AMD�̎�����CPU�ɂ��Č�낤 ��22����
�e���v���͎��R�ɂ��\�肭�������B
|
|
|
8���ɊJ�Â���鐢�E�ő��CG�ՓT
SIGGRAPH��Larrabee�̏ڍׂ����\�����͗l
SIGGRAPH��Larrabee�̏ڍׂ����\�����͗l
���A�����������ˁc
�h���}�C >>1
�f�l������ɃX�����Ă��Ⴄ�̂͗ǂ����鎖������B
�Ȍ���u�Ń��� >>ALL
#�Ɩ��A���F���X����� >>�g�s�}�X�a
�h���}�C >>1
�f�l������ɃX�����Ă��Ⴄ�̂͗ǂ����鎖������B
�Ȍ���u�Ń��� >>ALL
#�Ɩ��A���F���X����� >>�g�s�}�X�a
5 �F�R�E�L�́M�E,,�j�����������������F2008/06/24(��) 13:23:03 ID:UAl3M5Yx
�ŋ߂�GPU�Ȃ�Đ�[�v���Z�X��Fab���XeonMP�Ȃ݂̋���_�C�����č���������
�������Đ���������債�Ėׂ���͂��Ȃ��Ǝv����B
NVIDIA/AMD(ATI)��GPGPU�헪�͂����܂ł��ꂼ��Tesla/FireStream�̗����̍���HPC�s��i�o���_���B
�����炱��x86�x�[�X�ō��X���[�v�b�g��_��Larrabee����Ɏs���H���r�炷�̂�����Ă���B
��ΐ��\�ł̗D���ł͂�86�������Ȃ��̂͂킩���Ă邩��ˁB
����AMD�͎���x86�̃n�C�G���h�`�b�v��HPC�s��ɓ��������������������
�܂��A�Ȃ��ALarrabee�̘b���Intel�X���̕����K����
�������Đ���������債�Ėׂ���͂��Ȃ��Ǝv����B
NVIDIA/AMD(ATI)��GPGPU�헪�͂����܂ł��ꂼ��Tesla/FireStream�̗����̍���HPC�s��i�o���_���B
�����炱��x86�x�[�X�ō��X���[�v�b�g��_��Larrabee����Ɏs���H���r�炷�̂�����Ă���B
��ΐ��\�ł̗D���ł͂�86�������Ȃ��̂͂킩���Ă邩��ˁB
����AMD�͎���x86�̃n�C�G���h�`�b�v��HPC�s��ɓ��������������������
�܂��A�Ȃ��ALarrabee�̘b���Intel�X���̕����K����
6 �F�R�E�L�́M�E,,�j�����������������F2008/06/24(��) 13:43:20 ID:UAl3M5Yx
SSE5��GPU�ɓ�����ɂ��Ă�
�v���t�B�b�N�X���ăx�N�g�������₷�Ƃ����Ȃ��Ɠ����Ȃ��́H
�ł��������SSE6�Ƃ�SSE7�ɂȂ��Ȃ����H
128bit(�P���x�~�S�������͔{���x�~�Q�j�̂܂�GPU�x�����g���Ƃ����\�����l���Ă݂��B
Phenom��32�o�C�g�̖��߃t�F�b�`�ш�Ȃ�ASSE5��5�`6�o�C�g�̖��߁iSIB/DISP����)���U���ߕ����炢�̓t�F�b�`�ł���B
������f�R�[�h�܂őΉ�����A�S�R�A�Ȃ�N���b�N������20�`24���߂𓊂�����v�Z�ɂȂ�B
�P���xFMA�Ȃ�160SP�����x�Ƃ������ƂɂȂ�B
�������Ȃ���t�����g�G���h�����������������Ŕ��M�ɂȂ��Ă�Phenom��
�p�C�v���C�����X�ɋ������Ă����Ƃ����̂͋��C�̍����Ƃ��������悤�������B
256bit���邢�͂���ȏ�̃x�N�^�g���łP���߂�����̗v�f�����₵���ق����܂��n�[�h�ɗD�����ȁB
�ł��v���t�B�b�N�X���čs���ǂ�ǂߒ��������Ȃ�̂�
AVX�t�H�[�}�b�g�̂ق��������I�Ƃ������ƂɁB
�v���t�B�b�N�X���ăx�N�g�������₷�Ƃ����Ȃ��Ɠ����Ȃ��́H
�ł��������SSE6�Ƃ�SSE7�ɂȂ��Ȃ����H
128bit(�P���x�~�S�������͔{���x�~�Q�j�̂܂�GPU�x�����g���Ƃ����\�����l���Ă݂��B
Phenom��32�o�C�g�̖��߃t�F�b�`�ш�Ȃ�ASSE5��5�`6�o�C�g�̖��߁iSIB/DISP����)���U���ߕ����炢�̓t�F�b�`�ł���B
������f�R�[�h�܂őΉ�����A�S�R�A�Ȃ�N���b�N������20�`24���߂𓊂�����v�Z�ɂȂ�B
�P���xFMA�Ȃ�160SP�����x�Ƃ������ƂɂȂ�B
�������Ȃ���t�����g�G���h�����������������Ŕ��M�ɂȂ��Ă�Phenom��
�p�C�v���C�����X�ɋ������Ă����Ƃ����̂͋��C�̍����Ƃ��������悤�������B
256bit���邢�͂���ȏ�̃x�N�^�g���łP���߂�����̗v�f�����₵���ق����܂��n�[�h�ɗD�����ȁB
�ł��v���t�B�b�N�X���čs���ǂ�ǂߒ��������Ȃ�̂�
AVX�t�H�[�}�b�g�̂ق��������I�Ƃ������ƂɁB
Larrabee�Ȃ�ċ����ɑ���܂���
8 �F>>1 �܂Ƃ��ɃX�����Ă��ł��Ȃ��Ȃ痧�Ă�ȃS�~���B�F2008/06/24(��) 15:30:58 ID:ph+OUr07
���O�X��
AMD�̎�����CPU�ɂ��Č�낤 ��21����
http://pc11.2ch.net/test/read.cgi/jisaku/1209908499/
�����AMD�n�X���b�h�ߋ����O�ۑ��T�C�g�l
http://amd.jisakuita.net/
���֘A�X��
Intel�̎�����CPU�ɂ��Č�낤 34
http://pc11.2ch.net/test/read.cgi/jisaku/1209622524/
CPU�A�[�L�e�N�`���ɂ��Č�� 9
http://pc11.2ch.net/test/read.cgi/jisaku/1202913839/
�Q�Q�Q_
�_.�Q�@ | �r�炵�E����E�~�[�͕��u����ԁB
�^|�Q|�@| �ނ�ꂸ�ɃX���[���܂��傤�B
|�Q�^�_! sage�i�s�Ń}�^�[�������܂��傤�B
AMD�̎�����CPU�ɂ��Č�낤 ��21����
http://pc11.2ch.net/test/read.cgi/jisaku/1209908499/
�����AMD�n�X���b�h�ߋ����O�ۑ��T�C�g�l
http://amd.jisakuita.net/
���֘A�X��
Intel�̎�����CPU�ɂ��Č�낤 34
http://pc11.2ch.net/test/read.cgi/jisaku/1209622524/
CPU�A�[�L�e�N�`���ɂ��Č�� 9
http://pc11.2ch.net/test/read.cgi/jisaku/1202913839/
�Q�Q�Q_
�_.�Q�@ | �r�炵�E����E�~�[�͕��u����ԁB
�^|�Q|�@| �ނ�ꂸ�ɃX���[���܂��傤�B
|�Q�^�_! sage�i�s�Ń}�^�[�������܂��傤�B
���ߋ��X���ꗗ
20 ttp://pc11.2ch.net/test/read.cgi/jisaku/1203947286/
19 ttp://pc11.2ch.net/test/read.cgi/jisaku/1199338832/
18 ttp://pc11.2ch.net/test/read.cgi/jisaku/1197562571/
17 ttp://pc11.2ch.net/test/read.cgi/jisaku/1195270082/
16 ttp://pc11.2ch.net/test/read.cgi/jisaku/1192923006/
15 ttp://pc11.2ch.net/test/read.cgi/jisaku/1190954072/
14 ttp://pc11.2ch.net/test/read.cgi/jisaku/1189440665/
13 ttp://pc11.2ch.net/test/read.cgi/jisaku/1187934610/
12 ttp://pc11.2ch.net/test/read.cgi/jisaku/1183558273/
11 ttp://pc11.2ch.net/test/read.cgi/jisaku/1181563841/
10 ttp://pc11.2ch.net/test/read.cgi/jisaku/1177368830/
09 ttp://pc11.2ch.net/test/read.cgi/jisaku/1172183431/
08 ttp://pc9.2ch.net/test/read.cgi/jisaku/1167003467/
07 ttp://pc7.2ch.net/test/read.cgi/jisaku/1161618220/
06 ttp://pc7.2ch.net/test/read.cgi/jisaku/1157327883/
05 ttp://pc7.2ch.net/test/read.cgi/jisaku/1150393478/
04 ttp://pc7.2ch.net/test/read.cgi/jisaku/1145187468/
03 ttp://pc7.2ch.net/test/read.cgi/jisaku/1138983969/
02 ttp://pc7.2ch.net/test/read.cgi/jisaku/1133374045/
01 ttp://pc7.2ch.net/test/read.cgi/jisaku/1124542812/
20 ttp://pc11.2ch.net/test/read.cgi/jisaku/1203947286/
19 ttp://pc11.2ch.net/test/read.cgi/jisaku/1199338832/
18 ttp://pc11.2ch.net/test/read.cgi/jisaku/1197562571/
17 ttp://pc11.2ch.net/test/read.cgi/jisaku/1195270082/
16 ttp://pc11.2ch.net/test/read.cgi/jisaku/1192923006/
15 ttp://pc11.2ch.net/test/read.cgi/jisaku/1190954072/
14 ttp://pc11.2ch.net/test/read.cgi/jisaku/1189440665/
13 ttp://pc11.2ch.net/test/read.cgi/jisaku/1187934610/
12 ttp://pc11.2ch.net/test/read.cgi/jisaku/1183558273/
11 ttp://pc11.2ch.net/test/read.cgi/jisaku/1181563841/
10 ttp://pc11.2ch.net/test/read.cgi/jisaku/1177368830/
09 ttp://pc11.2ch.net/test/read.cgi/jisaku/1172183431/
08 ttp://pc9.2ch.net/test/read.cgi/jisaku/1167003467/
07 ttp://pc7.2ch.net/test/read.cgi/jisaku/1161618220/
06 ttp://pc7.2ch.net/test/read.cgi/jisaku/1157327883/
05 ttp://pc7.2ch.net/test/read.cgi/jisaku/1150393478/
04 ttp://pc7.2ch.net/test/read.cgi/jisaku/1145187468/
03 ttp://pc7.2ch.net/test/read.cgi/jisaku/1138983969/
02 ttp://pc7.2ch.net/test/read.cgi/jisaku/1133374045/
01 ttp://pc7.2ch.net/test/read.cgi/jisaku/1124542812/
>>7
�s���̈��������͒����������Ȃ����̂�(�E�L��`�E)
�s���̈��������͒����������Ȃ����̂�(�E�L��`�E)
GPGPU�̉��b���ł���̂�PS3�G�~�����[�^�ɈႢ�Ȃ�
nv�����������intel�ɎC��������
�n����
�n����
���X��������
�O�X��7���ƃ����R����������
����>1��
�O�X��7���ƃ����R����������
����>1��
14 �F�R�E�L�́M�E,,�j�����������������F2008/06/24(��) 18:52:02 ID:UAl3M5Yx
����AGPU��SSE5�]�X�̓u���t�̈���o�Ȃ��A�Ǝv���Ă���B
CPU�A�[�L�e�N�`���ɕs�ē��ȓ�������t�@���{�[�C��ނ邽�߂̉a����
������ReverseHT�̂悤�ȁA�ˁB
�����ł���x86�ɂ����ĕ����������Z�̓��C�e���V�傫���ăp�C�v���C���n�U�[�h���N�����₷���B
����FPU����������Ƃ����̂͂����������\����̍�ł͂Ȃ��B
�x�N�^���𑝂₵����SMT�ɂ�郌�C�e���V�B���̂ق������ʓI���B
������SSE5�͊�����SSE�̉�����128bit SIMD�ł���AGPU���ӎ������悤�Ȑv�ł͂Ȃ��B
�܂�AVX���̗p��������AMD�ɂƂ��Ă������b�g�͑傫���B
�Ȃ����4�I�y�����h�Ȃ�Ďg�������Ȃ���\�t�g�J���҂����āB
CPU�A�[�L�e�N�`���ɕs�ē��ȓ�������t�@���{�[�C��ނ邽�߂̉a����
������ReverseHT�̂悤�ȁA�ˁB
�����ł���x86�ɂ����ĕ����������Z�̓��C�e���V�傫���ăp�C�v���C���n�U�[�h���N�����₷���B
����FPU����������Ƃ����̂͂����������\����̍�ł͂Ȃ��B
�x�N�^���𑝂₵����SMT�ɂ�郌�C�e���V�B���̂ق������ʓI���B
������SSE5�͊�����SSE�̉�����128bit SIMD�ł���AGPU���ӎ������悤�Ȑv�ł͂Ȃ��B
�܂�AVX���̗p��������AMD�ɂƂ��Ă������b�g�͑傫���B
�Ȃ����4�I�y�����h�Ȃ�Ďg�������Ȃ���\�t�g�J���҂����āB
AMD��GPGPU�͓�������HPC�������炢�����l���ĂȂ��������ɐ헪�����������Ȃ�Ȃ��E�E�E
HPC���y�����Ă�NVIDIA�̕������̕���ł�1�N���炢����s��������Ă邵
�J���҃R�~���j�e�B�̋K�͂ɂ��炢�������Ă�
HPC���y�����Ă�NVIDIA�̕������̕���ł�1�N���炢����s��������Ă邵
�J���҃R�~���j�e�B�̋K�͂ɂ��炢�������Ă�
SIMD�̃x�N�^����傫������ƁA�œK��������Ȃ�
GPU��4WAY SIMD�~�߂���������Ă̂�����
�x�N�^����������ł��g���ł����Ȃ�
���ł��x�N�g���X�p�R���������ς��Ȃ͂�
GPU��4WAY SIMD�~�߂���������Ă̂�����
�x�N�^����������ł��g���ł����Ȃ�
���ł��x�N�g���X�p�R���������ς��Ȃ͂�
AVX�_�C�X�b�p�C
����̃j���[�X�����ǁA���Atom/Nano�R�̐V�^K8�̎d�l��HKEPC���`���Ă��邷�B
http://www.hkepc.com/?id=1366&fs=c1n
�V����p�b�P�[�W�W�����ˁB�B�B
�@�E�R�A: K8
�@�E�v���Z�X: 65nm
�@�E�p�b�P�[�W: 822 pin BGA, 22mm x 22mm
�@�ECore/Thread: 1/1
�@�EHyperTransport: 800MHz/HT1
�@�EL1: 128KB
�@�EL2: 256KB
�@�EMemory: DDR2-400
�@�ETDP: 8W (�`�b�v�Z�b�g��)
�@�EAvailability: 2008Q4
http://www.hkepc.com/?id=1366&fs=c1n
�V����p�b�P�[�W�W�����ˁB�B�B
�@�E�R�A: K8
�@�E�v���Z�X: 65nm
�@�E�p�b�P�[�W: 822 pin BGA, 22mm x 22mm
�@�ECore/Thread: 1/1
�@�EHyperTransport: 800MHz/HT1
�@�EL1: 128KB
�@�EL2: 256KB
�@�EMemory: DDR2-400
�@�ETDP: 8W (�`�b�v�Z�b�g��)
�@�EAvailability: 2008Q4
K8�x�[�X�̓p�t�H�[�}���X�I�ɂ��Ȃ�ڋ�
�����I�ɂ�nano�̑R���낤����
L2�����������߁A������̕������K�͂ƂȂ邾�낤
nano�ɑ��Ă͐����ł����AFPU(x87)�ŏ��銴����
�����I�ɂ�nano�̑R���낤����
L2�����������߁A������̕������K�͂ƂȂ邾�낤
nano�ɑ��Ă͐����ł����AFPU(x87)�ŏ��銴����
�Ȃق�Sempron���̂��̂̂悤�ȁE�E�E�B
���A22mmx22mm��822pin�������[��
VIA��nanoBGA2(21x21)��400pin��
VIA��nanoBGA2(21x21)��400pin��
�m�[�X�E�T�E�X���݂�8W��������c
23 �FMAC�I�^���⑫�F2008/06/24(��) 21:59:50 ID:8GgM4hC8
24 �F�R�E�L�́M�E,,�j�����������������F2008/06/24(��) 22:12:15 ID:UAl3M5Yx
>>16
GPU�Ƃ͈���āAx86�ł͎��v���������̓x�N�^�����̂��Ă�����Ǝv����B
AVX�͓���SIMD�����������Z��128�r�b�g�ł�256�r�b�g�ł�p�ӂ��Ă邩��ɉ����čD���ȕ����g�������B
�A�����[���ł��镔������256bit�ł��g���ăA�����[����������B
�P����256�r�b�g�Ɉ��������������ł��A���W�X�^��Ԃ��{�ɂȂ������ʂŐ��\���L�т���̂͑����Ǝv�����ǂˁB
���ƁA�R�I�y�����h�`���̗̍p�ɂ��Ń��W�X�^�ޔ��̂��߂�movdqa��
�K�v�Ȃ��Ȃ邾���ł����\�͌��シ�邩��128bit�~�܂�ł��\�����b�͂���B
���ʓI�ɁA��������ł�AVX��SSE5���R���p�N�g���B
x86�̒P���xSIMD�œ���2Way(64bit) vs ����4Way(256bit)�̐킢���������̂͋L���ɐV������
���̍��ɂ��A128�r�b�g�͒��߂���݂����Ȃ��ƌ������l��������B
���ʂ͒m���Ă̒ʂ�B
>>17
�����܂��[
GPU�Ƃ͈���āAx86�ł͎��v���������̓x�N�^�����̂��Ă�����Ǝv����B
AVX�͓���SIMD�����������Z��128�r�b�g�ł�256�r�b�g�ł�p�ӂ��Ă邩��ɉ����čD���ȕ����g�������B
�A�����[���ł��镔������256bit�ł��g���ăA�����[����������B
�P����256�r�b�g�Ɉ��������������ł��A���W�X�^��Ԃ��{�ɂȂ������ʂŐ��\���L�т���̂͑����Ǝv�����ǂˁB
���ƁA�R�I�y�����h�`���̗̍p�ɂ��Ń��W�X�^�ޔ��̂��߂�movdqa��
�K�v�Ȃ��Ȃ邾���ł����\�͌��シ�邩��128bit�~�܂�ł��\�����b�͂���B
���ʓI�ɁA��������ł�AVX��SSE5���R���p�N�g���B
x86�̒P���xSIMD�œ���2Way(64bit) vs ����4Way(256bit)�̐킢���������̂͋L���ɐV������
���̍��ɂ��A128�r�b�g�͒��߂���݂����Ȃ��ƌ������l��������B
���ʂ͒m���Ă̒ʂ�B
>>17
�����܂��[
25 �FSocket774�F2008/06/24(��) 22:13:29 ID:cwTjVj1k
����K8�x�[�X���āAIntel�̌����Ƃ���̃m�[�X�u���b�W�����Ă�Ȃ�AGPU���������Ă����H
26 �F�R�E�L�́M�E,,�j�����������������F2008/06/24(��) 22:13:53 ID:UAl3M5Yx
�~����2Way(64bit) vs ����4Way(256bit)
������2Way(64bit) vs ����4Way(128bit)
������2Way(64bit) vs ����4Way(128bit)
>>22
nano 1GHz��VX800U�i�k�쓝���j��8.5W�ƂȂ�̂�
���肦�Ȃ��͖���
�����AAMD�ɂ���ȃ`�b�v�Z�b�g����������
�����[�͑�X�b�p�C
nano 1GHz��VX800U�i�k�쓝���j��8.5W�ƂȂ�̂�
���肦�Ȃ��͖���
�����AAMD�ɂ���ȃ`�b�v�Z�b�g����������
�����[�͑�X�b�p�C
28 �F�R�E�L�́M�E,,�j�����������������F2008/06/24(��) 22:18:52 ID:UAl3M5Yx
>>27�͎_���ς��Ȃ�
�p��ɖ|�ēǂ�ł݂����ǁA�`�b�v�Z�b�g�����Ă��Ȃ��āA
CPU�{�`�b�v�Z�b�g��TDP���ő�8W�܂ł̂悤�ɓǂ߂�B
�ŁA�g�ݍ��킹��`�b�v�Z�b�g�ɂĂ͂܂��A�i�E���X�Ȃ��炵���B
CPU�{�`�b�v�Z�b�g��TDP���ő�8W�܂ł̂悤�ɓǂ߂�B
�ŁA�g�ݍ��킹��`�b�v�Z�b�g�ɂĂ͂܂��A�i�E���X�Ȃ��炵���B
�����[���ʂ����������
31 �F�R�E�L�́M�E,,�j�����������������F2008/06/24(��) 22:27:47 ID:UAl3M5Yx
���Ȃ݂�Linux��Windows��AVX�T�|�[�g�̓���������(YMM���W�X�^�X�e�[�g�ۑ��ɑΉ�)�̂�
AMD�������ł���͂����Ȃ��B
3DNow!�̂Ƃ��Ɠ�������ł��ˁB
AMD�͌������Ă�SSSE3��SSE4.x�����������Ή��\��ɓ��ꂿ����Ă܂��B
AMD�������ł���͂����Ȃ��B
3DNow!�̂Ƃ��Ɠ�������ł��ˁB
AMD�͌������Ă�SSSE3��SSE4.x�����������Ή��\��ɓ��ꂿ����Ă܂��B
32 �F�R�E�L�́M�E,,�j�����������������F2008/06/24(��) 22:30:02 ID:UAl3M5Yx
>>30
����Ȏ���������Phenom�̃p�C�v���C�����ʂ̉��
����Ȏ���������Phenom�̃p�C�v���C�����ʂ̉��
�����[����x86����搂��Ă���Ă��Ƃ�
���Rx86�f�R�[�_���݂��ł���
�ŁAx86����g���˂��Ă��AVX���g���Ƃ����̂���
����Ax86�͉��̂��߂ɍ݂�̂�
���Rx86�f�R�[�_���݂��ł���
�ŁAx86����g���˂��Ă��AVX���g���Ƃ����̂���
����Ax86�͉��̂��߂ɍ݂�̂�
�C�O�̃j���[�X�T�C�g�ŏE�������
http://sylphys.ddo.jp/upld2nd/pc3/src/1214314332032.png
http://sylphys.ddo.jp/upld2nd/pc3/src/1214314332032.png
{kind=link}
35 �F�R�E�L�́M�E,,�j�����������������F2008/06/24(��) 22:44:57 ID:UAl3M5Yx
x86���g��Ȃ��Ȃ�Ăǂ��ɏ����Ă���́H
�A�h���X�v�Z�ɂ����Ĕėp�������ߕK�v�ł���Bbranch���߂����ėv��B
�X�J�����߂��g��������������B
x87��SSE���g���Ă��̂܂܈ڍs�ł��A�������I�ȐV���߂��g�����Ŗ{���̃p�t�H�[�}���X���ł���B
�����������Ƃ���B
OoO����蕥����2issue�ɂ���Intel�A�[�L�e�N�`����Atom��1.6GHz��L2 512KB�ł��P�R�ATDP2.5�`4W�ł��B
�債���Ӓ��ł͂Ȃ��B
������32byte���߃t�F�b�`�����ĂȂ���ăN�A�b�h��Core 2 Quad���Ԃ�������\�肾����Phenom��
�N���b�N�オ��Ȃ������d�͔n���H������Ō��ʓI�ɒᐫ�\�ɂȂ��Ă܂���
�o�����X���厖�Ƃ������ł��ˁB
�͂����ǂ����B
�A�h���X�v�Z�ɂ����Ĕėp�������ߕK�v�ł���Bbranch���߂����ėv��B
�X�J�����߂��g��������������B
x87��SSE���g���Ă��̂܂܈ڍs�ł��A�������I�ȐV���߂��g�����Ŗ{���̃p�t�H�[�}���X���ł���B
�����������Ƃ���B
OoO����蕥����2issue�ɂ���Intel�A�[�L�e�N�`����Atom��1.6GHz��L2 512KB�ł��P�R�ATDP2.5�`4W�ł��B
�債���Ӓ��ł͂Ȃ��B
������32byte���߃t�F�b�`�����ĂȂ���ăN�A�b�h��Core 2 Quad���Ԃ�������\�肾����Phenom��
�N���b�N�オ��Ȃ������d�͔n���H������Ō��ʓI�ɒᐫ�\�ɂȂ��Ă܂���
�o�����X���厖�Ƃ������ł��ˁB
�͂����ǂ����B
������x86��GPU�ɍڂ��Ă����ʂł���
GPU����Ȃ��H
��������GPU�̌`�ɂ��Ȃ��ᕁ�y���Ȃ����[���m����
S3 Chrome 400
ttp://img144.imageshack.us/img144/3791/0005929201aeb476buz6.jpg
GS�p�t�H�[�}���X�ŋ�
ttp://xs128.xs.to/xs128/08261/440car390.jpg
ttp://xs228.xs.to/xs228/08261/3870car895.jpg
GPU����Ȃ��H
��������GPU�̌`�ɂ��Ȃ��ᕁ�y���Ȃ����[���m����
S3 Chrome 400
ttp://img144.imageshack.us/img144/3791/0005929201aeb476buz6.jpg
{kind=link}
GS�p�t�H�[�}���X�ŋ�
ttp://xs128.xs.to/xs128/08261/440car390.jpg
{kind=link}
ttp://xs228.xs.to/xs228/08261/3870car895.jpg
{kind=link}
Larrabee���Č��ǃJ�[�h1���ŏ]���̃N���X�^1�ȏ�̐��\���o�āA
������M/B�ɕ�����Larrabee�������ăJ�[�h�Ԃ̒ʐM�������Ƃ������̂�����Ȃ�ˁH
�������AAVX�ɑΉ��������ɑ��x�A�b�v�Ƃ��B
���ۂ��܂����\�o�邩�͕����łȂ��Ƃ킩��Ȃ����ǁB
������M/B�ɕ�����Larrabee�������ăJ�[�h�Ԃ̒ʐM�������Ƃ������̂�����Ȃ�ˁH
�������AAVX�ɑΉ��������ɑ��x�A�b�v�Ƃ��B
���ۂ��܂����\�o�邩�͕����łȂ��Ƃ킩��Ȃ����ǁB
Phenom��AMD�̒�����āA�����̑z�肩��啝�ɂ����
�N���b�N�オ��Ȃ��̂Ə���d�͔n���H���̂������ۂɂ͍��Ȃ������̂������̑S�ĂȂ́H
���ꂳ������ɃN���A���Ă���{���ɂԂ�������Ă��́H
�N���b�N�オ��Ȃ��̂Ə���d�͔n���H���̂������ۂɂ͍��Ȃ������̂������̑S�ĂȂ́H
���ꂳ������ɃN���A���Ă���{���ɂԂ�������Ă��́H
39 �F�R�E�L�́M�E,,�j�����������������F2008/06/24(��) 23:01:40 ID:UAl3M5Yx
�܁AXeonMP�݊��\�P�b�g�̐��i�Ƃ��ē���������ł�GPU������Ă݂܂����A���{������B
���ʂ̂Ȃ��A�[�L�e�N�`�����s����x�z�������͖����͂������ȁB
������A�݂͖݉��B
GPU���[�J�[��GPGPU�����GPU�{���̋@�\�ɐ�O���邫�����������̂��厖
Larrabee�ɂ�����GPU�Ȃ�Ă����̂��܂������낭�Ɏg�������Ȃ�GPGPU�͖��ʂ̋ɂ݁B
���ʂ̂Ȃ��A�[�L�e�N�`�����s����x�z�������͖����͂������ȁB
������A�݂͖݉��B
GPU���[�J�[��GPGPU�����GPU�{���̋@�\�ɐ�O���邫�����������̂��厖
Larrabee�ɂ�����GPU�Ȃ�Ă����̂��܂������낭�Ɏg�������Ȃ�GPGPU�͖��ʂ̋ɂ݁B
�ȂALarrabee���Fusion�̘b���Ă邯�ǁA�ꏏ�̂悤�ŕʂ̎s����^�[�Q�b�g
�ɂ��Ă��Ȃ��́H���̓�́B�B
Larrabee�͍��܂ł̏��ɂ��ƃA�N�Z�����[�^�I�ȕ�������Ă�悤�ȋC�����邵
Fusion�̓��o�C���o�b�̎s���_�����v���b�g�t�H�[���̂悤�ȋC������
�`�l�c�I�ɂ̓��o�C���s��Ƃ������A�����̃V�F�A�g��H������߂ĂȂ����낤���A
�����������̓X�p�R���A�T�[�o�[����ł̃V�F�A�D�҂�ڎw���Ă�悤�ȋC������B
�������������悤�Ȃ��̂�����Ă邯�ǂ܂������ʕ��i�ŏI�I�ɂ͕�����j
�Ŕ��Ⴂ�̘b�̂悤�ȋC������B
������Larrabee�̓O���t�B�b�N��艉�Z���\�d���ł�86���^�[�Q�b�g�ɂ���̂������邵
Fusion�͂�86�Ƃ������̓O���t�B�b�N���\�i�����܂Ń��o�C���ł́j��Nj����Ă����̂��낤�ˁB
�ł��A�`�l�c���A�N�Z�����[�^�̊J���͂��Ă���Ęb�͕��������Ƃ���̂ŁALarrabee�Ƃ̑R��
�������ɂȂ�Ƃ������E�E�E
�ɂ��Ă��Ȃ��́H���̓�́B�B
Larrabee�͍��܂ł̏��ɂ��ƃA�N�Z�����[�^�I�ȕ�������Ă�悤�ȋC�����邵
Fusion�̓��o�C���o�b�̎s���_�����v���b�g�t�H�[���̂悤�ȋC������
�`�l�c�I�ɂ̓��o�C���s��Ƃ������A�����̃V�F�A�g��H������߂ĂȂ����낤���A
�����������̓X�p�R���A�T�[�o�[����ł̃V�F�A�D�҂�ڎw���Ă�悤�ȋC������B
�������������悤�Ȃ��̂�����Ă邯�ǂ܂������ʕ��i�ŏI�I�ɂ͕�����j
�Ŕ��Ⴂ�̘b�̂悤�ȋC������B
������Larrabee�̓O���t�B�b�N��艉�Z���\�d���ł�86���^�[�Q�b�g�ɂ���̂������邵
Fusion�͂�86�Ƃ������̓O���t�B�b�N���\�i�����܂Ń��o�C���ł́j��Nj����Ă����̂��낤�ˁB
�ł��A�`�l�c���A�N�Z�����[�^�̊J���͂��Ă���Ęb�͕��������Ƃ���̂ŁALarrabee�Ƃ̑R��
�������ɂȂ�Ƃ������E�E�E
�Ȃ�Ă������A�c�q�̃��X�����Ă����(�Z�p�_�͓e���p)���\intel�̖{��������������Ă�l�Ɍ����邩��s�v�c��
�GPGPU����߂룂��Ă̂͗v�͢nVidia��intel�̌R��ɉ��ꣂ��Č����Ă�悤�ȃ��m�����Aintel����Ԗ]��ł���W�J�Ȃ��
�����GPGPU���̂͂�������o���Ă���̂�����A���X�~�߂邱�Ƃ͖������낤(intel�ɏo���邱�Ƃ�GPGPU�H���ɏ��������GPU�V�F�A��~���������Ƃ���)
�����Larrabee��GPU�Ƃ��Đ������Ȃ���APhsyX�Ɠ����l�ȉ^����H��C�����邯�ǁAGPU�Ƃ���Larrabee���������邩�A�ƌ����Ɠ����Ȃ����H
�GPGPU����߂룂��Ă̂͗v�͢nVidia��intel�̌R��ɉ��ꣂ��Č����Ă�悤�ȃ��m�����Aintel����Ԗ]��ł���W�J�Ȃ��
�����GPGPU���̂͂�������o���Ă���̂�����A���X�~�߂邱�Ƃ͖������낤(intel�ɏo���邱�Ƃ�GPGPU�H���ɏ��������GPU�V�F�A��~���������Ƃ���)
�����Larrabee��GPU�Ƃ��Đ������Ȃ���APhsyX�Ɠ����l�ȉ^����H��C�����邯�ǁAGPU�Ƃ���Larrabee���������邩�A�ƌ����Ɠ����Ȃ����H
Larrabee�̓��j�[�R�A�̃V���v���R�A�̈�����낤����ALarrabee��GPU�Ƃ���
�������悤�����܂����A�����I�ɂ͎嗬��CPU�ɓ�������Ă������낤�B
�ނ���AHPC�����̃A�N�Z�����[�^�Ƃ��Đ��\���S���łȂ��Ƃ������ƂɂȂ�������
�ɂ���Ȃ����낤���B
�������悤�����܂����A�����I�ɂ͎嗬��CPU�ɓ�������Ă������낤�B
�ނ���AHPC�����̃A�N�Z�����[�^�Ƃ��Đ��\���S���łȂ��Ƃ������ƂɂȂ�������
�ɂ���Ȃ����낤���B
��������Intel�X���ɂȂ��Ă邗
�ʔ������炢������
�ʔ������炢������
44 �FSocket774�F2008/06/25(��) 00:36:54 ID:alUiIP3g
�����āAAMD�̘b���ƁA��̖ϑz�ʂ����o�Ă��Ȃ�����B
�����AMD�h���āAIntel�̂���̍D������B
�����AMD�h���āAIntel�̂���̍D������B
45 �F�R�E�L�́M�E,,�j�����������������F2008/06/25(��) 00:37:22 ID:d92IAJsE
GPU�@�\�����˂�CPU�Ƃ��Ă̗p�r���ɂ��Őv���ꂽCell�́A
�{���]�|�ȍ\���̃Q�[���@�ɉ������܂ꂽ�������Ă̒�
�Q�[���@�s��ł͂��܂�g���Ȃ��q�ɂȂ��Ă�悤�����A
���ł̃J�X�^���ł�Qosmio��GPU�Ƃ��ĖړI��S�����Ă�Ƃ����B
Larrabee�̓����O�o�X�\���Ȃ�Cell�̂���P���Ă邵
GPU�Ƃ��Ďg���Ďg���Ȃ����͖����Ǝv���B
���Ɏg���Ȃ�����Ƃ����ėv��Ȃ��q�ɂȂ��Ȃ�����
HPC�s��ŋ��߂��Ă�v���Z�b�T����
GPGPU�Ƃ̌���I�ȈႢ�́A�ėp�v���Z�b�T�Ƃ��Ďg���ꍇ�A
���Ԍ�����ƃh���C�o������l�C�e�B�u�R�[�h�Ŏ��s�ł��鎖�B
�������t���Z�b�g��x86���߁B
�܁A���݂����ȕϑԂɂ͋v�X�ɐG���Ă݂����A�[�L�e�N�`������B
PPU�̃|�W�V�����㓙����ˁH
�ł�Larrabee��nVIDIA�������Ȃ�Ă܂��Ȃ���
�����APhysX PPU���ăA�������������\�ł��Ȃ������ȁB
�A�[�L�̒�x���G��Ȃ����B
�{���]�|�ȍ\���̃Q�[���@�ɉ������܂ꂽ�������Ă̒�
�Q�[���@�s��ł͂��܂�g���Ȃ��q�ɂȂ��Ă�悤�����A
���ł̃J�X�^���ł�Qosmio��GPU�Ƃ��ĖړI��S�����Ă�Ƃ����B
Larrabee�̓����O�o�X�\���Ȃ�Cell�̂���P���Ă邵
GPU�Ƃ��Ďg���Ďg���Ȃ����͖����Ǝv���B
���Ɏg���Ȃ�����Ƃ����ėv��Ȃ��q�ɂȂ��Ȃ�����
HPC�s��ŋ��߂��Ă�v���Z�b�T����
GPGPU�Ƃ̌���I�ȈႢ�́A�ėp�v���Z�b�T�Ƃ��Ďg���ꍇ�A
���Ԍ�����ƃh���C�o������l�C�e�B�u�R�[�h�Ŏ��s�ł��鎖�B
�������t���Z�b�g��x86���߁B
�܁A���݂����ȕϑԂɂ͋v�X�ɐG���Ă݂����A�[�L�e�N�`������B
PPU�̃|�W�V�����㓙����ˁH
�ł�Larrabee��nVIDIA�������Ȃ�Ă܂��Ȃ���
�����APhysX PPU���ăA�������������\�ł��Ȃ������ȁB
�A�[�L�̒�x���G��Ȃ����B
46 �FSocket774�F2008/06/25(��) 00:37:43 ID:alUiIP3g
�~�����AMD�h���āAIntel�̂���̍D������
�������AMD�h���āAIntel�̘b����̍D������
�������AMD�h���āAIntel�̘b����̍D������
Intel�h����AMD�X���r�炷�̍D������ˁB
48 �F�R�E�L�́M�E,,�j�����������������F2008/06/25(��) 00:44:35 ID:d92IAJsE
���̉䖝���m��Ȃ����ߓd�̂��ߍ������PPC Macmini����J�L�R���܂���
����ł��܂�����̎v�z�͖����ɗ����ł��܂���
����ł��܂�����̎v�z�͖����ɗ����ł��܂���
�G�R���˂�
>>44
AMD�̎�����̘b������ɂ́AIntel�̎����オ�ǂ����Ă����ނ���ȁB
�t�Ɍ����Intel�̎�����̘b�́A���݂͐��\�ʂ�Intel�D�ʂŐi��ł���̂ŁA
AMD�̎�����̘b�͗��܂Ȃ��Ă��Ȃ�Ƃ��Ȃ���ăI�`�B
AMD�̎�����̘b������ɂ́AIntel�̎����オ�ǂ����Ă����ނ���ȁB
�t�Ɍ����Intel�̎�����̘b�́A���݂͐��\�ʂ�Intel�D�ʂŐi��ł���̂ŁA
AMD�̎�����̘b�͗��܂Ȃ��Ă��Ȃ�Ƃ��Ȃ���ăI�`�B
>���ł̃J�X�^���ł�Qosmio��GPU�Ƃ��ĖړI��S�����Ă�Ƃ����B
GPU����˂��Ă�
GPU����˂��Ă�
52 �FSocket774�F2008/06/25(��) 09:24:15 ID:KJMfw5zW
�C���e��CPU�Ȃ����C��������A���̎�������ǂ��ł��������B
�C���e��������̘b�͊Y���X���ł���A�z���B
�C���e��������̘b�͊Y���X���ł���A�z���B
>>51
����]��Qosmio��GeForce���ڂ����A��̃��f����SpursEngine�ɒu���ւ���Ă�B
�܂�GPU�@�\�����˂Ă���B
�o�b�e���[���p�������I���{�œ����B
GPU���X�g���[���v���Z�b�T�Ƃ��Ďg����悤�ɂ���̂����̋t���A�����̈Ⴂ�͂���Ǔ����Ƃ���ɍs��������
GPU���X�g���[���v���Z�b�T�Ƃ̍��ʉ����v�낤�Ƃ���Α������̗����ʒu�ɉ�A����
����]��Qosmio��GeForce���ڂ����A��̃��f����SpursEngine�ɒu���ւ���Ă�B
�܂�GPU�@�\�����˂Ă���B
�o�b�e���[���p�������I���{�œ����B
GPU���X�g���[���v���Z�b�T�Ƃ��Ďg����悤�ɂ���̂����̋t���A�����̈Ⴂ�͂���Ǔ����Ƃ���ɍs��������
GPU���X�g���[���v���Z�b�T�Ƃ̍��ʉ����v�낤�Ƃ���Α������̗����ʒu�ɉ�A����
>>53
���ł�PC�X�y�b�N�\�ςĂ����B9600M GT+SpursEngine�̃R���{���B
SpursEngine�͂����܂ł�GPU�̃T�u�`�b�v���B
���ł�PC�X�y�b�N�\�ςĂ����B9600M GT+SpursEngine�̃R���{���B
SpursEngine�͂����܂ł�GPU�̃T�u�`�b�v���B
>>52
�C���e�������I�т悤���Ȃ��Ȃ邩����(�E�L��`�E)
�C���e�������I�т悤���Ȃ��Ȃ邩����(�E�L��`�E)
Qosmio��SpursEngine��SPE���Ē��𑜂Ƃ������A�b�v�X�P�[�����O�Ɖf�����̊�F�����炢�ɂ����g���ĂȂ�����H
�f�R�[�_��G���R�[�_�͕ʂɉ�H�����Ă邵
�f�R�[�_��G���R�[�_�͕ʂɉ�H�����Ă邵
�f�R�[�_��G���R�[�_���n�[�h�E�F�A�Ŏ������Ȃ��ƁA�p���[�s���ɂȂ邩�炾�낤�B
PS3��Cell�ƈ���āASPE�̌������āA�N���b�N�������Ă镪�A�\�t�g�E�F�A������
�o���邱�Ƃ͌��肳��邾�낤���B
AMD��GPU�����������p�r�Ŏg���Ă��炤�悤���������Ȃ��Ƃ����Ȃ��낤���B
NVIDIA�̕��ɐ�ɍœK�����ꂽ��A2�{���炢�̍������Ȃ�AMD�ANVIDIA�Ԃł́A
AMD�̕��ɂȂ��Ȃ��v���O�������������Ă��炦�Ȃ����Ă��ƂɂȂ肻�������B
PS3��Cell�ƈ���āASPE�̌������āA�N���b�N�������Ă镪�A�\�t�g�E�F�A������
�o���邱�Ƃ͌��肳��邾�낤���B
AMD��GPU�����������p�r�Ŏg���Ă��炤�悤���������Ȃ��Ƃ����Ȃ��낤���B
NVIDIA�̕��ɐ�ɍœK�����ꂽ��A2�{���炢�̍������Ȃ�AMD�ANVIDIA�Ԃł́A
AMD�̕��ɂȂ��Ȃ��v���O�������������Ă��炦�Ȃ����Ă��ƂɂȂ肻�������B
58 �F�R�E�L�́M�E,,�j�����������������F2008/06/25(��) 12:07:15 ID:d92IAJsE
GPU�̎x���ł�����B�V�F�[�_��ւŁB
PS2�̂Ƃ���EE��VU�����Ĕėp��GPU�̋@�\�̌����肾�����B
�����炭��PS3��SPE�����̗\�肾�����B
���s��PS3���ǂ����{���]�|������SPE��SIMD�����Ȃ̂ɔėp�v���Z�b�T�����iPPE�j��
�シ���邹����PPE�̌�����������悤�Ƃ�������B
GS2���]����RSX(��7800GTX)�ɑ��������_��SPE�̖{���̎d���̑啔����
RSX�ɂ����Ă��܂����B
PPE+RSX�ōς�ł�Q�[�������邭�炢��
PPE�~�Q���炢��SPE�����炵�Ă��肷��܂��ǂ����������B
��̍Ղ肾���ǁB
GPU��SSE5�]�X���n�������b����B
PS2�̂Ƃ���EE��VU�����Ĕėp��GPU�̋@�\�̌����肾�����B
�����炭��PS3��SPE�����̗\�肾�����B
���s��PS3���ǂ����{���]�|������SPE��SIMD�����Ȃ̂ɔėp�v���Z�b�T�����iPPE�j��
�シ���邹����PPE�̌�����������悤�Ƃ�������B
GS2���]����RSX(��7800GTX)�ɑ��������_��SPE�̖{���̎d���̑啔����
RSX�ɂ����Ă��܂����B
PPE+RSX�ōς�ł�Q�[�������邭�炢��
PPE�~�Q���炢��SPE�����炵�Ă��肷��܂��ǂ����������B
��̍Ղ肾���ǁB
GPU��SSE5�]�X���n�������b����B
x86��GPU���}�V
�l�I�Ɏv�����ƂȂ��ǁAintel�͎����Ƃ���̐��i�ŐV�����s����l�����邱�Ƃ͏o���Ȃ���Ƃ��Ǝv����
�Ⴆ�AHPC�p�r��Op������������AOp�N���[����CPU�������Op�̃V�F�A��~���������͏o���Ă��A���ꂾ�����Ċ���
�Ȃ̂ŁALarrabee��GPGPU�̌�ǂ��Ƃ����J�^�`�ł����������Ȃ���(intel�P�Ƃł͐V�@���Ő��������鐻�i�͍��Ȃ�)
Itanum�Ɠ����悤�ɃL�`���ƑΉ�����ΐ��\�͂��邯�ǁA���\�o���Ȃ��A�V�F�A�͒Ⴂ�Ŏ��s��̃��b�e����\����A���Ċ����ɂȂ邾�낤��
GPU�Ƃ��Ă݂��ꍇ��GeForceFX�V���[�Y���Q�l�ɂȂ肻��
�V�@���Ŏ��s����̂�intel���Z�p�I�ɗ���Ă���̂ł͖����A�S���̃[������X�^�[�g�����悤�Ƃ��邩��Ȃ��ǂ�(���ʃj�b�`�ɏI���)
�Ⴆ�AHPC�p�r��Op������������AOp�N���[����CPU�������Op�̃V�F�A��~���������͏o���Ă��A���ꂾ�����Ċ���
�Ȃ̂ŁALarrabee��GPGPU�̌�ǂ��Ƃ����J�^�`�ł����������Ȃ���(intel�P�Ƃł͐V�@���Ő��������鐻�i�͍��Ȃ�)
Itanum�Ɠ����悤�ɃL�`���ƑΉ�����ΐ��\�͂��邯�ǁA���\�o���Ȃ��A�V�F�A�͒Ⴂ�Ŏ��s��̃��b�e����\����A���Ċ����ɂȂ邾�낤��
GPU�Ƃ��Ă݂��ꍇ��GeForceFX�V���[�Y���Q�l�ɂȂ肻��
�V�@���Ŏ��s����̂�intel���Z�p�I�ɗ���Ă���̂ł͖����A�S���̃[������X�^�[�g�����悤�Ƃ��邩��Ȃ��ǂ�(���ʃj�b�`�ɏI���)
>>60
intel��x86�ȊO�ł͂��܂萬�����Ă��Ȃ����Ă͓̂��ӂ��邪�AHPC�p�r��Opteron��
����������A�Ȃ�Ă������ɏ��Ȃ������c�B
HPC�p�r��Opteron���������Ă̂ƁAHPC�s���Opteron��������̓C�R�[������Ȃ����B
intel��x86�ȊO�ł͂��܂萬�����Ă��Ȃ����Ă͓̂��ӂ��邪�AHPC�p�r��Opteron��
����������A�Ȃ�Ă������ɏ��Ȃ������c�B
HPC�p�r��Opteron���������Ă̂ƁAHPC�s���Opteron��������̓C�R�[������Ȃ����B
62 �F�R�E�L�́M�E,,�j�����������������F2008/06/25(��) 12:33:50 ID:d92IAJsE
>>60
HPC�s���x86��Ȑ�`����Ĕ��荞�̂�Intel�B
Opteron����Xeon�̍�����s���Intel�̃R�[�h���Y�����ăV�F�A���g��ł����킯�ŁB
�T�A�U�N�O�̃X�p�R���g�b�v500�̃V�F�A���Ă݂���H
HPC�s���x86��Ȑ�`����Ĕ��荞�̂�Intel�B
Opteron����Xeon�̍�����s���Intel�̃R�[�h���Y�����ăV�F�A���g��ł����킯�ŁB
�T�A�U�N�O�̃X�p�R���g�b�v500�̃V�F�A���Ă݂���H
63 �F�R�E�L�́M�E,,�j�����������������F2008/06/25(��) 12:41:02 ID:d92IAJsE
2003�N11���̃V�F�A
AMD 9 1.80 % 5420 9843 3046
Intel IA-32 159 31.80 % 177352 394107 86354
Intel IA-64 32 6.40 % 40344 54581 10322
AMD x86_64 4 0.80 % 10894 15667
http://www.top500.org/stats/list/22/procfam
����ǂ��Ă݂�Ɍ��s��Intel 64(EM64T)�̃V�F�A��IA-32�����̂܂�܈ڍs������������
AMD 9 1.80 % 5420 9843 3046
Intel IA-32 159 31.80 % 177352 394107 86354
Intel IA-64 32 6.40 % 40344 54581 10322
AMD x86_64 4 0.80 % 10894 15667
http://www.top500.org/stats/list/22/procfam
����ǂ��Ă݂�Ɍ��s��Intel 64(EM64T)�̃V�F�A��IA-32�����̂܂�܈ڍs������������
>HPC�p�r��Op������������AOp�N���[����CPU�������Op�̃V�F�A��~���������͏o���Ă�
�ϑz���ȊO�̐����z�������悤�ł��ˁi�O�|�O�j
�ϑz���ȊO�̐����z�������悤�ł��ˁi�O�|�O�j
����AOp��HPC�s���������A�Ȃ�čl���Ă͂��Ȃ���(�J��Op��Alpha��u�������������ł���)
���m�̗Ⴆ�Ȃ̂ɁA�����Ɋ��݂����c�c
Op��x86�n��CPU�Ƃ��Ă݂�Ȃ�c�q�̒ʂ肾���AAlpha�n��CPU�Ƃ��Ă݂��HPC�p�r��������CPU���ĉ��߂��o����Ǝv�����̂���
K8���̂������x86�E���Alpha���CPU�������͂�����
���m�̗Ⴆ�Ȃ̂ɁA�����Ɋ��݂����c�c
Op��x86�n��CPU�Ƃ��Ă݂�Ȃ�c�q�̒ʂ肾���AAlpha�n��CPU�Ƃ��Ă݂��HPC�p�r��������CPU���ĉ��߂��o����Ǝv�����̂���
K8���̂������x86�E���Alpha���CPU�������͂�����
66 �F�R�E�L�́M�E,,�j�����������������F2008/06/25(��) 13:30:39 ID:d92IAJsE
AMD�̃s�[�N��������
http://www.top500.org/stats/list/28/procfam
Intel IA-32 120 24.00 % 448066 802549 131962
Intel IA-64 35 7.00 % 317096 374798 60862
Intel EM64T 108 21.60 % 602989 1021525 123242
AMD x86_64 113 22.60 % 766659 1118476 230061
>>65
�ϑz������
���߃Z�b�g�̌݊����������̂�Opteron��Alpha�̌�p���Ă̂͗��\�����錾�������B
Opteron�������オ�������ɂ�Alpha�̃V�F�A��IA-32�iXeon�j�Ƀ_�u���X�R�A�Ŕ�����Ă��B
HPC��x86�݊��A�[�L�������y�䂪�o���������̂�������Intel�̌��тȂ�
http://www.top500.org/stats/list/28/procfam
Intel IA-32 120 24.00 % 448066 802549 131962
Intel IA-64 35 7.00 % 317096 374798 60862
Intel EM64T 108 21.60 % 602989 1021525 123242
AMD x86_64 113 22.60 % 766659 1118476 230061
>>65
�ϑz������
���߃Z�b�g�̌݊����������̂�Opteron��Alpha�̌�p���Ă̂͗��\�����錾�������B
Opteron�������オ�������ɂ�Alpha�̃V�F�A��IA-32�iXeon�j�Ƀ_�u���X�R�A�Ŕ�����Ă��B
HPC��x86�݊��A�[�L�������y�䂪�o���������̂�������Intel�̌��тȂ�
DEC�̊J���҂�����������AAthlon��Alpha�̐v�v�z�������Ă�Ƃ����Ӗ��ł�
Alpha�̌�p�ƌ����Ȃ����Ȃ����AOpteron��Alpha��u���������Ȃ��
�\�_�߂��邗
Alpha�̌�p�ƌ����Ȃ����Ȃ����AOpteron��Alpha��u���������Ȃ��
�\�_�߂��邗
http://www.4gamer.net/games/045/G004578/20080625008/
GPGPU�Ƃ��Ďg�����ꍇ�̃A�v���Ή���NVIDIA�Ɣ�r���Ēx��Ă��悤�Ɋ����Ă����ǁA
HD4870��Photoshop��Cyberlink Power Director���Ή�����炵���B
Adobe��NVIDIA�Ɉ�{�ނ肳��Ă����̂ł͂Ȃ������悤���B
GPGPU�Ƃ��Ďg�����ꍇ�̃A�v���Ή���NVIDIA�Ɣ�r���Ēx��Ă��悤�Ɋ����Ă����ǁA
HD4870��Photoshop��Cyberlink Power Director���Ή�����炵���B
Adobe��NVIDIA�Ɉ�{�ނ肳��Ă����̂ł͂Ȃ������悤���B
�l�I�Ɏv�����ƂȂ��ǁAAMD�͎����Ƃ���̐��i�ŐV�����s����l�����邱�Ƃ͏o���Ȃ���Ƃ��Ǝv����(�E�L��`�E)
�ق��ق��A����͋v�X�ɗǂ��j���[�X�B
Photoshop��CUDA�ɑΉ��̌��ŁA���ꂩ���NVIDIA������A�Ǝv��������
�Q�[���ȊO�ɂ��̕ӂ̍œK���őI�Ԋy���݂����������B
Photoshop��CUDA�ɑΉ��̌��ŁA���ꂩ���NVIDIA������A�Ǝv��������
�Q�[���ȊO�ɂ��̕ӂ̍œK���őI�Ԋy���݂����������B
71 �FSocket774�F2008/06/25(��) 14:57:50 ID:KJMfw5zW
72 �FSocket774�F2008/06/25(��) 15:04:11 ID:KJMfw5zW
>>69
���܂ł͂��������A���f�����邢�܂́AGPGPU�s����l���o����\���͍����Ƃ��������B
���܂ł͂��������A���f�����邢�܂́AGPGPU�s����l���o����\���͍����Ƃ��������B
ttp://opentechpress.jp/opensource/08/06/24/0447254.shtml
�^�ɃI�[�v���Ȃ��̂�ڎw���Ȃ�A�m���Ɏx���҂͑�����Ǝv��
�^�ɃI�[�v���Ȃ��̂�ڎw���Ȃ�A�m���Ɏx���҂͑�����Ǝv��
MAC�̉e���͂Ȃ�Ă����w�ǖ����ˁH
>>76
�N���G�C�^�[��MAC�M��͂܂��������B
�N���G�C�^�[��MAC�M��͂܂��������B
78 �FSocket774�F2008/06/25(��) 17:05:38 ID:KJMfw5zW
OPEN Cl�̕��y����ʼne���͂��傫���Ȃ��ˁH
>>77
�����H
�����H
80 �F�R�E�L�́M�E,,�j�����������������F2008/06/25(��) 18:02:58 ID:d92IAJsE
Alpha�̗Ⴞ�ƁAAMD������Ă�̂͂悭������y�n������ē]��������ɂ�����
�y�n�̊J�̂��̂͂���ĂȂ����ƂɂȂ�B
�����������̊��ɋy���Intel�A�[�L��AMD64�݊��Ȃ�Ă̂͏��Ȃ���k����B
AMD�����i�j�̊g�����߂ł���SSE4A�ASSE5��Intel�̓K���������Ă����ŁA
AMD�́A�H���݊����[�J�[�i�j�̊g�����߂�SSSE3, SSE4.x�̗̍p�v���ł��o���B
AMD��x64�A�[�L�̖��߃Z�b�g�̎哱���������ł����K���ɁuIntel 64�݊��v������Ă�
���������낻�뒼���������������B
>>74
�l�C�e�B�u���߃Z�b�g�܂ŃI�[�v����Larrabee�̎x���͌����Ƃ������Ƃł��ˁB�킩��܂��B
>>79
�R�N�O���炢��Win:Mac 6:4��������K�X
Adobe��Mac�ł̎������i��x64�ł�p�ӂ��Ȃ����j�ł��o���Ă邩��
���낻���̂Ăɂ�������̂ƌ��Ă�B
�y�n�̊J�̂��̂͂���ĂȂ����ƂɂȂ�B
�����������̊��ɋy���Intel�A�[�L��AMD64�݊��Ȃ�Ă̂͏��Ȃ���k����B
AMD�����i�j�̊g�����߂ł���SSE4A�ASSE5��Intel�̓K���������Ă����ŁA
AMD�́A�H���݊����[�J�[�i�j�̊g�����߂�SSSE3, SSE4.x�̗̍p�v���ł��o���B
AMD��x64�A�[�L�̖��߃Z�b�g�̎哱���������ł����K���ɁuIntel 64�݊��v������Ă�
���������낻�뒼���������������B
>>74
�l�C�e�B�u���߃Z�b�g�܂ŃI�[�v����Larrabee�̎x���͌����Ƃ������Ƃł��ˁB�킩��܂��B
>>79
�R�N�O���炢��Win:Mac 6:4��������K�X
Adobe��Mac�ł̎������i��x64�ł�p�ӂ��Ȃ����j�ł��o���Ă邩��
���낻���̂Ăɂ�������̂ƌ��Ă�B
������߰��ipod��������Ď��̃I�T������ɔ����Ă��B
iphone��MAC���ȁB
iphone��MAC���ȁB
��́u�O���t�B�b�N�Ȃ�Mac�v
�́i01���炢�j�u����W�Ȃ�܂��܂�Mac�v
���̔����MS�\�t�g���g����悤�ɂȂ���Windows�݊����i���Ƃ��炢�H
�܂��l�i��DOSV���x��CPU��intel�ȊO�Ȃ�P���͎����Ƃ��������ǂ�
�́i01���炢�j�u����W�Ȃ�܂��܂�Mac�v
���̔����MS�\�t�g���g����悤�ɂȂ���Windows�݊����i���Ƃ��炢�H
�܂��l�i��DOSV���x��CPU��intel�ȊO�Ȃ�P���͎����Ƃ��������ǂ�
84 �FSocket774�F2008/06/25(��) 19:34:20 ID:KJMfw5zW
�����r�[�ς�Ŗ����Ă��A���f�ς�ł�Ή��b���邵�ȁB
http://pc.watch.impress.co.jp/docs/2008/0625/amd.htm
GPGPU�L�^�[�I�I�V���O���R�ACPU��2.5�{���ŃG���R�I�I�I
�V���O���R�ACPU��2.5�I�H�E�E�g����(�E�L��`�E)
GPGPU�L�^�[�I�I�V���O���R�ACPU��2.5�{���ŃG���R�I�I�I
�V���O���R�ACPU��2.5�I�H�E�E�g����(�E�L��`�E)
���͏\���ɑ���
�Ȃ�����cos���̒��z����������̂�shader����T���j�b�g�̂�
�܂�͗��_�p�t�H�[�}���X��240gflops���x
�Ȃ�����cos���̒��z����������̂�shader����T���j�b�g�̂�
�܂�͗��_�p�t�H�[�}���X��240gflops���x
>>80
AMD��GPU�̖��߃Z�b�g��CAL�̃o�C�i���t�H�[�}�b�g�����J���Ă��B
AMD��GPU�̖��߃Z�b�g��CAL�̃o�C�i���t�H�[�}�b�g�����J���Ă��B
������SSE5�Ƃ����p���������l�[�~���O�͂ǂ��ɂ��Ȃ�Ȃ��������̂�
Larrabee����X86�ȊO�̊��ł��D�G�Ȃ́H
�͂��H(�E�L��`�E)�H�H�H�H�H
Larrabee��100���R�P��B
�Q�[���O���t�B�b�N�̓}�C�N���\�t�g��DirectX�̂�������geforce��radeon���C�ɂ����ɂ��ނ�
GPGPU���}�C�N���\�t�g���哱���ăl�B�e�B�u���߃Z�b�g���B�����Ă���Ȃ����낤���H
���̂܂܂����Ɗm���ɖ��߃Z�b�g���������v���O���}�̕��S������ѓ�������
GPGPU���}�C�N���\�t�g���哱���ăl�B�e�B�u���߃Z�b�g���B�����Ă���Ȃ����낤���H
���̂܂܂����Ɗm���ɖ��߃Z�b�g���������v���O���}�̕��S������ѓ�������
�����DX11��
>>82
����B����̊�V�X�e����Mac�����荞����Ă��邩��A
�啪�l�X�ȋ@�킪���������悤�ɂȂ��Ă��Ă��邪�A
�\�t�g�E�F�A�Ȃǂ��l�����獡�ł������Ȃ�B
�Ȃɂ�����p�̃t�H���g��{���\���̐��E�����H
����B����̊�V�X�e����Mac�����荞����Ă��邩��A
�啪�l�X�ȋ@�킪���������悤�ɂȂ��Ă��Ă��邪�A
�\�t�g�E�F�A�Ȃǂ��l�����獡�ł������Ȃ�B
�Ȃɂ�����p�̃t�H���g��{���\���̐��E�����H
�y�m������X86�ȊO�̊��ł��D�G�Ȃ́H(�E�L��`�E)
�͂��H�H�H�H�H�H
�y�m��100���R�P��(�E�L��`�E)
�͂��H�H�H�H�H�H
�y�m��100���R�P��(�E�L��`�E)
>>85
�N�A�b�h�R�A�I�����������G�R�����M���Ȃ������̗p�r�ɂ��L�������E�E�E
�N�A�b�h�R�A�I�����������G�R�����M���Ȃ������̗p�r�ɂ��L�������E�E�E
�܂��A�G���R���悤�Ƃf�o�t�����l�̕��������Ȃ��Ƃ��������Ȃ��ł��傗
�Q�[����낤�Ƃ��ăG���R���ł����I�}�P�݂����Ȃ����A���܂���
�ł���Ȃ炢����Ȃ��B
���̂����b�o�t��葁���Ȃ邾�낤���˂�
�Q�[����낤�Ƃ��ăG���R���ł����I�}�P�݂����Ȃ����A���܂���
�ł���Ȃ炢����Ȃ��B
���̂����b�o�t��葁���Ȃ邾�낤���˂�
>>85
http://pc.nikkeibp.co.jp/article/news/20080625/1005478/?P=2
>�Z�p������ł́AAVT���̗p����HD�r�f�I�ϊ��̍����������������uPower Director 7�v�iCyberLink�j�����J���ꂽ�B
>AMD�ɂ��AAVT���g�����Ƃɂ��CPU�݂̂ɂ��HD�f���̕ϊ��ɔ�ׁA
>CPU�{�O���t�B�N�X�`�b�v�ŏ��������ꍇ�͖�19�{�̍��������\���Ƃ����B
�c�O�ł���(�E�L��`�E)
http://pc.nikkeibp.co.jp/article/news/20080625/1005478/?P=2
>�Z�p������ł́AAVT���̗p����HD�r�f�I�ϊ��̍����������������uPower Director 7�v�iCyberLink�j�����J���ꂽ�B
>AMD�ɂ��AAVT���g�����Ƃɂ��CPU�݂̂ɂ��HD�f���̕ϊ��ɔ�ׁA
>CPU�{�O���t�B�N�X�`�b�v�ŏ��������ꍇ�͖�19�{�̍��������\���Ƃ����B
�c�O�ł���(�E�L��`�E)
99 �F�R�E�L�́M�E,,�j�����������������F2008/06/26(��) 07:23:30 ID:JWHYg+6B
�ő偛FLOPS�����\�̐�Ύw�W�Ȃ��GK���_�����������߂悤��
���ꂾ��GPU��Larrabee��������Ȃ����ǂ��̉���
������������������Nehalem����Phenom(��)�ɂȂ邺�H
���ꂾ��GPU��Larrabee��������Ȃ����ǂ��̉���
������������������Nehalem����Phenom(��)�ɂȂ邺�H
���炩�ɔn��
101 �F�R�E�L�́M�E,,�j�����������������F2008/06/26(��) 07:41:48 ID:JWHYg+6B
>>92
�l�C�e�B�u���B���Ȃ�Ă��Ȃ��Ă���
�Ȃ��Ȃ炻���ɌN�Ղ���̂͂���ς�x86������
��������CUDA�Ƃ����Ԍ��ꂾ��
CPU�ł�����Java��.NET��W���ɂ���悤�Ȃ���
�������ɕϊ����K�v������l�C�e�B�u�ɔ�ׂĂ�������
�l�C�e�B�u���B���Ȃ�Ă��Ȃ��Ă���
�Ȃ��Ȃ炻���ɌN�Ղ���̂͂���ς�x86������
��������CUDA�Ƃ����Ԍ��ꂾ��
CPU�ł�����Java��.NET��W���ɂ���悤�Ȃ���
�������ɕϊ����K�v������l�C�e�B�u�ɔ�ׂĂ�������
102 �F�R�E�L�́M�E,,�j�����������������F2008/06/26(��) 07:48:30 ID:JWHYg+6B
������GPGPU�̋��ʒ��ԃR�[�h��x86�ł�����ˁH
����Ȃ�CPU��GPU�̖��߃Z�b�g�̈Ⴂ�Ƃ�����ǂ��Ȃ��Ȃ�B
����Ȃ�CPU��GPU�̖��߃Z�b�g�̈Ⴂ�Ƃ�����ǂ��Ȃ��Ȃ�B
http://journal.mycom.co.jp/news/2008/06/25/043/index.html
�ł��������ɂ�CPU1�R�A�Ɣ�r�����1.5�{���Đ}�������ȁB
�f���A���R�A���m��RV770�̗L���ł̔�r����1.7�{����ۂ��B
CPU�̐��\���킩��Ȃ��̂ŁA����Q�l�ɂȂ�Ȃ��O���t�����ǁB
�ł��������ɂ�CPU1�R�A�Ɣ�r�����1.5�{���Đ}�������ȁB
�f���A���R�A���m��RV770�̗L���ł̔�r����1.7�{����ۂ��B
CPU�̐��\���킩��Ȃ��̂ŁA����Q�l�ɂȂ�Ȃ��O���t�����ǁB
��CPU1�R�A�Ɣ�r�����1.5�{���Đ}
��2.5�{�̊ԈႢ�ˁB
��2.5�{�̊ԈႢ�ˁB
Larrabee��16�R�A����32�R�A�������邪�n�}���Nehalem�̏\���{�A���ɐVSIMD���ߎg��Ȃ��Ă�
Atom���x�~�R�A���̐��\�͏o�邾�낤����܂��������̂ق����}�V
GPU��GPU������������
Atom���x�~�R�A���̐��\�͏o�邾�낤����܂��������̂ق����}�V
GPU��GPU������������
Transmeta������x86��SSE?��Fusion�p
�������߃Z�b�g�Ƀ_�C�i�~�b�N�R���p�C��
�������߃Z�b�g�Ƀ_�C�i�~�b�N�R���p�C��
����Transmeta�����Ă��Z�p�w���Ȃ�����A�����̓���������ɓ�����Ȃ��B
���̐l��Intel�ɍs������ˁB
>>92
���̂ւ��XBOX��p�@�Ƃ��݊��̎���K�i���l���Ă��Ȃ����Ȃ��B
�C���e�������D�G�Ȃ̂��o���킩��ǁANVIDIA�͌����_�ł͓G�w�c�����A
MS�哱��AMD�����̕����Ői�݂����B
���̂ւ��XBOX��p�@�Ƃ��݊��̎���K�i���l���Ă��Ȃ����Ȃ��B
�C���e�������D�G�Ȃ̂��o���킩��ǁANVIDIA�͌����_�ł͓G�w�c�����A
MS�哱��AMD�����̕����Ői�݂����B
Linus��CMS�̊J���ɂ�������Ă���OSS�s���Ď���Transmeta�Ƃ��Ă�
�����͂���ĂȂ��B
VLIW��x86���ăR���p�C�����Ď��s����A�v���[�`�Ȃ�đ債�Č��ʏオ���ĂȂ��̂�
Efficeon�̎��s��Itanium/IA32EL�̕����\����킩�邾��B
x86�ł�IPC�����3�`4�������Ƃ���B
���Ƃ̓}���`�X���b�h�i�}���`�R�A�j�����炢�B
�ł����X���b�h�ɕ����ł���Ȃ炻������x86�����Ń}���`�R�A������ق����}�V
�����͂���ĂȂ��B
VLIW��x86���ăR���p�C�����Ď��s����A�v���[�`�Ȃ�đ債�Č��ʏオ���ĂȂ��̂�
Efficeon�̎��s��Itanium/IA32EL�̕����\����킩�邾��B
x86�ł�IPC�����3�`4�������Ƃ���B
���Ƃ̓}���`�X���b�h�i�}���`�R�A�j�����炢�B
�ł����X���b�h�ɕ����ł���Ȃ炻������x86�����Ń}���`�R�A������ق����}�V
>>111
http://pc.watch.impress.co.jp/docs/2007/1025/transmeta.htm
���Ȃ��Ƃ�intel�ɑ��Ă͗L���ȕ���ɂȂ�Ȃ����ǂˁB
http://pc.watch.impress.co.jp/docs/2007/1025/transmeta.htm
���Ȃ��Ƃ�intel�ɑ��Ă͗L���ȕ���ɂȂ�Ȃ����ǂˁB
http://www.itmedia.co.jp/news/articles/0710/25/news032.html
�\��Ȃ炱�����̕����ǂ������ȁB�P�v�I��intel��Transmeta�̓����g����_��ɂȂ��Ă�B
�\��Ȃ炱�����̕����ǂ������ȁB�P�v�I��intel��Transmeta�̓����g����_��ɂȂ��Ă�B
>>112-113
��Intel�Ƃ��W�Ȃ���"�����͏d�v"�B
�A�����J�Ȃ�ē����S�����S���S�����Ă��邩��ȁB
�������Ƃ��Ă��܂��ƁA��肽�������킩���Ă��܂��̂ŁA
�t�ɓ������Ƃ�Ȃ��Ŏ���i�߂��Ђ������炵�����B
�ʔ��������̂̓R���B�Ђǂ��ˁH
ttp://www.technobahn.com/cgi-bin/news/read2?f=200801261048
��Intel�Ƃ��W�Ȃ���"�����͏d�v"�B
�A�����J�Ȃ�ē����S�����S���S�����Ă��邩��ȁB
�������Ƃ��Ă��܂��ƁA��肽�������킩���Ă��܂��̂ŁA
�t�ɓ������Ƃ�Ȃ��Ŏ���i�߂��Ђ������炵�����B
�ʔ��������̂̓R���B�Ђǂ��ˁH
ttp://www.technobahn.com/cgi-bin/news/read2?f=200801261048
�f�B�b�c�F����Intel���肵�����_��Transmeta�͂��ł�
Intel�̘��S�ɂȂ��Ă�\�����ے�ł���
Intel�̘��S�ɂȂ��Ă�\�����ے�ł���
�O�O������o�ė���
ttp://bogusne.ws/article/80969864.html
ttp://bogusne.ws/article/80969864.html
bogusnews�͏�k�j���[�X�̃T�C�g�ł�
����ȓ�����ʂ̘b����Ă��ȁ`�B
AMD�̖@�����傪�i�׃��X�N�l���āA�K�v�ȓ�����Transmeta�������Ă�����A
���C�Z���X�_�邩�A�Ȃ��邾�낤�B
�Z�p�w���Ȃ�IP���������ő������鍡��Transmeta�͂��邢�ݓ����S���Ɠ����Ȃ��B
AMD�̖@�����傪�i�׃��X�N�l���āA�K�v�ȓ�����Transmeta�������Ă�����A
���C�Z���X�_�邩�A�Ȃ��邾�낤�B
�Z�p�w���Ȃ�IP���������ő������鍡��Transmeta�͂��邢�ݓ����S���Ɠ����Ȃ��B
�Ȃɂ��̔��z
SIMD�̃x�N�g�������̂�������VLIW�ϊ����̕���x��啝�ɉ҂���B
����Itanium2��IA32EL�ł�MMX�g�����R�[�h��SSE2�ɒ����������Ő��\���\������B
�ǂ��Ȃ�ɂ���AVX��AMD�������ł��Ȃ��B
����Itanium2��IA32EL�ł�MMX�g�����R�[�h��SSE2�ɒ����������Ő��\���\������B
�ǂ��Ȃ�ɂ���AVX��AMD�������ł��Ȃ��B
121 �F�R�E�L�́M�E,,�j�����������������F2008/06/26(��) 14:17:36 ID:JWHYg+6B
Efficeon�̃p�t�H�[�}���X���WWay(256bit) VLIW�ōő��M�A�̂��������Ƃ��ł��疽�ߏ[�U��5/8���x�A
IA32���x���ł�IPC=�Q���x�������Ƃ���ŁA�܂�ǂ���Banias���x�B
1.8GHz�Ȃ�25W���ʏ�d���ł�Banias���M���Ƃ�����CPU�������B
���IVLIW�̃A�v���[�`�ōł������I�Ɏ��s�ł���̂�SIMD���߂�
�ł�SIMD�Ɠ��������Ȃ�ŏ�����SIMD�̂ق������ߒ����Z���čςށB
������{���]�|�Ȃ�B
x86�X�g���[���v���Z�b�T��GPGPU�I�ȍ�Ƃ�����ق��������I
IA32���x���ł�IPC=�Q���x�������Ƃ���ŁA�܂�ǂ���Banias���x�B
1.8GHz�Ȃ�25W���ʏ�d���ł�Banias���M���Ƃ�����CPU�������B
���IVLIW�̃A�v���[�`�ōł������I�Ɏ��s�ł���̂�SIMD���߂�
�ł�SIMD�Ɠ��������Ȃ�ŏ�����SIMD�̂ق������ߒ����Z���čςށB
������{���]�|�Ȃ�B
x86�X�g���[���v���Z�b�T��GPGPU�I�ȍ�Ƃ�����ق��������I
>>120
���ȁB����AVX���T�|�[�g���邱�ƂɂȂ�͂������c�B
�f����Intel�����C�Z���X����邩�ǂ�������肾�B
AVX�Ɏ���256bit����SSE�������u�͂߂邩������Ȃ����A
�V�g�����߂ɑΉ��ł��Ȃ���c�˂��B
���ȁB����AVX���T�|�[�g���邱�ƂɂȂ�͂������c�B
�f����Intel�����C�Z���X����邩�ǂ�������肾�B
AVX�Ɏ���256bit����SSE�������u�͂߂邩������Ȃ����A
�V�g�����߂ɑΉ��ł��Ȃ���c�˂��B
���Z�@�̎����Ɩ��߃Z�b�g�͕ʂł���������
����Intel��Core2�܂ł�SIMD���Z�@��64�r�b�g�̂܂܂�������
AVX�����C�Z���X���Ȃ����Ă��Ƃ͂Ȃ��Ǝv�����ˁB
�ǂ������ƌ�����VEX�t�H�[�}�b�g�̃y�C���[�h�̈�̂����ǂ��܂ł�AMD�Ǝ��t�B�[���h�Ƃ��ĖႦ�邩�̂ق���AMD�I�ɂ͏d�v�����B
OPCODE3�{DREX�g���̖��߃t�H�[�}�b�g��66�Ƃ��̃v���t�B�N�X�t����SSE5��256�r�b�g�����s���������B
����Intel��Core2�܂ł�SIMD���Z�@��64�r�b�g�̂܂܂�������
AVX�����C�Z���X���Ȃ����Ă��Ƃ͂Ȃ��Ǝv�����ˁB
�ǂ������ƌ�����VEX�t�H�[�}�b�g�̃y�C���[�h�̈�̂����ǂ��܂ł�AMD�Ǝ��t�B�[���h�Ƃ��ĖႦ�邩�̂ق���AMD�I�ɂ͏d�v�����B
OPCODE3�{DREX�g���̖��߃t�H�[�}�b�g��66�Ƃ��̃v���t�B�N�X�t����SSE5��256�r�b�g�����s���������B
124 �FSocket774�F2008/06/26(��) 15:39:06 ID:f2o0iTkv
�܂肱���������Ƃ���
�����r:atom 32��SSE������
�t���[�W����:�V�F�[�_���S��SSE������
�A�v���[�`�͈Ⴄ���A��邱�Ƃ͓����B
���ׂ̈ɐV���ߍ�낤�Ƃ������Ƃł́B
�����r�[�̓}���`�X���b�h�����ɂ���x86���x������PC���ᗬ�s��Ȃ�����B
�Q�[���������x���Ȃ����B
�����r:atom 32��SSE������
�t���[�W����:�V�F�[�_���S��SSE������
�A�v���[�`�͈Ⴄ���A��邱�Ƃ͓����B
���ׂ̈ɐV���ߍ�낤�Ƃ������Ƃł́B
�����r�[�̓}���`�X���b�h�����ɂ���x86���x������PC���ᗬ�s��Ȃ�����B
�Q�[���������x���Ȃ����B
���ς�炸�AGPGPU�ƃQ�[���ł�3D���\�Ƃ��킴�Ƃ��킩��Ȃ���
�������Ă���������ȁB
Larrabee�͊����̃}���`CPU�����̃v���O���������̂܂܂��A�ꕔ�C����������邪�A
GPGPU���ƁA����p�ɏ��������Ȃ��Ƃ��߂Ȃ��ǁB
���ƃ}���`�X���b�h�����ɂ���x86���Ă̂��悭�킩���̂����B
3D�Q�[���͑����x�����낤�Ƃ����̂ɂ͓��ӂ��邯�ǁB
�������Ă���������ȁB
Larrabee�͊����̃}���`CPU�����̃v���O���������̂܂܂��A�ꕔ�C����������邪�A
GPGPU���ƁA����p�ɏ��������Ȃ��Ƃ��߂Ȃ��ǁB
���ƃ}���`�X���b�h�����ɂ���x86���Ă̂��悭�킩���̂����B
3D�Q�[���͑����x�����낤�Ƃ����̂ɂ͓��ӂ��邯�ǁB
126 �FSocket774�F2008/06/26(��) 16:51:16 ID:f2o0iTkv
PC�̃\�t�g�̓N�A�b�h�R�A�ȏ�͉��b���Ȃ��Ƃ����Ӗ�����B
���j�C�R�A�̓I�t�B�X��u���E�U�ɂ͊W�����B
�G���R�ȊO�̓V���O���X���b�h���\���d�v������Aatom���x���̃����r�[�Ɏ��v�͂Ȃ��ȁB
���j�C�R�A�̓I�t�B�X��u���E�U�ɂ͊W�����B
�G���R�ȊO�̓V���O���X���b�h���\���d�v������Aatom���x���̃����r�[�Ɏ��v�͂Ȃ��ȁB
>>126
�����|�����āAIntel�͂�������p�ł���\�t�g�E�F�A���A
���Ђɒł��邾�낤���ď����|����B
���������́A�̗p���邩�ǂ����͊�Ƃ̎��R�����ǂȁB
�����|�����āAIntel�͂�������p�ł���\�t�g�E�F�A���A
���Ђɒł��邾�낤���ď����|����B
���������́A�̗p���邩�ǂ����͊�Ƃ̎��R�����ǂȁB
>>125
����
���т̕`��\�͂͂��܂�
�m�u�Ƃ��`�s�h�̂u�f�`��havok�Ή��Ƃ��͂��܂�
�߂����������_�łԂ����Ăǂ��Ȃ邩��
3�N�Ƃ���̘b
����
���т̕`��\�͂͂��܂�
�m�u�Ƃ��`�s�h�̂u�f�`��havok�Ή��Ƃ��͂��܂�
�߂����������_�łԂ����Ăǂ��Ȃ邩��
3�N�Ƃ���̘b
�G���h���[�U�����̃\�t�̑��}���`�X���b�h�����ɂ����g��
x86���}���`�X���b�h�����ɂ������Ă̂͑S�R�ʂ̘b���낤�B
Larrabee�̓}���`�X���b�h���̉��b���傫���p�r�����Ȃ̂ɁA
�V���O���X���b�h�ɂ͖��ɗ����Ȃ��˂��Č����Ă��ǂ����ƁB
�����I�ɂ�GPGPU��Larrabee�Ɍ������A�v�����G���h���[�U�����ɂ��o�Ă���Ƃ�
intel���l���Ă邯�ǁALarrabee�������ɃG���h���[�U�����ɕ��y��������
�Ƃ͎v���ĂȂ����낤�B
x86���}���`�X���b�h�����ɂ������Ă̂͑S�R�ʂ̘b���낤�B
Larrabee�̓}���`�X���b�h���̉��b���傫���p�r�����Ȃ̂ɁA
�V���O���X���b�h�ɂ͖��ɗ����Ȃ��˂��Č����Ă��ǂ����ƁB
�����I�ɂ�GPGPU��Larrabee�Ɍ������A�v�����G���h���[�U�����ɂ��o�Ă���Ƃ�
intel���l���Ă邯�ǁALarrabee�������ɃG���h���[�U�����ɕ��y��������
�Ƃ͎v���ĂȂ����낤�B
http://www.itmedia.co.jp/enterprise/articles/0806/13/news043.html
http://pc11.2ch.net/test/read.cgi/jisaku/1209622524/303
http://pc11.2ch.net/test/read.cgi/jisaku/1209622524/473
http://pc11.2ch.net/test/read.cgi/jisaku/1209622524/303
http://pc11.2ch.net/test/read.cgi/jisaku/1209622524/473
>Larrabee�͊����̃}���`CPU�����̃v���O���������̂܂܂��A�ꕔ�C����������邪�A
�܂�x�����Ď�����
�܂�x�����Ď�����
1���̃{�[�h�ŕ��U�������Ă���N���X�^�̂P��2���̎d��������Ǝv���邪�A
���������f�����܂��Ȃ̂ŁA�����Ȃ�HPC�p�r�ł���������ĉ\�����Ȃ��ɂ������炸�����ǁB
���������f�����܂��Ȃ̂ŁA�����Ȃ�HPC�p�r�ł���������ĉ\�����Ȃ��ɂ������炸�����ǁB
133 �F�R�E�L�́M�E,,�j�����������������F2008/06/26(��) 19:20:12 ID:JWHYg+6B
>>124
256�r�b�gSIMD�̗p��FP���\��1�R�A�ӂ�ł�Core 2�ȏ�A���Ƃ�����H
AVX�̎d�l���́A�Q�[�����̎��v�ɉ��������ʂ���
256�r�b�gSIMD�̗p��FP���\��1�R�A�ӂ�ł�Core 2�ȏ�A���Ƃ�����H
AVX�̎d�l���́A�Q�[�����̎��v�ɉ��������ʂ���
134 �F�R�E�L�́M�E,,�j�����������������F2008/06/26(��) 19:32:14 ID:JWHYg+6B
����Larrabee�ł̓L���b�V���R�q�[�����X��������閽�߂�
�lj�����Ă邩��A�}���`�R�A�ɂ�����x86�̌��_�i�R�q�[�����X�����j��
������x��������Ă�ƌ����Ă����B
4�R�A���Ƃ�L2�L���b�V�������L���AL2�Ԃ͍��������O�o�X�ɂ��f�[�^��������B
Cell�̗��_���z�����|���܂Ƃ߂��ȂƎv���B
�lj�����Ă邩��A�}���`�R�A�ɂ�����x86�̌��_�i�R�q�[�����X�����j��
������x��������Ă�ƌ����Ă����B
4�R�A���Ƃ�L2�L���b�V�������L���AL2�Ԃ͍��������O�o�X�ɂ��f�[�^��������B
Cell�̗��_���z�����|���܂Ƃ߂��ȂƎv���B
135 �F�R�E�L�́M�E,,�j�����������������F2008/06/26(��) 19:41:25 ID:JWHYg+6B
>>129
���������V���O���X���b�h�ɂ�GPGPU�Ȃ�Ė��p�̒���������˂�
������̌������ł͂���Ȋ�������ˁH
nVIDIA�E�E�EGPGPU������GPU�{���̐��\�͏��X�c�O
ATi�E�E�EGPU�{���̋@�\���d��������ɂ܂Ƃ߂�
��������CPU��GPU����S�R�v���O�����̎��R�x���Ⴄ���B
GPU�p��F@H�N���C�A���g�Ȃ�PC��PS3��葬�������
���f���̑傫������������Ă�B
�܂茵���ɂ�CPU�Ɠ��������������ɂ��Ă�킯����Ȃ��B
���������V���O���X���b�h�ɂ�GPGPU�Ȃ�Ė��p�̒���������˂�
������̌������ł͂���Ȋ�������ˁH
nVIDIA�E�E�EGPGPU������GPU�{���̐��\�͏��X�c�O
ATi�E�E�EGPU�{���̋@�\���d��������ɂ܂Ƃ߂�
��������CPU��GPU����S�R�v���O�����̎��R�x���Ⴄ���B
GPU�p��F@H�N���C�A���g�Ȃ�PC��PS3��葬�������
���f���̑傫������������Ă�B
�܂茵���ɂ�CPU�Ɠ��������������ɂ��Ă�킯����Ȃ��B
>����Larrabee�ł̓L���b�V���R�q�[�����X��������閽�߂�
>�lj�����Ă邩��
����ȃ\�[�X��������??
