AMD�̎�����CPU�ɂ��Č�낤 ��25����
���O�X��
AMD�̎�����CPU�ɂ��Č�낤 ��24����
http://pc11.2ch.net/test/read.cgi/jisaku/1226628399/
�����AMD�n�X���b�h�ߋ����O�ۑ��T�C�g�l
http://amd.jisakuita.net/
���֘A�X��
Intel�̎�����CPU�ɂ��Č�낤 36
http://pc11.2ch.net/test/read.cgi/jisaku/1228400588/
CPU�A�[�L�e�N�`���ɂ��Č�� Part.13
http://pc11.2ch.net/test/read.cgi/jisaku/1223189876/
�Q�Q�Q_
�_.�Q�@ | �r�炵�E����E�~�[�͕��u����ԁB
�^|�Q|�@| �ނ�ꂸ�ɃX���[���܂��傤�B
|�Q�^�_! sage�i�s�Ń}�^�[�������܂��傤�B
AMD�̎�����CPU�ɂ��Č�낤 ��24����
http://pc11.2ch.net/test/read.cgi/jisaku/1226628399/
�����AMD�n�X���b�h�ߋ����O�ۑ��T�C�g�l
http://amd.jisakuita.net/
���֘A�X��
Intel�̎�����CPU�ɂ��Č�낤 36
http://pc11.2ch.net/test/read.cgi/jisaku/1228400588/
CPU�A�[�L�e�N�`���ɂ��Č�� Part.13
http://pc11.2ch.net/test/read.cgi/jisaku/1223189876/
�Q�Q�Q_
�_.�Q�@ | �r�炵�E����E�~�[�͕��u����ԁB
�^|�Q|�@| �ނ�ꂸ�ɃX���[���܂��傤�B
|�Q�^�_! sage�i�s�Ń}�^�[�������܂��傤�B
|
|
|
���ߋ��X���ꗗ
23 ttp://pc11.2ch.net/test/read.cgi/jisaku/1219751351/
22 ttp://pc11.2ch.net/test/read.cgi/jisaku/1214276833/
21 ttp://pc11.2ch.net/test/read.cgi/jisaku/1209908499/
20 ttp://pc11.2ch.net/test/read.cgi/jisaku/1203947286/
19 ttp://pc11.2ch.net/test/read.cgi/jisaku/1199338832/
18 ttp://pc11.2ch.net/test/read.cgi/jisaku/1197562571/
17 ttp://pc11.2ch.net/test/read.cgi/jisaku/1195270082/
16 ttp://pc11.2ch.net/test/read.cgi/jisaku/1192923006/
15 ttp://pc11.2ch.net/test/read.cgi/jisaku/1190954072/
14 ttp://pc11.2ch.net/test/read.cgi/jisaku/1189440665/
13 ttp://pc11.2ch.net/test/read.cgi/jisaku/1187934610/
12 ttp://pc11.2ch.net/test/read.cgi/jisaku/1183558273/
11 ttp://pc11.2ch.net/test/read.cgi/jisaku/1181563841/
10 ttp://pc11.2ch.net/test/read.cgi/jisaku/1177368830/
09 ttp://pc11.2ch.net/test/read.cgi/jisaku/1172183431/
08 ttp://pc9.2ch.net/test/read.cgi/jisaku/1167003467/
07 ttp://pc7.2ch.net/test/read.cgi/jisaku/1161618220/
06 ttp://pc7.2ch.net/test/read.cgi/jisaku/1157327883/
05 ttp://pc7.2ch.net/test/read.cgi/jisaku/1150393478/
04 ttp://pc7.2ch.net/test/read.cgi/jisaku/1145187468/
03 ttp://pc7.2ch.net/test/read.cgi/jisaku/1138983969/
02 ttp://pc7.2ch.net/test/read.cgi/jisaku/1133374045/
01 ttp://pc7.2ch.net/test/read.cgi/jisaku/1124542812/
23 ttp://pc11.2ch.net/test/read.cgi/jisaku/1219751351/
22 ttp://pc11.2ch.net/test/read.cgi/jisaku/1214276833/
21 ttp://pc11.2ch.net/test/read.cgi/jisaku/1209908499/
20 ttp://pc11.2ch.net/test/read.cgi/jisaku/1203947286/
19 ttp://pc11.2ch.net/test/read.cgi/jisaku/1199338832/
18 ttp://pc11.2ch.net/test/read.cgi/jisaku/1197562571/
17 ttp://pc11.2ch.net/test/read.cgi/jisaku/1195270082/
16 ttp://pc11.2ch.net/test/read.cgi/jisaku/1192923006/
15 ttp://pc11.2ch.net/test/read.cgi/jisaku/1190954072/
14 ttp://pc11.2ch.net/test/read.cgi/jisaku/1189440665/
13 ttp://pc11.2ch.net/test/read.cgi/jisaku/1187934610/
12 ttp://pc11.2ch.net/test/read.cgi/jisaku/1183558273/
11 ttp://pc11.2ch.net/test/read.cgi/jisaku/1181563841/
10 ttp://pc11.2ch.net/test/read.cgi/jisaku/1177368830/
09 ttp://pc11.2ch.net/test/read.cgi/jisaku/1172183431/
08 ttp://pc9.2ch.net/test/read.cgi/jisaku/1167003467/
07 ttp://pc7.2ch.net/test/read.cgi/jisaku/1161618220/
06 ttp://pc7.2ch.net/test/read.cgi/jisaku/1157327883/
05 ttp://pc7.2ch.net/test/read.cgi/jisaku/1150393478/
04 ttp://pc7.2ch.net/test/read.cgi/jisaku/1145187468/
03 ttp://pc7.2ch.net/test/read.cgi/jisaku/1138983969/
02 ttp://pc7.2ch.net/test/read.cgi/jisaku/1133374045/
01 ttp://pc7.2ch.net/test/read.cgi/jisaku/1124542812/
��������������
�b�@�^�@�@�_�@..�b�@�T�J������
�b�^��ڰ..�_�b�@���܂���]�݂����キ
�b�@ �^�P�_ �@�b�@�N���ɔ]����p���K�v�ł�
�b�@|�@�Oo�O�@|.�@�b
�b�@ �_�Q�^..�@�b�@��������p�ɂ͕��ώ�����5%�K�v�ł�
�b�@ �Q|�@|�Q�@�b�@�T�J�������~�����߂ɂ��肢�������܂�
��������������
���T�J�����
�c�O�I�I�I�I3.40�ł�����������������������������
�������̂�������[�����M���W�F�C�I�i�j-2008
*4.6% 03/08 14:00-16:00 TBS �J��������lFM�~�Y�a��@�@�@ ���T�J�؎����̐��E�R�ʂ̊J��
*2.2% 03/09 13:55-16:00 NHK �J��������F�~����V��@�@�@ ���[��ԑg�ƍ��o
*4.4% 03/15 13:55-16:00 NHK ��Y�a�~���É�� �@�@�@�@�@�@�@�@���������т������ŗ��̕�
*2.3% 04/19 16:00-18:00 NHK ������~G��� �@�@�@�@�@�@�@�@�@���ǂ����͂ł���
*4.9% 04/20 14:00-16:00 TBS ��Y�a�~��{��@�@�@�@�@�@ �@�@�@�@������ŗ��Ɍ����͂���!!�c�O!!
*3.1% 05/03 15:00-17:00 NTV �����V�~���lF� �@�@�@�@�@�@�@�@���O��̓����u�̕������140%���㏸!!�싅�s���`!!(��)
*5.6% 05/10 14:00-16:00 TBS ����F�~�Y�a� �@�@�@�@�@�@�@�@�@������ŗ��ɏ���!!�T�J�؊���!!!
*3.1% 05/20 14:00-16:00 NHK ��Y�a�~G��㣁@�@�@�@ �@�@�@�@�@��������ŗ��ɏ���!!����!!
*2.4% 09/23 13:55-16:00 NHK ����lFM�~��� �@�@�@�@�@�@�@�@������łɃ_�u���X�R�A!!(��)
*3.4% 10/05 14:00-16:00 TBS ���t�~�Y�a� �@�@�@�@�@�@�@�@�@�@
*3.1% 10/26 14:00-16:00 TBS �FC�����~�����
*3.4% 11/08 14:00-16:00 NHK ����~���É���@�@�@�@�@�@�@�@�@�@ ������'�ĕ���'�̖싅�A�j���ɎS�s�B
*2.5% 11/23 13:10-15:00 NHK ��啪�~����� �@�@�@�@�@�@�@�@�@�@���i���[�O�D���������m�̐킢
*3.2% 11/30 14:00-16:00 NHK �u�֓c�~�����v�@�@�@�@�@�@�@�@�@�@������ȗD��������3%����!!�I�t�V�[�Y���̖싅�s���`(�܁G�G)
*2.9% 12/06�@�@�@�@�@�@�@�@NHK �u�����~�D�y�v���D�����莎�����D�����莎���Ȃ̂ɑO���莋�����_�E��
���[�O�핽�ώ������F3.40%
5�������F1��
�F�l�̂�����(��)���肪�Ƃ��������܂���
�b�@�^�@�@�_�@..�b�@�T�J������
�b�^��ڰ..�_�b�@���܂���]�݂����キ
�b�@ �^�P�_ �@�b�@�N���ɔ]����p���K�v�ł�
�b�@|�@�Oo�O�@|.�@�b
�b�@ �_�Q�^..�@�b�@��������p�ɂ͕��ώ�����5%�K�v�ł�
�b�@ �Q|�@|�Q�@�b�@�T�J�������~�����߂ɂ��肢�������܂�
��������������
���T�J�����
�c�O�I�I�I�I3.40�ł�����������������������������
�������̂�������[�����M���W�F�C�I�i�j-2008
*4.6% 03/08 14:00-16:00 TBS �J��������lFM�~�Y�a��@�@�@ ���T�J�؎����̐��E�R�ʂ̊J��
*2.2% 03/09 13:55-16:00 NHK �J��������F�~����V��@�@�@ ���[��ԑg�ƍ��o
*4.4% 03/15 13:55-16:00 NHK ��Y�a�~���É�� �@�@�@�@�@�@�@�@���������т������ŗ��̕�
*2.3% 04/19 16:00-18:00 NHK ������~G��� �@�@�@�@�@�@�@�@�@���ǂ����͂ł���
*4.9% 04/20 14:00-16:00 TBS ��Y�a�~��{��@�@�@�@�@�@ �@�@�@�@������ŗ��Ɍ����͂���!!�c�O!!
*3.1% 05/03 15:00-17:00 NTV �����V�~���lF� �@�@�@�@�@�@�@�@���O��̓����u�̕������140%���㏸!!�싅�s���`!!(��)
*5.6% 05/10 14:00-16:00 TBS ����F�~�Y�a� �@�@�@�@�@�@�@�@�@������ŗ��ɏ���!!�T�J�؊���!!!
*3.1% 05/20 14:00-16:00 NHK ��Y�a�~G��㣁@�@�@�@ �@�@�@�@�@��������ŗ��ɏ���!!����!!
*2.4% 09/23 13:55-16:00 NHK ����lFM�~��� �@�@�@�@�@�@�@�@������łɃ_�u���X�R�A!!(��)
*3.4% 10/05 14:00-16:00 TBS ���t�~�Y�a� �@�@�@�@�@�@�@�@�@�@
*3.1% 10/26 14:00-16:00 TBS �FC�����~�����
*3.4% 11/08 14:00-16:00 NHK ����~���É���@�@�@�@�@�@�@�@�@�@ ������'�ĕ���'�̖싅�A�j���ɎS�s�B
*2.5% 11/23 13:10-15:00 NHK ��啪�~����� �@�@�@�@�@�@�@�@�@�@���i���[�O�D���������m�̐킢
*3.2% 11/30 14:00-16:00 NHK �u�֓c�~�����v�@�@�@�@�@�@�@�@�@�@������ȗD��������3%����!!�I�t�V�[�Y���̖싅�s���`(�܁G�G)
*2.9% 12/06�@�@�@�@�@�@�@�@NHK �u�����~�D�y�v���D�����莎�����D�����莎���Ȃ̂ɑO���莋�����_�E��
���[�O�핽�ώ������F3.40%
5�������F1��
�F�l�̂�����(��)���肪�Ƃ��������܂���
>>1�@��
�S�O�̃A���h
������A�O�̓A���h�ƌĂ��o�P���m�ɕϐg���Ă��܂��B
���M�Ŗ\������A���h�̑O�Ɍ��ꂽ�̂́A�Ԃ����������ٍ��̏���C3�������c�c
������A�O�̓A���h�ƌĂ��o�P���m�ɕϐg���Ă��܂��B
���M�Ŗ\������A���h�̑O�Ɍ��ꂽ�̂́A�Ԃ����������ٍ��̏���C3�������c�c
6 �FSocket774�F2008/12/10(��) 07:09:48 ID:5O1zy23n
>>1��
7 �F,,�E�L�́M�E,,�j��-�������F2008/12/10(��) 07:34:35 ID:8Fl+s2D7
>> http://pc11.2ch.net/test/read.cgi/jisaku/1226628399/999
�ǂ������AAMD�̔��\�ɂ���SSE5��SSSE3�܂ł����Ă܂��B
http://tuvantinhoc1088.com/my_documents/my_pictures/Giainghia/SSE5/hinh2.png
AMD�̖��߃Z�b�g�}�j���A���ɂ����Ă�SSE4.1��Feature Flag�r�b�g����`�ς݂ŁA
�ǂ����̃^�C�~���O�Ńt���T�|�[�g����邱�Ƃ͊m���i���Ȃ݂�SSE5��SSE4.1�̈ꕔ���߂����Ă�j
���Ƃ���Bulldozer��45nm�œo��\�肾�����̂ŁA32nm��Orochi��SSE4.1���t���T�|�[�g�����\����
�o�Ă��邵�A����ȑO�ɑΉ�����\�����B
���ƁA���Ȃ��Ƃ�AMD��SSE4.2�܂ł͑Ή��̈ӎu�����邱�Ƃ͊ԈႢ�Ȃ��ł��B
�łȂ��Ⴑ��ȃ��C�u�������Ȃ��ł���B
http://sseplus.sourceforge.net/
AVX��SSE�`SSE4.x��Opcode�e�[�u���g���Ă邩��A�f�R�[�_�̉��ǂɂ͎��͂���ȂɃR�X�g������Ȃ��炵���B
AVX�I���W�i���̐V���߂�0F, 0F38, 0F3A�̂����ꂩ�Ɏ��܂��Ă�B�i�Ԃ����Ⴏ0F38, 0F3A�����ł��Ȃ�]�T������j
�t�����g�G���h�͂Ƃ肠�����AVEX�v���t�B�N�X�����̃f�R�[�h���W�b�N�������邾���ł���
�o�b�N�G���h�́AALU�̃f�[�^�o�X��3-4Way�����邾���ł����B
���Ȃ݂�Sandy Bridge�ł̓f�[�^�o�X��256bit�͐摗�肳���ƌ����܂��i���j�b�g���̂��̂�256�r�b�g���͍s���Ȃ��ׁj
AVX�ڍs��������x��������v���f�R�[�h�A���S���Y�������Ȃ�P�����ł��邽��
�����I�ɂ͏ȓd�͉��ɂ��Ȃ���Ƃ������܂��t���B���̈Ӗ��ł�Atom�n��̃A�[�L�ɂƂ��Ă����b�͂��Ȃ�傫���B
Intel��AMD�̃p���[�Q�[�������ɂ��Ă�AVX�̂ق����L���B
���X�f�R�[�_�̕��S���̖ړI�ŐV�v���ꂽ���߃Z�b�g�Ȃ̂�AMD�ɂƂ��Ă���ΓI�ɂ̓����b�g�͂���Ǝv���܂��B
�ǂ������AAMD�̔��\�ɂ���SSE5��SSSE3�܂ł����Ă܂��B
http://tuvantinhoc1088.com/my_documents/my_pictures/Giainghia/SSE5/hinh2.png
{kind=link}
AMD�̖��߃Z�b�g�}�j���A���ɂ����Ă�SSE4.1��Feature Flag�r�b�g����`�ς݂ŁA
�ǂ����̃^�C�~���O�Ńt���T�|�[�g����邱�Ƃ͊m���i���Ȃ݂�SSE5��SSE4.1�̈ꕔ���߂����Ă�j
���Ƃ���Bulldozer��45nm�œo��\�肾�����̂ŁA32nm��Orochi��SSE4.1���t���T�|�[�g�����\����
�o�Ă��邵�A����ȑO�ɑΉ�����\�����B
���ƁA���Ȃ��Ƃ�AMD��SSE4.2�܂ł͑Ή��̈ӎu�����邱�Ƃ͊ԈႢ�Ȃ��ł��B
�łȂ��Ⴑ��ȃ��C�u�������Ȃ��ł���B
http://sseplus.sourceforge.net/
AVX��SSE�`SSE4.x��Opcode�e�[�u���g���Ă邩��A�f�R�[�_�̉��ǂɂ͎��͂���ȂɃR�X�g������Ȃ��炵���B
AVX�I���W�i���̐V���߂�0F, 0F38, 0F3A�̂����ꂩ�Ɏ��܂��Ă�B�i�Ԃ����Ⴏ0F38, 0F3A�����ł��Ȃ�]�T������j
�t�����g�G���h�͂Ƃ肠�����AVEX�v���t�B�N�X�����̃f�R�[�h���W�b�N�������邾���ł���
�o�b�N�G���h�́AALU�̃f�[�^�o�X��3-4Way�����邾���ł����B
���Ȃ݂�Sandy Bridge�ł̓f�[�^�o�X��256bit�͐摗�肳���ƌ����܂��i���j�b�g���̂��̂�256�r�b�g���͍s���Ȃ��ׁj
AVX�ڍs��������x��������v���f�R�[�h�A���S���Y�������Ȃ�P�����ł��邽��
�����I�ɂ͏ȓd�͉��ɂ��Ȃ���Ƃ������܂��t���B���̈Ӗ��ł�Atom�n��̃A�[�L�ɂƂ��Ă����b�͂��Ȃ�傫���B
Intel��AMD�̃p���[�Q�[�������ɂ��Ă�AVX�̂ق����L���B
���X�f�R�[�_�̕��S���̖ړI�ŐV�v���ꂽ���߃Z�b�g�Ȃ̂�AMD�ɂƂ��Ă���ΓI�ɂ̓����b�g�͂���Ǝv���܂��B
��AMD�I�ɂ͎����̌������Ƃ������ƕ����t�@�u�������Ȃ���
�ׂ���LSI�Ȃ�t�@�u�̕����炤���ō���Ă���Ƃ����b�ɂȂ邾�낤��
�t�@�u���瑳�ɂ����悤�ȃ`�b�v�Ȃ�t�@�u�m�ۂɕK���ɂȂ�Ȃ����
�Ȃ�Ȃ��قǔ���Ȃ���Ȃ�����
�ׂ���LSI�Ȃ�t�@�u�̕����炤���ō���Ă���Ƃ����b�ɂȂ邾�낤��
�t�@�u���瑳�ɂ����悤�ȃ`�b�v�Ȃ�t�@�u�m�ۂɕK���ɂȂ�Ȃ����
�Ȃ�Ȃ��قǔ���Ȃ���Ȃ�����
�K���@�K��
�ނ���ǂ����炩���Ƃ��Ă��ăt�@�E���_�������Ƃ���Ƃ��o���Ȃ������낤���B
nVidia��intel�����`�b�v�Z�b�g�Ƃ����n���ɂȂ���������ǁB
nVidia��intel�����`�b�v�Z�b�g�Ƃ����n���ɂȂ���������ǁB
10nm���炢�̎{�݂����������Ă�����C���e���ɏ��Ă��I
�N��AMD�ɋt�]�̃`�����X���I
�N��AMD�ɋt�]�̃`�����X���I
>>10
�������邽�߂�"����"�Ȃ��c�B
>>11
�{���ɂ���ȗʎY�{�݂��ˑR��������A
10-20�N�P�ʂŋZ�p��s���鎖�ɂȂ�Ȃ��B
�t�]���̑�������Ȃ����B
�������邽�߂�"����"�Ȃ��c�B
>>11
�{���ɂ���ȗʎY�{�݂��ˑR��������A
10-20�N�P�ʂŋZ�p��s���鎖�ɂȂ�Ȃ��B
�t�]���̑�������Ȃ����B
�X�L�b�v���Đ�s���邽�߂ɂ͏��Ԃɂ��������Ԃ��˔\�������K�v�ɂȂ�
���Ǐ��ԂɃX�e�b�v�A�b�v����̂ƕς��Ȃ������܂ł�����
���Ǐ��ԂɃX�e�b�v�A�b�v����̂ƕς��Ȃ������܂ł�����
PC98����ɍ���CPU�����Ă�������X�S�C����ȁ[�@�@���炢�̃A�z�炵��������
15 �FSocket774�F2008/12/10(��) 17:30:23 ID:mpXIIMSb
>>13
�������o���オ��܂ł�Intel�ɂ�����ςȂ�������A���X�N�����Ȃ肷������
�������o���オ��܂ł�Intel�ɂ�����ςȂ�������A���X�N�����Ȃ肷������
�ŁA����������C���e���̃Z�J���h�\�[�X����炳�����A������
SOI�Ŏ���CPU��Ƃ�����AMD�̃t�@�u���A���Љ��������炢��TSMC�ɑR�ł���
�C�͂���̂�����ǁB���Ȃ��Ƃ��ڍs����GPU�r�W�l�X�̓K�^�K�^�ɂȂ�B
�t�@�E���h���Ƃ����܂��Ȃ�āA�A�u�_�r����������o�����߂̃��b�v�T�[�r�X�A
�G�ɕ`�����݂���Ȃ��́B
�ł����ۂ̂Ƃ���A�o���N�V���R����GPU��SOI��CPU���Ăǂ�����ē����������Ȃ낤�B
�C�͂���̂�����ǁB���Ȃ��Ƃ��ڍs����GPU�r�W�l�X�̓K�^�K�^�ɂȂ�B
�t�@�E���h���Ƃ����܂��Ȃ�āA�A�u�_�r����������o�����߂̃��b�v�T�[�r�X�A
�G�ɕ`�����݂���Ȃ��́B
�ł����ۂ̂Ƃ���A�o���N�V���R����GPU��SOI��CPU���Ăǂ�����ē����������Ȃ낤�B
�I�C���}�l�[�̖����͈��ׂł����H
http://www.dojima.ecnet.jp/Es-NYOIL.htm
http://www.dojima.ecnet.jp/Es-NYOIL.htm
�A�u�_�r�͂܂��]�T�����邾�낤
���o���̂͌����̍����C�����Ƃ�
���o���̂͌����̍����C�����Ƃ�
SOI���g�����Ƃ�O��Ƃ����v�ɂ����Ȃ����H>GPU
FUSION���̂͂܂��悾���AFUSION���o�鍠�ɂ�6x00��7x00�܂Ői�ނ��낤����
�܂�����ĂȂ��Ƃ��Ă��ASOI���g�����ƑO��Ń`�b�v�v���鎞�Ԃ͂����Ȃ����H
FUSION���̂͂܂��悾���AFUSION���o�鍠�ɂ�6x00��7x00�܂Ői�ނ��낤����
�܂�����ĂȂ��Ƃ��Ă��ASOI���g�����ƑO��Ń`�b�v�v���鎞�Ԃ͂����Ȃ����H
21 �F,,�E�L�́M�E,,�j��-�������F2008/12/11(��) 00:19:11 ID:Hi2hW7Yq
���ʂقǃ��o�C�Ȃ̂ɃV�F�A50���Ȃ�Ė������AMD�o�c�w�́A������Ȃ̂��A
�}�W�ŗ����������̂��B
Nehalem-Westmere���҈Ђ�U�邤�ł��낤2009-2010�N���45nm Shanghai�n�R�A��
���̃}�C�i�[�`�F���W�ŐH���q�������ł��A���Ȃ茵�����̂ɁB
Bulldozer�A�[�L������ۂǏo�����ǂ��āAIntel��32nm�ő�R�P���邱�Ƃ��肤�����Ȃ��Ƃ��낾�낤���B
�ǂ������Ƃ�����Atom�R��Bobcat�̂ق���Intel�ɂƂ��Ă͋��ЂɂȂ邩������Ȃ��B
�n�C�G���h�Ƃ͒��ڐ��\��r���Ȃ��Ă�������˂��̎s��́B
Atom�̓f�X�N�g�b�v�s��ɂ�����Celeron�AUMPC�ɂ�����Core 2 Duo��ULV��H��Ȃ��悤��
�Â��M����@�\�̃`�b�v�Z�b�g���̗p�����瑫�g�������u�����낤�����낤�v�ɗ}������ł�B
�{�C�o�����Ⴄ�Ǝ����̎s���j���Ⴄ���ƂɂȂ邩��ˁB
�t�ɁA���̃����W�Ŏ��s�ꂪ����AMD�͐��\�E���i�ʂŐϋɓI�ɍU�߂Ă������Ƃ��ł���B
�ł��A���g���O�ꂽIntel�͂���ς苭����ȁB
NetBurst�����n�ɒǂ����A�C�X���G���̃��o�C��CPU���f�X�N�g�b�v�ȏ�Ɏ����Ă�������
���ʂ�����AMD����B
�}�W�ŗ����������̂��B
Nehalem-Westmere���҈Ђ�U�邤�ł��낤2009-2010�N���45nm Shanghai�n�R�A��
���̃}�C�i�[�`�F���W�ŐH���q�������ł��A���Ȃ茵�����̂ɁB
Bulldozer�A�[�L������ۂǏo�����ǂ��āAIntel��32nm�ő�R�P���邱�Ƃ��肤�����Ȃ��Ƃ��낾�낤���B
�ǂ������Ƃ�����Atom�R��Bobcat�̂ق���Intel�ɂƂ��Ă͋��ЂɂȂ邩������Ȃ��B
�n�C�G���h�Ƃ͒��ڐ��\��r���Ȃ��Ă�������˂��̎s��́B
Atom�̓f�X�N�g�b�v�s��ɂ�����Celeron�AUMPC�ɂ�����Core 2 Duo��ULV��H��Ȃ��悤��
�Â��M����@�\�̃`�b�v�Z�b�g���̗p�����瑫�g�������u�����낤�����낤�v�ɗ}������ł�B
�{�C�o�����Ⴄ�Ǝ����̎s���j���Ⴄ���ƂɂȂ邩��ˁB
�t�ɁA���̃����W�Ŏ��s�ꂪ����AMD�͐��\�E���i�ʂŐϋɓI�ɍU�߂Ă������Ƃ��ł���B
�ł��A���g���O�ꂽIntel�͂���ς苭����ȁB
NetBurst�����n�ɒǂ����A�C�X���G���̃��o�C��CPU���f�X�N�g�b�v�ȏ�Ɏ����Ă�������
���ʂ�����AMD����B
http://pc.watch.impress.co.jp/docs/2008/1114/kaigai476.htm
Bulldozer, Bobcat, ������ Fusion...
�ŐV32nm�v���Z�X�E�A�[�L�e�B�N�`����V��2011�N��C�o��!!!
��@�@���@���@�Ł@��
Bulldozer, Bobcat, ������ Fusion...
�ŐV32nm�v���Z�X�E�A�[�L�e�B�N�`����V��2011�N��C�o��!!!
��@�@���@���@�Ł@��
http://www.pcgameshardware.com/aid,669910/News/AMD_Phenom_II_X4_940-_First_game_benchmarks/
�Q�[���ɂ���Ă�i7�ȏ�(������O����)
AM3�ł����ƐL�т邩�H
�Q�[���ɂ���Ă�i7�ȏ�(������O����)
AM3�ł����ƐL�т邩�H
�A�i���X�g�̗\�z�ɂ��ƁAAMD�̍��l������$350M-400M�̉c�ƐԎ��Ƃ��B�B�B
http://biz.yahoo.com/ap/081210/advanced_micro_devices_rating_downgrade.html?.v=1
�@�@---------------------
�@�@In a statement, the agency said that AMD's revenue shortfall in the fourth quarter will
�@�@likely result "an operating loss of approximately $350 million to $400 million ... excluding
�@�@any potential restructuring charges." Moody's said it expects a similar loss at AMD in
�@�@the first quarter of next year.
�@�@---------------------
http://biz.yahoo.com/ap/081210/advanced_micro_devices_rating_downgrade.html?.v=1
�@�@---------------------
�@�@In a statement, the agency said that AMD's revenue shortfall in the fourth quarter will
�@�@likely result "an operating loss of approximately $350 million to $400 million ... excluding
�@�@any potential restructuring charges." Moody's said it expects a similar loss at AMD in
�@�@the first quarter of next year.
�@�@---------------------
>>21-22
�V�`�b�v�S���x�ꂽ�̂́A���̃L���p����C���i�b�v�𑝂₹�Ȃ��������Ă̂��w�i�ɗL�邩����
���̐����\�͂��ᗘ�v���̒Ⴂ���̂Ń��C���߂��ɂ͍s���Ȃ����痘�v�o����̂�������Ȃ�
�܂�Opteron�ƁAOpteron�̒P�������������邽�߂�Phenom�𒆐S�ɍ��Ȃ��Ⴂ���Ȃ�
������SOI�O��Őv���ꂽ���s��CPU�Q�ł͊O�����邱�Ƃ��o���Ȃ�
�t�@�u���X�����ǂ��ق��ɏo�Ă����Ƃ�����
�V�`�b�v�S���x�ꂽ�̂́A���̃L���p����C���i�b�v�𑝂₹�Ȃ��������Ă̂��w�i�ɗL�邩����
���̐����\�͂��ᗘ�v���̒Ⴂ���̂Ń��C���߂��ɂ͍s���Ȃ����痘�v�o����̂�������Ȃ�
�܂�Opteron�ƁAOpteron�̒P�������������邽�߂�Phenom�𒆐S�ɍ��Ȃ��Ⴂ���Ȃ�
������SOI�O��Őv���ꂽ���s��CPU�Q�ł͊O�����邱�Ƃ��o���Ȃ�
�t�@�u���X�����ǂ��ق��ɏo�Ă����Ƃ�����
��������AMD�̐����L���p������Ȃ����Ă��̘b�����Ă�B
Fab36�����ɂ����2008�N���ɂ͐��E�V�F�A50%���܂��Ȃ���\�肾������B
����ȂɃV�F�A�����ĂȂ����烉�C���̈ꕔ���~�߂Ă��邪�B
Fab36�����ɂ����2008�N���ɂ͐��E�V�F�A50%���܂��Ȃ���\�肾������B
����ȂɃV�F�A�����ĂȂ����烉�C���̈ꕔ���~�߂Ă��邪�B
�G�̑听���Ǝ����̑厸�s���d�Ȃ����̂����̌���
�������Ȃ���I
29 �FSocket774�F2008/12/11(��) 08:57:19 ID:MrMFnqim
Intel���{�C�ɂ����Ȃ�Ȃ���AC2D���J�������v���X�R�b�g�H���𑱂��ċ��Ă��ꂽ��
�����͏������ł��낤��AMD�����������ł��邱�Ƃ��낤
�����͏������ł��낤��AMD�����������ł��邱�Ƃ��낤
30 �FSocket774�F2008/12/11(��) 08:58:00 ID:lHOG5bCv
K7�̒n���ȉ��ǂƃ��W���[�����A�������R���g���[���̓����ɂ��
���C�e���V�팸�A���̂�����͌����H���ŗǂ������̂�
������o�������Ȃ���������ƂɂȂ��Ă��܂����̂��낤�B
���C�e���V�팸�A���̂�����͌����H���ŗǂ������̂�
������o�������Ȃ���������ƂɂȂ��Ă��܂����̂��낤�B
�J���`�[���̑w�ł����AIntel��Ђ�ɐ키�����ł�2�Ђ��
�키�悤�Ȃ��́B2�Е������Ă���ǂ��炩�ɏ��Ă�P�[�X�ł�
Intel�̓^�b�O��g��ł��邩�̂悤�ɋ��������o�Ă���B
�Ɨ�����2�Ђ��������������B
�키�悤�Ȃ��́B2�Е������Ă���ǂ��炩�ɏ��Ă�P�[�X�ł�
Intel�̓^�b�O��g��ł��邩�̂悤�ɋ��������o�Ă���B
�Ɨ�����2�Ђ��������������B
Intel�̊J���͂�Itanium�ɂ�����Ă邩��ȁBAMD�̂R�{�͂���B
34 �FSocket774�F2008/12/11(��) 10:21:40 ID:wWQl2lDN
i7���ăQ�[���͑債�����Ɩ�������
���N���b�NQ9xxx��������Ə�����x
AMD�̓}���`�X���b�h�A�v���łǂ̈ʒǂ����낤��
���N���b�NQ9xxx��������Ə�����x
AMD�̓}���`�X���b�h�A�v���łǂ̈ʒǂ����낤��
>AMD�̓}���`�X���b�h�A�v���łǂ̈ʒǂ����낤��
Corei7�ɂ�����گ�ނ̃x���`�ł͕�����Ǝv����
���ׂ̈�����ʲ�߰�گ�ިݸނ��ꂽ�݂����Ȃ�����
�܂��A�I���ƑO���HTT�����Ŗw�ǂ̎I�ǂ�HTT-ON�ɂ��Ȃ����낤����
�ǂ������ǂ���������Ȃ�����
Corei7�ɂ�����گ�ނ̃x���`�ł͕�����Ǝv����
���ׂ̈�����ʲ�߰�گ�ިݸނ��ꂽ�݂����Ȃ�����
�܂��A�I���ƑO���HTT�����Ŗw�ǂ̎I�ǂ�HTT-ON�ɂ��Ȃ����낤����
�ǂ������ǂ���������Ȃ�����
>>26
����������Ȃ�������
AMD�ł����C����Phnome��Athlon�̂ق��ɂ��������v��͂���
�ł���������Ɉڂ����Ƃ����ꍇ
�@���݉ғ�����Fab�̋ŏ��ʂ������Y�ƂȂ�Ɛ����P�����オ���Č������Ȃ��i���i�ɓ]������Ή��i���オ���Ĕ���Ȃ��j
�A��������Fab���ғ������ĐV���i�������ō�낤�Ƃ���ƁA��ʂɎ��v���o�邩���邢�͗��v���̍������i�Ŗ����ƍH����ғ���������p������ł��Ȃ�
�E�E�E�ƂȂ�
���ꂶ�ᐻ�i�̃��C���i�b�v�𑝂₹�Ȃ����Ď�
����������Ȃ�������
AMD�ł����C����Phnome��Athlon�̂ق��ɂ��������v��͂���
�ł���������Ɉڂ����Ƃ����ꍇ
�@���݉ғ�����Fab�̋ŏ��ʂ������Y�ƂȂ�Ɛ����P�����オ���Č������Ȃ��i���i�ɓ]������Ή��i���オ���Ĕ���Ȃ��j
�A��������Fab���ғ������ĐV���i�������ō�낤�Ƃ���ƁA��ʂɎ��v���o�邩���邢�͗��v���̍������i�Ŗ����ƍH����ғ���������p������ł��Ȃ�
�E�E�E�ƂȂ�
���ꂶ�ᐻ�i�̃��C���i�b�v�𑝂₹�Ȃ����Ď�
>>36
�A��������Fab���ғ������ĐV���i�������ō�낤�Ƃ���ƁA��ʂɎ��v���o�邩���邢�͗��v���̍������i�Ŗ����ƍH����ғ���������p������ł��Ȃ�
�Ȃ�V�K��Fab���o���Ă������͕ς��Ȃ��B
�A��������Fab���ғ������ĐV���i�������ō�낤�Ƃ���ƁA��ʂɎ��v���o�邩���邢�͗��v���̍������i�Ŗ����ƍH����ғ���������p������ł��Ȃ�
�Ȃ�V�K��Fab���o���Ă������͕ς��Ȃ��B
�t�@�u���X��Ƃ��Ă̂́A���̂Ƃ��Ɉ�ԃx�X�g�ȃt�@�u��I�ׂ��ЁB
AMD��The Foundry Company�ɋ������ѕt�����Ă��āA�O�݂���Chartered
��CPU�������ϑ�����킯�ɂ����Ȃ��A�ނ���킴�킴�o���N�V���R��
�n�߂Ă܂�TSMC����GPU���������グ�Ȃ��Ƃ����Ȃ�����A�^�t�B
�������AThe Foundry Company���x�X�g�ȃt�@�u�ɂȂ�Ηǂ����ɉ�邯�ǁA
��]�E�ϑz�����Ƃɉ�Ђ̐헪�𗧂Ăď�肭�������ǂ����B
AMD��The Foundry Company�ɋ������ѕt�����Ă��āA�O�݂���Chartered
��CPU�������ϑ�����킯�ɂ����Ȃ��A�ނ���킴�킴�o���N�V���R��
�n�߂Ă܂�TSMC����GPU���������グ�Ȃ��Ƃ����Ȃ�����A�^�t�B
�������AThe Foundry Company���x�X�g�ȃt�@�u�ɂȂ�Ηǂ����ɉ�邯�ǁA
��]�E�ϑz�����Ƃɉ�Ђ̐헪�𗧂Ăď�肭�������ǂ����B
�x�X�g�Ƃ������ATFC�ȊOAMD���v�����鐫�\���������`�b�v������Ƃ��낪
���������قƂ�ǂȂ���Ȃ��́H
IBM�Ȃ���邾�낤���ǁA�����R�X�g�������ɂȂ邾�낤���B
�ނ���AAMD���t�@�u���X�ɂȂ����Ƃ������AAMD�ȊO���琻��������ł���悤�ɂ����̂�
���C�����Ǝv�����ǁB
�����ȒP�Ɍ_�����Ƃ͎v��Ȃ����B
���������قƂ�ǂȂ���Ȃ��́H
IBM�Ȃ���邾�낤���ǁA�����R�X�g�������ɂȂ邾�낤���B
�ނ���AAMD���t�@�u���X�ɂȂ����Ƃ������AAMD�ȊO���琻��������ł���悤�ɂ����̂�
���C�����Ǝv�����ǁB
�����ȒP�Ɍ_�����Ƃ͎v��Ȃ����B
>>38
�t�@�u���Ќ��GPU��TSMC�ɂ�����x�ϑ�����炵���B
�l�I�ɂ�GPU�͂��̂܂�TSMC�ϑ��̂܂܂Ɏv����B
"�`�b�v�Z�b�g���������ЍH��Ɉڂ��邱��"�����C�����ƁB
�Ă��A�u�x�X�g�ȃt�@�u�v�Ɏ����Ă����悤�ɂ����B
��]�E�ϑz�Ƃ��ł͂Ȃ��āA��Ɠw�͂̃��x���B
�ŏ����瓪���Ȃ��ɔے肾�����Ă��Ӗ����Ȃ��B
12/9��10�̌㓡�̋L����ǂ߂Ε����邪�A
AMD�����ł͊��S�ɍs���l�܂邱�Ƃ͊m�肵�Ă���B
�܂�12/9�̋L���ɂ��鋦�͊J����������A���Y�ϑ����邱�Ƃ��o����A
"The Foundry Company"�͂���Ȃ�̗��v�����邾�낤���ˁB
���ЍH�������Ђ����邵�A�u����v�̘b�ɂ͂Ȃ邪�B
�t�@�u���Ќ��GPU��TSMC�ɂ�����x�ϑ�����炵���B
�l�I�ɂ�GPU�͂��̂܂�TSMC�ϑ��̂܂܂Ɏv����B
"�`�b�v�Z�b�g���������ЍH��Ɉڂ��邱��"�����C�����ƁB
�Ă��A�u�x�X�g�ȃt�@�u�v�Ɏ����Ă����悤�ɂ����B
��]�E�ϑz�Ƃ��ł͂Ȃ��āA��Ɠw�͂̃��x���B
�ŏ����瓪���Ȃ��ɔے肾�����Ă��Ӗ����Ȃ��B
12/9��10�̌㓡�̋L����ǂ߂Ε����邪�A
AMD�����ł͊��S�ɍs���l�܂邱�Ƃ͊m�肵�Ă���B
�܂�12/9�̋L���ɂ��鋦�͊J����������A���Y�ϑ����邱�Ƃ��o����A
"The Foundry Company"�͂���Ȃ�̗��v�����邾�낤���ˁB
���ЍH�������Ђ����邵�A�u����v�̘b�ɂ͂Ȃ邪�B
���̃X���ɂ������Ƃ���
cata8.12�Ń��f��2D�������肪�������ꂽ�悤����
cata8.12�Ń��f��2D�������肪�������ꂽ�悤����
>>43
IBM������Ȃ�Intel�����č����
IBM������Ȃ�Intel�����č����
>>46�̐��E�ł�Intel�͎��Ђ̍Ő�[Fab�ő��Ђ̃`�b�v�̐��Y�ϑ��Ă��
>42
���NK7�g���܂킷�C�H
���NK7�g���܂킷�C�H
http://pc.watch.impress.co.jp/docs/2008/1008/hot574.htm
> SOI�v���Z�X�̂܂܂ł́A�t�@�E���_�����Ƃ�W�J���邱�Ƃ�������߁A
> ����A32nm���[������SOI�ƕ��s���āA�o���N�V���R���v���Z�X�̊J�����s
> �Ȃ����Ƃ��\�����ꂽ�B
ATI��������2�N�o���Ă邱�Ƃ��l����AAMD�����܂܂�GPU��`�b�v�Z�b�g��
�����ɋ����������Ă��Ȃ������̂͊ԈႢ�Ȃ��B���炽�߂ăo���N�V���R����
�������Ď��ЍH��ō����ATSMC�Ɉϑ���������������炾�B�t�@�u�̃L��
�p�V�e�B���]���Ă��āA��ɂ�CPU�EGPU�������T���Ă���ɂ��ւ�炸�A�ł�
��B
���Ѓu�����h�̃`�b�v�����܂ő��ЂɈϑ����Ă���AMD���A���Љ������r�[��
�t�@�E���h�����Ƃւ̎Q����錾����180�x�̕ϐS�Ԃ�B����ȃI�C���}�l�[
�ē������\�ɂȂ�������Ƃ������邪�A�H��邽�߂̌������(CPU
��������H�ꂶ�ᔄ��Ȃ�) �ɂ�������B�t�@�E���h�����Ƃ����ۂ�����Ȃ�A
TSMC�ɂǂ��R����̂��̃r�W�������܂������ׂ��ł͂Ȃ��������B
> SOI�v���Z�X�̂܂܂ł́A�t�@�E���_�����Ƃ�W�J���邱�Ƃ�������߁A
> ����A32nm���[������SOI�ƕ��s���āA�o���N�V���R���v���Z�X�̊J�����s
> �Ȃ����Ƃ��\�����ꂽ�B
ATI��������2�N�o���Ă邱�Ƃ��l����AAMD�����܂܂�GPU��`�b�v�Z�b�g��
�����ɋ����������Ă��Ȃ������̂͊ԈႢ�Ȃ��B���炽�߂ăo���N�V���R����
�������Ď��ЍH��ō����ATSMC�Ɉϑ���������������炾�B�t�@�u�̃L��
�p�V�e�B���]���Ă��āA��ɂ�CPU�EGPU�������T���Ă���ɂ��ւ�炸�A�ł�
��B
���Ѓu�����h�̃`�b�v�����܂ő��ЂɈϑ����Ă���AMD���A���Љ������r�[��
�t�@�E���h�����Ƃւ̎Q����錾����180�x�̕ϐS�Ԃ�B����ȃI�C���}�l�[
�ē������\�ɂȂ�������Ƃ������邪�A�H��邽�߂̌������(CPU
��������H�ꂶ�ᔄ��Ȃ�) �ɂ�������B�t�@�E���h�����Ƃ����ۂ�����Ȃ�A
TSMC�ɂǂ��R����̂��̃r�W�������܂������ׂ��ł͂Ȃ��������B
>>49
Core MA��P6�}�C�N���A�[�L�e�B�N�`���R��������APentium Pro����Nehalem
�܂�15�N�g���Ă�BILP���d�͐��\������I�ȉ��P�͊��ҏo���Ȃ�(�̂���
������) �̂ŁA�R�A�͎g���ł����̂���B�n���ȉ��ǂƎ��ӂ̓�����ς�
�d�˂�̂��d�v�B
�t�ɁA���X���Ȃ����Ă�Bulldozer���ĉ�? �Ƃ����b�Ȃ̂����B�Ȃɂ��Q�[
�����Ђ�����Ԃ��l�^�������Ă̑唎�łȂ犴�������A��Ђɗ]�T�Ȃ��̂�
�i�����x������o���ɂ��݂��Ă���̂́A�������B
Core MA��P6�}�C�N���A�[�L�e�B�N�`���R��������APentium Pro����Nehalem
�܂�15�N�g���Ă�BILP���d�͐��\������I�ȉ��P�͊��ҏo���Ȃ�(�̂���
������) �̂ŁA�R�A�͎g���ł����̂���B�n���ȉ��ǂƎ��ӂ̓�����ς�
�d�˂�̂��d�v�B
�t�ɁA���X���Ȃ����Ă�Bulldozer���ĉ�? �Ƃ����b�Ȃ̂����B�Ȃɂ��Q�[
�����Ђ�����Ԃ��l�^�������Ă̑唎�łȂ犴�������A��Ђɗ]�T�Ȃ��̂�
�i�����x������o���ɂ��݂��Ă���̂́A�������B
Pentium Pro��Nehalem���ꏏ�ɂ���Ȃ�
Bulldozer�����Ă������Athlon�n���낤��B
���܂��獪�{�I�ɈႤ�A�[�L�e�N�`���̊J���Ȃ�Ă���Ƃł��H
Bulldozer�����Ă������Athlon�n���낤��B
���܂��獪�{�I�ɈႤ�A�[�L�e�N�`���̊J���Ȃ�Ă���Ƃł��H
>>50
ATi��������킸��2�N�����o���Ă��܂��H�@���������Ȃǂ̐��X�̖�肩��A
�w���n�������������Ƃ��������́A�F�X�ȏꏊ�ł����Ă����b�B
����Ɂu�����͂��邪�������������v�����邾�낤�ˁB
GPU�͂킩��Ȃ����A�`�b�v�Z�b�g�͎��Ђł���������L���B
Intel��CPU�ƃ`�b�v�Z�b�g�����Ђň��苟���ł��邩��AOEM�����ɗL���ł����āA
�uCPU�ƃ`�b�v�Z�b�g�����Ђň��苟���ł��܂��v�Ƃ��������b�g�́A
OEM������胁�[�J�[�ɂ͈��S���čw���ł��郁���b�g�ɂȂ肤��B
�����"The Foundry Company"�Ŗ{����"�t�@�E���h������"���������̂�����B
�܂����㓡�̋L���Ő\����Ȃ����u12/10�v�̋L���ɂ���ux86�s��V�F�A50%�̐헪�v��
�{���ɂ�肽���̂ł���A"�t�@�E���h������"�����b�́A����ɐ�B
���݂�"Fab36"���ŐV�v���Z�X����O��Ĉȍ~�̘b������Ȃ����Ǝv���Ă���B
�Ԃ����Ⴏ�A"The Foundry Company"��"�t�@�E���h������"�Ƃ́A
AMD����̈ϑ������̂��Ƃ������Ă����Ȃ����Ƃ����C���������Ă���c�B
ATi��������킸��2�N�����o���Ă��܂��H�@���������Ȃǂ̐��X�̖�肩��A
�w���n�������������Ƃ��������́A�F�X�ȏꏊ�ł����Ă����b�B
����Ɂu�����͂��邪�������������v�����邾�낤�ˁB
GPU�͂킩��Ȃ����A�`�b�v�Z�b�g�͎��Ђł���������L���B
Intel��CPU�ƃ`�b�v�Z�b�g�����Ђň��苟���ł��邩��AOEM�����ɗL���ł����āA
�uCPU�ƃ`�b�v�Z�b�g�����Ђň��苟���ł��܂��v�Ƃ��������b�g�́A
OEM������胁�[�J�[�ɂ͈��S���čw���ł��郁���b�g�ɂȂ肤��B
�����"The Foundry Company"�Ŗ{����"�t�@�E���h������"���������̂�����B
�܂����㓡�̋L���Ő\����Ȃ����u12/10�v�̋L���ɂ���ux86�s��V�F�A50%�̐헪�v��
�{���ɂ�肽���̂ł���A"�t�@�E���h������"�����b�́A����ɐ�B
���݂�"Fab36"���ŐV�v���Z�X����O��Ĉȍ~�̘b������Ȃ����Ǝv���Ă���B
�Ԃ����Ⴏ�A"The Foundry Company"��"�t�@�E���h������"�Ƃ́A
AMD����̈ϑ������̂��Ƃ������Ă����Ȃ����Ƃ����C���������Ă���c�B
�㓡��12/10�̋L�����ăR���ˁB
>>52
����K7�̉��ǂ��Ƃ���ƁA���[�h�}�b�v����ꎞ����������2011�N��32nm�܂�
�����z���ꂽ���R���킩��Ȃ��B
http://pc.watch.impress.co.jp/docs/2008/1114/kaigai476.htm
�ɂ��ADEC Alpha AXP�R���̃`�[���������K7����APower4�̃`�[�t�G��
�W�j�A���}����IBM�F�̋������̂Ɉ�V����Ă���悤���B
���Ȃ݂�Power4=PowerPC 970�Ȃ̂ŁA���܂�ϑԓI�Ȃ��̂ł͂Ȃ��Ɛ�������B
(���Ⴀ�Ȃ��K7�����V�����? ���Ăȋ^��͂���)
����K7�̉��ǂ��Ƃ���ƁA���[�h�}�b�v����ꎞ����������2011�N��32nm�܂�
�����z���ꂽ���R���킩��Ȃ��B
http://pc.watch.impress.co.jp/docs/2008/1114/kaigai476.htm
�ɂ��ADEC Alpha AXP�R���̃`�[���������K7����APower4�̃`�[�t�G��
�W�j�A���}����IBM�F�̋������̂Ɉ�V����Ă���悤���B
���Ȃ݂�Power4=PowerPC 970�Ȃ̂ŁA���܂�ϑԓI�Ȃ��̂ł͂Ȃ��Ɛ�������B
(���Ⴀ�Ȃ��K7�����V�����? ���Ăȋ^��͂���)
>55
���镳�R�e�H���A
���ۂ�IBM�F��r�����Ă��邷
���镳�R�e�H���A
���ۂ�IBM�F��r�����Ă��邷
TFC�̊�����7���߂��̓A�u�_�r�������Ă����ATFC��TFC�ׂ̈̐����헪�𗧂Ă�͓̂�����O
�A�u�_�r��AMD�Ɂg�قǂ����h��������Ȃ�
�A�u�_�r��AMD�Ɂg�قǂ����h��������Ȃ�
TFC��Fab���Ƃ����̂͂������ǁATFC�Ƃ��Ă͑劔��ł���Ƃ����AMD����̎��ŗD�悵�Ȃ����Ȃ�낤����A
��������Əꍇ�ɂ���Ă͋������s����ɂȂ肤��Fab�𗘗p��������ڋq�͂ǂꂾ������́H���Ă�������������B
���K�͂Ȑ��Y�Ȃ炢���낤���ǁA�ŐV�v���Z�X�ŏ��K�͂Ȑ��Y���Č����̂͊��ɍ���Ȃ����낤���B
��������Əꍇ�ɂ���Ă͋������s����ɂȂ肤��Fab�𗘗p��������ڋq�͂ǂꂾ������́H���Ă�������������B
���K�͂Ȑ��Y�Ȃ炢���낤���ǁA�ŐV�v���Z�X�ŏ��K�͂Ȑ��Y���Č����̂͊��ɍ���Ȃ����낤���B
PowerPC 970��POWER4�����ɍ��ꂽ���Ă����ŁA�p�C�v���C���̐}�T���Ă݂�킩�邪�A
���Ƃ͓��ꌋ�ׂȂ����B
���Ƃ͓��ꌋ�ׂȂ����B
>>59
>TFC�Ƃ��Ă͑劔��ł���Ƃ����AMD����̎��ŗD�悵�Ȃ����Ȃ�낤����
���ʋt�B���Y�͂��V���[�g����ꍇ�͑��Е���D�悵�Ď��Е����V���[�g������B
���ЗD��Ȃ�Ă���Ă����x�Ǝ��Ȃ���B
>TFC�Ƃ��Ă͑劔��ł���Ƃ����AMD����̎��ŗD�悵�Ȃ����Ȃ�낤����
���ʋt�B���Y�͂��V���[�g����ꍇ�͑��Е���D�悵�Ď��Е����V���[�g������B
���ЗD��Ȃ�Ă���Ă����x�Ǝ��Ȃ���B
�g�����߂ɂ��Ă������Ƃ����������Ăق�����B
�C���e���̖��ߌQ���̗p���Ȃ��Ȃ玩�Њg���[��������
�\�t�g�n�E�X�ւ̗̍p���ϋɓI�ɐi�߂Ȃ��ƁB
�C���e���̖��ߌQ���̗p���Ȃ��Ȃ玩�Њg���[��������
�\�t�g�n�E�X�ւ̗̍p���ϋɓI�ɐi�߂Ȃ��ƁB
>>63
http://www.nikkei.co.jp/news/kaigai/media/djCNR3808.html
���ى�Ђւ�AMD�̏o���䗦��34���ɒቺ���邱�ƂɂȂ����B
2�J���O�ɍ��ى�Ђ�ݗ�����Ɣ��\�������_�ł�44���̗\�肾�����B
http://www.nikkei.co.jp/news/kaigai/media/djCNR3808.html
���ى�Ђւ�AMD�̏o���䗦��34���ɒቺ���邱�ƂɂȂ����B
2�J���O�ɍ��ى�Ђ�ݗ�����Ɣ��\�������_�ł�44���̗\�肾�����B
������CPU�R�[�h�l�[�����Y�C���Ƃ́B
���{������CM�L�����N�^�[�͓c�����a�Ɋm�肾�ȁB
���{������CM�L�����N�^�[�͓c�����a�Ɋm�肾�ȁB
>>63
�\�t�g�J���͂�邾�����Ӗ��A���ƃ��\�[�X�̖��ʌ������Ǝv����
������Ƃ����3DNow!�̓�̕��ɂ����Ȃ�Ȃ����AAMD���J���p�\�t�g�E�F�A���o�����Ƃ���Ō���ƕς��Ȃ�
����AMD��x86�R���p�C�����o���Ƃ��Ă��A�\�t�g�x���_��Intel�p�o�C�i���Ɩw�Ǖς��Ȃ�AMD�p�o�C�i����ʓr����Ă����Ƃł��H
�o�������@�s�ׂ����Aintel�Ȃ�AMD�R���p�C�����g���Ȃ�\�t�g�E�F�A�J���̎x����ł��飂Ƃ������o�����������
�\�t�g�x���_�ɂ��Ă݂�ƁAintel�̕⏕�������Ȃ�����L�c�C���낤����A����AMD������u���邾�낤��
�Ȃ̂ŁAAMD��������撣���ă\�t�g�E�F�A�������Ă��A�N�����C���Ɏg��Ȃ����A���肷��Ƃ���𗝗R��intel�ɕt�����錄��^���鎖�ɂȂ�
�o���Ƃ���Ŏg���Ƃ�����A���ꂱ���吨�ɂ͉e���͂��w�ǖ����t���[�\�t�g���炢����(Linux�n�Ŏg���Ƃ��낪���邩���A���x)
���p�\�t�g�Ŏg���Ƃ���͢������ƌ����Ă�������Ȃ�����
SSE5��intel��AVX���o���������ƂŎg�����I�����ƌ����ėǂ����낤��(���Ƃ�AVX�ɑΉ��������ł���)
�\�t�g�J���͂�邾�����Ӗ��A���ƃ��\�[�X�̖��ʌ������Ǝv����
������Ƃ����3DNow!�̓�̕��ɂ����Ȃ�Ȃ����AAMD���J���p�\�t�g�E�F�A���o�����Ƃ���Ō���ƕς��Ȃ�
����AMD��x86�R���p�C�����o���Ƃ��Ă��A�\�t�g�x���_��Intel�p�o�C�i���Ɩw�Ǖς��Ȃ�AMD�p�o�C�i����ʓr����Ă����Ƃł��H
�o�������@�s�ׂ����Aintel�Ȃ�AMD�R���p�C�����g���Ȃ�\�t�g�E�F�A�J���̎x����ł��飂Ƃ������o�����������
�\�t�g�x���_�ɂ��Ă݂�ƁAintel�̕⏕�������Ȃ�����L�c�C���낤����A����AMD������u���邾�낤��
�Ȃ̂ŁAAMD��������撣���ă\�t�g�E�F�A�������Ă��A�N�����C���Ɏg��Ȃ����A���肷��Ƃ���𗝗R��intel�ɕt�����錄��^���鎖�ɂȂ�
�o���Ƃ���Ŏg���Ƃ�����A���ꂱ���吨�ɂ͉e���͂��w�ǖ����t���[�\�t�g���炢����(Linux�n�Ŏg���Ƃ��낪���邩���A���x)
���p�\�t�g�Ŏg���Ƃ���͢������ƌ����Ă�������Ȃ�����
SSE5��intel��AVX���o���������ƂŎg�����I�����ƌ����ėǂ����낤��(���Ƃ�AVX�ɑΉ��������ł���)
>>67
�g�����߂͏�ɑ啝�Ɍ����Ђ����낤�ˁB
�����������̕���͕s�m��v�f�������Ȃ��c�B
�C���e����512bit�܂Ŋg���\�肠�邵�A���̌��Larrabee�����Șb�����邵�B
�g�����߂͏�ɑ啝�Ɍ����Ђ����낤�ˁB
�����������̕���͕s�m��v�f�������Ȃ��c�B
�C���e����512bit�܂Ŋg���\�肠�邵�A���̌��Larrabee�����Șb�����邵�B
���₻�̗����͂�������
{kind=link}
intel�̈�@�s�ׂ͑O�ȂƢintel�ƌ�����Ђ́A�����������Ƃ����C�ł���Ђ����磂��Ď��őz���̈���o�Ȃ�����
�ǂ���ɂ��Ă�AMD���J�����𐮂���̂́A���Ǝ��ԂƘJ�̖͂��ʌ����ȊO�̉��҂ł��Ȃ���
���ǃ\�t�g�x���_��intel�̗p�ӂ����J�������g�������ŁAAMD�̊J�����͕��D���ȊO�ɂ͌�����������Ȃ���
�ǂ���ɂ��Ă�AMD���J�����𐮂���̂́A���Ǝ��ԂƘJ�̖͂��ʌ����ȊO�̉��҂ł��Ȃ���
���ǃ\�t�g�x���_��intel�̗p�ӂ����J�������g�������ŁAAMD�̊J�����͕��D���ȊO�ɂ͌�����������Ȃ���
75 �FSocket774�F2008/12/11(��) 23:25:38 ID:5hHS5wI9
���D����Linux���œK�����邩��w
�œK������Ă���Intel�ɑf�Œ��܂Ȃ��Ⴂ���Ȃ��̂�AMD��
>>76
������intel�ւ̍œK����AMD�ւ̍œK����̌��x�X�g
������intel�ւ̍œK����AMD�ւ̍œK����̌��x�X�g
>>77
Intel��AMD�g�����߂̈������ʂ�Ă����\��������̂ɁA
�u�\�t�g�J�������Ӗ��v�Ɠd�g�����Ӗ����킩��܂���I
Intel�ɂ���AMD�ɂ���GPU�����Ɍ������Ă��邪�A
����GPU�̈���������Ă��邾�낤�Ɂc�B
Intel��AMD�g�����߂̈������ʂ�Ă����\��������̂ɁA
�u�\�t�g�J�������Ӗ��v�Ɠd�g�����Ӗ����킩��܂���I
Intel�ɂ���AMD�ɂ���GPU�����Ɍ������Ă��邪�A
����GPU�̈���������Ă��邾�낤�Ɂc�B
>>31
�O�X��980�ɂ��q�ׂ����A����AOpteron�Ɋւ��ẮA���z����p�����T�[�o��
�K�v�ł��낤���l�Ȗ��߂������悭���s����A�ėpCPU�R�A�Ƃ��ẮA����Ȃ��
�n���ȉ��ǂ��Ȃ���A�ǂ����̂ƂȂ��Ă���̂ł͂Ȃ����B
VMmark Results������ƁAShanghai��p�����T�[�o�ɂ��X�R�A���A16cores��
8cores�ɂ����āA�����_�ł̓g�b�v�ł���AShanghai 2.7GHz/16cores(4x4)�ƁA
XeonMP 2.66GHz/24cores(6x4)�Ƃ������ł���B
ttp://www.vmware.com/products/vmmark/results.html
���㔭�\�����ł��낤�A�T�[�o������Nehalem�ɂ��X�R�A�ƁAShanghai
(Opteron SE)�ɂ��X�R�A���ǂ��Ȃ邩�A����玟��ł́A����A���z����
���p����Ă����ł��낤�T�[�o����ł́AAMD�̃V�F�A���g�傷�邩������Ȃ��B
�O�X��980�ɂ��q�ׂ����A����AOpteron�Ɋւ��ẮA���z����p�����T�[�o��
�K�v�ł��낤���l�Ȗ��߂������悭���s����A�ėpCPU�R�A�Ƃ��ẮA����Ȃ��
�n���ȉ��ǂ��Ȃ���A�ǂ����̂ƂȂ��Ă���̂ł͂Ȃ����B
VMmark Results������ƁAShanghai��p�����T�[�o�ɂ��X�R�A���A16cores��
8cores�ɂ����āA�����_�ł̓g�b�v�ł���AShanghai 2.7GHz/16cores(4x4)�ƁA
XeonMP 2.66GHz/24cores(6x4)�Ƃ������ł���B
ttp://www.vmware.com/products/vmmark/results.html
���㔭�\�����ł��낤�A�T�[�o������Nehalem�ɂ��X�R�A�ƁAShanghai
(Opteron SE)�ɂ��X�R�A���ǂ��Ȃ邩�A����玟��ł́A����A���z����
���p����Ă����ł��낤�T�[�o����ł́AAMD�̃V�F�A���g�傷�邩������Ȃ��B
>>78
> Intel��AMD�g�����߂̈������ʂ�Ă����\��������̂�
���₻�̕�������AMD�͖łԁA�Ǝ��ɑ��ݏo����قǂ̋Z�p���̗͂��������킹�Ă͂��Ȃ�
> Intel��AMD�g�����߂̈������ʂ�Ă����\��������̂�
���₻�̕�������AMD�͖łԁA�Ǝ��ɑ��ݏo����قǂ̋Z�p���̗͂��������킹�Ă͂��Ȃ�
>>80
�����Ȃ�Ȃ����߂̃\�t�g�J���BIntel��AVX�����C�Z���X����̂��䂾���B
�����ǁA�Ȃ����\�t�g�J���͖��Ӗ��Ƃ����z������B�s�v�c�I
�����Ȃ�Ȃ����߂̃\�t�g�J���BIntel��AVX�����C�Z���X����̂��䂾���B
�����ǁA�Ȃ����\�t�g�J���͖��Ӗ��Ƃ����z������B�s�v�c�I
>>81
���△�Ӗ�����A�͂������Ń\�t�g�J����������Intel�̃\�t�g�J���ɒǏ]�ł��锤���Ȃ�
�����胀�_���͎g�킸�A�d�l��Intel�ɍ��킹���n�[�h���J������ق��������b�g�͑傫��
���△�Ӗ�����A�͂������Ń\�t�g�J����������Intel�̃\�t�g�J���ɒǏ]�ł��锤���Ȃ�
�����胀�_���͎g�킸�A�d�l��Intel�ɍ��킹���n�[�h���J������ق��������b�g�͑傫��
>>82
�����炻�ꂪ�o����̂��H�@Intel AVX�����C�Z���X�����̂��H
GPU������Intel��AMD�ł͑S���Ǝ��̘H�������ł���B
Intel��"Larrabee"��AMD��"ATi-GPU"�Ƃ����悤�ɑS���Ⴄ��������B
���łɏ��������͕���������BAMD�͂��̂܂܂ł̓��o�C�́B�}�W�ŁB
CPU�J���Ɋւ��Ắc�܂��B���Ƃ��Ȃ�\�������邪�A
����Ƀv���Z�X�J���ł��A��������Intel�ɂ͒P�Ƃł͏��ĂȂ��B
���ЂŘA�����Ă���̂������c��헪�̈�B
������������IBM�Ƃ�����\�t�g�E�F�A�J���ŋ������邩������Ȃ��B
�����A"��ǂ��헪"�����ł͉��Ƃ��Ȃ�ł͂Ȃ���ł���B
�����炻�ꂪ�o����̂��H�@Intel AVX�����C�Z���X�����̂��H
GPU������Intel��AMD�ł͑S���Ǝ��̘H�������ł���B
Intel��"Larrabee"��AMD��"ATi-GPU"�Ƃ����悤�ɑS���Ⴄ��������B
���łɏ��������͕���������BAMD�͂��̂܂܂ł̓��o�C�́B�}�W�ŁB
CPU�J���Ɋւ��Ắc�܂��B���Ƃ��Ȃ�\�������邪�A
����Ƀv���Z�X�J���ł��A��������Intel�ɂ͒P�Ƃł͏��ĂȂ��B
���ЂŘA�����Ă���̂������c��헪�̈�B
������������IBM�Ƃ�����\�t�g�E�F�A�J���ŋ������邩������Ȃ��B
�����A"��ǂ��헪"�����ł͉��Ƃ��Ȃ�ł͂Ȃ���ł���B
84 �FMAC�I�^��60 �����F2008/12/12(��) 00:02:24 ID:RQXB5Xzx
>>60
�@�@------------------
�@�@PowerPC 970��POWER4�����ɍ��ꂽ���Ă����ŁA�p�C�v���C���̐}�T���Ă݂�킩�邪�A
�@�@���Ƃ͓��ꌋ�ׂȂ����B
�@�@------------------
�m�������Ԃ��Ă悢�C���̂Ƃ���\����Ȃ������ǁAPPC970�R�A��POWER4�Ɠ������B
http://www.ibm.com/developerworks/power/library/pa-powerppl/
�@�@==================
�@�@The 64-bit PowerPC 970, a single-core version of the POWER4
�@�@==================
�@�@------------------
�@�@PowerPC 970��POWER4�����ɍ��ꂽ���Ă����ŁA�p�C�v���C���̐}�T���Ă݂�킩�邪�A
�@�@���Ƃ͓��ꌋ�ׂȂ����B
�@�@------------------
�m�������Ԃ��Ă悢�C���̂Ƃ���\����Ȃ������ǁAPPC970�R�A��POWER4�Ɠ������B
http://www.ibm.com/developerworks/power/library/pa-powerppl/
�@�@==================
�@�@The 64-bit PowerPC 970, a single-core version of the POWER4
�@�@==================
85 �FMAC�I�^��63 �����F2008/12/12(��) 00:03:36 ID:RQXB5Xzx
>>83
�@�@-----------------
�@�@Intel AVX�����C�Z���X�����̂��H
�@�@-----------------
�N���X���C�Z���X�_���邷����A�����ȑ㉿�����C�Z���X����邷���ǁH
�@�@-----------------
�@�@Intel AVX�����C�Z���X�����̂��H
�@�@-----------------
�N���X���C�Z���X�_���邷����A�����ȑ㉿�����C�Z���X����邷���ǁH
86 �FSocket774�F2008/12/12(��) 00:03:44 ID:E1xsctW7
VT�̌���͂��̕�(��)�ɏڂ����ڂ��Ă���AAMD-V�̕��͌y���O�O���Ă��o�Ă��Ȃ��B�N�������y�[�W�m���Ă��狳���Ă���B
IDF 2008�Ō���Intel�̉��z���Ή���
ttp://enterprise.watch.impress.co.jp/cda/topic/2008/09/05/13785.html
IDF 2008�Ō���Intel�̉��z���Ή���
ttp://enterprise.watch.impress.co.jp/cda/topic/2008/09/05/13785.html
Power4�ɂ���PPC970�ɂ���A�听��������������v���Z�b�T�Ƃ����ᖳ������
�Ⴈ�����������낤���ǂ����ł��uK7�����蒼���Ӗ��Ȃ��ˁH�v���͕ς���ȁB
�uSSE5�ɍœK���������R�[�h�Ő��\�����ސ~���ް݁v�ȃp�^�[����1�X�D
�Ⴈ�����������낤���ǂ����ł��uK7�����蒼���Ӗ��Ȃ��ˁH�v���͕ς���ȁB
�uSSE5�ɍœK���������R�[�h�Ő��\�����ސ~���ް݁v�ȃp�^�[����1�X�D
>>63
����Ȃ�ɂ���Ă���A�ア�Ƃ����قǂł͂Ȃ��Ǝv���̂��A�ǂ����낤���H
ttp://developer.amd.com/zones/shanghai/Pages/default.aspx
�ŋ߂́A�I�[�v���\�[�X�ɂ��J���������Ă��邩�Ǝv�����A���̏ꍇ��
�R���p�C���Ƃ��ėp�����邱�Ƃ������ł��낤gcc��
Barcelona�ȍ~��CPU�p�̍œK���@�\��������A�Ƃ������Ƃ��s���Ă���A
ttp://developer.amd.com/assets/AMDGCCQuickRef.pdf
AMD CodeAnalyst Performance Analyzer�ȂǂƂ������̂��o���Ă����肷��B
�܂��AAMD Core Math Library (ACML)��PGI�R���p�C���ɂ��ẮA��Ƃ��w�Ȃǂ́A
�J���҂⌤���҂ɂ́A��r�I�A�m���Ă���̂ł͂Ȃ����B
����Ȃ�ɂ���Ă���A�ア�Ƃ����قǂł͂Ȃ��Ǝv���̂��A�ǂ����낤���H
ttp://developer.amd.com/zones/shanghai/Pages/default.aspx
�ŋ߂́A�I�[�v���\�[�X�ɂ��J���������Ă��邩�Ǝv�����A���̏ꍇ��
�R���p�C���Ƃ��ėp�����邱�Ƃ������ł��낤gcc��
Barcelona�ȍ~��CPU�p�̍œK���@�\��������A�Ƃ������Ƃ��s���Ă���A
ttp://developer.amd.com/assets/AMDGCCQuickRef.pdf
AMD CodeAnalyst Performance Analyzer�ȂǂƂ������̂��o���Ă����肷��B
�܂��AAMD Core Math Library (ACML)��PGI�R���p�C���ɂ��ẮA��Ƃ��w�Ȃǂ́A
�J���҂⌤���҂ɂ́A��r�I�A�m���Ă���̂ł͂Ȃ����B
AMD�Ǝ����߂Ȃ͂��߂�����Ȃ��̂��\�t�g�E�F�A�J���҂ւ̍ő�̃T�|�[�g�B
�V�F�A�̑召�l������A������c�[�����[�����ĂĂ��Ή���Ƃ̗D��x�͒Ⴂ�B
�Ƃ͂���AMD64�̂悤��MS�̈��͂�Intel�ɋt�̗p�����P�[�X�����邩��
�Ǝ��̎��݂���T�ɑʖڂƂ������Ȃ��č���B
�V�F�A�̑召�l������A������c�[�����[�����ĂĂ��Ή���Ƃ̗D��x�͒Ⴂ�B
�Ƃ͂���AMD64�̂悤��MS�̈��͂�Intel�ɋt�̗p�����P�[�X�����邩��
�Ǝ��̎��݂���T�ɑʖڂƂ������Ȃ��č���B
�܂�SSE5�ł̑_����MS�̗p�AMS����Intel�ւ̈��͂�Intel�̗p�̗���?
