CPUアーキテクチャについて語れ 5
お前らいい加減、無能なAMD房・Intel房・GKに振りまわされず、
エンコ時間がどうとかPIがどうとかPS3がどうとかじゃなく、
CPUコアのアーキテクチャについて語りましょう。
x86/RISC/CISC/スーパースカラ/VLIW/MIMD/SIMD
等について語ってもよし、
フリップフロップ回路が小さいPentium Mマンセー、
CISCなのに内部はRISCなPentium 4マンセー、
x86なのに32/64bitコンパチなOpteronマンセー、
昔々8086の時代は(以下略・・・等もよし。
さあ、不毛な争いを止めてCPUアーキテクチャについて語ろう!
ただし、Cellに関する話題、Cellとの比較は、スレがまともに進行しなくなるので厳禁。
Cellも絡めて話をしたければ、自作PC板ではない場所でやっておくんなまし。
前スレ
Part 1 http://pc5.2ch.net/test/read.cgi/jisaku/1082357989/
Part 2 http://pc7.2ch.net/test/read.cgi/jisaku/1101041110/
Part 3 http://pc7.2ch.net/test/read.cgi/jisaku/1139046363/
Part 4 http://pc7.2ch.net/test/read.cgi/jisaku/1151732227/
エンコ時間がどうとかPIがどうとかPS3がどうとかじゃなく、
CPUコアのアーキテクチャについて語りましょう。
x86/RISC/CISC/スーパースカラ/VLIW/MIMD/SIMD
等について語ってもよし、
フリップフロップ回路が小さいPentium Mマンセー、
CISCなのに内部はRISCなPentium 4マンセー、
x86なのに32/64bitコンパチなOpteronマンセー、
昔々8086の時代は(以下略・・・等もよし。
さあ、不毛な争いを止めてCPUアーキテクチャについて語ろう!
ただし、Cellに関する話題、Cellとの比較は、スレがまともに進行しなくなるので厳禁。
Cellも絡めて話をしたければ、自作PC板ではない場所でやっておくんなまし。
前スレ
Part 1 http://pc5.2ch.net/test/read.cgi/jisaku/1082357989/
Part 2 http://pc7.2ch.net/test/read.cgi/jisaku/1101041110/
Part 3 http://pc7.2ch.net/test/read.cgi/jisaku/1139046363/
Part 4 http://pc7.2ch.net/test/read.cgi/jisaku/1151732227/
|
|
|
2 :Socket774:2006/09/26(火) 11:43:52 ID:0RqZfazB
>>1
随分とひまだな
随分とひまだな
3 : ◆R77rap64x2 :2006/09/26(火) 11:46:08 ID:fJLAGEHw
明日論は雷鳥以降、銅配線ではなくなったという思い込み
,、::::::::::::::::::::::::::::. 、
/::::::::::::::::::::::::::::::::::: \
{;;;ゝ-=・=- i -=・=- !i;;;;;
,;ぇハ、 -=ニ=- ,f゙: Y;;f そんなふうに思っていました
~''戈ヽ `二´ r'´:::. `!
,、::::::::::::::::::::::::::::. 、
/::::::::::::::::::::::::::::::::::: \
{;;;ゝ-=・=- i -=・=- !i;;;;;
,;ぇハ、 -=ニ=- ,f゙: Y;;f そんなふうに思っていました
~''戈ヽ `二´ r'´:::. `!
>>1乙
ダンゴ氏ね
ダンゴ氏ね
Cell・PS3関連はこっちかゲハ板でどうぞ
http://pc7.2ch.net/test/read.cgi/jisaku/1149175437/l50
http://pc7.2ch.net/test/read.cgi/jisaku/1158777125/l50
http://pc7.2ch.net/test/read.cgi/jisaku/1149175437/l50
http://pc7.2ch.net/test/read.cgi/jisaku/1158777125/l50
ダンゴとMACヲタはスルーでお願いします。
>ただし、Cellに関する話題、Cellとの比較は、スレがまともに進行しなくなるので厳禁。
もともとまともに進行して無いだろ
もともとまともに進行して無いだろ
トイレは遠くなりにけり
マルチコアなのでBoston CircuitsのgCOREとかどうだ。タイルアレイプロセッサだ。単体コアARCだけど。
ところで、有名どころ(x86とかcellとか)以外の情報は
おいらみたいな一般人にはあんまし入ってこないんだが
どのへん見ると珍しいCPUの情報があるんでしょ?
おいらみたいな一般人にはあんまし入ってこないんだが
どのへん見ると珍しいCPUの情報があるんでしょ?
ARMとSH,H8、POWER,x86,Cell、MIPS以外になんかあったっけ?
マイコンボードとかあさればマイナーな8bitやら16bitのもんがいくつか転がってるけど。
マイコンボードとかあさればマイナーな8bitやら16bitのもんがいくつか転がってるけど。
SPARCわすれてるぞw
死にかけだし。
でも、既に死んでるって…
うはっ、4秒差w
16 :Socket774:2006/09/26(火) 23:21:57 ID:bZrk18f4
PA-RISCとDEC-ALPHAMもわすれてる
17 :Socket774:2006/09/26(火) 23:26:02 ID:bZrk18f4
ALPHAM⇒ALPHA
間違えた、、、
間違えた、、、
18 :Socket774:2006/09/26(火) 23:33:48 ID:bZrk18f4
とりあえず 有名どころ
x86 IA-64 POWER&POWER-PC 68000系 MIPS SPARC PA-RISC
DEC-ALPHA SH ARM
x86 IA-64 POWER&POWER-PC 68000系 MIPS SPARC PA-RISC
DEC-ALPHA SH ARM
Alphaって書いてよw
>>18
なにそのATH-LONとかCORD-UOみたいなPowerPC
なにそのATH-LONとかCORD-UOみたいなPowerPC
POWE-RPC
今度のコンロー、メロンって、バスの取り合いしたりしないの?
AMDのは、マルチコアになればなるほど、メリットが出るって聞いたけど?
AMDのは、マルチコアになればなるほど、メリットが出るって聞いたけど?
Xtensa
>22
うん、しない
メモリコントローラの動作クロックがちと低いが、
二次キャッシュその他の構造で充分に埋め合わせされてる模様
うん、しない
メモリコントローラの動作クロックがちと低いが、
二次キャッシュその他の構造で充分に埋め合わせされてる模様
L1とL2の間にキャッシュ・バスコントローラがある感じだよな
>19
それをいうなら AlphaAXP じゃね?
それをいうなら AlphaAXP じゃね?
28 :Socket774:2006/09/27(水) 13:07:34 ID:fmlptzaq
インテル、超低消費電力型チップ「Steeley」でUMPCの低価格化を目指す
http://headlines.yahoo.co.jp/hl?a=20060927-00000003-cnet-sci
http://headlines.yahoo.co.jp/hl?a=20060927-00000003-cnet-sci
29 :Socket774:2006/09/27(水) 13:29:01 ID:fmlptzaq
Intel、80コアのTFLOPSプロセッサの開発計画を公開
http://www.itmedia.co.jp/news/articles/0609/27/news016.html
http://www.itmedia.co.jp/news/articles/0609/27/news016.html
次世代データセンターの技術を紹介
http://pc.watch.impress.co.jp/docs/2006/0928/idf02.htm
http://pc.watch.impress.co.jp/docs/2006/0928/idf02.htm
32 :Socket774:2006/09/28(木) 01:25:10 ID:WMEqKbna
ついにCELLまるまるパクッテきますたw
33 :Socket774:2006/09/28(木) 01:25:49 ID:WMEqKbna
コピペスレになってるな
34 :・∀・)っ-○◎●新世紀ダンゴリオン ◆DanGorION6 :2006/09/28(木) 01:39:13 ID:8MJ8HWw7
80コアの試作品は45nmプロセスぽいけど。
Core2そのまんまなら300mm^2程度のダイに8コア、
L2なしでも16〜20コアくらいがいいところですな。
L2を追い出してダイの下に重ねて貼り付ける、にしても
Core2の数分の1のサイズで作らないといけない。
これそのまま使うとしたら、たぶんSPEみたいな独自命令セットになるんだろな
DirectX10〜11世代の物理エンジンコア?
Core2そのまんまなら300mm^2程度のダイに8コア、
L2なしでも16〜20コアくらいがいいところですな。
L2を追い出してダイの下に重ねて貼り付ける、にしても
Core2の数分の1のサイズで作らないといけない。
これそのまま使うとしたら、たぶんSPEみたいな独自命令セットになるんだろな
DirectX10〜11世代の物理エンジンコア?
>>23
知らないならレスしないでいいよ坊や
知らないならレスしないでいいよ坊や
SSEユニットを抜き出しただけじゃないのか?
コアあたり12.5GFlopsでしょ。
コアあたり12.5GFlopsでしょ。
>>34
記事くらい読んでから書こうよ。
記事くらい読んでから書こうよ。
38 :・∀・)っ-○◎●新世紀ダンゴリオン ◆DanGorION6 :2006/09/28(木) 03:39:56 ID:8MJ8HWw7
浮動小数専用プロセッサってちゃんと書いてあるね、うん。
欲を言えばSIMD整数も欲しいが・・・。
欲を言えばSIMD整数も欲しいが・・・。
CELLは9コアで内部バスはリング4本だし、ダイ上でSRAMとSPE/PPEが分離しているわけでもない。
プロトタイプのコアはシンプルすぎてSPEともPPEとも似てないし、どの辺がパクリなのかさっぱりわからん。
プロトタイプのコアはシンプルすぎてSPEともPPEとも似てないし、どの辺がパクリなのかさっぱりわからん。
shader 80本?
41 :MACオタ>39 さん:2006/09/28(木) 06:33:00 ID:dXpf0Fag
>>39
----------------------
どの辺がパクリなのかさっぱりわからん。
----------------------
結局"Many Core"のコアとして,in-orderのSIMDプロセッサを選んだということだと思うす。
詳細わ"Terascale"プロセッサ関係のプレゼンでも見れば判るす。
----------------------
どの辺がパクリなのかさっぱりわからん。
----------------------
結局"Many Core"のコアとして,in-orderのSIMDプロセッサを選んだということだと思うす。
詳細わ"Terascale"プロセッサ関係のプレゼンでも見れば判るす。
単なる見解の相違だということがわかった。
43 :Socket774:2006/09/28(木) 07:57:33 ID:Jh2q7R2j
前スレで散々ウザがられたのにまたノコノコ顔出してくるとは、
二人ともどういう神経してんだ。
二人ともどういう神経してんだ。
ダンゴとMACヲタはスルーでお願いします。
http://www.hkepc.com/bbs/itnews.php?tid=675864&starttime=0&endtime=0
YorkField@2007/Q2
FSB1333MHz , 4coreで shared L2$
DDR3-1333/DDR2-800 and dual PCI-Express 2.0 interface
Bearlake X chipset
vs K8Lどっちが速いのかな。
YorkField@2007/Q2
FSB1333MHz , 4coreで shared L2$
DDR3-1333/DDR2-800 and dual PCI-Express 2.0 interface
Bearlake X chipset
vs K8Lどっちが速いのかな。
46 :Socket774:2006/09/30(土) 06:11:38 ID:qgh3q5Ok
AMDとIntel、
3〜4年後に、パフォーマンスが優れてそうなのはどっちのアーキテクチャかな?
素人目には、AMDの「XMLとか分野毎にコア作っちゃおうよ」ってのが、良い感じに見える
3〜4年後に、パフォーマンスが優れてそうなのはどっちのアーキテクチャかな?
素人目には、AMDの「XMLとか分野毎にコア作っちゃおうよ」ってのが、良い感じに見える
47 : ◆fdijei3882 :2006/09/30(土) 07:06:01 ID:3/zPOWun
覚えたての言葉あつあつでわけがわからない
マルチコアねえ
アスロン64を3コア化してトライアスロンって語呂も良いし出してくれないかなあ
アスロン64を3コア化してトライアスロンって語呂も良いし出してくれないかなあ
quad が出たら、不良品を3コア版として売ってくれると思われ。> Athlon
あと1年後ぐらいの辛抱ダ。
あと1年後ぐらいの辛抱ダ。
WindowsなどのOSが、2^Nではないプロセッサ数に対応していないと思う。
デュアルコアのOpteronとシングルコアのOpteronのデュアルCPUできたっけ?
デュアルコアのOpteronとシングルコアのOpteronのデュアルCPUできたっけ?
Xbox360 は Windows 系 OS が動いてる筈だが 3core だよ。
2または4でないとNGなのは、インテルのSMPだったかも。
>2^N
Nは自然数ではなく0以上の整数、と断っておくとしよう。
無駄が多いかもしれないが不良で3コアだったら1コアコプロ扱いしてもいいかもしれない。
Nは自然数ではなく0以上の整数、と断っておくとしよう。
無駄が多いかもしれないが不良で3コアだったら1コアコプロ扱いしてもいいかもしれない。
また新しいコプロ定義か。
>>53
いったらSSEみたいなもんだぞ。コプロって。
いったらSSEみたいなもんだぞ。コプロって。
>>55
それは知ってるけどね。
BIOSとかピンとかで制限かけて、OSから認識されるのが2コア、
1コアが不良で残り1コアが他のコアから投げられた処理を行う、という形で。
それでは速度が上がらないと思うだろうけど、その通り。
あくまで>>50のような制限がホントにあって、さらに1コア不良だった場合の話。
それは知ってるけどね。
BIOSとかピンとかで制限かけて、OSから認識されるのが2コア、
1コアが不良で残り1コアが他のコアから投げられた処理を行う、という形で。
それでは速度が上がらないと思うだろうけど、その通り。
あくまで>>50のような制限がホントにあって、さらに1コア不良だった場合の話。
57 :・∀・)っ-○◎●新世紀ダンゴリオン ◆DanGorION6 :2006/09/30(土) 21:51:13 ID:v0HFRmdD
こないだ発表したメニーコアは80コアじゃないか。どうみても2の冪乗じゃないです。本当にありがとうございました。
まあx86 ISAじゃないかもしれんが。
まあx86 ISAじゃないかもしれんが。
http://www.geocities.jp/andosprocinfo/wadai06/20060930.htm
8x10で80コアというのは中途半端ですが,3.1GHzクロックで4Fop/Cycleのコアは12.4GFlopsで,
80個持ってこないと1Tflopsにならないと言うのが80コアにした理由でしょう。
8x10で80コアというのは中途半端ですが,3.1GHzクロックで4Fop/Cycleのコアは12.4GFlopsで,
80個持ってこないと1Tflopsにならないと言うのが80コアにした理由でしょう。
80コアというのを、80個のコアではなく、i8080の80だと思っていた人がいたんだよね。
かなり前に、インテルがZ80を大量に積んだメニーコアCPUを試作している、なんてトンデモニュースがあった。
かなり前に、インテルがZ80を大量に積んだメニーコアCPUを試作している、なんてトンデモニュースがあった。
>>59
それ冗談ニュースだよ
それ冗談ニュースだよ
インテルなら8085とかそのへんだよなあ本当だとしても
かつて日本のどこかの大学で、Z80をメッシュ接続したマルチプロセッサマシンを構築した
なんていう話を目にしたことがあるよ。
なんていう話を目にしたことがあるよ。
それZ8000じゃなかったっけか
>>62
z80を使ったマルチプロセッサ機は20年ぐらい前、色々な研究機関でやってたよね…
z80を使ったマルチプロセッサ機は20年ぐらい前、色々な研究機関でやってたよね…
なぜ6809ではなくZ80だったんだろうね。
ICの数と配線が少なくて済むからかな。
ICの数と配線が少なくて済むからかな。
ゴルゴのレンダリングか。
いっそハード的にコアを自己最適化するコア作れよ誰か
69 :・∀・)っ-○◎●新世紀ダンゴリオン ◆DanGorION6 :2006/10/02(月) 02:33:02 ID:8sT24f1b
> ハードコア
まで読んだ
まで読んだ
71 :Socket774:2006/10/02(月) 12:35:01 ID:FqALgv2t
SSE4でやっと内積命令実装か
SH-4にやっと追いつきました
SH-4にやっと追いつきました
>>68
つ[PLD]
つ[PLD]
>>71
むしろSH4(-DSP)のISAが変態だと思うんだ。
むしろSH4(-DSP)のISAが変態だと思うんだ。
>>68
それなんてPARROT?
それなんてPARROT?
CPUにどこまで内蔵させるか。
メモコン・ビデオ専用PCI Ex16内蔵にすれば
パフォーマンスなんとかなると思うんだけどね〜
メモコン・ビデオ専用PCI Ex16内蔵にすれば
パフォーマンスなんとかなると思うんだけどね〜
それなんてH8?
SSE4命令とアクセラレータから見えるIntel CPUの方向性
http://pc.watch.impress.co.jp/docs/2006/1004/kaigai307.htm
http://pc.watch.impress.co.jp/docs/2006/1004/kaigai307.htm
Penryn(ペンリャン)って、また微妙な名前を…
なんかPentiumのできそこないみたいだなw
なんかPentiumのできそこないみたいだなw
79 :・∀・)っ-○◎●新世紀ダンゴリオン ◆DanGorION6 :2006/10/04(水) 01:45:40 ID:SNLCLFpr
ペンリン オブ ジョイトイ
ギャグのセンスは無いようだ。
IBM、電力効率を高めた「PowerPC 750CL」「同970GX」を発表
http://journal.mycom.co.jp/news/2006/10/04/100.html
PowerPC 750CLは、組み込みアプリケーション向けシングルコアの
32-bitプロセッサだ。256KBのL2キャッシュを搭載。前モデルの
半分程度の消費電力で、400MHz〜1GHzのスピードを実現している。
PowerPC 970FXの後継となる970GXは、32-bitおよび64-bitを
サポートするシングルコアプロセッサ。省電力技術を引き継ぎ
ながらL2キャッシュが強化された。動作周波数は1.2〜2.5GHz。
http://journal.mycom.co.jp/news/2006/10/04/100.html
PowerPC 750CLは、組み込みアプリケーション向けシングルコアの
32-bitプロセッサだ。256KBのL2キャッシュを搭載。前モデルの
半分程度の消費電力で、400MHz〜1GHzのスピードを実現している。
PowerPC 970FXの後継となる970GXは、32-bitおよび64-bitを
サポートするシングルコアプロセッサ。省電力技術を引き継ぎ
ながらL2キャッシュが強化された。動作周波数は1.2〜2.5GHz。
Apple 亡き今、970GX って誰が使うの?
玄箱III
IBMサイトにてBroadway(PowerPC 750CL Revision Level DD2.X)のデータシートが公開
http://www-3.ibm.com/chips/techlib/techlib.nsf/techdocs/2F33B5691BBB8769872571D10065F7D5/$file/750cl_dd2_ds.pdf
Die Size 15.92 sq. mm (3.99x3.99mm) (Page 14)
http://www-3.ibm.com/chips/techlib/techlib.nsf/techdocs/2F33B5691BBB8769872571D10065F7D5/$file/750cl_dd2_ds.pdf
Die Size 15.92 sq. mm (3.99x3.99mm) (Page 14)
>>82 さん
こういう所で使うす。
http://rac.uits.iu.edu/rats/research/bigred/hardware.shtml
>>84 さん
その書き込みゲーハー板で見て,750CLって単なるG3の256KB L2版じゃないかと思いながら
よく読むと,
-----------------------------
- Support for paired single floating point arithmetic
-----------------------------
と,Gekkoで追加された特殊命令が正式に採用されたみたいす。
こういう所で使うす。
http://rac.uits.iu.edu/rats/research/bigred/hardware.shtml
>>84 さん
その書き込みゲーハー板で見て,750CLって単なるG3の256KB L2版じゃないかと思いながら
よく読むと,
-----------------------------
- Support for paired single floating point arithmetic
-----------------------------
と,Gekkoで追加された特殊命令が正式に採用されたみたいす。
>>81
PowerPC 750CLの亜種がWiiに載るのか
PowerPC 750CLの亜種がWiiに載るのか
87 :Socket774:2006/10/05(木) 15:20:35 ID:T+9FYctW
古木 トロンチップは68の真似じゃないですか。
回路なんかそっくり・・・
新田 最初にトロンチップ設計作業を実際にやったのは、
68のセカンドソースやってた日立の技術陣ですから、
Gマイクロのような具体的な製品の回路で、
トロンチップ仕様で決めてないインプリメントに任された部分で
似てる部分はあるかも知れませんが、
トロンチップ仕様そのものが「真似」というのは違いますよ。
こういう「〜の真似」という言い方でトロンチップを非難した人が、
一方で同様に68と似てるNECのV70を
「本物の独自MPU」などとおだてたりしてるんですから・・・
古木 トロンチップだって絶滅寸前でしょうが!
新田 そうでもありませんよ。
そもそも「RISCの時代だ」なんて言ったって、
アメリカで作られたMPUで売れてるのは
インテルとスパークだけでしょう。インテルはCISCだし。
パソコン・ワークステーションは「互換性」の壁で、
結局は入る隙間が無いですが、
組み込みチップとしてGマイクロでもローエンドなやつとか、
93年頃に開発されたM16はかなり広範囲で使われています。
中野 M16ってトロンチップだったんですか?
SHマイコンあたりと並べてトロンチップと対比して、
「落ち目のトロンチップに比べて、日本製でも売れてる」と
引き合いに出す人もいるけど・・・
新田 トロンチップですよ。
三菱はトロンチップの最ローエンド品の、Gマイクロ100が
一番売れたんで、さらに下のM16を造ったんです。
回路なんかそっくり・・・
新田 最初にトロンチップ設計作業を実際にやったのは、
68のセカンドソースやってた日立の技術陣ですから、
Gマイクロのような具体的な製品の回路で、
トロンチップ仕様で決めてないインプリメントに任された部分で
似てる部分はあるかも知れませんが、
トロンチップ仕様そのものが「真似」というのは違いますよ。
こういう「〜の真似」という言い方でトロンチップを非難した人が、
一方で同様に68と似てるNECのV70を
「本物の独自MPU」などとおだてたりしてるんですから・・・
古木 トロンチップだって絶滅寸前でしょうが!
新田 そうでもありませんよ。
そもそも「RISCの時代だ」なんて言ったって、
アメリカで作られたMPUで売れてるのは
インテルとスパークだけでしょう。インテルはCISCだし。
パソコン・ワークステーションは「互換性」の壁で、
結局は入る隙間が無いですが、
組み込みチップとしてGマイクロでもローエンドなやつとか、
93年頃に開発されたM16はかなり広範囲で使われています。
中野 M16ってトロンチップだったんですか?
SHマイコンあたりと並べてトロンチップと対比して、
「落ち目のトロンチップに比べて、日本製でも売れてる」と
引き合いに出す人もいるけど・・・
新田 トロンチップですよ。
三菱はトロンチップの最ローエンド品の、Gマイクロ100が
一番売れたんで、さらに下のM16を造ったんです。
88 :Socket774:2006/10/05(木) 15:21:31 ID:T+9FYctW
新田 大体、日本企業がみんなRISCを
作るようになった・・・って言っても、
SH1なんかそれほど早い訳じゃないですしね。
中野 むしろ、構造が単純で
低コストだけど性能はそこそこ・・・ってあたりが、
日本企業が組み込みチップとして
RISCを多用したメリットじゃないかな。
新田 なるほど、SHマイコンは安さで売ってるわけか。
古木 家電の組み込みには必須な長所だと思いますよ。
中野 多様な整合性ある命令セットが必要なら、
インテル互換チップがやってるみたいに、
中身をRISCで作って、トロンチップの命令セットは
エミュレーションで・・・って訳にはいかないんですか。
新田 別にそれでもいいんですよ。
M16なんかは、どちらかというと、そういう作り方をしてます。
要は多様なチップでの命令に整合性が取れればいいんですから。
そこらへんが互換の要で、知的所有権でも一番やっかいな所ですからね。
作るようになった・・・って言っても、
SH1なんかそれほど早い訳じゃないですしね。
中野 むしろ、構造が単純で
低コストだけど性能はそこそこ・・・ってあたりが、
日本企業が組み込みチップとして
RISCを多用したメリットじゃないかな。
新田 なるほど、SHマイコンは安さで売ってるわけか。
古木 家電の組み込みには必須な長所だと思いますよ。
中野 多様な整合性ある命令セットが必要なら、
インテル互換チップがやってるみたいに、
中身をRISCで作って、トロンチップの命令セットは
エミュレーションで・・・って訳にはいかないんですか。
新田 別にそれでもいいんですよ。
M16なんかは、どちらかというと、そういう作り方をしてます。
要は多様なチップでの命令に整合性が取れればいいんですから。
そこらへんが互換の要で、知的所有権でも一番やっかいな所ですからね。
89 :Socket774:2006/10/05(木) 15:24:09 ID:T+9FYctW
中野 それと、日本企業がRISCを作るようになったのは、
政治的な要因もかなりあるんですよ。
半導体摩擦の「20%」の押し売り規定をクリアするために、
各企業がアメリカ製半導体の購入を迫られたんだけど、
実際は使い物にならない。
「無理に買って捨てるしかない」って状態を何とかするためには、
日本企業の微細加工技術をただ同然で差し出すしか無かったんです。
「共同開発」という名目でね。
そのためには名目上「アメリカから得るもの」が必要で、
それ用に貰えるのはRISC技術くらいしか無かったんですね。
新田 それが、半導体の日米再逆転の原因ですか?
中野 全部じゃありませんが、半分以上はそうです。
そういえばSHマイコンの開発にはトロンチップの経験が
大きく役立った・・・っていうのは一致した意見ですね。
その点ではトロンは日本の技術に大きく貢献したのは事実だと思います。
政治的な要因もかなりあるんですよ。
半導体摩擦の「20%」の押し売り規定をクリアするために、
各企業がアメリカ製半導体の購入を迫られたんだけど、
実際は使い物にならない。
「無理に買って捨てるしかない」って状態を何とかするためには、
日本企業の微細加工技術をただ同然で差し出すしか無かったんです。
「共同開発」という名目でね。
そのためには名目上「アメリカから得るもの」が必要で、
それ用に貰えるのはRISC技術くらいしか無かったんですね。
新田 それが、半導体の日米再逆転の原因ですか?
中野 全部じゃありませんが、半分以上はそうです。
そういえばSHマイコンの開発にはトロンチップの経験が
大きく役立った・・・っていうのは一致した意見ですね。
その点ではトロンは日本の技術に大きく貢献したのは事実だと思います。
PowerPC 750CLは、組込み向けと言いつつも、DRAMコントローラやPCIコントローラを内蔵してないね。
ダイサイズが小さすぎるのもあれなんで、それくらい積めばいいのに。
ダイサイズが小さすぎるのもあれなんで、それくらい積めばいいのに。
逆に8641や8641Dなんかはリッチすぎるな
メモコン、ギガビットイーサ、PIC-Eコントローラ付きでキャッシュ1MB
82xxは性能より機能って感じでフリースケールらしいが
8560は何だっけ?
もちろん750CLとターゲットが違うんだけどさ
メモコン、ギガビットイーサ、PIC-Eコントローラ付きでキャッシュ1MB
82xxは性能より機能って感じでフリースケールらしいが
8560は何だっけ?
もちろん750CLとターゲットが違うんだけどさ
ナンバー1よりオンリー1。
Cellにしかなせない仕事がある。
ttp://pc.watch.impress.co.jp/docs/2006/1003/ceatec.htm
> MATプレロマが福井県工業技術センター、北海道大学大学院工学研究科と
> 協力して開発した気液2相流体ループ熱制御システム。
> 61度と沸点が低いハイドロフルオロエーテルをCPUヒートシンクに送り込み、
> CPUの熱で気化させ、温度を下げる。
> ここではCellのリファレンスセットを使っている。
> Cellを選んだのは、最新のIntel/AMD CPUの動作温度が沸点より低くなってしまったためだとか……
Cellにしかなせない仕事がある。
ttp://pc.watch.impress.co.jp/docs/2006/1003/ceatec.htm
> MATプレロマが福井県工業技術センター、北海道大学大学院工学研究科と
> 協力して開発した気液2相流体ループ熱制御システム。
> 61度と沸点が低いハイドロフルオロエーテルをCPUヒートシンクに送り込み、
> CPUの熱で気化させ、温度を下げる。
> ここではCellのリファレンスセットを使っている。
> Cellを選んだのは、最新のIntel/AMD CPUの動作温度が沸点より低くなってしまったためだとか……
なんか本末転倒っぽいぞ。
ワケ ワカ ラン♪
∧_∧ ∧_∧ ∧_∧
( ・∀・) ( ・∀・) ( ・∀・)
⊂ ⊂ ) ( つ つ ⊂__へ つ
く く く ) ) ) (_)/
(_(_) (__)_) 彡(_)
∧_∧ ∧_∧ ∧_∧
( ・∀・) ( ・∀・) ( ・∀・)
⊂ ⊂ ) ( つ つ ⊂__へ つ
く く く ) ) ) (_)/
(_(_) (__)_) 彡(_)
PenDのがいいけど、インテルに圧力かけられたのかね。
>液冷は作動流体変えれば
デモの意味ねー
デモの意味ねー
別にSPARCでもそれこそX1900XTでもよかったんだろうが、
知名度の問題じゃね?CEATECだから一般知名度高いほうがいいし。
で、CELLか。…やっぱPentiumDでもいいよなぁ。
知名度の問題じゃね?CEATECだから一般知名度高いほうがいいし。
で、CELLか。…やっぱPentiumDでもいいよなぁ。
PentiumDって最新なの?
Cellもネトバと一緒にかつて存在した高クロック指向CPUとして過去の遺物になってしまいそうだな。
>>101
そんなあなたに。
131 名前: It's@名無しさん [sage] 投稿日: 2006/09/14(木) 04:09:04
x86はコードネームで言えても、他の世界に出たこと無い井の中の蛙は多いからな
2001年にデュアルコアが出ていたのも知らず、2005年はついにデュアルコアか〜と思っていたところ、偶然Cellのニュースを目にしてしまった。
ずっと自分の井戸に閉じこもっていればいいのに、「8コア」の部分にだけ反応し、ファビョった。
8コア部分以外はわからない。なぜなら井の中の蛙だから。
132 名前: It's@名無しさん 投稿日: 2006/09/14(木) 04:14:56
>>131
そんなもんでしょw
Cellはちょうど、Athlon64 X2が出る直前に仕様が発表されたんだよな。
半導体シェアでもAMDが第二位だと思いこんでたり、SOIがAMDの技術だと思ってたりする連中だから、
8コア!?zqあwxせcrvtyふじこも;:@
マルチコアはCPUでも組み込みでも珍しいもんじゃないしな
ついでに言うと、CellはIBMの流れの1つにすぎない。
PowerPCも何種類もある。
133 名前: It's@名無しさん [sage] 投稿日: 2006/09/14(木) 04:59:25
「なぜかソニーがお小遣いまでくれて好きにやれっていうから
我がIBMがだんだん優位性を失ってきたHPC分野(の一部)に特化したCPUを
作ってみたYO、PS3とやらにフィットするかどうかは知らないけど
ウチはこれでベンチ上はXeon/Itanium2系に勝てるから満足満足」という理解でOK?
そんなあなたに。
131 名前: It's@名無しさん [sage] 投稿日: 2006/09/14(木) 04:09:04
x86はコードネームで言えても、他の世界に出たこと無い井の中の蛙は多いからな
2001年にデュアルコアが出ていたのも知らず、2005年はついにデュアルコアか〜と思っていたところ、偶然Cellのニュースを目にしてしまった。
ずっと自分の井戸に閉じこもっていればいいのに、「8コア」の部分にだけ反応し、ファビョった。
8コア部分以外はわからない。なぜなら井の中の蛙だから。
132 名前: It's@名無しさん 投稿日: 2006/09/14(木) 04:14:56
>>131
そんなもんでしょw
Cellはちょうど、Athlon64 X2が出る直前に仕様が発表されたんだよな。
半導体シェアでもAMDが第二位だと思いこんでたり、SOIがAMDの技術だと思ってたりする連中だから、
8コア!?zqあwxせcrvtyふじこも;:@
マルチコアはCPUでも組み込みでも珍しいもんじゃないしな
ついでに言うと、CellはIBMの流れの1つにすぎない。
PowerPCも何種類もある。
133 名前: It's@名無しさん [sage] 投稿日: 2006/09/14(木) 04:59:25
「なぜかソニーがお小遣いまでくれて好きにやれっていうから
我がIBMがだんだん優位性を失ってきたHPC分野(の一部)に特化したCPUを
作ってみたYO、PS3とやらにフィットするかどうかは知らないけど
ウチはこれでベンチ上はXeon/Itanium2系に勝てるから満足満足」という理解でOK?
>>101
俺はPOWERファンじゃないけど、もう1つ。
POWER6の高クロック、かつTDP維持をどうみる?
AMDファンのように、クロックを上げられないのを「必要が無いから上げない、上げるのはおかしい」とでも言うか?w
マルチコア化が業界のとれんど(笑)と言いたいかもしれないが、POWERはすでにクアッドコアだぞ
俺はPOWERファンじゃないけど、もう1つ。
POWER6の高クロック、かつTDP維持をどうみる?
AMDファンのように、クロックを上げられないのを「必要が無いから上げない、上げるのはおかしい」とでも言うか?w
マルチコア化が業界のとれんど(笑)と言いたいかもしれないが、POWERはすでにクアッドコアだぞ
Power6よりTukwilaとRockに期待してます
105 :Socket774:2006/10/07(土) 08:11:59 ID:K2B7ebFr
x86以外のCPUなんてUNIX-ワークステーションのことを知ってれば
すぐに分かるだろ。MIPSとかSPARCとか
ちなみにx86以外のRISCアーキテクチャを知ったのは昔読んだこと
のあるOH!FM-TOWNSでCPU特集の記事があったのがきっかけ。
当時はそれを読んで「いつかはパソコンより高性能なSPARCやSGIの
ワークステーションを買うぞ。」
と思ったもんだ。当然UNIXの使いかたなど知らずに。
そして現在に至るまでRISCなワークステーションを買うこともできた
が結局買わなかったな。
x86なPCでも性能的に必要十分だしソフトの方もWINの方がUNIXより充実
してる。
すぐに分かるだろ。MIPSとかSPARCとか
ちなみにx86以外のRISCアーキテクチャを知ったのは昔読んだこと
のあるOH!FM-TOWNSでCPU特集の記事があったのがきっかけ。
当時はそれを読んで「いつかはパソコンより高性能なSPARCやSGIの
ワークステーションを買うぞ。」
と思ったもんだ。当然UNIXの使いかたなど知らずに。
そして現在に至るまでRISCなワークステーションを買うこともできた
が結局買わなかったな。
x86なPCでも性能的に必要十分だしソフトの方もWINの方がUNIXより充実
してる。
>>105
PS3スレを覗いてみなよ。ある意味面白いよ
PS3スレを覗いてみなよ。ある意味面白いよ
罰ゲームはCellスレ閲覧だけで勘弁してください
POWER6が優れているのは、大量生産する必要がない、というのも大きいと思う。
サーバ用のCPUなわけで、選別品だけ出せばいいのだから。
サーバ用のCPUなわけで、選別品だけ出せばいいのだから。
> POWERはすでにクアッドコアだぞ
このスレ的には、あれをクアッドコアとは言わんだろ
このスレ的には、あれをクアッドコアとは言わんだろ
最低でも4GHzという動作速度を実現できれば、IBMは他社をリードすること
になる。だが、同社はPower6の開発で壁にぶつかっている。2004年に同
社はPower6を2006年に、また一段と高速な「Power6+」を2007年にリ
リースすると発表していた。しかし、McCredieによれば、現在Power6のリ
リースは2007年の予定になっているという。
になる。だが、同社はPower6の開発で壁にぶつかっている。2004年に同
社はPower6を2006年に、また一段と高速な「Power6+」を2007年にリ
リースすると発表していた。しかし、McCredieによれば、現在Power6のリ
リースは2007年の予定になっているという。
>>109
まあその通りだな、すまねぃ
まあその通りだな、すまねぃ
んでそのPower6とやらはもう手に入るの?114M-L3キャッシュだっけ?
あれも実際手に入るのはいつなの?んでそれでどれ程快適になるの?
さらにいつになったらPower6で自作できるの?
仮にLinuxでもUnixでもいいから入れてデスクトップとして使ってコンロやら
X2より快適だと思う?使い勝手は良いと思う?そういう大事な事何も考えずに
ベンチのグラフだけ見て優劣語っても何の意味もないよ。
あれも実際手に入るのはいつなの?んでそれでどれ程快適になるの?
さらにいつになったらPower6で自作できるの?
仮にLinuxでもUnixでもいいから入れてデスクトップとして使ってコンロやら
X2より快適だと思う?使い勝手は良いと思う?そういう大事な事何も考えずに
ベンチのグラフだけ見て優劣語っても何の意味もないよ。
>>109
Quad Coreじゃなかったらなんなの?(w
Quad Coreじゃなかったらなんなの?(w
>>112
PS3スレの、x86視点でしか語れない上に反論されたあとの逃げ文句「板違いだろ」にそっくりだな(笑)
PS3スレの、x86視点でしか語れない上に反論されたあとの逃げ文句「板違いだろ」にそっくりだな(笑)
>>113
デュアルコア
デュアルコア
>>115
意味不明
意味不明
MCMも視野に入れたら、POWER系はPOWER5の時点で既に8コアだよ。
デュアルコアのダイを4つと、L3キャッシュのダイを4つ積んだMCM。
ttp://www.theinquirer.net/default.aspx?article=12217
デュアルコアのダイを4つと、L3キャッシュのダイを4つ積んだMCM。
ttp://www.theinquirer.net/default.aspx?article=12217
>>120
だよねぇ
だよねぇ
123 :Socket774:2006/10/07(土) 12:28:58 ID:3hXYkNoa
とにかく、ID: xanxJRJb はもうちょっと落ち着くべきだと思います。
124 :MACオタ>120 さん:2006/10/07(土) 13:29:02 ID:3aMDiC/b
>>120
また知ったかさんがワラワラ涌いてきているすけど,
--------------------
POWER系はPOWER5の時点で既に8コアだよ。
--------------------
POWER4の時点で8-coreす。
http://en.wikipedia.org/wiki/POWER4
また知ったかさんがワラワラ涌いてきているすけど,
--------------------
POWER系はPOWER5の時点で既に8コアだよ。
--------------------
POWER4の時点で8-coreす。
http://en.wikipedia.org/wiki/POWER4
このMCMを4とL3チップを搭載した32-wayのマザーボード(つーかプロセッサカード)わ
こんな代物す。
http://www.llnl.gov/computing/tutorials/ibm_sp/images/power4board.gif
こんな代物す。
http://www.llnl.gov/computing/tutorials/ibm_sp/images/power4board.gif
{kind=link}
126 :Socket774:2006/10/07(土) 13:34:29 ID:K2B7ebFr
UltraSPARC II 相当を8個くっつけただけのゴミ
>>127
ウェブサーバのスループットだけをみれば既存の他のどのCPUにも負けないのにゴミは言いすぎ.
ウェブサーバのスループットだけをみれば既存の他のどのCPUにも負けないのにゴミは言いすぎ.
web鯖ならこちらが適任
「もう負荷分散は必要ない」---1台で同時50万接続のWebサーバーが登場
http://itpro.nikkeibp.co.jp/article/NEWS/20060707/242757/
「もう負荷分散は必要ない」---1台で同時50万接続のWebサーバーが登場
http://itpro.nikkeibp.co.jp/article/NEWS/20060707/242757/
>>129
SunFire T1000 が100万円未満で買えるのにか?(w
SunFire T1000 が100万円未満で買えるのにか?(w
劣化版を乗せたT1000一台じゃ太刀打ちできんだろ
> UltraSPARC II 相当を8個
ここだけ読めばあながち間違いでもない
ここだけ読めばあながち間違いでもない
134 :・∀・)っ-○◎●新世紀ダンゴリオン ◆DanGorION6 :2006/10/07(土) 17:39:12 ID:Sm0UUBfP
あの会社はJavaを作った技術力は凄いけどハード屋としてはイマイチですな
>>133
4スレッドを細かくローテーションして実行するあたりは、違うじゃん。
4スレッドを細かくローテーションして実行するあたりは、違うじゃん。
>103
オレもいちおうはAMDファンだが、
>クロックを上げられないのを「必要が無いから上げない、上げるのはおかしい」とでも言う
ことはないな。クロック上げるのに四苦八苦するのは、よくあることだ。
高クロックを望むユーザーが多いからこそ、高クロック版のチップが高値で売れるわけだしな。
Pen4/PenDほどの高クロックは必要ない、というのは事実だが、それだって過去の話。
できるだけ高性能を望むのはいつの世も同じ。
だが...
多くのスレッドを平行してこなす必要があるサーバと、
同時にひとりの人間しか使わないのが常識なPCじゃ、
マルチコアを必要とする度合いがまったく異なる。
だからこそ、PCではデュアルコアさえなかなか浸透しなかったんだよ。
作らなかったから浸透しなかったんじゃない、
作ったところで需要がないと誰もが考えていたから作られなかったんだ。
ひとりの人間が使う前提で言えば、デュアルコアよりもクロック上げる方が、確実にコストパフォーマンスが高かったんだからな。
あくまでも、ニーズとコストの問題。
オレもいちおうはAMDファンだが、
>クロックを上げられないのを「必要が無いから上げない、上げるのはおかしい」とでも言う
ことはないな。クロック上げるのに四苦八苦するのは、よくあることだ。
高クロックを望むユーザーが多いからこそ、高クロック版のチップが高値で売れるわけだしな。
Pen4/PenDほどの高クロックは必要ない、というのは事実だが、それだって過去の話。
できるだけ高性能を望むのはいつの世も同じ。
だが...