>�lj�����Ă邩��
����ȃ\�[�X��������??
956 ���O�F,,�E�L�́M�E,,�j��-������ ���e���F2008/06/22(��) 14:08:44 ID:YpuPayhY
�����������Z�̘_���s�[�N���\�������g�[�^�����\�����߂�Ȃ�ăg���f���_��
��ʂ̒��w�������ɂ��Ă���
�����������Z�̘_���s�[�N���\�������g�[�^�����\�����߂�Ȃ�ăg���f���_��
��ʂ̒��w�������ɂ��Ă���
138 �F�R�E�L�́M�E,,�j�����������������F2008/06/26(��) 22:21:05 ID:JWHYg+6B
Intel�͂����ɃR�q�[�����g����p�̊g�����߂̒lj��ɂ����y���Ă��B
Larrabee�œ��ڂ�����̂Ǝv���Ă������Ƃ��肩�������ȁB
http://www.intel.com/pressroom/archive/releases/20080317fact.htm
> In addition, Larrabee includes a major new hardware coherent cache
> design enabling the many-core architecture.
���ꂪ�����uCell�݂������v�ƕ]���������O�o�X�ɂ��Ă̐������낤���ǁA
�R�q�[�����g����̕���͂����ƍl���Ă�����Ă��ƂŁB
�܁A�g�����߂Ȃ��Ŏg���Â��̃}���`�X���b�h�̃R�[�h�Ńp�t�H�[�}���X
�����o����Ȃ�A����قǂ��肪�������̂͂Ȃ��ł���B
�����������j�[�R�A������ƃL���b�V���Ԃ̒��₪�l�b�N�ɂȂ���Ă̂�
x86�����Ɍ������b����Ȃ��B
Cell��SPE�݂����ȓƗ��������̕ϑԃA�[�L�e�N�`�����D���Ȑl�͂ǂ���
������ɂƂ����B
Larrabee�œ��ڂ�����̂Ǝv���Ă������Ƃ��肩�������ȁB
http://www.intel.com/pressroom/archive/releases/20080317fact.htm
> In addition, Larrabee includes a major new hardware coherent cache
> design enabling the many-core architecture.
���ꂪ�����uCell�݂������v�ƕ]���������O�o�X�ɂ��Ă̐������낤���ǁA
�R�q�[�����g����̕���͂����ƍl���Ă�����Ă��ƂŁB
�܁A�g�����߂Ȃ��Ŏg���Â��̃}���`�X���b�h�̃R�[�h�Ńp�t�H�[�}���X
�����o����Ȃ�A����قǂ��肪�������̂͂Ȃ��ł���B
�����������j�[�R�A������ƃL���b�V���Ԃ̒��₪�l�b�N�ɂȂ���Ă̂�
x86�����Ɍ������b����Ȃ��B
Cell��SPE�݂����ȓƗ��������̕ϑԃA�[�L�e�N�`�����D���Ȑl�͂ǂ���
������ɂƂ����B
139 �F�R�E�L�́M�E,,�j�����������������F2008/06/26(��) 22:30:27 ID:JWHYg+6B
>>137
���̌��t�C�ɓ����Ă��ꂽ�Ȃ�K�����B
������GPGPU�Ȃǔn�����Ă�B
GPU�͉��SGFLOPS���̕����������j�b�g�ڂ��Ă��L���b�V����������
�`�b�v�S�̂Ő��\�`���SKB�����Ȃ��B
�Ђ�CPU�͐��\GFLOPS���x�����A�L���b�V���������͉�MB���ς�ł���B
�����ŋt�ɍl����B
�L���b�V�����������Ĕėp�v���O�����ɕK�v�����炱��
�����Ă������킯�ŁA�t�ɂ��ꂪ���Ȃ��Ɛ��\���o�Ȃ��킯��B
F@H�̃��f���T�C�Y�ɗ��߂�ƕ�����₷�����ǁAGPU��
CPU�̌�����ł���͈͎��̂��A�������������Ă���킯�B
Larrabee�̓L���b�V�������Ƃ͌����GPU���͂܂��ėp�v���Z�b�T
����Ă邼
���A���̃L���b�V����������OoO�p�C�v���C���Ƃ��������Z���j�b�g�Ȃ�
�ɒu�������Ă�OK�ˁB
���̌��t�C�ɓ����Ă��ꂽ�Ȃ�K�����B
������GPGPU�Ȃǔn�����Ă�B
GPU�͉��SGFLOPS���̕����������j�b�g�ڂ��Ă��L���b�V����������
�`�b�v�S�̂Ő��\�`���SKB�����Ȃ��B
�Ђ�CPU�͐��\GFLOPS���x�����A�L���b�V���������͉�MB���ς�ł���B
�����ŋt�ɍl����B
�L���b�V�����������Ĕėp�v���O�����ɕK�v�����炱��
�����Ă������킯�ŁA�t�ɂ��ꂪ���Ȃ��Ɛ��\���o�Ȃ��킯��B
F@H�̃��f���T�C�Y�ɗ��߂�ƕ�����₷�����ǁAGPU��
CPU�̌�����ł���͈͎��̂��A�������������Ă���킯�B
Larrabee�̓L���b�V�������Ƃ͌����GPU���͂܂��ėp�v���Z�b�T
����Ă邼
���A���̃L���b�V����������OoO�p�C�v���C���Ƃ��������Z���j�b�g�Ȃ�
�ɒu�������Ă�OK�ˁB
�L���b�V���������͑ш��L���Ɏg�����߂ɂ͕K�{������Ȃ�
�����Ǝ��オ�i�߂L���b�V�������������Ȃ��Ă��ǂ��Ȃ��Ȃ����H
���Ȃ��Ƃ�RIMM���������Ă��瑫���̂ق��͍����5�N���炢�i�����Ă邾�낤
�����f�c�c�q4���炢�g���Ă��ˁH
�����Ǝ��オ�i�߂L���b�V�������������Ȃ��Ă��ǂ��Ȃ��Ȃ����H
���Ȃ��Ƃ�RIMM���������Ă��瑫���̂ق��͍����5�N���炢�i�����Ă邾�낤
�����f�c�c�q4���炢�g���Ă��ˁH
�����[�i��ɕK���ł���
>>141
���҂͎����Ă��
�����͂h�`64/�`�l�c64/intel64�Ɠ������������Ă��N���g�����Ȃ��Ȃ��āA
�g�����Ȃ��鎞���ɂ͓����̏��i������Ƃ������������Ό����Ă�
���҂͎����Ă��
�����͂h�`64/�`�l�c64/intel64�Ɠ������������Ă��N���g�����Ȃ��Ȃ��āA
�g�����Ȃ��鎞���ɂ͓����̏��i������Ƃ������������Ό����Ă�
GPU�Ƃ��ďo���ȏ�
GPU�Ƃ��ăR�P���Ȃ�
����͎��s
���y���Ȃ�
GPU�Ƃ��ėD�G�����畁�y���]�߂�
�������ꂾ��
�����[�̋K�͂͂ǂ�Ȃ���Ȃ̂���
20���g�����W�X�^�Ƃ��H
GPU�Ƃ��ăR�P���Ȃ�
����͎��s
���y���Ȃ�
GPU�Ƃ��ėD�G�����畁�y���]�߂�
�������ꂾ��
�����[�̋K�͂͂ǂ�Ȃ���Ȃ̂���
20���g�����W�X�^�Ƃ��H
144 �F�R�E�L�́M�E,,�j�����������������F2008/06/26(��) 22:48:07 ID:JWHYg+6B
�����v���O���}�r���e�B������Ⴄ��
Larrabee��x86�v���Z�b�T������A���Ƃ��s���ӂȂ��Ƃł�
x86�łł��邱�Ƃ͈�ʂ��点�邱�Ƃ͂ł���B
GPU�̏ꍇ�A���ӂ��s���ӂ�����Ȃ��āA�o���邩�o���Ȃ�����
�Ȃ����Ⴄ���B
���Ƃ������ǁARadeon�ɂ�SSE2��pmovmskb�݂�����MSB�k��̃I�y���[�V����
����܂����Hpsadbw�݂����ȓ������o�Ɏg���閽�߂͂���܂����H
�\�t�g�G�~�����[�V�������Ɖ��N���b�N���炢������܂����H
�v�͂����������Ƃ���
Larrabee��x86�v���Z�b�T������A���Ƃ��s���ӂȂ��Ƃł�
x86�łł��邱�Ƃ͈�ʂ��点�邱�Ƃ͂ł���B
GPU�̏ꍇ�A���ӂ��s���ӂ�����Ȃ��āA�o���邩�o���Ȃ�����
�Ȃ����Ⴄ���B
���Ƃ������ǁARadeon�ɂ�SSE2��pmovmskb�݂�����MSB�k��̃I�y���[�V����
����܂����Hpsadbw�݂����ȓ������o�Ɏg���閽�߂͂���܂����H
�\�t�g�G�~�����[�V�������Ɖ��N���b�N���炢������܂����H
�v�͂����������Ƃ���
�����b�o�t�̐��\����̗p�r�����揈���Ƃ����y�n�ɂȂ��Ă�����
�f�X�N�g�b�v�p�Ƃ��Ă͈����オ���̒�ĂƂ���
���������u�f�`���ǂ��̂f�o�t�𓋍ڂ���
�G���R�[�h�̏����\�͂�3�{�ɂ���Ƃ����A�v���[�`�̓A�����Ǝv��
����ɂ��Ă��`�s�h�ߑ�������
http://laputa.at.webry.info/200806/article_102.html
�f�X�N�g�b�v�p�Ƃ��Ă͈����オ���̒�ĂƂ���
���������u�f�`���ǂ��̂f�o�t�𓋍ڂ���
�G���R�[�h�̏����\�͂�3�{�ɂ���Ƃ����A�v���[�`�̓A�����Ǝv��
����ɂ��Ă��`�s�h�ߑ�������
http://laputa.at.webry.info/200806/article_102.html
intel�̓I���{��GPU�̃V�F�A�҂��܂����Ă邯�ǂˁA���\�Ⴂ�̂ɁB
�v���Z�X�I�ɖ�肪�Ȃ��Ȃ�AGMA����Larrabee�n�̃R�A�ɓ���ւ����Ȃ��́H
����ւ���Ƃ������A���j�[�R�A�̃V���v���R�A�Ƃ���GPU���Ƃœ����Ă��邩�ƁB
GPU�Ƃ��ėD�G����Ȃ��ƕ��y�������Ȃ����Ă̂͂ނ���NVIDIA����Ȃ����낤���B
AMD��Swift�ȍ~�ACPU��GPU�������Ă������낤���B
�v���Z�X�I�ɖ�肪�Ȃ��Ȃ�AGMA����Larrabee�n�̃R�A�ɓ���ւ����Ȃ��́H
����ւ���Ƃ������A���j�[�R�A�̃V���v���R�A�Ƃ���GPU���Ƃœ����Ă��邩�ƁB
GPU�Ƃ��ėD�G����Ȃ��ƕ��y�������Ȃ����Ă̂͂ނ���NVIDIA����Ȃ����낤���B
AMD��Swift�ȍ~�ACPU��GPU�������Ă������낤���B
147 �F�R�E�L�́M�E,,�j�����������������F2008/06/26(��) 23:18:03 ID:JWHYg+6B
OoO�̃��b�`�ȃR�A�Ȃ�ă��[�h�E�G�N�Z�����x�̕��ʂ̗p�r����
�����������R�A�������B�ł��G���R�Ƃ�DTM�Ƃ��ł͐��\�̗v���͑傫���B
�����x86�́A�ˁB
Larrabee�I��SIMD�����^�R�A���\�Ƃ̍��ڂɂ���̂��A�ł��o�ϓI�������I�B
�����Ă��炤�͈̂ꕔ�̃\�t�g���[�J�[�����ł����B
Larrabee�̗����ʒu��Cell�L���[�ł�����GPU�łȂ��͂��Ȃ�
����GPU�Ƃ��āu���v����o���̂��͗���s�\�B
�܂�GPU�Ƃ��ē������Ă�������x�̐��\�͓���ꂽ�낤�ȁB
SSE��CellSPE���l��SIMD�������Z���ߓ��ڂ����珶�Ԃ��C�͂���
�����������R�A�������B�ł��G���R�Ƃ�DTM�Ƃ��ł͐��\�̗v���͑傫���B
�����x86�́A�ˁB
Larrabee�I��SIMD�����^�R�A���\�Ƃ̍��ڂɂ���̂��A�ł��o�ϓI�������I�B
�����Ă��炤�͈̂ꕔ�̃\�t�g���[�J�[�����ł����B
Larrabee�̗����ʒu��Cell�L���[�ł�����GPU�łȂ��͂��Ȃ�
����GPU�Ƃ��āu���v����o���̂��͗���s�\�B
�܂�GPU�Ƃ��ē������Ă�������x�̐��\�͓���ꂽ�낤�ȁB
SSE��CellSPE���l��SIMD�������Z���ߓ��ڂ����珶�Ԃ��C�͂���
GMA�Ƃ��с`����ւ�����APC�̒l�i�����������ɂȂ肻������w
149 �F�R�E�L�́M�E,,�j�����������������F2008/06/26(��) 23:29:24 ID:JWHYg+6B
>>148
45nm��16�R�A��XeonMP���x�̃_�C�T�C�Y�Ɛ��肳���B
Larrabee�̃\�P�b�g�ł�Nehalem Xeon�ƃ\�P�b�g�݊�������
����d�͓I�ɂ������x���ɂ͂Ȃ邾�낤
�t��8�R�A�ʂɂȂ��C2Q���x�̃_�C�T�C�Y�Ȃ��
��������PC�����̉��i�тŔ���Ȃ����Ƃ͂Ȃ�
45nm��16�R�A��XeonMP���x�̃_�C�T�C�Y�Ɛ��肳���B
Larrabee�̃\�P�b�g�ł�Nehalem Xeon�ƃ\�P�b�g�݊�������
����d�͓I�ɂ������x���ɂ͂Ȃ邾�낤
�t��8�R�A�ʂɂȂ��C2Q���x�̃_�C�T�C�Y�Ȃ��
��������PC�����̉��i�тŔ���Ȃ����Ƃ͂Ȃ�
150 �F�R�E�L�́M�E,,�j�����������������F2008/06/26(��) 23:38:58 ID:JWHYg+6B
����
L2�L���b�V�����������i4�R�A��L2 256k���x�j����
�����Ə�������������Ȃ�
L2�L���b�V�����������i4�R�A��L2 256k���x�j����
�����Ə�������������Ȃ�
>>139
> �L���b�V�����������Ĕėp�v���O�����ɕK�v�����炱��
> �����Ă������킯�ŁA�t�ɂ��ꂪ���Ȃ��Ɛ��\���o�Ȃ��킯��B
���x�̒x���������ς�ł�Ⴛ���L���b�V������ʂɗv���ȁB
> �L���b�V�����������Ĕėp�v���O�����ɕK�v�����炱��
> �����Ă������킯�ŁA�t�ɂ��ꂪ���Ȃ��Ɛ��\���o�Ȃ��킯��B
���x�̒x���������ς�ł�Ⴛ���L���b�V������ʂɗv���ȁB
152 �F�R�E�L�́M�E,,�j�����������������F2008/06/26(��) 23:41:42 ID:JWHYg+6B
153 �F�R�E�L�́M�E,,�j�����������������F2008/06/26(��) 23:44:45 ID:JWHYg+6B
�~PC���
��CPU���
��CPU���
>>152
�����疾���I�Ɏg���鋤�L�����������Ă��
�����疾���I�Ɏg���鋤�L�����������Ă��
155 �F�R�E�L�́M�E,,�j�����������������F2008/06/26(��) 23:47:10 ID:JWHYg+6B
�����@����P���Ȃ��Ăł�100GHz���炢�̒������V���O���R�A����Ă����
>>148
����ւ���Ȃ�AGMA�ɂ����Ă�_�C�T�C�Y�Ɏ��܂���x��
Larrabee�n�̃R�A�����炷�������ˁH
Larrabee���̂��̂�����Ȃ�Ĉꌾ�������ĂȂ�����B
�������Ƃ�AMD��Fusion�̕��ɂ����Ă͂܂邩��B
����CPU�̃_�C�T�C�Y�ATDP�̘g���Ɏ��߂Ȃ��Ƃ����Ȃ�����B
�s�[�N���\�����݂���Fusion��GPU�R�A�g�������������������ǁB
����ւ���Ȃ�AGMA�ɂ����Ă�_�C�T�C�Y�Ɏ��܂���x��
Larrabee�n�̃R�A�����炷�������ˁH
Larrabee���̂��̂�����Ȃ�Ĉꌾ�������ĂȂ�����B
�������Ƃ�AMD��Fusion�̕��ɂ����Ă͂܂邩��B
����CPU�̃_�C�T�C�Y�ATDP�̘g���Ɏ��߂Ȃ��Ƃ����Ȃ�����B
�s�[�N���\�����݂���Fusion��GPU�R�A�g�������������������ǁB
����ւ��E�E�E�E
http://sylphys.ddo.jp/upld2nd/pc3/src/1214314332032.png
http://sylphys.ddo.jp/upld2nd/pc3/src/1214314332032.png
159 �F�R�E�L�́M�E,,�j�����������������F2008/06/26(��) 23:58:49 ID:JWHYg+6B
Intel����
���ނ���GPU�@�\���
���ނ���GPU�@�\���
>>155
SPE��XDR��LS���Ɨ����Ă邩��256KB���ς�ł��H�������R�[�h�ƃf�[�^�ŋ��L�����B
SPE��XDR��LS���Ɨ����Ă邩��256KB���ς�ł��H�������R�[�h�ƃf�[�^�ŋ��L�����B
161 �F�R�E�L�́M�E,,�j�����������������F2008/06/27(��) 00:04:54 ID:t8P1fobZ
��������4WaySIMD��MADD���j�b�g1�̃v���Z�b�T�������256k����
����ł���p�r���肳������
������GPU�ɔėp�v���Z�b�V���O��点��Əo���Ȃ����Ƃ�������
�킩�邾�낤�B
����ł���p�r���肳������
������GPU�ɔėp�v���Z�b�V���O��点��Əo���Ȃ����Ƃ�������
�킩�邾�낤�B
>>147
�G���R�Ő��\�R�A�ō������������тȂ�ĂȂ���̂�?
�G���R�[�_����T�͐��X���b�h����10�X���b�h���炢�܂ł������\����������B
�������A�t�B���^���H���������ނƂ܂�ł��߂ɂȂ�����B
���낢������A�}���`�X���b�h�́B
�G���R�Ő��\�R�A�ō������������тȂ�ĂȂ���̂�?
�G���R�[�_����T�͐��X���b�h����10�X���b�h���炢�܂ł������\����������B
�������A�t�B���^���H���������ނƂ܂�ł��߂ɂȂ�����B
���낢������A�}���`�X���b�h�́B
�ً}����! Core 2 Extreme QX6800�̎��͂ɔ���
http://journal.mycom.co.jp/special/2007/qx6800/007.html
���̂�����B
http://journal.mycom.co.jp/special/2007/qx6800/007.html
���̂�����B
164 �F�R�E�L�́M�E,,�j�����������������F2008/06/27(��) 00:18:40 ID:t8P1fobZ
SIMD�����Œʏ��IA�R�A���SIMD���������ӂƂ����O��B
Intel��IA++�ƌ����Ă邪
Intel��IA++�ƌ����Ă邪
�F�X�ߋ��̋L���������������ʁA��͂�Larrabee��AVX�ł͂Ȃ���
����͎v�����B�x�N�g�����܂ł͂킩��ǁB
����͎v�����B�x�N�g�����܂ł͂킩��ǁB
���Ȃ݂�Cell�ȊO�ł��A
Intel�͌Â�Tukwila�Ń����O�o�X��낤�Ƃ��Ă���A
Sandy Bridge�ł���낤�Ƃ��Ă���B
Intel�ȊO�ł�Sun������Ă邶���B
�R�A�����_��ɃX�P�[�������悤�Ƃ���ƁA�����O�ɂȂ�͕̂��ʂ炵���B
�Ȃ�ł�����ł�Cell�N�����������͊��فB
�������Larrabee�̓L���b�V���A�[�L�e�N�`���ŁA
������x87��SSE�Ȃ���2���������邩������Ȃ����Ď��_�ŁA
�啪Cell�Ƃ͈Ⴄ�N�w�Ő��藧���Ă�B
Intel�͌Â�Tukwila�Ń����O�o�X��낤�Ƃ��Ă���A
Sandy Bridge�ł���낤�Ƃ��Ă���B
Intel�ȊO�ł�Sun������Ă邶���B
�R�A�����_��ɃX�P�[�������悤�Ƃ���ƁA�����O�ɂȂ�͕̂��ʂ炵���B
�Ȃ�ł�����ł�Cell�N�����������͊��فB
�������Larrabee�̓L���b�V���A�[�L�e�N�`���ŁA
������x87��SSE�Ȃ���2���������邩������Ȃ����Ď��_�ŁA
�啪Cell�Ƃ͈Ⴄ�N�w�Ő��藧���Ă�B
�������Larrabee��(GP)GPU�̑R�n�ŁA
Cell�̑R�n�Ȃł͂Ȃ���B
�c�q��Anand��GT200�L�������������B
GPU�͒c�q���v���Ă�ȏ�ɒP�Ȃ�}�C�N���v���Z�b�T�̏W�ςɋ߂Â��Ă�B
Larrabee���o�鍠�ɂ͂���قǑ傫�ȈႢ�͂Ȃ��Ȃ��Ă邺�B
����ł̓e�N�X�`�����j�b�g�̐��Ƃ����S�R�Ⴄ����A
����3D�Q�[�O���t�B�b�N�X�ł�Larrabee�ڂ땉�����Ǝv�����ǁB
Cell�̑R�n�Ȃł͂Ȃ���B
�c�q��Anand��GT200�L�������������B
GPU�͒c�q���v���Ă�ȏ�ɒP�Ȃ�}�C�N���v���Z�b�T�̏W�ςɋ߂Â��Ă�B
Larrabee���o�鍠�ɂ͂���قǑ傫�ȈႢ�͂Ȃ��Ȃ��Ă邺�B
����ł̓e�N�X�`�����j�b�g�̐��Ƃ����S�R�Ⴄ����A
����3D�Q�[�O���t�B�b�N�X�ł�Larrabee�ڂ땉�����Ǝv�����ǁB
GT200�����_�ŃG���R��19�{�炵����
RV770�͂��������i�C�̂����b�����ς蕷�����Ȃ�
�߂���
RV770�͂��������i�C�̂����b�����ς蕷�����Ȃ�
�߂���
�R���V���[�}�A�v�������ėp���Z�p�r�ɂ�����
Larrabee�AGTxxx�ARVxxx�A�����v���������Ă݂�e�X�g
Larrabee�AGTxxx�ARVxxx�A�����v���������Ă݂�e�X�g
�ėp�ƌ����Ă����x�ɂ���ȁB
GPGPU�ő����Ȃ鏈����GPU�ł�炷���Ă��������̘b�ł���H
�S�Ẳ��Z����炷�K�v���������B
Larrabee�͍���GPU�݂����Ƀ}�V���̈�p���߂邩�͂킩��B
�A�N�Z�����[�^�Ƃ��đ�����������PhysX�Ɠ����^���ɂȂ�\���������B
GPGPU�ő����Ȃ鏈����GPU�ł�炷���Ă��������̘b�ł���H
�S�Ẳ��Z����炷�K�v���������B
Larrabee�͍���GPU�݂����Ƀ}�V���̈�p���߂邩�͂킩��B
�A�N�Z�����[�^�Ƃ��đ�����������PhysX�Ɠ����^���ɂȂ�\���������B
173 �FSocket774�F2008/06/27(��) 01:05:40 ID:6ZqXAqUZ
�G���R�Ȃ�ĒN�����܂���
�����s��ɍi��ƁA����҃j�[�Y�̑唼��
�E�]���̔ėpCPU�̐i��
�EASIC/�J�X�^��LSI�̐i��
�Řd���Ă��܂���
�E�]���̔ėpCPU�̐i��
�EASIC/�J�X�^��LSI�̐i��
�Řd���Ă��܂���
�����
>intel�̓I���{��GPU�̃V�F�A�҂��܂����Ă邯�ǂˁA���\�Ⴂ�̂ɁB
���[�U�[���I�������킯�ł��Ȃ�
�������t���Ă��Ă邾������
���[�U�[���I�������킯�ł��Ȃ�
�������t���Ă��Ă邾������
�R�E�L�́M�E,,�j��������������������
�N���ɍ\���ĖႤ�O�ƌ�ł͐������Ă���i�Ⴂ����
�N���ɍ\���ĖႤ�O�ƌ�ł͐������Ă���i�Ⴂ����
178 �F�R�E�L�́M�E,,�j�����������������F2008/06/27(��) 07:19:13 ID:t8P1fobZ
>>166
FMUL��FADD����B
FPU 2���j�b�g�Ȃ牽�疵�����Ȃ���
45nm 256bitAVX�iFMA�̂���)�Ή���8DP
32nm 256bit FMA�̗p��16DP
�Ƃ肠����256bitSIMD�̗p�̓K�`
�t�ɒʏ��IA�R�A��128bit�̂܂܁A�A�����[���ړI��AVX���̗p����B
FMUL��FADD����B
FPU 2���j�b�g�Ȃ牽�疵�����Ȃ���
45nm 256bitAVX�iFMA�̂���)�Ή���8DP
32nm 256bit FMA�̗p��16DP
�Ƃ肠����256bitSIMD�̗p�̓K�`
�t�ɒʏ��IA�R�A��128bit�̂܂܁A�A�����[���ړI��AVX���̗p����B
179 �F�R�E�L�́M�E,,�j�����������������F2008/06/27(��) 07:20:06 ID:t8P1fobZ
> 45nm 256bitAVX�iFMA�̂���)�Ή���8DP
> 32nm 256bit FMA�̗p��16DP
�͗\�z
> 32nm 256bit FMA�̗p��16DP
�͗\�z
25���g�����W�X�^
2tflops
8���~
������GPU�Ƃ��Ă�3870�ȉ��ł�
�������ꍇ�͂����Ĕ�������
2tflops
8���~
������GPU�Ƃ��Ă�3870�ȉ��ł�
�������ꍇ�͂����Ĕ�������
LRB��45nm�ł�nVIDIA�ɕ����邩������Ȃ���32nm�ő傫���t�]���邾�낤�Ƃ����ƊE�W�҂̗\��������B
�V�������N�����Ȃ�ǂ��̔����̃��[�J�[�ł��ł���̂ŁA�܂�A�[�L�Ɏ肪����̂ł́B
>>179�͈ӊO�Ƃ��������Ă邩��
>>180
RADEON��GPU�Ƃ��Ă̎����\��Nj�����nVIDIA���������������̂́AIntel�ɂƂ��Ă͓s���������B
Intel�̖ړI��GPU�s�ꂻ�̂��̂��x�z���邱�Ƃł͂Ȃ���GPGPU�s��̉��E�ނ��ƂȂ�ŁA
GPGPU�ɂ���s������ATI�A�[�L�͒[����G�ł͂Ȃ��Ȃ����B
�V�������N�����Ȃ�ǂ��̔����̃��[�J�[�ł��ł���̂ŁA�܂�A�[�L�Ɏ肪����̂ł́B
>>179�͈ӊO�Ƃ��������Ă邩��
>>180
RADEON��GPU�Ƃ��Ă̎����\��Nj�����nVIDIA���������������̂́AIntel�ɂƂ��Ă͓s���������B
Intel�̖ړI��GPU�s�ꂻ�̂��̂��x�z���邱�Ƃł͂Ȃ���GPGPU�s��̉��E�ނ��ƂȂ�ŁA
GPGPU�ɂ���s������ATI�A�[�L�͒[����G�ł͂Ȃ��Ȃ����B
�ȂF���Ⴂ���Ă��Ȃ����H
���Ɂ@�R�E�L�́M�E,,�j�����������������@���R�C�c
Fusion�͂����܂� CPU + GPGPU���B
�ėp������CPU�Ŏ��s���āASIMD�ő����Ȃ鏈����GPGPU�Ŏ��s����B
�t��Larrabee�̏ꍇ��atom���ǂ��Ŕėp�������邩��A���|�I�ɐ��\��������B
�u���h�[�U�[�R�A���ǂ̒��x�̐��\�������Ă��邩�͌��ݒm��R���Ȃ����A
IPC��phenom�ȉ��Ƃ������Ƃ͂���܂��B
�܂肾�A�ėp�����̐��\����atom �� Phenom�ʂ���Ƃ������Ƃ��B
SIMD���\�ɂ��ẮA
SIMD���j�b�g(�V�F�[�_�[)�̉��GPGPU���A
�R�A���ɔėp�������l������K�v������Larrabee�������\���o���₷��
���ǁA�ėp�������l������Ȃ�Fusion�̕����D��Ă��āA
SIMD�����́AGPGPU(FireStream)�̕����D��Ă���
���Ȃ݂ɏ����i�K�Ő��\������Ă����Ƃ��Ă��A
������ŃV�F�[�_�[�Ă���ɂ���Ηe�Ղɋt�]�ł���B
RV670��RV770�݂�����
�����AGPGPU��GPU�Ƃ͕ʂɐv�����ꍇ�ARBE��TMU������Ȃ�����A���̕��������A�܂���SP�𑽂��ł���B
RV770�̃_�C�������Ƃ���ARBE��TMU������ꍇ5���ȏ㑝�₹�����Ǝv�����B
RV770��GPGPU�ɓ��������ꍇ1200SP
�������R800(2000SP?)����������ꍇ3000SP?
R800�����Fusion�ɏ悹��Ɖ��肵�ė\�z(�ϑz)
Fusion�ɏ悹��Ƃ�����A
�m�[�g������R800��1/10��(200SP+TMU+RBE) = ��250Gflops + 780G�ʂ�GPU���\
�f�X�N�g�b�v������1/3��(700SP+TMU+RBE) = ��850Gflops + 780G�ʂ�GPU���\
�n�C�G���hPC������1/2��(SP�̂�1000SP) = 1.25TFlops
FireStream��3000SP(��4T)�AX2�\����6000SP(��7.5T)
���̒ʂ�ɂȂ�����A������v�f�͂Ȃ���
������ɂ̓C���e���̓Ɛ�֎~�@�ᔽ�܂����̈����ȉc�ƖW�Q�����Ȃ��Ȃ����
���Ɂ@�R�E�L�́M�E,,�j�����������������@���R�C�c
Fusion�͂����܂� CPU + GPGPU���B
�ėp������CPU�Ŏ��s���āASIMD�ő����Ȃ鏈����GPGPU�Ŏ��s����B
�t��Larrabee�̏ꍇ��atom���ǂ��Ŕėp�������邩��A���|�I�ɐ��\��������B
�u���h�[�U�[�R�A���ǂ̒��x�̐��\�������Ă��邩�͌��ݒm��R���Ȃ����A
IPC��phenom�ȉ��Ƃ������Ƃ͂���܂��B
�܂肾�A�ėp�����̐��\����atom �� Phenom�ʂ���Ƃ������Ƃ��B
SIMD���\�ɂ��ẮA
SIMD���j�b�g(�V�F�[�_�[)�̉��GPGPU���A
�R�A���ɔėp�������l������K�v������Larrabee�������\���o���₷��
���ǁA�ėp�������l������Ȃ�Fusion�̕����D��Ă��āA
SIMD�����́AGPGPU(FireStream)�̕����D��Ă���
���Ȃ݂ɏ����i�K�Ő��\������Ă����Ƃ��Ă��A
������ŃV�F�[�_�[�Ă���ɂ���Ηe�Ղɋt�]�ł���B
RV670��RV770�݂�����
�����AGPGPU��GPU�Ƃ͕ʂɐv�����ꍇ�ARBE��TMU������Ȃ�����A���̕��������A�܂���SP�𑽂��ł���B
RV770�̃_�C�������Ƃ���ARBE��TMU������ꍇ5���ȏ㑝�₹�����Ǝv�����B
RV770��GPGPU�ɓ��������ꍇ1200SP
�������R800(2000SP?)����������ꍇ3000SP?
R800�����Fusion�ɏ悹��Ɖ��肵�ė\�z(�ϑz)
Fusion�ɏ悹��Ƃ�����A
�m�[�g������R800��1/10��(200SP+TMU+RBE) = ��250Gflops + 780G�ʂ�GPU���\
�f�X�N�g�b�v������1/3��(700SP+TMU+RBE) = ��850Gflops + 780G�ʂ�GPU���\
�n�C�G���hPC������1/2��(SP�̂�1000SP) = 1.25TFlops
FireStream��3000SP(��4T)�AX2�\����6000SP(��7.5T)
���̒ʂ�ɂȂ�����A������v�f�͂Ȃ���
������ɂ̓C���e���̓Ɛ�֎~�@�ᔽ�܂����̈����ȉc�ƖW�Q�����Ȃ��Ȃ����
183 �F�R�E�L�́M�E,,�j�����������������F2008/06/27(��) 08:00:55 ID:t8P1fobZ
��������128bit�x�N�^��SSE5(��)��VLIW�ŁH
�ǂ�����āH�R�v���i�j�Ƃ��āH
�����Phenom���nj^���̃t�F�b�`�^�f�R�[�_�̃g�����W�X�^��������IA++�R�A������ꂻ������
AMD�̃n�b�^���ɂ��������Ȃ�
�ǂ�����āH�R�v���i�j�Ƃ��āH
�����Phenom���nj^���̃t�F�b�`�^�f�R�[�_�̃g�����W�X�^��������IA++�R�A������ꂻ������
AMD�̃n�b�^���ɂ��������Ȃ�
>>182
SP�������ǁA����FP32�ł̐�������A
GPGPU�ɓ��������ꍇ�A���Ԃ�FP64���J�����Ď��ւ���Ǝv��
���̏ꍇ�A�T�C�Y���傫���Ȃ�(�����{���炢)�ASP���͔����ɂȂ�AFlops���������ɂȂ�
�悤�ȋC������
SP�������ǁA����FP32�ł̐�������A
GPGPU�ɓ��������ꍇ�A���Ԃ�FP64���J�����Ď��ւ���Ǝv��
���̏ꍇ�A�T�C�Y���傫���Ȃ�(�����{���炢)�ASP���͔����ɂȂ�AFlops���������ɂȂ�
�悤�ȋC������
185 �F�R�E�L�́M�E,,�j�����������������F2008/06/27(��) 08:26:17 ID:t8P1fobZ
���Ƃ��Ƃ̓��[�G���h�v���Z�b�T�ɂ̓R�A���͂P�`�Q�R�A�ŏ\����
�g�����W�X�^�o�W�F�b�g���߂邽�߂�GPU���ڂ��܂��傤�����[����
��������ʂ͂W�R�A�A�P�U�R�A�ƓW�J����B
nVIDIA���Q�[�����\�̃R�X�g�p�t�H�[�}���X�ŕ������̂�
GPGPU�����̂������Ƃ������z�͖����̂��B
���ƁA�L���b�V���e�ʂ����ǁA���SKB��nVIDIA�Ő��\��ATI�ˁB
CPU��19�{�ƂP�R�A��1.5�{����̂��Ⴂ����
Larrabee�Ƌ�������̂͂����܂őO��
�u�g�b�v�K���Ȃ琫�\�����o����v�Ȃ��GK�݂����Ȏ������Ȃ�
GPU�Ƃ��Ă̐��\���d���������ō��{�I��GPGPU�Ɍ����ĂȂ�����B
�g�����W�X�^�o�W�F�b�g���߂邽�߂�GPU���ڂ��܂��傤�����[����
��������ʂ͂W�R�A�A�P�U�R�A�ƓW�J����B
nVIDIA���Q�[�����\�̃R�X�g�p�t�H�[�}���X�ŕ������̂�
GPGPU�����̂������Ƃ������z�͖����̂��B
���ƁA�L���b�V���e�ʂ����ǁA���SKB��nVIDIA�Ő��\��ATI�ˁB
CPU��19�{�ƂP�R�A��1.5�{����̂��Ⴂ����
Larrabee�Ƌ�������̂͂����܂őO��
�u�g�b�v�K���Ȃ琫�\�����o����v�Ȃ��GK�݂����Ȏ������Ȃ�
GPU�Ƃ��Ă̐��\���d���������ō��{�I��GPGPU�Ɍ����ĂȂ�����B
186 �F�R�E�L�́M�E,,�j�����������������F2008/06/27(��) 08:33:52 ID:t8P1fobZ
�����������f��GPGPU�Ƃ��Ďア�͔̂{���x���j�b�g���]�X�̖��ł͂Ȃ�
�{���x�̓Q�z�̕������Ȃ�����
�Ȃ̂�F@H��G���R��点���爳�|�I�ȍ��ŃQ�z�D��
FLOPS�Ȃ�Ďw�W�Ȃ�Ĕėp���Ƃ͑S���W�Ȃ���
�{���x�̓Q�z�̕������Ȃ�����
�Ȃ̂�F@H��G���R��点���爳�|�I�ȍ��ŃQ�z�D��
FLOPS�Ȃ�Ďw�W�Ȃ�Ĕėp���Ƃ͑S���W�Ȃ���
>>182
���܂��̊��Ⴂ�͂Ђǂ�����
Bulldozer���키�͔̂ėp�v���Z�b�T��Nehalem�̂܂��g����SandyBridge�B
Core2��Phenom�ł��獷������̂ɍX��1���㕪�}�C�N���A�[�L�̍����L����B
IA++�R�A�̓����͓�����̘b���B
���������ŏ���Fusion�̓��[�G���h������GPU�����ڂ��邾��
�n�C�G���h��x86������16�R�A�\������̂�
���[�G���h�Ŗ{�C�Ɏ�������킯�Ȃ�����
���܂��̊��Ⴂ�͂Ђǂ�����
Bulldozer���키�͔̂ėp�v���Z�b�T��Nehalem�̂܂��g����SandyBridge�B
Core2��Phenom�ł��獷������̂ɍX��1���㕪�}�C�N���A�[�L�̍����L����B
IA++�R�A�̓����͓�����̘b���B
���������ŏ���Fusion�̓��[�G���h������GPU�����ڂ��邾��
�n�C�G���h��x86������16�R�A�\������̂�
���[�G���h�Ŗ{�C�Ɏ�������킯�Ȃ�����
>>182
���̃R�e�͊F�̒��ڂ��W�߂邽�߂ɂ킴�ƕ������ԈႢ������߂Ă���ƌ����Ă���
���̃R�e�͊F�̒��ڂ��W�߂邽�߂ɂ킴�ƕ������ԈႢ������߂Ă���ƌ����Ă���
�Ȃ�ق�
FireStream��AMD�̃v���Z�b�T�Ƃ������ƂȂ̂�
>182��Larrabee�ȊO��intel�ėp�v���Z�b�T��atom�����b��ɂ��ĂȂ��킯����
Bulldozer��K10��IPC��r��
Bulldozer���키intel�v���Z�b�T�̘b�ɂ�����
Bulldozer��TDP���Ƃ����i���Ƃ����i���Ƃ������V�삪�ǂ������̂��Ƃ�
�^�R�e���ɂ킴�Ƙb����炷�������������ɏo�Ă��邨�Ȍ���
���͖����Ɍ����Ă���
FireStream��AMD�̃v���Z�b�T�Ƃ������ƂȂ̂�
>182��Larrabee�ȊO��intel�ėp�v���Z�b�T��atom�����b��ɂ��ĂȂ��킯����
Bulldozer��K10��IPC��r��
Bulldozer���키intel�v���Z�b�T�̘b�ɂ�����
Bulldozer��TDP���Ƃ����i���Ƃ����i���Ƃ������V�삪�ǂ������̂��Ƃ�
�^�R�e���ɂ킴�Ƙb����炷�������������ɏo�Ă��邨�Ȍ���
���͖����Ɍ����Ă���
>>191
�o�J����
>>182��������Larrabee���̂��̂�Core2�ɑւ���ă��[�G���h�ɓ��������Ɗ��Ⴂ���Ă�(Nehalem��SandyBridge�͖���)
���̏�őS���Z�O�����g�̈ႤBulldozer��Larrabee��IPC���ǂ������k�ق�M���Ă�
�o�J����
>>182��������Larrabee���̂��̂�Core2�ɑւ���ă��[�G���h�ɓ��������Ɗ��Ⴂ���Ă�(Nehalem��SandyBridge�͖���)
���̏�őS���Z�O�����g�̈ႤBulldozer��Larrabee��IPC���ǂ������k�ق�M���Ă�
Fusion��SIMD��GPGPU���Ăǂ������Ӗ��Ō����Ă�̂��낤���B
�܂����A�܂�SSE5��SIMD�����͂��̂܂�GPU�Ɋۓ����Ƃ���
���x���˂����݂���Ă��銨�Ⴂ���Ɩ������[�v���Ȃ�
GPGPU�͂���p�ɃR�[�h���������Ȃ��Ɠ����Ȃ��B
�ł��A�G���h���[�U�����A�v���ɂ��Ή����悤�₭�łĂ�������A
�������҂ł���悤�ɂȂ��Ă�����Ȃ����ƁB���\���d�v�����ǁA
���������Ή����Ă��炦�Ȃ���Ή����n�܂�Ȃ�����ȁB
�܂����A�܂�SSE5��SIMD�����͂��̂܂�GPU�Ɋۓ����Ƃ���
���x���˂����݂���Ă��銨�Ⴂ���Ɩ������[�v���Ȃ�
GPGPU�͂���p�ɃR�[�h���������Ȃ��Ɠ����Ȃ��B
�ł��A�G���h���[�U�����A�v���ɂ��Ή����悤�₭�łĂ�������A
�������҂ł���悤�ɂȂ��Ă�����Ȃ����ƁB���\���d�v�����ǁA
���������Ή����Ă��炦�Ȃ���Ή����n�܂�Ȃ�����ȁB
>>192
��SIMD���\�ɂ��ẮA
��SIMD���j�b�g(�V�F�[�_�[)�̉��GPGPU���A
���R�A���ɔėp�������l������K�v������Larrabee�������\���o���₷��
�Ƃ���̂�
�ʂ̕��ł�����قNj��łɁuLarrabee�͔ėp�v���Z�b�T���v�ƌ����Ă��邩�H
�ނ͑��������̖ϑz�N��
�m�������f�͂�������Ƒ���Ȃ��Ǝv���邪
���Ȃ��Ƃ����{��͂�����ƈ����Ă���Ǝv����
��SIMD���\�ɂ��ẮA
��SIMD���j�b�g(�V�F�[�_�[)�̉��GPGPU���A
���R�A���ɔėp�������l������K�v������Larrabee�������\���o���₷��
�Ƃ���̂�
�ʂ̕��ł�����قNj��łɁuLarrabee�͔ėp�v���Z�b�T���v�ƌ����Ă��邩�H
�ނ͑��������̖ϑz�N��
�m�������f�͂�������Ƒ���Ȃ��Ǝv���邪
���Ȃ��Ƃ����{��͂�����ƈ����Ă���Ǝv����
���N��MAC�I�^�̃t�@���{�[�C�N���l�^�ɂ����Ȃ���
RADEON��SIMD���\���Ƃ����i��
VLIW��SIMD��p�v���Z�b�T�Ƃ��Ċ��p����Ƃ����͎̂��́A
���߂������Ώۂ��ƂɓƗ����Ă�VLIW�̑��݈Ӌ`�̍�����ے肵�Ă�B
VLIW��SIMD��p�v���Z�b�T�Ƃ��Ċ��p����Ƃ����͎̂��́A
���߂������Ώۂ��ƂɓƗ����Ă�VLIW�̑��݈Ӌ`�̍�����ے肵�Ă�B
>>196
��SIMD���\�ɂ��ẮA
��SIMD���j�b�g(�V�F�[�_�[)�̉��GPGPU���A
���R�A���ɔėp�������l������K�v������Larrabee�������\���o���₷��
���₱��Ȃ��z���̂��̂��c�t�ł��Ȃ�
���������ėp�Ɛ�p�œ��ł�����̂ł͂Ȃ����E�E�E
�O��ƂȂ�m���╪�͂��̂��̂��������Č��������A�_�I�Ȋ�]�I�ϑ�����c�_�ɂȂ�܂���
AMD�t�@���{�[�C�ł���Ƃ����ӎu�����͋����`��邯�ǁA���ꂾ��
�܂��̖����̏��̃l�^�Ƃ��Ă͏G�킩����
��SIMD���\�ɂ��ẮA
��SIMD���j�b�g(�V�F�[�_�[)�̉��GPGPU���A
���R�A���ɔėp�������l������K�v������Larrabee�������\���o���₷��
���₱��Ȃ��z���̂��̂��c�t�ł��Ȃ�
���������ėp�Ɛ�p�œ��ł�����̂ł͂Ȃ����E�E�E
�O��ƂȂ�m���╪�͂��̂��̂��������Č��������A�_�I�Ȋ�]�I�ϑ�����c�_�ɂȂ�܂���
AMD�t�@���{�[�C�ł���Ƃ����ӎu�����͋����`��邯�ǁA���ꂾ��
�܂��̖����̏��̃l�^�Ƃ��Ă͏G�킩����
�ϑz�N�̑O��́A
�ESIMD�W��GPGPU�ɑS���ۓ����ł���B
�E�s�[�N���\���d�v�B���s���\�͓�̎��A�ނ���C�ɂ��Ă͂����Ȃ��B
�̓�_���ۂ����ˁB
AMD���ȑO����Ă���Fusion�̍ŏI�ڕW��Bulldozer����Ŏ���������
�v���Ă��邩��ςɂȂ�낤���B
�ESIMD�W��GPGPU�ɑS���ۓ����ł���B
�E�s�[�N���\���d�v�B���s���\�͓�̎��A�ނ���C�ɂ��Ă͂����Ȃ��B
�̓�_���ۂ����ˁB
AMD���ȑO����Ă���Fusion�̍ŏI�ڕW��Bulldozer����Ŏ���������
�v���Ă��邩��ςɂȂ�낤���B
�R�P���̖ڂɌ����Ă郉���[�i��ɕK���ł���
200 �FSocket774�F2008/06/27(��) 10:37:44 ID:hi7ccGn0
SSE5��GPGPU�Ɋۓ�������Ȃ��̂��H
��������Ȃ��ƈӖ��Ȃ�����B
�����̂��̂͂ǂ����m��Ȃ����A����������o�����ˁH
��������Ȃ��ƈӖ��Ȃ�����B
�����̂��̂͂ǂ����m��Ȃ����A����������o�����ˁH
201 �F�R�E�L�́M�E,,�j�����������������F2008/06/27(��) 10:47:38 ID:t8P1fobZ
>>200
��̓I�Șb�����悤���B
SSE5�V���߂�PSH* (�v�f�P�ʂ̃V�t�g)�Ƃ�PPERM(Altivec��VPERM���ǂ��̃V���b�t�����߁j
�Ȃ�ăV�t�^�E�Z���N�^���������˂Ȃ��Ɩ������ȁB
��������GPU�ɓ�����܂łɃ��C�e���V�����肷���Ď��p�ɂȂ�Ȃ��Ǝv���B
����VPERM���ǂ��Ȃ�SSSE3��pshufb��Atom�ł��烌�C�e���V1�ł��Ȃ��B
������SSE���j�b�g�̉��ǂōςނ��̂��A���G��SIMD�������߂�
1�N���b�N�ł��Ȃ��Ȃ��̂��ڂɌ����Ă�GPU�ɓ�����Ӗ�����́H
���������Ɋւ��ẮA���ߒP�ʂł͂Ȃ����P�ʂł̑Ή��Ȃ�A
nVIDIA���̐v�ɂȂ�ΐ��\���L�т�\���͂��邩������Ȃ��B
���Ɣn���ȊO�͂킩���Ă邯��Larrabee�̃R�A��Atom�͑S���̕ʐv�ł��B
��̓I�Șb�����悤���B
SSE5�V���߂�PSH* (�v�f�P�ʂ̃V�t�g)�Ƃ�PPERM(Altivec��VPERM���ǂ��̃V���b�t�����߁j
�Ȃ�ăV�t�^�E�Z���N�^���������˂Ȃ��Ɩ������ȁB
��������GPU�ɓ�����܂łɃ��C�e���V�����肷���Ď��p�ɂȂ�Ȃ��Ǝv���B
����VPERM���ǂ��Ȃ�SSSE3��pshufb��Atom�ł��烌�C�e���V1�ł��Ȃ��B
������SSE���j�b�g�̉��ǂōςނ��̂��A���G��SIMD�������߂�
1�N���b�N�ł��Ȃ��Ȃ��̂��ڂɌ����Ă�GPU�ɓ�����Ӗ�����́H
���������Ɋւ��ẮA���ߒP�ʂł͂Ȃ����P�ʂł̑Ή��Ȃ�A
nVIDIA���̐v�ɂȂ�ΐ��\���L�т�\���͂��邩������Ȃ��B
���Ɣn���ȊO�͂킩���Ă邯��Larrabee�̃R�A��Atom�͑S���̕ʐv�ł��B
202 �F�R�E�L�́M�E,,�j�����������������F2008/06/27(��) 11:02:08 ID:t8P1fobZ
�܂��A������Ƃ����O��ł���ɘb�����悤�B
AMD�͌y�����Ă邯��SIMD���W�X�^�E�ėp���W�X�^�Ԃ̃f�[�^���s��������
movd/pinsr*/insertp*/pextr*/extractp*���Ă��A���C�ɗ��p�p�x�����̂�
�ėp�X�J�����߂�SIMD���߂̃f�[�^�����������ɍs���邱�Ƃ�
SSE�̐ϋɊ��p�����i����Ă����B
������A�O���v���Z�b�T�ɓ�����Ƃ������Ƃ�XMM���W�X�^��
�ėp���W�X�^�Ԃ̃p�X���܂��܂������Ȃ�B
���̕ӂǂ���������̂�B
SSE����������v���Z�b�T�́A���̂����߂��Ƃ���Ŕėp�X�J�����Z��
���Ȃ����Ȃ���K�v������B�����炱��͑S���̐^�t
���R�A���ɔėp�������l������K�v������Larrabee�������\���o���₷��
AMD�͌y�����Ă邯��SIMD���W�X�^�E�ėp���W�X�^�Ԃ̃f�[�^���s��������
movd/pinsr*/insertp*/pextr*/extractp*���Ă��A���C�ɗ��p�p�x�����̂�
�ėp�X�J�����߂�SIMD���߂̃f�[�^�����������ɍs���邱�Ƃ�
SSE�̐ϋɊ��p�����i����Ă����B
������A�O���v���Z�b�T�ɓ�����Ƃ������Ƃ�XMM���W�X�^��
�ėp���W�X�^�Ԃ̃p�X���܂��܂������Ȃ�B
���̕ӂǂ���������̂�B
SSE����������v���Z�b�T�́A���̂����߂��Ƃ���Ŕėp�X�J�����Z��
���Ȃ����Ȃ���K�v������B�����炱��͑S���̐^�t
���R�A���ɔėp�������l������K�v������Larrabee�������\���o���₷��
>>202
�����ł��B
�ʂ̉\�����l���Ă݂悤
���с[���m���M�K�r�b�g�`�[�~���O�Ōq����悤��
������C���^�[�t�F�C�X�̉\�����B
�����ł��B
�ʂ̉\�����l���Ă݂悤
���с[���m���M�K�r�b�g�`�[�~���O�Ōq����悤��
������C���^�[�t�F�C�X�̉\�����B
http://journal.mycom.co.jp/articles/2007/09/15/barcelona/004.html
���̃C���^�r���[���炵�āAAMD���g��SSE5�̎��_��SSE��GPU�Ɋۓ����Ȃ��
�l���Ă��Ȃ����ˁB���̂��߂̏����ɂ����Ȃ��B
���̃C���^�r���[���炵�āAAMD���g��SSE5�̎��_��SSE��GPU�Ɋۓ����Ȃ��
�l���Ă��Ȃ����ˁB���̂��߂̏����ɂ����Ȃ��B
�ǂ߂����킩�����ϑzfan boy�ɍ\���K�v���Ȃ��̂ł́B
206 �FSocket774�F2008/06/27(��) 12:22:55 ID:5d/oaiCW
�ϑz�Ɖ��������ł���ȉ���Ȃ������������o����̂��A�܂���
207 �F�R�E�L�́M�E,,�j�����������������F2008/06/27(��) 13:06:33 ID:t8P1fobZ
>>204�̋L���������낢��
���̘_������FMA���R�I�y�����h�ɂ����g�����Ȃ�����SSE5��SRC���W�X�^��j�邵
���s���������Ė{���͗ǂ��Ȃ����ƂɂȂ�B
��k������(���S��DEST�Ɨ������jAVX�̕��������Ă��ˁH
������Larrabee�̃l�C�e�B�u���߃Z�b�g���x�����鎖�ɂȂ邯��
���̘_������FMA���R�I�y�����h�ɂ����g�����Ȃ�����SSE5��SRC���W�X�^��j�邵
���s���������Ė{���͗ǂ��Ȃ����ƂɂȂ�B
��k������(���S��DEST�Ɨ������jAVX�̕��������Ă��ˁH
������Larrabee�̃l�C�e�B�u���߃Z�b�g���x�����鎖�ɂȂ邯��
2�I�y�����h�ł���Ă������SSE��3�I�y�����h�ň�����悤�Ȋg���͗p�ӂ��Ȃ�����
���̎��_��SSE5���̂��̂̃A�v���[�`�͒��r���[�B
�ł�AMD��AVX�̎���{���ɒm��Ȃ������낤�ȁB�܂���SSE5������CPU�ɂԂ�����Ƃ��B
SSE�ł�AVX�ł�GPGPU�̓����́A���ɂ��Ă�ROB�E���^�C�������g��[�����Ȃ��Ƃ����Ȃ���
GPU���q����Ƃ������A�ނ���SSE���j�b�g���g�債��GPU�̃o�b�N�G���h�Ƃ��Ďg����悤��
���f�������x����Ȃ����Ǝv���B
����ł�x87�̒��z���Ƃ����Z�݂����ȉ��I�y���[�V�����������閽�߂ɂ͕��Ō��ʂ��邩���ˁi��
����ȊO�͂قƂ�NJԈႢ�Ȃ��V�Ⴄ�B������2�{�ł��o��Ώ�o������B
���̎��_��SSE5���̂��̂̃A�v���[�`�͒��r���[�B
�ł�AMD��AVX�̎���{���ɒm��Ȃ������낤�ȁB�܂���SSE5������CPU�ɂԂ�����Ƃ��B
SSE�ł�AVX�ł�GPGPU�̓����́A���ɂ��Ă�ROB�E���^�C�������g��[�����Ȃ��Ƃ����Ȃ���
GPU���q����Ƃ������A�ނ���SSE���j�b�g���g�債��GPU�̃o�b�N�G���h�Ƃ��Ďg����悤��
���f�������x����Ȃ����Ǝv���B
����ł�x87�̒��z���Ƃ����Z�݂����ȉ��I�y���[�V�����������閽�߂ɂ͕��Ō��ʂ��邩���ˁi��
����ȊO�͂قƂ�NJԈႢ�Ȃ��V�Ⴄ�B������2�{�ł��o��Ώ�o������B
>>199
Larrabee�����s�����AMD��Fusion�̐����������ƌ������Ƃ͂Ȃ�����B
fanboy�I�ɂ́uLarrabee�͎��s����i�̂ŁjAMD��Fusion�͐�������v�Ƃł����������낤���ǂˁB
Larrabee�����s�����AMD��Fusion�̐����������ƌ������Ƃ͂Ȃ�����B
fanboy�I�ɂ́uLarrabee�͎��s����i�̂ŁjAMD��Fusion�͐�������v�Ƃł����������낤���ǂˁB
>>208
������ SSE5 professional �Ƃ����`�ŁAAVX�݊��ɂ��Ă��锤�B�����ɈႢ�Ȃ��B
������ SSE5 professional �Ƃ����`�ŁAAVX�݊��ɂ��Ă��锤�B�����ɈႢ�Ȃ��B
"AMD"�̎�����CPU�X���Ńt�@���{�[�C�Ƃ��A�Ă��Ă�z�͔n���Ȃ́H
����Ƃ����ǂ߂Ȃ��́H
����Ƃ����ǂ߂Ȃ��́H
213 �FSocket774�F2008/06/27(��) 19:02:46 ID:hi7ccGn0
�����r�[�ƃt���[�W�������āA�������Ȃ���Ȃ����H
�_���Ă���s��≿�i�т��Ⴄ�Ǝv���B
�t���[�W�����̓m�[�g����n�܂�A�f�X�N�g�b�v��I�ɓW�J�ʼn��i�͈����A�����r�[�͎I�I�����[�ʼn��i�͍�����Ȃ����ȁB
�_���Ă���s��≿�i�т��Ⴄ�Ǝv���B
�t���[�W�����̓m�[�g����n�܂�A�f�X�N�g�b�v��I�ɓW�J�ʼn��i�͈����A�����r�[�͎I�I�����[�ʼn��i�͍�����Ȃ����ȁB
214 �F�R�E�L�́M�E,,�j�����������������F2008/06/27(��) 19:11:08 ID:t8P1fobZ
�����c�q�����������̂��킩���̂����ǁB
�Ō�Ɍ����������Ƃ܂Ƃ߂ĉӏ������ɂł����Ă���B
Larrabee���K�������������āA
�������X�������Ƃ��āA�����ˁ[����B
VCG������Ă�̂ɁB
�Ō�Ɍ����������Ƃ܂Ƃ߂ĉӏ������ɂł����Ă���B
Larrabee���K�������������āA
�������X�������Ƃ��āA�����ˁ[����B
VCG������Ă�̂ɁB
Bulldozer�̑R�n��SandyBridge�Ȃ̂ɁA�Ȃ�ŃA�N�Z�����[�^��Larrabee�Ɣ�ׂĂ�́H
��������Larrabee�Ȃ�Ăǂ����y�[�p�[����B
��������Larrabee�Ȃ�Ăǂ����y�[�p�[����B
Larrabee�W��intel���g�͓���GPU�Ƃ��Ă͑S���G��Ă��炸�A
x86�A�[�L�̃��j�[�R�A�Ƃ���GPGPU�R�Ƃ��Ă����������ĂȂ������B
DirectX��OpenGL�Ή�����Ƃ������o�����͍̂ŋ߁B
�}��GPU�Ƃ��Ďg����悤�ɕύX���Ă̂��ǂ����Ǝv���̂ŁA���Ƃ���GPU�Ƃ��Ă�
�g����悤�ɂ͐v���Ă����ǁA������GPU�Ƃ��Ĕ�����肪�Ȃ������̂��A
����ς����GPU�Ƃ��Ă����邱�ƂɂȂ�����Ȃ����낤���B
Larrabee��GPU�Ƃ��Ă̐��\�͊��҂ł���悤�Ȃ���Ȃ��Ǝv�����ǁB
x86�A�[�L�̃��j�[�R�A�Ƃ���GPGPU�R�Ƃ��Ă����������ĂȂ������B
DirectX��OpenGL�Ή�����Ƃ������o�����͍̂ŋ߁B
�}��GPU�Ƃ��Ďg����悤�ɕύX���Ă̂��ǂ����Ǝv���̂ŁA���Ƃ���GPU�Ƃ��Ă�
�g����悤�ɂ͐v���Ă����ǁA������GPU�Ƃ��Ĕ�����肪�Ȃ������̂��A
����ς����GPU�Ƃ��Ă����邱�ƂɂȂ�����Ȃ����낤���B
Larrabee��GPU�Ƃ��Ă̐��\�͊��҂ł���悤�Ȃ���Ȃ��Ǝv�����ǁB
>>217
����Ⴈ�O�̔F�����Ԉ���Ă�B
Larrabee�̂��킳���ŏ��ɂł��Ƃ��ɂ���discrete GPU�ɎQ�����ă��[�}�[�ɂȂ��Ă�����B
GPGPU�̑R�n���Ă����̂́AGPU���ėp�����Ă����Ȃ��ŋ�������Ƃ������x�̈Ӗ��̘b�B
����Ⴈ�O�̔F�����Ԉ���Ă�B
Larrabee�̂��킳���ŏ��ɂł��Ƃ��ɂ���discrete GPU�ɎQ�����ă��[�}�[�ɂȂ��Ă�����B
GPGPU�̑R�n���Ă����̂́AGPU���ėp�����Ă����Ȃ��ŋ�������Ƃ������x�̈Ӗ��̘b�B
�܂����킵���͂��̕ӌ��ĂˁB
http://www.theinquirer.net/en/inquirer/news/2007/02/09/meet-larrabee-intels-answer-to-a-gpu
http://www.theinquirer.net/en/inquirer/news/2007/02/09/meet-larrabee-intels-answer-to-a-gpu
>>218
������intel���g�͂��ď����Ă��邾��H
���ԂƂ��ẮAINQ�Ƃ����[�}�[�T�C�g��discrete GPU�J�����Ă�Ƃ������o���āA
VCG�̉���ɂ�discrete GPU�Ȃ�ďo������A�݂�ȋ������Ƃ���ŁA
���炭�����ɂ�GPU�Ƃ��Ă͑S���G���ꂸ�A��ULarrabee��GPU�Ȃ�Č����ق���
�n���ɂ���鎞�������������炢�B
GPU�Ƃ��čēx������悤�ɂȂ����̂́A���N�ɂȂ���intel���g��
DirectX��OpenGL�ɑΉ�������Č����o���Ă��炾��B
������intel���g�͂��ď����Ă��邾��H
���ԂƂ��ẮAINQ�Ƃ����[�}�[�T�C�g��discrete GPU�J�����Ă�Ƃ������o���āA
VCG�̉���ɂ�discrete GPU�Ȃ�ďo������A�݂�ȋ������Ƃ���ŁA
���炭�����ɂ�GPU�Ƃ��Ă͑S���G���ꂸ�A��ULarrabee��GPU�Ȃ�Č����ق���
�n���ɂ���鎞�������������炢�B
GPU�Ƃ��čēx������悤�ɂȂ����̂́A���N�ɂȂ���intel���g��
DirectX��OpenGL�ɑΉ�������Č����o���Ă��炾��B
>>220
��{�I�ɂ̓I���W�i���̏��ω����ĂȂ��B
�ω����Ă���̂́AGPU�ƃ��j�[�R�ACPU�̐������Ȃ��ł�
Larrabee�����Ȃ̂���`�ł��Ȃ��������[�}�[�T�C�g��n�[�h�E�G�A�T�C�g
�̔F���B
��������DirectX��OpenGL�ɑΉ������
GPU���ĔF���������������B
DirectX��OpenGL���̂���f�o�b�O��݊����̖��������āA
��{�I�Ƀ\�t�g�����ł��������ł���B
�Ԃ����Ⴏ�ANehalem��Sandy Bridge�ł��������B
�ǂ��܂Ő�p�n�[�h��p�ӂ��邩�̖��B
���̕ς��킩���ĂȂ��A�����Q�[���Ȃ̂�HPC�Ȃ̂��ł����ƍ������Ă���B
�ǂ����ł��g����B���\���ł邩�ǂ����͕ʂƂ��āB
��{�I�ɂ̓I���W�i���̏��ω����ĂȂ��B
�ω����Ă���̂́AGPU�ƃ��j�[�R�ACPU�̐������Ȃ��ł�
Larrabee�����Ȃ̂���`�ł��Ȃ��������[�}�[�T�C�g��n�[�h�E�G�A�T�C�g
�̔F���B
��������DirectX��OpenGL�ɑΉ������
GPU���ĔF���������������B
DirectX��OpenGL���̂���f�o�b�O��݊����̖��������āA
��{�I�Ƀ\�t�g�����ł��������ł���B
�Ԃ����Ⴏ�ANehalem��Sandy Bridge�ł��������B
�ǂ��܂Ő�p�n�[�h��p�ӂ��邩�̖��B
���̕ς��킩���ĂȂ��A�����Q�[���Ȃ̂�HPC�Ȃ̂��ł����ƍ������Ă���B
�ǂ����ł��g����B���\���ł邩�ǂ����͕ʂƂ��āB
�I���W�i�����͓����͂�����HPC�����Ƃ��Ă����������ĂȂ��������ǁH
VisualComputing�̗���f���CG���삾�����̂ɁA�����������
GPU�Ƃ��Ďg������Ă͓̂����Ƃ��Ă͘_����������B
GPU�Ƃ��Ďg���邩�ǂ����Ȃ�A�g������ĒN�ł������邾�낤�B
VisualComputing�̗���f���CG���삾�����̂ɁA�����������
GPU�Ƃ��Ďg������Ă͓̂����Ƃ��Ă͘_����������B
GPU�Ƃ��Ďg���邩�ǂ����Ȃ�A�g������ĒN�ł������邾�낤�B
223 �F�R�E�L�́M�E,,�j�����������������F2008/06/27(��) 20:53:58 ID:t8P1fobZ
Larrabee��Intel�̂�肽�����Ɓi�\�z�j
�@�E256bit SIMD�V���߁i�����炭AVX���̂��́j�̕��y
�@�E���j�[�R�A�̗L�p���̎s������i�j�̈Ӗ�����������
�@�EGPGPU�s��ł�nVIDIA�̌����i�r�f�I�J�[�h�s�ꂻ�̂��̂̔e���͋����Ȃ��j
�@�EGPU�ł̓f�X�N�g�b�v�R���s���[�e�B���O�ŕ��D���ɔ����Ă��炤���Ƃł̎s�����
�@�E�ŋ�HPC�s���Cell���������
�@�E256bit SIMD�V���߁i�����炭AVX���̂��́j�̕��y
�@�E���j�[�R�A�̗L�p���̎s������i�j�̈Ӗ�����������
�@�EGPGPU�s��ł�nVIDIA�̌����i�r�f�I�J�[�h�s�ꂻ�̂��̂̔e���͋����Ȃ��j
�@�EGPU�ł̓f�X�N�g�b�v�R���s���[�e�B���O�ŕ��D���ɔ����Ă��炤���Ƃł̎s�����
�@�E�ŋ�HPC�s���Cell���������
>�I���W�i�����͓����͂�����HPC�����Ƃ��Ă����������ĂȂ��������ǁH
�ł���\�[�X�\���Ăق����ȁB�����Ă�邩��B
>>219�ɂ���Ƃ���ALarrabee��x86���x�N�g�����j�b�g&���߂Ŋg������
in-order�̃V���v���R�A�ƁA���L�ш�̑o���������O�o�X�łԂ�Ƃ������́B
����Ɠ����ɑ�����GPU�@�\�����Ƃ����Ă���B
�͂����肢���Ă������牽��������Ă܂���B
�����킩��Ȃ�����A��������GPU��HPC���A�ς�����Ƒ����ł��������B
�ł���\�[�X�\���Ăق����ȁB�����Ă�邩��B
>>219�ɂ���Ƃ���ALarrabee��x86���x�N�g�����j�b�g&���߂Ŋg������
in-order�̃V���v���R�A�ƁA���L�ш�̑o���������O�o�X�łԂ�Ƃ������́B
����Ɠ����ɑ�����GPU�@�\�����Ƃ����Ă���B
�͂����肢���Ă������牽��������Ă܂���B
�����킩��Ȃ�����A��������GPU��HPC���A�ς�����Ƒ����ł��������B
>>223
Larrabee�̖{���̖ړI�́A�B���ł��邩�ǂ����͕ʂƂ���
�u���j�[�R�A���Ă����[�A���ꂩ��̓��j�[�R�A����!!�v
���ăC���p�N�g��^���A�ł���\�t�g�ƊE�̊S���A�b�v�����邱�ƁB
GPU�̎s��AHPC�̎s�ꂪ�ق����Ƃ��������A�P�Ȃ�}�[�P�e�N�`���ł��ˁB
�{���Ȃ�ΐ��i�����Ȃ��悤�Ȃ��́B
���������Ӗ��Œc�q��>>223�̏������݂͂Ȃ��Ȃ��I�Ă��邩�ƁB
Larrabee�̖{���̖ړI�́A�B���ł��邩�ǂ����͕ʂƂ���
�u���j�[�R�A���Ă����[�A���ꂩ��̓��j�[�R�A����!!�v
���ăC���p�N�g��^���A�ł���\�t�g�ƊE�̊S���A�b�v�����邱�ƁB
GPU�̎s��AHPC�̎s�ꂪ�ق����Ƃ��������A�P�Ȃ�}�[�P�e�N�`���ł��ˁB
�{���Ȃ�ΐ��i�����Ȃ��悤�Ȃ��́B
���������Ӗ��Œc�q��>>223�̏������݂͂Ȃ��Ȃ��I�Ă��邩�ƁB
���Ȃ�ň̂����ɍْ艺���������H(�E�L��`�E)
IDF2007Fall�̎��_�܂ł́AGPU�Ƃ��Ă͓��Ƀv�b�V�����ĂȂ������͂��Ȃ��ǁA
Spring�̃Q���V���K�[�̂����Ȃ����AFall�ł��O���t�B�b�N�X�֘A�ŐG����Ă��邩��A
GPU�Ƃ��Ă��v���Ă���Ƃ������ɓǂޕ����Z���X�����낤�ȁB
�����Ԉ���Ă������Ă��ƂŁB
Spring�̃Q���V���K�[�̂����Ȃ����AFall�ł��O���t�B�b�N�X�֘A�ŐG����Ă��邩��A
GPU�Ƃ��Ă��v���Ă���Ƃ������ɓǂޕ����Z���X�����낤�ȁB
�����Ԉ���Ă������Ă��ƂŁB
http://www.4gamer.net/news/history/2007.04/20070417154239detail.html
http://www.intel.com/pressroom/archive/releases/20070416supp.htm
The Larrabee architecture will include enhancements to accelerate applications
such as scientific computing, recognition, mining, synthesis, visualization,
financial analytics and health applications.
http://www.computerworld.jp/news/trd/62729.html
�}���j�[����Larrabee�ɂ��āA�u�Ȋw�Z�p�v�Z�A�f�[�^�E�}�C�j���O�A���Z���́A
��ÃP�A����Ȃǂŗ��p�����A�v���P�[�V�����̍������ɍv��������̂�
���҂��Ă���v�ƃR�����g�������A����ȏ�̏ڍ��͌��J���Ȃ������B
http://pc.watch.impress.co.jp/docs/2007/0611/kaigai364.htm
Gelsinger���u��X�́A�܂�(Larrabee��)���i�̃^�[�Q�b�g���ǂ��ɒu���̂�
���m�ɂ͖��m�ɂ��Ă��Ȃ��B�ʏ�A��X���A�[�L�e�N�`���Ƌ@�\�����߂�i�K�ł́A
�ǂ̎s��ɍŏ��̐��i��W�J���邩�͕`���Ă��Ȃ��B���X�g�ɂ̓O���t�B�b�N�X
���܂ރr�W���A���C�[�[�V�������܂܂�Ă���B������A(�O���t�B�b�N�X�s���
�_��)���ݐ��͂��邪�A�܂��A�_������̎s��Z�O�����g�͔��\���Ă��Ȃ��v
�@�@�@�@�@�@�@�@�@�@�@�@�@�@**************
http://pc.watch.impress.co.jp/docs/2007/1012/kaigai393.htm
�uLarrabee�́A�L�������W�̃R���s���[�e�B���O����_���Ă���B�X���[�v�b�g
�R���s���[�e�B���O�A�r�W���A���C�[�[�V�����A�������́AHPC�Ȃǂ��B�������A����
���\�����̂́A�ŏ��̐��i�̓O���t�B�b�N�X�ɂȂ�Ƃ������Ƃ��B�S�[���͍L�������W
�̃��[�N���[�h���J�o�[���鐻�i�Q�����A�ŏ��̐��i�̓O���t�B�b�N�X���v
http://techon.nikkeibp.co.jp/article/NEWS/20080318/149166/
http://techon.nikkeibp.co.jp/article/NEWS/20080403/149940/
�u�����܂ł�Intel�ЂƂ��ẮCLarrabee��GPU�����̂��̂Ƃ��Ă����\�����Ă��Ȃ��B�v
http://www.intel.com/pressroom/archive/releases/20070416supp.htm
The Larrabee architecture will include enhancements to accelerate applications
such as scientific computing, recognition, mining, synthesis, visualization,
financial analytics and health applications.
http://www.computerworld.jp/news/trd/62729.html
�}���j�[����Larrabee�ɂ��āA�u�Ȋw�Z�p�v�Z�A�f�[�^�E�}�C�j���O�A���Z���́A
��ÃP�A����Ȃǂŗ��p�����A�v���P�[�V�����̍������ɍv��������̂�
���҂��Ă���v�ƃR�����g�������A����ȏ�̏ڍ��͌��J���Ȃ������B
http://pc.watch.impress.co.jp/docs/2007/0611/kaigai364.htm
Gelsinger���u��X�́A�܂�(Larrabee��)���i�̃^�[�Q�b�g���ǂ��ɒu���̂�
���m�ɂ͖��m�ɂ��Ă��Ȃ��B�ʏ�A��X���A�[�L�e�N�`���Ƌ@�\�����߂�i�K�ł́A
�ǂ̎s��ɍŏ��̐��i��W�J���邩�͕`���Ă��Ȃ��B���X�g�ɂ̓O���t�B�b�N�X
���܂ރr�W���A���C�[�[�V�������܂܂�Ă���B������A(�O���t�B�b�N�X�s���
�_��)���ݐ��͂��邪�A�܂��A�_������̎s��Z�O�����g�͔��\���Ă��Ȃ��v
�@�@�@�@�@�@�@�@�@�@�@�@�@�@**************
http://pc.watch.impress.co.jp/docs/2007/1012/kaigai393.htm
�uLarrabee�́A�L�������W�̃R���s���[�e�B���O����_���Ă���B�X���[�v�b�g
�R���s���[�e�B���O�A�r�W���A���C�[�[�V�����A�������́AHPC�Ȃǂ��B�������A����
���\�����̂́A�ŏ��̐��i�̓O���t�B�b�N�X�ɂȂ�Ƃ������Ƃ��B�S�[���͍L�������W
�̃��[�N���[�h���J�o�[���鐻�i�Q�����A�ŏ��̐��i�̓O���t�B�b�N�X���v
http://techon.nikkeibp.co.jp/article/NEWS/20080318/149166/
http://techon.nikkeibp.co.jp/article/NEWS/20080403/149940/
�u�����܂ł�Intel�ЂƂ��ẮCLarrabee��GPU�����̂��̂Ƃ��Ă����\�����Ă��Ȃ��B�v
Larrabee�͉�����G�c�Ƃ����ƁA
>>219���o�Ă���A1�N�ȏソ���Ă��Ȃ��猋��
>>224�ɏ��������̎O�s�ł����Ȃ��B
> Larrabee��x86���x�N�g�����j�b�g&���߂Ŋg������
> in-order�̃V���v���R�A�ƁA���L�ш�̑o���������O�o�X�łԂ�Ƃ������́B
> ����Ɠ����ɑ�����GPU�@�\������
�E �ėpCPU�̒u�������Ƃ��Ă͔ėp�����p�̃R�A�������Ă��Ȃ����ߖw�ǎg���Ȃ�
�E ���Z�����́Ax86�̃x�N�g���g���ƃ}���`�R�A�ɂ�������v�̂���
���Ԃ�A������GPU�Ƃ��ăQ�[���O���t�B�b�N�X�p�Ƃ��Ă͊��҂ł��Ȃ�
Larrabee�͒N���ǂ��݂Ă����r���[�����A���i�Ƃ��Ċ����x���Ⴂ�B
���̒��r���[���������̌��B
�Ƃ肠����Intel�������R�A�̐��i�������������������ƌ�����B
�����ACore 2/Nehalem�ɂ���AMD�ɂ���A�d�͂����ɂȂ��Ă���A
���܂��܂����g���������Ȃ��Ă��Ă܂�Ȃ��Ȃ��Ă���Ƃ���ŁA
���̂悤�ȃQ�e���m�A�[�L��x86����v�X�ɂłĂ������Ƃɋ������������㩁B
>>219���o�Ă���A1�N�ȏソ���Ă��Ȃ��猋��
>>224�ɏ��������̎O�s�ł����Ȃ��B
> Larrabee��x86���x�N�g�����j�b�g&���߂Ŋg������
> in-order�̃V���v���R�A�ƁA���L�ш�̑o���������O�o�X�łԂ�Ƃ������́B
> ����Ɠ����ɑ�����GPU�@�\������
�E �ėpCPU�̒u�������Ƃ��Ă͔ėp�����p�̃R�A�������Ă��Ȃ����ߖw�ǎg���Ȃ�
�E ���Z�����́Ax86�̃x�N�g���g���ƃ}���`�R�A�ɂ�������v�̂���
���Ԃ�A������GPU�Ƃ��ăQ�[���O���t�B�b�N�X�p�Ƃ��Ă͊��҂ł��Ȃ�
Larrabee�͒N���ǂ��݂Ă����r���[�����A���i�Ƃ��Ċ����x���Ⴂ�B
���̒��r���[���������̌��B
�Ƃ肠����Intel�������R�A�̐��i�������������������ƌ�����B
�����ACore 2/Nehalem�ɂ���AMD�ɂ���A�d�͂����ɂȂ��Ă���A
���܂��܂����g���������Ȃ��Ă��Ă܂�Ȃ��Ȃ��Ă���Ƃ���ŁA
���̂悤�ȃQ�e���m�A�[�L��x86����v�X�ɂłĂ������Ƃɋ������������㩁B
>>228�����A������̔������炢�ŖO���Ă�߂�������悗
2007�N��IDF Fall�̂��炢����GPU�Ƃ��Ă̐F���ēx�o���n�߂Ă��ȁB
>>229
������ULarrabee��GPU�Ƃ��Ẳ\��������������Ȃ��Ȃ�����˂��Ďv�����̂́A
http://xtreview.com///images/davis.pdf
�����pdf�o���Ȃ���AIDF�ł͑S���G����Ȃ���������B
����ň�UGPU�Ƃ��Ă��������Ă̂̓L�����Z�����ꂽ�̂����Ďv���Ă���B
2007�N��IDF Fall�̂��炢����GPU�Ƃ��Ă̐F���ēx�o���n�߂Ă��ȁB
>>229
������ULarrabee��GPU�Ƃ��Ẳ\��������������Ȃ��Ȃ�����˂��Ďv�����̂́A
http://xtreview.com///images/davis.pdf
�����pdf�o���Ȃ���AIDF�ł͑S���G����Ȃ���������B
����ň�UGPU�Ƃ��Ă��������Ă̂̓L�����Z�����ꂽ�̂����Ďv���Ă���B
��N�O�Ɏ���В���IDF�Ō���Ă������Ƃ�
�Ȃ��������Ƃɂ���Q������G���`
�Ȃ��������Ƃɂ���Q������G���`
������25���ɉ����̃C�x���g�Ŕ�I���ꂽ�炵���v���[�����l�^�ɂ���Swift-fusion�̋L�����B
http://www.gottabemobile.com/AMD%20Coming%20To%20The%20LV%20ULV%20Space.aspx
�f�ڂ��ꂽ�摜�ɏ����Ă�����e��A����Ȋ������B
�@- �j�㏉(��)�̓���GPU (�I���_�C���H)
�@- 1"���ȉ��̃E���g���|�[�^�u������
�@- puma��+20%��CPU���\
�@- ������Puma��+35%��GPU���\
�@- Vista��6hr�ȏ�̃o�b�e������
http://www.gottabemobile.com/AMD%20Coming%20To%20The%20LV%20ULV%20Space.aspx
�f�ڂ��ꂽ�摜�ɏ����Ă�����e��A����Ȋ������B
�@- �j�㏉(��)�̓���GPU (�I���_�C���H)
�@- 1"���ȉ��̃E���g���|�[�^�u������
�@- puma��+20%��CPU���\
�@- ������Puma��+35%��GPU���\
�@- Vista��6hr�ȏ�̃o�b�e������
display�o�͌n�̓`�b�v�Z�b�g�i��j�ɔC����ׂ���������
Larrabee�̘b��Ő���オ���Ă��邷���ǁA�܂肵��JulesWorld�Ȃ��Ђ�DirectX9�T�|�[�g��
Radeon�Ń��A���^�C���E���C�g���[�V���O�̃f��������Ă��炵�����B
http://www.tgdaily.com/content/view/38145/135/
�@�@-----------------------------
�@�@In terms of performance, the Radeon 2900XT 1GB rendered Transformers scenes in 20-30
�@�@frames per second, in 720p resolution and no Anti-Aliasing. With the Radeon 3870, the test
�@�@scene jumped to 60 fps, with a drop to 20 fps when the proprietary Anti-Aliasing algorithm
�@�@was applied. Urbach mentioned that the Radeon 4870 hits the same 60 fps -- and stays at
�@�@that level with Anti-Aliasing (a ray-tracer is not expecting more than 60 fps.)
�@�@-----------------------------
Larrabee���o�ꂷ�鍠�ɂ�A����x��ɂȂ��Ă��邩���B�B�B�Ƃ�������t�������ǁB�ꉞ�A��������
��Theo Valich�Ƃ������Ƃ�����t�������Ă������B
�f���̎�����A�����炷�B
http://jp.youtube.com/watch?v=aT37b2QjkZc
Radeon�Ń��A���^�C���E���C�g���[�V���O�̃f��������Ă��炵�����B
http://www.tgdaily.com/content/view/38145/135/
�@�@-----------------------------
�@�@In terms of performance, the Radeon 2900XT 1GB rendered Transformers scenes in 20-30
�@�@frames per second, in 720p resolution and no Anti-Aliasing. With the Radeon 3870, the test
�@�@scene jumped to 60 fps, with a drop to 20 fps when the proprietary Anti-Aliasing algorithm
�@�@was applied. Urbach mentioned that the Radeon 4870 hits the same 60 fps -- and stays at
�@�@that level with Anti-Aliasing (a ray-tracer is not expecting more than 60 fps.)
�@�@-----------------------------
Larrabee���o�ꂷ�鍠�ɂ�A����x��ɂȂ��Ă��邩���B�B�B�Ƃ�������t�������ǁB�ꉞ�A��������
��Theo Valich�Ƃ������Ƃ�����t�������Ă������B
�f���̎�����A�����炷�B
http://jp.youtube.com/watch?v=aT37b2QjkZc
���A���^�C�����C�g���f���Ƃ�����4�N�O�ɂ���Ȃ��Ƃ���Ă�
http://www.itmedia.co.jp/news/articles/0402/20/news047_2.html
http://www.itmedia.co.jp/news/articles/0402/20/news047_2.html
�����[���o�邱��ɂ�GPU��1�`2����܂��i�ނ�
>>174
�{�c�̗\�z�i�ϑz�j�L�������ǃ^�C�~���O�悭����Șb�肪
http://dc.watch.impress.co.jp/cda/trend/2008/06/27/8751.html
> ���J������p�v���Z�b�T���i������
> PC��CPU�����J���������̉摜�v���Z�b�T�̕����A��荂�x��RAW�����������A
> ��荂���ɍs�Ȃ���悤�ɂȂ邩������Ȃ��B
> ���������Ȃ����ɁuRAW�����̓p�����[�^����PC�Ŏw�肵�Ă����āA
> �����̓J�����ɔC����̂���Ԃ����ˁv�Ȃ�Č������������̂�������Ȃ��B
�{�c�̗\�z�i�ϑz�j�L�������ǃ^�C�~���O�悭����Șb�肪
http://dc.watch.impress.co.jp/cda/trend/2008/06/27/8751.html
> ���J������p�v���Z�b�T���i������
> PC��CPU�����J���������̉摜�v���Z�b�T�̕����A��荂�x��RAW�����������A
> ��荂���ɍs�Ȃ���悤�ɂȂ邩������Ȃ��B
> ���������Ȃ����ɁuRAW�����̓p�����[�^����PC�Ŏw�肵�Ă����āA
> �����̓J�����ɔC����̂���Ԃ����ˁv�Ȃ�Č������������̂�������Ȃ��B
RAW�����Ȃ͂��ꂱ��Larrabee�݂����̂����ӂ���������
Larrabee�X�����ĂĂ����ł��您�܂���
>>238
�ō�2000����f���ɂȂ�RAW������
GPGPU�ł������ł���ł���B
�s�N�Z�����Ƃɕ������āB
�܂�RAW�����̏ꍇ100�`1000���P�ʂƂ��Ō������邱�ƂɂȂ�̂�
�摜�������R�A�����������
�������ш�̖�肱��������͊ȒP�����B
�ō�2000����f���ɂȂ�RAW������
GPGPU�ł������ł���ł���B
�s�N�Z�����Ƃɕ������āB
�܂�RAW�����̏ꍇ100�`1000���P�ʂƂ��Ō������邱�ƂɂȂ�̂�
�摜�������R�A�����������
�������ш�̖�肱��������͊ȒP�����B
287 ���O�F �A���~ [sage] ���e���F 2008/06/25(��) 19:02:49 ID:cPxyWYsU
�܂��ACPU�̏ꍇ�̓f���L��100���M�ɕς�����ő����d�͂ł�������ˁH
287 ���O�F �A���~ [sage] ���e���F 2008/06/25(��) 19:02:49 ID:cPxyWYsU
�܂��ACPU�̏ꍇ�̓f���L��100���M�ɕς�����ő����d�͂ł�������ˁH
�܂��ACPU�̏ꍇ�̓f���L��100���M�ɕς�����ő����d�͂ł�������ˁH
287 ���O�F �A���~ [sage] ���e���F 2008/06/25(��) 19:02:49 ID:cPxyWYsU
�܂��ACPU�̏ꍇ�̓f���L��100���M�ɕς�����ő����d�͂ł�������ˁH
Mac����OS��API�g���āARAW������GPU���֗^����炵���ˁB
Win�ł����̂����Ή��\�t�g�o���Ȃ����ȁB
Win�ł����̂����Ή��\�t�g�o���Ȃ����ȁB
��p�`�b�v���������̂͏���d��
GPGPU����[��1000����1
GPGPU����[��1000����1
>>236
������45n�ł͗��N�\�肾����
������45n�ł͗��N�\�肾����
>RAW����
�`�b�v���Ƃ̓���s����ƌ������A���[�J�[�����Ђɂ͓����ɂ��Ă��������m�E�n�E�����J�������Ȃ�����
�ƌ������R�̕����ł����A�����ł́B
�`�b�v���Ƃ̓���s����ƌ������A���[�J�[�����Ђɂ͓����ɂ��Ă��������m�E�n�E�����J�������Ȃ�����
�ƌ������R�̕����ł����A�����ł́B
GPU�͏H�~�łƏt�ĔłŔN���̍X�V������
���̂����Е��ő啝�ȍX�V������
45nm��GPU�͍��N�̏H�~�ɂ͏o�邾�낤
�����ďt�ĂŃA�[�L�̍X�V
�܂��AATI�̏ꍇ����n���ɍX�V�������
���̂����Е��ő啝�ȍX�V������
45nm��GPU�͍��N�̏H�~�ɂ͏o�邾�낤
�����ďt�ĂŃA�[�L�̍X�V
�܂��AATI�̏ꍇ����n���ɍX�V�������
>>246
���2�{������ȉ��P�ʂ̃v���Z�X���[���ύX�ƃ}�C�i�[�`�F���W�Ői���Ȃ�Č���ꂽ���ɂ́E�E�E�E
�P��1���゠���肪�����Ȃ�������B
���Ɠd�͂��\���Ȃ�����
���2�{������ȉ��P�ʂ̃v���Z�X���[���ύX�ƃ}�C�i�[�`�F���W�Ői���Ȃ�Č���ꂽ���ɂ́E�E�E�E
�P��1���゠���肪�����Ȃ�������B
���Ɠd�͂��\���Ȃ�����
�i���Ƃ���l�Ńu�c�u�c�ꂢ�Ă���܂�
�K�͂̓n�C�G���h�ُ�
�p�t�H�[�}���X�̓~�h���ȉ�
����ȃ����[�i��̂��߂�
���U���UAMD��CPU�X���ɂ܂ŗ���
����J�l�ł�
�p�t�H�[�}���X�̓~�h���ȉ�
����ȃ����[�i��̂��߂�
���U���UAMD��CPU�X���ɂ܂ŗ���
����J�l�ł�
�f�o�t�Ƃ��Ă�Larrabee�͐��\�����A�h���C�o�ň�
�b�o�t�Ƃ��Ă�Larrabee�͎I��p�A���i����
>>247
RV770 (55nm�A800SP)�@�� RV870?(45nm�A2000SP)
�A�[�L�e�N�`���[�Ƃ��Ă͏����̉��P���낤���ǁA���\��2�{�ȏ�̑啝�A�b�v�\�肾��?
����d�͂͊m���ɍ����A�����͂ǂ��ɂ����ė~�����ȁB
�b�o�t�Ƃ��Ă�Larrabee�͎I��p�A���i����
>>247
RV770 (55nm�A800SP)�@�� RV870?(45nm�A2000SP)
�A�[�L�e�N�`���[�Ƃ��Ă͏����̉��P���낤���ǁA���\��2�{�ȏ�̑啝�A�b�v�\�肾��?
����d�͂͊m���ɍ����A�����͂ǂ��ɂ����ė~�����ȁB
>>250
CPU����Ȃ��ăX�g���[���v���Z�b�T�������H
CPU����Ȃ��ăX�g���[���v���Z�b�T�������H
252 �FSocket774�F2008/06/29(��) 19:15:09 ID:hBSEV9Ll
45nm L3���� X4���Ė����Ȃ����́H
2.8GHz 65W�ł��肢���܂�
2.8GHz 65W�ł��肢���܂�
HT3.0�ȏ���lj���
Propus���̂͗��N���߂ɏo��\�肾���A2.8G�͂��ɂȂ邩������Ȃ��B
�ނ���o�邩��������Ȃ��B
�ނ���o�邩��������Ȃ��B
AMD��GPU�ɗ͂���ꂷ���Ė{�Ƃ����낻���ɂȂ��Ă���ȁB
�{���]�|�������Ƃ��낾�B
�{���]�|�������Ƃ��낾�B
�Ƃ����������APropus��2Ghz�䔼�ł̓o��\�肩�c�B
�Ȃ낤�c�{���ɒቿ�i�������H
>>256
K8������Ă������Ƀh���[����ǂ��������ȁB
�ǂ��ɂ������ɖ߂����ƕK���Ȃ낤�B
�Ȃ낤�c�{���ɒቿ�i�������H
>>256
K8������Ă������Ƀh���[����ǂ��������ȁB
�ǂ��ɂ������ɖ߂����ƕK���Ȃ낤�B
�{�Ƃł����ł�
���̊撣�肪���\����鍠�ɂ͂����������Ă邩��
���̊撣�肪���\����鍠�ɂ͂����������Ă邩��
�Ɂc2GH���H�H�H�H�H�H�H�H�H�H�H�H�H�H�H�H�H
Phenom�̑��݈Ӌ`���������Ȃ����߂ɂ��A���܂荂�N���b�N�ł͏o���Ă��Ȃ��Ǝv����
OC�ϐ���������N���b�N�Ⴍ�Ă��V�ׂ���ǂ˂�
OC�ϐ���������N���b�N�Ⴍ�Ă��V�ׂ���ǂ˂�
�u�f�`�̑ш��������Ƃɂ��Ȃ��Ƃb�o�t�P�̂ŏ����ڂȂ����炾��
�g�s����������������g����Ȃ�����S�u�f�`�J�����đS���g�����Ƃ������_
�ł�intel�����������R���ςނ��
�g�s����������������g����Ȃ�����S�u�f�`�J�����đS���g�����Ƃ������_
�ł�intel�����������R���ςނ��
Phenom�̂��ُ̈�Ȃ܂ł̏���d�͂̕��͂ǂ����痈�镨�Ȃ낤�H
Pen4�Ɠ������A�����̂̌��E�Ȃ�łȂ��́H
45nm�v���Z�X�Ō��I�ȉ��P���]�߂Ȃ�����A���\�̌���͐�]�I�ˁB
45nm�v���Z�X�Ō��I�ȉ��P���]�߂Ȃ�����A���\�̌���͐�]�I�ˁB
>>262
���၄
,1.1�u��89�v��4200+�Ƃ��Ĕ����ʂ��L��Ƃ���
1.3�u���i�ɂ���120�v�Ƃ��Ĕ����4800+�Ŕ����
�܂肱����������
�������ϐ�������ʂ�����Ǝ���悤�ɂȂ��ė�����
���၄
,1.1�u��89�v��4200+�Ƃ��Ĕ����ʂ��L��Ƃ���
1.3�u���i�ɂ���120�v�Ƃ��Ĕ����4800+�Ŕ����
�܂肱����������
�������ϐ�������ʂ�����Ǝ���悤�ɂȂ��ė�����
>>262
AMD�H���A�g���ĂȂ��R�A�ւ̓d�̓J�b�g�������ȁB
�펞�S�R�A�����Ă���悤�ȏȂ�Ƃ������A1�R�A�ōςގ��͑��̃R�A���J�b�g���Ă���炵���B
AMD�H���A�g���ĂȂ��R�A�ւ̓d�̓J�b�g�������ȁB
�펞�S�R�A�����Ă���悤�ȏȂ�Ƃ������A1�R�A�ōςގ��͑��̃R�A���J�b�g���Ă���炵���B
�킽���̓l�C�e�B�u3�R�A���ق���
4�R�A���Ƒш摫��Ȃ��݂�����
4�R�A���Ƒш摫��Ȃ��݂�����
>>262�̏���d�͂̕�����
TDP65W��140W�̍��̂��Ƃ������Ă�C��
TDP65W��140W�̍��̂��Ƃ������Ă�C��
�u���[�h�Ʊ���ق̏���d�͂̕��v��������
�K�x�Ƀ��[�h���ȓd�͋@�\�t����K10Phenom���
K8Athlon�̂ق����f�J����������
�����������d�͂̃\�[�X���Ȃ���
���������N�����̂ɓ��˂ɏo��b�肶��Ȃ�
�K�x�Ƀ��[�h���ȓd�͋@�\�t����K10Phenom���
K8Athlon�̂ق����f�J����������
�����������d�͂̃\�[�X���Ȃ���
���������N�����̂ɓ��˂ɏo��b�肶��Ȃ�
271 �FSocket774�F2008/06/30(��) 17:39:25 ID:DTpqXMbK
�t�F�m���͏���d�͂��C�ɂ���z���������m����Ȃ��B
�E�C���^�[�l�b�g��ɂ́A����̏����Ƃ͑S���W�̂Ȃ������̏����L�ҁA�Ј��l�̐l�i��
�@��������掁i�Ђڂ��j�E��������f���⏑�����݂��������ł���B�����V���͂����������_��
�@��������Ȃǖ��炩�Ȉ�@�s�ׂɑ��ẮA�@�I�[�u�������j�ł���B
�@�܂��A�����V���͍���̑Ή����Ó����������A�ЊO�̗L���҂ł����O�ҋ@�ցu�w�J���ꂽ
�@�V���x�ψ���v�Ɍ��������߂邱�Ƃɂ��Ă���B�i�����j
�@http://mainichi.jp/info/etc/20080627.html
���܂Ƃ߃T�C�g���
�@ttp://www9. atwiki.jp/maini chiwaiwai/
�@ttp://www8. atwiki.jp /mainichi-ma tome/pages/1.html
�@�i��L��URL�́A�r���X�����ċK������̂��ߋ��Ă���܂��̂ł����Ӊ������j
�����j���[�X�X��
�E�y�}�X�R�~�z �u���{�̕�e�A���q�̕��O�ɐ������v�u���{�̏��q�����͐H�ו��ŃZ�b�N�X�ˑ��ǂɁv�c�����V���A�C�O���ŋL���폜
�@http://mamono.2ch.net/test/read.cgi/newsplus/1213966124/
�E�y�����E�ϑԕz "���{�l�̃C���[�W����" �u�V���L�������玖������A�ƊO���l���c�v ���R�O�O���A�Q����ł��ᔻ�E�����T
�@http://mamono.2ch.net/test/read.cgi/newsplus/1214396493/
�E�y�����V���E�ϑԕz�S���҂̏�������I���В��͖�����V�P������10���ԏ�A�R�����S���L�҂͒����x�E�R�����Ȃǁ��V
�@http://mamono.2ch.net/test/read.cgi/newsplus/1214588265/
�E�y�����E�ϑԕz�c���֘A�̋L���ɂ��uhentai�v�̃��^�^�O���������I���{�̈��]�o���}�L�s�ׁA��БS�̂ōs���Ă����\�����������P�O
�@http://mamono.2ch.net/test/read.cgi/newsplus/1214549503/
��������
http://mamono.2ch.net/test/read.cgi/newsplus/1214814774/
�@��������掁i�Ђڂ��j�E��������f���⏑�����݂��������ł���B�����V���͂����������_��
�@��������Ȃǖ��炩�Ȉ�@�s�ׂɑ��ẮA�@�I�[�u�������j�ł���B
�@�܂��A�����V���͍���̑Ή����Ó����������A�ЊO�̗L���҂ł����O�ҋ@�ցu�w�J���ꂽ
�@�V���x�ψ���v�Ɍ��������߂邱�Ƃɂ��Ă���B�i�����j
�@http://mainichi.jp/info/etc/20080627.html
���܂Ƃ߃T�C�g���
�@ttp://www9. atwiki.jp/maini chiwaiwai/
�@ttp://www8. atwiki.jp /mainichi-ma tome/pages/1.html
�@�i��L��URL�́A�r���X�����ċK������̂��ߋ��Ă���܂��̂ł����Ӊ������j
�����j���[�X�X��
�E�y�}�X�R�~�z �u���{�̕�e�A���q�̕��O�ɐ������v�u���{�̏��q�����͐H�ו��ŃZ�b�N�X�ˑ��ǂɁv�c�����V���A�C�O���ŋL���폜
�@http://mamono.2ch.net/test/read.cgi/newsplus/1213966124/
�E�y�����E�ϑԕz "���{�l�̃C���[�W����" �u�V���L�������玖������A�ƊO���l���c�v ���R�O�O���A�Q����ł��ᔻ�E�����T
�@http://mamono.2ch.net/test/read.cgi/newsplus/1214396493/
�E�y�����V���E�ϑԕz�S���҂̏�������I���В��͖�����V�P������10���ԏ�A�R�����S���L�҂͒����x�E�R�����Ȃǁ��V
�@http://mamono.2ch.net/test/read.cgi/newsplus/1214588265/
�E�y�����E�ϑԕz�c���֘A�̋L���ɂ��uhentai�v�̃��^�^�O���������I���{�̈��]�o���}�L�s�ׁA��БS�̂ōs���Ă����\�����������P�O
�@http://mamono.2ch.net/test/read.cgi/newsplus/1214549503/
��������
http://mamono.2ch.net/test/read.cgi/newsplus/1214814774/
�ǂݕԂ��Ă݂�>>260�̔������{���ɍ����ȁB
�ӂƋ^��Ɏv�������ǁA�v���Z�X�ς������}�X�N���ē��R��蒼���H
GPU�̃n�[�t�m�[�h�ł���������蒼���H
GPU�̃n�[�t�m�[�h�ł���������蒼���H
>>274
�v�͎g���镔�������Ȃ肠�邪�A���R���ׂĂ�P�ɏk���Ƃ����킯�ł͂Ȃ��̂�
��蒼���B
��������Shangahi�͂����̃V�������N����Ȃ����ˁB
�v�͎g���镔�������Ȃ肠�邪�A���R���ׂĂ�P�ɏk���Ƃ����킯�ł͂Ȃ��̂�
��蒼���B
��������Shangahi�͂����̃V�������N����Ȃ����ˁB
�}�X�N��蒼���Ȃ�������ǂ�����ăV�������N������H
>>276
�k���R�s�[�ł�
�k���R�s�[�ł�
�P��Intel��65W�ŃN�A�b�h���f�X�N�g�b�v�p�ɏo���ĂȂ����Ă����B
�T�[�o�p�ɂ�50W�ŁA�m�[�g�p��45W�ł�����BTDP�̕��͂ނ���Intel�̕����傫���B
�T�[�o�p�ɂ�50W�ŁA�m�[�g�p��45W�ł�����BTDP�̕��͂ނ���Intel�̕����傫���B
>>278
Phenom���̂̃u���b�V���A�b�v�s�����Ă̂��}�C�R�~�ŒN��������ȋL���������Ă����ȁB
B2�̑�]�|��B3�ł��ׂ����������ǂ��扄���ɂȂ��Ă��邤���ɁA
45nm���҂����܂��Ă��邩��A�ׂ������ǂ���ɂ��Ă��Ȃ������B
����45nm�̏��㐢�������܂�ȓd�͉��ɂ͊��҂ł��Ȃ��Ǝv�����B
Phenom���̂̃u���b�V���A�b�v�s�����Ă̂��}�C�R�~�ŒN��������ȋL���������Ă����ȁB
B2�̑�]�|��B3�ł��ׂ����������ǂ��扄���ɂȂ��Ă��邤���ɁA
45nm���҂����܂��Ă��邩��A�ׂ������ǂ���ɂ��Ă��Ȃ������B
����45nm�̏��㐢�������܂�ȓd�͉��ɂ͊��҂ł��Ȃ��Ǝv�����B
�ł�����TDP�̕����Ă���ς�ُ킾��ˁH
�ʂɑS�R�ȏザ��Ȃ����B
TDP�̕��Ō�������45W����125W�܂ł���K8�̕����傫���B
�v�͏ȓd�͔ł��o�����ǂ��������̘b�B
�v�͏ȓd�͔ł��o�����ǂ��������̘b�B
K8���Ċ���Ȃ�8W����
���x�o��Phenom9950��140W������
���ɏo���Ȃ��Ǝv���Ă����̂ɁA
�Ăɏo���Ƃ��B���C���H�@AMD�c�B
���ɏo���Ȃ��Ǝv���Ă����̂ɁA
�Ăɏo���Ƃ��B���C���H�@AMD�c�B
����������Ȃ�nV�̂ق������C�̍������낤
���C�̍����قǖʔ����c�I
Core2��GeFo��TDP��2/3�قǂ�����
�����f�͒ʂ�z����Ȃ������Ă��炢�d�C��
�����f�͒ʂ�z����Ȃ������Ă��炢�d�C��
instlatx64.fw.hu ���
Griffin��Family ID��11h�ɂȂ�悤��
ttp://www.freeweb.hu/instlatx64/cpuid_AuthenticAMD0200f30_K11_Griffin.txt
�܂�Shanghai��SSSE3���̒lj��͂Ȃ��悤��
ttp://www.freeweb.hu/instlatx64/cpuid_AuthenticAMD0100f40_K10_Shanghai.txt
#AMD CPU ��Family ID
05h: K5/K6
06h: K7
0Fh: K8
10h: Barcelona/Shanghai
11h: Griffin
Griffin��Family ID��11h�ɂȂ�悤��
ttp://www.freeweb.hu/instlatx64/cpuid_AuthenticAMD0200f30_K11_Griffin.txt
�܂�Shanghai��SSSE3���̒lj��͂Ȃ��悤��
ttp://www.freeweb.hu/instlatx64/cpuid_AuthenticAMD0100f40_K10_Shanghai.txt
#AMD CPU ��Family ID
05h: K5/K6
06h: K7
0Fh: K8
10h: Barcelona/Shanghai
11h: Griffin
>>291
�M���Ă��郄�c������c�B
�M���Ă��郄�c������c�B
intel��35w�Ƃ�65w�̂�́A�O��̃��b�g����Ȃ�����
TDP����������d��
�܂�A�C�h�����ʂ�����intel�̂ق���������TDP
TDP����������d��
�܂�A�C�h�����ʂ�����intel�̂ق���������TDP
���点��\�t�g�ɂ����ǂ�
�܂�TDP�_�c���I
�Ȃ��������(�E�L��`�E)
�^�Z�M
�A�C�h����ԂȂ炤���̕�������d�͒Ⴂ�ł�!
�c
�����������ǂ�Ȋ炷��������킩��Ȃ���
�A�C�h����ԂȂ炤���̕�������d�͒Ⴂ�ł�!
�c
�����������ǂ�Ȋ炷��������킩��Ȃ���
300 �F�R�E�L�́M�E,,�j�����������������F2008/07/03(��) 12:15:30 ID:JIF1hK7F
�܂��`�v�Z�g���M�������Intel�́B
�������A�A�C�h�����Ԃ������Ȃ瑽����4�R�A�Ȃ�Ă���Ȃ����B
���R�A���Ƃ���TDP�͈͓��ŃN���b�N�グ��iIntel�ł���Foxton�j�@�\�ł���������̂ɁB
�������A�A�C�h�����Ԃ������Ȃ瑽����4�R�A�Ȃ�Ă���Ȃ����B
���R�A���Ƃ���TDP�͈͓��ŃN���b�N�グ��iIntel�ł���Foxton�j�@�\�ł���������̂ɁB
�v�͂Q�R�A�ʼn��z�P�R�A���삷�郆�[�e�B���e�B���o�Ă���������
����Șb���������悤�ȁH�܂����Ǐo�Ȃ��낤���ǁE�E�E
����Șb���������悤�ȁH�܂����Ǐo�Ȃ��낤���ǁE�E�E
>>301
�m�����o�[�XHTT���������H�@���̌v��͂ǂ��Ȃ����낤�Ȃ��B
�m�����o�[�XHTT���������H�@���̌v��͂ǂ��Ȃ����낤�Ȃ��B
���o�[�XHTT���L�Ӗ��Ȑ��\�A�b�v�ł���Ȃ�AIPC�����Əグ����Ǝv���B
HyperTransport�����������ꂽ���A
�R�A�Ԃ̃R�~���j�P�[�V�������x�͏オ��낤���ǁE�E�E�ǂ��Ȃ̂��B
���Lj�l�œ�����݂ɂ��Ȃ��̂͊ȒP�ł��Q�l�ň�����Ȃ��̂͊ȒP����Ȃ����Ă��Ƃ��ˁB
���Ƃ����������Ǒ�������Ȃ��B�}���`�X���b�h�̕����������������Ă��Ƃ��ȁB
�R�A�Ԃ̃R�~���j�P�[�V�������x�͏オ��낤���ǁE�E�E�ǂ��Ȃ̂��B
���Lj�l�œ�����݂ɂ��Ȃ��̂͊ȒP�ł��Q�l�ň�����Ȃ��̂͊ȒP����Ȃ����Ă��Ƃ��ˁB
���Ƃ����������Ǒ�������Ȃ��B�}���`�X���b�h�̕����������������Ă��Ƃ��ȁB
>>302
���Ƃ��Ƃ���Ȍv��͂Ȃ��B
���Ƃ��Ƃ���Ȍv��͂Ȃ��B
����������Ȃ������܂����̒ʂ�A���\�I�ɖ��炩�ɖ��ʂ�������ł��傤���ǁB
1�R�A��TDP45W�Ƃ�35W�̂��̂�d���グ��3.4GHz����[�A�Ƃ��̕����܂����\�オ�邾�낤���E�E�E
LE-1640��45W���Ċ�ł����āA
LE-1660�@2.8GHz��52W
LE-1680�@3GHz�@��60W
LE-1700�@3.2GHz��68W
LE-1720�@3.4GHz��77W
���炢�ŏo�����E�E�E���Ă����Ă��R�A�̌��E�Ɖ��x����ɗ������ł����B
�u�����ւ��ۂ��v�Z�v�ł�4GHz��CPU�P��106W�v�Z���B���140W�g���炢�ɂȂ肻�������ǁB
1�R�A��TDP45W�Ƃ�35W�̂��̂�d���グ��3.4GHz����[�A�Ƃ��̕����܂����\�オ�邾�낤���E�E�E
LE-1640��45W���Ċ�ł����āA
LE-1660�@2.8GHz��52W
LE-1680�@3GHz�@��60W
LE-1700�@3.2GHz��68W
LE-1720�@3.4GHz��77W
���炢�ŏo�����E�E�E���Ă����Ă��R�A�̌��E�Ɖ��x����ɗ������ł����B
�u�����ւ��ۂ��v�Z�v�ł�4GHz��CPU�P��106W�v�Z���B���140W�g���炢�ɂȂ肻�������ǁB
�����}���`�X���b�f�B���O�̋t�̓��@�}���`�X���b�f�B���O��������
intel�ł���܂������
intel�ł���܂������
�ށA3�悾�������B�Ȃ�E�E�E
3GHz��69W���x���B
3.2GHz��83W�E�E�E
3.4GHz��101W�N���X���ȁB
������ۂ������Ă����B
�����͓d���Ƃ����W���Ă���3.2GHz��89W�A3.4GHz��125W�N���X�Ȃ̂��Ȃ��B
�ɂ��Ă����Ȃ��Ǝv�����ǁE�E�E
3GHz��69W���x���B
3.2GHz��83W�E�E�E
3.4GHz��101W�N���X���ȁB
������ۂ������Ă����B
�����͓d���Ƃ����W���Ă���3.2GHz��89W�A3.4GHz��125W�N���X�Ȃ̂��Ȃ��B
�ɂ��Ă����Ȃ��Ǝv�����ǁE�E�E
���������d���̂R�悶��Ȃ������H
�Ă������r�[�~��ǂ��o������}�ɐÂ��ɂȂ�����w
�Ă������r�[�~��ǂ��o������}�ɐÂ��ɂȂ�����w
�d����2��ŁA�N���b�N�͔�Ⴞ�����Ǝv�����ǁA���̓��[�N�d���̉e�����傫���̂ŁA
�P���ɔ�Ⴕ�Ȃ��B
intel��OC��3.4��3.6GHz���炢����}�ɏ���d�͑����邵�B
�P���ɔ�Ⴕ�Ȃ��B
intel��OC��3.4��3.6GHz���炢����}�ɏ���d�͑����邵�B
�܂��ȂA���ǂ�AMD�͎ア�s��ɂ������ƎQ�킵�A���O��F�m���Ă����Ȃ���Ȃ��̂�ȁB
�m�[�g��CPU�Ƃ��Ă̒n�ʂ�D�����炢�����B�d�͌������グ�Ă��������B
�������Ƃ��Ă͂���ȏ��CPU���\��]��łȂ��E�E�ESSD�̕������҂��Ă�B
CPU�ɐ��\���d�͍팸�Ɋ��҂��Ă�l���ď����h�Ȃ̂��ȁH
�܂�Intel�ɂ͏����ė~�����Ƃ͎v�����ǂ�
�m�[�g��CPU�Ƃ��Ă̒n�ʂ�D�����炢�����B�d�͌������グ�Ă��������B
�������Ƃ��Ă͂���ȏ��CPU���\��]��łȂ��E�E�ESSD�̕������҂��Ă�B
CPU�ɐ��\���d�͍팸�Ɋ��҂��Ă�l���ď����h�Ȃ̂��ȁH
�܂�Intel�ɂ͏����ė~�����Ƃ͎v�����ǂ�
> CPU�ɐ��\���d�͍팸�Ɋ��҂��Ă�l���ď����h�Ȃ̂��ȁH
�����h�Ƃ������A����ȓz���Ȃ��̂�����ł�?
CPU�̐��\�����҂��Ȃ��̂Ȃ猻��ł��\���ɒ����d�͂�CPU�͂��邩��ˁB
�����h�Ƃ������A����ȓz���Ȃ��̂�����ł�?
CPU�̐��\�����҂��Ȃ��̂Ȃ猻��ł��\���ɒ����d�͂�CPU�͂��邩��ˁB
�قށB�l���Ă݂�Ⴛ��Ⴛ�����E�E�E�B
����X2��2.8GHz��45W�I�Ƃ��o�����т������B��C�ǂ߂Ȃ����Ă悭�����܂��B
����X2��2.8GHz��45W�I�Ƃ��o�����т������B��C�ǂ߂Ȃ����Ă悭�����܂��B
0.1W�Ƃ�����������Ȃ����Ă�������45W�Ő��\���C�ɂ��Ă��
�������܂���
�������܂���
5000BE��d��sage��4650e�݂����̂ł�����ˁH
�ȓd�͂�2010�N�ɂ͏o�邾�낤�f�X�N�g�b�v��Fusion�Ɋ���
>>313
�����������c���A�������߂郄�c���I������Core�Q�ł�����(�E�L��`�E)
�����������c���A�������߂郄�c���I������Core�Q�ł�����(�E�L��`�E)
320 �F�R�E�L�́M�E,,�j�����������������F2008/07/05(�y) 16:10:05 ID:SeM2cjfK
�A�����킢����A������
AMD����RAMDrive�̑��x��INTEL�Ɣ�ׂ�1/2���炢�����
>>321
�\�[�X�́H
�\�[�X�́H
32bit�ł�4GB�ȏ�g����Ղ�̎������̕����ċC�Â���
X2����Phenom�ő����Ȃ��Ă邯��Core2�ɂ͎��������Ȃ�AMD
X2����Phenom�ő����Ȃ��Ă邯��Core2�ɂ͎��������Ȃ�AMD
��������X���̒m�I��Q��
�X���`�����m���������
mobile AMD Sempron(tm) Processor 3000+��pentium���Ăǂ��������\�����́H
mobile AMD Sempron(tm) Processor 3000+��pentium���Ăǂ��������\�����́H
pentium����ǂꂩ�킩���悗
327 �F�R�E�L�́M�E,,�j�������������������F2008/07/06(��) 15:39:23 ID:oqfcK7TC
>Pentium
�������Ă��1��ނ����Ȃ��ˁH
PenDC�̂��Ƃł�������
�������Ă��1��ނ����Ȃ��ˁH
PenDC�̂��Ƃł�������
>>327
�ǂ��̐��̏Z�l�ł����H
�ǂ��̐��̏Z�l�ł����H
329 �F�R�E�L�́M�E,,�j�����������������F2008/07/07(��) 01:33:36 ID:p/5wzp0+
�����悤�₭�Ӗ���������
������ɂ��Ă���ԉ��̃��f���ł�Pentium DC�E�߂��B
������ɂ��Ă���ԉ��̃��f���ł�Pentium DC�E�߂��B
>>325�̓G�X�p�[���H
Larrabee��pentium�x�[�X�Ƃ������Ƃ���
�X�W��Weblog���k�X���ł����̌��L�����S��7/7�ȍ~�f�ڂ�
�O���ɗ\�m����Ȃ�Đ�����
����ɂ��Ă��n���͂����ז�����
Larrabee��pentium�x�[�X�Ƃ������Ƃ���
�X�W��Weblog���k�X���ł����̌��L�����S��7/7�ȍ~�f�ڂ�
�O���ɗ\�m����Ȃ�Đ�����
����ɂ��Ă��n���͂����ז�����
331 �F�R�E�L�́M�E,,�j�����������������F2008/07/08(��) 14:38:49 ID:DKuSoTKQ
>>330
����A�\���x���ł͊��o�����o
http://ja.wikipedia.org/wiki/Larrabee
> Ars Technica��Jon Stokes��Larrabee�̃}�C�N���A�[�L�e�N�`����Pentium MMX���x�[�X�Ƃ��Ă��邾�낤�Ǝ������Ă���B
�����̕ҏW�����̓��������ĂˁB
����A�\���x���ł͊��o�����o
http://ja.wikipedia.org/wiki/Larrabee
> Ars Technica��Jon Stokes��Larrabee�̃}�C�N���A�[�L�e�N�`����Pentium MMX���x�[�X�Ƃ��Ă��邾�낤�Ǝ������Ă���B
�����̕ҏW�����̓��������ĂˁB
Griffin��K11�炵��
http://www.lavalys.com/forum/index.php?showtopic=3267
http://www.lavalys.com/forum/index.php?showtopic=3267
AMD���g��K8���Č����Ă�̂ɁAK11���Ă������ɂȂ����낤�B
334 �FSocket774�F2008/07/08(��) 15:09:40 ID:ozTFIEUA
k6�R�A��32�ς����r�[���ǂ�������āA�����r�[�ɂԂ��������ˁH
����d�͂̎����l����APentium MMX���Atom���x�[�X�ɂ���̂����ʂ��Ǝv�����B
����SSE��64bit�ɂ��Ή����Ă邵�ASIMD���p�����C���Ȃ�in-order�Ń��[�}���^�C�����B
����SSE��64bit�ɂ��Ή����Ă邵�ASIMD���p�����C���Ȃ�in-order�Ń��[�}���^�C�����B
�E�������Ă��1��ނ����Ȃ��ˁH
�E�u�ǂ��������\�����́H�v���u�i�w�����j�E�߂��B�v
�E�uLarrabee��P5�x�[�X�Ƃ������v+�upentium�̐��\�̘b��v���uPenDC�̂��Ƃł������Ɓv
���ɎO���q�����Ă��܂��܂���
�Ȃ�ł����n����i��ŎN�����Ƃ���̂��E�E�E
>>335
atom��P5�x�[�X�Ŋ����Ǝv���Ă���
�܂�atomx32��Larrabee
�E�u�ǂ��������\�����́H�v���u�i�w�����j�E�߂��B�v
�E�uLarrabee��P5�x�[�X�Ƃ������v+�upentium�̐��\�̘b��v���uPenDC�̂��Ƃł������Ɓv
���ɎO���q�����Ă��܂��܂���
�Ȃ�ł����n����i��ŎN�����Ƃ���̂��E�E�E
>>335
atom��P5�x�[�X�Ŋ����Ǝv���Ă���
�܂�atomx32��Larrabee
intel�����畡���̃V���v���R�A����s���ĊJ�����āAAtom��Larrabee��
���i���������Ă��ƂɂȂ����\�������肻�������ǁB
P54C�x�[�X���Č����Ă��啝�g�����Ă�悤������AP54C�Ƌ��ʓ_�Ȃ��
�C���I�[�_�[�Ȃ������ĉ\�������邵�B
���i���������Ă��ƂɂȂ����\�������肻�������ǁB
P54C�x�[�X���Č����Ă��啝�g�����Ă�悤������AP54C�Ƌ��ʓ_�Ȃ��
�C���I�[�_�[�Ȃ������ĉ\�������邵�B
>>337
CISC�i�����RISC�j������
CISC�i�����RISC�j������
339 �F�R�E�L�́M�E,,�j�����������������F2008/07/08(��) 15:24:45 ID:DKuSoTKQ
Pentium MMX�r�߂ĂˁH0.25um�v���Z�X��Tillamook�̎��_��5W�����B
���o�C��Pentium II�͓����x�̐��\��30W���x�������B
>>335
�����A�����ʂ�
Atom�͒P��������P6�A�[�L�e�N�`���ƌ����ɃA�i�E���X����Ă܂���B
P5��P6�ɂ̓p�C�v���C���\���ɍ��{�I�ȈႢ������B
Family=6��Pentium Pro����Core 2, Atom��
�[��>>325���ǂ�Larrabee�̘b�����Ă�悤�Ɍ�����H
���o�C��Pentium II�͓����x�̐��\��30W���x�������B
>>335
�����A�����ʂ�
Atom�͒P��������P6�A�[�L�e�N�`���ƌ����ɃA�i�E���X����Ă܂���B
P5��P6�ɂ̓p�C�v���C���\���ɍ��{�I�ȈႢ������B
Family=6��Pentium Pro����Core 2, Atom��
�[��>>325���ǂ�Larrabee�̘b�����Ă�悤�Ɍ�����H
340 �F�R�E�L�́M�E,,�j�����������������F2008/07/08(��) 15:42:59 ID:DKuSoTKQ
��������
��Pentium�������鐻�i�Ń��e�[���s�ꂨ���PC�s��ɏo����Ă�̂�
Conroe�x�[�X�́uPentium Dual-Core Processer�v������������ނ��Č��������B
���Ãp�\�R���Ƃ��W�����N���������ɓ���Ă�Ȃ�ʂ����ȁB
1.6GHz��E2140��������Sempron 3800+�D�悷�邩�H
����ς肻��ł�Pentium DC���Ǝv�����ǂ�
�ۛ��ڂɌ��Ă��f���A���R�A�ƃV���O���R�A�����B
��Pentium�������鐻�i�Ń��e�[���s�ꂨ���PC�s��ɏo����Ă�̂�
Conroe�x�[�X�́uPentium Dual-Core Processer�v������������ނ��Č��������B
���Ãp�\�R���Ƃ��W�����N���������ɓ���Ă�Ȃ�ʂ����ȁB
1.6GHz��E2140��������Sempron 3800+�D�悷�邩�H
����ς肻��ł�Pentium DC���Ǝv�����ǂ�
�ۛ��ڂɌ��Ă��f���A���R�A�ƃV���O���R�A�����B
���߂������[
In-order��Atom��OoO��P6���ׂ��Ă��Ȃ��B
343 �F�R�E�L�́M�E,,�j�����������������F2008/07/08(��) 15:51:25 ID:DKuSoTKQ
P6��P5�̈Ⴂ��OoO�̗L�����Ǝv���Ă�̂ˁB
���ۂɂ́u�X�[�p�[�p�C�v���C���v�ɂ�����RISC�I�y���[�V��������P6�̖{��������
OoO�̗L���͊W�Ȃ��BOoO�͂����܂Ő��\�����B
���ۂɂ́u�X�[�p�[�p�C�v���C���v�ɂ�����RISC�I�y���[�V��������P6�̖{��������
OoO�̗L���͊W�Ȃ��BOoO�͂����܂Ő��\�����B
P5��P6�̈�Ԃ̈Ⴂ�����RISC�����Ƃ�
���cCISC�p�C�v���C����Atom��CISC���m��P5�ł͂Ȃ�����RISC��P6���Ƃ���
����Ȗ����X�Ɣ�������Ȃ�Ă��Ɖ��ɂ͂ƂĂ��o���Ȃ���
���ɉ��i��q�L��Pentium�V���[�Y�i�V�i�j�I���茩���Ȓn��
�ȊO�̏Z�l�Ȃ����̂��Ƃ͂���
���cCISC�p�C�v���C����Atom��CISC���m��P5�ł͂Ȃ�����RISC��P6���Ƃ���
����Ȗ����X�Ɣ�������Ȃ�Ă��Ɖ��ɂ͂ƂĂ��o���Ȃ���
���ɉ��i��q�L��Pentium�V���[�Y�i�V�i�j�I���茩���Ȓn��
�ȊO�̏Z�l�Ȃ����̂��Ƃ͂���
345 �F�R�E�L�́M�E,,�j�����������������F2008/07/08(��) 16:03:08 ID:DKuSoTKQ
�����cCISC�p�C�v���C����Atom
�ǂ����炻��Ȗϑz���H�N�������o�����H
���O��������H
Atom�͑���P6�A�[�L�Ɠ��������G���߂�Complex decorder�ɂĕ�����RISC���C�N��OP���ɕ������Ď��s���܂��B
�ǂ����炻��Ȗϑz���H�N�������o�����H
���O��������H
Atom�͑���P6�A�[�L�Ɠ��������G���߂�Complex decorder�ɂĕ�����RISC���C�N��OP���ɕ������Ď��s���܂��B
347 �F�R�E�L�́M�E,,�j�����������������F2008/07/08(��) 16:11:50 ID:DKuSoTKQ
��������Core 2����Nehalem�Ŗ��ߔ��s�|�[�g��5����6�|�[�g�ɑ������Ƃ�
��R�����Ă��L�҂���B
OoO��RISC�̂��̂��Ƃ��R�������B
OoO�̎����ł�Pentium Pro�̂ق���������RISC�ɐ�s���Ă���
��������OoO���̂�RISC�̎v�z�Ƃ͖���������̂�����ȁB
�Ȃɂ��Intel�����̌������AFamily=6�Ƃ����������B
�s�����Ƃł������̂��H
��R�����Ă��L�҂���B
OoO��RISC�̂��̂��Ƃ��R�������B
OoO�̎����ł�Pentium Pro�̂ق���������RISC�ɐ�s���Ă���
��������OoO���̂�RISC�̎v�z�Ƃ͖���������̂�����ȁB
�Ȃɂ��Intel�����̌������AFamily=6�Ƃ����������B
�s�����Ƃł������̂��H
ttp://home.att.ne.jp/theta/OSAKOH2/topics/Intel_Atom.html
���������ƌ��c�Ƃ������PenM-Core�A�[�L�ɂȂ����܂����H
���������ƌ��c�Ƃ������PenM-Core�A�[�L�ɂȂ����܂����H
349 �F�R�E�L�́M�E,,�j�����������������F2008/07/08(��) 16:29:44 ID:DKuSoTKQ
P5�A�[�L�e�N�`�����Ă��Ƃ͗��U/V�p�C�v�̐�������Ă��ƁB
���ꂱ��
http://www.pcmech.com/images/underhood/pentium_diagram.gif
Atom�͂���Ȃ��̂̑��݂͕����Ȃ������̐}�ɂ������B
���������S���ʕ�����Ȃ����B
Larrabee�̓N���b�N�グ�邽�߂ɂ�����x�̓X�e�[�W�̍ו����͂��Ă�Ǝv����
P6�̍\���Ƃ͂���ς�Ⴄ�Ǝv����B
���ꂱ��
http://www.pcmech.com/images/underhood/pentium_diagram.gif
{kind=link}
Atom�͂���Ȃ��̂̑��݂͕����Ȃ������̐}�ɂ������B
���������S���ʕ�����Ȃ����B
Larrabee�̓N���b�N�グ�邽�߂ɂ�����x�̓X�e�[�W�̍ו����͂��Ă�Ǝv����
P6�̍\���Ƃ͂���ς�Ⴄ�Ǝv����B
>>325���܂��������܂ōr���Ƃ͎v��Ȃ������̂ł�����
Larrabee�̎���Atom���B
�E���吙�B
�E���吙�B
AMD�̎�����CPU�l�^���قƂ�ǂȂ�����ȁB
2010�N�܂�CPU�R�A��K10.5�m�肾���AGPU�������e��Swift��
�_�C�������������Ȃ̂ŁA����I�ɂ��������Ă킯�ł��Ȃ����B
2010�N�܂�CPU�R�A��K10.5�m�肾���AGPU�������e��Swift��
�_�C�������������Ȃ̂ŁA����I�ɂ��������Ă킯�ł��Ȃ����B
353 �F�R�E�L�́M�E,,�j�����������������F2008/07/08(��) 16:56:40 ID:DKuSoTKQ
Atom�̓C���I�[�_�����f�R�[�h��Ƀ�OP���L���[�ɓ˂������
2�̎��s�|�[�g�̂����ǂ����Ŏ��s����̂��́u�U�蕪���v�͂���B
�P�ɑO��ŕ��בւ��Ȃ������B
P5�̓f�R�[�h������s�܂ň꒼���B
���G���߂�U���̃f�R�[�_�Ńf�R�[�h���邪�A���s�܂�U���ɔ�����B
V���͒P�����߂����B
�y�A�ɂł��閽�߂ɂ��K���������āE�E�E
���̂ւ��Agner���̉�͎������ڂ����B
Larrabee��P5�������Ă邩���Č����ƁA�����ĂȂ��Ƃ������Ȃ��B
�ŏ�����256�r�b�g��SIMD�������Ɏ��s�ł���悤�Ȏ��s���j�b�g�\���Ȃ�
V�p�C�v���ł��f�R�[�h�ł���킯�B
�܂����ۂ��������\���ɂ���̂��낤
���ɒ��j�Z�p�ƂȂ�ł��낤AVX�͐擪����1�`2�o�C�g����������ModRM�܂ł̖��ߒ�������ł��邩��
�t�����g�G���h�̕��S�͌y���ق����Ǝv����B
2�̎��s�|�[�g�̂����ǂ����Ŏ��s����̂��́u�U�蕪���v�͂���B
�P�ɑO��ŕ��בւ��Ȃ������B
P5�̓f�R�[�h������s�܂ň꒼���B
���G���߂�U���̃f�R�[�_�Ńf�R�[�h���邪�A���s�܂�U���ɔ�����B
V���͒P�����߂����B
�y�A�ɂł��閽�߂ɂ��K���������āE�E�E
���̂ւ��Agner���̉�͎������ڂ����B
Larrabee��P5�������Ă邩���Č����ƁA�����ĂȂ��Ƃ������Ȃ��B
�ŏ�����256�r�b�g��SIMD�������Ɏ��s�ł���悤�Ȏ��s���j�b�g�\���Ȃ�
V�p�C�v���ł��f�R�[�h�ł���킯�B
�܂����ۂ��������\���ɂ���̂��낤
���ɒ��j�Z�p�ƂȂ�ł��낤AVX�͐擪����1�`2�o�C�g����������ModRM�܂ł̖��ߒ�������ł��邩��
�t�����g�G���h�̕��S�͌y���ق����Ǝv����B
�\�[�X��2ch
ttp://en.expreview.com/2008/07/07/larrabee-unleashes-2-tflops-capacity/
Larrabee unleashes 2 TFLOPS capacity
Last month, Intel reported the Larrabee featuring IA(Intel Architecture) core,
which means it can adapt present x86 architecture. And now we get to know that
the IA core is actually P54C, which is well known for over 13 years since the Pentium 75, according
to Pat Gelsinger, the Intel�fs Chief Technology Officer.
And what�fs more, this monster requires a 300W TDP, which also frustrates NVIDIA�fs biggest monster.
�������������[��AVX�Ȃڂ�̂���
Larrabee unleashes 2 TFLOPS capacity
Last month, Intel reported the Larrabee featuring IA(Intel Architecture) core,
which means it can adapt present x86 architecture. And now we get to know that
the IA core is actually P54C, which is well known for over 13 years since the Pentium 75, according
to Pat Gelsinger, the Intel�fs Chief Technology Officer.
And what�fs more, this monster requires a 300W TDP, which also frustrates NVIDIA�fs biggest monster.
�������������[��AVX�Ȃڂ�̂���
356 �F�R�E�L�́M�E,,�j�����������������F2008/07/08(��) 17:25:13 ID:DKuSoTKQ
>>354
�u���b�N�_�C�A�O������������킩�邾��B
��������2ch�ł��̎�̒m������z�w�ǂ��Ȃ�
>>355
Intel��AVX�Ƃ͌݊����̖���256bit SIMD�����i��j�Ȃ�����B
�EAVX�ȊO�ɕʂɐV���ɗp�ӂ���ɂ�Opcode��Ԃɋ��Ȃ��B
�E�����I�ɂ͓������邽��Core MA�x�[�X�̃A�[�L�Ƃ�ISA���x���ł̌݊��������K�v������B
����AAVX�ł͂Ȃ��Ǝ咣����ق�������B
�uIA++�v�̍ŏ��̃v���[���ł�128�r�b�gSIMD��4GH���������Ǝv����
Larrabee�̒��g�����낢��ς�����ȂƎv����B
�u���b�N�_�C�A�O������������킩�邾��B
��������2ch�ł��̎�̒m������z�w�ǂ��Ȃ�
>>355
Intel��AVX�Ƃ͌݊����̖���256bit SIMD�����i��j�Ȃ�����B
�EAVX�ȊO�ɕʂɐV���ɗp�ӂ���ɂ�Opcode��Ԃɋ��Ȃ��B
�E�����I�ɂ͓������邽��Core MA�x�[�X�̃A�[�L�Ƃ�ISA���x���ł̌݊��������K�v������B
����AAVX�ł͂Ȃ��Ǝ咣����ق�������B
�uIA++�v�̍ŏ��̃v���[���ł�128�r�b�gSIMD��4GH���������Ǝv����
Larrabee�̒��g�����낢��ς�����ȂƎv����B
��U/V�p�C�v�̐���
�͒P�ɐ������Z���j�b�g���Q���������ɂ��Ă����̂悤��
ttp://tokushima.cool.ne.jp/msz006_2000/pentium.htm
Atom��CISC�p�C�v���ǂ����̘b��
�p�C�v���Q�{���邾�Ƃ�Larrabee��P6�Ƃ͈Ⴄ���Ƃ�
�ߋ���U��Ԃ��Ă���ɔn���������̂����̂Ђ�
�͒P�ɐ������Z���j�b�g���Q���������ɂ��Ă����̂悤��
ttp://tokushima.cool.ne.jp/msz006_2000/pentium.htm
Atom��CISC�p�C�v���ǂ����̘b��
�p�C�v���Q�{���邾�Ƃ�Larrabee��P6�Ƃ͈Ⴄ���Ƃ�
�ߋ���U��Ԃ��Ă���ɔn���������̂����̂Ђ�
358 �F�R�E�L�́M�E,,�j�����������������F2008/07/08(��) 17:49:23 ID:DKuSoTKQ
�܂��\�[�X�̓ǂݕ���������Ȃ����̈����q��
359 �F�R�E�L�́M�E,,�j�����������������F2008/07/08(��) 17:50:15 ID:DKuSoTKQ
�����Ђ���w���̒m���Ȃ̂Ő����ɊԈႢ������Ǝv���܂��B�f�����Ă���ӏ��ł���肪����\���͑��X����܂��̂�
���@���炩���߂������������B
�\�[�X�����_�����O���đf�G
���@���炩���߂������������B
�\�[�X�����_�����O���đf�G
360 �F�R�E�L�́M�E,,�j�����������������F2008/07/08(��) 17:52:11 ID:DKuSoTKQ
361 �F�R�E�L�́M�E,,�j�����������������F2008/07/08(��) 18:00:59 ID:DKuSoTKQ
>>357�̃e�L�X�g�����{�I�ɑʖڂȂ̂́A�p�C�v���C���̃X�e�[�W�̂P�\���v�f�ł���
�u���s���j�b�g�v�ƃp�C�v���C���S�̂��������ď����Ă邱�ƁB
�����Ă�����w�E�ł����ɓ��ӂ��Ɉ��p����̂͂���ȏ�̔n��
�u���s���j�b�g�v�ƃp�C�v���C���S�̂��������ď����Ă邱�ƁB
�����Ă�����w�E�ł����ɓ��ӂ��Ɉ��p����̂͂���ȏ�̔n��
�����т͂��������т��o����
2ch�ł��������
2ch�ł��������
363 �FMAC�I�^���c�q �����F2008/07/08(��) 18:08:53 ID:aP1OfaDq
>>347
�@�@------------------------------
�@�@��������Core 2����Nehalem�Ŗ��ߔ��s�|�[�g��5����6�|�[�g�ɑ������Ƃ�
�@�@��R�����Ă��L�҂���B
�@�@------------------------------
�܂��C�^���������݂�(��)
�������̌o����A�����炷�Bhttp://www.psi-project.jp/member/index.html
�@�@========================
�@�@���� �F �������
�@�@���� �F ������w�@�l��B��w ����Ռ����J���Z���^�[ �q������
�@�@�@�@�@ �x�m�ʊ�����Ё@�T�[�o�V�X�e�����Ɩ{���@�Z�t��
�@�@========================
���̑��A���X
http://www.cs.clemson.edu/~mark/architects.html#workstation
http://www2.dac.com/data2/44th/44AcceptedPapers.nsf/0/9BFD2FE7EFACF8728725728700632760
http://www.infoworld.com/article/04/02/18/HNgigahertz_1.html
�@�@------------------------------
�@�@��������Core 2����Nehalem�Ŗ��ߔ��s�|�[�g��5����6�|�[�g�ɑ������Ƃ�
�@�@��R�����Ă��L�҂���B
�@�@------------------------------
�܂��C�^���������݂�(��)
�������̌o����A�����炷�Bhttp://www.psi-project.jp/member/index.html
�@�@========================
�@�@���� �F �������
�@�@���� �F ������w�@�l��B��w ����Ռ����J���Z���^�[ �q������
�@�@�@�@�@ �x�m�ʊ�����Ё@�T�[�o�V�X�e�����Ɩ{���@�Z�t��
�@�@========================
���̑��A���X
http://www.cs.clemson.edu/~mark/architects.html#workstation
http://www2.dac.com/data2/44th/44AcceptedPapers.nsf/0/9BFD2FE7EFACF8728725728700632760
http://www.infoworld.com/article/04/02/18/HNgigahertz_1.html
>>636
���{�̋Z�p�҂��Ăق�ƃo�J�ȂȂ��Ďv���B
�^�ʖڂɍl��������Ƃ������Ƃ������Ƃ�������l(������Ύ�)�Ȃ̂ɁE�E�E
���\���������Ȕ��������Ă���̂��ɂ��l
���{�̋Z�p�҂��Ăق�ƃo�J�ȂȂ��Ďv���B
�^�ʖڂɍl��������Ƃ������Ƃ������Ƃ�������l(������Ύ�)�Ȃ̂ɁE�E�E
���\���������Ȕ��������Ă���̂��ɂ��l
363w
Wall Street Journal�ɂ��ƁADreamworks��CG����p�̃V�X�e����AMD����Intel�ɏ�芷����
�Ƃ̂��Ƃ��BNehalem�̕����f������̐��\���������ƂŌ��f�����Ƃ̂��Ƃ��B
http://online.wsj.com/article/SB121548418107834867.html
�Ƃ̂��Ƃ��BNehalem�̕����f������̐��\���������ƂŌ��f�����Ƃ̂��Ƃ��B
http://online.wsj.com/article/SB121548418107834867.html
�G�������͂������Ęb���炵���Ă������Ă��Ƃ�
Atom�̃\�[�X�͊F�������Ă��Ƃ�
Atom�̃\�[�X�͊F�������Ă��Ƃ�
http://www.watch.impress.co.jp/akiba/hotline/20080705/sp_fsegb.html
Phenom X4 9100e�̒�i1.8GHz��800MHz����Ƃ����_�E���N���b�N�����s�����Ƃ���g���u�������B
OS���N�����Ȃ��Ȃ��Ă��܂���
Phenom X4 9100e�̒�i1.8GHz��800MHz����Ƃ����_�E���N���b�N�����s�����Ƃ���g���u�������B
OS���N�����Ȃ��Ȃ��Ă��܂���
�������㓡�̋L���J���j���O���ē����ԈႢ���������͎̂��������ȁB
���F�_�ł����l�ł��Ȃ���B
��������P6�ȍ~��x86��CISC�p�C�v���C����RISC�p�C�v���C�����Ȃ�đ��ΓI�Ȃ��̂ɉ߂��Ȃ��B
�������ւ����SPARC�A�[�L�݂����ȏ�RISC���猩���x86�͂���ς�ǂ��܂ł�CISC�����A
P6�ȑO��x86���猩���RISC�I���B
Intel��PPro����Core2,������Atom�ɓ����t�@�~�������������̂͂���ς�
���F�_�ł����l�ł��Ȃ���B
��������P6�ȍ~��x86��CISC�p�C�v���C����RISC�p�C�v���C�����Ȃ�đ��ΓI�Ȃ��̂ɉ߂��Ȃ��B
�������ւ����SPARC�A�[�L�݂����ȏ�RISC���猩���x86�͂���ς�ǂ��܂ł�CISC�����A
P6�ȑO��x86���猩���RISC�I���B
Intel��PPro����Core2,������Atom�ɓ����t�@�~�������������̂͂���ς�
FamilyID��6�Ȃ̂̓\�t�g�E�F�A�̌݊����̓s���ザ��Ȃ��̂��B
�r���œ��e���������
Intel��6���Ă����Ȃ�6�Ȃ낤�B
�ŁA�����̊ԈႢ�̌���
Intel�A�[�L��Store��Store Adress��Store Data�ɕ�����Ă�̂�P6���ォ��Ȃ�
Intel�͎����ɂ����1�Ƃ��ď�������ʁX�ɏ������肵�Ă�B
�����Core2��Store 1�̐}�ANehalem�͕����ď����Ă���}�����āA�㓡�����Ⴂ�����̂��n�܂�B
�����Č㓡�Ɠ����ԈႢ��匴�A�����ƘA���I�ɂ�������Ƃ�
�ނ�̃J���j���O�̎���Intel�A�[�L�̗����̔������I�悵���킯�B
�܂��ނ�̋L���͉R����������b�����ɕ����Ȃ��ƃ_��
Intel��6���Ă����Ȃ�6�Ȃ낤�B
�ŁA�����̊ԈႢ�̌���
Intel�A�[�L��Store��Store Adress��Store Data�ɕ�����Ă�̂�P6���ォ��Ȃ�
Intel�͎����ɂ����1�Ƃ��ď�������ʁX�ɏ������肵�Ă�B
�����Core2��Store 1�̐}�ANehalem�͕����ď����Ă���}�����āA�㓡�����Ⴂ�����̂��n�܂�B
�����Č㓡�Ɠ����ԈႢ��匴�A�����ƘA���I�ɂ�������Ƃ�
�ނ�̃J���j���O�̎���Intel�A�[�L�̗����̔������I�悵���킯�B
�܂��ނ�̋L���͉R����������b�����ɕ����Ȃ��ƃ_��
>>370
���ۂ͊g��Model�g�������ƂŋN�����g���u���̂ق��������B
Adobe���i�ł���ConroeL��Mendocino,Penryn��Katmai�ƌ�F�����Čx����f����肪�N�����B
���ۂ͊g��Model�g�������ƂŋN�����g���u���̂ق��������B
Adobe���i�ł���ConroeL��Mendocino,Penryn��Katmai�ƌ�F�����Čx����f����肪�N�����B
373 �F�R�E�L�́M�E,,�j�����������������F2008/07/08(��) 19:16:37 ID:DKuSoTKQ
Family�l8�`14�g�����Ƃ��Ăăg���u���N�����\���̂���悤�ȃv���O������
Ext.Model�Ȃ���Ȃ��Ȃ�ėL�蓾�Ȃ����ƁB
Ext.Model�Ȃ���Ȃ��Ȃ�ėL�蓾�Ȃ����ƁB
FamilyID�i&cpu�j�ŃO�O������
CPU�A�[�L�e�N�`���ɂ��Č�� 9
���q�b�g���Ă��̒���
ttp://pc.watch.impress.co.jp/docs/2008/0207/kaigai417.htm
��Atom�͂��W�U���߂��f�R�[�_�Ń�OP���ɂ������ڎ��s����
�Ƃ������X�ɁF,,�E�L�́M�E,,�j��-�������F�͕��ʂɘb��ɏ�������Ă���s�����H
���_�C���N�g�Ɂi���������Ɂj���s�ł���낤�ˁB
����Ƃ��P�ɑS�������o���ĂȂ��������H
�܂�����
�Ƃ肠����Atom��CoreMA�ɋ߂��Ƃ����
����CoreMA�́u���͂����RISC�ł͂Ȃ��v�A�[�L
Larrabee��P5�x�[�X�Ƃ̂��Ƃ���
���ۂ�CoreMA�̈������x�Ȃ̂�
����Ƃ����̈���ݏo����P5�ɂȂ��Ă��܂��̂�
CPU�A�[�L�e�N�`���ɂ��Č�� 9
���q�b�g���Ă��̒���
ttp://pc.watch.impress.co.jp/docs/2008/0207/kaigai417.htm
��Atom�͂��W�U���߂��f�R�[�_�Ń�OP���ɂ������ڎ��s����
�Ƃ������X�ɁF,,�E�L�́M�E,,�j��-�������F�͕��ʂɘb��ɏ�������Ă���s�����H
���_�C���N�g�Ɂi���������Ɂj���s�ł���낤�ˁB
����Ƃ��P�ɑS�������o���ĂȂ��������H
�܂�����
�Ƃ肠����Atom��CoreMA�ɋ߂��Ƃ����
����CoreMA�́u���͂����RISC�ł͂Ȃ��v�A�[�L
Larrabee��P5�x�[�X�Ƃ̂��Ƃ���
���ۂ�CoreMA�̈������x�Ȃ̂�
����Ƃ����̈���ݏo����P5�ɂȂ��Ă��܂��̂�
375 �F�R�E�L�́M�E,,�j�����������������F2008/07/08(��) 19:43:00 ID:DKuSoTKQ
Google�����\�̒m�b��^���Ă����Ǝv���Ă�ɂ��q������ˁB
�f�R�[�h�����鎞�_�Łu���ڎ��s�v�Ƃ͌���Ȃ���
�������A�h���b�V���O�����߂������Ɏ��s�ł���Ƃ����Ӗ��ł�
EU�̎�O�ŕ�������PenM/CoreMA���͒��ړI�ƌ������܂ł���
�f�R�[�h�����鎞�_�Łu���ڎ��s�v�Ƃ͌���Ȃ���
�������A�h���b�V���O�����߂������Ɏ��s�ł���Ƃ����Ӗ��ł�
EU�̎�O�ŕ�������PenM/CoreMA���͒��ړI�ƌ������܂ł���
376 �F�R�E�L�́M�E,,�j�����������������F2008/07/08(��) 19:53:37 ID:DKuSoTKQ
���Ȃ݂ɊeALU�̎�O��AGU���Ԃ牺�����Ă���ĈӖ��ł�Athlon�ȍ~��AMD�v���Z�b�T�ɋ߂�
���������˂����݂����̂͂�����B
P54C��MMX��������E�E�E
�Ƃ����ܖ�������̘b�͂Ƃ������A
�ϑ�2�p�C�v�܂܂Ȃ̂��˂�>����
32bit���ɂ�����P5�A�[�L�e�N�`���ł̍œK����@���āA
����ȂɌ������i��ł��C���[�W���Ȃ��̂����ǁB
P54C��MMX��������E�E�E
�Ƃ����ܖ�������̘b�͂Ƃ������A
�ϑ�2�p�C�v�܂܂Ȃ̂��˂�>����
32bit���ɂ�����P5�A�[�L�e�N�`���ł̍œK����@���āA
����ȂɌ������i��ł��C���[�W���Ȃ��̂����ǁB
378 �F�R�E�L�́M�E,,�j�����������������F2008/07/08(��) 20:14:11 ID:DKuSoTKQ
P54C��P55C����MMX�T�|�[�g�ƃN���b�N����̂��߃p�C�v���C���i����1�i�������ȊO
�قړ����\���Ȃ��B
MMX�̓C�X���G���`�[��������ł邩��Г������I�Ȗ���P54C���Ĕ��������\��������B
�[���A256�r�b�gSIMD���߂�4Way�X���b�h�T�|�[�g�A2GH���I�[�o�[�̃N���b�N�ɑς�����p�C�v���C���\��
������ǂ݂̂�P54C��P55C�̍��ȏ�ɑ啝�ɕʕ��ɂȂ邼
�قړ����\���Ȃ��B
MMX�̓C�X���G���`�[��������ł邩��Г������I�Ȗ���P54C���Ĕ��������\��������B
�[���A256�r�b�gSIMD���߂�4Way�X���b�h�T�|�[�g�A2GH���I�[�o�[�̃N���b�N�ɑς�����p�C�v���C���\��
������ǂ݂̂�P54C��P55C�̍��ȏ�ɑ啝�ɕʕ��ɂȂ邼
379 �FMAC�I�^���c�q �����F2008/07/08(��) 20:16:16 ID:jyYpyOba
>>375
�@�@----------------
�@�@�f�R�[�h�����鎞�_�Łu���ڎ��s�v�Ƃ͌���Ȃ���
�@�@----------------
���������g���f���ϑz�ɂ�A�ǂ̂悤�ɔ������ׂ��Ȃ��ˁB�B�B
http://www.intel.co.jp/jp/business/glossary/5785635.htm
�@�@=================
�@�@CPU ���O�����琧�䂷��ꍇ�̖��ߒP�ʂ́u�C���X�g���N�V�����v�����ACPU �����ł́A
�@�@���閽�߂����s���邽�߂ɕK�v�Ȉ�A�̎葱�����}�C�N���R�[�h�Ƃ��ċL�q����Ă��܂��B
�@�@[����]
�@�@�����̖��߃Z�b�g���T�|�[�g����]���̃}�C�N���R�[�h�x�[�X�̃R���s���[�^�[�� CISC
�@�@(Complex Instruction Set Computers) �ƌĂ��悤�ɂȂ�܂����B
�@�@=================
�@�@----------------
�@�@�f�R�[�h�����鎞�_�Łu���ڎ��s�v�Ƃ͌���Ȃ���
�@�@----------------
���������g���f���ϑz�ɂ�A�ǂ̂悤�ɔ������ׂ��Ȃ��ˁB�B�B
http://www.intel.co.jp/jp/business/glossary/5785635.htm
�@�@=================
�@�@CPU ���O�����琧�䂷��ꍇ�̖��ߒP�ʂ́u�C���X�g���N�V�����v�����ACPU �����ł́A
�@�@���閽�߂����s���邽�߂ɕK�v�Ȉ�A�̎葱�����}�C�N���R�[�h�Ƃ��ċL�q����Ă��܂��B
�@�@[����]
�@�@�����̖��߃Z�b�g���T�|�[�g����]���̃}�C�N���R�[�h�x�[�X�̃R���s���[�^�[�� CISC
�@�@(Complex Instruction Set Computers) �ƌĂ��悤�ɂȂ�܂����B
�@�@=================
�C�X���G��������ł�̂�P55C�ł͂Ȃ��m�[�g�p��Tilamook
381 �F�R�E�L�́M�E,,�j�����������������F2008/07/08(��) 20:24:33 ID:DKuSoTKQ
�������������́H
382 �F�R�E�L�́M�E,,�j�����������������F2008/07/08(��) 20:28:00 ID:DKuSoTKQ
383 �F�R�E�L�́M�E,,�j�����������������F2008/07/08(��) 20:33:12 ID:DKuSoTKQ
�K�Z���������
�łȂ��Ƃ�MMX���瑱���Ă���0f�`��SIMD���߃t�H�[�}�b�g��0����č\�z����̂�
MMX�̖��O�͏o�������Ȃ��v�f���������Ǝv��
�łȂ��Ƃ�MMX���瑱���Ă���0f�`��SIMD���߃t�H�[�}�b�g��0����č\�z����̂�
MMX�̖��O�͏o�������Ȃ��v�f���������Ǝv��
Turion X2 Ultra �� Family 11h �炵��
ttp://developer.amd.com/cpu/CodeAnalyst/codeanalystwindows/Pages/default.aspx
> Supports new performance monitoring events provided by the newest addition to
> our processor line up, the AMD Turion? X2 Ultra (AMD Family 11h) processors
ttp://developer.amd.com/cpu/CodeAnalyst/codeanalystwindows/Pages/default.aspx
> Supports new performance monitoring events provided by the newest addition to
> our processor line up, the AMD Turion? X2 Ultra (AMD Family 11h) processors
>380
������m�ɏ���Ă�z����������?
�������ő�300MHz�܂ł������z�B
>378
���A����A���ӂ͂Ȃ���B
�����A���������b���o���̂œ˂�����ł݂����Ȃ��������ŁB
�ǂ���SIMD�g���n�͍�蒼�����낤���A
���������Ӗ��Ő���P5�ƌ��������āAP54C�ƌ����Ă�̂��ȁA�Ƃ��v�����B
�������U��Ԃ�ƁAP5�n��16bit����32bit�ւ̈ڍs����S����CPU�Ȃ�Ȃ��B
���܂���64bit�Ɉڍs���悤�Ƃ������̎����ɁA�Ăюp�������ƂȂ�ƁA
�������S�[�����̂�����ˁB
������m�ɏ���Ă�z����������?
�������ő�300MHz�܂ł������z�B
>378
���A����A���ӂ͂Ȃ���B
�����A���������b���o���̂œ˂�����ł݂����Ȃ��������ŁB
�ǂ���SIMD�g���n�͍�蒼�����낤���A
���������Ӗ��Ő���P5�ƌ��������āAP54C�ƌ����Ă�̂��ȁA�Ƃ��v�����B
�������U��Ԃ�ƁAP5�n��16bit����32bit�ւ̈ڍs����S����CPU�Ȃ�Ȃ��B
���܂���64bit�Ɉڍs���悤�Ƃ������̎����ɁA�Ăюp�������ƂȂ�ƁA
�������S�[�����̂�����ˁB
387 �F�R�E�L�́M�E,,�j�����������������F2008/07/08(��) 20:38:30 ID:DKuSoTKQ
Bulldozer��12h����13h�����ɂȂ���ď��͂������ȁB
����FamilyID��Marketecture�͈�v���Ȃ��A�ƁB
����FamilyID��Marketecture�͈�v���Ȃ��A�ƁB
2ch�ȏ�̃\�[�X��ް�H
389 �FMAC�I�^��388 �����F2008/07/08(��) 20:40:07 ID:jyYpyOba
>>388
���̃\�[�X��T���Ă��邷���H
���̃\�[�X��T���Ă��邷���H
�_���S�̔����̖ϑz�ȊO�̃\�[�X�͂܂��ł����H
Andreas Stiller �̖ϑz�ȊO�̏ݖ����܂���
392 �F�R�E�L�́M�E,,�j�����������������F2008/07/08(��) 20:50:21 ID:DKuSoTKQ
Atom��CPUID��Family=6
http://download.intel.com/design/chipsets/embedded/specupdt/319536.pdf
�n�C�����s�������H
http://download.intel.com/design/chipsets/embedded/specupdt/319536.pdf
�n�C�����s�������H
��C�X���G���`�[���̋N���ɂ��āB
394 �F�R�E�L�́M�E,,�j�����������������F2008/07/08(��) 20:58:25 ID:DKuSoTKQ
Larrabee�V���߁�AVX�̍����i�\�[�X�͌㓡�j
http://pc.watch.impress.co.jp/docs/2007/1012/kaigai393.htm
>��Larrabee�����̑傫�Ȗ��߃Z�b�g�g��
>
>�@�������ALarrabee�ł͖��߃Z�b�g���̂��g������B���Ȃ��Ƃ�Intel��Digital Enterprise
>Group�́ALarrabee��IA���߃Z�b�g�̎��̃��x���̊g���ƌ��Ȃ��Ă���BPatrick(Pat)
> P. Gelsinger(�p�b�g�EP�E�Q���V���K�[)��(Senior Vice President and General Manager, Digital Enterprise Group)�́A���̂悤�Ɍ��B
>
>�@�u��X�́A���߃Z�b�g���f���́A�A�[�L�e�N�`���A�v���[�`�̖{���I�ȕ����ł���
> ��т���K�v������ƍl���Ă���BCell B.E.���n�߂Ƃ����A�v���[�`���������Ă��Ȃ��̂́A
> ����炪���߃Z�b�g�̊g���ɑ����т����l�����������Ă��Ȃ����߂��ƍl���Ă���B
>�@��X�́A�����ɂ킽���āA���߃Z�b�g������Ɋg���������邱�Ƃ��ł���ƌ��Ă���B
> SSE4�\�������A����ȍ~��SSE�̒�`���i�߂Ă���B����ɁA���傫�Ȗ��߃Z�b�g��
> �g�����ALarrabee�̈ꕔ�Ƃ��Đi�߂Ă���B�܂�AILP(Instruction-Level Parallelism)��
> ���߂邾���łȂ��A�V���߃Z�b�g���f���ɂ��A�x�N�^���x���̕������߂Ă䂭�B
> ���N(2008�N)�ɂ́A���߃Z�b�g�ɂ��Ă����Əڍׂ𖾂炩�ɂł��邾��
http://pc.watch.impress.co.jp/docs/2007/1012/kaigai393.htm
>��Larrabee�����̑傫�Ȗ��߃Z�b�g�g��
>
>�@�������ALarrabee�ł͖��߃Z�b�g���̂��g������B���Ȃ��Ƃ�Intel��Digital Enterprise
>Group�́ALarrabee��IA���߃Z�b�g�̎��̃��x���̊g���ƌ��Ȃ��Ă���BPatrick(Pat)
> P. Gelsinger(�p�b�g�EP�E�Q���V���K�[)��(Senior Vice President and General Manager, Digital Enterprise Group)�́A���̂悤�Ɍ��B
>
>�@�u��X�́A���߃Z�b�g���f���́A�A�[�L�e�N�`���A�v���[�`�̖{���I�ȕ����ł���
> ��т���K�v������ƍl���Ă���BCell B.E.���n�߂Ƃ����A�v���[�`���������Ă��Ȃ��̂́A
> ����炪���߃Z�b�g�̊g���ɑ����т����l�����������Ă��Ȃ����߂��ƍl���Ă���B
>�@��X�́A�����ɂ킽���āA���߃Z�b�g������Ɋg���������邱�Ƃ��ł���ƌ��Ă���B
> SSE4�\�������A����ȍ~��SSE�̒�`���i�߂Ă���B����ɁA���傫�Ȗ��߃Z�b�g��
> �g�����ALarrabee�̈ꕔ�Ƃ��Đi�߂Ă���B�܂�AILP(Instruction-Level Parallelism)��
> ���߂邾���łȂ��A�V���߃Z�b�g���f���ɂ��A�x�N�^���x���̕������߂Ă䂭�B
> ���N(2008�N)�ɂ́A���߃Z�b�g�ɂ��Ă����Əڍׂ𖾂炩�ɂł��邾��
������Ȃ����t�V�т͂�߂��B
������Ɛ̂��v���o���A�c�q����̒f���̐M�ߓx�Ȃ�Ă���ȃ������B
Nehalem�Ŋ��ɂ��̑̂��炭������A���ʂ邭������Ă����ė~�������B
http://pc11.2ch.net/test/read.cgi/jisaku/1174309818/396
�@�@--------------------
�@�@396 ���O�F�E�́E�j��-������ ���e���F2007/04/19(��) 21:00:02 ID:6E1sFwXl
�@�@�@�@�t�F�b�`�ш悪16�o�C�g�̂܂܂��Ǝv������������A�d�g�ł����Ȃ��B
�@�@--------------------
http://pc.watch.impress.co.jp/docs/2008/0428/kaigai438.htm
�@�@====================
�@�@��16bytes���߃t�F�b�`�͓d�͌�������g����������
�@�@====================
Nehalem�Ŋ��ɂ��̑̂��炭������A���ʂ邭������Ă����ė~�������B
http://pc11.2ch.net/test/read.cgi/jisaku/1174309818/396
�@�@--------------------
�@�@396 ���O�F�E�́E�j��-������ ���e���F2007/04/19(��) 21:00:02 ID:6E1sFwXl
�@�@�@�@�t�F�b�`�ш悪16�o�C�g�̂܂܂��Ǝv������������A�d�g�ł����Ȃ��B
�@�@--------------------
http://pc.watch.impress.co.jp/docs/2008/0428/kaigai438.htm
�@�@====================
�@�@��16bytes���߃t�F�b�`�͓d�͌�������g����������
�@�@====================
>374��>345�Ɩ������Ă邾��Ƃ����Ӑ}�ŏo�������̂���
�����G���߂�
�Ƃ����̂������Ƃ��Ă����̂Ŗ��Ӗ��Ɖ����Ă��܂���
���ǁuAtom�͕��G���߂�RISC�����邩�v�������Ȃ���Ȃ�Ȃ����ƂɂȂ邪
��������������
ttp://www.watch.impress.co.jp/pc/docs/article/20011102/kaigai01.jpg
����RISC��K8��x86�����ĕϊ����āE�E�E�Ƃ����̂����̐}�̐������画�邪
ttp://pc.watch.impress.co.jp/docs/2008/0207/kaigai417_05l.gif
�������͂ǂ��Ȃ��Ă����
������CoreMA�ł͔��s�̒��O�܂ł�
�P�����G�ɊW�����t���[�W��������悤��
ttp://pc.watch.impress.co.jp/docs/2006/0626/kaigai285.htm
�Ƃ������Ƃ�
�uAtom�͒P���Ȗ��߂͋�ʂ���Core����Fusion��
�@���G�Ȗ��߂���������P6���ɂ�����RISC�����Ă���v
���ǂ����Ƃ������ƂɂȂ�
�ȑf���̂��߂ɃC���I�[�_�ɂ���Atom�ɂ���Ȃ����ɂ����G�����ȋ@�\��t���邩�H
�܂��A�������낤��
�����G���߂�
�Ƃ����̂������Ƃ��Ă����̂Ŗ��Ӗ��Ɖ����Ă��܂���
���ǁuAtom�͕��G���߂�RISC�����邩�v�������Ȃ���Ȃ�Ȃ����ƂɂȂ邪
��������������
ttp://www.watch.impress.co.jp/pc/docs/article/20011102/kaigai01.jpg
{kind=link}
����RISC��K8��x86�����ĕϊ����āE�E�E�Ƃ����̂����̐}�̐������画�邪
ttp://pc.watch.impress.co.jp/docs/2008/0207/kaigai417_05l.gif
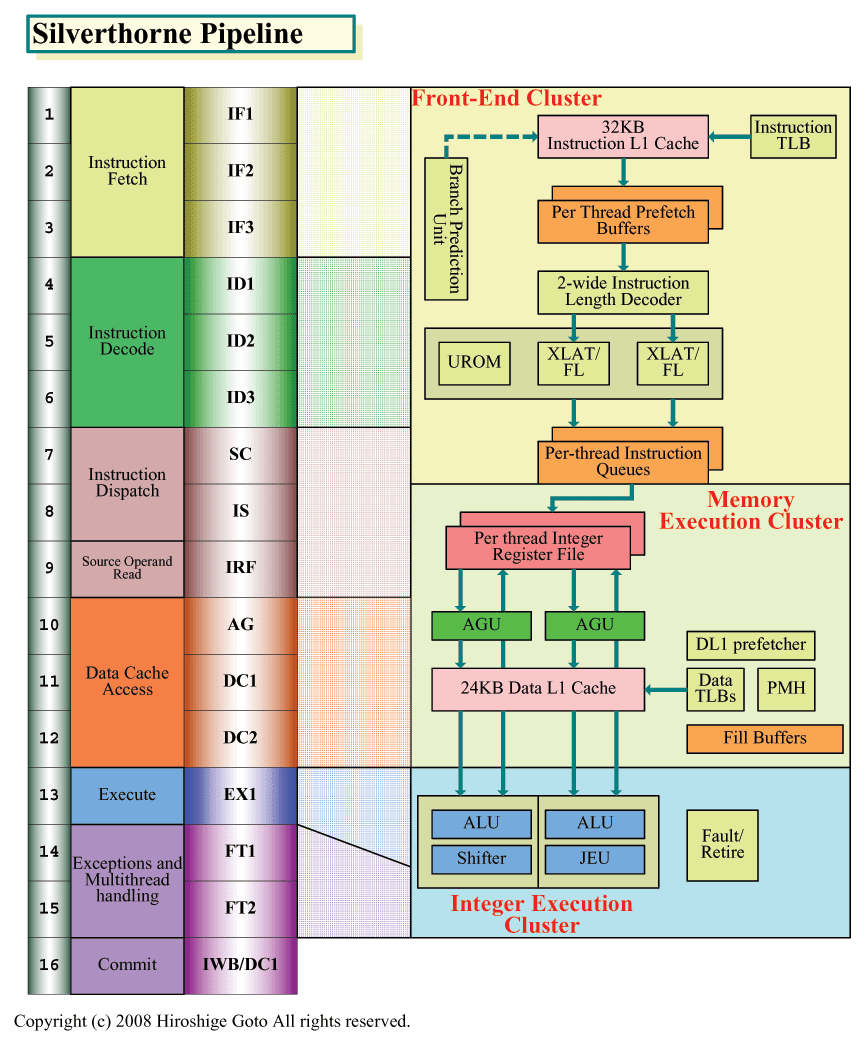{kind=link}
�������͂ǂ��Ȃ��Ă����
������CoreMA�ł͔��s�̒��O�܂ł�
�P�����G�ɊW�����t���[�W��������悤��
ttp://pc.watch.impress.co.jp/docs/2006/0626/kaigai285.htm
�Ƃ������Ƃ�
�uAtom�͒P���Ȗ��߂͋�ʂ���Core����Fusion��
�@���G�Ȗ��߂���������P6���ɂ�����RISC�����Ă���v
���ǂ����Ƃ������ƂɂȂ�
�ȑf���̂��߂ɃC���I�[�_�ɂ���Atom�ɂ���Ȃ����ɂ����G�����ȋ@�\��t���邩�H
�܂��A�������낤��
398 �FMAC�I�^��397 �����F2008/07/08(��) 21:45:57 ID:jyYpyOba
>>397
Atom�Ɋւ��Ă�AISSCC2008�̘_���ł����L�q����Ă��邷�B��������\�����l���Ă�
���܂�Ӗ��햳�����B
http://download.intel.com/pressroom/kits/isscc/ISSC_Intel_Paper_Silverthorne.pdf
�@�@------------------
�@�@The pipeline is tailored to execute IA instructions as single atomic operations consisting
�@�@of a single destination register and up to three source-registers and adheres to the
�@�@Load-Op-Store instruction format.
�@�@------------------
"atomic operation"�ɂ��Ă�A�����炷�B
http://ja.wikipedia.org/wiki/%E4%B8%8D%E5%8F%AF%E5%88%86%E6%93%8D%E4%BD%9C
Atom�Ɋւ��Ă�AISSCC2008�̘_���ł����L�q����Ă��邷�B��������\�����l���Ă�
���܂�Ӗ��햳�����B
http://download.intel.com/pressroom/kits/isscc/ISSC_Intel_Paper_Silverthorne.pdf
�@�@------------------
�@�@The pipeline is tailored to execute IA instructions as single atomic operations consisting
�@�@of a single destination register and up to three source-registers and adheres to the
�@�@Load-Op-Store instruction format.
�@�@------------------
"atomic operation"�ɂ��Ă�A�����炷�B
http://ja.wikipedia.org/wiki/%E4%B8%8D%E5%8F%AF%E5%88%86%E6%93%8D%E4%BD%9C
�E�E�E������Ƒ҂��Ă���Batom�͏�CISC�Ȃ̂��H
�E�E�E����͂��蓾��A�ƌl�I�ɂ͎v�����A
�Ȃ\�[�X������̂����ȁB
�l�g�o�Ƃ��Ɣ�ׂĂ��CISC���A�Ƃ��������x������Ȃ��āB
���̒m���Ă�͈͂ł́A�Ō�̏�CISC��x86�́A
cyrix��M2�������ƋL�����Ă���E�E�E
���łɎ֑��Ȃ���A
CISC���A�p�C�v���C���ƌĂ��@�\��L����x86�n�Ƃ��Ă�
���Ȃ��Ƃ�i486���������܂��B
���݂ł����Ƃ���̃p�C�v���C���Ƃ͂��ƈႤ���ǁB
���������A(���܂�ڂ����Ȃ��̂Ō����̂��݂��邪)�A
�X�e�[�W�������̃p�C�v���C���ŁA����CISC�Ƃ����̂�
�ǂ������\�����w���̂��悭������Ȃ��A���ȁH
�X�e�[�W���̃p�C�v���C���́A�܂���RISC�̖{�ہA��
�����ׂ����̂��ƋL�����Ă���ǁB
�E�E�E����͂��蓾��A�ƌl�I�ɂ͎v�����A
�Ȃ\�[�X������̂����ȁB
�l�g�o�Ƃ��Ɣ�ׂĂ��CISC���A�Ƃ��������x������Ȃ��āB
���̒m���Ă�͈͂ł́A�Ō�̏�CISC��x86�́A
cyrix��M2�������ƋL�����Ă���E�E�E
���łɎ֑��Ȃ���A
CISC���A�p�C�v���C���ƌĂ��@�\��L����x86�n�Ƃ��Ă�
���Ȃ��Ƃ�i486���������܂��B
���݂ł����Ƃ���̃p�C�v���C���Ƃ͂��ƈႤ���ǁB
���������A(���܂�ڂ����Ȃ��̂Ō����̂��݂��邪)�A
�X�e�[�W�������̃p�C�v���C���ŁA����CISC�Ƃ����̂�
�ǂ������\�����w���̂��悭������Ȃ��A���ȁH
�X�e�[�W���̃p�C�v���C���́A�܂���RISC�̖{�ہA��
�����ׂ����̂��ƋL�����Ă���ǁB
�E�E�E�܂��A���������ARISC��CISC�̋��E���ǂ��ɒu�����A�Ƃ����_��
�s��ł���ȏ�ARISC��CISC���A�Ƃ����c�_�͈Ӗ��Ȃ����ǂˁB
�E�E�E���A���̎�̋c�_�́A���X�����O�ɂ��������ɂȂ����L��������B
�l�I�ɂ́A�������߂ŃX���[�v�b�g���P�ȏ�̖��߂�
����̂���m�肽�����ǂˁB(x87�͕ʂƂ���)
����Ȃ�ACISC�Ƃ����咣���A�܂������͂ł��Ȃ��͂Ȃ��A�̂����B
�s��ł���ȏ�ARISC��CISC���A�Ƃ����c�_�͈Ӗ��Ȃ����ǂˁB
�E�E�E���A���̎�̋c�_�́A���X�����O�ɂ��������ɂȂ����L��������B
�l�I�ɂ́A�������߂ŃX���[�v�b�g���P�ȏ�̖��߂�
����̂���m�肽�����ǂˁB(x87�͕ʂƂ���)
����Ȃ�ACISC�Ƃ����咣���A�܂������͂ł��Ȃ��͂Ȃ��A�̂����B
401 �F�R�E�L�́M�E,,�j�����������������F2008/07/08(��) 22:08:12 ID:DKuSoTKQ
Core 2�ł̖��߃t�F�b�`�ш�̕s����SIMD�̖��ߒ����傫���Ȃ肷�������Ƃɒ[���Ă�킯��
���߃Z�b�g�̃��Z�b�g���K�v�����ǁA���܂�g���ĂȂ�1byte Opcode��ׂ��Ė��ߒ����R���p�N�g�ɂ���Ƃ����A�v���[�`���Ƃ��
�ш���g�[���ƂȂ������ł��邱�Ƃ��������猾�y���Ă��ȁB
���ƁAimm8�����W�X�^�w��Ɏg���I�y�����h�����₹����Č�������d�g�������ꂽ�̂������v���o�B
���ߒ��̐ߖ���Ċϓ_���炷���16bit disp�g���Ȃ��͕̂s�ւ��ˁB
���ƁASIB��Scale�r�b�g���g�����ė~�����ȁB1�r�b�g�lj���16, 32, 64, 128�{�ł���B
����16�{��SSE*�g���Ă�Ǝg���������Ƃ��悭����B
���߃Z�b�g�̃��Z�b�g���K�v�����ǁA���܂�g���ĂȂ�1byte Opcode��ׂ��Ė��ߒ����R���p�N�g�ɂ���Ƃ����A�v���[�`���Ƃ��
�ш���g�[���ƂȂ������ł��邱�Ƃ��������猾�y���Ă��ȁB
���ƁAimm8�����W�X�^�w��Ɏg���I�y�����h�����₹����Č�������d�g�������ꂽ�̂������v���o�B
���ߒ��̐ߖ���Ċϓ_���炷���16bit disp�g���Ȃ��͕̂s�ւ��ˁB
���ƁASIB��Scale�r�b�g���g�����ė~�����ȁB1�r�b�g�lj���16, 32, 64, 128�{�ł���B
����16�{��SSE*�g���Ă�Ǝg���������Ƃ��悭����B
>>399
ttp://home.att.ne.jp/theta/OSAKOH2/topics/Intel_Atom.html
�����M�p����CoreMA�����ƌ��Ă�
������CoreMA�́u���͂����RISC�ł͂Ȃ�(it's no longer RISC Processor inside)�v��
�Ō��RISC�ł���ɂ��Ă����������邭�炢�Ȃ�CISC���Ȃ�
ttp://home.att.ne.jp/theta/OSAKOH2/topics/Intel_Atom.html
�����M�p����CoreMA�����ƌ��Ă�
������CoreMA�́u���͂����RISC�ł͂Ȃ�(it's no longer RISC Processor inside)�v��
�Ō��RISC�ł���ɂ��Ă����������邭�炢�Ȃ�CISC���Ȃ�
403 �FMAC�I�^���c�q �����F2008/07/08(��) 22:13:03 ID:jyYpyOba
>>401
�ϓ_����ɊԈ���Ă��Ȃ�������ŁA�v�����݂��L�c�߂��Ȃ���c�_�Ƃ��Ă퍡�ł��\�������[�����B
�����������ɓ˂����݂����邷���ǁA�C�ɂ����ɍD���Ȃ��Ə����ė~�������B
�ϓ_����ɊԈ���Ă��Ȃ�������ŁA�v�����݂��L�c�߂��Ȃ���c�_�Ƃ��Ă퍡�ł��\�������[�����B
�����������ɓ˂����݂����邷���ǁA�C�ɂ����ɍD���Ȃ��Ə����ė~�������B
�P�ȏ���ĉ���>���B
�P��葽���A����(�Q�ȏ�)�B
���A
ttp://pc.watch.impress.co.jp/docs/2008/0207/kaigai417_05l.gif
����������ł́A�R�i��InstructionDecode�����邵�A
x86�ڎ��s���Ă�悤�ɂ͌����Ȃ��ȁE�E�E����ς�B
�܂����̃p�C�v���C���ŁA1�������߂̎��s��
2�X�e�b�v�ȏォ����悤�ȍ\���ɂȂ��Ă���Ƃ́A�܂��ӂ��v���Ȃ����ǂˁB
�܂��A������l�̒��ł�RISC�ρACISC�ς̖��ł����Ȃ��̂��낤���ǁB
�P��葽���A����(�Q�ȏ�)�B
���A
ttp://pc.watch.impress.co.jp/docs/2008/0207/kaigai417_05l.gif
����������ł́A�R�i��InstructionDecode�����邵�A
x86�ڎ��s���Ă�悤�ɂ͌����Ȃ��ȁE�E�E����ς�B
�܂����̃p�C�v���C���ŁA1�������߂̎��s��
2�X�e�b�v�ȏォ����悤�ȍ\���ɂȂ��Ă���Ƃ́A�܂��ӂ��v���Ȃ����ǂˁB
�܂��A������l�̒��ł�RISC�ρACISC�ς̖��ł����Ȃ��̂��낤���ǁB
405 �F�R�E�L�́M�E,,�j�����������������F2008/07/08(��) 22:15:11 ID:DKuSoTKQ
������ALU��AGU�̃y�A�����O��AMD��K7����i����
�������ޑO�Ƀ����[�h����悩�����B
>402
�܂��ACoreMA�ɂ��Ă��Aatom�ɂ��Ă��A
MacroFusion�Ƃ����Ax86�̖��ߋ����ăf�R�[�h����A
�Ƃ����Ӗ��ł͍ݗ��^����RISC�Ƃ͈�����悷�A�Ƃ����͓̂��ӁB
�����A������CISC���A�ƌ�����ƁA�����f�R�[�h������ȏ�
�����ł͂Ȃ��A�Ɗ�������͂����v����킯�ŁB
���Ԃ�A���̕ӂ�486����P6�̐���������ʼn߂����Ă����l�ԂɂƂ��Ă�
����Ȃ�ɓ��ӂ��Ă��炦��Ǝv�����ǁB
RISC�̓����́A(�T�ˁA������)�X���[�v�b�g��1�ł���A
����̃p�C�v���C������������A�ƌl�I�ɂ͎v���Ă����
(���������ǂ����͂����)�ŁA
���������Ӗ��ł́A��L�̃p�C�v���C�����������ƁA
�P���߂����b�`��RISC�A�Ƃ����悤�Ɍ�����킯�ŁB
������ɂ���ARISC/CISC�̐������͌����ł͂Ȃ��Ǝv���̂ŁA
�l�̊����ɔC����镔�����傫���Ǝv���B���Ȃ��Ƃ�����ґ��łȂ���B
���������Ӗ��ł́A�����f�R�[�h�̗L���A�Ƃ����Ƃ����P5��P6�ȍ~��
�����Ă������Ǝv�����A
P5�Ńf�R�[�h���Ă������������H����܂�v���o���Ȃ��B(���Ԃ�Ȃ������Ǝv������)
>402
�܂��ACoreMA�ɂ��Ă��Aatom�ɂ��Ă��A
MacroFusion�Ƃ����Ax86�̖��ߋ����ăf�R�[�h����A
�Ƃ����Ӗ��ł͍ݗ��^����RISC�Ƃ͈�����悷�A�Ƃ����͓̂��ӁB
�����A������CISC���A�ƌ�����ƁA�����f�R�[�h������ȏ�
�����ł͂Ȃ��A�Ɗ�������͂����v����킯�ŁB
���Ԃ�A���̕ӂ�486����P6�̐���������ʼn߂����Ă����l�ԂɂƂ��Ă�
����Ȃ�ɓ��ӂ��Ă��炦��Ǝv�����ǁB
RISC�̓����́A(�T�ˁA������)�X���[�v�b�g��1�ł���A
����̃p�C�v���C������������A�ƌl�I�ɂ͎v���Ă����
(���������ǂ����͂����)�ŁA
���������Ӗ��ł́A��L�̃p�C�v���C�����������ƁA
�P���߂����b�`��RISC�A�Ƃ����悤�Ɍ�����킯�ŁB
������ɂ���ARISC/CISC�̐������͌����ł͂Ȃ��Ǝv���̂ŁA
�l�̊����ɔC����镔�����傫���Ǝv���B���Ȃ��Ƃ�����ґ��łȂ���B
���������Ӗ��ł́A�����f�R�[�h�̗L���A�Ƃ����Ƃ����P5��P6�ȍ~��
�����Ă������Ǝv�����A
P5�Ńf�R�[�h���Ă������������H����܂�v���o���Ȃ��B(���Ԃ�Ȃ������Ǝv������)
407 �FMAC�I�^��406 �����F2008/07/08(��) 22:38:06 ID:jyYpyOba
>>406
�@�@------------------
�@�@P5�Ńf�R�[�h���Ă������������H
�@�@------------------
�m�C�}���^�R���s���[�^��S�Ė��߃f�R�[�h�����邷���ǁB�B�B
�@�@------------------
�@�@P5�Ńf�R�[�h���Ă������������H
�@�@------------------
�m�C�}���^�R���s���[�^��S�Ė��߃f�R�[�h�����邷���ǁB�B�B
408 �F�R�E�L�́M�E,,�j�����������������F2008/07/08(��) 22:49:35 ID:DKuSoTKQ
>>406
������M�����������Ƃ�������Pentium�̍��܂Ńf�R�[�h��1�X�e�[�W�ōς�ł�B
���̍��̓����A�[�L�̓������Ăǂ������������Ē��ׂĂ���Intel���{��T�C�g�ɂ�����
http://download.intel.com/jp/developer/jpdoc/ia_opti.pdf
�܂����������̖����Ɏc���Ă�͓̂��{�@�l���d�����x������Ȃ��ǂ�
������M�����������Ƃ�������Pentium�̍��܂Ńf�R�[�h��1�X�e�[�W�ōς�ł�B
���̍��̓����A�[�L�̓������Ăǂ������������Ē��ׂĂ���Intel���{��T�C�g�ɂ�����
http://download.intel.com/jp/developer/jpdoc/ia_opti.pdf
�܂����������̖����Ɏc���Ă�͓̂��{�@�l���d�����x������Ȃ��ǂ�
>408
�B�������̓C���e���A�ƌ����ׂ����B
��ŁA2-1�`2-2�����肾�ˁB
�}2-1�Ō���ƁA���̐��ゾ�ƁA�m���L������������A
�n���h�V�F�[�N�^�̃p�C�v���C��(���ČĂ�ł����ȁH�L������ӂ�)�������悤�ȁB
�e�X�e�[�W�ŏ������I�������A���̃X�e�[�W�ɐi�ށA���Ă�B
������A����RISC�^�̃p�C�v���C���ƈ���āA
�e�X�e�[�W���P�X�e�b�v�ŏI���A�Ƃ������Ƃ͕ۏ���Ă��Ȃ��A���������ȁH
(������������486����Ɗ��Ⴂ���Ă邩��)
����ŁA�e�X�e�[�W�̖������ו�������ĂȂ��A�������悤�ȁB
������ɂ��Ă��A�t�^B�����ׂĂ���Ă�ˁB
P6������op �ւ̃f�R�[�h�d�l���L�ڂ���Ă��邠����ŁB
�E�E�E����op ���Ȃ�Č��J���Ă��B
�E�E�E��AP5�̃f�R�[�h���ĉ�����ˁB
�s�蒷�̖��߂̐蕪�����납�B
�B�������̓C���e���A�ƌ����ׂ����B
��ŁA2-1�`2-2�����肾�ˁB
�}2-1�Ō���ƁA���̐��ゾ�ƁA�m���L������������A
�n���h�V�F�[�N�^�̃p�C�v���C��(���ČĂ�ł����ȁH�L������ӂ�)�������悤�ȁB
�e�X�e�[�W�ŏ������I�������A���̃X�e�[�W�ɐi�ށA���Ă�B
������A����RISC�^�̃p�C�v���C���ƈ���āA
�e�X�e�[�W���P�X�e�b�v�ŏI���A�Ƃ������Ƃ͕ۏ���Ă��Ȃ��A���������ȁH
(������������486����Ɗ��Ⴂ���Ă邩��)
����ŁA�e�X�e�[�W�̖������ו�������ĂȂ��A�������悤�ȁB
������ɂ��Ă��A�t�^B�����ׂĂ���Ă�ˁB
P6������op �ւ̃f�R�[�h�d�l���L�ڂ���Ă��邠����ŁB
�E�E�E����op ���Ȃ�Č��J���Ă��B
�E�E�E��AP5�̃f�R�[�h���ĉ�����ˁB
�s�蒷�̖��߂̐蕪�����납�B
�E�E�E�t�^C�������E�E�E
�n����>��
�n����>��
������ƋC�ɂȂ���2001�t��Oh!X����������o���Ă݂���A
�����ɉ�����ڂ��Ă����B
D1�͐蕪���AD2�Ń������A�h���X�̌v�Z�A��������B
��ŁAP54C���ƁA�v���t�B�b�N�X�����邾��D1���J��Ԃ����A�Ƃ��B
�E�E�E���̕ӂ����Ȃ莞�Ԃ�H���̂́A��͂�h���Ȃ̂��˂��B
�Ƃ����AP55����F�X�e�[�W�lj��ŁA
�v���t�B�b�N�X�Ɏ��Ԃ�������͉̂��������A�炵���B
(�œK���}�j���A���ɂ������Ă邯��)
���̕ӁA�����͂ǂ��Ȃ�̂��ȁH
MMX�������A���̕ӂ�P54C��P55�̑傫�ȈႢ���ۂ����ǁB
�E�E�E�Ƃ������A�f�R�[�h�i���낤����蒼�����낤����A
���܂�Ӗ��͂Ȃ��̂�������Ȃ����ǁB
�����ɉ�����ڂ��Ă����B
D1�͐蕪���AD2�Ń������A�h���X�̌v�Z�A��������B
��ŁAP54C���ƁA�v���t�B�b�N�X�����邾��D1���J��Ԃ����A�Ƃ��B
�E�E�E���̕ӂ����Ȃ莞�Ԃ�H���̂́A��͂�h���Ȃ̂��˂��B
�Ƃ����AP55����F�X�e�[�W�lj��ŁA
�v���t�B�b�N�X�Ɏ��Ԃ�������͉̂��������A�炵���B
(�œK���}�j���A���ɂ������Ă邯��)
���̕ӁA�����͂ǂ��Ȃ�̂��ȁH
MMX�������A���̕ӂ�P54C��P55�̑傫�ȈႢ���ۂ����ǁB
�E�E�E�Ƃ������A�f�R�[�h�i���낤����蒼�����낤����A
���܂�Ӗ��͂Ȃ��̂�������Ȃ����ǁB
Intel�X���ł��
�������A�h���b�V���O���[�h���g�������߂Ȃ�
�}�C�N���R�[�h�ŕ����I�y���[�V�����ɕ���������
�n�[�h���C���[�h���W�b�N�ŏ����ł���̂͊m����
�u����RISC�v�ł͂Ȃ��ƌ������炻�����������
CISC�ɋt�߂肩���Č����������ς�Ⴄ�Ǝv�����B
���߂Ɠ���OPs���n�[�h���C���[�h���W�b�N��1:1
�Ή�����Ƃ����̂͂ނ��돃RISC�̓����B
�t��RISC�̌n���������A�[�L�ł��A���N���b�N���̈�
�����f�R�[�h���o�ĕ����}�C�N���I�y���[�V������
��������������o����B
(��\���POWER�����ARISC�ƌĂԂɂ͖��߂����G
�����邱�Ƃ͐̂���x�X�c�_�ɂȂ���)
���̂�������CISC/RISC�c�_���̂��ő��i���Z���X�B
�P�����\�~�̑g���≻�}�V���̕ێ�ł̂ݒʗp����B
�}�C�N���R�[�h�ŕ����I�y���[�V�����ɕ���������
�n�[�h���C���[�h���W�b�N�ŏ����ł���̂͊m����
�u����RISC�v�ł͂Ȃ��ƌ������炻�����������
CISC�ɋt�߂肩���Č����������ς�Ⴄ�Ǝv�����B
���߂Ɠ���OPs���n�[�h���C���[�h���W�b�N��1:1
�Ή�����Ƃ����̂͂ނ��돃RISC�̓����B
�t��RISC�̌n���������A�[�L�ł��A���N���b�N���̈�
�����f�R�[�h���o�ĕ����}�C�N���I�y���[�V������
��������������o����B
(��\���POWER�����ARISC�ƌĂԂɂ͖��߂����G
�����邱�Ƃ͐̂���x�X�c�_�ɂȂ���)
���̂�������CISC/RISC�c�_���̂��ő��i���Z���X�B
�P�����\�~�̑g���≻�}�V���̕ێ�ł̂ݒʗp����B
�m��Cyrix��CPU�����C���[�h���W�b�N��������ˁH
���A�ō��N���b�N������������ׂɁA���Ǐ��������Ă��܂����̂����B
�܂����N���b�N���o���Ȃ������̂́AL1�L���b�V�����R�[�h/�f�[�^�ɕ�����ĂȂ�
�\���i���O���O�j���������������邪�B
���A�ō��N���b�N������������ׂɁA���Ǐ��������Ă��܂����̂����B
�܂����N���b�N���o���Ȃ������̂́AL1�L���b�V�����R�[�h/�f�[�^�ɕ�����ĂȂ�
�\���i���O���O�j���������������邪�B
>>414
���ꂪ���W���Ă���ʔ����������ǂȂ�
���ꂪ���W���Ă���ʔ����������ǂȂ�
416 �F�R�E�L�́M�E,,�j�����������������F2008/07/09(��) 17:09:40 ID:Ey3SP3O1
�܂�x86�Ŏ���1:1�Ή����Ă�͈̂ꕔ�̒P�����߂��������ǂˁi���z���Ȃ����j�B
�t�ɋߑ�x86�ɂȂ�܂őS���̖��߂��}�C�N���R�[�h�Ŏ�������Ă��킯�ł��Ȃ��B
RISC�^SIMD�EMIMD�A�[�L�e�N�`����������Cell�ł���}�C�N���R�[�h���g���Ă邱�Ƃ͌��̂��݁B
�iPPE�̍����Ȗ��߂͂������ASPE�̔{���x���߂�PS3�ɍڂ��Ă��̂̓}�C�N���R�[�h�����j
����Ȃ킯��RISC��CISC�̈Ⴂ�Ȃ�Ă��̊Ԃɂ������Ȃ��Ă܂����B
Intel��SSE�V���߂Ƀ}�C�N���R�[�h�����̖��߂C�ōڂ��Ă���B
���ς␅�������Z�����������A���ߒ��Ƙ_�����W�X�^�̐ߖ�ɂȂ茋�ʓI�ɍ���������Ƃ̔��f�B
�t��IBM�Ȃ̓C���I�[�_PPC�ɂ����ă}�C�N���R�[�h�Ŏ����������߂͂Ȃ�ׂ��g��Ȃ����Ƃ𐄏����Ă�B
�}�C�N���R�[�h���߂ƒP�����߂̍��݂��l�������p�C�v���C���ɂȂ��Ă��炸�X�g�[�����邽�߁B
�t�ɋߑ�x86�ɂȂ�܂őS���̖��߂��}�C�N���R�[�h�Ŏ�������Ă��킯�ł��Ȃ��B
RISC�^SIMD�EMIMD�A�[�L�e�N�`����������Cell�ł���}�C�N���R�[�h���g���Ă邱�Ƃ͌��̂��݁B
�iPPE�̍����Ȗ��߂͂������ASPE�̔{���x���߂�PS3�ɍڂ��Ă��̂̓}�C�N���R�[�h�����j
����Ȃ킯��RISC��CISC�̈Ⴂ�Ȃ�Ă��̊Ԃɂ������Ȃ��Ă܂����B
Intel��SSE�V���߂Ƀ}�C�N���R�[�h�����̖��߂C�ōڂ��Ă���B
���ς␅�������Z�����������A���ߒ��Ƙ_�����W�X�^�̐ߖ�ɂȂ茋�ʓI�ɍ���������Ƃ̔��f�B
�t��IBM�Ȃ̓C���I�[�_PPC�ɂ����ă}�C�N���R�[�h�Ŏ����������߂͂Ȃ�ׂ��g��Ȃ����Ƃ𐄏����Ă�B
�}�C�N���R�[�h���߂ƒP�����߂̍��݂��l�������p�C�v���C���ɂȂ��Ă��炸�X�g�[�����邽�߁B
>>414
�v���o�����B�u���j�t�@�C�h�E�L���b�V���v���B
�R�[�h�����Ȃ����ɁA���̕��f�[�^�ɃL���b�V�����g���邩��A�����̓��J�^
�̂����A���̕��\�������G�ɂȂ������獂�N���b�N���o���Ȃ������݂���������
�Ȃ��B
�v���o�����B�u���j�t�@�C�h�E�L���b�V���v���B
�R�[�h�����Ȃ����ɁA���̕��f�[�^�ɃL���b�V�����g���邩��A�����̓��J�^
�̂����A���̕��\�������G�ɂȂ������獂�N���b�N���o���Ȃ������݂���������
�Ȃ��B
FPU�Ń}�C�N���R�[�h�g���̂͏펯
����Alpha�ł������z��etc.���}�C�N���R�[�h�Ŏ������Ă���
���[�h/�X�g�A�Ɖ��Z���p�C�v���C���Œ���ɂ��̂�
Cyrix586��atom�����łȂ��A������ƑO��IBM���C���t���[���Ƃ�������
68060������Ă�ۂ����悭�킩���
����Alpha�ł������z��etc.���}�C�N���R�[�h�Ŏ������Ă���
���[�h/�X�g�A�Ɖ��Z���p�C�v���C���Œ���ɂ��̂�
Cyrix586��atom�����łȂ��A������ƑO��IBM���C���t���[���Ƃ�������
68060������Ă�ۂ����悭�킩���
>>417
���j�t�@�C�h�L���b�V��+256byte���߃o�b�t�@����
�N���b�N�ɂ͂���܉e�����Ȃ��Ǝv��
�����256byte���Ɨe�ʃX�N�i�X�M��������ł��傤
���̗e�ʂ���68030�̃L���b�V��(���ߥ�f�[�^�e256B)�Ɠ���������W
���j�t�@�C�h�L���b�V��+256byte���߃o�b�t�@����
�N���b�N�ɂ͂���܉e�����Ȃ��Ǝv��
�����256byte���Ɨe�ʃX�N�i�X�M��������ł��傤
���̗e�ʂ���68030�̃L���b�V��(���ߥ�f�[�^�e256B)�Ɠ���������W
���[�h/�X�g�A�ȊO�̓A�h���b�V���O���[�h�Ȃ�(���l�͗�O�ŎZ�p��_�����Z�ł�ok)
RISC�̒�`�̂ЂƂł���
�ł����o�I��ATOM��RISC���Ċ�������
RISC�̒�`�̂ЂƂł���
�ł����o�I��ATOM��RISC���Ċ�������
>>420
�� ���[�h/�X�g�A�ȊO�̓A�h���b�V���O���[�h�Ȃ�
�u���[�h�E�X�g�A �A�[�L�e�N�`���v�̒�`���̂��̂��ˁB
�����RISC�̗v���Ƃ��邩�͏�������B
���̎����̓A�h���b�V���O���[�h�g�����_��
�n�[�h���C���[�h���W�b�N���s�\���������B
LSA�ł͂�����̂̃A�h���b�V���O�@�\��x86���
���b�`�Ȏ���RISC���̂͂������B
RISC�̖{���͖��߃Z�b�g��P�������ĉ�H���V���v���ɂ�
���N���b�N���ɂ���Đ��\���҂����ƁB
���̈Ӗ�����OoO�̎���������Ŋ��ɗ��O�͔j�]���Ă�B
90�N��Ŋ���RISC��CISC�̋��E�͞B���ɂȂ��Ă��B
Atom�͊m���ɍ��̃S�e�S�e��IPC�d���^�A�[�L���
RISC�̃A�v���[�`�ɋ߂��ȁB
����RISC�ō��������ɂ������߂��p�ꂽ���ʁA
�悭�g�����߂̓��e��RISC�̂���Ƒ卷�Ȃ��Ȃ���
�Ƃ����Ax86�R�[�h���̂̕ω������邵�B
�� ���[�h/�X�g�A�ȊO�̓A�h���b�V���O���[�h�Ȃ�
�u���[�h�E�X�g�A �A�[�L�e�N�`���v�̒�`���̂��̂��ˁB
�����RISC�̗v���Ƃ��邩�͏�������B
���̎����̓A�h���b�V���O���[�h�g�����_��
�n�[�h���C���[�h���W�b�N���s�\���������B
LSA�ł͂�����̂̃A�h���b�V���O�@�\��x86���
���b�`�Ȏ���RISC���̂͂������B
RISC�̖{���͖��߃Z�b�g��P�������ĉ�H���V���v���ɂ�
���N���b�N���ɂ���Đ��\���҂����ƁB
���̈Ӗ�����OoO�̎���������Ŋ��ɗ��O�͔j�]���Ă�B
90�N��Ŋ���RISC��CISC�̋��E�͞B���ɂȂ��Ă��B
Atom�͊m���ɍ��̃S�e�S�e��IPC�d���^�A�[�L���
RISC�̃A�v���[�`�ɋ߂��ȁB
����RISC�ō��������ɂ������߂��p�ꂽ���ʁA
�悭�g�����߂̓��e��RISC�̂���Ƒ卷�Ȃ��Ȃ���
�Ƃ����Ax86�R�[�h���̂̕ω������邵�B
45nm�v���Z�X��CPU�͂��������\��Ȃ́H
423 �FSocket774�F2008/07/10(��) 16:15:22 ID:QHyA1ryr
>>422
�N���܂ő҂�
�N���܂ő҂�
45nm��CPU�ɏ悹�����邱�Ƃ�O���ɒu���č�M/B��I�ԂƂ�����ǂ��I�ׂ����́H
����2�T�ԂقǑ҂��Ă���
790GX�̂��e�ڂ��U�炸��
790GX�̂��e�ڂ��U�炸��
790FX+SB750���������������
429 �F�R�E�L�́M�E,,�j�������������������F2008/07/11(��) 20:04:02 ID:zSpAZ5Y4
45nm(Shanghai)�ɂȂ��ď�ʂ�Q9450�ɂǂ��܂Ŕ���邩����
���b�g�p�t�H�[�}���X�̌���ɂ͂��܂���҂��Ă��Ȃ��B
Intel��Nehalem�Ńv���b�g�t�H�[���ς�邩��A
�����炠�܂�}�U�[�ɋ����������Ȃ����͖�����E8500��P35Neo����
�l���ꂵ������P45�ɍڂ��ς���\��B
���b�g�p�t�H�[�}���X�̌���ɂ͂��܂���҂��Ă��Ȃ��B
Intel��Nehalem�Ńv���b�g�t�H�[���ς�邩��A
�����炠�܂�}�U�[�ɋ����������Ȃ����͖�����E8500��P35Neo����
�l���ꂵ������P45�ɍڂ��ς���\��B
���߂�SSSE3����������Ă���ȁ[
>>429
�v���b�g�t�H�[���͕ς���Ă���ʂ����Ȃ̂ŁA
���ʂ͉�����Ȃ����낤�B
>>430
SSE3����������Ă��ASSE3�ɑΉ������x���`�����Ӗ����Ȃ��C������B
���Ƃ̓G���R�Ƃ����̒��x���H
�v���b�g�t�H�[���͕ς���Ă���ʂ����Ȃ̂ŁA
���ʂ͉�����Ȃ����낤�B
>>430
SSE3����������Ă��ASSE3�ɑΉ������x���`�����Ӗ����Ȃ��C������B
���Ƃ̓G���R�Ƃ����̒��x���H
����Əo�Ă���45nm K8L�̏��
http://en.hardspell.com/doc/showcont.asp?news_id=3721
�X�e�b�s���O��C0, 3.44GHz��SuperPi 20.5sec�Ȃ�đ㕨���B
http://en.hardspell.com/doc/showcont.asp?news_id=3721
�X�e�b�s���O��C0, 3.44GHz��SuperPi 20.5sec�Ȃ�đ㕨���B
��Ђ̕���A���������R������Ԃ��B$5����16�N���̈��l�Ƃ��B�B�B
http://www.nyse.com/about/listed/lcddata.html?ticker=AMD&fq=D&ezd=1M&index=3
http://www.nyse.com/about/listed/lcddata.html?ticker=AMD&fq=D&ezd=1M&index=3
���ł���Ȃɔn���Ȃ�
>>432
����
L3�L���b�V����6MB����
2.8GHz Vcore�d�� 1.224V �ΏĂ� 25.109s
3.0GHz Vcore�d�� 1.336V �ΏĂ� 23.547s (����p���E���ۂ�)
3.2GHz Vcore�d�� 1.424V �ΏĂ� 22.219s (�����p���E���ۂ�)
3.4GHz Vcore�d�� 1.568V �ΏĂ� 20.515s (OC���E���ۂ�)
���[��A�S�R�_�����X��w
����
L3�L���b�V����6MB����
2.8GHz Vcore�d�� 1.224V �ΏĂ� 25.109s
3.0GHz Vcore�d�� 1.336V �ΏĂ� 23.547s (����p���E���ۂ�)
3.2GHz Vcore�d�� 1.424V �ΏĂ� 22.219s (�����p���E���ۂ�)
3.4GHz Vcore�d�� 1.568V �ΏĂ� 20.515s (OC���E���ۂ�)
���[��A�S�R�_�����X��w
>>432
Nehalem��2.66GHz��SuperPi��15.475s�̂悤���ˁB
http://en.hardspell.com/doc/showcont.asp?news_id=3702
Nehalem��2.66GHz��SuperPi��15.475s�̂悤���ˁB
http://en.hardspell.com/doc/showcont.asp?news_id=3702
437 �FSocket774�F2008/07/11(��) 23:52:15 ID:keP2ZR4N
>>432
Nehalem�̓��[�v���Ƀf�R�[�h���Ȃ��Ă���������Ƒ�����Ȃ����H
Nehalem�̓��[�v���Ƀf�R�[�h���Ȃ��Ă���������Ƒ�����Ȃ����H
>>433
���R�������Ă����������g�����h�ɓ����Ă��Ԃł���
����������܂ŁA�������프��グ���܂ʼn����������
����������Ђ̏h�����Ă�ł���
2.3�N�łǂ��ɂ����Ȃ��Ɠ|�Y�����肦�����Ȋ�@�I��
�܂��A�|���Ĕ����Ȃ����낤����A�܂��܂��A������܂�
2010�N�ӂ肪�Љ^���������N�ɂȂ邾�낤�ˁB
���R�������Ă����������g�����h�ɓ����Ă��Ԃł���
����������܂ŁA�������프��グ���܂ʼn����������
����������Ђ̏h�����Ă�ł���
2.3�N�łǂ��ɂ����Ȃ��Ɠ|�Y�����肦�����Ȋ�@�I��
�܂��A�|���Ĕ����Ȃ����낤����A�܂��܂��A������܂�
2010�N�ӂ肪�Љ^���������N�ɂȂ邾�낤�ˁB
2012�N�ɓ]��15���h���̏��҂����邩��A���ʊ��֓]�����i�܂Ȃ�������
�������R���Ǝv���B������z���Ă�2015�N�E�E�E
�������R���Ǝv���B������z���Ă�2015�N�E�E�E
2010�N��12�N�Ƃ��A����Fusion���o�Ă���N����
Fusion���s = �|�Y���ȃ}�W��
Fusion���s = �|�Y���ȃ}�W��
���������̂�3800�N���X��
�����̘b�肷���ǁA�ǂ�����2�l�����ɕď،�����ψ���ɒ�o�������ނ̒��ŁA��ATI��
�g�ݍ��݊W��2����(�g�ѓd�b����уZ�b�g�g�b�v�{�b�N�X)�Ɋւ���$880M�̌����������s����
�炵�����B
��Ђ̉��l���̂��̂�����������悤�ȁB�B�B
http://biz.yahoo.com/ap/080711/amd_writedown.html
�g�ݍ��݊W��2����(�g�ѓd�b����уZ�b�g�g�b�v�{�b�N�X)�Ɋւ���$880M�̌����������s����
�炵�����B
��Ђ̉��l���̂��̂�����������悤�ȁB�B�B
http://biz.yahoo.com/ap/080711/amd_writedown.html
�܂�����AMD�o�c�w���V�Ɋւ���\������Ă��邷�B
�ł������������āw�S�[���f���p���V���[�g�x���p�ӂł��Ȃ����߂�Helctor Ruiz��ǂ��o���Ȃ��Ƃ�
���Ƃ�(��)�@���Ȃ݂Ƀ\�[�X��TGDaily��Theo Valich���B
http://www.tgdaily.com/content/view/38369/118/
�@�@-------------------
�@�@Industry sources close to AMD suggest that there will be a change of leadership at AMD.
�@�@But as it is the case so often with AMD, there is an interesting twist. AMD cannot fire Ruiz,
�@�@as the company is not in the position to pay for the executive�fs golden parachute.
�@�@The only possible solution could be that Ruiz will resign from his post and �gwill pursue
�@�@other interests�h - or transition into another capacity with AMD, such as into a non-active
�@�@position such as chairman of the board.
�@�@-------------------
�ł������������āw�S�[���f���p���V���[�g�x���p�ӂł��Ȃ����߂�Helctor Ruiz��ǂ��o���Ȃ��Ƃ�
���Ƃ�(��)�@���Ȃ݂Ƀ\�[�X��TGDaily��Theo Valich���B
http://www.tgdaily.com/content/view/38369/118/
�@�@-------------------
�@�@Industry sources close to AMD suggest that there will be a change of leadership at AMD.
�@�@But as it is the case so often with AMD, there is an interesting twist. AMD cannot fire Ruiz,
�@�@as the company is not in the position to pay for the executive�fs golden parachute.
�@�@The only possible solution could be that Ruiz will resign from his post and �gwill pursue
�@�@other interests�h - or transition into another capacity with AMD, such as into a non-active
�@�@position such as chairman of the board.
�@�@-------------------
444 �Fsage�F2008/07/12(�y) 12:59:31 ID:p+ituMd8
�l�`�b�I�^����́A���ł���Ȃ�AMD�̃l�K�e�B�u�ȏ����菑�����ނ�
�ł����H�@����Ȃ�AMD�������H�@Intel��D���ł����H
MAC��IntelCPU������ł����H�@MAC��AMD�ɂȂ�����ς��܂����H
�Ȃ��C�ɂȂ���̂ŁA�C�������������炲�߂�Ȃ����B
�ł����H�@����Ȃ�AMD�������H�@Intel��D���ł����H
MAC��IntelCPU������ł����H�@MAC��AMD�ɂȂ�����ς��܂����H
�Ȃ��C�ɂȂ���̂ŁA�C�������������炲�߂�Ȃ����B
446 �FMAC�I�^��444 �����F2008/07/12(�y) 13:35:26 ID:KULmXOzq
>>444
�������N���O���玖���������Ă��邾�����B
�̂�{�C��AMD�̃v���o�K���_���x����Ă����炵���~�[�������A�{�苶���ăR�s�y����������
���Ă��������ǁA�����{���������炩�ɂȂ������݂ł�A�L�`�K�C�̃q�g����掃J�L�R������x��
�Ȃ��Ă��邷�B
�������N���O���玖���������Ă��邾�����B
�̂�{�C��AMD�̃v���o�K���_���x����Ă����炵���~�[�������A�{�苶���ăR�s�y����������
���Ă��������ǁA�����{���������炩�ɂȂ������݂ł�A�L�`�K�C�̃q�g����掃J�L�R������x��
�Ȃ��Ă��邷�B
447 �FMAC�I�^���⑫�F2008/07/12(�y) 13:38:58 ID:KULmXOzq
Apple�̘b�Ƃ̊֘A��A���x�������Ă���ʂ肷�B
�O�X����� http://pc11.2ch.net/test/read.cgi/jisaku/1209908499/811
�O�X����� http://pc11.2ch.net/test/read.cgi/jisaku/1209908499/811
MAC�I�^���v���A���ˁB
>>442�Ɠ����\�[�X�����ǁAEETimes�ɂ��ƔN���܂łɎЈ���10%���Ƃ̂��Ƃ��B
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=208808603
�@�@--------------------
�@�@Advanced Micro Devices announced it will take nearly a billion dollars in charges in its
�@�@second quarter results to be reported July 17 including some related to a layoff of ten
�@�@percent of its workforce by the end of the year.
�@�@--------------------
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=208808603
�@�@--------------------
�@�@Advanced Micro Devices announced it will take nearly a billion dollars in charges in its
�@�@second quarter results to be reported July 17 including some related to a layoff of ten
�@�@percent of its workforce by the end of the year.
�@�@--------------------
�����̕ʃR�e���U�X�n���ɂ��ꂽ���肾����܂��Εa���Ă�낤
�Z�p�҂h���Ă邩��INTEL�̑��ɗ����Ă������
����Ȃ����h�ȗ��R�̊���ɐ����ƍs�V���������ǂ�
����Ƃ������f���ʼn��N�a�܂ꑱ���Ă��G�����Ƃ̃C���[�W�_�E���ɗ�ނ��Ƃ�
���h����Z�p�ҒB�ւ̂��߂Ă��̋C�������Ƃł��{�C�Ŏv���Ă�̂������H
�܂��ǂ����R�Ȃ낤����
���������ςɋC����Ă݂Ȃ������Ă�
����Ȃ����h�ȗ��R�̊���ɐ����ƍs�V���������ǂ�
����Ƃ������f���ʼn��N�a�܂ꑱ���Ă��G�����Ƃ̃C���[�W�_�E���ɗ�ނ��Ƃ�
���h����Z�p�ҒB�ւ̂��߂Ă��̋C�������Ƃł��{�C�Ŏv���Ă�̂������H
�܂��ǂ����R�Ȃ낤����
���������ςɋC����Ă݂Ȃ������Ă�
����ȂɋZ�p�҂ɍv���������Ȃ������CPU���Ă��H
���Ă̒ʂ�A�����ɔ��_�ł����ɂЂ�����l�𒆏����鏑�����݂𑱂���L�`�K�C�̃q�g���Ă̂����ꂷ(��)
>>450-453
>>450-453
�ʂ�AMD�̌����i�삵�Ă�킯�ł��Ȃ�
MAC�I�^���ւ̍����t���Ȃ����������Ă�킯�ł��Ȃ�
����MAC�I�^��������܂Ŏ��ۂɎ�����s���ƕ]���ɂ����G��Ă��Ȃ���������Ȃ��i�j
MAC�I�^���ւ̍����t���Ȃ����������Ă�킯�ł��Ȃ�
����MAC�I�^��������܂Ŏ��ۂɎ�����s���ƕ]���ɂ����G��Ă��Ȃ���������Ȃ��i�j
>>455
�{�l�ɂ͎��������Ă��邱�Ƃ͂Ȃ��Ȃ������Ȃ�����ˁB
�{�l�ɂ͎��������Ă��邱�Ƃ͂Ȃ��Ȃ������Ȃ�����ˁB
45nm Phenom Deneb�����[��AMD�I��
�@ 2.80GHz�F25.109sec
�@ 3.00GHz�F23.547sec
�@ 3.20GHz�F22.219sec
�@ 3.44GHz�F20.515sec
http://northwood.blog60.fc2.com/blog-entry-2121.html
�@ 2.80GHz�F25.109sec
�@ 3.00GHz�F23.547sec
�@ 3.20GHz�F22.219sec
�@ 3.44GHz�F20.515sec
http://northwood.blog60.fc2.com/blog-entry-2121.html
>>457
�����I�@����ES�̃x���`���[�N���o���̂��I
�N��������Nehalem��ES���o����Ă����̂ɁA
�������\���Deneb��ES���o�Ė����ĐS�z�����B
�ꉞ�����ɐi��ł���ȁB�ǂ����ƁB�ǂ����ƁB
�����I�@����ES�̃x���`���[�N���o���̂��I
�N��������Nehalem��ES���o����Ă����̂ɁA
�������\���Deneb��ES���o�Ė����ĐS�z�����B
�ꉞ�����ɐi��ł���ȁB�ǂ����ƁB�ǂ����ƁB
���̖��ɂ������Ȃ��~�����̌v�Z���Ђ�������Ȃ�
Intel�����Ȃ�
Intel�����Ȃ�
�Ƃ͌����Ă��C���p�N�g�͂���B
���́A�P���ȃ��[�v�Ȃ�f�R�[�h��ʂ��Ȃ����Ă����̂������܂ŕ֗��Ȃ̂��ǂ���
���́A�P���ȃ��[�v�Ȃ�f�R�[�h��ʂ��Ȃ����Ă����̂������܂ŕ֗��Ȃ̂��ǂ���
���̃C���p�N�g���Ȃ��˃Ȃ��
ttp://www.tcmagazine.com/comments.php?shownews=20797&catid=6
AMD taking a $948 million charge in Q2
ttp://www.tcmagazine.com/comments.php?shownews=20797&catid=6
AMD taking a $948 million charge in Q2
>>459
AMD�̂ق��������̃x���`���Ȃ����������H
�l�n�����̃x���`���ʌ������ǁAPhenom�Ƃ̃N���b�N������̐��\����1�����炢�����Ȃ���
PCMark05 �̃g�[�^��
�l�n���� 2.93G�@�F�@9852 (1GHz�ӂ� 3362)
Phenom 2.6G�@�F�@7680 (1GHz�ӂ� 2953)
�N���b�N�ӂ�̐��\��
3362 / 2953 = 1.13
���͑債�����ƂȂ��̂��H
P������������Deneb��1�����炵������قڌ݊p����ˁH
AMD�̂ق��������̃x���`���Ȃ����������H
�l�n�����̃x���`���ʌ������ǁAPhenom�Ƃ̃N���b�N������̐��\����1�����炢�����Ȃ���
PCMark05 �̃g�[�^��
�l�n���� 2.93G�@�F�@9852 (1GHz�ӂ� 3362)
Phenom 2.6G�@�F�@7680 (1GHz�ӂ� 2953)
�N���b�N�ӂ�̐��\��
3362 / 2953 = 1.13
���͑債�����ƂȂ��̂��H
P������������Deneb��1�����炵������قڌ݊p����ˁH
PCMArk�̃g�[�^�����r���Ă�CPU�̐��\����������邩�炠��܂�Ӗ��Ȃ���ˁH
http://itpro.nikkeibp.co.jp/article/NEWS/20080402/297797/
http://itpro.nikkeibp.co.jp/article/NEWS/20080402/297797/?SS=imgview&FD=-650025167&ST=ittrend
9850��CPU�X�R�A�̒l���Ⴂ�O���t�B6792���ƁA�������Nehalem�܂ʼn����B
http://plusd.itmedia.co.jp/pcuser/articles/0803/27/news058.html
�������̕����l�������āA7405�B���ꂾ�Ɠ��N���b�N��Shanghai���Ɠ͂������B
http://itpro.nikkeibp.co.jp/article/NEWS/20080402/297797/?SS=imgview&FD=-650025167&ST=ittrend
9850��CPU�X�R�A�̒l���Ⴂ�O���t�B6792���ƁA�������Nehalem�܂ʼn����B
http://plusd.itmedia.co.jp/pcuser/articles/0803/27/news058.html
�������̕����l�������āA7405�B���ꂾ�Ɠ��N���b�N��Shanghai���Ɠ͂������B
> AMD�̂ق��������̃x���`���Ȃ����������H
�܂Ƃ��Ȃ͈̂���Ȃ��Ȃ�
���܂Ɍ���������̂������蒼�������Intel�̕��������Ȃ邩��
�R�[�h�̕s���ɂ�肽�܂���AMD���������ʂɂȂ��Ă���̂���
�܂��A�h�f�l�삾���當��͌����Ȃ����ǁA�Ȃ��Ȃ��`���Ċ������B
�܂Ƃ��Ȃ͈̂���Ȃ��Ȃ�
���܂Ɍ���������̂������蒼�������Intel�̕��������Ȃ邩��
�R�[�h�̕s���ɂ�肽�܂���AMD���������ʂɂȂ��Ă���̂���
�܂��A�h�f�l�삾���當��͌����Ȃ����ǁA�Ȃ��Ȃ��`���Ċ������B
>>439
http://amd.edgarpro.com/redirect_frames.asp?filename=0001193125%2D08%2D105559%2Etxt&filepath=%5C2008%5C05%5C07%5C&cols=7%2C0%2C4&SortBy=receivedate&AD=D&startrec=26&res=25&pdf=0
��30�y�[�W�݂�ƁA2004�N�ɂ�2012�N���҂̎Ѝ�3.9���h�����s���Ă���B
2012�N��18.9���h�������ҁA2015�N��22���h���B
http://amd.edgarpro.com/redirect_frames.asp?filename=0001193125%2D08%2D105559%2Etxt&filepath=%5C2008%5C05%5C07%5C&cols=7%2C0%2C4&SortBy=receivedate&AD=D&startrec=26&res=25&pdf=0
��30�y�[�W�݂�ƁA2004�N�ɂ�2012�N���҂̎Ѝ�3.9���h�����s���Ă���B
2012�N��18.9���h�������ҁA2015�N��22���h���B
�܂�PC���R�O�����鎞�オ����̂��ȁB
>>444
MAC�I�^�͈ȑOMac��PowerPC�̗p���Ă�����
����Intel�̃l�K�L��������Ă��悤�Ȑl������
�C�`�C�`�C�ɂ��Ȃ����������悗
MAC�I�^�͈ȑOMac��PowerPC�̗p���Ă�����
����Intel�̃l�K�L��������Ă��悤�Ȑl������
�C�`�C�`�C�ɂ��Ȃ����������悗
�ǂ������D���Ȃ̂͐l�Ԃ������\�����A
���̍D���Ȋ�Ƃ̑Η���Ђ��Ȃ߂Ă��鎖���Ӗ����������
�����͂���ŗD�z���ɐZ���Ă�̂��ˁH
�m���ɁAAMD���Ȃ߂�ׂ̏����W�\�͂̊�n�O���͑��h�ɒl�����
���̍D���Ȋ�Ƃ̑Η���Ђ��Ȃ߂Ă��鎖���Ӗ����������
�����͂���ŗD�z���ɐZ���Ă�̂��ˁH
�m���ɁAAMD���Ȃ߂�ׂ̏����W�\�͂̊�n�O���͑��h�ɒl�����
��ԗ���s�\�Ȃ̂�
�o��x�o��x�n���ɂ���Ă�̂ɑS���ӂɉ�Ȃ����̌��疳�p��
�܂��u���͎G���R�e�Q�v�̈ꌾ������
�o��x�o��x�n���ɂ���Ă�̂ɑS���ӂɉ�Ȃ����̌��疳�p��
�܂��u���͎G���R�e�Q�v�̈ꌾ������
�C���e����C2D��2���ȉ��Ŕ���Ȃ���Ȃ��킯������A���J���Ă�̂��B
http://pc11.2ch.net/test/read.cgi/jisaku/1214836112/
117 ���O�FSocket774[sage] ���e���F2008/07/12(�y) 08:17:22 ID:KULmXOzq
�ʓ|�ł��o���Ŕ����������ǂ��l�i���t���ˁB3�N�O��19,000�Ŕ������p�[�c�������i���Õi�ŏo�i�B
���\���o����Ă����ȕ����������A�I�N��30,000�ȏ�ɂȂ��Ĕ��ꂽ�Ƃ��͊������̒ʂ蒴���ċ���������B�@
�o�b�N���Ƃ��C�^�Y�����z�肵�����A�N���[���������Ŗ����Ɏ���I�����Ĉ��S�����B
MAC�I�^�E�E�E
117 ���O�FSocket774[sage] ���e���F2008/07/12(�y) 08:17:22 ID:KULmXOzq
�ʓ|�ł��o���Ŕ����������ǂ��l�i���t���ˁB3�N�O��19,000�Ŕ������p�[�c�������i���Õi�ŏo�i�B
���\���o����Ă����ȕ����������A�I�N��30,000�ȏ�ɂȂ��Ĕ��ꂽ�Ƃ��͊������̒ʂ蒴���ċ���������B�@
�o�b�N���Ƃ��C�^�Y�����z�肵�����A�N���[���������Ŗ����Ɏ���I�����Ĉ��S�����B
MAC�I�^�E�E�E
474 �FMAC�I�^��473 �����F2008/07/12(�y) 21:36:33 ID:KULmXOzq
>>473
���̃J�L�R�~���ᖳ�������ǁA�����������Ƃ����邷�ˁB
���l�����Ɩʔ��������ǁA�����ɍ~�肩�����Ă݂�Ɠ��ꐫ�̏ؖ���ID�������Ă���������
�����V���b�N���B�B�B
���̃J�L�R�~���ᖳ�������ǁA�����������Ƃ����邷�ˁB
���l�����Ɩʔ��������ǁA�����ɍ~�肩�����Ă݂�Ɠ��ꐫ�̏ؖ���ID�������Ă���������
�����V���b�N���B�B�B
�͂��͂�
�Ƃ���Ń��^MAC��MAC���^���Ė��W?
�Q������ID��IP�̈ꕔ�Ɠ��t����Z�o�����B
������ʂ̃v���o�C�_�ł��낤�Ɠ���ID����������B
���ꐫ�̏ؖ��ɂȂ�Ǝv���Ă�₵�͂Q����S�ҁB
������ʂ̃v���o�C�_�ł��낤�Ɠ���ID����������B
���ꐫ�̏ؖ��ɂȂ�Ǝv���Ă�₵�͂Q����S�ҁB
��͂萫���ꐫ��Q��������
>P������������Deneb��1�����炵������قڌ݊p����ˁH
L3�̗e�ʈȊO�����ς��Ȃ��̂�IPC��10%�����シ��́H
L3�̗e�ʈȊO�����ς��Ȃ��̂�IPC��10%�����シ��́H
PCMark2005 CPU
http://www.tomshardware.co.uk/charts/desktop-cpu-charts/pcmark-2005-cpu,382.html?p=1308%2C1275
7753�@C2Q Q6600(2.4GHz)
7092�@Phenom 9700(2.4GHz)
Deneb�������撣�����Ƃ��ē��N���b�N��Kentsfield�Ɠ������炢�B
Nehalem����ł͂�����Ƃ��b�ɂȂ�Ȃ��B
http://www.tomshardware.co.uk/charts/desktop-cpu-charts/pcmark-2005-cpu,382.html?p=1308%2C1275
7753�@C2Q Q6600(2.4GHz)
7092�@Phenom 9700(2.4GHz)
Deneb�������撣�����Ƃ��ē��N���b�N��Kentsfield�Ɠ������炢�B
Nehalem����ł͂�����Ƃ��b�ɂȂ�Ȃ��B
��������L3�ȊO�͕ς��Ȃ����ă\�[�X�����ė�����
���ʂ�IPC�����コ������Č����Ă��낤��
���ʂ�IPC�����コ������Č����Ă��낤��
MAC���^������Dirk Meyer�̔������������ނł��傤�B
�܂��A���ꂾ
Phenom�݂����ɁAL3�܂Ŕr������̌����ň��̃L���b�V����������CPU�ƁA
C2Q�݂����ȁA�V���v���A�����A��e�ʂ̌����ō��ȃL���b�V��CPU�̑��x�����A
����N���b�N��1�������x�Ȃ�匒���ł���B
�������A�x���`�}�[�N�ł��悤�ȏ����ɓ������č���Ă��邵Intel�́B
(�����Ă��̃\�t�g�́A�悭�g���鏈���������̗ǂ��v���O���~���O�ő��邵�A
�x���`�}�[�N�͂���ȏ������Ђ����烋�[�v�����邵�AIntel�͂��̏����������Ɏ��s����\���ɂ���B)
����ƁANehalem�͂ǂ����A�ŏ���1�N���炢�̓n�C�G���h�ǂ܂肾�B
�����\�ȕ��A�v���b�g�t�H�[���\�z��20���~�ȏ�|����B
������p�[�c���ȉ��̉��i�ō\�z�ł���Deneb�Ɣ�r���Ă��d������܂��B
��������Deneb�R�́A�����R�������A��QPI�̋U�҃l�n�����gLynnfield�h�����B
(�������܂ł�Nehalem�͐^Nehalem�́gBloomfield�h)
����H�������X�������������H
Phenom�݂����ɁAL3�܂Ŕr������̌����ň��̃L���b�V����������CPU�ƁA
C2Q�݂����ȁA�V���v���A�����A��e�ʂ̌����ō��ȃL���b�V��CPU�̑��x�����A
����N���b�N��1�������x�Ȃ�匒���ł���B
�������A�x���`�}�[�N�ł��悤�ȏ����ɓ������č���Ă��邵Intel�́B
(�����Ă��̃\�t�g�́A�悭�g���鏈���������̗ǂ��v���O���~���O�ő��邵�A
�x���`�}�[�N�͂���ȏ������Ђ����烋�[�v�����邵�AIntel�͂��̏����������Ɏ��s����\���ɂ���B)
����ƁANehalem�͂ǂ����A�ŏ���1�N���炢�̓n�C�G���h�ǂ܂肾�B
�����\�ȕ��A�v���b�g�t�H�[���\�z��20���~�ȏ�|����B
������p�[�c���ȉ��̉��i�ō\�z�ł���Deneb�Ɣ�r���Ă��d������܂��B
��������Deneb�R�́A�����R�������A��QPI�̋U�҃l�n�����gLynnfield�h�����B
(�������܂ł�Nehalem�͐^Nehalem�́gBloomfield�h)
����H�������X�������������H
���ႠAMD�̏����ɂ��Ĉꌾ
�C���^�[�t�F�[�X�ނ͍ה����ɂ��k���������Ȃ��̂�
�v���Z�X���i�ނɂ�ă_�C�ʐς�苒���Ă��悤�Ȃ��Ƃ������Ƃ��邯��
�����I�ȊO�p�̃A�[�L����ɍ���悤�ɂȂ�����
�ėp�R�A1�`2���Ȑv�ł̓m�[�X�u���b�W����������悤�ɂȂ�̂���
����Ƃ�����Ȃ��͔̂p�����đ��R�A��GPU���K���Z�b�g�ŕt������2���ɂȂ�̂���
�C���^�[�t�F�[�X�ނ͍ה����ɂ��k���������Ȃ��̂�
�v���Z�X���i�ނɂ�ă_�C�ʐς�苒���Ă��悤�Ȃ��Ƃ������Ƃ��邯��
�����I�ȊO�p�̃A�[�L����ɍ���悤�ɂȂ�����
�ėp�R�A1�`2���Ȑv�ł̓m�[�X�u���b�W����������悤�ɂȂ�̂���
����Ƃ�����Ȃ��͔̂p�����đ��R�A��GPU���K���Z�b�g�ŕt������2���ɂȂ�̂���
�U���ɂ͏��낤�ȁA���̌��������ƁB
�^�́`�Ƃ������Ă����Ɠ����Q�܂Ȃ���ȁA����AMD�͂�
�^�́`�Ƃ������Ă����Ɠ����Q�܂Ȃ���ȁA����AMD�͂�
>>483
����������Deneb�R�́A�����R�������A��QPI�̋U�҃l�n�����gLynnfield�h�����B
��QPI�ł͂��邪�A�����R����2ch�����������肠��B
����������Deneb�R�́A�����R�������A��QPI�̋U�҃l�n�����gLynnfield�h�����B
��QPI�ł͂��邪�A�����R����2ch�����������肠��B
>>485
���������Ȃǂ��ł������B
���͂ǂ����l�n��������Ȃ����A�G�邱�Ƃ��Ȃ�����ȁB(��Ђ�����C2D���낤��)
���̖{����Swift�ȍ~��Fusion�ŁA����܂ł͏��Ƃ��������悤���ǂ��ł������B
>>486
������@�Ȃ�[�n���Ȋ��Ⴂ�����Ă���́B
���������Ȃǂ��ł������B
���͂ǂ����l�n��������Ȃ����A�G�邱�Ƃ��Ȃ�����ȁB(��Ђ�����C2D���낤��)
���̖{����Swift�ȍ~��Fusion�ŁA����܂ł͏��Ƃ��������悤���ǂ��ł������B
>>486
������@�Ȃ�[�n���Ȋ��Ⴂ�����Ă���́B
488 �FSocket774�F2008/07/13(��) 10:34:50 ID:8P3u9Iwj
>>483
�m�[�X�u���b�W�������ꂽ��QPI�Ȃ�Ă���Ȃ�����B
CPU���璼��PCIe��DMI���o�Ă����ȁB
������N���b�N��1�������x�Ȃ�匒���ł���B
����d�͂�3�������ŕ��B
�m�[�X�u���b�W�������ꂽ��QPI�Ȃ�Ă���Ȃ�����B
CPU���璼��PCIe��DMI���o�Ă����ȁB
������N���b�N��1�������x�Ȃ�匒���ł���B
����d�͂�3�������ŕ��B
�ǂ������������C���e���̘b��ł������肾��(�E�L��`�E)
��ް
492 �F,,�E�L�́M�E,,�j���F2008/07/13(��) 21:30:58 ID:fQY2QJ6V
>>488
AMD��HT�ƈꏏ���ȁBHT���Ӓ�����(�E�L��`�E)
AMD��HT�ƈꏏ���ȁBHT���Ӓ�����(�E�L��`�E)
�l�C�e�B�u3�R�A�Ȃ�~�������c
495 �F,,�E�L�́M�E,,�j���F2008/07/14(��) 16:53:17 ID:dyZabc0Z
��[Xbox360]
>>495
XBOX 360��"�l�C�e�B�u3�R�A"����Ȃ���c�B
XBOX 360��"�l�C�e�B�u3�R�A"����Ȃ���c�B
XBOX360��CPU���l�C�e�B�u3�R�A����Ȃ�������A�ǂ������̂��l�C�e�B�u3�R�A�ɂȂ�H
�y�m��X3�́u�l�C�e�B�u4�R�A������Ă�3�R�A�v������(�E�L��`�E)
3�R�A������Ȃ�10�N���炢�o������T�Ƃ�7���o�Ă��邩�ȁH
500 �FSocket774�F2008/07/14(��) 19:55:30 ID:u3K9JvoJ
�O���{�Ƀ��\�[�X���������Ė{�Ƃ����낻���ɂȂ肷�����낤�B
Intel�����Ă邺�B
Intel�����Ă邺�B
���낻���ɂȂ��Ă�̂͐����Z�p�i�����j
>>497
XBOX360�̓V���O��CPU���O�ς�ł��邾������B
XBOX360�̓V���O��CPU���O�ς�ł��邾������B
>>503
���Ⴀ�APhenom���V���O��CPU�S�ڂ��Ă邾������Ȃ��́H
XBOX360�ŃV���O��CPU3�ڂ��Ă邾�����Ă��ƂȂ�Ax86�Ńl�C�e�B�u�}���`�R�A��CPU��
���܂ň���o�Ă��Ȃ����ƂɂȂ�Ǝv�����B
���Ⴀ�APhenom���V���O��CPU�S�ڂ��Ă邾������Ȃ��́H
XBOX360�ŃV���O��CPU3�ڂ��Ă邾�����Ă��ƂȂ�Ax86�Ńl�C�e�B�u�}���`�R�A��CPU��
���܂ň���o�Ă��Ȃ����ƂɂȂ�Ǝv�����B
ttp://www.dvhardware.net/news/xbox360_processor_die.jpg
�\�[�X�\��ςނ��ƂŌ����������Ă�Ȃ�
{kind=link}
�\�[�X�\��ςނ��ƂŌ����������Ă�Ȃ�
�ǂ����x���Ⴂ�c
>>505
�i�@���@���������ӂ��ɕ���ł�Ǝv���Ă��B
�i�@���@���������ӂ��ɕ���ł�Ǝv���Ă��B
Puma�v���b�g�t�H�[���͍K��̗ǂ��X�^�[�g��ꂽ�݂�������
�yDELL�z Studio�v�V���[�Y Part1 �yIntel,AMD�z
http://pc11.2ch.net/test/read.cgi/notepc/1214518700/658
706 ���O�F701[sage] ���e���F2008/07/14(��) 21:11:11 ID:MhgWZzgs
�Ə����ĂāAAMD.jp�̃y�[�W��������A
���o�C���ł�CrossFireX�̋L�q���Ȃ��Ȃ��Ă���
�i�y�[�W�ς�����H�ۂ��[��j
721 ���O�F[Fn]�{[����������][] ���e���F2008/07/14(��) 21:39:58 ID:IzF9JADt
>>706�܂����������˂�����������������
http://amd.jp/personal/hd/hd_exp_mobile.html
http://s04.megalodon.jp/2008-0713-1701-20/amd.jp/personal/hd/hd_exp_mobile.html
�yDELL�z Studio�v�V���[�Y Part1 �yIntel,AMD�z
http://pc11.2ch.net/test/read.cgi/notepc/1214518700/658
706 ���O�F701[sage] ���e���F2008/07/14(��) 21:11:11 ID:MhgWZzgs
�Ə����ĂāAAMD.jp�̃y�[�W��������A
���o�C���ł�CrossFireX�̋L�q���Ȃ��Ȃ��Ă���
�i�y�[�W�ς�����H�ۂ��[��j
721 ���O�F[Fn]�{[����������][] ���e���F2008/07/14(��) 21:39:58 ID:IzF9JADt
>>706�܂����������˂�����������������
http://amd.jp/personal/hd/hd_exp_mobile.html
http://s04.megalodon.jp/2008-0713-1701-20/amd.jp/personal/hd/hd_exp_mobile.html
TheINQ��Charlie "Groo" Demerjian����AcesHardware�f����"bulldozer"�ɂ���
�v�킹�Ԃ�Ȃ��Ƃ���������ł��邷�B
http://aceshardware.freeforums.org/45nm-phenom-samples-in-the-wild-t562.html
�@�@---------------------
�@�@Intel has nothing to fear, but it will narrow the gap. I hear they might pull 45nm in a month or
�@�@so, but still, they will be in second place until Bulldozer.
�@�@---------------------
�Ƃ��A
�@�@---------------------
�@�@It is radically different, and IF it works, it MAY be on par with Intel. Until then there is no
�@�@hope, that is what I meant.
�@�@Platform vs platform it is more even, but CPU vs CPU, Intel owns.
�@�@---------------------
�Ƃ��B
�v�킹�Ԃ�Ȃ��Ƃ���������ł��邷�B
http://aceshardware.freeforums.org/45nm-phenom-samples-in-the-wild-t562.html
�@�@---------------------
�@�@Intel has nothing to fear, but it will narrow the gap. I hear they might pull 45nm in a month or
�@�@so, but still, they will be in second place until Bulldozer.
�@�@---------------------
�Ƃ��A
�@�@---------------------
�@�@It is radically different, and IF it works, it MAY be on par with Intel. Until then there is no
�@�@hope, that is what I meant.
�@�@Platform vs platform it is more even, but CPU vs CPU, Intel owns.
�@�@---------------------
�Ƃ��B
���L�L���b�V�����Ȃ����ĈӖ�����ˁH
�v�킹�Ԃ肾���ǁA���g�Ȃ������B
Bulldozer��������B�ł��A�o��܂ł�CPU��2�Ԏ�̂܂܁B
���ď����Ă邾�������B
Bulldozer��������B�ł��A�o��܂ł�CPU��2�Ԏ�̂܂܁B
���ď����Ă邾�������B
����
�u���h�[�U�[�łǂ҂�
�Z�R�C�A�̃n�[�h���������ɁE�E
�u���h�[�U��6�R�AMCM�ڎw����H
2.8G��12�R�A�Ȃ炩�Ȃ葁���������ATDP��VGA�����������Ȃ�
2.8G��12�R�A�Ȃ炩�Ȃ葁���������ATDP��VGA�����������Ȃ�
>>516
TDP��������Ȃ����Ƃ�O��ɘb���ˁB
TDP��������Ȃ����Ƃ�O��ɘb���ˁB
AthlonXP 1600+ TDP44W��Geode NX 1750@14W
>>509
AMD HD!����ATI Hybrid Graphics���Ȃ��Ȃ�AIntel�v���b�g�t�H�[���̈�ATI�͂������ƃh���C�o��p�ӂ���
�f����AMD�m�[�g�uStudio 1536�v��CrossFireX��Ή���
http://pc.watch.impress.co.jp/docs/2008/0715/dell.htm
���\�����̓`�b�v�Z�b�g�����O���t�B�b�N�X��GPU�Ƃŕ������s�Ȃ�CrossFireX�ɑΉ�����Ƃ���Ă������A
���ۂ͑Ή��ł��Ȃ����Ƃ��킩�����B������Ή��̗\��͂Ȃ��Ƃ����B
�uCentrino 2�vThinkPad�͂������ς�����I
�V�Z�p�̓��I�O���t�B�b�N�X�X�C�b�`���O�Ƃ́H
http://ascii.jp/elem/000/000/150/150705/index-6.html
���̋Z�p�͂��ł�ATI���甭�\����Ă���uATI XGP�e�N�m���W�v��G�k�r�f�B�A�́uHybrid Power�v�Ɠ����̂��̂��Ƃ����B
��������A���m�{��ATI�ƃC���e���Ƌ����J�����s�Ȃ��AATI�̃r�f�I�J�[�h�ƃC���e���̃`�b�v�Z�b�g�Ƃ����g�ݍ��킹�ł��̋Z�p�����������B
��Ƀh���C�o�[���쐬�����̂�ATI�����������AATI�����݂�AMD�̈ꕔ��ł��邱�Ƃ��l����ƁA����͂�����Ɩʔ����g�ݍ��킹�ł���B
������AMD��ATI�̐▭�ȃR���r�l�[�V����
AMD HD!����ATI Hybrid Graphics���Ȃ��Ȃ�AIntel�v���b�g�t�H�[���̈�ATI�͂������ƃh���C�o��p�ӂ���
�f����AMD�m�[�g�uStudio 1536�v��CrossFireX��Ή���
http://pc.watch.impress.co.jp/docs/2008/0715/dell.htm
���\�����̓`�b�v�Z�b�g�����O���t�B�b�N�X��GPU�Ƃŕ������s�Ȃ�CrossFireX�ɑΉ�����Ƃ���Ă������A
���ۂ͑Ή��ł��Ȃ����Ƃ��킩�����B������Ή��̗\��͂Ȃ��Ƃ����B
�uCentrino 2�vThinkPad�͂������ς�����I
�V�Z�p�̓��I�O���t�B�b�N�X�X�C�b�`���O�Ƃ́H
http://ascii.jp/elem/000/000/150/150705/index-6.html
���̋Z�p�͂��ł�ATI���甭�\����Ă���uATI XGP�e�N�m���W�v��G�k�r�f�B�A�́uHybrid Power�v�Ɠ����̂��̂��Ƃ����B
��������A���m�{��ATI�ƃC���e���Ƌ����J�����s�Ȃ��AATI�̃r�f�I�J�[�h�ƃC���e���̃`�b�v�Z�b�g�Ƃ����g�ݍ��킹�ł��̋Z�p�����������B
��Ƀh���C�o�[���쐬�����̂�ATI�����������AATI�����݂�AMD�̈ꕔ��ł��邱�Ƃ��l����ƁA����͂�����Ɩʔ����g�ݍ��킹�ł���B
������AMD��ATI�̐▭�ȃR���r�l�[�V����
����Centrino 2�ɂ�ATI�ςނ킯�ˁB
���̃m�[�gPC���Đ��E�V�F�A�W�������Ă�ł���B
���̃p�C�͂���������ȁB
���̃m�[�gPC���Đ��E�V�F�A�W�������Ă�ł���B
���̃p�C�͂���������ȁB
���o�C��CPU�̃��[�h�}�b�v�̓t�F�C�N���k�Ԃ̗ނŁA�ŏI�I�ɐ�̂Ă�C�Ȃ̂��H
Hybrid Graphics���Ȃ�Puma�̖��͂��ĉ���
Hybrid Graphics���Ȃ�Puma�̖��͂��ĉ���
�܂���GPU�������͂ɂ���CPU�����藣�����肵�Ȃ����낤�ȁA�����I��
>>520
Dell���Ή��o���Ȃ�������������B
Dell���Ή��o���Ȃ�������������B
>>520
�A�~�ɂ͂����͂���܂���B
�A�~�ɂ͂����͂���܂���B
>>510
���̂悤�ȁCCharlie Demerjian �ɂ��CBulldozer �� a great product
�Ƃ�����|�̘b�́C�ȑO�ɂ�����C
ttp://www.theinquirer.net/gb/inquirer/news/2007/12/19/bulldozer-roadmaps
�ڐV�������̂ł͂Ȃ��Ǝv�����C�������ʂȈӖ��������Ĉ��p���Ă���
�̂ł��傤���H
���̂悤�ȁCCharlie Demerjian �ɂ��CBulldozer �� a great product
�Ƃ�����|�̘b�́C�ȑO�ɂ�����C
ttp://www.theinquirer.net/gb/inquirer/news/2007/12/19/bulldozer-roadmaps
�ڐV�������̂ł͂Ȃ��Ǝv�����C�������ʂȈӖ��������Ĉ��p���Ă���
�̂ł��傤���H
527 �FMAC�I�^��526 �����F2008/07/17(��) 12:27:43 ID:tXjIclFY
>>526
��]�w����G���W�j�A�Ɏ���܂őގЂ�烊�X�g�����ŃO�_�O�_��AMD�̒��ŁA"Bulldozer"�̈ʒu�t��
�����ɕς���Ă��Ȃ��炵���Ƃ������́A����Ȃ�ɋM�d���B
��]�w����G���W�j�A�Ɏ���܂őގЂ�烊�X�g�����ŃO�_�O�_��AMD�̒��ŁA"Bulldozer"�̈ʒu�t��
�����ɕς���Ă��Ȃ��炵���Ƃ������́A����Ȃ�ɋM�d���B
DailyTech��AMD�̎����T�[�o�[�����\�P�b�g�K�i"G34"���X�N�[�v���Ă��邷�B
http://www.dailytech.com/Hello+AMD+Socket+G34/article12400c.htm
�@�@-------------------
�@�@The new socket, dubbed G34, will also ship with two new second-generation
�@�@45nm processors. The first of these processors, 8-core Sao Paolo, is described
�@�@as a "twin native-quadcore Shanghai processor" by one AMD engineer.
�@�@-------------------
Socket F�̌�p�ƌ���ꂽ"G3"��L�����Z���Ƃ̂��Ƃ��B����ɂ��Ă��ג����\�P�b�g��MCM��
���C���X�Ƃ������Ƃ��낷�B
http://www.dailytech.com/Hello+AMD+Socket+G34/article12400c.htm
�@�@-------------------
�@�@The new socket, dubbed G34, will also ship with two new second-generation
�@�@45nm processors. The first of these processors, 8-core Sao Paolo, is described
�@�@as a "twin native-quadcore Shanghai processor" by one AMD engineer.
�@�@-------------------
Socket F�̌�p�ƌ���ꂽ"G3"��L�����Z���Ƃ̂��Ƃ��B����ɂ��Ă��ג����\�P�b�g��MCM��
���C���X�Ƃ������Ƃ��낷�B
1974pin������ADDR3��4ch�͊m�����B
����ABarcelona���ڂ̃X�[�p�[�R���s���[�^"Ranger"�̋L�������ǁA�v���Z�b�T�`�b�v��S��
B3 stepping��2.3GHz�Ɍ��������炵�����B�A�����̍v����������A�Ȋw�̐i���̂��߂ɗL�v��
�g���Ă���Ƃ������ƂŁB�B�B
http://www.utexas.edu/news/2008/07/16/ranger_processor_boost/
�@�@---------------------
�@�@All 15,744 Quad-Core AMD OpteronTM processors (62,976 cores) operating
�@�@at 2.0 GHz have been replaced with 2.3 GHz processors, effectively adding 75.4
�@�@teraflops to the system's peak performance rating.
�@�@--------------------
B3 stepping��2.3GHz�Ɍ��������炵�����B�A�����̍v����������A�Ȋw�̐i���̂��߂ɗL�v��
�g���Ă���Ƃ������ƂŁB�B�B
http://www.utexas.edu/news/2008/07/16/ranger_processor_boost/
�@�@---------------------
�@�@All 15,744 Quad-Core AMD OpteronTM processors (62,976 cores) operating
�@�@at 2.0 GHz have been replaced with 2.3 GHz processors, effectively adding 75.4
�@�@teraflops to the system's peak performance rating.
�@�@--------------------
>>529
ttp://www.dailytech.com/Hello+AMD+Socket+G34/article12400c.htm
���̋L�����H�@�Ȃ\�P�b�g���ג����ȁB
ttp://www.dailytech.com/Hello+AMD+Socket+G34/article12400c.htm
���̋L�����H�@�Ȃ\�P�b�g���ג����ȁB
�u�\�P�b�g���������v
�y�R�c���z
�@�@�@ ��,,�ȁ@ ��,,��
�@�� (�L�E�ցE) (�E�ցE�M) �ȁ�
(�@�L�E��)�@�t) ( �� �(�ցE�M )
�b�@�t (�@�@�L�E) (�E�M�@�@)�@�� �
�@��-�� �il �@�@ ) (�@�@�@�u-��
�@�@�@�@ `��-��'.�@`��-u'
�@�@�@ ��,,�ȁ@ ��,,��
�@�� (�L�E�ցE) (�E�ցE�M) �ȁ�
(�@�L�E��)�@�t) ( �� �(�ցE�M )
�b�@�t (�@�@�L�E) (�E�M�@�@)�@�� �
�@��-�� �il �@�@ ) (�@�@�@�u-��
�@�@�@�@ `��-��'.�@`��-u'
>>528
Socket8�v���o������^
Socket8�v���o������^
AP�z�M�̃j���[�X�ɂ��ƁA�{��Hector Ruiz��CEO�̍���Dirk Meyer�ɏ���Ƃ̂��Ƃ��B
http://www.dailytech.com/AMDs+CEO+Steps+Down/article12412.htm
�@�@=====================
�@�@Today, AMD CEO Hector Ruiz stepped down from his position with the company. Ruiz
�@�@joined the company in January 2000 and became CEO in April 2002. Ruiz will be replaced
�@�@by the current Number 2 in charge, Dirk Meyer. Ruiz will stay on as the executive chairman
�@�@of AMD's Board of Directors.
�@�@=====================
�c�O�Ȃ�������Ƃ�A�Ȃ�Ȃ������̂ʼne���͂�c��͗l���B
http://www.dailytech.com/AMDs+CEO+Steps+Down/article12412.htm
�@�@=====================
�@�@Today, AMD CEO Hector Ruiz stepped down from his position with the company. Ruiz
�@�@joined the company in January 2000 and became CEO in April 2002. Ruiz will be replaced
�@�@by the current Number 2 in charge, Dirk Meyer. Ruiz will stay on as the executive chairman
�@�@of AMD's Board of Directors.
�@�@=====================
�c�O�Ȃ�������Ƃ�A�Ȃ�Ȃ������̂ʼne���͂�c��͗l���B
��2�l�����̌��ʂ킱���炷�B$1.180M�̑����Ƃ����Ռ��I�Ȑ������B�B�B
http://www.amd.com/us-en/Corporate/VirtualPressRoom/0,,51_104_543~127059,00.html
�@�@����グ 13.5���h�� (-7% from Q1-08)
�@�@�c�Ƒ��� 1.4���h��
�@�@�������@�@11.9���h��
�@�@�e�����@�@52%
http://www.amd.com/us-en/Corporate/VirtualPressRoom/0,,51_104_543~127059,00.html
�@�@����グ 13.5���h�� (-7% from Q1-08)
�@�@�c�Ƒ��� 1.4���h��
�@�@�������@�@11.9���h��
�@�@�e�����@�@52%
�悭���ݏo����ȁc
���ɂ����̂��炢�̎���������Ԃ���ԓ������ė~����
CEO�̃��C�Y
540 �FSocket774�F2008/07/18(��) 12:37:36 ID:9fA4trKu
Fusion�܂ł͐����c��ł���B
>540
��AMD��Q2���Z�͐Ԏ����啝�g��A�g�ݍ���/DTV�s�ꂩ��P��
�@ttp://journal.mycom.co.jp/news/2008/07/18/009/index.html
Puma���S�̃�����
��AMD��Q2���Z�͐Ԏ����啝�g��A�g�ݍ���/DTV�s�ꂩ��P��
�@ttp://journal.mycom.co.jp/news/2008/07/18/009/index.html
Puma���S�̃�����
AMD���ׂꂽ��VIA����ʂɗ�������
���Ǝv�������u�Ő��������
�o�O���炯�łǂ����悤���Ȃ�CPU��Intel�Ɛ�ɂȂ��Ă��܂�
���Ƃ��Ȃ��Ăق����Ƃ���
���Ǝv�������u�Ő��������
�o�O���炯�łǂ����悤���Ȃ�CPU��Intel�Ɛ�ɂȂ��Ă��܂�
���Ƃ��Ȃ��Ăق����Ƃ���
>543
����Intel�Ƃ���ȊO�S���A���ł�
Intel��Ђɏ��Ă������������E�E�E
����Intel�Ƃ���ȊO�S���A���ł�
Intel��Ђɏ��Ă������������E�E�E
IBM��Xeon�T�[�o�[����܂����Ă�Ԃ̓_�����ȁB
Op�����ɂ��Ă����Ȃ��ƁB
Op�����ɂ��Ă����Ȃ��ƁB
546 �FSocket774�F2008/07/18(��) 16:31:31 ID:9fA4trKu
�v�[�}�̓Z���g��2�ɐ�s�o���Ȃ������̂��ɂ��B
DELL�̃A�z�B
DELL�̃A�z�B
547 �FSocket774�F2008/07/18(��) 16:34:56 ID:9fA4trKu
>>527
bulldozer�͋t�P�̐�D��1������A������I���B
bulldozer�͋t�P�̐�D��1������A������I���B
Puma�͏���d�͂Ƃ����_�ŃZ���g��2�ɂ͏��ĂȂ�����Ȃ��B
�ނ�����{���[�J�[���ǂ��o��"�f�X�N�g�b�v�m�[�g"�ɍœK�Ȃ��B
�ނ�����{���[�J�[���ǂ��o��"�f�X�N�g�b�v�m�[�g"�ɍœK�Ȃ��B
549 �F,,�E�L�́M�E,,�j���F2008/07/18(��) 20:56:38 ID:T6A7gPNZ
>>548
������Puma�̗p�������ȃ��[�J�[��SHARP�ʂ����Ȃ��ˁH
�܂����{�s��ɂ�����Centrino�͍��t�����l�u�����h������ȁB
�ቿ�i�т�Celeron�ł����B
������Puma�̗p�������ȃ��[�J�[��SHARP�ʂ����Ȃ��ˁH
�܂����{�s��ɂ�����Centrino�͍��t�����l�u�����h������ȁB
�ቿ�i�т�Celeron�ł����B
���ł����n���Ȃ��ƌ������
>>550
���ȏЉ
���ȏЉ
�����L��������Ƃ肠�������ꂾ���u���Ƃ���
ttp://ja.wikipedia.org/wiki/Centrino
ttp://northwood.blog60.fc2.com/blog-entry-2133.html#more
ttp://ja.wikipedia.org/wiki/Centrino
ttp://northwood.blog60.fc2.com/blog-entry-2133.html#more
>>536
���@�@�e�����@�@52%
����́A200mm�E�G�n�Ή��������u�̔���グ��e���ɏ�悹���Ă��邾����
�{�Ƃ̑e������37%�B���Ȃ�Ⴂ
���@�@�e�����@�@52%
����́A200mm�E�G�n�Ή��������u�̔���グ��e���ɏ�悹���Ă��邾����
�{�Ƃ̑e������37%�B���Ȃ�Ⴂ
>>536
$1.180M �ł���A�Ռ��I�ł��Ȃ����낤�B
$1.180B �Ƃ������Ƃł��傤���B
>>528
�����`�ɋ߂��_�C��2���ׂ�MCM������A�ג����\�P�b�g�ƂȂ�A
�Ƃ����l�����́A�P�������܂��B
quad-channel �ƂȂ郁�����ւ̃}�U�[�{�[�h��̑����̔z���̒�����
�ł������Z�����AE-ATX�T�C�Y���� dual socket�������A�Ƃ����悤��
���Ƃ̂��߂Ƀ\�P�b�g�`����œK��������A���ʓI�ɁA���̂悤�ɂȂ���
�Ƃ������Ƃł͂Ȃ����B
$1.180M �ł���A�Ռ��I�ł��Ȃ����낤�B
$1.180B �Ƃ������Ƃł��傤���B
>>528
�����`�ɋ߂��_�C��2���ׂ�MCM������A�ג����\�P�b�g�ƂȂ�A
�Ƃ����l�����́A�P�������܂��B
quad-channel �ƂȂ郁�����ւ̃}�U�[�{�[�h��̑����̔z���̒�����
�ł������Z�����AE-ATX�T�C�Y���� dual socket�������A�Ƃ����悤��
���Ƃ̂��߂Ƀ\�P�b�g�`����œK��������A���ʓI�ɁA���̂悤�ɂȂ���
�Ƃ������Ƃł͂Ȃ����B
555 �FMAC�I�^��554 �����F2008/07/19(�y) 08:19:27 ID:2eUAebpx
>>554
�@�@-------------------
�@�@���ʓI�ɁA���̂悤�ɂȂ����Ƃ������Ƃł͂Ȃ����B
�@�@-------------------
�Ȃ�قǁB�m����Opteron�}�U�[���ʂ̗p��Ō���"�Дx"�\����MCM��I�Ȃ������i�K��
�����������\�P�b�g��V�v����K�v�ɔ���ꂽ�B�B�B�Ƃ������ƂȂ��ˁH
�@�@-------------------
�@�@���ʓI�ɁA���̂悤�ɂȂ����Ƃ������Ƃł͂Ȃ����B
�@�@-------------------
�Ȃ�قǁB�m����Opteron�}�U�[���ʂ̗p��Ō���"�Дx"�\����MCM��I�Ȃ������i�K��
�����������\�P�b�g��V�v����K�v�ɔ���ꂽ�B�B�B�Ƃ������ƂȂ��ˁH
556 �FMAC�I�^���⑫�F2008/07/19(�y) 08:20:48 ID:2eUAebpx
>>555
���ꂩ��A���l�̒������ӂ��邷�B�{����"$1,180M"�ŃR���}�ƃs���I�h�̃^�C�|���B
���ꂩ��A���l�̒������ӂ��邷�B�{����"$1,180M"�ŃR���}�ƃs���I�h�̃^�C�|���B
557 �FSocket774�F2008/07/20(��) 00:10:11 ID:O01E1DdO
AMD���ĂȂ�Œׂ�Ȃ��́H
�����������͂Ȃ��ׂ�Ȃ��́H�Ɠ������R����
559 �FSocket774�F2008/07/20(��) 00:43:18 ID:O01E1DdO
����v�������薜�N�Ԏ������
>>557
�����������l�A�݂��Ă����l�����邩��B
�����������l�A�݂��Ă����l�����邩��B
�������ɂ��낻�냄�o���[���ȁc
�C�O�̂��̌o�c��10�N������z���čs�Ȃ��Ă邩��
������Ă����Ɛ��N�ׂ͒�Ȃ���
���̂����Aintel�����肱�����炻�̎��ɂ܂�amd������鎞���������
������Ă����Ɛ��N�ׂ͒�Ȃ���
���̂����Aintel�����肱�����炻�̎��ɂ܂�amd������鎞���������
> �C�O�̂��̌o�c��10�N������z���čs�Ȃ��Ă邩��
�C�O���Ɠ����Ƃ�����������Ȃ��A���v�͏�ɓ����Ƃɖw�ǂ��Ҍ�����̂��|�B
���{���Ɨ��v�z���͏��Ȃ��čςނ��璷�������z���Ă̌o�c���\���B
�C�O���Ɠ����Ƃ�����������Ȃ��A���v�͏�ɓ����Ƃɖw�ǂ��Ҍ�����̂��|�B
���{���Ɨ��v�z���͏��Ȃ��čςނ��璷�������z���Ă̌o�c���\���B
�m����Core2���o�钼�O���s�[�N�ō��͉����葱���Ă�ˁc
�����������炢���������I�I
�����������炢���������I�I
��R��������$5�����荞�����
�������ɂ������
������ڗ������D�ޗ��͂Ȃ���
�������ɂ������
������ڗ������D�ޗ��͂Ȃ���
�n����������
�������Ƀ��o��������(�E�L��`�E)
����ł������N�̊Ԃɗݐς����Ԏ��z�����ł���50���h���ɒB�������ƂɂȂ�B
�܂�5000���~�̗ݐϐԎ��A�������ɂ����_������?
�܂�5000���~�̗ݐϐԎ��A�������ɂ����_������?
>>564
�Ȃ�A�����Ă���(�E�L��`�E)
�Ȃ�A�����Ă���(�E�L��`�E)
�{���̎R���2009�N�`2010�N����̐V�R�A�A
�V�v���b�g�t�H�[���̕]�����낤�ˁB
���ꂪ�����違�x������ƁA���Ƀ��o�C�B
�V�v���b�g�t�H�[���̕]�����낤�ˁB
���ꂪ�����違�x������ƁA���Ƀ��o�C�B
����AMD���|�Y�����Ƃ���ƁB
���܂ł�AMD�̃|�W�V������VIA������̂��B
�������ɑz�����t���Ȃ��ȁE�E�E
���܂ł�AMD�̃|�W�V������VIA������̂��B
�������ɑz�����t���Ȃ��ȁE�E�E
>>570
�V�R�A��2009�N�͖�������B������2010�N�㔼�B
�V�R�A��2009�N�͖�������B������2010�N�㔼�B
Bulldozer�͐��i�Ƃ��ă��m���o��̂�2010�N�����������炢�������
�܂�GPU���D�����������炻�����ł�����x�҂��邩���H
�Ƃ����Ă�ATI�̕���������Ƃ���Ԃ����A�������傱���Əo�������炢����
�Ă��ɐ������
�܂�GPU���D�����������炻�����ł�����x�҂��邩���H
�Ƃ����Ă�ATI�̕���������Ƃ���Ԃ����A�������傱���Əo�������炢����
�Ă��ɐ������
>>571
�������ɂǂ����̐��������������邾��(�E�L��`�E)
�������ɂǂ����̐��������������邾��(�E�L��`�E)
Phenom X5
577 �FSocket774�F2008/07/21(��) 02:17:42 ID:DUP5Mog8
�A���u�̐Ζ����ɂ����Ƃ��Ă��炦
�������{�}���ĕϊ������̂��E�E�E
�������{�}���ĕϊ������̂��E�E�E
>>577
�R��̂Ƃ���iMSIME2002�j�͂����イ�������w��������
�ǂ������ꂵ���Ȃ�����Ζ�������̫�Ă̼��ю����o�^���Ƃ��Ă��悳�����Ȃ��̂Ȃ̂�
�R��̂Ƃ���iMSIME2002�j�͂����イ�������w��������
�ǂ������ꂵ���Ȃ�����Ζ�������̫�Ă̼��ю����o�^���Ƃ��Ă��悳�����Ȃ��̂Ȃ̂�
�~ �����イ
���@������
���@������
�ӂ��i�����̂�ry
���������w
�w���iSCIM-Anthy�j
�I���������Ȃӂ�����(�E�L��`�E)
���O�̐l�����H
�ӂ����g���Ă݂�����(�E�L��`�E)
�I���ƏW���F
�v���Z�b�T���Ƃ�������AMD
http://www.itmedia.co.jp/enterprise/articles/0807/22/news038.html
�v���Z�b�T���Ƃ�������AMD
http://www.itmedia.co.jp/enterprise/articles/0807/22/news038.html
C2D������CPU���J���ł�����N�����Ă���
Dirk Meyer������̓d�b��c�Ō��y�������߂ɂ�����Ƙb���"Bobcat"�A����
��������ɂȂ肻�����B
�\�[�X��AeWeek��AMD�c�ƒS���d��Nigel Dessau�C���^�r���[���B
http://www.eweek.com/c/a/Desktops-and-Notebooks/AMD-Will-Pass-on-Netbooks-For-Now/
�@�@-------------------
�@�@"What we are saying is that we are a smaller company and we have
�@�@to focus on what we do well at this point. We are watching that
�@�@segment rather than playing in it, but as it matures we'll see
�@�@where it goes. At this moment, we are going to focus on what we
�@�@do best."
�@�@-------------------
�o�c�̋ꂵ��AMD�ɂ험���̏������s��ɎQ������]�͂햳���������B
����ɂ��Ă��uintel���s����J���Ă����̑҂��v�Ƃ����̂�A�����ɂ�
AMD�炵���ƌ��������ƌ������B�B�B
��������ɂȂ肻�����B
�\�[�X��AeWeek��AMD�c�ƒS���d��Nigel Dessau�C���^�r���[���B
http://www.eweek.com/c/a/Desktops-and-Notebooks/AMD-Will-Pass-on-Netbooks-For-Now/
�@�@-------------------
�@�@"What we are saying is that we are a smaller company and we have
�@�@to focus on what we do well at this point. We are watching that
�@�@segment rather than playing in it, but as it matures we'll see
�@�@where it goes. At this moment, we are going to focus on what we
�@�@do best."
�@�@-------------------
�o�c�̋ꂵ��AMD�ɂ험���̏������s��ɎQ������]�͂햳���������B
����ɂ��Ă��uintel���s����J���Ă����̑҂��v�Ƃ����̂�A�����ɂ�
AMD�炵���ƌ��������ƌ������B�B�B
589 �FMAC�I�^��586 �����F2008/07/22(��) 19:52:14 ID:rq/GdzuU
>>586
�@�@-----------------------
�@�@�uAMD�͉��Ƃ��Ă��~�b�h�}�[�P�b�g�ɂƂǂ܂�l�����B��ʔ̔��������߁A
�@�@�p�t�H�[�}���X�Ƃ������������d�͌����Ƃ������v�f���d�������s��
�@�@�ł���Ɠ��Ђ͍l���Ă��邩�炾�v�ƃu���b�N�E�b�h���͌��B
�@�@-----------------------
�������傫������s��ɂԂ牺���肽���̂헝���ł��邷���ǁAIntel������
�s�ꂩ��AMD��@���o�����߂ɍŗD��ŐV�A�[�L�e�N�`���𓊓����Ă���̂�
���Đ��ʏՓ˂��邱�ƂɂȂ邷�B
�����̌��ɓ����������Ă�̂��A�Ƌ֖@�l�^�ł���̏���v���ăV�F�A�̂���
�ڂ�ɂ����������Ȃ̂��B�B�B
�@�@-----------------------
�@�@�uAMD�͉��Ƃ��Ă��~�b�h�}�[�P�b�g�ɂƂǂ܂�l�����B��ʔ̔��������߁A
�@�@�p�t�H�[�}���X�Ƃ������������d�͌����Ƃ������v�f���d�������s��
�@�@�ł���Ɠ��Ђ͍l���Ă��邩�炾�v�ƃu���b�N�E�b�h���͌��B
�@�@-----------------------
�������傫������s��ɂԂ牺���肽���̂헝���ł��邷���ǁAIntel������
�s�ꂩ��AMD��@���o�����߂ɍŗD��ŐV�A�[�L�e�N�`���𓊓����Ă���̂�
���Đ��ʏՓ˂��邱�ƂɂȂ邷�B
�����̌��ɓ����������Ă�̂��A�Ƌ֖@�l�^�ł���̏���v���ăV�F�A�̂���
�ڂ�ɂ����������Ȃ̂��B�B�B
�������傫������s�������肽��Intel��
�l�n�����Ŋ��S�V�v�����s��CoreMA�g���Œ���
�l�n�����Ŋ��S�V�v�����s��CoreMA�g���Œ���
2P�I��������A����CoreMA��XeonDP�ł����������Ă���ǁB
FB-DIMM�ŕs������������d�͂�DDR3��DDR2���L���ɂȂ邵�c�B
�d�͌�����AMD����ɂȂ��ė������傫�����Ăǂ��̎s�ꂾ�H
FB-DIMM�ŕs������������d�͂�DDR3��DDR2���L���ɂȂ邵�c�B
�d�͌�����AMD����ɂȂ��ė������傫�����Ăǂ��̎s�ꂾ�H
INTEL�͂�������AMB���}�U�{�ɓ��ڂ���d�l�ɕς���
�Ȃ�Ő�̂Ȃ�FB-DIMM���w�����Ȃ���Ȃ�Ȃ���
�Ȃ�Ő�̂Ȃ�FB-DIMM���w�����Ȃ���Ȃ�Ȃ���
�[���uIntel�ł��痘�v�����₵���ቿ�i�m�[�gPC�s��͂�߂��v�ł�����
�uintel���s����J���Ă����̑҂��v�Ȃ�ăj���A���X�͖����悤����
�\�[�X�ǂ܂��ɂǂ����悤���Ȃ��n����MAC�I�^�̃��X�����ǂ�ň�u�M���Ă��܂���
�uintel���s����J���Ă����̑҂��v�Ȃ�ăj���A���X�͖����悤����
�\�[�X�ǂ܂��ɂǂ����悤���Ȃ��n����MAC�I�^�̃��X�����ǂ�ň�u�M���Ă��܂���
>>593
��������Ђ������̑I�����āA���[�R�X�gPC�s��͗l�q�����Ă̂�
AMD�Ɉ����Ƃ炦���炻���Ƃ�����B
���ƁAAMD�̓��[�R�X�gPC�s��p�ɕʐv��CPU�v�����͍��̂Ƃ���Ȃ����Ă��ƂȂ̂ŁA
Bobcat�������������͔����ɂȂ������Ă����ŁADirk Meyer�̌���Atom�RCPU��
K8���낤����o���Ȃ����ȁH
��������Ђ������̑I�����āA���[�R�X�gPC�s��͗l�q�����Ă̂�
AMD�Ɉ����Ƃ炦���炻���Ƃ�����B
���ƁAAMD�̓��[�R�X�gPC�s��p�ɕʐv��CPU�v�����͍��̂Ƃ���Ȃ����Ă��ƂȂ̂ŁA
Bobcat�������������͔����ɂȂ������Ă����ŁADirk Meyer�̌���Atom�RCPU��
K8���낤����o���Ȃ����ȁH
����Ղ�`��>>18
�������N�͐V�v���ꂽ�V�R�A�̂Ȃ�AMD�́A
�����ɏo�������Ȃ����������������ۑ肾�낤�ȁB
�����ɏo�������Ȃ����������������ۑ肾�낤�ȁB
�����v���ʂ͏o�Ă��܂����悤�ȋC��������c
�܂������Ă�Ԃ�ɂ͉������邯�ǁA�Ȃh��(�L�E�ցE`)
�܂������Ă�Ԃ�ɂ͉������邯�ǁA�Ȃh��(�L�E�ցE`)
>>590
�܂��A���g�̃l�n�����̓l�g�o�̊g�������������(�E�L��`�E)
�܂��A���g�̃l�n�����̓l�g�o�̊g�������������(�E�L��`�E)
K9�f�O���āAK10�s�U������ȁB
�����s����������E�E�E�E
�����s����������E�E�E�E
�������Ƀ��o���[����
601 �FMAC�I�^��593-594 �����F2008/07/23(��) 03:50:28 ID:xMx36JJT
>>593-594
�@�@---------------------
�@�@�uintel���s����J���Ă����̑҂��v�Ȃ�ăj���A���X�͖����悤����
�@�@---------------------
�VCEO��Dirk Meyer���g���ߎl�����̋Ɛѕd�b��c�œ���|�̂��Ƃ�����Ă��邷�B
http://www.123jump.com/earnings-calls/Advanced-Micro-Devices-Earnings-Call-Second-Quarter-2008/28686/61
�@�@=====================
�@�@Dirk Meyer: Yes. The extent Intel creates opportunity for X86 technology
�@�@�@�@�@�@�@�@by growing new markets that is good for us over time.
�@�@=====================
�@�@---------------------
�@�@�uintel���s����J���Ă����̑҂��v�Ȃ�ăj���A���X�͖����悤����
�@�@---------------------
�VCEO��Dirk Meyer���g���ߎl�����̋Ɛѕd�b��c�œ���|�̂��Ƃ�����Ă��邷�B
http://www.123jump.com/earnings-calls/Advanced-Micro-Devices-Earnings-Call-Second-Quarter-2008/28686/61
�@�@=====================
�@�@Dirk Meyer: Yes. The extent Intel creates opportunity for X86 technology
�@�@�@�@�@�@�@�@by growing new markets that is good for us over time.
�@�@=====================
���̏�Ԃ�CEO�Ȃ�ĒN������Ă��Ԏ�����
���܂������A���₢�₨�܂������A�݂����ȏ�Ԃ������肵�āB
���܂������A���₢�₨�܂������A�݂����ȏ�Ԃ������肵�āB
�ǂ�����̂Ă���V�i���I�Ȃ���A
�G�L�X�g���ł��ق���CEO�ɒu���Ƃ��Ⴂ�����(�E�L��`�E)
�G�L�X�g���ł��ق���CEO�ɒu���Ƃ��Ⴂ�����(�E�L��`�E)
�u���C�Y�v�Ńj���[���ɃX���������Ƃ��Ȃ��Ȃ�̂��낤
>>599
���������uK10=K8�v�����ˁBK9�̓l�g�o�n���ӎ��������肾�����݂��������B
Core2�̂悤�ɃR�A�����{����������Ă���Εʂ����ǁA
�����܂ō��{����͉��ǂ͂���ĂȂ�����A���͌������������B
���������uK10=K8�v�����ˁBK9�̓l�g�o�n���ӎ��������肾�����݂��������B
Core2�̂悤�ɃR�A�����{����������Ă���Εʂ����ǁA
�����܂ō��{����͉��ǂ͂���ĂȂ�����A���͌������������B
�l�g�o�̂����ʼn��g�����i��
PhenomX2�Ƃ����i�I�ɔ����₷���̂������
���ʖʂ����ł�intel�����Ԃ��Ȃ�����
���ʖʂ����ł�intel�����Ԃ��Ȃ�����
>>607
����Ȃ�Brisbane�ł�������
����Ȃ�Brisbane�ł�������
>>607
�����Kuma�̂��Ƃ��������������������������I�I�I�I�I�I�I�I�I
���Ԃ�Phenom�n�̗\�z�ȏ�̔��M�ɂ����
�N���b�N�㏸���܂܂Ȃ�Ȃ������߂ɁA
���sX2�R�A�Ƒ卷�����������R�A�̂ł�����CPU�ł����Ȃ��B
���ꂪ�̂Ɂc�̓W�J�ɂȂ��Ă���Ǝv�����H
�����Kuma�̂��Ƃ��������������������������I�I�I�I�I�I�I�I�I
���Ԃ�Phenom�n�̗\�z�ȏ�̔��M�ɂ����
�N���b�N�㏸���܂܂Ȃ�Ȃ������߂ɁA
���sX2�R�A�Ƒ卷�����������R�A�̂ł�����CPU�ł����Ȃ��B
���ꂪ�̂Ɂc�̓W�J�ɂȂ��Ă���Ǝv�����H
>>609
����͂ǂ����ŕ������悤�ȗ��ꂾ�ȁB
����͂ǂ����ŕ������悤�ȗ��ꂾ�ȁB
���M�̖�肶��Ȃ��A�P���Ƀ_�C���ł������ɃN���b�N10%�����x�̐��\���サ��
�Ȃ�����ʎY���Ă����ɍ���Ȃ���
�Ȃ�����ʎY���Ă����ɍ���Ȃ���
�P���ɃN���b�N���オ��Ȃ������Ȃ���(�E�L��`�E)
613 �FSocket774�F2008/07/24(��) 08:35:33 ID:ReY298cA
���������ΐ�z�_���Ă��������
>>612
48xx�X���Ō�Intel�g������ɍs������
48xx�X���Ō�Intel�g������ɍs������
>>611
�_�C�T�C�Y��L3�O��������
���\��SSE�{����ȓd�͋@�\��
���̑��n���ȁi�x���`�ŏo�ɂ����j����������
����45nm���߂������
����Ă����ɂȂ��̂��낤
�_�C�T�C�Y��L3�O��������
���\��SSE�{����ȓd�͋@�\��
���̑��n���ȁi�x���`�ŏo�ɂ����j����������
����45nm���߂������
����Ă����ɂȂ��̂��낤
>>615
SSE�{���Ȃ�G���R�͎��ʂقǑ����Ȃ肻���Ȃ��ǂ��Ȃ낤��
SSE�{���Ȃ�G���R�͎��ʂقǑ����Ȃ肻���Ȃ��ǂ��Ȃ낤��
617 �FSocket774�F2008/07/24(��) 14:36:55 ID:Vet+qCYP
�r���L���b�V�������\������ז����Ă��邩��A����ǂ����悤���Ȃ��B
���߃t�F�b�`�{����K10�̍ő�̊̂ł�������Ǝv���Ă鉴�́A
�Ȃ�ł���������Ƃ��Ƃ�45nm�̃f���A���R�A����ė~����
�Ȃ�ł���������Ƃ��Ƃ�45nm�̃f���A���R�A����ė~����
>615�͂��Ȃ茾�t���炸��������
��������65nm2�R�AK10��������i�v�����j
�������Ɉڍs�����琔�����Ȃ��i�����ł��Ȃ��j�Ƃ�������
���������̂͑����J�����t�@�u���ݔ�Ńh�o�b�Əo���
���i���ǂꂾ���������邩�Ō������̂�
TLB�G���b�^�ł���܂ō�������̂����ʂɂȂ�
���������炭�~�߂���Ȃ���������
���ꂳ���������2�R�A���o���]�T�����ԓI�ɂ����������m��Ȃ�
��������65nm2�R�AK10��������i�v�����j
�������Ɉڍs�����琔�����Ȃ��i�����ł��Ȃ��j�Ƃ�������
���������̂͑����J�����t�@�u���ݔ�Ńh�o�b�Əo���
���i���ǂꂾ���������邩�Ō������̂�
TLB�G���b�^�ł���܂ō�������̂����ʂɂȂ�
���������炭�~�߂���Ȃ���������
���ꂳ���������2�R�A���o���]�T�����ԓI�ɂ����������m��Ȃ�
Dirk Meyer���H��蕥����Austin American-statesman���̃C���^�r���[�ŘR�炵��
���AMD����ً}�̔ے�R�����g���o��Ƃ������������������B
eWeek�̋L�������̎����ǂ��܂Ƃ߂Ă��邷�B
http://www.eweek.com/c/a/Desktops-and-Notebooks/AMD-Denies-Fab-Sell-Off/
�@�@---------------------
�@�@AMD is denying a report that appeared in the Austin American-
�@�@Statesman that contains an interview with new CEO Dirk Meyer that
�@�@seemed to indicate that the chip maker was preparing to spin off
�@�@its manufacturing facilities in Germany and sell its two fabrication
�@�@plants, or fabs.
�@�@---------------------
�ȑO�̃��X�g���̎��Ɠ������w���͖{���ł����x�Ƃ����I�`�������ǂ����B�B�B
���AMD����ً}�̔ے�R�����g���o��Ƃ������������������B
eWeek�̋L�������̎����ǂ��܂Ƃ߂Ă��邷�B
http://www.eweek.com/c/a/Desktops-and-Notebooks/AMD-Denies-Fab-Sell-Off/
�@�@---------------------
�@�@AMD is denying a report that appeared in the Austin American-
�@�@Statesman that contains an interview with new CEO Dirk Meyer that
�@�@seemed to indicate that the chip maker was preparing to spin off
�@�@its manufacturing facilities in Germany and sell its two fabrication
�@�@plants, or fabs.
�@�@---------------------
�ȑO�̃��X�g���̎��Ɠ������w���͖{���ł����x�Ƃ����I�`�������ǂ����B�B�B
�o���Ă�����Ȃ���ΈӖ��Ȃ�
���
�Ƃ肠����HyperTransport3.0�ɑΉ�������������
Athlon64X2�Ƃ��o���ċ}��𗽂��Ȃ�����
Athlon64X2�Ƃ��o���ċ}��𗽂��Ȃ�����
���������Ɠ{���邩�������
�Ԃ����ႯAMD�͂��낻��̗͓I�Ɍ��E�����Ă���ۂ��Ȃ����H
���܂܂ŗǂ��撣�����Ǝv�����A����CPU���o���O��
���Ԃ�͐s������������Ǝv���B
�Ԃ����ႯAMD�͂��낻��̗͓I�Ɍ��E�����Ă���ۂ��Ȃ����H
���܂܂ŗǂ��撣�����Ǝv�����A����CPU���o���O��
���Ԃ�͐s������������Ǝv���B
���Ȃ��������Ă������nj��C������������B
> �Ƃ肠����HyperTransport3.0�ɑΉ�������������
> Athlon64X2�Ƃ��o���ċ}��𗽂��Ȃ�����
�������ȁA���\���Ⴗ����B
�������� X2 6400+��E7200�Ɠ����x�E�E�E�E
���ꂶ��ǂ����悤���Ȃ��B
> Athlon64X2�Ƃ��o���ċ}��𗽂��Ȃ�����
�������ȁA���\���Ⴗ����B
�������� X2 6400+��E7200�Ɠ����x�E�E�E�E
���ꂶ��ǂ����悤���Ȃ��B
>>624
Griffin��AM2+�ŏo����OK���Ă��Ƃ���B
2core�AHT3.0�AL2=1M*2�A�ȓd�͋@�\�����Ƃ��Ȃ���
Phenom�Ȃ�����ۂǖ��͓I�Ȃ�Ȃ��H
Griffin��AM2+�ŏo����OK���Ă��Ƃ���B
2core�AHT3.0�AL2=1M*2�A�ȓd�͋@�\�����Ƃ��Ȃ���
Phenom�Ȃ�����ۂǖ��͓I�Ȃ�Ȃ��H
45nm�ɑS�͂𓊓���
65nm�͐V���S���L�����Z�����邩����
AMD��65�͂͂����茾���đ����o��������
�������啪���Ƃ������Ă邵
65nm�͐V���S���L�����Z�����邩����
AMD��65�͂͂����茾���đ����o��������
�������啪���Ƃ������Ă邵
>>629
45nm��ES�̌��ʂ�������肠�܂�ǂ��Ȃ�
C2Q�Ɣ�r�����Vcore�d�������Ȃ荂��
45nm Phenom��ES
ttp://en.hardspell.com/doc/showcont.asp?news_id=3721
����
L3�L���b�V����6MB����
2.8GHz Vcore�d�� 1.224V �ΏĂ� 25.109s
3.0GHz Vcore�d�� 1.336V �ΏĂ� 23.547s (����p���E���ۂ�)
3.2GHz Vcore�d�� 1.424V �ΏĂ� 22.219s (�����p���E���ۂ�)
3.4GHz Vcore�d�� 1.568V �ΏĂ� 20.515s (OC���E���ۂ�)
45nm��ES�̌��ʂ�������肠�܂�ǂ��Ȃ�
C2Q�Ɣ�r�����Vcore�d�������Ȃ荂��
45nm Phenom��ES
ttp://en.hardspell.com/doc/showcont.asp?news_id=3721
����
L3�L���b�V����6MB����
2.8GHz Vcore�d�� 1.224V �ΏĂ� 25.109s
3.0GHz Vcore�d�� 1.336V �ΏĂ� 23.547s (����p���E���ۂ�)
3.2GHz Vcore�d�� 1.424V �ΏĂ� 22.219s (�����p���E���ۂ�)
3.4GHz Vcore�d�� 1.568V �ΏĂ� 20.515s (OC���E���ۂ�)
�����AMD�ɕK�v�Ȃ̂�X87�̂悤�ȃR�v���Z�b�T���낤��
Intel�͂ƌ����ALarrabee��X86�Ή��ACPU�Ɠ����x���̃N���b�N�A�����ȃR�A
����͂ǂ����Ă��R�v������
Intel�͂ƌ����ALarrabee��X86�Ή��ACPU�Ɠ����x���̃N���b�N�A�����ȃR�A
����͂ǂ����Ă��R�v������
������HT3.0�A2core�ADDR3��Regor�ł���B
�g�ѓd�b��45nm���s����܂����B
�ʐM/�A�v���P�[�V�����@�\��1�`�b�v������
�g�ѓd�b�@�pLSI
http://www.ednjapan.com/content/l_news/2008/07/u0o686000000jehe.html
�����d��Y�Ƃ�2008�N7���A�ʐM�@�\�ƃA�v���P�[�V�����@�\��1�`�b�v�ɓ��������g�ѓd�b�@�p�V�X�e��LSI
�uMN2CS0038�v���J�������Ɣ��\�����B���Ђ̃f�W�^���Ɠd�����v���b�g�t�H�[���uUniPhier�v����ɁA45nm
�v���Z�X���̗p����1�`�b�v���������́B�����i��p���邱�ƂŁA���l�ȕ����ɑΉ������ʐM�@�\�ƁA�O���t
�B�b�N�X�̕`�����Z�O�̎����Ƃ������A�v���P�[�V�����@�\���������邱�Ƃ��\�ɂȂ�B2008�N7����
�{���T���v���o�ׂ��J�n����B
�ʐM/�A�v���P�[�V�����@�\��1�`�b�v������
�g�ѓd�b�@�pLSI
http://www.ednjapan.com/content/l_news/2008/07/u0o686000000jehe.html
�����d��Y�Ƃ�2008�N7���A�ʐM�@�\�ƃA�v���P�[�V�����@�\��1�`�b�v�ɓ��������g�ѓd�b�@�p�V�X�e��LSI
�uMN2CS0038�v���J�������Ɣ��\�����B���Ђ̃f�W�^���Ɠd�����v���b�g�t�H�[���uUniPhier�v����ɁA45nm
�v���Z�X���̗p����1�`�b�v���������́B�����i��p���邱�ƂŁA���l�ȕ����ɑΉ������ʐM�@�\�ƁA�O���t
�B�b�N�X�̕`�����Z�O�̎����Ƃ������A�v���P�[�V�����@�\���������邱�Ƃ��\�ɂȂ�B2008�N7����
�{���T���v���o�ׂ��J�n����B
>634
�`�b�v�Z�b�g�����P�M�҂���A�܂�������قǗǂ����o���Ă��
�`�b�v�Z�b�g�����P�M�҂���A�܂�������قǗǂ����o���Ă��
�ŏ���45nm�ʎY�J�n�����̂͏���������� �iIntel��45nm�ʎY�J�n�͂���4������j
http://www.sijapan.com/content/l_news/2007/06/news070620_0101.html
http://www.sijapan.com/content/l_news/2007/06/news070620_0101.html
��PC�p��CPU�݂����ȑ�K�͂����G�ȉ�H�\���ɂȂ��Ă鐻�i��
�Ő�[�v���Z�X���ő��œ����ł��郁�[�J�[�Ȃ�Ă˂���
��{�I�ɍ��̓t���b�V�������������K�̓��W�b�N����K�̓��W�b�N
�̏��Ԃɍ̗p���������
�Ő�[�v���Z�X���ő��œ����ł��郁�[�J�[�Ȃ�Ă˂���
��{�I�ɍ��̓t���b�V�������������K�̓��W�b�N����K�̓��W�b�N
�̏��Ԃɍ̗p���������
641 �FSocket774�F2008/07/25(��) 22:06:19 ID:wLC0JDwr
SoC�ōŐ�[�v���Z�X���ő��œ��E�E�E
http://www.eetimes.jp/contents/200706/20706_2_20070619214113.cfm
����A�ʎY���J�n�����i��́A�f�W�^���Ɠd�����v���b�g�t�H�[���Z�p
�uUniPhier�v��K�p�����V�X�e��LSI�ł���B���Ђ��J�������v���Z�b�T�E�R�A
�uAM34-SMP�v��A�uH.264/MPEG-4 AVC�v�K�i�ɑΉ�����������/�������p
�A�v���P�[�V�����E�v���Z�b�T�A2����/3�����O���t�B�b�N������H�AQoS�@�\
����������ш�ۏؗp�������[�����H�Ȃǂ�1�`�b�v�ɏW�ς����B
http://journal.mycom.co.jp/articles/2008/07/24/tolapai/index.html
Photo04:�Ȃ�90nm�Ȃ̂��A�ɂ�2�̍l����������B���Pentium M�R�A��
���������������Ƃ����b�B65nm/45nm��Pentium M�����̂܂܈ڍs�����
�Ȃ�Core Solo�Ȃ�Atom������ق����}�V���������낤���A�����Ȃ�Ƃ����
�o�ꎞ�����x�ꂽ���낤�Ƒz�������B������́AMCH��ICH�A�����
Accelerator��65nm/45nm�����Ԃɍ����ĂȂ��Ƃ����\���B
http://www.eetimes.jp/contents/200706/20706_2_20070619214113.cfm
����A�ʎY���J�n�����i��́A�f�W�^���Ɠd�����v���b�g�t�H�[���Z�p
�uUniPhier�v��K�p�����V�X�e��LSI�ł���B���Ђ��J�������v���Z�b�T�E�R�A
�uAM34-SMP�v��A�uH.264/MPEG-4 AVC�v�K�i�ɑΉ�����������/�������p
�A�v���P�[�V�����E�v���Z�b�T�A2����/3�����O���t�B�b�N������H�AQoS�@�\
����������ш�ۏؗp�������[�����H�Ȃǂ�1�`�b�v�ɏW�ς����B
http://journal.mycom.co.jp/articles/2008/07/24/tolapai/index.html
Photo04:�Ȃ�90nm�Ȃ̂��A�ɂ�2�̍l����������B���Pentium M�R�A��
���������������Ƃ����b�B65nm/45nm��Pentium M�����̂܂܈ڍs�����
�Ȃ�Core Solo�Ȃ�Atom������ق����}�V���������낤���A�����Ȃ�Ƃ����
�o�ꎞ�����x�ꂽ���낤�Ƒz�������B������́AMCH��ICH�A�����
Accelerator��65nm/45nm�����Ԃɍ����ĂȂ��Ƃ����\���B
Anandtech��AMD�̐V�T�E�X�u���b�WSB750�̃��r���[�ŁA���(��)�I�[�o�[�N���b�N�x���@�\
�ɂ��ĉ�����Ă��邷�B
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=3360
�@�@------------------------
�@�@The SB750 now has a direct 6-pin interface to the AM2+ socket on the motherboard, there are
�@�@now pins on the Phenom CPU that connect directly to the SB750. These pins were previously
�@�@unused and are now used as a means of communication between the South Bridge and the CPU.
�@�@The SB750, in combination with an updated BIOS, can now override some of the CPU's internal
�@�@settings which can potentially increase the overclocking headroom of the chip.
�@�@------------------------
�ǂ����BIOS�őΉ��\�ȋ@�\���w�V�T�E�X�u���b�W�̃v���~�A���@�\�x�Ƃ��Ĕ���o�����͗l���B
�ɂ��ĉ�����Ă��邷�B
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=3360
�@�@------------------------
�@�@The SB750 now has a direct 6-pin interface to the AM2+ socket on the motherboard, there are
�@�@now pins on the Phenom CPU that connect directly to the SB750. These pins were previously
�@�@unused and are now used as a means of communication between the South Bridge and the CPU.
�@�@The SB750, in combination with an updated BIOS, can now override some of the CPU's internal
�@�@settings which can potentially increase the overclocking headroom of the chip.
�@�@------------------------
�ǂ����BIOS�őΉ��\�ȋ@�\���w�V�T�E�X�u���b�W�̃v���~�A���@�\�x�Ƃ��Ĕ���o�����͗l���B
�ǂ��������Ȃ��������������Ă�Ƃ����Ƃ�
����d�͂��C�ɂȂ��
����d�͂��C�ɂȂ��
OC�̃����b�g���Ď��������
��p�Ό��ʂ����コ����ړI������������
����C2D��OC���������ǂ����Ȃ��B
����C2D��OC���������ǂ����Ȃ��B
>>642
�}�[�W���M���M���̐ɂ͖��p�̒�������(�E�L��`�E)
�}�[�W���M���M���̐ɂ͖��p�̒�������(�E�L��`�E)
Core 2�̂������ŃJ�W���A��OC�̕~�������Ȃ�Ⴍ�Ȃ��������
�̂�OC�Ȃ�Ă͎̂�i�ƖړI������ւ���Ă�g�`�������悤�Ȃ��̂�������
�̂�OC�Ȃ�Ă͎̂�i�ƖړI������ւ���Ă�g�`�������悤�Ȃ��̂�������
>>647
���܂���������c�B
���܂���������c�B
649 �F�A���~ ��Fh2IQtNvbw �F2008/07/27(��) 13:31:42 ID:GHTjLSsH
�����̂��C���e����OC�}�[�W���������AAMD�͒Ⴂ�B
�������(�E�L��`�E)
�������(�E�L��`�E)
>>649
���m���p�������u�Ԃ����Ă��܂������B
���m���p�������u�Ԃ����Ă��܂������B
652 �F�A���~ ��Fh2IQtNvbw �F2008/07/27(��) 20:45:42 ID:GHTjLSsH
>>650
�٘_������Ό����Ă݂��܂�(�E�L��`�E)
�٘_������Ό����Ă݂��܂�(�E�L��`�E)
�������Ƃ`�s�h������Ȃ�h�m�s�d�k�����Ƀ}�U�{�o����
��������̐�������Љ�����Ƃ�Dirk Meyer�̃C���^�r���[���Austin Amrcian Stateman����AMD���X�g���Ɋւ���L�����B
http://www.statesman.com/business/content/business/stories/technology/07/29/0729amd.html
�@�@----------------------------
�@�@"It is fundamentally important to AMD to transform the way we build our wafers,"
�@�@Meyer said in a recent interview. "The price tag for technology goes up with every
�@�@generation. And the price tag for wafer (fabrication plants) goes up with every generation,
�@�@and we are simply too small and don't have the scale to stay in that game, and we are
�@�@not going to continue doing it that way."
�@�@----------------------------
���Ȃ��Ƃ�AMD������A������������ƔF�����Ă���͗l���B
http://www.statesman.com/business/content/business/stories/technology/07/29/0729amd.html
�@�@----------------------------
�@�@"It is fundamentally important to AMD to transform the way we build our wafers,"
�@�@Meyer said in a recent interview. "The price tag for technology goes up with every
�@�@generation. And the price tag for wafer (fabrication plants) goes up with every generation,
�@�@and we are simply too small and don't have the scale to stay in that game, and we are
�@�@not going to continue doing it that way."
�@�@----------------------------
���Ȃ��Ƃ�AMD������A������������ƔF�����Ă���͗l���B
AMD���܂������_�����(��)�Ƌ����J�����n�߂��͗l���B
http://www.globes.co.il/serveen/globes/docview.asp?did=1000367034&fid=942
�@�@----------------------
�@�@A few months ago, Plurality signed a cooperation agreement with AMD
�@�@under which Plurality's multicore processors will be integrated into
�@�@AMD's circuit boards.
�@�@----------------------
Plurality�Ђ�256-core�̃��j�[�R�A�v���Z�b�T���J�����Ă���C�X���G����
�V����Ƃ��Bhttp://www.plurality.co.il/
http://www.globes.co.il/serveen/globes/docview.asp?did=1000367034&fid=942
�@�@----------------------
�@�@A few months ago, Plurality signed a cooperation agreement with AMD
�@�@under which Plurality's multicore processors will be integrated into
�@�@AMD's circuit boards.
�@�@----------------------
Plurality�Ђ�256-core�̃��j�[�R�A�v���Z�b�T���J�����Ă���C�X���G����
�V����Ƃ��Bhttp://www.plurality.co.il/
790GX���?
�C�X���G���l��10�l��1�l���C���e���œ����Ă���đO�Ɍ��������Ȃ�[�����
>>656
���̉��ɓy��͂��Ȃ���c�B
������Intel�̂悤�ȊJ���`�[���͂����݂���Ȃ��B�炽�Ȃ���B
C2D�̊J���`�[����Timna���ォ��̊J���`�[���Ȃ����B
���̉��ɓy��͂��Ȃ���c�B
������Intel�̂悤�ȊJ���`�[���͂����݂���Ȃ��B�炽�Ȃ���B
C2D�̊J���`�[����Timna���ォ��̊J���`�[���Ȃ����B
���k�͔|�H
662 �FMAC�I�^��659 �����F2008/07/31(��) 23:56:22 ID:knyhyElr
>>659
�@�@---------------------
�@�@�C�X���G���l��10�l��1�l���C���e���œ����Ă���đO�Ɍ��������Ȃ�[�����
�@�@---------------------
���ς�炸�A������A��������悤�ɉR�������ˁB�B�B
http://www.inminds.co.uk/boycott-intel.html
�@�@=====================
�@�@By year 2000 they employ over 4000 israelis.
�@�@=====================
�C�X���G���̐l����4���l���ǂ�����A�e���m���߂Ă݂�Ηǂ����Ǝv����(��)
�@�@---------------------
�@�@�C�X���G���l��10�l��1�l���C���e���œ����Ă���đO�Ɍ��������Ȃ�[�����
�@�@---------------------
���ς�炸�A������A��������悤�ɉR�������ˁB�B�B
http://www.inminds.co.uk/boycott-intel.html
�@�@=====================
�@�@By year 2000 they employ over 4000 israelis.
�@�@=====================
�C�X���G���̐l����4���l���ǂ�����A�e���m���߂Ă݂�Ηǂ����Ǝv����(��)
���ł���Ȃɔn���̑��肷��z������́H
10�l��1�l���ėႦ�Ȃ�˂���
����ȕ��Ƃɂ��炸��Ώ�Ԃ̊�Ƃ������Ă��܂邩��
����ȕ��Ƃɂ��炸��Ώ�Ԃ̊�Ƃ������Ă��܂邩��
���A�W���[�N�̗ނ܂ŃA�����̖ϑz��������Ă���
�{���ɏA�Ɛl���̃\�[�X���������Ă������ȁB
�{���ɏA�Ɛl���̃\�[�X���������Ă������ȁB
�c���������͂ǂ�Ȋ������Ǝv���܂��H
MAC�I�^����B��Âɘ��Վ��_�ł̗\�z���������������̂ł����E�E�E
Yorkfield���{���ɑ����Ȃ�̂ł��傤���H
MAC�I�^����B��Âɘ��Վ��_�ł̗\�z���������������̂ł����E�E�E
Yorkfield���{���ɑ����Ȃ�̂ł��傤���H
�A���ł��B
�k�X�ł߂��Ⴍ����ɂ����Ă邯�ǁA
�����͂̂��锻�f��MAC�I�^����Ȃ牺����Ǝv���܂��B
�ǂ��Ȃ��ˁH
�k�X�ł߂��Ⴍ����ɂ����Ă邯�ǁA
�����͂̂��锻�f��MAC�I�^����Ȃ牺����Ǝv���܂��B
�ǂ��Ȃ��ˁH
670 �FMAC�I�^��668 �����F2008/08/01(��) 17:15:06 ID:GRi0Viq/
>>668-669
�k�X���łƂ������Ƃ�A�ǂ���"FUD"zilla���\�[�X�ɂ������ꃋ�[�}�[���Ǝv�����B
�A�����ĐM�S�[��AMD�M�҂�ނ��ăA�t�B���G�C�g�ʼn҂�����������A�}�g���Ɏ�荇�������ԈႢ���B
�k�X���łƂ������Ƃ�A�ǂ���"FUD"zilla���\�[�X�ɂ������ꃋ�[�}�[���Ǝv�����B
�A�����ĐM�S�[��AMD�M�҂�ނ��ăA�t�B���G�C�g�ʼn҂�����������A�}�g���Ɏ�荇�������ԈႢ���B
�������I�������ς荡������߂��Ă��ƁH
>>665-667
�W���[�N�Ƃ��Ⴆ�Ƃ����U���̂ɐ���t����(��)
�ł����̕ӂŖ��ȓˍ��݂�����Ă��܂����̂���ԈႢ���B
�@�@-----------------------
�@�@�A�Ɛl���Řb�����Ȃ��ƕs���m�ł��傤�B
�@�@-----------------------
���{��Ō������Ă��ȒP�Ɍ�����l�^�ň������N���̂�A�����ɂ��A�����]�ƌ����ׂ������B�B�B
http://jp.encarta.msn.com/encyclopedia_761575008_3/content.html
�@�@=======================
�@�@2005�N�̘J���l����273��372�l�ŁA���̂���47%(2005�N)�������ł���B
�@�@=======================
�W���[�N�Ƃ��Ⴆ�Ƃ����U���̂ɐ���t����(��)
�ł����̕ӂŖ��ȓˍ��݂�����Ă��܂����̂���ԈႢ���B
�@�@-----------------------
�@�@�A�Ɛl���Řb�����Ȃ��ƕs���m�ł��傤�B
�@�@-----------------------
���{��Ō������Ă��ȒP�Ɍ�����l�^�ň������N���̂�A�����ɂ��A�����]�ƌ����ׂ������B�B�B
http://jp.encarta.msn.com/encyclopedia_761575008_3/content.html
�@�@=======================
�@�@2005�N�̘J���l����273��372�l�ŁA���̂���47%(2005�N)�������ł���B
�@�@=======================
673 �FMAC�I�^��671 �����F2008/08/01(��) 17:22:46 ID:GRi0Viq/
>>671
�����AMD�̃f�X�N�g�b�v�����v���Z�b�T��A���i����������_���Ƃ������Ƃ햳���Ǝv�����B
�����AMD�̃f�X�N�g�b�v�����v���Z�b�T��A���i����������_���Ƃ������Ƃ햳���Ǝv�����B
MAC�I�^�]
�x������������������葬�����ǂ������ł��d�v�Ȃ�ł��B
�ꐢ��x��Ă��Ă���ς��Ȃ�����ł͂��܂�̂ł��B
�����ɂȂ��̂ł���B
�ꐢ��x��Ă��Ă���ς��Ȃ�����ł͂��܂�̂ł��B
�����ɂȂ��̂ł���B
�Ă̒苶�에�����Ă�
677 �FMAC�I�^��675 �����F2008/08/01(��) 17:41:37 ID:GRi0Viq/
>>675
Silverthorne��Core2��葬�����Ƃ�N�����҂��Ȃ��悤�ɁA��ΐ��\�������v���Z�b�T�̕]���
���ᖳ�����B
�w������q�����ł����A���i�Ƀ}�b�`�����s�ꂪ����Ηǂ�����B
�����Ƃ���������Ȃ��w���z�x��̔�����̂�A�܂Ƃ��ȋZ�p��ƂƂ팾���Ȃ������ǁB�B�B
Silverthorne��Core2��葬�����Ƃ�N�����҂��Ȃ��悤�ɁA��ΐ��\�������v���Z�b�T�̕]���
���ᖳ�����B
�w������q�����ł����A���i�Ƀ}�b�`�����s�ꂪ����Ηǂ�����B
�����Ƃ���������Ȃ��w���z�x��̔�����̂�A�܂Ƃ��ȋZ�p��ƂƂ팾���Ȃ������ǁB�B�B
�G���X�[�W�A�X�g�����͂�����߂Ď����̐�����ꏊ��T���Ƃ������Ƃł��ˁB�킩��܂��B
AMD�̓p���X�`�i�ɍH��������̂ɁE�E�E
ttp://japan.cnet.com/news/ent/story/0,2000056022,20091397,00.htm
HT�̐Ǝ㐫���Đ��\�܂ʼn�����̂�
���ς̘_���j��{�͗��Ƀ��x�F�Ƃ��v���Ă����ǂ����ł��Ȃ�����������
HT�̐Ǝ㐫���Đ��\�܂ʼn�����̂�
���ς̘_���j��{�͗��Ƀ��x�F�Ƃ��v���Ă����ǂ����ł��Ȃ�����������
>>680����AMD�ɑ��錃�������ӂ�������
HT�g���ĕʃX���b�h�Ń��C���X���b�h�̂��߂Ƀ��������v�����[�h����
�V���O���X���b�h���\���グ��Ȃ�Ęb����������
����̋t���ł�����Ă����̎��ł���B�Ǝ㐫�Ƃ͂Ȃ��W�����B
�V���O���X���b�h���\���グ��Ȃ�Ęb����������
����̋t���ł�����Ă����̎��ł���B�Ǝ㐫�Ƃ͂Ȃ��W�����B
�����Q2�ƐѕŁA���ׂ������܂�����ATI�̑g�������ABroadcom�֔��蕥���邱�Ƃ�
�Ȃ肻�����B
http://www.eetimes.com/news/latest/showArticle.jhtml;jsessionid=RVJY0DSA1WD0WQSNDLSCKHA?articleID=209900490
�@�@-------------------------
�@�@Broadcom is a likely buyer for some of ATI's products. ''We believe that Broadcom is a likely
�@�@candidate to acquire AMD's consumer TV business for about $250-$375 million as it has a
�@�@comfort level and history with integrating former ATI products and management,'' said analyst
�@�@Doug Freedman of American Technology Research Inc., in a report.
�@�@-------------------------
���̕���팸�������ς�(>>442�Q��)������A�����ƒ����̍������ɂ��^���������B
�Ȃ肻�����B
http://www.eetimes.com/news/latest/showArticle.jhtml;jsessionid=RVJY0DSA1WD0WQSNDLSCKHA?articleID=209900490
�@�@-------------------------
�@�@Broadcom is a likely buyer for some of ATI's products. ''We believe that Broadcom is a likely
�@�@candidate to acquire AMD's consumer TV business for about $250-$375 million as it has a
�@�@comfort level and history with integrating former ATI products and management,'' said analyst
�@�@Doug Freedman of American Technology Research Inc., in a report.
�@�@-------------------------
���̕���팸�������ς�(>>442�Q��)������A�����ƒ����̍������ɂ��^���������B
�v�[�}�����o������
���������Ȃ��f�X�N�g�b�v�ŏ���������
�T�[�o�[�A�m�[�g�ŏ������������Ȃ��B
�v�[�}�Ȃ��Ȃ��ǂ��Ǝv�����ǁB
���̓C���e���������R�������A�V���A���V�X�e���o�X�iQPI�j�����邩��
�T�[�o�[�ł͗D�ʐ����Ȃ��Ȃ邱�Ƃ��ȁB
AMD�̊�ՂƃC���e���������邱�Ƃ��F��݂̂��ȁB
���������Ȃ��f�X�N�g�b�v�ŏ���������
�T�[�o�[�A�m�[�g�ŏ������������Ȃ��B
�v�[�}�Ȃ��Ȃ��ǂ��Ǝv�����ǁB
���̓C���e���������R�������A�V���A���V�X�e���o�X�iQPI�j�����邩��
�T�[�o�[�ł͗D�ʐ����Ȃ��Ȃ邱�Ƃ��ȁB
AMD�̊�ՂƃC���e���������邱�Ƃ��F��݂̂��ȁB
Puma��CPU��2�N�O��Intel���x��
>>685
�}�W�ŁH
�}�W�ŁH
Deneb�̃G���W�j�A�����O�T���v���̃x���`�}�[�N�������̌f���ɓ��e����Ă��邷�B
http://www.itocp.com/thread-12164-1-1.html
�u�c��2.3GHz�i�ŁA3.28GHz��OC��̌��ʂ��f�ڂ��Ă��邷�BOC���ł��q�[�g�X�v���b�_��
�\�ʉ��x�̎������ʂ�42.9C�������Ƃ̂��Ƃ��B(Vdd=1.568V)
���̑��A�x���`�}�[�N���̏�����A���L�̒ʂ肷�B
�@�Emother: MSI K8A2 Platinum (AMD 790FX)
�@�EVideo: Asus Radeon HD 4870
�@�EMemory: DDR2-1066
���x���`�}�[�N����
�@- Super PI 1M
�@�@2.3GHz: 32.542 [s], 3.28GHz: 24.573 [s]
�@- Sandra memory test
�@�@2.3GHz: int 10.35 [GB/s] fp 10.33[GB/s], 3.28GHz: int 11.89 [GB/s] fp 11.92 [GB/s]
�@- WinRAR
�@�@2.3GHz: 518 [KB/s], 3.28GHz: 563 [KB/s]
�@- Fritz Chess Benchmark (4-threads)
�@�@2.3GHz: 5031 [kNode/s], 3.28GHz: 6829 [kNode/s]
�@- Cinebench 10
�@�@2.3GHz: 1993 (single) / 7120 (4-thread), 3.28GHz: 2639 (single) / 9834 (4-thread)
�@- 3DMark Vantage
�@�@2.3GHz: 6822 (CPU score) / 810.95 (CPU1) , 12.38 (CPU2)
�@�@3.28GHz: 9248 (CPU score) / 1087.48 (CPU1), 17.09 (CPU2)
http://www.itocp.com/thread-12164-1-1.html
�u�c��2.3GHz�i�ŁA3.28GHz��OC��̌��ʂ��f�ڂ��Ă��邷�BOC���ł��q�[�g�X�v���b�_��
�\�ʉ��x�̎������ʂ�42.9C�������Ƃ̂��Ƃ��B(Vdd=1.568V)
���̑��A�x���`�}�[�N���̏�����A���L�̒ʂ肷�B
�@�Emother: MSI K8A2 Platinum (AMD 790FX)
�@�EVideo: Asus Radeon HD 4870
�@�EMemory: DDR2-1066
���x���`�}�[�N����
�@- Super PI 1M
�@�@2.3GHz: 32.542 [s], 3.28GHz: 24.573 [s]
�@- Sandra memory test
�@�@2.3GHz: int 10.35 [GB/s] fp 10.33[GB/s], 3.28GHz: int 11.89 [GB/s] fp 11.92 [GB/s]
�@- WinRAR
�@�@2.3GHz: 518 [KB/s], 3.28GHz: 563 [KB/s]
�@- Fritz Chess Benchmark (4-threads)
�@�@2.3GHz: 5031 [kNode/s], 3.28GHz: 6829 [kNode/s]
�@- Cinebench 10
�@�@2.3GHz: 1993 (single) / 7120 (4-thread), 3.28GHz: 2639 (single) / 9834 (4-thread)
�@- 3DMark Vantage
�@�@2.3GHz: 6822 (CPU score) / 810.95 (CPU1) , 12.38 (CPU2)
�@�@3.28GHz: 9248 (CPU score) / 1087.48 (CPU1), 17.09 (CPU2)
688 �FMAC�I�^���⑫�F2008/08/02(�y) 11:03:55 ID:wM7rJRQ0
Everest�̌��ʂ����A����L3�̃��C�e���V��3�����������Ă���͗l���B
L3��e�ʉ��̑㏞�Ƃ��Ă�A���R�̒l��������Ȃ������ǁA���̕ӂ퐻�i�łŕς��\����
���邷�B
L3��e�ʉ��̑㏞�Ƃ��Ă�A���R�̒l��������Ȃ������ǁA���̕ӂ퐻�i�łŕς��\����
���邷�B
>>688
�ς�����Ƃ��Ă�Nehalen�ɂ͉����y�Ȃ����X�ˁ�
==== Nehalem 2.66GHz ====
�����̐��\
ttp://www.anandtech.com/cpuchipsets/intel/showdoc.aspx?i=3326&p=5
Nehalem (2.66GHz)
�L���b�V�� L1��4cycles L2��11cycles L3��39cycles
Nehalem (2.93GHz) �g���v���`���l�����X��
������ READ��13.1GB/s WRITE��12.7GB/s Copy��12.0GB/s ���C�e���V��46.9ns
����d�� PC�S�� (2.66GHz Vcore�d����1.176V 4�R�A/8�X���b�h)
ttp://www.anandtech.com/cpuchipsets/intel/showdoc.aspx?i=3326&p=8
�A�C�h����114W �t�����[�h��173W
==== Deneb ====
�ꉞL3��6MB���ڂ��X�ˁAVcore�d����2.3GHz��1.224V���X(���[����ƍ���������)
3.27GHz��OC����ɂ�1.568V���K�v���X�ˁA���ꂶ�ፂ�N���b�N�͊��҂ł��Ȃ����X�B
�����́E�E�E���Ȃ��������Ƃɂ�������A�����ƌv���~�X�����A����Ȃɒx���킯�Ȃ����X���?
CINEBENCHR10�͂ǂ����X����?
��i(2.3GHz)���ƃV���O���R�A 1993�A�}���`��7120 �}���`�X���b�h������ 3.57�{���X�ˁB
OC(3.27GHz).���ƃV���O���R�A 2639�A�}���`��9834 �}���`�X���b�h������ 3.73�{���X�ˁB
Nehalen 2.66GHz�͂ǂ��X����?
ttp://www.anandtech.com/cpuchipsets/intel/showdoc.aspx?i=3326&p=7
��i(2.66GHz)���ƃV���O���R�A 3015�A�}���`��12596 �}���`�X���b�h������ 4.18�{���X�ˁB
�Ȃ����ɂȂ��ĂȂ����X�ˁ�
�ς�����Ƃ��Ă�Nehalen�ɂ͉����y�Ȃ����X�ˁ�
==== Nehalem 2.66GHz ====
�����̐��\
ttp://www.anandtech.com/cpuchipsets/intel/showdoc.aspx?i=3326&p=5
Nehalem (2.66GHz)
�L���b�V�� L1��4cycles L2��11cycles L3��39cycles
Nehalem (2.93GHz) �g���v���`���l�����X��
������ READ��13.1GB/s WRITE��12.7GB/s Copy��12.0GB/s ���C�e���V��46.9ns
����d�� PC�S�� (2.66GHz Vcore�d����1.176V 4�R�A/8�X���b�h)
ttp://www.anandtech.com/cpuchipsets/intel/showdoc.aspx?i=3326&p=8
�A�C�h����114W �t�����[�h��173W
==== Deneb ====
�ꉞL3��6MB���ڂ��X�ˁAVcore�d����2.3GHz��1.224V���X(���[����ƍ���������)
3.27GHz��OC����ɂ�1.568V���K�v���X�ˁA���ꂶ�ፂ�N���b�N�͊��҂ł��Ȃ����X�B
�����́E�E�E���Ȃ��������Ƃɂ�������A�����ƌv���~�X�����A����Ȃɒx���킯�Ȃ����X���?
CINEBENCHR10�͂ǂ����X����?
��i(2.3GHz)���ƃV���O���R�A 1993�A�}���`��7120 �}���`�X���b�h������ 3.57�{���X�ˁB
OC(3.27GHz).���ƃV���O���R�A 2639�A�}���`��9834 �}���`�X���b�h������ 3.73�{���X�ˁB
Nehalen 2.66GHz�͂ǂ��X����?
ttp://www.anandtech.com/cpuchipsets/intel/showdoc.aspx?i=3326&p=7
��i(2.66GHz)���ƃV���O���R�A 3015�A�}���`��12596 �}���`�X���b�h������ 4.18�{���X�ˁB
�Ȃ����ɂȂ��ĂȂ����X�ˁ�
http://www.itocp.com/thread-12164-1-1.html
Code-named Deneb 45nm AMD quad-core processors for the second half of heavyweight
product has not published, because of rumours of 45 nm version still exist TLB
the wrong question, the next version will be introduced to amend.
Code-named Deneb 45nm AMD quad-core processors for the second half of heavyweight
product has not published, because of rumours of 45 nm version still exist TLB
the wrong question, the next version will be introduced to amend.
691 �FMAC�I�^��690 �����F2008/08/02(�y) 14:55:39 ID:wM7rJRQ0
>>690
�����N�撆���Ȃ��ǁB�B�B���p�̈Ӗ����Ԉ���ĂȂ�����(��)
�����N�撆���Ȃ��ǁB�B�B���p�̈Ӗ����Ԉ���ĂȂ�����(��)
WinRAR�x��������
>>690
�O���X�h�肷������c�B
�O���X�h�肷������c�B
�܂��E�E�E�m���ɐi�����Ă邵�A���Ԃ��|���������͂�����e���Ǝv����B
45nm�v���Z�X�����܂��������������珇���Ƃ��Ď���High-k�Q�[�g�≏�����������f���Ɋ��҂��悤�B
�����ł����core2q�ɒǂ�����Ȃ����ˁB���N�̕����ĂƂ����ȁE�E�E
���Ă��Ƃ͂S�N�x��Ă����intel�ɒǂ������Ă��Ƃ��B�ЂłԁE�E�E
45nm�v���Z�X�����܂��������������珇���Ƃ��Ď���High-k�Q�[�g�≏�����������f���Ɋ��҂��悤�B
�����ł����core2q�ɒǂ�����Ȃ����ˁB���N�̕����ĂƂ����ȁE�E�E
���Ă��Ƃ͂S�N�x��Ă����intel�ɒǂ������Ă��Ƃ��B�ЂłԁE�E�E
695 �FSocket774�F2008/08/02(�y) 19:05:34 ID:Hr1zMljO
�@- WinRAR
�@�@2.3GHz: 518 [KB/s], 3.28GHz: 563 [KB/s]
������ăV���O���X���b�h�H2.3GHz�͂ق�̏��������Ȃ��Ă邯��3.28GHz�ł���́c�ǂ��������ƁH
�@�@2.3GHz: 518 [KB/s], 3.28GHz: 563 [KB/s]
������ăV���O���X���b�h�H2.3GHz�͂ق�̏��������Ȃ��Ă邯��3.28GHz�ł���́c�ǂ��������ƁH
>>695
BIOS���œK������Ă��Ȃ��BOC�ɂ��ǂ����s�s�����o�Ă���B
������09Q1�\��Ȃ���A�����O�̃x���`�Ɋ��҂�����ʖڂ����H
BIOS���œK������Ă��Ȃ��BOC�ɂ��ǂ����s�s�����o�Ă���B
������09Q1�\��Ȃ���A�����O�̃x���`�Ɋ��҂�����ʖڂ����H
699 �FMAC�I�^��698 �����F2008/08/02(�y) 19:36:24 ID:wM7rJRQ0
>>698
���܂�ς��Ƃ��Ȃ��x���`�}�[�N���ʂ�TLB�p�b�`�̉e�����Ă���Ƃ��������������悤���B
Super-PI�������Ă��A�ˑR�o�Ă������ʂ��Ⴂ���B(>>457�Q��)
���܂�ς��Ƃ��Ȃ��x���`�}�[�N���ʂ�TLB�p�b�`�̉e�����Ă���Ƃ��������������悤���B
Super-PI�������Ă��A�ˑR�o�Ă������ʂ��Ⴂ���B(>>457�Q��)
cinebench R10 32bit
http://diy.pconline.com.cn/cpu/reviews/0804/1262586_4.html
Deneb2.3GHz 7120
9550e�@�@�@7076
http://diy.pconline.com.cn/cpu/reviews/0804/1262586_4.html
Deneb2.3GHz 7120
9550e�@�@�@7076
e�͗]�v������
�������̕����������B
http://pc.watch.impress.co.jp/docs/2008/0423/graph9.htm
Phenom9650�����@�@7376
����ρA�����������B
http://pc.watch.impress.co.jp/docs/2008/0423/graph9.htm
Phenom9650�����@�@7376
����ρA�����������B
�����m��Ȃ�CPU�ˑR�悹��ꂽ��ABIOS�����č��������Ⴄ���낤�ȁB
2008/02/27��BIOS��"Deneb"�̏��BIOS�ɂ����Ƃ̂��Ă�����A
���ꂱ�����Ă��܂���B
2008/02/27��BIOS��"Deneb"�̏��BIOS�ɂ����Ƃ̂��Ă�����A
���ꂱ�����Ă��܂���B
705 �FMAC�I�^��704 �����F2008/08/02(�y) 23:19:03 ID:wM7rJRQ0
>>704
���̉\�������邷�B�p�b�`�����̏������z���C�g���X�g������B3�݂̂ɂȂ��Ă���Ƃ��B�B�B
���̉\�������邷�B�p�b�`�����̏������z���C�g���X�g������B3�݂̂ɂȂ��Ă���Ƃ��B�B�B
X2����1���������Ȃ��ĂȂ���
�F��������
����ȂƂ肠�������܂����I�ȃo�O�L��܂���̏����T���v���̃x���`�}�[�N�ɁA
�������҂��Ă���H
2008�N��16�T���݂̂���������A4������5�����̐����i����H
�����I�ɂ� Phenom B2���x�[�X�ɂ��Ă���炵�����A
������B3���x�[�X�ɂ����o�O�t�B�b�N�X�ł��J�����āA�T���v���i�����Ă��邳�B
����ȂƂ肠�������܂����I�ȃo�O�L��܂���̏����T���v���̃x���`�}�[�N�ɁA
�������҂��Ă���H
2008�N��16�T���݂̂���������A4������5�����̐����i����H
�����I�ɂ� Phenom B2���x�[�X�ɂ��Ă���炵�����A
������B3���x�[�X�ɂ����o�O�t�B�b�N�X�ł��J�����āA�T���v���i�����Ă��邳�B
���ꂪB2�x�[�X�Ƃ������ƂȂ�
B3�x�[�X�ł���ɃN���b�N�A�b�v�̉\���������
B3�x�[�X�ł���ɃN���b�N�A�b�v�̉\���������
709 �FMAC�I�^��707 �����F2008/08/03(��) 08:51:59 ID:3itp9YiQ
>>707
�@�@--------------------
�@�@2008�N��16�T���݂̂���������A4������5�����̐����i����H
�@�@--------------------
���̎��_��65-nm K8L��A�G���b�^��ς�B3���ʎY����Ă��邷���ǁB�B�B
http://www.watch.impress.co.jp/akiba/hotline/20080405/etc_phenomx4.html
�@�@--------------------
�@�@2008�N��16�T���݂̂���������A4������5�����̐����i����H
�@�@--------------------
���̎��_��65-nm K8L��A�G���b�^��ς�B3���ʎY����Ă��邷���ǁB�B�B
http://www.watch.impress.co.jp/akiba/hotline/20080405/etc_phenomx4.html
>>706
������������H
������������H
����45nm K8L��TLB errata���c���Ă���Ƃ����b���{�����Ƃ���ƁAAMD�̂��̖���
�ւ���Ή���A����Ȏ��悾�������Ƃ������ł��邷�B
�@1. TLB errata�̍��{������A�����̃��j�b�g�̃^�C�~���O�����G�ɂ���݂�����
�@�@��Ԃ̂��߁A���\���ێ���������������̂���ɓ���B
�@2. �����̗\��ł�A���{�I�ȑ���{�������r�W���������NQ1�Ƀ����[�X
�@3. ���������s
�@4. �{���o�b�N�A�b�v�v�����������ꕔ�̃N���e�B�J���p�X�ɍ����g�����W�X�^��
�@�@�g�p���āA����������������B4�X�e�b�s���O��"B3"���̂ŗʎY��
�@5. ��L�̌��ʁAOC�ϐ��㏸ & ����d�͂��㏸
�@6. 45nm�ł�^�C�~���O���قȂ邽�߁A65nm�̍��{�����ł����s�����i�K��C0
�@�@�łł���u����
�N���Ƀ����[�X���邱�Ƃ��l����ƁA�S�Ă̖������ꂢ�ɉ�������̂����
����Ɍ����邷�B
�ւ���Ή���A����Ȏ��悾�������Ƃ������ł��邷�B
�@1. TLB errata�̍��{������A�����̃��j�b�g�̃^�C�~���O�����G�ɂ���݂�����
�@�@��Ԃ̂��߁A���\���ێ���������������̂���ɓ���B
�@2. �����̗\��ł�A���{�I�ȑ���{�������r�W���������NQ1�Ƀ����[�X
�@3. ���������s
�@4. �{���o�b�N�A�b�v�v�����������ꕔ�̃N���e�B�J���p�X�ɍ����g�����W�X�^��
�@�@�g�p���āA����������������B4�X�e�b�s���O��"B3"���̂ŗʎY��
�@5. ��L�̌��ʁAOC�ϐ��㏸ & ����d�͂��㏸
�@6. 45nm�ł�^�C�~���O���قȂ邽�߁A65nm�̍��{�����ł����s�����i�K��C0
�@�@�łł���u����
�N���Ƀ����[�X���邱�Ƃ��l����ƁA�S�Ă̖������ꂢ�ɉ�������̂����
����Ɍ����邷�B
>>711
���s���ĉ��Ɏ��s�����H
���s���ĉ��Ɏ��s�����H
5. ��L�̌��ʁAOC�ϐ��㏸ & ����d�͂��㏸
9950��9850������d�͉������Ă���B
9950��9850������d�͉������Ă���B
����45nm K8L��TLB errata���c���Ă���Ƃ����b���{�����Ƃ���ƁAAMD�̂��̖���
�ւ���Ή���A����Ȏ��悾�������Ƃ������ł��邷�B
1.MAC�I�^�͔n��
2.TLB errata�̍��{�����̓V���R���̖��
3.MAC�I�^�͐����n��
4.�V���R���ʂ����ǂ����̂�B3
5.MAC�I�^�͂Ƃ�ł��Ȃ��n��
6.C0�͂Ƃ肠����B2���x�[�X�ɂ��čה������Ă݂�
6.MAC�I�^�͂��̂������n��
�ւ���Ή���A����Ȏ��悾�������Ƃ������ł��邷�B
1.MAC�I�^�͔n��
2.TLB errata�̍��{�����̓V���R���̖��
3.MAC�I�^�͐����n��
4.�V���R���ʂ����ǂ����̂�B3
5.MAC�I�^�͂Ƃ�ł��Ȃ��n��
6.C0�͂Ƃ肠����B2���x�[�X�ɂ��čה������Ă݂�
6.MAC�I�^�͂��̂������n��
�������E���R�䖝���Ȃ��珑�����炩�Ȃ�ԈႦ����
C0��B3�x�[�X���Ƃ���
����ł�TLB�G���b�^�����������Ƃ����
�V�������N�Ƃ����̂̓g�����W�X�^���V�������N����
�ʕ��̕��i���g���Ɖ��߂��Ă���̂�
���̂��߃N���b�N��[�N�d���Ȃǂ��v���Z�X�Z�p�P�ʂň���Ă���
�Ƃ������Ƃ�B2��B3�̃V���R�����ǂ̎�@��
45nm�v���Z�X�Œʗp����Ƃ͌���Ȃ��Ƃ�������
C0��B3�x�[�X���Ƃ���
����ł�TLB�G���b�^�����������Ƃ����
�V�������N�Ƃ����̂̓g�����W�X�^���V�������N����
�ʕ��̕��i���g���Ɖ��߂��Ă���̂�
���̂��߃N���b�N��[�N�d���Ȃǂ��v���Z�X�Z�p�P�ʂň���Ă���
�Ƃ������Ƃ�B2��B3�̃V���R�����ǂ̎�@��
45nm�v���Z�X�Œʗp����Ƃ͌���Ȃ��Ƃ�������
716 �FMAC�I�^��714-715 �����F2008/08/03(��) 13:09:13 ID:v7s07392
>>714-715
�܂��L�`�K�C�̃q�g�́u�V���R���̎��v�k�`���͂��܂��������B�B�B
���N���Ƀ����[�X���T���Ă���T�[�o�[�����v���Z�b�T�����i�K�Łw�Ƃ肠����B2���x�[�X�ɂ��čה���
���Ă݂��x�Ȃ�ď��Ƃ���Α������o���Ƃ������Ƃ������ł��Ȃ��l���B
����@���Ă�AMD�̏����P����Ƃ��v���Ȃ������ǁA���XFUD�ɗ��ł�L�`�K�C�̃q�g��A��������
�����Ȃ��Ȃ��Ă���͗l��(��)
�܂��L�`�K�C�̃q�g�́u�V���R���̎��v�k�`���͂��܂��������B�B�B
���N���Ƀ����[�X���T���Ă���T�[�o�[�����v���Z�b�T�����i�K�Łw�Ƃ肠����B2���x�[�X�ɂ��čה���
���Ă݂��x�Ȃ�ď��Ƃ���Α������o���Ƃ������Ƃ������ł��Ȃ��l���B
����@���Ă�AMD�̏����P����Ƃ��v���Ȃ������ǁA���XFUD�ɗ��ł�L�`�K�C�̃q�g��A��������
�����Ȃ��Ȃ��Ă���͗l��(��)
�m�I��Q�̎G���ނ������ǂ��o�������
���̃X�����啝�ɉ��P�����͂�������Ӗ��͂���
�n���͖{���Ɏז��ɂ����Ȃ�Ȃ�
���̃X�����啝�ɉ��P�����͂�������Ӗ��͂���
�n���͖{���Ɏז��ɂ����Ȃ�Ȃ�
errata�̍��{�����̓V���R���̖����āA�n����w
AMD�ɕs���ȏ��͖����Ō��������A��
>>720
�s���ȏ����ĉ��H
�s���ȏ����ĉ��H
�ނ��덡�̃C���e���Ɠ����y�U�Ő������P�O��P�O�s����B
�I���{VGA�����ޒቿ�i�шȊO���Ꮯ���ɂȂ�B
�I���{VGA�����ޒቿ�i�шȊO���Ꮯ���ɂȂ�B
>>722
Intel���L���ȃx���`�Ő������AAMD�ł͏����ɂȂ�Ȃ�����B
AMD���L���ȃx���`�Ő������AIntel�ł͏����ɂȂ�Ȃ�����B
Intel���L���ȃx���`�Ő������AAMD�ł͏����ɂȂ�Ȃ�����B
AMD���L���ȃx���`�Ő������AIntel�ł͏����ɂȂ�Ȃ�����B
> AMD���L���ȃx���`
����Ȃ̂�������?
����Ȃ̂�������?
727 �FMAC�I�^���A���~ �����F2008/08/03(��) 21:07:17 ID:v7s07392
>>726
�����A���̕����N����Ă�Ǝv����(��)
�����A���̕����N����Ă�Ǝv����(��)
729 �F�A���~ ��Fh2IQtNvbw �F2008/08/04(��) 00:17:47 ID:cAvzAGX6
>>724
��������l�g�o�̕s���ӂȏ������g�����̂������������B
�`�[�g(�E�L��`�E)
>>726
������Ɩ��O�Ɗ�ƌ������������c����(�E�L��`�E)
��������l�g�o�̕s���ӂȏ������g�����̂������������B
�`�[�g(�E�L��`�E)
>>726
������Ɩ��O�Ɗ�ƌ������������c����(�E�L��`�E)
>>728
> �����ƁA�T�N���G�f�B�^�̒u�������ɑ���ᔻ�͂����܂ł��B
�����A�m��64bit�̂��?
32bit����C2D�����|�I�ɑ����āA64bit�ɂ����X2���ق�̏��������������Ă����?
�����������64bit�̕���32bit��萏���ƒx���Ȃ���������?
> �����ƁA�T�N���G�f�B�^�̒u�������ɑ���ᔻ�͂����܂ł��B
�����A�m��64bit�̂��?
32bit����C2D�����|�I�ɑ����āA64bit�ɂ����X2���ق�̏��������������Ă����?
�����������64bit�̕���32bit��萏���ƒx���Ȃ���������?
����������p�X���������̂�
�����C�ɓ���Ȃ��̂��������o���Ă������ő����n��
�����ƊF�ő�����Ă����Ă�̂�
�����C�ɓ���Ȃ��̂��������o���Ă������ő����n��
�����ƊF�ő�����Ă����Ă�̂�
732 �F�A���~ ��Fh2IQtNvbw �F2008/08/04(��) 16:08:22 ID:cAvzAGX6
>>730
���������A64bit��AMD���32bit�̃C���e���̕��������[��(�E�L��`�E)
���������A64bit��AMD���32bit�̃C���e���̕��������[��(�E�L��`�E)
�܂�731�݂����ȃX���[�ł��Ȃ��n��������̂������̈������
734 �FMAC�I�^�F2008/08/04(��) 17:05:57 ID:S9uVZvt2
TGDaily��Theo Valich�L�҂�TSMC�̏��Ƃ���Fusion�̃��[�N���������Ă邷�B
http://www.tgdaily.com/content/view/38703/135/
�@�@------------------------
�@�@The first Fusion processor is code-named Shrike, which will, if
�@�@our sources are right, consist of a dual-core Phenom CPU and an
�@�@ATI RV800 GPU core.
�@�@[����]
�@�@The Bulldozer-based chip, code-named �gFalcon�h, will debut with
�@�@TSMC's 32nm SOI process, instead of the originally planned 45 nm.
�@�@------------------------
�����튮�S��TSMC�ɔC����͗l���B
�ꉞTheo Valich�̉ߋ��L�����v���o���āA���ɑ�����ĕ����Ă����ׂ�����
�v�������ǁA����M�ߐ����L��Ǝv�����B
http://www.tgdaily.com/content/view/38703/135/
�@�@------------------------
�@�@The first Fusion processor is code-named Shrike, which will, if
�@�@our sources are right, consist of a dual-core Phenom CPU and an
�@�@ATI RV800 GPU core.
�@�@[����]
�@�@The Bulldozer-based chip, code-named �gFalcon�h, will debut with
�@�@TSMC's 32nm SOI process, instead of the originally planned 45 nm.
�@�@------------------------
�����튮�S��TSMC�ɔC����͗l���B
�ꉞTheo Valich�̉ߋ��L�����v���o���āA���ɑ�����ĕ����Ă����ׂ�����
�v�������ǁA����M�ߐ����L��Ǝv�����B
735 �FMAC�I�^���⑫�F2008/08/04(��) 17:33:02 ID:S9uVZvt2
MS-7376(K9A2 Platinum)��BIOS Ver1.3��TLB����OFF�������悤�ȁE�E�E
CPU��TSMC�ɂȂ����Ⴄ�̂��ȁH
>>734
�����Ɗ�����Athlon X2���݂̃N���b�N�ŏo����̂��ȁH
�����Ɗ�����Athlon X2���݂̃N���b�N�ŏo����̂��ȁH
>>736
BIOS��OFF�ł�OS�ŋ����I�Ƀp�b�`�����Ă��Ă���\��������B
>>737
��������ϑ��̘b�͂ǂ��Ȃ��������H
TSMC�ł͂Ȃ������͂������E�E�E�ł��A���N�㔼���炾�������H
BIOS��OFF�ł�OS�ŋ����I�Ƀp�b�`�����Ă��Ă���\��������B
>>737
��������ϑ��̘b�͂ǂ��Ȃ��������H
TSMC�ł͂Ȃ������͂������E�E�E�ł��A���N�㔼���炾�������H
�uBIOS��TLB����OFF�ɂȂ��Ă�OS�ŋ����I��TLB����OFF�p�b�`���[�Ă���v�H�H�H
>>740
�q���g�BVista SP1�B
�q���g�BVista SP1�B
XP SP3���������p�b�`��VistaSP1�̓X���[�ɂ��Ă�����
�uVista�����[�I�v�Ɗ��Ⴂ����l��������������Ȃ��̂ɁB
�uVista�����[�I�v�Ɗ��Ⴂ����l��������������Ȃ��̂ɁB
743 �FMAC�I�^��741 �����F2008/08/04(��) 22:12:46 ID:T1kV/8Us
>>741
OFF�̃��m���X��OFF�ɂ���H�B�B�B�Ƃ����ˍ��݂������Ă���Ǝv�����B
OFF�̃��m���X��OFF�ɂ���H�B�B�B�Ƃ����ˍ��݂������Ă���Ǝv�����B
�������MSI�̃T�C�g��K9�n�̃}�j���A�����ׂĂ݂����A�V�^�E���^���킸�S�ʓI��TLB�G���b�^�֘A��
�ݒ荀�ڂ��Ȃ�����ABIOS�ŋ����I��TLB��OFF�ɂ������ۂ��B
790FX�}�U�[��TLB�G���b�^�����ݒ�\�ȃ}�U�[�͑��ɂ����邵�AK9A2 Platinum���V�^��V2��������
BIOS��Ver1.5�܂ł���̂ɂ킴�킴�Â�BIOS�œ������Ă邠����A�ǂ����ӎU�L���x���`���ȁE�E�E
�ݒ荀�ڂ��Ȃ�����ABIOS�ŋ����I��TLB��OFF�ɂ������ۂ��B
790FX�}�U�[��TLB�G���b�^�����ݒ�\�ȃ}�U�[�͑��ɂ����邵�AK9A2 Platinum���V�^��V2��������
BIOS��Ver1.5�܂ł���̂ɂ킴�킴�Â�BIOS�œ������Ă邠����A�ǂ����ӎU�L���x���`���ȁE�E�E
TLB��OFF
TLB�p�b�`��OFF
TLB�p�b�`��OFF
MAC�I�^�͓��{��͕ς����Ǘp��͐��m
MAC�I�^�͕ϐl�����ǃR�e�̒��ł͂܂Ƃ��Ȃق����Ǝv���܂�
�������
�������
���ʂɒ����
�Ȃ����P���i�삪�ڗ��̂͂����̂��Ƃ��B
���܂ɑO��̘b�̗���ǂ܂��Ɏ������邯�ǂȁB
MAC�I�^�͓��ɂ����IQ��100�`50�قǗ���������
752 �F�A���~ ��Fh2IQtNvbw �F2008/08/05(��) 15:18:04 ID:sLtUZtFO
�������IQ�͈��肵�č���(�E�L��`�E)
�A���~�̐��_����x��Phenom�̔@��
�h�p�́E�E�E�ǂ��Ȃ��
�h�p�́E�E�E�ǂ��Ȃ��
>>753
����B����x�����ȁB
����B����x�����ȁB
755 �F�A���~ ��Fh2IQtNvbw �F2008/08/05(��) 17:19:47 ID:sLtUZtFO
�y�m���̓��x������IQ�Ⴂ����(�E�L��`�E)
756 �FSocket774�F2008/08/05(��) 17:50:07 ID:tA4nqpxh
�A���~�̓N���V�b�N�y���`�A���ł�����
�����r�[�ɂ����ڂ���Ă���ŐV�R�A����
x86�ɑΉ����Ă邩�������������������
�����r�[�ɂ����ڂ���Ă���ŐV�R�A����
x86�ɑΉ����Ă邩�������������������
����Z���ԈႦ���Ⴄ�h�W���q��
���Ɠ�N��12�R�A����
�������Ȃ�
���Ă����˂���B
��������
�������Ȃ�
���Ă����˂���B
��������
>>734��Fusion�̃l�^�̑����ǁA��p�̃}�U�[�{�[�h�x���_����̏��Ƃ��āATSMC��
��������̂�GPU�݂̂ŁAChartered��CPU����������Ƃ����b���o�Ă��Ă��邷�B
http://www.tradingmarkets.com/.site/news/Stock%20News/1804026/
�@�@---------------------
�@�@Taiwan's main board manufacturers forecast Taiwan Semiconductor Manufacturing Co., Ltd.
�@�@(TSMC) will only take charge of the production of the GPU (Graphic Processing Unit) of AMD's
�@�@Fusion serial processor. While its CPU will be made by its own factory or Singapore-based
�@�@Chartered Semiconductor Manufacturing Ltd. (CSM).
�@�@---------------------
���̏ꍇ��MCM�O��Ƃ������Ƃ����ǁA������ɂ��掩�Ѓt�@�u����߂���̂�m���Ɍ����邷�B
��������̂�GPU�݂̂ŁAChartered��CPU����������Ƃ����b���o�Ă��Ă��邷�B
http://www.tradingmarkets.com/.site/news/Stock%20News/1804026/
�@�@---------------------
�@�@Taiwan's main board manufacturers forecast Taiwan Semiconductor Manufacturing Co., Ltd.
�@�@(TSMC) will only take charge of the production of the GPU (Graphic Processing Unit) of AMD's
�@�@Fusion serial processor. While its CPU will be made by its own factory or Singapore-based
�@�@Chartered Semiconductor Manufacturing Ltd. (CSM).
�@�@---------------------
���̏ꍇ��MCM�O��Ƃ������Ƃ����ǁA������ɂ��掩�Ѓt�@�u����߂���̂�m���Ɍ����邷�B
TSMC��45nm�E40nm����High-K�{MG�Ƃ��͓��������́H
32nm�ł�High-k/Metal-gate�͎g��Ȃ��Ɣ��\�ς݁B
����Falcon�Ɏg����炵��32nm SOI�ɂ��Ă͕������ȁB
���Ԃ�g��Ȃ��Ƃ͎v�����B
����Falcon�Ɏg����炵��32nm SOI�ɂ��Ă͕������ȁB
���Ԃ�g��Ȃ��Ƃ͎v�����B
GPU�̓o���N�V���R��
CPU��SOI
AMD�̓o���N�V���R���͊O���ϑ����Ă邵�ATSMC��SOI��ʎY�ł��Ȃ�
�H�����������
���Ă��Ƃ�Fusion��CPU�R�A��Chartered�AGPU�R�A��TSMC���đg�ݍ��킹�͗L�肻������Ȃ��H
CPU��SOI
AMD�̓o���N�V���R���͊O���ϑ����Ă邵�ATSMC��SOI��ʎY�ł��Ȃ�
�H�����������
���Ă��Ƃ�Fusion��CPU�R�A��Chartered�AGPU�R�A��TSMC���đg�ݍ��킹�͗L�肻������Ȃ��H
TSMC��SOI�n�߂���ċL��������ƑO�������C���x��
�@�@�@�@�@�@ |
�@ �@�_�@�@__�@�@�^
�@ �@�Q�@�i���j�@�Q�ߺ��
�@ �@�@�@�@|�~|
�@ �@�^ �@.�M�L�@ �_
�@�@�@�@�@(߁��)�@�@�@�C���e���ɍ���ĖႦ������ˁI�H
�@�@�@�@�@�m�R�m�R
�@�@�@�@�@�@�@����
�@ �@�_�@�@__�@�@�^
�@ �@�Q�@�i���j�@�Q�ߺ��
�@ �@�@�@�@|�~|
�@ �@�^ �@.�M�L�@ �_
�@�@�@�@�@(߁��)�@�@�@�C���e���ɍ���ĖႦ������ˁI�H
�@�@�@�@�@�m�R�m�R
�@�@�@�@�@�@�@����
Phenom�X���b�h�ŋ����Ă������Deneb ES�̃x���`�}�[�N�L�����B
http://en.hardspell.com/doc/showcont.asp?news_id=3858&pageid=3149
���[�h���̏���d�͔�����A�f���ɃX�S�����B
http://en.hardspell.com/doc/showcont.asp?news_id=3858&pageid=3149
���[�h���̏���d�͔�����A�f���ɃX�S�����B
�U�҂���B
���������Ȃ����E�C���X�����o�邵�B
�����������[�h��������C2Q��艺���邶��˂����B
���������Ȃ����E�C���X�����o�邵�B
�����������[�h��������C2Q��艺���邶��˂����B
��������猩�ꂽ�B���ς�炸�E�C���X�������邯�ǁB
����v���������s���œ��ĂɂȂ�Ȃ���B
�܂��v�����ɂǂ̃\�t�g���g�����̂��s���A�O���t�̐���������\���Ă��邩�s���A
�V�X�e���S�̂̏���d�͂��Ƃ�����ł���ȂɒႢ�͂����Ȃ��A
CPU�P�̂��Ƃ�����ǂ�����Čv�������̂����s���A
���s���ȓ_�������̂ŁA�܂������Ȃ����炢����ˈʂɑ����Ă����������������ƁB
����v���������s���œ��ĂɂȂ�Ȃ���B
�܂��v�����ɂǂ̃\�t�g���g�����̂��s���A�O���t�̐���������\���Ă��邩�s���A
�V�X�e���S�̂̏���d�͂��Ƃ�����ł���ȂɒႢ�͂����Ȃ��A
CPU�P�̂��Ƃ�����ǂ�����Čv�������̂����s���A
���s���ȓ_�������̂ŁA�܂������Ȃ����炢����ˈʂɑ����Ă����������������ƁB
45nm��������Ȃ���65nm���ʖډ߂����낤��
Deneb�����������H
�R�A�d����������Ȃ��ᕉ���̏���d�͂͂��܂艺�������
�P����dynamic���������ō�낤�Ƃ����VDD��7�����x�ɂ��Ȃ���Ȃ��
static leakage�������Ă�Ȃ�����Ɨ]�T�͂��邩
�P����dynamic���������ō�낤�Ƃ����VDD��7�����x�ɂ��Ȃ���Ȃ��
static leakage�������Ă�Ȃ�����Ɨ]�T�͂��邩
771 �F�A���~ ��Fh2IQtNvbw �F2008/08/08(��) 01:11:13 ID:Zk1PtJMq
>>769
�o�l�F�u�[(�E�L��`�E)
�o�l�F�u�[(�E�L��`�E)
>>769
���N�B�������11���Ƃ��B
���N�B�������11���Ƃ��B
�������x�̃V���R���Ɏ��̈Ⴂ�ȂǂȂ��B
�t�ɂ����Ύ����t���b�g�ɂ���ׂɃC���u���i�C���ɂ܂ŏ��x�����߂�̂��B
������ƍl����킩�邾�낪�B
�t�ɂ����Ύ����t���b�g�ɂ���ׂɃC���u���i�C���ɂ܂ŏ��x�����߂�̂��B
������ƍl����킩�邾�낪�B
�u���b�N�z�[���Ŕ]�ł��N���ꂽ���H
775 �FSocket774�F2008/08/09(�y) 03:15:52 ID:gR3vLlAi
INTEL��45nm�v���Z�X�̓_�u���p�^�[�j���O�̎��p��1���݂��������A
�Ȃ�ő�����Ȃ��H
ttp://journal.mycom.co.jp/articles/2008/07/24/intel45nm/002.html
�h���C��NA��0.85�ʼnt����1.35�ɉ��ǂ���邩��A32nm�ւ̈ڍs�͊y��
�낤�ȁBHigh-k�����^���Q�[�g���o���ς݂ʼnt�Z�I���@�͎c�蕨�ɂ͕�
������Ŋ����x�̍����̂����������邵�B
�Ȃ�ő�����Ȃ��H
ttp://journal.mycom.co.jp/articles/2008/07/24/intel45nm/002.html
�h���C��NA��0.85�ʼnt����1.35�ɉ��ǂ���邩��A32nm�ւ̈ڍs�͊y��
�낤�ȁBHigh-k�����^���Q�[�g���o���ς݂ʼnt�Z�I���@�͎c�蕨�ɂ͕�
������Ŋ����x�̍����̂����������邵�B
��AMD�X����Intel�̃v���Z�X�ő��������������ς���
773�ƌ����Ȃ�ƌ������E�E�E
�X���Ɗ֘A���Ȃ��O��̂Ȃ��肪�L��킯�ł������l�^�ł��Ȃ����Ă̂́E�E�E�����낤
773�ƌ����Ȃ�ƌ������E�E�E
�X���Ɗ֘A���Ȃ��O��̂Ȃ��肪�L��킯�ł������l�^�ł��Ȃ����Ă̂́E�E�E�����낤
>>776
���Ō딚���v���t���Ȃ���
���Ō딚���v���t���Ȃ���
779 �F�A���~ ��Fh2IQtNvbw �F2008/08/09(�y) 11:52:22 ID:xyXz4JIJ
������xPC�m���Ă�l���đO�ȁB
�c�O�Ȃ��炤���̎���̕��ʂ̐l��
�C���e�������������Ƃ͂���B���̉�Ђ��m��Ȃ��B
AMD���m��Ȃ��B
������Ȃ��B
�c�O�Ȃ��炤���̎���̕��ʂ̐l��
�C���e�������������Ƃ͂���B���̉�Ђ��m��Ȃ��B
AMD���m��Ȃ��B
������Ȃ��B
781 �F�A���~ ��Fh2IQtNvbw �F2008/08/09(�y) 12:28:54 ID:xyXz4JIJ
AMD�̓��[�J�[�l�ɂ����ڂ������Ė�������ȁB
����Ҍ����Ɉ�ەt���悤�Ƃ���C���e���Ɣ�ׂ���m���x�F��(�E�L��`�E)
����Ҍ����Ɉ�ەt���悤�Ƃ���C���e���Ɣ�ׂ���m���x�F��(�E�L��`�E)
���̊̐S�̃��[�J�[�l�ɂ����z�s�����ꂻ�������E�E�E�E
�x�d�Ȃ�o�ׂ̒x��A�����Ȃ����̎p���A���ꂶ�ᐶ�Y���C���ɑ匊�܂��B
�x�d�Ȃ�o�ׂ̒x��A�����Ȃ����̎p���A���ꂶ�ᐶ�Y���C���ɑ匊�܂��B
���[�J�[�̐��Y���C���ɗ��ސ��i�ŏo�ׂ̒x��o�Ă�̂�
�����
�����
784 �F�A���~ ��Fh2IQtNvbw �F2008/08/09(�y) 22:45:25 ID:7/rpNPOn
�����NEC�͏o�ג�~���Ă��́H(�E�L��`�E)
NEC���ˑR�̎�̓r�W�l�XPC��~�œ������P
�@ttp://pc.watch.impress.co.jp/docs/2008/0808/gyokai254.htm
�����͕ʂ��ۂ�
�@ttp://pc.watch.impress.co.jp/docs/2008/0808/gyokai254.htm
�����͕ʂ��ۂ�
AMD�̒m���x���Ⴂ�̂͂����Ɛ헪���I�H
��ʑ�O�ɉ����AMD�̑��݂�F�m�����āAPC�����Łu���`Intel�����ĂʂȂ́`�H�v�ƈ��������A
��O�ɂ́uPC�ɂ͂��ׂ��炭Intel-CPU�������Ă�v�Ǝv�킹�Ă����A�uCPU���[�J�[�őI���v�Ƃ����l������
�������Ȃ��܂ܔ�����������ƍl���Ă���I
�ƌ������APC���[�J�[�̕�����u���Intel�ł͖������Ƃ͏o���邾���ق��Ă��ĉ������v�Ƃ��肢����Ă�Ƃ��E�E
��ʑ�O�ɉ����AMD�̑��݂�F�m�����āAPC�����Łu���`Intel�����ĂʂȂ́`�H�v�ƈ��������A
��O�ɂ́uPC�ɂ͂��ׂ��炭Intel-CPU�������Ă�v�Ǝv�킹�Ă����A�uCPU���[�J�[�őI���v�Ƃ����l������
�������Ȃ��܂ܔ�����������ƍl���Ă���I
�ƌ������APC���[�J�[�̕�����u���Intel�ł͖������Ƃ͏o���邾���ق��Ă��ĉ������v�Ƃ��肢����Ă�Ƃ��E�E
>>786
�P��Intel�Ɣ�ׂĉ�ЋK�͂��傫���Ȃ����ATV CM�����������ĂȂ����炾��B
���݁AIntel��CM�͂��邪�AAMD��CM�͖�������ˁB���{�ł͉ߋ��ɂ�������ƂȂ����B
����Ƀ��[�J�[��PC��`�̑O��ɂ悭Intel�̃T�E���h���S�ƃ}�[�N���o���Ă��邵�A
�����͂ɂ��̂����킹����`�͂�Intel�ɂ͂���AAMD�ɂ͂Ȃ��B�������ꂾ���B
AMD�����ċ��������CM�̈�����������Ǝv���Ă��邾�낤�ˁB
�P��Intel�Ɣ�ׂĉ�ЋK�͂��傫���Ȃ����ATV CM�����������ĂȂ����炾��B
���݁AIntel��CM�͂��邪�AAMD��CM�͖�������ˁB���{�ł͉ߋ��ɂ�������ƂȂ����B
����Ƀ��[�J�[��PC��`�̑O��ɂ悭Intel�̃T�E���h���S�ƃ}�[�N���o���Ă��邵�A
�����͂ɂ��̂����킹����`�͂�Intel�ɂ͂���AAMD�ɂ͂Ȃ��B�������ꂾ���B
AMD�����ċ��������CM�̈�����������Ǝv���Ă��邾�낤�ˁB
PC�ڂ����Ȃ��l�Ɍy����������Ƃ���
�u�C���e���̂������i�g���Ă�̂�������B�v
���Č����Ă܂��B
�u�C���e���̂������i�g���Ă�̂�������B�v
���Č����Ă܂��B
�������̂ق����y�������
�ڂ����Ȃ��l�ɐ������鎞�́A�u���̃}�V�����A������̃}�V���̕��������v�Ƃ��������܂��B
���ƁA����̉��i�тȂ�ACPU�Ȃ�Ė��ʂȃ��m���@�\��������܂��B
CPU���[�J�[�̖��O�Ƃ��K�v�̂Ȃ��P����o���Ă��Ӗ����Ȃ�����B
���ƁA����̉��i�тȂ�ACPU�Ȃ�Ė��ʂȃ��m���@�\��������܂��B
CPU���[�J�[�̖��O�Ƃ��K�v�̂Ȃ��P����o���Ă��Ӗ����Ȃ�����B
�ȑO�͏ڂ����Ȃ��l�����r���[�ɒm�����Ă���ƁAintel�A�Ƃ���Pentium����Ȃ��Ƃ��߂���A�݂����ɂȂ��Ă����ǁA
�ŋ߂�CPU�ȂȂ�ł���������Ċ����ɂȂ��Ă��Ă�͉̂��̎��肾�����낤���H
�ŋ߂�CPU�ȂȂ�ł���������Ċ����ɂȂ��Ă��Ă�͉̂��̎��肾�����낤���H
���ۂȂ�ł�������
�l�b�g���C���Ȃ牽�ł��ǂ�����B
CPU�̐��\���d�������̂̓Q�[�����炢�B
����G���R��GPGPU�Ɏ����čs���ꂻ�������B
CPU�̐��\���d�������̂̓Q�[�����炢�B
����G���R��GPGPU�Ɏ����čs���ꂻ�������B
��ʐl�̂�肻���ȁA�l�b�g������A�N��������肷��̂ɂ�
�����\��������X�y�b�N������ˁB���[�G���h�ł��B
�l�b�N�ɂȂ肪���ȃ��������A�ŋ߂̈��l�ł���܂�P�`���ĂȂ����������B
�����\��������X�y�b�N������ˁB���[�G���h�ł��B
�l�b�N�ɂȂ肪���ȃ��������A�ŋ߂̈��l�ł���܂�P�`���ĂȂ����������B
>>793
��������������A�l�b�g�����Ȃ�n�r�Ȃ�Linux���낤��Windows���낤���A
�w�NJW�������オ���邾�낤�ˁB
�g�ѓd�b�ȂA�N���n�r��CPU�̎��ȂǍl���Ďg���Ė����̂����B
��������������A�l�b�g�����Ȃ�n�r�Ȃ�Linux���낤��Windows���낤���A
�w�NJW�������オ���邾�낤�ˁB
�g�ѓd�b�ȂA�N���n�r��CPU�̎��ȂǍl���Ďg���Ė����̂����B
���ΑS�p�~�A�������B
797 �F�A���~ ��Fh2IQtNvbw �F2008/08/10(��) 20:17:45 ID:X3XYrHWX
�m�����t����celeron����Ӄu�����h���ƒm�������̗��_�U��Ƃ�����������E�E�E
Intel���ƍ߂܂݂���ĂƂ��܂Œm���Έ�l�O��
�Ȃ��ɂ������Ĕ����t��
�V�F�A�L���������烍�N�Ȃ��ƂȂ��̂ɂˁB��������
�V�F�A5���ȏ�̃��[�J�[�ɂ܂Ƃ��ȂƂ���͂Ȃ������
Intel�ANvidia�AMicrosoft�ANTT�c
Intel�ANvidia�AMicrosoft�ANTT�c
FUSION���Ă����łĂ���́H
���[�h�}�b�v���ƔN���������悤�ȋC�����邵
�������Ȃ�
���[�h�}�b�v���ƔN���������悤�ȋC�����邵
�������Ȃ�
2H/2009
�ŋ߉���������AMDCPU2�Ƃ�90nm��������
65nm�͑ʍ삾�����Ƃ��Â��v����
K10B3�ŃN���b�N�オ�������Ă����F�͐��̗�
���s�v���Z�X�Ƃ�����͏o�ĂȂ����낤��
45nm�������[��
65nm�͑ʍ삾�����Ƃ��Â��v����
K10B3�ŃN���b�N�オ�������Ă����F�͐��̗�
���s�v���Z�X�Ƃ�����͏o�ĂȂ����낤��
45nm�������[��
Dresden�H��S�����В�Elke Eckstein�������o�����Ƃ̂��Ƃ��B
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=210003329
�@�@----------------------
�@�@After less than two years at AMD's Dresden site, the company's manufacturing vice president
�@�@Elke Eckstein has moved on. One of Germany's very few female semiconductor managers now
�@�@is Chief Operating Officer for Osram Opto Semiconductor in Regensburg (Germany).
�@�@----------------------
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=210003329
�@�@----------------------
�@�@After less than two years at AMD's Dresden site, the company's manufacturing vice president
�@�@Elke Eckstein has moved on. One of Germany's very few female semiconductor managers now
�@�@is Chief Operating Officer for Osram Opto Semiconductor in Regensburg (Germany).
�@�@----------------------
�h���M���瓦����[
Turion 64 X2���ĈӊO�ƗD�G�������ȁc�B
����2.5���Ԃ͏��Ȃ����A����ȏ��^�f�o�C�X�ɂ����߂�Ƃ́c�B
ttp://japanese.engadget.com/2008/08/12/raon-digital-7-everun-note-amd-cpu/
����2.5���Ԃ͏��Ȃ����A����ȏ��^�f�o�C�X�ɂ����߂�Ƃ́c�B
ttp://japanese.engadget.com/2008/08/12/raon-digital-7-everun-note-amd-cpu/
1.2GHz��������ʂɏȓd�͉��������f������ˁB
GeodeNX�������킹�}�U�[�Ƃ������Ă�����
���������낢������TrionX2�������킹�}�U�[�Ƃ�
���ʂɓX�Ŕ�����悤�ɂȂ�Ȃ�
���������낢������TrionX2�������킹�}�U�[�Ƃ�
���ʂɓX�Ŕ�����悤�ɂȂ�Ȃ�
Turion X2�Ŏ��삵�����悤
IDC�ɂ�鍡�N��2�l������PC�����v���Z�b�T�̎s��V�F�A���B
Intel��O�����+0.9%�BAMD��-1.2%�B
http://www.idc.com/getdoc.jsp?containerId=prUS21385508
�@�@-----------------------
�@�@In terms of processor vendor shares, on an overall unit basis, Intel earned 79.7% market share,
�@�@a gain of 0.9%. AMD earned 19.7%, a loss of 1.2%.
�@�@-----------------------
������Barcelona���}�g���ɏo�ׂł���悤�ɂȂ��āA�T�[�o�[�����ŃV�F�A��0.8%���Ԃ��Ă��邷�B
Intel��O�����+0.9%�BAMD��-1.2%�B
http://www.idc.com/getdoc.jsp?containerId=prUS21385508
�@�@-----------------------
�@�@In terms of processor vendor shares, on an overall unit basis, Intel earned 79.7% market share,
�@�@a gain of 0.9%. AMD earned 19.7%, a loss of 1.2%.
�@�@-----------------------
������Barcelona���}�g���ɏo�ׂł���悤�ɂȂ��āA�T�[�o�[�����ŃV�F�A��0.8%���Ԃ��Ă��邷�B
AMD�Ђ��ꋫ�Ɋׂ�̂�Intel��Nehalem���o�ׂ������Ă��炾�낤�ȁB
Nehalem������������Intel�̎�_�ł���X�P�[���r���e�B�̒Ⴓ�����������B
�����Ȃ��AMD�Ђ̋��݂͖����Ȃ�T�[�o�[���삾�ƃV�F�A��Intel�ɒD�҂����͕̂K�����B
Nehalem������������Intel�̎�_�ł���X�P�[���r���e�B�̒Ⴓ�����������B
�����Ȃ��AMD�Ђ̋��݂͖����Ȃ�T�[�o�[���삾�ƃV�F�A��Intel�ɒD�҂����͕̂K�����B
�܂�MAC�I�^=�͌��c���Ď����E�E�E
Intel���Z�p�̐��ʂ\����IDF�ɑR���āAAMD�펩�Ђ̔�排����̐������J�����͗l��(��)
http://www.extremetech.com/slideshow/0,2850,pg%253D0%2526s%253D27771%2526a%253D230963,00.asp
���l�^�ɑ���̂��������ǁA�����s�b�^���߂���̂ŁB�B�B
�@- Nehalem��AMD�̋Z�p���ہX�R�s�[�������
�@- x86-64���d�͌����̌�����}���`�R�A��HD����Đ����S��AMD���N�����
�@- ��Intel��G45�̃O���t�B�b�N���\�퐢�E�I�Ɉ��]���
�@- Opteron��T�[�o�[�����Xeon�ɑ叟���������
http://www.extremetech.com/slideshow/0,2850,pg%253D0%2526s%253D27771%2526a%253D230963,00.asp
���l�^�ɑ���̂��������ǁA�����s�b�^���߂���̂ŁB�B�B
�@- Nehalem��AMD�̋Z�p���ہX�R�s�[�������
�@- x86-64���d�͌����̌�����}���`�R�A��HD����Đ����S��AMD���N�����
�@- ��Intel��G45�̃O���t�B�b�N���\�퐢�E�I�Ɉ��]���
�@- Opteron��T�[�o�[�����Xeon�ɑ叟���������
TomsHardware��Atom���ڂ�ITX�{�[�h��Athlon64 2000+���ڂ�MicroATX�̔�r���r���[��
�s���Ă��邷�B
http://www.tomshardware.com/reviews/Atom-Athlon-Efficient,1997.html
��ɂ���ă`�b�v�Z�b�g�̖��������ď���d�́A�d�͌�������AMD�̕����ǂ����т��B
�@- Idol: Atom230 40.5W, Athlon64 2000+ 38.8W
�@- load: Atom230 41.9W, Athlon64 2000+ 44.2W
�s���Ă��邷�B
http://www.tomshardware.com/reviews/Atom-Athlon-Efficient,1997.html
��ɂ���ă`�b�v�Z�b�g�̖��������ď���d�́A�d�͌�������AMD�̕����ǂ����т��B
�@- Idol: Atom230 40.5W, Athlon64 2000+ 38.8W
�@- load: Atom230 41.9W, Athlon64 2000+ 44.2W
Atom���ꂾ���V���v���ɂ����̂ɂ܂��o�O���炯������������
818 �FMAC�I�^�������F2008/08/16(�y) 12:16:06 ID:ahwTntRl
>>816��load�̐������Ђ�����Ԃ��Ă������B
��) - load: Atom230 41.9W, Athlon64 2000+ 44.2W
��) - load: Atom230 44.2W, Athlon64 2000+ 41.9W
��) - load: Atom230 41.9W, Athlon64 2000+ 44.2W
��) - load: Atom230 44.2W, Athlon64 2000+ 41.9W
atom�R��Athlon64�ł����̂�
822 �F,,�E�L�́M�E,,�j���F2008/08/16(�y) 13:11:38 ID:KySw3NiX
HD4850�݂����ȑ傫�ȃ_�C�{GDDR4��CPU�ɃI���`�b�v�ɂł���Ή\���낤��
�����I�ɖ�������
�����I�ɖ�������
823 �F,,�E�L�́M�E,,�j���F2008/08/16(�y) 13:13:12 ID:KySw3NiX
���A3850��
�ǂ����ɂ���A���ł���
�ǂ����ɂ���A���ł���
824 �F�A���~ ��Fh2IQtNvbw �F2008/08/16(�y) 13:15:48 ID:mLKzHeMz
�Ă��A��߂肠�x���`���������Ă��A��������(�E�L��`�E)
�N���C�A���g�Ŏg����Ȃ�
Athlon64 2000+�̂ق���������
nano���o���������������
Athlon64 2000+�̂ق���������
nano���o���������������
��������B�g������̂Ƃ���ł���ȃx���`���������B
ttp://www.tomshardware.com/reviews/Atom-Athlon-Efficient,1997.html
�@ �@ �@ �@ �@ �@ �@ �@Idle�@ �@Load
Athlon64 2000+�@38.8W�@ 41.9W
ATOM 230�@ �@ �@40.5W�@ 44.2W
ATOM��M-ITX��Ahlon64�͂ӂ���M-ATX�Ƃ����n���f�Ȃ�����A
Idle�y��Load�ŏ����Ă��܂��Ă���B
����"Bobcat"��m-ITX��CPU���t���A�]���ȋ@�\���Ȃ��ACPU�ƃ`�b�v�Z�b�g��
Turion�Ɋg�����ꂽ�悤�ȏȓd�͋@�\���g�����ꂽ���m�������Ƃ�����A
"Bobcat"�͂��Ȃ�\�����߂�CPU�ɂȂ��Ȃ����Ȃ��B
���\�ʂł�Dual�R�A��ATOM�ɂ͕������������ǁA�ȓd�͖ʂŏ��Ă��������B
�ቿ�i����"�ł�"�������낢�킢�������Ă��ꂻ�����B
�n�C�p�t�H�[�}���X�ł́E�E�EBulldozer�܂ł��@�����������c�B
ttp://www.tomshardware.com/reviews/Atom-Athlon-Efficient,1997.html
�@ �@ �@ �@ �@ �@ �@ �@Idle�@ �@Load
Athlon64 2000+�@38.8W�@ 41.9W
ATOM 230�@ �@ �@40.5W�@ 44.2W
ATOM��M-ITX��Ahlon64�͂ӂ���M-ATX�Ƃ����n���f�Ȃ�����A
Idle�y��Load�ŏ����Ă��܂��Ă���B
����"Bobcat"��m-ITX��CPU���t���A�]���ȋ@�\���Ȃ��ACPU�ƃ`�b�v�Z�b�g��
Turion�Ɋg�����ꂽ�悤�ȏȓd�͋@�\���g�����ꂽ���m�������Ƃ�����A
"Bobcat"�͂��Ȃ�\�����߂�CPU�ɂȂ��Ȃ����Ȃ��B
���\�ʂł�Dual�R�A��ATOM�ɂ͕������������ǁA�ȓd�͖ʂŏ��Ă��������B
�ቿ�i����"�ł�"�������낢�킢�������Ă��ꂻ�����B
�n�C�p�t�H�[�}���X�ł́E�E�EBulldozer�܂ł��@�����������c�B
Bobcat�͏o�Ȃ�����
�������L�����Z���Ƃ����\��������
���Ƃ����\�Ń��C�o���Ɋ��������Ƃ��Ă��ׂ��ɂȂ�Ȃ��ቿ�l������
>820
���ʂ�DT�pCPU�Ȃ�Z�[�t
�m�[�g�����Ȃ�A�E�g���炢��
���M/������
�������L�����Z���Ƃ����\��������
���Ƃ����\�Ń��C�o���Ɋ��������Ƃ��Ă��ׂ��ɂȂ�Ȃ��ቿ�l������
>820
���ʂ�DT�pCPU�Ȃ�Z�[�t
�m�[�g�����Ȃ�A�E�g���炢��
���M/������
MAC�I�^�͉ċx�݂̂������ŋߏ������ݑ�����
45nm�����TDP45W���i���o��̂͂����납�Ȃ��E�E
4850e���o���̂�65nm�ɂȂ��Ĕ��N�ギ�炢������A
2009�N�̉Ă���ɂ͏o���ė~�������E
4850e���o���̂�65nm�ɂȂ��Ĕ��N�ギ�炢������A
2009�N�̉Ă���ɂ͏o���ė~�������E
Atom�͈�����ł�����Ă̂��ő�̋��݂�����ȁB
�`�b�v�Z�b�g��130nm�Ȃ�ČÂ��H��̎g���܂킵�ň����肾���B
�`�b�v�Z�b�g��130nm�Ȃ�ČÂ��H��̎g���܂킵�ň����肾���B
Regor�̎����ė\��͂���H
32nm�܂�Regor�̂܂܂��Ă��Ƃ͂Ȃ���ˁB
32nm�܂�Regor�̂܂܂��Ă��Ƃ͂Ȃ���ˁB
Intel�͂���CPU�̍\�����wCPU�R�A�{�x�N�^�G���W���̃R�v���x�\���ɂ��鎖�����߂���
�R�v���̕����́E�E�ELarrabee�Ȃ̂��ȁH
Fusion�����炭�͒P�Ȃ�GPU����CPU�ł͂Ȃ��wCPU�R�A�{�x�N�^�G���W���̃R�v���x�̍\���Ɉڂ��čs���낤��
AMD�Ƃ��Ă͂����ŁE�E�E
CPU�R�A����SIMD�G���W��������ăV���v���ȃR�A�ɂ������
�EPC������CPU�R�A�{�x�N�^�[�G���W���R�A��MCM
�E�I������CPU�R�A�{CPU�R�A��MCM
�ɂ��������ǂ���Ȃ����낤��
�R�v���̕����́E�E�ELarrabee�Ȃ̂��ȁH
Fusion�����炭�͒P�Ȃ�GPU����CPU�ł͂Ȃ��wCPU�R�A�{�x�N�^�G���W���̃R�v���x�̍\���Ɉڂ��čs���낤��
AMD�Ƃ��Ă͂����ŁE�E�E
CPU�R�A����SIMD�G���W��������ăV���v���ȃR�A�ɂ������
�EPC������CPU�R�A�{�x�N�^�[�G���W���R�A��MCM
�E�I������CPU�R�A�{CPU�R�A��MCM
�ɂ��������ǂ���Ȃ����낤��
>>830
���̃`�b�v�Z�b�g���������������Ă��邯�ǂˁB
>>831
�܂����c�̂܂����BRegor�̉��ǂ͗\��ɂ��邾�낤���ǁA
��{�I�ɂ�K10�R�A�̉��ǂ��i�ނ����c�B
���̃`�b�v�Z�b�g���������������Ă��邯�ǂˁB
>>831
�܂����c�̂܂����BRegor�̉��ǂ͗\��ɂ��邾�낤���ǁA
��{�I�ɂ�K10�R�A�̉��ǂ��i�ނ����c�B
>>815
> Intel���Z�p�̐��ʂ\����IDF�ɑR���āAAMD�펩�Ђ̔�排����̐������J�����͗l��(��)
> http://www.extremetech.com/slideshow/0,2850,pg%253D0%2526s%253D27771%2526a%253D230963,00.asp
�������̂��Ƃ����X����w
AMD�͊�ƂƂ��Ēp�m�炸�A����ȏ�Ȃ��������ᓊ���Ƃɂ����̂Ă��Ă��܂��ȁB
> Intel���Z�p�̐��ʂ\����IDF�ɑR���āAAMD�펩�Ђ̔�排����̐������J�����͗l��(��)
> http://www.extremetech.com/slideshow/0,2850,pg%253D0%2526s%253D27771%2526a%253D230963,00.asp
�������̂��Ƃ����X����w
AMD�͊�ƂƂ��Ēp�m�炸�A����ȏ�Ȃ��������ᓊ���Ƃɂ����̂Ă��Ă��܂��ȁB
>>833
45nm�̌㔼��High-k��������݂���������A����Ɋ��҂��邵���Ȃ��ˁB
TDP45W��6400+���炢�̐��\������A�A�����Ǝv�����ǁB
45nm�̌㔼��High-k��������݂���������A����Ɋ��҂��邵���Ȃ��ˁB
TDP45W��6400+���炢�̐��\������A�A�����Ǝv�����ǁB
Atom���Ă̂�
���Ћ������l����Ηǂ�����������
���[�R�X�g�s�ꂪ��債��
���C���X�g���[�������������Ƃ��l����ƈ���������������
�����ȑ���
������`�b�v�Z�b�g���ǂ����邩�Ŕ����Ɋi�ߏo����̂͂Ȃ��Ȃ��ǂ��肾���
���Ћ������l����Ηǂ�����������
���[�R�X�g�s�ꂪ��債��
���C���X�g���[�������������Ƃ��l����ƈ���������������
�����ȑ���
������`�b�v�Z�b�g���ǂ����邩�Ŕ����Ɋi�ߏo����̂͂Ȃ��Ȃ��ǂ��肾���
>>831
AMD�͂���Athlon��Phenom����R�A�͉��ǂ��Ȃ�����
Intel��Nehalem�ŃR�A�����̉��ǂ͂قڏI������Ȃ���
��PC����CPU�ƎI����CPU�����p�v�Ƃ���ɂ́A�R�A�̐��𑝂₵�Ă����Ȃ���ΐ����c��Ȃ�
�v����Ɍo�ϓI�ȃ_�C�T�C�Y/�g�����W�X�^���̒��ɂ�葽���̃R�A�����Ȃ���Ȃ�Ȃ�
�ł����āA������O�̎������g�����W�X�^������̌������グ��ɂ̓R�A�����V���v���ɂ���A
�܂苌����̃R�A�̕����֑ލs����̂���ԗL���i�����_�����ǂ͕K�v�����j
���������̓R�A1�������Ƃ��̐��\�̐i���͂���������
AMD�͂���Athlon��Phenom����R�A�͉��ǂ��Ȃ�����
Intel��Nehalem�ŃR�A�����̉��ǂ͂قڏI������Ȃ���
��PC����CPU�ƎI����CPU�����p�v�Ƃ���ɂ́A�R�A�̐��𑝂₵�Ă����Ȃ���ΐ����c��Ȃ�
�v����Ɍo�ϓI�ȃ_�C�T�C�Y/�g�����W�X�^���̒��ɂ�葽���̃R�A�����Ȃ���Ȃ�Ȃ�
�ł����āA������O�̎������g�����W�X�^������̌������グ��ɂ̓R�A�����V���v���ɂ���A
�܂苌����̃R�A�̕����֑ލs����̂���ԗL���i�����_�����ǂ͕K�v�����j
���������̓R�A1�������Ƃ��̐��\�̐i���͂���������
����͗L�蓾�Ȃ�
Intel�Ȃ�[���L�蓾��
>>838
> �ł����āA������O�̎������g�����W�X�^������̌������グ��ɂ̓R�A�����V���v���ɂ���A
> �܂苌����̃R�A�̕����֑ލs����̂���ԗL���i�����_�����ǂ͕K�v�����j
��������Ă��܂��ƃV���O���X���b�h���\���K�^�����ő���ɔ��W����B
����āALarrabee�̂悤�ȕ����p��H����R�A�Ƃ͕ʂɓ��ڂ�������ƂȂ�B
�������ŏ���MCM�ɂȂ邾�낤�ȁB
> �ł����āA������O�̎������g�����W�X�^������̌������グ��ɂ̓R�A�����V���v���ɂ���A
> �܂苌����̃R�A�̕����֑ލs����̂���ԗL���i�����_�����ǂ͕K�v�����j
��������Ă��܂��ƃV���O���X���b�h���\���K�^�����ő���ɔ��W����B
����āALarrabee�̂悤�ȕ����p��H����R�A�Ƃ͕ʂɓ��ڂ�������ƂȂ�B
�������ŏ���MCM�ɂȂ邾�낤�ȁB
842 �F�A���~ ��Fh2IQtNvbw �F2008/08/16(�y) 19:56:32 ID:mLKzHeMz
>>838
�C���e���͉��ǂ̗]�n�������_�A�A���h�͉��ǂ̗̑͂��������u���Ă��ƁH(�E�L��`�E)
�C���e���͉��ǂ̗]�n�������_�A�A���h�͉��ǂ̗̑͂��������u���Ă��ƁH(�E�L��`�E)
>>841
���`���߂�
�R�A�����ۂ̑ލs�����邾�낤���Ď�����Ȃ���
�u�{���͗��Ƃ��������炢�Ȃ낤���炱��ȏ㕡�G����������͂��Ȃ����낤�v���Ď��ˁO�O
���`���߂�
�R�A�����ۂ̑ލs�����邾�낤���Ď�����Ȃ���
�u�{���͗��Ƃ��������炢�Ȃ낤���炱��ȏ㕡�G����������͂��Ȃ����낤�v���Ď��ˁO�O
>>838
2010�㔼����11�N�ɂ����ēo��\���"Bulldozer"�͐V�R�A�\��B
�����A��̃R�A���g���X�p���ɂȂ�̂͊m�����Ǝv���B
K8��K10�͗�O�߂������ǂˁB
2010�㔼����11�N�ɂ����ēo��\���"Bulldozer"�͐V�R�A�\��B
�����A��̃R�A���g���X�p���ɂȂ�̂͊m�����Ǝv���B
K8��K10�͗�O�߂������ǂˁB
intel�����j����SSE�u����������v���邵
���łɂ���������ƕ⑫���Ă�����
Opteron��Xeon���I�Ŏ����ꂽ�̂́A��ΐ��\���������炶��Ȃ��ăR�X�g�p�t�H�[�}���X���ǂ�����
�ł����Ă���炪�����̂́A�����̕����𐔂̏o��PC����CPU�Ƌ��ʉ����Ă��邩��i�v���b�g�t�H�[�������킹�Ăˁj
�܂�AMD��PC�pCPU�Ƃ͕ʂɎI��pCPU��������ꍇ�͈����͏o�����A�R�X�g�p�t�H�[�}���X�ł͏����ł��Ȃ�
������AMD�����ꂩ����I����ł�����Ă������Ǝv���Ȃ�APC�p�ƎI�p��CPU�͂قڋ��ʉ����Ȃ��Ⴂ���Ȃ�
�Ŋ̐S�̎I�ŕK�v�Ȑ��\�͉����Ƃ����ƁA���K�v�Ȃ̂̓R�A���\�ł͂Ȃ��R�A��
������AMD�̓R�A�͔�剻�������Ȃ����Ď�
�������A�t�Ɍ�����PC�p�Ƃ��Ă�����Ȃ�������Ȃ��Ƃ������́A
�V���O���X���b�h���\������ł���Ƃ�����ł͖����Ƃ������Ƃł�����
Opteron��Xeon���I�Ŏ����ꂽ�̂́A��ΐ��\���������炶��Ȃ��ăR�X�g�p�t�H�[�}���X���ǂ�����
�ł����Ă���炪�����̂́A�����̕����𐔂̏o��PC����CPU�Ƌ��ʉ����Ă��邩��i�v���b�g�t�H�[�������킹�Ăˁj
�܂�AMD��PC�pCPU�Ƃ͕ʂɎI��pCPU��������ꍇ�͈����͏o�����A�R�X�g�p�t�H�[�}���X�ł͏����ł��Ȃ�
������AMD�����ꂩ����I����ł�����Ă������Ǝv���Ȃ�APC�p�ƎI�p��CPU�͂قڋ��ʉ����Ȃ��Ⴂ���Ȃ�
�Ŋ̐S�̎I�ŕK�v�Ȑ��\�͉����Ƃ����ƁA���K�v�Ȃ̂̓R�A���\�ł͂Ȃ��R�A��
������AMD�̓R�A�͔�剻�������Ȃ����Ď�
�������A�t�Ɍ�����PC�p�Ƃ��Ă�����Ȃ�������Ȃ��Ƃ������́A
�V���O���X���b�h���\������ł���Ƃ�����ł͖����Ƃ������Ƃł�����
�Ȃ�[��������X����
����ȎG����L���ɏ����Ă��邱�Ƃ�
���̂܂�����Ă�����
����ȎG����L���ɏ����Ă��邱�Ƃ�
���̂܂�����Ă�����
�R�A�����ǂ���ɂ͔�剻�����Ȃ���Ȃ�Ȃ��Ƃ����O�܂���������
�I�����A�[�L�Ƃ��ē���RISC��K7�n������̂�������
���܂ł������̌v�悪�|�V�������낤��
�V�A�[�LBulldozer�͍����s�������Ă邾���ł܂��v��͎c���Ă��
�I�����A�[�L�Ƃ��ē���RISC��K7�n������̂�������
���܂ł������̌v�悪�|�V�������낤��
�V�A�[�LBulldozer�͍����s�������Ă邾���ł܂��v��͎c���Ă��
�Ƃ������ABulldozer��K10���Ȃ�ˁB
����͂Ȃ��BBulldozer�̏ꍇ�͖{���ɏo�邩����肾���B
851 �FMAC�I�^��846 �����F2008/08/16(�y) 21:59:50 ID:ahwTntRl
>>846
�@�@-------------------
�@�@�Ŋ̐S�̎I�ŕK�v�Ȑ��\�͉����Ƃ����ƁA���K�v�Ȃ̂̓R�A���\�ł͂Ȃ��R�A��
�@�@-------------------
�{�E�̃T�[�o�[�x���_��V���O���X���b�h���\�d���Ŏ�����v���Z�b�T���J�����Ă��邷�B
Niagara���J������Sun�ł���B�B�B�Ƃ����̂����ړ_���B
IBM http://www.theregister.co.uk/2008/01/10/ibm_itanium_five_years/
�@�@===================
�@�@Meanwhile, IBM will be married to Power6 and its follow-on, Power6+, for a number of years,
�@�@which will have Big Blue place a stronger emphasis on single thread performance because of
�@�@the high clock rate of the chips.
�@�@===================
SUN http://www.theregister.co.uk/2008/02/06/sun_servers_2008/
�@�@===================
�@�@And we're sure an awful lot of you will appreciate the single thread splendor of Rock.
�@�@===================
�@�@-------------------
�@�@�Ŋ̐S�̎I�ŕK�v�Ȑ��\�͉����Ƃ����ƁA���K�v�Ȃ̂̓R�A���\�ł͂Ȃ��R�A��
�@�@-------------------
�{�E�̃T�[�o�[�x���_��V���O���X���b�h���\�d���Ŏ�����v���Z�b�T���J�����Ă��邷�B
Niagara���J������Sun�ł���B�B�B�Ƃ����̂����ړ_���B
IBM http://www.theregister.co.uk/2008/01/10/ibm_itanium_five_years/
�@�@===================
�@�@Meanwhile, IBM will be married to Power6 and its follow-on, Power6+, for a number of years,
�@�@which will have Big Blue place a stronger emphasis on single thread performance because of
�@�@the high clock rate of the chips.
�@�@===================
SUN http://www.theregister.co.uk/2008/02/06/sun_servers_2008/
�@�@===================
�@�@And we're sure an awful lot of you will appreciate the single thread splendor of Rock.
�@�@===================
>>849
�E�E�E�܂��A�u���܂łɖ����v�V�I�Ȑv�v�Ƃ��Ȃ�Ƃ������Ă邯��
GPGPU�ɉ�H�Ȃ��������Łu�V�v�I�v�Ƃ�������s���͂���
�����Ȃ�Ɓu���\�[�X�I��Bulldozer��Swift�����o���Ȃ��v�uBulldozer�̓o�N�`�������v�ł͂Ȃ�
�uGPU������CPU�̗]���ȋ@�\�폜�v�Ƃ��������̏��Ԓʂ�ɂȂ��Ă��܂�
�E�E�E�܂��A�u���܂łɖ����v�V�I�Ȑv�v�Ƃ��Ȃ�Ƃ������Ă邯��
GPGPU�ɉ�H�Ȃ��������Łu�V�v�I�v�Ƃ�������s���͂���
�����Ȃ�Ɓu���\�[�X�I��Bulldozer��Swift�����o���Ȃ��v�uBulldozer�̓o�N�`�������v�ł͂Ȃ�
�uGPU������CPU�̗]���ȋ@�\�폜�v�Ƃ��������̏��Ԓʂ�ɂȂ��Ă��܂�
854 �F�A���~ ��Fh2IQtNvbw �F2008/08/16(�y) 22:13:34 ID:mLKzHeMz
�ǂ݂����Ȃ���������(�E�L��`�E)
�p����ǂ߂Ȃ��̂ɃA�[�L�e�N�`���ɂ��Č���Ă邷��(��)
�ƌ����Ă��܂����B
�ƌ����Ă��܂����B
YVR/1xGe�m�b�x�ꂷ���Đ�����
>>851
�܂��A������₷����������IBM��Power6������Ă܂����Ď����B
�܂��A������₷����������IBM��Power6������Ă܂����Ď����B
���ǂȂ�ď����Ă���̂��S�R�����Ė������ǁE�E�E
�R�A������̐��\���d�v�ȏꍇ������̂͊m�����Ǝv����
���ɂ����̏ꍇ��OS�̃��C�Z���X����CPU��ł͂Ȃ��R�A1���ƂɊ|���邩��
�R�A1�̐��\�����ƌڋq�͔[�����Ȃ�����������
�R�A������̐��\���d�v�ȏꍇ������̂͊m�����Ǝv����
���ɂ����̏ꍇ��OS�̃��C�Z���X����CPU��ł͂Ȃ��R�A1���ƂɊ|���邩��
�R�A1�̐��\�����ƌڋq�͔[�����Ȃ�����������
�R�A���ƌ�����Larrabee��32�R�A�����
������1�R�A��4�X���b�h
�R�A���~�X���b�h���Ń������ш戳������Ƃ������Ă�̂�
����ǂ��Ȃ�́H
������1�R�A��4�X���b�h
�R�A���~�X���b�h���Ń������ш戳������Ƃ������Ă�̂�
����ǂ��Ȃ�́H
861 �F�A���~ ��Fh2IQtNvbw �F2008/08/16(�y) 23:10:01 ID:mLKzHeMz
>>860
16�R�A�ŁA1�R�A��1�X���b�h (�E�L��`�E)
16�R�A�ŁA1�R�A��1�X���b�h (�E�L��`�E)
>>859 ����
�@�@--------------------
�@�@���ɂ����̏ꍇ��OS�̃��C�Z���X����CPU��ł͂Ȃ��R�A1���ƂɊ|����
�@�@--------------------
�Ԉ�����m������������O�ɁA������Ɗm���߂邱�Ƃ������߂��邷�B
���������Ȋo�����Ń��C�Z���X���]�X����ƊC���łŎ肪���ɉ�邱�Ƃ����邩������Ȃ����B
http://www.sun.com/software/solaris/licensing/policies.xml
http://www-03.ibm.com/software/sla/sladb.nsf/byformnum/2FB14EC3FFC241EA0025738E003E5DFA?opendocument
>>861 �A���~ ����
�@�@--------------------
�@�@16�R�A�ŁA1�R�A��1�X���b�h (�E�L��`�E)
�@�@--------------------
�R�A���햢��ŁA4thread/core�Ő������B
http://softwarecommunity.intel.com/UserFiles/en-us/File/larrabee_manycore.pdf
�@�@====================
�@�@Finally, Larrabee supports four threads of execution, with separate register sets per thread.
�@�@====================
�@�@--------------------
�@�@���ɂ����̏ꍇ��OS�̃��C�Z���X����CPU��ł͂Ȃ��R�A1���ƂɊ|����
�@�@--------------------
�Ԉ�����m������������O�ɁA������Ɗm���߂邱�Ƃ������߂��邷�B
���������Ȋo�����Ń��C�Z���X���]�X����ƊC���łŎ肪���ɉ�邱�Ƃ����邩������Ȃ����B
http://www.sun.com/software/solaris/licensing/policies.xml
http://www-03.ibm.com/software/sla/sladb.nsf/byformnum/2FB14EC3FFC241EA0025738E003E5DFA?opendocument
>>861 �A���~ ����
�@�@--------------------
�@�@16�R�A�ŁA1�R�A��1�X���b�h (�E�L��`�E)
�@�@--------------------
�R�A���햢��ŁA4thread/core�Ő������B
http://softwarecommunity.intel.com/UserFiles/en-us/File/larrabee_manycore.pdf
�@�@====================
�@�@Finally, Larrabee supports four threads of execution, with separate register sets per thread.
�@�@====================
�ƌ������{��y�[�W�Œ��ׂȂ����܂���
�������̓��C�Z���X���̓R�A���ɌW�����|�����ł���
�Ⴆ�R�A����8�ŌW����0.5�Ȃ�4�R�A���̃��C�Z���X����������
����ł����̂��ȁH
�������̓��C�Z���X���̓R�A���ɌW�����|�����ł���
�Ⴆ�R�A����8�ŌW����0.5�Ȃ�4�R�A���̃��C�Z���X����������
����ł����̂��ȁH
865 �FMAC�I�^��864 �����F2008/08/16(�y) 23:49:44 ID:ahwTntRl
>>864
�������Œ��ׂ��̂��wOS�x�̃��C�Z���X���������ǂ����v���o���Ηǂ��b��(��)
�������Œ��ׂ��̂��wOS�x�̃��C�Z���X���������ǂ����v���o���Ηǂ��b��(��)
>863
�Ԉ�����m�����I��������
�w�E�����̂�˂�������ƌ����Ă��˂�
�Ԉ�����m�����I��������
�w�E�����̂�˂�������ƌ����Ă��˂�
���������A�����̈ꕔ��Nvidia����@�I�ɂ���̂����ł���݂��������ǁA
AMD�̃T�[�o�[���[�h�}�b�v���������A�Œ�2009�N��t��Nvidia�̃`�b�v�Z�b�g
�r�W�l�X�ɐ����c���Ă����Ȃ��ƃG�������ƂɂȂ邷�B
http://news.cnet.com/8301-13579_3-9938372-37.html
AMD�̃T�[�o�[���[�h�}�b�v���������A�Œ�2009�N��t��Nvidia�̃`�b�v�Z�b�g
�r�W�l�X�ɐ����c���Ă����Ȃ��ƃG�������ƂɂȂ邷�B
http://news.cnet.com/8301-13579_3-9938372-37.html
�ׂɗv���
Broadcom�����邶���
Intel�ڍs���邵�C���l
���R�[���A�f�[�^�j��
����ȏ��̂��̃C���l
����ȏ��̂��̃C���l
AMD�iATI)��Nvidia��������C���e���Ŏg����O���{�������Ȃ�̂ł́H��
ttp://pc.watch.impress.co.jp/docs/2007/0727/kaigai376.htm
������Ə�Â���
Bulldozer����FUSION�̂��߂̃A�[�L��
�����d�͉��ƌ������Ƀt�H�[�J�X���Ă�炵�����
���̌������āE�E�E�x���`�H
����RISC���Ă̂͏���d�͂ɗ]�͂����鍠�Ɏ��ꂽ���̂�
�m���ɓd�͌����͈����Ǝv��
�������iꖂ������x�̒m�������jCISC���߂��Ƃɂ�����������
�����̃n�[�h���\�[�X�ň�C��1�T�C�N�����s��������͑��x�ł���ł����肵�Ă���Ǝv��
CISC�₻��̉��nj^�̂悤��OP��Fusion�͕��������i���܂����������P�ɓZ�߂āj���s��
�P�����߂Ȃ�1�N���b�N�ŏ����o������̂̕��G�Ȗ��߂̓}�C�N���R�[�h�Ő��N���b�N�|�����ď������Ȃ���Ȃ�Ȃ�
�iOPFu�̂ق��������悤�Ȋ����j
����ʂɍl����ƃx���`�ł͔n�������Ȃ邪�����ɂ���Ă͋��낵���x���Ȃ�
Core2�Ń}�C�N���R�[�h�G���b�^���p�����Ă�̂�����ƐM�����ł�����Ă���
AMD�ɂ͂���Ȏ�@����Ă��炢�����Ȃ����ȁE�E�E
�����ǂ��Ȃ邱�Ƃ��
������Ə�Â���
Bulldozer����FUSION�̂��߂̃A�[�L��
�����d�͉��ƌ������Ƀt�H�[�J�X���Ă�炵�����
���̌������āE�E�E�x���`�H
����RISC���Ă̂͏���d�͂ɗ]�͂����鍠�Ɏ��ꂽ���̂�
�m���ɓd�͌����͈����Ǝv��
�������iꖂ������x�̒m�������jCISC���߂��Ƃɂ�����������
�����̃n�[�h���\�[�X�ň�C��1�T�C�N�����s��������͑��x�ł���ł����肵�Ă���Ǝv��
CISC�₻��̉��nj^�̂悤��OP��Fusion�͕��������i���܂����������P�ɓZ�߂āj���s��
�P�����߂Ȃ�1�N���b�N�ŏ����o������̂̕��G�Ȗ��߂̓}�C�N���R�[�h�Ő��N���b�N�|�����ď������Ȃ���Ȃ�Ȃ�
�iOPFu�̂ق��������悤�Ȋ����j
����ʂɍl����ƃx���`�ł͔n�������Ȃ邪�����ɂ���Ă͋��낵���x���Ȃ�
Core2�Ń}�C�N���R�[�h�G���b�^���p�����Ă�̂�����ƐM�����ł�����Ă���
AMD�ɂ͂���Ȏ�@����Ă��炢�����Ȃ����ȁE�E�E
�����ǂ��Ȃ邱�Ƃ��
���������Ƃ�ˌN��
875 �FMAC�I�^��873 �����F2008/08/17(��) 10:13:24 ID:Zsenu7UF
>>873
�@�@-----------------
�@�@�P�����߂Ȃ�1�N���b�N�ŏ����o������̂̕��G�Ȗ��߂̓}�C�N���R�[�h�Ő��N���b�N�|������
�@�@�������Ȃ���Ȃ�Ȃ�
�@�@-----------------
�ǂ��œœd�g����M�����̂���m��Ȃ������ǁAK8�����ʂɕ��G���߂�}�C�N���R�[�h�ŕ�������邷�B
http://journal.mycom.co.jp/special/2008/phenom01/010.html
�@�@=================
�@�@Photo15��Phenom�̃R�A�̊T���}�ł��邪�AFetch���Decode��DirectPath��VectorPath��2��
�@�@���鎖������BDirectPath�̓n�[�h���C���[�h�Ńf�R�[�h�\�ȊȒP��x86���߂��������AVector
�@�@Path�̓}�C�N���R�[�h���g���ăf�R�[�h���镡�G��x86���߂���������B
�@�@=================
�@�@-----------------
�@�@�P�����߂Ȃ�1�N���b�N�ŏ����o������̂̕��G�Ȗ��߂̓}�C�N���R�[�h�Ő��N���b�N�|������
�@�@�������Ȃ���Ȃ�Ȃ�
�@�@-----------------
�ǂ��œœd�g����M�����̂���m��Ȃ������ǁAK8�����ʂɕ��G���߂�}�C�N���R�[�h�ŕ�������邷�B
http://journal.mycom.co.jp/special/2008/phenom01/010.html
�@�@=================
�@�@Photo15��Phenom�̃R�A�̊T���}�ł��邪�AFetch���Decode��DirectPath��VectorPath��2��
�@�@���鎖������BDirectPath�̓n�[�h���C���[�h�Ńf�R�[�h�\�ȊȒP��x86���߂��������AVector
�@�@Path�̓}�C�N���R�[�h���g���ăf�R�[�h���镡�G��x86���߂���������B
�@�@=================
876 �F,,�E�L�́M�E,,�j���F2008/08/17(��) 10:23:14 ID:C0ppS6h9
TLB�G���b�^�̃p�b�`���Ă���x���`�}�[�N�Ń^�C����2�{�y�L�т��zCPU�����������ǃA���Ȃ�����
�G�����u���ߎ��s�������v����
�}�ɂ��鉡�������g���ƁuALU/AGU��Decode�v�H
�}�ɂ��鉡�������g���ƁuALU/AGU��Decode�v�H
���ԃR�[�h�������āA���ߌ���������Ă���K7,K8�͂�߂āAK6�֖߂���Ă��Ƃ��H
�d�͌����Ō����Ζ߂���Ď�����B�߂�悪K6���͂Ƃ������B
AMD�͂���Ȃ��Ƃ��Ȃ����낤���ǁB
AMD�͂���Ȃ��Ƃ��Ȃ����낤���ǁB
>>879
873�͓�̎��_�Ń�opsFusion�̗p����Ɛ��\�����肵�Ȃ����ƂɂȂ邩��A
��opsFusion�ے肵�Ă邾������B�d�͌����Ȃ�Ĉ����Ă��������̕��������悤�Ȃ��Ə����Ă����B
���ƁAK7�AK8�Ń�opsFusion�Ǝ����悤�Ȃ��Ƃ��Ă���đ����m��Ȃ��B
873�͓�̎��_�Ń�opsFusion�̗p����Ɛ��\�����肵�Ȃ����ƂɂȂ邩��A
��opsFusion�ے肵�Ă邾������B�d�͌����Ȃ�Ĉ����Ă��������̕��������悤�Ȃ��Ə����Ă����B
���ƁAK7�AK8�Ń�opsFusion�Ǝ����悤�Ȃ��Ƃ��Ă���đ����m��Ȃ��B
�ʂɓ���RISC�}���Z�[�Ńl�g�o�ɂ�����Č����Ă�킯����Ȃ���
���G���߂ł̌����������Ȃ�K7�n����Ԃ��ƍl���Ă�킯��
OP��Fusion��K7�̊W�ɂ��Ă�
ttp://pc.watch.impress.co.jp/docs/2006/0626/kaigai285.htm
��AMD�́AK7/K8�A�[�L�e�N�`���ŁA���łɂ�����x�����悤�ȕ����������Ă���
���炢�ɂ����m��ǂ�������x�����
�p�C�v���C�����₵�߂��̃l�g�o�Ƃ�OP��Fusion���߂���(?)�G���b�^���炯��CoreMA�ȂɒǏ]����Ȃ��
���G���߂ł̌����������Ȃ�K7�n����Ԃ��ƍl���Ă�킯��
OP��Fusion��K7�̊W�ɂ��Ă�
ttp://pc.watch.impress.co.jp/docs/2006/0626/kaigai285.htm
��AMD�́AK7/K8�A�[�L�e�N�`���ŁA���łɂ�����x�����悤�ȕ����������Ă���
���炢�ɂ����m��ǂ�������x�����
�p�C�v���C�����₵�߂��̃l�g�o�Ƃ�OP��Fusion���߂���(?)�G���b�^���炯��CoreMA�ȂɒǏ]����Ȃ��
���A�����
ttp://tokushima.cool.ne.jp/msz006_2000/pentium.htm
�̌㔼�����̓f�R�[�h����Ȃ����ߎ��s�ɂ��ď�����Ă�悤�Ɍ����邯��
�����������߂�OK?
ttp://tokushima.cool.ne.jp/msz006_2000/pentium.htm
�̌㔼�����̓f�R�[�h����Ȃ����ߎ��s�ɂ��ď�����Ă�悤�Ɍ����邯��
�����������߂�OK?
�Q�l�܂ł�Intel��AMD�́u���ߌ����v�Ɋւ���p��������\���B
http://images.anandtech.com/reviews/cpu/intel/core-vs-k8/micro-macro.png
���ꌩ�ė������Ă��炦��Ȃ珕���邷���ǁB�B�B
http://images.anandtech.com/reviews/cpu/intel/core-vs-k8/micro-macro.png
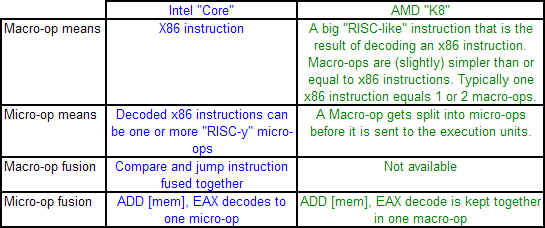{kind=link}
���ꌩ�ė������Ă��炦��Ȃ珕���邷���ǁB�B�B
�������������Ȃ����ŁA���s�X�e�[�W�Ń}�C�N���R�[�h���ւ�邩��B
>>894��Pentium������A�}�C�N���R�[�h�Ŏ��s�����B
���̒���P6�ȍ~�O��ɂȂ��Ă���A894�͉��̊ԈႢ�B
���̒���P6�ȍ~�O��ɂȂ��Ă���A894�͉��̊ԈႢ�B
886 �F�A���~ ��Fh2IQtNvbw �F2008/08/17(��) 11:45:13 ID:lXkZ5J/+
�Ă��A894���Ăǂ���H(�E�L��`�E)
884�̊ԈႢ���悗
Pentium�̃u���b�N�}�����������ǁA���ߐ��䕔�ɂ����}�C�N���R�[�h�ւ���ĂȂ����A
���s�X�e�[�W���̂ɂ͊W�Ȃ��ł悩�����̂��B
���̒m�����K���������Ȃ�
���̂�̎ז��ɂȂ邩���������ł��B
Pentium�̃u���b�N�}�����������ǁA���ߐ��䕔�ɂ����}�C�N���R�[�h�ւ���ĂȂ����A
���s�X�e�[�W���̂ɂ͊W�Ȃ��ł悩�����̂��B
���̒m�����K���������Ȃ�
���̂�̎ז��ɂȂ邩���������ł��B
888 �FMAC�I�^��887 �����F2008/08/17(��) 12:03:48 ID:Zsenu7UF
>>887
�����������Ă���悤�ň��S���������ǁA���ʂɃn�[�h���C�A�[�h���s��RISC�v���Z�b�T�ł�
�p�C�v���C��������Ă��Ȃ��Ŏ��s�ɕ����N���b�N�����閽�߂푶�݂��邷�B
���傤�Ǔ����T�C�g��������Ă���悤�ɁAPentium 4���P�����ߗp�̔{��ALU�ƕ��G���ߗp��
�ᑬALU�����邷�B
http://arstechnica.com/articles/paedia/cpu/p4andg4e2.ars/2
�����������Ă���悤�ň��S���������ǁA���ʂɃn�[�h���C�A�[�h���s��RISC�v���Z�b�T�ł�
�p�C�v���C��������Ă��Ȃ��Ŏ��s�ɕ����N���b�N�����閽�߂푶�݂��邷�B
���傤�Ǔ����T�C�g��������Ă���悤�ɁAPentium 4���P�����ߗp�̔{��ALU�ƕ��G���ߗp��
�ᑬALU�����邷�B
http://arstechnica.com/articles/paedia/cpu/p4andg4e2.ars/2
�����͂ǂ��ł������B
�ǂꂮ�炢�̐��\�Ɖ��i�ŁA��������������B
�ǂꂮ�炢�̐��\�Ɖ��i�ŁA��������������B
���I�^���\�肻���ȃl�^��ɓ\���Ƃ���
http://forums.vr-zone.com/showthread.php?t=315118
http://forums.vr-zone.com/showthread.php?t=315118
>>890
����20�N������Βǂ��z���������ȁB
����20�N������Βǂ��z���������ȁB
>>890
�s�[�N����30W���Ă̂ɋ�����
�����l����ƃG�l���M�[�̏[�U�͌��\�厖�Ȃ�
�����������~�ς��镔�����N�X��剻���Ă���̂��C�ɂȂ邪�E�E�E
�s�[�N����30W���Ă̂ɋ�����
�����l����ƃG�l���M�[�̏[�U�͌��\�厖�Ȃ�
�����������~�ς��镔�����N�X��剻���Ă���̂��C�ɂȂ邪�E�E�E
>>892
�����Ԃɂ킽���ăG�l���M�[��[���Ȃ��Ă��ǂ��Ȃ�đA�܂����ȁB
�����Ԃɂ킽���ăG�l���M�[��[���Ȃ��Ă��ǂ��Ȃ�đA�܂����ȁB
894 �F�A���~ ��Fh2IQtNvbw �F2008/08/17(��) 21:00:10 ID:lXkZ5J/+
>>890
48xx�̓J�X����(�E�L��`�E)
48xx�̓J�X����(�E�L��`�E)
895 �F,,�E�L�́M�E,,�j���F2008/08/17(��) 23:12:53 ID:C0ppS6h9
�Ȃ�Ƃ����I�J���g�X��
896 �F,,�E�L��`�E,,�j��-������ �F2008/08/17(��) 23:38:44 ID:E/ivLqEU
>>894
�J�X�͂��O���B
�J�X�͂��O���B
HyperTransport Consortium��HyperTransport 3.1�\�������B�v���G���t�@�V�X���N������
�g���[�j���O���Ɏ�������ē���N���b�N3.2GHz, 25.6GB/s (16-bit link)��B�����Ă��邷�B
http://www.hypertransport.org/default.cfm?page=HyperTransportSpecifications
�g���[�j���O���Ɏ�������ē���N���b�N3.2GHz, 25.6GB/s (16-bit link)��B�����Ă��邷�B
http://www.hypertransport.org/default.cfm?page=HyperTransportSpecifications
899 �FMAC�I�^��890 �����F2008/08/18(��) 20:19:40 ID:WrRnWAp9
>>899
�܂��
�܂��
�b��A���������ɏo����Ă��邷���猩���q�g�������Ǝv�������ǁAIDF�ɍ��킹��AMD��Shanghai��
���\����Ƃ̂��Ƃ��B
�������s��ɏo���̂�N�����痈�N(��)
�@�@-----------------------
�@�@Presumably, AMD OEM chums can expect to start punting early server systems based on the
�@�@firm�fs new line of processors by the end of 2008, if the chip maker delivers on its promise.
�@�@-----------------------
���\����Ƃ̂��Ƃ��B
�������s��ɏo���̂�N�����痈�N(��)
�@�@-----------------------
�@�@Presumably, AMD OEM chums can expect to start punting early server systems based on the
�@�@firm�fs new line of processors by the end of 2008, if the chip maker delivers on its promise.
�@�@-----------------------
902 �FMAC�I�^���⑫�F2008/08/18(��) 21:10:07 ID:WrRnWAp9
�\�[�X�̃����N�\��Y�ꂽ���B
http://www.theregister.co.uk/2008/08/18/amd_shanghai_new_chipset/
http://www.theregister.co.uk/2008/08/18/amd_shanghai_new_chipset/
GPU��SidePort�ɂ���˂�����HT3.1
904 �F,,�E�L�́M�E,,�j���F2008/08/18(��) 23:27:38 ID:TVU6DROr
FP�����Z�̃��C�e���V��1�̐l���܂��p���N���Ă��
�����̃I�����s�b�N�ɍ��킹�āA����Ȃ���IDF�ɍ��킹�āA���B
CPU�P�R�A�̃X�J�����\�́A�����w�ǔ��{�I�Ȑi���͊��ҏo���Ȃ��i�����I�ȉ��ǂ͂Ƃ������j����A
���Ƃ�AMD��SOI�̓������g���āAL3��Z-RAM�����ɂ���e�ʉ����炢�����v�������Ȃ��B
�ł�Z-RAM�͑S�R�b��ɂ��オ��Ȃ��Ȃ����̂ŁA�����|���ċC�����邪�B
���Ƃ�AMD��SOI�̓������g���āAL3��Z-RAM�����ɂ���e�ʉ����炢�����v�������Ȃ��B
�ł�Z-RAM�͑S�R�b��ɂ��オ��Ȃ��Ȃ����̂ŁA�����|���ċC�����邪�B
TGDaily�A Theo Valich��HyperTransport 3.1�L�����B
http://www.tgdaily.com/content/view/38945/135/
HT 3.1��Fusion��GPU�C���^�R�l�N�g�ɂȂ���AHTX (HT�̊g���J�[�h�K�i)�̐��i���o�Ă����
��������̘b���A�v���Ԃ�ɐ����Ă�B�B�B�Ƃ������e�����ǁA�����[���_��R�R�B
�@�@----------------------
�@�@HyperTransport 3.1 will also be included with every Shanghai processor. According to our
�@�@sources however, the technology will disabled and only HyperTransport 1.1 and 2.0 (up to
�@�@22.4 GB/s) will be supported.
�@�@----------------------
�܂Ƃ��ȃ`�b�v�Z�b�g�������߈��������ł��B�B�B
http://www.tgdaily.com/content/view/38945/135/
HT 3.1��Fusion��GPU�C���^�R�l�N�g�ɂȂ���AHTX (HT�̊g���J�[�h�K�i)�̐��i���o�Ă����
��������̘b���A�v���Ԃ�ɐ����Ă�B�B�B�Ƃ������e�����ǁA�����[���_��R�R�B
�@�@----------------------
�@�@HyperTransport 3.1 will also be included with every Shanghai processor. According to our
�@�@sources however, the technology will disabled and only HyperTransport 1.1 and 2.0 (up to
�@�@22.4 GB/s) will be supported.
�@�@----------------------
�܂Ƃ��ȃ`�b�v�Z�b�g�������߈��������ł��B�B�B
>>906
AMD��high-K�����ɍ��킹��SOI��߂��
AMD��high-K�����ɍ��킹��SOI��߂��
>>901�̃C�x���g�̕����Ă���l���B
http://www.4gamer.net/games/039/G003983/20080819040/
>>867�ɂ��������悤�ȃ��o���ɔ����āA�T�[�o�[�����`�b�v�Z�b�g��2009�N����
�O�|���ɂȂ����͗l���B
http://www.4gamer.net/games/039/G003983/20080819040/
>>867�ɂ��������悤�ȃ��o���ɔ����āA�T�[�o�[�����`�b�v�Z�b�g��2009�N����
�O�|���ɂȂ����͗l���B
Nvidia���ׂ�Ă����Ȃ��ˁB
>>908
��߂Ȃ����āB
���Ȃ��Ƃ�32nm��SOI�̔��\���Ă邵�B
>>909
AMD 890s�͂��Ƃ��Ƃ�2009�N��Montreal�ƈꏏ�̗\�肾�����̂ł����s�v�c�ł��Ȃ��B
��߂Ȃ����āB
���Ȃ��Ƃ�32nm��SOI�̔��\���Ă邵�B
>>909
AMD 890s�͂��Ƃ��Ƃ�2009�N��Montreal�ƈꏏ�̗\�肾�����̂ł����s�v�c�ł��Ȃ��B
912 �FMAC�I�^��911 �����F2008/08/20(��) 01:12:09 ID:Qtm6YmZc
>>911
�@�@-------------------
�@�@AMD 890s�͂��Ƃ��Ƃ�2009�N��Montreal�ƈꏏ�̗\�肾�����̂ł����s�v�c�ł��Ȃ��B
�@�@-------------------
�ꉞ�A>>867�̃����N����ǂ����B
�@�@-------------------
�@�@AMD 890s�͂��Ƃ��Ƃ�2009�N��Montreal�ƈꏏ�̗\�肾�����̂ł����s�v�c�ł��Ȃ��B
�@�@-------------------
�ꉞ�A>>867�̃����N����ǂ����B
�����ƌ������ǂ��ꂪ�����H
�����N��̃X���C�h��RD890s��2010�N�Ƃ��邷�B
�ƌ��������낤�B
���̌ケ���Ȃ�����
http://en.expreview.com/2008/07/01/amd-to-introduce-ddr3-790fx-in-09q1/
�ƌ��������낤�B
���̌ケ���Ȃ�����
http://en.expreview.com/2008/07/01/amd-to-introduce-ddr3-790fx-in-09q1/
915 �FMAC�I�^��914 �����F2008/08/20(��) 06:59:48 ID:Qtm6YmZc
>>914
���͂̕���ǂ����ǂ��Ǝv�����B
�@�@---------------------
�@�@According to CHW.net, AMD planning to release a DDR3 supported 790FX in the upcoming
�@�@year 2009. After that, the second DDR3 enthusiast mobo will be RD890 DDR3.
�@�@---------------------
"enthusiast mobo"��T�[�o�[�p���ᖳ�����B�܂����f�X�N�g�b�v�p�Ɠ������m���o���f�[�V����
�����ɔ���o���Ƃł��H�@�@�B�B�BAMD�Ȃ��肻������(��)
���͂̕���ǂ����ǂ��Ǝv�����B
�@�@---------------------
�@�@According to CHW.net, AMD planning to release a DDR3 supported 790FX in the upcoming
�@�@year 2009. After that, the second DDR3 enthusiast mobo will be RD890 DDR3.
�@�@---------------------
"enthusiast mobo"��T�[�o�[�p���ᖳ�����B�܂����f�X�N�g�b�v�p�Ɠ������m���o���f�[�V����
�����ɔ���o���Ƃł��H�@�@�B�B�BAMD�Ȃ��肻������(��)
ZRAM�ł�MRAM�ł�PRAM�ł��������lj����i��łȂ��́H
http://my.ocworkbench.com/bbs/showthread.php?p=424380#post424380
5���ȑO�̌v�悶�Ⴑ���Ȃ��Ă����獡�ɂȂ��Ė߂��Ă��s�v�c����Ȃ��Ƃ��������낤�B
Nvidia������Ȃ�����Ń`�b�v�Z�b�g�����ł����̌v��ɖ߂����Ƃ��l������ȁB
5���ȑO�̌v�悶�Ⴑ���Ȃ��Ă����獡�ɂȂ��Ė߂��Ă��s�v�c����Ȃ��Ƃ��������낤�B
Nvidia������Ȃ�����Ń`�b�v�Z�b�g�����ł����̌v��ɖ߂����Ƃ��l������ȁB
hfhfg
Phenom����������A�v���b�g�t�H�[���̑O�|�܂ł͂킩��܂���
920 �FSocket774�F2008/08/20(��) 12:28:52 ID:dx2e2SAO
�܂�A�t�F�m���Ɠ����I�v�e�����ɏ��ĂȂ�Xeon��c2�̓S�~�ȉ��̌��וi�ł��ˁB
������܂��B
������܂��B
����Z-RAM�̓������������Ă�̂́A�L���b�V���Ɏg���ɂ�L3�ł����x��
�s�����Ă�A���Ď����ȁH
�������P�X���b�h�ōl�����L2�L���b�V���́A�UMB���炢�Ő��\���オ���ł�
�ɂȂ�b�����������A�����Ȃ瑬�x�͒Ⴂ���Ǘe�ʂ��҂���̂�Z-RAM�̓���
�����A�V�������N�łUMB�L���b�V�������ʂɊm�ۉ\�Ȃ�A�킴�킴�x��Z-RAM
���g�����R���������Ď��Ȃ̂��ȁH
�s�����Ă�A���Ď����ȁH
�������P�X���b�h�ōl�����L2�L���b�V���́A�UMB���炢�Ő��\���オ���ł�
�ɂȂ�b�����������A�����Ȃ瑬�x�͒Ⴂ���Ǘe�ʂ��҂���̂�Z-RAM�̓���
�����A�V�������N�łUMB�L���b�V�������ʂɊm�ۉ\�Ȃ�A�킴�킴�x��Z-RAM
���g�����R���������Ď��Ȃ̂��ȁH
>>915
RIMM�̎���MTH�ȂƂĂ��o���f�[�V�����ʂ����Ƃ͎v���Ȃ��㕨���������A���ʂɎI�����ɂ�
�o�ׂ���Ă����ȁB
�܂��A�������ɂ���ē��ڐ��i�����ɏo��O�ɂقƂ�ǔ�������߂����B
RIMM�̎���MTH�ȂƂĂ��o���f�[�V�����ʂ����Ƃ͎v���Ȃ��㕨���������A���ʂɎI�����ɂ�
�o�ׂ���Ă����ȁB
�܂��A�������ɂ���ē��ڐ��i�����ɏo��O�ɂقƂ�ǔ�������߂����B
923 �FMAC�I�^��922 �����F2008/08/20(��) 19:05:34 ID:Qtm6YmZc
>>922
�@�@--------------------
�@�@�������ɂ���ē��ڐ��i�����ɏo��O�ɂقƂ�ǔ�������߂����B
�@�@--------------------
�����ASR5690/SP5100��Istanbul���Ɠ������Ƃ��J��Ԃ��Ƃ����\�������H
�@�@--------------------
�@�@�������ɂ���ē��ڐ��i�����ɏo��O�ɂقƂ�ǔ�������߂����B
�@�@--------------------
�����ASR5690/SP5100��Istanbul���Ɠ������Ƃ��J��Ԃ��Ƃ����\�������H
�o����ȉ�
����ō��N���ɂS�T�v���Z���̂b�o�t�o����́H
���ɏo�Ă邪
K8/K10�̓}���`�v���Z�b�T�\���ɂ���̂Ƀ`�b�v�Z�b�g�̃T�|�[�g��K�v�Ƃ��Ȃ����Ă̂����_�����A
�������R���g���[����CPU���ɓ������Ă����A�T�[�o�[�p�`�b�v�Z�b�g���Č����Ă��A������
�f�X�N�g�b�v�p�ƑS����������Ȃ��E�E�E
������MTH�݂����Ɋ��S�V�K����Ȃ��Ă��łɎ��т̂���`�b�v�̊g�������A�ň�HT3.0�܂ł̃T�|�[�g��
�}�������������B
�T�[�o�[�p�̃o���f�[�V�������Č����Ă��A����قǂ�邱�Ƃ͑����Ȃ���Ȃ��́H
K8�̂����VIA�`�b�v�̃f���A��CPU�}�U�[�Ȃ����������Ȃ��E�E�E
�������R���g���[����CPU���ɓ������Ă����A�T�[�o�[�p�`�b�v�Z�b�g���Č����Ă��A������
�f�X�N�g�b�v�p�ƑS����������Ȃ��E�E�E
������MTH�݂����Ɋ��S�V�K����Ȃ��Ă��łɎ��т̂���`�b�v�̊g�������A�ň�HT3.0�܂ł̃T�|�[�g��
�}�������������B
�T�[�o�[�p�̃o���f�[�V�������Č����Ă��A����قǂ�邱�Ƃ͑����Ȃ���Ȃ��́H
K8�̂����VIA�`�b�v�̃f���A��CPU�}�U�[�Ȃ����������Ȃ��E�E�E
�f�X�N�g�b�v�p���T�[�o�p�ɗ��p���邩�ǂ����͂����Ƃ��ɂ��Ă�
>>917�ŏo�Ă�悤�Ɍ��XRD890S��Montreal�ƈꏏ��2009�N�ɗ\�肳��Ă�����FA�B
>>917�ŏo�Ă�悤�Ɍ��XRD890S��Montreal�ƈꏏ��2009�N�ɗ\�肳��Ă�����FA�B
Bloomfield��HT8�X���b�h�ɑR���邽�߂ɁA
Shanghai3GHz��2�Z�b�g��999�h���̒l�i�Ŕ����Ă���Ȃ����낤���B
Quad FX���ۂ������ŁB
Shanghai3GHz��2�Z�b�g��999�h���̒l�i�Ŕ����Ă���Ȃ����낤���B
Quad FX���ۂ������ŁB
>>929
Windows�Ȃ�����m�炸�A�T�[�o�����CPU�ȂǍ\���ɍœK���ł�����ŁA
"Bloomfield"��"Shanghai"�ɏ��Ă邩���A�ŏ��̖��ɂȂ�킯�����c�B
Windows�Ȃ�����m�炸�A�T�[�o�����CPU�ȂǍ\���ɍœK���ł�����ŁA
"Bloomfield"��"Shanghai"�ɏ��Ă邩���A�ŏ��̖��ɂȂ�킯�����c�B
�T�[�o�[���Ƃ���Ȃ�AMD���Đ��\�����́H
����ȑO��Shanghai��3GHz�ʼn���
��i��2.8G�A�d���グ��3.5G�߂��܂�OC�o����݂��������ǁB
�T�[�o�p��CPU��OC��
��i�̘b�Ɍ��܂��Ƃ�
��i�̘b�Ɍ��܂��Ƃ�
Op�ł�1�V���[�Y�ŗ�O�����������ǂ�
�I�pCPU��OC�̘b�����͊�{�I�ɔ]�݂��������Ă�
�I�pCPU��OC�̘b�����͊�{�I�ɔ]�݂��������Ă�
��i�d����2.8�܂ʼn���ďグ��3.5�܂ʼn�����
3GHz���o���邾��ƌ������������������̂���
�Ȃ�ŎI�pCPU��OC����Ȃ�ċȉ����邩��
3GHz���o���邾��ƌ������������������̂���
�Ȃ�ŎI�pCPU��OC����Ȃ�ċȉ����邩��
http://northwood.blog60.fc2.com/blog-entry-2121.html
���ꂩ�B�����Shanghai��3GHz�ŏo����Ȃ�Ďv���̂��Ԕ������邼�B
�܂��ĂP��$500�̃o�[�Q�����i�Ƃ�����肦��B
$1500�̒��I�ʕi�Ȃ�Ƃ������B
���ꂩ�B�����Shanghai��3GHz�ŏo����Ȃ�Ďv���̂��Ԕ������邼�B
�܂��ĂP��$500�̃o�[�Q�����i�Ƃ�����肦��B
$1500�̒��I�ʕi�Ȃ�Ƃ������B
SMT���𗧂�����������ĕK���߂���
>>937
�œK���O��ES�i�ł��ꂾ���o�Ă�����Č����͖����ł����H�@�����ł����B
���܂܂ł�3.0GHz�I�[�o�[�Ȃ�Č��\���̃N���b�N������CPU�Ȃ̂ɁI
>>938
����B�l�g�o�n�̕]��������������A�������ǁASMT�͗D�G����H
Nehalem�ł͂��Ȃ���ǂ���Ă��邾�낤���A���Ȃ���ق��Ǝv����B
AMD��Shanghai����ō̗p��������Ǝv�������ǂȁB
�œK���O��ES�i�ł��ꂾ���o�Ă�����Č����͖����ł����H�@�����ł����B
���܂܂ł�3.0GHz�I�[�o�[�Ȃ�Č��\���̃N���b�N������CPU�Ȃ̂ɁI
>>938
����B�l�g�o�n�̕]��������������A�������ǁASMT�͗D�G����H
Nehalem�ł͂��Ȃ���ǂ���Ă��邾�낤���A���Ȃ���ق��Ǝv����B
AMD��Shanghai����ō̗p��������Ǝv�������ǂȁB
940 �FSocket774�F2008/08/23(�y) 10:28:54 ID:abP0meEG
Quad FX��Op�𓊂����肷��悤�ȕ��ł���B
���̂���胁������4�{�܂ŁB
���̂���胁������4�{�܂ŁB
Slot�ł�P�V�����������ȁ`
ATX�T�C�Y�Ńf���A���\�P�b�g�Ƃ��o���Ă���y�ɗV�ׂĊy��������
ATX�T�C�Y�Ńf���A���\�P�b�g�Ƃ��o���Ă���y�ɗV�ׂĊy��������
>>939
�M���������邭�炢�Ȃ�v���
CoreMA��HT�̃t���O��ON�ɂȂ��Ă���
���z�v���Z�b�T����1�ɂ��Ė����ɂ��Ă��炵��
�o�O���炯��Core2�����炱��ȏ�s���v�f�͑��₹�Ȃ������낤
�Ǝ㐫���������Ƃ�����Ȃ������Ƃ������Ȃ���
�Ƃ������Ƃ�
ttp://www.computerworld.jp/topics/vs/118430.html
�� 12���ɋy�ԑ��̐Ǝ㐫�ɂ��Ă͕��u
���ʂɍl����Intel�����璼���ĂȂ�
�M���������邭�炢�Ȃ�v���
CoreMA��HT�̃t���O��ON�ɂȂ��Ă���
���z�v���Z�b�T����1�ɂ��Ė����ɂ��Ă��炵��
�o�O���炯��Core2�����炱��ȏ�s���v�f�͑��₹�Ȃ������낤
�Ǝ㐫���������Ƃ�����Ȃ������Ƃ������Ȃ���
�Ƃ������Ƃ�
ttp://www.computerworld.jp/topics/vs/118430.html
�� 12���ɋy�ԑ��̐Ǝ㐫�ɂ��Ă͕��u
���ʂɍl����Intel�����璼���ĂȂ�
SMT�������C�R�[���M����������Ă킯����Ȃ����낤�B�l�g�o�̎��������������B
������Ƃ����āANehalem�Ŗ��͂Ȃ����Ă킯����Ȃ����ǁB
AMD�����͎������ĂȂ��������낤�B�I�n��CPU����SMT����Ȃ��āAMT�Z�p�̗p���Ă���CPU�͑������B
������Ƃ����āANehalem�Ŗ��͂Ȃ����Ă킯����Ȃ����ǁB
AMD�����͎������ĂȂ��������낤�B�I�n��CPU����SMT����Ȃ��āAMT�Z�p�̗p���Ă���CPU�͑������B
����SMT�͉��^�I���ȁB
Pen4�̃A���͖ܘ_�ʖڂ����ANiagara��Power��SMT���{���ɐ��\�o�Ă�̂�������
�C������BTPC-C��SPEC�ł������l�@���o���Ă����ꂪ�{�Ԃ̃g�����U�N�V��������
��X�N���v�g�����ɗL���Ȃ̂��^�₾���ȁB
���̎��_�ł͐��\�����߂�ׂ̋Z�p����Ȃ��ڋq�ɕ��������ׂ̋Z�p���Ǝv���Ă�B
Pen4�̃A���͖ܘ_�ʖڂ����ANiagara��Power��SMT���{���ɐ��\�o�Ă�̂�������
�C������BTPC-C��SPEC�ł������l�@���o���Ă����ꂪ�{�Ԃ̃g�����U�N�V��������
��X�N���v�g�����ɗL���Ȃ̂��^�₾���ȁB
���̎��_�ł͐��\�����߂�ׂ̋Z�p����Ȃ��ڋq�ɕ��������ׂ̋Z�p���Ǝv���Ă�B
�I�@�͂ǂ���SMT�I�t�ɂ��Ďg��������͂Ȃ��B
����t�@�C���t�H�[�}�b�g�̃R���o�[�g�݂����Ȕn���p�r�ɂ͂��傤�Ǘǂ��B
����t�@�C���t�H�[�}�b�g�̃R���o�[�g�݂����Ȕn���p�r�ɂ͂��傤�Ǘǂ��B
946 �F�A���~ ��Fh2IQtNvbw �F2008/08/23(�y) 13:06:29 ID:RIZyZrQ4
947 �FMAC�I�^��945 �����F2008/08/23(�y) 13:11:24 ID:yPEfu6rR
>>945
�@�@------------------
�@�@�I�@�͂ǂ���SMT�I�t�ɂ��Ďg��������͂Ȃ��B
�@�@------------------
�A�����̔]���T�[�o�[�ƌ�����قȂ邷�BServer P/C/T�̃R�����ɒ��ځB
http://www.tpc.org/tpcc/results/tpcc_advanced_sort.asp?PRINTVER=false&FLTCOL1=ALL&ADDFILTERROW=&filterRowCount=1&SRTCOL1=tpcc.c_tpmc&SRTDIR1=DESC&ADDSORTROW=&sortRowCount=1&DISPRES=100+PERCENT&include_withdrawn_results=none&include_server_cpu=ON
�@�@------------------
�@�@�I�@�͂ǂ���SMT�I�t�ɂ��Ďg��������͂Ȃ��B
�@�@------------------
�A�����̔]���T�[�o�[�ƌ�����قȂ邷�BServer P/C/T�̃R�����ɒ��ځB
http://www.tpc.org/tpcc/results/tpcc_advanced_sort.asp?PRINTVER=false&FLTCOL1=ALL&ADDFILTERROW=&filterRowCount=1&SRTCOL1=tpcc.c_tpmc&SRTDIR1=DESC&ADDSORTROW=&sortRowCount=1&DISPRES=100+PERCENT&include_withdrawn_results=none&include_server_cpu=ON
�]���T�[�o�[�@�����
950 �F�A���~ ��Fh2IQtNvbw �F2008/08/23(�y) 16:04:54 ID:RIZyZrQ4
>>949
����܂��Ă��Ƃ͗\�z�O���H(�E�L��`�E)
����܂��Ă��Ƃ͗\�z�O���H(�E�L��`�E)
��͂肻���Ȃ̂���
�������uSMT���𗧂����v�ł͂Ȃ��uIntelCPU���𗧂����v�Ƃ����j���A���X�ł�
���͎G��
�������uSMT���𗧂����v�ł͂Ȃ��uIntelCPU���𗧂����v�Ƃ����j���A���X�ł�
���͎G��
>>1
�s�˃J�X
�s�˃J�X
>>945
������IBM��SUN�̈����͂����܂ł�
������IBM��SUN�̈����͂����܂ł�
>>947
�x���`�}�[�N�͂Ƃ������A�K�͂��傫���Ƃ�������I�̓f�t�H��off�Ǝv���
�iPC�T�[�o��HT on���f�t�H�����j
HP-UX 11i Knowledge-on-Demand: performance optimization best-practices from our labs to you
http://h20338.www2.hp.com/hpux11i/downloads/HpUx11iV3Performance%20transcript.pdf
----
Hyper-threading is off by default at boot in 11i v3.
----
HP Integrity Servers with Microsoft Windows Server 2003 Release Notes
http://docs.hp.com/en/5991-3716/5991-3716.pdf
----
Enable hyper-threading on Integrity servers ? The default setting for hyper-threading is off.
----
�x���`�}�[�N�͂Ƃ������A�K�͂��傫���Ƃ�������I�̓f�t�H��off�Ǝv���
�iPC�T�[�o��HT on���f�t�H�����j
HP-UX 11i Knowledge-on-Demand: performance optimization best-practices from our labs to you
http://h20338.www2.hp.com/hpux11i/downloads/HpUx11iV3Performance%20transcript.pdf
----
Hyper-threading is off by default at boot in 11i v3.
----
HP Integrity Servers with Microsoft Windows Server 2003 Release Notes
http://docs.hp.com/en/5991-3716/5991-3716.pdf
----
Enable hyper-threading on Integrity servers ? The default setting for hyper-threading is off.
----
955 �FMAC�I�^��954 �����F2008/08/24(��) 07:43:43 ID:WF2KY+pZ
>>954
�ꐶ�������������̂�A�ǂ����邷�B���������{�I�Ȋ��Ⴂ���B�B�B
�@�@----------------------
�@�@HP-UX 11i Knowledge-on-Demand: performance optimization best-practices from our labs to you
�@�@----------------------
HP-UX��POWER��SPARC�ɈڐA����Ă����Ƃ평��������(��)
�ꐶ�������������̂�A�ǂ����邷�B���������{�I�Ȋ��Ⴂ���B�B�B
�@�@----------------------
�@�@HP-UX 11i Knowledge-on-Demand: performance optimization best-practices from our labs to you
�@�@----------------------
HP-UX��POWER��SPARC�ɈڐA����Ă����Ƃ평��������(��)
�����ł́A����Netburst Xeon�I��10�䂭�炢���邯�ǁA
�ǂ���AHTT��Off�ɂ��Ă��B
�ǂ���AHTT��Off�ɂ��Ă��B
957 �FMAC�I�^��956 �����F2008/08/24(��) 09:19:45 ID:WF2KY+pZ
>>956
�@�@------------------
�@�@����Netburst Xeon�I��10�䂭�炢���邯�ǁA
�@�@------------------
>>943���ǂ����B
�@�@------------------
�@�@����Netburst Xeon�I��10�䂭�炢���邯�ǁA
�@�@------------------
>>943���ǂ����B
�I������ON�ɂ��Ă���Ƃ���������݂��������ǂˁB
Neharem��HT��P4�Ƃ͂܂������ʂ炵�����炻��Ȃ�̌��ʂ��o�邩�������
Rock�͂ǂ��Ȃ�? >SMT
cxzc
>>683�̋�ATI�̔�R���s���[�^�����Broadcom�ɔ��蕥���Ƃ����b�A�m���o�����B
http://www.reuters.com/article/marketsNews/idUSN2550180720080825
�@�@-----------------------
�@�@Chip maker Broadcom Corp (BRCM.O: Quote, Profile, Research, Stock Buzz) said on Monday
�@�@it plans to buy Advanced Micro Devices' (AMD.N: Quote, Profile, Research, Stock Buzz)
�@�@digital television chip business for $192.8 million in cash to expand into the low-end television
�@�@screen market.
�@�@-----------------------
�L���b�V����$193M�̎����ɂȂ�Ƃ̂��Ƃ��B
���Ȃ݂�ATI�������ۂ̉��i��$5.4B���B
http://www.reuters.com/article/marketsNews/idUSN2550180720080825
�@�@-----------------------
�@�@Chip maker Broadcom Corp (BRCM.O: Quote, Profile, Research, Stock Buzz) said on Monday
�@�@it plans to buy Advanced Micro Devices' (AMD.N: Quote, Profile, Research, Stock Buzz)
�@�@digital television chip business for $192.8 million in cash to expand into the low-end television
�@�@screen market.
�@�@-----------------------
�L���b�V����$193M�̎����ɂȂ�Ƃ̂��Ƃ��B
���Ȃ݂�ATI�������ۂ̉��i��$5.4B���B
�Ȃ��i�I�Ɉ�Ԃ��������Ƃ���������肵��������悤�Ȉ�ۂ����邪�A�ǂ��Ȃ낤�ȁB
900���̐Ԃ��o���������������������H
x86�֘A����ȊO�ɊJ�����������]�͂������Ȃ���AAMD�ɂ́B
>>965
����A�����I�ɂ��BPC�Q�[������ɐL�т��떳�����������B
����A�����I�ɂ��BPC�Q�[������ɐL�т��떳�����������B
�����Ƃ����A�ߏ�Ƀn�C�p�t�H�[�}���X��CPU���s�v
�T�[�o�[�Ƃ�HPC�s��ɕK�v�Ȃ�
SMT�̓S�~���Č����Ă�z�݂Ă���v���o����
A�Ƃ����Z�p���v���Z�b�T�ƊE���ō̗p����n�߂�i�ƊE�̃g�����h�j
�����삪�����̂Œm������Ȃ�
�I�^�uA�Ƃ����Z�p�����ō̗p����Ă邷�BAMD��������̗p�����Ȃ������ˁv
���������B����Ȃ킯�Ȃ�����
�C���e����A�Z�p�̗̍p�\����i�C���e���t�@���ɂƂ��ăg�����h�j
�����ꂾ����C���e���͂�
AMD��A�Z�p�̗̍p���������n�߂�
�����ꂩ���A�̎��ゾ�I�i������AMD�t�@���̂����g�����h�B�ƊE�̃g�����h�ƍ������Ă͂����Ȃ��j
�����ƍL�����E�ɖڂ�������ׂ����Ǝv����
A�Ƃ����Z�p���v���Z�b�T�ƊE���ō̗p����n�߂�i�ƊE�̃g�����h�j
�����삪�����̂Œm������Ȃ�
�I�^�uA�Ƃ����Z�p�����ō̗p����Ă邷�BAMD��������̗p�����Ȃ������ˁv
���������B����Ȃ킯�Ȃ�����
�C���e����A�Z�p�̗̍p�\����i�C���e���t�@���ɂƂ��ăg�����h�j
�����ꂾ����C���e���͂�
AMD��A�Z�p�̗̍p���������n�߂�
�����ꂩ���A�̎��ゾ�I�i������AMD�t�@���̂����g�����h�B�ƊE�̃g�����h�ƍ������Ă͂����Ȃ��j
�����ƍL�����E�ɖڂ�������ׂ����Ǝv����
SMT�ł��x���`�Ȃ炿���Ɩ𗧂��Ƃ͖w�ǂ̓z���F�߂邾��
����Șb�����ĂȂ����Ƃ��n���ɗ����o���ĂȂ�������
����Șb�����ĂȂ����Ƃ��n���ɗ����o���ĂȂ�������
�����Ȃ�SMT�̓S�~�j�_���ăt�@�r����������ID:GzEdwIG5��
�܂���SMT�̓S�~�j�_�A���p���͊F���j�_���Č����o����>>944��
SMT�̓T�[�o�[�ł͂ǂ���OFF���펯�j�_���Č����o�����z�͖����ł����A�����ł�����
�܂���SMT�̓S�~�j�_�A���p���͊F���j�_���Č����o����>>944��
SMT�̓T�[�o�[�ł͂ǂ���OFF���펯�j�_���Č����o�����z�͖����ł����A�����ł�����
>>973
>>944��"���^�I"���Č����Ă��邾�������B
"���p���F��"���Ăǂ��ɏ����Ă���H
�l�g�o�n�ł̎����̂Ă����炭���ς���A���Ǔx�������킩��Ȃ����܁A
�P�Ƀx���`���ʂ�����"�g����"�Ǝv�����ނ̂̓o�J�̂��邱�Ƃ���H
���ƁASMT��Off�̏���������BHTT�̃G���b�^�����o������͓��ɂˁB
>>944��"���^�I"���Č����Ă��邾�������B
"���p���F��"���Ăǂ��ɏ����Ă���H
�l�g�o�n�ł̎����̂Ă����炭���ς���A���Ǔx�������킩��Ȃ����܁A
�P�Ƀx���`���ʂ�����"�g����"�Ǝv�����ނ̂̓o�J�̂��邱�Ƃ���H
���ƁASMT��Off�̏���������BHTT�̃G���b�^�����o������͓��ɂˁB
>���̎��_�ł͐��\�����߂�ׂ̋Z�p����Ȃ��ڋq�ɕ��������ׂ̋Z�p���Ǝv���Ă�B
����͂܂��Ɏ���SMT�͎��p���F���̂����̃}�[�P�e�B���O�̓���ł���Ǝv���Ă��܂��B
�ƕ\�����Ă���Ǝv�����ǁH
����͂܂��Ɏ���SMT�͎��p���F���̂����̃}�[�P�e�B���O�̓���ł���Ǝv���Ă��܂��B
�ƕ\�����Ă���Ǝv�����ǁH
�EIntelSMT���S�~�EInmtelCPU���o�O���炯�̃S�~
���Ă̂�
�ESMT���S�~
�Ƃ����Ⴂ�������o���Ȃ��̂��낤
���z��
���Ă̂�
�ESMT���S�~
�Ƃ����Ⴂ�������o���Ȃ��̂��낤
���z��
�I�݂̂ŏo�ׂ���ꍇ��SMT�I�t����
�ꕔ�\�t�g�ł�SMT���Ɗ��S�ɒ�~����ꍇ������
���Ƀ~�b�V�����N���e�B�J���ȁA���ɉғ����Ă���V�X�e���̃��v���C�X�p�r�ŏd�v�Ȃ̂́u���萫���m�ۂ�����ł̐��\�v������SMT�͕s�v
SMT�L�����̂��߂Ɋ����̃\�t�g�E�F�A�V�X�e���������邭�炢�Ȃ�A�f���ɂ��̗\�Z�Ŕ{�̎I�����ق����}�V
�O�̂��ߌ����Ēu�����ASMT�����ɗ����Ȃ��ƌ����Ă�킯�ł͖���
�ꕔ�\�t�g�ł�SMT���Ɗ��S�ɒ�~����ꍇ������
���Ƀ~�b�V�����N���e�B�J���ȁA���ɉғ����Ă���V�X�e���̃��v���C�X�p�r�ŏd�v�Ȃ̂́u���萫���m�ۂ�����ł̐��\�v������SMT�͕s�v
SMT�L�����̂��߂Ɋ����̃\�t�g�E�F�A�V�X�e���������邭�炢�Ȃ�A�f���ɂ��̗\�Z�Ŕ{�̎I�����ق����}�V
�O�̂��ߌ����Ēu�����ASMT�����ɗ����Ȃ��ƌ����Ă�킯�ł͖���
>>976
�����牴��Intel��HTT���S�~���Č������l�ɂ��Ă͕ʂɉ��������ĂȂ��ł���
SMT���̂��S�~���Č������l�ɍŏ��ɒ������R�s�y�̗�݂����Ɏ��삪�������Č����������ł����H
ID:GzEdwIG5�͂���܂�SMT�̘b�肪�o�ĂȂ������Ƃ����
�����W�Ȃ�Intel��@�����������ł����Ȃ�SMT���]�X���Č����o���Ă���
��>>939��Intel�͕̂�������SMT���̂͗D�G�ł���BShanghai�ō̗p����Ȃ�����
�ƌ���ꂽ�̂ɑ���Intel��HTT�̎����������SMT�͐M��������������AMD�ɂ�����Ȃ����Č����Ă�
���ۂ̎����ɂ���ĐM�������ς��̂ɑS�����������Intel��HTT��SMT�S�̂��������Ă���
>>944��IBM��SUN�̎���������Ă��̏��SMT���̂��}�[�P�e�B���O����ɉ߂��Ȃ�
���p�����Ȃ����Č����Ă邩�炱�̐l��SMT���̂�ᔻ���Ă��ˁH
���Ȃ��̕�������@����������ɁA����HTT��SMT���������Ă�Ɗ��Ⴂ����Ă���悤�Ɏv���܂���
����ƁeInmtelCPU�e���镨���o�O���炯�̃S�~���ǂ����ɂ��ẮA�m���ɉ��ɂ͗����ł��Ȃ��ł���
�����牴��Intel��HTT���S�~���Č������l�ɂ��Ă͕ʂɉ��������ĂȂ��ł���
SMT���̂��S�~���Č������l�ɍŏ��ɒ������R�s�y�̗�݂����Ɏ��삪�������Č����������ł����H
ID:GzEdwIG5�͂���܂�SMT�̘b�肪�o�ĂȂ������Ƃ����
�����W�Ȃ�Intel��@�����������ł����Ȃ�SMT���]�X���Č����o���Ă���
��>>939��Intel�͕̂�������SMT���̂͗D�G�ł���BShanghai�ō̗p����Ȃ�����
�ƌ���ꂽ�̂ɑ���Intel��HTT�̎����������SMT�͐M��������������AMD�ɂ�����Ȃ����Č����Ă�
���ۂ̎����ɂ���ĐM�������ς��̂ɑS�����������Intel��HTT��SMT�S�̂��������Ă���
>>944��IBM��SUN�̎���������Ă��̏��SMT���̂��}�[�P�e�B���O����ɉ߂��Ȃ�
���p�����Ȃ����Č����Ă邩�炱�̐l��SMT���̂�ᔻ���Ă��ˁH
���Ȃ��̕�������@����������ɁA����HTT��SMT���������Ă�Ɗ��Ⴂ����Ă���悤�Ɏv���܂���
����ƁeInmtelCPU�e���镨���o�O���炯�̃S�~���ǂ����ɂ��ẮA�m���ɉ��ɂ͗����ł��Ȃ��ł���
>>978
�����H�@�ŁH�@�������������́H�@�ȑf�ɒ[�I�ɁB
�Â��R�s�y�i>>970�j�ƈꕔ�̐l�����������ɏo���āA
�K����AMD�@���ɂ������ǁA�\�z�O�̔��_�ŗܖڈȊO�̗��R�ŁB
�����H�@�ŁH�@�������������́H�@�ȑf�ɒ[�I�ɁB
�Â��R�s�y�i>>970�j�ƈꕔ�̐l�����������ɏo���āA
�K����AMD�@���ɂ������ǁA�\�z�O�̔��_�ŗܖڈȊO�̗��R�ŁB
��������AMD�@���Ė������ǁH�����������������čŏ��ɏ����������H
SMT��K���ɒ@���Ă�l�����̃R�s�y���v���o����������Ă��ꂾ��
��������s����H���͓lj�͖����̂��H
�����ID:jzY+NFE3��ID:9L5YfJoS���I�O��Ȕ��_�ʼn���@���ɗ��Ă�����A���͂����������Ƃ������Ė����ł���H���Đ��������̂�
SMT��K���ɒ@���Ă�l�����̃R�s�y���v���o����������Ă��ꂾ��
��������s����H���͓lj�͖����̂��H
�����ID:jzY+NFE3��ID:9L5YfJoS���I�O��Ȕ��_�ʼn���@���ɗ��Ă�����A���͂����������Ƃ������Ė����ł���H���Đ��������̂�
981 �FMAC�I�^��977 �����F2008/08/26(��) 17:50:26 ID:u8LwGVma
>>977
�@�@----------------------
�@�@�I�݂̂ŏo�ׂ���ꍇ��SMT�I�t����
�@�@----------------------
�p���������m�������Ԃ肷(��)
http://publib.boulder.ibm.com/infocenter/systems/index.jsp?topic=/com.ibm.aix.cmds/doc/aixcmds5/smtctl.htm
�@�@======================
�@�@By default, AIX enables simultaneous multi-threading.
�@�@======================
�@�@----------------------
�@�@�I�݂̂ŏo�ׂ���ꍇ��SMT�I�t����
�@�@----------------------
�p���������m�������Ԃ肷(��)
http://publib.boulder.ibm.com/infocenter/systems/index.jsp?topic=/com.ibm.aix.cmds/doc/aixcmds5/smtctl.htm
�@�@======================
�@�@By default, AIX enables simultaneous multi-threading.
�@�@======================
>>981
�A�z�H
�A�z�H
>>980
�܂��B�܂��B�M���Ȃ�Ȃ�BID:jzY+NFE3��ID:9L5YfJoS��
�ʂɂ��O�����@���ĂȂ�����H
��������������ʂɏ������Ƃ��Ď��s���Ă��邼�B
>>970�Ŗ��x�̃R�e��"Mac�I�^"���ăR�e�͂ǂ������H
�܂��B�܂��B�M���Ȃ�Ȃ�BID:jzY+NFE3��ID:9L5YfJoS��
�ʂɂ��O�����@���ĂȂ�����H
��������������ʂɏ������Ƃ��Ď��s���Ă��邼�B
>>970�Ŗ��x�̃R�e��"Mac�I�^"���ăR�e�͂ǂ������H
����MAC�I�^���Ă��Ƃɂ��Ă���ނ�ɂ�������ł���
>>970�ʼn��̏��������͈�s�ڂ�����B�c��͍Ō�̍s�܂ŃR�s�y�ł����H��
�܂��A���p�����Ȃ����������s�e����������
�ߋ����O�����Ō�̍s�܂ŃR�s�y�Ȃ��Ƃ͈�ڗđR�����炢�����
�Ƃ���ł����������O����͂����������悤�ȕ��̂Ȃ̂�ID���ς���Ă�ˁA�ǂ������́H
>>970�ʼn��̏��������͈�s�ڂ�����B�c��͍Ō�̍s�܂ŃR�s�y�ł����H��
�܂��A���p�����Ȃ����������s�e����������
�ߋ����O�����Ō�̍s�܂ŃR�s�y�Ȃ��Ƃ͈�ڗđR�����炢�����
�Ƃ���ł����������O����͂����������悤�ȕ��̂Ȃ̂�ID���ς���Ă�ˁA�ǂ������́H
>>984
����B�ŁA�������������́H
����B�ŁA�������������́H
�킴�킴�l��MAC�I�^������Ďא����Ă��ꂽ����
���������킴�Ǝא�����ID�ς��Ă܂ŔS������J������Ĕ�����Č�������
���͓lj�͂��s�����Ă�悤�����ǁA����ŕ��������H
���������킴�Ǝא�����ID�ς��Ă܂ŔS������J������Ĕ�����Č�������
���͓lj�͂��s�����Ă�悤�����ǁA����ŕ��������H
�������W�Ȃ�Intel��@�����������ł����Ȃ�SMT���]�X���Č����o���Ă���
�ƁA���̕����ł�ID:GzEdwIG5��SMT�S����@�����̂ł͂Ȃ�Intel�̕�SMT��@�������Ƃ�F�߂Ă���̂�
���̂����̕����ł͔F�߂Ă��Ȃ�
�܂�Ől�i���������̂悤�ȉ��z��ID:rCGN85vj
������SMT���̂��I�p�r�ŗL�p���ǂ�����
���̃X���ł͌��������ĂȂ��̂�
���ɗD�G��FA�Ƃ��Ă�Ƃ���������
�u�x���`�Ŋ���o����Ȃ瑼�̂ǂ�ɑ��Ă�����o����v
�Ǝv������ł���悤�ōX�ɉ��z
>>983
�@���Ă�悗
�ƁA���̕����ł�ID:GzEdwIG5��SMT�S����@�����̂ł͂Ȃ�Intel�̕�SMT��@�������Ƃ�F�߂Ă���̂�
���̂����̕����ł͔F�߂Ă��Ȃ�
�܂�Ől�i���������̂悤�ȉ��z��ID:rCGN85vj
������SMT���̂��I�p�r�ŗL�p���ǂ�����
���̃X���ł͌��������ĂȂ��̂�
���ɗD�G��FA�Ƃ��Ă�Ƃ���������
�u�x���`�Ŋ���o����Ȃ瑼�̂ǂ�ɑ��Ă�����o����v
�Ǝv������ł���悤�ōX�ɉ��z
>>983
�@���Ă�悗
���ς�炸Intel�̘b��ł�������オ��Ȃ��ȁA����
�ŋ߁A�e����ID�^���Ԃɂ��ăX���Z���Ɛ���Ă�z�����Ȃ�
AMD�n�̃X���Ȃ�Ăǂ���Intel��ے肷�邱�ƂŐ���オ��܂�
>>991
����͉A�~���\��邾���ŐL�тĂ���B
����͉A�~���\��邾���ŐL�тĂ���B
����Ȃ���ȂŎ��X���B
AMD�̎�����CPU�ɂ��Č�낤 ��23����
http://pc11.2ch.net/test/read.cgi/jisaku/1219751351/
AMD�̎�����CPU�ɂ��Č�낤 ��23����
http://pc11.2ch.net/test/read.cgi/jisaku/1219751351/
�~
�P�O�O�O�Ȃ���݂䂫�Ƃ�������ł���
����
����
�~
�l��
1000�Ȃ�A���~�ƌ�������B
1001 �F�P�O�O�P�F
1��̃}�V�����g�ݏオ��܂����B�B�B
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://pc11.2ch.net/jisaku/
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://pc11.2ch.net/jisaku/