2�C�ڂ̂ǂ��傤�E�E�E�E��_��AMD���āE�E�E�E
2�C�ڂ̂ǂ��傤�E�E�E�E��_��AMD���āE�E�E�E
�����Ă�����Ȃ�SIMD���߂Ȃ�Ĉ��͂����闝�R����������B
>>90
����͂Ȃ��B�����R�[�h�̎��s���\�ō��ʉ��ł���x�X�g�Ȃ̂��������Ȃ̂�
��ނ��Ǝ����߃Z�b�g��p�ӂ��������B
(SSE5�ŏ�����)Bulldozer��FMA�ő����ł���A�ƃA�s�[���ł���悤�ɂ��邽�߂̏��u�B
SSE�I�Ȗ��߂͎g�p�ӏ����Ǐ��������̂ň�̃o�C�i����
�����̖��ߑ̌n���T�|�[�g�ł���B�J�����ʓ|�Ƃ͂����B
64bit���߂̓v���O�����S��̘b�Ȃ̂ŕ����̃o�C�i����p�ӂ��邵���Ȃ�
����Ă���̂�MS��Intel�ɑ҂������������B
����͂Ȃ��B�����R�[�h�̎��s���\�ō��ʉ��ł���x�X�g�Ȃ̂��������Ȃ̂�
��ނ��Ǝ����߃Z�b�g��p�ӂ��������B
(SSE5�ŏ�����)Bulldozer��FMA�ő����ł���A�ƃA�s�[���ł���悤�ɂ��邽�߂̏��u�B
SSE�I�Ȗ��߂͎g�p�ӏ����Ǐ��������̂ň�̃o�C�i����
�����̖��ߑ̌n���T�|�[�g�ł���B�J�����ʓ|�Ƃ͂����B
64bit���߂̓v���O�����S��̘b�Ȃ̂ŕ����̃o�C�i����p�ӂ��邵���Ȃ�
����Ă���̂�MS��Intel�ɑ҂������������B
windows7�ł�32bit���������āH������������
����ςˁA64bit�{�C�ł���Ȃ�IA-64�ɍs���ׂ����Ǝv����
����ςˁA64bit�{�C�ł���Ȃ�IA-64�ɍs���ׂ����Ǝv����
94 �F,,�E�L�́M�E,,�j��-�������F2008/12/12(��) 02:33:50 ID:LSddo0Nj
>>51
Pentium Pro�́uOoO��x86�v���Z�b�T�v�̊�{�`�Ƃ��Ă͖��ʂ������B
�ʎY���d������s����A���\����ɕK�v�ȂƂ��낾���ɂ��݂Ȃ���₵�A
���܂�d�v�łȂ��Ƃ���͒[�܂�B
�K�v�ȏ�Ƀ_�C�T�C�Y�𑝂₳�Ȃ��P�`�Ȑv�v�z���A�d�͌������d������
���o�C���₻�̌�̃}���`�R�A�ɂ��}�b�`�����B
�uPentium Pro��Intel�j��ő�̊v�V�v���Ď��猾���Ă�B
Core MA�Ńp�C�v���C����3issue����4issue�Ɋg�����ꂽ���_�Ŋ���Family���V���̉���
�ł��邱�Ƃ��t�������Ă����B���Ȃ��Ƃ�i486��Pentium�ɂȂ������炢�ȏ�́B
K7�̓g�����W�X�^�����E�d�͌��������œ�����Intel�A�[�L�R�̐��\�����߂邱�Ƃ�
�Ŏ�������Ӌ��C��`�̎Y������B
�����������߂�x87��64�r�b�g�g����TFP�����s���邽�߂Ɍ����̂����悤���ґ��
�g�����W�X�^��������Ő����E�������������^�p�C�v���C���A9Way�̎��s���j�b�g����Ȃ�
����ȃR�A�����グ���B
�R�A������̃g�����W�X�^��������K7�̎��_��2000���g�����W�X�^���APen3�̖�2.5�{�A
�M�����Ȃ����ƂɌ��sCoreMA��葽���B
������x87�͕ێ炳��ĂȂ��Â��v���O�����ł��낤���Č�����x�ATFP��64�r�b�g�g����
Intel�̖��߃Z�b�g�Ƃ̂��荇�킹�̉ߒ��ŁA���̂��̂��L�����Z�����ꂽ�B
K7��������p�����p�C�v���C���\���́A�͂����茾���Ă��̂��̂��Ӓ��ɂȂ����B
PenM��CoreMA�ɔ�ׂĖ��ʂɃ��W�b�N���̃g�����W�X�^������K7�����������Ă�ȏ�
�d�͌����ŏ���͓̂���B
Intel���哱����SSE*�̖��߃Z�b�g���̂������^�̃p�C�v���C���ɂ͕s���B
Intel��5�N���炢��Pentium 4�Ƃ������̑�Ӌ��C�ɗ����Ă��������C���i�b�v���̂��̂�p�~������H
AMD�ɂ�K6-III�x�[�X�Ń��_���ȉ��ǂ������Ă������炢�̕��j�]���͕K�v�������B
>>60
�Ƃ肠�����ASSE5�Œlj����ꂽ���߂�AltiVec�̂���ɂ͎��Ă�B
���ꂱ��IBM����̉e�����Ǝv�����B
>>89
MS�͈���ŕ���������Intel��SSE*���x���B
AMD�Ǝ���TFP���L�����Z����SSE*�݊��ɂ���ƈ��͂������ATFP��O���
�v���Ă���AMD�͑呹�����鎖�ɂȂ����킯�����i���R�͑O�q�j
Pentium Pro�́uOoO��x86�v���Z�b�T�v�̊�{�`�Ƃ��Ă͖��ʂ������B
�ʎY���d������s����A���\����ɕK�v�ȂƂ��낾���ɂ��݂Ȃ���₵�A
���܂�d�v�łȂ��Ƃ���͒[�܂�B
�K�v�ȏ�Ƀ_�C�T�C�Y�𑝂₳�Ȃ��P�`�Ȑv�v�z���A�d�͌������d������
���o�C���₻�̌�̃}���`�R�A�ɂ��}�b�`�����B
�uPentium Pro��Intel�j��ő�̊v�V�v���Ď��猾���Ă�B
Core MA�Ńp�C�v���C����3issue����4issue�Ɋg�����ꂽ���_�Ŋ���Family���V���̉���
�ł��邱�Ƃ��t�������Ă����B���Ȃ��Ƃ�i486��Pentium�ɂȂ������炢�ȏ�́B
K7�̓g�����W�X�^�����E�d�͌��������œ�����Intel�A�[�L�R�̐��\�����߂邱�Ƃ�
�Ŏ�������Ӌ��C��`�̎Y������B
�����������߂�x87��64�r�b�g�g����TFP�����s���邽�߂Ɍ����̂����悤���ґ��
�g�����W�X�^��������Ő����E�������������^�p�C�v���C���A9Way�̎��s���j�b�g����Ȃ�
����ȃR�A�����グ���B
�R�A������̃g�����W�X�^��������K7�̎��_��2000���g�����W�X�^���APen3�̖�2.5�{�A
�M�����Ȃ����ƂɌ��sCoreMA��葽���B
������x87�͕ێ炳��ĂȂ��Â��v���O�����ł��낤���Č�����x�ATFP��64�r�b�g�g����
Intel�̖��߃Z�b�g�Ƃ̂��荇�킹�̉ߒ��ŁA���̂��̂��L�����Z�����ꂽ�B
K7��������p�����p�C�v���C���\���́A�͂����茾���Ă��̂��̂��Ӓ��ɂȂ����B
PenM��CoreMA�ɔ�ׂĖ��ʂɃ��W�b�N���̃g�����W�X�^������K7�����������Ă�ȏ�
�d�͌����ŏ���͓̂���B
Intel���哱����SSE*�̖��߃Z�b�g���̂������^�̃p�C�v���C���ɂ͕s���B
Intel��5�N���炢��Pentium 4�Ƃ������̑�Ӌ��C�ɗ����Ă��������C���i�b�v���̂��̂�p�~������H
AMD�ɂ�K6-III�x�[�X�Ń��_���ȉ��ǂ������Ă������炢�̕��j�]���͕K�v�������B
>>60
�Ƃ肠�����ASSE5�Œlj����ꂽ���߂�AltiVec�̂���ɂ͎��Ă�B
���ꂱ��IBM����̉e�����Ǝv�����B
>>89
MS�͈���ŕ���������Intel��SSE*���x���B
AMD�Ǝ���TFP���L�����Z����SSE*�݊��ɂ���ƈ��͂������ATFP��O���
�v���Ă���AMD�͑呹�����鎖�ɂȂ����킯�����i���R�͑O�q�j
95 �FSocket774�F2008/12/12(��) 04:43:16 ID:Y4psMMnn
Corei7��������̌�����̃z�[���X�e�C��Œm�荇�����h�C�c�l(�݃C�X���G��)�Z�p�҂�
�̘b�Ő���オ�������łɃ_�����ŕ����Ă݂���A�������苳���Ă��ꂽ�B
Corei7�́AL1�`L2(XEON�ł�L3���܂�)�ƃp�C�v���C�����̖��ߑS�Ă��L�����Z������d�g��
���L���āA�n�[�h�I�� non maskable interrupt �܂�A�\�t�g�I�ȋ��ۂ��s�\��
���荞�ݐM�������p�ӂ���Ă���炵���B
�{���́A�T�[�o�@�p�Ƀf�b�h���b�N�������̍ŏI�����i�Ƃ��ėp�ӂ���Ă���炵��
�̂�����ǂ��A���ʂ̃p�\�R���ł������ȃ}�U�[�̏ꍇ�A���G�Ȕz����BIOS�\�����ȗ���
�����i�Ƃ��āAHDD�A�N�Z�X�̒���ȂǂɁA���̊��荞�ݐM�����g���ă������ƃL���b�V��
����v����悤�Ɉ�UL1�`L2�ƃp�C�v���C���̑S�Ă��N���A���Ă��܂����������炵���B
�܂�A�蔲�����B
��������ƁA���̊��荞�ݏ��������Ă�Ԃ́A���̊��荞�݂��֎~�����̂ŁA�v�`�t����
�������肪�������Ă��܂��ƌ������Ȃ��āB
�W�w�ȏ�̊���g�����}�U�[�Ȃ���v�ȉ\���������炵�����ǁA���P�T�O�ȉ���
�����ɏo����Ă���}�U�[�̏ꍇ�́A�܂��A���ꂪ�����ň����|�銴�G����(�܂�
�v�`�t�����������̎�)�ɂȂ�����ȁB
����Ȏ��A���\�ł��Ȃ����낤���A�\�[�X�͗F�l����̌��`��������A
�M���Ȃ��Ă����R����ˁB
�S���P������Ȃ���ŁA�R�͌����ĂȂ��Ǝv�����ǁA�s�s�`�����x����
�l���������������B
�R��͂W�w�ȏ�̂R���`�̕�őg�ݒ����Ă݂邩�A����Ƃ�X2�ɏ�芷��
�邩�Ŗ����Ă�B
�̘b�Ő���オ�������łɃ_�����ŕ����Ă݂���A�������苳���Ă��ꂽ�B
Corei7�́AL1�`L2(XEON�ł�L3���܂�)�ƃp�C�v���C�����̖��ߑS�Ă��L�����Z������d�g��
���L���āA�n�[�h�I�� non maskable interrupt �܂�A�\�t�g�I�ȋ��ۂ��s�\��
���荞�ݐM�������p�ӂ���Ă���炵���B
�{���́A�T�[�o�@�p�Ƀf�b�h���b�N�������̍ŏI�����i�Ƃ��ėp�ӂ���Ă���炵��
�̂�����ǂ��A���ʂ̃p�\�R���ł������ȃ}�U�[�̏ꍇ�A���G�Ȕz����BIOS�\�����ȗ���
�����i�Ƃ��āAHDD�A�N�Z�X�̒���ȂǂɁA���̊��荞�ݐM�����g���ă������ƃL���b�V��
����v����悤�Ɉ�UL1�`L2�ƃp�C�v���C���̑S�Ă��N���A���Ă��܂����������炵���B
�܂�A�蔲�����B
��������ƁA���̊��荞�ݏ��������Ă�Ԃ́A���̊��荞�݂��֎~�����̂ŁA�v�`�t����
�������肪�������Ă��܂��ƌ������Ȃ��āB
�W�w�ȏ�̊���g�����}�U�[�Ȃ���v�ȉ\���������炵�����ǁA���P�T�O�ȉ���
�����ɏo����Ă���}�U�[�̏ꍇ�́A�܂��A���ꂪ�����ň����|�銴�G����(�܂�
�v�`�t�����������̎�)�ɂȂ�����ȁB
����Ȏ��A���\�ł��Ȃ����낤���A�\�[�X�͗F�l����̌��`��������A
�M���Ȃ��Ă����R����ˁB
�S���P������Ȃ���ŁA�R�͌����ĂȂ��Ǝv�����ǁA�s�s�`�����x����
�l���������������B
�R��͂W�w�ȏ�̂R���`�̕�őg�ݒ����Ă݂邩�A����Ƃ�X2�ɏ�芷��
�邩�Ŗ����Ă�B
96 �F,,�E�L�́M�E,,�j��-�������F2008/12/12(��) 04:44:52 ID:LSddo0Nj
�~���
�����
�����
>>33
3�{�����Ă�1�͎��ɑ̂�����A����2�{����w
3�{�����Ă�1�͎��ɑ̂�����A����2�{����w
98 �F,,�E�L�́M�E,,�j��-�������F2008/12/12(��) 04:56:39 ID:LSddo0Nj
Atom���������邾��H
�n���ɍ�����Intel�̔���グ�x���Ă�
�n���ɍ�����Intel�̔���グ�x���Ă�
99 �FSocket774�F2008/12/12(��) 05:21:13 ID:pytdJpjE
�ŋ߂�Intel�Ŋm�F����Ă�̂�
Dunnington�������India�`�[��
Silverthorne�������Texus�`�[��
Tukwila�������Colorado(Hudson + Fort Collins)�`�[��
Nehalem�����Oregon�`�[��
Larrabee��S�����Ă���Oregon?�̕ʓ��`�[��
Penryn�������Israel�`�[��
�ʂ��H
Itanium�̃f�U�C���`�[���͐̂�Hudson(DEC) + Fort Collins(HP)��2�`�[���ŋ��͂��������Ǎ��͐l�����炳���Colorado��300�l�������Ǝv���B
Nehalem��Intel Turbo Boost Technology��IDA�̔��W�Ƃ������Foxton���ۂ����B
QPI�̊J����Whitefield(India)�ł�������A��HP(Fort Collins)�̕�����l���ꂽ�炵���B
���Ɛ̂�Santa Clara�Ő�[�������s���Ă����`�[����Oregon��RP1(D1D�̗�)�Ɉڂ��Ă���ƍl�����邪����̓v���Z�b�T�̃f�U�C���`�[���ł͂Ȃ��B
Dunnington�������India�`�[��
Silverthorne�������Texus�`�[��
Tukwila�������Colorado(Hudson + Fort Collins)�`�[��
Nehalem�����Oregon�`�[��
Larrabee��S�����Ă���Oregon?�̕ʓ��`�[��
Penryn�������Israel�`�[��
�ʂ��H
Itanium�̃f�U�C���`�[���͐̂�Hudson(DEC) + Fort Collins(HP)��2�`�[���ŋ��͂��������Ǎ��͐l�����炳���Colorado��300�l�������Ǝv���B
Nehalem��Intel Turbo Boost Technology��IDA�̔��W�Ƃ������Foxton���ۂ����B
QPI�̊J����Whitefield(India)�ł�������A��HP(Fort Collins)�̕�����l���ꂽ�炵���B
���Ɛ̂�Santa Clara�Ő�[�������s���Ă����`�[����Oregon��RP1(D1D�̗�)�Ɉڂ��Ă���ƍl�����邪����̓v���Z�b�T�̃f�U�C���`�[���ł͂Ȃ��B
100 �FSocket774�F2008/12/12(��) 05:28:53 ID:P98KomxE
Texus����Ȃ���Texas�������G
101 �FSocket774�F2008/12/12(��) 05:30:20 ID:P98KomxE
�ǂ��ł���������
Intel�̃`�[�������O��ID��
Intel�̃`�[�������O��ID��
103 �F,,�E�L�́M�E,,�j��-�������F2008/12/12(��) 09:28:21 ID:2ZoyJv/f
SSE5�Ɣ�r����AVX���D��Ă��闝�R
�y����1�F�\�[�X�ƃf�X�e�B�l�[�V�����̊��S�Ɨ��ɂ��mov*���߂̍팸�z
�E2�\�[�X�I�y�����h���Z���߁@dest=op(src1,src2)�ɂ���
SSE1�`4�F
dest��src1�͓���Bsrc1�̒l��ێ�����ɂ͑Ҕ����K�v
SSE5�F
DREX.dest�t�B�[���h��V�݂��Asrc1(ModRM.reg)����Ɨ����邱�ƂőҔ�s�v�ɁB
����SSE���߂�3�I�y�����h������Ȃ��B
AVX�F
VEX.vvvv�t�B�[���h��src1�����蓖��dest(ModRM.reg)�ƕ����B
�S�Ă�128bit SSE���߂�3�I�y�����h�łɃA�b�v�O���[�h�\
�E3�����Z���߁@dest=op(src1,src2,src3)
SSE1�`4�F
�t�B�[���h������Ȃ��̂Ŋ�{�I�ɑ��݂��Ȃ��BSSE4.1��pblendvb����xmm0�����߂�����src1��dest�ƌ��Ȃ����Ƃŋ[���I��3�\�[�X�ɑΉ����Ă���B�K�v�ɉ�����xmm0�̑Ҕ����K�v�B
SSE5�F
DREX.dest�����Ă�3�I�y�����h���̃t�B�[���h�����Ȃ��̂�
src1��src3�̂ǂ��炩��dest�Ɠ���Ƃ݂Ȃ����Ƃŋ^���I��4�I�y�����h���B
dest�Ɠ���ɂ��ꂽ�\�[�X���W�X�^�͕K�v�ɉ����đҔ����K�v�B
�Ϙa�Z�ȂƂ�����B
�܂�pblendvb�����g���邪SSE4.1�Ɠ���d�l�B
AVX�F
VEX.vvvv�ɉ���imm8�̈ꕔ���4�̃��W�X�^�t�B�[���h�Ɖ��߂���B
����ɂ�芮�S��4�I�y�����h���߂���������B
�V���߂̕��������Ϙa�Z�̂ق�pblendvb��4�I�y�����h�łɒu������B
�y����1�F�\�[�X�ƃf�X�e�B�l�[�V�����̊��S�Ɨ��ɂ��mov*���߂̍팸�z
�E2�\�[�X�I�y�����h���Z���߁@dest=op(src1,src2)�ɂ���
SSE1�`4�F
dest��src1�͓���Bsrc1�̒l��ێ�����ɂ͑Ҕ����K�v
SSE5�F
DREX.dest�t�B�[���h��V�݂��Asrc1(ModRM.reg)����Ɨ����邱�ƂőҔ�s�v�ɁB
����SSE���߂�3�I�y�����h������Ȃ��B
AVX�F
VEX.vvvv�t�B�[���h��src1�����蓖��dest(ModRM.reg)�ƕ����B
�S�Ă�128bit SSE���߂�3�I�y�����h�łɃA�b�v�O���[�h�\
�E3�����Z���߁@dest=op(src1,src2,src3)
SSE1�`4�F
�t�B�[���h������Ȃ��̂Ŋ�{�I�ɑ��݂��Ȃ��BSSE4.1��pblendvb����xmm0�����߂�����src1��dest�ƌ��Ȃ����Ƃŋ[���I��3�\�[�X�ɑΉ����Ă���B�K�v�ɉ�����xmm0�̑Ҕ����K�v�B
SSE5�F
DREX.dest�����Ă�3�I�y�����h���̃t�B�[���h�����Ȃ��̂�
src1��src3�̂ǂ��炩��dest�Ɠ���Ƃ݂Ȃ����Ƃŋ^���I��4�I�y�����h���B
dest�Ɠ���ɂ��ꂽ�\�[�X���W�X�^�͕K�v�ɉ����đҔ����K�v�B
�Ϙa�Z�ȂƂ�����B
�܂�pblendvb�����g���邪SSE4.1�Ɠ���d�l�B
AVX�F
VEX.vvvv�ɉ���imm8�̈ꕔ���4�̃��W�X�^�t�B�[���h�Ɖ��߂���B
����ɂ�芮�S��4�I�y�����h���߂���������B
�V���߂̕��������Ϙa�Z�̂ق�pblendvb��4�I�y�����h�łɒu������B
>>99
AMD�Ƃ͊J���͂��Ⴂ������B
�Ȃ̂ɃT�[�o�E�f�X�N�g�b�v�E�m�[�g����ɕʐv��Bobcat��MID�܂�
�S��Ő킢�܂��Ƃ�������
AMD�Ƃ͊J���͂��Ⴂ������B
�Ȃ̂ɃT�[�o�E�f�X�N�g�b�v�E�m�[�g����ɕʐv��Bobcat��MID�܂�
�S��Ő킢�܂��Ƃ�������
MS�uXbox720��GPU�ɁA���̖��߃Z�b�g�lj�����v
AMD�u�͂��v
MS�uPC�ł��g����悤�ɂ���v
AMD�u�͂��v
MS�̂����Ȃ�ɂȂ��Ă�ΊJ������MS������Ă����C������B
AMD�u�͂��v
MS�uPC�ł��g����悤�ɂ���v
AMD�u�͂��v
MS�̂����Ȃ�ɂȂ��Ă�ΊJ������MS������Ă����C������B
>>103
SSE5�͒P��CPU��VGA�̉˂����ł����āAAVX�Ƃ͑S���Ⴄ������B
�h���C�o�≽���ŃT�|�[�g���ĂȂ�ڂ̃��x���̋C������B
>>105
�ŏI�I�Ȏ�i�͖{���ɂ��ꂾ��ˁB
SSE5�͒P��CPU��VGA�̉˂����ł����āAAVX�Ƃ͑S���Ⴄ������B
�h���C�o�≽���ŃT�|�[�g���ĂȂ�ڂ̃��x���̋C������B
>>105
�ŏI�I�Ȏ�i�͖{���ɂ��ꂾ��ˁB
��Ȃ����ǃC���e��������t�炦�Ȃ�MS�̌����Ȃ�Ȃ���S����w
Intel��Windows��Ή��̌y�ʋ�CPU�J���n�߂���
�[�����MAC�̐V�J�e�S���[�������g�уQ�[���@�s�ꂶ��ˁH
�[�����MAC�̐V�J�e�S���[�������g�уQ�[���@�s�ꂶ��ˁH
Intel��MS������������ƍl���Ă���߂�����B
�����炱���ALinux�𐄐i���Ă����肷��̂����ǁA
OS��n�[�h���L�ł��钴�����Ƃ̒a������댯�ɁA
���̊�Ƃ��甽������A���X�J�����炤�\��������B
���ۂɂ�Intel���j�n��̏�Ԃœ����Ă���Ǝv���B
PC�ƊE��4-5�N�ȓ��ɑ匃���Ƒ�ĕ҂��}�������ȗ\���B
�����炱���ALinux�𐄐i���Ă����肷��̂����ǁA
OS��n�[�h���L�ł��钴�����Ƃ̒a������댯�ɁA
���̊�Ƃ��甽������A���X�J�����炤�\��������B
���ۂɂ�Intel���j�n��̏�Ԃœ����Ă���Ǝv���B
PC�ƊE��4-5�N�ȓ��ɑ匃���Ƒ�ĕ҂��}�������ȗ\���B
�v���Ԃ�ɗ�����
�Ȃ�ł���ȂɃL�����X���ɂȂ��Ă�́H
�Ȃ�ł���ȂɃL�����X���ɂȂ��Ă�́H
���Ȃ��Ƃ�2011�N�܂ł͎����オ���Ȃ����炵�傤���Ȃ��B
2011�N�ɂȂ����痈��̂��Ƃ����ƁA����ς薳���ł��낤���ǁB
�n����Γ݂��A�Ƃ������A���ɂ��̒ʂ�ł���B
2011�N�ɂȂ����痈��̂��Ƃ����ƁA����ς薳���ł��낤���ǁB
�n����Γ݂��A�Ƃ������A���ɂ��̒ʂ�ł���B
����Ȃ��Ƃ�������ٸ������������
113 �F,,�E�L�́M�E,,�j��-�������F2008/12/12(��) 16:22:18 ID:2ZoyJv/f
>>106
���_�����̂܂�܁u����2�v�Ȃ��B
�܂�������B
���_���猾���ƁuGPU�̉˂����v����AVX���Ó��Ȃ�ȁB
128�r�b�g��SIMD�������s����̂�3Way�̃f�R�[�_���t���Ɏg���Ă���������3���߂����f�R�[�h�ł��Ȃ��B
���ۂ̓��W�X�^�Ҕ���[�h�X�g�A�ɂƂ��Ď���2���߂��ĂƂ��납�ȁB
����Ȃ�CPU������SIMD���Z�@�ł��������������B
128bit�x�N�g������1���߂�4SP�ɃI�y���[�V�������s�ł�����x�ł����Ȃ�����ȁB
��N���b�N��FPU���ʓ��ڂ���GPU���t���Ɋ��p����ɂ́A������SIMD���߂̃x�N�g�������L���Ȃ��Ƃ����Ȃ��B
���邢��1���߂Œ��z������������Ƃ��A���Z�̖��x���������Ȃ��Ƃ����Ȃ��B
���ݔ��s����Ă�SSE5�̎d�l�ł͂ǂ�����s�K�B
128bit��SIMD���߂�CPU���o�R����GPU�Ŏ��s�Ȃ�āA����_�ł��ے�ł���q���x������B
������n�b�^���łȂ��Ė{�C�Ō����Ă�Ȃ炢�悢��AMD���o���B
������Ƃ��āA���Ƃ��x�N�g�������C�h������Ƃ��悤�B���Ƃ���512bit�Ɋg�������1���߂�16SP�ɃI�y���[�V�����s�ł���B
�������A��Ƃ���addps(�P���x�̕�����Z)��512�r�b�g�ɑΉ������悤�Ǝv������A���łɖ��ߊg���̗]�T���Ȃ��B
������\�ɂ���̂��A���߃Z�b�g�����g���r�b�g������ɗp�ӂ���AVX�Ȃ̂�B
�i�ŁALarrabee��VPU�p���߂��܂��ɁAAVX��512bit�g���ƌ����Ă�킯���j�B
���ɂ���AMD�Ǝ���AVX�ƌ݊����̂Ȃ����C�h�x�N�g�����߂��`���悤�Ƃ��Ă�Ȃ炻��͂���Ŗ��d���B
SSE5��Intel��AVX�̎d�l�����J�����邽�߂̃u���t�Ƃ��Ă͖��ɗ������Ƃ݂����������������Ȃ��B
���_�����̂܂�܁u����2�v�Ȃ��B
�܂�������B
���_���猾���ƁuGPU�̉˂����v����AVX���Ó��Ȃ�ȁB
128�r�b�g��SIMD�������s����̂�3Way�̃f�R�[�_���t���Ɏg���Ă���������3���߂����f�R�[�h�ł��Ȃ��B
���ۂ̓��W�X�^�Ҕ���[�h�X�g�A�ɂƂ��Ď���2���߂��ĂƂ��납�ȁB
����Ȃ�CPU������SIMD���Z�@�ł��������������B
128bit�x�N�g������1���߂�4SP�ɃI�y���[�V�������s�ł�����x�ł����Ȃ�����ȁB
��N���b�N��FPU���ʓ��ڂ���GPU���t���Ɋ��p����ɂ́A������SIMD���߂̃x�N�g�������L���Ȃ��Ƃ����Ȃ��B
���邢��1���߂Œ��z������������Ƃ��A���Z�̖��x���������Ȃ��Ƃ����Ȃ��B
���ݔ��s����Ă�SSE5�̎d�l�ł͂ǂ�����s�K�B
128bit��SIMD���߂�CPU���o�R����GPU�Ŏ��s�Ȃ�āA����_�ł��ے�ł���q���x������B
������n�b�^���łȂ��Ė{�C�Ō����Ă�Ȃ炢�悢��AMD���o���B
������Ƃ��āA���Ƃ��x�N�g�������C�h������Ƃ��悤�B���Ƃ���512bit�Ɋg�������1���߂�16SP�ɃI�y���[�V�����s�ł���B
�������A��Ƃ���addps(�P���x�̕�����Z)��512�r�b�g�ɑΉ������悤�Ǝv������A���łɖ��ߊg���̗]�T���Ȃ��B
������\�ɂ���̂��A���߃Z�b�g�����g���r�b�g������ɗp�ӂ���AVX�Ȃ̂�B
�i�ŁALarrabee��VPU�p���߂��܂��ɁAAVX��512bit�g���ƌ����Ă�킯���j�B
���ɂ���AMD�Ǝ���AVX�ƌ݊����̂Ȃ����C�h�x�N�g�����߂��`���悤�Ƃ��Ă�Ȃ炻��͂���Ŗ��d���B
SSE5��Intel��AVX�̎d�l�����J�����邽�߂̃u���t�Ƃ��Ă͖��ɗ������Ƃ݂����������������Ȃ��B
�˂������āH
GPU�̐��\���ő�������o���́H
GPU�̐��\���ő�������o���́H
>>108-109
����̎����ȁB
�Ȃ�Centrino Atom�u�����h�͒a�����炽�������N�ŏ��ł����̂�
http://pc.watch.impress.co.jp/docs/2008/1212/ubiq234.htm
���ɂ��AIntel�͂��ł�Moorestown�ł�Windows���T�|�[�g���Ȃ���OEM���[�J�[�ɒʒm���Ă���Ƃ����B
�܂�AMoorestown�ł�Moblin Linux�݂̂��T�|�[�g���邱�ƂɌ��肵���Ƃ����̂��B�Ȃ������Ȃ����̂��́A
�O�X��̋L���ł��G�ꂽ�Ƃ��ƂȂ̂ŁA�J��Ԃ��Ȃ����v�����Windows 7��Windows Vista�̃u���b�V���A�b�v
�łƂȂ�AIntel��Moorestown�Ń^�[�Q�b�g�ɂ��Ă���悤�ȃX�}�[�g�t�H���Ȃǂɂ̓}�b�`���Ȃ�OS�̂܂܂�
���邱�Ƃ�����I�����炾�낤�B
����̎����ȁB
�Ȃ�Centrino Atom�u�����h�͒a�����炽�������N�ŏ��ł����̂�
http://pc.watch.impress.co.jp/docs/2008/1212/ubiq234.htm
���ɂ��AIntel�͂��ł�Moorestown�ł�Windows���T�|�[�g���Ȃ���OEM���[�J�[�ɒʒm���Ă���Ƃ����B
�܂�AMoorestown�ł�Moblin Linux�݂̂��T�|�[�g���邱�ƂɌ��肵���Ƃ����̂��B�Ȃ������Ȃ����̂��́A
�O�X��̋L���ł��G�ꂽ�Ƃ��ƂȂ̂ŁA�J��Ԃ��Ȃ����v�����Windows 7��Windows Vista�̃u���b�V���A�b�v
�łƂȂ�AIntel��Moorestown�Ń^�[�Q�b�g�ɂ��Ă���悤�ȃX�}�[�g�t�H���Ȃǂɂ̓}�b�`���Ȃ�OS�̂܂܂�
���邱�Ƃ�����I�����炾�낤�B
����Ɖ����o��͗l�B
�ቿ�i�p�\�R�������l�o�t�A�Ă`�l�c���o�ׂ�
http://it.nikkei.co.jp/business/news/index.aspx?n=AS1D1105M%2011122008
�ቿ�i�p�\�R�������l�o�t�A�Ă`�l�c���o�ׂ�
http://it.nikkei.co.jp/business/news/index.aspx?n=AS1D1105M%2011122008
������Athlon64�̒�N���b�N�ł���
118 �F,,�E�L�́M�E,,�j��-�������F2008/12/12(��) 17:09:44 ID:2ZoyJv/f
>>107-109
Intel��MS����ʂɎ�������ʂ�Atom������XP Home���ʉ��i����B
Intel��Linux�R�~���j�e�B�����Ɏx�����Ă�̂͌��ޗ��Ƃ��Ă̈Ӗ������������B
Firefox��OpenOffice���G���h���[�U�[�ɏ\���F�m���ꂽ���ƂȂ��ẮA
�l�b�g���y��ƗpPC�Ƃ��Ă�Windows�͉��i�Ɍ������u���i�v�ł͂Ȃ��Ȃ����B
Atom�u�[���Ŗׂ��Ă�̂͒l�������͂ɎN����Ȃ�Intel��
�l�b�g�u�b�N�s��ɐ�ڂ�����ASUS���炢�ŁAMS���e���x���_�[���ɂ��y���̏�ԁB
Intel��MS����ʂɎ�������ʂ�Atom������XP Home���ʉ��i����B
Intel��Linux�R�~���j�e�B�����Ɏx�����Ă�̂͌��ޗ��Ƃ��Ă̈Ӗ������������B
Firefox��OpenOffice���G���h���[�U�[�ɏ\���F�m���ꂽ���ƂȂ��ẮA
�l�b�g���y��ƗpPC�Ƃ��Ă�Windows�͉��i�Ɍ������u���i�v�ł͂Ȃ��Ȃ����B
Atom�u�[���Ŗׂ��Ă�̂͒l�������͂ɎN����Ȃ�Intel��
�l�b�g�u�b�N�s��ɐ�ڂ�����ASUS���炢�ŁAMS���e���x���_�[���ɂ��y���̏�ԁB
Windows��Ή��̌y�ʋ�CPU�J���˂�
ARM�ɕԂ蓢���ɂ���Ȃ���������B
ARM�ɕԂ蓢���ɂ���Ȃ���������B
120 �F,,�E�L�́M�E,,�j��-�������F2008/12/12(��) 17:24:25 ID:2ZoyJv/f
>>114
�ނ���A�悭�킩���ĂȂ�����҂��x�����߂̃n�b�^��
�u���SGFLOPS����GPU��CPU���瑀��ł���v���Ă����Ă����o�J�͒ނ�邩��ȁB
128bit����AGPU���t�����p�ǂ��납CPU�ɂƂ��đ����ɂ�����Ȃ�Ȃ��B
Intel��SandyBridge��FPU���ő�2�{�̐��\���o����悤�������邪�A
128�r�b�gSIMD���߂���g������Ȃ�����256�r�b�g���ߒlj����邭�炢���B
����ȏ�FPU���₵�Ă����߂�128�r�b�g�P�ʂ���g������Ȃ����Ă�
�t�ɁABu(ry�́AGPU�x����SSE5�̐��\�オ��Ƃ�����ACPU����FPU����������ڂ����A�ނ���y�ڂ��ĂȂ��z��Ȃ��̂��H
�ނ���A�悭�킩���ĂȂ�����҂��x�����߂̃n�b�^��
�u���SGFLOPS����GPU��CPU���瑀��ł���v���Ă����Ă����o�J�͒ނ�邩��ȁB
128bit����AGPU���t�����p�ǂ��납CPU�ɂƂ��đ����ɂ�����Ȃ�Ȃ��B
Intel��SandyBridge��FPU���ő�2�{�̐��\���o����悤�������邪�A
128�r�b�gSIMD���߂���g������Ȃ�����256�r�b�g���ߒlj����邭�炢���B
����ȏ�FPU���₵�Ă����߂�128�r�b�g�P�ʂ���g������Ȃ����Ă�
�t�ɁABu(ry�́AGPU�x����SSE5�̐��\�オ��Ƃ�����ACPU����FPU����������ڂ����A�ނ���y�ڂ��ĂȂ��z��Ȃ��̂��H
121 �F,,�E�L�́M�E,,�j��-�������F2008/12/12(��) 17:31:00 ID:2ZoyJv/f
���Ȃ݂�SandyBridge��FPU��FADD�{FMUL�{FMAC��3�@�\���B
���
���
>SSE5��Intel��AVX�̎d�l�����J�����邽�߂̃u���t�Ƃ��Ă͖��ɗ������Ƃ݂����������������Ȃ��B
�u���t������SSE5�̖ړI���čŏ����炻�ꂶ��Ȃ��̂��H
�v��ATi�����ȗ��AAMD�͂Ȃ�Ƃ�����intel��GPGPU�̐��E�ֈ����C�荞�݂��������߂ɕK���������C�����邵
�����l�����intel��AMD�̎v�f�ɏ�������ƂɂȂ邩��A���̈Ӗ��ł�AVX�����[�X��AMD�ɂƂ��đ叟���Ƃ����Ă���������
�u���t������SSE5�̖ړI���čŏ����炻�ꂶ��Ȃ��̂��H
�v��ATi�����ȗ��AAMD�͂Ȃ�Ƃ�����intel��GPGPU�̐��E�ֈ����C�荞�݂��������߂ɕK���������C�����邵
�����l�����intel��AMD�̎v�f�ɏ�������ƂɂȂ邩��A���̈Ӗ��ł�AVX�����[�X��AMD�ɂƂ��đ叟���Ƃ����Ă���������
123 �F,,�E�L�́M�E,,�j��-�������F2008/12/12(��) 18:00:25 ID:2ZoyJv/f
>>122
�܁[FMA�Ȃ͋@�\�I��SSE5�̂܂��ʌ݊�������ȁB
�܂�AVX��Intel�����C�Z���X���Ȃ�������Ȃ�čl����K�v�͂Ȃ����Ƃ��ȁB
MMX�̍ٔ��́AMMX�Ƃ������W�̌�����Intel�ɂ��邪�A���߃Z�b�g�݊��Z�p�͌������̊ϓ_������Ȃ��Ƃ̂��Ƃ������B
���AIntel�����C�Z���X���邵�Ȃ��ȑO��Intel����F�̊g����SSE5�Ƃ����t���Ă�킯�����B
AVX�t�H�[�}�b�g��AMD�̗̍p�͒����I�ɂ�Intel�ɂ������b�g������B
GPU�����p���Ęb���{���Ȃ�512�r�b�g�ȏ�̃x�N�g�����͗~�����B
�ƂȂ��AMD��Larrabee�̃l�C�e�B�uISA�̕��y�ɋ��͂��Ă����悤�Ȃ����H
����łȂ��Ƃ���x���y�����Ă��܂���SSE�����ĐV�������߃Z�b�g�ɏ�芷���Ă��炤�ɂ�
AMD�̋��͂��~�����B
�܁[FMA�Ȃ͋@�\�I��SSE5�̂܂��ʌ݊�������ȁB
�܂�AVX��Intel�����C�Z���X���Ȃ�������Ȃ�čl����K�v�͂Ȃ����Ƃ��ȁB
MMX�̍ٔ��́AMMX�Ƃ������W�̌�����Intel�ɂ��邪�A���߃Z�b�g�݊��Z�p�͌������̊ϓ_������Ȃ��Ƃ̂��Ƃ������B
���AIntel�����C�Z���X���邵�Ȃ��ȑO��Intel����F�̊g����SSE5�Ƃ����t���Ă�킯�����B
AVX�t�H�[�}�b�g��AMD�̗̍p�͒����I�ɂ�Intel�ɂ������b�g������B
GPU�����p���Ęb���{���Ȃ�512�r�b�g�ȏ�̃x�N�g�����͗~�����B
�ƂȂ��AMD��Larrabee�̃l�C�e�B�uISA�̕��y�ɋ��͂��Ă����悤�Ȃ����H
����łȂ��Ƃ���x���y�����Ă��܂���SSE�����ĐV�������߃Z�b�g�ɏ�芷���Ă��炤�ɂ�
AMD�̋��͂��~�����B
124 �FMAC�I�^��106 �����F2008/12/12(��) 18:06:14 ID:AD6CndVQ
>>106
�@�@--------------------
�@�@SSE5�͒P��CPU��VGA�̉˂����ł����āAAVX�Ƃ͑S���Ⴄ������B
�@�@--------------------
�O�X���ɏ����������ǁAAMD���������ʂɂ�����o���Ă��邷�B
http://pc11.2ch.net/test/read.cgi/jisaku/1226628399/443
�@�@====================
�@�@443 ���O�FMAC�I�^ ���e���F2008/11/19(��) 23:41:05 ID:5QkxaR/H
�@�@�@�@AMD�����R���p�C���Ƃ��č�����PGI�R���p�C�����J�����Ă�The Portland Group���A
�@�@�@�@C��Fortran�ŋL�q���ꂽ�R�[�h���A�����I��GPU�Ɋ��蓖�Ă�Z�p��AMD�Ƌ���
�@�@�@�@�J������Ƃ̂��Ƃ��B
�@�@�@�@http://www.hpcwire.com/offthewire/PGI_AMD_to_Develop_Accelerator_Compiler_Technology.html
�@�@====================
�@�@--------------------
�@�@SSE5�͒P��CPU��VGA�̉˂����ł����āAAVX�Ƃ͑S���Ⴄ������B
�@�@--------------------
�O�X���ɏ����������ǁAAMD���������ʂɂ�����o���Ă��邷�B
http://pc11.2ch.net/test/read.cgi/jisaku/1226628399/443
�@�@====================
�@�@443 ���O�FMAC�I�^ ���e���F2008/11/19(��) 23:41:05 ID:5QkxaR/H
�@�@�@�@AMD�����R���p�C���Ƃ��č�����PGI�R���p�C�����J�����Ă�The Portland Group���A
�@�@�@�@C��Fortran�ŋL�q���ꂽ�R�[�h���A�����I��GPU�Ɋ��蓖�Ă�Z�p��AMD�Ƌ���
�@�@�@�@�J������Ƃ̂��Ƃ��B
�@�@�@�@http://www.hpcwire.com/offthewire/PGI_AMD_to_Develop_Accelerator_Compiler_Technology.html
�@�@====================
���ꂪAMD�̍H��ɂ�����������ł��ˁB
IEDM 2008�v���r���[�F�u32nm�ȍ~�v���œ_�Ɂi��ҁj
http://eetimes.jp/article/22645/
�bIBM�Ђ̓t�@�E���h���E�T�[�r�X����32nm�Z�p�\
IEDM 2008�v���r���[�F�u32nm�ȍ~�v���œ_�Ɂi��ҁj
http://eetimes.jp/article/22645/
�bIBM�Ђ̓t�@�E���h���E�T�[�r�X����32nm�Z�p�\
>>122
���̌��AVX�����C�Z���X�o����Ζ��X���ȁB
���̌��AVX�����C�Z���X�o����Ζ��X���ȁB
>>113
���B�悭�ǂ�łȂ����ʂɔ��_�����Ă��Ȃ����c�B
AVX���D��Ă��邩�ǂ����͒m��ǁA
SSE5���ĉ˂����ȊO�ɉ����g����������̂��H
���B�悭�ǂ�łȂ����ʂɔ��_�����Ă��Ȃ����c�B
AVX���D��Ă��邩�ǂ����͒m��ǁA
SSE5���ĉ˂����ȊO�ɉ����g����������̂��H
128 �FSocket774�F2008/12/12(��) 21:45:15 ID:wpDkcsaL
��`����
129 �F,,�E�L�́M�E,,�j��-�������F2008/12/12(��) 22:00:48 ID:LSddo0Nj
AVX������Ӗ��ł�GPU�iLarrabee�j�Ƃ̉˂����Ȃ�
http://journal.mycom.co.jp/articles/2007/09/15/barcelona/004.html
���ꂾ��H
�u�����v�Ƃ͌����Ă邯��SSE5���̂��̂�GPU�Ŕ��s����Ȃ�Č����ĂȂ����B
�ǂ������Ƃ����ƐϘa�Z�̃T�|�[�g�Ƃ��A�I�y�����h���̑����Ƃ���
x86���߂̊g���̕��������J�������Ƃ̈Ӗ����傫���B
SSE5�̔��z�̉��������AVX������A�X�ɂ��̐��Larrabee������B
���܂��ɂ���Ȍv�悪����Ƃ���A
AMD��Larrabee�N���[������낤�Ƃ��Ă�킯�����H
> A: ��ʂɃ��W�X�^��ߖ邽�߂ɂ�SRC��DST�ɓ������̂��w�肷��Ηǂ����A
> ���̏ꍇ��(SRC)�̒l�͓��R�j������邱�ƂɂȂ�B
> �����A��ʓI�Ƀ��W�X�^�̓��e���\�Ȍ���ێ��������ꍇ�́ASRC��DST�����鎖�ɂȂ�B
> ����ƂȂ�̂�Opcode�̐����Decoder(�̕��G��)�ł���A x86�ł͂��ꂪ��肾����(�̂�
> SRC��DST��Ƃ���)���A���̐���Ɋ|�����ł͂Ȃ��B
> SSE5��(�v���O����)�ė��p�̊ϓ_����Ax86 �݂̂Ȃ炸(GPGPU�Ȃǂ�)Data Flow Machine�Ȃǂ̏��
> Encode��Decode���s�������l�����Ă���(���߂ɁASRC��DST������)�B
��SSE5�̐Ϙa�Z�̓\�[�X���W�X�^��j�܂��B
�܂蒆�̐l�݂����玩����src���W�X�^��j��SSE5�̐Ϙa�Z���f�[�^�t���[�}�V���ɕs�������Ɣ��Ă܂�
http://journal.mycom.co.jp/articles/2007/09/15/barcelona/004.html
���ꂾ��H
�u�����v�Ƃ͌����Ă邯��SSE5���̂��̂�GPU�Ŕ��s����Ȃ�Č����ĂȂ����B
�ǂ������Ƃ����ƐϘa�Z�̃T�|�[�g�Ƃ��A�I�y�����h���̑����Ƃ���
x86���߂̊g���̕��������J�������Ƃ̈Ӗ����傫���B
SSE5�̔��z�̉��������AVX������A�X�ɂ��̐��Larrabee������B
���܂��ɂ���Ȍv�悪����Ƃ���A
AMD��Larrabee�N���[������낤�Ƃ��Ă�킯�����H
> A: ��ʂɃ��W�X�^��ߖ邽�߂ɂ�SRC��DST�ɓ������̂��w�肷��Ηǂ����A
> ���̏ꍇ��(SRC)�̒l�͓��R�j������邱�ƂɂȂ�B
> �����A��ʓI�Ƀ��W�X�^�̓��e���\�Ȍ���ێ��������ꍇ�́ASRC��DST�����鎖�ɂȂ�B
> ����ƂȂ�̂�Opcode�̐����Decoder(�̕��G��)�ł���A x86�ł͂��ꂪ��肾����(�̂�
> SRC��DST��Ƃ���)���A���̐���Ɋ|�����ł͂Ȃ��B
> SSE5��(�v���O����)�ė��p�̊ϓ_����Ax86 �݂̂Ȃ炸(GPGPU�Ȃǂ�)Data Flow Machine�Ȃǂ̏��
> Encode��Decode���s�������l�����Ă���(���߂ɁASRC��DST������)�B
��SSE5�̐Ϙa�Z�̓\�[�X���W�X�^��j�܂��B
�܂蒆�̐l�݂����玩����src���W�X�^��j��SSE5�̐Ϙa�Z���f�[�^�t���[�}�V���ɕs�������Ɣ��Ă܂�
VR-Zone�̓��肵���v���[���ɂ��Phenom II�̐��\���㕪�̓��B
http://vr-zone.com/articles/amd-phenom-ii-performance-uplift/6273.html?doc=6273
65-nm Phenom 9950���炨�悻24%���̐��\���オ����Ƃ̂��Ƃ����ǁA�����Ƃ���
����퉺�L�̒ʂ肷�B
�@- IPC����: +3%
�@- ���쑬�x���� (�`3GHz): +11.5%
�@- L3�L���b�V������ (+4MB): +5.5%
�@- ������������ (DDR3-1333): +4%
�R�A�̃_�C�ʐς�+3%, L3�̃_�C�ʐς�+5%�A���ꂼ��P���k����葝�����Ă���Ƃ������Ƃ�
���ǁA��̂悤�ȏ����������Ă��܂���AM3�܂Ŕ����T�����Ă��܂��悤�ȋC�����邷�B
http://vr-zone.com/articles/amd-phenom-ii-performance-uplift/6273.html?doc=6273
65-nm Phenom 9950���炨�悻24%���̐��\���オ����Ƃ̂��Ƃ����ǁA�����Ƃ���
����퉺�L�̒ʂ肷�B
�@- IPC����: +3%
�@- ���쑬�x���� (�`3GHz): +11.5%
�@- L3�L���b�V������ (+4MB): +5.5%
�@- ������������ (DDR3-1333): +4%
�R�A�̃_�C�ʐς�+3%, L3�̃_�C�ʐς�+5%�A���ꂼ��P���k����葝�����Ă���Ƃ������Ƃ�
���ǁA��̂悤�ȏ����������Ă��܂���AM3�܂Ŕ����T�����Ă��܂��悤�ȋC�����邷�B
IPC���゠��B
�������ǗL��������
�_�C�͊m���ɑ傫���Ȃ��Ă�݂�������
�V�����n�C������285mm2�ƌ���
http://www.amd.com/jp-ja/Processors/TechnicalResources/0,,30_182_861_8806~129019,00.html
�������ǗL��������
�_�C�͊m���ɑ傫���Ȃ��Ă�݂�������
�V�����n�C������285mm2�ƌ���
http://www.amd.com/jp-ja/Processors/TechnicalResources/0,,30_182_861_8806~129019,00.html
��J����IPC���܂��܉҂����N���b�N�ǂ���ƈꊄ�グ�������i���{���y�c�c
����Ȃ������ςȂ̂��B
����Ȃ������ςȂ̂��B
IPC�グ�����āA�X�P�W���[���[�̐��\���グ���̂��H
>>132
IPC��1���グ��̂ɂ�2���̃g�����W�X�^���ʂ��K�v�����A
����ł��ĕK�������S�Ẵ\�t�g�ő��x�����シ��킯����Ȃ��̂ɔ�ׁA
�N���b�N��1���グ��Α����̏ꍇ1���߂����x�����シ��i�������C���e���V�u�ȃ\�t�g���̂����j����B
IPC��1���グ��̂ɂ�2���̃g�����W�X�^���ʂ��K�v�����A
����ł��ĕK�������S�Ẵ\�t�g�ő��x�����シ��킯����Ȃ��̂ɔ�ׁA
�N���b�N��1���グ��Α����̏ꍇ1���߂����x�����シ��i�������C���e���V�u�ȃ\�t�g���̂����j����B
http://journal.mycom.co.jp/column/architecture/122/index.html
���̃R�����̎w�E���ƁA���܂���IPC1���グ��̂Ƀg�����W�X�^2�����ōςނ������₵���Ȃ��Ă�낤���ˁB
���̃R�����̎w�E���ƁA���܂���IPC1���グ��̂Ƀg�����W�X�^2�����ōςނ������₵���Ȃ��Ă�낤���ˁB
������256�r�b�g��AVX=���߃Z�b�g�lj��ɂ�鐫�\����ƂȂ�킯���ȁB
ISA�y������͂������Ȃ�AMD���p�t�H�[�}���X�s��Ő����c��͓̂���Ȃ��Ă����B
ISA�y������͂������Ȃ�AMD���p�t�H�[�}���X�s��Ő����c��͓̂���Ȃ��Ă����B
�p�t�H�[�}���X�ɐU��Ȃ��Ȃ�݊����[�J�[�炵�����������̐��\�̂��̂�
������ʂɔ����������Ȃ��c�c�Ǝv���ƁA���́u������ʂɍ��v���Ƃ���
Intel�̖{�̂ŁAAMD�͑S�������ł��ł��Ȃ��B
�Ȃ�A�h�o���e�[�W�̂���GPU���A�Ƃ����̂������v���Z�X���Ⴄ�̂œ���B
����t������ȁB
������ʂɔ����������Ȃ��c�c�Ǝv���ƁA���́u������ʂɍ��v���Ƃ���
Intel�̖{�̂ŁAAMD�͑S�������ł��ł��Ȃ��B
�Ȃ�A�h�o���e�[�W�̂���GPU���A�Ƃ����̂������v���Z�X���Ⴄ�̂œ���B
����t������ȁB
���߃Z�b�g�ŃC���e�����S�݊��ł���I���{VGA�܂ރ`�b�v�Z�b�g�Ƃ̃g�[�^�����\�ői���ł���B
�Ǝ��g���͂�������ăV�F�A�グ�Ă���ł�����Ȃ����ˁB
�Ǝ��g���͂�������ăV�F�A�グ�Ă���ł�����Ȃ����ˁB
TSMC��TFC������������ő��̃��[�J�[�͎��O�Ńt�@�u�����Ȃ��Ⴂ���Ȃ����R�͖����Ȃ���
����͐����ł��ăt�@�u���X�ɂȂ�
���̂ق��������t�����A�܂��������Ȃ���t�@�u���X�ɂȂ������C�o���ɑ��s���ɂȂ�
TFC�����n�߂�AAMD�͍���͎��Ђ̃t�@�u���ғ�����������ׂɖ��������Ȃ��Ă��ǂ��Ȃ�
�܂����d�Ȕ����Ƃ�����炸�ɖ���ɂ���Ă����A�����͕������������L�邾�낗
����͐����ł��ăt�@�u���X�ɂȂ�
���̂ق��������t�����A�܂��������Ȃ���t�@�u���X�ɂȂ������C�o���ɑ��s���ɂȂ�
TFC�����n�߂�AAMD�͍���͎��Ђ̃t�@�u���ғ�����������ׂɖ��������Ȃ��Ă��ǂ��Ȃ�
�܂����d�Ȕ����Ƃ�����炸�ɖ���ɂ���Ă����A�����͕������������L�邾�낗
AMD�́A�`�b�v�P����Intel��荂�R�X�g�Ȃ̂�
(Intel�����Ȃ�����)���\�ŏ��ĂȂ��A�Ƃ����r�~���[�ȗ���Ȃ̂���B
���ʂ��o�����Ƃ��ĉ��i���������Intel���Ō����傫������
�t�@�u���]���ĂĂ��V�F�A�����ɂ����Ȃ��B
http://pc.watch.impress.co.jp/docs/2008/1008/hot574.htm
> Fab38�́A200mm�E�F�n�̍H�ꂾ������Fab30��300mm�E�F�n�̍H��ɓ]������
> ���̂����A���ۂɂ͉ғ����Ă��炸�A���Ђ���ԂƂȂ��Ă����B
> �����_�ŁA2�J���̍H��(Fab36��Chartered��Fab7)�ł����t���ғ��ɂ͉���
> ��Ԃ��ƌ����Ă���
������AAMD���s��V�F�A50%(��)��ڎw���Ȃ�A���i�����͂̂��鐻�i�A
���Ȃ킿���R�X�g�Ɍ����������\���A�قǂقǂ̐��\�ł����v���o���R�X�g�����c�c
���K�{�B�ǂ��������[�h�}�b�v����͌����Ă��Ȃ����ǁB
(Intel�����Ȃ�����)���\�ŏ��ĂȂ��A�Ƃ����r�~���[�ȗ���Ȃ̂���B
���ʂ��o�����Ƃ��ĉ��i���������Intel���Ō����傫������
�t�@�u���]���ĂĂ��V�F�A�����ɂ����Ȃ��B
http://pc.watch.impress.co.jp/docs/2008/1008/hot574.htm
> Fab38�́A200mm�E�F�n�̍H�ꂾ������Fab30��300mm�E�F�n�̍H��ɓ]������
> ���̂����A���ۂɂ͉ғ����Ă��炸�A���Ђ���ԂƂȂ��Ă����B
> �����_�ŁA2�J���̍H��(Fab36��Chartered��Fab7)�ł����t���ғ��ɂ͉���
> ��Ԃ��ƌ����Ă���
������AAMD���s��V�F�A50%(��)��ڎw���Ȃ�A���i�����͂̂��鐻�i�A
���Ȃ킿���R�X�g�Ɍ����������\���A�قǂقǂ̐��\�ł����v���o���R�X�g�����c�c
���K�{�B�ǂ��������[�h�}�b�v����͌����Ă��Ȃ����ǁB
�Q�`�R�N����A�u�_�r�͖�������߂邾��
���̎����`�l�c�̏I��
���̎����`�l�c�̏I��
���オ�Â��Ă���������Ζׂ�������ATFC���ƌÂ��̂�SOI����������A
���炭������ˁB
���炭������ˁB
>>140
����͗����悩�{���悩�̘b�ɂȂ��
�㓡�L���ɂ��ƁA���܂ő��ɍ̗p����Ȃ������̂͐��Y�͂ɋ^�╄���t���Ă��������
�t���ɉĂ�30%�����V�F�A�����Ȃ����Y�͂����Ȃ��̂𗝗R��Dell�Ȃ�AMD�̗p���������Ă���(���Ȃ��Ƃ��\������)
�ŁA�����͂̂��鏤�i���������Ƃ��Ă����Y�͂��l�b�N�ō̗p����Ȃ������̂�AMD�̉ۑ�̈������
����̘b�͐��Y�ʂł̕s������菜���V�F�A50%�ׂ̈̐��Y�͂��������Ęb�ŁA�����͂̂��鐻�i�Ƃ͕ʌ̘b����
������Phenom�͔���قǂɐԎ��ł��A���̕�K8�ŃV�F�A�m�ۂ��o����Ό�̎��Ȃ�
����ɔ���Ă���̂��Ėw�ǂ�Sempron�Ƃ��̒ቿ�i�����ŁAPhenom��AMD�S�̂̏o�א���10%���x���������
���Ƒ��Ђ�intel��50%�߂���Celeron��PentiumDC�̂悤�ȗ����ł������͂��ŁA���̕ӂ̎����AMD����������Ȃ����H
AMD�����ꂽ�`�b�v�̓�������\���Ă��邩�͕s�������c�c
����͗����悩�{���悩�̘b�ɂȂ��
�㓡�L���ɂ��ƁA���܂ő��ɍ̗p����Ȃ������̂͐��Y�͂ɋ^�╄���t���Ă��������
�t���ɉĂ�30%�����V�F�A�����Ȃ����Y�͂����Ȃ��̂𗝗R��Dell�Ȃ�AMD�̗p���������Ă���(���Ȃ��Ƃ��\������)
�ŁA�����͂̂��鏤�i���������Ƃ��Ă����Y�͂��l�b�N�ō̗p����Ȃ������̂�AMD�̉ۑ�̈������
����̘b�͐��Y�ʂł̕s������菜���V�F�A50%�ׂ̈̐��Y�͂��������Ęb�ŁA�����͂̂��鐻�i�Ƃ͕ʌ̘b����
������Phenom�͔���قǂɐԎ��ł��A���̕�K8�ŃV�F�A�m�ۂ��o����Ό�̎��Ȃ�
����ɔ���Ă���̂��Ėw�ǂ�Sempron�Ƃ��̒ቿ�i�����ŁAPhenom��AMD�S�̂̏o�א���10%���x���������
���Ƒ��Ђ�intel��50%�߂���Celeron��PentiumDC�̂悤�ȗ����ł������͂��ŁA���̕ӂ̎����AMD����������Ȃ����H
AMD�����ꂽ�`�b�v�̓�������\���Ă��邩�͕s�������c�c
>>143
PenDC��Celeron�Ŕ����߂����Ă̂̓f�X�N�g�b�v������
http://pc.watch.impress.co.jp/docs/2007/1026/kaigai397.htm
����ɂ��ƌÂ����ǁA�m�[�g������2�����x��Celeron�B���Core2�ɂȂ��Ă���B
�I���������邵�AAtom�����ʑ����Ă邩��Ȃ�Ƃ������Ȃ����A�����߂�������p���Ă��Ƃ�
Intel��x86CPU�S�̂ł͂��肦�Ȃ��B
PenDC��Celeron�Ŕ����߂����Ă̂̓f�X�N�g�b�v������
http://pc.watch.impress.co.jp/docs/2007/1026/kaigai397.htm
����ɂ��ƌÂ����ǁA�m�[�g������2�����x��Celeron�B���Core2�ɂȂ��Ă���B
�I���������邵�AAtom�����ʑ����Ă邩��Ȃ�Ƃ������Ȃ����A�����߂�������p���Ă��Ƃ�
Intel��x86CPU�S�̂ł͂��肦�Ȃ��B
>>143
�uAMD�͐��Y�͂��ۑ�v�Ƃ����ƌ����Ă������A
�t�@�u��2�ɑ��₵�Ă��A�Е����Ђ��ɂ��ė]�点�Ă����ԁB
���܂́u�t�@�u�̃L���p�߂���悤�ȋ����͂̂��鐻�i���Ȃ��̂��ۑ�v���B
������AMD���t�@�u��Ƃǂ��Ȃ邩�B
AMD�ׂ͖���Ȃ��t�@�u���S���Ȃ��Ȃ�A���������ł悭�����X�S���`�b�v��v�ł���悤�ɂȂ�B
TFC�̕����A�X�S���Ȃ���AMD���i�⑼�А��i�����܂����ăt�@�u�t���ғ��ŃE�n�E�n�ƁA
�o���ꗼ���c�c�z���g��?
�uAMD�͐��Y�͂��ۑ�v�Ƃ����ƌ����Ă������A
�t�@�u��2�ɑ��₵�Ă��A�Е����Ђ��ɂ��ė]�点�Ă����ԁB
���܂́u�t�@�u�̃L���p�߂���悤�ȋ����͂̂��鐻�i���Ȃ��̂��ۑ�v���B
������AMD���t�@�u��Ƃǂ��Ȃ邩�B
AMD�ׂ͖���Ȃ��t�@�u���S���Ȃ��Ȃ�A���������ł悭�����X�S���`�b�v��v�ł���悤�ɂȂ�B
TFC�̕����A�X�S���Ȃ���AMD���i�⑼�А��i�����܂����ăt�@�u�t���ғ��ŃE�n�E�n�ƁA
�o���ꗼ���c�c�z���g��?
>>131
> IPC���゠��B
> �������ǗL��������
L3��2GB����6GB�Ɋg���A����ɂ��L���b�V���e�ʂɕq���ȃ\�t�g�̐��\�����サ�Ă���̂ŕ��ϒl����݂��3%���x��IPC����ƂȂ�
> IPC���゠��B
> �������ǗL��������
L3��2GB����6GB�Ɋg���A����ɂ��L���b�V���e�ʂɕq���ȃ\�t�g�̐��\�����サ�Ă���̂ŕ��ϒl����݂��3%���x��IPC����ƂȂ�
�㓡����50%�V�F�A�Ƃ�邩�����ĊT�Z�͑S��CPU����������Ă��ƂȂ̂ŁA
�o���N�ɂ��Ή��������A���ۂ�GPU��`�b�v�Z�b�g�A�o����Α��Ђ��璍���Ƃ���
Fab�̉ғ����グ�āA���܂�����CPU�̃V�F�A������Fab�̃L���p���������Ȃ�A
GPU��`�b�v�Z�b�g�Ȃ�TSMC�ɒ������Đ��Y�ʂ�������ĂƂ��낶��Ȃ��́H
�o���N�ɂ��Ή��������A���ۂ�GPU��`�b�v�Z�b�g�A�o����Α��Ђ��璍���Ƃ���
Fab�̉ғ����グ�āA���܂�����CPU�̃V�F�A������Fab�̃L���p���������Ȃ�A
GPU��`�b�v�Z�b�g�Ȃ�TSMC�ɒ������Đ��Y�ʂ�������ĂƂ��낶��Ȃ��́H
������Q�[���@�̎���E�n�E�n
GPU�͂Ƃ������ACPU�Ŏ�����킯�Ȃ�
>>146
�Ƃ�ł��Ȃ��e�ʂ�L3�ɑ��ʂł���
�Ƃ�ł��Ȃ��e�ʂ�L3�ɑ��ʂł���
6GB����i7�̃��C������������
>>144
�X�}�\�A���̕ӂ͂���o������������K���u�b������
�����Aatom�̓����ɒቿ�i���������ACore2�ɂ��Ă�����PentiumDC�̌�p�ƌ�����E�V���[�Y�̔䗦�������ĂȂ���
���o�C�������ɂ��Ă�Core2�œZ�߂��Ă��ė����ł̖{���̔䗦�͌����Ă��Ȃ�����
���Ƀ��o�C��������Core2�łقڈ�Z�߂Ȃ̂ŁA�����łɓ�����T5000�A8000�n���ǂ̒��x�̃V�F�A���ǂ̒��x�Ȃ̂�������Ȃ���
����������̔䗦�͏o�Ă��Ȃ���Ȃ����H
>>145
����͍��͂��������Ď��ŕ��Љ��O��(����Core2�o���)
�E���v�ɑ��đΉ��\�Ȑ��Y��
�E���Ƒ��Ђɑ��ċ����͂̂��鐻�i
�̓���ۑ肾������ŁA��҂̉ۑ�����͂��ꂩ����Ď�����
�X�}�\�A���̕ӂ͂���o������������K���u�b������
�����Aatom�̓����ɒቿ�i���������ACore2�ɂ��Ă�����PentiumDC�̌�p�ƌ�����E�V���[�Y�̔䗦�������ĂȂ���
���o�C�������ɂ��Ă�Core2�œZ�߂��Ă��ė����ł̖{���̔䗦�͌����Ă��Ȃ�����
���Ƀ��o�C��������Core2�łقڈ�Z�߂Ȃ̂ŁA�����łɓ�����T5000�A8000�n���ǂ̒��x�̃V�F�A���ǂ̒��x�Ȃ̂�������Ȃ���
����������̔䗦�͏o�Ă��Ȃ���Ȃ����H
>>145
����͍��͂��������Ď��ŕ��Љ��O��(����Core2�o���)
�E���v�ɑ��đΉ��\�Ȑ��Y��
�E���Ƒ��Ђɑ��ċ����͂̂��鐻�i
�̓���ۑ肾������ŁA��҂̉ۑ�����͂��ꂩ����Ď�����
>>148
AMD�u�V��Ѝ��܂����B32nm����̓��C�o���ɂȂ�܂��B
�H��ł�����S�ʈ����グ�܂����ǁA����܂ň�������GPU�̐��Y�����B
���A����߂��ăL���p����Ȃ��Ȃ����Ƃ��̓w���v���肢���܂��l�v
CPU���猩��t�@�u���X�������AGPU���猩���AMD�ɂ�鎩�Ќn��H�ꎝ���܂��錾�B
nVidia�Ƃ�GPU�푈�̐^�Œ��ŁA����2�N��TSMC�Ɉˑ����Ȃ���Ȃ�Ȃ��̂ɁA
������TSMC��nVidia��������������Ă���̂ɁA
TSMC�ƈ�㒅�Ȃ��Ɉڍs�ł�����̂Ȃ̂��Ȃ��Ǝv���̂ł���B
AMD�u�V��Ѝ��܂����B32nm����̓��C�o���ɂȂ�܂��B
�H��ł�����S�ʈ����グ�܂����ǁA����܂ň�������GPU�̐��Y�����B
���A����߂��ăL���p����Ȃ��Ȃ����Ƃ��̓w���v���肢���܂��l�v
CPU���猩��t�@�u���X�������AGPU���猩���AMD�ɂ�鎩�Ќn��H�ꎝ���܂��錾�B
nVidia�Ƃ�GPU�푈�̐^�Œ��ŁA����2�N��TSMC�Ɉˑ����Ȃ���Ȃ�Ȃ��̂ɁA
������TSMC��nVidia��������������Ă���̂ɁA
TSMC�ƈ�㒅�Ȃ��Ɉڍs�ł�����̂Ȃ̂��Ȃ��Ǝv���̂ł���B
�Ԃ����ႯAMD��TFC�͂������ꂪ�t�]���邾�낤��
>>141
�A�u�_�r���~���������̂�TFC�ŁA������o�߂������AMD�͕@������ǂ��ł�������Ȃ��H
>>141
�A�u�_�r���~���������̂�TFC�ŁA������o�߂������AMD�͕@������ǂ��ł�������Ȃ��H
>>155
�A�u�_�r��TFC��������Ȃ�AMD�{�̂ɂ����낵���z�𓊎����Ă��
�A�u�_�r��TFC��������Ȃ�AMD�{�̂ɂ����낵���z�𓊎����Ă��
>>154
�������Ȃ��H�@�P��GPU�Ɋւ��Ă�TSMC�Ɉϑ��̂܂܂̋C������B
�������Ȃ��H�@�P��GPU�Ɋւ��Ă�TSMC�Ɉϑ��̂܂܂̋C������B
>>157
CPU��GPU����������P��GPU�̐��Y�ʂȂ�ăJ�X�݂����Ȃ���
CPU��GPU����������P��GPU�̐��Y�ʂȂ�ăJ�X�݂����Ȃ���
>>158
(߄D�)ʧ?
(߄D�)ʧ?
����ꂾ��
>>157
��[�v���Z�X��v�����锼���̕���͏��Ȃ��Ȃ��Ă��Ă���̂�
TFC��32nm�߂�̂�GPU�͕K�{�B
>>158
���\���K�v�ȃ��[�U�̂��߂ɁA�����ăQ�t�H�~�̂��߂�:-)�A
�ˑR�Ƃ��ăf�B�X�N���[�g�͐����c��B
�`�b�v�Z�b�g�����Ƃ͋������A�R�X�g�����b�g���Ȃ����
GPU����CPU�͂������������オ��Ȃ���������Ȃ��B
��[�v���Z�X��v�����锼���̕���͏��Ȃ��Ȃ��Ă��Ă���̂�
TFC��32nm�߂�̂�GPU�͕K�{�B
>>158
���\���K�v�ȃ��[�U�̂��߂ɁA�����ăQ�t�H�~�̂��߂�:-)�A
�ˑR�Ƃ��ăf�B�X�N���[�g�͐����c��B
�`�b�v�Z�b�g�����Ƃ͋������A�R�X�g�����b�g���Ȃ����
GPU����CPU�͂������������オ��Ȃ���������Ȃ��B
�悭�l�����SOI�g���Ă�`�b�v���Č��\�������C�����邵
������SOI���g���Ă���Ƃ���ɂ�TFC�͖��͓I��Fab�ɉf��\���������
�m�����l�T�X�Ƃ����d�C�Ȃ�SOI�g�����`�b�v�������[�X���Ă����͂�����
���ł�TFC���g�������b�g�͂��肻��������
�l�I�ɂ�TFC��Cell�����悤�ɂȂ�����ʔ����Ǝv�����ǁA���������͓̂����������낤��
������SOI���g���Ă���Ƃ���ɂ�TFC�͖��͓I��Fab�ɉf��\���������
�m�����l�T�X�Ƃ����d�C�Ȃ�SOI�g�����`�b�v�������[�X���Ă����͂�����
���ł�TFC���g�������b�g�͂��肻��������
�l�I�ɂ�TFC��Cell�����悤�ɂȂ�����ʔ����Ǝv�����ǁA���������͓̂����������낤��
>>162
> ������SOI���g���Ă���Ƃ���ɂ�TFC�͖��͓I��Fab�ɉf��\���������
���Y�͉ߏ苟���ɂ�鉿�i�\���ŃE�n�E�n�ɂȂ邩����
> ������SOI���g���Ă���Ƃ���ɂ�TFC�͖��͓I��Fab�ɉf��\���������
���Y�͉ߏ苟���ɂ�鉿�i�\���ŃE�n�E�n�ɂȂ邩����
IBM�A���̃��C���t�@�E���h���Ƃ��Ă̗�����m���ł����TFC�ɂ������͂���B
�N�P�ʂŒx��Ă���V�R�A�J�������������H���ɖ߂��A
AMD�͍Đ����ʂ�����Ǝv�����A���̂Ƃ��낻�̒���͂Ȃ��B
�Ƃ������A�����������ŁuBulldozer��Bobcat��Fusion�ʎY�̋łɂ́I�v
�Ƃ������o���āA�ނ���gdgd�ɔ��Ԃ�������n���B
AMD�͍Đ����ʂ�����Ǝv�����A���̂Ƃ��낻�̒���͂Ȃ��B
�Ƃ������A�����������ŁuBulldozer��Bobcat��Fusion�ʎY�̋łɂ́I�v
�Ƃ������o���āA�ނ���gdgd�ɔ��Ԃ�������n���B
���������H�����ċ�̓I�ɂȂɂ����H
Phenom��PhenomII�̊J���͌����H�����̂��̂��Ǝv�����B
����ł���x���킯�����B
Phenom��PhenomII�̊J���͌����H�����̂��̂��Ǝv�����B
����ł���x���킯�����B
���Ȃ݂�SOI�Ő��ʂłĂ�̂́AAMD��CPU��������PowerPC(����т��̔h���i)�����B
�\�j�[�������̐��Y����P�ނ����u�ŐV�t�@�u�̃L���p�傫�߂��v�Ƃ������R���l����A
���ł�Chartered��IBM�����������TFC��PowerPC���Y���W���A�Ƃ����̂�
�L�蓾�Ȃ��b�ł͂Ȃ��B
�\�j�[�������̐��Y����P�ނ����u�ŐV�t�@�u�̃L���p�傫�߂��v�Ƃ������R���l����A
���ł�Chartered��IBM�����������TFC��PowerPC���Y���W���A�Ƃ����̂�
�L�蓾�Ȃ��b�ł͂Ȃ��B
>>166
Bulldozer/Bobcat/Fusion���L�����Z�����āA���̕��̐l����U��������
�x��܂��BTLB�G���b�^�݂����Ȓv���I�ȕs�n�����h���邾�낤�B
���ƁAx86�R�A���̂��̂��A���ӂ̃������R���g���[����HT�ɂ�����
�������P�̗]�n������̂ł͂Ȃ����Ǝv���B
Bulldozer/Bobcat/Fusion���L�����Z�����āA���̕��̐l����U��������
�x��܂��BTLB�G���b�^�݂����Ȓv���I�ȕs�n�����h���邾�낤�B
���ƁAx86�R�A���̂��̂��A���ӂ̃������R���g���[����HT�ɂ�����
�������P�̗]�n������̂ł͂Ȃ����Ǝv���B
>>167
�@�@-----------------
�@�@���ł�Chartered��IBM�����������TFC��PowerPC���Y���W���
�@�@-----------------
����Chartered���Ɛї\���������C�����Ă���̂��s��̌��������ǁB�B�B
http://www.mellanox.com/related-docs/prod_hca/IH3LX_X4.pdf
�@�@=================
�@�@Under the revised guidance, Chartered said its revenue would be down 24 to 26 percent
�@�@sequentially. Chartered said now expects a capacity utilization rate of 58 to 62 percent
�@�@for the fourth quarter, down from 85 percent in the third quarter. The company said
�@�@previously it expected utilization to be 60 to 66 percent.
�@�@=================
���Ɨ���6���O��Ƃ��B�B�B
�@�@-----------------
�@�@���ł�Chartered��IBM�����������TFC��PowerPC���Y���W���
�@�@-----------------
����Chartered���Ɛї\���������C�����Ă���̂��s��̌��������ǁB�B�B
http://www.mellanox.com/related-docs/prod_hca/IH3LX_X4.pdf
�@�@=================
�@�@Under the revised guidance, Chartered said its revenue would be down 24 to 26 percent
�@�@sequentially. Chartered said now expects a capacity utilization rate of 58 to 62 percent
�@�@for the fourth quarter, down from 85 percent in the third quarter. The company said
�@�@previously it expected utilization to be 60 to 66 percent.
�@�@=================
���Ɨ���6���O��Ƃ��B�B�B
>>168
>Bulldozer/Bobcat/Fusion���L�����Z������
�ŁA�������H�@PhenomII�̑�����̉��ǂ�����Intel�ɑR����̂��B
>Bulldozer/Bobcat/Fusion���L�����Z������
�ŁA�������H�@PhenomII�̑�����̉��ǂ�����Intel�ɑR����̂��B
Istanbul��Nehalem���ă_�C�T�C�Y���������炢�ł��������̂悤�ȋS��������ǁA
���̍���Intel��32nm�Ȃ��
���̍���Intel��32nm�Ȃ��
�S���C
>>169
����B������Chartered�͓P�ނ��邾�낤�B�����ē��ł����Ђł�Cell���Y���~�߁A
IBM���܂߂āASOI�Ƃ���SOI���݂�TFC���ɂȂ�Ƃ����\��(��])�B
>>170
������̉��ǁu�����v�Ƃ������AHPC�ł��f�X�N�g�b�v�ł�
���\����̎���̓o�X�ł͂Ȃ����낤���B
AMD���g�������R�������ʼnΊW����Ă���B
�R�A����������Α�����قǁA�������R�q�[�����V�ێ��̂��߂ɑш��
�H����̂ŁA��ԉɂ�������]�n������A���B
����B������Chartered�͓P�ނ��邾�낤�B�����ē��ł����Ђł�Cell���Y���~�߁A
IBM���܂߂āASOI�Ƃ���SOI���݂�TFC���ɂȂ�Ƃ����\��(��])�B
>>170
������̉��ǁu�����v�Ƃ������AHPC�ł��f�X�N�g�b�v�ł�
���\����̎���̓o�X�ł͂Ȃ����낤���B
AMD���g�������R�������ʼnΊW����Ă���B
�R�A����������Α�����قǁA�������R�q�[�����V�ێ��̂��߂ɑш��
�H����̂ŁA��ԉɂ�������]�n������A���B
Chartered��SOI�����@��SOI�̒��ł��嗬����O�ꂽ����������
�R�X�g�������̂�����
�R�X�g�������̂�����
>>173
�f�X�N�g�b�v���Ƒ����̉��ǂŐ��\����̕����]�n���������낤�B
���Ƃ���Nehalem��2ch��3ch�Ő��\����%���x���̕����������B
����ɁA���R�A�����f�X�N�g�b�v���Ɖ��b�ɂ����B
HPC�ɓ�������Ȃ炠�肩������Ȃ����B
���ƁA�������R�q�[�����V���ĂȂɁH
�f�X�N�g�b�v���Ƒ����̉��ǂŐ��\����̕����]�n���������낤�B
���Ƃ���Nehalem��2ch��3ch�Ő��\����%���x���̕����������B
����ɁA���R�A�����f�X�N�g�b�v���Ɖ��b�ɂ����B
HPC�ɓ�������Ȃ炠�肩������Ȃ����B
���ƁA�������R�q�[�����V���ĂȂɁH
>>175
�f�X�N�g�b�v�Ȃ�č��㔖�������ɐ��炴��Ȃ������������m�[�g�ɒD���Ďs�ꂪ�ǂ�ǂ�k������
�`�b�v�Z�b�g���݂Ȃ�`�l�c�͏\���m�[�g�Ő킦���
�f�X�N�g�b�v�Ȃ�č��㔖�������ɐ��炴��Ȃ������������m�[�g�ɒD���Ďs�ꂪ�ǂ�ǂ�k������
�`�b�v�Z�b�g���݂Ȃ�`�l�c�͏\���m�[�g�Ő킦���
>>168
�N������Ȕ��H�����Ƃ�Ǝv���H
�N������Ȕ��H�����Ƃ�Ǝv���H
179 �F,,�E�L�́M�E,,�j��-�������F2008/12/14(��) 15:29:00 ID:Dlzj/LNa
>>173
�˂�����ł����H
�ʏ�f�X�N�g�b�v��1�\�P�b�g����ȁH
�V���O���_�C�\���Ȃ畁�ʂ̓L���b�V���R�q�[�����g�̓N���X�o�[�X�C�b�`��
�����O�l�b�g���[�N�Ȃǂ̃`�b�v���o�X�ʼn������邩��O���o�X����̐��\�͊W�Ȃ��B
�܂�MCM�\���ŁAFSB�|�`�b�v�Z�b�g���o�R���Ē��₷��A�z��CPU�����݂��邯��
���̓T�^��Core 2 Quad�ł����ʂ̃��[�N���[�h�ł̓l�C�e�B�u�N�A�b�h�Ƒ��F�Ȃ�
���\�������Ă�킯�ŁA�܂��������Ȃ���ȁB
�˂�����ł����H
�ʏ�f�X�N�g�b�v��1�\�P�b�g����ȁH
�V���O���_�C�\���Ȃ畁�ʂ̓L���b�V���R�q�[�����g�̓N���X�o�[�X�C�b�`��
�����O�l�b�g���[�N�Ȃǂ̃`�b�v���o�X�ʼn������邩��O���o�X����̐��\�͊W�Ȃ��B
�܂�MCM�\���ŁAFSB�|�`�b�v�Z�b�g���o�R���Ē��₷��A�z��CPU�����݂��邯��
���̓T�^��Core 2 Quad�ł����ʂ̃��[�N���[�h�ł̓l�C�e�B�u�N�A�b�h�Ƒ��F�Ȃ�
���\�������Ă�킯�ŁA�܂��������Ȃ���ȁB
180 �F,,�E�L�́M�E,,�j��-�������F2008/12/14(��) 15:50:07 ID:Dlzj/LNa
>>171
���Ȃ݂Ƀ_�C�T�C�Y�́@Shanghai(4�R�A) �� Gainestown (4�R�A)�ȁB
6�R�A���Ƃ����ƍ����J������[��B
Istanbul(6�R�A) 2009�NH2
Beckton(8�R�A; XeonMP) 2009�N��
XeonMP�Ɍ����Penryn�x�[�X�̃V���O���_�C��6�R�A�v���Z�b�T�o�Ă��B
L2 3MB�~3, L3 16MB�̃f�J�������ǁB
���Ȃ݂Ƀ_�C�T�C�Y�́@Shanghai(4�R�A) �� Gainestown (4�R�A)�ȁB
6�R�A���Ƃ����ƍ����J������[��B
Istanbul(6�R�A) 2009�NH2
Beckton(8�R�A; XeonMP) 2009�N��
XeonMP�Ɍ����Penryn�x�[�X�̃V���O���_�C��6�R�A�v���Z�b�T�o�Ă��B
L2 3MB�~3, L3 16MB�̃f�J�������ǁB
Nehalem-EX��8P�܂őΉ������A�]����XeonMP���A�V�X�e���x���_�[��
��낤�Ǝv����4P���ɂ��ł���B
Intel�������Ƃ�������Itanium�ł���4P�܂ł������Ή����ĂȂ��B
��낤�Ǝv����4P���ɂ��ł���B
Intel�������Ƃ�������Itanium�ł���4P�܂ł������Ή����ĂȂ��B
183 �FSocket774�F2008/12/14(��) 16:33:54 ID:AR5X0nO6
>>181
Opteron��RAS�@�\����Itanium�ȏ�ɒɂ��ڂɂ����Ǝv����B
Tukwila = SPARC64 IIV = POWER6 �� Montvale �������� XeonMP �� Opteron ������B
�����Itanium��HP�݂����ȃm�E�n�E�̂���Ƃ��낪��͂Ŕ����Ă邯��Opteron��Sun�ł��炻���������ɂ���Ă���邩�������B
���ЊJ�����Ă���Rock�ƕx�m�ʂ�SPARC64�����邩��B
Opteron��RAS�@�\����Itanium�ȏ�ɒɂ��ڂɂ����Ǝv����B
Tukwila = SPARC64 IIV = POWER6 �� Montvale �������� XeonMP �� Opteron ������B
�����Itanium��HP�݂����ȃm�E�n�E�̂���Ƃ��낪��͂Ŕ����Ă邯��Opteron��Sun�ł��炻���������ɂ���Ă���邩�������B
���ЊJ�����Ă���Rock�ƕx�m�ʂ�SPARC64�����邩��B
184 �F,,�E�L�́M�E,,�j��-�������F2008/12/14(��) 16:37:33 ID:Dlzj/LNa
>>181
���Ȃ݂�Beckton�̓L���[�u�l�b�g���[�N��8�\�P�b�g�ȏ�Ή�������Ă��B
HT2�X���b�h�~8�R�A�~8�\�P�b�g��128�_���v���Z�b�T�̍\����F
http://pc.watch.impress.co.jp/docs/2007/1022/kaigai04l.gif
�����͈ꉞ32�\�P�b�g�܂őΉ����Ă�Ƃ��B
�i32�\�P�b�g�̏ꍇ�̏ꍇBoxboro��16��K�v�ɂȂ�̂��ȁH�j
Windows Server 2008���ƍő�256�_��CPU�܂ł����Ή����Ȃ��̂ŕs���͖����B
�ʔ������ƂɁA���̃R���V���[�}����OS�ł���Windows 7�ł��i1�`2�\�P�b�g�܂ł̔��肾���j
256�_��CPU�܂őΉ�����炵���B
����͂܂�ALarrabee�݂����ȃ��j�[�R�Ax86 CPU�����C��CPU�Ƃ��Ďg����
�v���b�g�t�H�[�����o���Ă��L�����p�o����]�n�͂�����Ă��ƂɂȂ�B
���Ȃ݂�Beckton�̓L���[�u�l�b�g���[�N��8�\�P�b�g�ȏ�Ή�������Ă��B
HT2�X���b�h�~8�R�A�~8�\�P�b�g��128�_���v���Z�b�T�̍\����F
http://pc.watch.impress.co.jp/docs/2007/1022/kaigai04l.gif
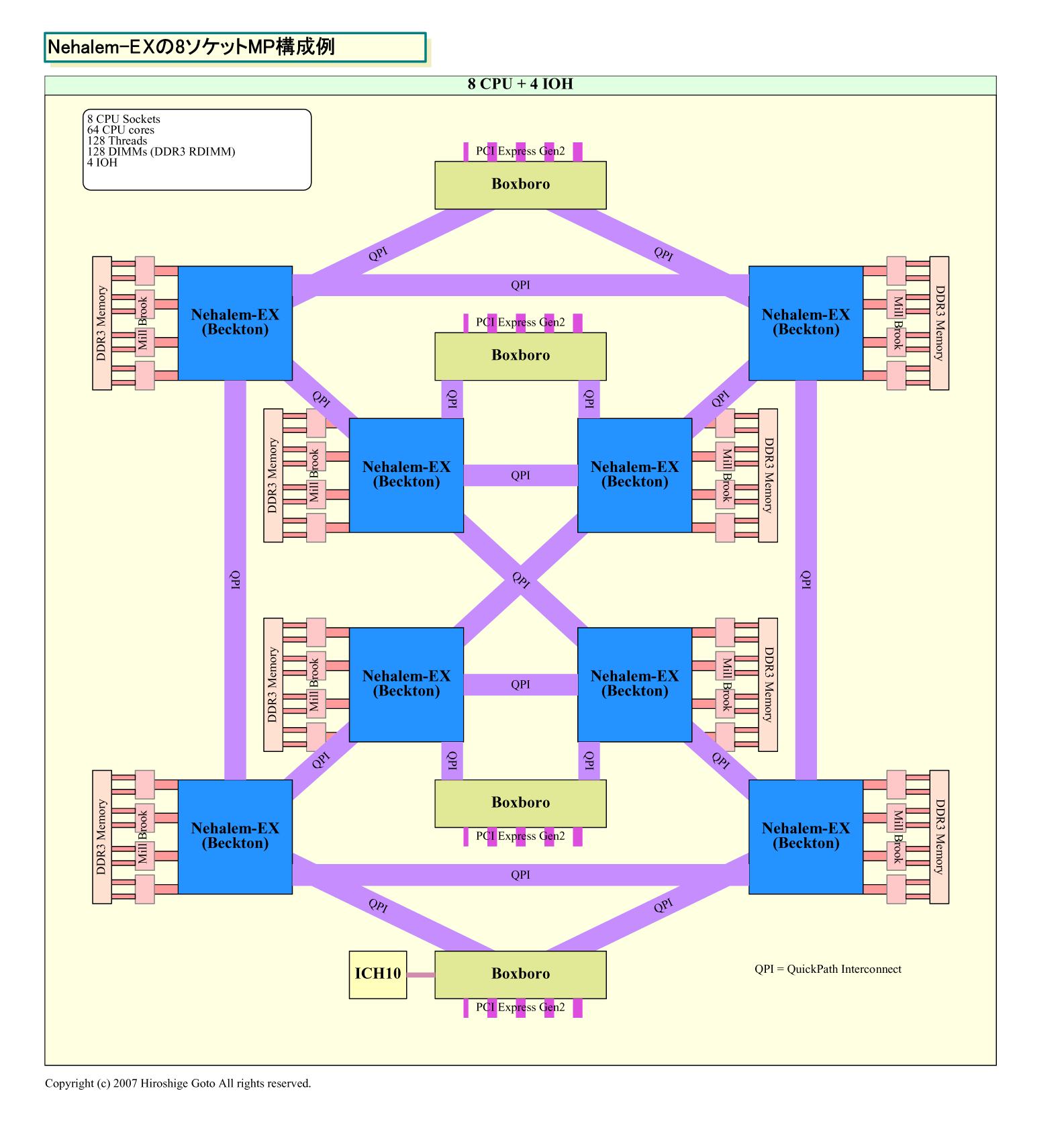{kind=link}
�����͈ꉞ32�\�P�b�g�܂őΉ����Ă�Ƃ��B
�i32�\�P�b�g�̏ꍇ�̏ꍇBoxboro��16��K�v�ɂȂ�̂��ȁH�j
Windows Server 2008���ƍő�256�_��CPU�܂ł����Ή����Ȃ��̂ŕs���͖����B
�ʔ������ƂɁA���̃R���V���[�}����OS�ł���Windows 7�ł��i1�`2�\�P�b�g�܂ł̔��肾���j
256�_��CPU�܂őΉ�����炵���B
����͂܂�ALarrabee�݂����ȃ��j�[�R�Ax86 CPU�����C��CPU�Ƃ��Ďg����
�v���b�g�t�H�[�����o���Ă��L�����p�o����]�n�͂�����Ă��ƂɂȂ�B
�܂�������Ȃɑ����Q�[�����\�Œǂ����Ȃ����͋t�]�ł���Ƃ͖��ɂ��v��Ȃ�����
�����x��܂����
http://northwood.blog60.fc2.com/blog-entry-2495.html
�I�[�o�[�N���b�N���\�Ɋւ��Ă͂c�e�h���������͂��҂傤���Ă��Ăl�a���[�J�[�Ƃ��Ă͑�ϒ��������Ƃ�
��������
http://blog.livedoor.jp/amd646464/archives/51295879.html
�k�m�Q��6.2G�܂ł̌����H�X�N���[���V���b�g�o�����g�[�^���R�X�g�l����Ɠ��{�ȊO�̓g�b�v�V�F�A��邩����
�����x��܂����
http://northwood.blog60.fc2.com/blog-entry-2495.html
�I�[�o�[�N���b�N���\�Ɋւ��Ă͂c�e�h���������͂��҂傤���Ă��Ăl�a���[�J�[�Ƃ��Ă͑�ϒ��������Ƃ�
��������
http://blog.livedoor.jp/amd646464/archives/51295879.html
�k�m�Q��6.2G�܂ł̌����H�X�N���[���V���b�g�o�����g�[�^���R�X�g�l����Ɠ��{�ȊO�̓g�b�v�V�F�A��邩����
���X
187 �FSocket774�F2008/12/14(��) 18:45:51 ID:TgsHLVZ0
�Z���v�����~4�o�Ȃ��́H
�o�Ă�����Ȃ����Ǐo���Ăx�n�c�B
�o�Ă�����Ȃ����Ǐo���Ăx�n�c�B
�M���������
���Z���v
���1600MHz�~4�݂����Ȃ̂��~�����낤����
����Ȃ������炢�Ȃ�3.2GHz�f���A���̂��ǂ���
�������C�Ȃ��Ȃ�o��������
�~�������m���o���ƌ���
���1600MHz�~4�݂����Ȃ̂��~�����낤����
����Ȃ������炢�Ȃ�3.2GHz�f���A���̂��ǂ���
�������C�Ȃ��Ȃ�o��������
�~�������m���o���ƌ���
>>184
���x���Ă����@�w�������ɂ��������Ȃ�
���x���Ă����@�w�������ɂ��������Ȃ�
191 �FSocket774�F2008/12/14(��) 20:18:25 ID:AR5X0nO6
���@�w�N�\�����^������������
�R�A��CPU���������Ă����ƃR���V���[�}�����ł��ŒZ�l�b�g���[�N���l���Đv���ɂ�Ȃ����
�R�X�g���オ��v���ɂȂ邩��g���[�h�I�t��T���Ă����Ȃ��Ƃ܂�����ˁ[��
�R�X�g���オ��v���ɂȂ邩��g���[�h�I�t��T���Ă����Ȃ��Ƃ܂�����ˁ[��
AMD�͎����ǂ��Ȃ邩���܂̂Ƃ���悭�킩���ȁB
Intel��SandyBridge����R�A�Ԑڑ��̓����O�o�X�ɂȂ�炵�����B
Intel��SandyBridge����R�A�Ԑڑ��̓����O�o�X�ɂȂ�炵�����B
�ЂƂ��������̂���
�ŋ߂�CPU�ő�ʂ̂R���L���b�V�����̂��Ă�̂�
�������ƒʐM�ł���̂͂P�R�A�����Ō�͑҂��Ă��Ԃ�����
���̊ԒʐM���ĂȂ��R�A�͂R���L���b�V�����Ōv�Z���Ă���Ă��ƂȂ�ł��傤���H
�ŋ߂�CPU�ő�ʂ̂R���L���b�V�����̂��Ă�̂�
�������ƒʐM�ł���̂͂P�R�A�����Ō�͑҂��Ă��Ԃ�����
���̊ԒʐM���ĂȂ��R�A�͂R���L���b�V�����Ōv�Z���Ă���Ă��ƂȂ�ł��傤���H
�����O�o�X����ATi��HD1xxx/HD2xxx�n��ɍ̗p����ď������z�������H
GPU�݂����Ƀf�[�^�Ǎݐ����鏈����炳���ɂ͌����ĂȂ����ۂ��������ǁACPU���Ƃǂ��Ȃ낤
�����ς�킩����A�N���ڂ����l�����
GPU�݂����Ƀf�[�^�Ǎݐ����鏈����炳���ɂ͌����ĂȂ����ۂ��������ǁACPU���Ƃǂ��Ȃ낤
�����ς�킩����A�N���ڂ����l�����
�������ƃR�A�̊ԂɃ������R���g���[���[�������āA�R�A�ƃ������͒�������Ė����̂ŊW�Ȃ�
�L���b�V���������͑傫���Ȃ�Ȃ�قǁA�R�A�̃L���b�V���̃f�[�^�̂����Ɏ��Ԃ��|����
���邢�͍����d�����K�v�ɂȂ�
�����̃y�i���e�B�[���傫���Ȃ肷����Ɛ��\���オ��ǂ��납���������˂Ȃ��̂�
L1��L2�͓K�x�ȑ傫���ɗ}���āA�����L3��lj�
L3�̓T�C�Y���傫�����R�A�Ƃ̂����ɂ͎��Ԃ��|���邪�A�����MB��ɂ��郁�C���������[�܂ōs�����͑���
�L���b�V���������͑傫���Ȃ�Ȃ�قǁA�R�A�̃L���b�V���̃f�[�^�̂����Ɏ��Ԃ��|����
���邢�͍����d�����K�v�ɂȂ�
�����̃y�i���e�B�[���傫���Ȃ肷����Ɛ��\���オ��ǂ��납���������˂Ȃ��̂�
L1��L2�͓K�x�ȑ傫���ɗ}���āA�����L3��lj�
L3�̓T�C�Y���傫�����R�A�Ƃ̂����ɂ͎��Ԃ��|���邪�A�����MB��ɂ��郁�C���������[�܂ōs�����͑���
Fab���]���Ă邩��2�R�A���4�R�A������̃��[�h�}�b�v�Ȃ�
���͂𒍂���
�댯����Ȃ��I��
x86�������Ȃ�����PC�n����傫���O�ꂽ�f�o�C�X�����̃`�b�v�͂Ȃ���
>>201
�̂͂��������ǂǂ�ǂ���Ă���������
�̂͂��������ǂǂ�ǂ���Ă���������
203 �F,,�E�L�́M�E,,�j��-�������F2008/12/15(��) 04:52:28 ID:7/5SpZFX
��ArtX���č��ǂ��̉�Ђ�H
Wii������GPU�������Ă�͂��Ȃ���
Wii������GPU�������Ă�͂��Ȃ���
AMD
ARM�Ƃ�MIPS�̏��^�̎���L�b�g�ł��o���Ă����������낢�̂�
>>206
�����܂�l����ƒP���ɂ͂킩��Ȃ��B
�����܂�l����ƒP���ɂ͂킩��Ȃ��B
http://pc.watch.impress.co.jp/docs/2008/1215/tawada159.htm
> �悤�₭�o�ꂵ��K10�f���A���R�A�uAthlon X2 7750 Black Edition�v
�l�C�e�B�u�N�A�b�h�̌��_�ł�������܂�̈�����
�s�ǃR�A�E����X2, X3�Ƃ��Ĕ��邱�Ƃʼn�������B
�������A�f���A���ƃN�A�b�h�̐����䗦�����₷��Intel��MCM�ɔ�ׂ�AMD��
�N�A�b�h�̏o�חʂ𑝂₻���Ǝv���Ύv���ق�
X2, X3���ςݏオ���Ă��܂��悤�ȋC�����Ȃ��ł��Ȃ��B
> �悤�₭�o�ꂵ��K10�f���A���R�A�uAthlon X2 7750 Black Edition�v
�l�C�e�B�u�N�A�b�h�̌��_�ł�������܂�̈�����
�s�ǃR�A�E����X2, X3�Ƃ��Ĕ��邱�Ƃʼn�������B
�������A�f���A���ƃN�A�b�h�̐����䗦�����₷��Intel��MCM�ɔ�ׂ�AMD��
�N�A�b�h�̏o�חʂ𑝂₻���Ǝv���Ύv���ق�
X2, X3���ςݏオ���Ă��܂��悤�ȋC�����Ȃ��ł��Ȃ��B
>>208
Nehalem����ɂȂ��Intel���������ƁB
�[��Kuma�͂����܂ŗ�O�ł����āA�Q�R�A�E���Ă܂ł̃f���A���i��
���͂ɂȂ邱�Ƃ͂Ȃ���BAMD��45nm�ł̓f���A���R�A��p�_�C�ł���Regor���\�肳��Ă�B
Nehalem����ɂȂ��Intel���������ƁB
�[��Kuma�͂����܂ŗ�O�ł����āA�Q�R�A�E���Ă܂ł̃f���A���i��
���͂ɂȂ邱�Ƃ͂Ȃ���BAMD��45nm�ł̓f���A���R�A��p�_�C�ł���Regor���\�肳��Ă�B
���܂�X2���o�Ȃ��������Ă��Ƃ͕����܂�͂�����Ȃ��̂��H
�����X4�̒l�i������Ε����܂肪�ǂ��͕̂����邾��B
���v���o�Ă邩�͉��������ǁB
���v���o�Ă邩�͉��������ǁB
http://techon.nikkeibp.co.jp/article/NEWS/20080912/157935/
���̋L���ɂ��ƁACoreMA�̃V���O���R�ACeleron��1�R�A�E���炵���B
����Tigerton��2�R�A���i��2�R�A�̂����Е���ׂ����̂�MCM�Ŏg����
L2�ʂ��ӂ₷�Ƃ������Ƃ����Ă��肷��B
���̋L���ɂ��ƁACoreMA�̃V���O���R�ACeleron��1�R�A�E���炵���B
����Tigerton��2�R�A���i��2�R�A�̂����Е���ׂ����̂�MCM�Ŏg����
L2�ʂ��ӂ₷�Ƃ������Ƃ����Ă��肷��B
>>208
�����Ȃ��R�A���Q���ڂ��Ă�̂��C�ɓ���A�A�C�h�����̏���d�͂�
������x2���Ⴂ���烂�[�}���^�C���ĂƂ��납�B
����780G���ڂ�MicroATX��MB���ƁAK10�A�[�L�Ń��C���������A�N�Z�X��CPU
�R�A�ƓƗ����삷�邩��A�����b�g���傫�����B
�����Ȃ��R�A���Q���ڂ��Ă�̂��C�ɓ���A�A�C�h�����̏���d�͂�
������x2���Ⴂ���烂�[�}���^�C���ĂƂ��납�B
����780G���ڂ�MicroATX��MB���ƁAK10�A�[�L�Ń��C���������A�N�Z�X��CPU
�R�A�ƓƗ����삷�邩��A�����b�g���傫�����B
>>214
> �A�C�h�����̏���d�͂�������x2���Ⴂ���烂�[�}���^�C���ĂƂ��납
�L���ɗx�炳��Ăǂ�����A�A�C�h���������������[�N�d�����ꗬ������
http://www.xbitlabs.com/articles/cpu/display/athlon-x2-7750_9.html#sect0
> �A�C�h�����̏���d�͂�������x2���Ⴂ���烂�[�}���^�C���ĂƂ��납
�L���ɗx�炳��Ăǂ�����A�A�C�h���������������[�N�d�����ꗬ������
http://www.xbitlabs.com/articles/cpu/display/athlon-x2-7750_9.html#sect0
216 �FSocket774�F2008/12/15(��) 19:26:50 ID:itvzQLxu
AMD�A����(P)���h�[�v����Si:C���ߍ��ݘc�݃V���R���Z�p�ɂ�鍂���\nMOS�g�����W�X�^�Z�p�\����
http://dubai.2ch.net/test/read.cgi/news/1229336663/
http://dubai.2ch.net/test/read.cgi/news/1229336663/
>>216
SOI�Z�p��������_�B
SOI�Z�p��������_�B
http://www.4gamer.net/games/040/G004032/20081214003/
��������7750BE��Pen4�ė����d�͂��ۂ���
ES�ƗʎY�ňႤ�Ƃ� BIOS�Ή����Ă邩�ۂ��Ƃ�
�q�}�l����낵��
��������7750BE��Pen4�ė����d�͂��ۂ���
ES�ƗʎY�ňႤ�Ƃ� BIOS�Ή����Ă邩�ۂ��Ƃ�
�q�}�l����낵��
�F����͎��b�𗭂߂���œ~�����Ȃ̂ꂷ
220 �FSocket774�F2008/12/15(��) 21:43:51 ID:nhNWCXVZ
�����Ȃ�25
�y���E�ŏ��z AMD�A25nm�v���Z�X�̊��S����ɐ����I
http://dubai.2ch.net/test/read.cgi/news/1229337008/
�y���E�ŏ��z AMD�A25nm�v���Z�X�̊��S����ɐ����I
http://dubai.2ch.net/test/read.cgi/news/1229337008/
����A�v���Z�X���i��Ő������������Ȃ�Ȃ�قǃC���p�N�g�����Ȃ�ȁB
�t���ŕ\�����Ȃ��ƁB
�t���ŕ\�����Ȃ��ƁB
222 �F,,�E�L�́M�E,,�j��-�������F2008/12/15(��) 22:11:05 ID:7/5SpZFX
32nm�̃n�[�t�m�[�h�����B
�t�ɁA�n�[�t�m�[�h�ł���Intel�ɕ����Ă���IBM�A���̖ʖڊےׂ�ł���
����ł�SRAM���쐬�����琻�i���܂ł̃T�C�N���l����Δ�������B
Intel�͍ŏ���45nm SRAM���삩��A���C���X�g���[�����i��Core 2 Duo(Wolfdale)��
�����オ��܂łɑ��2�N��v���Ă�B���ʂɏo�邾���ɂƂǂ܂���Core 2 Extreme��1�N��10�������x�B
http://journal.mycom.co.jp/news/2006/01/26/300.html
�t�ɁA�n�[�t�m�[�h�ł���Intel�ɕ����Ă���IBM�A���̖ʖڊےׂ�ł���
����ł�SRAM���쐬�����琻�i���܂ł̃T�C�N���l����Δ�������B
Intel�͍ŏ���45nm SRAM���삩��A���C���X�g���[�����i��Core 2 Duo(Wolfdale)��
�����オ��܂łɑ��2�N��v���Ă�B���ʂɏo�邾���ɂƂǂ܂���Core 2 Extreme��1�N��10�������x�B
http://journal.mycom.co.jp/news/2006/01/26/300.html
�ł��AIBM�A����22nm��SRAM�J��������8���ɂ͊��ɔ��\������̂ɁA
Intel��22nm�ɂ��Ă͒��ق����܂܂��Ă̂�EUV���݂Ȃ̂�������Ȃ�����킵�Ă�낤�ȁB
Intel��22nm�ɂ��Ă͒��ق����܂܂��Ă̂�EUV���݂Ȃ̂�������Ȃ�����킵�Ă�낤�ȁB
224 �F,,�E�L�́M�E,,�j��-�������F2008/12/15(��) 22:32:10 ID:7/5SpZFX
25nm�̓Q�[�g���Ńv���Z�X���[����22nm�炵���B���܂�B
Intel�͗ʎY��2�N���炢�O�ɁA���p�����O���x���̃T���v���\����̂��ʗႾ��
http://www.intel.co.jp/jp/technology/architecture-silicon/32nm/index.htm
http://www.intel.com/pressroom/archive/releases/20070918corp_a.htm
���NQ4���炢�ɂ�Westmere���o���炵���B
����̂͒P��IBM�A�����C�������������ƁB
�ʎY��������Ȃ���K�X
Intel�͗ʎY��2�N���炢�O�ɁA���p�����O���x���̃T���v���\����̂��ʗႾ��
http://www.intel.co.jp/jp/technology/architecture-silicon/32nm/index.htm
http://www.intel.com/pressroom/archive/releases/20070918corp_a.htm
���NQ4���炢�ɂ�Westmere���o���炵���B
����̂͒P��IBM�A�����C�������������ƁB
�ʎY��������Ȃ���K�X
225 �FSocket774�F2008/12/15(��) 22:33:09 ID:2E/FjGR6
�ˑ��̃X���ɏ����Ă��������Ǎ����SRAM�͓d�q�r�[���I���Ȃ̂ŗʎY�v���Z�X����Ȃ��炵���B
226 �F,,�E�L�́M�E,,�j��-�������F2008/12/15(��) 22:37:02 ID:7/5SpZFX
IBM�͉t�Z�I����22nm�܂ʼn���������Č����Ă邩��ˁB
�d�q�Ȃ̂ɘI���Ƃ͂��ꂢ���ɁB�@�@�@�@�@�@�@�@�܂��ȁA�X�}��
>>218
���܂��BPen4�n���ɂ���Ȃ�I
���܂��BPen4�n���ɂ���Ȃ�I
>>224
32nm��SRAM��IBM�A����Intel�Ɠ������ɂ��łɍ���Ă�B
����̔��\��FinFET����Ȃ��ăv���[�i�^�ł�22nm�܂ł���������
�Ƃ������Ƃ��d�v�B
FinFET�g���Ƒ���v�ɂȂ邩��B
32nm��SRAM��IBM�A����Intel�Ɠ������ɂ��łɍ���Ă�B
����̔��\��FinFET����Ȃ��ăv���[�i�^�ł�22nm�܂ł���������
�Ƃ������Ƃ��d�v�B
FinFET�g���Ƒ���v�ɂȂ邩��B
230 �F,,�E�L�́M�E,,�j��-�������F2008/12/16(��) 07:57:48 ID:saujXdd1
�@�@�@�@�@�@�@�@Intel�@�@�@AMD
130nm�@�@�@2002/01�@ 2002/04
90nm�@�@�@ 2004/02�@ 2004/08
65nm�@�@�@ 2006/01�@ 2006/12
45nm�@�@�@ 2007/10�@ 2008/12�@�@
32nm�@�@�@ 2009/Q3?�@2011?
>>230
�ׂ����Ƃ���ł����������BQX9650���\/������2007/11�AShanghai���\��2008/11�B
�ׂ����Ƃ���ł����������BQX9650���\/������2007/11�AShanghai���\��2008/11�B
130nm�@ 3�����x��
90nm�@ 6�����x��
65nm�@11�����x��
45nm�@14�����x��
32nm�@19�����x��
����Ȋ����ɂȂ�낤���B
90nm�@ 6�����x��
65nm�@11�����x��
45nm�@14�����x��
32nm�@19�����x��
����Ȋ����ɂȂ�낤���B
Intel��32nm��2010�N���Ęb������ȁB
�ʎY�J�n��2009�N��4�l�����ŁB
Intel���g���j�R���̘I�����u�̏o�ׂ���4�l���������Ȃ��B
�ʎY�J�n��2009�N��4�l�����ŁB
Intel���g���j�R���̘I�����u�̏o�ׂ���4�l���������Ȃ��B
�܁A��[�v���Z�X�����������̂���Ȃ�����I
���v�����������������I���v��������[�ԁI
���v�����������������I���v��������[�ԁI
�V�����v���Z�X�ō��ɂ͐V�����H�ꂪ�K�v
�ŐV�����H����ɂ͍H���ɂ����S���Ƃ�����
�C���e���͎��ʂقNj������邩��H����̂��ŋ���ɂȂ��Ăނ���y�B
AMD�͍H����܂��邾���̋����Ȃ�����Ȃ��Ȃ��ʎY�ɂ�������Ȃ��B
���������x���ł͂���قǒx��ĂȂ��̂�
���Y�ōa����������̂͂������������R������
�ŐV�����H����ɂ͍H���ɂ����S���Ƃ�����
�C���e���͎��ʂقNj������邩��H����̂��ŋ���ɂȂ��Ăނ���y�B
AMD�͍H����܂��邾���̋����Ȃ�����Ȃ��Ȃ��ʎY�ɂ�������Ȃ��B
���������x���ł͂���قǒx��ĂȂ��̂�
���Y�ōa����������̂͂������������R������
����Ȃ��̂����Ȃ�x86�r�W�l�X��߂��? �Ƃ����̂������B
AMD����ɂ͂����b�ɂȂ��Ă܂��������T�[�Z����������
AMD����������
��
����������Intel��CPU�������ǂ��Ȃ�
��
PC�������Ȃ�
��
����҃E�}�[
AMD����ɂ͂����b�ɂȂ��Ă܂��������T�[�Z����������
AMD����������
��
����������Intel��CPU�������ǂ��Ȃ�
��
PC�������Ȃ�
��
����҃E�}�[
�������{���ɁA������Z�p��Intel�̕�(����)���痈��悤�ɂȂ���������˂��B
Intel�̃|�W�V�����ł͏o���Ȃ����������Ƃ���͂��Ȃ��ǁB
http://www.eetimes.jp/article/22586/
>�@���̂ق�ISSCC 2009�ł́A�����\�f�W�^���E�`�b�v�������Z�b�V����
> �uMicroprocessor Technologies�v�ɂ����āA��Intel�Ђ�23�����̃g��
> ���W�X�^���W�ς���8�R�A�̃T�[�o�[����x86�`�b�v�\����i�u���ԍ�
> 3.1�j�B����A���̃Z�b�V�����ō̑����ꂽ8�{�̘_���̂���4�{��Intel��
> ����̂��̂ŁA������Ƃł����Advanced Micro Devices�iAMD�j�Ђ��
> IBM�ЁASPARC�v���Z�b�T�������J�������x�m�ʂƕ�Sun Microsystems�Ђ�
> �ǂ���̘_����1�{���Ȃ��B
Intel�̃|�W�V�����ł͏o���Ȃ����������Ƃ���͂��Ȃ��ǁB
http://www.eetimes.jp/article/22586/
>�@���̂ق�ISSCC 2009�ł́A�����\�f�W�^���E�`�b�v�������Z�b�V����
> �uMicroprocessor Technologies�v�ɂ����āA��Intel�Ђ�23�����̃g��
> ���W�X�^���W�ς���8�R�A�̃T�[�o�[����x86�`�b�v�\����i�u���ԍ�
> 3.1�j�B����A���̃Z�b�V�����ō̑����ꂽ8�{�̘_���̂���4�{��Intel��
> ����̂��̂ŁA������Ƃł����Advanced Micro Devices�iAMD�j�Ђ��
> IBM�ЁASPARC�v���Z�b�T�������J�������x�m�ʂƕ�Sun Microsystems�Ђ�
> �ǂ���̘_����1�{���Ȃ��B
>>237
�����⎟���㐻�i�ɗ��ޕ������邩��A��������Ɣ��\���Ȃ��ꍇ�������B
�t��������Intel�ɂ͗Ⴆ�ǐ��҂��łĂ��A�R�ł����i������Ƃ��l������B
�����⎟���㐻�i�ɗ��ޕ������邩��A��������Ɣ��\���Ȃ��ꍇ�������B
�t��������Intel�ɂ͗Ⴆ�ǐ��҂��łĂ��A�R�ł����i������Ƃ��l������B
����ʐM�݂����ȌQ�Y�����ȕ���͂Ƃ�����
�����̊֘A�͍ō��@�����̋Z�p�̂Ԃ�����������
��������Ɣ��\�o���Ȃ����Ă̂����邩���B
�����ɍ����\�����̗̂A�o�������Ă邭�炢����
�����̊֘A�͍ō��@�����̋Z�p�̂Ԃ�����������
��������Ɣ��\�o���Ȃ����Ă̂����邩���B
�����ɍ����\�����̗̂A�o�������Ă邭�炢����
�C���e�������ł��C�X���G���͘_�����\�ɏ��ɓI����B
�A�C�f�A�𓐂܂��\�������邩�玩�����������ŖفX����Ă������������ė��R�ŁB
�A�C�f�A�𓐂܂��\�������邩�玩�����������ŖفX����Ă������������ė��R�ŁB
�v���O��������킩�邪ISSCC�̒���MicroprocessorTechnologies��
29�Z�b�V�����̂���1�Z�b�V�����ɂ����Ȃ��B
CPU�̋Z�p�ɂ��ĂȂ�Β��ڂ��ׂ���c��ISSCC�ł͂Ȃ��B
29�Z�b�V�����̂���1�Z�b�V�����ɂ����Ȃ��B
CPU�̋Z�p�ɂ��ĂȂ�Β��ڂ��ׂ���c��ISSCC�ł͂Ȃ��B
>>237
paper�Z�b�V��������Ȃ�����Multi-Domain Processors Forums�ł�
IBM�AARM�AAMD�A���l�T�X���b����݂�������
paper�Z�b�V��������Ȃ�����Multi-Domain Processors Forums�ł�
IBM�AARM�AAMD�A���l�T�X���b����݂�������
�ǂ��܂ŏ��������Ă����H
�i�m���[�g����肳��ɏ��������Ă����̂��H
�i�m���[�g����肳��ɏ��������Ă����̂��H
32nm����22nm�܂ł͌����Ă��Ă���ˁB���łɌ��q���̌��������Ȃ��w��
�����Ă���炵���B
http://ascii24.com/news/i/tech/article/2001/06/12/626899-000.html
2007�N��45nm�v���Z�X��20GHz��CPU�A�ƌ����Ă����̂�2001�N��130nm�v���Z�X�̎���
Intel������A3�����̂��Ƃ͂悭�킩��Ȃ��悤���B
���[�A�̖@�������q�̕ǂ̑O�ɔs��āA22nm�Ŕ������ł��~�߂ɂȂ����Ƃ��Ă��A
�ʂɂ��������͂Ȃ��B����������A�����ł܂��Q�[���̃��[�������Z�b�g����A
������Intel�ɒǏ]�ł��Ȃ��������[�J�ɂ��`�����X���^������B
�����Ă���炵���B
http://ascii24.com/news/i/tech/article/2001/06/12/626899-000.html
2007�N��45nm�v���Z�X��20GHz��CPU�A�ƌ����Ă����̂�2001�N��130nm�v���Z�X�̎���
Intel������A3�����̂��Ƃ͂悭�킩��Ȃ��悤���B
���[�A�̖@�������q�̕ǂ̑O�ɔs��āA22nm�Ŕ������ł��~�߂ɂȂ����Ƃ��Ă��A
�ʂɂ��������͂Ȃ��B����������A�����ł܂��Q�[���̃��[�������Z�b�g����A
������Intel�ɒǏ]�ł��Ȃ��������[�J�ɂ��`�����X���^������B
�撣���10nm�܂ōs�����ĂȂ��������H�@�ł�����ȉ��̓������낤�ˁB
�u���q�̑傫�������Ɂv�Ƃ��킯�킩��E������B
����ȉ��͉����ʂ̎�i���K�v�ɂȂ��Ă���B�ʎq�g�����W�X�^�Ƃ��B
���łȂ��Ƃ��F�X����Ă����͂��B
�u���q�̑傫�������Ɂv�Ƃ��킯�킩��E������B
����ȉ��͉����ʂ̎�i���K�v�ɂȂ��Ă���B�ʎq�g�����W�X�^�Ƃ��B
���łȂ��Ƃ��F�X����Ă����͂��B
�������X�g�b�v���Ă��ޗ��̕ύX�Ƃ����肪�c���Ă���
SiC��GaN�A�ʂĂ̓_�C�A�����h�܂�
SiC��GaN�A�ʂĂ̓_�C�A�����h�܂�
���E�܂ŒB�������x��LSI�Ɋւ��Ă͍ޗ���ς����͖]�ݔ�����B
�P�̂��牻�����ɂȂ�ƒP�����̌��ז��x���������Փx���ʎ����B
���\���㕝����Փx�㏸�R�X�g�ɂ͑S�R������Ȃ��B
�_�C�������h�͒P�̂ŁA���q�Ԋu��Si��0.66�{�ƁA���͓I����
CVD�ł������Ȃ�����n�����ė�₹����Si�Ƃ͕ʐ��E�B
����̍ޗ����i���E������LSI�ł͂Ȃ��j���̕���ł͊��邪�B
�P�̂��牻�����ɂȂ�ƒP�����̌��ז��x���������Փx���ʎ����B
���\���㕝����Փx�㏸�R�X�g�ɂ͑S�R������Ȃ��B
�_�C�������h�͒P�̂ŁA���q�Ԋu��Si��0.66�{�ƁA���͓I����
CVD�ł������Ȃ�����n�����ė�₹����Si�Ƃ͕ʐ��E�B
����̍ޗ����i���E������LSI�ł͂Ȃ��j���̕���ł͊��邪�B
(*߄t�)y-��~~�ޗ��Ƀ_�C�������h�Ƃ��g���悤�ɂȂ��
�Z������1��20���~�Ƃ��̐��E������͂���Ŗ����������B
�Z������1��20���~�Ƃ��̐��E������͂���Ŗ����������B
�u�����A���J�b�g��CPU�_�C��������l�ɂȂ��ł��ˁB������܂��B
CNT������I
>>240
�C�X���G�����̃A�C�f�A�ł��A�����J�̃T�u�}�����ɂł���̂��ȁH
�C�X���G�����̃A�C�f�A�ł��A�����J�̃T�u�}�����ɂł���̂��ȁH
>>250
����u���[�E�H�[�^�[�H
����u���[�E�H�[�^�[�H
254 �FSocket774�F2008/12/16(��) 19:00:19 ID:u3t7HTBn
>>245
����̓v���Z�X�̖��Ƃ������}�[�P�b�g�̖�肾�����C��
����̓v���Z�X�̖��Ƃ������}�[�P�b�g�̖�肾�����C��
>>230
���߁[�̓v���Z�X�̒m���ˁ[����ق��Ă�
���߁[�̓v���Z�X�̒m���ˁ[����ق��Ă�
>>246
�u�����͒�R�����邩����ɂ��邵���Ȃ��v
�炵���B10nm�Ƃ��̐��E���Ɣz���̗����������ɂȂ邩��
������������ĒZ�k����Ƃ��Ȃ�Ƃ�
�u�����͒�R�����邩����ɂ��邵���Ȃ��v
�炵���B10nm�Ƃ��̐��E���Ɣz���̗����������ɂȂ邩��
������������ĒZ�k����Ƃ��Ȃ�Ƃ�
>>256
�g�����d���ʼn��Z���W�X�^�̋��L�Ȃ��ł�����Ă��ƁH
�g�����d���ʼn��Z���W�X�^�̋��L�Ȃ��ł�����Ă��ƁH
>>258
�o����Ȃ��邾�낤�ˁB
�o����Ȃ��邾�낤�ˁB
http://www.anandtech.com/weblog/showpost.aspx?i=532
SAP���ĉ��H
Nehalem-2Way��Barcelona-4Way���Ԃ��������Ă邪�B
SAP���ĉ��H
Nehalem-2Way��Barcelona-4Way���Ԃ��������Ă邪�B
261 �F,,�E�L�́M�E,,�j��-�������F2008/12/16(��) 22:59:12 ID:saujXdd1
IBM��ގЂ����G���W�j�A�̍���������\�t�g�E�F�A���
���̐����̓r�W�l�X�\�����[�V�����p�̓����x���`�݂����Ȃ��Ǝv�������B
���̐����̓r�W�l�X�\�����[�V�����p�̓����x���`�݂����Ȃ��Ǝv�������B
262 �FSocket774�F2008/12/16(��) 23:00:31 ID:u3t7HTBn
���i�̍ɊǗ��������������C������
��\�I�ȃT�[�o�[�x���`�̈��
��\�I�ȃT�[�o�[�x���`�̈��
263 �FSocket774�F2008/12/16(��) 23:04:41 ID:fwWrxzgE
>260
Dunnington-4Way��Nehalem-2Way���قړ��X�R�A����
Dunnington�͂Ȃ�̂��߂ɂ킴�킴�J���������킩����
Dunnington�͂Ȃ�̂��߂ɂ킴�킴�J���������킩����
265 �FSocket774�F2008/12/16(��) 23:05:46 ID:fwWrxzgE
�悭�l������
���q�Ȃ��0.1nm�Ȃ̂�
40nm���32nm�Ȃ��
�l�ނ�����������Ă����̈�Ȃ̂���
���q�Ȃ��0.1nm�Ȃ̂�
40nm���32nm�Ȃ��
�l�ނ�����������Ă����̈�Ȃ̂���
267 �FSocket774�F2008/12/16(��) 23:25:16 ID:u3t7HTBn
�O�O����
ttp://primeserver.fujitsu.com/sparcenterprise/news/article/08/0822/
>�e�x���`�}�[�N�e�X�g�ɂ���
>2�K�wSAP SD
>
>SD (Sales & Distribution�j�́ASAP R/3�Ɋ܂܂��I�����C���g�����U�N�V�����n�̔̔��Ǘ��A�v���P�[�V�����ł��B
>�x���`�}�[�N�ł́A����2�b�ȓ��̃��X�|���X���ێ�/�p�������u�����A�N�Z�X���[�U���v���J�E���g���܂��B
>SAP SD�x���`�}�[�N�̓r�W�l�X�A�v���P�[�V�����̐��\���v������̂ɍœK�ȃx���`�}�[�N�ł��B
>2�K�wSAP SD�x���`�}�[�N�e�X�g�Ɋւ���ڍׂ́ASAP Standard Application Benchmarks���������������B
ttp://www.sap.com/solutions/benchmark/sd.epx
>The Sales and Distribution (SD) Benchmark covers a sell-from-stock scenario,
> which includes the creation of a customer order with five line items and the corresponding delivery with subsequent goods movement and invoicing.
>It consists of the following transactions:
>�@�ECreate an order with five line items. (VA01)
>�@�ECreate a delivery for this order. (VL01N)
>�@�EDisplay the customer order. (VA03)
>�@�EChange the delivery (VL02N) and post goods issue.
>�@�EList 40 orders for one sold-to party. (VA05)
>�@�ECreate an invoice. (VF01)
>
>Note: Each benchmark user has his or her own master data, such as material, vendor, or customer master data to avoid data-locking situations.
ttp://primeserver.fujitsu.com/sparcenterprise/news/article/08/0822/
>�e�x���`�}�[�N�e�X�g�ɂ���
>2�K�wSAP SD
>
>SD (Sales & Distribution�j�́ASAP R/3�Ɋ܂܂��I�����C���g�����U�N�V�����n�̔̔��Ǘ��A�v���P�[�V�����ł��B
>�x���`�}�[�N�ł́A����2�b�ȓ��̃��X�|���X���ێ�/�p�������u�����A�N�Z�X���[�U���v���J�E���g���܂��B
>SAP SD�x���`�}�[�N�̓r�W�l�X�A�v���P�[�V�����̐��\���v������̂ɍœK�ȃx���`�}�[�N�ł��B
>2�K�wSAP SD�x���`�}�[�N�e�X�g�Ɋւ���ڍׂ́ASAP Standard Application Benchmarks���������������B
ttp://www.sap.com/solutions/benchmark/sd.epx
>The Sales and Distribution (SD) Benchmark covers a sell-from-stock scenario,
> which includes the creation of a customer order with five line items and the corresponding delivery with subsequent goods movement and invoicing.
>It consists of the following transactions:
>�@�ECreate an order with five line items. (VA01)
>�@�ECreate a delivery for this order. (VL01N)
>�@�EDisplay the customer order. (VA03)
>�@�EChange the delivery (VL02N) and post goods issue.
>�@�EList 40 orders for one sold-to party. (VA05)
>�@�ECreate an invoice. (VF01)
>
>Note: Each benchmark user has his or her own master data, such as material, vendor, or customer master data to avoid data-locking situations.
269 �FSocket774�F2008/12/16(��) 23:45:55 ID:u3t7HTBn
Aceshardware�ŃX�g���[�W��SSD�g���Ă��˂��H�Ƃ������Ă�ȁB
SPECjbb�܂��[�H(����
SPECjbb�܂��[�H(����
>>266
���̋^��̓^�C�~���O��20�N���炢�x����Ȃ����ȁB
1980�N��I����STM�i�����g���l���������j�̒T�j���g����
���q�����ׂ�ꂽ���Ȃ�^�C�����[
���̋^��̓^�C�~���O��20�N���炢�x����Ȃ����ȁB
1980�N��I����STM�i�����g���l���������j�̒T�j���g����
���q�����ׂ�ꂽ���Ȃ�^�C�����[
>>260
Core i7�̑����ǂ���Intel��SSD�����͂Ȃ낤�Ɛ���
Core i7�̑����ǂ���Intel��SSD�����͂Ȃ낤�Ɛ���
272 �FSocket774�F2008/12/17(��) 01:13:53 ID:loPaWed/
>>260�̃O���t�A�x�m�ʃW�[�����X�̃X�R�A��HTT OF�ɒ�������Ă�B
HTT��5.7%�������\��p���Ȃ��̂͂�����ƈӊO�B
HTT��5.7%�������\��p���Ȃ��̂͂�����ƈӊO�B
���̂܂܂ǂ�ǂ������Ȃ���10^-10m�܂ł������������ǂ��Ȃ�́H
�ގ��ς��ăJ�[�{���Ƃ��ɂ����Ƃ�������
���q��̒P�ʂ܂ł��������Ȃ����B����
���̌�ǂ��Ȃ�́H���Ċ����Ȃ̂���
�܂��A�Ƃ肠�����̓J�[�{���łb�o�t���Ȃ��Ǝ��Ȃ����
���q��̒P�ʂ܂ł��������Ȃ����B����
���̌�ǂ��Ȃ�́H���Ċ����Ȃ̂���
�܂��A�Ƃ肠�����̓J�[�{���łb�o�t���Ȃ��Ǝ��Ȃ����
Phenom II X4 940(3.0GHz)�̃x���`������Ă��܂�
Zalman CNPS9700 NT��Biostar TA790GX A2+�Ƃ̑g�ݍ��킹��@4.2GHz�ň��肵���Ə�����Ă��܂����A���ۂɃx���`��������̂�ASUS M3A32-MVP Deluxe���g���Ă�@3.8GHz�ƂȂ��Ă��܂�
��i��@3.0GHz�̑��A��r�ΏۂƂ���Phenom X4 9950(2.6GHz)�̃X�R�A���f�ڂ���Ă��܂�
�p�t�H�[�}���X������ƁAX4 940��X4 9950����20�`25%���x�̃p�t�H�[�}���X�A�b�v�������܂���
@3.8GHz�ł͏����ɃX�R�A���L�тĂ���AX4 9950���30�`50%���x�͌��サ�Ă��܂���
Zalman 9700NT���g���Ă̔��M����ł́A�A�C�h������5�����x�A���[�h����@3.0GHz��7�����x�A@3.8GHz��17�����x�����Ȃ��Ă��܂���
9700NT�̗�p�\�͂��������Ƃ������Ă��A@3.8GHz�ł��\���}�����Ă��܂���
http://blog.livedoor.jp/amd646464/
���ꂻ��
Zalman CNPS9700 NT��Biostar TA790GX A2+�Ƃ̑g�ݍ��킹��@4.2GHz�ň��肵���Ə�����Ă��܂����A���ۂɃx���`��������̂�ASUS M3A32-MVP Deluxe���g���Ă�@3.8GHz�ƂȂ��Ă��܂�
��i��@3.0GHz�̑��A��r�ΏۂƂ���Phenom X4 9950(2.6GHz)�̃X�R�A���f�ڂ���Ă��܂�
�p�t�H�[�}���X������ƁAX4 940��X4 9950����20�`25%���x�̃p�t�H�[�}���X�A�b�v�������܂���
@3.8GHz�ł͏����ɃX�R�A���L�тĂ���AX4 9950���30�`50%���x�͌��サ�Ă��܂���
Zalman 9700NT���g���Ă̔��M����ł́A�A�C�h������5�����x�A���[�h����@3.0GHz��7�����x�A@3.8GHz��17�����x�����Ȃ��Ă��܂���
9700NT�̗�p�\�͂��������Ƃ������Ă��A@3.8GHz�ł��\���}�����Ă��܂���
http://blog.livedoor.jp/amd646464/
���ꂻ��
276 �FSocket774�F2008/12/17(��) 07:28:45 ID:GLKSpDn7
http://slashdot.jp/developers/comments.pl?sid=430428&threshold=1&commentsort=0&mode=nested&cid=1473471
�g���b�v�����c�[���u�܂��A�҂ĉ��B�v(Radeon�Ή��j
�ǂ����̕��c�q�Ƃ̓��x�����Ⴄ�H
�g���b�v�����c�[���u�܂��A�҂ĉ��B�v(Radeon�Ή��j
�ǂ����̕��c�q�Ƃ̓��x�����Ⴄ�H
>>274
���x�͌��q�̕\�ʍ���ĉ�H����B
���x�͌��q�̕\�ʍ���ĉ�H����B
�f���q�������Đ��E�ł��ˁH
279 �F,,�E�L�́M�E,,�j��-�������F2008/12/17(��) 09:16:25 ID:bvOffjeK
�ǂ����̕��c�q��John the Ripper�{�ƂɃR�[�h���R�~�b�g���܂�����
280 �F,,�E�L�́M�E,,�j��-�������F2008/12/17(��) 09:21:59 ID:bvOffjeK
����CUDA�����G��Ȃ��������܂��BNVIDIA�̍L��ɕ����Ă��������B
�S�z����ȁA���̐l���c�q�������Ă����͂����ƒc�q�̋Z�ʂ͔F�߂Ă邺
282 �FSocket774�F2008/12/17(��) 10:19:33 ID:KyzOl0Qz
Turion�~4�o����
�Z�ʂƐl���͂��܂�W�Ȃ������
286 �F,,�E�L�́M�E,,�j��-�������F2008/12/17(��) 13:12:04 ID:bvOffjeK
�����A���Ƃ����
�p����������
�p����������
�p���������Ȃ�A�P�[�E�E�E�E�E�E�c�q��H�ׂ��������Ȃ��́B
288 �F,,�E�L�́M�E,,�j��-�������F2008/12/17(��) 13:25:35 ID:bvOffjeK
CUDA�́E�E�E����������B
NVIDIA���̐S�ȂƂ���̎d�l���J���Ă���Ȃ��B
�uAMD�ɕ����Ă��ǂ���ł����H�v�Ƃ����胁�[���ł��ł��Ă݂邩�H
NVIDIA���̐S�ȂƂ���̎d�l���J���Ă���Ȃ��B
�uAMD�ɕ����Ă��ǂ���ł����H�v�Ƃ����胁�[���ł��ł��Ă݂邩�H
CUDA Zone��Forum�̊Y���X���ւ̃|�C���^���ڂ��
290 �F,,�E�L�́M�E,,�j��-�������F2008/12/17(��) 14:29:07 ID:fhfGTO/O
�g��
�����̊��Ⴂ��m���s���������Łu�d�l����������! ����ł̓R�[�h��������
��!�v�ƉΕa��v���O���}�͎��݂���B�Ă����\�����BCUDA Zone��Forum�͐���
��topic �������ăA�N�e�B�u�Ɍ����邩��A�����Ŗ��ӎ����f�x���b�p�Ԃ�
���L����ĂȂ��Ƃ�����A����͂��Ǝ}�t���߂Șb�ł͂Ȃ��̂���? �ƁB
�܂������{�ʂ̖쎟�n�̘b�Ȃ�ŕ��������Ă��[�����B
��!�v�ƉΕa��v���O���}�͎��݂���B�Ă����\�����BCUDA Zone��Forum�͐���
��topic �������ăA�N�e�B�u�Ɍ����邩��A�����Ŗ��ӎ����f�x���b�p�Ԃ�
���L����ĂȂ��Ƃ�����A����͂��Ǝ}�t���߂Șb�ł͂Ȃ��̂���? �ƁB
�܂������{�ʂ̖쎟�n�̘b�Ȃ�ŕ��������Ă��[�����B
294 �F,,�E�L�́M�E,,�j��-�������F2008/12/17(��) 14:54:15 ID:fhfGTO/O
���[��I�O��B
�ʂɋ@�\�I�ɕs���͂Ȃ������\�ʂŖ�肪�����Ă��ȁB
�œK���̎肪����ɕK�v���������ISA�̎����n�����ėv�����Ă�킯��B
�e���߂̃��C�e���V�E�X���[�v�b�g�ꗗ�݂����Ȃ́B
Intel��AMD�͓�����O�Ɍ��J���Ă鎑����B
�ł��Ȃ����Č����́B
���̂��߂�VIP�ҋ�����B
�ʂɋ@�\�I�ɕs���͂Ȃ������\�ʂŖ�肪�����Ă��ȁB
�œK���̎肪����ɕK�v���������ISA�̎����n�����ėv�����Ă�킯��B
�e���߂̃��C�e���V�E�X���[�v�b�g�ꗗ�݂����Ȃ́B
Intel��AMD�͓�����O�Ɍ��J���Ă鎑����B
�ł��Ȃ����Č����́B
���̂��߂�VIP�ҋ�����B
�Z�c�R�A����VIP��Ȃ��AVIPPER�ҋ���
����/IBM/AMD�A���E�ŏ��̗��̍\���g�����W�X�^SRAM�Z�����J��
http://pc.watch.impress.co.jp/docs/2008/1217/sram.htm
�v���[�i�^��������Ȃ�FinFET����
�����ƊJ�����Ă��悤�ň��S�B
HKMG��SRAM�Z���܂ō��Ă�̂͐����ȁB
http://pc.watch.impress.co.jp/docs/2008/1217/sram.htm
�v���[�i�^��������Ȃ�FinFET����
�����ƊJ�����Ă��悤�ň��S�B
HKMG��SRAM�Z���܂ō��Ă�̂͐����ȁB
������IBM
>>297
�\�z�ʂ�̃��X�������āA����ł��W���[�X��������
�\�z�ʂ�̃��X�������āA����ł��W���[�X��������
299 �F,,�E�L�́M�E,,�j��-�������F2008/12/17(��) 18:07:52 ID:bvOffjeK
���₳��B
�Ȃ���SSE5��pcmov�����͊��҂��Ă�B
�Ԃ����ႯIntel�ɍ̗p�����������炢�̗ǂ����߂��B
�܂�Intel�̂��Ƃ�����ǂ����P�`�Ȏ�������낤����
�Ȃ���SSE5��pcmov�����͊��҂��Ă�B
�Ԃ����ႯIntel�ɍ̗p�����������炢�̗ǂ����߂��B
�܂�Intel�̂��Ƃ�����ǂ����P�`�Ȏ�������낤����
>>281���e�w���G��
http://hissi.org/read.php/jisaku/20081217/WUlkQngvRGs.html
�K���ɒc�q�Ɍ}�����Ȃ��Ă�����A�e�w��
�c�q�ɂ͐X��N���x�����Č����Ă����w
>299 ���O�F,,�E�L�́M�E,,�j��[sage] ���e���F2008/08/19(��) 21:44:42 ID:wyv3H8Wc
>�������̉��i������Ă鎩�o�͈ꉞ����ȁB���S�����B
>�܂��m����SIMD��SIMM�̐l�Ɠ����x��
>�X�ØN��IT�ɂ��Č�邭�炢�ɕ������l���Ȃ��B
�uSIMD��SIMM�̐l�v���G�����e�w
http://hissi.org/read.php/jisaku/20081217/WUlkQngvRGs.html
�K���ɒc�q�Ɍ}�����Ȃ��Ă�����A�e�w��
�c�q�ɂ͐X��N���x�����Č����Ă����w
>299 ���O�F,,�E�L�́M�E,,�j��[sage] ���e���F2008/08/19(��) 21:44:42 ID:wyv3H8Wc
>�������̉��i������Ă鎩�o�͈ꉞ����ȁB���S�����B
>�܂��m����SIMD��SIMM�̐l�Ɠ����x��
>�X�ØN��IT�ɂ��Č�邭�炢�ɕ������l���Ȃ��B
�uSIMD��SIMM�̐l�v���G�����e�w
301 �FSocket774�F2008/12/17(��) 22:29:04 ID:JR9BBKz1
�@�@�@�@�@�@�@�@�@�@�@�@ �@ ���Q
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�q�q�q�@�R
�@�@�@�@�@�@�Q�Q�Q_�@�@�@�q���@�@}
�@�@�@�@ �^�܁@�@�܁_�@�@ |�@�@ |
�@�@�@�^�i ���j �@�i���j�_�@ !�@�@ !
�@ �^ :::::�܁i__�l__�j��:::::�_|�@�@ l
�@ |�@�@�@�@�@|r��-| �@ �@ �@ | �@�^�@�������E��
�@ �_ �@ �@�@�M �['�L �@ �@ �^�^
�@�@/�@�Q�Q�@ �@�@�@�@�@�@/
�@�@(�Q�Q�Q�j�@�@�@�@�@�@/
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�q�q�q�@�R
�@�@�@�@�@�@�Q�Q�Q_�@�@�@�q���@�@}
�@�@�@�@ �^�܁@�@�܁_�@�@ |�@�@ |
�@�@�@�^�i ���j �@�i���j�_�@ !�@�@ !
�@ �^ :::::�܁i__�l__�j��:::::�_|�@�@ l
�@ |�@�@�@�@�@|r��-| �@ �@ �@ | �@�^�@�������E��
�@ �_ �@ �@�@�M �['�L �@ �@ �^�^
�@�@/�@�Q�Q�@ �@�@�@�@�@�@/
�@�@(�Q�Q�Q�j�@�@�@�@�@�@/
http://oshiete1.goo.ne.jp/qa4563925.html
���������҂���Phenom II�Ƃ����I���͂Ȃ��̂ł��傤���B
Core i7�̊���薾�炩�Ɉ����ACore2�̊����m���ɐ��\�̏���������Ȃ�I�����ł��B
���s��SocketAM2+�Ή�M/B��SocketAM3�Ή�CPU�ɑΉ��ł��܂��B
SocketAM3�̎���Socket��2011�N�\��ł��B
�������ƃR�X�g�p�t�H�[�}���X�𗼗�������ŗǂ̑I���ł��B
Intel�͗��N�㔼�ɂ�������Socket�������܂��B
LGA775��2011�N�܂ʼn��������Ƃ�����������Ă��܂��B
Intel��I������ƍň��㒆����Socket���قȂ�Ƃ����ɂȂ�\��������܂��B
AMD��Phenom II�̏�ʃN���X��I�����A2�N���2011�N��Socket���ς��O�ɂ��̎��_��CPU���������A��1�N���x��������Ƃ���������3�N���xM/B���������邱�Ƃ��\�ł��傤�B
���������҂���Phenom II�Ƃ����I���͂Ȃ��̂ł��傤���B
Core i7�̊���薾�炩�Ɉ����ACore2�̊����m���ɐ��\�̏���������Ȃ�I�����ł��B
���s��SocketAM2+�Ή�M/B��SocketAM3�Ή�CPU�ɑΉ��ł��܂��B
SocketAM3�̎���Socket��2011�N�\��ł��B
�������ƃR�X�g�p�t�H�[�}���X�𗼗�������ŗǂ̑I���ł��B
Intel�͗��N�㔼�ɂ�������Socket�������܂��B
LGA775��2011�N�܂ʼn��������Ƃ�����������Ă��܂��B
Intel��I������ƍň��㒆����Socket���قȂ�Ƃ����ɂȂ�\��������܂��B
AMD��Phenom II�̏�ʃN���X��I�����A2�N���2011�N��Socket���ς��O�ɂ��̎��_��CPU���������A��1�N���x��������Ƃ���������3�N���xM/B���������邱�Ƃ��\�ł��傤�B
303 �FSocket774�F2008/12/18(��) 02:20:33 ID:kUmfLEmx
TDP35W��Turion�~4���Ȃ������܂�
���݂����ɒP�̂œ��삷��R�A���W�ς����Ȃ���
�����̉��Z����̃n�[�h�E�F�A�X���b�h�ŋ��L�����
���̎��̃��[�h�ɉ����ăV���O���X���b�h�̃p�t�H�[�}���X�ɂ�
�}���`�X���b�h�̃X���[�v�b�g�ɂ��U���
���SCMT�ȃA�[�L�e�N�`���ɂȂ�˂��B
Bulldozer���u�X���b�h��Z��������v�Ȃ�Ęb��������
������Ƃ���Ȏ���ϑz�����B
�����̉��Z����̃n�[�h�E�F�A�X���b�h�ŋ��L�����
���̎��̃��[�h�ɉ����ăV���O���X���b�h�̃p�t�H�[�}���X�ɂ�
�}���`�X���b�h�̃X���[�v�b�g�ɂ��U���
���SCMT�ȃA�[�L�e�N�`���ɂȂ�˂��B
Bulldozer���u�X���b�h��Z��������v�Ȃ�Ęb��������
������Ƃ���Ȏ���ϑz�����B
���A���h�����Ȃ牽�������̂ł����H�N���ɑg��ł��B�}�U�{�������Ă��������B
307 �FSocket774�F2008/12/18(��) 16:39:25 ID:tq1lPTYE
�R�A���m��SOAP�ŒʐM����̂�
>>304
�܂��X�P�W���[�����O���j�b�g����ς��ȁB
���s���j�b�g��10�@���������Ƃ��āA�ˑ��W�肵�Ċ���U��@�\���������ɂ����B
�Ă��o����Ȃ�Athlon�͐������j�b�g��4�@�ȏ�ɑ����Ă������낤�E�E�E
�܂��X�P�W���[�����O���j�b�g����ς��ȁB
���s���j�b�g��10�@���������Ƃ��āA�ˑ��W�肵�Ċ���U��@�\���������ɂ����B
�Ă��o����Ȃ�Athlon�͐������j�b�g��4�@�ȏ�ɑ����Ă������낤�E�E�E
309 �F,,�E�L�́M�E,,�j��-�������F2008/12/18(��) 20:46:29 ID:uSOJtl0/
����
�����炱���uSSE5��GPU�Ŏ��s�v���Č������Ƃ�
�����n��������Ďv������
AMD��CoreMA�Ɠ�����3ALU�{L/S��4issue���炢�ɂ͑��₵�Ă����Ǝv��
�����炱���uSSE5��GPU�Ŏ��s�v���Č������Ƃ�
�����n��������Ďv������
AMD��CoreMA�Ɠ�����3ALU�{L/S��4issue���炢�ɂ͑��₵�Ă����Ǝv��
����ȃx���`�Ԓ��͂���܂���
��AMD Shanghai�n
. $989�@2.7GHz�@Opteron 2384
. $873�@2.6GHz�@Opteron 2382
. $698�@2.5GHz�@Opteron 2380
��$300 3.0GHz�@PhenomII X4 940BE
��$250 2.8GHz�@PhenomII X4 920
��AMD Barcelona�n
$1165�@2.5GHz�@Opteron 2360SE
. $873�@2.4GHz�@Opteron 2358SE
. $690�@2.3GHz�@Opteron 2356
. $174�@2.6GHz�@Phenom X4 9950BE
. $154�@2.4GHz�@Phenom X4 9750
��Intel Nehalem�n
$1600�@3.20GHz�@Xeon EP W5580
$1386�@2.93GHz�@Xeon EP X5570
. $958�@2.66GHz�@Xeon EP X5550
. $999�@3.20GHz�@Core i7 965
. $562�@2.93GHz�@Core i7 940
. $284�@2.66GHz�@Core i7 920
��Intel Harpertown�n
$1493�@3.40GHz�@Xeon X5492
$1279�@3.20GHz�@Xeon X5482
. $915�@3.00GHz�@Xeon E5450
. $690�@2.83GHz�@Xeon E5440
$1399�@3.20GHz�@Core2 Quad QX9770
. $530�@3.00GHz�@Core2 Quad Q9650
. $316�@2.83GHz�@Core2 Quad Q9550
. $989�@2.7GHz�@Opteron 2384
. $873�@2.6GHz�@Opteron 2382
. $698�@2.5GHz�@Opteron 2380
��$300 3.0GHz�@PhenomII X4 940BE
��$250 2.8GHz�@PhenomII X4 920
��AMD Barcelona�n
$1165�@2.5GHz�@Opteron 2360SE
. $873�@2.4GHz�@Opteron 2358SE
. $690�@2.3GHz�@Opteron 2356
. $174�@2.6GHz�@Phenom X4 9950BE
. $154�@2.4GHz�@Phenom X4 9750
��Intel Nehalem�n
$1600�@3.20GHz�@Xeon EP W5580
$1386�@2.93GHz�@Xeon EP X5570
. $958�@2.66GHz�@Xeon EP X5550
. $999�@3.20GHz�@Core i7 965
. $562�@2.93GHz�@Core i7 940
. $284�@2.66GHz�@Core i7 920
��Intel Harpertown�n
$1493�@3.40GHz�@Xeon X5492
$1279�@3.20GHz�@Xeon X5482
. $915�@3.00GHz�@Xeon E5450
. $690�@2.83GHz�@Xeon E5440
$1399�@3.20GHz�@Core2 Quad QX9770
. $530�@3.00GHz�@Core2 Quad Q9650
. $316�@2.83GHz�@Core2 Quad Q9550
>>311
Opteron�̉��i�ݒ�͂ڂ������肷���B
Intel�����X�y�b�N��1WAY�p��2WAY�p�ʼn��i�v���~�A���Q�D�T�{�O��ɐݒ肵��
����̂ɑ��AAMD�͂S�`�T�{�Őݒ肵�Ă���B
Shanghai 3.0G��$500���炢�ŏo����Nehalem-EP�ɂ��\���R�ł��邾�낤�B
Opteron�̉��i�ݒ�͂ڂ������肷���B
Intel�����X�y�b�N��1WAY�p��2WAY�p�ʼn��i�v���~�A���Q�D�T�{�O��ɐݒ肵��
����̂ɑ��AAMD�͂S�`�T�{�Őݒ肵�Ă���B
Shanghai 3.0G��$500���炢�ŏo����Nehalem-EP�ɂ��\���R�ł��邾�낤�B
>>312
����Ȃ���Ή�����B���ꂾ���̂��ƁB
����Ȃ���Ή�����B���ꂾ���̂��ƁB
���i�����d�|���Ď��ʂ̂�AMD�̕��������
�V�F�A�g��ȏ�ɗ��v�m�ۂ��d�v
�V�F�A�g��ȏ�ɗ��v�m�ۂ��d�v
���������AMD�@�������ᔄ���
���E�I�s���̂�������
�g���^�ł����Ԏ��ɂȂ肻������
�g���^�ł����Ԏ��ɂȂ肻������
��������Ȃ��A��������ł��Ȃ��AIntel�͎��Ă���Ȃ����A
������R�A�͑�����2�N��B�I�C���}�l�[�ʼn����͂�������ǁA
��]�͂ǂ����痈��낤�B
������R�A�͑�����2�N��B�I�C���}�l�[�ʼn����͂�������ǁA
��]�͂ǂ����痈��낤�B
319 �F,,�E�L�́M�E,,�j��-�������F2008/12/19(��) 19:44:38 ID:OAMgvfgk
�܂�Intel��32nm�ő厸�s���Ă���邵���Ȃ���ȁB
�����Ƃ�2011�N�܂ł͏�C�x�[�X�ő������錻�݂̃��[�h�}�b�v����
����Westmere���L�����Z���ɂȂ��Ă�2�N�Ԃ͏����ڂȂ����B
�����Ƃ�2011�N�܂ł͏�C�x�[�X�ő������錻�݂̃��[�h�}�b�v����
����Westmere���L�����Z���ɂȂ��Ă�2�N�Ԃ͏����ڂȂ����B
�ė��N�I���ɂ�Op���S�쒀(Op�̗p�}�V�������C���i�b�v���������)�͊����������Ȑ�������
�ƌ�������Istanbul���o�����ɂ͏��Ő��O�ȋC������
�ƌ�������Istanbul���o�����ɂ͏��Ő��O�ȋC������
>>319
TSMC��28nm�v���Z�X�̓d���݂Ă�������B
�Ȃ��X�Ƀv���Z�X�ʂł̓C���e���ɓ͂��Ȃ��Ȃ��Ă�B
�C���e������H�ʂł����āA�t�@�u��ЂɂȂ�Ȃ��ƓƋւ���ނȂ��B
�����A�t�F�m��2��i7�̈Ⴂ�̗R�����ăg�����W�X�^���̍������Œ~�ς���
���܂�Ă���悤�ɂ��������Ȃ��B
TSMC��28nm�v���Z�X�̓d���݂Ă�������B
�Ȃ��X�Ƀv���Z�X�ʂł̓C���e���ɓ͂��Ȃ��Ȃ��Ă�B
�C���e������H�ʂł����āA�t�@�u��ЂɂȂ�Ȃ��ƓƋւ���ނȂ��B
�����A�t�F�m��2��i7�̈Ⴂ�̗R�����ăg�����W�X�^���̍������Œ~�ς���
���܂�Ă���悤�ɂ��������Ȃ��B
TSMC�͂ނ���Intel�ɃL���b�`�A�b�v������悤�Ɍ�����̂����B
PC�x���_��Opteron�̓��ڂ��~�߂Ȃ��Ǝv���B
Intel�Ɏ哱��������Ȃ����߂ɁB
���i�������ė��v�͏o���A�V�F�A���������A���������2�N�ԑς����
�|�b�Ɨǂ��V�R�A���N���ďo�āc�c���Ȃ����B
PC�x���_��Opteron�̓��ڂ��~�߂Ȃ��Ǝv���B
Intel�Ɏ哱��������Ȃ����߂ɁB
���i�������ė��v�͏o���A�V�F�A���������A���������2�N�ԑς����
�|�b�Ɨǂ��V�R�A���N���ďo�āc�c���Ȃ����B
>>322
��Nehalem��Shanghai���w�ǂ̕��ʂőR�ł��Ȃ��A�ƂȂ�Ɨ��Ɏ��ł��Ă���Ǝv��(��]�I�ϑ�����)
����ɁA�g�b�v��Hector Ruiz����Dirk Meyer�֕ς��������Istanbul�̓��������ł̃T�v���C�Y�����҂�����
�l�I�ȗ\�z�Ƃ��ẮAIstanbul�̓������`���l����3or4ch����G34�̈�N�O�|��or�j�R�C�`Shanghai����Montreal�������Ǝv��
bulldozer�͒c�q��K7�ȗ����I�Ǝw�E���Ă��镔���ւ̉��P�A����Ɣr���L���b�V�����~�߂�L1�Ƀg���[�X�L���b�V���̓���
����MAC�I�^��Turion���w���Ĕ��������CoreMA�����bulldozerCPU���̎p���ė\�z���邯��
��Nehalem��Shanghai���w�ǂ̕��ʂőR�ł��Ȃ��A�ƂȂ�Ɨ��Ɏ��ł��Ă���Ǝv��(��]�I�ϑ�����)
����ɁA�g�b�v��Hector Ruiz����Dirk Meyer�֕ς��������Istanbul�̓��������ł̃T�v���C�Y�����҂�����
�l�I�ȗ\�z�Ƃ��ẮAIstanbul�̓������`���l����3or4ch����G34�̈�N�O�|��or�j�R�C�`Shanghai����Montreal�������Ǝv��
bulldozer�͒c�q��K7�ȗ����I�Ǝw�E���Ă��镔���ւ̉��P�A����Ɣr���L���b�V�����~�߂�L1�Ƀg���[�X�L���b�V���̓���
����MAC�I�^��Turion���w���Ĕ��������CoreMA�����bulldozerCPU���̎p���ė\�z���邯��
Istanbul���������`���l�����₷���߂�G34�ƃZ�b�g�őO�|���ɂ�����A�����Istanbul����Ȃ���
�ނ���Sao Paolo�̑O�|������Ȃ����H
�ނ���Sao Paolo�̑O�|������Ȃ����H
�P�N�O�|���Ƃ����肦�Ȃ���������Shanghai��K�����i�ɉ����Ĕ���̂�
�Ó����Ǝv����
�Ó����Ǝv����
���肦�Ȃ���������Ă̂��邭�炢����Ȃ���
�v���Z�X��1�N�x��Ă�������Ƃ�����ƂȁB
�v���Z�X����̈Ⴂ�́ACPU�p�t�H�[�}���X�̌���I�ȍ��ł͂Ȃ��B
�_�C�T�C�Y���������������ݓI�ɂ̓R�X�g�I�D�ʂ����邯�ǁA��������
�����܂肪�������邭�炢�Ȃ狌����v���Z�X�ň��肵�����Y���o����
�������ۂ̃R�X�g�����オ��ɂ��Ȃ肤��B
�_�C�T�C�Y���������������ݓI�ɂ̓R�X�g�I�D�ʂ����邯�ǁA��������
�����܂肪�������邭�炢�Ȃ狌����v���Z�X�ň��肵�����Y���o����
�������ۂ̃R�X�g�����オ��ɂ��Ȃ肤��B
329 �FSocket774�F2008/12/20(�y) 05:06:48 ID:wd2S5D2W
OpenCL�Ή��ŗ��N�㔼�ȍ~��Gpgpu����C�ɕ��y�����Ȃ�����
�����ド�f�A�Q�t�H��Z�����s���Ȋ����ăl�n��������ᐫ�\�������������邩��
�Ƃ������Ax86�̑��݉��l���Ȃ��Ȃ�C������B
Cpu�̉��Z���\�͑債�ĕK�v����Ȃ��Ȃ�A�d�ʃ\�t�g��gpgpu�ɑ��}�ɑΉ����Ă������낤�ȁB
���������AAMD��AMD64��pcpu���o�����ꍇ�A�C���e���Ƃ�x86���C�Z���X�͂ǂ��Ȃ�낤���H
�����ド�f�A�Q�t�H��Z�����s���Ȋ����ăl�n��������ᐫ�\�������������邩��
�Ƃ������Ax86�̑��݉��l���Ȃ��Ȃ�C������B
Cpu�̉��Z���\�͑債�ĕK�v����Ȃ��Ȃ�A�d�ʃ\�t�g��gpgpu�ɑ��}�ɑΉ����Ă������낤�ȁB
���������AAMD��AMD64��pcpu���o�����ꍇ�A�C���e���Ƃ�x86���C�Z���X�͂ǂ��Ȃ�낤���H
>>329
�������ド�f�A�Q�t�H��Z�����s���Ȋ����ăl�n��������ᐫ�\�������������邩��
���Ƃ������Ax86�̑��݉��l���Ȃ��Ȃ�C������
����͖���
GPGPU�����ӂȂ̂͌v�Z�����Ń��W�b�N�͓��ӂ���Ȃ�
Pentium4��Ƃ�Cell�Ƃ����ǂ����������v���o���Ă݂悤
�������ド�f�A�Q�t�H��Z�����s���Ȋ����ăl�n��������ᐫ�\�������������邩��
���Ƃ������Ax86�̑��݉��l���Ȃ��Ȃ�C������
����͖���
GPGPU�����ӂȂ̂͌v�Z�����Ń��W�b�N�͓��ӂ���Ȃ�
Pentium4��Ƃ�Cell�Ƃ����ǂ����������v���o���Ă݂悤
331 �FSocket774�F2008/12/20(�y) 06:11:33 ID:wd2S5D2W
���ӂ���Ȃ������ł���Ȃ�̐��\�͏o���邾��
���ꂪ�s���Ȃ��ܒ��x�̐��\��Cpu�ŕ₦�������A�����͕���\�����\�Ƃ����l���������̂��łĂ��邾�낤���炠�܂�C�ɂ��邱�Ƃ��Ȃ�����
���ꂪ�s���Ȃ��ܒ��x�̐��\��Cpu�ŕ₦�������A�����͕���\�����\�Ƃ����l���������̂��łĂ��邾�낤���炠�܂�C�ɂ��邱�Ƃ��Ȃ�����
���ς�炸���������Ȃ̂��������Ȃ��B
>>328
�R�A���d���̌��݂̃T�[�o�s��ł͌���I�ȍ�����B
45nm�łS�R�A��32nm�ɃV�������N���邾���łU�R�A��L3�e�ʂ��P�D�T�{�Ń_�C�T�C�Y��
�ނ��돬�����ł���B45nm�łU�R�A����������قǁu�������ĕ����܂肪�����v����B
�R�A���d���̌��݂̃T�[�o�s��ł͌���I�ȍ�����B
45nm�łS�R�A��32nm�ɃV�������N���邾���łU�R�A��L3�e�ʂ��P�D�T�{�Ń_�C�T�C�Y��
�ނ��돬�����ł���B45nm�łU�R�A����������قǁu�������ĕ����܂肪�����v����B
>>329
����er�ɂƂ��̌�������Ȃ��Łu���y�v�ƌ����ɂ�
�l�b�g�u�b�N���炢�̐�������Ȃ��ƁB
�܂��s�݂̃L���[�A�v���̓o����y�ώ�����������Ȃ����ȁB
����er�ɂƂ��̌�������Ȃ��Łu���y�v�ƌ����ɂ�
�l�b�g�u�b�N���炢�̐�������Ȃ��ƁB
�܂��s�݂̃L���[�A�v���̓o����y�ώ�����������Ȃ����ȁB
335 �FSocket774�F2008/12/20(�y) 08:46:28 ID:EbkiC3vT
>>333
���ɕ����܂藦�������ł��E�F�n��������������Ă��邵�ˁ[�B
���ɕ����܂藦�������ł��E�F�n��������������Ă��邵�ˁ[�B
336 �FSocket774�F2008/12/20(�y) 08:52:26 ID:pryWA8dB
�Ռ��̎����I�I
�������U�̐��\���㗦�́A�Ȃ�Ƃ������u�R���v������
> 3% �` IPC�̌���ɂ�����
> 3% �` IPC�̌���ɂ�����
> 3% �` IPC�̌���ɂ�����
http://nueda.main.jp/blog/archives/004028.html
AMD�̒��̐l����ăz���g�ɓ����Ă�낤��
�o�c�w���v�w�����\�Ƃ����v����
�o�c�w���v�w�����\�Ƃ����v����
>>336
���낵���܂ł̔n���������ďo����
���\����̗v���Ȃ�ă��[�U�[�ɂƂ��Ă͂Ȃ�ł�����
�g�[�^���łQ�����炢�������g���A�v�������シ��Ζ��X��
�����炐�U�̂��������R%�����サ���̂͗\�z�O�̌���
�����������Ȃ肐�U�̃Q�[�����\�Ɋ�@�������Ă�̂��ȁ@�R�X�g�p�t�H�[�}���X��������
���낵���܂ł̔n���������ďo����
���\����̗v���Ȃ�ă��[�U�[�ɂƂ��Ă͂Ȃ�ł�����
�g�[�^���łQ�����炢�������g���A�v�������シ��Ζ��X��
�����炐�U�̂��������R%�����サ���̂͗\�z�O�̌���
�����������Ȃ肐�U�̃Q�[�����\�Ɋ�@�������Ă�̂��ȁ@�R�X�g�p�t�H�[�}���X��������
http://northwood.blog60.fc2.com/blog-entry-2518.html
�Q�[�����\�@�l�i���l�����Ȃ��Ă��\���ȋ����́@�@����X�ɋ����͂ŗD�ʂ�
����Ȃɑ����ǂ����Ƃ͎v��Ȃ�����
�Q�[�����\�@�l�i���l�����Ȃ��Ă��\���ȋ����́@�@����X�ɋ����͂ŗD�ʂ�
����Ȃɑ����ǂ����Ƃ͎v��Ȃ�����
>>337
�u���\��AMD�v�Ɛ���āA���̂��ǂ��o���Ȃ�Intel�ł��ˁB�킩��܂��B
����AMD�����݂̏ɒǂ����܂�Ă��邩���l���Ȃ��ŁA
��{�I�ɂ��̎��"���В@��"�����Ă��u�[�������Ȃ�ˁB
AMD�̏ꍇ��130nm�ł�SOI�����x�����S�Ă̌��������B
�u���\��AMD�v�Ɛ���āA���̂��ǂ��o���Ȃ�Intel�ł��ˁB�킩��܂��B
����AMD�����݂̏ɒǂ����܂�Ă��邩���l���Ȃ��ŁA
��{�I�ɂ��̎��"���В@��"�����Ă��u�[�������Ȃ�ˁB
AMD�̏ꍇ��130nm�ł�SOI�����x�����S�Ă̌��������B
341 �F,,�E�L�́M�E,,�j��-�������F2008/12/20(�y) 12:20:57 ID:e6T6yCXA
>>329
���[��A���l�͖����ȁB���̂��߂̖��߃Z�b�g��ʌ݊����B
Vista x64�g���Ă邯�ǂقƂ��32bit�A�v�������B
DOS�̃c�[����Win��œ������Ȃ������ł��܂������ȁ[�Ǝv�����B
���[��A���l�͖����ȁB���̂��߂̖��߃Z�b�g��ʌ݊����B
Vista x64�g���Ă邯�ǂقƂ��32bit�A�v�������B
DOS�̃c�[����Win��œ������Ȃ������ł��܂������ȁ[�Ǝv�����B
core i7�X���̉ߋ����O���e���v������
2 ���O�FSocket774 ���e���F2008/11/11(��) 08:57:40 ID:GpO0oId3
�EKentsfield��Yorkfield ����3%�̏㏸�A�Q�[����1���̏㏸�B
http://en.expreview.com/2007/11/30/reviewintel-45nm-wolfdale-processor-core-2-duo-e8400.html?page=5
Intel�����ď���45nm�ł̐��\����͂���Ȃ������̂ɂ�
2 ���O�FSocket774 ���e���F2008/11/11(��) 08:57:40 ID:GpO0oId3
�EKentsfield��Yorkfield ����3%�̏㏸�A�Q�[����1���̏㏸�B
http://en.expreview.com/2007/11/30/reviewintel-45nm-wolfdale-processor-core-2-duo-e8400.html?page=5
Intel�����ď���45nm�ł̐��\����͂���Ȃ������̂ɂ�
Intel�͌��XL2���傫����������A45nm�����Ă�SSE�֘A�ȊO�͐��\�̐L�т͏����������ˁB
�Ƃ�����CPU�̐v��IPC�̌���͂��͂�C���^�[�Q�b�g�ł͂Ȃ�����
�Ԃ����Ⴏ�ߋ��̂�����݂������Ȃ�IPC������Ăł��R�A���y�ʉ��������Ƃ���
�Ԃ����Ⴏ�ߋ��̂�����݂������Ȃ�IPC������Ăł��R�A���y�ʉ��������Ƃ���
345 �FSocket774�F2008/12/20(�y) 12:45:20 ID:EbkiC3vT
Nehalem�ł��R�A���h���X�e�B�b�N�Ɋg�������킯����Ȃ���ˁB��R�M���Ă͂�����ǁB
���������N���C�A���g������CPU�Ƃ��ďd�v�������̂�Power Gate��Turbo Boost����Ȃ����ȁB
���̓�Ń}���`�R�A�H���̎����͂��Ȃ�L�т��C������B
���������N���C�A���g������CPU�Ƃ��ďd�v�������̂�Power Gate��Turbo Boost����Ȃ����ȁB
���̓�Ń}���`�R�A�H���̎����͂��Ȃ�L�т��C������B
>>339
�O���t�B�b�N���{�g���l�b�N�ɂȂ��Ă��邾���ł́H
CrossFire���ł�Phenom II X4 940@3GHz �x���`�}�[�N
http://northwood.blog60.fc2.com/blog-entry-2520.html
�O���t�B�b�N���{�g���l�b�N�ɂȂ��Ă��邾���ł́H
CrossFire���ł�Phenom II X4 940@3GHz �x���`�}�[�N
http://northwood.blog60.fc2.com/blog-entry-2520.html
>>338
���ۂ͏�C�̃x���`��15%�ȏ�UP��������r�r�b���낤��w
���ۂ͏�C�̃x���`��15%�ȏ�UP��������r�r�b���낤��w
���𑜓x�A���掿�ɂ����CPU���Ȃ��Ȃ邩��ˁB
>>348
> ���𑜓x�A���掿�ɂ����CPU���Ȃ��Ȃ邩���
���̏펯�������݂�Core i7����?
>>339
> ����Ȃɑ����ǂ����Ƃ͎v��Ȃ�����
Phenom�U�͂܂Ƃ���CPU�Ɏd�オ���Ă��邩��ˁAC2Q�Ɨǂ������ɂȂ��
�Ƃ�����AMD��65nm�i�����߂�����łˁAPhenom�U���������ꂽ��S�~���Ɏ̂Ăđ����Ƃ���芷���Ȃ�
> ���𑜓x�A���掿�ɂ����CPU���Ȃ��Ȃ邩���
���̏펯�������݂�Core i7����?
>>339
> ����Ȃɑ����ǂ����Ƃ͎v��Ȃ�����
Phenom�U�͂܂Ƃ���CPU�Ɏd�オ���Ă��邩��ˁAC2Q�Ɨǂ������ɂȂ��
�Ƃ�����AMD��65nm�i�����߂�����łˁAPhenom�U���������ꂽ��S�~���Ɏ̂Ăđ����Ƃ���芷���Ȃ�
�{���̃e�wID:Nesla8J6
>>349
����B�����̃Q�[���x���`�ō��𑜓x�Ő��l���������Ă����ˁB�r�b�N���B
�C���v���X�̃x���`������M�p�x�́u�H�v�����ǁB
����B�����̃Q�[���x���`�ō��𑜓x�Ő��l���������Ă����ˁB�r�b�N���B
�C���v���X�̃x���`������M�p�x�́u�H�v�����ǁB
ttp://pc.watch.impress.co.jp/docs/2008/1103/graph16.htm
ttp://pc.watch.impress.co.jp/docs/2008/1103/graph17.htm
���𑜓x��QX9770/QX9650�����CPU�B���ꂪCore i7�I
1600�~1200�ł��ꂾ����A1920�~1200���Ƃǂ��Ȃ����Ⴄ�낤�ȁB
ttp://pc.watch.impress.co.jp/docs/2008/1103/graph17.htm
���𑜓x��QX9770/QX9650�����CPU�B���ꂪCore i7�I
1600�~1200�ł��ꂾ����A1920�~1200���Ƃǂ��Ȃ����Ⴄ�낤�ȁB
>>352
> ���𑜓x��QX9770/QX9650�����CPU�B���ꂪCore i7�I
> 1600�~1200�ł��ꂾ����A1920�~1200���Ƃǂ��Ȃ����Ⴄ�낤�ȁB
�����Ȃ��Ȃ�����?
http://www.tomshardware.com/reviews/core-i7-gaming,2061-11.html
> ���𑜓x��QX9770/QX9650�����CPU�B���ꂪCore i7�I
> 1600�~1200�ł��ꂾ����A1920�~1200���Ƃǂ��Ȃ����Ⴄ�낤�ȁB
�����Ȃ��Ȃ�����?
http://www.tomshardware.com/reviews/core-i7-gaming,2061-11.html
>>327
AMD�̍ŏ��CPU�����ƁA���̂P�N�O��Intel�ŏ��CPU�̔�r
2007/08�@6400+�@�@�@X6800(06/07)
2007/11�@P9600�@�@�@QX6700(06/11)
2008/03�@P9850BE�@ QX6800(07/04)
2008/07�@P9950BE�@ QX6850(07/07)
2009/01�@II 940BE�@�@QX9650(07/11)
�P�N�O��Intel�ŏ�ʂ̂P���̃����N�Ƃ����������炢���B
�v���Z�X���P�N�x��Ƃ��������łȂ����v���Z�X�ł����������B
AMD�̍ŏ��CPU�����ƁA���̂P�N�O��Intel�ŏ��CPU�̔�r
2007/08�@6400+�@�@�@X6800(06/07)
2007/11�@P9600�@�@�@QX6700(06/11)
2008/03�@P9850BE�@ QX6800(07/04)
2008/07�@P9950BE�@ QX6850(07/07)
2009/01�@II 940BE�@�@QX9650(07/11)
�P�N�O��Intel�ŏ�ʂ̂P���̃����N�Ƃ����������炢���B
�v���Z�X���P�N�x��Ƃ��������łȂ����v���Z�X�ł����������B
>>355
�I����x86�̓��l�̔�r�����Ȃ������܂�
�I����x86�̓��l�̔�r�����Ȃ������܂�
>>356
CPU���C���i�b�v��AKIBA PC Hotline!�Ŋm�F���Ă�̂ŃT�[�o�����͍ڂ��ĂȂ��̂Ŗ�����
�T�[�o�����̃��C���i�b�v�͉ߋ���CPU�v���C�X���X�g�ł��m�F���Ȃ��ƁB
Barcelona�Ȃ�Ă������Ƃ��Ĉ����Ă������̂��B
CPU���C���i�b�v��AKIBA PC Hotline!�Ŋm�F���Ă�̂ŃT�[�o�����͍ڂ��ĂȂ��̂Ŗ�����
�T�[�o�����̃��C���i�b�v�͉ߋ���CPU�v���C�X���X�g�ł��m�F���Ȃ��ƁB
Barcelona�Ȃ�Ă������Ƃ��Ĉ����Ă������̂��B
�݊��`�b�v�r�W�l�X�Ȃ���1�N�x��Ȃ̂͂�����ˁB
�{�����[���]�[���Ɉ����h�J���Əo���A
���邢�̓j�b�`�łڂ�������A
�ǂ������o���������B
�{�����[���]�[���Ɉ����h�J���Əo���A
���邢�̓j�b�`�łڂ�������A
�ǂ������o���������B
>>359
�P�N�x��Ȃ̂ɐ��\�d���̃T�[�o�ɒ��͂���͖̂��d���Ǝv�����Ȃ��B
�P�N�x��Ȃ̂ɐ��\�d���̃T�[�o�ɒ��͂���͖̂��d���Ǝv�����Ȃ��B
>>361
�������ˁA�����ǂ����Nehalem���o���犮�S�ɏI���E�E�E
�I���ǂ���̑����ł͂Ȃ��A�S�������ł��o���ʂقLj���������Ă��܂�
�������ˁA�����ǂ����Nehalem���o���犮�S�ɏI���E�E�E
�I���ǂ���̑����ł͂Ȃ��A�S�������ł��o���ʂقLj���������Ă��܂�
363 �F,,�E�L�́M�E,,�j��-�������F2008/12/20(�y) 21:30:47 ID:6EAARJs5
XeonMP��8�\�P�b�g��64�R�A128�X���b�h��NUMA�V�X�e�����\�z�ł��邩���
>>362
�ꍇ�ɂ���Ă͂�
�������A�ォ��Ԃ������Ԃ��A�ň��ǂ������Ƃ��o����`�����X�͂܂�����
���A��Ԃ̖��͒ǂ������Ƃ���
����Istanbul��Nehalem�ɑR�\���Ƃ����ƁA������Ɖ����炢(Phenom�U��Core2Q�̊W)�ɂȂ�Ǝv��
�Ȃ̂ŁAOp�̈����肪�{���ɂȂ邩������Ȃ���(���ۂ�Op�̃V�F�A��5%�ȉ��ɂȂ肻������)
�ꍇ�ɂ���Ă͂�
�������A�ォ��Ԃ������Ԃ��A�ň��ǂ������Ƃ��o����`�����X�͂܂�����
���A��Ԃ̖��͒ǂ������Ƃ���
����Istanbul��Nehalem�ɑR�\���Ƃ����ƁA������Ɖ����炢(Phenom�U��Core2Q�̊W)�ɂȂ�Ǝv��
�Ȃ̂ŁAOp�̈����肪�{���ɂȂ邩������Ȃ���(���ۂ�Op�̃V�F�A��5%�ȉ��ɂȂ肻������)
>>359
���������B
���������B
366 �FSocket774�F2008/12/20(�y) 23:59:46 ID:EbkiC3vT
>>364
SAP�ł�Shanghai��Nehalem-EP�ɂ�80%�قǍ�������悤�����B
80%����20�����ɂ��Ēǂ������Ƃ�����̂��H
����ɃR�A��1.5�{��50%���\���オ��킯����Ȃ���ˁB
�R�A��������N���b�N�͉����邾�낤���B
SAP�ł�Shanghai��Nehalem-EP�ɂ�80%�قǍ�������悤�����B
80%����20�����ɂ��Ēǂ������Ƃ�����̂��H
����ɃR�A��1.5�{��50%���\���オ��킯����Ȃ���ˁB
�R�A��������N���b�N�͉����邾�낤���B
>>365
AMD���ǂ������o���Ȃ��̂����m��>>359�������B
���N�P�ʂ̎��Ԃ������āA�������u��������̌݊����[�J�[�v�̈ʒu�A
�܂�VIA�Ɠ����Ƃ���ɖ߂��Ă䂭�̂��낤�B
AMD���ǂ������o���Ȃ��̂����m��>>359�������B
���N�P�ʂ̎��Ԃ������āA�������u��������̌݊����[�J�[�v�̈ʒu�A
�܂�VIA�Ɠ����Ƃ���ɖ߂��Ă䂭�̂��낤�B
Shanghai�V�X�e����HT3.0�Ȃ�܂��Ⴄ���ʂ�������̂���
>>368
�������Ⴄ���\�ɂȂ邪�Ă��ɐ�����
�������Ⴄ���\�ɂȂ邪�Ă��ɐ�����
DDR2��DDR3�̐��\���A�R�X�g�������Ăǂ������L���Ƃ�
�����Ȃ���Ȃ����BDDR3�������Ȃ���DDR2�ɃR�X�g�����b�g��
�Ȃ��Ȃ鍠�ɂ�AMD��DDR3�ł��łĂ��Ȃ���
�����Ȃ���Ȃ����BDDR3�������Ȃ���DDR2�ɃR�X�g�����b�g��
�Ȃ��Ȃ鍠�ɂ�AMD��DDR3�ł��łĂ��Ȃ���
371 �F,,�E�L�́M�E,,�j��-�������F2008/12/21(��) 01:35:51 ID:lrai2dwW
���\������HPC����őO����K�i�̃��������R�X�g�����b�g�]�X�Ƃ��B�B�B
�f���A���R�ACeleron�ō��I�ɂȂ����܂���H
�f���A���R�ACeleron�ō��I�ɂȂ����܂���H
����DDR3�͋��N��DDR2��葊�ꂪ�����Ȃ�����
�T�[�o�[�s��ŃR�X�g�����b�g�i�j�Ȃ�Č��t���o��킯�Ȃ�����
�T�[�o�[�s��ŃR�X�g�����b�g�i�j�Ȃ�Č��t���o��킯�Ȃ�����
HTT���ď�ʂ��Ɛ��\�v�Z�Ɏז��ɂȂ邩��Ǝ~�߂�I���������悤�ȋC������
�X�p�R�����Ɗm����OFF������
�X�p�R�����Ɗm����OFF������
>>355
���U�̓o��ŏ͏����ς��ȁ@���ɃQ�[���ł�
���U�̓o��ŏ͏����ς��ȁ@���ɃQ�[���ł�
>371
HPC�ŏd�v�Ȃ̂̓R�X�g�i������p�A�ێ���j�������
���\�ł����ă\�P�b�g������̐��\����Ȃ�
HPC�ŏd�v�Ȃ̂̓R�X�g�i������p�A�ێ���j�������
���\�ł����ă\�P�b�g������̐��\����Ȃ�
376 �F,,�E�L�́M�E,,�j��-�������F2008/12/21(��) 12:11:14 ID:lrai2dwW
�킩���B�m�[�h������̐��\�������ɂȂ�ΐ��\������̑䐔�����炷���Ƃ��o���AInfiniband�̔z�������Ȃ��čςނˁB
���������i���ǂ������Ȃ�Ă��������S�̂̃R�X�g�ɉe���������Ȃ�
�ǂ����g���͉̂��i�ϓ��̏��Ȃ�ECC�����B
���������i���ǂ������Ȃ�Ă��������S�̂̃R�X�g�ɉe���������Ȃ�
�ǂ����g���͉̂��i�ϓ��̏��Ȃ�ECC�����B
377 �F,,�E�L�́M�E,,�j��-�������F2008/12/21(��) 12:12:04 ID:lrai2dwW
�~�m�[�h������̐��\�������ɂȂ��
���m�[�h������̐��\��2�{�ɂȂ��
���m�[�h������̐��\��2�{�ɂȂ��
378 �F,,�E�L�́M�E,,�j��-�������F2008/12/21(��) 12:13:28 ID:lrai2dwW
�������̉��i����������DDR2�I�ԂȂ�Ĕn���炵���Ǝv��Ȃ�����
http://www.hpc-technologies.co.jp/option/infini-7000p-price.html
http://www.hpc-technologies.co.jp/option/infini-7000p-price.html
�\�P�b�g������̐��\��DualCore Opteron �������
PowerPC4x0 �̃V�X�e����Top500��20�V�X�e���ȏ�����Ă��邵�A
�\�P�b�g������̐��\��Xeon������Power6�̃V�F�A��Xeon�����Ⴂ
PowerPC4x0 �̃V�X�e����Top500��20�V�X�e���ȏ�����Ă��邵�A
�\�P�b�g������̐��\��Xeon������Power6�̃V�F�A��Xeon�����Ⴂ
380 �FSocket774�F2008/12/21(��) 12:33:45 ID:Mjs81X8p
POWER6�̓\�P�b�g�팸����Ӗ����Ȃ��قǍ�������
���l��Tukwila���o�Ă�����Ȃ�
PowerPC�͉ߋ��̈╨
�\�P�b�g��������R�X�g��������
�R�X�g�d���ƃ\�P�b�g������̐��\�d���͕ʂɂ���������T�O�ł͂Ȃ�
���l��Tukwila���o�Ă�����Ȃ�
PowerPC�͉ߋ��̈╨
�\�P�b�g��������R�X�g��������
�R�X�g�d���ƃ\�P�b�g������̐��\�d���͕ʂɂ���������T�O�ł͂Ȃ�
381 �F,,�E�L�́M�E,,�j��-�������F2008/12/21(��) 12:42:30 ID:lrai2dwW
�܂��AHPC��4�\�P�b�g�ȏ�͋H�Ńf���A���\�P�b�g�̃N���X�^�������ˁB
�ǂ݂̂��v���Z�b�T�R�A�ɔ�Ⴕ�����͐ς܂Ȃ��Ƃ����Ȃ�����\�P�b�g���]�X��
�������̃R�X�g�̖��Ƃ͒��ڊW�Ȃ��킯�����B
�v�́ADDR2�̂ق����L���Ƃ��ǂ����Ă��Ƃ����ǁB
ECC�����̈������i��ōl���Ă��Ӗ��ˁ[�����
�ǂ������Ƃ����Ɩ��́ANehalem��1�\�P�b�g�ł̐��\�ł���2�\�P�b�g�̃N�A�b�h�R�A
Opteron�ɏ����Ă邶��Ȃ��ł������Ă��Ƃ���ˁB
�ǂ݂̂��v���Z�b�T�R�A�ɔ�Ⴕ�����͐ς܂Ȃ��Ƃ����Ȃ�����\�P�b�g���]�X��
�������̃R�X�g�̖��Ƃ͒��ڊW�Ȃ��킯�����B
�v�́ADDR2�̂ق����L���Ƃ��ǂ����Ă��Ƃ����ǁB
ECC�����̈������i��ōl���Ă��Ӗ��ˁ[�����
�ǂ������Ƃ����Ɩ��́ANehalem��1�\�P�b�g�ł̐��\�ł���2�\�P�b�g�̃N�A�b�h�R�A
Opteron�ɏ����Ă邶��Ȃ��ł������Ă��Ƃ���ˁB
SAP�ȊO�ł������Ă�́H
383 �F,,�E�L�́M�E,,�j��-�������F2008/12/21(��) 12:47:40 ID:lrai2dwW
SPEC
DRAM���i���オ�����炵������DDR2����̑O�̉��i�ɖ߂邩��
�p�t�H�[�}���X��Nehalem
�ȓd�͂�Shanghai
�ȓd�͂�Shanghai
386 �FSocket774�F2008/12/21(��) 12:53:28 ID:eZHKqijz
>380
�����N�C�����Ă���PPC450�V�X�e���͔����ȏオ2008�N�ғ��J�n
�����N�C�����Ă���PPC450�V�X�e���͔����ȏオ2008�N�ғ��J�n
387 �FSocket774�F2008/12/21(��) 12:56:57 ID:Mjs81X8p
POWER6�̉��i
1�R�A��������300���~(�v���Z�b�T���W���[������)
http://www.tpc.org/results/individual_results/IBM/IBM_595_20080610_ES.pdf
>>386
�ǂ����p�r��QCD�v�Z�ł���
�ő������ʒu�̓x�N�g���X�p�R���Ƃ����ˁ[�킯����
1�R�A��������300���~(�v���Z�b�T���W���[������)
http://www.tpc.org/results/individual_results/IBM/IBM_595_20080610_ES.pdf
>>386
�ǂ����p�r��QCD�v�Z�ł���
�ő������ʒu�̓x�N�g���X�p�R���Ƃ����ˁ[�킯����
388 �F,,�E�L�́M�E,,�j��-�������F2008/12/21(��) 12:58:00 ID:lrai2dwW
>>385
�܂��A����͂���ŁA�d�͂����萫�\�͂ǂ��Ȃ́H���Ęb�ɂȂ�킯�����B
Opteron��DP�ȏ��1000�h���ȏ�̉��i��ۂ��Ă����̂ɁAShanghai�ɂȂ��Ă���
Nehalem DP�̃��[�G���h�N���X���x�̉��i�ɗ}���Ă��ˁB
�҂�����Opteron��������ɏo������v�\���ǂ��Ȃ�̂�H
�܂��A����͂���ŁA�d�͂����萫�\�͂ǂ��Ȃ́H���Ęb�ɂȂ�킯�����B
Opteron��DP�ȏ��1000�h���ȏ�̉��i��ۂ��Ă����̂ɁAShanghai�ɂȂ��Ă���
Nehalem DP�̃��[�G���h�N���X���x�̉��i�ɗ}���Ă��ˁB
�҂�����Opteron��������ɏo������v�\���ǂ��Ȃ�̂�H
389 �F,,�E�L�́M�E,,�j��-�������F2008/12/21(��) 13:01:10 ID:lrai2dwW
POWER�A�[�L�̘b��Ŏv���o������
Apple��Intel�ڍs���Ă���PPC970���[�N�X�e�[�V�������܂��܂��������݂ɂȂ���
Apple�̑��݂��ăX�P�[�������b�g��d�v��������
Apple��Intel�ڍs���Ă���PPC970���[�N�X�e�[�V�������܂��܂��������݂ɂȂ���
Apple�̑��݂��ăX�P�[�������b�g��d�v��������
������AMD�ɍŐ�[�̋Z�p�����݂���Ǝv������ł���M�[���A�������C�^�������ǁA
���F�������ɂȂ��Ă��猳�C���o�Ă�������̃q�g�B���C�^���{�������B�B�B
���āA�����O��EETimes�̋L��������AMD��45nm�v���Z�X��A���҂ɂ͍D�]���B
http://www.eetimes.com/news/latest/showArticle.jhtml?articleID=212300482
(���p��3�y�[�W�ڂ��)
�@�@---------------------
�@�@The transistor drive current for AMD's 45-nm devices is much lower than the Intel HKMG
�@�@transistors. But power consumption is quickly becoming a high priority for server chips. Our
�@�@transistor benchmarking indicates that leakage current is less than one-third of AMD's
�@�@65-nm process. It's also significantly lower than the Intel 45-nm HKMG process. In fact, the
�@�@Ion/Ioff ratio for AMD's pFET is nearly 10 times better than the Intel pFET.
�@�@---------------------
���i���x���ł̓d�͌����ɂ����f����邱�Ƃ����҂��邷�B
���F�������ɂȂ��Ă��猳�C���o�Ă�������̃q�g�B���C�^���{�������B�B�B
���āA�����O��EETimes�̋L��������AMD��45nm�v���Z�X��A���҂ɂ͍D�]���B
http://www.eetimes.com/news/latest/showArticle.jhtml?articleID=212300482
(���p��3�y�[�W�ڂ��)
�@�@---------------------
�@�@The transistor drive current for AMD's 45-nm devices is much lower than the Intel HKMG
�@�@transistors. But power consumption is quickly becoming a high priority for server chips. Our
�@�@transistor benchmarking indicates that leakage current is less than one-third of AMD's
�@�@65-nm process. It's also significantly lower than the Intel 45-nm HKMG process. In fact, the
�@�@Ion/Ioff ratio for AMD's pFET is nearly 10 times better than the Intel pFET.
�@�@---------------------
���i���x���ł̓d�͌����ɂ����f����邱�Ƃ����҂��邷�B
1GHz�ɖ����Ȃ��N���b�N�ŋ쓮����PowerPC 440�̓d�͐��\��̓n���p�Ȃ����B
�������A130nm�v���Z�X�����Ȃ̂���?
�Ԃ����Ⴏ�u�v���Z�X�Z�p���x��Ă邩��c�c�v�Ȃ�Ă̂͌�����ɉ߂���B
�莝���̋�ŏo���邱�Ƃ����A�ƁB
�������A130nm�v���Z�X�����Ȃ̂���?
�Ԃ����Ⴏ�u�v���Z�X�Z�p���x��Ă邩��c�c�v�Ȃ�Ă̂͌�����ɉ߂���B
�莝���̋�ŏo���邱�Ƃ����A�ƁB
392 �F,,�E�L�́M�E,,�j��-�������F2008/12/21(��) 13:05:53 ID:lrai2dwW
>>391
PPC440�́A���܂�CPU���\�]�X�Ō�����Ȃ��āA�ǂ������Ƃ����ƃA�N�Z�����[�^�́u�R���g���[���v�Ƃ��Ďg���Ă�C������B
����Ȃ�
http://www.kumikomi.net/article/news/2008/04/01_01.html
PPC440�́A���܂�CPU���\�]�X�Ō�����Ȃ��āA�ǂ������Ƃ����ƃA�N�Z�����[�^�́u�R���g���[���v�Ƃ��Ďg���Ă�C������B
����Ȃ�
http://www.kumikomi.net/article/news/2008/04/01_01.html
>�v���Z�X�Z�p��
����̓}�W�Ō�����ł����Ȃ��B
AMD���̂���Pen4/PenD����Ŏ����Ă���B
�t��Intel�͂��̐���ł̓v���Z�X�I�ɗL���ł��A
�c�O�Ȍ��ʂŏI����Ă����B
����̓}�W�Ō�����ł����Ȃ��B
AMD���̂���Pen4/PenD����Ŏ����Ă���B
�t��Intel�͂��̐���ł̓v���Z�X�I�ɗL���ł��A
�c�O�Ȍ��ʂŏI����Ă����B
�v���X�R�̎��s�ōł��[���������̂�90nm�ł̃��[�N�d������Ɏ��s�������Ԑ��ꗬ�����������Ƃ������ƁE�E�E
���̂悤�Ȏ��s������ƃ��W�b�N�����ł͂ǂ����悤���Ȃ��}���ɋ����͂��������ʂɏI������B
����Ɠ��l��AMD�ł�65nm�Ń��[�N�d������Ɏ��s�APhenom��M���Ƀ��[�N�d�����ꗬ���ɏI�n�E�E�E
����̌��ʁA����N���b�N���グ�邱�Ƃ��o�����Ԏ��o��̈��l�̔�������Ɛт͍D�]����Fab�����Ђ������Y�ʂ�}��
�H�꒷�⑽���̖������ّ����Ј����ʉ��ق��Ă��ǂ��t�����A�����J��s���l�܂�A���u�̉��l��Fab�p���閘�Ɏ���
�K��45nm�͏����ł܂Ƃ��Ȑ��i���o����悤�ɂ͂Ȃ����悤�����E�E�E
���ꓙ�𑍍�����Ƃ�͂�CPU���\�̓v���Z�X�Z�p�̐��ʂ̈ˑ����傫���ƌ�����
��Ă��A���[�N�d�����ꗬ����ԂŃR���g���[���s�\�Ɋׂ�ƌ��ʂ͔ߎS�Ȃ��̂ɂȂ�
�������A��ǍD�Ȍ��ʂ����x�̕i���Ȃ����͑傫�ȕ���ɂ��Ȃ�
���̂悤�Ȏ��s������ƃ��W�b�N�����ł͂ǂ����悤���Ȃ��}���ɋ����͂��������ʂɏI������B
����Ɠ��l��AMD�ł�65nm�Ń��[�N�d������Ɏ��s�APhenom��M���Ƀ��[�N�d�����ꗬ���ɏI�n�E�E�E
����̌��ʁA����N���b�N���グ�邱�Ƃ��o�����Ԏ��o��̈��l�̔�������Ɛт͍D�]����Fab�����Ђ������Y�ʂ�}��
�H�꒷�⑽���̖������ّ����Ј����ʉ��ق��Ă��ǂ��t�����A�����J��s���l�܂�A���u�̉��l��Fab�p���閘�Ɏ���
�K��45nm�͏����ł܂Ƃ��Ȑ��i���o����悤�ɂ͂Ȃ����悤�����E�E�E
���ꓙ�𑍍�����Ƃ�͂�CPU���\�̓v���Z�X�Z�p�̐��ʂ̈ˑ����傫���ƌ�����
��Ă��A���[�N�d�����ꗬ����ԂŃR���g���[���s�\�Ɋׂ�ƌ��ʂ͔ߎS�Ȃ��̂ɂȂ�
�������A��ǍD�Ȍ��ʂ����x�̕i���Ȃ����͑傫�ȕ���ɂ��Ȃ�
>>389
Intel�Ɉڍs���钼�O��Apple�͔N�Ԃ��悻300�����PowerPC����Mac���o��
���Ă�������A���̕��̃X�P�[�������b�g�������Ă�ˁB
�ł�PowerPC��Apple�����ꂽ�v���́u�Q�[���@�ւ̊J�����\�[�X�̌X�|�v
�ŁAPowerPC��Mac�s�������������ɁAXbox360�̔����ȗ��ݐ�2000����
���x�̎s����J�Ă���B
�ǂ����̓����ǂ������̂��H
Intel�Ɉڍs���钼�O��Apple�͔N�Ԃ��悻300�����PowerPC����Mac���o��
���Ă�������A���̕��̃X�P�[�������b�g�������Ă�ˁB
�ł�PowerPC��Apple�����ꂽ�v���́u�Q�[���@�ւ̊J�����\�[�X�̌X�|�v
�ŁAPowerPC��Mac�s�������������ɁAXbox360�̔����ȗ��ݐ�2000����
���x�̎s����J�Ă���B
�ǂ����̓����ǂ������̂��H
�Ȃ�apple��AMD���̗p���Ȃ������̂������ɋꂵ��
intel+nVidia���āE�E�E
intel+nVidia���āE�E�E
>>396
���Ȃ���
���Ȃ���
>>395
�f�X�N�g�b�vPC�Ŏg����x86�R�̃p�t�H�[�}���XCPU�͂ƂĂ��Ȃ��J���������̂ŁA
Mac���v�����ł͎x�����Ȃ��B���\����̖���ꂸ�A
�Ƃ�����IBM�����g���[����Apple���������͐U�ꂸ�A�ʂ�邵���Ȃ������B
�Q�[���@�p��CPU�͑g���݂Ȃ̂Ō݊������v�炸�A�p���I�Ȑi�����s�v�ŁA
�����Ɗy�ɂȂ�B
>>396
AMD�̎�蕿�̓R�X�g�p�t�H�[�}���X�B���t�����l�u�����h��Mac�Ɉ����͕K�v�����B
�f�X�N�g�b�vPC�Ŏg����x86�R�̃p�t�H�[�}���XCPU�͂ƂĂ��Ȃ��J���������̂ŁA
Mac���v�����ł͎x�����Ȃ��B���\����̖���ꂸ�A
�Ƃ�����IBM�����g���[����Apple���������͐U�ꂸ�A�ʂ�邵���Ȃ������B
�Q�[���@�p��CPU�͑g���݂Ȃ̂Ō݊������v�炸�A�p���I�Ȑi�����s�v�ŁA
�����Ɗy�ɂȂ�B
>>396
AMD�̎�蕿�̓R�X�g�p�t�H�[�}���X�B���t�����l�u�����h��Mac�Ɉ����͕K�v�����B
399 �F,,�E�L�́M�E,,�j��-�������F2008/12/21(��) 15:01:57 ID:lrai2dwW
NVIDIA�`�b�v�Z�b�g�͈��萫���E�E�E
Mac�ɍ̗p���ꂽNVIDIA��IGP���Ă̒�g���u���������Ă�悤�ŁB
i945GC�͏���d�͓I�ɂ͕������͂�Ă镪���萫�����͊������}�V������ȁB
���x�o��Atom�{9400M�v���b�g�t�H�[�����Ăǂ������p�r�����Ȃ̂��ˁB
�����Q�[���v���b�g�t�H�[���Ƃ��Ĕ���Ȃ�܂��f���A���R�ACeleron�Ƒg�ݍ��킹���ق����}�V����Ȃ����Ǝv�����B
Atom���m���X�g�b�v�̃T�[�o�Ƃ��Ďg���ɂ�D945GCLF2�̂ق����܂��y�}�V�z����
�i�Ԉ���Ă��x�X�g�ƌ����C�͖����j
�E������B
Mac�ɍ̗p���ꂽNVIDIA��IGP���Ă̒�g���u���������Ă�悤�ŁB
i945GC�͏���d�͓I�ɂ͕������͂�Ă镪���萫�����͊������}�V������ȁB
���x�o��Atom�{9400M�v���b�g�t�H�[�����Ăǂ������p�r�����Ȃ̂��ˁB
�����Q�[���v���b�g�t�H�[���Ƃ��Ĕ���Ȃ�܂��f���A���R�ACeleron�Ƒg�ݍ��킹���ق����}�V����Ȃ����Ǝv�����B
Atom���m���X�g�b�v�̃T�[�o�Ƃ��Ďg���ɂ�D945GCLF2�̂ق����܂��y�}�V�z����
�i�Ԉ���Ă��x�X�g�ƌ����C�͖����j
�E������B
400 �FSocket774�F2008/12/21(��) 15:14:27 ID:Mjs81X8p
>>388
>Opteron��DP�ȏ��1000�h���ȏ�̉��i��ۂ��Ă����̂ɁAShanghai�ɂȂ��Ă���
>Nehalem DP�̃��[�G���h�N���X���x�̉��i�ɗ}���Ă��ˁB
>�҂�����Opteron��������ɏo������v�\���ǂ��Ȃ�̂�H
�����Ȃ�
http://www.mercurynews.com/chris_obrien/ci_11200791
>Opteron��DP�ȏ��1000�h���ȏ�̉��i��ۂ��Ă����̂ɁAShanghai�ɂȂ��Ă���
>Nehalem DP�̃��[�G���h�N���X���x�̉��i�ɗ}���Ă��ˁB
>�҂�����Opteron��������ɏo������v�\���ǂ��Ȃ�̂�H
�����Ȃ�
http://www.mercurynews.com/chris_obrien/ci_11200791
>>396
���ꂽ���i���낤�ˁB��͋����ɑ���s���Ƃ��H
Intel+NVIDIA�͂܂��������AIntel�I���{�[�h����̓}�W�ł킩������B
���ꂽ���i���낤�ˁB��͋����ɑ���s���Ƃ��H
Intel+NVIDIA�͂܂��������AIntel�I���{�[�h����̓}�W�ł킩������B
403 �F,,�E�L�́M�E,,�j��-�������F2008/12/21(��) 16:44:28 ID:lrai2dwW
>>401
�u�^�_���R�v�͂Ȃ����������i�Ȃ���ʑҋ��Œ��Ă�̂͊ԈႢ�Ȃ��ȁB
�����i��CPU�������̗p���Ă���郁�[�J�[���đ��ɂȂ����B
�u�^�_���R�v�͂Ȃ����������i�Ȃ���ʑҋ��Œ��Ă�̂͊ԈႢ�Ȃ��ȁB
�����i��CPU�������̗p���Ă���郁�[�J�[���đ��ɂȂ����B
Apple���݂̏o�ב䐔��PowerPC����PC��̔����郁�[�J�[�����ɂQ�C�R�Ђ����PC����PowerPC���������Ă��̂��ȁH
405 �F,,�E�L�́M�E,,�j��-�������F2008/12/21(��) 16:56:29 ID:lrai2dwW
PWRficient�͊��҂��Ă����ǂˁB
Amiga�������������B
Amiga�������������B
>>398
�u�����h�Ƃ����_�ł͑傢�ɓ䂾��
�悭MAC����rade�̗p���ĂȂ����������H�Ƃ����̂�
PC�ɂ�intel�����Ă�Ȃ�đ�X�I�ɐ�`���Ă�intel���̗p����Ƃ������Ƃ�
MAC��PC����Ȃ�MAC��MAC�Ƃ�����`���Ă�̂Ɛ^��������Η����Ă�悤��
�u�����h�Ƃ����_�ł͑傢�ɓ䂾��
�悭MAC����rade�̗p���ĂȂ����������H�Ƃ����̂�
PC�ɂ�intel�����Ă�Ȃ�đ�X�I�ɐ�`���Ă�intel���̗p����Ƃ������Ƃ�
MAC��PC����Ȃ�MAC��MAC�Ƃ�����`���Ă�̂Ɛ^��������Η����Ă�悤��
�������܂��炠����߂�B�A���h�̓I���^�B
408 �F,,�E�L�́M�E,,�j��-�������F2008/12/21(��) 19:06:17 ID:lrai2dwW
iMac����radeon����Ȃ����������H
�N�����ɐV�����̂��o�邻�������ǒERadeon���Ă������
�N�����ɐV�����̂��o�邻�������ǒERadeon���Ă������
GeForce�͗����ڂ��ȍ����
���N��GeForce�̔N�ɂȂ�Ƃ�����
���N��GeForce�̔N�ɂȂ�Ƃ�����
���N��OpenCL���o��̂�GeForce��iMac�ō̗p����Ȃ�������GPGPU�s��ŏI��肾����
���Ƃ��Ăł��ڂ��Ă��炤�悤��Apple�ɗ��ނ��낤
���Ƃ��Ăł��ڂ��Ă��炤�悤��Apple�ɗ��ނ��낤
>>388
�ŏ��$989�̂ǂ���Nehalem DP�̃��[�G���h�N���X�����āH
Nehalem DP�̍ʼn��ʂ�$188�����B
http://www.xbitlabs.com/news/cpu/display/20081118082708_Intel_to_Initiate_Shipments_of_Nehalem_Processors_Early_Next_Year.html
�ŏ��$989�̂ǂ���Nehalem DP�̃��[�G���h�N���X�����āH
Nehalem DP�̍ʼn��ʂ�$188�����B
http://www.xbitlabs.com/news/cpu/display/20081118082708_Intel_to_Initiate_Shipments_of_Nehalem_Processors_Early_Next_Year.html
412 �F,,�E�L�́M�E,,�j��-�������F2008/12/21(��) 20:15:25 ID:lrai2dwW
414 �F,,�E�L�́M�E,,�j��-�������F2008/12/21(��) 20:21:42 ID:lrai2dwW
��������QPI�̑ш悪�Ⴄ���
>>408
iMac�Ȃo��H�@�A����NVIDA��������ARADEON��������F�X�B
Mac mini���o����Ęb�����A����͊m����NVIDIA���ځB
G5�����Mac mini��RADEON������Ă������ǁA
Intel Mac�ɂȂ��Ă����Intel�I���{�[�h������˂��c�B
�m����Intel�̃`�b�v�Z�b�g�͎̂ĂĂ���Ǝv���B
�\�z��ꡂ��ߏ���Ԃ����ŁAAthlon�Ƃ����ڂ��Ȃ�����͂�
iMac�Ȃo��H�@�A����NVIDA��������ARADEON��������F�X�B
Mac mini���o����Ęb�����A����͊m����NVIDIA���ځB
G5�����Mac mini��RADEON������Ă������ǁA
Intel Mac�ɂȂ��Ă����Intel�I���{�[�h������˂��c�B
�m����Intel�̃`�b�v�Z�b�g�͎̂ĂĂ���Ǝv���B
�\�z��ꡂ��ߏ���Ԃ����ŁAAthlon�Ƃ����ڂ��Ȃ�����͂�
��������Stream���炵��Mac��Ή��Ȃ���ARadeon��Apple�̊ᒆ�ɂȂ�
�����NV��Geforce���荞�ނ܂ł��Ȃ�
�����NV��Geforce���荞�ނ܂ł��Ȃ�
417 �F,,�E�L�́M�E,,�j��-�������F2008/12/21(��) 20:24:08 ID:lrai2dwW
OpenCL���ꏈ���n��CUDA�Ɏ����Ă����W��A������NVIDIA�ɂ�����ȁ[�Ǝv���Ă���B
419 �F,,�E�L�́M�E,,�j��-�������F2008/12/21(��) 20:28:11 ID:lrai2dwW
�킩�����Bi7�̒��̃��[�G���h�����̃f���A���łɒ�������B
420 �F,,�E�L�́M�E,,�j��-�������F2008/12/21(��) 20:30:40 ID:lrai2dwW
�܂�����͂���ŁAXeon EP E�V���[�Y��ShanghaiOpteron�͉��i�т��N���b�N����������킯����ȁB
��������邾�낤������OpenGL��NVIDIA�̕����o���������炵��
������OpenCL1.0�̊J���n�[�h��NVIDIA�������Ȃ�]���̎���������Ηh�炮�܂���
������OpenCL1.0�̊J���n�[�h��NVIDIA�������Ȃ�]���̎���������Ηh�炮�܂���
nv�ɂ͎��s�n�[�h���ǂ�������
Apple�́A������Ə����ɍs���Ă�Ǝv���Ƃ����R�P�邩���w
Intel�Ɉڍs���Ă���ߔN�͏������������A�����ɗ���OpenCL��
nVidia�Ɋ��߂����̂��A�܂��uApple�̕����t���O�v���Ĉ���w
Intel�Ɉڍs���Ă���ߔN�͏������������A�����ɗ���OpenCL��
nVidia�Ɋ��߂����̂��A�܂��uApple�̕����t���O�v���Ĉ���w
���������ǂ��������ڂŔ����Ă���B
>>425
�@�����ڂ�GUI���A�b�v������������n�[�h���ǂ����낤��OS�̃J�[�l�����ǂ����낤��
�Ƃɂ���Mac�ɂȂ�Ƃ����̂ɂ͓���
�@���ێg���ĂĈ����Ȃ��Ƃ͎v�����A�ޮ�ޔ��肪���܂�ɂЂǂ��ċ��������邵�A
����Linux�ɓ��������B
�@����er���炷���MacPro�͐��\�]�X�͂Ƃ������ێ���������B���̏C����ُ�B
�@�����ڂ�GUI���A�b�v������������n�[�h���ǂ����낤��OS�̃J�[�l�����ǂ����낤��
�Ƃɂ���Mac�ɂȂ�Ƃ����̂ɂ͓���
�@���ێg���ĂĈ����Ȃ��Ƃ͎v�����A�ޮ�ޔ��肪���܂�ɂЂǂ��ċ��������邵�A
����Linux�ɓ��������B
�@����er���炷���MacPro�͐��\�]�X�͂Ƃ������ێ���������B���̏C����ُ�B
���[�J�[���p�\�R�������Ē����ۏ��Ȃ��z���ăA�z����
9400M�ł��łɌ��ׂ��܂���Ă邯�ǂ�
good job nv !
good job nv !
�Ԃ����ႯOpenGL��������ATI�͘b�ɂȂ�Ȃ�����
OpenCL���Ƃǂ�����
OpenCL���Ƃǂ�����
http://www.techpowerup.com/index.php?79451
�v���Ԃ�ɐ����j���[�X���@�S�T��Phenom��3��ނ̃R�A��������Rigor�͂Ȃ��80mmsq�ȉ���������
����͂Ђ�Ƃ���ƂЂ���Ƃ��邩�ȁ@��������
�v���Ԃ�ɐ����j���[�X���@�S�T��Phenom��3��ނ̃R�A��������Rigor�͂Ȃ��80mmsq�ȉ���������
����͂Ђ�Ƃ���ƂЂ���Ƃ��邩�ȁ@��������
>>432
K10.5�n�_�C��3��ށA����Ȃ�Phenom�X���̃e���v���ɏ����Ă����E�E�E
���̋L����Propus��Regor�̃_�C�T�C�Y�͂����̗\�z�����B
K10.5�n�_�C��3��ށA����Ȃ�Phenom�X���̃e���v���ɏ����Ă����E�E�E
���̋L����Propus��Regor�̃_�C�T�C�Y�͂����̗\�z�����B
>>394
�h�^��
�h�^��
AMD�̃l�b�g�u�b�N�����\�����[�V�����E�E�ECPU+�m�[�X+�T�E�X��20�h���ȉ�������
Intel��Atom�̃R���|�[�l���g�͓�����50�h���i���j
��Intel����߂�l�b�g�u�b�N�̎d�l�Ɏ��܂�Ȃ��p�r�Ɏg�����Ƃ����100�h��
���̉��i�ݒ�́E�E�E
���ケ�̃N���X�ł́g���\�̌���ɂ�蔃���ւ��𑣂��h�Ƃ����r�W�l�X���f���͏I�����
���i���������Ȃ艄�т�i�ЂƂ̐��i���������Ԃ�����������j���Ɨ\�������̂�����
Intel��Atom�̃R���|�[�l���g�͓�����50�h���i���j
��Intel����߂�l�b�g�u�b�N�̎d�l�Ɏ��܂�Ȃ��p�r�Ɏg�����Ƃ����100�h��
���̉��i�ݒ�́E�E�E
���ケ�̃N���X�ł́g���\�̌���ɂ�蔃���ւ��𑣂��h�Ƃ����r�W�l�X���f���͏I�����
���i���������Ȃ艄�т�i�ЂƂ̐��i���������Ԃ�����������j���Ɨ\�������̂�����
CPU�P�̂Ȃ�Ƃ������A�`�b�v�Z�b�g�܂Ŋ܂߂�20�h������AMD�̗��v�ǂꂭ�炢�Ȃ낤�H
�V�F�A�Ƃꂽ��AASP�A�e���v���Ƃ��ɑ啝�ɉ����肻���B
�V�F�A�Ƃꂽ��AASP�A�e���v���Ƃ��ɑ啝�ɉ����肻���B
>>435
�\�[�X��ǂ�ł݂����@�����j���[�X��
�\�[�X��ǂ�ł݂����@�����j���[�X��
�n�[�h�͕ʂɍ��Â���������A�����I�ȍX�V�Ŗׂ��Ă���MS�Ƃ���
��ςɂȂ��Ă���̂���
��ςɂȂ��Ă���̂���
>>439
���肪�Ƃ�
���肪�Ƃ�
>>442
�k�R�ɂ�鐫�\�����3%���炢����@�������炱��͂ł����j���[�X��
�k�R�ɂ�鐫�\�����3%���炢����@�������炱��͂ł����j���[�X��
L3��5%�A3%�̓R�A���ǁB
�L���b�V����������ۂ̕��̔�r���Ȃ��Ƃ킩��Ȃ����A
���܂荷���Ȃ��̂ƁA�����荷�����̂ɕ�������Ȃ����낤���B
�L���b�V����������ۂ̕��̔�r���Ȃ��Ƃ킩��Ȃ����A
���܂荷���Ȃ��̂ƁA�����荷�����̂ɕ�������Ȃ����낤���B
>>442
���̋L�����u�s�Ǎɏ����v�Ƃ����ǂ߂Ȃ��͔̂߂������邼�B
>>443
�ł��������Ă������c���́B���N�ȏ���O�̏��Ɂc�����B���ł��Ȃ��B
���̋L�����u�s�Ǎɏ����v�Ƃ����ǂ߂Ȃ��͔̂߂������邼�B
>>443
�ł��������Ă������c���́B���N�ȏ���O�̏��Ɂc�����B���ł��Ȃ��B
Propus���ʃ_�C�����Ă͈̂ȑO����U�X�����Ă��ȁB
����L3�̑��ʂɂ�鐫�\���オ5%�Ȃ���
L3�̗L���ɂ�鐫�\����5%�ȏ゠��ł���B
����L3�̑��ʂɂ�鐫�\���オ5%�Ȃ���
L3�̗L���ɂ�鐫�\����5%�ȏ゠��ł���B
>>446
���̕�L2�{���Ŋ撣���Ȃ��@�N���b�N���グ�₷�����낤���M�ʂ����Ȃ����낤��
�ʐς�3����1�ȉ����@�R�X�g��3����1�����Ȃ艺��邩��
���̕�L2�{���Ŋ撣���Ȃ��@�N���b�N���グ�₷�����낤���M�ʂ����Ȃ����낤��
�ʐς�3����1�ȉ����@�R�X�g��3����1�����Ȃ艺��邩��
>>447
Regor��L2��1MB*2�����ǁAPropus��L2��512KB*4������L3�̗L���̐��\���͂���ł邼�B
L3�̐��\���̐����ԈႦ�Ă���A���Ⴂ�����Ȃ����H
Regor��L2��1MB*2�����ǁAPropus��L2��512KB*4������L3�̗L���̐��\���͂���ł邼�B
L3�̐��\���̐����ԈႦ�Ă���A���Ⴂ�����Ȃ����H
>>445
���i$20�ŗ��v�o�����߂̐����R�X�g�팸�̋Z�p�v�V�͉����Ȃ��̂�����
�I�C���}�l�[�������ɂ����V�F�A�m�ۂ̂��߂̃_���s���O�A�Ɠǂ��
�����x���Ȃ��̂ł͂Ȃ����H
���i$20�ŗ��v�o�����߂̐����R�X�g�팸�̋Z�p�v�V�͉����Ȃ��̂�����
�I�C���}�l�[�������ɂ����V�F�A�m�ۂ̂��߂̃_���s���O�A�Ɠǂ��
�����x���Ȃ��̂ł͂Ȃ����H
Phenom�T�Ƃ̔�r���ƁA�R�A���ǂ�+3%��2MB��L3�J�b�g�Ł}�[�����炢�������肵��>Propus
L3�̌��ʂ������̂̓Q�[��
�Ⴂ�̂̓G���R
�Ⴂ�̂̓G���R
>>450
�}�[���ǂ��납���N���b�N�Ȃ�Propus��Agena���x���Ȃ��B
Agena���N���b�N�グ�₷���������R�X�g�������̂������b�g�B
������d�͂ł̐��\�ł������炭Agena������B
Windsor��Brisbane�̊W���ȁB
�}�[���ǂ��납���N���b�N�Ȃ�Propus��Agena���x���Ȃ��B
Agena���N���b�N�グ�₷���������R�X�g�������̂������b�g�B
������d�͂ł̐��\�ł������炭Agena������B
Windsor��Brisbane�̊W���ȁB
453 �FSocket774�F2008/12/22(��) 14:48:21 ID:sXzuijWC
>>452
�Ȃ�ŃR�e�O���Ă�́H
�Ȃ�ŃR�e�O���Ă�́H
>>453
�R�e�Ȃ�Ă����T�N���炢�t���ĂȂ���
�R�e�Ȃ�Ă����T�N���炢�t���ĂȂ���
�������R���g���[�������ɑ����āA
�������A�N�Z�X�̃��C�e���V������ɍ팸����悤�Ȗ��@�̈�肪����������ǂ˂��B
�L���b�V���e�ʏ����ɂȂ����Ⴄ�ƁA�ǂ���������AMD�͕s�����B
�������A�N�Z�X�̃��C�e���V������ɍ팸����悤�Ȗ��@�̈�肪����������ǂ˂��B
�L���b�V���e�ʏ����ɂȂ����Ⴄ�ƁA�ǂ���������AMD�͕s�����B
>>455
L1�L���b�V���e�ʏ����Ȃ�AMD�������Ă��w
L1�L���b�V���e�ʏ����Ȃ�AMD�������Ă��w
���āA���Phenom�U��������ɂȂ�̂��ƁAAM3�̃}�U�[�̒l�i�������炮�炢��
�Ȃ邩���A�����̂��ȁHAM3�̍ŏ㋉�̃}�U�[�ł�2���㔼���낤����A�V�����g�݂Ȃ����Ă�
Intel���͊m����1�����炢�͈����͂�����ˁHCPU�A�}�U�[�A�������[(DDR3 2GBx2)���炢�ŁB
�Ȃ邩���A�����̂��ȁHAM3�̍ŏ㋉�̃}�U�[�ł�2���㔼���낤����A�V�����g�݂Ȃ����Ă�
Intel���͊m����1�����炢�͈����͂�����ˁHCPU�A�}�U�[�A�������[(DDR3 2GBx2)���炢�ŁB
>>447
3000�~��Ŕ����邩�ȁB
3000�~��Ŕ����邩�ȁB
i7��葬��������^���o�Ȃ��悤�Ȃ�AMD��ق���}�W��
�V�F�A���_���_���������Ă��������ŁA�ʂɏI���͂��Ȃ��B�n�܂�����Ȃ����ǁB
>>457
�����T�ň��l
http://www.watch.impress.co.jp/akiba/hotline/20071110/newitem.html
32,523�~�@GIGABYTE GA-MA790FX-DQ6
http://www.watch.impress.co.jp/akiba/hotline/20080119/newitem.html
30,980�~�@ASUS M3A32-MVP DELUXE/WIFI
http://www.watch.impress.co.jp/akiba/hotline/20081115/newitem.html
44,770�~�@ASUS Rampage II Extreme
39,800�~�@GIGABYTE GA-EX58-EXTREME
Phenom��������i7�������Ńn�C�G���h�}�U�[��AMD�̕���1���~�قLj����ȁB
��������DDR3�őg�ނȂ瓯�������ACPU��PhenomII 940BE��i7 920�ʼn��i��
�卷�Ȃ����낤�B
�����T�ň��l
http://www.watch.impress.co.jp/akiba/hotline/20071110/newitem.html
32,523�~�@GIGABYTE GA-MA790FX-DQ6
http://www.watch.impress.co.jp/akiba/hotline/20080119/newitem.html
30,980�~�@ASUS M3A32-MVP DELUXE/WIFI
http://www.watch.impress.co.jp/akiba/hotline/20081115/newitem.html
44,770�~�@ASUS Rampage II Extreme
39,800�~�@GIGABYTE GA-EX58-EXTREME
Phenom��������i7�������Ńn�C�G���h�}�U�[��AMD�̕���1���~�قLj����ȁB
��������DDR3�őg�ނȂ瓯�������ACPU��PhenomII 940BE��i7 920�ʼn��i��
�卷�Ȃ����낤�B
>>462
AMD�̕��̃}�U�[�͏�ʂł͂��邪�B
��ԏ�̃}�U�[�ł͂Ȃ��ȁB
���������}�U�{���[�J�[�ɂ��o���Ă��炦�Ȃ��̂�������Ȃ����B
AMD�̕��̃}�U�[�͏�ʂł͂��邪�B
��ԏ�̃}�U�[�ł͂Ȃ��ȁB
���������}�U�{���[�J�[�ɂ��o���Ă��炦�Ȃ��̂�������Ȃ����B
>>462 �����X
>CPU��PhenomII 940BE��i7 920�ʼn��i�͑卷�Ȃ����낤�B
AM3�}�U�[�O����945BE���ˁB2���ɔ����Ȃ�ŏ�ʂ�925�B���ꂾ��
i7 920��肾���Ԉ������낤�B
>CPU��PhenomII 940BE��i7 920�ʼn��i�͑卷�Ȃ����낤�B
AM3�}�U�[�O����945BE���ˁB2���ɔ����Ȃ�ŏ�ʂ�925�B���ꂾ��
i7 920��肾���Ԉ������낤�B
>>464
�ǂ����Ȃ�AM3�܂ő҂Ƃ����ƁB���������AAM3��3GHz��4���܂ő҂��Ȃ��Ƃ��߂������H
�ł���i�h�Ȃ̂ŁATDP95W��925�����Ǝv���B
�ǂ����Ȃ�AM3�܂ő҂Ƃ����ƁB���������AAM3��3GHz��4���܂ő҂��Ȃ��Ƃ��߂������H
�ł���i�h�Ȃ̂ŁATDP95W��925�����Ǝv���B
>>448
���̖{��Regor������@���߂�@�Q�[���ɂ͍œK�ȋC������@�R�X�g���܂�
���̖{��Regor������@���߂�@�Q�[���ɂ͍œK�ȋC������@�R�X�g���܂�
>>449
��ʐ��Y�̔����̃��[�J�[�ɂƂ��Č����팸�Z�p�͎����I�ȋZ�p����
��ʐ��Y�̔����̃��[�J�[�ɂƂ��Č����팸�Z�p�͎����I�ȋZ�p����
>>466
Regor�͈������낤�ȁB����Brisbane�̂��̂܂܌�p�|�W�V�������낤�B
�ō��N���b�N��2.8G/65W�̓z�Ő��\��6400+�Ɠ������炢�A���i��7000�~����
�Ƃ�����Ȃ����B
Regor�͈������낤�ȁB����Brisbane�̂��̂܂܌�p�|�W�V�������낤�B
�ō��N���b�N��2.8G/65W�̓z�Ő��\��6400+�Ɠ������炢�A���i��7000�~����
�Ƃ�����Ȃ����B
>>468
�����܂Ő��\�Ⴍ�������낤�@���U�}�C�i�X�T�p�[�Z���g�Ƃ���Ƃ��Ȃ萫�\������
�����܂Ő��\�Ⴍ�������낤�@���U�}�C�i�X�T�p�[�Z���g�Ƃ���Ƃ��Ȃ萫�\������
470 �FSocket774�F2008/12/22(��) 18:31:22 ID:lxpfS2TJ
�����A2�Ŋ���̂�Y��Ă���
>>470
�Q�[��������V���O���X���b�h�������Ǝv����
�Q�[��������V���O���X���b�h�������Ǝv����
>>469
PhenomII�̐��\�����N���b�N��Phenom��8%��ŁA����
L3 : 2MB��6MB�A�b�v���ɂ��5%�ƁA����ȊO�̗v���ł�3%�B
Regor��L3���Ȃ�������L2��Kuma�̂Q�{�Ȃ̂ő��E�ƍl����
���N���b�N��Kuma��3%��Ƃ���ƁAKuma-2.7G��6000+�Ɠ����x�Ȃ̂�
Regor-2.8G��6400+�Ɠ����x�B
PhenomII�̐��\�����N���b�N��Phenom��8%��ŁA����
L3 : 2MB��6MB�A�b�v���ɂ��5%�ƁA����ȊO�̗v���ł�3%�B
Regor��L3���Ȃ�������L2��Kuma�̂Q�{�Ȃ̂ő��E�ƍl����
���N���b�N��Kuma��3%��Ƃ���ƁAKuma-2.7G��6000+�Ɠ����x�Ȃ̂�
Regor-2.8G��6400+�Ɠ����x�B
>>472
�T�o�[���[�J�[���Ȃ�24%�A�b�v�̃x���`�o���Ă���
�Q�[���͍��ₐ�U�ł������������t�]���Ă�̂����邵�قڒǂ������Ƃ����Ă���
���͂q���������I�o�[�N���b�N���Ďg�����肾����Q�[���p�r�Ȃ疞���ł�����
�T�o�[���[�J�[���Ȃ�24%�A�b�v�̃x���`�o���Ă���
�Q�[���͍��ₐ�U�ł������������t�]���Ă�̂����邵�قڒǂ������Ƃ����Ă���
���͂q���������I�o�[�N���b�N���Ďg�����肾����Q�[���p�r�Ȃ疞���ł�����
>>472
�R�e�O���Ȃ�B
�R�e�O���Ȃ�B
475 �F,,�E�L�́M�E,,�j��-�������F2008/12/22(��) 23:10:08 ID:VR8BIXAn
�@
>>474
�R�e�Ȃ�Ă����T�N���炢�t���ĂȂ���
�R�e�Ȃ�Ă����T�N���炢�t���ĂȂ���
477 �F,,�E�L�́M�E,,�j��-�������F2008/12/22(��) 23:13:36 ID:VR8BIXAn
>>476
�悤���̕��g
�悤���̕��g
478 �F ��O47sMVBmgM �F2008/12/22(��) 23:33:34 ID:MjZP+pTk
�g���b�v�Ȃ炽�܂Ɏg�����ˁB�Ăт����Ȃ炱�̃g���b�v�ŌĂ�ł���B
pII����phII �Ɨ���������
6�������x�̒Z���𗪂��K�v�͂Ȃ���������Ȃ���
6�������x�̒Z���𗪂��K�v�͂Ȃ���������Ȃ���
�����Q�����̂����x���`�o��ł��傤
�]�萫�\�ǂ����Ă�(�Q�[����)�c��������������Ȃ��Ȃ邵�ɂ��y������
���̎��͗]������Ȃ�Ȃ�������
�]�萫�\�ǂ����Ă�(�Q�[����)�c��������������Ȃ��Ȃ邵�ɂ��y������
���̎��͗]������Ȃ�Ȃ�������
1T-SRAM���Ă��̃Q�[���L���[�u�ɏ���Ă����@�̃`�b�v��
>>480
L2��512KB��1MB�ł̐��\up�́AK8���Q�l�ɂ����+200MHz(���10%)������Ȃ����H
L3��2��6MB�ɂȂ邱�Ƃł�up����5%���Ă��Ƃ́A�N���b�N���Z�ő��130�`150MHz���x
L3��2MB���̌��㗦���l������ƁAL3���������Ƃł�down���E�ł��邩�ǂ����A�̃��C���ゾ�Ǝv������
�l�I��L3��L2��3�{�̗e�ʂ��m�ۂ��ē����ƌ��Ă��邯�ǁA�ǂ����낤(�e�ʂ�����̐��\��L2��3����1)
L2��512KB��1MB�ł̐��\up�́AK8���Q�l�ɂ����+200MHz(���10%)������Ȃ����H
L3��2��6MB�ɂȂ邱�Ƃł�up����5%���Ă��Ƃ́A�N���b�N���Z�ő��130�`150MHz���x
L3��2MB���̌��㗦���l������ƁAL3���������Ƃł�down���E�ł��邩�ǂ����A�̃��C���ゾ�Ǝv������
�l�I��L3��L2��3�{�̗e�ʂ��m�ۂ��ē����ƌ��Ă��邯�ǁA�ǂ����낤(�e�ʂ�����̐��\��L2��3����1)
485 �F,,�E�L�́M�E,,�j��-�������F2008/12/23(��) 17:41:55 ID:ScZ+x1f2
����d�͂��ł������R�X�g�����������e�ʉ��͓��
1T-SRAM����FDRAM����H
DRAM���ȃg�����W�X�^���ŁA�A�N�Z�X���H�v����SRAM���ɑ������܂�����A���Ċ����ŁB
DRAM���ȃg�����W�X�^���ŁA�A�N�Z�X���H�v����SRAM���ɑ������܂�����A���Ċ����ŁB
L2��1MB�~�S�AL3��6MB
�̋���CPU�͍��Ȃ��̂��Ȃ�
�̋���CPU�͍��Ȃ��̂��Ȃ�
���ɂ��Ă����ƁA�_�C�X�^�b�N��������4GB�������C����������L3���݂̑��x�A
���炢��z������̂���
���炢��z������̂���
>>483
> �l�I��L3��L2��3�{�̗e�ʂ��m�ۂ��ē����ƌ��Ă��邯�ǁA�ǂ����낤(�e�ʂ�����̐��\��L2��3����1)
����ȒP���Ȃ��̂���Ȃ�����
�L���b�V���̕K�v�e�ʂ̓\�t�g�ɂ���ĕς��A�N���b�N���Z�ƌ����Ă��ғ��\�t�g�ɂ���ă}�`�}�`�Ȃ̂������
���ۃL���b�V���s���ő啝�ɑ��x�ቺ���Ă�����̂��N���b�N�ŕ₤�̂͂��Ȃ���
�����Ē��ᑬ�ȃ��������x���l�b�N�ƂȂ邩���
> �l�I��L3��L2��3�{�̗e�ʂ��m�ۂ��ē����ƌ��Ă��邯�ǁA�ǂ����낤(�e�ʂ�����̐��\��L2��3����1)
����ȒP���Ȃ��̂���Ȃ�����
�L���b�V���̕K�v�e�ʂ̓\�t�g�ɂ���ĕς��A�N���b�N���Z�ƌ����Ă��ғ��\�t�g�ɂ���ă}�`�}�`�Ȃ̂������
���ۃL���b�V���s���ő啝�ɑ��x�ቺ���Ă�����̂��N���b�N�ŕ₤�̂͂��Ȃ���
�����Ē��ᑬ�ȃ��������x���l�b�N�ƂȂ邩���
���Ȃ�̏㗬���畽�ς̘b�ɂȂ��Ă�̂������̂��낤��
���̕��ςɈӖ��͖�������
Phenom��X2�����������͓̂��ڃL���b�V���e�ʕs���������̂P��
�L���b�V���s���̈׃Q�[���n�őS�������������E�E�E
������܂��AAMD�Ђ̍L�u�ቿ�i���ɂ��Ԏ��g�刳�k�̍�ł���L���b�V�����炷�v�������A
�uX2�͒��D�G������L���b�V����1M����512K�Ɍ��炵�Ă����v�A�����Ǝ��N���b�N��100MHz�グ�܂�����ˁv
�Ƃ����U��L��Ō떂���������Ƃ���肾�E�E�E
Phenom��X2�����������͓̂��ڃL���b�V���e�ʕs���������̂P��
�L���b�V���s���̈׃Q�[���n�őS�������������E�E�E
������܂��AAMD�Ђ̍L�u�ቿ�i���ɂ��Ԏ��g�刳�k�̍�ł���L���b�V�����炷�v�������A
�uX2�͒��D�G������L���b�V����1M����512K�Ɍ��炵�Ă����v�A�����Ǝ��N���b�N��100MHz�グ�܂�����ˁv
�Ƃ����U��L��Ō떂���������Ƃ���肾�E�E�E
�����m�I��Q�҂�
�e�w�Ȃ̂͂����ɋC�Â��Ȃ��ƁB
>>489
���̂��߂̃����R�������Ȃ�
�x���`�o��܂ŕ������ˁ@�����`�l�c���q�����������̂̓Q�[�}�[���ƔF�����Ă�͂�
���҂͏o����Ǝv���@L�R�ŃQ�[�����\�オ��Ƃ͂��܂�v���Ȃ�����
���̂��߂̃����R�������Ȃ�
�x���`�o��܂ŕ������ˁ@�����`�l�c���q�����������̂̓Q�[�}�[���ƔF�����Ă�͂�
���҂͏o����Ǝv���@L�R�ŃQ�[�����\�オ��Ƃ͂��܂�v���Ȃ�����
11���ɃI�[�X�`���ōs��ꂽAMD�̃C�x���g�ł�Phenom II�̉t�̒��f��p��6GHz�������H�̘b�ȍ~�APhenom II�̃I�[�o�[�N���b�N�ϐ��Ɋ��҂��W�܂��Ă��܂����ACPU-Z��Validation database��OCWRDB�ɂ�6G�I�[�o�[�̋L�^���o�^����n�߂܂����B
CPU-Z - Hall of Fame�̃g�b�v3�͂������Phenom II X4 940(3.0G)��6G�I�[�o�[�������A4��5�ʂ�6G�ɋ߂��N���b�N���o�^����Ă��܂��B
1) Phenom II X4 940�F 6221.19MHz (200.68x31)�AASUS M3A79-T DELUXE
2) Phenom II X4 940�F 6168.93MHz (212.72x29)�AASUS M4A79 Deluxe�H
3) Phenom II X4 940�F 6020.16MHz (200.67x30)�AASUS M3A79-T DELUXE
CPU-Z - Hall of Fame�̃g�b�v3�͂������Phenom II X4 940(3.0G)��6G�I�[�o�[�������A4��5�ʂ�6G�ɋ߂��N���b�N���o�^����Ă��܂��B
1) Phenom II X4 940�F 6221.19MHz (200.68x31)�AASUS M3A79-T DELUXE
2) Phenom II X4 940�F 6168.93MHz (212.72x29)�AASUS M4A79 Deluxe�H
3) Phenom II X4 940�F 6020.16MHz (200.67x30)�AASUS M3A79-T DELUXE
�Ђǂ���{�c���\
Intel��45nm���g�����W�X�^�������ǂ��Ƃ���>>390�̘b��
�I�[�o�[�N���b�N�ϐ��ɂ�����Ă��Ȃ����ˁB
���[�N�d���}���Ĕ��M�h����45nm�̂܂�6GHz�܂ōs����Ƃ������ŁA
���������ȊO�ł̐��\����̊��҂ɂ�wktk�ł��B
�I�[�o�[�N���b�N�ϐ��ɂ�����Ă��Ȃ����ˁB
���[�N�d���}���Ĕ��M�h����45nm�̂܂�6GHz�܂ōs����Ƃ������ŁA
���������ȊO�ł̐��\����̊��҂ɂ�wktk�ł��B
IEDM�ł̔��\����������Intel�̕����g�����W�X�^�̐��\�͍������ǂˁB
�Ƃ͌������i�Ƃ͓d�����Ⴄ�̂Ő��i�łł�AMD�̕����L���Ȃ̂����B
HKMG�������Ă��\������ȁB
�Ƃ͌������i�Ƃ͓d�����Ⴄ�̂Ő��i�łł�AMD�̕����L���Ȃ̂����B
HKMG�������Ă��\������ȁB
�X�̐��\���ǂ��Ă��o�����X�������Ƃ����̂���т��Ă���Ǝv��
���̉�Ђ̂ɂ�
���̉�Ђ̂ɂ�
�̂���A��̔�ꖇ�łȂ�Ƃ��������������
�S�p�p����������C���������z������ȁB
>>355
PhenomII 940BE��QX9650�ɒǂ��������ǂ������ˁB
�ǂ�����Ȃ�Intel�Ƃ̍��̓v���Z�X���������̖�P�N���݂̂ƂȂ�B
���O���Q9550�Ƃ����������炢�̊��������B
PhenomII 940BE��QX9650�ɒǂ��������ǂ������ˁB
�ǂ�����Ȃ�Intel�Ƃ̍��̓v���Z�X���������̖�P�N���݂̂ƂȂ�B
���O���Q9550�Ƃ����������炢�̊��������B
AMD�v���Z�X�̎_�������̕ψ�
90nm�@1.05nm
65nm�@1.05nm
45nm�@1.2nm
45nm�Ŗ����オ���Ă�̂Ƀg�����W�X�^�̐��\���オ���Ă�̂������ȁB
�ޗ��ς����낤���B
���Ȃ݂�Intel��65nm�͎_��������1.2nm�Ȃ̂ł���܂ł�
AMD�̕����Q�[�g���[�N�͑��������\���������ȁB
65nm�̏o���������ƌ����Ă�̂́A90nm�Ɣ�ׂăQ�[�g���[�N����
���������ǁA�T�u�X���b�V�����h���[�N�����債���������炩���B
90nm�@1.05nm
65nm�@1.05nm
45nm�@1.2nm
45nm�Ŗ����オ���Ă�̂Ƀg�����W�X�^�̐��\���オ���Ă�̂������ȁB
�ޗ��ς����낤���B
���Ȃ݂�Intel��65nm�͎_��������1.2nm�Ȃ̂ł���܂ł�
AMD�̕����Q�[�g���[�N�͑��������\���������ȁB
65nm�̏o���������ƌ����Ă�̂́A90nm�Ɣ�ׂăQ�[�g���[�N����
���������ǁA�T�u�X���b�V�����h���[�N�����債���������炩���B
�܂��A���������̂ɔ������������₷���Ȃ��˂��B
�����ʼn�H�̒������Z���Ȃ�Β�R�͌���
����ʼn�H�̉����������Ȃ��Ēf�ʐς�����ƒ�R�͋t�ɑ�����
�������H�̕��������Ȃ�قǍ����͋t�ɑ��₵�Ă���Ēf�ʐς��m�ۂ��Ȃ���Ȃ�Ȃ�
�ł��[����H����鐻���Z�p�̊J���͊ȒP����Ȃ�����Z�p�͂̍����o��
���Ȃ݂ɁAHKMG�������Ă�����ɕC�G�����Z�p������Γ����\�A�����͏���`�b�v�͍��邾�낤���E�E�E
�����R�X�g����������Α̗͕�������
AMD��CPU�̐����R�X�g��Intel��7�`8���葝���Ƃ����b�����邩��AAMD��45nm�����������ł͊�ׂȂ�
����ʼn�H�̉����������Ȃ��Ēf�ʐς�����ƒ�R�͋t�ɑ�����
�������H�̕��������Ȃ�قǍ����͋t�ɑ��₵�Ă���Ēf�ʐς��m�ۂ��Ȃ���Ȃ�Ȃ�
�ł��[����H����鐻���Z�p�̊J���͊ȒP����Ȃ�����Z�p�͂̍����o��
���Ȃ݂ɁAHKMG�������Ă�����ɕC�G�����Z�p������Γ����\�A�����͏���`�b�v�͍��邾�낤���E�E�E
�����R�X�g����������Α̗͕�������
AMD��CPU�̐����R�X�g��Intel��7�`8���葝���Ƃ����b�����邩��AAMD��45nm�����������ł͊�ׂȂ�
> AMD��CPU�̐����R�X�g��Intel��7�`8���葝��
�܂��������Ȃ�Ƃ����Ȃ��ƁA�V�F�A���₹�Α��₷�قǐԎ������݂������B
�܂��������Ȃ�Ƃ����Ȃ��ƁA�V�F�A���₹�Α��₷�قǐԎ������݂������B
�A�����J�̃A�i���X�g���C���e����8�������̃R�X�g���������Ă�
���̑��������̃R�X�g�͂قƂ��SOI�ɔ�₳��Ă���ċL�������Ă��悤�ȁE�E�E
���ۂǂ̂��炢���͂킩��ASOI���R�X�g�ɂ�����
�傫�Ȕ�d�������Ă�̂͊m��
���̑��������̃R�X�g�͂قƂ��SOI�ɔ�₳��Ă���ċL�������Ă��悤�ȁE�E�E
���ۂǂ̂��炢���͂킩��ASOI���R�X�g�ɂ�����
�傫�Ȕ�d�������Ă�̂͊m��
> �܂��������Ȃ�Ƃ����Ȃ��ƁA�V�F�A���₹�Α��₷�قǐԎ������݂�����
����͓��ʋC�ɂ��Ȃ��Ă悢�̂ł�?
�V�F�A�͍��㌸������Ɨ\�z������
����͓��ʋC�ɂ��Ȃ��Ă悢�̂ł�?
�V�F�A�͍��㌸������Ɨ\�z������
�f�X�N�g�b�v�s���PhenomII��Regor�ŏ\���킦��������
�T�[�o�s�ꂪNehalem�ɍ������������čs���ꂻ�����ȁB
�T�[�o�s�ꂪNehalem�ɍ������������čs���ꂻ�����ȁB
����邾�낤���ǁA�����������Ď��͂Ȃ����낤�B
HTT���x���`���ʂŐ��������o�Ă��Ă��A
���ۂł͂ǂ̒��x�̍����o�邩�킩��Ȃ����A
���������T�[�o�[�����ł�Off�ɂ����\��������B
�ꂵ���Ȃ邱�Ƃɂ͕ς�肪�Ȃ����B
HTT���x���`���ʂŐ��������o�Ă��Ă��A
���ۂł͂ǂ̒��x�̍����o�邩�킩��Ȃ����A
���������T�[�o�[�����ł�Off�ɂ����\��������B
�ꂵ���Ȃ邱�Ƃɂ͕ς�肪�Ȃ����B
SOI�ł͗��v�o�Ȃ�
SOI�łȂ���ΐ��\�łԂ�������
������AMD�V�F�A50%�Ȃ�Ė��̂܂����̐��E�ȃC���^�[�l�b�c�ł���
SOI�łȂ���ΐ��\�łԂ�������
������AMD�V�F�A50%�Ȃ�Ė��̂܂����̐��E�ȃC���^�[�l�b�c�ł���
>>512
20%��10%�ɂȂ�����\���u���������v����Ȃ����ȁB
20%��10%�ɂȂ�����\���u���������v����Ȃ����ȁB
>>514
������
������
>>504
cp�ǂ���Ώ\�������ɂȂ�ȁ@����ddr2�ŏ\������@�o�J�����}�U�[������Ȃ���
cp�ǂ���Ώ\�������ɂȂ�ȁ@����ddr2�ŏ\������@�o�J�����}�U�[������Ȃ���
�ł�SOI���ăv���Z�X���ׂ����Ȃ�قnj��ʂ��傫���Ȃ��Ȃ���������
>>517
IBM���O�ɁA�v���Z�X���i�ނق�SOI�ɂ��R�X�g���͑��ΓI�ɏ������Ȃ�Ɣ��\���Ă��ȁB
IBM���O�ɁA�v���Z�X���i�ނق�SOI�ɂ��R�X�g���͑��ΓI�ɏ������Ȃ�Ɣ��\���Ă��ȁB
519 �FSocket774�F2008/12/24(��) 18:00:27 ID:ozBDR96k
130nm 90nm 65nm 45nm�E�E�E
�������낻��PD-SOI�͍������ɐ��\�������Ƃ������ƂŌ��_���Ă������낤�B
Intel��������Bulk�v���Z�X�Ŋ撣���Ă����B
>>517
����͑���FD-SOI�B
��������Intel����������B
http://techon.nikkeibp.co.jp/article/NEWS/20061214/125404/
�������낻��PD-SOI�͍������ɐ��\�������Ƃ������ƂŌ��_���Ă������낤�B
Intel��������Bulk�v���Z�X�Ŋ撣���Ă����B
>>517
����͑���FD-SOI�B
��������Intel����������B
http://techon.nikkeibp.co.jp/article/NEWS/20061214/125404/
�ܘ_�����ւڂ��N�[���[����Ȃ����|���Ă̋�₾���
�����蔲���Ɖ��g���Ă���������
�����蔲���Ɖ��g���Ă���������
������4.2GHz���炢��������Ȃ������H
>>522
���Ƃ�����HP��p��5G��ʂ���
���Ƃ�����HP��p��5G��ʂ���
524 �FSocket774�F2008/12/24(��) 19:39:35 ID:15wJl175
Turion�~4�o����
��Nehalem�ŕ����Ă���̂��ĒP���Ƀ������ш�̍�����Ȃ����H
2chDDR2-800or667��3chDDR3-1066�Ȃ�ш悪��҂̕����{���邵�A���ꂪ���̂܂܃x���`�̐����ƂȂ��ďo�Ă����̂�
2WayNehalem��4wayOP�ɏ����Ă��܂������ƌl�I�Ɍ��Ă�����ǂ�(������HT�͂���܂�W�Ȃ�)
������Istanbul��4ch�Ȃ�t�]�\�A3ch�Ȃ�݊p�ŃV�F�A����n�A2ch�Ȃ�Op�I���Ǝv��
2chDDR2-800or667��3chDDR3-1066�Ȃ�ш悪��҂̕����{���邵�A���ꂪ���̂܂܃x���`�̐����ƂȂ��ďo�Ă����̂�
2WayNehalem��4wayOP�ɏ����Ă��܂������ƌl�I�Ɍ��Ă�����ǂ�(������HT�͂���܂�W�Ȃ�)
������Istanbul��4ch�Ȃ�t�]�\�A3ch�Ȃ�݊p�ŃV�F�A����n�A2ch�Ȃ�Op�I���Ǝv��
527 �FSocket774�F2008/12/24(��) 21:00:13 ID:ozBDR96k
mid09 Istanbul (Socket F) �� 2H09 Beckton �� 4Q09 Westmere �� 1H10 Sao Paolo (Socket G34)
�L�������ƃA�o�E�g
�L�������ƃA�o�E�g
Nehalem�����[��3ch�Ȃ̂́A4ch���d�͂Ƃ���ՃR�X�g�Ƃ��g�[�^���ł݂�
�r�~���[������Ȃ̂ł͂Ȃ����˂��B
����Ƃ�32bit��Windows��3GB�܂ł�����?
�r�~���[������Ȃ̂ł͂Ȃ����˂��B
����Ƃ�32bit��Windows��3GB�܂ł�����?
529 �F,,�E�L�́M�E,,�j��-�������F2008/12/24(��) 21:16:14 ID:UYorAobG
���[�J�[��BTO���Ă݂�A�قƂ��6GB��Vista x64����B
�n�C�G���h�Q�[���͂ǂ݂̂��r�f�I�J�[�h�̃�������Ԃ̐����64�r�b�gOS�K�{�ɂȂ���邩��
���������ʂ̈ڍs�͉�������Ǝv����B
���Ƃ͎��Ӌ@�탁�[�J�[���B
���܂ł�32bit�p�̃h���C�o�������Ȃ�IODATA�Ƃ��o�b�t�@���[�Ƃ��ׂ�Ȃ��Ƒʖڂ��ˁB
�n�C�G���h�Q�[���͂ǂ݂̂��r�f�I�J�[�h�̃�������Ԃ̐����64�r�b�gOS�K�{�ɂȂ���邩��
���������ʂ̈ڍs�͉�������Ǝv����B
���Ƃ͎��Ӌ@�탁�[�J�[���B
���܂ł�32bit�p�̃h���C�o�������Ȃ�IODATA�Ƃ��o�b�t�@���[�Ƃ��ׂ�Ȃ��Ƒʖڂ��ˁB
>>525
�̃������ш�̘b�����ɐ����������Ƃ��Ă��A
8�R�A��Nehalem-EX��FB-DIMM2�C���^�[�t�F�C�X�g����4ch������A
�P��4ch�����邾���ł͏�ʐ��i�ł͕������Ⴄ���ǁB
�̃������ш�̘b�����ɐ����������Ƃ��Ă��A
8�R�A��Nehalem-EX��FB-DIMM2�C���^�[�t�F�C�X�g����4ch������A
�P��4ch�����邾���ł͏�ʐ��i�ł͕������Ⴄ���ǁB
���r�f�I�J�[�h�̃�������Ԃ̐����64�r�b�gOS�K�{
������Ăǂ�Ȑ���������́H
������Ăǂ�Ȑ���������́H
64bit��Windows Vista�ł��������Ȃ��n�C�G���h�Q�[������Ɏ��ʂƎv���B
533 �F,,�E�L�́M�E,,�j��-�������F2008/12/24(��) 21:39:48 ID:UYorAobG
�������ш悾���グ�Ă����Z�\�͂��ǂ����Ȃ��Ɛ��\�͏o�Ȃ��킯�łȁB
�܂�6�R�A��Istanbul�Ȃ�Nehalem�Ƃ͂��������ł��������B
�܂�6�R�A��Istanbul�Ȃ�Nehalem�Ƃ͂��������ł��������B
>>533
�Ȃ�Ń��C����������VGA��VRAM���Z�O�����g�ɒu���K�v������H
�Ȃ�Ń��C����������VGA��VRAM���Z�O�����g�ɒu���K�v������H
536 �F,,�E�L�́M�E,,�j��-�������F2008/12/24(��) 21:46:11 ID:UYorAobG
>>535
�܂�PSE���L���Ȃ炻����\���낤����
�܂�PSE���L���Ȃ炻����\���낤����
GPU�ɐڑ����ꂽVRAM�́ACPU�̃A�h���X��Ԃɂ��}�b�v����邪�A�S�Ăł͂Ȃ��B
���Ƃ���VRAM2GB�̃r�f�I�J�[�h��ڑ���������Ƃ����āA
32bit OS�Ń��C����������2GB�����ɐ��ꂽ��͂��Ȃ��B
�����炭256MB���x��L���邾���ł��낤�B
���Ƃ���VRAM2GB�̃r�f�I�J�[�h��ڑ���������Ƃ����āA
32bit OS�Ń��C����������2GB�����ɐ��ꂽ��͂��Ȃ��B
�����炭256MB���x��L���邾���ł��낤�B
538 �F,,�E�L�́M�E,,�j��-�������F2008/12/24(��) 22:00:00 ID:UYorAobG
�܁A���������ǂ��B64bit���ƃ��j�A�ɃA�h���b�V���O�ł�����ăp�t�H�[�}���X��̗��_�����邵�A
32bit�A�v���ł�1�v���Z�X������̘_���A�h���X��4GB�܂Ŏg����悤�ɂȂ���B
32bit�A�v���ł�1�v���Z�X������̘_���A�h���X��4GB�܂Ŏg����悤�ɂȂ���B
�����͂��������r�炷��
���Ȃ݂�64bit�����ւ̍œK���Ƃ����̂��ANehalem����ւ̈ڍs��
AMD�������Z�[���X�|�C���g��1������A�����ł���B
AMD�������Z�[���X�|�C���g��1������A�����ł���B
541 �F,,�E�L�́M�E,,�j��-�������F2008/12/24(��) 23:04:09 ID:UYorAobG
�Ƃ͂����Ă�Nehalem��64bit�ł̐��\���P����Active Register�̖{�������Ȃ��������瑝�₵�����炢�Ȃ��ǁB
�C�X���G���`�[���I�ɂ͏���d�͂𑝂₵�����Ȃ���������P�`���Ă����̂��^���B
�T�[�o�E�n�C�G���h�f�X�N�g�b�v�����ɂ͂������ǃ��o�C�������Ƃ��Ă͔����ȃv���Z�b�T�ɂȂ�ˁB
�C�X���G���`�[���I�ɂ͏���d�͂𑝂₵�����Ȃ���������P�`���Ă����̂��^���B
�T�[�o�E�n�C�G���h�f�X�N�g�b�v�����ɂ͂������ǃ��o�C�������Ƃ��Ă͔����ȃv���Z�b�T�ɂȂ�ˁB
>>537
����ς�������ˁB
�r�f�I�J�[�h�̃������͕ʘg�����ĕ����Ă�����
64bit����Ȃ��Ɛ����������ĕ����ĂȂς��Ǝv������B
����ς�������ˁB
�r�f�I�J�[�h�̃������͕ʘg�����ĕ����Ă�����
64bit����Ȃ��Ɛ����������ĕ����ĂȂς��Ǝv������B
���C����Video�����j�A�A�h���X�ŊǗ��ł�����PCI-E�C���^�[�t�F�C�X��
�܂����ł��Ă��p�t�H�[�}���X��̗��_������́H
�v���O���~���O���y�ɂȂ邾���̂悤�ȋC�����邪
�܂����ł��Ă��p�t�H�[�}���X��̗��_������́H
�v���O���~���O���y�ɂȂ邾���̂悤�ȋC�����邪
544 �FSocket774�F2008/12/25(��) 02:19:58 ID:vNVs/SPs
3000+����E8500�ɕς������ǁA
�A�v���N���Ȃǂ̓��얈�Ɉ�u�Ԃ������悤�Ȋ��o��������悤�ɂȂ����B
�Q�[���E�G���R���͔�r�ɂȂ�A���̑��̓_�ł�Athlon�X���[�Y���Ă̂͂ق�Ƃ��Ǝv���B
�������R���g���[���[�����̍����낤���ANehalem�܂ł�������H�͎���Ȃ��Ǝv����B
�T�N�T�N�����Ⴄ���Ă̂͂킩���ł��Ȃ��BE8400����6000+��
�ς����甽������������������B�ł�OS���ꂽ�Ăő�������
������������Ȃ��B �ł�E8500��Q8300��OS����ւ����Ƃ���
�͕ς�����悤�ɂ͎v���Ȃ������ȁB
�ł�Q8300�E�b�p������[email protected]�ɕς������A�̊��Ńg������
������Ă��Ƃ��Ȃ����Ȃ�
C2D�͑����̏������Ԃ͑������ǃv�`�v�`���������邩�烁�C���Ɏg�����Ƃ͎v���
���������镨����������PC���u�Ŏg���Ă�B
���삳���Ă��PC�G��Ȃ��悤�ȏd�������Ƃ��ȊO�ŁA���ʂ�PC�g���Ȃ�X2�����C���Ŏg���Ă�B
�x���`�ł�������̗L�����͂��낤�Ƃ��Ă�n�������邯�ǁA
���l��ł͌덷�Ƃ��������悤�̂Ȃ����l������Ӗ�������ȁB
�̊��ł̓R���}���b�Ƃ��ł�������l�͊����邵�B
�C���e����C�o�t��
�P�P�̍�Ƃ̑����͂���ς��������ǁA���傱���傱���������銴���������ȏ�ɃX�g���X����E�E�E
Phenom���p���Ă邯�ǁA�Q�[����Core2�����K�Ƃ͎g����
�Ă��S�������Ȃ��ȁB�g�b�v�X�s�[�h��Core2�̂ق���
OC�}�[�W�����݂ŗy���ɏ�ł���B
�����}���`�X���b�h�Ƃ����������̃X���b�h�������ɑ���ŁA
�R�A���ꂼ�ꂪOS�S�̂̑��x�ቺ���N�������ɏo�����Ɨ�
���ĈӖ��ł�Core2���D�G�B
CoreMA�Ɣ�r�����F1�}�V���ƃ����[�J�[���ׂĂ�悤��̲ݷ�B
�������Ⴂ�����B
�A�v���N���Ȃǂ̓��얈�Ɉ�u�Ԃ������悤�Ȋ��o��������悤�ɂȂ����B
�Q�[���E�G���R���͔�r�ɂȂ�A���̑��̓_�ł�Athlon�X���[�Y���Ă̂͂ق�Ƃ��Ǝv���B
�������R���g���[���[�����̍����낤���ANehalem�܂ł�������H�͎���Ȃ��Ǝv����B
�T�N�T�N�����Ⴄ���Ă̂͂킩���ł��Ȃ��BE8400����6000+��
�ς����甽������������������B�ł�OS���ꂽ�Ăő�������
������������Ȃ��B �ł�E8500��Q8300��OS����ւ����Ƃ���
�͕ς�����悤�ɂ͎v���Ȃ������ȁB
�ł�Q8300�E�b�p������[email protected]�ɕς������A�̊��Ńg������
������Ă��Ƃ��Ȃ����Ȃ�
C2D�͑����̏������Ԃ͑������ǃv�`�v�`���������邩�烁�C���Ɏg�����Ƃ͎v���
���������镨����������PC���u�Ŏg���Ă�B
���삳���Ă��PC�G��Ȃ��悤�ȏd�������Ƃ��ȊO�ŁA���ʂ�PC�g���Ȃ�X2�����C���Ŏg���Ă�B
�x���`�ł�������̗L�����͂��낤�Ƃ��Ă�n�������邯�ǁA
���l��ł͌덷�Ƃ��������悤�̂Ȃ����l������Ӗ�������ȁB
�̊��ł̓R���}���b�Ƃ��ł�������l�͊����邵�B
�C���e����C�o�t��
�P�P�̍�Ƃ̑����͂���ς��������ǁA���傱���傱���������銴���������ȏ�ɃX�g���X����E�E�E
Phenom���p���Ă邯�ǁA�Q�[����Core2�����K�Ƃ͎g����
�Ă��S�������Ȃ��ȁB�g�b�v�X�s�[�h��Core2�̂ق���
OC�}�[�W�����݂ŗy���ɏ�ł���B
�����}���`�X���b�h�Ƃ����������̃X���b�h�������ɑ���ŁA
�R�A���ꂼ�ꂪOS�S�̂̑��x�ቺ���N�������ɏo�����Ɨ�
���ĈӖ��ł�Core2���D�G�B
CoreMA�Ɣ�r�����F1�}�V���ƃ����[�J�[���ׂĂ�悤��̲ݷ�B
�������Ⴂ�����B
Windows�݂����ȁA�����牞������������Ƀo�b�N�O���E���h�ő�ʂɗ]�v��
�T�[�r�X�������V�X�e���ŁACPU�̋������u�̊��v����͖̂������ƁB
�܂��u���Z�{�����h�Ȍ��ʂȂ̂ł����ł����ǁB
�T�[�r�X�������V�X�e���ŁACPU�̋������u�̊��v����͖̂������ƁB
�܂��u���Z�{�����h�Ȍ��ʂȂ̂ł����ł����ǁB
546 �F,,�E�L�́M�E,,�j��-�������F2008/12/25(��) 02:44:30 ID:13RGDD9z
Windows���v��Ȃ��T�[�r�X��Ό��\�y���Ȃ��B
���������H��Ȃ��Ȃ邵�B
���������H��Ȃ��Ȃ邵�B
��������A���[�́u�̊��v���������肾�������w
��ϓI�Ŗ������ȁu�̊��v������
��ϓI�Ŗ������ȁu�̊��v������
548 �F,,�E�L�́M�E,,�j��-�������F2008/12/25(��) 04:38:46 ID:13RGDD9z
�̊��Ȃ�ĐM�ҕ���Ă������u��]�v�̋�����₷�����̂����瓖�ĂɂȂ�Ȃ����
�u���C���h�e�X�g�Ńv���V�[�{���ʔr�������炱�̌��ʂ������
http://www.dosv.jp/feature/0606/index.htm
> �ǂ̃}�V���������Ƃ������Ɗ����܂������H
> Core Duo�}�V���@�@�@�@�@�@�@�@�@�@11�l
> Athlon 64 X2�}�V���@�@�@�@�@�@�@�@6�l
> Pentium 4�}�V���@�@�@�@�@�@�@�@�@�@3�l
�u���C���h�e�X�g�Ńv���V�[�{���ʔr�������炱�̌��ʂ������
http://www.dosv.jp/feature/0606/index.htm
> �ǂ̃}�V���������Ƃ������Ɗ����܂������H
> Core Duo�}�V���@�@�@�@�@�@�@�@�@�@11�l
> Athlon 64 X2�}�V���@�@�@�@�@�@�@�@6�l
> Pentium 4�}�V���@�@�@�@�@�@�@�@�@�@3�l
549 �FSocket774�F2008/12/25(��) 06:16:48 ID:C+UwG6ec
591 ���O�FSocket774 [sage]�F 2008/06/06(��) 20:57:46 ID:+e+B88mm
���X�����ǁA�������Ń|�`���Ă��܂������ǖZ�����ĕ��u���Ă�����E7200��
�悤�₭�J�������B�J���邾���J���Ē��߂Ă�4850e�ƍ��킹�ĂƂ肠�����v��
2350�͉ғ����Ȃ̂ŁA���͗]�蕨�Ŕ�r
�ȉ����ʁ@(�����̂��q���ς��ăC���X�g�[��)
�yHDD�z HITACHI HDT725050VLA360 500G 3.5
�y���w�z �Ȃ�
�y�������z UMAXPulsar DDR800 2Gx1
�y�d���z ���l500W
�yFAN�z �Ȃ��@�܂Ȕ�
�yVGA�ASound�ALAN�z �I���{�[�h�@LAN�͖��ڑ�
�yOS�z Windows XP SP3
�ǂ�����C���X�g�[����A�p�b�`�����ĂĒ�i��CnQEIST����
�d����VID�ʂ�̃f�t�H��Ԃ̑f
�yCPU�z Athlon X2 4850e�iTDP45W�Ɛ�`�j
�yM/B�z JW-RS780UVD-AM2+ 64M orz
�A�C�h���@35W
����(ORTHOS) 82W
�yCPU�z C2D E7200�iTDP65W)
�yM/B�z Gigabyte GA-G33M-DS2R
�A�C�h���@40W
����(ORTHOS) 62W
���\��E7200>>>>>>>>>�S�~4850e
���X�����ǁA�������Ń|�`���Ă��܂������ǖZ�����ĕ��u���Ă�����E7200��
�悤�₭�J�������B�J���邾���J���Ē��߂Ă�4850e�ƍ��킹�ĂƂ肠�����v��
2350�͉ғ����Ȃ̂ŁA���͗]�蕨�Ŕ�r
�ȉ����ʁ@(�����̂��q���ς��ăC���X�g�[��)
�yHDD�z HITACHI HDT725050VLA360 500G 3.5
�y���w�z �Ȃ�
�y�������z UMAXPulsar DDR800 2Gx1
�y�d���z ���l500W
�yFAN�z �Ȃ��@�܂Ȕ�
�yVGA�ASound�ALAN�z �I���{�[�h�@LAN�͖��ڑ�
�yOS�z Windows XP SP3
�ǂ�����C���X�g�[����A�p�b�`�����ĂĒ�i��CnQEIST����
�d����VID�ʂ�̃f�t�H��Ԃ̑f
�yCPU�z Athlon X2 4850e�iTDP45W�Ɛ�`�j
�yM/B�z JW-RS780UVD-AM2+ 64M orz
�A�C�h���@35W
����(ORTHOS) 82W
�yCPU�z C2D E7200�iTDP65W)
�yM/B�z Gigabyte GA-G33M-DS2R
�A�C�h���@40W
����(ORTHOS) 62W
���\��E7200>>>>>>>>>�S�~4850e
�Ȃ��AMD�͏���d�͂ʼnR���Ă܂Ŕ��낤�Ƃ����H
�u���C���h�e�X�g���Ɖ��肷���i7 965�ƃZ����D�����ʂ��Ȃ�������
���~�͂ǂ����x���`�}�[�N�ɗx�炳��߂��Ĕn���݂�����
�����铹��͑̊������d�v���낤�B���ꂵ���g���₷���}�E�X��L�[�{�[�h�Ƃ��̂��C�ɓ���̈���͂�����B
CPU�̏u�ԓI�Ŕ����ȃ��X�|���X�������B
�x���`�}�[�N�Ȃ̏��F�Ɉꕔ�̃R�[�h��f�[�^���Ђ�����J��Ԃ������̂��̂�CPU�̑S�Ă����܂�Ȃ�čl����ق����ǂ������Ă�B
���������A�C���e���̃R�A��L���b�V���̍\���͐��Ƀx���`�}�[�N��ɖ��|���Ă܂�������ȁA�n���Ȉ��~�����Ⴂ����͎̂d���������B
���~�͂ǂ����x���`�}�[�N�ɗx�炳��߂��Ĕn���݂�����
�����铹��͑̊������d�v���낤�B���ꂵ���g���₷���}�E�X��L�[�{�[�h�Ƃ��̂��C�ɓ���̈���͂�����B
CPU�̏u�ԓI�Ŕ����ȃ��X�|���X�������B
�x���`�}�[�N�Ȃ̏��F�Ɉꕔ�̃R�[�h��f�[�^���Ђ�����J��Ԃ������̂��̂�CPU�̑S�Ă����܂�Ȃ�čl����ق����ǂ������Ă�B
���������A�C���e���̃R�A��L���b�V���̍\���͐��Ƀx���`�}�[�N��ɖ��|���Ă܂�������ȁA�n���Ȉ��~�����Ⴂ����͎̂d���������B
J.P. Morgan��Dell��HP�̒����ɂ��ƁA���l������Intel�̃V�F�A��2%�L�тĂ���Ƃ̂��Ƃ��B
http://www.xbitlabs.com/news/cpu/display/20081223103209_Intel_Gains_Market_Share_as_a_Result_of_Design_Wins_with_Dell_and_HP.html
�@�@-------------------
�@�@Intel�fs share at Dell increased from 95% in August 2008 to 97% in December 2008, while
�@�@its share at Hewlett Packard increased from 65% in August 2008 to 67% in December 2008,
�@�@according to a note by J.P. Morgan for clients.
�@�@[����]
�@�@In servers, Intel�fs share of Dell and HP offerings was roughly flat at 72% from August 2008
�@�@to December 2008,
�@�@-------------------
http://www.xbitlabs.com/news/cpu/display/20081223103209_Intel_Gains_Market_Share_as_a_Result_of_Design_Wins_with_Dell_and_HP.html
�@�@-------------------
�@�@Intel�fs share at Dell increased from 95% in August 2008 to 97% in December 2008, while
�@�@its share at Hewlett Packard increased from 65% in August 2008 to 67% in December 2008,
�@�@according to a note by J.P. Morgan for clients.
�@�@[����]
�@�@In servers, Intel�fs share of Dell and HP offerings was roughly flat at 72% from August 2008
�@�@to December 2008,
�@�@-------------------
554 �FSocket774�F2008/12/25(��) 06:57:35 ID:MViLJhin
�Ȃ�ň��~�͎�����X���ŃV�F�A�⋌����̔�r�Ƃ��̓��������b�肵�����Ȃ���B
���Ƃ͓Ƌ֖@�ᔽ�C�ł��鈫�̊�Ƃ�����A�̐��\�ǂ��Ă������ɒl���Ȃ��B
�x���`�}�[�N���S�Ă̓��������n������������������B
���Ƃ͓Ƌ֖@�ᔽ�C�ł��鈫�̊�Ƃ�����A�̐��\�ǂ��Ă������ɒl���Ȃ��B
�x���`�}�[�N���S�Ă̓��������n������������������B
555 �F,,�E�L�́M�E,,�j��-�������F2008/12/25(��) 07:12:50 ID:13RGDD9z
�u���s����ł͑̊����x�͏����Ă�ɈႢ�Ȃ��v�ł��ˁB�킩��܂��B
����a�C����
�}�J�[�Ɠ����a�C
����a�C����
�}�J�[�Ɠ����a�C
����A�����̂͂�������
���ꂪ�H�ȂɁH
�z�[�����[�X�ŕK�v�H
4�R�A�H�v��́H���ɁH
8�X���b�h�H�ǂ�����̂���H
celeron430��Radeon HD4550�ŏ\������
���ꂪ�H�ȂɁH
�z�[�����[�X�ŕK�v�H
4�R�A�H�v��́H���ɁH
8�X���b�h�H�ǂ�����̂���H
celeron430��Radeon HD4550�ŏ\������
557 �FMAC�I�^��554 �����F2008/12/25(��) 07:26:38 ID:by/c+D10
>>554
�@�@-----------------
�@�@�Ȃ�ň��~�͎�����X���ŃV�F�A�⋌����̔�r�Ƃ��̓��������b�肵�����Ȃ���B
�@�@-----------------
������u���������b��v�ƍl����̂�A���Ȃ�����Ƃ�̃q�g�����炷�B
�v���Z�b�T�J���ɂ퐔�N�̍Ό����K�v�Ȃ��߁A�����̋Z�p�I�ۑ���Ђ̌o�c���(�����J��
�����z)��4-5�N��Ɍ����Ă��邷�B
�t�Ɍ����A���N�o��̃v���Z�b�T�̐V�@�\��4�N�O�ɖ�莋���ꂽ�_�����ǂ������m�ɉ߂��Ȃ����B
�@�@-----------------
�@�@�Ȃ�ň��~�͎�����X���ŃV�F�A�⋌����̔�r�Ƃ��̓��������b�肵�����Ȃ���B
�@�@-----------------
������u���������b��v�ƍl����̂�A���Ȃ�����Ƃ�̃q�g�����炷�B
�v���Z�b�T�J���ɂ퐔�N�̍Ό����K�v�Ȃ��߁A�����̋Z�p�I�ۑ���Ђ̌o�c���(�����J��
�����z)��4-5�N��Ɍ����Ă��邷�B
�t�Ɍ����A���N�o��̃v���Z�b�T�̐V�@�\��4�N�O�ɖ�莋���ꂽ�_�����ǂ������m�ɉ߂��Ȃ����B
���ɂ����܂Ř_�����̂͂ǂ����Ǝv����
�����Y�ꂽ>>555�ɂ�
8�X���b�h
����
����
����
����
����
����
����
����
���܂����H
����
����
����
����
����
����
����
����
���܂����H
561 �F,,�E�L�́M�E,,�j��-�������F2008/12/25(��) 07:30:55 ID:13RGDD9z
Apple��x86�ڍs�\����̐VMAC�͖ʔ���������
�ux86��CISC������x���IRISC��XScale���̗p����I�v
�Ƃ��B�ާ�����ˁ[�̂���
�܂�IA32�̓N�\�Ƃ�����ς��肫�B���_���肫�B
�ux86��CISC������x���IRISC��XScale���̗p����I�v
�Ƃ��B�ާ�����ˁ[�̂���
�܂�IA32�̓N�\�Ƃ�����ς��肫�B���_���肫�B
562 �F,,�E�L�́M�E,,�j��-�������F2008/12/25(��) 07:36:38 ID:13RGDD9z
�����オ�s�v�Ȑl�����Ă��������ǁA���̃X���Ō������Ƃ���Ȃ��ȁB
Mac��PPC����Intel�ɂȂ����Ƃ��ɂ킴�킴IBM��OS�̃X���܂ł���
�Ȃ��C�����������������Ă���Mac���^�̃X���͂����ł��H
�Ȃ��C�����������������Ă���Mac���^�̃X���͂����ł��H
565 �FMAC�I�^���c�q �����F2008/12/25(��) 07:50:57 ID:by/c+D10
>>561
�@�@---------------
�@�@Apple��x86�ڍs�\����̐VMAC�͖ʔ���������
�@�@---------------
�V�Emac�ŃC�W�����ėǂ�����������Ă��Ȃ��̂헝�����Ă����邷���ǁA�����̋�C��
������̕����ǂ��\�����Ă���Ǝv�����B
http://pc7.2ch.net/test/read.cgi/mac/1118140482/870
�@�@===============
�@�@870 ���O�F���̖��ݒ� ���e���F2005/06/11(�y) 18:37:42 ID:5e1jhuGp
�@�@�@�@�Ȃɂ��날�ꂾ��intel�����̐����̂悤�ɕ]���Ă���
�@�@�@�@Mac�I�^�ȉ��}�J�R�c���Aintel-Mac�ɑO�����Ȃ̂��ʔ����B
�@�@�@�@Jobs���u����܂ł̃J���[�̓E���R�������B���ꂩ��̓E���R�����J���[��!�v
�@�@�@�@�ƌ����Ζ{�C�ŃJ���[���o�J�ɂ��ăE���R��H����������
�@�@===============
�@�@---------------
�@�@Apple��x86�ڍs�\����̐VMAC�͖ʔ���������
�@�@---------------
�V�Emac�ŃC�W�����ėǂ�����������Ă��Ȃ��̂헝�����Ă����邷���ǁA�����̋�C��
������̕����ǂ��\�����Ă���Ǝv�����B
http://pc7.2ch.net/test/read.cgi/mac/1118140482/870
�@�@===============
�@�@870 ���O�F���̖��ݒ� ���e���F2005/06/11(�y) 18:37:42 ID:5e1jhuGp
�@�@�@�@�Ȃɂ��날�ꂾ��intel�����̐����̂悤�ɕ]���Ă���
�@�@�@�@Mac�I�^�ȉ��}�J�R�c���Aintel-Mac�ɑO�����Ȃ̂��ʔ����B
�@�@�@�@Jobs���u����܂ł̃J���[�̓E���R�������B���ꂩ��̓E���R�����J���[��!�v
�@�@�@�@�ƌ����Ζ{�C�ŃJ���[���o�J�ɂ��ăE���R��H����������
�@�@===============
566 �F,,�E�L�́M�E,,�j��-�������F2008/12/25(��) 07:57:49 ID:13RGDD9z
������B
x86����Ȃ���Itanium2�ł�������݂����Ȃ��Ƃ������Ă��B
���͓���WWDC�̎����X�������A���^�C����ROM���Ă����킩���B
x86����Ȃ���Itanium2�ł�������݂����Ȃ��Ƃ������Ă��B
���͓���WWDC�̎����X�������A���^�C����ROM���Ă����킩���B
���킠�r���R�e���Җ\��
568 �FMAC�I�^���c�q �����F2008/12/25(��) 08:03:55 ID:by/c+D10
>>566
���Ɂu�k�ق̓����̃K�C�h���C���v�ʂ�̏������݂���(��)
���Ɂu�k�ق̓����̃K�C�h���C���v�ʂ�̏������݂���(��)
569 �F,,�E�L�́M�E,,�j��-�������F2008/12/25(��) 08:14:11 ID:13RGDD9z
���߂��t���Ȃ��z�͈�l���l����Ȃ��������B
570 �F,,�E�L�́M�E,,�j��-�������F2008/12/25(��) 08:16:46 ID:13RGDD9z
���Ɠ���@���̖^���́uPowerPC�ƐS�����Ă��v�݂����Ȃ��ƌ����Ă�
>>566
Itanium2��������ʔ��������̂ɂȁB�[���猩�Ėʔ������Ă��������ǁB
Itanium2��������ʔ��������̂ɂȁB�[���猩�Ėʔ������Ă��������ǁB
>568
���O�̂����Ɂu�k�ق̓����̃K�C�h���C���v�ʂ�̏������݂���(��)
���O�̂����Ɂu�k�ق̓����̃K�C�h���C���v�ʂ�̏������݂���(��)
>>571
�u�̊��͂��ĂɂȂ�Ȃ��v�̈�
�u�̊��͂��ĂɂȂ�Ȃ��v�̈�
���P���̂P�F�̊��͂��ĂɂȂ�Ȃ�
���P���̂Q�F�l�I�̌��k�͂��ĂɂȂ�Ȃ�
���P���̂R�F�}�X�S�~�͂��ĂɂȂ�Ȃ�
���P���̂S�F�u���O�͂��ĂɂȂ�Ȃ�
���P���̂T�F���[�J�[�̐�`�͂��ĂɂȂ�Ȃ�
���P���̂U�`�W�F�ȗ�
���P���̂X�F2ch�͂��ĂɂȂ�Ȃ�
���P���̂Q�F�l�I�̌��k�͂��ĂɂȂ�Ȃ�
���P���̂R�F�}�X�S�~�͂��ĂɂȂ�Ȃ�
���P���̂S�F�u���O�͂��ĂɂȂ�Ȃ�
���P���̂T�F���[�J�[�̐�`�͂��ĂɂȂ�Ȃ�
���P���̂U�`�W�F�ȗ�
���P���̂X�F2ch�͂��ĂɂȂ�Ȃ�
>>575
���Ⴀ���̃��X���A�e�ɂȂ�Ȃ��Ƃ������Ƃł���
���Ⴀ���̃��X���A�e�ɂȂ�Ȃ��Ƃ������Ƃł���
MAC�I�^ VS �c�q
���҂͂ǂ��炩�A�s���͂ǂ��炩�H��
���҂͂ǂ��炩�A�s���͂ǂ��炩�H��
>>561
�������AApple�M�҂�PowerPC G3�����PentiumII�̔��M���U�X�������낵������
���̌��PentiumM�⌻�݂�Core�Ɍq���������A�܂�G4����Ɂu�M�K�w���c�_�b�v
�Ƃ��������ɂ��݂���AMD���N���b�N��������E�������ۂ̘H���ύX�����ʓI
�ɋ����㉟���������Ȃǂ́Ax86�����悭�i�������邽�߂̊O���Ƃ��Ė��ɗ�������
�v���B
�o�J�ƃn�T�~�͎g���l���A����̌����Ƃ����ׂ���w�A�n���ł��}�J�[�ł�����
�A���`x86�����݂��������Ax86�̏����ɂƂ��Ă̓v���X�ɍ�p����B
�������AApple�M�҂�PowerPC G3�����PentiumII�̔��M���U�X�������낵������
���̌��PentiumM�⌻�݂�Core�Ɍq���������A�܂�G4����Ɂu�M�K�w���c�_�b�v
�Ƃ��������ɂ��݂���AMD���N���b�N��������E�������ۂ̘H���ύX�����ʓI
�ɋ����㉟���������Ȃǂ́Ax86�����悭�i�������邽�߂̊O���Ƃ��Ė��ɗ�������
�v���B
�o�J�ƃn�T�~�͎g���l���A����̌����Ƃ����ׂ���w�A�n���ł��}�J�[�ł�����
�A���`x86�����݂��������Ax86�̏����ɂƂ��Ă̓v���X�ɍ�p����B
���܂ł͋��͂Ɂu�A���`x86�v�̗�������̂�SPARC�M�҂��炢�B
>>577
���|�ꂷ��Ύ���ɕ�������
���|�ꂷ��Ύ���ɕ�������
>>574
�Ȃ�c�b�R�~������悤�ȍ����ɗ���Ȃ��ňӂ������Ȃ���
�Ȃ�c�b�R�~������悤�ȍ����ɗ���Ȃ��ňӂ������Ȃ���
�V�F�A��20%�O���AMD���炵����2%��������A���Ȃ蔄��ɉe�������Ȃ����H
����I�Ɍ����Ƃ��́A���ϒP���̉�����2%�ǂ���ł͂Ȃ��Ǝv���B
>>578
apple�M�҂̐l���Ď��ӎ��ߏ肾��ˁB
Intel��AMD�̋����̌��ʁA��������Intel���g�̊J���\�͂̍����������Ă����Ȃ̂ɁA
�Ȃ�ł��A�b�v���̂������ɂ����Ⴄ�Ƃ��낪������
�����ߋ��ɂ��ꂾ��Intel���������낵�Ă��Ȃ���
Mac�ɍ̗p�����܂�����}�ɑԓx�������̂��������B
apple�M�҂̐l���Ď��ӎ��ߏ肾��ˁB
Intel��AMD�̋����̌��ʁA��������Intel���g�̊J���\�͂̍����������Ă����Ȃ̂ɁA
�Ȃ�ł��A�b�v���̂������ɂ����Ⴄ�Ƃ��낪������
�����ߋ��ɂ��ꂾ��Intel���������낵�Ă��Ȃ���
Mac�ɍ̗p�����܂�����}�ɑԓx�������̂��������B
�c�q�̓h���C�o�Ƃ������Ȃ��̂��ȁB
intel�ݾ����Ă������ICH�̃h���C�o������ė~�������B
intel�ݾ����Ă������ICH�̃h���C�o������ė~�������B
>>571
fanboy�͂��̍���DDR1�̂ق���DDR2��背�C�e���V�����Ȃ��̂ő����Ǝ咣���Ă����A����Ӗ�����Ő�������ˁH
fanboy�͂��̍���DDR1�̂ق���DDR2��背�C�e���V�����Ȃ��̂ő����Ǝ咣���Ă����A����Ӗ�����Ő�������ˁH
GMCH��(ry
���̃h���C�o�͍�����ۂ����w
���̃h���C�o�͍�����ۂ����w
590 �F,,�E�L�́M�E,,�j��-�������F2008/12/25(��) 16:53:37 ID:13RGDD9z
Intel�ڍs�̗���Ɍ}���ł��Ȃ��}�J�[�͋�MAC�Ɉړ������������ƃI��
591 �FSocket774�F2008/12/25(��) 17:07:30 ID:fDEFNVV2
>>543
��32bit��Oracle�̔ߎS�Ȑ��\
��32bit��Oracle�̔ߎS�Ȑ��\
>>591
�r�f�I�̃p�t�H�[�}���X�̌�����DB�̘b�������o���Ă��d���Ȃ��̂ł�
�r�f�I�̃p�t�H�[�}���X�̌�����DB�̘b�������o���Ă��d���Ȃ��̂ł�
593 �F,,�E�L�́M�E,,�j��-�������F2008/12/25(��) 18:05:28 ID:13RGDD9z
Vista x64��8GB�ς�ł邯��GPU�p�Ƀ��C��������2GB���蓖�Ă��Ă�
��������Ԃɗ]�T����Η��Ƀp�t�H�[�}���X�ɉe���o���łˁH
��������Ԃɗ]�T����Η��Ƀp�t�H�[�}���X�ɉe���o���łˁH
>538�@�ɑ���>543�@�̋^��́i�Е���PCI-E�̌��������݂�����
����Ă���ꍇ�Ɂj���C����V�̃A�h���X��Ԃ��������Ă�����
�p�t�H�[�}���X���ڂɌ����ĉ�����̂����Ęb�ŁA
�ǂ���̕��@�ł������e�ʂ̊m�ۂ�z�肵���ꍇ�̍����m�肽����
����Ă���ꍇ�Ɂj���C����V�̃A�h���X��Ԃ��������Ă�����
�p�t�H�[�}���X���ڂɌ����ĉ�����̂����Ęb�ŁA
�ǂ���̕��@�ł������e�ʂ̊m�ۂ�z�肵���ꍇ�̍����m�肽����
595 �F,,�E�L�́M�E,,�j��-�������F2008/12/25(��) 18:59:51 ID:13RGDD9z
�Ƃ肠����Vista x64����f�B�X�N���[�gVGA���g���ƁA�r�f�I�J�[�h����VRAM�����e�ʁi��p�r�f�I�������j
�{���C����������̃r�f�I�p�̈�i���L�V�X�e���������j���u���p�\�ȑS�O���t�B�b�N�������v�̑��e�ʂɂȂ�B
�܂����C�����������̂ق��̓X���b�v�������݂����Ȋ����Ŏg���Ă�Ǝv���邪
�{���C����������̃r�f�I�p�̈�i���L�V�X�e���������j���u���p�\�ȑS�O���t�B�b�N�������v�̑��e�ʂɂȂ�B
�܂����C�����������̂ق��̓X���b�v�������݂����Ȋ����Ŏg���Ă�Ǝv���邪
596 �F,,�E�L�́M�E,,�j��-�������F2008/12/25(��) 19:03:54 ID:13RGDD9z
32�r�b�g����VGA��p�Ƀ��C����������2GB�����蓖�Ă邱�Ǝ��̕s�\����H
1GB���x�����g���Ȃ��Ȃ邩��ȁB
1GB���x�����g���Ȃ��Ȃ邩��ȁB
>>584
http://albany.bizjournals.com/albany/stories/2008/12/01/daily47.html?ana=yfcpc
AMD�̗\�z�́AQ4�̔���グ�O����25%���i�O�N��������33%���j�������ł��B
http://albany.bizjournals.com/albany/stories/2008/12/01/daily47.html?ana=yfcpc
AMD�̗\�z�́AQ4�̔���グ�O����25%���i�O�N��������33%���j�������ł��B
9�l�����A���Ԏ���
�����������́E�E�E�E�ς��`�E�E�E�E
�����ɗ����̂�������荂���R�X�g�ō���Ă���炵�傤���Ȃ��B
�A���J�ԈႦ���@>538
603 �FSocket774�F2008/12/25(��) 21:22:25 ID:/u2MCNXT
Turion�~4�o����
Bulldozer�����͓I�Ȏ�����R�A�Ƃ��ēo�ꂷ�����
�ʂ����Ă���̂��낤��
�ʂ����Ă���̂��낤��
AMD�m�[�g���������悤�Ƃ��Ă邵�A�������}�W�ʼn����������B
����Ȃ����ǁB
����Ȃ����ǁB
intel�����g�������Ƃ̂Ȃ����~�ł����A
x86�n�b�o�t�S�̂̂��߂ɂ��A�����Ƃ`�l�c�ɂ͊撣���Ăق����Ǝv���܂��B
x86�n�b�o�t�S�̂̂��߂ɂ��A�����Ƃ`�l�c�ɂ͊撣���Ăق����Ǝv���܂��B
��TL-50�m�[�g�g���Ă邪���ʂɗǂ����E�E�E�H
AMD���P�ނ�����Intel�͍��@�\CPU�̉��i�������܂肳���đ����ȗ��v���Â邾�낤�ȁB
OS���l��CPU�̐i�����˂��܂�����PC�s�ꂪ���ނ���m���͂��Ȃ荂���B
OS���l��CPU�̐i�����˂��܂�����PC�s�ꂪ���ނ���m���͂��Ȃ荂���B
>>607
�`�b�v�Z�b�g���܂߂čl����ƁA���^B5�m�[�g�ȊO��AMD���x�X�g���Ǝv�����ǂ˂��B
���^B5�m�[�g��AMD��CPU�ƃ`�b�v�Z�b�g���ꂽ��A�ꎞ�Ԓ��x�œd�r�ꂵ����������
�`�b�v�Z�b�g���܂߂čl����ƁA���^B5�m�[�g�ȊO��AMD���x�X�g���Ǝv�����ǂ˂��B
���^B5�m�[�g��AMD��CPU�ƃ`�b�v�Z�b�g���ꂽ��A�ꎞ�Ԓ��x�œd�r�ꂵ����������
http://h50146.www5.hp.com/products/portables/personal/tx2505/specs/amd_athlon_64x2_ql62.html
����Ȃ���3���ԋ�����킯�ŁB
����Ȃ���3���ԋ�����킯�ŁB
>>610
B5�Ŕ��^�m�[�g���Əd�ʂ�1kg�O��Ȃ킯�����E�E�E�B
�������T�C�Y��A4�m�[�g�̃T�C�Y����Ȃ����B
���̃N���X����AMD�̕������������Ǝv����B
B5�Ŕ��^�m�[�g���Əd�ʂ�1kg�O��Ȃ킯�����E�E�E�B
�������T�C�Y��A4�m�[�g�̃T�C�Y����Ȃ����B
���̃N���X����AMD�̕������������Ǝv����B
ttp://pc.watch.impress.co.jp/docs/2008/1226/kaigai483.htm
> ������CPU��DRAM�_�C����������
�����h�C�c�ɍH���u���悵�݂ŁA���܂̂����L�����_�ł������Ă݂Ă͂ǂ����ˁB
�����A���ʂ̒��͋^��Ȃ̂����c�c
> ������CPU��DRAM�_�C����������
�����h�C�c�ɍH���u���悵�݂ŁA���܂̂����L�����_�ł������Ă݂Ă͂ǂ����ˁB
�����A���ʂ̒��͋^��Ȃ̂����c�c
DRAM���ڂ݂����Ȃ͖̂ʔ����������琥�����Ăق����Ȃ�
�ւ���DDR4�Ƃ�����Ȃ��C�Ȃ���
�ւ���DDR4�Ƃ�����Ȃ��C�Ȃ���
���̃R���s���[�^�A�R�A��������������ш����肾���ǁA
�V���O���X���b�h���\�̌����j�Q���Ă���̂̓������̃��C�e���V�B
�L���b�V���K�w���ςݏd�Ȃ�A���C���������͉����Ȃ背�C�e���V�͋t�ɑ�����B
�T�[�o�ƃf�X�N�g�b�v�̐i���̎}�́A������Ŗ��m�ɕ��邵���Ȃ��̂��˂��B
�V���O���X���b�h���\�̌����j�Q���Ă���̂̓������̃��C�e���V�B
�L���b�V���K�w���ςݏd�Ȃ�A���C���������͉����Ȃ背�C�e���V�͋t�ɑ�����B
�T�[�o�ƃf�X�N�g�b�v�̐i���̎}�́A������Ŗ��m�ɕ��邵���Ȃ��̂��˂��B
DRAM���ڂ́APS2�ɂ͂�������PS3�ł͂�߂Ă��܂����B
Wii��GC�������p����1T-SRAM��GPU�ɍ��ڂ��Ă��邪�A24MB�����Ȃ��B
�ʂ�64MB��GDDR3���ڂ��Ă���B
�L�ш�̃����b�g��e�ʁE�R�X�g�̐���ƈꏏ�ɔ��ɂ�����ƁA
�Ȃ��Ȃ��n�}��g�����͌��o���Ȃ��̂ł͂Ȃ��낤���B
Wii��GC�������p����1T-SRAM��GPU�ɍ��ڂ��Ă��邪�A24MB�����Ȃ��B
�ʂ�64MB��GDDR3���ڂ��Ă���B
�L�ш�̃����b�g��e�ʁE�R�X�g�̐���ƈꏏ�ɔ��ɂ�����ƁA
�Ȃ��Ȃ��n�}��g�����͌��o���Ȃ��̂ł͂Ȃ��낤���B
>>612
�̂̊O�t���L���b�V���̕����ł��ˁB������܂��B
�̂̊O�t���L���b�V���̕����ł��ˁB������܂��B
>>614
���C�e���V�C�ɂ���悤�ȃR�[�h���Ń��C���������ɒ��ŃA�N�Z�X���Ăǂ�����B
���C�e���V�C�ɂ���悤�ȃR�[�h���Ń��C���������ɒ��ŃA�N�Z�X���Ăǂ�����B
>>614
�m�b�x�ꂩ�H
�m�b�x�ꂩ�H
�������ɃA�N�Z�X���Ȃ��A�v��������g���Ăǂ�����
�f�[�^�̎Q�Ƃ̋Ǐ����͑��邪�A��ɂ���킯�ł͂Ȃ���B�ɒ[�ȗ�̓X�g���[�������ǁB
���ʂƂ���CPU�́A�����Ȃ�Ȃ�قǁA����������̃f�[�^�̓�����҂���
�߂������Ԃ������Ȃ�B
�ėpDRAM��CPU�_�C�ɒ������čL�ш���������Ă��A���C�e���V�͂����Ȃ��B
���ƁA�L���b�V�����C���̗��x�̖����c��B�����_���A�N�Z�X�ɂ͎ア�܂܂��낤�B
AMD���f�X�N�g�b�v������Propus�ł�L3�L���b�V�����ȗ����ăR�X�g�_�E�����Ă��邱�Ƃ���
�@������悤�ɁA�����X���b�h����ɑ���T�[�o�ł͗L���ȑ�L���b�V�����A
�f�X�N�g�b�v�ł͌��ʂ��������B�����Ă���s�[�X�́A���Ƃ���Rambus��XDR��
�悤�ȃA�v���[�`�Ȃ̂�������Ȃ��B
���ʂƂ���CPU�́A�����Ȃ�Ȃ�قǁA����������̃f�[�^�̓�����҂���
�߂������Ԃ������Ȃ�B
�ėpDRAM��CPU�_�C�ɒ������čL�ш���������Ă��A���C�e���V�͂����Ȃ��B
���ƁA�L���b�V�����C���̗��x�̖����c��B�����_���A�N�Z�X�ɂ͎ア�܂܂��낤�B
AMD���f�X�N�g�b�v������Propus�ł�L3�L���b�V�����ȗ����ăR�X�g�_�E�����Ă��邱�Ƃ���
�@������悤�ɁA�����X���b�h����ɑ���T�[�o�ł͗L���ȑ�L���b�V�����A
�f�X�N�g�b�v�ł͌��ʂ��������B�����Ă���s�[�X�́A���Ƃ���Rambus��XDR��
�悤�ȃA�v���[�`�Ȃ̂�������Ȃ��B
> AMD���f�X�N�g�b�v������Propus�ł�L3�L���b�V�����ȗ����ăR�X�g�_�E�����Ă��邱�Ƃ���
> �@������悤�ɁA�����X���b�h����ɑ���T�[�o�ł͗L���ȑ�L���b�V�����A�f�X�N�g�b�v�ł͌��ʂ��������B
�Q�[���p�r����L3�L���b�V���ȗ��͂��Ȃ萫�\�ɉe�������
> �@������悤�ɁA�����X���b�h����ɑ���T�[�o�ł͗L���ȑ�L���b�V�����A�f�X�N�g�b�v�ł͌��ʂ��������B
�Q�[���p�r����L3�L���b�V���ȗ��͂��Ȃ萫�\�ɉe�������
����ϒm�b�x�ꂾ����
�Q�[���A�Ƃ��ɃA�N�V�����Q�[���́A�L���b�V���������ӎ����čœK������v���O�����ŁA
������u���E�U��[���Ƃ������f�X�N�g�b�v�A�v���P�[�V����(OS�{�̂��܂ނ���)�Ƃ�
�ѐF��������ƈႤ�A�Ǝv���B
�݂�Ȃ̗p�r���Q�[��(����уQ�[���I�ɏ����ꂽ�A�v���P�[�V����)�Ȃ�A
�f�X�N�g�b�v����CPU������Ƃ����āAL3�L���b�V�����ȗ����ꂽ��͂��Ȃ��͂��B
������u���E�U��[���Ƃ������f�X�N�g�b�v�A�v���P�[�V����(OS�{�̂��܂ނ���)�Ƃ�
�ѐF��������ƈႤ�A�Ǝv���B
�݂�Ȃ̗p�r���Q�[��(����уQ�[���I�ɏ����ꂽ�A�v���P�[�V����)�Ȃ�A
�f�X�N�g�b�v����CPU������Ƃ����āAL3�L���b�V�����ȗ����ꂽ��͂��Ȃ��͂��B
�ȗ����ꂽ�̂͒P�ɃR�X�g�Ə���d�̖͂�肾��
�C���e����Core�n�݂����Ȃ̂��������炵�傤���Ȃ�
���݂����ȍ̎Z�x�O���̏��܂������Ă��H
�C���e����Core�n�݂����Ȃ̂��������炵�傤���Ȃ�
���݂����ȍ̎Z�x�O���̏��܂������Ă��H
>>622
�|�`����
ttp://www.amazon.co.jp/%E3%81%8F%E3%81%86%E3%81%AD%E3%82%8B%E3%81%AE%E3%81%90%E3%81%9D-%E8%87%AA%E7%84%B6%E3%81%AB%E6%84%9B%E3%81%AE%E3%81%8A%E8%BF%94%E3%81%97%E3%82%92-%E4%BC%8A%E6%B2%A2-%E6%AD%A3%E5%90%8D/dp/4635310280
�|�`����
ttp://www.amazon.co.jp/%E3%81%8F%E3%81%86%E3%81%AD%E3%82%8B%E3%81%AE%E3%81%90%E3%81%9D-%E8%87%AA%E7%84%B6%E3%81%AB%E6%84%9B%E3%81%AE%E3%81%8A%E8%BF%94%E3%81%97%E3%82%92-%E4%BC%8A%E6%B2%A2-%E6%AD%A3%E5%90%8D/dp/4635310280
>>624
L1��L2���ȗ������珤�i�Ƃ��Đ������Ȃ���
L3�L���b�V���ɂ́u�R�X�g�Ə���d�͂������鉿�l���Ȃ������v�Ƃ������ƁB
�K�w�����ɂȂ�ɂ�āA���C�e���V�͑����ă��C���������ɋ߂��Ȃ�
�����ʂ�����̂ɕK�v�ȃ_�C�T�C�Y���傫���Ȃ邩��
�u���v����_�v���z���₷���Ȃ��Ă��܂��B
DRAM��CPU�̉���ׂɍڂ��ăL���b�V���K�w�𑝂₵�Ă��A���I�ȉ��P�͖]�߂Ȃ��B
��͂胁�C���������A�N�Z�X���̂��̂Ɏ�����Ȃ���A�Ǝv����
Intel�͓Ǝ���RDRAM�Ŏ��s���āA���̗̈�ɂ͕ێ�I�ɂȂ��Ă��܂����B
Intel���ɂ͑傫���Ȃ�(���������[�J�[���x������e�����������Ȃ�)�A
���C���������ɐ�s���đш悪�K�v��GPU���[�J�[�ł�����AMD�́A
�Ђ���Ƃ�����������s����|�W�V�����ɂ���̂�������Ȃ���B
L1��L2���ȗ������珤�i�Ƃ��Đ������Ȃ���
L3�L���b�V���ɂ́u�R�X�g�Ə���d�͂������鉿�l���Ȃ������v�Ƃ������ƁB
�K�w�����ɂȂ�ɂ�āA���C�e���V�͑����ă��C���������ɋ߂��Ȃ�
�����ʂ�����̂ɕK�v�ȃ_�C�T�C�Y���傫���Ȃ邩��
�u���v����_�v���z���₷���Ȃ��Ă��܂��B
DRAM��CPU�̉���ׂɍڂ��ăL���b�V���K�w�𑝂₵�Ă��A���I�ȉ��P�͖]�߂Ȃ��B
��͂胁�C���������A�N�Z�X���̂��̂Ɏ�����Ȃ���A�Ǝv����
Intel�͓Ǝ���RDRAM�Ŏ��s���āA���̗̈�ɂ͕ێ�I�ɂȂ��Ă��܂����B
Intel���ɂ͑傫���Ȃ�(���������[�J�[���x������e�����������Ȃ�)�A
���C���������ɐ�s���đш悪�K�v��GPU���[�J�[�ł�����AMD�́A
�Ђ���Ƃ�����������s����|�W�V�����ɂ���̂�������Ȃ���B
627 �F,,�E�L�́M�E,,�j��-�������F2008/12/27(�y) 04:32:34 ID:SJNGgzd6
�t�ɃQ�[�����Ȃ��i���f�B�X�N���[�gGPU�����Ă���Ȃ��j�w�ɍ����ȋ@�\�t���Ă����ʂ���H
�����L���p�̖�肾���炵���������
# MAC���^������͒��ߑ��������悤�����ǁAIntel�����̒ɂ��}�J�[�͖����Ɋ撣���Ă�
# http://www.musin.co.jp/Computer/PowerPC.html
# �撣��Q�C�c�N�i�O��̃T�C�g�j�͍ŋߌ��ĂȂ��ȁB
�����L���p�̖�肾���炵���������
# MAC���^������͒��ߑ��������悤�����ǁAIntel�����̒ɂ��}�J�[�͖����Ɋ撣���Ă�
# http://www.musin.co.jp/Computer/PowerPC.html
# �撣��Q�C�c�N�i�O��̃T�C�g�j�͍ŋߌ��ĂȂ��ȁB
��������ˁH
�������ƌ�����ƁA���_�ޗ����Ȃ����B
���X�N������ĐV�������݂ɒ��킵�Ȃ���A�傫�ȃ��^�[���͖]�߂Ȃ��B
�ł��������J���͂��K�͏���������A�o����ʂ͌����Ă���B
GPU�����Ƃ��A�R�A���V�݂����Ȗ�����Ɍ�������簐i����
���ʂ��o���Ȃ���������A���ނ̂���ނȂ������ǁA�₵���˂��B
���X�N������ĐV�������݂ɒ��킵�Ȃ���A�傫�ȃ��^�[���͖]�߂Ȃ��B
�ł��������J���͂��K�͏���������A�o����ʂ͌����Ă���B
GPU�����Ƃ��A�R�A���V�݂����Ȗ�����Ɍ�������簐i����
���ʂ��o���Ȃ���������A���ނ̂���ނȂ������ǁA�₵���˂��B
�ŁA�q���[�W�����Ă��ł�́H
AMD��2011�N�ɖ{�C�o���B
Fusion��Bulldozer��Bobcat���A�V�A�[�L�e�B�N�`���͑S���܂Ƃ߂�2011�N�ɁA
�܂������32nm�v���Z�X�ŁB
http://pc.watch.impress.co.jp/docs/2008/1114/kaigai476.htm
�����������[�h�}�b�v���A�i���X�g�����J���t�@�����X�Ŕ��\���Ă��A
�N�������������ē˂����܂Ȃ��̂��ȁB
Fusion��Bulldozer��Bobcat���A�V�A�[�L�e�B�N�`���͑S���܂Ƃ߂�2011�N�ɁA
�܂������32nm�v���Z�X�ŁB
http://pc.watch.impress.co.jp/docs/2008/1114/kaigai476.htm
�����������[�h�}�b�v���A�i���X�g�����J���t�@�����X�Ŕ��\���Ă��A
�N�������������ē˂����܂Ȃ��̂��ȁB
32nm�͂����Ȃ�V�R�A��32nm��K10�͏o�Ȃ��̂��Ȃ�
45nm�̎����l����ƁA32nm��2010�N������Production�Ȃ�Q3�ɂ͏o������������
Bulldozer�ɏW������̂�
45nm�̎����l����ƁA32nm��2010�N������Production�Ȃ�Q3�ɂ͏o������������
Bulldozer�ɏW������̂�
K11=K10.5+0.5������Ȃ���
2009�N��45nm�v���Z�X�œo��Ƃ������Ă������́A
Power4�̃`�[�t�A�[�L�e�N�g���}�������S�V�K�v�������͂��B
���ꂪ�������[�h�}�b�v��������āA2011�N�ɑ傫���x��ĕ�����������A
�Ђ���Ƃ�����K10.5+0.5�Őv�������Ă�̂����Ȃ��Ǝv���B
Power4�̃`�[�t�A�[�L�e�N�g���}�������S�V�K�v�������͂��B
���ꂪ�������[�h�}�b�v��������āA2011�N�ɑ傫���x��ĕ�����������A
�Ђ���Ƃ�����K10.5+0.5�Őv�������Ă�̂����Ȃ��Ǝv���B
>>635
"Bulldozer"�͍��{�I�ɕς��炵������A
K8�̊g����K10�Ƌꂵ����ɌĂA��K10����Ƃ͑傫���Ⴄ�Ǝv���B
�����A���ꂾ���ɐ��\�I�ɂǂ��]�Ԃ����܂������킩��Ȃ��B
�ǂ����ɍl����A�m���ɊJ�����Ԃ�K9�L�����Z�������������A
���̊��Ԃ̑S�Ă����ʂł͂Ȃ��̂ŁA
���v��10�N���x�̑O�i�K���܂ފJ�����Ԃ����������Ď��B
�����l����A10�N�߂����A�[�L�e�B�N�`���̍X�V���Ȃ��A
�悤�₭�o��K11���]��c�����Ŗ{���Ɏ����I�����Ď��B
"Bulldozer"�͍��{�I�ɕς��炵������A
K8�̊g����K10�Ƌꂵ����ɌĂA��K10����Ƃ͑傫���Ⴄ�Ǝv���B
�����A���ꂾ���ɐ��\�I�ɂǂ��]�Ԃ����܂������킩��Ȃ��B
�ǂ����ɍl����A�m���ɊJ�����Ԃ�K9�L�����Z�������������A
���̊��Ԃ̑S�Ă����ʂł͂Ȃ��̂ŁA
���v��10�N���x�̑O�i�K���܂ފJ�����Ԃ����������Ď��B
�����l����A10�N�߂����A�[�L�e�B�N�`���̍X�V���Ȃ��A
�悤�₭�o��K11���]��c�����Ŗ{���Ɏ����I�����Ď��B
�ǂ���ɂ���A���g��������x�o�Ă��Ȃ����Ƃɂ͔����̂܂܂ł����Ȃ�����ȁE�E�E
���̂܂܂��ዻ������Ȃ�
���̂܂܂��ዻ������Ȃ�
>>636
Power�F�̋���CPU���āc���܂�K11�̌v�悶���B
Power�F�̋���CPU���āc���܂�K11�̌v�悶���B
K11��K9���l�A�����I�ɃL�����Z�����ꂽ�̂ł͂Ȃ����Ƌ^���Ă���B
�Ȃɂ��\�[�X�͂Ȃ��̂Ŗϑz���ƌ����Ă��d���Ȃ����A
���Ƃ��Ƃ�2009�N�o��\��̂��́B�x�ꂽ�ɂ��Ă�2010�N�Ɍ͂ꂽ45nm�v���Z�X��
�f�r���[�����A32nm�Ɉڍs����̂��퓹���낤�B
�J�����i��ł���ɂ��ẮA�Ȃɂ�������������B
���܂�AMD�ɁA���Ђ̎�����Z�p�̗D�ʂ�铽����悤�ȗ]�T�͂Ȃ��͂��B
��o�Ă��Ȃ��Ƃ������Ƃ́A�܂����m���Ȃ��̂ł͂Ȃ��낤���B
�Ȃɂ��\�[�X�͂Ȃ��̂Ŗϑz���ƌ����Ă��d���Ȃ����A
���Ƃ��Ƃ�2009�N�o��\��̂��́B�x�ꂽ�ɂ��Ă�2010�N�Ɍ͂ꂽ45nm�v���Z�X��
�f�r���[�����A32nm�Ɉڍs����̂��퓹���낤�B
�J�����i��ł���ɂ��ẮA�Ȃɂ�������������B
���܂�AMD�ɁA���Ђ̎�����Z�p�̗D�ʂ�铽����悤�ȗ]�T�͂Ȃ��͂��B
��o�Ă��Ȃ��Ƃ������Ƃ́A�܂����m���Ȃ��̂ł͂Ȃ��낤���B
>>640
�ŏ�����32nm�����z�����v�Ȃ�Ζ�肪�Ȃ��B
�r���ŏo���\�z�ł�8-16�R�A���Ƃ����b������̂ŁA
�u45nm�͖���������A32nm�ɂ��悤���v�Ƃ����I�`���ƁB
���ƁA�͂ꂽ�v���Z�X����V�v���Z�X�Ȃ�Ă̂́A
Intel�݂����ɗ]�T�������Ƃ���邱�Ƃ��ƁB
�ŏ�����32nm�����z�����v�Ȃ�Ζ�肪�Ȃ��B
�r���ŏo���\�z�ł�8-16�R�A���Ƃ����b������̂ŁA
�u45nm�͖���������A32nm�ɂ��悤���v�Ƃ����I�`���ƁB
���ƁA�͂ꂽ�v���Z�X����V�v���Z�X�Ȃ�Ă̂́A
Intel�݂����ɗ]�T�������Ƃ���邱�Ƃ��ƁB
����ł��A�f�o�t���������Ƃ���
������ă����r�[���̔ėp��������킯�H
�ȂP�ɂf�o�t�������܂������Ă����ō��̂f�o�f�o�t�Əo���邱�Ƃ��ē����ł����Ȃ��́H
������ă����r�[���̔ėp��������킯�H
�ȂP�ɂf�o�t�������܂������Ă����ō��̂f�o�f�o�t�Əo���邱�Ƃ��ē����ł����Ȃ��́H
���Ƃ�����b�o�t�R�A�̐��\�͂܂������Ȃ�����
���������Ԃ��A�d�͂ƃR�X�g������܂����Ă̂����ʂ̗��_�H
���ă����r�[�́`�A�܂��A�ŏ��͒P�Ȃ�x���f�o�t��
�܂��A�ǂ��������Ă����ŏ��̓q���[�W�����̂��܂��g���邩
���������Ԃ��A�d�͂ƃR�X�g������܂����Ă̂����ʂ̗��_�H
���ă����r�[�́`�A�܂��A�ŏ��͒P�Ȃ�x���f�o�t��
�܂��A�ǂ��������Ă����ŏ��̓q���[�W�����̂��܂��g���邩
���с[�i�j
�ł������r�[���đ��U�ŃG���R�Ή����������
������ςȂ���G���R�����Ή����������ςȂ��炠����x�̎��v�͌����߂�ȁ[
���Ƃ̓C���e�����ǂ��܂ŋ�C�ǂ߂��
������ςȂ���G���R�����Ή����������ςȂ��炠����x�̎��v�͌����߂�ȁ[
���Ƃ̓C���e�����ǂ��܂ŋ�C�ǂ߂��
�t�̕�������l���āA��DEC��Alpha�`�[���������K7���̂āA
Power�I�v�z��������ăX�N���b�`����K11���������A
K7�����{���\�̃R�A�ɂȂ�̂�? �Ƃ����ƁA������^�╄�����B
Intel��PentiumPro�ŁAAMD��K7��RISC�������ꂽ���_�Ŋ�{�A�[�L�e�B�N�`��
�͒�܂��Ă��āA���Ƃ͑Q�i�I�Ȑi���ɉ߂��Ȃ��B(Sun��Niagara��Larrabee�̂悤��
Pentium����܂ők���ăX���[�v�b�g��Nj���������������邪)
���ɁARISC�����ɕC�G�����_�ȕϊv��ILP�̕ǂ�ł��j�邱�Ƃ��w�����A
����������̂Ȃ�c�c����͂����A�o���������AMD��������Bulldozer��wktk���邵���Ȃ��B
���������X�S�C���́A�܂��Ȃ�����ǁB
Power�I�v�z��������ăX�N���b�`����K11���������A
K7�����{���\�̃R�A�ɂȂ�̂�? �Ƃ����ƁA������^�╄�����B
Intel��PentiumPro�ŁAAMD��K7��RISC�������ꂽ���_�Ŋ�{�A�[�L�e�B�N�`��
�͒�܂��Ă��āA���Ƃ͑Q�i�I�Ȑi���ɉ߂��Ȃ��B(Sun��Niagara��Larrabee�̂悤��
Pentium����܂ők���ăX���[�v�b�g��Nj���������������邪)
���ɁARISC�����ɕC�G�����_�ȕϊv��ILP�̕ǂ�ł��j�邱�Ƃ��w�����A
����������̂Ȃ�c�c����͂����A�o���������AMD��������Bulldozer��wktk���邵���Ȃ��B
���������X�S�C���́A�܂��Ȃ�����ǁB
647 �F,,�E�L�́M�E,,�j��-�������F2008/12/27(�y) 18:58:08 ID:SJNGgzd6
Bobcat��K6������Ȃ����Ǝv���Ă�
>>637
�Ȃꂩ��ς��݂����Ɍ����Ă���Nehalem�ł���Core2�̉��nj^�Ȃ��A
K7��K8����{�I�ȕ����͖w�Ǔ�������������AK8 Rev.H=K10(�o��)�ɑ�����C��K8 Rev.I=K10.5�ŁA
K8 Rev.J=K11�Ƃ��A����Ȋ����ɂȂ��Ȃ����Ɨ\�z���Ă�����B
�Ȃꂩ��ς��݂����Ɍ����Ă���Nehalem�ł���Core2�̉��nj^�Ȃ��A
K7��K8����{�I�ȕ����͖w�Ǔ�������������AK8 Rev.H=K10(�o��)�ɑ�����C��K8 Rev.I=K10.5�ŁA
K8 Rev.J=K11�Ƃ��A����Ȋ����ɂȂ��Ȃ����Ɨ\�z���Ă�����B
>>647
���ꂾ�������Δ���
���ꂾ�������Δ���
>>645
���������̂����܂�RADEON�̌`�Ƃ͌���Ȃ����A
���W�n������A�G���R���x�Ȃ���łɑΉ��\�t�g�͂���ȁB
>>648
Core2��Nehalem���x�̉��ǂȂ�������ǁA
K8=K10�Ȃ�Č����Ă��邾���ŁA���Ȃ�ĂقƂ�ǂȂ����B
�قƂ�ǂ��c�ƖړI�ŕς���ꂽ���x����B
�����A�������Ȃ�AAMD�͏I��肾��B
���������̂����܂�RADEON�̌`�Ƃ͌���Ȃ����A
���W�n������A�G���R���x�Ȃ���łɑΉ��\�t�g�͂���ȁB
>>648
Core2��Nehalem���x�̉��ǂȂ�������ǁA
K8=K10�Ȃ�Č����Ă��邾���ŁA���Ȃ�ĂقƂ�ǂȂ����B
�قƂ�ǂ��c�ƖړI�ŕς���ꂽ���x����B
�����A�������Ȃ�AAMD�͏I��肾��B
��pDigitimes��胍�[�G���h��45-nm K8L�����[�X��B
http://www.digitimes.com/news/a20081226PD204.html
�@�@------------------
�@�@AMD desktop CPU schedule updated
�@�@Monica Chen, Taipei; Joseph Tsai, DIGITIMES [Friday 26 December 2008]
�@�@�@AMD plans to launch six 45nm CPUs under its Athlon line including the quad-core
�@�@Athlon X4 615 and 605 and triple-core Athlon X3 420 and 410 in April next year and
�@�@dual-core Athlon X2 240 and 235 in June, according to sources at motherboard makers.
�@�@�@Last order notice for the company's upcoming 45nm AM2+ Phenom II X4 920 and 940
�@�@Black Edition CPUs, will be issued in May next year, while AMD has already stopped
�@�@taking orders for its quad-core Phenom X4 9650 this month. AMD's Phenom X4 9950
�@�@(140W) and 9850 (125W) will have their last order notice issued in March next year,
�@�@and Phenom X4 9750, 9850 (95W) and 9950 (125W) will be in June.
�@�@�@AMD's triple-core Phenom X3 8450 and 8550 CPUs have started phasing out of the
�@�@market, while the Phenom X3 8650 is scheduled to have its last order notice issued in
�@�@March next year followed by the Phenom X3 8850 and 8750 in June.
�@�@�@AMD's low-power Athlon X2 4450e CPU will have its last order notice issued in March
�@�@next year.
�@�@�@AMD declined the opportunity to respond to this report saying it cannot comment on
�@�@unannounced products.
�@�@------------------
http://www.digitimes.com/news/a20081226PD204.html
�@�@------------------
�@�@AMD desktop CPU schedule updated
�@�@Monica Chen, Taipei; Joseph Tsai, DIGITIMES [Friday 26 December 2008]
�@�@�@AMD plans to launch six 45nm CPUs under its Athlon line including the quad-core
�@�@Athlon X4 615 and 605 and triple-core Athlon X3 420 and 410 in April next year and
�@�@dual-core Athlon X2 240 and 235 in June, according to sources at motherboard makers.
�@�@�@Last order notice for the company's upcoming 45nm AM2+ Phenom II X4 920 and 940
�@�@Black Edition CPUs, will be issued in May next year, while AMD has already stopped
�@�@taking orders for its quad-core Phenom X4 9650 this month. AMD's Phenom X4 9950
�@�@(140W) and 9850 (125W) will have their last order notice issued in March next year,
�@�@and Phenom X4 9750, 9850 (95W) and 9950 (125W) will be in June.
�@�@�@AMD's triple-core Phenom X3 8450 and 8550 CPUs have started phasing out of the
�@�@market, while the Phenom X3 8650 is scheduled to have its last order notice issued in
�@�@March next year followed by the Phenom X3 8850 and 8750 in June.
�@�@�@AMD's low-power Athlon X2 4450e CPU will have its last order notice issued in March
�@�@next year.
�@�@�@AMD declined the opportunity to respond to this report saying it cannot comment on
�@�@unannounced products.
�@�@------------------
652 �FMAC�I�^�������F2008/12/27(�y) 20:08:51 ID:fkX7CF0A
����ɂ܂Ƃ߂�Ƃ����Ȃ邷�B
�@�@�� 2008�N12��
�@�@�@- Phenom X4 9650 Discon.
�@�@�� 2009�N3��
�@�@�@- Phenom X4 9950(140W), 9850(125W) Discon.
�@�@�@- Phenom X3 8650 Discon.
�@�@�@- Athlon X2 4450e Discon.
�@�@�� 2009�N4��
�@�@�@- Athlon X4 615, 605 Launch
�@�@�@- Athlon X3 420, 410 Launch
�@�@�� 2009�N5��
�@�@�@- Phenom II 920, 940BE Discon.
�@�@�� 2009�N6��
�@�@�@- Athlon X2 240, 235 Launch
�@�@�@- Phenom X4 9750, 9850(95W), 0050(125W) Discon.
�@�@�@- Phenom X3 8850, 8750 Discon.
45-nm��AM3���i�ւ̃V�t�g��A�}���ɐi�ޖ͗l���B
�@�@�� 2008�N12��
�@�@�@- Phenom X4 9650 Discon.
�@�@�� 2009�N3��
�@�@�@- Phenom X4 9950(140W), 9850(125W) Discon.
�@�@�@- Phenom X3 8650 Discon.
�@�@�@- Athlon X2 4450e Discon.
�@�@�� 2009�N4��
�@�@�@- Athlon X4 615, 605 Launch
�@�@�@- Athlon X3 420, 410 Launch
�@�@�� 2009�N5��
�@�@�@- Phenom II 920, 940BE Discon.
�@�@�� 2009�N6��
�@�@�@- Athlon X2 240, 235 Launch
�@�@�@- Phenom X4 9750, 9850(95W), 0050(125W) Discon.
�@�@�@- Phenom X3 8850, 8750 Discon.
45-nm��AM3���i�ւ̃V�t�g��A�}���ɐi�ޖ͗l���B
Phenom��߂�Athlon�ɖ߂��Ηǂ��̂�
PhenomX3���Č��\��ނ�������
�قƂ�Ǔ��{�ɗ��ĂȂ���
�قƂ�Ǔ��{�ɗ��ĂȂ���
���傗����������������
8850�͓��{�ɗ��ĂȂ��̂�Discon���悗������
�܂�45nm�̕��������R�X�g�����݂�������
�d���Ȃ��̂�(߁��)
8850�͓��{�ɗ��ĂȂ��̂�Discon���悗������
�܂�45nm�̕��������R�X�g�����݂�������
�d���Ȃ��̂�(߁��)
���N�Ń��[�G���h�܂œ���ւ��Ƃ����̂͑������Ȃ���
2�R�A�͂���ł��x����Ȃ�
2�R�A�͂���ł��x����Ȃ�
>>646
K6
K6
�ԈႦ��
RISC��K5���炩
RISC��K5���炩
�l�I��K11�ƌ�����bulldozer��CPU�R�A���́A�c�q���ȑO�Ɍ����Ă���
K7�ȗ��̍\���ŁA���ƂȂ��Ă͖Ӓ��̂��Ƃ��s�����I�ȍ��ɂȂ��Ă��镔���̉��������S�ɂȂ�Ǝv�����ǂ�
K7�ȗ��̍\���ŁA���ƂȂ��Ă͖Ӓ��̂��Ƃ��s�����I�ȍ��ɂȂ��Ă��镔���̉��������S�ɂȂ�Ǝv�����ǂ�
Z-RAM��128M-L3�Ȗ����͂܂��ł����H
SRAM��菬������SRAM��������ȏ�ɍ����Ƃ���Ε������͂�����
���C�Z���X���Ƃ��Ďg��Ȃ��̂́A����ς������������Ȃ�����
���C�Z���X���Ƃ��Ďg��Ȃ��̂́A����ς������������Ȃ�����
662 �FSocket774�F2008/12/28(��) 04:24:43 ID:rCDvOgNE
FD-SOI�ł����g���Ȃ�����
Core2��4����f�R�[�h�Ƃ����G�ꍞ�݂������ۂ͂���قǂł��Ȃ�
�L���b�V���̃`���[�j���O�ʼn҂��ł���Ƃ����b�������ˁB
http://journal.mycom.co.jp/special/2006/conroe/006.html �Ƃ��A
http://pc.watch.impress.co.jp/docs/2008/0428/kaigai438.htm �Ƃ��B
�Ƃ���ƁA�R�A���Đv������A�L���b�V���������������ق���������ł͂Ȃ����ƁB
AMD�͗D�����������B
�������������������ق����A�ǂ����ʂ��o�邱�Ƃ�����B
�L���b�V���̃`���[�j���O�ʼn҂��ł���Ƃ����b�������ˁB
http://journal.mycom.co.jp/special/2006/conroe/006.html �Ƃ��A
http://pc.watch.impress.co.jp/docs/2008/0428/kaigai438.htm �Ƃ��B
�Ƃ���ƁA�R�A���Đv������A�L���b�V���������������ق���������ł͂Ȃ����ƁB
AMD�͗D�����������B
�������������������ق����A�ǂ����ʂ��o�邱�Ƃ�����B
>>659
�Ђ���Ƃ��Ĕn���̔����^�Ɏ�����Ă�H
�Ђ���Ƃ��Ĕn���̔����^�Ɏ�����Ă�H
665 �F,,�E�L�́M�E,,�j��-�������F2008/12/28(��) 07:07:30 ID:rWoPv8A5
���Ⴀ�N�����l���܂��Ƃ��ȋZ�p�_�����Ă݂��܂�
666 �F,,�E�L�́M�E,,�j��-�������F2008/12/28(��) 07:28:16 ID:rWoPv8A5 BE:501746966-PLT(12022)
���x�ł��咣���Ă�邺
�y�����^�p�C�v���C���̃����b�g�z
�Ex87 FP�X�^�b�N�ɓ����������͂ȃX�P�W���[��������邽�߃N���b�N������ł�x87���\���i���ΓI�Ɂj����
��SSE�̕��y��x64�ł�SSE�̗p��x87���̂��̂����K�V�[�R�[�h��
�y�����^�p�C�v���C���̃f�����b�g�z
�EFP�p�C�v���̓^�O�C���f�b�N�X�������̗p���Ă��邽��SIMD�������ߊԂ̃��C�e���V���傫��
�@�i�P���ȉ����_�����Z�ł�Intel�̓��C�e���V1�AAMD��2�j
�E�����ESIMD�����̃f�[�^�������x��
�@�iIntel��Active Register�����L���Ă��邽�߃_�C���N�g�ɒl�����\�j
�E�������̃X�P�W���[�����n��
�@36�G���g���̋��͂ȃX�P�W���[��������FP�ɑ��A3Way�̐���ALU����6�`8Way��
�@�p�C�v���ׂ����Ĕz�u���s�\��RS�����n��ȍ\���B�ӊO�ƃX�J�X�J�ɂȂ�₷���B
�@�����������̃X�P�W���[���Ƀg�����W�X�^���������Q�H
�E�g�����W�X�^���i�������_�C�T�C�Y���d�͂��j��H��
�@�@Intel Core 2(65nm) 1900���g�����W�X�^/Core
�@�@AMD K7�i����j�@2200���g�����W�X�^
��ŁAK11�ł�K7�p�C�v���C�����y�̂Ă܂��z�B
�y�����^�p�C�v���C���̃����b�g�z
�Ex87 FP�X�^�b�N�ɓ����������͂ȃX�P�W���[��������邽�߃N���b�N������ł�x87���\���i���ΓI�Ɂj����
��SSE�̕��y��x64�ł�SSE�̗p��x87���̂��̂����K�V�[�R�[�h��
�y�����^�p�C�v���C���̃f�����b�g�z
�EFP�p�C�v���̓^�O�C���f�b�N�X�������̗p���Ă��邽��SIMD�������ߊԂ̃��C�e���V���傫��
�@�i�P���ȉ����_�����Z�ł�Intel�̓��C�e���V1�AAMD��2�j
�E�����ESIMD�����̃f�[�^�������x��
�@�iIntel��Active Register�����L���Ă��邽�߃_�C���N�g�ɒl�����\�j
�E�������̃X�P�W���[�����n��
�@36�G���g���̋��͂ȃX�P�W���[��������FP�ɑ��A3Way�̐���ALU����6�`8Way��
�@�p�C�v���ׂ����Ĕz�u���s�\��RS�����n��ȍ\���B�ӊO�ƃX�J�X�J�ɂȂ�₷���B
�@�����������̃X�P�W���[���Ƀg�����W�X�^���������Q�H
�E�g�����W�X�^���i�������_�C�T�C�Y���d�͂��j��H��
�@�@Intel Core 2(65nm) 1900���g�����W�X�^/Core
�@�@AMD K7�i����j�@2200���g�����W�X�^
��ŁAK11�ł�K7�p�C�v���C�����y�̂Ă܂��z�B
667 �FSocket774�F2008/12/28(��) 08:33:30 ID:rCDvOgNE
�D�����ƌ����Ε������͂������v�̂��������
Tr����
Tr����
668 �FMAC�I�^���c�q �����F2008/12/28(��) 09:05:05 ID:CyWsZRm4
>>666
���ƍ������������Ǝv�����B
�@�@-----------------
�@�@�E�g�����W�X�^���i�������_�C�T�C�Y���d�͂��j��H��
�@�@Intel Core 2(65nm) 1900���g�����W�X�^/Core
�@�@AMD K7�i����j�@2200���g�����W�X�^
�@�@-----------------
���l���́A���ꂼ��M���ł���\�[�X�퉺�L�̒ʂ�ŊԈ���Ė������B
�@CMA�̃g�����W�X�^��: http://www.hotchips.org/archives/hc18/3_Tues/HC18.S9/HC18.S9T4.pdf (p.5)
�@K7�̃g�����W�X�^��: http://studies.ac.upc.edu/ETSETB/SEGPAR/microprocessors/amdk7%20(mpr).pdf (p.7 Table 2)
�������Ȃ���AK7�`K8L��R�A�Ɋ܂܂��L1�L���b�V����Core Microarchitecture��2�{��128KB���B
�g�����W�X�^���ɐ�߂�L1�̊����̎����팩�����Ȃ����������ǁA��LMicroprocessor
Report�L���̃_�C�ʐ^������ƁAL1D + L1I�Ń_�C�S�̖̂�18%�A�R�A�����̖�21%���߂Ă��邷�B
�}���`�|�[�g�Ȃ̂�L2���Ŗ����Ƃ팾���ASRAM�̃g�����W�X�^���x�푼�̃��W�b�N�����傫��
���Ƃ��l������ƁAK7��22M�g�����W�X�^��10%�ȏ��P����L1�T�C�Y���傫�����ƂłŐ����ł��邷�B
���������p�C�v���C���\���̂����ɂ���̂�A�Ԉ���Ă���Ƃ������ƂŁB
���ƍ������������Ǝv�����B
�@�@-----------------
�@�@�E�g�����W�X�^���i�������_�C�T�C�Y���d�͂��j��H��
�@�@Intel Core 2(65nm) 1900���g�����W�X�^/Core
�@�@AMD K7�i����j�@2200���g�����W�X�^
�@�@-----------------
���l���́A���ꂼ��M���ł���\�[�X�퉺�L�̒ʂ�ŊԈ���Ė������B
�@CMA�̃g�����W�X�^��: http://www.hotchips.org/archives/hc18/3_Tues/HC18.S9/HC18.S9T4.pdf (p.5)
�@K7�̃g�����W�X�^��: http://studies.ac.upc.edu/ETSETB/SEGPAR/microprocessors/amdk7%20(mpr).pdf (p.7 Table 2)
�������Ȃ���AK7�`K8L��R�A�Ɋ܂܂��L1�L���b�V����Core Microarchitecture��2�{��128KB���B
�g�����W�X�^���ɐ�߂�L1�̊����̎����팩�����Ȃ����������ǁA��LMicroprocessor
Report�L���̃_�C�ʐ^������ƁAL1D + L1I�Ń_�C�S�̖̂�18%�A�R�A�����̖�21%���߂Ă��邷�B
�}���`�|�[�g�Ȃ̂�L2���Ŗ����Ƃ팾���ASRAM�̃g�����W�X�^���x�푼�̃��W�b�N�����傫��
���Ƃ��l������ƁAK7��22M�g�����W�X�^��10%�ȏ��P����L1�T�C�Y���傫�����ƂłŐ����ł��邷�B
���������p�C�v���C���\���̂����ɂ���̂�A�Ԉ���Ă���Ƃ������ƂŁB
�E�g�����W�X�^���i�������_�C�T�C�Y���d�͂��j��H��
�@�@Intel Core 2(65nm) 1900���g�����W�X�^/Core
�@�@AMD K7�i����j�@2200���g�����W�X�^
�R���Ȃ�
Core2�̓R�AK8��1.5�{�ʂ̃_�C�T�C�Y����
�@�@Intel Core 2(65nm) 1900���g�����W�X�^/Core
�@�@AMD K7�i����j�@2200���g�����W�X�^
�R���Ȃ�
Core2�̓R�AK8��1.5�{�ʂ̃_�C�T�C�Y����
>>668
�c�q�̂ӂ���̎咣��m���Ă���̓˂����݂͋t����
�c�q�̂ӂ���̎咣��m���Ă���̓˂����݂͋t����
671 �FMAC�I�^��669 �����F2008/12/28(��) 09:10:41 ID:CyWsZRm4
>>669
�@�@--------------
�@�@Core2�̓R�AK8��1.5�{�ʂ̃_�C�T�C�Y����
�@�@--------------
�_�C�̏�ɂ�A��̃R�A�Ƌ��勤�LL2�A�N���X�o�[�X�C�b�`�A�o�X�C���^�[�t�F�[�X���j�b�g����
�܂܂�邷�B
�@�@--------------
�@�@Core2�̓R�AK8��1.5�{�ʂ̃_�C�T�C�Y����
�@�@--------------
�_�C�̏�ɂ�A��̃R�A�Ƌ��勤�LL2�A�N���X�o�[�X�C�b�`�A�o�X�C���^�[�t�F�[�X���j�b�g����
�܂܂�邷�B
�}�J�[������ɏ�������ł�ˁ[��w
http://www.chip-architect.com/news/DC_65nm_compare_2007_01_27.jpg
�R�A���W�b�N���̘b���Ă��
{kind=link}
�R�A���W�b�N���̘b���Ă��
674 �FMAC�I�^��672 �����F2008/12/28(��) 09:17:05 ID:CyWsZRm4
>>672
�@�@------------------
�@�@�}�J�[������ɏ�������ł�ˁ[��w
�@�@------------------
���펩��ōŌÎQ�̂ЂƂ�Ȃ��ǁB�B�B
http://piza.2ch.net/log2/jisaku/kako/945/945651630.html
�@�@------------------
�@�@�}�J�[������ɏ�������ł�ˁ[��w
�@�@------------------
���펩��ōŌÎQ�̂ЂƂ�Ȃ��ǁB�B�B
http://piza.2ch.net/log2/jisaku/kako/945/945651630.html
>>674
����ራ�������B�����c�q�ƃZ�b�g�Ō������邵��ʂ����ĂȂ�������w
�c�q�����͂ƈꏏ��AMD�X���r�炷��������E�U���Ă�
����ራ�������B�����c�q�ƃZ�b�g�Ō������邵��ʂ����ĂȂ�������w
�c�q�����͂ƈꏏ��AMD�X���r�炷��������E�U���Ă�
676 �FMAC�I�^��673 �����F2008/12/28(��) 09:52:16 ID:CyWsZRm4
>>673
�@�@-----------------
�@�@�R�A���W�b�N���̘b���Ă��
�@�@-----------------
chip-architect�̋L����ǂ�ł���Ȃ�AAMD�̃R�A�̕����_�C�ʐςɂ�����L1�̔䗦���傫��
���Ƃ��A�L���b�V���̕����v���Z�X�k���ɔ����X�P�[�����O���ǍD�Ȃ��Ƃ������m���Ǝv�����B
L1�̃R�A�S�̂ɑ���䗦���傫��K8��A�ʐς̊��Ƀg�����W�X�^���푽������B
�@�@-----------------
�@�@�R�A���W�b�N���̘b���Ă��
�@�@-----------------
chip-architect�̋L����ǂ�ł���Ȃ�AAMD�̃R�A�̕����_�C�ʐςɂ�����L1�̔䗦���傫��
���Ƃ��A�L���b�V���̕����v���Z�X�k���ɔ����X�P�[�����O���ǍD�Ȃ��Ƃ������m���Ǝv�����B
L1�̃R�A�S�̂ɑ���䗦���傫��K8��A�ʐς̊��Ƀg�����W�X�^���푽������B
>>673
���y�[�W�ɐ��l�����������邩�炻�����̂ق����ǂ���
ttp://www.chip-architect.com/news/2007_02_19_Various_Images.html
Die, Core and Cache Sram areas.
�g�����W�X�^���̘b�Ƃ͈��邪
�ʂɔn���̔������b�葱����K�v������܂���
���y�[�W�ɐ��l�����������邩�炻�����̂ق����ǂ���
ttp://www.chip-architect.com/news/2007_02_19_Various_Images.html
Die, Core and Cache Sram areas.
�g�����W�X�^���̘b�Ƃ͈��邪
�ʂɔn���̔������b�葱����K�v������܂���
679 �F,,�E�L�́M�E,,�j��-�������F2008/12/28(��) 10:41:14 ID:rWoPv8A5
�܁AK7�Ɣ�r����Ȃ�Pentium III��Pentium M�ł����Ǝv�����ǂˁB
128bit SIMD���j�b�g�~3�������4issue���C�h�p�C�v���C����K8�Ɣ�r����̂��A�Ԃ����Ⴏ����Șb�ɂȂ邵�B
128bit SIMD���j�b�g�~3�������4issue���C�h�p�C�v���C����K8�Ɣ�r����̂��A�Ԃ����Ⴏ����Șb�ɂȂ邵�B
Banias�̃g�����W�X�^����L2�����Ă�K7���͂邩�ɑ������Ȃ���
681 �F,,�E�L�́M�E,,�j��-�������F2008/12/28(��) 10:53:50 ID:rWoPv8A5
����͂���Ƃ��āAL1�L���b�V�����u���W�b�N���v�̈ꕔ�ł��̂ŁB
x86�p�C�v���C����L1�q�b�g�O��ŃX�P�W���[�����O���Ȃ����B
�{���̏��Ȃ����W�X�^��₤���݂ł����邩��ˁB
1900���g�����W�X�^�̏o���͌㓡�����ǂ܂��ǂ��ł�������
ttp://pc.watch.impress.co.jp/docs/2007/0426/kaigai356.htm
����45nm�Ń_�C�T�C�Y��Shanghai(L3 6MB) ��Core i7 (L3 8MB)�����ljʂ����ă��W�b�N���̓R���p�N�g�ƌ�����́H
�܂������������Ƃ��B
x86�p�C�v���C����L1�q�b�g�O��ŃX�P�W���[�����O���Ȃ����B
�{���̏��Ȃ����W�X�^��₤���݂ł����邩��ˁB
1900���g�����W�X�^�̏o���͌㓡�����ǂ܂��ǂ��ł�������
ttp://pc.watch.impress.co.jp/docs/2007/0426/kaigai356.htm
����45nm�Ń_�C�T�C�Y��Shanghai(L3 6MB) ��Core i7 (L3 8MB)�����ljʂ����ă��W�b�N���̓R���p�N�g�ƌ�����́H
�܂������������Ƃ��B
682 �F,,�E�L�́M�E,,�j��-�������F2008/12/28(��) 11:00:58 ID:rWoPv8A5
>>680
�q���g�F�N���b�N�Q�[�e�B���O
���Ȃ݂�L2�L���b�V����4T SRAM���Ǝv���Čv�Z�����ǂ����̔n���̌v�Z������2200���Ƃ��ɂȂ���Ă����A������ˁH
���̔n���̓~�X�ɋC�Â��Čv�Z����������L2�ƊO���o�X�����Ă�1700���g�����W�X�^���x�������ƋL�������Ă���
http://pc.watch.impress.co.jp/docs/2005/0906/kaigai209.htm
> Yonah�̃g�����W�X�^����1��5,160��(151.6M)�ŁADothan��1��4,000��(140M)�B
> CPU�R�A����2�{�ɑ������̂ɁA�g�����W�X�^�����킸��1,160�����������Ă��Ȃ��B
�EYonah�@151.6M
�EDothan�@140M
�EBanias�@77M
�q���g�F�N���b�N�Q�[�e�B���O
���Ȃ݂�L2�L���b�V����4T SRAM���Ǝv���Čv�Z�����ǂ����̔n���̌v�Z������2200���Ƃ��ɂȂ���Ă����A������ˁH
���̔n���̓~�X�ɋC�Â��Čv�Z����������L2�ƊO���o�X�����Ă�1700���g�����W�X�^���x�������ƋL�������Ă���
http://pc.watch.impress.co.jp/docs/2005/0906/kaigai209.htm
> Yonah�̃g�����W�X�^����1��5,160��(151.6M)�ŁADothan��1��4,000��(140M)�B
> CPU�R�A����2�{�ɑ������̂ɁA�g�����W�X�^�����킸��1,160�����������Ă��Ȃ��B
�EYonah�@151.6M
�EDothan�@140M
�EBanias�@77M
683 �FMAC�I�^��680 �����F2008/12/28(��) 11:14:13 ID:CyWsZRm4
>>680
�@�@------------------
�@�@Banias�̃g�����W�X�^����L2�����Ă�K7���͂邩�ɑ������Ȃ���
�@�@------------------
�ԈႢ���B
http://www.intel.com/pressroom/kits/quickreffam.htm
�@- Banias: 77M transistors, 1024KB L2
�@- Dothan: 140M transistors, 2048KB L2
�]����1MB����L2�̃g�����W�X�^����A���悻63M���B�]���ăR�A�g�����W�X�^����A���悻14M�B
�@�@------------------
�@�@Banias�̃g�����W�X�^����L2�����Ă�K7���͂邩�ɑ������Ȃ���
�@�@------------------
�ԈႢ���B
http://www.intel.com/pressroom/kits/quickreffam.htm
�@- Banias: 77M transistors, 1024KB L2
�@- Dothan: 140M transistors, 2048KB L2
�]����1MB����L2�̃g�����W�X�^����A���悻63M���B�]���ăR�A�g�����W�X�^����A���悻14M�B
>>682-683
�T���N�X�B�悭�킩�����B���̓ǂL�����Ԉ���Ă���B
�T���N�X�B�悭�킩�����B���̓ǂL�����Ԉ���Ă���B
685 �F,,�E�L�́M�E,,�j��-�������F2008/12/28(��) 11:20:01 ID:rWoPv8A5
Dothan��Banias�̌��w�V�������N���Ƃł��v���Ă�̂��H
���[�N�d����Ƃ��ăN���b�N�Q�[�e�B���O����łĂ����ꂵ�Ă邵�A���Z�@��Banias��胊�b�`�ɂȂ��Ă邼
���[�N�d����Ƃ��ăN���b�N�Q�[�e�B���O����łĂ����ꂵ�Ă邵�A���Z�@��Banias��胊�b�`�ɂȂ��Ă邼
686 �FMAC�I�^���c�q �����F2008/12/28(��) 11:21:29 ID:CyWsZRm4
>>681
�@�@----------------
�@�@x86�p�C�v���C����L1�q�b�g�O��ŃX�P�W���[�����O���Ȃ����B
�@�@----------------
�������NetBurst���肾�����������ǁH
http://www.xbitlabs.com/articles/cpu/display/replay.html
�@�@----------------
�@�@x86�p�C�v���C����L1�q�b�g�O��ŃX�P�W���[�����O���Ȃ����B
�@�@----------------
�������NetBurst���肾�����������ǁH
http://www.xbitlabs.com/articles/cpu/display/replay.html
687 �FMAC�I�^���c�q �����F2008/12/28(��) 11:25:13 ID:CyWsZRm4
>>685
�@�@----------------
�@�@���[�N�d����Ƃ��ăN���b�N�Q�[�e�B���O����łĂ����ꂵ�Ă邵�A���Z�@��Banias���
�@�@���b�`�ɂȂ��Ă邼
�@�@----------------
�w�T�Z�x�Ƃ������m�������ł�����������ό���o�Ă��Ȃ��Ǝv�����B
20M�g�����W�X�^�̃R�A��10%�g�����ꂽ�Ƃ��Ă��g�����W�X�^�̑�������2M�BL2�{���ɂ�鑝���ʂƂ�
�����Ⴄ���B
�@�@----------------
�@�@���[�N�d����Ƃ��ăN���b�N�Q�[�e�B���O����łĂ����ꂵ�Ă邵�A���Z�@��Banias���
�@�@���b�`�ɂȂ��Ă邼
�@�@----------------
�w�T�Z�x�Ƃ������m�������ł�����������ό���o�Ă��Ȃ��Ǝv�����B
20M�g�����W�X�^�̃R�A��10%�g�����ꂽ�Ƃ��Ă��g�����W�X�^�̑�������2M�BL2�{���ɂ�鑝���ʂƂ�
�����Ⴄ���B
688 �F,,�E�L�́M�E,,�j��-�������F2008/12/28(��) 11:26:20 ID:rWoPv8A5
>>686
�́H
�ǂ���CPU�ł�L1�q�b�g��O��ɂ���͈̂ꏏ����B
NetBurst������Ȃ̂̓L���b�V���~�X����ƕ���~�X���l�Ƀp�C�v���C�����t���b�V������
�X�P�W���[�����O�����蒼�����Ƃ��炢����B
L2���C�e���V�ƃp�C�v���C���i�����قڈ�v���Ă��̂͂��̂����B
����ȊO�͑ҋ@�i�X�g�[���j���邾���B
�́H
�ǂ���CPU�ł�L1�q�b�g��O��ɂ���͈̂ꏏ����B
NetBurst������Ȃ̂̓L���b�V���~�X����ƕ���~�X���l�Ƀp�C�v���C�����t���b�V������
�X�P�W���[�����O�����蒼�����Ƃ��炢����B
L2���C�e���V�ƃp�C�v���C���i�����قڈ�v���Ă��̂͂��̂����B
����ȊO�͑ҋ@�i�X�g�[���j���邾���B
689 �F,,�E�L�́M�E,,�j��-�������F2008/12/28(��) 11:28:17 ID:rWoPv8A5
690 �FMAC�I�^���c�q �����F2008/12/28(��) 11:28:24 ID:CyWsZRm4
>>688
�@�@---------------
�@�@����ȊO�͑ҋ@�i�X�g�[���j���邾���B
�@�@---------------
�ҋ@����̂�A�����Љ�l�ɃX�P�W���[�����O����Ă��Ȃ����炷���ǁB�B�B
�@�@---------------
�@�@����ȊO�͑ҋ@�i�X�g�[���j���邾���B
�@�@---------------
�ҋ@����̂�A�����Љ�l�ɃX�P�W���[�����O����Ă��Ȃ����炷���ǁB�B�B
ttp://chip-architect.com/news/Shanghai_Nehalem.jpg
ϼ�����
1.5�{���炢���H
65nm�o�����O�̃R�A�T�C�Y��25.5�u������
���ς�65nm���Z�ɂ�����ǂ̂��炢�ɂȂ邾�낤��
{kind=link}
ϼ�����
1.5�{���炢���H
65nm�o�����O�̃R�A�T�C�Y��25.5�u������
���ς�65nm���Z�ɂ�����ǂ̂��炢�ɂȂ邾�낤��
692 �F,,�E�L�́M�E,,�j��-�������F2008/12/28(��) 11:35:04 ID:rWoPv8A5
���ҋ@����̂�A�����Љ�l�ɃX�P�W���[�����O����Ă��Ȃ����炷���ǁB�B�B
�͂��H�ق����J�X
���[�h���j�b�g�ɖ��߂s���ā����N���b�N��Ƀ��W�X�^�Ƀ��[�h����Č㑱���߂��]�X
���Ă����X�P�W���[���I�ɑg��Ŏ��s����̂��A�E�g�I�u�I�[�_���s���Č�����
�X�g�[������͕̂��䌀�Ŏ剉���D�̓������x��ĊJ�����Ԃ�x�点��̂Ɠ����B
NetBurst��
���Ƃ���Ȃ畑��̃Z�b�e�B���O�����蒼���悤�Ȋ����B
�͂��H�ق����J�X
���[�h���j�b�g�ɖ��߂s���ā����N���b�N��Ƀ��W�X�^�Ƀ��[�h����Č㑱���߂��]�X
���Ă����X�P�W���[���I�ɑg��Ŏ��s����̂��A�E�g�I�u�I�[�_���s���Č�����
�X�g�[������͕̂��䌀�Ŏ剉���D�̓������x��ĊJ�����Ԃ�x�点��̂Ɠ����B
NetBurst��
���Ƃ���Ȃ畑��̃Z�b�e�B���O�����蒼���悤�Ȋ����B
693 �F,,�E�L�́M�E,,�j��-�������F2008/12/28(��) 11:48:36 ID:rWoPv8A5
add eax, [esi+16]
���Ė��߂����s����Ƃ���
L1�̃��C�e���V��3�N���b�N�Ȃ�add�s����\���3�N���b�N�O�ɐ�s���ă��[�h�I�y���[�V������
���s����K�v������B������X�P�W���[�����O���Č����́B
�uL1�q�b�g��O��ɂ����X�P�W���[�����O�v���Ă��������Ӗ��ł�����NetBurst���낤���Ȃ낤����������
����Ƃ�L2�q�b�g���O�Ƃł��v�������H
�f�B���C�X���b�g���n���ł����Ȃ邪�H
MAC���^�̒��_�ɂ���[esi+16]��L1�Ƀq�b�g���Ȃ��ꍇ�X�P�W���[�����g�܂�ĂȂ����ƂɂȂ�炵�����B
�X�P�W���[�����g�܂�Ȃ���Ήi�v�ɓ����܂���B�n���O�A�b�v�ł��B
�n���Ȃ̎��ʂ́H
���Ė��߂����s����Ƃ���
L1�̃��C�e���V��3�N���b�N�Ȃ�add�s����\���3�N���b�N�O�ɐ�s���ă��[�h�I�y���[�V������
���s����K�v������B������X�P�W���[�����O���Č����́B
�uL1�q�b�g��O��ɂ����X�P�W���[�����O�v���Ă��������Ӗ��ł�����NetBurst���낤���Ȃ낤����������
����Ƃ�L2�q�b�g���O�Ƃł��v�������H
�f�B���C�X���b�g���n���ł����Ȃ邪�H
MAC���^�̒��_�ɂ���[esi+16]��L1�Ƀq�b�g���Ȃ��ꍇ�X�P�W���[�����g�܂�ĂȂ����ƂɂȂ�炵�����B
�X�P�W���[�����g�܂�Ȃ���Ήi�v�ɓ����܂���B�n���O�A�b�v�ł��B
�n���Ȃ̎��ʂ́H
ttp://www.pcper.com/images/reviews/486/penryn_vs_nehalem_die.jpg
�������͉�����
�y���M����Ń_�C�T�C�Y��2.5�{�ŃR�A�T�C�Y��1.4�`1.5�{���Ă��Ƃ��H
�y���M���̃R�A��22�u�Ōv�Z�����
45nm���ς�65nm�o����1.2�{���炢�̃R�A�T�C�Y���Ă��ƂɂȂ�i�v�Z�����Ă�H���j
���[�v�����̎d�l�ύX�̂�����HTT�̂������iCore2�ł��t���O�͗����Ă邻�������炱�̐��͔������j
���ɂ��Ă��X�Q�[��
{kind=link}
�������͉�����
�y���M����Ń_�C�T�C�Y��2.5�{�ŃR�A�T�C�Y��1.4�`1.5�{���Ă��Ƃ��H
�y���M���̃R�A��22�u�Ōv�Z�����
45nm���ς�65nm�o����1.2�{���炢�̃R�A�T�C�Y���Ă��ƂɂȂ�i�v�Z�����Ă�H���j
���[�v�����̎d�l�ύX�̂�����HTT�̂������iCore2�ł��t���O�͗����Ă邻�������炱�̐��͔������j
���ɂ��Ă��X�Q�[��
>>693 �c�q ����
�@�@-------------
�@�@add�s����\���3�N���b�N�O�ɐ�s���ă��[�h�I�y���[�V�����s����
�@�@-------------
���\�[�X������3�N���b�N�u�ȏ�v�O�̒i�K�Ń��[�h���߂s���邷����(��)
>>691 ����
�@�@--------------
�@�@ϼ�����
�@�@1.5�{���炢���H
�@�@--------------
������Ɛ���������ANehalem: 246mm^2, Shanghai: 243mm^2�Ƃ������ƂŁA�_�C�T�C�Y��
�����L���b�V���e�ʂ����܂�ς���Ă��Ȃ����ƂɋC�t�������B
�@�@-------------
�@�@add�s����\���3�N���b�N�O�ɐ�s���ă��[�h�I�y���[�V�����s����
�@�@-------------
���\�[�X������3�N���b�N�u�ȏ�v�O�̒i�K�Ń��[�h���߂s���邷����(��)
>>691 ����
�@�@--------------
�@�@ϼ�����
�@�@1.5�{���炢���H
�@�@--------------
������Ɛ���������ANehalem: 246mm^2, Shanghai: 243mm^2�Ƃ������ƂŁA�_�C�T�C�Y��
�����L���b�V���e�ʂ����܂�ς���Ă��Ȃ����ƂɋC�t�������B
696 �F,,�E�L�́M�E,,�j��-�������F2008/12/28(��) 12:02:17 ID:rWoPv8A5
>>695
����͔��z���t����
add [mem]���ɂ���A���[�h���������錩���݂̃T�C�N������i3�N���b�N�j�ȍ~�ɉ��Z�I�y���[�V�����s�����B
����͔��z���t����
add [mem]���ɂ���A���[�h���������錩���݂̃T�C�N������i3�N���b�N�j�ȍ~�ɉ��Z�I�y���[�V�����s�����B
�N�_���B���Ȃ܂܁u�O�v�Ƃ��u��v�Ƃ��ŝ��߂Ă��Ӗ��Ȃ��ˁH
�f�R�[�h����E���[�h����E�f�[�^���͂����牉�Z����
�f�[�^���͂��O�ɂ��A���̖��߂��\�Ȃ���s����
�܂��A���ʂ��B
NetBurst��L1���烍�[�h�o���Ȃ��ƁA�҂����Ƀf�R�[�h�����蒼���H
���܂�Ӗ��Ȃ��C�����邪�A�Ȃ�̂��߂��낤�B
�f�R�[�h����E���[�h����E�f�[�^���͂����牉�Z����
�f�[�^���͂��O�ɂ��A���̖��߂��\�Ȃ���s����
�܂��A���ʂ��B
NetBurst��L1���烍�[�h�o���Ȃ��ƁA�҂����Ƀf�R�[�h�����蒼���H
���܂�Ӗ��Ȃ��C�����邪�A�Ȃ�̂��߂��낤�B
>>697 ����
NetBurst��"Replay"�@�\�ɂ��Ă�A>>686�̃����N��ɏ����Ă��邷���ǁA�v�����
L1 hit/miss���m�F���郌�C�e���V���ɂ����Ƃ������Ƃ��B
http://software.intel.com/en-us/articles/differences-in-optimizing-for-the-pentiumr-4-processor-vs-the-pentiumr-iii-processor
�@�@-------------------
�@�@In addition, because the NetBurst architecture schedules µops that are dependent on
�@�@loads as if the load will hit the L1 cache, it needs to replay (discard the results and
�@�@reschedule) them if an L1 cache miss actually occurs.
�@�@-------------------
>>698 ����
�R�A�E�A�[�L�e�N�`�����R�A/�A���R�A�̐蕪�����قȂ�v���Z�b�T������A���l������
�������u�R�A�v�̖ʐςɘf�킳�ꂸ�ɁA�_�C�S�̂ŕ]�����ׂ��Ƃ������Ƃ��B
NetBurst��"Replay"�@�\�ɂ��Ă�A>>686�̃����N��ɏ����Ă��邷���ǁA�v�����
L1 hit/miss���m�F���郌�C�e���V���ɂ����Ƃ������Ƃ��B
http://software.intel.com/en-us/articles/differences-in-optimizing-for-the-pentiumr-4-processor-vs-the-pentiumr-iii-processor
�@�@-------------------
�@�@In addition, because the NetBurst architecture schedules µops that are dependent on
�@�@loads as if the load will hit the L1 cache, it needs to replay (discard the results and
�@�@reschedule) them if an L1 cache miss actually occurs.
�@�@-------------------
>>698 ����
�R�A�E�A�[�L�e�N�`�����R�A/�A���R�A�̐蕪�����قȂ�v���Z�b�T������A���l������
�������u�R�A�v�̖ʐςɘf�킳�ꂸ�ɁA�_�C�S�̂ŕ]�����ׂ��Ƃ������Ƃ��B
>>651-652
Athlonx4 x3 ����Phenom��L3�����o�[�W�������Ęb�Ȃ̂��ȁH
Athlonx4 x3 ����Phenom��L3�����o�[�W�������Ęb�Ȃ̂��ȁH
701 �FMAC�I�^�������F2008/12/28(��) 13:23:32 ID:CyWsZRm4
>>699�ɏ�����NetBurst��L1�q�b�g�����肵�����@���s�̘b�A�ǂݒ����Ă݂�ƈ��p���܂߂�
��Ȃ����낵���Ȃ����e���B�ŁA�����B
http://download.intel.com/jp/developer/jpdoc/2001q1_art02_j.pdf (p. 11)
�@�@-------------------
�@�@Pentium 4 �v���Z�b�T�͓�����g���������A�p�C�v���C���̒i�����[�����߁A���[�h�E
�@�@�X�P�W���[��������s�Ɏ���܂ł̃N���b�N���̓��[�h�����s���郌�C�e���V���̂���
�@�@���������Ȃ�܂��B�����Ń�op �X�P�W���[���́A���[�h���s����������O�ɁA����
�@�@���[�h�Ɉˑ��������߂��f�B�X�p�b�`���܂��B�قƂ�ǂ̏ꍇ�A��op �X�P�W���[����
�@�@���[�h�� L1 �f�[�^�E�L���b�V���Ƀq�b�g������̂Ɖ��肵�܂��B
�@�@-------------------
�܂�NetBurst��Hyper Pipeline���ƃ��[�h���߂��X�P�W���[�����Ă���A���ۂɃ��[�h
���߂����s�����܂ł̃��C�e���V���n���ɂȂ�Ȃ����߁A���̕����P�`�邽�߂Ɉˑ�
���߂𓊋@�I�ɃX�P�W���[�����Ă����Ƃ������Ƃ��B
��Ȃ����낵���Ȃ����e���B�ŁA�����B
http://download.intel.com/jp/developer/jpdoc/2001q1_art02_j.pdf (p. 11)
�@�@-------------------
�@�@Pentium 4 �v���Z�b�T�͓�����g���������A�p�C�v���C���̒i�����[�����߁A���[�h�E
�@�@�X�P�W���[��������s�Ɏ���܂ł̃N���b�N���̓��[�h�����s���郌�C�e���V���̂���
�@�@���������Ȃ�܂��B�����Ń�op �X�P�W���[���́A���[�h���s����������O�ɁA����
�@�@���[�h�Ɉˑ��������߂��f�B�X�p�b�`���܂��B�قƂ�ǂ̏ꍇ�A��op �X�P�W���[����
�@�@���[�h�� L1 �f�[�^�E�L���b�V���Ƀq�b�g������̂Ɖ��肵�܂��B
�@�@-------------------
�܂�NetBurst��Hyper Pipeline���ƃ��[�h���߂��X�P�W���[�����Ă���A���ۂɃ��[�h
���߂����s�����܂ł̃��C�e���V���n���ɂȂ�Ȃ����߁A���̕����P�`�邽�߂Ɉˑ�
���߂𓊋@�I�ɃX�P�W���[�����Ă����Ƃ������Ƃ��B
�n����\��
>>701
L1�~�X�q�b�g���炢�Ńp�C�v���C���̓r���܂ŗ�����ops���L�����Z�������Ⴄ�̂�
�ܑ̖����C�����邯��ǁA���[�h�Ɉˑ��������߂����s�����Ȃ��X�g�[��������̂�
��������Ƃ������ƂȂ�ł����ˁB
L1�~�X�q�b�g���炢�Ńp�C�v���C���̓r���܂ŗ�����ops���L�����Z�������Ⴄ�̂�
�ܑ̖����C�����邯��ǁA���[�h�Ɉˑ��������߂����s�����Ȃ��X�g�[��������̂�
��������Ƃ������ƂȂ�ł����ˁB
704 �F,,�E�L�́M�E,,�j��-�������F2008/12/28(��) 16:47:55 ID:rWoPv8A5
�u�g���[�X�v�L���b�V��������B
�t���b�V�����J��Ԃ��Ȃ����OP����̍œK���������B
�t���b�V�����J��Ԃ��Ȃ����OP����̍œK���������B
705 �FMAC�I�^���c�q �����F2008/12/28(��) 17:39:47 ID:CyWsZRm4
>>704
"trace"��W�����v��[�v�����s���ɕ��בւ��Ċi�[������x�ŁA�ϑz���Ă���悤��
�_�C�i�~�b�N�ȍœK���@�\�햳�����B
http://download.intel.com/jp/developer/jpdoc/2001q1_art02_j.pdf (p. 6)
�@�@----------------------
�@�@���s�g���[�X�E�L���b�V���́AIA-32 ���߃f�R�[�_�ɂ���ĕϊ����ꂽ��op ���A�g���[�X��
�@�@�Ă��v���O�������s�����ɑg�ݗ��Ă܂��B�����ł́A1�g���[�X�E���C�����Ƃ�6�̃�op
�@�@ �ɃO���[�v�����܂��B1�̃g���[�X�͐������̃g���[�X�E���C���ō\������܂��B�e�g���[�X
�@�@�ɂ́A�\�������IA-32 �v���O�����̎��s�p�X�ɉ����ă�op ���i�[����Ă����܂��B����
�@�@���߁A����Ƃ��̕����̖��߂��v���O�������Ő���o�C�g���ꂽ�ꏊ�ɂ����Ă��A����
�@�@�g���[�X�E�L���b�V���E���C���Ɋi�[�ł��邱�ƂɂȂ�܂��B
�@�@----------------------
"trace"��W�����v��[�v�����s���ɕ��בւ��Ċi�[������x�ŁA�ϑz���Ă���悤��
�_�C�i�~�b�N�ȍœK���@�\�햳�����B
http://download.intel.com/jp/developer/jpdoc/2001q1_art02_j.pdf (p. 6)
�@�@----------------------
�@�@���s�g���[�X�E�L���b�V���́AIA-32 ���߃f�R�[�_�ɂ���ĕϊ����ꂽ��op ���A�g���[�X��
�@�@�Ă��v���O�������s�����ɑg�ݗ��Ă܂��B�����ł́A1�g���[�X�E���C�����Ƃ�6�̃�op
�@�@ �ɃO���[�v�����܂��B1�̃g���[�X�͐������̃g���[�X�E���C���ō\������܂��B�e�g���[�X
�@�@�ɂ́A�\�������IA-32 �v���O�����̎��s�p�X�ɉ����ă�op ���i�[����Ă����܂��B����
�@�@���߁A����Ƃ��̕����̖��߂��v���O�������Ő���o�C�g���ꂽ�ꏊ�ɂ����Ă��A����
�@�@�g���[�X�E�L���b�V���E���C���Ɋi�[�ł��邱�ƂɂȂ�܂��B
�@�@----------------------
706 �F,,�E�L�́M�E,,�j��-�������F2008/12/28(��) 17:46:02 ID:rWoPv8A5
���ϑz���Ă���悤��
���O�����̌��������Ƃ��D������]�����߂��Ă邾������
���O�����̌��������Ƃ��D������]�����߂��Ă邾������
707 �F,,�E�L�́M�E,,�j��-�������F2008/12/28(��) 17:49:14 ID:rWoPv8A5
���͂킴�킴�u�g���[�X�v���ċ������Ă�킯�����ȁB
MAC���^�̓g���[�X�̈Ӗ���m��Ȃ��낤�ȁB
MAC���^�̓g���[�X�̈Ӗ���m��Ȃ��낤�ȁB
708 �FMAC�I�^���c�q �����F2008/12/28(��) 18:42:14 ID:CyWsZRm4
>>707
�@�@-----------------
�@�@MAC���^�̓g���[�X�̈Ӗ���m��Ȃ��낤�ȁB
�@�@-----------------
����ł�A���́w�g���[�X�x�Ȃ�]���p��Ńp�C�v���C�����t���b�V�����J��Ԃ��ƍœK�����\�Ƃ���
�������I���ė~�������B
��X�̃R�s�y�p�ɁA�Ƃ��Ă��y���݂ɂ��Ă���̂ł�낵�����肢���邷(��)
�@�@-----------------
�@�@MAC���^�̓g���[�X�̈Ӗ���m��Ȃ��낤�ȁB
�@�@-----------------
����ł�A���́w�g���[�X�x�Ȃ�]���p��Ńp�C�v���C�����t���b�V�����J��Ԃ��ƍœK�����\�Ƃ���
�������I���ė~�������B
��X�̃R�s�y�p�ɁA�Ƃ��Ă��y���݂ɂ��Ă���̂ł�낵�����肢���邷(��)
709 �F,,�E�L�́M�E,,�j��-�������F2008/12/28(��) 18:49:13 ID:rWoPv8A5
���������APowerPC�̕����������Z���߂̃��C�e���V��1���Ǝv���Ă���̐����Ȏv�l�ɂ͋y�т܂���̂�
��������������Ă��������܂�
��������������Ă��������܂�
�Ƃ�����MAC�I�^�N���q�����ۉ߂�
����̃_���S�N�̔����u�t���b�V�����J��Ԃ��Ȃ����OP����̍œK���������v�͔���ȊO�̂Ȃɂ��̂ł��Ȃ�����?
�����>705�ŕԂ��Ăǂ�����E�E�E�E�A�_���S�������ł���
�Ƃ������Ƃō���̓_���S�N�̏������X��
����̃_���S�N�̔����u�t���b�V�����J��Ԃ��Ȃ����OP����̍œK���������v�͔���ȊO�̂Ȃɂ��̂ł��Ȃ�����?
�����>705�ŕԂ��Ăǂ�����E�E�E�E�A�_���S�������ł���
�Ƃ������Ƃō���̓_���S�N�̏������X��
711 �F,,�E�L�́M�E,,�j��-�������F2008/12/28(��) 18:50:31 ID:rWoPv8A5
����>>710���قڐ����B���͑��NetBurst��������
�R�n����������
������ւ�g���I�����ɁE�E�E�E�E����B
�S�O���ȁE�E�E
�W�܂��Ėʔ����̂́uMAC�I�^�v�u�_���S�v�u�@���v�N����
�Ƃɂ����ޓ��͌����̒��Ƃ������E�E�E�����������Ƃ������E�E�E�Փ˂���Ƒ�\�����X
�܂��A���Ȃ͖\�����~�߂�ׂ����ق��Ă��鑤�����E�E�E
�W�܂��Ėʔ����̂́uMAC�I�^�v�u�_���S�v�u�@���v�N����
�Ƃɂ����ޓ��͌����̒��Ƃ������E�E�E�����������Ƃ������E�E�E�Փ˂���Ƒ�\�����X
�܂��A���Ȃ͖\�����~�߂�ׂ����ق��Ă��鑤�����E�E�E
3�n���ɂ���̉�������肢�������B���ɃY���m�B
ttp://media.arstechnica.com/reviews/hardware/atom-nano-review.media/PCM2K5-2.jpg
ttp://media.arstechnica.com/reviews/hardware/atom-nano-review.media/PCM2K5-2.jpg
{kind=link}
�ꂳ��A���������Ă��Ȃ����E�E
�E�E����́A���j�����E�E
�E�E����́A���j�����E�E
>>715
��������܂ł��Ȃ��APCMark�́c���Ď�����B
���X�g�����߃Z�b�g��̗L���ŁA���ʂ̐��l��
���グ�����x���`�ɉ������߂Ă���̂��Ɓc�B
��������܂ł��Ȃ��APCMark�́c���Ď�����B
���X�g�����߃Z�b�g��̗L���ŁA���ʂ̐��l��
���グ�����x���`�ɉ������߂Ă���̂��Ɓc�B
�����
719 �FMAC�I�^��715 �����F2008/12/28(��) 19:48:52 ID:CyWsZRm4
>>715
�n��������S�O�����ǁA�A�����̃R�s�y�l�^�̔��_�p�ɏ����Ă������B
�܂�VIA nano��PCMark2005�̌��ʂ�ACPUID��"AMD"�w��ɂ��Ă����l�ɏ㏸���邱�Ƃ���
�摜�̒ʂ肷�B�܂艼��Intel�������Ƃ������Ɏg�������̂Ȃ�AAMD�����l�ɉ������
�g���Ă���Ƃ������Ƃ��B
���ɉ��̃A���������L����\�炸�ɉ摜�����������N���邩�ɋC�t���ׂ����B���L���ɂ�A������
���ʂ����ɔ����悤�ȃ��m�Ŗ������Ƃ������Ă��邷�B
http://arstechnica.com/reviews/hardware/atom-nano-review.ars/6
�@�@---------------------
�@�@None of this constitutes proof of wrongdoing, but it flies in the face of Futuremark's neutrality
�@�@claims. Bad code is a fact of life, but companies that write benchmarks for a living and sell
�@�@those benchmarks as evaluation tools have a responsibility to ensure that their software
�@�@delivers the neutral framework that it promises. Based on the information I've gathered thus
�@�@far, it seems Futuremark may have created three paths�\one for Intel, one for AMD, and one
�@�@generic "other" path. There's nothing wrong with optimized code paths, but our results would
�@�@seem to indicate that some paths are decidedly more optimized than others.
�@�@---------------------
Futuremark�̒�������u�œK���v���̂ɕ���������y��A�z�E�Ƃ������ƂŁB
�Ō�ɁAArstechnica��Intel���玑�{���Đ�p�`�����l����݂��Ă���T�C�g�Ƃ������Ƃ�
�m���Ă��đ��햳���Ǝv�����B
http://blogs.intel.com/technology/2008/03/intel_on_ars_technica_intel_ta.php
�n��������S�O�����ǁA�A�����̃R�s�y�l�^�̔��_�p�ɏ����Ă������B
�܂�VIA nano��PCMark2005�̌��ʂ�ACPUID��"AMD"�w��ɂ��Ă����l�ɏ㏸���邱�Ƃ���
�摜�̒ʂ肷�B�܂艼��Intel�������Ƃ������Ɏg�������̂Ȃ�AAMD�����l�ɉ������
�g���Ă���Ƃ������Ƃ��B
���ɉ��̃A���������L����\�炸�ɉ摜�����������N���邩�ɋC�t���ׂ����B���L���ɂ�A������
���ʂ����ɔ����悤�ȃ��m�Ŗ������Ƃ������Ă��邷�B
http://arstechnica.com/reviews/hardware/atom-nano-review.ars/6
�@�@---------------------
�@�@None of this constitutes proof of wrongdoing, but it flies in the face of Futuremark's neutrality
�@�@claims. Bad code is a fact of life, but companies that write benchmarks for a living and sell
�@�@those benchmarks as evaluation tools have a responsibility to ensure that their software
�@�@delivers the neutral framework that it promises. Based on the information I've gathered thus
�@�@far, it seems Futuremark may have created three paths�\one for Intel, one for AMD, and one
�@�@generic "other" path. There's nothing wrong with optimized code paths, but our results would
�@�@seem to indicate that some paths are decidedly more optimized than others.
�@�@---------------------
Futuremark�̒�������u�œK���v���̂ɕ���������y��A�z�E�Ƃ������ƂŁB
�Ō�ɁAArstechnica��Intel���玑�{���Đ�p�`�����l����݂��Ă���T�C�g�Ƃ������Ƃ�
�m���Ă��đ��햳���Ǝv�����B
http://blogs.intel.com/technology/2008/03/intel_on_ars_technica_intel_ta.php
Futuremark(�j�Ƃ������Ƃł���
721 �FSocket774�F2008/12/28(��) 19:59:22 ID:rCDvOgNE
�m��VIA�̃V�F�A��1%�Ȃ��������
�������K���ł��d�����Ȃ��Ǝv������
�������K���ł��d�����Ȃ��Ǝv������
> �n��������S�O������
�S�z�͖��p����A�uMAC�I�^�v�u�_���S�v�u�@���v�N�B���D�G�Ȃ��Ƃ͓��e���e���ؖ����Ă���X����E�E�E
�N�B���D�G�Ȃ̂ł����i�݁A�Ƃ�ŌN�B���Ȃ����X������͎̂d���̖������Ƃ��X���疳���ŋX����
�S�z�͖��p����A�uMAC�I�^�v�u�_���S�v�u�@���v�N�B���D�G�Ȃ��Ƃ͓��e���e���ؖ����Ă���X����E�E�E
�N�B���D�G�Ȃ̂ł����i�݁A�Ƃ�ŌN�B���Ȃ����X������͎̂d���̖������Ƃ��X���疳���ŋX����
>>722
������ȃn�Q
������ȃn�Q
724 �FMAC�I�^��722 �����F2008/12/28(��) 20:09:29 ID:CyWsZRm4
>>722
�@�@------------------
�@�@�uMAC�I�^�v�u�_���S�v�u�@���v�N�B���D�G
�@�@------------------
�h�T�N�T�ɕ���āA���炩�ɋZ�p�_�c�ɊW�Ȃ��q�g���������Ă���悤�ȋC�����邷(��)
�@�@------------------
�@�@�uMAC�I�^�v�u�_���S�v�u�@���v�N�B���D�G
�@�@------------------
�h�T�N�T�ɕ���āA���炩�ɋZ�p�_�c�ɊW�Ȃ��q�g���������Ă���悤�ȋC�����邷(��)
�c�q�AMAC���A�S�~�͏������݂��s���ł����Ȃ�����A�{�[�����Ă邪�G����
�A�{�[�����ĂȂ���
�L���K�C�x���G���͂܂�3�l�ɔ�ב���ĂȂ����Ď����Ȃ���
���łɌ����ƒ��N�l����Ȃ����畁�ʂ̓��{�l�͂��������i�肵�Ȃ�
�A�{�[�����ĂȂ���
�L���K�C�x���G���͂܂�3�l�ɔ�ב���ĂȂ����Ď����Ȃ���
���łɌ����ƒ��N�l����Ȃ����畁�ʂ̓��{�l�͂��������i�肵�Ȃ�
>>724
> �h�T�N�T�ɕ���āA���炩�ɋZ�p�_�c�ɊW�Ȃ��q�g���������Ă���悤�ȋC�����邷(��)
���̒ʂ�A�@���N�͂��̕���ł͑f�l�����m�������ɏ��Ȃ�����Z�p�_�c�͖������X
�����ǔނ͗D�G����A���̗ǂ������Ȃ�MAC�I�^�N��肾�Ԃ�ゾ��A���̈Ӗ��Ŋ܂߂����X
> �h�T�N�T�ɕ���āA���炩�ɋZ�p�_�c�ɊW�Ȃ��q�g���������Ă���悤�ȋC�����邷(��)
���̒ʂ�A�@���N�͂��̕���ł͑f�l�����m�������ɏ��Ȃ�����Z�p�_�c�͖������X
�����ǔނ͗D�G����A���̗ǂ������Ȃ�MAC�I�^�N��肾�Ԃ�ゾ��A���̈Ӗ��Ŋ܂߂����X
���R�e�O�l�O��������
���̃X���͂��������܂����I
���̃X���͂��������܂����I
��]�����̏��Ȃ��Œm�\�����߂�Ƃ����
�A���~�i�R�e���j����ԓ����ǂ��������ƂɂȂ�
�����뒆�g�̖������肵�����Ȃ���������
�A���~�i�R�e���j����ԓ����ǂ��������ƂɂȂ�
�����뒆�g�̖������肵�����Ȃ���������
729 �F,,�E�L�́M�E,,�j��-�������F2008/12/28(��) 20:26:50 ID:rWoPv8A5
�_���g�c�̔n���������\���Ă���܂��B�����́A�|��
MAC�I�^�͐��i�������B
�_���S�����i�������B
�e�w�͓��������B
�_���S�����i�������B
�e�w�͓��������B
731 �FSocket774�F2008/12/28(��) 22:16:46 ID:UFiERAy+
�d���m�̉���܂��H>>715
733 �F,,�E�L�́M�E,,�j��-�������F2008/12/28(��) 22:28:21 ID:rWoPv8A5
���w���x�̉p�ꂳ���ǂ߂�Ȃ������Ȃ��Ă�̂������킩��̂�
�ǂ߂Ȃ����Ď��_�ő����p���������Ǝv�����ǁB
�ǂ߂Ȃ����Ď��_�ő����p���������Ǝv�����ǁB
734 �FSocket774�F2008/12/28(��) 22:43:46 ID:UFiERAy+
>>732-733
���߂�ˁB�G���̉���ɋ����Ȃ��B
���߂�ˁB�G���̉���ɋ����Ȃ��B
Hi�standard Lagwagon no use for a name hide
737 �F,,�E�L�́M�E,,�j��-�������F2008/12/28(��) 22:56:01 ID:rWoPv8A5
�������Ǝ��̒p����������B�v����ɉp�ꂪ�ǂ߂Ȃ���
>737
�������Ȃ�(�L�t�M)
�w�X�i�̃~���N�`���R���[�g���~�����x�ƌ����Ă�l��
�w�����̃~���N�`���R���[�g�x�������Ă��Ӗ����Ȃ��ƌ����Ă�̂���B
�������Ȃ�(�L�t�M)
�w�X�i�̃~���N�`���R���[�g���~�����x�ƌ����Ă�l��
�w�����̃~���N�`���R���[�g�x�������Ă��Ӗ����Ȃ��ƌ����Ă�̂���B
��[���p�p�AExcite�e�L�X�g�|��ɓ������Ⴄ����
���̂Ȃɂ����s�̏؋����\�����܂��A�����Futuremark�̒����N���[���ɔ����܂��B
�����R�[�h�͌����ł����A�����Ńx���`�}�[�N�������āA�]���c�[���Ƃ��Ă����̃x���`�}�[�N��̔������Ђ������̃\�t�g�E�F�A�����ꂪ���钆���g�g�݂𑗂�̂�ۏ���ӔC�������Ă��܂��B
���Ɋ�Â��āA���́A����܂ł̂Ƃ���Futuremark��3�̌o�H���쐬������������Ȃ��悤�Ɏv����Ɛ������܂���--�C���e���̂��߂̂��́AAMD�̂��߂̂��́A����сu���v��1�̈�ʓI�Ȍo�H�B
�������̌��ʈȊO�̍œK���R�[�h�o�H�ɋ���������͉̂�������܂���B
���̂Ȃɂ����s�̏؋����\�����܂��A�����Futuremark�̒����N���[���ɔ����܂��B
�����R�[�h�͌����ł����A�����Ńx���`�}�[�N�������āA�]���c�[���Ƃ��Ă����̃x���`�}�[�N��̔������Ђ������̃\�t�g�E�F�A�����ꂪ���钆���g�g�݂𑗂�̂�ۏ���ӔC�������Ă��܂��B
���Ɋ�Â��āA���́A����܂ł̂Ƃ���Futuremark��3�̌o�H���쐬������������Ȃ��悤�Ɏv����Ɛ������܂���--�C���e���̂��߂̂��́AAMD�̂��߂̂��́A����сu���v��1�̈�ʓI�Ȍo�H�B
�������̌��ʈȊO�̍œK���R�[�h�o�H�ɋ���������͉̂�������܂���B
740 �FMAC�I�^��738 �����F2008/12/28(��) 23:01:39 ID:CyWsZRm4
>>738
�����ɂ��Z�p�I�������ɂ������������A��������B��A��������X���Ɉ����U������
���z�ɐZ���Ă��ė~�������m���B�B�B
�����ɂ��Z�p�I�������ɂ������������A��������B��A��������X���Ɉ����U������
���z�ɐZ���Ă��ė~�������m���B�B�B
AMD��Intel�ɂ����牺����낤�ȁE�E�E
743 �F,,�E�L�́M�E,,�j��-�������F2008/12/28(��) 23:05:08 ID:rWoPv8A5
>>739
���̕ӂ���Ȃ��ȁB
�x���_�[�X�g�����O�Ŕ���]�X�̂Ƃ����Ă݁H
�`�[�g�ł��Ȃ�ł��Ȃ��v���O�����̐v�~�X�Ɖ������Ă�B
���̕ӂ���Ȃ��ȁB
�x���_�[�X�g�����O�Ŕ���]�X�̂Ƃ����Ă݁H
�`�[�g�ł��Ȃ�ł��Ȃ��v���O�����̐v�~�X�Ɖ������Ă�B
744 �FMAC�I�^��742 �����F2008/12/28(��) 23:06:41 ID:CyWsZRm4
ID:UFiERAy+���p��̓ǂ߂Ȃ��������ȓz���Ƃ������Ƃ͂킩������
�p��͓ǂ߂Ă����{�ꂪ�킩��Ȃ��l������Ƃ�����
��MAC�I�^���c�q�����������Ƃ����v���Ȃ��B
>>731���m�肽���̂́w�d���m�̔]����>>715���ǂ����߂���Ă��邩�x�����Ȃ�ł�����
>>715�̐^���Ȃ�ĂƂ����ɂ킩�肫���Ă�̂ɁB
>>731���m�肽���̂́w�d���m�̔]����>>715���ǂ����߂���Ă��邩�x�����Ȃ�ł�����
>>715�̐^���Ȃ�ĂƂ����ɂ킩�肫���Ă�̂ɁB
748 �F,,�E�L�́M�E,,�j��-�������F2008/12/28(��) 23:10:35 ID:rWoPv8A5
�ʃX���ʼn����Y�Ƃʼn�����݂������
�����̂͑S���d���m���I
MCS Website
Core i7 2.66GHz(HT) 54
Core i7 2.66GHz(HT-off) 49.3
Opteron 8384 2.7GHz 42.9
MySQL OLAP
Core i7 2.66GHz(HT) 2800
Core i7 2.66GHz(HT-off) 2950
Opteron 8384 2.7GHz 2170
Oracle Charbench
Core i7 2.66GHz(HT) 910
Core i7 2.66GHz(HT-off) 808.5
Opteron 8384 2.7GHz 745.4
1CPU�݂̂Ōv��
http://it.anandtech.com/IT/showdoc.aspx?i=3484&p=11
Core i7 2.66GHz(HT) 54
Core i7 2.66GHz(HT-off) 49.3
Opteron 8384 2.7GHz 42.9
MySQL OLAP
Core i7 2.66GHz(HT) 2800
Core i7 2.66GHz(HT-off) 2950
Opteron 8384 2.7GHz 2170
Oracle Charbench
Core i7 2.66GHz(HT) 910
Core i7 2.66GHz(HT-off) 808.5
Opteron 8384 2.7GHz 745.4
1CPU�݂̂Ōv��
http://it.anandtech.com/IT/showdoc.aspx?i=3484&p=11
�ꉞ��������X�����m�F���Ă݂���A�{����Intel�̈��s�̏؋��Ƃ������ƂɂȂ��Ă�����(��)
http://pc11.2ch.net/test/read.cgi/jisaku/1226323629/457
���N�O�̋L�����l�^�Ő���オ���Ă�����Ղ肾���ł��p���������̂ɁA�L���̓��e��
�����������ł��Ȃ��A�������āB�B�B
http://pc11.2ch.net/test/read.cgi/jisaku/1226323629/457
���N�O�̋L�����l�^�Ő���オ���Ă�����Ղ肾���ł��p���������̂ɁA�L���̓��e��
�����������ł��Ȃ��A�������āB�B�B
754 �F,,�E�L�́M�E,,�j��-�������F2008/12/28(��) 23:20:20 ID:rWoPv8A5
��[��
���₳���
VenderString���uAuthenticAMD�v�̂Ƃ��ȊO�œK������ĂȂ��p�X��ʂ�v���O�����������
AMD�̈��s�Y���܂��B
���₳���
VenderString���uAuthenticAMD�v�̂Ƃ��ȊO�œK������ĂȂ��p�X��ʂ�v���O�����������
AMD�̈��s�Y���܂��B
755 �FMAC�I�^��753 �����F2008/12/28(��) 23:22:13 ID:CyWsZRm4
>>753
�@�@---------------
�@�@����͂�������X���Ō�����B
�@�@---------------
���ǂ̂Ƃ���A���̒��ɂ�o�b�`�C����G�ꂸ�ɕ��u���Ă������ق����ǂ����m��������Ă��Ƃ��ƁB�B�B
�@�@---------------
�@�@����͂�������X���Ō�����B
�@�@---------------
���ǂ̂Ƃ���A���̒��ɂ�o�b�`�C����G�ꂸ�ɕ��u���Ă������ق����ǂ����m��������Ă��Ƃ��ƁB�B�B
>>755
�b�̒ʂ��Ȃ��n�����Ȃ��B
���̃X���̘b���A�����œ�����ԂɂȂ��ĂȂ��ɂ��ւ�炸
�����Ă���Ȃ�B�X���Ⴂ���
���������B
�b�̒ʂ��Ȃ��n�����Ȃ��B
���̃X���̘b���A�����œ�����ԂɂȂ��ĂȂ��ɂ��ւ�炸
�����Ă���Ȃ�B�X���Ⴂ���
���������B
�c�q��HybridPower���܂Ƃ��ɓ����悤�ɂȂ�h���C�o�����Ƃ�
ICH10R���܂Ƃ��ɂȂ�悤�ȃh���C�o�����Ƃ���������̂ɁB
ICH10R���܂Ƃ��ɂȂ�悤�ȃh���C�o�����Ƃ���������̂ɁB
�I�������ꂵ���Ȃ邩
>>752
> ���S���x���`���o���Ă���ȏ��ɔ���PIO�s��w
������PIO����Ȃ���Ɖ��x�����Ε�����̂�?
PIO���Ƃ���Ȃɑ���OS�͋N�����܂�����Ă�
http://www9.uploader.jp/dl/ledline/ledline_uljp00032.rar.html
�ǐL
�N���A�b�v����ledline_uljp00069.wmv�͍폜�v���܂�
���R
1)ledline_uljp00032.rar�Əd�����Ă���
2)�����rar���ň��k���ăA�b�v���Ă�������
> ���S���x���`���o���Ă���ȏ��ɔ���PIO�s��w
������PIO����Ȃ���Ɖ��x�����Ε�����̂�?
PIO���Ƃ���Ȃɑ���OS�͋N�����܂�����Ă�
http://www9.uploader.jp/dl/ledline/ledline_uljp00032.rar.html
�ǐL
�N���A�b�v����ledline_uljp00069.wmv�͍폜�v���܂�
���R
1)ledline_uljp00032.rar�Əd�����Ă���
2)�����rar���ň��k���ăA�b�v���Ă�������
761 �F,,�E�L�́M�E,,�j��-�������F2008/12/28(��) 23:35:32 ID:rWoPv8A5
���ǂ̂Ƃ���uSSE3���g����VIA�v���Z�b�T�v��z�肵�ĂȂ���B
�Ȃ��Ȃ�2005�N���_�ł͂����CPU�����݂��Ȃ���������B
if (vender == "GenuineIntel") {
�@if (SSE3���g����) {
�@�@//SSE3�p���[�`�����g�p
�@}else if (SSE2���g����) {�i����
�@�@//SSE2�p���[�`�����g�p
�@}else
�@�E
�@�E
�@�E
} elseif (vender == "AuthenticAMD") {
�@if (SSE2���g����) {
�@�@//SSE2�p���[�`�����g�p
�@}else
�@�E
�@�E
�@�E
} else if (vender == "CentaurHauls"){
�@if(3DNow���g����) {
�@�@//3DNow�p���[�`�����g�p
�@}else(����
}
VenderString������FeatureFlag�Ŕ��肷��悤�ɂ��Ă���������ԈႢ�͋N���Ȃ��B
Intel�v���Z�b�T�Ɍ��������邱�Ƃ�SSE3���g�������[�`�����g���܂�����Ă���
�������{���I��Nano��Atom���X�R�A���o��̂��^���B
�Ȃ��Ȃ�2005�N���_�ł͂����CPU�����݂��Ȃ���������B
if (vender == "GenuineIntel") {
�@if (SSE3���g����) {
�@�@//SSE3�p���[�`�����g�p
�@}else if (SSE2���g����) {�i����
�@�@//SSE2�p���[�`�����g�p
�@}else
�@�E
�@�E
�@�E
} elseif (vender == "AuthenticAMD") {
�@if (SSE2���g����) {
�@�@//SSE2�p���[�`�����g�p
�@}else
�@�E
�@�E
�@�E
} else if (vender == "CentaurHauls"){
�@if(3DNow���g����) {
�@�@//3DNow�p���[�`�����g�p
�@}else(����
}
VenderString������FeatureFlag�Ŕ��肷��悤�ɂ��Ă���������ԈႢ�͋N���Ȃ��B
Intel�v���Z�b�T�Ɍ��������邱�Ƃ�SSE3���g�������[�`�����g���܂�����Ă���
�������{���I��Nano��Atom���X�R�A���o��̂��^���B
762 �FMAC�I�^��759 �����F2008/12/28(��) 23:37:12 ID:CyWsZRm4
>>759
�����������ራ�������ǁACray�����ƃv���W�F�N�g�̔[���������Ă�����Ă܂�Intel�ɏ�芷����
���Ƃ����f�����i�K�ŋC�t���ׂ��b���B
http://www.eetasia.com/ART_8800520031_1034362_NT_bfb60721.HTM
�@�@--------------------
�@�@Cray is seeking approval from Darpa for its plans to shift the Cascade design to Intel
�@�@processors using QPI that provides links at up to 6.4GTransfers/s.
�@�@--------------------
�����������ራ�������ǁACray�����ƃv���W�F�N�g�̔[���������Ă�����Ă܂�Intel�ɏ�芷����
���Ƃ����f�����i�K�ŋC�t���ׂ��b���B
http://www.eetasia.com/ART_8800520031_1034362_NT_bfb60721.HTM
�@�@--------------------
�@�@Cray is seeking approval from Darpa for its plans to shift the Cascade design to Intel
�@�@processors using QPI that provides links at up to 6.4GTransfers/s.
�@�@--------------------
763 �FMAC�I�^���c�q �����F2008/12/28(��) 23:40:01 ID:CyWsZRm4
>>761
�@�@----------------
�@�@VenderString������FeatureFlag�Ŕ��肷��悤�ɂ��Ă���������ԈႢ�͋N���Ȃ��B
�@�@----------------
Phenom�X���b�h�ɂ������������ǁA�݊����̂��߂ɖ��߂�T�|�[�g���邪���\��o�Ȃ��Ƃ���
�����݂���̂ŁAFeature Flag�Ŕ��f�����OK�Ƃ����̂��Z�����Ǝv�����B
���ǂ̂Ƃ���A�v���O�����J�����_�ő��݂��Ȃ��v���Z�b�T�ɍœK������Ȃ�ĕs�\���B
�@�@----------------
�@�@VenderString������FeatureFlag�Ŕ��肷��悤�ɂ��Ă���������ԈႢ�͋N���Ȃ��B
�@�@----------------
Phenom�X���b�h�ɂ������������ǁA�݊����̂��߂ɖ��߂�T�|�[�g���邪���\��o�Ȃ��Ƃ���
�����݂���̂ŁAFeature Flag�Ŕ��f�����OK�Ƃ����̂��Z�����Ǝv�����B
���ǂ̂Ƃ���A�v���O�����J�����_�ő��݂��Ȃ��v���Z�b�T�ɍœK������Ȃ�ĕs�\���B
764 �F,,�E�L�́M�E,,�j��-�������F2008/12/28(��) 23:53:49 ID:rWoPv8A5
�܁APentium M��MMX��SSE2�����Ƃ�����K7/K8��SSE�Ƃ�����������ł��̕ӂ͔c�����Ă��B
Feature Flag�S���E���グ����Ńx���_�[�X�g�����O���肵�ĐU�蕪��
�ȒP�ȃx���`��SIMD���Z���j�b�g�̍\���肷��
���m�̃v���Z�b�T�̏ꍇ�͂Ƃ肠������ʋ@�\�g���Ă����Ăȕ��j�ŗǂ��Ǝv�����ǂȁB
�I�v�V�����ŋ@�\�I���ł���悤�ɂ���Ƃ��B�ߌ�̂��[���̃t�����g�G���h�ł�����Ă�悤�ȁB
���Ȃ݂�Pentium M�ł�SSE2���x���Ȃ闝������
AVX�ɂ����Đ����֘A��SIMD���߂�128bit�~�܂�̂��������R���ˁB
�������Z�łQ�{���̉��Z���T�|�[�g�����1���߂�����Future File��2�G���g���H���Ă��܂�����p���Đ��\�ቺ����B
Sandy Bridge�̓f�[�^�o�X128�r�b�g�����BPentium M/Core�܂ł�64�r�b�g�������B
Feature Flag�S���E���グ����Ńx���_�[�X�g�����O���肵�ĐU�蕪��
�ȒP�ȃx���`��SIMD���Z���j�b�g�̍\���肷��
���m�̃v���Z�b�T�̏ꍇ�͂Ƃ肠������ʋ@�\�g���Ă����Ăȕ��j�ŗǂ��Ǝv�����ǂȁB
�I�v�V�����ŋ@�\�I���ł���悤�ɂ���Ƃ��B�ߌ�̂��[���̃t�����g�G���h�ł�����Ă�悤�ȁB
���Ȃ݂�Pentium M�ł�SSE2���x���Ȃ闝������
AVX�ɂ����Đ����֘A��SIMD���߂�128bit�~�܂�̂��������R���ˁB
�������Z�łQ�{���̉��Z���T�|�[�g�����1���߂�����Future File��2�G���g���H���Ă��܂�����p���Đ��\�ቺ����B
Sandy Bridge�̓f�[�^�o�X128�r�b�g�����BPentium M/Core�܂ł�64�r�b�g�������B
���ځ[�炯�����A�܂����̂��킢�����ȕ��X���t�@�r�����ĔS�����Ă�́H
>>765
760����764�܂őS�����R�e3�l�ɂ�郌�X
760����764�܂őS�����R�e3�l�ɂ�郌�X
>>715�̂́ACPUID��ύX���邾���ŁA��쓮���N�����ɂ���A
�@�\�ł͂Ȃ��ACPUID������CPU�Ƃ��̋@�\�f���Ă�����ۂ��x���`�́A
���f�����Ƃ��Ĕ������Ď��ł�����ˁ[�́H
AMD�ɕς��Ă����l�͏オ�邾�낤���ǁA
�u�����AMD���s�����v�Ƃ����������o�J�������������ǁA
���������o�J�͓��̒��ɃE�W���킢�Ă���Ǝv���̂ŕ��u�ł����ȁB
�@�\�ł͂Ȃ��ACPUID������CPU�Ƃ��̋@�\�f���Ă�����ۂ��x���`�́A
���f�����Ƃ��Ĕ������Ď��ł�����ˁ[�́H
AMD�ɕς��Ă����l�͏オ�邾�낤���ǁA
�u�����AMD���s�����v�Ƃ����������o�J�������������ǁA
���������o�J�͓��̒��ɃE�W���킢�Ă���Ǝv���̂ŕ��u�ł����ȁB
intel�̕s���Ƃ������Ă�A���ɂ͉��������Ă�̂��ˁB
�܂��A���~�̓��̃C�J����Ղ�͍��Ɏn�܂������Ƃ���Ȃ����ǂ�w
���C�ʼn��̂悤�ȉR�𐁒��ł���
http://pc11.2ch.net/test/read.cgi/jisaku/1226755074/574
574 ���O�FSocket774[sage] ���e���F2008/12/29(��) 02:25:57 ID:ODqGZJZY
��������X�g�[�u�ȏ�ɔ��S���x���`�ŗD�ʂɌ���������
�����킯������A�����H������K���ɂȂ��ȁB
���C�ʼn��̂悤�ȉR�𐁒��ł���
http://pc11.2ch.net/test/read.cgi/jisaku/1226755074/574
574 ���O�FSocket774[sage] ���e���F2008/12/29(��) 02:25:57 ID:ODqGZJZY
��������X�g�[�u�ȏ�ɔ��S���x���`�ŗD�ʂɌ���������
�����킯������A�����H������K���ɂȂ��ȁB
�w�m���U�̐V���ł����Ă邩�Ǝv������
���ς�炸PIO��Y�Ɲs����D���L�`�K�C���R�e���\��Ă邾������
���ς�炸PIO��Y�Ɲs����D���L�`�K�C���R�e���\��Ă邾������
�̂�������
773 �F,,�E�L�́M�E,,�j��-�������F2008/12/29(��) 07:01:55 ID:GF8Qy4lX
>>767
�x���_�[�X�g�����O�ς��ăX�R�A�����P����邱�Ǝ��̂͌�쓮����ˁ[
VIA�ɂ́uSSE3�������ĂȂ����l�C�e�B�u128�r�b�g��SIMD���j�[�g�ɂ��MMX/3DNow!�������̂���VIA�̃v���Z�b�T�v��
�x���`�����ꂽ���_�ő��݂��Ȃ������B
Intel����Prescott�����݂��ĂāASSE3���g����ꍇ�͂��������g�����ق������������B
AMD����Athlon 64�ł�SSE2������Ȃ�Ɍ����悭�������B
VIA��C3��MMX/3DNow!�قڈ�������Ȃ����������AC7�ł�SIMD���j�b�g��SSE�ɍœK������ĂȂ���
128�r�b�gSIMD���g���Ƃ������Ēx���Ȃ�P�[�X���������B
������x���_�[�X�g�����O��VIA��������SSE2/3���g���悤����������3DNow!�p���[�`�����g���悤�ɂ�����B
������Nano�ł�SIMD���j�b�g��128�r�b�g�������SSE2/SSE3�������悭���s�ł���悤�ɂȂ����B
��ŁA�x���_�[�X�g�����O�ς���AMD���ƌ�F���������SSE2�p�̃p�X���L���ɂȂ�AIntel�ɂ����SSE3�p�p�X���g����B
����Ő��\���オ�����킯���B
���Ă������A���ݓI�ɂ͐��\��Nano��Atom���B����3issue��2issue�͕����Ȃ��B
��������d�͂ł͔������ˁB
�x���_�[�X�g�����O�ς��ăX�R�A�����P����邱�Ǝ��̂͌�쓮����ˁ[
VIA�ɂ́uSSE3�������ĂȂ����l�C�e�B�u128�r�b�g��SIMD���j�[�g�ɂ��MMX/3DNow!�������̂���VIA�̃v���Z�b�T�v��
�x���`�����ꂽ���_�ő��݂��Ȃ������B
Intel����Prescott�����݂��ĂāASSE3���g����ꍇ�͂��������g�����ق������������B
AMD����Athlon 64�ł�SSE2������Ȃ�Ɍ����悭�������B
VIA��C3��MMX/3DNow!�قڈ�������Ȃ����������AC7�ł�SIMD���j�b�g��SSE�ɍœK������ĂȂ���
128�r�b�gSIMD���g���Ƃ������Ēx���Ȃ�P�[�X���������B
������x���_�[�X�g�����O��VIA��������SSE2/3���g���悤����������3DNow!�p���[�`�����g���悤�ɂ�����B
������Nano�ł�SIMD���j�b�g��128�r�b�g�������SSE2/SSE3�������悭���s�ł���悤�ɂȂ����B
��ŁA�x���_�[�X�g�����O�ς���AMD���ƌ�F���������SSE2�p�̃p�X���L���ɂȂ�AIntel�ɂ����SSE3�p�p�X���g����B
����Ő��\���オ�����킯���B
���Ă������A���ݓI�ɂ͐��\��Nano��Atom���B����3issue��2issue�͕����Ȃ��B
��������d�͂ł͔������ˁB
atom�i�j
���܂����330��������
�l�b�g�z���̑��삪��������
2���ł��Ƃ�vb8001�߂��܂���w
���܂����330��������
�l�b�g�z���̑��삪��������
2���ł��Ƃ�vb8001�߂��܂���w
���Ȃ݂ɓ˂�����ł����ƁAC5XL nehemiah�ȍ~SSE�����ڂ���Ă����
3DNow!�͎g���Ȃ��Ȃ��Ă���܂��̂�
3DNow!���g����̂� C5N Ezra-T�܂łł�
C5J esther(C7)�ȍ~��SSE3�܂ŁACNA isaiah (nano)��SSSE3�ɑΉ����܂�
CNB��SSE4�ɑΉ�����\��
3DNow!�͎g���Ȃ��Ȃ��Ă���܂��̂�
3DNow!���g����̂� C5N Ezra-T�܂łł�
C5J esther(C7)�ȍ~��SSE3�܂ŁACNA isaiah (nano)��SSSE3�ɑΉ����܂�
CNB��SSE4�ɑΉ�����\��
Nano��Atom��萫�\��������ɃR�X�g��������?
��������HP�ł̗̍p���т�������̂Ɉ�����B
VIA��AMD�ȏ�ɋꂵ���݊��r�W�l�X�����Ă���͂������A
�ʂ����Ă��Ă�����낤���B
��������HP�ł̗̍p���т�������̂Ɉ�����B
VIA��AMD�ȏ�ɋꂵ���݊��r�W�l�X�����Ă���͂������A
�ʂ����Ă��Ă�����낤���B
[H]ard|OCP�f���ɓ��e���ꂽPhenom II 940BE�̃x���`�摜���B
SuperPI���3DMark06���B�B�B
http://www.hardforum.com/showpost.php?p=1033481302&postcount=1
http://www.hardforum.com/showpost.php?p=1033482191&postcount=10
3.86GHz��OC���Ă��邷���ǁA���e�҂ɂ���OC��y�X�Ƃ̂��ƁB
�ł�1.49V�Ƃ����̂�A�����d�������悤�ȋC�����邷�B
SuperPI���3DMark06���B�B�B
http://www.hardforum.com/showpost.php?p=1033481302&postcount=1
http://www.hardforum.com/showpost.php?p=1033482191&postcount=10
3.86GHz��OC���Ă��邷���ǁA���e�҂ɂ���OC��y�X�Ƃ̂��ƁB
�ł�1.49V�Ƃ����̂�A�����d�������悤�ȋC�����邷�B
���K�͂̉�Ђ��x����ɂ͏\���ł���
centuar�Ȃ��100�l���˂���
centuar�Ȃ��100�l���˂���
�C�O�����w�̌������̔�p���Ă̂͑�w���͏o���Ȃ�
�����̊�ʂŁA�_���⌤���ɑ��Ċ�Ƃ��瓊�����Ă��炤
�܂��A��w�@���ɑ��Ă͋�����������
���R�w����K�v����
����Ȗ�ŋ����͗L�]�Ȍ������s�����z�̎������W�߁A�����̗L�\�Ȍ�������@��
���ق�Ȃ��Ⴂ���Ȃ�
�ł����Ă��̕���ł�Intel�̏o���z�����|�I
�v�ł������ł��Z�p�v�V���Ă̂͑���w�̌��������琶�܂��̂�����AIntel��������������
�����̊�ʂŁA�_���⌤���ɑ��Ċ�Ƃ��瓊�����Ă��炤
�܂��A��w�@���ɑ��Ă͋�����������
���R�w����K�v����
����Ȗ�ŋ����͗L�]�Ȍ������s�����z�̎������W�߁A�����̗L�\�Ȍ�������@��
���ق�Ȃ��Ⴂ���Ȃ�
�ł����Ă��̕���ł�Intel�̏o���z�����|�I
�v�ł������ł��Z�p�v�V���Ă̂͑���w�̌��������琶�܂��̂�����AIntel��������������
781 �FMAC�I�^��780 �����F2008/12/29(��) 12:42:41 ID:dSbXbEG6
>>780
�@�@-------------------
�@�@�v�ł������ł��Z�p�v�V���Ă̂͑���w�̌��������琶�܂��
�@�@-------------------
���Ɣ������߂����ƁB
Intel��A�m�[�x���܂����悤�Ȋw�҂��������Ђł��邽�߂ɁA�����ɑ�����j��č����
�Ƃ��Ă����ꂷ�B
http://www.nli-research.co.jp/report/report/2007/08/repo0708-3.pdf
�@�@===================
�@�@�܂����ɒ����������������Ȃ�
�@�@���ƕ�����̃T�|�[�g�������Ȃ������͍s��Ȃ��B
�@�@��O�Ɏ��Ɖ��܂łɂT�N�ȏ�i�T�`10�N�j������w�p�I���T�[�`�͑�w�𒆐S��
�@�@�O�����������p����
�@�@===================
�@�@-------------------
�@�@�v�ł������ł��Z�p�v�V���Ă̂͑���w�̌��������琶�܂��
�@�@-------------------
���Ɣ������߂����ƁB
Intel��A�m�[�x���܂����悤�Ȋw�҂��������Ђł��邽�߂ɁA�����ɑ�����j��č����
�Ƃ��Ă����ꂷ�B
http://www.nli-research.co.jp/report/report/2007/08/repo0708-3.pdf
�@�@===================
�@�@�܂����ɒ����������������Ȃ�
�@�@���ƕ�����̃T�|�[�g�������Ȃ������͍s��Ȃ��B
�@�@��O�Ɏ��Ɖ��܂łɂT�N�ȏ�i�T�`10�N�j������w�p�I���T�[�`�͑�w�𒆐S��
�@�@�O�����������p����
�@�@===================
>>781
�܂��N�́u�Ăɂ��́v�����w�Z������ł�蒼���B
�܂��N�́u�Ăɂ��́v�����w�Z������ł�蒼���B
>>780
�P�ɉ�Ђ��傫���A�傫�����Ɏ���L���Ă��Ȃ�����
���蕪��ɒ��ڂ��Ă����Intel���ڗ��������Ǝv�����B
�����S�����������ɘ_���Ƃ������Ƃ��ɁA
��ƋK�͑��������ڂ����đ������H
�P�ɉ�Ђ��傫���A�傫�����Ɏ���L���Ă��Ȃ�����
���蕪��ɒ��ڂ��Ă����Intel���ڗ��������Ǝv�����B
�����S�����������ɘ_���Ƃ������Ƃ��ɁA
��ƋK�͑��������ڂ����đ������H
785 �FSocket774�F2008/12/30(��) 10:44:02 ID:WP1znixq
�d������������
786 �F,,�E�L�́M�E,,�j��-�������F2008/12/30(��) 17:29:30 ID:EfrppfGz
SSE5���܂��߂ɕ]�����悤�Ƃ��Ă�z�����͉������������Ȃ��đS�Ă�������
�Ȃ��Ă��I�I
�Ƃ肠����cuda�ł�����Ă�
�Ƃ肠����cuda�ł�����Ă�
788 �F,,�E�L�́M�E,,�j��-�������F2008/12/30(��) 17:41:51 ID:EfrppfGz
����3���Ԃ̎��R�����i�j�̐���
http://tripper2.kousaku.in/?SSE5+and+Bitslice+DES
SSE5��AVX���ǂ�������I�ׂƌ���ꂽ��AVX�̕����D�ʂ��ȁB
������p�r�ɂ����āA3�I�y�����h���ɂ��movdqa�̍팸�̂ق������\����������炷�\���������B
http://tripper2.kousaku.in/?SSE5+and+Bitslice+DES
SSE5��AVX���ǂ�������I�ׂƌ���ꂽ��AVX�̕����D�ʂ��ȁB
������p�r�ɂ����āA3�I�y�����h���ɂ��movdqa�̍팸�̂ق������\����������炷�\���������B
�܂�AVX���\����Ă����SSE5�Ɋւ���AMD�̖ق���Ղ�������
SSE5�Ȃ�āACPU��GPU���q�������̖��߃Z�b�g�Ȃ̂ɁA
���܂���SSE5�ɉߓx�Ȋ��҂�����z������̂��c�B
���܂���SSE5�ɉߓx�Ȋ��҂�����z������̂��c�B
791 �F,,�E�L�́M�E,,�j��-�������F2008/12/30(��) 20:21:39 ID:EfrppfGz
>>790
���x�������Ă邪SSE5���̂��̂�GPU�̂��߂̖��߃Z�b�g�ł͂Ȃ���B
�����܂ʼnߓn����SSE�g���B
128�r�b�g�̃f�[�^�P�ʂ���S�R����x���҂��Ȃ��B
Larrabee�ŃT�|�[�g����512bit�Ƃ�����ȏ�̕����C�h�x�N�g�����K�v�B
���́u�X�J�����v��NVIDIA�ł�������I��1024�r�b�g����SIMD���Z�i���Z���j�b�g���̂�256bit�j��
���\������ɂ��Ȃ��\���ɂȂ��Ă���H
���x�������Ă邪SSE5���̂��̂�GPU�̂��߂̖��߃Z�b�g�ł͂Ȃ���B
�����܂ʼnߓn����SSE�g���B
128�r�b�g�̃f�[�^�P�ʂ���S�R����x���҂��Ȃ��B
Larrabee�ŃT�|�[�g����512bit�Ƃ�����ȏ�̕����C�h�x�N�g�����K�v�B
���́u�X�J�����v��NVIDIA�ł�������I��1024�r�b�g����SIMD���Z�i���Z���j�b�g���̂�256bit�j��
���\������ɂ��Ȃ��\���ɂȂ��Ă���H
�X�p�R���Ńx�N�g�����Z��ɂ��X�y�b�N��̃p�t�H�[�}���X���Ɍ��܂ŏグ�Ă����āA
���ۂ̉��Z�ł͏����̃}�X�L���O�ȂǂőΉ����Ďg��Ȃ��x�N�g���������������Ă������B
����Ȋ����ł��A���ۂ̃A�v���P�[�V���������ł̓x�N�g�����Z�����p�ł���V�`���G�[�V������
��r�I�����Ă������������p�t�H�[�}���X�邱�Ƃ��o�����B(�v���O�����E�A���S���Y�����x�N�g�������ɐF�X���ς��Ă������ǂ�)
�����Ă̂͂���ɋ߂��Ƃ������قƂ�Ǔ����̂悤�����A�̂̃X�p�R���ɋ߂��@�\��
�V���O���`�b�v�ɓ�����Ď����B�@�W�ϓx�̌���Ƃ͋��낵�����̂��B
���ۂ̉��Z�ł͏����̃}�X�L���O�ȂǂőΉ����Ďg��Ȃ��x�N�g���������������Ă������B
����Ȋ����ł��A���ۂ̃A�v���P�[�V���������ł̓x�N�g�����Z�����p�ł���V�`���G�[�V������
��r�I�����Ă������������p�t�H�[�}���X�邱�Ƃ��o�����B(�v���O�����E�A���S���Y�����x�N�g�������ɐF�X���ς��Ă������ǂ�)
�����Ă̂͂���ɋ߂��Ƃ������قƂ�Ǔ����̂悤�����A�̂̃X�p�R���ɋ߂��@�\��
�V���O���`�b�v�ɓ�����Ď����B�@�W�ϓx�̌���Ƃ͋��낵�����̂��B
793 �F,,�E�L�́M�E,,�j��-�������F2008/12/30(��) 21:07:42 ID:EfrppfGz
����Ƃ͂���3���W�X�^�I�y�����h���߂����s�o���邾���ŕ@���u�[�ł���
794 �FSocket774�F2008/12/30(��) 21:44:12 ID:wxE+WyC7
BUCK-TICK �U�f stay gold
�o�c��@�̑���AMD�����ǁA���l�����͍X��600�������C�I�t�����Ƃ̂��Ƃ��B
http://www.tgdaily.com/content/view/40755/118/
�@�@---------------------
�@�@In an SEC filing, the company said that it cut 600 people from its staff during the current
�@�@quarter, about 100 more than previously announced.
�@�@---------------------
http://www.tgdaily.com/content/view/40755/118/
�@�@---------------------
�@�@In an SEC filing, the company said that it cut 600 people from its staff during the current
�@�@quarter, about 100 more than previously announced.
�@�@---------------------
AMD���������̑����ˁBINTEL�͂��������̖����́H�������H
>>796
Intel�͂����Ɣ���
AMD�̏ꍇ�A�Ԏ��ɚb���Ŏd���Ȃ����C�I�t
Intel�̏ꍇ�A���v���o�Ă��̎����P�̕K�v������Ɣ��f����Ƃ������背�C�I�t
�����ƂȂ̂ɑ̎��̓x���`���[��Ƃ��̂܂܁A�����Ƃ��������Ȃ�
Intel�͂����Ɣ���
AMD�̏ꍇ�A�Ԏ��ɚb���Ŏd���Ȃ����C�I�t
Intel�̏ꍇ�A���v���o�Ă��̎����P�̕K�v������Ɣ��f����Ƃ������背�C�I�t
�����ƂȂ̂ɑ̎��̓x���`���[��Ƃ��̂܂܁A�����Ƃ��������Ȃ�
>>790
Roadrunner�̃~�j�}���ł��o���オ����H
Roadrunner�̃~�j�}���ł��o���オ����H
���v��A��Ђ̒��ŎЂɂƂ��ėL�v�Ȑl�ނ̔䗦�͈�ʓI�Ȋ�Ƃ�10��
�D�NJ�Ƃł�20��
�t�Ɍ����A20���܂ň����グ�邱�Ƃ��o����ΗD�NJ�Ƃɋ߂Â���ƌ�����
�o�c�҂ɂƂ��Ă̓��C�I�t�i�Čٗp���O��̈ꎞ�I���فj�ǂ��납����I�ɗv���]�ƈ��̎��肽���̂��{�����낤
�D�NJ�Ƃł�20��
�t�Ɍ����A20���܂ň����グ�邱�Ƃ��o����ΗD�NJ�Ƃɋ߂Â���ƌ�����
�o�c�҂ɂƂ��Ă̓��C�I�t�i�Čٗp���O��̈ꎞ�I���فj�ǂ��납����I�ɗv���]�ƈ��̎��肽���̂��{�����낤
800 �F,,�E�L�́M�E,,�j��-�������F2008/12/31(��) 00:35:21 ID:d4lj2QsG
AVX�Ή���GCC�u�����`�o�Ă��ˁB
AVX�̃G�~�����[�^�����邱�Ƃ����n���ł�����ł݂邩�ȁB
SSE5�p�G�~�����[�^�܂��[�H
AVX�̃G�~�����[�^�����邱�Ƃ����n���ł�����ł݂邩�ȁB
SSE5�p�G�~�����[�^�܂��[�H
���̓D������ǂ��ɂ����Ăق����̂���
�v���v���Z�X�����ŃN���b�N�{���Ȃ��
�������ゾ�����Ȃ��E�E�E�E�E
���͂f�o�f�o�t�Ŗ{���ɂ�����Ȃ�
���i���łă\�t�g���Ή����W���ɂȂ���
���čl����ƍŒ�T�N�͂���ȃO�_�O�_��
�����P�O�N�͂���Ȋ����Ȃ낤��
���̌�͂ȂA�ʎq�R���s���[�^�[���Ă��ł��
�v���v���Z�X�����ŃN���b�N�{���Ȃ��
�������ゾ�����Ȃ��E�E�E�E�E
���͂f�o�f�o�t�Ŗ{���ɂ�����Ȃ�
���i���łă\�t�g���Ή����W���ɂȂ���
���čl����ƍŒ�T�N�͂���ȃO�_�O�_��
�����P�O�N�͂���Ȋ����Ȃ낤��
���̌�͂ȂA�ʎq�R���s���[�^�[���Ă��ł��
�ʎq�R���s���[�^�̓A�C���V���^�C����m�C�}�����̓V�˂���b���_���������Ȃ��ƁA
�����������W�b�N���ł��ĂȂ����疳���Ƃ����������ǂǂ��Ȃ̂���
�����������W�b�N���ł��ĂȂ����疳���Ƃ����������ǂǂ��Ȃ̂���
�ʎq�R���s���[�^��GRAPE�݂����Ȑ�p�v�Z�@�i�����ɈႤ���ǁj�Ƃ��Ă̎����͐��\�N��ɂ͗��邩������Ȃ����ǁA
���������CPU�݂����ɂ��낢��Ȍv�Z���o����`�ɂ���̂͂���ɑ�ς��Ƃ��������B
�����_�ł͘_���̈ꕔ�����o���オ���ĂȂ��炵����
���������CPU�݂����ɂ��낢��Ȍv�Z���o����`�ɂ���̂͂���ɑ�ς��Ƃ��������B
�����_�ł͘_���̈ꕔ�����o���オ���ĂȂ��炵����
�Ȃ߂������f�o�f�o�t�ɂȂ�����ш悪����Ȃ����烁��������̉�����Ƃ��ǂ���
�����R���s���[�^�[���ꖇ�ɂȂ��ăC���[�W�Ƃ��Ă̓}�U�{�ꖇ��
�������Ƃ��f�o�t�Ƃ��̑��ݕs�\���Ċ����Ȃ낤��
���̑��萫�\�ɑ��Ă͉��i�������`�b�v���Ƃ��ň����Ȃ�̂���
���̑S���l�ߍ��݂܂������ď�ԂɂȂ�܂ł�
�܁[�v����ɓ����O�_�O�_�ł����Ă��Ƃ���
�����R���s���[�^�[���ꖇ�ɂȂ��ăC���[�W�Ƃ��Ă̓}�U�{�ꖇ��
�������Ƃ��f�o�t�Ƃ��̑��ݕs�\���Ċ����Ȃ낤��
���̑��萫�\�ɑ��Ă͉��i�������`�b�v���Ƃ��ň����Ȃ�̂���
���̑S���l�ߍ��݂܂������ď�ԂɂȂ�܂ł�
�܁[�v����ɓ����O�_�O�_�ł����Ă��Ƃ���
�O�_�O�_���I���Ǝ�����I����Ă��܂���B
���_���E�E�E
�t�F�b�`���v���t�F�b�`�ӂ�łǂ����H
�t�F�b�`���v���t�F�b�`�ӂ�łǂ����H
>>804
���݂̎��R�x��������A�قȂ�p�r�����ɐF�X�ȃ��C���A�b�v��
�����Ȃ���Ȃ�Ȃ��Ȃ��āA����̓R�X�g�オ���Ȃ�����
���R�x���̂ĂȂ��Ƃ�����ςȕ����͕K�v�B
��̉����郁�����̓��W���[���X���b�g�`�������������Ǘe�ʂ�
���Ȃ�����A���ꂾ���ł̓J�o�[�ł���p�r�͌�����B
NAND�������ʼn䖝����DRAM���W���[����
�������ꍇ�����邩������Ȃ����B
���݂̎��R�x��������A�قȂ�p�r�����ɐF�X�ȃ��C���A�b�v��
�����Ȃ���Ȃ�Ȃ��Ȃ��āA����̓R�X�g�オ���Ȃ�����
���R�x���̂ĂȂ��Ƃ�����ςȕ����͕K�v�B
��̉����郁�����̓��W���[���X���b�g�`�������������Ǘe�ʂ�
���Ȃ�����A���ꂾ���ł̓J�o�[�ł���p�r�͌�����B
NAND�������ʼn䖝����DRAM���W���[����
�������ꍇ�����邩������Ȃ����B
���R�x���̂Ă�Ƃ����MIni-ITX�݂����Ȍ`���낤�ȁB
10GB���傢�̃X�g���[�W�A2GB���x�̃������������ς݂Œ����^�݂����ȁB
10GB���傢�̃X�g���[�W�A2GB���x�̃������������ς݂Œ����^�݂����ȁB
�@���������AZ-RAM���Ăǂ��Ȃ�����H
�@32nm�ȍ~SOI���g�����ǂ������܂��͂����肵�Ȃ����ǁc�c�B
�@32nm�ȍ~SOI���g�����ǂ������܂��͂����肵�Ȃ����ǁc�c�B
IBM��SOI��eDRAM�J�����Ă邩��g���Ȃ炻�ꂶ��ˁB
���ꂩ��32nm�ȍ~��SOI���g�����ǂ����͎U�X����Ă�B
���ꂩ��32nm�ȍ~��SOI���g�����ǂ����͎U�X����Ă�B
>>801
�[���P�O�N��������v���Z�X�����E���낤��
�܂��A�f�o�f�o�t�̎��̒i�K�Ȃ�����\�z���Ă����傤���Ȃ��낤����
�Ȃ���̂��Ȃ��E�E�E�E
�P�O�N��ȍ~�v���Z�X���ו��������āA�f�o�f�o�t���W���ɂȂ�����
�ו������Ȃ��ō��������āA�P�ɕ��ʂӂ��Ăł����Ȃ邾���Ȃ낤��
����Ƃ����̍��ɂ̓l�b�g�����⍂�������ăO���b�h����ʓI�ɁE�E�E�E�Ȃ�ĂȂ����
�[���P�O�N��������v���Z�X�����E���낤��
�܂��A�f�o�f�o�t�̎��̒i�K�Ȃ�����\�z���Ă����傤���Ȃ��낤����
�Ȃ���̂��Ȃ��E�E�E�E
�P�O�N��ȍ~�v���Z�X���ו��������āA�f�o�f�o�t���W���ɂȂ�����
�ו������Ȃ��ō��������āA�P�ɕ��ʂӂ��Ăł����Ȃ邾���Ȃ낤��
����Ƃ����̍��ɂ̓l�b�g�����⍂�������ăO���b�h����ʓI�ɁE�E�E�E�Ȃ�ĂȂ����
812 �F,,�E�L�́M�E,,�j��-�������F2008/12/31(��) 14:23:39 ID:d4lj2QsG
���Œr���Εa���Ă�́H
814 �F,,�E�L�́M�E,,�j��-�������F2008/12/31(��) 14:44:31 ID:d4lj2QsG
���������
815 �F,,�E�L�́M�E,,�j��-�������F2008/12/31(��) 14:46:03 ID:d4lj2QsG
AMD�ׂꂽ��INTEL�Ŏ��삷�������������(^��^)
AMD�������Ȃ���������I�Ɏ���PC�͏I�����邾��
�r�f�I�J�[�h��HDD�̓X���b�g���Ə��ł��āA�S�Ă̋@�\��Intel���`�b�v�̃G�~�����[�g
�ŒB�����鎖�����߂��鐢�E�ɂȂ�
�s�ꂩ�狣������������Ă̂͂�����������
�r�f�I�J�[�h��HDD�̓X���b�g���Ə��ł��āA�S�Ă̋@�\��Intel���`�b�v�̃G�~�����[�g
�ŒB�����鎖�����߂��鐢�E�ɂȂ�
�s�ꂩ�狣������������Ă̂͂�����������
�_���S�͑���Intel��HybridPower�����K�ɐ�ւ��\�ȃc�[�����h���C�o�̊J���ɖ߂�B
GTX260�Ƃ����g���Ă����\�ቺ���Ȃ��悤�ɗ��ށB
GTX260�Ƃ����g���Ă����\�ቺ���Ȃ��悤�ɗ��ށB
VIA���R�ł���Ǝv���Ȃ�
�߂������Ƀ��C����������CPU�ƃI���_�C���A�Œ�ł�MCM�ڑ��ɂȂ邾�낤�ȁB
������-CPU�Ԃ̍��ш�f�[�^���\�P�b�g�ʂ��Ȃ�ċ��̍����B
������-CPU�Ԃ̍��ш�f�[�^���\�P�b�g�ʂ��Ȃ�ċ��̍����B
�����ł��Ȃ�
nano���e�̌��sCNA�̓L���b�V���A���������x���x������
���Z��̑������������Ă��邪�A���̏�Ԃł��N���b�N�������K8�ɂȂ��
ALU,AGU3�Z�b�g�œ��ڂ��郊�b�`��K8�ɁAALU2��Isaiah��
�ŁA���N��CNB�ł̓L���b�V���̉��P�ƁA���Z��̉��ǂ��{����
�����SSE4���T�|�[�g����
nano���e�̌��sCNA�̓L���b�V���A���������x���x������
���Z��̑������������Ă��邪�A���̏�Ԃł��N���b�N�������K8�ɂȂ��
ALU,AGU3�Z�b�g�œ��ڂ��郊�b�`��K8�ɁAALU2��Isaiah��
�ŁA���N��CNB�ł̓L���b�V���̉��P�ƁA���Z��̉��ǂ��{����
�����SSE4���T�|�[�g����
>>821
�㓡�L����
�㓡�L����
>>823
�㓡���L���ɂ��邸���ƑO���牴�͓������Ə����Ă邪
�㓡���L���ɂ��邸���ƑO���牴�͓������Ə����Ă邪
����˂���
�N���您�O
�N���您�O
>>825
���ꂨ��
���ꂨ��
����PC���I�������瑽���}�J�[�ɂȂ�ȁB
�ǂ����Ă��K�v�Ȃ�Windows�����������B
Mac�I�����[�ō���̂̓~�j�m�[�g���B
�ǂ����Ă��K�v�Ȃ�Windows�����������B
Mac�I�����[�ō���̂̓~�j�m�[�g���B
���ɂȂ��Ȃ��Ă��A���[�J�[PC�ł͖������Ȃ��l��������莩��͂Ȃ��Ȃ�Ȃ�
�Ǝv���BMS�݂����Ɉ�ГƐ�ɂȂ��Ă��ʂɕs�ւł͂Ȃ����������ǁAOS�͈�ГƐ�
�ł��قƂ�Ǖs���Ȑl�͂��Ȃ����B
�Ǝv���BMS�݂����Ɉ�ГƐ�ɂȂ��Ă��ʂɕs�ւł͂Ȃ����������ǁAOS�͈�ГƐ�
�ł��قƂ�Ǖs���Ȑl�͂��Ȃ����B
829 �F,,�E�L�́M�E,,�j��-�������F2008/12/31(��) 20:09:10 ID:d4lj2QsG
>>822
����P��K8�����ʂ����������ł́H���N���b�N��Pentium M�ɂ����^���͂��Ă������B
�L���b�V���e�ʂ����̂�������Ȃ���B
LSU��2����Ȃ��̂ɁAALU+AGU��3�Z�b�g�Ƃ��������̈Ӗ�����Ƃ���킩��H
�t�ɂ����Ɛ������Z�p�C�v�̃��U�x�[�V�����@�\���v�A�Ȃ�B
�f�B�X�p�b�`���ꂽ���Ԃ�3Way�̃f�R�[�_�Ɋ���U����ALU+AGU�܂ŃY�h�[���B
������s�����3���ߊԂ̈ˑ��W�ł�������イ�X�g�[�����邯�ǁARS��ALU���ƂɓƗ����ĂāA
�܂����邱�Ƃ��ł��Ȃ��B
�K�[�h���[���������ĎԐ��ύX�̂ł��Ȃ�3�Ԑ����H
���ꂼ��̎Ԑ��̊e���ɒljz�Ԑ��i�A�E�g�I�u�I�[�_�@�\�j�����邯�ǁA�Ă�ʂ̃��C���ɓ��邱�Ƃ͂ł��Ȃ��B
�t�ɁA�܂Ƃ��Ɉˑ��W�������܂��߂ɂ���Ă�Ȃ�AGU��LSU�̌��������������
2Way ALU���x�ł�K8�Ɠ����̐������Z���\�͏o����Ƃ����킯�B
����P��K8�����ʂ����������ł́H���N���b�N��Pentium M�ɂ����^���͂��Ă������B
�L���b�V���e�ʂ����̂�������Ȃ���B
LSU��2����Ȃ��̂ɁAALU+AGU��3�Z�b�g�Ƃ��������̈Ӗ�����Ƃ���킩��H
�t�ɂ����Ɛ������Z�p�C�v�̃��U�x�[�V�����@�\���v�A�Ȃ�B
�f�B�X�p�b�`���ꂽ���Ԃ�3Way�̃f�R�[�_�Ɋ���U����ALU+AGU�܂ŃY�h�[���B
������s�����3���ߊԂ̈ˑ��W�ł�������イ�X�g�[�����邯�ǁARS��ALU���ƂɓƗ����ĂāA
�܂����邱�Ƃ��ł��Ȃ��B
�K�[�h���[���������ĎԐ��ύX�̂ł��Ȃ�3�Ԑ����H
���ꂼ��̎Ԑ��̊e���ɒljz�Ԑ��i�A�E�g�I�u�I�[�_�@�\�j�����邯�ǁA�Ă�ʂ̃��C���ɓ��邱�Ƃ͂ł��Ȃ��B
�t�ɁA�܂Ƃ��Ɉˑ��W�������܂��߂ɂ���Ă�Ȃ�AGU��LSU�̌��������������
2Way ALU���x�ł�K8�Ɠ����̐������Z���\�͏o����Ƃ����킯�B
�������f�B�X�A���r�O�G�[�V�����̈Ӗ�����Ƃ���킩��H
�t�ɂ����ƋZ�p���̐��ő̐����Z�p�Ȃ�B
�t�ɂ����ƋZ�p���̐��ő̐����Z�p�Ȃ�B
LSU�𑝂₵���ꍇ�͉��P�����̂��ȁH
�����Ƃ�K8�x�[�X�͂������߂�炵������
�ւ������V�K�R�A���o��܂�
�N���b�N�������AMD��Centauar�ɔ����ꂿ�Ⴄ����
�}���`���f�B�A�n���͂��łɁE�E
�܂��A�V���O��������̘b�����ǂ�
�����Ƃ�K8�x�[�X�͂������߂�炵������
�ւ������V�K�R�A���o��܂�
�N���b�N�������AMD��Centauar�ɔ����ꂿ�Ⴄ����
�}���`���f�B�A�n���͂��łɁE�E
�܂��A�V���O��������̘b�����ǂ�
832 �F,,�E�L�́M�E,,�j��-�������F2008/12/31(��) 20:40:17 ID:d4lj2QsG
�O�̖��߁E�ʂ̃p�C�v���C�������̗v���ŃX�g�[�����邩�s�m��v�f�������̂ɁA�����i�K�Ńf�B�X�p�b�`��������Ă�̂����B
8�G���g���~3Way����Ȃ��āA24�G���g���S�̂ňˑ��W���������ăA�E�g�I�u�I�[�_���s����Ηǂ��̂�B
�v����Ɏ��s���O�܂�ALU��U�蕪�������ɋ����C�����瓊������悤�ɂ�������B
��������Ώ璷�\���ɂ���K�v�������Ȃ�
Efficeon��10��̉��Z���j�b�g�𓋍ڂ��ő�8������s�ł��邯�ǐ��\�͒Ⴉ�����ˁB
FP���ł�Intel�Ȃ݂�����ȏ�̃��I�[�_�����O�@�\�������Ă��B
�ł��������œ����̍\���ɂ�����Ⴄ�ƃg�����W�X�^�����A�z�݂����ɑ�����B
��������FP�Ɛ����Ńp�C�v���C���������Ȃ��Ⴂ����B
�ǂ݂̂��������3���߂����f�R�[�h�ł��Ȃ�����B
8�G���g���~3Way����Ȃ��āA24�G���g���S�̂ňˑ��W���������ăA�E�g�I�u�I�[�_���s����Ηǂ��̂�B
�v����Ɏ��s���O�܂�ALU��U�蕪�������ɋ����C�����瓊������悤�ɂ�������B
��������Ώ璷�\���ɂ���K�v�������Ȃ�
Efficeon��10��̉��Z���j�b�g�𓋍ڂ��ő�8������s�ł��邯�ǐ��\�͒Ⴉ�����ˁB
FP���ł�Intel�Ȃ݂�����ȏ�̃��I�[�_�����O�@�\�������Ă��B
�ł��������œ����̍\���ɂ�����Ⴄ�ƃg�����W�X�^�����A�z�݂����ɑ�����B
��������FP�Ɛ����Ńp�C�v���C���������Ȃ��Ⴂ����B
�ǂ݂̂��������3���߂����f�R�[�h�ł��Ȃ�����B
>>831
�c"Centaur"�̎��H
�c"Centaur"�̎��H
������
�t�F�b�`�Ɋւ��Ă���������Ȃ��̂�
��͂�t�F�b�`���v���t�F�b�`��FA�E�E�E��
�t�F�b�`�Ɋւ��Ă���������Ȃ��̂�
��͂�t�F�b�`���v���t�F�b�`��FA�E�E�E��
836 �F,,�E�L�́M�E,,�j��-�������F2008/12/31(��) 21:13:56 ID:d4lj2QsG
���Ƃ�����Ȗ��ߗ���Ƃ���
xchg eax, ecx�E�E�E(1)
add ecx, 1�E�E�E(2)
and eax, edx�E�E�E(3)
(2)��(3)��(1)�̌��ʂɑ��Ĉˑ��W�����B
K7/K8�p�C�v���C����(1)��ALU0�ɁA(2)��ALU1�ɁA(3)��ALU2�Ɋ���U��ꂽ�ꍇ(1)����������܂�(2)��(3)�����s�ł��Ȃ��B
�㑱���߂�(1)�ɂ�(2)�ɂ�(3)�ɂ��ˑ��W�̖������߂�����A(2)��(3)����ɔ��s���ĊԂ߂邱�Ƃ��ł������
�����ꍇ�́E�E�E�X�g�[������B
�܂��A(2)��(3)�Ɉˑ��W�̖������߂�(1)�̌��ɃL���[�C���O����Ă��AALU1��ALU2�ɂ͋������Ă�邱�Ƃ��ł��Ȃ��B
�����܂�(2)��(3)�Ɠ����p�C�v�Ɋ���U��ꂽ���ߊԂł������בւ����ł��Ȃ��B
���ꂪK7/K8�p�C�v���C�����X�J�X�J�ɂȂ闝�R�B
��{�v���A���p�[�Z���g�̐��\����̂��߂ɐ����̃g�����W�X�^�����������ꂽ����̎Y��������ˁB
Intel��NetBurst��Pentium M�����������炠������L�����Z���ł�����AMD�ɂ̓o�b�N�A�b�v�v�������Ȃ������B
xchg eax, ecx�E�E�E(1)
add ecx, 1�E�E�E(2)
and eax, edx�E�E�E(3)
(2)��(3)��(1)�̌��ʂɑ��Ĉˑ��W�����B
K7/K8�p�C�v���C����(1)��ALU0�ɁA(2)��ALU1�ɁA(3)��ALU2�Ɋ���U��ꂽ�ꍇ(1)����������܂�(2)��(3)�����s�ł��Ȃ��B
�㑱���߂�(1)�ɂ�(2)�ɂ�(3)�ɂ��ˑ��W�̖������߂�����A(2)��(3)����ɔ��s���ĊԂ߂邱�Ƃ��ł������
�����ꍇ�́E�E�E�X�g�[������B
�܂��A(2)��(3)�Ɉˑ��W�̖������߂�(1)�̌��ɃL���[�C���O����Ă��AALU1��ALU2�ɂ͋������Ă�邱�Ƃ��ł��Ȃ��B
�����܂�(2)��(3)�Ɠ����p�C�v�Ɋ���U��ꂽ���ߊԂł������בւ����ł��Ȃ��B
���ꂪK7/K8�p�C�v���C�����X�J�X�J�ɂȂ闝�R�B
��{�v���A���p�[�Z���g�̐��\����̂��߂ɐ����̃g�����W�X�^�����������ꂽ����̎Y��������ˁB
Intel��NetBurst��Pentium M�����������炠������L�����Z���ł�����AMD�ɂ̓o�b�N�A�b�v�v�������Ȃ������B
��荞�ݐ�̋Z�p�������܂킷����������ˁA��{�I��
�ق�Ƃɍ��܂ʼn����Ă��̂��Ċ���
ATI�̑���������Ȃ��ł����
�ق�Ƃɍ��܂ʼn����Ă��̂��Ċ���
ATI�̑���������Ȃ��ł����
>>836
�����������Ƃ͂킩�邯�ǁA���̃R�[�h�Ⴞ��xchg�̓��W�X�^���l�[�~���O��
�Ώ�����āA�p�C�v���C�����X�g�[�������Ȃ��悤�ȋC���B
�����͖≮�����낳�Ȃ��̂��ȁH
�����������Ƃ͂킩�邯�ǁA���̃R�[�h�Ⴞ��xchg�̓��W�X�^���l�[�~���O��
�Ώ�����āA�p�C�v���C�����X�g�[�������Ȃ��悤�ȋC���B
�����͖≮�����낳�Ȃ��̂��ȁH
839 �F,,�E�L�́M�E,,�j��-������ �y���g�z �y673�~�z �F2009/01/01(��) 02:10:46 ID:MJvfLyZb
x87��fxch�͂Ƃ������Axchg�����W�X�^���l�[�~���O�ʼn�������CPU�͖������݂��Ȃ��ł��B
�������Ԃ̑����lock�v���t�B�b�N�X�����ăA�g�~�b�N�ȃ��������������Ƃ�
����ȋ@�\���L�閽�߂Ȃ̂łȂ��Ȃ����܂������Ȃ��̂ł́B
�����A�����Ɍ�����xchg��K7�ł�K8�ł�Vector Path�Ńf�R�[�h�����3�}�C�N���I�y���[�V����������܂��B
�ˑ��W�`�F�C���������p�C�v�ɂ܂�����Ɨe�ՂɃX�g�[������P�[�X��������ē_�ł�
��_�ƔF�����ׂ����ƁB
ALU�����b�`�Ȃ̂Ɏ������\���Ⴂ�̂̓X�P�W���[�����ア���Č��_�ȊO�ɂ���܂���̂ŁB
�������Ԃ̑����lock�v���t�B�b�N�X�����ăA�g�~�b�N�ȃ��������������Ƃ�
����ȋ@�\���L�閽�߂Ȃ̂łȂ��Ȃ����܂������Ȃ��̂ł́B
�����A�����Ɍ�����xchg��K7�ł�K8�ł�Vector Path�Ńf�R�[�h�����3�}�C�N���I�y���[�V����������܂��B
�ˑ��W�`�F�C���������p�C�v�ɂ܂�����Ɨe�ՂɃX�g�[������P�[�X��������ē_�ł�
��_�ƔF�����ׂ����ƁB
ALU�����b�`�Ȃ̂Ɏ������\���Ⴂ�̂̓X�P�W���[�����ア���Č��_�ȊO�ɂ���܂���̂ŁB
>>839
������-���W�X�^��xchg�ƃ��W�X�^-���W�X�^��xchg�͕ʂ̖��߂�
�f�R�[�h�����̂ł́H(��ops�I�ɍl����)
���������Ȃ��Ă��Ȃ��Ƃ�����A�m���ɉ��Z��ȑO�̒i�ɉ��P�̗]�n������
�Ƃ����b�ɂȂ�܂����B
AMD�͂Ƃ�����Intel������ĂȂ��̂��ȁB
������-���W�X�^��xchg�ƃ��W�X�^-���W�X�^��xchg�͕ʂ̖��߂�
�f�R�[�h�����̂ł́H(��ops�I�ɍl����)
���������Ȃ��Ă��Ȃ��Ƃ�����A�m���ɉ��Z��ȑO�̒i�ɉ��P�̗]�n������
�Ƃ����b�ɂȂ�܂����B
AMD�͂Ƃ�����Intel������ĂȂ��̂��ȁB
���Z�����𑝂₷�̂͊ȒP�����A�g�����W�X�^�����Z��̌��������邾������
���̑O�i�K�̕����̌������グ�悤�Ƃ���ƃg�����W�X�^���i������d�́j���]��ɑ���������
��_�Ɣ����Ă��Ă����X����������������͂��Ȃ�����
�d�͌����I�ɗ��_�����肻���ȕ����ɂ����C����������邮�炢����
���̑O�i�K�̕����̌������グ�悤�Ƃ���ƃg�����W�X�^���i������d�́j���]��ɑ���������
��_�Ɣ����Ă��Ă����X����������������͂��Ȃ�����
�d�͌����I�ɗ��_�����肻���ȕ����ɂ����C����������邮�炢����
��]�R�e�͕��u�̕�����
>>832
24�G���g���S�̂ňˑ��W���������Ă������d�͓I�ɂ͑��v�Ȃ́H
3way�ɕ�����Ă��Ă��R���p�C������ŗL���Ɏg����\���͂Ȃ��H
���ɂ�AMD�������܂ň��������Ă����A�[�L�e�N�`���Ȃ̂ɖ��炩�Ƀ_���_����
���Ȃ�Ă���̂��Ȃ��B
�܂��f�l�Ȃ�łƂ����炲�߂�B
24�G���g���S�̂ňˑ��W���������Ă������d�͓I�ɂ͑��v�Ȃ́H
3way�ɕ�����Ă��Ă��R���p�C������ŗL���Ɏg����\���͂Ȃ��H
���ɂ�AMD�������܂ň��������Ă����A�[�L�e�N�`���Ȃ̂ɖ��炩�Ƀ_���_����
���Ȃ�Ă���̂��Ȃ��B
�܂��f�l�Ȃ�łƂ����炲�߂�B
>>843
�O�Ⴄ����?
Athlon64�����Đ̂͌����̗ǂ��D�G��CPU���������E�E�E
�����������C2D�����������܂ł̘b�A�X�ɗD�G��CPU������������
����܂ŗD�G�Ə̂��ꂽCPU�����Δ�r����_���_����CPU�ɂȂ�͎̂d���Ȃ����Ƃ���
���ꂱ������̗��ꂾ��AAMD�����Ă��̌�����ǂ����������Ă��邪�E�E�E�E
���{�I�ɒǂ��t���Ȃ��Ȃ̂��m�����낤
�S�ʓI�ɉ�H�\����ς��Ȃ��ƃ_���ȏƌ����邾�낤
�O�Ⴄ����?
Athlon64�����Đ̂͌����̗ǂ��D�G��CPU���������E�E�E
�����������C2D�����������܂ł̘b�A�X�ɗD�G��CPU������������
����܂ŗD�G�Ə̂��ꂽCPU�����Δ�r����_���_����CPU�ɂȂ�͎̂d���Ȃ����Ƃ���
���ꂱ������̗��ꂾ��AAMD�����Ă��̌�����ǂ����������Ă��邪�E�E�E�E
���{�I�ɒǂ��t���Ȃ��Ȃ̂��m�����낤
�S�ʓI�ɉ�H�\����ς��Ȃ��ƃ_���ȏƌ����邾�낤
845 �F,,�E�L�́M�E,,�j��-�������F2009/01/02(��) 19:16:31 ID:6wpxuO7z
>>843
����x86�R�[�h�̑唼��Intel CPU�ɍœK���������H
�����ABulldozer�iOrochi�Ȃǁj��K7�x�[�X�̃A�[�L�e�N�`�����̂Ă���Č����Ă���玖�������Ȃ�낤��B
32nm�Ńl�C�e�B�u8�R�A�AMCM��16�R�A�܂őΉ��ł��邻�������A�R�A���̂��̂𑊓��R���p�N�g�ɂ��Ȃ��Ƃ����Ȃ��B
����x86�R�[�h�̑唼��Intel CPU�ɍœK���������H
�����ABulldozer�iOrochi�Ȃǁj��K7�x�[�X�̃A�[�L�e�N�`�����̂Ă���Č����Ă���玖�������Ȃ�낤��B
32nm�Ńl�C�e�B�u8�R�A�AMCM��16�R�A�܂őΉ��ł��邻�������A�R�A���̂��̂𑊓��R���p�N�g�ɂ��Ȃ��Ƃ����Ȃ��B
�t�ɁA�œK������Ă��Ȃ��R�[�h�ł�����Ȃ�Ƀ^������Ă����̂��Ƃ�����
���̐v�����͌��\�ǂ������Ƃ��H
�������O�̃R���p�C���ƃV�F�A�������CPU�̐v���̂��ς�邩�ȁB
����ɂ��Ă��_���S�փe�i���j���ĂȂ�̈Ӗ�����H
���̐v�����͌��\�ǂ������Ƃ��H
�������O�̃R���p�C���ƃV�F�A�������CPU�̐v���̂��ς�邩�ȁB
����ɂ��Ă��_���S�փe�i���j���ĂȂ�̈Ӗ�����H
�_���S�w�e���e�w�S���_���͌��c
>>846
���ɐ��]����Ă���̂�����A�v�͌����Ĉ����͂Ȃ���c�B
���ɐ��]����Ă���̂�����A�v�͌����Ĉ����͂Ȃ���c�B
�w�e���̋t�̓z������
�����ăV���O���X���b�h���\���]���ɂ���
�R�A�̃_�C�T�C�Y��d�͐��\������P������@���������
(���鎋�_�ł݂�)�����Ȃ�Ȃ��Ƃ����ۏȂ�ĉ����Ȃ���łȂ����ȁB
�������]���ɂ��邱�ƂȂ��ɁAIntel�Ƃ̍��ʉ��Ȃ�Ăł��Ȃ��B
�R�A�̃_�C�T�C�Y��d�͐��\������P������@���������
(���鎋�_�ł݂�)�����Ȃ�Ȃ��Ƃ����ۏȂ�ĉ����Ȃ���łȂ����ȁB
�������]���ɂ��邱�ƂȂ��ɁAIntel�Ƃ̍��ʉ��Ȃ�Ăł��Ȃ��B
Intel���V���O���X���b�h���\�̂Ăă}���`�R�A�ɑ����Ă邩��
AMD�̓f���A���R�A�ō��N���b�N�H���ōs���ׂ��������̂ɁA
�^�t�ŃT�[�o�d���H���ɂȂ������������ȁB
SMT���Ȃ�MCM���アAMD���T�[�o��Intel�ɏ��Ă�킯�Ȃ��̂ɁB
AMD�̓f���A���R�A�ō��N���b�N�H���ōs���ׂ��������̂ɁA
�^�t�ŃT�[�o�d���H���ɂȂ������������ȁB
SMT���Ȃ�MCM���アAMD���T�[�o��Intel�ɏ��Ă�킯�Ȃ��̂ɁB
�ʘH����_���Ă��d�����Ȃ�����
�ނ���D�s���Ȃ�
���܂Œʂ�C���e����肿����ƈ���
�𑱂��Ă��������Ȃ���
�ނ���D�s���Ȃ�
���܂Œʂ�C���e����肿����ƈ���
�𑱂��Ă��������Ȃ���
���c�̓z���H
>>851
���̕������ɓ������̂�Hammer�n�̐����ƁA�l�g�o�n�̎��s���炾�낤�B
�����āA�������������������Ă�2011�N�܂ŐV�R�A�͂���܂���B
���̕������ɓ������̂�Hammer�n�̐����ƁA�l�g�o�n�̎��s���炾�낤�B
�����āA�������������������Ă�2011�N�܂ŐV�R�A�͂���܂���B
856 �F,,�E�L�́M�E,,�j��-������!omikuji!dama�F2009/01/03(�y) 01:11:42 ID:VhroDbb4
Bulldozer���čŏ���2009�N�����������ǂ�
45nm�v���Z�X���͈̂����Ȃ��̂ɓ�����x�点���̂�
Sandy Bridge���ӎ������Đv�ł�����Ă�̂��ȁH
����������MCM�ɂ��16�R�A�]�X�̃v������45nm�̎����炠��������
������ɂ��摊���������R�A�ɂȂ肻�����B
45nm�v���Z�X���͈̂����Ȃ��̂ɓ�����x�点���̂�
Sandy Bridge���ӎ������Đv�ł�����Ă�̂��ȁH
����������MCM�ɂ��16�R�A�]�X�̃v������45nm�̎����炠��������
������ɂ��摊���������R�A�ɂȂ肻�����B
�������[�h�}�b�v��������Ė����������Ƃɂ���āA
�I�C���}�l�[�p���[��2�N�������ĕ����A
�{���̏o�ח\�莞�����߂��̂ɋ�̓I�ȏ��͉����Ȃ��A�Ƃ����̂́A
�u�J�����s�Ŏ����I�ȃL�����Z���v���Ǝv���邯�ǁB
���͓����`�[���E�����R�[�h�l�[���̂܂�K10���LjĂŎd�蒼���Ă��Ȃ��́B
�I�C���}�l�[�p���[��2�N�������ĕ����A
�{���̏o�ח\�莞�����߂��̂ɋ�̓I�ȏ��͉����Ȃ��A�Ƃ����̂́A
�u�J�����s�Ŏ����I�ȃL�����Z���v���Ǝv���邯�ǁB
���͓����`�[���E�����R�[�h�l�[���̂܂�K10���LjĂŎd�蒼���Ă��Ȃ��́B
>���ɐ��]����Ă���̂�����A�v�͌����Ĉ����͂Ȃ���c�B
�g�����W�X�^���x���̃N�I���e�B�Ŕ�ׂ悤���Č�����?
���ꂱ�������悤���Ȃ��Ǝv�����B
�v�ŏ����ĂȂ��ƁA�ǂ����悤���Ȃ��Ƃ������B
�g�����W�X�^���x���̃N�I���e�B�Ŕ�ׂ悤���Č�����?
���ꂱ�������悤���Ȃ��Ǝv�����B
�v�ŏ����ĂȂ��ƁA�ǂ����悤���Ȃ��Ƃ������B
859 �F,,�E�L�́M�E,,�j��-�������F2009/01/03(�y) 06:02:11 ID:VhroDbb4
http://northwood.blog60.fc2.com/blog-entry-1919.html
Fab���Љ������܂�O��Bulldozer�́u�ʕ��v���Ĕ�����������Ă邩��ˁB
�C�ɂȂ�̂͂���ł��ˁB
> �u�i������A�[�L�e�N�`���́j���݁A�n�[�h�E�F�A�������Ȃ��Ǝv���Ă�����������������̂ɂȂ�v
���̃n�[�h�E�F�A���Ă̂��ǂ��܂ł��w���̂��H
AMD���[�J���̘b�Ȃ̂��AIntel���܂߂�x86�ł̘b�Ȃ̂��A�R���s���[�^�S�ʂ̘b�Ȃ̂�
Fab���Љ������܂�O��Bulldozer�́u�ʕ��v���Ĕ�����������Ă邩��ˁB
�C�ɂȂ�̂͂���ł��ˁB
> �u�i������A�[�L�e�N�`���́j���݁A�n�[�h�E�F�A�������Ȃ��Ǝv���Ă�����������������̂ɂȂ�v
���̃n�[�h�E�F�A���Ă̂��ǂ��܂ł��w���̂��H
AMD���[�J���̘b�Ȃ̂��AIntel���܂߂�x86�ł̘b�Ȃ̂��A�R���s���[�^�S�ʂ̘b�Ȃ̂�
�Z�R�C�A�H
>>857
�J�����s�Ƃ������A��̓I�Ȑv�͎n�܂��Ă��炢�Ȃ���������B
������ɂ��悠�ƂP�N�͏ڂ������͂Ȃ���o�Ă��Ȃ��ł���B
Barcelona�����ď��o���̂͐������\�̂��傤�ǂP�N�O���������B
�J�����s�Ƃ������A��̓I�Ȑv�͎n�܂��Ă��炢�Ȃ���������B
������ɂ��悠�ƂP�N�͏ڂ������͂Ȃ���o�Ă��Ȃ��ł���B
Barcelona�����ď��o���̂͐������\�̂��傤�ǂP�N�O���������B
�������ĂH
�A�[�L�e�N�`���̒�`�Ȃ�3�N�O�ɂ͏I����Ă邾��
�A�[�L�e�N�`���̒�`�Ȃ�3�N�O�ɂ͏I����Ă邾��
�n�[�h�E�F�A�������Ȃ����˂��E�E�E�l�I�ɂ͗��s�̉��z���֘A���Ǝv��������
�o�C�i������͂��ĕ��𒊏o�A�Ƃ����Ƒ�����Ȃ��ǁB
�c�܂�������ȁBAMD�ɂ�
�c�܂�������ȁBAMD�ɂ�
>>864
�R���p�C���ł���ł��Ȃ����Ƃ�CPU���ł���킯�Ȃ�����
�R���p�C���ł���ł��Ȃ����Ƃ�CPU���ł���킯�Ȃ�����
�Z�R�C�A���ă������K�w��肪�ǂ�������Ă��
>>853
===============================================================================
�^���V���^�^�f
570 ���O�F ��Rb.XJ8VXow [sage] ���e���F 04/02/28 17:36 ID:3+LxDO83
559
UP�������B
571 ���O�F Socket774 [sage] ���e���F 04/02/28 17:37 ID:9RFnYVfw
570
�����B�^�X�N�g���C�����������ƂɂȂ��Ă�ȁ@��
573 ���O�F Socket774 [sage] ���e���F 04/02/28 17:41 ID:MltrmMzF
EnaSoft?�˂��c
574 ���O�F Socket774 [sage] ���e���F 04/02/28 17:42 ID:s+AjKmJv?
ENASOFT���H
575 ���O�F Socket774 [sage] ���e���F 04/02/28 17:44 ID:W9m+7Cjk
�܂������E�E�E�H��
577 ���O�F ��Rb.XJ8VXow [sage] ���e���F 04/02/28 17:46 ID:3+LxDO83
573-574
�����͎��̗F�l�̉�Ђ��B
���ɊO���Ƃ��Ďg���Ă�B
578 ���O�F Socket774 ���e���F 04/02/28 17:47 ID:zacDar2L
ttp://orumaki.cool.ne.jp/enatop.html
�ń������������i߁�߁j������������ !!
579 ���O�F Socket774 [sage] ���e���F 04/02/28 17:47 ID:+eqkXS/n
Enasoft�Ō����������ƁE�E�E�ȂႱ���i�Øm
===============================================================================
����Google�̃L���b�V���ɂ��c���ĂȂ���Pukiwiki�̃y�[�W���
===============================================================================
�^���V���^�^�f
570 ���O�F ��Rb.XJ8VXow [sage] ���e���F 04/02/28 17:36 ID:3+LxDO83
559
UP�������B
571 ���O�F Socket774 [sage] ���e���F 04/02/28 17:37 ID:9RFnYVfw
570
�����B�^�X�N�g���C�����������ƂɂȂ��Ă�ȁ@��
573 ���O�F Socket774 [sage] ���e���F 04/02/28 17:41 ID:MltrmMzF
EnaSoft?�˂��c
574 ���O�F Socket774 [sage] ���e���F 04/02/28 17:42 ID:s+AjKmJv?
ENASOFT���H
575 ���O�F Socket774 [sage] ���e���F 04/02/28 17:44 ID:W9m+7Cjk
�܂������E�E�E�H��
577 ���O�F ��Rb.XJ8VXow [sage] ���e���F 04/02/28 17:46 ID:3+LxDO83
573-574
�����͎��̗F�l�̉�Ђ��B
���ɊO���Ƃ��Ďg���Ă�B
578 ���O�F Socket774 ���e���F 04/02/28 17:47 ID:zacDar2L
ttp://orumaki.cool.ne.jp/enatop.html
�ń������������i߁�߁j������������ !!
579 ���O�F Socket774 [sage] ���e���F 04/02/28 17:47 ID:+eqkXS/n
Enasoft�Ō����������ƁE�E�E�ȂႱ���i�Øm
===============================================================================
����Google�̃L���b�V���ɂ��c���ĂȂ���Pukiwiki�̃y�[�W���
>>865
�ÓI�ɂ͏o���Ȃ������s���Ȃ�o����œK���͂����ς�����B
Transmeta�̃R�[�h�����t�B���O���A�R�A���\�����ł��ɂȂ���
���̃^�C�~���O�Őv����A�Ȃɂ������̃����b�g���o�邩���m�ꂸ�B
CPU�̃p���_�C���V�t�g�̉\���̓[������Ȃ��Ǝv���B
AMD���o���邩�͕ʂɂ��āB
�ÓI�ɂ͏o���Ȃ������s���Ȃ�o����œK���͂����ς�����B
Transmeta�̃R�[�h�����t�B���O���A�R�A���\�����ł��ɂȂ���
���̃^�C�~���O�Őv����A�Ȃɂ������̃����b�g���o�邩���m�ꂸ�B
CPU�̃p���_�C���V�t�g�̉\���̓[������Ȃ��Ǝv���B
AMD���o���邩�͕ʂɂ��āB
869 �FMAC�I�^��868 �����F2009/01/03(�y) 10:59:20 ID:yz8/uy+J
>>868
�@�@------------------
�@�@�R�A���\�����ł��ɂȂ���
�@�@------------------
�������Ƃ������Ă��������̕��ɂ����܂����A������ƌ���F�����Â��悤�ł��B
Core2�̓o��ȗ��A���ԓI�ɂ́u�^�_�т��A���Ă����v�Ƃ����]���ɂȂ��Ă���킯�ł����A�ˑR��
���Ė��Ȃ̂́u�M(����d��)�̕ǁv�Ƃ�����ł��B
������̕��͐��\���グ�悤�Ƃ��āA���G�ȋ@�\�𓊓�����قǏ�Ԃ��������邱�ƂɂȂ�܂�����
�V�����A�C�f�A�́A�����琫�\���オ�����Ă�����d�͂��������Ȃ��ƍ̗p����錩���݂�
����܂���B
���������Ӗ��ŁA���Ȃ��̋��߂Ă�����s���œK�������A��H�K�͂Ə���d�͂����傷�������
�ł͂Ȃ��ł��傤���H
�@�@------------------
�@�@�R�A���\�����ł��ɂȂ���
�@�@------------------
�������Ƃ������Ă��������̕��ɂ����܂����A������ƌ���F�����Â��悤�ł��B
Core2�̓o��ȗ��A���ԓI�ɂ́u�^�_�т��A���Ă����v�Ƃ����]���ɂȂ��Ă���킯�ł����A�ˑR��
���Ė��Ȃ̂́u�M(����d��)�̕ǁv�Ƃ�����ł��B
������̕��͐��\���グ�悤�Ƃ��āA���G�ȋ@�\�𓊓�����قǏ�Ԃ��������邱�ƂɂȂ�܂�����
�V�����A�C�f�A�́A�����琫�\���オ�����Ă�����d�͂��������Ȃ��ƍ̗p����錩���݂�
����܂���B
���������Ӗ��ŁA���Ȃ��̋��߂Ă�����s���œK�������A��H�K�͂Ə���d�͂����傷�������
�ł͂Ȃ��ł��傤���H
���ς�炸MAC�I�^�̓��{��͋C���������Ȃ�
MAC�I�^���܂Ƃ��Ȍ���ŏ����Ă��
�C���������Ȃ�
�����̒��q�ŏ����Ă���
�C���������Ȃ�
�����̒��q�ŏ����Ă���
���{��͕ς�������]���X�����ς�炸���Ă��ƂȂ�Ȃ���
>>869
�����ǂ����낤�BCore2����Nehalem�Ń^�_�тɂ�������C�͂��Ȃ��̂����B
PhenomII�ł��ǂ����A�N���b�N�͏����ɏオ��̂��ˁH
��͂�R�[�h��MT-Safe�ɏ����������Ƃɖ߂�Ȃ��ƃ_���Ȃ̂ł͂Ȃ����ˁB
�����ǂ����낤�BCore2����Nehalem�Ń^�_�тɂ�������C�͂��Ȃ��̂����B
PhenomII�ł��ǂ����A�N���b�N�͏����ɏオ��̂��ˁH
��͂�R�[�h��MT-Safe�ɏ����������Ƃɖ߂�Ȃ��ƃ_���Ȃ̂ł͂Ȃ����ˁB
875 �F,,�E�L�́M�E,,�j��-�������F2009/01/03(�y) 13:24:32 ID:VhroDbb4
>>873
SSE5�ŃO�O���Ă����̓d�g�T�C�g��3�Ԗڂ��炢�Ƀq�b�g�����ł���
���ۂɂ���GCC 4.3���g���Ă݂����ǁA���\���ߍœK���ւڂ���B���ʂɃ��W�X�^�Ԉړ����₵�₪��B
�ŁA�A�Z���u���Ŏ蓮�`���[�����݂Ō��Ă��ASSE5�̌��ʂ́A�L�������ȏ����ł���1�`2�����ߐ������������炢�H
���ۂ̃X���[�v�b�g���Ȃ����Ƃɂ͂Ȃ�Ƃ������Ȃ����A�債�����\����ɂ͂Ȃ�Ȃ������B
���̓_�ASandy Bridge�ł�AVX�͏]��SSE��u�������邾����20�����炢�͐��\���P�ł������B
���ߐ�����������ƂˁB
SSE5�ŃO�O���Ă����̓d�g�T�C�g��3�Ԗڂ��炢�Ƀq�b�g�����ł���
���ۂɂ���GCC 4.3���g���Ă݂����ǁA���\���ߍœK���ւڂ���B���ʂɃ��W�X�^�Ԉړ����₵�₪��B
�ŁA�A�Z���u���Ŏ蓮�`���[�����݂Ō��Ă��ASSE5�̌��ʂ́A�L�������ȏ����ł���1�`2�����ߐ������������炢�H
���ۂ̃X���[�v�b�g���Ȃ����Ƃɂ͂Ȃ�Ƃ������Ȃ����A�債�����\����ɂ͂Ȃ�Ȃ������B
���̓_�ASandy Bridge�ł�AVX�͏]��SSE��u�������邾����20�����炢�͐��\���P�ł������B
���ߐ�����������ƂˁB
>>SSE5�ŃO�O���Ă����̓d�g�T�C�g��3�Ԗڂ��炢�Ƀq�b�g�����ł���
���ς�炸����kitty�݂����Ȃ��ƌ����Ă��www
���ς�炸����kitty�݂����Ȃ��ƌ����Ă��www
Crusoe�̃}���`�R�A�ŁA
1�R�A���Ђ�����R�[�h���[�t�B���O�S���ɂ�������
�������s����Ȃ����Ǝv�����肵������������
1�R�A���Ђ�����R�[�h���[�t�B���O�S���ɂ�������
�������s����Ȃ����Ǝv�����肵������������
�g�����X���^��Efficeon�̓x���`�͐U���Ȃ����A���ۂ̎g�p���͓��N���b�N��Pentium-M�i���������ȁH�j
���͂�����Ƒ̊��ł���قǑ������Č����Ă���
���͂�����Ƒ̊��ł���قǑ������Č����Ă���
879 �F,,�E�L�́M�E,,�j��-�������F2009/01/03(�y) 20:27:42 ID:VhroDbb4
�ŏ���SSE5�̔��\�����Ƃ��͊��҂������ǂ��̌�̎c�O���≹�����Ȃ����Ղ������ɁA
�����Ȃ��������Ƃɂ��ău���h�[�U�ł͕ʂ̐V���ߎ����Ă��Ă������ɒ��͂������ȋC������B
���ꂪAMD�Ǝ���AVX���͕ʂɂ��āB
�����Ȃ��������Ƃɂ��ău���h�[�U�ł͕ʂ̐V���ߎ����Ă��Ă������ɒ��͂������ȋC������B
���ꂪAMD�Ǝ���AVX���͕ʂɂ��āB
881 �F,,�E�L�́M�E,,�j��-�������F2009/01/03(�y) 21:10:27 ID:VhroDbb4
>>876
����ʔ������Ə����Ă��ˉ�
�uPowerPC��AltiVec�̉e�����H�v���Č����Ă����Ǎ��x�̃`�[�t�A�[�L�e�N�g��POWER�̐l���ˁB
�Ȃ��Ȃ��s���ˈ��N�̉�
�����A2010�N���CPU�̕����������Z���߂͈�C��2�{�ɂȂ�悤���ˁB����͉��̗\�z�ɖ��������B
������Sandy Bridge��FMAC+FADD+FMUL��7DP/clk�iFMA���߂��T�|�[�g���邱�Ƃ�8DP/clk)�ɒB����
����̓\�[�X���W�X�^��j��̃I�y�����h�g����256-bit SIMD���߂��T�|�[�g���邩�炱���\���ȃ|�e���V������������B
SSE5��GPU�ʼn]�X�͓�������^���Ă��B
����ʔ������Ə����Ă��ˉ�
�uPowerPC��AltiVec�̉e�����H�v���Č����Ă����Ǎ��x�̃`�[�t�A�[�L�e�N�g��POWER�̐l���ˁB
�Ȃ��Ȃ��s���ˈ��N�̉�
�����A2010�N���CPU�̕����������Z���߂͈�C��2�{�ɂȂ�悤���ˁB����͉��̗\�z�ɖ��������B
������Sandy Bridge��FMAC+FADD+FMUL��7DP/clk�iFMA���߂��T�|�[�g���邱�Ƃ�8DP/clk)�ɒB����
����̓\�[�X���W�X�^��j��̃I�y�����h�g����256-bit SIMD���߂��T�|�[�g���邩�炱���\���ȃ|�e���V������������B
SSE5��GPU�ʼn]�X�͓�������^���Ă��B
882 �FMAC�I�^���c�q �����F2009/01/03(�y) 22:54:47 ID:yz8/uy+J
>>881
�@�@----------------
�@�@�Ȃ��Ȃ��s���ˈ��N�̉�
�@�@----------------
�c�q����͍ŋߏ���㓡�L���╅�ꃋ�[�}�[�T�C�g����̂悤�ł���(��)
Chuck Moore�̘b��͑O�X�����ǂ����B
http://pc11.2ch.net/test/read.cgi/jisaku/1226628399/209
�@�@================
�@�@IBM�̃A�[�L�e�N�`���Ƃ̊W�ɂ��Ă�A�O�X���ɏ������悤�Ɍ㓡���̐����Ƌt��
�@�@IBM�n�̐l�ނ� ���E������͗l���B
�@�@================
�@�@----------------
�@�@�Ȃ��Ȃ��s���ˈ��N�̉�
�@�@----------------
�c�q����͍ŋߏ���㓡�L���╅�ꃋ�[�}�[�T�C�g����̂悤�ł���(��)
Chuck Moore�̘b��͑O�X�����ǂ����B
http://pc11.2ch.net/test/read.cgi/jisaku/1226628399/209
�@�@================
�@�@IBM�̃A�[�L�e�N�`���Ƃ̊W�ɂ��Ă�A�O�X���ɏ������悤�Ɍ㓡���̐����Ƌt��
�@�@IBM�n�̐l�ނ� ���E������͗l���B
�@�@================
883 �FMAC�I�^���⑫�F2009/01/03(�y) 23:16:11 ID:yz8/uy+J
���łɕē����ǂ̃f�[�^�[�x�[�X��Moore����IBM����ɂ��Ē��ׂĂ݂������ǁA
�ŐV�̓����̐\����2000�N��9�����B>>882�̃����N��ɏ������悤��2002�N�ɂ�IBM��
���߂���̃e�L�T�X��w����̋Ɛт��L�^����Ă��邷����A2000�N��ꂩ��2001�N��
��IBM�����߂Ă��邷�B
POWER6��CELL/B.E.�̂悤�Ȍ��s�A�[�L�e�N�`���Ƃ�A�����I�ɂ��S�����ւ햳�����ˁB
�ŐV�̓����̐\����2000�N��9�����B>>882�̃����N��ɏ������悤��2002�N�ɂ�IBM��
���߂���̃e�L�T�X��w����̋Ɛт��L�^����Ă��邷����A2000�N��ꂩ��2001�N��
��IBM�����߂Ă��邷�B
POWER6��CELL/B.E.�̂悤�Ȍ��s�A�[�L�e�N�`���Ƃ�A�����I�ɂ��S�����ւ햳�����ˁB
884 �FMAC�I�^���⑫�̒����F2009/01/03(�y) 23:21:01 ID:yz8/uy+J
>>883�͂�����ƕ��̂��ԈႦ�܂����̂ŁA�ȉ��̂悤�ɒ����������܂��B
--------------------
���łɕē����ǂ̃f�[�^�x�[�X��Moore����IBM����̋ƐтׂĂ݂܂������A
�ŐV�̓����̐\����2000�N��9���ł����B>>882�̃����N��ɏ������l��2002�N�ɂ�
IBM�����߂���̃e�L�T�X��w����̋Ɛт������邱�Ƃ��ł��܂�����A2000�N���
����2001�N��IBM�����߂Ă���l�ł��ˁB
POWER6��CELL/B.E.�̂悤��IBM�̌��s�A�[�L�e�N�`���Ƃ͎����I�ɂ��S�����֖��������ł��B
--------------------
--------------------
���łɕē����ǂ̃f�[�^�x�[�X��Moore����IBM����̋ƐтׂĂ݂܂������A
�ŐV�̓����̐\����2000�N��9���ł����B>>882�̃����N��ɏ������l��2002�N�ɂ�
IBM�����߂���̃e�L�T�X��w����̋Ɛт������邱�Ƃ��ł��܂�����A2000�N���
����2001�N��IBM�����߂Ă���l�ł��ˁB
POWER6��CELL/B.E.�̂悤��IBM�̌��s�A�[�L�e�N�`���Ƃ͎����I�ɂ��S�����֖��������ł��B
--------------------
AMD inside Apple in 2009?
http://news.cnet.com/8301-13924_3-10130235-64.html
http://news.cnet.com/8301-13924_3-10130235-64.html
MAC�I�^�ǂ�����H������
�\�ł���Ȃ��u�l���Ă݂��v�Ƃ�������̋L������
888 �F,,�E�L�́M�E,,�j��-�������F2009/01/04(��) 01:32:24 ID:Rl/DixMx
�VMAC�ŁuPowerPC�����I�v�Ƃ��ϑz�Ƃ��Ă�z�ƃ��x���I�ɂ͂�����
�������܂���G5�Ƃ�G4�̎���ɖ߂肽�����Ă�z������̂���
������v�����̎���͈����ł����Ȃ������Ǝv������
������v�����̎���͈����ł����Ȃ������Ǝv������
890 �F,,�E�L�́M�E,,�j��-�������F2009/01/04(��) 04:22:52 ID:Rl/DixMx
���W�X�^�����Ȃ����畳
2�I�y�����h�����畳
���Ⴀ���ۖ��x86�̃p�t�H�[�}���X��̃f�����b�g�͂ǂ̂��炢�Ȃ̂��H
�z��͒�ʓI�ɐ����ł��Ȃ��B�Ƃɂ����x���Ǝv���Ă���B
�@������B
Powe��PC�}���Z�[�̓d�g�Ȋ�ƃT�C�g���������ǎc�}�̎v�l��H�͂���Ȃ���B
2�I�y�����h�����畳
���Ⴀ���ۖ��x86�̃p�t�H�[�}���X��̃f�����b�g�͂ǂ̂��炢�Ȃ̂��H
�z��͒�ʓI�ɐ����ł��Ȃ��B�Ƃɂ����x���Ǝv���Ă���B
�@������B
Powe��PC�}���Z�[�̓d�g�Ȋ�ƃT�C�g���������ǎc�}�̎v�l��H�͂���Ȃ���B
���Ƃ́A���ꃋ�[�}�[�T�C�g(2ch��)�̋L���ɕ���͎̂d���Ȃ��Ƃ���
�A�����Ƃ������n�߂Ă��]�������Ȃ���̂����d����Εs�����͂����ƌ����?
�P�Ȃ�R�s�y�ƈ���āA�\�[�X�̑I�т��Ղ�͊��S���Č��Ă��B
(�R�s�y��������Ĕ]���ӌ��������Ȃ���x�X�g�������ꂶ��R�e�Ƃ��ĉ���������)
��2009�Ɋ��ҁB
�����ăj�t�o�g����Ȃ����?
�A�����Ƃ������n�߂Ă��]�������Ȃ���̂����d����Εs�����͂����ƌ����?
�P�Ȃ�R�s�y�ƈ���āA�\�[�X�̑I�т��Ղ�͊��S���Č��Ă��B
(�R�s�y��������Ĕ]���ӌ��������Ȃ���x�X�g�������ꂶ��R�e�Ƃ��ĉ���������)
��2009�Ɋ��ҁB
�����ăj�t�o�g����Ȃ����?
>>889
�Ȃ�ID���ɂ������ƂɂȂ��Ă�
�Ȃ�ID���ɂ������ƂɂȂ��Ă�
MAC�I�^�͈ꌾ�]�v�Ȃ̂��f�t�H���g
>>889 ����
�@�@---------------
�@�@�������܂���G5�Ƃ�G4�̎���ɖ߂肽�����Ă�z������̂���
�@�@---------------
Intel�ڍs�Ɠ��l�ɁAApple���������f����ޗ�������Ȃ犽�}���܂��B���̃X���b�h�ŏ�X�uCray��
�����ɒ��ڂ���v�Ə����Ă����̂��������R�ŁA�ŗD��Ń��[�h�}�b�v���J�������tier 1�x���_��
���f�͕��ꃋ�[�}�[���y���ɐM���x���������Ƃɗ��ӂ��ׂ��ł��B
>>890 �c�q ����
�@�@---------------
�@�@Powe��PC�}���Z�[�̓d�g�Ȋ�ƃT�C�g
�@�@---------------
��ƃT�C�g�Ƃ����̂́A������ƌꕾ������̂ł͂Ȃ��ł��傤���H
http://www.musin.co.jp/index.html
�@�@===============
�@�@���@10���Ԃ�20���~�̒Ⴂ���\�Z�ŊJ���v���܂��B
�@�@===============
>>891 ����
�@�@---------------
�@�@�A�����Ƃ������n�߂�
�@�@---------------
��������ڂ����炵�āA�]���ϑz�ɂ����݂�AMD�t�@���{�[�C�����Ƃ��܂�ς��Ȃ��̂�
�P�Ȃ鎖������Ȃ��ł��傤���H�v���R�s�y��\��܂����Ă��邳���Ƃ�������Ȃ݂ł����ˁB
�@�@---------------
�@�@�������܂���G5�Ƃ�G4�̎���ɖ߂肽�����Ă�z������̂���
�@�@---------------
Intel�ڍs�Ɠ��l�ɁAApple���������f����ޗ�������Ȃ犽�}���܂��B���̃X���b�h�ŏ�X�uCray��
�����ɒ��ڂ���v�Ə����Ă����̂��������R�ŁA�ŗD��Ń��[�h�}�b�v���J�������tier 1�x���_��
���f�͕��ꃋ�[�}�[���y���ɐM���x���������Ƃɗ��ӂ��ׂ��ł��B
>>890 �c�q ����
�@�@---------------
�@�@Powe��PC�}���Z�[�̓d�g�Ȋ�ƃT�C�g
�@�@---------------
��ƃT�C�g�Ƃ����̂́A������ƌꕾ������̂ł͂Ȃ��ł��傤���H
http://www.musin.co.jp/index.html
�@�@===============
�@�@���@10���Ԃ�20���~�̒Ⴂ���\�Z�ŊJ���v���܂��B
�@�@===============
>>891 ����
�@�@---------------
�@�@�A�����Ƃ������n�߂�
�@�@---------------
��������ڂ����炵�āA�]���ϑz�ɂ����݂�AMD�t�@���{�[�C�����Ƃ��܂�ς��Ȃ��̂�
�P�Ȃ鎖������Ȃ��ł��傤���H�v���R�s�y��\��܂����Ă��邳���Ƃ�������Ȃ݂ł����ˁB
�g�ݍ��݂�PowerPC�}���Z�[�Ŗ��Ȃ��Ǝv�����ǁB
896 �FMAC�I�^��895 �����F2009/01/04(��) 19:00:30 ID:3NBBjJhf
����R�s�y�̓A���~�Ƃ��W�Ȃ������̐~����
�ǂ������猩�Ă����f
�ǂ������猩�Ă����f
>>894
�ݒ��ύX�����̂͂����ނ˕]���������݂�������()��
�ȉ����ꂽ����⑫���邪�A�����������������̂�
�A�����Ƃ����P��ɂ��Ăł͂Ȃ��AAMD�l�^�S�ʂɑ��Ă̔����ɂ��āB
OK? (Y/y)
����ቴ��AMD�̃}�[�P�e�B���O�Ƃ����ĂĒɂ��v�����ȁB
���������AMD�̑n�Ǝ҂��[����͉c�Ɣ��Ȃ��B
�M�W�c�ɂ��Č���Ă���B����͂��ꂩ����劽�}���B
�ݒ��ύX�����̂͂����ނ˕]���������݂�������()��
�ȉ����ꂽ����⑫���邪�A�����������������̂�
�A�����Ƃ����P��ɂ��Ăł͂Ȃ��AAMD�l�^�S�ʂɑ��Ă̔����ɂ��āB
OK? (Y/y)
����ቴ��AMD�̃}�[�P�e�B���O�Ƃ����ĂĒɂ��v�����ȁB
���������AMD�̑n�Ǝ҂��[����͉c�Ɣ��Ȃ��B
�M�W�c�ɂ��Č���Ă���B����͂��ꂩ����劽�}���B
�Z�p�ɂ��Č���Ă��ꁨ�X����~
�Ƃ���������ǂ����Ǝv��
�Ƃ���������ǂ����Ǝv��
��E�E�E���Ⴀ�R�e�̃I�c���ɂ��Ă�
����c�������o�C��Sempron���l�b�g�u�b�N������CPU+�m�[�X+�T�E�X��$20�ȉ��Ŕ���B
Atom�ɔ�ׂ�ፂ���\�B�s�Ǎɂ̏��������甄��Δ���قǗ��v�ɂȂ�B
���ꂼAMD��������Z�p�A�Ȃ̂���?
Atom�ɔ�ׂ�ፂ���\�B�s�Ǎɂ̏��������甄��Δ���قǗ��v�ɂȂ�B
���ꂼAMD��������Z�p�A�Ȃ̂���?
AMD�̎�������Ă̂�Fusion����Ȃ���
Athlon neo
ttp://news.cnet.com/8301-13924_3-10132097-64.html?part=rss&subj=news&tag=2547-1_3-0-5
New HP ultraportable first to use AMD Neo chip
ttp://www.amd.com/us-en/Corporate/VirtualPressRoom/0,,51_104_543~129565,00.html
AMD Delivers Groundbreaking Platform for Ultrathin Notebooks
ttp://news.cnet.com/8301-13924_3-10132097-64.html?part=rss&subj=news&tag=2547-1_3-0-5
New HP ultraportable first to use AMD Neo chip
ttp://www.amd.com/us-en/Corporate/VirtualPressRoom/0,,51_104_543~129565,00.html
AMD Delivers Groundbreaking Platform for Ultrathin Notebooks
���[�G���h�Y�p������Ƃ��ċt��ɂƂ�����B
�������������\�ŁA�ɂ���r�I�����Ȃ����
�i�����@�şz�����
�������������\�ŁA�ɂ���r�I�����Ȃ����
�i�����@�şz�����
�@���Ƃ��ƁAIntel���}�[�P�e�B���O�̓s���Ńf�`���[�����Ă���u���ԁv��
�˂������������������킯�ŁA�����̂��Ƃł���B
�@�܂���������Ďs��ɐH������ł����āA�{���̒ᐻ���R�X�g�`�b�v��
�q����ꂽ��ǂ���Ȃ����ȁB
�˂������������������킯�ŁA�����̂��Ƃł���B
�@�܂���������Ďs��ɐH������ł����āA�{���̒ᐻ���R�X�g�`�b�v��
�q����ꂽ��ǂ���Ȃ����ȁB
Intel��3�l�������Z�Ɍ���ASP�������e���v�㏸��Atom�}�W�b�N
http://pc.watch.impress.co.jp/docs/2008/1218/ubiq237.htm
���̗��R��
http://www.aivy.co.jp/BLOG_TEST/nagasawa/images/intel-atom-1.jpg
http://i.yimg.jp/images/netadguide_cp/feature/8/8_feature_5.jpg
http://pc.watch.impress.co.jp/docs/2008/1218/ubiq237.htm
���̗��R��
http://www.aivy.co.jp/BLOG_TEST/nagasawa/images/intel-atom-1.jpg
{kind=link}
http://i.yimg.jp/images/netadguide_cp/feature/8/8_feature_5.jpg
{kind=link}
>>903
> New HP ultraportable first to use AMD Neo chip
1.8kg������m�[�g��UltraPotable�Ə̂���Ƃ́B�������A�����J�l���ȁB
> New HP ultraportable first to use AMD Neo chip
1.8kg������m�[�g��UltraPotable�Ə̂���Ƃ́B�������A�����J�l���ȁB
1.8Kg 13�^�t���̃m�[�g���ƕ��ʂ�Core 2 Duo P8400�Ƃ����ڂ��Ă邩��ȁB
Athlon neo�ł���K�v�͕ʂɂȂ��B�������Ă������ȁB
Athlon neo�ł���K�v�͕ʂɂȂ��B�������Ă������ȁB
����� AMD�ڂȂ̂ɂȂے�I
>>909
��N���b�N�̃��o�C��Sempron���i���Ŕ�����Ă���������Ȃ�
��N���b�N�̃��o�C��Sempron���i���Ŕ�����Ă���������Ȃ�
>>903
������I�HNano�����Ⴄ�I�~�߂āI
������I�HNano�����Ⴄ�I�~�߂āI
>>909
AMD�́u������vCPU�X���Ȃ̂�
�Z�p�I�Ɍ���ׂ��Ƃ��낪�Ȃ��V���i�Ȃǂ��ĂтłȂ��B
�������A����Ȃɗ]���Ă���̂��낤���AK8�_�C�B
AMD�́u������vCPU�X���Ȃ̂�
�Z�p�I�Ɍ���ׂ��Ƃ��낪�Ȃ��V���i�Ȃǂ��ĂтłȂ��B
�������A����Ȃɗ]���Ă���̂��낤���AK8�_�C�B
Neo�ǂ��납Old����Ȃ����Ǝv���̂����A
�ǂ������V�K�v�ɂȂ��Ă��肷��̂��H
�ǂ������V�K�v�ɂȂ��Ă��肷��̂��H
�@��������Bobcat�͊Ԃɍ���Ȃ����낤����AK8�̍ɏ����̎���
��d����Ragor�������Ă���̂��ȁB
��d����Ragor�������Ă���̂��ȁB
917 �F,,�E�L�́M�E,,�j��-�������F2009/01/07(��) 06:50:24 ID:yOINOa5/
�l�b�g�u�b�N�̌��^����10�N�O��VAIO C1�������肷��낤����
�������ŊȒP�ɔ�����悤�ɂȂ��Ă��܂��ƒ��荇�����Ȃ���
�������ŊȒP�ɔ�����悤�ɂȂ��Ă��܂��ƒ��荇�����Ȃ���
>>917
�ł����ۂ��������Ŕ�����悤����Ȃ��Ⴂ��Ȃ����
����Ȃ��������̃��C���Ŏg���킯�Ȃ����A�T�u�ł��܂Ƃ��ɍ�Ƃ��悤�Ǝv������ł����m�[�g������
�o��ł�����ƃl�b�g������t�@�C���J���ĊȒP�ȕҏW������Ƃ����ėp�r������
���������[�ق��[�I�Ƃ��v�������ǁA�悭�l�����炢���ȂƎv���Ă�
�ł����ۂ��������Ŕ�����悤����Ȃ��Ⴂ��Ȃ����
����Ȃ��������̃��C���Ŏg���킯�Ȃ����A�T�u�ł��܂Ƃ��ɍ�Ƃ��悤�Ǝv������ł����m�[�g������
�o��ł�����ƃl�b�g������t�@�C���J���ĊȒP�ȕҏW������Ƃ����ėp�r������
���������[�ق��[�I�Ƃ��v�������ǁA�悭�l�����炢���ȂƎv���Ă�
Geneva�̓o���2010�N�Ȃ��A��������܂ł������Ƃ�����A
�ǂ�K8�̕s�Ǎɕ����Ă���Ċ������ȁB
�ǂ�K8�̕s�Ǎɕ����Ă���Ċ������ȁB
���������A�O��Ƃ��āu�ɂȂ̂��H�v���ď�����ԓ�Ȃ��B
922 �FSocket774�F2009/01/07(��) 18:23:35 ID:BP7+RgDN
�A�C�h������4850e��E5200��1.2W���A������20W�̍��ɋt�]�����B
TDP45W��4850e��TDP65W��E5200��舳�|�I�ɏ���d�͂���������
����ǂ��납�����d�͔�Q9550��蕉���͍�����E�E�E
TDP45W��4850e��TDP65W��E5200��舳�|�I�ɏ���d�͂���������
����ǂ��납�����d�͔�Q9550��蕉���͍�����E�E�E
�������Ȃ�Εa���Ă�
���߂��I
���͎��̎����AMD��VIA�ɂ��邼�B
�u��C���e���}�V�����[�߁v�ɂȂ肻�������ȁB
���͎��̎����AMD��VIA�ɂ��邼�B
�u��C���e���}�V�����[�߁v�ɂȂ肻�������ȁB
�ʂɎ��ɂ͂��Ȃ��Ǝv������
>>925
�`�l�c���u�h�`��������\������������A
��C���e���}�V�������`�����X������Ȃ��Ȃ��Ă��Ă���A
���Ă��Ƃ���B
�C���e�������ɂȂ�����A�������肪���Ȃ��̂�
�Z�p�i�����x���Ȃ��Ĕ����ւ����݂��Ȃ����ȁH
���������ă\�j�[�̂悤�ɁA�^�C�}�[�d���݂łR�N���Ƃ�
�����ւ�������悤�Ȃb�o�t���o������C�����ȁ��C���e��
�`�l�c���u�h�`��������\������������A
��C���e���}�V�������`�����X������Ȃ��Ȃ��Ă��Ă���A
���Ă��Ƃ���B
�C���e�������ɂȂ�����A�������肪���Ȃ��̂�
�Z�p�i�����x���Ȃ��Ĕ����ւ����݂��Ȃ����ȁH
���������ă\�j�[�̂悤�ɁA�^�C�}�[�d���݂łR�N���Ƃ�
�����ւ�������悤�Ȃb�o�t���o������C�����ȁ��C���e��
AMD�͂Ƃ�����VIA�͏����Ȃ���
AMD��������Ƃ��ǂ�2�����]�Ȃ̂��Ɓc�c
������R�A�̐V���i��2�N��3�N�o�Ȃ���������B
������R�A�̐V���i��2�N��3�N�o�Ȃ���������B
���ʂǂ���̑�������Ȃ�
931 �F,,�E�L�́M�E,,�j��-�������F2009/01/08(��) 10:46:58 ID:Een5kEL3
�EWeb�J�����W������
�E�����̃f�B�X�v���C
EeePC�ɂ͐̓��ꂾ����C1�̑������������̂�
�E�����̃f�B�X�v���C
EeePC�ɂ͐̓��ꂾ����C1�̑������������̂�
���ɂł������J���������ς�VAIO����������ȁB
���^�ȂǂƏ�������˂����܂��
�ŏ�����>931�݂����Ɍl�I�Ȍo���Ƃ��ď����Ⴂ���̂�
�ŏ�����>931�݂����Ɍl�I�Ȍo���Ƃ��ď����Ⴂ���̂�
��������{�ꂪ�s���R���Ƃ���ق�
936 �F,,�E�L�́M�E,,�j��-�������F2009/01/08(��) 11:44:32 ID:Een5kEL3
�\�̃A����
�W���X�g�L�[�{�[�h�T�C�Y
���ꂼ�܂��ɖ��@C1�̐�����p
��������
�W���X�g�L�[�{�[�h�T�C�Y
���ꂼ�܂��ɖ��@C1�̐�����p
��������
���{�̂̃J���[�o���G�[�V�����̓O���[�����b�h�A�G�������h�O���[���A
���I�j�L�X�u���b�N�A�N���X�^���z���C�g�A�N���V�b�N�u���b�N��5�F���A�i�E���X�������B
�u���b�N�I�j�L�X�ɂ����
���I�j�L�X�u���b�N�A�N���X�^���z���C�g�A�N���V�b�N�u���b�N��5�F���A�i�E���X�������B
�u���b�N�I�j�L�X�ɂ����
�C���C�b�J�C�Y�c�Ȃ�ăI�b�T�������m��Ȃ����[��
939 �F,,�E�L�́M�E,,�j��-�������F2009/01/08(��) 13:29:30 ID:Een5kEL3
>>939
�ǂ����Ȃ痼���ɉt�����W�J����3��ʂɂ��Ăق��������ȁB
�ǂ����Ȃ痼���ɉt�����W�J����3��ʂɂ��Ăق��������ȁB
941 �F,,�E�L�́M�E,,�j��-�������F2009/01/08(��) 13:42:32 ID:Een5kEL3
PDF���L����ɂ͂��傤�ǂ悳������
AMD�̔���グ�\�������C���̎��͐^����ɔ��ł����z��������
Intel�̏ꍇ�͔��ł��Ȃ��ȁB
Intel�̏ꍇ�͔��ł��Ȃ��ȁB
943 �F,,�E�L�́M�E,,�j��-�������F2009/01/08(��) 14:59:49 ID:Een5kEL3
Intel�͎E���Ă����ȂȂ��č���Ƃł�����
�@�R���\�[���p�ɂ�Phenom�̕������K�Ȃ��Ƃ��APhenomII���o��
����ƌ����đމ������Ȃ����ˁB
����ƌ����đމ������Ȃ����ˁB
AMD���R�A�T�C�Y���剻�����Ăł����[�v��������������̂�
�O������ǂݏo���s�\�ȃt���b�V�����������������
�x���_���Z�L���A��PC������悤�ɂ�����ǂ����낤�B
����Ȃ͎̂��v�Ȃ����B
�x���_���Z�L���A��PC������悤�ɂ�����ǂ����낤�B
����Ȃ͎̂��v�Ȃ����B
�ǂ�ȂɌ��łȃn�[�h�E�F�A����Ă����g�̐l�Ԃ��匊�Ȃ̂�
949 �FSocket774�F2009/01/08(��) 23:36:54 ID:cQ/v1AG/
�d�Ԃ̂��ȂɃf�X�N�g�b�v�̖{�̂����̂܂ܒu���Y����ł��ˁB
�����킩��܂��B
����͂����ƛ��U��OC���\���Ăǂ�Ȃ���H
�����Ă�Ƃ�����4G������́H
�����킩��܂��B
����͂����ƛ��U��OC���\���Ăǂ�Ȃ���H
�����Ă�Ƃ�����4G������́H
4G�Ƃ����X����
PhenomII�͂�����������邾�낤���A
AMD�̌o�c���ꂵ���͕̂ς��Ȃ��낤�ȁ[�E�E�E
AMD�̌o�c���ꂵ���͕̂ς��Ȃ��낤�ȁ[�E�E�E
���Љ��������A���N���͊y�ɂȂ邾��B�c�c�����B
�P���ɕ��Љ�������Ȃ��Ďq��Љ�����ˁH
�����͖������炾���Ă�����āA
���łɕ������͂���Ă������
�����͖������炾���Ă�����āA
���łɕ������͂���Ă������
Phenom�U���ă��r�W�����ς����SSE4�Ƃ�AVX�������H
����ڂ�������Ă��Ƃ͂Ȃ��̂��ȁB
�O��64���������ɂ�������ꂽ�C���B
����ڂ�������Ă��Ƃ͂Ȃ��̂��ȁB
�O��64���������ɂ�������ꂽ�C���B
���̖������E�E�E�E
http://news.livedoor.com/article/detail/3964242/
http://news.livedoor.com/article/detail/3964242/
�R�X�g�����\�����݊��i�䂦Intel�Ɠ����s��ł̓W���n�A
���Ƃ�����Intel�̂��Ȃ��ʂ̎s����ꂩ����C�͂��̗͂��Ȃ��A
�����͂ł������ǁA�����c��헪�͖����Ȃ��B
���Ƃ�����Intel�̂��Ȃ��ʂ̎s����ꂩ����C�͂��̗͂��Ȃ��A
�����͂ł������ǁA�����c��헪�͖����Ȃ��B
>>951
���������f�X�N�g�b�v�s��ŃN�A�b�hCPU����Ќo�c�ɉe������قǔ���邱�Ƃ�
2009�N���ɂ͂��肦�Ȃ��B
�T�[�o�s��ł�Nehalem�ɃR�e���p�����낤���ȁB
45nm�̃f���A��������6���ɂȂ邩��A�㔼����Brisbane�ƃ��o�C���s���
����邵���B
���������f�X�N�g�b�v�s��ŃN�A�b�hCPU����Ќo�c�ɉe������قǔ���邱�Ƃ�
2009�N���ɂ͂��肦�Ȃ��B
�T�[�o�s��ł�Nehalem�ɃR�e���p�����낤���ȁB
45nm�̃f���A��������6���ɂȂ邩��A�㔼����Brisbane�ƃ��o�C���s���
����邵���B
>>958
�������l���悤��
�������l���悤��
���̂Ƃ���́A��V���~����AMD�̌o�c�w�����܂��A�u�_�r��Ƃ߂��悤�ɂ���������Ȃ��B
��̓I�Șb�������Ȃ��B
�Ђ���Ƃ�����2�N���32nm�Œe����̂�������B
���邢�͂��������\�������邾���ł��A�\���ɓ����̑ΏۂȂ̂�������Ȃ��B
��̓I�Șb�������Ȃ��B
�Ђ���Ƃ�����2�N���32nm�Œe����̂�������B
���邢�͂��������\�������邾���ł��A�\���ɓ����̑ΏۂȂ̂�������Ȃ��B
��������d�͂��������������݂�������(�X�Q�O�͂X�T�����炵��)�n�b���\���啝�Ɍ��サ��
�ޗ����������̋}�ɏオ�����낤�H
�ޗ����������̋}�ɏオ�����낤�H
�`�b�v�Z�b�g��GPU��1�t�@�u���]�T�Ŗ��߂���Ȃ��̂��H
�`�b�v�Z�b�g��GPU�̓o���N�v���Z�X�ŁATFC�̃o���N�v���Z�X��32nm����B
�Ő�[�v���Z�X�Ń`�b�v�Z�b�g���̂������C������̂ŁA�v����ɓ�����B
�Ő�[�v���Z�X�Ń`�b�v�Z�b�g���̂������C������̂ŁA�v����ɓ�����B
45nm�̃o���N�����炵����
����͏����B
AMD��TSMC/UMC�Ƀt�@�E���_���r�W�l�X�ł̃��C�o���錾�����Ȃ���A
�`�b�v�Z�b�g��GPU�̐��Y���ϑ����Ă���ڋq�ł�����Ƃ��������ȊW�ŁA
�o���N�v���Z�X�̗����グ�Ɏ�Ԏ��悤���ƁA
�ڍs����AMD���i�͂������gdgd���邩������Ȃ��B
AMD��TSMC/UMC�Ƀt�@�E���_���r�W�l�X�ł̃��C�o���錾�����Ȃ���A
�`�b�v�Z�b�g��GPU�̐��Y���ϑ����Ă���ڋq�ł�����Ƃ��������ȊW�ŁA
�o���N�v���Z�X�̗����グ�Ɏ�Ԏ��悤���ƁA
�ڍs����AMD���i�͂������gdgd���邩������Ȃ��B
http://pc.watch.impress.co.jp/docs/2008/1114/kaigai_10.jpg
45nm�̓`�b�v�Z�b�g����Ƃ����b������B
���Ƃ����RD890�����TFC�ł̐��Y���Ă��Ƃ��ȁB
{kind=link}
45nm�̓`�b�v�Z�b�g����Ƃ����b������B
���Ƃ����RD890�����TFC�ł̐��Y���Ă��Ƃ��ȁB
�Ǝv��������RD890�̒����ɂ͂�����ƊԂɍ���Ȃ���
���̋L�������ǂ݂��Ă�����A�C�Â��Ȃ�������B
45nm��n�[�t�m�[�h��40nm��Fab38�ł����Ă��ƂɂȂ�̂��ȁH
http://pc.watch.impress.co.jp/docs/2008/1114/kaigai_09.jpg
���ꂩ�炷��ƁB
45nm��n�[�t�m�[�h��40nm��Fab38�ł����Ă��ƂɂȂ�̂��ȁH
http://pc.watch.impress.co.jp/docs/2008/1114/kaigai_09.jpg
{kind=link}
���ꂩ�炷��ƁB
http://pc.watch.impress.co.jp/docs/2008/1008/hot574.htm
> SOI�v���Z�X�̂܂܂ł́A�t�@�E���_�����Ƃ�W�J���邱�Ƃ�������߁A
> ����A32nm���[������SOI�ƕ��s���āA�o���N�V���R���v���Z�X�̊J����
> �s�Ȃ����Ƃ��\�����ꂽ�B
��
http://pc.watch.impress.co.jp/docs/2008/1114/kaigai476.htm
> GPU��`�b�v�Z�b�g�����̃o���N(Bulk)�v���Z�X��45nm�v���Z�X���琻������B
�Ȃ�قǁA�O�|���ɂȂ����̂��B
> SOI�v���Z�X�̂܂܂ł́A�t�@�E���_�����Ƃ�W�J���邱�Ƃ�������߁A
> ����A32nm���[������SOI�ƕ��s���āA�o���N�V���R���v���Z�X�̊J����
> �s�Ȃ����Ƃ��\�����ꂽ�B
��
http://pc.watch.impress.co.jp/docs/2008/1114/kaigai476.htm
> GPU��`�b�v�Z�b�g�����̃o���N(Bulk)�v���Z�X��45nm�v���Z�X���琻������B
�Ȃ�قǁA�O�|���ɂȂ����̂��B
168 ���O�FSocket774[] ���e���F2009/01/10(�y) 18:58:18 ID:qtbWo37U
AMD��ނ͏���d�͂��������Ă���
790GX�̃V�X�e����58W�͊m���ɐ���
k10stat�Ȃ�����Ɖ����邾�낤
AMD��ނ͏���d�͂��������Ă���
790GX�̃V�X�e����58W�͊m���ɐ���
k10stat�Ȃ�����Ɖ����邾�낤
>>964
Ati��Nvidia���̂���`�b�v�Z�b�g���ŐV�v���Z�X�����B
�����狌Fab���g��Intel�̓`�b�v�Z�b�g���ꐢ��ȏ�x��Ă��āA
����IGP�����M�ɂȂ��Ă�B
Ati��Nvidia���̂���`�b�v�Z�b�g���ŐV�v���Z�X�����B
�����狌Fab���g��Intel�̓`�b�v�Z�b�g���ꐢ��ȏ�x��Ă��āA
����IGP�����M�ɂȂ��Ă�B
Intel�ȊO�́u�ŐV�v�v���Z�X��Intel�̈ꐢ��O�̃v���Z�X
������Ȃ��B
������Ȃ��B
>>974
TSMC�͂����Ⴄ��
TSMC�͂����Ⴄ��
intel���Ē��D�NJ�Ƃ݂����Ɍ����邯�NJ����Q�O�h�����Ă���
�������ɂ��傤���Ȃ���
�������ɂ��傤���Ȃ���
TSMC�̔������h���C�u���Ă���͂���ATI��NVIDIA������55nm�ł͂Ȃ����B
���i���o�鎞����1�N�ȏ�x��Ă�B
���i���o�鎞����1�N�ȏ�x��Ă�B
����A�ȑO��MAC�I�^�Ǝ����悤�Ȏ������Ă����炿���Ɠǂ܂��ɏ�������ł��܂����B
���͔��Ȃ��Ă���B
���͔��Ȃ��Ă���B
Phenom�V��ް�H
���͖��O���ς���ˁH
Phenom2+��ް�H
Phenom2 TurboR�ł���
�_�b�V���^�[�{��
Intel��IGP�̓��[�G���h�̃{�����[���]�[���_���Ȃ̂ŁA
�ꐢ��O�̃v���Z�X�ň����d�グ��̂͐������Ǝv���B
����ƍ��ʉ����Ȃ��Ƃ����Ȃ�AMD/nVidia��IGP����[�v���Z�X���g����
���p�t�H�[�}���X���w������̂��������B
���v���o��̂́A�O�҂ł��낤�Ȃ��B�O�t���ŗǂ��̂�����ȏ�A
�����r�f�I�ō��p�t�H�[�}���X���~�����w�A�Ƃ����̂̓j�b�`���B
Vista���v�����҂��Ă������낤���AVista���̂��h������Ă���B
�ꐢ��O�̃v���Z�X�ň����d�グ��̂͐������Ǝv���B
����ƍ��ʉ����Ȃ��Ƃ����Ȃ�AMD/nVidia��IGP����[�v���Z�X���g����
���p�t�H�[�}���X���w������̂��������B
���v���o��̂́A�O�҂ł��낤�Ȃ��B�O�t���ŗǂ��̂�����ȏ�A
�����r�f�I�ō��p�t�H�[�}���X���~�����w�A�Ƃ����̂̓j�b�`���B
Vista���v�����҂��Ă������낤���AVista���̂��h������Ă���B
986 �FMAC�I�^��942 �����F2009/01/11(��) 13:02:37 ID:zIHSxZkM
>>942
�x���Ȃ��čς݂܂��A�C���e��������X���b�h�̕��ɏ����Ă����܂����̂ł����������B
http://pc11.2ch.net/test/read.cgi/jisaku/1228400588/661
�x���Ȃ��čς݂܂��A�C���e��������X���b�h�̕��ɏ����Ă����܂����̂ł����������B
http://pc11.2ch.net/test/read.cgi/jisaku/1228400588/661
�������
>>985
Vista��AERO�Ȃ��G33�ł��y�������č��ʉ��ɂȂȂ�Ȃ���
Vista��AERO�Ȃ��G33�ł��y�������č��ʉ��ɂȂȂ�Ȃ���
���OC�C�x���g�A6.2GHz�z���Đ��E�L�^�X�V�����悤�ł���
http://valid.canardpc.com/show_oc.php?id=481986
�����A���̌�t�B�������h�̐l��6.4GHz�@���o����Ĕ����ꂽ�͗l��
http://www.ripping.org/database.php?cpuid=892
�Ƃ�����A����o���ő���������������̋����Ƃ͌i�C�̂����b��
http://valid.canardpc.com/show_oc.php?id=481986
�����A���̌�t�B�������h�̐l��6.4GHz�@���o����Ĕ����ꂽ�͗l��
http://www.ripping.org/database.php?cpuid=892
�Ƃ�����A����o���ő���������������̋����Ƃ͌i�C�̂����b��
�O�O�����畦�_��-268.9����������
��Η�x�܂ŕ�����5���A�݂����ȁB
��Η�x�܂ŕ�����5���A�݂����ȁB
�R�A���ܯ�ق��炢���f�J�Ci7������5.5�f�o���Ă����
�o������������s���ė~�����Ƃ���
�o������������s���ė~�����Ƃ���
L3�L���b�V�������łƂ��Q�R�A�ł��Ƃ���������ƐL�т�̂���
�t���6.4GHz�܂ōs���Ȃ����i5GHz�̑I�ʕi��20���ʂŔ���Ȃ����H
996 �F,,�E�L�́M�E,,�j��-�������F2009/01/11(��) 23:29:51 ID:uJrTAOif
�t�̃w���E�����C�����Ĉ������ނ݂����Ȑ��ł��ˁB�킩��܂��B
�f���A���R�A�̐��E�L�^���t�̒��f���g����45nmCore2Duo��6.67GHz(2008�N8��)������
L3�L���b�V����ςN�A�b�h�R�A��6.4GHz�͂��Ȃ�̌���
L3�L���b�V����ςN�A�b�h�R�A��6.4GHz�͂��Ȃ�̌���
�v���X�����f���A���R�A�̒��Ԃɓ���Ă����Ă�������
999
1000
1001 �F�P�O�O�P�F
1��̃}�V�����g�ݏオ��܂����B�B�B
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://pc11.2ch.net/jisaku/
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://pc11.2ch.net/jisaku/