多くのスレッドを平行してこなす必要があるサーバと、
同時にひとりの人間しか使わないのが常識なPCじゃ、
マルチコアを必要とする度合いがまったく異なる。
だからこそ、PCではデュアルコアさえなかなか浸透しなかったんだよ。
作らなかったから浸透しなかったんじゃない、
作ったところで需要がないと誰もが考えていたから作られなかったんだ。
ひとりの人間が使う前提で言えば、デュアルコアよりもクロック上げる方が、確実にコストパフォーマンスが高かったんだからな。
あくまでも、ニーズとコストの問題。
>>137
安く高性能な物は1CPUが良かった
クロックも今までムーアの法則どおり伸びていった
だがボラックだかの法則のおかげで頭打ちになったから
マルチにせざるおえないだけだと思う
まあ後藤ちゃんの記事だから話半分で
http://pc.watch.impress.co.jp/docs/2006/0818/kaigai295.htm
1CPUより製造コストが2倍でもこれしか方法がないのが現実
最近、CPUの進化というよりチップセットが追いついていかない気がするんだよな
安く高性能な物は1CPUが良かった
クロックも今までムーアの法則どおり伸びていった
だがボラックだかの法則のおかげで頭打ちになったから
マルチにせざるおえないだけだと思う
まあ後藤ちゃんの記事だから話半分で
http://pc.watch.impress.co.jp/docs/2006/0818/kaigai295.htm
1CPUより製造コストが2倍でもこれしか方法がないのが現実
最近、CPUの進化というよりチップセットが追いついていかない気がするんだよな
ていうかメモリがウンコ詰まってる
140 :Socket774:2006/10/09(月) 11:48:09 ID:6QDA1DKs
だからXDR DRAMを使えと。
アプリによって全然違うが・・・つまりTLPやDLPの度合いによってまったく異なるが、
大雑把に世に存在するアプリを平均化して考えると、コア数を増やしていっても
ポラックの法則からは抜け出せない。
大雑把に世に存在するアプリを平均化して考えると、コア数を増やしていっても
ポラックの法則からは抜け出せない。
>>141
その通りだな。アプリ自体を根本的に変えていくしかない。
その通りだな。アプリ自体を根本的に変えていくしかない。
日経エレにマルチコア時代の
プロセッサ・アーキテクチャとプログラミング・モデルを
絡めた特集が組まれてるね
プロセッサ・アーキテクチャとプログラミング・モデルを
絡めた特集が組まれてるね
Fall Microprocessor Forumが10月9日に開幕
〜メインテーマは「電力効率の向上」
http://pc.watch.impress.co.jp/docs/2006/1010/fmpf01.htm
Intelの次世代モバイルCPU「Penryn」が見えてきた
http://pc.watch.impress.co.jp/docs/2006/1010/kaigai309.htm
〜メインテーマは「電力効率の向上」
http://pc.watch.impress.co.jp/docs/2006/1010/fmpf01.htm
Intelの次世代モバイルCPU「Penryn」が見えてきた
http://pc.watch.impress.co.jp/docs/2006/1010/kaigai309.htm
145 :MACオタ>144 さん:2006/10/10(火) 00:29:19 ID:TWRRozcF
146 :Socket774:2006/10/10(火) 01:19:33 ID:DrDPApwF
POWER6は4.0GHz〜5.0GHzか。
IPCは、PowerPC G4なんかと比べて、どうなんだろう。
AltiVecみたいなSIMD機構は持ってるの?
IPCは、PowerPC G4なんかと比べて、どうなんだろう。
AltiVecみたいなSIMD機構は持ってるの?
「これがジオンの最新のモビルスーツ…じゃなかった。Intelの新プロセッサー。すごい!5倍以上のエネルギーゲインがある。すごい!それにこれは違うぞ。ザクなんかと装甲もパワーも消費電力も。Core 2 Duoは伊達じゃない!」
http://www.watch.impress.co.jp/akiba/hotline/20061007/image/niaf_m.wmv
http://www.watch.impress.co.jp/akiba/hotline/20061007/image/niaf_m.wmv
(;´Д`) 若井おさむレベル
IBM cranks dual-core Power6 beyond 4GHz
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=193105767
>IBM Corp. will go back to the future with its next-generation Power6 design by pushing raw speed rather than trying to pack more cores on a die.
>The CPU will run at speeds between 4-5GHz with a total of 8Mbytes L2 cache and a 75Gbyte/second link to external memory.
>Thus the big news for IBM is how it can double frequency while holding the line on power consumption and pipeline depth.
>New circuit designs and process technology improvements plow the way for the advances.
>The chip uses "new and highly complex latch and static gate circuits," said McCredie.
>IBM applied new techniques in variable gate lengths and variable threshold voltages to squeeze maximum performance per Watt at the transistor level.
>The chip can be fully operated at as little as 0.8V.
>In addition, IBM will link its Power CPU for the first time to an external embedded controller.
>The controller will monitor and adjust power and performance parameters on the CPU based on set power management policies.
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=193105767
>IBM Corp. will go back to the future with its next-generation Power6 design by pushing raw speed rather than trying to pack more cores on a die.
>The CPU will run at speeds between 4-5GHz with a total of 8Mbytes L2 cache and a 75Gbyte/second link to external memory.
>Thus the big news for IBM is how it can double frequency while holding the line on power consumption and pipeline depth.
>New circuit designs and process technology improvements plow the way for the advances.
>The chip uses "new and highly complex latch and static gate circuits," said McCredie.
>IBM applied new techniques in variable gate lengths and variable threshold voltages to squeeze maximum performance per Watt at the transistor level.
>The chip can be fully operated at as little as 0.8V.
>In addition, IBM will link its Power CPU for the first time to an external embedded controller.
>The controller will monitor and adjust power and performance parameters on the CPU based on set power management policies.
PPC6なんてベイパーウェアだろ。
出る出る詐欺。
出る出る詐欺。
ほんとに0.8Vで動くのかなぁ
東工大がスーパコンの演算性能を2割向上,「ヘテロ構成では世界一に」
http://techon.nikkeibp.co.jp/article/NEWS/20061010/122095/
価格対性能が恐ろしく低いのは公然の…
http://techon.nikkeibp.co.jp/article/NEWS/20061010/122095/
価格対性能が恐ろしく低いのは公然の…
>>151
PPC6ってなんだ?
>>152
2GHzを越える90nm製品だと、だいたい1Vちょいのところが多いから65nmなら不思議じゃあないな
1.2とか1.3VなのはインテルやAMDくらいじゃね
PPC6ってなんだ?
>>152
2GHzを越える90nm製品だと、だいたい1Vちょいのところが多いから65nmなら不思議じゃあないな
1.2とか1.3VなのはインテルやAMDくらいじゃね
> 65nmなら不思議じゃあないな
だってケータイ向けとかじゃなくて、4GHzオーバーで動く石だよ?
Vthが低くなるとリークがすごいことになるはずなのに
どんなマジック使ってるんだろ
だってケータイ向けとかじゃなくて、4GHzオーバーで動く石だよ?
Vthが低くなるとリークがすごいことになるはずなのに
どんなマジック使ってるんだろ
IntelとAMD以外に2GHz超えてる90nm製品なんてあったっけ?
ああPOWER5とPowerPCか
ぼけとったわ
ぼけとったわ
158 :・∀・)っ-○◎●新世紀ダンゴリオン ◆DanGorION6 :2006/10/11(水) 00:28:58 ID:u4NtH0Uv
凶三朗のことも
たまには思い出してあげてください
たまには思い出してあげてください
パイプライン7段のPowerPC G4でも、130nmで1.7GHz、オーバークロック版で2GHz達成してるぜ
ああ電圧の話に戻るが、たしかにIntel AMDは高めだな。
ある程度のクロックを達成するために高電圧が必要だ
ある程度のクロックを達成するために高電圧が必要だ
POWERは選別品だけ出荷すればいいから電圧を下げてクロックを上げられるけど、
そうも言ってられないx86は、電圧を上げることになるよね。
個体によって電圧がまちまちになることが許されれば、違ってくるのだろうけれど。
そうも言ってられないx86は、電圧を上げることになるよね。
個体によって電圧がまちまちになることが許されれば、違ってくるのだろうけれど。
国産品で唯一2GHzを越えてるハイエンドプロセッサ、SPARC64 Vのことも
たまには思いだしてあげてください。^^;
たまには思いだしてあげてください。^^;
って実は >>159 は SPARC64 Vの話だったのか。
リンク辿ってなかった。
リンク辿ってなかった。
いや、選別できるつっても、1.2Vを1.0Vに下げるのと
1.0Vを0.8Vに下げるのじゃ、難易度がぜんぜん違うはずなのよね
リークって論理でなんとかなるものじゃないし
ゲートの構造か材料になんか秘密があると思うんだけど
1.0Vを0.8Vに下げるのじゃ、難易度がぜんぜん違うはずなのよね
リークって論理でなんとかなるものじゃないし
ゲートの構造か材料になんか秘密があると思うんだけど
読んでるとは思うけどこのあたりか
http://pc.watch.impress.co.jp/docs/2006/0829/kaigai298.htm
http://pc.watch.impress.co.jp/docs/2006/0831/kaigai299.htm
http://pc.watch.impress.co.jp/docs/2006/0829/kaigai298.htm
http://pc.watch.impress.co.jp/docs/2006/0831/kaigai299.htm
CNETから,も少し詳しい記事が来てるす。今日には翻訳も出るんじゃないすかね。
http://news.com.com/2100-1006_3-6124451.html
・4-5GHz (5GHzにより近いとか。。。)
・デュアルコア
・4MB独立L2, 32MB共有L3
・SMT
・BCD(10進)演算サポート
・AltiVecサポート
・"CPU hot spare"を含む強力なRAS
・1024のパーティション迄仮想化可能
・4-chip MCM対応
私が以前から書いているように,Netburstの衣鉢わIBMが継いだ形になるす。
http://news.com.com/2100-1006_3-6124451.html
・4-5GHz (5GHzにより近いとか。。。)
・デュアルコア
・4MB独立L2, 32MB共有L3
・SMT
・BCD(10進)演算サポート
・AltiVecサポート
・"CPU hot spare"を含む強力なRAS
・1024のパーティション迄仮想化可能
・4-chip MCM対応
私が以前から書いているように,Netburstの衣鉢わIBMが継いだ形になるす。
Brad McCredie氏のインタビューを折り込んでる別の記事を読むと
http://www.statesman.com/business/content/business/stories/technology/10/10/10ibm.html
POWER6の開発にわ,4-5年かけられているす。おそら開発当初の技術動向から
考えて,独立L2わシングルコア版のPowerPC9xxへの展開を考えてのことだと
思われるす。
-----------------------------
During the four to five years it took to develop the chip, the team became a close-knit unit.
-----------------------------
http://www.statesman.com/business/content/business/stories/technology/10/10/10ibm.html
POWER6の開発にわ,4-5年かけられているす。おそら開発当初の技術動向から
考えて,独立L2わシングルコア版のPowerPC9xxへの展開を考えてのことだと
思われるす。
-----------------------------
During the four to five years it took to develop the chip, the team became a close-knit unit.
-----------------------------
169 :Socket774:2006/10/11(水) 07:48:45 ID:8jnXtpVB
独立L2、共有L3か…。パフォーマンス的にどうなんすかねえ。
>>168の件,POWER6派生プロセッサ開発について書いたEDNの記事す。
http://www.edn.com/article/CA6379673.html
-----------------------
IBM has been talking about this tack for the past couple years, calling it “holistic”
design that extends well beyond the processor. By modifying the components around
the processor, the same processor―or at least derivatives of the design―can be used
for different purposes with entirely different results. For example, McCredie said the
busses in the chip can run in 2 byte mode at lower power in what he calls “cost-
effective mode,” or they can run in 8 byte mode for higher-performance computing
applications.
-----------------------
16-bitバスの組込向けPOWER6コアにまで言及しているすけど,動作電圧を0.8Vまで下げられる
という事実が説得力をかもしだしているすね。。。
http://www.edn.com/article/CA6379673.html
-----------------------
IBM has been talking about this tack for the past couple years, calling it “holistic”
design that extends well beyond the processor. By modifying the components around
the processor, the same processor―or at least derivatives of the design―can be used
for different purposes with entirely different results. For example, McCredie said the
busses in the chip can run in 2 byte mode at lower power in what he calls “cost-
effective mode,” or they can run in 8 byte mode for higher-performance computing
applications.
-----------------------
16-bitバスの組込向けPOWER6コアにまで言及しているすけど,動作電圧を0.8Vまで下げられる
という事実が説得力をかもしだしているすね。。。
EDNの記事わJavaプロセッサへの拡張について言及してるすから,BCD演算等わ
いわゆる"Accelerator"として実装されていることが判るす。
アクセラレータの実装についてわ,以下のいずれになっているのか,追加の発表が待たれるす。
1. SOC的にチップ内バスでコアと接続されている
2. Book-E APU的にオプションの実行ユニットとして実行パイプラインに直接追加される
いわゆる"Accelerator"として実装されていることが判るす。
アクセラレータの実装についてわ,以下のいずれになっているのか,追加の発表が待たれるす。
1. SOC的にチップ内バスでコアと接続されている
2. Book-E APU的にオプションの実行ユニットとして実行パイプラインに直接追加される
>>169
共有L2にするとレイテンシの面で得しないと判断したのかも?
コアは0.8Vだとすると、SRAMの動作電圧はどうなのかね。
ISSCC 2006じゃL1はコア+150mVほどだったみたいだが。
しかしどこもかしこもアクセラレータだな。
でもサーバだからむしろ本家か。
それにしても0.8Vでこのクロックは…ほんとどういう風に達成してるのかねえ。
消費電力はそのままだって言うし。
共有L2にするとレイテンシの面で得しないと判断したのかも?
コアは0.8Vだとすると、SRAMの動作電圧はどうなのかね。
ISSCC 2006じゃL1はコア+150mVほどだったみたいだが。
しかしどこもかしこもアクセラレータだな。
でもサーバだからむしろ本家か。
それにしても0.8Vでこのクロックは…ほんとどういう風に達成してるのかねえ。
消費電力はそのままだって言うし。
173 :MACオタ>172 さん:2006/10/11(水) 08:33:40 ID:h0GVHGbP
そうなのかな。
> The chip can be fully operated at as little as 0.8V.
とあるけどこれって省電力モードになるのか?
> The chip can be fully operated at as little as 0.8V.
とあるけどこれって省電力モードになるのか?
>>175
それもレイテンシとのトレードオフ
それもレイテンシとのトレードオフ
MACオタよ
その「わ」は何とかならんか?
おっさんのギャル文字は鳥肌が立つ
その「わ」は何とかならんか?
おっさんのギャル文字は鳥肌が立つ
>>177よ
その勘違いは何とかならんか?
その勘違いは何とかならんか?
>>175
パソコンみたいにCPU 1個だけで使うのがメインターゲットなら、共有L2にすると思う。
POWER搭載のサーバのように多数並べたら、同じダイ上のコア同士が同じメモリを
参照する確率よりも、他のダイ上のコアと同じメモリを参照する確率のほうが高く
なるわけで、共有L2にする意味がないのだと思う。
パソコンみたいにCPU 1個だけで使うのがメインターゲットなら、共有L2にすると思う。
POWER搭載のサーバのように多数並べたら、同じダイ上のコア同士が同じメモリを
参照する確率よりも、他のダイ上のコアと同じメモリを参照する確率のほうが高く
なるわけで、共有L2にする意味がないのだと思う。
0.8Vで5GHz駆動か。IBMは神だな。
{kind=link}
>>178
じゃあ池沼のふりか?
じゃあ池沼のふりか?
MACオタは女だってさ。
178が言ってた。
178が言ってた。
>>163
国産品唯一というが、あきる野のEfficeonも2GHz版が有ったらしい。
国産品唯一というが、あきる野のEfficeonも2GHz版が有ったらしい。
186 :MACオタ>185 さん:2006/10/11(水) 19:11:02 ID:h0GVHGbP
富士通が次期SPARC64「SPARC64 VI」の詳細を明らかに
http://pc.watch.impress.co.jp/docs/2006/1011/fmpf02.htm
http://pc.watch.impress.co.jp/docs/2006/1011/fmpf02.htm
サンと富士通、「Niagara 2」および「SPARC64 VI」の詳細を発表--高速化を目指す
http://japan.cnet.com/news/ent/story/0,2000056022,20267807,00.htm
http://japan.cnet.com/news/ent/story/0,2000056022,20267807,00.htm
ドイツ語のサイトすけど,tecChannel.deがPOWER6の発表のプレゼン画像をたくさん掲載しているす。
http://www.tecchannel.de/news/themen/technologie/450386
追加情報としてわ,
- POWER5を超える大規模コア
2x FXU, 2x FPU, 1x Branch Unit, 1x 十進FPU, 1x VMX, Recovery Unit
- 10進FPUレジスタフォーマット
- 32MB L3わ外付け 2x16-bit アドレスバス + 2x64-bit Data-In + 2x64-bit Data-Out, 80GB/s
- MCM内接続バス x 3 (,80GB/s) MCM間接続バス x 2 (50GB/s)
- on-dieメモリコントローラ x 2
- メモリわバッファチップを介して接続。例によってread/write非対称
- トランジスタ性能わ最新の歪SOI採用で90nm世代より30%高速
- BCD演算等50命令追加
- SMTの効率も向上。OLTPアプリで+55%
- ダイサイズ: 340 [mm^2]
- トランジスタ数: 750 [百万]
http://www.tecchannel.de/news/themen/technologie/450386
追加情報としてわ,
- POWER5を超える大規模コア
2x FXU, 2x FPU, 1x Branch Unit, 1x 十進FPU, 1x VMX, Recovery Unit
- 10進FPUレジスタフォーマット
- 32MB L3わ外付け 2x16-bit アドレスバス + 2x64-bit Data-In + 2x64-bit Data-Out, 80GB/s
- MCM内接続バス x 3 (,80GB/s) MCM間接続バス x 2 (50GB/s)
- on-dieメモリコントローラ x 2
- メモリわバッファチップを介して接続。例によってread/write非対称
- トランジスタ性能わ最新の歪SOI採用で90nm世代より30%高速
- BCD演算等50命令追加
- SMTの効率も向上。OLTPアプリで+55%
- ダイサイズ: 340 [mm^2]
- トランジスタ数: 750 [百万]
FPFのPOWER6講演の日本語記事す。IDG配信の翻訳すね。
http://opentechpress.jp/enterprise/06/10/11/1019258.shtml
http://opentechpress.jp/enterprise/06/10/11/1019258.shtml
http://www.extremetech.com/article2/0,1697,2027634,00.asp
> There's also a capability now to support an unaligned load/execute mode,
> which can improve instruction packing and decoding efficiency.
これってaddpd xmmreg,mem128とかでmem128のアライメントが合ってなくても
エラーが出ないってこと?
> There's also a capability now to support an unaligned load/execute mode,
> which can improve instruction packing and decoding efficiency.
これってaddpd xmmreg,mem128とかでmem128のアライメントが合ってなくても
エラーが出ないってこと?
例外は出なくてもアラインメント整合はあってたほうがいいだろ
193 :MACオタ>191 さん:2006/10/11(水) 23:36:02 ID:h0GVHGbP
>>191
ペナルティわ有るのかもしれないすけど,使い易くなって結構な話すね。
オリジナルの仕様わ,こうなってるす。
---------------------------
Protected Mode Exceptions
#GP(0) :For an illegal memory operand effective address in the CS, DS, ES, FS or
GS segments.
If a memory operand is not aligned on a 16-byte boundary, regardless of
segment.
---------------------------
ペナルティわ有るのかもしれないすけど,使い易くなって結構な話すね。
オリジナルの仕様わ,こうなってるす。
---------------------------
Protected Mode Exceptions
#GP(0) :For an illegal memory operand effective address in the CS, DS, ES, FS or
GS segments.
If a memory operand is not aligned on a 16-byte boundary, regardless of
segment.
---------------------------
EETimes記事とCNET記事の翻訳が来たす。
http://www.eetimes.jp/contents/200610/11775_1_20061011225925.cfm
http://japan.cnet.com/news/ent/story/0,2000056022,20268747,00.htm
http://www.eetimes.jp/contents/200610/11775_1_20061011225925.cfm
http://japan.cnet.com/news/ent/story/0,2000056022,20268747,00.htm
久々にワクワクする石だ
cell で培ったノウハウがイカされてたりしてw
少なくとも、ソニーの出したお金は役に立ってるだろうね
ゲーム関連が無けりゃIBMのファブは干上がってたかもしれないし
ゲーム関連が無けりゃIBMのファブは干上がってたかもしれないし
過剰なまでのアンチクロック主義が蔓延る中においてPOWER6は貴重な存在
>>197
IBMじゃないけど、Freescaleがアップルに出荷してたCPUが全体の2%ほどだったって、知ってる?
アップルはパソコンメーカーシェア第4位よ(Freescaleはそのうちの半分くらいだけど)?
IBMとFreescaleじゃ売ってるものも違うけどさ
IBMじゃないけど、Freescaleがアップルに出荷してたCPUが全体の2%ほどだったって、知ってる?
アップルはパソコンメーカーシェア第4位よ(Freescaleはそのうちの半分くらいだけど)?
IBMとFreescaleじゃ売ってるものも違うけどさ
>>199
別にPowerPCの話してるわけじゃないよ
別にPowerPCの話してるわけじゃないよ
201 :MACオタ>196 さん:2006/10/12(木) 01:40:08 ID:B0JQA5k/
>>196
CELLとPOWER6わ,全く異なる回路形式でどちらも超高クロックを実現しているのが
面白いところす。ただ,命令の実行レイテンシだけ見ても1-cycleで単純整数演算が実行できる
POWER6の方が良くできているす。消費電力も低そうだし。。。
CELLとPOWER6わ,全く異なる回路形式でどちらも超高クロックを実現しているのが
面白いところす。ただ,命令の実行レイテンシだけ見ても1-cycleで単純整数演算が実行できる
POWER6の方が良くできているす。消費電力も低そうだし。。。
> 全く異なる回路形式
へぇ、どう違うの?
へぇ、どう違うの?
203 :Socket774:2006/10/12(木) 02:01:30 ID:Xf3tVuJ9
POWER6はPOWER5+と比べて倍以上のクロックになってるわけだけど、
クロックあたりの性能はどうなってるの? コアが大規模になって、SMTも
効率が向上してるってことは、クロックあたりの性能も上がってるのかな。
POWER6無敵じゃね?
クロックあたりの性能はどうなってるの? コアが大規模になって、SMTも
効率が向上してるってことは、クロックあたりの性能も上がってるのかな。
POWER6無敵じゃね?
なぜPOWERオタと名乗らなかったのか不思議だ>MACオタ
でも最近のMACオタはIntelマンセーだよ
>>202
NANDとNORぐらい違うんじゃ?
NANDとNORぐらい違うんじゃ?
ナ、ナンドッテー
で、どこまでがMACオタの自演なん?
209 :Socket774:2006/10/12(木) 13:33:39 ID:GCNGT0u7
Transmeta、特許侵害でIntelを提訴
〜Core 2プロセッサなどの販売停止を請求
http://pc.watch.impress.co.jp/docs/2006/1012/transmeta.htm
トランスメタもとうとう特許ゴロにまで堕ちたか…
〜Core 2プロセッサなどの販売停止を請求
http://pc.watch.impress.co.jp/docs/2006/1012/transmeta.htm
トランスメタもとうとう特許ゴロにまで堕ちたか…
MACオタならこう言う。
裏でAMDが操ってるんじゃないすかね(笑)
裏でAMDが操ってるんじゃないすかね(笑)
で、どういう特許にひっかかるって話なの?
Yonah以降のDeeper Sleepは動的Vdd/Vthコントロールの特許に引っかかってるだろうなどうみても。
Transmeta、経営再建へ - 知財と技術ライセンス重視へ
http://journal.mycom.co.jp/news/2005/01/24/003.html
http://journal.mycom.co.jp/news/2005/01/24/003.html
まあTransmetaがIntel/AMDに与えた影響ってかなり大きなものだったし
相応の対価はあってもいいんじゃねーの。
GPU界のTransmetaも早く現れないものか。
相応の対価はあってもいいんじゃねーの。
GPU界のTransmetaも早く現れないものか。
するとAMDあたりもひっかからないか?和解済み?
買っちゃえ
買っちゃえって・・
今イヒ、AMDで作ってるのにか?w
今イヒ、AMDで作ってるのにか?w
ほぅ、それは初耳ですな。
Sun Niagara2の詳細が明らかに
ttp://pc.watch.impress.co.jp/docs/2006/1012/fmpf03.htm
>>218
「AMD Efficeon」で甦るTransmeta
米Transmeta、David R.Ditzel氏に聞く
ttp://pc.watch.impress.co.jp/docs/2006/0609/gyokai164.htm
>Ditzel: AMD Efficeonの生産は、すべて富士通が行ないます。
ttp://pc.watch.impress.co.jp/docs/2006/1012/fmpf03.htm
>>218
「AMD Efficeon」で甦るTransmeta
米Transmeta、David R.Ditzel氏に聞く
ttp://pc.watch.impress.co.jp/docs/2006/0609/gyokai164.htm
>Ditzel: AMD Efficeonの生産は、すべて富士通が行ないます。
流れぶったぎってスマソ
昔286がPascalの関数呼び出しに合わせた仕様にしてたとかいう話なかったっけ?
昔286がPascalの関数呼び出しに合わせた仕様にしてたとかいう話なかったっけ?
Cコンパイラに、
関数呼出しをPascal形式にする
なんていうオプションもあるね。
関数呼出しをPascal形式にする
なんていうオプションもあるね。
ルネサスがマルチコア対応のSuperHコアを開発
http://pc.watch.impress.co.jp/docs/2006/1013/fmpf04.htm
AMDがクアッドコアCPU「Barcelona」の詳細を発表
http://pc.watch.impress.co.jp/docs/2006/1013/kaigai311.htm
http://pc.watch.impress.co.jp/docs/2006/1013/fmpf04.htm
AMDがクアッドコアCPU「Barcelona」の詳細を発表
http://pc.watch.impress.co.jp/docs/2006/1013/kaigai311.htm
>>221
286〜386 の頃は Intel の設計者たちは Pascal が本流になると
考えていたから、それを意識した命令は多いよ。
ENTER 命令がそうだね。
Pascal で使える関数内の関数を簡単に実現するための機能もついてる。
一番目の引数はC言語等でも使うけど、二番目の引数は関数内関数のため。
ただ、関数内関数の実現方法には二つあるけど ENTER 命令は効率悪い方で
実現しているから案外活用されていない。
Pascal と関係無いものとしては、当時の大型コンピューターを意識して
セグメントによる仮想メモリ空間とセキュリティモデルを実装してるのもある。
現在はページングが主流で x86-64 では廃止されている。
ページングはセグメントよりセキュリティは弱いけど NX bit で補強している。
また速度でも不利だけど専用システムコール命令の追加で補強してる。
286〜386 の頃は Intel の設計者たちは Pascal が本流になると
考えていたから、それを意識した命令は多いよ。
ENTER 命令がそうだね。
Pascal で使える関数内の関数を簡単に実現するための機能もついてる。
一番目の引数はC言語等でも使うけど、二番目の引数は関数内関数のため。
ただ、関数内関数の実現方法には二つあるけど ENTER 命令は効率悪い方で
実現しているから案外活用されていない。
Pascal と関係無いものとしては、当時の大型コンピューターを意識して
セグメントによる仮想メモリ空間とセキュリティモデルを実装してるのもある。
現在はページングが主流で x86-64 では廃止されている。
ページングはセグメントよりセキュリティは弱いけど NX bit で補強している。
また速度でも不利だけど専用システムコール命令の追加で補強してる。
SH-Mobileなんかもうヘテロジニアスマルチコアって呼んでもいいくらいの構成じゃなかったっけ
より高度なデジタルビデオを扱うプロセッサ群
http://pc.watch.impress.co.jp/docs/2006/1013/fmpf06.htm
http://pc.watch.impress.co.jp/docs/2006/1013/fmpf06.htm
SHもいい加減に32ビット命令載せりゃいいのに
さすがに当然の感想だと思うす。
http://www.geocities.jp/andosprocinfo/wadai06/20061014.htm
-------------------------
しかし,私は,この4件の汎用プロセサの発表の中ではIBMのPOWER6が一番凄いと
思ったのですが,これだけが報道されていないのはどうしてでしょうね?
-------------------------
多分,後藤宏茂が当番なんで記事が遅れているんだと思うすけど,かつてCELLが高クロックを
達成した原因をシンプル,シンプル連呼してたのを,どう取り繕うすかね(笑)
現実にPOWER6わ,スーパースケーラ+SMT+RASという史上最も複雑構造のプロセッサすから。。。
http://pc.watch.impress.co.jp/docs/2005/0209/kaigai154.htm
=========================
Cellはどうしてこれだけの短FO4化=高クロック化ができたのか。Cell関係者は、その理由
について「プロセッサの構造をよりシンプルにしたからでしょう。逆に、Pentium 4があれだけ
複雑な構造で高クロックを達成するのはすごい」と言う。
=========================
http://www.geocities.jp/andosprocinfo/wadai06/20061014.htm
-------------------------
しかし,私は,この4件の汎用プロセサの発表の中ではIBMのPOWER6が一番凄いと
思ったのですが,これだけが報道されていないのはどうしてでしょうね?
-------------------------
多分,後藤宏茂が当番なんで記事が遅れているんだと思うすけど,かつてCELLが高クロックを
達成した原因をシンプル,シンプル連呼してたのを,どう取り繕うすかね(笑)
現実にPOWER6わ,スーパースケーラ+SMT+RASという史上最も複雑構造のプロセッサすから。。。
http://pc.watch.impress.co.jp/docs/2005/0209/kaigai154.htm
=========================
Cellはどうしてこれだけの短FO4化=高クロック化ができたのか。Cell関係者は、その理由
について「プロセッサの構造をよりシンプルにしたからでしょう。逆に、Pentium 4があれだけ
複雑な構造で高クロックを達成するのはすごい」と言う。
=========================
234 :MACオタ>210 さん:2006/10/15(日) 00:15:32 ID:Jp9t2wIS
MACオタの引用のしかたもキチガイの兆候す(笑)
Fall Processor ForumのNiagara2のプレゼン資料が公開されているす。
http://www.opensparc.net/pubs/preszo/06/04-Sun-Golla.pdf
http://www.opensparc.net/pubs/preszo/06/04-Sun-Golla.pdf
○弘茂
録音といい後藤嫌いな奴って、なんか似ているな
あと、MACオタって0時過ぎてから元気になるよね
録音といい後藤嫌いな奴って、なんか似ているな
あと、MACオタって0時過ぎてから元気になるよね
シンプル言ってるのはCell関係者なのにいつのまにか後藤に
摩り替わってるあたりがキチガイの兆候すw
摩り替わってるあたりがキチガイの兆候すw
俺のほうが詳しいのに何で奴の方が名前が売れているんだムキー
ってことなんだろw
ってことなんだろw
じゃあライターになればいいのに
241 :Socket774:2006/10/15(日) 00:46:31 ID:+Gq40o/1
{kind=link}
242 :MACオタ>237-239 さん:2006/10/15(日) 00:47:28 ID:Jp9t2wIS
>>237-239
信者さんもご苦労様す。以下,全部ご本尊のお言葉なんすけど(笑)
http://pc.watch.impress.co.jp/docs/2005/0209/kaigai154.htm
-------------------------
今回のCellは、再びCPUコア自体をシンプル化して高クロックを達成しようという点
-------------------------
http://pc.watch.impress.co.jp/docs/2005/0212/kaigai157.htm
-------------------------
●シンプルなプロセッサアーキテクチャが高クロック設計を容易に
-------------------------
http://pc.watch.impress.co.jp/docs/article/20000121/kaigai01.htm
-------------------------
MPUが単純になると、こうした問題も緩和され、クロックは上げやすくなる。
-------------------------
もちろんダメなのわ,後藤氏というよりわ後藤氏に半端な知識を吹き込んだブレーンのヒト
なんすけど。。。
信者さんもご苦労様す。以下,全部ご本尊のお言葉なんすけど(笑)
http://pc.watch.impress.co.jp/docs/2005/0209/kaigai154.htm
-------------------------
今回のCellは、再びCPUコア自体をシンプル化して高クロックを達成しようという点
-------------------------
http://pc.watch.impress.co.jp/docs/2005/0212/kaigai157.htm
-------------------------
●シンプルなプロセッサアーキテクチャが高クロック設計を容易に
-------------------------
http://pc.watch.impress.co.jp/docs/article/20000121/kaigai01.htm
-------------------------
MPUが単純になると、こうした問題も緩和され、クロックは上げやすくなる。
-------------------------
もちろんダメなのわ,後藤氏というよりわ後藤氏に半端な知識を吹き込んだブレーンのヒト
なんすけど。。。
後藤氏の記事はさておき、要するにPower6が驚異的な実装なのであって
シンプルコアまたは長大パイプラインが高クロックを達成しやすいと
いう見解そのものはこれまでの常識といっていいと思うが。
シンプルコアまたは長大パイプラインが高クロックを達成しやすいと
いう見解そのものはこれまでの常識といっていいと思うが。
オタ氏も他人の批判ではなく、なぜIBMがこのような常識を覆すような
奇跡的な性能のプロセッサを開発できたのか技術的な解説でも書いて
くれるとありがたい。
奇跡的な性能のプロセッサを開発できたのか技術的な解説でも書いて
くれるとありがたい。
246 :Socket774:2006/10/15(日) 01:06:43 ID:lggBWlVa
>>245
禿同
禿同
↓期待に応えて登場
↓
↓ 後藤本人
↓
↓ 後藤本人
↓
249 :MACオタ>243 さん:2006/10/15(日) 01:11:48 ID:Jp9t2wIS
>>243
-------------------
シンプルコアまたは長大パイプラインが高クロックを達成しやすいと
いう見解そのものはこれまでの常識といっていいと思うが。
-------------------
それが半端な知識というヤツす。デジタル回路と同期という問題の基礎が判っていれば,
動作クロックというのわステージあたりのゲートの数で決定されるということが判る筈す。
従って,
長大なパイプライン = 高クロック
の方わ正しいすけど,"複雑"の方がOoOEのような命令処理なのか,スーパースケーラ的な
パイプライン数の問題なのか,キャッシュのway数のような配線の問題なのか,FPUとIUの比較
のような回路規模の問題なのか。。。等を無視して,「シンプル=高クロック」と主張するのわ
頭が悪すぎるす。
-------------------
シンプルコアまたは長大パイプラインが高クロックを達成しやすいと
いう見解そのものはこれまでの常識といっていいと思うが。
-------------------
それが半端な知識というヤツす。デジタル回路と同期という問題の基礎が判っていれば,
動作クロックというのわステージあたりのゲートの数で決定されるということが判る筈す。
従って,
長大なパイプライン = 高クロック
の方わ正しいすけど,"複雑"の方がOoOEのような命令処理なのか,スーパースケーラ的な
パイプライン数の問題なのか,キャッシュのway数のような配線の問題なのか,FPUとIUの比較
のような回路規模の問題なのか。。。等を無視して,「シンプル=高クロック」と主張するのわ
頭が悪すぎるす。
うんうん、その調子で>>245についても詳細におながいします
そういや「全く異なる回路形式」についての説明まだー?
>>244 さん
----------------------
構成がシンプルではなくても難易度は同程度だと言うんだな?
----------------------
複雑なプロセッサも高クロックのプロセッサも開発が難しいのわ,当たり前す。
>>245 さん
私わISSCCにもFPFにも参加した訳じゃ無いすから,両方に参加した安藤氏の解説を
楽しみに待つのが良いと思うす。
----------------------
構成がシンプルではなくても難易度は同程度だと言うんだな?
----------------------
複雑なプロセッサも高クロックのプロセッサも開発が難しいのわ,当たり前す。
>>245 さん
私わISSCCにもFPFにも参加した訳じゃ無いすから,両方に参加した安藤氏の解説を
楽しみに待つのが良いと思うす。
敗北宣言きましたw
>多分,後藤宏茂が当番なんで記事が遅れているんだと思うすけど,かつてCELLが高クロックを
>達成した原因をシンプル,シンプル連呼してたのを,どう取り繕うすかね(笑)
>現実にPOWER6わ,スーパースケーラ+SMT+RASという史上最も複雑構造のプロセッサすから。。。
単にアプローチが違うってだけだろ。
後藤が今後設計される高クロックなCPUはすべてCell同等のシンプル化以外に道はないとでも言ってるなら
オタの指摘は尤もかもしれない。
>達成した原因をシンプル,シンプル連呼してたのを,どう取り繕うすかね(笑)
>現実にPOWER6わ,スーパースケーラ+SMT+RASという史上最も複雑構造のプロセッサすから。。。
単にアプローチが違うってだけだろ。
後藤が今後設計される高クロックなCPUはすべてCell同等のシンプル化以外に道はないとでも言ってるなら
オタの指摘は尤もかもしれない。
オタはスルーしとけよ
http://news.com.com/IBM+chip+architect+guns+for+gigahertz+-+page+2/2008-1006_3-6038941-2.html
How do you get up to that speed?
McCredie: That's what Brian Curran (the lead author on IBM's 4GHz paper for ISSCC)
showed. If you're holding the pipe depth constant, you have to put half as much logic
between each pipe stage. We had to get to the point where our circuits were doing
double and triple duty, where one set of transistors were doing multiple functions.
We had half as much gate delay between latches but had to get more work out of them.
How do you get up to that speed?
McCredie: That's what Brian Curran (the lead author on IBM's 4GHz paper for ISSCC)
showed. If you're holding the pipe depth constant, you have to put half as much logic
between each pipe stage. We had to get to the point where our circuits were doing
double and triple duty, where one set of transistors were doing multiple functions.
We had half as much gate delay between latches but had to get more work out of them.
258 :MACオタ>251 さん:2006/10/15(日) 01:37:14 ID:Jp9t2wIS
>>251
CELLわ,1998年頃に試作されたGHz PowerPCの血を引くダイナミックロジックを多用した
設計す。
http://ieeexplore.ieee.org/xpl/freeabs_all.jsp?arnumber=726542
この時代からCELLの主要アーキテクトの一人 Hofstee氏が名前を連ねているすね。
一方POWER6わ,ほとんどスタティック回路のみで構成していることを誇っているす。
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=193105767
--------------------------
The chip uses "new and highly complex latch and static gate circuits," said McCredie.
--------------------------
CELLわ,1998年頃に試作されたGHz PowerPCの血を引くダイナミックロジックを多用した
設計す。
http://ieeexplore.ieee.org/xpl/freeabs_all.jsp?arnumber=726542
この時代からCELLの主要アーキテクトの一人 Hofstee氏が名前を連ねているすね。
一方POWER6わ,ほとんどスタティック回路のみで構成していることを誇っているす。
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=193105767
--------------------------
The chip uses "new and highly complex latch and static gate circuits," said McCredie.
--------------------------
ちなみに,後藤弘茂が>>233のリンク先のような記事を書き飛ばしていた頃の,私のコメントす。
http://pc7.2ch.net/test/read.cgi/jisaku/1105726380/211
--------------------------
211 名前:MACオタ 投稿日:05/02/09 21:57:55 ID:ugRDR3cy
どうやら後藤氏のプロセッサ関係の後藤氏のブレーンって知ったか電波系のヒトみたいすね。
------------------------------
Cellはどうしてこれだけの短FO4化=高クロック化ができたのか。Cell関係者は、その理由について「プロ
セッサの構造をよりシンプルにしたからでしょう。逆に、Pentium 4があれだけ複雑な構造で高クロックを達
成するのはすごい」と言う。
------------------------------
シンプル=高クロック化って都市伝説わ、Mac方面でG3の方がG4よりクロックが高くなるってデマをばら撒いて
た厨房の戯言す(笑)
--------------------------
http://pc7.2ch.net/test/read.cgi/jisaku/1105726380/211
--------------------------
211 名前:MACオタ 投稿日:05/02/09 21:57:55 ID:ugRDR3cy
どうやら後藤氏のプロセッサ関係の後藤氏のブレーンって知ったか電波系のヒトみたいすね。
------------------------------
Cellはどうしてこれだけの短FO4化=高クロック化ができたのか。Cell関係者は、その理由について「プロ
セッサの構造をよりシンプルにしたからでしょう。逆に、Pentium 4があれだけ複雑な構造で高クロックを達
成するのはすごい」と言う。
------------------------------
シンプル=高クロック化って都市伝説わ、Mac方面でG3の方がG4よりクロックが高くなるってデマをばら撒いて
た厨房の戯言す(笑)
--------------------------
>>247-249の流れを見ているとMACオタが後藤本人と思えてしまう件について
POWER Mac復活するか。
また荒れてきてるな。
キチガイはスルーしろ
キチガイはスルーしろ
ID:hDLDy2l2は自ら反省しているようです。
>>262
しないでしょう。
POWERは、
・売れる個数が少ない
・CPU単体で利益を出すつもりがない
ということで、目標の歩留率が非常に低いのだと思う。
そのために、x86系ではありえない選択肢も使えるために、クロックが高くできるのだと思う。
しないでしょう。
POWERは、
・売れる個数が少ない
・CPU単体で利益を出すつもりがない
ということで、目標の歩留率が非常に低いのだと思う。
そのために、x86系ではありえない選択肢も使えるために、クロックが高くできるのだと思う。
x86の最高クロック版はほかの用途ではありえない選別率だから
その理屈はおかしいて
その理屈はおかしいて
x86やGPUのハイエンドはオタ向け、ベンチマーカー向けという特殊な市場があるから比較したってしょうがない。
PowerMacのCPUをPOWER6に載せ替えられないのか?
