C
> �uGelsinger���ƂƂ��ɁC��v�G���W�j�A��Intel���������v�Ƃ�����������B
���H
Larrabee��CellGPU�݂����ɓڍ�����
�ߑ����Ȃ��Ȃ�
NVIDIA�̂ق����������
Nvidia kills GTX285, GTX275, GTX260, abandons the mid and high end market
Full on retreat, can't compete with ATI
ttp://www.semiaccurate.com/2009/10/06/nvidia-kills-gtx285-gtx275-gtx260-abandons-mid-and-high-end-market/
285�͊���EOL�A260��11or12����EOL�A275��2�T�Ԉȓ���EOL�A295���I��肻���B
�n�C�G���h�A�~�h�������W����E������B
Fermi�̔h�����f���̓e�[�v�A�E�g���炵�Ă��Ȃ��̂ŁA���Ȃ��Ƃ�2Q�͊|����B
Fermi�̓_�C�T�C�Y������̐��\���Ⴍ�h�����f��������Ă��t�����C���i�b�v�ʼn��i�����͂ŗ��B
�n���_�̌��ז��AG212�̎��s�AG214�̑厸�s�AG215�̒x���AG216��G218�̉�ꂽGDDR5�R���g���[���B
�~����ƂȂ�`�b�v�͂Ȃ��A�v����B�͂Ȃ��A�S�Ď��s�����B
�Ԏ��̔��𑱂��邩�A�P�ނ��ď��Ȃ��Ԏ����o���������Ȃ��B
�������s����O�ɊJ���̖����C���������͂̂��鐻�i���o���邩�����B
1���ɂ̓��[�G���h������E������B
Nvidia�͑S�Ẵp�[�g�i�[���瑞�܂�Ă��菕���Ă����p�[�g�i�[�͂��Ȃ��B
Nvidia�ɕK�v�Ȃ̂͌o�c�w�̑�����ւ������A���̏o�čs���ׂ��z��͊���Ȃ̂ŋN���肻�����Ȃ��B
�Q�[���I�[�o�[�B
�W�F���Z���͔N��1�h���ł��Ⴂ�߂��ł���B
--------------------
GT300���R�P��Ȃ�R���i�ł���Larrabee�̐��i�����}���K�v�͂Ȃ��Ȃ�B
AMD������Ă邩��LGA1366�̃��C���k������̂Ɠ��������łˁB
NVIDIA�̂ق����������
Nvidia kills GTX285, GTX275, GTX260, abandons the mid and high end market
Full on retreat, can't compete with ATI
ttp://www.semiaccurate.com/2009/10/06/nvidia-kills-gtx285-gtx275-gtx260-abandons-mid-and-high-end-market/
285�͊���EOL�A260��11or12����EOL�A275��2�T�Ԉȓ���EOL�A295���I��肻���B
�n�C�G���h�A�~�h�������W����E������B
Fermi�̔h�����f���̓e�[�v�A�E�g���炵�Ă��Ȃ��̂ŁA���Ȃ��Ƃ�2Q�͊|����B
Fermi�̓_�C�T�C�Y������̐��\���Ⴍ�h�����f��������Ă��t�����C���i�b�v�ʼn��i�����͂ŗ��B
�n���_�̌��ז��AG212�̎��s�AG214�̑厸�s�AG215�̒x���AG216��G218�̉�ꂽGDDR5�R���g���[���B
�~����ƂȂ�`�b�v�͂Ȃ��A�v����B�͂Ȃ��A�S�Ď��s�����B
�Ԏ��̔��𑱂��邩�A�P�ނ��ď��Ȃ��Ԏ����o���������Ȃ��B
�������s����O�ɊJ���̖����C���������͂̂��鐻�i���o���邩�����B
1���ɂ̓��[�G���h������E������B
Nvidia�͑S�Ẵp�[�g�i�[���瑞�܂�Ă��菕���Ă����p�[�g�i�[�͂��Ȃ��B
Nvidia�ɕK�v�Ȃ̂͌o�c�w�̑�����ւ������A���̏o�čs���ׂ��z��͊���Ȃ̂ŋN���肻�����Ȃ��B
�Q�[���I�[�o�[�B
�W�F���Z���͔N��1�h���ł��Ⴂ�߂��ł���B
--------------------
GT300���R�P��Ȃ�R���i�ł���Larrabee�̐��i�����}���K�v�͂Ȃ��Ȃ�B
AMD������Ă邩��LGA1366�̃��C���k������̂Ɠ��������łˁB
nvidia������Ă邩��]�T���܂��Ă�̂��Alarrabee����������Ȃ�����GT300������ɂ��킹�Ă�̂�
�ǂ��������肻������
�ǂ��������肻������
�܂��A�O�삪�ǂ������������������Ɖ����b�ɑ����̂Ƃ͊W�Ȃ��A
�ǂ̌�����Z�p�I�ɕ�����������Ƃɒ��ʂ����킵�Ă���Ă������ˁB
������Fermi�����߂Ȃ��Ő��ɏo�Ă��Ăق������B
�ǂ̌�����Z�p�I�ɕ�����������Ƃɒ��ʂ����킵�Ă���Ă������ˁB
������Fermi�����߂Ȃ��Ő��ɏo�Ă��Ăق������B
���C�^�[���u�ƊE���`�v���ď����Ƃ��́A�����炳���FUD�������Ă�Ƃ��̏퓅�傾���ǂ�
Larrabee�̕s�������ē�����w�c���āA�ǂ����킩�����悤�Ȃ���B
���v������Q�[���̗v���X�y�b�N�͑��ΓI�Ƀ��[�G���h�ɉ������Ă��Ă邵
Intel�͂���GMA�ŘJ��������GPU�̔e���悤�Ƃ��Ă�킯�ŁA
�_�C�T�C�Y�̊��ɒP���̈����f�B�X�N���[�g�s��Ȃ��
���ׂ����肪���Ȃ��Ȃ�Ό����̈��������ł����Ȃ��B
�uGMA�̐��\���C�ɓ���Ȃ��Ȃ�Radeon�ł��h���Ă�v����Intel�̖{�S����B
�o��O����킩�肫���Ă邱�Ƃ���GPGPU�v�f�̔����]��GPU�̉����Ƃ��ĂȂ�
Larrabee���Radeon�̂ق����D�G���B
CPU�s������������Ƃ���NVIDIA�����ł���Ȃ�A�f�B�X�N���[�g��Larrabee
�Ƃ�������Ȗh�g��͖��ʂȓ����ɏI���B
Larrabee�̕s�������ē�����w�c���āA�ǂ����킩�����悤�Ȃ���B
���v������Q�[���̗v���X�y�b�N�͑��ΓI�Ƀ��[�G���h�ɉ������Ă��Ă邵
Intel�͂���GMA�ŘJ��������GPU�̔e���悤�Ƃ��Ă�킯�ŁA
�_�C�T�C�Y�̊��ɒP���̈����f�B�X�N���[�g�s��Ȃ��
���ׂ����肪���Ȃ��Ȃ�Ό����̈��������ł����Ȃ��B
�uGMA�̐��\���C�ɓ���Ȃ��Ȃ�Radeon�ł��h���Ă�v����Intel�̖{�S����B
�o��O����킩�肫���Ă邱�Ƃ���GPGPU�v�f�̔����]��GPU�̉����Ƃ��ĂȂ�
Larrabee���Radeon�̂ق����D�G���B
CPU�s������������Ƃ���NVIDIA�����ł���Ȃ�A�f�B�X�N���[�g��Larrabee
�Ƃ�������Ȗh�g��͖��ʂȓ����ɏI���B
�A�N�Z�����[�^�v���Z�b�T�낤�Ƃ��Ă��AHPC��
����G���R�[�h��p���႟�s�ꂪ�������Ĕ���鉿�i�ŏo���Ȃ��B
�@��
�~�h���`�n�C�G���hGPU�@�\�����܂��ɕt���Ă��A��������o�邩��
�����o���邼�BGPU -> Tesla�̋t������������܂����B
�@��
���������f�B�X�N���[�gGPU�̎s�ꂪ�ǂ�ǂ��Ȃ��Ă������@��������
�@��
���傤���Ȃ�CPU�R�A�ɓ������邩�A2014�`2015�N�ʂ܂ő҂��āB�܂��ˁ`
����G���R�[�h��p���႟�s�ꂪ�������Ĕ���鉿�i�ŏo���Ȃ��B
�@��
�~�h���`�n�C�G���hGPU�@�\�����܂��ɕt���Ă��A��������o�邩��
�����o���邼�BGPU -> Tesla�̋t������������܂����B
�@��
���������f�B�X�N���[�gGPU�̎s�ꂪ�ǂ�ǂ��Ȃ��Ă������@��������
�@��
���傤���Ȃ�CPU�R�A�ɓ������邩�A2014�`2015�N�ʂ܂ő҂��āB�܂��ˁ`
238 �FSocket774�F2009/10/08(��) 16:19:20 ID:6ixaHlGr
�ێ�I�Ȑl�Ԃ��Ȃ�Ƒ������Ƃ�
�����Fermi����Y�Ƃ킩�����烌�X���t���Ȃ��Ȃ�����
�����X��
242 �FSocket774�F2009/10/13(��) 10:54:04 ID:Z2yHuX/g
An Inconvenient Truth: Intel Larrabee story revealed - Bright Side Of News*
http://www.brightsideofnews.com/news/2009/10/12/an-inconvenient-truth-intel-larrabee-story-revealed.aspx
http://www.brightsideofnews.com/news/2009/10/12/an-inconvenient-truth-intel-larrabee-story-revealed.aspx
>Intel knows that the future of the company is at stake
�n�C�n�CFUD��
�n�C�n�CFUD��
>>243
���̕��������ƁA�������������ł́A�C���e���̖��^����B����Ȃ����H�H
���̕��������ƁA�������������ł́A�C���e���̖��^����B����Ȃ����H�H
���@���ɂƂ��Ă͒Z���ŗ��v�̏o���Ȃ��J���v��Ȃ��
�s���̎�ł����Ȃ�����ȁB
���|�I�����o���ĂĂ��O�N������ŗ��v�������瑦�����ɒ��˕Ԃ�B
���̓_�A�M�S�[���i�����͖����j�M�ҒB�ɖ��X���ꑱ����^��Ƃ�
���Ƃ��|�Y���X�N�̂����ƂɃ��X�g�A�b�v����ĂĂ�
����Ӗ����ڏo�x����牽���B
�s���̎�ł����Ȃ�����ȁB
���|�I�����o���ĂĂ��O�N������ŗ��v�������瑦�����ɒ��˕Ԃ�B
���̓_�A�M�S�[���i�����͖����j�M�ҒB�ɖ��X���ꑱ����^��Ƃ�
���Ƃ��|�Y���X�N�̂����ƂɃ��X�g�A�b�v����ĂĂ�
����Ӗ����ڏo�x����牽���B
246 �F,,�E�L�́M�E,,�j��-�������F2009/10/14(��) 01:44:35 ID:BZHRxyoI
Fermi���ė�Larrabee����B
�ǂ��������\�l�b�N��������
�ǂ��������\�l�b�N��������
��������Larrabee�o����
248 �F,,�E�L�́M�E,,�j��-�������F2009/10/14(��) 01:50:33 ID:BZHRxyoI
�������烂�b�N�A�b�v�o����
249 �F,,�E�L�́M�E,,�j��-�������F2009/10/14(��) 02:01:11 ID:BZHRxyoI
Fermi could run an OS
ttp://www.fudzilla.com/content/view/15940/34/
SIMD�S���߃v���f�B�P�[�g�Ή��Ƃ���
�ǂ��܂ł��R�s�[�����
ttp://www.fudzilla.com/content/view/15940/34/
SIMD�S���߃v���f�B�P�[�g�Ή��Ƃ���
�ǂ��܂ł��R�s�[�����
Intel knows that they've completely messed up with the current generation
and the company decided to trash away the part of current design
and re-design the SIMD units from ground up.
This means the current diagrams featuring 16-wide SIMD unit are out the door,
because that design doesn't work.
Newly designed SIMD units will still probably be 16-wide and take AVX instructions,
but it will be GPU-like and not CPU-like.
and the company decided to trash away the part of current design
and re-design the SIMD units from ground up.
This means the current diagrams featuring 16-wide SIMD unit are out the door,
because that design doesn't work.
Newly designed SIMD units will still probably be 16-wide and take AVX instructions,
but it will be GPU-like and not CPU-like.
251 �FSocket774�F2009/10/14(��) 06:27:17 ID:g43xzJRl
��larrabee�̃f�������b�N�����ǂ�
PenD���l
PenD���l
Fermi��Larrabee�Ńx�C�p�[����Ă���
�O�ɕ�����B0�V���R����8/15�Ƀe�[�v�A�E�g�Ƃ����\���{���Ȃ�
���N���ɏo��@�����
�������A���i������̂�B0�Ƃ͌���Ȃ�
���̎d�l�ύX�Ȃ炳��ɎO�����lj��Ƃ����2010�ɏo�������Ȃ点���������ƎO��...
���N���ɏo��@�����
�������A���i������̂�B0�Ƃ͌���Ȃ�
���̎d�l�ύX�Ȃ炳��ɎO�����lj��Ƃ����2010�ɏo�������Ȃ点���������ƎO��...
���[��A���ԂN�����炢�Ɏv���Ă����Đ������Ǝv����B
�����������ƂȂ����ǁBHD68xx�͊Ԃɍ���Ȃ��ł��傤�B
�ł�����x86���\�݂����ȏ@���͐i���̕��Q�ɂ����Ȃ��Ǝv�����A
HPC�Ɋւ��Ă�Magny-Cours��Fermi���������ق��������Ǝv���B
�����������ƂȂ����ǁBHD68xx�͊Ԃɍ���Ȃ��ł��傤�B
�ł�����x86���\�݂����ȏ@���͐i���̕��Q�ɂ����Ȃ��Ǝv�����A
HPC�Ɋւ��Ă�Magny-Cours��Fermi���������ق��������Ǝv���B
>>255
CPU�Ɏ�荞�ނ̂��O����x86�Ȃ�
CPU�Ɏ�荞�ނ̂��O����x86�Ȃ�
�����{����َ̈퍬���̂ق����������āB���炭�B
�C���I�[�_�[��Pentium��~���W�߂Ă��Ȃ��c�c�Ƃ����C���B
���C�g���͓��ӂ��낤���ǁB
�C���I�[�_�[��Pentium��~���W�߂Ă��Ȃ��c�c�Ƃ����C���B
���C�g���͓��ӂ��낤���ǁB
258 �F,,�E�L�́M�E,,�j��-�������F2009/10/15(��) 00:41:06 ID:I+UKJFoq
x86�݂����ȃt�H�[�}�b�g�����炱���������A�h���b�V���O���ăp�C�v���C�����s�ł�����B
�C���I�[�_��x86�ł���Atom�ɂ���X�J�����\�ŏ��Ă�RISC�͏��Ȃ��̂�����
�i���Ȃ݂ɖ��ߑш�/clk��P5���Atom�̂ق��������ł��j
���Ȃ݂ɍŋߕ@���e�����Ă�Cortex-A9�̓A�E�g�I�u�I�[�_
�C���I�[�_��x86�ł���Atom�ɂ���X�J�����\�ŏ��Ă�RISC�͏��Ȃ��̂�����
�i���Ȃ݂ɖ��ߑш�/clk��P5���Atom�̂ق��������ł��j
���Ȃ݂ɍŋߕ@���e�����Ă�Cortex-A9�̓A�E�g�I�u�I�[�_
259 �F,,�E�L�́M�E,,�j��-�������F2009/10/15(��) 00:46:28 ID:I+UKJFoq
�������{����َ̈퍬���̂ق����������āB���炭�B
���́u�����{����َ̈퍬���v���I���_�C�Ŏ������Ă�̂�Larrabee�ȁB
����512SP�����Ȃ�FLOPS����Larrabee�̂ق���Fermi���҂���B
�s�[�N�E�����l�Ƃ��ɂˁB
Fermi�̃z���C�g�y�[�p�[�ǂ߂ǂ������ʖڎd�l�Ȃ̂��킩��
���́u�����{����َ̈퍬���v���I���_�C�Ŏ������Ă�̂�Larrabee�ȁB
����512SP�����Ȃ�FLOPS����Larrabee�̂ق���Fermi���҂���B
�s�[�N�E�����l�Ƃ��ɂˁB
Fermi�̃z���C�g�y�[�p�[�ǂ߂ǂ������ʖڎd�l�Ȃ̂��킩��
260 �FSocket774�F2009/10/15(��) 00:54:20 ID:rkKfNFR3
�v�V�I�ȃA�[�L�e�N�`����ڎw���Ă������J����
�x��ɒx�ꐻ�i������鍠�ɂ͒����ɉ��ǂ�
�d�˂Ă��������ɑ����ł��ł��Ȃ��Ȃ����ł�����̊�
�x��ɒx�ꐻ�i������鍠�ɂ͒����ɉ��ǂ�
�d�˂Ă��������ɑ����ł��ł��Ȃ��Ȃ����ł�����̊�
262 �F,,�E�L�́M�E,,�j��-�������F2009/10/15(��) 00:59:29 ID:I+UKJFoq
Fermi���ȁB
512SP�Ŕ{���x650GFLOPS���I
������Larrabee��512SP�����ŏ��Ȃ��Ƃ�800GFLOPS�I�[�o�[���I
�����d�͂ŏ���H
����Ⴀ�̃G���W�j�A�����O�T���v���i�j�ɓd�������ł��Ȃ�����Ȃ���
512SP�Ŕ{���x650GFLOPS���I
������Larrabee��512SP�����ŏ��Ȃ��Ƃ�800GFLOPS�I�[�o�[���I
�����d�͂ŏ���H
����Ⴀ�̃G���W�j�A�����O�T���v���i�j�ɓd�������ł��Ȃ�����Ȃ���
���C�g���Ȃ�Ă��ꂱ��GPU�̕������ӂȏ�������
264 �F,,�E�L�́M�E,,�j��-�������F2009/10/15(��) 01:04:38 ID:I+UKJFoq
index * scale + base + disp�̃������A�h���b�V���O�����ł����ԃI�y���[�V�������x�҂��ł��ˁB
�{���̈Ӗ���GPU�̕���x��x86�̃X�J���̗��_��Fusion���Ă�B
Fermi��SP������̃��[�h�E�X�g�A���߂̍ő唭�s��GT200�̔����ɗ����Ă���B
FLOPS���e���o���ȑO�ɁA�f�[�^�������l�b�N�B�d�l���炵�Ă��h��
�{���̈Ӗ���GPU�̕���x��x86�̃X�J���̗��_��Fusion���Ă�B
Fermi��SP������̃��[�h�E�X�g�A���߂̍ő唭�s��GT200�̔����ɗ����Ă���B
FLOPS���e���o���ȑO�ɁA�f�[�^�������l�b�N�B�d�l���炵�Ă��h��
265 �F,,�E�L�́M�E,,�j��-�������F2009/10/15(��) 01:09:30 ID:I+UKJFoq
>>263
���[�ł��Ȃ��B
���Z���j�b�g�̃X���[�v�b�g�͖ܘ_�K�v�����A���������グ�邽�߂ɂ�
���C�g���[�X���ʂ��ė��p���邽�߂̓ǂݏ������Ή��ł��������̗e�ʂ̃L���b�V�����K�v�B
������Fermi��L2�L���b�V���͂�������768KB�ILarrabee�i8MB�j��10����1�B
�ш悪�\������킯�ł��Ȃ��B
�Ă��A�m�ۂ����炵���Ń������ш敪������TDP300W�I�[�o�[�ɂȂ邾��B
�L���b�V���̂ق����d�͓I�ɗD�����B
���[�ł��Ȃ��B
���Z���j�b�g�̃X���[�v�b�g�͖ܘ_�K�v�����A���������グ�邽�߂ɂ�
���C�g���[�X���ʂ��ė��p���邽�߂̓ǂݏ������Ή��ł��������̗e�ʂ̃L���b�V�����K�v�B
������Fermi��L2�L���b�V���͂�������768KB�ILarrabee�i8MB�j��10����1�B
�ш悪�\������킯�ł��Ȃ��B
�Ă��A�m�ۂ����炵���Ń������ш敪������TDP300W�I�[�o�[�ɂȂ邾��B
�L���b�V���̂ق����d�͓I�ɗD�����B
>>264
>index * scale + base + disp�̃������A�h���b�V���O
������݂̂Ȃ��V�K�v���Z�b�T�����A���̃p�C�v���C�����������ƃX�}�[�g��
����Ă��悳�����Ȃ����A�ǂ�����낤�Ƃ��Ȃ��͉̂��ł����H
���O�ǂ����悤���Ȃ�(�N�_���i�C)���R�̂悤�ȋC�����邪�B
>index * scale + base + disp�̃������A�h���b�V���O
������݂̂Ȃ��V�K�v���Z�b�T�����A���̃p�C�v���C�����������ƃX�}�[�g��
����Ă��悳�����Ȃ����A�ǂ�����낤�Ƃ��Ȃ��͉̂��ł����H
���O�ǂ����悤���Ȃ�(�N�_���i�C)���R�̂悤�ȋC�����邪�B
Larrabee RAM�Ԃ̃o���h���͂����J������
268 �FSocket774�F2009/10/15(��) 01:42:28 ID:zLyfGi2G
����ȂɃn�[�h���グ�܂����Ăǂ����邗
Larrabee�̏ꍇ�A�ǂꂭ�炢�����O���ш敝�ł���̂����y����
270 �F,,�E�L�́M�E,,�j��-�������F2009/10/15(��) 01:54:51 ID:I+UKJFoq
�L���b�V����傫�߂Ɏ���ă^�C�������_�ɓ��������Ԃ�A�O���ш�͑��ΓI�ɍL�����K�v���Ȃ�����ˁB
���ꂾ����TDP�ߖ�ł��A�N���b�N�ɐU��]�T���o����B
Fermi��TDP�̔�����GDDR5�łł��Ă��܂�
���Ă̂͏��Ȃ���k�B
������x����GPU�̓^�C�������_�Ɉڍs����B���̐l���g�����������Ă邵�B
NVIDIA���܂��扄���ɂ��Ă邾���ɂ����Ȃ��B
���ꂾ����TDP�ߖ�ł��A�N���b�N�ɐU��]�T���o����B
Fermi��TDP�̔�����GDDR5�łł��Ă��܂�
���Ă̂͏��Ȃ���k�B
������x����GPU�̓^�C�������_�Ɉڍs����B���̐l���g�����������Ă邵�B
NVIDIA���܂��扄���ɂ��Ă邾���ɂ����Ȃ��B
>>261
���̔���ĂȂ��Q�[���@�Ɠ������ˁB
���̔���ĂȂ��Q�[���@�Ɠ������ˁB
272 �F,,�E�L�́M�E,,�j��-�������F2009/10/15(��) 02:15:09 ID:I+UKJFoq
NVIDIA��GPU���ڂ�����Q�[���@���ď��ĂȂ��@����������
273 �F,,�E�L�́M�E,,�j��-�������F2009/10/15(��) 02:33:02 ID:I+UKJFoq
>>268
�t��Fermi�̖��炩�Ȓ�X�y�b�N���\���ꂽ���A�ǂ��܂�Intel���蔲�����Ă��邩�S�z�łȂ�Ȃ�
������������
�P�DHPC�ɂ�����CUDA��Cell����
�Q�DIGP��Larrabee�̃e�X�g
�R�D�Ђ���Ƃ�����GPU�Ƃ��Ă��ĊO������ˁH
���̃p���m�C�A��Intel�ɂƂ��čő�̐헪�ڕW�͌����܂ł��Ȃ��P�B
Xeon�œ���HPC�s��̃V�F�A�����������݂̔r���B
���Ƃ͂���قǗD��x�����͂Ȃ��B
���Ȃ݂�Radeon�͍ŏ�����G�ł͂Ȃ��B�����Č�����NVIDIA�ׂ��Ƃ����_�ŗ��Q�W����v���Ă�B
�t��Fermi�̖��炩�Ȓ�X�y�b�N���\���ꂽ���A�ǂ��܂�Intel���蔲�����Ă��邩�S�z�łȂ�Ȃ�
������������
�P�DHPC�ɂ�����CUDA��Cell����
�Q�DIGP��Larrabee�̃e�X�g
�R�D�Ђ���Ƃ�����GPU�Ƃ��Ă��ĊO������ˁH
���̃p���m�C�A��Intel�ɂƂ��čő�̐헪�ڕW�͌����܂ł��Ȃ��P�B
Xeon�œ���HPC�s��̃V�F�A�����������݂̔r���B
���Ƃ͂���قǗD��x�����͂Ȃ��B
���Ȃ݂�Radeon�͍ŏ�����G�ł͂Ȃ��B�����Č�����NVIDIA�ׂ��Ƃ����_�ŗ��Q�W����v���Ă�B
�K�����Ȃ�
�c�q�����GDDR5�̏���d�͂ɂ��ď������A
Rambus�̌����Ă��鐔�����g������ǁA
Samsung�͑��������������o���Ă��܂���B
http://pc.watch.impress.co.jp/img/pcw/docs/319/593/html/ph05.jpg.html
Rambus�̌����Ă��鐔�����g������ǁA
Samsung�͑��������������o���Ă��܂���B
http://pc.watch.impress.co.jp/img/pcw/docs/319/593/html/ph05.jpg.html
{kind=link}
samsung��GDDR����Ă�VGA�͔����C���N���Ȃ��B
����A�g���C���N���Ȃ��B
����A�g���C���N���Ȃ��B
>>275
�{���ɑ����̌덷�ł����Ȃ���
�����������Ȃ猋�Ǒш���ɂ͈Ⴂ�Ȃ���
GPU�_�C���̃C���^�[�t�F�C�X���p�t�@�����l�������
����������ꡂ��ɐH���Ă�킯��
�������̂Ȃ��v�Ȃ͈̂Ⴂ�Ȃ��B
�{���ɑ����̌덷�ł����Ȃ���
�����������Ȃ猋�Ǒш���ɂ͈Ⴂ�Ȃ���
GPU�_�C���̃C���^�[�t�F�C�X���p�t�@�����l�������
����������ꡂ��ɐH���Ă�킯��
�������̂Ȃ��v�Ȃ͈̂Ⴂ�Ȃ��B
Fermi��L2��Victim Cache�H
�X�N���b�`�p�b�h��L1�ɍő�܂Ŋ��蓖�Ă��ꍇ�_�C�S�̂�48KB�~16=768KB
Inclusive����L2�̈Ӗ����w�ǂȂ��Ȃ�B
�ǂ����ɂ��Ă�HPC�ɂ͏��Ȃ����邪�B
�X�N���b�`�p�b�h��L1�ɍő�܂Ŋ��蓖�Ă��ꍇ�_�C�S�̂�48KB�~16=768KB
Inclusive����L2�̈Ӗ����w�ǂȂ��Ȃ�B
�ǂ����ɂ��Ă�HPC�ɂ͏��Ȃ����邪�B
>>272
�C�V�������Ⴄ���������������������������������������������B
ttp://gigazine.net/index.php?/news/comments/20091014_next_ds/
�C�V�������Ⴄ���������������������������������������������B
ttp://gigazine.net/index.php?/news/comments/20091014_next_ds/
���C�g���f���A����
http://journal.mycom.co.jp/articles/2009/10/14/gtc06/001.html
http://journal.mycom.co.jp/articles/2009/10/14/gtc06/001.html
�A�e�Ă����e�N�X�`���ő���ۂ����͌떂�����邩��
�����ڂ���ڂ��ق����������ă��C�g���̌��ʂ��킩��₷���B
���C�g�������Ń��A���^�C���`��ł���̂�������ł����܂ł���
�����Ă��܂������Ȃ��B
���Ƃ�Larrabee�ł�������悤�ȃ��A���^�C���̐��ʕ\�����ȁB
N�����M������Ȃ瓯���悤�ȃf���łԂ��Ă���낤���B
�����ڂ���ڂ��ق����������ă��C�g���̌��ʂ��킩��₷���B
���C�g�������Ń��A���^�C���`��ł���̂�������ł����܂ł���
�����Ă��܂������Ȃ��B
���Ƃ�Larrabee�ł�������悤�ȃ��A���^�C���̐��ʕ\�����ȁB
N�����M������Ȃ瓯���悤�ȃf���łԂ��Ă���낤���B
Is Intel's Larrabee suffering from Boeing 787 syndrome?
http://www.glgroup.com/News/Is-Intels-Larrabee-suffering-from-Boeing-787-syndrome--44083.html
http://www.glgroup.com/News/Is-Intels-Larrabee-suffering-from-Boeing-787-syndrome--44083.html
���C�g�������A���^�C���`�揟���Ń��X�^���C�Y�̕`��N�I���e�B�������̂���
�n�[�h���\�I�ɂ��܂�������|���肻���Ȋ����B
�ǂ����ɂ���ƒ�p�Q�[���@���Ή����Ȃ��Ǝn�܂�Ȃ����ǁB
�n�[�h���\�I�ɂ��܂�������|���肻���Ȋ����B
�ǂ����ɂ���ƒ�p�Q�[���@���Ή����Ȃ��Ǝn�܂�Ȃ����ǁB
�ꑫ��тɃ��C�g���͖����Ǝv���̂����ǂȃ@
�܂��̓^�C�������_�Ɉڍs���ă��X�^���C�Y�ɂ�����ш�E���Z�̃��_��
�O��I�Ɏ�菜���Ă����Ȃ���
�܂��̓^�C�������_�Ɉڍs���ă��X�^���C�Y�ɂ�����ш�E���Z�̃��_��
�O��I�Ɏ�菜���Ă����Ȃ���
���C�g�����Ă̂͌��nj��̕��������Ȃ�
286 �F,,�E�L�́M�E,,�j��-�������F2009/10/15(��) 22:46:11 ID:I+UKJFoq
GPU���O���t�B�b�N�v���Z�b�T�Ƃ��Č������悩�����̂͂قڑS���Œ�@�\�ł���Ă���̑O�܂ł̘b��
���r���[�Ƀ\�t�g�����Ă���N�\������
VRAM�̃��������C�e���V������
��
�����ғ��X���b�h���𑝂₷�����Ȃ�
��
�X���b�h������̃��[�J�����W�X�^�^�������̊����Ă����Ȃ�
��
���C���������ɑҔ����邵���Ȃ�
���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@��
(�ŏ��ɖ߂�)�@�@�@�@�@�@VRAM�ш悪�K�v
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@��
�@�@�@�@�@�@�@�@�@�@�@�@�@�@���₵����d�͔n���H��
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@��
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�悪�Ȃ���������
�L���b�V�����ʂ��ă^�C�������_����X���b�h������Ȃɑ��₳�Ȃ��Ă���C�e���V�ɂł���B
�ŋߌ����o�����r�A�ђʁ{EDRAM���̂͌��ǂ̓^�C�������_�ڍs�O��̕���B
���r���[�Ƀ\�t�g�����Ă���N�\������
VRAM�̃��������C�e���V������
��
�����ғ��X���b�h���𑝂₷�����Ȃ�
��
�X���b�h������̃��[�J�����W�X�^�^�������̊����Ă����Ȃ�
��
���C���������ɑҔ����邵���Ȃ�
���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@��
(�ŏ��ɖ߂�)�@�@�@�@�@�@VRAM�ш悪�K�v
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@��
�@�@�@�@�@�@�@�@�@�@�@�@�@�@���₵����d�͔n���H��
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@��
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�悪�Ȃ���������
�L���b�V�����ʂ��ă^�C�������_����X���b�h������Ȃɑ��₳�Ȃ��Ă���C�e���V�ɂł���B
�ŋߌ����o�����r�A�ђʁ{EDRAM���̂͌��ǂ̓^�C�������_�ڍs�O��̕���B
�\�t�g���i�V�F�[�_���j���Ă̂��A�����ڈێ�����VRAM�ш�̍팸��ړI�Ƃ������̂������̂����ǁA
���ǃV�F�[�_���H������f�����肷��f�[�^�ʂ��ی�����������n���ɂȂ�������Ă�
�S�R�v���V�[�W�����Ȕ]�~�\�ɂȂ�ĂȂ���ȁ[�Q�[���v���O���}�ǂ���
����ɕt����������������Ă�VGA���[�J�[��MS�c
���ǃV�F�[�_���H������f�����肷��f�[�^�ʂ��ی�����������n���ɂȂ�������Ă�
�S�R�v���V�[�W�����Ȕ]�~�\�ɂȂ�ĂȂ���ȁ[�Q�[���v���O���}�ǂ���
����ɕt����������������Ă�VGA���[�J�[��MS�c
VRAM�ш�̑������A���܂�ɂ����j�A�ŃN���e�B�J���ɃQ�[����
FPS�����ɒ������錻��͖{���ɒQ���킵��
FPS�����ɒ������錻��͖{���ɒQ���킵��
289 �F,,�E�L�́M�E,,�j��-�������F2009/10/16(��) 00:00:16 ID:I+UKJFoq
GeForce�ɓ�����������ȃO���t�B�b�N��FPS�o�����Ƃ���
���Ǐo�ė����̂��e�N�X�`���f�[�^�����ŏ\��GB��Crysis�Ƃ����������\�t�g
���ǂ��̗���͕s�K�Ȃ�ˁB
�e�N�X�`�����̂����ăR�X�g�����A���ʂɕ����킹���͋Z�ʼn����郋�[�v���甲���o���Ȃ���
�܂��A���̂��߂ɕ������Z�������ăv���V�[�W���������������Ƃ������Ă�킯�Ȃ��B
�[���A��呲��̂̓��{�̃Q�[���v���O���}�͍������w�g�����Ȃ��悤�Ȍ�������Ȃ�����
�ǂ������������ɂȂ��Ă��]��L������Ȃ��Ǝv����
DS�݂����Ȍ���ꂽ�X�y�b�N�Ŕ���Q�[�������̂���Ԍ����Ă���Ęb�ɂȂ�B
���Ǐo�ė����̂��e�N�X�`���f�[�^�����ŏ\��GB��Crysis�Ƃ����������\�t�g
���ǂ��̗���͕s�K�Ȃ�ˁB
�e�N�X�`�����̂����ăR�X�g�����A���ʂɕ����킹���͋Z�ʼn����郋�[�v���甲���o���Ȃ���
�܂��A���̂��߂ɕ������Z�������ăv���V�[�W���������������Ƃ������Ă�킯�Ȃ��B
�[���A��呲��̂̓��{�̃Q�[���v���O���}�͍������w�g�����Ȃ��悤�Ȍ�������Ȃ�����
�ǂ������������ɂȂ��Ă��]��L������Ȃ��Ǝv����
DS�݂����Ȍ���ꂽ�X�y�b�N�Ŕ���Q�[�������̂���Ԍ����Ă���Ęb�ɂȂ�B
�c�q����͖{����Larrabee���D���ȂȁB
�����ȑO�͊��҂��Ă����ǁA�����̌�����CPU��GPU�̎��͍���
�g�ɐ��݂Ă��܂��āA���ł�Fermi�҂��ł��ꒆ�ł��B
Larra����͔r�M�����C�����Ă���Ă��������B
�����ȑO�͊��҂��Ă����ǁA�����̌�����CPU��GPU�̎��͍���
�g�ɐ��݂Ă��܂��āA���ł�Fermi�҂��ł��ꒆ�ł��B
Larra����͔r�M�����C�����Ă���Ă��������B
>>261
����ITANIUM���v���o����
����ITANIUM���v���o����
Merced�A���ɏo�������ł��������������̍��B
293 �F,,�E�L�́M�E,,�j��-�������F2009/10/16(��) 00:12:35 ID:CyybyJRa
>>290
���[��A�����ŏ��̓s�[�N�����������Z���\�ł�Fermi��Larrabee����Ǝv���Ă�����
�����o�Ă������_�Ŗ������Ƃ킩�����B
x86�̖��߃t�H�[�}�b�g�͕����̃I�y���[�V���������h���Ńp�b�L���O��
�p�C�v���C���Œ�����s���邱�Ƃ�e�Ղɂ��Ă���B
�����Č������ALarrabee��x86�̃R�[�h���Y�̂��߂ł͂Ȃ��p�t�H�[�}���X�̂��߂�x86�ł���K�v�������B
������ɖ�����RISC�M�҂��x����Ă͂����Ȃ��B
POWER���ǂ����BCore MA�Ɏ��������Ȃ���IPC�d����PPC970��������A
�d�͌������Ȃ���̂Ăč��N���b�N�łԂ�܂킷�Ƃ���NetBurst�ɂ������\��
�������g�b�V������B
GeForce�̃V�F�[�_�̓l�C�e�B�u�R�[�h��SIMD��RISC�x�[�XISA�Ȃ�
���ߋ�������2�ƌ��܂��ĂăI�y���[�V���������҂��Ȃ��̂������B
���̕ӂ��������\�ōX��Larrabee�ɕ�����ƒf�����闝�R
����V�~�����[�V�����͂���Ă݂Ă�
���[�A�ėp���Z����Ȃ���GPU�̂ق��̃X�y�b�N�Ƃ��Ă͂ǂ����͂킩����B
�p���_�C�����̂��̂��ς��Ȃ�����GPU�Ƃ��Ă�Radeon�P������Ȃ���
���[��A�����ŏ��̓s�[�N�����������Z���\�ł�Fermi��Larrabee����Ǝv���Ă�����
�����o�Ă������_�Ŗ������Ƃ킩�����B
x86�̖��߃t�H�[�}�b�g�͕����̃I�y���[�V���������h���Ńp�b�L���O��
�p�C�v���C���Œ�����s���邱�Ƃ�e�Ղɂ��Ă���B
�����Č������ALarrabee��x86�̃R�[�h���Y�̂��߂ł͂Ȃ��p�t�H�[�}���X�̂��߂�x86�ł���K�v�������B
������ɖ�����RISC�M�҂��x����Ă͂����Ȃ��B
POWER���ǂ����BCore MA�Ɏ��������Ȃ���IPC�d����PPC970��������A
�d�͌������Ȃ���̂Ăč��N���b�N�łԂ�܂킷�Ƃ���NetBurst�ɂ������\��
�������g�b�V������B
GeForce�̃V�F�[�_�̓l�C�e�B�u�R�[�h��SIMD��RISC�x�[�XISA�Ȃ�
���ߋ�������2�ƌ��܂��ĂăI�y���[�V���������҂��Ȃ��̂������B
���̕ӂ��������\�ōX��Larrabee�ɕ�����ƒf�����闝�R
����V�~�����[�V�����͂���Ă݂Ă�
���[�A�ėp���Z����Ȃ���GPU�̂ق��̃X�y�b�N�Ƃ��Ă͂ǂ����͂킩����B
�p���_�C�����̂��̂��ς��Ȃ�����GPU�Ƃ��Ă�Radeon�P������Ȃ���
���̃p���_�C�����������Ă���̂��ADirectX�Ƃ���API
PowerVR�́A1��2������API�����W���ꂽ
�^�C�������_�����O�ɂ͐�p�̃O��API���ǂ��������ĕK�v�c��A���Ȏv���o�����n���̂悤��
PowerVR�́A1��2������API�����W���ꂽ
�^�C�������_�����O�ɂ͐�p�̃O��API���ǂ��������ĕK�v�c��A���Ȏv���o�����n���̂悤��
295 �F,,�E�L�́M�E,,�j��-�������F2009/10/16(��) 00:23:56 ID:CyybyJRa
Larrabee��32�R�A�ł�Fermi�Ɠ���512SP�����Ȃ�ŁA�P���ɃN���b�N�o���������B
���Ƃ��A>>290
Fermi���\���胁�����ш�Ë������̂͂��̕ӂœV��i300W�����j�ɂԂ��������Ă��Ƃ�����
�܂�����d�͂�Larrabee��荂���Ȃ邱�Ƃ͊o�債���ق���������B
���Ƃ��A>>290
Fermi���\���胁�����ш�Ë������̂͂��̕ӂœV��i300W�����j�ɂԂ��������Ă��Ƃ�����
�܂�����d�͂�Larrabee��荂���Ȃ邱�Ƃ͊o�債���ق���������B
296 �F,,�E�L�́M�E,,�j��-�������F2009/10/16(��) 00:31:45 ID:CyybyJRa
���x�����W����邱�Ƃ����ꂸ�Ƀp���_�C���V�t�g���N����܂œ������������邾����
�̗͂������ƂȂ�Č����I�ɂ�Intel�����Ȃ���Ȃ��́H
���Intel�͎��ۋ�̓I�ɉ�����Ă邩�Ƃ����ƁA���x�����C�u�����J�����Ă��Ƃ����܂����Ă�悤�����B
�L���ǂ��낾��RapidMind�Ƃ�
�̗͂������ƂȂ�Č����I�ɂ�Intel�����Ȃ���Ȃ��́H
���Intel�͎��ۋ�̓I�ɉ�����Ă邩�Ƃ����ƁA���x�����C�u�����J�����Ă��Ƃ����܂����Ă�悤�����B
�L���ǂ��낾��RapidMind�Ƃ�
297 �FSocket774�F2009/10/16(��) 00:34:10 ID:7OF5t5B7
>>294
�����I��DirectX�͎哱����������Ђ��d�l�����肷�銴�������ȁB
�����I��DirectX�͎哱����������Ђ��d�l�����肷�銴�������ȁB
298 �F,,�E�L�́M�E,,�j��-�������F2009/10/16(��) 00:39:42 ID:CyybyJRa
9.0c������܂ł�NV�哱�œ����Ă����C������
Xbox360�ł̗̍p���@��10.1������ł���ATI�哱
�Ƃ������NVIDIA�����Ă��ĂȂ�
Xbox360�ł̗̍p���@��10.1������ł���ATI�哱
�Ƃ������NVIDIA�����Ă��ĂȂ�
299 �F,,�E�L�́M�E,,�j��-�������F2009/10/16(��) 00:57:45 ID:CyybyJRa
�܂�Larrabee���u�����I�Ɂv���y�������API�푈�����@�͂����ˁB
���ꂪIntel�ɉ\�Ȃ̂�GMA���ؖ����Ă���B
���������̃T�C�Y�ɃJ�b�g�_�E������CPU�ɓ�������B
���ۏo����悤�ɂȂ�̂�Haswell����ȍ~�Ȃ낤����
���ꂪIntel�ɉ\�Ȃ̂�GMA���ؖ����Ă���B
���������̃T�C�Y�ɃJ�b�g�_�E������CPU�ɓ�������B
���ۏo����悤�ɂȂ�̂�Haswell����ȍ~�Ȃ낤����
����Larrabee��DX�̑z�肷��W���n�[�h�E�F�A�ɂ���Ȃ�A
DirectX 9����10�����傫�ȕs�A���͊ԈႢ�Ȃ����A
nv��ATI���t���Ă��Ȃ����낤�������LRB��pAPI�ɂȂ邾�낤�B
NSP�̓�̕��ɂȂ�Ȃ���������ǂˁB
DirectX 9����10�����傫�ȕs�A���͊ԈႢ�Ȃ����A
nv��ATI���t���Ă��Ȃ����낤�������LRB��pAPI�ɂȂ邾�낤�B
NSP�̓�̕��ɂȂ�Ȃ���������ǂˁB
301 �F,,�E�L�́M�E,,�j��-�������F2009/10/16(��) 01:19:13 ID:CyybyJRa
�uIntel��SIMD�g���v�Ƃ����A����������B
1024�r�b�g��SIMD�܂őz�肵���t���L�V�u���ȃ��W�X�^�Ҕ𖽗߁iXSAVE�j�����Ă邩��
Windows7�ȍ~��MS�̓s���W�Ȃ���Intel�̓s���łǂ��ɂł�SIMD�g���ł���
1024�r�b�g��SIMD�܂őz�肵���t���L�V�u���ȃ��W�X�^�Ҕ𖽗߁iXSAVE�j�����Ă邩��
Windows7�ȍ~��MS�̓s���W�Ȃ���Intel�̓s���łǂ��ɂł�SIMD�g���ł���
DirectX�������n�[�h�E�F�A�𒊏ۉ�����������ɂ��Ă邩��
ATi�AnV�哱��API�ł�Larrabee����������悤�ɂȂ����肵�Ȃ��̂���
ATi�AnV�哱��API�ł�Larrabee����������悤�ɂȂ����肵�Ȃ��̂���
303 �F,,�E�L�́M�E,,�j��-�������F2009/10/16(��) 01:23:33 ID:CyybyJRa
���ʃt���[�����[�N�ƌ����Ă��e�A�[�L�e�N�`�������œK���͂Ȃ��ŌʑΉ��������
NVIDIA�̓Q�[���f�x���b�p�[�ɂ��܂�J���x�����Ȃ��Ȃ���
ATI�����ߍ��킹��`�Ŏx�����Đl�C�L���Ă�B
�Q�[�����\��~���郆�[�U�[�����Ă��ĂȂ��̂�GPGPU�ɂ��܂��Ă�NVIDIA�̎��Ǝ���
NVIDIA�̓Q�[���f�x���b�p�[�ɂ��܂�J���x�����Ȃ��Ȃ���
ATI�����ߍ��킹��`�Ŏx�����Đl�C�L���Ă�B
�Q�[�����\��~���郆�[�U�[�����Ă��ĂȂ��̂�GPGPU�ɂ��܂��Ă�NVIDIA�̎��Ǝ���
304 �F,,�E�L�́M�E,,�j��-�������F2009/10/16(��) 01:35:41 ID:CyybyJRa
�܂�DirectX��VLIW�A���C�v���Z�b�T��SIMD�^RISC�v���Z�b�T�œ����悤�ɓ������x�ɂ͒��ۉ�����Ă�B
�O���t�B�b�N�p�C�v���C���͂����܂Œ��ۉ����ꂽ���̂ŁA�X�e�[�W�Ԃ̃f�[�^�̎n��������
��`����Ă��Ȃ��B
�ɘ_Larrabee�̏ꍇ�W�I���g���V�F�[�f�B���O�����X�^���C�Y���s�N�Z���V�F�[�f�B���O�̏�����
�������߃X�g���[���œ������W�X�^�g���ĘA���ł���Ă������킯�B
NVIDIA��1�Q�[��1�h���C�o�݂����Ȕn���n�������J���T�|�[�g������Ȃ�Intel�͉��ł����肾��
�O���t�B�b�N�p�C�v���C���͂����܂Œ��ۉ����ꂽ���̂ŁA�X�e�[�W�Ԃ̃f�[�^�̎n��������
��`����Ă��Ȃ��B
�ɘ_Larrabee�̏ꍇ�W�I���g���V�F�[�f�B���O�����X�^���C�Y���s�N�Z���V�F�[�f�B���O�̏�����
�������߃X�g���[���œ������W�X�^�g���ĘA���ł���Ă������킯�B
NVIDIA��1�Q�[��1�h���C�o�݂����Ȕn���n�������J���T�|�[�g������Ȃ�Intel�͉��ł����肾��
�ŏI�I�ɓ���̉摜�������_�����O����Ă���A���ꂪ�S�ۂ���Ă���Ηǂ�
�`��r���̃X�e�[�g�A�o�b�t�@���͈���[�U�[�v���O��������Q�ƕs��
�����������S���ۉ�3DAPI�����z�Ȃ̂ɂ�
�n�[�h���̃A�[�L��API�ɔ���ꂷ���Ă܂���
�`��r���̃X�e�[�g�A�o�b�t�@���͈���[�U�[�v���O��������Q�ƕs��
�����������S���ۉ�3DAPI�����z�Ȃ̂ɂ�
�n�[�h���̃A�[�L��API�ɔ���ꂷ���Ă܂���
306 �F,,�E�L�́M�E,,�j��-�������F2009/10/16(��) 02:16:08 ID:CyybyJRa
����������
DirectX���̂��̂͊�{�I��API�݂̂ŁA����ł����Ȃ�Q�[�����n�߂�f�x���b�p�[��
��������܂肢�Ȃ��ł���
1����2�������܂����Q�[���G���W�����x�[�X�ɍ��ł���B
PS3�Ƃ�Mac�Ƃ��̔�DirectX���ł������悤�ɂ��悤�Ǝv����������ł���B
���ǃQ�[���G���W�����ɑ��ALarrabee�ł̓��쎞��DirectX�ƕ��s����
Larrabee�l�C�e�B�u���߂��|���g���Ă����悤�Ɏx�����邱�Ƃ��厖�Ȃ̂ł́H
�܂��Œ�@�\�ɔ���ꂸ�ɃG���W�����������J���҂̐S����������͂ނ��Ƃ��ˁB
DirectX���̂��̂͊�{�I��API�݂̂ŁA����ł����Ȃ�Q�[�����n�߂�f�x���b�p�[��
��������܂肢�Ȃ��ł���
1����2�������܂����Q�[���G���W�����x�[�X�ɍ��ł���B
PS3�Ƃ�Mac�Ƃ��̔�DirectX���ł������悤�ɂ��悤�Ǝv����������ł���B
���ǃQ�[���G���W�����ɑ��ALarrabee�ł̓��쎞��DirectX�ƕ��s����
Larrabee�l�C�e�B�u���߂��|���g���Ă����悤�Ɏx�����邱�Ƃ��厖�Ȃ̂ł́H
�܂��Œ�@�\�ɔ���ꂸ�ɃG���W�����������J���҂̐S����������͂ނ��Ƃ��ˁB
�ŁA���N���ɂ͏o��̂��H
�Ȃ��API�Ƃ���DirectX�ɍS��̂��킩���B
OpenGL�ł������낤�ɁB
OpenGL�ł������낤�ɁB
ATI��NVIDIA�ŕʁX�Ɋg�����Č݊������Ȃ�����B
IPP�̊g���Ƃ��ł��܂�����ˁH�O���t�B�b�N���܂߂āB
����OpenCL��OpenGL���܂���Ƃ������Ă邯�ǁA
������Ɩ����Ȃ̂ł́H
DirectX compute shader�͐����̊ɘa���ꂽPixel Shader�̂悤�Ȑv�ŁA
Direct3D�ɗǂ��Ȃ���ł���B�t�Ɍ����ƃT�[�o���ł͎g���Ȃ��Ƃ�
Direct3D�̊�b�m�������ƃ}�j���A���ǂ�ł�����Ղ�ՂƂ�
�����͂��邯�ǁA��Ƀf�X�N�g�b�v�̃O���t�B�b�N���H�p�i���Pixel Shader�j
�Ƃ��Ċ�����Ă�B���Ƃ������A���������Ⴄ����Η�������̂���Ȃ���
�Q�[���p�r�Ȃ�Direct3D�ł��������A�Ǝv���B
������Ɩ����Ȃ̂ł́H
DirectX compute shader�͐����̊ɘa���ꂽPixel Shader�̂悤�Ȑv�ŁA
Direct3D�ɗǂ��Ȃ���ł���B�t�Ɍ����ƃT�[�o���ł͎g���Ȃ��Ƃ�
Direct3D�̊�b�m�������ƃ}�j���A���ǂ�ł�����Ղ�ՂƂ�
�����͂��邯�ǁA��Ƀf�X�N�g�b�v�̃O���t�B�b�N���H�p�i���Pixel Shader�j
�Ƃ��Ċ�����Ă�B���Ƃ������A���������Ⴄ����Η�������̂���Ȃ���
�Q�[���p�r�Ȃ�Direct3D�ł��������A�Ǝv���B
�uWindows����v�Ȃ��
�n�[�h�ɔ����邩OS�ɔ����邩�ŁA���lj��I�ȕ��@���Ȃ���
�n�[�h�ɔ����邩OS�ɔ����邩�ŁA���lj��I�ȕ��@���Ȃ���
ttp://pc.watch.impress.co.jp/docs/news/20091016_322120.html
�J���R�[�h�l�[���gLarrabee�h(�����r�[)�ŊJ����i�߂Ă���f�B�X�N���[�gGPU�ɂ��ĐG��
���{���Ԃ�17���ɁALarrabee�̐��\�f�[�^�����߂Č��J���邱�Ƃ𖾂炩�ɂ����B
�J���R�[�h�l�[���gLarrabee�h(�����r�[)�ŊJ����i�߂Ă���f�B�X�N���[�gGPU�ɂ��ĐG��
���{���Ԃ�17���ɁALarrabee�̐��\�f�[�^�����߂Č��J���邱�Ƃ𖾂炩�ɂ����B
>>313
�X���C�h�ɂ���texture logic ����Ȃ�fixed function �Ē��g�܂��s���H
�X���C�h�ɂ���texture logic ����Ȃ�fixed function �Ē��g�܂��s���H
315 �FSocket774�F2009/10/16(��) 15:10:47 ID:hlVVOAN6
���������������Ferimi���b�������������������������������I�I�I
���K�V�[GPU�@�\���̂Ă��Ȃ��܂ܒ��r���[��HPC�ɐU����NVIDIA��
��������GPU�@�\�Ɋւ��Ă�����݂������̂Ŕėp�ɐU����Intel
��������GPU�@�\�Ɋւ��Ă�����݂������̂Ŕėp�ɐU����Intel
317 �FSocket774�F2009/10/16(��) 16:10:10 ID:go1RpYLW
���\�f�[�^���ĂȂɂ�H
Intel���č��̃��C���[�a�@�Ƌ����ŊJ���������f�B�J���p�̃A�v���P�[�V�����𗘗p����Larrabee�̐��\�f�[�^�A
�Ƃ��邩��CT�X�L�����̃{�N�Z���f�[�^����Ȃ����ȁB
�Ƃ��邩��CT�X�L�����̃{�N�Z���f�[�^����Ȃ����ȁB
�t�[���G��́HFFT�����H
Larrabee�́A�hGPU�h�ł͂Ȃ��B
�C���e���́A�V�����T�O�̌ď̂�^����ׂ����B
���t���邱�Ƃɂ���āA�V���Ȑ��i�J�e�S���[�����m�������B
�C���e���́A�V�����T�O�̌ď̂�^����ׂ����B
���t���邱�Ƃɂ���āA�V���Ȑ��i�J�e�S���[�����m�������B
�����Iwktk�I�I�I
fixed function=�Œ�@�\
�����K�V�[GPU�@�\���̂Ă��Ȃ��܂ܒ��r���[��HPC�ɐU����NVIDIA��
����������GPU�@�\�Ɋւ��Ă�����݂������̂Ŕėp�ɐU����Intel
�H�H
�����K�V�[GPU�@�\���̂Ă��Ȃ��܂ܒ��r���[��HPC�ɐU����NVIDIA��
����������GPU�@�\�Ɋւ��Ă�����݂������̂Ŕėp�ɐU����Intel
�H�H
>>322
fixed function�ǂ��H�ǂꂾ���H���Ă�H
http://www.pcgameshardware.com/&menu=browser&mode=article&image_id=1127811&article_id=695022&page=1
fixed function�ǂ��H�ǂꂾ���H���Ă�H
http://www.pcgameshardware.com/&menu=browser&mode=article&image_id=1127811&article_id=695022&page=1
������
CPU�̃m�E�n�E���Ȃ�NVIDIA��GP�H����˂��i�߂��Ƃ���ŃJ�X�������ݏo����Ȃ���
>>324
�㓡�̋L�����炢�Œ���ǂ�ł���B
GPU�ŗL�̌Œ�@�\�Ȃ�ăe�N�X�`�����j�b�g���炢�����Ȃ��̂͊���B
http://pc.watch.impress.co.jp/docs/2008/0804/kaigai457.htm
�㓡�̋L�����炢�Œ���ǂ�ł���B
GPU�ŗL�̌Œ�@�\�Ȃ�ăe�N�X�`�����j�b�g���炢�����Ȃ��̂͊���B
http://pc.watch.impress.co.jp/docs/2008/0804/kaigai457.htm
�����炻�̃e�N�X�`�����j�b�g�ȊO�ɌŒ�@�\���݂�G�ɂȂ��Ă��
��̃v���[���͂悗
��̃v���[���͂悗
Power Control Unit
��
���Ȃ������A�듚�L�����悭�ǂ�ǂ���Ȃ�
Larrabee�p�C�v���C���̍ő�̓����́A�Œ�n�[�h�E�F�A(Fixed Function Hardware)���ł������r�����A
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@^^^^^^^^^^^^^^^^^
�قڃt���v���O���}�u���ȃv���Z�b�T�����グ�����Ƃ�
^^^^^
���Ȃ������A�듚�L�����悭�ǂ�ǂ���Ȃ�
Larrabee�p�C�v���C���̍ő�̓����́A�Œ�n�[�h�E�F�A(Fixed Function Hardware)���ł������r�����A
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@^^^^^^^^^^^^^^^^^
�قڃt���v���O���}�u���ȃv���Z�b�T�����グ�����Ƃ�
^^^^^
GPU���L�̌Œ�@�\��TMU�ȊO�ɂ���Ȃ�ĒN�������ĂȂ�
������
�e�R�A�g�ݍ��݂�Structure Converter���]��x86�ɂ͂Ȃ�
����Ӗ��ł�GPU�̂��߂̌Œ�@�\������
����Ӗ��ł�GPU�̂��߂̌Œ�@�\������
�ց[��
�d�͊Ǘ����j�b�g��fixed function�ł����H
�o�i�i�͂���ł����H
�o�i�i�͂���ł����H
�Œ�@�\�Ɉˑ����Ă邩�ǂ����͂���Ȃ�����Ȃ���
�ǂꂾ���̊����H���Ă邩�̒��x��肾�B
http://i40.tinypic.com/20iv3oj.png
http://www.geeks3d.com/20080912/nvidias-gt200-inside-a-parallel-processor/
�ǂꂾ���̊����H���Ă邩�̒��x��肾�B
http://i40.tinypic.com/20iv3oj.png
{kind=link}
http://www.geeks3d.com/20080912/nvidias-gt200-inside-a-parallel-processor/
>>313
GTX280����Ȃ���Tesla�Ɣ�r��������̂�
GTX280����Ȃ���Tesla�Ɣ�r��������̂�
337 �F,,�E�L�́M�E,,�j��-�������F2009/10/17(�y) 00:53:27 ID:6Eq7iFe7
Tesla���ċt�ɌŒ�@�\���j�b�g�����_�C�̍ė��p�Ȃ�Ȃ����Ǝv���Ă���
larrabee�ɌŒ�@�\�͂Ȃ��I�I��
>>314
Larrabee��Fixed Function Logic��Texture Filter Logic��������SIGGRAPH2008�̘_���ɏ����Ă���
���̃X���C�h��2006�N�ӂ肩��g���܂킵�Ă邩��A������HD decoder�Ƃ����������Ă��̂����ȁ`
Larrabee��Fixed Function Logic��Texture Filter Logic��������SIGGRAPH2008�̘_���ɏ����Ă���
���̃X���C�h��2006�N�ӂ肩��g���܂킵�Ă邩��A������HD decoder�Ƃ����������Ă��̂����ȁ`
�̒��������Ƃ����̂Ɍ��\�͂܂��Ȃ̂�
341 �FSocket774�F2009/10/17(�y) 07:33:31 ID:WOYbKCgb
Innovation@Intel
ttp://www.intel.com/pressroom/innovation/innovation.htm#101609a
ttp://techresearch.intel.com/UserFiles/en-us/File/terascale/Mayo_IEEE_VIS2009_FINAL.PDF
ttp://www.intel.com/pressroom/innovation/innovation.htm#101609a
ttp://techresearch.intel.com/UserFiles/en-us/File/terascale/Mayo_IEEE_VIS2009_FINAL.PDF
64core�Ƃ�
>>341
�E�܂��V�~�����[�^�[�ł̌��ς���@������cycle�@accurate�Ȃ̂ő�R�ł͂Ȃ�����
�E�]�����{�g���l�b�N�B�����ň��k�W�J����͂₢�A�Ǝ咣
�E��������Larrabee�����A���S���Y���̒�ĂƃZ�b�g�B
�@HPC�ł̕p�o����悭�m��ꂽ�ۑ�̃e�X�g�͔����Ă���H
�E�܂��V�~�����[�^�[�ł̌��ς���@������cycle�@accurate�Ȃ̂ő�R�ł͂Ȃ�����
�E�]�����{�g���l�b�N�B�����ň��k�W�J����͂₢�A�Ǝ咣
�E��������Larrabee�����A���S���Y���̒�ĂƃZ�b�g�B
�@HPC�ł̕p�o����悭�m��ꂽ�ۑ�̃e�X�g�͔����Ă���H
GTX280�Ɨ]��ς��Ȃ����Ăǂ��������H
�ق�CONCLUSIONS�����ǂ�
�ELarrabee�̃p�t�H�[�}���X�͍����x�̃V�~�����[�^�[�ɂ����́B
�E����N���b�N��1GHz��16, 32, 64�R�A�ŃV�~�����[�V�������Ă���B
�E16�R�A@1GHz��Larrabee��GTX 280��蕽��1.5�{�����A�V���O���R�A��Harpertown��10�{�����B
�E32�R�A��64�R�A�ł�CPU-Larrabee�Ԃł̃f�[�^�]�����{�g���l�b�N�ɂȂ�B
�@�����A���̃f�[�^�]���̃R�X�g��0�Ȃ��32�R�A�ł�(CPU��)24�{�����Ȃ�A64�R�A�ł�42�{�����Ȃ�B
�E���������̃{�g���l�b�N����u�����32�R�A�ł�64�R�A�ł�11�{���������Ȃ�Ȃ��B
�E���̖����������邽�߂Ƀf�[�^�Z�b�g���t���k����SIMD�Ɛe�a���̍����A���S���Y�������������B
�@����ɂ���ăf�[�^���O���̈�ȉ��Ɉ��k�ł���B�܂��A�𓀂̃I�[�o�[�w�b�h��30�p�[�Z���g�����ł���B
�E�f�[�^�Z�b�g�̈��k�ɂ���ē]���ɗv���鎞�Ԃς���20-30�p�[�Z���g�ɍ팸�����B
�E����ɂ���āA32�R�A�ł�19�{���\������A64�R�A�ł�31�{���\�����シ��Ƃ����������ʂ�����ꂽ�B
�ELarrabee�̃p�t�H�[�}���X�͍����x�̃V�~�����[�^�[�ɂ����́B
�E����N���b�N��1GHz��16, 32, 64�R�A�ŃV�~�����[�V�������Ă���B
�E16�R�A@1GHz��Larrabee��GTX 280��蕽��1.5�{�����A�V���O���R�A��Harpertown��10�{�����B
�E32�R�A��64�R�A�ł�CPU-Larrabee�Ԃł̃f�[�^�]�����{�g���l�b�N�ɂȂ�B
�@�����A���̃f�[�^�]���̃R�X�g��0�Ȃ��32�R�A�ł�(CPU��)24�{�����Ȃ�A64�R�A�ł�42�{�����Ȃ�B
�E���������̃{�g���l�b�N����u�����32�R�A�ł�64�R�A�ł�11�{���������Ȃ�Ȃ��B
�E���̖����������邽�߂Ƀf�[�^�Z�b�g���t���k����SIMD�Ɛe�a���̍����A���S���Y�������������B
�@����ɂ���ăf�[�^���O���̈�ȉ��Ɉ��k�ł���B�܂��A�𓀂̃I�[�o�[�w�b�h��30�p�[�Z���g�����ł���B
�E�f�[�^�Z�b�g�̈��k�ɂ���ē]���ɗv���鎞�Ԃς���20-30�p�[�Z���g�ɍ팸�����B
�E����ɂ���āA32�R�A�ł�19�{���\������A64�R�A�ł�31�{���\�����シ��Ƃ����������ʂ�����ꂽ�B
>16�R�A@1GHz��Larrabee��GTX 280��蕽��1.5�{�����`
������Ɛ��m����Ȃ������B�������͂����B
16�R�A@1GHz��Larrabee�͗��_���Z���\��GTX 280�̔��������A����ł�GTX 280��蕽��1.5�{�����`
������Ɛ��m����Ȃ������B�������͂����B
16�R�A@1GHz��Larrabee�͗��_���Z���\��GTX 280�̔��������A����ł�GTX 280��蕽��1.5�{�����`
347 �F,,�E�L�́M�E,,�j��-�������F2009/10/17(�y) 11:10:05 ID:6Eq7iFe7
> �E���̖����������邽�߂Ƀf�[�^�Z�b�g���t���k����SIMD�Ɛe�a���̍����A���S���Y�������������B
>�@����ɂ���ăf�[�^���O���̈�ȉ��Ɉ��k�ł���B�܂��A�𓀂̃I�[�o�[�w�b�h��30�p�[�Z���g�����ł���B
�܂�����gzip�]���E�E�E
�ǂ���UNIX�R�s�y������Ďv�������ǁA����SIMD�Ƒ����ǂ���
>�@����ɂ���ăf�[�^���O���̈�ȉ��Ɉ��k�ł���B�܂��A�𓀂̃I�[�o�[�w�b�h��30�p�[�Z���g�����ł���B
�܂�����gzip�]���E�E�E
�ǂ���UNIX�R�s�y������Ďv�������ǁA����SIMD�Ƒ����ǂ���
>>251
���̒��ɓ����Ă����̂�geforce�Ȃ�ł��B�{���ɂ��߂�Ȃ����B
http://www.4gamer.net/games/049/G004963/20090923003/screenshot.html?num=002
���̒��ɓ����Ă����̂�geforce�Ȃ�ł��B�{���ɂ��߂�Ȃ����B
http://www.4gamer.net/games/049/G004963/20090923003/screenshot.html?num=002
349 �FSocket774�F2009/10/17(�y) 11:21:23 ID:6Td23772
>algolithm ZLIB
�ق�Ƃ�GZIP�]����w
�ق�Ƃ�GZIP�]����w
350 �F,,�E�L�́M�E,,�j��-�������F2009/10/17(�y) 11:26:34 ID:6Eq7iFe7
�u��Fermi�ɂ�gzip�f�R�[�h��p���W�b�N�𓋍ڂ�����ށI�v
351 �FSocket774�F2009/10/17(�y) 11:26:43 ID:aImjh/H4
GZIP�͉摜�f�[�^�̈��k�Ɏg���Ă�݂�������
���X���XJPEG�Ƃ̔�r�Ɍ��y���Ă邩��
���X���XJPEG�Ƃ̔�r�Ɍ��y���Ă邩��
>>350
604 �FSocket774 [sage] �F2009/10/15(��) 15:27:58 ID:fjojjPvn
���m�l�̊炪�S���؍��l�Ɍ�����a�C���E�E�E�J���C�\�E�ɁE�E�E
�W�F���E�X���E�t�A���͑�p�o�g�Ȃ̂ɁB
604 �FSocket774 [sage] �F2009/10/15(��) 15:27:58 ID:fjojjPvn
���m�l�̊炪�S���؍��l�Ɍ�����a�C���E�E�E�J���C�\�E�ɁE�E�E
�W�F���E�X���E�t�A���͑�p�o�g�Ȃ̂ɁB
353 �F,,�E�L�́M�E,,�j��-�������F2009/10/17(�y) 11:31:31 ID:6Eq7iFe7
>>349
���Ă��Ƃ̓f�[�^�Z�b�g�]��������GPL����
���Ă��Ƃ̓f�[�^�Z�b�g�]��������GPL����
�悭�ǂނ�
���B�̈��k�A���S���Y������ʓI�Ɏg����ZLIB�Ɣ�ׂ�Ɓc
���ď����Ă��邩��AZLIB�͂����܂ł���r�ΏƂ���ˁH
���B�̈��k�A���S���Y������ʓI�Ɏg����ZLIB�Ɣ�ׂ�Ɓc
���ď����Ă��邩��AZLIB�͂����܂ł���r�ΏƂ���ˁH
357 �F,,�E�L�́M�E,,�j��-�������F2009/10/17(�y) 11:38:33 ID:6Eq7iFe7
����ς�u����̈��k�A���S���Y����ZLIB���SIMD�Ɛe�a���������Ă������v
���Ęb�ɂȂ��Ă�ȁB�ǂ�ȃA���S���Y�����m��B
���Ęb�ɂȂ��Ă�ȁB�ǂ�ȃA���S���Y�����m��B
�Œ蒷�̈��k�A���S���Y���Ƃ����������
360 �F,,�E�L�́M�E,,�j��-�������F2009/10/17(�y) 11:43:54 ID:6Eq7iFe7
�܂�SIMD������Deflate�����Ǝv�����
GPGPU�ɂ�����PCIe���{�g���l�b�N���Ă����ƑO���猾���Ă����Ƃ����B
����̃|�[�^�u���Ȏ���������痬�s���ˁH
�܂�Radeon����GeForce���̂̃V�F�[�_��x86���̂��̂�Larrabee�قǂ̏_�������Ƃ͎v����
GPGPU�ɂ�����PCIe���{�g���l�b�N���Ă����ƑO���猾���Ă����Ƃ����B
����̃|�[�^�u���Ȏ���������痬�s���ˁH
�܂�Radeon����GeForce���̂̃V�F�[�_��x86���̂��̂�Larrabee�قǂ̏_�������Ƃ͎v����
����A�_����厖������
Nehalem�|SandyBridge�|IvyBridge�|Haswell�|�\�t����S
�g�����Ƃɂ����
Nehalem�|SandyBridge�|IvyBridge�|Haswell�|�\�t����S
�g�����Ƃɂ����
�V�~�����[�^�[������̂ɁAGPU�Ƃ��Ă̐��\�����J���Ȃ����A
HPC����ł悭����ۑ�̏����\�͂����J���Ȃ��B
�����������̂��瓦���Ă�悤�Ɍ����Ĉ�ۂ͂悭�Ȃ��̂��A���̏���
HPC����ł悭����ۑ�̏����\�͂����J���Ȃ��B
�����������̂��瓦���Ă�悤�Ɍ����Ĉ�ۂ͂悭�Ȃ��̂��A���̏���
�������������Ƃ���ɂ�����]�����o���Ȃ��̂��ȁH
����̂̓R�}�[�V�����y�[�p�[�ł͂Ȃ���B
����Ɉ�Ì����͒��N�_���Ă�������B
����̂̓R�}�[�V�����y�[�p�[�ł͂Ȃ���B
����Ɉ�Ì����͒��N�_���Ă�������B
364 �F,,�E�L�́M�E,,�j��-�������F2009/10/17(�y) 17:24:22 ID:6Eq7iFe7
����̂͏��ƃC�x���g�ł͂Ȃ�IEEE�Ƃ������Ђ���w�����ˁB
1�N�ȏ�d���u�����_���v���B
1�N�ȏ�d���u�����_���v���B
>341�̓��e��Intel�̓��ֈȊO���ǎ��\�Ȃ̂���
�s�\���Ƃ����炻��͊w�p�_���Ƃ͌����Ȃ�
�s�\���Ƃ����炻��͊w�p�_���Ƃ͌����Ȃ�
366 �F,,�E�L�́M�E,,�j��-�������F2009/10/17(�y) 17:39:04 ID:6Eq7iFe7
�u�l�̍l�����ŋ���CPU�v�̐��\�]���n�̘_���͂������ǂ��Ƃ����邪
�V�~�����[�^�̃\�[�X�����J����Ă���̂͌������Ƃ��Ȃ�
�܂��A���k�A���S���Y���ɂ��Ă��A���i�Ƃ��Ĕ���镨���݂��݂��������J����Ƃ͎v���B
�V�~�����[�^�̃\�[�X�����J����Ă���̂͌������Ƃ��Ȃ�
�܂��A���k�A���S���Y���ɂ��Ă��A���i�Ƃ��Ĕ���镨���݂��݂��������J����Ƃ͎v���B
�d��������ĕ����Ă݂��B
601 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/02/06(��) 07:50:39 ID:36Q+eCpY
����Larrabee�̃T���v����Dreamworks�ŕ]������Ă�悤����
����Larrabee�̃T���v����Dreamworks�ŕ]������Ă�悤����
369 �F,,�E�L�́M�E,,�j��-�������F2009/10/17(�y) 17:42:38 ID:6Eq7iFe7
��������B�T���v���I�ȃT�C�N���A�L�����[�g�V�~�����[�^����B
�������ɂ͖����ł������ꌟ�ł�������Ƃ�����ō��ǒʂ��Ă�̂��ˁB
�܂����ǎ҂̕Ґ��ɂ��c����Ƃ̐l�Ԃ��������邾�낤��
�����̑������e���鎞�̂��Ƃ��l������
���ؕs�\��paper�͒ʂ��Ȃ��Ȃ�Č��i�ȑԓx�͎��Ȃ��̂�����
�܂����ǎ҂̕Ґ��ɂ��c����Ƃ̐l�Ԃ��������邾�낤��
�����̑������e���鎞�̂��Ƃ��l������
���ؕs�\��paper�͒ʂ��Ȃ��Ȃ�Č��i�ȑԓx�͎��Ȃ��̂�����
371 �F,,�E�L�́M�E,,�j��-�������F2009/10/17(�y) 17:55:19 ID:6Eq7iFe7
�T���v���������I�ȃ_�C�Ƃ���͂��Ȏv�����݂��ȁB
�����I�ȃ_�C���Ȃ��ƃ\�t�g�J���ł��Ȃ��Ȃ�Ă̂͂܂Ƃ��ȃV�~�����[�^���Ⴆ�Ȃ��㏬�x���_�[���k��
��ŁALRB SDK���Ă�������̂͋@���ێ��_������Q�[���G���W��������_�����ɐ�s�]���ł�
����Ă���̂�2008�N���_�̘b�B
�܂���́u�A���v�͂�����ƃ��C�Z���X�ɂ����牴�ł��A�N�Z�X�ł���킯����
Core MA�݂����ȃA�E�g�I�u�I�[�_��CPU�܂Ő��m�ɏ��v�T�C�N���f���o������т����肷��
�����I�ȃ_�C���Ȃ��ƃ\�t�g�J���ł��Ȃ��Ȃ�Ă̂͂܂Ƃ��ȃV�~�����[�^���Ⴆ�Ȃ��㏬�x���_�[���k��
��ŁALRB SDK���Ă�������̂͋@���ێ��_������Q�[���G���W��������_�����ɐ�s�]���ł�
����Ă���̂�2008�N���_�̘b�B
�܂���́u�A���v�͂�����ƃ��C�Z���X�ɂ����牴�ł��A�N�Z�X�ł���킯����
Core MA�݂����ȃA�E�g�I�u�I�[�_��CPU�܂Ő��m�ɏ��v�T�C�N���f���o������т����肷��
372 �F,,�E�L�́M�E,,�j��-�������F2009/10/17(�y) 17:58:54 ID:6Eq7iFe7
>>370
NVIDIA�̖������X�^���t�H�[�h�̋����Ƃ������ꗘ�p����Larrabee�̈����������炢������n���ɍ���B
�A�����J�ɂ͉Ȋw������⏕���݂����Ȑ��x���Ȃ����猴����Ƃ̓s���Ő��藧���Ă�B
�A�����J�̊w��ɓ��{�قǂ̃N���[�����͂Ȃ��B
NVIDIA�̖������X�^���t�H�[�h�̋����Ƃ������ꗘ�p����Larrabee�̈����������炢������n���ɍ���B
�A�����J�ɂ͉Ȋw������⏕���݂����Ȑ��x���Ȃ����猴����Ƃ̓s���Ő��藧���Ă�B
�A�����J�̊w��ɓ��{�قǂ̃N���[�����͂Ȃ��B
�����炫�܂���
NVIDIA�I���L�O�p�s�R
NVIDIA�I���L�O�p�s�R
�T���v���V���R���͂悭�������ǁA�T���v���V�~�����[�^�Ȃ�Ĉ�ʓI����Ȃ���
Larrabee�H���~�ł���
�������\�̃f�[�^���ďo�Ă�H�H
�������͂܂�16���������肷��H�H�H
�������͂܂�16���������肷��H�H�H
�o�Ă邯�ǃC���e���K�����Ȃ�������
���������ĂȂ��B
���������ĂȂ��B
378 �F,,�E�L�́M�E,,�j��-�������F2009/10/17(�y) 19:03:06 ID:6Eq7iFe7
>>374
���������ł���
���������ł���
�Ȃ܂��� C'est la vie�ɕς����܂��`
�V�~�����[�^�[�̃x���`���ʂ��ăn�[�h�E�F�A�����z�ʂ�̓���������ꍇ�̒l�Ȃ�ł���H
���݂��ꂪ�o����T���v���n�[�h�E�F�A�͑��݂���̂ł����ˁB
�܂��A���Ȃ�����V�~�����[�^�[�Ȃ�ł��傤���ǁB
�Ȃ�Nvidia��Intel���u�l���l�����ŋ��̃v���Z�b�T�[�v�Ό������Ă��邾���ɂ݂���̂͋C�̂������ȁB
�����ɂȂ�������@���g�����f����x���`�}�[�N���o�Ă���낤���B
���݂��ꂪ�o����T���v���n�[�h�E�F�A�͑��݂���̂ł����ˁB
�܂��A���Ȃ�����V�~�����[�^�[�Ȃ�ł��傤���ǁB
�Ȃ�Nvidia��Intel���u�l���l�����ŋ��̃v���Z�b�T�[�v�Ό������Ă��邾���ɂ݂���̂͋C�̂������ȁB
�����ɂȂ�������@���g�����f����x���`�}�[�N���o�Ă���낤���B
382 �F,,�E�L�́M�E,,�j��-�������F2009/10/17(�y) 21:06:59 ID:6Eq7iFe7
Intel�̂̓L���b�V���~�X��y�[�W�t�H���g�܂ŃV�~�����[�V�����ł��邼
���S�ɃV�~�����[�g�ł���Ȃ�A�ǂ̐��i�ł��o�O�͖�����Ȃ�����
������V�~�����[�g�Ȃ��
������V�~�����[�g�Ȃ��
384 �F,,�E�L�́M�E,,�j��-�������F2009/10/17(�y) 22:15:42 ID:6Eq7iFe7
�V�~�����[�g��ے肵����GPGPU�̎g�������i����
�Ȃ���Ȃ�ɂ�IDF�Ńf���������̂ɐ��\�]���͎�������Ȃ��V�~�����[�g���Ă����̂��c�O�Ȋ���
����̃T���v������܂Ƃ��ȕ]�����o������Ă��Ƃł���
����̃T���v������܂Ƃ��ȕ]�����o������Ă��Ƃł���
386 �F,,�E�L�́M�E,,�j��-�������F2009/10/17(�y) 23:24:57 ID:6Eq7iFe7
�H
���k�A���S���Y���̊J������1�T�Ԃ�2�T�Ԃŏ����郌�x���̘_�����Ƃł��v���Ă�̂��H
�Ƃ������펯�I�ɍl����Θ_����IDF���O�ɒ�o���Ă�
�܂����ǂ������āA�ʂ������̂���X�I�ɔ��\�����
������������̘_���̈Ӑ}���鏊�͂ȂƎv��
���k�t�H�[�}�b�g�̓��I�W�J�͌����������Ǝv���Ă邪�ш���Z�[�u�����ŗL�p�ł��邱�Ƃ������ꂽ�B
����́Ax86�̕��G�������ߖ��x�̍������߃Z�b�g�̒�͂ɑ���A�i�O�����ɂ��Ȃ��Ă���B
���k�A���S���Y���̊J������1�T�Ԃ�2�T�Ԃŏ����郌�x���̘_�����Ƃł��v���Ă�̂��H
�Ƃ������펯�I�ɍl����Θ_����IDF���O�ɒ�o���Ă�
�܂����ǂ������āA�ʂ������̂���X�I�ɔ��\�����
������������̘_���̈Ӑ}���鏊�͂ȂƎv��
���k�t�H�[�}�b�g�̓��I�W�J�͌����������Ǝv���Ă邪�ш���Z�[�u�����ŗL�p�ł��邱�Ƃ������ꂽ�B
����́Ax86�̕��G�������ߖ��x�̍������߃Z�b�g�̒�͂ɑ���A�i�O�����ɂ��Ȃ��Ă���B
���t����l����IEEE VisWeek 2009 �̃v���[���^�[�̌��e���ߐ��
IDF���O�Ȃ�Ȃ���
IDF���O�Ȃ�Ȃ���
�A�i�O�������ā@ ���̓��� �� �A���g�j�I����
�݂����Ȃ���H
�݂����Ȃ���H
�A�i���W�[���������������Ⴄ��H
390 �F,,�E�L�́M�E,,�j��-�������F2009/10/17(�y) 23:31:25 ID:6Eq7iFe7
�����Ƃ������i�د
>>384
����
����
392 �F,,�E�L�́M�E,,�j��-�������F2009/10/17(�y) 23:33:44 ID:6Eq7iFe7
�����Ă��AHPC�̗p�r���ăV�~�����[�V������������
�E�F�n�����J���ꂽ�̂�4��������9���̃f�����t�@�[�X�g�V���R�����Ă킯����Ȃ�����
���Ԃ������ƌ������Ƃ͂Ȃ�
����ł������`�b�v���g���Ȃ�����o�O������������
���邢�͉\�ɂ���悤�ɑ����̐v�ύX���s��ꂽ��
���Ȃ��Ƃ������ł͖����悤�Ɍ������
���Ԃ������ƌ������Ƃ͂Ȃ�
����ł������`�b�v���g���Ȃ�����o�O������������
���邢�͉\�ɂ���悤�ɑ����̐v�ύX���s��ꂽ��
���Ȃ��Ƃ������ł͖����悤�Ɍ������
�n�[�h�E�F�A���V�~�����[�g���āA�x���`�}�[�N���V�~�����[�g���邩�E�E�E��
Dreamworks�Ƃ��ɂ͑�������ĕ]�����Ă�����Ă�̂��H
�ڋq���V�~�����[�^�[�ŕ]���Ƃ�����悤�ȋC������B
�ڋq���V�~�����[�^�[�ŕ]���Ƃ�����悤�ȋC������B
396 �F,,�E�L�́M�E,,�j��-�������F2009/10/17(�y) 23:46:23 ID:6Eq7iFe7
�܂�L2�L���b�V���̃`���[���Ȃ͍Ō�܂ʼn�����
����ł������Ƃ��}1���ȓ��ɂ͌덷��}���Ă���̂��v������
�Ƃ���������̌��ʂ͌덷�����ĕ����郌�x���̍�����Ȃ����Ƃ��炢�킩�邾�낤
����ł������Ƃ��}1���ȓ��ɂ͌덷��}���Ă���̂��v������
�Ƃ���������̌��ʂ͌덷�����ĕ����郌�x���̍�����Ȃ����Ƃ��炢�킩�邾�낤
397 �F,,�E�L�́M�E,,�j��-�������F2009/10/17(�y) 23:49:07 ID:6Eq7iFe7
>>395
���Ƃ���Opteron�N���X�^��CG����Ă���Ђ����ǃN�\�������Ɏ��]����Intel�ɏ�芷�����B
�ȍ~Intel�͂�����CG�f��̃X�|���T�[�ŃG���W���J���̋Z�p���͂����Ă�
���Ƃ���Opteron�N���X�^��CG����Ă���Ђ����ǃN�\�������Ɏ��]����Intel�ɏ�芷�����B
�ȍ~Intel�͂�����CG�f��̃X�|���T�[�ŃG���W���J���̋Z�p���͂����Ă�
>>397
�Ȃ�قǃf�[�^�Z���^�[��A�r�������t���A�A�J���l������ɑ�����炢�o���Ă�̂��B
�Ȃ�قǃf�[�^�Z���^�[��A�r�������t���A�A�J���l������ɑ�����炢�o���Ă�̂��B
399 �F,,�E�L�́M�E,,�j��-�������F2009/10/17(�y) 23:54:09 ID:6Eq7iFe7
400 �F,,�E�L�́M�E,,�j��-�������F2009/10/17(�y) 23:59:06 ID:6Eq7iFe7
Intel��Core MA���܂߂�CPU�̃V�~�����[�^������Ă�
�Ă�VTune�̋Z�p�]�p�����炨��̕������B
���̐l�ɁuLarrabee�X�Q�[�v�ƌ��킵�߂��̂�
��������Intel�̃V�~�����[�^�̐��x�̍����̎��т������Ă����̂���
�[���������o�ׂ����܂Ń\�t�g�J�����o���Ȃ��Ȃ�Ă̂�
�������Ђɒx�����邱�ƂɂȂ邩��
�J���c�[���ƃV�~�����[�^�̐�s�z�z�Ȃ�Ă̂͐e���ȃp�[�g�i�[�Ȃ瓖����O
�Ă�VTune�̋Z�p�]�p�����炨��̕������B
���̐l�ɁuLarrabee�X�Q�[�v�ƌ��킵�߂��̂�
��������Intel�̃V�~�����[�^�̐��x�̍����̎��т������Ă����̂���
�[���������o�ׂ����܂Ń\�t�g�J�����o���Ȃ��Ȃ�Ă̂�
�������Ђɒx�����邱�ƂɂȂ邩��
�J���c�[���ƃV�~�����[�^�̐�s�z�z�Ȃ�Ă̂͐e���ȃp�[�g�i�[�Ȃ瓖����O
>>397
Pen4�Ƃ�C2D�̂��납��H
Pen4�Ƃ�C2D�̂��납��H
402 �F,,�E�L�́M�E,,�j��-�������F2009/10/18(��) 00:05:21 ID:ug3wQg4J
>>401
������45nm��Harpertown�̍��B
���C�g����SIMD���\�ƃL���b�V���e�ʂ���������ˁB
���̍�����傫�����������Ă��ł���B
������45nm��Harpertown�̍��B
���C�g����SIMD���\�ƃL���b�V���e�ʂ���������ˁB
���̍�����傫�����������Ă��ł���B
�e���ȃp�[�g�i�[�E�E�E
�������̃p�[�g�i�[�����łȂ��A���̏�Ƀx���`���\���o�����̂��S���n�[�h���܂߃V�~�����[�g������
�������̃p�[�g�i�[�����łȂ��A���̏�Ƀx���`���\���o�����̂��S���n�[�h���܂߃V�~�����[�g������
404 �F,,�E�L�́M�E,,�j��-�������F2009/10/18(��) 00:12:21 ID:ug3wQg4J
NVIDIA�͑e�G�ȍ��̃��b�N�A�b�v���o�����ƂŊ����ɂǂ��e�����邩�̌o�c�V�~�����[�g���K�v����
Intel 740�݂����ɂȂ�Ƃ��F�����(-�l-)�@
Larrabee�͒P���ȃ��j�[�R�A�Ƃ��Ă��g����낤��
Fusion�Ƃ�Fermi��Cell�̓�̕��ɂȂ邩��
Fusion�Ƃ�Fermi��Cell�̓�̕��ɂȂ邩��
407 �F,,�E�L�́M�E,,�j��-�������F2009/10/18(��) 00:25:27 ID:ug3wQg4J
Intel�ƂĂ���܂萫�\�ǂ��̂������o����Xeon��6�R�A�Ƃ�8�R�A�𒍖ڂ��Ȃ��Ȃ����炻��͂����
�o�c�헪�~�X�Ȃ킯�����B
�o�c�헪�~�X�Ȃ킯�����B
>>406
����ᖳ�����킢�܂���Pen3�N���X�̃R�A�Ƃ���
������SIMD���j�b�g�Ɍ݊�����������B
���Z���\��fermi���|����GPU���\�ŋ͍��܂ŋl�߂Ȃ��ƃ|�V���邪�ȁB
����ᖳ�����킢�܂���Pen3�N���X�̃R�A�Ƃ���
������SIMD���j�b�g�Ɍ݊�����������B
���Z���\��fermi���|����GPU���\�ŋ͍��܂ŋl�߂Ȃ��ƃ|�V���邪�ȁB
409 �F,,�E�L�́M�E,,�j��-�������F2009/10/18(��) 00:33:37 ID:ug3wQg4J
������ᖳ�����킢�܂���Pen3�N���X�̃R�A�Ƃ���
�͂��_�E�g
�͂��_�E�g
411 �F,,�E�L�́M�E,,�j��-�������F2009/10/18(��) 00:36:46 ID:ug3wQg4J
�͂��A�ϑz���������܂���
���Ⴀpen3 500�R�A��CPU�������Ă��Ă��������ˁB
413 �F,,�E�L�́M�E,,�j��-�������F2009/10/18(��) 00:42:28 ID:ug3wQg4J
����uPentium�v�̃p�C�v���C�����y��Ȃ�������
�킸��550���g�����W�X�^�œ����E���S����RISC�}�V���̐��\�ɔ���������
�킸��550���g�����W�X�^�œ����E���S����RISC�}�V���̐��\�ɔ���������
�l�I�����̓G���R���
GPGPU��Spurs�͎�����������
intel�͊�{����Ƃɂ��Ă邪
�������x�����b�g�p�t�H����{�Ƃ�����ꂽ�炳������
���킴����
GPGPU��Spurs�͎�����������
intel�͊�{����Ƃɂ��Ă邪
�������x�����b�g�p�t�H����{�Ƃ�����ꂽ�炳������
���킴����
>>413
���������������˃C���I�[�_�[���ˁB�P�Ȃ銨�Ⴂ�B
���������������˃C���I�[�_�[���ˁB�P�Ȃ銨�Ⴂ�B
CPU�͂R�N�O����R�N��܂Ői���Ȃ����ł��B
2012�N��Dual GPU cardPC�̊�����50%�B
2015�N nvidia GPU ��5000SP��
�����ǂ��Ȃ邩
2012�N��Dual GPU cardPC�̊�����50%�B
2015�N nvidia GPU ��5000SP��
�����ǂ��Ȃ邩
����Ȃ����炳�܂ɘb���炳�Ȃ��Ă����ł���(-�l-)
418 �F,,�E�L�́M�E,,�j��-�������F2009/10/18(��) 00:45:53 ID:ug3wQg4J
500mm²�g���Ă��V�F�[�_�����̖ʐς�1/3�Ƃ�����Ȃ�i��CUDA�Ƃ��Ďg����̂͂����܂ł��̕����j
����Ńs�[�N���\�Ȃ�܂������������\�ŏ��Ƃ��ȂNJÂ�
����Ńs�[�N���\�Ȃ�܂������������\�ŏ��Ƃ��ȂNJÂ�
420 �F,,�E�L�́M�E,,�j��-�������F2009/10/18(��) 00:48:13 ID:ug3wQg4J
����A550����Pentium Pro����
P54C��310��
P54C��310��
421 �F,,�E�L�́M�E,,�j��-�������F2009/10/18(��) 00:50:58 ID:ug3wQg4J
>>419
GT200����
http://www.anandtech.com/video/showdoc.aspx?i=3341&p=8
GPGPU�Ƃ��Ďg���Ȃ��u���b�N������������
GT200����
http://www.anandtech.com/video/showdoc.aspx?i=3341&p=8
GPGPU�Ƃ��Ďg���Ȃ��u���b�N������������
�r�b�g���Z���n�[�h�E�F�A�Őς�ł邵
�C���e�����_���ŏo�����悤�Ȃ��Ƃ͊��ɉ����ς݂̂ɂق��B
�C���e�����_���ŏo�����悤�Ȃ��Ƃ͊��ɉ����ς݂̂ɂق��B
423 �F,,�E�L�́M�E,,�j��-�������F2009/10/18(��) 00:54:22 ID:ug3wQg4J
> �r�b�g���Z���n�[�h�E�F�A�Őς�ł邵
AND NOT OR XOR�Ȃ�G80���ォ�炠�������n����
AND NOT OR XOR�Ȃ�G80���ォ�炠�������n����
425 �F,,�E�L�́M�E,,�j��-�������F2009/10/18(��) 00:57:50 ID:ug3wQg4J
L2�͗L�p����BVRAM�ɉ��x���ǂ�ŏ����Ă��̂̓g���t�B�b�N�Ɠd�̖͂���
���ɔėp���Z�ɂ����Ă͂�
���ɔėp���Z�ɂ����Ă͂�
�X���[�v�b�g�R���s���[�e�B���O�Ƌt�̍l���ł��ȁB
�ߋ��̈�Y�Ƀg�����W�X�^�Ƒ�ʂɗ̂͂ǂ��Ȃ�ł����ȁB
�܂�L2�̘b�������Ă�GPU�Ƃ��Ďg���ȏ�ROP�ȊO��nvidia�Ƃ�����B
�ߋ��̈�Y�Ƀg�����W�X�^�Ƒ�ʂɗ̂͂ǂ��Ȃ�ł����ȁB
�܂�L2�̘b�������Ă�GPU�Ƃ��Ďg���ȏ�ROP�ȊO��nvidia�Ƃ�����B
>>423
�}�X�N����Ȃ��Ă˒lj�����Ă邩�璲�ׂĂ݂ĂˁB
�}�X�N����Ȃ��Ă˒lj�����Ă邩�璲�ׂĂ݂ĂˁB
428 �F,,�E�L�́M�E,,�j��-�������F2009/10/18(��) 01:15:31 ID:ug3wQg4J
�́H
�O���[�o���������̑ш摝���̓s�������ƂƂ��ɏ���d�͂̑����ɒ��������\����̑j�Q�v���ɂȂ���邩��
���[�J���������𑝂₵�ē`���R�X�g���팸������̂����̃X���[�v�b�g�R���s���[�e�B���O�̃g�����h�����B
NVIDIA���g�̃g�b�v�������Ă�B
���������z�Ƃ͗�����Fermi�ɂ������Ă�VRAM�ш�ˑ��̎���x��̃A�[�L�Ŋ撣���Ă�킯�����B
GPU�̂�����݂Ŕėp�R���s���[�e�B���O���\���オ�j�Q����Ă��
����Ƃ�x86�f�R�[�_�̂��Ƃ��H
�ŋ߂�x86�̃t�H�[�}�b�g�͖��߂̖��x�������x�^�[VLIW�Ƃ��Č�������Ă�̂�
�����ɃN�\���N�\�Ƃ�߂��U�炷�A�z������B
Larrabee�p�ɍX�ɃA�h���b�V���O���[�h���������ꖽ�ߖ��x���X�ɑ����Ă���B
�O���[�o���������̑ш摝���̓s�������ƂƂ��ɏ���d�͂̑����ɒ��������\����̑j�Q�v���ɂȂ���邩��
���[�J���������𑝂₵�ē`���R�X�g���팸������̂����̃X���[�v�b�g�R���s���[�e�B���O�̃g�����h�����B
NVIDIA���g�̃g�b�v�������Ă�B
���������z�Ƃ͗�����Fermi�ɂ������Ă�VRAM�ш�ˑ��̎���x��̃A�[�L�Ŋ撣���Ă�킯�����B
GPU�̂�����݂Ŕėp�R���s���[�e�B���O���\���オ�j�Q����Ă��
����Ƃ�x86�f�R�[�_�̂��Ƃ��H
�ŋ߂�x86�̃t�H�[�}�b�g�͖��߂̖��x�������x�^�[VLIW�Ƃ��Č�������Ă�̂�
�����ɃN�\���N�\�Ƃ�߂��U�炷�A�z������B
Larrabee�p�ɍX�ɃA�h���b�V���O���[�h���������ꖽ�ߖ��x���X�ɑ����Ă���B
429 �F,,�E�L�́M�E,,�j��-�������F2009/10/18(��) 01:17:01 ID:ug3wQg4J
���܂ł̃X���[�v�b�g�R���s���[�e�B���O���A10�̃g�����W�X�^��10�̐��\��ڎw����������
10�̃g�����W�X�^��5�̐��\�A�ƑË�����Ηp�r���i�i�ɍL�����Intel�͍l����
10�̃g�����W�X�^��5�̐��\�A�ƑË�����Ηp�r���i�i�ɍL�����Intel�͍l����
Cell�̋t�P���͂��܂��E�E�E�E
432 �F,,�E�L�́M�E,,�j��-�������F2009/10/18(��) 01:19:48 ID:ug3wQg4J
���Z���\��fermi���|����GPU���\�ŋ͍��܂ŋl�߂Ȃ��ƃ|�V����B
���Ƃ͑o���o�Ă݂Ȃ��Ƃ킩��Ȃ��Blarrabee���ʖڂ��ۂ��͉̂��ƂȂ��킩��B
���Ƃ͑o���o�Ă݂Ȃ��Ƃ킩��Ȃ��Blarrabee���ʖڂ��ۂ��͉̂��ƂȂ��킩��B
x86���܂邲�ƃt�B�[�`���[���鎖�ŁA����L1L2�L���b�V���̗e�ʁE���C�e���V�E�ш悪�ύX�ł���
SIMD�G���W���̑��x�E���v�N���b�N�������ǂł���
�����Pentium�p�C�v���C������v�ύX�ł��Ă��܂�
�݊����̋S�AIntel�炵���v�z
SIMD�G���W���̑��x�E���v�N���b�N�������ǂł���
�����Pentium�p�C�v���C������v�ύX�ł��Ă��܂�
�݊����̋S�AIntel�炵���v�z
>>431
�t�P���Č������A7�R�A�ȏ�ň�ԑ����o�ׂ��Ă�̂�Cell�ł��傤�B
GPU�͂܂��A�N�Z�����[�^�[�Ƃ��Ă����@�\�����Ă�����ĂȂ�����
GPU�̕��������Ƒ��R�A�ɑ�������Ƃ�����Ȃ��ł�
�t�P���Č������A7�R�A�ȏ�ň�ԑ����o�ׂ��Ă�̂�Cell�ł��傤�B
GPU�͂܂��A�N�Z�����[�^�[�Ƃ��Ă����@�\�����Ă�����ĂȂ�����
GPU�̕��������Ƒ��R�A�ɑ�������Ƃ�����Ȃ��ł�
Cell��LS���f���炵���������Ƃ��������ȁB
437 �F,,�E�L�́M�E,,�j��-�������F2009/10/18(��) 01:29:40 ID:ug3wQg4J
Fermi�������͂��������Ƃ����͂킩���Ă���B
�����ł���GT200�Ɏ��]�����̂ɂ�����X�ɗւ������ăN�\�ɂȂ��Ă�
�����ł���GT200�Ɏ��]�����̂ɂ�����X�ɗւ������ăN�\�ɂȂ��Ă�
438 �F,,�E�L�́M�E,,�j��-�������F2009/10/18(��) 01:30:32 ID:ug3wQg4J
>>435
GT200��SM��1�R�A�Ƃ��Č����30�R�A����
GT200��SM��1�R�A�Ƃ��Č����30�R�A����
���C���[�a�@�Ƃ̋����_�����c�c
������v���o���Ȃ�
>ttp://www-03.ibm.com/press/us/en/attachment/23251.wss?fileId=ATTACH_FILE2&fileName=cell-reg.pdf
������v���o���Ȃ�
>ttp://www-03.ibm.com/press/us/en/attachment/23251.wss?fileId=ATTACH_FILE2&fileName=cell-reg.pdf
32�R�A�̂����A�ŏ���2�R�A���l�n�����R�A�ɍ����ւ���L3�lj����ĐVCPU�ł�������
441 �F,,�E�L�́M�E,,�j��-�������F2009/10/18(��) 01:32:40 ID:ug3wQg4J
>>435
Cell�̓V���O���R�APPC�{�_�C�g�ݍ��݂̃A�N�Z�����[�^8�i���邢��1���S�j
C�����time������g���Ȃ��悤�Ȃ̂�����ɃR�A�ɃJ�E���g����Ȃ�B
Cell�̓V���O���R�APPC�{�_�C�g�ݍ��݂̃A�N�Z�����[�^8�i���邢��1���S�j
C�����time������g���Ȃ��悤�Ȃ̂�����ɃR�A�ɃJ�E���g����Ȃ�B
��������Ζ������Ǝv�����A�v���Z�b�T�S���̉����ѓ��v��
��ꂽ��ʔ������낤�ȁB�@���������������l�Ɏg�����Ă��炦�ĂȂ�
CPU�Ƃ��A�x�������g����Ă�CPU�Ƃ����邩������Ȃ�
��ꂽ��ʔ������낤�ȁB�@���������������l�Ɏg�����Ă��炦�ĂȂ�
CPU�Ƃ��A�x�������g����Ă�CPU�Ƃ����邩������Ȃ�
443 �F,,�E�L�́M�E,,�j��-�������F2009/10/18(��) 01:35:01 ID:ug3wQg4J
Turbo Boost�݂����ȋ@�\�����肪�������邱�Ǝ��́A���j�[�R�A�H���̃A���`�e�[�[�I����
Cell��SPE�͔ėp�Ɏg���ɂ�ISA��肷��
GPU�Ɏg���ɂ�SIMD���V���[�g�߂��ăg�����W�X�^�������߂�����Ȃ����H
GPU�Ɏg���ɂ�SIMD���V���[�g�߂��ăg�����W�X�^�������߂�����Ȃ����H
SPE��n���ɂ���z��CELL��m�������ɂȂ��Ă邾����
SPE�����C���ɏ�(ry
�����ŏ��͐M�����Ȃ��������c�c
SPE�����C���ɏ�(ry
�����ŏ��͐M�����Ȃ��������c�c
1���߂����Z����̂ɁA�R�[�hL1�̑ш��4�o�C�g�����A�Ƃ����⌵�Ȏ���
RISC�������Ă�Ƃ����C�ɂȂ邱�̃��_��
RISC�������Ă�Ƃ����C�ɂȂ邱�̃��_��
SPE����RISC�v�z���т��ʂ��߂��ăA�h���b�V���O�Ƃ��Œ��ꒃ�ア�����H
�R���p�C�����ӎ�����SIMD��4����ɗ��߂��̂ɁA����ς�n���h�R�[�f�B���O����Ȃ���
�܂Ƃ��Ȑ��\�o�Ȃ��Ƃ����������ǁA���ۂɂ������Ă�l���炷��Ƃ��̕]���͖{���Ȃ̂��H
�R���p�C�����ӎ�����SIMD��4����ɗ��߂��̂ɁA����ς�n���h�R�[�f�B���O����Ȃ���
�܂Ƃ��Ȑ��\�o�Ȃ��Ƃ����������ǁA���ۂɂ������Ă�l���炷��Ƃ��̕]���͖{���Ȃ̂��H
448 �F,,�E�L�́M�E,,�j��-�������F2009/10/18(��) 01:51:10 ID:ug3wQg4J
�X�J�����Z���ǂ����������Atom 1.6GHz(HT)��SPE2��(3.2GHz)�Ȃ�Ă��Ƃ��������Ȃ���
�ǂ���SIMD�����̃R�A����ʂɂ����Ă���邱�Ƃ̓f�[�^���x����������̏������炢�����Ȃ���
�X�J�����Z���j�b�g�Ƃ�胏�C�h��SIMD���j�b�g�̂������ق������p�I���Ƃ����Ō����
���Z�ړI���ƂɃ��W�X�^�̎�ʂ��Ȃ����Ƃ⍂�N���b�N�H����
�ÓT�I��RISC�̋��ȏ��ǂ���̃A�v���[�`������͂�ÓT�͌ÓT�������B
���s��Ȃ��Ȃ����͕̂K�����R������B
SPE��������̂̓o�b�h�m�E�n�E�̍Ď��s�������킯���B
�ǂ���SIMD�����̃R�A����ʂɂ����Ă���邱�Ƃ̓f�[�^���x����������̏������炢�����Ȃ���
�X�J�����Z���j�b�g�Ƃ�胏�C�h��SIMD���j�b�g�̂������ق������p�I���Ƃ����Ō����
���Z�ړI���ƂɃ��W�X�^�̎�ʂ��Ȃ����Ƃ⍂�N���b�N�H����
�ÓT�I��RISC�̋��ȏ��ǂ���̃A�v���[�`������͂�ÓT�͌ÓT�������B
���s��Ȃ��Ȃ����͕̂K�����R������B
SPE��������̂̓o�b�h�m�E�n�E�̍Ď��s�������킯���B
����Ⴡ�C���`
http://medgadget.com/archives/2007/04/playstation_3s_cell_chip_to_handle_medical_imaging.html
http://www-03.ibm.com/technology/resources/technology_cell_pdf_IBM_Mayo_Demo.pdf
http://medgadget.com/archives/2007/04/playstation_3s_cell_chip_to_handle_medical_imaging.html
http://www-03.ibm.com/technology/resources/technology_cell_pdf_IBM_Mayo_Demo.pdf
>>341>>345 >>439>>449
�u���傢�O�̃��C���X�g���[��x86�v���Z�b�T�Ɣ�r���ăE���\�{�������I�v
���_�a�@�t���O��������
�u���傢�O�̃��C���X�g���[��x86�v���Z�b�T�Ɣ�r���ăE���\�{�������I�v
���_�a�@�t���O��������
Larrabee����1�R�A������L2������4000�`5000���g�����W�X�^���炢���銴��������
���Z��̑唼�̓x�N�g�����j�b�g���Ȃ̂��H
���Z��̑唼�̓x�N�g�����j�b�g���Ȃ̂��H
452 �F,,�E�L�́M�E,,�j��-�������F2009/10/18(��) 02:24:44 ID:ug3wQg4J
�����܂ő傫���͂Ȃ�
�܂����Z��ň�Ԗʐϐ�߂Ă�̂̓x�N�g���W���낤�ȁB
�܂����Z��ň�Ԗʐϐ�߂Ă�̂̓x�N�g���W���낤�ȁB
LSU�����ɂȂ����Ƃ���������LSU�܂߂�L1&���L�������܂œ����ɂȂ����̂����m��Ȃ��ȁB
���܂ł�3SM�܂Ƃ߂ŗp�ӂ��Ă������̂�1SM������ɕς���Ă邩��B
�܂��Ƃɂ����o�Ă݂Ȃ��Ƃ킩���ȁB
���܂ł�3SM�܂Ƃ߂ŗp�ӂ��Ă������̂�1SM������ɕς���Ă邩��B
�܂��Ƃɂ����o�Ă݂Ȃ��Ƃ킩���ȁB
���Ɛ������Z�p�C�v�����S�ɕ�������Ă邩���͂�_���ɏ����Ă������悤�Ȃ��Ƃ͑z����̉\���͋ɑ傾�B
455 �F,,�E�L�́M�E,,�j��-�������F2009/10/18(��) 02:39:40 ID:ug3wQg4J
Larrabee���Ɗe�R�A���ɏ�艺��512bit/clk�̃f�[�^�ǂݏ������o����L1��������
���Z�̂ق���512bit Load��Store��dual issue�\
�������낤��32SP������16Way��LSU1��̎��_�Ŋ��ɋ����͂Ȃ�
���Z�̂ق���512bit Load��Store��dual issue�\
�������낤��32SP������16Way��LSU1��̎��_�Ŋ��ɋ����͂Ȃ�
512bit�������瓯������Ȃ����B
457 �F,,�E�L�́M�E,,�j��-�������F2009/10/18(��) 02:50:00 ID:ug3wQg4J
�����Ȃ킯���Ȃ�����
Fermi�̏ꍇ2�̖��߃X�g���[���ɋ������Ȃ��Ⴂ���Ȃ��̂ɁB
Fermi�̏ꍇ2�̖��߃X�g���[���ɋ������Ȃ��Ⴂ���Ȃ��̂ɁB
�ȁB�`���b�g������Ń{�P�Ă��B
�����ŃV�F�A�[�h�������̂��悤���ƁB
������LSU���̂̐��\��GT200�ƕς���ĂȂ��\��������Ƃ������ƁB
�����ŃV�F�A�[�h�������̂��悤���ƁB
������LSU���̂̐��\��GT200�ƕς���ĂȂ��\��������Ƃ������ƁB
�Ȃ��A�f�l����ň�����Larrabee�ɁA�������A
Cell��PPU�ɑ�������悤�ȓ�����
x86�R�A��1���炢�悹����1�`�b�v�Ŋ������Ă��܂��̂��H
Cell��PPU�ɑ�������悤�ȓ�����
x86�R�A��1���炢�悹����1�`�b�v�Ŋ������Ă��܂��̂��H
460 �F,,�E�L�́M�E,,�j��-�������F2009/10/18(��) 03:11:38 ID:ug3wQg4J
>>407
�Ȃ�قǂȁA���̎��_����������
Larrabee�͂��܂�ɂ����������\��������i�������j��
�헪�I�ɒx�炳��Ă邩�A���邢�͎Г��Œׂ������ɂȂ��Ă�̂��������
�Ȃ�قǂȁA���̎��_����������
Larrabee�͂��܂�ɂ����������\��������i�������j��
�헪�I�ɒx�炳��Ă邩�A���邢�͎Г��Œׂ������ɂȂ��Ă�̂��������
>>385
>>341��pdf��ǂ߂킩�邪�A���̘_����2009�N3��31���ɏ����グ��ꂽ���̂����B
���M���Ԃ�2008�N10���`2009�N3�������肾�Ɛ�������邩��V���R��������킯���Ȃ��B
>>341��pdf��ǂ߂킩�邪�A���̘_����2009�N3��31���ɏ����グ��ꂽ���̂����B
���M���Ԃ�2008�N10���`2009�N3�������肾�Ɛ�������邩��V���R��������킯���Ȃ��B
TDP100W�ʂ�Larrabee(16�R�A 2GHz)��CPU�\�P�b�g�ɍ�����Windows��������Ai7 920�����K�ɂȂ�̂��H
Web�u���E�U��Office(Word excel)�A���f�B�A�v���[���[�Ƃ��͂ǂ��Ȃ�낤�B
Web�u���E�U��Office(Word excel)�A���f�B�A�v���[���[�Ƃ��͂ǂ��Ȃ�낤�B
>>460
����͓䂾�ȁA�m���ɁB
�Ȃ�16�~2��SP�ɑ��ă��[�h�X�g�A���j�b�g��16way�����Ȃ��̂��B
�������t�Ɍ����V�~�����[�V�����̌��ʁA
16way�Ŗ��Ȃ��Ɣ��f���ꂽ�̂ł͂Ȃ����H
�Ⴆ�A���W�X�^�Ŋ�������T�C�N��������B
�e���[�v�̓A�E�g�I�u�I�[�_�[�ɐ�ւ��Ď��s�����̂�����A
�Е������[�h�X�g�A���j�b�g���g���Ă���Ԃ́A
�����Е��̓��W�X�^�Ŋ������郏�[�v�ɐ�ւ��Ď��s����Ƃ��B
����͓䂾�ȁA�m���ɁB
�Ȃ�16�~2��SP�ɑ��ă��[�h�X�g�A���j�b�g��16way�����Ȃ��̂��B
�������t�Ɍ����V�~�����[�V�����̌��ʁA
16way�Ŗ��Ȃ��Ɣ��f���ꂽ�̂ł͂Ȃ����H
�Ⴆ�A���W�X�^�Ŋ�������T�C�N��������B
�e���[�v�̓A�E�g�I�u�I�[�_�[�ɐ�ւ��Ď��s�����̂�����A
�Е������[�h�X�g�A���j�b�g���g���Ă���Ԃ́A
�����Е��̓��W�X�^�Ŋ������郏�[�v�ɐ�ւ��Ď��s����Ƃ��B
465 �F,,�E�L�́M�E,,�j��-�������F2009/10/18(��) 19:05:57 ID:ug3wQg4J
L/S�҂��̃��[�v�����܂��Ă�������B
466 �F,,�E�L�́M�E,,�j��-�������F2009/10/18(��) 19:33:40 ID:ug3wQg4J
SPARC�̏ꍇ����Load�̕p�x��4���߂�1��AStore�͂���1/5���炢�̊���������
����SPARC�̓A�h���b�V���O���[�h���n��Ȃ̂Ŏ����I�ɂ�
GT300�̏ꍇ�͊�{Scatter/Gather���삾����A1�T�C�N���͂����܂Ńx�X�g�P�[�X��
�����512�r�b�g���C���Ɏ��܂��ĂȂ��ꍇ�́A�ň�16�T�C�N����������iGT200�܂ł̎d�l�j
����Ƃ��A16����Ă͕̂����ʂ�16��Ȃ낤���H
���̂������ш悪�����邪�B
����SPARC�̓A�h���b�V���O���[�h���n��Ȃ̂Ŏ����I�ɂ�
GT300�̏ꍇ�͊�{Scatter/Gather���삾����A1�T�C�N���͂����܂Ńx�X�g�P�[�X��
�����512�r�b�g���C���Ɏ��܂��ĂȂ��ꍇ�́A�ň�16�T�C�N����������iGT200�܂ł̎d�l�j
����Ƃ��A16����Ă͕̂����ʂ�16��Ȃ낤���H
���̂������ш悪�����邪�B
�����ς��Ǝv�����A���Ȃ����炻���Ȃ��Ă��Ȃ����Ď��B
�b�ɂȂ�炢�p�t�H�[�}���X��������Ȃ�A����Ȑv���Ȃ����낤�B
�b�ɂȂ�炢�p�t�H�[�}���X��������Ȃ�A����Ȑv���Ȃ����낤�B
468 �F,,�E�L�́M�E,,�j��-�������F2009/10/18(��) 19:41:11 ID:ug3wQg4J
CUDA�̐��\���ǂ�Ȃ��͒m���Ă邩��
���̕Ӊ��P���Ă���Ƃ͎v���Ȃ��B
�܂�GPU�Ƃ��Ă͓����l���R�s�[���Ďg���P�[�X����������摜�����ɂ͏\���Ȃ낤��
���{�I��GPGPU�̃j�[�Y�ɍ��킹�Đv������Ĕ��z���Ȃ��Ǝv���B
�܂��AGPU�Ƃ��Ă͂���ł������B
���̕Ӊ��P���Ă���Ƃ͎v���Ȃ��B
�܂�GPU�Ƃ��Ă͓����l���R�s�[���Ďg���P�[�X����������摜�����ɂ͏\���Ȃ낤��
���{�I��GPGPU�̃j�[�Y�ɍ��킹�Đv������Ĕ��z���Ȃ��Ǝv���B
�܂��AGPU�Ƃ��Ă͂���ł������B
����͂��Ȃ�ORNL�̗v���ʂ�ɐv���Ă�C������̂���
�{���x�ɂ���ECC�ɂ���
�{���x�ɂ���ECC�ɂ���
ORNL�ƍ��ӂȂ̂�������Ȃ����Adouble��ECC��HPC�̖{�i�I��
���[�U�[�Ȃ�N�ł��v�����鍀�ڂ���
���[�U�[�Ȃ�N�ł��v�����鍀�ڂ���
�����"Fermi"�̖������R�Ƃ͎v���܂�
472 �F,,�E�L�́M�E,,�j��-�������F2009/10/18(��) 20:05:43 ID:ug3wQg4J
�����ECC�Ȃ��Ȃ̓X�p�R���p�Ƃ��Ă͘_�O������ˁB
Tesla��Cell�ɔ�ׂăN�\���������̂͂��̕ӁB
ECC�T�|�[�g������e�͂Ȃ��{�邾��B
����͋@�\�̖��ł����Đ��\�Ƃ͊W�Ȃ�
�Ƃ������AGT200�͔{���x���\���Ⴂ�����ΓI�ɂ̓��[�h�E�X�g�A�̐��\�ɂ�Ƃ肪�]�T���������킯��
���̈Ӗ�����{���x�̎������\�̌��㗦�͒Ⴍ���܂�\��������
Larrabee�ł�Scatter/Gather�͂��邵64�o�C�g���C���Ɏ��܂�Ȃ��ꍇ�͂�͂蕡���T�C�N�����͂�����
�����炱��Load/Store�̓X���b�h�P�ʂŊ�{���T�C�N�����s�o����悤�ɂȂ��Ă邵�A
�L���b�V���R���g���[���ɔ��s���ăv���t�F�b�`�Ɠ����ɃL���b�V����Ōł߂Ă����ĖႤ�悤��
���߂܂ŗp�ӂ���Ă�킯����
Tesla��Cell�ɔ�ׂăN�\���������̂͂��̕ӁB
ECC�T�|�[�g������e�͂Ȃ��{�邾��B
����͋@�\�̖��ł����Đ��\�Ƃ͊W�Ȃ�
�Ƃ������AGT200�͔{���x���\���Ⴂ�����ΓI�ɂ̓��[�h�E�X�g�A�̐��\�ɂ�Ƃ肪�]�T���������킯��
���̈Ӗ�����{���x�̎������\�̌��㗦�͒Ⴍ���܂�\��������
Larrabee�ł�Scatter/Gather�͂��邵64�o�C�g���C���Ɏ��܂�Ȃ��ꍇ�͂�͂蕡���T�C�N�����͂�����
�����炱��Load/Store�̓X���b�h�P�ʂŊ�{���T�C�N�����s�o����悤�ɂȂ��Ă邵�A
�L���b�V���R���g���[���ɔ��s���ăv���t�F�b�`�Ɠ����ɃL���b�V����Ōł߂Ă����ĖႤ�悤��
���߂܂ŗp�ӂ���Ă�킯����
Larrabee����ECC���Ȃ���Ȃ��́H
474 �F,,�E�L�́M�E,,�j��-�������F2009/10/19(��) 00:35:45 ID:lG+f+kn0
�����ɉ��R�A�ʼn�GH���ŏo�邩���c�����ĂȂ��z�̉\���x���ł͂����Ȃ��Ă�ˁB
���₠�A���ہA���͉��R�A�ʼn�GHz�����m��Ȃ����ǁA������Ƃ��ǂ��Ȃ́H
477 �F,,�E�L�́M�E,,�j��-�������F2009/10/19(��) 00:40:58 ID:lG+f+kn0
�Ȃ��Intel����o�郌�|�[�g�̃N���b�N�����1GHz���Ǝv���H
�ǂ����v��Ȃ�
479 �F,,�E�L�́M�E,,�j��-�������F2009/10/19(��) 01:00:17 ID:lG+f+kn0
�E���̐l�H���u�p�C�v���C����Atom���Z���v
���ƁANehalem�͖ʐϓ�����̃g�����W�X�^����Penryn�̂قڔ���������
Nehalem�����ɂ��ăg�����W�X�^���̗\�z����͓̂��ĂɂȂ�Ȃ��B
SRAM���N���b�N�쓮���ʂ͂���Ȃ�Ƀg�����W�X�^���x�͍����Ȃ�B
���ƁANehalem�͖ʐϓ�����̃g�����W�X�^����Penryn�̂قڔ���������
Nehalem�����ɂ��ăg�����W�X�^���̗\�z����͓̂��ĂɂȂ�Ȃ��B
SRAM���N���b�N�쓮���ʂ͂���Ȃ�Ƀg�����W�X�^���x�͍����Ȃ�B
480 �FSocket774�F2009/10/19(��) 01:13:48 ID:CWnMOC2L
Intel�W���X�e�B���E���g�i�[CTO�����
http://pc.watch.impress.co.jp/docs/news/20091016_322120.html
>��Larrabee�̐��\�f�[�^�͖����y�j���̒��Ɍ��J
>�Ȃ��A��������Intel���č��̃��C���[�a�@�Ƌ����ŊJ���������f�B�J���p
>�̃A�v���P�[�V�����𗘗p����Larrabee�̐��\�f�[�^���A���{���Ԃ� 17����
>���Ɍ��J���邱�Ƃ𖾂炩�ɂ����B�f�[�^��Core i7+NVIDIA��GeForce GTX
>280��Larrabee�Ƃ̔�r�f�[�^�ɂȂ��Ă��邻���ŁA���߂�Larrabee�̐��\
>�f�[�^�����J����邱�ƂɂȂ�B
������Ăǂ��Ō��J����Ă���́H
http://pc.watch.impress.co.jp/docs/news/20091016_322120.html
>��Larrabee�̐��\�f�[�^�͖����y�j���̒��Ɍ��J
>�Ȃ��A��������Intel���č��̃��C���[�a�@�Ƌ����ŊJ���������f�B�J���p
>�̃A�v���P�[�V�����𗘗p����Larrabee�̐��\�f�[�^���A���{���Ԃ� 17����
>���Ɍ��J���邱�Ƃ𖾂炩�ɂ����B�f�[�^��Core i7+NVIDIA��GeForce GTX
>280��Larrabee�Ƃ̔�r�f�[�^�ɂȂ��Ă��邻���ŁA���߂�Larrabee�̐��\
>�f�[�^�����J����邱�ƂɂȂ�B
������Ăǂ��Ō��J����Ă���́H
>>341�H
atom�̓o���o���̍��N���b�N�}�V������Ȃ���
Lrb��4GH�����ᓮ���炢�Ȃ���
����16��2��2Ghz���8��2��4Ghz�̂ق���
������˂Ƃ��������̂͂Ȃ��̂���
Lrb��4GH�����ᓮ���炢�Ȃ���
����16��2��2Ghz���8��2��4Ghz�̂ق���
������˂Ƃ��������̂͂Ȃ��̂���
�̂̏��1.7-2.5GHz���ė���Ă����ǂ�
2GHz�͒������ˁ[��
2GHz�͒������ˁ[��
���т�ӂ���݃N���X�̂ł������`�b�v��2GH���ł��������炠���Ă���
�M���x�̖�肶��Ȃ����H
�ʐς�����̋ɏ��M�̘b�ˁB
487 �F,,�E�L�́M�E,,�j��-�������F2009/10/19(��) 02:03:42 ID:lG+f+kn0
488 �F,,�E�L�́M�E,,�j��-�������F2009/10/19(��) 02:08:11 ID:lG+f+kn0
�����܂ł����2.385GHz
http://i4memory.com/f15/msi-wind-u100-meets-ln2-11829/#post100631
Atom��2GHz��������̏���ł���
http://i4memory.com/f15/msi-wind-u100-meets-ln2-11829/#post100631
Atom��2GHz��������̏���ł���
���ǁA�N���b�N�́ANvidia��SP�Ƃǂ������ǂ��������A��◎���邭�炢���B
����Xbox��ATI��GPU�����������̗p�Ƃ����\���オ���Ă邯��
Larrabee�̔��荞�݂Ɏ��s�����̂���
http://digimaga.net/2008/09/the-rumor-that-intel-begins-in-xbox-720.html
�@�\�ɂ��ƁA�C���e����Xbox 720��2009�`2010�N�ɐ��i������錩�ʂ��̐V����GPU�wLarrabee�x���̗p���Ă��炤���߂ɁA
�}�C�N���\�t�g�̂��@�����ɕK�����Ƃ������Ƃ��B
Larrabee�̔��荞�݂Ɏ��s�����̂���
http://digimaga.net/2008/09/the-rumor-that-intel-begins-in-xbox-720.html
�@�\�ɂ��ƁA�C���e����Xbox 720��2009�`2010�N�ɐ��i������錩�ʂ��̐V����GPU�wLarrabee�x���̗p���Ă��炤���߂ɁA
�}�C�N���\�t�g�̂��@�����ɕK�����Ƃ������Ƃ��B
Larrabee��GPU���ȒP�ɖłڂ��Ă��܂��Ă�
�ʔ����Ȃ��̂ŁA����͂���ŗǂ�
�ʔ����Ȃ��̂ŁA����͂���ŗǂ�
��ł�Intel�Ȃ�A��낤�Ǝv���ΕK�E�̃v���Z�X�Z�p��
���������܂ő�K�͉�����]�����Ă����Ȃ��H
�ꔭ�ڂ̓n�C�G���h�ƌ��肵�Ă邩��A
�������E��300W���Ȃ���Ώ���d�͂͂���܂�C�ɂ��Ȃ��Ă������B
���������܂ő�K�͉�����]�����Ă����Ȃ��H
�ꔭ�ڂ̓n�C�G���h�ƌ��肵�Ă邩��A
�������E��300W���Ȃ���Ώ���d�͂͂���܂�C�ɂ��Ȃ��Ă������B
493 �FSocket774�F2009/10/19(��) 11:55:27 ID:S7PjmKPV
����Ŏ��@�f�����o���Ȃ������x�Ȃ̂ɖ�������B
494 �FSocket774�F2009/10/19(��) 12:38:40 ID:VE93KYWI
�C�\�e���̓N�\�h���C�o�[���������Ȃ�����GPU�͖�����
�C�V�̎�����g�ы@��Tegra�݂��������ǁA���u�͂ǂ�����ˁB
�͂ꂽ�Z�p�g������ATI����Ȃ�����
499 �FSocket774�F2009/10/19(��) 15:28:29 ID:Z0d3nTly
Larrabee�݂����ȏ����Q�[���@�Ɏg������Cell�̓�̕�����E�E�E
�Ȃ����C���e���̍L��݂����Ȃ̂������
AMD�̍L��͖����ʂōr�炵����Ă邪��
502 �FSocket774�F2009/10/19(��) 19:24:15 ID:S7PjmKPV
intel�̍L����ł��Ȃ�
���������u�ڂ��̂������������傤�̂��т��v�����y���݂��������B
http://www.donanimhaber.com/AMDden_Nvidia_Fermi_atagi_iste_detaylar-16160.htm
�`�s�h��fud�X���C�h��
ttp://resources.vr-zone.com/image_deposit/up2/12558204291df7f95851.jpg
�`�s�h��fud�X���C�h��
ttp://resources.vr-zone.com/image_deposit/up2/12558204291df7f95851.jpg
{kind=link}
�Ό����܂���Ȃ̂͊m��
ATI���{�C��Fermi��HD5870�ŏ��Ă�Ƃ͎v���Ă��Ȃ����낤
HD4800�ň��̐M�����������炱��FUD������
HD4800�ň��̐M�����������炱��FUD������
����ł�OpenCL�Ȃ�AOpenCL�Ȃ牽�Ƃ����Ă����B�B�B
���̑O��OpenCL�̎d�l��CUDA���Ȃ̂��Ȃ�Ƃ����Ȃ���
510 �F,,�E�L�́M�E,,�j��-�������F2009/10/20(��) 01:46:52 ID:WF20KXbI
PaperDragon�v���b�g�t�H�[���������[
larrabee�̂��Ƃ���
Dragon�ƌ�����AMD
5870��2.72�itflops�j�Ƃ�1600�isp)�Ƃ�����
5970��5.44�itflops�j�Ƃ�3200�isp)�Ƃ�����
�����邾�낤�Ȃ�
5970��5.44�itflops�j�Ƃ�3200�isp)�Ƃ�����
�����邾�낤�Ȃ�
larrabee��ROP�lj������GPU�Ƃ��Ă��Ȃ�}�V�ɂȂ�Ǝv����
����Ȏ��͌������炳��ĂȂ��̂��낤���H
����Ȏ��͌������炳��ĂȂ��̂��낤���H
�q�n�o���Ă̂̓������ւ̏o�͑��u�ɉ߂���
�|���S���̃��X�^���C�Y�́H
���_�p�C�v���C����VS��PS�̊ԂɈʒu����A�����郉�X�^���C�U���j�b�g�����ꂾ��
�������Ə��2��
ttp://www.4gamer.net/games/085/G008506/20091016074/images/block_F.gif
���X�^���C�U�͂��܂�GPU�ɂƂ��Ĉ�Ԃ̃l�b�N�ɂȂ��Ă���Ƃ���
�������Ə��2��
ttp://www.4gamer.net/games/085/G008506/20091016074/images/block_F.gif
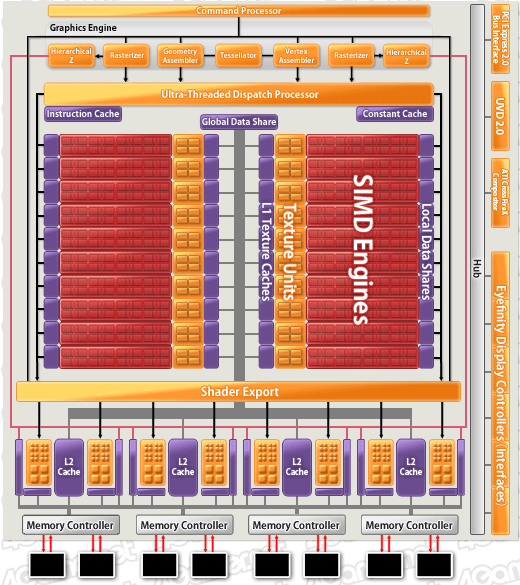{kind=link}
���X�^���C�U�͂��܂�GPU�ɂƂ��Ĉ�Ԃ̃l�b�N�ɂȂ��Ă���Ƃ���
�Œ�n�[�h�E�F�A���Ă�́A���\���{�g���l�b�N�ɂȂ������ʂɗV��Z�ʂ�����
�e�N�X�`�����j�b�g���A�e�R�A�ɗL���Ȗ��ߒlj����ĊO���Ă���
�e�N�X�`�����j�b�g���A�e�R�A�ɗL���Ȗ��ߒlj����ĊO���Ă���
�܂��A�R�A�����Z�ʂ��ă{�g���l�b�N�ɂȂ��Ă�Œ�n�[�h�E�F�A��
�G�~�����[�g���Ď�`�킹���ǂ��̂�
�G�~�����[�g���Ď�`�킹���ǂ��̂�
�C���e���̃V�~�����[�^�[���D�G�����邪�̂ɏo���Ȃ�㩂ɂ͂܂��Ă�Ƃ݂邗
�����ʓ|������G�~�����[�^�[�������[�X���������ˁH
>>518
�R�A�ɗL���Ȗ��ߒlj��������炠���������Ȃ�����
�R�A�ɗL���Ȗ��ߒlj��������炠���������Ȃ�����
�����r�[�q��
�Ƃ��������k�e�N�X�`�����x�Ȃ�_�C���N�g�Ƀ��[�h���߂Ŏ��o���@�\������B
�t�ɂȂ�Ő�p�n�[�h�E�F�A������̂���
�t�ɂȂ�Ő�p�n�[�h�E�F�A������̂���
���E�E�E�Œ�@�\�̓e�N�X�`���t�F�b�`��p����
����ALarabee�̐��\�f�[�^�ǂ��Ȃ����́H
�ߋ����O�ǂ܂Ȃ��z���ĉ��Ȃ́H
�ߌ�
larrabee�̐�y��Cell����̘b����������B�悭�����Ă�����I
http://pc.watch.impress.co.jp/docs/news/event/20091020_322898.html
>�Ƃ͂����APS3�̂悤�Ɂu����ł�SPE���g�킴��Ȃ��v�Ƃ����ǂ�����
>��������ƁA���N��SPE Programming�����y���n�߂邱�Ƃ�����킯�ŁA
>���̍�������Ƃ�������
���߂ɂȂ�ȁ`�B�̂��ˁ`�B
http://pc.watch.impress.co.jp/docs/news/event/20091020_322898.html
>�Ƃ͂����APS3�̂悤�Ɂu����ł�SPE���g�킴��Ȃ��v�Ƃ����ǂ�����
>��������ƁA���N��SPE Programming�����y���n�߂邱�Ƃ�����킯�ŁA
>���̍�������Ƃ�������
���߂ɂȂ�ȁ`�B�̂��ˁ`�B
������Radeon���V�������̂ł������B
534 �F,,�E�L�́M�E,,�j��-�������F2009/10/21(��) 02:02:15 ID:pXjOHmBL
>>533
�����Intel��AMD�������I�ɂ͎���CPU�ɓ�������ăf�B�X�N���[�g�K�v�Ȃ��Ȃ�܂���Ƃ�������
�ق��Ă͂������ł����ł��邩���ȁB
����ł����H���Ă����Ȃ��̂�
�����Intel��AMD�������I�ɂ͎���CPU�ɓ�������ăf�B�X�N���[�g�K�v�Ȃ��Ȃ�܂���Ƃ�������
�ق��Ă͂������ł����ł��邩���ȁB
����ł����H���Ă����Ȃ��̂�
>>526
�Q�[�����Ƃɂ��ꂾ�����[�N���[�h������Ă���Ȃ�
�g�����W�X�^�����̗ǂ��Œ�@�\�Ƀn�[�h�E�F�A����������U��ׂ�����
�Q�[�����Ƃɂ��ꂾ�����[�N���[�h������Ă���Ȃ�
�g�����W�X�^�����̗ǂ��Œ�@�\�Ƀn�[�h�E�F�A����������U��ׂ�����
>>535
�n�����`
�n�����`
40nm���s�i��4�N�O��90nm����Ƃ��r
944 �F214=884�F2009/10/20(��) 21:46:36 ID:aIGOM8X3
>>928
�A�C�h���Ƃ�߂肠���s���݂̂����Ǒ����Ă݂��B
���b�g�`�F�b�J�[�ǂ݁B
�\����>>214
GT220 DDR2(���l�u�� GF-GT220-E512HD) >>884
�A�C�h�����F55W
��߂肠���F91W
��߂肠�X�R�A�F27000
7600GT(ELSA GRADIAC 776GT)
�A�C�h�����F58W
��߂肠���F89W
��߂肠�X�R�A�F24500
944 �F214=884�F2009/10/20(��) 21:46:36 ID:aIGOM8X3
>>928
�A�C�h���Ƃ�߂肠���s���݂̂����Ǒ����Ă݂��B
���b�g�`�F�b�J�[�ǂ݁B
�\����>>214
GT220 DDR2(���l�u�� GF-GT220-E512HD) >>884
�A�C�h�����F55W
��߂肠���F91W
��߂肠�X�R�A�F27000
7600GT(ELSA GRADIAC 776GT)
�A�C�h�����F58W
��߂肠���F89W
��߂肠�X�R�A�F24500
��߂肠�ʼn��������Ǝv���Ă��
Tropics v1.2
�y�ݒ�z�f�t�H���g�{�t���X�N���[��
�y���l�zOC�����S����i
�yVGA�zMSI NX7900GS-T2D256E-HD�iGeforce7900GS 256MB
�@�yDirectX9.0�z
�@�EFPS�F8.7
�@�EScores:220
�yVGA�zLeadtek WinFast GT220 1024MB DDR3�@LP�iGeforce GT220
�@�yDirectX9.0�z
�@�EFPS�F26.4
�@�EScores�F665
�y�ݒ�z�f�t�H���g�{�t���X�N���[��
�y���l�zOC�����S����i
�yVGA�zMSI NX7900GS-T2D256E-HD�iGeforce7900GS 256MB
�@�yDirectX9.0�z
�@�EFPS�F8.7
�@�EScores:220
�yVGA�zLeadtek WinFast GT220 1024MB DDR3�@LP�iGeforce GT220
�@�yDirectX9.0�z
�@�EFPS�F26.4
�@�EScores�F665
540 �F,,�E�L�́M�E,,�j��-�������F2009/10/21(��) 07:38:35 ID:pXjOHmBL
>>538
�u�N���̂Ȃ���
�u�N���̂Ȃ���
�c�q��HENTAI
�e�X�g�ɏo�܂�
�e�X�g�ɏo�܂�
�e�N�X�`�����j�b�g���āADX11�̐V�����e�N�X�`�����kBC6�EBC7�Ƃ��A�Ή������Ƃł��Ă�̂��H
norm,srgb,float16�Ȃ�x86�R�A�Ńn�[�h���x���őΉ����Ă�B
�K�v�Ȃ�1�R�A���炢�W�J�p�ɂ܂킵�ăp�C�v���C����������悢�̂ł́B
�K�v�Ȃ�1�R�A���炢�W�J�p�ɂ܂킵�ăp�C�v���C����������悢�̂ł́B
�H ����͕s�������_�����k�e�N�X�`���W�J����AF�ŕ�Ԃ��ăs�N�Z��1�o�͂���LRB�R�A�ɓn��
���ĂƂ��܂łł��Ȃ��ƌŒ胆�j�b�g�̈Ӗ��Ȃ�ɂ��Ȃ��ł���H
�u�W�J�v�ł��Ȃ���S�~
���ĂƂ��܂łł��Ȃ��ƌŒ胆�j�b�g�̈Ӗ��Ȃ�ɂ��Ȃ��ł���H
�u�W�J�v�ł��Ȃ���S�~
545 �F,,�E�L�́M�E,,�j��-�������F2009/10/21(��) 21:24:33 ID:pXjOHmBL
�u�W�J�v�@�\�͂�����Ă�
�b�����ݍ����ĂȂ��ă����^
547 �F,,�E�L�́M�E,,�j��-�������F2009/10/21(��) 21:48:25 ID:pXjOHmBL
�s�������_���p���Fixed Precision
548 �F,,�E�L�́M�E,,�j��-�������F2009/10/21(��) 21:51:06 ID:pXjOHmBL
fixed point orz
���܂������_�˂� HDR���k�e�N�X�`�������ƑΉ����Ă��Ȃ�A���Ȃ���
���ƕ�ԏ������ADX11�ł͑����_������߂��Ă邯�ǑΉ�������Ă��
Radeon�͕�ԏ������t�ɌŒ胆�j�b�g����V�F�[�_�����ɐ�ւ��Ă邯�ǂ�
���ƕ�ԏ������ADX11�ł͑����_������߂��Ă邯�ǑΉ�������Ă��
Radeon�͕�ԏ������t�ɌŒ胆�j�b�g����V�F�[�_�����ɐ�ւ��Ă邯�ǂ�
bycubic��������B
551 �F,,�E�L�́M�E,,�j��-�������F2009/10/22(��) 22:42:20 ID:QfHQkvVn
Intel�R���p�C�����R�[�h�f����������A���肷���SPEC�o�^�ł����ȁB
552 �F,,�E�L�́M�E,,�j��-�������F2009/10/22(��) 22:54:23 ID:QfHQkvVn
���ʂ�C/C++��Fortran�ŏ������R�[�h�����̂܂�ܓ����āA
�����x�N�g�����R���p�C�����������SIMD���܂Ŏ����ł���Ă����̂�Larrabee
GPGPU�炵���v���O���~���O��@�ȂǕK�v�Ȃ��B
�Ђ�A��p�̃v���O���~���O��������ꂩ�琮�����悤���Ƃ��������x���̃n�[�h����B
���������������ł͑O�җD�ʂ��ۂ����ƁB
�����Ȃ�X�g���[�~���O�v���Z�b�T�Ƃ��Ă݂��ꍇ�����ɂȂ�x���̍��͂���ȁB
GPU�Ƃ��Ă͂܂��ʂ����B
�����x�N�g�����R���p�C�����������SIMD���܂Ŏ����ł���Ă����̂�Larrabee
GPGPU�炵���v���O���~���O��@�ȂǕK�v�Ȃ��B
�Ђ�A��p�̃v���O���~���O��������ꂩ�琮�����悤���Ƃ��������x���̃n�[�h����B
���������������ł͑O�җD�ʂ��ۂ����ƁB
�����Ȃ�X�g���[�~���O�v���Z�b�T�Ƃ��Ă݂��ꍇ�����ɂȂ�x���̍��͂���ȁB
GPU�Ƃ��Ă͂܂��ʂ����B
553 �FSocket774�F2009/10/23(��) 03:41:57 ID:amFZOc2d
��Intel�W���X�e�B���E���g�i�[CTO�����
��http://pc.watch.impress.co.jp/docs/news/20091016_322120.html
��>��Larrabee�̐��\�f�[�^�͖����y�j���̒��Ɍ��J
��>�Ȃ��A��������Intel���č��̃��C���[�a�@�Ƌ����ŊJ���������f�B�J���p
��>�̃A�v���P�[�V�����𗘗p����Larrabee�̐��\�f�[�^���A���{���Ԃ� 17����
��>���Ɍ��J���邱�Ƃ𖾂炩�ɂ����B�f�[�^��Core i7+NVIDIA��GeForce GTX
��>280��Larrabee�Ƃ̔�r�f�[�^�ɂȂ��Ă��邻���ŁA���߂�Larrabee�̐��\
��>�f�[�^�����J����邱�ƂɂȂ�B
��������Ăǂ��Ō��J����Ă���́H
���̓����͂ǂ̔����Ȃ́H
��http://pc.watch.impress.co.jp/docs/news/20091016_322120.html
��>��Larrabee�̐��\�f�[�^�͖����y�j���̒��Ɍ��J
��>�Ȃ��A��������Intel���č��̃��C���[�a�@�Ƌ����ŊJ���������f�B�J���p
��>�̃A�v���P�[�V�����𗘗p����Larrabee�̐��\�f�[�^���A���{���Ԃ� 17����
��>���Ɍ��J���邱�Ƃ𖾂炩�ɂ����B�f�[�^��Core i7+NVIDIA��GeForce GTX
��>280��Larrabee�Ƃ̔�r�f�[�^�ɂȂ��Ă��邻���ŁA���߂�Larrabee�̐��\
��>�f�[�^�����J����邱�ƂɂȂ�B
��������Ăǂ��Ō��J����Ă���́H
���̓����͂ǂ̔����Ȃ́H
554 �F,,�E�L�́M�E,,�j��-�������F2009/10/23(��) 07:42:09 ID:Ue3qZdbi
���ӂ�
>>553
����Ȕ������Ȃ��Ă�������ˁH���i
����Ȕ������Ȃ��Ă�������ˁH���i
������
fermi�̏ꍇ2�T�C�N����1WARP�Ȃ�
�Ă�����1�T�C�N�����Ǝv���Ă�
�Ă�����1�T�C�N�����Ǝv���Ă�
559 �F,,�E�L�́M�E,,�j��-�������F2009/10/24(�y) 11:45:56 ID:/pRpwPyp
�߯
�����O����S�����Ă�558���A�z�����錏�ɂ���
Fermi�̓��b�N�����Ŕ�r���ʂ���Ȃ����
563 �FSocket774�F2009/10/24(�y) 12:56:45 ID:H3hCSfz9
>>558
http://techresearch.intel.com/UserFiles/en-us/File/terascale/Mayo_IEEE_VIS2009_FINAL.PDF
���̓���
http://techresearch.intel.com/UserFiles/en-us/File/terascale/Mayo_IEEE_VIS2009_FINAL.PDF
���̓���
http://www.shader.jp/xoops/html/modules/wordpress/index.php?p=896
>Geeks3D.com����̃l�^�ł���,NVIDIA��Fermi���g����PhysX�̃f���̃r�f�I�Ƃ����̂�YouTube�ɂ���݂����ł��ˁD
>NVIDIA Fermi: PhysX Destruction Demo from GPU Technology Conference
>http://www.geeks3d.com/20091003/nvidia-fermi-physx-destruction-demo-from-gpu-technology-
>Geeks3D.com����̃l�^�ł���,NVIDIA��Fermi���g����PhysX�̃f���̃r�f�I�Ƃ����̂�YouTube�ɂ���݂����ł��ˁD
>NVIDIA Fermi: PhysX Destruction Demo from GPU Technology Conference
>http://www.geeks3d.com/20091003/nvidia-fermi-physx-destruction-demo-from-gpu-technology-
>�gFermi�h��11�����{�Ɍ��J�����Ƃ������Ƃ������B�����A���̗\��͗e��
>�ɂ��ꂤ����̂炵���B�ŏ��̃T���v���͊��ɂł��Ă���A�d�v�ڋq��
>�A�i���X�g�ɂ͂���I�ڂ��Ă���Ƃ����B
http://northwood.blog60.fc2.com/blog-entry-3183.html
>�ɂ��ꂤ����̂炵���B�ŏ��̃T���v���͊��ɂł��Ă���A�d�v�ڋq��
>�A�i���X�g�ɂ͂���I�ڂ��Ă���Ƃ����B
http://northwood.blog60.fc2.com/blog-entry-3183.html
NVIDIA�u�ǂ��ł��H���̗��̃V�~�����[�V�����B�����A���ł��傤�H�v
�Q�[�����u�J�N�J�N�����B����Ȃ̎����ꂽ��Q�[���ɂȂ�Ȃ���v
�Q�[�����u�J�N�J�N�����B����Ȃ̎����ꂽ��Q�[���ɂȂ�Ȃ���v
���A�������_�����O�ƃt�F�C�N3D���t�]��������āA���Ȃ�H
CG�͑S�ăt�F�C�N����
>>564
GPU Technology Conference �̃f���̓��b�N�A�b�v�����p�ӂł��Ȃ���������
�f���\�����Ă�PC�̂�����J�őS�R�M�p����ĂȂ��B
GPU Technology Conference �̃f���̓��b�N�A�b�v�����p�ӂł��Ȃ���������
�f���\�����Ă�PC�̂�����J�őS�R�M�p����ĂȂ��B
570 �F,,�E�L�́M�E,,�j��-�������F2009/10/24(�y) 17:28:32 ID:/pRpwPyp
���b�N�����o���Ȃ����Ă̂�
�����ϑ���ɂ���n���ĂȂ����Ă��Ƃ�����ˁB
11���ɏo����Č����Ă鐻�i������
���肦�Ȃ�
�����ϑ���ɂ���n���ĂȂ����Ă��Ƃ�����ˁB
11���ɏo����Č����Ă鐻�i������
���肦�Ȃ�
larrabee�̂��Ƃ�
IDF���J�̐��{�[�h�̓��b�N����Ȃ����H��
�V���R�����̍�蒼���ł���
>IDF���J�̐��{�[�h�̓��b�N����Ȃ����H��
���̍����͏o�͒[�q�ƕ⏕�d���[�q���݂������炩��
���̍����͏o�͒[�q�ƕ⏕�d���[�q���݂������炩��
���H���Ⴀ����Gulftown�̃f���@�͋U�����Ă��ƁH��
���̃��x������^���n�߂���L������������
N�~�̌��������肫�߂���
N�~�̌��������肫�߂���
�Ȃ�intel�̓��b�N�f�������ӂł�����
PenD�����Y�ꂩ��
PenD�����Y�ꂩ��
578 �F,,�E�L�́M�E,,�j��-�������F2009/10/24(�y) 18:30:55 ID:/pRpwPyp
�������O��A�V��NVIDIA���܂������TDP0W�̉���I��GPU��n���ɂ���Ȃ悗����
PenD���������b�ɂȂ�܂���˂�������
����Ŗ{���̃f���Ȃ炵��ډ߂��邱�Ɨт̔@��
���Ȃ݂�
>Intel��4GHz�N���b�N��Pentium 4���C�����͍��N��4Q�ɏo���ƌ����Ă����̂��C
>���N��7���ɂ͗��N1Q�ɉ�������C�����č���͉����ł͂Ȃ����~�Ɣ��\����܂����B
>�N���b�N���グ�����ɁC�����L���b�V����1MB����2MB�ɑ���������C
>FSB�ɃX�s�[�h���グ��Ȃǂ̕ʂ̕��@�Ő��\�����P���Ă����Ƃ��������̘H���]���̈�ł���C
>���̐��Pentium�n�̃f���A���R�A�`�b�v�����Ƀe�[�v�A�E�g�����ƁC�����Intel�̃v���b�g�t�H�[���̃}�[�P�e�B���O�������q�ׂ��ƕ���Ă��܂��B
>�ʔ����̂́u�f���A���R�A�`�b�v�����Ƀe�[�v�A�E�g�����v�Ƃ��������ŁC
>���̗����l����ƃe�[�v�A�E�g�͂������E�G�t�@�͂܂��o���Ă��Ȃ��Ƃ������Ƃł���C
>�܂�C9����Fall Developer's Forum�̃f���̎��ɂ̓f���A���R�A�`�b�v�͖����������Ƃ�F�߂������R�ł��B
>�Ƃ������ƂŁC9��18���̘b��ŏЉ��Intel�̃f���̓��b�N�A�b�v���Ƃ��������𗠂Â��Ă��܂��B
���Ȃ݂�
>Intel��4GHz�N���b�N��Pentium 4���C�����͍��N��4Q�ɏo���ƌ����Ă����̂��C
>���N��7���ɂ͗��N1Q�ɉ�������C�����č���͉����ł͂Ȃ����~�Ɣ��\����܂����B
>�N���b�N���グ�����ɁC�����L���b�V����1MB����2MB�ɑ���������C
>FSB�ɃX�s�[�h���グ��Ȃǂ̕ʂ̕��@�Ő��\�����P���Ă����Ƃ��������̘H���]���̈�ł���C
>���̐��Pentium�n�̃f���A���R�A�`�b�v�����Ƀe�[�v�A�E�g�����ƁC�����Intel�̃v���b�g�t�H�[���̃}�[�P�e�B���O�������q�ׂ��ƕ���Ă��܂��B
>�ʔ����̂́u�f���A���R�A�`�b�v�����Ƀe�[�v�A�E�g�����v�Ƃ��������ŁC
>���̗����l����ƃe�[�v�A�E�g�͂������E�G�t�@�͂܂��o���Ă��Ȃ��Ƃ������Ƃł���C
>�܂�C9����Fall Developer's Forum�̃f���̎��ɂ̓f���A���R�A�`�b�v�͖����������Ƃ�F�߂������R�ł��B
>�Ƃ������ƂŁC9��18���̘b��ŏЉ��Intel�̃f���̓��b�N�A�b�v���Ƃ��������𗠂Â��Ă��܂��B
DX10�̎���ATi�����N�x�ꂽ���ǁA���̎��͂ǂ������Ă����낤��
R600�̓{���N�\�ɂ����Ă���
�Ȃn���ł����ĔM�������ɒx������
�����R��GDDR4�Ή��̃N�Z�ɂ�64bit�Ǘ��őO�����藱�x���ł����Ȃ���
��Ԃ̃K���͖��ʂɑш悾���ł������������O�o�X����
�Ȃn���ł����ĔM�������ɒx������
�����R��GDDR4�Ή��̃N�Z�ɂ�64bit�Ǘ��őO�����藱�x���ł����Ȃ���
��Ԃ̃K���͖��ʂɑш悾���ł������������O�o�X����
>>580
�ق����Ȃ�قǂ�������Fermi�̓��b�N�A�b�v�Ȃ̂˂�
�ق����Ȃ�قǂ�������Fermi�̓��b�N�A�b�v�Ȃ̂˂�
PenD�̃f����2P��Xeon�ő�ւł����Ȃ��́H
larrabee���b�N�̃f�����P�ɍ݂蕨�������ɉ߂���
586 �F,,�E�L�́M�E,,�j��-�������F2009/10/24(�y) 19:13:50 ID:/pRpwPyp
�@�@�@�@�@�@�@�@�@�@�@��
�@�@�@�@�@ �@ �@ �@ �@ |:|ID:eFEbHVaV
�@�@�@ �@ �@ _�Q�Q�Q|:|�Q�Q�Q
�@�@�@ �@,��L�@ �@�m�L�@�@�@�@�R. �M�R.�@�V�����o�C�g��������
�@�@ �@ {�@�@ ���@�@�i__�l__�j �@��.}�@�@Win7�ǂ��낶��
�@ �@ �@ �'�T�A �@�@�@�M �܁L �@ _ .,�m�@�@�Ȃ����
�@�@�@ �@/�@ �P�P�P�P�P�P��R
�@ �@ �@/ �@�@�@�@�@�@�@�@�@�@�@�@|
�@�@ �@ |.�@�܁_�@�@�@ ,.��������.��@�ް��@�ް�
�@�@ �@ ���@�_/�P�_�i(| i'�P�P�P�Mi | ).�j�j
�@�@ �@ ���@ �@uUUU��| |..||�P,','�P| |�P�P�P�P�P.�u�Q�Q�Q�Q�Q
�P�P�P�P�P�P�P�P|_|~|| �@~~~~|_|.�@ Fermi�@�@.|
�@�@�@�@�@�@�@�@�@�@�@ �@�@||�Q�Q�Q�Q_�@�@�@�@ �@__|]
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��!!_______!!.!
�@�@�@�@�@ �@ �@ �@ �@ |:|ID:eFEbHVaV
�@�@�@ �@ �@ _�Q�Q�Q|:|�Q�Q�Q
�@�@�@ �@,��L�@ �@�m�L�@�@�@�@�R. �M�R.�@�V�����o�C�g��������
�@�@ �@ {�@�@ ���@�@�i__�l__�j �@��.}�@�@Win7�ǂ��낶��
�@ �@ �@ �'�T�A �@�@�@�M �܁L �@ _ .,�m�@�@�Ȃ����
�@�@�@ �@/�@ �P�P�P�P�P�P��R
�@ �@ �@/ �@�@�@�@�@�@�@�@�@�@�@�@|
�@�@ �@ |.�@�܁_�@�@�@ ,.��������.��@�ް��@�ް�
�@�@ �@ ���@�_/�P�_�i(| i'�P�P�P�Mi | ).�j�j
�@�@ �@ ���@ �@uUUU��| |..||�P,','�P| |�P�P�P�P�P.�u�Q�Q�Q�Q�Q
�P�P�P�P�P�P�P�P|_|~|| �@~~~~|_|.�@ Fermi�@�@.|
�@�@�@�@�@�@�@�@�@�@�@ �@�@||�Q�Q�Q�Q_�@�@�@�@ �@__|]
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��!!_______!!.!
�ŁH
�ǂ������惂�b�N��
�ǂ������惂�b�N��
�����������Larrabee��ET: QuakeWars�Ƃ����݂蕨���g���ă��A���^�C�����C�g���̃f���������ɉ߂���̂悗
�ŁA���ꂪlarrabee�ł��鍪���͂�
�܁A���̒��x�Ō��E���Ă̂�larrabee�̎��͂���
�܁A���̒��x�Ō��E���Ă̂�larrabee�̎��͂���
�Ă��A�Ȃ�Ŗڋʂ̉��Z�f���͖����Ȃ�H
core i7�����̃��b�N���ăo��������H
core i7�����̃��b�N���ăo��������H
591 �F,,�E�L�́M�E,,�j��-�������F2009/10/24(�y) 19:34:16 ID:/pRpwPyp
�������悠�̒��x����B���ʂ�����\�������̒��x����B
����ȊO�̃e�N�X�`���܂ŕώ������炽���̍��\�Ƃ����B
����ȊO�̃e�N�X�`���܂ŕώ������炽���̍��\�Ƃ����B
�ؒf�͌^��W�����ă��b�N�A�b�v���Ɠ˂����܂��̂�NVIDIA
���@�Ńf�������ă��b�N�A�b�v���ƌ����������t������̂�Intel
���@�Ńf�������ă��b�N�A�b�v���ƌ����������t������̂�Intel
��̐������X�^�[
http://www.hardwarezone.com/img/data/articles/2009/3023/others_larrabee1.jpg
http://techon.nikkeibp.co.jp/article/NEWS/20090924/175534/fig3.jpg
http://www.4gamer.net/games/049/G004963/20090923003/SS/002.jpg
http://global.hkepc.com/database/images/200909250739084879200016.jpg
http://www.hardwarezone.com/img/data/articles/2009/3023/others_larrabee1.jpg
{kind=link}
http://techon.nikkeibp.co.jp/article/NEWS/20090924/175534/fig3.jpg
{kind=link}
http://www.4gamer.net/games/049/G004963/20090923003/SS/002.jpg
{kind=link}
http://global.hkepc.com/database/images/200909250739084879200016.jpg
{kind=link}
�����O�o�X�̐��i�͋S�傾�ˁACell�AR600�ALarrabee�c�c
595 �F,,�E�L�́M�E,,�j��-�������F2009/10/24(�y) 19:37:31 ID:/pRpwPyp
Xeon MP�E�E�E
�������������Ɍ��h���̂���
�ǂ��f���������Ȃ�
�ǂ��f���������Ȃ�
597 �F,,�E�L�́M�E,,�j��-�������F2009/10/24(�y) 19:39:16 ID:/pRpwPyp
�ʓd���Ȃ��r�f�I�J�[�h�̂��Ƃ��[
���̃f���͓����Ȃ�����������
��������������ʂ����Č�����͉\�����A
���\��������Ȃ瑼�̃\�[�X�I�ׂ���Ęb
��������������ʂ����Č�����͉\�����A
���\��������Ȃ瑼�̃\�[�X�I�ׂ���Ęb
599 �F,,�E�L�́M�E,,�j��-�������F2009/10/24(�y) 19:41:58 ID:/pRpwPyp
���̃��x���̐��ʕ\�����ǂ���ς������ĂȂ�����
���̒��x�����o���Ȃ������烌�C�g���Ȃ��Ӗ��Ȃ���
intel��larrabee�����ɍ�点�Ă郂�m�����������Ȃ�
����̓����intel�̃T�C�g�Ō����L��������
�Ȃ�ł��ꂶ��ˁ[����Ďv������
�悸
����̓����intel�̃T�C�g�Ō����L��������
�Ȃ�ł��ꂶ��ˁ[����Ďv������
�悸
602 �F,,�E�L�́M�E,,�j��-�������F2009/10/24(�y) 19:45:39 ID:/pRpwPyp
>>600
�ш�ɔC���ďĂ����݃e�N�X�`���\��N���C�V�X��@�����܂ł��ʗp����Ȃ��
�ш�ɔC���ďĂ����݃e�N�X�`���\��N���C�V�X��@�����܂ł��ʗp����Ȃ��
��J�𐔂��Ċ��_����V�тɉ߂������
N�~�̓f�o�b�O�I����ĂȂ��V���R���Ő��i�łƓ����̃p�t�H�[�}���X���o��Ǝv���Ă���̂��ɂ�
���~�͋��c�l�����ׂĐ������Ǝv���Ă���̂��ʔ���
606 �F,,�E�L�́M�E,,�j��-�������F2009/10/24(�y) 19:54:03 ID:/pRpwPyp
http://www.guru3d.com/news/intel-larrabee-larrabee-demo-surfaces/
�Ō��URL����Ή��邪�A"server"�Ȃ�ˁB
�͂Ȃ���Q�[���p����Ȃ��B
�Ō��URL����Ή��邪�A"server"�Ȃ�ˁB
�͂Ȃ���Q�[���p����Ȃ��B
NV�͂���ȏ�G�����Ȃ������ǂ���H�������ł����l�ʑ^�̏�ԂȂ̂ɂ�
608 �F,,�E�L�́M�E,,�j��-�������F2009/10/24(�y) 19:56:10 ID:/pRpwPyp
�R��100�x������Fermi�������o��I
�R��100�x������larrabee�̎������o�Ă���I
�����r��1�R�A��fermi��4�{�̃p�t�H�[�}���X���o��킯�ł���
OpenGL�̃G�~�����[�V�����ł�ati,nvidia���y�X�Ɣ��������Ă���邱�Ƃ����҂��Ă܂�
���ɌŒ�p�C�v���C���ł͏��ĂȂ��ł��傤���A���ꂩ���OpenGL�͌Œ�p�C�v���C���p�~�Ȃ��
��w���тɗL���ɂȂ��ł��傤��
OpenGL�̃G�~�����[�V�����ł�ati,nvidia���y�X�Ɣ��������Ă���邱�Ƃ����҂��Ă܂�
���ɌŒ�p�C�v���C���ł͏��ĂȂ��ł��傤���A���ꂩ���OpenGL�͌Œ�p�C�v���C���p�~�Ȃ��
��w���тɗL���ɂȂ��ł��傤��
�܂�A�悤�₭DX10�����ɂȂ����̂�opengl
612 �F,,�E�L�́M�E,,�j��-�������F2009/10/24(�y) 22:14:05 ID:/pRpwPyp
OpenGL���OpenRT���낤
���C�g���[�V���O����ʓI�ɐ����fermi���S�~�ɂȂ�̂͊�Ɍ����Ă���B
Fermi��[���`��Larrabee�����͂̎�����
�܂����C�g���[�V���O����ʓI�ɂȂ鎞������Ȃ��B
��ʓI�ɂȂ鎞���ɂȂ�����nv�́i����܂Ő����Ă����炾���j���Ԃ�
������ƕς��Ă���B����܂ł��R���R���ς��Ă���
�܂����C�g���[�V���O����ʓI�ɂȂ鎞������Ȃ��B
��ʓI�ɂȂ鎞���ɂȂ�����nv�́i����܂Ő����Ă����炾���j���Ԃ�
������ƕς��Ă���B����܂ł��R���R���ς��Ă���
���C�g���[�V���O����ʓI�ɂȂ������Ax86�������Ȃ�NVIDIA��PC�s�ꂩ�������
����͖��ꂽ�s�k�ł���m�肵������
����͖��ꂽ�s�k�ł���m�肵������
�Ȃ��C�g���ɖ������Ă�l������݂���������
���W�I�V�e�B��Ȃ������ǐՂ������đ債�ă��A���ɂȂ�ˁ[��H
���f�����O�̖�肾���Ă��邵�B
�ŁA���W�I�V�e�B�̃G�l���M�[��v�Z�͂���Ȃ�Ƀp���[���邯��
�v�Z�����܂����C�g���ɂ��]���@�ɂ��K�p�͉\�B
���W�I�V�e�B��Ȃ������ǐՂ������đ債�ă��A���ɂȂ�ˁ[��H
���f�����O�̖�肾���Ă��邵�B
�ŁA���W�I�V�e�B�̃G�l���M�[��v�Z�͂���Ȃ�Ƀp���[���邯��
�v�Z�����܂����C�g���ɂ��]���@�ɂ��K�p�͉\�B
617 �F,,�E�L�́M�E,,�j��-�������F2009/10/27(��) 22:07:13 ID:p0qmGqi2
���A���^�C���Ń��W�I�͖�������E�E�E
�ނ��댻����Larrabee�������ɉ\�ɂȂ肻���ȃ��\�b�h����A-Buffer����Ȃ���
�ނ��댻����Larrabee�������ɉ\�ɂȂ肻���ȃ��\�b�h����A-Buffer����Ȃ���
�ȂA����ς藎�Ƃ���������̂��B
���ǂ���Ȃ��܂��b�͂Ȃ��ȁc�B
���ǂ���Ȃ��܂��b�͂Ȃ��ȁc�B
619 �F,,�E�L�́M�E,,�j��-�������F2009/10/27(��) 22:50:20 ID:p0qmGqi2
�Ă�A-Buffer�ׂ̈ɍ��ꂽ�悤�ȍ\����
DirectX���ז�
DirectX���ז�
�ǂ�A-Buffer�������Ă�m��ǁALucasFilm�l�Ă̂�Ȃ�
�����A���S���Y���̊g�������炻�ꂱ��Larrabee�ł���K�v���͒Ⴂ��B
�ނ���s�N�Z���V�F�[�_�̊g�������B
�K�v�ȏ��ʂ������ē]���ʂ��オ�镪�A�ނ���Larrabee�ɂ͕s���B
���C�g����Larrabee�Ɍ����̂̓s�N�Z�����������������f�̉��Z������
�͂邩�ɖc��ɂȂ���Ă�����r�̖��ł����āA���A���ȕ`�拁�߂���
���ǃI�����C�������_�����O�Ȃ�Ė�����ɏI��邵�A�܂������ȂƂ���B
�����Ƀ��A���^�C�������_�����O�ɍS��Ȃ��ق��������B
�����A���S���Y���̊g�������炻�ꂱ��Larrabee�ł���K�v���͒Ⴂ��B
�ނ���s�N�Z���V�F�[�_�̊g�������B
�K�v�ȏ��ʂ������ē]���ʂ��オ�镪�A�ނ���Larrabee�ɂ͕s���B
���C�g����Larrabee�Ɍ����̂̓s�N�Z�����������������f�̉��Z������
�͂邩�ɖc��ɂȂ���Ă�����r�̖��ł����āA���A���ȕ`�拁�߂���
���ǃI�����C�������_�����O�Ȃ�Ė�����ɏI��邵�A�܂������ȂƂ���B
�����Ƀ��A���^�C�������_�����O�ɍS��Ȃ��ق��������B
621 �F,,�E�L�́M�E,,�j��-�������F2009/10/28(��) 00:34:47 ID:y5ysAT1N
�R�A�����₷�����ŃX�P�[���r���e�B��������Ƃ����_�ŏ�����������̂ł́H
Stencil Routed�`���ȁB
�������NVIDIA���_�������Ă邵�A���̂����������o���Ă���Ǝv���Ă�B
���ЂɗL���ȃ��\�b�h��I�Ԃ��Ƃł̍��ʉ����厖�����A�ƊE�S�̂����Ă��Ȃ����Ƃɂ́B
Stencil Routed�`���ȁB
�������NVIDIA���_�������Ă邵�A���̂����������o���Ă���Ǝv���Ă�B
���ЂɗL���ȃ��\�b�h��I�Ԃ��Ƃł̍��ʉ����厖�����A�ƊE�S�̂����Ă��Ȃ����Ƃɂ́B
622 �F,,�E�L�́M�E,,�j��-�������F2009/10/28(��) 00:49:32 ID:y5ysAT1N
�o�P�����`�b�v�ł�����������Ƃ��o�ꂵ����ł������ɓ]�ڂ��Ă���
100�R�A�̔ėp�v���Z�b�T�uTILE-Gx100�v���o�� - ��Tilera
http://journal.mycom.co.jp/news/2009/10/27/011/?rt=na
TILE-Gx Processors Family
http://tilera.com/products/TILE-Gx.php
100�R�A�̔ėp�v���Z�b�T�uTILE-Gx100�v���o�� - ��Tilera
http://journal.mycom.co.jp/news/2009/10/27/011/?rt=na
TILE-Gx Processors Family
http://tilera.com/products/TILE-Gx.php
�X���Ⴂ���E���R
624 �F,,�E�L�́M�E,,�j��-�������F2009/10/28(��) 01:00:07 ID:y5ysAT1N
���Ƃ��Ί����A�[�L�e�N�`���ł́AROP����f���o�����s�N�Z���f�[�^��
�s�N�Z���V�F�[�_�Ƀ_�C���N�g�ɓn���������̂�VRAM�ɓs�x�f���o����
�܂���������[�h���Ă�킯�ŁB
�L���b�V���e�ʉ��P�ɂ�郁�����ш����̍팸�̗]�n�͂��Ȃ肠��B
GDDR5�ł���Ȃ�ɂ͑ш�͊m�ۂ���悤���������L���b�V���~�X���Ă�
�g�[�^���őш���Z�[�u�ł���Ώ\����������̂ł́B
�s�N�Z���V�F�[�_�Ƀ_�C���N�g�ɓn���������̂�VRAM�ɓs�x�f���o����
�܂���������[�h���Ă�킯�ŁB
�L���b�V���e�ʉ��P�ɂ�郁�����ш����̍팸�̗]�n�͂��Ȃ肠��B
GDDR5�ł���Ȃ�ɂ͑ш�͊m�ۂ���悤���������L���b�V���~�X���Ă�
�g�[�^���őш���Z�[�u�ł���Ώ\����������̂ł́B
625 �F,,�E�L�́M�E,,�j��-�������F2009/10/28(��) 01:33:15 ID:y5ysAT1N
A-Buffer�͍ŏI�H���܂ł͕����Ɍ��������łȂ��ď����̏����W����ˑ�����r���ł���B
Z-Buffer��1000�l1001�l�r�Ȃ�AA-Buffer��1000�l�o���o���ɑ����ăS�[���e�[�v��O��
�S���̑������ׂΗǂ��悤�ȃC���[�W�ˁB�����܂ł̑�����͎��R���B
�����ł��A������������X���b�h���������点���ꂾ��1�X���b�h�ŃL���b�V����L�����p�ł����ȁH
�X���b�h���A�N�e�B�u�ȊԁA�L���b�V���~�X�����炷���Ƃ��o��������������B
GeForce��1SM������32KB��Shared Memory���������A16���[�v��������
1���[�v������2KB���x�̊����Ă����Ȃ��B
�ǂ̃s�N�Z���������悤�ɏ�����i�s������K�v�����邩�炾�B
��ŁA��ΓI�Ɋ��蓖�Ă����Ȃ�����AVRAM��GPU�R�A�Ƃ̉���������f�[�^�ǂݏ�������H�ڂɂȂ�B
Larrabee��1�`4�X���b�h�ŊeL2�f�Ђ�256KB�B
�L���b�V���߂����ς����蓖�Ă��܂ܘA���������āA�L�����ǂ��Ƃ���ŕʂ̃R���e�N�X�g�ɓn�������B
����ł��܂�A-Buffer��Larrabee�����L���ɂȂ闝�R�������z�͎�݂��Ď��˂����Ǝv���B
Z-Buffer��1000�l1001�l�r�Ȃ�AA-Buffer��1000�l�o���o���ɑ����ăS�[���e�[�v��O��
�S���̑������ׂΗǂ��悤�ȃC���[�W�ˁB�����܂ł̑�����͎��R���B
�����ł��A������������X���b�h���������点���ꂾ��1�X���b�h�ŃL���b�V����L�����p�ł����ȁH
�X���b�h���A�N�e�B�u�ȊԁA�L���b�V���~�X�����炷���Ƃ��o��������������B
GeForce��1SM������32KB��Shared Memory���������A16���[�v��������
1���[�v������2KB���x�̊����Ă����Ȃ��B
�ǂ̃s�N�Z���������悤�ɏ�����i�s������K�v�����邩�炾�B
��ŁA��ΓI�Ɋ��蓖�Ă����Ȃ�����AVRAM��GPU�R�A�Ƃ̉���������f�[�^�ǂݏ�������H�ڂɂȂ�B
Larrabee��1�`4�X���b�h�ŊeL2�f�Ђ�256KB�B
�L���b�V���߂����ς����蓖�Ă��܂ܘA���������āA�L�����ǂ��Ƃ���ŕʂ̃R���e�N�X�g�ɓn�������B
����ł��܂�A-Buffer��Larrabee�����L���ɂȂ闝�R�������z�͎�݂��Ď��˂����Ǝv���B
�ł�A-Buffer���ƃ������H����ˁ[��
627 �F,,�E�L�́M�E,,�j��-�������F2009/10/28(��) 01:47:40 ID:y5ysAT1N
�S�̓I�ɂ͐H�����NjǏ��I�ɂ͌��点��B
�������̗ʂ��\���ł��Ȃ��̂��h�����B
��ꂻ���ɂȂ�����r���ň�U�������đ�����H
��ꂻ���ɂȂ�����r���ň�U�������đ�����H
629 �F,,�E�L�́M�E,,�j��-�������F2009/10/28(��) 01:52:05 ID:y5ysAT1N
Vista������Ńz�X�g���������ɃX���b�v�ł���悤�ɂȂ�����ˁB
A-Buffer�����z���Ẳ��ǂ��Ǝv���Ă���
A-Buffer�����z���Ẳ��ǂ��Ǝv���Ă���
630 �F,,�E�L�́M�E,,�j��-�������F2009/10/28(��) 01:53:08 ID:y5ysAT1N
���ƁA64�r�b�g�������A�h���b�V���O���K�v�ȗ��R������
�����[
����������L���b�V�������ǃ������o���h�H�����Ă킩���ĂăQ�t�H��f�̃L���b�V���e�ʂ��傫���Ȃ�Ȃ��͉̂��Ł[�H
����������L���b�V�������ǃ������o���h�H�����Ă킩���ĂăQ�t�H��f�̃L���b�V���e�ʂ��傫���Ȃ�Ȃ��͉̂��Ł[�H
632 �F,,�E�L�́M�E,,�j��-�������F2009/10/28(��) 02:00:16 ID:y5ysAT1N
�L���b�V���̓_�C�T�C�Y�H�����炾�B
�Ƃ�������N���b�N�̉��Z���j�b�g��ʕ������镪�ɂ͏Ă��ɐ��B
����SP�̌����炵�č��N���b�N�ʼn�]��������Ȃ�L���b�V���̈Ӗ����o�Ă���
�i�N���b�N�������Ȃ�قǑ��ΓI�ɃL���b�V���̃g�����W�X�^���x�͍����Ȃ�j
�Ƃ�������N���b�N�̉��Z���j�b�g��ʕ������镪�ɂ͏Ă��ɐ��B
����SP�̌����炵�č��N���b�N�ʼn�]��������Ȃ�L���b�V���̈Ӗ����o�Ă���
�i�N���b�N�������Ȃ�قǑ��ΓI�ɃL���b�V���̃g�����W�X�^���x�͍����Ȃ�j
�R�A�́h���W�h�ɈӖ�������悤�ȉғ���z�肵�Ă�݂�������
ttp://www.tgdaily.com/images/stories/article_images/tilera/tilera4.jpg
ttp://www.tgdaily.com/content/view/44417/135/
ttp://www.tgdaily.com/images/stories/article_images/tilera/tilera4.jpg
{kind=link}
ttp://www.tgdaily.com/content/view/44417/135/
>>625
�������Ⴂ�����Ă��邯�ǁA�ʂ�ZBuffer�����čŏI�H���܂ŕ����ł���B
���ߏ����𐳂����s���ɂ͎��O�Ƀ|�����S�����\�[�g���Ă����K�v������i����͂����������ׂ���Ȃ�)�̂ƁA
����ł��|���S�����������Ă��܂����ۂɐ������Ȃ����ʂ������Ƃ��������B
����͉������Ă��������Ȃ����AA-Buffer��Z-Buffer�����s�����x�͕ς��Ȃ��B
A-Buffer�̓s�N�Z�����ƍŏI�������݂̍ۂɓ��ߏ����p�������Ă���ŕt������
Z�[�x��r�Ɠ����ɓ��߉��Z�܂ōs���㕨�B����Ń|���S���������Ă���肪�Ȃ��Ȃ�B
�܂�Z-Buffer�@�ł�Z���(�s�N�Z��������32bit��64bit)��ǂݏo�����ނ����̘b��
A-Buffer�@�ł͗֊s�}�X�N�ⓧ�ߓx�A����ɂ͓��ߍ������邽�߂ɉߋ��̃s�N�Z�����܂�
�ǂݒ����Ȃ��Ƃ����Ȃ��B
�c��ȃ�����������Ăł����ߕ`��𐳂����s���̂� A-Buffer �̖ړI�ł����āA
���x����ւ̊�^�Ȃ���B
�����ӂ̃^�C�������_�����O�ŋǏ��I�Ɉ����L���b�V���Ɏ��܂�`�Ƃ����̑䎌��
�A���Ă����������ǁA��x�Ɉ�����^�C������������͖̂��炩�ł��̕�����x��������ˁB
Larrabee�i�삵���������̑f�l���K���Ȃ��ƌ����Ă�ƒp�����悗
>>628
���A���^�C���ŏ�������ɂ͂�������������肪�K�v�ɂȂ��Ă���ˁB
ATI��Larrabee������͋��Ő��Ă�����������NVIDIA�̓o�X���L���ė͂ʼn������Ă�������
�������Ⴂ�����Ă��邯�ǁA�ʂ�ZBuffer�����čŏI�H���܂ŕ����ł���B
���ߏ����𐳂����s���ɂ͎��O�Ƀ|�����S�����\�[�g���Ă����K�v������i����͂����������ׂ���Ȃ�)�̂ƁA
����ł��|���S�����������Ă��܂����ۂɐ������Ȃ����ʂ������Ƃ��������B
����͉������Ă��������Ȃ����AA-Buffer��Z-Buffer�����s�����x�͕ς��Ȃ��B
A-Buffer�̓s�N�Z�����ƍŏI�������݂̍ۂɓ��ߏ����p�������Ă���ŕt������
Z�[�x��r�Ɠ����ɓ��߉��Z�܂ōs���㕨�B����Ń|���S���������Ă���肪�Ȃ��Ȃ�B
�܂�Z-Buffer�@�ł�Z���(�s�N�Z��������32bit��64bit)��ǂݏo�����ނ����̘b��
A-Buffer�@�ł͗֊s�}�X�N�ⓧ�ߓx�A����ɂ͓��ߍ������邽�߂ɉߋ��̃s�N�Z�����܂�
�ǂݒ����Ȃ��Ƃ����Ȃ��B
�c��ȃ�����������Ăł����ߕ`��𐳂����s���̂� A-Buffer �̖ړI�ł����āA
���x����ւ̊�^�Ȃ���B
�����ӂ̃^�C�������_�����O�ŋǏ��I�Ɉ����L���b�V���Ɏ��܂�`�Ƃ����̑䎌��
�A���Ă����������ǁA��x�Ɉ�����^�C������������͖̂��炩�ł��̕�����x��������ˁB
Larrabee�i�삵���������̑f�l���K���Ȃ��ƌ����Ă�ƒp�����悗
>>628
���A���^�C���ŏ�������ɂ͂�������������肪�K�v�ɂȂ��Ă���ˁB
ATI��Larrabee������͋��Ő��Ă�����������NVIDIA�̓o�X���L���ė͂ʼn������Ă�������
���ƁA�O�Ɏw�E�����̂ɂ܂��������ĂȂ��݂��������ǁA
�ʏ��Z-Buffer�i��A-Buffer)�ł̓|���S���͂��̂܂ܕ`���̂Ă�������ǁA
Larrabee�Ŏg���^�C�������_�����O�ł͋�悪�ς�閈�ɑS�Ẵ|���S�����ĕ]�����Ȃ��Ƃ����Ȃ��B
�ߋ��̕]�����ʂ��ė��p�\�ł͂��邯�ǁA�L���b�V���ɏ���Ȃ��ꍇ�͂����������������ˁB
�L���b�V���ɗ��錋�ʁA���\���ێ�����ɂ̓V�[���ň�����|���S��������������̂�Larrabee�̖��B
���C�g���ɂ����NURBS��MetaBall�g���ăI�u�W�F�N�g���A�c��ȉ��Z�ʂ�������
����ɃI�u�W�F�N�g�������f�[�^�ʂ����炷���Ƃ��o����̂ŁA���̂ւ���܂߂�
�u���ΓI�ɁvLarrabee�������Ă����n�i�V�B
�ʏ��Z-Buffer�i��A-Buffer)�ł̓|���S���͂��̂܂ܕ`���̂Ă�������ǁA
Larrabee�Ŏg���^�C�������_�����O�ł͋�悪�ς�閈�ɑS�Ẵ|���S�����ĕ]�����Ȃ��Ƃ����Ȃ��B
�ߋ��̕]�����ʂ��ė��p�\�ł͂��邯�ǁA�L���b�V���ɏ���Ȃ��ꍇ�͂����������������ˁB
�L���b�V���ɗ��錋�ʁA���\���ێ�����ɂ̓V�[���ň�����|���S��������������̂�Larrabee�̖��B
���C�g���ɂ����NURBS��MetaBall�g���ăI�u�W�F�N�g���A�c��ȉ��Z�ʂ�������
����ɃI�u�W�F�N�g�������f�[�^�ʂ����炷���Ƃ��o����̂ŁA���̂ւ���܂߂�
�u���ΓI�ɁvLarrabee�������Ă����n�i�V�B
636 �F,,�E�L�́M�E,,�j��-�������F2009/10/28(��) 08:30:40 ID:y5ysAT1N
>>634
> �����ӂ̃^�C�������_�����O�ŋǏ��I�Ɉ����L���b�V���Ɏ��܂�`�Ƃ����̑䎌��
> �A���Ă����������ǁA��x�Ɉ�����^�C������������͖̂��炩�ł��̕�����x��������ˁB
���̂��[�A��������32�R�A�`64�R�A�������̂�
�E����X���b�h�K�v�Ȃ��v�Ȃ��B�������GPU�݂����ɁB
> �����ӂ̃^�C�������_�����O�ŋǏ��I�Ɉ����L���b�V���Ɏ��܂�`�Ƃ����̑䎌��
> �A���Ă����������ǁA��x�Ɉ�����^�C������������͖̂��炩�ł��̕�����x��������ˁB
���̂��[�A��������32�R�A�`64�R�A�������̂�
�E����X���b�h�K�v�Ȃ��v�Ȃ��B�������GPU�݂����ɁB
637 �F,,�E�L�́M�E,,�j��-�������F2009/10/28(��) 08:46:36 ID:y5ysAT1N
�E���������C�e���V���B�����邽�߂ɑ�ʂ̃X���b�h�������v�ɂȂ��Ă���
�E�ł��A�L���b�V���������Ȃ�����VRAM�̃��C�e���V���傫����B
�E�����ɓ������X���b�h����ɑ�ʂɂ��邩��L���b�V���Ȃ�Ă����悤���Ȃ�
�@�i�{�_�C�T�C�Y�̐�������邩��ȒP�ɂ͑��₹�Ȃ��j
�������Y�̓����ɉ�������A�[�L�e�N�`���Ȃ�čl���悤���Ȃ���AGPU���ɂ́B
Larrabee�̓X���b�h���𑽂����Ȃ��Ƃ����Ȃ����Ȃ�
�����Ă������L���b�V���ɍڂ����肫��K�v�Ȃ�ĂȂ���A�|�����S������
���Ƃ��g���t�B�b�N�����x�ɍ팸�ł���Ȃ�A2�{�̃w�b�h���[�����o����̂Ɠ������ƂɂȂ�
�N���[���q�b�g�Ȃ�ċ��߂��ĂȂ��B
�|�����S������̓L���b�V���ɗ����VRAM�̑ш悪�啝�ɍ��ꂽ��A���C�e���V���啝�ɐL�т���
����ϑz�Ɏ����Ă�悤�����A����GDDR5(or XDR2)���g�����肻��͂Ȃ����낤�B
�|�����S������͂��A�n�[�h�̓����𐳂��������������
���ΓI�ɂǂ��Ȃ̂��f���悤
�E�ł��A�L���b�V���������Ȃ�����VRAM�̃��C�e���V���傫����B
�E�����ɓ������X���b�h����ɑ�ʂɂ��邩��L���b�V���Ȃ�Ă����悤���Ȃ�
�@�i�{�_�C�T�C�Y�̐�������邩��ȒP�ɂ͑��₹�Ȃ��j
�������Y�̓����ɉ�������A�[�L�e�N�`���Ȃ�čl���悤���Ȃ���AGPU���ɂ́B
Larrabee�̓X���b�h���𑽂����Ȃ��Ƃ����Ȃ����Ȃ�
�����Ă������L���b�V���ɍڂ����肫��K�v�Ȃ�ĂȂ���A�|�����S������
���Ƃ��g���t�B�b�N�����x�ɍ팸�ł���Ȃ�A2�{�̃w�b�h���[�����o����̂Ɠ������ƂɂȂ�
�N���[���q�b�g�Ȃ�ċ��߂��ĂȂ��B
�|�����S������̓L���b�V���ɗ����VRAM�̑ш悪�啝�ɍ��ꂽ��A���C�e���V���啝�ɐL�т���
����ϑz�Ɏ����Ă�悤�����A����GDDR5(or XDR2)���g�����肻��͂Ȃ����낤�B
�|�����S������͂��A�n�[�h�̓����𐳂��������������
���ΓI�ɂǂ��Ȃ̂��f���悤
638 �F,,�E�L�́M�E,,�j��-�������F2009/10/28(��) 08:53:02 ID:y5ysAT1N
�Ԃ����Ⴏ��ƁA�^�C�������_�����O�ł���K�v����Ȃ��B
�L���b�V���̓v���C�I���e�B�������f�[�^���c��Ƃ��������͕ς��Ȃ�����ˁB
�ǂ������Ƃ�����Larrabee�̏ꍇ���W�X�^�Ԃ���L1�L���b�V���ԃI�y���[�V�����̂ق���
���Z���x���҂���ςȃ��[��������B
�L���b�V���̓v���C�I���e�B�������f�[�^���c��Ƃ��������͕ς��Ȃ�����ˁB
�ǂ������Ƃ�����Larrabee�̏ꍇ���W�X�^�Ԃ���L1�L���b�V���ԃI�y���[�V�����̂ق���
���Z���x���҂���ςȃ��[��������B
639 �F,,�E�L�́M�E,,�j��-�������F2009/10/28(��) 09:23:53 ID:y5ysAT1N
�����u���Ȃ��Ƃ����Ȃ��v�X���b�h�����ΓI�Ɍ���B
�������ăL���b�V������荇�����炢�Ȃ璀�����������ق����}�V�ƌ������Ƃ����Ƃ��Ă���B
GT200�ł�CUDA�ł�16���[�v�AGPU�Ƃ��Ă͍ő�32�A�N�e�B�u���[�v��������悤�ɂȂ��Ă��邪�A
Larrabee�̓R�A������1�`4�X���b�h���B�ނ���A����ȏ�̃A�N�e�B�u�X���b�h�͓����Ȃ��B
��O��Ƃ��ē��N���X��GPU���ɂ̓X���b�h���������Ȃ����A
���σ��������C�e���V��ꡂ��ɏ������̂œ������K�v���Ȃ��B
���܂̂Ƃ���Larrabee�̕��j�́A�������ш�͌��炷�̂ł͂Ȃ��A�m�ۂ��A�L���b�V���ɂ���ē�����
�ꌅ�Ⴂ�̍L�ш�ƈ��|�I�Ȓ�C�e���V��L�����p���邱�ƂōX�Ȃ鐫�\�A�b�v��ڎw�����̂�
�O���ш��Radeon���x�ɂ͊m�ۂ���B������GeForce�قǂɂ͕K�v�Ȃ��B
����������
> ���\���ێ�����ɂ̓V�[���ň�����|���S��������������
�Ƃ����ϑz���������铹�����Ȃ��B
�������ăL���b�V������荇�����炢�Ȃ璀�����������ق����}�V�ƌ������Ƃ����Ƃ��Ă���B
GT200�ł�CUDA�ł�16���[�v�AGPU�Ƃ��Ă͍ő�32�A�N�e�B�u���[�v��������悤�ɂȂ��Ă��邪�A
Larrabee�̓R�A������1�`4�X���b�h���B�ނ���A����ȏ�̃A�N�e�B�u�X���b�h�͓����Ȃ��B
��O��Ƃ��ē��N���X��GPU���ɂ̓X���b�h���������Ȃ����A
���σ��������C�e���V��ꡂ��ɏ������̂œ������K�v���Ȃ��B
���܂̂Ƃ���Larrabee�̕��j�́A�������ш�͌��炷�̂ł͂Ȃ��A�m�ۂ��A�L���b�V���ɂ���ē�����
�ꌅ�Ⴂ�̍L�ш�ƈ��|�I�Ȓ�C�e���V��L�����p���邱�ƂōX�Ȃ鐫�\�A�b�v��ڎw�����̂�
�O���ш��Radeon���x�ɂ͊m�ۂ���B������GeForce�قǂɂ͕K�v�Ȃ��B
����������
> ���\���ێ�����ɂ̓V�[���ň�����|���S��������������
�Ƃ����ϑz���������铹�����Ȃ��B
�A�N�e�B�u�X���b�h������̃L���b�V����啝�ɑ��₷���ƂŎ�VRAM�ԕ��σf�[�^�X���[�v�b�g������̂�
�ǂ������킯���v��̑ш�܂Ō��邢���v�����݂��������Ă���B
S3���������s��GPU���ш日���ɋ߂���Ԃ����疳�����Ȃ����B
�ǂ������킯���v��̑ш�܂Ō��邢���v�����݂��������Ă���B
S3���������s��GPU���ш日���ɋ߂���Ԃ����疳�����Ȃ����B
blog�������ɂɂ܂Ƃ߂Ăق����B
�c�q����̓h���C�����Ǝ҂Ɏ��ꂽ���烂�`�x�������Ă�
A-buffer�����ΓI�ɂ�Larrabee�����B
�Ȃ��Ȃ�Œ�@�\�ɔ���ꂸ�S�R�A�ŕ�����s�o���邩��B
�����{���Ɍ����Ă�̂�irregular Z-buffer�̂ق����낤���ǁB
�Ȃ��Ȃ�Œ�@�\�ɔ���ꂸ�S�R�A�ŕ�����s�o���邩��B
�����{���Ɍ����Ă�̂�irregular Z-buffer�̂ق����낤���ǁB
A-buffer�Ă���Radeon��DirectCompute�ł���Ă邶���
�L�`�I�ɂ�MSAA��A-buffer�̉��p
ttp://journal.mycom.co.jp/photo/column/graphics/008/images/003l.jpg
���ۂɂ͎��X�e�[�W�ւ̃f�[�^�t���[��VRAM���o�R���Ă�B
�f�[�^�̔����ł��I���_�C�Ŏ��̃X�e�[�W�ɑ��荞�߂��
���ꂾ���ł��g���t�B�b�N�͌��点�܂���
{kind=link}
���ۂɂ͎��X�e�[�W�ւ̃f�[�^�t���[��VRAM���o�R���Ă�B
�f�[�^�̔����ł��I���_�C�Ŏ��̃X�e�[�W�ɑ��荞�߂��
���ꂾ���ł��g���t�B�b�N�͌��点�܂���
RADEON��ShaderExport���ĉ��̂��߂ɂ���́H
>>648
Xbox��Xenos�Ȃ�eDRAM�ɏo�͂��Ē��߂Ă����邯��
Radeon��GeForce���l����VRAM�ɗ��ꂿ�Ⴂ�܂���
�f�[�^�{�̂Ɋւ��Ă�
Xbox��Xenos�Ȃ�eDRAM�ɏo�͂��Ē��߂Ă����邯��
Radeon��GeForce���l����VRAM�ɗ��ꂿ�Ⴂ�܂���
�f�[�^�{�̂Ɋւ��Ă�
����x�Ɉ�����^�C������������͖̂��炩�ł��̕�����x���������
�����Ƃ���24�̈������ 64x64�T�C�Y�̃^�C����\�������ꍇ�A �����Ɉ�����t���[���̈��512x192���x�ł����Ȃ�
�Ȃ��1�t���[���ɂ��ALarrabee�̊e�R�A�͊e�^�C����1���������������Ȃ���A�ǂ�ȕ�������
�e�^�C���̏������Ԃ������f�[�^�ʂ��o���o���Ȃ̂Ɂc�����Œ�ϔO����
�����Ƃ���24�̈������ 64x64�T�C�Y�̃^�C����\�������ꍇ�A �����Ɉ�����t���[���̈��512x192���x�ł����Ȃ�
�Ȃ��1�t���[���ɂ��ALarrabee�̊e�R�A�͊e�^�C����1���������������Ȃ���A�ǂ�ȕ�������
�e�^�C���̏������Ԃ������f�[�^�ʂ��o���o���Ȃ̂Ɂc�����Œ�ϔO����
A-buffer�́A�Ō�̃u�����f�B���O����������܂ŁA
�f���o�����������s�N�Z�����L���b�V���O�ɓ������邩��ǂ���
�L���b�V����Z�e�X�g�ɏW���ł���
�f���o�����������s�N�Z�����L���b�V���O�ɓ������邩��ǂ���
�L���b�V����Z�e�X�g�ɏW���ł���
>>650
������Larrabee�u�����́v�L���b�V�����S��������Ԃ��Ǝv������ł�
�r��������n���ɍ���B
���x�w�E����Ă������Ɋw�K�ł��ĂȂ��B
Larrabee��VRAM�ɃX�g���[���I�ɃA�N�Z�X����͍̂��܂łƕς��Ȃ��B
Larrabee��Radeon��GeForce�ƈႤ�̂̓R���e�N�X�g�������
���[�N�������̋K�́i��KB�Ɛ��\�`�SKB�j�ƃ��[�N��������VRAM�ւ�
�ޔA�̉̈Ⴂ�B�v�̓s�N�Z�����C���P�ʂ��^�C���P�ʂ��̈Ⴂ���B
CPU�R�A��1�̃^�C�����������Ă���ԁA�����̏I������^�C����
VRAM�ɗ����A���̃^�C���̏��������Ă���B
�܂�A�A�z�݂����Ƀ������ш悪�K�v�Ȃ͕̂ς��Ȃ����A�����P�ʂ�
�傫���Ȃ邱�Ƃŏo�����������A���ʑш����ʂ�����B
������O�����I���L���b�V���ōς܂��ɂ̓L���b�V���e�ʂ�256KB/core�ł�
�S�R����Ȃ��B�����ɉz�������Ƃ͂Ȃ���Larrabee�ł��\�����Ă��Ƃ͂Ȃ��B
������Larrabee�u�����́v�L���b�V�����S��������Ԃ��Ǝv������ł�
�r��������n���ɍ���B
���x�w�E����Ă������Ɋw�K�ł��ĂȂ��B
Larrabee��VRAM�ɃX�g���[���I�ɃA�N�Z�X����͍̂��܂łƕς��Ȃ��B
Larrabee��Radeon��GeForce�ƈႤ�̂̓R���e�N�X�g�������
���[�N�������̋K�́i��KB�Ɛ��\�`�SKB�j�ƃ��[�N��������VRAM�ւ�
�ޔA�̉̈Ⴂ�B�v�̓s�N�Z�����C���P�ʂ��^�C���P�ʂ��̈Ⴂ���B
CPU�R�A��1�̃^�C�����������Ă���ԁA�����̏I������^�C����
VRAM�ɗ����A���̃^�C���̏��������Ă���B
�܂�A�A�z�݂����Ƀ������ш悪�K�v�Ȃ͕̂ς��Ȃ����A�����P�ʂ�
�傫���Ȃ邱�Ƃŏo�����������A���ʑш����ʂ�����B
������O�����I���L���b�V���ōς܂��ɂ̓L���b�V���e�ʂ�256KB/core�ł�
�S�R����Ȃ��B�����ɉz�������Ƃ͂Ȃ���Larrabee�ł��\�����Ă��Ƃ͂Ȃ��B
����̈ӌ� vs ��]�̈ӌ�
�K���`�F�b�J�[�݂���c�q1�ʂ����B���߂łƂ�
�������Ƃ��������ĂȂ����ǂ�
Larrabee�֘A�̃Z�b�V�����^�ʖڂɕ����Ă���킩�闝���Ȃ̂�
Larrabee�֘A�̃Z�b�V�����^�ʖڂɕ����Ă���킩�闝���Ȃ̂�
���A���^�C�������_�����O���DirectX11�̃p�t�H�[�}���X���ǂ��Ȃ邩�C�ɂȂ�B
���ꎟ��ŁA��Ђ���C�ɔ����\�������Ȃ��B
���ꎟ��ŁA��Ђ���C�ɔ����\�������Ȃ��B
���A���^�C�������_�����O�����A���^�C�����C�g���[�V���O
������
��
������ăE���R�H
��
������ăE���R�H
659 �F,,�E�L�́M�E,,�j��-�������F2009/10/29(��) 00:05:51 ID:uFX20jKt
�O���[�o���������̒������郌�C�e���V��₤���߂�
GPU���͑�ʂɃX���b�h�𑖂点�邱�ƂŃT�C�N�����ߍ��킹
CPU���͒�C�e���V�̃L���b�V���Ń��W�X�^�����ꂽ��ƕϐ����~�߂��B
>>648
�A���͂����̃X�g�A�o�b�t�@����B�f�[�^�̓������R���g���[����ʂ���VRAM�ɃX�g�A�����
�X�e�[�W�Ԃŗ����̂̓R���g���[���p�p�P�b�g�B
�uVRAM�́����Ԓn�ɃX�g�A������ł�������ǂ�ŏ������Ƃ��Ăˁv���ď�ȁB
GPU���͑�ʂɃX���b�h�𑖂点�邱�ƂŃT�C�N�����ߍ��킹
CPU���͒�C�e���V�̃L���b�V���Ń��W�X�^�����ꂽ��ƕϐ����~�߂��B
>>648
�A���͂����̃X�g�A�o�b�t�@����B�f�[�^�̓������R���g���[����ʂ���VRAM�ɃX�g�A�����
�X�e�[�W�Ԃŗ����̂̓R���g���[���p�p�P�b�g�B
�uVRAM�́����Ԓn�ɃX�g�A������ł�������ǂ�ŏ������Ƃ��Ăˁv���ď�ȁB
��Xbox��CPU���y�d���AMD����Intel�ɂȂ����悤�ɂ܂��`�����X�͂���
����Xbox�ō̗p�����悤�ɏo���o��Ŕ��荞�ނ�
����Xbox�ō̗p�����悤�ɏo���o��Ŕ��荞�ނ�
661 �F,,�E�L�́M�E,,�j��-�������F2009/10/29(��) 00:33:59 ID:uFX20jKt
�Ȃ����낤�ȁB
Intel�����Larrabee�̎����ł�낤�Ƃ��Ă邱�Ƃ���Windows 7��Linux��KVM�̃n�C�p�[�o�C�U���
�����Q�X�gOS�𑖂点�A���̏�Ńz�X�gOS�Ɉˑ����Ȃ��A�v���P�[�V�����������Ƃ��B
Intel�����Larrabee�̎����ł�낤�Ƃ��Ă邱�Ƃ���Windows 7��Linux��KVM�̃n�C�p�[�o�C�U���
�����Q�X�gOS�𑖂点�A���̏�Ńz�X�gOS�Ɉˑ����Ȃ��A�v���P�[�V�����������Ƃ��B
,,�E�L�́M�E,,�j��-�������Ƃ������L�`�K�C�R�e���m�f�ɂ�����X�b�L������
663 �F,,�E�L�́M�E,,�j��-�������F2009/10/30(��) 22:11:01 ID:Qwa7YnBV
�@
>>663
������߂���B
������߂���B
Larrabee���� iAPX432�ȗ��̎��s�삾��H
10�N�キ�炢�Ɍ������ʂ��ԊJ����������Ȃ����ǁB
10�N�キ�炢�Ɍ������ʂ��ԊJ����������Ȃ����ǁB
666 �F,,�E�L�́M�E,,�j��-�������F2009/10/30(��) 23:12:30 ID:Qwa7YnBV
�����Itanium����B
x86��ے肷����̂�x86�ɔs���̂���B
Atom�Ɏ���������S���Ax86�̑��s�ꐧ���̖��ł���HPC�s��̏�
x86��ے肷����̂�x86�ɔs���̂���B
Atom�Ɏ���������S���Ax86�̑��s�ꐧ���̖��ł���HPC�s��̏�
667 �F,,�E�L�́M�E,,�j��-�������F2009/10/30(��) 23:41:02 ID:Qwa7YnBV
���Ə��Ƃ�����
Fermi�̃A�[�L�e�N�`���͕������̂܂������Ⴄ���̂�ǂ����߂āu�����v�����A�[�L�e�N�`���ɂȂ��Ă邪�ȁB
�f�����邪����Ȃ��̂̐��\��Larrabee�̑����ɂ��y�Ȃ��B
�Ϙa�Z�ɑ���L1�̃��[�h�^�X�g�A�̑ш悪��������HPC�ɂ͎g�����ɂȂ��B
OpenCL�i�j�݂����ȐV���ꂪ�K�v�Ȏ��_��PG�P���I�ɂ��s���B
Fermi�̃A�[�L�e�N�`���͕������̂܂������Ⴄ���̂�ǂ����߂āu�����v�����A�[�L�e�N�`���ɂȂ��Ă邪�ȁB
�f�����邪����Ȃ��̂̐��\��Larrabee�̑����ɂ��y�Ȃ��B
�Ϙa�Z�ɑ���L1�̃��[�h�^�X�g�A�̑ш悪��������HPC�ɂ͎g�����ɂȂ��B
OpenCL�i�j�݂����ȐV���ꂪ�K�v�Ȏ��_��PG�P���I�ɂ��s���B
�f�������Ȃ� ���̌��t�Y���Ȃ�
669 �F,,�E�L�́M�E,,�j��-�������F2009/10/30(��) 23:59:28 ID:Qwa7YnBV
http://journal.mycom.co.jp/special/2008/cuda/007.html
��
�Ƃ܂��A���̕ӌ���킩��悤��NVIDIA�̃V�F�[�_�͍��{�I��HPC�ł��悤��
�s�Z�ɂ͕s�����Ȃ�ˁB
���[�J���������ɑ��郍�[�h�E�X�g�A�̃X���[�v�b�g���Ⴗ���邩�瓖����O���B
�}�g���N�X���Z���ăO���[�o���������̑ш�͔�r�I�H��Ȃ���
�L���b�V�����邢�̓��[�J���������̃X���[�v�b�g�Ƃ��A����l�̃u���[�h�L���X�g��
�@���Ɍ����I�ɏ����ł��邩���d�v�ɂȂ�B
��ŁA�V�~�����[�V�������Ă݂��Larrabee�̖��߃Z�b�g�͂��̎�̍s�Z���₽�狭���B
1���߂Ƀ��[�h�ƃu���[�h�L���X�g�ƐϘa�Z����ݍ��߂�悤�Ȗ��߃Z�b�g�g����
x86�̃t�H�[�}�b�g�ƌ����Ƀ}�b�`����B
����͊ԈႢ�Ȃ�LINPACK�����X�^�[�B
��
�Ƃ܂��A���̕ӌ���킩��悤��NVIDIA�̃V�F�[�_�͍��{�I��HPC�ł��悤��
�s�Z�ɂ͕s�����Ȃ�ˁB
���[�J���������ɑ��郍�[�h�E�X�g�A�̃X���[�v�b�g���Ⴗ���邩�瓖����O���B
�}�g���N�X���Z���ăO���[�o���������̑ш�͔�r�I�H��Ȃ���
�L���b�V�����邢�̓��[�J���������̃X���[�v�b�g�Ƃ��A����l�̃u���[�h�L���X�g��
�@���Ɍ����I�ɏ����ł��邩���d�v�ɂȂ�B
��ŁA�V�~�����[�V�������Ă݂��Larrabee�̖��߃Z�b�g�͂��̎�̍s�Z���₽�狭���B
1���߂Ƀ��[�h�ƃu���[�h�L���X�g�ƐϘa�Z����ݍ��߂�悤�Ȗ��߃Z�b�g�g����
x86�̃t�H�[�}�b�g�ƌ����Ƀ}�b�`����B
����͊ԈႢ�Ȃ�LINPACK�����X�^�[�B
670 �F,,�E�L�́M�E,,�j��-�������F2009/10/31(�y) 19:17:20 ID:i+EhVJVU
���ʂɂ͉�����Ă������o���Ȃ����낤���������16x16�s�m�̏�Z�̃R�[�h�����Ă݂��B
http://www.dotup.org/uploda/www.dotup.org320005.txt.html
���_FLOPS�l��8���ȏ�͊ȒP�ɒe���o����
vstore�͑��̃x�N�g�����Z���߂ƃy�A�����O�ł��邩��A�����Ƒ傫�ȍs�ƁA�|���g�߂�9���͂��������ȁB
Larrabee�̌������ǂ����邩���Ă����ƔہA���ꂪ�X�g���[���v���Z�b�T�Ƃ��ē�����O�Ȃ̂ł�����
Tesla�i�j�Ȃ��b�ɂȂ�Ȃ�����킯�����ǂˁB
http://www.dotup.org/uploda/www.dotup.org320005.txt.html
���_FLOPS�l��8���ȏ�͊ȒP�ɒe���o����
vstore�͑��̃x�N�g�����Z���߂ƃy�A�����O�ł��邩��A�����Ƒ傫�ȍs�ƁA�|���g�߂�9���͂��������ȁB
Larrabee�̌������ǂ����邩���Ă����ƔہA���ꂪ�X�g���[���v���Z�b�T�Ƃ��ē�����O�Ȃ̂ł�����
Tesla�i�j�Ȃ��b�ɂȂ�Ȃ�����킯�����ǂˁB
671 �F,,�E�L�́M�E,,�j��-�������F2009/11/01(��) 01:56:41 ID:mtXW/RVq
�������ɂ��\���Ă������B
Larrabee��Gather�@�\�̎����ɂ�������������
http://www.freepatentsonline.com/20090172364.pdf
Larrabee��Gather�@�\�̎����ɂ�������������
http://www.freepatentsonline.com/20090172364.pdf
��Larrabee�o����nVidia���ɂ�������
�Ł@Larrabee��GT300����̂��ɂȂ����甭�\������
���n����
675 �F,,�E�L�́M�E,,�j��-�������F2009/11/03(��) 01:15:18 ID:b3VqoWan
http://www.nvidia.com/content/PDF/fermi_white_papers/NVIDIAFermiArchitectureWhitepaper.pdf
Fermi�A�[�N�e�N�`���̔���������������������
Fermi�A�[�N�e�N�`���̔���������������������
�悻�������Ă�ɂ������炳������Larrabee������
���������Ȃ悗����
�o���Ȃ���������Č떂�����Ă����
�o���Ȃ���������Č떂�����Ă����
678 �F,,�E�L�́M�E,,�j��-�������F2009/11/03(��) 15:48:45 ID:b3VqoWan
Fermi�̂��Ƃł��˂킩��܂�
>>143
�܂��������
http://photos.macnn.com/news/0910/nvidiafermi-demolg3.jpg
http://photos.macnn.com/news/0910/nvidiafermi-demolg1.jpg
�܂��������
http://photos.macnn.com/news/0910/nvidiafermi-demolg3.jpg
{kind=link}
http://photos.macnn.com/news/0910/nvidiafermi-demolg1.jpg
{kind=link}
���C�g���悱���ꂽ��
���t�T�o�ǂ݂������낗����������
�딚���܂���
683 �F,,�E�L�́M�E,,�j��-�������F2009/11/03(��) 16:58:47 ID:b3VqoWan
>>679
�Ȃ�������������Ă�悤�������̒��x�̐Î~������C�g���ō����x�Ȃ�Pentium 90MHz�ł��o���邼
�Ȃ�������������Ă�悤�������̒��x�̐Î~������C�g���ō����x�Ȃ�Pentium 90MHz�ł��o���邼
���C�g�������A���^�C���Ŏ��ۂɃf�����Ĉ�Ԑi��ł�̂̓��f�Ȃ��ǂ�
���̃f�����J���Ȃ��̂��ȁH
686 �F,,�E�L�́M�E,,�j��-�������F2009/11/03(��) 17:26:23 ID:b3VqoWan
687 �F,,�E�L�́M�E,,�j��-�������F2009/11/03(��) 22:01:46 ID:b3VqoWan
�`���[���[�f�}�����ɂ���ȋL���������ΐ�]��������
�x��ɒx�ꂽLarrabee�ł���B0�܂ł����Ă�̂�
http://www.semiaccurate.com/2009/11/02/nvidia-finally-gets-fermi-a2-taped-out/
�x��ɒx�ꂽLarrabee�ł���B0�܂ł����Ă�̂�
http://www.semiaccurate.com/2009/11/02/nvidia-finally-gets-fermi-a2-taped-out/
Intel�̏ꍇ�f�o�b�O�����Ȃ葁���I�����Merom��B2����������B0�͂܂��ŏI�V���R������ˁ[�Ǝv����
�܂��ł����j�[�R�A���ŃR�A���̂͂��Ȃ�V���v��������f�o�b�O�͊y�Ȃ̂����m���
�����ł��J�����\�[�X���ǂ̒��x����U�邩�ɂ���邵�A�A�A
�v����ɂȂ�Ƃ�������
�܂��ł����j�[�R�A���ŃR�A���̂͂��Ȃ�V���v��������f�o�b�O�͊y�Ȃ̂����m���
�����ł��J�����\�[�X���ǂ̒��x����U�邩�ɂ���邵�A�A�A
�v����ɂȂ�Ƃ�������
�c�q����i752�����\���ꂽ�Ƃ������������ӂ��Ɋ��҂��܂����Ă��낤��
690 �F,,�E�L�́M�E,,�j��-�������F2009/11/03(��) 23:27:50 ID:b3VqoWan
���Ăˁ[��
691 �F,,�E�L�́M�E,,�j��-�������F2009/11/03(��) 23:30:05 ID:b3VqoWan
Fermi�͐Ϙa�Z�ɑ���LSU�̃X���[�v�b�g���Ⴗ����Ƃ����A��������ĂȂ����m�ȃ{�g���l�b�N������B
�{���x�ł���������\5�����FireStream�͂͂Ȃ�����ɂȂ��ĂȂ��B
Larrabee�ȊO�I�����ɂȂ���B
�P�������ȏ����@���B
�{���x�ł���������\5�����FireStream�͂͂Ȃ�����ɂȂ��ĂȂ��B
Larrabee�ȊO�I�����ɂȂ���B
�P�������ȏ����@���B
�s�[�N���Ⴄ�̂Ɏ��s����������ׂĂ�
Fermi�̔��[�ȋ��LL2�L���b�V����NVIDIA�̋�S���f����
694 �F,,�E�L�́M�E,,�j��-�������F2009/11/03(��) 23:38:10 ID:b3VqoWan
Larrabee��32�R�A��Fermi�Ɠ���512SP�����H
����Fermi���������\50%���x�Ȃ�Larrabee���Z750MHz���ˁB
����Fermi���������\50%���x�Ȃ�Larrabee���Z750MHz���ˁB
695 �F,,�E�L�́M�E,,�j��-�������F2009/11/03(��) 23:39:06 ID:b3VqoWan
696 �F,,�E�L�́M�E,,�j��-�������F2009/11/04(��) 00:25:39 ID:4Ohrun5l
BLAS Performance����
http://www.lunarc.lu.se/Documents/nvidia-workshop/files/presentation/50_Case_Studies.pdf
CPU�ɔ�ׂĈ��|�I����Ȃ������Ďv�����Ⴄ���낤����
�P���x���ăs�[�N��3�������x�����o�ĂȂ���ł����B
�܂��ASFU�ł̏�Z���S�����ɗ����Ȃ���ɁALSU���l�b�N���Ⴑ�̒��x����ȁB
�{���x�͂قڊz�ʒʂ�̐��\�ɂȂ��Ă邪�A����͔{���x���j�b�g�����̃��j�b�g�ɔ�ׂ�
�n��ȕ��A���ΓI�ɑ��̃I�y���[�V�����̋������Ԃɍ����Ă�ɉ߂��Ȃ��B
Larrabee�ł�SGEMM�EDGEMM�Ƃ���90%�͒e���o����ƌ��Ă���B
�Ȃ��Ȃ��Z�l�̃A�h���X�Z�o�E���[�h�E�u���[�h�L���X�g�E�Ϙa�Z��1���߂œ����ɍs���Ȃ���A
�X�J�����ŃL���b�V���R���g���[���̑����x�N�g���X�g�A�������ꂩ1���߃y�A�ɂ���
���s���邱�Ƃ��ł��邩�炾�B
���Ė��ł��BGEMM�ɂ����āA32Way�̐Ϙa�Z���j�b�g�ɑ��A�����ɏ�Z�l����������̂�
���[�h���j�b�g�͍ŒችWay�łȂ�������Ȃ��ł��傤���H
���ꂪ�����Fermi��GPGPU���\�ɔ��o�����҂ł��Ȃ��Ȃ�
http://www.lunarc.lu.se/Documents/nvidia-workshop/files/presentation/50_Case_Studies.pdf
CPU�ɔ�ׂĈ��|�I����Ȃ������Ďv�����Ⴄ���낤����
�P���x���ăs�[�N��3�������x�����o�ĂȂ���ł����B
�܂��ASFU�ł̏�Z���S�����ɗ����Ȃ���ɁALSU���l�b�N���Ⴑ�̒��x����ȁB
�{���x�͂قڊz�ʒʂ�̐��\�ɂȂ��Ă邪�A����͔{���x���j�b�g�����̃��j�b�g�ɔ�ׂ�
�n��ȕ��A���ΓI�ɑ��̃I�y���[�V�����̋������Ԃɍ����Ă�ɉ߂��Ȃ��B
Larrabee�ł�SGEMM�EDGEMM�Ƃ���90%�͒e���o����ƌ��Ă���B
�Ȃ��Ȃ��Z�l�̃A�h���X�Z�o�E���[�h�E�u���[�h�L���X�g�E�Ϙa�Z��1���߂œ����ɍs���Ȃ���A
�X�J�����ŃL���b�V���R���g���[���̑����x�N�g���X�g�A�������ꂩ1���߃y�A�ɂ���
���s���邱�Ƃ��ł��邩�炾�B
���Ė��ł��BGEMM�ɂ����āA32Way�̐Ϙa�Z���j�b�g�ɑ��A�����ɏ�Z�l����������̂�
���[�h���j�b�g�͍ŒችWay�łȂ�������Ȃ��ł��傤���H
���ꂪ�����Fermi��GPGPU���\�ɔ��o�����҂ł��Ȃ��Ȃ�
HD5870�������͏����g���Ă��Ƃł���
�J�X�ȉ��ł�
http://japan.cnet.com/blog/petaflops/2009/10/30/entry_27035208/
>�@�V�͂̏ڍׂ͕s���ł��邪�AIntel��CPU��Nehalem-EP�ŁAAMD��GPU��
> FireStream9270S�ł��낤�Ɛ��肳��Ă���B�܂��A�V�X�e���̗��_���\��
> FireStream�̐��\�ɂ����̂Ɛ��肳��Ă���A���s���\�䂪46.7%��
> �������ڂ�������قǂ̒ᐫ�\�̌�����GPU�Ɉˑ����Ă��鎖��[�I��
> �����Ă�����̂Ǝv����B
>
>�@�L���Ӗ��ł�GPU�����Ƃ͂����ACell+Opteron��Roadrunner�͎��s�䗦��
> �����Ă�75.9����CPU�@�Ɉ��������Ȃ����\�������Ă���A������A
> �Z�p�͂�m���������邪�A50�����悤�ł́A���������A���̗��_���\��
> �v�Z����������Ă���Ƃ��������l���������ƂɂȂ�B
ATI�Ȃ炸�Ƃ�NVIDIA�ɂ����ʂ̖�肾�Ȃ���́B
>�@�V�͂̏ڍׂ͕s���ł��邪�AIntel��CPU��Nehalem-EP�ŁAAMD��GPU��
> FireStream9270S�ł��낤�Ɛ��肳��Ă���B�܂��A�V�X�e���̗��_���\��
> FireStream�̐��\�ɂ����̂Ɛ��肳��Ă���A���s���\�䂪46.7%��
> �������ڂ�������قǂ̒ᐫ�\�̌�����GPU�Ɉˑ����Ă��鎖��[�I��
> �����Ă�����̂Ǝv����B
>
>�@�L���Ӗ��ł�GPU�����Ƃ͂����ACell+Opteron��Roadrunner�͎��s�䗦��
> �����Ă�75.9����CPU�@�Ɉ��������Ȃ����\�������Ă���A������A
> �Z�p�͂�m���������邪�A50�����悤�ł́A���������A���̗��_���\��
> �v�Z����������Ă���Ƃ��������l���������ƂɂȂ�B
ATI�Ȃ炸�Ƃ�NVIDIA�ɂ����ʂ̖�肾�Ȃ���́B
���u���O�\��Ȃ�
����̓V�~�����[�^����Ȃ���ˁH
ttp://blog.livedoor.jp/amd646464/archives/51447036.html
ttp://blog.livedoor.jp/amd646464/archives/51447036.html
702 �F,,�E�L�́M�E,,�j��-�������F2009/11/04(��) 22:55:33 ID:4Ohrun5l
�����Ƃ͌����Ă邯�Ǒ�p����
�����ʂ�̃`�b�v�Ȃ�Ȃ��́HB0���o�����ɓ���������Ǝv���Ă����E�E�E
���悢��Fermi����Ȃ��Ă����ȁB
�����ʂ�̃`�b�v�Ȃ�Ȃ��́HB0���o�����ɓ���������Ǝv���Ă����E�E�E
���悢��Fermi����Ȃ��Ă����ȁB
>>701
���̂������ڔ��荞�݂����ɂ������A�Ƃ����L���ł���ȏ�ł��ȉ��ł��Ȃ���
���̂������ڔ��荞�݂����ɂ������A�Ƃ����L���ł���ȏ�ł��ȉ��ł��Ȃ���
�`�b�v�Z�b�g�������Ƀo���h������ƈ����Ȃ�݂�������
���ɏo��Intel�}�U�[�̐� = Larrabee�̐��݂����ȏɂȂ�Ƌ����ɂȂ�낤��
���ɏo��Intel�}�U�[�̐� = Larrabee�̐��݂����ȏɂȂ�Ƌ����ɂȂ�낤��
�x���_�̒��̐l�����ǁA�����猩������
�u��������̗p����A����邩��v�ƘA�Ă���Ĉ�����������B
�u��������̗p����A����邩��v�ƘA�Ă���Ĉ�����������B
706 �F,,�E�L�́M�E,,�j��-�������F2009/11/04(��) 23:03:21 ID:4Ohrun5l
���{�ɃJ�[�h�x���_�Ȃ�Ă����������H
�J�m�v�[
708 �F,,�E�L�́M�E,,�j��-�������F2009/11/04(��) 23:05:51 ID:4Ohrun5l
>>704
�~�b�h�����W�ȉ���Intel CPU�̐���GMA�̐��ɋ߂����Ă����ł����˂�B
�~�b�h�����W�ȉ���Intel CPU�̐���GMA�̐��ɋ߂����Ă����ł����˂�B
CPU�ƃI���_�C�ɂ����Ȃ��́H�ǂ�����������ł���̂��m��Ȃ�����
Larrabee��Haswell�ɓ���B
�I���S���`�[��������������B
�I���S���`�[��������������B
712 �F,,�E�L�́M�E,,�j��-�������F2009/11/05(��) 00:02:27 ID:4Ohrun5l
LRBni��AVX�i256�r�b�gSIMD�j�����グ�̂��߂ɈӐ}�I�ɏ��K�����Ă�C������B
������������ƃA�E�g�I�u�I�[�_�p�C�v���C����LRBni�����s���郂�f�����o�Ă���ǂˁB
������������ƃA�E�g�I�u�I�[�_�p�C�v���C����LRBni�����s���郂�f�����o�Ă���ǂˁB
:::::::::::.:�@.:. . �ȁQ�� . . . .: ::::::::
:::::::: :.: . .�@/�c�~�J�R;)�R�A. ::: : ::�@�@>�I���S���`�[��������������B
::::::: :.: . . / :::/:: �R�A�R�Ai . .:: :.: ::�@�@
�P�P�P�i_,�m �P�P�R�_�m�P
:::::::: :.: . .�@/�c�~�J�R;)�R�A. ::: : ::�@�@>�I���S���`�[��������������B
::::::: :.: . . / :::/:: �R�A�R�Ai . .:: :.: ::�@�@
�P�P�P�i_,�m �P�P�R�_�m�P
714 �F�C���~ ��0tc5JBFuqkkI �F2009/11/06(��) 10:40:55 ID:itubXr6g
�I���S���`�[����AMD�̐S������������
���XLarrabee�ɂ̓l�g�o�̃A�[�L�e�N�g���ւ���Ă���̂ɁB
�A������Nehalem-EP�Ƀ{�R���Ă����Ă܂��I���S���n���ɂ���̂�������
Core MA�𗬗p�����������I���S�����������āH��
�ƈӖ��s���ȋ��q�����Ă���
�I���S�����J������P6�𗬗p����(ry
Larrabee���ڂ̃{�[�h����10���ȓ��Ŕ����邩�ȁH
�ŏ���Extream����������`����999�h���Ƃ��AGT300�Ɠ����i�тƂ��B����Ȋ�������Ȃ��́B
���C���X�g���[�������������o�邩�͂���ˁB
���C���X�g���[�������������o�邩�͂���ˁB
���ǁAGT300�̎��s���\��50%�ŁALarrabee��90%�Ƃ��̍����o�Ă��A
���i��������ȏ�ŋt�]���Ă���A��ʌ����̑I������GT300�����Ȃ���ȁB
Larrabee�͂���܂��ʌ����ŏo���܂���Ƃ��Ȃ�ƁACell�̃{�[�h�݂�����
100���߂��Ƃ��Ȃ肻���ȋC�����ĂȁB
�ł��Alarrabee��5���O��Ŕ�����ĂȂ�����A�{�C��GT300���E���邩�����Ă���
�C�͂���ȁB
���i��������ȏ�ŋt�]���Ă���A��ʌ����̑I������GT300�����Ȃ���ȁB
Larrabee�͂���܂��ʌ����ŏo���܂���Ƃ��Ȃ�ƁACell�̃{�[�h�݂�����
100���߂��Ƃ��Ȃ肻���ȋC�����ĂȁB
�ł��Alarrabee��5���O��Ŕ�����ĂȂ�����A�{�C��GT300���E���邩�����Ă���
�C�͂���ȁB
(`��֥�L)
http://www.4gamer.net/games/049/G004963/20090923003/SS/002.jpg
http://www.brightsideofnews.com/Data/2009_10_12/An-Inconvenient-Truth-Intel-Larrabee-story-revealed/INTC_Larrabee_PCB_Board_675.jpg
http://www.4gamer.net/games/049/G004963/20090923003/SS/002.jpg
http://www.brightsideofnews.com/Data/2009_10_12/An-Inconvenient-Truth-Intel-Larrabee-story-revealed/INTC_Larrabee_PCB_Board_675.jpg
{kind=link}
Larabee���o�鍠�ɂ͑��Ђ�GPGPU���i�����Ă�i740�̓�̕��ɂȂ肻��
�����Ɛ��i�������܂��}�V����
�x�C�p�[�n�[�h�ɂȂ�Ȃ��Ⴂ�����ǂ�
�x�C�p�[�n�[�h�ɂȂ�Ȃ��Ⴂ�����ǂ�
727 �F,,�E�L�́M�E,,�j��-�������F2009/11/08(��) 11:23:55 ID:g0j+SMPB
�R�s�y�������
�f�l�Ȃ�ŁA��{�I�Ȃ��Ƃ�������Ȃ����ǁA
������āA���j�C�R�A��CPU�Ɖ����Ⴄ�́H
������āA���j�C�R�A��CPU�Ɖ����Ⴄ�́H
>>729
��{�̓��j�[�R�A�Ɠ������́B
OS�����K�v���Ȃ�����A�V���v���R�A�ł��ށB�V���v���Ƃ������Ƃ́A�������Ȃ�B
������A���̃V���R���\�Z�ł���������B�ŁA���ł�����Ȃ����A�����CPU���s�[�N�������ɁB
���с[�̓R�A�̃x�[�X��MMX�y���e�B�A��+�V���߂��Č����Ă�݂���������A
OS�����������Ǝv���Γ�����������Ȃ����ǂˁB
�܂��A�ǂ��������Č����ƃA�N�Z�����[�^�̃^�O�C���Ǝv����B
��{�̓��j�[�R�A�Ɠ������́B
OS�����K�v���Ȃ�����A�V���v���R�A�ł��ށB�V���v���Ƃ������Ƃ́A�������Ȃ�B
������A���̃V���R���\�Z�ł���������B�ŁA���ł�����Ȃ����A�����CPU���s�[�N�������ɁB
���с[�̓R�A�̃x�[�X��MMX�y���e�B�A��+�V���߂��Č����Ă�݂���������A
OS�����������Ǝv���Γ�����������Ȃ����ǂˁB
�܂��A�ǂ��������Č����ƃA�N�Z�����[�^�̃^�O�C���Ǝv����B
>>725
i740���ē����̌������������Ƃ��邩��A�t�@�C�i�����A���e�B�ł��ꂢ�ɂ�����`�B
�����č����ȃ{�[�h�ł͂Ȃ��������A�Z�p�I�ɂ͂����{�[�h�������B
i740���ē����̌������������Ƃ��邩��A�t�@�C�i�����A���e�B�ł��ꂢ�ɂ�����`�B
�����č����ȃ{�[�h�ł͂Ȃ��������A�Z�p�I�ɂ͂����{�[�h�������B
�������{�I�Ȃ��ƂȂ̂�������Ȃ����ǁA
Larrabee�����ɂ́A
Larrabee��p�̃v���O�����������Ȃ��Ⴂ���Ȃ��́H
Larrabee�����ɂ́A
Larrabee��p�̃v���O�����������Ȃ��Ⴂ���Ȃ��́H
>>732
����܂�悭�m��Ȃ����ǁA
���с[��������R�[�h�Ƃ�����Ȃ��Ƃ����Ȃ��Ǝv���B
��́A�C���e���̊J�����ɂ��C�����������x�̐��\�͂ł邩�������B
��{�̓y���e�B�A�������A�X���b�h�ɂ܂��s��Ƃ��œK���Ƃ��̒m�������ɗ��C������B
�����́A�c�q�̐l���悭�m���Ă��Ȃ����ȁH�H
����܂�悭�m��Ȃ����ǁA
���с[��������R�[�h�Ƃ�����Ȃ��Ƃ����Ȃ��Ǝv���B
��́A�C���e���̊J�����ɂ��C�����������x�̐��\�͂ł邩�������B
��{�̓y���e�B�A�������A�X���b�h�ɂ܂��s��Ƃ��œK���Ƃ��̒m�������ɗ��C������B
�����́A�c�q�̐l���悭�m���Ă��Ȃ����ȁH�H
���낢�뎿�����Ő\����Ȃ����ǁA
����Larrabee���o���Ƃ��āA������GPU�{�[�h�Ƃ��Ďg���āA
�Ⴆ�A������FPS�̃Q�[��Call of Duty4:MW�Ȃ����̃p�b�`������邱�ƂȂ������́H
����Larrabee���o���Ƃ��āA������GPU�{�[�h�Ƃ��Ďg���āA
�Ⴆ�A������FPS�̃Q�[��Call of Duty4:MW�Ȃ����̃p�b�`������邱�ƂȂ������́H
������߂�
>>738
���с[�̉������ǂ����Č����ƁB�������B
���ꂩ��̔ėp�����d����������ɏ�邽�߂ɐ��ӊJ�����B���Ă��ƁB
�����ォ�O�̌Œ�@�\�Ŏ��������@�\�ɑ��Ă͎ア�B
�n�[�h�̔ėp���Ƌ@�\�̐��\�͔���Ⴗ��Ǝv���Ă���B
�Œ�@�\������A���\���オ�邪�ėp��������B����ȃC���[�W�B
���с[�̉������ǂ����Č����ƁB�������B
���ꂩ��̔ėp�����d����������ɏ�邽�߂ɐ��ӊJ�����B���Ă��ƁB
�����ォ�O�̌Œ�@�\�Ŏ��������@�\�ɑ��Ă͎ア�B
�n�[�h�̔ėp���Ƌ@�\�̐��\�͔���Ⴗ��Ǝv���Ă���B
�Œ�@�\������A���\���オ�邪�ėp��������B����ȃC���[�W�B
>>734
DirectX�ɑΉ����Ă�Ή\�Ȃ͂�
DirectX�ɑΉ����Ă�Ή\�Ȃ͂�
738 �F,,�E�L�́M�E,,�j��-�������F2009/11/08(��) 19:55:31 ID:g0j+SMPB
DLL�x�����[�h�̃e�N�j�b�N���d�ɂ��g��Ȃ��Ƃ����Ȃ�����
�u���j�o�[�T��GPGPU�v�ȃA�v�����̂͂߂�����܂�邼
�܂���x�d�g�ݍ���Ă��܂�������
API���ς��x�ɍ�蒼������H�ڂɁE�E�E
�u���j�o�[�T��GPGPU�v�ȃA�v�����̂͂߂�����܂�邼
�܂���x�d�g�ݍ���Ă��܂�������
API���ς��x�ɍ�蒼������H�ڂɁE�E�E
>>738
�̂�3D�}�[�N�݂����Ȋ������B
�m��P3�p��DLL�Ƃ�CPU��p�̃R�[�h���������W���[���ɕ����Ă��݂����������ȁB
�t�@�C��������̐��������ǂˁB�B�B
�̂�3D�}�[�N�݂����Ȋ������B
�m��P3�p��DLL�Ƃ�CPU��p�̃R�[�h���������W���[���ɕ����Ă��݂����������ȁB
�t�@�C��������̐��������ǂˁB�B�B
http://pc.watch.impress.co.jp/docs/column/kaigai/20091109_327607.html
Larrabee��SIMD��MIMD�̃o�����X--Intel CTO�����
Larrabee��SIMD��MIMD�̃o�����X--Intel CTO�����
����HD5800���o�Ă邵���N�ɂ�HD6xxx���o��̂ɂ��܂ł����Ă���������Ȃ�Larabee�ɖ]�݂�������C���e���M�҂̔]���X���^����
HPC����ł�RADEON�i�j�Ȃ�Ē[���瑊��ɂ���ĂȂ�
>>742
�����v���Ă����A�����l�͉����l���Ă���̂��c�c
�����v���Ă����A�����l�͉����l���Ă���̂��c�c
>>743
>>699�����
�؍��C�ے���Cray�@�Ɏ����R�X�g�p�t�H�[�}���X�ő啝�ɕ����Ă邵���l���Ă��
http://japan.cnet.com/blog/petaflops/2009/10/02/entry_27034798/
>>699�����
�؍��C�ے���Cray�@�Ɏ����R�X�g�p�t�H�[�}���X�ő啝�ɕ����Ă邵���l���Ă��
http://japan.cnet.com/blog/petaflops/2009/10/02/entry_27034798/
�G��������HPC�����������X�p�R�����V���L�i�j
�\�V�̎w�E�ɂ͗����I�Ȕ��_���ł��Ȃ����������
rade�͂��ɂȂ�����VLIW����߂�̂��ˁH
�z��2.7TFLOPS, ����500GFLOPS���x�ł��В���邤���͎��߂Ȃ����낤
>>746
���N�̌㔼�ɓ���V�X�e�������N�̃V�X�e���̂Q�{��CP���Ƃ��ĉ������������B
LINPACK�̐��\��10�N��1000�{�����B
���������V�͂̃V�X�e�����K���ǂ����͓V�͂œ����A�v���P�[�V�������悾�B
�X�p�R����LINPACK�̏��ʑ������߂ɍ����̂���ˁ[��B
���N�̌㔼�ɓ���V�X�e�������N�̃V�X�e���̂Q�{��CP���Ƃ��ĉ������������B
LINPACK�̐��\��10�N��1000�{�����B
���������V�͂̃V�X�e�����K���ǂ����͓V�͂œ����A�v���P�[�V�������悾�B
�X�p�R����LINPACK�̏��ʑ������߂ɍ����̂���ˁ[��B
��LINPACK�̐��\��10�N��1000�{�����B
����20���I���Ⴀ��܂����H
GPU�ł���8800GTX��2�N�߂����ŋ����ւ��Ă��悤�ȁA����ȕNJ��Y��
�������̍��B
����20���I���Ⴀ��܂����H
GPU�ł���8800GTX��2�N�߂����ŋ����ւ��Ă��悤�ȁA����ȕNJ��Y��
�������̍��B
���łɌ�����2010�N�㔼�Ƃ������Ƃ�Nehalem��Westmere, AMD����
Istanubul�Ȃ�ȁB����Ȃ�FLOPS�P���ς�邩�H
���łɌ����ƃg�����W�X�^�����������邾���Ńx�N�g�����Z���\��
�{�Ƀu�[�X�g����悤��AVX/FMA�݂�����SIMD�g���̃L���p�r���e�B��
GPU�͂Ƃ����̐̂Ɏg���ʂ����Ă�B���Ƃ̓������ш�͊��ō����l�߂���̂݁B
Istanubul�Ȃ�ȁB����Ȃ�FLOPS�P���ς�邩�H
���łɌ����ƃg�����W�X�^�����������邾���Ńx�N�g�����Z���\��
�{�Ƀu�[�X�g����悤��AVX/FMA�݂�����SIMD�g���̃L���p�r���e�B��
GPU�͂Ƃ����̐̂Ɏg���ʂ����Ă�B���Ƃ̓������ш�͊��ō����l�߂���̂݁B
>>750
�����ꂽ�B���Ƀg�b�v�̃V�X�e����11�N��TFLOPS����PFLOPS�ɂȂ������B
�X�p�R�����V���L�i�j�͌����Ă�Top500�{�Ƃ̃T�C�g�͌����Ȃ��낤���B
http://www.top500.org/list/1997/06/100
http://www.top500.org/list/2008/06/100
�ė��N�ɂ�10PFLOPS����V�X�e�����\�肳��Ă��āA2001�N�̃g�b�v��
7.2TFLOPS�����������l�����21���I�ɓ����Ă���������͑S�������Ă��Ȃ��B
�����ꂽ�B���Ƀg�b�v�̃V�X�e����11�N��TFLOPS����PFLOPS�ɂȂ������B
�X�p�R�����V���L�i�j�͌����Ă�Top500�{�Ƃ̃T�C�g�͌����Ȃ��낤���B
http://www.top500.org/list/1997/06/100
http://www.top500.org/list/2008/06/100
�ė��N�ɂ�10PFLOPS����V�X�e�����\�肳��Ă��āA2001�N�̃g�b�v��
7.2TFLOPS�����������l�����21���I�ɓ����Ă���������͑S�������Ă��Ȃ��B
���ꂽ�B
�Ζ������s���ɕ����Ă���Ƃł��v���Ă�̂��낤���H
���́u�g�b�v�v�̏���d�͂����ׂĂ݂�Ƃ�����B
�����ŃG�l���M�[����卑�̃A�����J�����c���ĂȂ��킯���B
�Ζ������s���ɕ����Ă���Ƃł��v���Ă�̂��낤���H
���́u�g�b�v�v�̏���d�͂����ׂĂ݂�Ƃ�����B
�����ŃG�l���M�[����卑�̃A�����J�����c���ĂȂ��킯���B
>>753
�R���s���[�^�̕����I���E�͂܂��܂��y���悾���B���O�������Ă���Ԃ͐S�z�Ȃ���
�R���s���[�^�̕����I���E�͂܂��܂��y���悾���B���O�������Ă���Ԃ͐S�z�Ȃ���
755 �F,,�E�L�́M�E,,�j��-�������F2009/11/11(��) 01:22:44 ID:4AjAynUS
�v���Z�X�J���̎����I���E�Ńo�b�^�o�b�^���Ă܂����ǂˁB
�܂��A�����̏��͓���Intel���撣���Ă����ł���B
��J����ASIC����Ă����N�Ŕėp�v���Z�b�T�ɔ�����錻��̏I����
�C�R�[��x86����̉���Ȃ���B
��J����ASIC����Ă����N�Ŕėp�v���Z�b�T�ɔ�����錻��̏I����
�C�R�[��x86����̉���Ȃ���B
�����I�Ȍ��E���������Ă��o�ϓI���E�̕����悾�ȁB
�������ė�₹��5GH���A6GHz�œ������̂��R�X�g�̂������p���@��
�����Ă邩��3GH�����x�ł����g���ĂȂ��̂���
�������ė�₹��5GH���A6GHz�œ������̂��R�X�g�̂������p���@��
�����Ă邩��3GH�����x�ł����g���ĂȂ��̂���
758 �F,,�E�L�́M�E,,�j��-�������F2009/11/12(��) 00:52:38 ID:gjkqx3Og
�ߔN��x86�̌X���Ƃ��āASIMD�g��������t�H�[�J�X����Ă邪
bsr, bsf�݂����Ȗ��߂��Ȃɂ���1�T�C�N���ŏ����ł���悤�ɂȂ�����
�n���ɃX�J�����\�̒�グ�𑱂��Ă��ˁB
�̐�10�T�C�N���������Ă����߂�1�T�C�N���ɂȂ�悤��
����ȗ]�n���c���Ă邩��A�ǂ̐w�c�������݃N���b�N�㏸�ɍs���l�܂��Ă�
x86�����͉��Z���x���オ���Ă����B
���Ă̓p�C�v���C���𗐂������RISC�M�҂���n���ɂ���Ă����߂̐��X��
�p�t�H�[�}���X�̗v�ɂȂ��Ă����̂�����ʔ����B
x86�̃g�����h�͌Œ�@�\�̏[�����BWestmere��AES�g�����߂�����B
GPU�Ƌt���s���Ă�ȁB
bsr, bsf�݂����Ȗ��߂��Ȃɂ���1�T�C�N���ŏ����ł���悤�ɂȂ�����
�n���ɃX�J�����\�̒�グ�𑱂��Ă��ˁB
�̐�10�T�C�N���������Ă����߂�1�T�C�N���ɂȂ�悤��
����ȗ]�n���c���Ă邩��A�ǂ̐w�c�������݃N���b�N�㏸�ɍs���l�܂��Ă�
x86�����͉��Z���x���オ���Ă����B
���Ă̓p�C�v���C���𗐂������RISC�M�҂���n���ɂ���Ă����߂̐��X��
�p�t�H�[�}���X�̗v�ɂȂ��Ă����̂�����ʔ����B
x86�̃g�����h�͌Œ�@�\�̏[�����BWestmere��AES�g�����߂�����B
GPU�Ƌt���s���Ă�ȁB
AES�g�����ߒlj���m��Ȃ������B�Ȃ�����Nano�̑��݈Ӌ`���Ȃ��Ȃ邶��Ȃ����B
760 �F,,�E�L�́M�E,,�j��-�������F2009/11/12(��) 01:49:32 ID:gjkqx3Og
VIA�̂�����Đ�p�R�v���Z�b�T�ɓ������Ȃ����������B
Westmere��AES��SSE�p��ROM�e�[�u�����g�����ă\�t�g�I�Ɏ��s����B
Atom�Ŏg������ARM�R�̈Ӗ��ł������������ǁB
Westmere��AES��SSE�p��ROM�e�[�u�����g�����ă\�t�g�I�Ɏ��s����B
Atom�Ŏg������ARM�R�̈Ӗ��ł������������ǁB
Fermi�������̉��ǂ������Ă邾�낤������҂��Ă��邪�A
Larrabee���C�ɂȂ��ȁB
�K�����̃n�[�h�E�F�A�������ăg�����W�X�^�̂��ȁB
CUDA�̃v���O���~���O���f���͊��ꂽ�番����₷������D�������A
Ct�͂ǂ��Ȃ�B�Q�[���͑����̂�Larrabee�c�c�H
��ɓ��ꂽ�玩���p�̃G���R�[�_�[�ł������Ă݂����ˁB
�������A������̘b�͓�����Ax86�͉��ŕ���������̂��B
Larrabee���C�ɂȂ��ȁB
�K�����̃n�[�h�E�F�A�������ăg�����W�X�^�̂��ȁB
CUDA�̃v���O���~���O���f���͊��ꂽ�番����₷������D�������A
Ct�͂ǂ��Ȃ�B�Q�[���͑����̂�Larrabee�c�c�H
��ɓ��ꂽ�玩���p�̃G���R�[�_�[�ł������Ă݂����ˁB
�������A������̘b�͓�����Ax86�͉��ŕ���������̂��B
�g�����߂̊g�[��CPU-GPU�������i�߂�
GPGPU?����Ȃ̂���������
�݂����ɂȂ��Ă����낤�Ȃ����
GPGPU?����Ȃ̂���������
�݂����ɂȂ��Ă����낤�Ȃ����
�T�E���h�{�[�h�Ƃ�NIC���I���{�ŏ\���ɂȂ������������
Larabee��i752�̓�̕��ɂȂ�\��
�Ȃ�قǓ������Ő�������킯�ł���
Larabee���o���Ƃ��ɁA�����̃Q�[�������̂܂܂œ������ǂ����ɂ��ă\�[�X����H
�������Ƃ��āA�����œ��삷�錩���݂���́H
Larabee��p�ɓ���ȃv���O�������K�v�Ȃ畁�y���Ȃ��B�����PS3�����ɁA�����Ɏ������B
�Q�[���Ɍ�����3D�ȂǕK�v�Ȃ��B�X�[�p�[�R���s���[�^�p�r�H��X��ʃ��[�U�[�ɂ͈�؊W�Ȃ��B
�������Ƃ��āA�����œ��삷�錩���݂���́H
Larabee��p�ɓ���ȃv���O�������K�v�Ȃ畁�y���Ȃ��B�����PS3�����ɁA�����Ɏ������B
�Q�[���Ɍ�����3D�ȂǕK�v�Ȃ��B�X�[�p�[�R���s���[�^�p�r�H��X��ʃ��[�U�[�ɂ͈�؊W�Ȃ��B
Larrabee�X�^�C�������s��̂́E�E�E5�N�ゾ�I
>Larabee���o���Ƃ��ɁA�����̃Q�[�������̂܂܂œ������ǂ����ɂ��ă\�[�X����H
�����H
>�������Ƃ��āA�����œ��삷�錩���݂���́H
�����H
>Larabee��p�ɓ���ȃv���O�������K�v�Ȃ畁�y���Ȃ��B
�n�����B
>�Q�[���Ɍ�����3D�ȂǕK�v�Ȃ��B�X�[�p�[�R���s���[�^�p�r�H��X��ʃ��[�U�[�ɂ͈�؊W�Ȃ��B
�Q�[���̐i����ے肷��Ȃ�AGPU�͕ʂ̗p�r���J�Ȃ���ˁB���Ɠ������B
�����H
>�������Ƃ��āA�����œ��삷�錩���݂���́H
�����H
>Larabee��p�ɓ���ȃv���O�������K�v�Ȃ畁�y���Ȃ��B
�n�����B
>�Q�[���Ɍ�����3D�ȂǕK�v�Ȃ��B�X�[�p�[�R���s���[�^�p�r�H��X��ʃ��[�U�[�ɂ͈�؊W�Ȃ��B
�Q�[���̐i����ے肷��Ȃ�AGPU�͕ʂ̗p�r���J�Ȃ���ˁB���Ɠ������B
�������B
���������̒��x���Ⴑ�������Ă�����͖̂������Ǝv��
�ǂ����̃X���݂����ɍŋ��Ƃ������Ƃ������Ӓn�̒��荇���Ƃ͖��������B
���������̒��x���Ⴑ�������Ă�����͖̂������Ǝv��
�ǂ����̃X���݂����ɍŋ��Ƃ������Ƃ������Ӓn�̒��荇���Ƃ͖��������B
>>766
����GPU�ɍœK�����ꂽ�Q�[���������ɓ��삷�邩�ƌ�����No���B������A��B
�Q�[���������Ȃ��~�[����ʃ��[�U�[��\�݂����ȃc������˂���B
����GPU�ɍœK�����ꂽ�Q�[���������ɓ��삷�邩�ƌ�����No���B������A��B
�Q�[���������Ȃ��~�[����ʃ��[�U�[��\�݂����ȃc������˂���B
�ꉞ�A��b�̊�b�Ƃ���
�����Č����Ȃ�f�B�X�v���C�h���C�o���̂��e�Ђ̃`�b�v�����́u����ȃv���O�����v����
���ꂪ�ׂɁu��X��ʃ��[�U�[�v����͊e��̕Ȃ��������`�b�v�̓��삪���������̃p�t�H�[�}���X�̍�����x�̈Ⴂ���������Ȃ��Ȃ�
GPU�Ɋւ��Ă���Ɂ{���ē���ȃv���O�������K�v���ƌ�����NO���Ǝv����
���̗p�r�Ɏg���Ȃ牽�������̃A�N�Z�����[�^�\�t�g���p�ӂ���邩������Ȃ����ǁB
�����Č����Ȃ�f�B�X�v���C�h���C�o���̂��e�Ђ̃`�b�v�����́u����ȃv���O�����v����
���ꂪ�ׂɁu��X��ʃ��[�U�[�v����͊e��̕Ȃ��������`�b�v�̓��삪���������̃p�t�H�[�}���X�̍�����x�̈Ⴂ���������Ȃ��Ȃ�
GPU�Ɋւ��Ă���Ɂ{���ē���ȃv���O�������K�v���ƌ�����NO���Ǝv����
���̗p�r�Ɏg���Ȃ牽�������̃A�N�Z�����[�^�\�t�g���p�ӂ���邩������Ȃ����ǁB
�Q�[��������ے肷��Ȃ�NVIDIA��GT300�n����ɐ�����̎~�߂���
�L�����p�ł���A�v���̂��Ă��Ȃ��n�[�h�����i������ق�Intel����������Ȃ�����
�L�����p�ł���A�v���̂��Ă��Ȃ��n�[�h�����i������ق�Intel����������Ȃ�����
�������ĂȂ���BHPC����ł͑���ɂȂ�Ȃ�������B������HPC����̃p�t�H�[�}���X�͌�̃Q�[�������Ă����B
NV�~�̎v�l�͑��ς�炸�x���ŗ�
AMD�~�ȉ���������
AMD�~�ȉ���������
CUDA���Ă��Ȃ蕁�y���Ă�C���[�W�����邯�ǁA���ۂ͑Ή��\�t�g�͐�����قǂ����Ȃ����Č�����
�w�ǃz�r�[�v���O���}�[�̋Y��Ɏg���Ă邮�炢��
�w�ǃz�r�[�v���O���}�[�̋Y��Ɏg���Ă邮�炢��
�ȁ[�ςȂ̂��܂��撣���Ă�̂���
Larrabee�̖ʔ��������͑S����x86���߂̑���v���Z�b�T�ł��邱�ƁB
GPU�Ƃ��Ďg���Ȃ�\�t�g�E�F�A�`��(��)�ƌ����Ă����_�ł��Ȃ������ꂪ���̂܂ܗ��_
GPGPU�Ƃ��Ďg���ꍇ�����l�Bx86�Ƃ��Ă̎d�l�̐���͂�������Ƃ��Ă�
����GPU�̃`�b�v�Ɣ�ׂ�Ηy���ɔėp���ɕx�ށB���ʂ��o�ɂ����B
���[����̏��������\�ȃ`�b�v�g���������ި���۾���Ȃ���̂��������˂����
Larrabee�̖ʔ��������͑S����x86���߂̑���v���Z�b�T�ł��邱�ƁB
GPU�Ƃ��Ďg���Ȃ�\�t�g�E�F�A�`��(��)�ƌ����Ă����_�ł��Ȃ������ꂪ���̂܂ܗ��_
GPGPU�Ƃ��Ďg���ꍇ�����l�Bx86�Ƃ��Ă̎d�l�̐���͂�������Ƃ��Ă�
����GPU�̃`�b�v�Ɣ�ׂ�Ηy���ɔėp���ɕx�ށB���ʂ��o�ɂ����B
���[����̏��������\�ȃ`�b�v�g���������ި���۾���Ȃ���̂��������˂����
���Ă�Larrabee�ɔے�I�Ȃ̂���NVIDIA���炢�ł���
�ϑz��
768K�ۂ����̃L���b�V���Ńp�t�H�[�}���X���҂���Ȃ��J�͂��ˁ[��
781 �F,,�E�L�́M�E,,�j��-�������F2009/11/12(��) 23:15:54 ID:gjkqx3Og
> Larabee��p�ɓ���ȃv���O�������K�v�Ȃ畁�y���Ȃ��B�����PS3�����ɁA�����Ɏ������B
�Ȃ�ŁuCUDA�v�Ƃ��uOpenCL�v�ɒu�������Ă����̂܂�ܒʗp����悤�Ȃ��ƌ����́H
Larrabee�͕��ʂ�CPU�̂悤��C�őg�߂�B
�Ȃ�ŁuCUDA�v�Ƃ��uOpenCL�v�ɒu�������Ă����̂܂�ܒʗp����悤�Ȃ��ƌ����́H
Larrabee�͕��ʂ�CPU�̂悤��C�őg�߂�B
782 �F,,�E�L�́M�E,,�j��-�������F2009/11/12(��) 23:16:35 ID:gjkqx3Og
>>777
����ID����ISA
����ID����ISA
>>782
�s�o�ɂ������X
�s�o�ɂ������X
�c�q���ăX���[�ϐ��������
�^��������MMO�̃v���f���[�T�[��Larrabee�ɋ����������Ă�݂�������
���႟ISA�Ȃ���ł�
�c�q��x86�ɒlj����Ăق����C���X�g���N�V�������ĉ�������H
�X�J���[�ł�AVX�n�ł�������B
������AMD SSE5��IMAC�n�̂���͂�~�����B���ƃr�b�g���H�F�X�B
�c�q��x86�ɒlj����Ăق����C���X�g���N�V�������ĉ�������H
�X�J���[�ł�AVX�n�ł�������B
������AMD SSE5��IMAC�n�̂���͂�~�����B���ƃr�b�g���H�F�X�B
AMD discovers several Fusion mantras, disses Larrabee
http://www.tgdaily.com/hardware-features/44524-amd-discovers-several-fusion-mantras-disses-larrabee
�u�����r�[�̓_�C�T�C�Y�傫�߂��A���ЂɂȂ�Ȃ��v
Is Larrabee For the Rest of Us?
http://www.ddj.com/hpc-high-performance-computing/221601028
�����r�[�֑͌�L���A�_��A�_���Ɏ��͂܂�Ă��܂��B
�����̃v���O���}���v���O���~���O�̓�ǂɒ��ʂ���ł��傤�B
http://www.tgdaily.com/hardware-features/44524-amd-discovers-several-fusion-mantras-disses-larrabee
�u�����r�[�̓_�C�T�C�Y�傫�߂��A���ЂɂȂ�Ȃ��v
Is Larrabee For the Rest of Us?
http://www.ddj.com/hpc-high-performance-computing/221601028
�����r�[�֑͌�L���A�_��A�_���Ɏ��͂܂�Ă��܂��B
�����̃v���O���}���v���O���~���O�̓�ǂɒ��ʂ���ł��傤�B
�Ȃ�ق�NVIDIA GPU�̌���ł��ˁB
790 �F,,�E�L�́M�E,,�j��-�������F2009/11/12(��) 23:36:07 ID:gjkqx3Og
�EAssembler
�E���ʂ�C
�E���ʂ�C++
�E���ʂ�C++ �� Threading Building Blocks
�ECt
�EOpenCL
�ECompute Shader
�D���Ȍ���E�t���[�����[�N�Ŋ撣��
�A�Z���u���͓��I�R���p�C���Ȃ�ĐM�p�ł��Ȃ����͂Ő��\�����E�܂ň����o�������l�����̍ŏI��i�ł�����
�ʂɃA�v�������͈ӎ�����K�v�Ȃ�Ė����B
�K�v�ɉ����ăQ�[���G���W�������Ή���������b�����B
>>786
AMD XOP��IMAC�̓C�}�C�`�Ȃ�ȁB�����Ŏg����́H
VPCMOV�Ƃ�VPPERM�͍D���B
�Ƃɂ���SIMD������4�I�y�����h�̗Z�����Z���߂͂����Ɨ~�����B�r�b�g���[�e�[�g�{���Z�Ƃ��A���Z�{���Z�Ƃ��B
����FMA4��imm8��4�r�b�g�]���Ă邩��u���[�h�L���X�g�̃I�v�V�������~�����B
Larrabee�� fmadd231ps v1, v2, [rsi] {1to16} �Ń��[�h�E�u���[�h�L���X�g�E�Ϙa��1�T�C�N���ł܂Ƃ߂Ď��s�ł���͖̂ʔ����B
�ł����I�u�[����Ajax�Ȃ��
�E���ʂ�C
�E���ʂ�C++
�E���ʂ�C++ �� Threading Building Blocks
�ECt
�EOpenCL
�ECompute Shader
�D���Ȍ���E�t���[�����[�N�Ŋ撣��
�A�Z���u���͓��I�R���p�C���Ȃ�ĐM�p�ł��Ȃ����͂Ő��\�����E�܂ň����o�������l�����̍ŏI��i�ł�����
�ʂɃA�v�������͈ӎ�����K�v�Ȃ�Ė����B
�K�v�ɉ����ăQ�[���G���W�������Ή���������b�����B
>>786
AMD XOP��IMAC�̓C�}�C�`�Ȃ�ȁB�����Ŏg����́H
VPCMOV�Ƃ�VPPERM�͍D���B
�Ƃɂ���SIMD������4�I�y�����h�̗Z�����Z���߂͂����Ɨ~�����B�r�b�g���[�e�[�g�{���Z�Ƃ��A���Z�{���Z�Ƃ��B
����FMA4��imm8��4�r�b�g�]���Ă邩��u���[�h�L���X�g�̃I�v�V�������~�����B
Larrabee�� fmadd231ps v1, v2, [rsi] {1to16} �Ń��[�h�E�u���[�h�L���X�g�E�Ϙa��1�T�C�N���ł܂Ƃ߂Ď��s�ł���͖̂ʔ����B
�ł����I�u�[����Ajax�Ȃ��
791 �F,,�E�L�́M�E,,�j��-�������F2009/11/12(��) 23:43:28 ID:gjkqx3Og
������͂��������������̃I�y���[�V�����ɑ���OpenCL�Ƃ�CUDA�Ȃ͌���d�l����s���R�Ȃ��
GPU�ɂ͑S�������ĂȂ�
Larrabee����Ɏg���Ƃ��āA����UTF32�ň����f�[�^�x�[�X�ł͂���Ȃ�Ɏg���邩������Ȃ��ˁB
Ct�ɂ̓T�[�`��_�N�V������API�����邵�B
GPU�ɂ͑S�������ĂȂ�
Larrabee����Ɏg���Ƃ��āA����UTF32�ň����f�[�^�x�[�X�ł͂���Ȃ�Ɏg���邩������Ȃ��ˁB
Ct�ɂ̓T�[�`��_�N�V������API�����邵�B
>>787
x86�ł��闘�_��LRBni�̗��_���ɐ��������Ƃ͓���݂������ˁB
x86�ł��邱�Ƃ��ő���������A�����̃A���S���Y����o�C�i�����p�ł�
LRBni�͑S�R����Larrabee�̐��ݔ\�͂̑唼�͗V�ԁBLRBni���ő��
���������Ƃ�����A���S���Y�������f�B�J���Ɍ������Ȃ���Ȃ炸�A
������x86���Y�ɏo�Ԃ͂Ȃ��B
x86�ł��闘�_��LRBni�̗��_���ɐ��������Ƃ͓���݂������ˁB
x86�ł��邱�Ƃ��ő���������A�����̃A���S���Y����o�C�i�����p�ł�
LRBni�͑S�R����Larrabee�̐��ݔ\�͂̑唼�͗V�ԁBLRBni���ő��
���������Ƃ�����A���S���Y�������f�B�J���Ɍ������Ȃ���Ȃ炸�A
������x86���Y�ɏo�Ԃ͂Ȃ��B
�����@�o�C�i�����p�@���@�\�[�X���p
794 �F,,�E�L�́M�E,,�j��-�������F2009/11/12(��) 23:54:53 ID:gjkqx3Og
>>792
�����������ĂȂ��݂������ȁB
���Ȃ��Ƃ����@�\�ȃ��������Z�@�\�t���̃��[�h�ƃu���[�h�L���X�g�ƐϘa�Z���v���f�B�P�[�g����1���߂Ŏ��s����̂�
x86�̂悤�ȃp�C�v���C�������ꂽCISC�ł���K�v�͂���B
�����������ĂȂ��݂������ȁB
���Ȃ��Ƃ����@�\�ȃ��������Z�@�\�t���̃��[�h�ƃu���[�h�L���X�g�ƐϘa�Z���v���f�B�P�[�g����1���߂Ŏ��s����̂�
x86�̂悤�ȃp�C�v���C�������ꂽCISC�ł���K�v�͂���B
Rade��Gefo�Ȃ�GPU��Larrabee��
�����̃p�[�g�̂������ƃC���e���W�F���g�ȃp�[�g�̂�����炢�̈Ⴂ������
�����̃p�[�g�̂������ƃC���e���W�F���g�ȃp�[�g�̂�����炢�̈Ⴂ������
796 �F,,�E�L�́M�E,,�j��-�������F2009/11/13(��) 00:03:47 ID:gjkqx3Og
Fermi�͂悭�P�����ꂽ�p�[�g�̂�����炢�H
���Ⴀ68000�n�̏I�Ղ̓z�ł������̂��ȁH�@�p�C�v���C��������Ă�炵�����ǁB
RP2�����Ƃ�SuperH�Ń����r�[�ł��Ȃ����ȁA�Ǝv�������ǂ����RISC������_�����ˁB
�a��GPGPU�̖��͊���Ȃ����B
RP2�����Ƃ�SuperH�Ń����r�[�ł��Ȃ����ȁA�Ǝv�������ǂ����RISC������_�����ˁB
�a��GPGPU�̖��͊���Ȃ����B
>>790
���ɒc�q���g�[�^���t�b�g�{�[���ɖڊo�߂���
���ɒc�q���g�[�^���t�b�g�{�[���ɖڊo�߂���
�}�j�A�b�N���ȁB�C���O�����h��X�y�C���Ȃ�킩�邪�B
�y�Q�����˂�10�T�N�z�_��́u��,,�E�L�́M�E,,�j��-�������v�̔閧�Ƃ́H
http://pc11.2ch.net/test/read.cgi/jisaku/9240911011/
http://pc11.2ch.net/test/read.cgi/jisaku/9240911011/
�I�����_���}�j�A�b�N�Ƃ��A���G��
802 �F,,�E�L�́M�E,,�j��-�������F2009/11/13(��) 00:41:29 ID:TwafIZZ/
Larrabee�Ƃ͘b������邪
Atom�̊J���҃R�~���j�e�B�T�C�g
http://appdeveloper.intel.com/en-us/contest/contest-entry?id=199
Atom�����App Store�݂����ȃT�C�g�����グ��C�炵���ȁB
OS��Windows��Moblin�Ή�
Atom�̊J���҃R�~���j�e�B�T�C�g
http://appdeveloper.intel.com/en-us/contest/contest-entry?id=199
Atom�����App Store�݂����ȃT�C�g�����グ��C�炵���ȁB
OS��Windows��Moblin�Ή�
�㓡��Atom���\���g����Larrabee����낤�Ǝv���Ώo����Ƃ������Ă����A
Bobcat���\���g����AMD Larrabee����낤�Ǝv���Ώo����̂��ȁH
Bobcat���\���g����AMD Larrabee����낤�Ǝv���Ώo����̂��ȁH
����������ƃV���v���ȃR�A�̕����������낤
Bobcat�͖����B
in-order�g���Ă邵�_�C�T�C�Y�ł������B
in-order�g���Ă邵�_�C�T�C�Y�ł������B
>>805
http://pc.watch.impress.co.jp/docs/column/kaigai/20091112_328392.html
���̓_�͑��v�I�@Bobcat��Out-of-Order������Bin-order����Ȃ�����B
http://pc.watch.impress.co.jp/docs/column/kaigai/20091112_328392.html
���̓_�͑��v�I�@Bobcat��Out-of-Order������Bin-order����Ȃ�����B
��ׁA�f�ŊԈ������
����32nm�v���Z�X�Ō��s���[���X�g���[�������T�C�Y���Ă��Ƃ�CPU�R�A������25mm2�ȏゾ�낤�H
�S�R�b�ɂȂ�Ȃ��B�V���v���R�A��out-of-order���Ď��_�ł����A�E�g�B
����32nm�v���Z�X�Ō��s���[���X�g���[�������T�C�Y���Ă��Ƃ�CPU�R�A������25mm2�ȏゾ�낤�H
�S�R�b�ɂȂ�Ȃ��B�V���v���R�A��out-of-order���Ď��_�ł����A�E�g�B
BOBCAT�͂��蓾�Ȃ��ɂ��Ă��̂�CPU���v���Z�X1���ゲ�ƂɃN���b�N���������A���Ă����P���v�Z�����Ă����ƁA
1GHz�`2GHz�ɒB������̂͌��\����BAMD�Ń����r�[�����Ȃ��Ƃ͎v��Ȃ��B
��Ȃ��Ƃ���Ȃ�Ȃ�̂��߂�Ati�����̂��A�ƁB
1GHz�`2GHz�ɒB������̂͌��\����BAMD�Ń����r�[�����Ȃ��Ƃ͎v��Ȃ��B
��Ȃ��Ƃ���Ȃ�Ȃ�̂��߂�Ati�����̂��A�ƁB
�����I��AMD��Larrabee���K���o��Ǝv����
�\������Larrabee���s���܂ŏo�Ă��Ȃ�
�\������Larrabee���s���܂ŏo�Ă��Ȃ�
810 �F,,�E�L�́M�E,,�j��-�������F2009/11/14(�y) 00:28:15 ID:8rfW0ww8
811 �F,,�E�L�́M�E,,�j��-�������F2009/11/14(�y) 00:30:43 ID:8rfW0ww8
�L���b�V�����肪gdgd����
>>807
Ontario��40nm
Ontario��40nm
>>807�C812
�v���Z�X���ゲ�ƂɌ���ꂽ�g�����W�X�^���ő�R�ς߂�̂́A���Ď��Ȃ�
�_�C�T�C�Y��r���g�����W�X�^���Ŕ�r�������������̂ł͂Ȃ����ˁB
�v���Z�X���ゲ�ƂɌ���ꂽ�g�����W�X�^���ő�R�ς߂�̂́A���Ď��Ȃ�
�_�C�T�C�Y��r���g�����W�X�^���Ŕ�r�������������̂ł͂Ȃ����ˁB
����Fermi���\���ꂽ��
���_�X���[�v�b�g1.26TFLOPS�Ƃ�����ɂȂ��B
Larrabee��32core�ł�1GHz�ł����܂��Ȃ��Ă��������\�ŏ��Ă�͈́B
Larrabee��32core�ł�1GHz�ł����܂��Ȃ��Ă��������\�ŏ��Ă�͈́B
816 �FSocket774�F2009/11/18(��) 02:05:55 ID:nEWQ2AiR
���E�̔����̋ƊE�s�n�o�Q�O
��F
�C���e���@TI�@�N�A���R���@AMD�@ �t���[�X�P�[���E�Z�~�R���_�N�^�[�@�u���[�h�R���@�}�C�N�����@NVIDIA�@Marvell�@�A�i���O�E�f�o�C�Z�Y
���{�F
���Ł@���l�T�X �e�N�m���W�[�@�\�j�[�@NEC�@�p�i�\�j�b�N�@�V���[�v�@�G���s�[�_�������@���[���@�x�m��
�؍��F
�T���X���d�q�@�n�C�j�b�N�X
����ȊO�F
ST�}�C�N���G���N�g���j�N�X�i�ɁE���E�X�C�X�̍��فj�@�C���t�B�j�I���i�h�C�c�j�@NXP�Z�~�R���_�N�^�[�Y�i�I�����_�j�@MediaTek�i��p�j
���E�I�ɂ͂R�J���ɔ����̊�Ƃ̕��z�����Ă���B
��������l������ƊE�ő��̂h���������ɑR����̂͒N�����ɂ��Ă���ς����`�E�E�E�E�B
�`�l�c�͍����������o���āA���͂�P�ƂŐ����c��̂���������Ă��Ă���B
�����炱���A�g����\������B���͂m�u�h�c�h�`�A�h�a�l�ASamsung�̂R�Ђ炵���B
�����A�������A���Ƃ��`�l�c���؍��E�����̊�ƂɂȂ����Ƃ��Ă����AMD��ׂ��Ă͂����Ȃ��B
�������`�l�c���ׂ���Intel���V�F�A�Ɖ��i�̗��ʂŃn�C�X�R�A��@���o���悤�ɂȂ�B
��F
�C���e���@TI�@�N�A���R���@AMD�@ �t���[�X�P�[���E�Z�~�R���_�N�^�[�@�u���[�h�R���@�}�C�N�����@NVIDIA�@Marvell�@�A�i���O�E�f�o�C�Z�Y
���{�F
���Ł@���l�T�X �e�N�m���W�[�@�\�j�[�@NEC�@�p�i�\�j�b�N�@�V���[�v�@�G���s�[�_�������@���[���@�x�m��
�؍��F
�T���X���d�q�@�n�C�j�b�N�X
����ȊO�F
ST�}�C�N���G���N�g���j�N�X�i�ɁE���E�X�C�X�̍��فj�@�C���t�B�j�I���i�h�C�c�j�@NXP�Z�~�R���_�N�^�[�Y�i�I�����_�j�@MediaTek�i��p�j
���E�I�ɂ͂R�J���ɔ����̊�Ƃ̕��z�����Ă���B
��������l������ƊE�ő��̂h���������ɑR����̂͒N�����ɂ��Ă���ς����`�E�E�E�E�B
�`�l�c�͍����������o���āA���͂�P�ƂŐ����c��̂���������Ă��Ă���B
�����炱���A�g����\������B���͂m�u�h�c�h�`�A�h�a�l�ASamsung�̂R�Ђ炵���B
�����A�������A���Ƃ��`�l�c���؍��E�����̊�ƂɂȂ����Ƃ��Ă����AMD��ׂ��Ă͂����Ȃ��B
�������`�l�c���ׂ���Intel���V�F�A�Ɖ��i�̗��ʂŃn�C�X�R�A��@���o���悤�ɂȂ�B
VIA�c
818 �F,,�E�L�́M�E,,�j��-�������F2009/11/18(��) 02:53:21 ID:r93Gw0lQ
Intel������ꂵ�߂�̂�ARM���Ǝv�����A�t�ɒቿ�i�����Ƃ������ݕ�����ARM���ꂵ�߂邱�ƂɂȂ�Ǝv���B
�}�X�N�쐬�̃R�X�g�����Đ�����d�˂邲�Ƃɏオ���Ă邵�A�����Ȃ�ƖʐϒP���̍����ق������ΓI�ɗL���ɂȂ�
�}�X�N�쐬�̃R�X�g�����Đ�����d�˂邲�Ƃɏオ���Ă邵�A�����Ȃ�ƖʐϒP���̍����ق������ΓI�ɗL���ɂȂ�
�g����Ƃ��o����GF�̍X�ɑO����n������ˁ[��
820 �FSocket774�F2009/11/18(��) 03:12:24 ID:nEWQ2AiR
AMD�̊����́A�l�C�e�B�u�N�A�b�h�R�APhenom�̎��s�Ŕ��Ɉ����Ȃ��Ă��܂��B
AMD��ATI���������z�ŁAAMD��ATI�������Ă��܂��ɂ���܂��B
���݁A�`�l�c�Ɏ�������Ă���̂́u���o�_���J�����Ёv�u�`�s�h�b�v�Ƃ����A���u���A�M�̐��{�n������ЂŁA
�o�b�N�ɂ���t�`�d�Ƃ��Ă͖L�x�ȃL���b�V��������ɔ����̎Y�Ƃ𒆋ߓ��ɗ����グ�悤�Ƃ��Ă���B
�ړI�͐Ζ��ˑ��o�ς���̒E�p�̂��߁B
���̈�Ƃ��Ă`�l�c�̉��l�f�����낤�B���{�n������Ђ͖L�x�ȐΖ���V�R�K�X�ɂ�������f�Ս������ɂ��O�ݏ������Ȃǂ�
���������B���邪�A�����J���}�g���ɂ���Ă��Ȃ��̂����_�ŁA�^�c���Ԃ͔��ɕs�����B
http://eetimes.jp/news/3486
http://eetimes.jp/article/20643
http://d.hatena.ne.jp/dubai_investment/20080601/1212333615
http://dobizdubai.blogspot.com/2008_06_01_archive.html
http://www.energyjl.com/2008_folder/October/08new1014_1.html
http://www.uaeinteract.com/japanese/business/
http://www.dso.ae/
�C���e���ɑR���悤�Ƃ�����o�����鑤������Ȃ�̑g�D�ɂȂ��Ă���B
http://www.heise.de/newsticker/meldung/SC09-Intel-demonstriert-Larrabee-mit-ueber-1-Teraflops-862305.html
�P���x�s��ςŎ���1TFLOPS���x�炵��
�P���x�s��ςŎ���1TFLOPS���x�炵��
441 ���O�F���̖��ݒ�[sage] ���e���F2009/11/18(��) 18:52:34 ID:EopSiN2r0
�M���x��߂̓��{���
ttp://www.heise.de/newsticker/meldung/SC09-Intel-demonstriert-Larrabee-mit-ueber-1-Teraflops-862305.html
SC09�ŃV���O���J�[�h��Larrabee��SGEMM��1TFover�Ƃ����f�����s��ꂽ�B���s�ő���Tesla C1060��320GF�B
1TF�̃f���͎���i��OC�ɂ���čs��ꂽ�B(����2006�N��80�R�A�Ɠ�����@)
OC���Ȃ��ꍇ�͗��_���\712GF��SGEMM��417GF�H
���łȏ���̍s���Ă���Larrabee�����A�u�x���͖�������(by ���g�i�[)�v�B
GPGPU��CPU�Ƃ̃f�[�^�̂���肪�{�g���l�b�N�B
Intel��QPI��CPU��Larrabee������������Ԃ����L(M-Y-O)���郂�f�����o���B
Nehalem-EX '��' 2010�N�O���ɏo���BHPC������6�R�A�̍��N���b�N�ł��o���B
�M���x��߂̓��{���
ttp://www.heise.de/newsticker/meldung/SC09-Intel-demonstriert-Larrabee-mit-ueber-1-Teraflops-862305.html
SC09�ŃV���O���J�[�h��Larrabee��SGEMM��1TFover�Ƃ����f�����s��ꂽ�B���s�ő���Tesla C1060��320GF�B
1TF�̃f���͎���i��OC�ɂ���čs��ꂽ�B(����2006�N��80�R�A�Ɠ�����@)
OC���Ȃ��ꍇ�͗��_���\712GF��SGEMM��417GF�H
���łȏ���̍s���Ă���Larrabee�����A�u�x���͖�������(by ���g�i�[)�v�B
GPGPU��CPU�Ƃ̃f�[�^�̂���肪�{�g���l�b�N�B
Intel��QPI��CPU��Larrabee������������Ԃ����L(M-Y-O)���郂�f�����o���B
Nehalem-EX '��' 2010�N�O���ɏo���BHPC������6�R�A�̍��N���b�N�ł��o���B
823 �FSocket774�F2009/11/18(��) 20:16:40 ID:PEHftHnx
>GPGPU��CPU�Ƃ̃f�[�^�̂���肪�{�g���l�b�N�B
���ǂǂ�ȃJ�[�h�o���Ă��������Ȃ���
���ǂǂ�ȃJ�[�h�o���Ă��������Ȃ���
>GPGPU��CPU�Ƃ̃f�[�^�̂���肪�{�g���l�b�N�B
��͂�Haswell��Larrabee��������Intel�叟���Ƃ������Ƃ�
��͂�Haswell��Larrabee��������Intel�叟���Ƃ������Ƃ�
�Ł@���ł��@���������Ă������Ȃ�����
����1�N���炢285�ł�����
����1�N���炢285�ł�����
ttp://www.hardware-infos.com/news.php?news=3308
���̋L�����ǂނƁA�ʏ�417GFlops�ŁA���܂ɍő�l��712GFlops���ł����Ċ����Ȃ��ǁB
OC���ďo��1006GFlops���ő�l�炵�����ǁB
SGEMM���Đ��l417�`712GFlops�݂����ɕϓ�����悤�Ȃ��́H
����Ƃ����܂ɃL���b�V���ɏ�肭�q�b�g���Ē��ˏオ���Ă��邾���H
���̋L�����ǂނƁA�ʏ�417GFlops�ŁA���܂ɍő�l��712GFlops���ł����Ċ����Ȃ��ǁB
OC���ďo��1006GFlops���ő�l�炵�����ǁB
SGEMM���Đ��l417�`712GFlops�݂����ɕϓ�����悤�Ȃ��́H
����Ƃ����܂ɃL���b�V���ɏ�肭�q�b�g���Ē��ˏオ���Ă��邾���H
827 �F,,�E�L�́M�E,,�j��-�������F2009/11/20(��) 10:02:00 ID:OfG4YBQO
��B
�����\�t�g���̓`���[�j���O�s�����Ǝv���B
�����\�t�g���̓`���[�j���O�s�����Ǝv���B
�ʏ�417GFlops/���_��800GFlops�ł��債������B
�����̋K�͂��オ���Ă���i�K��GPGPU�͊��S�ɒE������B
�����̋K�͂��オ���Ă���i�K��GPGPU�͊��S�ɒE������B
4.7TFLOPS��GPU�������鎞���417GFLOPS�ƂȂ�
�S����ALU���t���ғ�����FP�Ϙa�Z���������s�����ꍇ�Ƃ������肦�Ȃ�
�����ł̍ő嗝�_�l�����������ɏo���Ă��˂�
���������Ȃ炻��4.7TFLOPS�i�د �̃J�[�h�͎���300GF���o�Ȃ��Ǝv���B
����Ӗ��őO����ł̎��т����邵�B
���Z���j�b�g������̃������ш�̋����A�L���b�V���������̏��Ȃ��A
�z�X�g�ԓ]���ш�E�E�E�����S�ă{�g���l�b�N�v���B
�����ł̍ő嗝�_�l�����������ɏo���Ă��˂�
���������Ȃ炻��4.7TFLOPS�i�د �̃J�[�h�͎���300GF���o�Ȃ��Ǝv���B
����Ӗ��őO����ł̎��т����邵�B
���Z���j�b�g������̃������ш�̋����A�L���b�V���������̏��Ȃ��A
�z�X�g�ԓ]���ш�E�E�E�����S�ă{�g���l�b�N�v���B
���Ȃ݂�NVIDIA��AMD��HPC�����Ƀf���A��GPU�J�[�h���o�������т��Ȃ���
�o���Ă��z�X�g�ԑш施��GPGPU�ł͖��ɗ����Ȃ��B
�ʐM�ш悪�l�b�N�ɂȂ��Đ��\���X�P�[�����Ȃ�����ȁB
�O���t�B�b�N�Ƃ͏��肪�Ⴄ�B�A�z�B
�o���Ă��z�X�g�ԑш施��GPGPU�ł͖��ɗ����Ȃ��B
�ʐM�ш悪�l�b�N�ɂȂ��Đ��\���X�P�[�����Ȃ�����ȁB
�O���t�B�b�N�Ƃ͏��肪�Ⴄ�B�A�z�B
�͂��E�E�E���тł���
����TOP500��5�ʁA�d�͐��\��4�ʂɂ��Ă邾���˂���
�������O�����4000�V���[�Y�ł�
�����H�Q�t�H�H����Ȃ̂ǂ��ɂ���̂ł����H��
�����炪�o�Ă��鍠�ɂ͒P�̂�10TFLOPS����HD6000�V���[�Y�Ƀt���{�b�R����Ă�悗
����TOP500��5�ʁA�d�͐��\��4�ʂɂ��Ă邾���˂���
�������O�����4000�V���[�Y�ł�
�����H�Q�t�H�H����Ȃ̂ǂ��ɂ���̂ł����H��
�����炪�o�Ă��鍠�ɂ͒P�̂�10TFLOPS����HD6000�V���[�Y�Ƀt���{�b�R����Ă�悗
���Ⴀ���т��݂Ă݂悤���B
���ʂ��킩��Ȃ�Z�����炢�͂킩�邾��H
http://www.top500.org/system/performance/10186
CPU���̐��\�������������Ɍv�Z���Ă�
563,100GFLOPS/2560�� �� 219GFLOPS/��
ACML-GPU����SGEMM�i�P���x�j�ł����������{���x��2�{��
440GFLOPS���x���ւ̎R�B
�f���A���J�[�h�̓X�P�[�����Ȃ�����������Radeon���̂��̂������������B
���ꂪ�����B
10TF�H
���肦�Ȃ����ϑz���قǂقǂɁB
���ʂ��킩��Ȃ�Z�����炢�͂킩�邾��H
http://www.top500.org/system/performance/10186
CPU���̐��\�������������Ɍv�Z���Ă�
563,100GFLOPS/2560�� �� 219GFLOPS/��
ACML-GPU����SGEMM�i�P���x�j�ł����������{���x��2�{��
440GFLOPS���x���ւ̎R�B
�f���A���J�[�h�̓X�P�[�����Ȃ�����������Radeon���̂��̂������������B
���ꂪ�����B
10TF�H
���肦�Ȃ����ϑz���قǂقǂɁB
�V�͂�GPU�����̐��\���Ď��ۂǂꂭ�炢�Ȃ낤�ˁB
ttp://www.geocities.jp/andosprocinfo/wadai09/20091114.htm
�ɂ���\���̐�����������������ALINPACK�̐����̔����߂���
CPU�����ł������o���Ă�悤�ȋC��������ǁB
ttp://www.geocities.jp/andosprocinfo/wadai09/20091114.htm
�ɂ���\���̐�����������������ALINPACK�̐����̔����߂���
CPU�����ł������o���Ă�悤�ȋC��������ǁB
>>834
�����������Ă�ˁB
Harpertown��Nehalem�I�����[�̃N���X�^��90��������B�����Ă邵
GPU�̃h���C�o�^�C���������������Ă����ƊT�Z���Ă�200TF���x��CPU���ʼn҂��ł�ƌ�����B
�������ш�͉��Z���j�b�g������ł݂�Ƒ��ΓI�ɐ�����d�˂邲�Ƃɋ����Ȃ��Ă���B
�X���b�h������̃X�N���b�`�p�b�h�����������Ȃ�����B
���_���\�������摖�肵�Ď������\�����Ă����Ȃ��̂��������B
�����������Ă�ˁB
Harpertown��Nehalem�I�����[�̃N���X�^��90��������B�����Ă邵
GPU�̃h���C�o�^�C���������������Ă����ƊT�Z���Ă�200TF���x��CPU���ʼn҂��ł�ƌ�����B
�������ш�͉��Z���j�b�g������ł݂�Ƒ��ΓI�ɐ�����d�˂邲�Ƃɋ����Ȃ��Ă���B
�X���b�h������̃X�N���b�`�p�b�h�����������Ȃ�����B
���_���\�������摖�肵�Ď������\�����Ă����Ȃ��̂��������B
CPU����200������Ƃ���GPU�������140GFlops���x�H
�`���[�j���O�łǂ̂��炢���P�o����̂��R��
�`���[�j���O�łǂ̂��炢���P�o����̂��R��
>>836
4870�P�̂�AMD�����̃`���[�j���O�ς݂̎����l������Ȃ��́B
SGEMM - 300 GFLOPS
DGEMM - 137 GFLOPS
X2�̃f�[�^�͌�����Ȃ������B
575/750MHz�ɃN���b�N�_�E�������105GFLOPS/s
�P���v�Z�Ńf���A��GPU������210GFLOPS/s���炢�͖ڎw����������
PCIe���l�b�N���������ˁB
Larrabee��SIMD��float�~16�܂���double�~8�̃t���b�g�\���Ȃ̂ŁA
DGEMM�̃X���[�v�b�g��SGEMM�̂��傤�ǔ������x�B
����ȂɈ����Ȃ��ˁB
4870�P�̂�AMD�����̃`���[�j���O�ς݂̎����l������Ȃ��́B
SGEMM - 300 GFLOPS
DGEMM - 137 GFLOPS
X2�̃f�[�^�͌�����Ȃ������B
575/750MHz�ɃN���b�N�_�E�������105GFLOPS/s
�P���v�Z�Ńf���A��GPU������210GFLOPS/s���炢�͖ڎw����������
PCIe���l�b�N���������ˁB
Larrabee��SIMD��float�~16�܂���double�~8�̃t���b�g�\���Ȃ̂ŁA
DGEMM�̃X���[�v�b�g��SGEMM�̂��傤�ǔ������x�B
����ȂɈ����Ȃ��ˁB
���̃A�[�L�ŒP��10T�Ƃ��o�����Ƃ�����J�[�h����������悗
HD6xxx�̓A�[�L�ς����Ȃ�������
�Ȃ����s���\�������̂�HD4870X2��2560�����g���Ă�́H
Project X
Radeon HD4870�̃s�[�N�l��ڎw�����ҒB
Radeon HD4870�̃s�[�N�l��ڎw�����ҒB
�����������ǁA1��100�`200GFlops�Ȃ�Xeon��Opteron�g����萫�\�ゾ���炶��Ȃ��́H
���ƈ���������Ȃ����낤���B
���ƈ���������Ȃ����낤���B
����1��������̐��\���{���x�Ɋւ��ẮA����ł�Cell��Tesla C1060�̃s�[�N���邵
FireStream����Ȃ���4870X2�Ȃ̂��܂��������炾�낤�ȁB
�J����ُ�ɍ����C�����邪�Ǝ҂��{���Ă銴���ۂ߂Ȃ��B
Intel���{�C���o���ƕ|�����Ă��Ƃ͊m����
FireStream����Ȃ���4870X2�Ȃ̂��܂��������炾�낤�ȁB
�J����ُ�ɍ����C�����邪�Ǝ҂��{���Ă銴���ۂ߂Ȃ��B
Intel���{�C���o���ƕ|�����Ă��Ƃ͊m����
ID:7qiryw4n�́A�T�^�I�ȃ��f�M�҂���
flops�ł������f�ł��Ȃ��]�݂����ɁX����
flops�ł������f�ł��Ȃ��]�݂����ɁX����
845 �F,,�E�L�́M�E,,�j��-�������F2009/11/21(�y) 00:57:23 ID:9TZ5jYVD
FLOPS�̓p���[���I
���`���I
������������ł��������Ȃ��悤�ȕ����������j�b�g�Ȃ�ė��_�l�ɓ����ȕ���킵���B
Load��Swizzle����삳���ďo����FLOPS�������𗝘_�l�Ƃ���B
���`���I
������������ł��������Ȃ��悤�ȕ����������j�b�g�Ȃ�ė��_�l�ɓ����ȕ���킵���B
Load��Swizzle����삳���ďo����FLOPS�������𗝘_�l�Ƃ���B
�Ȃ�x���`�}�[�N����蒼��
���s�̃x���`�}�[�N�ł����\�o�Ė������낗������
>>826
���ꉽ�R�A�H
���ꉽ�R�A�H
Larrabee(16�R�A�Ɖ���)
�����W�X�^
1�R�A��512-bit�~ 128�{
16�R�A 32bit���Z�ŁA���v32,768�{
��L1�L���b�V�� 1�R�A 32KB �{ 32KB
1024KB
��L2�L���b�V�� 1�R�A 256KB
�@4096KB
Fermi
http://pc.watch.impress.co.jp/img/pcw/docs/326/442/kaigai11.jpg
HD5870
�����W�X�^
����J
��L1�L���b�V�� 800KB
32KB �{ 8KB * 20
��L2�L���b�V�� 512KB
�@128KB * 4
Larrabee�̓��W�X�^�̖{���͏��Ȃ����AL2�L���b�V���͈��|�I�ɑ�����
HD5870�͂Ȃ������W�X�^����J�����܂����̂��ˌ��J�����
�����W�X�^
1�R�A��512-bit�~ 128�{
16�R�A 32bit���Z�ŁA���v32,768�{
��L1�L���b�V�� 1�R�A 32KB �{ 32KB
1024KB
��L2�L���b�V�� 1�R�A 256KB
�@4096KB
Fermi
http://pc.watch.impress.co.jp/img/pcw/docs/326/442/kaigai11.jpg
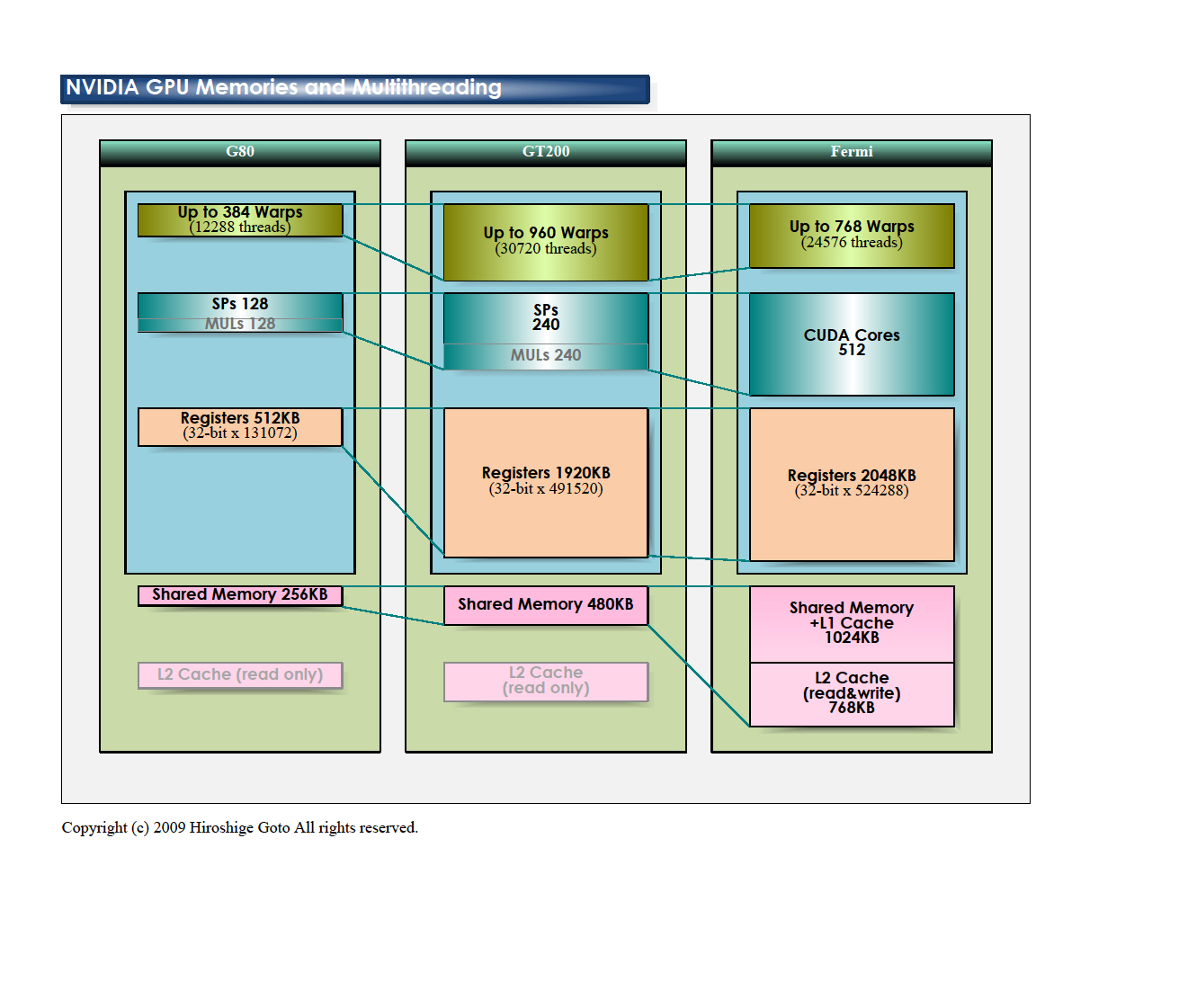{kind=link}
HD5870
�����W�X�^
����J
��L1�L���b�V�� 800KB
32KB �{ 8KB * 20
��L2�L���b�V�� 512KB
�@128KB * 4
Larrabee�̓��W�X�^�̖{���͏��Ȃ����AL2�L���b�V���͈��|�I�ɑ�����
HD5870�͂Ȃ������W�X�^����J�����܂����̂��ˌ��J�����
TSMC��40nm�����������32nm�ł��g���u���Ă�炵��
LRB�����t���O���ǂ�ǂ��Ă�����
ttp://www.semiaccurate.com./2009/11/20/tsmc-rumored-have-killed-their-32nm-node/
LRB�����t���O���ǂ�ǂ��Ă�����
ttp://www.semiaccurate.com./2009/11/20/tsmc-rumored-have-killed-their-32nm-node/
IBM���咣���Ă�悤��32nm�N���X�ɂȂ��High-k���K�{���Ď��������̂���
TSMC��High-k�̗p��28nm���炾��
TSMC��High-k�̗p��28nm���炾��
852 �F,,�E�L�́M�E,,�j��-�������F2009/11/21(�y) 11:49:30 ID:9TZ5jYVD
����L�҂̖ϑz
32�R�A��750MHz�������\����������
�Ȃ�ES�̓���N���b�N����
32�R�A��750MHz�������\����������
�Ȃ�ES�̓���N���b�N����
854 �F,,�E�L�́M�E,,�j��-�������F2009/11/21(�y) 17:27:12 ID:9TZ5jYVD
�܂��������ȁB
������417GFlops�͉��R�A�ŃN���b�N�����킩��Ȃ����
���s�����������ʂ�悤���Ȃ���
���s�����������ʂ�悤���Ȃ���
Larrabee�x����
���̂܂܂��邸��x���AVX�ł�����˂Ƃ�������ɂȂ肻��
���̂܂܂��邸��x���AVX�ł�����˂Ƃ�������ɂȂ肻��
AVX�̐�ɂ�����̂Ȃ̂ɁE�E�E
���̃T�C�g��5���ɏ�����Ă�32�R�A2GHz�͏o�Ȃ������m��Ȃ���
Fermi�̃N���b�N��20%������������
Fermi�̃N���b�N��20%������������
�L���b�V���͂܂��킩�邪���W�X�^���ĉ���
sp�Ƃ�FPU�Ƃ����̒��g�̂��ƂȂ̂��H
sp�Ƃ�FPU�Ƃ����̒��g�̂��ƂȂ̂��H
���W�X�^�̓��W�X�^��
Larrabee�̓\�t�g�E�F�A�p�C�v���C���ɂ���Ƃ��ɂ����
�Ⴆ�A�Œ�@�\��ROP���Z�����Ƃ��ɂ͌Œ肾�ƒN�������ɗ��Ȃ���
�t�ɁA�ɂȂƂ��͑��̖Z���������̏����ɂ����Ȃ�
�܂�A���ו��U�ł��Ȃ��������������
�ƌ����������ĂȂ�قǁI�Ǝv��������������Ȃ�Larrabee�̓e�N�X�`���͌Œ�ȂƁE�E�E
�Ⴆ�A�Œ�@�\��ROP���Z�����Ƃ��ɂ͌Œ肾�ƒN�������ɗ��Ȃ���
�t�ɁA�ɂȂƂ��͑��̖Z���������̏����ɂ����Ȃ�
�܂�A���ו��U�ł��Ȃ��������������
�ƌ����������ĂȂ�قǁI�Ǝv��������������Ȃ�Larrabee�̓e�N�X�`���͌Œ�ȂƁE�E�E
862 �F,,�E�L�́M�E,,�j��-�������F2009/11/22(��) 00:38:24 ID:Htnio03U
��ɂ���ăV�~�����[�V�����Ō����̌��ʂł���B
�e�N�X�`�����j�b�g�͗��p�p�x����������Œ�I�Ƀ��\�[�X���蓖�Ă������������čl�����̂ł́H
�Ƃ͂����Ă��Œ���̐������Ȃ����A�e�N�X�`���̗ʂ������ꍇ��
�K�v�ɉ����ăR�A���Ń\�t�g��������K�v�����肻���ȁB
�e�N�X�`�����j�b�g�͗��p�p�x����������Œ�I�Ƀ��\�[�X���蓖�Ă������������čl�����̂ł́H
�Ƃ͂����Ă��Œ���̐������Ȃ����A�e�N�X�`���̗ʂ������ꍇ��
�K�v�ɉ����ăR�A���Ń\�t�g��������K�v�����肻���ȁB
���ו��U�Ō�����搂��Ȃ�A�O�ꂵ�ăe�N�X�`�����\�t�g�E�F�A�ł���ė~����������
�܂��A����ł����C�o��GPU�����S�R��i�I������
���̋ƊE�́A�i�������������
���f���Ă���ƁA�����ɑΉ�����Ă��܂�
�܂��A����ł����C�o��GPU�����S�R��i�I������
���̋ƊE�́A�i�������������
���f���Ă���ƁA�����ɑΉ�����Ă��܂�
���ו��U�Ō�����搂��Ȃ�A�O�ꂵ�ăe�N�X�`�����\�t�g�E�F�A�ł���ė~����������
�܂��A����ł����C�o��GPU�����S�R��i�I������
���̋ƊE�́A�i�������������
���f���Ă���ƁA�����ɑΉ�����Ă��܂�
�܂��A����ł����C�o��GPU�����S�R��i�I������
���̋ƊE�́A�i�������������
���f���Ă���ƁA�����ɑΉ�����Ă��܂�
�厖�Ȃ��ƁH
>>861
>Why use fixed function texture logic?
>�ETexture filtering needs specialized data access to unaligned 2x2 blocks of pixels
>�EFiltering is optimized for 8-bit color values
>�ECode would take 12x longer for filtering or 40x longer if texture decompression is required
�v����ɑ����̃R�A���e�N�X�`���̏����ɐH���Ă��܂�
�������ĕ��ו��U�̃����b�g���킮���ƂɂȂ邩��
>Why use fixed function texture logic?
>�ETexture filtering needs specialized data access to unaligned 2x2 blocks of pixels
>�EFiltering is optimized for 8-bit color values
>�ECode would take 12x longer for filtering or 40x longer if texture decompression is required
�v����ɑ����̃R�A���e�N�X�`���̏����ɐH���Ă��܂�
�������ĕ��ו��U�̃����b�g���킮���ƂɂȂ邩��
���Ȃ݂ɗ�̃V�~�����[�^�[�ł͐�p�̃e�N�X�`�����j�b�g�͎�������ĂȂ��i�S�Ă̏�����x86�R�A�ł���Ă���j�̂�
1GHz�Ƃ����Ⴂ�N���b�N�������܂��āA���i�ł͍X�ɐ��\���オ��]�n������ƌ�����
1GHz�Ƃ����Ⴂ�N���b�N�������܂��āA���i�ł͍X�ɐ��\���オ��]�n������ƌ�����
�܂�A���ו��U���ĒS���̃p�C�v���C���ŏd�������������
���̃p�C�v���C����S������l�Ԃ������̎d���𓊂��o����
�����ɂ�������S�̂̌�������������Ď�����
�Ȃ�ƂȂ��A���ו��U�̎d�g�݂�����������
���̃p�C�v���C����S������l�Ԃ������̎d���𓊂��o����
�����ɂ�������S�̂̌�������������Ď�����
�Ȃ�ƂȂ��A���ו��U�̎d�g�݂�����������
869 �F,,�E�L�́M�E,,�j��-�������F2009/11/22(��) 02:02:17 ID:Htnio03U
{kind=link}
�Œ�@�\=3D�Q�[���p�r�A�N�Z�����[�^�[
����GPU�ł��ALarrabee�݂����ȃ\�t�g�E�F�A���ł����
SP�݂̂Ŏ��s���āA�Œ�@�\�͌o�R���Ȃ����������
�Ⴆ�A���C�g���Ƃ��̓��X�^���C�Y����Ȃ�����Œ�@�\�͌o�R���Ȃ�
�܂��A�C���e���M�҂�����Larrabee�͐�Δ������ǂ�
����GPU�ł��ALarrabee�݂����ȃ\�t�g�E�F�A���ł����
SP�݂̂Ŏ��s���āA�Œ�@�\�͌o�R���Ȃ����������
�Ⴆ�A���C�g���Ƃ��̓��X�^���C�Y����Ȃ�����Œ�@�\�͌o�R���Ȃ�
�܂��A�C���e���M�҂�����Larrabee�͐�Δ������ǂ�
872 �F,,�E�L�́M�E,,�j��-�������F2009/11/22(��) 11:12:02 ID:Htnio03U
���C�g���ł��e�N�X�`���͎g������H
���C�g���ł��e�N�X�`���g����
�����āALarrabee�����̃e�N�X�`���g��
�����āALarrabee�����̃e�N�X�`���g��
�e�N�X�`���̓ǂݍ��݂͌Œ�@�\����Ȃ��̂���
������Ɠ��͂��Ȃ��ƁA���s�ł��Ȃ��o�������Ȃ��̃R���s���[�^�݂�����
����ɂȂ��Ă�����
�e�N�X�`���́A�Œ�@�\����Larrabee���e�N�X�`���͌Œ�@�\����
�܂�A����GPU��Larrabee�݂����ȃ\�t�g�E�F�A���������邽�߂�
�e�N�X�`�����Œ�@�\���ǂ����Ȃ�Ă܂������W�Ȃ�
����ɂȂ��Ă�����
�e�N�X�`���́A�Œ�@�\����Larrabee���e�N�X�`���͌Œ�@�\����
�܂�A����GPU��Larrabee�݂����ȃ\�t�g�E�F�A���������邽�߂�
�e�N�X�`�����Œ�@�\���ǂ����Ȃ�Ă܂������W�Ȃ�
������Ɠ��͂��Ă��A���s�ł��Ȃ��o�������Ȃ��̃R���s���[�^�݂����ȃ��X���ȁB
���C�g���͌Œ�@�\�g��Ȃ����Ĕ����ɑ���˂����݂Ȃ̂Ƀ����r�[�݂�����
�\�t�g�������ǂ��̂����̂Ƃ�����Ă�B
���C�g���͌Œ�@�\�g��Ȃ����Ĕ����ɑ���˂����݂Ȃ̂Ƀ����r�[�݂�����
�\�t�g�������ǂ��̂����̂Ƃ�����Ă�B
�O���t�B�b�N�X�Ȃ�Ă����ǂ��ł�������
�����Ă����V�ԃQ�[������������APC�Q�[�ɂ͂�
�R���V���[�}�[����̎c�тŃx���`��60fps�ȏ�ŋ��肗
PC�ŏo���Ă����グ�䗦10�p�[�ȉ����i��MW2
ø����Ƃ��ǂ��ł������̂�
�����Ă����V�ԃQ�[������������APC�Q�[�ɂ͂�
�R���V���[�}�[����̎c�тŃx���`��60fps�ȏ�ŋ��肗
PC�ŏo���Ă����グ�䗦10�p�[�ȉ����i��MW2
ø����Ƃ��ǂ��ł������̂�
�܂�PC�ŃQ�[���V��ł郄�V���k�r�̒�������ԂȂ�Ď����s�ȊO�̂Ȃɂ��̂ł��Ȃ��
�A�����Z�p�x���^���Ē�グ���Ă�����
�A�����Z�p�x���^���Ē�グ���Ă�����
>>877
���ŋ��̃G���Q���S�R�����Ȃ���
�c�N�[����RPG�ł������50���ԂƂ����ʂɗV�ׂ邩��Ȃ�
�O���t�B�b�N�X�̃N�I���e�B�����������������Ȃ����ۂ�
���ŋ��̃G���Q���S�R�����Ȃ���
�c�N�[����RPG�ł������50���ԂƂ����ʂɗV�ׂ邩��Ȃ�
�O���t�B�b�N�X�̃N�I���e�B�����������������Ȃ����ۂ�
�X�N�G�A���Ă������ʋ��t�����邾��
���Ɛl�ɂ���Ă�MGS4��
�O�����������Ƃɉz�������͖������������̔�d�����ɂȂ��Q�[���͂܂�Ȃ��Ȃ�
KOF�Ƃ��S�~�O�����������l�C�͂ł��낤
���Ɛl�ɂ���Ă�MGS4��
�O�����������Ƃɉz�������͖������������̔�d�����ɂȂ��Q�[���͂܂�Ȃ��Ȃ�
KOF�Ƃ��S�~�O�����������l�C�͂ł��낤
�~�t�H�g���A���͑S�ẴQ�[���ɕs�v
���t�H�g���A���͈ꕔ�̃Q�[���ɂ����K�v����Ȃ�
���t�H�g���A���͈ꕔ�̃Q�[���ɂ����K�v����Ȃ�
>>880
���{�ɂ����Ȃ��C������v�������_�����O3D�Q�[���ł�GPU��
����Đ��x���ɕK�v�B
�����GPU�̃p���[��3D�Q�[���ɂ͂ƂĂ��d�v�B
��H
���{�ɂ����Ȃ��C������v�������_�����O3D�Q�[���ł�GPU��
����Đ��x���ɕK�v�B
�����GPU�̃p���[��3D�Q�[���ɂ͂ƂĂ��d�v�B
��H
>>879
�t�@�~�R���G�~���ŗV�猋�\�ʔ����������Ă̂Ɠ������B
�t�@�~�R���G�~���ŗV�猋�\�ʔ����������Ă̂Ɠ������B
�O�����特�y�܂őS���t���[�f�ނ���elona�������ʔ����悗����
�I�u�����D���Ȃ��n�}���͂�
�I�u�����D���Ȃ��n�}���͂�
�L���b�V���R�q�[�����V�̔��肪�����
�ǂ����Ă��X�P�[�����O�̑������ɂȂ�Ǝv�����Ǒ��v�Ȃ낤���B
45n��32n�ł悭�Ă��X�ɂ��̐�̃g�����W�X�^����������̂��ǂ����B
�ǂ����Ă��X�P�[�����O�̑������ɂȂ�Ǝv�����Ǒ��v�Ȃ낤���B
45n��32n�ł悭�Ă��X�ɂ��̐�̃g�����W�X�^����������̂��ǂ����B
Intel��3D�g�[���X�܂Ō������Ă���
�܂������O�o�X�Ȃ����͗]�T�ƌ��Ă�������
�܂������O�o�X�Ȃ����͗]�T�ƌ��Ă�������
887 �F,,�E�L�́M�E,,�j��-�������F2009/11/23(��) 11:23:48 ID:nT9DryEJ
889 �F,,�E�L�́M�E,,�j��-�������F2009/11/23(��) 14:46:27 ID:nT9DryEJ
L2�ɂ���f�[�^��L1�Ɋm�ۂ����ɓǂݏo���Ƃ��ɂ��g�����B
���L�f�[�^��L1�Ɋm�ۂ������Ȃ���X�k�[�v�͕K�v�Ȃ��B
���Ƒ���gatherpfd/scatterpfd���߂��Ă̂������Ă���
���L�f�[�^��L1�Ɋm�ۂ������Ȃ���X�k�[�v�͕K�v�Ȃ��B
���Ƒ���gatherpfd/scatterpfd���߂��Ă̂������Ă���
890 �F,,�E�L�́M�E,,�j��-�������F2009/11/23(��) 15:06:21 ID:nT9DryEJ
1�L���b�V�����C�����x�N�g�����W�X�^1�{��
����Ƃ��Ă�
�E���̃��W�X�^�Ɋm�ۂ���܂ŕʂ̃��W�X�^�����œǂ�ł���
�E�X���b�h�ؑւ��ĕʂ̃X���b�h�����s����
�ǂݍ���͊e�X���b�h���[�J���Ŏg���Ă�A�h���X�̈�Ɋi�[���čė��p���邱�Ƃ��ł���B
SSE4.1�ɗގ����߂����邾��
http://gpu.fixstars.com/index.php/WriteCombine%E3%83%A1%E3%83%A2%E3%83%AA%E3%82%A2%E3%82%AF%E3%82%BB%E3%82%B9%E3%82%92%E9%AB%98%E9%80%9F%E5%8C%96%E3%81%99%E3%82%8B
����Ƃ��Ă�
�E���̃��W�X�^�Ɋm�ۂ���܂ŕʂ̃��W�X�^�����œǂ�ł���
�E�X���b�h�ؑւ��ĕʂ̃X���b�h�����s����
�ǂݍ���͊e�X���b�h���[�J���Ŏg���Ă�A�h���X�̈�Ɋi�[���čė��p���邱�Ƃ��ł���B
SSE4.1�ɗގ����߂����邾��
http://gpu.fixstars.com/index.php/WriteCombine%E3%83%A1%E3%83%A2%E3%83%AA%E3%82%A2%E3%82%AF%E3%82%BB%E3%82%B9%E3%82%92%E9%AB%98%E9%80%9F%E5%8C%96%E3%81%99%E3%82%8B
Larrabee�́A�X�[�p�[�R���s���[�^�p�r�����C�����ĔF����OK�ł���ˁH
��������Ȃ�
�ł́A�Ԉ���Ă�����Ă������ƁH�v
���j�[�R�A�\�z�̋���̈��
Cell�̃p�N���Ȃ�Č����Ă܂����H
342 ���O�F �W�C�r��(�R�l�`�J�b�g�B)[sage] ���e���F2009/11/24(��) 12:22:49.92 ID:Ar1dyVcR
�̂�Cell�̎����o�J�ɂ��ď����ɂ��Ă�Intel��
�u����ς�Cell�̕����������������������A�ͯ///�v�Ƃ������ĘI���Ƀp�N���Ă��Ă邵
�������c�_����Ăă��C���X�g���[���ɂȂ���邵
��͂苐�lIBM�̐挩�����������Ƃ������A�N�^���M���������l���Ǝv����B
379 ���O�F �w(�R�`��)[] ���e���F2009/11/24(��) 15:21:25.64 ID:cnLIpv5I
>>342
Larrabee�̂ǂ���Cell�Ɏ��Ă�
�j���J���قǂقǂɂ�
383 ���O�F �r�[�J�[(���n��)[sage] ���e���F2009/11/24(��) 15:41:09.99 ID:oEkrjBen
>379
Cell�̘_�����Ă���Core�V���[�Y�̊J�����n�܂������ǁA�����s���l����Larrabee�ɂȂ����B
���ĂȂ������Ȃ�����������Ȃ���ARM�A�[�L��Cell�̍Č��������������낤�H
���̑㏞���R�A�������E����d�́E���g�����]���ɂ���n���ɂȂ��������
Larrabee�̐v���̂͂��Ȃ�ǂ����Ȃ���
387 ���O�F ���(�x�R��)[sage] ���e���F2009/11/24(��) 15:48:21.73 ID:UDNWPfFk
>>379
���Ă镔���͌��\�����
ISA��x86�����ǃR�A���̂̓V���v���ȃx�N�^�v���Z�b�T��SPE�Ǝ��Ă�
�L���b�V���@�\��SPE��LS�̂悤�ɍő含�\���ł���悤LS�̂悤�ȃX�N���b�`�p�b�h���[�h������
�i�L���b�V���@�\�̂܂܂��Ɛ��̃R�A�����A���ł������j�[�R�A��Larrabee�ɂƂ��Č����������K���Ȃ��j
�Ⴂ���������Ǎ��̂Ƃ���Cell�ɍł��߂��v�v�z�ƌ�����̂�Larrabee
IBM�u�ȂQ�n�E�G�ŃA���`�\�j�[��Cell�P�ނ��đ����ł邯�ǓP�ނ��ˁ[��B�J�X�B�v
ttp://tsushima.2ch.net/test/read.cgi/news/1259015555/387
342 ���O�F �W�C�r��(�R�l�`�J�b�g�B)[sage] ���e���F2009/11/24(��) 12:22:49.92 ID:Ar1dyVcR
�̂�Cell�̎����o�J�ɂ��ď����ɂ��Ă�Intel��
�u����ς�Cell�̕����������������������A�ͯ///�v�Ƃ������ĘI���Ƀp�N���Ă��Ă邵
�������c�_����Ăă��C���X�g���[���ɂȂ���邵
��͂苐�lIBM�̐挩�����������Ƃ������A�N�^���M���������l���Ǝv����B
379 ���O�F �w(�R�`��)[] ���e���F2009/11/24(��) 15:21:25.64 ID:cnLIpv5I
>>342
Larrabee�̂ǂ���Cell�Ɏ��Ă�
�j���J���قǂقǂɂ�
383 ���O�F �r�[�J�[(���n��)[sage] ���e���F2009/11/24(��) 15:41:09.99 ID:oEkrjBen
>379
Cell�̘_�����Ă���Core�V���[�Y�̊J�����n�܂������ǁA�����s���l����Larrabee�ɂȂ����B
���ĂȂ������Ȃ�����������Ȃ���ARM�A�[�L��Cell�̍Č��������������낤�H
���̑㏞���R�A�������E����d�́E���g�����]���ɂ���n���ɂȂ��������
Larrabee�̐v���̂͂��Ȃ�ǂ����Ȃ���
387 ���O�F ���(�x�R��)[sage] ���e���F2009/11/24(��) 15:48:21.73 ID:UDNWPfFk
>>379
���Ă镔���͌��\�����
ISA��x86�����ǃR�A���̂̓V���v���ȃx�N�^�v���Z�b�T��SPE�Ǝ��Ă�
�L���b�V���@�\��SPE��LS�̂悤�ɍő含�\���ł���悤LS�̂悤�ȃX�N���b�`�p�b�h���[�h������
�i�L���b�V���@�\�̂܂܂��Ɛ��̃R�A�����A���ł������j�[�R�A��Larrabee�ɂƂ��Č����������K���Ȃ��j
�Ⴂ���������Ǎ��̂Ƃ���Cell�ɍł��߂��v�v�z�ƌ�����̂�Larrabee
IBM�u�ȂQ�n�E�G�ŃA���`�\�j�[��Cell�P�ނ��đ����ł邯�ǓP�ނ��ˁ[��B�J�X�B�v
ttp://tsushima.2ch.net/test/read.cgi/news/1259015555/387
�͂����茾���ăj���[���̃X���Ȃǂ��ł�����
�Q�n�j�[�g��Cell�N�����ɂ͕���邪
> ���ĂȂ������Ȃ�����������Ȃ���ARM�A�[�L��Cell�̍Č��������������낤�H
������
�@A�@R�@M�@
�ɂȂ���������
> �L���b�V���@�\��SPE��LS�̂悤�ɍő含�\���ł���悤LS�̂悤�ȃX�N���b�`�p�b�h���[�h������
Fermi��L1�Ɗ��Ⴂ���Ă�悤�����X�N���b�`�p�b�h�u���[�h�v�Ȃ�ĂȂ��B
prefetch�ƃR�q�[�����g������write-through�̐�p���߂Ȃ�
Pentium III���瑶�݂��Ă��邪�A�����܂ł���̉����̋Z�p�Ƃ���
�X�k�[�v�̉����@������Ă���B
������ō��ɃA�z
> ���ĂȂ������Ȃ�����������Ȃ���ARM�A�[�L��Cell�̍Č��������������낤�H
������
�@A�@R�@M�@
�ɂȂ���������
> �L���b�V���@�\��SPE��LS�̂悤�ɍő含�\���ł���悤LS�̂悤�ȃX�N���b�`�p�b�h���[�h������
Fermi��L1�Ɗ��Ⴂ���Ă�悤�����X�N���b�`�p�b�h�u���[�h�v�Ȃ�ĂȂ��B
prefetch�ƃR�q�[�����g������write-through�̐�p���߂Ȃ�
Pentium III���瑶�݂��Ă��邪�A�����܂ł���̉����̋Z�p�Ƃ���
�X�k�[�v�̉����@������Ă���B
������ō��ɃA�z
�悻�̔̒�x���Ȍ��܂�����������������ł���Ȃ�c
899 �FSocket774�F2009/11/24(��) 17:43:57 ID:7n+zc8OS
�����r�[�̓L�����Z���Ȃ́H
�t�F���~�[�̓L�����Z�����ꂻ������
���̃X���Ƃ�Intel������X���Ƃ��A�ǂ��납�t�����ĐX���Ȃ��悤�Ȃ��������
902 �F,,�E�L�́M�E,,�j��-�������F2009/11/24(��) 22:11:54 ID:hPX1Nh9Y
BYTE
WORD
DWORD
QWORD
DQWORD/XMMWORD
YMMWORD
???
WORD
DWORD
QWORD
DQWORD/XMMWORD
YMMWORD
???
���̃X���I��GPU�Ƃ�LRB�͊��҂ł��Ȃ��ł����H
�O���{�̓��f���ł����������Ǝv���� by Intel
�����B�育���HD5850�����Ă���B
�Ȃ�Ńe�N�X�`�����j�b�g���Ă��H
>>907
���y�����邽�߂ɉ��ʂ��Ԃ��Ă邩�炳�B
���y�����邽�߂ɉ��ʂ��Ԃ��Ă邩�炳�B
�Ȃ�Ń^�C�����O�����H
910 �F,,�E�L�́M�E,,�j��-�������F2009/11/24(��) 23:29:27 ID:hPX1Nh9Y
VRAM�̑ш����ʂ�ߖ邽�߁B
�s�N�Z�����C���P�ʂł��т��ѓ]�����ď������邩�炠�̃f�[�^������Ȃ��Ƃ�������
�ш���Ђ�����Q���B
������x�̑傫�����L���b�V���Ɋm�ۂ��ēZ�߂ď��������ق����g���t�B�b�N�팸�ł���B
�����APowerVR���ǂ��Ƃ������Ă�̂̓A�z�Ȃ�ō\���K�v�Ȃ��B
����ȑш拷���킯���Ȃ�����B
�s�N�Z�����C���P�ʂł��т��ѓ]�����ď������邩�炠�̃f�[�^������Ȃ��Ƃ�������
�ш���Ђ�����Q���B
������x�̑傫�����L���b�V���Ɋm�ۂ��ēZ�߂ď��������ق����g���t�B�b�N�팸�ł���B
�����APowerVR���ǂ��Ƃ������Ă�̂̓A�z�Ȃ�ō\���K�v�Ȃ��B
����ȑш拷���킯���Ȃ�����B
>>909
�ߋ���DX�Ƃ��Ƃ̌݊����ł������ق��������̂��Ȃ��H�H
�^�C�����O�A�[�L�e�N�`����Dx�ł̓L�����Z������Ă��܂����̂ŁA�O���C�h�݂����ȗ����ʒu����ˁH
�ߋ���DX�Ƃ��Ƃ̌݊����ł������ق��������̂��Ȃ��H�H
�^�C�����O�A�[�L�e�N�`����Dx�ł̓L�����Z������Ă��܂����̂ŁA�O���C�h�݂����ȗ����ʒu����ˁH
912 �F,,�E�L�́M�E,,�j��-�������F2009/11/24(��) 23:41:34 ID:hPX1Nh9Y
VRAM�]�������ʼn��\W�������̂ŁA�L���b�V�����|���g���ď���d�͂�}�����
���̕��̗]��TDP�L���p�̘g���ŃR�A���I�[�o�[�N���b�N���邱�Ƃ��ł���
�Ȃ�Ď������o�ꂷ�邩������Ȃ��ˁB
���̕��̗]��TDP�L���p�̘g���ŃR�A���I�[�o�[�N���b�N���邱�Ƃ��ł���
�Ȃ�Ď������o�ꂷ�邩������Ȃ��ˁB
�^�C�����O�����_�Ŕ�������V�F�[�_�Ԃ̒��ԃf�[�^�͂ǂ��ɒu����H
914 �F,,�E�L�́M�E,,�j��-�������F2009/11/25(��) 00:16:31 ID:XnXiDy9n
�^���ǂ�����̂܂�L2�L���b�V���ɂ��̂܂ܕێ��B
Cell����Ȃ�����o�P�c�����[����K�v�Ȃ�ĂȂ���B
�X�g���[�������̗��x�͑e���Ȃ�A���܂ł�GPU�ł͐₦�ԂȂ��Ȃ�����Ă�
VRAM�̃t���[�͓r��r��ɂȂ�B
����A���ꂪIntel�̖ژ_���Ȃ��ǁB
�i�K�I�Ƀ^�C���Ɉڍs���A�䂭�䂭��CPU�R�A�Ɠ������AL3�L���b�V���Ńo�b�t�@�����O���邱�Ƃ�
��苷���ш�̃������œ�������悤�ɂȂ�����ACPU�Ԃƍ����Ƀf�[�^���Ƃ肵������Ă��Ƃ�
�ł���悤�ɂȂ�B
GPU�͑ш�H���̃C���[�W�����邪�A���͈ӊO�ƐH��Ȃ����Ă̂͂��܂�m���ĂȂ������B
���Z���j�b�g�P�ʂŌ���ƃ������ш�͂��̂����������B
�v����Ƀf�[�^�̋Ǐ�����CPU�Ɣ�ׂĂ��̂����������B
�Ǐ���������Ȃ�L���b�V���͗L�����B
�\���ȃL���b�V���e�ʂ�^���Ȃ����炱�����ʂɃg���t�B�b�N���Q����킯�ŁB
Cell����Ȃ�����o�P�c�����[����K�v�Ȃ�ĂȂ���B
�X�g���[�������̗��x�͑e���Ȃ�A���܂ł�GPU�ł͐₦�ԂȂ��Ȃ�����Ă�
VRAM�̃t���[�͓r��r��ɂȂ�B
����A���ꂪIntel�̖ژ_���Ȃ��ǁB
�i�K�I�Ƀ^�C���Ɉڍs���A�䂭�䂭��CPU�R�A�Ɠ������AL3�L���b�V���Ńo�b�t�@�����O���邱�Ƃ�
��苷���ш�̃������œ�������悤�ɂȂ�����ACPU�Ԃƍ����Ƀf�[�^���Ƃ肵������Ă��Ƃ�
�ł���悤�ɂȂ�B
GPU�͑ш�H���̃C���[�W�����邪�A���͈ӊO�ƐH��Ȃ����Ă̂͂��܂�m���ĂȂ������B
���Z���j�b�g�P�ʂŌ���ƃ������ш�͂��̂����������B
�v����Ƀf�[�^�̋Ǐ�����CPU�Ɣ�ׂĂ��̂����������B
�Ǐ���������Ȃ�L���b�V���͗L�����B
�\���ȃL���b�V���e�ʂ�^���Ȃ����炱�����ʂɃg���t�B�b�N���Q����킯�ŁB
GPU���Ă��������A���^�C��3D�O���t�B�b�N�X�́A�����Ƒш�H��Ȃ����@����R����Ƃ���������
�n�[�h���C���[�h�����Ń����_�����O�p�C�v���C�����Œ肳�ꑱ����15�N���o�����A��
���������[�̃v���O���}�͂��̃n�[�h�̎d�g�݂ɏ]�������Ȃ�����ȁ[
�n�[�h���C���[�h�����Ń����_�����O�p�C�v���C�����Œ肳�ꑱ����15�N���o�����A��
���������[�̃v���O���}�͂��̃n�[�h�̎d�g�݂ɏ]�������Ȃ�����ȁ[
�L���b�V�����^�C�������_�őш�n�b�s�[�Ȃ��
�ƂĂ�����Ȃ���Larrabee����Ŏ����ł���悤�Șb����Ȃ��B
��v���Z�X3���キ�炢�i�߂Ε��ɂȂ�̂�������B
�ƂĂ�����Ȃ���Larrabee����Ŏ����ł���悤�Șb����Ȃ��B
��v���Z�X3���キ�炢�i�߂Ε��ɂȂ�̂�������B
918 �F,,�E�L�́M�E,,�j��-�������F2009/11/25(��) 08:10:36 ID:XnXiDy9n
>>916
�Ȃ�Łu�q���v�H
�������炠�����Ńg���t�B�b�N���邵�A�����Ȃ疳���ł��܂��̂���B
�L���b�V���ɂȂ��Ȃ�A����������Ƃ��Ă����������Ȃ��B
�����͏]����GPU�ƕς���B
���[�h���ĕK�v�f�[�^���L���b�V���ɂ���ʂ̕��ʂ���������^�X�N�ɐ�ւ��ĊԂ��q���B
�������]����GPU�Ƃ����A�ނ�������͗ǂ��B
�������v�A���̒��x�Ŗ]�ݔ����Ƃ���������A10����1�ȉ���L2�L���b�V���e�ʂ����Ȃ�GeForce��Radeon��
�u��]�I�ɂ��肦�Ȃ��v����B
�Ȃ��^�C���ɂȂ邩���āAOS�����邩��B�J�[�l���^�C���ŏ������Ղ��邵�A�ꍇ�ɂ���ăL���b�V�����������B
�������S���̃R�A�ŃJ�[�l���������킯����Ȃ��B
�����������������A�����I�ɃR���g���[�����邱�Ƃ���\���B
����Fermi���܂߃e�b�Z���[�^�̓\�t�g������������S����B
Fermi�ł�CUDA�Ŏ��������ˁH
�\�t�g�����ł�Hull Shader�X�e�[�W�Ɠ����������x���œ������Ă��܂��Ă����܂��̂���B
�ނ��낻�����̂ق����D�s�����낤�B
�Ȃ�Łu�q���v�H
�������炠�����Ńg���t�B�b�N���邵�A�����Ȃ疳���ł��܂��̂���B
�L���b�V���ɂȂ��Ȃ�A����������Ƃ��Ă����������Ȃ��B
�����͏]����GPU�ƕς���B
���[�h���ĕK�v�f�[�^���L���b�V���ɂ���ʂ̕��ʂ���������^�X�N�ɐ�ւ��ĊԂ��q���B
�������]����GPU�Ƃ����A�ނ�������͗ǂ��B
�������v�A���̒��x�Ŗ]�ݔ����Ƃ���������A10����1�ȉ���L2�L���b�V���e�ʂ����Ȃ�GeForce��Radeon��
�u��]�I�ɂ��肦�Ȃ��v����B
�Ȃ��^�C���ɂȂ邩���āAOS�����邩��B�J�[�l���^�C���ŏ������Ղ��邵�A�ꍇ�ɂ���ăL���b�V�����������B
�������S���̃R�A�ŃJ�[�l���������킯����Ȃ��B
�����������������A�����I�ɃR���g���[�����邱�Ƃ���\���B
����Fermi���܂߃e�b�Z���[�^�̓\�t�g������������S����B
Fermi�ł�CUDA�Ŏ��������ˁH
�\�t�g�����ł�Hull Shader�X�e�[�W�Ɠ����������x���œ������Ă��܂��Ă����܂��̂���B
�ނ��낻�����̂ق����D�s�����낤�B
919 �F,,�E�L�́M�E,,�j��-�������F2009/11/25(��) 08:19:40 ID:XnXiDy9n
>>917
���������Ă邱�Ƃ����Ȃ��Ă��\������B�s�ԓǂ߂Ȃ��l�H
���䂭�䂭��CPU�R�A�Ɠ������A
��1����̘b�Ɍ����邩�H
������ɂ���X�g���[�������ɂ͕ς��Ȃ����A����߂č��m���ŏ����Ώۂ̋ߖT�̃f�[�^��
�L���b�V���ɍڂ��Ă邩�烁�����܂Ŏ��ɍs���p�x�͌�������B
���������Ă邱�Ƃ����Ȃ��Ă��\������B�s�ԓǂ߂Ȃ��l�H
���䂭�䂭��CPU�R�A�Ɠ������A
��1����̘b�Ɍ����邩�H
������ɂ���X�g���[�������ɂ͕ς��Ȃ����A����߂č��m���ŏ����Ώۂ̋ߖT�̃f�[�^��
�L���b�V���ɍڂ��Ă邩�烁�����܂Ŏ��ɍs���p�x�͌�������B
�ŁA�ꐢ��ڂ͂��o��́H
������x���ꗈ�N�̒���
�Ȃɂ��Ɋy���݂��������ǁA���\�x���ȁB
http://www.ddj.com/architect/221601028
http://domino.research.ibm.com/comm/research_people.nsf/pages/scarpazza.pubs.html/$FILE/2009-11-10-ddj-larrabee.pdf
IBM���g�\���������̒��̐l��Larrabee����B
�l���Z����A���Ƃ��ΐ��K�\���}�b�`���O�ł��g�����ɂȂ�Ƃ���
�������ʂ̂��b���������B
�Ȃɂ��d�v�Ȃ̂�IBM�X�p�R����Larrabee���̗p����\�����J���Ă������ƁB
���̌����҂�Cell�Ɋւ���_�����������肪���Ă���B
http://domino.research.ibm.com/comm/research_people.nsf/pages/scarpazza.pubs.html/$FILE/2009-11-10-ddj-larrabee.pdf
IBM���g�\���������̒��̐l��Larrabee����B
�l���Z����A���Ƃ��ΐ��K�\���}�b�`���O�ł��g�����ɂȂ�Ƃ���
�������ʂ̂��b���������B
�Ȃɂ��d�v�Ȃ̂�IBM�X�p�R����Larrabee���̗p����\�����J���Ă������ƁB
���̌����҂�Cell�Ɋւ���_�����������肪���Ă���B
���̘_���̂��Ƃ���Ȃ����A
�_���čm��I�Ȏ������o����Ȃ����B�}�ǂ���ł������B
����͂��̂悤�ɑʖڂł����A�ł��Ɛш�҂������
�_���čm��I�Ȏ������o����Ȃ����B�}�ǂ���ł������B
����͂��̂悤�ɑʖڂł����A�ł��Ɛш�҂������
���������l�B�͑f�lfanboy�݂����ɁA�m��Ȃ��܂ܔے肷��A�Ƃ������Ƃ�
���Ȃ��B�K����������B�����Č����Ɏ��Ԃ��₵���ȏ��
���̘J�͂������̃L�����A�E�ƐтƂ��ăJ�E���g�����`�Ŏc�����Ƃ���B
���������Ƃ������ƂƁA�̗p�X�����Ƃ������ƂƂ͂قƂ�ǓƗ����Ă���B
���Ȃ��B�K����������B�����Č����Ɏ��Ԃ��₵���ȏ��
���̘J�͂������̃L�����A�E�ƐтƂ��ăJ�E���g�����`�Ŏc�����Ƃ���B
���������Ƃ������ƂƁA�̗p�X�����Ƃ������ƂƂ͂قƂ�ǓƗ����Ă���B
���̌��������ƁA�ނɌ������炳��ĂȂ�
Tesla��FireStream�͌����ɂ���l���Ȃ����Ă��Ƃ����ǂ�
Tesla��FireStream�͌����ɂ���l���Ȃ����Ă��Ƃ����ǂ�
>>924
�N���v���Ă�ȏ�ɕč��̊�ƌ������͗��v���Ɋւ��ăV�r�A�����B
�Ȃ�ő��Ђ̐��i�̗L�p�����֎����A���А��i��Cell�̏�����
�s���v�ɂȂ肩�˂Ȃ����|�[�g��IBM�̖��O�ŏ�������K�v������H
IBM���������o���Č����҂�Larrabee�̉��p�@�������������Ƃ�
�����Ӗ�����̂��A������݊��ł��킩��Ȃ��킯���Ȃ����낤�B
�N���v���Ă�ȏ�ɕč��̊�ƌ������͗��v���Ɋւ��ăV�r�A�����B
�Ȃ�ő��Ђ̐��i�̗L�p�����֎����A���А��i��Cell�̏�����
�s���v�ɂȂ肩�˂Ȃ����|�[�g��IBM�̖��O�ŏ�������K�v������H
IBM���������o���Č����҂�Larrabee�̉��p�@�������������Ƃ�
�����Ӗ�����̂��A������݊��ł��킩��Ȃ��킯���Ȃ����낤�B
>>927
Intel��Larabee��x86�ł��邱�Ƃ�傫�Ȓ��Ƃ��Đ�`���Ă邯��
>923�@�ɂ͊����̎��Y�ł͂��߂ŐV���ɏ������낳�Ȃ��Ɛ��\��
�����������Ȃ��Ƃ����Ӗ��̎���������Ă���B
����Ȃ̂�>927�̖ڂɂ́AIntel�̎咣�S�m��́h�L�p���̌֎��h�ɂ݂���̂��H
Intel��Larabee��x86�ł��邱�Ƃ�傫�Ȓ��Ƃ��Đ�`���Ă邯��
>923�@�ɂ͊����̎��Y�ł͂��߂ŐV���ɏ������낳�Ȃ��Ɛ��\��
�����������Ȃ��Ƃ����Ӗ��̎���������Ă���B
����Ȃ̂�>927�̖ڂɂ́AIntel�̎咣�S�m��́h�L�p���̌֎��h�ɂ݂���̂��H
>>927
> Intel��Larabee��x86�ł��邱�Ƃ�傫�Ȓ��Ƃ��Đ�`���Ă邯��
�����x86�͌݊������炢���������b�g�������Ǝv�����݂������O�̊��z���낤�B
[x86] [compatibility]�ł��܂Ȃ��������Ă݂�킩�邪
���͈�����������ĂȂ��B
> �����̎��Y�ł͂��߂ŐV���ɏ������낳�Ȃ��Ɛ��\��
> �����������Ȃ�
����Ȃ̂�Cell�͖��_�̂��Ɨ��POWER�A�[�L���ʂ��Ă�������
�l�K�L�����ɂ͐��肦�Ȃ��B
> Intel��Larabee��x86�ł��邱�Ƃ�傫�Ȓ��Ƃ��Đ�`���Ă邯��
�����x86�͌݊������炢���������b�g�������Ǝv�����݂������O�̊��z���낤�B
[x86] [compatibility]�ł��܂Ȃ��������Ă݂�킩�邪
���͈�����������ĂȂ��B
> �����̎��Y�ł͂��߂ŐV���ɏ������낳�Ȃ��Ɛ��\��
> �����������Ȃ�
����Ȃ̂�Cell�͖��_�̂��Ɨ��POWER�A�[�L���ʂ��Ă�������
�l�K�L�����ɂ͐��肦�Ȃ��B
������͎������g�̂��Ƃ������Ă���
> �f�lfanboy�݂����ɁA�m��Ȃ��܂ܔے肷��
> �f�lfanboy�݂����ɁA�m��Ȃ��܂ܔے肷��
�e�b�Z���[�^���Č��Ǖ������̂��
�����̒��_�����̂ق����d�������肷��
�����̒��_�����̂ق����d�������肷��
IBM��Xeon�T�[�o�[����Ă�Ԃ̓C���e���l�����C�V�����Ȃ��Ƃ�
Larrabee���肢���܂���������
Larrabee���肢���܂���������
934 �F,,�E�L�́M�E,,�j��-�������F2009/11/25(��) 22:53:09 ID:XnXiDy9n
���炩�ȋȐ��`�����߂ɒ��_�𑝂₷�Ƃ����Ȃ��Ă��\�t�g��������郉�X�^�I�y���[�V��������
�⊮�����ق�������ۂǏ����͌y���Ǝv�����ˁB
�Ƃ��R���������Ă݂�
�⊮�����ق�������ۂǏ����͌y���Ǝv�����ˁB
�Ƃ��R���������Ă݂�
935 �F,,�E�L�́M�E,,�j��-�������F2009/11/25(��) 23:05:37 ID:XnXiDy9n
>>923�͕̂��ʂɃu�b�N�}�[�N�ɓ���Ă���B
Is Larrabee For the Rest of Us?
- Larrabee�͒u������ɂ��ꂽ�l�X�ɂƂ��ċ~����ɂȂ肤�邩�H
�g���Â��ꂽ���������i"the computer for the rest of us"���Đ̖̂��ؓʎ�̔��蕶��j
���X���[�v�b�g�w���̃v���Z�b�T�����l�v�Z�ɓ����������̂��蕝������������
����������Љ�鐳�K�\���G���W���̂悤�Ȕl�v�Z�p�r�ɂ����Ă����p�ɑς�����
�v���Z�b�T�����߂��Ă���Ă̂������̘_�_�B
�ǂ������Ƃ������Ȃ���Ă�̂�GPGPU�BCell��������������Ȃ��ˁB
IBM�͋������Ђ̋Z�p�ł����Ă��A�C�ɓ��������̂����ꂪ�H�������ɂ͂����Ȃ��B
Sun�ɎU�X���݂���Ȃ����Java�Ɍ����ꂵ�Ă���������
���������Е������炱��JVM-JIT�Ƃ�Eclipse�݂����Ȍ��삪���݂����ꂽ�킯�ŁB
Is Larrabee For the Rest of Us?
- Larrabee�͒u������ɂ��ꂽ�l�X�ɂƂ��ċ~����ɂȂ肤�邩�H
�g���Â��ꂽ���������i"the computer for the rest of us"���Đ̖̂��ؓʎ�̔��蕶��j
���X���[�v�b�g�w���̃v���Z�b�T�����l�v�Z�ɓ����������̂��蕝������������
����������Љ�鐳�K�\���G���W���̂悤�Ȕl�v�Z�p�r�ɂ����Ă����p�ɑς�����
�v���Z�b�T�����߂��Ă���Ă̂������̘_�_�B
�ǂ������Ƃ������Ȃ���Ă�̂�GPGPU�BCell��������������Ȃ��ˁB
IBM�͋������Ђ̋Z�p�ł����Ă��A�C�ɓ��������̂����ꂪ�H�������ɂ͂����Ȃ��B
Sun�ɎU�X���݂���Ȃ����Java�Ɍ����ꂵ�Ă���������
���������Е������炱��JVM-JIT�Ƃ�Eclipse�݂����Ȍ��삪���݂����ꂽ�킯�ŁB
936 �F,,�E�L�́M�E,,�j��-�������F2009/11/25(��) 23:33:20 ID:XnXiDy9n
��������IBM�͔����̐����Ƃł���O�Ƀ\�����[�V������������
�\�j�[���ł�3�n���A���̕��ꉏ���������ď��@���悤�Ȕn���Ȑ^���͂��Ȃ��B
�\�j�[���ł�3�n���A���̕��ꉏ���������ď��@���悤�Ȕn���Ȑ^���͂��Ȃ��B
>>918
> >>916
> �Ȃ�Łu�q���v�H
> �������炠�����Ńg���t�B�b�N���邵�A�����Ȃ疳���ł��܂��̂���B
> �L���b�V���ɂȂ��Ȃ�A����������Ƃ��Ă����������Ȃ��B
> �����͏]����GPU�ƕς���B
�]����GPU�̃O���t�B�N�X�̓X�g���[������������A�����Ń������ɃA�N�Z�X���邱�Ƃ͂Ȃ��ł���B
GPU�̒������邮�����B
���Larrabee�̓^�C�������_�̂��߂��ꂪ�ł��Ȃ��B
VRAM�Ɉꎞ�o�b�t�@��݂��Ȃ��Ƃ����Ȃ��B
�Ⴆ�e�b�Z���[�V��������ꍇ�A����������ő咸�_�����o�b�t�@�m�ۂ��Ȃ��Ƃ����Ȃ��B
�ł��ꂪ�I����ă^�C�������_�n�߂�Ƃ���L2�ɒ��_���c���Ă�\���Ȃ�čl���邾�����ʁB
Larrabee�Ń^�C�����g���̂�>>910�̂悤�ȐϋɓI�ȗ��R�łȂ��A
�������Ȃ��Ƃ�����ROP�̏���(����ZCull)�Ő��\���o�Ȃ�����d���Ȃ��Ƃ����ʂ�
�����Ǝv���ȁB
�c�q�����GPU�Ƃ���Larrabee�Ɋ��҂��ĂȂ��ł���H
> >>916
> �Ȃ�Łu�q���v�H
> �������炠�����Ńg���t�B�b�N���邵�A�����Ȃ疳���ł��܂��̂���B
> �L���b�V���ɂȂ��Ȃ�A����������Ƃ��Ă����������Ȃ��B
> �����͏]����GPU�ƕς���B
�]����GPU�̃O���t�B�N�X�̓X�g���[������������A�����Ń������ɃA�N�Z�X���邱�Ƃ͂Ȃ��ł���B
GPU�̒������邮�����B
���Larrabee�̓^�C�������_�̂��߂��ꂪ�ł��Ȃ��B
VRAM�Ɉꎞ�o�b�t�@��݂��Ȃ��Ƃ����Ȃ��B
�Ⴆ�e�b�Z���[�V��������ꍇ�A����������ő咸�_�����o�b�t�@�m�ۂ��Ȃ��Ƃ����Ȃ��B
�ł��ꂪ�I����ă^�C�������_�n�߂�Ƃ���L2�ɒ��_���c���Ă�\���Ȃ�čl���邾�����ʁB
Larrabee�Ń^�C�����g���̂�>>910�̂悤�ȐϋɓI�ȗ��R�łȂ��A
�������Ȃ��Ƃ�����ROP�̏���(����ZCull)�Ő��\���o�Ȃ�����d���Ȃ��Ƃ����ʂ�
�����Ǝv���ȁB
�c�q�����GPU�Ƃ���Larrabee�Ɋ��҂��ĂȂ��ł���H
938 �F,,�E�L�́M�E,,�j��-�������F2009/11/26(��) 00:13:46 ID:Y7m0S63w
���]����GPU�̃O���t�B�N�X�̓X�g���[������������A�����Ń������ɃA�N�Z�X���邱�Ƃ͂Ȃ��ł���B
��GPU�̒������邮�����B
�͂��`�H
��GPU�̒������邮�����B
�͂��`�H
939 �F,,�E�L�́M�E,,�j��-�������F2009/11/26(��) 00:15:30 ID:Y7m0S63w
Larrabee�ɔᔻ�I�ȂЂƂ���
Larrabee�ɑ��闝���ǂ��납
GPU�̍\���ɑ��闝����������ł���
Larrabee�ɑ��闝���ǂ��납
GPU�̍\���ɑ��闝����������ł���
940 �F,,�E�L�́M�E,,�j��-�������F2009/11/26(��) 00:21:49 ID:Y7m0S63w
�������iVRAM�j��GPU�́u�O�v�ɂ���܂��B�J�[�h��ɂ͗n�ڂ���Ă܂����ǂˁB
�c�O�Ȃ��ƂɁAGPU�́u���v�ɑS���f�[�^�u���Ă�����ق�FLIP-FLOP��H������ł���
�c�O�Ȃ��ƂɁAGPU�́u���v�ɑS���f�[�^�u���Ă�����ق�FLIP-FLOP��H������ł���
>>938
> ���]����GPU�̃O���t�B�N�X�̓X�g���[������������A�����Ń������ɃA�N�Z�X���邱�Ƃ͂Ȃ��ł���B
> ��GPU�̒������邮�����B
>
> �͂��`�H
���c�q����w
�e�N�X�`���Ƃ��̂��ƂłȂ�>>913�̂��ƂˁB
���������]����GPU�̓������ɒu���ꏊ�m�ۂ��Ȃ�����u���悤���Ȃ���B
> ���]����GPU�̃O���t�B�N�X�̓X�g���[������������A�����Ń������ɃA�N�Z�X���邱�Ƃ͂Ȃ��ł���B
> ��GPU�̒������邮�����B
>
> �͂��`�H
���c�q����w
�e�N�X�`���Ƃ��̂��ƂłȂ�>>913�̂��ƂˁB
���������]����GPU�̓������ɒu���ꏊ�m�ۂ��Ȃ�����u���悤���Ȃ���B
942 �F,,�E�L�́M�E,,�j��-�������F2009/11/26(��) 00:39:40 ID:Y7m0S63w
���Ƃ���Xbox360��VRAM�̑ш拷�������12MB��eDRAM��������
ROP����f���o���ꂽ���X�^�o�̓f�[�^�́i�ȉ���
ROP����f���o���ꂽ���X�^�o�̓f�[�^�́i�ȉ���
943 �F,,�E�L�́M�E,,�j��-�������F2009/11/26(��) 00:48:38 ID:Y7m0S63w
������������ő咸�_�����o�b�t�@�m�ۂ��Ȃ��Ƃ����Ȃ��B
���Ȃ݂ɂ���͊�������Ȃ�A�L���b�V����Ƀo�b�t�@�̒f�Ђ��m�ۂł��镪�����̒��_�P�ʂ�
������������L���b�V���~�X�Ȃ��ŃX�e�[�W�Ԃ��q�����Ƃ��ł�����Ă��Ƃ�
���Ȃ݂ɂ���͊�������Ȃ�A�L���b�V����Ƀo�b�t�@�̒f�Ђ��m�ۂł��镪�����̒��_�P�ʂ�
������������L���b�V���~�X�Ȃ��ŃX�e�[�W�Ԃ��q�����Ƃ��ł�����Ă��Ƃ�
>>942
���ꂪLarrabee�Ƃǂ��W����́H
360�̃^�C�����O��Predicated Tiling�Ƃ��������ōő�4�����܂łƌ��܂��Ă�B
�Ńv���~�e�B�u�P�ʂłǂ̃^�C���Ɋ܂܂�邩��2bit��tag�Ŏc���Ă����B
Larrabee�̃^�C�����O��PowerVR�Ɠ����Ȃ̂�360�Ƃ͈Ⴄ�B
>>943
Larrabee��p�ɂ������Ή\���낤�ˁB
�ł��s�N�Z���V�F�[�_��������Ȃ��Ƃ����Ȃ��̂Ō��nj�����������������B
���ꂪLarrabee�Ƃǂ��W����́H
360�̃^�C�����O��Predicated Tiling�Ƃ��������ōő�4�����܂łƌ��܂��Ă�B
�Ńv���~�e�B�u�P�ʂłǂ̃^�C���Ɋ܂܂�邩��2bit��tag�Ŏc���Ă����B
Larrabee�̃^�C�����O��PowerVR�Ɠ����Ȃ̂�360�Ƃ͈Ⴄ�B
>>943
Larrabee��p�ɂ������Ή\���낤�ˁB
�ł��s�N�Z���V�F�[�_��������Ȃ��Ƃ����Ȃ��̂Ō��nj�����������������B
945 �F,,�E�L�́M�E,,�j��-�������F2009/11/26(��) 01:07:23 ID:Y7m0S63w
��Larrabee�̃^�C�����O��PowerVR�Ɠ���
��n�O�L�^�[
��n�O�L�^�[
�����S����������Ȃ����ǂ��A
�����͌��t�̂�����Ă��Ƃŋ����Ă�B
�����͌��t�̂�����Ă��Ƃŋ����Ă�B
947 �F,,�E�L�́M�E,,�j��-�������F2009/11/26(��) 01:23:19 ID:Y7m0S63w
���A���Ȃ݂�L2�Ƀq�b�g����悤�ɃX�P�W���[�����O���ē��������Ă̂�Larrabee����
�^�X�N�X�P�W���[���̎d���ł����āA�u��p�v�ɑg�ޕK�v�͖���������B
�������ꃉ���^�C���Œ����API�Ō���J�肾���Ȃ�ˁB
����������DirectX�ȂǃN�\�H�炦�ƌ����Ă����B
���y�z�M�ɂ�����Apple�A�����G���W���ɂ�����Google�������ł���悤��
�L���ێq��MS�Ɏ哱����������K�v�Ȃǖ����B
�^�X�N�X�P�W���[���̎d���ł����āA�u��p�v�ɑg�ޕK�v�͖���������B
�������ꃉ���^�C���Œ����API�Ō���J�肾���Ȃ�ˁB
����������DirectX�ȂǃN�\�H�炦�ƌ����Ă����B
���y�z�M�ɂ�����Apple�A�����G���W���ɂ�����Google�������ł���悤��
�L���ێq��MS�Ɏ哱����������K�v�Ȃǖ����B
>>947
�N�\�����ɂ��������玩���ō���
�N�\�����ɂ��������玩���ō���
950 �F,,�E�L�́M�E,,�j��-�������F2009/11/26(��) 01:51:30 ID:Y7m0S63w
�R���V���[�}�D��̂����́AXbox�Ƃ菟���ɂł��Ȃ�Ȃ������
�ǂ݂̂��N���X�v���b�g�t�H�[���̃~�h���E�F�A�őΉ����邱�ƂɂȂ邩��ˁB
��̑���DirectX�Ɏ���ꂸ���R�ɃJ�X�^���G���W���������������ȃG���W���������邩����
�\�t�g�E�F�A�����_���͂���Ȃ�Ɏg���邱�ƂɂȂ�ł��傤��
���Ȃ݂�EPIC��Larrabee�ׂ��J��
�ǂ݂̂��N���X�v���b�g�t�H�[���̃~�h���E�F�A�őΉ����邱�ƂɂȂ邩��ˁB
��̑���DirectX�Ɏ���ꂸ���R�ɃJ�X�^���G���W���������������ȃG���W���������邩����
�\�t�g�E�F�A�����_���͂���Ȃ�Ɏg���邱�ƂɂȂ�ł��傤��
���Ȃ݂�EPIC��Larrabee�ׂ��J��
951 �F,,�E�L�́M�E,,�j��-�������F2009/11/26(��) 02:04:03 ID:Y7m0S63w
���݂Ɍ�����EPIC����FPS�̃f�t�@�N�g�X�^���_�[�h����Ǘ�����G���W������Ă鏊�ˁB
���܂�Intel�ƃK�`������ԁB�����炱��RTRT�̃f����Quake Wars�Ȃ킯�ŁB
>>948
> ���C�g������͑����Ă��̌ゾ��ȁ[�B
�ǂ݂̂�UE4�̓��C�g���x�[�X�ɂȂ�킯��������B
����Larrabee�Ŗ{�̔�������G���W���ɂȂ�̂͂قڊm��B
���܂�Intel�ƃK�`������ԁB�����炱��RTRT�̃f����Quake Wars�Ȃ킯�ŁB
>>948
> ���C�g������͑����Ă��̌ゾ��ȁ[�B
�ǂ݂̂�UE4�̓��C�g���x�[�X�ɂȂ�킯��������B
����Larrabee�Ŗ{�̔�������G���W���ɂȂ�̂͂قڊm��B
�� 360�̃^�C�����O��Predicated Tiling�Ƃ��������ōő�4�����܂łƌ��܂��Ă�B
�� �Ńv���~�e�B�u�P�ʂłǂ̃^�C���Ɋ܂܂�邩��2bit��tag�Ŏc���Ă����B
tag��8bit�ɂ����APredicated Tiling�͍ő�256�����ł�����Ă�������H
��ŁA�e�^�C����ʃR�A�ʃX���b�h�Ńo���o���ɒS������
PowerVR�����Ď�����̓z�͂���Ȋ����̏����ɂȂ��Ă�ł���A�\��PSP2��4�R�A�łƂ���
�� �Ńv���~�e�B�u�P�ʂłǂ̃^�C���Ɋ܂܂�邩��2bit��tag�Ŏc���Ă����B
tag��8bit�ɂ����APredicated Tiling�͍ő�256�����ł�����Ă�������H
��ŁA�e�^�C����ʃR�A�ʃX���b�h�Ńo���o���ɒS������
PowerVR�����Ď�����̓z�͂���Ȋ����̏����ɂȂ��Ă�ł���A�\��PSP2��4�R�A�łƂ���
�����Atag�̓^�C���܂�����̂��A��256bit�˂�
���܂ł�3D�`����āA���_�����P�`�肷������
���܂ł�3D�`����āA���_�����P�`�肷������
954 �FSocket774�F2009/11/26(��) 06:20:07 ID:MCZHFaAT
Intel Larrabee to surprise with performance, launch in 1H 2010? - Bright Side Of News*
ttp://www.brightsideofnews.com/news/2009/11/25/intel-larrabee-to-surprise-with-performance2c-launch-in-1h-2010.aspx
ttp://www.brightsideofnews.com/news/2009/11/25/intel-larrabee-to-surprise-with-performance2c-launch-in-1h-2010.aspx
URL������FUD���Ƃ킩��
>>948
���Ȃ݂ɍ��̃Q�[���ƊE�ł̓}���`�J�����O����DX�͑債���x�z�͖����B
��������DX�ɒ@���ăQ�[�����f�x���b�p�[�Ȃ�č����w�ǂ��Ȃ��B
�~�h���E�F�A�����Q�[��API�̎������������Ă�B
����łȂ��Ƃ��f�t�H���g�̍���n�ł͂Ȃ�OpenGL�Ɠ����E��n�ł̗��p����ԉ����Ă�B
��������Intel��Larrabee���Q�[��GPU�Ƃ��Ĕ��荞�ނ��Ƃɋ��C�Ȃ̂́A
DirectX(MS)�̃q�G�����L�ɔ����Ȃ��t���v���O���}�u��GPU�Ƃ��āA
Tim Sweeney������Epic Games��̋����x���������Ă邩��ɑ��Ȃ��B
DirectX��OpenGL�͍ŏ����烌�K�V�[API�Ƃ����ʒu�Â��B
Epic�͋}�i�I�ŁAC++��CUDA�őS�Ă�GPU�p�C�v���C���������ł���悤��
���ׂ����Ǝ咣���Ă���BFermi��HPC�s���ǂ������Ă�悤�Ɍ�����
����Epic�ɍ��킹�ăv���O���}�u������i�߂Ă���B
���_�AEpic�̘A����DirectX��OpenGL�͎��ł���Ȃ�Ă�����MS�͋@���悭�Ȃ��B
GPGPU���̂��i��GeForce��DirectX�����Radeon�̉��ʂɈʒu�Â��邱�Ƃ�
GeForce�̂ق����u����x��v���ƃ~�X���[�h����Ɏ����Ă�B
PS3�̃~�h���E�F�A�ł���\�t�g�E�F�A��������Ă�e�b�Z���[�^��
���X�Œ�@�\�Ȃ�Ď��������͂Ȃ͂��������B
���Ȃ݂ɍ��̃Q�[���ƊE�ł̓}���`�J�����O����DX�͑債���x�z�͖����B
��������DX�ɒ@���ăQ�[�����f�x���b�p�[�Ȃ�č����w�ǂ��Ȃ��B
�~�h���E�F�A�����Q�[��API�̎������������Ă�B
����łȂ��Ƃ��f�t�H���g�̍���n�ł͂Ȃ�OpenGL�Ɠ����E��n�ł̗��p����ԉ����Ă�B
��������Intel��Larrabee���Q�[��GPU�Ƃ��Ĕ��荞�ނ��Ƃɋ��C�Ȃ̂́A
DirectX(MS)�̃q�G�����L�ɔ����Ȃ��t���v���O���}�u��GPU�Ƃ��āA
Tim Sweeney������Epic Games��̋����x���������Ă邩��ɑ��Ȃ��B
DirectX��OpenGL�͍ŏ����烌�K�V�[API�Ƃ����ʒu�Â��B
Epic�͋}�i�I�ŁAC++��CUDA�őS�Ă�GPU�p�C�v���C���������ł���悤��
���ׂ����Ǝ咣���Ă���BFermi��HPC�s���ǂ������Ă�悤�Ɍ�����
����Epic�ɍ��킹�ăv���O���}�u������i�߂Ă���B
���_�AEpic�̘A����DirectX��OpenGL�͎��ł���Ȃ�Ă�����MS�͋@���悭�Ȃ��B
GPGPU���̂��i��GeForce��DirectX�����Radeon�̉��ʂɈʒu�Â��邱�Ƃ�
GeForce�̂ق����u����x��v���ƃ~�X���[�h����Ɏ����Ă�B
PS3�̃~�h���E�F�A�ł���\�t�g�E�F�A��������Ă�e�b�Z���[�^��
���X�Œ�@�\�Ȃ�Ď��������͂Ȃ͂��������B
>>954
Tesla�͂Ԃ��ׂ���ڏ����������낤��
Tesla�͂Ԃ��ׂ���ڏ����������낤��
�~�h���E�F�A�₳�����MS�قǕ����u�ĂȂ��i�����͂Ƃ��������O��́j
GPU���[�J�[�ɔz�����邩�ȁH
DX�������Ƃ����悤�ɂȂ�����~�h���E�F�A�₳�C�ɓ�����
1�A2�ЈȊO�̓X���[�����悤�ɂȂ��Ȃ����B
���ł����R����GPU�n�[�h�̎�ނ������ƍi��ꂻ��
GPU���[�J�[�ɔz�����邩�ȁH
DX�������Ƃ����悤�ɂȂ�����~�h���E�F�A�₳�C�ɓ�����
1�A2�ЈȊO�̓X���[�����悤�ɂȂ��Ȃ����B
���ł����R����GPU�n�[�h�̎�ނ������ƍi��ꂻ��
MS�Ƃׂ������AMD�͂ǂ��Ȃ��Ă��܂��̂��
Unreal Engine 3��360�d����PS3�͎c�O�Ȃ��ƂɂȂ��Ă邩��ˁB
�i�킩��₷���Ƃ���Ō�����PS3�Ń��X�g�����i���g�J�������j
360�͌��X256MB�����ς܂Ȃ��\�肾������Tim���S�l��512MB�ɂȂ����B
CPU��GPU�̃��������p�����z�ŁA���̎��̐����CPU�@�\��������GPU
�i���邢�͂��̋t�j��O��ɃG���W������낤�Ƃ��Ă��B
Epic�ɂƂ���CPU��GPU���u�Ă�DirectX�͎ז��Ŏז��ł��傤���Ȃ��B
�\�j�[��PS4��Larrabee�����������̂�Cell�̒u���������Ă�������
Epic�̋@�����Ƃ肽������B
CPU��Cell�AGPU��Larrabee�i���邢��Fermi�j�Ƃ����\�����Ƃ�
�\���͂��邪�A�ǂ��I��ł�Cell��SPE�����Ă��܂��̂�
�Y�܂����Ƃ���ł��傤�ȁB
�i�킩��₷���Ƃ���Ō�����PS3�Ń��X�g�����i���g�J�������j
360�͌��X256MB�����ς܂Ȃ��\�肾������Tim���S�l��512MB�ɂȂ����B
CPU��GPU�̃��������p�����z�ŁA���̎��̐����CPU�@�\��������GPU
�i���邢�͂��̋t�j��O��ɃG���W������낤�Ƃ��Ă��B
Epic�ɂƂ���CPU��GPU���u�Ă�DirectX�͎ז��Ŏז��ł��傤���Ȃ��B
�\�j�[��PS4��Larrabee�����������̂�Cell�̒u���������Ă�������
Epic�̋@�����Ƃ肽������B
CPU��Cell�AGPU��Larrabee�i���邢��Fermi�j�Ƃ����\�����Ƃ�
�\���͂��邪�A�ǂ��I��ł�Cell��SPE�����Ă��܂��̂�
�Y�܂����Ƃ���ł��傤�ȁB
�ł���������ł��傤�H
Epic�̃h�����^�C�g���ł���Gears of War3��������@�ŏo���Ƃ����Ă����
�p�u���b�V���[��MS�ƃx�b�^�����Ă��������������낤��
Tim Sweeney�̃����r�}���Z�[�́A�v�����360�̎�����@��Larrabee�ς߂�Ƃ������̗v������
�p�u���b�V���[��MS�ƃx�b�^�����Ă��������������낤��
Tim Sweeney�̃����r�}���Z�[�́A�v�����360�̎�����@��Larrabee�ς߂�Ƃ������̗v������
����Ȃ鎟����ł́AGPU�͂��с[�����ʂŁACPU���ς�[�V���[�Y�̓������č\�}�ɂȂ肦��̂��˂��B
����ɁA����Ă邪�A���с[�̗p���Ă��ꂽ��A�J�X�^������Ł[�Ԃ����������ŁI�Ƃ��������肷��낤���B
����ɁA����Ă邪�A���с[�̗p���Ă��ꂽ��A�J�X�^������Ł[�Ԃ����������ŁI�Ƃ��������肷��낤���B
PC�ł̎���UE��DirectX, CUDA(Fermi), LRBni �̃}���`�o�b�N�G���h�Ή�
���Ă̂����Ƃ��ǂ���ɂȂ肻���B
PS4, Xbox3��2012�N����ƌ����Ă邵�ALarrabee�̃��[���`�ɍۂ�
�Ȃ�炩�̃^�C�g����p�ӂ��Ă�Ƃ�����ꂪ�ŏ��ōŌ��
�v���[���̋@��ɂȂ肻�����ˁB
���Ă̂����Ƃ��ǂ���ɂȂ肻���B
PS4, Xbox3��2012�N����ƌ����Ă邵�ALarrabee�̃��[���`�ɍۂ�
�Ȃ�炩�̃^�C�g����p�ӂ��Ă�Ƃ�����ꂪ�ŏ��ōŌ��
�v���[���̋@��ɂȂ肻�����ˁB
�������������������Fermi�����
966 �FSocket774�F2009/11/26(��) 18:05:41 ID:zXd9r/pq
DXCS�Ńv���O����������Fermi�ł���������CUDA�g���Ӗ����킩��Ȃ�
Larrabee�͏]����GPU�ɔ�ׂđ傫���ς���Ă邩�玟����G���W���̉��v�������Ă��邪
Fermi�͊�����DX�p�C�v���C�������̕����������悢
Fermi�͊�����DX�p�C�v���C�������̕����������悢
PhysX�E�E�E
969 �FSocket774�F2009/11/26(��) 21:21:37 ID:cgpBtAkP
>>967
?
?
970 �F,,�E�L�́M�E,,�j��-�������F2009/11/26(��) 22:20:49 ID:Y7m0S63w
����������Compute Shader��œ��������G���W�����Ă����������H
�ꉞHavok��OpenCL�Ή��̂�����v���b�g�t�H�[���ɈڐA����邪
UT3�Ƃ��Ŏg���Ă�PhysX�̂ق��́E�E�E
�Ȃ�Ȃ̂���NVIDIA�̉��̋�����
�ꉞHavok��OpenCL�Ή��̂�����v���b�g�t�H�[���ɈڐA����邪
UT3�Ƃ��Ŏg���Ă�PhysX�̂ق��́E�E�E
�Ȃ�Ȃ̂���NVIDIA�̉��̋�����
971 �F,,�E�L�́M�E,,�j��-�������F2009/11/26(��) 22:45:48 ID:Y7m0S63w
�Ȃɂ�獁�����b�ɂȂ��Ă�Ȃ�
PLAYSTATION 4��POWER7�̗p
http://ps3clan.nl/2009/11/sony-kiest-voor-ibm-power7-cpu-playstation-4/
PLAYSTATION 4��POWER7�̗p
http://ps3clan.nl/2009/11/sony-kiest-voor-ibm-power7-cpu-playstation-4/
GPU��Evergreen����ŏ���������������PS4����
Larrabee�̗p�������A���e�B�����
974 �F,,�E�L�́M�E,,�j��-�������F2009/11/26(��) 23:04:10 ID:Y7m0S63w
> TBDR based PowerVR 6
�Ȃɂ���
�Ȃɂ���
>>970
Compute Shader�Ή��͂܂�����Ȃ����ȁB
SM5.0�O��ɂ���Ǝg�����ɂȂ�ȂȂ�����A
����DX11�Ή��n�[�h�̕��y���{�g���l�b�N��
�Ȃ��Ȃ����Ǝv���B
Compute Shader�Ή��͂܂�����Ȃ����ȁB
SM5.0�O��ɂ���Ǝg�����ɂȂ�ȂȂ�����A
����DX11�Ή��n�[�h�̕��y���{�g���l�b�N��
�Ȃ��Ȃ����Ǝv���B
>>971
�w�l���l�����ŋ��Q�[���@PS4�͂������I�I�x
�w�l���l�����ŋ��Q�[���@PS4�͂������I�I�x
PS4��Power7���Ă��Ƃ͎�������Power7���̂�
�ǂ������N���b�N���E�������Ă�Power5�̃J�X�^���`�b�v����݊����������܂ܐ��\���サ�悤�Ƃ����炻�ꂵ���Ȃ���������
�ǂ������N���b�N���E�������Ă�Power5�̃J�X�^���`�b�v����݊����������܂ܐ��\���サ�悤�Ƃ����炻�ꂵ���Ȃ���������
>>957
HPC��XeonMP(Nehalem-EX 6C)��Larrabee��DMI�����N���邽�߂̕�͂��Ǝv���B
CPU�R�A�����Ȃ�Westmere-EP�̕������i���\��ŏ��邾�낤���B
FLOPS/$�̈�����͂��Ȃ����Ă��Ƃ���
HPC��XeonMP(Nehalem-EX 6C)��Larrabee��DMI�����N���邽�߂̕�͂��Ǝv���B
CPU�R�A�����Ȃ�Westmere-EP�̕������i���\��ŏ��邾�낤���B
FLOPS/$�̈�����͂��Ȃ����Ă��Ƃ���
larrabee�������̂�xeon���v��̂��H���ꂪ�����}�ł�larrabee���݂���4�����N����Ă�
����͓����B
�Ă�DMI����Ȃ���QPI���B
�n�[�h�E�F�A�����z�����Ę_���I��1�`�b�v1�R���s���[�^�œ��������f���ɂȂ�Ƃ��B
�A�v������̓z�X�g�ƃQ�X�g�͕ʃ}�V���ŁA�����ȃl�b�g���[�N�Ɍq����Ă�悤�Ɍ�����B
�O���{�łƓ����v���O���~���O���f�����Ƃ��B
�Ă�DMI����Ȃ���QPI���B
�n�[�h�E�F�A�����z�����Ę_���I��1�`�b�v1�R���s���[�^�œ��������f���ɂȂ�Ƃ��B
�A�v������̓z�X�g�ƃQ�X�g�͕ʃ}�V���ŁA�����ȃl�b�g���[�N�Ɍq����Ă�悤�Ɍ�����B
�O���{�łƓ����v���O���~���O���f�����Ƃ��B
���߂ēǂ����{���͐M���x�Ⴂ�ȁB
M-Y-O�����狤�L���z���������f�����Ė�̂��Ó��B
�V�����T�O�ƌ��������Č��s��GPGPU-�z�X�g�Ԃ̐ڑ����f���ƕς���B
M-Y-O�����狤�L���z���������f�����Ė�̂��Ó��B
�V�����T�O�ƌ��������Č��s��GPGPU-�z�X�g�Ԃ̐ڑ����f���ƕς���B
�ʂѐ~�͒m�������ł��̂��������獢��