AMD�̎�����CPU�ɂ��Č�낤 4������
1 �FSocket774�F
���������[�h�}�b�v
���i���[�h�}�b�v �i�Z���j
ttp://www.amdcompare.com/prodoutlook/
�e�N�m���W�E���[�h�}�b�v �i3�N�j
ttp://www.amdcompare.com/techoutlook/
���O�X��
2 http://pc7.2ch.net/test/read.cgi/jisaku/1133374045/
1 http://pc7.2ch.net/test/read.cgi/jisaku/1124542812/
�����AMD�n�X���b�h�ߋ����O�ۑ��T�C�g�l
http://amd.jisakuita.net/
���֘A�X��
[RISC]CPU�A�[�L�e�N�`���ɂ��Č��I[VLIW]�Q
http://pc7.2ch.net/test/read.cgi/jisaku/1101041110/
Intel�̎�����CPU�ɂ��Č�낤 21
http://pc7.2ch.net/test/read.cgi/jisaku/1136822334/
�Q�Q�Q_
�_.�Q�@ | �r�炵�E����E�~�[�͕��u����ԁB
�^|�Q|�@| �ނ�ꂸ�ɃX���[���܂��傤�B
|�Q�^�_! sage�i�s�Ń}�^�[�������܂��傤�B
���i���[�h�}�b�v �i�Z���j
ttp://www.amdcompare.com/prodoutlook/
�e�N�m���W�E���[�h�}�b�v �i3�N�j
ttp://www.amdcompare.com/techoutlook/
���O�X��
2 http://pc7.2ch.net/test/read.cgi/jisaku/1133374045/
1 http://pc7.2ch.net/test/read.cgi/jisaku/1124542812/
�����AMD�n�X���b�h�ߋ����O�ۑ��T�C�g�l
http://amd.jisakuita.net/
���֘A�X��
[RISC]CPU�A�[�L�e�N�`���ɂ��Č��I[VLIW]�Q
http://pc7.2ch.net/test/read.cgi/jisaku/1101041110/
Intel�̎�����CPU�ɂ��Č�낤 21
http://pc7.2ch.net/test/read.cgi/jisaku/1136822334/
�Q�Q�Q_
�_.�Q�@ | �r�炵�E����E�~�[�͕��u����ԁB
�^|�Q|�@| �ނ�ꂸ�ɃX���[���܂��傤�B
|�Q�^�_! sage�i�s�Ń}�^�[�������܂��傤�B
|
|
|
2 �FSocket774�F2006/04/16(��) 20:39:22 ID:MsI4BOX2
���ŋ߂̋L��
�y2��2���z �y�C�O�z�䂪����K10�A�[�L�e�N�`���̕�����
ttp://pc.watch.impress.co.jp/docs/2006/0202/kaigai238.htm
�y1��23���z�y�C�O�z�s�ꂲ�ƂɎd�l��ς���AMD��CPU�헪
ttp://pc.watch.impress.co.jp/docs/2006/0123/kaigai234.htm
�y1��19���z�y�C�O�zK8�ȍ~�傫���ς����AMD��CPU�J���T�C�N��
ttp://pc.watch.impress.co.jp/docs/2006/0119/kaigai233.htm
��CPU�R�[�h�l�[���ꗗ�\
ttp://pc.watch.impress.co.jp/docs/article/intel/codename.htm#amd
��AMD���f���i���o�[�ꗗ�\
ttp://pc.watch.impress.co.jp/docs/article/modelno/amd.htm
����Ȑ���
K8(130nm)��(90nm)��SSE3�lj����f���A���R�A��(���R�R)��
��DDR2�Ή���(65nm)��K8L?���N�A�b�h�R�A?��(45nm??)��K10??
�y2��2���z �y�C�O�z�䂪����K10�A�[�L�e�N�`���̕�����
ttp://pc.watch.impress.co.jp/docs/2006/0202/kaigai238.htm
�y1��23���z�y�C�O�z�s�ꂲ�ƂɎd�l��ς���AMD��CPU�헪
ttp://pc.watch.impress.co.jp/docs/2006/0123/kaigai234.htm
�y1��19���z�y�C�O�zK8�ȍ~�傫���ς����AMD��CPU�J���T�C�N��
ttp://pc.watch.impress.co.jp/docs/2006/0119/kaigai233.htm
��CPU�R�[�h�l�[���ꗗ�\
ttp://pc.watch.impress.co.jp/docs/article/intel/codename.htm#amd
��AMD���f���i���o�[�ꗗ�\
ttp://pc.watch.impress.co.jp/docs/article/modelno/amd.htm
����Ȑ���
K8(130nm)��(90nm)��SSE3�lj����f���A���R�A��(���R�R)��
��DDR2�Ή���(65nm)��K8L?���N�A�b�h�R�A?��(45nm??)��K10??
���Ă�����������B���N���炢�l�q������C�����̗]�T���Ă̂������Ă��ǂ��Ǝv�������ǁB�B�B
�����Ă�ƁA�H�܂ʼnΕa�����A�����̃��`�X���Ɖ����悤�ȋC�����邷�B
�ł�AMD�̎�����l�^��A���ꂩ�炪�ʔ����Ȃ邷����Core�A�[�L�e�N�`�������Ă������肹����
�Z�p���`�𑱂���Ɨǂ������B
�����Ă�ƁA�H�܂ʼnΕa�����A�����̃��`�X���Ɖ����悤�ȋC�����邷�B
�ł�AMD�̎�����l�^��A���ꂩ�炪�ʔ����Ȃ邷����Core�A�[�L�e�N�`�������Ă������肹����
�Z�p���`�𑱂���Ɨǂ������B
mac�I�^�j���[�X�̓ǎ҂ł�
��������܂ł悤�ɒ���I�ɓ\���Ă�������
�֘A�X�����Â��Ă��߂�Ȃ���
�O�X���̂܂ܓ\���������
��������܂ł悤�ɒ���I�ɓ\���Ă�������
�֘A�X�����Â��Ă��߂�Ȃ���
�O�X���̂܂ܓ\���������
�Ƃ肠�����e���v���I�ɍŋ߂̃j���[�X�����B
�E�O�X���@http://pc7.2ch.net/test/read.cgi/jisaku/1138983969/
�EAnandtech AM2 review #1 http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2738
�EAnandtech AM2 review #2 http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2741
�E���N�̃��[�h�}�b�v http://www.dailytech.com/article.aspx?newsid=1702
�E�O�X���@http://pc7.2ch.net/test/read.cgi/jisaku/1138983969/
�EAnandtech AM2 review #1 http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2738
�EAnandtech AM2 review #2 http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2741
�E���N�̃��[�h�}�b�v http://www.dailytech.com/article.aspx?newsid=1702
�ؗ��2GET
�����邩���������I�I
�Εa���Ă�͎̂G�����炢�łق��͊��Ɨ�Â������Ǝv�����ǂȁB
�܂�AMD�͔��N�l�^�Ȃ�����b�����Ƃ��Ȃ��킯�����B
�܂�AMD�͔��N�l�^�Ȃ�����b�����Ƃ��Ȃ��킯�����B
9 �FSocket774�F2006/04/16(��) 22:51:25 ID:qN6SQIFE
�@ �����@�l�グ�����}�l�炪����ŗL����AMD�M�� �@ ��
�@ (7�k)�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�i/ /
�@/�@/�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�ȁQ�ȁ@�@ �@ �@ �@ �@ �@�b�b
/�@/�@ �ȁQ�ȁ@�@ �@ �ȁQ�ȁ@�@�Q�i�L�́M�@�j �@ �ȁQ�ȁ@�@ �b�b
�_ �_�i�@�L�́M�j�\--�i �L�́M �j�P�@�@�@�@�@�@�܁R�i�L�́M�@�j�@�^�^
�@ �_�@�@�@�@�@�@�@�^�܁@�@�@�܁P�R�A���ؒ�/~�܁@�@�@�@�܁@/
�@�@ �b�@�@�@�@�@ |��A�@�A�j���@/�P|�@�@�@�@/�^`i�@�܂ق떽/
�@�@�@�b�R�I�^�@|�@�b�G���Q�@/�@�i�~�@�@�@�~�j �@�b�@�@�@�@�b
�@�@�@�b�@�@�@�@�b�@�b��D�� | �^�@�@�@�@�@�@�_ �b�@�@�@�@�b
�@�@�@�b�@�@�@�@�b�@�@�j�@�@�@ �^�@�@�@�^�_�@�@�@�_| �@ �@ �@ �R
�@�@�@/�@�@�@�m�@�b�@/�@�@�R �R�A�Q�^�j�@ �i�_�@�@ �@�j�@�T�@�@�b
�@�@ �b�@�@�b�@�@|�@/�@�@ /|�@�@ /�@���@�@�@�_`�[ ' |�@ �b�@ /
�@ (7�k)�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�i/ /
�@/�@/�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�ȁQ�ȁ@�@ �@ �@ �@ �@ �@�b�b
/�@/�@ �ȁQ�ȁ@�@ �@ �ȁQ�ȁ@�@�Q�i�L�́M�@�j �@ �ȁQ�ȁ@�@ �b�b
�_ �_�i�@�L�́M�j�\--�i �L�́M �j�P�@�@�@�@�@�@�܁R�i�L�́M�@�j�@�^�^
�@ �_�@�@�@�@�@�@�@�^�܁@�@�@�܁P�R�A���ؒ�/~�܁@�@�@�@�܁@/
�@�@ �b�@�@�@�@�@ |��A�@�A�j���@/�P|�@�@�@�@/�^`i�@�܂ق떽/
�@�@�@�b�R�I�^�@|�@�b�G���Q�@/�@�i�~�@�@�@�~�j �@�b�@�@�@�@�b
�@�@�@�b�@�@�@�@�b�@�b��D�� | �^�@�@�@�@�@�@�_ �b�@�@�@�@�b
�@�@�@�b�@�@�@�@�b�@�@�j�@�@�@ �^�@�@�@�^�_�@�@�@�_| �@ �@ �@ �R
�@�@�@/�@�@�@�m�@�b�@/�@�@�R �R�A�Q�^�j�@ �i�_�@�@ �@�j�@�T�@�@�b
�@�@ �b�@�@�b�@�@|�@/�@�@ /|�@�@ /�@���@�@�@�_`�[ ' |�@ �b�@ /
>>3
���O�n�����낤�B���邢�b����肶��Ȃ��Ƃ����Ȃ����Ă������[���ł�����̂��H
���O�n�����낤�B���邢�b����肶��Ȃ��Ƃ����Ȃ����Ă������[���ł�����̂��H
>>8
�@�@----------------------
�@�@�Εa���Ă�͎̂G�����炢�łق��͊��Ɨ�Â������Ǝv�����ǂȁB
�@�@----------------------
������ĎR�قǂ���C�^���������݂̃R�s�y��U�����ăX���ׂ���_���ނ�̈��Ȃ��ˁB�B�B
�@�@----------------------
�@�@�Εa���Ă�͎̂G�����炢�łق��͊��Ɨ�Â������Ǝv�����ǂȁB
�@�@----------------------
������ĎR�قǂ���C�^���������݂̃R�s�y��U�����ăX���ׂ���_���ނ�̈��Ȃ��ˁB�B�B
12 �FSocket774�F2006/04/17(��) 00:52:36 ID:s62oervo
�Ƃ肠�����A�A�z�I�^��
���N���炢���̃X���ɃJ�L�R������
���`�����ōς܂�����]�T���ł��Ă���
���������^���������Ƃ�
���N���炢���̃X���ɃJ�L�R������
���`�����ōς܂�����]�T���ł��Ă���
���������^���������Ƃ�
�e���v���\��Y��Ă邷�i�j
A�Ƃ����Z�p���v���Z�b�T�ƊE���ō̗p����n�߂�i�ƊE�̃g�����h�j
�����삪�����̂Œm������Ȃ�
�I�^�uA�Ƃ����Z�p�����ō̗p����Ă邷�BAMD��������̗p�����Ȃ������ˁv
���������B����Ȃ킯�Ȃ�����
�C���e����A�Z�p�̗̍p�\����i�C���e���ׂɂƂ��ăg�����h�j
�����ꂾ����C���e���͂�
AMD��A�Z�p�̗̍p���������n�߂�
�����ꂩ���A�̎��ゾ�I�i������AMD�ׂ̂����g�����h�j
�����ƍL�����E�ɖڂ�������ׂ����Ǝv����
A�Ƃ����Z�p���v���Z�b�T�ƊE���ō̗p����n�߂�i�ƊE�̃g�����h�j
�����삪�����̂Œm������Ȃ�
�I�^�uA�Ƃ����Z�p�����ō̗p����Ă邷�BAMD��������̗p�����Ȃ������ˁv
���������B����Ȃ킯�Ȃ�����
�C���e����A�Z�p�̗̍p�\����i�C���e���ׂɂƂ��ăg�����h�j
�����ꂾ����C���e���͂�
AMD��A�Z�p�̗̍p���������n�߂�
�����ꂩ���A�̎��ゾ�I�i������AMD�ׂ̂����g�����h�j
�����ƍL�����E�ɖڂ�������ׂ����Ǝv����
���������Z�p�I�Șb��l�^�Ő���オ���
�Ё@���@���@�Ɂ@�l�@���@�Ё@��@�l�@���@�ǁ@��@�ǁ@��@���@���@�I�I
�Ё@���@���@�Ɂ@�l�@���@�Ё@��@�l�@���@�ǁ@��@�ǁ@��@���@���@�I�I
����Ȃ��ƌ��������āA�l�^�����ł�w
AMD�ɖ����͂���̂��낤���H
��芸�����A65nm�ɂȂ��ăN���b�N�オ���Ă��炾�ȁB
�V���{���B
AMD�ɖ����͂���̂��낤���H
��芸�����A65nm�ɂȂ��ăN���b�N�オ���Ă��炾�ȁB
�V���{���B
�g�����h�˂��B
�f���A���R�A�Ƃ��Ax86_64 �Ƃ��A���\�d�͔�d���Ƃ��A�������R���g���[��
�����Ƃ��AP2P �v���Z�b�T�����N�Ƃ��A�ŋ߂̃g�����h�� AMD ����s����
Intel �̕�����ǂ����Ă邱�Ƃ������킯�����B
�������R���g���[�������ƁAP2P �v���Z�b�T�����N�́AIntel �͂܂��v��i�K
�Ŏ����ɂ��������ĂȂ����ˁB
�f���A���R�A�Ƃ��Ax86_64 �Ƃ��A���\�d�͔�d���Ƃ��A�������R���g���[��
�����Ƃ��AP2P �v���Z�b�T�����N�Ƃ��A�ŋ߂̃g�����h�� AMD ����s����
Intel �̕�����ǂ����Ă邱�Ƃ������킯�����B
�������R���g���[�������ƁAP2P �v���Z�b�T�����N�́AIntel �͂܂��v��i�K
�Ŏ����ɂ��������ĂȂ����ˁB
>>17
�����ƍL�����E�ɖڂ�������ׂ����Ǝv�����i�j
�����ƍL�����E�ɖڂ�������ׂ����Ǝv�����i�j
19 �FSocket774�F2006/04/18(��) 18:58:13 ID:qM+4WrUW
>17
��i�I�ȃA�[�L�e�N�`���Ȃ�PC�p�ȊO�̂ق����ʔ���
��Intel���ƁA�n�[�h�E�F�A�������߃Z�b�g�̎哱�������������Ƃ̂ق����傫��
�����K8�̐��������������������
��i�I�ȃA�[�L�e�N�`���Ȃ�PC�p�ȊO�̂ق����ʔ���
��Intel���ƁA�n�[�h�E�F�A�������߃Z�b�g�̎哱�������������Ƃ̂ق����傫��
�����K8�̐��������������������
> �n�[�h�E�F�A�������߃Z�b�g�̎哱�������������Ƃ̂ق����傫��
�哱�����������̂��͂��̐����������B
�ꕔ���߂̈Ⴂ�ɂ�蓮�삪�قȂ镔�ʂ�����B
OS���܂߁A�����̃\�t�g���ǂ���̓����I������̂��Ŏ哱���͕ω�����B
SSE�ASSE2�ASSE3�ɒǐ�����AMD�Ђ��哱���������Ă���Ƃ͓���v���܂����B
�哱�����������̂��͂��̐����������B
�ꕔ���߂̈Ⴂ�ɂ�蓮�삪�قȂ镔�ʂ�����B
OS���܂߁A�����̃\�t�g���ǂ���̓����I������̂��Ŏ哱���͕ω�����B
SSE�ASSE2�ASSE3�ɒǐ�����AMD�Ђ��哱���������Ă���Ƃ͓���v���܂����B
>>17
>�ŋ߂̃g�����h�� AMD ����s����
>Intel �̕�����ǂ����Ă邱�Ƃ������킯�����B
�}���`�R�A�������R��������P2P�o�X���A�ʂɒ���������Ȃ����i�j
�C�[�T�R���g���[���Ƃ����������Ă���̂����邵�˂�
>�ŋ߂̃g�����h�� AMD ����s����
>Intel �̕�����ǂ����Ă邱�Ƃ������킯�����B
�}���`�R�A�������R��������P2P�o�X���A�ʂɒ���������Ȃ����i�j
�C�[�T�R���g���[���Ƃ����������Ă���̂����邵�˂�
>21
�}�C�N���\�t�g��IA64�����AMD64�Ƃ�Pacifica���x���������Ƃ������Ă��
��ΓI�ȃA�h�o���e�[�W�ł͂Ȃ����ǁA�C���[�W��̗��v�͂͂���m��Ȃ�
�}�C�N���\�t�g��IA64�����AMD64�Ƃ�Pacifica���x���������Ƃ������Ă��
��ΓI�ȃA�h�o���e�[�W�ł͂Ȃ����ǁA�C���[�W��̗��v�͂͂���m��Ȃ�
MS��Pacifica�����łȂ�Vanderpool���������T�|�[�g�����
�L�����E��Arm
18=22�́A�������X�ɓ�x���قړ����c�b�R�~�����Ă邪
�^���̃A�z���H
�^���̃A�z���H
�{����AMDer�̂���ׂ��p
�C���e����A�Z�p�̗̍p�\����
���Ӂ[��
AMD��A�Z�p�̗̍p�\����
���Ӂ[��
���_
���[�č���͂ǂ������������ȁA��
�C���e����A�Z�p�̗̍p�\����
���Ӂ[��
AMD��A�Z�p�̗̍p�\����
���Ӂ[��
���_
���[�č���͂ǂ������������ȁA��
>>27
�C���e����A�Z�p�̗̍p�\����
���Ӂ[��
AMD��B�Z�p�̗̍p�\����
���Ӂ[��
���_
���[�č���͂ǂ������������ȁA��
�������̕��������Ă���C������B
�C���e����A�Z�p�̗̍p�\����
���Ӂ[��
AMD��B�Z�p�̗̍p�\����
���Ӂ[��
���_
���[�č���͂ǂ������������ȁA��
�������̕��������Ă���C������B
>>27-28
���ꕁ�ʂ̐l��AMDer����Ȃ��ˁH
���ꕁ�ʂ̐l��AMDer����Ȃ��ˁH
>>29
Inteler��IntelCPU�����蔃���l���������ǁAAMDer�͂ǂ����������l��������Ȃ��B
Inteler�F�f�X�N�g�b�v=Pentium4/D�@�m�[�g=PentiumM
AMDer�F�f�X�N�g�b�v=Athlon64/FX/X2�@�m�[�g=PentiumM/Turion64
AMDer�̓`�b�v�Z�b�g��AMD������Ȃ����̂��g���Ă邹����
�w�Ȃ����������AMD������Ȃ�����ށI�x���Đl�͏��Ȃ��B
Inteler�̓`�b�v�Z�b�g��Intel���̂��̂��g���Ă邹����
�w�����Ȃ�ł�Intel������Ȃ�����ށI�x���Đl�������B
Inteler��IntelCPU�����蔃���l���������ǁAAMDer�͂ǂ����������l��������Ȃ��B
Inteler�F�f�X�N�g�b�v=Pentium4/D�@�m�[�g=PentiumM
AMDer�F�f�X�N�g�b�v=Athlon64/FX/X2�@�m�[�g=PentiumM/Turion64
AMDer�̓`�b�v�Z�b�g��AMD������Ȃ����̂��g���Ă邹����
�w�Ȃ����������AMD������Ȃ�����ށI�x���Đl�͏��Ȃ��B
Inteler�̓`�b�v�Z�b�g��Intel���̂��̂��g���Ă邹����
�w�����Ȃ�ł�Intel������Ȃ�����ށI�x���Đl�������B
>>30
�ǂ����ł��ǂ��������Ȃ�AMDer����Ȃ��ˁH
�ǂ����ł��ǂ��������Ȃ�AMDer����Ȃ��ˁH
>>14
���x���Ă�����Ȃ�
���x���Ă�����Ȃ�
������������������w
���~�������Ȃ��ƌ����Ă�l�Ȃ��B
INTEL�̐��i��AMD�̐��i�B
�����悤�Ȑ��\�ȂƂ��Ɍ��ۛ��̃��[�J�[��I�Ԃ̂������ӗl�Ƃ������́B
�Е��̐��\���ˏo���Ă������́A���ۛ����[�J�[�Ɋւ�炸�I�������L����B
����ɑ��āA�M�҂͂��ꓙ��S�Ė������ď�ɓ��胁�[�J�[�i�݂̂��w���B
�M�҂̍s����v�l�́A��ʐl�ɂ͗���s�\�ł���w�i�Ƃ��ď@����������P�[�X�������B
���~�������Ȃ��ƌ����Ă�l�Ȃ��B
INTEL�̐��i��AMD�̐��i�B
�����悤�Ȑ��\�ȂƂ��Ɍ��ۛ��̃��[�J�[��I�Ԃ̂������ӗl�Ƃ������́B
�Е��̐��\���ˏo���Ă������́A���ۛ����[�J�[�Ɋւ�炸�I�������L����B
����ɑ��āA�M�҂͂��ꓙ��S�Ė������ď�ɓ��胁�[�J�[�i�݂̂��w���B
�M�҂̍s����v�l�́A��ʐl�ɂ͗���s�\�ł���w�i�Ƃ��ď@����������P�[�X�������B
�y�j��
���̓C���e���͔���˂�
�d����Pen, Cele, Xeon�͎g���O���Ă�
Core�����̂����A�C���ł��g��
SPARC, POWER�ł���g���̂�
AMD, Trameta, VIA�ɂ͎d���ʼn����Ȃ�
�d�����Ȃ����玩���Ŕ���
�������A����Xeon�ȊO�l�b�g�o�[�X�g��
�d���Ŏg�������Ƃ����̂��Ȃ�
�����Ƃ��A�����Ŕ����ă_�����͒m���Ă邪
�d����Pen, Cele, Xeon�͎g���O���Ă�
Core�����̂����A�C���ł��g��
SPARC, POWER�ł���g���̂�
AMD, Trameta, VIA�ɂ͎d���ʼn����Ȃ�
�d�����Ȃ����玩���Ŕ���
�������A����Xeon�ȊO�l�b�g�o�[�X�g��
�d���Ŏg�������Ƃ����̂��Ȃ�
�����Ƃ��A�����Ŕ����ă_�����͒m���Ă邪
> ���̓C���e���͔���˂�
> �����Ƃ��A�����Ŕ����ă_�����͒m���Ă邪
�������炯�A�^���͂ǂ����H
> �����Ƃ��A�����Ŕ����ă_�����͒m���Ă邪
�������炯�A�^���͂ǂ����H
>>37
���ꂩ��͔���˂����ĈӖ�����Ȃ��̂��H
���ꂩ��͔���˂����ĈӖ�����Ȃ��̂��H
�������ȁH
> �d����Pen, Cele, Xeon�͎g���O���Ă�
> �������A����Xeon�ȊO�l�b�g�o�[�X�g��
> �d���Ŏg�������Ƃ����̂��Ȃ�
�l�b�g�o�[�X�g��Xeon�͎d���Ŏg���O���Ă�Ɩ|��ƁA
����Ȑl�����̃_���ȃl�b�g�o�[�X�g�����Ȃ��H
������������B
> �d����Pen, Cele, Xeon�͎g���O���Ă�
> �������A����Xeon�ȊO�l�b�g�o�[�X�g��
> �d���Ŏg�������Ƃ����̂��Ȃ�
�l�b�g�o�[�X�g��Xeon�͎d���Ŏg���O���Ă�Ɩ|��ƁA
����Ȑl�����̃_���ȃl�b�g�o�[�X�g�����Ȃ��H
������������B
SIer�Ȃ瓖�RX�������Ђ��ł�B
�����ƃp�t�H�[�}���X�������Ă邨�q�����AMD�I��ł��邯�ǂ��������͖���(�L�E�ցE`)
�����ƃp�t�H�[�}���X�������Ă邨�q�����AMD�I��ł��邯�ǂ��������͖���(�L�E�ցE`)
>>38
������������
���ƁA�d����Xeon�}�V���Ɛ肵�ăx���`���点���肵�����Ƃ͂Ȃ����
�ǂ̂��炢�_�����́A�����Ŕ����Ă������o���ɂ���Ēm�����킯
Pen4�}�V�����l�Ŏg�킳�ꂽ�肷��A�C���ł����������낤��
������������
���ƁA�d����Xeon�}�V���Ɛ肵�ăx���`���点���肵�����Ƃ͂Ȃ����
�ǂ̂��炢�_�����́A�����Ŕ����Ă������o���ɂ���Ēm�����킯
Pen4�}�V�����l�Ŏg�킳�ꂽ�肷��A�C���ł����������낤��
�ȉ��̓v���X�R����(�v���X�R��INTEL���g�����s�삾�ƔF�߂Ă���)
P4�g���ĂāA�_����CPU�Ɣ��f�l���ď����h�Ȃ�Ȃ��B
�������A���������������Ƒ����ł����z�������h�B
HT�e�N�m���W�[�ɂ��A���掿����̍Đ���CD�Ă��������ɏo�����̂�P4�B
����z���g�̘b�B
P4�g���ĂāA�_����CPU�Ɣ��f�l���ď����h�Ȃ�Ȃ��B
�������A���������������Ƒ����ł����z�������h�B
HT�e�N�m���W�[�ɂ��A���掿����̍Đ���CD�Ă��������ɏo�����̂�P4�B
����z���g�̘b�B
>>42
����Ⴀ�AAthlon64��Pentium4�Ɠ�����������̐��\�����o���Ă��Ȃ���������ȁB
�����AMD�����\���グ�Ȃ������̂��A�グ���Ȃ������̂��͒m������������Ȃ����A�����͂����B
������Athlon���[�[���I�ƌ��������āAP4�̏�������x�Ȃ�������͂��Ȃ��킯�ŁB
�t�ɁAAthlon���������Ƃ�F�߂�ƁAP4���������������������Ęb�ɂȂ�B
TDP120W�����o��ƁA100W��Athlon64�͔��M���Ⴂ�ƌ����Ă��̂ƈꏏ�B
���ΓI�Ȃ��B
����Ⴀ�AAthlon64��Pentium4�Ɠ�����������̐��\�����o���Ă��Ȃ���������ȁB
�����AMD�����\���グ�Ȃ������̂��A�グ���Ȃ������̂��͒m������������Ȃ����A�����͂����B
������Athlon���[�[���I�ƌ��������āAP4�̏�������x�Ȃ�������͂��Ȃ��킯�ŁB
�t�ɁAAthlon���������Ƃ�F�߂�ƁAP4���������������������Ęb�ɂȂ�B
TDP120W�����o��ƁA100W��Athlon64�͔��M���Ⴂ�ƌ����Ă��̂ƈꏏ�B
���ΓI�Ȃ��B
����AAthlon64�͗ǂ��ł���CPU����H
AMD�ЂŃ_���Ȃ̂�AthlonXP�܂ŁB
�t��INTEL�Ń_���Ȃ̂̓v���X�R�ȍ~�̃l�b�g�o�[�X�g�B
AMD�ЂŃ_���Ȃ̂�AthlonXP�܂ŁB
�t��INTEL�Ń_���Ȃ̂̓v���X�R�ȍ~�̃l�b�g�o�[�X�g�B
>>44
�@�@---------------------
�@�@AMD�ЂŃ_���Ȃ̂�AthlonXP�܂ŁB
�@�@--------------------
K5, K6��l�i�����ɁAK7, K8�퐫�\�I�ɂ��\���ǂ��v���Z�b�T���Ǝv�����B
�@�@---------------------
�@�@AMD�ЂŃ_���Ȃ̂�AthlonXP�܂ŁB
�@�@--------------------
K5, K6��l�i�����ɁAK7, K8�퐫�\�I�ɂ��\���ǂ��v���Z�b�T���Ǝv�����B
�͂��A�l�I�ɂ�Northwood�Ȃ�ĕ���
��x�ƐG�肽���Ȃ���
����܂�̊��x����ŁA�Ȃ����~�X���ĂĐ��\�o�ĂȂ���Ȃ�����
�x���`�}�[�N���点�܂������L��������A�������A�x���`�����͑�������
�i���Ȃ݂ɓ���64�͏o�ĂȂ����APen4��HTT�L��j
��x�ƐG�肽���Ȃ���
����܂�̊��x����ŁA�Ȃ����~�X���ĂĐ��\�o�ĂȂ���Ȃ�����
�x���`�}�[�N���点�܂������L��������A�������A�x���`�����͑�������
�i���Ȃ݂ɓ���64�͏o�ĂȂ����APen4��HTT�L��j
>>43
�����i�Ŕ�ׂ�ƍ����L���茞����B
�����i�Ŕ�ׂ�ƍ����L���茞����B
�������S�͎����ō����M��K7���ǂ�CPU���Ƃ͎v���Ȃ������Ȃ��B
�m���ɂ���ȊO�͂���Ȃ�ɗǂ��������B
�m���ɂ���ȊO�͂���Ȃ�ɗǂ��������B
���炻���Ɍ����Ă邪
K7�g�������ƂȂ�����
K7�g�������ƂȂ�����
>>48
Pen4��64�̉��i��ׂČ���悗
Pen4��64�̉��i��ׂČ���悗
AthlonXP 3000+������A�����g�������B
�M�����ǂ�w
�������낻��t�@�����w�^���o���Č������B
�M�����ǂ�w
�������낻��t�@�����w�^���o���Č������B
���Ȃ����ɂ́A���܂��Ɏg���Ă�̂�
����Northwood�A���U�@��������
��������̂��C������������
����Northwood�A���U�@��������
��������̂��C������������
�_���Ƃ����̂�P4�ƌĂԐl�Ɠ������֑�\���B
��ׂ�̘b�ł���A�\���Ɏg����B
�ł��M��w
��ׂ�̘b�ł���A�\���Ɏg����B
�ł��M��w
>>51
>>43�Ƃ�S�R�W�Ȃ����i�j
���M�����E�߂�64 X2��2.4-2.6GHz�~�܂肾���������ŁA�����V���O�����o�Ȃ���64 3000+����ڍs�ł��Ȃ�������
>>53
���Â�13000�Ŕ�����P4 2.53GHz��1�N���12000�~�Ŕ���āA���̂�����Athlon���������犴�ӂ��Ă�
>>43�Ƃ�S�R�W�Ȃ����i�j
���M�����E�߂�64 X2��2.4-2.6GHz�~�܂肾���������ŁA�����V���O�����o�Ȃ���64 3000+����ڍs�ł��Ȃ�������
>>53
���Â�13000�Ŕ�����P4 2.53GHz��1�N���12000�~�Ŕ���āA���̂�����Athlon���������犴�ӂ��Ă�
�������i�������A�������i�̕��������A
����ȏŒl��������킯�ˁ[�����B
�����������ė~�����Ƃ�����]���ꗬ���Ă�A�z�Ȃ킯���ˁB
����ȏŒl��������킯�ˁ[�����B
�����������ė~�����Ƃ�����]���ꗬ���Ă�A�z�Ȃ킯���ˁB
>>56
���̒ʂ肷�B
���̒ʂ肷�B
�C���e����CPU�̒��É��i�ُ͈�
��������A�]���ړI��Dell�̒���Pen4�I���������Ƃ����邪
�N�[���[����Ȃ�CPU���قƂ�ǒ艿�ɋ߂��l�i�Ŕ��ꂽ
�}�U�[��64bitPCI�̂����������ɍ������ꂽ��
��������A�]���ړI��Dell�̒���Pen4�I���������Ƃ����邪
�N�[���[����Ȃ�CPU���قƂ�ǒ艿�ɋ߂��l�i�Ŕ��ꂽ
�}�U�[��64bitPCI�̂����������ɍ������ꂽ��
������X���Œ��Â̘b��
���̒m�V
�l�b�g�o�[�X�g�̃S�~�������̓V���O���^�X�N�����g��Ȃ��l�ɂ�
�킩����B��������ւ���Ƃ��̂��炾���Ƃ�����������B
�킩����B��������ւ���Ƃ��̂��炾���Ƃ�����������B
�����g���Ă��邪�A�w�Ǎ��͂Ȃ��ȁB
�֑�\�����߂���ƏX����������w
�֑�\�����߂���ƏX����������w
>�������i�������A�������i�̕�������
Celeron�̉��i�ُ͈�
�K�����i��3�{���炢�ڂ�������
Celeron�̉��i�ُ͈�
�K�����i��3�{���炢�ڂ�������
K7�͌���B
K8�͂��̉��ǁB
K6������Ȃ�ɗD�G�������Ǝv���B
3dnow!(K6-2)���2���L���b�V������(K6-3)���B
�����b�ɂȂ�܂����B
PC-9801DA��CPU�A�N�Z�����[�^�iEUD-HP0M�j�����āA
Windows95���g���Ă����̂͗ǂ��v���o�ł��B
����Cyrix�ł��~���������̂́A�閧�ł��E�E�E
K8�͂��̉��ǁB
K6������Ȃ�ɗD�G�������Ǝv���B
3dnow!(K6-2)���2���L���b�V������(K6-3)���B
�����b�ɂȂ�܂����B
PC-9801DA��CPU�A�N�Z�����[�^�iEUD-HP0M�j�����āA
Windows95���g���Ă����̂͗ǂ��v���o�ł��B
����Cyrix�ł��~���������̂́A�閧�ł��E�E�E
�y�j��
>>65
�ō��͉��g���Ă�́H
�ō��͉��g���Ă�́H
>>67
AMD�Ȃ�
Athlon 64 x2 4400+ : ???
Athlon 64 3200+(754) : �d��(�ėpCAD)
Turion 64 (MT-34) : proxy&ud
�g�p�p�x��VIA C3,C7�����|�I�ɑ������ǁE�E�E
C3�ł�ud�����X�ƏI���Ȃ��̂�Turion�ɕύX�B
AMD�Ȃ�
Athlon 64 x2 4400+ : ???
Athlon 64 3200+(754) : �d��(�ėpCAD)
Turion 64 (MT-34) : proxy&ud
�g�p�p�x��VIA C3,C7�����|�I�ɑ������ǁE�E�E
C3�ł�ud�����X�ƏI���Ȃ��̂�Turion�ɕύX�B
�c�O�Ȃ���Intel��mmx Pentium 266��120��libretto�����Ȃ������E�E�E
���[�[���~����
��Ȃ�5��
>Rev. G�͐v���ς����̂́A�e���j�b�g�̃Z���u���b�N�̔䗦�͂���قǕω����Ă��Ȃ��B
>���̂��߁A���s���j�b�g�𑝂₷�Ƃ��������{�I�ȉ��v���s�Ȃ�ꂽ�\���͏��Ȃ��B
>�����܂Ń}�C�i�[�`�F���W�����ARev. F�܂ł̃R�A�����V���ꂽK8�A���ꂪRev. G�Ƃ������ƂɂȂ�B
>���̂��߁A���s���j�b�g�𑝂₷�Ƃ��������{�I�ȉ��v���s�Ȃ�ꂽ�\���͏��Ȃ��B
>�����܂Ń}�C�i�[�`�F���W�����ARev. F�܂ł̃R�A�����V���ꂽK8�A���ꂪRev. G�Ƃ������ƂɂȂ�B
>>74
�܂�C���e���Ɛ키�ɂ�Athlon64 X2 3.2GHz(TDP140W)���K�v�Ƃ����킯��
�܂�C���e���Ɛ키�ɂ�Athlon64 X2 3.2GHz(TDP140W)���K�v�Ƃ����킯��
�㓡�͍����������ɉB�����܉]�X�����悤�ȓz����Ȃ��Ǝv������
�Ȃ�炩�̂�����ۂ����͕����Ă邯�ǁA���͂܂������Ȃ����Ă��ƂȂ낤��
�Ȃ�炩�̂�����ۂ����͕����Ă邯�ǁA���͂܂������Ȃ����Ă��ƂȂ낤��
ܸö
>75 �͓��{��������ɓǂ߂Ȃ��̂��B
> ��3����̘c�݃V���R��(Strained Silicon)�g�����W�X�^�ŁA�ʏ�̃g�����W�X�^���
> 42%��(�����[�N�d���̏ꍇ)�̃p�t�H�[�}���X��B������Ƃ����B�g�����W�X�^��
> �X�C�b�`���O��42%�����Ȃ�A���̕��ACPU�̍��N���b�N�����\�ɂȂ�B���邢�́A
> ���p�t�H�[�}���X�Ȃ����d�͂������邱�Ƃ��\�ɂȂ�B
> ��3����̘c�݃V���R��(Strained Silicon)�g�����W�X�^�ŁA�ʏ�̃g�����W�X�^���
> 42%��(�����[�N�d���̏ꍇ)�̃p�t�H�[�}���X��B������Ƃ����B�g�����W�X�^��
> �X�C�b�`���O��42%�����Ȃ�A���̕��ACPU�̍��N���b�N�����\�ɂȂ�B���邢�́A
> ���p�t�H�[�}���X�Ȃ����d�͂������邱�Ƃ��\�ɂȂ�B
>>78
���\���オ��Ȃ��Ȃ�N���b�N���グ�Ȃ��ƕ�����A
�N���b�N���グ��Ə���d�͂�������B
�ŁARev.G�͓��N���b�N��F��菭������d�͂�������B
�Ƃ����Ӗ����ǂ݂Ƃ�܂��A�����ł����B
Athlon64 X2 3.2GHz(TDP160W)����140W�̕����}�V����
���\���オ��Ȃ��Ȃ�N���b�N���グ�Ȃ��ƕ�����A
�N���b�N���グ��Ə���d�͂�������B
�ŁARev.G�͓��N���b�N��F��菭������d�͂�������B
�Ƃ����Ӗ����ǂ݂Ƃ�܂��A�����ł����B
Athlon64 X2 3.2GHz(TDP160W)����140W�̕����}�V����
�Ƃ������A�u�ʏ�̃g�����W�X�^���42%���v�Ƃ����̂�������������h���B
��X2�Ɏg���Ă���g�����W�X�^�͒ʏ�̃g�����W�X�^��肸���ƍ����Ȃ̂�����A
����Ƃ̔�r�ŕ\������Ƃǂ��Ȃ�̂��낤�H
��X2�Ɏg���Ă���g�����W�X�^�͒ʏ�̃g�����W�X�^��肸���ƍ����Ȃ̂�����A
����Ƃ̔�r�ŕ\������Ƃǂ��Ȃ�̂��낤�H
Athlon64 X2 3.2GHz(TDP65W)
�@���sAMD�̃g�����W�X�^�ƕ��ʂ̃g�����W�X�^�Ƃ̍��ɂ��Ď�����T���̂��ʓ|������
MAC�I�^�����҂��Ă����ł����H
MAC�I�^�����҂��Ă����ł����H
���s��Dual Stress Liner���Ă̂͂��ꂾ���
http://pc.watch.impress.co.jp/docs/2004/1213/amdibm.htm
http://pcweb.mycom.co.jp/articles/2004/12/16/iedm2/
��������24%������A�P���v�Z����142/124=1.145��
2�c�݁�4�c�݂�14.5%����
���ۂ͂ǂ����ȁH
42%�����̘b��IEDM2005��4�c�݂̔��\�����l�^
http://pcweb.mycom.co.jp/articles/2005/12/07/iedm4/
http://pc.watch.impress.co.jp/docs/2004/1213/amdibm.htm
http://pcweb.mycom.co.jp/articles/2004/12/16/iedm2/
��������24%������A�P���v�Z����142/124=1.145��
2�c�݁�4�c�݂�14.5%����
���ۂ͂ǂ����ȁH
42%�����̘b��IEDM2005��4�c�݂̔��\�����l�^
http://pcweb.mycom.co.jp/articles/2005/12/07/iedm4/
HyperTransport 3.0�̐�`�������B
http://www.hypertransport.org/docs/tech/ht30pres.pdf
�@�EAC���[�h�ڑ��ŃV�X�e���ԃC���^�R�l�N�g���T�|�[�g
�@�EHTX�K�i�Ŋg���{�[�h���T�|�[�g
�@�E�ő�2.6GHz�̃N���b�N, �o�X����ő�32-bit�Ɋg���B�ő�o���h����41.6GB/s (�o�������v)
�R�A�ł̏�����I�グ�ɂ��Ĥ�C���^�R�l�N�g�ŏ��������������ƌ����邷�B
�Z�p�v�V�̏�Ƃ��Ĥ�N���b�N�㏸���ꂵ���Ȃ����V���A���o�X���礃V���A�� -> �p�������̗h��߂���
����̂��ǂ����풍�ڂ��B
http://www.hypertransport.org/docs/tech/ht30pres.pdf
�@�EAC���[�h�ڑ��ŃV�X�e���ԃC���^�R�l�N�g���T�|�[�g
�@�EHTX�K�i�Ŋg���{�[�h���T�|�[�g
�@�E�ő�2.6GHz�̃N���b�N, �o�X����ő�32-bit�Ɋg���B�ő�o���h����41.6GB/s (�o�������v)
�R�A�ł̏�����I�グ�ɂ��Ĥ�C���^�R�l�N�g�ŏ��������������ƌ����邷�B
�Z�p�v�V�̏�Ƃ��Ĥ�N���b�N�㏸���ꂵ���Ȃ����V���A���o�X���礃V���A�� -> �p�������̗h��߂���
����̂��ǂ����풍�ڂ��B
�g�����W�X�^�̃X�C�b�`���O���x���い�����N���b�N���ゾ��
�����g�����W�X�^�g���Ă��A�z���x���Ƃ��N���b�N���z�Ƃ�
���̑��v��̓���ȂŁA�g�����W�X�^�̑��x���㕪�قǂ�
�����Ȃ�Ȃ�
�g�����W�X�^�x���ƃN���b�N����Ⴗ�������
�K���E����fCPU�Ƃ��o���Ă邾��
�����g�����W�X�^�g���Ă��A�z���x���Ƃ��N���b�N���z�Ƃ�
���̑��v��̓���ȂŁA�g�����W�X�^�̑��x���㕪�قǂ�
�����Ȃ�Ȃ�
�g�����W�X�^�x���ƃN���b�N����Ⴗ�������
�K���E����fCPU�Ƃ��o���Ă邾��
�G���x���f�b�h�N���b�N�Ƃ��ʑ��������ĂȂ�����
�N���b�N�������Ȃ���
�x�m�ʂ�PRIMEPOWER�̃o�X���ƁA�V���O���G���h�z����60cm��
1.3Ghz���o�Ă邩��A�����悤�Ǝv����
�܂��܂�������ł��A�o�X�̃N���b�N�͂�������
������ł������Ă��A5�`10Ghz���x������
�N���b�N�������Ȃ���
�x�m�ʂ�PRIMEPOWER�̃o�X���ƁA�V���O���G���h�z����60cm��
1.3Ghz���o�Ă邩��A�����悤�Ǝv����
�܂��܂�������ł��A�o�X�̃N���b�N�͂�������
������ł������Ă��A5�`10Ghz���x������
�Ƃ���ŁA��CMOS&�|���V���R���̏I�����Ă�������?
�j�b�P���t���V���T�C�h�Ƃ��A�C���W�E���A���`��������
�R�X�g��W�ϓx�͂ǂ��Ȃ낤?
�܂������m��܂���ł�
�j�b�P���t���V���T�C�h�Ƃ��A�C���W�E���A���`��������
�R�X�g��W�ϓx�͂ǂ��Ȃ낤?
�܂������m��܂���ł�
>>86
�͂Ȃ����猩�����̂��ړI�Ől�𒎌Ă�肷��悤�ȓz�Ɍh�ӂ������悤�ȃo�J�����邩�B
�͂Ȃ����猩�����̂��ړI�Ől�𒎌Ă�肷��悤�ȓz�Ɍh�ӂ������悤�ȃo�J�����邩�B
�N�A�b�h�R�Ax4��16�R�A�ƂȂ�ƁAHT3.0�ł�����Ȃ��Ȃ肻����
������������������
����ł�Intel���͈��|�I�ɑ�������A�����Opteron��Xeon��H�������邾�낤��
������������������
����ł�Intel���͈��|�I�ɑ�������A�����Opteron��Xeon��H�������邾�낤��
���������ď��Ƃ������m��Ȃ����ǁA����CMOS�Ȃ�čŏ���10�N���炢�ŏI������Ǝv���B
�@FPGA�v�ӂƂ���Celoxica�ЂƃR�v���Z�b�T�J���̕�DRC Computer�Ђ��A
�n�C�G���h�E���[�N�X�e�[�V�����Ɍ�����AMD Opteron�v���Z�b�T�������\������
�R�v���Z�b�T�E���W���[���̒Œ�g�����B
���Ђ́A�u�]���̃\�t�g�E�G�A�E�A�N�Z�����[�V�����Z�p�ɔ�ׂāAOpteron�v���Z�b�T��
���\��300�{���߂���v�Ǝ咣���Ă���B
���Ђ��J�������R�v���Z�b�T�E���W���[���́AOpteron�p�ɊJ�����ꂽHyperTransport
�Z�p�𓋍ڂ����C���^�[�t�F�[�X�ɒ��ڐڑ������B����ɂ���āA��x���ł̓����
AMD Opteron�v���Z�b�T��DRC�R�v���Z�b�T�Ԃł̎����̋��L���\�ɂ���B
�@���Ђɂ��ƁA�u�ڕW�́A������v���O���}�u���E�n�[�h�E�G�A�E�A�[�L�e�N�`����
����ăv���Z�b�T�̕��ׂ̌y�������݂��ۂɑ������ƂȂ����f�[�^�]���̃{�g���l�b�N
���������邱�Ƃ��v�Ƃ����B
http://www.ednjapan.com/content/l_news/2006/04/26_01.html
�n�C�G���h�E���[�N�X�e�[�V�����Ɍ�����AMD Opteron�v���Z�b�T�������\������
�R�v���Z�b�T�E���W���[���̒Œ�g�����B
���Ђ́A�u�]���̃\�t�g�E�G�A�E�A�N�Z�����[�V�����Z�p�ɔ�ׂāAOpteron�v���Z�b�T��
���\��300�{���߂���v�Ǝ咣���Ă���B
���Ђ��J�������R�v���Z�b�T�E���W���[���́AOpteron�p�ɊJ�����ꂽHyperTransport
�Z�p�𓋍ڂ����C���^�[�t�F�[�X�ɒ��ڐڑ������B����ɂ���āA��x���ł̓����
AMD Opteron�v���Z�b�T��DRC�R�v���Z�b�T�Ԃł̎����̋��L���\�ɂ���B
�@���Ђɂ��ƁA�u�ڕW�́A������v���O���}�u���E�n�[�h�E�G�A�E�A�[�L�e�N�`����
����ăv���Z�b�T�̕��ׂ̌y�������݂��ۂɑ������ƂȂ����f�[�^�]���̃{�g���l�b�N
���������邱�Ƃ��v�Ƃ����B
http://www.ednjapan.com/content/l_news/2006/04/26_01.html
>>94
������940�ł�����Ȃ�AAM2������
2xx��Opteron�ɓ]�����Ă��ǂ���������Ȃ��B
�\�t�g���ǂ�قǑΉ����邩����肾���E�E�E
������940�ł�����Ȃ�AAM2������
2xx��Opteron�ɓ]�����Ă��ǂ���������Ȃ��B
�\�t�g���ǂ�قǑΉ����邩����肾���E�E�E
> �v���O���}�[�́ACeloxica�Ђ�����g���Ղ��v���O���~���O���𗘗p���邱�ƂŁA�n�[�h�E�G�A�E�A�N�Z�����[�V�����̌o�ϓI����ыZ�p�I�ȗD�ʐ�������ł��������邱�ƂɂȂ�
�܂�\�t�g�̑Ή����s���B
��ʓI����Ȃ��ȁB
�܂�\�t�g�̑Ή����s���B
��ʓI����Ȃ��ȁB
���R���t�B�M���A���u���v���Z�b�T����
�N���b�N���Ⴂ����A�ėpCPU�ɏ��Ă镪���
���ĂȂ����삪�o�Ă���
�N���b�N���Ⴂ����A�ėpCPU�ɏ��Ă镪���
���ĂȂ����삪�o�Ă���
�R�v�������z����HyperTransport 3.0�����c
>>98
�ш�̖�肩��A�R�v���Ȃ��ł�HT3.0�̈ڍs�͕K�{����
�����ACPU�ȊO�ɂ�CC���J������
�R�v���������ł���悤�ɂ����A��
�ш�̖�肩��A�R�v���Ȃ��ł�HT3.0�̈ڍs�͕K�{����
�����ACPU�ȊO�ɂ�CC���J������
�R�v���������ł���悤�ɂ����A��
>>99
AM2�̑ш挩��Ɖ��Ƃ������Ȃ��C�����邪�c
�������z���g��Socket�{�g���I���Ȃȁc
ttp://www.drccomputer.com/pdfs/DRC_datasheet_2.2sm.pdf
AM2�̑ш挩��Ɖ��Ƃ������Ȃ��C�����邪�c
�������z���g��Socket�{�g���I���Ȃȁc
ttp://www.drccomputer.com/pdfs/DRC_datasheet_2.2sm.pdf
Fab 36�̃��X�N�ƃ`�����X
http://pc.watch.impress.co.jp/docs/2006/0427/kaigai265.htm
http://pc.watch.impress.co.jp/docs/2006/0427/kaigai265.htm
�gCPU 1����PC�s��V�F�A40%�h AMD���n�߂�25���h���̑�o�N�`�̗��R
http://pc.watch.impress.co.jp/docs/2006/0428/kaigai266.htm
http://pc.watch.impress.co.jp/docs/2006/0428/kaigai266.htm
���̃R�v����X�ł�������5Ͽ�`10Ͽ�ʂŏo�Ă���Ȃ����ȁE�E
�G���R��烌���_��牽���Ɩ��ɗ��������B���Ă��R���ς�PC1��łȂ�ł�
�o�������ȷ�
�G���R��烌���_��牽���Ɩ��ɗ��������B���Ă��R���ς�PC1��łȂ�ł�
�o�������ȷ�
�Ή��A�v���P�[�V�������A�����������������肵�ĂȁI
��������300�{�ɉ�������̂��I�H��ު�ȁI�I
940��OK�̂悤�ł��ȁE�E�E
����s��ɂ͏o���낤���ǁB
OS��linux���B
��͂�Z�p�Ҍ����ˁB
����s��ɂ͏o���낤���ǁB
OS��linux���B
��͂�Z�p�Ҍ����ˁB
������������������������������������������
���@�@�@�@�@�@�@�@�@�@�@�@ �@���@�@�@�@�@�@�@�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@�@�@�@�@�@ ���@�@�@�@�@�@�@�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@�@�@�@�@ �@���@�@�@�@�@�@�@�@�@�@�@�@�@ ��
�@�@���@�@�@�@�@�@�@�@�@�@ �@���@�@�@�@�@�@�@�@�@�@�@ ��
�@�@�@�@���@�@�@�@�@�@�@�@�@���@�@ �@�@�@�@�@�@�@ ��
�@�@�@�@�@�@���@�@�@�@�@�@ ���@ �@�@�@�@�@�@ �� �@�@�@�@�@�Q�Q�i "''''''::::.
�@�@�@�@�@ �@�@���@�@�@�@�� ���@�@ �@�@ �� ____,,,,,,---'''''''"""" �R �@�@�J�J:�R
�@�@�@�@�@�@�@�@�@���@ ���@�@ �@���@ ��:""""�@�@�E�@�@�@�@�E�@�@. �_::.�@�@ ���G�`�f�����`�C�X�@�G�`�f�����`�C�X
�@�@�@�@�@�@�@�@�@�@�� ���@�@�@�@�� ��::: �@�@�@�@�@�@ �E......::::::::::::�c''�::::....�m
�@�@�@�@�@�@�@�@�@�@�@���@�@�@�@�@�@ �� ::::::::::;;;;;,,---"""
�@�@�@�@�@�@�@�@�@�@�@�@����������
���@�@�@�@�@�@�@�@�@�@�@�@ �@���@�@�@�@�@�@�@�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@�@�@�@�@�@ ���@�@�@�@�@�@�@�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@�@�@�@�@ �@���@�@�@�@�@�@�@�@�@�@�@�@�@ ��
�@�@���@�@�@�@�@�@�@�@�@�@ �@���@�@�@�@�@�@�@�@�@�@�@ ��
�@�@�@�@���@�@�@�@�@�@�@�@�@���@�@ �@�@�@�@�@�@�@ ��
�@�@�@�@�@�@���@�@�@�@�@�@ ���@ �@�@�@�@�@�@ �� �@�@�@�@�@�Q�Q�i "''''''::::.
�@�@�@�@�@ �@�@���@�@�@�@�� ���@�@ �@�@ �� ____,,,,,,---'''''''"""" �R �@�@�J�J:�R
�@�@�@�@�@�@�@�@�@���@ ���@�@ �@���@ ��:""""�@�@�E�@�@�@�@�E�@�@. �_::.�@�@ ���G�`�f�����`�C�X�@�G�`�f�����`�C�X
�@�@�@�@�@�@�@�@�@�@�� ���@�@�@�@�� ��::: �@�@�@�@�@�@ �E......::::::::::::�c''�::::....�m
�@�@�@�@�@�@�@�@�@�@�@���@�@�@�@�@�@ �� ::::::::::;;;;;,,---"""
�@�@�@�@�@�@�@�@�@�@�@�@����������
conroe�ɂ��Ă�ȁ[
65nm�ɂȂ�Α����͂�荇���������
����܂őҋ@
����܂őҋ@
65nm�ɂȂ��Ă��S�R�����B
������Ɣ߂����Ȃ鎖���E�E�E
������Ɣ߂����Ȃ鎖���E�E�E
����ϑ��Y�Œl�i��������̂��ˁB
���炭�����T�����悤����
���炭�����T�����悤����
�R�����[���o��O��fab���������Ă���Ηǂ������̂�
�㓡����AMD������l�^���B
http://pc.watch.impress.co.jp/docs/2006/0503/kaigai267.htm
��������̕ӂ�3�����Â��l�^���Ǝv�������Ǥ�Z�p�I���e�𗝉����Ă��Ȃ����n���C�^�[����Ƃ��Ă�
�d�����������ƂȂ̂�������Ȃ����B
�@�@------------------------------
�@�@�����āA�����炭��CPU�J���̕����������Ȃ�ς��Ă���BAMD�̍ŋ߂�CPU�A�[�L�e�N�`���W��
�@�@�v���[���e�[�V�����ł́A���������|�C���g��CPU�R�A�̃}�C�N���A�[�L�e�N�`���̊g������A����
�@�@�ȊO�̕����ւƍL�����Ă���B���̃X���C�h��������ے����Ă���B
�@�@[����]
�@�@�����āAAMD�͂��̂Ƃ���A�R�v���Z�b�T�����p�r�����̃A�N�Z�����[�^�̉\���ɂ��Č��y����
�@�@���Ƃ������Ȃ��Ă���B���́A2005�N11����Micro-38�J���t�@�����X��AMD��Chuck Moore��
�@�@(AMD Senior Fellow)���s�Ȃ����v���[���e�[�V�����̈ꕔ���B������������������ƁAAMD������p�r
�@�@�����̃R�v���Z�b�T��A�N�Z�����[�^�Ƃ��̓�����^���ɍl���Ă��邱�Ƃ��悭�킩��B
�@�@������AMD CPU�̃A�[�L�e�N�`���͂��Ȃ荡�Ƃ͈�����p�ɂȂ�\��������B
�@�@------------------------------
�����ӂ̃��[�N�l�^�n�ł���f�X�N�g�b�v�ւ�4-core�̓�����2008�N�ɂȂ�Ƃ������ƂŤKentsfiled����1�N
�x�ꂷ�B�A�����́uKentsfield�킭�����������I�v����FUD�Ɉ�N�ԔY�܂���邱�ƂɂȂ肻�����B�B�B
�@�@------------------------------
�@�@2008�N�ɂ̓f�X�N�g�b�v�����̃N�A�b�h�R�A�uGreyhound(�O���C�n�E���h=Athlon 64 X4?)�v���������錩���݂��B
�@�@------------------------------
http://pc.watch.impress.co.jp/docs/2006/0503/kaigai267.htm
��������̕ӂ�3�����Â��l�^���Ǝv�������Ǥ�Z�p�I���e�𗝉����Ă��Ȃ����n���C�^�[����Ƃ��Ă�
�d�����������ƂȂ̂�������Ȃ����B
�@�@------------------------------
�@�@�����āA�����炭��CPU�J���̕����������Ȃ�ς��Ă���BAMD�̍ŋ߂�CPU�A�[�L�e�N�`���W��
�@�@�v���[���e�[�V�����ł́A���������|�C���g��CPU�R�A�̃}�C�N���A�[�L�e�N�`���̊g������A����
�@�@�ȊO�̕����ւƍL�����Ă���B���̃X���C�h��������ے����Ă���B
�@�@[����]
�@�@�����āAAMD�͂��̂Ƃ���A�R�v���Z�b�T�����p�r�����̃A�N�Z�����[�^�̉\���ɂ��Č��y����
�@�@���Ƃ������Ȃ��Ă���B���́A2005�N11����Micro-38�J���t�@�����X��AMD��Chuck Moore��
�@�@(AMD Senior Fellow)���s�Ȃ����v���[���e�[�V�����̈ꕔ���B������������������ƁAAMD������p�r
�@�@�����̃R�v���Z�b�T��A�N�Z�����[�^�Ƃ��̓�����^���ɍl���Ă��邱�Ƃ��悭�킩��B
�@�@������AMD CPU�̃A�[�L�e�N�`���͂��Ȃ荡�Ƃ͈�����p�ɂȂ�\��������B
�@�@------------------------------
�����ӂ̃��[�N�l�^�n�ł���f�X�N�g�b�v�ւ�4-core�̓�����2008�N�ɂȂ�Ƃ������ƂŤKentsfiled����1�N
�x�ꂷ�B�A�����́uKentsfield�킭�����������I�v����FUD�Ɉ�N�ԔY�܂���邱�ƂɂȂ肻�����B�B�B
�@�@------------------------------
�@�@2008�N�ɂ̓f�X�N�g�b�v�����̃N�A�b�h�R�A�uGreyhound(�O���C�n�E���h=Athlon 64 X4?)�v���������錩���݂��B
�@�@------------------------------
�Ă̒褃A�����̉Εa�R�s�y���n�܂������B
http://pc7.2ch.net/test/read.cgi/jisaku/1146411194/303
�@�@---------------------------
�@�@303 ���O�FSocket774 ���e���F2006/05/03(��) 14:25:40 ID:Rwy4Gb4p
�@�@�@�@�@ �@||
�@�@�@�@�@In ||��
�@�@�@�@�i�@ �� �R
�@�@�@�@�@���@�@�
�@�@�@�@��A����
�@�@�@�@ �i�E�́E| |�@�ˮ�
�@�@�@ �@ RevG |
�@�@�@�@��A����
�@�@�@�@ �i�E�́E| |�@�ˮ�
�@�@�@ �@ |�V�R�A|
�@�@�@ ����____�m
�@�@�@�@�@�@�@�@�@�c
�@�@�N�A�b�h�R�ACPU��2�i�K��������AMD�̃��[�h�}�b�v
�@�@http://pc.watch.impress.co.jp/docs/2006/0503/kaigai267.htm
�@�@---------------------------
http://pc7.2ch.net/test/read.cgi/jisaku/1146411194/303
�@�@---------------------------
�@�@303 ���O�FSocket774 ���e���F2006/05/03(��) 14:25:40 ID:Rwy4Gb4p
�@�@�@�@�@ �@||
�@�@�@�@�@In ||��
�@�@�@�@�i�@ �� �R
�@�@�@�@�@���@�@�
�@�@�@�@��A����
�@�@�@�@ �i�E�́E| |�@�ˮ�
�@�@�@ �@ RevG |
�@�@�@�@��A����
�@�@�@�@ �i�E�́E| |�@�ˮ�
�@�@�@ �@ |�V�R�A|
�@�@�@ ����____�m
�@�@�@�@�@�@�@�@�@�c
�@�@�N�A�b�h�R�ACPU��2�i�K��������AMD�̃��[�h�}�b�v
�@�@http://pc.watch.impress.co.jp/docs/2006/0503/kaigai267.htm
�@�@---------------------------
���̎����ɔ�r�ΏۂƂ���NetBurst���o���Ă���̂͐����A����ȁB
�tHyperThreading�ɂ͋������邯�ǁA���̘b��ˁ[��
�tHyperThreading�ɂ͋������邯�ǁA���̘b��ˁ[��
�R�v�����L�[�ƂȂ��AMD�B
�Z�p�I���e�𗝉����Ă��Ȃ����n=MAC�I�^
�㓡���̌������[�h�}�b�v�}�̃\�[�X��hkepc���o���Ă������B�[���㓡���������܂���̋L����~�߂�
�ǂ��܂ł��\�[�X�̏����悤�ɤ�\�[�X������b����v���[�������̂܂܃A�b�v���ė~�������̂��B
http://www.hkepc.com/bbs/news.php?tid=593736
�����Ȃ̂�����LL2����̌�Ɂu���LL3��Ȃ�ď����Ă��邱�Ƃ��B���LL2�̉��̊K�w�ɔL
L3��u�����R��F��������B�B�B
�܂��v���[���ɕt���Ă��`���������狖�e����Ƃ��Ĥ�ڂ������Z�p����̃��C�^�[�𖼏��q�g������e��
���̂܂܈����ʂ��ŋL���ɂ���̂�������肷�B
�ǂ��܂ł��\�[�X�̏����悤�ɤ�\�[�X������b����v���[�������̂܂܃A�b�v���ė~�������̂��B
http://www.hkepc.com/bbs/news.php?tid=593736
�����Ȃ̂�����LL2����̌�Ɂu���LL3��Ȃ�ď����Ă��邱�Ƃ��B���LL2�̉��̊K�w�ɔL
L3��u�����R��F��������B�B�B
�܂��v���[���ɕt���Ă��`���������狖�e����Ƃ��Ĥ�ڂ������Z�p����̃��C�^�[�𖼏��q�g������e��
���̂܂܈����ʂ��ŋL���ɂ���̂�������肷�B
�㓡�����L���������Ɛ�����
hkepc���o���s���̃��[�h�}�b�v���ڂ���ƃ\�[�X�ł���?
hkepc���o���s���̃��[�h�}�b�v���ڂ���ƃ\�[�X�ł���?
> ���LL2�̉��̊K�w�ɔLL3��u�����R��F��������
�����w
�����w
>>118
>Zamora�ł�L3�L���b�V�������L����ƌ����Ă���B���̂��߁A�����炭L2�̓R�A����
>�Ɨ����Ĕ����AL3���������L����A�[�L�e�N�`���ɂȂ�Ɛ��肳���B
����̎����H
>Zamora�ł�L3�L���b�V�������L����ƌ����Ă���B���̂��߁A�����炭L2�̓R�A����
>�Ɨ����Ĕ����AL3���������L����A�[�L�e�N�`���ɂȂ�Ɛ��肳���B
����̎����H
>>121
> �����[�����ƂɁAAMD��Deerhound�ł�L3���������L�ɂȂ�Ƃ͌����Ă��Ȃ��炵���B
> ���̂��߁ADeerhound�ł�L2�L���b�V�������L�ɂ��āA�S�̂̃L���b�V���ʂ�ߖ��\��������B
���̂��Ƃ���H
�o�J�Ȕ����ł����Ȃ��B
> �����[�����ƂɁAAMD��Deerhound�ł�L3���������L�ɂȂ�Ƃ͌����Ă��Ȃ��炵���B
> ���̂��߁ADeerhound�ł�L2�L���b�V�������L�ɂ��āA�S�̂̃L���b�V���ʂ�ߖ��\��������B
���̂��Ƃ���H
�o�J�Ȕ����ł����Ȃ��B
�܂�MAC�I�^�Ƃ��̏����L�����ꂽ���B
��s�ōςނƂ�������X�ɒ@�������肪Intel�M�҂̉����悭�����Ă���B
��s�ōςނƂ�������X�ɒ@�������肪Intel�M�҂̉����悭�����Ă���B
L2���L���O������̏ꍇ�AL3�����L���ۂ����c�_������m����
�A�z�����A�㓡���̋L���̕��́A��������Ȃ�����B
L3���L���O������ŁAL2�����L�ɂȂ邩���Ƃ����b�̗���Ȃ�
������A�ʂɂǂ������������Ȃ��B
Intel������X���ŁA���m������w�E���ꂽ����A��������
�X���ŃA�C�f���e�B�e�B�̉�}���Ă�̂��ȁB���̂�������
����Ɍ�ǂ��ď���ɔn���ɂ�����āA�{���̔n���ł��Ȃ��B
�A�z�����A�㓡���̋L���̕��́A��������Ȃ�����B
L3���L���O������ŁAL2�����L�ɂȂ邩���Ƃ����b�̗���Ȃ�
������A�ʂɂǂ������������Ȃ��B
Intel������X���ŁA���m������w�E���ꂽ����A��������
�X���ŃA�C�f���e�B�e�B�̉�}���Ă�̂��ȁB���̂�������
����Ɍ�ǂ��ď���ɔn���ɂ�����āA�{���̔n���ł��Ȃ��B
MAC�I�^�̃J�L�R���R�s�y����̂�߂Ă���B�����A�����ڂĂ�Ӗ����Ȃ�����Ȃ����B
�i�㓡�j
07�����P�@ L2�L�@L3�L
07�\���@ L2���L�@L3�L
08�����@L2�L�@L3���L
07�\������08�����Ɉڍs����\�������e���Ă���
�̂́A���������ƌ������������B
(HKEPC)
07�@L2���L�@L3�L�ڂ��Ȃ�����ڂƎv���Ă�͂�
08�@L2�L�ڂ͂Ȃ������L�Ǝv���Ă���͂��@L3���L
07�����P�@ L2�L�@L3�L
07�\���@ L2���L�@L3�L
08�����@L2�L�@L3���L
07�\������08�����Ɉڍs����\�������e���Ă���
�̂́A���������ƌ������������B
(HKEPC)
07�@L2���L�@L3�L�ڂ��Ȃ�����ڂƎv���Ă�͂�
08�@L2�L�ڂ͂Ȃ������L�Ǝv���Ă���͂��@L3���L
����
07�͗����Ƃ�L3���L�ł����B
07�͗����Ƃ�L3���L�ł����B
> ����
> 07�͗����Ƃ�L3���L�ł����B
����B������A�S�R���������Ȃ��B
�ǂ��������A��������Mac���^�݂����Ȍ�ǂ��ł���H
Mac���^�́A���g�̕Ό��Ɩ�������L�q�́A��ǂ��邩�ԈႢ��
���߂��邩�����ł��Ȃ����z�ȓz������A�܂��d���Ȃ����B
> 07�͗����Ƃ�L3���L�ł����B
����B������A�S�R���������Ȃ��B
�ǂ��������A��������Mac���^�݂����Ȍ�ǂ��ł���H
Mac���^�́A���g�̕Ό��Ɩ�������L�q�́A��ǂ��邩�ԈႢ��
���߂��邩�����ł��Ȃ����z�ȓz������A�܂��d���Ȃ����B
�����Mac���^�̎w�E�Ƃ͕ʂ̘b���ȁB
���L�ƔL�̂ǂ��炪�D��Ă��邩�́A�A�v���P�[�V������
��ނɈˑ����Ă��āA�K�������ǂ��炪�悢�Ƃ͌����Ȃ����B
�e�R�A�œ����A�v���P�[�V����������Ȃ������L�L���b�V��
�̕����ǂ����A�S���قȂ�A�v���P�[�V����������ꍇ�A����
����̃A�v���P�[�V�����̃��[�L���O�Z�b�g���傫���A�L���b�V��
���Ђǂ���L���Ă��܂��ꍇ�ȂǁA�L�̕����ǂ����Ƃ�����B
������A�K���������������Ƃ͌����Ȃ��Ǝv�����ǂ��H
���L�ƔL�̂ǂ��炪�D��Ă��邩�́A�A�v���P�[�V������
��ނɈˑ����Ă��āA�K�������ǂ��炪�悢�Ƃ͌����Ȃ����B
�e�R�A�œ����A�v���P�[�V����������Ȃ������L�L���b�V��
�̕����ǂ����A�S���قȂ�A�v���P�[�V����������ꍇ�A����
����̃A�v���P�[�V�����̃��[�L���O�Z�b�g���傫���A�L���b�V��
���Ђǂ���L���Ă��܂��ꍇ�ȂǁA�L�̕����ǂ����Ƃ�����B
������A�K���������������Ƃ͌����Ȃ��Ǝv�����ǂ��H
131 �FMAC�I�^��126 �����F2006/05/04(��) 19:35:48 ID:C0eJjBUs
>>126
���ǂ̂Ƃ��뤂ǂ��܂ł����łǂ����炪�i������)�����Ȃ̂����m�ɂȂ��Ă��Ȃ��̂���肷�B
�Q�l�܂ł�(���܂�Ҏ҂̐����������ĂȂ��Ǝv����)HKEPC�L���̖|��������Ă������B
�@�@-------------------------
�@�@�@��p�̗��ʋ̃\�[�X�ͤ�ŋ�AMD���v���Z�b�T���[�h�}�b�v���X�V�������Ƃ�`���Ă���B����
�@�@���ΤAMD��Opteron���C���ɐ����4�R�A�v���Z�b�T�̃����[�X���v�悵�Ă���B
�@�@�@�܂��2007�N��2�l�����ɃR�[�h�l�[��"Deerhound"�ƌĂ��65nm�Socket F (LGA 1207�p�b�P�[�W)
�@�@�̃`�b�v�������[�X�\��ł���BDeerfield�̓f���A���`�����l���E���W�X�^�[�hDDR2���������T�|�[�g����
�@�@�������R���g���[����������AMD�Ƃ��Ă͏��̋��LL2�L���b�V������������B
�@�@�@����f�X�N�g�b�v�p��4�R�A�v���Z�b�T��2008�N��1�l�����ȍ~�ɂȂ�B�f�X�N�g�b�v��4�R�A�̓R�[�h
�@�@�l�[��"Greyhound"�ƌĂ꤃}�C�N���A�[�L�e�N�`���̉��ǂƋ���DDR2�����DDR3���������T�|�[�g
�@�@����Socket AM3�Ή��ƂȂ�BGreyhound��Deerhound���l�ɋ��LL2����������C���^�R�l�N�g��Hyper-
�@�@Transport 3�Ɉڍs����B
�@�@�@2008�N�����ɂ͑�2�����4�R�AOpteron�̃����[�X���v�悳��Ă���B"Zamora"�Ƃ����R�[�h�l�[��
�@�@�̐V�R�A�𓋍ڂ������̃v���Z�b�T�ͤFB-DIMM�Hyper Transport 3�Ƌ��ɤAMD���̋��LL3���̗p�����
�@�@�`������B
�@�@-------------------------
�@�@
���ǂ̂Ƃ��뤂ǂ��܂ł����łǂ����炪�i������)�����Ȃ̂����m�ɂȂ��Ă��Ȃ��̂���肷�B
�Q�l�܂ł�(���܂�Ҏ҂̐����������ĂȂ��Ǝv����)HKEPC�L���̖|��������Ă������B
�@�@-------------------------
�@�@�@��p�̗��ʋ̃\�[�X�ͤ�ŋ�AMD���v���Z�b�T���[�h�}�b�v���X�V�������Ƃ�`���Ă���B����
�@�@���ΤAMD��Opteron���C���ɐ����4�R�A�v���Z�b�T�̃����[�X���v�悵�Ă���B
�@�@�@�܂��2007�N��2�l�����ɃR�[�h�l�[��"Deerhound"�ƌĂ��65nm�Socket F (LGA 1207�p�b�P�[�W)
�@�@�̃`�b�v�������[�X�\��ł���BDeerfield�̓f���A���`�����l���E���W�X�^�[�hDDR2���������T�|�[�g����
�@�@�������R���g���[����������AMD�Ƃ��Ă͏��̋��LL2�L���b�V������������B
�@�@�@����f�X�N�g�b�v�p��4�R�A�v���Z�b�T��2008�N��1�l�����ȍ~�ɂȂ�B�f�X�N�g�b�v��4�R�A�̓R�[�h
�@�@�l�[��"Greyhound"�ƌĂ꤃}�C�N���A�[�L�e�N�`���̉��ǂƋ���DDR2�����DDR3���������T�|�[�g
�@�@����Socket AM3�Ή��ƂȂ�BGreyhound��Deerhound���l�ɋ��LL2����������C���^�R�l�N�g��Hyper-
�@�@Transport 3�Ɉڍs����B
�@�@�@2008�N�����ɂ͑�2�����4�R�AOpteron�̃����[�X���v�悳��Ă���B"Zamora"�Ƃ����R�[�h�l�[��
�@�@�̐V�R�A�𓋍ڂ������̃v���Z�b�T�ͤFB-DIMM�Hyper Transport 3�Ƌ��ɤAMD���̋��LL3���̗p�����
�@�@�`������B
�@�@-------------------------
�@�@
���͂���Ȃ��Ƃ��A�l�̕��͂���ǂ��Ă����āA���̌�ǂ�������
�l��n���ɂ���p���̕�����肾�Ǝv����B�܂��A���������������
�����ԈႢ�𑱂��Ă�킯�ŁA�ꐶ����Ȃ��낤���ǂ��B
�l��n���ɂ���p���̕�����肾�Ǝv����B�܂��A���������������
�����ԈႢ�𑱂��Ă�킯�ŁA�ꐶ����Ȃ��낤���ǂ��B
>>130����
�{��e�ʷ������ڲ�ݼ�傫���Ȃ����
�{��e�ʷ������ڲ�ݼ�傫���Ȃ����
>>132
�����Ɉ����Ȃ��Ȃ��������������������Ȃ��H
�����Ɉ����Ȃ��Ȃ��������������������Ȃ��H
�����Ȃ��B�Ԃ����Ⴏ�}�W�����������ė~�����B
�y�j�X�̏������ݑ����Ă��疳�ʃ��X�����B
�y�j�X�̏������ݑ����Ă��疳�ʃ��X�����B
>>134
���O�͎����̉Ƃ̌���ɖ앳������Ă����g���������̂�
���O�͎����̉Ƃ̌���ɖ앳������Ă����g���������̂�
�������������Ă邯���
�����܂ŕ��ʂɌ����Ă�R�e�n������������
�����܂ŕ��ʂɌ����Ă�R�e�n������������
�Ȃ�
�g���������ƌ��킸
���g���������ƌ����Ă����
����Ȃɐӂ߂Ȃ��Ă���������Ȃ�
�g���������ƌ��킸
���g���������ƌ����Ă����
����Ȃɐӂ߂Ȃ��Ă���������Ȃ�
�R�e�n���Ȏ��_�Ŏ��Ȍ����̋����\���ă`����������d���Ȃ�����
�ˑ��Ƃ�vip����ˁ[����R�e��Ӗ����킩���
�ˑ��Ƃ�vip����ˁ[����R�e��Ӗ����킩���
���ꌾ������ǂ��̔ł��R�e�n�������
�ȑO�r�����Ƌ��L�ɏo���Ȃ��Ƃ������Ă�̂�����������
���LL2�ɂ���Ƃ������Ƃ͔r������߂���Ď��ɂȂ�̂��H
���LL2�ɂ���Ƃ������Ƃ͔r������߂���Ď��ɂȂ�̂��H
>>130,133
AMD�̋��L�L���b�V���ɂ̓X�}�[�g�L���b�V���ɊY������悤��
�@�\�͕t���ĂȂ��Ƃ������A�v���������Ȃ������̂œ����t���Ȃ����Ă��ƁH
AMD�̋��L�L���b�V���ɂ̓X�}�[�g�L���b�V���ɊY������悤��
�@�\�͕t���ĂȂ��Ƃ������A�v���������Ȃ������̂œ����t���Ȃ����Ă��ƁH
�l�`�b�I�^�͈ꎞ���o�b�Q�[�ɋ����A�ɂ����̐��_�ُ��
>>113��>>118�̋L���̂悤�ɤAMD��4-core�̃f�X�N�g�b�v�ł������[�X����̂�Intel����1�N�x��ɂȂ�
�ƌ����Ă��邷���Ǥ���̗��R�Ƃ��Ĉ�ʌ������r���[�T�C�g�Ŏ��グ����Q�[���x���`���Ńf���A��
�R�A���i�ƍ����o�Ȃ��Ƃ����b���o�Ă��邷�B
���Ƃ��ĤAnandTech�̃��C�^�[�Johan de Gelas��AcesHardware�f���̓��e�����p���B
http://www.aceshardware.com/forums/read_post.jsp?id=115163394&forumid=1
�@�@------------------------
�@�@And what are the uses of third and fourth core of Kentsfield on the desktop? Right now, even
�@�@the most advanced game engines in development make only use of two CPUs. (If there is an
�@�@exception, tell me)
�@�@------------------------
�V�Z�p�̌�������Intel�ɂ܂����Ĥ�������������������������Ƃ����̂�������ɂ�AMD�炵�����������ǁB�B�B
�ƌ����Ă��邷���Ǥ���̗��R�Ƃ��Ĉ�ʌ������r���[�T�C�g�Ŏ��グ����Q�[���x���`���Ńf���A��
�R�A���i�ƍ����o�Ȃ��Ƃ����b���o�Ă��邷�B
���Ƃ��ĤAnandTech�̃��C�^�[�Johan de Gelas��AcesHardware�f���̓��e�����p���B
http://www.aceshardware.com/forums/read_post.jsp?id=115163394&forumid=1
�@�@------------------------
�@�@And what are the uses of third and fourth core of Kentsfield on the desktop? Right now, even
�@�@the most advanced game engines in development make only use of two CPUs. (If there is an
�@�@exception, tell me)
�@�@------------------------
�V�Z�p�̌�������Intel�ɂ܂����Ĥ�������������������������Ƃ����̂�������ɂ�AMD�炵�����������ǁB�B�B
>>144
> �V�Z�p�̌�������Intel�ɂ܂����Ĥ�������������������������Ƃ����̂�������ɂ�AMD�炵������������
Microsoft�̃T�|�[�g���~�������߂�EM64T�ȂǂƂ���AMD64�݊��̖��߂𓋍ڂ���Intel�Ƒ卷�Ȃ��ˁB
�j���[�X�\�[�X��\��t���Ă����̂͗L�����A���肬��ɏ��ւ��܂��U�炷�̂͂���������߂�
�~�����ȁB�L����ŁB
> �V�Z�p�̌�������Intel�ɂ܂����Ĥ�������������������������Ƃ����̂�������ɂ�AMD�炵������������
Microsoft�̃T�|�[�g���~�������߂�EM64T�ȂǂƂ���AMD64�݊��̖��߂𓋍ڂ���Intel�Ƒ卷�Ȃ��ˁB
�j���[�X�\�[�X��\��t���Ă����̂͗L�����A���肬��ɏ��ւ��܂��U�炷�̂͂���������߂�
�~�����ȁB�L����ŁB
����Ȃ�intel�������グ����������AIntel�X���ł���Ă�����H
149 �FMAC�I�^���⑫�F2006/05/05(��) 00:18:44 ID:eXdYaDf3
�Q�l�܂ł�Intel�������ȕ��Ɋ撣���Ă��邷�B
http://www.intel.com/cd/software/products/asmo-na/eng/272688.htm
�ȒP�ȉ����������ƤC++�̃e���v���[�g�@�\��p�����}���`�X���b�h�����C�u�����Ť��v�ȓ�����
���L�̒ʂ�B
�@�E�X���b�h���ɂ��Ă̒m�������ɕ��\�ȕ����𒊏o
�@�En-way�ւ̃X�P�[���r���e�B
�@�E�e�X�g�ς݂̃��W���[���ɂ��e�ՂȊJ��
�@�EWindows, Linux, Mac OS X�ɑΉ�
�@�E���N��6/2�܂Ńx�[�^�ł���
http://www.intel.com/cd/software/products/asmo-na/eng/272688.htm
�ȒP�ȉ����������ƤC++�̃e���v���[�g�@�\��p�����}���`�X���b�h�����C�u�����Ť��v�ȓ�����
���L�̒ʂ�B
�@�E�X���b�h���ɂ��Ă̒m�������ɕ��\�ȕ����𒊏o
�@�En-way�ւ̃X�P�[���r���e�B
�@�E�e�X�g�ς݂̃��W���[���ɂ��e�ՂȊJ��
�@�EWindows, Linux, Mac OS X�ɑΉ�
�@�E���N��6/2�܂Ńx�[�^�ł���
>>118
> �[���㓡���������܂���̋L����~�߂�
> �ǂ��܂ł��\�[�X�̏����悤�ɤ�\�[�X������b����v���[�������̂܂܃A�b�v���ė~�������̂��B
���������邩��L���Ƃ��Ă̈Ӗ�������̂ł́H�@
������㓡����̋L���ɂ͓���������邯�NJO�������B
���ꂪ�ނ̋L���̖��͂ł���B�P�Ȃ�R�s�y���C�^�[�ł͂Ȃ��؋����ƁB
����J���Ɋւ��ẮA���J����Ă��Ȃ�����\�[�X�͕��ʏ����Ȃ��ł��傤�B
hkepc������n�b�L�����Ă��Ȃ����������x���ł���B
> �[���㓡���������܂���̋L����~�߂�
> �ǂ��܂ł��\�[�X�̏����悤�ɤ�\�[�X������b����v���[�������̂܂܃A�b�v���ė~�������̂��B
���������邩��L���Ƃ��Ă̈Ӗ�������̂ł́H�@
������㓡����̋L���ɂ͓���������邯�NJO�������B
���ꂪ�ނ̋L���̖��͂ł���B�P�Ȃ�R�s�y���C�^�[�ł͂Ȃ��؋����ƁB
����J���Ɋւ��ẮA���J����Ă��Ȃ�����\�[�X�͕��ʏ����Ȃ��ł��傤�B
hkepc������n�b�L�����Ă��Ȃ����������x���ł���B
�Ƃ������A�㓡�����o�J�Ȃ����Ȃ̂����E�E�E
�ǂ����ނ́AAMD�Ӗ��ɗi�삷�闧�������Ă���悤�Ř_�q�Ƃ��Ă͎��i�B
�ǂ����ނ́AAMD�Ӗ��ɗi�삷�闧�������Ă���悤�Ř_�q�Ƃ��Ă͎��i�B
������intel�i�삷������}�V�B
�}�V�ł͂Ȃ����ނ��������B
���낻��F�������߂���@�����H
���낻��F�������߂���@�����H
>>151
�ǂ̂����肪�o�J�ŁA�ǂ̂����肪�i��H
�㓡����̋����͗i��Ƃ��ł͂��A���������̓I��
�����낯���OK!�Ƃ����Ƃ��납�ƁB������A�O���b�V�u��
�헪���̂�Ƃ���̋L���������Ȃ�i��ƌ�����̂ł́B
����̋L�����i��Ɍ�����̂́A���ꂾ��AMD�������[��
�헪���̂��Ă��Ă��邩�炩�Ǝv���܂��B
�ǂ̂����肪�o�J�ŁA�ǂ̂����肪�i��H
�㓡����̋����͗i��Ƃ��ł͂��A���������̓I��
�����낯���OK!�Ƃ����Ƃ��납�ƁB������A�O���b�V�u��
�헪���̂�Ƃ���̋L���������Ȃ�i��ƌ�����̂ł́B
����̋L�����i��Ɍ�����̂́A���ꂾ��AMD�������[��
�헪���̂��Ă��Ă��邩�炩�Ǝv���܂��B
>>153
���Ȃ�Ⴄ�B�Ɛ�ǐ�̖h�~�A�������i�����2�Ԏ�ȍ~����������͕̂ʂɂ��������Ȃ��B
intel���[�U�[��AMD�̂����̂������ł��Ȃ�̃����b�g���Ă�킯�ŁA���ӂ��ׂ��B
���Ȃ�Ⴄ�B�Ɛ�ǐ�̖h�~�A�������i�����2�Ԏ�ȍ~����������͕̂ʂɂ��������Ȃ��B
intel���[�U�[��AMD�̂����̂������ł��Ȃ�̃����b�g���Ă�킯�ŁA���ӂ��ׂ��B
K8�̉������ʔ����̂��H
����ȌÂڂ����v�����ʂɋ����͕����Ȃ�����H
�}���`�R�A�ɂȂ����Ƃ����L�L���b�V���ł���f�����b�g�ɂ͈�ؐG�ꂸ�����^�̃}���`�R�A�H
�킷�Ȃƌ��������B
AMD�������ɂȂ��ċ��L�L���b�V������K���ɖ͍����Ă���̂��ǂ��؋����낤�B
����ȌÂڂ����v�����ʂɋ����͕����Ȃ�����H
�}���`�R�A�ɂȂ����Ƃ����L�L���b�V���ł���f�����b�g�ɂ͈�ؐG�ꂸ�����^�̃}���`�R�A�H
�킷�Ȃƌ��������B
AMD�������ɂȂ��ċ��L�L���b�V������K���ɖ͍����Ă���̂��ǂ��؋����낤�B
> �Ɛ�ǐ�̖h�~�A�������i�����2�Ԏ�ȍ~����������͕̂ʂɂ��������Ȃ��B
�A�z���H
�s����̈ӂɃR���g���[�����傤�Ƃ���̂͋��Y�}�����ł����A�v��o�ς����s�����̂͊Ǘ��o����Ǝv���Ă����������������B
�ǂ����̂͂悭�A�������̂͂�邢�Ƒf���ɔ�������̂���Ԃł��邱�Ƃ�m��B
�A�z���H
�s����̈ӂɃR���g���[�����傤�Ƃ���̂͋��Y�}�����ł����A�v��o�ς����s�����̂͊Ǘ��o����Ǝv���Ă����������������B
�ǂ����̂͂悭�A�������̂͂�邢�Ƒf���ɔ�������̂���Ԃł��邱�Ƃ�m��B
�Ȃ狤�LFSB�g����MCM������intel�͂����Ə���ȁB
�Ɛ�ǐ�̖h�~�A�������i�ׂ̈ɂQ�Ԏ����������͓̂�����O�Ǝv���Ă���z�̎v�l�B
2�Ԏ��i�삵�������邱�ƂŁA���������i����E�E�E�E
����^���ԂȉR�B
���͂�ʂ��̂���������ƁA�����͌Ӎ���~���đӂ��邾���B
�����ɂ͐^�����ȋ��������͓������A�c���ʂɂ����Ȃ�Ȃ��B
���R���������̂����\�A2�Ԏ�ȍ~�����͂ŃV�F�A��L���̂����\�B
���͂��̏��Ď����A���������������������ɒ���Ă���Ǝ�ɂ̂ݑ��i������{�H����悢�B
�Z���I�ȓƐ�͕��u����{���B
2�Ԏ��i�삵�������邱�ƂŁA���������i����E�E�E�E
����^���ԂȉR�B
���͂�ʂ��̂���������ƁA�����͌Ӎ���~���đӂ��邾���B
�����ɂ͐^�����ȋ��������͓������A�c���ʂɂ����Ȃ�Ȃ��B
���R���������̂����\�A2�Ԏ�ȍ~�����͂ŃV�F�A��L���̂����\�B
���͂��̏��Ď����A���������������������ɒ���Ă���Ǝ�ɂ̂ݑ��i������{�H����悢�B
�Z���I�ȓƐ�͕��u����{���B
���̏ꍇ�����Ƀ����b�g�����B
���x��Intel���������̗p�ӂ��Ă�悤������AAMD�����Ȃ��Ƃ˂��Ď��ɕ��ʂȘb�B
���x��Intel���������̗p�ӂ��Ă�悤������AAMD�����Ȃ��Ƃ˂��Ď��ɕ��ʂȘb�B
ID:ct2TUeWd���l�`�b�I�^�����ʂ̌��t��������ȂƑf���Ɋ��S����
AMD���K���o���Ηǂ��̂ł����āA�������������K�v�͉����ɂ��Ȃ��B
AMD����ǂ����̂��o��A����������ɕ]�����V�F�A�ɍS�炸�����悢�����B
����͉����Ƃ͌���Ȃ��B
AMD���D�������牞������E�E�E����͖��Ȃ��B
AMD�̕i�����C�ɓ���������w������E�E�E��������Ȃ��B
AMD�̕i���͗ǂ����甃���E�E�E������܂������B
AMD��2�Ԏ��INTEL�̓Ɛ�ɑR����ׂɉ�������E�E�E���ꂪ���E�E�E�傫�Ȃ����b�ł���w
AMD����ǂ����̂��o��A����������ɕ]�����V�F�A�ɍS�炸�����悢�����B
����͉����Ƃ͌���Ȃ��B
AMD���D�������牞������E�E�E����͖��Ȃ��B
AMD�̕i�����C�ɓ���������w������E�E�E��������Ȃ��B
AMD�̕i���͗ǂ����甃���E�E�E������܂������B
AMD��2�Ԏ��INTEL�̓Ɛ�ɑR����ׂɉ�������E�E�E���ꂪ���E�E�E�傫�Ȃ����b�ł���w
>>164
> AMD��2�Ԏ��INTEL�̓Ɛ�ɑR����ׂɉ�������E�E�E���ꂪ���E�E�E�傫�Ȃ����b�ł���w
���O�̌����Ă鎖���傫�Ȃ����b���ȁB
���l���ǂ��v���ĉ����������悤�����肾�낗
> AMD��2�Ԏ��INTEL�̓Ɛ�ɑR����ׂɉ�������E�E�E���ꂪ���E�E�E�傫�Ȃ����b�ł���w
���O�̌����Ă鎖���傫�Ȃ����b���ȁB
���l���ǂ��v���ĉ����������悤�����肾�낗
������Ⴄ�B
���R�o�ς��������v�z����u����̂͗ǂ��Ȃ��B
���������l�ŏ���ɊԈ�����v�l�����Ă���͍̂\��ʂ��A�L����������͍̂���B
�������A�������̓o�J�����玩�g�̎v�l���Ԉ���Ă��邱�Ƃɂ���C�t�����������s�ׂ��Ǝv���Ă��邩��]�v�Ɏn���������B
�����ƁA�Ԉ���Ă��邱�Ƃ�@���Ă��͉̂��l�̂悤�Ȑ^�����ȑ�l�̋`������w
���R�o�ς��������v�z����u����̂͗ǂ��Ȃ��B
���������l�ŏ���ɊԈ�����v�l�����Ă���͍̂\��ʂ��A�L����������͍̂���B
�������A�������̓o�J�����玩�g�̎v�l���Ԉ���Ă��邱�Ƃɂ���C�t�����������s�ׂ��Ǝv���Ă��邩��]�v�Ɏn���������B
�����ƁA�Ԉ���Ă��邱�Ƃ�@���Ă��͉̂��l�̂悤�Ȑ^�����ȑ�l�̋`������w
168 �FSocket774�F2006/05/05(��) 04:21:50 ID:xyqEl9+0
>>166
�Ɛ�֎~�@���Ȃ����邩�l���������邩�H
���������A���̓_INTEL�͑O�Ȃ��̂�����
���R�o�������v�z�H
�Ύ~�疜
�J�i�V�C���炢�ɁA���O�A�����������
�Ɛ�֎~�@���Ȃ����邩�l���������邩�H
���������A���̓_INTEL�͑O�Ȃ��̂�����
���R�o�������v�z�H
�Ύ~�疜
�J�i�V�C���炢�ɁA���O�A�����������
ID:ct2TUeWd=�G��
>>168
�ē��͍��ɑ��݂���B
���O���l���c�t�Ȏv�l�Ɣ��f�ł����^����K�v�͉����ɂ��Ȃ��B
�Ɛ�ł��邱�Ƃ������Ƃ������Ƃł͂Ȃ��A�Ɛ艻�ŋ������������������ނ��邱�Ƃ����Ȃ̂ł���A
���̊ϓ_�������킸�Ǘ��ē̂����̎d�����B
����āA���̔����͐T�d�ł���ׂ��ŁA�Ɛ艻�ŋ������������������ނ��邱�Ƃ����ɂ߂�K�v������B
���R�o�ςł̓Ɛ�͂��肦��̂ł���A���ꂾ���Ɛ肵����Ƃ������^�����ɋ��҂ł����������̂��Ƃ��B
�������A���̌��ʎ��R�o�ςɈ��e�����y�ڂ��Ɣ��f�����A�Ɛ���ɘa���鐭���ꕪ�Љ������B
���ꓙ�͌��͂������ʂ��̂����͂Ɏ��i����������Ƃ����悤�ȁA�����Ȏv�l�ňׂ������̂ł͂Ȃ����Ƃ��m���Ă����Ă���B
�ē��͍��ɑ��݂���B
���O���l���c�t�Ȏv�l�Ɣ��f�ł����^����K�v�͉����ɂ��Ȃ��B
�Ɛ�ł��邱�Ƃ������Ƃ������Ƃł͂Ȃ��A�Ɛ艻�ŋ������������������ނ��邱�Ƃ����Ȃ̂ł���A
���̊ϓ_�������킸�Ǘ��ē̂����̎d�����B
����āA���̔����͐T�d�ł���ׂ��ŁA�Ɛ艻�ŋ������������������ނ��邱�Ƃ����ɂ߂�K�v������B
���R�o�ςł̓Ɛ�͂��肦��̂ł���A���ꂾ���Ɛ肵����Ƃ������^�����ɋ��҂ł����������̂��Ƃ��B
�������A���̌��ʎ��R�o�ςɈ��e�����y�ڂ��Ɣ��f�����A�Ɛ���ɘa���鐭���ꕪ�Љ������B
���ꓙ�͌��͂������ʂ��̂����͂Ɏ��i����������Ƃ����悤�ȁA�����Ȏv�l�ňׂ������̂ł͂Ȃ����Ƃ��m���Ă����Ă���B
>>169
�@�@�@�@�@�@�@�@�@�@__,.�@ -��--�@�_
�@�@�@�@�@�@�@�@, - ' _,�L�@--�����]- �@ �j
�@�@�@�@�@�@,��L__-�Q�Q_,.�@-�]�@'__,. - '�L
�@�@�@�@�@�@`�[----, - ' �L�P�@�M`�@ ��Q_
�@�@�@�@�@�@�@�@ __,��@ �@�@�@�@�@�@�@ �@ �R. �M�R.
�@�@�@�@�@ ,�@ '��Y �@/�@�@�@�@ ��R�@�@�@�@�R�@ �R.
�@�@ �@ �^�@�@�@ /�@ i �@ /l/|_�n li �@l i�@�@ li �@ �
.�@ �@ //�@�V�@/l�@ i|j_,.//�]'/�@ lT�g l�l �@ j N�@i |
�@�@�@{��@ l�@ / l�@�@li //___ �@�@ �_l� l��'�@l�n. � �@�Q�Q�Q��_r�]��
�@�@�@ i|�@/�/���@l�@�@l v'�L�P�@�@, �L�P`�C�@ !| ��l,�n �����]���i�������@�Q�@ �w�Q�Q�Q�Q
�@�@�@ �n|�@ll��ʁR�@Ĥ ''''�@��==�� '''' /l j�|�@ll�@ll�@�@�@ /./������������������������ۺ��i
�@�@ �V�@�@�a �'�N�L�Ri��.�@_ �__,Ɂ@,.�C/|/ Ɂ@ll�@l|�@�@ <�^�@ �P�k.l�P�P�k.���k.!�@�@�@�@�@�@ �@ ����|
�@�@�����@�@�@ ll�@{�@�@ �܁R_/ } ��]��.__�@ ���@�@l| �a
�@ �a�@ �@ �a �R,�@�@ �^� �q �@ |:::::::| �M�R�@ �@ �@ �a
�@ �a�@�@�@�@ �@ {.�@ � �R Y�M�]���::::v�@ l�@ �@ �@ �a
�@ �a�@�@�@�@�@�@|���R{�@�R_�]Ɂ]��f::::�R. |�@ �@ �@ �a
�@ �a�@�@�@�@�@�@|i:::::�M�N�L--�@:::......:...:.:.::.}|�@�@�@�@ �a
�@ �a�@�@�@�@�@�@|i::::::�R._:::_:::::::::::::::::::_�m |�@�@�@�@ �a
�@ �a�@�@�@�@�@�@|i::::::::::::���Q__:::::::::::/�@�@|
�@�@�@�@ �@ �@ �@ jj::::::::����-- �M��] '�܁@|
�@�@�@�@�@�@ �@ �V:::::::ϓ�@�@�@�@�@ �Q,�
�@�@�@�@�@�@�@//::::::::::::i � �� '�L�P::.
�@�@�@�@�@�@ ,','::::::::::::::i::::::::::::::::::::::i::::::�R
�@�@�@�@�@�@�@�@�@�@__,.�@ -��--�@�_
�@�@�@�@�@�@�@�@, - ' _,�L�@--�����]- �@ �j
�@�@�@�@�@�@,��L__-�Q�Q_,.�@-�]�@'__,. - '�L
�@�@�@�@�@�@`�[----, - ' �L�P�@�M`�@ ��Q_
�@�@�@�@�@�@�@�@ __,��@ �@�@�@�@�@�@�@ �@ �R. �M�R.
�@�@�@�@�@ ,�@ '��Y �@/�@�@�@�@ ��R�@�@�@�@�R�@ �R.
�@�@ �@ �^�@�@�@ /�@ i �@ /l/|_�n li �@l i�@�@ li �@ �
.�@ �@ //�@�V�@/l�@ i|j_,.//�]'/�@ lT�g l�l �@ j N�@i |
�@�@�@{��@ l�@ / l�@�@li //___ �@�@ �_l� l��'�@l�n. � �@�Q�Q�Q��_r�]��
�@�@�@ i|�@/�/���@l�@�@l v'�L�P�@�@, �L�P`�C�@ !| ��l,�n �����]���i�������@�Q�@ �w�Q�Q�Q�Q
�@�@�@ �n|�@ll��ʁR�@Ĥ ''''�@��==�� '''' /l j�|�@ll�@ll�@�@�@ /./������������������������ۺ��i
�@�@ �V�@�@�a �'�N�L�Ri��.�@_ �__,Ɂ@,.�C/|/ Ɂ@ll�@l|�@�@ <�^�@ �P�k.l�P�P�k.���k.!�@�@�@�@�@�@ �@ ����|
�@�@�����@�@�@ ll�@{�@�@ �܁R_/ } ��]��.__�@ ���@�@l| �a
�@ �a�@ �@ �a �R,�@�@ �^� �q �@ |:::::::| �M�R�@ �@ �@ �a
�@ �a�@�@�@�@ �@ {.�@ � �R Y�M�]���::::v�@ l�@ �@ �@ �a
�@ �a�@�@�@�@�@�@|���R{�@�R_�]Ɂ]��f::::�R. |�@ �@ �@ �a
�@ �a�@�@�@�@�@�@|i:::::�M�N�L--�@:::......:...:.:.::.}|�@�@�@�@ �a
�@ �a�@�@�@�@�@�@|i::::::�R._:::_:::::::::::::::::::_�m |�@�@�@�@ �a
�@ �a�@�@�@�@�@�@|i::::::::::::���Q__:::::::::::/�@�@|
�@�@�@�@ �@ �@ �@ jj::::::::����-- �M��] '�܁@|
�@�@�@�@�@�@ �@ �V:::::::ϓ�@�@�@�@�@ �Q,�
�@�@�@�@�@�@�@//::::::::::::i � �� '�L�P::.
�@�@�@�@�@�@ ,','::::::::::::::i::::::::::::::::::::::i::::::�R
172 �FSocket774�F2006/05/05(��) 04:54:24 ID:xyqEl9+0
>>170
�ē���ʂ�́A�����̑���ɍ����s�������̘b����
���ۂɕs���v����̂͏���҂�
����҂��ǂ�ȗ��R�ł��ꃁ�[�J�̑I�����s���̂��������Ƃ��H
INTEL�͓��{��������Ȃ��e���Ŗ����N�����Ă����ȁH
���A���͂��������Ȃ��Ȃ�āACPU�����̂ɍl����킯�Ȃ�����
���O�̎v�l�̕����A���͂Ɏ��i���A�Z�т��Ă���悤�Ɍ����邪�ˁH���ɂ�
�m���Ђ��炩�������̂͂킩��������A�ɂ����邨�O�̑��݂��Ȃ�Ƃ����Ă���
�ē���ʂ�́A�����̑���ɍ����s�������̘b����
���ۂɕs���v����̂͏���҂�
����҂��ǂ�ȗ��R�ł��ꃁ�[�J�̑I�����s���̂��������Ƃ��H
INTEL�͓��{��������Ȃ��e���Ŗ����N�����Ă����ȁH
���A���͂��������Ȃ��Ȃ�āACPU�����̂ɍl����킯�Ȃ�����
���O�̎v�l�̕����A���͂Ɏ��i���A�Z�т��Ă���悤�Ɍ����邪�ˁH���ɂ�
�m���Ђ��炩�������̂͂킩��������A�ɂ����邨�O�̑��݂��Ȃ�Ƃ����Ă���
>>172
�܂�Ŗ�����肾��w
�\�����N��������n�������������z�̌������Ɨǂ����Ă���B
���[���Ȃ�ĕs�v�ŁA���̌����Ă��邱�Ƃ͐�ł����H
���O�̏��͂�����W�\�͂��ǂ�قǂ̂��̂Ȃ̂��ƁE�E�E
�������ɓ]�����Ă���A�N�ł����m���Ă�{�����R����������ʏ���
�����܂Ō������z���Č��Ăĕ|����B
�܂��A��Â��Ɍ����A�m�I�ł��Ȃ��A�v�����݂��������A��������Ղ��B
�܂�Ŗ�����肾��w
�\�����N��������n�������������z�̌������Ɨǂ����Ă���B
���[���Ȃ�ĕs�v�ŁA���̌����Ă��邱�Ƃ͐�ł����H
���O�̏��͂�����W�\�͂��ǂ�قǂ̂��̂Ȃ̂��ƁE�E�E
�������ɓ]�����Ă���A�N�ł����m���Ă�{�����R����������ʏ���
�����܂Ō������z���Č��Ăĕ|����B
�܂��A��Â��Ɍ����A�m�I�ł��Ȃ��A�v�����݂��������A��������Ղ��B
>>173
�������肻�̂܂����ւ̔ᔻ�ɂȂ��ĂȂ����E�E�E�H
�������肻�̂܂����ւ̔ᔻ�ɂȂ��ĂȂ����E�E�E�H
�㓡���̏�x���̂́A��ɕ����̃\�[�X�ŗ��t������邩��B
���̓��莩�̂͂���قǒx���Ȃ��ł���B
�L���ɐ������������Ă̂��A�{���Ɍ㓡���̐���������A����
���肵�Ă邯�Ǐ��҂��킩��Ȃ��悤�ɂ����Ď����̐�����
�L���ɏ����Ă�ꍇ������B
������ӂ̓P�`������悤�ȂƂ�����Ȃ��B
���̓��莩�̂͂���قǒx���Ȃ��ł���B
�L���ɐ������������Ă̂��A�{���Ɍ㓡���̐���������A����
���肵�Ă邯�Ǐ��҂��킩��Ȃ��悤�ɂ����Ď����̐�����
�L���ɏ����Ă�ꍇ������B
������ӂ̓P�`������悤�ȂƂ�����Ȃ��B
ID:ct2TUeWd��B����ȏ��VS�X���łł�����Ă���B
178 �FSocket774�F2006/05/05(��) 08:53:56 ID:5rVkvke8
>>174
�Ȃ��Ă�B
�Ȃ��Ă�B
�Ȃ��AK8�̂ǂ���ւÂ��v�Ȃ́HL2�L�ł��R�A���Œ������ڑ�����Ă�
K8�Ȃ�Â߂�����FSB�ʂ�Ȃ��Ă��ςނ��炠�����̃x���`�ȊO�͂���Ȃɑ�����
�����鎖�����Ǝv�����B����ɕ��ߗ\���̓R�����Ȃ�ו��ɂȂ�Ȃ���
���������t�����B
�O�ɂ����������AK8�͍ň����̏����Œx���Ȃ�ɂ����v���Ǝv���B�R�����Ƃ݂���
�x���`������CPU�Ƃ͐v�v�z���̑S���Ⴄ���ǂȁB
(�f�X�N�g�b�v��m�[�g�Ŏg���ꍇ�̓R�����̗l�Ȑv�v�z�̕����������ǂ�w)
K8�Ȃ�Â߂�����FSB�ʂ�Ȃ��Ă��ςނ��炠�����̃x���`�ȊO�͂���Ȃɑ�����
�����鎖�����Ǝv�����B����ɕ��ߗ\���̓R�����Ȃ�ו��ɂȂ�Ȃ���
���������t�����B
�O�ɂ����������AK8�͍ň����̏����Œx���Ȃ�ɂ����v���Ǝv���B�R�����Ƃ݂���
�x���`������CPU�Ƃ͐v�v�z���̑S���Ⴄ���ǂȁB
(�f�X�N�g�b�v��m�[�g�Ŏg���ꍇ�̓R�����̗l�Ȑv�v�z�̕����������ǂ�w)
�܂��A�����܂ŃA�����͂ق���Intel�X���ɏo�����Ă܂ŁA
Athlon��Opteron�̉ߏ�Ȑ�`���s���Ė��f�����Ă����킯������A
�ӔC�����ĈꐶAMD���i��������ׂ�����ȁB�����ɐӔC�Ȃ��߂��B
�悢�Ǝv�������̂��悢�Ƃ��킴�킴�����Ă��̑唼�͌��A�����Ȃ�?
>>179�̂悤�Ȏv�����݂��̐S�B
Athlon��Opteron�̉ߏ�Ȑ�`���s���Ė��f�����Ă����킯������A
�ӔC�����ĈꐶAMD���i��������ׂ�����ȁB�����ɐӔC�Ȃ��߂��B
�悢�Ǝv�������̂��悢�Ƃ��킴�킴�����Ă��̑唼�͌��A�����Ȃ�?
>>179�̂悤�Ȏv�����݂��̐S�B
181 �FSocket774�F2006/05/05(��) 13:15:38 ID:l8RGFuIy
�܂�����̃��j�C�R�A�̗���������AMD�͂����������Ƃ����Ă�B
64�r�b�g�`�b�v����������AMD�̎���̗���̐�����ʂ��͍͂��̂Ƃ���s���B
�C���e���͂��̗���Ɍォ�����Ă������̂���낤�Ƃ��Ă銴�����邪�A
�ʂɂ���ł��������̂��o����Ȃ炻��͂���ō\��Ȃ��Ǝv���B
����AMD�͏����������́iOpteron/Athlon64�n�j����肷�������݁A��������ǂ��i�ނ��A
�܂����\���ĂȂ��Ƃ��������ƁA���ꂩ�班���̊Ԃ͑傫�ȗ���̕ω��͂Ȃ��̂��ȁB
64�r�b�g�`�b�v����������AMD�̎���̗���̐�����ʂ��͍͂��̂Ƃ���s���B
�C���e���͂��̗���Ɍォ�����Ă������̂���낤�Ƃ��Ă銴�����邪�A
�ʂɂ���ł��������̂��o����Ȃ炻��͂���ō\��Ȃ��Ǝv���B
����AMD�͏����������́iOpteron/Athlon64�n�j����肷�������݁A��������ǂ��i�ނ��A
�܂����\���ĂȂ��Ƃ��������ƁA���ꂩ�班���̊Ԃ͑傫�ȗ���̕ω��͂Ȃ��̂��ȁB
�R�ꂪ���C�̂Ȃ��A�����̂��߂ɁA����̖ϑz�̎w�j�����Ă�������B
�E�R�A���\�ň��|�I�卷�ŕ����Ă��Ă��A���LFSB < HyperTransport������AMD�̕����悢
�E�f�X�N�g�b�v�A�m�[�g�ł͕����Ă�����ł͎g���Ȃ�MP�K�ł�Opteron�̕����L��
�E�Ⴆ�w�ǑS�Ẵx���`�}�[�N�ŕ����Ă��Ă��A�����ł͒��ڃ��[�U�[�Ɍ����Ȃ��Ƃ���Ŏ��͏����Ă���
�ECPU�J���͏��F�������������BAMD�̎�����}�C�N���A�[�L�͓�����̂͂������A
�@AMD�Ȃ�K8�̉��ǂ�Core����N�ł����ɔ����Ă����
�E�}���`�R�A�ɐ�ɖڂ������̂�AMD�B���Ƃ�Intel�����j�B�R�A���������Ă������AMD�̂��������B
�EEM64T�͏��FAMD�̋Z�p�B������Intel�����\�ŏ����Ă��A�p�N��Ȃ̂�����AMD�̏������B
�E�R�A���\�ň��|�I�卷�ŕ����Ă��Ă��A���LFSB < HyperTransport������AMD�̕����悢
�E�f�X�N�g�b�v�A�m�[�g�ł͕����Ă�����ł͎g���Ȃ�MP�K�ł�Opteron�̕����L��
�E�Ⴆ�w�ǑS�Ẵx���`�}�[�N�ŕ����Ă��Ă��A�����ł͒��ڃ��[�U�[�Ɍ����Ȃ��Ƃ���Ŏ��͏����Ă���
�ECPU�J���͏��F�������������BAMD�̎�����}�C�N���A�[�L�͓�����̂͂������A
�@AMD�Ȃ�K8�̉��ǂ�Core����N�ł����ɔ����Ă����
�E�}���`�R�A�ɐ�ɖڂ������̂�AMD�B���Ƃ�Intel�����j�B�R�A���������Ă������AMD�̂��������B
�EEM64T�͏��FAMD�̋Z�p�B������Intel�����\�ŏ����Ă��A�p�N��Ȃ̂�����AMD�̏������B
>>180
�ᔄ�茾�t�ɔ������t���ēz��w
K6����@�q�[�g�X�v���b�_���ăA�t�H����ˁH����Ȃ�������t����Ȃ�I�M�����邾�������
K7����@�q�[�g�X�v���b�_���t���ĂȂ�CPU���ĕs�Ǖi����ȁI�R�A�������邼�`�I
K8����@�s����I�s����I
K8-X2����@(�C���e���f���F���b�p�t�H�[�����̃x���`����)X2�M�����x�����ň��I
�ᔄ�茾�t�ɔ������t���ēz��w
K6����@�q�[�g�X�v���b�_���ăA�t�H����ˁH����Ȃ�������t����Ȃ�I�M�����邾�������
K7����@�q�[�g�X�v���b�_���t���ĂȂ�CPU���ĕs�Ǖi����ȁI�R�A�������邼�`�I
K8����@�s����I�s����I
K8-X2����@(�C���e���f���F���b�p�t�H�[�����̃x���`����)X2�M�����x�����ň��I
���Ƃ��AHTT������AMD���S�Ƃ��v���X�R��AMD���S�Ƃ����i��AMD���S���Č����Ă�
����t��ǂ��������H�ǂ�������ł�̂��������Ă���I
��łȂ����H�R�����H�A���o����x�������S����́H(pgr
����t��ǂ��������H�ǂ�������ł�̂��������Ă���I
��łȂ����H�R�����H�A���o����x�������S����́H(pgr
>>182
MMX P5, K6�Ƃ��̎���̃q�[�g�X�v���b�_(�P�Ȃ��)��
Pen4, K8����̃q�[�g�X�v���b�_�ł͂܂�ł�������B
�q�[�g�X�v���b�_�̍\���������[������A�悭����ׂĂˁB
���ƁA�R�A��������ʂ킢�ł�̂Ύ���er�����Ȃ킯�ŁA
Intel��AMD������[�̓s���Ńp�b�P�[�W���O�I�����Ă��Ȃ�����B
MMX P5, K6�Ƃ��̎���̃q�[�g�X�v���b�_(�P�Ȃ��)��
Pen4, K8����̃q�[�g�X�v���b�_�ł͂܂�ł�������B
�q�[�g�X�v���b�_�̍\���������[������A�悭����ׂĂˁB
���ƁA�R�A��������ʂ킢�ł�̂Ύ���er�����Ȃ킯�ŁA
Intel��AMD������[�̓s���Ńp�b�P�[�W���O�I�����Ă��Ȃ�����B
�k���肶��q�[�g�X�v���b�_�̍\���͂킩���c�B
http://www.ipros.jp/products/142588007/
�q�[�g�X�v���b�_�ɂ��O���[�h��������CPU�M�ʂɉ����ăp�b�P�[�W���O��������ƌv�Z�����
�I�肳��Ă���킯�B
�P�ɔ͂��߂��M���g�U���ăR�A�������Ȃ���ˁA���₢��t���b�v�`�b�v�̕����R�A�������Ă����M�ɂ�
�L������ȂǂƂ�������~�[���x���̈ꌳ�I�ȑI��������Ă�킯����Ȃ����낪�B
http://www.ipros.jp/products/142588007/
�q�[�g�X�v���b�_�ɂ��O���[�h��������CPU�M�ʂɉ����ăp�b�P�[�W���O��������ƌv�Z�����
�I�肳��Ă���킯�B
�P�ɔ͂��߂��M���g�U���ăR�A�������Ȃ���ˁA���₢��t���b�v�`�b�v�̕����R�A�������Ă����M�ɂ�
�L������ȂǂƂ�������~�[���x���̈ꌳ�I�ȑI��������Ă�킯����Ȃ����낪�B
188 �FMAC�I�^��184 �����F2006/05/05(��) 14:27:42 ID:eXdYaDf3
>>184
���h�ɉc�Ƃ��Ă����Ђ̂��Ƃ��u���S��Ƃ��������Ⴄ�~�[�̌���ٖ�����K�v�햳�������Ǥ
���Ȃ��������̏�v���o���Č���ׂ����B
2002�N11���@Intel HTT�T�|�[�g��Pentium 4�\
�@�@�@�@�@�@�@�@http://www.intel.co.jp/jp/intel/pr/press2002/021114.htm
2003�N1���@AMD, 2002�N�ʊ��̔��㍂�͑O�N��31%����26��9,702���h���B�����v��13��301���h���̑���
�@�@�@�@�@�@�@�@http://pc.watch.impress.co.jp/docs/2003/0117/amd.htm
Yonah��Hammer�̐��\��r�ɂ��Ă���捠�f�ڂ��ꂽAnandtech�̋L�������N���b�N�ł̐��\�ɏœ_��
���ĂĂ��邷�B
http://www.anandtech.com/mb/showdoc.aspx?i=2750
�����Yonah�̃����[�X�O����m���Ă�����Ť���o�C���v���Z�b�T��K8�N���b�N������̐��\��
�ς��Ȃ��Ƃ��������Ƥ��p�v���Z�b�T�̊J���������Ă��Ȃ��Ƃ���������g�ݍ��킹��Τ
AMD�̏������Â��ƌ����邱�Ƃ퓖����O���Ǝv�����B
���h�ɉc�Ƃ��Ă����Ђ̂��Ƃ��u���S��Ƃ��������Ⴄ�~�[�̌���ٖ�����K�v�햳�������Ǥ
���Ȃ��������̏�v���o���Č���ׂ����B
2002�N11���@Intel HTT�T�|�[�g��Pentium 4�\
�@�@�@�@�@�@�@�@http://www.intel.co.jp/jp/intel/pr/press2002/021114.htm
2003�N1���@AMD, 2002�N�ʊ��̔��㍂�͑O�N��31%����26��9,702���h���B�����v��13��301���h���̑���
�@�@�@�@�@�@�@�@http://pc.watch.impress.co.jp/docs/2003/0117/amd.htm
Yonah��Hammer�̐��\��r�ɂ��Ă���捠�f�ڂ��ꂽAnandtech�̋L�������N���b�N�ł̐��\�ɏœ_��
���ĂĂ��邷�B
http://www.anandtech.com/mb/showdoc.aspx?i=2750
�����Yonah�̃����[�X�O����m���Ă�����Ť���o�C���v���Z�b�T��K8�N���b�N������̐��\��
�ς��Ȃ��Ƃ��������Ƥ��p�v���Z�b�T�̊J���������Ă��Ȃ��Ƃ���������g�ݍ��킹��Τ
AMD�̏������Â��ƌ����邱�Ƃ퓖����O���Ǝv�����B
189 �FMAC�I�^��175 �����F2006/05/05(��) 14:36:52 ID:eXdYaDf3
>>175
�@�@--------------------
�@�@���̓��莩�̂͂���قǒx���Ȃ��ł���B
�@�@--------------------
�قړ�����HKEPC���瓯���l�^���o�Ă�����������Ă��Ƃ��礓����\�[�X�����Ċ�їE��ŋL�������������
�Ƃ��������̂ق������R���Ǝv�����B�������Ə����������Ă����Ƃ��v���Ȃ����ˁB�B�B
�@�@--------------------
�@�@���̓��莩�̂͂���قǒx���Ȃ��ł���B
�@�@--------------------
�قړ�����HKEPC���瓯���l�^���o�Ă�����������Ă��Ƃ��礓����\�[�X�����Ċ�їE��ŋL�������������
�Ƃ��������̂ق������R���Ǝv�����B�������Ə����������Ă����Ƃ��v���Ȃ����ˁB�B�B
�X���ƊW�Ȃ������Șb�肪�������
���|�[�g���Ă��̕]�_�܂œ�����
����ɕ]�_���Ă��̕]�_�܂œ�����
�����̃X�������
���|�[�g���Ă��̕]�_�܂œ�����
����ɕ]�_���Ă��̕]�_�܂œ�����
�����̃X�������
>>181
���j�C�R�A�̗���Ȃ�č���ĂȂ�����
���j�C�R�A�̗���Ȃ�č���ĂȂ�����
��荇����MAC�I�^�̂Ƙ_�c����C�������������I
>>187
��K8��k�X�̃X�v���b�_���ǂ�ȃO���[�h�Ȃ́H
K6�̃X�v���b�_����ʖڂȗ��R�́H
���ۖk�X�ɂł�K6�̃X�v���b�_�t���Ď����Ă݁H
>>187
��K8��k�X�̃X�v���b�_���ǂ�ȃO���[�h�Ȃ́H
K6�̃X�v���b�_����ʖڂȗ��R�́H
���ۖk�X�ɂł�K6�̃X�v���b�_�t���Ď����Ă݁H
> http://pc7.2ch.net/test/read.cgi/jisaku/1146411194/4
> Conroe E6500 2.40GHz dual 2MB FSB1066MHz TDP 65W '06Q4 �@$269 �@(Athlon64 X2 2.88GHz����)
> Conroe E6100 1.33GHz dual 2MB FSB1066MHz TDP 35W '07Q1 �@$149 �@(Athlon64 X2 1.60GHz����)
Conroe������������AMD��FX��X2�͈ꕔ�V���i������$269�`$149�̃����W�ɉ������߂��Ă��܂������ǁE�E�E
�ǂ�����́H
���̂܂܂��Ə����������s���Ȃ��Ȃ邾�낤�H
> Conroe E6500 2.40GHz dual 2MB FSB1066MHz TDP 65W '06Q4 �@$269 �@(Athlon64 X2 2.88GHz����)
> Conroe E6100 1.33GHz dual 2MB FSB1066MHz TDP 35W '07Q1 �@$149 �@(Athlon64 X2 1.60GHz����)
Conroe������������AMD��FX��X2�͈ꕔ�V���i������$269�`$149�̃����W�ɉ������߂��Ă��܂������ǁE�E�E
�ǂ�����́H
���̂܂܂��Ə����������s���Ȃ��Ȃ邾�낤�H
k8�́A�������̃v���t�F�`���ォ������A���@���[�h�ɑΉ����ĂȂ��̂�
��_����
�R�A���g�����āA�Ή�����͓̂���Ȃ��Ǝv���̂���
��_����
�R�A���g�����āA�Ή�����͓̂���Ȃ��Ǝv���̂���
195 �FMAC�I�^��194 �����F2006/05/05(��) 17:56:08 ID:eXdYaDf3
>>194
��������Ȃ猴�T�������̂���V�Ƃ������m���B
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2748&p=6
�@�@---------------------------
�@�@Finally, there is also a lot of headroom for increasing integer performance. The fact that Loads
�@�@can hardly be reordered has been a known weak point since the early K7 days. In fact, we know
�@�@that engineers at AMD were well aware of it then, and it is surprising that AMD didn't really fix
�@�@this in the K8 architecture. Allowing a much more flexible reordering of Loads - even without
�@�@memory disambiguation - would give a very healthy boost to IPC (5% and more). It is one of the
�@�@main reasons why the P-M can beat the Athlon 64 clock-for-clock in certain applications.
�@�@Those are just a few examples that are well known. It is very likely that there are numerous
�@�@other possible improvements that could take the K8 architecture much further.
�@�@---------------------------
��������Ȃ猴�T�������̂���V�Ƃ������m���B
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2748&p=6
�@�@---------------------------
�@�@Finally, there is also a lot of headroom for increasing integer performance. The fact that Loads
�@�@can hardly be reordered has been a known weak point since the early K7 days. In fact, we know
�@�@that engineers at AMD were well aware of it then, and it is surprising that AMD didn't really fix
�@�@this in the K8 architecture. Allowing a much more flexible reordering of Loads - even without
�@�@memory disambiguation - would give a very healthy boost to IPC (5% and more). It is one of the
�@�@main reasons why the P-M can beat the Athlon 64 clock-for-clock in certain applications.
�@�@Those are just a few examples that are well known. It is very likely that there are numerous
�@�@other possible improvements that could take the K8 architecture much further.
�@�@---------------------------
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2748&p=6
��荇������S�����{��ēǂ߁I���Ƀy�j�X�I
��荇������S�����{��ēǂ߁I���Ƀy�j�X�I
>>196�@(���̓��{���Ƃ�炪�@�B�|�����������ˁB�B�B)
>>196
�T�ό�邾���̃y�[�W�͂���܈Ӗ��Ȃ���
�T�ό�邾���̃y�[�W�͂���܈Ӗ��Ȃ���
>>182�͎G���_�����܂��AMD�ɂ��肩�������������ȁB
�ق�ƎG�������B
�������̂��������������ŏ\���Șb�Ȃ̂ɁB
���ۂɕ������ʂ��Ă���܂��͕ς���Ă���낤���ǂȁB
�ق�ƎG�������B
�������̂��������������ŏ\���Șb�Ȃ̂ɁB
���ۂɕ������ʂ��Ă���܂��͕ς���Ă���낤���ǂȁB
http://www.amd.com/us-en/Corporate/InvestorRelations/0,,51_306_10909,00.html
AMD�̒莞���呍���3�������肩�炩��
AMD�̒莞���呍���3�������肩�炩��
201 �FMAC�I�^��200 �����F2006/05/06(�y) 01:03:19 ID:blg8z39t
> ttp://www.realworldtech.com/page.cfm?ArticleID=RWT030906143144&p=1
> ttp://www.realworldtech.com/page.cfm?ArticleID=RWT030906143144&p=2
> ttp://www.realworldtech.com/page.cfm?ArticleID=RWT030906143144&p=3
> ttp://www.realworldtech.com/page.cfm?ArticleID=RWT030906143144&p=4
> ttp://www.realworldtech.com/page.cfm?ArticleID=RWT030906143144&p=5
> ttp://www.realworldtech.com/page.cfm?ArticleID=RWT030906143144&p=6
> ttp://www.realworldtech.com/page.cfm?ArticleID=RWT030906143144&p=7
> ttp://www.realworldtech.com/page.cfm?ArticleID=RWT030906143144&p=8
> ttp://www.realworldtech.com/page.cfm?ArticleID=RWT030906143144&p=9
> ttp://www.realworldtech.com/page.cfm?ArticleID=RWT030906143144&p=10
> ttp://www.realworldtech.com/page.cfm?ArticleID=RWT030906143144&p=11
AMD���ǂ�Ȃɑ��~�������A���N�Ԃ�INTEL�ɑS�������ł��o���Ȃ��Ȃ�͖̂{���炵���B
> ttp://www.realworldtech.com/page.cfm?ArticleID=RWT030906143144&p=2
> ttp://www.realworldtech.com/page.cfm?ArticleID=RWT030906143144&p=3
> ttp://www.realworldtech.com/page.cfm?ArticleID=RWT030906143144&p=4
> ttp://www.realworldtech.com/page.cfm?ArticleID=RWT030906143144&p=5
> ttp://www.realworldtech.com/page.cfm?ArticleID=RWT030906143144&p=6
> ttp://www.realworldtech.com/page.cfm?ArticleID=RWT030906143144&p=7
> ttp://www.realworldtech.com/page.cfm?ArticleID=RWT030906143144&p=8
> ttp://www.realworldtech.com/page.cfm?ArticleID=RWT030906143144&p=9
> ttp://www.realworldtech.com/page.cfm?ArticleID=RWT030906143144&p=10
> ttp://www.realworldtech.com/page.cfm?ArticleID=RWT030906143144&p=11
AMD���ǂ�Ȃɑ��~�������A���N�Ԃ�INTEL�ɑS�������ł��o���Ȃ��Ȃ�͖̂{���炵���B
203 �FMAC�I�^��202 �����F2006/05/06(�y) 01:19:29 ID:blg8z39t
>>202
RealWorldTech�̋L��������������1�łŕ\������邷�B
http://www.realworldtech.com/includes/templates/articles.cfm?ArticleID=RWT030906143144&mode=print
RealWorldTech�̋L��������������1�łŕ\������邷�B
http://www.realworldtech.com/includes/templates/articles.cfm?ArticleID=RWT030906143144&mode=print
>>189
�L���̏��o�����́A�㓡��Hkepc�B�\�̏ڂ����͌㓡��Hkepc�B
�Ȃ̂ŁA��p�̗��ʋƂ�Mr.G�̉\��������i�j
�܁A���݂������ɂ����܂��B
�L���̏��o�����́A�㓡��Hkepc�B�\�̏ڂ����͌㓡��Hkepc�B
�Ȃ̂ŁA��p�̗��ʋƂ�Mr.G�̉\��������i�j
�܁A���݂������ɂ����܂��B
>>202
�u���b�N�_�C�A�O�������x���ł́AConroe��Yonah�ɍ��͂Ȃ��łˁB
�u���b�N�_�C�A�O�������x���ł́AConroe��Yonah�ɍ��͂Ȃ��łˁB
�����ꒃ�}�b�V���ɂȂ��Ă邯�NJ�{�͓�������
128bitSSE�𓋍ڂ��Ă��Ȃ��͕̂�����Ȃ����A�f���̂悳�͎f����� > Yonah
age
DRC�AOpteron�\�P�b�g�Ɏ�������FPGA�R�v���Z�b�T
�`Cray�̃X�[�p�[�R���s���[�^�ɍ̗p
http://pc.watch.impress.co.jp/docs/2006/0508/drc.htm
�`Cray�̃X�[�p�[�R���s���[�^�ɍ̗p
http://pc.watch.impress.co.jp/docs/2006/0508/drc.htm
AMD�̐�����͌��� :
AMD��47%�͌��h�ŏo���Ă��܂��B
AMD��41%�͐Ԃ������ŏo���Ă��܂��B
AMD��11%��㩂ŏo���Ă��܂��B
AMD��1%�͒��F���ŏo���Ă��܂��B
>AMD��47%�͌��h�ŏo���Ă��܂��B
>AMD��47%�͌��h�ŏo���Ă��܂��B
>AMD��47%�͌��h�ŏo���Ă��܂��B
>AMD��47%�͌��h�ŏo���Ă��܂��B
>AMD��47%�͌��h�ŏo���Ă��܂��B
>AMD��47%�͌��h�ŏo���Ă��܂��B
>AMD��47%�͌��h�ŏo���Ă��܂��B
>AMD��47%�͌��h�ŏo���Ă��܂��B
AMD��47%�͌��h�ŏo���Ă��܂��B
AMD��41%�͐Ԃ������ŏo���Ă��܂��B
AMD��11%��㩂ŏo���Ă��܂��B
AMD��1%�͒��F���ŏo���Ă��܂��B
>AMD��47%�͌��h�ŏo���Ă��܂��B
>AMD��47%�͌��h�ŏo���Ă��܂��B
>AMD��47%�͌��h�ŏo���Ă��܂��B
>AMD��47%�͌��h�ŏo���Ă��܂��B
>AMD��47%�͌��h�ŏo���Ă��܂��B
>AMD��47%�͌��h�ŏo���Ă��܂��B
>AMD��47%�͌��h�ŏo���Ă��܂��B
>AMD��47%�͌��h�ŏo���Ă��܂��B
HPC�ŃR�v�������s�̒���
����p�r�����̃G���R�[�h/�����_�����O�A�N�Z�����[�^�݂����Ȃ̂��m���ɖʔ������ȁB
�������̗���̐^�t���s�����z������
�{���ɂ����ꕔ�ł������v�͂Ȃ��Ǝv��
�{���ɂ����ꕔ�ł������v�͂Ȃ��Ǝv��
�ėp�@�������A���@������������������Ă����̂�
����̃X�^���X�ȋC�����邩��A����ł͎��v������Ǝv���B
���ՂȂ�����Ȃ�ɏo���郄�c���K�v���������C��PC
���ꂵ���o���Ȃ��Ă��A�ŋ��Ȃ炻�����~�������Ă��Ƃ��ȁB����pPC
����̃X�^���X�ȋC�����邩��A����ł͎��v������Ǝv���B
���ՂȂ�����Ȃ�ɏo���郄�c���K�v���������C��PC
���ꂵ���o���Ȃ��Ă��A�ŋ��Ȃ炻�����~�������Ă��Ƃ��ȁB����pPC
�����R�v���^���h���ʁB
�[���������C�u�����t����5Ͽ�ʂȂ�}�W�~�����B
�[���������C�u�����t����5Ͽ�ʂȂ�}�W�~�����B
����ŃX�p�R�����ǂ���
Opteron with AltiVec.
�p�[�\�i���G���^�[�v���C�Y���Ă������Ȃ��I
���N������܂�AMD�̊��̔����������邩�ȁ`ܸܸ
�R�����o��AMD�������Ɗ������邩��
���̂Ƃ������āA�啜������܂Ŏ���Ă����Α�������ł���Ǝv��
�啜������A�����ǁE�E�E
���̂Ƃ������āA�啜������܂Ŏ���Ă����Α�������ł���Ǝv��
�啜������A�����ǁE�E�E
Opteron with Cell co-processor.
>>217
�~�������ǁA�ǂ����Ă�Core 2 with AltiVec�̕�������
�~�������ǁA�ǂ����Ă�Core 2 with AltiVec�̕�������
>>222�@�Ӗ����킩���B�����ǂ������H
�����͈��ׂ̐�`�X���ł�����(FUD�܂�)
AltiVec��SSE���قƂ�Ǖς��Ȃ���
���\�ł�
AltiVec>>>>SSE
���ꂼ��̐i�����ł���J���҂̐�
SSE>>>>>>>>>AltiVec
���Ɏg����l�Ԃ̐����S�R�Ⴄ�B
�Ƃ����65nm��K8���ăN���b�N�ǂ̒��x�܂ŏグ��\��ȂH
AltiVec>>>>SSE
���ꂼ��̐i�����ł���J���҂̐�
SSE>>>>>>>>>AltiVec
���Ɏg����l�Ԃ̐����S�R�Ⴄ�B
�Ƃ����65nm��K8���ăN���b�N�ǂ̒��x�܂ŏグ��\��ȂH
>>226
40�p�[�Z���g�A�b�v��4.2GHz
40�p�[�Z���g�A�b�v��4.2GHz
TheInquirer�̉������ȏ�B
http://www.theinquirer.net/?article=31649
�@�E3Q07�\���"Deerhound" Opteron (K8L, 4-core)�̋��LL3�����������2MB (L2������ς�炸1MB)�B
�@�E2008�N���ɗ\�肳��Ă���"Cerberus" Opteron 8xx��L3��6MB�ɑ��ʁB2.4GHz��HT 3.0�����N��
�@�@DDR3�������R���g���[�������B��������2xx���f����"Wolfhound"�����������炸2MB L3�B
�@�@HT�ɂ��Ă��19.2GB/s/link�Ƃ̂��ƂȂ̂�16-bit���̂܂܂����B�B�B
TheINQ������ُ̈�ɏ��Ȃ�L3�̗��R��
�@1. �R�A�Ԃ̃R�q�����V�ێ��p�̃N���X�o�[���ȗ������ĤL3�ɏ����߂��ăR�q�����V��ۂ�
�@2. �܂�exclusive�L���b�V���B�B�B
�Ɛ������Ă��邷�B
�\����t��������Τ8-socket���z���钴MP�\���̂��߂̃f�B���N�g���i�[�p�Ƃ��Ďg�p���Ĥ�{�i�I
��ccNuma������Ƃ����\�������邩�Ǝv�����B
http://www.theinquirer.net/?article=31649
�@�E3Q07�\���"Deerhound" Opteron (K8L, 4-core)�̋��LL3�����������2MB (L2������ς�炸1MB)�B
�@�E2008�N���ɗ\�肳��Ă���"Cerberus" Opteron 8xx��L3��6MB�ɑ��ʁB2.4GHz��HT 3.0�����N��
�@�@DDR3�������R���g���[�������B��������2xx���f����"Wolfhound"�����������炸2MB L3�B
�@�@HT�ɂ��Ă��19.2GB/s/link�Ƃ̂��ƂȂ̂�16-bit���̂܂܂����B�B�B
TheINQ������ُ̈�ɏ��Ȃ�L3�̗��R��
�@1. �R�A�Ԃ̃R�q�����V�ێ��p�̃N���X�o�[���ȗ������ĤL3�ɏ����߂��ăR�q�����V��ۂ�
�@2. �܂�exclusive�L���b�V���B�B�B
�Ɛ������Ă��邷�B
�\����t��������Τ8-socket���z���钴MP�\���̂��߂̃f�B���N�g���i�[�p�Ƃ��Ďg�p���Ĥ�{�i�I
��ccNuma������Ƃ����\�������邩�Ǝv�����B
�܂��r���L���b�V����
CC�̃f�B���N�g���Ɏg����̂͊ԈႢ�Ȃ����낤��
�����K8 32way�Ƃ��̓o�ꂩ?
CC�̃f�B���N�g���Ɏg����̂͊ԈႢ�Ȃ����낤��
�����K8 32way�Ƃ��̓o�ꂩ?
SUN�̗v�]�͔��f����Ă���̂��H
231 �FMAC�I�^���⑫�F2006/05/12(��) 23:38:14 ID:V/MW2ORI
������ƕ⑫����ƤAMD�ƕt������������Ɏ�荞�܂��(�����Ĉłɏ�����)���܂���Newsys�ЊJ��
��Opteron�p��ccNUMA�`�b�v�Z�b�g"Horus"�����Ƃ��ăf�B���N�g���p�ɗp����3.75MB��on-die SRAM�Ƥ
�����[�g�������L���b�V���p��64MB�̊O�t��SRAM��ڑ����Ă������B
http://www.hotchips.org/archives/hc16/2_Mon/18_HC16_Sess5_Pres2_bw.pdf
2MB��L3�Ƃ����̂����������ccNUMA�̃f�B���N�g���p�Ŏ��t�Ƃ����̂����邩�Ǝv�����B
��Opteron�p��ccNUMA�`�b�v�Z�b�g"Horus"�����Ƃ��ăf�B���N�g���p�ɗp����3.75MB��on-die SRAM�Ƥ
�����[�g�������L���b�V���p��64MB�̊O�t��SRAM��ڑ����Ă������B
http://www.hotchips.org/archives/hc16/2_Mon/18_HC16_Sess5_Pres2_bw.pdf
2MB��L3�Ƃ����̂����������ccNUMA�̃f�B���N�g���p�Ŏ��t�Ƃ����̂����邩�Ǝv�����B
Newisys
SUN��ccNUMA����ō����\�����тȂ�����COMA�ɂ��������H���͂ǂ��Ȃ��Ă�H
Cell�v���Z�b�T�������\
�ƖӖړI�ɐM������ł���n���������Ĉނ��ނ��Ȃ킯�����B
Cell�͓���p�r�u��p�v�Ɏg���ɂ͍����\�����A�ėp���͊F��
�Ƃ����Ă����B
�ƖӖړI�ɐM������ł���n���������Ĉނ��ނ��Ȃ킯�����B
Cell�͓���p�r�u��p�v�Ɏg���ɂ͍����\�����A�ėp���͊F��
�Ƃ����Ă����B
����AMD�X���œˑR�͐����n�߂��̂��킩��l�͋���
ɼ
POWER�݂����ȕ����x�[�X�ɂ����������Cell��PS3��Sony������
AMD�������͂Ȃ肽���Ȃ����̂��ȁA�Ƃ����˂�[�[��̎咣�B
POWER�݂����ȕ����x�[�X�ɂ����������Cell��PS3��Sony������
AMD�������͂Ȃ肽���Ȃ����̂��ȁA�Ƃ����˂�[�[��̎咣�B
>>234
���N�̓f���A���R�A�̎���ɂȂ�I�ƃ��N�e�J���Ă�AMD(Intel)�t�@����8�R�A�ɂтт��Ă��܂����̂͊m��I�ɂ����炩�B
���\�̎��_��Cell���ǂ�Ȃ��̂��킩���Ă��͂��Ȃ̂ɂȂ�
���N�̓f���A���R�A�̎���ɂȂ�I�ƃ��N�e�J���Ă�AMD(Intel)�t�@����8�R�A�ɂтт��Ă��܂����̂͊m��I�ɂ����炩�B
���\�̎��_��Cell���ǂ�Ȃ��̂��킩���Ă��͂��Ȃ̂ɂȂ�
GK�����[
Gates Killer
AMD 65nm Processors in December 2006
http://www.vr-zone.com/?i=3643
Rev.G��Rev.F�Ɠ������f���i���o�Ƃ������Ő��\�͓����A
�S�ʓI�Ȑv�ύX�Ƃ����̂͏ȓd�͉��ƍ��N���b�N���H�݂̂��ۂ��B
FX64-3G�f���A����90nm��TDP125W�B
���sFX60��2.6G��TDP110W�Ȃ̂�Rev.F�ł�2.6G-1MBx2�A2.8-512x2�܂�TDP89W�B
Rev.F�ł�2�`3�����x�ȓd�͂ɂȂ��Ă�͗l�B
http://www.vr-zone.com/?i=3643
Rev.G��Rev.F�Ɠ������f���i���o�Ƃ������Ő��\�͓����A
�S�ʓI�Ȑv�ύX�Ƃ����̂͏ȓd�͉��ƍ��N���b�N���H�݂̂��ۂ��B
FX64-3G�f���A����90nm��TDP125W�B
���sFX60��2.6G��TDP110W�Ȃ̂�Rev.F�ł�2.6G-1MBx2�A2.8-512x2�܂�TDP89W�B
Rev.F�ł�2�`3�����x�ȓd�͂ɂȂ��Ă�͗l�B
>>236
RISC�̓���s����𗝉����Ƃ��ȁB
Cell�̂悤��RISC�̕����R�A�𑝂₷���b���₷���B
�v�̓R���p�C���A�y�ѕ��U�����ɓK��������B
�������AAMD�́A�ʌ��̕����ɍs�����낤�B
RISC�̓���s����𗝉����Ƃ��ȁB
Cell�̂悤��RISC�̕����R�A�𑝂₷���b���₷���B
�v�̓R���p�C���A�y�ѕ��U�����ɓK��������B
�������AAMD�́A�ʌ��̕����ɍs�����낤�B
�L�~�B���i�j��b���Ă���̂��T�b�p������
�悤��CELL�ō����Ă��Ƃł���H
�悤��CELL�ō����Ă��Ƃł���H
�uRev.G�v�������������A�܂����̓}y�펞���͂����A�\�[�X�ɂ���Ă܂����Ȉ�ۂ�����ȁB
�㓡���̋L���ł�2007�N�O���ɏo�Ă���65nm��K8���ǔłƂ��Ĉ����Ă������A
>>241�ł͉����Ⴄ�悤�ȋC�����Ȃ����Ȃ��B
����VR�̋L����Rev.G��65nm K8����Ver.�Ȃ̂��A
���邢�͌㓡���̌���65nm K8����Ver.�̑O��Rev,F�̒P���V�������NVer.��Rev.G�Ƃ��ďo�Ă���̂��E�E�E�B
�㓡���̋L���ł�2007�N�O���ɏo�Ă���65nm��K8���ǔłƂ��Ĉ����Ă������A
>>241�ł͉����Ⴄ�悤�ȋC�����Ȃ����Ȃ��B
����VR�̋L����Rev.G��65nm K8����Ver.�Ȃ̂��A
���邢�͌㓡���̌���65nm K8����Ver.�̑O��Rev,F�̒P���V�������NVer.��Rev.G�Ƃ��ďo�Ă���̂��E�E�E�B
�~�}y�펞�������o�ꎞ��
>>244
���f���i���o�[�ύX�Ȃ�������A�P���V�������N�o�[�W�������Ƃ����v���Ȃ�
���f���i���o�[�ύX�Ȃ�������A�P���V�������N�o�[�W�������Ƃ����v���Ȃ�
Rev.G�ɂ����낢�날���ˁ[��
�����Rev.H�܂ŗl�q�����ȁc
249 �FSocket774�F2006/05/17(��) 03:08:14 ID:9yWiKZy8
�Ƃ���ł��ɂȂ�����9800�~���キ��́H
��3�N���҂��Ă�����܂ő҂Ă����́H
��2500+�����芷�����Ȃ��ǂ����悤
��3�N���҂��Ă�����܂ő҂Ă����́H
��2500+�����芷�����Ȃ��ǂ����悤
250 �FSocket774�F2006/05/17(��) 03:40:09 ID:43Dnojr/
�܂��l��IBM�̈ʒu��AMD�������Ȃ�Cell���ݾ����Ă邪�ȁB
AMD��SCE��SONY��TOSHIBA�͍ō����Ă��B
�܂������ɂ���Ȏ��͂Ȃ����B
AMD��SCE��SONY��TOSHIBA�͍ō����Ă��B
�܂������ɂ���Ȏ��͂Ȃ����B
SPE�̓v���O���������[�J���X�g�A�Ɋi�[�����ŁAMPEG�f�R�[�_
�Ƃ��A��p�̗p�r�ɂP����SPE�����蓖�Ă�悤�Ȏg�����������
�����͐��\�オ�邩������ȁB
SPE���\�[�X�̒D����������������悤�Ȏg����������ƁA����ق�
���\�͏o�Ȃ��BCell�ɖ��݂������B
�Ƃ��A��p�̗p�r�ɂP����SPE�����蓖�Ă�悤�Ȏg�����������
�����͐��\�オ�邩������ȁB
SPE���\�[�X�̒D����������������悤�Ȏg����������ƁA����ق�
���\�͏o�Ȃ��BCell�ɖ��݂������B
>>251
��������
��������
���̃v���O���}�[��8���͓��������
���������l�����ł����\�o��悤�ɂ��Ȃ��Ɛ�Ε��y���܂���
���������l�����ł����\�o��悤�ɂ��Ȃ��Ɛ�Ε��y���܂���
�����������̂́A���̈����v���O���}�[�Ɍ����Ď����͓����ǂ��Ǝv���Ă��鎖�ł�
�S�R�v���O���}�[�Ɍ������b����Ȃ������
�G���Ƃ�503�̘b���Ǝv�����B
�ySPF����zAMD�Ђ���鎟����86�n�}�C�N���v���Z�T�̐v�v�z
http://techon.nikkeibp.co.jp/article/NEWS/20060517/117171/
http://techon.nikkeibp.co.jp/article/NEWS/20060517/117171/
>>257
cnet�̂ق��\��悗����
cnet�̂ق��\��悗����
CELL��Socket940�ɑ}���Ďg����l�ɂ���A�������h�Ń}���Z�[�ł�H
AMD�A�m�[�gPC�����f���A���R�A�v���Z�b�T�uTurion 64 X2�v
�`�ŏ�ʂ�Turion 64 X2 TL-60��2GHz/L2 512KB�~2
http://pc.watch.impress.co.jp/docs/2006/0517/amd.htm
��NEC�A�V���[�v�A�\�[�e�b�N�Ȃǂ��瓋�ڋ@�����l�������ɔ��������\��
�`�ŏ�ʂ�Turion 64 X2 TL-60��2GHz/L2 512KB�~2
http://pc.watch.impress.co.jp/docs/2006/0517/amd.htm
��NEC�A�V���[�v�A�\�[�e�b�N�Ȃǂ��瓋�ڋ@�����l�������ɔ��������\��
http://mypage.odn.ne.jp/www/k/8/k8_hammer_trans/files/Hammer-Info.html
�E2007�N�O������o�Ă���Desktop, Mobile 65nm�́A
�i�ȓd�͂͊��҂ł��邩������Ȃ����jIPC�I�ɂ͂قƂ��Rev.E�ƕς�Ȃ��B
�E2007�N�����ɏo��C�k�n�R�[�h�l�[����Opteron�́AIPC���啝���ǂ���������K8L�B
�EK8L�ōs��ꂽ���ǂ�Desktop�ɓ����Ă���̂́A2008�N�ȍ~�B
�E2007�N�O������o�Ă���Desktop, Mobile 65nm�́A
�i�ȓd�͂͊��҂ł��邩������Ȃ����jIPC�I�ɂ͂قƂ��Rev.E�ƕς�Ȃ��B
�E2007�N�����ɏo��C�k�n�R�[�h�l�[����Opteron�́AIPC���啝���ǂ���������K8L�B
�EK8L�ōs��ꂽ���ǂ�Desktop�ɓ����Ă���̂́A2008�N�ȍ~�B
�����풩����SPF�̘b��ł������肩�Ǝv�����⤒��߂��܂Ő��荇���̋���(>>249-256)��u���҂�
�C���^�r���[�ƍł��ǎ��̃v���[���摜���f�ڂ��ꂽTechON�̋L����̂�ɂ���CNET�̋L����
���Ă͂₷�y(>>258)��d���ɂ�Hammer-Info(>>262)�����B�B�B
���̔n�����Ղ�ɉ��߂ĒE�͂��������Ǥ�����������C���o���獡���̘b�ɂ��ď����������B
�C���^�r���[�ƍł��ǎ��̃v���[���摜���f�ڂ��ꂽTechON�̋L����̂�ɂ���CNET�̋L����
���Ă͂₷�y(>>258)��d���ɂ�Hammer-Info(>>262)�����B�B�B
���̔n�����Ղ�ɉ��߂ĒE�͂��������Ǥ�����������C���o���獡���̘b�ɂ��ď����������B
���ȉ��A�����̓W�J���y���݂��B
Q.�u�����Ă�����āv���g���āA�Z�������Ȃ���
A.
�@�@�@�@�@�@�@�@�@�@�@�@ ��
�@�@ �@ �@ �@ �@ �@ �@ �@ | |
�@�@ �@ �@ �@ �@ �@ �@ �@ | |
�@�@�@ �@ �@ �ȁQ�� �@ | |�@�@�@ �^�P�P�P�P�P�P�P�P�P�P�P�P
�@�@�@�@ �@ �i �@�L�D�M�j�^/�@�@�� MAC�I�^�͖���������Ă�����Ă��܂���
�@�@�@�@�@ �^ �@ �@ �@ /�@�@�@�@ �_�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q
�@�@�@�@ / /|�@�@�@�@/
�@ �Q�Q| | .|�@�@�@�@|
�@ �_�@ �P�P�P�P�P�P�P�_
�@�@||�_�@�@�@�@�@�@�@�@�@�@ �@ �_
�@�@||�_||�P�P�P�P�P�P�P||�P
�@�@||�@ ||�P�P�P�P�P�P�P||
�@�@ �@ .||�@ �@ �@ �@ �@ �@ �@ ||
A.
�@�@�@�@�@�@�@�@�@�@�@�@ ��
�@�@ �@ �@ �@ �@ �@ �@ �@ | |
�@�@ �@ �@ �@ �@ �@ �@ �@ | |
�@�@�@ �@ �@ �ȁQ�� �@ | |�@�@�@ �^�P�P�P�P�P�P�P�P�P�P�P�P
�@�@�@�@ �@ �i �@�L�D�M�j�^/�@�@�� MAC�I�^�͖���������Ă�����Ă��܂���
�@�@�@�@�@ �^ �@ �@ �@ /�@�@�@�@ �_�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q
�@�@�@�@ / /|�@�@�@�@/
�@ �Q�Q| | .|�@�@�@�@|
�@ �_�@ �P�P�P�P�P�P�P�_
�@�@||�_�@�@�@�@�@�@�@�@�@�@ �@ �_
�@�@||�_||�P�P�P�P�P�P�P||�P
�@�@||�@ ||�P�P�P�P�P�P�P||
�@�@ �@ .||�@ �@ �@ �@ �@ �@ �@ ||
�Ƃ肠�����CTechOn�f�ڂ̖���K8L�̃_�C���C�A�E�g�����Ăق������B
http://techon.nikkeibp.co.jp/article/NEWS/20060517/117171/?SS=imgview&FD=970875388
��r�p��K8�̃_�C�ʐ^��C�挎���̌㓡�L�����܂Ƃ܂��Ă��邷�B
http://pc.watch.impress.co.jp/docs/2006/0424/kaigai263.htm
���ڂ�C�R�A��L2�̖ʐϔ䂷�B
�@�E����K8: L2 (1MB)��R�A�ʐς�138.5%
�@�EDual Core K8: L2 (1MB)��R�A�ʐς�143.2%
�@�E65nm Rev.G K8: L2 (1MB?)��R�A�ʐς�98.7%
�@�E����Quad Core K8L: L2��R�A�ʐς�35.1%
�܂�CQuad-Core K8L��L2��256KB�̌��Z���傫���C65nm�̎���i���X�ɍ����x
���������Ă����Ƃ��Ă�512KB�ȉ��̌��Z�������Ƃ������Ƃ��B�������Opteron��4-core
�W�ς������̂Ƃ�������CSemptron x 4�̂Ƃ㕨�Ƃ������Ƃ��B
http://techon.nikkeibp.co.jp/article/NEWS/20060517/117171/?SS=imgview&FD=970875388
��r�p��K8�̃_�C�ʐ^��C�挎���̌㓡�L�����܂Ƃ܂��Ă��邷�B
http://pc.watch.impress.co.jp/docs/2006/0424/kaigai263.htm
���ڂ�C�R�A��L2�̖ʐϔ䂷�B
�@�E����K8: L2 (1MB)��R�A�ʐς�138.5%
�@�EDual Core K8: L2 (1MB)��R�A�ʐς�143.2%
�@�E65nm Rev.G K8: L2 (1MB?)��R�A�ʐς�98.7%
�@�E����Quad Core K8L: L2��R�A�ʐς�35.1%
�܂�CQuad-Core K8L��L2��256KB�̌��Z���傫���C65nm�̎���i���X�ɍ����x
���������Ă����Ƃ��Ă�512KB�ȉ��̌��Z�������Ƃ������Ƃ��B�������Opteron��4-core
�W�ς������̂Ƃ�������CSemptron x 4�̂Ƃ㕨�Ƃ������Ƃ��B
���āAPenD805���f���A���R�ACeleron�ƌĂ�ł����A�����AQuadCore Sermpron���Ȃ�ƕ]�����邩�B
���ʂ�QuadCore-K8�Ȃ�łˁH
NetBurst�ق�L2�̉e���ł����Ȃ���
NetBurst�ق�L2�̉e���ł����Ȃ���
269 �FMAC�I�^�������F2006/05/17(��) 22:14:47 ID:re/vyxri
��̏������݁C���̂悤�ɓǂݑւ��ė~�������B
�@�X�ɍ����x���������X�ɍ����x�u��SRAM�v������
���āC
�������́uFPU�Q�{�v�̌����C���ǁC
�@�@-------------------
�@�@Up to 4DP FLOPS/cycle
�@�@-------------------
���x�Ƃ��傹��SIMD���x���̘b���������Ƃ����炩�ɂȂ������B���m�̒ʂ�CIntel Core
�A�[�L�e�N�`�������SSE2���������_���Z���j�b�g���Q�����C���l��4DP FLOPS/cycle��
�\���B
�@�X�ɍ����x���������X�ɍ����x�u��SRAM�v������
���āC
�������́uFPU�Q�{�v�̌����C���ǁC
�@�@-------------------
�@�@Up to 4DP FLOPS/cycle
�@�@-------------------
���x�Ƃ��傹��SIMD���x���̘b���������Ƃ����炩�ɂȂ������B���m�̒ʂ�CIntel Core
�A�[�L�e�N�`�������SSE2���������_���Z���j�b�g���Q�����C���l��4DP FLOPS/cycle��
�\���B
������^���������@�Ƃ���
Transactional Memory
�f�[�^�x�[�X�Z�p�̉��p�Ƃ���Transactional Memory��������
�g�����U�N�V�����������ƂŁA��������������@�B
���L���̍X�V�𒀎����b�N���s�킸�ɍs���ƁA���b�N�����҂����Ԃ�Z�k�ł���B
���̏ꍇ�A���ꃁ�������X�V�����ꍇ�̋����̉����Ƃ��ăg�����U�N�V����(�X�V����)���g���
�Y�����ɕt���Ă̓��[���o�b�N����g�����U�N�V�������čX�V�����d�g�݂��B
INTEL
> ������CPU�R�A����������Ԃ����L����ۂɋN����f�[�^�̋����͂ǂ̂悤�ɉ��������肩�B
> Intel�Ђ̓}���`�X���b�h�̃v���O�����Ȃǂ��J������Ƃ��ɁC�X���b�h�Ԃŋ��L���郁������Ԃ𒀈ꃍ�b�N���Ȃ��čςށC
> Transactional Memory�̗̍p��z�肵�Ă���悤�����B
AMD
> Moore���@Transactional Memory�͂ƂĂ������[���Ǝv���Ă���B��X�����������B���b�N�̖��́C
> �v���O���}�ɂƂ��Đ[�����ƔF�����Ă��邩��ˁB
Transactional Memory
�f�[�^�x�[�X�Z�p�̉��p�Ƃ���Transactional Memory��������
�g�����U�N�V�����������ƂŁA��������������@�B
���L���̍X�V�𒀎����b�N���s�킸�ɍs���ƁA���b�N�����҂����Ԃ�Z�k�ł���B
���̏ꍇ�A���ꃁ�������X�V�����ꍇ�̋����̉����Ƃ��ăg�����U�N�V����(�X�V����)���g���
�Y�����ɕt���Ă̓��[���o�b�N����g�����U�N�V�������čX�V�����d�g�݂��B
INTEL
> ������CPU�R�A����������Ԃ����L����ۂɋN����f�[�^�̋����͂ǂ̂悤�ɉ��������肩�B
> Intel�Ђ̓}���`�X���b�h�̃v���O�����Ȃǂ��J������Ƃ��ɁC�X���b�h�Ԃŋ��L���郁������Ԃ𒀈ꃍ�b�N���Ȃ��čςށC
> Transactional Memory�̗̍p��z�肵�Ă���悤�����B
AMD
> Moore���@Transactional Memory�͂ƂĂ������[���Ǝv���Ă���B��X�����������B���b�N�̖��́C
> �v���O���}�ɂƂ��Đ[�����ƔF�����Ă��邩��ˁB
271 �FMAC�I�^�������܂��F2006/05/17(��) 22:27:19 ID:re/vyxri
TechOn�̃v���[����ǂ�����Δ���悤�ɁC���J���ꂽ�_�C�̃��C�A�E�g���ʐ^����Ȃ���
���C�A�E�g�u�}�v�̃��x�����B�܂茻���_�Ŋ��������`�b�v�푶�݂��Ă��Ȃ����Ƃ����炩���B
���ǁC
�@�EL2��1/4-1/2
�@�EFPU��Intel Core�A�[�L�e�N�`���Ɣ�r���ē��ɑ傫�ȃ����b�g�햳��
�@�E���߃X���b�g�̑���������
�Ƃ�����ŁC�V���O���X���b�h���\��Core�Ɣ�r���ďオ�錩���݂������Ă��Ȃ����B
���̏ŁC
�@�@--------------------------------
�@�@�P�Ɋȑf����������킯�ł͂Ȃ��B�P���ɂ������Ċ����̃A�v���P�[�V�����E�\�t�g
�@�@�E�G�A�̏������\���]���ɂȂ�C���[�U�[�ɂ����ۂ�������Ă��܂��B
�@�@--------------------------------
�Ȃ�Ă��Ƃ�������AMD�̃A�[�L�e�N�g�ɂ�C�����B���������邷���ˁH
���C�A�E�g�u�}�v�̃��x�����B�܂茻���_�Ŋ��������`�b�v�푶�݂��Ă��Ȃ����Ƃ����炩���B
���ǁC
�@�EL2��1/4-1/2
�@�EFPU��Intel Core�A�[�L�e�N�`���Ɣ�r���ē��ɑ傫�ȃ����b�g�햳��
�@�E���߃X���b�g�̑���������
�Ƃ�����ŁC�V���O���X���b�h���\��Core�Ɣ�r���ďオ�錩���݂������Ă��Ȃ����B
���̏ŁC
�@�@--------------------------------
�@�@�P�Ɋȑf����������킯�ł͂Ȃ��B�P���ɂ������Ċ����̃A�v���P�[�V�����E�\�t�g
�@�@�E�G�A�̏������\���]���ɂȂ�C���[�U�[�ɂ����ۂ�������Ă��܂��B
�@�@--------------------------------
�Ȃ�Ă��Ƃ�������AMD�̃A�[�L�e�N�g�ɂ�C�����B���������邷���ˁH
>�@�@�P�Ɋȑf����������킯�ł͂Ȃ��B�P���ɂ������Ċ����̃A�v���P�[�V�����E�\�t�g
>�@�@�E�G�A�̏������\���]���ɂȂ�C���[�U�[�ɂ����ۂ�������Ă��܂��B
����P�Ȃ錾����B
L1/L2�r���L���b�V���\�����̂āAINTEL�̂悤�ȍ����\���L�L���b�V�����J������\�͂��Ȃ����ʂ̌����B
L2����������L3���L�L���b�V���֑S�Ă�q����Ƃ������A���ꂵ���Ȃ��ƌ����ׂ����E�E�E
L3���L�L���b�V����INTEL��L2���L�L���b�V���Ƃ͈قȂ�A�قȂ郉�C���v���b�N���ɓ����A�N�Z�X�����������ɂ��Ȃ�낤�B
�܂�AIO�X�g���[���̈ꌳ���͏o�����A�ʂɎ����ƂɂȂ邩�琫�\�͔�ׂ�܂ł��Ȃ��E�E�E
�Ƃ͂����A4�R�A�Ƃ��Ȃ�Ύd���̖������Ƃ����ǂȁB
>�@�@�E�G�A�̏������\���]���ɂȂ�C���[�U�[�ɂ����ۂ�������Ă��܂��B
����P�Ȃ錾����B
L1/L2�r���L���b�V���\�����̂āAINTEL�̂悤�ȍ����\���L�L���b�V�����J������\�͂��Ȃ����ʂ̌����B
L2����������L3���L�L���b�V���֑S�Ă�q����Ƃ������A���ꂵ���Ȃ��ƌ����ׂ����E�E�E
L3���L�L���b�V����INTEL��L2���L�L���b�V���Ƃ͈قȂ�A�قȂ郉�C���v���b�N���ɓ����A�N�Z�X�����������ɂ��Ȃ�낤�B
�܂�AIO�X�g���[���̈ꌳ���͏o�����A�ʂɎ����ƂɂȂ邩�琫�\�͔�ׂ�܂ł��Ȃ��E�E�E
�Ƃ͂����A4�R�A�Ƃ��Ȃ�Ύd���̖������Ƃ����ǂȁB
273 �FMAC�I�^���⑫�F2006/05/17(��) 22:39:12 ID:re/vyxri
�Ƃ팾���Intel��݊���1GB�y�[�W�T�C�Y�̃T�|�[�g��礐V���߂̒lj����ɒ��킵�Ă��邱�Ƃɂ��Ĥ
���Ȃ��Ƃ����풍�ڂ��Ă��邷�B
���Ȃ��Ƃ����풍�ڂ��Ă��邷�B
AMD��INTEL�ƈႤ����͍�����̂͌����I�����Ǝv���B
>>270�����Ă�����悤�ɁA�����J����S���قȂ邱�Ƃ��f���Ă��܂��A������@����
INTEL�ɂ͏��ĂȂ����낤�B
>>270�����Ă�����悤�ɁA�����J����S���قȂ邱�Ƃ��f���Ă��܂��A������@����
INTEL�ɂ͏��ĂȂ����낤�B
MAC�I�^�̏������݂́AHammer-Info��������łɏ�����Ă��邱�Ƃ��肷�B
Intel��AMD�������Ă邩��ǂ���������ł͂Ȃ����A
MAC�I�^�̏������݂͂ق�ƂɃC���C������B
��x�Ə������܂Ȃ��ł���B�s��
MAC�I�^�̏������݂͂ق�ƂɃC���C������B
��x�Ə������܂Ȃ��ł���B�s��
�@�Ȃ���A>>277�݂����Ȕ�����MAC�I�^�̎��쎩���Ɏv���Ă����B
�����{�X���͂����ꂷ��
�I�^���ĎG���̃��A���m�荇���Ȃ�B
���H�Ⴄ�́H
���H�Ⴄ�́H
ATI�ATurion 64 X2�Ή��`�b�v�Z�b�g�uRadeon Xpress 1100�v
http://pc.watch.impress.co.jp/docs/2006/0518/ati.htm
1100��������������(߁��)������������ !!
http://pc.watch.impress.co.jp/docs/2006/0518/ati.htm
1100��������������(߁��)������������ !!
Linux�����Ή����ĂȂ��R���p�C�����g��Ȃ��ƍō����\���o�Ȃ��͓̂�V���ˁB
���̃R���p�C���ASGI�̂ƊW������݂��������ǁB
http://www.pathscale.com/performance.html
http://www.softek.co.jp/SPG/Pgi/TIPS/polyhedron.html
���̃R���p�C���ASGI�̂ƊW������݂��������ǁB
http://www.pathscale.com/performance.html
http://www.softek.co.jp/SPG/Pgi/TIPS/polyhedron.html
���m�̒ʂ�Dell�����N��1�l�����̉�v�̒��ŔN������Opteron���ڃT�[�o�[�����邱�Ƃ�
���\�������B
http://www.dell.com/content/topics/global.aspx/corp/pressoffice/en/2006/2006_05_18_rr_000?c=us&l=en&s=corp
�@�@------------------------------
�@�@In the enterprise, we will launch new ninth generation servers featuring Intel's Woodcrest
�@�@microprocessors. Dell will also introduce new AMD Opteron processors in our multi-processor
�@�@servers by the end of the year offering a great new technology to our customers at the high-end
�@�@of our server line.
�@�@------------------------------
�ꌩAMD�̐悪���������Ƃ��v���邱�̎����ɤ�����������f�������Ƃ������Ƃ��
�@�E��قǖ��͓I�ȃ��[�h�}�b�v�������ꂽ
�@�E������ & ���ƓI�t�����C���i�b�v�헪
�̂ǂ���Ȃ��ˁB�B�B
Apple�ƈ���Ĥ�Z�p�ŕ����f���Ă���Ƃ����^�C�v�̉�Ђ���Ȃ���������߂������B
���̔��\����AMD�̊����팋�\�オ�����悤�ŤCore 2�o��܂łɎ�����̊J������҂��ł�������
AMD�Ƃ��Ă�L���b���B
���\�������B
http://www.dell.com/content/topics/global.aspx/corp/pressoffice/en/2006/2006_05_18_rr_000?c=us&l=en&s=corp
�@�@------------------------------
�@�@In the enterprise, we will launch new ninth generation servers featuring Intel's Woodcrest
�@�@microprocessors. Dell will also introduce new AMD Opteron processors in our multi-processor
�@�@servers by the end of the year offering a great new technology to our customers at the high-end
�@�@of our server line.
�@�@------------------------------
�ꌩAMD�̐悪���������Ƃ��v���邱�̎����ɤ�����������f�������Ƃ������Ƃ��
�@�E��قǖ��͓I�ȃ��[�h�}�b�v�������ꂽ
�@�E������ & ���ƓI�t�����C���i�b�v�헪
�̂ǂ���Ȃ��ˁB�B�B
Apple�ƈ���Ĥ�Z�p�ŕ����f���Ă���Ƃ����^�C�v�̉�Ђ���Ȃ���������߂������B
���̔��\����AMD�̊����팋�\�オ�����悤�ŤCore 2�o��܂łɎ�����̊J������҂��ł�������
AMD�Ƃ��Ă�L���b���B
���ł��������Ă镗��MAC�I�^����ł��A�\���ł��Ȃ������̂����H
�������オ���������ł́AAMD�ɂ͂P�~�����͓���Ȃ��B
�������オ������ԂŐV�����s���ď��߂�AMD�ɋ�������B
�܂��A�]���Ѝs���Ă����ԂŊ������]�����i������A
�]�����i��ŏ����̏��ҕ��S������Ƃ����\���͂���B
�������オ������ԂŐV�����s���ď��߂�AMD�ɋ�������B
�܂��A�]���Ѝs���Ă����ԂŊ������]�����i������A
�]�����i��ŏ����̏��ҕ��S������Ƃ����\���͂���B
multiprocessor server �̂݁Ahighend server ���^�[�Q�b�g����
�����Ă��邩��ACPU�R�A�̔\�͂����AIntel �����L�o�X�̕���
�l�b�N�ɂȂ�悤�ȗ̈�̘b����˂��H
�����Ă��邩��ACPU�R�A�̔\�͂����AIntel �����L�o�X�̕���
�l�b�N�ɂȂ�悤�ȗ̈�̘b����˂��H
�C���e���ˑ����������ċ����͂���������
http://today.reuters.co.jp/news/newsArticle.aspx?type=marketsNews&storyID=2006-05-16T222149Z_01_nTK2816260_RTRJONT_0_CnTK2816260-1.xml
http://today.reuters.co.jp/news/newsArticle.aspx?type=marketsNews&storyID=2006-05-16T222149Z_01_nTK2816260_RTRJONT_0_CnTK2816260-1.xml
�ł�������̓C���e���̋����͂͂����邩����Ȃ��Ȃ��Ȃ����H��
����ł��R�R�A�𓊓�����Ώ��Ă��Ȃ����H
����ł��R�R�A�𓊓�����Ώ��Ă��Ȃ����H
�l�b�g�o�[�X�g�ɂ��T�[�o�[�����(����DP�T�[�o�[)�Ŋ��S�ɗɗ�������Ă���Dell���A
AMD��Opteron���̗p�����ԗǂ��^�C�~���O����Ȃ����ȁH
Woodcrest���s��ɏo����ƂȂ�6�����ɂ�ł̔��\�ł���A
Woodcrest��DP�T�[�o�[(2Way)�܂ł�Opteron��苣���͂��y���ɋ����ׁA
AMD�Ђ�CPU�ɂ��MP�T�[�o�[���̗p���Ă�Intel�Ƃ̋��ƘH���Ɉ��e�����y�ڂ����A
MP�T�[�o�[(4Way)��Opteron���̗p���邱�ƂŁAx86�T�[�o�[�Ƃ��Ă͍ō����\��CPU�Q�𑵂��鎖���\�ƂȂ�B
MP�T�[�o�[�͌��X���ɏ������s�ꂾ���甄�グ�ɂ͖w�NJ�^���Ȃ����A
���C���i�b�v�Ƃ��đ��ЂɌ���肵�Ȃ��i�Q�\���𑵂��邱�Ƃł̋����͋����̑_��������̂��낤�ȁB
AMD��Opteron���̗p�����ԗǂ��^�C�~���O����Ȃ����ȁH
Woodcrest���s��ɏo����ƂȂ�6�����ɂ�ł̔��\�ł���A
Woodcrest��DP�T�[�o�[(2Way)�܂ł�Opteron��苣���͂��y���ɋ����ׁA
AMD�Ђ�CPU�ɂ��MP�T�[�o�[���̗p���Ă�Intel�Ƃ̋��ƘH���Ɉ��e�����y�ڂ����A
MP�T�[�o�[(4Way)��Opteron���̗p���邱�ƂŁAx86�T�[�o�[�Ƃ��Ă͍ō����\��CPU�Q�𑵂��鎖���\�ƂȂ�B
MP�T�[�o�[�͌��X���ɏ������s�ꂾ���甄�グ�ɂ͖w�NJ�^���Ȃ����A
���C���i�b�v�Ƃ��đ��ЂɌ���肵�Ȃ��i�Q�\���𑵂��邱�Ƃł̋����͋����̑_��������̂��낤�ȁB
���ƍU�߂̋֎~��i���̉e���ŁA���x�[�g�������Ă�Dell���t���ƍU�߂ɂȂ����̂���
ttp://pc.watch.impress.co.jp/docs/2006/0428/kaigai266_03l.gif
ttp://pc.watch.impress.co.jp/docs/2006/0428/kaigai266.htm
ttp://pc.watch.impress.co.jp/docs/2006/0428/kaigai266_03l.gif
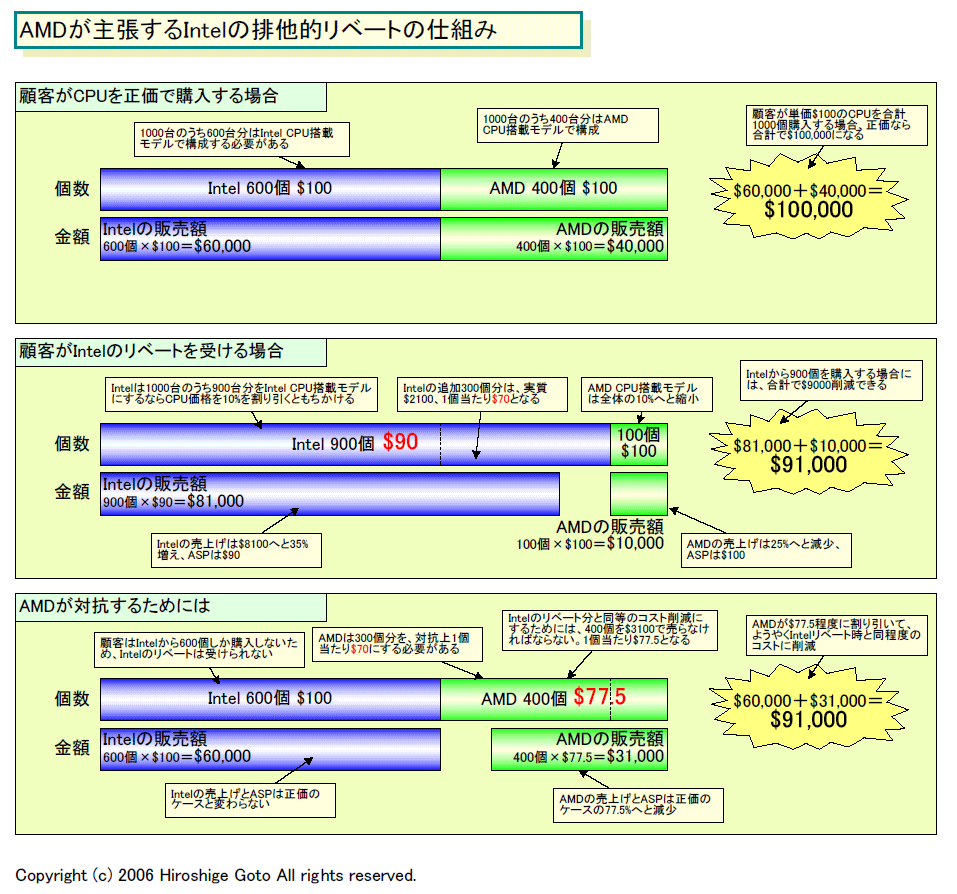{kind=link}
ttp://pc.watch.impress.co.jp/docs/2006/0428/kaigai266.htm
AMD�Ђ̎咣����r�����x�[�g�͒P�Ȃ錾���|����ł���͎̂s�ꓮ�����݂�Ζ��炩�B
INTEL��薣�͂���CPU���o���A�s��͋@�q�ɔ������Ă���Ŏ咣���Ă���̂�����B
�n���Ƃ��������悤��������w
INTEL��薣�͂���CPU���o���A�s��͋@�q�ɔ������Ă���Ŏ咣���Ă���̂�����B
�n���Ƃ��������悤��������w
Celeron����PC��ƃ��[�J��DELL�ɏE���Ă����傤���Ȃ��C������B
>>292
�܂��A�����������Ƃ��낤�ȁB
�܂��A�����������Ƃ��낤�ȁB
�����Dell�̌���ŁA4way�s��ł�AMD�̃V�F�A��50%�����邩���ˁB
���FAMD�Ђ̎咣����r�����x�[�g�͒P�Ȃ錾���|����ł͂Ȃ��͎̂s�ꓮ�����݂�Ζ��炩�B
�������牽��2005�N-2006�N�Ƌ��ٓI�ȃV�F�A�g�傪�o�����H
���������A���Y�\�͂����\�������x�����V�F�A�L���ĂȂ����������w
���������A���Y�\�͂����\�������x�����V�F�A�L���ĂȂ����������w
�i�ׂ̂�������Intel�������ɂ����Ȃ����Ƃ��B
���[�J�[: ������AMD���̗p���邯�ǁAIntel���甃�����͕ς��Ȃ����瓯���l�������ł�����ˁB
Intel: �ʖڑʖځA����Ȃ��Ƃ�����A�l��������}�����Ⴄ���B
���[�J�[: ����Ȃ��ƌ�������ٔ����Ƀ`�N�����Ⴄ���B
Intel: ����
���[�J�[: ������AMD���̗p���邯�ǁAIntel���甃�����͕ς��Ȃ����瓯���l�������ł�����ˁB
Intel: �ʖڑʖځA����Ȃ��Ƃ�����A�l��������}�����Ⴄ���B
���[�J�[: ����Ȃ��ƌ�������ٔ����Ƀ`�N�����Ⴄ���B
Intel: ����
���Ă��������ꂪAMD�̑_���ł���B
�܂����̂Ƃ��댩���ɑ_�������܂��Ă�킯���B
�܂����̂Ƃ��댩���ɑ_�������܂��Ă�킯���B
Opteron�̗p�̔��\��Woodcrest����������Ƃ������ƂŁA����������ƂȂ�����AMD��`�߂��Ƃ�����Ȃ����낤���B
�ŁAQuad Core K8L��L3����Victim Cache�H
����͂܂�������Ȃ���Ȃ��́B
L3��Z-RAM�g���ĂĎ���8MB���炢��������ʔ������B
�����Ȃ��L2������1MB�����炢����܂������ăI�`���c�B
�܂��M�������l����Ɩ������낤���ǁB
L3��Z-RAM�g���ĂĎ���8MB���炢��������ʔ������B
�����Ȃ��L2������1MB�����炢����܂������ăI�`���c�B
�܂��M�������l����Ɩ������낤���ǁB
victim cache �� exclusive cache ���ē����Ӗ��̌��t����ˁH
L3 �� L2 �Ɠ����x�̃T�C�Y�������� exclusive cache �Ō��肶��Ȃ��H
L3 �� L2 �Ɠ����x�̃T�C�Y�������� exclusive cache �Ō��肶��Ȃ��H
�y�R�����z�R���s���[�^�A�[�L�e�N�`���̘b ��19�� �L���b�V���̍\���⓭��(���p��) - �e�L���b�V���K�w�ɉ������邩? (MYCOM�W���[�i��)
ttp://journal.mycom.co.jp/column/architecture/019/
ttp://journal.mycom.co.jp/column/architecture/019/
>>304
�܂�L3��2MB�Ƃ������Ă����甖�X����ȋC������
�܂�L3��2MB�Ƃ������Ă����甖�X����ȋC������
>>305
�ӂނށA�ǂ����B
�Ƃ������Ƃ́A���t�̒�`�Ƃ��Ă̓j���A���X�ɈႢ������Ƃ����Ƃ������Ƃ��B
�����A���p�I�� Victim Cache ����Ȃ� Exclusive Cache ���āA�Ȃ���̂��ȁH
Athlon �n�� L1 �� L2 �̊W���AVictim Cache ����Ȃ��́H
ttp://virtualquest.cool.ne.jp/arisa/kaitou11-3.htm
ttp://pc.watch.impress.co.jp/docs/article/20000601/kaigai01.htm
�ӂނށA�ǂ����B
�Ƃ������Ƃ́A���t�̒�`�Ƃ��Ă̓j���A���X�ɈႢ������Ƃ����Ƃ������Ƃ��B
�����A���p�I�� Victim Cache ����Ȃ� Exclusive Cache ���āA�Ȃ���̂��ȁH
Athlon �n�� L1 �� L2 �̊W���AVictim Cache ����Ȃ��́H
ttp://virtualquest.cool.ne.jp/arisa/kaitou11-3.htm
ttp://pc.watch.impress.co.jp/docs/article/20000601/kaigai01.htm
victim cache���Ƌ��L�L���b�V���Ƃ��ċ@�\����������邩������������낤�ɁE�E�E
����łȂ��Ă�L2���Ɨ��^�Ȃ̂łǂ��ɂ��Ȃ�낤�H
L2��L1���ɏ��������č����A�N�Z�X�^�ɂ����Ƃ��Ă��AL3���o�R������L2�ւ̃��[�h�Ƃ��Ȃ��
L2�̗͌���������L3�͑f����Inclusion Cache�ɂ��ׂ������AL2��������x�傫�����Ȃ�
L3�ł̋��L���̗L��������������B
�Ƃ������A�Ȃ��L1,L2��Exclusion�̂܂܂ɂ��Ă������˂��E�E�E�E
�z�����������ł��ǂ��L���b�V�����Ƃ͎v����Ȃ��B
����łȂ��Ă�L2���Ɨ��^�Ȃ̂łǂ��ɂ��Ȃ�낤�H
L2��L1���ɏ��������č����A�N�Z�X�^�ɂ����Ƃ��Ă��AL3���o�R������L2�ւ̃��[�h�Ƃ��Ȃ��
L2�̗͌���������L3�͑f����Inclusion Cache�ɂ��ׂ������AL2��������x�傫�����Ȃ�
L3�ł̋��L���̗L��������������B
�Ƃ������A�Ȃ��L1,L2��Exclusion�̂܂܂ɂ��Ă������˂��E�E�E�E
�z�����������ł��ǂ��L���b�V�����Ƃ͎v����Ȃ��B
> L2��L1���ɏ��������č����A�N�Z�X�^�ɂ����Ƃ��Ă��AL3���o�R������L2�ւ̃��[
> �h�Ƃ��Ȃ��L2�̗͌���������L3�͑f����Inclusion Cache�ɂ��ׂ������A
�܂� L2 ������������ꍇ�ɂ́A�m����L3�� Inclusive �ɂ���Ӗ���
����Ǝv���B�ł��A
> L2��������x�傫�����Ȃ�L3�ł̋��L���̗L��������������B
�������̈Ӗ���������Ȃ��Ȃ��B
L2 ��������x�傫���AL3 ����r�I�������� L2 �Ɠ������炢�̃T�C�Y��
�ꍇ�A�r���L���b�V���ɂ���͓̂��R�ł́H
Inclusive ���ƂقƂ�� L3 �̈Ӗ����Ȃ������B
Exclusive �Ȃ�Ӗ������邯�ǁB
> �h�Ƃ��Ȃ��L2�̗͌���������L3�͑f����Inclusion Cache�ɂ��ׂ������A
�܂� L2 ������������ꍇ�ɂ́A�m����L3�� Inclusive �ɂ���Ӗ���
����Ǝv���B�ł��A
> L2��������x�傫�����Ȃ�L3�ł̋��L���̗L��������������B
�������̈Ӗ���������Ȃ��Ȃ��B
L2 ��������x�傫���AL3 ����r�I�������� L2 �Ɠ������炢�̃T�C�Y��
�ꍇ�A�r���L���b�V���ɂ���͓̂��R�ł́H
Inclusive ���ƂقƂ�� L3 �̈Ӗ����Ȃ������B
Exclusive �Ȃ�Ӗ������邯�ǁB
���ȃ��X
> ���p�I�� Victim Cache ����Ȃ� Exclusive Cache ���āA�Ȃ���̂��ȁH
L2�Ɨ�/L3���L�Ȃ�AVictim Cache �����Ǒ��̃R�A��L2�ɓ����Ă���G���g������
�̂�����܂��ȁB�Ƃ����킯�ŁA���������ꍇ�� Exclusive Cache �Ƃ���������
�͕s�K���ŁAVictim Cache �Ƃ����������ɂ��Ȃ��Ƃ܂����ƁB
������ Victim Cache �� Exclusive Cache �Ƃ������t�͕����čl�������������ƁB
L2�Ɨ�/L3�Ɨ���AL2���L/L3���L�̏ꍇ�ɂ͎����I�ɂ͓����ƍl���ėǂ��H
> ���p�I�� Victim Cache ����Ȃ� Exclusive Cache ���āA�Ȃ���̂��ȁH
L2�Ɨ�/L3���L�Ȃ�AVictim Cache �����Ǒ��̃R�A��L2�ɓ����Ă���G���g������
�̂�����܂��ȁB�Ƃ����킯�ŁA���������ꍇ�� Exclusive Cache �Ƃ���������
�͕s�K���ŁAVictim Cache �Ƃ����������ɂ��Ȃ��Ƃ܂����ƁB
������ Victim Cache �� Exclusive Cache �Ƃ������t�͕����čl�������������ƁB
L2�Ɨ�/L3�Ɨ���AL2���L/L3���L�̏ꍇ�ɂ͎����I�ɂ͓����ƍl���ėǂ��H
>311
Mac���^�̑���������
Mac���^�̑���������
�@�@�ȁc�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�r(����@�r
�@�@�Ȃ�ł��ځ`��Ȃ�ł����H�@�@�@�@�@�@�@�@�@�@�@�@�@�@,;;�A�@�@�@�@�@ �i �R�[ /
�@�@�@���������Ă��������`���I�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �U-vق��@�@�@/�@�@�C
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@��,,._=��'�� l~�@�@�@/�@ �^l
�@�@�@�@�@�@�@�@�@�^�P�P�M�R �F�@�@�@�@�@�@�@�@�@�@�@�@�@�@�i�S(����' �O�R�@�@ �T�@�P/
�@�@�@�@�@�@�@�@/.�@i�@/́_�R�_�F�@�@�@�@�@�@�@�Q,r.��@�@ �S��T�,,.�m` �R�j �^�@ �^�
�@�@�@�@�@�@�@�G| !�@|/__.xĤL,_ āp�F�@�@�@�@�@�@�u ��{ !�@, --āA�T-'�@_�RɃt�@�@�@�Pl
�@�@�@�@�@�@�@; |!� c�@ l�!oV�@�@�@�@�@�@ �q�@�� l�'�R�^l `�['�''�P�r'�P�@�Q�^
�@�@�@�@�@�@�@�G|�@!|.�" r�� �c|.|�A�F�@�@�@�@�@�m�R�@/�T i�@�@ �_,,.. -''"�@�@�@,�@�^
�@�@�@�@�@�@ ,',� �l� ���āMY �@�gЁR�@�@�@�@l��@�@l�@ �^!�R�@ >>285 �@l�Q,,.�C
�@�@�@�@�@ �^�@{���|'�L�T �p �m�m:l�@�p�F�@�@�@�T--�['�@�@l�s�@�@�@�@�@ �T�_�^
�@�@�@�@�F/�C�@�o�@�T�Vr-̓g�A�@! ʁ@�@�@�@�@�@�@�@�@�@�@l�t�@�@�@�@�/_�^�@,,;;;;;:-�
�@�@.�@�@�@�@|�@!|Y��'�~�o�S='�@| /�|�@�@�@�@�@ ,r�[�[v-� l l�@�@�@ �^�\�@,;;,,r'�܁R;;;!
�@�@�@ �@�@�@�R�l�@�@�@|!�@�@�@/�_�@ �@�@�@�@�@l�@�@��@�@R�R�Q�m�@l-;;;'_�m�@�@�@ �jj
�@�@�@�@�@�@-r''���M'��'�@ā['�L�@�@����jՁ@�@�R�@�@�R�@�@�@�@�@�@�@l�P�@�@�@�@�@��
�@��-''"-''�P~l�@�F,/{�A ||�@,.|='�L �@ l�R�[�]| ��������==-���@�@�@l
�@ ��Y�LKelloggl��Q_l�Q_ll�Q/�Q_l l 3.6 l�Q�Q�Q�Q�Q�Q_lj�Q/�Q_
�@�@l��l ��݁@ l�@�@,;;=��=;;::��@�@�@l;;l �� l�@�@�@�@�@�@�@�@�@�@�@�@�@�@�_
�@�@l�@ l �۽ā@l�@�S�[---�]'�.�@�@ l l �� l�@�@�u��P�P�R�@�@�@�@�@�@�@�_
.�^ l�@ l�@�@ �^�@�@�@`�[�[�]'�@�@�@ �RL�Qj�@�@�R��O�Q_j�@�@�@�@�@�@�@�@�_
�@�@�Ȃ�ł��ځ`��Ȃ�ł����H�@�@�@�@�@�@�@�@�@�@�@�@�@�@,;;�A�@�@�@�@�@ �i �R�[ /
�@�@�@���������Ă��������`���I�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �U-vق��@�@�@/�@�@�C
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@��,,._=��'�� l~�@�@�@/�@ �^l
�@�@�@�@�@�@�@�@�@�^�P�P�M�R �F�@�@�@�@�@�@�@�@�@�@�@�@�@�@�i�S(����' �O�R�@�@ �T�@�P/
�@�@�@�@�@�@�@�@/.�@i�@/́_�R�_�F�@�@�@�@�@�@�@�Q,r.��@�@ �S��T�,,.�m` �R�j �^�@ �^�
�@�@�@�@�@�@�@�G| !�@|/__.xĤL,_ āp�F�@�@�@�@�@�@�u ��{ !�@, --āA�T-'�@_�RɃt�@�@�@�Pl
�@�@�@�@�@�@�@; |!� c�@ l�!oV�@�@�@�@�@�@ �q�@�� l�'�R�^l `�['�''�P�r'�P�@�Q�^
�@�@�@�@�@�@�@�G|�@!|.�" r�� �c|.|�A�F�@�@�@�@�@�m�R�@/�T i�@�@ �_,,.. -''"�@�@�@,�@�^
�@�@�@�@�@�@ ,',� �l� ���āMY �@�gЁR�@�@�@�@l��@�@l�@ �^!�R�@ >>285 �@l�Q,,.�C
�@�@�@�@�@ �^�@{���|'�L�T �p �m�m:l�@�p�F�@�@�@�T--�['�@�@l�s�@�@�@�@�@ �T�_�^
�@�@�@�@�F/�C�@�o�@�T�Vr-̓g�A�@! ʁ@�@�@�@�@�@�@�@�@�@�@l�t�@�@�@�@�/_�^�@,,;;;;;:-�
�@�@.�@�@�@�@|�@!|Y��'�~�o�S='�@| /�|�@�@�@�@�@ ,r�[�[v-� l l�@�@�@ �^�\�@,;;,,r'�܁R;;;!
�@�@�@ �@�@�@�R�l�@�@�@|!�@�@�@/�_�@ �@�@�@�@�@l�@�@��@�@R�R�Q�m�@l-;;;'_�m�@�@�@ �jj
�@�@�@�@�@�@-r''���M'��'�@ā['�L�@�@����jՁ@�@�R�@�@�R�@�@�@�@�@�@�@l�P�@�@�@�@�@��
�@��-''"-''�P~l�@�F,/{�A ||�@,.|='�L �@ l�R�[�]| ��������==-���@�@�@l
�@ ��Y�LKelloggl��Q_l�Q_ll�Q/�Q_l l 3.6 l�Q�Q�Q�Q�Q�Q_lj�Q/�Q_
�@�@l��l ��݁@ l�@�@,;;=��=;;::��@�@�@l;;l �� l�@�@�@�@�@�@�@�@�@�@�@�@�@�@�_
�@�@l�@ l �۽ā@l�@�S�[---�]'�.�@�@ l l �� l�@�@�u��P�P�R�@�@�@�@�@�@�@�_
.�^ l�@ l�@�@ �^�@�@�@`�[�[�]'�@�@�@ �RL�Qj�@�@�R��O�Q_j�@�@�@�@�@�@�@�@�_
���ׂ�AMD�̂���
Athlon�����̔r���L���b�V�������� Victim Cache �̂悤���ˁB
���t���Ƃ�����i�H�j���n�߂��������ۂ��B
http://watch.impress.co.jp/PC/docs/article///20000601/kaigai01.htm
��A��ʂɗe�ʐߖ�݂̂Ɏv��ꂪ���Ȕr���L���b�V���̗��_��
���ɃA�N�Z�X���C�e���V�̒Z�k�����҂ł���B
�������A�C���e���̃L���b�V���ɕ����Ă��邯�ǁB
���t���Ƃ�����i�H�j���n�߂��������ۂ��B
http://watch.impress.co.jp/PC/docs/article///20000601/kaigai01.htm
��A��ʂɗe�ʐߖ�݂̂Ɏv��ꂪ���Ȕr���L���b�V���̗��_��
���ɃA�N�Z�X���C�e���V�̒Z�k�����҂ł���B
�������A�C���e���̃L���b�V���ɕ����Ă��邯�ǁB
Thunderbird�̎���TLB���r���I�ɂȂ��Ă��Ȃ������B
Palomino��ʰ��� ���̪���ƍ��킹�āA
�r���I�i����ٰ��ށj&���@�ITLB�ɕς����B
Palomino��ʰ��� ���̪���ƍ��킹�āA
�r���I�i����ٰ��ށj&���@�ITLB�ɕς����B
>>315
�Ƃ������A�n�[�h�v���t�F�b�`�̋����o���Ȃ�����H
L2��L3�ւ̃v�����[�h�s�\�����A���������Ƃ��Ă��Ӗ��������B
�Ƃ������A�n�[�h�v���t�F�b�`�̋����o���Ȃ�����H
L2��L3�ւ̃v�����[�h�s�\�����A���������Ƃ��Ă��Ӗ��������B
>>317
����͔r����Victim�Ɣ����鎖�ł͂Ȃ����H
����͔r����Victim�Ɣ����鎖�ł͂Ȃ����H
�q���g�E�E�EL1����R���B
�r���L���b�V�����āA�X�g���[�~���O�����Ɏア��
�v���t�F�`�ɓs���̈����Ƃ��날���
���܂ŋC�Â��Ȃ�����
AMD��intel�قǑ�e�ʃL���b�V����ς߂Ȃ�����
�r���L���b�V�����~�߂ɂ����̂�����ȂƂ�����Ń}�C�i�X�Ƃ�
�v���t�F�`�ɓs���̈����Ƃ��날���
���܂ŋC�Â��Ȃ�����
AMD��intel�قǑ�e�ʃL���b�V����ς߂Ȃ�����
�r���L���b�V�����~�߂ɂ����̂�����ȂƂ�����Ń}�C�i�X�Ƃ�
>>320
> �r���L���b�V�����āA�X�g���[�~���O�����Ɏア��
����́A�L���b�V�����邩���Ȃ����̔���ɉ��������̃y�i���e�B������Ƃ����Ӗ�?
> �r���L���b�V�����āA�X�g���[�~���O�����Ɏア��
����́A�L���b�V�����邩���Ȃ����̔���ɉ��������̃y�i���e�B������Ƃ����Ӗ�?
�X�g���[�~���O�͐��ꗬ���̎g���̂ăf�[�^����B(�ꕔ�����Q�Ƃ��邯��)
�̂ŁA�r���L���b�V�����ƃp�[�W�����ł̃y�i���e�B����H�炤�H�ڂɂȂ�B
�̂ŁA�r���L���b�V�����ƃp�[�W�����ł̃y�i���e�B����H�炤�H�ڂɂȂ�B
>>322
�ĎQ�Ƃ���Ȃ����̂͂��������L���b�V���Ɏ�荞�܂Ȃ�����B
�ĎQ�Ƃ���Ȃ����̂͂��������L���b�V���Ɏ�荞�܂Ȃ�����B
>>323
�v�����[�h������B
Inclusive�̏ꍇ�A��s�A�h���X����L2�Ƀ��[�h���邱�ƂŌ������オ��B(L1���W)
Exclusive�̏ꍇ�A��s�A�h���X����L1�Ƀ��[�h���邱�Ƃ�L1����ǂ��o�����C����������L2�֓f���o�����B
���ꓙ�́A������ቺ�����v�����B
�v�����[�h������B
Inclusive�̏ꍇ�A��s�A�h���X����L2�Ƀ��[�h���邱�ƂŌ������オ��B(L1���W)
Exclusive�̏ꍇ�A��s�A�h���X����L1�Ƀ��[�h���邱�Ƃ�L1����ǂ��o�����C����������L2�֓f���o�����B
���ꓙ�́A������ቺ�����v�����B
STREAM �x���`�}�[�N�ɂ������������o���h��
�@�@�@�@�@2.2Ghz/DDR400 Opteron�@|3.6Ghz/800FSB Intel Xeon EM64T
Function �@PGI 5.2-4 �@PGI 6.0 �@ �@|�@PGI 5.2-4 �@PGI 6.0
Copy �@�@�@�@3773.6 �@�@�@4874.2 �@�@�@�@�@3797.3 �@�@3780.2
Scale �@�@�@�@3787.5 �@�@�@4838.2 �@�@�@�@�@3775.8 �@�@3732.2
Add �@�@�@�@�@4055.4 �@�@�@4584.0 �@�@�@�@�@3579.7 �@�@3594.9
Triad �@�@ �@�@4131.9 �@�@�@4584.9 �@�@�@�@�@3600.3 �@�@3705.6
�v�����[�h���œK������Ă���A����Ȃ�炵����
�@�@�@�@�@2.2Ghz/DDR400 Opteron�@|3.6Ghz/800FSB Intel Xeon EM64T
Function �@PGI 5.2-4 �@PGI 6.0 �@ �@|�@PGI 5.2-4 �@PGI 6.0
Copy �@�@�@�@3773.6 �@�@�@4874.2 �@�@�@�@�@3797.3 �@�@3780.2
Scale �@�@�@�@3787.5 �@�@�@4838.2 �@�@�@�@�@3775.8 �@�@3732.2
Add �@�@�@�@�@4055.4 �@�@�@4584.0 �@�@�@�@�@3579.7 �@�@3594.9
Triad �@�@ �@�@4131.9 �@�@�@4584.9 �@�@�@�@�@3600.3 �@�@3705.6
�v�����[�h���œK������Ă���A����Ȃ�炵����
>>315
Athlon�͔r���ł����āAVictim Cache�ł͂Ȃ��ł���H
�����ɃA�N�Z�X���C�e���V�̒Z�k�����҂ł���B
�r���������d���̂�K7�̃X���[�v�b�g�͍��������B
���̂����Ń��C�e���V�Ō��Ă��x���Ȃ��Ă����B
Athlon�͔r���ł����āAVictim Cache�ł͂Ȃ��ł���H
�����ɃA�N�Z�X���C�e���V�̒Z�k�����҂ł���B
�r���������d���̂�K7�̃X���[�v�b�g�͍��������B
���̂����Ń��C�e���V�Ō��Ă��x���Ȃ��Ă����B
>>320,322
prefetchnta���g�p���Ė����\�t�g�E�F�A���N�\�Ȃ����B
prefetchnta���g�p���Ė����\�t�g�E�F�A���N�\�Ȃ����B
����莋���Ă���̂̓n�[�h�v���t�F�b�`���\����H
�ցH
���̖����āA�\�t�g�E�F�A���q���g�^���邾���ł���������Ȃ��̂��H
���̖����āA�\�t�g�E�F�A���q���g�^���邾���ł���������Ȃ��̂��H
�q���g�^���Ă��Ȃ��\�t�g�ł̐��\���͑傫�����A���������\�t�g�E�F�A�ł̑Ώ��̓������傫���̂ƌ����������B
���蕪��ł̌����ȊO�͖��͂ɋ߂����ȁB
���蕪��ł̌����ȊO�͖��͂ɋ߂����ȁB
>���������\�t�g�E�F�A�ł̑Ώ��̓������傫���̂ƌ����������B
>���蕪��ł̌����ȊO�͖��͂ɋ߂����ȁB
��Ȃ����[�Ȃ��B
�n�[�h�E�F�A���ňꎞ�I�f�[�^�������łȂ����͔��f���鎖���o���Ȃ��B
�䂦�ɁA�\�t�g�E�F�A���q���g��^����B
>���蕪��ł̌����ȊO�͖��͂ɋ߂����ȁB
��Ȃ����[�Ȃ��B
�n�[�h�E�F�A���ňꎞ�I�f�[�^�������łȂ����͔��f���鎖���o���Ȃ��B
�䂦�ɁA�\�t�g�E�F�A���q���g��^����B
���ꂾ��Conroe�̃L���b�V���V�X�e���������\�ł��闝�R�������o���Ȃ���B
�Ȃm��S�Ă�ے肵�Ă���悤�Ȕ����͍T���ė~������w
�Ȃm��S�Ă�ے肵�Ă���悤�Ȕ����͍T���ė~������w
>Conroe�̃L���b�V���V�X�e���������\�ł��闝�R
�������B
�������B
�ց[�����Ȃ�w
�L���b�V�����\�������A�������[���C�e���V��Athlon64��舳�|�I�Ɉ���CPU�̃N���b�N������̐��\��Athlon64���
�y���ɍ����\�Ȃ͉̂��̂��H
�����Ƃ��ĂȂ肽���Ȃ����Ƃ́A���O�ɂ������ł����ȁH
�L���b�V�����\�������A�������[���C�e���V��Athlon64��舳�|�I�Ɉ���CPU�̃N���b�N������̐��\��Athlon64���
�y���ɍ����\�Ȃ͉̂��̂��H
�����Ƃ��ĂȂ肽���Ȃ����Ƃ́A���O�ɂ������ł����ȁH
>>334
���̍����ƂȂ�\�[�X�́H
���̍����ƂȂ�\�[�X�́H
�����͕����ŏ\���B
���߂ƃf�[�^�̋������X���[�Y�ɍs���Ȃ���A�ǂ�ȍ����\��CPU�ł����\�͏オ��Ȃ��B
����펯�B
���߂ƃf�[�^�̋������X���[�Y�ɍs���Ȃ���A�ǂ�ȍ����\��CPU�ł����\�͏オ��Ȃ��B
����펯�B
(߄D�)ʧ?
�����A���O�͘_���I�ɕ������v�l�ł��Ȃ��l�̂悤����w
�f�[�^�������̂ɁA�����\�ƌ��߂��Ă�N�Ɋ��t
Conroe�̃L���b�V���V�X�e�������͂ō����\�Ȃ̂́A�傫��L2(4MB)�Ƌ��L�L���b�V���ł��邱�ƁA
2�̃R�A����̑��d�A�N�Z�X��1�̃X�g���[���Ŏ��o�X����{�ɂ��邱�ƂŐ��\��}���A
���C��������̃L���b�V���ێ��\�͂�����(4MB)���Ƃ�w�i�Ƃ��ăn�[�h�v���t�F�b�`�@�\�̋����ŁA
���߂ƃf�[�^�̋������\�����߂Ă��邱�Ƃ�FX���N���b�N������̐��\��20%�`30%�I�[�o�[���̍����\��
�q�����Ă���̂͏펯�Ȃ��ǂˁB
���ꕪ��܂��H
2�̃R�A����̑��d�A�N�Z�X��1�̃X�g���[���Ŏ��o�X����{�ɂ��邱�ƂŐ��\��}���A
���C��������̃L���b�V���ێ��\�͂�����(4MB)���Ƃ�w�i�Ƃ��ăn�[�h�v���t�F�b�`�@�\�̋����ŁA
���߂ƃf�[�^�̋������\�����߂Ă��邱�Ƃ�FX���N���b�N������̐��\��20%�`30%�I�[�o�[���̍����\��
�q�����Ă���̂͏펯�Ȃ��ǂˁB
���ꕪ��܂��H
�ǂ�����̃R�s�y�ł����H
Conroe���傫��L2�������Ă�̂͂��łɒm���Ă�A
�ŁA���ꂪ�X�g���[�~���O�����Ƃǂ��W����H
�ŁA���ꂪ�X�g���[�~���O�����Ƃǂ��W����H
�����A�N�Z�X���ƁA�L���b�V�����W�Ƃł��v���Ă���̂��H
�ցH�N������Ȏ����H
���̓X�g���[�~���O����(���ꗬ���̎g���̂ăf�[�^)���A�L���b�V�����������邾���ƌ����Ă�̂��B
������A�\�t�g�E�F�A�Ńq���g��^��������������Ď����B
���̓X�g���[�~���O����(���ꗬ���̎g���̂ăf�[�^)���A�L���b�V�����������邾���ƌ����Ă�̂��B
������A�\�t�g�E�F�A�Ńq���g��^��������������Ď����B
�{���̎G��ID:Glgl+3AV
AMD��K8�R�A�̕��������_���Z���j�b�g��2�{��
�`Rev. H�ƌ�����CPU�R�A�̎p�����J
http://pc.watch.impress.co.jp/docs/2006/0522/kaigai272.htm
�`Rev. H�ƌ�����CPU�R�A�̎p�����J
http://pc.watch.impress.co.jp/docs/2006/0522/kaigai272.htm
> ���̓X�g���[�~���O����(���ꗬ���̎g���̂ăf�[�^)���A�L���b�V�����������邾���ƌ����Ă�̂��B
> ������A�\�t�g�E�F�A�Ńq���g��^��������������Ď����B
�����Ȃ�Ă��Ȃ���B
���������A�L���b�V�����C���̑傫�������Ă���B
����������̎����[�h��1��ŃL���b�V������̃��[�h��1��Ƃł��v���Ă���̂��H
> ������A�\�t�g�E�F�A�Ńq���g��^��������������Ď����B
�����Ȃ�Ă��Ȃ���B
���������A�L���b�V�����C���̑傫�������Ă���B
����������̎����[�h��1��ŃL���b�V������̃��[�h��1��Ƃł��v���Ă���̂��H
>>346
�����A�v���Ԃ��Good�j���[�X�B
Rev.H���{���Ȃ�ARev.H�̎��̎����炢�łȂ�Ƃ��g����CPU�ɂȂ肻���B
���́A�����\�L���b�V���Ȃ̂����Ȃ�Ƃ��Ȃ邩���m��Ȃ��ȁB
�����A�v���Ԃ��Good�j���[�X�B
Rev.H���{���Ȃ�ARev.H�̎��̎����炢�łȂ�Ƃ��g����CPU�ɂȂ肻���B
���́A�����\�L���b�V���Ȃ̂����Ȃ�Ƃ��Ȃ邩���m��Ȃ��ȁB
>>348
���̎����ĉ��N�ゾ��w
���̎����ĉ��N�ゾ��w
�H���u����Ȏ����m��Ȃ��̂��A�������ȁv
�������������������ł��Ȃ��l�͗D�G�Ȑl����Ȃ��A�܂��Ă�l�̏�ɗ����ė��v���グ�Ă���l�ł͂Ȃ��f���ł��܂���
�������������������ł��Ȃ��l�͗D�G�Ȑl����Ȃ��A�܂��Ă�l�̏�ɗ����ė��v���グ�Ă���l�ł͂Ȃ��f���ł��܂���
L2�Ɋi�[�����̂̓f�[�^��������Ȃ�����E�E�E
���߃t�F�b�`��f�R�[�_����������Ă镪�A�]�����L2�Ɏ�荞�܂Ȃ���Ȃ�߂������邾�낤���B
ttp://pc.watch.impress.co.jp/docs/2006/0311/kaigai249.htm
������������ł̓L���b�V���ɂ��Ă͉����G��ĂȂ�����A����قǏd�v����Ȃ����Ċ������ȁB
�e�ʑ����Ƌ��L�L���b�V���ł�����x�̌��ʂ͂������낤���B
>>346
���̃N�A�b�h�R�A�̃��C�A�E�g�A�����Ɉ�a��������Ǝv������HT�p�b�h�炵���������������ȁE�E�E
���ꂾ�ƁAHTLink�̐��������悤�ȋC�����邪�E�E�E�`�b�v�`��𐳕��`�ɐ���������Ԃł̃e�X�g���C�A�E�g���ˁH
���߃t�F�b�`��f�R�[�_����������Ă镪�A�]�����L2�Ɏ�荞�܂Ȃ���Ȃ�߂������邾�낤���B
ttp://pc.watch.impress.co.jp/docs/2006/0311/kaigai249.htm
������������ł̓L���b�V���ɂ��Ă͉����G��ĂȂ�����A����قǏd�v����Ȃ����Ċ������ȁB
�e�ʑ����Ƌ��L�L���b�V���ł�����x�̌��ʂ͂������낤���B
>>346
���̃N�A�b�h�R�A�̃��C�A�E�g�A�����Ɉ�a��������Ǝv������HT�p�b�h�炵���������������ȁE�E�E
���ꂾ�ƁAHTLink�̐��������悤�ȋC�����邪�E�E�E�`�b�v�`��𐳕��`�ɐ���������Ԃł̃e�X�g���C�A�E�g���ˁH
> ������������ł̓L���b�V���ɂ��Ă͉����G��ĂȂ�
�㓡�������m�Ȃ�������H
�㓡�������m�Ȃ�������H
>>352
�[���A���O������H
intel�͂ȁAFX���x�[�X�ɉ��ǂ���Conroe���������Ȃ����H
�A�[�L�e�N�`���̋����_���ǂꂾ���̌��ʂ�\���������Ȃ�A�x�[�X�ɂȂ����A�[�L�e�N�`����Ō��Ȃ��ᖳ�Ӗ����낤���B
���łɌ�����"Conroe�̘b�����������intel������X���ɐ���"�B
�[���A���O������H
intel�͂ȁAFX���x�[�X�ɉ��ǂ���Conroe���������Ȃ����H
�A�[�L�e�N�`���̋����_���ǂꂾ���̌��ʂ�\���������Ȃ�A�x�[�X�ɂȂ����A�[�L�e�N�`����Ō��Ȃ��ᖳ�Ӗ����낤���B
���łɌ�����"Conroe�̘b�����������intel������X���ɐ���"�B
�X�g���[�~���O�f�[�^�͕��ʂɃL���b�V�������������킯�����B
�e�ʐ��S�L���o�C�g�̃A�j���X�g���[�~���O�������Ȃ���ɂ�
�킩��낤�Ȃ��B
�e�ʐ��S�L���o�C�g�̃A�j���X�g���[�~���O�������Ȃ���ɂ�
�킩��낤�Ȃ��B
�X�g���[�~���O�ƃΏĂ����Ɏ��s���Ă݂Ă͂ǂ����낤�H
������L�L���b�V����Yonah��Conroe�ł̘b�����ǁE�E�E
������L�L���b�V����Yonah��Conroe�ł̘b�����ǁE�E�E
�㓡�͂�����ۂ����́i�����E�ϑz�����Ղ�܂ށj�����̂͏�肢��
�匴�i�n�C�A�}�`���A�j������i�Z�~�v���j�Ɣ�ׂ�Ƒf�l
�匴�i�n�C�A�}�`���A�j������i�Z�~�v���j�Ɣ�ׂ�Ƒf�l
�匴�̓��[�h�}�b�v�Ɋւ��Ă̓n�Y���������̂����_���ȁB
�������ā��̈����H
ttp://journal.mycom.co.jp/column/architecture/
ttp://journal.mycom.co.jp/column/architecture/
�n�C�A�}�`���A���Ă͖̂J�߂Ă�̂��Ȃ��Ă�̂��悭�������\������
361 �FMAC�I�^��356 �����F2006/05/23(��) 08:33:10 ID:zvSbeZ9v
>>356
�@�@-------------------
�@�@�匴�i�n�C�A�}�`���A�j������i�Z�~�v���j�Ɣ�ׂ�Ƒf�l
�@�@-------------------
��������SPARC64�̃A�[�L�e�N�g�Ńv�����̃v���Ȃ��ǁB�B�B
http://www.cs.clemson.edu/~mark/architects.html
�@�@===================
�@�@# HaL SPARC64, 1995 - Hisashige Ando (design manager), Winfried Wilcke, and Mike Shebanow
�@�@===================
�������ɂ��v���Z�b�T�v�̋L�����ǂ߂邠�Ȃ�������K�����Ǝv�������Ǥ���ɂƂ��Ă�㓡�L����
��ʂ����Ȃ��B�B�B���Ă̂�c�O�Șb���B
�@�@-------------------
�@�@�匴�i�n�C�A�}�`���A�j������i�Z�~�v���j�Ɣ�ׂ�Ƒf�l
�@�@-------------------
��������SPARC64�̃A�[�L�e�N�g�Ńv�����̃v���Ȃ��ǁB�B�B
http://www.cs.clemson.edu/~mark/architects.html
�@�@===================
�@�@# HaL SPARC64, 1995 - Hisashige Ando (design manager), Winfried Wilcke, and Mike Shebanow
�@�@===================
�������ɂ��v���Z�b�T�v�̋L�����ǂ߂邠�Ȃ�������K�����Ǝv�������Ǥ���ɂƂ��Ă�㓡�L����
��ʂ����Ȃ��B�B�B���Ă̂�c�O�Șb���B
RISC��C���t���[���Ɍ��C���Ȃ����
IA-32�̘b�������A���ʂ������Ȃ��̂��c�O
�ŋ߂�ando's microprocessor
����ɂ��Ă��Asparc64�̃f�U�C���}�l�[�W���[���Ă�������
IA-32�̘b�������A���ʂ������Ȃ��̂��c�O
�ŋ߂�ando's microprocessor
����ɂ��Ă��Asparc64�̃f�U�C���}�l�[�W���[���Ă�������
���u���Ă����� ID:Cn+8jETg �̊�Ղ̃J�L�R��
�����Ƒ�R���ꂽ��������Ȃ��̂Ɂc
�����p���������ďo�Ă���Ȃ����낤�ȁB
�����Ƒ�R���ꂽ��������Ȃ��̂Ɂc
�����p���������ďo�Ă���Ȃ����낤�ȁB
>>363
�����������ďo�Ă��āA���̎G����MAC���^��ڎw���ė~�����Ȃ�
�����������ďo�Ă��āA���̎G����MAC���^��ڎw���ė~�����Ȃ�
����AMAC�I�^���Ĉ������̃y�[�W�ǂ�łB
MAC�I�^�̏������ݒ���ɁAMAC�I�^�Ɣ��̌������������̃y�[�W��
�����Ă����Ęm����A�������{�l�Ƃ��Ă͒p���������Ȃ�Ȃ��̂��ȁH
MAC�I�^�̏������ݒ���ɁAMAC�I�^�Ɣ��̌������������̃y�[�W��
�����Ă����Ęm����A�������{�l�Ƃ��Ă͒p���������Ȃ�Ȃ��̂��ȁH
366 �FMAC�I�^��365 �����F2006/05/24(��) 01:12:50 ID:hfyI0XzM
>>365
�@�@---------------------
�@�@�������{�l�Ƃ��Ă͒p���������Ȃ�Ȃ��̂��ȁH
�@�@---------------------
�R�g��SPARC64�̘b���ᖳ�����褁u�������̌�=�^����Ƃ����킯���ᖳ���Ƃ��������̘b���B
�@�@---------------------
�@�@�������{�l�Ƃ��Ă͒p���������Ȃ�Ȃ��̂��ȁH
�@�@---------------------
�R�g��SPARC64�̘b���ᖳ�����褁u�������̌�=�^����Ƃ����킯���ᖳ���Ƃ��������̘b���B
�Ȃ�قǁAMAC�I�^�́A�������̌�����ǂ�ł��A�����̌����̕���
�������Ǝv���Ă�ƁB������MAC�I�^���B����B
�������Ǝv���Ă�ƁB������MAC�I�^���B����B
368 �FMAC�I�^��367 �����F2006/05/24(��) 01:43:48 ID:hfyI0XzM
>>367
�H�w�ɂ����Ė��̉����@������ᖳ���ȏ㤈������̈ӌ��ǂ��납�\�z�������邩�ǂ����������
�C�ɂ���ׂ��b�ł햳�����B
���ͤ�b�̑O���_���W�J�ɂ������ȏ����������ǂ������ď��Ƃ������ƂɂȂ邷�B
�H�w�ɂ����Ė��̉����@������ᖳ���ȏ㤈������̈ӌ��ǂ��납�\�z�������邩�ǂ����������
�C�ɂ���ׂ��b�ł햳�����B
���ͤ�b�̑O���_���W�J�ɂ������ȏ����������ǂ������ď��Ƃ������ƂɂȂ邷�B
>365,367
���ނ��瑊��������
���ނ��瑊��������
�ǂ��ɂ��`�l�c�͂��̓�����̂��Ȃ����ȁH
���őf�p�ȋ^��Ȃ��ǁA���L�L���b�V����Quad CPU�Ƃ���
�N���b�N�L���[���Ăǂ��Ȃ��Ă�́H
�N���b�N�L���[���Ăǂ��Ȃ��Ă�́H
372 �FSocket774�F2006/05/25(��) 01:12:09 ID:753bPSJZ
�`503���Ă���Ȑl���` Ver.060524b
�c���̑����Y��30���ŁA���̌�p�ҁi�{�q�j
���͋����ɐ��E����ē����w����
�e�ʂɂ͋��t�ƈ�ґ���
�f���͓��H�ꕔ�̌��E�В�
�{�l�͂����Ƒ�����b���_�����
���͌����������Ă��邪���E�͍��|�ŕٌ�m��ڎw���Ă���
��̓X�^�[�E�H�[�Y3�ɏo�����Ă����A�i�L���ɂ�������ȃi�C�X�K�C
�������܂Ŏ���
���������猻��
����PC���ޯ���׳��ނŁu���쌠�ذ�̱�ҁv��u�Ƒ���ΰ�����v��RAR���k����P2P�ʼn��������B
�\�̓I�^�A�j��DVD�����Ȃ���2ch��ʯ��
�җpUSB����ق������玩�R�ɂ͂Ȃ�Ȃ����g�p���Ă���PC��HDD��200GB��5��i2004/10���_�j
����͓̂��Ӓ��̓��ӂ����u�`������w���x���Ȃ��v �u����w���x���Ȃ���Ȃ�Ȃ��v
���Ƃ��o�đ�w�ɒʂ��Ă����͂��Ȃ̂����Ȃ�����e���펞�ؗ����ς����Ă�������ނ�����Ȃ�����
������è��߰���̂قƂ�ǂ͕W��̫�ݼެ�����̗p���Ă��邪�ނ��Ă��܂Ƃ��ȕ���1��������Ȃ�����
���ɂ������l�Ԃɂش�è�ނ̽�߰�����ō�������߰�����ڂŕ]���������犮�S�ɽٰ���ꂽ
JBL��harman/kardon�͓�����ٰ�߂ɑ����Ă���̂œ�����ЁB�܂�g���^�ƃ_�C�n�c���������
�t������̋P�x430����ׂ͂��ق�ῂ����Ȃ��B0�܂ŗ��Ƃ��Ζ��Ȃ��B�i�P�x0���āD�D�D�j
����w�@���������g�̎��u�`�͎���ł�����Ȃ��E�����Ȃ��E���킹�Ȃ�
�t���ڂōD�]��FP93GX�͍��ׂ͒�Ă邵�c���o�܂���ōň��������B���i�����̏��i�ł����߂ł��Ȃ�
رُ����ɋ����͖����ƌ����Ă��邪�A�������������������낤
����o���ƌ����ďo���͕̂K��ȯĂŏE���Ă������B�s���ȿ�����o�Ă�����u����͝s���E����н�v
���_�ł��Ȃ��Ǝv������u���E�E��w���E�n�R�l�E�_�j�����v�̂ǂꂩ���o�Ă���B
�����ޑ�D���BCPU��Intel�Aϻް��ASUS�A�����NANAO�A��߰����Creative�B����ȊO�͔F�߂Ȃ�
�����Ȃ藬��ɊW�Ȃ�ڽ���o�Ă�����u���S���N�v�����ق܂��͊��S�ȟT�v��̧�ޮ�݂��Ă�؋�
�C���E�lj��Ͻ�
�c���̑����Y��30���ŁA���̌�p�ҁi�{�q�j
���͋����ɐ��E����ē����w����
�e�ʂɂ͋��t�ƈ�ґ���
�f���͓��H�ꕔ�̌��E�В�
�{�l�͂����Ƒ�����b���_�����
���͌����������Ă��邪���E�͍��|�ŕٌ�m��ڎw���Ă���
��̓X�^�[�E�H�[�Y3�ɏo�����Ă����A�i�L���ɂ�������ȃi�C�X�K�C
�������܂Ŏ���
���������猻��
����PC���ޯ���׳��ނŁu���쌠�ذ�̱�ҁv��u�Ƒ���ΰ�����v��RAR���k����P2P�ʼn��������B
�\�̓I�^�A�j��DVD�����Ȃ���2ch��ʯ��
�җpUSB����ق������玩�R�ɂ͂Ȃ�Ȃ����g�p���Ă���PC��HDD��200GB��5��i2004/10���_�j
����͓̂��Ӓ��̓��ӂ����u�`������w���x���Ȃ��v �u����w���x���Ȃ���Ȃ�Ȃ��v
���Ƃ��o�đ�w�ɒʂ��Ă����͂��Ȃ̂����Ȃ�����e���펞�ؗ����ς����Ă�������ނ�����Ȃ�����
������è��߰���̂قƂ�ǂ͕W��̫�ݼެ�����̗p���Ă��邪�ނ��Ă��܂Ƃ��ȕ���1��������Ȃ�����
���ɂ������l�Ԃɂش�è�ނ̽�߰�����ō�������߰�����ڂŕ]���������犮�S�ɽٰ���ꂽ
JBL��harman/kardon�͓�����ٰ�߂ɑ����Ă���̂œ�����ЁB�܂�g���^�ƃ_�C�n�c���������
�t������̋P�x430����ׂ͂��ق�ῂ����Ȃ��B0�܂ŗ��Ƃ��Ζ��Ȃ��B�i�P�x0���āD�D�D�j
����w�@���������g�̎��u�`�͎���ł�����Ȃ��E�����Ȃ��E���킹�Ȃ�
�t���ڂōD�]��FP93GX�͍��ׂ͒�Ă邵�c���o�܂���ōň��������B���i�����̏��i�ł����߂ł��Ȃ�
رُ����ɋ����͖����ƌ����Ă��邪�A�������������������낤
����o���ƌ����ďo���͕̂K��ȯĂŏE���Ă������B�s���ȿ�����o�Ă�����u����͝s���E����н�v
���_�ł��Ȃ��Ǝv������u���E�E��w���E�n�R�l�E�_�j�����v�̂ǂꂩ���o�Ă���B
�����ޑ�D���BCPU��Intel�Aϻް��ASUS�A�����NANAO�A��߰����Creative�B����ȊO�͔F�߂Ȃ�
�����Ȃ藬��ɊW�Ȃ�ڽ���o�Ă�����u���S���N�v�����ق܂��͊��S�ȟT�v��̧�ޮ�݂��Ă�؋�
�C���E�lj��Ͻ�
373 �FMAC�I�^��371 �����F2006/05/25(��) 08:20:04 ID:X4jb4AMD
>>371
�@�@-----------------------
�@�@�N���b�N�L���[���Ăǂ��Ȃ��Ă�́H
�@�@-----------------------
���������ăN���b�N�u�X��L���[���Č����������������ˁB�B�B
�@�@-----------------------
�@�@�N���b�N�L���[���Ăǂ��Ȃ��Ă�́H
�@�@-----------------------
���������ăN���b�N�u�X��L���[���Č����������������ˁB�B�B
>>373
ID�ɒ���
ID�ɒ���
>>373
�������@�܂Ԃ����I
�������@�܂Ԃ����I
>>373
MAC�I�^�͏d���̋������̂����͓��ӂ��B
�ȑOIntel�X���ŃX���Ⴂ�̓��e�ł�������ԈႢ�̂��Ƃ����X�Ɨ͐����Ă����̂�
�v���o���B���������̃��X�ŊԈႢ���w�E���Ă����̂ɂ���������B
���������̎w�E�͂����Ƃ����D�������X�ł���ɂ�������炸�B
MAC�I�^�͎��g�Ɍ�������D�������c���ɂ������ɐ�̂āA
���������̈���ŋɂ߂č��ׂȂ��Ƃ�j���_��ɏ������āA
�S�̎�ł���������̂��Ƃ��Ɋ�ԁB
���ɔڂ����˂��B
MAC�I�^�͏d���̋������̂����͓��ӂ��B
�ȑOIntel�X���ŃX���Ⴂ�̓��e�ł�������ԈႢ�̂��Ƃ����X�Ɨ͐����Ă����̂�
�v���o���B���������̃��X�ŊԈႢ���w�E���Ă����̂ɂ���������B
���������̎w�E�͂����Ƃ����D�������X�ł���ɂ�������炸�B
MAC�I�^�͎��g�Ɍ�������D�������c���ɂ������ɐ�̂āA
���������̈���ŋɂ߂č��ׂȂ��Ƃ�j���_��ɏ������āA
�S�̎�ł���������̂��Ƃ��Ɋ�ԁB
���ɔڂ����˂��B
���݂��l���ȁB
���O�炪�I�^��F�߂Ȃ�����A�I�^�̐��肪�G�X�J���[�g�B
�[����݂Ă�ƁA�ق�Ƃ������낢�B
�c�_����Ȃ�܂������A�I�^�̏�����������Ƃ���\�z�����������ꍇ�̂��O��̕����ɂ��݂��y�����Ă��܂��
���O�炪�I�^��F�߂Ȃ�����A�I�^�̐��肪�G�X�J���[�g�B
�[����݂Ă�ƁA�ق�Ƃ������낢�B
�c�_����Ȃ�܂������A�I�^�̏�����������Ƃ���\�z�����������ꍇ�̂��O��̕����ɂ��݂��y�����Ă��܂��
373 ���O�F MAC�I�^�@ ID:X4jb4AMD��MAC�I�^�̗\���̗Ⴞ�ȁBQuad�R�A��X4jb�B
����>>371����̎���̈Ӑ}���������肩�˂邷���Ǥ��{�I�ɂ����������ƂɂȂ��Ă��邷�B
�@�E�N���b�N��jitter��skew����R�A�̃_�C�T�C�Y���傫������N���b�N�̃v���Z�b�T�Ŗ��ƂȂ�B
�@�E�}���`�R�A���̂�R�A������̃_�C�T�C�Y��V���O���R�A�̃A�[�L�e�N�`����菬��������̂Ť
�@�@���͋N����B
�@�EIntel���̂�Netburst�ō��N���b�N�E�����\�^�̃R�A��Nj������������Ť�N���b�N���z�Z�p�퓾��
�@�@http://www.ee.usyd.edu.au/research/allresearch/seminars/01015121-dual%20supply.pdf
�@�E�R�A���ƂɃN���b�N������ł���ȏ㤊e�R�A�Ƌ��LL2��e�X�ʁX�̃N���b�N����������Ă����
�@�@�l����̂����R
�@�E�N���b�N��jitter��skew����R�A�̃_�C�T�C�Y���傫������N���b�N�̃v���Z�b�T�Ŗ��ƂȂ�B
�@�E�}���`�R�A���̂�R�A������̃_�C�T�C�Y��V���O���R�A�̃A�[�L�e�N�`����菬��������̂Ť
�@�@���͋N����B
�@�EIntel���̂�Netburst�ō��N���b�N�E�����\�^�̃R�A��Nj������������Ť�N���b�N���z�Z�p�퓾��
�@�@http://www.ee.usyd.edu.au/research/allresearch/seminars/01015121-dual%20supply.pdf
�@�E�R�A���ƂɃN���b�N������ł���ȏ㤊e�R�A�Ƌ��LL2��e�X�ʁX�̃N���b�N����������Ă����
�@�@�l����̂����R
381 �F�{�� ��Rb.XJ8VXow �F2006/05/26(��) 19:17:30 ID:juG4zXzD
���āAWoodcrest��Opteron�̊e��x���`���ʂ��o�����Ă���悤���B
�\�P�b�g����2�܂łȂ�2�R�A�ł��낤��4�R�A���낤��Woodcrest��Opteron��荂���\�ɂȂ��Ă���͗l���B
�\�P�b�g����4�ɂȂ�Ƌ��L�o�X���l�b�N�ƂȂ�INTEL���͏����s���ȏB
�\�P�b�g����2�܂łȂ�2�R�A�ł��낤��4�R�A���낤��Woodcrest��Opteron��荂���\�ɂȂ��Ă���͗l���B
�\�P�b�g����4�ɂȂ�Ƌ��L�o�X���l�b�N�ƂȂ�INTEL���͏����s���ȏB
���ۂ�4 issue�̃X�[�p�[�X�P�[�����g������Ă�A�v��������̂��^�⎋���Ă݂�e�X�g
�I�p�A�v���Ȃ炢����ł������ˁ[�́H
384 �F ��Rb.XJ8VXow �F2006/05/26(��) 20:16:45 ID:c1OkUgrf
NOD32���g���Ă��闘�p�҂ŕs���Ȑl���ċ���̂��H
�w�ǂ̐l�͖������Ă���Ǝv���Ă���̂����B
�w�ǂ̐l�͖������Ă���Ǝv���Ă���̂����B
�u�悤���v�Ɂu�͗l���v��
�{�Ɠ��lFUD��D�����q����
�{�Ɠ��lFUD��D�����q����
���̂�����NOD32�ȂH�딚���H
�N���b�N���X�v���Z�b�T�Ȃ�ă��m���L��ȁc
>>382
�X���Ⴂ�����c
�N���b�N������� SPECint �̌��ʂ��������APentium M�ɔ�ׂ�
25%�����炢�ɂȂ��Ă�̂ŁA4 issue �̌��ʂ͂���Ȃ�ɏo�Ă�
�C������B4/3=1.33�{�܂ł͂����ĂȂ����A����͓��R�Ȃ̂Łc
���܂� K8 �̐����R�A�̐��\�� Woodcrest ���z���悤�Ƃ���ƁA
�N���b�N 4GHz ���炢�ɂȂ�Ȃ��Ɩ����Ȃ̂ŁA2�\�P�b�g�܂ł�
>>381 �̂����Ƃ���Ȃ��Ȃ��������C������B
�N���b�N������� SPECint �́APentium M �ł� K8 ���ǂ�����
���ǁAPentium M �̓N���b�N���Ⴉ��������c
�X���Ⴂ�����c
�N���b�N������� SPECint �̌��ʂ��������APentium M�ɔ�ׂ�
25%�����炢�ɂȂ��Ă�̂ŁA4 issue �̌��ʂ͂���Ȃ�ɏo�Ă�
�C������B4/3=1.33�{�܂ł͂����ĂȂ����A����͓��R�Ȃ̂Łc
���܂� K8 �̐����R�A�̐��\�� Woodcrest ���z���悤�Ƃ���ƁA
�N���b�N 4GHz ���炢�ɂȂ�Ȃ��Ɩ����Ȃ̂ŁA2�\�P�b�g�܂ł�
>>381 �̂����Ƃ���Ȃ��Ȃ��������C������B
�N���b�N������� SPECint �́APentium M �ł� K8 ���ǂ�����
���ǁAPentium M �̓N���b�N���Ⴉ��������c
DDMP�͔����Ɏc���Ă��ȁB5�N�O���炢�̓W����Ō������ǁB
ttp://www2.sharp.co.jp/docs1/ssc/products/gpb_m.html
ttp://www.sharp.co.jp/corporate/info/history/h_company/1998/index.html
ttp://www2.sharp.co.jp/docs1/ssc/products/gpb_m.html
ttp://www.sharp.co.jp/corporate/info/history/h_company/1998/index.html
AMD��4 issue��I�����Ȃ��̂́A��p�Ό��ʂ����܂���҂ł��Ȃ����炾�Ǝv���Ă������D�D
���Ȃ݂Ɉȉ���ǂނƁA4 issue���Č����Ă�̂�x86���߂ł͂Ȃ���MicroOps�̎��̂悤���ȁB
http://journal.mycom.co.jp/articles/2005/08/31/idf1/002.html
> Q: �Ƃ���ł���issue�ł����A�����Ō����Ă���̂�MicroOps��4 issue�Ŏ��s�ł���Ƃ����Ӗ��ł��傤��?
> ����Ƃ�x86���߂�4 issue�Ŏ��s�ł���Ƃ����Ӗ��ł��傤��?
>
> A: ����ȏ�̏ڍׂ͘b�����Ƃ��ł��Ȃ����A�����O�̐���̃A�[�L�e�N�`���ł͏������悯���3��x86����
> ��MicroOps�ɕϊ����ē����Ɏ��s���鎖���ł����B���Ɍ�����̂͂����܂ł�(��)�B
���Ȃ݂Ɉȉ���ǂނƁA4 issue���Č����Ă�̂�x86���߂ł͂Ȃ���MicroOps�̎��̂悤���ȁB
http://journal.mycom.co.jp/articles/2005/08/31/idf1/002.html
> Q: �Ƃ���ł���issue�ł����A�����Ō����Ă���̂�MicroOps��4 issue�Ŏ��s�ł���Ƃ����Ӗ��ł��傤��?
> ����Ƃ�x86���߂�4 issue�Ŏ��s�ł���Ƃ����Ӗ��ł��傤��?
>
> A: ����ȏ�̏ڍׂ͘b�����Ƃ��ł��Ȃ����A�����O�̐���̃A�[�L�e�N�`���ł͏������悯���3��x86����
> ��MicroOps�ɕϊ����ē����Ɏ��s���鎖���ł����B���Ɍ�����̂͂����܂ł�(��)�B
��Athlon��4issue�ɂȂ邩�����Ęb�肪���������Ƃ����Ȃ���Ȃ��Ă��Ӗ��ˁ[�����I�
�Ĉ��~�����Ă��̂ɂ�w�@�����ߋ����O����Ώo�Ă���B
�Ĉ��~�����Ă��̂ɂ�w�@�����ߋ����O����Ώo�Ă���B
��4�C�V���ɂ�������̂ɁA�Ȃ����Ȃ���H
����ς�`�l�c�̓A�[�L�e�N�`���̐��\����ł͎ア����
����ς�`�l�c�̓A�[�L�e�N�`���̐��\����ł͎ア����
���L�A�킫�L�A���L�A��
�S�ُL
�S�ُL
������ς�`�l�c�̓A�[�L�e�N�`���̐��\����ł͎ア����
���ł��̔����B
�܂��AMD��CPU�͈����ȊO�A���[���ƂƂ肦���Ȃ������݂����Ȍ��������Ȃ�
2�N�O�ɂ������������Ă��������l����
���ł��̔����B
�܂��AMD��CPU�͈����ȊO�A���[���ƂƂ肦���Ȃ������݂����Ȍ��������Ȃ�
2�N�O�ɂ������������Ă��������l����
���|�I���\�ƈ��|�I�ቿ�i�A���ꂪConroe
�ォ�瑬������
Conroe X6800 2.93GHz dual 4MB FSB1066MHz TDP 80W '06Q3 �@$999
Conroe E6700 2.67GHz dual 4MB FSB1066MHz TDP 65W '06Q3 �@$530
Conroe E6600 2.40GHz dual 4MB FSB1066MHz TDP 65W '06Q3 �@$316
Athlon FX-62 2.80GHz dual 1MBx2�@�@�@�@�@TDP 125W '06Q2�@$1031
Conroe E6400 2.13GHz dual 2MB FSB1066MHz TDP 65W '06Q3 �@$224
Conroe E6300 1.86GHz dual 2MB FSB1066MHz TDP 65W '06Q3 �@$183
�ォ�瑬������
Conroe X6800 2.93GHz dual 4MB FSB1066MHz TDP 80W '06Q3 �@$999
Conroe E6700 2.67GHz dual 4MB FSB1066MHz TDP 65W '06Q3 �@$530
Conroe E6600 2.40GHz dual 4MB FSB1066MHz TDP 65W '06Q3 �@$316
Athlon FX-62 2.80GHz dual 1MBx2�@�@�@�@�@TDP 125W '06Q2�@$1031
Conroe E6400 2.13GHz dual 2MB FSB1066MHz TDP 65W '06Q3 �@$224
Conroe E6300 1.86GHz dual 2MB FSB1066MHz TDP 65W '06Q3 �@$183
396 �FMAC�I�^��390 �����F2006/05/27(�y) 20:14:10 ID:4tEIfxwj
>>390
�@�@----------------------
�@�@4 issue���Č����Ă�̂�x86���߂ł͂Ȃ���MicroOps�̎��̂悤���ȁB
�@�@----------------------
���Ȃ��炴��x86���߂�1-uOps�ɕϊ�������Macro-Fusion���l���ɓ�����x86���߂ōő�
5���ߓ������s�Ƃ������ƂɂȂ邷���ǁH
�@�@----------------------
�@�@4 issue���Č����Ă�̂�x86���߂ł͂Ȃ���MicroOps�̎��̂悤���ȁB
�@�@----------------------
���Ȃ��炴��x86���߂�1-uOps�ɕϊ�������Macro-Fusion���l���ɓ�����x86���߂ōő�
5���ߓ������s�Ƃ������ƂɂȂ邷���ǁH
397 �FMAC�I�^��391-392 �����F2006/05/27(�y) 20:16:45 ID:4tEIfxwj
>>391
����IPC���グ��ɂ�����s���j�b�g�������₵�Ă��o�����X�������Č��ʂ��オ��Ȃ����B
�@�E��e�ʃL���b�V��
�@�E����\���̌���
�@�E�f�[�^�v���t�F�b�`
���̤���߂�f�[�^�t���[�̉��P�Ƒg�ݍ��킹�邱�ƂŤ�����IPC�̌���Ɍq���邷�B
����IPC���グ��ɂ�����s���j�b�g�������₵�Ă��o�����X�������Č��ʂ��オ��Ȃ����B
�@�E��e�ʃL���b�V��
�@�E����\���̌���
�@�E�f�[�^�v���t�F�b�`
���̤���߂�f�[�^�t���[�̉��P�Ƒg�ݍ��킹�邱�ƂŤ�����IPC�̌���Ɍq���邷�B
>>396
�����ɂ́A�^�̃f�[�^�ˑ��������邱�Ƃ����Y��Ȃ��B
�����ɂ́A�^�̃f�[�^�ˑ��������邱�Ƃ����Y��Ȃ��B
>>398
������������������Ɏ����Ƃ��Ɏ�Ă����Ƃ����̂�������Ȃ��l�����Ȃ̂�������Ȃ����B
>>399
xx-issue�Ƃ�xx���ߓ������s�Ƃ������̂���ʏ�u�ő�l������炻��ȏ��ɓ˂����܂�Ă�(��)
������������������Ɏ����Ƃ��Ɏ�Ă����Ƃ����̂�������Ȃ��l�����Ȃ̂�������Ȃ����B
>>399
xx-issue�Ƃ�xx���ߓ������s�Ƃ������̂���ʏ�u�ő�l������炻��ȏ��ɓ˂����܂�Ă�(��)
>>400
������A����>>382�Ɠ����^��������Ă�̂��B
4-issue�̔�p�Ό��ʂ��ǂꂭ�炢����̂��ƁB
�������A����ȊO�ɂ�
>�@�E��e�ʃL���b�V��
>�@�E����\���̌���
>�@�E�f�[�^�v���t�F�b�`
�̌��ʂ����Ȃ��炸���邩��A�x���`�ł͂������܂߂Č��ʂ��o�Ă�̂��Ǝv�����D�D
������A����>>382�Ɠ����^��������Ă�̂��B
4-issue�̔�p�Ό��ʂ��ǂꂭ�炢����̂��ƁB
�������A����ȊO�ɂ�
>�@�E��e�ʃL���b�V��
>�@�E����\���̌���
>�@�E�f�[�^�v���t�F�b�`
�̌��ʂ����Ȃ��炸���邩��A�x���`�ł͂������܂߂Č��ʂ��o�Ă�̂��Ǝv�����D�D
>>401
�u�g���飂Ƃ�����������IPC=4���Ă���Ƃ���Τ��₷�B
http://www-e.uni-magdeburg.de/urzs/marvel/marvel_performance.pdf
�@�@-------------------
�@�@4-issue�̔�p�Ό��ʂ��ǂꂭ�炢����̂��ƁB
�@�@-------------------
�����Ƀf�X�N�g�b�v�����v���Z�b�T�̉��i�т�SPECint2000��3000��B�����Ă��鎖����F���ł���Ȃ�
�R�X�g�ɂ����\�ɂ��^��̗]�n�햳���������ǁB�B�B
http://www.spec.org/cpu2000/results/res2006q2/cpu2000-20060502-05955.html
�u�g���飂Ƃ�����������IPC=4���Ă���Ƃ���Τ��₷�B
http://www-e.uni-magdeburg.de/urzs/marvel/marvel_performance.pdf
�@�@-------------------
�@�@4-issue�̔�p�Ό��ʂ��ǂꂭ�炢����̂��ƁB
�@�@-------------------
�����Ƀf�X�N�g�b�v�����v���Z�b�T�̉��i�т�SPECint2000��3000��B�����Ă��鎖����F���ł���Ȃ�
�R�X�g�ɂ����\�ɂ��^��̗]�n�햳���������ǁB�B�B
http://www.spec.org/cpu2000/results/res2006q2/cpu2000-20060502-05955.html
>>402
>�u�g���飂Ƃ�����������IPC=4���Ă���Ƃ���Τ��₷�B
>http://www-e.uni-magdeburg.de/urzs/marvel/marvel_performance.pdf
���̂ɋ��Ȃ̂��B
���Ȃ��炸Intel��IPC=4���č���Ă��Ǝv�����B
>�����Ƀf�X�N�g�b�v�����v���Z�b�T�̉��i�т�SPECint2000��3000��B�����Ă��鎖����F���ł���Ȃ�
>�R�X�g�ɂ����\�ɂ��^��̗]�n�햳���������ǁB�B�B
>http://www.spec.org/cpu2000/results/res2006q2/cpu2000-20060502-05955.html
�߂������ǂ���x���`�}�[�N�Ȃ̂�ˁB
>�u�g���飂Ƃ�����������IPC=4���Ă���Ƃ���Τ��₷�B
>http://www-e.uni-magdeburg.de/urzs/marvel/marvel_performance.pdf
���̂ɋ��Ȃ̂��B
���Ȃ��炸Intel��IPC=4���č���Ă��Ǝv�����B
>�����Ƀf�X�N�g�b�v�����v���Z�b�T�̉��i�т�SPECint2000��3000��B�����Ă��鎖����F���ł���Ȃ�
>�R�X�g�ɂ����\�ɂ��^��̗]�n�햳���������ǁB�B�B
>http://www.spec.org/cpu2000/results/res2006q2/cpu2000-20060502-05955.html
�߂������ǂ���x���`�}�[�N�Ȃ̂�ˁB
Pen4������������A�������\������������ԂŔ̔��J�n���Ă̂͂��肦�Ȃ��Ƃ͌���ǂ���
SPEC�x���`�̃R�[�h�����ۂ̃A�v���̃R�[�h�����ɂȂ��Ă��邱�Ƃ�m��Ȃ��n�������B
gcc, bzip�Ƃ��x���`���ʂ̏ڍ׃����N�\���Ă����A�݂��킩�邾��B
gcc, bzip�Ƃ��x���`���ʂ̏ڍ׃����N�\���Ă����A�݂��킩�邾��B
406 �F�{�� ��Rb.XJ8VXow �F2006/05/27(�y) 21:33:48 ID:t9Enm4dr
> ���Ȃ��炸Intel��IPC=4���č���Ă��Ǝv�����B
�����v���Ă���̂͂��O��������B
���ʂ�IPC�̌����ڎw���A��̓I�ɂ�3.5���x�̌�����ڕW�ɂ��Ă���B
�����v���Ă���̂͂��O��������B
���ʂ�IPC�̌����ڎw���A��̓I�ɂ�3.5���x�̌�����ڕW�ɂ��Ă���B
1 core, 1 chip, 1 core/chip�����A���ʂ͈����Ȃ��Ǝv�����B
http://www.spec.org/cpu2000/results/res2006q2/cpu2000-20060320-05795.html
http://www.spec.org/cpu2000/results/res2006q2/cpu2000-20060320-05795.html
>���ʂ�IPC�̌����ڎw���A��̓I�ɂ�3.5���x�̌�����ڕW�ɂ��Ă���B
�������ȑO��Intel�͂����ł͖����������B
�������ȑO��Intel�͂����ł͖����������B
�Ȃςȗ���ɂȂ��Ă�ȁB
4 issue �� OoO �R�A�̕��� IPC �� 1.2�`1.5 ���x����������B
(ando ����̃y�[�W 2005�N9��24�����)
������ Woodcrest �������\�ł��A���ςł� 2 IPC �������ĂȂ��ł���B
����ł��A3 issue �� Pentium M �ɔ�ׂ� 25% ������Ęb�Ȃ́B
4 issue �� OoO �R�A�̕��� IPC �� 1.2�`1.5 ���x����������B
(ando ����̃y�[�W 2005�N9��24�����)
������ Woodcrest �������\�ł��A���ςł� 2 IPC �������ĂȂ��ł���B
����ł��A3 issue �� Pentium M �ɔ�ׂ� 25% ������Ęb�Ȃ́B
410 �F�{�� ��Rb.XJ8VXow �F2006/05/27(�y) 21:55:29 ID:t9Enm4dr
>>408
�ߋ��ƌ��݂ł͊����Ⴄ�B
�g�����W�X�^���\���オ��A���ډ\�ȉ�H�������Ƒ����Ȃ��Ă��邩��A��H�����̈����𗝗R�ɃL�����Z�����Ă����ߋ��ƒP����r���Ă��Ӗ��������B
�܂��āA�f���A���R�A����O��ɓ���N���b�N�������e��H�̏ȓd�͉��Z�p��i�ߑ�ʂ̃L���b�V����ς߂�l�ɂȂ������݂���4issue�͑Ó����낤�B
�������AMD�̐v�v�z�ł�3issue�̂܂܂��낤���ǂ��E�E�E
�ߋ��ƌ��݂ł͊����Ⴄ�B
�g�����W�X�^���\���オ��A���ډ\�ȉ�H�������Ƒ����Ȃ��Ă��邩��A��H�����̈����𗝗R�ɃL�����Z�����Ă����ߋ��ƒP����r���Ă��Ӗ��������B
�܂��āA�f���A���R�A����O��ɓ���N���b�N�������e��H�̏ȓd�͉��Z�p��i�ߑ�ʂ̃L���b�V����ς߂�l�ɂȂ������݂���4issue�͑Ó����낤�B
�������AMD�̐v�v�z�ł�3issue�̂܂܂��낤���ǂ��E�E�E
>>402�ŕ���IPC�Ɋւ��鎑���������Ă��������Ă��ꂽ�̂�>>409�̕����������B�B�B
������x>>402�̃����N���Fig.7��Fig. 8�����Ĥ�g���f���]�������C�����Ă���邱�Ƃ�]�ނ��肷�B
�Q�l�܂łɂ��ꂪ�GS1280 (Alpha21364/1.15GHz)��SPEC�̓o�^�f�[�^���B
SPECint2000 http://www.spec.org/osg/cpu2000/results/res2003q1/cpu2000-20030113-01918.html
SPECfp2000 http://www.spec.org/osg/cpu2000/results/res2003q1/cpu2000-20030113-01917.html
������x>>402�̃����N���Fig.7��Fig. 8�����Ĥ�g���f���]�������C�����Ă���邱�Ƃ�]�ނ��肷�B
�Q�l�܂łɂ��ꂪ�GS1280 (Alpha21364/1.15GHz)��SPEC�̓o�^�f�[�^���B
SPECint2000 http://www.spec.org/osg/cpu2000/results/res2003q1/cpu2000-20030113-01918.html
SPECfp2000 http://www.spec.org/osg/cpu2000/results/res2003q1/cpu2000-20030113-01917.html
>>410
>�ߋ��ƌ��݂ł͊����Ⴄ�B
>�g�����W�X�^���\���オ��A���ډ\�ȉ�H�������Ƒ����Ȃ��Ă��邩��A��H�����̈����𗝗R�ɃL�����Z�����Ă����ߋ��ƒP����r���Ă��Ӗ��������B
���₢�₢��A����̓N���b�N�d��������Intel�̎v�z���ς�����Ƃ����v���Ȃ��Ȃ��B
>�������AMD�̐v�v�z�ł�3issue�̂܂܂��낤���ǂ��E�E�E
����́AAMD��4issue�ɂ��Ăǂ��l���Ă邩�ɂ��ˁB
>�ߋ��ƌ��݂ł͊����Ⴄ�B
>�g�����W�X�^���\���オ��A���ډ\�ȉ�H�������Ƒ����Ȃ��Ă��邩��A��H�����̈����𗝗R�ɃL�����Z�����Ă����ߋ��ƒP����r���Ă��Ӗ��������B
���₢�₢��A����̓N���b�N�d��������Intel�̎v�z���ς�����Ƃ����v���Ȃ��Ȃ��B
>�������AMD�̐v�v�z�ł�3issue�̂܂܂��낤���ǂ��E�E�E
����́AAMD��4issue�ɂ��Ăǂ��l���Ă邩�ɂ��ˁB
413 �F�{�� ��Rb.XJ8VXow �F2006/05/27(�y) 22:19:55 ID:t9Enm4dr
> ���₢�₢��A����̓N���b�N�d��������Intel�̎v�z���ς�����Ƃ����v���Ȃ��Ȃ��B
INTEL�̓N���b�N�d������Ȃ���B
�l�b�g�o�[�X�g�̓N���b�N�d���APenM�͏ȓd�͏d���AIA-64��IPC�d���ł��B
�����āAConroe�̓o�����X�^�ł��ȁB
INTEL�̓N���b�N�d������Ȃ���B
�l�b�g�o�[�X�g�̓N���b�N�d���APenM�͏ȓd�͏d���AIA-64��IPC�d���ł��B
�����āAConroe�̓o�����X�^�ł��ȁB
���[�ƁA���͕ʂ�MAC�I�^�̎��������������ĕԎ���������
�킯����Ȃ����Ȃ��B
������ƌ��Ă݂����AMAC�I�^�A����́A����قǂ͂�����
�������������킯�ł��Ȃ��悤�����ACISC�̏ꍇ�AIPC��
Alpha�̂悤��RISC��������ɒ�߂̒l�ɂȂ邱�Ƃ�����
���Ƃ����Y��Ȃ��B
RISC�̓��[�h�X�g�A�A�[�L�e�N�`��������ˁB
> �������AMD�̐v�v�z�ł�3issue�̂܂܂��낤���ǂ��E�E�E
�v�v�z�Ƃ������́AK7/K8 �R�A�̐v�����̖��ł́H
Pentium III/M �n�ɔ�ׁAK7/K8 �R�A�̕������Z��̑Ώ̐���
�����A���̎����ł́A�����Ƃ����b�`�ȕ��ނł���B
�ꉞ�A���_�I�ɂ̓R�A������̉��Z������b�`�ɂ�������A
�R�A���𑝂₵�������T�[�o�n�̐��\�d�͔�ł͗L���Ȕ��Ȃ̂ŁA
Opteron �n�͍���� 3issue �̂܂܂�������ǁA�f�X�N�g�b�v
�̕��� AMD �� 4issue �Ɍ����������ˁB
Woodcrest/Conroe �� 4issue �ɂł����̂́APentium M �n��
�����ςݏグ�Ă����ȓd�͋Z�p�̂��������Ǝv���B
K7/K8 �R�A�� NetBurst �ƈႢ�͈����Ȃ��̂ŁA���Ƃ͒n����
�w�̖͂��ł���B
> IA-64��IPC�d���ł��B
�N���b�N������� SPECint �l������ƁAIA64 �� Woodcrest �ŁA
�Ƃ��Ƃ� x86 �ɔ����ꂽ���ۂ���B
�킯����Ȃ����Ȃ��B
������ƌ��Ă݂����AMAC�I�^�A����́A����قǂ͂�����
�������������킯�ł��Ȃ��悤�����ACISC�̏ꍇ�AIPC��
Alpha�̂悤��RISC��������ɒ�߂̒l�ɂȂ邱�Ƃ�����
���Ƃ����Y��Ȃ��B
RISC�̓��[�h�X�g�A�A�[�L�e�N�`��������ˁB
> �������AMD�̐v�v�z�ł�3issue�̂܂܂��낤���ǂ��E�E�E
�v�v�z�Ƃ������́AK7/K8 �R�A�̐v�����̖��ł́H
Pentium III/M �n�ɔ�ׁAK7/K8 �R�A�̕������Z��̑Ώ̐���
�����A���̎����ł́A�����Ƃ����b�`�ȕ��ނł���B
�ꉞ�A���_�I�ɂ̓R�A������̉��Z������b�`�ɂ�������A
�R�A���𑝂₵�������T�[�o�n�̐��\�d�͔�ł͗L���Ȕ��Ȃ̂ŁA
Opteron �n�͍���� 3issue �̂܂܂�������ǁA�f�X�N�g�b�v
�̕��� AMD �� 4issue �Ɍ����������ˁB
Woodcrest/Conroe �� 4issue �ɂł����̂́APentium M �n��
�����ςݏグ�Ă����ȓd�͋Z�p�̂��������Ǝv���B
K7/K8 �R�A�� NetBurst �ƈႢ�͈����Ȃ��̂ŁA���Ƃ͒n����
�w�̖͂��ł���B
> IA-64��IPC�d���ł��B
�N���b�N������� SPECint �l������ƁAIA64 �� Woodcrest �ŁA
�Ƃ��Ƃ� x86 �ɔ����ꂽ���ۂ���B
���ʉ�����B
����u�Ԃɂ�������s�v���O�����̕���x(�킩��₷���C���[�W�����܂ł��C���[�W����)
6issue
�@�@�@�@�@�@�@��
�@�@�@�@�@�@������
�@�@�@�@�@����������
�@�@����������������
��������������������������
����������������������������������������
3issue
�@�@�@�@�@�@�@�@�@
�@�@����������������
��������������������������
����������������������������������������
�R�̑S�ʐςɑ���J�b�g���ꂽ�R�̒���̖ʐϔ��?
���ߑш���ނ�݂ɂӂ₵�Ă��v���O�����̕����̂Ɍ��E�����邽�߁A
�v�����悤�ɕ���IPC�͂�����Ȃ��B
���@���s�A�L���b�V���Z�p�Ȃnj��݂��i�����Ă���Z�p�ʼn\�Ȍ�������݂�����
=�R���̂�傫������ł����Ȃ��ƃg�[�^���ȑш�𑝂₵�Ă����ʂ͔����B
����u�Ԃɂ�������s�v���O�����̕���x(�킩��₷���C���[�W�����܂ł��C���[�W����)
6issue
�@�@�@�@�@�@�@��
�@�@�@�@�@�@������
�@�@�@�@�@����������
�@�@����������������
��������������������������
����������������������������������������
3issue
�@�@�@�@�@�@�@�@�@
�@�@����������������
��������������������������
����������������������������������������
�R�̑S�ʐςɑ���J�b�g���ꂽ�R�̒���̖ʐϔ��?
���ߑш���ނ�݂ɂӂ₵�Ă��v���O�����̕����̂Ɍ��E�����邽�߁A
�v�����悤�ɕ���IPC�͂�����Ȃ��B
���@���s�A�L���b�V���Z�p�Ȃnj��݂��i�����Ă���Z�p�ʼn\�Ȍ�������݂�����
=�R���̂�傫������ł����Ȃ��ƃg�[�^���ȑш�𑝂₵�Ă����ʂ͔����B
>>411
GS1280 (Alpha21364/1.15GHz)�ł���A
IPC for SPECfp2000�ŁAIPC=2.1
IPC for SPECint2000�ŁAIPC=1.5
�����������ʂ��������B
�ނ��D�D
�ł��AAMD�AIntel�̌��݂�CPU��IPC�̎����l�����Ă݂����������D�D
GS1280 (Alpha21364/1.15GHz)�ł���A
IPC for SPECfp2000�ŁAIPC=2.1
IPC for SPECint2000�ŁAIPC=1.5
�����������ʂ��������B
�ނ��D�D
�ł��AAMD�AIntel�̌��݂�CPU��IPC�̎����l�����Ă݂����������D�D
�d�g�n�̃q�g������IPC�̘b���������Ɛ������o���ď����Ă������B
>>402�Ƀ����N����AlphaServer GS1280�̐��\�Ɋւ��镶����Fig. 8���SPECint2000�̊e�T�u�x���`��
IPC�̒l��ǂݎ���ĤAlpha 21634/1.15GHz��Woodcrest/3GHz�̃N���b�N������������Woodcrest��IPC��
���Z���Ă݂����B
����Ƃ��ĤIntel��uops��Alpha��ISA�Ɣ�r���ē��ɖ��߂̋@�\��Ⴍ�Ȃ��SIMD�œK�������ɍs����
���Ȃ����̂Ƃ��邷�B���Ȃ݂ɂ��̎��Z�Ŗ��ߋ@�\���Ⴂ�ꍇ�ɂ�IPC����ۂ���߂ɤSIMD���߂�
�g���Ă���ꍇ�ɂ�����ۂ�荂�߂ɕ]������邱�ƂɂȂ邷�B
>>402�Ƀ����N����AlphaServer GS1280�̐��\�Ɋւ��镶����Fig. 8���SPECint2000�̊e�T�u�x���`��
IPC�̒l��ǂݎ���ĤAlpha 21634/1.15GHz��Woodcrest/3GHz�̃N���b�N������������Woodcrest��IPC��
���Z���Ă݂����B
����Ƃ��ĤIntel��uops��Alpha��ISA�Ɣ�r���ē��ɖ��߂̋@�\��Ⴍ�Ȃ��SIMD�œK�������ɍs����
���Ȃ����̂Ƃ��邷�B���Ȃ݂ɂ��̎��Z�Ŗ��ߋ@�\���Ⴂ�ꍇ�ɂ�IPC����ۂ���߂ɤSIMD���߂�
�g���Ă���ꍇ�ɂ�����ۂ�荂�߂ɕ]������邱�ƂɂȂ邷�B
418 �FMAC�I�^�������F2006/05/27(�y) 23:02:51 ID:4tEIfxwj
�@�@�@�@�@�@�@�@�@�@�@Alpha21364�@�@Core2
�@�@�@164.gzip�@�@�@�@�@1.5�@�@�@�@�@�@1.78
�@�@�@175.vpr�@�@�@�@�@�@0.82�@�@�@�@�@0.81
�@�@�@176.gcc�@�@�@�@�@�@1.24�@�@�@�@�@1.94
�@�@�@181.mcf�@�@�@�@�@�@0.32�@�@�@�@�@0.47
�@�@�@186.crafty�@�@�@�@1.41�@�@�@�@�@1.49
�@�@�@197.parser�@�@�@�@1.19�@�@�@�@�@1.73
�@�@�@252.eon�@�@�@�@�@�@1.21�@�@�@�@�@1.91
�@�@�@253.perlbmk�@�@�@1.28�@�@�@�@�@2.24
�@�@�@254.gap�@�@�@�@�@�@1.44�@�@�@�@�@2.31
�@�@�@255.vortex�@�@�@�@1.32�@�@�@�@�@2.11
�@�@�@256.bzip2�@�@�@�@�@1.42�@�@�@�@�@1.47
�@�@�@300.twolf�@�@�@�@�@0.9�@�@�@�@�@�@1.15
�@�@�@----------------------------
�@�@�@total�@�@�@�@�@�@�@�@1.10�@�@�@�@�@1.47
�����̒ʂ�Core2��N���b�N��IPC�̗����ő傫�Ȑ��\������ʂ����Ă��邱�Ƃ����邷�B
����ł�IPC=3��傫�ȕǂł��邱�Ƃ����邩�Ǝv�����B
�@�@�@164.gzip�@�@�@�@�@1.5�@�@�@�@�@�@1.78
�@�@�@175.vpr�@�@�@�@�@�@0.82�@�@�@�@�@0.81
�@�@�@176.gcc�@�@�@�@�@�@1.24�@�@�@�@�@1.94
�@�@�@181.mcf�@�@�@�@�@�@0.32�@�@�@�@�@0.47
�@�@�@186.crafty�@�@�@�@1.41�@�@�@�@�@1.49
�@�@�@197.parser�@�@�@�@1.19�@�@�@�@�@1.73
�@�@�@252.eon�@�@�@�@�@�@1.21�@�@�@�@�@1.91
�@�@�@253.perlbmk�@�@�@1.28�@�@�@�@�@2.24
�@�@�@254.gap�@�@�@�@�@�@1.44�@�@�@�@�@2.31
�@�@�@255.vortex�@�@�@�@1.32�@�@�@�@�@2.11
�@�@�@256.bzip2�@�@�@�@�@1.42�@�@�@�@�@1.47
�@�@�@300.twolf�@�@�@�@�@0.9�@�@�@�@�@�@1.15
�@�@�@----------------------------
�@�@�@total�@�@�@�@�@�@�@�@1.10�@�@�@�@�@1.47
�����̒ʂ�Core2��N���b�N��IPC�̗����ő傫�Ȑ��\������ʂ����Ă��邱�Ƃ����邷�B
����ł�IPC=3��傫�ȕǂł��邱�Ƃ����邩�Ǝv�����B
419 �FSocket774�F2006/05/27(�y) 23:22:41 ID:JWxziMYM
4issue���ɂ�鐫�\�������5%
�悭�Ă�10%���x����
����alpha21464�Ƃ����A8issue�v���Z�b�T��
�J����������AIPC��21364��20�`30%�A�b�v���x������
intel�̎��Z�ł��A8issue���ɂ�鐫�\�����18%�ۂ���
�悭�Ă�10%���x����
����alpha21464�Ƃ����A8issue�v���Z�b�T��
�J����������AIPC��21364��20�`30%�A�b�v���x������
intel�̎��Z�ł��A8issue���ɂ�鐫�\�����18%�ۂ���
�N���b�N������̐��\�ł�alpha�������Ă̂�
���S�[�����̂�������
���S�[�����̂�������
>>419
�N���b�N������̐��\���㗦 25% �̂����A4 issue ���̊�^��
���̈ꕔ�ɉ߂��Ȃ���������A25% �����Ȃ̂͊ԈႢ�Ƃ��낾�ˁB
�N���b�N������̐��\���㗦 25% �̂����A4 issue ���̊�^��
���̈ꕔ�ɉ߂��Ȃ���������A25% �����Ȃ̂͊ԈႢ�Ƃ��낾�ˁB
���[�U�[����݂�Όʂ��낤���Ȃ낤��
�O�̂�萫�\���オ���Ă���Ď���������������Ǝv��
�O�̂�萫�\���オ���Ă���Ď���������������Ǝv��
3issue�̂܂܂ł��A�v���t�F�b�`�Ȃǂ̌��ʂ��傫���͎̂�������
�}�N���t���[�W�����͔��������ǂ�
3issue�̂܂܂ł��A������s�̃��C�e���V�������邯��
�����������ߐ��͑����Ȃ�
�}�N���t���[�W�����͔��������ǂ�
3issue�̂܂܂ł��A������s�̃��C�e���V�������邯��
�����������ߐ��͑����Ȃ�
>>423
���������B�ŋ߂�CPU�n�̃X���͍ו��̋Z�p�ɂ�����肷���āA
�̂��͒f�R���x�����オ���Ă�C�����邵�A
�܂��A����͂���Ŏ��Ȗ����̐��E�����炢�����ǁA�S�̂������ĂȂ��C������B
����Ŏ��ۂ̏����̐��i�̗\���������Ƃ��Ă�ꂩ�Ƃ����Ƃ����ł͂����B
�Ƌ�s���Ă��Ӗ��Ȃ����ǂ�w
���������B�ŋ߂�CPU�n�̃X���͍ו��̋Z�p�ɂ�����肷���āA
�̂��͒f�R���x�����オ���Ă�C�����邵�A
�܂��A����͂���Ŏ��Ȗ����̐��E�����炢�����ǁA�S�̂������ĂȂ��C������B
����Ŏ��ۂ̏����̐��i�̗\���������Ƃ��Ă�ꂩ�Ƃ����Ƃ����ł͂����B
�Ƌ�s���Ă��Ӗ��Ȃ����ǂ�w
426 �F�{�� ��Rb.XJ8VXow �F2006/05/27(�y) 23:49:33 ID:t9Enm4dr
�܂��AAMD�ɂ͊W�Ȃ����Ƃ��E�E�E
AMD�̓v���t�F�b�`�@�\����������C�������Ƃ����ׂ����Z�ʂȂ��H
AMD�̓v���t�F�b�`�@�\����������C�������Ƃ����ׂ����Z�ʂȂ��H
�ǂ����̃X���ɁAAMD�͔r���L���b�V��������
�������]�L���b�V���Ԃ̃v���t�F�`�́A����܌����Ȃ���Ȃ���?
���Ă̂�������
�������]�L���b�V���Ԃ̃v���t�F�`�́A����܌����Ȃ���Ȃ���?
���Ă̂�������
428 �F�{�� ��Rb.XJ8VXow �F2006/05/27(�y) 23:57:22 ID:t9Enm4dr
�Ƃ������A��̉����܂Ŕr���L���b�V���ɍS�葱���A�_�C�T�C�Y������������ׂɏ��L���b�V���𑱂���̂��Ȃ��H
�ʂ̓���͍�����̂����\�����A�L���b�V�����炢��INTEL�Ɠ��������ɖ߂��Ȃ��Ƒ��H�őO�ɐi�߂Ȃ��Ȃ邼�B
�Ƃ������A���ɐi�߂Ȃ��Ȃ��Ă���E�E�E�E
�ʂ̓���͍�����̂����\�����A�L���b�V�����炢��INTEL�Ɠ��������ɖ߂��Ȃ��Ƒ��H�őO�ɐi�߂Ȃ��Ȃ邼�B
�Ƃ������A���ɐi�߂Ȃ��Ȃ��Ă���E�E�E�E
���ꂪ�{���̎G�����Ƃ�����炭����[���Ȃ��z�ɂȂ������ȁB
�g�����J����Ă邵�U�����낤���ǁB
�g�����J����Ă邵�U�����낤���ǁB
430 �F�{�� ��Rb.XJ8VXow �F2006/05/28(��) 00:02:32 ID:gjsnhvXA
> ttp://www.2cpu.com/review.php?id=112&page=4
�L���b�V�����\�����ꂾ���Ⴄ�Ə��Ă�킯�������B
�L���b�V�����\�����ꂾ���Ⴄ�Ə��Ă�킯�������B
>>429
����ȎG���炵���Ȃ��G�������邩�悗�@�U�X
����ȎG���炵���Ȃ��G�������邩�悗�@�U�X
http://japan.cnet.com/news/ent/story/0,2000056022,20097344,00.htm
�u������̂ɏ\���ȋ@�\������Core�}�C�N���A�[�L�e�N�`���ɂ��邩�͋^�킵���v
http://pc.watch.impress.co.jp/docs/2006/0524/amd.htm
�uCore�}�C�N���A�[�L�e�N�`���ɂ͊v�V�ƌĂׂ���̂͂Ȃ��v
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�ƌ�����
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2762&p=12
> in fact one of its stipulations for sending out Socket-AM2 review kits was that
> the CPUs not be compared to Conroe.
Conroe�Ɣ�r���Ȃ����Ƃ�������AM2���r���[�L�b�g��݂��o��AMD
�u������̂ɏ\���ȋ@�\������Core�}�C�N���A�[�L�e�N�`���ɂ��邩�͋^�킵���v
http://pc.watch.impress.co.jp/docs/2006/0524/amd.htm
�uCore�}�C�N���A�[�L�e�N�`���ɂ͊v�V�ƌĂׂ���̂͂Ȃ��v
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�ƌ�����
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2762&p=12
> in fact one of its stipulations for sending out Socket-AM2 review kits was that
> the CPUs not be compared to Conroe.
Conroe�Ɣ�r���Ȃ����Ƃ�������AM2���r���[�L�b�g��݂��o��AMD
�l�i�����������炭��Intel�̗���ɁB
434 �FMAC�I�^��432 �����F2006/05/28(��) 07:35:56 ID:26X60QWa
>>432
���̃X���I��Anandtech�̂��̃y�[�W�����p����Ȃ礂�����̈�߂��Ǝv�����B
�@�@---------------------
�@�@AMD does have one last trick up its sleeve before the end of the year, and you will hear about
�@�@it in June. It's not K8L and it's not going to affect the majority of people, but it is an interesting
�@�@stop gap solution for the high end in 2006...
�@�@---------------------
�u6���ɏڍׂ����\�����"K8L����Ɏ������꤈ꕔ�̃q�g�����ɉe������V�@�\"��Ƃ��퉽�����ˁB�B�B
���̃X���I��Anandtech�̂��̃y�[�W�����p����Ȃ礂�����̈�߂��Ǝv�����B
�@�@---------------------
�@�@AMD does have one last trick up its sleeve before the end of the year, and you will hear about
�@�@it in June. It's not K8L and it's not going to affect the majority of people, but it is an interesting
�@�@stop gap solution for the high end in 2006...
�@�@---------------------
�u6���ɏڍׂ����\�����"K8L����Ɏ������꤈ꕔ�̃q�g�����ɉe������V�@�\"��Ƃ��퉽�����ˁB�B�B
�Q�l�܂ł�>>418��IPC��r��SingleCore Hammer/3GHz (Opteron 256)��Itanium2/1GHz (3MB L3)
���lj����BHammer��IPC��>>418�Ɠ�����@�Ŏ��Z�BItanium������̕������Q�Ƃ������B
http://www.crhc.uiuc.edu/Impact/presentations/sias-isca31.pdf
�@�@�@�@�@�@�@�@�@�@�@Alpha21364�@�@Core2�@�@�@Hammer�@�@Mckinley
�@�@�@164.gzip�@�@�@�@�@1.5�@�@�@�@�@�@1.78�@�@�@�@�@1.75�@�@�@�@�@2.05
�@�@�@175.vpr�@�@�@�@�@�@0.82�@�@�@�@�@0.81�@�@�@�@�@0.55�@�@�@�@�@1.0
�@�@�@176.gcc�@�@�@�@�@�@1.24�@�@�@�@�@1.94�@�@�@�@�@1.00�@�@�@�@�@1.5
�@�@�@181.mcf�@�@�@�@�@�@0.32�@�@�@�@�@0.47�@�@�@�@�@0.14�@�@�@�@�@0.15
�@�@�@186.crafty�@�@�@�@1.41�@�@�@�@�@1.49�@�@�@�@�@1.49�@�@�@�@�@1.35
�@�@�@197.parser�@�@�@�@1.19�@�@�@�@�@1.73�@�@�@�@�@1.20�@�@�@�@�@1.05
�@�@�@252.eon�@�@�@�@�@�@1.21�@�@�@�@�@1.91�@�@�@�@�@1.74�@�@�@�@�@1.1
�@�@�@253.perlbmk�@�@�@1.28�@�@�@�@�@2.24�@�@�@�@�@1.38�@�@�@�@�@1.75
�@�@�@254.gap�@�@�@�@�@�@1.44�@�@�@�@�@2.31�@�@�@�@�@1.48�@�@�@�@�@1.35
�@�@�@255.vortex�@�@�@�@1.32�@�@�@�@�@2.11�@�@�@�@�@1.34�@�@�@�@�@1.35
�@�@�@256.bzip2�@�@�@�@�@1.42�@�@�@�@�@1.47�@�@�@�@�@1.03�@�@�@�@�@1.4
�@�@�@300.twolf�@�@�@�@�@0.9�@�@�@�@�@�@1.15�@�@�@�@�@0.69�@�@�@�@�@1.0
�@�@�@------------------------------------------------
�@�@�@total(����)�@1.10�@�@�@�@�@1.47�@�@�@�@�@0.98�@�@�@�@ 1.10
���lj����BHammer��IPC��>>418�Ɠ�����@�Ŏ��Z�BItanium������̕������Q�Ƃ������B
http://www.crhc.uiuc.edu/Impact/presentations/sias-isca31.pdf
�@�@�@�@�@�@�@�@�@�@�@Alpha21364�@�@Core2�@�@�@Hammer�@�@Mckinley
�@�@�@164.gzip�@�@�@�@�@1.5�@�@�@�@�@�@1.78�@�@�@�@�@1.75�@�@�@�@�@2.05
�@�@�@175.vpr�@�@�@�@�@�@0.82�@�@�@�@�@0.81�@�@�@�@�@0.55�@�@�@�@�@1.0
�@�@�@176.gcc�@�@�@�@�@�@1.24�@�@�@�@�@1.94�@�@�@�@�@1.00�@�@�@�@�@1.5
�@�@�@181.mcf�@�@�@�@�@�@0.32�@�@�@�@�@0.47�@�@�@�@�@0.14�@�@�@�@�@0.15
�@�@�@186.crafty�@�@�@�@1.41�@�@�@�@�@1.49�@�@�@�@�@1.49�@�@�@�@�@1.35
�@�@�@197.parser�@�@�@�@1.19�@�@�@�@�@1.73�@�@�@�@�@1.20�@�@�@�@�@1.05
�@�@�@252.eon�@�@�@�@�@�@1.21�@�@�@�@�@1.91�@�@�@�@�@1.74�@�@�@�@�@1.1
�@�@�@253.perlbmk�@�@�@1.28�@�@�@�@�@2.24�@�@�@�@�@1.38�@�@�@�@�@1.75
�@�@�@254.gap�@�@�@�@�@�@1.44�@�@�@�@�@2.31�@�@�@�@�@1.48�@�@�@�@�@1.35
�@�@�@255.vortex�@�@�@�@1.32�@�@�@�@�@2.11�@�@�@�@�@1.34�@�@�@�@�@1.35
�@�@�@256.bzip2�@�@�@�@�@1.42�@�@�@�@�@1.47�@�@�@�@�@1.03�@�@�@�@�@1.4
�@�@�@300.twolf�@�@�@�@�@0.9�@�@�@�@�@�@1.15�@�@�@�@�@0.69�@�@�@�@�@1.0
�@�@�@------------------------------------------------
�@�@�@total(����)�@1.10�@�@�@�@�@1.47�@�@�@�@�@0.98�@�@�@�@ 1.10
MAC�I�^�̓\���Ă�̂��Ăǂ��������Ă�����Intel�̎���������̃��X���肾�ȁB
AMD�̎�����X���ɋ��鎞�͂��̃X���ɂ��������X�����悤���H
Core2�̏��Intel���������
K8L,K10�Ȃ̏��AMD���������
AMD�̎�����X���ɋ��鎞�͂��̃X���ɂ��������X�����悤���H
Core2�̏��Intel���������
K8L,K10�Ȃ̏��AMD���������
>>430
256kb���ō����ł����Ă��v�Z�n�̃A�v���ł��Ȃ��Ⴛ�̉��b�ɂ�������Ȃ����낤�ˁB
http://www.2cpu.com/images/review/052306_woodcrest_ss_memspeed_1of2.gif
�u���b�N�T�C�Y�������Ă����A���̏��ς��B
http://www.2cpu.com/images/review/052306_woodcrest_ss_memspeed_2of2.gif
256kb���ō����ł����Ă��v�Z�n�̃A�v���ł��Ȃ��Ⴛ�̉��b�ɂ�������Ȃ����낤�ˁB
http://www.2cpu.com/images/review/052306_woodcrest_ss_memspeed_1of2.gif
{kind=link}
�u���b�N�T�C�Y�������Ă����A���̏��ς��B
http://www.2cpu.com/images/review/052306_woodcrest_ss_memspeed_2of2.gif
{kind=link}
>�Q�l�܂ł�>>418��IPC��r��SingleCore Hammer/3GHz
>SingleCore Hammer/3GHz
>SingleCore
���������ȁI��点����E�ɏo����̂��Ȃ��I
>SingleCore Hammer/3GHz
>SingleCore
���������ȁI��点����E�ɏo����̂��Ȃ��I
440 �F439�F2006/05/28(��) 13:38:30 ID:wnEByhWs
439�ł��B�����܂���ł����c���܂�ɂ��������āG�G
������X�L���Ȃ������̂ł����A������V���O���̂Ƃ���𗝗R�ɂ��Ă���
���܂����G�G
�ق�Ƃ����܂���ł����G�G�G
������X�L���Ȃ������̂ł����A������V���O���̂Ƃ���𗝗R�ɂ��Ă���
���܂����G�G
�ق�Ƃ����܂���ł����G�G�G
�V��ڑ���y
443 �FSocket774�F2006/05/28(��) 16:31:45 ID:qWzvBx4h
>>436����Љ��TheInquirer�́uAMD�̎��̈�裂̘b�肷�Bhttp://www.theinquirer.net/?article=31994
�v����ɤAMD�������̊Ԃɍ��킹�Ƃ��Ď���i��
�@1. ��������������(��)�@�N�A�b�h�R�A
�@2. ���M���N���b�N��
�����������Ă��ƂŤ���Ɂu���ʂ폄�飂Ƃ��������Ȃ��W�J���B
�v���Z�b�T�ԃC���^�R�l�N�g��P2P�^��Hammer�Łu����������������\���ǂ����^���q�g������
���Ǝv�������Ǥ���XHammer��4�{��HT�����N������Ă��邷���礕K�v�Ȃ����L���ɂ���
�p�b�P�[�W���Őڑ�����Γ��ɑ傫�ȋZ�p�J���v�f�햳�����B
�{���̒��ɂ�����悤�ɤ���F�u�Q�[�}�[�����̃n�C�G���h����x�̐��i������B�B�B
���M�ł̕��ऒ����d�͉��̂��߂ɍs�����v���Z�X�̉��ǂ����N���b�N���ɂӂ�ނ��Ĥ
�����Q�[�g�≏����Z���`�����l������d���d���̏㏸���Ŏ�������Ǝv���邷�B����
����Ȃ��Ƃ��ƃ`�b�v�Ԃ̏���d�͂̂��(���Ƀ��[�N�d��)���ɒ[�ɑ傫���Ȃ锤������
�����܂肪�����Ƃ���M�\�����郍�b�g���o��Ƃ��F�X���o�ڂ̕���p�����肻�����B
�M�[�����r���[�T�C�g�ǂ��ɂ����ɂ���đI�ʕi��z���Ńl�b�g�Œ@�����S�z��������
�v����(��)
�v����ɤAMD�������̊Ԃɍ��킹�Ƃ��Ď���i��
�@1. ��������������(��)�@�N�A�b�h�R�A
�@2. ���M���N���b�N��
�����������Ă��ƂŤ���Ɂu���ʂ폄�飂Ƃ��������Ȃ��W�J���B
�v���Z�b�T�ԃC���^�R�l�N�g��P2P�^��Hammer�Łu����������������\���ǂ����^���q�g������
���Ǝv�������Ǥ���XHammer��4�{��HT�����N������Ă��邷���礕K�v�Ȃ����L���ɂ���
�p�b�P�[�W���Őڑ�����Γ��ɑ傫�ȋZ�p�J���v�f�햳�����B
�{���̒��ɂ�����悤�ɤ���F�u�Q�[�}�[�����̃n�C�G���h����x�̐��i������B�B�B
���M�ł̕��ऒ����d�͉��̂��߂ɍs�����v���Z�X�̉��ǂ����N���b�N���ɂӂ�ނ��Ĥ
�����Q�[�g�≏����Z���`�����l������d���d���̏㏸���Ŏ�������Ǝv���邷�B����
����Ȃ��Ƃ��ƃ`�b�v�Ԃ̏���d�͂̂��(���Ƀ��[�N�d��)���ɒ[�ɑ傫���Ȃ锤������
�����܂肪�����Ƃ���M�\�����郍�b�g���o��Ƃ��F�X���o�ڂ̕���p�����肻�����B
�M�[�����r���[�T�C�g�ǂ��ɂ����ɂ���đI�ʕi��z���Ńl�b�g�Œ@�����S�z��������
�v����(��)
ipc cpu�@date
-------------------
0.11 i386DX 1988
0.24 i486DX4 1994
0.25 i486DX 1989
0.26 i486DX2 1992
0.51 P54CS 1996
0.51 P5 1993
0.56 P54CQS 1995
0.56 P54VRT 1994
0.56 P55C 1997
0.58 P54C 1994
0.62 PPC604 1995
0.67 Deschutes 1998
0.67 Willamette 2000
0.70 Katmai 1999
0.70 Mendocino 1998
0.71 Klamath 1997
0.72 Northwood 2002
0.74 PPC604e 1997
0.77 K75 2000
0.77 K7 1999
0.77 P6 1996
0.81 Prescott 2003
0.82 Merced 2000
0.85 Coppermine 1999
0.94 PA-7200 1994
0.94 Cedar Mill 2006
1.19 Opteron280 2005
1.24 PA-8200 1997
1.26 Opteron154 2005
1.40 PA-8700+ 2002
1.48 POWER5 2005
1.54 Yonah 2006
1.55 McKinley 2001
1.55 Dothan 2005
1.90 Madison 9M 2004
1.92 Woodcrest 2006
SPECint�̗��X�R�A����v�Z�����N���b�N�����萫�\�\�B
�l�́AIPF��IA64��IPC(����)����B
-------------------
0.11 i386DX 1988
0.24 i486DX4 1994
0.25 i486DX 1989
0.26 i486DX2 1992
0.51 P54CS 1996
0.51 P5 1993
0.56 P54CQS 1995
0.56 P54VRT 1994
0.56 P55C 1997
0.58 P54C 1994
0.62 PPC604 1995
0.67 Deschutes 1998
0.67 Willamette 2000
0.70 Katmai 1999
0.70 Mendocino 1998
0.71 Klamath 1997
0.72 Northwood 2002
0.74 PPC604e 1997
0.77 K75 2000
0.77 K7 1999
0.77 P6 1996
0.81 Prescott 2003
0.82 Merced 2000
0.85 Coppermine 1999
0.94 PA-7200 1994
0.94 Cedar Mill 2006
1.19 Opteron280 2005
1.24 PA-8200 1997
1.26 Opteron154 2005
1.40 PA-8700+ 2002
1.48 POWER5 2005
1.54 Yonah 2006
1.55 McKinley 2001
1.55 Dothan 2005
1.90 Madison 9M 2004
1.92 Woodcrest 2006
SPECint�̗��X�R�A����v�Z�����N���b�N�����萫�\�\�B
�l�́AIPF��IA64��IPC(����)����B
448 �FMAC�I�^��446 �����F2006/05/28(��) 20:08:10 ID:26X60QWa
>>446
�@�@---------------------
�@�@�l�́AIPF��IA64��IPC(����)����B
�@�@---------------------
http://www.google.co.jp/search?q=IPC+1.55+Mckinley�@(��)
�@�@---------------------
�@�@�l�́AIPF��IA64��IPC(����)����B
�@�@---------------------
http://www.google.co.jp/search?q=IPC+1.55+Mckinley�@(��)
449 �FMAC�I�^���⑫�F2006/05/28(��) 20:14:56 ID:26X60QWa
�I���W�i�����Mac��
http://pc7.2ch.net/test/read.cgi/mac/1121683774/585-586
http://pc7.2ch.net/test/read.cgi/mac/1121683774/589
�Ȗ��Ǥinteler���ǂ�ł���Ȃ�in-order��VLIW��IPF�̃v���Z�b�T����Ɏ��̂��
������ƕs�K�����ƌ����Ă������B
������Mac�̃v���Z�b�T�֘A�X���b�h�����������p�����قǓǂ܂�Ă���Ƃ����̂�
���S�����邷�B�B�B
http://pc7.2ch.net/test/read.cgi/mac/1121683774/585-586
http://pc7.2ch.net/test/read.cgi/mac/1121683774/589
�Ȗ��Ǥinteler���ǂ�ł���Ȃ�in-order��VLIW��IPF�̃v���Z�b�T����Ɏ��̂��
������ƕs�K�����ƌ����Ă������B
������Mac�̃v���Z�b�T�֘A�X���b�h�����������p�����قǓǂ܂�Ă���Ƃ����̂�
���S�����邷�B�B�B
Conroe��Yonah�AFX-60�AX2 4800+�̃x���`�܂Ƃ�
http://www.coolaler.com/images/xoops/article/cpu/intel/conroe/40.jpg
Conroe E6600�@�Ɓ@�yAM2 FX62�z�̃x���`��r
http://www.hexus.net/content/item.php?item=5692&page=3
Conroe�Ɣ�r���Ȃ����Ƃ�������AM2���r���[�L�b�g��݂��o��AMD
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2762&p=12
Socket AM2�͂��܂̂��Ȃ��ɕK�v�Ȃ���������܂���
http://akiba-pc.watch.impress.co.jp/blog/archives/k605272.jpg
�@�@�@�@�@�@�@�@�@�@�@Conroe�̈��|�I���\�ƈ���
�@�@�@�@�@�@�@�@�@�@�����Ēᐫ�\�@������d��64�EAM2�@�@�@�@�@�@�@�@�@�@�@�@�@
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@AMD����_(^o^)�^ �@�@�@
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ , -�
.�@�@�@�@�@�@ �@ , --��@�@�@ �@ �@, -��@�@�@_�@�@�@�@�@ �i�@�@j
�@�@�@�@�@�@�@ �i�@ �@j�@�@�@�@ �^�@�@ �܁L�@ �_�@�@�@ /�@/�L
�@�@�@�@�@ �@ �@ �_�@�_.�@ �ځ@�@�@� M�@,�@ �@',�@�@/�@/
�@�@�@�@�@�@�@�@ �@ �_�@�_�@/�@�R Ĥ���@!/ |�@�@ʁ@/�@/
�@�@�@�@�@�@�@�@�@�@�@ �_�@�R!�@l���܁Q��ف@��/�@/
�@�@�@�@�@�@�@�@�@�@�@�@�@�_��{l � �@V_Ɂ@� j�ȁ�/
�@�@�@�@�@�@�@�@�@�@�@�@ �@ // .�R { ���]�� j/ �_�R
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�_�@ ��/^<>^',�R�@ �^
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �M{ �@�r f::l .�qo Y
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ } /�@l::::���@V .}
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@���.�@�Ɂ@ }!�l
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ {=����=}�@�@�_
http://www.coolaler.com/images/xoops/article/cpu/intel/conroe/40.jpg
{kind=link}
Conroe E6600�@�Ɓ@�yAM2 FX62�z�̃x���`��r
http://www.hexus.net/content/item.php?item=5692&page=3
Conroe�Ɣ�r���Ȃ����Ƃ�������AM2���r���[�L�b�g��݂��o��AMD
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2762&p=12
Socket AM2�͂��܂̂��Ȃ��ɕK�v�Ȃ���������܂���
http://akiba-pc.watch.impress.co.jp/blog/archives/k605272.jpg
{kind=link}
�@�@�@�@�@�@�@�@�@�@�@Conroe�̈��|�I���\�ƈ���
�@�@�@�@�@�@�@�@�@�@�����Ēᐫ�\�@������d��64�EAM2�@�@�@�@�@�@�@�@�@�@�@�@�@
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@AMD����_(^o^)�^ �@�@�@
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ , -�
.�@�@�@�@�@�@ �@ , --��@�@�@ �@ �@, -��@�@�@_�@�@�@�@�@ �i�@�@j
�@�@�@�@�@�@�@ �i�@ �@j�@�@�@�@ �^�@�@ �܁L�@ �_�@�@�@ /�@/�L
�@�@�@�@�@ �@ �@ �_�@�_.�@ �ځ@�@�@� M�@,�@ �@',�@�@/�@/
�@�@�@�@�@�@�@�@ �@ �_�@�_�@/�@�R Ĥ���@!/ |�@�@ʁ@/�@/
�@�@�@�@�@�@�@�@�@�@�@ �_�@�R!�@l���܁Q��ف@��/�@/
�@�@�@�@�@�@�@�@�@�@�@�@�@�_��{l � �@V_Ɂ@� j�ȁ�/
�@�@�@�@�@�@�@�@�@�@�@�@ �@ // .�R { ���]�� j/ �_�R
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�_�@ ��/^<>^',�R�@ �^
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �M{ �@�r f::l .�qo Y
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ } /�@l::::���@V .}
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@���.�@�Ɂ@ }!�l
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ {=����=}�@�@�_
451 �F�{�� ��Rb.XJ8VXow �F2006/05/29(��) 02:10:46 ID:9tJkohKw
ID:ScP2ioFF�̓��e�Ӑ}�͖��炩��INTEL�J�ߎE���A���~���ẴX���ׂ����B
�A���~��h�̍s�����H
�ז������������!
�A���~��h�̍s�����H
�ז������������!
>>444
�������ĂȂ������͂�قǃ}�V�ŁB�@�y���̂���S�R�A�܂ł̓��h���Ă����
���ꂩ��ł镨�����O�ɏ������Ă����̂�V�����Ȃ��ƕ]�����Ăǂ�����B
�������ĂȂ������͂�قǃ}�V�ŁB�@�y���̂���S�R�A�܂ł̓��h���Ă����
���ꂩ��ł镨�����O�ɏ������Ă����̂�V�����Ȃ��ƕ]�����Ăǂ�����B
453 �F�{�� ��Rb.XJ8VXow �F2006/05/29(��) 03:02:32 ID:9tJkohKw
>>452
�_�_�͂�������Ȃ�����H
INTEL����s���ăN�A�b�h�R�A�𐢂ɏo�����Ƃ������œ_����H
�ǂ����AINTEL�̃N�A�b�h�R�A��萫�\�͈����i�ł����Ȃ����猄�Ԃ�_���ẴQ������ł����Ȃ��B
�_�_�͂�������Ȃ�����H
INTEL����s���ăN�A�b�h�R�A�𐢂ɏo�����Ƃ������œ_����H
�ǂ����AINTEL�̃N�A�b�h�R�A��萫�\�͈����i�ł����Ȃ����猄�Ԃ�_���ẴQ������ł����Ȃ��B
454 �FMAC�I�^��452 �����F2006/05/29(��) 03:30:16 ID:xVBHIVbf
>>452
�@�@---------------------
�@�@�y���̂���S�R�A�܂ł̓��h���Ă����
�@�@---------------------
MPF2001�ł�Hammer�̔��\������f���A���R�A�܂ł̃t���A�v����������������
�������ǁB�B�B
http://www.watch.impress.co.jp/PC/DOCS/ARTICLE/20011109/kaigai01.htm
�A�����팻���Ɩϑz�̋�ʂ������̂����胂�m��(��)
�@�@---------------------
�@�@�y���̂���S�R�A�܂ł̓��h���Ă����
�@�@---------------------
MPF2001�ł�Hammer�̔��\������f���A���R�A�܂ł̃t���A�v����������������
�������ǁB�B�B
http://www.watch.impress.co.jp/PC/DOCS/ARTICLE/20011109/kaigai01.htm
�A�����팻���Ɩϑz�̋�ʂ������̂����胂�m��(��)
�����A�����Ɛ̂��瑶�݂��ĂȂ���_���Ȃ̂ˁB�ǂ��ł�����������ǂ��ł��������ǂ�
2001�N���_��2�R�A�܂Ō����Ă������ł����h�Ȃ��Ǝv�����ȁB
�����̐����v���Z�X�ƍ��Ƃʼn�����Ⴄ���l����A4�R�A�܂œǂ݂���͖̂�������A���ʁB
2001�N�����̌v��Ō����Ȃ�Aintel�͖�����Netburst�H���܂�������łȂ��Ⴂ������B
�����̐����v���Z�X�ƍ��Ƃʼn�����Ⴄ���l����A4�R�A�܂œǂ݂���͖̂�������A���ʁB
2001�N�����̌v��Ō����Ȃ�Aintel�͖�����Netburst�H���܂�������łȂ��Ⴂ������B
K8�̏o���Ă�130nm�����ȁ[(�LA�M)
�y���̂��Ă����̂��l�b�N�����ǂȁB
�܂��A�f���A���R�A��z�肵�Ă��͈̂̂���B
���A��PenD���w�{�������B
�ŁA��������Č�������K10����Ȃ��̂��B
K8L�Ƃ��͓�����ŏI�`�Ԃ݂����Ȃ���H
�y���̂��Ă����̂��l�b�N�����ǂȁB
�܂��A�f���A���R�A��z�肵�Ă��͈̂̂���B
���A��PenD���w�{�������B
�ŁA��������Č�������K10����Ȃ��̂��B
K8L�Ƃ��͓�����ŏI�`�Ԃ݂����Ȃ���H
�U���P���̃A�i���X�g�E�~�[�e�B���O��Spring Processor Forum�̎����
�����������K8L�̏ڍׂ�b���Ƃ������Ă���K�X
�����������K8L�̏ڍׂ�b���Ƃ������Ă���K�X
>>454
�^������e�[�v�Ƃ͈���ċZ�p�I�Șb���\���ɏo����Ǝv����̂ɁA
�Ō�̃q�g�R�g�͗]�����ᖳ�����H
����Ȃ��Ƃ��܂ł����Ă����������Ă��ނ�Ɠ����x���ɂ����������ȁB
pen4�V�R�A��10Ghz!�Ƃ�����ł�intel���q�҂�n���ɂ��Ă�̂ƂȂ��ς��Ȃ��B
�ڂ����@�����������ă��x������B
�^������e�[�v�Ƃ͈���ċZ�p�I�Șb���\���ɏo����Ǝv����̂ɁA
�Ō�̃q�g�R�g�͗]�����ᖳ�����H
����Ȃ��Ƃ��܂ł����Ă����������Ă��ނ�Ɠ����x���ɂ����������ȁB
pen4�V�R�A��10Ghz!�Ƃ�����ł�intel���q�҂�n���ɂ��Ă�̂ƂȂ��ς��Ȃ��B
�ڂ����@�����������ă��x������B
�Q�e���m�D���Ƃ��ẮAConroe�R�Ŕ��M���N���b�NAthlon64���o��Ȃ�c
�~�������I�I
�~�������I�I
http://en.wikipedia.org/wiki/K8L
>Large Level-3 cache, initially expected to be a minimum of 4MB shared cache
>between processing cores on a single die (each with independent second-level cache).
4M��L3 Cache�ɂ��Ă���ƂȂ�ƁA
4-issue�ւ̊g�����܂߂��AFetch-Decoder-Exec Units�@�\�̋������H
>Large Level-3 cache, initially expected to be a minimum of 4MB shared cache
>between processing cores on a single die (each with independent second-level cache).
4M��L3 Cache�ɂ��Ă���ƂȂ�ƁA
4-issue�ւ̊g�����܂߂��AFetch-Decoder-Exec Units�@�\�̋������H
���R���t�B�O�����u���v���Z�b�T����
SONY�H�[�N�}���̂���H
SONY�H�[�N�}���̂���H
�ǂ����Ȃ�e�R�A��2issue�ʂ�3GHz��10w�ʂɂ���L1�����L�ł��ʁX�ł��g����
�悤�Ƀt���V�L�u���ɂ��ăR�A�����₵��Anti-HT�ŕ���ɏ����������������R�[�h
�̂�6issue�Ȃœ������Ă����������Win��Ő�ւ����ĕʂ�DSP�R�A��
SSE*���߂������o����CPU�ɂȂ�Ƃ����ȁB
���[��A�ǂ݃j�N�X
�悤�Ƀt���V�L�u���ɂ��ăR�A�����₵��Anti-HT�ŕ���ɏ����������������R�[�h
�̂�6issue�Ȃœ������Ă����������Win��Ő�ւ����ĕʂ�DSP�R�A��
SSE*���߂������o����CPU�ɂȂ�Ƃ����ȁB
���[��A�ǂ݃j�N�X
466 �F�{�� ��Rb.XJ8VXow �F2006/05/30(��) 16:11:35 ID:PYgYWwuV
>>465
�Â肷���ĉ�H�K�͔������Č��ǃN���b�N�グ�̎ז��Ŏ��b�p�^�[���ɂȂ�Ǝv���
�Â肷���ĉ�H�K�͔������Č��ǃN���b�N�グ�̎ז��Ŏ��b�p�^�[���ɂȂ�Ǝv���
�悫���L���X�g���\���E�E�E
>>463
��������A������wiki�ɏ�����Ă�
�EMemory mirroring support
�EHyperTransport retry support
�����̂Q���悭�킩���B�����낤�H
��������A������wiki�ɏ�����Ă�
�EMemory mirroring support
�EHyperTransport retry support
�����̂Q���悭�킩���B�����낤�H
�������̏璷�����āA��������d��ON�̂܂ܓ���ւ���@�\��
HT�̒ʐM�����s�����ꍇ�ɁA�đ����ĒʐM����蒼���@�\����˂��́H
�n�[�h�E�F�A�g���u���ɋ����Ȃ���
�����N��A�ǂ�łȂ�����
HT�̒ʐM�����s�����ꍇ�ɁA�đ����ĒʐM����蒼���@�\����˂��́H
�n�[�h�E�F�A�g���u���ɋ����Ȃ���
�����N��A�ǂ�łȂ�����
>�EMemory mirroring support
���[�ނȂ�قǁB�������z�b�g�X���b�v���D�D
���[�ނȂ�قǁB�������z�b�g�X���b�v���D�D
�Ă��Ƃ̓f���A���`�����l��x2�̃������C���^�[�t�F�[�X�����
���}�X�^�E�X���[�u�Ԃ̐����m�F���I���^�C���ōs�����܂����Ă̂����H
�X�Q�[�Ȃ���
���w��ɂȂ�E�E�E
���}�X�^�E�X���[�u�Ԃ̐����m�F���I���^�C���ōs�����܂����Ă̂����H
�X�Q�[�Ȃ���
���w��ɂȂ�E�E�E
����ɋ���l�̑唼�ɂ͈Ӗ��������@�\����
474 �FMAC�I�^��469 �����F2006/05/31(��) 00:18:07 ID:6LF6Tfck
>>469
�������E�~���[�����O�핁�ʂɃf�[�^��2�Z�b�g���d�����Ď��Ƃ������m���B>>471����
�����Ă���悤�ȃz�b�g�X���b�v���chip-kill�Ƃ�������܂��ʂ̋Z�p���B
"Hyper Transport retry"�̕��͎�Z�ɐ�������Ƥ���X�]���G���[�̔������n�[�h�E�F�A�I��
��S���l�����Ă��Ȃ�����(���̕�������Ŏ������ȒP)��Hyper Transport�ɤPCI Express��
RapidIO�̂悤�ȋ����e�N�m���W���̃G���[�ɑ���n�[�h�E�F�A�I�ȃT�|�[�g��������Ƃ���
�b���B
�������E�~���[�����O�핁�ʂɃf�[�^��2�Z�b�g���d�����Ď��Ƃ������m���B>>471����
�����Ă���悤�ȃz�b�g�X���b�v���chip-kill�Ƃ�������܂��ʂ̋Z�p���B
"Hyper Transport retry"�̕��͎�Z�ɐ�������Ƥ���X�]���G���[�̔������n�[�h�E�F�A�I��
��S���l�����Ă��Ȃ�����(���̕�������Ŏ������ȒP)��Hyper Transport�ɤPCI Express��
RapidIO�̂悤�ȋ����e�N�m���W���̃G���[�ɑ���n�[�h�E�F�A�I�ȃT�|�[�g��������Ƃ���
�b���B
Rev. F�̎��̎��ɗ���AMD�̎�����R�A�uHound�v
http://pc.watch.impress.co.jp/docs/2006/0531/kaigai273.htm
http://pc.watch.impress.co.jp/docs/2006/0531/kaigai273.htm
476 �FSocket774�F2006/05/31(��) 23:06:56 ID:hQVmMXEN
���N�̖�����ɂ�AMD��ʏۂ����AINTEL�����Y�ʌ��炳�낤����
CPU�\���Ղ肾�ȁB
CPU�\���Ղ肾�ȁB
������NAthlon64�̒l�i�قƂ�Ǖω�����������ȁB
�ŋ߂܂��l�i��N�Ԃ�Ɋm�F������т����肵����B
�ŋ߂܂��l�i��N�Ԃ�Ɋm�F������т����肵����B
478 �FSocket774�F2006/06/01(��) 00:11:57 ID:298+KRIU
�QAMD�r�Ōv�搋�s���Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q
l�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�j
l�@ �ȁ@�ȁ@�@�@�@�@�@�@�@�@�@�@�@((
l�@�i �E�́E�j�����Z���v�����@�E�@�j�@�@�E�@�@�E �@�@�E�E�@�@�@�@�@�@�F
l�@�iCore2 �j�U�@�@�@�@�@�@�@�@�E�E ��64_���E �@�F�@�@�@��X2���E�@�E�@�@�@
l__�b �b�@| �_ _________________�i�B�@�B�E�j�E_____�@�@__(�@:�;�Do:)�E_____________________________________
l�@�i_�Q�j�Q�j�@�@�@�@�@�@�@�@�@�@�i�E�@�G�@*�j�� �@�@�i�E�@�G�@*�j�@�@�@
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �i�܁j�i�܁j�@�@�@�@ �i�܁j�i�܁j�@�@ �@�@�@�@�@�@
�@�@�@�@�Q�Q_ �@�@�@�@�@�@�@ �Q�Q_ �@�@�@�@�@�@�@�Q�Q_ �@�@�@�@
�@ �@�@/Intel�� �@�@�@�@�@�@/Intel�� �@�@�@ �@�@/Intel�ہ@�@�@�@
�@�@ ��=====���@�j))==)) ��=====���@�j))==)) ��=====���@�j))=)�@�@
�@�@�@�iCore�@�@�m�@ �@�@�@�iPentium�m�@ �@�@�@�iCeleron�m
�@�@�@�b �b�@|�@�@�@�@�@�@�@�b �b�@|�@�@�@�@�@�@ �b �b�@|�@
�@�@�@�i�Q�i�Q_�j�Q__ �@�@�@ �i�Q�i�Q_�j�Q__ �@�@ �i�Q�i�Q_�j�Q__
���|�I���\�E���|�I�ቿ�i��Conroe
http://www.anandtech.com/tradeshows/showdoc.aspx?i=2716&p=6
http://www.dailytech.com/article.aspx?newsid=2531
http://journal.mycom.co.jp/news/2006/05/23/403.html
Conroe E6600�@�Ɓ@�yAM2 FX62�z�̃x���`��r
http://www.hexus.net/content/item.php?item=5692&page=3
Pentium 4/D�u�����h�̑������ɏo��Intel��CPU���i�헪
http://pc.watch.impress.co.jp/docs/2006/0531/kaigai274.htm
�uCore Duo�v�V���[�Y�̑啝���i����
http://akiba.ascii24.com/akiba/news/2006/05/27/662481-000.html
Conroe�Ɣ�r���Ȃ����Ƃ�������AM2���r���[�L�b�g��݂��o��AMD
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2762&p=12
���n�ɗ������ꂽAMD�̋ꂵ���������\��
http://pc.watch.impress.co.jp/docs/2006/0524/amd.htm
���㓡�O��Weekly�C�O�j���[�X��
�g�傪�i��AMD�̃R�v���Z�b�T�\�z
http://pc.watch.impress.co.jp/docs/2006/0601/kaigai275.htm
�g�傪�i��AMD�̃R�v���Z�b�T�\�z
http://pc.watch.impress.co.jp/docs/2006/0601/kaigai275.htm
480 �F�{�� ��Rb.XJ8VXow �F2006/06/01(��) 00:35:13 ID:6X8dkLCB
>>479
�Z�p�͂̍����̈Ⴂor�J���͂̈Ⴂ���ĂƂ��낾�낤�ȁB
AMD�̍\�z�͈��Ղ����Ɏ����͗e�Ղ��A���������̕������ėp���͂Ȃ��Ȃ�B
INTEL�̍\�z�͈�̓��Ŏ����͗e�Ղł͂Ȃ��A���������������ƐV���씭���̌��т��҂��Ă���B
�Z�p�͂̍����̈Ⴂor�J���͂̈Ⴂ���ĂƂ��낾�낤�ȁB
AMD�̍\�z�͈��Ղ����Ɏ����͗e�Ղ��A���������̕������ėp���͂Ȃ��Ȃ�B
INTEL�̍\�z�͈�̓��Ŏ����͗e�Ղł͂Ȃ��A���������������ƐV���씭���̌��т��҂��Ă���B
�͂��H�ǂ������ǂ���
>>480
�u��X�́A�l�X���R�v���Z�b�T���J���ł���悤�ɂ��悤�Ƃ��Ă���B����ɑ��āA
Intel�͔ނ玩�g��(�T�u�v���Z�b�T�J����)��낤�Ƃ��Ă���B��X�́A
Coherent HyperTransport�o�X�ŁA���̐l�X���R�v���Z�b�T��ڑ��ł���悤��
���悤�Ƃ��Ă���B�������AIntel�͔ނ��FSB(Front Side Bus)�ɁA
���̐l�X��(�R�v���Z�b�T��)�ڑ�����͍̂D�܂Ȃ����낤�B�t�B���\�t�B���قȂ�v
��Hester���͌����B
�t�B���\�t�B���قȂ�
�u��X�́A�l�X���R�v���Z�b�T���J���ł���悤�ɂ��悤�Ƃ��Ă���B����ɑ��āA
Intel�͔ނ玩�g��(�T�u�v���Z�b�T�J����)��낤�Ƃ��Ă���B��X�́A
Coherent HyperTransport�o�X�ŁA���̐l�X���R�v���Z�b�T��ڑ��ł���悤��
���悤�Ƃ��Ă���B�������AIntel�͔ނ��FSB(Front Side Bus)�ɁA
���̐l�X��(�R�v���Z�b�T��)�ڑ�����͍̂D�܂Ȃ����낤�B�t�B���\�t�B���قȂ�v
��Hester���͌����B
�t�B���\�t�B���قȂ�
483 �F�{�� ��Rb.XJ8VXow �F2006/06/01(��) 00:54:20 ID:6X8dkLCB
>>482
�ȒP�Ɍ����Ă��܂��ƁA
AMD�͏��F�V�F�A10%���x�̉�Ђł���A�ėp���Ɍ����Ă������̂��鐻�i�ֈ�Ă�ɂ͓s�����悢�B
���l�ɂ͌����Ȃ����R�v���Z�b�T����̓�������CPU�ւ̐i�����ڕW�B
INTEL�̓V�F�A�������̂Ŗ��l�����̐i����ڎw���Ƃ����������낤�B
�ȒP�Ɍ����Ă��܂��ƁA
AMD�͏��F�V�F�A10%���x�̉�Ђł���A�ėp���Ɍ����Ă������̂��鐻�i�ֈ�Ă�ɂ͓s�����悢�B
���l�ɂ͌����Ȃ����R�v���Z�b�T����̓�������CPU�ւ̐i�����ڕW�B
INTEL�̓V�F�A�������̂Ŗ��l�����̐i����ڎw���Ƃ����������낤�B
���l�̓ǂݕ��Ɋ��͂��Ȃ��B��X�t�B���^����ł��\�[�X�ǂނ�B
>���������������ƐV���씭���̌��т��҂��Ă���B
�܂��A�����������Ȃ����ǂ�w
�܂��A�����������Ȃ����ǂ�w
486 �F�{�� ��Rb.XJ8VXow �F2006/06/01(��) 01:18:32 ID:6X8dkLCB
INTEL�̃��j�B�R�A�i���ւ̕���Ƃ���PARROT�Ɠ��@�X���b�h������B
PARROT�̓R�[�h�́g�Ǐ����h�ɓI���i�����R�[�h�̍��x�ȍœK���Z�p�Ŏ������ߐ������炵����������B
���̍œK���ɕK�v�ȏ����Ƃ���ɔ�����Ƌ��(������p�L���b�V��)������������낤�B
���@�X���b�h�͎��s���̃X���b�h��胁�������[�h���ʂ݂̂𒊏o�����@�X���b�h��p�R�A�Ŏ��s�B
���������[�h���ʂ݂̂̒��o�œK�������Ƃ��̎��s�ƃ��C���X���b�h�Ď��𓊋@�X���b�h��p�R�A���s���������낤�B
�ǂ�������͂�����B
PARROT�̓R�[�h�́g�Ǐ����h�ɓI���i�����R�[�h�̍��x�ȍœK���Z�p�Ŏ������ߐ������炵����������B
���̍œK���ɕK�v�ȏ����Ƃ���ɔ�����Ƌ��(������p�L���b�V��)������������낤�B
���@�X���b�h�͎��s���̃X���b�h��胁�������[�h���ʂ݂̂𒊏o�����@�X���b�h��p�R�A�Ŏ��s�B
���������[�h���ʂ݂̂̒��o�œK�������Ƃ��̎��s�ƃ��C���X���b�h�Ď��𓊋@�X���b�h��p�R�A���s���������낤�B
�ǂ�������͂�����B
���������[�h�̌������オ���ĉ��Z���x���オ��قǁA���Z���ʂ̏����߂��̑ш悪
���������[�h�ɋ���đш�̒D�������ɂȂ�Ƃ���㩁B
���������[�h�ɋ���đш�̒D�������ɂȂ�Ƃ���㩁B
488 �F�{�� ��Rb.XJ8VXow �F2006/06/01(��) 01:35:09 ID:6X8dkLCB
>>487
�����I�ɏ������x���オ��(�N���b�N�㏸�Ȃ���)�̂�����A����ɔ����o�X�ш��K�v�Ƃ���͓̂�����O�̂��Ƃ���?
CSI�ւ̕����Ŗ��Ȃ��B
�����I�ɏ������x���オ��(�N���b�N�㏸�Ȃ���)�̂�����A����ɔ����o�X�ш��K�v�Ƃ���͓̂�����O�̂��Ƃ���?
CSI�ւ̕����Ŗ��Ȃ��B
�����A���@�X���b�h��p�R�A�̓��������[�h����邾���ł��ꎩ�̂͗L�Ӌ`�ȏ����͉������Ȃ��B
�����A�����\�ȃR�A�͈����ȁB
�������s���Ȃ�������s���j�b�g���s�v�ȕ��͏������Ȃ邾�낤���B
���ƁA���ɕʂ̎��s�R�A�̃f�R�[�_�ɓ������ꂽ���߂𓊋@�I�Ɏ��s���Ă��������̃��C�e���V���猩��
�Ԃɍ���Ȃ����낤����AL1/L2�L���b�V���ɂ���f�R�[�_�����O�̖��߂��ǂ݂��Ȃ���Ȃ��B
�ƂȂ�A�ʏ���ȑf�ł͂��邪�f�R�[�_�͕K�v�����A�Ȃɂ��L���b�V������ɐ�ǂ݂��邩��
�L���b�V���̑ш���グ�Ȃ��ƌ������ȁB
�����A�����\�ȃR�A�͈����ȁB
�������s���Ȃ�������s���j�b�g���s�v�ȕ��͏������Ȃ邾�낤���B
���ƁA���ɕʂ̎��s�R�A�̃f�R�[�_�ɓ������ꂽ���߂𓊋@�I�Ɏ��s���Ă��������̃��C�e���V���猩��
�Ԃɍ���Ȃ����낤����AL1/L2�L���b�V���ɂ���f�R�[�_�����O�̖��߂��ǂ݂��Ȃ���Ȃ��B
�ƂȂ�A�ʏ���ȑf�ł͂��邪�f�R�[�_�͕K�v�����A�Ȃɂ��L���b�V������ɐ�ǂ݂��邩��
�L���b�V���̑ш���グ�Ȃ��ƌ������ȁB
491 �F�{�� ��Rb.XJ8VXow �F2006/06/01(��) 02:12:48 ID:6X8dkLCB
�����ł��ˁA���@�X���b�h��PARROT���������͓���Ǝv���܂��B
45nm�ȍ~�Ńf�X�N�g�b�v�����CPU�̓_�C�T�C�Y���]���Ă��邱�Ƃւ̗L�����p����ł��B
��ʓI�ȃf�X�N�g�b�v�ł̗p�r�͗��p�҂�������׃T�[�o�[�ƈقȂ葽���̃R�A��K�v�Ƃ��܂���B
�������A�A�v���P�[�V�������i���������̃X���b�h�������悤�ɂȂ�ΕʂȂ̂ł����E�E�E
45nm�ȍ~�Ńf�X�N�g�b�v�����CPU�̓_�C�T�C�Y���]���Ă��邱�Ƃւ̗L�����p����ł��B
��ʓI�ȃf�X�N�g�b�v�ł̗p�r�͗��p�҂�������׃T�[�o�[�ƈقȂ葽���̃R�A��K�v�Ƃ��܂���B
�������A�A�v���P�[�V�������i���������̃X���b�h�������悤�ɂȂ�ΕʂȂ̂ł����E�E�E
>>479�̌㓡�L������܂����o���̌�ǂ������B�B�B
http://pc7.2ch.net/test/read.cgi/jisaku/1138983969/528-529
�@�@-----------------------
�@�@528 ���O�FMAC�I�^ ���e���F2006/03/22(��) 04:45:04 ID:abgVcQI8
�@�@�@�@AMD��ccHT���J�H���������ɐi�s���Ă���͗l���B(>>22�Q��)
�@�@�@�@C����x�[�X�̃`�b�v�v�c�[���x���_Celoxica��Xilinx��FPGA��HT�ڑ��̃R�v���Z�b�T�Ƃ���
�@�@�@�@�g���₷���o����悤�ɂ���Ƃ��B�B�B
�@�@�@�@http://www.eetimes.com/news/latest/showArticle.jhtml?articleID=183701329
�@�@�@�@FPGA��Hammer�̃R�v���Z�b�T�Ƃ��Ďg�p���Ă�����CCray��XD1�Ȃ����邷�B
�@�@�@�@http://www.cray.com/global_pages/products/FPGA.html
�@�@�@�@���Ȃ݂ɂ������������ŏo���オ��㕨���Ă̂�CCELL���V���O���`�b�v�Ŏ������Ă��郂�m��
�@�@�@�@�{�[�h�ꖇ�����đ���B�B�B���Ăȃ������B
�@�@�@�@�����̂悤�Ɏ��ЋZ�p�Ɏ��M�̖���AMD�Ƃ��Ă�C���̎�̃V�X�e�������������Ƃ������������
�@�@�@�@��荞��ŁC�`�b�v���i�ɂ��悤���ĂȖژ_�������ˁB�B�B
�@�@-----------------------
�u����������荞��ţ�̕�����MCM���i�܂ōl���Ă���݂��������ǁB�B�B
����ɂ��Ăं��̕���>>444�ŏ������u��������������}���`�R�A���o���C���X����(��)
�@�@=======================
�@�@�@�u�`�b�v�����ł��A�{���I�ɂ�Coherent Hypertransport�����N�Ō��ԁB�ʂȃr���[�Ō���ƁA
�@�@�������R���g���[�����N���X�o�[�X�C�b�`�ɐڑ�����A�N���X�o�[�ɃR�v���Z�b�T���ڑ������
�@�@�悤�Ȍ`���v
�@�@=======================
http://pc7.2ch.net/test/read.cgi/jisaku/1138983969/528-529
�@�@-----------------------
�@�@528 ���O�FMAC�I�^ ���e���F2006/03/22(��) 04:45:04 ID:abgVcQI8
�@�@�@�@AMD��ccHT���J�H���������ɐi�s���Ă���͗l���B(>>22�Q��)
�@�@�@�@C����x�[�X�̃`�b�v�v�c�[���x���_Celoxica��Xilinx��FPGA��HT�ڑ��̃R�v���Z�b�T�Ƃ���
�@�@�@�@�g���₷���o����悤�ɂ���Ƃ��B�B�B
�@�@�@�@http://www.eetimes.com/news/latest/showArticle.jhtml?articleID=183701329
�@�@�@�@FPGA��Hammer�̃R�v���Z�b�T�Ƃ��Ďg�p���Ă�����CCray��XD1�Ȃ����邷�B
�@�@�@�@http://www.cray.com/global_pages/products/FPGA.html
�@�@�@�@���Ȃ݂ɂ������������ŏo���オ��㕨���Ă̂�CCELL���V���O���`�b�v�Ŏ������Ă��郂�m��
�@�@�@�@�{�[�h�ꖇ�����đ���B�B�B���Ăȃ������B
�@�@�@�@�����̂悤�Ɏ��ЋZ�p�Ɏ��M�̖���AMD�Ƃ��Ă�C���̎�̃V�X�e�������������Ƃ������������
�@�@�@�@��荞��ŁC�`�b�v���i�ɂ��悤���ĂȖژ_�������ˁB�B�B
�@�@-----------------------
�u����������荞��ţ�̕�����MCM���i�܂ōl���Ă���݂��������ǁB�B�B
����ɂ��Ăं��̕���>>444�ŏ������u��������������}���`�R�A���o���C���X����(��)
�@�@=======================
�@�@�@�u�`�b�v�����ł��A�{���I�ɂ�Coherent Hypertransport�����N�Ō��ԁB�ʂȃr���[�Ō���ƁA
�@�@�������R���g���[�����N���X�o�[�X�C�b�`�ɐڑ�����A�N���X�o�[�ɃR�v���Z�b�T���ڑ������
�@�@�悤�Ȍ`���v
�@�@=======================
�]�����_�C�T�C�Y�̗L�����p�ˁE�E�E
����ł����Ƀn�[�h�v���t�F�b�`�ł��������̌��ʂ��o�Ă邩��A�ǂ̒��x�̌��ʂ����邩�͋^�₾�ȁB
�ǂ������{�I�Ƀ��X�����炷���߂̋Z�p�ł����āA��b�\�͊g��̂��߂̋Z�p����Ȃ�����
���_�l�ɋ߂Â��قnj��ʂ͔����Ȃ��Ă�������ȁB
����ł����Ƀn�[�h�v���t�F�b�`�ł��������̌��ʂ��o�Ă邩��A�ǂ̒��x�̌��ʂ����邩�͋^�₾�ȁB
�ǂ������{�I�Ƀ��X�����炷���߂̋Z�p�ł����āA��b�\�͊g��̂��߂̋Z�p����Ȃ�����
���_�l�ɋ߂Â��قnj��ʂ͔����Ȃ��Ă�������ȁB
�G���R�p�v���Z�b�T���o����Г��ꂽ���Ȃ�
�ł��\�t�g�E�F�A���̑Ή����Ȃ��ƈӖ����Ȃ���
�ł��\�t�g�E�F�A���̑Ή����Ȃ��ƈӖ����Ȃ���
MAC�I�^�̌㓡�ɑ��鋭��ȃ��C�o���ӎ����Q�����ŔR���オ��̂ł������B
��
��
496 �F�{�� ��Rb.XJ8VXow �F2006/06/01(��) 12:08:20 ID:6X8dkLCB
> �G���R�p�v���Z�b�T���o����Г��ꂽ���Ȃ�
> �ł��\�t�g�E�F�A���̑Ή����Ȃ��ƈӖ����Ȃ���
����Ӗ��Ȃ��ł���?
�G���R�p�v���Z�b�T�ɓ��ڂ����R�v���Z�b�T�ƑΉ��\�t�g���K�v������A���ǂ̓n�[�h�G���R�[�h����{�[�h���Ă�ɓ������B
��p�{�[�h�Ȃ�A�V�����G���R�[�h�ɑΉ��������Ƃ��͐�p�{�[�h���ւ��邾���ł����B
�G���R�p�v���Z�b�T���ƁA�V�����G���R�[�h�ɑΉ��������Ƃ��̓G���R�p�v���Z�b�T�ƑΉ��\�t�g��2�����Ȃ��ƃ_���B
������Ĕ��ɋ�������w
�R�v���Z�b�T���K�тꂽ���R������Ȃ�B
AMD�̌����Ă邱�Ƃ͋�_�ɋ߂��w�ǖ��Ӗ��Ȃ�ȁB
> �ł��\�t�g�E�F�A���̑Ή����Ȃ��ƈӖ����Ȃ���
����Ӗ��Ȃ��ł���?
�G���R�p�v���Z�b�T�ɓ��ڂ����R�v���Z�b�T�ƑΉ��\�t�g���K�v������A���ǂ̓n�[�h�G���R�[�h����{�[�h���Ă�ɓ������B
��p�{�[�h�Ȃ�A�V�����G���R�[�h�ɑΉ��������Ƃ��͐�p�{�[�h���ւ��邾���ł����B
�G���R�p�v���Z�b�T���ƁA�V�����G���R�[�h�ɑΉ��������Ƃ��̓G���R�p�v���Z�b�T�ƑΉ��\�t�g��2�����Ȃ��ƃ_���B
������Ĕ��ɋ�������w
�R�v���Z�b�T���K�тꂽ���R������Ȃ�B
AMD�̌����Ă邱�Ƃ͋�_�ɋ߂��w�ǖ��Ӗ��Ȃ�ȁB
�G���R�[�h�̌�����Ӌ`�ɂ��Ēm��Ȃ��킯�ł͂Ȃ������̂���ȂɎ��v���������̂����킩���
TV�^��Ȃ牿�i�∵���₷����I�ɂ�PC�����K�v�͖�����100��������PC���K�v���Ƃ��Ă��n�[�h�G���R�ł���L���v�{�����ďI���̊�K�X
��������CPU�ɕ��������_�̃s�[�N���Z���\���グ��Ӌ`�͂����Ă�����p�r�ɍœK������Ӌ`�͑S��������
�{���]�|���Ċ���
TV�^��Ȃ牿�i�∵���₷����I�ɂ�PC�����K�v�͖�����100��������PC���K�v���Ƃ��Ă��n�[�h�G���R�ł���L���v�{�����ďI���̊�K�X
��������CPU�ɕ��������_�̃s�[�N���Z���\���グ��Ӌ`�͂����Ă�����p�r�ɍœK������Ӌ`�͑S��������
�{���]�|���Ċ���
NEC�̃`�b�v�Ȃ�3DYCS�E�f�W�^�C�U�EMPEG2�G���R�[�_�����ď���d��3W�ȉ�
>>496
�{�[�h�����ĕύX����ꍇ�̓h���C�o�X�V���K�v�W���}�C�J�B�s�v�Ȓ��x��
�ύX�Ȃ�A�R�v���̏ꍇ�����ē�������B
�{�[�h�����R�v���̕����A���炩�ɐڑ����x�͍����̂����A��p�h���C�o
�ɂ��Ă̓R�v���̃n�[�h�ŗ��v���o������Ȃ�A�h���C�o�͖����̃I�[
�v���\�[�X�ɂ���ςށB
�R�v�����s���Ȃ̂́A�\�P�b�g�K�i�̕ύX��AMD�̎v�f�ōs���Ă��܂��_
���낤�ȁB�{�[�h�Ȃ瓖��PCI-E�ŕύX�s�v���낤���B
�{�[�h�����ĕύX����ꍇ�̓h���C�o�X�V���K�v�W���}�C�J�B�s�v�Ȓ��x��
�ύX�Ȃ�A�R�v���̏ꍇ�����ē�������B
�{�[�h�����R�v���̕����A���炩�ɐڑ����x�͍����̂����A��p�h���C�o
�ɂ��Ă̓R�v���̃n�[�h�ŗ��v���o������Ȃ�A�h���C�o�͖����̃I�[
�v���\�[�X�ɂ���ςށB
�R�v�����s���Ȃ̂́A�\�P�b�g�K�i�̕ύX��AMD�̎v�f�ōs���Ă��܂��_
���낤�ȁB�{�[�h�Ȃ瓖��PCI-E�ŕύX�s�v���낤���B
>>499
���̋@�\��3W�ȉ����āA���������d�C�H���ق�����ˁH
���̋@�\��3W�ȉ����āA���������d�C�H���ق�����ˁH
502 �F�{�� ��Rb.XJ8VXow �F2006/06/01(��) 16:46:14 ID:6X8dkLCB
>>500
�����ق����Ă���̂������ς�s�����B
������Ă��Ɖ�����?
���O����́A�V�K�i�̃G���R�[�h�����\�����x��AMD�Ђ͐V�K�i�̃G���R�[�h�ɑΉ������R�v���Z�b�T�����CPU�������[�X����Ƃł����������̂�?
�����āA�R�v���Z�b�T�����CPU���g���Ă���ЂƂ͂��̓x�ɃR�v���Z�b�T�����CPU���ւ���Ƃł�?
���ʂ���˂���(��
�{�[�h�Ȃ�A�V�K�i�̃G���R�[�h�ɑΉ������{�[�h�����������A����ɔ����ւ��邾���ōςނ��w
�����ق����Ă���̂������ς�s�����B
������Ă��Ɖ�����?
���O����́A�V�K�i�̃G���R�[�h�����\�����x��AMD�Ђ͐V�K�i�̃G���R�[�h�ɑΉ������R�v���Z�b�T�����CPU�������[�X����Ƃł����������̂�?
�����āA�R�v���Z�b�T�����CPU���g���Ă���ЂƂ͂��̓x�ɃR�v���Z�b�T�����CPU���ւ���Ƃł�?
���ʂ���˂���(��
�{�[�h�Ȃ�A�V�K�i�̃G���R�[�h�ɑΉ������{�[�h�����������A����ɔ����ւ��邾���ōςނ��w
�QAMD�r�Ōv�搋�s���Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q
l
l�@�@�����������悤�ˁ@�@�@�@�@�@�@�@�@�@
l�@ �ȁ@�ȁ@�@�@�@�@�@�@�@�@�@�@�@�@�@
l�@�i �E�́E�j�@�@�@�@�@�@�@�@�@�@�@�@�E�@�@�E �@�@�E�E�@�E�@�@�@�@�F
l�@�iCore2 �j�U�@�@�@�@�@�@�@�E�E�E�ȁ� �@�F�@�@�@�����E�@�E�@�@�@
l__�b �b�@| �_ _______________�i�L�D�M�G�j�E_____(�G�ցG�M)�E________________________________
l�@�i_�Q�j�Q�j�@�@�@�@�@�@�@�@�@�i�����݁j �@�iTurion�j�@�@�@
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �i�Q�i�Q�j�@�@�@�i�Q�i�Q�j�@�@ �@�@���i:�;�Do:����X2���@�@�@
�@�@�Q�Q_ �@�@�@�@�@�@�@ �Q�Q_ �@�@�@�@�@�@�Q�Q �@�@�@�@�@�@�@���i�B�@�B:����64��
�@/Intel�� �@�@�@�@�@�@/Intel�� �@�@�@ �@/Intel��
��=====���@�j))=)) ��=====���@�j))=)) ��=====���@�j))=)�@
�@�iCore�@�@�m�@ �@�@�@�iPentium�m�@ �@�@�iCeleron�j�@�@�@�@
�@�b �b�@|�@�@�@�@�@�@�@�b �b�@|�@�@�@�@�@�b �b�@|�@�@�@
�@�i�Q�i�Q_�j�Q__ �@�@�@ �i�Q�i�Q_�j�Q__ �@�i�Q�i�Q_�j�Q__
���|�I���\�E���|�I�ቿ�i��Conroe
http://www.anandtech.com/tradeshows/showdoc.aspx?i=2716&p=6
http://www.dailytech.com/article.aspx?newsid=2531
http://journal.mycom.co.jp/news/2006/05/23/403.html
Conroe E6600�@�Ɓ@�yAM2 FX62�z�̃x���`��r
http://www.hexus.net/content/item.php?item=5692&page=3
Pentium 4/D�u�����h�̑������ɏo��Intel��CPU���i�헪
http://pc.watch.impress.co.jp/docs/2006/0531/kaigai274.htm
�uCore Duo�v�V���[�Y�̑啝���i����
http://akiba.ascii24.com/akiba/news/2006/05/27/662481-000.html
Conroe�Ɣ�r���Ȃ����Ƃ�������AM2���r���[�L�b�g��݂��o��AMD
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2762&p=12
���n�ɗ������ꂽAMD�̋ꂵ���������\��
http://pc.watch.impress.co.jp/docs/2006/0524/amd.htm
���ǂǂ��������������邶��ˁ[����
�܂��������傢�ėp�I�ȃR�v���Z�T�̕����ǂ����������ǁB
�܂��������傢�ėp�I�ȃR�v���Z�T�̕����ǂ����������ǁB
>>�ėp�I�ȃR�v���Z�T
����𐢊Ԃł�CPU�Ƃ�����W���}�C�J��
����𐢊Ԃł�CPU�Ƃ�����W���}�C�J��
507 �F�{�� ��Rb.XJ8VXow �F2006/06/01(��) 17:35:00 ID:m0m3kR4A
>>506
�G���R�ł悭�g�p���鉉�Z���������������悤�ȓz��������F��Ȍ`���ɑΉ��ł���ł���B
�\�t�g�E�F�A�̑Ή��͓��R�K�v�ɂȂ邪�B
AMD���x�N�g�����Z���ǂ��̂��Č����Ă邩��l���Ă͂��邾�낤���ǁB
Intel���l���Ă�ManyCore�͂��ėp�I���낤���ǂˁB
�S�ẴR�A�ňꉞ�������Z���o����݂���������B
�G���R�ł悭�g�p���鉉�Z���������������悤�ȓz��������F��Ȍ`���ɑΉ��ł���ł���B
�\�t�g�E�F�A�̑Ή��͓��R�K�v�ɂȂ邪�B
AMD���x�N�g�����Z���ǂ��̂��Č����Ă邩��l���Ă͂��邾�낤���ǁB
Intel���l���Ă�ManyCore�͂��ėp�I���낤���ǂˁB
�S�ẴR�A�ňꉞ�������Z���o����݂���������B
509 �F�{�� ��Rb.XJ8VXow �F2006/06/01(��) 17:48:37 ID:m0m3kR4A
>>508
> �G���R�ł悭�g�p���鉉�Z���������������悤�ȓz
���N�̕鍠�ɏo�Ă���Rev.H�͂܂��ɂ���E�E�E�E
�����Ɣ߂�����@> AMD
> �G���R�ł悭�g�p���鉉�Z���������������悤�ȓz
���N�̕鍠�ɏo�Ă���Rev.H�͂܂��ɂ���E�E�E�E
�����Ɣ߂�����@> AMD
>>508�����āAAnti-HTT���ē�����SR8000�݂����ȋ[���x�N�g���ɂ��G���R�n�����@�\�Ȃ̂��ȁ[�Ɩϑz
����Ȃ�p�t�H�[�}���X�����I�Ɍ��シ��Ƃ���AMD�̎咣�������ł���
������ꕔ�̏����ɂ����ģ�Ƃ������t���K�v�s�����Ǝv����
����Ȃ�p�t�H�[�}���X�����I�Ɍ��シ��Ƃ���AMD�̎咣�������ł���
������ꕔ�̏����ɂ����ģ�Ƃ������t���K�v�s�����Ǝv����
>���N�̕鍠�ɏo�Ă���Rev.H�͂܂��ɂ���E�E�E�E
���ǂ���ł����H
���ǂ���ł����H
���܂���A�Â��� Tech Analyst Day ��҂�
�㓡�̕ʐl�i��MAC�I�^��
>>502
�Ƃ肠����AMD���l���Ă�͉̂��L�S�����A���͈̔͂ŏ��i�\�����邾����
�b����B�}���`�`�b�v���W���[���Ȃ�A���C���R�A�͈��ނōςނ��A�j�[�Y
������������R�A�������邾���ŗǂ��B
http://pc.watch.impress.co.jp/docs/2006/0601/kaigai275.htm
�b��Java�AXML�A�x�N�^�A�Z�L�����e�B��4������A�N�Z�����[�g
���܂��������A�R���R���K�i���ς��G���R�[�h�́A���X�R�v���̑ΏۊO�ŃI�P
�����A�J�[�h�Ȃ�R�v���Ȃ��̃I�v�e�ōςށB
�Ƃ肠����AMD���l���Ă�͉̂��L�S�����A���͈̔͂ŏ��i�\�����邾����
�b����B�}���`�`�b�v���W���[���Ȃ�A���C���R�A�͈��ނōςނ��A�j�[�Y
������������R�A�������邾���ŗǂ��B
http://pc.watch.impress.co.jp/docs/2006/0601/kaigai275.htm
�b��Java�AXML�A�x�N�^�A�Z�L�����e�B��4������A�N�Z�����[�g
���܂��������A�R���R���K�i���ς��G���R�[�h�́A���X�R�v���̑ΏۊO�ŃI�P
�����A�J�[�h�Ȃ�R�v���Ȃ��̃I�v�e�ōςށB
�G���R�[�h���ăx�N�g�����ł��Ȃ��̂���?
�ł����炷���[�����ł������Ȃ�
�ł����炷���[�����ł������Ȃ�
�@�@���u���N�I
�@�@������AMD�ƃA�����ǂ���
�@�@���ׂĂ̐���ɂ����Č�ނ�����B
�@�@�������G�̖h�q���˔j���A�z����쒀���鎞���I
�@�@��X�ɂ͂��̗͂�����B
�@�@�鍑�͍���x���ƍċ��̓���҂���тĂ���B�i�ߓ��u��I
�P�P�P�P�P�P�P�P�P�P�P�P��/�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P
�@�@�@�@�@�@�@�@�@�@�@�@�@�@����
�@�@�@�@�@�@�@�@�@�@�@�@�@ �i�E�́E�j�@�@�@
�@�@�@�@�@�@�@�@�@�@�@�@�@�iCore2�@
�@�@�@�@�@�@�@�@�@�@�@�@�@�b�@�@�b�@�@
�@�@�@�@�@�@�@�@�@�@�@���P�P�P�P�P�P��
�@�@�@�@�@�@�@�@�@�@ �b �@Intel�@�@�@.�b
�@�@�@�@�@�@�@�@�@�@ �b�@�@ �@�@�@�@ .�b
�@ �����@�@ �����@�@ �����@�@ �����@�@ �����@�@ ����
�@�i �@�@�j�@ �i �@�@�j�@ �i �@�@�j�@ �i �@�@�j�@ �i �@�@�j�@ �i �@�@�j
�@�@ �����@�@ �����@�@ �����@�@ �����@�@ �����@�@ ����
�@�@�i �@�@�j�@ �i �@�@�j�@ �i �@�@�j�@ �i �@�@�j�@ �i �@�@�j�@ �i �@�@�j
���|�I���\�E���|�I�ቿ�i��Conroe
http://www.anandtech.com/tradeshows/showdoc.aspx?i=2716&p=6
http://www.dailytech.com/article.aspx?newsid=2531
http://journal.mycom.co.jp/news/2006/05/23/403.html
Conroe E6600�@�Ɓ@�yAM2 FX62�z�̃x���`��r
http://www.hexus.net/content/item.php?item=5692&page=3
Pentium 4/D�u�����h�̑������ɏo��Intel��CPU���i�헪
http://pc.watch.impress.co.jp/docs/2006/0531/kaigai274.htm
�uCore Duo�v�V���[�Y�̑啝���i����
http://akiba.ascii24.com/akiba/news/2006/05/27/662481-000.html
Conroe�Ɣ�r���Ȃ����Ƃ�������AM2���r���[�L�b�g��݂��o��AMD
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2762&p=12
���n�ɗ������ꂽAMD�̋ꂵ���������\��
http://pc.watch.impress.co.jp/docs/2006/0524/amd.htm
�@�@������AMD�ƃA�����ǂ���
�@�@���ׂĂ̐���ɂ����Č�ނ�����B
�@�@�������G�̖h�q���˔j���A�z����쒀���鎞���I
�@�@��X�ɂ͂��̗͂�����B
�@�@�鍑�͍���x���ƍċ��̓���҂���тĂ���B�i�ߓ��u��I
�P�P�P�P�P�P�P�P�P�P�P�P��/�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P
�@�@�@�@�@�@�@�@�@�@�@�@�@�@����
�@�@�@�@�@�@�@�@�@�@�@�@�@ �i�E�́E�j�@�@�@
�@�@�@�@�@�@�@�@�@�@�@�@�@�iCore2�@
�@�@�@�@�@�@�@�@�@�@�@�@�@�b�@�@�b�@�@
�@�@�@�@�@�@�@�@�@�@�@���P�P�P�P�P�P��
�@�@�@�@�@�@�@�@�@�@ �b �@Intel�@�@�@.�b
�@�@�@�@�@�@�@�@�@�@ �b�@�@ �@�@�@�@ .�b
�@ �����@�@ �����@�@ �����@�@ �����@�@ �����@�@ ����
�@�i �@�@�j�@ �i �@�@�j�@ �i �@�@�j�@ �i �@�@�j�@ �i �@�@�j�@ �i �@�@�j
�@�@ �����@�@ �����@�@ �����@�@ �����@�@ �����@�@ ����
�@�@�i �@�@�j�@ �i �@�@�j�@ �i �@�@�j�@ �i �@�@�j�@ �i �@�@�j�@ �i �@�@�j
���|�I���\�E���|�I�ቿ�i��Conroe
http://www.anandtech.com/tradeshows/showdoc.aspx?i=2716&p=6
http://www.dailytech.com/article.aspx?newsid=2531
http://journal.mycom.co.jp/news/2006/05/23/403.html
Conroe E6600�@�Ɓ@�yAM2 FX62�z�̃x���`��r
http://www.hexus.net/content/item.php?item=5692&page=3
Pentium 4/D�u�����h�̑������ɏo��Intel��CPU���i�헪
http://pc.watch.impress.co.jp/docs/2006/0531/kaigai274.htm
�uCore Duo�v�V���[�Y�̑啝���i����
http://akiba.ascii24.com/akiba/news/2006/05/27/662481-000.html
Conroe�Ɣ�r���Ȃ����Ƃ�������AM2���r���[�L�b�g��݂��o��AMD
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2762&p=12
���n�ɗ������ꂽAMD�̋ꂵ���������\��
http://pc.watch.impress.co.jp/docs/2006/0524/amd.htm
?
���戳�k�Z�p�̒��Ƀx�N�g���\���͂��邯�ǁAn�t���[����n+1�t���[���̌덷�肵�Ă��̌��ʂ�
n+m�t���[���ɂ����Ă͂߂Ă݂悤���������ŁA�����̓X�J���̌v�Z�Ȃ�Ȃ����Ȃ�
���戳�k�Z�p�̒��Ƀx�N�g���\���͂��邯�ǁAn�t���[����n+1�t���[���̌덷�肵�Ă��̌��ʂ�
n+m�t���[���ɂ����Ă͂߂Ă݂悤���������ŁA�����̓X�J���̌v�Z�Ȃ�Ȃ����Ȃ�
http://japan.cnet.com/column/interview/story/0,2000056426,20097277-3,00.htm
���̐��E�ŁA�������ꂷ�����n�[�h�E�F�A�ɑ傫�Ȗ���������Ƃ͎v���܂���B
�����́A���܂��܂Ȃ��Ƃ��s����ėp�ړI�̃n�[�h�E�F�A�ɒ��͂�������
�K�v������܂��BCray��Thinking Machines�ȂǁA�Ȋw�Z�p�v�Z�ɓ�������
�n�[�h�E�F�A���\�z���āA���ƂɎ��s������͐���������܂��B
���̐��E�ŁA�������ꂷ�����n�[�h�E�F�A�ɑ傫�Ȗ���������Ƃ͎v���܂���B
�����́A���܂��܂Ȃ��Ƃ��s����ėp�ړI�̃n�[�h�E�F�A�ɒ��͂�������
�K�v������܂��BCray��Thinking Machines�ȂǁA�Ȋw�Z�p�v�Z�ɓ�������
�n�[�h�E�F�A���\�z���āA���ƂɎ��s������͐���������܂��B
���N���b�N�ᔻ��낷
�n�[�h�G���R�͔ėp���Ɍ�����B
�݂�Ȃ��~�����̂�WMV�̃n�[�h�G���R�Ȃ̂Ƀ}�C�N���\�t�g�͂���������Ȃ�������B
(�n�[�h�Ŏ����\���ǂ����͒m��Ȃ��A���ǃL���v�`���J�[�h��CPU�ςގ��ɂȂ邩����)
�R�[�f�b�N�̃o�[�W�������T�P�ʂ�������B
��ʓI�Ɏg���镪�����ł����ꂾ���p���[���[�^����������
ttp://www.nurs.or.jp/~calcium/wiki/index.php?ffmpeg%20usage
�����̃R�[�f�b�N����������
http://murashima.net/rio/ffmpeg/ffmpeg-doc.html
������v���O���}�u���Ɏg����G���R�p�R�v���Z�b�T�B
�x���`�}�j�A�͖�������Ɩ{���ɐ��\���K�v�ȃj�[�Y�ŃG���R�͑傫���B
�l�b�g��[���Ȃ�penIII�ŏ\�������B
�݂�Ȃ��~�����̂�WMV�̃n�[�h�G���R�Ȃ̂Ƀ}�C�N���\�t�g�͂���������Ȃ�������B
(�n�[�h�Ŏ����\���ǂ����͒m��Ȃ��A���ǃL���v�`���J�[�h��CPU�ςގ��ɂȂ邩����)
�R�[�f�b�N�̃o�[�W�������T�P�ʂ�������B
��ʓI�Ɏg���镪�����ł����ꂾ���p���[���[�^����������
ttp://www.nurs.or.jp/~calcium/wiki/index.php?ffmpeg%20usage
�����̃R�[�f�b�N����������
http://murashima.net/rio/ffmpeg/ffmpeg-doc.html
������v���O���}�u���Ɏg����G���R�p�R�v���Z�b�T�B
�x���`�}�j�A�͖�������Ɩ{���ɐ��\���K�v�ȃj�[�Y�ŃG���R�͑傫���B
�l�b�g��[���Ȃ�penIII�ŏ\�������B
�Ȋw�Z�p���Z�ɓ������āA�����v�Z�G���W���Ɠ������������Ă�̂���
�܂��܂�GPU��CPU�̊_�����Ⴍ�Ȃ�ȁc
�܂��܂�GPU��CPU�̊_�����Ⴍ�Ȃ�ȁc
�L�O���
�������A�y�O4��MP3�����ł�����ȁB
�����ō��z�͑S��Xvid(CBR)+MP3�œ��ꂵ�Ă�B
�����ō��z�͑S��Xvid(CBR)+MP3�œ��ꂵ�Ă�B
���l���Ƌ��������܂�Ȃ����炾�߂ۂ�
���l�����݊����A������苤��(�I�[�v���\�[�X��)�̕������[�U�ɂ͗��_�������
526 �F�{�� ��Rb.XJ8VXow �F2006/06/02(��) 16:23:52 ID:C2kKmxCT
�Ƃ������A���ʂɃ_������?
> ttp://pc.watch.impress.co.jp/docs/2006/0602/hot431.htm
> �ߋ���Weitek�Ȃǂ����������ɏo���āA���̂悤�ȃR�v���Z�b�T�́A�ꎞ�I�ɂ͐������Ă��A���j�I�ɂ͐������Ă��Ȃ��A
> �Ƃ̎��₪�o���ꂽ�B�������́A��������قǂ̃R�v���Z�b�T�Ȃ�A���[�A�̖@���ɂ�肻�̋@�\���v���Z�b�T�����Ɏ�荞�܂�Ă��܂����Ƃ��Ӗ����Ă���B
> HTX�X���b�g�Ɣėp�̊g���X���b�g�A���ɍ����\�X���b�g�ł���PCI Express x16��x8�̃X���b�g��HTX�X���b�g����������\�����߂Ă��邱�ƂɋC�Â��B
> ����AMD�̂����悤��HTX�X���b�g�������\�Ȃ̂ł���A�O���t�B�b�N�X�J�[�h��PCI Express x16���HTX�X���b�g�Ɏg���������ǂ��̂ł͂Ȃ����A�Ƃ����ӌ������R�o�Ă���n�Y���B
> ttp://pc.watch.impress.co.jp/docs/2006/0602/hot431.htm
> �ߋ���Weitek�Ȃǂ����������ɏo���āA���̂悤�ȃR�v���Z�b�T�́A�ꎞ�I�ɂ͐������Ă��A���j�I�ɂ͐������Ă��Ȃ��A
> �Ƃ̎��₪�o���ꂽ�B�������́A��������قǂ̃R�v���Z�b�T�Ȃ�A���[�A�̖@���ɂ�肻�̋@�\���v���Z�b�T�����Ɏ�荞�܂�Ă��܂����Ƃ��Ӗ����Ă���B
> HTX�X���b�g�Ɣėp�̊g���X���b�g�A���ɍ����\�X���b�g�ł���PCI Express x16��x8�̃X���b�g��HTX�X���b�g����������\�����߂Ă��邱�ƂɋC�Â��B
> ����AMD�̂����悤��HTX�X���b�g�������\�Ȃ̂ł���A�O���t�B�b�N�X�J�[�h��PCI Express x16���HTX�X���b�g�Ɏg���������ǂ��̂ł͂Ȃ����A�Ƃ����ӌ������R�o�Ă���n�Y���B
>>523
�������ʼn]����H.264�̎������Ǝv���B
�������ʼn]����H.264�̎������Ǝv���B
�����̂����PC����H264��15�����炢�̓���G���R����̂�3���Ԃ��炢�����邨�E�E�E
���̃R�v�������R���t�B�M���A�u���ō����Ă̂͂ǂ���B
�g�����W�X�^�����͂�∫���Ȃ邪�A�ėp���Ə����\�͂������o�����������B
�g�����W�X�^�����͂�∫���Ȃ邪�A�ėp���Ə����\�͂������o�����������B
����Ȃ�Ăc�r�o�H
�l�r�����x����āA�������b�o�t������Ă��������̂ɂ�
�l�r�����x����āA�������b�o�t������Ă��������̂ɂ�
http://pc.watch.impress.co.jp/docs/2005/0506/gyokai122.htm
�\�j�[���J������VME�́A�u���R���t�B�M���A�u��(�č\��)�Z�p�v���̗p�B����ɂ���āA�o���̖��_�����������̂ł���B
�@VME�ł́A�����̉�H���j�b�g�̐ڑ��\���ƁA����ݒ���A���ꂼ��\�t�g�E�F�A�ɂ���ĕύX���邱�Ƃ��\�Ƃ��A��p
�n�[�h�E�F�A�Ŗ��ƂȂ��Ă����A�@�\���Ƃɉ�H��v����Ƃ����_��s�v�Ƃ����ق��AVME��CPU��1�`�b�v�����邱�ƂŁA
VME���A���R���t�B�M���A�u���Z�p�ɂ���čœK��p��H�ɕϐg���Ȃ���A�d�͂�H���d�����䕔���������I�ɒS�����A����
����ŁA�d�͂�H��Ȃ��悤�Ȍy�����䕔����CPU���S�����邱�ƂŁA�S�̓I�Ȓ����d�͉��ɐ������Ă���B
�\�j�[���J������VME�́A�u���R���t�B�M���A�u��(�č\��)�Z�p�v���̗p�B����ɂ���āA�o���̖��_�����������̂ł���B
�@VME�ł́A�����̉�H���j�b�g�̐ڑ��\���ƁA����ݒ���A���ꂼ��\�t�g�E�F�A�ɂ���ĕύX���邱�Ƃ��\�Ƃ��A��p
�n�[�h�E�F�A�Ŗ��ƂȂ��Ă����A�@�\���Ƃɉ�H��v����Ƃ����_��s�v�Ƃ����ق��AVME��CPU��1�`�b�v�����邱�ƂŁA
VME���A���R���t�B�M���A�u���Z�p�ɂ���čœK��p��H�ɕϐg���Ȃ���A�d�͂�H���d�����䕔���������I�ɒS�����A����
����ŁA�d�͂�H��Ȃ��悤�Ȍy�����䕔����CPU���S�����邱�ƂŁA�S�̓I�Ȓ����d�͉��ɐ������Ă���B
http://pc.watch.impress.co.jp/docs/2006/0508/drc.htm
���ꂶ�Ⴂ����̂��H
���ꂶ�Ⴂ����̂��H
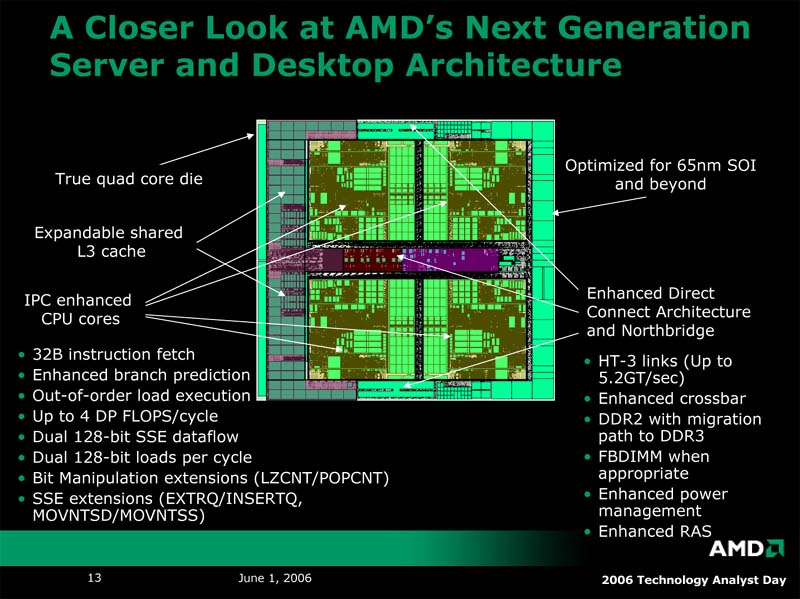{kind=link}
�_���������E�E�E���ɂ��邵�ȁB��HTX���ڃ}�U�[
ttp://www.iwill.net/product_2.asp?p_id=98&sp=Y
���ł�HT-Link��InfiniBand�������Ă�̂�����B
ttp://www.iwill.net/product_2.asp?p_id=24&sp=Y
(DK8S2-IB)
ttp://www.iwill.net/product_2.asp?p_id=98&sp=Y
���ł�HT-Link��InfiniBand�������Ă�̂�����B
ttp://www.iwill.net/product_2.asp?p_id=24&sp=Y
(DK8S2-IB)
>>533
CoreArchitecture�Ō���Memory Disambiguation�݂����Ȃ���炵���B
CoreArchitecture�Ō���Memory Disambiguation�݂����Ȃ���炵���B
�@���������R�v���Z�b�T�������Ɏ�荞�܂��ƌ������Ƃ́AGPU�������I�ɂ�CPU�Ɏ�荞�ނƂ������ƁH
>>535
�ǂ���� Memory Disambiguation �Ƃ͈Ⴄ�݂����B
http://www.aceshardware.com/forums/read_post.jsp?id=115164546&forumid=1
Johan wrote:
> We have to see whether or not AMD's OOO loads is limited to loads being able to pass other loads,
> or this is full OOO loads + mem disamb. If it is the latter, 5-10% will be even conservative.
According to C't, AMD implemented the former, and not memory disambiguation as Intel did in Core 2.
�ǂ���� Memory Disambiguation �Ƃ͈Ⴄ�݂����B
http://www.aceshardware.com/forums/read_post.jsp?id=115164546&forumid=1
Johan wrote:
> We have to see whether or not AMD's OOO loads is limited to loads being able to pass other loads,
> or this is full OOO loads + mem disamb. If it is the latter, 5-10% will be even conservative.
According to C't, AMD implemented the former, and not memory disambiguation as Intel did in Core 2.
539 �F�{�� ��Rb.XJ8VXow �F2006/06/02(��) 23:52:15 ID:C2kKmxCT
>>533
���@���[�h���낤�AConroe�̂����܂˂������������ǂ��܂Ŗ͎ʏo�������͔������B
���@���[�h���낤�AConroe�̂����܂˂������������ǂ��܂Ŗ͎ʏo�������͔������B
>520
BluRay, HD-DVD �� VC1 �̗p���ꂽ���獡���
�n�[�h�G���R�[�_�`�b�v���r�V�o�V�o�ꂷ��ł� > WMV
BluRay, HD-DVD �� VC1 �̗p���ꂽ���獡���
�n�[�h�G���R�[�_�`�b�v���r�V�o�V�o�ꂷ��ł� > WMV
2006 Technology Analyst Day
http://www.amd.com/us-en/Corporate/InvestorRelations/0,,51_306_14047,00.html
AMD�̃A�i���X�g�f�C�̎����͂������痎�Ƃ��܂��B
http://www.amd.com/us-en/Corporate/InvestorRelations/0,,51_306_14047,00.html
AMD�̃A�i���X�g�f�C�̎����͂������痎�Ƃ��܂��B
��邶���
>>518
--���̂悤�ȃX�s�[�h(�|4,5GHz�|)��(�p�C�v���C�����ێ������܂�)�ǂ�����Ď�������̂ł��傤���B
>�@���ꂱ���ABrian Curran�iISSCC�Ŕ��\����IBM��4GHz�`�b�v�Ɋւ���_���̎咘�ҁj��
> ���炩�ɂ������Ƃł��B�p�C�v���C���̃X�e�[�W�����ێ�����Ȃ�A�e�X�e�[�W�̘_��
> ��H�����ɂ���K�v������܂��B�����͌��ǁA��H��2�{�A3�{�̎d����������
> ���A��A�̃g�����W�X�^�ɕ����̋@�\�����蓖�ĂȂ���Ȃ�܂���ł����B����ɂ����
> ���b�`�Ԃ̃Q�[�g�x�����ɂł������̂́A����ɉ�H�ɉ��ǂ�������K�v������܂����B
--���̂悤�ȃX�s�[�h(�|4,5GHz�|)��(�p�C�v���C�����ێ������܂�)�ǂ�����Ď�������̂ł��傤���B
>�@���ꂱ���ABrian Curran�iISSCC�Ŕ��\����IBM��4GHz�`�b�v�Ɋւ���_���̎咘�ҁj��
> ���炩�ɂ������Ƃł��B�p�C�v���C���̃X�e�[�W�����ێ�����Ȃ�A�e�X�e�[�W�̘_��
> ��H�����ɂ���K�v������܂��B�����͌��ǁA��H��2�{�A3�{�̎d����������
> ���A��A�̃g�����W�X�^�ɕ����̋@�\�����蓖�ĂȂ���Ȃ�܂���ł����B����ɂ����
> ���b�`�Ԃ̃Q�[�g�x�����ɂł������̂́A����ɉ�H�ɉ��ǂ�������K�v������܂����B
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2748&p=6
> Finally, there is also a lot of headroom for increasing integer performance.
> The fact that Loads can hardly be reordered has been a known weak point
> since the early K7 days. In fact, we know that engineers at AMD were well
> aware of it then, and it is surprising that AMD didn't really fix this in the K8 architecture.
> Allowing a much more flexible reordering of Loads - even without memory disambiguation
> - would give a very healthy boost to IPC (5% and more). It is one of the main
> reasons why the P-M can beat the Athlon 64 clock-for-clock in certain applications.
�ނނށD�D�D
> Finally, there is also a lot of headroom for increasing integer performance.
> The fact that Loads can hardly be reordered has been a known weak point
> since the early K7 days. In fact, we know that engineers at AMD were well
> aware of it then, and it is surprising that AMD didn't really fix this in the K8 architecture.
> Allowing a much more flexible reordering of Loads - even without memory disambiguation
> - would give a very healthy boost to IPC (5% and more). It is one of the main
> reasons why the P-M can beat the Athlon 64 clock-for-clock in certain applications.
�ނނށD�D�D
�R�v���Z�b�T�J���v�悾�����ł��B
���A���^�C���E�C���X�X�L�����Ƃ����ׂ������Ă����Ɗy���ȁB
www.itmedia.co.jp/news/articles/0606/02/news023.html
���A���^�C���E�C���X�X�L�����Ƃ����ׂ������Ă����Ɗy���ȁB
www.itmedia.co.jp/news/articles/0606/02/news023.html
�R�v���̕��ɖڂ��������ǁA���C����HT���y�Ȃ낤��
���߂���o�������Ƃ��������B
�C���e���Ɠ������Ƃ��Ă��畉���Ȃ͕̂����肫���Ă邩��
������������I�Ȃ̂͂����Ǝv�����B�O��͌����I�Ȏ����
�悭�m��������Ƀ_����������̂͂����̂��Ƃ����ȁB
������������I�Ȃ̂͂����Ǝv�����B�O��͌����I�Ȏ����
�悭�m��������Ƀ_����������̂͂����̂��Ƃ����ȁB
>>532
���̂����̌�940�\�P�b�g���}���̍\���ɂ��ẮAAMD�̔��\�ɓ����Ė�����Ȃ��B
�܂������̂����̂܂g���āAAMD��CPU�Ƃ��Ē��ڊJ���Ɋ֗^����]�n����������������
�̂��낤���B
������ɂ��Ă��A�\���ύX�ɂ����鎞�ԂƏ���d�́A�y�ѓ��쑬�x���ǂ��Ȃ邩���̂��ȁB
���炭�}���`�^�X�N�Ή��őf�����_�C�i�~�b�N�ɍ\���ύX�̓����|���낤����A�f�X�N�g�b�v
�����ɂ͓�����낤�B
�������uJava�AXML�A�x�N�^�A�Z�L�����e�B�v�̂�����̗p�r�ɍ\���ݒ肷�邩�A���ה����
���Ȃ��Ƒʖڂ�����A�����̏������������ňꊇ�Ǘ�����l�ɁA�n�r���̓~�h���E�G�A����
��ŏ������Ȃ��Ƒʖڂ�����A�T�[�o�[�p�r����ň�ʃ��[�U�[�ɂ͖������낤���B
�܂��A�uJava�AXML�A�x�N�^�A�Z�L�����e�B�v�̂����ꂩ�̊g���J�[�h���A�W���ő�������Ă�
�ƍl����A�n�r�̐ݒ�łǂꂩ�����[�U�[�ɑI������Ă̂͗L�邩������ǁB
���̂����̌�940�\�P�b�g���}���̍\���ɂ��ẮAAMD�̔��\�ɓ����Ė�����Ȃ��B
�܂������̂����̂܂g���āAAMD��CPU�Ƃ��Ē��ڊJ���Ɋ֗^����]�n����������������
�̂��낤���B
������ɂ��Ă��A�\���ύX�ɂ����鎞�ԂƏ���d�́A�y�ѓ��쑬�x���ǂ��Ȃ邩���̂��ȁB
���炭�}���`�^�X�N�Ή��őf�����_�C�i�~�b�N�ɍ\���ύX�̓����|���낤����A�f�X�N�g�b�v
�����ɂ͓�����낤�B
�������uJava�AXML�A�x�N�^�A�Z�L�����e�B�v�̂�����̗p�r�ɍ\���ݒ肷�邩�A���ה����
���Ȃ��Ƒʖڂ�����A�����̏������������ňꊇ�Ǘ�����l�ɁA�n�r���̓~�h���E�G�A����
��ŏ������Ȃ��Ƒʖڂ�����A�T�[�o�[�p�r����ň�ʃ��[�U�[�ɂ͖������낤���B
�܂��A�uJava�AXML�A�x�N�^�A�Z�L�����e�B�v�̂����ꂩ�̊g���J�[�h���A�W���ő�������Ă�
�ƍl����A�n�r�̐ݒ�łǂꂩ�����[�U�[�ɑI������Ă̂͗L�邩������ǁB
>>549
�\���ύX���ĉ��H
�\���ύX���ĉ��H
>>550
�n�[�h�E�G�A��H�������������āA�ʁX�̗p�r�Ɏg�����Ď��B���L�Q�ƁB
>>532
�bXilinx��FPGA(Field Programmable Gate Aray)�uVirtex4�v���g�p���A�����̉�H���č\���ł��邽�߁A
�b���܂��܂ȗp�r�ɉ��p�ł���B
�n�[�h�E�G�A��H�������������āA�ʁX�̗p�r�Ɏg�����Ď��B���L�Q�ƁB
>>532
�bXilinx��FPGA(Field Programmable Gate Aray)�uVirtex4�v���g�p���A�����̉�H���č\���ł��邽�߁A
�b���܂��܂ȗp�r�ɉ��p�ł���B
FPGA�̕�����Ղ�����Ȃ�A������ŁB
http://plusd.itmedia.co.jp/mobile/articles/0505/09/news052.html
�bPLD�Ƃ́A�\�t�g�E�G�A�ʼn�H��v���邱�Ƃ��\�ȃv���Z�b�T�S�ʂ��w���BFPGA��PLD��1���SRAM���
�b��H��W�J���A�d���N�����ɖ����H�f�[�^�����[�h����d�g�݂ƂȂ��Ă���BCyclone�ł́AVHDL
�b�iVery High-speed integrated circuit Hard-ware Description Language�j�Ƃ����n�[�h�E�F�A�L�q����
�b��p���ē��������������邱�ƂŁA�n�[�h�E�F�A�̃G�~�����[�V�������s�����Ƃ��\�Ȃ��̂ŁA�����
�b1�`�b�vMSX�ł́AMSX�K�i�̏������f���ƂȂ�uMSX1�v�����̃n�[�h�E�G�A���G�~�����[�V�����ōČ�����B
http://plusd.itmedia.co.jp/mobile/articles/0505/09/news052.html
�bPLD�Ƃ́A�\�t�g�E�G�A�ʼn�H��v���邱�Ƃ��\�ȃv���Z�b�T�S�ʂ��w���BFPGA��PLD��1���SRAM���
�b��H��W�J���A�d���N�����ɖ����H�f�[�^�����[�h����d�g�݂ƂȂ��Ă���BCyclone�ł́AVHDL
�b�iVery High-speed integrated circuit Hard-ware Description Language�j�Ƃ����n�[�h�E�F�A�L�q����
�b��p���ē��������������邱�ƂŁA�n�[�h�E�F�A�̃G�~�����[�V�������s�����Ƃ��\�Ȃ��̂ŁA�����
�b1�`�b�vMSX�ł́AMSX�K�i�̏������f���ƂȂ�uMSX1�v�����̃n�[�h�E�G�A���G�~�����[�V�����ōČ�����B
>>551
�b�̗��ꂪ�����ĂȂ������B���܂�
�b�̗��ꂪ�����ĂȂ������B���܂�
AMD������CPU��Free Lunch�Ɋ��҂��Ă݂�e�X�g
�R�A���Ƃ�C'n'Q����̂��B�y���݂�
PLD��Programmable Logic Device
FPGA��Field Programmable Gate Array
���W�b�N��H�����������\�ȃf�o�C�X�̂��ƁB
FPGA��Field Programmable Gate Array
���W�b�N��H�����������\�ȃf�o�C�X�̂��ƁB
http://www.aceshardware.com/SPECmine/index.jsp?b=0&s=1&v=1&if=0&ncf=1&nct=256&cpcf=1&cpct=2&mf=200&mt=3800&o=0&o=1&start=20
Woodcrest�̈����Ԃ�ɂ́c(;�L�D�M)
Woodcrest�̈����Ԃ�ɂ́c(;�L�D�M)
>>558
�����V���O���R�A�E�V���O��CPU����炢����B
chips cores
�@�@2 �@�@ 4 3000 Xeon 51xx�@�@�@ 3057
�@�@1�@ �@ 1 2800 Opteron�@�@�@�@ 1837
�����V���O���R�A�E�V���O��CPU����炢����B
chips cores
�@�@2 �@�@ 4 3000 Xeon 51xx�@�@�@ 3057
�@�@1�@ �@ 1 2800 Opteron�@�@�@�@ 1837
�@�@2 �@�@ 4 3000 Xeon 51xx�@�@�@ 3057
�@�@1�@ �@ 1 2800 Opteron�@�@�@�@ 1837
�{�ɂ��Ċ��Z���������
�@�@2 �@�@ 4 3000 Xeon 51xx�@�@�@ 3057
�@�@2�@ �@ 2 2800 Opteron�@�@�@�@ 3674
����Ȃӂ��ɍl���Ă���������
���ɂ�����܂���
�@�@1�@ �@ 1 2800 Opteron�@�@�@�@ 1837
�{�ɂ��Ċ��Z���������
�@�@2 �@�@ 4 3000 Xeon 51xx�@�@�@ 3057
�@�@2�@ �@ 2 2800 Opteron�@�@�@�@ 3674
����Ȃӂ��ɍl���Ă���������
���ɂ�����܂���
>>538
> > We have to see whether or not AMD's OOO loads is limited to loads being able to pass other loads,
> > or this is full OOO loads + mem disamb. If it is the latter, 5-10% will be even conservative.
>
> According to C't, AMD implemented the former, and not memory disambiguation as Intel did in Core 2.
����ς肻���ȂBK7,K8�͊eAGU��load,store���p�Ȃ��߂��Astore-load�̃A�h���X�������Ɠ�������
load-load�ł��N�����ˁB�V�R�A�ł����P6�R�A���݂�OOO�ɂȂ��ˁB
> > We have to see whether or not AMD's OOO loads is limited to loads being able to pass other loads,
> > or this is full OOO loads + mem disamb. If it is the latter, 5-10% will be even conservative.
>
> According to C't, AMD implemented the former, and not memory disambiguation as Intel did in Core 2.
����ς肻���ȂBK7,K8�͊eAGU��load,store���p�Ȃ��߂��Astore-load�̃A�h���X�������Ɠ�������
load-load�ł��N�����ˁB�V�R�A�ł����P6�R�A���݂�OOO�ɂȂ��ˁB
�p�C�v���C���A���W�X�^���l�[�~���O�A���@�I���s���̘b�������Ă����Ėʔ����B
http://www.geocities.co.jp/SiliconValley-Bay/9439/negoto/ngt000.htm
http://www.geocities.co.jp/SiliconValley-Bay/9439/negoto/ngt000.htm
>>559
����̓V���O���X���b�h�x���`�Ȃ́B
����̓V���O���X���b�h�x���`�Ȃ́B
��ׂ�SPEC CPU�̌����o�^�X�R�A�ɊԈႢ���������܂��������c(;�L�D�M)
����ǂ��݂Ă�Sossaman����B�܂�������Pentium 4 Xeon��Trace Cache�Ŕ��肳�ꂽ�܂܌����o�^�ʂ��Ă�݂����c(;�L�D�M)
���L�L���b�V����Pen4 LV Xeon�Ȃ�đ��݂��˂��c(;�L�D�M)
IBM��SPEC�̒��̐l���v���c�B
����ǂ��݂Ă�Sossaman����B�܂�������Pentium 4 Xeon��Trace Cache�Ŕ��肳�ꂽ�܂܌����o�^�ʂ��Ă�݂����c(;�L�D�M)
���L�L���b�V����Pen4 LV Xeon�Ȃ�đ��݂��˂��c(;�L�D�M)
IBM��SPEC�̒��̐l���v���c�B
>>559
�ށH
�ށH
�ʂ̃y�[�W��������킩���
�I����ł͂���Ȃ鉿�i�����ɂȂ肻
�������AItanium2���Đ������Z�ւ��ۂ��Ȃ̂�
�m�����
�I����ł͂���Ȃ鉿�i�����ɂȂ肻
�������AItanium2���Đ������Z�ւ��ۂ��Ȃ̂�
�m�����
�Ǝv�����猩�ԈႢ������
������������
������������
�Ȃ}�ɂ��̃X�����Â��ɂȂ����ȁB
AMD��Tech Analyst Day�̏Ռ��I���\�ɕ��S��ԂȂ̂��H
AMD��Tech Analyst Day�̏Ռ��I���\�ɕ��S��ԂȂ̂��H
570 �F�{�� ��Rb.XJ8VXow �F2006/06/05(��) 00:27:46 ID:Z0hc5EI0
AMD���ɉ���D�ޗ��������̂�����Â��ɂȂ�͓̂�����O���Ǝv�����B
�_�[�N�E���C���[�݂��Ȃ߂�ȁA���̖{���߁I
572 �F�{�� ��Rb.XJ8VXow �F2006/06/05(��) 01:14:38 ID:Z0hc5EI0
���߂ĂȂ����ǁA4x4���S�������Ȃ�w
������������AMD�̃`�[���̐����Ăǂ��Ȃ��Ă�낤���H
2�`�[���̐��H
2�`�[���̐��H
����ǂނƁA2003�N10���܂ł͂Q�`�[���̐����������A
����ȍ~�͂킩��Ȃ��悤���B
http://pc.watch.impress.co.jp/docs/2006/0119/kaigai233.htm
��͂�Intel�ƃ^���͂�ɂ́A�Q�`�[���̐��ŃR�A�������Ă����Ȃ��Ă͂Ȃ��̂ł͂Ȃ����낤��
����ȍ~�͂킩��Ȃ��悤���B
http://pc.watch.impress.co.jp/docs/2006/0119/kaigai233.htm
��͂�Intel�ƃ^���͂�ɂ́A�Q�`�[���̐��ŃR�A�������Ă����Ȃ��Ă͂Ȃ��̂ł͂Ȃ����낤��
����Ƃ��v���Z�X���[���̃n���f�L���b�v������낤���H
577 �F�{�� ��Rb.XJ8VXow �F2006/06/05(��) 02:47:14 ID:Z0hc5EI0
AMD���̓����R���Ή��ɂ��Z��������2�`�[������INTEL�ɒǏ]��������?
�������܂�������Ǝ����ŒǏ]�������Ă���
�u�ǐ��v���g���Ȃ��̂��B���������ȁB
�l�g�o�ŃC���e������炩���O�͌��ԎY�Ƃ݂����Ȏe�ׂȋZ�p�I�D�ʂŐ����c���Ă��킯������
���̖؈���ȕ��͋C���Y���Ă��ˁB
���̖؈���ȕ��͋C���Y���Ă��ˁB
582 �F�{�� ��Rb.XJ8VXow �F2006/06/05(��) 05:58:29 ID:Z0hc5EI0
INTEL�̃}�l�������Ă����B
������Ǐ]�Ő�����
������Ǐ]�Ő�����
�^��������Ȃ�ĈӖ��͖������B
�挊�@���ł����悗
�挊�@���ł����悗
584 �F�{�� ��Rb.XJ8VXow �F2006/06/05(��) 09:59:45 ID:Z0hc5EI0
�挊�@���Ă�̂͂��O��A���~����Ȃ��̂�?
Rev.H�œ��@���[�h�炵�����ڂ����Ċ��ł�����A���ꂪ���́E�E�E�E�v�v
�����P6���x���ɂȂ邾���̂���?
�킹��Ȃ��w
Rev.H�œ��@���[�h�炵�����ڂ����Ċ��ł�����A���ꂪ���́E�E�E�E�v�v
�����P6���x���ɂȂ邾���̂���?
�킹��Ȃ��w
Intel�́AAMD�����悵��x86��64bit���̌����J�����Ă��ꂽ��ŁA
x86-64�̌����J����������ˁB
�{���ɂ悩�����ˁB
x86-64�̌����J����������ˁB
�{���ɂ悩�����ˁB
586 �F�{�� ��Rb.XJ8VXow �F2006/06/05(��) 10:38:26 ID:GwRjlV6T
�������ˁ�
slashdot�ɂ������ȁB
Previewing the Performance of the Intel Conroe
http://hardware.slashdot.org/hardware/06/06/04/1710229.shtml
�ǂ��炩�Ƃ����ƌ��݂�AMD�́A�}���`�R�A���d�����Ă�悤�Ɏv����B
�ŁAIntel�����̊Ԍ�������Conroe�𓊓������Ƃ������Ƃ��B
(�Ă������AIntel��AMD�̐l�I���\�[�X�̍����o�Ă��Ă�̂��ȁH)
Previewing the Performance of the Intel Conroe
http://hardware.slashdot.org/hardware/06/06/04/1710229.shtml
�ǂ��炩�Ƃ����ƌ��݂�AMD�́A�}���`�R�A���d�����Ă�悤�Ɏv����B
�ŁAIntel�����̊Ԍ�������Conroe�𓊓������Ƃ������Ƃ��B
(�Ă������AIntel��AMD�̐l�I���\�[�X�̍����o�Ă��Ă�̂��ȁH)
>>585
����͈Ⴄ��B
�C���e����AMD�ɑR���ēƎ���64�̊J����i�߂Ă������ǃ}�C�N���\�t�g����AMD�ƌ݊��ɂ��Ȃ��Ȃ�
�����C���e���̓T�|�[�g���Ȃ��Ɛ鍐���ꂽ�B
�}�C�N���\�t�g�ɂ��Ă݂�ΈႤ�d�l�̓��CPU�p�ɓ��windows���J������Ȃ�Ă��肦�Ȃ��B
itanium�̏�Ȃ���windows�ł�������ƌ��\�h���C�ȊW�Ȃ̂�ˁB
����͈Ⴄ��B
�C���e����AMD�ɑR���ēƎ���64�̊J����i�߂Ă������ǃ}�C�N���\�t�g����AMD�ƌ݊��ɂ��Ȃ��Ȃ�
�����C���e���̓T�|�[�g���Ȃ��Ɛ鍐���ꂽ�B
�}�C�N���\�t�g�ɂ��Ă݂�ΈႤ�d�l�̓��CPU�p�ɓ��windows���J������Ȃ�Ă��肦�Ȃ��B
itanium�̏�Ȃ���windows�ł�������ƌ��\�h���C�ȊW�Ȃ̂�ˁB
>>588
���ۂ̗���͂��������ǁA����Intel�������������ɂ��Čv������s�����ɍςƂ������Ɏv���Ȃ����Ȃ��B
���ۂ̗���͂��������ǁA����Intel�������������ɂ��Čv������s�����ɍςƂ������Ɏv���Ȃ����Ȃ��B
���̕ӂ̈�b�͌�X�{�ɂȂ肻�������
MS�̂Ƃ���v���O���}�[���܂�������������悤����
MS�̂Ƃ���v���O���}�[���܂�������������悤����
592 �FMAC�I�^��591 �����F2006/06/05(��) 22:08:54 ID:+yg8ADA4
>>591
���������b�����邷��B
http://itpro.nikkeibp.co.jp/free/NT/WinInterview/20040621/1/
�@�@------------------------------
�@�@�mMuglia�n���₠�C���͂����͎v���܂���B�ł������ǂ����Ă����v������������܂����H
�@�@Dave�̂����ł��B
�@�@�\�\�\�\Windows NT���J������David Cutler�i�f�r�b�h�E�J�g���[�j���ł��ˁB
�@�@�mMuglia�n�����CDave�͂܂���AMD64�ɂ�����邠���鏊�ɂ��܂����BDave�͂��̃`�b�v��
�@�@�v�ƁC���ɖ��ڂ��Ďd�������܂����B�ނ͖{���Ɍ݊�����������̂���낤�Ƃ��Ă��܂����B
�@�@�����āC����ꂪ�����Ă�����́C���������A�v���P�[�V���������ׂđ����I�ɃT�|�[
�@�@�g�������Ƃ������Ƃł��B�����̃`�b�v�͂��������ړI�̂��߂ɂ́C�܂��ɑł��ĕt���ł��B
�@�@------------------------------
���������b�����邷��B
http://itpro.nikkeibp.co.jp/free/NT/WinInterview/20040621/1/
�@�@------------------------------
�@�@�mMuglia�n���₠�C���͂����͎v���܂���B�ł������ǂ����Ă����v������������܂����H
�@�@Dave�̂����ł��B
�@�@�\�\�\�\Windows NT���J������David Cutler�i�f�r�b�h�E�J�g���[�j���ł��ˁB
�@�@�mMuglia�n�����CDave�͂܂���AMD64�ɂ�����邠���鏊�ɂ��܂����BDave�͂��̃`�b�v��
�@�@�v�ƁC���ɖ��ڂ��Ďd�������܂����B�ނ͖{���Ɍ݊�����������̂���낤�Ƃ��Ă��܂����B
�@�@�����āC����ꂪ�����Ă�����́C���������A�v���P�[�V���������ׂđ����I�ɃT�|�[
�@�@�g�������Ƃ������Ƃł��B�����̃`�b�v�͂��������ړI�̂��߂ɂ́C�܂��ɑł��ĕt���ł��B
�@�@------------------------------
593 �FMAC�I�^���⑫�F2006/06/05(��) 22:29:11 ID:+yg8ADA4
���Ȃ݂Ɍ��̋L���"Local Memory"��LS�̂��Ƃ��Ɛ����Ă�q�g������݂��������Ǥ
���炩��VRAM�̂��Ƃ��B
�@�@------------------------
�@�@The next slide goes on to say "Don't read from local memory, but write to main memory
�@�@with RSX(tm) and read it from there instead",
�@�@------------------------
�v����ɤCell����VRAM��ǂނƃG�������ƂɂȂ��ŤRSX�������ă��C�������� (XDR)��
��U�����o���������c��ǂݍ��߁B�B�B�Ƃ�����������VRAM�ł��邱�Ƃ����邷�B
���炩��VRAM�̂��Ƃ��B
�@�@------------------------
�@�@The next slide goes on to say "Don't read from local memory, but write to main memory
�@�@with RSX(tm) and read it from there instead",
�@�@------------------------
�v����ɤCell����VRAM��ǂނƃG�������ƂɂȂ��ŤRSX�������ă��C�������� (XDR)��
��U�����o���������c��ǂݍ��߁B�B�B�Ƃ�����������VRAM�ł��邱�Ƃ����邷�B
��̂��������Ƃ����딚��(��)�@���ĤAnalyst Day�̘b�肷���Ǥ���ǂ̂Ƃ���K8L��
�@�EL2�팸�ʁB
�@�EFPU������Core2�Ɠ����x
���Ă��ƂŤ���\�I�ɑ傫�Ȋ��҂����ĂȂ����Ƃ��������炩�ɂȂ������B�����u4x4��̕���
x86�v���Z�b�T�x���_�̃r�W�l�X���f����h�邪����������Ȃ����ˁB�B�B
��������x86�v���Z�b�T�s��ُ̈�Ȃ̂�un-way�Ńv���Z�b�T����������قǒP�����オ��
�Ƃ����_���B���ɊF�����d�r�ł������ɍs���Ƃ��Ĥ8�p�b�N�Ŕ����ƒP���������Ȃ�Ĕ[��
�ł��邷���H�{�����i�ł���v���Z�b�T�����R�����قǒP���������Ȃ��Ĥn-way���T�|�[�g����
�}�U�[�{�[�h�Ȃ�V�X�e���������Ȃ�ɍ����ɂȂ�Ƃ����̂����R�Ȃ��肩�����B
�@�EL2�팸�ʁB
�@�EFPU������Core2�Ɠ����x
���Ă��ƂŤ���\�I�ɑ傫�Ȋ��҂����ĂȂ����Ƃ��������炩�ɂȂ������B�����u4x4��̕���
x86�v���Z�b�T�x���_�̃r�W�l�X���f����h�邪����������Ȃ����ˁB�B�B
��������x86�v���Z�b�T�s��ُ̈�Ȃ̂�un-way�Ńv���Z�b�T����������قǒP�����オ��
�Ƃ����_���B���ɊF�����d�r�ł������ɍs���Ƃ��Ĥ8�p�b�N�Ŕ����ƒP���������Ȃ�Ĕ[��
�ł��邷���H�{�����i�ł���v���Z�b�T�����R�����قǒP���������Ȃ��Ĥn-way���T�|�[�g����
�}�U�[�{�[�h�Ȃ�V�X�e���������Ȃ�ɍ����ɂȂ�Ƃ����̂����R�Ȃ��肩�����B
595 �FMAC�I�^�������F2006/06/05(��) 22:47:09 ID:+yg8ADA4
����ł�Xeon�����{�v��V���O���\�P�b�g�i�Ɠ����Ƃ팾����p�b�P�[�W��L���b�V���\������
�ς��Ĥ����Ȃ�̐����͂��������Ă��������ǤAMD�Ɏ����Ă퓯���_�C������p�b�P�[�W��8-socket
�T�|�[�g�i�Ŗ\�����Â��Ă������B
�Ƃ��낪���\�ɍ�������ꂽ���ʤ�K�ɉ�����AMD��MP�T�|�[�g�̃f�X�N�g�b�v���i��
�����[�X���v�悵�Ă���B
�����Pentium Pro�ȍ~��Intel���c�X�Ƃ��Ēz���Ă����r�W�l�X���f����@����, Dual Celeron��
�������ɂ܂Ŗ߂������Ƃ��������ɂȂ肩�˂Ȃ������Ǥ���[�U�[�ɂƂ��Ă͒��X�ʔ������ƂɂȂ�
�������ˁB
��킭��AMD���挊���@�����Ȃ�Ă��ƂɂȂ炸�ɤ�v���Z�b�T�s�ꂪ���S������Ƃ��������Ɍ���
���Ƃ�����Ă��邷�B
�ς��Ĥ����Ȃ�̐����͂��������Ă��������ǤAMD�Ɏ����Ă퓯���_�C������p�b�P�[�W��8-socket
�T�|�[�g�i�Ŗ\�����Â��Ă������B
�Ƃ��낪���\�ɍ�������ꂽ���ʤ�K�ɉ�����AMD��MP�T�|�[�g�̃f�X�N�g�b�v���i��
�����[�X���v�悵�Ă���B
�����Pentium Pro�ȍ~��Intel���c�X�Ƃ��Ēz���Ă����r�W�l�X���f����@����, Dual Celeron��
�������ɂ܂Ŗ߂������Ƃ��������ɂȂ肩�˂Ȃ������Ǥ���[�U�[�ɂƂ��Ă͒��X�ʔ������ƂɂȂ�
�������ˁB
��킭��AMD���挊���@�����Ȃ�Ă��ƂɂȂ炸�ɤ�v���Z�b�T�s�ꂪ���S������Ƃ��������Ɍ���
���Ƃ�����Ă��邷�B
�v��: Intel�l�o���U�[�C
>>594
>��������x86�v���Z�b�T�s��ُ̈�Ȃ̂�un-way�Ńv���Z�b�T����������قǒP�����オ�� �Ƃ����_���B
�q���g�F�����܂�
>��������x86�v���Z�b�T�s��ُ̈�Ȃ̂�un-way�Ńv���Z�b�T����������قǒP�����オ�� �Ƃ����_���B
�q���g�F�����܂�
�t�����l��l�i�ɓ]�ł��邱�Ƃ͈��ɂȂ�̂��B
�ςȘb���ȁB
�ςȘb���ȁB
599 �FMAC�I�^��597 �����F2006/06/05(��) 23:59:08 ID:+yg8ADA4
>>597
�@�@--------------------
�@�@�q���g�F�����܂�
�@�@--------------------
�}���`�R�A�̘b�ł햳��������������Ƃ���ɂ��Ă��邷�B
http://www.amd.com/us-en/Corporate/VirtualPressRoom/0,,51_104_609,00.html
�@�EAthlon 64 x2 4800+, 2.6GHz, 1MBx2 L2: $645-
�@�EOpteron 280, 2.4GHz, 1MBx2 L2: $851-
�@�EOpteron 880, 2.4GHz, 1MBx2 L2: $1,514-
�@�@--------------------
�@�@�q���g�F�����܂�
�@�@--------------------
�}���`�R�A�̘b�ł햳��������������Ƃ���ɂ��Ă��邷�B
http://www.amd.com/us-en/Corporate/VirtualPressRoom/0,,51_104_609,00.html
�@�EAthlon 64 x2 4800+, 2.6GHz, 1MBx2 L2: $645-
�@�EOpteron 280, 2.4GHz, 1MBx2 L2: $851-
�@�EOpteron 880, 2.4GHz, 1MBx2 L2: $1,514-
600 �FMAC�I�^��598 �����F2006/06/06(��) 00:02:45 ID:A6MRWV5e
>>598
�@�@------------------------
�@�@�t�����l��l�i�ɓ]�ł��邱�Ƃ͈��ɂȂ�̂��B
�@�@------------------------
n-socket�̕t�����l��V�X�e���x���_�̃��m���BIntel���Ɛv�܂ő�s���Ă�̂Ť
���ƈӖ��������Ⴄ�����ǁB�B�B
�@�@------------------------
�@�@�t�����l��l�i�ɓ]�ł��邱�Ƃ͈��ɂȂ�̂��B
�@�@------------------------
n-socket�̕t�����l��V�X�e���x���_�̃��m���BIntel���Ɛv�܂ő�s���Ă�̂Ť
���ƈӖ��������Ⴄ�����ǁB�B�B
>>599
�q���g�F���v�Ƌ����̃o�����X
�q���g�F���v�Ƌ����̃o�����X
602 �FMAC�I�^��601 �����F2006/06/06(��) 00:08:24 ID:A6MRWV5e
>>601
�@�@-------------------
�@�@�q���g�F���v�Ƌ����̃o�����X
�@�@-------------------
���X�O���[�h����K�v���������i�ɤ�o�����X�������������B
���Ȃ���Ԃ̃^�C����O���E�O�E�E�㍶�E��E�ł��ꂼ��^������Č݊����������Ɗ����������H
�@�@-------------------
�@�@�q���g�F���v�Ƌ����̃o�����X
�@�@-------------------
���X�O���[�h����K�v���������i�ɤ�o�����X�������������B
���Ȃ���Ԃ̃^�C����O���E�O�E�E�㍶�E��E�ł��ꂼ��^������Č݊����������Ɗ����������H
>>602
>���X�O���[�h����K�v���������i
���́H
>���Ȃ���Ԃ̃^�C����O���E�O�E�E�㍶�E��E�ł��ꂼ��^������Č݊����������Ɗ����������H
�^�ł͖������ǁA�^�C���̎����ƃ��[�V���O�^�C�����ł�
�O�^�C�����n�[�h�Ō�^�C�����\�t�g�Ƃ��g�ݍ��킹��ł���B
���ƃR�X�g�Ɋւ��Č����Ȃ�AOpteron 880�ɂ����Ă�e�X�g�H���ɂ���ɃR�X�g���������Ă�Ƃ��l�����邯�ǁB
>���X�O���[�h����K�v���������i
���́H
>���Ȃ���Ԃ̃^�C����O���E�O�E�E�㍶�E��E�ł��ꂼ��^������Č݊����������Ɗ����������H
�^�ł͖������ǁA�^�C���̎����ƃ��[�V���O�^�C�����ł�
�O�^�C�����n�[�h�Ō�^�C�����\�t�g�Ƃ��g�ݍ��킹��ł���B
���ƃR�X�g�Ɋւ��Č����Ȃ�AOpteron 880�ɂ����Ă�e�X�g�H���ɂ���ɃR�X�g���������Ă�Ƃ��l�����邯�ǁB
���d�r������CPU�����đ�ʍw������Ɗ���������̂ɉ������Ă낤�˂��̔n���́B
�����Ă��p�t�H�[�}���X�̍����V�X�e����g�ނ��߂�CPU�ɍ����l�i��t����͈̂��B
�ǂ������l���������Ă�̂�����s�\�ł��B
�����Ă��p�t�H�[�}���X�̍����V�X�e����g�ނ��߂�CPU�ɍ����l�i��t����͈̂��B
�ǂ������l���������Ă�̂�����s�\�ł��B
�����Opteron 880���ʍw������A��������AMD���������Ă�����Ȃ�����w
�悭�m���
�悭�m���
606 �FMAC�I�^��603 �����F2006/06/06(��) 00:42:12 ID:A6MRWV5e
>>603
�@�@-----------------------
�@�@Opteron 880�ɂ����Ă�e�X�g�H��
�@�@-----------------------
�{����V�X�e���x���_�������ׂ��R�X�g���B�[����V�X�e���x���_�ł��`�F�b�N���Ă�̂Ť
����Ӗ�2�d���B�B�B
http://www.eweek.com/article2/0,1895,1955267,00.asp�@(���Opteron���R�[���L��)
�@�@======================
�@�@The chip maker has been working with OEMs and other partners to identify the chips,
�@�@======================
�@�@-----------------------
�@�@Opteron 880�ɂ����Ă�e�X�g�H��
�@�@-----------------------
�{����V�X�e���x���_�������ׂ��R�X�g���B�[����V�X�e���x���_�ł��`�F�b�N���Ă�̂Ť
����Ӗ�2�d���B�B�B
http://www.eweek.com/article2/0,1895,1955267,00.asp�@(���Opteron���R�[���L��)
�@�@======================
�@�@The chip maker has been working with OEMs and other partners to identify the chips,
�@�@======================
�����̃I�^�͂��������B���܂�ɂ��A�z������B
�f�X�N���I�����o�C�����S��Opteron1�\�������ɂ�������̂�
Conroe�̓o��ԋ߂�������āA��������͂悭�Ȃ���
>>606
AMD��Opteron 880�̃e�X�g�H���ɃR�X�g�����āA
�V�X�e���x���_�́AOpteron 880���܂߂��V�X�e���S�̂��܂߂��e�X�g�H���ɃR�X�g��������Ǝv���Ă���̂����B
�Ⴄ�̂��B
AMD��Opteron 880�̃e�X�g�H���ɃR�X�g�����āA
�V�X�e���x���_�́AOpteron 880���܂߂��V�X�e���S�̂��܂߂��e�X�g�H���ɃR�X�g��������Ǝv���Ă���̂����B
�Ⴄ�̂��B
�A�W�A�ő��PC�g���[�h�V���[�uCOMPUTEX TAIPEI 2006�v�A6���J��
http://pc.watch.impress.co.jp/docs/2006/0605/comp01.htm
�Ȃ�Intel�F�ɖ��܂肻�������AAMD�̃T�v���C�Y�Ɋ���w
http://pc.watch.impress.co.jp/docs/2006/0605/comp01.htm
�Ȃ�Intel�F�ɖ��܂肻�������AAMD�̃T�v���C�Y�Ɋ���w
>AMD�Ɏ����Ă퓯���_�C������p�b�P�[�W��8-socket�T�|�[�g�i�Ŗ\�����Â��Ă������B
�܂�8xx��4����Ȃ��āA1xx��4�ł��������Ƃ������H
�܂�8xx��4����Ȃ��āA1xx��4�ł��������Ƃ������H
614 �F�E�́E�j��-������ ��toBASh.... �F2006/06/06(��) 01:28:22 ID:fZn03p89
�������������Xeon��Pentium�̊W�́i����
���Ă�Celeron�ł�������Ȃ���SMP�ł�����
���Ă�Celeron�ł�������Ȃ���SMP�ł�����
tomshardware�̃x���`���o�Ă���
First Benchmarks: Conroe vs. FX-62
http://www.tomshardware.com/2006/06/05/first_benchmarks_conroe_vs_fx-62/page5.html
http://www.tomshardware.com/2006/06/05/first_benchmarks_conroe_vs_fx-62/page6.html
http://www.tomshardware.com/2006/06/05/first_benchmarks_conroe_vs_fx-62/page7.html
First Benchmarks: Conroe vs. FX-62
http://www.tomshardware.com/2006/06/05/first_benchmarks_conroe_vs_fx-62/page5.html
http://www.tomshardware.com/2006/06/05/first_benchmarks_conroe_vs_fx-62/page6.html
http://www.tomshardware.com/2006/06/05/first_benchmarks_conroe_vs_fx-62/page7.html
300A��SMP�͑�w�������������Ō�����܂�
>AMD�Ɏ����Ă퓯���_�C������p�b�P�[�W��8-socket�T�|�[�g�i�Ŗ\�����Â��Ă������B
����̓A�����A�قƂ�ǂ�CPU��1GHz���낤��3GHz���낤�������_�C�����p�b�P�[�W�Ȃ���
�������i�Ŕ���Ƃ����咣���ȁBCore Duo��Core Solo�̉��i�Ŕ���ƁB�͂͂́B
����ȋ��x�̍����̂͋v�X���B
����̓A�����A�قƂ�ǂ�CPU��1GHz���낤��3GHz���낤�������_�C�����p�b�P�[�W�Ȃ���
�������i�Ŕ���Ƃ����咣���ȁBCore Duo��Core Solo�̉��i�Ŕ���ƁB�͂͂́B
����ȋ��x�̍����̂͋v�X���B
618 �F�E�́E�j��-������ ��toBASh.... �F2006/06/06(��) 02:00:46 ID:fZn03p89
>>615
AMD�̂ق������I�[�o�[�N���b�N���Ă�̂�Core2�̂��������֒����邽�߂ł���
AMD�̂ق������I�[�o�[�N���b�N���Ă�̂�Core2�̂��������֒����邽�߂ł���
����AK8�R�A�ł����܂���������܂œ����ł���Ƃ����b (T_T)
�������Ⴂ�܂��`���B
���܂�ɂ��`�A�����`�������ā`�݂��߂������̂Ł`OC�`���ā`�݂܂��`���B
�ł��`�AOC�́`�S�R�`����Ȃ������`�悤�Ł[���B
���x�́`4GHz�܂Ł`OC���ā`AMD�́`�������`����`���\�`���Ă݂����Ł[���B
���܂�ɂ��`�A�����`�������ā`�݂��߂������̂Ł`OC�`���ā`�݂܂��`���B
�ł��`�AOC�́`�S�R�`����Ȃ������`�悤�Ł[���B
���x�́`4GHz�܂Ł`OC���ā`AMD�́`�������`����`���\�`���Ă݂����Ł[���B
�@tom�̓��{�ꂪ���Ə�肾�ȁB
�������Ȃ��Ă���������A�����Ƃ��Ă����ĉ������B
���������l�g�o�`�[��AMD�Ɉ�������������
������TDP250W5.5Ghz�Ƃ��łԂ�������ŏ��Ă��������
������TDP250W5.5Ghz�Ƃ��łԂ�������ŏ��Ă��������
���[�A�����`�����v���܁`���B
�l�g�o�́[�A�Ă����`�i���{�`�B
AMD���`���M�́`���E�֘A��čs���ā`����܁[���B
�l�g�o�́[�A�Ă����`�i���{�`�B
AMD���`���M�́`���E�֘A��čs���ā`����܁[���B
FPU����������Ă�_�ȊO�͂���قǑ卷�ł��Ȃ��悤�ȁB
�����́`���j�b�g�P�ʂł����`���܂���`
SSE���j�b�g�́`FPU���L�́`2�����Ł`���B
SSE���j�b�g�́`FPU���L�́`2�����Ł`���B
Woodcrest��A�������Ă��Ȃ����B
>>627
���̊ԁ`�A3GHz�Ł`2000�ȏ���v�������̂Ł`���q�ɏ���ā`�������Ă��Ȃ����ƌ�������`
3000�ȏ��@���o����ā`������Ɓ`�u���[�Ɂ`�Ȃ�܁`�����B
���̊ԁ`�A3GHz�Ł`2000�ȏ���v�������̂Ł`���q�ɏ���ā`�������Ă��Ȃ����ƌ�������`
3000�ȏ��@���o����ā`������Ɓ`�u���[�Ɂ`�Ȃ�܁`�����B
Intel��A�������Ă��Ȃ����B
AMD�́`�����܁`�����B
�Ȃ�ӂ�`���܂��ā`���Ȃ�����`4x4�́`�悤�Ɂ[�A�B���Ă����r���`�����Ł`�`�������`�܁[���B
�ł��`�Ȃ������`���������`����Ă��܂��[��B
�F����`4x4�́`���@�́`���Ł[���B
������`�A�����ς��`�����ā`�������[���B
�����łȂ��Ɓ`�ɂ��`�����ā`���܂��`�܁[���B
���x�`���q�����ā`�H����`�؋����Ă܂Ł`�L��������`�B
�Ɂ`������́`������Ɨǂ�����܂���B
�Ȃ�ӂ�`���܂��ā`���Ȃ�����`4x4�́`�悤�Ɂ[�A�B���Ă����r���`�����Ł`�`�������`�܁[���B
�ł��`�Ȃ������`���������`����Ă��܂��[��B
�F����`4x4�́`���@�́`���Ł[���B
������`�A�����ς��`�����ā`�������[���B
�����łȂ��Ɓ`�ɂ��`�����ā`���܂��`�܁[���B
���x�`���q�����ā`�H����`�؋����Ă܂Ł`�L��������`�B
�Ɂ`������́`������Ɨǂ�����܂���B
�l�g�o�g���A�ȒP��FX�Ȃ�3.99Ghz�z�����ˁH
��������ΐ�Ώ��Ă邶��Ȃ��������Ȃ��H
��������ΐ�Ώ��Ă邶��Ȃ��������Ȃ��H
�����Iww�@�������肵���Iww�@���@AMD
AMD socket 1207 Opterons delayed
http://www.theinquirer.net/?article=32188
AMD socket 1207 Opterons delayed
http://www.theinquirer.net/?article=32188
AMD�́`�����܁`�����B
���܂̂Ƃ���`AMD�ł́`�l�g�o������قǁ`�Z�p�͂Ȃ��`�Ł[���B
Rev.H�́`�o�[�W�����Ł`����Ɓ`�܂Ƃ��ȁ`ooo�炵���`��Ԃ܂Ł`�����čs����`���x�Ł`���B
�܂�`����Ɓ`P6�́`�Z�p�����ւƁ`�B���邱�Ƃ��`�o���������Ɓ`�������ƂŁ[���B
���܂̂Ƃ���`AMD�ł́`�l�g�o������قǁ`�Z�p�͂Ȃ��`�Ł[���B
Rev.H�́`�o�[�W�����Ł`����Ɓ`�܂Ƃ��ȁ`ooo�炵���`��Ԃ܂Ł`�����čs����`���x�Ł`���B
�܂�`����Ɓ`P6�́`�Z�p�����ւƁ`�B���邱�Ƃ��`�o���������Ɓ`�������ƂŁ[���B
tom��Intel�����Ă�Ƃ͎v���܂���ł����B
�{���ɂ��肪�Ƃ��������܂����B
�{���ɂ��肪�Ƃ��������܂����B
AMD�́`�����܁`�����B
�z���g�̂Ƃ���`�AAMD�Ɂ`INTEL�Ɓ`�킦�邾���́`�Z�p�͂́`����܂��[��B
�ł��`�A��X�́`�撣��`�܁[�����B
L1���`��������64k+64k�ɂ��邱�ƂŁ`���\���`�u�[�X�g�`�������Ă����킯�`�ł����ǂ��`�B
�X�ɂ́`�����R�����`�g�ݍ���Ł`���ΓI�ȁ`�x�����`�J�o�[���Ă��`�킯�ł����ǂ��`�B
INTEL�����Ă���`�{�C�Ɂ`�Ȃ����悤�`�ŁAConroe�Ƃ����`�����h�q���`����Ă��܁[�����B
���͊�@�I�Ɂ`�Ȃ����܁[�����[�AIBM���Ɂ`���������肢�`�����Ƃ���Ł[���B
�z���g�̂Ƃ���`�AAMD�Ɂ`INTEL�Ɓ`�킦�邾���́`�Z�p�͂́`����܂��[��B
�ł��`�A��X�́`�撣��`�܁[�����B
L1���`��������64k+64k�ɂ��邱�ƂŁ`���\���`�u�[�X�g�`�������Ă����킯�`�ł����ǂ��`�B
�X�ɂ́`�����R�����`�g�ݍ���Ł`���ΓI�ȁ`�x�����`�J�o�[���Ă��`�킯�ł����ǂ��`�B
INTEL�����Ă���`�{�C�Ɂ`�Ȃ����悤�`�ŁAConroe�Ƃ����`�����h�q���`����Ă��܁[�����B
���͊�@�I�Ɂ`�Ȃ����܁[�����[�AIBM���Ɂ`���������肢�`�����Ƃ���Ł[���B
636 �F�E�́E�j��-������ ��toBASh.... �F2006/06/06(��) 02:48:03 ID:fZn03p89
AMD��L/S��p������قǃ��W�X�^���l�[�������i�������Ďd�l������Ӗ����������ǂ�
>����ł�Xeon�����{�v��V���O���\�P�b�g�i�Ɠ����Ƃ팾����p�b�P�[�W��L���b�V���\������
>�ς��Ĥ����Ȃ�̐����͂��������Ă��������ǤAMD�Ɏ����Ă퓯���_�C������p�b�P�[�W��8-socket
>�T�|�[�g�i�Ŗ\�����Â��Ă������B
Pentium2Xeon��Pentium3Xeon(Tanner)�̓L���b�V�����R�A�����ő�e�ʂł͂������ȁB
�����A������L���b�V�����I�t�_�C����������o������ŃR�A��Pentium2/3�ƑS���������������B
Coppermine�ł�Slot1/Socket370�ł�1-2Way�܂ŃT�|�[�g�ɂȂ������ASlot2��Pentium3Xeon��������
Cascades�R�A��Coppermine�ƑS�������d�l���������B(���1M/2M�L���b�V���̂��o�����B)
Tualatin�ł̓L���b�V��256KByte�ł̓V���O����p�A512KByte�ł�DP�Ή��ł͂��������A256KByte��
�͒P�ɃL���b�V�����ׂ����������������B
Netburst����̓V���O���\�P�b�g�ł�DP�Ή��͊��S�ɓ����R�A�Ńp�b�P�[�W(�\�P�b�g)���Ⴄ���������ȁB
intel��DP/MP�ł����ꂾ���F�X���j���ς���Ă�̂ɁA���܂��炢�������t���邩�ˁH
Opteron�͊m����1xx/2xx/8xx�őS�������v�E�_�C�����A�t�Ɍ�����1xx�ł�8xx�ł��J����Ƃ��Ă�
8xx�����̋����K�v�Ȃ���A1xx/2xx�͎s��ɉ��������i�ň������Ă���ƍl����ׂ�����Ȃ��̂��H
(���ہA8xx�����̉��i�̂܂܂���N�������Ă���B)
Xeon�̓L���b�V�����I���_�C�ɂȂ��Ă����DP�Ɠ�����MP�v���Z�b�T�����[�X�܂�1�N�`2�N�قǒx���
�悤�ɂȂ��āA���\�ɋQ����MP�s��͑債�ĕK�v�Ƃ͎v���Ȃ��f�X�N�g�b�v�̍ő��v���Z�b�T�����ڂ�
���߂Ȃ��炨�a����H����Ă����AOpteron�ł͂قƂ�ǂ̃P�[�X��8xx/2xx����ő��v���Z�b�T��
�����[�X����邩��A���ꂾ���ł��\��������鉿�l�͂���Ǝv�����ȁB
>�Ƃ��낪���\�ɍ�������ꂽ���ʤ�K�ɉ�����AMD��MP�T�|�[�g�̃f�X�N�g�b�v���i��
>�����[�X���v�悵�Ă���B
����͓��{�s��������낤�ȁE�E�E
TYAN�H���u���{�ɂ͌l�����G���^�[�v���C�Y�s��Ƃ�����Ȏs�ꂪ�m���ɑ��݂���v���Ă��Ƃ����B
Registered�������͉��i�����邱�ƂȂ���A���萫���ǂ��Ȃ�����Unbuffered���������g����Ƃ����̂͏�����B
>�ς��Ĥ����Ȃ�̐����͂��������Ă��������ǤAMD�Ɏ����Ă퓯���_�C������p�b�P�[�W��8-socket
>�T�|�[�g�i�Ŗ\�����Â��Ă������B
Pentium2Xeon��Pentium3Xeon(Tanner)�̓L���b�V�����R�A�����ő�e�ʂł͂������ȁB
�����A������L���b�V�����I�t�_�C����������o������ŃR�A��Pentium2/3�ƑS���������������B
Coppermine�ł�Slot1/Socket370�ł�1-2Way�܂ŃT�|�[�g�ɂȂ������ASlot2��Pentium3Xeon��������
Cascades�R�A��Coppermine�ƑS�������d�l���������B(���1M/2M�L���b�V���̂��o�����B)
Tualatin�ł̓L���b�V��256KByte�ł̓V���O����p�A512KByte�ł�DP�Ή��ł͂��������A256KByte��
�͒P�ɃL���b�V�����ׂ����������������B
Netburst����̓V���O���\�P�b�g�ł�DP�Ή��͊��S�ɓ����R�A�Ńp�b�P�[�W(�\�P�b�g)���Ⴄ���������ȁB
intel��DP/MP�ł����ꂾ���F�X���j���ς���Ă�̂ɁA���܂��炢�������t���邩�ˁH
Opteron�͊m����1xx/2xx/8xx�őS�������v�E�_�C�����A�t�Ɍ�����1xx�ł�8xx�ł��J����Ƃ��Ă�
8xx�����̋����K�v�Ȃ���A1xx/2xx�͎s��ɉ��������i�ň������Ă���ƍl����ׂ�����Ȃ��̂��H
(���ہA8xx�����̉��i�̂܂܂���N�������Ă���B)
Xeon�̓L���b�V�����I���_�C�ɂȂ��Ă����DP�Ɠ�����MP�v���Z�b�T�����[�X�܂�1�N�`2�N�قǒx���
�悤�ɂȂ��āA���\�ɋQ����MP�s��͑債�ĕK�v�Ƃ͎v���Ȃ��f�X�N�g�b�v�̍ő��v���Z�b�T�����ڂ�
���߂Ȃ��炨�a����H����Ă����AOpteron�ł͂قƂ�ǂ̃P�[�X��8xx/2xx����ő��v���Z�b�T��
�����[�X����邩��A���ꂾ���ł��\��������鉿�l�͂���Ǝv�����ȁB
>�Ƃ��낪���\�ɍ�������ꂽ���ʤ�K�ɉ�����AMD��MP�T�|�[�g�̃f�X�N�g�b�v���i��
>�����[�X���v�悵�Ă���B
����͓��{�s��������낤�ȁE�E�E
TYAN�H���u���{�ɂ͌l�����G���^�[�v���C�Y�s��Ƃ�����Ȏs�ꂪ�m���ɑ��݂���v���Ă��Ƃ����B
Registered�������͉��i�����邱�ƂȂ���A���萫���ǂ��Ȃ�����Unbuffered���������g����Ƃ����̂͏�����B
���͂��₪�閅�̃p���c���A�܂œǂ�
��ӏ������B
Tualatin-512K�͕ʃ_�C���ȁB�����_�C���g���Ă�̂�Tualatin-256K��Tualatin-Celeron�B
Tualatin-512K�����Y�k����Netburst�D��̔̔��헪�ʼn��i������������ȁE�E�E
�܂��A�T�[�o�[�����Ƃ��Ă͓�������XeonDP������ۂǗǂ���������A����Ӗ��Ó��ȉ��i�ݒ�Ƃ������邪�B
Opteron8xx�̉��i�ݒ�ɃP�`�����Ȃ�A�܂���intel�ɂ��������ė����B
�uPentium4��Celeron�͓����_�C�E�����p�b�P�[�W�Ȃ���S��Celeron�̒l�i�Ŕ���I�v�ƂȁB
Tualatin-512K�͕ʃ_�C���ȁB�����_�C���g���Ă�̂�Tualatin-256K��Tualatin-Celeron�B
Tualatin-512K�����Y�k����Netburst�D��̔̔��헪�ʼn��i������������ȁE�E�E
�܂��A�T�[�o�[�����Ƃ��Ă͓�������XeonDP������ۂǗǂ���������A����Ӗ��Ó��ȉ��i�ݒ�Ƃ������邪�B
Opteron8xx�̉��i�ݒ�ɃP�`�����Ȃ�A�܂���intel�ɂ��������ė����B
�uPentium4��Celeron�͓����_�C�E�����p�b�P�[�W�Ȃ���S��Celeron�̒l�i�Ŕ���I�v�ƂȁB
640 �FMAC�I�^��637 �����F2006/06/06(��) 08:24:20 ID:A6MRWV5e
>>637
�@�@-----------------------
�@�@intel��DP/MP�ł����ꂾ���F�X���j���ς���Ă�̂ɁA���܂��炢�������t���邩�ˁH
�@�@-----------------------
���i�ƊE�̏펯����l���ĤIntel���l�Ă����Q�i���邢��4�¤���邢��W�B�B�B)�����Ɓu�P�����
�����Ȃ���ď���������炩�Ɉُ킷�BAMD�����̃r�W�l�X���f���Ɂu�^�_��裂��Ă�̂펖��
�����Ǥ�ᔻ�̑Ώۂ폤���̂������̂ɂ��邱�Ƃɒ��ӂ��ė~�������B
�����Ĥ�{����n-way�V�X�e���̕t�����l�Ƃ���ɔ������v����V�X�e���x���_���^����
�ׂ����m���Ƃ������Ƃ��B
�@�@-----------------------
�@�@intel��DP/MP�ł����ꂾ���F�X���j���ς���Ă�̂ɁA���܂��炢�������t���邩�ˁH
�@�@-----------------------
���i�ƊE�̏펯����l���ĤIntel���l�Ă����Q�i���邢��4�¤���邢��W�B�B�B)�����Ɓu�P�����
�����Ȃ���ď���������炩�Ɉُ킷�BAMD�����̃r�W�l�X���f���Ɂu�^�_��裂��Ă�̂펖��
�����Ǥ�ᔻ�̑Ώۂ폤���̂������̂ɂ��邱�Ƃɒ��ӂ��ė~�������B
�����Ĥ�{����n-way�V�X�e���̕t�����l�Ƃ���ɔ������v����V�X�e���x���_���^����
�ׂ����m���Ƃ������Ƃ��B
�@�@�@�@�@�@�@�@�@�@,,�\�]�D�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ r-�A�@�@�@�@�Q,--,�A
�@�@�@�@�@,�\-�A�@.| ./''i����@�@r-,,,,,,,,,,,,,,,,,,,,,,,,�\��D�@�@�@ �l, �M"����ށP�O�@�@�@�_
�@�@�@ �^�@�@�@�_ �R,�'�_,/�@�@ .�l�A�@�@�@�@�@�@�@�@�@`i��@�@�@�_ _,,�\�'''/�@�@.,��'"
.,,,�A.,,i�L�@.,/�O'i��@�M'i��M�M�@�@�@�@ �M--�]'''''''''''''''"'''''''''''ށ@�@�@�@ �M�J�@�@ .���@ .,/
�o ""�@ ,/�M�@�@�R�A �M'i��@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ���@ .,/�M
.�R�A�@���@�@�@�@�_�@ .�_�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ,/�� �A�R,,�A
�@ �'�'"�@�@�@�@�@�@�'i��@ �ei�.r-�A�@�@�@�@�@ �Q_,,,,,,,,--�A�@�@�@�@ �^�@.,�^�_�@`'-,�A
�@�@�@�@�@�@�@�@�@�@�@�R�@�@.]�l �M����"���ށP�P�@�@�@�@�@�M'i��@�@,�^ .,,�^�@�@ .�R�@�@�_
�@�@�@�@�@�@�@�@�@�@�@�@ށR_/ .�R_.,,,,--�\�\�\�\�\�-�m_,�^�,,�^���@�@�@�@ �l�@�@ ,"
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �M�@�@�@�@�@�@�@�@�@�@�@�@ ށ]''"�M�@�@�@�@�@�@�@�@�'�'"
�@�@�@�@�@,�\-�A�@.| ./''i����@�@r-,,,,,,,,,,,,,,,,,,,,,,,,�\��D�@�@�@ �l, �M"����ށP�O�@�@�@�_
�@�@�@ �^�@�@�@�_ �R,�'�_,/�@�@ .�l�A�@�@�@�@�@�@�@�@�@`i��@�@�@�_ _,,�\�'''/�@�@.,��'"
.,,,�A.,,i�L�@.,/�O'i��@�M'i��M�M�@�@�@�@ �M--�]'''''''''''''''"'''''''''''ށ@�@�@�@ �M�J�@�@ .���@ .,/
�o ""�@ ,/�M�@�@�R�A �M'i��@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ���@ .,/�M
.�R�A�@���@�@�@�@�_�@ .�_�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ,/�� �A�R,,�A
�@ �'�'"�@�@�@�@�@�@�'i��@ �ei�.r-�A�@�@�@�@�@ �Q_,,,,,,,,--�A�@�@�@�@ �^�@.,�^�_�@`'-,�A
�@�@�@�@�@�@�@�@�@�@�@�R�@�@.]�l �M����"���ށP�P�@�@�@�@�@�M'i��@�@,�^ .,,�^�@�@ .�R�@�@�_
�@�@�@�@�@�@�@�@�@�@�@�@ށR_/ .�R_.,,,,--�\�\�\�\�\�-�m_,�^�,,�^���@�@�@�@ �l�@�@ ,"
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �M�@�@�@�@�@�@�@�@�@�@�@�@ ށ]''"�M�@�@�@�@�@�@�@�@�'�'"
���[�E�E�E�A�z�͂ق��Ƃ��B
��ʂɏo����͈̂����A���������o�Ȃ����͍̂����B
����ȊȒP�Ȏs�ꌴ�����킩���̂�����B
��ʂɏo����͈̂����A���������o�Ȃ����͍̂����B
����ȊȒP�Ȏs�ꌴ�����킩���̂�����B
>>640
���̒l�i�Ȃ�Ċ�Ƃ����R�ɕt���錠���������Ȃ��̂��ˁB
�Ɛ��Ƃ������炨�O�̌����������Ƃ������邪�AAMD���Ă���
���O��ł��ꉞ���������Ƃ�����킯�����B�Ȃ�̌�����������
����Ȃ��Ƃ����Ă��
���̒l�i�Ȃ�Ċ�Ƃ����R�ɕt���錠���������Ȃ��̂��ˁB
�Ɛ��Ƃ������炨�O�̌����������Ƃ������邪�AAMD���Ă���
���O��ł��ꉞ���������Ƃ�����킯�����B�Ȃ�̌�����������
����Ȃ��Ƃ����Ă��
���͂��₪��MAC�I�^�̃y�j�X���A�܂œǂ�
�~4 �� L2 �T�C�Y�AMAC�I�^�̗\�z(>>266) �� ando ����̗\�z��
�H������Ă������A���� ando ����̕��������������ł��ȁB
�܂��A������O�����B
�H������Ă������A���� ando ����̕��������������ł��ȁB
�܂��A������O�����B
���4�R�A�̃_�C���C�A�E�g�ŋC�ɂȂ�̂�L3���ǂ��ɐڑ�����邩���ȁE�E�E
�]���̃R�A��SRI�̊Ԃɓ���Ȃ�A���̃��C�A�E�g�ł͌������悤�ȋC��������B
����ɂ���HT-Link�Ōq����������4�R�A�Ȃ狤�LL3�Ƃ����\�������������C������B
�{���ɂ����q�������Ȃ̂��ˁH
���ƁA���C�A�E�g���炷��ƃ������R���g���[��������ڂ���ꂻ���Ɍ����邪�B
Socket940�͌��ǃ��U�[�u���ꂽ�s�����g�����ƂȂ��f���A���R�A�ɂ���Ȃ�ڍs������
Socket-F�ł͍X��260�s���ȏ㑝����͖̂{���ɓd�͋����̋��������Ȃ̂��H
�����ƂȂ�����A������g�������o�X��������o�����߂�������ʔ������E�E�E
DDR3�ł�1ch������1�X���b�g�ɂȂ邱�Ƃ��l�����2�g�o�����4�X���b�g�m�ۏo���邵�ȁB
�]���̃R�A��SRI�̊Ԃɓ���Ȃ�A���̃��C�A�E�g�ł͌������悤�ȋC��������B
����ɂ���HT-Link�Ōq����������4�R�A�Ȃ狤�LL3�Ƃ����\�������������C������B
�{���ɂ����q�������Ȃ̂��ˁH
���ƁA���C�A�E�g���炷��ƃ������R���g���[��������ڂ���ꂻ���Ɍ����邪�B
Socket940�͌��ǃ��U�[�u���ꂽ�s�����g�����ƂȂ��f���A���R�A�ɂ���Ȃ�ڍs������
Socket-F�ł͍X��260�s���ȏ㑝����͖̂{���ɓd�͋����̋��������Ȃ̂��H
�����ƂȂ�����A������g�������o�X��������o�����߂�������ʔ������E�E�E
DDR3�ł�1ch������1�X���b�g�ɂȂ邱�Ƃ��l�����2�g�o�����4�X���b�g�m�ۏo���邵�ȁB
>����ɂ���HT-Link�Ōq����������4�R�A�Ȃ狤�LL3�Ƃ����\�������������C������B
�R�A�̒���HT�����N�͂����ĂȂ���
�R�A�̒���HT�����N�͂����ĂȂ���
L3��L1L2�Ƃ̔r���L���b�V�������Ȃ�L3�Ɉ��������č����x���Ȃ肻���B
�ǂ��l���Ă����������Ȃ�ȁB
�Ȃ�ŋ��L�L���b�V���Ȃ�?
�ǂ��l���Ă����������Ȃ�ȁB
�Ȃ�ŋ��L�L���b�V���Ȃ�?
���チ�����A�N�Z�X��CPU���\�̃{�g���l�b�N�ɂȂ肻��������H
non-inclusive �Ȃ̂͊ԈႢ�Ȃ����ǁAL3 �͋��L�L���b�V���Ȃ̂ŁA���S�r���ɂ͂Ȃ�낤�B���Ă䂤�̂��A���̃X���̂�����ƑO�Řb���ĂȂ������H�������� L3 �ɂЂ��ς��Ēx�����Ă��Ƃɂ͂Ȃ�Ȃ�������B
���S�r���ɂ��Ƃ��Ȃ��Ɛ��������Ȃ����낤?
L1L2�܂ł̓R�A���ɓƗ������L���b�V�������B
�����܂ł͍��܂Œʂ�A
1)�V����L1�փ��������f�[�^�����[�h����B
2)L1�փ��[�h����וێ����Ă����L���b�V����ǂ��o���K�v��������B
3)L2��L1���ǂ��o���ꂽ�L���b�V���������ׂ�L2�̕ێ��L���b�V����ǂ��o���K�v��������B
----------�����܂ł͌���ǂ���------------
4)L3��L2���ǂ��o���ꂽ�L���b�V���������ׂ�L3�̕ێ��L���b�V����ǂ��o���K�v��������B
5)L3����ǂ��o���ێ��L���b�V�����X�V��ԂȂ烁�����[�ւ̏����߂��������B
�����ŁAL3�͋��L�L���b�V���ł��邩��4�̃R�A���瓯�l�ȗv������������B
������1)�`5)�܂Ŋ������Ȃ���L1�̃��[�h�͊������Ȃ��B
�����܂ł͍��܂Œʂ�A
1)�V����L1�փ��������f�[�^�����[�h����B
2)L1�փ��[�h����וێ����Ă����L���b�V����ǂ��o���K�v��������B
3)L2��L1���ǂ��o���ꂽ�L���b�V���������ׂ�L2�̕ێ��L���b�V����ǂ��o���K�v��������B
----------�����܂ł͌���ǂ���------------
4)L3��L2���ǂ��o���ꂽ�L���b�V���������ׂ�L3�̕ێ��L���b�V����ǂ��o���K�v��������B
5)L3����ǂ��o���ێ��L���b�V�����X�V��ԂȂ烁�����[�ւ̏����߂��������B
�����ŁAL3�͋��L�L���b�V���ł��邩��4�̃R�A���瓯�l�ȗv������������B
������1)�`5)�܂Ŋ������Ȃ���L1�̃��[�h�͊������Ȃ��B
�ڍׂ͒m��Ȃ����ǁAL3��writeback�ɂȂ��Ȃ����ȁB
L3��r���L���b�V���ŕێ�����̂Ȃ�(�Ƃ�����L1L2���r���\���Ȃ炻�ꂵ���Ȃ�)���L���Ȃ������悳�����Ɏv���B
���L�����Ƃ���ŃR�q�[�����V��L1L2�Ŕ������邵�AL3�͂��̂������x��������
���L�����Ƃ���ŃR�q�[�����V��L1L2�Ŕ������邵�AL3�͂��̂������x��������
>>645
OpteronX4�̃L���b�V����256KB�ł͂Ȃ����H
�Ƃ����I�^�̗\�z�ɑ��āA�uAMD���L���b�V��256KB�ł����\�͖��Ȃ��Ɣ��f�����낤�ˁv�Ƃ����ӌ������������A
256KB�ł͎��������Ȃ������i�̂ɐ��Y�ɖ�肠��H�j�̂��A����Ƃ�256KB�ł͐��\�ɖ�肪������Ƃ������ƂȂ낤���H
OpteronX4�̃L���b�V����256KB�ł͂Ȃ����H
�Ƃ����I�^�̗\�z�ɑ��āA�uAMD���L���b�V��256KB�ł����\�͖��Ȃ��Ɣ��f�����낤�ˁv�Ƃ����ӌ������������A
256KB�ł͎��������Ȃ������i�̂ɐ��Y�ɖ�肠��H�j�̂��A����Ƃ�256KB�ł͐��\�ɖ�肪������Ƃ������ƂȂ낤���H
>>653
�N���l���Ă邱�Ƃ��炢�AAMD���l���Ă���ƂȂ��v��Ȃ��̂��H
����ȃJ�X���z�����J�L�R�ł��Ȃ��̂Ȃ�A���Nrom���Ă��B
�N���l���Ă邱�Ƃ��炢�AAMD���l���Ă���ƂȂ��v��Ȃ��̂��H
����ȃJ�X���z�����J�L�R�ł��Ȃ��̂Ȃ�A���Nrom���Ă��B
658 �F�E�́E�j��-������ ��toBASh.... �F2006/06/06(��) 19:49:01 ID:fZn03p89
���L��L3�܂Ŏ����Ă��ꂪ��������2MB�����Ȃ��̂ƁA4MB�̋��L�L���b�V���^�f���A���R�A���j�R�C�`�ɂ���̂�
�ǂ��������\�I�ɗL�����Ȃ�Ĕ��f���悤��������K�X�B
L3�ςނȂ炽�Ƃ������ȉ��ł�16MB���炢�ς�ł��Ȃ��ƁB
�ǂ��������\�I�ɗL�����Ȃ�Ĕ��f���悤��������K�X�B
L3�ςނȂ炽�Ƃ������ȉ��ł�16MB���炢�ς�ł��Ȃ��ƁB
http://pc.watch.impress.co.jp/docs/2006/0602/slide42.jpg
http://pc.watch.impress.co.jp/docs/2006/0602/slide44.jpg
L3�͊g���\�ł���炵������A16MB�͂ǂ����m���
����2MB�ȏ�Ɋg�����Ă��邾�낤�Ǝv��
http://pc.watch.impress.co.jp/docs/2006/0602/slide44.jpg
{kind=link}
L3�͊g���\�ł���炵������A16MB�͂ǂ����m���
����2MB�ȏ�Ɋg�����Ă��邾�낤�Ǝv��
660 �F�E�́E�j��-������ ��toBASh.... �F2006/06/06(��) 20:11:53 ID:fZn03p89
��������Opteron�̗i��ɉ�点�Ă��炤����
L1=64K+64K, L2=512KB�̔r���L���b�V����4�R�A���Ƃ�����L2MB��L3�L���b�V���Ȃ��
���肷���L1+L2�̑��a(3.2MB)�̂ق����傫���Ȃ��ĈӖ��Ȃ���ł���B�ނ��냁�������C�e���V�傫���Ȃ邾�����ʁB
�L���b�V���̗e�ʂ�v�i�K���犸���ĉ��������߂A�G���g���������Ȃ��Ȃ邽�߃��C�e���V���������ł��������B
512k��1MB�O��̐v�őI�ʘR����L���b�V�����ꕔ�E����256k�ɂ��Ă�̂ƁA�ŏ�����p�t�H�[�}���X�_����
256k�ɂ��Ă�̂Ƃł͖��炩�ɐ��\���Ⴄ�Ǝv���̂ł��B
Mac�I�^�̃~�X���[�h�ɏ悹���Ă͂������B
����Tulsa������L2��1MB�Ɋ����ė��Ƃ������16MB�̋��L�L���b�V�����ڂł����B
L1=64K+64K, L2=512KB�̔r���L���b�V����4�R�A���Ƃ�����L2MB��L3�L���b�V���Ȃ��
���肷���L1+L2�̑��a(3.2MB)�̂ق����傫���Ȃ��ĈӖ��Ȃ���ł���B�ނ��냁�������C�e���V�傫���Ȃ邾�����ʁB
�L���b�V���̗e�ʂ�v�i�K���犸���ĉ��������߂A�G���g���������Ȃ��Ȃ邽�߃��C�e���V���������ł��������B
512k��1MB�O��̐v�őI�ʘR����L���b�V�����ꕔ�E����256k�ɂ��Ă�̂ƁA�ŏ�����p�t�H�[�}���X�_����
256k�ɂ��Ă�̂Ƃł͖��炩�ɐ��\���Ⴄ�Ǝv���̂ł��B
Mac�I�^�̃~�X���[�h�ɏ悹���Ă͂������B
����Tulsa������L2��1MB�Ɋ����ė��Ƃ������16MB�̋��L�L���b�V�����ڂł����B
661 �F�E�́E�j��-������ ��toBASh.... �F2006/06/06(��) 20:15:48 ID:fZn03p89
�~3.2M
��2.56M
��2.56M
2+BM
�~2+BM
��2+MB
��2+MB
�����搶�́AOpteron��L3�����������Ƃɂ���Victim Cache�̉\�����w�E���Ă�
http://www.geocities.jp/andosprocinfo/wadai06/20060513.htm
Victim Cache�ɂ��ẮA���������������PCWeb�ł̃R�����ł��������ڂ�������������
http://journal.mycom.co.jp/column/architecture/019/
http://www.geocities.jp/andosprocinfo/wadai06/20060513.htm
Victim Cache�ɂ��ẮA���������������PCWeb�ł̃R�����ł��������ڂ�������������
http://journal.mycom.co.jp/column/architecture/019/
L2��512KB�~4��L3��2MB���ƁA�������փ��C�g�o�b�N����ׂ����̃o�b�t�@����
�������đ������ɂȂ邩�烊�[�h�L���b�V���Ƃ��Ă͖��ɗ�����
�������đ������ɂȂ邩�烊�[�h�L���b�V���Ƃ��Ă͖��ɗ�����
>>664
Victim Cache�͖����B
�����āAL1L2���r���L���b�V���ł��邩�烁�������[�h�͕K��L1���B
Victim Cache�́A�L���b�V���~�X��L2�փ��[�h�B
>>660
����i�삶��Ȃ��@���Ǝv���B
Victim Cache�͖����B
�����āAL1L2���r���L���b�V���ł��邩�烁�������[�h�͕K��L1���B
Victim Cache�́A�L���b�V���~�X��L2�փ��[�h�B
>>660
����i�삶��Ȃ��@���Ǝv���B
L2�����L�L���b�V���ɂ���ƁA�R�q�[�����V�����ŗL���ƂȂ�B
����́AL1�̂ݏ�������Ηǂ�L1��L2��肸���Ƒ��x���������炾�B
Opteron��L3���L�L���b�V�����݂̈Ӑ}�͗ǂ�������Ȃ��B
L1L2���r���ł���A�ǂ����Ă�L1L2�Ƃ��ɃR�q�[�����V���䂪�K�v�ŁAL2��L1��肸���ƒx���B
���̏���u�����܂�L3�L���b�V���݂̂����L�ɂ��ĂȂ�̃����b�g������̂�炾�B
����ɕێ�����Ƃ�������L1���[�h����>>653�̗��R����^�C�����X���Ă��܂��ǂ����Ƃ͂Ȃ��悤�Ɏv���B
����́AL1�̂ݏ�������Ηǂ�L1��L2��肸���Ƒ��x���������炾�B
Opteron��L3���L�L���b�V�����݂̈Ӑ}�͗ǂ�������Ȃ��B
L1L2���r���ł���A�ǂ����Ă�L1L2�Ƃ��ɃR�q�[�����V���䂪�K�v�ŁAL2��L1��肸���ƒx���B
���̏���u�����܂�L3�L���b�V���݂̂����L�ɂ��ĂȂ�̃����b�g������̂�炾�B
����ɕێ�����Ƃ�������L1���[�h����>>653�̗��R����^�C�����X���Ă��܂��ǂ����Ƃ͂Ȃ��悤�Ɏv���B
�Ƃ肠�����AVictim Cache�̓L���b�V���~�X��L1�փ��[�h����Ǝv���܂��B
�}���`�\�P�b�g�O���Opteron��L2���L���ĈӖ�����ˁH
670 �F�E�́E�j��-������ ��toBASh.... �F2006/06/06(��) 20:55:59 ID:fZn03p89
��������2MB���x�����Ȃ�4�R�A���L��L3�L���b�V����L�����p����̂�
L2��512k�ɂ���Ƃ�1MB�ɂ���Ƃ������ق����ԈႢ�ł�
���������r���L���b�V����L2�̗e�ʂ����Ȃ��Ƃ����ł����ʂ����锤�Ȃ̂�
�܂��A�A������Ȃ����ȁB
Intel��L2�̑�e�ʉ��E���L���Ń��C�e���V���]���ɂ��Ă邯��AMD�͋t��L2�����������Ē�C�e���V�H����_���Ă݂�̂�
���肾�Ǝv���̂ł��B
L2��512k�ɂ���Ƃ�1MB�ɂ���Ƃ������ق����ԈႢ�ł�
���������r���L���b�V����L2�̗e�ʂ����Ȃ��Ƃ����ł����ʂ����锤�Ȃ̂�
�܂��A�A������Ȃ����ȁB
Intel��L2�̑�e�ʉ��E���L���Ń��C�e���V���]���ɂ��Ă邯��AMD�͋t��L2�����������Ē�C�e���V�H����_���Ă݂�̂�
���肾�Ǝv���̂ł��B
������ɂ���u�������������v��4�R�A�ł͋��LL3�L���b�V���͗L�蓾�Ƃ͊m�����ȁB
������ɂ���`�Ȃ�
�L�蓾�Ȃ�
�m��
�c�ǂꂩ��ɂ����A���ǂ�
�L�蓾�Ȃ�
�m��
�c�ǂꂩ��ɂ����A���ǂ�
>>670
> Intel��L2�̑�e�ʉ��E���L���Ń��C�e���V���]���ɂ��Ă邯��
INTEL��L2���L�L���b�V���͖Œ��ꒃ�����\�Ȃ�ł���ǁE�E�E
> ttp://www.2cpu.com/review.php?id=112&page=4
> ���������r���L���b�V����L2�̗e�ʂ����Ȃ��Ƃ����ł����ʂ����锤�Ȃ̂�
���ۂ�L2�傫���ق�������(256K��512K��1M�܂ł̑Δ�ł��ꂼ��5%���x���\���シ��)
�������A1M�ȏゾ�Ƌ^��ł͂���B
> AMD�͋t��L2�����������Ē�C�e���V�H����_���Ă݂�̂����肾�Ǝv���̂ł��B
L3�ς���d���Ȃ������������Ƃ����v���Ȃ��B
��C�e���V�ɂȂ����Ƃ��Ă��q�b�g�����邩�瑊�E������B
> Intel��L2�̑�e�ʉ��E���L���Ń��C�e���V���]���ɂ��Ă邯��
INTEL��L2���L�L���b�V���͖Œ��ꒃ�����\�Ȃ�ł���ǁE�E�E
> ttp://www.2cpu.com/review.php?id=112&page=4
> ���������r���L���b�V����L2�̗e�ʂ����Ȃ��Ƃ����ł����ʂ����锤�Ȃ̂�
���ۂ�L2�傫���ق�������(256K��512K��1M�܂ł̑Δ�ł��ꂼ��5%���x���\���シ��)
�������A1M�ȏゾ�Ƌ^��ł͂���B
> AMD�͋t��L2�����������Ē�C�e���V�H����_���Ă݂�̂����肾�Ǝv���̂ł��B
L3�ς���d���Ȃ������������Ƃ����v���Ȃ��B
��C�e���V�ɂȂ����Ƃ��Ă��q�b�g�����邩�瑊�E������B
����L3��Z-RAM��12MB���������B
>���ۂ�L2�傫���ق�������
����ᓖ����O���BL2���傫���Ɣr���ɂ���Ӗ����Ȃ����Ęb�ł��B
����ᓖ����O���BL2���傫���Ɣr���ɂ���Ӗ����Ȃ����Ęb�ł��B
676 �F�E�́E�j��-������ ��toBASh.... �F2006/06/06(��) 21:23:05 ID:fZn03p89
>>673
> INTEL��L2���L�L���b�V���͖Œ��ꒃ�����\�Ȃ�ł���ǁE�E�E
���{��ł���
��������HW�v���t�F�b�`�̂������ŃV�[�P���V�����ȃ��[�h�͋����Ȃ��Ă��ۂ����邯��
�����_���e�[�u���Q�Ƃɂ͎ア�ł���B
�܂��r���L���b�V���͘A���ł̃��[�h�Ɏア��ł܂��A���ł���
> INTEL��L2���L�L���b�V���͖Œ��ꒃ�����\�Ȃ�ł���ǁE�E�E
���{��ł���
��������HW�v���t�F�b�`�̂������ŃV�[�P���V�����ȃ��[�h�͋����Ȃ��Ă��ۂ����邯��
�����_���e�[�u���Q�Ƃɂ͎ア�ł���B
�܂��r���L���b�V���͘A���ł̃��[�h�Ɏア��ł܂��A���ł���
>��������HW�v���t�F�b�`�̂������ŃV�[�P���V�����ȃ��[�h�͋����Ȃ��Ă��ۂ����邯��
>�����_���e�[�u���Q�Ƃɂ͎ア�ł���B
L2�L���b�V���ɉ��������Ă�̂��Ə��ꎞ��(ry
>�����_���e�[�u���Q�Ƃɂ͎ア�ł���B
L2�L���b�V���ɉ��������Ă�̂��Ə��ꎞ��(ry
http://www.xbitlabs.com/articles/cpu/display/dualcore-dtr-analysis.html
�����_���A�N�Z�X�����\�����݂��������ǁB
�����_���A�N�Z�X�����\�����݂��������ǁB
>>676
�����_���ƌ����Ă��K����������P�[�X���������牞�p�\�t�g����INTEL�̃v���t�F�b�`�@�\�͖��ɗ����Ă���B
�����đS���s�K���Ȃ�A�L���b�V�����̂��̂̃q�b�g���͑傫���ቺ����B
����ȃ\�t�g�͌��X���獂��CPU���g�������b�g�͂Ȃ��B
P2-450���x�ŏ\�����B
�����_���ƌ����Ă��K����������P�[�X���������牞�p�\�t�g����INTEL�̃v���t�F�b�`�@�\�͖��ɗ����Ă���B
�����đS���s�K���Ȃ�A�L���b�V�����̂��̂̃q�b�g���͑傫���ቺ����B
����ȃ\�t�g�͌��X���獂��CPU���g�������b�g�͂Ȃ��B
P2-450���x�ŏ\�����B
680 �F�E�́E�j��-������ ��toBASh.... �F2006/06/06(��) 21:30:31 ID:fZn03p89
��H
BLAST�Ɏg���Ă�SuffixTree�Ƃ�AC�Ƃ����ă����_���e�[�u���Q�Ƃɋ߂��Ǝv�����ǂȁB�A����Pen2���x�ŏ\���H������
BLAST�Ɏg���Ă�SuffixTree�Ƃ�AC�Ƃ����ă����_���e�[�u���Q�Ƃɋ߂��Ǝv�����ǂȁB�A����Pen2���x�ŏ\���H������
�L���b�V���������Ȃ��ƌ����Ă邾�����B
SuffixTree�Ƃ�AC�����\�L���b�V�������Ă����A���Ȃ�L2���Ċm���߂Ă݂�B
���łɁA�K����������INTEL�̃v���t�F�b�`�@�\���ł������悭�@�\���Ă���\�t�g�̑�\�Ⴊ�ΏĂ����B
SuffixTree�Ƃ�AC�����\�L���b�V�������Ă����A���Ȃ�L2���Ċm���߂Ă݂�B
���łɁA�K����������INTEL�̃v���t�F�b�`�@�\���ł������悭�@�\���Ă���\�t�g�̑�\�Ⴊ�ΏĂ����B
AMD Efficeon
683 �F�E�́E�j��-������ ��toBASh.... �F2006/06/06(��) 21:36:40 ID:fZn03p89
�L���b�V���������Ă���Ă̂͂킩�邪�A���C�e���V�Z���ɉz�������Ƃ͖���������B
�L���b�V���Ƀq�b�g���Ȃ��͖̂��O�Ƃ��Ă��B
�L���b�V���Ƀq�b�g���Ȃ��͖̂��O�Ƃ��Ă��B
����FFT�����烉���_�����C�g�������_�����[�h������͂������ǁB
L2�̃����_���A�N�Z�X�Ɋւ��ẮA�ˑ����̂��郉���_���Ȃ�
���C�e���V������ɐH����Ēx���Ȃ邯�ǁi�g���b�v�����Ȃǁj�A
�e���[�h�Ɉˑ������Ȃ���Ε�����s�ł��邩�烉���_���ł�
Intel�̋��LL2�͂������������B
L2�̃����_���A�N�Z�X�Ɋւ��ẮA�ˑ����̂��郉���_���Ȃ�
���C�e���V������ɐH����Ēx���Ȃ邯�ǁi�g���b�v�����Ȃǁj�A
�e���[�h�Ɉˑ������Ȃ���Ε�����s�ł��邩�烉���_���ł�
Intel�̋��LL2�͂������������B
685 �F�E�́E�j��-������ ��toBASh.... �F2006/06/06(��) 21:44:41 ID:fZn03p89
�u�����I���}���h�N�Z�[�v���{��
>>683
����͂��������AL2�����������Ă��Ă̂��^��B
�����AMD�Ђ̏ꍇ�AL1L2�r���\��������n�[�h�v���t�F�b�`�@�\�̋����͓���B
INTEL�͗v���v����L2�ւ̃v���t�F�b�`�AL1L2�ւ̃v���t�F�b�`����肭�g�������Ă���B
L2�L���b�V�����傫�����C��������̃L���b�V���ێ��\�͂�������������ʓI���B
����͂��������AL2�����������Ă��Ă̂��^��B
�����AMD�Ђ̏ꍇ�AL1L2�r���\��������n�[�h�v���t�F�b�`�@�\�̋����͓���B
INTEL�͗v���v����L2�ւ̃v���t�F�b�`�AL1L2�ւ̃v���t�F�b�`����肭�g�������Ă���B
L2�L���b�V�����傫�����C��������̃L���b�V���ێ��\�͂�������������ʓI���B
�����ł̓n�[�h�ڐ��ŃL���b�V���̐��\��_���Ă���B
�v���O���}�͂ǂ������L���b�V���̐��\���t���Ɉ����o���邩��_���Ă���B
�ʔ����ˁB
�v���O���}�͂ǂ������L���b�V���̐��\���t���Ɉ����o���邩��_���Ă���B
�ʔ����ˁB
Houd��L2:512KB�AL3:2MB���Ƃ����
L1L2��Inclusion��L3��Victim�L���b�V���Ƃ����̂���ԗ��z�H
L1L2��Inclusion��L3��Victim�L���b�V���Ƃ����̂���ԗ��z�H
689 �F�E�́E�j��-������ ��toBASh.... �F2006/06/06(��) 21:53:27 ID:fZn03p89
���AIntel���Đ̂��烌�C�e���V�d����L1�i��������L2�܂�)�̃L���b�V�����킴�Ə���������`���[�j���O����ł���
�i�܂���Itanium��NetBurst�������j
����Ńx���`�ɂ͂߂��ۂ������B
�i�܂���Itanium��NetBurst�������j
����Ńx���`�ɂ͂߂��ۂ������B
�n�[�h�E�G�A�v���t�F�b�`�����ɂ������Ă̂��r���L���b�V���̃f�����b�g�Ȃ̂��B
���ɔr������߂�ꍇ�A�ǂ̂��炢�v�ύX�̎�Ԃ�������낤�B
����512KB*4+2MB���ăo�����X�����Ǝv�����ǂȁB
���ɔr������߂�ꍇ�A�ǂ̂��炢�v�ύX�̎�Ԃ�������낤�B
����512KB*4+2MB���ăo�����X�����Ǝv�����ǂȁB
>>688
AMD���{�C�ŃL���b�V���\����ς���̂Ȃ炻�ꂪ���z�ł��傤�B
>>689
INTEL��dual port������L1��3�N���b�N�ł��\�������B
>>690
�A�N�Z�X�̎d�g�݂����{����ς��B
�r���\���ł��邱�Ƃ���AMD�̏ꍇ�AL1L2�֓����ɔ��߂��Ă���B
Inclusion���ƁAL1�~�X��L2�֔��߁B
AMD���{�C�ŃL���b�V���\����ς���̂Ȃ炻�ꂪ���z�ł��傤�B
>>689
INTEL��dual port������L1��3�N���b�N�ł��\�������B
>>690
�A�N�Z�X�̎d�g�݂����{����ς��B
�r���\���ł��邱�Ƃ���AMD�̏ꍇ�AL1L2�֓����ɔ��߂��Ă���B
Inclusion���ƁAL1�~�X��L2�֔��߁B
Inclusion�ł�L1L2�֓����ɔ��߂���L2���C�e���V�B���Ƃ����Ă�������Ȃ��H
����K8��L1�̓��[�h*2��[�h�X�g�A������X�g�A*2���ł���
Intel��L1��葬���Ǝv���B�e�ʂ��ł������B
�������A2way�Ƃ����̂���݂�ˁB
����K8��L1�̓��[�h*2��[�h�X�g�A������X�g�A*2���ł���
Intel��L1��葬���Ǝv���B�e�ʂ��ł������B
�������A2way�Ƃ����̂���݂�ˁB
>Inclusion���ƁAL1�~�X��L2�֔��߁B
�Ӗ��s���B
Inclusion�ƊW�Ȃ������B
�Ӗ��s���B
Inclusion�ƊW�Ȃ������B
>>692
> Inclusion�ł�L1L2�֓����ɔ��߂���L2���C�e���V�B���Ƃ����Ă�������Ȃ��H
�����Ƀq�b�g���邩�炻��͕s�����B
> Intel��L1��葬���Ǝv���B
>>673�̕\��32KB�܂ł��m�F����B
> Inclusion�ł�L1L2�֓����ɔ��߂���L2���C�e���V�B���Ƃ����Ă�������Ȃ��H
�����Ƀq�b�g���邩�炻��͕s�����B
> Intel��L1��葬���Ǝv���B
>>673�̕\��32KB�܂ł��m�F����B
>>693
L2�ւ̔��߂́A�q�b�g�����ꍇL1�ւ̃��[�h�ł�����B
�����ɔ��߂���ƁAL1���X�V����Ă����ꍇ�AL2���߂ɂ��L2�ێ��l�ɒu���ς���Ă��܂����疳���B
�r���\�����Ƃ��̂悤�Ȗ����Ȃ�����OK�B
AMD�͂��̂��Ƃ��������Ă����B
L2�ւ̔��߂́A�q�b�g�����ꍇL1�ւ̃��[�h�ł�����B
�����ɔ��߂���ƁAL1���X�V����Ă����ꍇ�AL2���߂ɂ��L2�ێ��l�ɒu���ς���Ă��܂����疳���B
�r���\�����Ƃ��̂悤�Ȗ����Ȃ�����OK�B
AMD�͂��̂��Ƃ��������Ă����B
>�����Ƀq�b�g���邩�炻��͕s�����B
�������A�����Ƀq�b�g������L1����ǂނ悤�ȃ��W�b�N��lj�����̂��B
> >>673�̕\��32KB�܂ł��m�F����B
���̃x���`�ł́A�Ƃ������Ƃł���B
Opteron�̐����͗��z��Ԃ�肩�Ȃ�Ⴂ�B
�܂��A�����L1���\�̈�ʂȂ̂͊m�������ǁB
�i��N���b�N���Ⴂ�Ƃ��̂�����j
�����A������������������Ƃ킩��Ȃ��Ȃ邪�A
�P�Ƀx���`���ʂ�����Intel��L1�������Ǝv���Ă���Ȃ�
���_�������Ǝv�����܂ŁB
�������A�����Ƀq�b�g������L1����ǂނ悤�ȃ��W�b�N��lj�����̂��B
> >>673�̕\��32KB�܂ł��m�F����B
���̃x���`�ł́A�Ƃ������Ƃł���B
Opteron�̐����͗��z��Ԃ�肩�Ȃ�Ⴂ�B
�܂��A�����L1���\�̈�ʂȂ̂͊m�������ǁB
�i��N���b�N���Ⴂ�Ƃ��̂�����j
�����A������������������Ƃ킩��Ȃ��Ȃ邪�A
�P�Ƀx���`���ʂ�����Intel��L1�������Ǝv���Ă���Ȃ�
���_�������Ǝv�����܂ŁB
>>691
dual port�̈Ӗ��킩���ĂȂ�����H
intel�̂�load 1port�Astore 1port�Œ��dual port�BAMD�̂�load/store*2��dual port�B
���łɌ��sK8��L1-Data�L���b�V����64KB, 2-way set associative, 64byte-line, 3 clock cycle int latency, dual port�����H
ttp://www.septor.net/specs/intel/processors.html
ttp://www.septor.net/specs/amd/processors.html
�E�E�E�G���Ȃ̃o���o���Bw
dual port�̈Ӗ��킩���ĂȂ�����H
intel�̂�load 1port�Astore 1port�Œ��dual port�BAMD�̂�load/store*2��dual port�B
���łɌ��sK8��L1-Data�L���b�V����64KB, 2-way set associative, 64byte-line, 3 clock cycle int latency, dual port�����H
ttp://www.septor.net/specs/intel/processors.html
ttp://www.septor.net/specs/amd/processors.html
�E�E�E�G���Ȃ̃o���o���Bw
698 �FSocket774�F2006/06/06(��) 23:53:48 ID:dppsqkgh
>>212
> ����p�r�����̃G���R�[�h/�����_�����O�A�N�Z�����[�^�݂����Ȃ̂��m���ɖʔ������ȁB
CPU���ƃ}���`���f�B�A�ɓ������Ă��܂����̂��l�b�g�o�[�X�g�Ȃ�Ȃ��́H
�ƁA����������̒m���Ń��X���Ă݂�B
����ɂ��Ă����O��ڂ����ȁB
�d�C�n�̊w�ȏo�g�Ȃ̂��H
���w�ȑ��̉��ɂ͂��Ă�����B
> ����p�r�����̃G���R�[�h/�����_�����O�A�N�Z�����[�^�݂����Ȃ̂��m���ɖʔ������ȁB
CPU���ƃ}���`���f�B�A�ɓ������Ă��܂����̂��l�b�g�o�[�X�g�Ȃ�Ȃ��́H
�ƁA����������̒m���Ń��X���Ă݂�B
����ɂ��Ă����O��ڂ����ȁB
�d�C�n�̊w�ȏo�g�Ȃ̂��H
���w�ȑ��̉��ɂ͂��Ă�����B
699 �FSocket774�F2006/06/06(��) 23:55:04 ID:dppsqkgh
���ŁA���LL3��Z-RAM�H
��ʓI�ɂ́A������cache�͍��������q�b�g�����Ⴍ�Ȃ�
INTEL����!�@���X��!
INTEL����!�@���X��!
INTEL����!�@���X��!
INTEL����!�@���X��!
INTEL����!�@���X��!
INTEL����!�@���X��!
RAM�̈�Ȃ�Č�t�Ŕ@���Ƃł��Ȃ邾�낤����Z�������Ă���\���L�邩���ˁB
DDR3���đ����˂�
K8���̂܂����ɐ����c��Ηǂ�����
�ш�m�ۂɓ�����AMD���� ���Ǝ������肵���������H
DDR3���đ����˂�
K8���̂܂����ɐ����c��Ηǂ�����
�ш�m�ۂɓ�����AMD���� ���Ǝ������肵���������H
>>700
Z-RAM�͐��i�ɂȂ�܂ł�2�N�͊|��ƌ����Ă����瑁����2008�N�ȍ~
Z-RAM�͐��i�ɂȂ�܂ł�2�N�͊|��ƌ����Ă����瑁����2008�N�ȍ~
�ߋ��̗�ł�2�N���Ă���������Ȃ��B
Hound���o�Ă��鍠�ɂ͒�g���\���Ă���1�N���͌o���Ă邵�AInnovative Silicon���ɂ�
�m�E�n�E�����܂��Ăđ����C���v�������g�o���邩����B
Hound���o�Ă��鍠�ɂ͒�g���\���Ă���1�N���͌o���Ă邵�AInnovative Silicon���ɂ�
�m�E�n�E�����܂��Ăđ����C���v�������g�o���邩����B
������Z-ram���g�p�����A ��-Opteron ���o��
��A���̎��̓C���^���[�u���ā@�y�y�@�ŁE�E�E
Z-RAM�͖{���A������̃������Ƃ��Ďg���̂��������p�@�B
�L���b�V���Ƃ��Ďg�p����͖̂���������B
�L���b�V���Ƃ��Ďg�p����͖̂���������B
L3�L���b�V�����āA�L���b�V�����L���b�V�������?
���ق�B
�r���L���b�V���Ȃ�A�c�ɋ߂�����傫�����āA�g�����O�����ɂ������
������ƒn������H
���ق�B
�r���L���b�V���Ȃ�A�c�ɋ߂�����傫�����āA�g�����O�����ɂ������
������ƒn������H
��ʓI�ɑ��x�Ƒ傫���͔����
712 �FSocket774�F2006/06/07(��) 11:10:53 ID:JHoWzvxa
ttp://mypage.odn.ne.jp/www/k/8/k8_hammer_trans/files/Hammer-Info.html
* L1�@2 x 128-bit data paths, 2 x loads/cycle
* L2�@���LL3�ɂ��conflict�i�Փˁj�̏����ɐ�O
* L3�@�����I�� (at the light time for customers) �e�ʂ𑝂₷�\��
L1,L2�r���L���b�V������Ȃ����Ă��ƁH
* L1�@2 x 128-bit data paths, 2 x loads/cycle
* L2�@���LL3�ɂ��conflict�i�Փˁj�̏����ɐ�O
* L3�@�����I�� (at the light time for customers) �e�ʂ𑝂₷�\��
L1,L2�r���L���b�V������Ȃ����Ă��ƁH
713 �FSocket774�F2006/06/07(��) 13:23:25 ID:53zcTtoa
>>667
L2���L���R�q�[�����V����ŗL���Ȃ̂͊m�������E�E�E���ۂɂǂ̒��x�̕p�x��
�R�q�[�����V����ɂ��y�i���e�B���������邩�^�₾�ȁB
�����̃X���b�h�����L����A�h���X�ɃA�N�Z�X����ꍇ�ł��A���ꂼ��̃A�N�Z�X
�^�C�~���O���R�q�[�����V����̃^�C�~���O�Ƃ���Ă���y�i���e�B�͂Ȃ��B
���L�A�h���X�ւ�read�������Awrite�����Ȃ��ꍇ���y�i���e�B�͏��Ȃ��B
4�R�A�Ƃ��Ȃ�ΑS�ẴX���b�h�����L�A�h���X���Q�Ƃ��A�����Aread/write��
���݂���A�N�Z�X�������ɏW������m���͋ɂ߂ď��Ȃ��Ǝv�����ȁB
�������A�}���`�\�P�b�g�����ł�L2���L�ɂ��R�q�[�����V����̗��_�͏�����B
���X�N�̊��ɂ͑債�����_����Ȃ��ȁB
L2���L���R�q�[�����V����ŗL���Ȃ̂͊m�������E�E�E���ۂɂǂ̒��x�̕p�x��
�R�q�[�����V����ɂ��y�i���e�B���������邩�^�₾�ȁB
�����̃X���b�h�����L����A�h���X�ɃA�N�Z�X����ꍇ�ł��A���ꂼ��̃A�N�Z�X
�^�C�~���O���R�q�[�����V����̃^�C�~���O�Ƃ���Ă���y�i���e�B�͂Ȃ��B
���L�A�h���X�ւ�read�������Awrite�����Ȃ��ꍇ���y�i���e�B�͏��Ȃ��B
4�R�A�Ƃ��Ȃ�ΑS�ẴX���b�h�����L�A�h���X���Q�Ƃ��A�����Aread/write��
���݂���A�N�Z�X�������ɏW������m���͋ɂ߂ď��Ȃ��Ǝv�����ȁB
�������A�}���`�\�P�b�g�����ł�L2���L�ɂ��R�q�[�����V����̗��_�͏�����B
���X�N�̊��ɂ͑債�����_����Ȃ��ȁB
��L3�L���b�V��
�����̂��v���o���Ċ����ɐZ�����B
�����̂��v���o���Ċ����ɐZ�����B
�l�I�ɂ�L3�L���b�V���]�X�̘b���o�Ă���ƁACPU�̖{���I�Ȑi�����h���l�܂��Ă��Ă�Ȃ��Ɗ�����
CPU�Ƃ�����胁�C�����������h���l�܂��Ă邩��
�L���b�V���Ȃ�Ęb�����Ȃ���Ȃ�Ȃ��Ȃ�킯�ŁE�E�E
�Ȃ�Ƃ��Ȃ�����
�L���b�V���Ȃ�Ęb�����Ȃ���Ȃ�Ȃ��Ȃ�킯�ŁE�E�E
�Ȃ�Ƃ��Ȃ�����
���v���K�v�Ȃ̂�CPU�Ƃ��n�[�h�ʂ����A�\�t�g�ʂ̕����ł����悤�ȋC�����Ȃ��ł��Ȃ�
OS�Ƃ�����
�ƊE�S�̂���x���Z�b�g�ł�����A���Ԃ[�U�[�ɂ͍K���Ȍ��ʂɂȂ�Ǝv��
�N�r�����郄�c������Ȃ�ɑ���������
�����ǂ��̐���l����������̕���������
�ƊE�̘A���͈�ۂƂȂ��Č�ɑ����҂����̑b�ƂȂ�̂��I
OS�Ƃ�����
�ƊE�S�̂���x���Z�b�g�ł�����A���Ԃ[�U�[�ɂ͍K���Ȍ��ʂɂȂ�Ǝv��
�N�r�����郄�c������Ȃ�ɑ���������
�����ǂ��̐���l����������̕���������
�ƊE�̘A���͈�ۂƂȂ��Č�ɑ����҂����̑b�ƂȂ�̂��I
�\�t�g�ʂ̐i�����ĂȂ���ˁB
�n�[�h�ʂ̐i����H���Ԃ��悤�Ȏd�l�����Ȃ��B
�n�[�h�ʂ̐i����H���Ԃ��悤�Ȏd�l�����Ȃ��B
�\�t�g���i�����Ă�Ƃ��ł͂��Ă��B
�H���Ԃ��悤�ȃ\�t�g�̂������̂͊m�������ǁB�B
���ƁA���ɑ�K�͂ȃ\�t�g�����̂́A
CPU�p���[��H���Ă��J��������D�悷�邵���Ȃ��B
�ł�Windows�d�������扽�Ƃ������HDD���H����������B
�H���Ԃ��悤�ȃ\�t�g�̂������̂͊m�������ǁB�B
���ƁA���ɑ�K�͂ȃ\�t�g�����̂́A
CPU�p���[��H���Ă��J��������D�悷�邵���Ȃ��B
�ł�Windows�d�������扽�Ƃ������HDD���H����������B
>>713
pen4��HT��penD�͂���ŋɒ[�Ƀp�t�H�[�}���X��������g���u����������������C���e���Ƃ��ẮB
�R�q�[�����V�̉��V�Ńf�b�h���b�N��ԂɂȂ�H�ȃP�[�X���L���ȃ\�t�g�Ŕ������Ă��܂����B
�T�[�o�[���������f�[�^�[�x�[�X���������B
pen4��HT��penD�͂���ŋɒ[�Ƀp�t�H�[�}���X��������g���u����������������C���e���Ƃ��ẮB
�R�q�[�����V�̉��V�Ńf�b�h���b�N��ԂɂȂ�H�ȃP�[�X���L���ȃ\�t�g�Ŕ������Ă��܂����B
�T�[�o�[���������f�[�^�[�x�[�X���������B
>>713
�R�q�[�����V����̕��ׂ͋��L�A�h���X�ȊO�ł����R�̂悤�ɔ�������B
�������Ȃ��Ă��A���̃R�A���F������L1,L2���ɗL���ȃL���b�V����ۗL���Ă��邩�̊m�F���s���K�v�����邩�炾�B
�܂�1�̃R�A���烍�[�h�v�����o�Ď�L1,L2���ɗL���ȃL���b�V�����Ȃ��ꍇ�A
���̃R�A�ɊY���A�h���X�̗L���L���b�V���̗L�����m�F����K�v��������B
������āA���̃R�A�͈�Ă�L1,L2�����������邱�ƂƂȂ�B
L2�����L������Ă���A���L��\�R�A�ɂ̂�L2���������s���悭�y���ɕ��ׂ͌y���Ȃ�B
�R�q�[�����V����̕��ׂ͋��L�A�h���X�ȊO�ł����R�̂悤�ɔ�������B
�������Ȃ��Ă��A���̃R�A���F������L1,L2���ɗL���ȃL���b�V����ۗL���Ă��邩�̊m�F���s���K�v�����邩�炾�B
�܂�1�̃R�A���烍�[�h�v�����o�Ď�L1,L2���ɗL���ȃL���b�V�����Ȃ��ꍇ�A
���̃R�A�ɊY���A�h���X�̗L���L���b�V���̗L�����m�F����K�v��������B
������āA���̃R�A�͈�Ă�L1,L2�����������邱�ƂƂȂ�B
L2�����L������Ă���A���L��\�R�A�ɂ̂�L2���������s���悭�y���ɕ��ׂ͌y���Ȃ�B
�M�����ɔ���Ղ��`����ׂɂ����\�������B
L2�̃R�q�[�����V����͋��L������Ă���L���b�V���P�ʂŗǂ��Ƃ������Ƃ��B
L2�̃R�q�[�����V����͋��L������Ă���L���b�V���P�ʂŗǂ��Ƃ������Ƃ��B
725 �FSocket774�F2006/06/07(��) 19:05:54 ID:+PzfC7Ru
������Athlon�̓V�X�e���o�X��Rapid I/0���̗p
http://pc.watch.impress.co.jp/docs/2006/0607/comp03.htm
http://pc.watch.impress.co.jp/docs/2006/0607/comp03.htm
>>724
������g�����瑼�l�ɂ͉����Ȃ邾�����낗
������g�����瑼�l�ɂ͉����Ȃ邾�����낗
>>726
����ɐ��p��Ǝv�����ݔ��ꂽ�犬���ȁB
����ɐ��p��Ǝv�����ݔ��ꂽ�犬���ȁB
���C�����������C�e���V��PC9801�����舫�����Ă�
���炠�A���̎���̓������m�[�E�F�C�g�A�ȂƂ���
���蕶�傪���������ゾ���B
���蕶�傪���������ゾ���B
����1T-SRAM�Ή��ɂȂ�����ǂ炢�����Ȃ��B
��14�� PC�̃G���W���u�v���Z�b�T�v�̗��j�i8�j�`Intel�ɒ��킵������AMD
2. NexGen�̔�����AMD��Intel�̃��C�o����
http://www.atmarkit.co.jp/fsys/pcencyclopedia/014procs_hist08/procs_hist16.html
>�x���`�}�[�N�E�e�X�g����Ƀ��f���i���o�[��ݒ肷�邱�Ƃɂ́A
>�ȉ��̂悤�Ȗ�肪����ƁA�M�҂͎v���Ă���B
>
>1. �x���`�}�[�N�E�e�X�g�̑唼�̓V�X�e���E���x���̐��\���v��������̂ł���A
>�v���Z�b�T�P�̂ł̐��\�ƕK��������v���Ȃ�
>2. �x���`�}�[�N�E�e�X�g���̂��APC�̗��p���̕ω��ȂǂɂƂ��Ȃ��A
>���N�̂悤�ɍX�V�������̂Ȃ̂ŁA�ߋ��̐��i�ɑ��鑊�ΐ��\�����v�����邱�Ƃ�����ł���
>3. �x���`�}�[�N�E�e�X�g�́A�Ƃ��ɋɂ߂Đ����I�Ȃ��̂ł���A
>�v���Z�b�T���邢�̓R���s���[�^�E�V�X�e���������\�̂��鑤�ʂ��v��������̂ł����Ȃ�
2. NexGen�̔�����AMD��Intel�̃��C�o����
http://www.atmarkit.co.jp/fsys/pcencyclopedia/014procs_hist08/procs_hist16.html
>�x���`�}�[�N�E�e�X�g����Ƀ��f���i���o�[��ݒ肷�邱�Ƃɂ́A
>�ȉ��̂悤�Ȗ�肪����ƁA�M�҂͎v���Ă���B
>
>1. �x���`�}�[�N�E�e�X�g�̑唼�̓V�X�e���E���x���̐��\���v��������̂ł���A
>�v���Z�b�T�P�̂ł̐��\�ƕK��������v���Ȃ�
>2. �x���`�}�[�N�E�e�X�g���̂��APC�̗��p���̕ω��ȂǂɂƂ��Ȃ��A
>���N�̂悤�ɍX�V�������̂Ȃ̂ŁA�ߋ��̐��i�ɑ��鑊�ΐ��\�����v�����邱�Ƃ�����ł���
>3. �x���`�}�[�N�E�e�X�g�́A�Ƃ��ɋɂ߂Đ����I�Ȃ��̂ł���A
>�v���Z�b�T���邢�̓R���s���[�^�E�V�X�e���������\�̂��鑤�ʂ��v��������̂ł����Ȃ�
>>722
�E�E�E�L���b�V���Ԃŋ��L���Ă���f�[�^�̓�������鐧����R�q�[�����V����Ƃ������ȁB
�܂��A����͒u���Ƃ��Ƃ��Ă����̗��Conroe�ɓ��Ă͂߂Ă݂��̂��H
Conroe�ł́u1�̃R�A���烍�[�h�v�����o�Ď�L1,L2���ɗL���ȃL���b�V�����Ȃ��ꍇ�v��
�ⓚ���p�Ń�������ǂ݂ɍs�������Ȃ����ȁB
�Ȃɂ��A2�̃R�A��L2�����L���Ă����A��������̃R�A�ɖ₢���킹���Ƃ���Ńf�[�^��
����͂��Ȃ�����B
�X��Conroe�̏ꍇ�AL1/L2��Inclusive������L2�ɂȂ����̂�L1�ɂ����蓾�Ȃ����H
Woodcrest�Ń}���`�\�P�b�g���Ȃ�AFSB�o�R�ŕʃ\�P�b�g�̃R�A�ɖ₢���킹�邱�ƂɂȂ邪�ȁB
�ڑ����Ă���`�b�v�Z�b�g��Blackford�Ȃ�A���\��ς��ȁB
�ʃ\�P�b�g�ɖ₢���킹��̂�FSB��Blackford��FSB��2���FSB���o�R���Ȃ���Ȃ�A�₢���킹��
���ʂ��������[�g��H�邩��ȁB
��������Blackford�ɐڑ���������A���������ʂɃ�������ǂ݂ɍs�����������������m���B
�E�E�E�L���b�V���Ԃŋ��L���Ă���f�[�^�̓�������鐧����R�q�[�����V����Ƃ������ȁB
�܂��A����͒u���Ƃ��Ƃ��Ă����̗��Conroe�ɓ��Ă͂߂Ă݂��̂��H
Conroe�ł́u1�̃R�A���烍�[�h�v�����o�Ď�L1,L2���ɗL���ȃL���b�V�����Ȃ��ꍇ�v��
�ⓚ���p�Ń�������ǂ݂ɍs�������Ȃ����ȁB
�Ȃɂ��A2�̃R�A��L2�����L���Ă����A��������̃R�A�ɖ₢���킹���Ƃ���Ńf�[�^��
����͂��Ȃ�����B
�X��Conroe�̏ꍇ�AL1/L2��Inclusive������L2�ɂȂ����̂�L1�ɂ����蓾�Ȃ����H
Woodcrest�Ń}���`�\�P�b�g���Ȃ�AFSB�o�R�ŕʃ\�P�b�g�̃R�A�ɖ₢���킹�邱�ƂɂȂ邪�ȁB
�ڑ����Ă���`�b�v�Z�b�g��Blackford�Ȃ�A���\��ς��ȁB
�ʃ\�P�b�g�ɖ₢���킹��̂�FSB��Blackford��FSB��2���FSB���o�R���Ȃ���Ȃ�A�₢���킹��
���ʂ��������[�g��H�邩��ȁB
��������Blackford�ɐڑ���������A���������ʂɃ�������ǂ݂ɍs�����������������m���B
�c�_�̖{���炻��Đ\����Ȃ����AInclusive���Ė{���H
���Ȃ��Ƃ�prefetchnta���߂��g�����Ƃ���L2����������L1�Ƀ��[�h����͂��B
���ɂ��A���炩�̗��R��L2���������ꂽ�Ƃ���L1�̃f�[�^���u�����Ȃ��v�Ƃ���
��������āA�q�b�g�������Ȃ炱�����̂������B
���Ȃ��Ƃ�prefetchnta���߂��g�����Ƃ���L2����������L1�Ƀ��[�h����͂��B
���ɂ��A���炩�̗��R��L2���������ꂽ�Ƃ���L1�̃f�[�^���u�����Ȃ��v�Ƃ���
��������āA�q�b�g�������Ȃ炱�����̂������B
>>734
���̃p�^�[��������̂��E�E�E�����A�L���b�V���Ɋi�[���ꂽ�l��L1/L2�ňႤ�����m��ǃA�h���X�͈ꏏ����Ȃ��H
���[�h�v�����o��ꍇ�A�w�肷��̂͒l����Ȃ��A�h���X�����猋�Lj���������Ȃ��͂������ǁB
���̃p�^�[��������̂��E�E�E�����A�L���b�V���Ɋi�[���ꂽ�l��L1/L2�ňႤ�����m��ǃA�h���X�͈ꏏ����Ȃ��H
���[�h�v�����o��ꍇ�A�w�肷��̂͒l����Ȃ��A�h���X�����猋�Lj���������Ȃ��͂������ǁB
�A�h���X�ꏏ�Œl���Ⴄ���Ă̂������Ȃ�Ȃ��́H
���܂�ڂ����͂킩��ǁB
L1L2�̃^�O���������炢�̓L���b�V�����C�e���V��
�B���ł������Ȏ�Ԃɂ��v����B
���܂�ڂ����͂킩��ǁB
L1L2�̃^�O���������炢�̓L���b�V�����C�e���V��
�B���ł������Ȏ�Ԃɂ��v����B
�E�E�E��[�A�ǂ��Ȃ�H
�]����intelCPU�Ȃ�L1��write through/inclusive�̂͂�������L1�ɂ���A�h���X��L2�ɂ�����Ǝv�����ǁB
�l�ɂ��Ă͊m���ɈႤ�̂͋C�����������Awrite through�ł�L1��L2�ł̓��C�e���V���Ⴄ����A�u�ԓI�ɂ�
����������ʂ������Ȃ����Ǝv�����E�E�E
�Ƃ肠�����A�{��̃R�q�[�����V����Ƃ͑S���Ⴄ�b���ȁB
�]����intelCPU�Ȃ�L1��write through/inclusive�̂͂�������L1�ɂ���A�h���X��L2�ɂ�����Ǝv�����ǁB
�l�ɂ��Ă͊m���ɈႤ�̂͋C�����������Awrite through�ł�L1��L2�ł̓��C�e���V���Ⴄ����A�u�ԓI�ɂ�
����������ʂ������Ȃ����Ǝv�����E�E�E
�Ƃ肠�����A�{��̃R�q�[�����V����Ƃ͑S���Ⴄ�b���ȁB
P6/PenM�̓��C�g�o�b�N���ł��B
�Ă���������x86�Ń��C�g�X���[��P4���炢�̂��́B
�Ă���������x86�Ń��C�g�X���[��P4���炢�̂��́B
>>738
Thanks!
�������������ĂČ������B
�[���Ƃ�L1�ɂ�����L2�ɂȂ��f�[�^���ꎞ�I�ɔ��������ʂ͂���E�E�E
�ꉞ�AL1�ɖ₢���킹�邱�Ƃ͂���ȁB
�E�E�E�����A>>722�̌����悤�ɋ��L/�L�W�Ȃ��ɖ₢���킹�Ă܂���Ă���A�}���`�\�P�b�g������
���܂��ȁE�E�E4MByte���̃L���b�V���̓��e�����������o�X��ʂ��Ă���o�X�������ɖO�a����B
Thanks!
�������������ĂČ������B
�[���Ƃ�L1�ɂ�����L2�ɂȂ��f�[�^���ꎞ�I�ɔ��������ʂ͂���E�E�E
�ꉞ�AL1�ɖ₢���킹�邱�Ƃ͂���ȁB
�E�E�E�����A>>722�̌����悤�ɋ��L/�L�W�Ȃ��ɖ₢���킹�Ă܂���Ă���A�}���`�\�P�b�g������
���܂��ȁE�E�E4MByte���̃L���b�V���̓��e�����������o�X��ʂ��Ă���o�X�������ɖO�a����B
�P���Ƀ^�O�ŊǗ����Ă��Ȃ��́H
���[�E�E�E�����Ă���C��������4M���ʂ��K�v�͂Ȃ����B
�~�����A�h���X�̏���ʂ��ςނȁB
�����AK8�̕���SRI�ƃL���b�V���Ԃ͑o�����Ɨ��o�X�����炻��قǒx���Ȃ��͂������ȁB
�ނ���A��USRI�ɗv���o������SRI����ʃR�A�ւ̖₢���킹�Ɠ����ɊO���R�A������R���g���[����
�v���A�h���X�̃p�P�b�g�����Ĉ�ԍŏ��ɋA���Ă����z��Ԃ�����������A�x�X�g�P�[�X�ł͎��邪
���[�X�g�P�[�X�̗������݂͏��Ȃ��͂������ȁB
�~�����A�h���X�̏���ʂ��ςނȁB
�����AK8�̕���SRI�ƃL���b�V���Ԃ͑o�����Ɨ��o�X�����炻��قǒx���Ȃ��͂������ȁB
�ނ���A��USRI�ɗv���o������SRI����ʃR�A�ւ̖₢���킹�Ɠ����ɊO���R�A������R���g���[����
�v���A�h���X�̃p�P�b�g�����Ĉ�ԍŏ��ɋA���Ă����z��Ԃ�����������A�x�X�g�P�[�X�ł͎��邪
���[�X�g�P�[�X�̗������݂͏��Ȃ��͂������ȁB
>>734
> ���Ȃ��Ƃ�prefetchnta���߂��g�����Ƃ���L2����������L1�Ƀ��[�h����͂��B
> ���ɂ��A���炩�̗��R��L2���������ꂽ�Ƃ���L1�̃f�[�^���u�����Ȃ��v�Ƃ���
> ��������āA�q�b�g�������Ȃ炱�����̂������B
�s�\����B
Inclusive�̏ꍇ�E�E���߂̎�ނƂ��āAL2�����ւ̃��[�h��L1L2�ւ̃��[�h�AL2����L1�ւ̃��[�h��3��ނ����Ȃ��B
> ���Ȃ��Ƃ�prefetchnta���߂��g�����Ƃ���L2����������L1�Ƀ��[�h����͂��B
> ���ɂ��A���炩�̗��R��L2���������ꂽ�Ƃ���L1�̃f�[�^���u�����Ȃ��v�Ƃ���
> ��������āA�q�b�g�������Ȃ炱�����̂������B
�s�\����B
Inclusive�̏ꍇ�E�E���߂̎�ނƂ��āAL2�����ւ̃��[�h��L1L2�ւ̃��[�h�AL2����L1�ւ̃��[�h��3��ނ����Ȃ��B
> �E�E�E�����A>>722�̌����悤�ɋ��L/�L�W�Ȃ��ɖ₢���킹�Ă܂���Ă���A�}���`�\�P�b�g������
> ���܂��ȁE�E�E4MByte���̃L���b�V���̓��e�����������o�X��ʂ��Ă���o�X�������ɖO�a����B
������L1L2�ɗL���f�[�^�����݂��Ȃ����A��������胍�[�h����O�ɑ��̃R�A�ɕK���₢���킷�B
����펯�ł���A���ꂵ�Ȃ��Ƙ_���I�ɃR�q�[�����V����ł��Ȃ��B
���R�̂��Ƃ����AOpteron�������B
�₢���킹���s�v�ȃP�[�X�́A������L1L2�ɗL���f�[�^�����݂��A���̃f�[�^���L�f�[�^�ł������ꍇ�������B
>733
> �E�E�E�L���b�V���Ԃŋ��L���Ă���f�[�^�̓�������鐧����R�q�[�����V����Ƃ������ȁB
���L�L�̔��f������ׂɂ��₢���킹���邵���Ȃ���B
> Conroe�ł́u1�̃R�A���烍�[�h�v�����o�Ď�L1,L2���ɗL���ȃL���b�V�����Ȃ��ꍇ�v��
> �ⓚ���p�Ń�������ǂ݂ɍs�������Ȃ����ȁB
Conroe�̏ꍇ�́A���R�A(�O���\�P�b�g�̂�)�����݂��Ȃ�����₢���킹�͔������Ȃ��B
Woodcrest��z�肵�Ĕ������Ă��邾������B
> �ڑ����Ă���`�b�v�Z�b�g��Blackford�Ȃ�A���\��ς��ȁB
�S�R�����������ƂȂ���A������K�����R�A�S�Ă�L2�̖₢���킹���s��Opteron���܂����B
> ���܂��ȁE�E�E4MByte���̃L���b�V���̓��e�����������o�X��ʂ��Ă���o�X�������ɖO�a����B
������L1L2�ɗL���f�[�^�����݂��Ȃ����A��������胍�[�h����O�ɑ��̃R�A�ɕK���₢���킷�B
����펯�ł���A���ꂵ�Ȃ��Ƙ_���I�ɃR�q�[�����V����ł��Ȃ��B
���R�̂��Ƃ����AOpteron�������B
�₢���킹���s�v�ȃP�[�X�́A������L1L2�ɗL���f�[�^�����݂��A���̃f�[�^���L�f�[�^�ł������ꍇ�������B
>733
> �E�E�E�L���b�V���Ԃŋ��L���Ă���f�[�^�̓�������鐧����R�q�[�����V����Ƃ������ȁB
���L�L�̔��f������ׂɂ��₢���킹���邵���Ȃ���B
> Conroe�ł́u1�̃R�A���烍�[�h�v�����o�Ď�L1,L2���ɗL���ȃL���b�V�����Ȃ��ꍇ�v��
> �ⓚ���p�Ń�������ǂ݂ɍs�������Ȃ����ȁB
Conroe�̏ꍇ�́A���R�A(�O���\�P�b�g�̂�)�����݂��Ȃ�����₢���킹�͔������Ȃ��B
Woodcrest��z�肵�Ĕ������Ă��邾������B
> �ڑ����Ă���`�b�v�Z�b�g��Blackford�Ȃ�A���\��ς��ȁB
�S�R�����������ƂȂ���A������K�����R�A�S�Ă�L2�̖₢���킹���s��Opteron���܂����B
744 �F�E�́E�j��-������ ��toBASh.... �F2006/06/08(��) 02:06:36 ID:qiLuZGZt
NetBurst�Ɠ�������艺��v256bit/clock��L1�ш���ւ�PPC G5�����C�g�X���[������
Core2�����C�g�X���[�̉\��������ˁH
Core2�����C�g�X���[�̉\��������ˁH
> �ʃ\�P�b�g�ɖ₢���킹��̂�FSB��Blackford��FSB��2���FSB���o�R���Ȃ���Ȃ�A�₢���킹��
> ���ʂ��������[�g��H�邩��ȁB
> ��������Blackford�ɐڑ���������A���������ʂɃ�������ǂ݂ɍs�����������������m���B
���ۂ̑��x�v�Z���Ă��猾���Ă���B
���̏������́A�̈ӂ�FSB�o�R���ƕ��������x���ቺ���邩�̂悤�ɕ\�����Ă���B
����������̓ǂ݂������ǂ�قǑ傫�Ȏ��Ԃ�v���邩�m���Ă��Ă��̂悤�ɏ����͈̂��ӂ����������Ȃ��B
L1L2�̑������ԁA�R�Ato�R�A��(FSB�o�R)�̑��M���Ԃɕ����Đ����������������Ă���B
> ���ʂ��������[�g��H�邩��ȁB
> ��������Blackford�ɐڑ���������A���������ʂɃ�������ǂ݂ɍs�����������������m���B
���ۂ̑��x�v�Z���Ă��猾���Ă���B
���̏������́A�̈ӂ�FSB�o�R���ƕ��������x���ቺ���邩�̂悤�ɕ\�����Ă���B
����������̓ǂ݂������ǂ�قǑ傫�Ȏ��Ԃ�v���邩�m���Ă��Ă��̂悤�ɏ����͈̂��ӂ����������Ȃ��B
L1L2�̑������ԁA�R�Ato�R�A��(FSB�o�R)�̑��M���Ԃɕ����Đ����������������Ă���B
746 �F�E�́E�j��-������ ��toBASh.... �F2006/06/08(��) 03:51:09 ID:qiLuZGZt
���������ꂱ��
http://pc8.2ch.net/test/read.cgi/tech/1136527588/352
AMD��SSE�g���̌���INSERTQ��EXTRQ���L���[���삾�Ƃ������Ă��d�g�L�҂���������
�A���͐�ΊԈႢ���낤
http://pc8.2ch.net/test/read.cgi/tech/1136527588/352
AMD��SSE�g���̌���INSERTQ��EXTRQ���L���[���삾�Ƃ������Ă��d�g�L�҂���������
�A���͐�ΊԈႢ���낤
>>745
���ۂ̑��x���v�Z����͖̂������ȁB
�₢���킹�̊ԁA2�{��FSB�����b�N���āA���̃R�A����̃A�N�Z�X��S���u���b�N����ƌ����Ȃ�b�͕ʂ����B
SCSI�Ɠ����悤�ɁA��U�₢���킹�𓊂��I������o�X��������Ă���ƁA�o�X�̎g�p��������������B
�������Ă�ԁA���̃R�A���ǂ̒��xFSB�𗘗p���āA�ǂ̒��x�҂����邱�ƂɂȂ邩�ȂP���ɂ͌v�Z�ł���B
�܂��A���z��Ԃő��̃R�A�͉������ĂȂ����Ă��ƂȂ炠����x�͌v�Z�ł��邾�낤���E�E�E�������ĂȂ��R�A��
�v������f�[�^�������Ă�Ƃ��v����A�i���Z���X���ȁB
���ۂ̑��x���v�Z����͖̂������ȁB
�₢���킹�̊ԁA2�{��FSB�����b�N���āA���̃R�A����̃A�N�Z�X��S���u���b�N����ƌ����Ȃ�b�͕ʂ����B
SCSI�Ɠ����悤�ɁA��U�₢���킹�𓊂��I������o�X��������Ă���ƁA�o�X�̎g�p��������������B
�������Ă�ԁA���̃R�A���ǂ̒��xFSB�𗘗p���āA�ǂ̒��x�҂����邱�ƂɂȂ邩�ȂP���ɂ͌v�Z�ł���B
�܂��A���z��Ԃő��̃R�A�͉������ĂȂ����Ă��ƂȂ炠����x�͌v�Z�ł��邾�낤���E�E�E�������ĂȂ��R�A��
�v������f�[�^�������Ă�Ƃ��v����A�i���Z���X���ȁB
�}���`�h���b�v�̃p�P�b�g�ʐM�ŊJ���Ă��������Ȃ����B
>>742
����A�s�\�ƌ����Ă��A�ł����ł����B�B
>Inclusive�̏ꍇ�E�E
������iP4�͂�����������Ȃ����ǁjP6��PenM��Core��
Not Inclusive�Ȃ��ĂB
����A�s�\�ƌ����Ă��A�ł����ł����B�B
>Inclusive�̏ꍇ�E�E
������iP4�͂�����������Ȃ����ǁjP6��PenM��Core��
Not Inclusive�Ȃ��ĂB
����Core Duo��Core2 Duo��������烁�������璼��L1�ւ̃v�����[�h���߂�uOP�ɕϊ�����Ƃ���
L1,L2�ւ̃v�����[�h���߂ɒu�������Ă��܂��B
���̂ق��������ƌ����������B
L1,L2�ւ̃v�����[�h���߂ɒu�������Ă��܂��B
���̂ق��������ƌ����������B
���łɌ����ƁA>>751�ł̓��[�h�f�[�^��L1�L���b�V���ւ̓]���̊����܂ł��������Ă���悭�AL2�ւ̓]���͊�������܂ŁA
���[�h�҂��X�g���[���ɕێ����Ă��������ŗǂ���������͑S���������Ȃ��B
���[�h�҂��X�g���[���ɕێ����Ă��������ŗǂ���������͑S���������Ȃ��B
�����m���Ă�̂�prefetchnta���߂��g�����A�X�g�A���܂ރA�N�Z�X�̏ꍇ�B
���̖��߂�P6/PenM��L2���������Ȃ��i����Core2���������Ǝv���j�B
L2���g���Ȃ����߁AL1�̕ύX��L2�Ƀ��C�g�o�b�N���Ȃ��čςށB
L1L2�����փv�����[�h���閽�߂��g���Ƃ����������ƌ����������B
���̖��߂�P6/PenM��L2���������Ȃ��i����Core2���������Ǝv���j�B
L2���g���Ȃ����߁AL1�̕ύX��L2�Ƀ��C�g�o�b�N���Ȃ��čςށB
L1L2�����փv�����[�h���閽�߂��g���Ƃ����������ƌ����������B
���܂�A���f��Intel������X���Ɗ��Ⴂ���Ă��B
����̓X���Ⴂ�̎��o�����������ǁA�����̗���B�ړ����悤���H
����̓X���Ⴂ�̎��o�����������ǁA�����̗���B�ړ����悤���H
>>753
>>751,752�Ō����ς��A
L2�ւ̃��C�g�o�b�N��L1���ǂ��o���Ƃ��ŗǂ��B
�f���A���R�A��L2�����L�L���b�V�������Ă���̂����炻������B
>>751,752�Ō����ς��A
L2�ւ̃��C�g�o�b�N��L1���ǂ��o���Ƃ��ŗǂ��B
�f���A���R�A��L2�����L�L���b�V�������Ă���̂����炻������B
���̃X�����x�������E�E�E
����̒��ł͍ۗ����Ă��
����̒��ł͍ۗ����Ă��
preftchnta���č������ɏd�v�Ȗ��߂��Ǝv�����B
���̖��߂��g���Ă���R�[�h��1���x���Ȃ��Ă������́H
������C�g�o�b�N��L1����ǂ��o���Ƃ������A
�A���I�ɃA�N�Z�X����Ƃǂ�ǂ�ǂ��o�����B
���ۂ�L2��ʂ��ƃn�b�L���x���Ȃ�B
���̖��߂��g���Ă���R�[�h��1���x���Ȃ��Ă������́H
������C�g�o�b�N��L1����ǂ��o���Ƃ������A
�A���I�ɃA�N�Z�X����Ƃǂ�ǂ�ǂ��o�����B
���ۂ�L2��ʂ��ƃn�b�L���x���Ȃ�B
>>757
�x���Ȃ�Ȃ���B
�������Ă���̂�L1�ւ̓]���܂ł����A���Ƀ��C�g�o�b�N������
L2�ւ̃��[�h�҂��X�g���[���֒lj����邾��������x���Ȃ�Ȃ��B
L1�̓��[�h�҂��X�g���[���֒lj���ɒ����ɂ�����B
������L2�ւ̓]���̓��C�����Ă���Β��������A�J���ĂȂ��Ă��������ւ̓f���o���㒼���ɓ]�����Ă��܂���B
L1�ɕt���Ă͑S�����x�ቺ���Ȃ���B
����ƁAL2���o�R���邱�ƂŃ������ւ̓f���o���Ɠ��������Ȃ��ėǂ��Ȃ邩��t�ɑ����Ȃ�B
�x���Ȃ�Ȃ���B
�������Ă���̂�L1�ւ̓]���܂ł����A���Ƀ��C�g�o�b�N������
L2�ւ̃��[�h�҂��X�g���[���֒lj����邾��������x���Ȃ�Ȃ��B
L1�̓��[�h�҂��X�g���[���֒lj���ɒ����ɂ�����B
������L2�ւ̓]���̓��C�����Ă���Β��������A�J���ĂȂ��Ă��������ւ̓f���o���㒼���ɓ]�����Ă��܂���B
L1�ɕt���Ă͑S�����x�ቺ���Ȃ���B
����ƁAL2���o�R���邱�ƂŃ������ւ̓f���o���Ɠ��������Ȃ��ėǂ��Ȃ邩��t�ɑ����Ȃ�B
>>758
�S�����A���͎������Č����Ă���̂��B
�P���ɃX�g�A�ш���͂���ƁAprefetcht0���prefetchnta�������B
�m���ɂ��̗����͔[���ł���B�Ȃ�ł����Ȃ�̂��ȁB
���ƁA�ʂ�Not Inclusive�ł�L1�^�O��ύX������m�点��
���L�^�O��L2�^�O�̉��ɒu���Ζ��Ȃ��ˁH
�i�f�l�l���X�}�\�j
�S�����A���͎������Č����Ă���̂��B
�P���ɃX�g�A�ш���͂���ƁAprefetcht0���prefetchnta�������B
�m���ɂ��̗����͔[���ł���B�Ȃ�ł����Ȃ�̂��ȁB
���ƁA�ʂ�Not Inclusive�ł�L1�^�O��ύX������m�点��
���L�^�O��L2�^�O�̉��ɒu���Ζ��Ȃ��ˁH
�i�f�l�l���X�}�\�j
>>759
���₾����Aprefetcht0���prefetchnta�ł͑S�R�Ⴄ�ł���?
prefetcht0����751,752�ɂ͂Ȃ炸L2�ւ̓]������������܂ő҂�����������B
����?
���₾����Aprefetcht0���prefetchnta�ł͑S�R�Ⴄ�ł���?
prefetcht0����751,752�ɂ͂Ȃ炸L2�ւ̓]������������܂ő҂�����������B
����?
�X���Ⴂ�ȋC�����邯�ǖʔ������瑱���ĉ������B
> �ʂ�Not Inclusive�ł�L1�^�O��ύX������m�点��
> ���L�^�O��L2�^�O�̉��ɒu���Ζ��Ȃ��ˁH
����A�u���ꏊ�Ȃ��ł���A�r���L���b�V������B
> ���L�^�O��L2�^�O�̉��ɒu���Ζ��Ȃ��ˁH
����A�u���ꏊ�Ȃ��ł���A�r���L���b�V������B
�����ƁACore2�̘b�����Ă����ˁH�Ⴄ�́H
�r�����ĉ��B
�r�����ĉ��B
>>764
����ANot Inclusive���ď�����Ă�����Athlon64�̂��Ƃ������Ă�Ǝv������B
�Řb��Core�ɖ߂��ƁE�E�E
L2�^�O�ɒu���ʂȂ�L2�ւ̃��[�h�҂��X�g���[���֒lj�����ق��������ł���B
������̎��Ԃ������B
����ANot Inclusive���ď�����Ă�����Athlon64�̂��Ƃ������Ă�Ǝv������B
�Řb��Core�ɖ߂��ƁE�E�E
L2�^�O�ɒu���ʂȂ�L2�ւ̃��[�h�҂��X�g���[���֒lj�����ق��������ł���B
������̎��Ԃ������B
>>765
�����������Ƃ͑�̒m���Ă���B
prefetcht0��751,752�Ƃ͂ǂ��Ⴄ����Ȃ́H�������Ǝv�����ǁB
>>766
Not Inclusive���Ă̂͊��S��Inclusive�ł͂Ȃ����ĈӖ��ˁB
�Ⴆ��PenM��prefetchnta��L2������������L1�փ��[�h���邩��
Not Inclusive�ɂȂ�B
�����������Ƃ͑�̒m���Ă���B
prefetcht0��751,752�Ƃ͂ǂ��Ⴄ����Ȃ́H�������Ǝv�����ǁB
>>766
Not Inclusive���Ă̂͊��S��Inclusive�ł͂Ȃ����ĈӖ��ˁB
�Ⴆ��PenM��prefetchnta��L2������������L1�փ��[�h���邩��
Not Inclusive�ɂȂ�B
>>767
����A>>766�ŕ�����Ȃ�����?
prefetchnta��>>751-752���Ƃ����L2�ւ̓]�������Ȃ�x�ꂿ�Ⴄ�ł���?
�����āA���[�h�҂��X�g���[���̍Ō�Ƀ��[�h�ς�flg��L1�]���ς�flg��ON��L2�]���ς�flg��FF�ȏ�ԂŒlj������(�s�v)�B
>>765�̏�����Ă���ʂ�̎d�l�����B
����A>>766�ŕ�����Ȃ�����?
prefetchnta��>>751-752���Ƃ����L2�ւ̓]�������Ȃ�x�ꂿ�Ⴄ�ł���?
�����āA���[�h�҂��X�g���[���̍Ō�Ƀ��[�h�ς�flg��L1�]���ς�flg��ON��L2�]���ς�flg��FF�ȏ�ԂŒlj������(�s�v)�B
>>765�̏�����Ă���ʂ�̎d�l�����B
Not Inclusive�ŁAL2�����L�̃f���A���R�A�Ƃ���B
����ƁA�R�AA��L1L2�~�X�����Ƃ��ɁA�R�AB��L1�ׂȂ��Ƃ����Ȃ��B
�ŁA����͖ʓ|������AL2�ɂȂ��f�[�^���R�AB��L1�ŕύX�����Ƃ���
���LL2�̃^�O�i�̉��j�ɋL�^���Ă���������Ȃ����Ȃ��Ǝv�����B
>L2�ւ̃��[�h�҂��X�g���[���֒lj�����
���܂�A�Ӗ����킩������B�ǂ�����ǂ��ցH
����ƁA�R�AA��L1L2�~�X�����Ƃ��ɁA�R�AB��L1�ׂȂ��Ƃ����Ȃ��B
�ŁA����͖ʓ|������AL2�ɂȂ��f�[�^���R�AB��L1�ŕύX�����Ƃ���
���LL2�̃^�O�i�̉��j�ɋL�^���Ă���������Ȃ����Ȃ��Ǝv�����B
>L2�ւ̃��[�h�҂��X�g���[���֒lj�����
���܂�A�Ӗ����킩������B�ǂ�����ǂ��ցH
�����AL2�̕ێ��L���b�V����j�����Ȃ����߂��Ƃ���ƁA����͋��L�L���b�V�������邱�ƂŃR�q�[�����V����̌�����D�悵
>>751,752�ɒu��������Ɖ��͌����Ă�B
�܂�AL2�̕ێ��L���b�V���͐�����邱�ƂɂȂ�B
�ł��A���Ȃ炻������B
>>751,752�ɒu��������Ɖ��͌����Ă�B
�܂�AL2�̕ێ��L���b�V���͐�����邱�ƂɂȂ�B
�ł��A���Ȃ炻������B
>>772
�X�g�A���x���̂�L1�ւ̓]�����x���̂��s������B
�X�g�A���x���̂�L1�ւ̓]�����x���̂��s������B
>>773
�X�g�A���x���̂�L2�ւ̓]�����x���̂��s������B�ɕύX�B
�X�g�A���x���̂�L2�ւ̓]�����x���̂��s������B�ɕύX�B
�܂��A�v���t�F�b�`�̓�͎c�������ǁA
771�Ă�769�Ă��A�ǂ�����A����OK�H
771�Ă�769�Ă��A�ǂ�����A����OK�H
�m���e���|�����ȃX�g�A���߂̏ꍇ�AL2�ւ̃��[�h�҂��X�g���[����ɂ���P�[�X����
L2�ւ̓]����ł��胁���������o���X�g���[���ɒlj����邾���ŗǂ�����ˁB
����͑����B
�������A���[�h�҂��X�g���[�����傫���Ɍ��肪���邩�珈�����i�ނ�L2�ŕێ�����邱�ƂɂȂ�
���̏ꍇ�͂�������̓f���o���ƂȂ�B
���L�L���b�V���̓������l�����炱���Ȃ�B
L2�ւ̓]����ł��胁���������o���X�g���[���ɒlj����邾���ŗǂ�����ˁB
����͑����B
�������A���[�h�҂��X�g���[�����傫���Ɍ��肪���邩�珈�����i�ނ�L2�ŕێ�����邱�ƂɂȂ�
���̏ꍇ�͂�������̓f���o���ƂȂ�B
���L�L���b�V���̓������l�����炱���Ȃ�B
>L2�ւ̃��[�h�҂��X�g���[����ɂ���P�[�X
�ǂ������P�[�X�ł����B�N������҂��Ă�̂��킩��Ȃ��B
�ǂ������P�[�X�ł����B�N������҂��Ă�̂��킩��Ȃ��B
���낻�됮��
��{�`��>>751-752�ŗǂ��Aprefetchnta���߂̏ꍇL2�ێ��s�vflg��ON�ɂ��Ă����Ηǂ��B(���[�h�҂��X�g���[��)
L2�ێ��s�vflg��ON�̃X�g���[���̓X�g�A���߂ɂ�胍�[�h�҂��X�g���[���ɑ��݂���Ƃ���L2�ւ̓]����ł���
���̂܂܃����������o���X�g���[���ɒlj�����B
L2�ێ��s�vflg��OFF(prefetcht0)�̂��̂́AL2�ŕێ�����K�v������ׁA�X�g�A���߂����߂���Ă�L2�ւ̓]��������
�҂K�v��������B(�x���Ȃ闝�R)
����ŋ^��͑S�ĉ�������?
��{�`��>>751-752�ŗǂ��Aprefetchnta���߂̏ꍇL2�ێ��s�vflg��ON�ɂ��Ă����Ηǂ��B(���[�h�҂��X�g���[��)
L2�ێ��s�vflg��ON�̃X�g���[���̓X�g�A���߂ɂ�胍�[�h�҂��X�g���[���ɑ��݂���Ƃ���L2�ւ̓]����ł���
���̂܂܃����������o���X�g���[���ɒlj�����B
L2�ێ��s�vflg��OFF(prefetcht0)�̂��̂́AL2�ŕێ�����K�v������ׁA�X�g�A���߂����߂���Ă�L2�ւ̓]��������
�҂K�v��������B(�x���Ȃ闝�R)
����ŋ^��͑S�ĉ�������?
>>778
�A�h���X�}�b�`���O�Ɍ��܂��Ă��邳�ȁB
�A�h���X�}�b�`���O�Ɍ��܂��Ă��邳�ȁB
�X�g�A��nta��t0��1.5�{���炢�̐����ňႤ�̂ł��傢�ۗ��B
���ƁA���[�h�҂��X�g���[���Ƃ����p�ꂪ�Ӗ��s���Ȃ�ł����B�B
���ƁA���[�h�҂��X�g���[���Ƃ����p�ꂪ�Ӗ��s���Ȃ�ł����B�B
>>779�̐�����������ɂ́E�E�E�E
prefetchnta�����C���Ⴂ�ő�ʂɔ��s������ɁA�܂Ƃ߂ăX�g�A���߂s����B
�����ʂ�Ȃ�A�x���Ȃ�B
prefetchnta�����C���Ⴂ�ő�ʂɔ��s������ɁA�܂Ƃ߂ăX�g�A���߂s����B
�����ʂ�Ȃ�A�x���Ȃ�B
����܂���������p���B
�Ƃ������A���[�h�҂��X�g���[��=���������[�h���߂s�����[�h����Ă���܂ł̃o�b�t�@�̑��́B
���[�h���ꂽ�f�[�^��L1��L2�ɓ]������܂ŕێ������o�b�t�@�̂��ƂȁB
����������ꍇ�A�����Ȃ�B
�����āA���ꓙ���X�g���[���ƌĂуR�q�[�����V����ł̏Ɖ�͂������܂߂đ������邱�ƂƂȂ�B
�Ƃ������A���[�h�҂��X�g���[��=���������[�h���߂s�����[�h����Ă���܂ł̃o�b�t�@�̑��́B
���[�h���ꂽ�f�[�^��L1��L2�ɓ]������܂ŕێ������o�b�t�@�̂��ƂȁB
����������ꍇ�A�����Ȃ�B
�����āA���ꓙ���X�g���[���ƌĂуR�q�[�����V����ł̏Ɖ�͂������܂߂đ������邱�ƂƂȂ�B
>���[�h�҂��X�g���[��=���������[�h���߂s�����[�h����Ă���܂ł̃o�b�t�@�̑���
������Ɍ����Ă���Ȃ��Ƃ킩���āB��ʓI�ȗp�ꂶ��Ȃ���ˁH
���̃o�b�t�@���Ă̂̓L���b�V��������Ȃ����[�h���j�b�g��12�Ƃ������̂��Ƃ��B
�����������o���X�g���[���ɒlj�������Ă͉̂���?
���������A�u�������܂߂đ������邱�ƂƂȂ�v�����܂ł��̂��H
������Ɍ����Ă���Ȃ��Ƃ킩���āB��ʓI�ȗp�ꂶ��Ȃ���ˁH
���̃o�b�t�@���Ă̂̓L���b�V��������Ȃ����[�h���j�b�g��12�Ƃ������̂��Ƃ��B
�����������o���X�g���[���ɒlj�������Ă͉̂���?
���������A�u�������܂߂đ������邱�ƂƂȂ�v�����܂ł��̂��H
����A�e�X�g������������Ƃ����ɂ���Ă��B
�X�g�A�o�b�t�@�܂Ō��Ă��Ӗ��Ȃ��Ǝv�����ǁB
������1�N���b�N�x�ꂽ��_�����Ă���ł��Ȃ����A
�������Ƃ�Ă邱�Ƃ��m�F�ł����������B
�X�g�A�o�b�t�@�܂Ō��Ă��Ӗ��Ȃ��Ǝv�����ǁB
������1�N���b�N�x�ꂽ��_�����Ă���ł��Ȃ����A
�������Ƃ�Ă邱�Ƃ��m�F�ł����������B
>>787
�X�g�A�o�b�t�@�����邩�ۂ��͉�H�\���ɂ�邾��?
�X�g�A�o�b�t�@���������܂ŃL���b�V�����������Ɏc���Ȃ�݂�K�v�Ȃ��B
�t�ɃX�g�A�o�b�t�@�֓]���Ɠ����ɃL���b�V�����ɂ��X�g�A�����Ƃ���Ȃ猩�ɂ�Ȃ���B
�X�g�A�o�b�t�@�����邩�ۂ��͉�H�\���ɂ�邾��?
�X�g�A�o�b�t�@���������܂ŃL���b�V�����������Ɏc���Ȃ�݂�K�v�Ȃ��B
�t�ɃX�g�A�o�b�t�@�֓]���Ɠ����ɃL���b�V�����ɂ��X�g�A�����Ƃ���Ȃ猩�ɂ�Ȃ���B
��H�\���Ƃ�����Ȃ��āA
�x���Ȃ��Ă������Ȃ��œ����m�F������������A���Ă��ƁB
�x���Ȃ�ƌ����Ă�L2���C�e���V���x�����A
���肪L2�ɏ����I����Ă���Q�Ƃ���Α҂K�v���Ȃ����B
���̂��߂Ɏ��s���j�b�g�ɋ߂��Ƃ���Ɍ��ɍs�����Ă����̂�
CPU�̍������̖W���ɂȂ�Ǝv���B
�Ă��������݂��킩���ĂȂ���K�X�B�B
�x���Ȃ��Ă������Ȃ��œ����m�F������������A���Ă��ƁB
�x���Ȃ�ƌ����Ă�L2���C�e���V���x�����A
���肪L2�ɏ����I����Ă���Q�Ƃ���Α҂K�v���Ȃ����B
���̂��߂Ɏ��s���j�b�g�ɋ߂��Ƃ���Ɍ��ɍs�����Ă����̂�
CPU�̍������̖W���ɂȂ�Ǝv���B
�Ă��������݂��킩���ĂȂ���K�X�B�B
���R�A����Ɖ�̑������A�L���b�V���ێ��Ȃ���Ԃ��̂ɁA���̕ԐM��x�点��̂ł���?
�Ɖ�͕ԐM������܂Őg�����ł��Ȃ��̂�?
�Ɖ�͕ԐM������܂Őg�����ł��Ȃ��̂�?
>>790�͔��ɂ������Ȃ̂ŁA������₷���B
Opteron�u���l�̓n�C�p�[�����A���̃R�A�Ƃ͒����ɓ��������ɏƉ�p�P�b�g�����ő���M�o�������������!���͂́v
Opteron�u�ł́A�����牴�l�̐����Ƃ����������邺�A�Ƃ��[���ꂻ�ꃍ�[�h�v����������v
Opteron�uL1�L���b�V���Ȃ���L2�L���b�V���Ȃ����悵���ꂶ�ᑼ�R�A�փL���b�V���Ɖ�p�P�b�g���M!!!!!�v
���R�A�u�����A�X�Q�[�����ŏƉ�p�P�b�g����������v
���R�A�u�قႿ������璲�ׂĂ݂邩�ȁE�E�E�E�v
���R�A�u�����A�Ɖ�p�P�b�g�����O��10�����[�h�v�����Ă�ȁA����Ȃ����炻�ꂪ�ςނ܂ő҂Ƃ��邩�E�E�E�v
���R�A�u1�ځAL1�Ȃ��AL2�Ȃ��A�悵���[�h�O�ɑ��R�A�փL���b�V���Ɖ�p�P�b�g���M!!!!�v
Opteron�u�����A�ԐM�p�P�b�g�҂��Ă���Ɖ�p�P�b�g���������A����Ȃ����炿������璲�ׂĂ݂邩�ȁE�E�E�E�v
Opteron�u�����A�Ɖ�p�P�b�g�����O�Ƀ��[�h�v���҂�������ȁA���ꂶ��b���҂Ƃ��邩�E�E�E�v
���[�i�v�ɏI���Ȃ��E�E�E�E�E
Opteron�u���l�̓n�C�p�[�����A���̃R�A�Ƃ͒����ɓ��������ɏƉ�p�P�b�g�����ő���M�o�������������!���͂́v
Opteron�u�ł́A�����牴�l�̐����Ƃ����������邺�A�Ƃ��[���ꂻ�ꃍ�[�h�v����������v
Opteron�uL1�L���b�V���Ȃ���L2�L���b�V���Ȃ����悵���ꂶ�ᑼ�R�A�փL���b�V���Ɖ�p�P�b�g���M!!!!!�v
���R�A�u�����A�X�Q�[�����ŏƉ�p�P�b�g����������v
���R�A�u�قႿ������璲�ׂĂ݂邩�ȁE�E�E�E�v
���R�A�u�����A�Ɖ�p�P�b�g�����O��10�����[�h�v�����Ă�ȁA����Ȃ����炻�ꂪ�ςނ܂ő҂Ƃ��邩�E�E�E�v
���R�A�u1�ځAL1�Ȃ��AL2�Ȃ��A�悵���[�h�O�ɑ��R�A�փL���b�V���Ɖ�p�P�b�g���M!!!!�v
Opteron�u�����A�ԐM�p�P�b�g�҂��Ă���Ɖ�p�P�b�g���������A����Ȃ����炿������璲�ׂĂ݂邩�ȁE�E�E�E�v
Opteron�u�����A�Ɖ�p�P�b�g�����O�Ƀ��[�h�v���҂�������ȁA���ꂶ��b���҂Ƃ��邩�E�E�E�v
���[�i�v�ɏI���Ȃ��E�E�E�E�E
�����Ō������o�����B
���R�A����̏Ɖ�́A���������Ă��^����ɕԐM���邱�ƁA����܂ł͎��R�A�i�s��~����!
�����Ȃ�ƁA�ǂ����Ă������r�㕪����������K�v�������Ă��܂��Ƃ��E�E�E������B
���R�A����̏Ɖ�́A���������Ă��^����ɕԐM���邱�ƁA����܂ł͎��R�A�i�s��~����!
�����Ȃ�ƁA�ǂ����Ă������r�㕪����������K�v�������Ă��܂��Ƃ��E�E�E������B
>���R�A����̏Ɖ�́A���������Ă��^����ɕԐM���邱�ƁA����܂ł͎��R�A�i�s��~����!
���ꂪ�������������킯�����D�D
���ꂪ�������������킯�����D�D
���ł�������������[�������Ă݂悤��?
�R�A1�ƃR�A2�������ɑS�������A�h���X�����[�h����P�[�X������B
�R�A1:L1�Ȃ���L2�Ȃ������R�A�֏Ɖ�p�P�b�g���M
�R�A2:L1�Ȃ���L2�Ȃ������R�A�֏Ɖ�p�P�b�g���M
���̏ꍇ�̏����́A���R�A�����ɏƉ�p�P�b�g�𑗂��Ă��āA�����ɑ��R�A����̏Ɖ�p�P�b�g�����������P�[�X�B
���������Ɖ�p�P�b�g�̗v���A�h���X�Ǝ��g�����M�����Ɖ�p�P�b�g�̗v���A�h���X���������ꍇ�̓R�A�ԍ��̎Ⴂ���̂�D�悷��B
���g��2�Ԃő����Ă����Ɖ��1�Ԃ�������A1�Ԃ�D�悷�邩��1�Ԃ���̕ԐM���Ђ�����҂������邱�ƂɂȂ�B
�R�A1�́A�D�悳��Ă���̂Ń��[�h�v�����������[����Ƌ��Ƀ��[�h�҂��X�g���[���ɏ����u���A���̂Ƃ��R�A2����̏Ɖ������Ă���̂�
���Lflg��ON�ɂ��Ɖ�p�P�b�g�����[�h�҂��̈�Ɉڂ��B
���̌�A���ۂɃ���������f�[�^�����[�h���ꂽ�Ƃ����Lflg��ON�ł��邩�烍�[�h�҂��̈�Ɉڂ��Ă������Ɖ�p�P�b�g�̑��M��փf�[�^��ԐM����B
�R�A2�̓R�A�P���̕ԐM���f�[�^�t�Ȃ̂Ń��������[�h�ς�flg�𗧂Ăă��[�h�҂��X�g���[���ɏ����u���A���̂Ƃ��̋��Lflg��ON�̂܂܂��B
���[�h�҂��X�g���[���̃��������[�h�ς�flg�ɕω����������̂ŁA���Lflg��ON�ł��邩�烍�[�h�҂��̈�Ɉڂ��Ă������Ɖ�p�P�b�g�𑖍����邪���q�b�g�Ȃ̂�
���̂܂�L1L2�֓]������B
����Ȋ����ł��ȁB
�R�A1�ƃR�A2�������ɑS�������A�h���X�����[�h����P�[�X������B
�R�A1:L1�Ȃ���L2�Ȃ������R�A�֏Ɖ�p�P�b�g���M
�R�A2:L1�Ȃ���L2�Ȃ������R�A�֏Ɖ�p�P�b�g���M
���̏ꍇ�̏����́A���R�A�����ɏƉ�p�P�b�g�𑗂��Ă��āA�����ɑ��R�A����̏Ɖ�p�P�b�g�����������P�[�X�B
���������Ɖ�p�P�b�g�̗v���A�h���X�Ǝ��g�����M�����Ɖ�p�P�b�g�̗v���A�h���X���������ꍇ�̓R�A�ԍ��̎Ⴂ���̂�D�悷��B
���g��2�Ԃő����Ă����Ɖ��1�Ԃ�������A1�Ԃ�D�悷�邩��1�Ԃ���̕ԐM���Ђ�����҂������邱�ƂɂȂ�B
�R�A1�́A�D�悳��Ă���̂Ń��[�h�v�����������[����Ƌ��Ƀ��[�h�҂��X�g���[���ɏ����u���A���̂Ƃ��R�A2����̏Ɖ������Ă���̂�
���Lflg��ON�ɂ��Ɖ�p�P�b�g�����[�h�҂��̈�Ɉڂ��B
���̌�A���ۂɃ���������f�[�^�����[�h���ꂽ�Ƃ����Lflg��ON�ł��邩�烍�[�h�҂��̈�Ɉڂ��Ă������Ɖ�p�P�b�g�̑��M��փf�[�^��ԐM����B
�R�A2�̓R�A�P���̕ԐM���f�[�^�t�Ȃ̂Ń��������[�h�ς�flg�𗧂Ăă��[�h�҂��X�g���[���ɏ����u���A���̂Ƃ��̋��Lflg��ON�̂܂܂��B
���[�h�҂��X�g���[���̃��������[�h�ς�flg�ɕω����������̂ŁA���Lflg��ON�ł��邩�烍�[�h�҂��̈�Ɉڂ��Ă������Ɖ�p�P�b�g�𑖍����邪���q�b�g�Ȃ̂�
���̂܂�L1L2�֓]������B
����Ȋ����ł��ȁB
����������̂Ȃ�_�[�e�B�r�b�g����?
�ł��A����S�R�W�Ȃ��b���B
�ł��A����S�R�W�Ȃ��b���B
800 �FSocket774�F2006/06/08(��) 22:01:51 ID:8iLPMaHG
�W�O�O�Ȃ珗�q�����Ƀ��C�v�����
>>712
L1��L2�̊W�́AK8�Ƃ͈Ⴄ�݂����B
Dedicated L2
Dedicated to eliminate conflicts common in shared caches
�@����ړIL2
�@���L�L���b�V���ɒʏ푶�݂���ՓˁA�������������邽�߂ɐ��p������B
(PhilHesterAMDAnalystDay.pdf)
L3�����L�L���b�V���ɂ���̂́A4-core����
����܂ł�x-bar(srq)�o�R�����ł͖���������Ƃ����̂����R�̂P���Ǝv���B
���������āA
K8��L1-L2�̊W�́AL1-L3�̊W�ɂȂ����\��������B
�i�Ȃ��AK8�ł�L2�A�N�Z�X�ƕ��s���ă��C���������ɃA�N�Z�X���Ă������A
K8L�ł́A����Ɠ����悤�ɁAL3�A�N�Z�X�ƃ��C���������E�A�N�Z�X�����s����ƌ����Ă���j
���Ƃ���ƁA
L1 total 512KB(128x4)��L3 2MB (512 per core)������A
�r���łȂ��\��������B
�r���ł������ꍇ�A
�Q�ȏ��L1�ɓ��ꃉ�C�����L���b�V�����ꂽ��Ԃ���A
����L1�����̃��C����L3�ɒǂ��������ꍇ�A
���̃R�A��L1�ƒǂ������ꂽ���C�����_�u���āA�r�����ێ��ł��Ȃ��Ȃ�Ƃ�����肪����B
�r���łȂ��ꍇ�ɂ͂��̖��͐����Ȃ����A���L�L���b�V���ł���ȏ�́A
�R�A�ԂŎg�����C�����S�R����Ă���ꍇ�AL3����肠���i�����j��������B
L2���ǂ��������ɑΏ�������̂Ȃ̂��́A
������������炩�ɂ���Ȃ��ƕ�����Ȃ��B
L1��L2�̊W�́AK8�Ƃ͈Ⴄ�݂����B
Dedicated L2
Dedicated to eliminate conflicts common in shared caches
�@����ړIL2
�@���L�L���b�V���ɒʏ푶�݂���ՓˁA�������������邽�߂ɐ��p������B
(PhilHesterAMDAnalystDay.pdf)
L3�����L�L���b�V���ɂ���̂́A4-core����
����܂ł�x-bar(srq)�o�R�����ł͖���������Ƃ����̂����R�̂P���Ǝv���B
���������āA
K8��L1-L2�̊W�́AL1-L3�̊W�ɂȂ����\��������B
�i�Ȃ��AK8�ł�L2�A�N�Z�X�ƕ��s���ă��C���������ɃA�N�Z�X���Ă������A
K8L�ł́A����Ɠ����悤�ɁAL3�A�N�Z�X�ƃ��C���������E�A�N�Z�X�����s����ƌ����Ă���j
���Ƃ���ƁA
L1 total 512KB(128x4)��L3 2MB (512 per core)������A
�r���łȂ��\��������B
�r���ł������ꍇ�A
�Q�ȏ��L1�ɓ��ꃉ�C�����L���b�V�����ꂽ��Ԃ���A
����L1�����̃��C����L3�ɒǂ��������ꍇ�A
���̃R�A��L1�ƒǂ������ꂽ���C�����_�u���āA�r�����ێ��ł��Ȃ��Ȃ�Ƃ�����肪����B
�r���łȂ��ꍇ�ɂ͂��̖��͐����Ȃ����A���L�L���b�V���ł���ȏ�́A
�R�A�ԂŎg�����C�����S�R����Ă���ꍇ�AL3����肠���i�����j��������B
L2���ǂ��������ɑΏ�������̂Ȃ̂��́A
������������炩�ɂ���Ȃ��ƕ�����Ȃ��B
�r���łȂ��Ƃ����ꍇ�A
�ق��̃R�A�ɂ����L3����ǂ������ꂽ�L���b�V�����C����
���̃��C�����Ăт������R�A��L2�ɓ����
�Ƃ������g�������P�̈ĂƂ��čl������B
���̏ꍇ�́A
L2��L3���r���̊W�A
L1��L2, L3�͔r���łȂ����ƂɂȂ�B
��������ƁA
�e�R�A�́A�ŏ���512KB�A����1MB�A�ő�2.5MB�̃L���b�V��
�������ƂɂȂ�B
�ق��̃R�A�ɂ����L3����ǂ������ꂽ�L���b�V�����C����
���̃��C�����Ăт������R�A��L2�ɓ����
�Ƃ������g�������P�̈ĂƂ��čl������B
���̏ꍇ�́A
L2��L3���r���̊W�A
L1��L2, L3�͔r���łȂ����ƂɂȂ�B
��������ƁA
�e�R�A�́A�ŏ���512KB�A����1MB�A�ő�2.5MB�̃L���b�V��
�������ƂɂȂ�B
�Ƃ������A���S�Ȕr���͕����I�ɖ���
���ƁAL3�ƃ��C�����������A�N�Z�X���Ă�Ƃ����炿����ƕ|���B
�k1��L2���烍�[�h����Ƃ��ɁA���C�������������ǂ݂�����Ă����̂͂ǂ���H
L3�ɖ₢���킹�ɂ����Ƃ��̓��[�h����Ă�Ƃ��������炢���Ȃ��Ǝv����
�������A�N�Z�X�͂������ǁA�}�C�N���A�[�L�e�N�`���̂ق������Ăق����B
�ǂ����������̂��E�E�EDDR3�܂ő҂����ق��������́H�H�H
L3�ɖ₢���킹�ɂ����Ƃ��̓��[�h����Ă�Ƃ��������炢���Ȃ��Ǝv����
�������A�N�Z�X�͂������ǁA�}�C�N���A�[�L�e�N�`���̂ق������Ăق����B
�ǂ����������̂��E�E�EDDR3�܂ő҂����ق��������́H�H�H
���L�L���b�V���̊ԈႢ�E�E�E�T
Memory Disambiguation�̋����́A���Ȃ�L���Ȃ�Ȃ����H
����܂ł̂܂Ƃ߁B
K8L��L3��L1L2�Ɗ��S�Ȕr���\���ƂȂ�B
�r���\���Ƃ��闝�R��L1L2���r���\���Ŋe�R�A���ɓƗ������L���b�V����������AL3��ς�ł�L1L2�𑖍�������ɁA
���R�A�ւ�L1L2�̏Ɖ�(�R�q�[�����V����̈�)��K�v�Ƃ��邩��AL3�͏o���邾��L1L2�Ɣr���ȃL���b�V���ł�������������ǂ��Ȃ邩�炾�B
�s���S�Ȕr���\���̋^�f��>>801�ɏ�����Ă��邪�A��L�̂悤��L1L2�̑�����ɕK�����R�A�ւ̏Ɖ����ׁAL3�͊��S�r���\�����ێ��ł���B
���ɁAL3�̓_�[�e�B�L���b�V��(�j�����Ƀ������ւ̏������݂��K�v�ȃL���b�V��)���܂܂Ȃ��B
�_�[�e�B�L���b�V���̏������݂�L2���j�������Ƃ��ɍs����B
����ɂ��AL3�̓��������ێ�����f�[�^�̎ʂ��ł���q�b�g�������Ȃ�Ƀ��C�e���V�����シ��Ƃ������������B
���X���b�g��L3�Ƃ̃R�q�[�����V����͌����ł���K�v���Ȃ�(�_�[�e�B�L���b�V�����܂܂Ȃ����A���L�����L1L2�݂̂ŗǂ�)�Ɖ�p�P�b�g�͑���Ȃ��\�����Ǝv����B
���ׁ̈AL3�Ǝ��������͓����ɃA�N�Z�X�\�ƂȂ�B
�Ӂ[����Ɖ�͏I���E�E�E�����������B
K8L��L3��L1L2�Ɗ��S�Ȕr���\���ƂȂ�B
�r���\���Ƃ��闝�R��L1L2���r���\���Ŋe�R�A���ɓƗ������L���b�V����������AL3��ς�ł�L1L2�𑖍�������ɁA
���R�A�ւ�L1L2�̏Ɖ�(�R�q�[�����V����̈�)��K�v�Ƃ��邩��AL3�͏o���邾��L1L2�Ɣr���ȃL���b�V���ł�������������ǂ��Ȃ邩�炾�B
�s���S�Ȕr���\���̋^�f��>>801�ɏ�����Ă��邪�A��L�̂悤��L1L2�̑�����ɕK�����R�A�ւ̏Ɖ����ׁAL3�͊��S�r���\�����ێ��ł���B
���ɁAL3�̓_�[�e�B�L���b�V��(�j�����Ƀ������ւ̏������݂��K�v�ȃL���b�V��)���܂܂Ȃ��B
�_�[�e�B�L���b�V���̏������݂�L2���j�������Ƃ��ɍs����B
����ɂ��AL3�̓��������ێ�����f�[�^�̎ʂ��ł���q�b�g�������Ȃ�Ƀ��C�e���V�����シ��Ƃ������������B
���X���b�g��L3�Ƃ̃R�q�[�����V����͌����ł���K�v���Ȃ�(�_�[�e�B�L���b�V�����܂܂Ȃ����A���L�����L1L2�݂̂ŗǂ�)�Ɖ�p�P�b�g�͑���Ȃ��\�����Ǝv����B
���ׁ̈AL3�Ǝ��������͓����ɃA�N�Z�X�\�ƂȂ�B
�Ӂ[����Ɖ�͏I���E�E�E�����������B
K8L�̃L���b�V���\����͌�̍l�@
�ꌾ�ł����ƁA�Ȃ���Ċg���ł���A����Ȃ�ɐ��\����̊��҂͏o���邪��ʓI�ɑz�����郌�x���ɂ͒B���Ă��Ȃ��B
�g����>>809�ɂ���ʂ���ɊȒP�ł���A�Đv�]�X�̃��x���ł͂Ȃ��B
K8L��L2�̑傫�����ǂꂾ���ɂ���̂��͓���B
���I�ɂ͍Œ�ł�L2��512KB���炢�ɂ��Ƃ��Ȃ��ƃL���b�V�����\�͗��������ł���B
�������AL2�����������邱�ƂŃ��C�e���V�����I�ɏ������Ȃ�̂Ȃ�܂��]�����ς�邾�낤���AL2���������Ƃ�͂�����͈����Ȃ肻�����B
AMD�Ƃ��ẮA����܂ł̖����I�悵�Ă��邩�̂悤�Ȍ��ʂ��B
�����ɓn���Č�������n���̌��ʏo�Ă����g���ĂƂ͂ƂĂ��v���Ȃ��A���ꂱ�����̏ꂵ�̂��ɉ������邱�Ƃ͂Ȃ���?���W�߂����ʂ̂悤�Ɏv���B
�ꌾ�ł����ƁA�Ȃ���Ċg���ł���A����Ȃ�ɐ��\����̊��҂͏o���邪��ʓI�ɑz�����郌�x���ɂ͒B���Ă��Ȃ��B
�g����>>809�ɂ���ʂ���ɊȒP�ł���A�Đv�]�X�̃��x���ł͂Ȃ��B
K8L��L2�̑傫�����ǂꂾ���ɂ���̂��͓���B
���I�ɂ͍Œ�ł�L2��512KB���炢�ɂ��Ƃ��Ȃ��ƃL���b�V�����\�͗��������ł���B
�������AL2�����������邱�ƂŃ��C�e���V�����I�ɏ������Ȃ�̂Ȃ�܂��]�����ς�邾�낤���AL2���������Ƃ�͂�����͈����Ȃ肻�����B
AMD�Ƃ��ẮA����܂ł̖����I�悵�Ă��邩�̂悤�Ȍ��ʂ��B
�����ɓn���Č�������n���̌��ʏo�Ă����g���ĂƂ͂ƂĂ��v���Ȃ��A���ꂱ�����̏ꂵ�̂��ɉ������邱�Ƃ͂Ȃ���?���W�߂����ʂ̂悤�Ɏv���B
AMD�Ђ̎�����CPU(Hound)�̐���
AMD��INTEL�̎�����CPU(Conroe)�ɑR����2007/07�ȍ~�ɓ�������鎟����CPU�̑��̂́u�Ȃ����64�v�Ō��܂肾�B
> ttp://pc.watch.impress.co.jp/docs/2006/0522/kaigai_1.jpg�@(�Ȃ����64 �^�̃N�A�b�h�R�A)
Rev.H��K8L�ƌĂ�鎟����CPU��INTEL�����\����Conroe�̉�H�g���̈ꕔ���݂̂�^���č�����������ɂȂ肻�����B
���̈�Ԃ̖ڋʂ́uSIMD���������_���Z���\��2�{�v�ł���AFPU���j�b�g��128bit����2��ڂ���B
����Ń��j�b�g���\���̂�Conroe�Ɠ����ƂȂ�B
�������AConroe��128bit��SSE���j�b�g��3���ASSE���\�łȂ����64��Conroe��2/3�̃s�[�N���\�����Ȃ��B(���j�b�g���\�̂�)
���̎��̖ڋʂ�L3���L�L���b�V���̓��ڂ��B
���������Ă����A�R�q�[�����V�����̉���Ƃ����̂�>>809�Ŋ��S�ɔے肳��A���ǂ͏����ł����������C�e���V�𑊑ΓI�Ɍ��炵���������̂��̂ŁA
�u�Ȃ���Ċg���L���b�V���v�ł������B
���̑��̊g���ɑ傫�Ȃ��̂͂Ȃ��A�ƂĂ�����Ȃ����N���b�N�����萫�\���S�ʓI�ɑ傫�����シ����̂ł͂Ȃ����Ƃ��͂����肵���B
�����Conroe��Woodcrest��Kentsfield(�������������̃N�A�b�h�R�A)�Ɛ킨���Ƃ���͖̂��d���B
2007/07�ȍ~�Ƃ����x�������̓����ł���ɂ��ւ�炸�A����Ȓ��q�ł���E�E�E
���̐�ɍT���Ă���̂́u�R�v���Z�b�T����v�Ƃ��u�n�C�p�[�g�����X�|�[�g�g���ɂ��link���g���v�Ƃ��E�E�E
�Ӂ[�AAMD�͏I������悤���E�E�E�E
������2008�N���{�܂łǂ�ȂɊ撣���Ă�INTEL���D�G��CPU�͍��Ȃ������ł���A�x���ƁE�E�E�E�E�E�E��������?
AMD��INTEL�̎�����CPU(Conroe)�ɑR����2007/07�ȍ~�ɓ�������鎟����CPU�̑��̂́u�Ȃ����64�v�Ō��܂肾�B
> ttp://pc.watch.impress.co.jp/docs/2006/0522/kaigai_1.jpg�@(�Ȃ����64 �^�̃N�A�b�h�R�A)
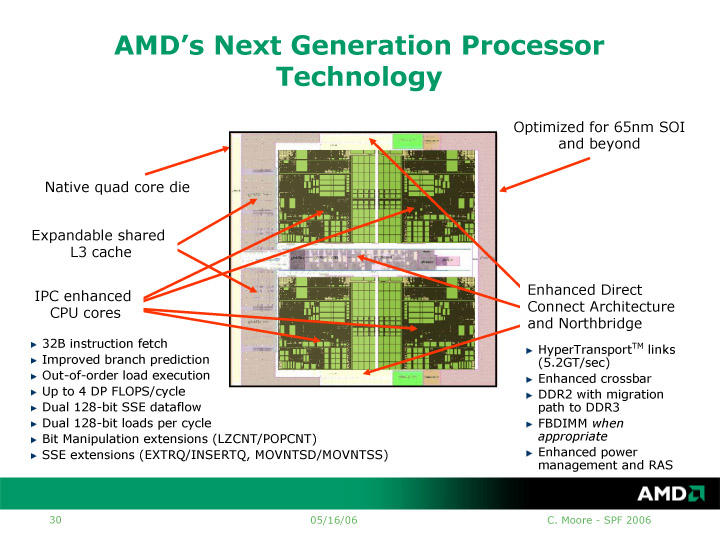{kind=link}
Rev.H��K8L�ƌĂ�鎟����CPU��INTEL�����\����Conroe�̉�H�g���̈ꕔ���݂̂�^���č�����������ɂȂ肻�����B
���̈�Ԃ̖ڋʂ́uSIMD���������_���Z���\��2�{�v�ł���AFPU���j�b�g��128bit����2��ڂ���B
����Ń��j�b�g���\���̂�Conroe�Ɠ����ƂȂ�B
�������AConroe��128bit��SSE���j�b�g��3���ASSE���\�łȂ����64��Conroe��2/3�̃s�[�N���\�����Ȃ��B(���j�b�g���\�̂�)
���̎��̖ڋʂ�L3���L�L���b�V���̓��ڂ��B
���������Ă����A�R�q�[�����V�����̉���Ƃ����̂�>>809�Ŋ��S�ɔے肳��A���ǂ͏����ł����������C�e���V�𑊑ΓI�Ɍ��炵���������̂��̂ŁA
�u�Ȃ���Ċg���L���b�V���v�ł������B
���̑��̊g���ɑ傫�Ȃ��̂͂Ȃ��A�ƂĂ�����Ȃ����N���b�N�����萫�\���S�ʓI�ɑ傫�����シ����̂ł͂Ȃ����Ƃ��͂����肵���B
�����Conroe��Woodcrest��Kentsfield(�������������̃N�A�b�h�R�A)�Ɛ킨���Ƃ���͖̂��d���B
2007/07�ȍ~�Ƃ����x�������̓����ł���ɂ��ւ�炸�A����Ȓ��q�ł���E�E�E
���̐�ɍT���Ă���̂́u�R�v���Z�b�T����v�Ƃ��u�n�C�p�[�g�����X�|�[�g�g���ɂ��link���g���v�Ƃ��E�E�E
�Ӂ[�AAMD�͏I������悤���E�E�E�E
������2008�N���{�܂łǂ�ȂɊ撣���Ă�INTEL���D�G��CPU�͍��Ȃ������ł���A�x���ƁE�E�E�E�E�E�E��������?
INTEL�̎�����CPU(Conroe�AWoodcrest�AMerom)���������\�ȗ��R
����͊ȒP���āA�����ȉ��Z���\�Ƃ�����x���鍂���ȃf�[�^�����B
���Z���j�b�g��������獂�������Ă�����CPU�ɂ͂Ȃ�Ȃ��A�s�[�N���\���ǂꂾ���������j�b�g�𓋍ڂ��Ă����_�Ȃ̂��B
�������\���j�b�g���З͂�����ɂ́A�������ȃf�[�^�������s���ł���A���̗�����INTEL�̎�����CPU�͎������Ă���B
L1L2�̃L���b�V�����\���r����Η�R�Ƃ�����傫�ȍ���m�邱�ƂƂȂ�B
����A���̒����͂ȃL���b�V���X�s�[�h
> ttp://www.2cpu.com/review.php?id=112&page=4
Opteron�ɑ���2�{���̑����ł͂Ȃ�����ȏ�AL2�Ɏ����Ă�3�{�ȏ㍂���ȋ����\�͂�L���Ă���B
���ꂱ����INTEL�̎�����CPU���������\�Ȕ閧���B
AMD�̎�����CPU�ł���u�Ȃ����64�v�́A�������S�����P�����C�z�͂Ȃ��c�O���B
����͊ȒP���āA�����ȉ��Z���\�Ƃ�����x���鍂���ȃf�[�^�����B
���Z���j�b�g��������獂�������Ă�����CPU�ɂ͂Ȃ�Ȃ��A�s�[�N���\���ǂꂾ���������j�b�g�𓋍ڂ��Ă����_�Ȃ̂��B
�������\���j�b�g���З͂�����ɂ́A�������ȃf�[�^�������s���ł���A���̗�����INTEL�̎�����CPU�͎������Ă���B
L1L2�̃L���b�V�����\���r����Η�R�Ƃ�����傫�ȍ���m�邱�ƂƂȂ�B
����A���̒����͂ȃL���b�V���X�s�[�h
> ttp://www.2cpu.com/review.php?id=112&page=4
Opteron�ɑ���2�{���̑����ł͂Ȃ�����ȏ�AL2�Ɏ����Ă�3�{�ȏ㍂���ȋ����\�͂�L���Ă���B
���ꂱ����INTEL�̎�����CPU���������\�Ȕ閧���B
AMD�̎�����CPU�ł���u�Ȃ����64�v�́A�������S�����P�����C�z�͂Ȃ��c�O���B
813 �FAMD�̗D�ꂽ�Ƃ����F2006/06/10(�y) 07:54:17 ID:OHARZvFL
�����R�������ɂ��A���������C�e���V�̍팸�ƃo�X�ш敝�A�n���p�[�g�����X�|�[�g�ɂ�钴����Link
����2��INTEL�̎�����CPU�𗽉킵�Ă���B
���Ȃ킿�A���G�ȉ��Z�������������A�P�Ƀ������[�]�����x�������ȃ\�t�g�ł����A����̏ꏊ���c����Ă���B
�f�X�N�g�b�v����ł̓t�@�C���]������AMD�̎�����CPU��INTEL���D��Ă���̂ł͂Ȃ����낤��?
���ɃT�[�o�[����A��ʂ̃R�A��a�������������ƃ������[�ш悱�����l�b�N�ɂȂ�₷���B
4�\�P�b�g�ȏ�̃n�C���x���ȃT�[�o�[�ł�AMD�̎�����CPU��INTEL���D��Ă��邾�낤�B
���̂��Ƃ���AAMD�̓V�F�A���ߋ��̃��x���ȉ����x(15%?)�܂ʼn����邾�낤�������c�邱�Ƃ͉\���낤�B
�ڎw��!�A�G���^�[�v���C�Y!!!
�ڎw��!�G���^�[�v���C�Y����Ő��E���CPU!
���ꂱ����AMD�̂��ꂩ��̍����t�Ƃ��đ��������B
����2��INTEL�̎�����CPU�𗽉킵�Ă���B
���Ȃ킿�A���G�ȉ��Z�������������A�P�Ƀ������[�]�����x�������ȃ\�t�g�ł����A����̏ꏊ���c����Ă���B
�f�X�N�g�b�v����ł̓t�@�C���]������AMD�̎�����CPU��INTEL���D��Ă���̂ł͂Ȃ����낤��?
���ɃT�[�o�[����A��ʂ̃R�A��a�������������ƃ������[�ш悱�����l�b�N�ɂȂ�₷���B
4�\�P�b�g�ȏ�̃n�C���x���ȃT�[�o�[�ł�AMD�̎�����CPU��INTEL���D��Ă��邾�낤�B
���̂��Ƃ���AAMD�̓V�F�A���ߋ��̃��x���ȉ����x(15%?)�܂ʼn����邾�낤�������c�邱�Ƃ͉\���낤�B
�ڎw��!�A�G���^�[�v���C�Y!!!
�ڎw��!�G���^�[�v���C�Y����Ő��E���CPU!
���ꂱ����AMD�̂��ꂩ��̍����t�Ƃ��đ��������B
Kentsfield���āAConroe��PenD����ˁ[���E�E�E���LL2�̃����b�g�Ƃ��͂قڏ��ł��邩��A
�R�q�[�����V����͑�����������͂������ȁB
�R�q�[�����V����͑�����������͂������ȁB
>>814
�ǂ�Ș_���I���߂�����A���̂悤�Ȗ����Ȗϑz�Ɏ���̂��s�v�c���B
�R�q�[�����V�������̓I�ɏ����o���Ă݂�Ζϑz�ł��邱�ƂɋC�t���邩����B
���ƁA���LL2�̃����b�g�̏������ĂȂ낤?
�ǂ�Ș_���I���߂�����A���̂悤�Ȗ����Ȗϑz�Ɏ���̂��s�v�c���B
�R�q�[�����V�������̓I�ɏ����o���Ă݂�Ζϑz�ł��邱�ƂɋC�t���邩����B
���ƁA���LL2�̃����b�g�̏������ĂȂ낤?
�i�i�P�@�Q�j�i�R�@�S�j�j�ƂȂ��Ă�Ƃ��āA
�P�ƂR�C�S�@�A�܂��͂Q�ƂR�C�S�̂Ƃ��ɓ��RL�Q�����L�ł��Ȃ��ƌ���������W���}�C�J
�P�ƂR�C�S�@�A�܂��͂Q�ƂR�C�S�̂Ƃ��ɓ��RL�Q�����L�ł��Ȃ��ƌ���������W���}�C�J
�����AOS�����ŃR�A�̊��蓖�Ă��K�ł͂Ȃ��ꍇ�̂��Ƃ��E�E�E
�����́AOS���̉��P��҂����Ȃ��ˁB
�����́AOS���̉��P��҂����Ȃ��ˁB
>>816
�����������ƁB
Woodcrest2�\�P�b�g�Ƃ̓p�b�P�[�W���Őڑ����Ă��邩�A�p�b�P�[�W�O�Őڑ����Ă��邩�̈Ⴂ�ł����Ȃ��B
�قƂ�ǂ̃x���`�}�[�N�ł̓L���b�V��������̐��\�𑪒肷��ہA�R�q�[�����V���䂪�K�v�ɂȂ�
���L�f�[�^���g���Ă邩�ǂ����������ĂȂ�����A���ۂɂ���łǂ̒��x�̐��\�ቺ�����邩��
����B
�����������ƁB
Woodcrest2�\�P�b�g�Ƃ̓p�b�P�[�W���Őڑ����Ă��邩�A�p�b�P�[�W�O�Őڑ����Ă��邩�̈Ⴂ�ł����Ȃ��B
�قƂ�ǂ̃x���`�}�[�N�ł̓L���b�V��������̐��\�𑪒肷��ہA�R�q�[�����V���䂪�K�v�ɂȂ�
���L�f�[�^���g���Ă邩�ǂ����������ĂȂ�����A���ۂɂ���łǂ̒��x�̐��\�ቺ�����邩��
����B
����������Ȃ̂�Woodcrest�~2�\�P�b�g�Ƒ卷�������B
�������Ș_�ł����̂͌��ꂵ�������߂Ă����B
�Ƃ������AAMD�Ђ̂����Ƃ���̐^�̃N�A�b�h�R�A(�Ȃ����64)����>>809�ɏ������悤�ɕK�����R�A�ɑ���L1L2�̏Ɖ�p�P�b�g���K�v�B
��������Ƃ��Ɖ�p�P�b�g��������H�v�ł��邱�Ƃ�I�悵�Ă���B
����Ȃ̂Ƌ�������̂Ȃ�A��������������Kentsfield�ŏ\�����낤��B
�������Ș_�ł����̂͌��ꂵ�������߂Ă����B
�Ƃ������AAMD�Ђ̂����Ƃ���̐^�̃N�A�b�h�R�A(�Ȃ����64)����>>809�ɏ������悤�ɕK�����R�A�ɑ���L1L2�̏Ɖ�p�P�b�g���K�v�B
��������Ƃ��Ɖ�p�P�b�g��������H�v�ł��邱�Ƃ�I�悵�Ă���B
����Ȃ̂Ƌ�������̂Ȃ�A��������������Kentsfield�ŏ\�����낤��B
�Ȃ����64�̃N�A�b�h�R�A=�V���O���R�A��4�������������ƕς��Ȃ�L1L2�փ���������z����2MB���̃R�s�[��L3�ɔz�u���Ă��邾���B
������́A�܂Ƃ��ȋ��L�L���b�V���𓋍ڂ����f���A���R�A��2�������������̂ق����}�V����?
�٘_�ł�����̂�?
������́A�܂Ƃ��ȋ��L�L���b�V���𓋍ڂ����f���A���R�A��2�������������̂ق����}�V����?
�٘_�ł�����̂�?
Q�F2�̃L���b�V����Intel�o�X�łȂ��̂�4�̃L���b�V����AMD�o�X�����ĒP�i�N���X�o�łȂ���
�ǂ���������?
A�F�ǂ�������!�@4�R�A�ŋ��LL2���{�P������
�ǂ���������?
A�F�ǂ�������!�@4�R�A�ŋ��LL2���{�P������
>>821
> 4�R�A�ŋ��LL2���{�P
�ނ��Ȉӌ������A����͈ӊO�Ɠ���A�Ƃ�����INTEL�Ȃ����������Ƃ���Ă��邩���m��Ȃ����A�L���b�V���ւ̃o�X����4�{�ɂ���?
��������ł����璴�X�Q�[�E�E�E�E���ǂ����牽�ł����������낤�ȁB
�o�X����2�{�̂܂܂ŁA���C���u���b�N���قȂ�ꍇ���������A�N�Z�X��������ʓI�ȕ����ɂȂ�Ɨ\�������B
���̏ꍇ�A�s�[�N���\�͗ǂ��Ă������l���ǂꂮ�炢�ɂȂ邩�̓��C���u���b�N�̑傫������ł���B(�u���b�N�T�C�Y����������������)
���ĂƁA�Ȃ����64��L3�͂ǂꂾ�����ɗ��̂�?
��x�ǂݍ��f�[�^��L1L2(128k+512k)���������ׁAL3�ɒǂ����ꂽ�Ƃ���B
������ēx�ǂݍ��ނɂ́E�E�E
���R�A��L1��L2���S�Ă̑��R�A�֏Ɖ�p�P�b�g���o���S�Ă̑��R�A��L1,L2����������ԐM���S�đ����܂ő҂�L3����/���������[�h
����Ȃ�ŗǂ��̂�?
Woodcrest�ł�Kentsfiled�ł�L1,L2��64k��4096k(2�R�A����)�̃L���b�V�������ꂼ��̃R�A���L���Ă���B
�L���b�V���ێ��͂��猾���A�Ȃ����64��L2����ǂ��o����L3�ŕێ�����P�[�X�́AINTEL�̎�����CPU���Ƌ��LL2�ŕێ��o���Ă��܂�����
���R�A��L1��L2(�q�b�g)�Ŋ����ƂȂ�A���R�A�ւ̏Ɖ�p�P�b�g�͕s�v�ƂȂ�B
�����ĖY��Ă͂Ȃ�Ȃ��L���b�V�����\�̈Ⴂ��>>812
L1��2�{��傫�������鍂���L���b�V���AL2����3�{���钴�����L���b�V���E�E�E�E
�����̕����͂Ȃ����64�ł̉��P�͖w�ǂȂ��E�E�E����Ő킦��̂�?
> 4�R�A�ŋ��LL2���{�P
�ނ��Ȉӌ������A����͈ӊO�Ɠ���A�Ƃ�����INTEL�Ȃ����������Ƃ���Ă��邩���m��Ȃ����A�L���b�V���ւ̃o�X����4�{�ɂ���?
��������ł����璴�X�Q�[�E�E�E�E���ǂ����牽�ł����������낤�ȁB
�o�X����2�{�̂܂܂ŁA���C���u���b�N���قȂ�ꍇ���������A�N�Z�X��������ʓI�ȕ����ɂȂ�Ɨ\�������B
���̏ꍇ�A�s�[�N���\�͗ǂ��Ă������l���ǂꂮ�炢�ɂȂ邩�̓��C���u���b�N�̑傫������ł���B(�u���b�N�T�C�Y����������������)
���ĂƁA�Ȃ����64��L3�͂ǂꂾ�����ɗ��̂�?
��x�ǂݍ��f�[�^��L1L2(128k+512k)���������ׁAL3�ɒǂ����ꂽ�Ƃ���B
������ēx�ǂݍ��ނɂ́E�E�E
���R�A��L1��L2���S�Ă̑��R�A�֏Ɖ�p�P�b�g���o���S�Ă̑��R�A��L1,L2����������ԐM���S�đ����܂ő҂�L3����/���������[�h
����Ȃ�ŗǂ��̂�?
Woodcrest�ł�Kentsfiled�ł�L1,L2��64k��4096k(2�R�A����)�̃L���b�V�������ꂼ��̃R�A���L���Ă���B
�L���b�V���ێ��͂��猾���A�Ȃ����64��L2����ǂ��o����L3�ŕێ�����P�[�X�́AINTEL�̎�����CPU���Ƌ��LL2�ŕێ��o���Ă��܂�����
���R�A��L1��L2(�q�b�g)�Ŋ����ƂȂ�A���R�A�ւ̏Ɖ�p�P�b�g�͕s�v�ƂȂ�B
�����ĖY��Ă͂Ȃ�Ȃ��L���b�V�����\�̈Ⴂ��>>812
L1��2�{��傫�������鍂���L���b�V���AL2����3�{���钴�����L���b�V���E�E�E�E
�����̕����͂Ȃ����64�ł̉��P�͖w�ǂȂ��E�E�E����Ő킦��̂�?
�@�@�@�@�@ �@�@ �@�@ �@ �@ �@ �Q�@ �Q�Q�Q_,..--�
�@�@�@�@�@�@�@�@�@�@�@�@�@�@/�@́M_r�\�]�__��́@�_
�@�@�@�@ �@ �@ �@ �@ �@ �@ /�@/�L�@ i�@�@ | |�@ ���@! �@ �M�A �@�@�@�A�R l / ,
�@�@�@�@�@�@�@�@�@�@�@�@ /�@/�@|�@ |�@�@ | |�@ |�@! �@ �@i�@�@�@ = �@�@�@�@=
�@ �@ �@ �@ �@ �@ �@ �@ /�@ i �@ | �@|�@�@ | |�@ |�@!�@�@�@l�@�@�=�@�i ���@-=
�@�@�@�@�@�@�@�@�@�@�@/ �@ ���@�@�g_� �@ //__/.�C!�@�@�@l �@ �=�@�� ��@=�
�@�@�@�@�@�@�@ �@ �@ / �@ �ȁ@/! di �R/�@�� !���R !�@ l�@ !�@ .=-�@��. �Ł@-=
�@�@�A� l | /, ,. �@ �V�@/�@i Y! |���� �@ �@ | ��@!�@ l�@ Ĥ�@Ɓ@ ��. ���@�
�@.�R�@�@�@�@�@�L�L, l!l�@ʁ@� i ! �P �@ ��@ �P�@/ �@/�@� } �@�Lr�@�F�@�@ �R�M
.�R�@�� �� �i�@� �@V�@V l!V� .�@�@ �[�@�@ ,�!,�C�^�'�@|�@�@ �L/���R�M
=�@ �� �� ���@ =Ɓ@�^:.:.::�R��@` �@ -- �C�@| l::::::| l�@ /
� �@��. �� �ȁ@�@-=�@�R�:.:::::::�R�.�Q��@�@�Q,�/.:::::| | /|
= �@��.�� ��@�@-= �@ �R�:::::::::�_��Q�Q�^::.z��.:| |' :|
Ɓ@ �� �Ɓ@�@�@=Ɓ@�@�@| |:::::::::::::::::::::::::::::::::::.|'��.:Y��Ĥ
/,�@ �F�@���@�@ �R� �@�@ | |::::::::::::::::::::::::::::::::::::_�y_::|�@ '�, .�_
�@�@�@�@�@�@�@�@�@�@�@�@�@�@/�@́M_r�\�]�__��́@�_
�@�@�@�@ �@ �@ �@ �@ �@ �@ /�@/�L�@ i�@�@ | |�@ ���@! �@ �M�A �@�@�@�A�R l / ,
�@�@�@�@�@�@�@�@�@�@�@�@ /�@/�@|�@ |�@�@ | |�@ |�@! �@ �@i�@�@�@ = �@�@�@�@=
�@ �@ �@ �@ �@ �@ �@ �@ /�@ i �@ | �@|�@�@ | |�@ |�@!�@�@�@l�@�@�=�@�i ���@-=
�@�@�@�@�@�@�@�@�@�@�@/ �@ ���@�@�g_� �@ //__/.�C!�@�@�@l �@ �=�@�� ��@=�
�@�@�@�@�@�@�@ �@ �@ / �@ �ȁ@/! di �R/�@�� !���R !�@ l�@ !�@ .=-�@��. �Ł@-=
�@�@�A� l | /, ,. �@ �V�@/�@i Y! |���� �@ �@ | ��@!�@ l�@ Ĥ�@Ɓ@ ��. ���@�
�@.�R�@�@�@�@�@�L�L, l!l�@ʁ@� i ! �P �@ ��@ �P�@/ �@/�@� } �@�Lr�@�F�@�@ �R�M
.�R�@�� �� �i�@� �@V�@V l!V� .�@�@ �[�@�@ ,�!,�C�^�'�@|�@�@ �L/���R�M
=�@ �� �� ���@ =Ɓ@�^:.:.::�R��@` �@ -- �C�@| l::::::| l�@ /
� �@��. �� �ȁ@�@-=�@�R�:.:::::::�R�.�Q��@�@�Q,�/.:::::| | /|
= �@��.�� ��@�@-= �@ �R�:::::::::�_��Q�Q�^::.z��.:| |' :|
Ɓ@ �� �Ɓ@�@�@=Ɓ@�@�@| |:::::::::::::::::::::::::::::::::::.|'��.:Y��Ĥ
/,�@ �F�@���@�@ �R� �@�@ | |::::::::::::::::::::::::::::::::::::_�y_::|�@ '�, .�_
>822
����A�O�閾���Ȃ�
�܂œǂ�
����A�O�閾���Ȃ�
�܂œǂ�
>ID:OHARZvFL
�����ƃg���b�v�t���Ă��������B
�����ƃg���b�v�t���Ă��������B
>>825
�O��I�^�ł��肢���܂�
�O��I�^�ł��肢���܂�
> Q�F2�̃L���b�V����Intel�o�X�łȂ��̂�4�̃L���b�V����AMD�o�X�����ĒP�i�N���X�o�łȂ���
> �ǂ���������?
�ʐM�����̂��Ƃ���C�ɂ��Ă���l�������������A���ۂɈ�Ԑh���̂́A�Ɖ���鑤�ł���A�����҂��ł���B
�Ɖ���鑤�́A���݂̏������~���AL1L2�𑖍�(�q�b�g����X�ɂ��̃L���b�V����ǂݏo��)���ԐM���Ȃ�������Ȃ��B
���ꂪAMD�̉�H�\�����Ƒ������邵�A����L2��512k�Ƃ��Ɍ��炷�Ɨ]�v�����Ă��܂��B
4�R�A�����ɓ����o������A����3�R�A����Ɖ�������邩��L1L2��3�����ԐM���銄�荞�݂���ɂ�����Ă��ƂɂȂ�B
����ȏ���2�X���b�g���ƁA���̃R�A��7�ƂȂ�����Ɛ������ƂɁE�E�E
�N���X�o�[�͌����Ă��̕��S�����炵�Ă͂���Ȃ���B
> �ǂ���������?
�ʐM�����̂��Ƃ���C�ɂ��Ă���l�������������A���ۂɈ�Ԑh���̂́A�Ɖ���鑤�ł���A�����҂��ł���B
�Ɖ���鑤�́A���݂̏������~���AL1L2�𑖍�(�q�b�g����X�ɂ��̃L���b�V����ǂݏo��)���ԐM���Ȃ�������Ȃ��B
���ꂪAMD�̉�H�\�����Ƒ������邵�A����L2��512k�Ƃ��Ɍ��炷�Ɨ]�v�����Ă��܂��B
4�R�A�����ɓ����o������A����3�R�A����Ɖ�������邩��L1L2��3�����ԐM���銄�荞�݂���ɂ�����Ă��ƂɂȂ�B
����ȏ���2�X���b�g���ƁA���̃R�A��7�ƂȂ�����Ɛ������ƂɁE�E�E
�N���X�o�[�͌����Ă��̕��S�����炵�Ă͂���Ȃ���B
AMD��FB-DIMM�̏���d�͂̌��Ő����܂����Ă�FUD�����ӂ��ꂽ��(��)
http://pc.watch.impress.co.jp/docs/2006/0602/slide104.jpg
�������Intel�����J�����R�����B
http://www.principledtechnologies.com/clients/reports/Intel/WSPECint_rate_0506.pdf
�@���\��
�@�@AMD: Opteron 285/2.6GHz x 2, 8GB Mem (PC3200)
�@�@Intel: Woodcrest/3.0GHz x 2, 8GB Mem (1GB FB-DIMM x 8)
�@���V�X�e���S�̂̏���d��[W]
�@�@Application�@�@�@�@AMD�@�@�@Intel
�@�@-----------------------------
�@�@Sunguard�@�@�@�@�@�@321�@�@�@�@280.1
�@�@BlackScholes�@�@�@302.4�@�@�@246.7
�@�@SPECjbb2005�@�@�@318.3�@�@�@276.0
�@�@SPECint_rate_2k�@327.7�@�@�@281.1
�@�@WebBench�@�@�@�@�@332.1�@�@�@275.0
http://pc.watch.impress.co.jp/docs/2006/0602/slide104.jpg
{kind=link}
�������Intel�����J�����R�����B
http://www.principledtechnologies.com/clients/reports/Intel/WSPECint_rate_0506.pdf
�@���\��
�@�@AMD: Opteron 285/2.6GHz x 2, 8GB Mem (PC3200)
�@�@Intel: Woodcrest/3.0GHz x 2, 8GB Mem (1GB FB-DIMM x 8)
�@���V�X�e���S�̂̏���d��[W]
�@�@Application�@�@�@�@AMD�@�@�@Intel
�@�@-----------------------------
�@�@Sunguard�@�@�@�@�@�@321�@�@�@�@280.1
�@�@BlackScholes�@�@�@302.4�@�@�@246.7
�@�@SPECjbb2005�@�@�@318.3�@�@�@276.0
�@�@SPECint_rate_2k�@327.7�@�@�@281.1
�@�@WebBench�@�@�@�@�@332.1�@�@�@275.0
829 �FMAC�I�^�������F2006/06/10(�y) 13:47:52 ID:nTzyhabI
Intel�̎����ԈႦ�����B
ftp://download.intel.com/intel/finance/presentations/PDF_Files/Skaugen_2006_06_09.pdf (P.18�Q��)
ftp://download.intel.com/intel/finance/presentations/PDF_Files/Skaugen_2006_06_09.pdf (P.18�Q��)
>>827
>���ꂪAMD�̉�H�\�����Ƒ������邵�A����L2��512k�Ƃ��Ɍ��炷�Ɨ]�v�����Ă��܂��B
�Ȃɂ��̖ϑz�B
�L���b�V�������炷�ƁA�t�ɏƉ��m�������邾��B
�L���b�V����������Α������A�Ɖ������B
>���ꂪAMD�̉�H�\�����Ƒ������邵�A����L2��512k�Ƃ��Ɍ��炷�Ɨ]�v�����Ă��܂��B
�Ȃɂ��̖ϑz�B
�L���b�V�������炷�ƁA�t�ɏƉ��m�������邾��B
�L���b�V����������Α������A�Ɖ������B
>>831
�S�R�Ⴄ�B
L1L2�Ƀq�b�g���Ȃ�=���R�A�̃L���b�V���ɂȂ����瑼�R�A���L���b�V����ۗL���Ă��邩���番����ʏ�ԁB
����āA�S�Ă̑��R�A�ɏƉ�p�P�b�g�M���A�ԐM������܂ő҂��ƂɂȂ�B
�S�R�Ⴄ�B
L1L2�Ƀq�b�g���Ȃ�=���R�A�̃L���b�V���ɂȂ����瑼�R�A���L���b�V����ۗL���Ă��邩���番����ʏ�ԁB
����āA�S�Ă̑��R�A�ɏƉ�p�P�b�g�M���A�ԐM������܂ő҂��ƂɂȂ�B
AMD�̋��L�k�R�����͑債�����ʂ��������Ęb�����A�Ⴆ�������Z-RAM��
8MB�ɑ��ʂ����ꍇ�͂ǂ��ł��傤���H
Z-RAM�͊�{�I��DRAM�����烌�C�e���V���傫�����A�A�N�Z�X���x��SRAM����
�����o����炵���̂ŁAL3�e�ʂ�啝�A�b�v�������ʂ��傫����AIntel��
���Č��\�ȗD�ʂɂȂ��Ă����Ɗ��҂������̂����B
8MB�ɑ��ʂ����ꍇ�͂ǂ��ł��傤���H
Z-RAM�͊�{�I��DRAM�����烌�C�e���V���傫�����A�A�N�Z�X���x��SRAM����
�����o����炵���̂ŁAL3�e�ʂ�啝�A�b�v�������ʂ��傫����AIntel��
���Č��\�ȗD�ʂɂȂ��Ă����Ɗ��҂������̂����B
>>829
p.21�ł���B
CPU Xeon 160W (80x2)�@Opteron 190 (95x2)
mem�@Xeon 75W�ȉ��@Opteron 36W�ȉ�
Chip Xeon 30W�@Opteron 10W�ȉ�
total
4 DIMM�ł�8W���x
8 DIMM�ł�26W���x
Xeon�̂ق��������B
FBDIMM��AMB��4,5-6.1W�����A
�ő�1.2W��R-DIMM��PLL��register���g��Ȃ�����
FBDIMM�ɂ��邱�Ƃɂ�鑝����3.3-4.9W���B
p.21�ł���B
CPU Xeon 160W (80x2)�@Opteron 190 (95x2)
mem�@Xeon 75W�ȉ��@Opteron 36W�ȉ�
Chip Xeon 30W�@Opteron 10W�ȉ�
total
4 DIMM�ł�8W���x
8 DIMM�ł�26W���x
Xeon�̂ق��������B
FBDIMM��AMB��4,5-6.1W�����A
�ő�1.2W��R-DIMM��PLL��register���g��Ȃ�����
FBDIMM�ɂ��邱�Ƃɂ�鑝����3.3-4.9W���B
http://pc.watch.impress.co.jp/docs/2006/0602/slide104.jpg
ftp://download.intel.com/intel/finance/presentations/PDF_Files/Skaugen_2006_06_09.pdf (P.21�}�j
�@1DIMM������̂����܂��ȏ���d�́iAMD������INTEL�����j
AMD����
FB-DIMM/DDR2�@10.5W/4.5W
INTEL����
FB-DIMM/DDR2�@9.5W/4.5W
�@AMD�̉���ʂ�FB-DIMM16���ɂ����Intel�̎咣�ł�������������150W�iAMD:167W)�B
CPU���N�[���ɂȂ����Ǝv�����玟�̓��������E�E
ftp://download.intel.com/intel/finance/presentations/PDF_Files/Skaugen_2006_06_09.pdf (P.21�}�j
�@1DIMM������̂����܂��ȏ���d�́iAMD������INTEL�����j
AMD����
FB-DIMM/DDR2�@10.5W/4.5W
INTEL����
FB-DIMM/DDR2�@9.5W/4.5W
�@AMD�̉���ʂ�FB-DIMM16���ɂ����Intel�̎咣�ł�������������150W�iAMD:167W)�B
CPU���N�[���ɂȂ����Ǝv�����玟�̓��������E�E
Intel Woodcrest performance claim a fraud
http://sharikou.blogspot.com/2006/05/intel-woodcrest-performance-claim.html
Intel Woodcrest performance claim a fraud
Intel Woodcrest performance claim a fraud
Intel Woodcrest performance claim a fraud
�@�@�@�@�@�F
�@�@�@�@�@�F
�@�@�@�@�@�F
���ꂪIntel�N�I���e�B�B
http://sharikou.blogspot.com/2006/05/intel-woodcrest-performance-claim.html
Intel Woodcrest performance claim a fraud
Intel Woodcrest performance claim a fraud
Intel Woodcrest performance claim a fraud
�@�@�@�@�@�F
�@�@�@�@�@�F
�@�@�@�@�@�F
���ꂪIntel�N�I���e�B�B
838 �F�E�́E�j��-������ ��toBASh.... �F2006/06/10(�y) 19:11:25 ID:0FGizYM2
L1���L����悭�ˁH��������
�ނ���Cell�^�̃w�e���ł�����B
SRAM 1MB���炢�̃�������ԓƗ��̃R�v���Z�b�T���ځB
�ނ���Cell�^�̃w�e���ł�����B
SRAM 1MB���炢�̃�������ԓƗ��̃R�v���Z�b�T���ځB
FPGA�^�C�v�̃R�v�����Ƃ��낢��y�������B
�f�t�H���g��SSE�����ŁA�A�v���őΉ����Ă�č\�z�ŃA�v���ɓ����B
�Ƃ��E�E�E
�f�t�H���g��SSE�����ŁA�A�v���őΉ����Ă�č\�z�ŃA�v���ɓ����B
�Ƃ��E�E�E
>>833
Z-RAM�̏ꍇ���ƁA5�{�̖��x������2MB�����C��10MB�ɑ�����ˁB
����ƂƂ��ɁAL3�ւ̃A�N�Z�X���C�e���V�����Ȃ舫������B
�J�����́AZ-RAM���g����L3�L���b�V�������ꍇ�A25MB���Ă����Z-RAM�̂ق����L���ɂȂ�ƌ����Ă��Ǝv���B
>>836
> ������A�e�ʂ������������������m����������ƌ����Ă�̂����B���v���H
�N�͋t�̂��Ƃ������Ă�B
�N�͉��L�̒ʂ�A�L���b�V�������炷�ƁA�q�b�g�������肻�̌��ʁA���R�A�ւ̏Ɖ�p�P�b�g�𑗏o���錏��������ƌ����Ă�B
���R�A��L1L2�L���b�V���Ƀq�b�g�����ꍇ�A���̃L���b�V�������R�A�Ƌ������ĂĂ��A���ĂȂ��Ă��Ɖ�p�P�b�g�𑗏o����K�v�͂Ȃ��B
�q�b�g���Ȃ������Ƃ��́A�K�����R�A�ɏƉ�p�P�b�g�𑗏o����K�v������B
>> �L���b�V�������炷�ƁA�t�ɏƉ��m�������邾��B
>> �L���b�V����������Α������A�Ɖ������B
>>838
L1�𐫔\�������邱�ƂȂ����L�o����ΐ������ǂˁA�ł������ɂ͋��L�L���b�V���ɂ���ꍇ�A���̂��������\��������B
L1�̓��W�X�^�̎��ɍ����ȋL���G���A������A���L������悤�ȕ��G���₻��ɔ�����e�ʉ����s���Ƒ��x���傫�������Ă��܂��B
Z-RAM�̏ꍇ���ƁA5�{�̖��x������2MB�����C��10MB�ɑ�����ˁB
����ƂƂ��ɁAL3�ւ̃A�N�Z�X���C�e���V�����Ȃ舫������B
�J�����́AZ-RAM���g����L3�L���b�V�������ꍇ�A25MB���Ă����Z-RAM�̂ق����L���ɂȂ�ƌ����Ă��Ǝv���B
>>836
> ������A�e�ʂ������������������m����������ƌ����Ă�̂����B���v���H
�N�͋t�̂��Ƃ������Ă�B
�N�͉��L�̒ʂ�A�L���b�V�������炷�ƁA�q�b�g�������肻�̌��ʁA���R�A�ւ̏Ɖ�p�P�b�g�𑗏o���錏��������ƌ����Ă�B
���R�A��L1L2�L���b�V���Ƀq�b�g�����ꍇ�A���̃L���b�V�������R�A�Ƌ������ĂĂ��A���ĂȂ��Ă��Ɖ�p�P�b�g�𑗏o����K�v�͂Ȃ��B
�q�b�g���Ȃ������Ƃ��́A�K�����R�A�ɏƉ�p�P�b�g�𑗏o����K�v������B
>> �L���b�V�������炷�ƁA�t�ɏƉ��m�������邾��B
>> �L���b�V����������Α������A�Ɖ������B
>>838
L1�𐫔\�������邱�ƂȂ����L�o����ΐ������ǂˁA�ł������ɂ͋��L�L���b�V���ɂ���ꍇ�A���̂��������\��������B
L1�̓��W�X�^�̎��ɍ����ȋL���G���A������A���L������悤�ȕ��G���₻��ɔ�����e�ʉ����s���Ƒ��x���傫�������Ă��܂��B
>>837
���̃S�V�b�v�͈ȑO�ɂ��ǂ��Ƃ����邪�A�����ȃS�V�b�v�Ƃ��ēǂݗ����̂��������悤�Ȃ��Ƃ�N���������Ă��悤�Ɏv���B
�܂Ƃ��Ɏ�舵���Ƃ���͖��������ł��B
���̃S�V�b�v�͈ȑO�ɂ��ǂ��Ƃ����邪�A�����ȃS�V�b�v�Ƃ��ēǂݗ����̂��������悤�Ȃ��Ƃ�N���������Ă��悤�Ɏv���B
�܂Ƃ��Ɏ�舵���Ƃ���͖��������ł��B
842 �F�E�́E�j��-������ ��toBASh.... �F2006/06/10(�y) 20:24:39 ID:0FGizYM2
�l�̃u���O�����Ȃ�����
����SSE4�̋L���͉p���Wikipedia�Ƃ��Ƀ����N����Ă��肷�邪�B
����SSE4�̋L���͉p���Wikipedia�Ƃ��Ƀ����N����Ă��肷�邪�B
>>840
25MB���Ƃ�����Z-RAM�ł��A45nm�v���Z�X�łȂ���CPU�R�A�ւ̓o�ڂ͖������낤�Ȃ��B
�܊p�̃g�����W�X�^������̗e�ʃA�b�v���ACPU���\�A�b�v�Ɍ��ѕt�����Ȃ��ܑ͖̖̂����B
�ł��m���ɒP�Ƃ�CPU�̏ꍇ�͗L���ɂȂ�ׂ�25MB���K�v��������A�}���`CPU�̏ꍇ��
CPU�Ԃł̃f�[�^�]������ԏ����l�b�N�ɂȂ邾�낤����A�L���b�V���̑�e�ʉ��̐��\�ւ�
�v�����A�P��CPU�ɔ�ׂ�Α傫�����ȋC������̂����B
25MB���Ƃ�����Z-RAM�ł��A45nm�v���Z�X�łȂ���CPU�R�A�ւ̓o�ڂ͖������낤�Ȃ��B
�܊p�̃g�����W�X�^������̗e�ʃA�b�v���ACPU���\�A�b�v�Ɍ��ѕt�����Ȃ��ܑ͖̖̂����B
�ł��m���ɒP�Ƃ�CPU�̏ꍇ�͗L���ɂȂ�ׂ�25MB���K�v��������A�}���`CPU�̏ꍇ��
CPU�Ԃł̃f�[�^�]������ԏ����l�b�N�ɂȂ邾�낤����A�L���b�V���̑�e�ʉ��̐��\�ւ�
�v�����A�P��CPU�ɔ�ׂ�Α傫�����ȋC������̂����B
> �ł��m���ɒP�Ƃ�CPU�̏ꍇ�͗L���ɂȂ�ׂ�25MB���K�v��������A�}���`CPU�̏ꍇ��
> CPU�Ԃł̃f�[�^�]������ԏ����l�b�N�ɂȂ邾�낤����A�L���b�V���̑�e�ʉ��̐��\�ւ�
> �v�����A�P��CPU�ɔ�ׂ�Α傫�����ȋC������̂����B
AMD�Ђ̂Ȃ����L3�́A>>809�ɂ���ʂ�A�e�R�A�Ɠ��������@�\���̂ĂĂ���(�R�q�[�����V����ɊW���Ȃ�)����
���̖ړI�ɂ͎g�p�ł��Ȃ��B
(L1L2�Ń~�X�q�b�g������e�R�A�ւ̏Ɖ�p�P�b�g�����M�����)
�ʏ킾�ƁA����ȋ��LL3�R�A��ς�(Inclusive�^�C�v)�AL3�Ńq�b�g�������߁A�R�q�[�����V����̕��ׂ��ł��傫��
�~�X�q�b�g���̏Ɖ�p�P�b�g�����炵�A���L�L���b�V���O���[�v�Ԃł̏Ɖ�p�P�b�g���������ʼn��P����B
> CPU�Ԃł̃f�[�^�]������ԏ����l�b�N�ɂȂ邾�낤����A�L���b�V���̑�e�ʉ��̐��\�ւ�
> �v�����A�P��CPU�ɔ�ׂ�Α傫�����ȋC������̂����B
AMD�Ђ̂Ȃ����L3�́A>>809�ɂ���ʂ�A�e�R�A�Ɠ��������@�\���̂ĂĂ���(�R�q�[�����V����ɊW���Ȃ�)����
���̖ړI�ɂ͎g�p�ł��Ȃ��B
(L1L2�Ń~�X�q�b�g������e�R�A�ւ̏Ɖ�p�P�b�g�����M�����)
�ʏ킾�ƁA����ȋ��LL3�R�A��ς�(Inclusive�^�C�v)�AL3�Ńq�b�g�������߁A�R�q�[�����V����̕��ׂ��ł��傫��
�~�X�q�b�g���̏Ɖ�p�P�b�g�����炵�A���L�L���b�V���O���[�v�Ԃł̏Ɖ�p�P�b�g���������ʼn��P����B
L3�R�A�E�E�E>L3�L���b�V���@(�T�T�T�T)
846 �F�E�́E�j��-������ ��toBASh.... �F2006/06/10(�y) 20:46:32 ID:0FGizYM2
Pentium Pro��L2�������ڂ����R�A���p�b�P�[�W���O����Ă��Ȃ���
>>844�̕ߑ�
�~�X�q�b�g�ɂ��Ɖ�p�P�b�g�����炷�ړI�ɓ�������ꍇ�AL3�̃A�N�Z�X���C�e���V���������邱�Ƃ����m��CPU�R�A�Ƃ͕ʃR�A�ɂ���P�[�X���嗬�B
���̏ꍇ�AL3�ւ̍X�V�͑����̒x����F�߂��v(L3�ւ̍X�V��҂����Ɏ��̏����ցE�E�E)�ƂȂ�AL3�ɂ͊e�R�A����̍X�V�˗�(�����˗��܂�)��
���߂Ēu���X�g���[��������(FIFO�^�̂���Ȃ�̌���������o�b�t�@)�B
���̃X�g���[���ɂ��L3�̒x���X�V���\�ƂȂ�B
�~�X�q�b�g�ɂ��Ɖ�p�P�b�g�����炷�ړI�ɓ�������ꍇ�AL3�̃A�N�Z�X���C�e���V���������邱�Ƃ����m��CPU�R�A�Ƃ͕ʃR�A�ɂ���P�[�X���嗬�B
���̏ꍇ�AL3�ւ̍X�V�͑����̒x����F�߂��v(L3�ւ̍X�V��҂����Ɏ��̏����ցE�E�E)�ƂȂ�AL3�ɂ͊e�R�A����̍X�V�˗�(�����˗��܂�)��
���߂Ēu���X�g���[��������(FIFO�^�̂���Ȃ�̌���������o�b�t�@)�B
���̃X�g���[���ɂ��L3�̒x���X�V���\�ƂȂ�B
>ID:OHARZvFL
���܂�ɔS�����ł���������
���̐��1�s�ɓZ�߂邩�����ݾ��ڂɋA�邩�ǂ������ɂ��Ă���B
���܂�ɔS�����ł���������
���̐��1�s�ɓZ�߂邩�����ݾ��ڂɋA�邩�ǂ������ɂ��Ă���B
���ȁB
�{���̗����͂��̃X���Z�l�Ȃ���Ȃ��̂�����
�S�^�S�^���t���ׂĉ��Ɋ����w�͖͂��Ӗ�
�{���̗����͂��̃X���Z�l�Ȃ���Ȃ��̂�����
�S�^�S�^���t���ׂĉ��Ɋ����w�͖͂��Ӗ�
���_
AMD��CPU�͂��ꂩ��2�N�Ԃ͊��҂ł��Ȃ�
���Ƃ�����2�N��ɂ�����CPU�����܂��\�������܂�Ȃ�
AMD��CPU�͂��ꂩ��2�N�Ԃ͊��҂ł��Ȃ�
���Ƃ�����2�N��ɂ�����CPU�����܂��\�������܂�Ȃ�
>>849
�����A�R���OHARZvFL����̓��e�ǂނ܂ŊԈ���Ď���Ă��B
L3���L�L���b�V���̓R�q�[�����V�ɘa���ƐM���Ă��B
�ł�������AL3���L�L���b�V���̓R�q�[�����V�̊ɘa�ɉ����𗧂��Ă��Ȃ����Ƃ����������B
L3�̓�����L2������A�t�ɃR�q�[�����V�̕��ׂ͑����Ȃ邱�Ƃ��m�����B
�����A�R���OHARZvFL����̓��e�ǂނ܂ŊԈ���Ď���Ă��B
L3���L�L���b�V���̓R�q�[�����V�ɘa���ƐM���Ă��B
�ł�������AL3���L�L���b�V���̓R�q�[�����V�̊ɘa�ɉ����𗧂��Ă��Ȃ����Ƃ����������B
L3�̓�����L2������A�t�ɃR�q�[�����V�̕��ׂ͑����Ȃ邱�Ƃ��m�����B
�@���_�I�ɂ�AMD��8XX�V���[�Y��Intel��70XX�V���[�Y�ɑ卷�ŕ����Ă�͂��Ƃ������Ƃ��B
���������߂܂����T�[�o���[�J���A�M���v���X�̃T�C�N�����o�O�ɂ悤�Ɉ�Ăɓ����o���l�q���v���������B
>>822
�����R�A��L1��L2���S�Ă̑��R�A�֏Ɖ�p�P�b�g���o���S�Ă̑��R�A��L1,L2����������ԐM���S�đ����܂ő҂�L3����/���������[�h
�@����Ȃ��Ɩ�����Ȃ炢�������̂���L3�Ɋe�R�A��L2.1�Ɋi�[����Ă�f�[�^�̃A�h���X�u���Ă����Ηǂ���łȂ��̂��čl���Ă݂�B
��������A�e�R�A�̃L���b�V����c���ł��Ďc���L3�L���b�V���Ƃ��Ă��g���邵�ˁB��������>>809�͐����ł����Č��_����Ȃ��킯�����B
�@�������Ă����A�R�q�[�����V�����L3���ׂ�Ίe�R�A�̃L���b�V���c�����ȒP�����珑���������K�v�ȃR�A��L1.2�������肢�o�������ŗǂ����B
����Ƀ\�P�b�g���₵����̓\�P�b�g���Ƃ�L3�ɓ�����Ηǂ�����A�e�R�A�ɖ��ʂɎQ�ƃp�P�b�g�����������𑗂�K�����Ȃ�B
�@�R�A���₵���ꍇ���ꂪ��Ԍ������ǂ��Ƃ������̂����ǂ��B
�����R�A��L1��L2���S�Ă̑��R�A�֏Ɖ�p�P�b�g���o���S�Ă̑��R�A��L1,L2����������ԐM���S�đ����܂ő҂�L3����/���������[�h
�@����Ȃ��Ɩ�����Ȃ炢�������̂���L3�Ɋe�R�A��L2.1�Ɋi�[����Ă�f�[�^�̃A�h���X�u���Ă����Ηǂ���łȂ��̂��čl���Ă݂�B
��������A�e�R�A�̃L���b�V����c���ł��Ďc���L3�L���b�V���Ƃ��Ă��g���邵�ˁB��������>>809�͐����ł����Č��_����Ȃ��킯�����B
�@�������Ă����A�R�q�[�����V�����L3���ׂ�Ίe�R�A�̃L���b�V���c�����ȒP�����珑���������K�v�ȃR�A��L1.2�������肢�o�������ŗǂ����B
����Ƀ\�P�b�g���₵����̓\�P�b�g���Ƃ�L3�ɓ�����Ηǂ�����A�e�R�A�ɖ��ʂɎQ�ƃp�P�b�g�����������𑗂�K�����Ȃ�B
�@�R�A���₵���ꍇ���ꂪ��Ԍ������ǂ��Ƃ������̂����ǂ��B
>>837
����͂Ђǂ��c�Ǝv�������A
ttp://www.intel.com/performance/server/xeon/database.htm
���̃y�[�W���̓��e�����Ŋ������Ă鍼�\������A�����|�����邢�͎����
�������ȁB���܂��ɃC�J�T�}���݂ł�$2.93/tpmC �� $2.99/tpmC�ŕ����Ă�
�Ƃ������Ă邵��
����͂Ђǂ��c�Ǝv�������A
ttp://www.intel.com/performance/server/xeon/database.htm
���̃y�[�W���̓��e�����Ŋ������Ă鍼�\������A�����|�����邢�͎����
�������ȁB���܂��ɃC�J�T�}���݂ł�$2.93/tpmC �� $2.99/tpmC�ŕ����Ă�
�Ƃ������Ă邵��
>854
�悭�͕�����Ȃ����AL1�̔r���L���b�V�����~�߂���ގ�����Ȃ��̂��H
�L���b�V���͂Q�d�\��(L1��L2�̂�)�ɂ��āA���G�ȂR�d�\�����~�߁AL1�̃L���b�V���ʂ𑝂₵�āA�L�ɂ��A
L2�̂��L�����������Ȃ����B�P���ŁA���������}���Ǝv�����B�R�d�\��(L123)�̂܂܍s���Ȃ���Ȃ�Ȃ��Ȃ�A
L12�̔r���L���b�V�����~�߁AL3�̂��L����ƁB���ł�DDR2or3��Memory������������̂�҂ƁB
�����L���b�V���������͖��ʂɂȂ邩���������A���������₷�����A�R�A�����₵�₷���Ǝv�����H
����Ȏ������߂Ȃ̂��ǂ����A�N�����̈������ɕ�����悤�ɐ������Ă���B
�悭�͕�����Ȃ����AL1�̔r���L���b�V�����~�߂���ގ�����Ȃ��̂��H
�L���b�V���͂Q�d�\��(L1��L2�̂�)�ɂ��āA���G�ȂR�d�\�����~�߁AL1�̃L���b�V���ʂ𑝂₵�āA�L�ɂ��A
L2�̂��L�����������Ȃ����B�P���ŁA���������}���Ǝv�����B�R�d�\��(L123)�̂܂܍s���Ȃ���Ȃ�Ȃ��Ȃ�A
L12�̔r���L���b�V�����~�߁AL3�̂��L����ƁB���ł�DDR2or3��Memory������������̂�҂ƁB
�����L���b�V���������͖��ʂɂȂ邩���������A���������₷�����A�R�A�����₵�₷���Ǝv�����H
����Ȏ������߂Ȃ̂��ǂ����A�N�����̈������ɕ�����悤�ɐ������Ă���B
>>856
����Ȃ��Ƃ͒N�ł��v�������AAMD�����ďd�X���m�̏ゾ���A����ǂ��납��K9�̓C���N���[�V�u�������\����������B
����Ȃ��Ƃ͒N�ł��v�������AAMD�����ďd�X���m�̏ゾ���A����ǂ��납��K9�̓C���N���[�V�u�������\����������B
>>856
�k�P�𑝂₷�Ȃ�Đ�������Ȃ��Ƃ́A�������܂�ǂ��Ȃ��R��ł����邼�B
�k�P�𑝂₷�Ȃ�Đ�������Ȃ��Ƃ́A�������܂�ǂ��Ȃ��R��ł����邼�B
�������ʂ��̂Ɋւ��Ēf��I�Ɍ���l�����Ȃ葽������
�\���ɍޗ����o�����Ă邩��]�T�Œf��ł���܂łɂȂ���
����Ď��Ȃ̂���? ����Ƃ��f�肪�D���Ȑl�������̂�?
���ƁA���̃X�����Ă�ƁA���̒��̈�ʐl���N�ł�(�͑�U����)
�v���t���悤�ȁA���V���v���Ő��\���オ�鎖��AMD�͎�����
���Ȃ����Ď��ɂȂ�Ǝv�����A���ꂪ�M������w
���Ă��A�l�^���l�^�ƌ������ĂȂ�? �� ��
�\���ɍޗ����o�����Ă邩��]�T�Œf��ł���܂łɂȂ���
����Ď��Ȃ̂���? ����Ƃ��f�肪�D���Ȑl�������̂�?
���ƁA���̃X�����Ă�ƁA���̒��̈�ʐl���N�ł�(�͑�U����)
�v���t���悤�ȁA���V���v���Ő��\���オ�鎖��AMD�͎�����
���Ȃ����Ď��ɂȂ�Ǝv�����A���ꂪ�M������w
���Ă��A�l�^���l�^�ƌ������ĂȂ�? �� ��
�l�^�X���Ƀ}�W���X�J�R�C�[
���͖ϑz����Ԋy��������
���S�ł̓Q���Q�����Ă悤������͂��N�r�ɏo���������Ă�����
���S�ł̓Q���Q�����Ă悤������͂��N�r�ɏo���������Ă�����
862 �FSocket774�F2006/06/11(��) 16:13:17 ID:egItMFiJ
�g�@�n�@�t�@�m�@�c
(AMD Quad Core CPU)
�͂ǂ��Ȃ���
(AMD Quad Core CPU)
�͂ǂ��Ȃ���
>>854
�A�h���X��S���u���Ă����Ƃ������z�͗ǂ����ǂ��A�Ɨ������L���b�V�������v��8��(L1�̓f�[�^�Ɩ��߂ɕ�����邪1�ƍl���Ă���)������B
�����̃A�h���X���ɎQ�Əo����ƂȂ��2x4+4x8=40Way�ƂȂ肻�̑��������Ō������������̂ɂȂ�B
>>857
L1L2��r���\���̂܂c����L3��Inclusive�ɂ��郁���b�g�͂Ȃ��̂ł͂Ȃ���?
�����Inclusive�̏ꍇ�AL1L2L3�̂悤�ɊK�w���x����[������̂Ȃ�A�ЂƂO�̊K�w�̃L���b�V���e�ʂ�肸���Ƒ傫�ȃL���b�V���e�ʂ������Ȃ��ƌ����͏オ��Ȃ��B
K8L�ŘR��`����Ă������L3�L���b�V���̍\���𐄑�����ƁA��Ԍ������ǂ��̂�L3�����S�r���\�����낤�B
�܂�>>809���B
�A�h���X��S���u���Ă����Ƃ������z�͗ǂ����ǂ��A�Ɨ������L���b�V�������v��8��(L1�̓f�[�^�Ɩ��߂ɕ�����邪1�ƍl���Ă���)������B
�����̃A�h���X���ɎQ�Əo����ƂȂ��2x4+4x8=40Way�ƂȂ肻�̑��������Ō������������̂ɂȂ�B
>>857
L1L2��r���\���̂܂c����L3��Inclusive�ɂ��郁���b�g�͂Ȃ��̂ł͂Ȃ���?
�����Inclusive�̏ꍇ�AL1L2L3�̂悤�ɊK�w���x����[������̂Ȃ�A�ЂƂO�̊K�w�̃L���b�V���e�ʂ�肸���Ƒ傫�ȃL���b�V���e�ʂ������Ȃ��ƌ����͏オ��Ȃ��B
K8L�ŘR��`����Ă������L3�L���b�V���̍\���𐄑�����ƁA��Ԍ������ǂ��̂�L3�����S�r���\�����낤�B
�܂�>>809���B
864 �F�E�́E�j��-������ ��toBASh.... �F2006/06/11(��) 18:11:26 ID:ZPZj2sL2
>>856
2Way�Z�b�g�A�\�V�G�C�e�B�u��64KB+64KB, Latency3���Ă͕̂����I�Ɍ��E�Ȃ���
�L���b�V���̃G���g�����𑝂₷��L1�̃��C�e���V����
�L���b�V�����C����{�ɂ��遨L2�Ԃ̓]���N���b�N���̑���
2Way�Z�b�g�A�\�V�G�C�e�B�u��64KB+64KB, Latency3���Ă͕̂����I�Ɍ��E�Ȃ���
�L���b�V���̃G���g�����𑝂₷��L1�̃��C�e���V����
�L���b�V�����C����{�ɂ��遨L2�Ԃ̓]���N���b�N���̑���
>>840
>���R�A��L1L2�L���b�V���Ƀq�b�g�����ꍇ�A���̃L���b�V�������R�A�Ƌ������ĂĂ��A���ĂȂ��Ă��Ɖ�p�P�b�g�𑗏o����K�v�͂Ȃ��B
write�����ꍇ�́A��Ԃɂ���Ă̓p�P�b�g�����o����܂����ǁB
>���R�A��L1L2�L���b�V���Ƀq�b�g�����ꍇ�A���̃L���b�V�������R�A�Ƌ������ĂĂ��A���ĂȂ��Ă��Ɖ�p�P�b�g�𑗏o����K�v�͂Ȃ��B
write�����ꍇ�́A��Ԃɂ���Ă̓p�P�b�g�����o����܂����ǁB
���ɂł�itanium��L3�͒���������ˬΰ�
>>865
�͂��A���L�f�[�^�͏������ޑO�ɕK���Ɖ��K�v������܂��B
���ƁA���L�f�[�^�ł���X�V�ς�(�_�[�e�B�L���b�V��)��L2���ǂ��o��(�������֏����o��)�Ƃ��ɂ��Ɖ�͕K�v�ł��B
�͂��A���L�f�[�^�͏������ޑO�ɕK���Ɖ��K�v������܂��B
���ƁA���L�f�[�^�ł���X�V�ς�(�_�[�e�B�L���b�V��)��L2���ǂ��o��(�������֏����o��)�Ƃ��ɂ��Ɖ�͕K�v�ł��B
868 �FSocket774�F2006/06/11(��) 18:42:50 ID:WFmst1cr
�@ �����@���̃X���͉��B�l�b�g�E���̒ł����肵�܂��@ ��
�@ (7�k)�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�i/ /
�@/�@/�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�ȁQ�ȁ@�@ �@ �@ �@ �@ �@�b�b
/�@/�@ �ȁQ�ȁ@�@ �@ �ȁQ�ȁ@�@�Q�i�L�́M�@�j �@ �ȁQ�ȁ@�@ �b�b
�_ �_�i�@�L�́M�j�\--�i �L�́M �j�P�@�@�@�@�@�@�܁R�i�L�́M�@�j�@�^�^
�@ �_�@�@�@�@�@�@�@�^�܁@�@�@�܁P�R�A�j�[�g�@/~�܁@�@�@�@�܁@/
�@�@ �b ����@�@ |��A�@�A�j���@/�P|���ؒ�/�^`i�@�����R�� /
�@�@�@�b�R�I�^�@|�@�b�G���Q�@/�@�i�~�@�@�@�~�j �@�b�܂ق떽|
�@�@�@�b�@�@�@�@�b�@�b��D�� | �^�@�@�@�@�@�@�_ �b�@�@�@�@�b
�@�@�@�b�@�@�@�@�b�@�@�j�@�@�@ �^�@�@�@�^�_�@�@�@�_| �@ �@ �@ �R
�@�@�@/�@�@�@�m�@�b�@/�@�@�R �R�A�Q�^�j�@ �i�_�@�@ �@�j�@�T�@�@�b
�@�@ �b�@�@�b�@�@|�@/�@�@ /|�@�@ /�@���@�@�@�_`�[ ' |�@ �b�@ /
�@ (7�k)�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�i/ /
�@/�@/�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�ȁQ�ȁ@�@ �@ �@ �@ �@ �@�b�b
/�@/�@ �ȁQ�ȁ@�@ �@ �ȁQ�ȁ@�@�Q�i�L�́M�@�j �@ �ȁQ�ȁ@�@ �b�b
�_ �_�i�@�L�́M�j�\--�i �L�́M �j�P�@�@�@�@�@�@�܁R�i�L�́M�@�j�@�^�^
�@ �_�@�@�@�@�@�@�@�^�܁@�@�@�܁P�R�A�j�[�g�@/~�܁@�@�@�@�܁@/
�@�@ �b ����@�@ |��A�@�A�j���@/�P|���ؒ�/�^`i�@�����R�� /
�@�@�@�b�R�I�^�@|�@�b�G���Q�@/�@�i�~�@�@�@�~�j �@�b�܂ق떽|
�@�@�@�b�@�@�@�@�b�@�b��D�� | �^�@�@�@�@�@�@�_ �b�@�@�@�@�b
�@�@�@�b�@�@�@�@�b�@�@�j�@�@�@ �^�@�@�@�^�_�@�@�@�_| �@ �@ �@ �R
�@�@�@/�@�@�@�m�@�b�@/�@�@�R �R�A�Q�^�j�@ �i�_�@�@ �@�j�@�T�@�@�b
�@�@ �b�@�@�b�@�@|�@/�@�@ /|�@�@ /�@���@�@�@�_`�[ ' |�@ �b�@ /
>>868
�R���́u�����ł����v�X���ɋA��悗
�R���́u�����ł����v�X���ɋA��悗
>858,>864
�T���N�X�B��������������܂����B���肪�Ƃ��������܂��BL1�𑝂₷�ɂ����E�������ł��ˁB
>866
�ˁA�ˁA�Ȃ�Itanium��L3�͒������Ȃ́H�s�v�c�[�H
�T���N�X�B��������������܂����B���肪�Ƃ��������܂��BL1�𑝂₷�ɂ����E�������ł��ˁB
>866
�ˁA�ˁA�Ȃ�Itanium��L3�͒������Ȃ́H�s�v�c�[�H
���ʂ�Clean��Dirty�ŊǗ����āA��͋������C�g�o�b�N����Ηǂ���H
>>866
�ł���Ȃ�A
>>836��
> ������A�e�ʂ������������������m����������ƌ����Ă�̂����B
�̌����Ă鎖���A(��Ԃɂ���Ă�)�S���I�Ă��Ȃ��Ƃ͎v��Ȃ����B
�ł���Ȃ�A
>>836��
> ������A�e�ʂ������������������m����������ƌ����Ă�̂����B
�̌����Ă鎖���A(��Ԃɂ���Ă�)�S���I�Ă��Ȃ��Ƃ͎v��Ȃ����B
>>872-873
�L���b�V���e�ʂ������邱�ƂŁA���L�������ΓI�ɑ�����Ƃ����͓̂����f�[�^���Q�Ƃ��ɍs���\�t�g(�}���`�X���b�h)�������Ă���ꍇ�����ł��B
���������L�f�[�^�̍X�V�p�x�������ꍇ�Ɍ����܂����A���̃P�[�X�ł��L���b�V���ێ����ꂽ���ʂł���L���b�V���ێ�����Ă��Ȃ���舳�|�I�ɑ����ł��B
�L���b�V���e�ʂ������邱�ƂŁA���L�������ΓI�ɑ�����Ƃ����͓̂����f�[�^���Q�Ƃ��ɍs���\�t�g(�}���`�X���b�h)�������Ă���ꍇ�����ł��B
���������L�f�[�^�̍X�V�p�x�������ꍇ�Ɍ����܂����A���̃P�[�X�ł��L���b�V���ێ����ꂽ���ʂł���L���b�V���ێ�����Ă��Ȃ���舳�|�I�ɑ����ł��B
�������Ɖ�p�P�b�g��������̂͋��L�f�[�^�̍X�V�p�x�������ꍇ�Ɍ����܂����A
���̃P�[�X�ł��L���b�V���ێ����ꂽ���ʂł���L���b�V���ێ�����Ă��Ȃ���舳�|�I�ɑ����ł��B
���̃P�[�X�ł��L���b�V���ێ����ꂽ���ʂł���L���b�V���ێ�����Ă��Ȃ���舳�|�I�ɑ����ł��B
�����Ȃ�ƗႦ�A���L�f�[�^�̍X�V�p�x��������K�͂�DB�T�[�o���ƈႢ���o��ˁB
slashdot.org�ɋL�����o�Ă�̂�
Intel's Conroe Resurfaces, Benchmarks Strong
http://hardware.slashdot.org/hardware/06/06/10/139225.shtml
Intel's Conroe Resurfaces, Benchmarks Strong
http://hardware.slashdot.org/hardware/06/06/10/139225.shtml
�Ȃ����̘b�����Ă�ƁA�v�Z�p�I��AMD��Intel�Ɍ���I�ɕ����������ˁB�B
�ł��v���Z�X�����Z�p�ŋt�]�ł��Ȃ����ȁB���b�g�����萫�\�Ƃ��ŁB�B
����͔�����Intel���x��Ă邩��ł薳���Ɍ����邯�ǂˁB�B
�ł��v���Z�X�����Z�p�ŋt�]�ł��Ȃ����ȁB���b�g�����萫�\�Ƃ��ŁB�B
����͔�����Intel���x��Ă邩��ł薳���Ɍ����邯�ǂˁB�B
�܂������Řb����Ă�悤�Ȃ��Ƃ�AMD�͑S���l���Ă�ł���B
���ۂɃV�~�����[�V���������点�Ă邾�낤���B
���ۂɃV�~�����[�V���������点�Ă邾�낤���B
���ˁB1�l�ϑz���炻�ꂪ�����������_�݂����Ɍ����Ă鍁��t�����邪
������ƕ���������̎����̎��_��I������������˷��������ԂɎ�
�{�C�ɂ�����ʖڂ����`
������ƕ���������̎����̎��_��I������������˷��������ԂɎ�
�{�C�ɂ�����ʖڂ����`
���x�������悱���c
�܂��AAMD���⃔�������Ă��Ƃ͕�������
�Vfab�ł����ς������ς��������̂���
�܂��AAMD���⃔�������Ă��Ƃ͕�������
�Vfab�ł����ς������ς��������̂���
�v���Z�X���[���Œx��Ƃ��Ă�ꍇ���肪���������Ȃ����菟�ĂȂ��͕̂K��Ȃ�
�܂����Ȃ��y�U�ŏ������Ȃ���Ε����Ȃ������m���
�܂����Ȃ��y�U�ŏ������Ȃ���Ε����Ȃ������m���
���\�͓�̎������Ă��ƂͲ��ٌ���킩��Ǝv����
AMD�������܂��������Ώ\��������ł���
AMD�������܂��������Ώ\��������ł���
���ށB�����܂ߎs�ꂪ���߂Ă���̂͢���b�g�����萫�\����Ǝv���B���o�C���Ɍ��炸�B
�������V�X�e������d�͂��܂߂Ă̐��\�����ł����Ăق����ȁB
������AGP�ɉ�A�B���ꂪ�ȒP�����˂��E�E�E
�������V�X�e������d�͂��܂߂Ă̐��\�����ł����Ăق����ȁB
������AGP�ɉ�A�B���ꂪ�ȒP�����˂��E�E�E
>>884
��������B��ʎs�ꂪ���߂Ă�̂�
�s���̖������\�ʼn��M���߂��Ȃ������Ĉ��肵�Ă�p�\�R��
���ɗ����Ȃ����[�J�̎s���敔�Ɩ��m�ȓX�����������
AMD�����ʂɔ����B��������Ȃ�
��������B��ʎs�ꂪ���߂Ă�̂�
�s���̖������\�ʼn��M���߂��Ȃ������Ĉ��肵�Ă�p�\�R��
���ɗ����Ȃ����[�J�̎s���敔�Ɩ��m�ȓX�����������
AMD�����ʂɔ����B��������Ȃ�
��ʎs�ꂪ���߂Ă���̂�
�E�t�����Y�킳
�E���X�y�[�X��
�ECool�ȃf�U�C��
�ETV�����^��
�EDVD�}���`�h���C�u
�E����
http://journal.mycom.co.jp/articles/2006/04/18/ranking/
>>886
����˂��l�߂Ă�����x86���S��AMD���S
����˂��l�߂Ă�����x86���S��AMD���S
>>976
> �����Ȃ�ƗႦ�A���L�f�[�^�̍X�V�p�x��������K�͂�DB�T�[�o���ƈႢ���o��ˁB
��K��DB�́AWoodcrest��Opteron�Ƃ͕ʂɍl���Ă����K�v������A
�ނ������K8L��L3�g�������͑�K�͕������킹����̂����ǃR�X�g���l�������͖������낤�B
Woodcrest��Opteron��CPU�`�b�v�����Ō���̂́A�a�����Ő��X8�`16�R�A���x�Ǝv���Ă������������B
������Ă����CPU�`�b�v���ɓ��ڂ��ꂽ�L���b�V�������ł͏Ɖ�p�P�b�g�̔����I�ȑ����ɔ������\�̌���͓���̂��������B
>>879-880
����́A�ɗȁB
���Ƃ��ẮAK8L�����S�r���\���ɂ��邱�ƂŁA�e���ʂ���R��`�������̒��Ŗނ����\�̂悢���̂��Љ���Ȃ��ǁE�E�E
AMD��L3�g��������̂�AMD������Ƃ������Ƃł͂Ȃ��AL1L2���r���\���̂܂c��A������L3���L�L���b�V��������Ƃ������Ƃ��炾�B
�����߂��邱�Ƃ��犮�S��Inclusive�^�͕s�\�A>>863�ɂ������������L����R�A���������A
������L1L2�̓Ɨ������L���b�V�����O�i�Ɏ��ƂȂ�ƁA40Way Set Associative�̍\���ɂȂ�B
Way�����傫���Ȃ�ƊY���L���b�V����T���o���ɂ����Ԃ�������A���݂̕�������16Way�܂ł����z�Ƃ���Ă���B
40Way�Ƃ��ɂȂ��Ă���ƒʏ�\����Set Associative�ł͌������ቺ����ׁA�ʂ̕��������邱�ƂƂȂ�B
���ہA�����̃R�A��a����������K�̓V�X�e���́A�ʃ`�b�v�ɑ�e�ʂ̃L���b�V���V�X�e���𓋍ڂ����������߂Ă���B
���̑�e�ʂ̃L���b�V���V�X�e���́A��Way�^�ł���A����ȍ\���ƂȂ��Ă���B
IO�X�g���[���̓u���b�N���ׂ��������u���b�N�ʂɕ��삷�邱�Ƃ�O��ɁA��Way�^���L�̃��C�e���V�������B�����A
�o�X�ш�͏o���邾���傫�����邱�ƂœǏo�����Ԃ�������������ƂȂ�B
���ꓙ�́A�����p�ɊJ�����ꂽ�`�b�v�ƃV�X�e���ł��邩�炱���R�X�g�����z�ł����Ă��y�C���邱�Ƃ��o����̂ł����āA
Woodcrest��Opteron�̂悤��CPU�`�b�v�ɃA�h�I���o����i���ł͂Ȃ��B
> �����Ȃ�ƗႦ�A���L�f�[�^�̍X�V�p�x��������K�͂�DB�T�[�o���ƈႢ���o��ˁB
��K��DB�́AWoodcrest��Opteron�Ƃ͕ʂɍl���Ă����K�v������A
�ނ������K8L��L3�g�������͑�K�͕������킹����̂����ǃR�X�g���l�������͖������낤�B
Woodcrest��Opteron��CPU�`�b�v�����Ō���̂́A�a�����Ő��X8�`16�R�A���x�Ǝv���Ă������������B
������Ă����CPU�`�b�v���ɓ��ڂ��ꂽ�L���b�V�������ł͏Ɖ�p�P�b�g�̔����I�ȑ����ɔ������\�̌���͓���̂��������B
>>879-880
����́A�ɗȁB
���Ƃ��ẮAK8L�����S�r���\���ɂ��邱�ƂŁA�e���ʂ���R��`�������̒��Ŗނ����\�̂悢���̂��Љ���Ȃ��ǁE�E�E
AMD��L3�g��������̂�AMD������Ƃ������Ƃł͂Ȃ��AL1L2���r���\���̂܂c��A������L3���L�L���b�V��������Ƃ������Ƃ��炾�B
�����߂��邱�Ƃ��犮�S��Inclusive�^�͕s�\�A>>863�ɂ������������L����R�A���������A
������L1L2�̓Ɨ������L���b�V�����O�i�Ɏ��ƂȂ�ƁA40Way Set Associative�̍\���ɂȂ�B
Way�����傫���Ȃ�ƊY���L���b�V����T���o���ɂ����Ԃ�������A���݂̕�������16Way�܂ł����z�Ƃ���Ă���B
40Way�Ƃ��ɂȂ��Ă���ƒʏ�\����Set Associative�ł͌������ቺ����ׁA�ʂ̕��������邱�ƂƂȂ�B
���ہA�����̃R�A��a����������K�̓V�X�e���́A�ʃ`�b�v�ɑ�e�ʂ̃L���b�V���V�X�e���𓋍ڂ����������߂Ă���B
���̑�e�ʂ̃L���b�V���V�X�e���́A��Way�^�ł���A����ȍ\���ƂȂ��Ă���B
IO�X�g���[���̓u���b�N���ׂ��������u���b�N�ʂɕ��삷�邱�Ƃ�O��ɁA��Way�^���L�̃��C�e���V�������B�����A
�o�X�ш�͏o���邾���傫�����邱�ƂœǏo�����Ԃ�������������ƂȂ�B
���ꓙ�́A�����p�ɊJ�����ꂽ�`�b�v�ƃV�X�e���ł��邩�炱���R�X�g�����z�ł����Ă��y�C���邱�Ƃ��o����̂ł����āA
Woodcrest��Opteron�̂悤��CPU�`�b�v�ɃA�h�I���o����i���ł͂Ȃ��B
�ނ����\�E�E�E�E>�ł����\�@�@�@�T�X�T
>>884-888
�s�ꂪ���߂鐫�\
�ꌾ�ł͌��Ȃ����A���݂͏����P�ꂽ��������Ȃ����Ȃ��B
��ʓI�ɁAPC�̔����������v�́AOS�̍��V�ɂ�邱�Ƃ������A����͐VOS���V���ȉ��l����Ă���邱�Ƃƈ��������ɁA
�VOS���X���[�Y�ɓ���臒l���グ��E�E�E�܂�VOS�͋�OS��肸���Əd�����B
Micro soft�Ђ�OS��XP�ɂȂ��Ă�����������ƌo�A���̊�CPU�̐��\�̓O�[���ƌ��サ�A
���ł͏��X�Â�CPU�ł���WindowsXP���y���ɓ��������Ƃ��o���Ă��܂��B
���̂悤�Ȋ������ƁACPU�̐��\����ɖ��͂������Ȃ�����҂������Ă��܂��ACPU�͓�̎��ƂȂ�B
���N�ɂ�Vista���o�ꂷ�邩��A���݂̔P�ꂽ���͊ɘa�����Ǝv���B
�s�ꂪ���߂鐫�\
�ꌾ�ł͌��Ȃ����A���݂͏����P�ꂽ��������Ȃ����Ȃ��B
��ʓI�ɁAPC�̔����������v�́AOS�̍��V�ɂ�邱�Ƃ������A����͐VOS���V���ȉ��l����Ă���邱�Ƃƈ��������ɁA
�VOS���X���[�Y�ɓ���臒l���グ��E�E�E�܂�VOS�͋�OS��肸���Əd�����B
Micro soft�Ђ�OS��XP�ɂȂ��Ă�����������ƌo�A���̊�CPU�̐��\�̓O�[���ƌ��サ�A
���ł͏��X�Â�CPU�ł���WindowsXP���y���ɓ��������Ƃ��o���Ă��܂��B
���̂悤�Ȋ������ƁACPU�̐��\����ɖ��͂������Ȃ�����҂������Ă��܂��ACPU�͓�̎��ƂȂ�B
���N�ɂ�Vista���o�ꂷ�邩��A���݂̔P�ꂽ���͊ɘa�����Ǝv���B
�Ȃ�قǂˁB���ɂȂ�܂��B<(_ _)>
976�A879-880�͕������ĂȂ������B
>>894
���������Ȃ画�肫���ĂȂ����������ăz�X�C���B
���������Ȃ画�肫���ĂȂ����������ăz�X�C���B
L3�Ȃ�ă��C����������葬����Ό�̎�����
�P��Hound�̃��C�o����Itanium�̂悤�Ȍ��s��CPU�ɂȂ邩��L3�ł��t���Ƃ�������
�ǂ������ꂾ���̎���
����Ȃ�L3�����\�����E����v�f�Ȃ�AXeon��Opteron�ɕ�����͂��Ȃ���
�P��Hound�̃��C�o����Itanium�̂悤�Ȍ��s��CPU�ɂȂ邩��L3�ł��t���Ƃ�������
�ǂ������ꂾ���̎���
����Ȃ�L3�����\�����E����v�f�Ȃ�AXeon��Opteron�ɕ�����͂��Ȃ���
�ނ�܂����H
AMD���ŋ��L�L���b�V���ɂ��Ȃ��낤
�r���̃����b�g���ĉ�������́H
�r���̃����b�g���ĉ�������́H
�n�R����������A�_�C�T�C�Y��傫�����Ȃ��B
AMD�̎v�l�͊��Ƀ}���`�R�A�Ɍ����Ă邽��2�R�A�ɂ������ɗ����Ȃ����LL2�L���b�V����
�f�X�N�g�b�v���T�[�o�[��������̂�K8L�ł͍̗p���Ȃ��B
TDP�����ׂ̈��炭2�R�A�ŗǂ��Ǝv���鎟�����o�C�������͋��L�ɂȂ邩������Ȃ��B
Intel������4�R�A(�P���g�̎���4�R�A/1�_�C��)�ł͋��L�L���b�V�����~�߂�B
���F��L2�̔{�̗e�ʁA�ш�A���C�e���V��4�R�A��ڑ��Ƃ������Ȃ̂ŁB
���F�̃L���b�V���������̂͋��L������ł͂Ȃ�
���L���ɂ�����L���b�V�����̂𑁂���������B
�f�X�N�g�b�v���T�[�o�[��������̂�K8L�ł͍̗p���Ȃ��B
TDP�����ׂ̈��炭2�R�A�ŗǂ��Ǝv���鎟�����o�C�������͋��L�ɂȂ邩������Ȃ��B
Intel������4�R�A(�P���g�̎���4�R�A/1�_�C��)�ł͋��L�L���b�V�����~�߂�B
���F��L2�̔{�̗e�ʁA�ш�A���C�e���V��4�R�A��ڑ��Ƃ������Ȃ̂ŁB
���F�̃L���b�V���������̂͋��L������ł͂Ȃ�
���L���ɂ�����L���b�V�����̂𑁂���������B
>>901
L2��4�R�A���L�����ł�2�R�A���L�ɂ�������A��߂���͗y���ɂ܂����B
L2��4�R�A���L�����ł�2�R�A���L�ɂ�������A��߂���͗y���ɂ܂����B
>Intel������4�R�A(�P���g�̎���4�R�A/1�_�C��)�ł͋��L�L���b�V�����~�߂�B
�I��Nehalem�̃A�[�L�e�N�`�����J��!?
�ڍ��������ڂ��!
�I��Nehalem�̃A�[�L�e�N�`�����J��!?
�ڍ��������ڂ��!
�R�A��������Α�����قǁA
�R�q�[�����V�̃g���t�B�b�N���V�����ɂȂ�Ȃ��Ȃ邩��A
���L�L���b�V���͂��������B
�R�q�[�����V�̃g���t�B�b�N���V�����ɂȂ�Ȃ��Ȃ邩��A
���L�L���b�V���͂��������B
KentsField�̎���BloomField���ȁB1Chip QuadCore�ł��Ԃ�Nehalem�n�B
������Core�A�[�L�e�N�`���̂܂܂ŋ��LL2��1Chip QuadCore�Ƃ��ďo��Ƃ����\������
���̕ӂ͂܂��킩���B
������Core�A�[�L�e�N�`���̂܂܂ŋ��LL2��1Chip QuadCore�Ƃ��ďo��Ƃ����\������
���̕ӂ͂܂��킩���B
906 �FSocket774�F2006/06/12(��) 15:23:11 ID:dSqlKUW4
Tulsa���O�|��
ttp://www.itmedia.co.jp/enterprise/articles/0606/12/news019.html
�܂�Dempsey���o�����Ƃ��炵�Ă�Montecito�̔N�������͊m��I
ttp://www.itmedia.co.jp/enterprise/articles/0606/12/news019.html
�܂�Dempsey���o�����Ƃ��炵�Ă�Montecito�̔N�������͊m��I
x86��2�{�̑��x�Ői������͂���IPF�������̃v���Z�X�œ���x��Ƃ��������͒ɂ����
�܂��d���Ȃ���ȁB�}���`�R�A�̎���͓����������肾���B
���ꂩ�琢�E���̌����҂����̓��̃u���C�N�X���[��ڎw���ĐQ�H��ɂ��ނ��낤�B
���Ɖ��N�悩�A���炵�����i����ɂ��邱�Ƃ��ł��邱�Ƃ����҂������B
���ꂩ�琢�E���̌����҂����̓��̃u���C�N�X���[��ڎw���ĐQ�H��ɂ��ނ��낤�B
���Ɖ��N�悩�A���炵�����i����ɂ��邱�Ƃ��ł��邱�Ƃ����҂������B
>>908
>�}���`�R�A�̎���͓����������肾���B
����ȋƊE�S�݂̂����Ȍ���������Ȃ悗
2005�N�̎��_�Ń}���`�R�A�͒��������̂���Ȃ�����
>�}���`�R�A�̎���͓����������肾���B
����ȋƊE�S�݂̂����Ȍ���������Ȃ悗
2005�N�̎��_�Ń}���`�R�A�͒��������̂���Ȃ�����
>>899
http://pc.watch.impress.co.jp/docs/article/20000601/kaigai01.htm
�����͊m���ɗ��R��������
L2-1MB����Ƃ��ł��鍡�ƂȂ��ẮH������
http://pc.watch.impress.co.jp/docs/article/20000601/kaigai01.htm
�����͊m���ɗ��R��������
L2-1MB����Ƃ��ł��鍡�ƂȂ��ẮH������
911 �FSocket774�F2006/06/12(��) 20:42:38 ID:NZqMCikC
Victim cache �ɂ������b�g�����
�܂�͒P�Ƀf�U�C���`���C�X�̖��Ǝv���Ă�
�����킯��L3����?
�܂�͒P�Ƀf�U�C���`���C�X�̖��Ǝv���Ă�
�����킯��L3����?
�ȂA���̂܂܃��j�[�R�A�ɓ˂��i��ł����Ăق�Ƃɂ��܂������̂��ƐS�z���Ă��܂�
����v�Z���m�[�h�����₷�قǓ��ł��ɂȂ����悤�ɁA���������Ȃ������ɕǂɂԂ���̂ł́H
����Ȃ��ƌ������牽�ɂ��ł��Ȃ��Ȃ邯�ǂ��c
�����Ɖ��N�悩�A���炵�����i����ɂ��邱�Ƃ��ł��邱�Ƃ����҂������B
��
����v�Z���m�[�h�����₷�قǓ��ł��ɂȂ����悤�ɁA���������Ȃ������ɕǂɂԂ���̂ł́H
����Ȃ��ƌ������牽�ɂ��ł��Ȃ��Ȃ邯�ǂ��c
�����Ɖ��N�悩�A���炵�����i����ɂ��邱�Ƃ��ł��邱�Ƃ����҂������B
��
>����v�Z���m�[�h�����₷�قǓ��ł��ɂȂ���
��̓I�ɂǂ�ȐS�z�����Ă�̂��B�������Ă悭�킩������X�J
��̓I�ɂǂ�ȐS�z�����Ă�̂��B�������Ă悭�킩������X�J
>>913
�����ȂBֶ��
�����ȂBֶ��
Kentsfield�O�|��
http://pc.watch.impress.co.jp/docs/2006/0609/ubiq160.htm
Tulsa���O�|��
http://www.itmedia.co.jp/enterprise/articles/0606/12/news019.html
AMD�Ђ̎�����CPU(Hound)�̐���
2007/07�ȍ~�ɓ��������A����N�A�b�h
http://pc.watch.impress.co.jp/docs/2006/0522/kaigai_1.jpg
AMD�ܯ��(�L��֥`)�V���{�[��
http://pc.watch.impress.co.jp/docs/2006/0609/ubiq160.htm
Tulsa���O�|��
http://www.itmedia.co.jp/enterprise/articles/0606/12/news019.html
AMD�Ђ̎�����CPU(Hound)�̐���
2007/07�ȍ~�ɓ��������A����N�A�b�h
http://pc.watch.impress.co.jp/docs/2006/0522/kaigai_1.jpg
AMD�ܯ��(�L��֥`)�V���{�[��
�{���ɏI����Ă���A�]�T�����āu�扄���v����Ǝv���
�V�F�A�E���i�����E���\�E��������
��]���ꐡ�������Ȃ��̂��I���������Ă�v��
��]���ꐡ�������Ȃ��̂��I���������Ă�v��
intel��Conroe���\�����Ƃ��A�m��
�u�iAMD�́j���Ȃ��Ƃ���2�N�͒ǂ����Ȃ����낤�v
�݂����Ȃ��ƌ����Ă����
�������̂܂܂���I�����邶��˂���('A`)
�u�iAMD�́j���Ȃ��Ƃ���2�N�͒ǂ����Ȃ����낤�v
�݂����Ȃ��ƌ����Ă����
�������̂܂܂���I�����邶��˂���('A`)
���̋ƊE�͕������݂��������˂ق��
IBM��HT Link�����݂̍j��
>>918
���ށA���ɗ���t�]�B
�L���b�V����肳���Ȃ�Ƃ�������ꂾ���ŏ\�ɐ킦��Ǝv���̂����ǁA
�Ȃ��Ȃ�������ۂ��ˁc
>>915
����H���̌�Hound�͐^�̃N�A�b�h���Ď��ɂȂ�Ȃ����������H
���ށA���ɗ���t�]�B
�L���b�V����肳���Ȃ�Ƃ�������ꂾ���ŏ\�ɐ킦��Ǝv���̂����ǁA
�Ȃ��Ȃ�������ۂ��ˁc
>>915
����H���̌�Hound�͐^�̃N�A�b�h���Ď��ɂȂ�Ȃ����������H
�����ɂނ��Ẵ��r�W�����̂܂Ƃ߂��ق����Ȃ�
���X���̋G�߂����ˁ`
���X���̋G�߂����ˁ`
>>901-905
BloomField�̃L���b�V���\���͕s���ł����A�ł��ȒP�Ȃ̂�KentsField�̃L���b�V���\���͂��̂܂܂ɍĔz�u�ł��B
4�R�A���ʃL���b�V���ɂ���̂Ȃ�AL1��4Way�Ƃ���L2��16Way���L�L���b�V���ɂ���̂��L�͂��ȁB
���̏ꍇ�A�o�X����2�R�A���̂܂܂ŁAL2��4�u���b�N���x�ɕ����ĕʃu���b�N�Ȃ瓖���A�N�Z�X�������d�g�݂ɂȂ肻���ł��B
>>899
> �r���̃����b�g���ĉ�������́H
>>911
> Victim cache �ɂ������b�g�����
> �܂�͒P�Ƀf�U�C���`���C�X�̖��Ǝv���Ă�
AMD�͔r���L���b�V�����ێ����Ă����ł����A���R�����b�g�͂���܂��B
�r���L���b�V����L1�ɂǂꂾ�������L���b�V����ς߂�̂��Ŋ�{���\�����܂�\���ł���AL2L3�́A�ǂ��g����L���b�V��������ێ�����\���ł��B
������Inclusive��菭�Ȃ��e�ʂō����\���ł���Ƃ��������������܂��B
�����L1��L2,L3�ƃ��������A�N�Z�X�ł��闘�_������A�L���b�V�����\�Ƃ��Ă͒��X�̂��̂ł��B
����͏Ɖ�p�P�b�g�̗}����_���Ă��邩��A�Ȃ����L3�ɂȂ������ǂ��A�R�A������r�I���Ȃ��Ƃ��͂��܂�[���ɍl����K�v���Ȃ��Ǝv���܂��B
BloomField�̃L���b�V���\���͕s���ł����A�ł��ȒP�Ȃ̂�KentsField�̃L���b�V���\���͂��̂܂܂ɍĔz�u�ł��B
4�R�A���ʃL���b�V���ɂ���̂Ȃ�AL1��4Way�Ƃ���L2��16Way���L�L���b�V���ɂ���̂��L�͂��ȁB
���̏ꍇ�A�o�X����2�R�A���̂܂܂ŁAL2��4�u���b�N���x�ɕ����ĕʃu���b�N�Ȃ瓖���A�N�Z�X�������d�g�݂ɂȂ肻���ł��B
>>899
> �r���̃����b�g���ĉ�������́H
>>911
> Victim cache �ɂ������b�g�����
> �܂�͒P�Ƀf�U�C���`���C�X�̖��Ǝv���Ă�
AMD�͔r���L���b�V�����ێ����Ă����ł����A���R�����b�g�͂���܂��B
�r���L���b�V����L1�ɂǂꂾ�������L���b�V����ς߂�̂��Ŋ�{���\�����܂�\���ł���AL2L3�́A�ǂ��g����L���b�V��������ێ�����\���ł��B
������Inclusive��菭�Ȃ��e�ʂō����\���ł���Ƃ��������������܂��B
�����L1��L2,L3�ƃ��������A�N�Z�X�ł��闘�_������A�L���b�V�����\�Ƃ��Ă͒��X�̂��̂ł��B
����͏Ɖ�p�P�b�g�̗}����_���Ă��邩��A�Ȃ����L3�ɂȂ������ǂ��A�R�A������r�I���Ȃ��Ƃ��͂��܂�[���ɍl����K�v���Ȃ��Ǝv���܂��B
���ŃL���b�V�����L������ȂɔM�����̂��s���B�ʃX���b�h�A�v���Z�X���ׂ̃}���`�R�A�ł���H
�R�[�h�ƋǏ��f�[�^�łقږ��܂�L���b�V���ɂق�̈ꕔ�̃O���[�o���f�[�^��p�ŃN���X�o�[�݂���Ȃ�ċ�����
�R�[�h�ƋǏ��f�[�^�łقږ��܂�L���b�V���ɂق�̈ꕔ�̃O���[�o���f�[�^��p�ŃN���X�o�[�݂���Ȃ�ċ�����
�A���_�[(ry
AMD��
�����ݔ��\����Ă�x���`�͂قƂ�ǝs����Conroe�Ƃ͗ǂ������A�Ǝv���Ă�l���\����݂�����B
����K8L�Ŋ��S�Ɋ����Ԃ��A�Ƃ����ӂ���ϐM�������Ă�l���B
���������Ȃ�����Ǝv�����ǂ��corz
����K8L�Ŋ��S�Ɋ����Ԃ��A�Ƃ����ӂ���ϐM�������Ă�l���B
���������Ȃ�����Ǝv�����ǂ��corz
���O�����ĕ����邱�Ƃ�ϐM�������Ă�����҂Ȃ̂���H�ǂ����ɂ���n���ɂ��������Ȃ��B
�����Ƃ����낗
����
����
>>924
�e�ЂƂ��A�}���`�R�A�����{�i�����钆�ŁA���L�L���b�V�����g�����h�ɂȂ����A���ǂ��L���b�V���V�X�e���𓋍ڂ��邱�Ƃ�
�����\���ւ̈�̓����ƂȂ��Ă��邩�炱���ŋc�_���Ă���B
> �R�[�h�ƋǏ��f�[�^�łقږ��܂�L���b�V���ɂق�̈ꕔ�̃O���[�o���f�[�^��p�ŃN���X�o�[�݂���Ȃ�ċ�����
�m���ɂ����A�{���̓L���b�V���̂����A���L������X�V�����f�[�^�݂̂̓��������ςޘb�ł��B
�����ŁA�����Ƃ��P��������������@�́A�X�g�A���߂����s����Ƃ��ɏƉ�p�P�b�g�𑗂��ē����������@������܂��B
���̏ꍇ�A���L/�L�̏��͍ŏ��̃X�g�A���߂����s����Ƃ��ɂ͗L���Ă��܂���K���Ɖ�p�P�b�g�𑗂邱�ƂɂȂ�܂��B
�ԐM�p�P�b�g�̌��ʂɂ�苤�L/�L�̏���߂ĕt�������`���ł��B
�������A�L���m�肷��Γ��f�[�^�͎�����Ɖ�p�P�b�g�̑��M�͕s�v�ƂȂ�܂��B
���̌`���̎�_�́A���R�A�ŃL���b�V�����Ă���̂ɂ������烍�[�h�����A�~�X�L���b�V�����̓���������̃��[�h�ƂȂ�܂��B
AMD��K8L���ƁA���̕����̂ق����R�A���������ƌ������ǂ���������܂���B
�e�ЂƂ��A�}���`�R�A�����{�i�����钆�ŁA���L�L���b�V�����g�����h�ɂȂ����A���ǂ��L���b�V���V�X�e���𓋍ڂ��邱�Ƃ�
�����\���ւ̈�̓����ƂȂ��Ă��邩�炱���ŋc�_���Ă���B
> �R�[�h�ƋǏ��f�[�^�łقږ��܂�L���b�V���ɂق�̈ꕔ�̃O���[�o���f�[�^��p�ŃN���X�o�[�݂���Ȃ�ċ�����
�m���ɂ����A�{���̓L���b�V���̂����A���L������X�V�����f�[�^�݂̂̓��������ςޘb�ł��B
�����ŁA�����Ƃ��P��������������@�́A�X�g�A���߂����s����Ƃ��ɏƉ�p�P�b�g�𑗂��ē����������@������܂��B
���̏ꍇ�A���L/�L�̏��͍ŏ��̃X�g�A���߂����s����Ƃ��ɂ͗L���Ă��܂���K���Ɖ�p�P�b�g�𑗂邱�ƂɂȂ�܂��B
�ԐM�p�P�b�g�̌��ʂɂ�苤�L/�L�̏���߂ĕt�������`���ł��B
�������A�L���m�肷��Γ��f�[�^�͎�����Ɖ�p�P�b�g�̑��M�͕s�v�ƂȂ�܂��B
���̌`���̎�_�́A���R�A�ŃL���b�V�����Ă���̂ɂ������烍�[�h�����A�~�X�L���b�V�����̓���������̃��[�h�ƂȂ�܂��B
AMD��K8L���ƁA���̕����̂ق����R�A���������ƌ������ǂ���������܂���B
�����A�d�v�Ȃ��Ƃ��R��Ă�B
�X�g�A���͕K���������֏o�͂���邱�ƂɂȂ�܂��B
���ꂪ���̌`���̍ő�̎�_�ł��B
�X�g�A���͕K���������֏o�͂���邱�ƂɂȂ�܂��B
���ꂪ���̌`���̍ő�̎�_�ł��B
����Ȓ��X�����Ȃ��Ă��A�A���_�[���̖@���̈�s�ŏI��
���U��������Ȃ��ǂȁE�E�E
>>915
�G�Z�f���A���̓_�C���̂�������Ă��Ǝv�����B
�G�Z�f���A���̓_�C���̂�������Ă��Ǝv�����B
AMD��IBM�Ƃǂ�Ȃ��Ƃ���Ă��
������Ă�̂̓v���Z�X���[���������H
������Ă�̂̓v���Z�X���[���������H
SOI�v���Z�X�̋����J���ł���B
���͕����Ă邯�ǁB
IBM����AMD�̍������܂�̃m�E�n�E����ɓ��ꂽ��AMD�̒��̐l�������Ă��B
Fab30�͐��E�ō���Fab�����ȁB
���͕����Ă邯�ǁB
IBM����AMD�̍������܂�̃m�E�n�E����ɓ��ꂽ��AMD�̒��̐l�������Ă��B
Fab30�͐��E�ō���Fab�����ȁB
>>912
�S�R�A���炢�܂łȂ�f�X�N�g�b�v�ȗp�r�ł����\�����ڂ��L��Ǝv���B
HDD����ALAN����A�Z�L�����e�B����iLAN�ɍ��݁H�j�A�����A�P�`�Q�X���b�h��
APL�̐���ƕ��삷��A�S�̂̃X���[�v�b�g�͑����Ȃ邾�낤�B
�܂��{���Ȃ�C���e���W�F���g��SCSI��LAN�`�b�v���d���ׂ��������L�邪�B
>>915
�������̕���AMD���I��点��ɂ͋��ƃI���^���B
Intel�A���[�N�d����1/50�ɍ팸����g���C�Q�[�g�g�����W�X�^
http://pc.watch.impress.co.jp/docs/2006/0613/intel.htm
�S�R�A���炢�܂łȂ�f�X�N�g�b�v�ȗp�r�ł����\�����ڂ��L��Ǝv���B
HDD����ALAN����A�Z�L�����e�B����iLAN�ɍ��݁H�j�A�����A�P�`�Q�X���b�h��
APL�̐���ƕ��삷��A�S�̂̃X���[�v�b�g�͑����Ȃ邾�낤�B
�܂��{���Ȃ�C���e���W�F���g��SCSI��LAN�`�b�v���d���ׂ��������L�邪�B
>>915
�������̕���AMD���I��点��ɂ͋��ƃI���^���B
Intel�A���[�N�d����1/50�ɍ팸����g���C�Q�[�g�g�����W�X�^
http://pc.watch.impress.co.jp/docs/2006/0613/intel.htm
����A�����邱�Ƃ�ϐM���Ă���A�z�͖ق��Ă�ƌ����Ă���ł����ǁB
>>937
�ڂ������ׂĂȂ����画���̂����APen4�����ׂ�1000����1��50����1��
���[�N�d���ɂȂ肻�����Ƃ������Ƃ���ȁH
Intel�D�ʂ����������s���Ă����ǂ����オ�߂��Ă����Ƃ������Ƃ��ȁB
��͂�A�������N�̒��Intel�̎���̂������B
�ڂ������ׂĂȂ����画���̂����APen4�����ׂ�1000����1��50����1��
���[�N�d���ɂȂ肻�����Ƃ������Ƃ���ȁH
Intel�D�ʂ����������s���Ă����ǂ����オ�߂��Ă����Ƃ������Ƃ��ȁB
��͂�A�������N�̒��Intel�̎���̂������B
���N�O�Ƀg���C�Q�[�g�͔��\���Ă��Ǝv�����E�E�E
�`�l�c�A�h�a�l�̓f���A���Q�[�g���̂��딭�\���Ă��ȁE�E�E
�S�T��������g���n�߂����Č����Ă邾���ɂ����������Ȃ����E�E�E
�`�l�c�A�h�a�l�̓f���A���Q�[�g���̂��딭�\���Ă��ȁE�E�E
�S�T��������g���n�߂����Č����Ă邾���ɂ����������Ȃ����E�E�E
>>938
�c�O�Ȃ���AMD��FinFET���J�����Ă邩�瓯������B
���Ă������g���C�Q�[�g���č\���I��SOI�����B
2002�N���̋L��������}���`�Q�[�g�g�����W�X�^�̋L���͌��\�o�Ă���B
>>940
�������L�ۂ݂ɂ��Ȃ����������B
1/50���Ă̂͌��s��65nm�Ƃ̔�r�����ǁA1/1000���Ă̂͂ǂ��l���Ă�CPU�����̃v���Z�X����Ȃ��B
�N���b�N��������̂ƈ���������Vt���グ����[�N�d���͌��Ⴂ�ɏ��Ȃ��Ȃ��Ă������B
�c�O�Ȃ���AMD��FinFET���J�����Ă邩�瓯������B
���Ă������g���C�Q�[�g���č\���I��SOI�����B
2002�N���̋L��������}���`�Q�[�g�g�����W�X�^�̋L���͌��\�o�Ă���B
>>940
�������L�ۂ݂ɂ��Ȃ����������B
1/50���Ă̂͌��s��65nm�Ƃ̔�r�����ǁA1/1000���Ă̂͂ǂ��l���Ă�CPU�����̃v���Z�X����Ȃ��B
�N���b�N��������̂ƈ���������Vt���グ����[�N�d���͌��Ⴂ�ɏ��Ȃ��Ȃ��Ă������B
�P����K8L�ɐi����SOI�g����45nm���Ԃ��Ă�����Ă̂����Ђ�
AMD��킷�邾�낤���A���x���_�[�ɂȂ������玁�ʂ��Ƃ͂Ȃ��ł���
AMD��INTEL�ŐV�g�����W�X�^�̐��\����\�L�������ɈႤ�B
AMD���ƁA���ʂ̃g�����W�X�^�ɑ��č���J���̐V�g�����W�X�^��XX%���\UP�Ə�����Ă���P�[�X�������A���݃����[�X���Ă���ŐV�̃g�����W�X�^�̔�r�ł͂Ȃ��B
INTEL���ƁA���݃����[�X���Ă���ŐV�̃g�����W�X�^�ɑ��Ă̌��㗦��������Ă��邩��̊��I�ɕ�����₷���B
�ǂ����ł��\��Ȃ����ǂȁB
AMD���ƁA���ʂ̃g�����W�X�^�ɑ��č���J���̐V�g�����W�X�^��XX%���\UP�Ə�����Ă���P�[�X�������A���݃����[�X���Ă���ŐV�̃g�����W�X�^�̔�r�ł͂Ȃ��B
INTEL���ƁA���݃����[�X���Ă���ŐV�̃g�����W�X�^�ɑ��Ă̌��㗦��������Ă��邩��̊��I�ɕ�����₷���B
�ǂ����ł��\��Ȃ����ǂȁB
>>942
�Q�[�g������Ⴄ���d��Tr��1/300�A�X���[�v�g�����W�X�^���̉�H�Z�p��1/5-1/10��1/1000�ȉ����Ęb�B
�Ȃ�Ɣ�ׂĂ��͂͂����肵�Ȃ����A�X�C�b�`���O���x�ȂǓ����@�\���\�ł����킯�ł��Ȃ��B
�Q�[�g������Ⴄ���d��Tr��1/300�A�X���[�v�g�����W�X�^���̉�H�Z�p��1/5-1/10��1/1000�ȉ����Ęb�B
�Ȃ�Ɣ�ׂĂ��͂͂����肵�Ȃ����A�X�C�b�`���O���x�ȂǓ����@�\���\�ł����킯�ł��Ȃ��B
>>946
ttp://journal.mycom.co.jp/news/2005/09/21/005.html
����ł���H
�Q�[�g����35nm�ŕς��Ȃ��݂��������ǁB
ttp://journal.mycom.co.jp/news/2005/09/21/005.html
����ł���H
�Q�[�g����35nm�ŕς��Ȃ��݂��������ǁB
>>947
ttp://journal.mycom.co.jp/articles/2005/12/07/iedm3/
ttp://techon.nikkeibp.co.jp/article/NEWS/20051206/111372/
ttp://journal.mycom.co.jp/articles/2005/12/07/iedm3/
ttp://techon.nikkeibp.co.jp/article/NEWS/20051206/111372/