POWER6の高クロックと消費電力据え置きわ
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=193105767
----------------------
IBM applied new techniques in variable gate lengths and variable threshold voltages
to squeeze maximum performance per Watt at the transistor level.
----------------------
ゲート長やVthの異なる様々なトランジスタを使って実現しているす。量産で過去に様々な
ヘマをしでかしているIBMに造れる代物なのかどうかわ,確かに疑問す。
ちなみにIntelの最新プロセスでもゲート長,Vth,各2種類程度だったと思うす。
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=193105767
----------------------
IBM applied new techniques in variable gate lengths and variable threshold voltages
to squeeze maximum performance per Watt at the transistor level.
----------------------
ゲート長やVthの異なる様々なトランジスタを使って実現しているす。量産で過去に様々な
ヘマをしでかしているIBMに造れる代物なのかどうかわ,確かに疑問す。
ちなみにIntelの最新プロセスでもゲート長,Vth,各2種類程度だったと思うす。
271 :Socket774:2006/10/15(日) 23:14:47 ID:tPPtB9Dy
IBMが設計してIntelに作ってもらえばいいんじゃね?
272 :・∀・)っ-○◎●創聖のダンゴリオン ◆DanGorION6 :2006/10/15(日) 23:17:16 ID:3gL5uuP1
NetBurstチーム出番だな
AMDのVthは3種類らしい
ttp://journal.mycom.co.jp/articles/2006/02/07/isscc2/
ttp://journal.mycom.co.jp/articles/2006/02/07/isscc2/
>230
SH-2A/SH-4A系は、命令を拡張してた気がする。
SH-2A/SH-4A系は、命令を拡張してた気がする。
Multi-Gate LengthはIBMのPD-SOIではかなり多くデザインできるはず。
さらに技術自体のマージはやったから、
Dynamic Vthもライセンスさえ受ければEastFishKillでは手がけられる。
元々製造時のMulti-Vth/Vddはやってるし。
回路自体の方はたぶん最近のやり方の一つなら隠れてるFalse Pathを徹底的に洗い出して、
残ったクリティカルパスは多重化回路を組んでばらつき対策としても使うか。
65nmだと統計的予測でマージン決めるのがもはや当たり前だし。
さらに技術自体のマージはやったから、
Dynamic Vthもライセンスさえ受ければEastFishKillでは手がけられる。
元々製造時のMulti-Vth/Vddはやってるし。
回路自体の方はたぶん最近のやり方の一つなら隠れてるFalse Pathを徹底的に洗い出して、
残ったクリティカルパスは多重化回路を組んでばらつき対策としても使うか。
65nmだと統計的予測でマージン決めるのがもはや当たり前だし。
>>266
x86の場合は、正常に動作するCPUの中からの選別でしょ。
たとえば3.0〜3.4GHzで動作することを狙って作って、3.6GHzで動作するものを抜き出す。
もし、3.6GHz動作を狙って作った場合、3.6GHzで動作するものは増えるが、
その代わり、3.0〜3.4GHzでも動作しない捨てるしかないダイが激増してしまう。
x86の場合は、正常に動作するCPUの中からの選別でしょ。
たとえば3.0〜3.4GHzで動作することを狙って作って、3.6GHzで動作するものを抜き出す。
もし、3.6GHz動作を狙って作った場合、3.6GHzで動作するものは増えるが、
その代わり、3.0〜3.4GHzでも動作しない捨てるしかないダイが激増してしまう。
POWER vs x86の構図が続きそうでなによりか?
歩留まりのことを言うと、Itaniumなんかどうするんだと…
x86にしても、インテル65nmで1.2Vは高すぎるし、AMDの90nmでも1.35Vも同様
それと、POWER5+のTDPが80Wで、POWER6が70Wだっけ?
x86にしても、インテル65nmで1.2Vは高すぎるし、AMDの90nmでも1.35Vも同様
それと、POWER5+のTDPが80Wで、POWER6が70Wだっけ?
「これがジオンの最新のモビルスーツ…じゃなかった。Intelの新プロセッサー。すごい!5倍以上のエネルギーゲインがある。すごい!それにこれは違うぞ。ザクなんかと装甲もパワーも消費電力も。Core 2 Duoは伊達じゃない!」
http://www.watch.impress.co.jp/akiba/hotline/20061007/image/niaf_m.wmv
http://www.watch.impress.co.jp/akiba/hotline/20061007/image/niaf_m.wmv
5倍もエネルギー食うのか
IBM Previews the POWER6
http://www.realworldtech.com/page.cfm?ArticleID=RWT101606194731
この記事の情報が正しいかどうかわからんけど、とりあえず気になった点
噂の0.8Vは出てきてないけど、SRAMはlogicより低電圧で動かせるみたい。
今年のISSCCの時点では無理だったのにね。
Intelと同じくチャネル長を長くしたトランジスタを使ったという話が別の記事にあるから、これが低電圧化のキーポイントだったりして。
キャッシュ構成は興味深い。
L1が倍増してるのは良いとして(latencyは 4-cycles 増えてるが…)、POWER5では共有L2だったのにわざわざ分離してる。
8MBにするとlatencyが悪くなるらしいので分離したとか。
代わりにL2の外にバッファを用意してL2間で猛烈に通信する。
外付けのL3は共有キャッシュだがvictimらしい。
もしかしてK8Lと同じような処理をしてるのだろうか。
キャッシュ構成は似てる気がするのだが。
Figure2なんかHT3.0のスライドにそっくり。
POWER7がOpteronと共通プラットホームになるという噂もわかる気がするな。
他に気づいたことあったらよろ。
http://www.realworldtech.com/page.cfm?ArticleID=RWT101606194731
この記事の情報が正しいかどうかわからんけど、とりあえず気になった点
噂の0.8Vは出てきてないけど、SRAMはlogicより低電圧で動かせるみたい。
今年のISSCCの時点では無理だったのにね。
Intelと同じくチャネル長を長くしたトランジスタを使ったという話が別の記事にあるから、これが低電圧化のキーポイントだったりして。
キャッシュ構成は興味深い。
L1が倍増してるのは良いとして(latencyは 4-cycles 増えてるが…)、POWER5では共有L2だったのにわざわざ分離してる。
8MBにするとlatencyが悪くなるらしいので分離したとか。
代わりにL2の外にバッファを用意してL2間で猛烈に通信する。
外付けのL3は共有キャッシュだがvictimらしい。
もしかしてK8Lと同じような処理をしてるのだろうか。
キャッシュ構成は似てる気がするのだが。
Figure2なんかHT3.0のスライドにそっくり。
POWER7がOpteronと共通プラットホームになるという噂もわかる気がするな。
他に気づいたことあったらよろ。
>チャネル長を長くしたトランジスタを使った
ここだけ読むとTulsaの記事に見えるね。
>L1が倍増してるのは良いとして(latencyは 4-cycles 増えてるが…)、POWER5では共有L2だったのにわざわざ分離してる。
>8MBにするとlatencyが悪くなるらしいので分離したとか。
高クロック志向のプロセッサは事実上、Power6が最後になりそう。
>外付けのL3は共有キャッシュだがvictimらしい。
Power5の時からそう。
>もしかしてK8Lと同じような処理をしてるのだろうか。
「L2の外にバッファを用意してL2間で猛烈に通信する。」と自分で書いてるじゃない。
それに、Power6のL3は36MBと大きい(当然オフダイ)のでK8Lみたいな事はやらないと思う。
デュアルコアだし。
ここだけ読むとTulsaの記事に見えるね。
>L1が倍増してるのは良いとして(latencyは 4-cycles 増えてるが…)、POWER5では共有L2だったのにわざわざ分離してる。
>8MBにするとlatencyが悪くなるらしいので分離したとか。
高クロック志向のプロセッサは事実上、Power6が最後になりそう。
>外付けのL3は共有キャッシュだがvictimらしい。
Power5の時からそう。
>もしかしてK8Lと同じような処理をしてるのだろうか。
「L2の外にバッファを用意してL2間で猛烈に通信する。」と自分で書いてるじゃない。
それに、Power6のL3は36MBと大きい(当然オフダイ)のでK8Lみたいな事はやらないと思う。
デュアルコアだし。
>>外付けのL3は共有キャッシュだがvictimらしい。
>Power5の時からそう。
知ってるけど、独立L2に共有L3でvictimってのがどうなのかなあと思って。
共有L2にvictimな共有L3ならわかりやすいけどさ。
>>もしかしてK8Lと同じような処理をしてるのだろうか。
>「L2の外にバッファを用意してL2間で猛烈に通信する。」と自分で書いてるじゃない。
L3やメインメモリを使わずL2間で通信出来るということで、これはK8Lもそうだと思うよ。
現状がそうだし、K8LにはL3が無いデュアルコアも用意されてるみたいだから。
POWER6のL3はオプションみたいだから、L2間で通信出来なきゃ大変なことになる。
と言いつつも詳しく知らんので間違ってたらすまん。
>Power5の時からそう。
知ってるけど、独立L2に共有L3でvictimってのがどうなのかなあと思って。
共有L2にvictimな共有L3ならわかりやすいけどさ。
>>もしかしてK8Lと同じような処理をしてるのだろうか。
>「L2の外にバッファを用意してL2間で猛烈に通信する。」と自分で書いてるじゃない。
L3やメインメモリを使わずL2間で通信出来るということで、これはK8Lもそうだと思うよ。
現状がそうだし、K8LにはL3が無いデュアルコアも用意されてるみたいだから。
POWER6のL3はオプションみたいだから、L2間で通信出来なきゃ大変なことになる。
と言いつつも詳しく知らんので間違ってたらすまん。
最大144TFLOPSに高めたNEC「SX-8R」
http://www.itmedia.co.jp/news/articles/0610/17/news088.html
> 同社は、1CPUで100GFLOPSを超えるベクタープロセッサを搭載した
> 次期スーパーコンピュータの開発に着手している。
CPUの数が一緒なら最大構成で約500TFLOPSってことで京速計算機の
「大規模処理計算機部」(0.5PFLOPS)はこれで決まりだよなぁ
「逐次処理計算機部」(1PFLOPS)はSPARC64 or FR-V + SIMD だと思うし
「特定処理計算加速部」(20PFLOPS)はGRAPEの発展形だと思うし
たるさん予想のどこが間違ってるんだろう?
http://www.itmedia.co.jp/news/articles/0610/17/news088.html
> 同社は、1CPUで100GFLOPSを超えるベクタープロセッサを搭載した
> 次期スーパーコンピュータの開発に着手している。
CPUの数が一緒なら最大構成で約500TFLOPSってことで京速計算機の
「大規模処理計算機部」(0.5PFLOPS)はこれで決まりだよなぁ
「逐次処理計算機部」(1PFLOPS)はSPARC64 or FR-V + SIMD だと思うし
「特定処理計算加速部」(20PFLOPS)はGRAPEの発展形だと思うし
たるさん予想のどこが間違ってるんだろう?
285 :Socket774:2006/10/18(水) 01:07:09 ID:UsGX8h5o
どうでもいいけど、汎用京速計算機の各部位の、日本語盛りだくさん感がカコイイ。
変な横文字を過剰に多用する文って
なんか詐偽とか宗教とかの広告っぽいからな
それなら分かりにくい漢字多用の日本語のほうがしっくりくるよな。
なんか詐偽とか宗教とかの広告っぽいからな
それなら分かりにくい漢字多用の日本語のほうがしっくりくるよな。
カタカナ外来語の羅列のが分かりづらい。
カタカナ英語が和製英語なら、音読みの漢字並べるのは和製中文だよな
オモイカネどこぉ?
オモイカネどこぉ?
中国に典拠が無いどころか、日本国内じゃないと存在し得ない
純正の和製熟語も氾濫してるから何とも言えん。
それどころか漢字そのものも自前で作っちまう昔の日本人。
純正の和製熟語も氾濫してるから何とも言えん。
それどころか漢字そのものも自前で作っちまう昔の日本人。
表意文字の漢字と表音文字のアルファベットじゃそらねえ。
一見して意味まで伝える漢字の機能がアルファベットには無いからわかりにくくても仕方ない。
漢字は偉大だよ、アルファベットが薄っぺらくわかりにくいのはデフォ。
一見して意味まで伝える漢字の機能がアルファベットには無いからわかりにくくても仕方ない。
漢字は偉大だよ、アルファベットが薄っぺらくわかりにくいのはデフォ。
つまんね。はい次の話題ドゾー
漢字を捨ててしまった韓国人は、もったいないことしたね、と。
開いた口が塞がらなくて<#`∀´>ヲ|Eト!!!
音は図形と違って後に残らないから。
だからズレが生じて屋上屋が架される。
だからズレが生じて屋上屋が架される。
296 :Socket774:2006/10/18(水) 14:08:37 ID:atgi+svh
古木 坂村教授はRISCを批判してますよね。
トロンチップの仕様そのものはともかく、
現実にRISC技術がMPUで主流となりつつあり、
トロンチップの一部にもRISC技術を
取り入れたものがあるというのは、
彼のRISC批判が的外れだという証拠じゃないんですか?
中野 ただね、今のMPUは、CISCはRISCの技術を
どんどん取り入れる一方で、RISCチップ自体が
命令数をどんどん増やすとか、CISCに近づいているような状態で、
RISCかCISCか、という論争は無意味に
なりつつあるのは事実ですよ。
新田 そこなんです。結局のところ坂村教授が考えたものの一つは、
多様な用途向けに作られた様々な種類のMPUが、
統合化された電脳環境の中でスムーズに命令をやり取りできるための、
整合性のある命令セットの統一なんです。
だから当時のワークステーションの用途に合せて
命令セットを制限するのは困ると。
そのワークステーションですら「マルチメディア機能」とかの
付加が必要になって、命令数を増やしてCISCに近づいているのは、
坂村教授の見通しが正しかったという証拠じゃないでしょうか。
トロンチップの仕様そのものはともかく、
現実にRISC技術がMPUで主流となりつつあり、
トロンチップの一部にもRISC技術を
取り入れたものがあるというのは、
彼のRISC批判が的外れだという証拠じゃないんですか?
中野 ただね、今のMPUは、CISCはRISCの技術を
どんどん取り入れる一方で、RISCチップ自体が
命令数をどんどん増やすとか、CISCに近づいているような状態で、
RISCかCISCか、という論争は無意味に
なりつつあるのは事実ですよ。
新田 そこなんです。結局のところ坂村教授が考えたものの一つは、
多様な用途向けに作られた様々な種類のMPUが、
統合化された電脳環境の中でスムーズに命令をやり取りできるための、
整合性のある命令セットの統一なんです。
だから当時のワークステーションの用途に合せて
命令セットを制限するのは困ると。
そのワークステーションですら「マルチメディア機能」とかの
付加が必要になって、命令数を増やしてCISCに近づいているのは、
坂村教授の見通しが正しかったという証拠じゃないでしょうか。
297 :Socket774:2006/10/18(水) 14:09:46 ID:atgi+svh
野 それとトロンチップの特徴の一つは、「対象命令」ですね。
あれはアセンブラでソフトを組む人には、やりづらいとして不評でした。
新田 でもCとかの高級言語を作るのに非常にやりやすいとして、
そっちの人達には好評ですよ。
今やOSだってCとかで作ってる時代で、
いまさらアセンブラもないと思いますけど。
中野 でもアセンブラでやりたい、と言う人もいる訳ですよね
新田 68アーキテクチャーはアセンブラが使いやすいって事で
人気がありました。けど、今では絶滅寸前ですね。
あれはアセンブラでソフトを組む人には、やりづらいとして不評でした。
新田 でもCとかの高級言語を作るのに非常にやりやすいとして、
そっちの人達には好評ですよ。
今やOSだってCとかで作ってる時代で、
いまさらアセンブラもないと思いますけど。
中野 でもアセンブラでやりたい、と言う人もいる訳ですよね
新田 68アーキテクチャーはアセンブラが使いやすいって事で
人気がありました。けど、今では絶滅寸前ですね。
298 :Socket774:2006/10/18(水) 14:10:44 ID:atgi+svh
中野 130MIPSのGマイクロ500はよく言われていたようですが。
古木 130MIPS?、トロンチップが、ですか?
中野 そうですよ。
トロンチップはCISCだから
遅くて使い物にならないから潰れた・・・
なんて言ってる人がいるけど、それは大間違いなんです。
新田 大体、日本企業がみんなRISCを
作るようになった・・・って言っても、
SH1なんかそれほど早い訳じゃないですしね。
中野 むしろ、構造が単純で
低コストだけど性能はそこそこ・・・ってあたりが、
日本企業が組み込みチップとして
RISCを多用したメリットじゃないかな。
新田 なるほど、SHマイコンは安さで売ってるわけか。
古木 家電の組み込みには必須な長所だと思いますよ。
古木 130MIPS?、トロンチップが、ですか?
中野 そうですよ。
トロンチップはCISCだから
遅くて使い物にならないから潰れた・・・
なんて言ってる人がいるけど、それは大間違いなんです。
新田 大体、日本企業がみんなRISCを
作るようになった・・・って言っても、
SH1なんかそれほど早い訳じゃないですしね。
中野 むしろ、構造が単純で
低コストだけど性能はそこそこ・・・ってあたりが、
日本企業が組み込みチップとして
RISCを多用したメリットじゃないかな。
新田 なるほど、SHマイコンは安さで売ってるわけか。
古木 家電の組み込みには必須な長所だと思いますよ。
299 :Socket774:2006/10/18(水) 19:42:59 ID:mkRjBwAa
SOI基板はどうも駄目という印象、漏洩電流が少なくクロックも揚げ易いという
売り込みだったが実際は同じルールなら普通のバルクの基板の方が速い。
売り込みだったが実際は同じルールなら普通のバルクの基板の方が速い。
SOIなんて使ったことあるんだ
PD-SOIで遅い?FD-SOIでOKIのはクロックは重視してないけど…はて。
トロンチップは専用命令だらけで廃れたと聞きましたが。
Microsoft starts CPU architecture team
http://www.theinquirer.net/default.aspx?article=35219
Nvidia at work on combined CPU with graphic
http://www.theinquirer.net/default.aspx?article=35216
http://www.theinquirer.net/default.aspx?article=35219
Nvidia at work on combined CPU with graphic
http://www.theinquirer.net/default.aspx?article=35216
グラフィック統合CPUと聞くとMediaGXを思い出す俺。
Nvidia製てぃうな?
>低価格パソコン向けの統合型プロセッサーであるTimna
これを思い出した。
これを思い出した。
待望の安藤氏のFPFレポートす。まず,POWER6から
http://www.geocities.jp/andosprocinfo/wadai06/20061021.htm
あまり新しい情報も無かったすけど,システム構成とインタコネクトに関する記述があるす。
---------------------
また,POWER5では,MCM上の4チップをリング接続し,このMCMを最大8個リング接続する
という構成になっていましたが,POWER6ではMCM 上の接続は1対1の完全結合とし,
各CPUチップから2本のMCM間接続を出し,MCM当たり計8本で,8個のMCM間(最大9個か?)
を1対1の完全結合で結んでいます。他のMCMや同一MCMでも他のチップに接続された
メモリをアクセスする場合のレーテンシが短くなり,性能が上がる筈です。AMDの QuadCoreも
同様の方向で4/8チップを完全結合する方式となると発表されており,数年前はリングが
ファッションだったのですが,来年はフルクロスがファッションのようです。
---------------------
ちなみに,過去POWER4系のプロセッサ間インタコネクトわ,次のような変遷を辿っているす。
POWER4: MCM内-direct/MCM間-loop
POWER5: MCM内-loop/MCM間-loop
http://www.geocities.jp/andosprocinfo/wadai06/20061021.htm
あまり新しい情報も無かったすけど,システム構成とインタコネクトに関する記述があるす。
---------------------
また,POWER5では,MCM上の4チップをリング接続し,このMCMを最大8個リング接続する
という構成になっていましたが,POWER6ではMCM 上の接続は1対1の完全結合とし,
各CPUチップから2本のMCM間接続を出し,MCM当たり計8本で,8個のMCM間(最大9個か?)
を1対1の完全結合で結んでいます。他のMCMや同一MCMでも他のチップに接続された
メモリをアクセスする場合のレーテンシが短くなり,性能が上がる筈です。AMDの QuadCoreも
同様の方向で4/8チップを完全結合する方式となると発表されており,数年前はリングが
ファッションだったのですが,来年はフルクロスがファッションのようです。
---------------------
ちなみに,過去POWER4系のプロセッサ間インタコネクトわ,次のような変遷を辿っているす。
POWER4: MCM内-direct/MCM間-loop
POWER5: MCM内-loop/MCM間-loop
POWER6がすばらしいのはわかるが,2年遅過ぎだろ。
安藤氏のFPFレポート,詳細版がMYCOMの方にきたす。スライド付きなので更に
有り難味が増してるす。
キーノート http://journal.mycom.co.jp/articles/2006/10/21/fpf1/
サーバープロセッサ http://journal.mycom.co.jp/articles/2006/10/21/fpf2/
組込プロセッサ http://journal.mycom.co.jp/articles/2006/10/21/fpf3/
有り難味が増してるす。
キーノート http://journal.mycom.co.jp/articles/2006/10/21/fpf1/
サーバープロセッサ http://journal.mycom.co.jp/articles/2006/10/21/fpf2/
組込プロセッサ http://journal.mycom.co.jp/articles/2006/10/21/fpf3/
>>308
AMDのデュアルコアOpteronがすばらしいのはわかるが、POWER4に4年遅過ぎだろ。
AMDのデュアルコアOpteronがすばらしいのはわかるが、POWER4に4年遅過ぎだろ。
311 :Socket774:2006/10/22(日) 11:49:30 ID:90wBpxDt
IBM、次期プロセッサ「POWER6」で「5GHzに近い高速化」を実現--10進数にも対応
カリフォルニア州サンノゼ発--米IBMの次期デュアルコアプロセッサ「POWER6」では、
10まで数えることが可能になる。
http://japan.cnet.com/news/ent/story/0,2000056022,20268747,00.htm
カリフォルニア州サンノゼ発--米IBMの次期デュアルコアプロセッサ「POWER6」では、
10まで数えることが可能になる。
http://japan.cnet.com/news/ent/story/0,2000056022,20268747,00.htm
ネタ古すぎだ馬鹿
313 :Socket774:2006/10/22(日) 17:50:39 ID:OO7Ow0JM
CPUなんかにバグなんてあるわけないだろ
プログラムが仕込まれているわけでもあるまいし
プログラムが仕込まれているわけでもあるまいし
この台まだ発表されてないけどお祭りモードでで確率あがるね
Fall Microprocessor Forum 2006 - IBMが次世代サーバプロセッサPOWER6を発表
http://journal.mycom.co.jp/articles/2006/10/22/fpf1/
0.8VというのはSRAMの動作を確認出来た電圧でチップの動作電圧ではないらしい。
だから当然動作電圧はもっと上。
消費電力も据え置きではなさそうな書き方。
eetimesなんかの記事とはえらく違うな。
http://journal.mycom.co.jp/articles/2006/10/22/fpf1/
0.8VというのはSRAMの動作を確認出来た電圧でチップの動作電圧ではないらしい。
だから当然動作電圧はもっと上。
消費電力も据え置きではなさそうな書き方。
eetimesなんかの記事とはえらく違うな。
>>315
>もっとも、IBMはPOWER PC970、CELL、Xbox360のCPUなどで高いクロックを実現しており、
>時間を掛けて高クロック設計法を開発してきたのだと思われる。
>これらの 90nmプロセスのチップで3〜4GHzのクロックが実現されていることから、
>65nmプロセスを使うPOWER6が4〜5GHzクロックに達するということは不思議ではない。
こんな文があるが、
もっとも、IntelはPentium4で高いクロックを(中略)これらの90nmプロセスのチップで3-4GHzのクロックが実現されていることから、
65nmプロセスを使うCore 2 Duoが4-6GHzクロックに達するということは不思議ではない。
って言ってるのと同じだよな。
POWER6はCellやPowerPC970とはまったく違うやり方だろうに
>もっとも、IBMはPOWER PC970、CELL、Xbox360のCPUなどで高いクロックを実現しており、
>時間を掛けて高クロック設計法を開発してきたのだと思われる。
>これらの 90nmプロセスのチップで3〜4GHzのクロックが実現されていることから、
>65nmプロセスを使うPOWER6が4〜5GHzクロックに達するということは不思議ではない。
こんな文があるが、
もっとも、IntelはPentium4で高いクロックを(中略)これらの90nmプロセスのチップで3-4GHzのクロックが実現されていることから、
65nmプロセスを使うCore 2 Duoが4-6GHzクロックに達するということは不思議ではない。
って言ってるのと同じだよな。
POWER6はCellやPowerPC970とはまったく違うやり方だろうに
Intel Macより数倍高速なPower Mac6をぜひ体験してください。
とかまた迷走してくんないかな
とかまた迷走してくんないかな
最後まで読んだけど、なんだか筆者の予想ばかりが目に付くな。
それほど情報が出てないのかもしれないが…
CELLやPOWER PC(スペース有り)と表記するなら、途中のOpteronもOPTERONなどと表記して欲しかったw
それほど情報が出てないのかもしれないが…
CELLやPOWER PC(スペース有り)と表記するなら、途中のOpteronもOPTERONなどと表記して欲しかったw
ああ、思い出した…
この記事書いてる人、「PowerPC970が2003年後半に1.8GHzで登場する、と発表」されたときに
「PowerPC970は1.8GHzに達するそうだが、これは最終目標と思われ、登場予定の03年後半では1.4GHz程度だと思われる」
とか書いてた人じゃね?
「Up to 1.8GHz」とでも書かれてたのを誤解したか
真偽は不明だが、デュアルコアPowerPC G4を75W程度だと「思われる」って書いたのもこの人じゃね?
POWER関連だけでもこんなもんだが、もっと前科ありそうだな
と、ここまで書いたが別人だった
http://journal.mycom.co.jp/news/2002/10/18/16.html
安藤さんすまねぇ
この記事書いてる人、「PowerPC970が2003年後半に1.8GHzで登場する、と発表」されたときに
「PowerPC970は1.8GHzに達するそうだが、これは最終目標と思われ、登場予定の03年後半では1.4GHz程度だと思われる」
とか書いてた人じゃね?
「Up to 1.8GHz」とでも書かれてたのを誤解したか
真偽は不明だが、デュアルコアPowerPC G4を75W程度だと「思われる」って書いたのもこの人じゃね?
POWER関連だけでもこんなもんだが、もっと前科ありそうだな
と、ここまで書いたが別人だった
http://journal.mycom.co.jp/news/2002/10/18/16.html
安藤さんすまねぇ
IBMの宣伝やらせたら安藤の右に出るものは無いな
Intel x パルオ級の名コンビ
Intel x パルオ級の名コンビ
俺の予想では 2ch には ando さんより上の技術者はいない
>313
微笑ましいな。
CPUI内部には、実は「マイクロプログラム」ってのがある。
CISCのCPUは、Athlon64とかCore2Duoも含めて、どれもが持ってるよ。
近年は、単純命令ではマイクロプログラムを使わないように進化してきたが、
マイクロプログラムを完全排除できてるのはRISCだけだ。
Athlon64とかCore2Duoの場合は、いくつか持ってる命令デコーダのうち、1つだけがマイクロプログラムを使う。他のデコーダは単純命令用。
具体的に、どの程度の処理なら単純命令か、って基準は、それこそCPUによって違う。
486では、マイクロプログラムを必要としない単純命令は、案外と少なかったみたいだな。
一部の演算命令では、オペランドと演算結果を、表としてマイクロROMに持ってる場合もある。
この表に誤データが載ってたことによる演算バグで、Pentium(だったかPentiumProだったか)が回収された事件もあった。
あと。ハードワイヤド命令でも、設計ミスによるバグが絶対にないって事はなく、バグは有り得る。
微笑ましいな。
CPUI内部には、実は「マイクロプログラム」ってのがある。
CISCのCPUは、Athlon64とかCore2Duoも含めて、どれもが持ってるよ。
近年は、単純命令ではマイクロプログラムを使わないように進化してきたが、
マイクロプログラムを完全排除できてるのはRISCだけだ。
Athlon64とかCore2Duoの場合は、いくつか持ってる命令デコーダのうち、1つだけがマイクロプログラムを使う。他のデコーダは単純命令用。
具体的に、どの程度の処理なら単純命令か、って基準は、それこそCPUによって違う。
486では、マイクロプログラムを必要としない単純命令は、案外と少なかったみたいだな。
一部の演算命令では、オペランドと演算結果を、表としてマイクロROMに持ってる場合もある。
この表に誤データが載ってたことによる演算バグで、Pentium(だったかPentiumProだったか)が回収された事件もあった。
あと。ハードワイヤド命令でも、設計ミスによるバグが絶対にないって事はなく、バグは有り得る。
323 :・∀・)っ-○◎●創聖のダンゴリオン ◆DanGorION6 :2006/10/22(日) 21:51:27 ID:YNOGGqte
AMDは全デコーダが複合デコーダな罠
tureta-
Intelのもう1つの次世代CPU「LPP」
http://pc.watch.impress.co.jp/docs/2006/1023/kaigai313.htm
http://pc.watch.impress.co.jp/docs/2006/1023/kaigai313.htm
安藤さん自分のサイトに比べてPOWERの記事はトーンダウンさせてるみたいだから、
わざと記事向けにプレゼンのアウトラインそのままに近い形で出したんじゃない?
PPC970は一部近い。ブロックレイアウトがバスに制約されてる上で層厚を変えてたはず。
アーキテクチャじゃないけどな。
わざと記事向けにプレゼンのアウトラインそのままに近い形で出したんじゃない?
PPC970は一部近い。ブロックレイアウトがバスに制約されてる上で層厚を変えてたはず。
アーキテクチャじゃないけどな。
329 :・∀・)っ-○◎●創聖のダンゴリオン ◆DanGorION6 :2006/10/23(月) 01:17:27 ID:kLPI976x
Efficeonもいよいよ死ぬ
つーかLPPはノートに使っちゃってもいいのかな?
どうなるのか想像つかんね。
どうなるのか想像つかんね。
EfficeonやC7やGeodeシリーズはx86だからこそ生きられたんだ。
どれも絶対消費電力は低くないし、かといってワットあたりのパフォーマンスは非x86のものより弱い。
と、いうわけで死亡
インターフェース系統合プロセッサは玄箱に載ってるのが603e+統合プロセッサだっけ?
G4系にもPCI-Eやギガビットイーサやメモコン統合のがあったよな
どれも絶対消費電力は低くないし、かといってワットあたりのパフォーマンスは非x86のものより弱い。
と、いうわけで死亡
インターフェース系統合プロセッサは玄箱に載ってるのが603e+統合プロセッサだっけ?
G4系にもPCI-Eやギガビットイーサやメモコン統合のがあったよな
>323
どのデコーダもマイクロプログラムを展開できたのは、K5だけじゃなかったか。
そのせいで回路が複雑化して(?)、クロックが上がらなかったんだった気が。
まあいいや。オレより詳しいヤツが何人もいるみたいだから、
そのうち誰か解説してくれるだろ。見るに見かねて
どのデコーダもマイクロプログラムを展開できたのは、K5だけじゃなかったか。
そのせいで回路が複雑化して(?)、クロックが上がらなかったんだった気が。
まあいいや。オレより詳しいヤツが何人もいるみたいだから、
そのうち誰か解説してくれるだろ。見るに見かねて
333 :・∀・)っ-○◎●創聖のダンゴリオン ◆DanGorION6 :2006/10/23(月) 01:48:29 ID:kLPI976x
正確に言うとVectorPathだね。
複合命令は全デコーダパス使ってデコード。
複合命令は全デコーダパス使ってデコード。
335 :Socket774:2006/10/24(火) 07:37:18 ID:RpeHKNKl
113 名前: 名称未設定 Mail: sage 投稿日: 2006/10/24(火) 01:53:32 ID: ru8vlPti0
そもそもGPGPUが注目されたのって、
ClearSpeedとかの100万超える高価で高性能なボードに「近い」特徴のものが10万以下で手に入る「かも知れない」
からなわけで。。。
これが何で「CPUに統合だー!!つまりコンピューターは性能大幅アップだあー!!」ってなってるのか、さっぱりワケワカラン
GPUという専用プロセッサを例にすれば、
「グラフィックス関連の処理しかしない」という特徴に、
「べったり甘えている」からああいった性能が出るんですよ
無理矢理統合して上手くいくわけがない
そもそもGPGPUが注目されたのって、
ClearSpeedとかの100万超える高価で高性能なボードに「近い」特徴のものが10万以下で手に入る「かも知れない」
からなわけで。。。
これが何で「CPUに統合だー!!つまりコンピューターは性能大幅アップだあー!!」ってなってるのか、さっぱりワケワカラン
GPUという専用プロセッサを例にすれば、
「グラフィックス関連の処理しかしない」という特徴に、
「べったり甘えている」からああいった性能が出るんですよ
無理矢理統合して上手くいくわけがない
>>335
あんたが書いたわけじゃないんだろうが、ClearSpeedって本当に性能が出るの?
オンボードメモリの帯域が6.4GB/sしかないってベクトル計算機としては
絶望的な気がする。
GPUの世代が進めばあっという間に淘汰されそう。
あんたが書いたわけじゃないんだろうが、ClearSpeedって本当に性能が出るの?
オンボードメモリの帯域が6.4GB/sしかないってベクトル計算機としては
絶望的な気がする。
GPUの世代が進めばあっという間に淘汰されそう。
200 Gbytes/s internal memoryというところがミソなのかな。
しかしどことなく256KBのローカルメモリに依存するcellと
同じ臭いがw
しかしどことなく256KBのローカルメモリに依存するcellと
同じ臭いがw
338 :・∀・)っ-○◎●創聖のダンゴリオン ◆DanGorION6 :2006/10/24(火) 19:58:56 ID:ccGjp1cY
45nmになってもダイに乗っかるSRAMなんてせいぜい数MB。
CPUコアとダイレクトにデータ交換できるにせよ、GPUだけで完結する処理は、
従来通りXDRと専用メモリバスで接続する方式のほうが性能稼げると思うのだけど。
CPUコアとダイレクトにデータ交換できるにせよ、GPUだけで完結する処理は、
従来通りXDRと専用メモリバスで接続する方式のほうが性能稼げると思うのだけど。
ミドル〜ハイエンドGPUは、今と同様CPUとは別チップで専用VRAMをつけるでしょ。
GPU統合CPUは、今現在チップセット統合グラフィックを使っているような
マーケット向け。それでも十分意味はあるって話でしょ。
GPU統合CPUは、今現在チップセット統合グラフィックを使っているような
マーケット向け。それでも十分意味はあるって話でしょ。
>>339
それは映像出力機能をCPUに付けるということか?
それは映像出力機能をCPUに付けるということか?
PixelShaderやROPつけるかは知らんけど
VertexShaderつけてVectorUnitとして流用しましょって話でしょ。
VertexShaderつけてVectorUnitとして流用しましょって話でしょ。
342 :Socket774:2006/10/24(火) 22:03:40 ID:RpeHKNKl
汎用SIMDエンジンとして使いましょうってことじゃないの?
>>342
SIMDの意味わかってるか?
SIMDの意味わかってるか?
ここは一つx86非互換のSPEみたいなのをAMDが開発して
出遅れたIntelがISAパクってめでたく業界標準にって流れをキボンヌ。
出遅れたIntelがISAパクってめでたく業界標準にって流れをキボンヌ。
345 :・∀・)っ-○◎●創聖のダンゴリオン ◆DanGorION6 :2006/10/25(水) 06:27:19 ID:N/+jnLTH
実際問題としてメーカー毎(ヒョットスルトGPU毎)にISAは違っているらしく
これまで、GPGPUを広める上の問題の1つでもあった。
ハード的にもnVIDIAはレジスタが8本したなかったりとか・・・
DX10世代で実現されるGPGPUは、あくまでShaderを使ったものが前程ですが
DPVMなんかだと更に低レベルでGPUにアクセス可能の模様。
ttp://www.behardware.com/news/8316/acces-bas-niveau-x-gpus-ati.html
ttp://www.graphicshardware.org/presentations/gerstmann-dpvm-hot3d-gh06.pdf
これまで、GPGPUを広める上の問題の1つでもあった。
ハード的にもnVIDIAはレジスタが8本したなかったりとか・・・
DX10世代で実現されるGPGPUは、あくまでShaderを使ったものが前程ですが
DPVMなんかだと更に低レベルでGPUにアクセス可能の模様。
ttp://www.behardware.com/news/8316/acces-bas-niveau-x-gpus-ati.html
ttp://www.graphicshardware.org/presentations/gerstmann-dpvm-hot3d-gh06.pdf
結局DirectXみたく一段かぶせるしかないんじゃね?
でなきゃ表示のほうのパフォーマンスをある程度あきらめるか
でなきゃ表示のほうのパフォーマンスをある程度あきらめるか
ローエンド、ハイエンドどっちに向いてるのかよくわからんが・・・
AMD、GPUを統合した「Fusion」プロセッサ提供へ
ATI買収を完了したAMDは、CPUとGPUを統合したプロセッサを2008年末か2009年初頭に投入する計画だ。
http://www.itmedia.co.jp/news/articles/0610/25/news045.html
AMD、GPUを統合した「Fusion」プロセッサ提供へ
ATI買収を完了したAMDは、CPUとGPUを統合したプロセッサを2008年末か2009年初頭に投入する計画だ。
http://www.itmedia.co.jp/news/articles/0610/25/news045.html
CPUにGPUを内蔵する。
外部GPUがなければ内蔵GPUとして動作し、
外部GPUがあれば、マルチメディア処理プロセッサとして動作する
っていうことが出来ればいいのになw
外部GPUがなければ内蔵GPUとして動作し、
外部GPUがあれば、マルチメディア処理プロセッサとして動作する
っていうことが出来ればいいのになw
それなんてコプロ?
日経エレクトロニクスを読んだ。
ソニーは時代を先取りしていたんだな。
しかも製品化までして。
ソニーは時代を先取りしていたんだな。
しかも製品化までして。
352 :Socket774:2006/10/25(水) 23:45:18 ID:HqucS8kR
>>351
マビカのことか?
マビカのことか?
>>352
拭いた
拭いた
>>352
全社員が泣いた
全社員が泣いた
>>352-353
拭くピカを思い出した
拭くピカを思い出した
破片専用PhysXは次スレたたなかったのか
ネタがないとはいえ哀れなものよ
ネタがないとはいえ哀れなものよ
PhysXみたいに汎用でもなく数が出てないと、対応ソフトも出にくいし
AMDかインテル、でなきゃMSといった大手が正式対応しないと
広めるの難しいよな
AMDかインテル、でなきゃMSといった大手が正式対応しないと
広めるの難しいよな
大手とは言い難いがSEGAは採用するっぽいな。
リンドバーグがほぼ完全にPCになっちゃってたから独自性が出せるならよい。
リンドバーグがほぼ完全にPCになっちゃってたから独自性が出せるならよい。
いよいよ秒読み態勢に入ったPLAYSTATION 3
http://pc.watch.impress.co.jp/docs/2006/1027/kaigai314.htm
http://pc.watch.impress.co.jp/docs/2006/1027/kaigai314.htm
PhysXってソフト側が使わないと意味ないんでしょ?
はやらんやろそれは・・・。
はやらんやろそれは・・・。
>>360
逆にアーケード基板だったらソフトメーカーが使えばいいだけ。
「あのゲームが家のPCでも出来る!」とやれば多少は数でるかも。
……過去に同じ様な売り方で失敗したハードもあったけど、
PhysXはある程度性能優位があるからまだ可能性はある……と思う。
逆にアーケード基板だったらソフトメーカーが使えばいいだけ。
「あのゲームが家のPCでも出来る!」とやれば多少は数でるかも。
……過去に同じ様な売り方で失敗したハードもあったけど、
PhysXはある程度性能優位があるからまだ可能性はある……と思う。
ある程度使える環境になる頃には世代落ちして逆噴射とか言う罠も有るけどね・・
簡単に試食できる。絶望でし。
IBM、新しいチップ冷却技術を発表
ttp://www.itmedia.co.jp/news/articles/0610/28/news003.html
図
ttp://www.zurich.ibm.com/news/06/cooling.html
ttp://www.itmedia.co.jp/news/articles/0610/28/news003.html
図
ttp://www.zurich.ibm.com/news/06/cooling.html
IBMがAMDとソケット互換のPOWERを真剣に検討していることを公式に表明した模様す。
http://www.news4gamers.com/xbox360/NewsCom-13073.aspx
----------------
He confirmed rumours that IBM was looking at using the AMD Opteron Hypertransport
Bus as one of the platform options for Power 7.
----------------
正直言ってAIM連合の時代に,色々難癖をつけてわIBMが約束を反故にするを見慣れているすから,
あまり真剣に受け止める気もしないすけど,IBMが莫大な投資と開発期間をかけたプロセッサコアを
積極的に売っていこうという方針なことわ確かす。
あくまでライセンス商売で,市場リスクわ提携先に負わせようというのわ,いかにもという感じすけど。。。
http://www.news4gamers.com/xbox360/NewsCom-13073.aspx
----------------
He confirmed rumours that IBM was looking at using the AMD Opteron Hypertransport
Bus as one of the platform options for Power 7.
----------------
正直言ってAIM連合の時代に,色々難癖をつけてわIBMが約束を反故にするを見慣れているすから,
あまり真剣に受け止める気もしないすけど,IBMが莫大な投資と開発期間をかけたプロセッサコアを
積極的に売っていこうという方針なことわ確かす。
あくまでライセンス商売で,市場リスクわ提携先に負わせようというのわ,いかにもという感じすけど。。。
格が違いすぎるAMDは光栄に思うといいす
292 :login:Penguin:2006/02/05(日) 19:47:36 ID:xAc4kBVr
余談だけど、Blue LightningはIBM生産だけど
CPUコア自体はintelからのライセンス生産品。
i486SXそのもので、これをi386ピン互換にしたのがIBM。
先行した、Cx486SLC等があってこそのものだった。
PhysXでなくてもいいけどその類のがメジャーならねーかなあ
>>365
いよいよ、AMD>IBMに乗っ取られ、の流れが発動してきましたね。
数年後には、CPUアーキテクチャの戦いというのはIA vs POWER の
ことになっているでしょう。
そのときは、MACオタさんはどちらを応援するすか?w
いよいよ、AMD>IBMに乗っ取られ、の流れが発動してきましたね。
数年後には、CPUアーキテクチャの戦いというのはIA vs POWER の
ことになっているでしょう。
そのときは、MACオタさんはどちらを応援するすか?w
Macに載ってる方だろ
http://www.geocities.jp/andosprocinfo/wadai06/20061028.htm
> このような動きを受けて,The InquirerにNovakovic氏が「AMD,Intelは
> x86のベクトル化に向かう」という記事を書いています。今のSSEは
> 64ビット倍精度の浮動小数点演算を2個並列に実行できるだけであるが,
> Nehalemかその次の世代では,16個程度の倍精度浮動小数点演算を並列に
> 実行できるようなユニットを持つのではないかと推測しています。
> このコア8個を1チップに入れると128個の演算器で,4GHzのクロックで
> 積和演算を行うと1TFlopsのチップになる。また,AMDのGPUの統合のように,
> 比較的遅い1GHz程度のクロックで動作する演算器を256個というような
> やり方も有りうると述べています。
> このような動きを受けて,The InquirerにNovakovic氏が「AMD,Intelは
> x86のベクトル化に向かう」という記事を書いています。今のSSEは
> 64ビット倍精度の浮動小数点演算を2個並列に実行できるだけであるが,
> Nehalemかその次の世代では,16個程度の倍精度浮動小数点演算を並列に
> 実行できるようなユニットを持つのではないかと推測しています。
> このコア8個を1チップに入れると128個の演算器で,4GHzのクロックで
> 積和演算を行うと1TFlopsのチップになる。また,AMDのGPUの統合のように,
> 比較的遅い1GHz程度のクロックで動作する演算器を256個というような
> やり方も有りうると述べています。
>>369
応援、という言葉を使っている意味では、常にIAを「応援」する自作板の人間の方が信者と言えるな
応援、という言葉を使っている意味では、常にIAを「応援」する自作板の人間の方が信者と言えるな
373 :Socket774:2006/10/28(土) 19:31:25 ID:9pHz0aAU
Cellを四個集積すればTFLOPS超えるじゃないか
374 :Socket774:2006/10/28(土) 21:20:22 ID:rYGeWOOV
POWER6の整数演算のパイプライン段数は13段なのか
この浅さで5GHzを達成できるのは凄いな
浮動小数点演算のパイプライン段数はどれくらいなんだろう?
しかしこんなCPU開発できるのにCELLやXBOX360向けには
パイプライン段数の深い空回りCPUを提供するあたり
根性悪いね。
この浅さで5GHzを達成できるのは凄いな
浮動小数点演算のパイプライン段数はどれくらいなんだろう?
しかしこんなCPU開発できるのにCELLやXBOX360向けには
パイプライン段数の深い空回りCPUを提供するあたり
根性悪いね。
375 :・∀・)っ-○◎●創聖のダンゴリオン ◆DanGorION6 :2006/10/28(土) 21:28:37 ID:I96As3io
90nmだからそんなもんでしょ。
POWER6はまだESすら出てないでしょ。
POWER6はまだESすら出てないでしょ。
376 :Socket774:2006/10/28(土) 21:42:35 ID:FHf+OYLt
CacheのレイテンシがPrescott並のPower6
4GHzとの闘いは65nmでも痛み分けに終わった
Penrynに期待
4GHzとの闘いは65nmでも痛み分けに終わった
Penrynに期待
378 :Socket774:2006/10/28(土) 21:45:54 ID:rO3de02C
>>375 団子 さん
-------------------
POWER6はまだESすら出てないでしょ。
-------------------
外販しないチップわ顧客にESなんか提供しないす。
また来年半ばにサーバー製品として販売されるチップが,今現在動いていない筈も無いす。
>>374 さん
-------------------
浮動小数点演算のパイプライン段数はどれくらいなんだろう?
-------------------
今年のISSCCの論文によると2進FPUの実行レイテンシが7-cycleという話すから,6段増えて
19-stageになると思われるす。
-------------------
POWER6はまだESすら出てないでしょ。
-------------------
外販しないチップわ顧客にESなんか提供しないす。
また来年半ばにサーバー製品として販売されるチップが,今現在動いていない筈も無いす。
>>374 さん
-------------------
浮動小数点演算のパイプライン段数はどれくらいなんだろう?
-------------------
今年のISSCCの論文によると2進FPUの実行レイテンシが7-cycleという話すから,6段増えて
19-stageになると思われるす。
米エネルギー省が米IBMに発注したスパコン、ブチ上げたはいいが
まだまだ絵に画いた餅状態みたいだな。
324 :名刺は切らしておりまして :2006/10/26(木) 06:12:58 ID:82oCqZQZ
日経エレクトロニクス最新号(10月23日号)120ページより:
実際、256GFLOPSというCellの演算性能は単精度での数字で、科学技術計算に
不可欠な倍精度計算を実行した場合の性能は「その35%程度」(日本マーキュリー
コンピュータシステムズ)に低下してしまう。
「Cellを用いた科学技術向けの計算は、意外なほどスピードが上がらないことを
シミュレーションで確認した。」(九州大学大学院システム情報科学研究院教授)
こうした課題の克服に向け、IBM社が倍精度の浮動小数点演算を強化した
Cellを開発しているというウワサもある。
このほか、AMD社とIBM社はOpteronとCellを組み合わせたスーパーコンピュータ
の開発について、共にソフトウェアの課題が多いという見方で一致する。
「ハードウェアに関してのロードマップは明確になっているが、異なるマイクロ
プロセッサを連携させて動かすためのソフトウェアには、どのような課題があるかをこれから調べるという段階」(AMD社)
まだまだ絵に画いた餅状態みたいだな。
324 :名刺は切らしておりまして :2006/10/26(木) 06:12:58 ID:82oCqZQZ
日経エレクトロニクス最新号(10月23日号)120ページより:
実際、256GFLOPSというCellの演算性能は単精度での数字で、科学技術計算に
不可欠な倍精度計算を実行した場合の性能は「その35%程度」(日本マーキュリー
コンピュータシステムズ)に低下してしまう。
「Cellを用いた科学技術向けの計算は、意外なほどスピードが上がらないことを
シミュレーションで確認した。」(九州大学大学院システム情報科学研究院教授)
こうした課題の克服に向け、IBM社が倍精度の浮動小数点演算を強化した
Cellを開発しているというウワサもある。
このほか、AMD社とIBM社はOpteronとCellを組み合わせたスーパーコンピュータ
の開発について、共にソフトウェアの課題が多いという見方で一致する。
「ハードウェアに関してのロードマップは明確になっているが、異なるマイクロ
プロセッサを連携させて動かすためのソフトウェアには、どのような課題があるかをこれから調べるという段階」(AMD社)
>>371
SSEの性能がここまで上がってくるとGPU統合って意味あるのかね
SSEの性能がここまで上がってくるとGPU統合って意味あるのかね
382 :・∀・)っ-○◎●創聖のダンゴリオン ◆DanGorION6 :2006/10/28(土) 22:58:23 ID:I96As3io
ある種の演算でCPUとGPU間のレイテンシを削減する狙いはあるんじゃね?
クロック上昇で行き詰まり、コア数を増やしてもクライアントアプリでは限界がある。
余ったダイサイズの有効活用が必要だと。
クロック上昇で行き詰まり、コア数を増やしてもクライアントアプリでは限界がある。
余ったダイサイズの有効活用が必要だと。
>>382
ダイが余ってるならGPU統合するよりSSE強化した方がよくね?
ダイが余ってるならGPU統合するよりSSE強化した方がよくね?
SSE強化っていうなら今の形だとL1からのデータ供給とかも強化しないといけないから辛くないか?
結局コア全体に手を入れてバランス調整しないと。
GPU統合みたいに専用コアにすれば強化するのはそのポイントだけで済むので楽と言えば楽な気もする。
結局コア全体に手を入れてバランス調整しないと。
GPU統合みたいに専用コアにすれば強化するのはそのポイントだけで済むので楽と言えば楽な気もする。
>>376
強化型を4つ集積したのとかは考えられる、ってしゃべってたのはHotChipsでだっけ?
強化型を4つ集積したのとかは考えられる、ってしゃべってたのはHotChipsでだっけ?
CellがあるのにPOWERやらAMDに手を出すのがわからん。
IBMから見たCELL BEのロードマップなら,このインタビューに倍精度強化の話も
SPU山盛りの話も語られているす。
http://blogs.mercurynews.com/aei/2006/10/the_playstation.html
Intelの80-core chip同様に,目下のマイルストーンわ"TFLOPS on a chip"ということす。
SPU山盛りの話も語られているす。
http://blogs.mercurynews.com/aei/2006/10/the_playstation.html
Intelの80-core chip同様に,目下のマイルストーンわ"TFLOPS on a chip"ということす。
マルチスレッド化しようとするとやたら複雑になるコードもあればその逆もあるわけで。
脳味噌筋肉なGPUに対抗するだけなら多コア路線で十分な気が。
Intel Threading Building Blocksとか適切なツールが既に発売されてるし。
脳味噌筋肉なGPUに対抗するだけなら多コア路線で十分な気が。
Intel Threading Building Blocksとか適切なツールが既に発売されてるし。
SIMD系命令ははL1を使わずにL2からダイレクトにロードすべきでしょ。
なんで?
ごめん、>>384へのアンカー付け忘れてた。
>>391
SIMD命令の扱うデータは、
・サイズが大きい
・レイテンシを隠蔽しやすい
という特徴があるので、
L1を通さずL2にロードストアしても性能が犠牲にならないから。
>>391
SIMD命令の扱うデータは、
・サイズが大きい
・レイテンシを隠蔽しやすい
という特徴があるので、
L1を通さずL2にロードストアしても性能が犠牲にならないから。
確かにそういうL1非汚染のロード命令が「存在してもいい」
とは思うが、現状(128bit, 16本)でL1使えないとなると冗談じゃない。
ベクトル長がずっと長くなってレジスタの本数もずっと増えて、
なおかつそれを使いこなせるような用途ならそれもありかも。
それでもL2とかメインメモリのアクセスをよほどか強化しなければ
性能を引き出すのは難しい。
とは思うが、現状(128bit, 16本)でL1使えないとなると冗談じゃない。
ベクトル長がずっと長くなってレジスタの本数もずっと増えて、
なおかつそれを使いこなせるような用途ならそれもありかも。
それでもL2とかメインメモリのアクセスをよほどか強化しなければ
性能を引き出すのは難しい。
使えないのではなく使わない
確かに在ってもいいかもな
確かに在ってもいいかもな
395 :・∀・)っ-○◎●創聖のダンゴリオン ◆DanGorION6 :2006/10/30(月) 20:59:49 ID:h5I+bcaS
レイテンシを隠蔽するために少ないレジスタ数でアンロールし、更にロード・ストアを繰り返しgdgdになるだろが
せっかく整数加減論理演算をレイテンシ1クロックで処理できるんだから、それを生かそうぜ。
せっかく整数加減論理演算をレイテンシ1クロックで処理できるんだから、それを生かそうぜ。
インテルやAMDの開発者は、
おまえらなんかよりも遥かに頭が良くて実地で経験を積んでいるわけで、
彼らがやらないのだから、それなりの理由があると見るべきだろう。
本当に役に立つ改良案があるなら、自分でインテルやAMDに入って実装しろよ。
それができない人間は、せいぜい、現状の実装を理解すべく努力するこった。
おまえらなんかよりも遥かに頭が良くて実地で経験を積んでいるわけで、
彼らがやらないのだから、それなりの理由があると見るべきだろう。
本当に役に立つ改良案があるなら、自分でインテルやAMDに入って実装しろよ。
それができない人間は、せいぜい、現状の実装を理解すべく努力するこった。
| | | | | | | | | | || | |
| | | レ | | | | | J || | |
| | | J | | | し || | |
| レ | | レ| || J |
J し | | || J
| し J|
J レ
| | | レ | | | | | J || | |
| | | J | | | し || | |
| レ | | レ| || J |
J し | | || J
| し J|
J レ
地球シュミレータ(?)は、メインのベクトル部は
あえてキャッシュを積んで無いとか言ってたな。
ストリーム処理に特化していてキャッシュはほとんど無意味だとか。
馬鹿みたいな帯域を持ってるから実現できたんだろうけど。
あえてキャッシュを積んで無いとか言ってたな。
ストリーム処理に特化していてキャッシュはほとんど無意味だとか。
馬鹿みたいな帯域を持ってるから実現できたんだろうけど。
つーかさ、SSEのプリフェッチ命令でL1/L2汚染しないよう指定できるじゃん
それは、どこにプリフェッチするかの指定であって、
L2から直接ロードしてL1に入れないようになるわけではなく。
L2から直接ロードしてL1に入れないようになるわけではなく。
>>401
だからL2から直接ロードしてどうやってレイテンシを隠蔽するんだと
だからL2から直接ロードしてどうやってレイテンシを隠蔽するんだと
やっぱ並列性で勝負なんじゃないの。
だからコア数個程度じゃお話にならないと思う。
だからコア数個程度じゃお話にならないと思う。
>>403
コア数はあまり増やさずにSIMDで並列数を稼ぐって手もあり。
シングルスレッド性能も重視されるx86ではこっちの方が現実的なような。
最低でも倍精度浮動小数点x8並列/clock(現在の4倍)ぐらいまでは
SIMDは強化されるだろう。
コア数はあまり増やさずにSIMDで並列数を稼ぐって手もあり。
シングルスレッド性能も重視されるx86ではこっちの方が現実的なような。
最低でも倍精度浮動小数点x8並列/clock(現在の4倍)ぐらいまでは
SIMDは強化されるだろう。
>>400
意味不明な上に、現実に実装されているものに対して「どうしようもない」発言は痛い。
>>402
Itanium2のFPUはL1キャッシュを介さず直接L2にロードストアするようになっているから勉強してみたら。
意味不明な上に、現実に実装されているものに対して「どうしようもない」発言は痛い。
>>402
Itanium2のFPUはL1キャッシュを介さず直接L2にロードストアするようになっているから勉強してみたら。
コアの整数演算は現状維持かそこそこで、後はFPUとマルチコアに注ぎ込むってのがいいんじゃね。
コアは処理性能が要求されるマルチメディア等のためにSIMDの強化に注力し、
エンプラ等(鯖とか)の整数演算が必要な処理は、下手にシングルスレッドの整数演算無駄に強化していくより、
マルチコアで全体の性能上げたほうが却って効率いいんじゃね。
既に比較的マルチスレッド化も進んでるだろうし、用途上幾つものタスクが並行動作することが多いだろうし。
コアは処理性能が要求されるマルチメディア等のためにSIMDの強化に注力し、
エンプラ等(鯖とか)の整数演算が必要な処理は、下手にシングルスレッドの整数演算無駄に強化していくより、
マルチコアで全体の性能上げたほうが却って効率いいんじゃね。
既に比較的マルチスレッド化も進んでるだろうし、用途上幾つものタスクが並行動作することが多いだろうし。
SSE3に、x87用の命令があったような・・・。
いや、別に特定のモノ指してるわけじゃないんだがスレの流れ適に適当に。
GPUにしろSIMDにしろなんにしろ、FP強化がって流れじゃん。
GPUにしろSIMDにしろなんにしろ、FP強化がって流れじゃん。
411 :Socket774:2006/10/31(火) 19:47:42 ID:PP6xqS8+
Core MAも、なんか結局、爆熱化の道を進んでいるような気がしてならない。
KentsfieldのTDPなんかヤバいし。
KentsfieldのTDPなんかヤバいし。
「省エネコアをいっぱい並べて高効率化」のはずなのに、
実際は、「大型コアをいっぱい並べている」から、爆熱化して当たり前じゃね。
AMDのRev.HなんてRev.Fデュアルコアの3割り増しのサイズだし、
Conroe(Merom)も、Yonahの1.5倍のサイズだし。
実際は、「大型コアをいっぱい並べている」から、爆熱化して当たり前じゃね。
AMDのRev.HなんてRev.Fデュアルコアの3割り増しのサイズだし、
Conroe(Merom)も、Yonahの1.5倍のサイズだし。
むしろ暖房器具として爆熱を極めるってのはどうだ
もっともっとシングルスレッド性能あげてくれ
NiagaraでZeusをチューニングしてやるとTpsはスレッド分やたら伸びるぞ。
それ以外ではアホのように遅いがな。
それ以外ではアホのように遅いがな。
>>412
キャッシュ増えてるからダイサイズで単純比較しちゃ駄目だぞ
キャッシュ増えてるからダイサイズで単純比較しちゃ駄目だぞ
418 :Socket774:2006/10/31(火) 22:54:49 ID:PP6xqS8+
ConroeとYonahって、ワットあたりの性能はどっちが高い?
Yonah
420 :・∀・)っ-○◎●創聖のダンゴリオン ◆DanGorION6 :2006/11/01(水) 00:28:01 ID:ux7u4Tff
IA-64にL2直接読み書きする命令があるのは、L1に退避する必要ないほどレジスタが十分にあるからで
あと、L1小さいし。
レジスタ数少ないx86であんま有効な手段じゃナス
まあ、L1ミスしてからL2探索かけるよりは確実にレイテンシ短くなるけど、汚くなるだけじゃん
むしろx86やめればいいじゃん。それがIA-64なんだよね
あと、L1小さいし。
レジスタ数少ないx86であんま有効な手段じゃナス
まあ、L1ミスしてからL2探索かけるよりは確実にレイテンシ短くなるけど、汚くなるだけじゃん
むしろx86やめればいいじゃん。それがIA-64なんだよね
>>418
比べるならmeromだろ
比べるならmeromだろ
>>423
モバイル用途では全く意味がないと思う。
モバイルに必要な性能はマルチスレッドではないから。
現状のYonah-ULV以下の消費電力のマルチコアでは、
シングルスレッド処理でパワー不足だと思うよ。
しかし、動画エンコなどのマルチスレッド処理をするのにはいい。
問題はシングルスレッド性能が下がることだが、これは実に痛い。
やはり、Out of Orderの大コア+小コアたくさんのヘテロ、
ということになるだろうね。
現状ではシングルスレッド性能を下げる余裕はないし、
ヘテロにするだけのトランジスタリソースもない。
モバイル用途では全く意味がないと思う。
モバイルに必要な性能はマルチスレッドではないから。
現状のYonah-ULV以下の消費電力のマルチコアでは、
シングルスレッド処理でパワー不足だと思うよ。
しかし、動画エンコなどのマルチスレッド処理をするのにはいい。
問題はシングルスレッド性能が下がることだが、これは実に痛い。
やはり、Out of Orderの大コア+小コアたくさんのヘテロ、
ということになるだろうね。
現状ではシングルスレッド性能を下げる余裕はないし、
ヘテロにするだけのトランジスタリソースもない。
>>424
4コア以上ならともかくデュアルコアがモバイル用途でそこまで不要とは思えん。
消費電力効率にフォーカスしたシンプルコアにするならYonah-ULVと同じ消費電力で
シングルスレッド性能がYonah-ULVの2割減のデュアルコアというのが可能。
それが商品価値がないとは思えないが?
4コア以上ならともかくデュアルコアがモバイル用途でそこまで不要とは思えん。
消費電力効率にフォーカスしたシンプルコアにするならYonah-ULVと同じ消費電力で
シングルスレッド性能がYonah-ULVの2割減のデュアルコアというのが可能。
それが商品価値がないとは思えないが?
EPIC(Montvale) + HTT(Pentium4) + AdvancedBranchPrediction(CoreDuo)が一番ワット性能よさげ
×Montvale
○Itanium2
○Itanium2
>>425
シングルスレッド性能が2割下がっていいなら、
現状のYonahのクロックを2割下げればいい。
消費電力は大きく下がる。
IntelがCore2でIPCを上げる方向に振ってきたのも、
IPCを上げてクロックあたりの消費電力を上げてまでして
クロックを下げたいと考えたから。
つまり消費電力を下げるためにコアを複雑にしてるのだ。
あと、デュアルコアがそこまで不要とは思っていない。
もうちょっと多いコア数を想定しているのかと勘違いしていた。すまん。
ただ、それでもULVの2割減は痛い。ULVのCoreDuo U2500とか出てるが、
これもシングル性能はCoreSolo U1400から下げずに消費電力を上げている。
シングルスレッド性能が2割下がっていいなら、
現状のYonahのクロックを2割下げればいい。
消費電力は大きく下がる。
IntelがCore2でIPCを上げる方向に振ってきたのも、
IPCを上げてクロックあたりの消費電力を上げてまでして
クロックを下げたいと考えたから。
つまり消費電力を下げるためにコアを複雑にしてるのだ。
あと、デュアルコアがそこまで不要とは思っていない。
もうちょっと多いコア数を想定しているのかと勘違いしていた。すまん。
ただ、それでもULVの2割減は痛い。ULVのCoreDuo U2500とか出てるが、
これもシングル性能はCoreSolo U1400から下げずに消費電力を上げている。
IntelがローエンドモバイルをLPPデュアルコアにしてくれればいいんだよ。
で、それがITXに流れてくれば自作板的にもOK。
で、それがITXに流れてくれば自作板的にもOK。
新約・見てわかる パソコン解体新書:Coreマイクロアーキテクチャ [前編]
http://plusd.itmedia.co.jp/pcuser/articles/0611/01/news005.html
http://plusd.itmedia.co.jp/pcuser/articles/0611/01/news005.html
431 :Socket774:2006/11/01(水) 23:59:45 ID:UIM/07WV
Cell BE Roadmap
http://www.ppcnux.de/modules.php?name=News&file=article&sid=6664
http://www.ppcnux.de/modules.php?name=News&file=article&sid=6664
432 :Socket774:2006/11/02(木) 00:14:41 ID:oTRU38vK
最強の名を有するCPUには代々セレロンという名を付けると言う
セロリンがCelleronだったらCellの名前は変わっていたんだろうか
>>429
LPPはシングルコア専門な気がす
LPPはシングルコア専門な気がす
>>411
実際かなりヤヴァイ
http://www.4gamer.net/review/kentsfield/img/g010.gif
http://www.4gamer.net/review/kentsfield/img/g011.gif
実際かなりヤヴァイ
http://www.4gamer.net/review/kentsfield/img/g010.gif
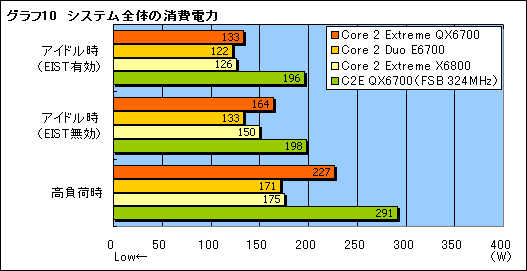{kind=link}
http://www.4gamer.net/review/kentsfield/img/g011.gif
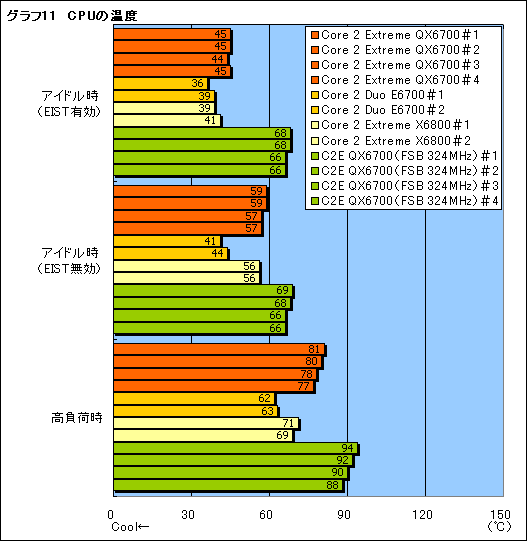{kind=link}
437 :・∀・)っ-○◎●創聖のダンゴリオン ◆DanGorION6 :2006/11/02(木) 21:58:42 ID:4phS6vQB
そんなもんで済むなら十分じゃないか。
439 :・∀・)っ-○◎●創聖のダンゴリオン ◆DanGorION6 :2006/11/02(木) 22:58:51 ID:4phS6vQB
プログラムマニア向けだな。
ケンツも4x4もエンスージアストゲーマーにとって無意味であることが明らかになった良い日
ABS命令載せてくれ
分岐が大苦手なんだからせめて条件実効を
分岐が大苦手なんだからせめて条件実効を
442 :・∀・)っ-○◎●創聖のダンゴリオン ◆DanGorION6 :2006/11/03(金) 23:35:57 ID:yWrYglIW
あるじゃんCMOV命令っていう10年前からの遺物が。
コンパイルオプションに -arch:SSE とかやってないの?
パックド整数の絶対値求める命令ならCore2に乗っかってたと思うけど。
コンパイルオプションに -arch:SSE とかやってないの?
パックド整数の絶対値求める命令ならCore2に乗っかってたと思うけど。
cdq
xor eax, edx
sub eax, edx
xor eax, edx
sub eax, edx
444 :・∀・)っ-○◎●創聖のダンゴリオン ◆DanGorION6 :2006/11/04(土) 00:38:55 ID:qoM9Erdo
pabswの代替方法
pxor mm1, mm1
psubw mm1, mm0
pmaxsw mm0, mm1
pxor mm1, mm1
psubw mm1, mm0
pmaxsw mm0, mm1
445 :Socket774:2006/11/05(日) 03:30:57 ID:VISmYjiW
http://pc7.2ch.net/test/read.cgi/jisaku/1162381694/l50#tag528
論破1
>ではETERNAL=SPUの設定にはどういうものがあるか答えてください。
>そしてその意味も。
>せめてエミュレーションソフト名くらい言えよ
>あーあやっちまった。
>SPUプラグインはエミュソフトによらず使える。
>ググルつもりだったんだろうけど、SPUプラグインはエミュソフト自体とは
>スタンドアロン。
論破2
>普通に、Homeでも32コアまでおk
>その根拠がわからない人は、2論理プロセッサ以上のシステム使ったこと無い人かもね。
>もったいぶらずに書けよ。俺にはわからんな。
>Core 2 DuoもX2も持って無い人ってこと証明しちゃいましたね
ダンゴの中では”かも”=”証明”
論破1
>ではETERNAL=SPUの設定にはどういうものがあるか答えてください。
>そしてその意味も。
>せめてエミュレーションソフト名くらい言えよ
>あーあやっちまった。
>SPUプラグインはエミュソフトによらず使える。
>ググルつもりだったんだろうけど、SPUプラグインはエミュソフト自体とは
>スタンドアロン。
論破2
>普通に、Homeでも32コアまでおk
>その根拠がわからない人は、2論理プロセッサ以上のシステム使ったこと無い人かもね。
>もったいぶらずに書けよ。俺にはわからんな。
>Core 2 DuoもX2も持って無い人ってこと証明しちゃいましたね
ダンゴの中では”かも”=”証明”
pxor mm1, mm1
pcmpgtd mm1, mm0
pxor mm0, mm1
psubd mm0, mm1
pcmpgtd mm1, mm0
pxor mm0, mm1
psubd mm0, mm1
AcesHardware掲示板で面白い話を見つけたす。
元々の質問わ,「なんでFP性能が高いはずのItaniumをマルチメディアのオーサリング用途で
使わないの?」というモノだったす。
http://www.aceshardware.com/forums/read_post.jsp?id=120069655&forumid=1
色々ともっともなコメントが付いているすけど,TheInquierのChrlie Demerjianが非常に面白い
コメントをつけているす。
http://www.aceshardware.com/forums/read_post.jsp?id=120069656&forumid=1
---------------------
I know, I know!!!! It blows at the task that's probably why. :)
I had a friend involved in the testing at a 'halo account' early in, and he said that even with
a fleet of engineers from intel hand tuning the code, it was destroyed clock for clock by a
celeron. Even with free boxes, they went with P4s.
Basically, it teh sux.
---------------------
Celoron以下って。。。(笑)
しかし,SIMD vs VLIWの参考としてわ面白い話だと思うす。
元々の質問わ,「なんでFP性能が高いはずのItaniumをマルチメディアのオーサリング用途で
使わないの?」というモノだったす。
http://www.aceshardware.com/forums/read_post.jsp?id=120069655&forumid=1
色々ともっともなコメントが付いているすけど,TheInquierのChrlie Demerjianが非常に面白い
コメントをつけているす。
http://www.aceshardware.com/forums/read_post.jsp?id=120069656&forumid=1
---------------------
I know, I know!!!! It blows at the task that's probably why. :)
I had a friend involved in the testing at a 'halo account' early in, and he said that even with
a fleet of engineers from intel hand tuning the code, it was destroyed clock for clock by a
celeron. Even with free boxes, they went with P4s.
Basically, it teh sux.
---------------------
Celoron以下って。。。(笑)
しかし,SIMD vs VLIWの参考としてわ面白い話だと思うす。
ひたすらItaniumの歴史や特徴が書かれているだけなのにVLIW vs SIMDに拡大解釈しちゃう辺りは流石だな
質問自体あんま面白くないし
質問自体あんま面白くないし
449 :MACオタ>448 さん:2006/11/05(日) 14:08:54 ID:yn9rP92q
>>448
------------------
ひたすらItaniumの歴史や特徴が書かれているだけ
------------------
「歴史や特徴」で実コードの動作速度まで判る脳内妄想さんにわ,不要な情報なんで
読み飛ばせば良いかと思うす。
------------------
ひたすらItaniumの歴史や特徴が書かれているだけ
------------------
「歴史や特徴」で実コードの動作速度まで判る脳内妄想さんにわ,不要な情報なんで
読み飛ばせば良いかと思うす。
> SIMD vs VLIW
ItaniumにもSIMD命令があるのになぜvsになるのでしょうか?
ItaniumにもSIMD命令があるのになぜvsになるのでしょうか?
まったく価値の無い情報を面白いと思うバカ。
>>450
FPに関しては、
ItaniumのSIMD命令は単精度2つをパックするだけで、
しかもItanium2になってからは演算ユニットを削られて、意味がなくなった。
だったと思うけど、違うかな。
FPに関しては、
ItaniumのSIMD命令は単精度2つをパックするだけで、
しかもItanium2になってからは演算ユニットを削られて、意味がなくなった。
だったと思うけど、違うかな。
453 :MACオタ>450 さん:2006/11/05(日) 14:53:15 ID:yn9rP92q
>>450
---------------------
ItaniumにもSIMD命令があるのになぜvsになるのでしょうか?
---------------------
IPFとNetburstを比較すると
■IPF
- 最高 6 issues / cycle。ただし動作クロックわ半分
- MMX, SSEサポート (うち1 slot)
■Netburst
- 最高 3 issues / cycle。クロック2倍
- MMX, SSE, SSE2/3サポート (うち1-slot)
ということで、マルチメディアアプリでx86わSIMD最適化が有効で、IA-64わVLIWを
そのまま生かした最適化の方が良いす。
---------------------
ItaniumにもSIMD命令があるのになぜvsになるのでしょうか?
---------------------
IPFとNetburstを比較すると
■IPF
- 最高 6 issues / cycle。ただし動作クロックわ半分
- MMX, SSEサポート (うち1 slot)
■Netburst
- 最高 3 issues / cycle。クロック2倍
- MMX, SSE, SSE2/3サポート (うち1-slot)
ということで、マルチメディアアプリでx86わSIMD最適化が有効で、IA-64わVLIWを
そのまま生かした最適化の方が良いす。
454 :・∀・)っ-○◎●創聖のダンゴリオン ◆DanGorION6 :2006/11/05(日) 15:20:34 ID:uoXQ7m7z
Montecitoではソフトウェア(IA32 EL)実行オンリーになったみたいすね。。。
どうせその方がパフォーマンスがいい
カビの生えたネタだな。
2003 SP2には次のバージョンが入る予定。どの程度性能が上がるかしらんけど某社は
こだわっていたからねぇ。32ELの性能に・・・
2003 SP2には次のバージョンが入る予定。どの程度性能が上がるかしらんけど某社は
こだわっていたからねぇ。32ELの性能に・・・
IA-32ELを入れるとシングルスレッド性能は2倍になるものの、
マルチスレッド動作しなくなって、ションボリしたことが・・・。
マルチスレッド動作しなくなって、ションボリしたことが・・・。
ttp://download.intel.com/jp/developer/jpdoc/25110901_j.pdf
> 2.3 実行
> Itanium 2 プロセッサの実行ロジックは、6 個のマルチメディア・ユニット、6 個の整数ユニット、
> 2 個の浮動小数点ユニット、3 個の分岐ユニット、4 個のロード/ ストア・ユニットで構成される。
> マルチメディア・エンジンは、64 ビット・データを、2 × 32 ビット、4 × 16 ビット、または8 ×
> 8 ビットのパックド・データ・タイプとして扱う。パックド・データ・タイプ、すなわちSIMD
> (Single Instruction Multiple Data) データ・タイプには、算術演算、シフト演算、データ整列演算の3
> つのクラスの算術演算を実行できる。一方、整数エンジンは、最大6 つの非パックド整数算術演
> 算および論理演算をサポートしている。各サイクルで、最大6 つの整数演算またはマルチメディ
> ア演算を実行できる。
整数のSIMD命令は一クロックあたり、最大6個実行できるってこと?
> 2.3 実行
> Itanium 2 プロセッサの実行ロジックは、6 個のマルチメディア・ユニット、6 個の整数ユニット、
> 2 個の浮動小数点ユニット、3 個の分岐ユニット、4 個のロード/ ストア・ユニットで構成される。
> マルチメディア・エンジンは、64 ビット・データを、2 × 32 ビット、4 × 16 ビット、または8 ×
> 8 ビットのパックド・データ・タイプとして扱う。パックド・データ・タイプ、すなわちSIMD
> (Single Instruction Multiple Data) データ・タイプには、算術演算、シフト演算、データ整列演算の3
> つのクラスの算術演算を実行できる。一方、整数エンジンは、最大6 つの非パックド整数算術演
> 算および論理演算をサポートしている。各サイクルで、最大6 つの整数演算またはマルチメディ
> ア演算を実行できる。
整数のSIMD命令は一クロックあたり、最大6個実行できるってこと?
459 :・∀・)っ-○◎●創聖のダンゴリオン ◆DanGorION6 :2006/11/06(月) 00:33:53 ID:94LJHXiI
SIMDじゃなくてVLIW。
128ビット長の「バンドル」に3つの演算を並列に記述できるんだけど
そのバンドルを1クロック2つずつ処理できる。
その整数ユニットも、アドレッシングモードに対応したユニットと
レジスタ間オペレーションのみ対応したものがある。
x86より多倍長演算のための命令が充実してる感じかな。
128ビット長の「バンドル」に3つの演算を並列に記述できるんだけど
そのバンドルを1クロック2つずつ処理できる。
その整数ユニットも、アドレッシングモードに対応したユニットと
レジスタ間オペレーションのみ対応したものがある。
x86より多倍長演算のための命令が充実してる感じかな。
462 :・∀・)っ-○◎●創聖のダンゴリオン ◆DanGorION6 :2006/11/06(月) 01:08:56 ID:94LJHXiI
それたしか、正確には、汎用整数ユニット自体がパックド整数演算を扱えるんじゃなかったっけ
Xeon(Woodcrest)は128bit×3Wayの3GHz
Itanium 2は64bit×6Wayの1.7GHz
あれ?
Xeon(Woodcrest)は128bit×3Wayの3GHz
Itanium 2は64bit×6Wayの1.7GHz
あれ?
>>460
> 各サイクルで、最大6 つの整数演算またはマルチメディア演算を実行できる。
と書いてある通り。
>>458のリンク先のPDFの図2-3を見てほしい。
整数とマルチメディア(SIMD)は同じユニットで実行される。
> 各サイクルで、最大6 つの整数演算またはマルチメディア演算を実行できる。
と書いてある通り。
>>458のリンク先のPDFの図2-3を見てほしい。
整数とマルチメディア(SIMD)は同じユニットで実行される。
466 :Socket774:2006/11/06(月) 21:03:54 ID:EeXSxXS8
>また、消費電力は最大60W、アイドル時30Wで、こちらも汎用プロセッサとして演算速度
>当たり世界最低だという。
GRAPEは「汎用プロセッサ」か?
>当たり世界最低だという。
GRAPEは「汎用プロセッサ」か?
いわゆる汎用ではないな。
一般販売されたらそれはそれで凄いが。
一般販売されたらそれはそれで凄いが。
これで我慢してください
http://www.ricoh.co.jp/LSI/product_assp/img/tool5.jpg
http://www.innotech.co.jp/products/product_list/lsi/dsp/images/ld_ph_005.gif
http://www.ricoh.co.jp/LSI/product_assp/img/tool5.jpg
{kind=link}
http://www.innotech.co.jp/products/product_list/lsi/dsp/images/ld_ph_005.gif
{kind=link}
GRAPE-DR は GRAPE より汎用性拡大の設計らしいが…
インターコネクトはInfiniBand使うにしても10GbE使うにしても相当数束ねないとキツそう
GRAPEに比べれば遥かに汎用。
ぱっと見た感じではベクトルプロセッサそのものだね。
ぱっと見た感じではベクトルプロセッサそのものだね。
ちなみに、
> 製造はTSMCの90nmプロセス。
このあたりが心配なのですが、どうなんでしょう。
> 製造はTSMCの90nmプロセス。
このあたりが心配なのですが、どうなんでしょう。
何が心配なのか解らない
ほどなくして中国あたりからGRAPE-DR丸パクリだが
日本よりも予算大量投入したスパコンが登場する予感。
日本よりも予算大量投入したスパコンが登場する予感。
TSMCって台湾でなかったかな?
http://www.google.co.jp/search?hl=ja&q=TSMC
>>474みたいなこと言い出すとATIやnVIDIAのGPUの
偽者が出てないとおかしいのだけど
http://www.google.co.jp/search?hl=ja&q=ATI+TSMC
http://www.google.co.jp/search?hl=ja&q=nVIDIA+TSMC
http://www.google.co.jp/search?hl=ja&q=TSMC
>>474みたいなこと言い出すとATIやnVIDIAのGPUの
偽者が出てないとおかしいのだけど
http://www.google.co.jp/search?hl=ja&q=ATI+TSMC
http://www.google.co.jp/search?hl=ja&q=nVIDIA+TSMC
> できる限り機能を絞って小型化したというコプロセッサを512コア搭載し、
> 動作周波数500MHzで512G FLOPSの演算性能を1チップで実現
簡素化したわりにクロックは低いまま種。
高クロック設計で Cell みたいに 4GHz というのは無理なのかな?
> 動作周波数500MHzで512G FLOPSの演算性能を1チップで実現
簡素化したわりにクロックは低いまま種。
高クロック設計で Cell みたいに 4GHz というのは無理なのかな?
TSMCを知らないアホがいるとは・・・
>>475
大量に出まわるようなものはパクっても意味がない。
ヤミルートを作るよりも、既存の正規ルートのほうが効率的だし、パクったことがバレやすい。
特定ユーザにしか渡らないような、こういうチップこそ、パクってもバレないし、パクる価値がある。
大量に出まわるようなものはパクっても意味がない。
ヤミルートを作るよりも、既存の正規ルートのほうが効率的だし、パクったことがバレやすい。
特定ユーザにしか渡らないような、こういうチップこそ、パクってもバレないし、パクる価値がある。
中国と言えばSMIC
メモリはどうなってるのかな?
チップ内共有メモリは極小に見えるが
チップ内共有メモリは極小に見えるが
http://journal.mycom.co.jp/news/2002/10/24/17.html
http://japan.renesas.com/fmwk.jsp?cnt=press_release20060209.htm&fp=/company_info/news_and_events/press_releases
http://www.innotech.co.jp/products/product_list/lsi/dsp/linedancer.html
http://japan.renesas.com/fmwk.jsp?cnt=press_release20060209.htm&fp=/company_info/news_and_events/press_releases
http://www.innotech.co.jp/products/product_list/lsi/dsp/linedancer.html
483 :・∀・)っ-○◎●創聖のダンゴリオン ◆DanGorION6 :2006/11/07(火) 00:26:07 ID:gPP7FHna
おまいら龍芯なめんなよ
GRAPE-DR を AMD の Torrenza に適用できたらいいな
GRAPE-DR は日本の誇りだ。がむばってホスイ。
龍芯なんてレベル低すぎ。しかもパクリっぽいしな。
龍芯なんてレベル低すぎ。しかもパクリっぽいしな。
487 :Socket774:2006/11/07(火) 01:51:52 ID:d718pufq
お茶の水博士
http://pc.watch.impress.co.jp/docs/2006/1106/tokyou05.jpg
ttp://www.i.u-tokyo.ac.jp/edu/training/ss/pic/hiraki.jpg
ttp://www.i.u-tokyo.ac.jp/edu/training/ss/report/pic/02.jpg
ttp://www.i.u-tokyo.ac.jp/edu/training/ss/COEimg/hiraki.jpg
_,, ---一 ー- ,,,_
、_,,,, _,, -.'" ` 、
ミ三ミ三ミ三ミミ ヽ_,
-==三ミ彡三ミミ ,,=-== ==、 iミ=-、_
_,,ンミミ三ミ三ミミ] -彡-一 ー-、 r一 ーミ、|ミミ三ミ=-'
_, -==彡ミ彡ミミミ| ン| ,=て)> (|ー| ,て)>、 ||三ミ彡==-'
_,彡彡三ミ三ミミレ'~ .|. ' | ヽ ` |ミ三彡三=-、
(_彡三ミ彡ミミミ' ヽ、 ノ \__ノiミ彡ミ三=ー
ー-=二三ンーミミミ `ー /(_r-、r-_) .|彡ミ三=-、
)(_ミ彡ミ| i' ヽヽミ | : : : __ : :__: :i .|彡ミ三=-、_
と彡ミ彡ミヽヽ<ヽミミ |: ン=-ニ-ヽ、 .|彡ミ三==-
彡ミ彡ミミヽ ) ` 、 .' <=ェェェェェン | |彡ン=-=
-==彡三ミ `ーヽ : : : : : :i: : `ー--一'' : : ノミ三==''
'' てノこミ彡三ミ`i : : : : : :ヽ: : : . .:, :/ミ三=-、
'' 三ミ=三三ミ|ヾ、: : : : :ヽ: : : : : : : : :_ノ:./三=-'
http://pc.watch.impress.co.jp/docs/2006/1106/tokyou05.jpg
{kind=link}
ttp://www.i.u-tokyo.ac.jp/edu/training/ss/pic/hiraki.jpg
{kind=link}
ttp://www.i.u-tokyo.ac.jp/edu/training/ss/report/pic/02.jpg
{kind=link}
ttp://www.i.u-tokyo.ac.jp/edu/training/ss/COEimg/hiraki.jpg
{kind=link}
_,, ---一 ー- ,,,_
、_,,,, _,, -.'" ` 、
ミ三ミ三ミ三ミミ ヽ_,
-==三ミ彡三ミミ ,,=-== ==、 iミ=-、_
_,,ンミミ三ミ三ミミ] -彡-一 ー-、 r一 ーミ、|ミミ三ミ=-'
_, -==彡ミ彡ミミミ| ン| ,=て)> (|ー| ,て)>、 ||三ミ彡==-'
_,彡彡三ミ三ミミレ'~ .|. ' | ヽ ` |ミ三彡三=-、
(_彡三ミ彡ミミミ' ヽ、 ノ \__ノiミ彡ミ三=ー
ー-=二三ンーミミミ `ー /(_r-、r-_) .|彡ミ三=-、
)(_ミ彡ミ| i' ヽヽミ | : : : __ : :__: :i .|彡ミ三=-、_
と彡ミ彡ミヽヽ<ヽミミ |: ン=-ニ-ヽ、 .|彡ミ三==-
彡ミ彡ミミヽ ) ` 、 .' <=ェェェェェン | |彡ン=-=
-==彡三ミ `ーヽ : : : : : :i: : `ー--一'' : : ノミ三==''
'' てノこミ彡三ミ`i : : : : : :ヽ: : : . .:, :/ミ三=-、
'' 三ミ=三三ミ|ヾ、: : : : :ヽ: : : : : : : : :_ノ:./三=-'
ttp://grape.astron.s.u-tokyo.ac.jp/~makino/journal/journal-2006-10.html
2006/10/26
AMD、 GPU 統合 CPUを提供へ。サーバまで使うとのこと。
演算ピーク性能でどれくらいまで出してくるかな?これの数字によっては
GRAPE-DR も結構苦しい。もう 10倍くらい速くする方法を考えたいところである。
2006/10/25
GRAPE-DR ボードだが、いつのまにかちゃんと計算ができるのみならず
重力計算では GRAPE-6 より速く計算ができるところまでできている。
まあ、もちろん 64 Tflops よりも速いってわけではなくて、 500Gflops の
1チップ GDR ボードが 130 Gflops とか 1 Tflops のGRAPE-6 カードより
実効性能で速い、という話。低精度だと G7 に若干負けてるかな?チップの
理論ピークでは 10倍以上、現在のインターフェースも 8 倍とか速いんだから
当然とはいえ、本当に動いているとその少なくとも個人的には感動的である。
2006/10/26
AMD、 GPU 統合 CPUを提供へ。サーバまで使うとのこと。
演算ピーク性能でどれくらいまで出してくるかな?これの数字によっては
GRAPE-DR も結構苦しい。もう 10倍くらい速くする方法を考えたいところである。
2006/10/25
GRAPE-DR ボードだが、いつのまにかちゃんと計算ができるのみならず
重力計算では GRAPE-6 より速く計算ができるところまでできている。
まあ、もちろん 64 Tflops よりも速いってわけではなくて、 500Gflops の
1チップ GDR ボードが 130 Gflops とか 1 Tflops のGRAPE-6 カードより
実効性能で速い、という話。低精度だと G7 に若干負けてるかな?チップの
理論ピークでは 10倍以上、現在のインターフェースも 8 倍とか速いんだから
当然とはいえ、本当に動いているとその少なくとも個人的には感動的である。
Cell スレよりコピペ
168 :名無しさん必死だな:2006/11/07(火) 01:24:24 ID:SOAig1yv
汎用処理の為のチップで汎用処理をする ←ノーマル
グラフィックの為のチップでグラフィック処理をする ←ノーマル
GRAPE-DRを使う人 :科学技術計算の為のチップで科学技術計算をする ←ノーマル
GPGPUとか言ってる連中 :グラフィックの為のチップで汎用処理をする ←変態
Cellな人 :何をやらせたいのか分からないチップでゲーム処理をする ←ド変態
168 :名無しさん必死だな:2006/11/07(火) 01:24:24 ID:SOAig1yv
汎用処理の為のチップで汎用処理をする ←ノーマル
グラフィックの為のチップでグラフィック処理をする ←ノーマル
GRAPE-DRを使う人 :科学技術計算の為のチップで科学技術計算をする ←ノーマル
GPGPUとか言ってる連中 :グラフィックの為のチップで汎用処理をする ←変態
Cellな人 :何をやらせたいのか分からないチップでゲーム処理をする ←ド変態
CPU-GPU統合でローエンドだけじゃなくサーバまで使うってのは
CPUにGPU統合するんじゃなく今のGPUにCPU統合したような
高帯域メモリのCPU-GPUカードになるんかね?
CPUにGPU統合するんじゃなく今のGPUにCPU統合したような
高帯域メモリのCPU-GPUカードになるんかね?
>>489
人種差別主義者こそ生きる価値ないと思うぞ
人種差別主義者こそ生きる価値ないと思うぞ
>>494
不当な圧力をかける在日・同和ですか?w
不当な圧力をかける在日・同和ですか?w
496 :・∀・)っ-○◎●創聖のダンゴリオン ◆DanGorION6 :2006/11/07(火) 06:11:11 ID:gPP7FHna
>>491
まぁまぁ、そう心の狭いことを言わずに。もちろんそんなことを知ら
なくてもPCは自作できるし(俺もあまりよく知らん)、それで困らないけど、
自作PC派にはそっちの人もいっぱいいるはず。俺は柔物出身だからなぁ、
院生の頃は超並列柔物アーキテクチャとかやってたわけ。硬物は他人任せさ。
>>490
GRAPEって元は特定分野問題解決向けのサブプロセッサ集合だと思って
いたんですが、違うんでしょうか。QCD(量子色力学)問題解決向けに
アメリカで作られたシステムのように。多体問題の近似計算が初期の
動機だったはずでは。間違っていたらごみんなさい。
>>489
そう、その理念が知りたい。
>>492
んー、ソフトアーキテクチャ屋の思考だとねぇ。ちょっと違うんだね。
与えられたハードアーキテクチャに対して、どういうコードを人間が
書くべきか、それに対してコンパイラはどういうコードを吐くべきか、
それを考える。それが仕事。
理想は、より抽象的なアルゴリズムを表現すればベストな計算方法に
変換する(自動並列化も含めて)ってのが理想なんだけど、現実問題
そんなことはできていないし、この先当分できそうにないんだよね。
微小粒度並列の自動ベクトル化の世界はかなり研究済みだけど、
大粒度並列化の世界はまだまだ手作業の世界ですよ。
まぁまぁ、そう心の狭いことを言わずに。もちろんそんなことを知ら
なくてもPCは自作できるし(俺もあまりよく知らん)、それで困らないけど、
自作PC派にはそっちの人もいっぱいいるはず。俺は柔物出身だからなぁ、
院生の頃は超並列柔物アーキテクチャとかやってたわけ。硬物は他人任せさ。
>>490
GRAPEって元は特定分野問題解決向けのサブプロセッサ集合だと思って
いたんですが、違うんでしょうか。QCD(量子色力学)問題解決向けに
アメリカで作られたシステムのように。多体問題の近似計算が初期の
動機だったはずでは。間違っていたらごみんなさい。
>>489
そう、その理念が知りたい。
>>492
んー、ソフトアーキテクチャ屋の思考だとねぇ。ちょっと違うんだね。
与えられたハードアーキテクチャに対して、どういうコードを人間が
書くべきか、それに対してコンパイラはどういうコードを吐くべきか、
それを考える。それが仕事。
理想は、より抽象的なアルゴリズムを表現すればベストな計算方法に
変換する(自動並列化も含めて)ってのが理想なんだけど、現実問題
そんなことはできていないし、この先当分できそうにないんだよね。
微小粒度並列の自動ベクトル化の世界はかなり研究済みだけど、
大粒度並列化の世界はまだまだ手作業の世界ですよ。
512コアとは凄いな。使いきれるのか、とか、帯域足りるのか、とか心配もあるが。
つかPC用のアクセラレータボード出してくれて、
UDや3DCGが爆速になってくれれば俺としては万々歳。
つかPC用のアクセラレータボード出してくれて、
UDや3DCGが爆速になってくれれば俺としては万々歳。
そうだね。512コアじゃなくて512プロセッサだね。
すまんw
512PE
512プロセッサというのも違うでしょう。
演算ユニットが512個あるのだけれども、
個別に違う演算ができるわけではなく、
32演算のSIMDプロセッサが16個と見たほうが。
演算ユニットが512個あるのだけれども、
個別に違う演算ができるわけではなく、
32演算のSIMDプロセッサが16個と見たほうが。
CPUにGPUを統合なんて在日を帰化させる以上に困難だと。
>>460,463
×最大6 つの「整数演算またはマルチメディア演算」を実行できる。
○「最大6 つの整数演算」またはマルチメディア演算を実行できる。
しかし数値と「or and」がからむと(自然言語は)誤解しやすくなるね
あえてわかりにくくしとくのも技術だったりするけど
# プログラム言語でも演算子の優先順位こんがらがったりしてw
×最大6 つの「整数演算またはマルチメディア演算」を実行できる。
○「最大6 つの整数演算」またはマルチメディア演算を実行できる。
しかし数値と「or and」がからむと(自然言語は)誤解しやすくなるね
あえてわかりにくくしとくのも技術だったりするけど
# プログラム言語でも演算子の優先順位こんがらがったりしてw
>>506
ttp://developer.intel.com/design/itanium2/manuals/25110901.pdf
> Up to six integer or multimedia operations can be executed each cycle.
ttp://developer.intel.com/design/itanium2/manuals/25110901.pdf
> Up to six integer or multimedia operations can be executed each cycle.
509 :Socket774:2006/11/07(火) 19:45:59 ID:MOF0BqPj
よくわかりませんが、AVCのエンコードとかトリップの検索とかが爆速になるんですか?
510 :・∀・)っ-○◎●創聖のダンゴリオン ◆DanGorION6 :2006/11/07(火) 23:44:11 ID:uVSKIiJH
512 :・∀・)っ-○◎●創聖のダンゴリオン ◆DanGorION6 :2006/11/08(水) 00:06:14 ID:xr91Xr9z
長期出張に出ちゃった同僚のコードの保守
テストしてみたらどうも出力おかしくて、
たった1行のために半日潰れた。
== 演算子の順位って言語によっても変わるから困る。
テストしてみたらどうも出力おかしくて、
たった1行のために半日潰れた。
== 演算子の順位って言語によっても変わるから困る。
>>512
何だか親近感がわくぜw
何だか親近感がわくぜw
40Gbps動作のVCSEL素子がいるんだよなぁ
いまは今年三月にNECが発表した25Gbpsのが最高らしいけど
そこまで辿り着けるんだろうか
いまは今年三月にNECが発表した25Gbpsのが最高らしいけど
そこまで辿り着けるんだろうか
ttp://grape.astron.s.u-tokyo.ac.jp/~makino/articles/future_sc/face.html#TOC
GRAPE-DR関係は35と36に書いてるが、メモリ帯域が必要な計算はそもそも相手にしてないようだ。
GRAPE-DR関係は35と36に書いてるが、メモリ帯域が必要な計算はそもそも相手にしてないようだ。
>>515
C2Dと一緒だなwww
C2Dと一緒だなwww
517 :・∀・)っ-○◎●創聖のダンゴリオン ◆DanGorION6 :2006/11/08(水) 21:45:28 ID:iJYtA4sW
Core 2 Duoはなまじ4MBの広帯域SRAMが載っかってるし
FSBネックっていっても現状たかが知れてる。
GRAPE-DRはキャッシュすらまともに載っかってなさそうじゃん
FSBネックっていっても現状たかが知れてる。
GRAPE-DRはキャッシュすらまともに載っかってなさそうじゃん
今必要なのはメモリの革新だろ。
それは昔から言われてたこと。
業界盟主のIntelはバリバリの革新派だが協調性が無い。
まあPCI-SIGみたいな無様な迷走もどうかと思うが。
業界盟主のIntelはバリバリの革新派だが協調性が無い。
まあPCI-SIGみたいな無様な迷走もどうかと思うが。
メモリ業界の足手まとい>AMD
DDR3マダー?ってことか
MYCOMの記事の方が踏み込んだ内容になってるな。
http://journal.mycom.co.jp/news/2006/11/07/300.html
↓得意・不得意分野についても自分たちで発表してるやん
http://journal.mycom.co.jp/news/2006/11/07/300gl.jpg
MDや天体シミュレーションでPCクラスタ以上のコストパフォーマンスってのが
こいつの売りだろう。
大規模計算・大域的通信において他のベクトルスパコンの実効性能優位は揺るがない。
http://journal.mycom.co.jp/news/2006/11/07/300.html
↓得意・不得意分野についても自分たちで発表してるやん
http://journal.mycom.co.jp/news/2006/11/07/300gl.jpg
{kind=link}
MDや天体シミュレーションでPCクラスタ以上のコストパフォーマンスってのが
こいつの売りだろう。
大規模計算・大域的通信において他のベクトルスパコンの実効性能優位は揺るがない。
ttp://grape.astron.s.u-tokyo.ac.jp/~makino/articles/future_sc/face.html
マキーノたんが利点も欠点も開発方針も綺麗にまとめてるよ
(まめに更新してるなあ)
マキーノたんが利点も欠点も開発方針も綺麗にまとめてるよ
(まめに更新してるなあ)
ちなみにこの「GRAPE-DRプロジェクト」、考案者・設計者は ご存知 ”メタルラッカー” マキーノ国立天文台教授。
http://grape.astron.s.u-tokyo.ac.jp/pub/people/makino/images/g6boxwithmakino.jpg
「演算性能を大幅に上げるにはSIMD構造にすればいい。
しかしSIMDだと、メモリ帯域が問題になる。 どうするか?
CELLはSPEの中に超高速LS(ローカル・ストア)を設置し、その領域をメモリとして使う方式を発明。
対してGRAPE-DRでは、要求性能が 「重力計算に使用でき、最低限Linpackが動けば十分」
という程度の汎用性で構想し、各演算機ごとに少量のレジスタを設置。 一般のプログラムには
小さすぎるが、惑星の重力計算では演算量の割にはメモリ帯域は小さくて済むのでこのような構造に。
”シンプルな演算機+少量のレジスタ”を1ブロック(PE)とし、↓
http://pc.watch.impress.co.jp/docs/2006/1106/tokyou10.jpg
そのブロックを大量にツリー構造で並列。↓
http://pc.watch.impress.co.jp/docs/2006/1106/tokyou09.jpg
結果、得意分野は「”重力計算・天体運動”・”分子動力学計算”・”ナノテクノロジーシミュレーション”などのような、
膨大な演算量の割に、データ量が意外と少ないもの」。
この分野では、5000万円で地球シミュレータに匹敵するスパコンを構築可能。
苦手な分野は、「次々にデータを入れ替え、やり取りしなければならない、メモリ帯域が重要な演算」。
つまり、これまでの重力計算専用システムGRAPEを進化させたもの。
Linpackが動くので、2ペタ(2000テラ)Flopsのシステムが完成すれば、スパコンTOP500では
米ローレンス・リバモア研究所の280テラFlopsのIBM BlueGene/Lを抜き去り、トップに踊り出る可能性がある?
が、汎用性は狭く、得意分野の狭いスパコンになりそう。
考えをまとめたマキーノ、15億円の予算を申請してみたが政治力が足りずに却下、
そこで信頼と実績のある、お茶の水博士、もとい平木東大教授をまきこみ、共同でプレゼン、
http://pc.watch.impress.co.jp/docs/2006/1106/tokyou05.jpg
審査員は平木教授のヘアに圧倒され、無意識の内に合格の判を押してしまい、見事15億円の予算を勝ち取る。
予定通りチップは完成し、お披露目>>1
http://grape.astron.s.u-tokyo.ac.jp/pub/people/makino/images/g6boxwithmakino.jpg
{kind=link}
「演算性能を大幅に上げるにはSIMD構造にすればいい。
しかしSIMDだと、メモリ帯域が問題になる。 どうするか?
CELLはSPEの中に超高速LS(ローカル・ストア)を設置し、その領域をメモリとして使う方式を発明。
対してGRAPE-DRでは、要求性能が 「重力計算に使用でき、最低限Linpackが動けば十分」
という程度の汎用性で構想し、各演算機ごとに少量のレジスタを設置。 一般のプログラムには
小さすぎるが、惑星の重力計算では演算量の割にはメモリ帯域は小さくて済むのでこのような構造に。
”シンプルな演算機+少量のレジスタ”を1ブロック(PE)とし、↓
http://pc.watch.impress.co.jp/docs/2006/1106/tokyou10.jpg
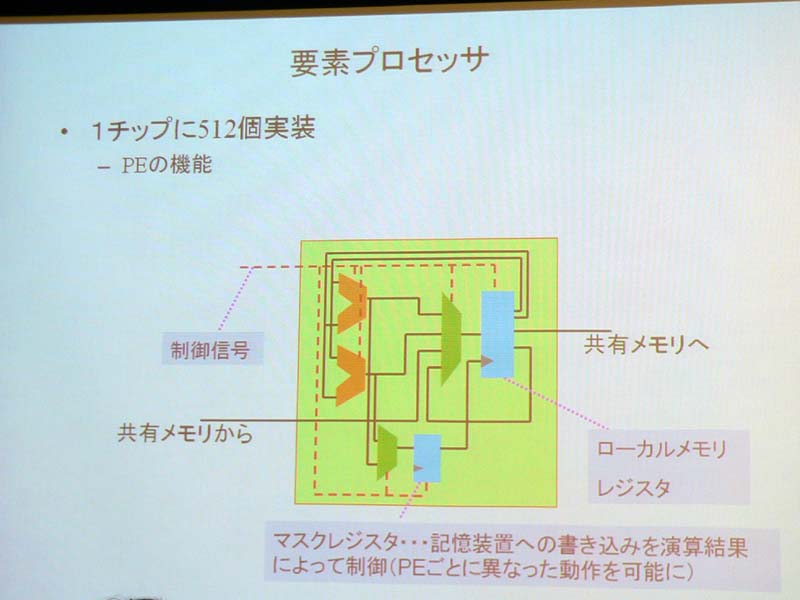{kind=link}
そのブロックを大量にツリー構造で並列。↓
http://pc.watch.impress.co.jp/docs/2006/1106/tokyou09.jpg
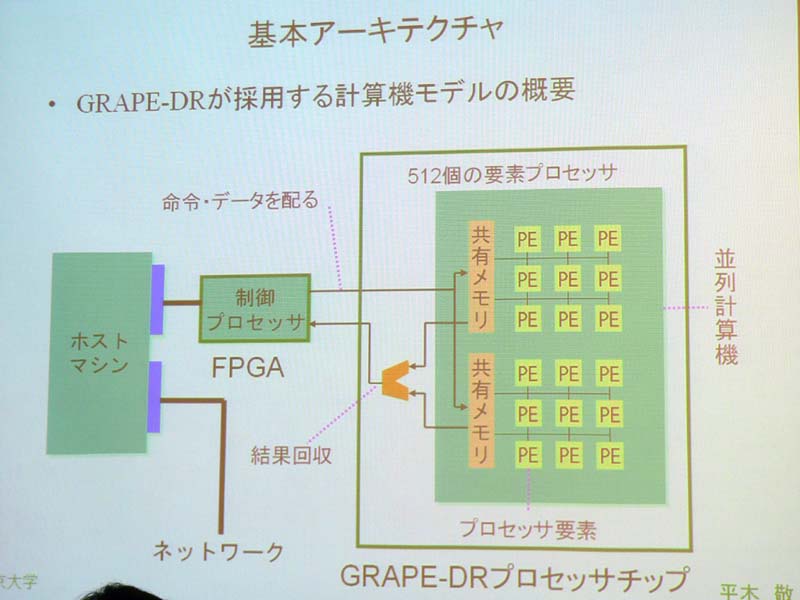{kind=link}
結果、得意分野は「”重力計算・天体運動”・”分子動力学計算”・”ナノテクノロジーシミュレーション”などのような、
膨大な演算量の割に、データ量が意外と少ないもの」。
この分野では、5000万円で地球シミュレータに匹敵するスパコンを構築可能。
苦手な分野は、「次々にデータを入れ替え、やり取りしなければならない、メモリ帯域が重要な演算」。
つまり、これまでの重力計算専用システムGRAPEを進化させたもの。
Linpackが動くので、2ペタ(2000テラ)Flopsのシステムが完成すれば、スパコンTOP500では
米ローレンス・リバモア研究所の280テラFlopsのIBM BlueGene/Lを抜き去り、トップに踊り出る可能性がある?
が、汎用性は狭く、得意分野の狭いスパコンになりそう。
考えをまとめたマキーノ、15億円の予算を申請してみたが政治力が足りずに却下、
そこで信頼と実績のある、お茶の水博士、もとい平木東大教授をまきこみ、共同でプレゼン、
http://pc.watch.impress.co.jp/docs/2006/1106/tokyou05.jpg
審査員は平木教授のヘアに圧倒され、無意識の内に合格の判を押してしまい、見事15億円の予算を勝ち取る。
予定通りチップは完成し、お披露目>>1
乙。
しかし下から2行目はw
しかし下から2行目はw
>>525
良く分かった。特に下(ry
良く分かった。特に下(ry
>>524
これ、読みやすいしおもしろいな
これ、読みやすいしおもしろいな
>524 マキーノ本人が書いてたりしてな
> 2004年度に開発を始めた当時は、「世界最高速のスパコンになる」としていたが、
> 「残念ながら世界の情勢は非常に厳しい」と平木教授。
アメリカのスパコン開発に火をつけてるのは日本だっていう認識がないなぁ。
もう地球シミュレータの時のような失態は許さないとばかりに、
GRAPE-DRの計画が判明した時点で、アメリカはテコ入れしてるでしょう。
> 「残念ながら世界の情勢は非常に厳しい」と平木教授。
アメリカのスパコン開発に火をつけてるのは日本だっていう認識がないなぁ。
もう地球シミュレータの時のような失態は許さないとばかりに、
GRAPE-DRの計画が判明した時点で、アメリカはテコ入れしてるでしょう。
C言語でプログラムできる500GFLOPSのプロセッサ
http://pc.watch.impress.co.jp/docs/2006/1109/kaigai316.htm
http://pc.watch.impress.co.jp/docs/2006/1109/kaigai316.htm
500平方mmって
これはジョークプロセッサだよな?
これはジョークプロセッサだよな?
でも大量生産されるから、290平方mm の GRAPE-DR よりはるかに安く
入手できるんだよな。性能電力比なら GRAPE-DR の圧勝なんだけど。
入手できるんだよな。性能電力比なら GRAPE-DR の圧勝なんだけど。
これまでもそうだけど一番上の価格帯は大量生産しないだろ
両方同じTSMCで生産されていたという情景を浮かべるとなんか泣けてくるな。
Direct3D 10といいCUDAといい、MSもnVIDIAも本気だな>GPGPU
Direct3D 10といいCUDAといい、MSもnVIDIAも本気だな>GPGPU
>>532
GPGPUとしてオープンにするということは中身をコロコロ変えられなくなる。
だから現時点で実現可能なギリギリまで背伸びしておく必要がある。
ゲーム機と同じで、性能据え置きで値段がどんどん下がるようなものだと思う。
GPGPUとしてオープンにするということは中身をコロコロ変えられなくなる。
だから現時点で実現可能なギリギリまで背伸びしておく必要がある。
ゲーム機と同じで、性能据え置きで値段がどんどん下がるようなものだと思う。
恐らくCUDAは仮想マシン的なもの。
ttp://pc.watch.impress.co.jp/docs/2006/1109/kaigai316_08l.gif
Runtimeとdriverを今後出る(恐らくnVIDIA専用?)GPU毎に用意してやれば
GPUの世代が変わって使い物にならなくなる
なんて事はないはずだ。
ATIの場合はDPVMって名前で同様の機構を開発中。
身近なもので例えるとJAVAや.NET Frameworkに似ているかもね。
ttp://pc.watch.impress.co.jp/docs/2006/1109/kaigai316_08l.gif
{kind=link}
Runtimeとdriverを今後出る(恐らくnVIDIA専用?)GPU毎に用意してやれば
GPUの世代が変わって使い物にならなくなる
なんて事はないはずだ。
ATIの場合はDPVMって名前で同様の機構を開発中。
身近なもので例えるとJAVAや.NET Frameworkに似ているかもね。
>>534
GRAPE に比べれば、最高価格帯のGPUの出荷数でも量産になるの。
GRAPE に比べれば、最高価格帯のGPUの出荷数でも量産になるの。
>>535
MSは段階踏めばいいと思ってる感じ。
NVIDIAはAMD+ATIとハードでは他Intel(多分)、ソフトはMS(多分)と
(利権奪われないように)ガチで闘わなきゃいけないから
まさに野獣の目のよう、つうか社員さん死に物狂いで
仕事してるんだろうなぁ。
>>537
Cg .NET ナンチテ
高級シェーディング言語が出たときもそんなこと言ってたけどね。
MSは段階踏めばいいと思ってる感じ。
NVIDIAはAMD+ATIとハードでは他Intel(多分)、ソフトはMS(多分)と
(利権奪われないように)ガチで闘わなきゃいけないから
まさに野獣の目のよう、つうか社員さん死に物狂いで
仕事してるんだろうなぁ。
>>537
Cg .NET ナンチテ
高級シェーディング言語が出たときもそんなこと言ってたけどね。
量産効果で言えばAMDATIに軍杯が上がるだろうけど。
>>540
???
???
「地球シミュレータ程度の性能が,100チップでラック1本,5000万円,20KWで実現」
とか,「ClearSpeedのCSX-600は2.5GFlops/W,NECのSX-8は0.2GFlops/W(これに
対して,Grape-DRは6GFlops/W)」という刺激的なスライドを使って発表したので,
NECなどはカチンと来ているのではないかと思います
Grape-DRのチップ内メモリが合計で256KBとすると,倍精度浮動小数点データでは
32K要素で,演算と転送をオーバラップさせるためにダブルバッファを使うと,各行列
は5K要素以下でMは70程度が限界です。倍精度の演算性能は384GFlopsとなってい
ますから,M=70の場合のメモリアクセスは4*384/70で約22GB/s,単精度の場合は,
M=100まで行けますが,4*512/100=20.5GB/sが必要となります。しかし,64ビット幅で
DDR-2並の速度とすると,5GB/s程度のメモリアクセスしか出来ないので,ここで性能
が1/4以下に制限されてしまいます。ということで,筆者は,Grape-DRチップ100個で,
線形方程式に対して,地球シミュレータ並の性能が出るというのは,疑問だと思っています。
とか,「ClearSpeedのCSX-600は2.5GFlops/W,NECのSX-8は0.2GFlops/W(これに
対して,Grape-DRは6GFlops/W)」という刺激的なスライドを使って発表したので,
NECなどはカチンと来ているのではないかと思います
Grape-DRのチップ内メモリが合計で256KBとすると,倍精度浮動小数点データでは
32K要素で,演算と転送をオーバラップさせるためにダブルバッファを使うと,各行列
は5K要素以下でMは70程度が限界です。倍精度の演算性能は384GFlopsとなってい
ますから,M=70の場合のメモリアクセスは4*384/70で約22GB/s,単精度の場合は,
M=100まで行けますが,4*512/100=20.5GB/sが必要となります。しかし,64ビット幅で
DDR-2並の速度とすると,5GB/s程度のメモリアクセスしか出来ないので,ここで性能
が1/4以下に制限されてしまいます。ということで,筆者は,Grape-DRチップ100個で,
線形方程式に対して,地球シミュレータ並の性能が出るというのは,疑問だと思っています。
543 :MACオタ>542 さん:2006/11/12(日) 02:24:57 ID:O7tGDPKW
まあ、100チップでピークが38.4Tしかいかないのに、
地球シミュレータ程度出すのはきついのは自明だけど、
必要バンド幅の試算もおかしいな。
地球シミュレータ程度出すのはきついのは自明だけど、
必要バンド幅の試算もおかしいな。
地球シミュレータと同等のものがラック1本で実現できるというのが、
ごくごく限られた条件下での話だというのは、当たり前のことなわけで。
いちいち言わなくたって当然。
用途を限定することで効率を桁違いに高くできますよ、というお話なのだから。
ごくごく限られた条件下での話だというのは、当たり前のことなわけで。
いちいち言わなくたって当然。
用途を限定することで効率を桁違いに高くできますよ、というお話なのだから。
スカラ型に対するベクトル型の優位性とか実効性能については随分昔から言ってるわけで…
http://enterprise.watch.impress.co.jp/cda/hardware/2004/10/20/3669.html
http://www.nec.co.jp/effort/eng/2005_0204/
BlueGeneならともかくGRAPEにまで文句言ってたらキリが無いような…だから
>NECなどはカチンと来ているのではないか
というより「またかよ」と思ったのではないかと
http://enterprise.watch.impress.co.jp/cda/hardware/2004/10/20/3669.html
http://www.nec.co.jp/effort/eng/2005_0204/
BlueGeneならともかくGRAPEにまで文句言ってたらキリが無いような…だから
>NECなどはカチンと来ているのではないか
というより「またかよ」と思ったのではないかと
547 :・∀・)っ-○◎●創聖のダンゴリオン ◆DanGorION6 :2006/11/12(日) 21:14:30 ID:QMJBB7zy
地球シミュレータもあるいみ地球のシミュレーションに特化したスパコンだけどなー
>>547
恥かくだけだから、偉そうにコメントしなくてもいいよ
恥かくだけだから、偉そうにコメントしなくてもいいよ
549 :・∀・)っ-○◎●創聖のダンゴリオン ◆DanGorION6 :2006/11/12(日) 21:29:07 ID:QMJBB7zy
スパコンの性能評価基準が浮動小数積和算での話だから困るのよね。
浮動小数に特化したマシンさえ作ればいいだけの話になる。
浮動小数に特化したマシンさえ作ればいいだけの話になる。
結局電力効率の高いシステムを組もうとするなら,ある程度目的に特化せざるを得ないわけで。
アメ公のバカ付き合う必要はないかと。
アメ公のバカ付き合う必要はないかと。
551 :Socket774:2006/11/12(日) 22:05:44 ID:62FBzMat
やっぱ、某氏が言ってるように、ベクトル+専用のハイブリッドスパコンですかね。
某氏って誰よ?
はいはいたるの自演乙
量子コンピュータマダー?(チンチン
555 :・∀・)っ-○◎●創聖のダンゴリオン ◆DanGorION6 :2006/11/12(日) 23:39:29 ID:QMJBB7zy
マジワラエルたる√さん
CPUにSRAMを載せるんじゃなくて、メインメモリ(DRAM)にCPUを載せちまえばいいんだよ。
64MByteのDRAM1チップに64bitFPx4並列のSIMD演算特化CPUを載せ、自分自身の
64MByteの中だけでぶん回す。コヒーレンシとか一切なし(そういう用途tは考えない)
こいつを16チップ載せたものをDIMMソケットに刺すw
制御用にx86-CPUは別に要る。
64MByteのDRAM1チップに64bitFPx4並列のSIMD演算特化CPUを載せ、自分自身の
64MByteの中だけでぶん回す。コヒーレンシとか一切なし(そういう用途tは考えない)
こいつを16チップ載せたものをDIMMソケットに刺すw
制御用にx86-CPUは別に要る。
4)余談だが、この一般公開の直後に最新作であるGRAPE-DRが発表された。
当サイトの眼にはこのチップは今までのGRAPEシリーズとは設計思想が異なる
様に思えるが、少ないメモリバンド幅を有効活用することでチップ内のトランジスタ
を可能な限り演算器に回そうという発想は同じ。
以前当サイトもCPUのリストラと称してDLPを使って非演算ユニットをダイ内部から
リストラせよと主張したこともあるが、GRAPE-DRは当サイトの主張以上に過激な
リストラ策を採用している。必要最小限のオンチップメモリを別とすれば、ダイ内部
のトランジスタはごっそり演算器に回されているらしい。
当サイトの予想が正しければ、このチップは適した問題(低Byte/FLOP)では
超高性能だが、適していない問題(高Byte/FLOP)では全然性能が出ないという
白黒のハッキリしたキャラクターになると思われる。
当サイトの眼にはこのチップは今までのGRAPEシリーズとは設計思想が異なる
様に思えるが、少ないメモリバンド幅を有効活用することでチップ内のトランジスタ
を可能な限り演算器に回そうという発想は同じ。
以前当サイトもCPUのリストラと称してDLPを使って非演算ユニットをダイ内部から
リストラせよと主張したこともあるが、GRAPE-DRは当サイトの主張以上に過激な
リストラ策を採用している。必要最小限のオンチップメモリを別とすれば、ダイ内部
のトランジスタはごっそり演算器に回されているらしい。
当サイトの予想が正しければ、このチップは適した問題(低Byte/FLOP)では
超高性能だが、適していない問題(高Byte/FLOP)では全然性能が出ないという
白黒のハッキリしたキャラクターになると思われる。
>>556
お前さんでも思いつくようなアイデアなんだから、
本業の人たちだって既に検討しているだろう。
現実にそういったものが華々しくデビューしていない以上、
それには何らかの重大な問題があるということだろう。
答えを言ってしまうと、
CPUとDRAMでは最適な製造プロセスがまるで違うので、
1つのダイに混載するとパフォーマンスが出ない。
お前さんでも思いつくようなアイデアなんだから、
本業の人たちだって既に検討しているだろう。
現実にそういったものが華々しくデビューしていない以上、
それには何らかの重大な問題があるということだろう。
答えを言ってしまうと、
CPUとDRAMでは最適な製造プロセスがまるで違うので、
1つのダイに混載するとパフォーマンスが出ない。
コピペ乙
メモリに金かけていないんだから帯域依存の演算で性能が出ないのは誰でも指摘できる
メモリに金かけていないんだから帯域依存の演算で性能が出ないのは誰でも指摘できる
>>560
混載DRAMって何時まで経っても微妙じゃないか? MCMのがまだマシだと思う。
混載DRAMって何時まで経っても微妙じゃないか? MCMのがまだマシだと思う。
>>558
>それには何らかの重大な問題があるということだろう。
各演算スレッドに依存性がまったくない問題解決はべらぼうに早くなる。
依存性が少しでもあるとまったく性能が出ない。
そういう性格のPCに需要があるのか、ってことだろう。
>それには何らかの重大な問題があるということだろう。
各演算スレッドに依存性がまったくない問題解決はべらぼうに早くなる。
依存性が少しでもあるとまったく性能が出ない。
そういう性格のPCに需要があるのか、ってことだろう。
>>562
まあロジック&SRAMの技術も進んでるわけで、相対では何時まで経っても微妙だわな
まあロジック&SRAMの技術も進んでるわけで、相対では何時まで経っても微妙だわな
むかしMicronという会社がYukonという(ry
566 :MACオタ>556 さん:2006/11/13(月) 03:27:39 ID:DQGIR+gn
>>556
そう珍しいアイデアでも無いす。
http://citeseer.ist.psu.edu/479001.html
最近実装された代表例わ,xbox360のGPU "Xenos"のeDRAMすか。。。
http://techreport.com/etc/2005q2/xbox360-gpu/index.x?pg=2
そう珍しいアイデアでも無いす。
http://citeseer.ist.psu.edu/479001.html
最近実装された代表例わ,xbox360のGPU "Xenos"のeDRAMすか。。。
http://techreport.com/etc/2005q2/xbox360-gpu/index.x?pg=2
>>566
珍しいもなにも、マルチCPUのシステムを考える場合に
各CPU毎にローカルメモリを密結合するというというのは
もっともオーソドックスな思想では?
256CPUとかそれ以上になったらCPU群とメインメモリの間にソケットやら
M/B上の配線やらを挟んだらそこがボトルネックになるのはわかりきった話であって。
珍しいもなにも、マルチCPUのシステムを考える場合に
各CPU毎にローカルメモリを密結合するというというのは
もっともオーソドックスな思想では?
256CPUとかそれ以上になったらCPU群とメインメモリの間にソケットやら
M/B上の配線やらを挟んだらそこがボトルネックになるのはわかりきった話であって。
>>567
お前の最初のカキコだと、まだ存在しないみたいな言い方だが?
お前の最初のカキコだと、まだ存在しないみたいな言い方だが?
>>567
往生際が悪いな。
本業の人たちが作った例を1つ挙げよう。
BlueGene/L
こいつのCPUはDRAM混載で4MB積んでいて、それをL3キャッシュまたはメインメモリ代わりに使える。
しかも、各種周辺回路を内蔵していて、基板上にCPUを並べて繋ぐだけで構成できる優れもの。
>>556に書かれているものに限りなく近いようだけれども決定的な違いが1つ。
DRAMの容量が>>556では64MBだが、BlueGene/LのCPUのは4MBしかない。
22GB/secという、演算スピードに比べて十分な帯域幅を持つものの、容量が少ない。
用途によっては外付けDRAMが不要で高速に処理できるし、そういった実績はあるのだけれども、
それでは済まないからこそ、DRAMコントローラを積んでいて5GB/secの外付けDRAMを使うようになっている。
往生際が悪いな。
本業の人たちが作った例を1つ挙げよう。
BlueGene/L
こいつのCPUはDRAM混載で4MB積んでいて、それをL3キャッシュまたはメインメモリ代わりに使える。
しかも、各種周辺回路を内蔵していて、基板上にCPUを並べて繋ぐだけで構成できる優れもの。
>>556に書かれているものに限りなく近いようだけれども決定的な違いが1つ。
DRAMの容量が>>556では64MBだが、BlueGene/LのCPUのは4MBしかない。
22GB/secという、演算スピードに比べて十分な帯域幅を持つものの、容量が少ない。
用途によっては外付けDRAMが不要で高速に処理できるし、そういった実績はあるのだけれども、
それでは済まないからこそ、DRAMコントローラを積んでいて5GB/secの外付けDRAMを使うようになっている。
>>569
BlueGene/Lの混載DRAM(L3キャッシュ)は残念ながら外付けDRAMとほとんど性能が変わらない
ttp://www.research.ibm.com/journal/rd/492/ohmacht.html
ttp://www.research.ibm.com/journal/rd/492/ohmac4.gif
BlueGene/Lの混載DRAM(L3キャッシュ)は残念ながら外付けDRAMとほとんど性能が変わらない
ttp://www.research.ibm.com/journal/rd/492/ohmacht.html
ttp://www.research.ibm.com/journal/rd/492/ohmac4.gif
{kind=link}
AMD、HPC専用のストリームプロセッサを発表
http://www.itmedia.co.jp/news/articles/0611/14/news102.html
中身はX1kかR600?
上の方であったDPVMがClose To Metalて名前に変わったみたい
意外と早く投入してきたなぁ。
http://www.amd.com/jp-ja/Corporate/VirtualPressRoom/0,,51_104_543~114151,00.html
http://www.itmedia.co.jp/news/articles/0611/14/news102.html
中身はX1kかR600?
上の方であったDPVMがClose To Metalて名前に変わったみたい
意外と早く投入してきたなぁ。
http://www.amd.com/jp-ja/Corporate/VirtualPressRoom/0,,51_104_543~114151,00.html
ttp://ati.amd.com/products/streamprocessor/specs.html
Powered by AMD R580 GPU
Scalable ultra-threaded architecture
Fast dynamic branching
High performance parallel processing
48 shader processors
Full Shader Model 3.0 for vertex and pixel shaders
1GB GDDR3 memory configuration
512-bit ring bus memory controller
32-bit full floating point precision
Native high bandwidth PCI Express x16 lane support
API and OS Support
OpenGL 2.0 with OpenGL Shading Language
Microsoft DirectX 9.0 with DX9 HLSL
Linux 32 and Linux 64
Windows XP and Windows XP64
AMD CTM Driver
^^^^^^^^^^^^^^^^^
>>571
R580です。
$2,600です。
Powered by AMD R580 GPU
Scalable ultra-threaded architecture
Fast dynamic branching
High performance parallel processing
48 shader processors
Full Shader Model 3.0 for vertex and pixel shaders
1GB GDDR3 memory configuration
512-bit ring bus memory controller
32-bit full floating point precision
Native high bandwidth PCI Express x16 lane support
API and OS Support
OpenGL 2.0 with OpenGL Shading Language
Microsoft DirectX 9.0 with DX9 HLSL
Linux 32 and Linux 64
Windows XP and Windows XP64
AMD CTM Driver
^^^^^^^^^^^^^^^^^
>>571
R580です。
$2,600です。
なあんだ、びっくりして損した
ttp://www.xbitlabs.com/news/cpu/display/20061114015455.html
>CTM is available to developers to license today at no cost.
>AMD plans to sell the Stream Processor for $2600.
RadeonでもCTMが提供されれば・・・(る?)
>CTM is available to developers to license today at no cost.
>AMD plans to sell the Stream Processor for $2600.
RadeonでもCTMが提供されれば・・・(る?)
$2,600だって?!
100万円以下で提供される予定で、倍精度0.7TF/s超のGRAPE-DRカードが輝いて見えるな…
100万円以下で提供される予定で、倍精度0.7TF/s超のGRAPE-DRカードが輝いて見えるな…
プログラム1行も書いたことないか目がおかしいかのどっちかだな
どこの石屋も誇大広告合戦
この業界も終わりだな
この業界も終わりだな
じゃあ次はどの業界がいいんだ?
>>579
広告業界に決まってらぁ
広告業界に決まってらぁ
かくして第3次産業が増える
電通は日本の癌
しかも切除不可
しかも切除不可
切除は不可だが、だんだん衰退するだろうよ。
乗算器やシフタやルックアップテーブルの配置を定義して
スループット1でデータを流せるようなCPUはありませんか?
スループット1でデータを流せるようなCPUはありませんか?
データフロー・アーキテクチャのことか?
587 :・∀・)っ-○◎●創聖のダンゴリオン ◆DanGorION6 :2006/11/19(日) 11:37:21 ID:I2eKt9AW
暗号のエンコーダでも作るの?
ルックアップテーブルのスループット1ならAltiVecのVPERM命令なんかが強力だし
Core 2 はpshufb mm, mmを使った8ビット×8のテーブル参照に限れば1クロックで住むね
小さすぎて使いもんにならんが。
正直、FPGAでも使われたほうがよろしいかと。
ルックアップテーブルのスループット1ならAltiVecのVPERM命令なんかが強力だし
Core 2 はpshufb mm, mmを使った8ビット×8のテーブル参照に限れば1クロックで住むね
小さすぎて使いもんにならんが。
正直、FPGAでも使われたほうがよろしいかと。
平木研の開発コード、「お茶の水1号」とかなのね…
京速計算機の立場危うし!?
DARPA、2010年までにペタスケールのコンピュータの設計と技術開発
ttp://www.geocities.jp/andosprocinfo/wadai06/20061125.htm
DARPA、2010年までにペタスケールのコンピュータの設計と技術開発
ttp://www.geocities.jp/andosprocinfo/wadai06/20061125.htm
汎用京速計算機は2010年に10PFLOPSだろ? 一桁違うよ。
593 :・∀・)っ-○◎●創聖のダンゴリオン ◆DanGorION6 :2006/11/26(日) 01:10:18 ID:zqjEHEea
京速も竜芯だけで作るんなら褒められるんだけどな
>>592
リンク先ちゃんと嫁
> Top500の性能指標であるLinpack(巨大連立一次方程式の解)ベンチマーク
> では70〜80%でるのですが,実際のアプリケーションとなると30%も出れば
> 御の字で,10%にも遥かに届かないというアプリケーションもあります。
> 従って,実効2PFlopsというのがピークではどの程度のシステムになるのか
> 不明ですが,5PFlopsよりは上で,10PFlops級のシステムになるのではない
> かと思われます。
>
> となると,10PFlopsを目指すとした日本の次期スパコン計画に対抗する
> 規模にターゲットを引き上げたように思われます。日本の目標は2010年度,
> つまり2011年3月の完成ですから,この計画で,米国が2010年末までに
> 10PFlopsを実現してしまうと,抜かれてしまう恐れがあります。
リンク先ちゃんと嫁
> Top500の性能指標であるLinpack(巨大連立一次方程式の解)ベンチマーク
> では70〜80%でるのですが,実際のアプリケーションとなると30%も出れば
> 御の字で,10%にも遥かに届かないというアプリケーションもあります。
> 従って,実効2PFlopsというのがピークではどの程度のシステムになるのか
> 不明ですが,5PFlopsよりは上で,10PFlops級のシステムになるのではない
> かと思われます。
>
> となると,10PFlopsを目指すとした日本の次期スパコン計画に対抗する
> 規模にターゲットを引き上げたように思われます。日本の目標は2010年度,
> つまり2011年3月の完成ですから,この計画で,米国が2010年末までに
> 10PFlopsを実現してしまうと,抜かれてしまう恐れがあります。
日米、ガチで競争だな。
単純に祭りとしてこういうのは好きなので、もっとやってほしい。
単純に祭りとしてこういうのは好きなので、もっとやってほしい。
何に使うか、どう使うかが重要なんだけどねw
いい加減、全てをアメリカ依存は良くないのでがんがれ
特に外交と経済
いい加減、全てをアメリカ依存は良くないのでがんがれ
特に外交と経済
そんな巨大なスパコンを作るのは無駄。
どうせ複数のプロジェクトで共同利用するんだから、
半分のサイズのスパコンを2台作ったほうがマシ。
Top500なんてのは余興なんであって、
それに国威をかけて取り組むなんてアホ。
どうせ複数のプロジェクトで共同利用するんだから、
半分のサイズのスパコンを2台作ったほうがマシ。
Top500なんてのは余興なんであって、
それに国威をかけて取り組むなんてアホ。
> 半分のサイズのスパコンを2台作ったほうがマシ。
それだ!
それだ!
二倍の性能のスパコンを 0.5台でよろ
よし、1万分の1のコンピュータを1万台作るのだ!
>>599
半分の性能のスパコンで
2倍の時間をかけて計算しても
2台あれば
マクロなスループットは同じ。
一方、
同じ技術で作った場合、性能を2倍にするために必要なコストは、
地球シミュレータのようなタイプでは、2倍では済まない。
だから、半分の性能のスパコン2台のほうがコストパフォーマンスが良い。
もちろん、分割しすぎれば、それはそれで効率が悪くなるけれどね。
半分の性能のスパコンで
2倍の時間をかけて計算しても
2台あれば
マクロなスループットは同じ。
一方、
同じ技術で作った場合、性能を2倍にするために必要なコストは、
地球シミュレータのようなタイプでは、2倍では済まない。
だから、半分の性能のスパコン2台のほうがコストパフォーマンスが良い。
もちろん、分割しすぎれば、それはそれで効率が悪くなるけれどね。
短期的にはそれで(・∀・)イイ!!けど
「技術が蓄積されない」とか「意気が上がらない」とかなるんだよね
で長期的には逆が正解だったりするからタチが悪い
「技術が蓄積されない」とか「意気が上がらない」とかなるんだよね
で長期的には逆が正解だったりするからタチが悪い
結局はスパコンで何を計算させたいかによる。
> 半分の性能のスパコンで
> 2倍の時間をかけて計算しても
って時点で既におかしいわけだが。
その「性能」って奴が具体的に何を指しているのか曖昧だけど。
> 同じ技術で作った場合、性能を2倍にするために必要なコストは、
> 地球シミュレータのようなタイプでは、2倍では済まない。
考え方が逆でさ、デカイのを1台作る能力があれば、
半分の物を半額では作れないよ。
> 2倍の時間をかけて計算しても
って時点で既におかしいわけだが。
その「性能」って奴が具体的に何を指しているのか曖昧だけど。
> 同じ技術で作った場合、性能を2倍にするために必要なコストは、
> 地球シミュレータのようなタイプでは、2倍では済まない。
考え方が逆でさ、デカイのを1台作る能力があれば、
半分の物を半額では作れないよ。
>>605
> って時点で既におかしいわけだが。
どう、おかしいの?
> その「性能」って奴が具体的に何を指しているのか曖昧だけど。
計算速度に決まっておろう。
> 考え方が逆でさ、デカイのを1台作る能力があれば、
> 半分の物を半額では作れないよ。
それは個別のノードの性能の話でしょう。
> って時点で既におかしいわけだが。
どう、おかしいの?
> その「性能」って奴が具体的に何を指しているのか曖昧だけど。
計算速度に決まっておろう。
> 考え方が逆でさ、デカイのを1台作る能力があれば、
> 半分の物を半額では作れないよ。
それは個別のノードの性能の話でしょう。
悠長に「マクロなスループット」を語っていられない時限のある解析への対処はどうすれば?
今日のデータを入力して明日の予報を得たいときに処理に二日かかったら意味ないよね。
今日のデータを入力して明日の予報を得たいときに処理に二日かかったら意味ないよね。
地球シミュレータの場合、ノード間の通信が単段クロスバーネットワークなので、
ノード数を半分にすれば、スイッチの規模は1/4で済む。
ノード数を半分にすれば、スイッチの規模は1/4で済む。
>>606
> どう、おかしいの?
だから性能と計算時間が単純にリニアになる話。
> 計算速度に決まっておろう。
技術的な用語でおながい。
> それは個別のノードの性能の話でしょう。
スパコン単体で野原にでも飾っておく話?
>>607
それもかなり重要ですね。
> どう、おかしいの?
だから性能と計算時間が単純にリニアになる話。
> 計算速度に決まっておろう。
技術的な用語でおながい。
> それは個別のノードの性能の話でしょう。
スパコン単体で野原にでも飾っておく話?
>>607
それもかなり重要ですね。
>>607
地球シミュレータは、そういう用途のために作られたのではないし。
地球シミュレータは、そういう用途のために作られたのではないし。
ん、用途によっては巨大スパコンも必要となれば、
当初の主張である「そんな巨大なスパコンを作るのは無駄。」ってのは
実は無駄じゃないって事にならんか?
当初の主張である「そんな巨大なスパコンを作るのは無駄。」ってのは
実は無駄じゃないって事にならんか?
>>609
> だから性能と計算時間が単純にリニアになる話。
そりゃリニアにはならないけど、大雑把な話だから、いいじゃないか。
より正確な話をすれば、
640ノード使って計算した場合の所要時間は、
320ノード使って計算した場合の所要時間の半分にはならない。
ただし、320ノードでもメモリが足りるという条件がつくが。
> 技術的な用語でおながい。
所要時間。
> スパコン単体で野原にでも飾っておく話?
その飛躍はなに?
地球シミュレータのノード数を320ノードx2セットにしても設置面積は同じだよ。
ストレージとの接続が2つに増えるから、ほんの少しだけ機器が増えるけどさ。
> だから性能と計算時間が単純にリニアになる話。
そりゃリニアにはならないけど、大雑把な話だから、いいじゃないか。
より正確な話をすれば、
640ノード使って計算した場合の所要時間は、
320ノード使って計算した場合の所要時間の半分にはならない。
ただし、320ノードでもメモリが足りるという条件がつくが。
> 技術的な用語でおながい。
所要時間。
> スパコン単体で野原にでも飾っておく話?
その飛躍はなに?
地球シミュレータのノード数を320ノードx2セットにしても設置面積は同じだよ。
ストレージとの接続が2つに増えるから、ほんの少しだけ機器が増えるけどさ。
ごめん訂正
> 地球シミュレータのノード数を320ノードx2セットにしても設置面積は同じだよ。
スイッチの容量が1/4になるので、その分のラックが減る。
> 地球シミュレータのノード数を320ノードx2セットにしても設置面積は同じだよ。
スイッチの容量が1/4になるので、その分のラックが減る。
>>612
> ただし、320ノードでもメモリが足りるという条件がつくが。
そういう話ならおk。
で、巨大JOBでは話にならんという事でデカイ奴の意味が
出てくるわけね。
>> 技術的な用語でおながい。
> 所要時間。
勘弁してよ。
> ただし、320ノードでもメモリが足りるという条件がつくが。
そういう話ならおk。
で、巨大JOBでは話にならんという事でデカイ奴の意味が
出てくるわけね。
>> 技術的な用語でおながい。
> 所要時間。
勘弁してよ。
>ID: DyAGoqH1
1万分の1の性能のコンピュータを1万台作ればいいとか、そういう話ですか?
1万分の1の性能のコンピュータを1万台作ればいいとか、そういう話ですか?
ベクトルスパコンが "速くて大きいパソコン" と
勘違いしている香具師が紛れ込んでない?
勘違いしている香具師が紛れ込んでない?
IBM経験もある平木先生はGF11をえらい褒めていたな。
RP3はゴミ扱いだったが。
RP3はゴミ扱いだったが。
>>613
> 現実に地球シミュレータを使って行われている研究は、リアルタイム性を求めるものではないのですよ。
何を言いたいのかわからんのだが、ある程度のリアルタイム性は必要なのでああいう物を作った。
> 現実に地球シミュレータを使って行われている研究は、リアルタイム性を求めるものではないのですよ。
何を言いたいのかわからんのだが、ある程度のリアルタイム性は必要なのでああいう物を作った。
>>620
天気予報には使っていないのだけど。
天気予報には使っていないのだけど。
地球シミュレータを何日もフルパワーで借り切ることなんてまずないと思うけどなあ。
ああいうスパコンってふつう一日に何十ものジョブをシェアして使うもんだぜ
ああいうスパコンってふつう一日に何十ものジョブをシェアして使うもんだぜ
640ノードで作ったスパコンを320ノードだけ貸し売りはできるけど
320ノードで作っちゃったら640ノード必要な仕事には売り込めない。
要はそれだけの話では。
http://www.es.jamstec.go.jp/esc/jp/ES/facilities.html
この水色の部分が1/4になったってコストは1割源程度だろう。
売り込みにくくなるデメリットの方が大きい。
320ノードで作っちゃったら640ノード必要な仕事には売り込めない。
要はそれだけの話では。
http://www.es.jamstec.go.jp/esc/jp/ES/facilities.html
この水色の部分が1/4になったってコストは1割源程度だろう。
売り込みにくくなるデメリットの方が大きい。
>>623
地球シミュレータじゃないスパコンだったが
・フル構成を使うときはだいぶ前から予約する。
・だいたいはパーティション切ってバッチで使う。ジョブ開始から終了までのTATはわりと短かいので便利。
・TSSはあんまりやらないんじゃね?効率下がるし。
地球シミュレータじゃないスパコンだったが
・フル構成を使うときはだいぶ前から予約する。
・だいたいはパーティション切ってバッチで使う。ジョブ開始から終了までのTATはわりと短かいので便利。
・TSSはあんまりやらないんじゃね?効率下がるし。
携帯電話のCPUって、最新のモデルでどれぐらいの性能なの?
カタログ見ても全然載ってないので当惑する。
カタログ見ても全然載ってないので当惑する。
見るところが間違ってる
例えば日経エレとかには時々でてくるし
組み込みエンジニア向け資料とかを何か探すんじゃね?
例えば日経エレとかには時々でてくるし
組み込みエンジニア向け資料とかを何か探すんじゃね?
>>627
W-ZERO3とかだとCPU名が出てるけど、いわゆる普通の携帯でCPU名乗ってるのは見たこと無いな。
http://journal.mycom.co.jp/news/2006/06/06/381.html
http://pc.watch.impress.co.jp/docs/2004/0421/pda34.htm
W-ZERO3とかだとCPU名が出てるけど、いわゆる普通の携帯でCPU名乗ってるのは見たこと無いな。
http://journal.mycom.co.jp/news/2006/06/06/381.html
http://pc.watch.impress.co.jp/docs/2004/0421/pda34.htm
>>624
いっそ、160ノード×4セットにすれば、ノードとスイッチの間の距離が短くなるぞ。
地球シミュレータのようにノード間が密に接続されているものを、分割して使ったら、
ノード間の通信が存在しないパスのリソースが、丸々無駄になってしまう。
>>626
何日も連続で計算する = リアルタイム性ない
いっそ、160ノード×4セットにすれば、ノードとスイッチの間の距離が短くなるぞ。
地球シミュレータのようにノード間が密に接続されているものを、分割して使ったら、
ノード間の通信が存在しないパスのリソースが、丸々無駄になってしまう。
>>626
何日も連続で計算する = リアルタイム性ない
リアルタイムと言っても、
1時間以内に結果が必要なものもあれば
1週間以内に結果が必要なものもあるだろう。
1時間以内に結果が必要なものもあれば
1週間以内に結果が必要なものもあるだろう。
同じWillcomでもNINEってのはARM9の9から名前を取ったってことらしいけど
ARM9コアのどれなのかってのは公式サイトでは公表されてないな
ARM9コアのどれなのかってのは公式サイトでは公表されてないな
フルブラウザなんか使うと、機種によって快適さが違うから、携帯電話もCPUや搭載メモリの仕様は公開してほしい。
数増やした方がいいならZ80を1億個使えよ。
むしろi4004を一京個でいいんじゃまいか
~makino更新
書き忘れ
地球シミュレータは、NECのSXの救済措置のためのプロジェクトなので、
あえて無駄でも大規模構成でTop500で1位になる必要があった、
という側面がある。
地球シミュレータは、NECのSXの救済措置のためのプロジェクトなので、
あえて無駄でも大規模構成でTop500で1位になる必要があった、
という側面がある。
救済措置ってどういうこと?売れないから、国で買ってくれって意味?
IBMが超高速の混載DRAM,SOI基板と65nm技術でランダム・アクセス1.5ns
ttp://techon.nikkeibp.co.jp/article/NEWS/20061128/124562/
(要登録)
> 米IBM Corp.は,ランダム・アクセス時間が1.5ns,ランダム・サイクル時間が2nsと
> 超高速の混載DRAMマクロを開発した。
ttp://techon.nikkeibp.co.jp/article/NEWS/20061128/124562/
(要登録)
> 米IBM Corp.は,ランダム・アクセス時間が1.5ns,ランダム・サイクル時間が2nsと
> 超高速の混載DRAMマクロを開発した。
>>643
そういう急ぎの計算でないのなら、320ノード構成でも構わないんじゃないか?
そういう急ぎの計算でないのなら、320ノード構成でも構わないんじゃないか?
>>642
「バブル崩壊により著しく落ち込んでいた日本のHPCリテラシー維持」
「バブル崩壊により著しく落ち込んでいた日本のHPCリテラシー維持」
各々が好き勝手な前提で議論しても無駄。
で、誰かが全ノードを何時間も使ったら、他の人の研究はどうなるのさ。
>>649
その誰かが使い終わってから使えばいいだろう。どうせ数時間なんだろ?
その誰かが使い終わってから使えばいいだろう。どうせ数時間なんだろ?
ああいうのは予約を事前に入れて使うもんだが
ttp://www.es.jamstec.go.jp/esc/jp/ESC/allocation.html
ttp://www.es.jamstec.go.jp/esc/jp/ESC/allocation.html
>>641
何処でこんなネタを仕込まれたんだろ〜。w
何処でこんなネタを仕込まれたんだろ〜。w
>>654
6時間って数字はどこからでてきたの?
6時間って数字はどこからでてきたの?
数時間の2倍。
半分のノードで6時間で終わるのなら、八分の一のノードで24時間かけて計算したって構わないじゃないか。
>640-641
カワイソス…
カワイソス…
細かい奴だ
ゆっくり小規模でよければ今でもみんなZ80使ってるよ
なんだかんだいって大規模高速なのは便利だしな
なんだかんだいって大規模高速なのは便利だしな
約一名以外はただの例だって承知しているようだが。
>>665
>656とかですか?
>656とかですか?
>>667
小規模/低速のマシンより大規模/高速のマシンの方がいいってだけで、
共有なんて話はしてないのでは?
>663のどこに小規模/低速を占有より大規模/高速を共有する方がいい
なんてかいてあるの?
小規模/低速のマシンより大規模/高速のマシンの方がいいってだけで、
共有なんて話はしてないのでは?
>663のどこに小規模/低速を占有より大規模/高速を共有する方がいい
なんてかいてあるの?
>>669
>663のどこに大規模なスパコンの話をしていると書いているのか教えてください。
>663のどこに大規模なスパコンの話をしていると書いているのか教えてください。
何の話になっとるんじゃ。> ES叩きがしたいんだったら、他へ逝け!
1コアで4GHzのCPUよりも、
2コアで2GHzのCPUのほうが、
演算あたりのコストが安い
という話でしょ。
2コアで2GHzのCPUのほうが、
演算あたりのコストが安い
という話でしょ。
うんうん、そうだね
4コアで1GHzのクピュよりも
8コアで500MHzのクピュよりも
16コアで250MHzのクピュよりも
32コアで125MHzのクピュよりも
64コアで62.5MHzのクピュよりも
128コアで31.25MHzのクピュよりも
256コアで15.625MHzのクピュよりも
(以下無限に続く)
4コアで1GHzのクピュよりも
8コアで500MHzのクピュよりも
16コアで250MHzのクピュよりも
32コアで125MHzのクピュよりも
64コアで62.5MHzのクピュよりも
128コアで31.25MHzのクピュよりも
256コアで15.625MHzのクピュよりも
(以下無限に続く)
じゃぁ、初代のコネクションマシンで(w
http://ja.wikipedia.org/wiki/%E3%82%B3%E3%83%8D%E3%82%AF%E3%82%B7%E3%83%A7%E3%83%B3%E3%83%9E%E3%82%B7%E3%83%B3
http://ja.wikipedia.org/wiki/%E3%82%B3%E3%83%8D%E3%82%AF%E3%82%B7%E3%83%A7%E3%83%B3%E3%83%9E%E3%82%B7%E3%83%B3
676 :・∀・)っ-○◎●創聖のダンゴリオン ◆DanGorION6 :2006/12/01(金) 23:05:24 ID:SQKbh20M
通信のオーバーヘッドと並列化できない処理が足枷になるからね
1スレッドの性能を上がる限り上げ続けたほうがええ罠
1スレッドの性能を上がる限り上げ続けたほうがええ罠
仔猫ちゃんマシン
>>675
利用コストも考えてくださいよ。
利用コストも考えてくださいよ。
>>678
それもコストに入れてあげて下さい。
それもコストに入れてあげて下さい。
コスト無視(に近い)プロジェクトも最先端にはないと
それはそれでマズいんじゃね?
それはそれでマズいんじゃね?
2000年前の計算機ハッケソ
http://www.geocities.jp/andosprocinfo/wadai06/20061202.htm
4.世界初のコンピュータ Antikythera Mechanism
2006年11月30日のCNETが,Antikythera Mechanismと呼ばれる世界初のコンピュータに
ついて報じています。1901年にギリシャのクレタ島の北にあるAntikythera島の沖合いの
沈没船から発見された82個の真鍮の破片で,これまで用途が分かっていなかったのですが,
このほど,英国,ギリシャ,米国の科学者がX線トモグラフィーなどの技術を使って解析し,
30個以上の歯車を組み合わせて,天体の運行を計算するメカニカルなアナログコンピュータ
であったと発表しました。日蝕や月蝕の時期を計算することが出来たそうです。なお,CNETの
ページにはAntikythera Mechanismの実物の写真とともに,CGで再現した写真も載っています。
製造時期は,ギリシャの科学者であったヒッパルコスの名前が引用されている銘文があること
などから,140〜200BC頃と考えられています。メカニカルディジタルコンピュータである,
1837年のバベッジのアナリティカルエンジンから遡ること,2000年前の製作です。
http://www.geocities.jp/andosprocinfo/wadai06/20061202.htm
4.世界初のコンピュータ Antikythera Mechanism
2006年11月30日のCNETが,Antikythera Mechanismと呼ばれる世界初のコンピュータに
ついて報じています。1901年にギリシャのクレタ島の北にあるAntikythera島の沖合いの
沈没船から発見された82個の真鍮の破片で,これまで用途が分かっていなかったのですが,
このほど,英国,ギリシャ,米国の科学者がX線トモグラフィーなどの技術を使って解析し,
30個以上の歯車を組み合わせて,天体の運行を計算するメカニカルなアナログコンピュータ
であったと発表しました。日蝕や月蝕の時期を計算することが出来たそうです。なお,CNETの
ページにはAntikythera Mechanismの実物の写真とともに,CGで再現した写真も載っています。
製造時期は,ギリシャの科学者であったヒッパルコスの名前が引用されている銘文があること
などから,140〜200BC頃と考えられています。メカニカルディジタルコンピュータである,
1837年のバベッジのアナリティカルエンジンから遡ること,2000年前の製作です。
天体の動作を計算する技術はギリシャではすでに2000年以上前から行われており、
今回の東大の発表には新しさはなく、これもMarkitectureだと思われます。
今回の東大の発表には新しさはなく、これもMarkitectureだと思われます。
>>682
座布団6枚www
座布団6枚www
http://journal.mycom.co.jp/articles/2006/12/04/sc1/002.html
CELLのロードマップ
ロードランナーは砂漠地帯に住むカラスくらいの大きさ鳥の名前で、
飛ぶよりも歩いたり走ったりする方が得意で、
時速30Km程度の(体のサイズと比べて)猛スピードで走るという面白い鳥である。
CELLのロードマップ
ロードランナーは砂漠地帯に住むカラスくらいの大きさ鳥の名前で、
飛ぶよりも歩いたり走ったりする方が得意で、
時速30Km程度の(体のサイズと比べて)猛スピードで走るという面白い鳥である。
685 :Socket774:2006/12/04(月) 17:39:33 ID:ee6sBWfF
詳しい方お教え下さい。
デュアルコアXeonなんですが、3G一基と、2G二基ではどっちが速いでしょうか?
やりたいのはもっぱらビデオの編集をしながらファイル移動などです。
よろしくお願いします。
デュアルコアXeonなんですが、3G一基と、2G二基ではどっちが速いでしょうか?
やりたいのはもっぱらビデオの編集をしながらファイル移動などです。
よろしくお願いします。
CPUアーキテクチャよりソフトやOSや使用状況による
ソフトとかの専門スレ池
ソフトとかの専門スレ池
688 :・∀・)っ-○◎●創聖のダンゴリオン ◆DanGorION6 :2006/12/05(火) 00:44:00 ID:C1YgKy0n
萌えるなこういうの
PenDベースかC2Dベースかで違うだろうけど、C2Dベースだとしたら3GHzのデュアルコアx1のが速いんじゃないか?
あとチップセット周りはFB-DIMMが熱くて遅いらしいからDDR2のが良いかも。
あとチップセット周りはFB-DIMMが熱くて遅いらしいからDDR2のが良いかも。
>687
通常10万って一般ユーザには高すぎるよな
PCとかにさくっと挿して使えて数万円とかはないのか
通常10万って一般ユーザには高すぎるよな
PCとかにさくっと挿して使えて数万円とかはないのか
組込みユーザ向けだから。
ttp://pc.watch.impress.co.jp/docs/2006/1204/kaigai323.htm
> Cellはヘテロジニアスマルチコア構成で、200GFLOPSを超える圧倒的な
> 浮動小数点演算パフォーマンスを達成している。これまでのゲーム機は、
> 優れた性能を持っていても、すぐにPCに追い抜かれた。しかし、PS3の
> 場合は、演算性能だけを見るなら、PC CPUとのギャップが巨大で、
> すぐにPCが追い抜くことはできない。つまり、コンピュータとしてPCとの
> 違いを打ち出しやすい。
さてさて、Core2Quadの単精度の理論ピークわかるお方どうぞ〜
SSEとOpenMPその他のスレッド化の方がローカルストアへの明示的な
転送よか圧倒的に生産性高いのも織り込んでね。
> Cellはヘテロジニアスマルチコア構成で、200GFLOPSを超える圧倒的な
> 浮動小数点演算パフォーマンスを達成している。これまでのゲーム機は、
> 優れた性能を持っていても、すぐにPCに追い抜かれた。しかし、PS3の
> 場合は、演算性能だけを見るなら、PC CPUとのギャップが巨大で、
> すぐにPCが追い抜くことはできない。つまり、コンピュータとしてPCとの
> 違いを打ち出しやすい。
さてさて、Core2Quadの単精度の理論ピークわかるお方どうぞ〜
SSEとOpenMPその他のスレッド化の方がローカルストアへの明示的な
転送よか圧倒的に生産性高いのも織り込んでね。
理論ピーク値に生産性とか関係なかろ
4個にするか、3個+16個ぐらいのかと思ってたんだけどなぁ
GPUが来年にも1TFlopsを達成しそうなことを考えると今のCellよりはインパクト弱いな。
>>699
理論ピーク値を計算するのになんで生産性が関係して来るんだ?
はっきりと
>692は適当に自分と知っているキーワードをちりばめて知ったかぷりを
したんだろ。バッカじゃねー。
ってコメントもつけないと分かってもらえないかね。
理論ピーク値を計算するのになんで生産性が関係して来るんだ?
はっきりと
>692は適当に自分と知っているキーワードをちりばめて知ったかぷりを
したんだろ。バッカじゃねー。
ってコメントもつけないと分かってもらえないかね。
>>700さんも、好意的に解釈して、補足する書き込みをしたらいいじゃないですか。
703 :Socket774:2006/12/05(火) 17:59:20 ID:sxZrGvC1
PS3のcellが実効性能で256Gflops出ると思ってるやついるの?
御めでたいなw
実際にはCore2や箱360に負けてるのが事実だけどね。
御めでたいなw
実際にはCore2や箱360に負けてるのが事実だけどね。
PCが追い抜くことはできないエンターテインメントスーパーコンピューターPS3
その驚くべき性能が今ここに
http://bb.watch.impress.co.jp/cda/special/16154.html
ブラウザに関してはWebブラウザの表示には十分なものの、
PCと比べるとやや動作にもたつきを感じる。
http://game.g.hatena.ne.jp/Nao_u/20061111#p1
Flashを使っているサイトは極端に動作が重くなり、
Flashアニメーションを多用したサイトではPCで見るのと比べて
3倍くらい処理が遅くなっていたりするサイトもあった。
また、メモリを多量に使う重いサイトのウインドウを複数開いたり、
長いアニメーションを見続けていると簡単に「メモリ不足です」という
エラーが出て止まってしまうことも。
http://japanese.engadget.com/2006/11/12/ps3-eric-s-raymond/
ダウンロード中は何もできなくなるシングルタスクの
「エンタテインメント・コンピュータ」ってありですか。
その驚くべき性能が今ここに
http://bb.watch.impress.co.jp/cda/special/16154.html
ブラウザに関してはWebブラウザの表示には十分なものの、
PCと比べるとやや動作にもたつきを感じる。
http://game.g.hatena.ne.jp/Nao_u/20061111#p1
Flashを使っているサイトは極端に動作が重くなり、
Flashアニメーションを多用したサイトではPCで見るのと比べて
3倍くらい処理が遅くなっていたりするサイトもあった。
また、メモリを多量に使う重いサイトのウインドウを複数開いたり、
長いアニメーションを見続けていると簡単に「メモリ不足です」という
エラーが出て止まってしまうことも。
http://japanese.engadget.com/2006/11/12/ps3-eric-s-raymond/
ダウンロード中は何もできなくなるシングルタスクの
「エンタテインメント・コンピュータ」ってありですか。
整数がP4-2GHz強、倍精度がP3-866MHz、単精度がP4-3.2GHz強
http://rian.s26.xrea.com/nicky.cgi?DT=20061121A#20061121A
・Dhrystone v2.1
PS3 Cell 3.2GHz: 1879.630
PowerPC G4 1.25GHz: 2202.600
PentiumIII 866MHz: 1124.311
Pentium4 2.0AGHz: 1694.717
Pentium4 3.2GHz: 3258.068
・Linpack 100x100 Benchmark In C/C++ (Rolled Double Precision)
PS3 Cell 3.2GHz: 315.71
PentiumIII 866MHz: 313.05
Pentium4 2.0AGHz: 683.91
Pentium4 3.2GHz: 770.66
Athlon64 X2 4400+ (2.2GHz): 781.58
・Linpack 100x100 Benchmark In C/C++ (Rolled Single Precision)
PS3 Cell 3.2GHz: 312.64
PentiumIII 866MHz: 198.7
Pentium4 2.0AGHz: 82.57
Pentium4 3.2GHz: 276.14
Athlon64 X2 4400+ (2.2GHz): 538.05
http://rian.s26.xrea.com/nicky.cgi?DT=20061121A#20061121A
・Dhrystone v2.1
PS3 Cell 3.2GHz: 1879.630
PowerPC G4 1.25GHz: 2202.600
PentiumIII 866MHz: 1124.311
Pentium4 2.0AGHz: 1694.717
Pentium4 3.2GHz: 3258.068
・Linpack 100x100 Benchmark In C/C++ (Rolled Double Precision)
PS3 Cell 3.2GHz: 315.71
PentiumIII 866MHz: 313.05
Pentium4 2.0AGHz: 683.91
Pentium4 3.2GHz: 770.66
Athlon64 X2 4400+ (2.2GHz): 781.58
・Linpack 100x100 Benchmark In C/C++ (Rolled Single Precision)
PS3 Cell 3.2GHz: 312.64
PentiumIII 866MHz: 198.7
Pentium4 2.0AGHz: 82.57
Pentium4 3.2GHz: 276.14
Athlon64 X2 4400+ (2.2GHz): 538.05
Digg.com "PS3 equals 800 Mhz Pentium III"
http://digg.com/hardware/PS3_equals_800_Mhz_Pentium_III
PS3 Linuxで簡単なテストをした結果、Pentium III 800MHzと同じくらいの速度だった。
PS3は通常の玄箱HGの3倍!(ベンチマークテスト)
http://type-x.ddo.jp/wordpress/archives/245
・PS3 vs PowerPC/MPC8241LZQ266D/266MHz 比 → INTは3.3倍、FPは4.6倍
・PS3 vs Pentium-M 1.7GHz/vmware/WinXP SP2 比 → INTは0.3倍、FPは0.18倍
http://digg.com/hardware/PS3_equals_800_Mhz_Pentium_III
PS3 Linuxで簡単なテストをした結果、Pentium III 800MHzと同じくらいの速度だった。
PS3は通常の玄箱HGの3倍!(ベンチマークテスト)
http://type-x.ddo.jp/wordpress/archives/245
・PS3 vs PowerPC/MPC8241LZQ266D/266MHz 比 → INTは3.3倍、FPは4.6倍
・PS3 vs Pentium-M 1.7GHz/vmware/WinXP SP2 比 → INTは0.3倍、FPは0.18倍
>>704-706
ヒドス
ヒドス
これが5000億円かけた結果とは
最適化してなくてそれだけ出ればもうけもんだろ
cellは子分を働かせてナンボのプロセッサなんだから
制御用コアだけ動かしてもそう速くないのは信者でも知ってる
cellは子分を働かせてナンボのプロセッサなんだから
制御用コアだけ動かしてもそう速くないのは信者でも知ってる
>>710
SPEなんて使ってるわけないだろ。
SPEなんて使ってるわけないだろ。
先生!子分が動いてくれません><
>>706
MPC8241って…PowerPC603e(アップルが採用したなかでは、第一世代と同レベル性能)+チップセット統合プロセッサじゃないか
MPC8241って…PowerPC603e(アップルが採用したなかでは、第一世代と同レベル性能)+チップセット統合プロセッサじゃないか
某がんばってる人いわく
LAMEエンコード速度は
PPUで3.2901倍速(gccコンパイル)
PPUで4.8229倍速(xlcコンパイル)
SPUx1で8.165倍速(gccコンパイル)
Athlon 64 [email protected]で14.531倍速
LAMEエンコード速度は
PPUで3.2901倍速(gccコンパイル)
PPUで4.8229倍速(xlcコンパイル)
SPUx1で8.165倍速(gccコンパイル)
Athlon 64 [email protected]で14.531倍速
PPUはG5ベースだとばかり思ってたんだが・・ 何故ここまでパフォーマンスが出ないんだろうか?
PPEはIn order
“互換”であって“相当”では無い。
“互換”であって“相当”では無い。
PPEはOoOEが無いほか、いろいろ機能削減されてますんで。
G5と同列には語れない。
G5と同列には語れない。
まあ、今後のCELLの展開として、PPEを強化するってのもアリか。
720 :・∀・)っ-○◎●創聖のダンゴリオン ◆DanGorION6 :2006/12/06(水) 00:18:44 ID:At82ZlrU
SPEがコンパイルオプション替えるだけで使ってくれるようにならないと
使い物になるとは言えんわな。
使い物になるとは言えんわな。
>>720
そんな人工知能搭載コンパイラは、登場して来ないだろう。
自動ベクトル化とは訳が違うのだから。
>>719
強化するくらいなら最初から削ったりはしなかったと思う。
設計した人たちは、
ずっと設計を変えないのだから、コンパイラでドンピシャの最適化をすればいい
と考えていたのだと思うよ。
そんな人工知能搭載コンパイラは、登場して来ないだろう。
自動ベクトル化とは訳が違うのだから。
>>719
強化するくらいなら最初から削ったりはしなかったと思う。
設計した人たちは、
ずっと設計を変えないのだから、コンパイラでドンピシャの最適化をすればいい
と考えていたのだと思うよ。
722 :・∀・)っ-○◎●創聖のダンゴリオン ◆DanGorION6 :2006/12/06(水) 01:59:41 ID:At82ZlrU
デュアルCPU化したのに多くのタイトルでは1CPUしか使われなかったセガサターンと同じ臭いがする。
むしろサターン以上に臭う。
むしろサターン以上に臭う。
「コアの数なんて どうでもいい」
http://www.arch.cs.titech.ac.jp/event/fit2006/fit2006_goshima.pdf
http://www.arch.cs.titech.ac.jp/event/fit2006/fit2006_goshima.pdf
もさもさもっさりPS3
で、現行で最も有望なCPUアーキテクチャって何なわけ?
用途によるとしか
EPIC + OoO
ニーソ+ツンデレ
VLIW・・・誰か拾ってやって下さい。
>それは実行ユニットの数が増減した場合の話
はいはい電波乙
はいはい電波乙
>>716
CPUの場合その「〜ベース」というのがくせ者。
原型になった石の機能をそのまま引き継いでるわけでは無い。
CELLは今までCPU側がやってた事を
全部ソフトに丸投げした、ソフト開発者を殺る気満々の欠陥CPU。
CPUの場合その「〜ベース」というのがくせ者。
原型になった石の機能をそのまま引き継いでるわけでは無い。
CELLは今までCPU側がやってた事を
全部ソフトに丸投げした、ソフト開発者を殺る気満々の欠陥CPU。
>>733
実行ユニットの数が増減すると、OoOやらないと性能が出なくなるのが、EPICの弱点なのだが。
事実、Itanium→Itanium2で実行ユニットが増減したため、そのままのコードでは速度が少し落ちる。
インテルのコンパイラには、どちらのCPUを対象に最適化するかオプションで設定するようになってる。
Itanium2がOoOを積まなかったのは、Itaniumがプロトタイプの域を出るほど売れなかったし、1年の命だったからでしょう。
実行ユニットの数が増減すると、OoOやらないと性能が出なくなるのが、EPICの弱点なのだが。
事実、Itanium→Itanium2で実行ユニットが増減したため、そのままのコードでは速度が少し落ちる。
インテルのコンパイラには、どちらのCPUを対象に最適化するかオプションで設定するようになってる。
Itanium2がOoOを積まなかったのは、Itaniumがプロトタイプの域を出るほど売れなかったし、1年の命だったからでしょう。
G5ベースと標榜してるけど、
本音を言うと、PPC603かX704あたりの高クロック版でしかないだろ。
並列実行度は低いし、OoOしない。
命令セットのレベルで大差がないから、
一番高性能っぽいイメージのG5の名前を出してるだけ。
本音を言うと、PPC603かX704あたりの高クロック版でしかないだろ。
並列実行度は低いし、OoOしない。
命令セットのレベルで大差がないから、
一番高性能っぽいイメージのG5の名前を出してるだけ。
G5とISA互換てことだろ?
>>735
EPICでわざわざOoOやるのは一にも二にもIPC向上のためだろ〜?
既存のバイナリなんてうごきゃーいいんだよwそのためのEPIC。
そもそもユーザーがリコンパイルやらなんやらして最適化してくれるのが前提のアーキに何言ってるんだ。
EPICでわざわざOoOやるのは一にも二にもIPC向上のためだろ〜?
既存のバイナリなんてうごきゃーいいんだよwそのためのEPIC。
そもそもユーザーがリコンパイルやらなんやらして最適化してくれるのが前提のアーキに何言ってるんだ。
重量級のRockは2008年中に投入される見込み。
Power6(+?)やItanium2(Montvale)の命運は如何に?
Sun puts 16 cores on its 'Rock' chip
http://news.com.com/Sun+puts+16+cores+on+its+Rock+chip+-+page+2/2100-1006_3-6141961-2.html?tag=st.num
Power6(+?)やItanium2(Montvale)の命運は如何に?
Sun puts 16 cores on its 'Rock' chip
http://news.com.com/Sun+puts+16+cores+on+its+Rock+chip+-+page+2/2100-1006_3-6141961-2.html?tag=st.num
命運を心配されるのはRockの方だと思うが
>>738
コンパイラが最適なコードを出力していてもなお、OoOをすると、どれくらいIPCが向上するの?
コンパイラが命令グループの切り方が下手だと、OoOでIPCが向上するだろうけれどもさ。
OoOを持たないItanium2が、OoOを持つ他のCPUと、競争できているのは凄いことだと思うよ。
コンパイラが最適なコードを出力していてもなお、OoOをすると、どれくらいIPCが向上するの?
コンパイラが命令グループの切り方が下手だと、OoOでIPCが向上するだろうけれどもさ。
OoOを持たないItanium2が、OoOを持つ他のCPUと、競争できているのは凄いことだと思うよ。
いや、凄いというよりも、本質的にOoOが必要ないから、OoOを持つCPUと競争できているのだと思う。
>>734
膨大な時間をかければ効率的に機能するかもしれないCPU
という時点でゲーム機にしか使えないのは当然だろうね
日進月歩のPCの世界では導入が難しいと思う
>>743
CellもItanuimもx86系CPUほどには柔軟性に富んでいない(ソフト側の最適化が必須)から
コンパイラが全てのEPIC系プロセッサがコンシューマPCに落ちてこなかったのは
幸せだったのかも知れないね
膨大な時間をかければ効率的に機能するかもしれないCPU
という時点でゲーム機にしか使えないのは当然だろうね
日進月歩のPCの世界では導入が難しいと思う
>>743
CellもItanuimもx86系CPUほどには柔軟性に富んでいない(ソフト側の最適化が必須)から
コンパイラが全てのEPIC系プロセッサがコンシューマPCに落ちてこなかったのは
幸せだったのかも知れないね
>>742
しない。
ただ、プロセッサの構成によって「最適なコード」が変わるから、すべての構成のマシンに対して
最適なコードを供給するのは不可能。
#たとえばFRVも400系450系500系550系で全部バイナリが変わる...変えないと性能が出ない。
だからOoOする意味はある...というかしないと性能が出ない。
だからPCみたいに多用なハードウェアの上で単一バイナリを走らせないといけないような構成のシステムで
VLIWなんか使っちゃダメなんだよな。
しない。
ただ、プロセッサの構成によって「最適なコード」が変わるから、すべての構成のマシンに対して
最適なコードを供給するのは不可能。
#たとえばFRVも400系450系500系550系で全部バイナリが変わる...変えないと性能が出ない。
だからOoOする意味はある...というかしないと性能が出ない。
だからPCみたいに多用なハードウェアの上で単一バイナリを走らせないといけないような構成のシステムで
VLIWなんか使っちゃダメなんだよな。
746 :Socket774:2006/12/09(土) 10:21:20 ID:ltxHmgrp
結構頑張って最適化して、SPE1つ辺り、シングルコアAthlonの半分程度の模様。
クアッドコアには勝てそうに無いな。
lameでmp3エンコ速度を比較
Cell(PPU): 3.3倍速
Cell(SPEx1): 8.2倍速
[email protected]: 14.5倍速
http://d.hatena.ne.jp/hagecell/
クアッドコアには勝てそうに無いな。
lameでmp3エンコ速度を比較
Cell(PPU): 3.3倍速
Cell(SPEx1): 8.2倍速
[email protected]: 14.5倍速
http://d.hatena.ne.jp/hagecell/
そりゃQuadになるとCellの1.5倍程度のトランジスタ規模になりそうだし
勝てなくても仕方が無いんじゃない?
勝てなくても仕方が無いんじゃない?
X1300はGeForce8800に勝てそうもないな、って言ってるのと同じだな
まあCellもSPE強化バージョンとかコア増量バージョンとかのロードマップがあるわけで
K8Lの次はどうなってるの?
新K9?とかあるのかな。
新K9?とかあるのかな。
754 :MACオタ>739 さん:2006/12/09(土) 14:57:07 ID:/0zHaCgA
>>739
"Scout Threading"わ興味深いすけど,この方面でわ頑張ったところでコアに追いつかれてしまう
という分析わ有るす。
"Exploring the limits of prefetching", P. G. Emma, et al., IBM J. R&D, v48, n1 (2005)
http://www.research.ibm.com/journal/rd/491/emma.pdf
"Scout Threading"わ興味深いすけど,この方面でわ頑張ったところでコアに追いつかれてしまう
という分析わ有るす。
"Exploring the limits of prefetching", P. G. Emma, et al., IBM J. R&D, v48, n1 (2005)
http://www.research.ibm.com/journal/rd/491/emma.pdf
755 :MACオタ>753 さん:2006/12/09(土) 14:59:46 ID:/0zHaCgA
>>753
--------------------
価格は馬鹿高いだろうけれど…
--------------------
970搭載の安物ブレードJS-2xの後継機がPOWER6を搭載するとのことすから,ローエンドモデル
わ安いと思われるす。
http://news.com.com/2100-1006_3-6141435.html
====================
Today, IBM's blade servers are available with the company's PowerPC 970 processors.
But the Power6 will replace those lower-end sibling in blade servers, Tim Doughtery,
IBM's BladeCenter strategist, said in an interview Wednesday.
====================
--------------------
価格は馬鹿高いだろうけれど…
--------------------
970搭載の安物ブレードJS-2xの後継機がPOWER6を搭載するとのことすから,ローエンドモデル
わ安いと思われるす。
http://news.com.com/2100-1006_3-6141435.html
====================
Today, IBM's blade servers are available with the company's PowerPC 970 processors.
But the Power6 will replace those lower-end sibling in blade servers, Tim Doughtery,
IBM's BladeCenter strategist, said in an interview Wednesday.
====================
L3あるなしとかを含めて上と下で幅の広いラインナップになるのか
POWER6は、宣伝文句を聞いてると本当に凄い。
高クロックと高IPCを両立してる。
本当に出るのかよ、と疑ってしまう。
高クロックと高IPCを両立してる。
本当に出るのかよ、と疑ってしまう。
Rockがミスった時は、SPARC64 VII(4core×2th)かね?
最近のMIPSやARMは何処へ?
最近のMIPSやARMは何処へ?
759 :MACオタ>758 さん:2006/12/09(土) 15:29:04 ID:/0zHaCgA
>>758
-------------------
最近のMIPSやARMは何処へ?
--------------------
BlueGene, CELL, GRAPEなんかの流れで,カスタムCPUをHPC用途に使うのわ注目の分野す。
とりあえずMIPSでわ,こんなんとか。
http://www.linuxdevices.com/news/NS3651965718.html
-------------------
最近のMIPSやARMは何処へ?
--------------------
BlueGene, CELL, GRAPEなんかの流れで,カスタムCPUをHPC用途に使うのわ注目の分野す。
とりあえずMIPSでわ,こんなんとか。
http://www.linuxdevices.com/news/NS3651965718.html
760 :Socket774:2006/12/09(土) 15:50:40 ID:mOQDs55Y
こんなんとか
こんなんとか
こんなんとか
こんなんとか
こんなんとか
こんなんとか
判りやすいねえw
こんなんとか
こんなんとか
こんなんとか
こんなんとか
こんなんとか
判りやすいねえw
>>759
MIPS64を束ねてPathScale(IBでも有名)の最適化で何とかするって話ね。
やってる事は、PPC405を束ねたBG/Lと似てるけど…パフォーマンス的に
一桁多いプロセッサを結ぶネットワークの効率が一番重要になりそう。
MIPS64を束ねてPathScale(IBでも有名)の最適化で何とかするって話ね。
やってる事は、PPC405を束ねたBG/Lと似てるけど…パフォーマンス的に
一桁多いプロセッサを結ぶネットワークの効率が一番重要になりそう。
MACオタ的には、汎用京速計算機はどう見る?
>>745
やっぱり、しないよね。
>>738さんには、違う観点があるのだろうか。
>>746
それはSPEを汎用プロセッサとして使っていると思います。
しかも演算はみんな倍精度でしょう。
lameのコアを丸ごとSPEで走らせたら、そりゃぁ遅くて当たり前です。
単精度にし、
PPUとSPEで適切に作業分担をするようにコードを直す
というよりは、書きなおさなければ。
やっぱり、しないよね。
>>738さんには、違う観点があるのだろうか。
>>746
それはSPEを汎用プロセッサとして使っていると思います。
しかも演算はみんな倍精度でしょう。
lameのコアを丸ごとSPEで走らせたら、そりゃぁ遅くて当たり前です。
単精度にし、
PPUとSPEで適切に作業分担をするようにコードを直す
というよりは、書きなおさなければ。
764 :・∀・)っ-○◎●創聖のダンゴリオン ◆DanGorION6 :2006/12/09(土) 17:09:12 ID:TtR1FRVA
倍精度ならPPEより性能出るわけないと思うが。
「適切に作業分担」
言うのは簡単、この言葉。
言うのは簡単、この言葉。
766 :・∀・)っ-○◎●創聖のダンゴリオン ◆DanGorION6 :2006/12/09(土) 17:20:01 ID:TtR1FRVA
PS3買ってきて作業分担が簡単にできること証明してよ
767 :MACオタ>762 さん:2006/12/09(土) 17:53:47 ID:/0zHaCgA
>>762
-------------------
MACオタ的には、汎用京速計算機はどう見る?
-------------------
HPCSプロジェクトで,米国わ本気で「汎用スーパーコンピューティング」を開発しているす。
http://techon.nikkeibp.co.jp/article/NEWS/20061123/124281/
---------------------------
HPCSは,単なる演算性能の高さだけでなく,従来のスーパーコンピュータの課題だった使い
難さやプログラミングの難しさの解消を図り,生産性の高いシステムを開発することを目標と
したプロジェクト。
---------------------------
しかし,これ2002年から始まっているほぼ10年がかりのプロジェクトす。平成18年度から始めたとか
いう,怪しい宗教とわモノが違うかと思うす。
-------------------
MACオタ的には、汎用京速計算機はどう見る?
-------------------
HPCSプロジェクトで,米国わ本気で「汎用スーパーコンピューティング」を開発しているす。
http://techon.nikkeibp.co.jp/article/NEWS/20061123/124281/
---------------------------
HPCSは,単なる演算性能の高さだけでなく,従来のスーパーコンピュータの課題だった使い
難さやプログラミングの難しさの解消を図り,生産性の高いシステムを開発することを目標と
したプロジェクト。
---------------------------
しかし,これ2002年から始まっているほぼ10年がかりのプロジェクトす。平成18年度から始めたとか
いう,怪しい宗教とわモノが違うかと思うす。
汎用京速計算機プロジェクトの趣旨を読むと,こんなことが書いてあるす。
http://www.mext.go.jp/b_menu/shingi/gijyutu/gijyutu2/shiryo/007/05092001/004_2/004_2_6.pdf
-------------------------
京速計算機システム開発事業では、スーパーコンピュータの開発のみにとどめず、
COEとして、世界の英知を結集し、最高の英知による最上の教育研究を通じた
準の人材育成を継続することが重要である。
-------------------------
つまり,次世代スーパーコンピュータのハードウェア開発を行うことが日米共に前提となっている
すけど,その次の段階として
米国: 利用の裾野が広くなるようなシステムを整備する
日本: 難しい計算機を利用できる人材を育成する
と,別々の道を選んでいるように見えるす。
で,これ何処のグラマンと零戦の比較かと(笑)
http://www.mext.go.jp/b_menu/shingi/gijyutu/gijyutu2/shiryo/007/05092001/004_2/004_2_6.pdf
-------------------------
京速計算機システム開発事業では、スーパーコンピュータの開発のみにとどめず、
COEとして、世界の英知を結集し、最高の英知による最上の教育研究を通じた
準の人材育成を継続することが重要である。
-------------------------
つまり,次世代スーパーコンピュータのハードウェア開発を行うことが日米共に前提となっている
すけど,その次の段階として
米国: 利用の裾野が広くなるようなシステムを整備する
日本: 難しい計算機を利用できる人材を育成する
と,別々の道を選んでいるように見えるす。
で,これ何処のグラマンと零戦の比較かと(笑)
汎用京速計算機はNとFとHのための公共事業
>>763
IPC向上するしw後藤が挙げた論文ぐらい嫁とwww
IPC向上するしw後藤が挙げた論文ぐらい嫁とwww
まあ、それで今まで食ってきた人間もいて、しかも莫大な人数を
今更何もさせないわけにはいかないから公費で食わせてやるかってところだねぇ
今更何もさせないわけにはいかないから公費で食わせてやるかってところだねぇ
>>763
レイテンシ不定の命令(ロードくらいしかないけど)がある限り、OoOは有効。定量的にはシラネ。
レイテンシ不定の命令(ロードくらいしかないけど)がある限り、OoOは有効。定量的にはシラネ。
>>765
だがしかし、
CellはDSP付きCPUみたいなものなんだから、
それに相応しいコードを書かないと、
本領を発揮できないのは当たり前でしょう。
不適切なコードで、遅い! と叩くのは良くない。
だがしかし、
CellはDSP付きCPUみたいなものなんだから、
それに相応しいコードを書かないと、
本領を発揮できないのは当たり前でしょう。
不適切なコードで、遅い! と叩くのは良くない。
>>766
なぜ?
作業分担はコードの書き直しになるから、えらく大変なのは当たり前ですが。
>>770
具体的にURLをお願いします。
>>773
EPICではロードを投機的に行ってレイテンシを隠蔽するようなコードをコンパイラが出力することが前提かと。
パーフェクトに決まることはないので漏れる部分は出てくるけれども、
それを拾うためにOoOを入れるくらいなら、IPCを落してコア数を増やしたほうマシ。
なぜ?
作業分担はコードの書き直しになるから、えらく大変なのは当たり前ですが。
>>770
具体的にURLをお願いします。
>>773
EPICではロードを投機的に行ってレイテンシを隠蔽するようなコードをコンパイラが出力することが前提かと。
パーフェクトに決まることはないので漏れる部分は出てくるけれども、
それを拾うためにOoOを入れるくらいなら、IPCを落してコア数を増やしたほうマシ。
そんな夢を見ていたことが俺にもありました
>>775
EPICの投機的メモリアクセスはページフォールト除けのためのものだよ。
キャッシュミス時のレイテンシー隠蔽とは全然関係ないの。
> それを拾うためにOoOを入れるくらいなら、IPCを落してコア数を増やしたほうマシ。
どっちがマシという議論をしているのでもないね。
EPICの投機的メモリアクセスはページフォールト除けのためのものだよ。
キャッシュミス時のレイテンシー隠蔽とは全然関係ないの。
> それを拾うためにOoOを入れるくらいなら、IPCを落してコア数を増やしたほうマシ。
どっちがマシという議論をしているのでもないね。
780 :MACオタ>779 さん:2006/12/09(土) 22:43:19 ID:/0zHaCgA
>>779
IPFのOoOEの話で,一番有名な論文わ,ITJのこれだと思うすけど。。。
ftp://download.intel.com/technology/itj/2002/volume06issue01/art03_specprecomp/vol6iss1_art03.pdf
IPFのOoOEの話で,一番有名な論文わ,ITJのこれだと思うすけど。。。
ftp://download.intel.com/technology/itj/2002/volume06issue01/art03_specprecomp/vol6iss1_art03.pdf
>>779-780
ありがとう。
OOOで更に速くなるのか・・・
L1やL2キャッシュミスを隠蔽するのならld.a等の命令をバンバン使えばいいと思っていたけど、
それだと、それらに命令数を食ってしまうので、OOOのほうが性能が出るということなのかな。
>>777
自動的にハードウェアが処理するのではなく、
明示的にld.a命令などを使う話なのですが・・・。
ありがとう。
OOOで更に速くなるのか・・・
L1やL2キャッシュミスを隠蔽するのならld.a等の命令をバンバン使えばいいと思っていたけど、
それだと、それらに命令数を食ってしまうので、OOOのほうが性能が出るということなのかな。
>>777
自動的にハードウェアが処理するのではなく、
明示的にld.a命令などを使う話なのですが・・・。
IDがNECだ。可変長RISCマンセー。
>>784
オレの言ってること間違ってるか?
オレの言ってること間違ってるか?
>>785
GJ!
GJ!
>>786
間違っている以前に流れを読んでないだろ。
フェッチもしていなのにメインスレッドと同じことを予測だけでやるなんて、
物理的に不可能だから、考えても全く意味が無い。
また、プリフェッチなんて不要なデータがロードされて当たり前で
たいした容量の無駄にはならなくて効果もあるから、実際普及している。
間違っている以前に流れを読んでないだろ。
フェッチもしていなのにメインスレッドと同じことを予測だけでやるなんて、
物理的に不可能だから、考えても全く意味が無い。
また、プリフェッチなんて不要なデータがロードされて当たり前で
たいした容量の無駄にはならなくて効果もあるから、実際普及している。
書いてなくても既知の情報から十分推論できるやん。
分岐先両方を処理するスカウトスレッドより、メインで
必要な処理しかしないほうが追いつく。
はしょれば、現行のプリフェッチをたんに沢山とるだけになる。
分岐先両方を処理するスカウトスレッドより、メインで
必要な処理しかしないほうが追いつく。
はしょれば、現行のプリフェッチをたんに沢山とるだけになる。
Scout Threadingという命名があれだ
そもそも、MACヲタの出した論文はストライドとマルコフプリフェッチの評価しかしとらんのじゃヽ(`д´)ノ
793 :MACオタ>792 さん:2006/12/10(日) 13:01:01 ID:tBphQQgW
>>792
-----------------
ストライドとマルコフプリフェッチの評価しかしとらんのじゃヽ(`д´)ノ
-----------------
どうやってもプリフェッチわ,プリフェッチなんすけど。。。
-----------------
ストライドとマルコフプリフェッチの評価しかしとらんのじゃヽ(`д´)ノ
-----------------
どうやってもプリフェッチわ,プリフェッチなんすけど。。。
おいMACオタ、嘘をつくならせめて自分の出してきた論文くらい呼んでからにしろ。
POWER6なんてベーパーウェア(ソフトじゃないが)みたいなもんじゃないの?
マジックじゃないんだから同世代とこれだけかけ離れた性能のプロセッサを
出す出すと必死に訴えても説得力に欠ける。
マジックじゃないんだから同世代とこれだけかけ離れた性能のプロセッサを
出す出すと必死に訴えても説得力に欠ける。
796 :MACオタ>794 さん:2006/12/10(日) 22:02:24 ID:tBphQQgW
>>794
--------------------
嘘をつくならせめて自分の出してきた論文くらい呼んでからにしろ。
--------------------
誹謗さんわ,いつも元気すね(笑) 3章の "Performance metrics"の章を読んで,プリフェッチに
関する基礎理論を理解してから,結論だけでも読むと良いかと思うす。
「完全」プリフェッチ効率における基本的な問題わ結論でこう述べられれているす。
====================
With perfect coverage and accuracy, sufficient timeliness, ample bandwidth, and
sufficient buffering, prefetching can eliminate (almost) all delay caused by
cache misses. Interestingly, when portions of this delay are eliminated, a superscalar
processor runs farther down speculative paths and generates new misses. This effect is
not major, but in principle it prevents prefetching from eliminating all misses.
====================
--------------------
嘘をつくならせめて自分の出してきた論文くらい呼んでからにしろ。
--------------------
誹謗さんわ,いつも元気すね(笑) 3章の "Performance metrics"の章を読んで,プリフェッチに
関する基礎理論を理解してから,結論だけでも読むと良いかと思うす。
「完全」プリフェッチ効率における基本的な問題わ結論でこう述べられれているす。
====================
With perfect coverage and accuracy, sufficient timeliness, ample bandwidth, and
sufficient buffering, prefetching can eliminate (almost) all delay caused by
cache misses. Interestingly, when portions of this delay are eliminated, a superscalar
processor runs farther down speculative paths and generates new misses. This effect is
not major, but in principle it prevents prefetching from eliminating all misses.
====================
798 :MACオタ>795 さん:2006/12/11(月) 00:50:10 ID:aycpmdpf
>>795
------------------
POWER6なんてベーパーウェア(ソフトじゃないが)みたいなもんじゃないの?
------------------
このクラスのプロセッサわ,チップが動くようになってからバリデーションに要する期間が長いす。
動作するチップを学会で発表してる代物に「ベイパー(ハード)ウェア」呼ばわりわ,あなたの頭の
中身の方が疑われるかと思うす。また,5GHzというクロックを聞いて2GHzのPOWER5+の2倍以上
の性能と思い込むのも,単純すぎるかと。。。
------------------
POWER6なんてベーパーウェア(ソフトじゃないが)みたいなもんじゃないの?
------------------
このクラスのプロセッサわ,チップが動くようになってからバリデーションに要する期間が長いす。
動作するチップを学会で発表してる代物に「ベイパー(ハード)ウェア」呼ばわりわ,あなたの頭の
中身の方が疑われるかと思うす。また,5GHzというクロックを聞いて2GHzのPOWER5+の2倍以上
の性能と思い込むのも,単純すぎるかと。。。
POWER5+のほぼ2倍の性能ってIBMの人が言ってたんじゃなかったっけ?
>>796
阿呆かお前は。
「完璧なプリフェッチをしてキャッシュミスでストールしなくなったとすると、その分先まで投機的実行できるようになって新たなミスを起こす。
これは大した影響はないが、原理的にはキャッシュミスを完全になくすことはできない。」
ということを書いとるんじゃ。
> "Scout Threading"わ興味深いすけど,この方面でわ頑張ったところでコアに追いつかれてしまう
> という分析わ有るす。
こんな分析はどこにもない。
阿呆かお前は。
「完璧なプリフェッチをしてキャッシュミスでストールしなくなったとすると、その分先まで投機的実行できるようになって新たなミスを起こす。
これは大した影響はないが、原理的にはキャッシュミスを完全になくすことはできない。」
ということを書いとるんじゃ。
> "Scout Threading"わ興味深いすけど,この方面でわ頑張ったところでコアに追いつかれてしまう
> という分析わ有るす。
こんな分析はどこにもない。
801 :MACオタ>799 さん:2006/12/11(月) 01:07:15 ID:aycpmdpf
>>799
----------------------
POWER5+のほぼ2倍の性能ってIBMの人が言ってたんじゃなかったっけ?
----------------------
たとえば,こういう記事すか?
http://news.zdnet.com/2100-9584_22-6124451.html
======================
Each core can simultaneously handle two instruction sequences, called "threads."
The performance of the second thread is about 55 percent of the first on database
transaction tasks, McCredie said, which is about double the performance of the second
thread on Power5.
======================
SMTの効率の話題で,シングルスレッドの性能の話じゃ無いす。
----------------------
POWER5+のほぼ2倍の性能ってIBMの人が言ってたんじゃなかったっけ?
----------------------
たとえば,こういう記事すか?
http://news.zdnet.com/2100-9584_22-6124451.html
======================
Each core can simultaneously handle two instruction sequences, called "threads."
The performance of the second thread is about 55 percent of the first on database
transaction tasks, McCredie said, which is about double the performance of the second
thread on Power5.
======================
SMTの効率の話題で,シングルスレッドの性能の話じゃ無いす。
802 :MACオタ>800 さん:2006/12/11(月) 01:09:44 ID:aycpmdpf
SPARC64は全然駄目だとして、わずかでも対抗できそうなMontvaleの詳細が出てこないなあ。
↓Itanium信者の妄想
MontvaleはMCMの4コア + Foxtonで性能2倍。
↓現実路線で妄想
Foxton等でプロセッサ単体の性能を20%程度向上させて128S/256C/512TのSuperdomeで性能2倍。
/* ミッドレンジやローエンドでもIntelからItaniumを買い叩いて軒並み値下げしてC/Pで勝負する。
Montecitoが遅延している時と同じ商法w */
↓Itanium信者の妄想
MontvaleはMCMの4コア + Foxtonで性能2倍。
↓現実路線で妄想
Foxton等でプロセッサ単体の性能を20%程度向上させて128S/256C/512TのSuperdomeで性能2倍。
/* ミッドレンジやローエンドでもIntelからItaniumを買い叩いて軒並み値下げしてC/Pで勝負する。
Montecitoが遅延している時と同じ商法w */
件の論文は、いかなるプリフェッチも云々という書き方をしているが、
実際の内容はストライドやマルコフを拡大して理想値で検証しただけ。
Scout Threadは詳細不明だけど投機スレッドのやつは、従来のHW/SWプリフェッチとはまるで違う。
実際の内容はストライドやマルコフを拡大して理想値で検証しただけ。
Scout Threadは詳細不明だけど投機スレッドのやつは、従来のHW/SWプリフェッチとはまるで違う。
ID変わってるけど799です
>>801
いやそんな細かい話じゃなくて…
いろいろ読み返してみたけど、パイプライン段数変えずにクロックが倍
メモリのバンド幅も倍、とは書いてあったけど、確かに性能が倍とは
どこにも書いてなかったわ、すまそ
>>801
いやそんな細かい話じゃなくて…
いろいろ読み返してみたけど、パイプライン段数変えずにクロックが倍
メモリのバンド幅も倍、とは書いてあったけど、確かに性能が倍とは
どこにも書いてなかったわ、すまそ
富士通「SPARC64 VI」マイクロプロセサの動作 - Fall MPF 2006より
ttp://journal.mycom.co.jp/articles/2006/12/11/sparc64/
ttp://journal.mycom.co.jp/articles/2006/12/11/sparc64/
論文の読み方を知らないバカはこれだから困るぜ。
MACオタの引用した部分は
「理想的なプリフェッチヤーならプロセッサの性能をほぼ100%引き出せる。どんなに頑張っても75%とかいうことはないので安心しる。」
という意味だ。
MACオタの理解とは正反対なんだよ。
MACオタの引用した部分は
「理想的なプリフェッチヤーならプロセッサの性能をほぼ100%引き出せる。どんなに頑張っても75%とかいうことはないので安心しる。」
という意味だ。
MACオタの理解とは正反対なんだよ。
ここにも貼っとこ
ttp://grape.astron.s.u-tokyo.ac.jp/~makino/journal/journal-2006-12.html#9
> でも、 Rock とか早く止めて Niagara に資源投入したほうがいいと思う。
ttp://grape.astron.s.u-tokyo.ac.jp/~makino/journal/journal-2006-12.html#9
> でも、 Rock とか早く止めて Niagara に資源投入したほうがいいと思う。
MACオタは相手にする意味なしと歴史的に証明されているんだから
いい加減 kill file 送りにしとけって
いい加減 kill file 送りにしとけって
>>810
AMDの次世代スレに現れると信者の反応が面白いのでオススメ
AMDの次世代スレに現れると信者の反応が面白いのでオススメ
POWER6って、SPECintとかSPECfpの値は公表されてる?
【IEDM】IBMが65nm世代のSOI用混載DRAM,「プロセサに大容量キャッシュ必要」
ttp://techon.nikkeibp.co.jp/article/NEWS/20061214/125415/
ttp://techon.nikkeibp.co.jp/article/NEWS/20061214/125415/
WikipediaのPS3に関する記述なんだけど、
>2 TFLOPS(システム全体の理論値)という、スーパーコンピュータ並の浮動小数点演算性能を持つ。
これおかしくね?
http://ja.wikipedia.org/wiki/PLAYSTATION3
>2 TFLOPS(システム全体の理論値)という、スーパーコンピュータ並の浮動小数点演算性能を持つ。
これおかしくね?
http://ja.wikipedia.org/wiki/PLAYSTATION3
くそしてねろ
クーソーしてから寝てください
頭の中をディグダグのテーマが駆け巡った
それだと、RSXが1.8TFLOPSぐらいか…。
Wikipediaの記事にもそう書いてあるな。
http://ja.wikipedia.org/wiki/PLAYSTATION3#GPU
しかし、GeForce8800が500GFLOPS程度だろ?
RSXが1.8TFLOPSってのはおかしくね?
Wikipediaの記事にもそう書いてあるな。
http://ja.wikipedia.org/wiki/PLAYSTATION3#GPU
しかし、GeForce8800が500GFLOPS程度だろ?
RSXが1.8TFLOPSってのはおかしくね?
本来は加味しない固定機能も加味しとる。
まぁ中国人の言う事は1/10、SONYの言う事は1/3位に受け取っとけば丁度良いしょ。
メタルラッカーの日記
昨日の外部評価で評価委員の某氏(スーパーコンピュータに関する著作も あるジャーナリスト、って殆ど特定されてますね)が、 CELL のことを2Tflops の能力でどうこうとコメントしていた。
こういうアレな話をジャーナリストに 吹き込むのは勘弁して欲しい。
CELL は 3.2MHz なら 218 Gflops しかなくて、 RSX とかいう GPU のほうをなんかインチキな方法で浮動小数点演算能力に換 算すれば 1.8 Tflops になるというだけである。
RSX は GeForce 6800 と7800 中間くらいらしい(詳細不明)。
6800 を GPGPU に使ったら 100Gflops なんて まずでないわけで、RSX だって大して変わらんだろう、というか 8800 に比べ て数倍遅いことは間違いない。
8800 で300Gflops を超えるのは限りなく不 可能に近いわけで、、、
まあ、GRAPE-6 で 1 チップ 32 Gflops といってるのに比べてどっちが アレかというと難しいかもしれないけど、 GeForce 7800 と同等以下の GPU をのっけただけで 1.8Tflops だと言われたらそれは 100% アレであろう。
ま あ、 MS が Xbox 360 で同じようにアレな計算で 1Tflops といってたから対抗上、と いうのはあるんだと思うけど。
京速で最初は汎用 1 P、準汎用 10P とかいっていたのもしかしいろんな 人にはこういう CELL というか PS3 が 2Tflops というのなみにいい加減な話 と思われたんだろうな。
せいぜい 8800 で 300Gflops、というくらいの話だか ら、 PS3 で 2Tflops とかいうのに比べたら 10倍くらいアレ具合は低い。
さ らにいうと、準汎用 10Pは、倍精度で、という話だからもう 4-5倍はアレでな いわけで、PS3 が 2Tflops という主張に比べると大体 50倍くらいアレ程度が低 い。
昨日の外部評価で評価委員の某氏(スーパーコンピュータに関する著作も あるジャーナリスト、って殆ど特定されてますね)が、 CELL のことを2Tflops の能力でどうこうとコメントしていた。
こういうアレな話をジャーナリストに 吹き込むのは勘弁して欲しい。
CELL は 3.2MHz なら 218 Gflops しかなくて、 RSX とかいう GPU のほうをなんかインチキな方法で浮動小数点演算能力に換 算すれば 1.8 Tflops になるというだけである。
RSX は GeForce 6800 と7800 中間くらいらしい(詳細不明)。
6800 を GPGPU に使ったら 100Gflops なんて まずでないわけで、RSX だって大して変わらんだろう、というか 8800 に比べ て数倍遅いことは間違いない。
8800 で300Gflops を超えるのは限りなく不 可能に近いわけで、、、
まあ、GRAPE-6 で 1 チップ 32 Gflops といってるのに比べてどっちが アレかというと難しいかもしれないけど、 GeForce 7800 と同等以下の GPU をのっけただけで 1.8Tflops だと言われたらそれは 100% アレであろう。
ま あ、 MS が Xbox 360 で同じようにアレな計算で 1Tflops といってたから対抗上、と いうのはあるんだと思うけど。
京速で最初は汎用 1 P、準汎用 10P とかいっていたのもしかしいろんな 人にはこういう CELL というか PS3 が 2Tflops というのなみにいい加減な話 と思われたんだろうな。
せいぜい 8800 で 300Gflops、というくらいの話だか ら、 PS3 で 2Tflops とかいうのに比べたら 10倍くらいアレ具合は低い。
さ らにいうと、準汎用 10Pは、倍精度で、という話だからもう 4-5倍はアレでな いわけで、PS3 が 2Tflops という主張に比べると大体 50倍くらいアレ程度が低 い。
>>814
>これおかしくね?
システム全体の「理論値」だから全然問題なし。
オーバーヘッドがゼロという
現実のシステムでは絶対有り得ない想定での
ソニー得意のお花畑スペックにあれこれ言ってもしょうがない。
>これおかしくね?
システム全体の「理論値」だから全然問題なし。
オーバーヘッドがゼロという
現実のシステムでは絶対有り得ない想定での
ソニー得意のお花畑スペックにあれこれ言ってもしょうがない。
>>821
甘い。PS関係についてはSONYの言う数字は実効の1/10だよ
甘い。PS関係についてはSONYの言う数字は実効の1/10だよ
10倍だ
flops、int自体に意味がないような気がする
演算の種類は全く考えていないんでしょ?
演算の種類は全く考えていないんでしょ?
>>826
ごめん、intじゃなくてMIPS
ごめん、intじゃなくてMIPS
だいたい理論値そのものが、インテルだろうがソニーだろうが
現実ではありえないお花畑スペックなんだから、ソニーについてだけ
ぐだぐだ言うのも妙な話
でも実地の性能を言い出したら、AMDとインテルでさえ得意不得意が
それぞれあるし、ましてcellみたいにまるっきり違えばソフトからして
まるっきり別物なので、ソフトとセットでしか比較しようがないわけで
所詮それも「ベンチでだけ」みたいに言われるものでしかない
というわけで俺基準は「おもしろそうなほうの勝ち」
現実ではありえないお花畑スペックなんだから、ソニーについてだけ
ぐだぐだ言うのも妙な話
でも実地の性能を言い出したら、AMDとインテルでさえ得意不得意が
それぞれあるし、ましてcellみたいにまるっきり違えばソフトからして
まるっきり別物なので、ソフトとセットでしか比較しようがないわけで
所詮それも「ベンチでだけ」みたいに言われるものでしかない
というわけで俺基準は「おもしろそうなほうの勝ち」
829 :Socket774:2006/12/16(土) 12:23:20 ID:yzhStzXx
>>828
>だいたい理論値そのものが、インテルだろうがソニーだろうが
>現実ではありえないお花畑スペックなんだから、ソニーについてだけ
>ぐだぐだ言うのも妙な話
つ[程度問題]
メタルラッカーの言うところの「アレ程度」の大小の問題だよ。
ソニーの2TFLOPSってのは「アレ程度」が抜群に高い。
>だいたい理論値そのものが、インテルだろうがソニーだろうが
>現実ではありえないお花畑スペックなんだから、ソニーについてだけ
>ぐだぐだ言うのも妙な話
つ[程度問題]
メタルラッカーの言うところの「アレ程度」の大小の問題だよ。
ソニーの2TFLOPSってのは「アレ程度」が抜群に高い。
sony が言ってるわけじゃないっしょ?
アレな太鼓持ち(?)かもしれんが
アレな太鼓持ち(?)かもしれんが
ここ注目すべきだと思うすけど。。。
>>822
---------------------
ま あ、 MS が Xbox 360 で同じようにアレな計算で 1Tflops といってたから対抗上、と
いうのはあるんだと思うけど。
---------------------
次世代ゲームコンソールでこの計算法によるFUDを仕掛けてのわ,本家本元Microsoftす(笑)
http://www.watch.impress.co.jp/game/docs/20050513/xbox2.htm
=====================
浮動小数点演算性能(システム全体) 1T FLOPS
=====================
>>822
---------------------
ま あ、 MS が Xbox 360 で同じようにアレな計算で 1Tflops といってたから対抗上、と
いうのはあるんだと思うけど。
---------------------
次世代ゲームコンソールでこの計算法によるFUDを仕掛けてのわ,本家本元Microsoftす(笑)
http://www.watch.impress.co.jp/game/docs/20050513/xbox2.htm
=====================
浮動小数点演算性能(システム全体) 1T FLOPS
=====================
その数日後のSCEの発表わ,MS互換の性能表記になった。。。という事情す。
http://www.watch.impress.co.jp/game/docs/20050517/sce1.htm
--------------
浮動小数点演算性能 2 TFLOPS
--------------
http://www.watch.impress.co.jp/game/docs/20050517/sce1.htm
--------------
浮動小数点演算性能 2 TFLOPS
--------------
まあゲーム機のマーケティングなんてそんなものだよな。
ドリキャスを128bitと称したのに比べれば、まだしも一片の真実は
あると言えなくもない。
おお珍しくMACオタと意見が一致。(w
ドリキャスを128bitと称したのに比べれば、まだしも一片の真実は
あると言えなくもない。
おお珍しくMACオタと意見が一致。(w
835 :Socket774:2006/12/16(土) 14:59:30 ID:yzhStzXx
SSE性能がすげえ強化されるってのは、いつの世代から? Nehalem?
836 :・∀・)っ-○◎●創聖のダンゴリオン ◆DanGorION6 :2006/12/16(土) 15:01:10 ID:gqZ7c7f6
Core 2 Duoですでにすげー強化なんですが
dual core で 128bit級!
>>834
さすがだなw
さすがだなw
839 :・∀・)っ-○◎●創聖のダンゴリオン ◆DanGorION6 :2006/12/16(土) 15:09:10 ID:gqZ7c7f6
>>834
PS3ですらいまだ実現してない美しい映像表現だな
PS3ですらいまだ実現してない美しい映像表現だな
>>835
SSE4が出る4コアからじゃないか?
SSE4が出る4コアからじゃないか?
841 :Socket774:2006/12/16(土) 16:01:21 ID:9WruzT7F
ゲハ板のCellスレ
完全に終戦状態ワロス
完全に終戦状態ワロス
843 :・∀・)っ-○◎●創聖のダンゴリオン ◆DanGorION6 :2006/12/16(土) 16:43:28 ID:gqZ7c7f6
>>826
考えていない。
考えていない。
>>834
PS2がまだ現役なことを考えれば十分な性能だと思われ。
PS2がまだ現役なことを考えれば十分な性能だと思われ。
848 :Socket774:2006/12/17(日) 00:07:04 ID:GaeVaEVr
でもゲームキューブの方が性能高いんだよね?
なんの性能?
顔だけえんえんと映してるゲームってのも想像すると怖いな
>>828
そもそも「理論値」という名称が変だ。
理論上これだけの性能を出すことはできる、というのならいいけれど、
理論上、出せるかどうか定かでない値を「理論値」として掲げるのはどうかと。
たとえば、PCIバスのデータ転送速度の理論値は133Mバイト/sec、なんて平然と言う人がいる。
PCIバスはアドレスとデータがマルチプレクスになっているし、その他にもクロックを消費するものがある。
だから理論上の上限は133Mバイト/secよりも低くなるはずだけれども、そういう値を見たことがない。
ところで、NECがPCI Expressのパケットをイーサネットフレームに載せる代物を出したね。
これはPCクラスタ計算機に使える代物なのだろうか。
そもそも「理論値」という名称が変だ。
理論上これだけの性能を出すことはできる、というのならいいけれど、
理論上、出せるかどうか定かでない値を「理論値」として掲げるのはどうかと。
たとえば、PCIバスのデータ転送速度の理論値は133Mバイト/sec、なんて平然と言う人がいる。
PCIバスはアドレスとデータがマルチプレクスになっているし、その他にもクロックを消費するものがある。
だから理論上の上限は133Mバイト/secよりも低くなるはずだけれども、そういう値を見たことがない。
ところで、NECがPCI Expressのパケットをイーサネットフレームに載せる代物を出したね。
これはPCクラスタ計算機に使える代物なのだろうか。
>>853
> 理論上、出せるかどうか定かでない値を「理論値」として掲げるのはどうかと。
理論上それ以上出せない数値だからそれでいいんじゃない。
> たとえば、PCIバスのデータ転送速度の理論値は133Mバイト/sec、なんて平然と言う人がいる。
そういう時ってただ単に「転送速度」っていわない?
「データ転送速度」ではなく、ただ単に「転送速度」なら正しいわけよ。
アドレスやらコマンドやらを含んだ「転送速度」だからね。
> 理論上、出せるかどうか定かでない値を「理論値」として掲げるのはどうかと。
理論上それ以上出せない数値だからそれでいいんじゃない。
> たとえば、PCIバスのデータ転送速度の理論値は133Mバイト/sec、なんて平然と言う人がいる。
そういう時ってただ単に「転送速度」っていわない?
「データ転送速度」ではなく、ただ単に「転送速度」なら正しいわけよ。
アドレスやらコマンドやらを含んだ「転送速度」だからね。
>853
ま、そのへんは習慣もあるしね。「理論値」ならあれでいいと思うよ
比較的>853の言い分に近いのは「実効性能」じゃないかなあ。
いい悪いじゃなく言葉の定義の問題だと思う。
ま、そのへんは習慣もあるしね。「理論値」ならあれでいいと思うよ
比較的>853の言い分に近いのは「実効性能」じゃないかなあ。
いい悪いじゃなく言葉の定義の問題だと思う。
紛らわしいからTop500にあやかってRmaxとRpeakで語ろうぜw
HansRapidsの32bitPCIは125MB/sぐらいまで出るよ、とスペックシートか何かに書いてあったな
>>853
PCI specification rev2.2には3.5にlatencyってな章があるのだが。
3.5.4.1. Bandwidth and Latency Considerationsだと、
合計クロック数は8+(転送ワード数-1)+1(この1はバス転送切り替えのアイドルタイム)になる、とある。
この式から、クロック速度と最大転送ワード数が与えられればバス帯域幅は計算できるよと。
PCI specification rev2.2には3.5にlatencyってな章があるのだが。
3.5.4.1. Bandwidth and Latency Considerationsだと、
合計クロック数は8+(転送ワード数-1)+1(この1はバス転送切り替えのアイドルタイム)になる、とある。
この式から、クロック速度と最大転送ワード数が与えられればバス帯域幅は計算できるよと。
ウェディングピーチは、とってもご機嫌ななめだわ!
理論的じゃないよ
メーカーのハード設計者が
お為ごかしで大仰に理論なんて言うから
勘違いする人が出てくる
メーカーのハード設計者が
お為ごかしで大仰に理論なんて言うから
勘違いする人が出てくる
>853-854
瞬間最大転送速度(バースト転送中の、データ転送期間だけ取り出した値)
なんだから、「瞬間最大値」がいいんじゃないの?
瞬間最大転送速度(バースト転送中の、データ転送期間だけ取り出した値)
なんだから、「瞬間最大値」がいいんじゃないの?
864 :・∀・)っ-○◎●創聖のダンゴリオン ◆DanGorION6 :2006/12/19(火) 01:18:55 ID:8Ss4I3HN
「理想値」でおk
うむ
866 :Socket774:2006/12/20(水) 02:00:28 ID:nRtcXvdZ
Lock-free synchronizationの続きキターage
http://www.nminoru.jp/~nminoru/data/b2con2006_nminoru.pdf
http://www.nminoru.jp/~nminoru/data/b2con2006_nminoru.pdf
>>864
75-56-83
75-56-83
貧乳すぎ
Aカップ好きは卑屈すぎます。自分に自身が無い証拠です。
AAカップこそが最強
サンのSPARCサーバ戦略に疑問の声──2つの新CPUラインが“競合”するおそれも
http://www.computerworld.jp/news/hw/54971.html
http://www.computerworld.jp/news/hw/54971.html
AMD opens next-gen chip tech think-tank
http://www.reghardware.co.uk/2006/12/22/amd_opens_chip_tech_lab/
よくわからんが元DECの人?
http://www.reghardware.co.uk/2006/12/22/amd_opens_chip_tech_lab/
よくわからんが元DECの人?
>>874
AMDがAlchemyを買収したときのプレスリリースです
ttp://www.amd.com/jp-ja/Corporate/VirtualPressRoom/0,,51_104_543_8001~43508,00.html
> Witek氏はDigital Equipment Corporationにおいて、Alphaの共同設計者(アーキテクト)および
> StrongARMのアーキテクトを務めました。
AMDがAlchemyを買収したときのプレスリリースです
ttp://www.amd.com/jp-ja/Corporate/VirtualPressRoom/0,,51_104_543_8001~43508,00.html
> Witek氏はDigital Equipment Corporationにおいて、Alphaの共同設計者(アーキテクト)および
> StrongARMのアーキテクトを務めました。
なるほど
だからintel互換劣化CPUの前身から急に化けたのか
(正確にはintelに頼まれて互換CPUをチップメーカーであるAMDが請け負ってた)
Alpha好きだったからそれだけでAMDに好印象
(正確にはintelに頼まれて互換CPUをチップメーカーであるAMDが請け負ってた)
Alpha好きだったからそれだけでAMDに好印象
DECのエンジニアほとんど全部と特許全部はIntelが
>>877
違うよ。
インテルのセカンドソース(インテル設計、AMD製造)
↓
インテルの互換CPU(AMD設計)
↓
NexGen買収により、インテルとソケット互換でより高性能なCPU(実質NexGen設計)
↓
DEC出身者を引き込むことで、インテルとソケット非互換でより高性能なCPU
違うよ。
インテルのセカンドソース(インテル設計、AMD製造)
↓
インテルの互換CPU(AMD設計)
↓
NexGen買収により、インテルとソケット互換でより高性能なCPU(実質NexGen設計)
↓
DEC出身者を引き込むことで、インテルとソケット非互換でより高性能なCPU
最後の行だけ、時系列が無茶苦茶。
2002年に引き抜いた技術者たちが作った?
インテルとソケット非互換の旧Athlonは99年頃出たんじゃなかったか。
2000年にはPenIIIとのクロック競争が激しかった。
Athlon64だって、開発開始は99年以前まで遡るしな。
2002年に引き抜いた技術者たちが作った?
インテルとソケット非互換の旧Athlonは99年頃出たんじゃなかったか。
2000年にはPenIIIとのクロック競争が激しかった。
Athlon64だって、開発開始は99年以前まで遡るしな。
>>881
大体あってるけどすこし違うように感じる
アーキテクチャ自体変更に5年掛かるといわれてるが小変更は2年程度
2002年に引き抜いた奴がアーキテクチャ作ってロールアウトするとしたらしたら2007年から
小変更したのがathlon64でAlphaの息吹がはいってるんじゃないかというお話
今のconroeの元のPENMも元を正せばPEN3のファミリーネーム6
つまりは小変更にしか過ぎない
ネトバ系アーキは一旦封印されたのかね
ということは2007年のAMDのCPUはすごいことになるんじゃないか?
大体あってるけどすこし違うように感じる
アーキテクチャ自体変更に5年掛かるといわれてるが小変更は2年程度
2002年に引き抜いた奴がアーキテクチャ作ってロールアウトするとしたらしたら2007年から
小変更したのがathlon64でAlphaの息吹がはいってるんじゃないかというお話
今のconroeの元のPENMも元を正せばPEN3のファミリーネーム6
つまりは小変更にしか過ぎない
ネトバ系アーキは一旦封印されたのかね
ということは2007年のAMDのCPUはすごいことになるんじゃないか?
Netburstってこのまま闇に葬り去られるの?
それともNehalemで復活とか?
それともNehalemで復活とか?
なんだこのレベルの低さ…
http://pc.watch.impress.co.jp/docs/2003/0912/kaigai022.htm
ということで、881が間違い。
俺も名前までは覚えてなかったけど、K7のアーキテクトが旧DEC出身で、Alphaのアーキテクトだったってのは、
有名な話だと思うが。
ということで、881が間違い。
俺も名前までは覚えてなかったけど、K7のアーキテクトが旧DEC出身で、Alphaのアーキテクトだったってのは、
有名な話だと思うが。
>>882
K7のFSBは、DECのAlphaのEVバスを元にしてるよ。
K7のFSBは、DECのAlphaのEVバスを元にしてるよ。
AMD、社長 兼 最高執行責任者(COO)にダーク・マイヤーを任命
ttp://www.amd.com/jp-ja/Corporate/VirtualPressRoom/0,,51_104_543~104601,00.html
> マイヤー(44歳)は1995年にAMDに入社し、1996年にはテキサス州オースティンでAMD
>Athlon(TM)マイクロプロセッサ開発プログラムのエンジニアリング・ディレクタに昇進しました。
> AMDに入社する以前はDigital Equipment Corporationに約10年間勤務し、Alpha 21064
> および21264マイクロプロセッサの設計に携わりました。
ttp://www.amd.com/jp-ja/Corporate/VirtualPressRoom/0,,51_104_543~104601,00.html
> マイヤー(44歳)は1995年にAMDに入社し、1996年にはテキサス州オースティンでAMD
>Athlon(TM)マイクロプロセッサ開発プログラムのエンジニアリング・ディレクタに昇進しました。
> AMDに入社する以前はDigital Equipment Corporationに約10年間勤務し、Alpha 21064
> および21264マイクロプロセッサの設計に携わりました。
889 :Socket774:2006/12/26(火) 19:54:49 ID:GyL21tY+
2007年はスゴイ年になるぜ!
なるほど。
つまり、「2002年に引き抜いた」ってのが間違いで(読み間違ったのか、orz)
90年代後半にはすでに参加してたんだな。
96年より以前か?
K7で使ったEV6バスは、(SlotA時代から最後の明日XPまで全部)、
「EVバスを元にしてる」ってか、まだDECが現存してた頃からライセンス受けて使ってただろ
つまり、「2002年に引き抜いた」ってのが間違いで(読み間違ったのか、orz)
90年代後半にはすでに参加してたんだな。
96年より以前か?
K7で使ったEV6バスは、(SlotA時代から最後の明日XPまで全部)、
「EVバスを元にしてる」ってか、まだDECが現存してた頃からライセンス受けて使ってただろ
Rambus Developer Forum Japan 2006 - 基調講演、セッションレポート編
ttp://journal.mycom.co.jp/articles/2006/12/26/rdf1/
Rambus Developer Forum Japan 2006 - XDR DRAM、PCIeの将来など、インタビュー編
ttp://journal.mycom.co.jp/articles/2006/12/26/rdf2/
ttp://journal.mycom.co.jp/articles/2006/12/26/rdf1/
Rambus Developer Forum Japan 2006 - XDR DRAM、PCIeの将来など、インタビュー編
ttp://journal.mycom.co.jp/articles/2006/12/26/rdf2/
>>869
ttp://www.sanspo.com/geino/idol/ya/yamauchi_emiri/yamauchi_emiri.html
チューニング次第でほぼ理想値が出ることがわかった。
もちっと痩せれ。
ttp://www.sanspo.com/geino/idol/ya/yamauchi_emiri/yamauchi_emiri.html
チューニング次第でほぼ理想値が出ることがわかった。
もちっと痩せれ。
896 :Socket774:2007/01/04(木) 16:23:32 ID:YwP5cs4+
age
スーパーコンは米国と互角か?
ttp://journal.mycom.co.jp/articles/2007/01/07/supercomputer/
ttp://journal.mycom.co.jp/articles/2007/01/07/supercomputer/
要約:
死に体の技術にまた無駄金突っ込んでるけど
カミカゼが吹くかもしんないからがんばれば?
死に体の技術にまた無駄金突っ込んでるけど
カミカゼが吹くかもしんないからがんばれば?
結論:
具体的な希望は何一つ無いが大和魂で勝つる
具体的な希望は何一つ無いが大和魂で勝つる
MICRO39 - 最優秀論文に見るアーキテクチャ研究の最前線
ttp://journal.mycom.co.jp/articles/2007/01/08/micro1/
ttp://journal.mycom.co.jp/articles/2007/01/08/micro1/
SPARC64の中の人だから担当は違うけど
いちおうちょっとだけスカラageベクトルsageはなんとなく入ってるのかも?
とか邪推されないように最初に軽く触れといたらよかったのかもね
いちおうちょっとだけスカラageベクトルsageはなんとなく入ってるのかも?
とか邪推されないように最初に軽く触れといたらよかったのかもね
日本語でおk
でもさ,ビジネス的にイイか,理論上で性能的にイイか,という話を混同している気がするのだけど…
昔々ノイマンのコンピュータとチューリング他のコンピュータが争ったのと同じ.
つまり,NECとかが今でも取り組んでいるように/主張しているようにベクトル型にも利点はあるはずだけど
スカラ型というかPOWER,x64,SPARCなんかはサーバにも載っているわけで,安価だから費用対効果は
良いでしょう.石自体が安価で量産できると高価&少量生産と比べて改良も早いと思う.
結果として安価な石の方がビジネス的には有利になっていると.これは共通認識としてOKだと思う.
序盤で日経の記事について以下のようにまとめていて
> この文章を読むと、(中略)日本は米国より優れた技術があり互角以上に戦いを進めているという印象であるが、
> 本当にそうであろうか?
後半部分では自論として以下のように書いている
> 日本のスパコン技術が米国を凌駕する強みがあるとは思われない。
だけど,これってビジネス的な話なんだよね.性能とか技術とか一行も論じてないと思う.
勿論,企業もビジネスでやっているのでビジネス面を論じるのはいいけど,結論だけ「技術」になっているのが変…
昔々ノイマンのコンピュータとチューリング他のコンピュータが争ったのと同じ.
つまり,NECとかが今でも取り組んでいるように/主張しているようにベクトル型にも利点はあるはずだけど
スカラ型というかPOWER,x64,SPARCなんかはサーバにも載っているわけで,安価だから費用対効果は
良いでしょう.石自体が安価で量産できると高価&少量生産と比べて改良も早いと思う.
結果として安価な石の方がビジネス的には有利になっていると.これは共通認識としてOKだと思う.
序盤で日経の記事について以下のようにまとめていて
> この文章を読むと、(中略)日本は米国より優れた技術があり互角以上に戦いを進めているという印象であるが、
> 本当にそうであろうか?
後半部分では自論として以下のように書いている
> 日本のスパコン技術が米国を凌駕する強みがあるとは思われない。
だけど,これってビジネス的な話なんだよね.性能とか技術とか一行も論じてないと思う.
勿論,企業もビジネスでやっているのでビジネス面を論じるのはいいけど,結論だけ「技術」になっているのが変…
まぁねぇ…
単純に順位が欲しいってだけだったら、それこそGrape-DRに補助金全額ぶち込めばとにかくLinpackの1位にはなれそうな気がする訳で…
単純に順位が欲しいってだけだったら、それこそGrape-DRに補助金全額ぶち込めばとにかくLinpackの1位にはなれそうな気がする訳で…
そのGRAPE-DRだって設計はAlchipで製造はTSMCだし…
907 :Socket774:2007/01/13(土) 19:24:00 ID:fxkKOh3R
日経の記事は軍事的に求められるようなトップ性能の話かと思って読み進むと
何故かビジネス上のボリュームの話に摩り替わってる駄目記事。単位欲しけりゃ
書きなおせってかんじw。
何故かビジネス上のボリュームの話に摩り替わってる駄目記事。単位欲しけりゃ
書きなおせってかんじw。
>>907
日経にまともな記事を望むな
日経にまともな記事を望むな
現状でそれはない
価格じゃなく生産コストの話でないの。
>>909
どういうスカラ型とどういうベクタ型を比較しているの?
(ひとつの)スカラレジスタ/演算器と、ベクタレジスタ/演算器では後者の方が
はるかに高コストだからベクトル型のほうが高価。
というのも正しいわけだが。
というか普通はそういう見方をする。
どういうスカラ型とどういうベクタ型を比較しているの?
(ひとつの)スカラレジスタ/演算器と、ベクタレジスタ/演算器では後者の方が
はるかに高コストだからベクトル型のほうが高価。
というのも正しいわけだが。
というか普通はそういう見方をする。
いや性能当たりのコストだろ
>>897
この記事、不快だな。
だっらた一回こっきり作って捨てる
何年も何年も性能欠陥とバグだらけなlinpakが速いだけのハードとシステムソフトで
「本当のスパコンの価値は、それを使って、どれだけ役に立つ研究や開発ができるかにかかっている。」
「各種のアプリケーションプログラムや利用技術の開発が必要」
そんなまね出来るわけないのに。
この記事、不快だな。
だっらた一回こっきり作って捨てる
何年も何年も性能欠陥とバグだらけなlinpakが速いだけのハードとシステムソフトで
「本当のスパコンの価値は、それを使って、どれだけ役に立つ研究や開発ができるかにかかっている。」
「各種のアプリケーションプログラムや利用技術の開発が必要」
そんなまね出来るわけないのに。
♪うっさぎっのだっんす〜
♪行っくっぜっハーリケーン グレートダーッシュ!グレートダーッシュ!
血税つぎ込んで
変なコンピューター作るのは止めて欲しい
事業として自立できなかったメーカーの
糊口をしのぐために大切なお金と時間が浪費されるだけ
税金を払うのが空しくなる
変なコンピューター作るのは止めて欲しい
事業として自立できなかったメーカーの
糊口をしのぐために大切なお金と時間が浪費されるだけ
税金を払うのが空しくなる
生きたお金の使い方を吟味して欲しいね。
精査するためのコンペとかやんないのかな。
やってるけど機能してないのかな。
精査するためのコンペとかやんないのかな。
やってるけど機能してないのかな。
SunのRockのブロック図?が載ってる
Sun cheers two SPARC advances in one week (true)
http://www.theregister.co.uk/2007/01/18/sun_rock_tape/
Sun cheers two SPARC advances in one week (true)
http://www.theregister.co.uk/2007/01/18/sun_rock_tape/
cache missしたらドカンと効率が落ちるんじゃなくて
ブロードに性能が予測可能なarch.は
ブロードに性能が予測可能なarch.は
>>919
安藤さんのコメント
http://www.geocities.jp/andosprocinfo/wadai07/20070120.htm
> ということで,この図の諸元でまともに動くような気がしないのですが,
> The Registerの記者がSunからの情報に基づかないで,上に書いたような
> 詳細な情報が書けるとも思われないので,この矛盾は謎です。
> 唯一,合理的な解釈は,Sunは偽の情報を流して敵を混乱させる
> Dis-Informationやっているということでしょうか?
安藤さんのコメント
http://www.geocities.jp/andosprocinfo/wadai07/20070120.htm
> ということで,この図の諸元でまともに動くような気がしないのですが,
> The Registerの記者がSunからの情報に基づかないで,上に書いたような
> 詳細な情報が書けるとも思われないので,この矛盾は謎です。
> 唯一,合理的な解釈は,Sunは偽の情報を流して敵を混乱させる
> Dis-Informationやっているということでしょうか?
>>910->>913
元の>>904の書き込みをもっかい読んでみてね。
>スカラ型というかPOWER,x64,SPARCなんかはサーバにも載っているわけで,安価だから費用対効果は
>良いでしょう.石自体が安価で量産できると高価&少量生産と比べて改良も早いと思う.
・スカラ型はサーバにも載っていて、安価で費用対効果はよい
・石自体が安価で量産できる
と書いているが、ベクトル機は確かにマシンとしては高価だが、石自体はスカラ型の方が高い。
スカラ型の方が製造技術が最先端であり、dieサイズも大きく、開発コストも大きいのが普通。
数が出ているからさも安いようにに見えるが、PCやサーバの方がチップ技術としては進んでいる。
しかも、同じ理論flopsを達成するには、スカラ型は多数のチップが必要。
安価な石がビジネス的に有利なのではなく、数が出るものが有利が正解。
元の>>904の書き込みをもっかい読んでみてね。
>スカラ型というかPOWER,x64,SPARCなんかはサーバにも載っているわけで,安価だから費用対効果は
>良いでしょう.石自体が安価で量産できると高価&少量生産と比べて改良も早いと思う.
・スカラ型はサーバにも載っていて、安価で費用対効果はよい
・石自体が安価で量産できる
と書いているが、ベクトル機は確かにマシンとしては高価だが、石自体はスカラ型の方が高い。
スカラ型の方が製造技術が最先端であり、dieサイズも大きく、開発コストも大きいのが普通。
数が出ているからさも安いようにに見えるが、PCやサーバの方がチップ技術としては進んでいる。
しかも、同じ理論flopsを達成するには、スカラ型は多数のチップが必要。
安価な石がビジネス的に有利なのではなく、数が出るものが有利が正解。
結局、値段あたりの性能の問題だろ?
数が多く出ているから安くできるという事実を除外して考えることに果たして何の意味があるのか。
プロセスが進んでるのも量産効果のおかげで投資が早く回収できるからだし。
それにベクトル型はメモリ高い。
プロセスが進んでるのも量産効果のおかげで投資が早く回収できるからだし。
それにベクトル型はメモリ高い。
簡単に
価格 = 製造コスト + (開発コスト / 製造個数) + 利益
とすれば、製造コストがスカラ型の方が大きくても、製造個数が多いから
開発コストの項が小さくなって、スカラ型の方が安くなる可能性はあるだろ
逆に、スカラ型の方が高いと結論付ける具体的な数字はあるのか?
価格 = 製造コスト + (開発コスト / 製造個数) + 利益
とすれば、製造コストがスカラ型の方が大きくても、製造個数が多いから
開発コストの項が小さくなって、スカラ型の方が安くなる可能性はあるだろ
逆に、スカラ型の方が高いと結論付ける具体的な数字はあるのか?
まあ、石の価格がどっちの方が高いかなんてどうでもいいんだよな
システムとしての値段が安きゃ、石が高くっても問題ないわけで
システムとしての値段が安きゃ、石が高くっても問題ないわけで
価格という言葉は不適切だったな。
>石自体が安価で量産できると高価&少量生産と比べて改良も早いと思う。
ベクトルプロセッサの方が同等のチップ技術で高flopsを原理的に達成しやすいのは、
大体このスレの住人ならわかると思うけど、実際のチップの販売価格なら、どうだろう?
スパコン用のベクトルチップが単体で売られているわけじゃないし、
スカラ型もXeonとPOWERとじゃまるで違う価格だし、多分比較は無理。
>石自体が安価で量産できると高価&少量生産と比べて改良も早いと思う。
ベクトルプロセッサの方が同等のチップ技術で高flopsを原理的に達成しやすいのは、
大体このスレの住人ならわかると思うけど、実際のチップの販売価格なら、どうだろう?
スパコン用のベクトルチップが単体で売られているわけじゃないし、
スカラ型もXeonとPOWERとじゃまるで違う価格だし、多分比較は無理。
ピーク性能を合わせるだけなら価格で一桁二桁の差が付く
>>921
安藤さんへのコメント???
http://grape.astron.s.u-tokyo.ac.jp/~makino/journal/journal-2007-01.html#19
> なんか、もうちょっと敵の情報は集めてるものかと思ったけど、本当に知らないのか?
安藤さんへのコメント???
http://grape.astron.s.u-tokyo.ac.jp/~makino/journal/journal-2007-01.html#19
> なんか、もうちょっと敵の情報は集めてるものかと思ったけど、本当に知らないのか?
交換日記
富士通はもうIntelに移行だろうし、Sunは孤立無援だな。
UNIXの時代は終わりLinux or Windows + ミドルウェアの時代になる。
(なるというか時代の流れとしてはとっくの昔にそうなってるな。)
UNIXの時代は終わりLinux or Windows + ミドルウェアの時代になる。
(なるというか時代の流れとしてはとっくの昔にそうなってるな。)
peak性能/値段
実効性能/値段
そういう単純化しすぎた数値の比較で
compulerの優劣を決めようとしている限り
いつまで経っても
使いやすくてまともに動き
役に立つ代物は出来ないだろうな
そのcomputer使って何成し遂げようとしていますか?
単純なBMTですか?
虚しい
実効性能/値段
そういう単純化しすぎた数値の比較で
compulerの優劣を決めようとしている限り
いつまで経っても
使いやすくてまともに動き
役に立つ代物は出来ないだろうな
そのcomputer使って何成し遂げようとしていますか?
単純なBMTですか?
虚しい
FMOとかQCDとか
そういう話はどうでも良いんだよ
役立たず
そういう話はどうでも良いんだよ
役立たず
穀潰しだな
まともに動かない内に製品寿命を迎える
欠陥computer
なんのために開発費かけるんだ
そんなものに
欠陥computer
なんのために開発費かけるんだ
そんなものに
> ベクトルプロセッサの方が同等のチップ技術で高flopsを原理的に達成しやすいのは、
> 大体このスレの住人ならわかると思うけど、
いや、スカラもベクタも浮動小数点の演算器にはほとんどトランジスタを
割いてはいない。どちらもflopsは増やす気になれば増やせるけど、
メモリバンドが不足するから増やしたところで性能は出ない。
ベクトル機が高いのはチップのせいじゃなくて強力なメモリアクセス能力
のため(連続、ストライド、ランダムアクセスにおける高いバンド幅)。
大量のバンクを確保するし、基板も配線も複雑で大規模なものになる。
(4-wayのOpteronのうち3つをメモリコントローラに、1つを演算に使うことを
想像すればいいかな。実際はもっと大変)
ベクトル機が効率がいいというのは強力なメモリアクセス能力のため。
つまりベクトル機を買うというのはメモリバンド幅にお金を払うということ。
チップ側の演算器以外の回路規模が小さくて済むというベクトル機の
メリットが(つってもベクトルレジスタに面積相当食うよな)、ほとんど
生かせなくなってベクトル機は衰退したわけ。
どうしたの、4連投もして。
何か辛いことでもあったのかな。
世界一を狙った巨大なスパコンを1台作るのもいいけど、
特定の計算に特化した計算機を、
超ローコストかつ短納期で作るために特化した共通プラットホームを開発するのはどうだろう。
何か辛いことでもあったのかな。
世界一を狙った巨大なスパコンを1台作るのもいいけど、
特定の計算に特化した計算機を、
超ローコストかつ短納期で作るために特化した共通プラットホームを開発するのはどうだろう。
メモリーのアクセスパターンはアプリで決まることであって
ベクトルだスカラーだで変わるもんじゃないだろ
1)キャッシュヒットの見込めるアプリはスカラーがダントツ早くて
2)メモリーを舐めるアプリではベクトルが早い
コストあたりのピーク性能比でいえば
もはや10倍以上スカラーの方が良い
実効効率は1)2)の配分でで決まる
金になるのは1)2)の配分の比で決まる
そう言う話だろばかばかしい
ベクトルだスカラーだで変わるもんじゃないだろ
1)キャッシュヒットの見込めるアプリはスカラーがダントツ早くて
2)メモリーを舐めるアプリではベクトルが早い
コストあたりのピーク性能比でいえば
もはや10倍以上スカラーの方が良い
実効効率は1)2)の配分でで決まる
金になるのは1)2)の配分の比で決まる
そう言う話だろばかばかしい
レジスターレジスター間積和演算性能をピーク性能として分母にし
実アプリの実行効率を割り残して騒いだり
白痴かよあいつら
実アプリの実行効率を割り残して騒いだり
白痴かよあいつら
性能欠陥もあるし、たまらんわ
役に立つという見方をすれば
ありふれたコモデティ部品使った
安物のサーバーの方がはるかにいい
役に立つという見方をすれば
ありふれたコモデティ部品使った
安物のサーバーの方がはるかにいい
ちなみにスカラ機のチップあたりのflopsの限界はというと、
CISC系だと1クロックに加算と乗算をそれぞれ1発(2演算)、
RISC系だと積和を1,2発(2, 4演算)までは発行できるようで
(更に同時にLoad/Storeも出せる)、それ以上はSIMDか
マルチコアで稼ぐことになる。
SSEのベクトル幅を128bitから256bitにしてピークを2倍に
することも恐らくは可能だが、そうやってSIMDを強化した
スカラプロセッサはベクトル機とは根本的に異なったものになる。
オリジナルのベクトル機というのは1個の演算器に対して
ベクトル算をさせることで演算器の利用効率を最大限に
しようというものだった。その後クロックも上がり複数の
演算器を載せるようになり、プロセッサ数も増えることで、
どんどん(プログラム側の)ベクトル長を長くしないと性能が
出せなくなってきた。ベクトル機衰退の一因はここにもある。
CISC系だと1クロックに加算と乗算をそれぞれ1発(2演算)、
RISC系だと積和を1,2発(2, 4演算)までは発行できるようで
(更に同時にLoad/Storeも出せる)、それ以上はSIMDか
マルチコアで稼ぐことになる。
SSEのベクトル幅を128bitから256bitにしてピークを2倍に
することも恐らくは可能だが、そうやってSIMDを強化した
スカラプロセッサはベクトル機とは根本的に異なったものになる。
オリジナルのベクトル機というのは1個の演算器に対して
ベクトル算をさせることで演算器の利用効率を最大限に
しようというものだった。その後クロックも上がり複数の
演算器を載せるようになり、プロセッサ数も増えることで、
どんどん(プログラム側の)ベクトル長を長くしないと性能が
出せなくなってきた。ベクトル機衰退の一因はここにもある。
コモデティーで十分
変なもの作らなくて良い
変なもの作らなくて良い
「分伝」ってなんだよ・・・
ちなみにいろんなFPUで遊ぶのは好きだけど
ベクトル機は使う機会なかった世代だよ。
ちなみにいろんなFPUで遊ぶのは好きだけど
ベクトル機は使う機会なかった世代だよ。
なんでプロセッサ数増えると
pipeline長くする必用があるんだ
自作板はここまでのものか
pipeline長くする必用があるんだ
自作板はここまでのものか
パイプライン長じゃなくって、ループの長さ。
ベクトル機は
for(i=0; i<LOOP_LEN; i++){
c[i] += a[i] * b[i];
}
みたいな計算が得意で(とうかこういう風に書かないと性能出せない)、
性能出すために必要なLOOP_LENがどんどん大きくなってしまった、
ということを伝え聞いている。
ベクトル機は
for(i=0; i<LOOP_LEN; i++){
c[i] += a[i] * b[i];
}
みたいな計算が得意で(とうかこういう風に書かないと性能出せない)、
性能出すために必要なLOOP_LENがどんどん大きくなってしまった、
ということを伝え聞いている。
がんばって勉強しておくれやす
付き合いきれん
付き合いきれん
Crayのどの機種?
Crayの初期のものと日本の後期のもの比べてるつもりだったんだけど。
Crayの初期のものと日本の後期のもの比べてるつもりだったんだけど。
>>946
最悪共通化されたのはガワと電源装置だけ、とかなりそうだ。
最悪共通化されたのはガワと電源装置だけ、とかなりそうだ。
そういや自分で回路を最適化する奴はどうなった。
効率よくてもやっぱ遅いのか。
効率よくてもやっぱ遅いのか。
まあ、ClearspeedやGRAPE-DRじゃないけど、同一CPLDで、
スカラ型とベクトル型で回路構成してどっちが高flopsに
構成することができるかを考えれば、ベクトル方の方がリソース効率がいいのは
わかると思うけどね。この単純な事実がこのスレでなかなか受け入れられないのはなぜか?
実際のプラグラムを動かしてどちらが速いかはプログラムしだい。
もちろんベクトル機はシステムでは高くなるのは理解できるけど。
スカラ型とベクトル型で回路構成してどっちが高flopsに
構成することができるかを考えれば、ベクトル方の方がリソース効率がいいのは
わかると思うけどね。この単純な事実がこのスレでなかなか受け入れられないのはなぜか?
実際のプラグラムを動かしてどちらが速いかはプログラムしだい。
もちろんベクトル機はシステムでは高くなるのは理解できるけど。
どこが間違ってるのか教えて
>>960
> まあ、ClearspeedやGRAPE-DRじゃないけど、同一CPLDで、
> スカラ型とベクトル型で回路構成してどっちが高flopsに
> 構成することができるかを考えれば、ベクトル方の方がリソース効率がいいのは
> わかると思うけどね。
うははは。
あんたバカだろ。そんな出鱈目をしらふで吐けるんだから。
> まあ、ClearspeedやGRAPE-DRじゃないけど、同一CPLDで、
> スカラ型とベクトル型で回路構成してどっちが高flopsに
> 構成することができるかを考えれば、ベクトル方の方がリソース効率がいいのは
> わかると思うけどね。
うははは。
あんたバカだろ。そんな出鱈目をしらふで吐けるんだから。
>>963
ClearspeedもGRAPE-DRも純ベクトルプロセッサとは言いがたいけどSIMD系の技術の延長だから、
スカラとベクトルでどっちが安あがりかという例として示すのにはそう遠かないだろ。
ClearspeedもGRAPE-DRも純ベクトルプロセッサとは言いがたいけどSIMD系の技術の延長だから、
スカラとベクトルでどっちが安あがりかという例として示すのにはそう遠かないだろ。
>>964
kwsk
kwsk
ClearspeedもGRAPE-DRも作り手がSIMD系だといっている。
http://www.clearspeed.com/docs/resources/ClearSpeed_Architecture_Whitepaper_0611.pdf
>The poly execution unit may consist of tens, hundreds or even thousands of PE
>cores. This array of PE cores operates in asynchronous manner, similar to a Single
>Instruction, Multiple Data (SIMD) processor, where every PE core executes the same
>instruction on its piece of data.
関係ないけど今のご時勢、素人が3分で検索できるHPで誰でも拾える資料にも目を通さずに
VLIWとか96コアだとか報道する馬鹿で怠慢なマスコミ連中ははやく淘汰されて、
ネットの世界から消えてほしい。
http://www.itmedia.co.jp/news/articles/0410/07/news039.html
http://www.clearspeed.com/docs/resources/ClearSpeed_Architecture_Whitepaper_0611.pdf
>The poly execution unit may consist of tens, hundreds or even thousands of PE
>cores. This array of PE cores operates in asynchronous manner, similar to a Single
>Instruction, Multiple Data (SIMD) processor, where every PE core executes the same
>instruction on its piece of data.
関係ないけど今のご時勢、素人が3分で検索できるHPで誰でも拾える資料にも目を通さずに
VLIWとか96コアだとか報道する馬鹿で怠慢なマスコミ連中ははやく淘汰されて、
ネットの世界から消えてほしい。
http://www.itmedia.co.jp/news/articles/0410/07/news039.html
いや、失礼
>Each PE core in the poly execution unit is similar to a VLIW processor
とも書いてあるな。さっき検索したばかりなのでよくよんでないわ。
>Each PE core in the poly execution unit is similar to a VLIW processor
とも書いてあるな。さっき検索したばかりなのでよくよんでないわ。
おまえもなーって言われる前に気がついて良かったねw
969 :Socket774:2007/01/21(日) 21:20:23 ID:vx/zJ8NY
Linpack専用のチップを作ればよくね?
そしたら安価に世界最高速狙えるんじゃね?
そしたら安価に世界最高速狙えるんじゃね?
牧野日記ワロスwww
つか足跡プロジェクトのS担いでるほうの人にしか思えません…
>>956
インテルはカスタムLSIとかマスクROMやってないじゃん。
日本の半導体メーカー各社には、かつて、任天堂というお客様がいて、
ファミコン&スーパーファミコンのソフトのカセットに使うマスクROMを、
あまりまとまってない分量を、極めて短納期で製造するシステムがあったのです。
インテルはカスタムLSIとかマスクROMやってないじゃん。
日本の半導体メーカー各社には、かつて、任天堂というお客様がいて、
ファミコン&スーパーファミコンのソフトのカセットに使うマスクROMを、
あまりまとまってない分量を、極めて短納期で製造するシステムがあったのです。
CPUアーキテクチャについて語れ 6
http://pc9.2ch.net/test/read.cgi/jisaku/1169393906/
http://pc9.2ch.net/test/read.cgi/jisaku/1169393906/
>>973
乙!
乙!
足跡プロジェクト?
>>972
あのねー、、、GRAPEだって最初は20万円だったのが今は50億だぜ?
あのねー、、、GRAPEだって最初は20万円だったのが今は50億だぜ?
Intelが最先端プロセスを利用して数千円でプロセッサを売られるのはx86だから。
研究開発とか、そういう理想ですらない妄想を語られてもな。
あ、もしかして、奴隷が沢山居るアカデミーで云々とかそういう話?(w
それともホワイt(ry
研究開発とか、そういう理想ですらない妄想を語られてもな。
あ、もしかして、奴隷が沢山居るアカデミーで云々とかそういう話?(w
それともホワイt(ry
何回読んでもオタクコアにしか見えない
>>969
つ[BlueGene/L]
チップじゃなくてシステムだけど
事実上Linpack(とほんの少しの実用アプリ)しか実行効率が出ないらしい
最初からそれしか狙ってない開発だろうから最良の設計なんだろうけどさ
どっかアメリカ以外がLinpack専用機つくればHPCチャレンジベンチ(だったっけ?)がメジャーになるんじゃね?
つ[BlueGene/L]
チップじゃなくてシステムだけど
事実上Linpack(とほんの少しの実用アプリ)しか実行効率が出ないらしい
最初からそれしか狙ってない開発だろうから最良の設計なんだろうけどさ
どっかアメリカ以外がLinpack専用機つくればHPCチャレンジベンチ(だったっけ?)がメジャーになるんじゃね?
そういう意味のない遊びに金を突っ込める米国がうらやましい。
SC05 - スパコンもう一つのベンチマーク「HPC Challenge」 - BlueGene/Lが圧勝
http://journal.mycom.co.jp/articles/2006/01/08/sc1/
>>978
なに言ってんだよ、ホワイトー
なに言ってんだよ、ホワイトー
>>980
ベクトル機用に進化したアプリを基準に考えると実用性は
ないということになるけど・・・
メモリをひたすらなめるという以外の演算量の多い用途では
努力次第で威力を発揮すると思う。
メモリバンド幅もネットワークバンド幅も不足しがちではある。
QCD専用計算機にDRAMつければLINPACKもいけそうって
いうプロジェクトだったんだっけ?
マキノも書いてたけどLINPACKで性能出るように作っておけば
使い道はそれなりにいろいろあるらしい。
LINPACKでTopを取られてから、
「ベクトル機じゃなきゃ実アプリで性能は出ない」キャンペーンが
始まってこの国はおかしくなったような気がする。
ベクトル機用に進化したアプリを基準に考えると実用性は
ないということになるけど・・・
メモリをひたすらなめるという以外の演算量の多い用途では
努力次第で威力を発揮すると思う。
メモリバンド幅もネットワークバンド幅も不足しがちではある。
QCD専用計算機にDRAMつければLINPACKもいけそうって
いうプロジェクトだったんだっけ?
マキノも書いてたけどLINPACKで性能出るように作っておけば
使い道はそれなりにいろいろあるらしい。
LINPACKでTopを取られてから、
「ベクトル機じゃなきゃ実アプリで性能は出ない」キャンペーンが
始まってこの国はおかしくなったような気がする。
xj7ZXQ5qにはまっきー以外だれも突っ込まないの?真理をついてると思うんだけど。
クソみたいなコードのツケをシステムにカネぶっこんでクソみたいな研究
してる連中には税金返せと言いたい。おまえら坂村と同類の国賊だ。
クソみたいなコードのツケをシステムにカネぶっこんでクソみたいな研究
してる連中には税金返せと言いたい。おまえら坂村と同類の国賊だ。
>>981
付き合わされるsoftwar開発者の見にも成ってくれ
何の答えを出すわけでもない積和演算の秒数測定、
つまんなくてつまんなくて。何も生み出さなないし
そのための準備、tuningやらcompiler OS libraryの気が遠くなるような
bugだし検証など莫大な手間かけて
それがホント人生の無駄に思えてきて泣ける
そのくせチョット複雑な実用的ソフトは地を這う遅さ
ホントくだらねぇ
付き合わされるsoftwar開発者の見にも成ってくれ
何の答えを出すわけでもない積和演算の秒数測定、
つまんなくてつまんなくて。何も生み出さなないし
そのための準備、tuningやらcompiler OS libraryの気が遠くなるような
bugだし検証など莫大な手間かけて
それがホント人生の無駄に思えてきて泣ける
そのくせチョット複雑な実用的ソフトは地を這う遅さ
ホントくだらねぇ
apacheは2からmulti thread化されていて
たしかデフォは8個だったかな、同時に走っている
そういう用途でも多分ありがたいんだろうな
俺はopenMPで行くか、自動並列化で行くか
それとも手抜きでithreadとしゃれ込むか…
たしかデフォは8個だったかな、同時に走っている
そういう用途でも多分ありがたいんだろうな
俺はopenMPで行くか、自動並列化で行くか
それとも手抜きでithreadとしゃれ込むか…
いけねぇ誤爆した…
なに言ってんだよ、ホワイトー
るせー、ブルー
単純に格子QCD計算が速くなると俺はうれしい。
ホワイトセックス?
QCD専用機なら用途も予算もそれで閉じて欲しいんだよ
他の用途で使い物にならないんだから
それを他の解析でも性能が出るようなレトリック使うから
周りが迷惑するんだよ
他の用途で使い物にならないんだから
それを他の解析でも性能が出るようなレトリック使うから
周りが迷惑するんだよ
レトリック君は以前HP-UX 11v3も叩いてたね
どこの中の人なんだろうw
どこの中の人なんだろうw
それは別人だな
いまどきHP-UX なんて使っていない
いまどきHP-UX なんて使っていない
次世代スレ26の>>850のことね
http://search.mimizun.com:82/perl/dattohtml.pl?http://mimizun.com:81/log/2ch/jisaku/pc9.2ch.net/jisaku/kako/1157/11570/1157019837.dat
http://search.mimizun.com:82/perl/dattohtml.pl?http://mimizun.com:81/log/2ch/jisaku/pc9.2ch.net/jisaku/kako/1157/11570/1157019837.dat
これ俺だw
しかし良く覚えているな…
迂闊なことはかけないわ。
じゃあね。ノシ
しかし良く覚えているな…
迂闊なことはかけないわ。
じゃあね。ノシ
はきゅ〜ん
ニョーン
1001 :1001: