Intelの次世代CPUについて語ろう 32
HKEPCよりNehelem詳報す。
http://www.hkepc.com/?id=568
・x1.2-2 MP性能
・x1.1-1.25 シングルスレッド性能
・同一性能で30%(Penryn比)省電力
・QuickPath x 4
■Bloomfield (highend)
・2008Q4
・8MB L2
・LGA1366
・外付メモリコントローラ "Tylersburg"
- 3ch DDR3-1600, 2DIMMs/channel
- 8x PCIe2 x 4 + 1x PCIe2 x 4
- DMI接続 ICH10
・130W TDP
・VRM 11.1
http://www.hkepc.com/?id=568
・x1.2-2 MP性能
・x1.1-1.25 シングルスレッド性能
・同一性能で30%(Penryn比)省電力
・QuickPath x 4
■Bloomfield (highend)
・2008Q4
・8MB L2
・LGA1366
・外付メモリコントローラ "Tylersburg"
- 3ch DDR3-1600, 2DIMMs/channel
- 8x PCIe2 x 4 + 1x PCIe2 x 4
- DMI接続 ICH10
・130W TDP
・VRM 11.1
|
|
|
>>439
BFはメモコンはCPU側にはない?
BFはメモコンはCPU側にはない?
■Lynnfield (midrange)
・2009Q1
・4-core
・8MB L2
・LGA1160
・内蔵メモリコントローラ 2ch DDR3
・内蔵 8x PCIe2 x 2
・DMI接続ICH "lbexpeak"
・95W TDP
・VRM 11.1
・2009Q1
・4-core
・8MB L2
・LGA1160
・内蔵メモリコントローラ 2ch DDR3
・内蔵 8x PCIe2 x 2
・DMI接続ICH "lbexpeak"
・95W TDP
・VRM 11.1
■Havendale (IGP)
・2009Q2
・2-core
・4MB L2
・LGA1160
・内蔵GPU (DirectX 10, Shader Model 4.0, OpenGL 2.1)
・内蔵メモリコントローラ 2ch. DDR
・内蔵8x PCIe2 x 1?
・DMI&DisplayLink接続ICH "lbexpeak"
・75W TDP
・VRM 11.1
・2009Q2
・2-core
・4MB L2
・LGA1160
・内蔵GPU (DirectX 10, Shader Model 4.0, OpenGL 2.1)
・内蔵メモリコントローラ 2ch. DDR
・内蔵8x PCIe2 x 1?
・DMI&DisplayLink接続ICH "lbexpeak"
・75W TDP
・VRM 11.1
Penryn比30%減ってのはすげーなぁ・・・
444 :MACオタ@ここまで:2008/01/03(木) 21:45:40 ID:0OGEg5J1
その他、TDPの枠内で一部のコアをOCする"Turbo Mode"の解説と、2009Q2に
"Clarksfield"や"Auburndale"のモバイル版Nehalemが予定されているという話す。
"Clarksfield"や"Auburndale"のモバイル版Nehalemが予定されているという話す。
歩留まり向上とリスク削減、OCのポテンシャル向上のために、メモコンとPCIeは統合されてない
って書いてるっぽい。Googleの中英翻訳かますと。
でも1ページめのNehalemのプラットフォームの図だとメモリはCPUにつながってるから、
Bloomfieldだけ外付けメモコンで、Xeonでは内蔵メモコンってことなのかな?
って書いてるっぽい。Googleの中英翻訳かますと。
でも1ページめのNehalemのプラットフォームの図だとメモリはCPUにつながってるから、
Bloomfieldだけ外付けメモコンで、Xeonでは内蔵メモコンってことなのかな?
446 :MACオタ>445 さん:2008/01/03(木) 22:04:39 ID:0OGEg5J1
>>445
1ページの図わ、去年のIDFのスライドであると注釈が入っているす。
ただ、Xeonわ競合上メモリコントローラわ内蔵し、遅めのメモリクロックで
大容量メモリをサポートするようにすることになる筈す。
1ページの図わ、去年のIDFのスライドであると注釈が入っているす。
ただ、Xeonわ競合上メモリコントローラわ内蔵し、遅めのメモリクロックで
大容量メモリをサポートするようにすることになる筈す。
進捗の方わ、記事中の図にあるようにマザーボードのリファレンスデザインわ完成しているよう
だし、Bloomfieldのサンプルもマザボベンダに配布されているとのことす。
良きにつけ悪しきにつけ、直に実物ベースの色々なリーク情報が見られることになりそうす。
だし、Bloomfieldのサンプルもマザボベンダに配布されているとのことす。
良きにつけ悪しきにつけ、直に実物ベースの色々なリーク情報が見られることになりそうす。
今年の"WPC TOKYO 2008"が楽しみだ
ぜんぜん
WPCって年々しょぼくなってね?
去年とかかなり空きブースあったし・・・
去年とかかなり空きブースあったし・・・
サーバ向けがメモコン外付け?
なんか、前言われていたのと逆のような。
なんか、前言われていたのと逆のような。
Bloomfieldは外付けだけど、鯖用まで外付けとは決まってないんじゃないかな。
速度を落とさずにDIMMソケット数を増やすためのソリューションじゃないか?
E8500のXMBのようなCPUとは専用IFでつながるメモリコントローラか、あるいはバッファチップか、
どっちなのかはまだ不明確だけど。
AMDも次世代向けにG3MXというバッファチップソリューションを推進していたりする。
今後の超ハイエンドサーバ向けには、大量の物理メモリ対応が必要だと両社とも考えてるだろうし。
E8500のXMBのようなCPUとは専用IFでつながるメモリコントローラか、あるいはバッファチップか、
どっちなのかはまだ不明確だけど。
AMDも次世代向けにG3MXというバッファチップソリューションを推進していたりする。
今後の超ハイエンドサーバ向けには、大量の物理メモリ対応が必要だと両社とも考えてるだろうし。
ちら裏!
予定では、今年ららびーでるんだな。
銀棘も楽しみだが、ららびーがどういう風になるかも楽しみだな。
案外ららびーの1エレメントが銀棘だったとかあったりして。。。
すんげー楽しみ。
予定では、今年ららびーでるんだな。
銀棘も楽しみだが、ららびーがどういう風になるかも楽しみだな。
案外ららびーの1エレメントが銀棘だったとかあったりして。。。
すんげー楽しみ。
PCI-Eで直結させるのではないかと予想。その為にコントローラを内蔵させたんじゃないかな。
対応ソフトが無きゃ使い道が全く無さそうだけどね。
対応ソフトが無きゃ使い道が全く無さそうだけどね。
明日からCESか。自作とは関係ないが、SilverthorneとPenryn搭載のノートがお披露目かな。
E8500/8400/8200も発表あるかもな
>>459
予定より二週間近く前倒しデスか? ないとおもうなぁ。さすがに。
予定より二週間近く前倒しデスか? ないとおもうなぁ。さすがに。
>>460
発売じゃないよ発表
発売じゃないよ発表
近年の傾向からすると発表と同時に発売じゃないかな。
厳密に言うと発売後に発表
>>462
http://pc.watch.impress.co.jp/docs/2007/1221/ubiq207.htm
Core 2 Quad/Duo、Celeron Dual-Coreに関しては、2008年1月7日に米国のラスベガスで
開催されるInternational CESにあわせて発表され、製品の出荷開始が1月20日(米国時間)
という予定になっていた。ちょうど、1月7日にCESにおいてIntelのCEO、ポール・オッテリーニ社長
による基調講演が行なわれるので、それにあわせてこれらの製品も発表されることに
なっていた。
現時点では、1月7日に予定されている製品の発表がどうなるかは未定で、発表が
取りやめになり改めて第1四半期の後半に発表される案と、製品出荷は先だが
とりあえず発表だけされるという2つの案があるという。
http://pc.watch.impress.co.jp/docs/2007/1221/ubiq207.htm
Core 2 Quad/Duo、Celeron Dual-Coreに関しては、2008年1月7日に米国のラスベガスで
開催されるInternational CESにあわせて発表され、製品の出荷開始が1月20日(米国時間)
という予定になっていた。ちょうど、1月7日にCESにおいてIntelのCEO、ポール・オッテリーニ社長
による基調講演が行なわれるので、それにあわせてこれらの製品も発表されることに
なっていた。
現時点では、1月7日に予定されている製品の発表がどうなるかは未定で、発表が
取りやめになり改めて第1四半期の後半に発表される案と、製品出荷は先だが
とりあえず発表だけされるという2つの案があるという。
>>465
Conroeの発売はないぞ
Conroeの発売はないぞ
あ、Celelon DCのことをConroeと呼んだってこと?
いちおうあれはAllendale。
いちおうあれはAllendale。
468 :Socket774:2008/01/06(日) 23:26:32 ID:M6C8PwAt
>>468
つ QX9650
つ QX9650
470 :Socket774:2008/01/06(日) 23:29:24 ID:M6C8PwAt
ところで何方かXeon系のプロセッサとCore 2 Quad系のプロセッサの比較とかしているサイト誰かご存知ないですか?
Win32ベースの範囲内で動作可能な最速計算サーバーを作りたいのですが
Win32ベースの範囲内で動作可能な最速計算サーバーを作りたいのですが
http://slashdot.jp/hardware/article.pl?sid=08/01/06/223245
IntelがOLPCから手を引くらしい
Silverthorne向きのプロジェクトだと思ったんだが…
IntelがOLPCから手を引くらしい
Silverthorne向きのプロジェクトだと思ったんだが…
473 :Socket774:2008/01/07(月) 10:50:58 ID:RHrhs8Yj
>CPUの内部にGPUを内蔵したノースブリッジ
これ完璧なAMD潰しじゃね?
CPUを買い換えればGPUも付いてくるって事は、GPUを買う人が少なからず減るわけで
しかもチップセットに付いてるオンボGPUは世代が古くなっても買い換えづらいけど、
CPUに内蔵ならCPUを買い換えるだけでいい。常にブラッシュアップされてる。
ATI買収したAMD終了
これ完璧なAMD潰しじゃね?
CPUを買い換えればGPUも付いてくるって事は、GPUを買う人が少なからず減るわけで
しかもチップセットに付いてるオンボGPUは世代が古くなっても買い換えづらいけど、
CPUに内蔵ならCPUを買い換えるだけでいい。常にブラッシュアップされてる。
ATI買収したAMD終了
>CPUに内蔵ならCPUを買い換えるだけでいい。常にブラッシュアップされてる。
言われてみればそうだな
チップセットが対応してる限りCPU強化がGPU強化につながるケースもあるってことか
言われてみればそうだな
チップセットが対応してる限りCPU強化がGPU強化につながるケースもあるってことか
素人意見で申し訳ないが、CPUとGPU一緒になったら爆熱CPUにならないか?
メモリ規格が変わらない限り、MBの互換性を維持するのは技術的には可能だろうけど
それはIntel次第だからな。
QPIを高速化しますた、DMIを高速化しますた・・・と言って互換性を切り捨てる予感が・・・。
それはIntel次第だからな。
QPIを高速化しますた、DMIを高速化しますた・・・と言って互換性を切り捨てる予感が・・・。
今までのIntel GPUを考えると歓迎できない。
どうせ昔みたいにOVERDRIVEプロセッサとか発売されないし
一年も経てばソケット変わるしなぁ
一年も経てばソケット変わるしなぁ
自作板のtukigataスレが落ちてたから探してきたぜ
http://oshiete1.goo.ne.jp/qa1152486.html?ans_count_asc=1
http://oshiete1.goo.ne.jp/qa1152486.html?ans_count_asc=1
>>476
微妙なところだな。
Intelはチップセット(GPU内蔵品も)を基本的に1世代前のプロセスで作って、
工場の使いまわしをしてるし、GPU内蔵CPUはMCMで作るみたいだから、CPUコア
だけ最新プロセスにして、GPUコア部分は旧プロセスの可能性があるからな。
微妙なところだな。
Intelはチップセット(GPU内蔵品も)を基本的に1世代前のプロセスで作って、
工場の使いまわしをしてるし、GPU内蔵CPUはMCMで作るみたいだから、CPUコア
だけ最新プロセスにして、GPUコア部分は旧プロセスの可能性があるからな。
台湾系の専業Fabがここまで躍進していなかったらその
一世代前のプロセスで作られたチップにさえ
他社は手も足も出ていなかったと思う。
一世代前のプロセスで作られたチップにさえ
他社は手も足も出ていなかったと思う。
ロードマップだとGPUも2009年には45nm、2010年には32nmの最新プロセスを使う。
これがダイ統合かMCMかは不明だけど。
これがダイ統合かMCMかは不明だけど。
プロセス:32ナノ
クロック:3.2GHz
FSB:1600MHz
L2キャッシュ:16MB
コア:8コア
とりあえず、この構成のCPUが出る事を祈念します。
クロック:3.2GHz
FSB:1600MHz
L2キャッシュ:16MB
コア:8コア
とりあえず、この構成のCPUが出る事を祈念します。
>>486
45nmのNehalemでほぼそのまんまが出るから余裕で出るだろ。
45nmのNehalemでほぼそのまんまが出るから余裕で出るだろ。
インテル、45nm Hi-kプロセス採用のノート向けプロセッサなど16製品を発表
http://enterprise.watch.impress.co.jp/cda/hardware/2008/01/08/11969.html
Intel、45nmプロセスによる初のモバイルプロセッサ発表
http://www.itmedia.co.jp/news/articles/0801/08/news017.html
http://enterprise.watch.impress.co.jp/cda/hardware/2008/01/08/11969.html
Intel、45nmプロセスによる初のモバイルプロセッサ発表
http://www.itmedia.co.jp/news/articles/0801/08/news017.html
マウス、新型Core 2 Duoを搭載した15.4型ワイドノート
http://pc.watch.impress.co.jp/docs/2008/0108/mcj.htm
http://pc.watch.impress.co.jp/docs/2008/0108/mcj.htm
>>486
数字的に美しい
数字的に美しい
>>486
FSB廃止されてるから絶対に無理と言ってみるテスト
FSB廃止されてるから絶対に無理と言ってみるテスト
>491
なるほどw
なるほどw
FSB廃止ってなるとどういう仕組みになるの?
FSBが数値的にガタ落ちする構造になるから表記しなくなるって事?
FSBが数値的にガタ落ちする構造になるから表記しなくなるって事?
>>493
AMDのHammer系と一緒。
AMDのHammer系と一緒。
だいたいの事が書いてあった
ttp://pcparts.fc2web.com/cpu-intel-future.html
普通パラレルからシリアル方式になるとピンの数とか
減りそうなものだけど1366本とかになるんだ。剣山以上に剣山。
そういえばAMDの方もメモコン内蔵だから940とかなんかな。
ttp://pcparts.fc2web.com/cpu-intel-future.html
普通パラレルからシリアル方式になるとピンの数とか
減りそうなものだけど1366本とかになるんだ。剣山以上に剣山。
そういえばAMDの方もメモコン内蔵だから940とかなんかな。
>>495
メモコンが内蔵されるから増えているのはあるかもね。
ちなみにAM2は940pinで、SocketFが1206のLGA。
SocketFは他のCPUとのHT接続もあるから増えている。
だから、もしかしたらNehalemも8コアと4コアで、
ハイエンドとそれ以下とではピン数が違う可能性もある?
メモコンが内蔵されるから増えているのはあるかもね。
ちなみにAM2は940pinで、SocketFが1206のLGA。
SocketFは他のCPUとのHT接続もあるから増えている。
だから、もしかしたらNehalemも8コアと4コアで、
ハイエンドとそれ以下とではピン数が違う可能性もある?
>>497
そのレス番になにがいるか見えないんだが…。
そのレス番になにがいるか見えないんだが…。
>>487
Nehalemの8コアのはXeonMP専用の超お高い奴だぞ
Nehalemの8コアのはXeonMP専用の超お高い奴だぞ
>>493
システムバスがFSBかそれ以外になるかどうかの違い
システムバスがFSBかそれ以外になるかどうかの違い
>>499
別にNehalemと限定しているわけじゃないし…
>>487はNehalemのXeonで出ているんだから次世代コアのライトユーザー向けで
そのくらいのは出るんじゃない?ってことじゃない?
まぁ、>>491の通りだけどw
別にNehalemと限定しているわけじゃないし…
>>487はNehalemのXeonで出ているんだから次世代コアのライトユーザー向けで
そのくらいのは出るんじゃない?ってことじゃない?
まぁ、>>491の通りだけどw
死ぬまでにL3キャッシュ1GBとか見てみたい。
>>502
あと3-40年生きたら普通にみられそうだよね。
あと3-40年生きたら普通にみられそうだよね。
そのころL3キャッシュという概念はあるのだろうか。
>>502
キャッシュって考え方そのものが廃れそうだけどな。
キャッシュって考え方そのものが廃れそうだけどな。
あと30年もしたらメインメモリという概念自体がなく1000以上のコアに
1GB程度の少量のローカルメモリが付随する形態になるよ
1GB程度の少量のローカルメモリが付随する形態になるよ
その頃はとっくにPCはょぅじょの形してるよ
シリコンの微細化の限界が2020年頃だから、その更に18年後か。
ノイマン型アーキテクチャーは現役かのう…。
大して発展がなければ現役な気もするし、
コンピューター(?)はプログラムを組むのではなくて教育を施す形態になっているかもしれない。
学習結果のコピーはできるだろうから量産は効きそうとか、想像してみる。
ノイマン型アーキテクチャーは現役かのう…。
大して発展がなければ現役な気もするし、
コンピューター(?)はプログラムを組むのではなくて教育を施す形態になっているかもしれない。
学習結果のコピーはできるだろうから量産は効きそうとか、想像してみる。
Intel、『Penryn』のラインナップを大幅に拡大
Intel は先ごろ、45ナノメートル (nm) プロセッサ ファミリ『Penryn』をリリースしたが、
その第1弾は、数種類のサーバ用『Xeon』とデスクトップ ファミリのハイエンドモデル
『Core 2 Extreme』のみという、やや地味な内容だった。だが、7日から開催されている
イベント『2008 International CES』では、デスクトップ、モバイル、ローエンドのサーバー
向け製品など、さらに多くの Penryn プロセッサが発表されることになった。
ttp://japan.internet.com/webtech/20080108/12.html?rss
AMDにとどめを刺しているねw
Intel は先ごろ、45ナノメートル (nm) プロセッサ ファミリ『Penryn』をリリースしたが、
その第1弾は、数種類のサーバ用『Xeon』とデスクトップ ファミリのハイエンドモデル
『Core 2 Extreme』のみという、やや地味な内容だった。だが、7日から開催されている
イベント『2008 International CES』では、デスクトップ、モバイル、ローエンドのサーバー
向け製品など、さらに多くの Penryn プロセッサが発表されることになった。
ttp://japan.internet.com/webtech/20080108/12.html?rss
AMDにとどめを刺しているねw
オーバーキル
>>508
シャノン並みの天才の降臨を待たなきゃいけないわけだなw
シャノン並みの天才の降臨を待たなきゃいけないわけだなw
赤ん坊の頃に植え付けられた脳内のチップが成長に合わせて死ぬまで進化するバイオチップといいな。
インターフェースは指先で互いに触れ合うだけ。
インターフェースは指先で互いに触れ合うだけ。
ゴーストは囁きますか?
電脳も結局はハッキングやウィルスが増加しまくって廃れるんだよね・・・
笑っとくか
来てみたらスレタイ通りの次世代の話題で
しかも、もの凄い次世代にぶっ飛んでたワロタ
しかも、もの凄い次世代にぶっ飛んでたワロタ
>>512
一、二年で旧型になってしまいそうなんだがw
一、二年で旧型になってしまいそうなんだがw
>>512
赤ん坊の間に知能だけえらく発展してしまうシュールな想像をしたw
赤ん坊の間に知能だけえらく発展してしまうシュールな想像をしたw
CPUとは全く掛け離れたお話だが、
"サヴァン症候群"で発現するような能力は誰にでもあって、
人間が集団生活をおこうなう中で意図的に捨てていったものらしい。
だから、それを誰にでも使える様にすることは可能ではないのか?
的な研究もあるのな。
"サヴァン症候群"で発現するような能力は誰にでもあって、
人間が集団生活をおこうなう中で意図的に捨てていったものらしい。
だから、それを誰にでも使える様にすることは可能ではないのか?
的な研究もあるのな。
シンボル的なアプローチ、神経回路的なアプローチ、そのハイブリット、その他
いずれにしても、もうちょっと人体に学んで工学的によりよいモデルが作れないと発展はなさそう。
いずれにしても、もうちょっと人体に学んで工学的によりよいモデルが作れないと発展はなさそう。
http://image.itmedia.co.jp/l/im/pcuser/articles/0801/09/l_kn_ces08um_07.jpg
|システム基板の中央に見えるのがワンチップ構成の「Poulsbo」で、その右に見える小さい
|チップがCPUの「Silverthorne」(ともに開発コード名)だ
CPUの方が脇役になってますね。(蚤の夫婦?)
今後もCPUの存在はこんな感じになるのかな?
{kind=link}
|システム基板の中央に見えるのがワンチップ構成の「Poulsbo」で、その右に見える小さい
|チップがCPUの「Silverthorne」(ともに開発コード名)だ
CPUの方が脇役になってますね。(蚤の夫婦?)
今後もCPUの存在はこんな感じになるのかな?
ダイサイズはともかくとしてCPUよりチップセットの方がピン数が増えるのは現時点では必然だから
526 :ヽ・´∀`・,,)っ━━━━━━┓:2008/01/10(木) 02:08:48 ID:l+bz7Jco
NehalemのCPUIDの取り方とかの資料って出てる?
AMDが潰れそうだから助け舟が来ました。
http://www.itmedia.co.jp/news/articles/0801/11/news010.html
http://www.itmedia.co.jp/news/articles/0801/11/news010.html
しかし、独禁法に守られながらってのは、ある意味屈辱的なんじゃなかろうか…
屈辱なんてどうでもいいけど、独禁法に守られてる限り勝てないからな。
屈辱なんて感じる会社ならSSE5とか命名しないから。
まあMSとアップルの事例も有るし、Intelが強大な製造能力を生かして、屁呑を
古くなった65nmプロセスで製造受託すれば良いのジャマイカ。
古くなった65nmプロセスで製造受託すれば良いのジャマイカ。
屈辱というか。独禁法にかかるようなことをしなければ、
物が売れなかったIntelの方が凹むべきだとおもうんだが…。
物が売れなかったIntelの方が凹むべきだとおもうんだが…。
物が売れようと売れまいとやることに変わりはないから
Intelの65nmはチップセットや巨大なダイサイズのTukwila、PenDCやCeleDCを
生産しないといけないので、他所のぶつを作る余裕まではないだろ。
生産しないといけないので、他所のぶつを作る余裕まではないだろ。
炭素の単原子シートにシリコンを超える半導体の可能性
ttp://slashdot.jp/science/article.pl?sid=08/01/11/0111214
NewScientist Tech記事経由、マンチェスター大学のプレスリリースより。
炭素の単原子シートであるグラフェン(graphene)は、以前からナノテクノロジー研究の対象となっている物質であった。
この物質の特性を研究したマンチェスター大学、ロシアInstitute for Microelectronics Technologyや
オランダラドバウト・ナイメーヘン大学、アメリカミシガン工科大学物理学科との合同研究チームは、
電子移動度がシリコンの百倍以上もの値である200000cm^2/Vsに達することを発見したという。
これまで知られているカーボンナノチューブやアンチモン化インジウムといった素材以上の適性を示しており、
非常に有望な素材だと研究に参加したAndre Geim教授は語っている。
グラフェンがシリコンを置き換えるようなことは20年以内にあるとは考えられないと教授も認めているが、
今後3年から5年以内にガスセンサーやテラヘルツ発振器/検出器といった装置へ応用されるようになるのではと
期待しているそうだ。この研究成果はPhysical Review Lettersの11 January 2008号にも掲載された。
とりあえずインテルとは無関係だが将来的にCPUに応用されそうってことで
ttp://slashdot.jp/science/article.pl?sid=08/01/11/0111214
NewScientist Tech記事経由、マンチェスター大学のプレスリリースより。
炭素の単原子シートであるグラフェン(graphene)は、以前からナノテクノロジー研究の対象となっている物質であった。
この物質の特性を研究したマンチェスター大学、ロシアInstitute for Microelectronics Technologyや
オランダラドバウト・ナイメーヘン大学、アメリカミシガン工科大学物理学科との合同研究チームは、
電子移動度がシリコンの百倍以上もの値である200000cm^2/Vsに達することを発見したという。
これまで知られているカーボンナノチューブやアンチモン化インジウムといった素材以上の適性を示しており、
非常に有望な素材だと研究に参加したAndre Geim教授は語っている。
グラフェンがシリコンを置き換えるようなことは20年以内にあるとは考えられないと教授も認めているが、
今後3年から5年以内にガスセンサーやテラヘルツ発振器/検出器といった装置へ応用されるようになるのではと
期待しているそうだ。この研究成果はPhysical Review Lettersの11 January 2008号にも掲載された。
とりあえずインテルとは無関係だが将来的にCPUに応用されそうってことで
http://finance.yahoo.com/charts#chart3:symbol=amd;range=1m;indicator=dividend+split;charttype=line;crosshair=on;logscale=on;source=undefined
独禁法のおかげでいきなり株価が反発してるな。
独禁法のおかげでいきなり株価が反発してるな。
アメリカは各州ごとに反トラスト法が制定されてるから国策とか関係ないんじゃね。
言いがかりで有罪にされるって大人の認識としてどうよ?Intelの中の人が主張するならまだしも
大分偏った意見だと思うけどね。
言いがかりで有罪にされるって大人の認識としてどうよ?Intelの中の人が主張するならまだしも
大分偏った意見だと思うけどね。
541 :ヽ・´∀`・,,)っ━━━━━━┓:2008/01/12(土) 05:30:07 ID:URArrAzO
AMDって100mm²程度のダイが採算ラインって昔から言われてたけど
近年は大きなダイでも採算とれるようになったのか?
270mm²を超える4コアは大きすぎると思うが。
近年は大きなダイでも採算とれるようになったのか?
270mm²を超える4コアは大きすぎると思うが。
昔っていつだ?
製造能力が限られてるからダイサイズを小さくしたいってのはあったけど。
製造能力が限られてるからダイサイズを小さくしたいってのはあったけど。
543 :ヽ・´∀`・,,)っ━━━━━━┓:2008/01/12(土) 06:54:15 ID:URArrAzO
200mmウエハー時代は普通に言われてたよ
ヽ・´∀`・,,)っ━━━━━━┓は感覚古すぎだろ。
WindsorFXのダイサイズ調べてみろ。
WindsorFXのダイサイズ調べてみろ。
K8だって200mmウェハから始まったけど普通に儲けてたはずだが。
なんか採算ラインがダイサイズで決まると言われると違和感を覚えるな。
なんか採算ラインがダイサイズで決まると言われると違和感を覚えるな。
546 :ヽ・´∀`・,,)っ━━━━━━┓:2008/01/12(土) 07:03:24 ID:URArrAzO
547 :ヽ・´∀`・,,)っ━━━━━━┓:2008/01/12(土) 07:09:12 ID:URArrAzO
ちなみにWindsorの頃には既に300mmに移行してますね。
X2が好調の頃にはASPがそれなりに上がってたから大きなダイでも採算とれたんじゃないの。
今は、最高モデルを10万円超で売ってた時代とくらべて製造コストが大して落ちないまま
価格だけがK6時代にもどっていってる。
この状況はAMDとしては相当厳しいんじゃないかなと。
X2が好調の頃にはASPがそれなりに上がってたから大きなダイでも採算とれたんじゃないの。
今は、最高モデルを10万円超で売ってた時代とくらべて製造コストが大して落ちないまま
価格だけがK6時代にもどっていってる。
この状況はAMDとしては相当厳しいんじゃないかなと。
採算ラインがなんぼか分からないけど
Fab増設して製造量上げたのにIntelの市場シェアをまったく切り崩せてない
現状は大分危機的なんじゃないか?
Fab増設して製造量上げたのにIntelの市場シェアをまったく切り崩せてない
現状は大分危機的なんじゃないか?
MYCOMにちょっと書かれてたけど、IBMと組んだ工場とのからみが無ければ、
この訴訟は無かっただろうね。つまり政治的配慮。
クオモ、まだNY州知事の地位を狙ってるんだろーね。以前親父がやってた。
まだ、どう展開するかわからんな。始まったばっかりで金額的なことも出てないし。
この訴訟は無かっただろうね。つまり政治的配慮。
クオモ、まだNY州知事の地位を狙ってるんだろーね。以前親父がやってた。
まだ、どう展開するかわからんな。始まったばっかりで金額的なことも出てないし。
自動車の工場にしても半導体の工場にしても
必ず政治的なやりとりが絡んでくる、しょうがない
必ず政治的なやりとりが絡んでくる、しょうがない
>>527
ガキかおまえはww
ガキかおまえはww
コピペ荒らししながら精神おかしくなる、今だ居座る化石だからな。
そろそろ2chのガン扱いされて追い出されればいいが。
そろそろ2chのガン扱いされて追い出されればいいが。
WindorFXのダイサイズは220mm2じゃなかったっけ?
65nmの512KBは126mm2程度だったと思うけど.
4コアは290mm2だっけかな.
65nmの512KBは126mm2程度だったと思うけど.
4コアは290mm2だっけかな.
558 :Socket774:2008/01/14(月) 20:38:16 ID:NfQjeX+7
a
559 :Socket774:2008/01/14(月) 23:29:24 ID:RzElBbbz
Intelの4年後に製品化されるであろうとかいう試作品がうちに流れてきたんだが
これなんて名前?
PenrynやNehalemとは見た目明らかに違う
これなんて名前?
PenrynやNehalemとは見た目明らかに違う
写真おくれば判定してあげるよ。
>>560
撮影機材持ち込めないから撮るのは無理だわ
撮影機材持ち込めないから撮るのは無理だわ
つーか、パッケージングは何?
4年前に製品化する予定のシリコンなんてないはずだろ。
研究用の試作品でそ?
4年前に製品化する予定のシリコンなんてないはずだろ。
研究用の試作品でそ?
4年後に出るCPUの試作品なんてあるわけないから
あるとしたらPolarisみたいな技術試作だろ
そんなもんが社外に流れるとも思えんが
あるとしたらPolarisみたいな技術試作だろ
そんなもんが社外に流れるとも思えんが
>>559
Pachimonos5じゃないの?
Pachimonos5じゃないの?
565 :MACオタ>562 さん:2008/01/15(火) 00:05:32 ID:3dxtK4i7
>>562
3DダイスタッキングのサンプルがDRAMベンダに送られているのかもしれないすよ。
3DダイスタッキングのサンプルがDRAMベンダに送られているのかもしれないすよ。
566 :ヽ・´∀`・,,)っ━━━━━━┓:2008/01/15(火) 00:07:31 ID:tZem3nYZ
例のテラスケールプロセッサか
いや、むしろパッケージング技術のメカニカルサンプルでしょ。
だからパッケージング形態がきになっているんだが。
だからパッケージング形態がきになっているんだが。
みんな釣られすぎ。
チップはまだ乗ってないパッケージングのみの状態だよ
Nehalemも試作で最近よく流れてくるけど>>559のは見た目が明らかに違う
>>567
パッケージング形態って何を答えればいいのかよく分からない
明日も仕事なんで寝る
まだ会社に残ってたらまた見てみるわ
Nehalemも試作で最近よく流れてくるけど>>559のは見た目が明らかに違う
>>567
パッケージング形態って何を答えればいいのかよく分からない
明日も仕事なんで寝る
まだ会社に残ってたらまた見てみるわ
NDAとか社内規定とかどーなんてんのよ
現段階でもこれらの書き込みバレたら君クビだよ
現段階でもこれらの書き込みバレたら君クビだよ
572 :Socket774:2008/01/15(火) 08:58:22 ID:L73ymEmj
都合の悪いことはスルーするコテハンワロス
まあ、あと困るところは楽しそうな人が勤めてるトコと、
そこに仕事出してるトコかな。
そこに仕事出してるトコかな。
こんなところで釣りやって面白いのか・・・
八つ当りしたいんだろ
釣りでなければ信濃あたりの会社か?
577 :Socket774:2008/01/19(土) 14:23:49 ID:2brLz3Gw
4年後てネハレンの次の次?
その頃にはネハレンセレロン出てるかな?
その頃にはネハレンセレロン出てるかな?
Intelの次世代CPUについて語ろう 32
nehalemが出たとして、penrynが4G近くで動いちゃってるから、
その性能を超えられるかってーと微妙じゃないのか?
OCでの限界性能ってコアだけの進化でどの程度上がるもの?
その性能を超えられるかってーと微妙じゃないのか?
OCでの限界性能ってコアだけの進化でどの程度上がるもの?
だからYorkFieldは3.2GHzで打ち止めの予定なわけでね。
Nehalemの立ち上げがもたついて、なおかつAMDが追い上げてくるんなら
すぐ高クロック品を投入してくるのだろうが、Nehalemの立ち上げが順調にいくなら
わざわざ性能的に競合するような品は出さない。
Nehalemの立ち上げがもたついて、なおかつAMDが追い上げてくるんなら
すぐ高クロック品を投入してくるのだろうが、Nehalemの立ち上げが順調にいくなら
わざわざ性能的に競合するような品は出さない。
>>579
上がるとは限らん。
QuickPathInterconnectのピン辺り6.4Gbpsという性能からすると、DDR動作で3.2GHz
ベースクロック200MHz*16ってところだろ。
多分、そっちがボトルネックになるから下がっても不思議じゃない。
上がるとは限らん。
QuickPathInterconnectのピン辺り6.4Gbpsという性能からすると、DDR動作で3.2GHz
ベースクロック200MHz*16ってところだろ。
多分、そっちがボトルネックになるから下がっても不思議じゃない。
ちょうどAMDが上がりにくいのと同じ状況になる可能性があるってことだな。
LynnfieldとHavendaleはQPI非搭載で従来のFSB
普通に考えるとGMCHとCPU間はQPIだけど
>>583
CPUパッケージ内のCPUとGMCHの接続はQPI
んで、CPUとPCH(チップセット)の接続はDMI
全然従来のFSBじゃないんだが・・・
ttp://pc.watch.impress.co.jp/docs/2008/0122/kaigai411_03l.gif
CPUパッケージ内のCPUとGMCHの接続はQPI
んで、CPUとPCH(チップセット)の接続はDMI
全然従来のFSBじゃないんだが・・・
ttp://pc.watch.impress.co.jp/docs/2008/0122/kaigai411_03l.gif
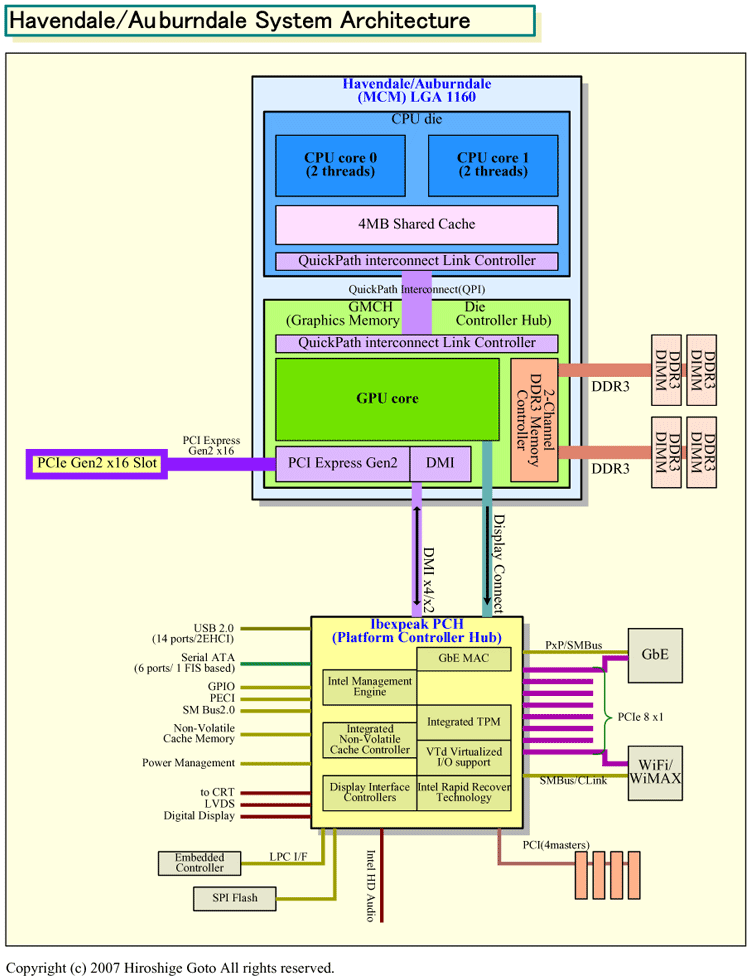{kind=link}
後藤の絵は間違っている!!
Lynnfield/HavendaleはQPIは使用していない説。
Lynnfield/HavendaleはQPIは使用していない説。
つーか、HKEPCにはQPI使ってないって書いてあるぞ。
どっちがほんとなんだが。
どっちがほんとなんだが。
これってようするに、ノースブリッジをCPUの横に持ってくるってことだよね。
従来型よりもメリットはあるのかな
従来型よりもメリットはあるのかな
配線長が極めて短いだけあって、いままでのFSBより格段に高速には出来るんじゃないかな。
いままでのMCMパッケージと違って、マルチドロップは要求されないし。
いままでのMCMパッケージと違って、マルチドロップは要求されないし。
おまいら、GPU統合とよべ。NorthだとかMCHということばは忘れろ。
ちなみに>>585は気がついていないようだが、
DMIは従来からあるものです。FSBよりも遅いのです。
DMIは従来からあるものです。FSBよりも遅いのです。
他のGPUやPCI-E統合CPUを参考にしてみるといい
NorthやMCHは忘れたけど、GPU統合とは呼ばない
>>591
PCHは従来のICHとほぼ同じ位置付けだからいいんじゃない?
DMIはMCH-ICH用のインターフェースだから実質的な性能低下はないし。
CPU側のPCI-Express Gen2とPCHに統合されるPCI-Express Gen1それにS-ATAやUSBの
存在を考えればシリアルインターフェースのまま伝送できる方が効率いいと思うけど。
わざわざ、シリアル−パラレル−シリアルと二度も変換かけるのは効率悪いし。
今のCPU-MCH間のFSB接続ほど帯域が必要な部分じゃないから、基板への実装を考えたら
動作クロックを落とすかバス幅を減らすかなりして、結局DMIと大して変わらないものに
なるんじゃないの?
PCHは従来のICHとほぼ同じ位置付けだからいいんじゃない?
DMIはMCH-ICH用のインターフェースだから実質的な性能低下はないし。
CPU側のPCI-Express Gen2とPCHに統合されるPCI-Express Gen1それにS-ATAやUSBの
存在を考えればシリアルインターフェースのまま伝送できる方が効率いいと思うけど。
わざわざ、シリアル−パラレル−シリアルと二度も変換かけるのは効率悪いし。
今のCPU-MCH間のFSB接続ほど帯域が必要な部分じゃないから、基板への実装を考えたら
動作クロックを落とすかバス幅を減らすかなりして、結局DMIと大して変わらないものに
なるんじゃないの?
1パッケージに実装されるCPUとGMCH間は従来のFSBより高速かつテイレイテンシ、しかも省ピン数なQPIで結合されるから、
CPUコアにダイレベルで統合される上位モデルに比べると劣るものの、CPUソケットを通してGMCHと結合していた従来よりは性能の向上が見込める。
バスもグラフィックス用の高速なPCIeと周辺機器用のDMIが出ているし、全く問題ない。
CPUコアにダイレベルで統合される上位モデルに比べると劣るものの、CPUソケットを通してGMCHと結合していた従来よりは性能の向上が見込める。
バスもグラフィックス用の高速なPCIeと周辺機器用のDMIが出ているし、全く問題ない。
>>483
CPU統合型はGPUプロセスも一気に微細化するとintelはおっしゃっています
CPU統合型はGPUプロセスも一気に微細化するとintelはおっしゃっています
PCを新しく買い換えようと思っているのですが
CPUで迷っています。
Core 2 Duo E8500 3.16GHz
Core2 Quad Q6600 2.40GHz
この2つなのですが、クロック数が高いほうが性能が良いのでしょうか?
いろいろな比較サイトを見るとQuadのほうがだいぶ性能が良いように書いてあり
凄く迷っています。クロック数はあまり関係ないのでしょうか
初心者で申し訳ないのですがご鞭撻の程よろしくお願い申し上げます
CPUで迷っています。
Core 2 Duo E8500 3.16GHz
Core2 Quad Q6600 2.40GHz
この2つなのですが、クロック数が高いほうが性能が良いのでしょうか?
いろいろな比較サイトを見るとQuadのほうがだいぶ性能が良いように書いてあり
凄く迷っています。クロック数はあまり関係ないのでしょうか
初心者で申し訳ないのですがご鞭撻の程よろしくお願い申し上げます
>>597
('A`)っQ6600買え
('A`)っQ6600買え
8500買えと言ってみるテスト。
ま、買う前にスレタイを100回読んだほうが勉強になるぜよ。
ま、買う前にスレタイを100回読んだほうが勉強になるぜよ。
>>597
なにをするかによる
なにをするかによる
>>597
それは貴方の用途次第だからなんとも言えない。
例えば負荷の高いアプリケーションを使うにしても、それがマルチスレッドに対応してない
シングルスレッドオンリーのアプリケーションを1つか2つくらいしか使わないとか、デュアルコア
対応のエンコーダを使うけどエンコ中は他の作業は一切やらないとかそういうことであれば、
クロックの高いE8500の方が速く処理できる。
逆に、クアッドコアに最適化されていてデュアルコアよりも格段に性能の向上するアプリケーション
(数は少ないけど)を使いたいとか、負荷の高いアプリケーションを3つも4つも同時に起動して
並行して作業させたいとかそういう用途なら、多少クロックは下がるけどコア数の多いQ6600の方が
有利になる。
ただし、多数のアプリケーションを同時起動してながら作業をさせる場合はE8500より有利だけど、
それはあくまでE8500に同じことをやらせると性能の落ち込みが無視できなくなるから。
例えながら作業でQ6600が有利だったとしても、そのうちどれか単一の処理をE8500で専念させれば
Q6600よりは速く作業が終わる。
要するに、ながら作業をやる場合のQ6600のメリットは「処理が速くなる」のではなく「遅くなりにくい」ことに
あるという点は理解しといてね。
後は自分の用途とよーく相談してどっちを選ぶか決めればいい。
それは貴方の用途次第だからなんとも言えない。
例えば負荷の高いアプリケーションを使うにしても、それがマルチスレッドに対応してない
シングルスレッドオンリーのアプリケーションを1つか2つくらいしか使わないとか、デュアルコア
対応のエンコーダを使うけどエンコ中は他の作業は一切やらないとかそういうことであれば、
クロックの高いE8500の方が速く処理できる。
逆に、クアッドコアに最適化されていてデュアルコアよりも格段に性能の向上するアプリケーション
(数は少ないけど)を使いたいとか、負荷の高いアプリケーションを3つも4つも同時に起動して
並行して作業させたいとかそういう用途なら、多少クロックは下がるけどコア数の多いQ6600の方が
有利になる。
ただし、多数のアプリケーションを同時起動してながら作業をさせる場合はE8500より有利だけど、
それはあくまでE8500に同じことをやらせると性能の落ち込みが無視できなくなるから。
例えながら作業でQ6600が有利だったとしても、そのうちどれか単一の処理をE8500で専念させれば
Q6600よりは速く作業が終わる。
要するに、ながら作業をやる場合のQ6600のメリットは「処理が速くなる」のではなく「遅くなりにくい」ことに
あるという点は理解しといてね。
後は自分の用途とよーく相談してどっちを選ぶか決めればいい。
EeePCを買うことにします。ありがとうございました。
過疎ってるから皆ヒマなんだな。こんなスレチに真面目に回答するなんて。
じゃあちょっとネタになりそうな話題で、こんなのはどう?
Diamondville(1.8GHz) + Intel 945GC 又は SiS671 (DeskTop又はITX)
と、
Isaiah(1.8GHz) + CN896
は、性能的に結構いい勝負をしそうな気がするが、果たして実際はどうなのか
気になってます。
見えてきたSilverthorneプロセッサの超低消費電力の秘密
http://pc.watch.impress.co.jp/docs/2007/1128/ubiq205.htm
VIA、新設計アーキテクチャCPU「Isaiah」を2008年前半に製品投入
http://pc.watch.impress.co.jp/docs/2008/0124/ubiq208.htm
じゃあちょっとネタになりそうな話題で、こんなのはどう?
Diamondville(1.8GHz) + Intel 945GC 又は SiS671 (DeskTop又はITX)
と、
Isaiah(1.8GHz) + CN896
は、性能的に結構いい勝負をしそうな気がするが、果たして実際はどうなのか
気になってます。
見えてきたSilverthorneプロセッサの超低消費電力の秘密
http://pc.watch.impress.co.jp/docs/2007/1128/ubiq205.htm
VIA、新設計アーキテクチャCPU「Isaiah」を2008年前半に製品投入
http://pc.watch.impress.co.jp/docs/2008/0124/ubiq208.htm
Diamondvilleはパフォーマンス的にIsaiahに適わないよ
パフォーマンス的にかぶるのはC7
だが、マーケット的にはIsaiahがかぶる
パフォーマンス的にかぶるのはC7
だが、マーケット的にはIsaiahがかぶる
Silverthorneはしょせんインオーダーなので、曲がりなりにもOoOであるIssaihには少なくともシングルスレッドにおいては
かなわないのではないかと思われる。
かなわないのではないかと思われる。
ダイサイズがIsaiahの半分以下だし
>>603 (補足)
Diamondville: in-order&HT / L2:512KB / 整数演算が強化されてる?
Isaiah : out-of-order / L2:1MB / 浮動小数点演算が強化
まあ消費電力では、トランジスタ数自体が圧倒的に少ないDiamondvilleの
勝ちでしょうけど、SilverthorneのSV版だから消費電力は多目な筈なので、
大差が付かない可能性があるし。
Diamondville: in-order&HT / L2:512KB / 整数演算が強化されてる?
Isaiah : out-of-order / L2:1MB / 浮動小数点演算が強化
まあ消費電力では、トランジスタ数自体が圧倒的に少ないDiamondvilleの
勝ちでしょうけど、SilverthorneのSV版だから消費電力は多目な筈なので、
大差が付かない可能性があるし。
あとDiamondvilleがIsaiahに同クロックだと敵わないとしても、同程度の消費
電力でという話なら、例えばクロック差を400MHzくらい稼げる気もしますが、
どうなんでしょう?
あとダイサイズが半分以下なら、値段差も考慮されますが、こればっかりは
市場にでてからでないと判断出来ませんし。
電力でという話なら、例えばクロック差を400MHzくらい稼げる気もしますが、
どうなんでしょう?
あとダイサイズが半分以下なら、値段差も考慮されますが、こればっかりは
市場にでてからでないと判断出来ませんし。
Isaiahって消費電力1W切れるの?
Silverthorneとはセグメントが違うと思う。
Silverthorneとはセグメントが違うと思う。
isaiahは整数も強化されてるよ
micro,macro-fusionもつくし
micro,macro-fusionもつくし
>>609
いまのC7と同等レベルらしいので、無理だとおもう。
それにIsaiahとSilverthorneとは絶対セグメント違うよね。
Isaiahは超低電力版のモバイルコアとは重なりそうだけどさ。
いまのC7と同等レベルらしいので、無理だとおもう。
それにIsaiahとSilverthorneとは絶対セグメント違うよね。
Isaiahは超低電力版のモバイルコアとは重なりそうだけどさ。
今のC7がTDP3.5〜20WくらいのはずでIsaiahはC7と同等ってことは
0.6〜2WのSilverthorneよりは5.5WのULV版C2Sと11WのULV版C2Dのが
TDP的には競合しそうな気がする
0.6〜2WのSilverthorneよりは5.5WのULV版C2Sと11WのULV版C2Dのが
TDP的には競合しそうな気がする
ぬこ好き某氏曰く
「消費電力の問題ではなく、マーケティング的な製品ポジションが、SilverThroneとぶつかる訳です。
勿論性能云々の問題もありますけどね。」
だそうだ。
「消費電力の問題ではなく、マーケティング的な製品ポジションが、SilverThroneとぶつかる訳です。
勿論性能云々の問題もありますけどね。」
だそうだ。
20WがUMPCやMIDか?たれだそいつw
CNに低クロック, Low Power版があるだけだろ。
1.6-2.0GHzのCNハイエンドはSilverthorne 1.86GHzとはかぶるわけないのに
早く気づけよ。
1.6-2.0GHzのCNハイエンドはSilverthorne 1.86GHzとはかぶるわけないのに
早く気づけよ。
SilverThorneの通常電圧版であるところのDiamondvilleは思いっきりかぶるけど。
DiamondvilleってそんなTDP高くなかっただろう?
しかも、Silverthorneの通常電圧版はSilverthorneだ。
DiamondvilleはTDPの制約をゆるくしただけ(3.5W)。
DiamondvilleはTDPの制約をゆるくしただけ(3.5W)。
消費電力の問題ではなく、投入されるセグメントがかぶるって言う話だわな。
Silverthorneとか?w
Diamondvilleとは一部かぶりそうだと思ったが。
Diamondvilleとは一部かぶりそうだと思ったが。
だからDiamondvilleと被るって言ってるじゃん。まったく・・・
深くは追求しないが、Diamondivlleはローコストノートとデスクトップ用なんだよ。
>>603みたいなITXボードはおまけ(笠原の勘違い)。全くかぶるということはないぞ。
>>603みたいなITXボードはおまけ(笠原の勘違い)。全くかぶるということはないぞ。
ローコストノートとローコストデスクトップ
低コストなノートやデスクトップならなおさら被るけど。
C7のマーケットやね
やっぱDiamonvilleとはかぶる。かぶるに訂正。
組み込みって一口に言っても色々あるからな。
小容量のバッテリーで動かすデバイスには3.5Wは大きいが、
ACアダプターで動かすような物なら、そんなに問題でもなさそう。
絶対性能については、物が出てこないと何とも言えないな。
小容量のバッテリーで動かすデバイスには3.5Wは大きいが、
ACアダプターで動かすような物なら、そんなに問題でもなさそう。
絶対性能については、物が出てこないと何とも言えないな。
工業用ブレードとかだって組み込みだし、炊飯器みたいなデバイスばっかりが組み込みじゃないからね
その程度じゃ10W超でもいいわけで、3.5Wとなると、他のとこが出してる1W未満と性能や機能的に被る、もしくは機能的に劣る気がするなあ・・・
1W未満でノースブリッジ内蔵なんてざらだし、わざわざ命令セットをx86に切り替えてまで、爆熱で機能の少ないのを採用するだろうか
Geodeのときも同じこと考えたな
1W未満でノースブリッジ内蔵なんてざらだし、わざわざ命令セットをx86に切り替えてまで、爆熱で機能の少ないのを採用するだろうか
Geodeのときも同じこと考えたな
炊飯器ww
炊飯器にx86積んだら何できるんだろうなw
炊飯器にx86積んだら何できるんだろうなw
Diamondvilleはローコストの市場用なんだろうな。
SilverthorneというかMenlowはチップセットのTDPが大きいので、まだWindows載せたUMPC、
MID用だろう。
intelが提供するチップ全体で1W切るようになれば、採用されうる用途が一気に増えるだろうけど。
>>631
炊飯器に64bitCPUってどれだけ飯炊くのにメモリ使うつもりだよw
SilverthorneというかMenlowはチップセットのTDPが大きいので、まだWindows載せたUMPC、
MID用だろう。
intelが提供するチップ全体で1W切るようになれば、採用されうる用途が一気に増えるだろうけど。
>>631
炊飯器に64bitCPUってどれだけ飯炊くのにメモリ使うつもりだよw
なんか組み込み用と聞いただけで勘違いしている人が多いな。面白いからこのまま放置で良いが。
組込ってひとえにいっても色々あるだろうにIntelが今更白物家電の制御の市場に魅力を感じたと思っているのかw
で、Diamondvilleは組み込み市場向けではないことは>>622->>623に書いたとおりなのです。
3.5Wが大電力と言っているやつはどういう市場なのかわかってないだけよ。
組込ってひとえにいっても色々あるだろうにIntelが今更白物家電の制御の市場に魅力を感じたと思っているのかw
で、Diamondvilleは組み込み市場向けではないことは>>622->>623に書いたとおりなのです。
3.5Wが大電力と言っているやつはどういう市場なのかわかってないだけよ。
Intelの位置付けはさておきとして、実際にはDiamondovileを採用した組み込み向けのブレードや
ITXボードその他はいっぱい出るだろうけどね。
ITXボードその他はいっぱい出るだろうけどね。
そういえばTorapaiの話は最近あまり聞かないな。
もっと組み込みっぽい組み込み用Intel chipといえば、Canmoreもある。
もっと組み込みっぽい組み込み用Intel chipといえば、Canmoreもある。
TorapaiじゃねぇじゃんTolapai。
おっ… _ _ _ _ _ っぱい!!
_ _ ( ゚∀゚)っ ノ⌒、 ) (∀゚ )ノ _ _
( ゚∀゚) / つ/ ⊂ 人) ⊂ / ( ゚∀゚)っ
⊂ と) ⊂.... / 彡 とノ ミ (⊃′ ゝつ /
|⊂_ノ 彡 し ∪ ミ ノ |
し (ノ ⌒J
_ _ ( ゚∀゚)っ ノ⌒、 ) (∀゚ )ノ _ _
( ゚∀゚) / つ/ ⊂ 人) ⊂ / ( ゚∀゚)っ
⊂ と) ⊂.... / 彡 とノ ミ (⊃′ ゝつ /
|⊂_ノ 彡 し ∪ ミ ノ |
し (ノ ⌒J
おっぱいでもねーw
せっかく消費電力の削減に成功しているCPUにわざわざ
GPUとかの発熱する機能を搭載しようしている
オレゴンチームって相当のアホだろ。
またしても爆熱&高消費電力への道を邁進するとはね。
やはりネハレンはスルーした方がいいやね。
GPUとかの発熱する機能を搭載しようしている
オレゴンチームって相当のアホだろ。
またしても爆熱&高消費電力への道を邁進するとはね。
やはりネハレンはスルーした方がいいやね。
>>639
熱源がCPUにあるかチップセットにあるかの違いなだけ。
そんな事をいったら、消費電力が削減しているCPUに
わざわざメモコンやノーズブリッジを統合さえも批判しないと。
さらにはPCI-eさえも統合していくんだからな。
結果的にはシステムのトータル消費電力が下がれば問題ないわけ、
メーカー側も冷却箇所を一カ所に集中させればいいし、
配線も簡素になるだろうから、たぶん歓迎すると思うぞ。
熱源がCPUにあるかチップセットにあるかの違いなだけ。
そんな事をいったら、消費電力が削減しているCPUに
わざわざメモコンやノーズブリッジを統合さえも批判しないと。
さらにはPCI-eさえも統合していくんだからな。
結果的にはシステムのトータル消費電力が下がれば問題ないわけ、
メーカー側も冷却箇所を一カ所に集中させればいいし、
配線も簡素になるだろうから、たぶん歓迎すると思うぞ。
641 :Socket774:2008/01/27(日) 11:03:37 ID:n3+gPkkA
メモコン統合したAMDはOC耐性で大きく差をつけられたじゃん
定格で消費電力やパフォーマンスUPしてもOC耐性が落ちたら自作市場じゃ評価ガタ落ちなんじゃないの?
自作市場は決して大きくはないけど一般消費者向けへの影響は少なからずある
自作市場で得た評判ががんばしくないものだったらヤバい可能性はあるよ
DDR3も今年末までに下がるかは分らんし
今のOSでいうVISTAのような位置づけのCPUになってしまう可能性はある
定格で消費電力やパフォーマンスUPしてもOC耐性が落ちたら自作市場じゃ評価ガタ落ちなんじゃないの?
自作市場は決して大きくはないけど一般消費者向けへの影響は少なからずある
自作市場で得た評判ががんばしくないものだったらヤバい可能性はあるよ
DDR3も今年末までに下がるかは分らんし
今のOSでいうVISTAのような位置づけのCPUになってしまう可能性はある
いや、熱源が1箇所に集まったほうが冷やすのは難しい。
644 :Socket774:2008/01/27(日) 15:34:47 ID:n3+gPkkA
OC耐性が同程度だったらここまでC2DとAMDCPUの人気差はなかったと思うけど
定格同士の比較ならAMDもコスト的に検討してるし>>643が本当ならここまで差がついてないよ
実際OCにそれほどこだわらない国ではAMD結構がんばってるし
定格同士の比較ならAMDもコスト的に検討してるし>>643が本当ならここまで差がついてないよ
実際OCにそれほどこだわらない国ではAMD結構がんばってるし
>>644
売れるのは普通にベンチ結果で性能が良いからだろ。
売れるのは普通にベンチ結果で性能が良いからだろ。
ピンの集中やら異なるクロックや電源電圧が入り混じるのが大変
今考えるとcellって何気に凄い事やろうとしてたのね。
>>646
ピンの集中はそれほど問題じゃない。
どうせintelがデザインガイドとか出すんだから、それに従ってりゃいい。
配線的には、等長配線が必要なパラレルFSBが消えて、配線が楽なPCI-ExpressとDMIに
なることの方がメリットは大きい。
FSBの配線スペースも減るから省スペースPCもデザインしやすくなる。
電源電圧は、どうせ統合の際には回路設計は一新するんだから、ついでにCPUに合わせりゃいい。
今、ノースブリッジに統合されてるGPUと同じ電源電圧を維持しなきゃならん理由はないんだから。
メモリだけじゃなく、PCI-ExpressやDMIもソケット経由になることで、OC耐性はシステム全体で
下がるだろうが、OCしないメーカーPCには何の関係もないしな。
ピンの集中はそれほど問題じゃない。
どうせintelがデザインガイドとか出すんだから、それに従ってりゃいい。
配線的には、等長配線が必要なパラレルFSBが消えて、配線が楽なPCI-ExpressとDMIに
なることの方がメリットは大きい。
FSBの配線スペースも減るから省スペースPCもデザインしやすくなる。
電源電圧は、どうせ統合の際には回路設計は一新するんだから、ついでにCPUに合わせりゃいい。
今、ノースブリッジに統合されてるGPUと同じ電源電圧を維持しなきゃならん理由はないんだから。
メモリだけじゃなく、PCI-ExpressやDMIもソケット経由になることで、OC耐性はシステム全体で
下がるだろうが、OCしないメーカーPCには何の関係もないしな。
どうにかして4層で作れるようにデザインガイドを出すはずだけど。
電源ドメインは結構重要かも。
CPUとGPUはたとえ同じ電圧で動作してもEISTを考えると分離したいところ。
というか最低でもCPUとNB(GPU)には分離される。
さらに各種IOも要求電圧は違うだろうし。
出来ればNBとGPUコアも分離したいしCPUコア毎の分離もしたいところだ。
さすがにコストがかかりすぎるだろうが。
ノート向けならあり得るかな。
CPUとGPUはたとえ同じ電圧で動作してもEISTを考えると分離したいところ。
というか最低でもCPUとNB(GPU)には分離される。
さらに各種IOも要求電圧は違うだろうし。
出来ればNBとGPUコアも分離したいしCPUコア毎の分離もしたいところだ。
さすがにコストがかかりすぎるだろうが。
ノート向けならあり得るかな。
CPU Voltage : 1.264V
CPU PLL Voltage : 1.5V
North Bridge Voltage : 1.47V
DRAM Voltage : 1.80V
FSB Termination Voltage : 1.42V
South Bridge Voltage : 1.075V
CPU PLL Voltage : 1.5V
North Bridge Voltage : 1.47V
DRAM Voltage : 1.80V
FSB Termination Voltage : 1.42V
South Bridge Voltage : 1.075V
電源を2〜3系統にして、CPU(Include NB)内で
複数電圧使うってのもありじゃね?
FSB信号線分ピンが減るから
電源、GND線増やせるだろうし
複数電圧使うってのもありじゃね?
FSB信号線分ピンが減るから
電源、GND線増やせるだろうし
654 :Socket774:2008/01/27(日) 23:13:13 ID:n3+gPkkA
age
オンダイCMOSレギュレータが使われるようになればパワーレーンの問題は多少は解決するんだろうけどね。
デスクトップでは無理だろうかもしれんが
デスクトップでは無理だろうかもしれんが
Nehalem情報でまた後藤氏が素人っぷりを晒している模様す。
http://pc.watch.impress.co.jp/docs/2008/0129/kaigai412.htm
-----------------------
浮動小数点演算(SPECfp_rate2006)で2.4倍以上とされている。実際にパフォーマンステストを
できるサンプルが出るまでは、本当の性能はわからないが、浮動小数点演算性能が異常に高
いことは確かだろう。2.4倍という数値は、かなり異常で、大幅な拡張が予想される。
-----------------------
SPECfpわSPECfpでも"rate"わメモリ帯域の要素が大きいす。コアがダメダメのK8ですら、ソケット
数につれてメモリ帯域が増やせるという特性のおかげでCore2に勝てるすから。。。
Intel X5365/3GHz x 8-core: 62.9(base)/66.5(peak)
http://www.spec.org/cpu2006/results/res2007q3/cpu2006-20070830-01903.html
AMD 8222SE/3GHz x 8-core: 92.6(base)/98.7(peak)
http://www.spec.org/cpu2006/results/res2007q2/cpu2006-20070430-00981.html
http://pc.watch.impress.co.jp/docs/2008/0129/kaigai412.htm
-----------------------
浮動小数点演算(SPECfp_rate2006)で2.4倍以上とされている。実際にパフォーマンステストを
できるサンプルが出るまでは、本当の性能はわからないが、浮動小数点演算性能が異常に高
いことは確かだろう。2.4倍という数値は、かなり異常で、大幅な拡張が予想される。
-----------------------
SPECfpわSPECfpでも"rate"わメモリ帯域の要素が大きいす。コアがダメダメのK8ですら、ソケット
数につれてメモリ帯域が増やせるという特性のおかげでCore2に勝てるすから。。。
Intel X5365/3GHz x 8-core: 62.9(base)/66.5(peak)
http://www.spec.org/cpu2006/results/res2007q3/cpu2006-20070830-01903.html
AMD 8222SE/3GHz x 8-core: 92.6(base)/98.7(peak)
http://www.spec.org/cpu2006/results/res2007q2/cpu2006-20070430-00981.html
「大幅な拡張」がメモリ帯域のことだとそのあと説明しているんだからいいじゃん。
spec*_rateを軽視する理由もないし。
spec*_rateを軽視する理由もないし。
658 :Socket774:2008/01/29(火) 00:57:42 ID:braTC+b5
CPUのコア部分で1.5倍のサイズだと性能は期待できそうだけど発熱はかなりありそうだ。
まぁ、しかしAMDとIntelの間を行ったりきたりしてる社員もいるとどっちも似たようなもんか。
まぁ、しかしAMDとIntelの間を行ったりきたりしてる社員もいるとどっちも似たようなもんか。
659 :MACオタ>658 さん:2008/01/29(火) 01:05:38 ID:U+YuE5q6
>>658
------------------
CPUのコア部分で1.5倍のサイズだと性能は期待できそうだけど発熱はかなりありそうだ。
------------------
現代でわ多くのトランジスタがクロックゲーティングやら、マルチゲートやらで省電力方面に費やされるすけど。。。
------------------
CPUのコア部分で1.5倍のサイズだと性能は期待できそうだけど発熱はかなりありそうだ。
------------------
現代でわ多くのトランジスタがクロックゲーティングやら、マルチゲートやらで省電力方面に費やされるすけど。。。
クロックゲーティングって、それほどトランジスタは食わないような
マルチゲートだとトランジスタ増えるってのはどういう理屈だろ
マルチゲートだとトランジスタ増えるってのはどういう理屈だろ
661 :ヽ・´∀`・,,)っ━━━━━━┓:2008/01/29(火) 01:35:11 ID:UUB91VxK
北橋統合するのにダイサイズ増えないわけがないだろ
またオタの難癖か。
文章を読む能力が無いのかね。
文章を読む能力が無いのかね。
オタに読解力が皆無なことが今更ながら良く分かった
665 :Socket774:2008/01/29(火) 12:50:40 ID:VVV5WqkK
オクタコアがオタクコアに見えて嫌
>>665
そのネタは使い古されすぎてageられても困るよ。パパ。
そのネタは使い古されすぎてageられても困るよ。パパ。
>現代でわ多くのトランジスタがクロックゲーティングやら、マルチゲートやらで省電力方面に費やされるすけど。。。
そりゃCMAだって一緒。
元がモバイル向けコアなんだから。
CMA比で色々拡張はされるだろうが、省電力向けの拡張だけで1.5倍はないだろ・・・
少なくとも増加分の半分は性能向上に振られてると思うが。
それに省電力向けの拡張はアイドル時には効果を発揮するが、フルパワーで動作してる時は関係ない。
電力制御回路だってトランジスタで構成されてんだから、フルパワーで動いてりゃ多少は電力を消費する。
そりゃCMAだって一緒。
元がモバイル向けコアなんだから。
CMA比で色々拡張はされるだろうが、省電力向けの拡張だけで1.5倍はないだろ・・・
少なくとも増加分の半分は性能向上に振られてると思うが。
それに省電力向けの拡張はアイドル時には効果を発揮するが、フルパワーで動作してる時は関係ない。
電力制御回路だってトランジスタで構成されてんだから、フルパワーで動いてりゃ多少は電力を消費する。
>>667
MACオタのキモい文章コピペすんな。氏ね。
MACオタのキモい文章コピペすんな。氏ね。
669 :ヽ・´∀`・,,)っ━━━━━━┓:2008/01/30(水) 02:02:38 ID:LR0BibTm
>>664
ああ、そっちね
1クロックで発行できる命令で同時参照できるレジスタ数が極端に少ないからそのへんを改良するとみた。
Nehalemが目指してるのはSMT対応のNコアというより、動的再編成可能な2×Nコアじゃないかと思う。
PenrynでのMPSADBWが意外と性能低いのと、テキストサーチ命令の追加もあるし
特にSIMD周りの強化が凄いことになると思っている。
ああ、そっちね
1クロックで発行できる命令で同時参照できるレジスタ数が極端に少ないからそのへんを改良するとみた。
Nehalemが目指してるのはSMT対応のNコアというより、動的再編成可能な2×Nコアじゃないかと思う。
PenrynでのMPSADBWが意外と性能低いのと、テキストサーチ命令の追加もあるし
特にSIMD周りの強化が凄いことになると思っている。
モバイルCPUに第3世代SPARC――IntelとSunが新CPU計画を披露へ
http://www.itmedia.co.jp/news/articles/0801/30/news063.html
SPARCがモバイルCPU化!!!!!!!!!
しかもIntelとの共同開発だってええええええええええ!!!!!!!!!
まんまとタイトルに騙されたぜ…。
http://www.itmedia.co.jp/news/articles/0801/30/news063.html
SPARCがモバイルCPU化!!!!!!!!!
しかもIntelとの共同開発だってええええええええええ!!!!!!!!!
まんまとタイトルに騙されたぜ…。
>>670
タイトルわろすw
タイトルわろすw
全くだまされなかった俺は、つまらない大人になってしまったのだろうか?
つまらない子供がつまらない大人になるのは正常進化ではないか。
なるほど、おっしゃる通り
釣り乙
>>651
そもそもターゲットクロックが違う物を
コア統合させてもしょうがない。
CPUで1GHzはアイドル状態だが、GPUじゃ超ハイエンドなクロック。
CPU部分とGPU部分で、全く別なレンジの可変クロックやるんだったら
最初から分離させる。
統合してしまうとCPUとGPUでメモリ帯域の取り合いになって
ロクな性能は出ない。
後藤某が何故あそこまで「GPU統合」に固執するのかさっぱり分からん。
性能的に何かメリットが有るのか?
そもそもターゲットクロックが違う物を
コア統合させてもしょうがない。
CPUで1GHzはアイドル状態だが、GPUじゃ超ハイエンドなクロック。
CPU部分とGPU部分で、全く別なレンジの可変クロックやるんだったら
最初から分離させる。
統合してしまうとCPUとGPUでメモリ帯域の取り合いになって
ロクな性能は出ない。
後藤某が何故あそこまで「GPU統合」に固執するのかさっぱり分からん。
性能的に何かメリットが有るのか?
>そもそもターゲットクロックが違う物を
>コア統合させてもしょうがない。
知恵遅れですか…
>コア統合させてもしょうがない。
知恵遅れですか…
>>676
電源ドメインの話なのになぜクロックが?
同一電源ドメインでもPLLを複数揃えればクロックは別々に制御可能。
実際PhenomのCPUコア部はそうだし。
GPUの統合はメリットあるよ。
少なくとも外部インターフェースの分の消費電力が減る。
消費電力減ればその分CPUのクロック上げることだって出来るし。
統合しようがしまいがメモリ帯域は取り合うと思うよ。
固執するもしないも実際IntelもAMDもGPU統合に向かってるからね。
電源ドメインの話なのになぜクロックが?
同一電源ドメインでもPLLを複数揃えればクロックは別々に制御可能。
実際PhenomのCPUコア部はそうだし。
GPUの統合はメリットあるよ。
少なくとも外部インターフェースの分の消費電力が減る。
消費電力減ればその分CPUのクロック上げることだって出来るし。
統合しようがしまいがメモリ帯域は取り合うと思うよ。
固執するもしないも実際IntelもAMDもGPU統合に向かってるからね。
一番脅威に思ってるのは他のベンターかな。
消費者として、Intelを応援する
消費者として、Intelを応援する
>>676
後藤はただのライターであって、intelがGPU統合をやると言ってるから記事を書いてるだけ。
後藤はただのライターであって、intelがGPU統合をやると言ってるから記事を書いてるだけ。
681 :ヽ・´∀`・,,)っ━━━━━━┓:2008/01/31(木) 00:39:22 ID:WzxBT/HC
Bulldozerは16ビット浮動小数と32ビット浮動小数を相互変換する命令を備えるから
何かしら統合によるシナジー効果(笑)狙って来るんだローな
何かしら統合によるシナジー効果(笑)狙って来るんだローな
Nehalemも真っ青なストレスソフトをお願いします
Bulldozerは恐らくヘテロなマルチコアとなるだろう
AMD版cell
AMD版cell
GPU統合するのはFSBがネックになりだしてるからじゃないの
メモコンがCPU側に移るからだよ
Intelの場合
Intelの場合
Nehalem出たらAMD死亡?
Nehalemが死亡する可能性もあるんじゃないの
Nehalemというよりオレゴンが死亡かもしれないけど
Nehalemというよりオレゴンが死亡かもしれないけど
そもそも、次のCPUからFSBの概念が消えるとか
ん、NehalemでFSBは廃止じゃなかったっけ?
FSBという名称は消えるが、FSBの代わりにQPIが載るだけ
気圧の単位 ミリバールが ヘクトパスカルになった程度の違いだよな。恐らく・・・。
構造自体ガ変わると聞いたが
サーバ/ワークステーション/エンスー向けのBloomfield、ハイエンド向けのLynnfieldではメモリコントローラが、
CPUにダイレベルで統合される。Bloomfieldではマルチソケット用にQPIが用意されるが、
Lynnfieldではマルチソケットへの使用が全く考える必要がないので、QPIは使われない。
CPUパッケージ内にMCMでCPUコアとGMCHが乗るメインストリームHavendaleではGMCH-CPU間にQPIが使われるのだろうが、
どのみち外部には出ない。
というのが現状で出ている情報ではあるが、どうもコアのバリエーションが多すぎるのがIntelらしくないようにも思う。
CPUにダイレベルで統合される。Bloomfieldではマルチソケット用にQPIが用意されるが、
Lynnfieldではマルチソケットへの使用が全く考える必要がないので、QPIは使われない。
CPUパッケージ内にMCMでCPUコアとGMCHが乗るメインストリームHavendaleではGMCH-CPU間にQPIが使われるのだろうが、
どのみち外部には出ない。
というのが現状で出ている情報ではあるが、どうもコアのバリエーションが多すぎるのがIntelらしくないようにも思う。
>>693
BloomfieldとLynnfieldは同一ダイと思われるので、ダイのバリエーションは2つは現状のCore2と同じだよ。
BloomfieldとLynnfieldは同一ダイと思われるので、ダイのバリエーションは2つは現状のCore2と同じだよ。
Intelが今必死になってDDR3値下げに動いてるけど
Nehalem+DDR3の構成よりPenryn+DDR3の構成の方が増えたりして
NehalemスルーでSandyBridgeに行く人が多かったりして
Nehalem+DDR3の構成よりPenryn+DDR3の構成の方が増えたりして
NehalemスルーでSandyBridgeに行く人が多かったりして
DDR3値下げはサムソンも動いてるみたいだぜ。
697 :MACオタ>693 さん:2008/01/31(木) 21:03:41 ID:0C6GGRXK
>>693
後藤信者以外わ、Bloomfiledのオンダイメモリコントローラわ無効化されているという認識すけど。。。
http://www.hkepc.com/?id=568&page=2&fs=idn#view
後藤信者以外わ、Bloomfiledのオンダイメモリコントローラわ無効化されているという認識すけど。。。
http://www.hkepc.com/?id=568&page=2&fs=idn#view
ただ同じページのリファレンスマザーの図でわ、DIMMソケットの位置がプロセッサから直接接続されていない
と等長配線が難しい配置に見えるす。
そんな訳で、結局誰が正しいのかを楽しみに経過を眺めているす。
と等長配線が難しい配置に見えるす。
そんな訳で、結局誰が正しいのかを楽しみに経過を眺めているす。
日本語でおk
ただ同じページのリファレンスマザーの図では、DIMMソケットの位置がプロセッサから直接接続されていない
と等長配線が難しい配置に見える。
そんな訳で、結局誰が正しいのかを楽しみに経過を眺めている。
と等長配線が難しい配置に見える。
そんな訳で、結局誰が正しいのかを楽しみに経過を眺めている。
701 :Socket774:2008/02/01(金) 01:44:06 ID:aYHzH/kq
>>673
つまり、問題児のガキの方が将来性が見込めるという事か???
つまり、問題児のガキの方が将来性が見込めるという事か???
>>701
そうだな
そうだな
703 :ヽ・´∀`・,,)っ━━━━━━┓:2008/02/01(金) 01:51:25 ID:6do3ongq
ハイ、ここで問題児と言われた俺様が通りますよ
年齢が10代なら将来性がある。
705 :ヽ・´∀`・,,)っ━━━━━━┓:2008/02/01(金) 01:54:15 ID:6do3ongq
問題を抱えた大人になりました。
intel純正のX38マザーでもほぼ同じ配置だから、等長配線は大した問題じゃないと思うがな。
問題はQPIの帯域だろう。
QPIはピンあたりの転送レートは6.4Gbpsと、現行のFSB1600MHzの4倍にもなるが、
バス幅は32bitで現行FSBの半分だから、バス全体としての転送レートは精々2倍。
UPサーバー向けではQPIは1本って話だから、デスクトップで2本載る事はまずない。
しかも、6.4Gbpsという転送レートはサーバー向けでデスクトップ向けでは少し落ちるって
話もあるから、実際にはFSB1333MHzの倍くらいかも知れん。
これじゃ一気にメモリ帯域が倍以上になるDDR3-3chは支え切れんだろ。
ボトルネック解消のためにFSB廃止してQPIに移行するのに、いきなりボトルネックになってたら意味がない。
問題はQPIの帯域だろう。
QPIはピンあたりの転送レートは6.4Gbpsと、現行のFSB1600MHzの4倍にもなるが、
バス幅は32bitで現行FSBの半分だから、バス全体としての転送レートは精々2倍。
UPサーバー向けではQPIは1本って話だから、デスクトップで2本載る事はまずない。
しかも、6.4Gbpsという転送レートはサーバー向けでデスクトップ向けでは少し落ちるって
話もあるから、実際にはFSB1333MHzの倍くらいかも知れん。
これじゃ一気にメモリ帯域が倍以上になるDDR3-3chは支え切れんだろ。
ボトルネック解消のためにFSB廃止してQPIに移行するのに、いきなりボトルネックになってたら意味がない。
オレゴンチームの常として、最初の世代はダメポな気がするが。
32ナノから実力発揮?
32ナノから実力発揮?
リファレンスマザーの図、よく見たらIOH+ICHになってるな・・・
チップセット側にメモリを接続するなら、intelのこれまでの慣例でいくと
IOHじゃなくてMCHかGMCHになるはずだが。
やっぱ、オンダイメモリコントローラ使うんじゃないか?
チップセット側にメモリを接続するなら、intelのこれまでの慣例でいくと
IOHじゃなくてMCHかGMCHになるはずだが。
やっぱ、オンダイメモリコントローラ使うんじゃないか?
あまりオレゴンチームを虐めるなよ…。
Intel内部で情報や技術のやり取りはあるだろう。
イスラエルチームの技術もオレゴンチームに導入されるはずだし、
そんなに酷い事にはならないと思うぜ。
ただ、色々統合した結果の消費電力上昇は確かに未知数。
だけど、その分システム全体の消費電力は減るんじゃない?
Intel内部で情報や技術のやり取りはあるだろう。
イスラエルチームの技術もオレゴンチームに導入されるはずだし、
そんなに酷い事にはならないと思うぜ。
ただ、色々統合した結果の消費電力上昇は確かに未知数。
だけど、その分システム全体の消費電力は減るんじゃない?
710 :Socket774:2008/02/02(土) 14:13:44 ID:77L0I4+r
NehalemのTDPはLynnfieldで150Wぐらいかな
ネハレムは今のAMDのCPUみたいにOCし難くなるんじゃないか?
色んなもの押し込めるわけだし。
色んなもの押し込めるわけだし。
ほぼ全ての人にとってDDR3よりDDR2の方がいいからね
>>711
OC耐性は悪くなるでしょうね。でも、OCなんて
所詮イレギュラーな楽しみだからどうでもよくね?
OC耐性より絶対性能が上がった方がいい。
まぁ。Nehalemがでてもどうせハイエンドだけなんて、
ほとんどの人には来年頭ぐらいまでは関係はないだろうな。
>>712
Intelが頑張って価格下げようとしているから、
今後はわからんぞ。
OC耐性は悪くなるでしょうね。でも、OCなんて
所詮イレギュラーな楽しみだからどうでもよくね?
OC耐性より絶対性能が上がった方がいい。
まぁ。Nehalemがでてもどうせハイエンドだけなんて、
ほとんどの人には来年頭ぐらいまでは関係はないだろうな。
>>712
Intelが頑張って価格下げようとしているから、
今後はわからんぞ。
http://pc.watch.impress.co.jp/docs/2008/0129/kaigai412.htm
■後藤弘茂のWeekly海外ニュース■
2つのCPU開発チームに競わせるIntelの社内戦略
燃料投下、今の流れにマッチした内容だと思うのだ。
■後藤弘茂のWeekly海外ニュース■
2つのCPU開発チームに競わせるIntelの社内戦略
燃料投下、今の流れにマッチした内容だと思うのだ。
すまんが既にそれを読んだものとしてすすんでるんだが。
競うといってもどちらか片方しか採用しないわけじゃないしねぇ。
売り上げに直結するじゃん
双方のCPUの売り上げを比較することで
双方のCPUの売り上げを比較することで
DiamondvilleはDual coreもあるなんてリーク情報らしきスライドが流出してるが、お得意のSilverthorneのMCM
なのだろうか?
http://xtreview.com/addcomment-id-4165-view-Diamondville-dual-core-processor.html
なのだろうか?
http://xtreview.com/addcomment-id-4165-view-Diamondville-dual-core-processor.html
MCMしかないっしょ。
FSBだろうしダイはすでに公開してるし。
とは言えDCの展開早いな。
これならMoorestownはMCMかと思ってたけどネイティブかな。
FSBだろうしダイはすでに公開してるし。
とは言えDCの展開早いな。
これならMoorestownはMCMかと思ってたけどネイティブかな。
ttp://www.ne.jp/asahi/comp/tarusan/main182.htm
「マルチコアだから速い。」を連呼するPC雑誌だが、
C7コアベースでもマルチコア化すればVistaが快適に動くだろうか? という点を
一度真剣に考えてみて欲しい気がする。 (当サイトの頭の中では、もちろん快適とは思えない。)
「マルチコアだから速い。」を連呼するPC雑誌だが、
C7コアベースでもマルチコア化すればVistaが快適に動くだろうか? という点を
一度真剣に考えてみて欲しい気がする。 (当サイトの頭の中では、もちろん快適とは思えない。)
VIAのCPUコアはシングルコアで性能向上の余地が
まだ十分存在するから、"C7"をマルチコア化するよりも、
基本性能を拡張した"Isaiah"が正しい。
って感じか。確かに現在のソフトウェハの対応具合から考えると、
デュアルよりシングルでの性能向上を目指した方がいいのか。
まぁ。記事中にもあるけどIntelとAMDのCPUは、
すでにコアが肥大化してしまいるので、
マルチコア化するのは確かに必然だろうなぁ。
まだ十分存在するから、"C7"をマルチコア化するよりも、
基本性能を拡張した"Isaiah"が正しい。
って感じか。確かに現在のソフトウェハの対応具合から考えると、
デュアルよりシングルでの性能向上を目指した方がいいのか。
まぁ。記事中にもあるけどIntelとAMDのCPUは、
すでにコアが肥大化してしまいるので、
マルチコア化するのは確かに必然だろうなぁ。
723 :MACオタ>721 さん:2008/02/03(日) 11:48:07 ID:hp7kyZWe
>>721
そこ電波系サイトで技術的な内容わ間違いなんで鵜呑みにすべきでわ無いす。
たとえば今回の記事でも、
-----------------
☆L2を大容量化するためにもOut-of-Order化は必須。
-----------------
のあたりに色々トンデモなことが書いてあるす。事実としてわ、キャッシュミスによるストール
で後に続く全ての命令実行が停止してしまうインオーダ実行の方が大容量キャッシュを
切実に必要とするす。
Itaniumが同世代のプロセッサと比べて格段に大きなオンダイキャッシュを搭載しているのも
そういう理由す。
そこ電波系サイトで技術的な内容わ間違いなんで鵜呑みにすべきでわ無いす。
たとえば今回の記事でも、
-----------------
☆L2を大容量化するためにもOut-of-Order化は必須。
-----------------
のあたりに色々トンデモなことが書いてあるす。事実としてわ、キャッシュミスによるストール
で後に続く全ての命令実行が停止してしまうインオーダ実行の方が大容量キャッシュを
切実に必要とするす。
Itaniumが同世代のプロセッサと比べて格段に大きなオンダイキャッシュを搭載しているのも
そういう理由す。
で、SilverthorneのDualでVistaは快適なんですか?
Nehalemについて少しだけ。
かつて報じられた初期情報で、 Nehalemわ多階層のキャッシュ構造を持つと言われ
ていたす。例えば http://www.ednjapan.com/content/l_news/2007/04/l_news070402_0501.html
----------------------
Gelsinger氏の説明によれば、Nehalemには、新しいSSE4およびATAインストラクション
セットアーキテクチャのほかに、高性能ダイナミックパワーマネージメント機能、スマート
キャッシュ技術、マルチレベルキャッシュなどが含まれる。
----------------------
このため、昨年秋のIDFでNehalemのダイ写真が公開された際にも下半分のブロックを
わざわざL2とL3に分ける説なんかが出ていたす。
http://chip-architect.com/news/Nehalem_at_1st_glance_.jpg
かつて報じられた初期情報で、 Nehalemわ多階層のキャッシュ構造を持つと言われ
ていたす。例えば http://www.ednjapan.com/content/l_news/2007/04/l_news070402_0501.html
----------------------
Gelsinger氏の説明によれば、Nehalemには、新しいSSE4およびATAインストラクション
セットアーキテクチャのほかに、高性能ダイナミックパワーマネージメント機能、スマート
キャッシュ技術、マルチレベルキャッシュなどが含まれる。
----------------------
このため、昨年秋のIDFでNehalemのダイ写真が公開された際にも下半分のブロックを
わざわざL2とL3に分ける説なんかが出ていたす。
http://chip-architect.com/news/Nehalem_at_1st_glance_.jpg
{kind=link}
ところが、現在最も詳細な情報が示されているHKEPC.comの記事でわ、わりと明確にL3の
存在が否定されているす。
http://www.hkepc.com/database/images/2008010316124060435399224.jpg
http://www.hkepc.com/?id=568&page=2
------------------
其實一線主機板廠商已拿到了初期的 Bloomfield 的處理器樣本了,這顆全新的四核
心處理器採用原生設計, 45 奈米生?技術,不再像 Yorkfield 般採用兩顆雙核心封裝的
架構,支援類似 Hyper-Threading 技術並定名為 SMT (Simultaneous Multi-hreading) ,
由於是四顆核心共用相同的 8MB Share Cache ,容量雖比 Yorkfield 的 6MB x 2 少,
但效率則有所提升。
[MACオタ訳]
一部のマザーボードベンダは既にBloomfieldのエンジニアリングサンプルを受領している。
Bloomfieldは現行のYorkfieldとは異なり、45-nmプロセスのシングルダイ上に4コアを集積
した、まったく新しい設計となっている。
BloomfieldはSMTと呼ぶHyperthreading技術と同様の機能をサポートするとともに4コア
全てが8MBのキャッシュを共有する。一見これはYorkfieldにおける6MB x 2のL2キャッシュ
と比較して退行しているように思われるが、実際にはより効率的に動作するという。
------------------
存在が否定されているす。
http://www.hkepc.com/database/images/2008010316124060435399224.jpg
{kind=link}
http://www.hkepc.com/?id=568&page=2
------------------
其實一線主機板廠商已拿到了初期的 Bloomfield 的處理器樣本了,這顆全新的四核
心處理器採用原生設計, 45 奈米生?技術,不再像 Yorkfield 般採用兩顆雙核心封裝的
架構,支援類似 Hyper-Threading 技術並定名為 SMT (Simultaneous Multi-hreading) ,
由於是四顆核心共用相同的 8MB Share Cache ,容量雖比 Yorkfield 的 6MB x 2 少,
但效率則有所提升。
[MACオタ訳]
一部のマザーボードベンダは既にBloomfieldのエンジニアリングサンプルを受領している。
Bloomfieldは現行のYorkfieldとは異なり、45-nmプロセスのシングルダイ上に4コアを集積
した、まったく新しい設計となっている。
BloomfieldはSMTと呼ぶHyperthreading技術と同様の機能をサポートするとともに4コア
全てが8MBのキャッシュを共有する。一見これはYorkfieldにおける6MB x 2のL2キャッシュ
と比較して退行しているように思われるが、実際にはより効率的に動作するという。
------------------
>>723
C7はキャッシュミスによるストールよりも実行時間の方が遙かに時間
かかってるからキャッシュを増やすのは不経済。
OoO化によって実行時間が短くなってきたので相対的にキャッシュミス
のペナルティが増えてきたからキャッシュを増やした。
そういう論調だと思うけど。
あとItaniumがキャッシュ多いのはそういうセグメントだからなんじゃ。
POWER5だってOoOでもキャッシュ多いし。
C7はキャッシュミスによるストールよりも実行時間の方が遙かに時間
かかってるからキャッシュを増やすのは不経済。
OoO化によって実行時間が短くなってきたので相対的にキャッシュミス
のペナルティが増えてきたからキャッシュを増やした。
そういう論調だと思うけど。
あとItaniumがキャッシュ多いのはそういうセグメントだからなんじゃ。
POWER5だってOoOでもキャッシュ多いし。
>>695
しっかし、DDR3って本当に効果するんだろうかね?
Core2の結果を見ていると、キャッシュが4メガバイト超えた辺りから、メモリーのバスバンド幅の効果が薄くなってきているように見える。
ならば、いっそのこと3次キャッシュ32メガバイトとか乗せて、メモリーはのろまでもよい様な気がする。
まぁ一部の科学計算のような、ストリーム処理をするが如く、読み込んで積和して書き出すだけとかなら意味はありそうだけど・・・そりゃGP-GPUでも強化したほうがいいなと。
しっかし、DDR3って本当に効果するんだろうかね?
Core2の結果を見ていると、キャッシュが4メガバイト超えた辺りから、メモリーのバスバンド幅の効果が薄くなってきているように見える。
ならば、いっそのこと3次キャッシュ32メガバイトとか乗せて、メモリーはのろまでもよい様な気がする。
まぁ一部の科学計算のような、ストリーム処理をするが如く、読み込んで積和して書き出すだけとかなら意味はありそうだけど・・・そりゃGP-GPUでも強化したほうがいいなと。
もちろんL2もL3も共有しているという説明もあるかもしれないすけど、こういう説明もある
とだけ書いておくす。
・デスクトップやワークステーションなど2ソケット以下のプラットフォームでわ
L2共有のみ
・マルチソケットプラットフォーム用わ、L2の一部をL3用のタグまたわスヌープフィルタ
として構成できる柔軟性を持っており、外付けL3を接続する。
・外付けL3わ外部メモリコントローラTylersburg同様にQPIで接続される。
・L3をMCMで同一パッケージに入れた構成も存在し、広幅、高クロックの専用QPIで
接続される
後ろの三項目わPOWERプロセッサ + wave pipelined interfaceでやっていることと同じす。
ちなみに、一応Intelの特許を検索してみたすけど、該当するような発明わ登録されていなかったす。
とだけ書いておくす。
・デスクトップやワークステーションなど2ソケット以下のプラットフォームでわ
L2共有のみ
・マルチソケットプラットフォーム用わ、L2の一部をL3用のタグまたわスヌープフィルタ
として構成できる柔軟性を持っており、外付けL3を接続する。
・外付けL3わ外部メモリコントローラTylersburg同様にQPIで接続される。
・L3をMCMで同一パッケージに入れた構成も存在し、広幅、高クロックの専用QPIで
接続される
後ろの三項目わPOWERプロセッサ + wave pipelined interfaceでやっていることと同じす。
ちなみに、一応Intelの特許を検索してみたすけど、該当するような発明わ登録されていなかったす。
>>727
Dual Core化されるといても当分先の話でしょう
45nmではやらないと思う
得られるパフォーマンスも十分に効果がある時期になれば
あるいはネイティブでやってくるかもしれないけど
それに、マザーのメーカー側で勝手にマルチCPU物出しそうだ
現在のパッケージならmini-ITXでも2 CPUは行けるスペースはあるし
>>729
nehemiah->estherでは一応L2は倍になってるんだよね
この効果も期待されたが実際のパフォーマンス差は実クロックの差分程度でしかなかった
恐らくestherの段階で限界を感じていたと思うわ、グレン
あとestherのままで、これ以上機能を詰め込むとパイプラインが長くなるし
パフォーマンスを上げるには結局クロックを上げるしかなくなるし
Dual Core化されるといても当分先の話でしょう
45nmではやらないと思う
得られるパフォーマンスも十分に効果がある時期になれば
あるいはネイティブでやってくるかもしれないけど
それに、マザーのメーカー側で勝手にマルチCPU物出しそうだ
現在のパッケージならmini-ITXでも2 CPUは行けるスペースはあるし
>>729
nehemiah->estherでは一応L2は倍になってるんだよね
この効果も期待されたが実際のパフォーマンス差は実クロックの差分程度でしかなかった
恐らくestherの段階で限界を感じていたと思うわ、グレン
あとestherのままで、これ以上機能を詰め込むとパイプラインが長くなるし
パフォーマンスを上げるには結局クロックを上げるしかなくなるし
733 :MACオタ>729 さん:2008/02/03(日) 12:51:03 ID:hp7kyZWe
>>729
-------------------
あとItaniumがキャッシュ多いのはそういうセグメントだからなんじゃ。
POWER5だってOoOでもキャッシュ多いし。
-------------------
各階層のキャッシュのレイテンシに注目してこの記事のTable 2を見てほしいす。
http://www.realworldtech.com/page.cfm?ArticleID=RWT100404214638&p=3
もちろんIntel自身も常識として認識している話す。
http://download.intel.com/technology/itj/2002/volume06issue01/art03_specprecomp/vol6iss1_art03.pdf
===================
Before the advent of thread-based prefetch techniques like SP, out-of-order (OOO)
execution [18][19][20] has been the primary microarchitecture technique to tolerate
cache miss latency. With the register renamer and reservation stations, an OOO
processor is able to dynamically schedule the in-flight instructions, and execute
those instructions independent of the missing loads, while the misses are being served.
===================
-------------------
あとItaniumがキャッシュ多いのはそういうセグメントだからなんじゃ。
POWER5だってOoOでもキャッシュ多いし。
-------------------
各階層のキャッシュのレイテンシに注目してこの記事のTable 2を見てほしいす。
http://www.realworldtech.com/page.cfm?ArticleID=RWT100404214638&p=3
もちろんIntel自身も常識として認識している話す。
http://download.intel.com/technology/itj/2002/volume06issue01/art03_specprecomp/vol6iss1_art03.pdf
===================
Before the advent of thread-based prefetch techniques like SP, out-of-order (OOO)
execution [18][19][20] has been the primary microarchitecture technique to tolerate
cache miss latency. With the register renamer and reservation stations, an OOO
processor is able to dynamically schedule the in-flight instructions, and execute
those instructions independent of the missing loads, while the misses are being served.
===================
いや、どう考えてもItaniumはそういう市場だからだろ。
"インオーダ実行の方が大容量キャッシュを切実に必要とするす"は
たるさん同様、MACオタの勝手な解釈の域をでてないだろう。>>733のソースなんてなんの証拠にもなってない。
現実にはL2の統合化はOOO普及と同時か、普及よりも後に進んできたわけだからな。
これでPOWER6だけが低latencyだったらまだ説得力は残されていたのだが、IBMとIntelの技術差が現れているだけのソースでした。
もちろんIntelのSilverthorne/Diamondvilleがin-orderだからcacheを特に強化したという事実もなかた。
"インオーダ実行の方が大容量キャッシュを切実に必要とするす"は
たるさん同様、MACオタの勝手な解釈の域をでてないだろう。>>733のソースなんてなんの証拠にもなってない。
現実にはL2の統合化はOOO普及と同時か、普及よりも後に進んできたわけだからな。
これでPOWER6だけが低latencyだったらまだ説得力は残されていたのだが、IBMとIntelの技術差が現れているだけのソースでした。
もちろんIntelのSilverthorne/Diamondvilleがin-orderだからcacheを特に強化したという事実もなかた。
735 :MACオタ>734 さん:2008/02/03(日) 14:31:25 ID:hp7kyZWe
>>734
---------------
たるさん同様、MACオタの勝手な解釈の域をでてないだろう。
---------------
そのたるさんや私ですら普通にやっている「参考文献をつけて自説を語る」という行為すら
できないことわ恥ずかしくないすか?
そんなことだから脳内妄想で完結してると言われるすよ(笑)
---------------
たるさん同様、MACオタの勝手な解釈の域をでてないだろう。
---------------
そのたるさんや私ですら普通にやっている「参考文献をつけて自説を語る」という行為すら
できないことわ恥ずかしくないすか?
そんなことだから脳内妄想で完結してると言われるすよ(笑)
MACオタは文献解釈に誤りがあるときに、
参考文献を示すのかw
参考文献を示すのかw
>>735
別に自説を展開しにきているわけじゃないからな。
>>733には、
cache missが発生しても、ミスったloadに依存しないパイプライン中の命令は実行できるから、
OOOはキャッシュミス遅延に寛大な技術だと書いてあるだけ。
これだけだとin-orderよりもOOOの方がキャッシュの遅延を隠蔽しながら効率良く読み出せるから
大容量化に向いているともとれるだろう。
"インオーダ実行の方が大容量キャッシュを切実に必要とするす"
ソースを貼ればなんでも許されるというわけではないということす。
別に自説を展開しにきているわけじゃないからな。
>>733には、
cache missが発生しても、ミスったloadに依存しないパイプライン中の命令は実行できるから、
OOOはキャッシュミス遅延に寛大な技術だと書いてあるだけ。
これだけだとin-orderよりもOOOの方がキャッシュの遅延を隠蔽しながら効率良く読み出せるから
大容量化に向いているともとれるだろう。
"インオーダ実行の方が大容量キャッシュを切実に必要とするす"
ソースを貼ればなんでも許されるというわけではないということす。
>これだけだとin-orderよりもOOOの方がキャッシュの遅延を隠蔽しながら効率良く読み出せるから
>大容量化に向いているともとれるだろう。
Isaiahが予想に反して1MBも積んできたのは
この辺の理由かもね
>大容量化に向いているともとれるだろう。
Isaiahが予想に反して1MBも積んできたのは
この辺の理由かもね
>>736
いつものことだw
いつものことだw
>>738
というか、シュリンクである程度以上小さくなると、ボンディングやホットスポット
の問題が出るから、キャッシュにトランジスタを多目に割り振ったって感じでは?
キャッシュ増量も4MB程度までなら性能アップに充分効果があるのは判ってるし、
OoOの度合いやスーパーパイプラインの多段化よりも、キャッシュを増やす方が
電力対性能で有利になるって判断もあったのでは?
あと論理回路部分よりもキャッシュの様なメモリ部分の方が、製造欠陥に対してリペア
がし易いから、歩留まりのアップも期待出来るし、リペア不能な欠陥品は暫く経って
から512KBキャッシュ品として出せるし。
というか、シュリンクである程度以上小さくなると、ボンディングやホットスポット
の問題が出るから、キャッシュにトランジスタを多目に割り振ったって感じでは?
キャッシュ増量も4MB程度までなら性能アップに充分効果があるのは判ってるし、
OoOの度合いやスーパーパイプラインの多段化よりも、キャッシュを増やす方が
電力対性能で有利になるって判断もあったのでは?
あと論理回路部分よりもキャッシュの様なメモリ部分の方が、製造欠陥に対してリペア
がし易いから、歩留まりのアップも期待出来るし、リペア不能な欠陥品は暫く経って
から512KBキャッシュ品として出せるし。
741 :MACオタ>737 さん:2008/02/03(日) 17:21:01 ID:hp7kyZWe
>>737
-------------
別に自説を展開しにきているわけじゃないからな。
-------------
中傷が目的と自白してるような気が(笑)
-------------
これだけだとin-orderよりもOOOの方がキャッシュの遅延を隠蔽しながら効率良く読み出せるから
大容量化に向いているともとれるだろう。
-------------
なかなか強引な解釈すね。メモリわその「キャッシュ遅延」とやらより何倍も遅いということわ
脳内から抜け落ちているようす。。。
-------------
別に自説を展開しにきているわけじゃないからな。
-------------
中傷が目的と自白してるような気が(笑)
-------------
これだけだとin-orderよりもOOOの方がキャッシュの遅延を隠蔽しながら効率良く読み出せるから
大容量化に向いているともとれるだろう。
-------------
なかなか強引な解釈すね。メモリわその「キャッシュ遅延」とやらより何倍も遅いということわ
脳内から抜け落ちているようす。。。
アウトオーダー型のプロセッサって、インオーダーに比べてチップ面積何割増しくらいにるんですかね?
アウトオーダー型のプロセッサはシングルプロセッサなら高速でありがたみ沢山だけれど、マルチプロセッサにすると同期処理を厳格にする必要があって
ソースコードから原因追求しにくい正体不明のバグが出やすいです。
厳格にすると、コードがロック処理だらけになってこのオーバーヘッドはアウトオーダーの効率化を抜くのかちょつと微妙な気もする。
と、今後は必ずしもあり難い訳ではないので、もしもインオーダーにする事によって減ったチップ面積にキャッシュを積むと効果はいかほどになるんでしょうね?
アウトオーダー型のプロセッサはシングルプロセッサなら高速でありがたみ沢山だけれど、マルチプロセッサにすると同期処理を厳格にする必要があって
ソースコードから原因追求しにくい正体不明のバグが出やすいです。
厳格にすると、コードがロック処理だらけになってこのオーバーヘッドはアウトオーダーの効率化を抜くのかちょつと微妙な気もする。
と、今後は必ずしもあり難い訳ではないので、もしもインオーダーにする事によって減ったチップ面積にキャッシュを積むと効果はいかほどになるんでしょうね?
743 :MACオタ>742 さん:2008/02/03(日) 17:37:13 ID:hp7kyZWe
>>742
-------------------
ソースコードから原因追求しにくい正体不明のバグが出やすいです。
-------------------
POWER ISAのように、元々メモリのオーダリング制限が緩いアーキテクチャわ別にしてx86でもそんなこと
起こるすか?
-------------------
ソースコードから原因追求しにくい正体不明のバグが出やすいです。
-------------------
POWER ISAのように、元々メモリのオーダリング制限が緩いアーキテクチャわ別にしてx86でもそんなこと
起こるすか?
>>732に
>nehemiah->estherでは一応L2は倍になってるんだよね
>この効果も期待されたが実際のパフォーマンス差は実クロックの差分程度でしかなかった
>恐らくestherの段階で限界を感じていたと思うわ、グレン
ってある
また
ttp://japan.cnet.com/blog/kichi/2008/01/28/entry_25004576/
にはIsaiahのL2除いた場合4500万トランジスタ程度と予想してる
Estherの約倍だね、もっともIsaiahは64bitや仮想機能なんてのも
まじめにやってきてるから、単純には比較できないだろうけど
>nehemiah->estherでは一応L2は倍になってるんだよね
>この効果も期待されたが実際のパフォーマンス差は実クロックの差分程度でしかなかった
>恐らくestherの段階で限界を感じていたと思うわ、グレン
ってある
また
ttp://japan.cnet.com/blog/kichi/2008/01/28/entry_25004576/
にはIsaiahのL2除いた場合4500万トランジスタ程度と予想してる
Estherの約倍だね、もっともIsaiahは64bitや仮想機能なんてのも
まじめにやってきてるから、単純には比較できないだろうけど
>>743
原因は手抜きif文から始まるので、格納先はレジスターでもメモリーでも発生しますね
出ると、まずそれを疑う事も無いし、どうして出るのかロジックを理解するのも難しく、相当頭悩ます羽目になります。
原因は手抜きif文から始まるので、格納先はレジスターでもメモリーでも発生しますね
出ると、まずそれを疑う事も無いし、どうして出るのかロジックを理解するのも難しく、相当頭悩ます羽目になります。
あとデバッガで追えないってのがハンパなくキツイ
>>744の補足(ってか思いつき)
トランジスタ数からすれば
C7のQuad Core(もし作ればね)と今回のIsaiahのSingle Coreは
同規模であるわけですな・・
たるさん風にいえば(理論上)4倍のパフォーマンスがあったわけだが
そうはしなかった
トランジスタ数からすれば
C7のQuad Core(もし作ればね)と今回のIsaiahのSingle Coreは
同規模であるわけですな・・
たるさん風にいえば(理論上)4倍のパフォーマンスがあったわけだが
そうはしなかった
もちろんC7のキャッシュだけ増やすこともできたはずだ
効果があればね
効果があればね
流れぶった切って申し訳ない。
並列処理での数値計算とかやるからクオッドコアのCPU積んだPC買いたいんだが、
できれば45nmの奴がいい。
となると現時点ではCore2Extremeしかないがさすがに高い。
そこで、他のYorkfieldコアのものが出るまで待とうかな〜と考えてたんだが、
どうせ今年の後半にはアーキテクチャの違うBloomfieldコアが出ること考えたら
(その後の拡張性とか考えたら)それまで購入待った方がいいかな。
それともその後また色々変わるだろうし意味ないだろうか・・・。
並列処理での数値計算とかやるからクオッドコアのCPU積んだPC買いたいんだが、
できれば45nmの奴がいい。
となると現時点ではCore2Extremeしかないがさすがに高い。
そこで、他のYorkfieldコアのものが出るまで待とうかな〜と考えてたんだが、
どうせ今年の後半にはアーキテクチャの違うBloomfieldコアが出ること考えたら
(その後の拡張性とか考えたら)それまで購入待った方がいいかな。
それともその後また色々変わるだろうし意味ないだろうか・・・。
くおっどこあならふぇのむがおすすめだにょ
TDPやダイサイズを考えると、Isaiahって勝負できるところがかなり少なそうだな。
上位の2GHzだとモバイル向けCeleron(TDP30W)とかなりかぶるし、Diamondvilleが勝負する
TDP4Wあたりだと、クロック下げないとそこまでTDP下がらないから、シングルスレッド性能も
似たような感じになって、ダイサイズでかいIsaiahの方がコスト的に厳しそうだし。
10W前後あたりがメインなんだろうか?
上位の2GHzだとモバイル向けCeleron(TDP30W)とかなりかぶるし、Diamondvilleが勝負する
TDP4Wあたりだと、クロック下げないとそこまでTDP下がらないから、シングルスレッド性能も
似たような感じになって、ダイサイズでかいIsaiahの方がコスト的に厳しそうだし。
10W前後あたりがメインなんだろうか?
失礼、買うとしたらLynnfieldだから来年前半になりますな。
待てるなら待てばいいし、待てないなら65nm。
65nmでいいならCore2 Quadでも、型落ちのMac Proでも、いっぱいあるだろ
65nmでいいならCore2 Quadでも、型落ちのMac Proでも、いっぱいあるだろ
1年も待てるって事はつまり別に必要としてないって事だ。
>>754
>>755
確かに・・・。
たとえばこの先アーキテクチャ(特に物理的な互換性とか)が大きく変わることがないなら
1年ぐらいは待てるんですが、
待ってもどうせまた1年後に似たような状況になるなら
今買っても同じかな・・・とは思います。
>>755
確かに・・・。
たとえばこの先アーキテクチャ(特に物理的な互換性とか)が大きく変わることがないなら
1年ぐらいは待てるんですが、
待ってもどうせまた1年後に似たような状況になるなら
今買っても同じかな・・・とは思います。
もう45nm買えます
http://www1.jpn.hp.com/info/newsroom/pr/fy2008/fy08-041.html
http://www.jcsn.co.jp/products/spec/vin_rack_1uxef.html
http://www.fanatic.co.jp/product/server/xeon_4u.html
http://www.nec.co.jp/press/ja/0801/2801.html
http://www1.jpn.hp.com/info/newsroom/pr/fy2008/fy08-041.html
http://www.jcsn.co.jp/products/spec/vin_rack_1uxef.html
http://www.fanatic.co.jp/product/server/xeon_4u.html
http://www.nec.co.jp/press/ja/0801/2801.html
今は Core2 Quadの45nm 欲しいな、消費電力そこそこでパワー有りそうだし
最近消費電力も馬鹿にならないし、また値を上げるとか、こっちはもう音を上げるよ
最近消費電力も馬鹿にならないし、また値を上げるとか、こっちはもう音を上げるよ
こんな深夜に音量上げんな
近所迷惑だ!
近所迷惑だ!
今のマザーにLynnfieldとかって載るの?
761 :ヽ・´∀`・,,)っ━━━━━━┓:2008/02/04(月) 01:32:20 ID:015DttvK
ソケット替わるので無理です。
E8000、Q9000シリーズはLGA775最後のシリーズです。
E8000、Q9000シリーズはLGA775最後のシリーズです。
最近情報ソースとしてよく見かけるxtreview.comもBloomfieldわ外部メモリコントローラと書いているすね。
http://xtreview.com/addcomment-id-4164-view-Bloomfield-will-cost-less-then-400-dollars.html
---------------------------
Bloomfield will use motherboard with the traditional layout, which has a north and south bridge. Such
motherboard will be expensive.
---------------------------
ここの腐れルーマー度ってどんなモンなんすか?
http://xtreview.com/addcomment-id-4164-view-Bloomfield-will-cost-less-then-400-dollars.html
---------------------------
Bloomfield will use motherboard with the traditional layout, which has a north and south bridge. Such
motherboard will be expensive.
---------------------------
ここの腐れルーマー度ってどんなモンなんすか?
ソケットより、メモリがDDR2からDDR3に換わるのが大きい
Nehalemが登場しても暫くはDDR3の高値が普及の足を引っ張るだろうな
Nehalemが登場しても暫くはDDR3の高値が普及の足を引っ張るだろうな
Nehalemに合わせて大きく増産してくる大丈夫。
766 :Socket774:2008/02/04(月) 06:51:32 ID:ZjwPjB30
767 :ヽ・´∀`・,,)っ━━━━━━┓:2008/02/04(月) 07:02:56 ID:015DttvK
NehalemはDDR3サポートと最低でも2コア4スレッドなのでミッドレンジ以上向け。
Wolfdaleをバリューセグメントに残すだけでしょ。
2010年なら32nmはまだ出始めだし。
32nmのPenrynシュリンクは、まあ無いでしょ。
Wolfdaleをバリューセグメントに残すだけでしょ。
2010年なら32nmはまだ出始めだし。
32nmのPenrynシュリンクは、まあ無いでしょ。
768 :Socket774:2008/02/04(月) 07:08:05 ID:ZjwPjB30
2010年頭までじゃくて後半まで残るよ
E8x50シリーズは確実に出るし、最後にE9000シリーズも出ると思う
32nmが出るかどうかはNehalemがコケるかどうかだね
E8x50シリーズは確実に出るし、最後にE9000シリーズも出ると思う
32nmが出るかどうかはNehalemがコケるかどうかだね
メモコンの統合に失敗したんか?
770 :Socket774:2008/02/04(月) 07:12:28 ID:ZjwPjB30
Nehalemで基本性能上がっててもOC耐性がPhenom並でDDR3が
うまく値下げできなかったらコケる可能性あると思うんだけどな
2010年までPenrynが引っ張られるならPenryn⇒SandyBridgeになる人も多そう
うまく値下げできなかったらコケる可能性あると思うんだけどな
2010年までPenrynが引っ張られるならPenryn⇒SandyBridgeになる人も多そう
自作ユーザーならPenrynのOCの方が速いっていう層が出てくる可能性あるだろうが、
Nehalem世代で3GHz前半を定格で出せれば、鯖や2CPUのワークステーションはNehalemに移行だろうな。
定格クロックがNehalemであまり落ちないなら、メーカー製PCもミドルレンジからハイエンドは
HavendaleやLynnfieldに2009年冬モデルくらいから移行し始めるだろうし。
むしろ発熱でNehalemが32nmでも苦戦するなら、ノート向けでPenrynも長生きするんじゃないだろうか。
Nehalem世代で3GHz前半を定格で出せれば、鯖や2CPUのワークステーションはNehalemに移行だろうな。
定格クロックがNehalemであまり落ちないなら、メーカー製PCもミドルレンジからハイエンドは
HavendaleやLynnfieldに2009年冬モデルくらいから移行し始めるだろうし。
むしろ発熱でNehalemが32nmでも苦戦するなら、ノート向けでPenrynも長生きするんじゃないだろうか。
メモコンの統合失敗はホットスポットが原因かな
G71よろしく突然死でもしたか?
まぁメモコン専用コアにHT似の接続すれば良いだけだろうけど
そうか、失敗したか・・
G71よろしく突然死でもしたか?
まぁメモコン専用コアにHT似の接続すれば良いだけだろうけど
そうか、失敗したか・・
Bloomfieldは理屈の上ではパフォーマンスがあっても実質パフォーマンスはあまり出ないんではないかというソフト屋として嫌な予感を感じる
第一の問題はマルチコアでのHTは、スレッドスケジューラーが良好に動作してくれないこと、むしろ悪影響。
Core2の勝因がキャッシュならDDR3に効果はなさそうな予感もする。
第一の問題はマルチコアでのHTは、スレッドスケジューラーが良好に動作してくれないこと、むしろ悪影響。
Core2の勝因がキャッシュならDDR3に効果はなさそうな予感もする。
OC耐性が普及に影響を与えるなんて100%ないから。
2.0GHzが4.0GHzに化けるような石だったら影響するだろうな。
>>776
そりゃそうだ。BIOS自体が・・・あれだからな。
そりゃそうだ。BIOS自体が・・・あれだからな。
778 :ヽ・´∀`・,,)っ¬:2008/02/04(月) 12:16:44 ID:mLPJzq7Y
>>773
ネトバのときもあったけど、HT×2コアのときに2スレッドを動かすと
1コアだけに両方のスレッドが割り当てられることがある問題とか?
ややこしいけどソフトで区別する方法があったはず。CodeZineを参照。
スレッド毎にアフィニティを設定すればプロセッサを固定できる。
パイプライン自体のスケジューリングの問題のことなら、ソフトでは対処しようがないね。
ネトバのときもあったけど、HT×2コアのときに2スレッドを動かすと
1コアだけに両方のスレッドが割り当てられることがある問題とか?
ややこしいけどソフトで区別する方法があったはず。CodeZineを参照。
スレッド毎にアフィニティを設定すればプロセッサを固定できる。
パイプライン自体のスケジューリングの問題のことなら、ソフトでは対処しようがないね。
>>778
HTの問題だけれど、ソフト解決なんてのは気持ち程度だよ、万能からは程遠いです。
性能だそうと思ったらそれこそゲームのチューンの如くやるしかないけれど
Windows等の汎用OSではOSが個々のアプリの特性まで捕らえるような事はできませんので。
HTの問題だけれど、ソフト解決なんてのは気持ち程度だよ、万能からは程遠いです。
性能だそうと思ったらそれこそゲームのチューンの如くやるしかないけれど
Windows等の汎用OSではOSが個々のアプリの特性まで捕らえるような事はできませんので。
ちょっと説明が無い感じがするので、説明もちょっと追加
マルチプロセッサに対応するなら、スレッドを自由に起動したり落としたりする事が肝心になります。
ハードやっているなら気持ちはわかると思いますが、要するにどんな回路でも作れるけれども、
実際に使うのは nor nand のみといったようなイメージを持ってもらえれば解ると思う。
コーディングテクニック的にプロセッサ固定はまずいんですね。
これをやってしまうと、場当たり回路ならぬ場当たりチューンになってしまいます、保守当を考えてもそれは避けたい所。
マルチプロセッサに対応するなら、スレッドを自由に起動したり落としたりする事が肝心になります。
ハードやっているなら気持ちはわかると思いますが、要するにどんな回路でも作れるけれども、
実際に使うのは nor nand のみといったようなイメージを持ってもらえれば解ると思う。
コーディングテクニック的にプロセッサ固定はまずいんですね。
これをやってしまうと、場当たり回路ならぬ場当たりチューンになってしまいます、保守当を考えてもそれは避けたい所。
HTはOSの最適化を期待できないと、ソフトの起動の順序次第で性能が変化したりして一般には使いにくくなりそうだな
Yorkfield次は32nmのタイミングで買い替えがいいかもしれん
Yorkfield次は32nmのタイミングで買い替えがいいかもしれん
HTにする理由というのは、とどのつまりレイテンシのあるリソースを無駄なく使いたいという事だと思う
であれば、同じ理由で機能するOoOもうまく機能するかも知れないとちょっと思った。
次の世代は一次キャッシュ強化とOoOが機能しやすいかも
であれば、同じ理由で機能するOoOもうまく機能するかも知れないとちょっと思った。
次の世代は一次キャッシュ強化とOoOが機能しやすいかも
将来的にはhelper threadとして動くんじゃないの?
ttp://pc.watch.impress.co.jp/docs/2008/0204/kaigai415.htm
■後藤弘茂のWeekly海外ニュース■
IntelがいよいよSilverthorneとTukwilaの概要を発表へ
キャッシュを除くとC7と同程度の規模くさいな
■後藤弘茂のWeekly海外ニュース■
IntelがいよいよSilverthorneとTukwilaの概要を発表へ
キャッシュを除くとC7と同程度の規模くさいな
その昔VIAが(ダイが大きく)コストがかかるためキャンセルしたC5XのHT版だな
Silverthorne
Silverthorne
>>783
SunのRockはHelper Thread使うらしいけど消費電力は250Wだってさ。
Helper Threadは消費電力増大させるんかなあ。
Rockが16コアだから単にそのせいだったら良いが。
>>784
整数と浮動小数で分離されてるのか。
SunのRockはHelper Thread使うらしいけど消費電力は250Wだってさ。
Helper Threadは消費電力増大させるんかなあ。
Rockが16コアだから単にそのせいだったら良いが。
>>784
整数と浮動小数で分離されてるのか。
NehalemのCPU-Zスクリーンショット
http://xtreview.com/addcomment-id-4172-view-Intel-Nehalem-cpuz.html
L1D: 4 x 16KB
L1I.: 4 x 32KB
L2: 4 x 256KB
L3: 8MB
なんじゃこりゃ
http://xtreview.com/addcomment-id-4172-view-Intel-Nehalem-cpuz.html
L1D: 4 x 16KB
L1I.: 4 x 32KB
L2: 4 x 256KB
L3: 8MB
なんじゃこりゃ
今の時点で、0.975Vで2GHz出てるのが凄いな。
>0.975Vで2Ghz
これはかなり省電力にも期待できそう
これはかなり省電力にも期待できそう
http://cgipocket.com/member/a115/celeron-D/2.html
90nmのNetburstで2GHz@0.95V
90nmのNetburstで2GHz@0.95V
90nm世代で2GHz程度だと、1V強が一般的じゃね
NetBurstでやっと0.95Vまで下げられる程度…x86は電圧たかいのう
NetBurstでやっと0.95Vまで下げられる程度…x86は電圧たかいのう
793 :ヽ・´∀`・,,)っ¬:2008/02/04(月) 20:58:14 ID:mLPJzq7Y
>>787
おkwwwww
おkwwwww
L2 7cycles キタ?
トレースキャッシュの復活か?
Netburstだとあれだけど、Coreアーキでコア1.5倍に拡張されてて0.975V(現時点)なら健闘してそう。
全てはCPU-Zが作り出した幻想
L2は512KBかと思ったけど256KBか
>>787
16ハードウェアスレッドが並ぶタスクマネージャーは豪快ですね
>>792
それよりL2小さめなのが気になる、Nehalemは評判が固まるまでちょっと怖いな
やはりバランス悪そうな予感がする
16ハードウェアスレッドが並ぶタスクマネージャーは豪快ですね
>>792
それよりL2小さめなのが気になる、Nehalemは評判が固まるまでちょっと怖いな
やはりバランス悪そうな予感がする
L2が256KBなんて俺のWilammetと変わらねえw
あと一年あるし、6MBくらいにならないだろうか。
あと一年あるし、6MBくらいにならないだろうか。
さらに一年後には144MBに!
>>801
増やしゃいいってもんじゃないでしょうがw
増やしゃいいってもんじゃないでしょうがw
BloomfieldのL2は8MBと前から情報でてるんだから
L3@8MBとなってるのがL2だろう、
L1とL2の部分がL1に該当するんじゃないか
CPU-Zがうまく認識できてないだけ
L3@8MBとなってるのがL2だろう、
L1とL2の部分がL1に該当するんじゃないか
CPU-Zがうまく認識できてないだけ
804 :ヽ・´∀`・,,)っ¬:2008/02/04(月) 22:01:14 ID:mLPJzq7Y
L2が小さいぶんミスヒットレイテンシも小さい
と言ってみる。
L2と推定されたブロックは256kにしてはデカいので何かしらギミックはあると思うが
案外、L2とL3に同時に探索をかけられる仕様かもしれんね。
それでなくとも、SMTは相対的にレイテンシを隠蔽できるし案外性能でるかもよ。
と言ってみる。
L2と推定されたブロックは256kにしてはデカいので何かしらギミックはあると思うが
案外、L2とL3に同時に探索をかけられる仕様かもしれんね。
それでなくとも、SMTは相対的にレイテンシを隠蔽できるし案外性能でるかもよ。
>>804
レイテンシの問題を気にするよりも、L2はCore2程度にして、L1の強化の効果がありそうな予感がします。
Core2がうまく行っているのは種類のアプリケーションについて、各プログラムが当座必要とするデータをL2におおむね全部取り込めたからではないかと思うので
次に追求すべき点はL1では無いかと・・・
最近思うことなんですが、メモリーはディスクつもりで、L2が実メモリー、ここにページングを行ってL1がいわゆるキャッシュという認識ぐらいにしてもいいのではと思ったりします。
DRAMからL2に取り込むとき、DRAMの内容なんでぶっ壊れてもいいと思うんですよ、ページアウトで書き込むときにDRAMにライトバックとかすれば問題ないですし
ページインされているDRAMについてはもうリフレッシュすらしないで電力消費量稼ぐとかね。
DRAMの構造の単純になってレイテンシ稼げるのではと思ったりするのですが、こういうのってのは無しですかね?
レイテンシの問題を気にするよりも、L2はCore2程度にして、L1の強化の効果がありそうな予感がします。
Core2がうまく行っているのは種類のアプリケーションについて、各プログラムが当座必要とするデータをL2におおむね全部取り込めたからではないかと思うので
次に追求すべき点はL1では無いかと・・・
最近思うことなんですが、メモリーはディスクつもりで、L2が実メモリー、ここにページングを行ってL1がいわゆるキャッシュという認識ぐらいにしてもいいのではと思ったりします。
DRAMからL2に取り込むとき、DRAMの内容なんでぶっ壊れてもいいと思うんですよ、ページアウトで書き込むときにDRAMにライトバックとかすれば問題ないですし
ページインされているDRAMについてはもうリフレッシュすらしないで電力消費量稼ぐとかね。
DRAMの構造の単純になってレイテンシ稼げるのではと思ったりするのですが、こういうのってのは無しですかね?
IntelはLLC以外は伝統的に小容量&高速派だろ。
256kBが小さいってなんのCPUを基準にいってんだよ。
256kBが小さいってなんのCPUを基準にいってんだよ。
>>806
大変よい結果をだしたCore2に対してですが何か?
大変よい結果をだしたCore2に対してですが何か?
>>807
L3までネイティブで持ってるCPUはL2は普通小さいだろ。外部や後付拡張は別としても。
ItaniumだってMadison 9Mまでずっと256kBが続いたが。
L3があるからL2はレイテンシを稼ぐ方向に行くのは無理もない。
しかし、NehalelmのCPU-Zがもうでるなんてな。
ISSCCの記事より遙かに衝撃的だわ。
L3までネイティブで持ってるCPUはL2は普通小さいだろ。外部や後付拡張は別としても。
ItaniumだってMadison 9Mまでずっと256kBが続いたが。
L3があるからL2はレイテンシを稼ぐ方向に行くのは無理もない。
しかし、NehalelmのCPU-Zがもうでるなんてな。
ISSCCの記事より遙かに衝撃的だわ。
>>806
Phenomと比べても小さいですが何か?
Phenomと比べても小さいですが何か?
無論、YorkfieldのL2 12MBよりもL1+L2 256kB、L3 8MBの方が強力だ。
これだけでIPCが1割あがってもおかしくはないよ。妄想だけど。
>>809
排他は各階層の容量差が少ないのが普通だ。
これだけでIPCが1割あがってもおかしくはないよ。妄想だけど。
>>809
排他は各階層の容量差が少ないのが普通だ。
http://pc.watch.impress.co.jp/docs/2008/0204/kaigai415.htm
>TukwilaはIA-64アーキテクチャのクアッドコアCPUで、
>FB-DIMMインターフェイスとQuickPathインターコネクトを実装し、30MBのキャッシュメモリも搭載する。65nmプロセスで、
>トランジスタ数は約2B(20億)に達し、ダイサイズも約700平方mmというモンスターだ。
>ターゲット動作周波数は2GHzでTDP(Thermal Design Power:熱設計消費電力)は170W(摂氏110度)。
>QuickPathはフル幅のインターコネクトが4とハーフ幅が2で合計の帯域は96GB/s、FB-DIMMの帯域は34GB/secとなる。
>TukwilaはIA-64アーキテクチャのクアッドコアCPUで、
>FB-DIMMインターフェイスとQuickPathインターコネクトを実装し、30MBのキャッシュメモリも搭載する。65nmプロセスで、
>トランジスタ数は約2B(20億)に達し、ダイサイズも約700平方mmというモンスターだ。
>ターゲット動作周波数は2GHzでTDP(Thermal Design Power:熱設計消費電力)は170W(摂氏110度)。
>QuickPathはフル幅のインターコネクトが4とハーフ幅が2で合計の帯域は96GB/s、FB-DIMMの帯域は34GB/secとなる。
>>811
詳細でてないけどTukwilaはだめオーラがでてるね。
2GHzじゃ当初の予定未満だし、前にでてたスライドとあまり内容かわらなそう。
4S同士の比較でMontvaleの2倍以上なんてありまえに出そうなものをわざわざ書いている時点
でまずい。
詳細でてないけどTukwilaはだめオーラがでてるね。
2GHzじゃ当初の予定未満だし、前にでてたスライドとあまり内容かわらなそう。
4S同士の比較でMontvaleの2倍以上なんてありまえに出そうなものをわざわざ書いている時点
でまずい。
Silverthorneのダイサイズが25mm2とのことだが、価格的にはどれぐらいだろうか。
チップセットとセットで50ドルは切ると思うが・・・。
チップセットとセットで50ドルは切ると思うが・・・。
814 :Socket774:2008/02/04(月) 23:00:51 ID:ZjwPjB30
小さいから安いってことはないと思うけど
TabletPCが約\25kだったら手をだす?
Silverthorneは、どういう市場戦略を考えているのかちょっと不思議な印象だな
せっかく小さくしたのなら、GPUやらムービーのデコーダーやら色々乗せてシステムLSIにしたほうが便利そうな予感がするんですけどね。
DSを丸ごと突っ込んで、DS付きTabletPCとかならちょっと手を出したい気持ち、ありえないだろうけどw
せっかく小さくしたのなら、GPUやらムービーのデコーダーやら色々乗せてシステムLSIにしたほうが便利そうな予感がするんですけどね。
DSを丸ごと突っ込んで、DS付きTabletPCとかならちょっと手を出したい気持ち、ありえないだろうけどw
>>787
Familyは6のままなのか
Familyは6のままなのか
だってNehalemはPenrynがベースだし
http://www.hkepc.com/?id=568&page=1#view
http://www.hkepc.com/database/images/2008010213523656679420453.jpg
http://www.hkepc.com/?id=568&page=1#view
http://www.hkepc.com/database/images/2008010213523656679420453.jpg
{kind=link}
>>816
それやると、他のシステムLSIの数倍の消費電力になるから…
それやると、他のシステムLSIの数倍の消費電力になるから…
Silverthorne、デュアルコア版が普通にあるってことは
モバイルデバイス以外にも、EeePCやLet'sNote R7クラスのミニノート、
B5モバイルの廉価版とかにも使われる感じはするなあ
実際このCPUつかえば、Let'sNoteみたいなノートがたいした技術力無くても作れるだろうし
モバイルデバイス以外にも、EeePCやLet'sNote R7クラスのミニノート、
B5モバイルの廉価版とかにも使われる感じはするなあ
実際このCPUつかえば、Let'sNoteみたいなノートがたいした技術力無くても作れるだろうし
822 :ヽ・´∀`・,,)っ━━━━━━┓:2008/02/05(火) 06:17:39 ID:hwruG8gV
っていうか、Let's Noteは筐体設計が神。
>>812
Tukwilaのターゲットクロックがどのくらいって話はあったっけ?
前期Tukwilaなら威勢のいい話はあったけど。
Madison以降、ずーっとクロックほとんど上がってないんだよね。
quadになって2GHzまで上がるんなら、いいんじゃないか?とか思ってしまう。
多分、頑張ってもこのコアでは劇的にクロックが上がることは無いでしょう。
まあ、Poulsonに期待するということで・・・。
MACオタが言ってたけど、キャッシュ容量の話は、経済的にどのくらい
のダイサイズが可能か、じゃ、キャッシュはどれくらいになるかって
話でしょ。Tukwilaでは1つあたりのL3はかなり削減されてる。
Tukwilaのターゲットクロックがどのくらいって話はあったっけ?
前期Tukwilaなら威勢のいい話はあったけど。
Madison以降、ずーっとクロックほとんど上がってないんだよね。
quadになって2GHzまで上がるんなら、いいんじゃないか?とか思ってしまう。
多分、頑張ってもこのコアでは劇的にクロックが上がることは無いでしょう。
まあ、Poulsonに期待するということで・・・。
MACオタが言ってたけど、キャッシュ容量の話は、経済的にどのくらい
のダイサイズが可能か、じゃ、キャッシュはどれくらいになるかって
話でしょ。Tukwilaでは1つあたりのL3はかなり削減されてる。
なんかキャッシュ階層がamdっぽくなったな
「0.975Vで2GHz出るほど出来がいい」のか、
「0.975Vで2GHzまで抑えないと電力的に厳しい」のか・・・
そこが問題だな。
「0.975Vで2GHzまで抑えないと電力的に厳しい」のか・・・
そこが問題だな。
数値が正しいとして
「0.975VでWindowsが起動する」
だけじゃね。
負荷かけたら落ちると。
もっとも負荷かけても大丈夫なほどのサンプルなのかは知らんが。
「0.975VでWindowsが起動する」
だけじゃね。
負荷かけたら落ちると。
もっとも負荷かけても大丈夫なほどのサンプルなのかは知らんが。
例のNehalemのCPU-Z
盛り上がっているのわXtremeSystems
http://www.xtremesystems.org/forums/showthread.php?t=175737
http://www.chiphell.com/?action-viewnews-itemid-178
XtremeSystems
http://www.xtremesystems.org/forums/showpost.php?p=2747254&postcount=118
--------------------
Contacted a buddy in D1D at Oregon about this SS and for what Nehalem info I
could get out of him.
He says:
1) not a fake, but CPU-Z is off on several things (he won't tell exactly what)
2) Nehalem boots and runs stable under load on all major OSes
3) Intel could have it "rushed" to market in 2 months if need be, but they don't
feel the competitive pressure to do so (thanks AMD).
4) most of what is being worked on now are the chipsets for the various platforms (desktop, server, etc.)
--------------------
盛り上がっているのわXtremeSystems
http://www.xtremesystems.org/forums/showthread.php?t=175737
http://www.chiphell.com/?action-viewnews-itemid-178
XtremeSystems
http://www.xtremesystems.org/forums/showpost.php?p=2747254&postcount=118
--------------------
Contacted a buddy in D1D at Oregon about this SS and for what Nehalem info I
could get out of him.
He says:
1) not a fake, but CPU-Z is off on several things (he won't tell exactly what)
2) Nehalem boots and runs stable under load on all major OSes
3) Intel could have it "rushed" to market in 2 months if need be, but they don't
feel the competitive pressure to do so (thanks AMD).
4) most of what is being worked on now are the chipsets for the various platforms (desktop, server, etc.)
--------------------
例のNehalemのCPU-Z画像について少し調べてみたすけど、この話題で一番盛り上がっているのわ
XtremeSystems掲示板だったす。
http://www.xtremesystems.org/forums/showthread.php?t=175737
で、情報の出所自体わ、この掲示板らしいす。偽画像と疑うヒトも多い様す。
http://www.chiphell.com/?action-viewnews-itemid-178
XtremeSystems掲示板に書き込まれた情報で面白そうなのわ、これすかね。。。
http://www.xtremesystems.org/forums/showpost.php?p=2747254&postcount=118
--------------------
Contacted a buddy in D1D at Oregon about this SS and for what Nehalem info I
could get out of him.
He says:
1) not a fake, but CPU-Z is off on several things (he won't tell exactly what)
2) Nehalem boots and runs stable under load on all major OSes
3) Intel could have it "rushed" to market in 2 months if need be, but they don't
feel the competitive pressure to do so (thanks AMD).
4) most of what is being worked on now are the chipsets for the various platforms
(desktop, server, etc.)
--------------------
画像自体の真偽わ別にしても、文字通り受け取るようなモノじゃ無さそうす。
XtremeSystems掲示板だったす。
http://www.xtremesystems.org/forums/showthread.php?t=175737
で、情報の出所自体わ、この掲示板らしいす。偽画像と疑うヒトも多い様す。
http://www.chiphell.com/?action-viewnews-itemid-178
XtremeSystems掲示板に書き込まれた情報で面白そうなのわ、これすかね。。。
http://www.xtremesystems.org/forums/showpost.php?p=2747254&postcount=118
--------------------
Contacted a buddy in D1D at Oregon about this SS and for what Nehalem info I
could get out of him.
He says:
1) not a fake, but CPU-Z is off on several things (he won't tell exactly what)
2) Nehalem boots and runs stable under load on all major OSes
3) Intel could have it "rushed" to market in 2 months if need be, but they don't
feel the competitive pressure to do so (thanks AMD).
4) most of what is being worked on now are the chipsets for the various platforms
(desktop, server, etc.)
--------------------
画像自体の真偽わ別にしても、文字通り受け取るようなモノじゃ無さそうす。
CPU-Zスクリーンショットのキャッシュ階層の部分すけど、丁度私も>>726-731でネタにしたところすから、
現状手に入る信頼できる情報についてだけ、書いておくす。
まず、去年の春のIDFで最初にNehalemのダイ写真が公開された頃にAnandがStephen L Smith氏 (Intel VP
and Director of the Digital Enterprise Group) や Gelsinger氏とのインタビューを元に書いた解説す。
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2955&p=3
----------------------------
Nehalem will also use multi-level shared cache. Pat Gelsinger indicated that only the highest level of
cache would be shared, meaning that Nehalem could very well have a similar cache hierarchy to AMD's
Barcelona (independent L1/L2 caches per core, but a shared L3 cache).
----------------------------
多階層のキャッシュを持ち、最終レベルのキャッシュのみが共有されるという言質を得ているす。Anandわ
AMD同様にL1, L2が独立でL3が共有と解釈しており、今回のスクリーンショットと一致するす。
一方秋のIDFの頃に後藤氏がIntel幹部の話を元に書いた記事わ、ちょっと違っているす、。
http://pc.watch.impress.co.jp/docs/2007/0927/kaigai389.htm
----------------------------
Gelsinger氏は、Nehalemが専用L1と共有L2を備えると認めた。また、Glenn J. Hinton(グレン・J・ヒントン)氏
(Intel Fellow, Digital Enterprise Group, Director, IA-32 Microarchitecture Development)は、IDFのFellow
Shop Talkで、次のように語った。
[中略]
現在、我々は数レベルのキャッシュ階層を持っている。Nehalemは3レベルのキャッシュ階層を持つ」
----------------------------
こちらわ「共有L2」と明示されているす。
現状手に入る信頼できる情報についてだけ、書いておくす。
まず、去年の春のIDFで最初にNehalemのダイ写真が公開された頃にAnandがStephen L Smith氏 (Intel VP
and Director of the Digital Enterprise Group) や Gelsinger氏とのインタビューを元に書いた解説す。
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2955&p=3
----------------------------
Nehalem will also use multi-level shared cache. Pat Gelsinger indicated that only the highest level of
cache would be shared, meaning that Nehalem could very well have a similar cache hierarchy to AMD's
Barcelona (independent L1/L2 caches per core, but a shared L3 cache).
----------------------------
多階層のキャッシュを持ち、最終レベルのキャッシュのみが共有されるという言質を得ているす。Anandわ
AMD同様にL1, L2が独立でL3が共有と解釈しており、今回のスクリーンショットと一致するす。
一方秋のIDFの頃に後藤氏がIntel幹部の話を元に書いた記事わ、ちょっと違っているす、。
http://pc.watch.impress.co.jp/docs/2007/0927/kaigai389.htm
----------------------------
Gelsinger氏は、Nehalemが専用L1と共有L2を備えると認めた。また、Glenn J. Hinton(グレン・J・ヒントン)氏
(Intel Fellow, Digital Enterprise Group, Director, IA-32 Microarchitecture Development)は、IDFのFellow
Shop Talkで、次のように語った。
[中略]
現在、我々は数レベルのキャッシュ階層を持っている。Nehalemは3レベルのキャッシュ階層を持つ」
----------------------------
こちらわ「共有L2」と明示されているす。
偽物疑惑ありか、この次点ででてくるのも変だしね
今は携帯なんで、リンク先は読んでないけど今回のスクリーンショットねつ造疑惑、ただし信頼できる情報に対しては矛盾なしという事ですか?
今は携帯なんで、リンク先は読んでないけど今回のスクリーンショットねつ造疑惑、ただし信頼できる情報に対しては矛盾なしという事ですか?
お笑い爆熱Skulltrailプラットフォームの話題そらしに決まってんだろ
http://journal.mycom.co.jp/articles/2008/02/04/skulltrail1/index.html
http://journal.mycom.co.jp/articles/2008/02/04/skulltrail2/index.html
http://journal.mycom.co.jp/articles/2008/02/04/skulltrail1/index.html
http://journal.mycom.co.jp/articles/2008/02/04/skulltrail2/index.html
まあ、答えを言ってしまうと、NehalemのCPU-Z画像は確実に偽物だけどな。
>http://journal.mycom.co.jp/articles/2008/02/04/skulltrail2/index.html
http://journal.mycom.co.jp/photo/articles/2008/02/04/skulltrail1/images/Photo42l.jpg
これ何が悪いんだろうな、スレッドスケジューラか死んでるのか、I/Oが詰っているのか、単にエンコアプリがタコなのか?
ついでに表示オプションでカーネル時間も表示して欲しかったな
1KW超とか、見ている分には面白いけど絶対買わないねw
http://pc.watch.impress.co.jp/docs/2007/0921/idf07_03.jpg
http://journal.mycom.co.jp/photo/articles/2008/02/04/skulltrail1/images/Photo42l.jpg
{kind=link}
これ何が悪いんだろうな、スレッドスケジューラか死んでるのか、I/Oが詰っているのか、単にエンコアプリがタコなのか?
ついでに表示オプションでカーネル時間も表示して欲しかったな
1KW超とか、見ている分には面白いけど絶対買わないねw
http://pc.watch.impress.co.jp/docs/2007/0921/idf07_03.jpg
{kind=link}
>>823
2.4〜2.5GHzだったよ。それから落ちた。
4SでのMontvaleとの比較なので、キャッシュが減っても2倍差で勝たなきゃどうしようもない。
せっかくQuickPath移行したんだよ。逆にいうと、QuickPathのおかげでキャッシュ減らせたといえなくもない。
2.4〜2.5GHzだったよ。それから落ちた。
4SでのMontvaleとの比較なので、キャッシュが減っても2倍差で勝たなきゃどうしようもない。
せっかくQuickPath移行したんだよ。逆にいうと、QuickPathのおかげでキャッシュ減らせたといえなくもない。
多コアの幻想は散ったな
QuickPathのおかげでキャッシュ減らせたは言い過ぎか。700もあるし
さすがのIntelもこれ以上でかいダイは考えてないかも試練もんな。
でもキャッシュがスケーラビリティに与える影響は減っただろう。
さすがのIntelもこれ以上でかいダイは考えてないかも試練もんな。
でもキャッシュがスケーラビリティに与える影響は減っただろう。
>>838
まぁまぁ、あれはあれでプログラムを作り始めると結構面白いんだよ蛸アは
ここの人たち余りキャッシュには興味なさそうな人多いけど、
肝はキャッシュ容量設計にあると思う、メモリバスバンド幅レイテンシ等が今まで以上に酷い有様で
演算量アップとかコア設計なんてどうでもいいってぐらい効果なし、でもキャッシュのっていればホイホイ大量計算できて
思わずおおぉぉとかなるんだ。
ユーザーには関係無い事だけどw
まぁまぁ、あれはあれでプログラムを作り始めると結構面白いんだよ蛸アは
ここの人たち余りキャッシュには興味なさそうな人多いけど、
肝はキャッシュ容量設計にあると思う、メモリバスバンド幅レイテンシ等が今まで以上に酷い有様で
演算量アップとかコア設計なんてどうでもいいってぐらい効果なし、でもキャッシュのっていればホイホイ大量計算できて
思わずおおぉぉとかなるんだ。
ユーザーには関係無い事だけどw
http://journal.mycom.co.jp/articles/2008/02/04/skulltrail1/images/Photo06l.jpg
>Photo06:CPUへの電源供給回路よりも、その左上に並ぶEPS 12Vの8Pコネクタが2つ並んでいる事に恐怖する。
大原を恐怖のズンドコに落とし入れるとはさすがだ。
{kind=link}
>Photo06:CPUへの電源供給回路よりも、その左上に並ぶEPS 12Vの8Pコネクタが2つ並んでいる事に恐怖する。
大原を恐怖のズンドコに落とし入れるとはさすがだ。
>>841
多和田の記事より
>前述の資料によれば“ノーマルオペレーションの場合は1つの2×4コネクタに接続、
>オーバークロック時は2つの2×4コネクタに接続”とあり、
>通常利用であれば、とりあえず1つで良いと書かれている。
大原はIntel様の資料を見ずにテストしてるっぽいなw
多和田の記事より
>前述の資料によれば“ノーマルオペレーションの場合は1つの2×4コネクタに接続、
>オーバークロック時は2つの2×4コネクタに接続”とあり、
>通常利用であれば、とりあえず1つで良いと書かれている。
大原はIntel様の資料を見ずにテストしてるっぽいなw
itaniumって、キャッシュが大容量だけどレイテンシが長いせいで
キャッシュ容量の割に速くないってのあるだろ
3→9MBにL3キャッシュが増える過程で
セットアソシエティブのWAY数をあんま増やさないとか
1コア12MB L3にしたとき、非同期化して平均レイテンシを下げるとかやったわけで
なんでTukwillaのキャッシュ減ったの、レイテンシ低下かんがえりゃ
あんま影響ないんじゃね?
わかんねーけどさ
あとitaniamのキャッシュの一番ダメなとこは
L1命令キャッシュの不足だろ
複雑なサーバーアプリうごかすと
L1命令ミス率は、10%以上とかのすごい数字になってんじゃね?
montecitoで、L2命令キャッシュ1MBなんてのをやったから
命令のキャッシュミスは高いんだよ
サーバーユースだからデーも高ミスだけど
これはマルチスレッディングでレイテンシを隠蔽するくらいしか対処法がない
キャッシュ容量の割に速くないってのあるだろ
3→9MBにL3キャッシュが増える過程で
セットアソシエティブのWAY数をあんま増やさないとか
1コア12MB L3にしたとき、非同期化して平均レイテンシを下げるとかやったわけで
なんでTukwillaのキャッシュ減ったの、レイテンシ低下かんがえりゃ
あんま影響ないんじゃね?
わかんねーけどさ
あとitaniamのキャッシュの一番ダメなとこは
L1命令キャッシュの不足だろ
複雑なサーバーアプリうごかすと
L1命令ミス率は、10%以上とかのすごい数字になってんじゃね?
montecitoで、L2命令キャッシュ1MBなんてのをやったから
命令のキャッシュミスは高いんだよ
サーバーユースだからデーも高ミスだけど
これはマルチスレッディングでレイテンシを隠蔽するくらいしか対処法がない
itaniumがダメなのはやる気ない空気でいっぱいだからじゃねかな
なんつーか開発陣のやる見るからに気折れてない?
なんつーか開発陣のやる見るからに気折れてない?
844 へんなまま書き込んでしまった
なんつーか開発陣のやる気が見るからに折れてない?
なんつーか開発陣のやる気が見るからに折れてない?
>>846
てか、2GHz/0.95Vって、65nm世代の数字だよな
てか、2GHz/0.95Vって、65nm世代の数字だよな
最上位のパフォーマンス達成できればいいんだろ?ほら四つ入れたぞ
的な感じはするな、まったく考えてないっつーか、どっかのC●llとかいうのを彷彿させるな
的な感じはするな、まったく考えてないっつーか、どっかのC●llとかいうのを彷彿させるな
>>842
・・・お前、大原の記事ちゃんと読んでないだろ?
しかし、あのマザー見てて気がついたが、もしかして一番下にある4ピンコネクタを
挿してなかったんじゃないか?
ASUSとかがSLI対応マザーでよく使うパターンだし。
・・・お前、大原の記事ちゃんと読んでないだろ?
しかし、あのマザー見てて気がついたが、もしかして一番下にある4ピンコネクタを
挿してなかったんじゃないか?
ASUSとかがSLI対応マザーでよく使うパターンだし。
>>847
今上がってるE8000シリーズの報告を見る限り
65nmと比べると低電圧耐性は期待したほどではないっぽい。
それでも消費電力は下がってるからいいんだけど。
この人はE8400で2GHz@0.85V
http://www2.ocn.ne.jp/~ayut/E8400_Idle.htm
今上がってるE8000シリーズの報告を見る限り
65nmと比べると低電圧耐性は期待したほどではないっぽい。
それでも消費電力は下がってるからいいんだけど。
この人はE8400で2GHz@0.85V
http://www2.ocn.ne.jp/~ayut/E8400_Idle.htm
>>851
スマン、2GHz程度のプロセッサ全般の話だ
スマン、2GHz程度のプロセッサ全般の話だ
消費電力が下がりにくいのは微細化そのものの理由なんですかね、これ別口だけど同様。
http://pc.watch.impress.co.jp/docs/2008/0206/kaigai416_01l.gif
http://pc.watch.impress.co.jp/docs/2008/0206/kaigai416_01l.gif
{kind=link}
おっと、電圧の話だったか・・・
低電圧化→Vtも低くしなければならない→リーク電流増大
ってわけで低電圧化は中々厳しい。
特に高速動作トランジスタは元からVtが低いのでなおさら。
ITRSでもリーク電流が問題になってきたせいで電源電圧の低下割合が緩くなったくらいだし。
ってわけで低電圧化は中々厳しい。
特に高速動作トランジスタは元からVtが低いのでなおさら。
ITRSでもリーク電流が問題になってきたせいで電源電圧の低下割合が緩くなったくらいだし。
ISSCC 2008 - Intel、超低消費電力IAプロセッサ「Sliverthorne」を発表
http://journal.mycom.co.jp/articles/2008/02/06/isscc3/index.html
SSE3以降は対応してなさげ?
でもC2D完全互換というなら対応しててもよさそうだが。
SSE4は無理にしても。
まあ性能が出るかは分からんけど。
あとキャッシュは
L1I 32KB
L1D 24KB
L2 512KB(8-way)
だそうで。
http://journal.mycom.co.jp/articles/2008/02/06/isscc3/index.html
SSE3以降は対応してなさげ?
でもC2D完全互換というなら対応しててもよさそうだが。
SSE4は無理にしても。
まあ性能が出るかは分からんけど。
あとキャッシュは
L1I 32KB
L1D 24KB
L2 512KB(8-way)
だそうで。
あ、あとPenrynと比べるとプロセス違うらしい。
このクラスだとリークは大敵だし当然か。
このクラスだとリークは大敵だし当然か。
>16 stageのdual-decode dual-issue in-order実行で、
チョイ長いな
チョイ長いな
ttp://pc.watch.impress.co.jp/docs/2007/1128/ubiq205.htm
>情報筋はHTテクノロジを活用した場合、つまりマルチスレッド環境でベンチマークをとると、
>Silverthorneの最上位SKUのSV版(1.86GHz/2W)は、現行のA110(800MHz)に比べて
>1.5〜1.6倍程度の性能を実現しているほか、MV版(1.1GHz/1W)もA110に匹敵するような
>性能を実現しているとIntelが説明していると伝える。ただし、シングルスレッドでは、
>SV版(1.8GHz)がA110と同じぐらい、MV版(1.1GHz)がA100(600MHz)と同じ程度の性能と見積もられているようだ。
Hyper-Threadingを実装することにより、15%程度の消費電力の上昇で、
30%のパフォーマンスゲインが得られるとしており、十分に効果的と判断している。
なんか控えめになったな
>情報筋はHTテクノロジを活用した場合、つまりマルチスレッド環境でベンチマークをとると、
>Silverthorneの最上位SKUのSV版(1.86GHz/2W)は、現行のA110(800MHz)に比べて
>1.5〜1.6倍程度の性能を実現しているほか、MV版(1.1GHz/1W)もA110に匹敵するような
>性能を実現しているとIntelが説明していると伝える。ただし、シングルスレッドでは、
>SV版(1.8GHz)がA110と同じぐらい、MV版(1.1GHz)がA100(600MHz)と同じ程度の性能と見積もられているようだ。
Hyper-Threadingを実装することにより、15%程度の消費電力の上昇で、
30%のパフォーマンスゲインが得られるとしており、十分に効果的と判断している。
なんか控えめになったな
>>850
フルサイズのE-ATXマザーでも、8ピンが2つ付いてるのはほとんどないからな。
4-Way用マザーだと標準的に付いてるが。
業務経験のある大原ならその辺はよく知ってるだろうから、まあびっくりするだろ。
信者用とはいえ一応デスクトップ向けのマザーだしな。
フルサイズのE-ATXマザーでも、8ピンが2つ付いてるのはほとんどないからな。
4-Way用マザーだと標準的に付いてるが。
業務経験のある大原ならその辺はよく知ってるだろうから、まあびっくりするだろ。
信者用とはいえ一応デスクトップ向けのマザーだしな。
「SkullTrail」はAMDがキャンセルしたアレと同じだろ?
信者用というかハイエンドゲーマー仕様のPCでしょ。
信者用というかハイエンドゲーマー仕様のPCでしょ。
ここまでくるとハイエンドゲーマーでも手なんか出さないよw
店頭デモ&ベンチマーカー用かと
店頭デモ&ベンチマーカー用かと
nvidiaがからんだプラットフォームは失敗する
初代XBOX
PS3
4X4
初代XBOX
PS3
4X4
>>861
Nehalemとの比較用だよ
UP環境だとPenrynとさほど性能が変わらないから
(OCを考慮するとデスクトップ環境では下がるかもしれない)
NehalemのDPを先行して投入すれば、いらない子のSkulltrailと比較して
「こんなに性能が上がりました」と、言い訳できるから。
Nehalemとの比較用だよ
UP環境だとPenrynとさほど性能が変わらないから
(OCを考慮するとデスクトップ環境では下がるかもしれない)
NehalemのDPを先行して投入すれば、いらない子のSkulltrailと比較して
「こんなに性能が上がりました」と、言い訳できるから。
Nehalemは大失敗でなくてはならない
オレゴンは爆熱でなくてはならない
俺のE8400がNehalemに負けるなどあってはならない
オレゴンは爆熱でなくてはならない
俺のE8400がNehalemに負けるなどあってはならない
4月にCore 2 Duoの価格改定あるみたいだけどどれくらいやすくなるの?
867 :Socket774:2008/02/06(水) 18:39:05 ID:LiKlk/JZ
俺なんて北森P4 2.6CGHzだ!!
もう4〜5年経つのだからムーアの法則により
Nehalemは10倍近い性能でなければならない!!
もう4〜5年経つのだからムーアの法則により
Nehalemは10倍近い性能でなければならない!!
>>866
いちきゅっぱ
いちきゅっぱ
869 :Socket774:2008/02/06(水) 19:04:19 ID:Wcddg2ae
オクタマックのついでに作った。
反省はしない。
反省はしない。
870 :ヽ・´∀`・,,)っ¬:2008/02/06(水) 19:11:19 ID:sSfBEA4n
>>869
奥多摩区の詳細キボンヌ
奥多摩区の詳細キボンヌ
>>867
2年前のCore2 Extreme 2.93GHzより、およそ10.0000%ほど速いE8500がわずか3万円台で買えてしまう!
2年前のCore2 Extreme 2.93GHzより、およそ10.0000%ほど速いE8500がわずか3万円台で買えてしまう!
>>867
ムーアの法則は、性能じゃなくて、トランジスタの集積密度なんだが…
ムーアの法則は、性能じゃなくて、トランジスタの集積密度なんだが…
10倍は諦める、せめて3.5〜4倍の性能UPを期待。
おれは諦めない!
ペンM1.2GHzからNehalemに変えたら目玉が飛び出るくらい速くなるんだろうな
熱も消費電力も跳ね上がるだろうけど
熱も消費電力も跳ね上がるだろうけど
>>871
点の位置を気にしてもいいですか?
点の位置を気にしてもいいですか?
な、なんだってー
ハイパースレッティングなんで復活させるん?
HTといえば、投機的マルチスレッディングは実現したのかね?
これが完成したから入れるんじゃないの。
ttp://pc.watch.impress.co.jp/docs/2003/0222/kaigai01.htm
これから5年ももう経ってる。
これが完成したから入れるんじゃないの。
ttp://pc.watch.impress.co.jp/docs/2003/0222/kaigai01.htm
これから5年ももう経ってる。
当時はスゲーと思った。
1CPUを2CPUにみせかけて空いてるところをフル活用だなんて
ハードウェア的にもソフトウェア的にも問題起きるんじゃないかとか思ったものけど
今では北森HTを4年以上使い倒してるし、いい買い物したと思ってる。
ネハレンの4コアを8スレッドにってのは微妙な気がするけど。
1CPUを2CPUにみせかけて空いてるところをフル活用だなんて
ハードウェア的にもソフトウェア的にも問題起きるんじゃないかとか思ったものけど
今では北森HTを4年以上使い倒してるし、いい買い物したと思ってる。
ネハレンの4コアを8スレッドにってのは微妙な気がするけど。
これが超低消費電力「Silverthorne」の正体だ
http://pc.watch.impress.co.jp/docs/2008/0207/kaigai417.htm
http://pc.watch.impress.co.jp/docs/2008/0207/kaigai417.htm
モバイル用よりハイエンドの情報欲しいよぉ
core2のときと違ってなかなか情報ながれてこないな
core2は事前にベンチとかの情報が結構流れてた気がする
core2は事前にベンチとかの情報が結構流れてた気がする
core2出る前まではAMDに性能的に劣ってましたんで…
今は情況が変わって、早めに情報出して煽る必要が無い
今は情況が変わって、早めに情報出して煽る必要が無い
まあ「早く出てた気がする」と感じるなら
coreduo(yonah)はとっくに発売されて2chでも話題になってたので
それと記憶がごっちゃになってるんだろう
coreduo(yonah)はとっくに発売されて2chでも話題になってたので
それと記憶がごっちゃになってるんだろう
今度のIDFでNehalemの情報があまり出てこなかったらやばいでいいとおも。
メモコン統合失敗の時点でヤバインジャナイノ
890 :MACオタ>879-881 さん:2008/02/07(木) 08:13:42 ID:bP9IwOOH
>>879-881
SMT (=HyperThreading)に関してわ、サポートのためにどの程度コアを拡張するかで全然性能が違うす。
Pentium4わ"たった5%(ダイサイズおよび消費電力)の拡張で、最大30%の性能向上"という設計す。
http://softwarecommunity.intel.com/articles/eng/2503.htm
逆に大きく拡張した例としてわ、POWER5が"10%(コアトランジスタ数)の拡張で最大41%の性能向上(ST
モードとSMTモードの比較結果)"という設計す。
http://www.research.ibm.com/journal/rd/494/sinharoy.html
http://www.research.ibm.com/journal/rd/494/mathis.html
Pentium4 HTTの経験から次世代のHyperThreadingわ、性能と消費電力を睨んで良いバランスを選んで
くると思われるす。
SMT (=HyperThreading)に関してわ、サポートのためにどの程度コアを拡張するかで全然性能が違うす。
Pentium4わ"たった5%(ダイサイズおよび消費電力)の拡張で、最大30%の性能向上"という設計す。
http://softwarecommunity.intel.com/articles/eng/2503.htm
逆に大きく拡張した例としてわ、POWER5が"10%(コアトランジスタ数)の拡張で最大41%の性能向上(ST
モードとSMTモードの比較結果)"という設計す。
http://www.research.ibm.com/journal/rd/494/sinharoy.html
http://www.research.ibm.com/journal/rd/494/mathis.html
Pentium4 HTTの経験から次世代のHyperThreadingわ、性能と消費電力を睨んで良いバランスを選んで
くると思われるす。
>>889
メモコン統合失敗って何だ?
メモコン統合失敗って何だ?
892 :MACオタ>891 さん:2008/02/07(木) 08:17:27 ID:bP9IwOOH
>>891
第一世代となるBloomfieldが外付メモリコントローラらしいという話からじゃないかと思われるす。
http://www.hkepc.com/database/images/2008010314080787929002081.jpg
私わ良いバックアッププランがあるという程度だと思うすけど。。。
第一世代となるBloomfieldが外付メモリコントローラらしいという話からじゃないかと思われるす。
http://www.hkepc.com/database/images/2008010314080787929002081.jpg
{kind=link}
私わ良いバックアッププランがあるという程度だと思うすけど。。。
>>879
ネトバ系であまりいい印象じゃないけど、HTTはよい技術。
なぜならばスレッドを効率的に使えるから。
>>888
もう、十分なほど出ているじゃないかw
>>885氏が言うとおりにC2Dの時はIntelも必死だったから、
性能面で煽りに煽ったが、性能が高くてもその手の情報を出してしまうと、
C2Dの売り上げに響く可能性もあるので、進捗以上の情報は出ないと思う。
>>891
ソースもない脳内妄想はいらない。
ネトバ系であまりいい印象じゃないけど、HTTはよい技術。
なぜならばスレッドを効率的に使えるから。
>>888
もう、十分なほど出ているじゃないかw
>>885氏が言うとおりにC2Dの時はIntelも必死だったから、
性能面で煽りに煽ったが、性能が高くてもその手の情報を出してしまうと、
C2Dの売り上げに響く可能性もあるので、進捗以上の情報は出ないと思う。
>>891
ソースもない脳内妄想はいらない。
>>893
>HTTはよい技術
おれはこれ良くないと思うよ、30%程度性能アップに寄与するとあり、実際にその程度はあると思うが
マルチコアでは、スレッドのスケジーュル性能が悪くなり30%以上の性能ダウンは避けられない。
シングルコアならこの技術は多いに賛成
>HTTはよい技術
おれはこれ良くないと思うよ、30%程度性能アップに寄与するとあり、実際にその程度はあると思うが
マルチコアでは、スレッドのスケジーュル性能が悪くなり30%以上の性能ダウンは避けられない。
シングルコアならこの技術は多いに賛成
今ふと思った、これの原因ってそういう事なんじゃねぇのかな?
エンコほどマルチコアに調子の良いものが無いはずなのに、まったく有効利用できていないってのは
>836 :Socket774:2008/02/05(火) 23:17:13 ID:hO/diETv
>>http://journal.mycom.co.jp/articles/2008/02/04/skulltrail2/index.html
>
>http://journal.mycom.co.jp/photo/articles/2008/02/04/skulltrail1/images/Photo42l.jpg
>これ何が悪いんだろうな、スレッドスケジューラか死んでるのか、I/Oが詰っているのか、単にエンコアプリがタコなのか?
>ついでに表示オプションでカーネル時間も表示して欲しかったな
エンコほどマルチコアに調子の良いものが無いはずなのに、まったく有効利用できていないってのは
>836 :Socket774:2008/02/05(火) 23:17:13 ID:hO/diETv
>>http://journal.mycom.co.jp/articles/2008/02/04/skulltrail2/index.html
>
>http://journal.mycom.co.jp/photo/articles/2008/02/04/skulltrail1/images/Photo42l.jpg
>これ何が悪いんだろうな、スレッドスケジューラか死んでるのか、I/Oが詰っているのか、単にエンコアプリがタコなのか?
>ついでに表示オプションでカーネル時間も表示して欲しかったな
>>896
あっゴメン間違いSkullTrailは単にQuad2丁で、HTは無かった・・・
あっゴメン間違いSkullTrailは単にQuad2丁で、HTは無かった・・・
Silverthorneって現行のC7よりもダイ面積が小さいっぽいけど、ボンディングの
問題は出ないのかな?
低発熱だからホットスポットの心配は無いのだろうけど。
45nmなCELLなんかIO配線スペースのせいで、シュリンクが邪魔されてる話が
あったし。
問題は出ないのかな?
低発熱だからホットスポットの心配は無いのだろうけど。
45nmなCELLなんかIO配線スペースのせいで、シュリンクが邪魔されてる話が
あったし。
>>895
スレッドのスケジーュル性能が悪くなる、ってのは、ソフト側の問題だろ。
ハードが効率の良い仕組みを提供しても、ソフトがそれを使いこなせる様に
なる迄には、当分かかるのは普通の話だし。(CELLやx64、仮想機能、etc)
スレッドのスケジーュル性能が悪くなる、ってのは、ソフト側の問題だろ。
ハードが効率の良い仕組みを提供しても、ソフトがそれを使いこなせる様に
なる迄には、当分かかるのは普通の話だし。(CELLやx64、仮想機能、etc)
>>899
>ハードが効率の良い仕組みを提供しても、ソフトがそれを使いこなせる様に
まっ、ありえないと思いますけどね
それが可能なのはせいぜいゲームのような、走行しているアプリケーションがすべて把握し切れている場合に限ると思いますよ。著しく限定されると思います。
お隣でどんなアプリが動作しているかわからない状況で最適化など想像不能だし
これからはどんどん規模が大きくなるなら、マルチスレッド対応のライブラリも当然どんどんでてくるでしょうが
ライブラリはブラックボックス化してなんぼのものです。
使っている側と、使われている側の意思疎通はどんどん薄くなってゆくでしょう、また独立性はソフトの世界では正義です。だからそういう研究は進まないと思います。
いちいちチューンするのと、ハードの性能向上待ちなら間違いなく後者を待つと思うんですよ、なぜなら高々30%程度ですから。
そうすると何が起こるのかというと、対応などしない、やっても適当という結論になると思われます。
こうなりますと、せっかく入れた機能も有効利用されることもなく、単に性能を不安定して、ロジック規模を意味無く増やして終わりだと思います。
ならば、その分を削るなしして、ばらつきを押さえ無駄な消費電力を削ってクロックでも向上したほうが遥かに効果的だと思うのですが・・・
>ハードが効率の良い仕組みを提供しても、ソフトがそれを使いこなせる様に
まっ、ありえないと思いますけどね
それが可能なのはせいぜいゲームのような、走行しているアプリケーションがすべて把握し切れている場合に限ると思いますよ。著しく限定されると思います。
お隣でどんなアプリが動作しているかわからない状況で最適化など想像不能だし
これからはどんどん規模が大きくなるなら、マルチスレッド対応のライブラリも当然どんどんでてくるでしょうが
ライブラリはブラックボックス化してなんぼのものです。
使っている側と、使われている側の意思疎通はどんどん薄くなってゆくでしょう、また独立性はソフトの世界では正義です。だからそういう研究は進まないと思います。
いちいちチューンするのと、ハードの性能向上待ちなら間違いなく後者を待つと思うんですよ、なぜなら高々30%程度ですから。
そうすると何が起こるのかというと、対応などしない、やっても適当という結論になると思われます。
こうなりますと、せっかく入れた機能も有効利用されることもなく、単に性能を不安定して、ロジック規模を意味無く増やして終わりだと思います。
ならば、その分を削るなしして、ばらつきを押さえ無駄な消費電力を削ってクロックでも向上したほうが遥かに効果的だと思うのですが・・・
901 :ヽ・´∀`・,,)っ¬:2008/02/07(木) 22:12:50 ID:V2BzcBFP
SSEを否定する人もいるけど、ほとんどのマシンで使える汎用演算アクセラレータとしての意味は大きい。
数学ライブラリや動画再生なんかでも内部的には使ってんだぜ。
数学ライブラリや動画再生なんかでも内部的には使ってんだぜ。
x64だとSSE2以上必須になっているんだぜ
903 :ヽ・´∀`・,,)っ¬:2008/02/07(木) 22:51:08 ID:V2BzcBFP
俺の調査(笑)によるとPen4ではHTが有効な場合、
ワーカースレッドのアフィニティを固定した方が
パフォーマンス上がるらしい。
自信ないならユーザーで指定できるようにすればよくね?
ワーカースレッドのアフィニティを固定した方が
パフォーマンス上がるらしい。
自信ないならユーザーで指定できるようにすればよくね?
>>903
固定するより回したほうが上がるよ、固定していけるときはOffにして問題ないっす
固定するより回したほうが上がるよ、固定していけるときはOffにして問題ないっす
ワーカースレッドが動的に生成されないソフトがどれだけあるかってもの問題だな、そもそも大半は動的生成だが
そんなのどうやって固定するんだw
しかもユーザーがwww
そんなのどうやって固定するんだw
しかもユーザーがwww
906 :ヽ・´∀`・,,)っ━━━━━━┓:2008/02/08(金) 00:23:50 ID:Mrud8d6W
はい?
http://msdn.microsoft.com/library/ja/default.asp?url=/library/ja/jpdllpro/html/_win32_setthreadaffinitymask.asp
http://www.linux.or.jp/JM/html/LDP_man-pages/man2/sched_setaffinity.2.html
その動的に生成するスレッドについて、プログラム側でコアがなるべく固定で動くようにアフィニティを設定する。
自信が無いなら、アプリからスレッドの割り当てを手動で指定するオプションをユーザーに開放してろ
って言ってるんですよ、単に。
タスクマネージャからプロセスアフィニティくらいは指定できるな。
スレッドや子プロセスのアフィニティは親スレッド/プロセスのアフィニティに従属だから
大元を1プロセッサに固定してしまえば子プロセス/スレッドはそれに従うことになる。
Win32や*NIX限定の話だけど変態OSは知らん。
http://msdn.microsoft.com/library/ja/default.asp?url=/library/ja/jpdllpro/html/_win32_setthreadaffinitymask.asp
http://www.linux.or.jp/JM/html/LDP_man-pages/man2/sched_setaffinity.2.html
その動的に生成するスレッドについて、プログラム側でコアがなるべく固定で動くようにアフィニティを設定する。
自信が無いなら、アプリからスレッドの割り当てを手動で指定するオプションをユーザーに開放してろ
って言ってるんですよ、単に。
タスクマネージャからプロセスアフィニティくらいは指定できるな。
スレッドや子プロセスのアフィニティは親スレッド/プロセスのアフィニティに従属だから
大元を1プロセッサに固定してしまえば子プロセス/スレッドはそれに従うことになる。
Win32や*NIX限定の話だけど変態OSは知らん。
もう一つ問題点ってほどのものじゃないけど挙げておきます
並列処理では、並列化しない部分がどうしても残ってこの部分が足を引っ張るのですが
世にいうアムダールの法則というものです
http://ja.wikipedia.org/wiki/%E3%82%A2%E3%83%A0%E3%83%80%E3%83%BC%E3%83%AB%E3%81%AE%E6%B3%95%E5%89%87
ハイパースレッディングもスレッドには違いないので、並列化される側のコードとなります。
これは何を意味しているかというと、せっかくの効率アップが薄まってしまうんですよ。
30%の効率アップがあってもアムダール則ですりつぶされると一体何パーセントが有効になるのか?
またそれを解決する高度なスレッドスケジュールができたと仮にします、しかしまたそのコード自身もまたオーバーヘッドとなって圧し掛かる事にもなります。
さて、ここでハイパースレッドをあきらめて、コア一つ頭一スレッドの性能向上を図ったとします。
問題です、どの部分に効果しますでしょうか?
数か所あります。
並列処理では、並列化しない部分がどうしても残ってこの部分が足を引っ張るのですが
世にいうアムダールの法則というものです
http://ja.wikipedia.org/wiki/%E3%82%A2%E3%83%A0%E3%83%80%E3%83%BC%E3%83%AB%E3%81%AE%E6%B3%95%E5%89%87
ハイパースレッディングもスレッドには違いないので、並列化される側のコードとなります。
これは何を意味しているかというと、せっかくの効率アップが薄まってしまうんですよ。
30%の効率アップがあってもアムダール則ですりつぶされると一体何パーセントが有効になるのか?
またそれを解決する高度なスレッドスケジュールができたと仮にします、しかしまたそのコード自身もまたオーバーヘッドとなって圧し掛かる事にもなります。
さて、ここでハイパースレッドをあきらめて、コア一つ頭一スレッドの性能向上を図ったとします。
問題です、どの部分に効果しますでしょうか?
数か所あります。
とまあ以上で、並列化における効率アップは決定的な結果をもたらさない限り意味がないと思います。
漸近的前進は、スカラー的な高速化の方が有利だと思います。
漸近的前進は、スカラー的な高速化の方が有利だと思います。
909 :ヽ・´∀`・,,)っ━━━━━━┓:2008/02/08(金) 00:41:31 ID:Mrud8d6W
的確にアフィニティを固定することでパフォーマンスが向上するのは何処のCPU/OSでも同じことです。
http://docs.sun.com/app/docs/doc/820-1930/6ndimh1kn?l=ja&a=view
>>779に言いそびれたけど、まあプロセッサの固定に臆病になってるチキンPGはマルチスレッド使わないことがいいかと思います。
アフィニティ絞ってないスレッドを半端に大量に作っても他のプロセスの迷惑になりかねません。
実際うちはHT Xeonでアフィニティ固定してやることでパフォーマンス改善した事例がある。
まあ、スレッドアフィニティは状況に応じて何度でも再設定できますのでそのへんは工夫でしょう。
ヒント:たとえばWin32は全てのプロセス・スレッドにメッセージキューがあります。
http://docs.sun.com/app/docs/doc/820-1930/6ndimh1kn?l=ja&a=view
>>779に言いそびれたけど、まあプロセッサの固定に臆病になってるチキンPGはマルチスレッド使わないことがいいかと思います。
アフィニティ絞ってないスレッドを半端に大量に作っても他のプロセスの迷惑になりかねません。
実際うちはHT Xeonでアフィニティ固定してやることでパフォーマンス改善した事例がある。
まあ、スレッドアフィニティは状況に応じて何度でも再設定できますのでそのへんは工夫でしょう。
ヒント:たとえばWin32は全てのプロセス・スレッドにメッセージキューがあります。
>>909
>アフィニティ絞ってないスレッドを半端に大量に作っても他のプロセスの迷惑になりかねません。
せんせー、ほとんどスリープとはいっても、今のOSでは当たり前のように100スレッド以上走ってますよ〜
>アフィニティ絞ってないスレッドを半端に大量に作っても他のプロセスの迷惑になりかねません。
せんせー、ほとんどスリープとはいっても、今のOSでは当たり前のように100スレッド以上走ってますよ〜
911 :ヽ・´∀`・,,)っ━━━━━━┓:2008/02/08(金) 00:47:13 ID:Mrud8d6W
ゲームなんかビジーループはザラだけど。
HTってのは同じパイプラインに状況が許せば二つのスレッドを同時にながす技術なんだよね?
これによる利点っていうのがメモリからデータやら命令をloadする時間の隠蔽が可能であること。
で問題になってるのは、HTで2スレッド同時処理ができない状況が頻繁におこって、
1スレッドのtotalの処理時間が増加することでその後の依存性をもったスレッドの処理が遅れるということ。
汎用計算機だと依存性のあるスレッドの処理が中心だから、
デメリットのほうがが大きいんじゃないかってことがスレでは言われてるんだよね。
レイテンシの隠蔽ができなくても他のコアを使用して処理時間を短くするほうが、
依存性のあるスレッド処理ではいいのではないか?ってのがHT否定派の意見だと推測したんだけどあってる?
そもそもintelが具体的にHTの性能上昇分がレイテンシ隠蔽によるものか
同時実効性によるものかしっかり説明しないのが悪いんだけどな。
intelからしてみればそんものマーケティングやら投機スレッドの布石以外、
価値がないっていってるっぽいけど。
あと、投機スレッジングについてそれっぽいのが。
ttp://pc.watch.impress.co.jp/docs/2008/0205/isscc02.htm
これによる利点っていうのがメモリからデータやら命令をloadする時間の隠蔽が可能であること。
で問題になってるのは、HTで2スレッド同時処理ができない状況が頻繁におこって、
1スレッドのtotalの処理時間が増加することでその後の依存性をもったスレッドの処理が遅れるということ。
汎用計算機だと依存性のあるスレッドの処理が中心だから、
デメリットのほうがが大きいんじゃないかってことがスレでは言われてるんだよね。
レイテンシの隠蔽ができなくても他のコアを使用して処理時間を短くするほうが、
依存性のあるスレッド処理ではいいのではないか?ってのがHT否定派の意見だと推測したんだけどあってる?
そもそもintelが具体的にHTの性能上昇分がレイテンシ隠蔽によるものか
同時実効性によるものかしっかり説明しないのが悪いんだけどな。
intelからしてみればそんものマーケティングやら投機スレッドの布石以外、
価値がないっていってるっぽいけど。
あと、投機スレッジングについてそれっぽいのが。
ttp://pc.watch.impress.co.jp/docs/2008/0205/isscc02.htm
スレッド数を2倍にした方が、コアを2倍にするより効率が高い
http://japan.cnet.com/news/ent/story/0,2000056022,20267807-2,00.htm
http://japan.cnet.com/news/ent/story/0,2000056022,20267807-2,00.htm
914 :ヽ・´∀`・,,)っ━━━━━━┓:2008/02/08(金) 02:08:47 ID:Mrud8d6W
スレッドの依存性はできるだけ無いほうがいいんだけどね。
でもさ、ニコイチクアッドとかNUMAとか、コアに対するスレッドの割り振り方で性能が大きく変わるでしょ。
SMTだとマルチコアよりキャッシュの調停が楽。というか実装によってはまったく不要。
ちなみにPentium 4のHTはSMTの実装としてはあんまりスマートじゃないらしい。
詳しいことは知らん
でもさ、ニコイチクアッドとかNUMAとか、コアに対するスレッドの割り振り方で性能が大きく変わるでしょ。
SMTだとマルチコアよりキャッシュの調停が楽。というか実装によってはまったく不要。
ちなみにPentium 4のHTはSMTの実装としてはあんまりスマートじゃないらしい。
詳しいことは知らん
915 :MACオタ>912 さん:2008/02/08(金) 02:42:43 ID:ZhH23SBF
>>912
-------------------
依存性をもったスレッドの処理が遅れるということ。
-------------------
>>914で団子さんが書いている通りす。
http://pc.watch.impress.co.jp/docs/2004/0812/kaigai110.htm
===================
だが、TLPによって複数スレッドを並列に走らせる場合には話が違ってくる。TLPでは依存性の薄い
複数のインストラクションフローから並列化できる命令をそれぞれ抽出するため、CPU全体での
IPCを従来アーキテクチャより大幅に高めることができる。言い換えると、CPUの処理の並列化を、
命令レベルからスレッドレベルへと引き上げることで、より高い並列度を実現するのがTLPという
わけだ。
===================
「依存性の薄い複数のインストラクションフロー」に注目す。
-------------------
依存性をもったスレッドの処理が遅れるということ。
-------------------
>>914で団子さんが書いている通りす。
http://pc.watch.impress.co.jp/docs/2004/0812/kaigai110.htm
===================
だが、TLPによって複数スレッドを並列に走らせる場合には話が違ってくる。TLPでは依存性の薄い
複数のインストラクションフローから並列化できる命令をそれぞれ抽出するため、CPU全体での
IPCを従来アーキテクチャより大幅に高めることができる。言い換えると、CPUの処理の並列化を、
命令レベルからスレッドレベルへと引き上げることで、より高い並列度を実現するのがTLPという
わけだ。
===================
「依存性の薄い複数のインストラクションフロー」に注目す。
916 :MACオタ>団子 さん:2008/02/08(金) 02:47:29 ID:ZhH23SBF
>>914
-----------------
ちなみにPentium 4のHTはSMTの実装としてはあんまりスマートじゃないらしい。
-----------------
この辺がP4 HTT以降のSMTの実装との違いす。
http://www.google.com/search?q=POWER5+dynamic-resource-balancing
ただ>>890で書いたように、どの程度機能強化のためのトランジスタを増やすかという選択の問題かと思うす。
-----------------
ちなみにPentium 4のHTはSMTの実装としてはあんまりスマートじゃないらしい。
-----------------
この辺がP4 HTT以降のSMTの実装との違いす。
http://www.google.com/search?q=POWER5+dynamic-resource-balancing
ただ>>890で書いたように、どの程度機能強化のためのトランジスタを増やすかという選択の問題かと思うす。
つまりSMT使用時は非使用時と比べて、OSなどのソフト側がそれに最適化されてないと性能がおちる可能性があるって事でしょ?
こうなるとソフト側の最適化の話になってくるから。
SMT自体はキャッシュを共有しているコアという見方ができるし確かに効率はいいと思うけど。
intelはSMTの方向としてトランジスタと並列度のコストパフォーマンスのとるのか、
それともデータや命令のプリフェッチ機構をとるのか、
このあたりはintelの政治を加味したアーキテクトの趣味になってくるんじゃないの?
すくなくとも両方満たそうとするほどオレゴンは横暴じゃないと思う。
こうなるとソフト側の最適化の話になってくるから。
SMT自体はキャッシュを共有しているコアという見方ができるし確かに効率はいいと思うけど。
intelはSMTの方向としてトランジスタと並列度のコストパフォーマンスのとるのか、
それともデータや命令のプリフェッチ機構をとるのか、
このあたりはintelの政治を加味したアーキテクトの趣味になってくるんじゃないの?
すくなくとも両方満たそうとするほどオレゴンは横暴じゃないと思う。
チューンは必ず大物を対処してそれから小物を対処する手順でければ必ず失敗するよ
今一番の大物は
1.キャッシュヒットミス
2.スレッドな何もしていない空き時間
1は、キャッシュの容量をうまく設計することで成功すると思う Core2 をよく見ておくべき
2は、コアの対称性が高ければう割合まくいく方法がある
それ以外は事実上やってもやらなくても効果はないよ
別のいい方法があるからといって上の二つをつぶす物は多分大失敗に終わると思うよ
たとえば、分岐命令がパイプラインを乱して効率悪いので、キャッシュを外すけど絶対パイプラインが乱れない良い方法があったので採用とかあり得ない。
今一番の大物は
1.キャッシュヒットミス
2.スレッドな何もしていない空き時間
1は、キャッシュの容量をうまく設計することで成功すると思う Core2 をよく見ておくべき
2は、コアの対称性が高ければう割合まくいく方法がある
それ以外は事実上やってもやらなくても効果はないよ
別のいい方法があるからといって上の二つをつぶす物は多分大失敗に終わると思うよ
たとえば、分岐命令がパイプラインを乱して効率悪いので、キャッシュを外すけど絶対パイプラインが乱れない良い方法があったので採用とかあり得ない。
「Core 2 Duo」は特許侵害--米大学、インテルを提訴
http://japan.cnet.com/news/ent/story/0,2000056022,20366876,00.htm
なんぞこれ。
分岐予測に関することかね。
2001年にすでにIntelに働きかけてたってことはNetBurstから採用された技術か。
http://japan.cnet.com/news/ent/story/0,2000056022,20366876,00.htm
なんぞこれ。
分岐予測に関することかね。
2001年にすでにIntelに働きかけてたってことはNetBurstから採用された技術か。
{kind=link}
(#゚Д゚)ゴゴゴゴルァ!!
見てもーたじゃないか!
見てもーたじゃないか!
>>919
Memory Disambiguationの事じゃない?
Memory Disambiguationの事じゃない?
うおあ、キモ!
これがウィスコンシン大学がインテルを訴えた訴状
ttp://www.warf.org/uploads/media/Complaint_with_patent_as_filed.pdf
これのページ5に、Core microarchitectureのSmart Memory Access、
memory disambiguation techniqueが特許を侵害していると書かれています。
ttp://www.warf.org/uploads/media/Complaint_with_patent_as_filed.pdf
これのページ5に、Core microarchitectureのSmart Memory Access、
memory disambiguation techniqueが特許を侵害していると書かれています。
いまP4使ってて一年後にPS買い変える身としては
Core2Duoなんかよりブッチギリで速いCPUにして欲しい
まぁ、いくらCPUが速くなってもHDDが遅くちゃあまり意味ないんだろうけど・・・
だから一年後にはSDDも64GBが12000円になってくれてるといいな
それとwindows7も出ているとうれしい
さらにGeforce11000Ultraを積む
とにかく最近PC買ったやつは負け組みm9(^Д^)
Core2Duoなんかよりブッチギリで速いCPUにして欲しい
まぁ、いくらCPUが速くなってもHDDが遅くちゃあまり意味ないんだろうけど・・・
だから一年後にはSDDも64GBが12000円になってくれてるといいな
それとwindows7も出ているとうれしい
さらにGeforce11000Ultraを積む
とにかく最近PC買ったやつは負け組みm9(^Д^)
貧乏ってかわいそうだね
PS3いちきゅっぱはまだですか
{kind=link}
「Tukwila」はダイサイズでかすぎw
NVidiaの次世代ハイエンドG100が10億トランジスタ超といってるのに、倍の20億超えだからなw
今ある技術で、金に物言わせてつくれる最大のダイサイズはどの程度なんすかね?
SRAM数十GByte + 数十コアのワンチップPCとか冗談で作れないのかな
SRAM数十GByte + 数十コアのワンチップPCとか冗談で作れないのかな
ウェハの最大が30cmだから考えtれ見れば?
つかこのスレにきてんのにSRAMのダイサイズとかも考えられないのなら
とっとと回線きって市ね
とっとと回線きって市ね
935 :ヽ・´∀`・,,)っ━━━━━━┓:2008/02/09(土) 09:39:29 ID:rIBi1EFd
ヴォルフデールの倍、いわゆるダブル
936 :MACオタ>934 さん:2008/02/09(土) 10:02:32 ID:37ie/uQZ
ところでin-order処理となるSilverthorneわコンパイラの最適化に性能が左右されることが容易に予想される
すけど、この辺どうなるすかね。。。
すけど、この辺どうなるすかね。。。
スパコンに歩留まり関係有るの?
チップ面積が増えると急激に悪くなるから、ないとは言えないと思う。
しかし、そういう問題じゃなくて決定的にできない理由があるのではないかと思うのだが。
しかし、そういう問題じゃなくて決定的にできない理由があるのではないかと思うのだが。
そもそもそんな大きいのテスタが対応できんのじゃね
今のデスクトップ用チップなら、クァッドコア+チップセットを完全1チップに統合しても
十分コスト的に見合うレベルになってる
単にそれをしないのはバリデーションが難しいから
十分コスト的に見合うレベルになってる
単にそれをしないのはバリデーションが難しいから
スーパーコンピュータ用のチップなら、
チップにコストをかけられると思っている奴が間違い。
スーパーコンピュータは金に糸目をつけない、
価格性能比で構成を考えないと思っているのか?
チップにコストをかけられると思っている奴が間違い。
スーパーコンピュータは金に糸目をつけない、
価格性能比で構成を考えないと思っているのか?
I/Oをたくさん統合してしまうと、かえって高コストになってしまうのでは?
後藤記事じゃないが、サウスブリッジ相当は今後も別チップだと思う。
後藤記事じゃないが、サウスブリッジ相当は今後も別チップだと思う。
ノースブリッジ機能もVGA統合は怪しい
MCMなら出るだろうけど
開発サイクルが合わない物は取り込まんだろ
MCMなら出るだろうけど
開発サイクルが合わない物は取り込まんだろ
たとえば宇宙船に積まなきゃ行けないとか特殊な状況ならやるかもね。
アポロって真空管がつめなくてトランジスタのコンピュータを作ったんじゃなかったか。
アポロって真空管がつめなくてトランジスタのコンピュータを作ったんじゃなかったか。
>>947
VRAMさえonboardまたはonchipで統合できれば、拡張カード上のGPUはほとんど不要になる。
そうでなくても、GPUは外付け可能だからダイ上に統合してしまってもニッチに対処できる。
VRAMさえonboardまたはonchipで統合できれば、拡張カード上のGPUはほとんど不要になる。
そうでなくても、GPUは外付け可能だからダイ上に統合してしまってもニッチに対処できる。
>>937
元々OoOが有効に働く様なコードを吐くコンパイラは、ある意味無能な訳で、
そんなコンパイラでコード化されたソフトは、かなり旧いのしか無いのでは?
今のコンパイラが、わざわざOoOを働かせる様なコードを吐くとは思いにくい
し、動的な条件変化によりOoOが有効になる場合ってのは、そんなに多くない
気もするし。
元々OoOが有効に働く様なコードを吐くコンパイラは、ある意味無能な訳で、
そんなコンパイラでコード化されたソフトは、かなり旧いのしか無いのでは?
今のコンパイラが、わざわざOoOを働かせる様なコードを吐くとは思いにくい
し、動的な条件変化によりOoOが有効になる場合ってのは、そんなに多くない
気もするし。
>>950
GPU内蔵チップセットも、外付けGPUと共同で働かせられる様になってきてるから、
GPUをオンダイで統合しても全くモーマンタイだよね。
サウス統合は流石に難しい(技術的にではなくて商品的に)と思うが。
GPU内蔵チップセットも、外付けGPUと共同で働かせられる様になってきてるから、
GPUをオンダイで統合しても全くモーマンタイだよね。
サウス統合は流石に難しい(技術的にではなくて商品的に)と思うが。
953 :MACオタ>951 さん:2008/02/09(土) 20:03:44 ID:37ie/uQZ
>>951
実行ユニット数も命令レイテンシも、ここ数年間で発売されているプロセッサと全く異なるすけど。。。
実行ユニット数も命令レイテンシも、ここ数年間で発売されているプロセッサと全く異なるすけど。。。
Dual Core+GPUとQuad Coreの2ダイで当面はOKじゃまいか?
Dual Coreで外付けGPU使いたい人やQuad Coreで外付けGPU不要な人は
ちょっとばかし余計なコストを負担することになるのはご愁傷様ということで。
Dual Coreで外付けGPU使いたい人やQuad Coreで外付けGPU不要な人は
ちょっとばかし余計なコストを負担することになるのはご愁傷様ということで。
Silverthorneに幻想抱いてる人たちは
一度C7使ってみると良いよ
一度C7使ってみると良いよ
C7が遅いのは知ってるよ。
ただ、それはC7が遅いのであって、
Silverthorneが遅いという証明になる訳では無い。
inorderってだけで、そこまで妄想できるのはおめでたい。
ただ、それはC7が遅いのであって、
Silverthorneが遅いという証明になる訳では無い。
inorderってだけで、そこまで妄想できるのはおめでたい。
Intelってだけで、そこまで妄想できるのはおめでたい。
あぁ、ベンチは速いかもね
とくにsandra
あぁ、ベンチは速いかもね
とくにsandra
>>953
それって>>937の in-orderへのコンパイラの最適化の話とは別だろ?
実行ユニット数の少なさや命令レイテンシーの多さに対して、コンパイラの
最適化が貢献出来る話は無いと思うが。
>>956
C7の遅さで一番の問題は、メモリアクセス性能の低さだったと思うので、その
ネックがSilverthorne無ければ、かなり違うと思う。
それって>>937の in-orderへのコンパイラの最適化の話とは別だろ?
実行ユニット数の少なさや命令レイテンシーの多さに対して、コンパイラの
最適化が貢献出来る話は無いと思うが。
>>956
C7の遅さで一番の問題は、メモリアクセス性能の低さだったと思うので、その
ネックがSilverthorne無ければ、かなり違うと思う。
まず無理
960 :ヽ・´∀`・,,)っ━━━━━━┓:2008/02/09(土) 21:18:03 ID:rIBi1EFd
だな。movやxorでレジスタリネーミングとかのノウハウはまあ使えないか
最悪逆効果だな。
NetBurst去りし後に左シフトを連続加算に置き換える某コンパイラ旧版の挙動は全く役に立たなくなった。
最悪逆効果だな。
NetBurst去りし後に左シフトを連続加算に置き換える某コンパイラ旧版の挙動は全く役に立たなくなった。
961 :MACオタ>958 さん:2008/02/09(土) 21:23:44 ID:37ie/uQZ
>>958
--------------
実行ユニット数の少なさや命令レイテンシーの多さに対して、コンパイラの
最適化が貢献出来る話は無いと思うが。
--------------
一応実行パイプラインわ2本あるすけど。。。
命令のペアリングとか頭に浮かばないヒトが出てきたということわ、Pentium時代も遠くなりにけり
ということなんすかね。
--------------
実行ユニット数の少なさや命令レイテンシーの多さに対して、コンパイラの
最適化が貢献出来る話は無いと思うが。
--------------
一応実行パイプラインわ2本あるすけど。。。
命令のペアリングとか頭に浮かばないヒトが出てきたということわ、Pentium時代も遠くなりにけり
ということなんすかね。
962 :ヽ・´∀`・,,)っ━━━━━━┓:2008/02/09(土) 21:30:29 ID:rIBi1EFd
OoOがあっても、どの命令とどの命令が並列実行できるかとか、大雑把にでも把握しておかないと
性能は引き出せません。
まあ、どのみち性能の大して必要の無いところはコンパイラ任せでいいんだけどね。
性能は引き出せません。
まあ、どのみち性能の大して必要の無いところはコンパイラ任せでいいんだけどね。
というかC7を遅いと思う層に
Silverthorneは合わないだろ
どう考えても
Silverthorneは合わないだろ
どう考えても
964 :ヽ・´∀`・,,)っ━━━━━━┓:2008/02/10(日) 10:21:48 ID:YVen/PEY
A100/A110(実質ULV-Dothan 512k)より速ければいいや
965 :MACオタ>MACオタ:2008/02/10(日) 11:04:39 ID:L+RPXY/9
>>964
------------------
A100/A110(実質ULV-Dothan 512k)より速ければいいや
------------------
シングルスレッドでわ同程度と伝えられているす。
http://pc.watch.impress.co.jp/docs/2007/1128/ubiq205.htm
==================
ただし、シングルスレッドでは、SV版(1.8GHz)がA110と同じぐらい、MV版(1.1GHz)がA100(600MHz)と同じ
程度の性能と見積もられているようだ。
==================
------------------
A100/A110(実質ULV-Dothan 512k)より速ければいいや
------------------
シングルスレッドでわ同程度と伝えられているす。
http://pc.watch.impress.co.jp/docs/2007/1128/ubiq205.htm
==================
ただし、シングルスレッドでは、SV版(1.8GHz)がA110と同じぐらい、MV版(1.1GHz)がA100(600MHz)と同じ
程度の性能と見積もられているようだ。
==================
そしてマルチなら60%速いといっていたはずだが
今回30%になった
今回30%になった
in-orderの場合、命令の並び替えが出来ないから、命令同時実行数も連続した2つで済ませ
てるから、コンパイラが同時実行可能な命令を連続した形で吐き出してくれないと駄目って
事で、これは今あるコンパイラなら普通に行ってる筈だから、Silverthorne専用で最適化す
る必要は無いって話をしたつもりだが。
OoOなら命令の並び替えが出来るから、例えば5〜6個程度の命令の並びから、内蔵してる実行ユニット
数分の同時実行、例えば3つ同時が可能だし2つ同時の頻度も高くなるから、in-orderより性能が高い、
って事だろ。
命令実行ユニット数(デコードユニット数も関係するが)が少ない事と、in-orderのせいで同時実行する
機会が少ない事を、ごっちゃにしないで欲しいのだが。
てるから、コンパイラが同時実行可能な命令を連続した形で吐き出してくれないと駄目って
事で、これは今あるコンパイラなら普通に行ってる筈だから、Silverthorne専用で最適化す
る必要は無いって話をしたつもりだが。
OoOなら命令の並び替えが出来るから、例えば5〜6個程度の命令の並びから、内蔵してる実行ユニット
数分の同時実行、例えば3つ同時が可能だし2つ同時の頻度も高くなるから、in-orderより性能が高い、
って事だろ。
命令実行ユニット数(デコードユニット数も関係するが)が少ない事と、in-orderのせいで同時実行する
機会が少ない事を、ごっちゃにしないで欲しいのだが。
連続スマソ
もし今のコンパイラが、OoOなCPUを前提にして、同時実行可能な命令コードを、
わざわざ連続に並べない様な手抜きをしてる場合が普通だ、って話なら、>>937
の疑問にも納得がいくが、そのあたりはどうなの?
もし今のコンパイラが、OoOなCPUを前提にして、同時実行可能な命令コードを、
わざわざ連続に並べない様な手抜きをしてる場合が普通だ、って話なら、>>937
の疑問にも納得がいくが、そのあたりはどうなの?
gccでmarchの設定して
それぞれ見てみれば
それぞれ見てみれば
MSのコンパイラはデータの依存性をなくして同時実行しやすいコードを生成するだけだよ。
972 :MACオタ>968 さん:2008/02/10(日) 15:38:53 ID:L+RPXY/9
>>968
-----------------
これは今あるコンパイラなら普通に行ってる筈だから
-----------------
OoOEにおいて、コンパイラ(=プログラマ)が命令を実行するタイミングを制御することが不可能す。
アドレス上連続した命令が同時にイシューされる保証わ全く無いす。
またインオーダーの場合、命令の並びわ実行レイテンシを考慮して先行命令が結果を生成する
タイミングに合わせて依存命令を配置しないと、バブルが発生するす。
アーキテクチャや世代ごとに命令の実行レイテンシわ異なるすから、最適化のやりかたも毎度
更新する必要が出てくるす。
この2点だけ見ても「今ある」OoOEのx86プロセッサ用のコンパイラがSilverthrone向きでないこと
わ判るかと思うす。
-----------------
これは今あるコンパイラなら普通に行ってる筈だから
-----------------
OoOEにおいて、コンパイラ(=プログラマ)が命令を実行するタイミングを制御することが不可能す。
アドレス上連続した命令が同時にイシューされる保証わ全く無いす。
またインオーダーの場合、命令の並びわ実行レイテンシを考慮して先行命令が結果を生成する
タイミングに合わせて依存命令を配置しないと、バブルが発生するす。
アーキテクチャや世代ごとに命令の実行レイテンシわ異なるすから、最適化のやりかたも毎度
更新する必要が出てくるす。
この2点だけ見ても「今ある」OoOEのx86プロセッサ用のコンパイラがSilverthrone向きでないこと
わ判るかと思うす。
そんな訳でIntelのコンパイラの中の人はがんばれって事です
だがしかし
>>972
>この2点だけ見ても「今ある」OoOEのx86プロセッサ用のコンパイラがSilverthrone向きでないこと
>わ判るかと思うす。
これくらいは誰でも分かっているのではなかろうか?
>>972
>この2点だけ見ても「今ある」OoOEのx86プロセッサ用のコンパイラがSilverthrone向きでないこと
>わ判るかと思うす。
これくらいは誰でも分かっているのではなかろうか?
NehalemのSuper Pi画像の続報すけど、捏造で確定とのことす。
http://www.xtremesystems.org/forums/showpost.php?p=1547196&postcount=21
投稿日に注目、また随分古いネタだったすね。。。
http://www.xtremesystems.org/forums/showpost.php?p=1547196&postcount=21
投稿日に注目、また随分古いネタだったすね。。。
制作者のコメントす。
http://www.xtremesystems.org/forums/showpost.php?p=2761352&postcount=194
------------------
5min photochop in 2006 posted in a joke thread turn in to this
------------------
ところで国内の腐れルーマーサイトから訂正わ出るすかね。。。
http://www.xtremesystems.org/forums/showpost.php?p=2761352&postcount=194
------------------
5min photochop in 2006 posted in a joke thread turn in to this
------------------
ところで国内の腐れルーマーサイトから訂正わ出るすかね。。。
腐れルーマーサイトじゃなくてルーマー紹介サイトだろ。
腐れなのはソースの方。どこまでも精神がゆがんでいる奴だ。
関係のない個人サイトまで攻撃しだすとはな。
どうせ自分でページを開く実力もないくせに。
腐れなのはソースの方。どこまでも精神がゆがんでいる奴だ。
関係のない個人サイトまで攻撃しだすとはな。
どうせ自分でページを開く実力もないくせに。
MACヲタがブログを作ったら、一瞬で炎上しそうw
979 :MACオタ>977-978 さん:2008/02/10(日) 17:42:45 ID:L+RPXY/9
言葉は悪いが激しく同意なんだが
>>979
>騙されて喜び、真実を知らされて叩く。
誰もだまされてなんかないですが何か?
信憑性の薄いページは別にみなきゃいいし、みても信じなければいい。
単に匿名掲示板で個人サイト叩きなんてやってるMACオタの精神がゆがんでいるだけのことだ。
>騙されて喜び、真実を知らされて叩く。
誰もだまされてなんかないですが何か?
信憑性の薄いページは別にみなきゃいいし、みても信じなければいい。
単に匿名掲示板で個人サイト叩きなんてやってるMACオタの精神がゆがんでいるだけのことだ。
というか脱線するけど、ニュース紹介系のサイトって
ソースが正しいかどうかはフィルタせずにとりあえず内容を垂れ流すのが普通の運営方針だろ。
あと信じるか信じないかは読み手の次第だよ。読み手もルーマーは所詮ルーマーだとわりきって
事前情報を収集しているんだからな。
そこまで真実を広めることにこだわるなら2chにこだわらずに、自らサイトを開くなどもって
精力的な活動をしてもらいたいものだ。それをしないMACオタはただ匿名掲示板という安全な場所で
ひっそり叩いて優越感に浸りたいだけなのだろう。
ソースが正しいかどうかはフィルタせずにとりあえず内容を垂れ流すのが普通の運営方針だろ。
あと信じるか信じないかは読み手の次第だよ。読み手もルーマーは所詮ルーマーだとわりきって
事前情報を収集しているんだからな。
そこまで真実を広めることにこだわるなら2chにこだわらずに、自らサイトを開くなどもって
精力的な活動をしてもらいたいものだ。それをしないMACオタはただ匿名掲示板という安全な場所で
ひっそり叩いて優越感に浸りたいだけなのだろう。
番号が飛んでると思ったらまた基地外MACオタが湧いてやがんのか。
MACオタは氏ね。ついでにその取り巻きも失せろ。
MACオタは氏ね。ついでにその取り巻きも失せろ。
MACオタいつになくキレがあるな
貼られて30分でつっこみを入れた>>936もGJ!
貼られて30分でつっこみを入れた>>936もGJ!
またクズが湧いてんのwww
いいかげん氏ねよ
いいかげん氏ねよ
嘘ソースでもいいから垂れ流せってwww
過疎るより盛り上がって議論が深まることもあるだろ?
今回のNehalemπに関しては紹介サイトも信憑性は怪しいと書いてた気がするが。
CELLをそのままソケット478にして発売してください
なになに?もう8コアとかでる時代なの?
BlueGene(PPC440特盛)みたいに銀棘特盛で一つ作ってくれるとネタになりそう
64コアのタスマネを見た事がある・・
>>972
何故MACオタが嫌われてるか、良く分かったよ。
何故MACオタが嫌われてるか、良く分かったよ。
994 :MACオタ>991 さん:2008/02/11(月) 18:08:26 ID:m5coYQS8
>>991
製品が出てくるかどうかわ別として、Intelがそういった方向性を検討していることだけわ間違い無いす。
http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/947-948
========================
■Intel (Shekhar Borkar 氏)
マルチコアにむけて、単一コアは極端にシンプルになる。
----------------
"A core will look like a NAND gate in the future. You won't want to mess with it," said Borkar.
----------------
ソフトウェア側は革命的な変遷が起こるとの事。
========================
製品が出てくるかどうかわ別として、Intelがそういった方向性を検討していることだけわ間違い無いす。
http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/947-948
========================
■Intel (Shekhar Borkar 氏)
マルチコアにむけて、単一コアは極端にシンプルになる。
----------------
"A core will look like a NAND gate in the future. You won't want to mess with it," said Borkar.
----------------
ソフトウェア側は革命的な変遷が起こるとの事。
========================
いずれSilverthorneに最適化されたPC向けソフトなんて出るわけ無い
主にスパコン分野でソフトウェアの革命が叫ばれ続けて30年
100年後も同じこと言ってそうだ
100年後も同じこと言ってそうだ
シンプル多コアってサーバー向けでしょ?
HPCの中の特定分野向け
>>995 さん
SilverthorneがPC用プロセッサで無いことわ同意するす。
しかし将来のモバイルデバイスが、現在PCで行っているような機能を持つことも容易に想像できるす。
>>996 さん
単に方向性というだけの話すけど、論理ゲートのごとくプロセッサコアを使用するようになるという比喩わ、
相当思い切ったことを考えていると見えるす。
SilverthorneがPC用プロセッサで無いことわ同意するす。
しかし将来のモバイルデバイスが、現在PCで行っているような機能を持つことも容易に想像できるす。
>>996 さん
単に方向性というだけの話すけど、論理ゲートのごとくプロセッサコアを使用するようになるという比喩わ、
相当思い切ったことを考えていると見えるす。
1001 :1001: