�y�X�p�R���z�X�[�p�[�R���s���[�^�֘A���2�yHPC�z
1 �F�s���ȃf�o�C�X�����F
��Itanium2��p�X���b�h�̌�p�X���b�h�ł��B
�{�X���b�h�ł͑Ώۂ��g�債�A�X�[�p�[�R���s���[�^�S�ʂɊւ���b��������܂��B
�X�[�p�[�R���s���[�^�֘A���
http://pc11.2ch.net/test/read.cgi/hard/1240026912/l50
Itanium2��p�X���E����5
http://pc11.2ch.net/test/read.cgi/hard/1158250417/
����4
http://pc8.2ch.net/test/read.cgi/hard/1126713905/
����3
http://pc7.2ch.net/test/read.cgi/jisaku/1097330852/
����2
http://pc5.2ch.net/test/read.cgi/jisaku/1078614189/
����1
http://pc3.2ch.net/test/read.cgi/jisaku/1045064542/
�{�X���b�h�ł͑Ώۂ��g�債�A�X�[�p�[�R���s���[�^�S�ʂɊւ���b��������܂��B
�X�[�p�[�R���s���[�^�֘A���
http://pc11.2ch.net/test/read.cgi/hard/1240026912/l50
Itanium2��p�X���E����5
http://pc11.2ch.net/test/read.cgi/hard/1158250417/
����4
http://pc8.2ch.net/test/read.cgi/hard/1126713905/
����3
http://pc7.2ch.net/test/read.cgi/jisaku/1097330852/
����2
http://pc5.2ch.net/test/read.cgi/jisaku/1078614189/
����1
http://pc3.2ch.net/test/read.cgi/jisaku/1045064542/
|
|
|
2 �F�s���ȃf�o�C�X�����F2009/06/25(��) 01:09:50 ID:vibJfO7N
Welcome to Year 1 AP
http://www.hpcwire.com/home/specialfeaturetopitem/Welcome-to-Year-1-AP-48967731.html
Julich Supercomputing Center Keeps Germany on the Cutting Edge of HPC
http://www.hpcwire.com/specialfeatures/isc09/features/Julich_Supercomputing_Center_Keeps_Germany_on_the_Cutting_Edge_of_HPC-48781997.html
PGI and NVIDIA team up on new CUDA compiler
http://insidehpc.com/2009/06/23/pgi-and-nvidia-team-up-on-new-cuda-compiler/
IMSL, now with 100% more BlueGene
http://insidehpc.com/2009/06/24/imsl-now-with-100-more-bluegene/
GPUs at ISC�f09
http://insidehpc.com/2009/06/24/gpus-at-isc09/
Microsoft Releases Linpack Tuning Tool
http://insidehpc.com/2009/06/24/microsoft-releases-linpack-tuning-tool/
http://www.hpcwire.com/home/specialfeaturetopitem/Welcome-to-Year-1-AP-48967731.html
Julich Supercomputing Center Keeps Germany on the Cutting Edge of HPC
http://www.hpcwire.com/specialfeatures/isc09/features/Julich_Supercomputing_Center_Keeps_Germany_on_the_Cutting_Edge_of_HPC-48781997.html
PGI and NVIDIA team up on new CUDA compiler
http://insidehpc.com/2009/06/23/pgi-and-nvidia-team-up-on-new-cuda-compiler/
IMSL, now with 100% more BlueGene
http://insidehpc.com/2009/06/24/imsl-now-with-100-more-bluegene/
GPUs at ISC�f09
http://insidehpc.com/2009/06/24/gpus-at-isc09/
Microsoft Releases Linpack Tuning Tool
http://insidehpc.com/2009/06/24/microsoft-releases-linpack-tuning-tool/
3 �F�s���ȃf�o�C�X�����F2009/06/26(��) 11:59:55 ID:LbEr0n5/
�I�E����z�ƂR�l�ʐ^�@
���c�@�M(44��)
http://www.keishicho.metro.tokyo.jp/jiken/tehai/image/hirata001.jpg
��������(51��)
http://www.keishicho.metro.tokyo.jp/jiken/tehai/image/takahashi001.jpg
�e�n���q(37��)
http://www.keishicho.metro.tokyo.jp/jiken/tehai/image/kikuchi001.jpg
���c�@�M(44��)
http://www.keishicho.metro.tokyo.jp/jiken/tehai/image/hirata001.jpg
{kind=link}
��������(51��)
http://www.keishicho.metro.tokyo.jp/jiken/tehai/image/takahashi001.jpg
{kind=link}
�e�n���q(37��)
http://www.keishicho.metro.tokyo.jp/jiken/tehai/image/kikuchi001.jpg
{kind=link}
4 �F�s���ȃf�o�C�X�����F2009/06/27(�y) 23:14:13 ID:4lWiwV6P
DARPA: Can we have a one-cabinet petaflop supercomputer?
http://www.theregister.co.uk/2009/06/26/darpa_supercomputer_slim_size/
IBM establishes exascale research effort in Ireland
http://insidehpc.com/2009/06/25/ibm-establishes-exascale-research-effort-in-ireland/
ORNL prepares for a 20-petaflops computer in 2011
http://blogs.knoxnews.com/knx/munger/2009/06/ornl_prepares_for_a_20-petaflo.html
Supercomputers go from biggest to cheapest
http://www.computerworld.com/action/article.do?command=viewArticleBasic&articleId=9134867
Intel Inside Nearly Eighty Percent of the World's Fastest Supercomputers
http://www.intel.com/pressroom/archive/releases/20090623corp_a.htm?cid=rss-90004-c1-235232
Intel and GlobalFoundries square off
http://www.theinquirer.net/inquirer/opinion/1405798/intel-globalfoundries-square
http://www.theregister.co.uk/2009/06/26/darpa_supercomputer_slim_size/
IBM establishes exascale research effort in Ireland
http://insidehpc.com/2009/06/25/ibm-establishes-exascale-research-effort-in-ireland/
ORNL prepares for a 20-petaflops computer in 2011
http://blogs.knoxnews.com/knx/munger/2009/06/ornl_prepares_for_a_20-petaflo.html
Supercomputers go from biggest to cheapest
http://www.computerworld.com/action/article.do?command=viewArticleBasic&articleId=9134867
Intel Inside Nearly Eighty Percent of the World's Fastest Supercomputers
http://www.intel.com/pressroom/archive/releases/20090623corp_a.htm?cid=rss-90004-c1-235232
Intel and GlobalFoundries square off
http://www.theinquirer.net/inquirer/opinion/1405798/intel-globalfoundries-square
5 �F�s���ȃf�o�C�X�����F2009/06/27(�y) 23:15:04 ID:4lWiwV6P
Intel's 34nm NAND SSDs launch in two weeks
http://www.theinquirer.net/inquirer/news/1406326/intel-34nm-nand-ssds-launch-weeks
Boston Limited Launches 1U Server with 4 AMD FireStream GPUs
http://www.hpcwire.com/specialfeatures/isc09/offthewire/Boston-Limited-Launches-1U-Server-with-4-AMD-FireStream-GPUs-49053261.html
One-stop shop for grid computing (w/ Video)
http://www.physorg.com/news165240346.html
NCSA, I-CHASS Provide Supercomputing Time
http://www.hpcwire.com/industry/academia/NCSA-I-CHASS-Provide-Supercomputing-Time-49184002.html
PRACE Organizes Seminar for Potential Industry Users
http://www.hpcwire.com/industry/academia/PRACE-Organizes-Seminar-for-Potential-Industry-Users-49184432.html
http://www.theinquirer.net/inquirer/news/1406326/intel-34nm-nand-ssds-launch-weeks
Boston Limited Launches 1U Server with 4 AMD FireStream GPUs
http://www.hpcwire.com/specialfeatures/isc09/offthewire/Boston-Limited-Launches-1U-Server-with-4-AMD-FireStream-GPUs-49053261.html
One-stop shop for grid computing (w/ Video)
http://www.physorg.com/news165240346.html
NCSA, I-CHASS Provide Supercomputing Time
http://www.hpcwire.com/industry/academia/NCSA-I-CHASS-Provide-Supercomputing-Time-49184002.html
PRACE Organizes Seminar for Potential Industry Users
http://www.hpcwire.com/industry/academia/PRACE-Organizes-Seminar-for-Potential-Industry-Users-49184432.html
6 �F�s���ȃf�o�C�X�����F2009/06/27(�y) 23:16:02 ID:4lWiwV6P
Intel's 34nm NAND SSDs launch in two weeks
http://www.theinquirer.net/inquirer/news/1406326/intel-34nm-nand-ssds-launch-weeks
Boston Limited Launches 1U Server with 4 AMD FireStream GPUs
http://www.hpcwire.com/specialfeatures/isc09/offthewire/Boston-Limited-Launches-1U-Server-with-4-AMD-FireStream-GPUs-49053261.html
One-stop shop for grid computing (w/ Video)
http://www.physorg.com/news165240346.html
NCSA, I-CHASS Provide Supercomputing Time
http://www.hpcwire.com/industry/academia/NCSA-I-CHASS-Provide-Supercomputing-Time-49184002.html
PRACE Organizes Seminar for Potential Industry Users
http://www.hpcwire.com/industry/academia/PRACE-Organizes-Seminar-for-Potential-Industry-Users-49184432.html
http://www.theinquirer.net/inquirer/news/1406326/intel-34nm-nand-ssds-launch-weeks
Boston Limited Launches 1U Server with 4 AMD FireStream GPUs
http://www.hpcwire.com/specialfeatures/isc09/offthewire/Boston-Limited-Launches-1U-Server-with-4-AMD-FireStream-GPUs-49053261.html
One-stop shop for grid computing (w/ Video)
http://www.physorg.com/news165240346.html
NCSA, I-CHASS Provide Supercomputing Time
http://www.hpcwire.com/industry/academia/NCSA-I-CHASS-Provide-Supercomputing-Time-49184002.html
PRACE Organizes Seminar for Potential Industry Users
http://www.hpcwire.com/industry/academia/PRACE-Organizes-Seminar-for-Potential-Industry-Users-49184432.html
7 �F�s���ȃf�o�C�X�����F2009/06/27(�y) 23:17:37 ID:4lWiwV6P
GPU�̐����v���Z�X��2010�N��32nm�A2011�N��28nm��
http://pc.watch.impress.co.jp/docs/column/kaigai/20090626_296571.html
�F�����H�͂���������!=�n���V�~�����[�^�ŗ\��-�C�m�@�\
http://jp.ibtimes.com/article/biznews/090627/36701.html
http://pc.watch.impress.co.jp/docs/column/kaigai/20090626_296571.html
�F�����H�͂���������!=�n���V�~�����[�^�ŗ\��-�C�m�@�\
http://jp.ibtimes.com/article/biznews/090627/36701.html
8 �F�s���ȃf�o�C�X�����F2009/06/30(��) 01:23:06 ID:GVP3k3Tl
A look inside the fastest supercomputer in Europe
http://royal.pingdom.com/2009/06/02/a-look-inside-the-fastest-supercomputer-in-europe/
Istanbul better price performance than Nehalem on HPL 06.29.2009
http://insidehpc.com/2009/06/29/istanbul-better-price-performance-than-nehalem-on-hpl/
Bull waves red flag at HPC with blade supers
http://www.theregister.co.uk/2009/06/29/bull_blade_supers/
Scientists Create First Electronic Quantum Processor
http://www.hpcwire.com/offthewire/Scientists-Create-First-Electronic-Quantum-Processor-49433182.html
http://royal.pingdom.com/2009/06/02/a-look-inside-the-fastest-supercomputer-in-europe/
Istanbul better price performance than Nehalem on HPL 06.29.2009
http://insidehpc.com/2009/06/29/istanbul-better-price-performance-than-nehalem-on-hpl/
Bull waves red flag at HPC with blade supers
http://www.theregister.co.uk/2009/06/29/bull_blade_supers/
Scientists Create First Electronic Quantum Processor
http://www.hpcwire.com/offthewire/Scientists-Create-First-Electronic-Quantum-Processor-49433182.html
9 �F�s���ȃf�o�C�X�����F2009/07/01(��) 02:47:16 ID:9EmLYOSA
PGI 9.0 Compilers Simplify x64+GPU Programming
http://www.ecnasiamag.com/article-25946-pgi90compilerssimplifyx64gpuprogramming-Asia.html
NVIDIA CUDA Technology Could Support AMD GPUs
http://news.softpedia.com/news/NVIDIA-CUDA-Technology-Could-Support-AMD-GPUs-115397.shtml
AMD SVP weighs in on graphics competition
http://www.theinquirer.net/inquirer/news/1432013/amd-svp-weighs-graphics-competition
Sun hardens OpenSolaris for EC2
http://www.theregister.co.uk/2009/06/29/opensolaris_on_ec2/
DARPA investigates extreme supercomputing
http://gcn.com/articles/2009/06/29/web-darpa-high-performance-computing.aspx
Seismic visualization supercomputer brings subsalt data into the light
http://offshore-mag.com/index/article-display/5445258116/s-articles/s-offshore/s-volume-69/s-issue-6/s-geology-__geophysics/s-seismic-visualization.html
�ߋ�10�N�Ō��ρ@�X�p�R����ʁAIntel�{Linux�F�����N����
http://www.atmarkit.co.jp/news/200906/30/top500.html
http://www.ecnasiamag.com/article-25946-pgi90compilerssimplifyx64gpuprogramming-Asia.html
NVIDIA CUDA Technology Could Support AMD GPUs
http://news.softpedia.com/news/NVIDIA-CUDA-Technology-Could-Support-AMD-GPUs-115397.shtml
AMD SVP weighs in on graphics competition
http://www.theinquirer.net/inquirer/news/1432013/amd-svp-weighs-graphics-competition
Sun hardens OpenSolaris for EC2
http://www.theregister.co.uk/2009/06/29/opensolaris_on_ec2/
DARPA investigates extreme supercomputing
http://gcn.com/articles/2009/06/29/web-darpa-high-performance-computing.aspx
Seismic visualization supercomputer brings subsalt data into the light
http://offshore-mag.com/index/article-display/5445258116/s-articles/s-offshore/s-volume-69/s-issue-6/s-geology-__geophysics/s-seismic-visualization.html
�ߋ�10�N�Ō��ρ@�X�p�R����ʁAIntel�{Linux�F�����N����
http://www.atmarkit.co.jp/news/200906/30/top500.html
10 �F�s���ȃf�o�C�X�����F2009/07/01(��) 06:51:31 ID:Duw8vZdo
�O�X���I�������̂���
11 �F�s���ȃf�o�C�X�����F2009/07/01(��) 17:11:57 ID:oeug1666
�@ �@ _, ,_ �@��ߺ��
�@�i�@�e�t�e�j
�@�@���c��))�D�L�j
�@�i�@�e�t�e�j
�@�@���c��))�D�L�j
12 �F�s���ȃf�o�C�X�����F2009/07/01(��) 19:34:17 ID:spMdOqt9
�i�@�L�́M�j�� �ʂ��
13 �F�s���ȃf�o�C�X�����F2009/07/01(��) 19:47:12 ID:L3KNWEtj
>>10
�݂�������
�݂�������
14 �F�s���ȃf�o�C�X�����F2009/07/02(��) 06:17:36 ID:9/jx9Psy
4�N�ȏ�O�̃R�s�y���������i�����ĂȂ��Ȃ���
�� �؍�IT�Y�Ƃ̎��� �` �T���X�����ǂ�����@��Ԃɓ˓� ��
�� ������ �i ������ �j �̃}�U�[�}�V���������F ���{90%�A�؍�5%
�@ �@���{�����킵�Ă���̂̓}�U�[�}�V�������łȂ��B
�@ �@���i�v�����{�l�G���W�j�A�ɍ�点�Ă���R�A���i���قƂ�Ǔ��{���B�g�ݗ��āu�ғ��v�̂݊؍��B
�@ �@�� ���{�̃}�U�[�}�V�����[�J�[���Ί؍����p��ŁA�V�@���5�N�͊؍��ɓn���Ȃ��_����A
�@ �@�@ �}�U�[�}�V���̃t�@�[�X�g���[�U�E�x���_�[�ƌ��Ԃ悤�ɂȂ����B
�@ �@ �����Ŋ؍��̓}�U�[�}�V�������X����͂��߂����A�܂Ƃ��ɓ����Ȃ��E�g���Ȃ��A�̂������B
�@ �@ LG�̃������}�X�N�ĕt���@��15�N���������Ă���̂ɁA12nm���܂Ƃ��Ɉ����Ȃ��B
�@ �@ ���{�ƃA�����J��9nm�ł�����͂⎞��x��B3���������Ă���̂��A�Z�p��i���؍���
�� LCD �i�t���p�l�� �j �̃}�U�[�}�V���������F ���{95%�A�؍�5%
�@ �@�T���X���������̑�7����t���H��̕����܂藦��7���B
�@ �@�V���[�v�̋T�R�H��͍ő勉 ( �؍���1.2�{�T�C�Y ) ��9��7�����A���������l�B
�@ �@�i ���̔閧�ێ��͔��Ɍ������A����ł������w�ł��Ȃ����� �j�B
�@ �@��6����H�����邽�߁A�؍���Ƃ͂����ӂ� �u ���{�l�Z�p�҈������� �v ���s��������肭�������B
�@ �@�I�����p�X�Ȃnj��w�@�탁�[�J����ŐV�̏ĕt���@��� �u �����ĖႦ�Ȃ����� �v �����
�@ �@���]��������悤�ɋƐт����������̂��T���X���̌���B
�@ �@�� �����܂�̈����T���\���� �u �Ђ����� �v �\�j�[�́A�V���[�v�⏼������8�|�Ŕ����@���Ă���B
�@ �@ �i ���̂��ߍ�N�ȗ��T���X���̉t�����Ƃ̗��v���K�^���� �j
�@ �@ �������\�j�[�͊̐S�̉f�������Z�p���T���X���Ɉ���n���Ă��炸���ɍI���B��
�� �؍�IT�Y�Ƃ̎��� �` �T���X�����ǂ�����@��Ԃɓ˓� ��
�� ������ �i ������ �j �̃}�U�[�}�V���������F ���{90%�A�؍�5%
�@ �@���{�����킵�Ă���̂̓}�U�[�}�V�������łȂ��B
�@ �@���i�v�����{�l�G���W�j�A�ɍ�点�Ă���R�A���i���قƂ�Ǔ��{���B�g�ݗ��āu�ғ��v�̂݊؍��B
�@ �@�� ���{�̃}�U�[�}�V�����[�J�[���Ί؍����p��ŁA�V�@���5�N�͊؍��ɓn���Ȃ��_����A
�@ �@�@ �}�U�[�}�V���̃t�@�[�X�g���[�U�E�x���_�[�ƌ��Ԃ悤�ɂȂ����B
�@ �@ �����Ŋ؍��̓}�U�[�}�V�������X����͂��߂����A�܂Ƃ��ɓ����Ȃ��E�g���Ȃ��A�̂������B
�@ �@ LG�̃������}�X�N�ĕt���@��15�N���������Ă���̂ɁA12nm���܂Ƃ��Ɉ����Ȃ��B
�@ �@ ���{�ƃA�����J��9nm�ł�����͂⎞��x��B3���������Ă���̂��A�Z�p��i���؍���
�� LCD �i�t���p�l�� �j �̃}�U�[�}�V���������F ���{95%�A�؍�5%
�@ �@�T���X���������̑�7����t���H��̕����܂藦��7���B
�@ �@�V���[�v�̋T�R�H��͍ő勉 ( �؍���1.2�{�T�C�Y ) ��9��7�����A���������l�B
�@ �@�i ���̔閧�ێ��͔��Ɍ������A����ł������w�ł��Ȃ����� �j�B
�@ �@��6����H�����邽�߁A�؍���Ƃ͂����ӂ� �u ���{�l�Z�p�҈������� �v ���s��������肭�������B
�@ �@�I�����p�X�Ȃnj��w�@�탁�[�J����ŐV�̏ĕt���@��� �u �����ĖႦ�Ȃ����� �v �����
�@ �@���]��������悤�ɋƐт����������̂��T���X���̌���B
�@ �@�� �����܂�̈����T���\���� �u �Ђ����� �v �\�j�[�́A�V���[�v�⏼������8�|�Ŕ����@���Ă���B
�@ �@ �i ���̂��ߍ�N�ȗ��T���X���̉t�����Ƃ̗��v���K�^���� �j
�@ �@ �������\�j�[�͊̐S�̉f�������Z�p���T���X���Ɉ���n���Ă��炸���ɍI���B��
15 �F�s���ȃf�o�C�X�����F2009/07/02(��) 06:18:55 ID:9/jx9Psy
�� �������X�[�p�[�R���s���[�^�[�̔\��
�@ �@���{�FTop.org�ɂ����ăA�����J�Ɏ����B�݂��ɗǂ���������B
�@ �@�@�@�@�n���V�~�����[�^�A�����㋞���v�Z�@�v��ȂǁB��������SGI�|�Y�B
�@ �@�؍��FLinux+���{���O���b�h��� ( SCore�̓��p ) ��03�N20�ʂ�1������o���B
�@ �@�X�[�p�[�R���s���[�^�̍��ۃV���|�W�E���iSCXX�j�Ƃ����̂����N����B
�@ �@�؍���HPC ( �n�C�p�t�H�[�}���X�R���s���[�^ ) �̃����L���O��SC05�����SC06��8�ʂ����A
����HPC�S�Ă��A�����J�������{���̃X�p�R���ɂ����̂ŁA�Ⴆ�C�ۗ\���pHPC��NEC��SX-7�B
�@ �@���̑�3��̓A�����J���̂��̂����A�ێ炪�܂Ƃ��ɏo�����A�ғ���2�� �i ���̂��߂ɔ������H�j�B
�@ �@�����p��PC�N���X�^�ɂ��HPC�́ASCore���Ă������{���\�t�g�̓��p�i�B
�@ �@�Ȃ̂Ɏ����J�������Ƃ����L���𐢊E�ɔz�M�A���E���̌����҂���}������邗�����B
�� �g�ђʐM���
�@�@���{�FNEC�A�x�m�ʁA�������̑�3����A3.5����i-mode�̃Q�[�g�E�F�C�͐��E20�J���ɗA�o
�@�@�؍��F�A�������łȂ��\�z�܂ŊO�����Ŏ������̓[���B
�� �g�ђ[��
�@�@���{�F Docomo�̐헪�~�X�ō��@�\�����i�ő�3����ł͎��s�B
�@ �@�@ �@ 3.5����ȍ~�́A�����ENEC�ɂ�鍂���\�E�ቿ�i�E���ʕ��i���Ŋ����Ԃ��\��B
�@�@�؍��F �����Ƃ̃A���C�A���X�Ȃǂ��蓾�Ȃ��B���āA�T���X���̃��C���ł���DRAM���ƒ����Ƌ��ɁE�E�E
�ȏ�A�헪�I���ƕ����ЂƂ��͂���ƁA�؍���IT�����3���ȉ� ( 2���͑�p�E�}���[�V�A�E�C���h�E���� �j
�ł��邱�Ƃ��ǂ��킩��B
�@ �@���{�FTop.org�ɂ����ăA�����J�Ɏ����B�݂��ɗǂ���������B
�@ �@�@�@�@�n���V�~�����[�^�A�����㋞���v�Z�@�v��ȂǁB��������SGI�|�Y�B
�@ �@�؍��FLinux+���{���O���b�h��� ( SCore�̓��p ) ��03�N20�ʂ�1������o���B
�@ �@�X�[�p�[�R���s���[�^�̍��ۃV���|�W�E���iSCXX�j�Ƃ����̂����N����B
�@ �@�؍���HPC ( �n�C�p�t�H�[�}���X�R���s���[�^ ) �̃����L���O��SC05�����SC06��8�ʂ����A
����HPC�S�Ă��A�����J�������{���̃X�p�R���ɂ����̂ŁA�Ⴆ�C�ۗ\���pHPC��NEC��SX-7�B
�@ �@���̑�3��̓A�����J���̂��̂����A�ێ炪�܂Ƃ��ɏo�����A�ғ���2�� �i ���̂��߂ɔ������H�j�B
�@ �@�����p��PC�N���X�^�ɂ��HPC�́ASCore���Ă������{���\�t�g�̓��p�i�B
�@ �@�Ȃ̂Ɏ����J�������Ƃ����L���𐢊E�ɔz�M�A���E���̌����҂���}������邗�����B
�� �g�ђʐM���
�@�@���{�FNEC�A�x�m�ʁA�������̑�3����A3.5����i-mode�̃Q�[�g�E�F�C�͐��E20�J���ɗA�o
�@�@�؍��F�A�������łȂ��\�z�܂ŊO�����Ŏ������̓[���B
�� �g�ђ[��
�@�@���{�F Docomo�̐헪�~�X�ō��@�\�����i�ő�3����ł͎��s�B
�@ �@�@ �@ 3.5����ȍ~�́A�����ENEC�ɂ�鍂���\�E�ቿ�i�E���ʕ��i���Ŋ����Ԃ��\��B
�@�@�؍��F �����Ƃ̃A���C�A���X�Ȃǂ��蓾�Ȃ��B���āA�T���X���̃��C���ł���DRAM���ƒ����Ƌ��ɁE�E�E
�ȏ�A�헪�I���ƕ����ЂƂ��͂���ƁA�؍���IT�����3���ȉ� ( 2���͑�p�E�}���[�V�A�E�C���h�E���� �j
�ł��邱�Ƃ��ǂ��킩��B
16 �F�s���ȃf�o�C�X�����F2009/07/02(��) 08:16:51 ID:YmPPilws
����ł��؍���DRAM��t���p�l���ɂ���āA���{�̃��[�J�[�͋ꂵ�߂��Ă��B
���ɃG���s�[�_�͋ꂵ�����B
�G���s�[�_�̋~�ςɂ��āA
�����V���Ȃł́A�Ɛѕs�U�̐ӔC��Nj������ɐŋ��𓊓�����̂͂�������
���Ę_���Ŕᔻ���Ċ؍��̉���ˌ�������Ă���̂����āA��������ς肻���ȂA�ƁB
�������A�������琔�S���~�𓊓��������čf�ɓB�Ȃ��A����������Ȃ��B
�ǂ������ƂŁA���z�̐ŋ��𓊓������̂Ɍ��ʂ��Ȃ������ƒ@���낤�ȁB
���ɃG���s�[�_�͋ꂵ�����B
�G���s�[�_�̋~�ςɂ��āA
�����V���Ȃł́A�Ɛѕs�U�̐ӔC��Nj������ɐŋ��𓊓�����̂͂�������
���Ę_���Ŕᔻ���Ċ؍��̉���ˌ�������Ă���̂����āA��������ς肻���ȂA�ƁB
�������A�������琔�S���~�𓊓��������čf�ɓB�Ȃ��A����������Ȃ��B
�ǂ������ƂŁA���z�̐ŋ��𓊓������̂Ɍ��ʂ��Ȃ������ƒ@���낤�ȁB
17 �F�s���ȃf�o�C�X�����F2009/07/02(��) 12:05:04 ID:y2WwTjsQ
>>16
>�؍���DRAM��t���p�l���ɂ���āA���{�̃��[�J�[�͋ꂵ�߂��Ă��B
�Ƃ������A�؍����璲�B���邩��ł���
�����̃}�V���ɃT����HDD������������Ă��ăL�����Ǝv��Ȃ��̂���
>�؍���DRAM��t���p�l���ɂ���āA���{�̃��[�J�[�͋ꂵ�߂��Ă��B
�Ƃ������A�؍����璲�B���邩��ł���
�����̃}�V���ɃT����HDD������������Ă��ăL�����Ǝv��Ȃ��̂���
18 �F�s���ȃf�o�C�X�����F2009/07/02(��) 13:11:23 ID:9/jx9Psy
>>16
���R�@�P�^�R
482 ���O�F�������O���� ���e���F2006/04/07(��) 16:18:41 ID:SSNe//wg
�A�����J��TRON��ׂ����w�i�́c���Ƃ��������헪�i�ꕔ�j���������B
�������@��l��H�Ə��L���R�c��ە���@�c������
http://www.jpo.go.jp/shiryou/toushin/shingikai/pdf/5kokusai/h11322.pdf
�U�D�H�Ə��L�����x����芪�����ۏ
�U-�P�@���x�̘g�g�݂Â���̓����ƍ��ی���
�P�D�ĉ��y�ѓr�㍑�̒m�I���Y����
�i�P�j�č�
_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/
_/�@�W�O�N��ɓ��莩���Y�Ƃ̍��ۋ����͂̑��ΓI�ቺ�ɑ����@������A
_/�@�Y�Ɗ������̂��߂ɒm�I���Y���ی십���𐄐i����
_/�@�u�v���p�e���g�v����ւƑ傫�������]���B�N�����g�������ɂ����Ă�������p���B
_/�A������u�v���p�e���g�v����̂��ƁA
_/�@�m�I���Y���̍��ۓI�ȕی삪�����̗��v�Ɍq����Ƃ��āA
_/�@����I�[�u��w�i�Ƃ����Ԍ��ƁA
_/�@�f�`�s�s�E���O�A�C���E���h���̂��Ƃł̑����Ԍ��Ƃ�
_/�@�g��������O�𐭍���̂��Ă����B
_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/
�@�`�D��������
�@�@A-1. �m�I���Y�ی십����ʂ����Y�ƐU����
�@�@�@�i���j�J�[�^�[�哝�́u�Y�ƋZ�p�v�V����Ɋւ��鋳���v�i�V�X�N�j
�@�@�@�@�@�@�U�O�N��y�тV�O�N�㏉���܂ŕč��͍����Z�p�͂�w�i�ɁA
�@�@�@�@�@���|�I�ȗD�ʂɗ����Ă������A
�@�@�@�@�@�V�O�N��㔼�̃G���N�g���j�N�X����Ȃǂł�
�@�@�@�@�@���{�y�уh�C�c�̒ǂ��グ�ɑ����@������A
�@�@�@�@�@�Y�Ƃ̋Z�p�v�V�̐U���Ɍ���
�@�@�@�@�@�m�I���Y���̕ی십�������
���R�@�P�^�R
482 ���O�F�������O���� ���e���F2006/04/07(��) 16:18:41 ID:SSNe//wg
�A�����J��TRON��ׂ����w�i�́c���Ƃ��������헪�i�ꕔ�j���������B
�������@��l��H�Ə��L���R�c��ە���@�c������
http://www.jpo.go.jp/shiryou/toushin/shingikai/pdf/5kokusai/h11322.pdf
�U�D�H�Ə��L�����x����芪�����ۏ
�U-�P�@���x�̘g�g�݂Â���̓����ƍ��ی���
�P�D�ĉ��y�ѓr�㍑�̒m�I���Y����
�i�P�j�č�
_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/
_/�@�W�O�N��ɓ��莩���Y�Ƃ̍��ۋ����͂̑��ΓI�ቺ�ɑ����@������A
_/�@�Y�Ɗ������̂��߂ɒm�I���Y���ی십���𐄐i����
_/�@�u�v���p�e���g�v����ւƑ傫�������]���B�N�����g�������ɂ����Ă�������p���B
_/�A������u�v���p�e���g�v����̂��ƁA
_/�@�m�I���Y���̍��ۓI�ȕی삪�����̗��v�Ɍq����Ƃ��āA
_/�@����I�[�u��w�i�Ƃ����Ԍ��ƁA
_/�@�f�`�s�s�E���O�A�C���E���h���̂��Ƃł̑����Ԍ��Ƃ�
_/�@�g��������O�𐭍���̂��Ă����B
_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/
�@�`�D��������
�@�@A-1. �m�I���Y�ی십����ʂ����Y�ƐU����
�@�@�@�i���j�J�[�^�[�哝�́u�Y�ƋZ�p�v�V����Ɋւ��鋳���v�i�V�X�N�j
�@�@�@�@�@�@�U�O�N��y�тV�O�N�㏉���܂ŕč��͍����Z�p�͂�w�i�ɁA
�@�@�@�@�@���|�I�ȗD�ʂɗ����Ă������A
�@�@�@�@�@�V�O�N��㔼�̃G���N�g���j�N�X����Ȃǂł�
�@�@�@�@�@���{�y�уh�C�c�̒ǂ��グ�ɑ����@������A
�@�@�@�@�@�Y�Ƃ̋Z�p�v�V�̐U���Ɍ���
�@�@�@�@�@�m�I���Y���̕ی십�������
19 �F�s���ȃf�o�C�X�����F2009/07/02(��) 13:12:05 ID:9/jx9Psy
>>16
���R�@�Q�^�R
483 ���O�F�������O���� ���e���F2006/04/07(��) 16:26:53 ID:???
>>1�Ɉ�����Ă������B
���������ɂɃA�C�A�R�b�J�𒆐S�Ɏ����ԋƊE��
�W���p���o�b�V���O��W�J�������A���{�Ԃ͍��ł�
���E�����[�h������B
TRON�͐��E�I�ɂ͕��y�ł��Ȃ������B
�ǂ���������u�A�d�v�������̈Ⴂ�͂Ȃ����Ǝv���H
���R�@�Q�^�R
483 ���O�F�������O���� ���e���F2006/04/07(��) 16:26:53 ID:???
>>1�Ɉ�����Ă������B
���������ɂɃA�C�A�R�b�J�𒆐S�Ɏ����ԋƊE��
�W���p���o�b�V���O��W�J�������A���{�Ԃ͍��ł�
���E�����[�h������B
TRON�͐��E�I�ɂ͕��y�ł��Ȃ������B
�ǂ���������u�A�d�v�������̈Ⴂ�͂Ȃ����Ǝv���H
20 �F�s���ȃf�o�C�X�����F2009/07/02(��) 13:12:47 ID:9/jx9Psy
>>16
���R�@�R�^�R
487 ���O�F�������O���� ���e���F2006/04/07(��) 16:37:14 ID:SSNe//wg
>>483
�ē��f�Ֆ��C�ɂ����āA�A�����J�̖��߂ɂ��A�ʎY�Ȃ́A
���{�̎����ԎY�Ƃ�������̃A�����J�Y�ƂƂ��Đ����c�点�邱�Ƃƃo�[�^�[�ŁA
���{�̃G���N�g���j�N�X�Y�Ƃ���ł����邱�Ƃ�I�������B
�A�����J�ƒʎY�Ȃ����͂��āA�S�͂�TRON��ׂ����̂͂��̈�ɂ����Ȃ��B
�܂��A�n�[�h�E�F�A�ɂ����Ă��A�A�����J�͑�p�E�؍��Ȃǂ̑�O���o�R�_���s���O�ɂ����
���{�̃n�[�h�E�F�A�Y�Ƃ���ł������B�������L�̈�ɂ����Ȃ��B
�����̔w�i�ɂ�����̂͂Ȃɂ��H
�A�����J�̐��E�e���ւ̈ӎu�ł���B
�A�����J�̓\�r�G�g�A�M��|���Z�i������70�N���
���E��Ɏx�z�̐����\�z�����헪�𗧂Ă��B
���̑�헪�Ɋ�Â��헪���A�A���`�p�e���g����v���p�e���g�ւ̑�]���ł���A
�v���U���ӂɂ�钴�~����r�h�����̐��̍\�z�ł���B
�����Ă��̂ǂ���ɂ����{�Ɛ��h�C�c���W���Ă����B
���h�C�c�́A�h�G�t�����X�Ǝ�����Ԃ��Ƃɂ���Ă������������B
���������{�́A�����ɃA�����J�̖��߂����s������ꂽ�B
�ȏ�B
���킩��H
���R�@�R�^�R
487 ���O�F�������O���� ���e���F2006/04/07(��) 16:37:14 ID:SSNe//wg
>>483
�ē��f�Ֆ��C�ɂ����āA�A�����J�̖��߂ɂ��A�ʎY�Ȃ́A
���{�̎����ԎY�Ƃ�������̃A�����J�Y�ƂƂ��Đ����c�点�邱�Ƃƃo�[�^�[�ŁA
���{�̃G���N�g���j�N�X�Y�Ƃ���ł����邱�Ƃ�I�������B
�A�����J�ƒʎY�Ȃ����͂��āA�S�͂�TRON��ׂ����̂͂��̈�ɂ����Ȃ��B
�܂��A�n�[�h�E�F�A�ɂ����Ă��A�A�����J�͑�p�E�؍��Ȃǂ̑�O���o�R�_���s���O�ɂ����
���{�̃n�[�h�E�F�A�Y�Ƃ���ł������B�������L�̈�ɂ����Ȃ��B
�����̔w�i�ɂ�����̂͂Ȃɂ��H
�A�����J�̐��E�e���ւ̈ӎu�ł���B
�A�����J�̓\�r�G�g�A�M��|���Z�i������70�N���
���E��Ɏx�z�̐����\�z�����헪�𗧂Ă��B
���̑�헪�Ɋ�Â��헪���A�A���`�p�e���g����v���p�e���g�ւ̑�]���ł���A
�v���U���ӂɂ�钴�~����r�h�����̐��̍\�z�ł���B
�����Ă��̂ǂ���ɂ����{�Ɛ��h�C�c���W���Ă����B
���h�C�c�́A�h�G�t�����X�Ǝ�����Ԃ��Ƃɂ���Ă������������B
���������{�́A�����ɃA�����J�̖��߂����s������ꂽ�B
�ȏ�B
���킩��H
21 �F�s���ȃf�o�C�X�����F2009/07/02(��) 23:56:14 ID:Tp9LZuMv
���ق���
���{�����E�W���Q���C���t�����������Ă���Β��~���Ȃ�����܂�����
���{�����E�W���Q���C���t�����������Ă���Β��~���Ȃ�����܂�����
22 �F�s���ȃf�o�C�X�����F2009/07/03(��) 07:35:10 ID:NsDn6LO4
HPC���[�U���m���Ă�������TCP/IP�̘b�A���B
IP���[�^�z���Ƃ��A�f�J��RTT���łƂ��A
�A�܂������A�܂����Ȃ����B
�Ă������A�Ȃ��TCP���g����?
�A�v���P�[�V�������g���g���q�b�N�p�^�[����ǂ��m���Ă���̂�����AUDP�ł������̂ɁB
IP���[�^�z���Ƃ��A�f�J��RTT���łƂ��A
�A�܂������A�܂����Ȃ����B
�Ă������A�Ȃ��TCP���g����?
�A�v���P�[�V�������g���g���q�b�N�p�^�[����ǂ��m���Ă���̂�����AUDP�ł������̂ɁB
23 �F�s���ȃf�o�C�X�����F2009/07/03(��) 12:45:38 ID:Dg7uEaWo
�V�₾���炳
24 �F�s���ȃf�o�C�X�����F2009/07/03(��) 19:38:56 ID:Ag0UaCUK
IBM������1000�{�ڎw�����Ă��B
25 �F�s���ȃf�o�C�X�����F2009/07/04(�y) 01:41:42 ID:99Y/H7LD
�u�A���v�������B
http://japan.cnet.com/blog/petaflops/2009/07/04/entry_27023493/
�܂����̃X���̗��ꂪ�����Ȃ邩�ȁH��
http://japan.cnet.com/blog/petaflops/2009/07/04/entry_27023493/
�܂����̃X���̗��ꂪ�����Ȃ邩�ȁH��
26 �F�s���ȃf�o�C�X�����F2009/07/04(�y) 02:17:40 ID:EdQTKEEe
�������̌|�O����
27 �F�s���ȃf�o�C�X�����F2009/07/04(�y) 07:42:39 ID:0p2RctId
28 �F�s���ȃf�o�C�X�����F2009/07/04(�y) 08:21:09 ID:99Y/H7LD
���]�X���Ă����̂͂��̃X�����܂ނ̂��ȁH�i�j
29 �F�s���ȃf�o�C�X�����F2009/07/04(�y) 08:28:02 ID:B+FFBDgV
�N���b�N����s�������Ⴂ�킯�Ƃ�����҂����ʂɌ���Ă�̂ɉؗ�ɃX���[
�����������N���炢�O����]���X����~���Ă���
�V��������͂ł��Ȃ����
�����������N���炢�O����]���X����~���Ă���
�V��������͂ł��Ȃ����
30 �F�s���ȃf�o�C�X�����F2009/07/04(�y) 08:33:11 ID:99Y/H7LD
�ǂݏI���ĂȂ�����Ȃ������������ǁA�ߋ��̋L���ǂݒ����Ă��̌������킩�����B
����͊W�҂̔��_������Ȃ�t����]�X���Ă̂��Ȃ��ˁB
����͊W�҂̔��_������Ȃ�t����]�X���Ă̂��Ȃ��ˁB
31 �F�s���ȃf�o�C�X�����F2009/07/04(�y) 08:48:13 ID:0p2RctId
>>29
cnet�̔ނ́A���̖q��搶�̌�肪��삾�Ǝv���Ă���̂ł��傤�B
����cnet�̔ނ͋C�ɓ���Ȃ����A�����Ă邱�Ƃ��x���ł��Ȃ����A�������AGRAPE-DR�ɂ͉��^�I����B
�����A�v�������Ƃ�f���Ɍ����̂�2ch������ł����āA���������ꏊ�ŏ����悤�ȗ��ꂾ������A��ɏ����Ȃ��B
cnet�̔ނ́A���̖q��搶�̌�肪��삾�Ǝv���Ă���̂ł��傤�B
����cnet�̔ނ͋C�ɓ���Ȃ����A�����Ă邱�Ƃ��x���ł��Ȃ����A�������AGRAPE-DR�ɂ͉��^�I����B
�����A�v�������Ƃ�f���Ɍ����̂�2ch������ł����āA���������ꏊ�ŏ����悤�ȗ��ꂾ������A��ɏ����Ȃ��B
32 �F�s���ȃf�o�C�X�����F2009/07/04(�y) 08:58:34 ID:0p2RctId
�����҂��s����ȃ{�[�h�v������Ė��ʂɎ��ԂƋ���Q��A�o�������̂́A���ɖ��ȃV�����m�B
����́A�����̗\��ʂ�̃p�t�H�[�}���X���o���Ƃ��Ă��A�ᔻ���Ă����Ǝv���B
������������Ƃ��Ă��A����������K&F�Ƀ{�[�h�v�������Ă͂����Ȃ��B�����ς�Ǝ���ׂ����B
����́A�����̗\��ʂ�̃p�t�H�[�}���X���o���Ƃ��Ă��A�ᔻ���Ă����Ǝv���B
������������Ƃ��Ă��A����������K&F�Ƀ{�[�h�v�������Ă͂����Ȃ��B�����ς�Ǝ���ׂ����B
33 �F�s���ȃf�o�C�X�����F2009/07/04(�y) 13:51:05 ID:bGWh6TYp
�����������́A�Ȍ���Ȃ�R�����鑤�ɂȂ��Ă��猾��������������Ȃ������H
����ȓ����X���ŃO�_�O�_���l�̔ᔻ�����Ă��A���̖��ɂ������Ȃ��Ǝv����
����ȓ����X���ŃO�_�O�_���l�̔ᔻ�����Ă��A���̖��ɂ������Ȃ��Ǝv����
34 �F�s���ȃf�o�C�X�����F2009/07/04(�y) 15:19:34 ID:bKWST4T6
���Ƃ����̖��ɗ����Ȃ��Ƃ��Ă������͎̂��R���낗
35 �F�s���ȃf�o�C�X�����F2009/07/04(�y) 15:42:07 ID:0p2RctId
>>33
�Ȍ�����Ă����̂́E�E�E�܂�������B
GRAPE-DR����낤���Ă̂́A�����Ȃ��B�ʔ����v���W�F�N�g������A���ׂ��B
�ł��AK&F�Ƀ{�[�h�v�������̂͊ԈႢ���Ǝv���B
�̂���̒m�荇����������āA�����Ɏd���𗊂ނ̂͗ǂ��Ȃ��B
�_���ȂƂ��ɃX�p�b�Ɛ�Ȃ�����B
�r�W�l�X�̊W�Ȃ�A�v���ǂ��Ȃ���Ό��������ۂ�������B
����������͕���Ȃ��ōςނ���A�ʂ̂Ƃ���ɗ��ݒ�����B
�Ȍ�����Ă����̂́E�E�E�܂�������B
GRAPE-DR����낤���Ă̂́A�����Ȃ��B�ʔ����v���W�F�N�g������A���ׂ��B
�ł��AK&F�Ƀ{�[�h�v�������̂͊ԈႢ���Ǝv���B
�̂���̒m�荇����������āA�����Ɏd���𗊂ނ̂͗ǂ��Ȃ��B
�_���ȂƂ��ɃX�p�b�Ɛ�Ȃ�����B
�r�W�l�X�̊W�Ȃ�A�v���ǂ��Ȃ���Ό��������ۂ�������B
����������͕���Ȃ��ōςނ���A�ʂ̂Ƃ���ɗ��ݒ�����B
36 �F�s���ȃf�o�C�X�����F2009/07/04(�y) 15:47:44 ID:0p2RctId
>>22�����AUDP�ł���Ă݂��B
TCP����CPU���ׂ��傫���ă_���������B
TCP����NIC��LSO(Large Send Offload)���g���邽�߁ACPU���ׂ��y���̂��ȁB
TCP����CPU���ׂ��傫���ă_���������B
TCP����NIC��LSO(Large Send Offload)���g���邽�߁ACPU���ׂ��y���̂��ȁB
37 �F�s���ȃf�o�C�X�����F2009/07/04(�y) 15:51:51 ID:0p2RctId
����� S �� send �ł͂Ȃ� segment �������B
LSO = Large Segment Offload
���������ۂ�NIC�Ɏ�������Ă���̂́ALSO�̂���TSO
TSO = TCP Segmentation Offload
�����B
LSO = Large Segment Offload
���������ۂ�NIC�Ɏ�������Ă���̂́ALSO�̂���TSO
TSO = TCP Segmentation Offload
�����B
38 �F�s���ȃf�o�C�X�����F2009/07/04(�y) 15:53:53 ID:MTWL0bsg
�{�[�h���������낤���ǁA���������̓A�[�L�������������[��B
39 �F�s���ȃf�o�C�X�����F2009/07/04(�y) 16:03:48 ID:0p2RctId
�A�[�L�e�N�`���́E�E�E�܂������͂Ȃ��Ǝv����B
Linpack�ŐU���Ȃ��̂́ALinpack�����̃A�[�L�e�N�`���ł͂Ȃ��̂�����A�Ó��ȂƂ���B
�ŏ��̃`�b�v���쐬������1�N�ȓ��ɁA
�n�[�h�E�\�t�g���ׂč\�z���ĉ^�p�J�n���Ă�����A���Ȃ荂�]���������Ǝv����B
Linpack�ŐU���Ȃ��̂́ALinpack�����̃A�[�L�e�N�`���ł͂Ȃ��̂�����A�Ó��ȂƂ���B
�ŏ��̃`�b�v���쐬������1�N�ȓ��ɁA
�n�[�h�E�\�t�g���ׂč\�z���ĉ^�p�J�n���Ă�����A���Ȃ荂�]���������Ǝv����B
40 �F�s���ȃf�o�C�X�����F2009/07/04(�y) 16:10:33 ID:MTWL0bsg
���[�I�@�킯���J���ˁ[���Ƃ����Ȃ�B
�����p�b�N�łQ�y�^������
������A�[�L���������[���
�I�c���@���v�H
�����p�b�N�łQ�y�^������
������A�[�L���������[���
�I�c���@���v�H
41 �F�s���ȃf�o�C�X�����F2009/07/04(�y) 16:13:47 ID:0p2RctId
>>40
�N��Linpack��2PF�Ȃ�Č����ĂȂ����B
�N��Linpack��2PF�Ȃ�Č����ĂȂ����B
42 �F�s���ȃf�o�C�X�����F2009/07/04(�y) 16:26:22 ID:9FUhhmS2
GRAPE-DR �́A�܂����ꂱ�ꌾ���̂͑����悤�ȋC������ȁB
GRAPE-DR�́A�Ȋw�Z�p�U��������̃v���W�F�N�g�Ȃ̂ŁA
���̂�������]�������J�����Ǝv���B
ttp://www.mext.go.jp/a_menu/kagaku/chousei/index.htm
GRAPE-DR�́A�Ȋw�Z�p�U��������̃v���W�F�N�g�Ȃ̂ŁA
���̂�������]�������J�����Ǝv���B
ttp://www.mext.go.jp/a_menu/kagaku/chousei/index.htm
43 �F�s���ȃf�o�C�X�����F2009/07/04(�y) 16:32:57 ID:9FUhhmS2
>>42 �Ə����Ă݂����̂́A�v���W�F�N�g�̐i�����S�z�ł��B
ttp://www.cfca.nao.ac.jp/hpc/muv/application/
�ɂ���V�X�e���T�v�ɂ�
"�{�V�X�e���́A�d�͑��̖���p�v�Z�@GRAPE-6�����GRAPE-7����
�\������Ă��܂��B�ߓ����ɂ̓e�X�g�^�p�̂���GRAPE-DR������
�\��ł��B "
�Ƃ��邯�ǁA�������ɂ� GRAPE-DR �̉e���`���Ȃ��B
�����V����GRAPE�V�X�e��
ttp://www.cfca.nao.ac.jp/muv/
ttp://www.cfca.nao.ac.jp/hpc/muv/application/
�ɂ���V�X�e���T�v�ɂ�
"�{�V�X�e���́A�d�͑��̖���p�v�Z�@GRAPE-6�����GRAPE-7����
�\������Ă��܂��B�ߓ����ɂ̓e�X�g�^�p�̂���GRAPE-DR������
�\��ł��B "
�Ƃ��邯�ǁA�������ɂ� GRAPE-DR �̉e���`���Ȃ��B
�����V����GRAPE�V�X�e��
ttp://www.cfca.nao.ac.jp/muv/
44 �F�s���ȃf�o�C�X�����F2009/07/04(�y) 18:15:21 ID:CUa0E3eE
>>35
�悭�킩��A���\���p�b�Ƃ��Ȃ��̂̓{�[�h�̂����Ȃ̂�?
�ǂ��������͎v���Ȃ����B�Z���Z������Ȃ��ƌ����ĂȂ����B
�����ƌ����Ȃ�{�[�h�v�̉����ǂ������Đ��\�ɂЂт��Ă���̂��A
��̓I�ɋ����Ă���Ȃ���?
�O�X�����炢��K&F�S��? �Ȃ�ʂɂǂ��ł��������B
�悭�킩��A���\���p�b�Ƃ��Ȃ��̂̓{�[�h�̂����Ȃ̂�?
�ǂ��������͎v���Ȃ����B�Z���Z������Ȃ��ƌ����ĂȂ����B
�����ƌ����Ȃ�{�[�h�v�̉����ǂ������Đ��\�ɂЂт��Ă���̂��A
��̓I�ɋ����Ă���Ȃ���?
�O�X�����炢��K&F�S��? �Ȃ�ʂɂǂ��ł��������B
45 �F�s���ȃf�o�C�X�����F2009/07/04(�y) 18:37:45 ID:0p2RctId
>>44
GRAPE-DR��2006�N���Ƀ`�b�v�̎���ɐ������A2008�N�ɂ͖{�ԉғ��J�n����Ƃ����X�P�W���[���������́B
���ꂪ2009�N�������߂��ɂȂ��āA�悤�₭���Ȃ��m�[�h���œ����͂��߂��́B
���̃X�P�W���[���x���̌����́A�{�[�h�̊������啝�ɒx�ꂽ����B
�Ȃ��{�[�h�̊������啝�ɒx�ꂽ���Ƃ����ƁA�q��搶�������ɂ́A
�g�����Ǝv���Ă���FPGA�̏o�ׂ��x�ꂽ����A�Ȃ��āB
����FPGA���g������l�i���������ė\�Z�I�[�o�[�Ȃ��āB
GRAPE-DR��2006�N���Ƀ`�b�v�̎���ɐ������A2008�N�ɂ͖{�ԉғ��J�n����Ƃ����X�P�W���[���������́B
���ꂪ2009�N�������߂��ɂȂ��āA�悤�₭���Ȃ��m�[�h���œ����͂��߂��́B
���̃X�P�W���[���x���̌����́A�{�[�h�̊������啝�ɒx�ꂽ����B
�Ȃ��{�[�h�̊������啝�ɒx�ꂽ���Ƃ����ƁA�q��搶�������ɂ́A
�g�����Ǝv���Ă���FPGA�̏o�ׂ��x�ꂽ����A�Ȃ��āB
����FPGA���g������l�i���������ė\�Z�I�[�o�[�Ȃ��āB
46 �F�s���ȃf�o�C�X�����F2009/07/04(�y) 19:22:16 ID:CUa0E3eE
���̉���͓ǂ�B�ł�����Ȃ猻���_�Ő��\���o���Ă��Ȃ��̂́A
�{�[�h�̐v����������Ȃ��āA�v���W�F�N�g�̓W�]���Â������Ƃ�
�����������Ƃ���Ȃ���?
�{�[�h�v�̐���(���ɂ��������l������Ƃ���)�ɔ������Ă�
�͕ς��Ȃ������̂ł�?
�{�[�h�̐v����������Ȃ��āA�v���W�F�N�g�̓W�]���Â������Ƃ�
�����������Ƃ���Ȃ���?
�{�[�h�v�̐���(���ɂ��������l������Ƃ���)�ɔ������Ă�
�͕ς��Ȃ������̂ł�?
47 �F�s���ȃf�o�C�X�����F2009/07/04(�y) 19:42:06 ID:0p2RctId
�[�������炵�Ȃ��Ⴂ���Ȃ��v���́A�^�C�g���[�v��n��Ȃ��ōς܂�����ȕ��@������ł���B
48 �F�s���ȃf�o�C�X�����F2009/07/04(�y) 19:42:10 ID:Ye/MMdXb
�������}�L�[�m�����ł�����������ɂ���̂��ˁB
���z�����Ă�Ƃ��Ȃ�Ƃ������A���̉e���͂��Ȃ��o�J�̑��肵�����Ė��ʂ���B
���z�����Ă�Ƃ��Ȃ�Ƃ������A���̉e���͂��Ȃ��o�J�̑��肵�����Ė��ʂ���B
49 �F�s���ȃf�o�C�X�����F2009/07/04(�y) 19:45:23 ID:B+FFBDgV
���z�����Ă���̂��n���ɗx�炳��钴�n��������ł͂�
50 �F�s���ȃf�o�C�X�����F2009/07/04(�y) 19:47:42 ID:RBdNrwHN
GRAPE-DR���_���Ă����傫�ȃj�b�`��GPGPU�Ŗ��܂������������A��ʓI�ȑi���͂��Ȃ��Ȃ����B
�^�����������Ƃ��������悤���Ȃ��B
�^�����������Ƃ��������悤���Ȃ��B
51 �F�s���ȃf�o�C�X�����F2009/07/04(�y) 19:53:25 ID:CUa0E3eE
>>47
���ȕ��@�Ƃ�? ����̓v���ɂ����������A�Ƃ������Ƃŋc�_�I�����B
��[�[��������B���A�v���̓^�C�g���[�v��n�肽���Ȃ���������
�d�����Ȃ������Ƃ��B
���ȕ��@�Ƃ�? ����̓v���ɂ����������A�Ƃ������Ƃŋc�_�I�����B
��[�[��������B���A�v���̓^�C�g���[�v��n�肽���Ȃ���������
�d�����Ȃ������Ƃ��B
52 �F�s���ȃf�o�C�X�����F2009/07/04(�y) 20:08:15 ID:4ts5wnYX
>>51
�ق炠�ꂾ��A�[����Ƀ`�[���}�C�i�X6%�ɍv�����Ă��炤�Ƃ���
�ق炠�ꂾ��A�[����Ƀ`�[���}�C�i�X6%�ɍv�����Ă��炤�Ƃ���
53 �F�s���ȃf�o�C�X�����F2009/07/04(�y) 20:10:50 ID:0p2RctId
>>51
���X�N�Ɍ����������z�Ő�����Ƃ��A���X�N�����Ђɕ����Ă��炤(���̕��A�����Ȃ邪)�Ƃ��B
�{�[�h�̎���́A��ʋ������D������A�N�����D���Ȃ��ŃX���[�������ʁA���ӌ_���K&F�ցB
�X�P�W���[�����x��Ă���̂́A�q��搶�̂Ƃ��낾���Ȃ̂��ȁB
������w�̏�H�w�����Ȃł͕���20�N9��8���_���30���[�i�ŁA
�uGRAPE-DR�V�X�e���v���Ă̂��1600���~�Ŕ����Ă��ˁB��ʋ������D�ŁB
�������K&F�ł͂Ȃ��AT2L�B
���̌���A����͍��N��3������[�������ɂ��āA11�����{�ɓ��D�����炵�����A�ǂ��Ȃ����낤�B
���X�N�Ɍ����������z�Ő�����Ƃ��A���X�N�����Ђɕ����Ă��炤(���̕��A�����Ȃ邪)�Ƃ��B
�{�[�h�̎���́A��ʋ������D������A�N�����D���Ȃ��ŃX���[�������ʁA���ӌ_���K&F�ցB
�X�P�W���[�����x��Ă���̂́A�q��搶�̂Ƃ��낾���Ȃ̂��ȁB
������w�̏�H�w�����Ȃł͕���20�N9��8���_���30���[�i�ŁA
�uGRAPE-DR�V�X�e���v���Ă̂��1600���~�Ŕ����Ă��ˁB��ʋ������D�ŁB
�������K&F�ł͂Ȃ��AT2L�B
���̌���A����͍��N��3������[�������ɂ��āA11�����{�ɓ��D�����炵�����A�ǂ��Ȃ����낤�B
54 �F�s���ȃf�o�C�X�����F2009/07/04(�y) 23:46:22 ID:Du5yE0UY
�}�L�[�m�������Ȃ��Ă��鍑�Y���[�J���̃X�[�p�[�����āA
�̔[���ɖ̐��\�o�����߂Ɏ��ɕ������ł���Ă�킯��
���̂��߂ɃR�X�g�x�O���őΉ����Ă�킯����B
�H�t���i��HDD��CPU�̒l�i���x�[�X�ɁA�ۏ��T�|�[�g�܂߂����i��
���[�J���X�[�p�[�ƃR�X�g�p�t�H�[�}���X���r���Ă��邪�A
�������Ƃ�\��ɂ���ė��Ɏ����̃C�^���ɋC�t���Ă������ĂƂ��낶��Ȃ����B
�̔[���ɖ̐��\�o�����߂Ɏ��ɕ������ł���Ă�킯��
���̂��߂ɃR�X�g�x�O���őΉ����Ă�킯����B
�H�t���i��HDD��CPU�̒l�i���x�[�X�ɁA�ۏ��T�|�[�g�܂߂����i��
���[�J���X�[�p�[�ƃR�X�g�p�t�H�[�}���X���r���Ă��邪�A
�������Ƃ�\��ɂ���ė��Ɏ����̃C�^���ɋC�t���Ă������ĂƂ��낶��Ȃ����B
55 �F�s���ȃf�o�C�X�����F2009/07/04(�y) 23:57:16 ID:2o6HWZDz
NEC���P�ނ����̂̓R�X�g�ɂ���Ȃ����炶��Ȃ������̂��B
56 �F�s���ȃf�o�C�X�����F2009/07/05(��) 00:29:37 ID:puDYz63c
���[�J�[�̕����A�R�X�g�Ɍ�������Ȃ�
�������鑤�́A���������ɒlj��̏o���悤���Ȃ����Ƃ���������
�������鑤�́A���������ɒlj��̏o���悤���Ȃ����Ƃ���������
57 �F�s���ȃf�o�C�X�����F2009/07/05(��) 00:33:01 ID:tPPyMBh0
���[�J�[�͌������Ȃ�Ė傶��Ȃ����疼
���������E�����Ōق��Ă�Z�p�҂�����ɐӂ߂��Ȃ���
���ɂ��̂��邢�ŗp�ӂ��Ă����
���������E�����Ōق��Ă�Z�p�҂�����ɐӂ߂��Ȃ���
���ɂ��̂��邢�ŗp�ӂ��Ă����
58 �F�s���ȃf�o�C�X�����F2009/07/05(��) 08:26:14 ID:HK1D4Not
���̌������i�j�p���̂������œ��{�͕��������ǂȂ�
59 �F�s���ȃf�o�C�X�����F2009/07/05(��) 09:00:01 ID:XYe3KOMM
NEC�Ƃ͕ʂ̉�Ђł̘b�ł����A�̎Z�����[�����D�悳��܂��B
�Ă������A�[���͎��炷����̂ł��B
�܂��̎Z�����Ȃ��Č��͉�����܂��B
�ŏ�����Ԏ��ɂȂ�Ƃ킩���Ă��邱�Ƃ́A�ł��܂���B
(��ォ��̂˂����݂�����ƁA�����Ȃ���Ԏ��Ő����܂����E�E�E)
�����LjČ�������o������A�Ԏ��ɂȂ��Ă��[���͎�낤�Ƃ��܂��B
�Ԏ��͎Г��I�Ȗ�肾���A�[���͑ΊO�I�Ȗ��ł�����B
��Ђ͑���Ȃ��\�Z���o���܂����A���̑���A���Y������
�Ԏ��ł����ł��Ȃ��\�����̃��b�e����\���A��̂Ă��܂��B
���Ȃ킿�A���Y�Č����I�����X�g���Ȃ̂ŁA�g���Ԃ���܂��B
�����́A�i�K���Ƃɕʌ_��ɂ��Ă����̂ŁANEC�͗��E�ł����B
�ŏ�����NEC���v���C�}���ɂ��đS���ꊇ�ł̌_��Ȃ�ANEC�͓������Ȃ��������낤�B
�Ă������A�[���͎��炷����̂ł��B
�܂��̎Z�����Ȃ��Č��͉�����܂��B
�ŏ�����Ԏ��ɂȂ�Ƃ킩���Ă��邱�Ƃ́A�ł��܂���B
(��ォ��̂˂����݂�����ƁA�����Ȃ���Ԏ��Ő����܂����E�E�E)
�����LjČ�������o������A�Ԏ��ɂȂ��Ă��[���͎�낤�Ƃ��܂��B
�Ԏ��͎Г��I�Ȗ�肾���A�[���͑ΊO�I�Ȗ��ł�����B
��Ђ͑���Ȃ��\�Z���o���܂����A���̑���A���Y������
�Ԏ��ł����ł��Ȃ��\�����̃��b�e����\���A��̂Ă��܂��B
���Ȃ킿�A���Y�Č����I�����X�g���Ȃ̂ŁA�g���Ԃ���܂��B
�����́A�i�K���Ƃɕʌ_��ɂ��Ă����̂ŁANEC�͗��E�ł����B
�ŏ�����NEC���v���C�}���ɂ��đS���ꊇ�ł̌_��Ȃ�ANEC�͓������Ȃ��������낤�B
60 �F�s���ȃf�o�C�X�����F2009/07/05(��) 09:06:53 ID:udlX5hXe
�����Ń\�R�\�R�H���Ă��܂������炾��B
�C�Â����Ƃ��ɂ͎s��K�͂��k�����Ăǂ��ɂ��Ȃ�Ȃ��Ȃ��Ă�B
����ɏȒ��ł����������ǁA�C�O�g�͓����̏o���R�[�X����O�ꂿ�Ⴄ�Ƃ������s������B
�C�Â����Ƃ��ɂ͎s��K�͂��k�����Ăǂ��ɂ��Ȃ�Ȃ��Ȃ��Ă�B
����ɏȒ��ł����������ǁA�C�O�g�͓����̏o���R�[�X����O�ꂿ�Ⴄ�Ƃ������s������B
61 �F�s���ȃf�o�C�X�����F2009/07/05(��) 09:19:45 ID:XYe3KOMM
>>54
�}�L�[�m��DIY������ȁB
�������������҂̓��]���A�ړI�ł͂Ȃ���i�ɖ��ʂÂ������Ă��邱�Ƃ��A���o���ׂ�����B
��������i���ꗬ�őf�����m���Ɏ����ł���Ȃ�Ƃ������A�����ł͂Ȃ��̂�����DIY��`�̕��Q���E�E�E�B
�ł��A�܂��A�X�g���[�W�ɂ��ẮADIY�������͂Ȃ��Ǝv���B
�G���^�[�v���C�Y�Ɨv�������������Ⴄ�̂�����A�G���^�[�v���C�Y�p���g���̂́A���������Ȃ����ˁB
�̂̌����҂��I�[�v�����[���̃e�[�v������Ă����悤�ɁA
�p�\�R���p�̊O�t��HDD���A���[�U�[�ɗp�ӂ��Ă��炦�����̂�B
20MB/sec�ł̏������݂ł��A24���Ԃ�1.7TB���������߂�B
���郆�[�U��50TB���g���Ƃ��Ă��A30��ő����B�璷���������B
30�����HDD���A�}���̉҂���USB��IEEE1394�Ōq���ŁA
�����Ɉ��肵�����x�œǂݏ�������̂͑�ς����ǂˁB
�}�L�[�m��DIY������ȁB
�������������҂̓��]���A�ړI�ł͂Ȃ���i�ɖ��ʂÂ������Ă��邱�Ƃ��A���o���ׂ�����B
��������i���ꗬ�őf�����m���Ɏ����ł���Ȃ�Ƃ������A�����ł͂Ȃ��̂�����DIY��`�̕��Q���E�E�E�B
�ł��A�܂��A�X�g���[�W�ɂ��ẮADIY�������͂Ȃ��Ǝv���B
�G���^�[�v���C�Y�Ɨv�������������Ⴄ�̂�����A�G���^�[�v���C�Y�p���g���̂́A���������Ȃ����ˁB
�̂̌����҂��I�[�v�����[���̃e�[�v������Ă����悤�ɁA
�p�\�R���p�̊O�t��HDD���A���[�U�[�ɗp�ӂ��Ă��炦�����̂�B
20MB/sec�ł̏������݂ł��A24���Ԃ�1.7TB���������߂�B
���郆�[�U��50TB���g���Ƃ��Ă��A30��ő����B�璷���������B
30�����HDD���A�}���̉҂���USB��IEEE1394�Ōq���ŁA
�����Ɉ��肵�����x�œǂݏ�������̂͑�ς����ǂˁB
62 �F�s���ȃf�o�C�X�����F2009/07/05(��) 09:21:16 ID:LjbtJz5k
INTEL�̓G���b�^�𑼏����������ƌ��J���Ă��邩��
������������
���ۂ̂Ƃ���͂ǂ����m��Ȃ�
������������
���ۂ̂Ƃ���͂ǂ����m��Ȃ�
63 �F�s���ȃf�o�C�X�����F2009/07/05(��) 09:31:43 ID:LjbtJz5k
��i���P�A���Ȃ��ƖړI�ɋ߂Â��Ȃ��Ȃ�
�ׂɍ˔\�̖��ʌ����ł��Ȃ���ˁ[�́H
�ׂɍ˔\�̖��ʌ����ł��Ȃ���ˁ[�́H
64 �F�s���ȃf�o�C�X�����F2009/07/05(��) 12:18:35 ID:XYe3KOMM
>>63
��������i�͕K�v�B
���̎�i���A�V���w�҂��{�Ƃɂ����鎞�Ԃ�����Ď��O�ŗp�ӂ���̂ł͂Ȃ��A
���̎�i���{�Ƃ̌v�Z�@���ɗp�ӂ��Ă�������ق����A�x�^�[���Ǝv����ˁB
��������i�͕K�v�B
���̎�i���A�V���w�҂��{�Ƃɂ����鎞�Ԃ�����Ď��O�ŗp�ӂ���̂ł͂Ȃ��A
���̎�i���{�Ƃ̌v�Z�@���ɗp�ӂ��Ă�������ق����A�x�^�[���Ǝv����ˁB
65 �F�s���ȃf�o�C�X�����F2009/07/05(��) 13:03:17 ID:A/wxwOny
������IBM�ł���A�ł�����
66 �F�s���ȃf�o�C�X�����F2009/07/05(��) 13:48:38 ID:XYe3KOMM
��胁�[�J�[�ł��������ǁA�����O�̌����҂ɗ��ނ̂��肾��A�Ă������A�������ׂ��B
67 �F�s���ȃf�o�C�X�����F2009/07/05(��) 14:00:48 ID:A/wxwOny
�����̖��������̂ɐ������ς���
���l�̌v�Z�@�̖ʓ|�����Ă�����ɂȃ��V��
�D�G�Ȃ̂Ȃ�ċ��Ȃ�
���l�̌v�Z�@�̖ʓ|�����Ă�����ɂȃ��V��
�D�G�Ȃ̂Ȃ�ċ��Ȃ�
68 �F�s���ȃf�o�C�X�����F2009/07/05(��) 14:12:39 ID:3vGlpWTT
Imagine Cup 2009 Report�F�\�t�g�E�F�A�f�U�C������
�܂��������͂����鐢�E�̕ǁ\�\���{��\�A�ꎟ�\�I�Őɔs
http://www.itmedia.co.jp/enterprise/articles/0907/05/news003.html
�܂��������͂����鐢�E�̕ǁ\�\���{��\�A�ꎟ�\�I�Őɔs
http://www.itmedia.co.jp/enterprise/articles/0907/05/news003.html
69 �F�s���ȃf�o�C�X�����F2009/07/05(��) 14:12:39 ID:XYe3KOMM
>>67
����͌v�Z�@���g�����̌����҂ł���B
DIY����Ȃ��Č����Ă����A�v�Z�@����鑤�̌����҂ɗ��ނ�ł���B
���Ă̓X�p�R���̃A�[�L�e�N�`���̌��������Ă������A
���@��Ȃ�Ă���Ⴕ�Ȃ��̂Ń��[�J�[�̌������Ƃ͒��荇�����A
��ނȂ��ʂ̕���E�E�E�L��l�b�g���[�N�ŕ��U���ĉ����E�E�E�Ȃǂɗ��ꂽ�l���������ĂˁB
�ނ�̒��ɂ͗\�Z�Ɨp�r�����^������A�X�p�R�����ɕ��A���������Đl������B
GRAPE-DR��A�܂������Ă�A�܂�A���ɂ�点����Ă����l������̂�B
�ł��A���{�ł͖q��搶����ƂƂ��ČN�Ղ��Ă��邩��A
�q��搶�������ł��Ƃ�������A�`�����X���Ȃ��킯��B
����͌v�Z�@���g�����̌����҂ł���B
DIY����Ȃ��Č����Ă����A�v�Z�@����鑤�̌����҂ɗ��ނ�ł���B
���Ă̓X�p�R���̃A�[�L�e�N�`���̌��������Ă������A
���@��Ȃ�Ă���Ⴕ�Ȃ��̂Ń��[�J�[�̌������Ƃ͒��荇�����A
��ނȂ��ʂ̕���E�E�E�L��l�b�g���[�N�ŕ��U���ĉ����E�E�E�Ȃǂɗ��ꂽ�l���������ĂˁB
�ނ�̒��ɂ͗\�Z�Ɨp�r�����^������A�X�p�R�����ɕ��A���������Đl������B
GRAPE-DR��A�܂������Ă�A�܂�A���ɂ�点����Ă����l������̂�B
�ł��A���{�ł͖q��搶����ƂƂ��ČN�Ղ��Ă��邩��A
�q��搶�������ł��Ƃ�������A�`�����X���Ȃ��킯��B
70 �F�s���ȃf�o�C�X�����F2009/07/05(��) 14:31:12 ID:A/wxwOny
�ނ͑�ƂƂ��ČN�Ղ�������ł���
71 �F�s���ȃf�o�C�X�����F2009/07/05(��) 14:34:50 ID:XYe3KOMM
������A�q��搶�͓V���w�҂���߂āA�X�p�R���w�҂ɈƑւ������ق��������Ǝv���̂�B
72 �F�s���ȃf�o�C�X�����F2009/07/05(��) 14:42:04 ID:A/wxwOny
�X�p�R������肽������X�p�R�������\�Z������Ȃ�Ēʂ�Ȃ����炠�Ȃ����������悤��
�Ƒւ������A���������ł���
����ɈƑւ����邩�ǂ����͔ގ��g�����߂邱�Ƃ���
�Ƒւ������A���������ł���
����ɈƑւ����邩�ǂ����͔ގ��g�����߂邱�Ƃ���
73 �F�s���ȃf�o�C�X�����F2009/07/05(��) 14:43:55 ID:LjbtJz5k
>>69
�����������l�͌v�Z�@�������łɎ�i�Ƃ��ĉF�������w��������ˁH
�����������l�͌v�Z�@�������łɎ�i�Ƃ��ĉF�������w��������ˁH
74 �F�s���ȃf�o�C�X�����F2009/07/05(��) 15:02:36 ID:XYe3KOMM
>>72
���p�҂��Ȃ��A�����X�p�R������肽���A�Ȃ�Ă����̂ł͗\�Z�͎��Ȃ��͎̂d���Ȃ��B
�X�p�R�����g�������l���\�Z������āA�������肽���l�Ɏg�킹�������ł���B
���ہA�q��搶�͕��ؐ搶���������킯������ǂ��E�E�E
���p�҂��Ȃ��A�����X�p�R������肽���A�Ȃ�Ă����̂ł͗\�Z�͎��Ȃ��͎̂d���Ȃ��B
�X�p�R�����g�������l���\�Z������āA�������肽���l�Ɏg�킹�������ł���B
���ہA�q��搶�͕��ؐ搶���������킯������ǂ��E�E�E
75 �F�s���ȃf�o�C�X�����F2009/07/05(��) 15:45:12 ID:GQD/gFS9
�����ŗ\�Z����ꂸ�A�i�g���l�Ɓj�Ղ��ă`�[�����g�߂��B
����Ȃ̂ɁA������������������Ȃ�Ē����ǂ����Ȃ����H
����Ȃ̂ɁA������������������Ȃ�Ē����ǂ����Ȃ����H
76 �F�s���ȃf�o�C�X�����F2009/07/05(��) 15:47:31 ID:LjbtJz5k
>>64
���Ⴀ���荞�݂ɍs��������ˁH
���Ⴀ���荞�݂ɍs��������ˁH
77 �F�s���ȃf�o�C�X�����F2009/07/05(��) 16:10:24 ID:XYe3KOMM
>>75
> �����ŗ\�Z����ꂸ
�����X�p�R������邾���E�E�E�ŗ\�Z������킯���Ȃ��ł��傤�ɁB
> �i�g���l�Ɓj�Ղ��ă`�[�����g�߂��B
�g���l�������ō�����܂��̂�����A�`�[�����g�߂Ȃ���ł���B
> ����Ȃ̂ɁA������������������Ȃ�Ē����ǂ����Ȃ����H
�t���[�n���h�̌����ł͂Ȃ���ł�����B
> �����ŗ\�Z����ꂸ
�����X�p�R������邾���E�E�E�ŗ\�Z������킯���Ȃ��ł��傤�ɁB
> �i�g���l�Ɓj�Ղ��ă`�[�����g�߂��B
�g���l�������ō�����܂��̂�����A�`�[�����g�߂Ȃ���ł���B
> ����Ȃ̂ɁA������������������Ȃ�Ē����ǂ����Ȃ����H
�t���[�n���h�̌����ł͂Ȃ���ł�����B
78 �F�s���ȃf�o�C�X�����F2009/07/05(��) 16:24:25 ID:GQD/gFS9
�o���Ȃ����R��K���ŒT���Ă�悤�ɂ��������Ȃ����ǁB
79 �F�s���ȃf�o�C�X�����F2009/07/05(��) 16:32:31 ID:XYe3KOMM
�����ɁA�o���ĂȂ��ł���B
80 �F�s���ȃf�o�C�X�����F2009/07/05(��) 16:33:44 ID:XYe3KOMM
��w�ł͂Ȃ����[�J�[���ƁA�x�m�ʂ�BioServer�����肪���[�U�[�Č��œ������č��ꂽ�X�p�R�����ˁB
81 �F�s���ȃf�o�C�X�����F2009/07/05(��) 17:00:33 ID:GQD/gFS9
ID:XYe3KOMM
���s���𐂂�����ʼn������Ă��Ȃ��A�ƌ����Ӗ��������̂�����ǁB
���������鎞�_�ŁA���������ɂ��������Ȃ��B�~�߂���H
�{�C�ŗJ�����Ă�̂Ȃ瓽���f���Ō�����Ȃ��đR��ׂ����ł��ׂ��ł���B
���s���𐂂�����ʼn������Ă��Ȃ��A�ƌ����Ӗ��������̂�����ǁB
���������鎞�_�ŁA���������ɂ��������Ȃ��B�~�߂���H
�{�C�ŗJ�����Ă�̂Ȃ瓽���f���Ō�����Ȃ��đR��ׂ����ł��ׂ��ł���B
82 �F�s���ȃf�o�C�X�����F2009/07/05(��) 21:27:57 ID:V6eXeo3d
�u���i���P�N�łP�O���̂P�ɉ�������悤�Ȕ����̃��[�J�[�ւ̗Z���͈��̃M�����u���v�i���K�o���N�����j
http://sankei.jp.msn.com/economy/business/090705/biz0907051802002-n1.htm
http://sankei.jp.msn.com/economy/business/090705/biz0907051802002-n1.htm
83 �F�s���ȃf�o�C�X�����F2009/07/05(��) 22:03:04 ID:js6pceCO
�P�ɖq�삪�[������v������ނɌ����ăn�[�h�����������Ă���Ɛ��������
�ǂ������ł��傤�H����������Ă�����l�����Ȃ�����u��ƂƂ��ČN�Ձv�������
���Ȃ������ŁB
�ǂ������ł��傤�H����������Ă�����l�����Ȃ�����u��ƂƂ��ČN�Ձv�������
���Ȃ������ŁB
84 �F�s���ȃf�o�C�X�����F2009/07/05(��) 22:27:31 ID:YuJ35x4W
>>83
�����Ă�ˁB�@���������B
���X�����҂Ƃ��Z�p�҂��āu���������v�I�Ȋ�������Ȃ菬�Ȃ肠�邵�B
���F�łȂ��Ƃ�肽���Ȃ���ˁH
������A�N����������Ȃ����B
�������A
�x���̌��́AFPGA���ɍ��������̂��B
ALTERA��Arria�������B
�����̂ɁA�������������̃V���A��ch���ڂ����̂��\�������ڏ��������ĂȂ������̂��ȁB
X�Ƃ��k�ɑ�֖��������݂��������B
��ʃ��[�J�̈�ʌ����r�W�l�X�ł́A
����ȃf�o�C�X�I��͕|���ďo���Ȃ��i�㒷�Ȃ�w������点�Ȃ��j�B
�{���A�\���ȗ\�Z������A
����FPGA�@�\�S������ASIC������A
������1�`�b�v������̃R�X�g����������A����̂��낤���A
�J����A�}�X�N�オ�ˁB
GRAPE-DR�Ő���t��������ł��傤�B
�i�����������\�o���V���A���̐������130nm�ȉ����낤����A
�@����Ȃ�ɍ����Ȃ̂��낤�j
�܁[���X�N���Ƃ��ă��X�N�������̂��B
�����Ă�ˁB�@���������B
���X�����҂Ƃ��Z�p�҂��āu���������v�I�Ȋ�������Ȃ菬�Ȃ肠�邵�B
���F�łȂ��Ƃ�肽���Ȃ���ˁH
������A�N����������Ȃ����B
�������A
�x���̌��́AFPGA���ɍ��������̂��B
ALTERA��Arria�������B
�����̂ɁA�������������̃V���A��ch���ڂ����̂��\�������ڏ��������ĂȂ������̂��ȁB
X�Ƃ��k�ɑ�֖��������݂��������B
��ʃ��[�J�̈�ʌ����r�W�l�X�ł́A
����ȃf�o�C�X�I��͕|���ďo���Ȃ��i�㒷�Ȃ�w������点�Ȃ��j�B
�{���A�\���ȗ\�Z������A
����FPGA�@�\�S������ASIC������A
������1�`�b�v������̃R�X�g����������A����̂��낤���A
�J����A�}�X�N�オ�ˁB
GRAPE-DR�Ő���t��������ł��傤�B
�i�����������\�o���V���A���̐������130nm�ȉ����낤����A
�@����Ȃ�ɍ����Ȃ̂��낤�j
�܁[���X�N���Ƃ��ă��X�N�������̂��B
85 �F�s���ȃf�o�C�X�����F2009/07/06(��) 02:00:39 ID:8eLielN2
�q��̏ꍇ�A�����ǂ��������ɂ�肽�����́A��肾������Ȃ��l�b�g�ł�
�U�X�Ɍ��J���Ă���킯�ŁA���̐��ɏ]���Ă��ނ��ǂ��A�C�f�A������
�Ȃ�A���邢�͔ނ̃A�C�f�A����������Z�p������Ȃ�A�����Ŕ��荞�߂�
��낵���B�q��̓V�X�e���𗝉����Ă���A����������������������m��
���[�U�[�Ƃ����A��L�ȑ��݂Ȃ���A�V�X�e���������q�Ƃ��Ĕ��荞��
��Ƃ��Ă͗��z�I�Ȃ͂�����ȁB
�U�X�Ɍ��J���Ă���킯�ŁA���̐��ɏ]���Ă��ނ��ǂ��A�C�f�A������
�Ȃ�A���邢�͔ނ̃A�C�f�A����������Z�p������Ȃ�A�����Ŕ��荞�߂�
��낵���B�q��̓V�X�e���𗝉����Ă���A����������������������m��
���[�U�[�Ƃ����A��L�ȑ��݂Ȃ���A�V�X�e���������q�Ƃ��Ĕ��荞��
��Ƃ��Ă͗��z�I�Ȃ͂�����ȁB
86 �F�s���ȃf�o�C�X�����F2009/07/06(��) 03:23:30 ID:+9hmrbXL
���z�I�ȋq�ɔ��荞�߂Ȃ�I��M�߷ެ����Ă��Ƃ�FA�H��
87 �F�s���ȃf�o�C�X�����F2009/07/06(��) 07:06:49 ID:GlvoeE8g
�܂��A�Ȃ�Ƃ������A
IBM���ċƊE�ɑ��l�Ȑl�ނ��������Ă��邱�ƂŗL���ł���ˁB
�Ƃ����킯�ŁA��������l�Ȓ��̂P�̐l�ނƂ����킯�ł��ˁB
���ɑ��l������������������
IBM���ċƊE�ɑ��l�Ȑl�ނ��������Ă��邱�ƂŗL���ł���ˁB
�Ƃ����킯�ŁA��������l�Ȓ��̂P�̐l�ނƂ����킯�ł��ˁB
���ɑ��l������������������
88 �F�s���ȃf�o�C�X�����F2009/07/06(��) 08:07:55 ID:K59UK6NL
>>84
���X�N�������̂��̂ɂȂ������_�ŁA������GRAPE-DR�v���W�F�N�g�͓������ׂ��������낤�ˁB
�Y���Y���Ƒ��������Ƃ��A�������A���ԕ]�����ăS�[�T�C���o���������ǂ������Ă���B
�d�蒼�����ł��Ȃ��̂ŁA������������Ȃ��������Ƃ͂킩�邪�A�������E�E�E�B
���X�N�������̂��̂ɂȂ������_�ŁA������GRAPE-DR�v���W�F�N�g�͓������ׂ��������낤�ˁB
�Y���Y���Ƒ��������Ƃ��A�������A���ԕ]�����ăS�[�T�C���o���������ǂ������Ă���B
�d�蒼�����ł��Ȃ��̂ŁA������������Ȃ��������Ƃ͂킩�邪�A�������E�E�E�B
89 �F�s���ȃf�o�C�X�����F2009/07/06(��) 22:05:55 ID:RtxcUyAI
90 �F�s���ȃf�o�C�X�����F2009/07/06(��) 22:06:02 ID:jKb0gS2j
����܂�@������}�b�L�[�i�{�����������
91 �F�s���ȃf�o�C�X�����F2009/07/06(��) 22:13:49 ID:rBqnMQZb
�{����������ˁB
92 �F�s���ȃf�o�C�X�����F2009/07/06(��) 22:15:29 ID:+9hmrbXL
�{���������
���߂�Ȃ���
���߂�Ȃ���
93 �F�s���ȃf�o�C�X�����F2009/07/06(��) 22:23:49 ID:ag2U4Pdi
CNET�̃^�C�g�����Ђǂ����邾�낤�B
����͊����̖\�͂��B
����͊����̖\�͂��B
94 �F�s���ȃf�o�C�X�����F2009/07/06(��) 22:26:07 ID:+9hmrbXL
�ŁA�ǂ�����H�����Q���肷�邩�H
95 �F�s���ȃf�o�C�X�����F2009/07/06(��) 23:07:17 ID:Xx0Z4Vhe
�{����?
96 �F�s���ȃf�o�C�X�����F2009/07/07(��) 00:17:15 ID:4o3005hE
�b�m�d�s�̂͂��̋C������Ζ��_�ʑ��ői���邱�Ƃ͂ł��邾�낤�ˁB
97 �F�s���ȃf�o�C�X�����F2009/07/07(��) 09:23:04 ID:P/xNv8Ev
>>90
���킵��
���킵��
98 �F�s���ȃf�o�C�X�����F2009/07/07(��) 09:48:40 ID:HyKWfD6J
99 �F�s���ȃf�o�C�X�����F2009/07/07(��) 10:56:31 ID:P/xNv8Ev
�V�K�����Ȃ��͖̂q��搶�̐v�ł����āB
100 �F�s���ȃf�o�C�X�����F2009/07/07(��) 11:30:58 ID:HyKWfD6J
���̌v�Z�̃A���S���Y���ŁA���܂łɂȂ��A�[�L�e�N�`���łȂ���
�����̂悭�����ł��Ȃ��A�Ƃ�������Ȃ�V�K�̃A�[�L�e�N�`����
���邾�낯�ǂ��B
����Ȃ̂����������H
�����̂悭�����ł��Ȃ��A�Ƃ�������Ȃ�V�K�̃A�[�L�e�N�`����
���邾�낯�ǂ��B
����Ȃ̂����������H
101 �F�s���ȃf�o�C�X�����F2009/07/07(��) 12:21:40 ID:P/xNv8Ev
GRAPE�ł͂Ȃ�GRAPE-DR�ł���
102 �F�s���ȃf�o�C�X�����F2009/07/07(��) 12:30:38 ID:HyKWfD6J
DR�ł����̌v�Z����p�r�����H
�܂������̔ėpHPC���J������v���W�F�N�g�Ɗ��Ⴂ���ĂȂ����H
�܂������̔ėpHPC���J������v���W�F�N�g�Ɗ��Ⴂ���ĂȂ����H
103 �F�s���ȃf�o�C�X�����F2009/07/07(��) 12:40:47 ID:3147AMpd
���Ȃ�������S�����Ă�l�ł���B
�ςɃv���C�h���������āA���������܂������Ȃ��͎̂���̂�������
�v������ł��Ȃ����ȁB
��i�ƖړI���A�����̓s���̗ǂ��悤�Ɏ��Ⴆ�Ă�̂����̈�[
�ςɃv���C�h���������āA���������܂������Ȃ��͎̂���̂�������
�v������ł��Ȃ����ȁB
��i�ƖړI���A�����̓s���̗ǂ��悤�Ɏ��Ⴆ�Ă�̂����̈�[
104 �F�s���ȃf�o�C�X�����F2009/07/07(��) 13:59:08 ID:HyKWfD6J
�ӂƎv�������ADR�̎��͐�p�@�ɖ߂邩���ȁB
�Ȃ�e��sic�ƃS�j���S�j�����Ă�݂��������AstructuredASIC�ň�������Ȃ�
�ėp���ɂ��ăX�|���T�[����K�v���Ȃ��킯�������B
�Ȃ�e��sic�ƃS�j���S�j�����Ă�݂��������AstructuredASIC�ň�������Ȃ�
�ėp���ɂ��ăX�|���T�[����K�v���Ȃ��킯�������B
105 �F�s���ȃf�o�C�X�����F2009/07/07(��) 14:35:43 ID:P/xNv8Ev
���ɉ������Ƃ�����AAMD��Torrenza����OpenFPGA�������ł��Ȃ����݂���ˁB
���������Ń{�[�h�����̂̓��X�L�[���Ǝv����B
�݂�Ȏ����悤�Ȃ��Ƃ��l����킯�ŁA
structuredASIC + Opteron�\�P�b�g�݊� �Ȑ��i���o����A�����{�[�h�͍��Ȃ��Ă悭�Ȃ�B
���������Ń{�[�h�����̂̓��X�L�[���Ǝv����B
�݂�Ȏ����悤�Ȃ��Ƃ��l����킯�ŁA
structuredASIC + Opteron�\�P�b�g�݊� �Ȑ��i���o����A�����{�[�h�͍��Ȃ��Ă悭�Ȃ�B
106 �F�s���ȃf�o�C�X�����F2009/07/07(��) 14:41:36 ID:pIRUQ3Th
AMD�ȂɊ��҂���͔̂n��
�{����PCI-E3.0
�{����PCI-E3.0
107 �F�s���ȃf�o�C�X�����F2009/07/07(��) 15:13:39 ID:HyKWfD6J
>>105
�f��socket-F�Ɏh����structuredASIC�̐Ȃ��������H
�����Ȃ�\�P�b�g�Ɏh���{�[�h�i������m�݂����Ȃ���j�����K�v������킯�����B
�ƌ������AstructuredASIC�̓C���T�[�L�b�g�Ńv���O�����ł��Ȃ�����{�[�h�ɑg�ޑO��
�i�ƌ������`�b�v�̐����H���Łj�v���O��������K�v��������B���̋@�\�������ĂȂ�
���}�U�{�Ɏh���ĉ��������炢���H
�f��socket-F�Ɏh����structuredASIC�̐Ȃ��������H
�����Ȃ�\�P�b�g�Ɏh���{�[�h�i������m�݂����Ȃ���j�����K�v������킯�����B
�ƌ������AstructuredASIC�̓C���T�[�L�b�g�Ńv���O�����ł��Ȃ�����{�[�h�ɑg�ޑO��
�i�ƌ������`�b�v�̐����H���Łj�v���O��������K�v��������B���̋@�\�������ĂȂ�
���}�U�{�Ɏh���ĉ��������炢���H
108 �F�s���ȃf�o�C�X�����F2009/07/07(��) 15:31:49 ID:HyKWfD6J
�����openFPGA�����̊W������̂��킩���̂����H
���̌v�Z�̌����̂悢FPGA�ւ̎����������o�[���������Ƃ����H
���̌v�Z�̌����̂悢FPGA�ւ̎����������o�[���������Ƃ����H
109 �F�s���ȃf�o�C�X�����F2009/07/07(��) 15:32:53 ID:F4SrS4Cl
>>107
> �f��socket-F�Ɏh����structuredASIC�̐Ȃ��������H
���ꂩ��o�Ă��邾�낤���Ęb����B
> �ƌ������AstructuredASIC�̓C���T�[�L�b�g�Ńv���O�����ł��Ȃ�����{�[�h�ɑg�ޑO��
> �i�ƌ������`�b�v�̐����H���Łj�v���O��������K�v��������B
���ẮA�t�@�~�R�������̃}�X�NROM�Ɠ����悤�Ȃ����ɂȂ��ł��傤�B
�����A���[�h�^�C������T�Ԃ�����Ƃ������炵����B
���[�J�[�Ƀf�[�^��n���Ă��犮������ROM���[�i�����܂ŁB
> �f��socket-F�Ɏh����structuredASIC�̐Ȃ��������H
���ꂩ��o�Ă��邾�낤���Ęb����B
> �ƌ������AstructuredASIC�̓C���T�[�L�b�g�Ńv���O�����ł��Ȃ�����{�[�h�ɑg�ޑO��
> �i�ƌ������`�b�v�̐����H���Łj�v���O��������K�v��������B
���ẮA�t�@�~�R�������̃}�X�NROM�Ɠ����悤�Ȃ����ɂȂ��ł��傤�B
�����A���[�h�^�C������T�Ԃ�����Ƃ������炵����B
���[�J�[�Ƀf�[�^��n���Ă��犮������ROM���[�i�����܂ŁB
110 �F�s���ȃf�o�C�X�����F2009/07/07(��) 15:33:49 ID:F4SrS4Cl
>>108
GRAPE-7�̌�p�ɂȂ肤��B
�l�i���悾���A���O�Ń{�[�h������ĉ]�X��������AOpteron��2�\�P�b�g��4�\�P�b�g�̃}�U�[�{�[�h���Ă����ق��������ƂȂ�B
GRAPE-7�̌�p�ɂȂ肤��B
�l�i���悾���A���O�Ń{�[�h������ĉ]�X��������AOpteron��2�\�P�b�g��4�\�P�b�g�̃}�U�[�{�[�h���Ă����ق��������ƂȂ�B
111 �F�s���ȃf�o�C�X�����F2009/07/07(��) 16:12:52 ID:HyKWfD6J
�����ꂩ��o�Ă��邾�낤���Ęb����B
�����A�Ȃ�قǁB
���܂ł̊e�Ђ�FPGA�̃��C���i�b�v�ŏo�ĂȂ����̂��㏬��eASIC��
�o���Ă��邱�ƂɊ��҂��ăv���W�F�N�g��g�ނ킯���B�I���W�i���̃{�[�h��
�g�ނ̂Ɠ������炢�X�������O���ȁB
�����ẮA�t�@�~�R�������̃}�X�NROM�Ɠ����悤�Ȃ����ɂȂ��ł��傤�B
�ʔ����A�C�f�A���ȁB�����A�܂��ǂ�������ĂȂ��T�[�r�X�Ɋ��҂��āiry
��GRAPE-7�̌�p�ɂȂ肤��B
DR�̘b�����Ă�킯�����H
�����A�Ȃ�قǁB
���܂ł̊e�Ђ�FPGA�̃��C���i�b�v�ŏo�ĂȂ����̂��㏬��eASIC��
�o���Ă��邱�ƂɊ��҂��ăv���W�F�N�g��g�ނ킯���B�I���W�i���̃{�[�h��
�g�ނ̂Ɠ������炢�X�������O���ȁB
�����ẮA�t�@�~�R�������̃}�X�NROM�Ɠ����悤�Ȃ����ɂȂ��ł��傤�B
�ʔ����A�C�f�A���ȁB�����A�܂��ǂ�������ĂȂ��T�[�r�X�Ɋ��҂��āiry
��GRAPE-7�̌�p�ɂȂ肤��B
DR�̘b�����Ă�킯�����H
112 �F�s���ȃf�o�C�X�����F2009/07/07(��) 17:04:44 ID:F4SrS4Cl
>>111
�o�Ă���ł��낤�I������eASIC�Ђ����ł͂Ȃ��Ǝv���B
OpenFPGA�Ȃǂ̎��g�݂��x�C�p�[�E�F�A�łȂ���A
�ʏ��FPGA�����n�C�p�t�H�[�}���X�Ȃ��̂�ڎw���āA
�����Ɠ��������̃A�v���[�`�̂��̂��o�Ă���Ǝv���B
����ɓq����ׂ����ǂ����͕ʂƂ��Ă��A
�����������̂������Ƃ��ēo�ꂷ�邱�Ƃ͑z�肵�Ă����Ȃ��ƁA
�u���ł�GPGPU������̂�GRAPE-DR�Ȃ��̂͐ŋ��̖��ʂÂ����v
�݂����ȕςȎ��������Ă��܂��B
> DR�̘b�����Ă�킯�����H
GRAPE���Ɨ\�Z�����Ȃ�����d���Ȃ����\�𗎂���GRAPE-DR��������킯�ł���A�q��搶�́B
����GRAPE�ŗ\�Z�����Ă�����AGRAPE-DR�Ȃ�č���Ă��Ȃ������ł��傤�B
�o�Ă���ł��낤�I������eASIC�Ђ����ł͂Ȃ��Ǝv���B
OpenFPGA�Ȃǂ̎��g�݂��x�C�p�[�E�F�A�łȂ���A
�ʏ��FPGA�����n�C�p�t�H�[�}���X�Ȃ��̂�ڎw���āA
�����Ɠ��������̃A�v���[�`�̂��̂��o�Ă���Ǝv���B
����ɓq����ׂ����ǂ����͕ʂƂ��Ă��A
�����������̂������Ƃ��ēo�ꂷ�邱�Ƃ͑z�肵�Ă����Ȃ��ƁA
�u���ł�GPGPU������̂�GRAPE-DR�Ȃ��̂͐ŋ��̖��ʂÂ����v
�݂����ȕςȎ��������Ă��܂��B
> DR�̘b�����Ă�킯�����H
GRAPE���Ɨ\�Z�����Ȃ�����d���Ȃ����\�𗎂���GRAPE-DR��������킯�ł���A�q��搶�́B
����GRAPE�ŗ\�Z�����Ă�����AGRAPE-DR�Ȃ�č���Ă��Ȃ������ł��傤�B
113 �F�s���ȃf�o�C�X�����F2009/07/07(��) 17:28:54 ID:HyKWfD6J
���o�Ă���ł��낤�I������eASIC�Ђ����ł͂Ȃ��Ǝv���B
structuredAsic���̉��Ȃ��H
�������Ɠ��������̃A�v���[�`�̂��̂��o�Ă���Ǝv���B
���Ȃ��Ƃ������_��x86CPU��socket�Ɏh����A�N�Z�����[�^�[��
�o���Ă��Ђ�web�Ŋm�F�ł������1�Ђ��������H�����2006�N
�ɍŏ��̐��i���o���č��܂�1�Ђ̋������o�Ă��ĂȂ��B
����ȏŁA�ǂ��������u�����Ƃ��ēo�ꂷ��v����z��ł���H
�������������̂������Ƃ��ēo�ꂷ�邱�Ƃ͑z�肵�Ă����Ȃ���
���i�����j�ςȎ��������Ă��܂��B
�ςȂ��Ƃ������������������̂ł����āA����ɑ���z��Ȃ��
���ʂȂ��Ƃ�����K�v�ȂǂȂ����낤�B
structuredAsic���̉��Ȃ��H
�������Ɠ��������̃A�v���[�`�̂��̂��o�Ă���Ǝv���B
���Ȃ��Ƃ������_��x86CPU��socket�Ɏh����A�N�Z�����[�^�[��
�o���Ă��Ђ�web�Ŋm�F�ł������1�Ђ��������H�����2006�N
�ɍŏ��̐��i���o���č��܂�1�Ђ̋������o�Ă��ĂȂ��B
����ȏŁA�ǂ��������u�����Ƃ��ēo�ꂷ��v����z��ł���H
�������������̂������Ƃ��ēo�ꂷ�邱�Ƃ͑z�肵�Ă����Ȃ���
���i�����j�ςȎ��������Ă��܂��B
�ςȂ��Ƃ������������������̂ł����āA����ɑ���z��Ȃ��
���ʂȂ��Ƃ�����K�v�ȂǂȂ����낤�B
114 �F�s���ȃf�o�C�X�����F2009/07/07(��) 17:42:41 ID:HyKWfD6J
��ł��A�b�̗���Ƃ��Ă�>>104��
��structuredASIC + Opteron�\�P�b�g�݊� �Ȑ��i���o����A�����{�[�h�͍��Ȃ��Ă悭�Ȃ�B
�ƁA���ۂɍ̗p����ƌ����b�̗���ɂȂ��Ă�킯�ŁA�����
>>112��
����ɓq����ׂ����ǂ����͕ʂƂ��Ă��A
�ƁA�u�����Z�p�Ƃ��đz�肵�Ă����v�ɃV���b�ƕς���̂͂ǂ����Ǝv�����H
�܂�ID���Ⴄ�����ʐl�Ȃ̂�������Ȃ����A���Ƃ��Ă�����͓ǂ�łق������B
��structuredASIC + Opteron�\�P�b�g�݊� �Ȑ��i���o����A�����{�[�h�͍��Ȃ��Ă悭�Ȃ�B
�ƁA���ۂɍ̗p����ƌ����b�̗���ɂȂ��Ă�킯�ŁA�����
>>112��
����ɓq����ׂ����ǂ����͕ʂƂ��Ă��A
�ƁA�u�����Z�p�Ƃ��đz�肵�Ă����v�ɃV���b�ƕς���̂͂ǂ����Ǝv�����H
�܂�ID���Ⴄ�����ʐl�Ȃ̂�������Ȃ����A���Ƃ��Ă�����͓ǂ�łق������B
115 �F�s���ȃf�o�C�X�����F2009/07/07(��) 17:45:24 ID:HyKWfD6J
��GRAPE���Ɨ\�Z�����Ȃ�����d���Ȃ����\�𗎂���GRAPE-DR��������킯�ł���A�q��搶�́B
������GRAPE�ŗ\�Z�����Ă�����AGRAPE-DR�Ȃ�č���Ă��Ȃ������ł��傤�B
���̐����ł��܂����������ł��Ȃ����B
����DR��7�ɂǂ������֘A������̂��m��B
������GRAPE�ŗ\�Z�����Ă�����AGRAPE-DR�Ȃ�č���Ă��Ȃ������ł��傤�B
���̐����ł��܂����������ł��Ȃ����B
����DR��7�ɂǂ������֘A������̂��m��B
116 �F�s���ȃf�o�C�X�����F2009/07/07(��) 18:11:18 ID:hUVFv0TN
������ߋ����X���ǂ܂Ȃ��Ĉ�����MDGRAPE-4�͗��N������H
����MDGRAPE���ėp�Ȃ�Ęb��O�ɂ�����ƌ�������
����MDGRAPE���ėp�Ȃ�Ęb��O�ɂ�����ƌ�������
117 �F�s���ȃf�o�C�X�����F2009/07/07(��) 19:01:40 ID:F4SrS4Cl
>>113
> ���Ȃ��Ƃ������_��x86CPU��socket�Ɏh����A�N�Z�����[�^�[���o���Ă��Ђ�web�Ŋm�F�ł������1�Ђ��������H
> �����2006�N�ɍŏ��̐��i���o���č��܂�1�Ђ̋������o�Ă��ĂȂ��B
�ӂƋC�ɂȂ��ăO�O���Ă݂����A������2�Ђ݂���
XtremeData
XD2000F 2007/12
XD2000i 2008/06
DRC
RPU110 family 2007/07
���[��A������ƌÂ����ȁB
> ���Ȃ��Ƃ������_��x86CPU��socket�Ɏh����A�N�Z�����[�^�[���o���Ă��Ђ�web�Ŋm�F�ł������1�Ђ��������H
> �����2006�N�ɍŏ��̐��i���o���č��܂�1�Ђ̋������o�Ă��ĂȂ��B
�ӂƋC�ɂȂ��ăO�O���Ă݂����A������2�Ђ݂���
XtremeData
XD2000F 2007/12
XD2000i 2008/06
DRC
RPU110 family 2007/07
���[��A������ƌÂ����ȁB
118 �F�s���ȃf�o�C�X�����F2009/07/07(��) 19:16:21 ID:HyKWfD6J
�����A������Ђ������킯���B
�ŁA��Б���������l�����ׂ��Ȃ̂��H
�ŁA��Б���������l�����ׂ��Ȃ̂��H
119 �F�s���ȃf�o�C�X�����F2009/07/07(��) 20:04:58 ID:Lx4TJXzW
�l�����ׂ�����H
120 �F�s���ȃf�o�C�X�����F2009/07/07(��) 21:27:51 ID:BM2luUVz
Going MKN way!
121 �F�s���ȃf�o�C�X�����F2009/07/07(��) 23:53:31 ID:XCQe93Dj
_,, ---�� �[- ,,,_
�A�Q,,,, �Q,, -.'" ` �A
�~�O�~�O�~�O�~�~ �R_,
-=���O�~�c�O�~�~ ,,=-��= ==�A i�~=-�A�Q
�Q,,���~�~�O�~�O�~�~] -�c-�� �[-�A r�� �[�~�A|�~�~�O�~=-'
_, -=���c�~�c�~�~�~| ��| ,=��)> (|�[| ,��)>�A ||�O�~�c��=-'
�Q,�c�c�O�~�O�~�~��'~ .|. ' | �R ` |�~�O�c�O=-�A
�i�Q�c�O�~�c�~�~�~' �R�A �m �_�Q�Q�mi�~�c�~�O=�[
�[-=��O���[�~�~�~ `�[ /(�Qr-�Ar-_�j .|�c�~�O��-�A
�j�i�Q�~�c�~| i' �R�R�~ | : : : __ : :__: :i .|�c�~�O=-�A_
�Ɯc�~�c�~�R�R<�R�~�~ |: ����-�j-�R�A .|�c�~�O��=-
�c�~�c�~�~�R ) ` �A .' <=�F�F�F�F�F�� | |�c��=-��
-=���c�O�~ `�[�R : : : : : :i: : `�[--��'' : : �m�~�O��=''
'' �ăm���~�c�O�~`i : : : : : :�R: : : . .:, :/�~�O=-�A
'' �O�~���O�O�~|�S�A: : : : :�R: : : : : : : : :_�m:./�O=-'
-=��''�P��.| : : : : : ::::::�P�P�P:::::::::|�c `
122 �F�s���ȃf�o�C�X�����F2009/07/08(��) 02:16:42 ID:16EBLQDl
�ŋ߂̘b�� 2009�N7��4��
http://www.geocities.jp/andosprocinfo/wadai09/20090704.htm
IT�ƊE�̖`���҂����@��32��@���[�i�X�E�g�[�o���Y���������j
http://www.fudzilla.com/content/view/14438/1/
PCIe-SSD������ł���L�b�g�o��A8���~
http://akiba-pc.watch.impress.co.jp/hotline/20090704/etc_pfast.html
http://www.geocities.jp/andosprocinfo/wadai09/20090704.htm
IT�ƊE�̖`���҂����@��32��@���[�i�X�E�g�[�o���Y���������j
http://www.fudzilla.com/content/view/14438/1/
PCIe-SSD������ł���L�b�g�o��A8���~
http://akiba-pc.watch.impress.co.jp/hotline/20090704/etc_pfast.html
123 �F�s���ȃf�o�C�X�����F2009/07/08(��) 02:17:55 ID:16EBLQDl
800TFLOPS Multicore IC for Realtime Ray Tracing
http://techon.nikkeibp.co.jp/article/HONSHI/20090629/172373/
Building the computer that could halt nuclear armageddon
http://www.techradar.com/news/computing/the-computer-that-could-halt-nuclear-armageddon-613121
NSA plans massive, 65MW, $2bn data center in Utah
http://www.theregister.co.uk/2009/07/03/new_nsa_data_center/
Datacenter pr0n: a tour of Blue Waters�f new home
http://insidehpc.com/2009/07/02/datacenter-pr0n-a-tour-of-blue-waters-new-home/
IBM Lab Working on Streaming Stock Analysis
http://insidehpc.com/2009/07/02/ibm-lab-working-on-streaming-stock-analysis/
IBM announces open source machine learning compiler
http://insidehpc.com/2009/06/30/ibm-announces-open-source-machine-learning-compiler/
Next-gen superdesktops: Nehalem-EX or EP
http://www.theinquirer.net/inquirer/news/1432724/next-generation-2010-superdesktops-nehalem-ex-nehalem-ep
European Vendors Offer Home-Grown Petascale Supers
http://www.hpcwire.com/blogs/European-Vendors-Offer-Home-Grown-Petascale-Supers-49756072.html
Creating a future in IT
http://www.sofiaecho.com/2009/07/03/748122_creating-a-future-in-it
http://techon.nikkeibp.co.jp/article/HONSHI/20090629/172373/
Building the computer that could halt nuclear armageddon
http://www.techradar.com/news/computing/the-computer-that-could-halt-nuclear-armageddon-613121
NSA plans massive, 65MW, $2bn data center in Utah
http://www.theregister.co.uk/2009/07/03/new_nsa_data_center/
Datacenter pr0n: a tour of Blue Waters�f new home
http://insidehpc.com/2009/07/02/datacenter-pr0n-a-tour-of-blue-waters-new-home/
IBM Lab Working on Streaming Stock Analysis
http://insidehpc.com/2009/07/02/ibm-lab-working-on-streaming-stock-analysis/
IBM announces open source machine learning compiler
http://insidehpc.com/2009/06/30/ibm-announces-open-source-machine-learning-compiler/
Next-gen superdesktops: Nehalem-EX or EP
http://www.theinquirer.net/inquirer/news/1432724/next-generation-2010-superdesktops-nehalem-ex-nehalem-ep
European Vendors Offer Home-Grown Petascale Supers
http://www.hpcwire.com/blogs/European-Vendors-Offer-Home-Grown-Petascale-Supers-49756072.html
Creating a future in IT
http://www.sofiaecho.com/2009/07/03/748122_creating-a-future-in-it
124 �F�s���ȃf�o�C�X�����F2009/07/08(��) 02:19:09 ID:16EBLQDl
IBM�fs CPUs POWER over Intel with new performance benchmarks
http://www.geek.com/articles/chips/ibms-cpus-power-over-intel-with-new-performance-benchmarks-2009072/
Optical Fiber Preps for High-Bandwidth Data Center
http://www.itbusinessedge.com/cm/blogs/cole/optical-fiber-preps-for-high-bandwidth-data-center/?cs=33774
Apple may be dumping NVIDIA graphics for next-gen Macs
http://arstechnica.com/apple/news/2009/07/apple-may-be-dumping-nvidia-graphics-for-next-gen-macs.ars
AMD won't let Nvidia's Cuda run on its GPUs
http://www.theinquirer.net/inquirer/news/1432307/amd-won-nvidia-cuda-run-gpus
AMD doesn't want a price war with Nvidia
http://www.fudzilla.com/content/view/14438/1/
Will Nvidia PhysX ever be worthwhile?
http://www.pcpro.co.uk/blogs/2009/06/30/will-nvidia-physx-ever-be-worthwhile/
Nehalem Bests Istanbul on STREAM Benchmark
http://www.hpcwire.com/blogs/Nehalem_Bests_Istanbul_on_STREAM_Benchmark-49508502.html?ref=502
Virginia Bioinformatics Institute to Develop Petascale System
http://www.hpcwire.com/topic/applications/Virginia-Bioinformatics-Institute-to-Develop-Petascale-System-50029142.html
TeraGrid '09: Thriving in an Exponentially Changing World
http://www.hpcwire.com/features/TeraGrid-09-Thriving-in-an-Exponentially-Changing-World-50066642.html
TeraGrid '09: OSG and TeraGrid Collaboration
http://www.hpcwire.com/features/TeraGrid-09-OSG-and-TeraGrid-Collaboration-50048842.html
http://www.geek.com/articles/chips/ibms-cpus-power-over-intel-with-new-performance-benchmarks-2009072/
Optical Fiber Preps for High-Bandwidth Data Center
http://www.itbusinessedge.com/cm/blogs/cole/optical-fiber-preps-for-high-bandwidth-data-center/?cs=33774
Apple may be dumping NVIDIA graphics for next-gen Macs
http://arstechnica.com/apple/news/2009/07/apple-may-be-dumping-nvidia-graphics-for-next-gen-macs.ars
AMD won't let Nvidia's Cuda run on its GPUs
http://www.theinquirer.net/inquirer/news/1432307/amd-won-nvidia-cuda-run-gpus
AMD doesn't want a price war with Nvidia
http://www.fudzilla.com/content/view/14438/1/
Will Nvidia PhysX ever be worthwhile?
http://www.pcpro.co.uk/blogs/2009/06/30/will-nvidia-physx-ever-be-worthwhile/
Nehalem Bests Istanbul on STREAM Benchmark
http://www.hpcwire.com/blogs/Nehalem_Bests_Istanbul_on_STREAM_Benchmark-49508502.html?ref=502
Virginia Bioinformatics Institute to Develop Petascale System
http://www.hpcwire.com/topic/applications/Virginia-Bioinformatics-Institute-to-Develop-Petascale-System-50029142.html
TeraGrid '09: Thriving in an Exponentially Changing World
http://www.hpcwire.com/features/TeraGrid-09-Thriving-in-an-Exponentially-Changing-World-50066642.html
TeraGrid '09: OSG and TeraGrid Collaboration
http://www.hpcwire.com/features/TeraGrid-09-OSG-and-TeraGrid-Collaboration-50048842.html
125 �F�s���ȃf�o�C�X�����F2009/07/08(��) 02:20:00 ID:16EBLQDl
RAID Inc. Launches Dual-Controller Razor SSD
http://www.hpcwire.com/topic/storage/RAID-Inc-Launches-Dual-Controller-Razor-SSD-50033827.html
Book Review: Petascale Computing: Algorithms and Applications
http://www.hpcwire.com/features/Book-Review-Petascale-Computing-Algorithms-and-Applications-49727607.html
A real-time HPC approach for optimizing Intel multi-core architectures (Part 1 of 3)
http://www.industrialcontroldesignline.com/howto/218100688
A real-time HPC approach for optimizing Intel multi-core architectures (Part 2 of 3)
http://www.embedded.com/design/218102152
A Better Understanding of Nanosized Minerals
http://www.azonano.com/news.asp?newsID=12415
Early Galaxies Were Destroyed by Immense Heat
http://news.softpedia.com/news/Early-Galaxies-Were-Destroyed-by-Immense-Heat-115534.shtml
Numerical Precision: How Much is Enough?
http://www.scientificcomputing.com/article-hpc-Numerical-Precision-How-Much-is-Enough-063009.aspx
Computing Climate Change: Just the Tip of the Iceberg
http://www.scientificcomputing.com/article-hpc-Computing-Climate-Change-Just-the-Tip-of-the-Iceberg-063009.aspx
http://www.hpcwire.com/topic/storage/RAID-Inc-Launches-Dual-Controller-Razor-SSD-50033827.html
Book Review: Petascale Computing: Algorithms and Applications
http://www.hpcwire.com/features/Book-Review-Petascale-Computing-Algorithms-and-Applications-49727607.html
A real-time HPC approach for optimizing Intel multi-core architectures (Part 1 of 3)
http://www.industrialcontroldesignline.com/howto/218100688
A real-time HPC approach for optimizing Intel multi-core architectures (Part 2 of 3)
http://www.embedded.com/design/218102152
A Better Understanding of Nanosized Minerals
http://www.azonano.com/news.asp?newsID=12415
Early Galaxies Were Destroyed by Immense Heat
http://news.softpedia.com/news/Early-Galaxies-Were-Destroyed-by-Immense-Heat-115534.shtml
Numerical Precision: How Much is Enough?
http://www.scientificcomputing.com/article-hpc-Numerical-Precision-How-Much-is-Enough-063009.aspx
Computing Climate Change: Just the Tip of the Iceberg
http://www.scientificcomputing.com/article-hpc-Computing-Climate-Change-Just-the-Tip-of-the-Iceberg-063009.aspx
126 �F�s���ȃf�o�C�X�����F2009/07/08(��) 08:13:09 ID:BZLjy20q
>>117
����XD2000F�AHT�����N���{����CPU�����i�i�ɒx����1.6GB/sec�����Ȃ��B
PCI Express 2.0��x4�����x���B���ꂶ��CPU�\�P�b�g���L���鉿�l���Ȃ��B
������I/F��DDR333��2ch����x�����A���ɕt���Ă�SRAM���x���B
����XD2000F�AHT�����N���{����CPU�����i�i�ɒx����1.6GB/sec�����Ȃ��B
PCI Express 2.0��x4�����x���B���ꂶ��CPU�\�P�b�g���L���鉿�l���Ȃ��B
������I/F��DDR333��2ch����x�����A���ɕt���Ă�SRAM���x���B
127 �F�s���ȃf�o�C�X�����F2009/07/08(��) 10:14:15 ID:BZLjy20q
>>113
> �ςȂ��Ƃ������������������̂ł����āA����ɑ���z��Ȃ�Ė��ʂȂ��Ƃ�����K�v�ȂǂȂ����낤�B
�u�ςȂ��Ƃ������������������v�ōς߂����̂����B
���Ƃ������X�p�R�����A���́u�ςȂ��Ɓv�������Ă�̂ł���B
> �ςȂ��Ƃ������������������̂ł����āA����ɑ���z��Ȃ�Ė��ʂȂ��Ƃ�����K�v�ȂǂȂ����낤�B
�u�ςȂ��Ƃ������������������v�ōς߂����̂����B
���Ƃ������X�p�R�����A���́u�ςȂ��Ɓv�������Ă�̂ł���B
128 �F�s���ȃf�o�C�X�����F2009/07/08(��) 12:26:04 ID:vbEP087y
������A����ꂽ���牽�H
129 �F�s���ȃf�o�C�X�����F2009/07/08(��) 13:04:57 ID:BZLjy20q
>>128
���̍��́A���������A�����`���Ȃ̂ŁA�]�������f����͈̂�ʂ̍����ł�����B
�����}�X�R�~���ᔻ�L�����y�[�����ΐ��_�͐����A�����Ė����͗\�Z���o���Ȃ��Ȃ�B
���̍��́A���������A�����`���Ȃ̂ŁA�]�������f����͈̂�ʂ̍����ł�����B
�����}�X�R�~���ᔻ�L�����y�[�����ΐ��_�͐����A�����Ė����͗\�Z���o���Ȃ��Ȃ�B
130 �F�s���ȃf�o�C�X�����F2009/07/08(��) 21:00:35 ID:2ImpNjuC
�S�z�ł������Ȃ�ɔ��_���Ă�������������
���{�_�����_�����I ����݃}���Z�[�I�I �ȋL�������܂���
http://news.livedoor.com/article/detail/4239719/
http://news.livedoor.com/article/detail/4239719/
132 �F�s���ȃf�o�C�X�����F2009/07/08(��) 22:49:07 ID:ijWYnfBg
������ƂɎ��Ԕ�₵�ĂȂ��ŃR�[�h�̈�ł�������A�r���B
133 �F�s���ȃf�o�C�X�����F2009/07/08(��) 22:50:17 ID:XU9jRYRo
�i�����G
134 �F�s���ȃf�o�C�X�����F2009/07/09(��) 07:03:23 ID:Y5i0zwpB
iPhone����
����͓d�b����Ȃ�
i�A�v�����T�[�o�ƒʐM�ł��Ȃ����_�ŃN�Y
�n�Q�̒��N�d�b�Ƃ��������ł��˂Ǝv��
�A���h���C�h�����y������������
����͓d�b����Ȃ�
i�A�v�����T�[�o�ƒʐM�ł��Ȃ����_�ŃN�Y
�n�Q�̒��N�d�b�Ƃ��������ł��˂Ǝv��
�A���h���C�h�����y������������
135 �F�s���ȃf�o�C�X�����F2009/07/09(��) 07:32:07 ID:tNuYTKzK
>>130
>>129�͏o�Ă��邩�ǂ�����������Ȃ����i��R�Z�p���l�^�Ƀl�K�e�B�u�L�����y�[����
�ł���鎖������Ă�킯�ŁA���݂��ĂȂ����̂ɔ��_�̂��悤���Ȃ��킯������
>>129�͏o�Ă��邩�ǂ�����������Ȃ����i��R�Z�p���l�^�Ƀl�K�e�B�u�L�����y�[����
�ł���鎖������Ă�킯�ŁA���݂��ĂȂ����̂ɔ��_�̂��悤���Ȃ��킯������
136 �F�s���ȃf�o�C�X�����F2009/07/09(��) 07:35:57 ID:tNuYTKzK
>>129
��ł��A�����̗\�Z�~�܂����킯�H
���݂��邩���^�킵���v���ɂ��N���邩�ǂ������^�킵�����X�N�������āA
���O�̃v���W�F�N�g�����o�����Ăǂ����a����`�҂��悗
��ł��A�����̗\�Z�~�܂����킯�H
���݂��邩���^�킵���v���ɂ��N���邩�ǂ������^�킵�����X�N�������āA
���O�̃v���W�F�N�g�����o�����Ăǂ����a����`�҂��悗
137 �F�s���ȃf�o�C�X�����F2009/07/09(��) 09:46:14 ID:MXM9j994
������ōς܂A���݂��Ȃ����̂ł��A���Ђɂ͂Ȃ肤���B
funding �o�����ǂ������߂鎞�Ȃ�A���N�ɂȂ邩��S�R���ς�邩��
�m��Ȃ��i�����Ȃ�A�����Ȃ�Aetc�j���̃v���W�F�N�g�͍��N�x�͗l�q
���܂��傤�A�Ƃ����̂͏R���Ƃ����R�ɂȂ肤��B���������邩��ˁB
�i���Z���X�ł���A�����ł���Ƃ������Ƃ������������ɂ͂������
�����Ȃ��Ƃ܂����B����͑f�l�ł���\���������B
������ɂ���A���z�̋������炦�ΐ����ӔC���傫���B�_����������
�Ƃ��������ł͂Ȃ��A�s���u���A���J�u���Ƃ��ɌĂꂽ��N����`��
�o���Ƃ��z�[���y�[�W�� PR ����Ƃ������Ƃ��Ă�����B�̂��͂�������
�ӎ����܂��Ă�Ǝv�����A�܂��܂����{�� PR ����ő����Ă�ʂ��傫���Ǝv���B
PR���킾�����Ē��g���������͂܂������B
funding �o�����ǂ������߂鎞�Ȃ�A���N�ɂȂ邩��S�R���ς�邩��
�m��Ȃ��i�����Ȃ�A�����Ȃ�Aetc�j���̃v���W�F�N�g�͍��N�x�͗l�q
���܂��傤�A�Ƃ����̂͏R���Ƃ����R�ɂȂ肤��B���������邩��ˁB
�i���Z���X�ł���A�����ł���Ƃ������Ƃ������������ɂ͂������
�����Ȃ��Ƃ܂����B����͑f�l�ł���\���������B
������ɂ���A���z�̋������炦�ΐ����ӔC���傫���B�_����������
�Ƃ��������ł͂Ȃ��A�s���u���A���J�u���Ƃ��ɌĂꂽ��N����`��
�o���Ƃ��z�[���y�[�W�� PR ����Ƃ������Ƃ��Ă�����B�̂��͂�������
�ӎ����܂��Ă�Ǝv�����A�܂��܂����{�� PR ����ő����Ă�ʂ��傫���Ǝv���B
PR���킾�����Ē��g���������͂܂������B
138 �F�s���ȃf�o�C�X�����F2009/07/09(��) 10:44:41 ID:5uUH1rWo
139 �F�s���ȃf�o�C�X�����F2009/07/09(��) 11:02:44 ID:Entr5Iou
>>135
>�@�o�Ă��邩�ǂ�����������Ȃ����i��R�Z�p���l�^�Ƀl�K�e�B�u�L�����y�[����ł����
�v���W�F�N�g�̃X�^�[�g���_�ł́A�o�Ă��邩�ǂ����\�������Ȃ��������i��R�Z�p���A
�v���W�F�N�g�̒��Ԃ��邢�͊������_�ŁA���ۂɏo�Ă��đ傫���������Ă����ꍇ�ɁA
�X�^�[�g������[�h�^�C���Ƃ��������̂����āA�}�X�R�~�ɒ@�����A���Ă��Ƃł���B
�}�X�R�~���@�����_�ł́A�������i�͊m���ɏo�Đ������Ă����ł���B
�}�X�R�~�́A
�X�^�[�g���_�ł͋������J�������Ȃ�Ēm��Ȃ������Ƃ��A�\�����t���܂���ł����Ƃ��A
���������̂������Ȃ�����B
>�@�o�Ă��邩�ǂ�����������Ȃ����i��R�Z�p���l�^�Ƀl�K�e�B�u�L�����y�[����ł����
�v���W�F�N�g�̃X�^�[�g���_�ł́A�o�Ă��邩�ǂ����\�������Ȃ��������i��R�Z�p���A
�v���W�F�N�g�̒��Ԃ��邢�͊������_�ŁA���ۂɏo�Ă��đ傫���������Ă����ꍇ�ɁA
�X�^�[�g������[�h�^�C���Ƃ��������̂����āA�}�X�R�~�ɒ@�����A���Ă��Ƃł���B
�}�X�R�~���@�����_�ł́A�������i�͊m���ɏo�Đ������Ă����ł���B
�}�X�R�~�́A
�X�^�[�g���_�ł͋������J�������Ȃ�Ēm��Ȃ������Ƃ��A�\�����t���܂���ł����Ƃ��A
���������̂������Ȃ�����B
140 �F�s���ȃf�o�C�X�����F2009/07/09(��) 11:06:54 ID:Entr5Iou
>>136
�����̑�ꍆ�̗\�Z�͎~���ĂȂ����A��ȍ~�̒������܂������Ȃ������̂��낤�B
����ŁA��ꍆ�͊J���Ɛ�`�̂��߂Ǝ����o���̐Ԏ��ł���Ă�NEC������������̂���B
��ȍ~������Ȃ���A��������������ł��܂���ˁB
�����āA�����̎�����̃X�p�R���̊J���́A�\�Z���Ȃ��Ȃ��t���Ȃ����낤�ˁB
�����̑�ꍆ�̗\�Z�͎~���ĂȂ����A��ȍ~�̒������܂������Ȃ������̂��낤�B
����ŁA��ꍆ�͊J���Ɛ�`�̂��߂Ǝ����o���̐Ԏ��ł���Ă�NEC������������̂���B
��ȍ~������Ȃ���A��������������ł��܂���ˁB
�����āA�����̎�����̃X�p�R���̊J���́A�\�Z���Ȃ��Ȃ��t���Ȃ����낤�ˁB
141 �F�s���ȃf�o�C�X�����F2009/07/09(��) 11:08:18 ID:Entr5Iou
>>137
GRAPE-DR��Web�T�C�g��2006�N��������u����Ă��ˁB
����Ȃ̂Ɏ�Ԃ������邭�炢�Ȃ�A�����Ƃ��ׂ����Ƃ�����Ƃ������Ƃ��낤���E�E�E�B
GRAPE-DR��Web�T�C�g��2006�N��������u����Ă��ˁB
����Ȃ̂Ɏ�Ԃ������邭�炢�Ȃ�A�����Ƃ��ׂ����Ƃ�����Ƃ������Ƃ��낤���E�E�E�B
142 �F�s���ȃf�o�C�X�����F2009/07/09(��) 20:28:34 ID:JLxVd31H
>�O923
���������H��1m��������̂�1000���`2000���~������B
���₢��A�P���[�g���P���~�ł��B
http://news.livedoor.com/article/detail/4242031/ �����Y�Ԋ�����
���������H��1m��������̂�1000���`2000���~������B
���₢��A�P���[�g���P���~�ł��B
http://news.livedoor.com/article/detail/4242031/ �����Y�Ԋ�����
143 �F�s���ȃf�o�C�X�����F2009/07/09(��) 20:41:37 ID:GBiFy69N
�����W�샏���^
1���~�����32nm�v���Z�X��Fab��3��4�V�݂ł���
22nm�v���Z�X��Fab�ł�2�͐V�݂ł���
1���~�����32nm�v���Z�X��Fab��3��4�V�݂ł���
22nm�v���Z�X��Fab�ł�2�͐V�݂ł���
144 �F�s���ȃf�o�C�X�����F2009/07/10(��) 02:19:20 ID:z+lkBGSQ
���������̗\�Z�E�H���Ŏ��܂�ۏ�͉����ɂ�������ȁB
��l�ƃ[�l�R���Ƌc������̃^�b�O������ׂ��̂͑�ρB
�y���Ώd�̂������Œn���Y�Ƃ��������݂̒�x���y���������̎Љ�\���ɂȂ����܂����B
��O�͗��C�R�̓�劯���̂����ō����ׂꂽ���A���̓Q���܂����ނ̂��ȁB
145 �F�s���ȃf�o�C�X�����F2009/07/10(��) 02:54:22 ID:k4wiTHl6
����Ƃ��͂�������݂邻����
�O�̎��͔s��ӔC������ނ�ɂȂ��������
�O�̎��͔s��ӔC������ނ�ɂȂ��������
146 �F�s���ȃf�o�C�X�����F2009/07/10(��) 07:21:08 ID:mwBadCqj
�s��ӔC�͌R��������Ȃ������B
���������Ă��A���{�����V���g���C�R�R�k��甲�����̂�1934�N�A
�V��̐�͌����������ĊJ���ꂽ���ǁA���̔N�̍��Ɨ\�Z�ɐ�߂�R����͊���40%���Ă�B
�����\�Z�̓��Ă������̂ɁA�R�k����E�ނ���Ӗ����������̂��ƁB
�Ă̒�A����ȍ~�������ꂽ��͂̐���
�E���{�F2��
�E�A�����J�F10�ǁi�\�Z�t�������ǏI��̖ڏ��������Č������~���{7�ǁj
�]�v�ɍ����t�����܂����B����Ȃ̂͂��O���画���Ă����ŁA�O���Ȃ�呠�Ȃ�
�h���Ⴆ�Ăł��j�~���ׂ��������̂ɁA�S�����C�R�̖\���̂����ɂ����܂��Ă邩��ȁB
���ł����̌X���͓����ŁA��@�q���Ƃ��R���p�r�������Ă�������JAXA��
���t�{�Ɉڂ����Ƃ����當���Ȋw�Ȃ��֎q�Ɨ\�Z�����邩����Ē�R���Ă邵�B
���ς�炸���v���ȉv�D��B
���������Ă��A���{�����V���g���C�R�R�k��甲�����̂�1934�N�A
�V��̐�͌����������ĊJ���ꂽ���ǁA���̔N�̍��Ɨ\�Z�ɐ�߂�R����͊���40%���Ă�B
�����\�Z�̓��Ă������̂ɁA�R�k����E�ނ���Ӗ����������̂��ƁB
�Ă̒�A����ȍ~�������ꂽ��͂̐���
�E���{�F2��
�E�A�����J�F10�ǁi�\�Z�t�������ǏI��̖ڏ��������Č������~���{7�ǁj
�]�v�ɍ����t�����܂����B����Ȃ̂͂��O���画���Ă����ŁA�O���Ȃ�呠�Ȃ�
�h���Ⴆ�Ăł��j�~���ׂ��������̂ɁA�S�����C�R�̖\���̂����ɂ����܂��Ă邩��ȁB
���ł����̌X���͓����ŁA��@�q���Ƃ��R���p�r�������Ă�������JAXA��
���t�{�Ɉڂ����Ƃ����當���Ȋw�Ȃ��֎q�Ɨ\�Z�����邩����Ē�R���Ă邵�B
���ς�炸���v���ȉv�D��B
147 �F�s���ȃf�o�C�X�����F2009/07/10(��) 07:55:54 ID:5WFbf8iY
������サ�Ă�����ɗ��@�{�Ƃ��Ă̒S���\�͖͂�������ǂ������߂ł�肽������Ȃ��
���ꂩ�|�[�^�u�����q�F����ĉ����ւŘF�S�Z�������˂�����
���ꂩ�|�[�^�u�����q�F����ĉ����ւŘF�S�Z�������˂�����
148 �F�s���ȃf�o�C�X�����F2009/07/10(��) 10:41:55 ID:CcarhdhB
>>145�̍l�����́A�����̎匠�̕������Ǝv����B
149 �F�s���ȃf�o�C�X�����F2009/07/10(��) 11:08:28 ID:CcarhdhB
ttp://slashdot.jp/article.pl?sid=09/07/09/0228232
���R�s�y
�����v������ (�X�R�A:5, �����[��)
Anonymous Coward : 2009�N07��09�� 13��16�� (#1602400)
�����v�����Ƃ���
�E�n�[�h�����猩���GRAPE�͐�p�p�C�v���C�����Z�����ׂ������̖ʔ��݂̂Ȃ��R���s���[�^�Ƃ͌ĂׂȂ��n�[�h�Ȃ̂ɁC
�n�[�h����ɂ͖����������i�����ł��n�[�h������Ƃ͍l���ĂȂ������j�\�t�g�����猩��Ƃ������]���������͕̂s�v�c
�E�n�[�h�����猩��ƒn���V�~�����[�^�͕��ʂɏ������\�[�X���x�N�g�����R���p�C���ʂ������Łi�`���[�j���O�ɑ�ςȋ�J�����Ȃ��Ă��j
�����œ��������R���s���[�^�Ȃ̂ɁC�\�t�g������̓R�X�g�E�p�t�H�[�}���X���������Ȃ����͕̂s�v�c
�E�X�p�R���̏��ʂ͘b��ɂȂ��Ă��C�X�p�R���łȂ���Ώo���Ȃ��������Ƃ��o���ėL�p�Ȑ��ʂ����ݏo���ꂽ�Ƃ����b�肪�F���Ȃ͕̂s�v�c
#�̂̓X�p�R���̉��Z�\�͂��Ȃ���Ώo���Ȃ����Ƃ���肽����������C�R�X�g�E�p�t�H�[�}���X�ȂǓx�O�����ăX�p�R������������̂Ȃ̂ɁC
������X�p�R���̃R�X�g�E�p�t�H�[�}���X���c�_����悤�ɂȂ����H�@����X�p�R�������̃R���f�B�e�B�����Ă��Ȃ��̂���
Re:�����v������ (�X�R�A:1, ���炵�����@)
Anonymous Coward : 2009�N07��09�� 16��31�� (#1602533)
2�̗v�f������Ǝv���܂�
1�́A�g�������P���ōH�v�̗]�n�����Ȃ����̂����A�g����������čH�v�̗]�n��������̂̂ق����A��i���ړI�ɂȂ��Ă���l�ɂ́u�ʔ����v�Ɗ����邩��ł��傤�B
����1�́A��啪��O�̂��Ƃɂ͑a���̂ŁA������Ƙb���������Ő����ƌ�����Ă��܂�����ł��傤�B
�ǂ̂悤�ɂ�����X�p�R�������Ɏg����̂��Ƃ����_���������Ă���l�����ɂƂ��ẮA
�ȒP�Ɏg����X�p�R���͓G�ł��炠��܂��B�Ȃɂ���A���������̎d����D���̂ł�����B
���R�s�y
�����v������ (�X�R�A:5, �����[��)
Anonymous Coward : 2009�N07��09�� 13��16�� (#1602400)
�����v�����Ƃ���
�E�n�[�h�����猩���GRAPE�͐�p�p�C�v���C�����Z�����ׂ������̖ʔ��݂̂Ȃ��R���s���[�^�Ƃ͌ĂׂȂ��n�[�h�Ȃ̂ɁC
�n�[�h����ɂ͖����������i�����ł��n�[�h������Ƃ͍l���ĂȂ������j�\�t�g�����猩��Ƃ������]���������͕̂s�v�c
�E�n�[�h�����猩��ƒn���V�~�����[�^�͕��ʂɏ������\�[�X���x�N�g�����R���p�C���ʂ������Łi�`���[�j���O�ɑ�ςȋ�J�����Ȃ��Ă��j
�����œ��������R���s���[�^�Ȃ̂ɁC�\�t�g������̓R�X�g�E�p�t�H�[�}���X���������Ȃ����͕̂s�v�c
�E�X�p�R���̏��ʂ͘b��ɂȂ��Ă��C�X�p�R���łȂ���Ώo���Ȃ��������Ƃ��o���ėL�p�Ȑ��ʂ����ݏo���ꂽ�Ƃ����b�肪�F���Ȃ͕̂s�v�c
#�̂̓X�p�R���̉��Z�\�͂��Ȃ���Ώo���Ȃ����Ƃ���肽����������C�R�X�g�E�p�t�H�[�}���X�ȂǓx�O�����ăX�p�R������������̂Ȃ̂ɁC
������X�p�R���̃R�X�g�E�p�t�H�[�}���X���c�_����悤�ɂȂ����H�@����X�p�R�������̃R���f�B�e�B�����Ă��Ȃ��̂���
Re:�����v������ (�X�R�A:1, ���炵�����@)
Anonymous Coward : 2009�N07��09�� 16��31�� (#1602533)
2�̗v�f������Ǝv���܂�
1�́A�g�������P���ōH�v�̗]�n�����Ȃ����̂����A�g����������čH�v�̗]�n��������̂̂ق����A��i���ړI�ɂȂ��Ă���l�ɂ́u�ʔ����v�Ɗ����邩��ł��傤�B
����1�́A��啪��O�̂��Ƃɂ͑a���̂ŁA������Ƙb���������Ő����ƌ�����Ă��܂�����ł��傤�B
�ǂ̂悤�ɂ�����X�p�R�������Ɏg����̂��Ƃ����_���������Ă���l�����ɂƂ��ẮA
�ȒP�Ɏg����X�p�R���͓G�ł��炠��܂��B�Ȃɂ���A���������̎d����D���̂ł�����B
150 �F�s���ȃf�o�C�X�����F2009/07/10(��) 11:11:25 ID:CcarhdhB
Re:��]����! JAXA FX1�ɂ��ĒN�����y���Ă��Ȃ��̂ɐ�]�����I (�X�R�A:2, �����[��)
Anonymous Coward : 2009�N07��10�� 1��30�� (#1602816)
���r���[�ɖ��[�Ŋւ���Ă��邯��, ����NDA����łȂ��̂ő����o������OK����
�v�����CNEC�Ɠ����P�ނœ���SPARC��{�Ō��܂�.
���������Ƀe�X�g�ł����K�̓N���X�^���Ȃ��̂�, ����ƒ}�g��
T2K�X�p�R��(Opteron�}�V��)�ŏd�_�J���A�v���P�[�V�����̃`���[�j���O
����Ă�Ƃ����̂�����.
��, Opteron�̃N�\�b�^���ȃL���b�V�����\�̂��߂�, T2K��̃`���[�j���O��
�L���b�V���q�b�g�グ�邽�߂̑啝�ȃ\�[�X��������, ���肷���A���S���Y��
�ύX��v���Ă���.
����ȃ}�V���X�y�V�t�B�b�N�ȃ`���[�j���O�͎��@�ł��Ȃ���Ӗ����Ȃ���,
�e�A�v���P�[�V���������@�̎g�p���Ԃ�ɂ�, ���@���܂�������ԂŎ������\��
�A�s�[�������Ȃ���Ȃ�Ȃ�.
�d�_�J���A�v���ɑI�肳��Ă���̂̑�����ES�Ő��ʂ�����������, ���Ȃ킿����
�x�N�g���@�x�^�x�^�̃`���[�j���O���s���Ă���.
�܂��ɕs�т̈ꌾ.
Anonymous Coward : 2009�N07��10�� 1��30�� (#1602816)
���r���[�ɖ��[�Ŋւ���Ă��邯��, ����NDA����łȂ��̂ő����o������OK����
�v�����CNEC�Ɠ����P�ނœ���SPARC��{�Ō��܂�.
���������Ƀe�X�g�ł����K�̓N���X�^���Ȃ��̂�, ����ƒ}�g��
T2K�X�p�R��(Opteron�}�V��)�ŏd�_�J���A�v���P�[�V�����̃`���[�j���O
����Ă�Ƃ����̂�����.
��, Opteron�̃N�\�b�^���ȃL���b�V�����\�̂��߂�, T2K��̃`���[�j���O��
�L���b�V���q�b�g�グ�邽�߂̑啝�ȃ\�[�X��������, ���肷���A���S���Y��
�ύX��v���Ă���.
����ȃ}�V���X�y�V�t�B�b�N�ȃ`���[�j���O�͎��@�ł��Ȃ���Ӗ����Ȃ���,
�e�A�v���P�[�V���������@�̎g�p���Ԃ�ɂ�, ���@���܂�������ԂŎ������\��
�A�s�[�������Ȃ���Ȃ�Ȃ�.
�d�_�J���A�v���ɑI�肳��Ă���̂̑�����ES�Ő��ʂ�����������, ���Ȃ킿����
�x�N�g���@�x�^�x�^�̃`���[�j���O���s���Ă���.
�܂��ɕs�т̈ꌾ.
151 �F�s���ȃf�o�C�X�����F2009/07/10(��) 12:25:46 ID:k4wiTHl6
152 �F�s���ȃf�o�C�X�����F2009/07/10(��) 12:49:09 ID:CcarhdhB
>>151
�K�Ȍ��҂�����ɑ���w�͂������A�u��オ�����v�Ƌ�s�^����̂̓������B
�K�Ȍ��҂�����ɑ���w�͂������A�u��オ�����v�Ƌ�s�^����̂̓������B
153 �F�s���ȃf�o�C�X�����F2009/07/10(��) 14:13:24 ID:k4wiTHl6
>>152
��������
�����������܂��O����s�퍑�������̂�
�ꑮ��Ԃʼn�������ꂽ�A�����J��̐��{��
�x���V�����Ė������Ȃ����H��
�{�C�ł��Ȃ�s�킵���̂ɂ��܂���联��𑱂��Ă钷�B����j���Ă���n�߂܂��悗����
��������
�����������܂��O����s�퍑�������̂�
�ꑮ��Ԃʼn�������ꂽ�A�����J��̐��{��
�x���V�����Ė������Ȃ����H��
�{�C�ł��Ȃ�s�킵���̂ɂ��܂���联��𑱂��Ă钷�B����j���Ă���n�߂܂��悗����
154 �F�s���ȃf�o�C�X�����F2009/07/10(��) 14:58:49 ID:CcarhdhB
>>153
���������Ő��}������č�������x�����ė^�}�ɂȂ���Ă��Ƃ��B
���������Ő��}������č�������x�����ė^�}�ɂȂ���Ă��Ƃ��B
155 �F�s���ȃf�o�C�X�����F2009/07/10(��) 15:44:17 ID:5WFbf8iY
�k�ق̃K�C�h���C��
10.���肦�Ȃ��������}��
10.���肦�Ȃ��������}��
156 �F�s���ȃf�o�C�X�����F2009/07/10(��) 16:40:38 ID:CcarhdhB
���₢��A��������肦�Ȃ����Č�������A�����`�͖����B
157 �F�s���ȃf�o�C�X�����F2009/07/10(��) 17:29:52 ID:5WFbf8iY
�i�`�X�h�C�c�������`���Ƃ���
158 �F�s���ȃf�o�C�X�����F2009/07/10(��) 17:40:22 ID:CcarhdhB
>>157
�����牽?
������ˑR�A�h�C�c���i�`�X���P���āA�����̈ӎv�ɔ����ēƍَx�z�����킯����Ȃ���B
�h�C�c�����̏��Ȃ��Ȃ��l�������I���Ńi�`�X��I���ʁA
�A���^�}�̈�p���Ȃ��邾���̋c�Ȑ��āA
�A���^�}�Ƃ��Ă̌��͂𗘗p���āA����ɋc�Ȑ��𑝂₵�Ă�������B
�h�C�c�l�̓i�`�X�̂����ɂ��Ă��邯�ǁA�{���́A�h�C�c�����̑I���̌��ʂȂ�ł���B
�����牽?
������ˑR�A�h�C�c���i�`�X���P���āA�����̈ӎv�ɔ����ēƍَx�z�����킯����Ȃ���B
�h�C�c�����̏��Ȃ��Ȃ��l�������I���Ńi�`�X��I���ʁA
�A���^�}�̈�p���Ȃ��邾���̋c�Ȑ��āA
�A���^�}�Ƃ��Ă̌��͂𗘗p���āA����ɋc�Ȑ��𑝂₵�Ă�������B
�h�C�c�l�̓i�`�X�̂����ɂ��Ă��邯�ǁA�{���́A�h�C�c�����̑I���̌��ʂȂ�ł���B
159 �F�s���ȃf�o�C�X�����F2009/07/10(��) 17:52:04 ID:5WFbf8iY
�i�`�X�̓ƍق̉��Łu���������Ő��}������č�������x�����ė^�}�ɂȂ�v�̂����肦�Ȃ��l��
���{�̋M�����̉��Łu���������Ő��}������č�������x�����ė^�}�ɂȂ�v�̂����肦�Ȃ�
���{�̋M�����̉��Łu���������Ő��}������č�������x�����ė^�}�ɂȂ�v�̂����肦�Ȃ�
160 �F�s���ȃf�o�C�X�����F2009/07/10(��) 17:55:37 ID:CcarhdhB
��? ����ȏ�Ԃł��O�͖�l��݂邷�Ƃ������Ă��?
161 �F�s���ȃf�o�C�X�����F2009/07/10(��) 17:57:04 ID:5WFbf8iY
������ID�������ĂȂ��̂���
162 �F�s���ȃf�o�C�X�����F2009/07/10(��) 18:06:18 ID:CcarhdhB
ID:5WFbf8iY = ID:k4wiTHl6 ���ȁA���̂���B
IP 2�g������J����B
IP 2�g������J����B
163 �F�s���ȃf�o�C�X�����F2009/07/10(��) 21:50:26 ID:A5YsHj7s
�悭�킩��A�����}����u����ƃ��o�����Ă��ƁH
164 �F�s���ȃf�o�C�X�����F2009/07/10(��) 22:10:45 ID:QmB7zXua
���Ԃ�Ⴄ�Ǝv��
165 �F�s���ȃf�o�C�X�����F2009/07/10(��) 22:13:38 ID:6FbWYNj2
���{���
166 �F�s���ȃf�o�C�X�����F2009/07/10(��) 22:45:35 ID:poPBkp1I
�ז�
167 �F�s���ȃf�o�C�X�����F2009/07/10(��) 23:03:46 ID:VEQk7nk4
���͂�A���̃X����������܂���ȁB
168 �F�s���ȃf�o�C�X�����F2009/07/10(��) 23:12:57 ID:VEQk7nk4
����,���łɁB
>>150
>�d�_�J���A�v���ɑI�肳��Ă���̂̑�����ES�Ő��ʂ�����������, ���Ȃ킿����
>�x�N�g���@�x�^�x�^�̃`���[�j���O���s���Ă���.
���̂ǂꂾ�낤�H
http://www.nsc.riken.jp/target-application/target-application.html
ES�����Ƃ����ƁA�uNICAM�@�S���_�𑜑�C��z���f���v���炢����Ȃ�
�悤�ȋC������B�܂��ANICAM �͕ʓr T2K �����Ƀ`���[�j���O����Ă���
�悤�����ǁB
>>150
>�d�_�J���A�v���ɑI�肳��Ă���̂̑�����ES�Ő��ʂ�����������, ���Ȃ킿����
>�x�N�g���@�x�^�x�^�̃`���[�j���O���s���Ă���.
���̂ǂꂾ�낤�H
http://www.nsc.riken.jp/target-application/target-application.html
ES�����Ƃ����ƁA�uNICAM�@�S���_�𑜑�C��z���f���v���炢����Ȃ�
�悤�ȋC������B�܂��ANICAM �͕ʓr T2K �����Ƀ`���[�j���O����Ă���
�悤�����ǁB
169 �F�s���ȃf�o�C�X�����F2009/07/11(�y) 00:22:49 ID:ywk+vrl3
>>168 ���̂��炢����ł̎��s���т��݂�킩�邾��B
����Ƃ��x�N�g���ł͊ȒP�Ɏ������\�������邩��x�^�x�^�̃`���[�j���O�Ȃ�
����ĂȂ��Ƃł����������̂��H
����Ƃ��x�N�g���ł͊ȒP�Ɏ������\�������邩��x�^�x�^�̃`���[�j���O�Ȃ�
����ĂȂ��Ƃł����������̂��H
>>169
���܂Ȃ��B�^�[�Q�b�g�A�v���̐��������ɂ��� ES �ł̎��s���т�
NICAM �����ł͂Ȃ��ACOCO�AFrontFlow/Blue�ALatticeQCD�A
PHASE�ASeism3D �� 21�A�v���� 6�������B���ꂩ��
>����Ƃ��x�N�g���ł͊ȒP�Ɏ������\�������邩��x�^�x�^�̃`���[�j���O�Ȃ�
>����ĂȂ��Ƃł����������̂��H
�͈Ⴄ�B�ނ���A�x�^�x�^�Ƀ`���[�j���O����Ă���Ǝv���B��ŁA>>168 �Ō�����������
�̂́A>>150 �ɂ���
>�d�_�J���A�v���ɑI�肳��Ă���̂̑�����ES�Ő��ʂ�����������
���ĂƂ���ŁA����Ȃɂ���́H�Ƃ����P���ȋ^��ł����B�ŁA���ǁA6/21 �` 29%�@������
�̂ŁA����ȂɂȂ������B
�����A>>150 �̑O�������͓��ӁB���@�Ȃ��Ƃ炢�͕̂�����܂��B
�܂��A�܂��͑����ł���Ȃ�̎��s���\�ƃX�P�[���r���e�B�[���o���Ȃ�
�Ƙb�ɂ͂Ȃ�Ȃ��Ƃ������Ƃ��l����ƁA���̂Ƃ��덑���ł� T2K �� run
���邵���Ȃ�(�V���Ȃ�A�V����� Cray �����邯��)�킯�ŁA������������
�����Ă���̂��ƁE�E�E
���Ȃ݂ɁAORNL jaguar �͊C�O��������p�\�炵���ˁB
���܂Ȃ��B�^�[�Q�b�g�A�v���̐��������ɂ��� ES �ł̎��s���т�
NICAM �����ł͂Ȃ��ACOCO�AFrontFlow/Blue�ALatticeQCD�A
PHASE�ASeism3D �� 21�A�v���� 6�������B���ꂩ��
>����Ƃ��x�N�g���ł͊ȒP�Ɏ������\�������邩��x�^�x�^�̃`���[�j���O�Ȃ�
>����ĂȂ��Ƃł����������̂��H
�͈Ⴄ�B�ނ���A�x�^�x�^�Ƀ`���[�j���O����Ă���Ǝv���B��ŁA>>168 �Ō�����������
�̂́A>>150 �ɂ���
>�d�_�J���A�v���ɑI�肳��Ă���̂̑�����ES�Ő��ʂ�����������
���ĂƂ���ŁA����Ȃɂ���́H�Ƃ����P���ȋ^��ł����B�ŁA���ǁA6/21 �` 29%�@������
�̂ŁA����ȂɂȂ������B
�����A>>150 �̑O�������͓��ӁB���@�Ȃ��Ƃ炢�͕̂�����܂��B
�܂��A�܂��͑����ł���Ȃ�̎��s���\�ƃX�P�[���r���e�B�[���o���Ȃ�
�Ƙb�ɂ͂Ȃ�Ȃ��Ƃ������Ƃ��l����ƁA���̂Ƃ��덑���ł� T2K �� run
���邵���Ȃ�(�V���Ȃ�A�V����� Cray �����邯��)�킯�ŁA������������
�����Ă���̂��ƁE�E�E
���Ȃ݂ɁAORNL jaguar �͊C�O��������p�\�炵���ˁB
171 �F�s���ȃf�o�C�X�����F2009/07/11(�y) 02:21:50 ID:/z06EqzC
�܂������}�̕��u�͂ǂ��ɂ������ق���������˂��炢��
172 �F�s���ȃf�o�C�X�����F2009/07/11(�y) 07:40:14 ID:ywk+vrl3
>>170 �^�[�Q�b�g�A�v���̓��A�o�C�I�E�i�m�Ɋւ�����̂́A������������������ĂȂ����̂������ƁA
�������̒S���҂��^�w��ŁA�Q���Ă����B�������́AES�̃A�v���ɂ�鏉�����ʂɊ��҂��Ă������Ƃ͊ԈႢ�Ȃ��Ǝv���B
ES�̃A�v���̓������o���h�����d�v�Ȃ��̂�����������������Ȃ����AT2K���ƃ}���`�R�A�����ہX���ʂɂȂ�ƕ��������Ƃ�����B
�����Ȃ�ƁA8�R�A�\���̋����ŁA������SPRAC64V�̂悤��4�������߂����ǁA���ꂪ�����ɓ����Ƃ͂܂����肦�܂���A�Ƃ�
FX1�̂悤�Ƀ������o���h���̎�����30%���x�Ƃ��������̂��A�[�߂Ă��郁�[�J�̂��̂���A�ǂ��`���[�j���O�����������
������Ȃ���ԂƂ����̂͂��肦��Ǝv���B
�������̒S���҂��^�w��ŁA�Q���Ă����B�������́AES�̃A�v���ɂ�鏉�����ʂɊ��҂��Ă������Ƃ͊ԈႢ�Ȃ��Ǝv���B
ES�̃A�v���̓������o���h�����d�v�Ȃ��̂�����������������Ȃ����AT2K���ƃ}���`�R�A�����ہX���ʂɂȂ�ƕ��������Ƃ�����B
�����Ȃ�ƁA8�R�A�\���̋����ŁA������SPRAC64V�̂悤��4�������߂����ǁA���ꂪ�����ɓ����Ƃ͂܂����肦�܂���A�Ƃ�
FX1�̂悤�Ƀ������o���h���̎�����30%���x�Ƃ��������̂��A�[�߂Ă��郁�[�J�̂��̂���A�ǂ��`���[�j���O�����������
������Ȃ���ԂƂ����̂͂��肦��Ǝv���B
173 �F�s���ȃf�o�C�X�����F2009/07/11(�y) 10:49:11 ID:Cxi9KyNB
���@���Ȃ��ƊJ���ł��Ȃ����Ă̂́A�����̏�k�ł��傤���B
����ȃ��x���Ȃ�X�p�R�������̂��g���̂��A��߂��ق��������Ǝv���B
>>172
����ł���B
> ������SPRAC64V�̂悤��4�������߂����ǁA���ꂪ�����ɓ����Ƃ͂܂����肦�܂���A�Ƃ�
���s���j�b�g�̐������A�����Ɏ��s�ł��閽�߂̐������Ȃ��Ȃ�̂́A�펯�ł��B
SPARC64 V ���L�ł͂Ȃ��A���̃v���Z�b�T�ł������ł���B
���Ȃ݂ɁASPARC64 V ��4���ߓ����Ƃ����̂́AEXA�AEXB�AFLA�AFLB��4�ŁA
EXA��EXB�͐������Z�AFLA��FLB�͕��������_���Z�BA�n��B�n�ɂ͑����̈Ⴂ���������Ǝv���B
���������_���Z��4���ߓ����Ɏ��s�ł���킯����Ȃ����A
���ׂĂ̎��s�p�C�v���C�������Ԗ������߂�̂͌����I�ɂ͖����B
> FX1�̂悤�Ƀ������o���h���̎�����30%���x�Ƃ��������̂��A�[�߂Ă��郁�[�J�̂��̂���A
������I/F�́A�f�[�^�o�X���~����N���b�N�~1�N���b�N�̓]���� �ɑ��āA
CPU�����ۂɓǂݏ����ł���o�C�g��/�b��30%���炢�ɂȂ�̂��A�펯�ł��B
SPARC64 V ���L�ł͂Ȃ��A���̃v���Z�b�T�ł������ł���B
����ȃ��x���Ȃ�X�p�R�������̂��g���̂��A��߂��ق��������Ǝv���B
>>172
����ł���B
> ������SPRAC64V�̂悤��4�������߂����ǁA���ꂪ�����ɓ����Ƃ͂܂����肦�܂���A�Ƃ�
���s���j�b�g�̐������A�����Ɏ��s�ł��閽�߂̐������Ȃ��Ȃ�̂́A�펯�ł��B
SPARC64 V ���L�ł͂Ȃ��A���̃v���Z�b�T�ł������ł���B
���Ȃ݂ɁASPARC64 V ��4���ߓ����Ƃ����̂́AEXA�AEXB�AFLA�AFLB��4�ŁA
EXA��EXB�͐������Z�AFLA��FLB�͕��������_���Z�BA�n��B�n�ɂ͑����̈Ⴂ���������Ǝv���B
���������_���Z��4���ߓ����Ɏ��s�ł���킯����Ȃ����A
���ׂĂ̎��s�p�C�v���C�������Ԗ������߂�̂͌����I�ɂ͖����B
> FX1�̂悤�Ƀ������o���h���̎�����30%���x�Ƃ��������̂��A�[�߂Ă��郁�[�J�̂��̂���A
������I/F�́A�f�[�^�o�X���~����N���b�N�~1�N���b�N�̓]���� �ɑ��āA
CPU�����ۂɓǂݏ����ł���o�C�g��/�b��30%���炢�ɂȂ�̂��A�펯�ł��B
SPARC64 V ���L�ł͂Ȃ��A���̃v���Z�b�T�ł������ł���B
174 �F�s���ȃf�o�C�X�����F2009/07/11(�y) 10:51:53 ID:b9+EreIn
Nehalem��STREAM�Ńs�[�N��50%�ʂ͏o���C������
175 �F�s���ȃf�o�C�X�����F2009/07/11(�y) 11:06:07 ID:LbPEEA88
�ǂ�������ǁA�����R���ς��炶��˂��́H
176 �F�s���ȃf�o�C�X�����F2009/07/11(�y) 11:14:19 ID:Cxi9KyNB
Intel��CPU�͗�O�ŁA�L���b�V������̖��߂�K�Ɏg��(���ɂ͎g���̂���߂邱�Ƃ��܂�)���ƂŁA80%���炢�o�܂��B
Pentium4�̍�����A�������A�N�Z�X�̃X�g���[�������o���ăv���t�F�b�`����@�\���n�[�h�E�F�A�ŕt���Ă��܂��B
����́A���Ȃ苭�͂ŁA�x���`�}�[�N��̃`�[�g���Ƃ������l���������炢�ł��B
Pentium4�̍�����A�������A�N�Z�X�̃X�g���[�������o���ăv���t�F�b�`����@�\���n�[�h�E�F�A�ŕt���Ă��܂��B
����́A���Ȃ苭�͂ŁA�x���`�}�[�N��̃`�[�g���Ƃ������l���������炢�ł��B
177 �F�s���ȃf�o�C�X�����F2009/07/11(�y) 11:33:23 ID:LbPEEA88
�ւ�
178 �F�s���ȃf�o�C�X�����F2009/07/11(�y) 11:47:01 ID:b9+EreIn
Intel���D���̂��x�m�ʂ��ʖڂȂ̂��A���ꂪ��肾��
179 �F�s���ȃf�o�C�X�����F2009/07/11(�y) 12:11:35 ID:Cxi9KyNB
DRAM�̓�����A�o���h���ƃ����_���A�N�Z�X���\�̓g���[�h�I�t�̊W�ɂ���̂ŁA��T�ɂ͌����Ȃ��B
180 �F�s���ȃf�o�C�X�����F2009/07/11(�y) 12:44:34 ID:Hzjoc+a5
�Í���ǂ̂��߂ɑ��z$1.93B�̃X�p�R�������F����L�`�K�C����
http://www.geocities.jp/andosprocinfo/wadai09/20090711.htm
http://www.geocities.jp/andosprocinfo/wadai09/20090711.htm
181 �F�s���ȃf�o�C�X�����F2009/07/11(�y) 12:49:50 ID:b9+EreIn
���v�@�l�ɖ��N�����~�������鍑�Ƃ̂ق����L�`�K�C����jk
182 �F�s���ȃf�o�C�X�����F2009/07/11(�y) 12:51:08 ID:Cxi9KyNB
>>180
�����Ԉ���Ă��Ȃ���A�����X�p�R���́A������2�{�̋��z���ˁB
�����Ԉ���Ă��Ȃ���A�����X�p�R���́A������2�{�̋��z���ˁB
183 �F�s���ȃf�o�C�X�����F2009/07/11(�y) 13:06:06 ID:Cxi9KyNB
�Ȃ��������̎����ш敝�����_�s�[�N��1/3���x�ɂ����Ȃ�Ȃ��̂��A
�C�ɂȂ�l��DRAM���[�J�[�̃f�[�^�V�[�g��ǂ߂A�[�����邾�낤�B
���Ƃ�������Ƃ�
ttp://www.samsung.com/global/business/semiconductor/products/dram/downloads/ddr2_device_operation_timing_diagram_may_07.pdf
���Ȃ݂ɁA�x�m�ʂ�FX1��DDR2��630MHz��(���R�o�����o�X)�A64bit����4�`���l�����˂�256bit���Ƃ��Ă���B
���̃������R���g���[����CPU 1�ɑ���2�Ȃ��ŁA���v40GB/sec�B
������CPU�ƃ������R���g���[���̊Ԃ͑o�����o�X�ł͂Ȃ��A�㉺��Ώ́B
���[�h��80bit�~1.26GHz�A���C�g��48bit�~1.26GHz�B
STREAM��Triad�Ȃ烊�[�h�ƃ��C�g��2:1�̔䗦�Ȃ̂ŁA���̏㉺��Ώ͖̂��Ȃ������B
�C�ɂȂ�l��DRAM���[�J�[�̃f�[�^�V�[�g��ǂ߂A�[�����邾�낤�B
���Ƃ�������Ƃ�
ttp://www.samsung.com/global/business/semiconductor/products/dram/downloads/ddr2_device_operation_timing_diagram_may_07.pdf
���Ȃ݂ɁA�x�m�ʂ�FX1��DDR2��630MHz��(���R�o�����o�X)�A64bit����4�`���l�����˂�256bit���Ƃ��Ă���B
���̃������R���g���[����CPU 1�ɑ���2�Ȃ��ŁA���v40GB/sec�B
������CPU�ƃ������R���g���[���̊Ԃ͑o�����o�X�ł͂Ȃ��A�㉺��Ώ́B
���[�h��80bit�~1.26GHz�A���C�g��48bit�~1.26GHz�B
STREAM��Triad�Ȃ烊�[�h�ƃ��C�g��2:1�̔䗦�Ȃ̂ŁA���̏㉺��Ώ͖̂��Ȃ������B
184 �F�s���ȃf�o�C�X�����F2009/07/11(�y) 13:52:09 ID:anZ+RmRI
�����痝�R�������Ă��AF�����\�Ȃ͕̂ς��Ȃ���
���i�ł��S�������ł��ł��ĂȂ�����B
HPC��SPARC���x�����邱�Ǝ��̂����Ӗ��B
���i�ł��S�������ł��ł��ĂȂ�����B
HPC��SPARC���x�����邱�Ǝ��̂����Ӗ��B
185 �F�s���ȃf�o�C�X�����F2009/07/11(�y) 13:57:26 ID:Z4uZraaO
>>181
�L�`�K�C���Ƃ͈ꖯ�Ԋ�Ƃ�16���~������ł܂���I
http://headlines.yahoo.co.jp/hl?a=20090711-00000531-yom-bus_all
�L�`�K�C���Ƃ͈ꖯ�Ԋ�Ƃ�16���~������ł܂���I
http://headlines.yahoo.co.jp/hl?a=20090711-00000531-yom-bus_all
186 �F�s���ȃf�o�C�X�����F2009/07/11(�y) 14:19:09 ID:Cxi9KyNB
>>184
�����痝�R���������Ă������ł��Ȃ��̂ōf�ɓB�A���B
�����痝�R���������Ă������ł��Ȃ��̂ōf�ɓB�A���B
187 �F�s���ȃf�o�C�X�����F2009/07/11(�y) 14:28:00 ID:Einn6EQi
>>172
����������������Ă��Ȃ����Ă����̂͒Q���킵���ȁB
���ꂩ��A���j�[�R�A�ɂȂ�ƁA��͂� MPI �����ł͑ʖ�
�ŁAOpenMP ���g�����n�C�u���b�h���K�v�ɂȂ��Ă���
����]�v�ɑ�ςƂ����̂�������BMPI �� OpenMP ���蓮��
�啝�Ƀ\�[�X������������K�v�����邵�A�x�N�g���@�̎���
����Ɋ��炳�ꂽ�����҂Ɉꂩ��\�[�X������������Ƃ���
�̂���ςȂ̂��������B�܂��A�����͒Q�������ł͂Ȃ��A
���̎�̃T�|�[�g�̐����������肵�Ȃ��ƌv�Z�@���\�[�X��
���ɂ͏����ȃA�v�����������Ă��Ȃ��Ƃ����ɂȂ肩�˂Ȃ��ȁB
����������������Ă��Ȃ����Ă����̂͒Q���킵���ȁB
���ꂩ��A���j�[�R�A�ɂȂ�ƁA��͂� MPI �����ł͑ʖ�
�ŁAOpenMP ���g�����n�C�u���b�h���K�v�ɂȂ��Ă���
����]�v�ɑ�ςƂ����̂�������BMPI �� OpenMP ���蓮��
�啝�Ƀ\�[�X������������K�v�����邵�A�x�N�g���@�̎���
����Ɋ��炳�ꂽ�����҂Ɉꂩ��\�[�X������������Ƃ���
�̂���ςȂ̂��������B�܂��A�����͒Q�������ł͂Ȃ��A
���̎�̃T�|�[�g�̐����������肵�Ȃ��ƌv�Z�@���\�[�X��
���ɂ͏����ȃA�v�����������Ă��Ȃ��Ƃ����ɂȂ肩�˂Ȃ��ȁB
188 �F�s���ȃf�o�C�X�����F2009/07/11(�y) 14:34:36 ID:Cxi9KyNB
�o�C�I�n�̓O���b�h�ł��\�������肵�Ȃ�?
189 �F�s���ȃf�o�C�X�����F2009/07/11(�y) 14:45:12 ID:Cxi9KyNB
�X�p�R���̗��p�҂Ƀ\�[�X�R�[�h������������`���[�j���O�����邱�Ǝ��̂��Ԉ���Ă�Ǝv����B
�S�������Ă��A���p�҂�Fortran��C/C++�ŃR�[�f�B���O���邱�Ƃ��Ԉ���Ă�Ǝv����B
C����Ȃ̉��ł��A���̎葱���^�̌���ŏ����ꂽ��A����������ς���Ȃ����B
���^����̂悤�ɁA��肽���v�Z���`������A���Ƃ̓R���p�C���ɔC����悤�Ȍ�����g���ׂ��B
�S�������Ă��A���p�҂�Fortran��C/C++�ŃR�[�f�B���O���邱�Ƃ��Ԉ���Ă�Ǝv����B
C����Ȃ̉��ł��A���̎葱���^�̌���ŏ����ꂽ��A����������ς���Ȃ����B
���^����̂悤�ɁA��肽���v�Z���`������A���Ƃ̓R���p�C���ɔC����悤�Ȍ�����g���ׂ��B
190 �F�s���ȃf�o�C�X�����F2009/07/11(�y) 14:52:20 ID:Einn6EQi
191 �F�s���ȃf�o�C�X�����F2009/07/11(�y) 15:00:25 ID:Einn6EQi
>>189
�������̂��˂����Ă��E�E�E
>�X�p�R���̗��p�҂Ƀ\�[�X�R�[�h������������`���[�j���O�����邱�Ǝ��̂��Ԉ���Ă�Ǝv����B
>�S�������Ă��A���p�҂�Fortran��C/C++�ŃR�[�f�B���O���邱�Ƃ��Ԉ���Ă�Ǝv����B
������x�͎d���Ȃ��Ǝv���ˁB��肽���v�Z�̂��߂̃��f�����\�z����d��
�͌�����(���p��)����Ȃ��Ƃł��Ȃ����B�Ⴆ�A��ꌴ������v�Z������
�Ƃ��A���\�[�X������Ȃ��Ƃ��v�Z���Ԃ�������߂���Ƃ��̗��R�ŁA
�ȗ������ꂽ���f���������肷�邱�Ƃ�����B���������Ӗ�
�`���[�j���O�Ȃ킯�����ǁA���̔��f�͌����҂���Ȃ��Ƃł��Ȃ��B
�������̂��˂����Ă��E�E�E
>�X�p�R���̗��p�҂Ƀ\�[�X�R�[�h������������`���[�j���O�����邱�Ǝ��̂��Ԉ���Ă�Ǝv����B
>�S�������Ă��A���p�҂�Fortran��C/C++�ŃR�[�f�B���O���邱�Ƃ��Ԉ���Ă�Ǝv����B
������x�͎d���Ȃ��Ǝv���ˁB��肽���v�Z�̂��߂̃��f�����\�z����d��
�͌�����(���p��)����Ȃ��Ƃł��Ȃ����B�Ⴆ�A��ꌴ������v�Z������
�Ƃ��A���\�[�X������Ȃ��Ƃ��v�Z���Ԃ�������߂���Ƃ��̗��R�ŁA
�ȗ������ꂽ���f���������肷�邱�Ƃ�����B���������Ӗ�
�`���[�j���O�Ȃ킯�����ǁA���̔��f�͌����҂���Ȃ��Ƃł��Ȃ��B
192 �F�s���ȃf�o�C�X�����F2009/07/11(�y) 15:05:21 ID:Cxi9KyNB
>>190
BOINC�̂ق�
�C���^�[�l�b�g�ŗ���N��������Ă����Ƃ����͖̂����������ŁA�a�����̃N���X�^�B
�ߋ��ɂ́A�x�m�ʂ�BioServer�̂悤�ȗ�����邵�B
�a�����̃N���X�^�ł��ςޖ��Ȃ�A�����̂悤�ȃC���^�[�R�l�N�g�ɋ��̂��������X�p�R�����g���̂͂��������Ȃ��B
BOINC�̂ق�
�C���^�[�l�b�g�ŗ���N��������Ă����Ƃ����͖̂����������ŁA�a�����̃N���X�^�B
�ߋ��ɂ́A�x�m�ʂ�BioServer�̂悤�ȗ�����邵�B
�a�����̃N���X�^�ł��ςޖ��Ȃ�A�����̂悤�ȃC���^�[�R�l�N�g�ɋ��̂��������X�p�R�����g���̂͂��������Ȃ��B
193 �F�s���ȃf�o�C�X�����F2009/07/11(�y) 15:10:03 ID:Cxi9KyNB
194 �F�s���ȃf�o�C�X�����F2009/07/11(�y) 15:18:24 ID:Einn6EQi
>>192
BOINC �̃v���W�F�N�g�͌��\����܂��ˁB�m��܂���ł����B
http://boinc.oocp.org/projects.php
BOINC �ŏ\���Ƃ����v���W�F�N�g�����肻�������A����_��
�Ƃ��T�C�G���X�̐��ʂ͂ǂ��Ȃ낤�B
>>193
�����B>>187 �͂����������ƁB�����҈ȊO�̐l�����ׂ�
�����̃T�|�[�g�𗝌��ɂ͂����ׂ��B
BOINC �̃v���W�F�N�g�͌��\����܂��ˁB�m��܂���ł����B
http://boinc.oocp.org/projects.php
BOINC �ŏ\���Ƃ����v���W�F�N�g�����肻�������A����_��
�Ƃ��T�C�G���X�̐��ʂ͂ǂ��Ȃ낤�B
>>193
�����B>>187 �͂����������ƁB�����҈ȊO�̐l�����ׂ�
�����̃T�|�[�g�𗝌��ɂ͂����ׂ��B
195 �F�s���ȃf�o�C�X�����F2009/07/11(�y) 16:24:58 ID:ZcmPQVeU
BOINC����낤�Ǝv�����炻�ꂱ�������҂�
���O�̂��Ƃɖz�����邱�ƂɂȂ肻��
WCG��IBM�݂����Ȗ�����N��������Ă���������
���O�̂��Ƃɖz�����邱�ƂɂȂ肻��
WCG��IBM�݂����Ȗ�����N��������Ă���������
196 �F�s���ȃf�o�C�X�����F2009/07/11(�y) 19:45:26 ID:/1g0nzYU
���\�Ƃ������Ă���z�炪�����ō���Ă��������̂ɁE�E�E�B
197 �F�s���ȃf�o�C�X�����F2009/07/11(�y) 19:54:17 ID:L0SvHYDI
>>180
NSA���ǂ������Ƃ����m��Ȃ��悤���ȁB
NSA���ǂ������Ƃ����m��Ȃ��悤���ȁB
198 �F�s���ȃf�o�C�X�����F2009/07/11(�y) 20:16:35 ID:L0SvHYDI
199 �F�s���ȃf�o�C�X�����F2009/07/11(�y) 21:42:06 ID:35QIa3IT
>197
���ӁB
NSA���A���ł��ACRAY�̃x�N�g���@���g�������Ă��邱�Ƃ́A
�ӊO�ƒm���Ă��Ȃ��B
���ӁB
NSA���A���ł��ACRAY�̃x�N�g���@���g�������Ă��邱�Ƃ́A
�ӊO�ƒm���Ă��Ȃ��B
200 �F�s���ȃf�o�C�X�����F2009/07/11(�y) 22:04:52 ID:TV0simIZ
DARPA to revolutionise supercomputing
http://www.domain-b.com/defence/general/20090708_supercomputing.html
Nehalem workstations: A new era in performance
http://www.computerworld.com/s/article/9135326/Nehalem_workstations_A_new_era_in_performance?source=rss_news
Spider Up and Spinning Connections to All Computing Platforms at ORNL
http://www.hpcwire.com/features/Spider-Up-and-Spinning-Connections-to-All-Computing-Platforms-at-ORNL-50398972.html
Social Security Number Vulnerability Findings Relied on Supercomputing
http://www.hpcwire.com/industry/government/Social-Security-Number-Vulnerability-Findings-Relied-on-Supercomputing-50292227.html
Wolfram Alpha: A Web-Based Application That Embraced Supercomputers
http://www.hpcwire.com/features/Wolfram-Alpha-A-Web-Based-Application-That-Embraced-Supercomputers-50388777.html
TeraGrid '09: Student Participation Soars
http://www.hpcwire.com/features/TeraGrid-09-Student-Participation-Soars-50246857.html
Simulations Illuminate Universe's First Twin Stars
http://www.sciencedaily.com/releases/2009/07/090709170805.htm
Confusing weather with climate
http://www.minnpost.com/pauldouglas/2009/07/08/10096/confusing_weather_with_climate
A real-time HPC approach for optimizing Intel multi-core architectures (Part 3 of 3)
http://www.embedded.com/design/218400849
Wintel�鍑����̑����ƂȂ邩�AGoogle Chrome OS�̏Ռ�
http://pc.watch.impress.co.jp/docs/column/ubiq/20090710_300897.html
������̊����Ă݂悤
http://www.atmarkit.co.jp/fcoding/articles/parallel/01/para01a.html
http://www.domain-b.com/defence/general/20090708_supercomputing.html
Nehalem workstations: A new era in performance
http://www.computerworld.com/s/article/9135326/Nehalem_workstations_A_new_era_in_performance?source=rss_news
Spider Up and Spinning Connections to All Computing Platforms at ORNL
http://www.hpcwire.com/features/Spider-Up-and-Spinning-Connections-to-All-Computing-Platforms-at-ORNL-50398972.html
Social Security Number Vulnerability Findings Relied on Supercomputing
http://www.hpcwire.com/industry/government/Social-Security-Number-Vulnerability-Findings-Relied-on-Supercomputing-50292227.html
Wolfram Alpha: A Web-Based Application That Embraced Supercomputers
http://www.hpcwire.com/features/Wolfram-Alpha-A-Web-Based-Application-That-Embraced-Supercomputers-50388777.html
TeraGrid '09: Student Participation Soars
http://www.hpcwire.com/features/TeraGrid-09-Student-Participation-Soars-50246857.html
Simulations Illuminate Universe's First Twin Stars
http://www.sciencedaily.com/releases/2009/07/090709170805.htm
Confusing weather with climate
http://www.minnpost.com/pauldouglas/2009/07/08/10096/confusing_weather_with_climate
A real-time HPC approach for optimizing Intel multi-core architectures (Part 3 of 3)
http://www.embedded.com/design/218400849
Wintel�鍑����̑����ƂȂ邩�AGoogle Chrome OS�̏Ռ�
http://pc.watch.impress.co.jp/docs/column/ubiq/20090710_300897.html
������̊����Ă݂悤
http://www.atmarkit.co.jp/fcoding/articles/parallel/01/para01a.html
201 �F�s���ȃf�o�C�X�����F2009/07/12(��) 10:31:32 ID:w8lM2jDi
���{�ɂ�NSA�݂����̂�����������
202 �F�s���ȃf�o�C�X�����F2009/07/12(��) 12:10:24 ID:WWFliYSY
>>1��
�u���̃X����HPC�̃��[�U�E����Ă���l�A�������͎g�p���������Ă���l�̂��߂̂��̂ł��B
�����Ȑl�́A�Ȋw�j���[�X��HPC�Ɋւ���X�����i���Ԃ�j����̂ŁA������ւǂ����v
�Ƃłɏ����Ă����Ă���ȁB
�u���̃X����HPC�̃��[�U�E����Ă���l�A�������͎g�p���������Ă���l�̂��߂̂��̂ł��B
�����Ȑl�́A�Ȋw�j���[�X��HPC�Ɋւ���X�����i���Ԃ�j����̂ŁA������ւǂ����v
�Ƃłɏ����Ă����Ă���ȁB
203 �F�s���ȃf�o�C�X�����F2009/07/12(��) 14:50:20 ID:HwQf9FbX
�R�s�y�����ōςނ悤�ɁA�e���v�����P�ĂƂ��āA�܂Ƃ߂Ă�����
���X�����Ă�Ƃ��Ɂu�e���v���v�Ō������Ĕ�������闦�����܂��B
���X�����Ă�Ƃ��Ɂu�e���v���v�Ō������Ĕ�������闦�����܂��B
204 �F�s���ȃf�o�C�X�����F2009/07/12(��) 15:40:57 ID:8DfvTS1k
>>202
��̓I�ɂǂ̃��X�̂悤�ȏ������݂�r���������̂��������ق����A
���P�Ă̂�������Ƃ��āA��茚�ݓI�Ȃ��̂ɂȂ�Ǝv����B
���邩�ǂ���������Ȃ��X���ɗU������͕̂s�e�Ȃ�Ȃ����ȁH
���Ȃ��Ƃ��A
http://find.2ch.net/?BBS=ALL&TYPE=TITLE&ENCODING=SJIS&STR=HPC
���̌������ʂ��������A�U����Ƃ��ēK�ȃX���͌�������Ȃ��l��
�v�����ǁB
��̓I�ɂǂ̃��X�̂悤�ȏ������݂�r���������̂��������ق����A
���P�Ă̂�������Ƃ��āA��茚�ݓI�Ȃ��̂ɂȂ�Ǝv����B
���邩�ǂ���������Ȃ��X���ɗU������͕̂s�e�Ȃ�Ȃ����ȁH
���Ȃ��Ƃ��A
http://find.2ch.net/?BBS=ALL&TYPE=TITLE&ENCODING=SJIS&STR=HPC
���̌������ʂ��������A�U����Ƃ��ēK�ȃX���͌�������Ȃ��l��
�v�����ǁB
205 �F�s���ȃf�o�C�X�����F2009/07/12(��) 15:50:34 ID:HwQf9FbX
���������}�b�L�[�m�{�������Č��A����2ch�̂��̃X���͌��Ȃ��������Ȃ����A���Ă��ƂȂ̂��ȁB
206 �F�s���ȃf�o�C�X�����F2009/07/12(��) 16:16:51 ID:DWUiL3fd
���܂łǂ���L�Ӌ`�Ŗʔ����l�^������ΏE����������ˁH
�n���������瑛���ł��{�Ƃɗ��ނƂ���Ȃ�GPGPU�l�^�̎��Ɠ����悤��
������Ƃ����_���łǂ����A�Ƃ����X�^���X���낤���B
���{��ʼn�b���Ă�̂ɓ��{�ꂪ�ʂ��ĂȂ����Ƃ̓}�b�L�[�m���炢����
���傭���傭�L�邾�낤���ǁA�v���C�x�[�g�ł܂ŃX�g���X���߂Ă��d���Ȃ����B
������ᑽ���̒��l�^�𗧏��o�������m��ǁB
�n���������瑛���ł��{�Ƃɗ��ނƂ���Ȃ�GPGPU�l�^�̎��Ɠ����悤��
������Ƃ����_���łǂ����A�Ƃ����X�^���X���낤���B
���{��ʼn�b���Ă�̂ɓ��{�ꂪ�ʂ��ĂȂ����Ƃ̓}�b�L�[�m���炢����
���傭���傭�L�邾�낤���ǁA�v���C�x�[�g�ł܂ŃX�g���X���߂Ă��d���Ȃ����B
������ᑽ���̒��l�^�𗧏��o�������m��ǁB
207 �F�s���ȃf�o�C�X�����F2009/07/13(��) 21:55:17 ID:WeWW1MFS
>>205
kwsk
kwsk
208 �F�s���ȃf�o�C�X�����F2009/07/15(��) 01:26:11 ID:/PcNkcU4
Beyond Speeds and Feeds
http://www.hpcwire.com/features/Beyond-Speeds-and-Feeds-50504362.html
Report Finds IBM Supercomputers Most Energy Efficient
http://www.hpcwire.com/topic/systems/Report-Finds-IBM-Supercomputers-Most-Energy-Efficient-in-the-World-50675882.html
Intel May Release New Nehalem Chips Next Month
http://www.pcworld.com/article/168337/intel_may_release_new_nehalem_chips_next_month.html
Project Trident: A Scientific Workflow Workbench
http://www.ddj.com/218500166?cid=RSSfeed_DDJ_All
Clusters That Produce: 25 Open HPC Applications
http://www.hpccommunity.org/f55/clusters-produce-25-open-hpc-applications-591/
15,000rpm��6Gbps SAS�Ή�HDD��������
http://akiba-pc.watch.impress.co.jp/hotline/20090711/etc_seagate.html
> �Ȃ��A6Gbps�ɑΉ�����SAS�C���^�[�t�F�C�X�Ȃǂ͍��̂Ƃ��떢�����B��̓I�Ȕ����\�������ɂȂ��B
http://www.hpcwire.com/features/Beyond-Speeds-and-Feeds-50504362.html
Report Finds IBM Supercomputers Most Energy Efficient
http://www.hpcwire.com/topic/systems/Report-Finds-IBM-Supercomputers-Most-Energy-Efficient-in-the-World-50675882.html
Intel May Release New Nehalem Chips Next Month
http://www.pcworld.com/article/168337/intel_may_release_new_nehalem_chips_next_month.html
Project Trident: A Scientific Workflow Workbench
http://www.ddj.com/218500166?cid=RSSfeed_DDJ_All
Clusters That Produce: 25 Open HPC Applications
http://www.hpccommunity.org/f55/clusters-produce-25-open-hpc-applications-591/
15,000rpm��6Gbps SAS�Ή�HDD��������
http://akiba-pc.watch.impress.co.jp/hotline/20090711/etc_seagate.html
> �Ȃ��A6Gbps�ɑΉ�����SAS�C���^�[�t�F�C�X�Ȃǂ͍��̂Ƃ��떢�����B��̓I�Ȕ����\�������ɂȂ��B
209 �F�s���ȃf�o�C�X�����F2009/07/16(��) 01:50:54 ID:uIZMD9Ib
DARPA��Extreme Scale Computing�Ɍ��������� - UHPC��RFI�����J
http://journal.mycom.co.jp/articles/2009/07/15/darpa_uhpc_rfi/?rt=na
Sandy Bridge��Nehalem��Core MA����������Intel��2011�N
http://pc.watch.impress.co.jp/docs/column/kaigai/20090716_302169.html
�N���C�̃X�p�R���A�S������������ - ���s�V�X�e����16�{�̏������\������
http://journal.mycom.co.jp/news/2009/07/15/078/?rt=na
http://journal.mycom.co.jp/articles/2009/07/15/darpa_uhpc_rfi/?rt=na
Sandy Bridge��Nehalem��Core MA����������Intel��2011�N
http://pc.watch.impress.co.jp/docs/column/kaigai/20090716_302169.html
�N���C�̃X�p�R���A�S������������ - ���s�V�X�e����16�{�̏������\������
http://journal.mycom.co.jp/news/2009/07/15/078/?rt=na
210 �F�s���ȃf�o�C�X�����F2009/07/16(��) 01:52:18 ID:uIZMD9Ib
Illinois tech community ready to greet state boost
http://www.dailyherald.com/story/?id=306958
New Video documentation on high-performance computing
http://www.isgtw.org/?pid=1001891
Blue Sky Studios Donates Animation Computers to Wesleyan
http://newsletter.blogs.wesleyan.edu/2009/07/14/company-donates-animation-computers-to-wesleyan/
Turbulence Is Responsible For Black Holes' Balancing Act
http://www.redorbit.com/news/space/1720492/turbulence_is_responsible_for_black_holes_balancing_act/
Surface Beneath Two Sunspots Revealed in Simulation
http://www.livescience.com/researchinaction/ria-090714.html
Birth of a star predicted
http://www.spaceref.com/news/viewpr.html?pid=28731
Computer Modeling Helps Build Sun-powered Stadium
http://www.pcworld.com/article/168445/computer_modeling_helps_build_sunpowered_stadium.html
http://www.dailyherald.com/story/?id=306958
New Video documentation on high-performance computing
http://www.isgtw.org/?pid=1001891
Blue Sky Studios Donates Animation Computers to Wesleyan
http://newsletter.blogs.wesleyan.edu/2009/07/14/company-donates-animation-computers-to-wesleyan/
Turbulence Is Responsible For Black Holes' Balancing Act
http://www.redorbit.com/news/space/1720492/turbulence_is_responsible_for_black_holes_balancing_act/
Surface Beneath Two Sunspots Revealed in Simulation
http://www.livescience.com/researchinaction/ria-090714.html
Birth of a star predicted
http://www.spaceref.com/news/viewpr.html?pid=28731
Computer Modeling Helps Build Sun-powered Stadium
http://www.pcworld.com/article/168445/computer_modeling_helps_build_sunpowered_stadium.html
211 �F�s���ȃf�o�C�X�����F2009/07/17(��) 00:53:33 ID:N5wadrVU
�m���������{��̃X�s�[�`��
212 �F�s���ȃf�o�C�X�����F2009/07/17(��) 00:54:10 ID:t9CH6jLL
�X�p�R���P�ށA��˗������������u����v�|���ȋZ�Z�~�ōu��
http://www.nikkan.co.jp/news/nkx0620090716eaal.html
�x�m�ʁA���{���q�͌����J���@�\���獂���\�X�[�p�[�R���s���[�^�V�X�e������
http://release.nikkei.co.jp/detail.cfm?relID=225668&lindID=1
Behind Oracle's Interest In Sun's Sparc Hardware
http://www.informationweek.com/news/global-cio/interviews/showArticle.jhtml?articleID=218500826
Bull to do homegrown Nehalem EX chipset
http://www.theregister.co.uk/2009/07/15/bull_fame2g_mesca/
Nehalem and Atom save Intel's Q2 cookies
http://www.theregister.co.uk/2009/07/15/intel_q2_nehalem_atom/
Intel roadmap leaked
http://www.theinquirer.net/inquirer/news/1433700/intel-roadmap-leaked
HP Makes Pitch to Sun Customers Prior to Oracle Vote
http://www.eweek.com/c/a/IT-Infrastructure/HP-Makes-Pitch-to-Sun-Customers-Prior-to-Oracle-Vote-350437/
Rumor: SGI breaks off NSF petaflops deal with Pittsburgh
http://insidehpc.com/2009/07/14/rumor-sgi-terminates-pflops-deal-psc/
It�fs About Time
http://www.linux-mag.com/cache/7426/1.html
Gore Introduces Low-Profile Copper Cable for QSFP Assemblies
http://www.businesswire.com/portal/site/google/?ndmViewId=news_view&newsId=20090714005010&newsLang=en
ETH board begins strategic planning for 2012-2016
http://bulletin.sciencebusiness.net/ebulletins/showissue.php3?page=/548/art/14481&ch=1
http://www.nikkan.co.jp/news/nkx0620090716eaal.html
�x�m�ʁA���{���q�͌����J���@�\���獂���\�X�[�p�[�R���s���[�^�V�X�e������
http://release.nikkei.co.jp/detail.cfm?relID=225668&lindID=1
Behind Oracle's Interest In Sun's Sparc Hardware
http://www.informationweek.com/news/global-cio/interviews/showArticle.jhtml?articleID=218500826
Bull to do homegrown Nehalem EX chipset
http://www.theregister.co.uk/2009/07/15/bull_fame2g_mesca/
Nehalem and Atom save Intel's Q2 cookies
http://www.theregister.co.uk/2009/07/15/intel_q2_nehalem_atom/
Intel roadmap leaked
http://www.theinquirer.net/inquirer/news/1433700/intel-roadmap-leaked
HP Makes Pitch to Sun Customers Prior to Oracle Vote
http://www.eweek.com/c/a/IT-Infrastructure/HP-Makes-Pitch-to-Sun-Customers-Prior-to-Oracle-Vote-350437/
Rumor: SGI breaks off NSF petaflops deal with Pittsburgh
http://insidehpc.com/2009/07/14/rumor-sgi-terminates-pflops-deal-psc/
It�fs About Time
http://www.linux-mag.com/cache/7426/1.html
Gore Introduces Low-Profile Copper Cable for QSFP Assemblies
http://www.businesswire.com/portal/site/google/?ndmViewId=news_view&newsId=20090714005010&newsLang=en
ETH board begins strategic planning for 2012-2016
http://bulletin.sciencebusiness.net/ebulletins/showissue.php3?page=/548/art/14481&ch=1
213 �F�s���ȃf�o�C�X�����F2009/07/17(��) 15:57:59 ID:vKkciuVe
����������[
������X�[�p�[�R���s���[�^�̐V�V�X�e���\��������
http://www.riken.jp/r-world/info/release/press/2009/090717/index.html
214 �F�s���ȃf�o�C�X�����F2009/07/17(��) 22:19:50 ID:aHPITYRU
>>213
�����V�������͂Ȃ��ȁB�Z�p�I�ɂ��ACPU �� SPARC64TM VIIIfx
���Ă����ŁA���ɂ͉����Ȃ��B�X�J���[�P�ƂɂȂ����e���͌���I
�Ƃ��邪�A LINPACK �͂�����������A���A�v���͂ǂ̒��x
���[�U�x�����ł��邩�s�������B
�����V�������͂Ȃ��ȁB�Z�p�I�ɂ��ACPU �� SPARC64TM VIIIfx
���Ă����ŁA���ɂ͉����Ȃ��B�X�J���[�P�ƂɂȂ����e���͌���I
�Ƃ��邪�A LINPACK �͂�����������A���A�v���͂ǂ̒��x
���[�U�x�����ł��邩�s�������B
215 �F�s���ȃf�o�C�X�����F2009/07/18(�y) 00:35:10 ID:wxaRVkRU
In Search for Intelligence, a Silicon Brain Twitches
http://online.wsj.com/article/SB124751881557234725.html#articleTabs%3Darticle
Business as Unusual
http://www.hpcwire.com/blogs/Business-as-Unusual-50974792.html?ref=792
Benchmarking Your Cloud
http://www.hpcwire.com/features/Benchmarking-Your-Cloud-50976307.html
The curious case of Sun's hardware biz
http://www.channelregister.co.uk/2009/07/16/oracle_sun_hardware_biz/
Govt. to aid chip designing in India
http://www.siliconindia.com/shownews/Govt_to_aid_chip_designing_in_India-nid-59414.html
Oak Ridge Supercomputers Provide First Simulation of Abrupt Climate Change
http://www.hpcwire.com/offthewire/Oak-Ridge-Supercomputers-Provide-First-Simulation-of-Abrupt-Climate-50956752.html
The search for dark matter
http://www.economist.com/sciencetechnology/displaystory.cfm?story_id=14030304
�X�p�R�������z�͑����̉\����---�A�v���A�{�݂̏[�������
http://itpro.nikkeibp.co.jp/article/NEWS/20090717/333845/
http://online.wsj.com/article/SB124751881557234725.html#articleTabs%3Darticle
Business as Unusual
http://www.hpcwire.com/blogs/Business-as-Unusual-50974792.html?ref=792
Benchmarking Your Cloud
http://www.hpcwire.com/features/Benchmarking-Your-Cloud-50976307.html
The curious case of Sun's hardware biz
http://www.channelregister.co.uk/2009/07/16/oracle_sun_hardware_biz/
Govt. to aid chip designing in India
http://www.siliconindia.com/shownews/Govt_to_aid_chip_designing_in_India-nid-59414.html
Oak Ridge Supercomputers Provide First Simulation of Abrupt Climate Change
http://www.hpcwire.com/offthewire/Oak-Ridge-Supercomputers-Provide-First-Simulation-of-Abrupt-Climate-50956752.html
The search for dark matter
http://www.economist.com/sciencetechnology/displaystory.cfm?story_id=14030304
�X�p�R�������z�͑����̉\����---�A�v���A�{�݂̏[�������
http://itpro.nikkeibp.co.jp/article/NEWS/20090717/333845/
216 �F�s���ȃf�o�C�X�����F2009/07/18(�y) 23:12:19 ID:wxaRVkRU
������X�p�R���͕x�m�ʒP�Ƃ� �����A�o��A�b�v
http://www.47news.jp/CN/200907/CN2009071701000605.html
> �]����ƕ���͗��Ђ̓P�ޕ\���O�̂S�����{�A��̉��Z������A�g������d�g�݂����܂��������^��������A
> �����Ɍ����������߂Ă����Ƃ����B
�F�����H�F�f�o�r�u�ٕρv�@���O�����}���A�d�g�ɉe���|�|�Y���Q�`�R���[�g���ȉ�
http://mainichi.jp/select/wadai/news/20090718dde001040009000c.html
Intel SSDs to launch on Tuesday
http://www.theinquirer.net/inquirer/news/1433725/intel-ssds-launch-tuesday
T-Platforms Joins Supercomputer Consortium of Russia's Universities
http://www.hpcwire.com/offthewire/T-Platforms-Joins-Supercomputer-Consortium-of-Russias-Universities-51031542.html
LSU Professor Tapped to Lead NSF's Mathematical and Physical Sciences Section
http://www.hpcwire.com/industry/government/LSU-Professor-Tapped-to-Lead-NSFs-Mathematical-and-Physical-Sciences-Section-51036587.html
Why Does Water Expand When it Cools? A New Explanation
http://www.physorg.com/news167040410.html
Ocean current changes predicted to be gradual
http://www.world-science.net/othernews/090718_currents.htm
http://www.47news.jp/CN/200907/CN2009071701000605.html
> �]����ƕ���͗��Ђ̓P�ޕ\���O�̂S�����{�A��̉��Z������A�g������d�g�݂����܂��������^��������A
> �����Ɍ����������߂Ă����Ƃ����B
�F�����H�F�f�o�r�u�ٕρv�@���O�����}���A�d�g�ɉe���|�|�Y���Q�`�R���[�g���ȉ�
http://mainichi.jp/select/wadai/news/20090718dde001040009000c.html
Intel SSDs to launch on Tuesday
http://www.theinquirer.net/inquirer/news/1433725/intel-ssds-launch-tuesday
T-Platforms Joins Supercomputer Consortium of Russia's Universities
http://www.hpcwire.com/offthewire/T-Platforms-Joins-Supercomputer-Consortium-of-Russias-Universities-51031542.html
LSU Professor Tapped to Lead NSF's Mathematical and Physical Sciences Section
http://www.hpcwire.com/industry/government/LSU-Professor-Tapped-to-Lead-NSFs-Mathematical-and-Physical-Sciences-Section-51036587.html
Why Does Water Expand When it Cools? A New Explanation
http://www.physorg.com/news167040410.html
Ocean current changes predicted to be gradual
http://www.world-science.net/othernews/090718_currents.htm
217 �F�s���ȃf�o�C�X�����F2009/07/18(�y) 23:14:51 ID:wxaRVkRU
�ŋ߂̘b�� 2009�N7��18��
http://www.geocities.jp/andosprocinfo/wadai09/20090718.htm
http://www.geocities.jp/andosprocinfo/wadai09/20090718.htm
218 �F�s���ȃf�o�C�X�����F2009/07/18(�y) 23:50:31 ID:YzTuYuiz
�����ƈ���āA�C���h�Ȃ琦��CPU��肻�����Ȃ�
219 �F�s���ȃf�o�C�X�����F2009/07/19(��) 11:52:39 ID:uVRGrGLH
venus10����LINPAC�l10PF���炢��
���낻��x�m�ʂ�3PF�X�p�R���Ƃ����̂Ŏ��͂������Ăق�����
���낻��x�m�ʂ�3PF�X�p�R���Ƃ����̂Ŏ��͂������Ăق�����
220 �F�s���ȃf�o�C�X�����F2009/07/19(��) 12:10:44 ID:87Tq4nkB
221 �F�s���ȃf�o�C�X�����F2009/07/19(��) 20:09:04 ID:uVRGrGLH
�����ł�
222 �F�s���ȃf�o�C�X�����F2009/07/20(��) 22:19:15 ID:FMGVPZjZ
�k������j�R��www
223 �F�s���ȃf�o�C�X�����F2009/07/20(��) 23:19:17 ID:L9351jJQ
Atom-splitting number-crunchers
http://www.yourindustrynews.com/atom-splitting+number-crunchers_36026.html
IBM Sunsets More Power Systems Features
http://www.itjungle.com/tfh/tfh072009-story03.html
Windows HPC 2008 MPI Cluster Debugger Pack Available
http://news.softpedia.com/news/Windows-HPC-2008-MPI-Cluster-Debugger-Pack-Available-117081.shtml
SC09 July newsletter is out and up
http://insidehpc.com/2009/07/19/sc09-july-newsletter-is-out-and-up/
Computers hurt students' test scores
http://www.theinquirer.net/inquirer/news/1468939/computers-hurt-students-test-scores
�y�m�̐�[�z���_���w�ҁE���F��������@���啪�q�̐U�镑����\��
http://sankei.jp.msn.com/science/science/090720/scn0907200852001-n1.htm
�A���V�X�E�W���p���AAnsys 12.0�̍��������[�X���J�n�A���̃\���o�[Fluent��Workbench 2.0�ɓ���
http://www.designnewsjapan.com/content/l_news/2009/07/o14nbe000001v5je.html
���E���A�r�N�^�[��4K�J������4K�v���W�F�N�^�[�ŊF�����H�f�������C�u�`��
http://journal.mycom.co.jp/news/2009/07/20/001/index.html
http://www.yourindustrynews.com/atom-splitting+number-crunchers_36026.html
IBM Sunsets More Power Systems Features
http://www.itjungle.com/tfh/tfh072009-story03.html
Windows HPC 2008 MPI Cluster Debugger Pack Available
http://news.softpedia.com/news/Windows-HPC-2008-MPI-Cluster-Debugger-Pack-Available-117081.shtml
SC09 July newsletter is out and up
http://insidehpc.com/2009/07/19/sc09-july-newsletter-is-out-and-up/
Computers hurt students' test scores
http://www.theinquirer.net/inquirer/news/1468939/computers-hurt-students-test-scores
�y�m�̐�[�z���_���w�ҁE���F��������@���啪�q�̐U�镑����\��
http://sankei.jp.msn.com/science/science/090720/scn0907200852001-n1.htm
�A���V�X�E�W���p���AAnsys 12.0�̍��������[�X���J�n�A���̃\���o�[Fluent��Workbench 2.0�ɓ���
http://www.designnewsjapan.com/content/l_news/2009/07/o14nbe000001v5je.html
���E���A�r�N�^�[��4K�J������4K�v���W�F�N�^�[�ŊF�����H�f�������C�u�`��
http://journal.mycom.co.jp/news/2009/07/20/001/index.html
224 �F�s���ȃf�o�C�X�����F2009/07/20(��) 23:23:25 ID:sGSOMUiF
��������2ch�͌����̂��ȁH
225 �F�s���ȃf�o�C�X�����F2009/07/21(��) 22:51:20 ID:FJuVwi5c
�A���u���O�܂��[�H
226 �F�s���ȃf�o�C�X�����F2009/07/22(��) 02:10:11 ID:EzWznjgC
IBM lifts the veil on Power7 chips
http://www.theregister.co.uk/2009/07/21/ibm_power7_details/
Japanese nuke lab erects 200 teraflop super
http://www.theregister.co.uk/2009/07/20/japan_nuke_supers/
Japan's Next-Generation Supercomputer Configuration Is Decided
http://www.hpcwire.com/offthewire/Japans-Next-Generation-Supercomputer-Configuration-Is-Decided-51225557.html?ref=557
Green500 list ranks NEC HPC Cluster LX-2400 as number one among systems with commodity processors published in the latest Green 500 List
http://www.tmcnet.com/usubmit/2009/07/20/4280904.htm
Fujitsu and Sun Boost SPARC Enterprise Server Performance and Virtualization Capabilities
http://www.japancorp.net/Article.Asp?Art_ID=21763
Undergraduates get up close with Kraken supercomputer
http://dailybeacon.utk.edu/showarticle.php?articleid=55214
Cloud-based simulation cuts engineers' design costs
http://www.computerweekly.com/Articles/2009/07/21/236976/cloud-based-simulation-cuts-engineers-design-costs.htm
Cray opening St. Paul office
http://www.finance-commerce.com/article.cfm/2009/07/21/Cray-opening-St-Paul-office-Computer-firm-moving-into-downtown-St-Pauls-Galtier-Plaza
Google running Belgian datacenter without chillers
http://insidehpc.com/2009/07/20/google-running-belgium-datacenter-without-chiller/
CilkArts Multicore Programming Lecture Series Videos
http://insidehpc.com/2009/07/20/cilkarts-multicore-programming-lecture-series-videos/
http://www.theregister.co.uk/2009/07/21/ibm_power7_details/
Japanese nuke lab erects 200 teraflop super
http://www.theregister.co.uk/2009/07/20/japan_nuke_supers/
Japan's Next-Generation Supercomputer Configuration Is Decided
http://www.hpcwire.com/offthewire/Japans-Next-Generation-Supercomputer-Configuration-Is-Decided-51225557.html?ref=557
Green500 list ranks NEC HPC Cluster LX-2400 as number one among systems with commodity processors published in the latest Green 500 List
http://www.tmcnet.com/usubmit/2009/07/20/4280904.htm
Fujitsu and Sun Boost SPARC Enterprise Server Performance and Virtualization Capabilities
http://www.japancorp.net/Article.Asp?Art_ID=21763
Undergraduates get up close with Kraken supercomputer
http://dailybeacon.utk.edu/showarticle.php?articleid=55214
Cloud-based simulation cuts engineers' design costs
http://www.computerweekly.com/Articles/2009/07/21/236976/cloud-based-simulation-cuts-engineers-design-costs.htm
Cray opening St. Paul office
http://www.finance-commerce.com/article.cfm/2009/07/21/Cray-opening-St-Paul-office-Computer-firm-moving-into-downtown-St-Pauls-Galtier-Plaza
Google running Belgian datacenter without chillers
http://insidehpc.com/2009/07/20/google-running-belgium-datacenter-without-chiller/
CilkArts Multicore Programming Lecture Series Videos
http://insidehpc.com/2009/07/20/cilkarts-multicore-programming-lecture-series-videos/
227 �F�s���ȃf�o�C�X�����F2009/07/22(��) 02:11:25 ID:EzWznjgC
�Ăh�a�l�A������v���Z�b�T�u�o�n�v�d�q�V�v���ڂ̃T�[�o�[�o�ׂ�2010�N�㔼���ɊJ�n
http://jp.reuters.com/article/marketsNews/idJPnTK850360120090721
�t�B�b�N�X�^�[�Y��OpenCL�R���p�C���uFOXC�v�̊J���ɒ���
http://techon.nikkeibp.co.jp/article/NEWS/20090721/173278/
�u�����ŗL���Ȃ̂̓t���b�V������PCM�v
http://pc.watch.impress.co.jp/docs/column/semicon/20090722_303210.html
�uRuby�����������̂́w���[�U�[��M�����Ă���x����v�C�v���O���~���O����Ruby�J���҂̂܂��Ǝ����
http://techon.nikkeibp.co.jp/article/NEWS/20090721/173265/
http://jp.reuters.com/article/marketsNews/idJPnTK850360120090721
�t�B�b�N�X�^�[�Y��OpenCL�R���p�C���uFOXC�v�̊J���ɒ���
http://techon.nikkeibp.co.jp/article/NEWS/20090721/173278/
�u�����ŗL���Ȃ̂̓t���b�V������PCM�v
http://pc.watch.impress.co.jp/docs/column/semicon/20090722_303210.html
�uRuby�����������̂́w���[�U�[��M�����Ă���x����v�C�v���O���~���O����Ruby�J���҂̂܂��Ǝ����
http://techon.nikkeibp.co.jp/article/NEWS/20090721/173265/
228 �F�s���ȃf�o�C�X�����F2009/07/22(��) 18:40:34 ID:gbW3pEc0
Power 7: Lots of Cores, Lots of Threads
http://www.itjungle.com/bns/bns072109-story01.html
http://www.itjungle.com/bns/bns072109-story01.html
229 �F�s���ȃf�o�C�X�����F2009/07/22(��) 21:10:21 ID:vQ6dl4Yd
�n���V�~�����[�^�[�@���V�X�e����������
http://jrecin.jst.go.jp/seek/SeekJorDetail?fn=1&id=D109070899&ln_jor=0
�N�� 1200�`1400���~
http://jrecin.jst.go.jp/seek/SeekJorDetail?fn=1&id=D109070899&ln_jor=0
�N�� 1200�`1400���~
230 �F�s���ȃf�o�C�X�����F2009/07/22(��) 21:36:41 ID:7NqodOTc
231 �F�s���ȃf�o�C�X�����F2009/07/22(��) 21:53:00 ID:RsvrEVWC
3����1�����x�݂�
232 �F�s���ȃf�o�C�X�����F2009/07/22(��) 23:18:36 ID:P02+DYzj
�����ɂ����݂̂�Ȃʼn��債�Ă݂邩��?w
233 �F�s���ȃf�o�C�X�����F2009/07/22(��) 23:55:26 ID:EzWznjgC
NERSC's Supercomputer Franklin Upgraded to Double Its Scientific Capability
http://www.hpcwire.com/topic/systems/NERSCs-Supercomputer-Franklin-Upgraded-to-Double-Its-Scientific-Capability-51349887.html
Supercomputer built in 4�@hours
http://www.wlfi.com/dpp/news/local/local_WLFI_westlafayette_supercomputer_built_in_4_hours_20090722
Larrabee has two HD decoders
http://www.semiaccurate.com/2009/07/21/larrabee-has-two-hd-decoders/
Samsung producing 2-Gb DDR 3 at 40-nm
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=218501668
Intel claims first 34-nm NAND flash SSDs
http://www.eetimes.com/news/latest/showArticle.jhtml?articleID=218501598
Could Crossbar Architecture be the Successor to Flash Memory
http://www.azom.com/news.asp?newsID=18193
Jupiter collision a warning call to Earth
http://www.csmonitor.com/2009/0722/p02s04-usgn.html
ASTRON's New LOFAR Telescope Shows First Fringes
http://www.spacedaily.com/reports/ASTRON_New_LOFAR_Telescope_Shows_First_Fringes_999.html
http://www.hpcwire.com/topic/systems/NERSCs-Supercomputer-Franklin-Upgraded-to-Double-Its-Scientific-Capability-51349887.html
Supercomputer built in 4�@hours
http://www.wlfi.com/dpp/news/local/local_WLFI_westlafayette_supercomputer_built_in_4_hours_20090722
Larrabee has two HD decoders
http://www.semiaccurate.com/2009/07/21/larrabee-has-two-hd-decoders/
Samsung producing 2-Gb DDR 3 at 40-nm
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=218501668
Intel claims first 34-nm NAND flash SSDs
http://www.eetimes.com/news/latest/showArticle.jhtml?articleID=218501598
Could Crossbar Architecture be the Successor to Flash Memory
http://www.azom.com/news.asp?newsID=18193
Jupiter collision a warning call to Earth
http://www.csmonitor.com/2009/0722/p02s04-usgn.html
ASTRON's New LOFAR Telescope Shows First Fringes
http://www.spacedaily.com/reports/ASTRON_New_LOFAR_Telescope_Shows_First_Fringes_999.html
234 �F�s���ȃf�o�C�X�����F2009/07/23(��) 02:56:07 ID:izOEFAI7
�����X�p�R���A���Ԃ����ăm���m������Ă邩��A�����_���ہB
�����͂��߂����ɂ�Venus�͎���x�ꂾ��B
�ǂ�����Ńv���Z�b�T���������邭�炢�Ȃ�A
�v���Z�b�T�̗ʎY���n�܂��čH�ꂩ��o�Ă���̂ɍ��킹�āA
�����m�[�h���ғ��J�n�����Ēi�K�I�ɉғ��m�[�h���𑝂₷
���炢�̂��Ƃ́A����Ă������Ǝv�����ȁB
���ہA�A�����J�̃X�p�R���́A�����ł���B
�S���̃m�[�h�����������O�ɁA�T�[�r�X�J�n���Ă�B
�������Ȃ��ƁA���������Ȃ��B
�����͂��߂����ɂ�Venus�͎���x�ꂾ��B
�ǂ�����Ńv���Z�b�T���������邭�炢�Ȃ�A
�v���Z�b�T�̗ʎY���n�܂��čH�ꂩ��o�Ă���̂ɍ��킹�āA
�����m�[�h���ғ��J�n�����Ēi�K�I�ɉғ��m�[�h���𑝂₷
���炢�̂��Ƃ́A����Ă������Ǝv�����ȁB
���ہA�A�����J�̃X�p�R���́A�����ł���B
�S���̃m�[�h�����������O�ɁA�T�[�r�X�J�n���Ă�B
�������Ȃ��ƁA���������Ȃ��B
235 �F�s���ȃf�o�C�X�����F2009/07/23(��) 08:44:10 ID:jPHJH8mR
2011�N�ғ��J�n�A2012�N��������B
236 �F�s���ȃf�o�C�X�����F2009/07/23(��) 09:09:04 ID:Ll3w2LzX
2011�N6���܂ł�10PF�B���ł��Ȃ��Ȃ��ʂ͖������ȁB��ʎ�����Ƃ��Ă�
11���ɂ�Sequoia�ɔ�����Ĕ��N�V���B12TF/rack��210TF/rack�Ƃ������E�E�E
�Ȃ�œ����v���Z�X����g���ĂĂ����܂łȂ�́H
11���ɂ�Sequoia�ɔ�����Ĕ��N�V���B12TF/rack��210TF/rack�Ƃ������E�E�E
�Ȃ�œ����v���Z�X����g���ĂĂ����܂łȂ�́H
237 �F�s���ȃf�o�C�X�����F2009/07/23(��) 11:12:04 ID:8WD2W1Lr
>>236
Sequoia �� 210TF/rack �Ƃ����͕̂����邯�ǁA 12TF/rack
�̍����́H������ core���� rack���̌����l��������Ȃ��B
���ꂩ��ASequoia �ɂ��ĕ⑫����ƁA20PF �͌��\�e��
���Ǝv���BSequoia �� POWER6 160��core 96rack ���Ƃ���ƁA
IBM �����\�����x���`�}�[�N�̌��ʂ���APOWER6 16core ��
��239GF �Ȃ̂ŁA160��core �� ��24PF �ɂȂ�B
(��L�� 210TF/rack �� 20PF �� 96 rack ������)
����A������ SPARC64 VIIIfx �� 8core 128G �Ȃ̂�
���Ȃ��Ƃ������x�� core����e�Ղ����A20PF ��
�_���Ȃ��͂Ȃ��悤�C������B�������Arack �ӂ��
core��(�ݒu�ʐ�)�����d�͂Ȃǂ��l������_��
�Ȃ̂�������Ȃ��B
Sequoia �� 210TF/rack �Ƃ����͕̂����邯�ǁA 12TF/rack
�̍����́H������ core���� rack���̌����l��������Ȃ��B
���ꂩ��ASequoia �ɂ��ĕ⑫����ƁA20PF �͌��\�e��
���Ǝv���BSequoia �� POWER6 160��core 96rack ���Ƃ���ƁA
IBM �����\�����x���`�}�[�N�̌��ʂ���APOWER6 16core ��
��239GF �Ȃ̂ŁA160��core �� ��24PF �ɂȂ�B
(��L�� 210TF/rack �� 20PF �� 96 rack ������)
����A������ SPARC64 VIIIfx �� 8core 128G �Ȃ̂�
���Ȃ��Ƃ������x�� core����e�Ղ����A20PF ��
�_���Ȃ��͂Ȃ��悤�C������B�������Arack �ӂ��
core��(�ݒu�ʐ�)�����d�͂Ȃǂ��l������_��
�Ȃ̂�������Ȃ��B
238 �F�s���ȃf�o�C�X�����F2009/07/23(��) 11:13:56 ID:8WD2W1Lr
�����B
�� ����A������ SPARC64 VIIIfx �� 8core 128GF �Ȃ̂�
�~ ����A������ SPARC64 VIIIfx �� 8core 128G �Ȃ̂�
�� ����A������ SPARC64 VIIIfx �� 8core 128GF �Ȃ̂�
�~ ����A������ SPARC64 VIIIfx �� 8core 128G �Ȃ̂�
239 �F�s���ȃf�o�C�X�����F2009/07/23(��) 11:14:09 ID:izOEFAI7
>>235
Venus�͗ʎY�ɓ�������? �Ȃ�A���N�x���ɂ͉ғ��J�n���Ă�������Ȃ�?
Venus�͗ʎY�ɓ�������? �Ȃ�A���N�x���ɂ͉ғ��J�n���Ă�������Ȃ�?
240 �F�s���ȃf�o�C�X�����F2009/07/23(��) 11:30:46 ID:izOEFAI7
BlueGene�V���[�Y�̍����x���Ղ�ɔ�ׂ�ƁA�x�m�ʂ�FX1�̓X�J�X�J�Ȃ�ˁB
4U�̃V���[�V��4�m�[�h�E�E�E���ꂶ�ᕁ�ʂ�1U��UNIX�T�[�o��Infiniband�̃J�[�h�}�����̂ƕς�Ȃ������A�ƁB
4U�̃V���[�V��4�m�[�h�E�E�E���ꂶ�ᕁ�ʂ�1U��UNIX�T�[�o��Infiniband�̃J�[�h�}�����̂ƕς�Ȃ������A�ƁB
241 �F�s���ȃf�o�C�X�����F2009/07/23(��) 11:59:51 ID:bWj5mg2w
1�{�[�h��venus��4�����āA1���b�N��24�{�[�h����̂��s�̌^�̗\�肾��H
ttp://pc.watch.impress.co.jp/docs/news/20090514_168533.html
������܂����悻12TF/rack
���������ɂ͂ǂ��Ȃ邩�m��Asequoia��210TF/rack�Ƃ����̂͂������ȁB
BG/L��PowerPC 700Mhz�����������Ă�������l�ߍ��킯����ȁB
�l������GDR�ɋ߂��Ǝv������
ttp://pc.watch.impress.co.jp/docs/news/20090514_168533.html
������܂����悻12TF/rack
���������ɂ͂ǂ��Ȃ邩�m��Asequoia��210TF/rack�Ƃ����̂͂������ȁB
BG/L��PowerPC 700Mhz�����������Ă�������l�ߍ��킯����ȁB
�l������GDR�ɋ߂��Ǝv������
242 �F�s���ȃf�o�C�X�����F2009/07/23(��) 12:00:26 ID:8WD2W1Lr
>>240
�Ȃ�قǁB���������B���� FX1 ���� SPARC64 (TM) VII
320�m�[�h(320CPU,1280core) �� 12TF �炵���̂ŁA
4U�̃V���[�V 80���Ƃ����v�Z�Ȃ�܂��ˁB
>>237
�����lj��B
�� ���Ȃ��Ƃ������x�� core����p�ӂ���A20PF ��
�~ ���Ȃ��Ƃ������x�� core����e�Ղ����A20PF ��
�Ȃ�قǁB���������B���� FX1 ���� SPARC64 (TM) VII
320�m�[�h(320CPU,1280core) �� 12TF �炵���̂ŁA
4U�̃V���[�V 80���Ƃ����v�Z�Ȃ�܂��ˁB
>>237
�����lj��B
�� ���Ȃ��Ƃ������x�� core����p�ӂ���A20PF ��
�~ ���Ȃ��Ƃ������x�� core����e�Ղ����A20PF ��
243 �F�s���ȃf�o�C�X�����F2009/07/23(��) 12:03:03 ID:8WD2W1Lr
244 �F�s���ȃf�o�C�X�����F2009/07/23(��) 12:29:14 ID:95ORoFMm
>>240
�������g�������炷��Ƃ��ꂪ������ȁB�m�[�h�ԒʐM�͑������A�m�[�h���̊������Ȃ��A
������ł̃p�t�H�[�}���X���悭�A�}�f��CPU�\�͂��J�o�[���Ă����Ƃ�������ۂ������B
�������g�������炷��Ƃ��ꂪ������ȁB�m�[�h�ԒʐM�͑������A�m�[�h���̊������Ȃ��A
������ł̃p�t�H�[�}���X���悭�A�}�f��CPU�\�͂��J�o�[���Ă����Ƃ�������ۂ������B
245 �F�s���ȃf�o�C�X�����F2009/07/23(��) 12:32:06 ID:izOEFAI7
>>241
4�v���Z�b�T���l�ߍ���1U�������ۂ��̂�1���b�N��24�����Ă��Ƃ́A
���b�N�̔����͓d����l�b�g���[�N�Ȃǂ���߂�̂��B
����������B
BlueGene/Q���AL��P�P����̂ł���A
2U�������ۂ��̐ς�32�v���Z�b�T�ŁA���ꂪ1���b�N��32U���B
�����ċ��B
��r����ƁA�v���Z�b�T������̃R�A����2�{�A1U������̃v���Z�b�T����4�{�B
�d����l�b�g���[�N�̑̐ς����Ȃ����Ƃ���������ƁA��������10�{���B
4�v���Z�b�T���l�ߍ���1U�������ۂ��̂�1���b�N��24�����Ă��Ƃ́A
���b�N�̔����͓d����l�b�g���[�N�Ȃǂ���߂�̂��B
����������B
BlueGene/Q���AL��P�P����̂ł���A
2U�������ۂ��̐ς�32�v���Z�b�T�ŁA���ꂪ1���b�N��32U���B
�����ċ��B
��r����ƁA�v���Z�b�T������̃R�A����2�{�A1U������̃v���Z�b�T����4�{�B
�d����l�b�g���[�N�̑̐ς����Ȃ����Ƃ���������ƁA��������10�{���B
246 �F�s���ȃf�o�C�X�����F2009/07/23(��) 13:36:03 ID:Ll3w2LzX
>>237
Sequoia��POWER6�Ȃ�ď����l���Ă����蓾�Ȃ��Ǝv����
Sequoia��POWER6�Ȃ�ď����l���Ă����蓾�Ȃ��Ǝv����
247 �F�s���ȃf�o�C�X�����F2009/07/23(��) 15:17:30 ID:8WD2W1Lr
>>246
�܂��A����͒P�Ȃ錩�ς�ł���B
���L�ɂ��ƁA�v���Z�b�T�Ɋւ���ŏI�X�y�b�N�͂܂�����B
http://japan.internet.com/webtech/20090204/12.html
�܂��A����͒P�Ȃ錩�ς�ł���B
���L�ɂ��ƁA�v���Z�b�T�Ɋւ���ŏI�X�y�b�N�͂܂�����B
http://japan.internet.com/webtech/20090204/12.html
248 �F�s���ȃf�o�C�X�����F2009/07/24(��) 00:05:11 ID:UR94OLKA
��������2ch�����ˁc
249 �F�s���ȃf�o�C�X�����F2009/07/24(��) 00:48:54 ID:z0YUm+xT
Russia to Use Supercomputers to Test Viability of Nuclear Arsenal
http://www.globalsecuritynewswire.org/gsn/nw_20090723_5131.php
Thinking outside the box
http://www.newelectronics.co.uk/article/19277/Thinking-outside-the-box.aspx
Projects Granted Access to PRACE Prototype Systems
http://www.hpcwire.com/industry/academia/Projects-Granted-Access-to-PRACE-Prototype-Systems-51404482.html
Sun Expands Open Network Systems Architecture
http://www.hpcwire.com/offthewire/Sun-Expands-Open-Network-Systems-Architecture-51314137.html?ref=137
Rad hard SPARC V8 processor that resists space radiation introduced by Atmel
http://mae.pennnet.com/display_article/366654/32/ARTCL/none/EXECW/1/Rad-hard-SPARC-V8-processor-that-resists-space-radiation-introduced-by-Atmel/
���ȏȁA������X�p�R���̐헪���������|�������猤���@����
http://www.nikkan.co.jp/news/nkx0320090723abak.html
http://www.globalsecuritynewswire.org/gsn/nw_20090723_5131.php
Thinking outside the box
http://www.newelectronics.co.uk/article/19277/Thinking-outside-the-box.aspx
Projects Granted Access to PRACE Prototype Systems
http://www.hpcwire.com/industry/academia/Projects-Granted-Access-to-PRACE-Prototype-Systems-51404482.html
Sun Expands Open Network Systems Architecture
http://www.hpcwire.com/offthewire/Sun-Expands-Open-Network-Systems-Architecture-51314137.html?ref=137
Rad hard SPARC V8 processor that resists space radiation introduced by Atmel
http://mae.pennnet.com/display_article/366654/32/ARTCL/none/EXECW/1/Rad-hard-SPARC-V8-processor-that-resists-space-radiation-introduced-by-Atmel/
���ȏȁA������X�p�R���̐헪���������|�������猤���@����
http://www.nikkan.co.jp/news/nkx0320090723abak.html
250 �F�s���ȃf�o�C�X�����F2009/07/24(��) 01:05:25 ID:z0YUm+xT
Google Chrome OS�͂Ȃ�Network Computer�Ɏ��Ă���̂�
http://pc.watch.impress.co.jp/docs/column/kaigai/20090723_303953.html
����������̊F�����H���p�A���̕��䗠 - �������l�b�g�q���u�����ȁv�ւ̊���
http://journal.mycom.co.jp/articles/2009/07/23/kizuna/index.html
http://pc.watch.impress.co.jp/docs/column/kaigai/20090723_303953.html
����������̊F�����H���p�A���̕��䗠 - �������l�b�g�q���u�����ȁv�ւ̊���
http://journal.mycom.co.jp/articles/2009/07/23/kizuna/index.html
251 �F�s���ȃf�o�C�X�����F2009/07/24(��) 05:34:34 ID:RYb+8cs3
�����ȁE�E�E���B
���{�̕����ƒʐM�̋ƊE�́A�݂��ɑ���̓����A���������̋Z�p�Ŏ�낤�Ƃ��Ă��ȁB
�ǁ[�݂Ă��A�����Ȃ̓C���^�[�l�b�g�Ƃ������́A�����Ȃ�B����f�[�^���u���[�h�L���X�g������́B
�����āA����������̍l����o�����ʐM�́A�n�f�W�̃A���̂悤�ɂ��e���Ȃ��́B
���{�̕����ƒʐM�̋ƊE�́A�݂��ɑ���̓����A���������̋Z�p�Ŏ�낤�Ƃ��Ă��ȁB
�ǁ[�݂Ă��A�����Ȃ̓C���^�[�l�b�g�Ƃ������́A�����Ȃ�B����f�[�^���u���[�h�L���X�g������́B
�����āA����������̍l����o�����ʐM�́A�n�f�W�̃A���̂悤�ɂ��e���Ȃ��́B
252 �F�s���ȃf�o�C�X�����F2009/07/24(��) 07:10:38 ID:UR94OLKA
�����Ȃ͂ǂ��̊NJ��Ȃ́H
253 �F�s���ȃf�o�C�X�����F2009/07/24(��) 10:47:35 ID:6eh8jgHS
254 �F�s���ȃf�o�C�X�����F2009/07/24(��) 12:04:55 ID:kPGJQsu9
JAXA�͎����ʐM�n�q����邩�͔ے�I����ˁA
�������iDocomo����j���ʐM�͖��Ԃŏ\���A�킴�킴JAXA����邱�����Ȃ��B
����������K�X�B
��������őł��~�߂Ȃ�ˁH
�������iDocomo����j���ʐM�͖��Ԃŏ\���A�킴�킴JAXA����邱�����Ȃ��B
����������K�X�B
��������őł��~�߂Ȃ�ˁH
255 �F�s���ȃf�o�C�X�����F2009/07/24(��) 12:58:08 ID:uW2ryIYU
���X���q���Ƃ��Ɏ����悤�ȋ@�\����������
256 �F�s���ȃf�o�C�X�����F2009/07/24(��) 22:43:59 ID:bSH9pBaq
�r�b�N���}���`���R�Ȃ�A�ǂ������ɖ��͂����o���邪�A
>>255�@����̓E�}�C�̂��ȁH��
>>255�@����̓E�}�C�̂��ȁH��
257 �F�s���ȃf�o�C�X�����F2009/07/25(�y) 01:20:42 ID:C6GsQy1I
Reading tealeaves-complete
http://laengsynt.de/laengsynt/index.php/reading-tealeaves-complete-mainmenu-151
Fujitsu says biz to pick up in 2010
http://www.theregister.co.uk/2009/07/23/fujitsu_future_super/
Cray punts smaller baby super
http://www.theregister.co.uk/2009/07/23/cray_cx1_lc_baby_super/
CUDA Toolkit and SDK 2.3 released
http://forums.nvidia.com/index.php?showtopic=102548
Apple makes 90 percent of expensive computers
http://www.theinquirer.net/inquirer/news/1495162/apple-makes-90-percent-expensive-computers
Open Space
http://www.linuxjournal.com/content/open-space
Atom�������ƃN�A�b�h�R�A��������d�g��
http://pc.watch.impress.co.jp/docs/column/kaigai/20090724_304602.html
�����Ɠ��k��A�X�s���g���j�N�X�f�o�C�X�V�~�����[�V�����Z�p���J��
http://journal.mycom.co.jp/news/2009/07/24/052/?rt=na
http://laengsynt.de/laengsynt/index.php/reading-tealeaves-complete-mainmenu-151
Fujitsu says biz to pick up in 2010
http://www.theregister.co.uk/2009/07/23/fujitsu_future_super/
Cray punts smaller baby super
http://www.theregister.co.uk/2009/07/23/cray_cx1_lc_baby_super/
CUDA Toolkit and SDK 2.3 released
http://forums.nvidia.com/index.php?showtopic=102548
Apple makes 90 percent of expensive computers
http://www.theinquirer.net/inquirer/news/1495162/apple-makes-90-percent-expensive-computers
Open Space
http://www.linuxjournal.com/content/open-space
Atom�������ƃN�A�b�h�R�A��������d�g��
http://pc.watch.impress.co.jp/docs/column/kaigai/20090724_304602.html
�����Ɠ��k��A�X�s���g���j�N�X�f�o�C�X�V�~�����[�V�����Z�p���J��
http://journal.mycom.co.jp/news/2009/07/24/052/?rt=na
258 �F�s���ȃf�o�C�X�����F2009/07/25(�y) 13:46:25 ID:VrsG653d
�����̋����͗Ջ@���ς���
259 �F�s���ȃf�o�C�X�����F2009/07/25(�y) 13:47:47 ID:ntug5H+T
�Ă������A����������{�Ɏ��R�Ɍq����Ǝv���Ă�ق����ԈႢ������B
��{�I�ɂ͌q����Ȃ����A���܂ɔ�����A�ƁB
��{�I�ɂ͌q����Ȃ����A���܂ɔ�����A�ƁB
260 �F�s���ȃf�o�C�X�����F2009/07/26(��) 01:35:33 ID:WnXHKscA
�q��������q����Ȃ���������Ă̂��悭�킩����
261 �F�s���ȃf�o�C�X�����F2009/07/26(��) 01:54:15 ID:4Jlg11+V
�ŋ߂̘b�� 2009�N7��25��
http://www.geocities.jp/andosprocinfo/wadai09/20090725.htm
��葁���n�k������A�C�ے����v�Z���ύX
http://www.yomiuri.co.jp/national/news/20090725-OYT1T00033.htm
�u�F�����v���ϑ����鏬�^�q���A�ʂ����Ė����i�͖��ɗ������̂�
http://www.eetimes.jp/content/2999
IT�ƊE�̖`���҂����@��32��@���[�i�X�E�g�[�o���Y���������j
http://jibun.atmarkit.co.jp/ljibun01/rensai/adventurer/032/01.html
IT�ƊE�̖`���҂����@��45��@���X�[�p�[�n�C�E�F�C�̊���
http://jibun.atmarkit.co.jp/ljibun01/rensai/adventurer/045/01.html
White House mulls making NASA a center for federal cloud computing
http://www.nextgov.com/nextgov/ng_20090724_6498.php?oref=topstory
SGI Sticks to Its Roadmap, But It's the End of the Line for the Itanium Supers
http://www.hpcwire.com/features/SGI-Sticks-to-Its-Roadmap-But-Its-the-End-of-the-Line-for-the-Itanium-Supers-51429127.html
AMD's happy day spoilt by analyst gloom
http://www.theinquirer.net/inquirer/news/1495165/amd-happy-day-spoilt-analyst-gloom
http://www.geocities.jp/andosprocinfo/wadai09/20090725.htm
��葁���n�k������A�C�ے����v�Z���ύX
http://www.yomiuri.co.jp/national/news/20090725-OYT1T00033.htm
�u�F�����v���ϑ����鏬�^�q���A�ʂ����Ė����i�͖��ɗ������̂�
http://www.eetimes.jp/content/2999
IT�ƊE�̖`���҂����@��32��@���[�i�X�E�g�[�o���Y���������j
http://jibun.atmarkit.co.jp/ljibun01/rensai/adventurer/032/01.html
IT�ƊE�̖`���҂����@��45��@���X�[�p�[�n�C�E�F�C�̊���
http://jibun.atmarkit.co.jp/ljibun01/rensai/adventurer/045/01.html
White House mulls making NASA a center for federal cloud computing
http://www.nextgov.com/nextgov/ng_20090724_6498.php?oref=topstory
SGI Sticks to Its Roadmap, But It's the End of the Line for the Itanium Supers
http://www.hpcwire.com/features/SGI-Sticks-to-Its-Roadmap-But-Its-the-End-of-the-Line-for-the-Itanium-Supers-51429127.html
AMD's happy day spoilt by analyst gloom
http://www.theinquirer.net/inquirer/news/1495165/amd-happy-day-spoilt-analyst-gloom
262 �F�s���ȃf�o�C�X�����F2009/07/26(��) 08:16:31 ID:TiC5DXHt
SGI��Altix��Itanium����߂�̂��B
�ނ��덡�܂ł悭���������̂��Ƃ������B
�X���̎��҂Ɏf���������A�Ȃ�Itanium���g��ꑱ�����̂��AItanium�̂ǂ��������b�g�������̂��A�����ė~�����B
�ނ��덡�܂ł悭���������̂��Ƃ������B
�X���̎��҂Ɏf���������A�Ȃ�Itanium���g��ꑱ�����̂��AItanium�̂ǂ��������b�g�������̂��A�����ė~�����B
263 �F�s���ȃf�o�C�X�����F2009/07/26(��) 13:02:21 ID:TiC5DXHt
>�@IT�ƊE�̖`���҂����@��45��@���X�[�p�[�n�C�E�F�C�̊���
����̕M�҂͎�����������F���Ă�B
�A�����J�� ���X�[�p�[�n�C�E�F�C�\�z ���āA
���{��NTT�𒆐S�ɊJ�����i��ł���ATM�Z�p�ւ̑R��B
���{�Ń_�C�A���A�b�v�̃C���^�[�l�b�g�v���o�C�_����ʌ����T�[�r�X���J�n��������O�A
���{�̂��������̊�Ƃ��w�̈ꕔ�̌������ɂ́AATM�Ԃ����菄�炳��Ă���B
����̕M�҂͎�����������F���Ă�B
�A�����J�� ���X�[�p�[�n�C�E�F�C�\�z ���āA
���{��NTT�𒆐S�ɊJ�����i��ł���ATM�Z�p�ւ̑R��B
���{�Ń_�C�A���A�b�v�̃C���^�[�l�b�g�v���o�C�_����ʌ����T�[�r�X���J�n��������O�A
���{�̂��������̊�Ƃ��w�̈ꕔ�̌������ɂ́AATM�Ԃ����菄�炳��Ă���B
264 �F�s���ȃf�o�C�X�����F2009/07/26(��) 17:29:23 ID:q57lqWEP
��ATM
53Byte��ATM�Z���t�H�[�}�b�g�Ȃ������B
�i�w�b�_5Byte�y�C���[�h48Byte�j
������āA
�y�C���[�h���Ɋւ��āA
���64Byte�i�R���s���[�^�e�a���l���j
���[���b�p��32Byte�i�d�b���A���^�C�����l���j
�ł��߂ĂāA
���{���Ԃɓ�����48Byte�ɐՈĂŒʂ����Ƃ��B
���ۉ�c�̋A�H�A
���c��������M�H�̐l���u�E�E�E�E�E���I�@�w�b�_5Byte��������S��53Byte���đf���W�����v�@�Ƃ����@�Ƃ��B
�Ƃ���l���畷�������Ƃ���B
53Byte��ATM�Z���t�H�[�}�b�g�Ȃ������B
�i�w�b�_5Byte�y�C���[�h48Byte�j
������āA
�y�C���[�h���Ɋւ��āA
���64Byte�i�R���s���[�^�e�a���l���j
���[���b�p��32Byte�i�d�b���A���^�C�����l���j
�ł��߂ĂāA
���{���Ԃɓ�����48Byte�ɐՈĂŒʂ����Ƃ��B
���ۉ�c�̋A�H�A
���c��������M�H�̐l���u�E�E�E�E�E���I�@�w�b�_5Byte��������S��53Byte���đf���W�����v�@�Ƃ����@�Ƃ��B
�Ƃ���l���畷�������Ƃ���B
265 �F�s���ȃf�o�C�X�����F2009/07/26(��) 17:31:20 ID:enHEvqIO
�ǂ��ł��������Ă��Ƃ�
266 �F�s���ȃf�o�C�X�����F2009/07/26(��) 19:42:40 ID:oRUqVBMM
>>263 �����Ă�́A�e�p������B
�̒������O�Y�������Ԃ������낵�Ă��ȁB
��{�I�ɁA�������������������L�������l����B
�̒������O�Y�������Ԃ������낵�Ă��ȁB
��{�I�ɁA�������������������L�������l����B
267 �F�s���ȃf�o�C�X�����F2009/07/27(��) 02:00:34 ID:cSxcql9z
������
268 �F�s���ȃf�o�C�X�����F2009/07/28(��) 02:04:54 ID:wwuFnsxX
New Supercomputer To Reel In Answers To Some Of Earth's Problems
http://www.sciencedaily.com/releases/2009/07/090727110637.htm
SGI renews Itanium super love (sort of)
http://www.theregister.co.uk/2009/07/27/sgi_server_roadmap/
> Barrenechea ends by saying "Read my FLOPS. SGI is 100% committed to Itanium."
Rumor: AMD Delays Fusion to Second Half of 2012
http://www.maximumpc.com/article/news/rumor_amd_delays_fusion_second_half_2012
NEC fumbles towards MRAM flip-flop
http://www.theregister.co.uk/2009/07/27/nec_mram_flip_flop/
Environmental Award Goes to Nanoparticle Scientist
http://www.azocleantech.com/Details.asp?newsID=6254
�g�N���E�h�h�ŕς��A���ꂩ��̉^�p�Ǘ�
http://www.atmarkit.co.jp/im/cop/serial/asset/01/01.html
http://www.sciencedaily.com/releases/2009/07/090727110637.htm
SGI renews Itanium super love (sort of)
http://www.theregister.co.uk/2009/07/27/sgi_server_roadmap/
> Barrenechea ends by saying "Read my FLOPS. SGI is 100% committed to Itanium."
Rumor: AMD Delays Fusion to Second Half of 2012
http://www.maximumpc.com/article/news/rumor_amd_delays_fusion_second_half_2012
NEC fumbles towards MRAM flip-flop
http://www.theregister.co.uk/2009/07/27/nec_mram_flip_flop/
Environmental Award Goes to Nanoparticle Scientist
http://www.azocleantech.com/Details.asp?newsID=6254
�g�N���E�h�h�ŕς��A���ꂩ��̉^�p�Ǘ�
http://www.atmarkit.co.jp/im/cop/serial/asset/01/01.html
269 �F�s���ȃf�o�C�X�����F2009/07/29(��) 01:19:35 ID:7FvYAvoP
Russia to cooperate with US to produce supercomputers
http://www.itar-tass.com/eng/level2.html?NewsID=14186318&PageNum=0
IBM Set to Launch 'Smart Analytics' Systems
http://www.pcworld.com/businesscenter/article/169177/ibm_set_to_launch_smart_analytics_systems.html
Fusion-io flush with flash success after demo
http://www.theregister.co.uk/2009/07/28/fusionio_tpch_result/
Fusion Gets Faster
http://www.hpcwire.com/features/Fusion-Gets-Faster-51820167.html
Global warming may make sea level rise between 7- 82 cm by century end
http://blog.taragana.com/n/global-warming-may-make-sea-level-rise-between-7-82-cm-by-century-end-122570/
Ian Foster reappointed Director of Computation Institute
http://media-newswire.com/release_1095371.html
���t�@�C�o�[�A�e�ʐ��E�ő� �j�c�c�h�Ȃ�
http://news.google.co.jp/news?hl=ja&q=KDDI&lr=lang_ja&rlz=&um=1&ie=UTF-8&sa=N&tab=wn
�}�C�N���\�t�g�A���ւ̎��g�݂���� �`Atom�v���Z�b�T���g�����f�[�^�Z���^�[���J��
http://pc.watch.impress.co.jp/docs/news/20090728_305398.html
�V���R���o���[101 ��328�� ����700�h�� - �~�܂�Ȃ�PC���i�̉����A�{�̂Ŗׂ��鎞��͏I���!?
http://journal.mycom.co.jp/column/svalley/328/index.html
��LSI�ЁC6G�r�b�g/�b��SAS�ɑΉ�����RAID�R���g���[���E�{�[�h��
http://techon.nikkeibp.co.jp/article/NEWS/20090728/173510/
http://www.itar-tass.com/eng/level2.html?NewsID=14186318&PageNum=0
IBM Set to Launch 'Smart Analytics' Systems
http://www.pcworld.com/businesscenter/article/169177/ibm_set_to_launch_smart_analytics_systems.html
Fusion-io flush with flash success after demo
http://www.theregister.co.uk/2009/07/28/fusionio_tpch_result/
Fusion Gets Faster
http://www.hpcwire.com/features/Fusion-Gets-Faster-51820167.html
Global warming may make sea level rise between 7- 82 cm by century end
http://blog.taragana.com/n/global-warming-may-make-sea-level-rise-between-7-82-cm-by-century-end-122570/
Ian Foster reappointed Director of Computation Institute
http://media-newswire.com/release_1095371.html
���t�@�C�o�[�A�e�ʐ��E�ő� �j�c�c�h�Ȃ�
http://news.google.co.jp/news?hl=ja&q=KDDI&lr=lang_ja&rlz=&um=1&ie=UTF-8&sa=N&tab=wn
�}�C�N���\�t�g�A���ւ̎��g�݂���� �`Atom�v���Z�b�T���g�����f�[�^�Z���^�[���J��
http://pc.watch.impress.co.jp/docs/news/20090728_305398.html
�V���R���o���[101 ��328�� ����700�h�� - �~�܂�Ȃ�PC���i�̉����A�{�̂Ŗׂ��鎞��͏I���!?
http://journal.mycom.co.jp/column/svalley/328/index.html
��LSI�ЁC6G�r�b�g/�b��SAS�ɑΉ�����RAID�R���g���[���E�{�[�h��
http://techon.nikkeibp.co.jp/article/NEWS/20090728/173510/
270 �F�s���ȃf�o�C�X�����F2009/07/29(��) 01:25:13 ID:7FvYAvoP
KDDI �������A�������`�������Ő��E�ō����g�����p������B��
http://japan.internet.com/webtech/20090728/4.html
���t�@�C�o�[�A�e�ʐ��E�ő�@�j�c�c�h�Ȃ�
http://www.nikkei.co.jp/news/sangyo/20090727AT2G2300127072009.html
http://japan.internet.com/webtech/20090728/4.html
���t�@�C�o�[�A�e�ʐ��E�ő�@�j�c�c�h�Ȃ�
http://www.nikkei.co.jp/news/sangyo/20090727AT2G2300127072009.html
271 �F�s���ȃf�o�C�X�����F2009/07/30(��) 23:30:30 ID:aZ02/hA1
>>262
Alpha����̏�芷���g�����������̂ł͂Ȃ��ł��傤���H
�����Ĉ����đ�K�͍\�����\��CPU�ƂȂ�ƁC�I�����͌����Ă����悤��
�v���܂��B
Alpha����̏�芷���g�����������̂ł͂Ȃ��ł��傤���H
�����Ĉ����đ�K�͍\�����\��CPU�ƂȂ�ƁC�I�����͌����Ă����悤��
�v���܂��B
272 �F�s���ȃf�o�C�X�����F2009/07/31(��) 00:06:28 ID:F2/byuVf
P4 �̓I�[�o�[�N���b�N���ăf�[�^�������Ă����C�œ��������邯��
�����Ǝ~�܂�Ƃ�
�����Ǝ~�܂�Ƃ�
273 �F�s���ȃf�o�C�X�����F2009/07/31(��) 01:41:00 ID:sVZerYBt
SGI, PSC, and NSF �H Update
http://www.vizworld.com/2009/07/sgi-psc-and-nsf-update/
U.S. supercomputing lead rings Sputnik-like alarm for Russia
http://www.computerworld.com/s/article/9136005/U.S._supercomputing_lead_rings_Sputnik_like_alarm_for_Russia?taxonomyId=12
Sandia Computer Scientists Boot One Million Linux Kernels as Virtual Machines
http://www.hpcwire.com/topic/systems/Sandia-Computer-Scientists-Boot-One-Million-Linux-Kernels-as-Virtual-Machines-51891292.html
Commodity Software
http://www.linux-mag.com/cache/7447/1.html
Linux clusters give Monash Uni a budget supercomputer
http://www.itnews.com.au/News/151490,linux-clusters-give-monash-uni-a-budget-supercomputer.aspx
Film Effects Are Battleground Between Chip Rivals
http://online.wsj.com/article/SB124873282919984939.html
NCSA Computers Power Honey Bee Research
http://www.hpcwire.com/industry/lifesciences/NCSA-Computers-Power-Honey-Bee-Research-51997442.html
LSU Professor Receives NSF Funding to Explore Alternative Energy Source
http://www.hpcwire.com/topic/systems/LSU-Professor-Receives-NSF-Funding-to-Explore-Alternative-Energy-Source-51996092.html
Dark Energy Computer Simulations by NASA / U.S. Department of Energy Could be Based on Drexler's Dark Matter / Dark Energy Link
http://newswire.ascribe.org/cgi-bin/behold.pl?ascribeid=20090724.215557&time=08%2029%20PDT&year=2009&public=0
http://www.vizworld.com/2009/07/sgi-psc-and-nsf-update/
U.S. supercomputing lead rings Sputnik-like alarm for Russia
http://www.computerworld.com/s/article/9136005/U.S._supercomputing_lead_rings_Sputnik_like_alarm_for_Russia?taxonomyId=12
Sandia Computer Scientists Boot One Million Linux Kernels as Virtual Machines
http://www.hpcwire.com/topic/systems/Sandia-Computer-Scientists-Boot-One-Million-Linux-Kernels-as-Virtual-Machines-51891292.html
Commodity Software
http://www.linux-mag.com/cache/7447/1.html
Linux clusters give Monash Uni a budget supercomputer
http://www.itnews.com.au/News/151490,linux-clusters-give-monash-uni-a-budget-supercomputer.aspx
Film Effects Are Battleground Between Chip Rivals
http://online.wsj.com/article/SB124873282919984939.html
NCSA Computers Power Honey Bee Research
http://www.hpcwire.com/industry/lifesciences/NCSA-Computers-Power-Honey-Bee-Research-51997442.html
LSU Professor Receives NSF Funding to Explore Alternative Energy Source
http://www.hpcwire.com/topic/systems/LSU-Professor-Receives-NSF-Funding-to-Explore-Alternative-Energy-Source-51996092.html
Dark Energy Computer Simulations by NASA / U.S. Department of Energy Could be Based on Drexler's Dark Matter / Dark Energy Link
http://newswire.ascribe.org/cgi-bin/behold.pl?ascribeid=20090724.215557&time=08%2029%20PDT&year=2009&public=0
274 �F�s���ȃf�o�C�X�����F2009/07/31(��) 10:05:09 ID:Z7vhozh8
��������Itanium�̃I�[�o�[�N���b�N�ϐ��Ȃ�Ęb�A���������ƂȂ��ȁB
�}�V���`�F�b�N�Ƃ����āA�����Ǝ�������ĂȂ��Ɠ����Ȃ��킯�ŁA
����炪�����悤�ȃn�C�G���h�̃T�[�o�ŃI�[�o�[�N���b�N�Ȃ����ł��Ȃ����B
�}�V���`�F�b�N�Ƃ����āA�����Ǝ�������ĂȂ��Ɠ����Ȃ��킯�ŁA
����炪�����悤�ȃn�C�G���h�̃T�[�o�ŃI�[�o�[�N���b�N�Ȃ����ł��Ȃ����B
275 �F�s���ȃf�o�C�X�����F2009/07/31(��) 21:32:24 ID:EsdprPSu
Nvidia Chief Scientist: 11nm Graphics Chips with 5000 Stream Processors Due in 2015.
http://www.xbitlabs.com/news/video/display/20090730072951_Nvidia_Chief_Scientist_11nm_Graphics_Chips_with_5000_Stream_Processors_Due_in_2015.html
http://www.xbitlabs.com/news/video/display/20090730072951_Nvidia_Chief_Scientist_11nm_Graphics_Chips_with_5000_Stream_Processors_Due_in_2015.html
276 �F�s���ȃf�o�C�X�����F2009/07/31(��) 22:17:13 ID:mOMfojhM
�����̓I�[�o�[�N���b�N��b��ɂ���悤�Ȓp���������X���������̂�
277 �F�s���ȃf�o�C�X�����F2009/07/31(��) 23:58:52 ID:sVZerYBt
Cray�fs Comeback: CEO Peter Ungaro on Clouds, Exaflops, and the Future of Supercomputing
http://www.xconomy.com/seattle/2009/07/30/crays-comeback-ceo-peter-ungaro-on-clouds-exaflops-and-the-future-of-supercomputing/
Next iteration of MPI standard set
http://insidehpc.com/2009/07/30/mpi-standard-22-accepted/
Seeking efficiency, scientists run visualizations directly on supercomputers
http://www.physorg.com/news168188994.html
Purdue partnership for putting idle computers to work on research wins international award
http://www.lafayette-online.com/purdue-news/2009/07/diagrid-wins-award/
Nirvanix Stores NASA Lunar Images on CloudNAS
http://www.thewhir.com/web-hosting-news/073009_Nirvanix_Stores_NASA_Lunar_Images_on_CloudNAS
Comets probably won't cause the end of life as we know it: study
http://news.ph.msn.com/topstories/article.aspx?cp-documentid=3501657
Pump Up the Volume
http://www.hpcwire.com/blogs/Pump-Up-the-Volume-52114457.html
�V�f�ނ̔����̃E�G�n�[�A�u���a�X�g�����ȃG�l�^10�N����ʎY
http://car.nikkei.co.jp/news/article.aspx?id=AS1D0908J%2030072009
���{HP�ƃ��b�h�n�b�g�A���Z�@������Linux�ڍs�x���v���O����
http://enterprise.watch.impress.co.jp/docs/news/20090730_305983.html
http://www.xconomy.com/seattle/2009/07/30/crays-comeback-ceo-peter-ungaro-on-clouds-exaflops-and-the-future-of-supercomputing/
Next iteration of MPI standard set
http://insidehpc.com/2009/07/30/mpi-standard-22-accepted/
Seeking efficiency, scientists run visualizations directly on supercomputers
http://www.physorg.com/news168188994.html
Purdue partnership for putting idle computers to work on research wins international award
http://www.lafayette-online.com/purdue-news/2009/07/diagrid-wins-award/
Nirvanix Stores NASA Lunar Images on CloudNAS
http://www.thewhir.com/web-hosting-news/073009_Nirvanix_Stores_NASA_Lunar_Images_on_CloudNAS
Comets probably won't cause the end of life as we know it: study
http://news.ph.msn.com/topstories/article.aspx?cp-documentid=3501657
Pump Up the Volume
http://www.hpcwire.com/blogs/Pump-Up-the-Volume-52114457.html
�V�f�ނ̔����̃E�G�n�[�A�u���a�X�g�����ȃG�l�^10�N����ʎY
http://car.nikkei.co.jp/news/article.aspx?id=AS1D0908J%2030072009
���{HP�ƃ��b�h�n�b�g�A���Z�@������Linux�ڍs�x���v���O����
http://enterprise.watch.impress.co.jp/docs/news/20090730_305983.html
278 �F�s���ȃf�o�C�X�����F2009/08/01(�y) 00:11:02 ID:Hc7m3NMi
>>208
�V����6Gbps SAS�R���g���[��RAID��I����`�b�vIC
http://www.incom.co.jp/newsroom/desc.php/3793
LSI Launches New Generation of High-Performance RAID Controller Cards Based on 6Gb/s SAS Technology
http://www.lsi.jp/news/product_news/2009/2009_07_28.html
�V����6Gbps SAS�R���g���[��RAID��I����`�b�vIC
http://www.incom.co.jp/newsroom/desc.php/3793
LSI Launches New Generation of High-Performance RAID Controller Cards Based on 6Gb/s SAS Technology
http://www.lsi.jp/news/product_news/2009/2009_07_28.html
279 �F�s���ȃf�o�C�X�����F2009/08/02(��) 01:57:19 ID:SEgU0HcO
�ŋ߂̘b�� 2009�N8 ��1��
http://www.geocities.jp/andosprocinfo/wadai09/20090801.htm
�����̍H��A�ċx�݂�ԏ�@�A�Q���ɒ�ł�
http://www.nikkei.co.jp/news/sangyo/20090801AT1D3106D31072009.html
T-Platforms, Finnish CSC-IT Center for Science Sign Letter of Interest
http://www.hpcwire.com/offthewire/T-Platforms-Finnish-CSC-IT-Center-for-Science-Sign-Letter-of-Interest-52197732.html?ref=732
Benchmarking Clouds? Let's Come Back Down to Earth
http://www.genomeweb.com/blog/benchmarking-clouds-lets-come-back-down-earth
Can Microsoft Grasp The Internet Cloud?
http://www.forbes.com/2009/08/01/microsoft-yahoo-google-internet-search-opinions-contributors-bret-swanson.html
AMD, HP propose extensions for PCI Express 3.0
http://www.eetimes.com/news/latest/showArticle.jhtml;jsessionid=UDYSX1HAAYKEUQSNDLPCKHSCJUNN2JVN?articleID=218900278
Silicon Valley, Wall Street meet at interconnect event
http://www.eetimes.com/news/latest/showArticle.jhtml?articleID=218900205
http://www.geocities.jp/andosprocinfo/wadai09/20090801.htm
�����̍H��A�ċx�݂�ԏ�@�A�Q���ɒ�ł�
http://www.nikkei.co.jp/news/sangyo/20090801AT1D3106D31072009.html
T-Platforms, Finnish CSC-IT Center for Science Sign Letter of Interest
http://www.hpcwire.com/offthewire/T-Platforms-Finnish-CSC-IT-Center-for-Science-Sign-Letter-of-Interest-52197732.html?ref=732
Benchmarking Clouds? Let's Come Back Down to Earth
http://www.genomeweb.com/blog/benchmarking-clouds-lets-come-back-down-earth
Can Microsoft Grasp The Internet Cloud?
http://www.forbes.com/2009/08/01/microsoft-yahoo-google-internet-search-opinions-contributors-bret-swanson.html
AMD, HP propose extensions for PCI Express 3.0
http://www.eetimes.com/news/latest/showArticle.jhtml;jsessionid=UDYSX1HAAYKEUQSNDLPCKHSCJUNN2JVN?articleID=218900278
Silicon Valley, Wall Street meet at interconnect event
http://www.eetimes.com/news/latest/showArticle.jhtml?articleID=218900205
280 �F�s���ȃf�o�C�X�����F2009/08/02(��) 06:42:23 ID:lHkWoe4D
�T�}�[�E�H�[�Y���ĉf���SX-9�炵���X�p�R������
�j���b�Ə��Ă��܂���
�j���b�Ə��Ă��܂���
281 �F�s���ȃf�o�C�X�����F2009/08/03(��) 01:13:38 ID:t0kcGOd2
Construction of supercomputer data center to begin spring of 2010
http://www.tmcnet.com/usubmit/2009/08/01/4303314.htm
New PNNL supercomputer tackling complex problems
http://www.thenewstribune.com/news/northwest/story/831463.html
Scientists secretly fear AI robot-machines may soon outsmart men
http://blog.taragana.com/n/scientists-secretly-fear-ai-robot-machines-may-soon-outsmart-men-127973/
http://www.tmcnet.com/usubmit/2009/08/01/4303314.htm
New PNNL supercomputer tackling complex problems
http://www.thenewstribune.com/news/northwest/story/831463.html
Scientists secretly fear AI robot-machines may soon outsmart men
http://blog.taragana.com/n/scientists-secretly-fear-ai-robot-machines-may-soon-outsmart-men-127973/
282 �F�s���ȃf�o�C�X�����F2009/08/03(��) 15:14:22 ID:PvtYtLdP
���낻��O���b�h�Ƃ��̕��U�����ŁA�قƂ�lj������������ł��邭�炢�܂ł�CPU�P�ʂ�
�����\�͂��オ���Ă����Ǝv�����ǁA�Ƃ������P���ɓ�����g���������邱�Ƃ�
�����\�͂��{���������オ�I�������������ɂ͂قڂ����������Ǝv�����ǁB
����A���S���Y���ƕ��i�̑g�ݍ��킹���̖�肾��B
CPU����J�����Ȃ��Ă��A�����g�ݍ���1U�Ƃ����P�ʂ�A�m�[�h�Ƃ����P�ʂŌ����
CPU�J�����Ă���̂Ǝ����悤�Ȃ��́B������������ɓ����Ă��BBG�V���[�Y���ǂ�
�Ⴞ��Bvenus�Ȃ�Ă���Ȃ�
�����\�͂��オ���Ă����Ǝv�����ǁA�Ƃ������P���ɓ�����g���������邱�Ƃ�
�����\�͂��{���������オ�I�������������ɂ͂قڂ����������Ǝv�����ǁB
����A���S���Y���ƕ��i�̑g�ݍ��킹���̖�肾��B
CPU����J�����Ȃ��Ă��A�����g�ݍ���1U�Ƃ����P�ʂ�A�m�[�h�Ƃ����P�ʂŌ����
CPU�J�����Ă���̂Ǝ����悤�Ȃ��́B������������ɓ����Ă��BBG�V���[�Y���ǂ�
�Ⴞ��Bvenus�Ȃ�Ă���Ȃ�
283 �F�s���ȃf�o�C�X�����F2009/08/03(��) 16:00:48 ID:NtKoLh1Y
>>282
�������������ނ�H�c
�������������ނ�H�c
284 �F�s���ȃf�o�C�X�����F2009/08/03(��) 21:45:09 ID:fZ82kOFu
>>282
�c�Ɗ�������J����
�c�Ɗ�������J����
285 �F�s���ȃf�o�C�X�����F2009/08/04(��) 05:54:46 ID:qVJJRin7
>>282
������������Ȃ�ˁB
������������Ȃ�ˁB
286 �F�s���ȃf�o�C�X�����F2009/08/04(��) 14:09:06 ID:OczpcQdI
���{�̓\�t�g�E�F�A�Z�p���x��ɒx��Ă���̂ŁA�ǂ����Ă��n�[�h�E�F�A�Ώd�ɂȂ��ł���B
�A�����J�ł�venus����Ȃ��Ă��A���{�ł�venus������B
�x�m�ʂ�FX1�́A���ꂼ���CPU�ŕ��ʂ�unix�nOS�������Ă�B
IBM��BlueGene�́A���ꂼ���CPU�ł͓���ȏ����ȃ��j�^�������Ă��邾���B
���̈Ⴂ�͑傫����B
�A�����J�ł�venus����Ȃ��Ă��A���{�ł�venus������B
�x�m�ʂ�FX1�́A���ꂼ���CPU�ŕ��ʂ�unix�nOS�������Ă�B
IBM��BlueGene�́A���ꂼ���CPU�ł͓���ȏ����ȃ��j�^�������Ă��邾���B
���̈Ⴂ�͑傫����B
287 �F�s���ȃf�o�C�X�����F2009/08/04(��) 16:29:57 ID:nk1eTf80
�\�t�g������藧�Ă�ɂ͂ǂ������炢���H
288 �F�s���ȃf�o�C�X�����F2009/08/04(��) 16:50:09 ID:o+MVEQ6C
�f�J�C�K�͂̋Z�p�͒f�R�A�����J�������
���{�����F�l�퍑�Ƃ̂����ɂ����܂ł悭�撣������
����������ȏ����ȍ��ł�
���{�����F�l�퍑�Ƃ̂����ɂ����܂ł悭�撣������
����������ȏ����ȍ��ł�
289 �F�s���ȃf�o�C�X�����F2009/08/04(��) 17:03:03 ID:DFWzAcY0
>>286
BlueGene�̕����ǂ��悤�Ɏv���̂͘R�ꂾ������
�����R����BlueGene���p�b��3D�g�[���X����
Android�ł����点���炢����܂���������
BlueGene�̕����ǂ��悤�Ɏv���̂͘R�ꂾ������
�����R����BlueGene���p�b��3D�g�[���X����
Android�ł����点���炢����܂���������
290 �F�s���ȃf�o�C�X�����F2009/08/04(��) 17:25:09 ID:khSRzq5m
GTX385�̐��\�V�[�g��Good
291 �F�s���ȃf�o�C�X�����F2009/08/04(��) 22:09:55 ID:ebOUJUJS
���w�҂̃\�t�g�n�̏A�E��ǂ�����B�g�|���W�[�Ƃ��킩��\�t�g�����Ȃ����́B
292 �F�s���ȃf�o�C�X�����F2009/08/04(��) 23:19:14 ID:OczpcQdI
>>287
���ꂪ�ł��Ă�����A����̂悤�ɂ͂Ȃ��ĂȂ����āB
���ꂪ�ł��Ă�����A����̂悤�ɂ͂Ȃ��ĂȂ����āB
293 �F�s���ȃf�o�C�X�����F2009/08/04(��) 23:37:27 ID:g3SpsyAr
�����n�[�h�͒��߂āAIBM BlueGene �ł� Cray Jaguar �ł�
�������āA�\�t�g�J���Ɏ����𓊓����ׂ����ȁB���{�̃x���_
�Ƀn�[�h��点�ĂƂ����Ă���ƁA���Ԃ������邵�R�X�g
�p�t�H�[�}���X���������BDR �݂����ɖ����ł���K�͂Ȃ�
�������ǁB
�������āA�\�t�g�J���Ɏ����𓊓����ׂ����ȁB���{�̃x���_
�Ƀn�[�h��点�ĂƂ����Ă���ƁA���Ԃ������邵�R�X�g
�p�t�H�[�}���X���������BDR �݂����ɖ����ł���K�͂Ȃ�
�������ǁB
294 �F�s���ȃf�o�C�X�����F2009/08/04(��) 23:48:02 ID:yjuA42da
���Ⴀ�\�t�g���O���瓱��������������B
295 �F�s���ȃf�o�C�X�����F2009/08/04(��) 23:54:07 ID:OczpcQdI
���{�̏ꍇ�A�ێ�I�������B
�����X�p�R���ɂ��Ă��A
10�`�[���ɕʁX�̃A�v���[�`�Ńv���g�^�C�v����点�āA
��������[�U�[�Ɏ��ۂɎg���Ă�����ĕ]�����āA
���̂�����2��3��{�i�I�ɓ�������Ƃ����A
�N�ł��l�����悤�ȕ��ʂ̂�肩������A
���{�ł͋�����Ȃ��B
�\�Z���Ȃ����Ă����̂����邾�낤���ǁA�ێ�I�Ȃ�B
�����X�p�R���ɂ��Ă��A
10�`�[���ɕʁX�̃A�v���[�`�Ńv���g�^�C�v����点�āA
��������[�U�[�Ɏ��ۂɎg���Ă�����ĕ]�����āA
���̂�����2��3��{�i�I�ɓ�������Ƃ����A
�N�ł��l�����悤�ȕ��ʂ̂�肩������A
���{�ł͋�����Ȃ��B
�\�Z���Ȃ����Ă����̂����邾�낤���ǁA�ێ�I�Ȃ�B
296 �F�s���ȃf�o�C�X�����F2009/08/05(��) 00:00:42 ID:aHn34v56
>>294
����͖����B���������\�t�g�͓����ł��Ȃ��B
�X�p�R���́u������́v�����甄���Ă���邯�ǁA�\�t�g�͒��g
������A�g�����̌�����(��ƌ����҂��܂߂�)���������肩��
���������ȊO�ŁA�\�t�g����邱�ƂȂ��蓾�Ȃ��B
����͖����B���������\�t�g�͓����ł��Ȃ��B
�X�p�R���́u������́v�����甄���Ă���邯�ǁA�\�t�g�͒��g
������A�g�����̌�����(��ƌ����҂��܂߂�)���������肩��
���������ȊO�ŁA�\�t�g����邱�ƂȂ��蓾�Ȃ��B
297 �F�s���ȃf�o�C�X�����F2009/08/05(��) 00:06:05 ID:Q1eTOHaA
298 �F�s���ȃf�o�C�X�����F2009/08/05(��) 00:15:37 ID:aHn34v56
>>297
�����^
�����^
299 �F�s���ȃf�o�C�X�����F2009/08/05(��) 00:17:29 ID:v4devK1g
>>296
�\�t�g�Ƃ����Ă�̂́A�A�v���P�[�V���������ł͂Ȃ��v���b�g�t�H�[�������ł��傤�B
���{�̃X�p�R���̏ꍇ�A�A�v���P�[�V�����ƃv���b�g�t�H�[���̊W���^�C�g������B
�\�t�g�Ƃ����Ă�̂́A�A�v���P�[�V���������ł͂Ȃ��v���b�g�t�H�[�������ł��傤�B
���{�̃X�p�R���̏ꍇ�A�A�v���P�[�V�����ƃv���b�g�t�H�[���̊W���^�C�g������B
300 �F�s���ȃf�o�C�X�����F2009/08/05(��) 08:57:01 ID:g1/soKyU
Cray Receives Contract to Upgrade "Jaguar" Supercomputer at Oak Ridge National Laboratory
http://www.earthtimes.org/articles/show/cray-receives-contract-to-upgrade,913884.shtml
Power 7: Lots of Cores, Lots of Threads
http://www.itjungle.com/tfh/tfh080309-story01.html
AMD to launch its fastest CPU ever on August 13th, 2009
http://www.brightsideofnews.com/news/2009/8/3/amd-to-launch-its-fastest-cpu-ever-on-august-13th2c-2009.aspx
Sun deals Sparc boxes, x64 iron
http://www.theregister.co.uk/2009/08/03/sun_server_update/
10 Gbit Ethernet lands on server motherboards
http://www.eetimes.com/news/latest/showArticle.jhtml?articleID=218900590
US govt IT departments still confused by cloud computing
http://www.futuregov.net/articles/2009/aug/03/us-govt-it-departments-still-confused-cloud-comput/
Scientists observe interior of Sun, forecast strength of the next solar cycle
http://www.examiner.com/x-13886-New-Haven-County-Environmental-Policy-Examiner~y2009m8d2-Scientists-Gaze-Inside-Sun-Predict-Strength-of-the-Next-Solar-Cycle
HPC CIOs drifting into clouds
http://www.theregister.co.uk/2009/08/04/hpc_private_clouds/
OpenGL 3.2 API released: Welcome OpenCL, WebGL
http://www.brightsideofnews.com/news/2009/8/3/opengl-32-api-released-welcome-opencl2c-webgl.aspx
Mock supernova created by supercomputer
http://www.tehrantimes.com/index_View.asp?code=200186
http://www.earthtimes.org/articles/show/cray-receives-contract-to-upgrade,913884.shtml
Power 7: Lots of Cores, Lots of Threads
http://www.itjungle.com/tfh/tfh080309-story01.html
AMD to launch its fastest CPU ever on August 13th, 2009
http://www.brightsideofnews.com/news/2009/8/3/amd-to-launch-its-fastest-cpu-ever-on-august-13th2c-2009.aspx
Sun deals Sparc boxes, x64 iron
http://www.theregister.co.uk/2009/08/03/sun_server_update/
10 Gbit Ethernet lands on server motherboards
http://www.eetimes.com/news/latest/showArticle.jhtml?articleID=218900590
US govt IT departments still confused by cloud computing
http://www.futuregov.net/articles/2009/aug/03/us-govt-it-departments-still-confused-cloud-comput/
Scientists observe interior of Sun, forecast strength of the next solar cycle
http://www.examiner.com/x-13886-New-Haven-County-Environmental-Policy-Examiner~y2009m8d2-Scientists-Gaze-Inside-Sun-Predict-Strength-of-the-Next-Solar-Cycle
HPC CIOs drifting into clouds
http://www.theregister.co.uk/2009/08/04/hpc_private_clouds/
OpenGL 3.2 API released: Welcome OpenCL, WebGL
http://www.brightsideofnews.com/news/2009/8/3/opengl-32-api-released-welcome-opencl2c-webgl.aspx
Mock supernova created by supercomputer
http://www.tehrantimes.com/index_View.asp?code=200186
301 �F�s���ȃf�o�C�X�����F2009/08/05(��) 09:44:38 ID:LYFuivGd
�����͂̈Ⴂ�ȋC�����邯�ǂȂ�
�v�����ꂽ���̂���邾���̎d���ƁA���i���猤�����Ă��Ă��̃m�E�n�E�ō��d���̈Ⴂ�Ƃ������B
�v�����ꂽ���̂���邾���̎d���ƁA���i���猤�����Ă��Ă��̃m�E�n�E�ō��d���̈Ⴂ�Ƃ������B
302 �F�s���ȃf�o�C�X�����F2009/08/05(��) 11:17:44 ID:fUCPHEql
>>299
�v���b�g�t�H�[������Ȃ��ăA�v���P�[�V�����̕����Ǝv���B
���ʁA���ꕨ���v���b�g�t�H�[�����œK�Ȃ��̂���
�����͂��B
>>301
����͊ԈႢ�B�Ⴆ�A�A���u���O�ɂ�����ẴR�X�g��r����
�l���Ă�������悤�ɁA�����̂������J���Ɏg��Ȃ��ŁA���̂܂�
���B�Ɏg���A���Ȃ�̋K�͂̂��̂������ł���B
�����ƌ����ƁATop500 �œ��{����߂銄�����ǂ�ǂ�ቺ���Ă���
�̂́A���{�������͂Ɍ��������v�Z�͂���ɓ���Ă��Ȃ������B
�v���b�g�t�H�[������Ȃ��ăA�v���P�[�V�����̕����Ǝv���B
���ʁA���ꕨ���v���b�g�t�H�[�����œK�Ȃ��̂���
�����͂��B
>>301
����͊ԈႢ�B�Ⴆ�A�A���u���O�ɂ�����ẴR�X�g��r����
�l���Ă�������悤�ɁA�����̂������J���Ɏg��Ȃ��ŁA���̂܂�
���B�Ɏg���A���Ȃ�̋K�͂̂��̂������ł���B
�����ƌ����ƁATop500 �œ��{����߂銄�����ǂ�ǂ�ቺ���Ă���
�̂́A���{�������͂Ɍ��������v�Z�͂���ɓ���Ă��Ȃ������B
303 �F�s���ȃf�o�C�X�����F2009/08/05(��) 13:22:09 ID:v4devK1g
>>302
�����A�����������Ƃ��B
���߂�A�����{�P�Ă��B
���{�ł��A�A�����J�̃X�p�R�����g���Ă���Ƃ��낪���邪�A
���Y�̃X�p�R�����g���Ă���Ƃ���ƁA���ʂɍ������邩�ȁB
���{�́E�E�E�����Ŗ��O���o���͎̂��炾���E�E�E�q��搶�̂悤�ɁA
�V���w�҂Ȃ̂ɁA���̋M�d�Ȏ��Ԃ��v�Z�@�ɘQ������āA
�{���̓V���w�̌����ɂ����鎞�Ԃ�����Ă���A
�����������ƂŁA�{���Ɍ����ōőO���𑖂��̂��A�ƁB
���낢�날���āA�������������v�Z�@����ɓ���邱�Ƃ��ł����̂ŁA
�������������x���邢�͑����ɂ͂ł��Ȃ��悤�Ȍv�Z���ł��܂����A
�Ƃ����͖̂ڊo�܂������ʂŐ��E�ōŐ�[���̂悤�Ɍ�����ꂪ�������ǁA
����͓V���w�̌����҂Ƃ��Ă̐��ʂł͂Ȃ��A�v�Z�@�̐��ʂ���ˁB
��葬���v�Z�@����ɓ��ꂽ���҂ɁA����ɒǂ�������Ă��܂��B
�����A�����������Ƃ��B
���߂�A�����{�P�Ă��B
���{�ł��A�A�����J�̃X�p�R�����g���Ă���Ƃ��낪���邪�A
���Y�̃X�p�R�����g���Ă���Ƃ���ƁA���ʂɍ������邩�ȁB
���{�́E�E�E�����Ŗ��O���o���͎̂��炾���E�E�E�q��搶�̂悤�ɁA
�V���w�҂Ȃ̂ɁA���̋M�d�Ȏ��Ԃ��v�Z�@�ɘQ������āA
�{���̓V���w�̌����ɂ����鎞�Ԃ�����Ă���A
�����������ƂŁA�{���Ɍ����ōőO���𑖂��̂��A�ƁB
���낢�날���āA�������������v�Z�@����ɓ���邱�Ƃ��ł����̂ŁA
�������������x���邢�͑����ɂ͂ł��Ȃ��悤�Ȍv�Z���ł��܂����A
�Ƃ����͖̂ڊo�܂������ʂŐ��E�ōŐ�[���̂悤�Ɍ�����ꂪ�������ǁA
����͓V���w�̌����҂Ƃ��Ă̐��ʂł͂Ȃ��A�v�Z�@�̐��ʂ���ˁB
��葬���v�Z�@����ɓ��ꂽ���҂ɁA����ɒǂ�������Ă��܂��B
304 �F�s���ȃf�o�C�X�����F2009/08/05(��) 13:42:12 ID:Q1eTOHaA
>>303
�����Ƃ́A��͂荂���Ă��g���₷���Đ��\�����o���₷����(�g�[�^����)���ʂ������o��v�Z�@
���Ă̂��d�v�Ȃ�Ȃ����H
�s�[�N���\�ƃR�X�g�Ŕ�r���Ăǂ�����B
�����Ƃ́A��͂荂���Ă��g���₷���Đ��\�����o���₷����(�g�[�^����)���ʂ������o��v�Z�@
���Ă̂��d�v�Ȃ�Ȃ����H
�s�[�N���\�ƃR�X�g�Ŕ�r���Ăǂ�����B
305 �F�s���ȃf�o�C�X�����F2009/08/05(��) 14:08:33 ID:fUCPHEql
>>303
GRAPE-DR �͘Q��ƌ�����قǁA�����������ł��Ă��Ȃ��̂�����ł́H
���ꂩ��A�V���w�ōőO���𑖂��Ă��邩�͕�����Ȃ����A���ʁA�ŐV
�̌������ʂ͉@����|�X�h�N�����C���Ȃ̂ŁA�q�쎁�� DR �ɏW������
�̂͂���͂���� OK ���Ǝv���B����ŁADR �������Ă͂��߂Čv�Z
�ł����Ƃ������ʂ���A���ꂪ�܂��ɍőO�����Ă��ƂɂȂ�Ǝv�����B
���ꂩ��A>>302 �ŏ������������邪�A�����ł��S�z����Ă���悤�ɁA
���{�̓A�v���P�[�V�������v�Z�@�ɍœK������ʂł̃T�|�[�g�̐�������
�����n��Ȃ̂����B�A�����J���ƁA���̖ʂł͂����Ƃ��̌v�Z�@��
�m��s�������v�����x���_������h������Ă��āA�œK���̃T�|�[�g
�����Ă���邵�A�v���b�g�z�[�����œK�����镔����������ƁA
���Ƒ̐�����������\�z����Ă���B
�ł��A���{�͂Ƃ����ƁA����������҂������ōs�����Ƃ��قƂ�ǁB
������ƈႤ���ǁA�n�ゾ�Ƃ������Ƃ�T�^�I�ȗ�͈ȉ��B
ttp://www.mext.go.jp/b_menu/shingi/uchuu/012/gijiroku/1263193.htm
[�c���^�̌㔼�����]
A�@"���̌܁A�Z�l�̃X�y�V�����X�g�͌����҂ł����A����Ƃ��A�X�y�V�����X�g�ł����B"
B "���̃`�[���ɂ�1�l�\�t�g�E�G�A�̃G���W�j�A�̐l�ɗ��Ă��������Ă��܂����ǁA���Ƃ��Ƃ́A
�ŏグ�O���炸���Ə������Ă���ł����ǁA�S�������҂ł��B��Ƀ|�X�h�N�ł��ˁB"
A "�|�X�h�N�B"
B "�|�X�h�N�����C���ł��B������Ɛ\����Ȃ��ł����ǂˁB"
���{���J���̃��C���̃v���W�F�N�g�ł�����ȃ��x���B
GRAPE-DR �͘Q��ƌ�����قǁA�����������ł��Ă��Ȃ��̂�����ł́H
���ꂩ��A�V���w�ōőO���𑖂��Ă��邩�͕�����Ȃ����A���ʁA�ŐV
�̌������ʂ͉@����|�X�h�N�����C���Ȃ̂ŁA�q�쎁�� DR �ɏW������
�̂͂���͂���� OK ���Ǝv���B����ŁADR �������Ă͂��߂Čv�Z
�ł����Ƃ������ʂ���A���ꂪ�܂��ɍőO�����Ă��ƂɂȂ�Ǝv�����B
���ꂩ��A>>302 �ŏ������������邪�A�����ł��S�z����Ă���悤�ɁA
���{�̓A�v���P�[�V�������v�Z�@�ɍœK������ʂł̃T�|�[�g�̐�������
�����n��Ȃ̂����B�A�����J���ƁA���̖ʂł͂����Ƃ��̌v�Z�@��
�m��s�������v�����x���_������h������Ă��āA�œK���̃T�|�[�g
�����Ă���邵�A�v���b�g�z�[�����œK�����镔����������ƁA
���Ƒ̐�����������\�z����Ă���B
�ł��A���{�͂Ƃ����ƁA����������҂������ōs�����Ƃ��قƂ�ǁB
������ƈႤ���ǁA�n�ゾ�Ƃ������Ƃ�T�^�I�ȗ�͈ȉ��B
ttp://www.mext.go.jp/b_menu/shingi/uchuu/012/gijiroku/1263193.htm
[�c���^�̌㔼�����]
A�@"���̌܁A�Z�l�̃X�y�V�����X�g�͌����҂ł����A����Ƃ��A�X�y�V�����X�g�ł����B"
B "���̃`�[���ɂ�1�l�\�t�g�E�G�A�̃G���W�j�A�̐l�ɗ��Ă��������Ă��܂����ǁA���Ƃ��Ƃ́A
�ŏグ�O���炸���Ə������Ă���ł����ǁA�S�������҂ł��B��Ƀ|�X�h�N�ł��ˁB"
A "�|�X�h�N�B"
B "�|�X�h�N�����C���ł��B������Ɛ\����Ȃ��ł����ǂˁB"
���{���J���̃��C���̃v���W�F�N�g�ł�����ȃ��x���B
306 �F�s���ȃf�o�C�X�����F2009/08/05(��) 14:27:43 ID:v4devK1g
>>304
�g���₷���Đ��\���ȒP�ɔ�����������v�Z�@���A
�n�[�h�E�F�A�Ŏ�������̂����{�̃X�p�R���A
�\�t�g�E�F�A�Ŏ�������̂��A�����J�̃X�p�R���A�Ȃ̂ł��傤�B
�����X�p�R���̂��߂̃A�v���P�[�V�����̃`���[�j���O���A
�V�~�����[�^�ł͂Ȃ��AOpteron��PC�N���X�^�ł���Ă���
�Ƃ����b������܂������A
�`���[�j���O���K�v���Ƃ������ƁA�V�~�����[�^�ŊJ���ł��Ȃ��Ƃ������ƂŁA��d�ɃK�b�J���ł��B
�g���₷���Đ��\���ȒP�ɔ�����������v�Z�@���A
�n�[�h�E�F�A�Ŏ�������̂����{�̃X�p�R���A
�\�t�g�E�F�A�Ŏ�������̂��A�����J�̃X�p�R���A�Ȃ̂ł��傤�B
�����X�p�R���̂��߂̃A�v���P�[�V�����̃`���[�j���O���A
�V�~�����[�^�ł͂Ȃ��AOpteron��PC�N���X�^�ł���Ă���
�Ƃ����b������܂������A
�`���[�j���O���K�v���Ƃ������ƁA�V�~�����[�^�ŊJ���ł��Ȃ��Ƃ������ƂŁA��d�ɃK�b�J���ł��B
307 �F�s���ȃf�o�C�X�����F2009/08/05(��) 14:38:12 ID:v4devK1g
>>305
���ӂł��B
���{�͕��Ƒ̐����ł��ĂȂ��āA���ꂼ��̒S���҂̏K�n�x���Ⴂ�̂́A��肾�Ǝv���܂��B
���������_�ł��A
�q��搶���ЂƂ�A���邢�͌����҈ȊO�̃X�^�b�t���g����
�v�Z�@������Ă����̂Ȃ炢�����A
�����̌����҂̏��Ȃ��Ȃ����Ԃ����Ă����A
��������������Ȃ������̂́A�q��搶�ł͂Ȃ��A�v�Z�@���������Ǝv����ł���B
���ӂł��B
���{�͕��Ƒ̐����ł��ĂȂ��āA���ꂼ��̒S���҂̏K�n�x���Ⴂ�̂́A��肾�Ǝv���܂��B
���������_�ł��A
�q��搶���ЂƂ�A���邢�͌����҈ȊO�̃X�^�b�t���g����
�v�Z�@������Ă����̂Ȃ炢�����A
�����̌����҂̏��Ȃ��Ȃ����Ԃ����Ă����A
��������������Ȃ������̂́A�q��搶�ł͂Ȃ��A�v�Z�@���������Ǝv����ł���B
308 �F�s���ȃf�o�C�X�����F2009/08/05(��) 14:55:56 ID:fUCPHEql
>>306
�ł��ˁB�����A������x�̓`���[�j���O���K�v�Ȃ͎̂d���Ȃ��ł��B
>>307
���������ł��B�v�Z�@���������Ƃ������A�T�|�[�g�ł���l�ނ�
���Ȃ��Ǝv���܂��B
�ł��ˁB�����A������x�̓`���[�j���O���K�v�Ȃ͎̂d���Ȃ��ł��B
>>307
���������ł��B�v�Z�@���������Ƃ������A�T�|�[�g�ł���l�ނ�
���Ȃ��Ǝv���܂��B
309 �F�s���ȃf�o�C�X�����F2009/08/05(��) 19:08:39 ID:l41Q7rmQ
>>297
F-22�݂����ɔ����Ă���Ȃ����Ƃ����邼
F-22�݂����ɔ����Ă���Ȃ����Ƃ����邼
310 �F�s���ȃf�o�C�X�����F2009/08/05(��) 19:26:32 ID:Q1eTOHaA
311 �F�s���ȃf�o�C�X�����F2009/08/05(��) 22:04:34 ID:aHn34v56
>>310
���S�ۏ��A�X�p�R�����d�v�Ȃ�J������߂�͖̂�肾���A
����Ȃ��Ƃ͂Ȃ����낤�ˁB����ɍ���A���{���X�p�R����
�H���čs���킯�ł��Ȃ�����H��߂Ă����Ȃ��B
������A���̂܂ܐ��E�ł͒N���g��Ȃ��n�[�h�̊J����
�����ăJ���p�S�X�����������肾�B���l������Ȃ炢�����A
����́E�E�E
���S�ۏ��A�X�p�R�����d�v�Ȃ�J������߂�͖̂�肾���A
����Ȃ��Ƃ͂Ȃ����낤�ˁB����ɍ���A���{���X�p�R����
�H���čs���킯�ł��Ȃ�����H��߂Ă����Ȃ��B
������A���̂܂ܐ��E�ł͒N���g��Ȃ��n�[�h�̊J����
�����ăJ���p�S�X�����������肾�B���l������Ȃ炢�����A
����́E�E�E
312 �F�s���ȃf�o�C�X�����F2009/08/05(��) 22:20:57 ID:Q1eTOHaA
>>311
�܂���{�̓R���s���[�^�̊J���͂�߂āA�O����S�������Ă����A�Ƃ����咣���ˁB
�܂�����ł���Ă��Ă鍑���قƂ�ǂ����B
�F���J������߂邩�H
�܂���{�̓R���s���[�^�̊J���͂�߂āA�O����S�������Ă����A�Ƃ����咣���ˁB
�܂�����ł���Ă��Ă鍑���قƂ�ǂ����B
�F���J������߂邩�H
313 �F�s���ȃf�o�C�X�����F2009/08/05(��) 22:24:32 ID:v4devK1g
��Ɋϑ���F���J���͂��A�Q�����Ƃ��Ȃ��ƁA�����I�Ɏ������R�����Ȃ�Ęb�ɂȂ����Ƃ��ɁA����̂ł���B
������Ƃ��낪�A�R���s���[�^�ƈႤ�Ƃ���B
������Ƃ��낪�A�R���s���[�^�ƈႤ�Ƃ���B
314 �F�s���ȃf�o�C�X�����F2009/08/05(��) 22:25:45 ID:Q1eTOHaA
>>313
�R���s���[�^�┼���̂���������B
�R���s���[�^�┼���̂���������B
315 �F�s���ȃf�o�C�X�����F2009/08/05(��) 22:37:24 ID:60QYMbt8
�X�p�R����Ȋw�Z�p�U���ɋ��˂����ނ͖̂���
��͂�d�v�Ȃ͓̂��H�Ɣ���
�����ɑ�ʂɐŋ��𒍂����ނׂ�
�y�����E�n�E�n�œ��{�o�ϑ啜���ԈႢ�Ȃ�
��͂�d�v�Ȃ͓̂��H�Ɣ���
�����ɑ�ʂɐŋ��𒍂����ނׂ�
�y�����E�n�E�n�œ��{�o�ϑ啜���ԈႢ�Ȃ�
316 �F�s���ȃf�o�C�X�����F2009/08/05(��) 22:41:56 ID:oY+pOJu0
����A�������ˁi�_�j
317 �F�s���ȃf�o�C�X�����F2009/08/05(��) 22:43:28 ID:nxIC23DP
318 �F�s���ȃf�o�C�X�����F2009/08/05(��) 22:49:09 ID:aHn34v56
�n�[�h�Ƃ��R���s���[�^�Ƃ������Ă��邯�ǁA��߂Ă��ǂ�
�̂� CPU �̊J���B���� Cray �̂悤�Ȑ헪�𗧂Ă�ׂ��B
�����͂���ɋ߂��������Ǝv�����A�����͂��S�R�Ȃ��ȁB
�̂� CPU �̊J���B���� Cray �̂悤�Ȑ헪�𗧂Ă�ׂ��B
�����͂���ɋ߂��������Ǝv�����A�����͂��S�R�Ȃ��ȁB
319 �F�s���ȃf�o�C�X�����F2009/08/05(��) 22:50:11 ID:Q1eTOHaA
>>317
������^�Ɏ�Ȃ�
�t����A���a�̓��{�͂����ƉȊw�Z�p�ɋ����g�������獡�̓��{������B
�V���ɂ���A�F���J���ɂ���A�R���s���[�^�ɂ���B
�����[�Ƀp�����g�����Ƀg�����W�X�^�B�����̕����łǂ���I���W�i���̏��p�@��
�o�Ă��͓̂��{���炢����B
�l�H�q���ɉ�����ɃR���s���[�^�A�ǂ�����E�Ɍւ����j������B
������^�Ɏ�Ȃ�
�t����A���a�̓��{�͂����ƉȊw�Z�p�ɋ����g�������獡�̓��{������B
�V���ɂ���A�F���J���ɂ���A�R���s���[�^�ɂ���B
�����[�Ƀp�����g�����Ƀg�����W�X�^�B�����̕����łǂ���I���W�i���̏��p�@��
�o�Ă��͓̂��{���炢����B
�l�H�q���ɉ�����ɃR���s���[�^�A�ǂ�����E�Ɍւ����j������B
320 �F�s���ȃf�o�C�X�����F2009/08/05(��) 22:53:44 ID:0dTk4jKI
�������{�͐ς�ł�
�@���Z�ɏo�O���Ƃɏo�����������҂����ߑ��܂���ɘb���Ă��ꂽ�B
�@�u�Ȋw�Z�p�����ɗ����Ă���Ǝv���l�H�v�Ɛ��k�ɕ�������A���炭���Ĕ������炢�肪���������B
�@�u�Ȋw�Z�p�������Ă���Ǝv���l�H�v�ƕ�������A�Ԕ����ꂸ�S���̎肪���������Ƃ����B
�@http://news.livedoor.com/article/detail/4236711/
�@���Z�ɏo�O���Ƃɏo�����������҂����ߑ��܂���ɘb���Ă��ꂽ�B
�@�u�Ȋw�Z�p�����ɗ����Ă���Ǝv���l�H�v�Ɛ��k�ɕ�������A���炭���Ĕ������炢�肪���������B
�@�u�Ȋw�Z�p�������Ă���Ǝv���l�H�v�ƕ�������A�Ԕ����ꂸ�S���̎肪���������Ƃ����B
�@http://news.livedoor.com/article/detail/4236711/
321 �F�s���ȃf�o�C�X�����F2009/08/05(��) 22:59:16 ID:aHn34v56
���̋����͑S�R�_���B���������A�v��̒i�K����_���������B
�����Ƃ��ėp�Ƃ������Ė��m�ȕ����������������B���ꂪ���
�̖�肾�Ǝv���B�܂��A�����͏��������ǁB
�����Ƃ��ėp�Ƃ������Ė��m�ȕ����������������B���ꂪ���
�̖�肾�Ǝv���B�܂��A�����͏��������ǁB
322 �F�s���ȃf�o�C�X�����F2009/08/06(��) 00:54:40 ID:CGORYIbM
���ɂƂ��ẮA���𐮂��邩�ǂ������Ă����̂͐ӔC��肾���ǁA
�ꌤ���҂Ƃ�����A�����������@�Ȃ�����ł�����Đ荞��ł����̂�
�ʔ�����ł����āA�����Ƃ������̖��Ō��͕̂ςȋC���B
���������ꌤ���҂̒T���́A��T�͈�P�[�X�Ƃ��ďI��邯��
�����͐V�����X�^���_�[�h�Ƃ��ď펯��ς��Ă����B
�ǂꂪ���������X�^���_�[�h�ɂȂ邩�͂킩��Ȃ����ǁA���ʂ͔������m��
�������Ă��Ȃ��Ƃ����Ȃ����낤�B
�ꌤ���҂Ƃ�����A�����������@�Ȃ�����ł�����Đ荞��ł����̂�
�ʔ�����ł����āA�����Ƃ������̖��Ō��͕̂ςȋC���B
���������ꌤ���҂̒T���́A��T�͈�P�[�X�Ƃ��ďI��邯��
�����͐V�����X�^���_�[�h�Ƃ��ď펯��ς��Ă����B
�ǂꂪ���������X�^���_�[�h�ɂȂ邩�͂킩��Ȃ����ǁA���ʂ͔������m��
�������Ă��Ȃ��Ƃ����Ȃ����낤�B
323 �F�s���ȃf�o�C�X�����F2009/08/06(��) 01:04:36 ID:JcggPbLv
>>322 �������Ă��錤���҂͍����Ȃ́H����Ƃ����p������Ȃ́H
�����́A���p���鑤�̃v���W�F�N�g������A�J�����Ȃ��Ă����B��
�ςނȂ瑁�����B���Č����҂��g��������ǂ��Ɍ��܂��Ă���B
�����́A���p���鑤�̃v���W�F�N�g������A�J�����Ȃ��Ă����B��
�ςނȂ瑁�����B���Č����҂��g��������ǂ��Ɍ��܂��Ă���B
324 �F�s���ȃf�o�C�X�����F2009/08/06(��) 01:14:39 ID:Ndr+YX1g
>>323
���m�ȕ��������Ȃ������A�Ƃ����ᔻ�������̂ɁA
�A����肪�o��قǗ~�����ƌ����Ă��闘�p�҂͂���́H
�����F����ȃ}�V����邩��g���Ă��������[�B�������K�͂Ɍ��������W���u������I
���[�U�F���Ⴀ�g����[�A�ꉞ������ۂ��v�]�o���Ă�����B
�Ċ���������������B
���m�ȕ��������Ȃ������A�Ƃ����ᔻ�������̂ɁA
�A����肪�o��قǗ~�����ƌ����Ă��闘�p�҂͂���́H
�����F����ȃ}�V����邩��g���Ă��������[�B�������K�͂Ɍ��������W���u������I
���[�U�F���Ⴀ�g����[�A�ꉞ������ۂ��v�]�o���Ă�����B
�Ċ���������������B
325 �F�s���ȃf�o�C�X�����F2009/08/06(��) 01:27:04 ID:JcggPbLv
>>323
���Ȃ��͂Ȃ��Ǝv����B�����̃^�[�Q�b�g�A�v���̐��Ƃ����Ă�
���̎��v�͂���͂��B����ƃX�p�R����ۗL���Ă���@�ւ�
�ғ����Ƃ����������B�����A
>�������K�͂Ɍ��������W���u������I
�́A>>305->>308 �̂悤�ȏȂ̂Ŕ��ɏ��Ȃ��Ǝv���B
���Ȃ��͂Ȃ��Ǝv����B�����̃^�[�Q�b�g�A�v���̐��Ƃ����Ă�
���̎��v�͂���͂��B����ƃX�p�R����ۗL���Ă���@�ւ�
�ғ����Ƃ����������B�����A
>�������K�͂Ɍ��������W���u������I
�́A>>305->>308 �̂悤�ȏȂ̂Ŕ��ɏ��Ȃ��Ǝv���B
326 �F�s���ȃf�o�C�X�����F2009/08/06(��) 01:34:56 ID:xfg8hPuH
�����w�������ɑ��鍑�ۓI�ȊO���]���ψ���u��7���w�������A�h�o�C�U���[�E�J�E���V���iRAC�j�v�̕��ɂ���
http://www.riken.jp/r-world/info/info/2009/090805/
NVIDIA�uOptiX�v�G���W�����\�AGPU���C�g���[�V���O����������
http://journal.mycom.co.jp/news/2009/08/05/009/?rt=na
SSTC�ACPU�^GPU���p�Ōv�Z����������������N���X�^���
http://www.keyman.or.jp/3w/prd/39/20026539/
Intel introduces 3.33GHz Xeon processor
http://www.macsimumnews.com/index.php/archive/intel_introduces_3.33ghz_xeon_processor/
AMD Delivers First OpenCL SDK for x86 CPUs
http://news.softpedia.com/news/AMD-Delivers-First-OpenCL-SDK-for-x86-CPUs-118376.shtml
HP add NVIDIA Tesla GPU and CS4 accelerator options to Z-series workstations
http://www.slashgear.com/hp-add-nvidia-tesla-gpu-and-cs4-accelerator-options-to-z-series-workstations-0551239/
Surveys Says: Cloud Computing Is Awesome
http://www.hpcwire.com/blogs/Surveys-Says-Cloud-Computing-Is-Awesome-52474502.html
An HPC Specialist Targets the Data Center
http://www.datacenterknowledge.com/archives/2009/08/05/an-hpc-specialist-targets-the-data-center/
http://www.riken.jp/r-world/info/info/2009/090805/
NVIDIA�uOptiX�v�G���W�����\�AGPU���C�g���[�V���O����������
http://journal.mycom.co.jp/news/2009/08/05/009/?rt=na
SSTC�ACPU�^GPU���p�Ōv�Z����������������N���X�^���
http://www.keyman.or.jp/3w/prd/39/20026539/
Intel introduces 3.33GHz Xeon processor
http://www.macsimumnews.com/index.php/archive/intel_introduces_3.33ghz_xeon_processor/
AMD Delivers First OpenCL SDK for x86 CPUs
http://news.softpedia.com/news/AMD-Delivers-First-OpenCL-SDK-for-x86-CPUs-118376.shtml
HP add NVIDIA Tesla GPU and CS4 accelerator options to Z-series workstations
http://www.slashgear.com/hp-add-nvidia-tesla-gpu-and-cs4-accelerator-options-to-z-series-workstations-0551239/
Surveys Says: Cloud Computing Is Awesome
http://www.hpcwire.com/blogs/Surveys-Says-Cloud-Computing-Is-Awesome-52474502.html
An HPC Specialist Targets the Data Center
http://www.datacenterknowledge.com/archives/2009/08/05/an-hpc-specialist-targets-the-data-center/
327 �F�s���ȃf�o�C�X�����F2009/08/06(��) 03:08:47 ID:CGORYIbM
�������X�p�R�����C�O���璲�B������
1. �悵�C�O���璲�B���悤�B
2. Roadrunner����ʂ炵�����炻�����{�\���ɂ��悤�B
3. �ց[�ACell���Ă����̂����C��CPU�ȂB
4. LS���Ă����̂����C���������ȂB256KB�����Ȃ��́H
5. DRAM�ɂ�DMA�ŃA�N�Z�X����c�B
6. Opteron����������H�H�H
7. �_�u���o�b�t�@�[����́I�H
8. �����҂������S�B
1. �悵�C�O���璲�B���悤�B
2. Roadrunner����ʂ炵�����炻�����{�\���ɂ��悤�B
3. �ց[�ACell���Ă����̂����C��CPU�ȂB
4. LS���Ă����̂����C���������ȂB256KB�����Ȃ��́H
5. DRAM�ɂ�DMA�ŃA�N�Z�X����c�B
6. Opteron����������H�H�H
7. �_�u���o�b�t�@�[����́I�H
8. �����҂������S�B
328 �F�s���ȃf�o�C�X�����F2009/08/06(��) 10:54:12 ID:xmblNyF1
329 �F�s���ȃf�o�C�X�����F2009/08/06(��) 13:01:34 ID:1S09cPCd
>>291
�|�A���J���\�z�����Ȃ������g�|���W���ɑ��݈Ӌ`����́H
�|�A���J���\�z�����Ȃ������g�|���W���ɑ��݈Ӌ`����́H
330 �F�s���ȃf�o�C�X�����F2009/08/06(��) 13:36:32 ID:iNQZ/nkL
���H
331 �F�s���ȃf�o�C�X�����F2009/08/06(��) 13:58:23 ID:i0pp5cb5
>>322
���܂̓��{�͈�{���Ȃ�B
�����ƕx�m�ʂ�NEC�ɁA���ꂼ�ꋞ���N���X�̂��̂���点�āA3���ׂċ��킹�邱�Ƃ���A�ł���B
�����ɋ�����������Ȃ���B
������ŋ��𒍂�����Ńr�b�N�v���W�F�N�g��1�{����Ă��A���������Ȃ��B
���܂̓��{�͈�{���Ȃ�B
�����ƕx�m�ʂ�NEC�ɁA���ꂼ�ꋞ���N���X�̂��̂���点�āA3���ׂċ��킹�邱�Ƃ���A�ł���B
�����ɋ�����������Ȃ���B
������ŋ��𒍂�����Ńr�b�N�v���W�F�N�g��1�{����Ă��A���������Ȃ��B
332 �F�s���ȃf�o�C�X�����F2009/08/06(��) 14:04:21 ID:i0pp5cb5
>>328
�m�[�h���̃A�[�L�e�N�`���ɑ傫�����E�����悤����A�_���Ȃ�Ȃ�?
���ꂩ���A�X�p�R���͂ǂ�ǂ�Aunix��SMP�@�Ƃ͈Ⴄ���̂ɂȂ��Ă�����B
�m�[�h���̃A�[�L�e�N�`���ɑ傫�����E�����悤����A�_���Ȃ�Ȃ�?
���ꂩ���A�X�p�R���͂ǂ�ǂ�Aunix��SMP�@�Ƃ͈Ⴄ���̂ɂȂ��Ă�����B
333 �F�s���ȃf�o�C�X�����F2009/08/06(��) 14:10:58 ID:i0pp5cb5
���Ƃ�
���ꂩ���A�X�p�R���͂ǂ�ǂ�Aunix��SMP�@�Ƃ͈Ⴄ���̂ɂȂ��Ă�����B
��
���ꂩ���A�X�p�R���͂ǂ�ǂ�Aunix��SMP�@�Ƃ��APC�N���X�^�Ƃ��Ⴄ���̂ɂȂ��Ă�����B
���ꂩ���A�X�p�R���͂ǂ�ǂ�Aunix��SMP�@�Ƃ͈Ⴄ���̂ɂȂ��Ă�����B
��
���ꂩ���A�X�p�R���͂ǂ�ǂ�Aunix��SMP�@�Ƃ��APC�N���X�^�Ƃ��Ⴄ���̂ɂȂ��Ă�����B
334 �F�s���ȃf�o�C�X�����F2009/08/06(��) 14:55:57 ID:h3B6OWKD
�ł��X�p�R���ăI�[�_�[���C�h�Ƃ������A�v���O�������炢�����ŏ����ׂ��Ƃ��낪���邶���
�v���Ă�Ƃ�����Ԗʔ�����B���ۂɍ��̂͂�����
�v���Ă�Ƃ�����Ԗʔ�����B���ۂɍ��̂͂�����
335 �F�s���ȃf�o�C�X�����F2009/08/06(��) 16:01:05 ID:i0pp5cb5
�X�p�R���̗��p�҂��A
��肽���v�Z���A�R���s���[�^�������ł��鉽�炩�̌`�ŁA�L�q����
�Ƃ����̂́A�K�v�s���Ƃ��Ă��A
�Ȃɂ��e�m�[�h�ő��点��R�[�h�܂ŋL�q����̂́A��肷�����Ǝv���B
��肽���v�Z���A�R���s���[�^�������ł��鉽�炩�̌`�ŁA�L�q����
�Ƃ����̂́A�K�v�s���Ƃ��Ă��A
�Ȃɂ��e�m�[�h�ő��点��R�[�h�܂ŋL�q����̂́A��肷�����Ǝv���B
336 �F�s���ȃf�o�C�X�����F2009/08/06(��) 17:42:39 ID:xmblNyF1
>>333
>���ꂩ���A�X�p�R���͂ǂ�ǂ�Aunix��SMP�@�Ƃ��APC�N���X�^�Ƃ��Ⴄ���̂ɂȂ��Ă�����B
�͋�̓I�ɉ���H
�ꉞ�APC�N���X�^�̒��ɂ̓A�N�Z�����[�^�I�Ȃ��̂𓋍ڂ����̂��܂܂��Ǝv�����B
>���ꂩ���A�X�p�R���͂ǂ�ǂ�Aunix��SMP�@�Ƃ��APC�N���X�^�Ƃ��Ⴄ���̂ɂȂ��Ă�����B
�͋�̓I�ɉ���H
�ꉞ�APC�N���X�^�̒��ɂ̓A�N�Z�����[�^�I�Ȃ��̂𓋍ڂ����̂��܂܂��Ǝv�����B
337 �F�s���ȃf�o�C�X�����F2009/08/06(��) 20:27:51 ID:i0pp5cb5
>>336
�z�X�gPC�Ȃ���GPGPU�����Ƀl�b�g���[�N��g�ނ悤�ȁA���������́B
�z�X�gPC���o�R���邱�ƂŐ����郌�C�e���V���A���������Ȃ�����B
�z�X�gPC�Ȃ���GPGPU�����Ƀl�b�g���[�N��g�ނ悤�ȁA���������́B
�z�X�gPC���o�R���邱�ƂŐ����郌�C�e���V���A���������Ȃ�����B
338 �F�s���ȃf�o�C�X�����F2009/08/06(��) 21:08:34 ID:JcggPbLv
339 �F�s���ȃf�o�C�X�����F2009/08/06(��) 21:40:12 ID:QlBFtYxJ
GPGPU�����\���Ƃ������Ă���l�Ԃ�������������̂�?
�ނ�������Ȃ��p�r�̕�����������B
�ނ�������Ȃ��p�r�̕�����������B
340 �F�s���ȃf�o�C�X�����F2009/08/06(��) 21:51:06 ID:Ndr+YX1g
�܂������ɂ�BG�݂����Ȃ̂ł����\���Ǝv���Ă�l������̂ŁB
341 �F�s���ȃf�o�C�X�����F2009/08/06(��) 22:23:39 ID:jYkrXuyp
���z�͉�FLOPS�~�����́H
342 �F�s���ȃf�o�C�X�����F2009/08/06(��) 22:34:12 ID:UOHEZLNq
IBM�̉c�ƃ}����������
�y������������
Cray�̉c�ƃ}����������
�H����L���X���ł���
�y������������
Cray�̉c�ƃ}����������
�H����L���X���ł���
343 �F�s���ȃf�o�C�X�����F2009/08/07(��) 00:52:17 ID:yWqBxmk7
Jaguar upgrade underway at ORNL; Kraken up next
http://www.tmcnet.com/usubmit/2009/08/05/4310702.htm
Russian Supercomputers Reach South Africa
http://www.hpcwire.com/offthewire/Russian-Supercomputers-Reach-South-Africa-52526982.html?ref=982
NCSA joins Darkstrand network
http://www.eetimes.com/news/latest/showArticle.jhtml?articleID=219100217
Next gen PCI standard delayed
http://www.theinquirer.net/inquirer/news/1496297/next-gen-pci-standard-delayed
SSD storage systems hit new performance marks
http://www.v3.co.uk/v3/news/2247392/ssd-storage-system-hits
SGI Announces the Scalable Workgroup Cluster
http://www.businesswire.com/portal/site/google/?ndmViewId=news_view&newsId=20090806005311&newsLang=en
PGI Visual Fortran 9.0 Adds Support for MPI Debugging on Windows HPC Server 2008 Clusters
http://news.prnewswire.com/DisplayReleaseContent.aspx?ACCT=104&STORY=/www/story/08-05-2009/0005072265&EDATE=
AMD beta seeks CPU-GPU harmony
http://www.theregister.co.uk/2009/08/05/amd_beta_opencl_for_cpus/
SDSC Launches 'Triton Resource'
http://www.hpcwire.com/topic/systems/San-Diego-Supercomputer-Center-Launches-Triton-Resource-52547092.html
Hyperactive dwarf galaxy puzzles astronomers
http://www.examiner.com/x-10722-Orlando-Science-Policy-Examiner~y2009m8d6-Hyperactive-dwarf-galaxy-puzzles-astronomers
Apollo 11 lunar landing film restored using GPU computing technology
http://channel.hexus.net/content/item.php?item=19630
http://www.tmcnet.com/usubmit/2009/08/05/4310702.htm
Russian Supercomputers Reach South Africa
http://www.hpcwire.com/offthewire/Russian-Supercomputers-Reach-South-Africa-52526982.html?ref=982
NCSA joins Darkstrand network
http://www.eetimes.com/news/latest/showArticle.jhtml?articleID=219100217
Next gen PCI standard delayed
http://www.theinquirer.net/inquirer/news/1496297/next-gen-pci-standard-delayed
SSD storage systems hit new performance marks
http://www.v3.co.uk/v3/news/2247392/ssd-storage-system-hits
SGI Announces the Scalable Workgroup Cluster
http://www.businesswire.com/portal/site/google/?ndmViewId=news_view&newsId=20090806005311&newsLang=en
PGI Visual Fortran 9.0 Adds Support for MPI Debugging on Windows HPC Server 2008 Clusters
http://news.prnewswire.com/DisplayReleaseContent.aspx?ACCT=104&STORY=/www/story/08-05-2009/0005072265&EDATE=
AMD beta seeks CPU-GPU harmony
http://www.theregister.co.uk/2009/08/05/amd_beta_opencl_for_cpus/
SDSC Launches 'Triton Resource'
http://www.hpcwire.com/topic/systems/San-Diego-Supercomputer-Center-Launches-Triton-Resource-52547092.html
Hyperactive dwarf galaxy puzzles astronomers
http://www.examiner.com/x-10722-Orlando-Science-Policy-Examiner~y2009m8d6-Hyperactive-dwarf-galaxy-puzzles-astronomers
Apollo 11 lunar landing film restored using GPU computing technology
http://channel.hexus.net/content/item.php?item=19630
344 �F�s���ȃf�o�C�X�����F2009/08/07(��) 00:53:10 ID:yWqBxmk7
Intel��Atom�헪�̌���SoC�ւ̐i��
http://pc.watch.impress.co.jp/docs/column/kaigai/20090806_307443.html
�����A���l�̐V�E���z���^�f�[�^�Z���^�[�K��L
http://enterprise.watch.impress.co.jp/docs/news/20090807_307483.html
1200MB/�b�̓]���������APCIe�o�X�����^�̃X�g���[�W�uExaRAID�v
http://enterprise.watch.impress.co.jp/docs/news/20090805_307191.html
������X�p�R�����p���i�ց@�����ƌ���������
http://www.kobe-np.co.jp/news/keizai/0002204145.shtml
http://pc.watch.impress.co.jp/docs/column/kaigai/20090806_307443.html
�����A���l�̐V�E���z���^�f�[�^�Z���^�[�K��L
http://enterprise.watch.impress.co.jp/docs/news/20090807_307483.html
1200MB/�b�̓]���������APCIe�o�X�����^�̃X�g���[�W�uExaRAID�v
http://enterprise.watch.impress.co.jp/docs/news/20090805_307191.html
������X�p�R�����p���i�ց@�����ƌ���������
http://www.kobe-np.co.jp/news/keizai/0002204145.shtml
345 �F�s���ȃf�o�C�X�����F2009/08/07(��) 10:32:38 ID:zR7i8i1w
�������GPGPU��(7)�݂����͔̂��Ɍ����悭���s�ł��āA���Z��̃s�[�N�ɋ߂����\���ł�B
�������o���h�͎��ė]�����ǁA�������A�N�Z�X��ߖ邱�Ƃ����܂�l���Ȃ��Ă����\�o��̂������Ƃ���B
�܂��A�V���R����d�͂̃��\�[�X���{���K�v�Ȃ��������A�N�Z�X�Ɋ�����Ă邱�Ƃɂ͂Ȃ邯�ǁA�������炢�Ȃ狖�e�͈́B
GPU�ő��̖����ƁA�ÓT�x�N�g���@�ł͎�L���A�N�Z�X�ɂȂ��Ă����Ԍv�Z���ʂ����W�X�^�ɏ��Ƃ����_�͂����Ƌ������Ă���Ă�������łȂ��H
�������o���h�͎��ė]�����ǁA�������A�N�Z�X��ߖ邱�Ƃ����܂�l���Ȃ��Ă����\�o��̂������Ƃ���B
�܂��A�V���R����d�͂̃��\�[�X���{���K�v�Ȃ��������A�N�Z�X�Ɋ�����Ă邱�Ƃɂ͂Ȃ邯�ǁA�������炢�Ȃ狖�e�͈́B
GPU�ő��̖����ƁA�ÓT�x�N�g���@�ł͎�L���A�N�Z�X�ɂȂ��Ă����Ԍv�Z���ʂ����W�X�^�ɏ��Ƃ����_�͂����Ƌ������Ă���Ă�������łȂ��H
346 �F�s���ȃf�o�C�X�����F2009/08/07(��) 13:17:23 ID:dzEgIZus
�������e���r��Venus��������Əo�Ă��ȁB
347 �F�s���ȃf�o�C�X�����F2009/08/07(��) 20:14:55 ID:Q3FCcNB3
>>338-339
�����GPGPU�ōl���Ȃ��ŁB
Xeon��Opteron���g���ɂ��Ă��A
PC�A�[�L�e�N�`���̃n�[�h��unix�n��OS�ł��̂ł͂Ȃ��A
CPU�����Z��t���̃������R���g���[���Ƃ��ĈႤ�g������������̂ɂȂ�Ǝv���B
�����GPGPU�ōl���Ȃ��ŁB
Xeon��Opteron���g���ɂ��Ă��A
PC�A�[�L�e�N�`���̃n�[�h��unix�n��OS�ł��̂ł͂Ȃ��A
CPU�����Z��t���̃������R���g���[���Ƃ��ĈႤ�g������������̂ɂȂ�Ǝv���B
348 �F�s���ȃf�o�C�X�����F2009/08/07(��) 22:01:36 ID:6aGSovzx
349 �F�s���ȃf�o�C�X�����F2009/08/07(��) 22:13:55 ID:cd3eOZaM
�Ȃɂ����Ă�
GRAPE-DR����
GRAPE-DR����
350 �F�s���ȃf�o�C�X�����F2009/08/07(��) 22:57:40 ID:a675uLLi
GRAPE-DR����GPGPU�Ȃ�
351 �F�s���ȃf�o�C�X�����F2009/08/07(��) 23:28:19 ID:Q3FCcNB3
352 �F�s���ȃf�o�C�X�����F2009/08/07(��) 23:47:21 ID:Q3FCcNB3
>>348
�Ȃ����������̃����h�C�̂ŁA
Cray��XMT��XR1���A����̐��\����A10�`100TF���ɂȂ�悤�ɁA�啝�Ɏ���������悤�Ȋ���
���Ă��������ŁA�z�����Ă��炦�܂���?
�Ȃ����������̃����h�C�̂ŁA
Cray��XMT��XR1���A����̐��\����A10�`100TF���ɂȂ�悤�ɁA�啝�Ɏ���������悤�Ȋ���
���Ă��������ŁA�z�����Ă��炦�܂���?
353 �F�s���ȃf�o�C�X�����F2009/08/07(��) 23:49:22 ID:Q3FCcNB3
�E�����邪�AGRAPE-DR��Opteron�ƃ\�P�b�g�݊���������A�ǂ������̂ɂˁB
FPGA�Ƃ̓Ǝ�I/F�̑���ɁA�������R���g���[����HT���������Ȃ���Ȃ�Ȃ����A
�������A➑̂Ƃ��{�[�h�Ƃ��A���������̂����O�ŊJ�������ɁA�ŐV�̗ʎY����Ă�����̂𗬗p�ł����낤�B
FPGA�Ƃ̓Ǝ�I/F�̑���ɁA�������R���g���[����HT���������Ȃ���Ȃ�Ȃ����A
�������A➑̂Ƃ��{�[�h�Ƃ��A���������̂����O�ŊJ�������ɁA�ŐV�̗ʎY����Ă�����̂𗬗p�ł����낤�B
354 �F�s���ȃf�o�C�X�����F2009/08/07(��) 23:57:54 ID:T7FAuuSe
>>353
ASIC�Ɏg��IP�̊J���ƃ{�[�h�v���Ƃ��������I�[�_�̋��z�Ȃ킯�Ȃ������
ASIC�Ɏg��IP�̊J���ƃ{�[�h�v���Ƃ��������I�[�_�̋��z�Ȃ킯�Ȃ������
355 �F�s���ȃf�o�C�X�����F2009/08/08(�y) 00:38:59 ID:nIHibRrO
�x�m�ʁA�����ɃX�p�R���[���@�o�b�N���X�^�[�^�ō����g�b�v�̐��\
http://www.nikkei.co.jp/news/sangyo/20090807AT1D0708107082009.html
�x�m�ʂ͂V���A�����w�������ɃX�[�p�[�R���s���[�^�[��[�������Ɣ��\�����B
�[�����z�͖�40���~�B��Ƃ̏��V�X�e���Ȃǂň�ʂɎg����p�\�R���i�o�b�j�T�[�o�[��
������A��������u�o�b�N���X�^�[�v�ƌĂ������̃X�p�R���Ƃ��ẮA
�����g�b�v�ɑ������鐫�\��B�������B
���Z���\��97.94�e���i�e���͂P���j�t���b�v�X�i�P�b������̕��������_���Z�̉j�B(23:01)
�����̐V�X�[�p�[�R���s���[�^�uRICC�v���ғ�
�|�����҂ɂƂ��āu�ŗǂ̃V�X�e���v�̊m����ڎw���|
http://www.riken.go.jp/r-world/info/info/2009/090807/index.html
http://www.nikkei.co.jp/news/sangyo/20090807AT1D0708107082009.html
�x�m�ʂ͂V���A�����w�������ɃX�[�p�[�R���s���[�^�[��[�������Ɣ��\�����B
�[�����z�͖�40���~�B��Ƃ̏��V�X�e���Ȃǂň�ʂɎg����p�\�R���i�o�b�j�T�[�o�[��
������A��������u�o�b�N���X�^�[�v�ƌĂ������̃X�p�R���Ƃ��ẮA
�����g�b�v�ɑ������鐫�\��B�������B
���Z���\��97.94�e���i�e���͂P���j�t���b�v�X�i�P�b������̕��������_���Z�̉j�B(23:01)
�����̐V�X�[�p�[�R���s���[�^�uRICC�v���ғ�
�|�����҂ɂƂ��āu�ŗǂ̃V�X�e���v�̊m����ڎw���|
http://www.riken.go.jp/r-world/info/info/2009/090807/index.html
356 �F�s���ȃf�o�C�X�����F2009/08/08(�y) 00:44:12 ID:3j/giFIT
����Xeon�ł������
357 �F�s���ȃf�o�C�X�����F2009/08/08(�y) 00:44:35 ID:BJdDccn/
>>354
> ASIC�Ɏg��IP�̊J��
�Ȃ�Ŏ��O�ŊJ���������邩�Ȃ��B
�������R���g���[����HT�́A������IP�������Ďg����������Ȃ��B
> ASIC�Ɏg��IP�̊J��
�Ȃ�Ŏ��O�ŊJ���������邩�Ȃ��B
�������R���g���[����HT�́A������IP�������Ďg����������Ȃ��B
358 �F�s���ȃf�o�C�X�����F2009/08/08(�y) 00:57:43 ID:uR4YWVqJ
359 �F�s���ȃf�o�C�X�����F2009/08/08(�y) 01:09:45 ID:BJdDccn/
>>358
������AMD�̃v�����[�V�����ɏ�������āA
���̊�ƂƓ����v���Z�X��IP���g���A
�O�̂���1��������̃��C�Z���X���ł��A
�Ȃ�Ƃ��Ȃ�\���A����Ǝv����B
������AMD�̃v�����[�V�����ɏ�������āA
���̊�ƂƓ����v���Z�X��IP���g���A
�O�̂���1��������̃��C�Z���X���ł��A
�Ȃ�Ƃ��Ȃ�\���A����Ǝv����B
360 �F�s���ȃf�o�C�X�����F2009/08/08(�y) 01:26:52 ID:iVLjBjRv
361 �F�s���ȃf�o�C�X�����F2009/08/08(�y) 02:07:27 ID:uR4YWVqJ
362 �F�s���ȃf�o�C�X�����F2009/08/08(�y) 02:21:44 ID:iyuESTft
IBM gets $16 million to bolster its brain-on-a-chip technology
http://www.networkworld.com/news/2009/080509-ibm-brain.html?hpg1=bn
Big Iron on the Rise
http://www.genomeweb.com/blog/big-iron-rise
SGI chases Cray with baby cluster
http://www.theregister.co.uk/2009/08/06/sgi_cloudrack_x2/
AMD's Fusion Is Coming Together
http://www.fool.com/investing/general/2009/08/06/amds-fusion-is-coming-together.aspx
CERN unveils computer grid linking 7,000 scientists
http://www.canada.com/technology/science/CERN+unveils+computer+grid+linking+scientists/1248576/story.html
10 Gigabit Ethernet Options for the Data Center
http://datacenterjournal.com/content/view/3073/41/
40 G InfiniBand off to a Quick Start
http://www.itbusinessedge.com/cm/blogs/cole/40-g-infiniband-off-to-a-quick-start/?cs=34758
http://www.networkworld.com/news/2009/080509-ibm-brain.html?hpg1=bn
Big Iron on the Rise
http://www.genomeweb.com/blog/big-iron-rise
SGI chases Cray with baby cluster
http://www.theregister.co.uk/2009/08/06/sgi_cloudrack_x2/
AMD's Fusion Is Coming Together
http://www.fool.com/investing/general/2009/08/06/amds-fusion-is-coming-together.aspx
CERN unveils computer grid linking 7,000 scientists
http://www.canada.com/technology/science/CERN+unveils+computer+grid+linking+scientists/1248576/story.html
10 Gigabit Ethernet Options for the Data Center
http://datacenterjournal.com/content/view/3073/41/
40 G InfiniBand off to a Quick Start
http://www.itbusinessedge.com/cm/blogs/cole/40-g-infiniband-off-to-a-quick-start/?cs=34758
363 �F�s���ȃf�o�C�X�����F2009/08/08(�y) 05:27:17 ID:8K/lOSk5
>>353
HTX���Ęb�͂������肵�����ȁB
���܂����������R����Opteron�̑����g���čς܂��A�Ƃ����ł����̂����B
FPGA�ł͂���Ȑ��i��������ˁi���y�����ɏ������݂��������ǁj�B
HTX���Ęb�͂������肵�����ȁB
���܂����������R����Opteron�̑����g���čς܂��A�Ƃ����ł����̂����B
FPGA�ł͂���Ȑ��i��������ˁi���y�����ɏ������݂��������ǁj�B
364 �F�s���ȃf�o�C�X�����F2009/08/08(�y) 05:31:06 ID:8K/lOSk5
�ėp��FPU�Ƃ������ƂɂȂ�ƁAIntel��AMD�ƒ��ǂ����ĂĂȂ��ŁA�Ƃ����킯�ɂ͂����Ȃ���ˁB
���݂������B�̕��@�ɂ��������������đ��̂ɂ͂Ȃ��A���Ď咣���Ă���B
���݂������B�̕��@�ɂ��������������đ��̂ɂ͂Ȃ��A���Ď咣���Ă���B
365 �F�s���ȃf�o�C�X�����F2009/08/09(��) 00:44:35 ID:MiwE65FS
Fujitsu Deploys Japan's Fastest Clustered HPC System
http://www.eweek.com/c/a/Data-Storage/Fujitsu-Deploys-Japans-Fastest-Clustered-HPC-System-116201/
High-performance Computing Isn�ft Always About Performance
http://gigaom.com/2009/08/07/high-performance-computing-isnt-always-about-performance/
Xeon W5590 breaks records - Part 1
http://www.theinquirer.net/inquirer/review/1528599/xeon-w5590-breaks-records-part
Moon may reveal elusive cosmic neutrinos
http://www.newscientist.com/article/dn17561-moon-may-reveal-elusive-cosmic-neutrinos.html?full=true
�ŐVCPU���ڂ́g�p�[�\�i���E�N���X�^�h�AHPC�V�X�e���Y
http://www.atmarkit.co.jp/news/200908/08/hpc.html
���\��I���\�ȃX�P�[���A�E�g�^�T�[�o�[
http://it.impressbm.co.jp/e/2009/08/07/1103
�����f�[�^�Z���^�[�̏���d�͗ʁA�s��S�̂�����L�ї��ő���
http://journal.mycom.co.jp/news/2009/08/07/037/index.html
�����V����A�ϑ��摜�̖��ԗ��p���i�|������{�����K�蓝��
http://www.nikkan.co.jp/news/nkx0620090806eaaj.html
[SIGGRAPH2009���|�[�g]Vol.01 �Q�[���J����b�Z�p�̔��\���[������SIGGRAPH
http://www.pronews.jp/special/0908060000.html
http://www.eweek.com/c/a/Data-Storage/Fujitsu-Deploys-Japans-Fastest-Clustered-HPC-System-116201/
High-performance Computing Isn�ft Always About Performance
http://gigaom.com/2009/08/07/high-performance-computing-isnt-always-about-performance/
Xeon W5590 breaks records - Part 1
http://www.theinquirer.net/inquirer/review/1528599/xeon-w5590-breaks-records-part
Moon may reveal elusive cosmic neutrinos
http://www.newscientist.com/article/dn17561-moon-may-reveal-elusive-cosmic-neutrinos.html?full=true
�ŐVCPU���ڂ́g�p�[�\�i���E�N���X�^�h�AHPC�V�X�e���Y
http://www.atmarkit.co.jp/news/200908/08/hpc.html
���\��I���\�ȃX�P�[���A�E�g�^�T�[�o�[
http://it.impressbm.co.jp/e/2009/08/07/1103
�����f�[�^�Z���^�[�̏���d�͗ʁA�s��S�̂�����L�ї��ő���
http://journal.mycom.co.jp/news/2009/08/07/037/index.html
�����V����A�ϑ��摜�̖��ԗ��p���i�|������{�����K�蓝��
http://www.nikkan.co.jp/news/nkx0620090806eaaj.html
[SIGGRAPH2009���|�[�g]Vol.01 �Q�[���J����b�Z�p�̔��\���[������SIGGRAPH
http://www.pronews.jp/special/0908060000.html
366 �F�s���ȃf�o�C�X�����F2009/08/09(��) 11:52:16 ID:IZ9Oh6sl
������10��ʍ��ΗʎY���ʂň�䔼�z�ʂō��Ȃ����H
367 �F�s���ȃf�o�C�X�����F2009/08/09(��) 12:25:18 ID:do0RGZOp
1/3���炢�ɂȂ��ˁH�v�1/10�ɔ��܂邩��ȁB
368 �F�s���ȃf�o�C�X�����F2009/08/09(��) 13:44:32 ID:YFsFZk1P
���z�Ƃ����ƌ��̒l�i�͂�����̌v�Z�ȂH
�v��ɂ��Ɣ���v�f�Z�p�̊J����1150���~�̔����ȏ�g���Ă���
�v��ɂ��Ɣ���v�f�Z�p�̊J����1150���~�̔����ȏ�g���Ă���
369 �F�s���ȃf�o�C�X�����F2009/08/09(��) 14:36:07 ID:oRJTXTP8
�J�����Ă݂�����������PSI�Ƃ��ǂ��Ȃ����悗
370 �F�s���ȃf�o�C�X�����F2009/08/10(��) 00:29:42 ID:/q9akxFP
�ŋ߂̘b�� 2009�N8 ��9��
http://www.geocities.jp/andosprocinfo/wadai09/20090808.htm
�ySIGGRAPH 2009�zOpenCL��BOF���J�ÁCIntel�ЁCNVIDIA�ЁCAMD�Ђ�������đΉ������
http://techon.nikkeibp.co.jp/article/NEWS/20090805/173896/
SIer���i�ނׂ��N���E�h�r�W�l�X�̕�����
http://www.itmedia.co.jp/enterprise/articles/0908/03/news019.html
NIST scales up quantum computing
http://www.eetimes.com/news/latest/showArticle.jhtml;jsessionid=UKQVWX3UTQHCVQE1GHOSKH4ATMY32JVN?articleID=219100318
Ryan Peters: NASA hits Wall Street
http://www.record-eagle.com/business/local_story_220194029.html
http://www.geocities.jp/andosprocinfo/wadai09/20090808.htm
�ySIGGRAPH 2009�zOpenCL��BOF���J�ÁCIntel�ЁCNVIDIA�ЁCAMD�Ђ�������đΉ������
http://techon.nikkeibp.co.jp/article/NEWS/20090805/173896/
SIer���i�ނׂ��N���E�h�r�W�l�X�̕�����
http://www.itmedia.co.jp/enterprise/articles/0908/03/news019.html
NIST scales up quantum computing
http://www.eetimes.com/news/latest/showArticle.jhtml;jsessionid=UKQVWX3UTQHCVQE1GHOSKH4ATMY32JVN?articleID=219100318
Ryan Peters: NASA hits Wall Street
http://www.record-eagle.com/business/local_story_220194029.html
371 �F�s���ȃf�o�C�X�����F2009/08/10(��) 18:03:09 ID:F8va3ZyY
�������Ă����������ł�
372 �F�s���ȃf�o�C�X�����F2009/08/11(��) 02:03:37 ID:+FUW5HZu
�l�H�q����q��@�̍��x�����@�R�����t�H�g�j�b�N�����A�쐻�@�̊ȗ����ɐ����@����`�[��
http://sankei.jp.msn.com/science/science/090810/scn0908100830008-n1.htm
������98TFLOPS�X�[�p�[�R���s���[�^���ғ�
http://www.itmedia.co.jp/news/articles/0908/10/news005.html
�uIA�T�[�o�[�N��50����v��ڎw���x�m�ʁ|�ŏ��̎l�����̐��ʂ́H
http://enterprise.watch.impress.co.jp/docs/series/ohkawara/20090811_308295.html
�x�m�ʂ�Oracle���N���E�h�A�������������
http://www.itmedia.co.jp/enterprise/articles/0908/10/news019.html
��������F���Ȃ��̃p�\�R���Ō����@���Ö��╨���i�荞�݁A�l�b�g���уX�p�R����p
http://mainichi.jp/select/science/news/20090810ddm002040148000c.html
http://sankei.jp.msn.com/science/science/090810/scn0908100830008-n1.htm
������98TFLOPS�X�[�p�[�R���s���[�^���ғ�
http://www.itmedia.co.jp/news/articles/0908/10/news005.html
�uIA�T�[�o�[�N��50����v��ڎw���x�m�ʁ|�ŏ��̎l�����̐��ʂ́H
http://enterprise.watch.impress.co.jp/docs/series/ohkawara/20090811_308295.html
�x�m�ʂ�Oracle���N���E�h�A�������������
http://www.itmedia.co.jp/enterprise/articles/0908/10/news019.html
��������F���Ȃ��̃p�\�R���Ō����@���Ö��╨���i�荞�݁A�l�b�g���уX�p�R����p
http://mainichi.jp/select/science/news/20090810ddm002040148000c.html
373 �F�s���ȃf�o�C�X�����F2009/08/11(��) 02:04:22 ID:+FUW5HZu
Supercomputing in Wired
http://insidehpc.com/2009/08/09/supercomputing-in-wired/
Sun's Rock is barefoot on Abbey Road
http://www.theregister.co.uk/2009/08/10/sun_rock_still_dead/
Mellanox looks to buy home networking start-up
http://www.theregister.co.uk/2009/08/10/mellanox_coppergate/
Windows 7 Influenced by AMD
http://itmanagement.earthweb.com/entdev/article.php/3833876/Windows-7-Influenced-by-AMD.htm
UK Government ditches Microsoft's Cloud in favour of Open Source?
http://www.computerworlduk.com/community/blogs/index.cfm?entryid=2432&blogid=17
Supermicro Announces 4 Teraflop GPU Computing System
http://www.prnewswire.com/cgi-bin/stories.pl?ACCT=PRNI2&STORY=/www/story/08-10-2009/0005074775&EDATE=
Melting the world�fs smallest raindrop
http://physics.aps.org/articles/v2/67
First Black Holes Born Starving
http://www.sciencedaily.com/releases/2009/08/090810122135.htm
http://insidehpc.com/2009/08/09/supercomputing-in-wired/
Sun's Rock is barefoot on Abbey Road
http://www.theregister.co.uk/2009/08/10/sun_rock_still_dead/
Mellanox looks to buy home networking start-up
http://www.theregister.co.uk/2009/08/10/mellanox_coppergate/
Windows 7 Influenced by AMD
http://itmanagement.earthweb.com/entdev/article.php/3833876/Windows-7-Influenced-by-AMD.htm
UK Government ditches Microsoft's Cloud in favour of Open Source?
http://www.computerworlduk.com/community/blogs/index.cfm?entryid=2432&blogid=17
Supermicro Announces 4 Teraflop GPU Computing System
http://www.prnewswire.com/cgi-bin/stories.pl?ACCT=PRNI2&STORY=/www/story/08-10-2009/0005074775&EDATE=
Melting the world�fs smallest raindrop
http://physics.aps.org/articles/v2/67
First Black Holes Born Starving
http://www.sciencedaily.com/releases/2009/08/090810122135.htm
374 �F�s���ȃf�o�C�X�����F2009/08/12(��) 12:42:32 ID:CZMJxxDD
Stream Processing ���f���� GRAPE-DR ���f��
http://jun.artcompsci.org/articles/future_sc/note073.html#rdocsect78
http://jun.artcompsci.org/articles/future_sc/note073.html#rdocsect78
375 �F�s���ȃf�o�C�X�����F2009/08/12(��) 22:40:01 ID:AoQwtQY6
>>374
eDRAM���玩�͂Ŗ��߂��t�F�b�`�^�f�R�[�h�ł��āAPCIe�Ȃ�HT/QPI�̃R���g���[���������Ă���Ȃ��Ȃ������Ǝv���B
���邢��SeaStar�ɒ����ł���Ƃ��B
eDRAM���玩�͂Ŗ��߂��t�F�b�`�^�f�R�[�h�ł��āAPCIe�Ȃ�HT/QPI�̃R���g���[���������Ă���Ȃ��Ȃ������Ǝv���B
���邢��SeaStar�ɒ����ł���Ƃ��B
376 �F�s���ȃf�o�C�X�����F2009/08/14(��) 23:02:42 ID:k9LHYIH0
377 �F�s���ȃf�o�C�X�����F2009/08/14(��) 23:52:18 ID:hkiwCGHi
�ł��J������w
378 �F�s���ȃf�o�C�X�����F2009/08/15(�y) 03:38:23 ID:lFTsSVz9
Computers Closing In On The Human Brain
http://www.redorbit.com/news/science/1736832/computers_closing_in_on_the_human_brain/
Hot Chips XXI Preview
http://www.realworldtech.com/page.cfm?ArticleID=RWT081209143650
Russia Aspires To Be a Supercomputing Power
http://www.hpcwire.com/blogs/Russia-Aspires-To-Be-a-Supercomputing-Power-53171607.html
Penguin Adds HPC On-Demand Service
http://www.hpcwire.com/features/Penguin-Adds-HPC-On-Demand-Services-53073557.html?ref=557
Students Develop Multicore Programming Skills
http://www.hpcwire.com/industry/academia/Students-Develop-Multicore-Programming-Skills-52989882.html
LSU Professor Develops Integrated Storm Surge and Hurricane Wave Modeling Capabilities
http://www.hpcwire.com/offthewire/LSU-Professor-Develops-Integrated-Storm-Surge-and-Hurricane-Wave-Modeling-Capabilities-53143582.html
Uncle Sam shells out $62m for 100GbE
http://www.theregister.co.uk/2009/08/14/doe_funds_100ge/
Sun sets on Solaris Express Community Edition
http://www.theregister.co.uk/2009/08/11/solaris_express_sunset/
Google File System II: Dawn of the Multiplying Master Nodes
http://www.theregister.co.uk/2009/08/12/google_file_system_part_deux/
RIKEN's New Cluster of Clusters
http://www.genomeweb.com/blog/rikens-new-cluster-clusters
http://www.redorbit.com/news/science/1736832/computers_closing_in_on_the_human_brain/
Hot Chips XXI Preview
http://www.realworldtech.com/page.cfm?ArticleID=RWT081209143650
Russia Aspires To Be a Supercomputing Power
http://www.hpcwire.com/blogs/Russia-Aspires-To-Be-a-Supercomputing-Power-53171607.html
Penguin Adds HPC On-Demand Service
http://www.hpcwire.com/features/Penguin-Adds-HPC-On-Demand-Services-53073557.html?ref=557
Students Develop Multicore Programming Skills
http://www.hpcwire.com/industry/academia/Students-Develop-Multicore-Programming-Skills-52989882.html
LSU Professor Develops Integrated Storm Surge and Hurricane Wave Modeling Capabilities
http://www.hpcwire.com/offthewire/LSU-Professor-Develops-Integrated-Storm-Surge-and-Hurricane-Wave-Modeling-Capabilities-53143582.html
Uncle Sam shells out $62m for 100GbE
http://www.theregister.co.uk/2009/08/14/doe_funds_100ge/
Sun sets on Solaris Express Community Edition
http://www.theregister.co.uk/2009/08/11/solaris_express_sunset/
Google File System II: Dawn of the Multiplying Master Nodes
http://www.theregister.co.uk/2009/08/12/google_file_system_part_deux/
RIKEN's New Cluster of Clusters
http://www.genomeweb.com/blog/rikens-new-cluster-clusters
379 �F�s���ȃf�o�C�X�����F2009/08/15(�y) 03:39:09 ID:lFTsSVz9
Why personal HPC systems haven�ft hit mainstream yet
http://www.itworldcanada.com/a/Daily-News/332d2d82-1456-4dc1-a9c9-2521ee7b58ae.html
A spending plan for tough times
http://www.twincities.com/opinion/ci_13039033?nclick_check=1
Nvidia's Chief Scientist Bill Dally about GPU technology, DirectX 11 and Intel's Larrabee
http://www.pcgameshardware.com/aid,692145/Nvidias-Chief-Scientist-Bill-Dally-about-GPU-technology-DirectX-11-and-Intels-Larrabee/News/
LAPACK on CUDA beta available for free, takes refreshing approach to HPC software
http://insidehpc.com/2009/08/13/lapack-cuda-free-beta-refreshing-approach-hpc-software/
GT300 to have an NVIO chip
http://www.semiaccurate.com/2009/08/13/gt300-have-nvio-chip/
The End of The GPU Roadmap
http://www.ubergizmo.com/15/archives/2009/08/tim_sweeney_the_end_of_the_gpu_roadmap.html
Gaming Hardware Reaching Limits
http://www.tomsguide.com/us/Carmack-id-Rage-Hardware-Consoles,news-4416.html
Design for Manycore Systems
http://www.ddj.com/hpc-high-performance-computing/219200099
WORLD�fS BIGGEST TELESCOPE CAMERA COMES TO CHILE
http://www.valparaisotimes.cl/content/view/586/1/
http://www.itworldcanada.com/a/Daily-News/332d2d82-1456-4dc1-a9c9-2521ee7b58ae.html
A spending plan for tough times
http://www.twincities.com/opinion/ci_13039033?nclick_check=1
Nvidia's Chief Scientist Bill Dally about GPU technology, DirectX 11 and Intel's Larrabee
http://www.pcgameshardware.com/aid,692145/Nvidias-Chief-Scientist-Bill-Dally-about-GPU-technology-DirectX-11-and-Intels-Larrabee/News/
LAPACK on CUDA beta available for free, takes refreshing approach to HPC software
http://insidehpc.com/2009/08/13/lapack-cuda-free-beta-refreshing-approach-hpc-software/
GT300 to have an NVIO chip
http://www.semiaccurate.com/2009/08/13/gt300-have-nvio-chip/
The End of The GPU Roadmap
http://www.ubergizmo.com/15/archives/2009/08/tim_sweeney_the_end_of_the_gpu_roadmap.html
Gaming Hardware Reaching Limits
http://www.tomsguide.com/us/Carmack-id-Rage-Hardware-Consoles,news-4416.html
Design for Manycore Systems
http://www.ddj.com/hpc-high-performance-computing/219200099
WORLD�fS BIGGEST TELESCOPE CAMERA COMES TO CHILE
http://www.valparaisotimes.cl/content/view/586/1/
380 �F�s���ȃf�o�C�X�����F2009/08/15(�y) 03:40:58 ID:lFTsSVz9
Successful First Flight for Parvus Mission Computers Onboard Aurora Flight Sciences' Excalibur UAV
http://www.marketwire.com/press-release/Parvus-Corporation-1028801.html
Technical Computing Throws a New Challenge to Science Budgets
http://www.scientificcomputing.com/article-hpc-Technical-Computing-Throws-a-New-Challenge-to-Science-Budgets-081109.aspx
Solving water�fs 66 known anomalies
http://www.rdmag.com/News/2009/08/General-Sciences-Solving-Waters-66-Known-Anomalies/
Finding my own voice
http://blogs.suntimes.com/ebert/2009/08/finding_my_own_voice.html
Research Corridor has new partner
http://www.grandforksherald.com/event/article/id/129823/group/Local%20News/
http://www.marketwire.com/press-release/Parvus-Corporation-1028801.html
Technical Computing Throws a New Challenge to Science Budgets
http://www.scientificcomputing.com/article-hpc-Technical-Computing-Throws-a-New-Challenge-to-Science-Budgets-081109.aspx
Solving water�fs 66 known anomalies
http://www.rdmag.com/News/2009/08/General-Sciences-Solving-Waters-66-Known-Anomalies/
Finding my own voice
http://blogs.suntimes.com/ebert/2009/08/finding_my_own_voice.html
Research Corridor has new partner
http://www.grandforksherald.com/event/article/id/129823/group/Local%20News/
381 �F�s���ȃf�o�C�X�����F2009/08/15(�y) 03:41:44 ID:lFTsSVz9
����21�N�x�u������X�[�p�[�R���s���[�^�헪�v���O�����v���{�\���������{�@�ցi�헪�@�ցj�̕�W�ɂ���
http://www.mext.go.jp/b_menu/boshu/detail/1282584.htm
�N��10���h���ȏ�𓊂��锼���̃��[�J�[�C2009�N��3�Ђɍi����
http://techon.nikkeibp.co.jp/article/NEWS/20090810/174039/
�����A�����\�R���s���[�^�[�������E��[���x����
http://www.asahi.com/international/jinmin/TKY200908110237.html
�}�g��A�S�Ղ����R�Ȍ`�ɍ���f�U�C���c�[���J��
http://www.nikkan.co.jp/news/nkx0620090814aaaa.html
�T�C�o�l�b�g�V�X�e���A���玖�ƂƂ��āu���䃂�f�����O�v�Ȃ�2�u�����J�u
http://journal.mycom.co.jp/news/2009/08/11/064/?rt=na
�X�p�R���אڒn�̖����n���@�_�ˎs���������s
http://www.kobe-np.co.jp/news/shakai/0002227978.shtml
http://www.mext.go.jp/b_menu/boshu/detail/1282584.htm
�N��10���h���ȏ�𓊂��锼���̃��[�J�[�C2009�N��3�Ђɍi����
http://techon.nikkeibp.co.jp/article/NEWS/20090810/174039/
�����A�����\�R���s���[�^�[�������E��[���x����
http://www.asahi.com/international/jinmin/TKY200908110237.html
�}�g��A�S�Ղ����R�Ȍ`�ɍ���f�U�C���c�[���J��
http://www.nikkan.co.jp/news/nkx0620090814aaaa.html
�T�C�o�l�b�g�V�X�e���A���玖�ƂƂ��āu���䃂�f�����O�v�Ȃ�2�u�����J�u
http://journal.mycom.co.jp/news/2009/08/11/064/?rt=na
�X�p�R���אڒn�̖����n���@�_�ˎs���������s
http://www.kobe-np.co.jp/news/shakai/0002227978.shtml
382 �F�s���ȃf�o�C�X�����F2009/08/16(��) 01:26:21 ID:diePzCQj
�ŋ߂̘b�� 2009�N8 ��16��
http://www.geocities.jp/andosprocinfo/wadai09/20090815.htm
�yDAC 2009�z�u���IDM��Intel������1�ЂɂȂ�\���v�CEDA��䏊�̈�lJim Hogan���ɕ���
http://techon.nikkeibp.co.jp/article/NEWS/20090815/174199/
�yDAC 2009�z�u�O���[���ȃf�[�^�E�Z���^�[�̂��߂ɂł��邱�Ɓv���e�[�}�ɓ��ʃZ�b�V����
http://techon.nikkeibp.co.jp/article/NEWS/20090813/174180/
http://www.geocities.jp/andosprocinfo/wadai09/20090815.htm
�yDAC 2009�z�u���IDM��Intel������1�ЂɂȂ�\���v�CEDA��䏊�̈�lJim Hogan���ɕ���
http://techon.nikkeibp.co.jp/article/NEWS/20090815/174199/
�yDAC 2009�z�u�O���[���ȃf�[�^�E�Z���^�[�̂��߂ɂł��邱�Ɓv���e�[�}�ɓ��ʃZ�b�V����
http://techon.nikkeibp.co.jp/article/NEWS/20090813/174180/
383 �F�s���ȃf�o�C�X�����F2009/08/16(��) 01:27:09 ID:diePzCQj
The Core-Diameter
http://www.linux-mag.com/id/7468
Argonne, North Dakota universities to form regional research partnership
http://nanotechwire.com/news.asp?nid=8384
Big Blue bundles pound down mainframe prices
http://www.theregister.co.uk/2009/08/14/ibm_mainframe_bundles/
InfiniBand Marches On Without Cisco
http://www.enterprisestorageforum.com/technology/features/article.php/3834666
Tim Sweeney: GPGPU Too Costly to Develop
http://www.tomshardware.com/news/Sweeney-Epic-GPU-GPGPU,8461.html
New Y-HPC improves Sony PS3 performance by 50%
http://www.linuxpr.com/releases/11577.html
Bionanoelectronic Devices Could Speed Up Electronics, Processing
http://www.dailytech.com/Bionanoelectronic+Devices+Could+Speed+Up+Electronics+Processing/article15977.htm
Some Creative Destruction on a Cosmic Scale
http://online.wsj.com/article/SB125020578491030557.html?mod=rss_Today's_Most_Popular
Planck Starts Observing the Beginning of the Universe
http://news.softpedia.com/news/Planck-Begins-Observing-the-Beginning-of-the-Universe-119299.shtml
http://www.linux-mag.com/id/7468
Argonne, North Dakota universities to form regional research partnership
http://nanotechwire.com/news.asp?nid=8384
Big Blue bundles pound down mainframe prices
http://www.theregister.co.uk/2009/08/14/ibm_mainframe_bundles/
InfiniBand Marches On Without Cisco
http://www.enterprisestorageforum.com/technology/features/article.php/3834666
Tim Sweeney: GPGPU Too Costly to Develop
http://www.tomshardware.com/news/Sweeney-Epic-GPU-GPGPU,8461.html
New Y-HPC improves Sony PS3 performance by 50%
http://www.linuxpr.com/releases/11577.html
Bionanoelectronic Devices Could Speed Up Electronics, Processing
http://www.dailytech.com/Bionanoelectronic+Devices+Could+Speed+Up+Electronics+Processing/article15977.htm
Some Creative Destruction on a Cosmic Scale
http://online.wsj.com/article/SB125020578491030557.html?mod=rss_Today's_Most_Popular
Planck Starts Observing the Beginning of the Universe
http://news.softpedia.com/news/Planck-Begins-Observing-the-Beginning-of-the-Universe-119299.shtml
384 �F�s���ȃf�o�C�X�����F2009/08/20(��) 23:39:30 ID:VnJoGqcK
Lawrence Livermore Selects TotalView Debugger for 20 Petaflop System
http://www.earthtimes.org/articles/show/lawrence-livermore-selects-totalview-debugger-for-20-petaflop-system,929533.shtml
Nuclear fusion research helps advance computer chips
http://www.tgdaily.com/content/view/43690/135/
IBM Works On Computer Program To Beat 'Jeopardy!'
http://www.courant.com/business/hc-ibm-jeopardy.artaug18,0,511899.story
IBM Using DNA to Create Semiconductors Below 22nm
http://www.dailytech.com/IBM+Using+DNA+to+Create+Semiconductors+Below+22nm/article15994.htm
Italian scientists make breakthrough in supercomputer
http://news.xinhuanet.com/english/2009-08/19/content_11906417.htm
I-CHASS/NICS Announce Availability of 2,000,000 CPU Hours
http://www.hpcwire.com/topic/systems/I-CHASSNICS-Announce-Availability-of-2000000-CPU-Hours-53579162.html
Green Computing, TCO By Any Other Name
http://www.hpcwire.com/blogs/Green-Computing-TCO-By-Any-Other-Name-53619192.html?ref=192
NSF TeraGrid Helps Hayden Planetarium Create Advanced Space Show
http://www.hpcwire.com/offthewire/NSF-TeraGrid-Helps-Hayden-Planetarium-Create-Advanced-Space-Show-53739862.html?ref=862
Texas Advanced Computing Center Announces Newly Formed Board of Visitors
http://www.utexas.edu/news/2009/08/18/tacc_board_visitors/
UCLA Neuroscientists Get $19 Million From NIH for Supercomputer
http://www.dotmed.com/news/story/9965/
http://www.earthtimes.org/articles/show/lawrence-livermore-selects-totalview-debugger-for-20-petaflop-system,929533.shtml
Nuclear fusion research helps advance computer chips
http://www.tgdaily.com/content/view/43690/135/
IBM Works On Computer Program To Beat 'Jeopardy!'
http://www.courant.com/business/hc-ibm-jeopardy.artaug18,0,511899.story
IBM Using DNA to Create Semiconductors Below 22nm
http://www.dailytech.com/IBM+Using+DNA+to+Create+Semiconductors+Below+22nm/article15994.htm
Italian scientists make breakthrough in supercomputer
http://news.xinhuanet.com/english/2009-08/19/content_11906417.htm
I-CHASS/NICS Announce Availability of 2,000,000 CPU Hours
http://www.hpcwire.com/topic/systems/I-CHASSNICS-Announce-Availability-of-2000000-CPU-Hours-53579162.html
Green Computing, TCO By Any Other Name
http://www.hpcwire.com/blogs/Green-Computing-TCO-By-Any-Other-Name-53619192.html?ref=192
NSF TeraGrid Helps Hayden Planetarium Create Advanced Space Show
http://www.hpcwire.com/offthewire/NSF-TeraGrid-Helps-Hayden-Planetarium-Create-Advanced-Space-Show-53739862.html?ref=862
Texas Advanced Computing Center Announces Newly Formed Board of Visitors
http://www.utexas.edu/news/2009/08/18/tacc_board_visitors/
UCLA Neuroscientists Get $19 Million From NIH for Supercomputer
http://www.dotmed.com/news/story/9965/
385 �F�s���ȃf�o�C�X�����F2009/08/20(��) 23:40:59 ID:VnJoGqcK
Cray Selects ASSET�fs ScanWorks Platform for Embedded Diagnostics in Next-Generation Supercomputers
http://www.businesswire.com/portal/site/google/?ndmViewId=news_view&newsId=20090819005418&newsLang=en
High hopes for high tech
http://www.twincities.com/business/ci_13097651?nclick_check=1
Force10 'supports new supercomputer'
http://www.zycko.com/news/19318329-Force10_supports_new_supercomputer
Intel to use Larrabee graphics on CPUs
http://www.semiaccurate.com/2009/08/19/intel-use-larrabee-graphics-cpus/
The Case for ECC Memory in Nvidia�fs Next GPU
http://www.realworldtech.com/page.cfm?ArticleID=RWT081909212132
BREAKING: SGI CEO Mark Barrenechea Responds
http://www.vizworld.com/2009/08/breaking-sgi-ceo-mark-barrenechea-responds/?utm_source=footer&utm_medium=recentposts&utm_campaign=layout
A third of desktops to go multi-GPU in 2012? Not likely
http://arstechnica.com/hardware/news/2009/08/analysis-jpr-is-likely-wrong-about-30-multi-gpu-in-2012-wait-for-jon.ars
http://www.businesswire.com/portal/site/google/?ndmViewId=news_view&newsId=20090819005418&newsLang=en
High hopes for high tech
http://www.twincities.com/business/ci_13097651?nclick_check=1
Force10 'supports new supercomputer'
http://www.zycko.com/news/19318329-Force10_supports_new_supercomputer
Intel to use Larrabee graphics on CPUs
http://www.semiaccurate.com/2009/08/19/intel-use-larrabee-graphics-cpus/
The Case for ECC Memory in Nvidia�fs Next GPU
http://www.realworldtech.com/page.cfm?ArticleID=RWT081909212132
BREAKING: SGI CEO Mark Barrenechea Responds
http://www.vizworld.com/2009/08/breaking-sgi-ceo-mark-barrenechea-responds/?utm_source=footer&utm_medium=recentposts&utm_campaign=layout
A third of desktops to go multi-GPU in 2012? Not likely
http://arstechnica.com/hardware/news/2009/08/analysis-jpr-is-likely-wrong-about-30-multi-gpu-in-2012-wait-for-jon.ars
386 �F�s���ȃf�o�C�X�����F2009/08/20(��) 23:42:05 ID:VnJoGqcK
Ars Says MultiGPU Unlikely, we say Inevitable
http://www.vizworld.com/2009/08/ars-says-multigpu-unlikely-we-say-inevitable/?utm_source=footer&utm_medium=recentposts&utm_campaign=layout
Reconsidering SAN in Wake of SCSI Disk's End
http://www.itjungle.com/tfh/tfh081709-story03.html
PS3 clusters hit as Sony gives Linux the flick
http://www.computerworld.com.au/article/315401/ps3_clusters_hit_sony_gives_linux_flick
Asus P7P55 WS Supercomputer P55 Motherboard Preview
http://www.tomshardware.com/picturestory/516-asus-p7p55-supercomputer.html
HP CEO Hurd: Business Is Stabilizing
http://www.eweek.com/c/a/Desktops-and-Notebooks/HP-CEO-Hurd-Business-is-Stabilizing-630296/
http://www.vizworld.com/2009/08/ars-says-multigpu-unlikely-we-say-inevitable/?utm_source=footer&utm_medium=recentposts&utm_campaign=layout
Reconsidering SAN in Wake of SCSI Disk's End
http://www.itjungle.com/tfh/tfh081709-story03.html
PS3 clusters hit as Sony gives Linux the flick
http://www.computerworld.com.au/article/315401/ps3_clusters_hit_sony_gives_linux_flick
Asus P7P55 WS Supercomputer P55 Motherboard Preview
http://www.tomshardware.com/picturestory/516-asus-p7p55-supercomputer.html
HP CEO Hurd: Business Is Stabilizing
http://www.eweek.com/c/a/Desktops-and-Notebooks/HP-CEO-Hurd-Business-is-Stabilizing-630296/
387 �F�s���ȃf�o�C�X�����F2009/08/20(��) 23:42:50 ID:VnJoGqcK
�~����2��5769��8037�����v�Z�̌��ʂɂ���
http://www.hpcs.cs.tsukuba.ac.jp/~daisuke/index-j.html
10�N��̒������\��A���E�C�ۋ@�ւ��e���ɗv����
http://www.nikkei.co.jp/news/kaigai/20090820AT2M1403220082009.html
�R�̕W��������قǍ����Ȃ��̂́u�C��v���v���A��������
http://www.afpbb.com/article/environment-science-it/science-technology/2631900/4467814
�V�C�^�P�Q�m����ǁ@���A���ʂɊ��ҁ^�X�ё����Ɠ��H��@�H�p��ŏ�
http://www.nougyou-shimbun.ne.jp/modules/bulletin5/article.php?storyid=1000
�S�|�ޗ������̔��ׂȉ�ݕ��̌`�Ԃ�3������͂���Z�p���m��
http://www.riken.jp/r-world/research/results/2009/090817/
http://www.hpcs.cs.tsukuba.ac.jp/~daisuke/index-j.html
10�N��̒������\��A���E�C�ۋ@�ւ��e���ɗv����
http://www.nikkei.co.jp/news/kaigai/20090820AT2M1403220082009.html
�R�̕W��������قǍ����Ȃ��̂́u�C��v���v���A��������
http://www.afpbb.com/article/environment-science-it/science-technology/2631900/4467814
�V�C�^�P�Q�m����ǁ@���A���ʂɊ��ҁ^�X�ё����Ɠ��H��@�H�p��ŏ�
http://www.nougyou-shimbun.ne.jp/modules/bulletin5/article.php?storyid=1000
�S�|�ޗ������̔��ׂȉ�ݕ��̌`�Ԃ�3������͂���Z�p���m��
http://www.riken.jp/r-world/research/results/2009/090817/
388 �F�s���ȃf�o�C�X�����F2009/08/21(��) 22:05:39 ID:ki6ab9UC
>>387
�����X���Ⴂ�ȋL���������ȁB���ɂ��̃X���̓l�^�ꂩ�ȁB
�����X���Ⴂ�ȋL���������ȁB���ɂ��̃X���̓l�^�ꂩ�ȁB
389 �F�s���ȃf�o�C�X�����F2009/08/21(��) 22:11:18 ID:+htiRBnM
���邹�[�J�X
390 �F�s���ȃf�o�C�X�����F2009/08/22(�y) 00:04:41 ID:FM9HLPUo
���܂�ڂ�
391 �F�s���ȃf�o�C�X�����F2009/08/22(�y) 00:40:58 ID:nQZcgi9d
�����A�{���J���[�H����
392 �F�s���ȃf�o�C�X�����F2009/08/22(�y) 02:07:21 ID:S7u8Hla8
Chip makers to flex their bits at Hot Chips
http://www.theregister.co.uk/2009/08/20/hot_chips_preview/
DOJ gives blessing to Oracle-Sun, awaiting EC approval
http://blogs.zdnet.com/BTL/?p=23032
IBM set to release first public information on POWER7
http://www.brightsideofnews.com/news/2009/8/21/ibm-set-to-release-first-public-information-on-power7.aspx
IBM Computing on Demand Evolves Toward Cloud Computing Service
http://www.hpcwire.com/features/IBM-Computing-on-Demand-Evolves-Toward-Cloud-Computing-Service-53745452.html
Intel buys multicore software specialist RapidMind
http://www.edn.com/article/CA6685291.html
SGI's Personal Cluster: Lots of Options, Lots of Challenges
http://www.hpcwire.com/features/SGIs-Personal-Cluster-Lots-of-Options-Lots-of-Challenges-53861232.html
Environmentalists Force New Review of LBNL�fs Proposed Computer Lab
http://www.berkeleydailyplanet.com/issue/2009-08-20/article/33555?headline=Environmentalists-Force-New-Review-of-LBNL-s-Proposed-Computer-Lab##33555
AMS To Seek Out Antimatter Galaxies
http://www.redorbit.com/news/space/1737977/ams_to_seek_out_antimatter_galaxies/
Platform shared with CUDA in software bundle deal
http://www.theregister.co.uk/2009/08/20/platform_does_tesla/
A weather eye on Africa
http://www.mg.co.za/article/2009-08-19-a-weather-eye-on-africa
Stretching universal boundaries
http://www.stuff.co.nz/dominion-post/opinion/2774487/Stretching-universal-boundaries
http://www.theregister.co.uk/2009/08/20/hot_chips_preview/
DOJ gives blessing to Oracle-Sun, awaiting EC approval
http://blogs.zdnet.com/BTL/?p=23032
IBM set to release first public information on POWER7
http://www.brightsideofnews.com/news/2009/8/21/ibm-set-to-release-first-public-information-on-power7.aspx
IBM Computing on Demand Evolves Toward Cloud Computing Service
http://www.hpcwire.com/features/IBM-Computing-on-Demand-Evolves-Toward-Cloud-Computing-Service-53745452.html
Intel buys multicore software specialist RapidMind
http://www.edn.com/article/CA6685291.html
SGI's Personal Cluster: Lots of Options, Lots of Challenges
http://www.hpcwire.com/features/SGIs-Personal-Cluster-Lots-of-Options-Lots-of-Challenges-53861232.html
Environmentalists Force New Review of LBNL�fs Proposed Computer Lab
http://www.berkeleydailyplanet.com/issue/2009-08-20/article/33555?headline=Environmentalists-Force-New-Review-of-LBNL-s-Proposed-Computer-Lab##33555
AMS To Seek Out Antimatter Galaxies
http://www.redorbit.com/news/space/1737977/ams_to_seek_out_antimatter_galaxies/
Platform shared with CUDA in software bundle deal
http://www.theregister.co.uk/2009/08/20/platform_does_tesla/
A weather eye on Africa
http://www.mg.co.za/article/2009-08-19-a-weather-eye-on-africa
Stretching universal boundaries
http://www.stuff.co.nz/dominion-post/opinion/2774487/Stretching-universal-boundaries
393 �F�s���ȃf�o�C�X�����F2009/08/22(�y) 02:08:06 ID:S7u8Hla8
��菬�������ቿ�i�ɂȂ����VPS3�̋Z�p
http://pc.watch.impress.co.jp/docs/column/kaigai/20090821_309940.html
�yFlash Memory Summit 2009�z
http://pc.watch.impress.co.jp/docs/news/event/20090820_309421.html
�u11nm�܂ł�1�ЂŊJ���ł��郁�h�������Ă���v�ƃC���e���̋Z�p�J���E�����Z�p�{����
http://techon.nikkeibp.co.jp/article/NEWS/20090821/174441/
����A�t���[�����������̐V��@�J��
http://www.nikkan.co.jp/news/nkx0620090821aaae.html
�b�s�b�A���Z�@�����ɃO���b�h�E�R���s���[�e�B���O���؊��u���Z�g�o�b���{�v���J��
http://release.nikkei.co.jp/detail.cfm?relID=228756&lindID=1
�āA���̒���������K���ց@�������Ɍ��O�A�������͂�
http://www.nishinippon.co.jp/nnp/item/116574
http://pc.watch.impress.co.jp/docs/column/kaigai/20090821_309940.html
�yFlash Memory Summit 2009�z
http://pc.watch.impress.co.jp/docs/news/event/20090820_309421.html
�u11nm�܂ł�1�ЂŊJ���ł��郁�h�������Ă���v�ƃC���e���̋Z�p�J���E�����Z�p�{����
http://techon.nikkeibp.co.jp/article/NEWS/20090821/174441/
����A�t���[�����������̐V��@�J��
http://www.nikkan.co.jp/news/nkx0620090821aaae.html
�b�s�b�A���Z�@�����ɃO���b�h�E�R���s���[�e�B���O���؊��u���Z�g�o�b���{�v���J��
http://release.nikkei.co.jp/detail.cfm?relID=228756&lindID=1
�āA���̒���������K���ց@�������Ɍ��O�A�������͂�
http://www.nishinippon.co.jp/nnp/item/116574
394 �F�s���ȃf�o�C�X�����F2009/08/26(��) 08:36:39 ID:nKKMAQZs
IBM's POWER7 and Sun's Rainbow Falls, Unveiled
http://www.pcmag.com/article2/0,2817,2351965,00.asp
http://www.pcmag.com/article2/0,2817,2351965,00.asp
395 �F�s���ȃf�o�C�X�����F2009/08/26(��) 14:55:25 ID:YA2lyxAE
power7�ł���
396 �F�s���ȃf�o�C�X�����F2009/08/26(��) 18:39:27 ID:7GM8VGTo
�������10PFLOPS�X�p�R�����E���_�� - �x�m��
http://journal.mycom.co.jp/articles/2009/08/26/fujitsu/index.html
http://journal.mycom.co.jp/articles/2009/08/26/fujitsu/index.html
397 �F�s���ȃf�o�C�X�����F2009/08/26(��) 21:18:50 ID:YA2lyxAE
�Ƃ肠����LINPAC20PF���炢��_���Ă�������
�ŏ��̉ғ��i�K��10PF������B������2012�N�܂łɔ{�������銴������
�ŏ��̉ғ��i�K��10PF������B������2012�N�܂łɔ{�������銴������
398 �F�s���ȃf�o�C�X�����F2009/08/26(��) 23:23:04 ID:v2KGEMIW
�uSPARC64 VIIIfx�̏���d�͂�2002�N�����Ɠ����x���v
����SPARC64 V���炢���Ă��Ƃ��H
����SPARC64 V���炢���Ă��Ƃ��H
399 �F�s���ȃf�o�C�X�����F2009/08/27(��) 05:30:55 ID:3evAafF0
>>398
58W�炵���ˁB
http://www.pcworld.com/businesscenter/article/170801/fujitsu_aims_for_10petaflop_supercomputer.html
58W�炵���ˁB
http://www.pcworld.com/businesscenter/article/170801/fujitsu_aims_for_10petaflop_supercomputer.html
400 �F�s���ȃf�o�C�X�����F2009/08/27(��) 16:20:50 ID:w2anozRH
>>396
>�J������10PFLOPS�Ƃ����̂́A�����h�[���̊ϋq5���l��1�b�Ԃ�1�x�v�Z���Ă��A6400�N������ʂ��Ƃ����B
�ǂ��ł��������Ƃ����A���̕\���͂�����������B
>�J������10PFLOPS�Ƃ����̂́A�����h�[���̊ϋq5���l��1�b�Ԃ�1�x�v�Z���Ă��A6400�N������ʂ��Ƃ����B
�ǂ��ł��������Ƃ����A���̕\���͂�����������B
401 �F�s���ȃf�o�C�X�����F2009/08/27(��) 21:05:01 ID:YwDneSet
>>400
����������������I
����������������I
402 �F�s���ȃf�o�C�X�����F2009/08/27(��) 21:23:38 ID:+d84HPlp
(�L��֥�M)
>>402
���܂�B�킩�����B�������������B
���܂�B�킩�����B�������������B
404 �F�s���ȃf�o�C�X�����F2009/08/28(��) 00:38:34 ID:bsD5SfvG
405 �F�s���ȃf�o�C�X�����F2009/08/28(��) 01:02:47 ID:7TOqEDnW
�����h�[���̖싅�J�Î��̓X����46000�l������Ƃ�����5���l�ɂ͒B���Ă��Ȃ��Ƃ����̂�
�˂����݃|�C���g���I
�˂����݃|�C���g���I
406 �F�s���ȃf�o�C�X�����F2009/08/28(��) 10:07:54 ID:2cJJlhTt
>>404
���Ƃ��Ƃm�d�b�̂ł����ăs�[�N���\�̒Ⴂ�����������\�肾��������
�X�y�[�X�����d�͓I�ɂ�20PF�����̗]�T������͂�
���Ȃ͕̂x�m�ʂ��ǂꂾ��������邩���Ă��Ƃ���Ȃ����H
���Ƃ��Ƃm�d�b�̂ł����ăs�[�N���\�̒Ⴂ�����������\�肾��������
�X�y�[�X�����d�͓I�ɂ�20PF�����̗]�T������͂�
���Ȃ͕̂x�m�ʂ��ǂꂾ��������邩���Ă��Ƃ���Ȃ����H
407 �F�s���ȃf�o�C�X�����F2009/08/28(��) 10:33:36 ID:c+uXuvzj
���ς�炸���Ђɓs���̈����͖̂������āA�r�[�i�X�̎��̐��E�ő����咣���Ă��
408 �F�s���ȃf�o�C�X�����F2009/08/28(��) 13:10:33 ID:sNRuCFp4
�^�p�J�n��2�N���炢�Ńv���Z�b�T�̃A�b�v�O���[�h�������?
���̊���ɂ́AVenus�̎��̘b���o�Ă��Ȃ��ȁB
���łɁA�v���Z�b�T�̃A�b�v�O���[�h��ƒ��̉^�p�A�ǂ��Ȃ�낤�B
�قȂ鑬�x�̃v���Z�b�T�����݂�����Ԃł��p�t�H�[�}���X���o��v�Ȃ̂��A
���݂������ɋ����̂��B
���̊���ɂ́AVenus�̎��̘b���o�Ă��Ȃ��ȁB
���łɁA�v���Z�b�T�̃A�b�v�O���[�h��ƒ��̉^�p�A�ǂ��Ȃ�낤�B
�قȂ鑬�x�̃v���Z�b�T�����݂�����Ԃł��p�t�H�[�}���X���o��v�Ȃ̂��A
���݂������ɋ����̂��B
409 �F�s���ȃf�o�C�X�����F2009/08/28(��) 15:48:45 ID:kpio742x
�A�z
410 �F�s���ȃf�o�C�X�����F2009/08/28(��) 17:07:29 ID:sNRuCFp4
>>409
�����فA���ēǂނ�
�����فA���ēǂނ�
411 �F�s���ȃf�o�C�X�����F2009/08/28(��) 20:18:55 ID:9E4DUtpb
>>405
�����h�[�����Ĕ��X������
�����h�[�����Ĕ��X������
412 �F�s���ȃf�o�C�X�����F2009/08/28(��) 22:48:22 ID:yG/Cv/SN
�܂����ɏo�ĂȂ��x�m�ʂ̐��E�ő�CPU�Ƃقړ����P�̐��\��SX-9���P�N�ȏ�O�Ɏs��ɏo�ĂȂ������H
413 �F�s���ȃf�o�C�X�����F2009/08/28(��) 23:05:31 ID:CRSR1NUe
SX-9��CPU�̖��O����Ȃ��̂ŁE�E�E
414 �F�s���ȃf�o�C�X�����F2009/08/28(��) 23:14:28 ID:yG/Cv/SN
>>413
������H
������H
415 �F�s���ȃf�o�C�X�����F2009/08/28(��) 23:32:29 ID:CRSR1NUe
SX-9�̒P�́��n���ł����m�[�h
����Ȃɂ��Ȃ��ꂽ���́H
����Ȃɂ��Ȃ��ꂽ���́H
416 �F�s���ȃf�o�C�X�����F2009/08/28(��) 23:53:40 ID:yG/Cv/SN
�x�m�ʎЈ��L���C���烄�_
417 �F�s���ȃf�o�C�X�����F2009/08/29(�y) 01:54:35 ID:efdfBxBe
4GHz�œ��삷��PowerXCell�̃V�X�e�������ɂ�����
������ŏ����琢�E�ő�����Ȃ���Ȃ����Ȃ�
������ŏ����琢�E�ő�����Ȃ���Ȃ����Ȃ�
418 �F�s���ȃf�o�C�X�����F2009/08/29(�y) 11:18:14 ID:KavKHD0F
SPARC�Ƃ��Ă͐��E�ő��A�Ȃ낤�B
419 �F�s���ȃf�o�C�X�����F2009/08/29(�y) 16:28:03 ID:44cfrTRf
�x�m�ʂ�CPU�Ƃ��Ă͐��E�ő��A�Ȃ낤�B
420 �F�s���ȃf�o�C�X�����F2009/08/29(�y) 16:51:29 ID:0fivbCB0
>>417
����ėp����Ȃ�����
����ėp����Ȃ�����
421 �F�s���ȃf�o�C�X�����F2009/08/29(�y) 18:34:21 ID:KavKHD0F
SPARC64VIIIfx����128Gflops������B
Intel��SandyBridge��1�\�P�b�g��128�`256Gflops�̗\��B
���ۂɃ��m���[������鎞���Ƃ��ẮA����������������Ȃ��B
Intel��SandyBridge��1�\�P�b�g��128�`256Gflops�̗\��B
���ۂɃ��m���[������鎞���Ƃ��ẮA����������������Ȃ��B
422 �F�s���ȃf�o�C�X�����F2009/08/30(��) 01:13:07 ID:iF4cmxQX
Researchers crack network latency nut with new algorithm
http://arstechnica.com/business/news/2009/08/new-protocol-could-enable-real-time-network-latency-data.ars
Intel to Focus on Next Generation of Chips
http://www.pcworld.com/article/170629/intel_to_focus_on_next_generation_of_chips.html
The economy changes the course of chip design at Hot Chips conference
http://venturebeat.com/2009/08/23/the-economy-changes-the-course-of-chip-design-at-hot-chips-conference/
NASA Expands High-End Computing System for Climate Simulation
http://news.prnewswire.com/DisplayReleaseContent.aspx?ACCT=104&STORY=/www/story/08-24-2009/0005082038&EDATE=
Silicon circuit board seeks to replace ASICs
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=219401184
Supermicro Ships 6Gb/s SAS 2.0 Solutions
http://sev.prnewswire.com/computer-electronics/20090824/AQ6463024082009-1.html
NEC, Stratus Put Intel �eNehalem` Chips into Fault-Tolerant Servers
http://www.eweek.com/c/a/IT-Infrastructure/NEC-Stratus-Put-Intel-Nehalem-Chips-into-FaultTolerant-Servers-195771/
AMD aims at slower, power-savvy Magny-Cours
http://www.theinquirer.net/inquirer/news/1530934/amd-aims-slower-power-savvy-magny-cours
Fujitsu Aims for 10-petaflop Supercomputer
http://www.pcworld.com/businesscenter/article/170801/fujitsu_aims_for_10petaflop_supercomputer.html
Sun, IBM push multicore boundaries
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=219500130
http://arstechnica.com/business/news/2009/08/new-protocol-could-enable-real-time-network-latency-data.ars
Intel to Focus on Next Generation of Chips
http://www.pcworld.com/article/170629/intel_to_focus_on_next_generation_of_chips.html
The economy changes the course of chip design at Hot Chips conference
http://venturebeat.com/2009/08/23/the-economy-changes-the-course-of-chip-design-at-hot-chips-conference/
NASA Expands High-End Computing System for Climate Simulation
http://news.prnewswire.com/DisplayReleaseContent.aspx?ACCT=104&STORY=/www/story/08-24-2009/0005082038&EDATE=
Silicon circuit board seeks to replace ASICs
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=219401184
Supermicro Ships 6Gb/s SAS 2.0 Solutions
http://sev.prnewswire.com/computer-electronics/20090824/AQ6463024082009-1.html
NEC, Stratus Put Intel �eNehalem` Chips into Fault-Tolerant Servers
http://www.eweek.com/c/a/IT-Infrastructure/NEC-Stratus-Put-Intel-Nehalem-Chips-into-FaultTolerant-Servers-195771/
AMD aims at slower, power-savvy Magny-Cours
http://www.theinquirer.net/inquirer/news/1530934/amd-aims-slower-power-savvy-magny-cours
Fujitsu Aims for 10-petaflop Supercomputer
http://www.pcworld.com/businesscenter/article/170801/fujitsu_aims_for_10petaflop_supercomputer.html
Sun, IBM push multicore boundaries
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=219500130
423 �F�s���ȃf�o�C�X�����F2009/08/30(��) 01:13:47 ID:iF4cmxQX
The coolest and scariest things coming in the chip industry�fs future
http://venturebeat.com/2009/08/26/the-coolest-and-scariest-things-coming-in-the-chip-industrys-future/
LLNL research reveals how blast waves may cause human brain injury even without direct head impacts
http://insciences.org/article.php?article_id=6609
Hot Chips: Server Processor Roadmaps Show Change in Direction
http://blogs.pcmag.com/miller/2009/08/hot_chips_server_processor_roa.php
Nvidia predicts 570x GPU performance boost
http://www.bit-tech.net/news/hardware/2009/08/27/nvidia-predicts-570-times-performance-boost/1
Cray Acquires PathScale Compiler Suite Assets From SiCortex
http://www.pr-inside.com/cray-acquires-pathscale-compiler-suite-r1455274.htm
Chipmakers Keep Pouring on the Cores
http://www.hpcwire.com/blogs/Chipmakers-Keep-Pouring-on-the-Cores-55476612.html
Met supercomputer contributing to CO2 problem
http://www.techradar.com/news/world-of-tech/met-supercomputer-contributing-to-co2-problem-629963
Amazon Goes into the Hybrid Cloud Business
http://cloudcomputing.sys-con.com/node/1085956
UIC Team Gets $1.9M Grant to Develop OptIPuter
http://www.hpcwire.com/topic/networks/UIC-Team-Gets-19M-Grant-to-Develop-OptIPuter-55757357.html
Platform Computing buys HP-MPI library
http://news.idg.no/cw/art.cfm?id=62198B6B-1A64-67EA-E42083F8C4D3718F
http://venturebeat.com/2009/08/26/the-coolest-and-scariest-things-coming-in-the-chip-industrys-future/
LLNL research reveals how blast waves may cause human brain injury even without direct head impacts
http://insciences.org/article.php?article_id=6609
Hot Chips: Server Processor Roadmaps Show Change in Direction
http://blogs.pcmag.com/miller/2009/08/hot_chips_server_processor_roa.php
Nvidia predicts 570x GPU performance boost
http://www.bit-tech.net/news/hardware/2009/08/27/nvidia-predicts-570-times-performance-boost/1
Cray Acquires PathScale Compiler Suite Assets From SiCortex
http://www.pr-inside.com/cray-acquires-pathscale-compiler-suite-r1455274.htm
Chipmakers Keep Pouring on the Cores
http://www.hpcwire.com/blogs/Chipmakers-Keep-Pouring-on-the-Cores-55476612.html
Met supercomputer contributing to CO2 problem
http://www.techradar.com/news/world-of-tech/met-supercomputer-contributing-to-co2-problem-629963
Amazon Goes into the Hybrid Cloud Business
http://cloudcomputing.sys-con.com/node/1085956
UIC Team Gets $1.9M Grant to Develop OptIPuter
http://www.hpcwire.com/topic/networks/UIC-Team-Gets-19M-Grant-to-Develop-OptIPuter-55757357.html
Platform Computing buys HP-MPI library
http://news.idg.no/cw/art.cfm?id=62198B6B-1A64-67EA-E42083F8C4D3718F
424 �F�s���ȃf�o�C�X�����F2009/08/30(��) 01:14:30 ID:iF4cmxQX
Silicon Israel
http://www.city-journal.org/2009/19_3_jewish-capitalism.html
SPARC�Ŗڎw��10�y�^FLOPS�A�x�m�ʂ����g�ރX�p�R��
http://www.itmedia.co.jp/enterprise/articles/0908/25/news077.html
������_�c������ŏI���Ɂ@�X�[�p�[�R���s���^�[�̐��E�I��
http://www.nagasaki-np.co.jp/kiji/20090829/07.shtml
IBM��Sun������RISC�v���Z�b�T���Љ�
http://www.itmedia.co.jp/news/articles/0908/27/news062.html
�P�O�N�x�\�Z�F���ȏȊT�Z�v���@�X�p�R���J����A������V�U���~��
http://mainichi.jp/select/seiji/news/20090829ddm002010094000c.html
http://www.city-journal.org/2009/19_3_jewish-capitalism.html
SPARC�Ŗڎw��10�y�^FLOPS�A�x�m�ʂ����g�ރX�p�R��
http://www.itmedia.co.jp/enterprise/articles/0908/25/news077.html
������_�c������ŏI���Ɂ@�X�[�p�[�R���s���^�[�̐��E�I��
http://www.nagasaki-np.co.jp/kiji/20090829/07.shtml
IBM��Sun������RISC�v���Z�b�T���Љ�
http://www.itmedia.co.jp/news/articles/0908/27/news062.html
�P�O�N�x�\�Z�F���ȏȊT�Z�v���@�X�p�R���J����A������V�U���~��
http://mainichi.jp/select/seiji/news/20090829ddm002010094000c.html
425 �F�s���ȃf�o�C�X�����F2009/08/30(��) 01:16:03 ID:iF4cmxQX
�ŋ߂̘b�� 2009�N8 ��22��
http://www.geocities.jp/andosprocinfo/wadai09/20090822.htm
�ŋ߂̘b�� 2009�N8 ��29��
http://www.geocities.jp/andosprocinfo/wadai09/20090829.htm
http://www.geocities.jp/andosprocinfo/wadai09/20090822.htm
�ŋ߂̘b�� 2009�N8 ��29��
http://www.geocities.jp/andosprocinfo/wadai09/20090829.htm
426 �F�s���ȃf�o�C�X�����F2009/08/30(��) 02:59:52 ID:tCKfQ7vA
>������_�c������ŏI���Ɂ@�X�[�p�[�R���s���^�[�̐��E�I��
DR ���^�����ȁB�m���A�O�X������������ DR �ƒ�q�Ύt�����č\�}
���������H
DR ���^�����ȁB�m���A�O�X������������ DR �ƒ�q�Ύt�����č\�}
���������H
427 �F���������������I���ɍs�����F2009/08/30(��) 10:08:24 ID:VXn+AHqt
POWER7��256Gflops��
���E�ő��E�E�E���������쎞�_�ŁA���Ă����x�m�ʂ̂�肩���́A���Ƃō���Ǝv���B
���E�ő��E�E�E���������쎞�_�ŁA���Ă����x�m�ʂ̂�肩���́A���Ƃō���Ǝv���B
428 �F���������������I���ɍs�����F2009/08/30(��) 10:35:57 ID:ZL4M7JkX
��������A�������̃`�b�v�̃o�O�����ăN���b�N���_���ʂ�ɏオ������
�v�Z��128GF���A����x������B
�܂����\���炾���Ԃ���������Ȃ�Ƃ������悤�ɂ͂Ȃ��Ă�̂�������B
�v�Z��128GF���A����x������B
�܂����\���炾���Ԃ���������Ȃ�Ƃ������悤�ɂ͂Ȃ��Ă�̂�������B
429 �F���������������I���ɍs�����F2009/08/30(��) 10:56:08 ID:8zEBFLO5
������胋�[�v�ŏ����ċ�J��������ŋ������
�����������Ȃ�or���ł��g�������Ȃ邩�������ċA
�����������Ȃ�or���ł��g�������Ȃ邩�������ċA
430 �F���������������I���ɍs�����F2009/08/30(��) 13:15:04 ID:VXn+AHqt
431 �F���������������I���ɍs�����F2009/08/30(��) 14:01:44 ID:Vuw4BI6s
NEC�̂ł����Ēx���`�b�v���̓}�V�ł��傗
432 �F���������������I���ɍs�����F2009/08/30(��) 15:35:06 ID:VXn+AHqt
>>431
����Șb�A�C�x�߂ɂ��Ȃ�B
�������������̂́A
���Ђ̗ʎY�o�ׂ���Ă��郂�m�Ǝ��Ђ̎���i�K�̂��̂��ׂĐ��E�ő��𖼏��悤�Ȃ��Ƃ�������A
�ʎY�̒i�K�ɐi���_�Ő��E�ő��𖼏��Ȃ����Ă��ƁB
Venus���ʎY����鍠�ɂ́AIBM��Intel�̎���i��128Gflops�ȏ�̐�����@���o���Ă邾�낤����ˁB
����Șb�A�C�x�߂ɂ��Ȃ�B
�������������̂́A
���Ђ̗ʎY�o�ׂ���Ă��郂�m�Ǝ��Ђ̎���i�K�̂��̂��ׂĐ��E�ő��𖼏��悤�Ȃ��Ƃ�������A
�ʎY�̒i�K�ɐi���_�Ő��E�ő��𖼏��Ȃ����Ă��ƁB
Venus���ʎY����鍠�ɂ́AIBM��Intel�̎���i��128Gflops�ȏ�̐�����@���o���Ă邾�낤����ˁB
433 �F���������������I���ɍs�����F2009/08/30(��) 17:14:29 ID:LxCPV8nb
>>432
���O�����܂�����
���O�����܂�����
434 �F���������������I���ɍs�����F2009/08/30(��) 17:49:13 ID:hCG3d3jo
SS���t�H�[������SR16000��FX1�̃x���`�}�[�N���ʂ��ڂ��Ă�B
��K�͌v�Z�i5000core�j�ł͋��Ɏ��s����8%���x������ƁB
����ł͋������łĂ��A�����v���O���������������Ȃ�����AES2�̕����������Ă��Ƃ��\�����肻�����ȁB
���������Ă�16000CPU�ix8core�j���g����ES2��2�{���x������Ƃ��������ȁB
�l�I�ɂ́ASR16000��F�Ƃ͈Ⴂ�A��������E�������o���h�����ɐ��\���悭�A�m�[�h�ԒʐM(18GB/s�~2)�������Əグ��A��K�͌v�Z�̌������オ�肻���Ȋ����B
ttp://www.ssken.gr.jp/MAINSITE/activity/sectionmeeting/sci/2009-1/program.html
��K�͌v�Z�i5000core�j�ł͋��Ɏ��s����8%���x������ƁB
����ł͋������łĂ��A�����v���O���������������Ȃ�����AES2�̕����������Ă��Ƃ��\�����肻�����ȁB
���������Ă�16000CPU�ix8core�j���g����ES2��2�{���x������Ƃ��������ȁB
�l�I�ɂ́ASR16000��F�Ƃ͈Ⴂ�A��������E�������o���h�����ɐ��\���悭�A�m�[�h�ԒʐM(18GB/s�~2)�������Əグ��A��K�͌v�Z�̌������オ�肻���Ȋ����B
ttp://www.ssken.gr.jp/MAINSITE/activity/sectionmeeting/sci/2009-1/program.html
435 �F���������������I���ɍs�����F2009/08/30(��) 17:55:04 ID:Vuw4BI6s
>>434
�d�r�Q�ł����炪����Ă����\TF�����E���낗
���������ɏ������炻��10�{�ȏ�s�����Ⴄ��
���\���ۂ���Ȃ��������B���Œ��̌i�C�g����Ƃ������āA
�h�J���Ɨ������Ƃ��납�甼�����炢�܂ʼn����������Ă�������
�d�r�Q�ł����炪����Ă����\TF�����E���낗
���������ɏ������炻��10�{�ȏ�s�����Ⴄ��
���\���ۂ���Ȃ��������B���Œ��̌i�C�g����Ƃ������āA
�h�J���Ɨ������Ƃ��납�甼�����炢�܂ʼn����������Ă�������
436 �F���������������I���ɍs�����F2009/08/30(��) 17:59:35 ID:hCG3d3jo
>>435
������A2PFLOPS(16000CPU)�g�������s����5%����A100TFLOPS
ES2��2�{���x������Ƃ��Ƃ����Ă�낗
�Z�����ł��Ȃ��̂���
������A2PFLOPS(16000CPU)�g�������s����5%����A100TFLOPS
ES2��2�{���x������Ƃ��Ƃ����Ă�낗
�Z�����ł��Ȃ��̂���
437 �F���������������I���ɍs�����F2009/08/30(��) 18:00:27 ID:VXn+AHqt
IBM��POWER7���ڋ@��2010�N�̗\�� (1�`�b�v8�R�A��256Gflops)
Intel��Sandy Bridge��2010�NQ4�̗\�� (1�`�b�v8�R�A��256Gflops)
�ŁA���̋�����2010�N�x���Ɉꕔ���ғ��J�n
���E�ő��v���Z�b�T�̗ʎY�o�J�n���[�X�ɕx�m�ʂ͏��Ă�̂��B
Intel��Sandy Bridge��2010�NQ4�̗\�� (1�`�b�v8�R�A��256Gflops)
�ŁA���̋�����2010�N�x���Ɉꕔ���ғ��J�n
���E�ő��v���Z�b�T�̗ʎY�o�J�n���[�X�ɕx�m�ʂ͏��Ă�̂��B
438 �F���������������I���ɍs�����F2009/08/30(��) 18:06:44 ID:gToB2K18
POWER7���\��ʂ�ɏo��Ǝv���Ă���z�͑f�l
439 �F�s���ȃf�o�C�X�����F2009/08/30(��) 20:09:56 ID:yZa9Wa+f
>>436
���{����ł��Ȃ��̂���
���{����ł��Ȃ��̂���
440 �F�s���ȃf�o�C�X�����F2009/09/01(��) 00:10:28 ID:U0jnnpzs
OpenCL: Parallel programmers' new best friend
http://news.cnet.com/8301-13512_3-10319075-23.html
Pumping Up Power Efficiency
http://www.scientificcomputing.com/article-hpc-Pumping-Up-Power-Efficiency-082809.aspx
NASA could outsource flights and insource IT
http://www.nextgov.com/nextgov/ng_20090828_3538.php?oref=topnews
Enterprise Technologies Will Change the Consumer PC Market
http://www.enterprisestorageforum.com/technology/features/article.php/3836776
Scientific Process Automation Improves Data Interaction
http://www.scientificcomputing.com/article-hpc-Scientific-Process-Automation-Improves-Data-Interaction-082809.aspx
Is Sony a Linux killer?
http://www.daniweb.com/blogs/entry4673.html#
FAQ: BOINC software for volunteer grid computing
http://www.networkworld.com/news/2009/083109-boinc.html
ATI Radeon HD 4800 GPUs Complement Snow Leopard With OpenCL
http://hothardware.com/News/ATI-Radeon-HD-4800-GPUs-Complement-Snow-Leopard-With-OpenCL-/
Argonne's new center really computes
http://www.southtownstar.com/news/1743653,083109ArgonneComputer.article
AF supercomputer named after WWII codebreaker
http://www.airforcetimes.com/news/2009/08/ap_airforce_supercomputer_083109/
http://news.cnet.com/8301-13512_3-10319075-23.html
Pumping Up Power Efficiency
http://www.scientificcomputing.com/article-hpc-Pumping-Up-Power-Efficiency-082809.aspx
NASA could outsource flights and insource IT
http://www.nextgov.com/nextgov/ng_20090828_3538.php?oref=topnews
Enterprise Technologies Will Change the Consumer PC Market
http://www.enterprisestorageforum.com/technology/features/article.php/3836776
Scientific Process Automation Improves Data Interaction
http://www.scientificcomputing.com/article-hpc-Scientific-Process-Automation-Improves-Data-Interaction-082809.aspx
Is Sony a Linux killer?
http://www.daniweb.com/blogs/entry4673.html#
FAQ: BOINC software for volunteer grid computing
http://www.networkworld.com/news/2009/083109-boinc.html
ATI Radeon HD 4800 GPUs Complement Snow Leopard With OpenCL
http://hothardware.com/News/ATI-Radeon-HD-4800-GPUs-Complement-Snow-Leopard-With-OpenCL-/
Argonne's new center really computes
http://www.southtownstar.com/news/1743653,083109ArgonneComputer.article
AF supercomputer named after WWII codebreaker
http://www.airforcetimes.com/news/2009/08/ap_airforce_supercomputer_083109/
441 �F�s���ȃf�o�C�X�����F2009/09/01(��) 00:11:13 ID:U0jnnpzs
Sandia team developing right-sized reactor
http://media-newswire.com/release_1097902.html
Mellanox Announces ConnectX-2, An Advanced High-Performance, Low Power, Connectivity Solution for Virtualized and Cloud Data Centers
http://newsticker.welt.de/?module=smarthouse&id=936309
High-end server chips breaking records
http://news.cnet.com/8301-13512_3-10321740-23.html
Mysterious Weather Pulses Help Predict Hurricanes
http://dsc.discovery.com/news/2009/08/31/hurricane-prediction.html
�m�d�b���E�ō����A����X�[�p�[�R���s���[�^�J��
http://www.toyokeizai.net/business/industrial/detail/AC/2208a678394e40cf6352f1217cace5de/
> �����H�Ƒ�w�̏����������́u�x�N�g���^�͎���x��B�P�K�̌����ŁA�J���v��͂܂Ƃ��Ȍ`�ɂȂ����v�Ǝw�E����B
> ������̗��p�̂��������������헪�ψ���̃����o�[�ł����鎛�q�����́A���[�U�[�ł��錤���҂��Ƃ̈ӌ���
> �����Ă���A�J���v����n�߂�ׂ����Ǝ咣����B
http://media-newswire.com/release_1097902.html
Mellanox Announces ConnectX-2, An Advanced High-Performance, Low Power, Connectivity Solution for Virtualized and Cloud Data Centers
http://newsticker.welt.de/?module=smarthouse&id=936309
High-end server chips breaking records
http://news.cnet.com/8301-13512_3-10321740-23.html
Mysterious Weather Pulses Help Predict Hurricanes
http://dsc.discovery.com/news/2009/08/31/hurricane-prediction.html
�m�d�b���E�ō����A����X�[�p�[�R���s���[�^�J��
http://www.toyokeizai.net/business/industrial/detail/AC/2208a678394e40cf6352f1217cace5de/
> �����H�Ƒ�w�̏����������́u�x�N�g���^�͎���x��B�P�K�̌����ŁA�J���v��͂܂Ƃ��Ȍ`�ɂȂ����v�Ǝw�E����B
> ������̗��p�̂��������������헪�ψ���̃����o�[�ł����鎛�q�����́A���[�U�[�ł��錤���҂��Ƃ̈ӌ���
> �����Ă���A�J���v����n�߂�ׂ����Ǝ咣����B
442 �F�s���ȃf�o�C�X�����F2009/09/01(��) 20:36:37 ID:aE2amTL2
����������
443 �F�s���ȃf�o�C�X�����F2009/09/01(��) 21:42:45 ID:GfC+RCLG
NEC���P�ނ�����A�s�[�N�p�t�H�[�}���X�����d�́A�ݒu�ʐςŗL���ȃX�J���^�����ɂȂ���
�]���v����啝�ɒ�R�X�g�A�������ɂȂ�͂��Ȃ̂ɁA�Ȃ�ŕx�m�ʂ̕��S����葝����
�lj���p�܂Ŕ�������H
���Ƃ��ƁA�V�X�e���̑唼��FLOPS�̓X�J���^�ʼn҂��͂���������H
�x�m�ʂɕЊł���Ȃ�A�J��������߂��ăE�n�E�n�ɂȂ�Ȃ��Ⴈ����������B
�Ȃ�ŕx�m�ʂ��ꂵ�����ǎ���H�������Ċ撣��A�Ȃ�Ă��ƂɂȂ�́H
�]���v����啝�ɒ�R�X�g�A�������ɂȂ�͂��Ȃ̂ɁA�Ȃ�ŕx�m�ʂ̕��S����葝����
�lj���p�܂Ŕ�������H
���Ƃ��ƁA�V�X�e���̑唼��FLOPS�̓X�J���^�ʼn҂��͂���������H
�x�m�ʂɕЊł���Ȃ�A�J��������߂��ăE�n�E�n�ɂȂ�Ȃ��Ⴈ����������B
�Ȃ�ŕx�m�ʂ��ꂵ�����ǎ���H�������Ċ撣��A�Ȃ�Ă��ƂɂȂ�́H
444 �F�s���ȃf�o�C�X�����F2009/09/01(��) 21:48:03 ID:eDByv1zF
���Ԃ�A�����\���蓞�B�ڕW���������낤�ˁB
�ォ��Ă�20PF�v��Ƃ��o�Ă�������A�m�d�b���P�ނ��邵�Ȃ��ɂ�����炸
���ǂ̂Ƃ���\�Z�͑��z���ꂽ��Ȃ�����
�ォ��Ă�20PF�v��Ƃ��o�Ă�������A�m�d�b���P�ނ��邵�Ȃ��ɂ�����炸
���ǂ̂Ƃ���\�Z�͑��z���ꂽ��Ȃ�����
445 �F�s���ȃf�o�C�X�����F2009/09/01(��) 21:52:37 ID:GfC+RCLG
>>444
�Ȃ�قǁB�ł���A�܂��܂��x�m�ʂׂ͖���Ȃ��Ƃ��������B
�J�����I����Ă�Ȃ�A�����قLj����Ȃ�̂������̂�����B
����ł��Ԏ���������Ȃ�A�ŏ�����v�悪���������B
�Ȃ�قǁB�ł���A�܂��܂��x�m�ʂׂ͖���Ȃ��Ƃ��������B
�J�����I����Ă�Ȃ�A�����قLj����Ȃ�̂������̂�����B
����ł��Ԏ���������Ȃ�A�ŏ�����v�悪���������B
446 �F�s���ȃf�o�C�X�����F2009/09/01(��) 21:57:26 ID:eDByv1zF
�A�����J�l��
447 �F�s���ȃf�o�C�X�����F2009/09/01(��) 22:18:01 ID:GfC+RCLG
����A���̕Ӑ����ł��Ȃ��Ȃ����ς�NEC�̓P�ނ͐���Ȕ��f���Ƃ������ƂɂȂ邪�B
���[�J�[���ɕ��S�|�������ȏ؋�����A����B
���[�J�[���ɕ��S�|�������ȏ؋�����A����B
448 �F�s���ȃf�o�C�X�����F2009/09/01(��) 22:28:19 ID:eDByv1zF
�v�擖�����烁�[�J���̎����o���͌��܂��Ă�����B
>>441�̃\�[�X�ɂ������Ă����
>>441�̃\�[�X�ɂ������Ă����
449 �F�s���ȃf�o�C�X�����F2009/09/01(��) 22:29:40 ID:FVXDp2S3
�����ᔻ�Ƃ��ŋ��̎g�����ᔻ�Ƃ������
���͂��킮�̂��D���ȃ}�]�����������Ȃ����炵�傤���Ȃ�
���͂��킮�̂��D���ȃ}�]�����������Ȃ����炵�傤���Ȃ�
450 �F�s���ȃf�o�C�X�����F2009/09/01(��) 22:41:07 ID:QQ5OsHay
451 �F�s���ȃf�o�C�X�����F2009/09/01(��) 22:41:09 ID:GfC+RCLG
452 �F�s���ȃf�o�C�X�����F2009/09/01(��) 22:46:38 ID:ovGxFNmo
���[�v����Ȃ�����
>>443�@���@>>444�@���@>>445�@���@>>448
�@���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@��
�@�@�@�@�@�@�@�@�@�@�@�@�@��
>>450
20PF�z���Ȃ炢������
>>443�@���@>>444�@���@>>445�@���@>>448
�@���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@��
�@�@�@�@�@�@�@�@�@�@�@�@�@��
>>450
20PF�z���Ȃ炢������
453 �F�s���ȃf�o�C�X�����F2009/09/01(��) 22:53:06 ID:QQ5OsHay
454 �F�s���ȃf�o�C�X�����F2009/09/01(��) 22:56:39 ID:H9Ulc7c3
455 �F�s���ȃf�o�C�X�����F2009/09/01(��) 23:02:25 ID:qL//RZce
TSUBAME2.0�I�ɂ́A�ėp���̃J�P�����Ȃ�����x���RISCSPARC�̕����^���Ղ����Ă��Ƃ��Ȃ�����������ʂ����ł͂Ȃ��Ƃ�
456 �F�s���ȃf�o�C�X�����F2009/09/01(��) 23:10:38 ID:GfC+RCLG
>>454
�����Ƃ����Ă���x�N�g���̐������ƁA�x�N�g���^�X�J���A���̃n�[�h�ƃ\�t�g�E�G�A�̊J����������A
����畂������p�S����x�m�ʂ̃n�[�h�ƃ\�t�g�J���Ɏg���A����ɓ����v����}�V����(20PF?)����
�J����啝�ɔ��܂�Ƃ����̂ɁA����ɐԎ���������A���Ăǂ��N�\�}�V���Ȃ�A
�������́A�ǂ������v�悪���d����������Ă��Ƃ�FA?
���ꂩ����܂Ƃ��ȉ��Ȃ��ȏ�A�������߂�����Ȃ����B
���̃v���W�F�N�g�͉������Ă����̂ɁA�c�O�Ȃ��Ƃ��B
�����Ƃ����Ă���x�N�g���̐������ƁA�x�N�g���^�X�J���A���̃n�[�h�ƃ\�t�g�E�G�A�̊J����������A
����畂������p�S����x�m�ʂ̃n�[�h�ƃ\�t�g�J���Ɏg���A����ɓ����v����}�V����(20PF?)����
�J����啝�ɔ��܂�Ƃ����̂ɁA����ɐԎ���������A���Ăǂ��N�\�}�V���Ȃ�A
�������́A�ǂ������v�悪���d����������Ă��Ƃ�FA?
���ꂩ����܂Ƃ��ȉ��Ȃ��ȏ�A�������߂�����Ȃ����B
���̃v���W�F�N�g�͉������Ă����̂ɁA�c�O�Ȃ��Ƃ��B
457 �F�s���ȃf�o�C�X�����F2009/09/01(��) 23:22:19 ID:kJ9ihaME
�J����啝�ɔ��܂���Ă̂��Ԉ���Ă��Ȃ��́H
458 �F�s���ȃf�o�C�X�����F2009/09/01(��) 23:28:04 ID:kJ9ihaME
>>450
���̕��͂��ƁA�m���ɕx�m�ʂ̌v�悪70MW���ēǂ߂邯��
70MW���Ă̂́AGreen500('09/06)�ŔėpCPU���g��������
�g�b�v�̃V�X�e����10PFLOPS�ŃX�P�[���������l�݂�������
���̕��͂��ƁA�m���ɕx�m�ʂ̌v�悪70MW���ēǂ߂邯��
70MW���Ă̂́AGreen500('09/06)�ŔėpCPU���g��������
�g�b�v�̃V�X�e����10PFLOPS�ŃX�P�[���������l�݂�������
459 �F�s���ȃf�o�C�X�����F2009/09/01(��) 23:35:19 ID:GfC+RCLG
>>457
�Q�{������A�J����͔����Ƃ܂ł͂����Ȃ��ɂ��Ă��啝�ɔ��܂邾��B
����Ƃ������@����Ă�̂��H
�������痝������������B
�Q�{������A�J����͔����Ƃ܂ł͂����Ȃ��ɂ��Ă��啝�ɔ��܂邾��B
����Ƃ������@����Ă�̂��H
�������痝������������B
460 �F�s���ȃf�o�C�X�����F2009/09/01(��) 23:47:27 ID:e/CZCqFp
461 �F�s���ȃf�o�C�X�����F2009/09/01(��) 23:51:55 ID:H9Ulc7c3
462 �F�s���ȃf�o�C�X�����F2009/09/01(��) 23:52:42 ID:HpajdB/m
>>456
�x�N�g�����̗��p��\�肵�Ă��������@�ւɐV���Ȕ�p���S��������
�Ə����Ă��邪�A�x�m�ʂ̕��S����葝����Ƃ͂ǂ��ɂ������ĂȂ��B
���P�[�u�������S�{�ɑ�����ȂǁA�lj���p����������\��������B
�l�I�ɂ͂�����ǂ����߂ł���̂��C�ɂȂ�B
�x�N�g�����̗��p��\�肵�Ă��������@�ւɐV���Ȕ�p���S��������
�Ə����Ă��邪�A�x�m�ʂ̕��S����葝����Ƃ͂ǂ��ɂ������ĂȂ��B
���P�[�u�������S�{�ɑ�����ȂǁA�lj���p����������\��������B
�l�I�ɂ͂�����ǂ����߂ł���̂��C�ɂȂ�B
463 �F�s���ȃf�o�C�X�����F2009/09/01(��) 23:53:07 ID:H9Ulc7c3
�ԈႦ��
�����J�����2�{�̐��\�̃X�p�R��������
���B
�����J�����2�{�̐��\�̃X�p�R��������
���B
464 �F�s���ȃf�o�C�X�����F2009/09/02(��) 00:01:34 ID:kJ9ihaME
465 �F�s���ȃf�o�C�X�����F2009/09/02(��) 00:17:09 ID:OppWdJtm
�}�b�`���O�t�@���h�Ƃ����ƕ������͂�����
�v�͊J����̒��ɐ�����܂ʼn�������ł����Ƃ������Ƃ���
NEC�������o���͂��������������̂܂ܕx�m�ʂɔ킹����j�]���邩��
�T�Z�v���ɏ�悹������Ȃ������낤
����A����}���R������ʔ�����
�����~���X�Ȃ炫���Ɗ��҂ɉ����Ă����͂�����
�v�͊J����̒��ɐ�����܂ʼn�������ł����Ƃ������Ƃ���
NEC�������o���͂��������������̂܂ܕx�m�ʂɔ킹����j�]���邩��
�T�Z�v���ɏ�悹������Ȃ������낤
����A����}���R������ʔ�����
�����~���X�Ȃ炫���Ɗ��҂ɉ����Ă����͂�����
466 �F�s���ȃf�o�C�X�����F2009/09/02(��) 00:35:41 ID:LHq4KU9k
�~���X�������ƍ��Y�X�p�R���S�ʒ��~���Ē����X�p�R���ɂ����o������
467 �F�s���ȃf�o�C�X�����F2009/09/02(��) 00:48:07 ID:WSXngZRA
���E��D��ւ̒���A���{�̃X�p�R���J����w�����x�m��
http://ascii.jp/elem/000/000/455/455962/
http://ascii.jp/elem/000/000/455/455962/
468 �F�s���ȃf�o�C�X�����F2009/09/02(��) 03:13:14 ID:SKkOzqaU
469 �F�s���ȃf�o�C�X�����F2009/09/02(��) 06:24:03 ID:81ymsH5g
sandy�͂�����
CPU��GPU�ɓ�҂�������Ȋw�Z�p���Z�ł͎g���Ȃ��㕨
CPU��GPU�ɓ�҂�������Ȋw�Z�p���Z�ł͎g���Ȃ��㕨
470 �F�s���ȃf�o�C�X�����F2009/09/02(��) 06:41:05 ID:gObWQ+Ay
>>452
1����ۯ�߽
1����ۯ�߽
471 �F�s���ȃf�o�C�X�����F2009/09/02(��) 06:46:41 ID:xx6L2YXf
>>469
��㉳
��㉳
472 �F�s���ȃf�o�C�X�����F2009/09/02(��) 10:22:36 ID:tmd9fH62
>>462
�L���ł͂�����Ɨ�����Ă��܂������C�������d�v�Ȃ��Ƃ���ȁD
�P�[�u������4�{�ɑ�����Ȃ�āC�����Ȑv�ύX���Ǝv�����D
�l�I�Ȑ��@�����C�V�X�e���̃l�b�g���[�N�����NEC���J����S�����Ă�����Ȃ��̂��ȁD
NEC�̓P�ނɂ���ăl�b�g���[�N�������蒼�����K�v��(�������x�m�ʂ��S������)
���ł�NEC�قǂ̐��\�̃l�b�g���[�N����ꂸ�C���s�������ቺ����10P�̎���������Ȃ�
���d�����Ȃ��̂ŁC�X�J���̃v���Z�b�T���𑝂₵�čő含�\�������グ
���P�[�u���������ʂɑ���
�v���X�����[�X��ǂݕԂ��Ă݂�ƁC����NEC�͐����i�K�ɎQ�����Ȃ��Ƃ���������Ă��Ȃ��āC
�������Ȃ��̂����Ď��������܂��ɂ���Ă��ˁD
�ڍׂȐv����J����ĂȂ���Ŏ��ۂ̂��Ƃ��܂������킩��Ȃ����C����Ȃ�����������ȁH
�L���ł͂�����Ɨ�����Ă��܂������C�������d�v�Ȃ��Ƃ���ȁD
�P�[�u������4�{�ɑ�����Ȃ�āC�����Ȑv�ύX���Ǝv�����D
�l�I�Ȑ��@�����C�V�X�e���̃l�b�g���[�N�����NEC���J����S�����Ă�����Ȃ��̂��ȁD
NEC�̓P�ނɂ���ăl�b�g���[�N�������蒼�����K�v��(�������x�m�ʂ��S������)
���ł�NEC�قǂ̐��\�̃l�b�g���[�N����ꂸ�C���s�������ቺ����10P�̎���������Ȃ�
���d�����Ȃ��̂ŁC�X�J���̃v���Z�b�T���𑝂₵�čő含�\�������グ
���P�[�u���������ʂɑ���
�v���X�����[�X��ǂݕԂ��Ă݂�ƁC����NEC�͐����i�K�ɎQ�����Ȃ��Ƃ���������Ă��Ȃ��āC
�������Ȃ��̂����Ď��������܂��ɂ���Ă��ˁD
�ڍׂȐv����J����ĂȂ���Ŏ��ۂ̂��Ƃ��܂������킩��Ȃ����C����Ȃ�����������ȁH
473 �F�s���ȃf�o�C�X�����F2009/09/02(��) 12:15:57 ID:SKkOzqaU
�P�[�u�������m�[�h����2��ɂȂ�悤�ȃl�b�g���[�N�Ȃ�A
�m�[�h����2�{�ɂȂ�P�[�u������4�{�Ƃ����͓̂��R�B
�m�[�h����2�{�ɂȂ�P�[�u������4�{�Ƃ����͓̂��R�B
474 �F�s���ȃf�o�C�X�����F2009/09/02(��) 13:40:19 ID:D9eZmlRf
>>473
�X�J�����̓g�[���X�����A�g�[���X��O(n)����B
�X�J�����̓g�[���X�����A�g�[���X��O(n)����B
475 �F�s���ȃf�o�C�X�����F2009/09/02(��) 15:02:59 ID:SKkOzqaU
476 �F�s���ȃf�o�C�X�����F2009/09/02(��) 16:35:00 ID:OppWdJtm
�̂��搶���l�͂�����k�قɂ�������x���ꂿ�Ⴄ�˂�
���X���̃V�X�e����HPL�x���`�̂��߂����ɂ������ƃu���b�W�ڑ��������
���������ȃf�U�C���Ȍv�悾�����̂�
���X4�{�̑ш�Őڑ���������ǂ��Ȃ���Ă����H
������3D�g�[���X�ł�
���X���̃V�X�e����HPL�x���`�̂��߂����ɂ������ƃu���b�W�ڑ��������
���������ȃf�U�C���Ȍv�悾�����̂�
���X4�{�̑ш�Őڑ���������ǂ��Ȃ���Ă����H
������3D�g�[���X�ł�
477 �F�s���ȃf�o�C�X�����F2009/09/02(��) 17:02:28 ID:g+1SwRjj
3�����g�[���X�Ȃ�P�[�u�����͂R��ő����Ȃ����H
���Ȃ݂ɍĐv��̃l�b�g���[�N�͂R�����g�[���X�g���Ɣ��\����Ă��邪�A
�Đv�O�̃l�b�g���[�N�̎d�l�ɂ��Č��J����Ă��������H
���Ȃ݂ɍĐv��̃l�b�g���[�N�͂R�����g�[���X�g���Ɣ��\����Ă��邪�A
�Đv�O�̃l�b�g���[�N�̎d�l�ɂ��Č��J����Ă��������H
�����A���߂�B�R�����g�[���X�ł�O(n)���ȁB���Ⴂ���Ă��B
479 �F�s���ȃf�o�C�X�����F2009/09/02(��) 18:41:36 ID:81ymsH5g
������������v���Z�T�ӂ�1�b�Ԃ�1000��������Z�o�����
����ɂ��ւ�炸�A������̃v���Z�T������Ȃ���Ȃ�Ȃ��v���O�����������ق����A�z�Ȃ�
�����ƍH�v�����
10�N�O�̕��ϓI�ȃx�N�g���^�X�[�p�[�R���s���[�^��������1�`�b�v�Ŏ����ł����
���������K�v������̂���
����ɂ��ւ�炸�A������̃v���Z�T������Ȃ���Ȃ�Ȃ��v���O�����������ق����A�z�Ȃ�
�����ƍH�v�����
10�N�O�̕��ϓI�ȃx�N�g���^�X�[�p�[�R���s���[�^��������1�`�b�v�Ŏ����ł����
���������K�v������̂���
480 �F�s���ȃf�o�C�X�����F2009/09/02(��) 19:31:37 ID:SKkOzqaU
>>479
�������U��������K�v������
�������U��������K�v������
481 �F�s���ȃf�o�C�X�����F2009/09/02(��) 19:40:37 ID:SKkOzqaU
10�N�O�Ƃ�����NEC����SX-5���B
�m�[�h������̔\�͂�
���Z128Gflops (32�`�b�v��CPU���\���A�����16�Z�b�g����)
������128GB
���Z�̓����`�b�v�ʼn\�ɂȂ������ǁA128GB�̃������̓����`�b�v�ɂȂ��ĂȂ��ˁB
�m�[�h������̔\�͂�
���Z128Gflops (32�`�b�v��CPU���\���A�����16�Z�b�g����)
������128GB
���Z�̓����`�b�v�ʼn\�ɂȂ������ǁA128GB�̃������̓����`�b�v�ɂȂ��ĂȂ��ˁB
482 �F�s���ȃf�o�C�X�����F2009/09/02(��) 20:11:48 ID:SD6/0kPi
3D�g�[���X�ŁAalltoall�ʐM���̃V�X�e�����ł̑�i���I�œK���V�X�e���H�j���ĂȂɂ��Ƃ�̂��ȁH
483 �F�s���ȃf�o�C�X�����F2009/09/02(��) 20:23:53 ID:NyG0+ukh
���̃N���X���ƁA�X�J���}�V���Ȃ�10PF��20PF�ŊJ����قƂ�Ǔ������Ƃ����Ȃ�킩�邪�A
�����ŕٌ삵�Ă��͂��ꂼ��ŕʂ�CPU�ł��J���������Ȃ̂��ˁB
����Ƃ�����̕x�m�ʃ}�V���̓X�P�[���r���e�B���������瓖���v�悩�班���ł�
�s�[�N���\���グ�邽�߂ɂ͐V���ȃn�[�h�̊J�����K�v�Ȃ̂����H
�����ŕٌ삵�Ă��͂��ꂼ��ŕʂ�CPU�ł��J���������Ȃ̂��ˁB
����Ƃ�����̕x�m�ʃ}�V���̓X�P�[���r���e�B���������瓖���v�悩�班���ł�
�s�[�N���\���グ�邽�߂ɂ͐V���ȃn�[�h�̊J�����K�v�Ȃ̂����H
484 �F�s���ȃf�o�C�X�����F2009/09/02(��) 20:58:13 ID:SKkOzqaU
������Ƒ҂�
>>456��
> �x�N�g���^�X�J���A���̃n�[�h�ƃ\�t�g�E�G�A�̊J����������A
> ��������p
> ��x�m�ʂ̃n�[�h�ƃ\�t�g�J���Ɏg��
��
�Ƃ����̂͊ԈႢ���낤�B
NEC�͐����t�F�[�Y�ȍ~�����������������ŁA
�x�N�g���ƃX�J���̘A�g�����̊J�����ł���ꂽ�Ƃ����b�͕����ĂȂ��B
�Ă������A�J���t�F�[�Y�͂����I����Ă�̂ł���B
>>456��
> �x�N�g���^�X�J���A���̃n�[�h�ƃ\�t�g�E�G�A�̊J����������A
> ��������p
> ��x�m�ʂ̃n�[�h�ƃ\�t�g�J���Ɏg��
��
�Ƃ����̂͊ԈႢ���낤�B
NEC�͐����t�F�[�Y�ȍ~�����������������ŁA
�x�N�g���ƃX�J���̘A�g�����̊J�����ł���ꂽ�Ƃ����b�͕����ĂȂ��B
�Ă������A�J���t�F�[�Y�͂����I����Ă�̂ł���B
485 �F�s���ȃf�o�C�X�����F2009/09/03(��) 17:46:49 ID:pIRXar+u
�X�p�R���Ƃ��ǂ��ł�������
�F���J���̂��ʔ���
�F���J���̂��ʔ���
486 �F�s���ȃf�o�C�X�����F2009/09/03(��) 18:09:39 ID:qvu2ZFxF
�q��F������̓V�~�����[�V�����Ƃ��Ńo���o���X�p�R���g����
487 �F�s���ȃf�o�C�X�����F2009/09/03(��) 18:11:34 ID:pIRXar+u
�܂��e���̂ЂƂł��邱�Ƃ͊m�������
488 �F�s���ȃf�o�C�X�����F2009/09/03(��) 18:17:06 ID:xCyNnefZ
1�l�����ނ�Ȃ�������
489 �F�s���ȃf�o�C�X�����F2009/09/03(��) 19:07:25 ID:pIRXar+u
�i�m�v�����g�Ђɓd�b���Ă�������
490 �F�s���ȃf�o�C�X�����F2009/09/05(�y) 11:20:49 ID:rUEL+895
�搶������Ƃ���
491 �F�s���ȃf�o�C�X�����F2009/09/06(��) 08:41:52 ID:bfR6CdCN
�X�V����ǂ��[
492 �F�s���ȃf�o�C�X�����F2009/09/10(��) 13:32:24 ID:EYQxAIbl
�ێ�[
493 �F�s���ȃf�o�C�X�����F2009/09/10(��) 22:32:51 ID:9V6Kcb0S
��������L���\��l���Ȃ��Ȃ����������
494 �F�s���ȃf�o�C�X�����F2009/09/10(��) 22:38:49 ID:N61bp7NQ
�v���o�A�N�։����܂ő҂��Ă�����
495 �F�s���ȃf�o�C�X�����F2009/09/11(��) 00:20:41 ID:bpAH1va+
���Ȃ�
496 �F�s���ȃf�o�C�X�����F2009/09/11(��) 00:24:16 ID:bpAH1va+
���Ⴀ�A����ɂ�
���\�����̃C�^�`����������E���� ������X�p�R���J���̍s��
http://itpro.nikkeibp.co.jp/article/COLUMN/20090828/336169/
���\�����̃C�^�`����������E���� ������X�p�R���J���̍s��
http://itpro.nikkeibp.co.jp/article/COLUMN/20090828/336169/
497 �F�s���ȃf�o�C�X�����F2009/09/11(��) 02:32:11 ID:aDk6SHd7
�ŋ߂̘b�� 2009�N9 ��05��
http://www.geocities.jp/andosprocinfo/wadai09/20090905.htm
GPGPU�̓K�p����͂ǂ��܂ōL����̂� - NEC/NVIDIA GPGPU�Z�~�i�[���J��
http://journal.mycom.co.jp/articles/2009/09/03/nec_nvidia_gpu/?rt=na
�V�̐��͂̏���
http://www.astroarts.co.jp/news/2009/09/07milky_way_fate/index-j.shtml
�����W�O���̃X�[�p�[�䕗�P���H�@���g���ō����I�㔼��
http://www.47news.jp/CN/200909/CN2009090701000157.html
�u���Ȃ����v���قǃ`�b�v���x�͍����Ȃ���������Ȃ��v�C���l�T�X���V���ȉ��x����@����
http://techon.nikkeibp.co.jp/article/NEWS/20090908/175046/
��B��w�AIBM/Google�̃N���E�h�C�j�V�A�e�B�u�ɎQ��
http://journal.mycom.co.jp/news/2009/09/09/052/?rt=na
�ĕ��]�������F���������́@�����A���W�䂪�߂�@�č������A���J�j�Y����
http://mainichi.jp/select/world/news/20090910dde001040007000c.html
Adaptec�ASSD���p�ɂ��T�[�o�̃p�t�H�[�}���X����\�����[�V�����\
http://journal.mycom.co.jp/articles/2009/09/10/adaptec_maxiq/?rt=na
http://www.geocities.jp/andosprocinfo/wadai09/20090905.htm
GPGPU�̓K�p����͂ǂ��܂ōL����̂� - NEC/NVIDIA GPGPU�Z�~�i�[���J��
http://journal.mycom.co.jp/articles/2009/09/03/nec_nvidia_gpu/?rt=na
�V�̐��͂̏���
http://www.astroarts.co.jp/news/2009/09/07milky_way_fate/index-j.shtml
�����W�O���̃X�[�p�[�䕗�P���H�@���g���ō����I�㔼��
http://www.47news.jp/CN/200909/CN2009090701000157.html
�u���Ȃ����v���قǃ`�b�v���x�͍����Ȃ���������Ȃ��v�C���l�T�X���V���ȉ��x����@����
http://techon.nikkeibp.co.jp/article/NEWS/20090908/175046/
��B��w�AIBM/Google�̃N���E�h�C�j�V�A�e�B�u�ɎQ��
http://journal.mycom.co.jp/news/2009/09/09/052/?rt=na
�ĕ��]�������F���������́@�����A���W�䂪�߂�@�č������A���J�j�Y����
http://mainichi.jp/select/world/news/20090910dde001040007000c.html
Adaptec�ASSD���p�ɂ��T�[�o�̃p�t�H�[�}���X����\�����[�V�����\
http://journal.mycom.co.jp/articles/2009/09/10/adaptec_maxiq/?rt=na
498 �F�s���ȃf�o�C�X�����F2009/09/11(��) 02:32:53 ID:aDk6SHd7
IBM to Build 20-Petaflop Computer for Energy Dept.
http://www.cio.com/article/480446/IBM_to_Build_20_Petaflop_Computer_for_Energy_Dept.
Fujitsu to face strike action
http://www.thomsons.com/page/9923/uk-and-europe/reward-news-knowledge/employee-rewards-and-benefits-news/articles/fujitsu-to-face-strike-action?fromSearch=true
AMD low power DDR3 Opteron is Q2 2010
http://www.fudzilla.com/content/view/15303/1/
TeraGrid Receives $30M NSF Grant
http://www.semiconductor.net/article/339088-TeraGrid_Receives_30M_NSF_Grant.php
OSC Deploys IBM System Expansion
http://www.hpcwire.com/industry/academia/OSC-Deploys-IBM-System-Expansion-56636752.html
Feature - New batch of science gateways hit the spot
http://www.isgtw.org/?pid=1002002
Renewable Energy Made by Mixing Salt and Fresh Water
http://www.physorg.com/news171102611.html
Metadata Performance of Four Linux File Systems
http://www.linux-mag.com/cache/7497/1.html
Cisco UCS, Nexus 1000 virtual switches power labs
http://www.cio.de/news/cio_worldnews/897022/
Supercomputer Uses Flash Storage Drives
http://www.pcworld.com/businesscenter/article/171335/supercomputer_uses_flash_storage_drives.html
http://www.cio.com/article/480446/IBM_to_Build_20_Petaflop_Computer_for_Energy_Dept.
Fujitsu to face strike action
http://www.thomsons.com/page/9923/uk-and-europe/reward-news-knowledge/employee-rewards-and-benefits-news/articles/fujitsu-to-face-strike-action?fromSearch=true
AMD low power DDR3 Opteron is Q2 2010
http://www.fudzilla.com/content/view/15303/1/
TeraGrid Receives $30M NSF Grant
http://www.semiconductor.net/article/339088-TeraGrid_Receives_30M_NSF_Grant.php
OSC Deploys IBM System Expansion
http://www.hpcwire.com/industry/academia/OSC-Deploys-IBM-System-Expansion-56636752.html
Feature - New batch of science gateways hit the spot
http://www.isgtw.org/?pid=1002002
Renewable Energy Made by Mixing Salt and Fresh Water
http://www.physorg.com/news171102611.html
Metadata Performance of Four Linux File Systems
http://www.linux-mag.com/cache/7497/1.html
Cisco UCS, Nexus 1000 virtual switches power labs
http://www.cio.de/news/cio_worldnews/897022/
Supercomputer Uses Flash Storage Drives
http://www.pcworld.com/businesscenter/article/171335/supercomputer_uses_flash_storage_drives.html
499 �F�s���ȃf�o�C�X�����F2009/09/11(��) 02:33:38 ID:aDk6SHd7
Supercomputer Doubles Power
http://www.mauiweekly.com/page/content.detail/id/500282/Supercomputer-Doubles-Power.html?nav=13
> MHPCC celebrates dedication of Mana, its newest and most powerful supercomputer. �gMaui is no longer just a tourist destination�c �h
SSDs Make Entrance into HPC... Finally
http://www.hpcwire.com/blogs/SSDs-Make-Entrance-into-HPC-Finally-57056287.html?ref=287
Water's Molecular Dance
http://www.laboratoryequipment.com/News-water-relationship-runs-hot-cold-090409.aspx?xmlmenuid=51
TACC, McCombs Receive Gifts from Chevron To Educate the Next Generation of Scientists
http://www.utexas.edu/news/2009/09/04/tacc_mccombs_chevron/
LSU Professor Receives Grant to Develop Innovative Data Scheduler
http://www.ddj.com/hpc-high-performance-computing/219501404
POWER7 vs Nehalem-EX
http://www.theinquirer.net/inquirer/review/1532674/power7-vs-nehalem-ex
Cray Awarded Supercomputer Contract From the Korea Meteorological Administration Valued at More Than $40 Million
http://www.earthtimes.org/articles/show/cray-awarded-supercomputer-contract-from,950376.shtml
San Diego supercomputer yields exceptional speed increase
http://www.examiner.com/x-21560-San-Diego-Geek-Culture-Examiner~y2009m9d8-San-Diego-supercomputer-yields-exceptional-speed-increase
Molecular Search For Happier Skin
http://www.emaxhealth.com/2/66/33396/molecular-search-happier-skin.html
NOAA finishes supercomputer
http://gcn.com/articles/2009/09/08/noaa-supercomputer.aspx
http://www.mauiweekly.com/page/content.detail/id/500282/Supercomputer-Doubles-Power.html?nav=13
> MHPCC celebrates dedication of Mana, its newest and most powerful supercomputer. �gMaui is no longer just a tourist destination�c �h
SSDs Make Entrance into HPC... Finally
http://www.hpcwire.com/blogs/SSDs-Make-Entrance-into-HPC-Finally-57056287.html?ref=287
Water's Molecular Dance
http://www.laboratoryequipment.com/News-water-relationship-runs-hot-cold-090409.aspx?xmlmenuid=51
TACC, McCombs Receive Gifts from Chevron To Educate the Next Generation of Scientists
http://www.utexas.edu/news/2009/09/04/tacc_mccombs_chevron/
LSU Professor Receives Grant to Develop Innovative Data Scheduler
http://www.ddj.com/hpc-high-performance-computing/219501404
POWER7 vs Nehalem-EX
http://www.theinquirer.net/inquirer/review/1532674/power7-vs-nehalem-ex
Cray Awarded Supercomputer Contract From the Korea Meteorological Administration Valued at More Than $40 Million
http://www.earthtimes.org/articles/show/cray-awarded-supercomputer-contract-from,950376.shtml
San Diego supercomputer yields exceptional speed increase
http://www.examiner.com/x-21560-San-Diego-Geek-Culture-Examiner~y2009m9d8-San-Diego-supercomputer-yields-exceptional-speed-increase
Molecular Search For Happier Skin
http://www.emaxhealth.com/2/66/33396/molecular-search-happier-skin.html
NOAA finishes supercomputer
http://gcn.com/articles/2009/09/08/noaa-supercomputer.aspx
500 �F�s���ȃf�o�C�X�����F2009/09/11(��) 02:34:19 ID:aDk6SHd7
NCAR partners shifts into high gear
http://www.wyomingbusinessreport.com/article.asp?id=102021
Resource Management in Seconds: The New Era for Virtual Organizations
http://www.hpcwire.com/features/Resource-Management-in-Seconds-The-New-Era-for-Virtual-Organizations-57824902.html
U.S. buys weather supercomputer with twin backup
http://www.computerworld.com/s/article/9137728/U.S._buys_weather_supercomputer_with_twin_backup_?taxonomyId=1
Leaders will need to move quickly on supercomputer facility
http://www.wyomingnews.com/articles/2009/09/09/news/19local_09-09-09.txt
Complete Genomics Demonstrates Its Technology`s Potential by Sequencing 14 Human Genomes for Customers
http://www.reuters.com/article/pressRelease/idUS128169+09-Sep-2009+BW20090909
Ice Gets Bent Out of Shape
http://www.physorg.com/news171729768.html
NOAA supercomputers to forecast better weather?
http://news.cnet.com/8301-17939_109-10347566-2.html
SGI Sets World Records on Standard Performance Evaluation Corporation (SPEC) Benchmarks
http://linux.sys-con.com/node/1100288
SC09 Draws Many New Faces to World`s Premier Supercomputing Event
http://www.reuters.com/article/pressRelease/idUS207797+09-Sep-2009+BW20090909
SC09 �g3D Internet�h Thrust Area
http://www.vizworld.com/2009/09/sc09-3d-internet-thrust-area/?utm_source=footer&utm_medium=recentposts&utm_campaign=layout
http://www.wyomingbusinessreport.com/article.asp?id=102021
Resource Management in Seconds: The New Era for Virtual Organizations
http://www.hpcwire.com/features/Resource-Management-in-Seconds-The-New-Era-for-Virtual-Organizations-57824902.html
U.S. buys weather supercomputer with twin backup
http://www.computerworld.com/s/article/9137728/U.S._buys_weather_supercomputer_with_twin_backup_?taxonomyId=1
Leaders will need to move quickly on supercomputer facility
http://www.wyomingnews.com/articles/2009/09/09/news/19local_09-09-09.txt
Complete Genomics Demonstrates Its Technology`s Potential by Sequencing 14 Human Genomes for Customers
http://www.reuters.com/article/pressRelease/idUS128169+09-Sep-2009+BW20090909
Ice Gets Bent Out of Shape
http://www.physorg.com/news171729768.html
NOAA supercomputers to forecast better weather?
http://news.cnet.com/8301-17939_109-10347566-2.html
SGI Sets World Records on Standard Performance Evaluation Corporation (SPEC) Benchmarks
http://linux.sys-con.com/node/1100288
SC09 Draws Many New Faces to World`s Premier Supercomputing Event
http://www.reuters.com/article/pressRelease/idUS207797+09-Sep-2009+BW20090909
SC09 �g3D Internet�h Thrust Area
http://www.vizworld.com/2009/09/sc09-3d-internet-thrust-area/?utm_source=footer&utm_medium=recentposts&utm_campaign=layout
501 �F�s���ȃf�o�C�X�����F2009/09/11(��) 02:35:39 ID:aDk6SHd7
Sun/Oracle deal leaves customers in the dark
http://www.computerweekly.com/Articles/2009/09/10/237649/sunoracle-deal-leaves-customers-in-the-dark.htm
UK investment helps European Bioinformatics Institute prepare for ELIXIR project
http://www.ethiopianreview.com/health/2250
http://www.computerweekly.com/Articles/2009/09/10/237649/sunoracle-deal-leaves-customers-in-the-dark.htm
UK investment helps European Bioinformatics Institute prepare for ELIXIR project
http://www.ethiopianreview.com/health/2250
502 �F�s���ȃf�o�C�X�����F2009/09/11(��) 20:13:10 ID:2P2TaJFJ
�܂Ƃ߂ăL�^�[�I
503 �F�s���ȃf�o�C�X�����F2009/09/12(�y) 06:58:39 ID:Y8s45Q+Z
ttp://itpro.nikkeibp.co.jp/article/COLUMN/20090828/336169/
> 04�N6���ɒn���V�~�����[�^���ăg�b�v�ɗ�����IBM�́uBlue Gene�v
> ������FORTRAN��C���ꂪ�g�����AECC�i�G���[���J�o���[�@�\�j�������Ă��Ȃ������B
> 08�N6���ɐ��E��ɂȂ����uRoadrunner�v��ECC���Ȃ��A
> FORTRAN��C���ꂪ�g���Ȃ�����R�[�h�g�p�̃}�V���ł���B
> �����҂���ʓI�ɗv������g�������ėp����Nj��������i�Ƃ������A
> �͂Â��ō��グ���Ƃ����������ʂ����Ȃ��B
�c��ȃm�[�h��̌ʂ̃v���Z�b�T��ŁA
�����҂�������FORTRAN��C�̃R�[�h������E�E�E���ꂱ���ς��낤�B
> 04�N6���ɒn���V�~�����[�^���ăg�b�v�ɗ�����IBM�́uBlue Gene�v
> ������FORTRAN��C���ꂪ�g�����AECC�i�G���[���J�o���[�@�\�j�������Ă��Ȃ������B
> 08�N6���ɐ��E��ɂȂ����uRoadrunner�v��ECC���Ȃ��A
> FORTRAN��C���ꂪ�g���Ȃ�����R�[�h�g�p�̃}�V���ł���B
> �����҂���ʓI�ɗv������g�������ėp����Nj��������i�Ƃ������A
> �͂Â��ō��グ���Ƃ����������ʂ����Ȃ��B
�c��ȃm�[�h��̌ʂ̃v���Z�b�T��ŁA
�����҂�������FORTRAN��C�̃R�[�h������E�E�E���ꂱ���ς��낤�B
504 �F�s���ȃf�o�C�X�����F2009/09/12(�y) 09:07:18 ID:lexNmNCP
�R���s���[�^�̐i���̗��j�̓v���O���~���O����i���̗��j�ł�����
���s�����������ʂ����e���Ď�y�ɓ����������i�����Ă����B
�Ƃ���ƁA���s����50%�����ō�������œ����悤�ȃV�X�e�����A������Ȃ����H
�m���ɁA���̋L���̓R���s���[�^�m��Ȃ��l�Ԃ��������悤�ɂ��������Ȃ��Ĉ�a�����邪�B
���s�����������ʂ����e���Ď�y�ɓ����������i�����Ă����B
�Ƃ���ƁA���s����50%�����ō�������œ����悤�ȃV�X�e�����A������Ȃ����H
�m���ɁA���̋L���̓R���s���[�^�m��Ȃ��l�Ԃ��������悤�ɂ��������Ȃ��Ĉ�a�����邪�B
505 �F�s���ȃf�o�C�X�����F2009/09/12(�y) 16:51:08 ID:xMr55Mrr
>IBM�́uBlue Gene�v�́A31�r�b�gPOWERPC604�̑g�ݍ��^�v���Z�b�T�𓋍�
>��
����Ȃ�����ˁB
>��
����Ȃ�����ˁB
506 �F�s���ȃf�o�C�X�����F2009/09/12(�y) 17:39:02 ID:Y8s45Q+Z
>>504
FORTRAN��C���A���ꂪ�g�����ꑱ���Ă���Ƃ͂����A�g��������̂́A
�v���O���~���O����̐i���ł��Ȃ���A��y�ɓ����������ł��Ȃ����낤�B
FORTRAN��C���A���ꂪ�g�����ꑱ���Ă���Ƃ͂����A�g��������̂́A
�v���O���~���O����̐i���ł��Ȃ���A��y�ɓ����������ł��Ȃ����낤�B
507 �F�s���ȃf�o�C�X�����F2009/09/12(�y) 18:36:31 ID:mtf4FOGt
>>503
�S�~�L�����ȁB�����Ė��������̂�������A
Cray Jaguar �͈Ӑ}�I�ɊO����Ă���B�����
�L���ɂ͉R�������Ă���B BlueGene �p��Fortran
���C�u�����͑��݂���B
�S�~�L�����ȁB�����Ė��������̂�������A
Cray Jaguar �͈Ӑ}�I�ɊO����Ă���B�����
�L���ɂ͉R�������Ă���B BlueGene �p��Fortran
���C�u�����͑��݂���B
508 �F�s���ȃf�o�C�X�����F2009/09/12(�y) 21:04:44 ID:rV/1nk4V
GPGPU�̌�`��S���ł��邠�̂����̉A�d�Ȃ悗
509 �F�s���ȃf�o�C�X�����F2009/09/12(�y) 21:18:47 ID:UeMjJnnb
cray�͐_������
�ǂ��ł���������GPGPU�ł����Ȃ�sparc�Ȃg��Ȃ���x86�ł�����
�ǂ��ł���������GPGPU�ł����Ȃ�sparc�Ȃg��Ȃ���x86�ł�����
510 �F�s���ȃf�o�C�X�����F2009/09/12(�y) 21:22:54 ID:qyQBmSEj
>>508
GPU�̉��Z��ɂ�ECC�Ȃ�ĕt���ĂȂ����Ă��Ƃ̓X���[�Ȃ�H
GPU�̉��Z��ɂ�ECC�Ȃ�ĕt���ĂȂ����Ă��Ƃ̓X���[�Ȃ�H
511 �F�s���ȃf�o�C�X�����F2009/09/12(�y) 21:53:32 ID:Y8s45Q+Z
���Z�ɂ킸���ȃG���[�������Ă����ʂւ̉e���������ł���悤�Ȍv�Z���@���m������A�Ƃ����I����������ˁB
512 �F�s���ȃf�o�C�X�����F2009/09/12(�y) 21:57:54 ID:UQun/qFS
��������Ȃ��ǁA>>503����Blue Gene��
ECC���Ȃ�����(�ق�ƂɂȂ���?)��ᔻ���Ă邩�炳
ECC���Ȃ�����(�ق�ƂɂȂ���?)��ᔻ���Ă邩�炳
513 �F�s���ȃf�o�C�X�����F2009/09/12(�y) 22:40:58 ID:Y8s45Q+Z
�������ˁE�E�E
�܂����o������A�x�m�ʂ��p�ӂ������e���ێʂ��ł��傤�B
�܂����o������A�x�m�ʂ��p�ӂ������e���ێʂ��ł��傤�B
514 �F�s���ȃf�o�C�X�����F2009/09/12(�y) 23:07:00 ID:hY/WX7/b
���ꂾ��GPGPU�̂����肪�C�~�t�Ȃ��
515 �F�s���ȃf�o�C�X�����F2009/09/12(�y) 23:11:45 ID:hY/WX7/b
�����APC�N���X�^�̕��ł͕x�m�ʂ�GPGPU������Ȃ̂��ȁH
516 �F�s���ȃf�o�C�X�����F2009/09/13(��) 00:30:19 ID:x4lVnINI
�~�b�V�����N���e�B�J���A���Z�@�փo�b�N�G���h�Ɏg����Ȃ�����
��p���A��Ϗ�Q���ł��܂�Ȃ�����i�_�j
��p���A��Ϗ�Q���ł��܂�Ȃ�����i�_�j
517 �F�s���ȃf�o�C�X�����F2009/09/13(��) 01:02:23 ID:8jrXjYrK
�����̏�Q����āA�ǂ��Ȃ��Ă�낤�B
�n���V�~�����[�^(����)�̂悤�ɒP�i�N���X�o�[�Ȃ�A
��Q���̃m�[�h�͐藣���Đ�͊O�ɂȂ邾�������A
3D�g�[���X���ƁA��Q���̃m�[�h�̓l�b�N�ɂȂ��?
�n���V�~�����[�^(����)�̂悤�ɒP�i�N���X�o�[�Ȃ�A
��Q���̃m�[�h�͐藣���Đ�͊O�ɂȂ邾�������A
3D�g�[���X���ƁA��Q���̃m�[�h�̓l�b�N�ɂȂ��?
518 �F�s���ȃf�o�C�X�����F2009/09/13(��) 01:06:13 ID:8jrXjYrK
����? Blue Gene���āAECC�t���Ă��悤�ȁE�E�E�B
519 �F�s���ȃf�o�C�X�����F2009/09/13(��) 01:14:58 ID:8jrXjYrK
���邥 Blue Gene�AFortran��C/C++��IBM�����Ă邼�B
�ق�ƃf�^�����Ȑ��n���ȁB
�ق�ƃf�^�����Ȑ��n���ȁB
520 �F�s���ȃf�o�C�X�����F2009/09/13(��) 02:04:17 ID:xlN/JLc2
IBM���N�Y�Ȃ͎̂��������R�͂������
521 �F�s���ȃf�o�C�X�����F2009/09/13(��) 02:38:21 ID:ecUU6ony
���Ă�[�ˁ���
522 �F�s���ȃf�o�C�X�����F2009/09/13(��) 12:37:55 ID:HM+ZJ+8c
>>517
���ʂ́A�\���m�[�h�������Ă���ƌ������낤�ˁB
���� 3D �g�[���X�� Cray XT �����������B
���Ȃ݂ɁAES2 �ɗ\��������B
���ʂ́A�\���m�[�h�������Ă���ƌ������낤�ˁB
���� 3D �g�[���X�� Cray XT �����������B
���Ȃ݂ɁAES2 �ɗ\��������B
523 �F�s���ȃf�o�C�X�����F2009/09/13(��) 12:54:37 ID:HM+ZJ+8c
�lj��ƏC���B
>522
���Ȃ݂ɁAES2 �ɂ��\���m�[�h������B
http://suchix.kek.jp/keksim06/Files/0207/BlueGene.pdf ����
p8 ���
���ׂẴ������A���C�A�o�X��ECC�Aparity�A�܂���CRC�ŕی�
p19 ���
FORTRAN/C/C++�ŏ����ꂽ�A�v���P�[�V����
�H IBM XL compiler for FORTRAN version 9.1(XLF)
�H IBM XL compiler for C/C++ version 7.0 (XLC)
�H GNU compiler (gcc, g++, g77 ��)
>522
���Ȃ݂ɁAES2 �ɂ��\���m�[�h������B
http://suchix.kek.jp/keksim06/Files/0207/BlueGene.pdf ����
p8 ���
���ׂẴ������A���C�A�o�X��ECC�Aparity�A�܂���CRC�ŕی�
p19 ���
FORTRAN/C/C++�ŏ����ꂽ�A�v���P�[�V����
�H IBM XL compiler for FORTRAN version 9.1(XLF)
�H IBM XL compiler for C/C++ version 7.0 (XLC)
�H GNU compiler (gcc, g++, g77 ��)
524 �F�s���ȃf�o�C�X�����F2009/09/13(��) 13:18:51 ID:HtzNYFNt
>>513
ttp://jp.fujitsu.com/solutions/saas/interview/crm/
�̍����ɂ���z���L���̃G�f�B�^�݂������ˁB
�x�m�ʂƂ̌q����͂���悤������A�˗��L���̐�������ȁB
ttp://jp.fujitsu.com/solutions/saas/interview/crm/
�̍����ɂ���z���L���̃G�f�B�^�݂������ˁB
�x�m�ʂƂ̌q����͂���悤������A�˗��L���̐�������ȁB
525 �F�s���ȃf�o�C�X�����F2009/09/13(��) 13:23:06 ID:HtzNYFNt
526 �F�s���ȃf�o�C�X�����F2009/09/13(��) 17:18:34 ID:9eoAMPdt
���w�C���e�^�̗�����C��������ߕ߁c�P�P�O�O���~�ˋ�
������C��������ߕ߁�1100���w�C�e�^�|�ˋ��Ō����߁E�x����
�ߋ��Ɍ�����s���������{�g�b�v���A�O���ł��]���|���R�Ȋw�ō����B��E����
�Ǝ҂ɍ������o����t��������������A�u��d���v���|�a�c�e�^�Ҕw�C����
�������w�C���������x�̕s�������p�@�[�i�̊m�F���蔲��
�u�̎��������Ă���Ζʓ|����v����C���i�Ŏ��_���|�����w�C�����E�x����
�����g�������A�������蔲�������`�F�b�N�J�n�Ŗ��ԗ��p�|������C�������w�C
�������w�C�������ʂ̋Ǝ҂Ɏ��������P�U�O�O���~�ԍ�
�t�����s��7�����o�����w�C�e�^�̗����������|�x����
�������w�C���u���̌����҂��܂˂��v�@�ߋ��ɂ��ˋ���
������C��������ߕ߁�1100���w�C�e�^�|�ˋ��Ō����߁E�x����
�ߋ��Ɍ�����s���������{�g�b�v���A�O���ł��]���|���R�Ȋw�ō����B��E����
�Ǝ҂ɍ������o����t��������������A�u��d���v���|�a�c�e�^�Ҕw�C����
�������w�C���������x�̕s�������p�@�[�i�̊m�F���蔲��
�u�̎��������Ă���Ζʓ|����v����C���i�Ŏ��_���|�����w�C�����E�x����
�����g�������A�������蔲�������`�F�b�N�J�n�Ŗ��ԗ��p�|������C�������w�C
�������w�C�������ʂ̋Ǝ҂Ɏ��������P�U�O�O���~�ԍ�
�t�����s��7�����o�����w�C�e�^�̗����������|�x����
�������w�C���u���̌����҂��܂˂��v�@�ߋ��ɂ��ˋ���
527 �F�s���ȃf�o�C�X�����F2009/09/13(��) 18:52:14 ID:8jrXjYrK
>>522
�e�m�[�h�ɁA��Q�m�[�h�̑���ɗ\���m�[�h�Ɛڑ����邽�߂̗]���Ȍ����t���Ă��?
����Ƃ��A��Q�̃m�[�h���g��Ȃ��悤�ɁA�W���u���m�[�h�Ɋ��蓖�Ă��?
�����K�͂̃W���u��ϖ؍H�̂悤�ɏ��ɔz�u���ď�Q�m�[�h�������̂͂ł��Ă��A
�قڑS�m�[�h������悤�ȑ�K�͂ȃW���u�ł́A�W���u���̂Ɏ������ɑΉ�����@�\���K�v����ˁB
�����āA�����͑�K�͂ȃW���u�Ƀ`�������W���邽�߂̃V�X�e������ˁB
�N�ɐ����x���`�}�[�N���点�邾���ŁA���i�͒����K�͂̃W���u�������点�Ȃ��E�E�E���Ă̂�����?
>>524
���o�Ƃ̑����ɂȂ��Ă����l���킭�A���o�ɋL���������Ă��炢������A
�܂����ɁA�������Ђ��������̍L������o�ɏo���ׂ�
���ɁA�L���������ė~�����^�C�~���O�Ńv���X�����[�X�𑗕t���A�ɂ߂ĒZ���Ԃŏ�����悤�ɔz��������������ׂ�
���������Ă��Ȃ���Ђ́A�Ȃ�ł����̐��i�͋L���ɂȂ�Ȃ�? ��ނ����Ȃ�? ���ĕs�v�c����Ƃ��B
�e�m�[�h�ɁA��Q�m�[�h�̑���ɗ\���m�[�h�Ɛڑ����邽�߂̗]���Ȍ����t���Ă��?
����Ƃ��A��Q�̃m�[�h���g��Ȃ��悤�ɁA�W���u���m�[�h�Ɋ��蓖�Ă��?
�����K�͂̃W���u��ϖ؍H�̂悤�ɏ��ɔz�u���ď�Q�m�[�h�������̂͂ł��Ă��A
�قڑS�m�[�h������悤�ȑ�K�͂ȃW���u�ł́A�W���u���̂Ɏ������ɑΉ�����@�\���K�v����ˁB
�����āA�����͑�K�͂ȃW���u�Ƀ`�������W���邽�߂̃V�X�e������ˁB
�N�ɐ����x���`�}�[�N���点�邾���ŁA���i�͒����K�͂̃W���u�������点�Ȃ��E�E�E���Ă̂�����?
>>524
���o�Ƃ̑����ɂȂ��Ă����l���킭�A���o�ɋL���������Ă��炢������A
�܂����ɁA�������Ђ��������̍L������o�ɏo���ׂ�
���ɁA�L���������ė~�����^�C�~���O�Ńv���X�����[�X�𑗕t���A�ɂ߂ĒZ���Ԃŏ�����悤�ɔz��������������ׂ�
���������Ă��Ȃ���Ђ́A�Ȃ�ł����̐��i�͋L���ɂȂ�Ȃ�? ��ނ����Ȃ�? ���ĕs�v�c����Ƃ��B
528 �F�s���ȃf�o�C�X�����F2009/09/13(��) 20:07:48 ID:zaPmjZlR
�S�m�[�h���āALINPAC�̂��Ƃł������H
�܂��e�w�P�̂悤�Ɏ��s���ԋL�^�����͖̂������Ǝv���܂����B�B�B
�܂��e�w�P�̂悤�Ɏ��s���ԋL�^�����͖̂������Ǝv���܂����B�B�B
529 �F�s���ȃf�o�C�X�����F2009/09/13(��) 20:53:59 ID:8jrXjYrK
>>528
linpack�x���`�}�[�N��(�X�|���T�[�ւ̃A�s�[���Ƃ���)������ǁA
10PF�łȂ���Όv�Z�ł��Ȃ��悤�ȃA�v���P�[�V��������������A�Ƃ����̂������ł��B
linpack�x���`�}�[�N��(�X�|���T�[�ւ̃A�s�[���Ƃ���)������ǁA
10PF�łȂ���Όv�Z�ł��Ȃ��悤�ȃA�v���P�[�V��������������A�Ƃ����̂������ł��B
>>527
��Q�m�[�h�Ɋւ��ẮA���ʂ͌�ҁB�W���u�����蓖�ĂȂ��悤�ɂ���B
��Q�����m�[�h�œ����Ă����W���u(�ُ�I������)�͍ē������邱�Ƃ�
�Ȃ�B���ꂩ��A���R�m�[�h��������Ȃ���W���u�͎��s�ł��Ȃ�
�킯������A�܂��S�m�[�h�������悤�ȃW���u�͏�Q���͎��s�s�B
���i�͒����K�͂Ƃ����b�́A�ǂ��̌v�Z�@�Z���^�[(ES�Z���^�[���܂�)
�ł����̒ʂ�B�������A>>529 �̂悤�ɔ��ɑ�K�͂ȃ��\�[�X��
�K�v�Ƃ���v�Z������̂ŁA����͓��ʂɎ��Ԃ����蓖�ĂĎ��s����B
�����A10PE �S���Ƃ����b�͂Ȃ��Ǝv���B�����������\���m�[�h��
�����ƃX�P�[���r���e�B���o��Ƃ����b�͂܂��Ȃ��͂��BCray jaguar
�ł�������1���m�[�h���炢�B
��Q�m�[�h�Ɋւ��ẮA���ʂ͌�ҁB�W���u�����蓖�ĂȂ��悤�ɂ���B
��Q�����m�[�h�œ����Ă����W���u(�ُ�I������)�͍ē������邱�Ƃ�
�Ȃ�B���ꂩ��A���R�m�[�h��������Ȃ���W���u�͎��s�ł��Ȃ�
�킯������A�܂��S�m�[�h�������悤�ȃW���u�͏�Q���͎��s�s�B
���i�͒����K�͂Ƃ����b�́A�ǂ��̌v�Z�@�Z���^�[(ES�Z���^�[���܂�)
�ł����̒ʂ�B�������A>>529 �̂悤�ɔ��ɑ�K�͂ȃ��\�[�X��
�K�v�Ƃ���v�Z������̂ŁA����͓��ʂɎ��Ԃ����蓖�ĂĎ��s����B
�����A10PE �S���Ƃ����b�͂Ȃ��Ǝv���B�����������\���m�[�h��
�����ƃX�P�[���r���e�B���o��Ƃ����b�͂܂��Ȃ��͂��BCray jaguar
�ł�������1���m�[�h���炢�B
531 �F�s���ȃf�o�C�X�����F2009/09/14(��) 01:56:13 ID:ty8Btchf
>>530
�܂�A
10PF���̑�K�͂ȃX�p�R���Ƃ����̂́A10PF�̌v�Z�����邽�߂̂��̂ł͂Ȃ��A
��Q�m�[�h������邱�ƂŐ��������W���u�̃T�C�Y��(�S�̂̃m�[�h���𑝂₷���Ƃ�)�ł������傫������
�Ƃ����̂��_����1�Ȃ̂ˁB
������Cray��XT�̂悤�ɃX�C�b�`�Ȃ���3D�g�[���X��g�ނ̂��낤���B
�x�m�ʂ́A�ʐM�@�탁�[�J�[�ł�����킯�ŁA��l�b�g���[�N�̌��N���X�R�l�N�g�̂��߂̋Z�p�������Ă�B
�ʐM�̒��g�����ĐU�蕪����悤�Ȃ��Ƃ͂ł����Ƃ��A��Q���ɐڑ���芷����͓̂��ӂ��Ǝv���B
�ƂȂ�ƁA3D�g�[���X�ɑg�ނ̂ł͂Ȃ��A�����p�b�`�x�C�̂悤�Ȃ��̂���āA3D�g�[���X��g�ނ̂��ȁB
����Ȃ�A��Q�����������m�[�h��\���̃m�[�h�Ƃ����������ւ��邱�Ƃ��\����ˁB
�܂�A
10PF���̑�K�͂ȃX�p�R���Ƃ����̂́A10PF�̌v�Z�����邽�߂̂��̂ł͂Ȃ��A
��Q�m�[�h������邱�ƂŐ��������W���u�̃T�C�Y��(�S�̂̃m�[�h���𑝂₷���Ƃ�)�ł������傫������
�Ƃ����̂��_����1�Ȃ̂ˁB
������Cray��XT�̂悤�ɃX�C�b�`�Ȃ���3D�g�[���X��g�ނ̂��낤���B
�x�m�ʂ́A�ʐM�@�탁�[�J�[�ł�����킯�ŁA��l�b�g���[�N�̌��N���X�R�l�N�g�̂��߂̋Z�p�������Ă�B
�ʐM�̒��g�����ĐU�蕪����悤�Ȃ��Ƃ͂ł����Ƃ��A��Q���ɐڑ���芷����͓̂��ӂ��Ǝv���B
�ƂȂ�ƁA3D�g�[���X�ɑg�ނ̂ł͂Ȃ��A�����p�b�`�x�C�̂悤�Ȃ��̂���āA3D�g�[���X��g�ނ̂��ȁB
����Ȃ�A��Q�����������m�[�h��\���̃m�[�h�Ƃ����������ւ��邱�Ƃ��\����ˁB
532 �F�s���ȃf�o�C�X�����F2009/09/14(��) 06:48:41 ID:ItaxtJCt
>>531
�ϑz��
�ϑz��
533 �F�s���ȃf�o�C�X�����F2009/09/14(��) 07:46:03 ID:1dT9PV1V
>>531
�܂��A�ǂ̂悤�ȕ��@����낤�Ƃ��^�p�m�[�h�����ێ�������
�ǂ��킯�ŁA���I�ɐ�ւ���͉̂^�p�S�̂��猩��A�����X�N
���Ǝv�����ǁB
>�x�m�ʂ́A�ʐM�@�탁�[�J�[�ł�����킯�ŁA��l�b�g���[�N�̌��N���X�R�l�N�g�̂��߂̋Z�p�������Ă�
���܂���҂��Ă͂����Ȃ��BCray �݂����� CPU �͔ėp�ł��̕� 3D�g�[���X
(SeaStar)�ɊJ���������W�����Ă���킯�ł͂Ȃ�����ȁB
�܂��A�ǂ̂悤�ȕ��@����낤�Ƃ��^�p�m�[�h�����ێ�������
�ǂ��킯�ŁA���I�ɐ�ւ���͉̂^�p�S�̂��猩��A�����X�N
���Ǝv�����ǁB
>�x�m�ʂ́A�ʐM�@�탁�[�J�[�ł�����킯�ŁA��l�b�g���[�N�̌��N���X�R�l�N�g�̂��߂̋Z�p�������Ă�
���܂���҂��Ă͂����Ȃ��BCray �݂����� CPU �͔ėp�ł��̕� 3D�g�[���X
(SeaStar)�ɊJ���������W�����Ă���킯�ł͂Ȃ�����ȁB
534 �F�s���ȃf�o�C�X�����F2009/09/14(��) 08:15:53 ID:DjkbCgxT
�P�ނ���NEC���ʐM�@�탁�[�J�[�������킯����
535 �F�s���ȃf�o�C�X�����F2009/09/14(��) 22:11:24 ID:ty8Btchf
����n���V�~�����[�^���A�R���s���[�^�Ƃ������̓l�b�g���[�N�̉������������̂́A�ʐM�@�탁�[�J�[�ł�����NEC�炵����ȁB
536 �F�s���ȃf�o�C�X�����F2009/09/15(��) 11:35:20 ID:fRWu/GwP
�G�`�[���N���Q�݂���
537 �F�s���ȃf�o�C�X�����F2009/09/15(��) 16:26:17 ID:aaTuQD7k
10PF�Ȃ��ƌv�Z�ł��Ȃ��悤�ȃA�v���P�[�V����������������ď�k����H
�R�A���Ȃ�Ƃ���������10PF�K�v�Ȃ�O���b�h�ŏW�߂�
�R�A���Ȃ�Ƃ���������10PF�K�v�Ȃ�O���b�h�ŏW�߂�
538 �F�s���ȃf�o�C�X�����F2009/09/15(��) 22:25:06 ID:PVQfu+tR
>>537
�������k����H
�������k����H
539 �F�s���ȃf�o�C�X�����F2009/09/15(��) 22:37:52 ID:0v2aJdvh
�x�m�ʂ͂��܂c�Ƃ��Ă邩��
540 �F�s���ȃf�o�C�X�����F2009/09/16(��) 00:03:52 ID:UTWniFtw
541 �F�s���ȃf�o�C�X�����F2009/09/16(��) 03:19:49 ID:ZcDBPQUr
�Ƃ肠������������S���g����Linpack���������āA�������U���ȏ�o����i�_�ł́B
542 �F�s���ȃf�o�C�X�����F2009/09/16(��) 15:13:29 ID:dJ++zR/B
>>538
���H
>>540
�ނ肾��
���̉�͂Ȃ̂ɁA���d�r�H480�m�[�h�ł���4.6TF�Ƃ��A����10���ȉ������B
��������A�v�Z�ʂ�2000�{�ɂ���ƁA�K�v�Ȍv�Z���Ԃ�2000�{�ɂȂ��
�����P�ɂd�r���Ⴡ����������Ȃ�������������
���H
>>540
�ނ肾��
���̉�͂Ȃ̂ɁA���d�r�H480�m�[�h�ł���4.6TF�Ƃ��A����10���ȉ������B
��������A�v�Z�ʂ�2000�{�ɂ���ƁA�K�v�Ȍv�Z���Ԃ�2000�{�ɂȂ��
�����P�ɂd�r���Ⴡ����������Ȃ�������������
543 �F�s���ȃf�o�C�X�����F2009/09/17(��) 16:50:51 ID:SutZpSqw
�}�b�L�[�m�����������������
ttp://jun.artcompsci.org/journal/journal-2009-09.html#14
ttp://jun.artcompsci.org/journal/journal-2009-09.html#14
544 �F�s���ȃf�o�C�X�����F2009/09/17(��) 20:35:36 ID:UsuT4k/E
Hot Chips 21 - 3���L���b�V�����������IBM��8�R�A�v���Z�T�uPOWER7�v
http://journal.mycom.co.jp/articles/2009/09/16/hot_chips21_power7/index.html
Computational Efficiency in Modern Processors
http://www.realworldtech.com/page.cfm?ArticleID=RWT090909050230
http://journal.mycom.co.jp/articles/2009/09/16/hot_chips21_power7/index.html
Computational Efficiency in Modern Processors
http://www.realworldtech.com/page.cfm?ArticleID=RWT090909050230
545 �F�s���ȃf�o�C�X�����F2009/09/18(��) 06:40:29 ID:dANn/JMM
herumi����GRAPE-DR�`���[��������
���E��ɂȂ�邩��?
���E��ɂȂ�邩��?
546 �F�s���ȃf�o�C�X�����F2009/09/19(�y) 02:27:21 ID:iXftjsRM
ttp://www.asahi.com/politics/update/0919/TKY200909180386.html
> �t�c�Ō��߂����������j�́A���s�����̑ΏۂƂ���
>�@�i�P�j�n�������c�̌����ȊO�̊������
> �i�Q�j�Ɨ��s���@�l�A������w�@�l�A�����̎{�ݐ�����
> �i�R�j�����ɂ��G�R�J�[��n��f�W�^���e���r�̍w����Ȃǂ�������
�e���ł̃X�p�R���̍w���A������ɑ�_���[�W�ł���?
�����������Ƃ��L�����Z���Ƃ����肤��̂��낤���B
> �t�c�Ō��߂����������j�́A���s�����̑ΏۂƂ���
>�@�i�P�j�n�������c�̌����ȊO�̊������
> �i�Q�j�Ɨ��s���@�l�A������w�@�l�A�����̎{�ݐ�����
> �i�R�j�����ɂ��G�R�J�[��n��f�W�^���e���r�̍w����Ȃǂ�������
�e���ł̃X�p�R���̍w���A������ɑ�_���[�W�ł���?
�����������Ƃ��L�����Z���Ƃ����肤��̂��낤���B
547 �F�s���ȃf�o�C�X�����F2009/09/19(�y) 10:23:09 ID:GxFYn1yB
�������ꂽ����(���Ăق�)����Θd�G���I�N����
548 �F�s���ȃf�o�C�X�����F2009/09/19(�y) 10:41:04 ID:Uf/QpDho
���ł�LINPAC���\���E��͖��������A�܂��������Ă��������Ȃ���Ȃ��Ǝv��
549 �F�s���ȃf�o�C�X�����F2009/09/19(�y) 11:07:40 ID:iXftjsRM
>>548
���Ƃ���1�N�������ĐQ�����Ă��A�v���Z�b�T�̐��\��1�N�����サ�܂����B
���ΓI�ɂ�1�N���̐��\���ቺ�����ł���B
���������͍̂ŏI�i�K�ł͈�C�萬�ō\�z�����܂�Ȃ��ƁA���Ȃ�ł��B
���Ƃ���1�N�������ĐQ�����Ă��A�v���Z�b�T�̐��\��1�N�����サ�܂����B
���ΓI�ɂ�1�N���̐��\���ቺ�����ł���B
���������͍̂ŏI�i�K�ł͈�C�萬�ō\�z�����܂�Ȃ��ƁA���Ȃ�ł��B
550 �F�s���ȃf�o�C�X�����F2009/09/19(�y) 13:30:40 ID:v8VvHhVq
�܂����N����V�����̂����������Ȃ�
551 �F�s���ȃf�o�C�X�����F2009/09/19(�y) 14:03:23 ID:iXftjsRM
��������GRAPE-DR�̑���A�Ȃ��ˁB
552 �F�s���ȃf�o�C�X�����F2009/09/20(��) 17:31:21 ID:b3cJZm2E
>>551
eAsic�̑㗝�X�Ɖ���Ă�݂���������A�����Ă͂���낤�ȁB
eAsic�̑㗝�X�Ɖ���Ă�݂���������A�����Ă͂���낤�ȁB
553 �F�s���ȃf�o�C�X�����F2009/09/20(��) 18:00:44 ID:wXCf1ADF
eASIC�Ȃ�ĉ������Ȃ�̉c�ƃg�[�N�ɂ܂�܂ƈ����������Ă�̂��B
�搶�͂��ꂾ����B
�搶�͂��ꂾ����B
554 �F�s���ȃf�o�C�X�����F2009/09/20(��) 18:04:26 ID:LI0fZRyH
>>553
�����Ƃ������c�̉c�Ƃ��������Ă��Ă�������
�����Ƃ������c�̉c�Ƃ��������Ă��Ă�������
555 �F�s���ȃf�o�C�X�����F2009/09/20(��) 18:20:24 ID:/fkrb+A6
����V-GRAPE�ւ̓�������
556 �F�s���ȃf�o�C�X�����F2009/09/20(��) 18:53:00 ID:b3cJZm2E
�Ƃ��g����Ȃ�V���̂܂܂͓������B
�}�L�[�m��V�ł̓������������Č����Ă邯�ǁA�Ƃ�nextreme2��
���\����Ă鎑���ł͂���ȂɃ��������Ȃ��݂����������B
�}�L�[�m��V�ł̓������������Č����Ă邯�ǁA�Ƃ�nextreme2��
���\����Ă鎑���ł͂���ȂɃ��������Ȃ��݂����������B
557 �F�s���ȃf�o�C�X�����F2009/09/20(��) 19:29:38 ID:/fkrb+A6
������DRAM�`�b�v�Ɏ�̉��Z��H��t������̂͂ǂ���B
�ʏ��DRAM�ƌ݊�������������A�z�X�gI/F���������}�b�v�Ŋm�ۂł���B
1���PC��DIMM��8���Ƃ���A���W�X�^�[�h��32�`�b�v�~8����256�`�b�v�B
GRAPE-DR��4�`�b�v�~2�{�[�h��4096PE�����Ȃ�A1�`�b�v��16PE������Ηǂ��B
16PE�̏���d�͂�2W���炢����?
���ʂ�DRAM�`�b�v�̍ő�p�b�P�[�W������0.5W���x������E�E�E�������B
�ʏ��DRAM�ƌ݊�������������A�z�X�gI/F���������}�b�v�Ŋm�ۂł���B
1���PC��DIMM��8���Ƃ���A���W�X�^�[�h��32�`�b�v�~8����256�`�b�v�B
GRAPE-DR��4�`�b�v�~2�{�[�h��4096PE�����Ȃ�A1�`�b�v��16PE������Ηǂ��B
16PE�̏���d�͂�2W���炢����?
���ʂ�DRAM�`�b�v�̍ő�p�b�P�[�W������0.5W���x������E�E�E�������B
558 �F�s���ȃf�o�C�X�����F2009/09/22(��) 00:47:01 ID:s0Hrrq7L
>>541
�ȂɐQ�ڂ������ƌ����Ă�́B
ES�͎��s�ƃA�������l�K�L���������B
TOP500�AHPCC�A�S�[�h���x���܂��̑����Œ�����낗
�ȂɐQ�ڂ������ƌ����Ă�́B
ES�͎��s�ƃA�������l�K�L���������B
TOP500�AHPCC�A�S�[�h���x���܂��̑����Œ�����낗
559 �F�s���ȃf�o�C�X�����F2009/09/22(��) 08:59:16 ID:PzfEpCN/
�����o�b�N������Ђ̉c�Ƃ���
560 �F�s���ȃf�o�C�X�����F2009/09/22(��) 09:58:18 ID:PIxo8ibB
�����v���W�F�N�g�ɉ��炩�̖�肪�������Ǝv����ANEC�Ɠ��������E�����̂́B
����ڂ��藧�h�œ��e������Ȃ��A
�u���C�N�X���[�̂��߂̊J��������͂����A
���ǂ͊������i���ʂɕ��ׂ�悤�Ȃ��̂ŁA
���[�J�[�̎����o���͑��������ŁA
�������A�u���C�N�X���[���Ȃ��̂�����A
���̃��[�U�[�ɔ��鐻�i�ւ̉��p���Ȃ��B
�x�m�ʂ͂��A�X�J���[�����琫�\���Ⴍ�Ă��S�����i�T�C�A
NEC�Ɠ������������̂Ő��\���Ⴍ�Ă����͈����Ȃ��A
���Č����闧��ɂ��邵�A
FX1���g�̂������̂Ő�`��Ƃ��Ċ��肫���Ă�̂��낤�B
����ڂ��藧�h�œ��e������Ȃ��A
�u���C�N�X���[�̂��߂̊J��������͂����A
���ǂ͊������i���ʂɕ��ׂ�悤�Ȃ��̂ŁA
���[�J�[�̎����o���͑��������ŁA
�������A�u���C�N�X���[���Ȃ��̂�����A
���̃��[�U�[�ɔ��鐻�i�ւ̉��p���Ȃ��B
�x�m�ʂ͂��A�X�J���[�����琫�\���Ⴍ�Ă��S�����i�T�C�A
NEC�Ɠ������������̂Ő��\���Ⴍ�Ă����͈����Ȃ��A
���Č����闧��ɂ��邵�A
FX1���g�̂������̂Ő�`��Ƃ��Ċ��肫���Ă�̂��낤�B
561 �F�s���ȃf�o�C�X�����F2009/09/22(��) 10:10:43 ID:PIxo8ibB
�����̎��Ԃ́A�e���ւ̗\�Z�̃o���T���A���Ǝv���B
�������A��������邽�߂̂��̂ł͂Ȃ��A�����̌���������Ă�Ƃ���̉^�]�����̒ŁA
���{�̑��͂����W����Ƃ͕������͂������A�L���\�Z��z�邽�߂̌��O���Ǝv���B
�ꎟ�\�[�X�͖ʓ|�Ȃ̂�wikipedia����������邪
ttp://ja.wikipedia.org/wiki/%E6%B1%8E%E7%94%A8%E4%BA%AC%E9%80%9F%E8%A8%88%E7%AE%97%E6%A9%9F
�u�e�v�f�n�̗\��v�̂Ƃ��������ƁA�o���T�����Ȃ��Ă킩��B
��w�̌������́A
�]���������Ă錤�����F�߂��ĉ^�]��������������o���A���ނ��o�C���_�[�t�@�C��1���������Ί����炦��
���Ă����������Ǝv����B
�������A��������邽�߂̂��̂ł͂Ȃ��A�����̌���������Ă�Ƃ���̉^�]�����̒ŁA
���{�̑��͂����W����Ƃ͕������͂������A�L���\�Z��z�邽�߂̌��O���Ǝv���B
�ꎟ�\�[�X�͖ʓ|�Ȃ̂�wikipedia����������邪
ttp://ja.wikipedia.org/wiki/%E6%B1%8E%E7%94%A8%E4%BA%AC%E9%80%9F%E8%A8%88%E7%AE%97%E6%A9%9F
�u�e�v�f�n�̗\��v�̂Ƃ��������ƁA�o���T�����Ȃ��Ă킩��B
��w�̌������́A
�]���������Ă錤�����F�߂��ĉ^�]��������������o���A���ނ��o�C���_�[�t�@�C��1���������Ί����炦��
���Ă����������Ǝv����B
562 �F�s���ȃf�o�C�X�����F2009/09/22(��) 10:15:07 ID:PIxo8ibB
�����Y�ꂽ
���Ƃ���
�u����ɂ͍������`�����܂ސV�K�f�o�C�X�\�z�Z�p�̊m�����ڕW�Ƃ����B�v
�Ƃ����ڕW�́A�����X�p�R���̎����ɕK�v�ȖڕW��1�ł͂Ȃ��ł��傤�B
�����̎��ȍ~�̃X�p�R���ɕK�v�Ȍ�������������o���Ȃ��Ƃ����Ȃ��̂͂������A
����͋����X�p�R���̗\�Z�̒�����o���ׂ����̂���Ȃ��B
��������X�p�R���J���̗\�Z�������Ƃ����āA��������o���Ȃ��ƁB
�����p�Ƃ��Č��O�Ǝ��Ԃ�ʂɂ��邱�Ƃ����s��������ƁA�������Ȃ��ƂɂȂ��B
���Ƃ���
�u����ɂ͍������`�����܂ސV�K�f�o�C�X�\�z�Z�p�̊m�����ڕW�Ƃ����B�v
�Ƃ����ڕW�́A�����X�p�R���̎����ɕK�v�ȖڕW��1�ł͂Ȃ��ł��傤�B
�����̎��ȍ~�̃X�p�R���ɕK�v�Ȍ�������������o���Ȃ��Ƃ����Ȃ��̂͂������A
����͋����X�p�R���̗\�Z�̒�����o���ׂ����̂���Ȃ��B
��������X�p�R���J���̗\�Z�������Ƃ����āA��������o���Ȃ��ƁB
�����p�Ƃ��Č��O�Ǝ��Ԃ�ʂɂ��邱�Ƃ����s��������ƁA�������Ȃ��ƂɂȂ��B
563 �F�s���ȃf�o�C�X�����F2009/09/22(��) 11:23:31 ID:plt0PAfL
�������~�܂�Ȃ�
���ʓI�ɂ͂悩������Ȃ����ȁB
���ʓI�ɂ͂悩������Ȃ����ȁB
564 �F�s���ȃf�o�C�X�����F2009/09/22(��) 12:57:57 ID:y4CIADGb
�\�Z�o���T���������̂ł͂Ȃ�
���r���[�Ɋz�����Ȃ��̂����
�R�������P�o����悤�ɏȒ��ɓ���������
���r���[�Ɋz�����Ȃ��̂����
�R�������P�o����悤�ɏȒ��ɓ���������
565 �F�s���ȃf�o�C�X�����F2009/09/22(��) 14:41:07 ID:klqMhMBi
���͐퓬�@�����C�Z���X���Y������Ȃ�
566 �F�s���ȃf�o�C�X�����F2009/09/22(��) 15:06:37 ID:UnkDrDoL
NAREGI�Ƃ�PSI�Ƃ����z���Ƃ����ł�GRAPE-DR�Ƃ����v�f�Z�p�݂͂�ȃ|�V�����Ă��>>561
567 �F�s���ȃf�o�C�X�����F2009/09/22(��) 15:25:55 ID:PIxo8ibB
>>564
�o���T������A�X�̎��z�����Ȃ��Ȃ��Ă��܂���ł���B
�\�Z�̓��[�J�[�����ɓn���ׂ��B
��w�Ȃǂ̌����@�ւ̋��͂��K�v�ȕ����́A
���[�J�[���������҂̏o������Ƃ����`�ŁA
���܂ł̌����̒~�ς���o���Ă��炤�ׂ����낤�B
�܂��A�������낤���B
�J���\�Z�������@�ւɃo���T���A���̐��ʕ��͖��ɗ����Ȃ����̎R�ŁA
���ۂ̓������m����郁�[�J�[�͎��O�̎������邢�͐�����ŊJ������A
���Ă�����˂��E�E�E�B
>>566
�Ă������A���p���ɂ͒������A�Ő�[�Z�p�Ƃ������͍Ő�[�������A�g�����Ƃ����̂��ԈႢ���Ǝv���B
�o���T������A�X�̎��z�����Ȃ��Ȃ��Ă��܂���ł���B
�\�Z�̓��[�J�[�����ɓn���ׂ��B
��w�Ȃǂ̌����@�ւ̋��͂��K�v�ȕ����́A
���[�J�[���������҂̏o������Ƃ����`�ŁA
���܂ł̌����̒~�ς���o���Ă��炤�ׂ����낤�B
�܂��A�������낤���B
�J���\�Z�������@�ւɃo���T���A���̐��ʕ��͖��ɗ����Ȃ����̎R�ŁA
���ۂ̓������m����郁�[�J�[�͎��O�̎������邢�͐�����ŊJ������A
���Ă�����˂��E�E�E�B
>>566
�Ă������A���p���ɂ͒������A�Ő�[�Z�p�Ƃ������͍Ő�[�������A�g�����Ƃ����̂��ԈႢ���Ǝv���B
568 �F�s���ȃf�o�C�X�����F2009/09/22(��) 15:37:15 ID:PIxo8ibB
�����̗\�Z�̓g�[�^����1150���~
����ANEC��SX�X�p�R�����Ƃ̔��㍂�͔N��300���~���x
1150���~�Ŕ[��3�N��NEC�ɔ���������A�ǂ�Ȃ��̂��o�����낤�ˁB
����ANEC��SX�X�p�R�����Ƃ̔��㍂�͔N��300���~���x
1150���~�Ŕ[��3�N��NEC�ɔ���������A�ǂ�Ȃ��̂��o�����낤�ˁB
569 �F�s���ȃf�o�C�X�����F2009/09/22(��) 18:50:53 ID:/mAf82wA
SX-10�̍ő�\��
���f���̂Ȃ��x�N�^SMP�̃t���N���X�o
����ɉ�����B/F�ƃA�Z���u�����炵���g���Ȃ��L���b�V��
�D�ӓI�Ɍ��ς���
256 Gflops
512 GB/s
32 SMP
8 Tflops/node, BF=2
512 node, 4 Pflops
1000���ō�ꂽ�炩�Ȃ萦��
���f���̂Ȃ��x�N�^SMP�̃t���N���X�o
����ɉ�����B/F�ƃA�Z���u�����炵���g���Ȃ��L���b�V��
�D�ӓI�Ɍ��ς���
256 Gflops
512 GB/s
32 SMP
8 Tflops/node, BF=2
512 node, 4 Pflops
1000���ō�ꂽ�炩�Ȃ萦��
570 �F�s���ȃf�o�C�X�����F2009/09/22(��) 19:15:46 ID:PIxo8ibB
�n���V�~�����[�^(����)��640�m�[�h��600���~����������A��ꂻ���ȋC������B
571 �F�s���ȃf�o�C�X�����F2009/09/22(��) 22:54:00 ID:plt0PAfL
����ł�����
572 �F�s���ȃf�o�C�X�����F2009/09/23(��) 00:16:27 ID:IAMqHqPY
571��600���o���Ă����̂��H
573 �F�s���ȃf�o�C�X�����F2009/09/23(��) 00:18:59 ID:ICCpDlsR
1000������Ȃ��́H
574 �F�s���ȃf�o�C�X�����F2009/09/23(��) 01:19:45 ID:Z9QXhjjb
�č��̃X�p�R���͂悢���ƃv���W�F�N�g�A���{�̃X�p�R���͈�����������
���{�̃X�p�R���͈�����������
���{�̃X�p�R���͈�����������
���{�̃X�p�R���͈����������� ���{�̃X�p�R���͈�����������
���_������
���{�̃X�p�R���͈�����������
���{�̃X�p�R���͈�����������
���{�̃X�p�R���͈����������� ���{�̃X�p�R���͈�����������
���_������
575 �F�s���ȃf�o�C�X�����F2009/09/23(��) 01:36:20 ID:IAMqHqPY
>>573
������
������
576 �F�s���ȃf�o�C�X�����F2009/09/23(��) 01:52:59 ID:DPVmWgDJ
577 �F�s���ȃf�o�C�X�����F2009/09/23(��) 02:07:59 ID:VQBw9T93
�o���T���o���T���o���T���o���T���o���T���o���T������
http://blog.livedoor.jp/amd646464/archives/51052291.html
http://blog.livedoor.jp/amd646464/archives/51052291.html
578 �F�s���ȃf�o�C�X�����F2009/09/23(��) 05:14:10 ID:VWP4CQ2i
�X�p�R���Ɋւ��Ă͓��{�̃��[�J�[�ɂ������������Ă���Ȃ�����Ȃ�����Ȃ��B
���ɍ��ۋ����͂̂Ȃ��Ȃ������Ѓv���_�N�g�̌p���i����邾���B
���Ƃ�����IA�ł͂ǂ����Ƃ����ƃT�[�o���i�ɃC���t�B�j�o���h�������̂�
�s��̐��{�̉��i�Ŕ[�����邾�������B
���ɍ��ۋ����͂̂Ȃ��Ȃ������Ѓv���_�N�g�̌p���i����邾���B
���Ƃ�����IA�ł͂ǂ����Ƃ����ƃT�[�o���i�ɃC���t�B�j�o���h�������̂�
�s��̐��{�̉��i�Ŕ[�����邾�������B
579 �F�s���ȃf�o�C�X�����F2009/09/23(��) 08:47:01 ID:ICCpDlsR
�uIA�T�[�o��InfiniBand���������̎s��v�̑���͂���Ȃ���Ȃ��́H
SX�Ƃ�SR���Č����قǍ��ۋ����͂Ȃ��́H
SX�Ƃ�SR���Č����قǍ��ۋ����͂Ȃ��́H
580 �F�s���ȃf�o�C�X�����F2009/09/23(��) 11:08:35 ID:rv65Q/Y1
>>578
��w�̌������ɋ����o���T�����̓}�V���낤
��w�̌������ɋ����o���T�����̓}�V���낤
581 �F�s���ȃf�o�C�X�����F2009/09/23(��) 11:16:33 ID:3NmdXLa7
���_���܂��������B
�@�l�ł��ԃR�X�g���܂������Ⴄ�̂ɊȒP�ɔ�ׂ�ȁB
���{�@���������Ȃ�A�܂��͂P���P���~�̍������H���ݔ��@����B
�@�l�ł��ԃR�X�g���܂������Ⴄ�̂ɊȒP�ɔ�ׂ�ȁB
���{�@���������Ȃ�A�܂��͂P���P���~�̍������H���ݔ��@����B
582 �F�s���ȃf�o�C�X�����F2009/09/23(��) 11:24:16 ID:ICCpDlsR
���₻��́c��
583 �F�s���ȃf�o�C�X�����F2009/09/23(��) 11:35:10 ID:3NmdXLa7
>>577
�������Ԃ��Ԃ��ȁB���c���w���g���l���ɂ��č��ł������݂܂���B�����Ȃ��B
�č��h���Ȃ�G�l���M�[�Ȃ���h�{������Ă�IBM��Cray�͍��c��Ƃ���ˁ[�̂��B
�������₻�̍��b��ƂȂ����R���e�i�^�f�[�^�Z���^�[���A���͂ƌ�����
�ČR�������̐��Ŏg�����߂�Sun�ɍ�点�����̂�������ȁB
�������Ԃ��Ԃ��ȁB���c���w���g���l���ɂ��č��ł������݂܂���B�����Ȃ��B
�č��h���Ȃ�G�l���M�[�Ȃ���h�{������Ă�IBM��Cray�͍��c��Ƃ���ˁ[�̂��B
�������₻�̍��b��ƂȂ����R���e�i�^�f�[�^�Z���^�[���A���͂ƌ�����
�ČR�������̐��Ŏg�����߂�Sun�ɍ�点�����̂�������ȁB
584 �F�s���ȃf�o�C�X�����F2009/09/23(��) 13:01:51 ID:DJqwsxiU
��ʔ̔����ꂽBlackBox�̎���
585 �F�s���ȃf�o�C�X�����F2009/09/24(��) 23:54:12 ID:XKWB/QVJ
�����Ƃ��C���^�r���[��L�҉�ȂǂŎw���҂炵���Ȃ��h����g��Ȃ��Ȃ�̂͂��̓����˂�
�N������J���Ȃ��Ⴂ���Ȃ����Ȃ̂ɁB
���ꂪ�ł�����X�p�R���͊e�i�ɑ����Ȃ��
�N������J���Ȃ��Ⴂ���Ȃ����Ȃ̂ɁB
���ꂪ�ł�����X�p�R���͊e�i�ɑ����Ȃ��
586 �F�s���ȃf�o�C�X�����F2009/09/25(��) 00:28:58 ID:aAHwKf3E
>>567
>���[�J�[���������҂̏o������Ƃ����`�ŁA
���[�J�[�̓��[�J�[�ŁA���ɗ����Ȃ����̎R��
���ʕ��Ȍ����҂ɗ\�Z�����蓖�ĂĂ��܂��̂ł���B
>���[�J�[���������҂̏o������Ƃ����`�ŁA
���[�J�[�̓��[�J�[�ŁA���ɗ����Ȃ����̎R��
���ʕ��Ȍ����҂ɗ\�Z�����蓖�ĂĂ��܂��̂ł���B
587 �F�s���ȃf�o�C�X�����F2009/09/25(��) 02:13:21 ID:82XInx3Q
>>585
���ꂪ�ǂ̂悤�Ɋ֘A���邩�𗎌ꕗ�ɏڂ�������Ă݂�
���ꂪ�ǂ̂悤�Ɋ֘A���邩�𗎌ꕗ�ɏڂ�������Ă݂�
588 �F�s���ȃf�o�C�X�����F2009/09/25(��) 09:30:25 ID:5tCcpwV9
>>586
�����҂����������������ȁ[�B
����ŁA�v���W�F�N�g�̔����ґ��̈ψ��̐搶�̂Ƃ���ɁA�_�~�[�̈ϑ��������o���Ȃ���Ȃ��Ƃ��B
�����҂����������������ȁ[�B
����ŁA�v���W�F�N�g�̔����ґ��̈ψ��̐搶�̂Ƃ���ɁA�_�~�[�̈ϑ��������o���Ȃ���Ȃ��Ƃ��B
589 �F�s���ȃf�o�C�X�����F2009/09/25(��) 21:56:46 ID:vQ1hbX0H
>>587
���オ��낵���l�ŁB
���オ��낵���l�ŁB
590 �F�s���ȃf�o�C�X�����F2009/09/26(�y) 04:07:14 ID:kE6kyfg2
>>551
2009/9/23
David Hoff ���� ClearSpeed->nVidia->AMD �ƈړ����Ă�̂��B�Ȃ������B
����A�������A 5870 �͂������Ȃ��A�A�A�Ƃ����b�B�l�̂��Ƃ�S�z ���Ă���ꍇ�ł͂Ȃ����A GT300 �̐悪�����ĂȂ����� nVidia �͑�ς������B
�l�̂��Ƃ�S�z ���Ă���ꍇ�ł͂Ȃ����A
�l�̂��Ƃ�S�z ���Ă���ꍇ�ł͂Ȃ����A
�l�̂��Ƃ�S�z ���Ă���ꍇ�ł͂Ȃ����A
�l�̂��Ƃ�S�z ���Ă���ꍇ�ł͂Ȃ����A
���[�ށA��قǖF�����Ȃ��̂��ˁB
2009/9/23
David Hoff ���� ClearSpeed->nVidia->AMD �ƈړ����Ă�̂��B�Ȃ������B
����A�������A 5870 �͂������Ȃ��A�A�A�Ƃ����b�B�l�̂��Ƃ�S�z ���Ă���ꍇ�ł͂Ȃ����A GT300 �̐悪�����ĂȂ����� nVidia �͑�ς������B
�l�̂��Ƃ�S�z ���Ă���ꍇ�ł͂Ȃ����A
�l�̂��Ƃ�S�z ���Ă���ꍇ�ł͂Ȃ����A
�l�̂��Ƃ�S�z ���Ă���ꍇ�ł͂Ȃ����A
�l�̂��Ƃ�S�z ���Ă���ꍇ�ł͂Ȃ����A
���[�ށA��قǖF�����Ȃ��̂��ˁB
591 �F�s���ȃf�o�C�X�����F2009/09/26(�y) 09:28:34 ID:RPM9BEP8
GRAPE-DR�́A�ݒu���镔�����Ȃ��ĉ��Ђ���ԂȂ���?
592 �F�s���ȃf�o�C�X�����F2009/09/26(�y) 09:31:08 ID:iqAfJd+P
nVidia�ɂ����Ă��炦��������Ȃ�Ϸ��
593 �F�s���ȃf�o�C�X�����F2009/09/26(�y) 10:14:15 ID:1mykioZP
����nVidia�̓t�@�u���X�����琻����TSMC�ȃ��P�����A�A�A
594 �F�s���ȃf�o�C�X�����F2009/09/26(�y) 12:37:33 ID:GbEZoGOO
>>591
ttp://www.cfca.nao.ac.jp/hpc/muv/application/
�ɂ́A
�u�ߓ����ɂ̓e�X�g�^�p�̂���GRAPE-DR������\��ł��B�v
��4�����炢���珑���Ă������݂��������ǁB�܂��݂���������A
�����̖�肾������Ȃ��̂����B
ttp://www.cfca.nao.ac.jp/hpc/muv/application/
�ɂ́A
�u�ߓ����ɂ̓e�X�g�^�p�̂���GRAPE-DR������\��ł��B�v
��4�����炢���珑���Ă������݂��������ǁB�܂��݂���������A
�����̖�肾������Ȃ��̂����B
595 �F�s���ȃf�o�C�X�����F2009/09/26(�y) 13:15:30 ID:RPM9BEP8
596 �F�s���ȃf�o�C�X�����F2009/09/27(��) 18:26:16 ID:d5LDkyk9
���E�ō��X�p�R���̋Z���f���Ł@���E�~�c�ɂo�q�{��
ttp://sankei.jp.msn.com/science/science/090926/scn0909261413002-n1.htm
�g�������Ȃ�HPC�̃f����邭�炢�Ȃ�A�t���[��CAE�c�[���Ƃ�����̂�PC��
�ǂ�����Ė����������邩�̒�ĂƂ��A�������Ƃł̐��l�v�Z�̊��p
����̏Љ�Ƃ��A�������Ƃ̎�ɓ͂������Ȃ��Ƃ����
ttp://sankei.jp.msn.com/science/science/090926/scn0909261413002-n1.htm
�g�������Ȃ�HPC�̃f����邭�炢�Ȃ�A�t���[��CAE�c�[���Ƃ�����̂�PC��
�ǂ�����Ė����������邩�̒�ĂƂ��A�������Ƃł̐��l�v�Z�̊��p
����̏Љ�Ƃ��A�������Ƃ̎�ɓ͂������Ȃ��Ƃ����
597 �F�s���ȃf�o�C�X�����F2009/09/27(��) 20:21:59 ID:nRVnuxsj
�����Ɠ����ŁA�����o���T�����߂ɂ���Ă�̂��낤�B
598 �F�s���ȃf�o�C�X�����F2009/09/28(��) 00:05:16 ID:avx9OIWn
�T������ɉ肪�o�Ď������n����Ƃ��܂ł����Ȃ��̂����
599 �F�s���ȃf�o�C�X�����F2009/09/28(��) 02:05:42 ID:rzke7dhF
600 �F�s���ȃf�o�C�X�����F2009/09/28(��) 03:15:02 ID:6/HjNP9U
����SPRAC�ŃX�p�R�����Ď��_�ŏI����Ă���
601 �F�s���ȃf�o�C�X�����F2009/09/28(��) 09:16:24 ID:7/rl7Bu8
>>599
���͂����͎v��Ȃ���
�܂���`�̕����d�v�Ȃ���
�Ƃ�����Ă����ɂ����ł��Ă����Ă���������
�݂�Ȃ��g���Ă邵���x��Ȃ��悤�ɂ��悤���Ċ��Ⴂ�����Ȃ���
��U�Ƃ���������̕��l�ނ��������������鎖�ɂȂ邩�猋�ʂ��v���悤�ɂłȂ��Ă��A�����₷�₷�ƈ���������Ȃ��Ȃ�
�����������������{�ɂ͂���Ȃ�����
���͂����͎v��Ȃ���
�܂���`�̕����d�v�Ȃ���
�Ƃ�����Ă����ɂ����ł��Ă����Ă���������
�݂�Ȃ��g���Ă邵���x��Ȃ��悤�ɂ��悤���Ċ��Ⴂ�����Ȃ���
��U�Ƃ���������̕��l�ނ��������������鎖�ɂȂ邩�猋�ʂ��v���悤�ɂłȂ��Ă��A�����₷�₷�ƈ���������Ȃ��Ȃ�
�����������������{�ɂ͂���Ȃ�����
602 �F�s���ȃf�o�C�X�����F2009/09/28(��) 11:17:02 ID:HqXHcsGy
603 �F�s���ȃf�o�C�X�����F2009/09/28(��) 11:51:11 ID:7/rl7Bu8
���̓X�p�R���Z���^�̗L�p���⏫���������\���Ƃ͎v���ĂȂ����B
604 �F�s���ȃf�o�C�X�����F2009/09/28(��) 14:03:41 ID:7ILXDcY9
���݂�Ȃ��g���Ă邵���x��Ȃ��悤�ɂ��悤���Ċ��Ⴂ�����Ȃ���
�牭�P�ʂ̋��g�������̃f�����ꂽ���āA�����̘A���ɂƂ�����
�������̂Ȃ��b�ŏ��x���x��Ȃ��ȑO�̘b���낤��B
�牭�P�ʂ̋��g�������̃f�����ꂽ���āA�����̘A���ɂƂ�����
�������̂Ȃ��b�ŏ��x���x��Ȃ��ȑO�̘b���낤��B
605 �F�s���ȃf�o�C�X�����F2009/09/28(��) 17:15:10 ID:HqXHcsGy
�����Ȃ�āA�[�l�R���̌����H���Ɠ����j�I�C�����邼�B
�ǂ�ȂɊ���U���Đ�`���Ă��A����������Ȃ���A�ˁB
�{���ɃX�p�R�����p�𑝂₵������A
�܂��A�ȒP�Ɏg����悤�ɂ���
�Ƃ������Ƃ���B
�ȒP�ɁA�Ƃ����̂́A������ʂłˁB
�ǂ�ȂɊ���U���Đ�`���Ă��A����������Ȃ���A�ˁB
�{���ɃX�p�R�����p�𑝂₵������A
�܂��A�ȒP�Ɏg����悤�ɂ���
�Ƃ������Ƃ���B
�ȒP�ɁA�Ƃ����̂́A������ʂłˁB
606 �F�s���ȃf�o�C�X�����F2009/09/28(��) 18:26:24 ID:ER9OK4ck
���ႠPS4�̊J���ƃZ�b�g�ł��ׂ�����
607 �F�s���ȃf�o�C�X�����F2009/09/28(��) 22:27:44 ID:HqXHcsGy
����_�ł́A����͐��������������Ǝv����B
���O�Ŏ��Ă�v�Z�T�[�o�ƁA
�����̂����ԂŎ��X�p�R���A
����2�̂������̒i�������������邱�Ƃ��A
�X�p�R���̍L�͂ȗ��p�𑣐i���邽�߂ɕK�v�Ȃ��Ƃ��Ǝv���B
���O�Ŏ��Ă�v�Z�T�[�o�ƁA
�����̂����ԂŎ��X�p�R���A
����2�̂������̒i�������������邱�Ƃ��A
�X�p�R���̍L�͂ȗ��p�𑣐i���邽�߂ɕK�v�Ȃ��Ƃ��Ǝv���B
608 �F�s���ȃf�o�C�X�����F2009/09/28(��) 22:35:41 ID:ShTmYgem
609 �F�s���ȃf�o�C�X�����F2009/09/29(��) 06:03:50 ID:FgWvWHE4
�݂�Ȃ������܌����Ȃ��B���U�@������B���z���w�p�I�Ȍ����҂̎��_���z�����Ȃ�����B
>>603
�����犨�Ⴂ�����Ȃ��Ƃ��ď����Ă�����(��)
>>603
�����犨�Ⴂ�����Ȃ��Ƃ��ď����Ă�����(��)
610 �F�s���ȃf�o�C�X�����F2009/09/29(��) 12:44:48 ID:mo6wzi0X
�����̃f�����挩����ꂽ���x�Ŋ��Ⴂ����悤�Ȕn���͗v���B
����Ȃ���Ŋ��Ⴂ��������Ƃ��v���o�J����
����Ȃ���Ŋ��Ⴂ��������Ƃ��v���o�J����
611 �F�s���ȃf�o�C�X�����F2009/09/30(��) 18:40:10 ID:GK0CXSet
�����͍��͖{���Ɋ��U���������ŋ����������ďo���Ȃ������Ȃ�
�Ȃ�Ȃ����
�Ȃ�Ȃ����
612 �F�s���ȃf�o�C�X�����F2009/09/30(��) 19:55:42 ID:irxy/Qbw
���͏o������
���������Ƃ������ڂŁA���������Ȃ��l������
���������Ƃ������ڂŁA���������Ȃ��l������
613 �F�s���ȃf�o�C�X�����F2009/09/30(��) 23:32:12 ID:U7xAQdwM
sage
614 �F�s���ȃf�o�C�X�����F2009/09/30(��) 23:52:34 ID:zpkDAKCw
�x�m�ʁA�������̐V�X�p�R������
ttp://www.rbbtoday.com/news/20090930/62671.html
���ς�炸HPC��p�@�̂͂���FX1�́A�������肢�܂��Ƃ̂��Ƃł��B
ttp://www.rbbtoday.com/news/20090930/62671.html
���ς�炸HPC��p�@�̂͂���FX1�́A�������肢�܂��Ƃ̂��Ƃł��B
615 �F�s���ȃf�o�C�X�����F2009/10/01(��) 00:21:26 ID:nnIrNxrk
>>614
FX1���Ē��r���[�Ȃ��
5U��4�m�[�h�A�e�m�[�h��1CPU��4�R�A�ASPARC64 VII 2.5GHz(����������)
4�m�[�h������V���[�V�ɓ����Ă��邾���ŁA�m�[�h�Ԑڑ��͕��ʂ�Infiniband
Xeon�Ȃ�1U�T�[�o��2CPU��8�R�A�A3GHz
5U�̃X�y�[�X�ɁA
FX1�Ȃ�16�R�A�AXeon�Ȃ�40�R�A
2.5�{�������J���Ă�����A�˂��B
FX1���Ē��r���[�Ȃ��
5U��4�m�[�h�A�e�m�[�h��1CPU��4�R�A�ASPARC64 VII 2.5GHz(����������)
4�m�[�h������V���[�V�ɓ����Ă��邾���ŁA�m�[�h�Ԑڑ��͕��ʂ�Infiniband
Xeon�Ȃ�1U�T�[�o��2CPU��8�R�A�A3GHz
5U�̃X�y�[�X�ɁA
FX1�Ȃ�16�R�A�AXeon�Ȃ�40�R�A
2.5�{�������J���Ă�����A�˂��B
616 �F�s���ȃf�o�C�X�����F2009/10/01(��) 02:51:09 ID:dz9d5zZ1
Xeon�ŋ�������E�E�E�E�E
617 �F�s���ȃf�o�C�X�����F2009/10/01(��) 11:57:23 ID:jA1VJq32
FX1��2�N�ʑO�ɔ��\���ꂽ����H
�m��2010�N�ɂ͋��������̋Z�p���g���čő�3�`4PF���炢�̃V���[�Y��o���\�肶��Ȃ���
�m��2010�N�ɂ͋��������̋Z�p���g���čő�3�`4PF���炢�̃V���[�Y��o���\�肶��Ȃ���
618 �F�s���ȃf�o�C�X�����F2009/10/01(��) 14:16:48 ID:nnIrNxrk
3�N�����ɓ�������鐻�i���g�b�v������Ă��A�����ɖ��N��������鐻�i�ɔ����ꂿ�Ⴄ��B
619 �F�s���ȃf�o�C�X�����F2009/10/01(��) 15:12:44 ID:nnIrNxrk
�ŁAGRAPE-DR�܂����B
���E����PF�}�V��
2008�N�܂ł�2PF
2009�N�x��������������킯�����B
���b�N10�{�ȉ��̃T�C�Y�̃}�V���Ȃ̂ɁA�ݒu�ꏊ���Ȃ��ĉ��Ђ�?
���E����PF�}�V��
2008�N�܂ł�2PF
2009�N�x��������������킯�����B
���b�N10�{�ȉ��̃T�C�Y�̃}�V���Ȃ̂ɁA�ݒu�ꏊ���Ȃ��ĉ��Ђ�?
620 �F�s���ȃf�o�C�X�����F2009/10/01(��) 16:34:10 ID:zjpE+Pep
NVIDIA Fermi
http://www.nvidia.com/object/fermi_architecture.html
NVIDIA's Fermi: Architected for Tesla, 3 Billion Transistors in 2010
http://www.anandtech.com/video/showdoc.aspx?i=3651&p=1
Nvidia's 'Fermi' GPU architecture revealed GPU computing grabs center stage
http://techreport.com/articles.x/17670/3
�㓡�O��Weekly�C�O�j���[�X
NVIDIA��������GPU�A�[�L�e�N�`���uFermi�v�\
http://pc.watch.impress.co.jp/docs/column/kaigai/20091001_318463.html
NVIDIA�CDirectX 11����̎�����GPU�uFermi�v��\���`30���g�����W�X�^�C512�V�F�[�_�v���Z�b�T�I
http://www.4gamer.net/games/099/G009929/20090930012/
�yGTC���|�[�g�z�W�F���X���E�t�A������u����
�`NVIDIA�̎���GPU�uFermi�v�����Ɍ��J
http://pc.watch.impress.co.jp/docs/news/event/20091001_318678.html
�yGTC���|�[�g�z
NVIDIA�̎�����GPU�A�[�L�e�N�`���uFermi�v����Tesla�����J
http://pc.watch.impress.co.jp/docs/news/event/20091001_318660.html
http://www.nvidia.com/object/fermi_architecture.html
NVIDIA's Fermi: Architected for Tesla, 3 Billion Transistors in 2010
http://www.anandtech.com/video/showdoc.aspx?i=3651&p=1
Nvidia's 'Fermi' GPU architecture revealed GPU computing grabs center stage
http://techreport.com/articles.x/17670/3
�㓡�O��Weekly�C�O�j���[�X
NVIDIA��������GPU�A�[�L�e�N�`���uFermi�v�\
http://pc.watch.impress.co.jp/docs/column/kaigai/20091001_318463.html
NVIDIA�CDirectX 11����̎�����GPU�uFermi�v��\���`30���g�����W�X�^�C512�V�F�[�_�v���Z�b�T�I
http://www.4gamer.net/games/099/G009929/20090930012/
�yGTC���|�[�g�z�W�F���X���E�t�A������u����
�`NVIDIA�̎���GPU�uFermi�v�����Ɍ��J
http://pc.watch.impress.co.jp/docs/news/event/20091001_318678.html
�yGTC���|�[�g�z
NVIDIA�̎�����GPU�A�[�L�e�N�`���uFermi�v����Tesla�����J
http://pc.watch.impress.co.jp/docs/news/event/20091001_318660.html
621 �F�s���ȃf�o�C�X�����F2009/10/01(��) 17:56:31 ID:nnIrNxrk
���X��GPU���g������̂ɂȂ����ˁB
622 �F�s���ȃf�o�C�X�����F2009/10/01(��) 18:23:40 ID:jA1VJq32
����10�������[�g�����炢�̃O���{������āA������100���R�A���炢�W�ς����
623 �F�s���ȃf�o�C�X�����F2009/10/01(��) 20:53:41 ID:nkcqNhY7
>>622
����Ȃ�ă}�U�{�H
����Ȃ�ă}�U�{�H
624 �F�s���ȃf�o�C�X�����F2009/10/01(��) 21:14:49 ID:mQT8yQvM
GT300�͎����I�ɂ��d�l�I�ɂ�LRB�Ɛ��ʂ��猃�˂����
625 �F�s���ȃf�o�C�X�����F2009/10/02(��) 02:35:37 ID:DXOC+twJ
�q��搶�A
Fermi��GRAPE-DR��8�{�̃g�����W�X�^����3�{�̐��\
�Ƃ����͈̂Ⴄ�ł��傤
GRAPE-DR��SING�����łȂ�FPGA���O�t���ŕK�v�Ȃ���A����̃g�����W�X�^�������ɓ���Ȃ��ƁB
Fermi��GRAPE-DR��8�{�̃g�����W�X�^����3�{�̐��\
�Ƃ����͈̂Ⴄ�ł��傤
GRAPE-DR��SING�����łȂ�FPGA���O�t���ŕK�v�Ȃ���A����̃g�����W�X�^�������ɓ���Ȃ��ƁB
626 �F�s���ȃf�o�C�X�����F2009/10/02(��) 12:42:31 ID:ZGEiM025
����B
Korea�C�ے��@2010�N��Cray��600Tflops�@��
http://japan.cnet.com/blog/petaflops/2009/10/02/entry_27034798/
Korea�C�ے��@2010�N��Cray��600Tflops�@��
http://japan.cnet.com/blog/petaflops/2009/10/02/entry_27034798/
627 �F�s���ȃf�o�C�X�����F2009/10/02(��) 12:45:41 ID:9mPWRESw
FPGA��Tr�����܂Ƃ��Ɋ��肷��ƃX�S�C���Ƃɂ�����
�Ƃ���Ń}�L�[�m�搶��
�@�@�i�P�jeASIC��������
�@�@�i�Q�jGRAPE-DR�Ȃ��Ȃ����\�łȂ��A�i�����ĂȂ�
�������珟��Ɏ@����A
�Ђ���Ƃ��Č�GRAPE-DR�ɂ͔����������o�O�Ƃ������āA
�����Ă������Ă��āA���͂��蒼���������A
�Z���x�[�X�ł�蒼���Ƌ����X�S�C�̂�eASIC�������Ă�@�@�Ƃ��H
�Ƃ���Ń}�L�[�m�搶��
�@�@�i�P�jeASIC��������
�@�@�i�Q�jGRAPE-DR�Ȃ��Ȃ����\�łȂ��A�i�����ĂȂ�
�������珟��Ɏ@����A
�Ђ���Ƃ��Č�GRAPE-DR�ɂ͔����������o�O�Ƃ������āA
�����Ă������Ă��āA���͂��蒼���������A
�Z���x�[�X�ł�蒼���Ƌ����X�S�C�̂�eASIC�������Ă�@�@�Ƃ��H
628 �F�s���ȃf�o�C�X�����F2009/10/02(��) 13:29:27 ID:iwWZGcHh
629 �F�s���ȃf�o�C�X�����F2009/10/02(��) 13:45:09 ID:iI+8xF4O
����A�C�ۃR�[�h�̓������o���h�����d�v������AIBM(����POWER575)��SX���D�ʁB
POWER575�Ɠ��l�̎d�l��������SR16000�������Ǝv���B
ttp://www-06.ibm.com/systems/jp/power/hardware/575/specs.html
�������o���h���̒ႢIstanbul��������A���Ȃ茵������Ȃ����ȁB
POWER575�Ɠ��l�̎d�l��������SR16000�������Ǝv���B
ttp://www-06.ibm.com/systems/jp/power/hardware/575/specs.html
�������o���h���̒ႢIstanbul��������A���Ȃ茵������Ȃ����ȁB
630 �F�s���ȃf�o�C�X�����F2009/10/02(��) 14:09:39 ID:udRdaWkK
>>628
�V�C������Ȃ��͕ʂ̗��R����Ȃ������H
���������W�I�]���f�ɕs��������Đ������f�[�^�𑗐M�ł����A
����ɋC�Â����C��Sim�Ƀf�[�^�������Ă��@����Ȃ������H
�V�C������Ȃ��͕ʂ̗��R����Ȃ������H
���������W�I�]���f�ɕs��������Đ������f�[�^�𑗐M�ł����A
����ɋC�Â����C��Sim�Ƀf�[�^�������Ă��@����Ȃ������H
631 �F�s���ȃf�o�C�X�����F2009/10/02(��) 15:42:47 ID:DXOC+twJ
>>626
���̋L���ł́A���{�̃X�p�R�����B�͊����Ȃ��̂킳��Ă���Ƃ����悤�Ș_�������A
���̋��z�̓��Ⴄ��Ȃ����ȁB
���{�ł́A�l�X�ȃT�[�r�X���n�[�h�E�F�A�̉��i�Ɋ܂߂Ă��邩��A�����Ȃ��Ă�̂ł͂Ȃ����ȁB
����ɁA���{�̊������₻��ɏ�����g�D�́A�K�`�K�`�ɋÂ�ł܂����_��̃J�P�����Ȃ����B
����ɍ��킹�ĐU���鑤�̃��X�N���ł��A�����Ȃ��Ȃ����ȁB
>>627
> �i�P�jeASIC��������
GRAPE-DR�̎��̃v���W�F�N�g�̂��߂��Ǝv���B
DRAM���O�t����������ɂ��ăo���h���Ƃ����₵�ĉ]�X�Ƃ��B
> �����Ă������Ă��āA���͂��蒼���������A
��蒼�����߂̗\�Z�͂��������Ǝv����B
���̋L���ł́A���{�̃X�p�R�����B�͊����Ȃ��̂킳��Ă���Ƃ����悤�Ș_�������A
���̋��z�̓��Ⴄ��Ȃ����ȁB
���{�ł́A�l�X�ȃT�[�r�X���n�[�h�E�F�A�̉��i�Ɋ܂߂Ă��邩��A�����Ȃ��Ă�̂ł͂Ȃ����ȁB
����ɁA���{�̊������₻��ɏ�����g�D�́A�K�`�K�`�ɋÂ�ł܂����_��̃J�P�����Ȃ����B
����ɍ��킹�ĐU���鑤�̃��X�N���ł��A�����Ȃ��Ȃ����ȁB
>>627
> �i�P�jeASIC��������
GRAPE-DR�̎��̃v���W�F�N�g�̂��߂��Ǝv���B
DRAM���O�t����������ɂ��ăo���h���Ƃ����₵�ĉ]�X�Ƃ��B
> �����Ă������Ă��āA���͂��蒼���������A
��蒼�����߂̗\�Z�͂��������Ǝv����B
632 �F�s���ȃf�o�C�X�����F2009/10/02(��) 16:09:08 ID:aoTYYvG1
�����{�ł́A�l�X�ȃT�[�r�X���n�[�h�E�F�A�̉��i�Ɋ܂߂Ă��邩��
������āA���Ȃ����̗����̉��E��C�������̎��wwww
������āA���Ȃ����̗����̉��E��C�������̎��wwww
633 �F�s���ȃf�o�C�X�����F2009/10/02(��) 19:03:13 ID:0Y39NCcv
>>628
�܂��A�v���O�������ڐA���邱�Ƃ��l������ Cray ���f�R�ǂ��Ǝv���B
>>629
SX �̗D�ʐ��͂��܂�Ȃ��ł��傤�ˁBXT �ł��v���O��������ŁA
MPI �ő�����(�ő�1��core�Ƃ�) �̗��̌v�Z�����Ȃ�ǂ�������
���s�\�Ȃ̂ŁB
�܂��A�v���O�������ڐA���邱�Ƃ��l������ Cray ���f�R�ǂ��Ǝv���B
>>629
SX �̗D�ʐ��͂��܂�Ȃ��ł��傤�ˁBXT �ł��v���O��������ŁA
MPI �ő�����(�ő�1��core�Ƃ�) �̗��̌v�Z�����Ȃ�ǂ�������
���s�\�Ȃ̂ŁB
634 �F�s���ȃf�o�C�X�����F2009/10/02(��) 19:26:32 ID:iI+8xF4O
>>633
���̌v�Z��SX�̗D�ʐ����Ȃ����炢�������ł�B�ڂ��������āB
���̌v�Z��SX�̗D�ʐ����Ȃ����炢�������ł�B�ڂ��������āB
635 �F�s���ȃf�o�C�X�����F2009/10/02(��) 20:00:51 ID:0Y39NCcv
>>634
�܂��� ORNL �� Cray jaguar �̉^�p���ł����ĕ��͋C��͂�łق����B
���Ƃ̓O�O���Ă���B
ttp://www.hpcuserforum.com/presentations/Norfolk/ORNL%20Update%20Kothe.pdf
���Ȃ݂� TOP500 �Ŏ��s�������v�Z����� ES2 �͖�90%�ACray ��
��70�`80% �ɂȂ�B���o�����ǁA�������Q�l�ɁB
ttp://jun.artcompsci.org/articles/future_sc/note072.html#rdocsect77
�܂��� ORNL �� Cray jaguar �̉^�p���ł����ĕ��͋C��͂�łق����B
���Ƃ̓O�O���Ă���B
ttp://www.hpcuserforum.com/presentations/Norfolk/ORNL%20Update%20Kothe.pdf
���Ȃ݂� TOP500 �Ŏ��s�������v�Z����� ES2 �͖�90%�ACray ��
��70�`80% �ɂȂ�B���o�����ǁA�������Q�l�ɁB
ttp://jun.artcompsci.org/articles/future_sc/note072.html#rdocsect77
636 �F�s���ȃf�o�C�X�����F2009/10/02(��) 20:19:11 ID:HAH9bHiQ
�}�L�[�m����������N�V�C�W��̃����ꂗ
637 �F�s���ȃf�o�C�X�����F2009/10/02(��) 20:27:43 ID:+fqpjr3t
�s�[�N�o���h���ɑ�������o���h�����x�N�g���@�͑f���炵�������A
�Ȃ�Ă��Ƃ͂Ȃ��̂ŁA���i������̃o���h�������Ă����ƁA
Nehalem�͐_�A�Ƃ������Ƃɂ����Ȃ�Ȃ���ˁB
Infiniband�̃N���X�^��600Tflops�͂��Ƃ������ȁA
�������炢�̍\�������x����B
�Ȃ�Ă��Ƃ͂Ȃ��̂ŁA���i������̃o���h�������Ă����ƁA
Nehalem�͐_�A�Ƃ������Ƃɂ����Ȃ�Ȃ���ˁB
Infiniband�̃N���X�^��600Tflops�͂��Ƃ������ȁA
�������炢�̍\�������x����B
638 �F�s���ȃf�o�C�X�����F2009/10/02(��) 20:37:54 ID:iI+8xF4O
>>635
���肪�Ƃ��B�ł����̎����ɂ͋C�ۃR�[�h�◬�̌v�Z�̎��s�����͏o�ĂȂ��ˁB
�X�J���[����r�I���ӂƂ����鈳�k�����̉�͂ł��ACray XT4 �ł�7.1TFLOPS(���s����11%)
ttp://sc07.supercomputing.org/schedule/pdf/gb110.pdf
���炢�Ȃ̂ŁA���̌v�Z�ł́ASX�̕����D�ʂƍl���Ă���B
���肪�Ƃ��B�ł����̎����ɂ͋C�ۃR�[�h�◬�̌v�Z�̎��s�����͏o�ĂȂ��ˁB
�X�J���[����r�I���ӂƂ����鈳�k�����̉�͂ł��ACray XT4 �ł�7.1TFLOPS(���s����11%)
ttp://sc07.supercomputing.org/schedule/pdf/gb110.pdf
���炢�Ȃ̂ŁA���̌v�Z�ł́ASX�̕����D�ʂƍl���Ă���B
639 �F�s���ȃf�o�C�X�����F2009/10/02(��) 20:54:42 ID:H9EFHux2
GT300 �J���̒x��
RV870 ����x��
Larrabee �������傤��
RV870 ����x��
Larrabee �������傤��
�����A�����Ԉ���Ă܂����B
FPGA�̃g�����W�X�^���������Ƃ����Ă��A�����FPGA������ł����āA
���̋@�\�Ƃ��Ẵg�����W�X�^���͔��X������̂Ȃ̂ˁB
���ɁA�����`�b�v�����Ă��A�قƂ�ǃg�����W�X�^���������Ȃ��ƁB
�Ƃ���Ŗq��搶�̂Ƃ����GRAPE-DR��Arria GX��50�ȂB
���႟60���g���Ă�KFCR��model450�Ƃ�1800�̊�ʐ^�����ĉ]�X�����Ⴂ���Ȃ��̂ˁB
�V�����ɂ͏�����ĂȂ����ǁAKFCR��model1800���������߂�2000/4000�ɂ����͗l�B�l�i���ς��Ă�?
���ǁAPCI Express��x4��PLX�Ȑl�ƌq���Ȃ�Amodel 450�p��x8���J�������͖̂��ʂ������悤�ȁE�E�E�B
FPGA�̃g�����W�X�^���������Ƃ����Ă��A�����FPGA������ł����āA
���̋@�\�Ƃ��Ẵg�����W�X�^���͔��X������̂Ȃ̂ˁB
���ɁA�����`�b�v�����Ă��A�قƂ�ǃg�����W�X�^���������Ȃ��ƁB
�Ƃ���Ŗq��搶�̂Ƃ����GRAPE-DR��Arria GX��50�ȂB
���႟60���g���Ă�KFCR��model450�Ƃ�1800�̊�ʐ^�����ĉ]�X�����Ⴂ���Ȃ��̂ˁB
�V�����ɂ͏�����ĂȂ����ǁAKFCR��model1800���������߂�2000/4000�ɂ����͗l�B�l�i���ς��Ă�?
���ǁAPCI Express��x4��PLX�Ȑl�ƌq���Ȃ�Amodel 450�p��x8���J�������͖̂��ʂ������悤�ȁE�E�E�B
641 �F�s���ȃf�o�C�X�����F2009/10/02(��) 21:31:32 ID:DXOC+twJ
����A��������Ȃ��āA�q��搶��GPU�����ȁ`���Ă��Ƃ��������������̂ˁB
���͂⎩���ō��Ȃ��Ă�GPU���g���ق��������Ȏ��オ�����ȁ[�A�ƁB
���͂⎩���ō��Ȃ��Ă�GPU���g���ق��������Ȏ��オ�����ȁ[�A�ƁB
642 �F�s���ȃf�o�C�X�����F2009/10/02(��) 22:02:28 ID:HAH9bHiQ
>>631
>GRAPE-DR�̎��̃v���W�F�N�g�̂��߂��Ǝv���B
>DRAM���O�t����������ɂ��ăo���h���Ƃ����₵�ĉ]�X�Ƃ��B
easic�Ƃ���Ă�̂�v-grape�Ƃ͈Ⴄ�悤�ȉ����̋C������B
�܂��Aeasic�����炩�̕��@��nextreme2��on-chip��������
�呝�B�������Ƃ��Ȃ�A�������B
>GRAPE-DR�̎��̃v���W�F�N�g�̂��߂��Ǝv���B
>DRAM���O�t����������ɂ��ăo���h���Ƃ����₵�ĉ]�X�Ƃ��B
easic�Ƃ���Ă�̂�v-grape�Ƃ͈Ⴄ�悤�ȉ����̋C������B
�܂��Aeasic�����炩�̕��@��nextreme2��on-chip��������
�呝�B�������Ƃ��Ȃ�A�������B
643 �F�s���ȃf�o�C�X�����F2009/10/02(��) 22:19:29 ID:dK4ytG+4
�S�e�S�e�����O���{��������Ϸ�ɐ搶���ϑ������H
644 �F�s���ȃf�o�C�X�����F2009/10/02(��) 22:30:24 ID:DXOC+twJ
GRAPE-DR��p�ł͂Ȃ��AGRAPE-7��p�̘b�Ȃ̂����ˁB
���邢�́AeASIC��DRAM�u�t���v�̃��f�����J�����Ȃ̂����B
���������`�b�v�ɊO�t����DRAM�Ԃ牺���Ă邱�Ƃ����������B
���邢�́AeASIC��DRAM�u�t���v�̃��f�����J�����Ȃ̂����B
���������`�b�v�ɊO�t����DRAM�Ԃ牺���Ă邱�Ƃ����������B
645 �F�s���ȃf�o�C�X�����F2009/10/02(��) 22:33:18 ID:+fqpjr3t
>>638
���������Ŕ�r���Ă��Ӗ��Ȃ��āA�l�i�����肩�d�͓������flops�Ȃ�GB/s���݂Ȃ���B
�Ƃ�������������O�̎w�E����A���N�����������Ă���l�������ˁB
���������Ŕ�r���Ă��Ӗ��Ȃ��āA�l�i�����肩�d�͓������flops�Ȃ�GB/s���݂Ȃ���B
�Ƃ�������������O�̎w�E����A���N�����������Ă���l�������ˁB
>>638
>�X�J���[����r�I���ӂƂ����鈳�k�����̉�͂ł��ACray XT4 �ł�7.1TFLOPS(���s����11%)
���[�ƁA�����R�[�h�Ńx�N�g���@�Ȃ狰�炭 50% ���炢�o�邾�낤����A
�m���ɒႢ�ˁB�ł��A�X�J���[�@�� core ���ŏ����ł���̂ŁA���s����
�����ŗD�ʐ������̂͂�����ƂˁB
���Ȃ݂ɁA�������ׂ��� Cray XT-5 ���Ƃ��̃R�[�h�Ō��� 50TF
(15��core�B�ő�1��core ���炢���Ǝv������A����10�{�ɂȂ��Ă����B)
�o�Ă���B���ς�炸�A���s�����͒Ⴂ���ǁB
ttp://www.cray.com/Assets/PDF/industrysolutions/CMMACSWRFPoster.pdf
���ꂩ��A���k���Ƃ��������A������̂ɗ̈敪������
�ōςނ悤�ȏꍇ�Ȃ痬�̌v�Z�ł������Ǝ��s�������ǂ��͂��B
�܂��A���A�v�����ƒP���ȗ̈敪���ł͕��ł��Ȃ��̂ŁA
�P���Ɏ��s�����Ō����ƃX�J���[�͕s���Ȃ�܂��B
���ƁA������ƌÂ����ǁA���̔�r����B
ttp://chikyu-to-umi.com/earth/jam_yes.htm
>�X�J���[����r�I���ӂƂ����鈳�k�����̉�͂ł��ACray XT4 �ł�7.1TFLOPS(���s����11%)
���[�ƁA�����R�[�h�Ńx�N�g���@�Ȃ狰�炭 50% ���炢�o�邾�낤����A
�m���ɒႢ�ˁB�ł��A�X�J���[�@�� core ���ŏ����ł���̂ŁA���s����
�����ŗD�ʐ������̂͂�����ƂˁB
���Ȃ݂ɁA�������ׂ��� Cray XT-5 ���Ƃ��̃R�[�h�Ō��� 50TF
(15��core�B�ő�1��core ���炢���Ǝv������A����10�{�ɂȂ��Ă����B)
�o�Ă���B���ς�炸�A���s�����͒Ⴂ���ǁB
ttp://www.cray.com/Assets/PDF/industrysolutions/CMMACSWRFPoster.pdf
���ꂩ��A���k���Ƃ��������A������̂ɗ̈敪������
�ōςނ悤�ȏꍇ�Ȃ痬�̌v�Z�ł������Ǝ��s�������ǂ��͂��B
�܂��A���A�v�����ƒP���ȗ̈敪���ł͕��ł��Ȃ��̂ŁA
�P���Ɏ��s�����Ō����ƃX�J���[�͕s���Ȃ�܂��B
���ƁA������ƌÂ����ǁA���̔�r����B
ttp://chikyu-to-umi.com/earth/jam_yes.htm
>>646
>�����R�[�h�Ńx�N�g���@�Ȃ狰�炭 50% ���炢�o�邾�낤����
�⑫�BES ���Ƃ����Əo�Ă��܂��ˁB
ttp://www.docstoc.com/docs/11302501/Weather-Research-and-Forecast--%28WRF%29-Model
>�����R�[�h�Ńx�N�g���@�Ȃ狰�炭 50% ���炢�o�邾�낤����
�⑫�BES ���Ƃ����Əo�Ă��܂��ˁB
ttp://www.docstoc.com/docs/11302501/Weather-Research-and-Forecast--%28WRF%29-Model
648 �F�s���ȃf�o�C�X�����F2009/10/02(��) 23:26:45 ID:HAH9bHiQ
>>644
�܂��Anextreme2�ŊJ���R�X�g����������Ȃ�V-GRAPE�Ƃ���炸��
��p�p�C�v�ɖ߂����ق����ǂ��Ǝv�����ǂȁBDR�͂��Ƃ��Ɨ\�Z��
���B����ׂɎd���Ȃ����p�͈͂��L�����킯�����ȁB
�܂��A�\�Z�l���������ɂ���Ϸ�ɂ��ėpHPC���ۂ��̂�����Ă݂�������
���ĉ\��������킯������
�܂��Anextreme2�ŊJ���R�X�g����������Ȃ�V-GRAPE�Ƃ���炸��
��p�p�C�v�ɖ߂����ق����ǂ��Ǝv�����ǂȁBDR�͂��Ƃ��Ɨ\�Z��
���B����ׂɎd���Ȃ����p�͈͂��L�����킯�����ȁB
�܂��A�\�Z�l���������ɂ���Ϸ�ɂ��ėpHPC���ۂ��̂�����Ă݂�������
���ĉ\��������킯������
649 �F�s���ȃf�o�C�X�����F2009/10/03(�y) 00:52:51 ID:TDDvua9V
>>639
Intel�̒P�̃Q�[�~���OGPU��2007�N�ā`�H���ɓo��
http://techreport.com/discussions.x/10549
Intel�̒P��VGA(Larrabee)��2008�N�O���ɓo�ꂵ
2008�N�̒P��VGA���o�חʂ�20�`30%���߂�A���i��$300�ȉ�
http://www.digitimes.com/mobos/a20070606VL207.html
�u2008�N�ɂ�Larrabee�̓���f�������J����v
���i�̓��������ɂ��Ắu2008�N���`2009�N�v
http://pc.watch.impress.co.jp/docs/2007/0611/kaigai364.htm
Larrabee�̊J���Ҍ����{�[�h��2008�N11���ɓo�ꂷ��
http://en.hardspell.com/doc/showcont.asp?news_id=3793
Larrabee�v���Z�b�T�̑��w�́C2009�N�I��肩��2010�N���߂ɂ����ēo��
http://itpro.nikkeibp.co.jp/article/NEWS/20080805/312163/
09�N1���ɏo��Ɨ\�z����Ă����V���R�����X��6�����x��
http://www.realworldtech.com/forums/index.cfm?action=detail&id=96437&threadid=96378&roomid=2
Larrabee���s��֓����ł���̂͑����Ă�2010�N�㔼
http://www.4gamer.net/games/085/G008505/20090217033/
����Intel�������gLarrabee�h��3����ځH
http://northwood.blog60.fc2.com/blog-entry-3071.html
�f���Ɏg��ꂽLarrabee��A6�V���R��
http://northwood.blog60.fc2.com/blog-entry-3150.html
Intel�̒P�̃Q�[�~���OGPU��2007�N�ā`�H���ɓo��
http://techreport.com/discussions.x/10549
Intel�̒P��VGA(Larrabee)��2008�N�O���ɓo�ꂵ
2008�N�̒P��VGA���o�חʂ�20�`30%���߂�A���i��$300�ȉ�
http://www.digitimes.com/mobos/a20070606VL207.html
�u2008�N�ɂ�Larrabee�̓���f�������J����v
���i�̓��������ɂ��Ắu2008�N���`2009�N�v
http://pc.watch.impress.co.jp/docs/2007/0611/kaigai364.htm
Larrabee�̊J���Ҍ����{�[�h��2008�N11���ɓo�ꂷ��
http://en.hardspell.com/doc/showcont.asp?news_id=3793
Larrabee�v���Z�b�T�̑��w�́C2009�N�I��肩��2010�N���߂ɂ����ēo��
http://itpro.nikkeibp.co.jp/article/NEWS/20080805/312163/
09�N1���ɏo��Ɨ\�z����Ă����V���R�����X��6�����x��
http://www.realworldtech.com/forums/index.cfm?action=detail&id=96437&threadid=96378&roomid=2
Larrabee���s��֓����ł���̂͑����Ă�2010�N�㔼
http://www.4gamer.net/games/085/G008505/20090217033/
����Intel�������gLarrabee�h��3����ځH
http://northwood.blog60.fc2.com/blog-entry-3071.html
�f���Ɏg��ꂽLarrabee��A6�V���R��
http://northwood.blog60.fc2.com/blog-entry-3150.html
650 �F�s���ȃf�o�C�X�����F2009/10/03(�y) 01:23:54 ID:3JZIxFmT
���̃R�s�y������������\�[�X���f���̏������݂�������L�҂̗\�z��������ŕK������Ȃ�
651 �F�s���ȃf�o�C�X�����F2009/10/03(�y) 01:29:17 ID:VpOKWTG6
2008�N�����܂ł͂��̃\�[�X�ŐM�ҒB���t�@���^�W�[���Ă����E�E�E�E
652 �F�s���ȃf�o�C�X�����F2009/10/03(�y) 01:59:49 ID:XPXLAl1T
�Ȃ�Intel��Larrabee��HPC�����ɃT���v�����Ȃ��̂��낤
GPU�Ƃ��Ă͔��蕨�ɂȂ�Ȃ��Ƃ��Ă��A���̗��p�Z�p�����[�U�[���g�ɂ���ɂ͎��Ԃ�������B
GPU�Ƃ��Ă͔��蕨�ɂȂ�Ȃ��Ƃ��Ă��A���̗��p�Z�p�����[�U�[���g�ɂ���ɂ͎��Ԃ�������B
653 �F�s���ȃf�o�C�X�����F2009/10/03(�y) 02:13:49 ID:BwvRXmbE
���������NHPC��Xeon�ŁA
�Ƃ������j������B
�Ƃ������j������B
654 �F�s���ȃf�o�C�X�����F2009/10/03(�y) 02:29:52 ID:XPXLAl1T
����͎��^�p�V�X�e���̘b����ˁB
Larrabee�����i�����ꂽ����������^�p���悤�Ǝv������A
�]���p�̃T���v����1�N��2�N���O�Ɏ�ɂ��ĂȂ��ƃ_�������B
Larrabee�����i�����ꂽ����������^�p���悤�Ǝv������A
�]���p�̃T���v����1�N��2�N���O�Ɏ�ɂ��ĂȂ��ƃ_�������B
655 �F�s���ȃf�o�C�X�����F2009/10/03(�y) 02:42:33 ID:3JZIxFmT
>>651
������H
������H
656 �F�s���ȃf�o�C�X�����F2009/10/03(�y) 02:47:08 ID:l/uvqr2J
�v���W�F�N�g�͏����ɐi��ł��āA�T���v�����o����Ă���炵����
http://www.intel.co.jp/jp/intel/pr/press/jointhp.htm
����Pentium�x�[�X�̍ŏ��̃��j�[�R�A�A�[�L�e�N�`���v���Z�b�T
�uLarrabee(TM)�v�́A�C���e���ɂ���Đv�A�����A�̔������\��ŁA
�ʎY�o�ׂ�2009�N�ɂȂ錩���݂ł��B
http://www.intel.co.jp/jp/intel/pr/press98/980601.htm
�C���e�� �R�[�|���[�V�����i�{�ЁF�č��J���t�H���j�A�B�T���^�N�����j
�́A�{���A�uLarrabee(TM) �v���Z�b�T�v�̐��Y�X�P�W���[���̕ύX��
�ڋq�ɘA�������Ɣ��\���܂����B�A�����ꂽ�ŐV�̐��Y�X�P�W���[��
�ɂ��ƁA���v���Z�b�T�̃T���v���o�ׂ�2009�N�ɁA�܂��A����
2009�N�ɗ\�肳��Ă����ʎY�o�ׂ́A2010�N���ɗ\�肳��Ă��܂��B
http://techon.nikkeibp.co.jp/article/NEWS/20080118/145725/
��Intel�Ђ́C�uLarrabee(�����r)�v�𓋍ڂ������@���g����
3�����O���t�B�b�N�X�f���������J�����B2009�N9��22������
�č��T���t�����V�X�R�ŊJ�Ò��́uIDF Fall 2009�v�̊�u���ŁC
�V���[���E�}���j�[�㋉���В����C�f�����I�����B
Larrabee�́C���łɓ��胁�[�J�����̃T���v���o�ׂ��n�܂��Ă���B
http://www.intel.co.jp/jp/intel/pr/press/jointhp.htm
����Pentium�x�[�X�̍ŏ��̃��j�[�R�A�A�[�L�e�N�`���v���Z�b�T
�uLarrabee(TM)�v�́A�C���e���ɂ���Đv�A�����A�̔������\��ŁA
�ʎY�o�ׂ�2009�N�ɂȂ錩���݂ł��B
http://www.intel.co.jp/jp/intel/pr/press98/980601.htm
�C���e�� �R�[�|���[�V�����i�{�ЁF�č��J���t�H���j�A�B�T���^�N�����j
�́A�{���A�uLarrabee(TM) �v���Z�b�T�v�̐��Y�X�P�W���[���̕ύX��
�ڋq�ɘA�������Ɣ��\���܂����B�A�����ꂽ�ŐV�̐��Y�X�P�W���[��
�ɂ��ƁA���v���Z�b�T�̃T���v���o�ׂ�2009�N�ɁA�܂��A����
2009�N�ɗ\�肳��Ă����ʎY�o�ׂ́A2010�N���ɗ\�肳��Ă��܂��B
http://techon.nikkeibp.co.jp/article/NEWS/20080118/145725/
��Intel�Ђ́C�uLarrabee(�����r)�v�𓋍ڂ������@���g����
3�����O���t�B�b�N�X�f���������J�����B2009�N9��22������
�č��T���t�����V�X�R�ŊJ�Ò��́uIDF Fall 2009�v�̊�u���ŁC
�V���[���E�}���j�[�㋉���В����C�f�����I�����B
Larrabee�́C���łɓ��胁�[�J�����̃T���v���o�ׂ��n�܂��Ă���B
657 �F�s���ȃf�o�C�X�����F2009/10/03(�y) 02:55:54 ID:82A78dUO
�Ƃ肠�������S�����B
658 �F�s���ȃf�o�C�X�����F2009/10/03(�y) 02:56:31 ID:XPXLAl1T
�������̃Q�[���̃\�t�g�n�E�X�ɂ͒���Ă��邯�ǁAHPC����͂���Ă�̂��ȁB
�q��搶�Ƃ�1��ɓ���āA�������Ǝg���Ă݂Ċ��z�������ė~������B
NDA�����邩��AIntel�̃}�[�P�e�B���O����`�ɂȂ�Ɣ��f�������t�����\�ɏo���Ȃ����낤���ǁB
�q��搶�Ƃ�1��ɓ���āA�������Ǝg���Ă݂Ċ��z�������ė~������B
NDA�����邩��AIntel�̃}�[�P�e�B���O����`�ɂȂ�Ɣ��f�������t�����\�ɏo���Ȃ����낤���ǁB
659 �F�s���ȃf�o�C�X�����F2009/10/03(�y) 03:31:37 ID:zQG1R4E6
���������A���������O�����A���N�̓��L��
Intel���P���L��������Ȃ��H
NDA�����邩�烂�j�����j���t�S�t�S�Ȋ����������L���B�B�B
����������Ă��Ȃ��́H
����Intel���u�ɎO���L����ĂăX�y�[�X�������႗
�܂��O��̃A�\�R���ӂ͎U�������ۂł悭�������ǁA
�~�n�̒��͍L������Ȃ��A�e���g�����ł������Ă��Ȃ����Ƃ��Ȃ���
��������A���̂܂����z�����d���u�Ƃ��ݒu���Ă��B
�]�T�����@�Ƃ��I���[�^��
Intel���P���L��������Ȃ��H
NDA�����邩�烂�j�����j���t�S�t�S�Ȋ����������L���B�B�B
����������Ă��Ȃ��́H
����Intel���u�ɎO���L����ĂăX�y�[�X�������႗
�܂��O��̃A�\�R���ӂ͎U�������ۂł悭�������ǁA
�~�n�̒��͍L������Ȃ��A�e���g�����ł������Ă��Ȃ����Ƃ��Ȃ���
��������A���̂܂����z�����d���u�Ƃ��ݒu���Ă��B
�]�T�����@�Ƃ��I���[�^��
660 �F�s���ȃf�o�C�X�����F2009/10/03(�y) 03:34:36 ID:WY9DecHk
�������\�ł́A
���̂������HPC�E�G���v�����ʂ̃A�s�[���̓t�F�[�h�A�E�g�B
����ɕ������Z�E�Q�[���E���C�g���p�r�ł̑i�����������Ă����B
Visual Computing Group�̊NJ��ł��邱�Ƃ����炩�ɂȂ����B
421 �FSocket774�F2008/03/18(��) 21:02:47 ID:F6cnWF/6
�C���e���A�V�����O���t�B�b�N�`�b�v�uLarrabee�v�̒lj��������J
http://japan.cnet.com/news/ent/story/0,2000056022,20369631,00.htm
GMA�V���[�Y�Ŏ肱�����Ă���̂��R�̂悤��
Larrabee�ł�DirectX�Ή�����肭�s�������F�������S�����T����
422 �FSocket774�F2008/03/18(��) 21:19:38 ID:BWjCmu1Q
�l�Ԃ̐U����ʼn��Ƃ��Ȃ邩����B
�����r�[�̓X�g���[�~���O�v���Z�b�T�ɂȂ�ȁB
CPU�݂����ȕ���\�������Ȃ���ɂȂ�ȁB
423 �FSocket774�F2008/03/18(��) 21:21:03 ID:spVK5LtJ
>>421
�Ή��h���C�o�܂�������������������������
428 �FSocket774�F2008/03/18(��) 23:44:51 ID:7U1qQAJk
���̋L���ł̓O���t�B�b�N�v���Z�b�T�ɂȂ�������Ă�̂ȁB
429 �FSocket774�F2008/03/18(��) 23:50:01 ID:GTt5hOom
GPU�Ƃł����Ȃ��ƕ��y���Ȃ���
����
430 �FSocket774�F2008/03/18(��) 23:53:45 ID:a8qFANyY
http://intel_im.edgesuite.net/2008/2-1030879/IM2008_Kilroy.pdf p16
�G���v���O���[�v�̓G���v���O���[�v��
���Z�A�����̌@�ACAD���^�[�Q�b�g�ɂ��Ă�
����Ȃ����������o����s���̂������̂ɂȂ�̂ł��傤��
���̂������HPC�E�G���v�����ʂ̃A�s�[���̓t�F�[�h�A�E�g�B
����ɕ������Z�E�Q�[���E���C�g���p�r�ł̑i�����������Ă����B
Visual Computing Group�̊NJ��ł��邱�Ƃ����炩�ɂȂ����B
421 �FSocket774�F2008/03/18(��) 21:02:47 ID:F6cnWF/6
�C���e���A�V�����O���t�B�b�N�`�b�v�uLarrabee�v�̒lj��������J
http://japan.cnet.com/news/ent/story/0,2000056022,20369631,00.htm
GMA�V���[�Y�Ŏ肱�����Ă���̂��R�̂悤��
Larrabee�ł�DirectX�Ή�����肭�s�������F�������S�����T����
422 �FSocket774�F2008/03/18(��) 21:19:38 ID:BWjCmu1Q
�l�Ԃ̐U����ʼn��Ƃ��Ȃ邩����B
�����r�[�̓X�g���[�~���O�v���Z�b�T�ɂȂ�ȁB
CPU�݂����ȕ���\�������Ȃ���ɂȂ�ȁB
423 �FSocket774�F2008/03/18(��) 21:21:03 ID:spVK5LtJ
>>421
�Ή��h���C�o�܂�������������������������
428 �FSocket774�F2008/03/18(��) 23:44:51 ID:7U1qQAJk
���̋L���ł̓O���t�B�b�N�v���Z�b�T�ɂȂ�������Ă�̂ȁB
429 �FSocket774�F2008/03/18(��) 23:50:01 ID:GTt5hOom
GPU�Ƃł����Ȃ��ƕ��y���Ȃ���
����
430 �FSocket774�F2008/03/18(��) 23:53:45 ID:a8qFANyY
http://intel_im.edgesuite.net/2008/2-1030879/IM2008_Kilroy.pdf p16
�G���v���O���[�v�̓G���v���O���[�v��
���Z�A�����̌@�ACAD���^�[�Q�b�g�ɂ��Ă�
����Ȃ����������o����s���̂������̂ɂȂ�̂ł��傤��
661 �F�s���ȃf�o�C�X�����F2009/10/03(�y) 05:52:29 ID:MxB9SKOu
>>645
SX���C�O�̋C�ۊW�̌������ɑ����[������Ă�͎̂����ł���B
LINPACK��ꕔ�̃R�[�h�Œl�i�����肩�d�͓������flops�Ȃ�GB/s�Ƃ����Ă邱�Ƃ���
�n�[�h���̎��Ȗ����B�O���@�ւ܂ŁANEC�Ɍb��ł����Ă�Ƃł��H
>>646
>���ꂩ��A���k���Ƃ��������A������̂ɗ̈敪������
>�ōςނ悤�ȏꍇ�Ȃ痬�̌v�Z�ł������Ǝ��s�������ǂ��͂��B
��L�ɓ��Ă͂܂�̂��A�����鈳�k����͂ɂ�����A�k���ƑS�̈��ΏۂƂ���
�ʐM���������������3D�g�[���X�ł͌������łɂ����Ƃ����͓̂��ӂł��B
�����炱���A���̉�͂���Ƃ���@�ւ�SX�̗D�ʐ����Ȃ��Ƃ͎v���܂��B
SX���C�O�̋C�ۊW�̌������ɑ����[������Ă�͎̂����ł���B
LINPACK��ꕔ�̃R�[�h�Œl�i�����肩�d�͓������flops�Ȃ�GB/s�Ƃ����Ă邱�Ƃ���
�n�[�h���̎��Ȗ����B�O���@�ւ܂ŁANEC�Ɍb��ł����Ă�Ƃł��H
>>646
>���ꂩ��A���k���Ƃ��������A������̂ɗ̈敪������
>�ōςނ悤�ȏꍇ�Ȃ痬�̌v�Z�ł������Ǝ��s�������ǂ��͂��B
��L�ɓ��Ă͂܂�̂��A�����鈳�k����͂ɂ�����A�k���ƑS�̈��ΏۂƂ���
�ʐM���������������3D�g�[���X�ł͌������łɂ����Ƃ����͓̂��ӂł��B
�����炱���A���̉�͂���Ƃ���@�ւ�SX�̗D�ʐ����Ȃ��Ƃ͎v���܂��B
662 �F�s���ȃf�o�C�X�����F2009/10/03(�y) 08:02:29 ID:WG6UXNU/
���s�����Ȃ�Ă̂���鑤�̎��Ȗ��������ȁB
�g�p�҂ɂƂ��Ă̐��\�͌���ꂽ���\�[�X�i�\�Z�A�ݒu�ꏊ�A�d�́A�l��etc.�j
�łǂꂾ���A�v���P�[�V�������������邩�A�ł����Ȃ��B
�g�p�҂ɂƂ��Ă̐��\�͌���ꂽ���\�[�X�i�\�Z�A�ݒu�ꏊ�A�d�́A�l��etc.�j
�łǂꂾ���A�v���P�[�V�������������邩�A�ł����Ȃ��B
663 �F�s���ȃf�o�C�X�����F2009/10/03(�y) 09:39:03 ID:Hn5yPR/2
���с[�͒ނ�
�f�o�f�o�t�H�㓙����R�����Ċ����Ō����ɂԂ������Ă݂�����
�f�o�f�o�t�H�㓙����R�����Ċ����Ō����ɂԂ������Ă݂�����
664 �F�s���ȃf�o�C�X�����F2009/10/03(�y) 09:39:49 ID:bxcg0ceQ
President Obama Recognizes IBM's Blue Gene Server Technology
http://news.softpedia.com/news/President-Obama-Recognizes-IBM-039-s-Blue-Gene-Server-Technology-122097.shtml
Pat Gelsinger left Intel because of Larrabee fiasco?
http://www.brightsideofnews.com/news/2009/9/18/pat-gelsinger-left-intel-because-of-larrabee-fiasco.aspx
InfiniBand and the Cloud
http://www.itbusinessedge.com/cm/blogs/cole/infiniband-and-the-cloud/?cs=35925
NNSA Issues RFP For Next Supercomputing Platform
http://nuclearstreet.com/blogs/nuclear_power_news/archive/2009/09/21/nnsa-issues-rfp-for-next-supercomputing-platform-9213.aspx
Intel used rebates to freeze out AMD, EC docs show
http://www.channelregister.co.uk/2009/09/21/intel_eu_fine_evidence/
AMD launches server platform
http://www.theinquirer.net/inquirer/news/1534182/amd-launches-server-platform
Intel CTO: Machines could ultimately match human intelligence
http://news.idg.no/cw/art.cfm?id=DDF6D072-1A64-6A71-CE3593B926E6D6CF
SGI Makes Leap Into 'Personal Supercomputing'
http://www.hpcwire.com/features/SGI-Makes-Leap-Into-Personal-Supercomputing-60079687.html?ref=687
Met Office launches airline weather tool
http://news.icm.ac.uk/business/met-office-launches-airline-weather-tool/3723/
Oracle's Larry Ellison says Sun losing $100 million a month
http://www.mercurynews.com/ci_13391182?source=most_emailed
http://news.softpedia.com/news/President-Obama-Recognizes-IBM-039-s-Blue-Gene-Server-Technology-122097.shtml
Pat Gelsinger left Intel because of Larrabee fiasco?
http://www.brightsideofnews.com/news/2009/9/18/pat-gelsinger-left-intel-because-of-larrabee-fiasco.aspx
InfiniBand and the Cloud
http://www.itbusinessedge.com/cm/blogs/cole/infiniband-and-the-cloud/?cs=35925
NNSA Issues RFP For Next Supercomputing Platform
http://nuclearstreet.com/blogs/nuclear_power_news/archive/2009/09/21/nnsa-issues-rfp-for-next-supercomputing-platform-9213.aspx
Intel used rebates to freeze out AMD, EC docs show
http://www.channelregister.co.uk/2009/09/21/intel_eu_fine_evidence/
AMD launches server platform
http://www.theinquirer.net/inquirer/news/1534182/amd-launches-server-platform
Intel CTO: Machines could ultimately match human intelligence
http://news.idg.no/cw/art.cfm?id=DDF6D072-1A64-6A71-CE3593B926E6D6CF
SGI Makes Leap Into 'Personal Supercomputing'
http://www.hpcwire.com/features/SGI-Makes-Leap-Into-Personal-Supercomputing-60079687.html?ref=687
Met Office launches airline weather tool
http://news.icm.ac.uk/business/met-office-launches-airline-weather-tool/3723/
Oracle's Larry Ellison says Sun losing $100 million a month
http://www.mercurynews.com/ci_13391182?source=most_emailed
665 �F�s���ȃf�o�C�X�����F2009/10/03(�y) 09:40:36 ID:bxcg0ceQ
Examining the Future of Scientific HPC
http://www.scientificcomputing.com/news-HPC-examining-the-future-of-scientific-hpc-092209.aspx
Microsoft acquires Waltham firm ISC
http://boston.bizjournals.com/boston/stories/2009/09/21/daily26.html
Is Intel's Atom really the future?
http://www.tgdaily.com/content/view/44062/135/
AMD confirms hexa-core desktop chip, Thuban
http://www.techspot.com/news/36314-amd-confirms-hexacore-desktop-chip-thuban.html
Computer Code Gives Astrophysicists First Full Simulation Of Star's Final Hours
http://www.sciencedaily.com/releases/2009/09/090922160108.htm
Mellanox kicks off race to 40 Gigabit Ethernet
http://www.channelregister.co.uk/2009/09/23/mellanox_40ge_adapters/
AMD's Radeon HD 5870 graphics processor
http://techreport.com/articles.x/17618
Molecular science research critical to DOE
http://www.nanotech-now.com/news.cgi?story_id=34786
Clouds Predicted in Barcelona for Annual Grid Conference
http://www.hpcwire.com/offthewire/Clouds-Predicted-in-Barcelona-for-Annual-Grid-Conference-60670377.html
HPC on Wall Street: Report From the Front
http://www.linux-mag.com/id/7534
http://www.scientificcomputing.com/news-HPC-examining-the-future-of-scientific-hpc-092209.aspx
Microsoft acquires Waltham firm ISC
http://boston.bizjournals.com/boston/stories/2009/09/21/daily26.html
Is Intel's Atom really the future?
http://www.tgdaily.com/content/view/44062/135/
AMD confirms hexa-core desktop chip, Thuban
http://www.techspot.com/news/36314-amd-confirms-hexacore-desktop-chip-thuban.html
Computer Code Gives Astrophysicists First Full Simulation Of Star's Final Hours
http://www.sciencedaily.com/releases/2009/09/090922160108.htm
Mellanox kicks off race to 40 Gigabit Ethernet
http://www.channelregister.co.uk/2009/09/23/mellanox_40ge_adapters/
AMD's Radeon HD 5870 graphics processor
http://techreport.com/articles.x/17618
Molecular science research critical to DOE
http://www.nanotech-now.com/news.cgi?story_id=34786
Clouds Predicted in Barcelona for Annual Grid Conference
http://www.hpcwire.com/offthewire/Clouds-Predicted-in-Barcelona-for-Annual-Grid-Conference-60670377.html
HPC on Wall Street: Report From the Front
http://www.linux-mag.com/id/7534
666 �F�s���ȃf�o�C�X�����F2009/10/03(�y) 09:41:27 ID:bxcg0ceQ
New Russian Top50 Supercomputers List Released
http://www.hpcwire.com/offthewire/New-Russian-Top50-Supercomputers-List-Released-60675082.html
Lawrence Livermore Builds Stable of Workhorse Clusters
http://www.hpcwire.com/features/Lawrence-Livermore-Builds-Stable-of-Workhorse-Clusters-60943337.html
Simulation of white dwarf sheds light on Type-1a supernovae
http://www.examiner.com/x-22392-St-Louis-Science-News-Examiner~y2009m9d23-Simulation-of-white-dwarf-sheds-light-on-Type1a-supernovae
Eurotech Presents Aurora, the New Petascale Supercomputer that Sets a Landmark in High Performance Computing
http://news.thomasnet.com/fullstory/566175
Oak Ridge National Laboratory to get 3rd supercomputer: Machine part of $215M research deal with NOAA
http://www.tmcnet.com/usubmit/2009/09/24/4389054.htm
Scientists look for a better way to build bridges
http://dcnonl.com/article/id35463
Communications of the ACM Reports: Building Parallel Computing to Sustain Performance Improvement
http://www.tmcnet.com/usubmit/-communications-the-acm-reports-building-parallel-computing-susta-/2009/09/24/4390000.htm
Mainframe emulator goes commercial
http://www.theregister.co.uk/2009/09/25/turbohercules_goes_commercial/
ATI Radeon HD5870
http://www.theinquirer.net/inquirer/review/1556348/ati-radeon-hd5870
Appro: Bringing HPC to the Mainstream Enterprise
http://www.serverwatch.com/article.php/3841006/Appro-Bringing-HPC-to-the-Mainstream-Enterprise
http://www.hpcwire.com/offthewire/New-Russian-Top50-Supercomputers-List-Released-60675082.html
Lawrence Livermore Builds Stable of Workhorse Clusters
http://www.hpcwire.com/features/Lawrence-Livermore-Builds-Stable-of-Workhorse-Clusters-60943337.html
Simulation of white dwarf sheds light on Type-1a supernovae
http://www.examiner.com/x-22392-St-Louis-Science-News-Examiner~y2009m9d23-Simulation-of-white-dwarf-sheds-light-on-Type1a-supernovae
Eurotech Presents Aurora, the New Petascale Supercomputer that Sets a Landmark in High Performance Computing
http://news.thomasnet.com/fullstory/566175
Oak Ridge National Laboratory to get 3rd supercomputer: Machine part of $215M research deal with NOAA
http://www.tmcnet.com/usubmit/2009/09/24/4389054.htm
Scientists look for a better way to build bridges
http://dcnonl.com/article/id35463
Communications of the ACM Reports: Building Parallel Computing to Sustain Performance Improvement
http://www.tmcnet.com/usubmit/-communications-the-acm-reports-building-parallel-computing-susta-/2009/09/24/4390000.htm
Mainframe emulator goes commercial
http://www.theregister.co.uk/2009/09/25/turbohercules_goes_commercial/
ATI Radeon HD5870
http://www.theinquirer.net/inquirer/review/1556348/ati-radeon-hd5870
Appro: Bringing HPC to the Mainstream Enterprise
http://www.serverwatch.com/article.php/3841006/Appro-Bringing-HPC-to-the-Mainstream-Enterprise
667 �F�s���ȃf�o�C�X�����F2009/10/03(�y) 09:42:27 ID:bxcg0ceQ
IBM Building 'Smarter City' Cloud In China
http://www.informationweek.com/news/services/saas/showArticle.jhtml?articleID=220200250
Supercomputing In The Enterprise
http://www.forbes.com/2009/09/26/adaptive-computing-jackson-technology-cio-network-supercomputing.html
> Why supercomputing techniques have filtered into corporate data centers.
U of Tennessee to Establish Data Analysis Center
http://www.hpcwire.com/offthewire/University-of-Tennessee-to-Establish-Data-Analysis-Center-62383082.html?ref=082
The fastest ATI 5870 card achieves 3TFLOPS
http://www.brightsideofnews.com/news/2009/9/29/the-fastest-ati-5870-card-achieves-3tflops!.aspx
PGI CUDA Fortran Compiler Beta Released
http://www.ddj.com/hpc-high-performance-computing/220300282
Cisco preps Nexus switches for third-party blades
http://www.theregister.co.uk/2009/09/29/cisco_blade_switches/
Fujitsu Wins Supercomputer Order from Japan's Institute of Statistical Mathematics
http://www.prdomain.com/companies/F/Fujitsu/newsreleases/200910177769.htm
The rise of in silico R&D
http://pharmtech.findpharma.com/pharmtech/Spotlight/The-rise-of-in-silico-RampD/ArticleStandard/Article/detail/629830?contextCategoryId=40939
Predictive simulation successes on Dawn supercomputer
http://www.physorg.com/news173548668.html
National Science Foundation Awards $7 Million To TACC for Remote Visualization and Data Analysis
http://www.cgw.com/Press-Center/News/2009/National-Science-Foundation-Awards-7-Million-To-.aspx
http://www.informationweek.com/news/services/saas/showArticle.jhtml?articleID=220200250
Supercomputing In The Enterprise
http://www.forbes.com/2009/09/26/adaptive-computing-jackson-technology-cio-network-supercomputing.html
> Why supercomputing techniques have filtered into corporate data centers.
U of Tennessee to Establish Data Analysis Center
http://www.hpcwire.com/offthewire/University-of-Tennessee-to-Establish-Data-Analysis-Center-62383082.html?ref=082
The fastest ATI 5870 card achieves 3TFLOPS
http://www.brightsideofnews.com/news/2009/9/29/the-fastest-ati-5870-card-achieves-3tflops!.aspx
PGI CUDA Fortran Compiler Beta Released
http://www.ddj.com/hpc-high-performance-computing/220300282
Cisco preps Nexus switches for third-party blades
http://www.theregister.co.uk/2009/09/29/cisco_blade_switches/
Fujitsu Wins Supercomputer Order from Japan's Institute of Statistical Mathematics
http://www.prdomain.com/companies/F/Fujitsu/newsreleases/200910177769.htm
The rise of in silico R&D
http://pharmtech.findpharma.com/pharmtech/Spotlight/The-rise-of-in-silico-RampD/ArticleStandard/Article/detail/629830?contextCategoryId=40939
Predictive simulation successes on Dawn supercomputer
http://www.physorg.com/news173548668.html
National Science Foundation Awards $7 Million To TACC for Remote Visualization and Data Analysis
http://www.cgw.com/Press-Center/News/2009/National-Science-Foundation-Awards-7-Million-To-.aspx
668 �F�s���ȃf�o�C�X�����F2009/10/03(�y) 09:43:17 ID:bxcg0ceQ
Maui AMOS Conference Provides Stellar Networking Opportunity
http://www.mauiweekly.com/page/content.detail/id/500400/Maui-AMOS-Conference-Provides-Stellar-Networking-Opportunity.html?nav=13
How Yahoo is betting its cloud will pay off
http://news.cnet.com/8301-30685_3-10364900-264.html
Supercomputer hopes to say Gotcha to future terrorists
http://media-newswire.com/release_1101053.html
Oracle cuts database tags for Sparc T2+ servers
http://www.theregister.co.uk/2009/10/01/oracle_sparct2_db_pricing/
Oak Ridge goes gaga for Nvidia GPUs
http://www.theregister.co.uk/2009/10/01/oak_ridge_fermi/
Fiber to the Library Gets Momentum with Google, NATOA Endorsements
http://broadbandcensus.com/2009/10/fiber-to-the-library-gets-momentum-with-google-natoa-endorsements/
Nvidia showcases next-generation Fermi GPU
http://www.tgdaily.com/content/view/44146/135/
Nvidia: Next big supercomputer player?
http://blogs.zdnet.com/BTL/?p=25259
Mellanox Loses focus
http://www.networkcomputing.com/storage-networking-management/mellanox-looses-focus.php
Nvidia shakes up supercomputer economics
http://www.theinquirer.net/inquirer/news/1557197/nvidia-shakes-supercomputer-economics
http://www.mauiweekly.com/page/content.detail/id/500400/Maui-AMOS-Conference-Provides-Stellar-Networking-Opportunity.html?nav=13
How Yahoo is betting its cloud will pay off
http://news.cnet.com/8301-30685_3-10364900-264.html
Supercomputer hopes to say Gotcha to future terrorists
http://media-newswire.com/release_1101053.html
Oracle cuts database tags for Sparc T2+ servers
http://www.theregister.co.uk/2009/10/01/oracle_sparct2_db_pricing/
Oak Ridge goes gaga for Nvidia GPUs
http://www.theregister.co.uk/2009/10/01/oak_ridge_fermi/
Fiber to the Library Gets Momentum with Google, NATOA Endorsements
http://broadbandcensus.com/2009/10/fiber-to-the-library-gets-momentum-with-google-natoa-endorsements/
Nvidia showcases next-generation Fermi GPU
http://www.tgdaily.com/content/view/44146/135/
Nvidia: Next big supercomputer player?
http://blogs.zdnet.com/BTL/?p=25259
Mellanox Loses focus
http://www.networkcomputing.com/storage-networking-management/mellanox-looses-focus.php
Nvidia shakes up supercomputer economics
http://www.theinquirer.net/inquirer/news/1557197/nvidia-shakes-supercomputer-economics
669 �F�s���ȃf�o�C�X�����F2009/10/03(�y) 09:44:14 ID:bxcg0ceQ
�ŋ߂̘b�� 2009�N9 ��19��
http://www.geocities.jp/andosprocinfo/wadai09/20090919.htm
�ő�5.3TB�̃t���b�V���ō������A�I���N����Exadata2���\
http://www.atmarkit.co.jp/news/200909/16/oracle.html
���{SGI��������f�[�^�Z���^�[�s��ɎQ�� - �����d�̓T�[�o�Ȃǂ��
http://journal.mycom.co.jp/articles/2009/09/17/cloudrack/?rt=na
�ăX�g���[�W�E�x���_�[���C���e����SSD�̓��ڂ𒆎~�\�\STEC���ɕύX
http://www.computerworld.jp/topics/storage/162730.html
IBM�ABlue Gene�ŕč��ƋZ�p�܂����
http://www.itmedia.co.jp/enterprise/articles/0909/21/news004.html
��Intel�AIDF�ŁuNehalem-EX�v���g�p�����T�[�o�[���f��
http://enterprise.watch.impress.co.jp/docs/news/20090925_317455.html
�ŋ߂̘b�� 2009�N9 ��26��
http://www.geocities.jp/andosprocinfo/wadai09/20090926.htm
�C���e���A32nm������N�A�b�h�R�AXeon��O�|���œ�����
http://www.computerworld.jp/news/hw/162989.html
Intel�̎�����CPU�uSandy Bridge�v�̐���
http://pc.watch.impress.co.jp/docs/column/kaigai/20090929_318033.html
���k��A�O���t�F���̋����������X�p�R���g���m�F
http://www.nikkan.co.jp/news/nkx0720090929eaac.html
Radeon HD 5800�ŃX�^�[�g�����DirectX 11�n�[�h�E�F�A
http://pc.watch.impress.co.jp/docs/column/kaigai/20091001_318458.html
http://www.geocities.jp/andosprocinfo/wadai09/20090919.htm
�ő�5.3TB�̃t���b�V���ō������A�I���N����Exadata2���\
http://www.atmarkit.co.jp/news/200909/16/oracle.html
���{SGI��������f�[�^�Z���^�[�s��ɎQ�� - �����d�̓T�[�o�Ȃǂ��
http://journal.mycom.co.jp/articles/2009/09/17/cloudrack/?rt=na
�ăX�g���[�W�E�x���_�[���C���e����SSD�̓��ڂ𒆎~�\�\STEC���ɕύX
http://www.computerworld.jp/topics/storage/162730.html
IBM�ABlue Gene�ŕč��ƋZ�p�܂����
http://www.itmedia.co.jp/enterprise/articles/0909/21/news004.html
��Intel�AIDF�ŁuNehalem-EX�v���g�p�����T�[�o�[���f��
http://enterprise.watch.impress.co.jp/docs/news/20090925_317455.html
�ŋ߂̘b�� 2009�N9 ��26��
http://www.geocities.jp/andosprocinfo/wadai09/20090926.htm
�C���e���A32nm������N�A�b�h�R�AXeon��O�|���œ�����
http://www.computerworld.jp/news/hw/162989.html
Intel�̎�����CPU�uSandy Bridge�v�̐���
http://pc.watch.impress.co.jp/docs/column/kaigai/20090929_318033.html
���k��A�O���t�F���̋����������X�p�R���g���m�F
http://www.nikkan.co.jp/news/nkx0720090929eaac.html
Radeon HD 5800�ŃX�^�[�g�����DirectX 11�n�[�h�E�F�A
http://pc.watch.impress.co.jp/docs/column/kaigai/20091001_318458.html
670 �F�s���ȃf�o�C�X�����F2009/10/03(�y) 09:45:17 ID:bxcg0ceQ
�yGTC���|�[�g�z���{���j�V�X�ACUDA���R�����h�V�X�e��������
http://pc.watch.impress.co.jp/docs/news/event/20091002_319220.html
IDF�ł������Ȃ��������̓�
http://pc.watch.impress.co.jp/docs/column/hot/20091002_318819.html
�X�p�R���J���S���҂��u���@�_�˂ŃZ�~�i�[
http://www.kobe-np.co.jp/news/keizai/0002411733.shtml
http://pc.watch.impress.co.jp/docs/news/event/20091002_319220.html
IDF�ł������Ȃ��������̓�
http://pc.watch.impress.co.jp/docs/column/hot/20091002_318819.html
�X�p�R���J���S���҂��u���@�_�˂ŃZ�~�i�[
http://www.kobe-np.co.jp/news/keizai/0002411733.shtml
671 �F�s���ȃf�o�C�X�����F2009/10/03(�y) 14:47:40 ID:CdYKbL8b
>>661
>>626 ����̗��ꂾ�ƁA�x�N�g���@����X�J���[�@�ɒu��������Ă���
�Ƃ������Ƃ́A�A�A���Ęb����Ȃ���?
�܂��A�����́A�x�N�g���@�� Cray X1E ����̒u�������̂悤������A
���� Cray �ɂȂ����Ƃ����b��������Ȃ����ǁA����͂����ƃX�J���[�@
�ɒu��������čs���悤�ȋC������B
�e���̋C�ی����@�ւ̃X�p�R��[�Â��f�[�^]
http://chikyu-to-umi.com/earth/jam_yes2.htm
>>626 ����̗��ꂾ�ƁA�x�N�g���@����X�J���[�@�ɒu��������Ă���
�Ƃ������Ƃ́A�A�A���Ęb����Ȃ���?
�܂��A�����́A�x�N�g���@�� Cray X1E ����̒u�������̂悤������A
���� Cray �ɂȂ����Ƃ����b��������Ȃ����ǁA����͂����ƃX�J���[�@
�ɒu��������čs���悤�ȋC������B
�e���̋C�ی����@�ւ̃X�p�R��[�Â��f�[�^]
http://chikyu-to-umi.com/earth/jam_yes2.htm
672 �F�s���ȃf�o�C�X�����F2009/10/03(�y) 19:01:39 ID:4lNuR3eP
>>626
>>636
�}�L�[�m�����������ȁB
N�V�����ORNL�̐V�W���K�[2.3�y�^�@�̂��Ƃ������Ă��B
A������̍��T�̘b��ɂ̂��Ă�A���e�X�g����11����TOP500��1�ԂɂȂ�
6�R�A�̃C�X�^���u�[�����g�����V�W���K�[2.3�y�^�@����B
�����̓n�b�L�����Ă��邶���B
>>636
�}�L�[�m�����������ȁB
N�V�����ORNL�̐V�W���K�[2.3�y�^�@�̂��Ƃ������Ă��B
A������̍��T�̘b��ɂ̂��Ă�A���e�X�g����11����TOP500��1�ԂɂȂ�
6�R�A�̃C�X�^���u�[�����g�����V�W���K�[2.3�y�^�@����B
�����̓n�b�L�����Ă��邶���B
673 �F�s���ȃf�o�C�X�����F2009/10/03(�y) 19:51:36 ID:QuOFprxL
Google��GRAPE-DR����������
���̃L�[���[�h: GRAPE-DR ���s
�����^��
�d�g�u���O��CNET�̊Ŕ��t���ƃo�J�ɂȂ��
���̃L�[���[�h: GRAPE-DR ���s
�����^��
�d�g�u���O��CNET�̊Ŕ��t���ƃo�J�ɂȂ��
674 �F�s���ȃf�o�C�X�����F2009/10/03(�y) 19:52:10 ID:XPXLAl1T
�Ɨ��s���@�l���X�P�[�v�S�[�g�ɂ��Ă��閯��}���A���낻��q��搶�ɖڂ����鍠�����ȁB
GRAPE-DR�v���W�F�N�g���A�ʂ�̐��ʂ��o���Ă��Ȃ��̂ɑ�������ĂȂ�(�~�i����ĂȂ�)�Ƃ��B
GRAPE-DR�v���W�F�N�g���A�ʂ�̐��ʂ��o���Ă��Ȃ��̂ɑ�������ĂȂ�(�~�i����ĂȂ�)�Ƃ��B
675 �F�s���ȃf�o�C�X�����F2009/10/03(�y) 19:53:59 ID:Hn5yPR/2
���s����Ȃ���H
676 �F�s���ȃf�o�C�X�����F2009/10/03(�y) 19:54:25 ID:XPXLAl1T
>>673
CNET�̃A�����Ȃ������āAGRAPE-DR�������Ƃ������͎��s�Ȃ̂́A�٘_�Ȃ��Ǝv�����ǂȂ��B
�v��ʂ�ɂł��Ȃ��������Ă����̂́A���Ԋ�ƂȂ�A�[�������Ȃ��������Ă��ƂȂ킯�ł��B
�v���W�F�N�g�̐ӔC�҂����炩�̏�������͓̂��R����B
CNET�̃A�����Ȃ������āAGRAPE-DR�������Ƃ������͎��s�Ȃ̂́A�٘_�Ȃ��Ǝv�����ǂȂ��B
�v��ʂ�ɂł��Ȃ��������Ă����̂́A���Ԋ�ƂȂ�A�[�������Ȃ��������Ă��ƂȂ킯�ł��B
�v���W�F�N�g�̐ӔC�҂����炩�̏�������͓̂��R����B
677 �F�s���ȃf�o�C�X�����F2009/10/03(�y) 20:08:47 ID:Hn5yPR/2
���{�̉Ȋw�Z�p�\�Z����������ˁH
��������ČR����ɂ��ׂ�
��������ČR����ɂ��ׂ�
678 �F�s���ȃf�o�C�X�����F2009/10/03(�y) 20:20:41 ID:XPXLAl1T
ttp://www.knoxnews.com/photos/2009/sep/25/66967/
Cray��Jaguar�̒��g�̃����e���̎ʐ^�Ȃ��A���̃q�[�g�V���N�A�K�тĂȂ���?
Cray��Jaguar�̒��g�̃����e���̎ʐ^�Ȃ��A���̃q�[�g�V���N�A�K�тĂȂ���?
679 �F�s���ȃf�o�C�X�����F2009/10/03(�y) 20:31:10 ID:QnClsXMm
677 �F�s���ȃf�o�C�X���� [sage] �F2009/10/03(�y) 20:08:47 ID:Hn5yPR/2
���{�̉Ȋw�Z�p�\�Z����������ˁH
��������ČR����ɂ��ׂ�
677 �F�s���ȃf�o�C�X���� [sage] �F2009/10/03(�y) 20:08:47 ID:Hn5yPR/2
���{�̉Ȋw�Z�p�\�Z����������ˁH
��������ČR����ɂ��ׂ�
677 �F�s���ȃf�o�C�X���� [sage] �F2009/10/03(�y) 20:08:47 ID:Hn5yPR/2
���{�̉Ȋw�Z�p�\�Z����������ˁH
��������ČR����ɂ��ׂ�
677 �F�s���ȃf�o�C�X���� [sage] �F2009/10/03(�y) 20:08:47 ID:Hn5yPR/2
���{�̉Ȋw�Z�p�\�Z����������ˁH
��������ČR����ɂ��ׂ�
���{�̉Ȋw�Z�p�\�Z����������ˁH
��������ČR����ɂ��ׂ�
677 �F�s���ȃf�o�C�X���� [sage] �F2009/10/03(�y) 20:08:47 ID:Hn5yPR/2
���{�̉Ȋw�Z�p�\�Z����������ˁH
��������ČR����ɂ��ׂ�
677 �F�s���ȃf�o�C�X���� [sage] �F2009/10/03(�y) 20:08:47 ID:Hn5yPR/2
���{�̉Ȋw�Z�p�\�Z����������ˁH
��������ČR����ɂ��ׂ�
677 �F�s���ȃf�o�C�X���� [sage] �F2009/10/03(�y) 20:08:47 ID:Hn5yPR/2
���{�̉Ȋw�Z�p�\�Z����������ˁH
��������ČR����ɂ��ׂ�
680 �F�s���ȃf�o�C�X�����F2009/10/03(�y) 20:35:30 ID:hpWgFBnX
>>672
11���̃I�[�N���b�W����Ȃ��ė��N�㔼�Ɋ؍��ɓ���V�X�e���̘b�ł���H
������uAMD��6core���AIntel��8core���g�����J�����̐V�V�X�e����ݒu
������̂ƍl�����Ă���B�v�Ǝ����\�[�X�������������莖���̂悤��
�b��i�߂�̂��A���Ȃ̂��ƁB
11���̃I�[�N���b�W����Ȃ��ė��N�㔼�Ɋ؍��ɓ���V�X�e���̘b�ł���H
������uAMD��6core���AIntel��8core���g�����J�����̐V�V�X�e����ݒu
������̂ƍl�����Ă���B�v�Ǝ����\�[�X�������������莖���̂悤��
�b��i�߂�̂��A���Ȃ̂��ƁB
681 �F�s���ȃf�o�C�X�����F2009/10/03(�y) 20:48:28 ID:WG6UXNU/
>>672
��N�V�����ORNL�̐V�W���K�[2.3�y�^�@�̂��Ƃ������Ă��B
�����Ă邩�H
N�V�̃e�L�X�g�����Ă݂�������Ȃ��Ƃ͂ǂ��ɂ������ĂȂ��Ǝv�����B
���AORNL�̂Ɗ؍��C�ے��̃V�X�e���������\���ɂȂ���Ăǂ����H
�܂��A�}�L�[�m�̌��������m����ɂ����̂���Ȃ����낤���A
�ǂ������ǂ��������B
��N�V�����ORNL�̐V�W���K�[2.3�y�^�@�̂��Ƃ������Ă��B
�����Ă邩�H
N�V�̃e�L�X�g�����Ă݂�������Ȃ��Ƃ͂ǂ��ɂ������ĂȂ��Ǝv�����B
���AORNL�̂Ɗ؍��C�ے��̃V�X�e���������\���ɂȂ���Ăǂ����H
�܂��A�}�L�[�m�̌��������m����ɂ����̂���Ȃ����낤���A
�ǂ������ǂ��������B
682 �F�s���ȃf�o�C�X�����F2009/10/03(�y) 21:29:03 ID:4lNuR3eP
>>681
>�����AAMD��6core���AIntel��8core���g�����J�����̐V�V�X�e����
�ݒu������̂ƍl�����Ă���B
����N�V����̕\���A���ʉ����ւƂ͎v���ˁ[�ȁB���ʂ���B
������AAMD��12�R�A���āA���N�o�ׂ������Ă̊m���Ȃ́H�@
����܂�AMD��4�R�A���Ēx��ɒx�ꂽ��B
����6�R�A�œ����Ă�V�X�e�����Ă���̂���H
���̂��ƒm���Ă��A���N��12�R�A�łȂƂ͂����ˁ[���ǂȁB
>�����AAMD��6core���AIntel��8core���g�����J�����̐V�V�X�e����
�ݒu������̂ƍl�����Ă���B
����N�V����̕\���A���ʉ����ւƂ͎v���ˁ[�ȁB���ʂ���B
������AAMD��12�R�A���āA���N�o�ׂ������Ă̊m���Ȃ́H�@
����܂�AMD��4�R�A���Ēx��ɒx�ꂽ��B
����6�R�A�œ����Ă�V�X�e�����Ă���̂���H
���̂��ƒm���Ă��A���N��12�R�A�łȂƂ͂����ˁ[���ǂȁB
683 �F�s���ȃf�o�C�X�����F2009/10/03(�y) 21:45:30 ID:WG6UXNU/
>>682
���ɂ�N�V�̓��̒����}�L�[�m�̐S�̓����`���Ȃ���ŁA
�ǂ������m����Řb���ĂȂ����瓯���悤�Ȃ��Ƃ���
�����Ȃ��킯�����B
����͂��炭N�V�̎v�l�ߒ��ɏڂ����悤�����ǂ���
���ɂ�N�V�̓��̒����}�L�[�m�̐S�̓����`���Ȃ���ŁA
�ǂ������m����Řb���ĂȂ����瓯���悤�Ȃ��Ƃ���
�����Ȃ��킯�����B
����͂��炭N�V�̎v�l�ߒ��ɏڂ����悤�����ǂ���
684 �F�s���ȃf�o�C�X�����F2009/10/03(�y) 22:29:51 ID:XPXLAl1T
>>682
������ɏo�Ă�Jaguar��6�R�A�Ƀ��v���[�X���B
������ɏo�Ă�Jaguar��6�R�A�Ƀ��v���[�X���B
685 �F�s���ȃf�o�C�X�����F2009/10/04(��) 00:04:01 ID:WyO1WomT
����Ȃ̂̓}�L�[�m���������x�����Ǝv���B
���̐��E�A���������������Ăق��͔n�����Ďv���Ă�y�������ˁB
���̐��E�A���������������Ăق��͔n�����Ďv���Ă�y�������ˁB
686 �F�s���ȃf�o�C�X�����F2009/10/04(��) 00:05:52 ID:D6eVNZvI
���ꂪ�悭������
687 �F�s���ȃf�o�C�X�����F2009/10/04(��) 00:08:37 ID:wYhcGTxy
�m��Ȃ��l���A�~�X�^�[�X�|�b�N�ɂ��������Ȃ��Ƃ�
�S���E�Ɍ��������̏�Ō������Ƃ��Ⴀ�Ȃ��ˁB
�S���E�Ɍ��������̏�Ō������Ƃ��Ⴀ�Ȃ��ˁB
688 �F�s���ȃf�o�C�X�����F2009/10/04(��) 00:29:55 ID:wYhcGTxy
GRAPE-DR model450
2008/7�̎��_��60���~�A����36���~
model2000 126���~
model1800 �͊�炾�������E�E�E
�ŐV��model2000�ł�400MHz����ȂE�E�E
2008/7�̎��_��60���~�A����36���~
model2000 126���~
model1800 �͊�炾�������E�E�E
�ŐV��model2000�ł�400MHz����ȂE�E�E
689 �F�s���ȃf�o�C�X�����F2009/10/04(��) 00:38:01 ID:wYhcGTxy
ttp://onokoro.cc.kyushu-u.ac.jp/forum08/talk/Koike.pdf
���ꌩ��ƁA�{�g���l�b�N��FPGA��Ɏ��O�ō�����������R���g���[���Ȃ̂ˁB
����Ȃ́A
��荂����FPGA���g���A�������R���g���[����IP���Ă���
���Ęb�����B
FPGA�����肪�{�ƂȂ�A�������ǂ��B
���ꌩ��ƁA�{�g���l�b�N��FPGA��Ɏ��O�ō�����������R���g���[���Ȃ̂ˁB
����Ȃ́A
��荂����FPGA���g���A�������R���g���[����IP���Ă���
���Ęb�����B
FPGA�����肪�{�ƂȂ�A�������ǂ��B
690 �F�s���ȃf�o�C�X�����F2009/10/04(��) 00:39:22 ID:D6eVNZvI
��荂����FPGA�ƃ������R���g���[���[��IP��T���Ă���d�����������܂����B
691 �F�s���ȃf�o�C�X�����F2009/10/04(��) 00:50:05 ID:wYhcGTxy
�Ȃ�Ă������K�v�ȃX�L��������Ȃ��̂ɒ��킵�A
����Ȃ��X�L���𑼏������킸�Ɏ��O�ʼn��Ƃ����悤�Ƃ���A
���ԂƗ\�Z�����s���ɂ���A����������낤���ǁA���B
���ǁA�ŋ���DIY�V�т������������Ă��ƂȂ̂��B
����Ȃ��X�L���𑼏������킸�Ɏ��O�ʼn��Ƃ����悤�Ƃ���A
���ԂƗ\�Z�����s���ɂ���A����������낤���ǁA���B
���ǁA�ŋ���DIY�V�т������������Ă��ƂȂ̂��B
692 �F�s���ȃf�o�C�X�����F2009/10/04(��) 01:11:15 ID:wYhcGTxy
GRAPE-DR���āA�����\��ł�SING��4000�`�b�v��������ˁB
ArriaGX�̔��\���A50�́A25���/���b�g�ŒP��50�h���܂�A���b�g125���h���B
4������K�v�Ȃ��Ă����b�g�P�ʂŔ���Ȃ���C�J���Ƃ������ƂŁA1��312.5�h�����B
������4��������Ȃ��V�����m�ŁA312.5�h����FPGA�́A����Ȃɍ����Ȃ��̂Ȃ̂��B
ArriaGX�̔��\���A50�́A25���/���b�g�ŒP��50�h���܂�A���b�g125���h���B
4������K�v�Ȃ��Ă����b�g�P�ʂŔ���Ȃ���C�J���Ƃ������ƂŁA1��312.5�h�����B
������4��������Ȃ��V�����m�ŁA312.5�h����FPGA�́A����Ȃɍ����Ȃ��̂Ȃ̂��B
693 �F�s���ȃf�o�C�X�����F2009/10/04(��) 01:28:47 ID:wYhcGTxy
����AStratixII GX���Ɛ��{�ɂȂ邩�B
15���̃v���W�F�N�g��FPGA��500�`750���h������������A��ς���B
15���̃v���W�F�N�g��FPGA��500�`750���h������������A��ς���B
694 �F�s���ȃf�o�C�X�����F2009/10/04(��) 01:36:40 ID:wYhcGTxy
ttp://www.kfcr.jp/daily/200905.html
�����[��
�C���^�[�I�y���r���e�B���y�������
�v���ɂȂ�ƁA���������̂���������A�����ō���Ƃ��Ă��A�v����������̂��Ă����ł��B
�����[��
�C���^�[�I�y���r���e�B���y�������
�v���ɂȂ�ƁA���������̂���������A�����ō���Ƃ��Ă��A�v����������̂��Ă����ł��B
695 �F�s���ȃf�o�C�X�����F2009/10/04(��) 11:03:40 ID:rJEP2HJL
GRAPE-DR���Ď��ہA�ǂꂭ�炢�o����H
696 �F�s���ȃf�o�C�X�����F2009/10/04(��) 17:25:24 ID:wYhcGTxy
�ȂX���Z�l�̓A�X�y���K�[�nj�Q���ƌ����������ȁB
697 �F�s���ȃf�o�C�X�����F2009/10/04(��) 22:32:09 ID:lO/VrgR/
698 �F�s���ȃf�o�C�X�����F2009/10/04(��) 22:35:38 ID:7Pei3EMW
Inside Fermi: Nvidia's HPC Push
http://www.realworldtech.com/page.cfm?ArticleID=RWT093009110932
http://www.realworldtech.com/page.cfm?ArticleID=RWT093009110932
699 �F�s���ȃf�o�C�X�����F2009/10/04(��) 22:50:51 ID:wYhcGTxy
>>697
����҂��A�������̓��[�U�[�̐ӔC�A���Ďv������ŊÂ₩���Ă�s��ł́A�ˁB
�p�\�R���̃r�f�I�J�[�h�ł�OpenGL�ȂǂɂȂ�ƁA
���쌟�؍ς݂œ��삪�ۏ��ꂽ�g�ݍ��킹�̃��X�g�����\����Ă�ł���B
�����ɍڂ��Ă��Ȃ��̂́A���삵�Ȃ��ƌ��Ȃ��čl����́B
�{�[�h�����Ƃ��ɂ��A�܂��͗v����`�Ƃ��āA���삷�ׂ���(�`�b�v�Z�b�g��)�����肷�郊�X�g�����́B
�����āA���̃��X�g�Ɍf������A���ۂɓ��쌟�����ĕۏ��Ȃ��Ƃ����Ȃ��́B
����҂��A�������̓��[�U�[�̐ӔC�A���Ďv������ŊÂ₩���Ă�s��ł́A�ˁB
�p�\�R���̃r�f�I�J�[�h�ł�OpenGL�ȂǂɂȂ�ƁA
���쌟�؍ς݂œ��삪�ۏ��ꂽ�g�ݍ��킹�̃��X�g�����\����Ă�ł���B
�����ɍڂ��Ă��Ȃ��̂́A���삵�Ȃ��ƌ��Ȃ��čl����́B
�{�[�h�����Ƃ��ɂ��A�܂��͗v����`�Ƃ��āA���삷�ׂ���(�`�b�v�Z�b�g��)�����肷�郊�X�g�����́B
�����āA���̃��X�g�Ɍf������A���ۂɓ��쌟�����ĕۏ��Ȃ��Ƃ����Ȃ��́B
700 �F�s���ȃf�o�C�X�����F2009/10/05(��) 02:30:06 ID:G8t+Xt6h
���Ďv������ł���킯�ł��ˁB
701 �F�s���ȃf�o�C�X�����F2009/10/05(��) 03:28:27 ID:86a0eMdm
�����r�[�p�\�t�g���CUDA�p�\�t�g�̂ق�������������
���₷��
���₷��
702 �F�s���ȃf�o�C�X�����F2009/10/05(��) 03:54:34 ID:RjOnn5pe
�C���e���̃y�^�X�P�[���R���s���[�e�B���O�֘A��R&D��p��AMD�̔������܂���Ă���Ė{��?
���ꂾ�����z�̔�p���g���Ă�̂�
Larrabee�͏���d�͂��傫���̂Ńv���Z�X�̔�����҂��܂����Ă͕̂ς���Ȃ���?
Larrabee�ȊO�ɉ����傫�Ȃ��Ƃ�����Ă���̂ł͂Ȃ���?
���ꂾ�����z�̔�p���g���Ă�̂�
Larrabee�͏���d�͂��傫���̂Ńv���Z�X�̔�����҂��܂����Ă͕̂ς���Ȃ���?
Larrabee�ȊO�ɉ����傫�Ȃ��Ƃ�����Ă���̂ł͂Ȃ���?
703 �F�s���ȃf�o�C�X�����F2009/10/05(��) 04:29:26 ID:tsqu+cyS
�R�ł�
704 �F�s���ȃf�o�C�X�����F2009/10/05(��) 04:36:03 ID:RjOnn5pe
ttp://www.computerworld.jp/topics/mcore/117549.html
����A�K�Z�Ȃ�?
����A�K�Z�Ȃ�?
705 �F�s���ȃf�o�C�X�����F2009/10/05(��) 04:39:18 ID:tsqu+cyS
����
706 �F�s���ȃf�o�C�X�����F2009/10/05(��) 06:01:16 ID:Eo3oEtJ8
Pat Gelsinger left Intel because of Larrabee fiasco?
http://www.brightsideofnews.com/news/2009/9/18/pat-gelsinger-left-intel-because-of-larrabee-fiasco.aspx
http://www.brightsideofnews.com/news/2009/9/18/pat-gelsinger-left-intel-because-of-larrabee-fiasco.aspx
707 �F�s���ȃf�o�C�X�����F2009/10/05(��) 06:16:11 ID:br8hbGZD
�Q���̑ގЂ�Larrabee�����ѕt����Ƃ������d�g��INQ��TheRegister�ł������ĂȂ��킯����
708 �F�s���ȃf�o�C�X�����F2009/10/05(��) 08:08:30 ID:YfZlXiFY
709 �F�s���ȃf�o�C�X�����F2009/10/05(��) 11:52:45 ID:qsI3veBi
�{�[�h�̎���Ȃ����Ƃ����Ԃɏo�������A���ʂ̓`�b�v���o�Ă���
�v���Ă������͌덷�͈̔͂���B
�v���Ă������͌덷�͈̔͂���B
710 �F�s���ȃf�o�C�X�����F2009/10/05(��) 14:13:26 ID:11/Q4G6m
>>702
�܂���킵���������A�e���X�P�[���E���T�[�`���肶��Ȃ�Intel��
R&D��p�S�̂�AMD�̎l�����̔��㍂�������Ă���Ă��Ƃ���B
�܂���킵���������A�e���X�P�[���E���T�[�`���肶��Ȃ�Intel��
R&D��p�S�̂�AMD�̎l�����̔��㍂�������Ă���Ă��Ƃ���B
711 �F�s���ȃf�o�C�X�����F2009/10/05(��) 14:42:44 ID:HM4TWGzU
��l������R&D�̔�p�킩���Ă��A
�e���X�P�[���E���T�[�`�̔�p�Ȃ�Ă킩��Ȃ��̂ɁA�Ӗ��̂���L�q�Ȃ̂��낤���B
�e���X�P�[���E���T�[�`�̔�p�Ȃ�Ă킩��Ȃ��̂ɁA�Ӗ��̂���L�q�Ȃ̂��낤���B
712 �F�s���ȃf�o�C�X�����F2009/10/05(��) 18:46:25 ID:YfZlXiFY
>>709
����{�[�h������āA����e�X�g�����āA
�{�Ԃ�����āA����e�X�g�����āA�ʎY���āA
�����t���V�X�e����g�ݏグ��A�Ƃ����i�K�܂�
����Ɠ����`�b�v�Z�b�g���g���Ƃ͍l���ɂ������B
����{�[�h������āA����e�X�g�����āA
�{�Ԃ�����āA����e�X�g�����āA�ʎY���āA
�����t���V�X�e����g�ݏグ��A�Ƃ����i�K�܂�
����Ɠ����`�b�v�Z�b�g���g���Ƃ͍l���ɂ������B
713 �F�s���ȃf�o�C�X�����F2009/10/05(��) 19:13:12 ID:RjOnn5pe
>>712
�d���x����
�d���x����
714 �F�s���ȃf�o�C�X�����F2009/10/05(��) 19:33:19 ID:xvtI6XkR
715 �F�s���ȃf�o�C�X�����F2009/10/05(��) 22:31:12 ID:8vSuCIEX
����Theo Valich�Ȃ���ǂވȑO�ɃN���b�N����Ȃ�
716 �F�s���ȃf�o�C�X�����F2009/10/05(��) 22:52:39 ID:sE2UADU3
�e�X���R�C���̂���
717 �F�s���ȃf�o�C�X�����F2009/10/06(��) 03:08:08 ID:5zho8eGl
�����܂œǂB
�F�X�ȈӖ��ł̋킪�J��L�����Ă�X���ł��˂�
���ꂩ�����낵���B
�F�X�ȈӖ��ł̋킪�J��L�����Ă�X���ł��˂�
���ꂩ�����낵���B
718 �F�s���ȃf�o�C�X�����F2009/10/06(��) 07:04:34 ID:d/jXMmra
TOP10����܂��[�H
719 �F�s���ȃf�o�C�X�����F2009/10/06(��) 13:05:38 ID:g3JE6tbZ
>>717
��www
>>673
Google�@����
GRAPE-DR
(���̃L�[���[�h�jGRAPE-DR ���s
A GREAT SENSE OF HUMOR
(��ԉ�)�@�����
���킢������"�����"�z�[���y�[�W
(���i) official page (2007�N3���܂Łj
����������
�i2007�N4������j
http://www.kfcr.jp/company.html#ak
�v����ɁAK&F�@�̐�`����www
��www
>>673
Google�@����
GRAPE-DR
(���̃L�[���[�h�jGRAPE-DR ���s
A GREAT SENSE OF HUMOR
(��ԉ�)�@�����
���킢������"�����"�z�[���y�[�W
(���i) official page (2007�N3���܂Łj
����������
�i2007�N4������j
http://www.kfcr.jp/company.html#ak
�v����ɁAK&F�@�̐�`����www
720 �F�s���ȃf�o�C�X�����F2009/10/07(��) 09:16:12 ID:oAojwboc
��? �ǂ䂱��?
721 �F���킢�F2009/10/07(��) 09:20:31 ID:oAojwboc
�����A�킩�����B����ȉ�肭�ǂ����Ƃ��Ă�ɂ˂��ł��B
���Ԃ���j�݂��N�����������ɏ�������ˁ[�́B
��������������A����������͌��邾���ɂ��܂����B
�ł̓o�C�i�� (����)�B
���Ԃ���j�݂��N�����������ɏ�������ˁ[�́B
��������������A����������͌��邾���ɂ��܂����B
�ł̓o�C�i�� (����)�B
722 �F�s���ȃf�o�C�X�����F2009/10/07(��) 09:56:45 ID:5GOWSZqb
�A�ނ��Ȃ���
723 �F�s���ȃf�o�C�X�����F2009/10/07(��) 21:01:18 ID:W2UMFqsx
>>721
s/����/����/
s/����/����/
724 �F�s���ȃf�o�C�X�����F2009/10/07(��) 23:18:39 ID:10xCxiot
�Ȃ��ق̂ڂ̂��Ă܂��˃R�R
725 �F�s���ȃf�o�C�X�����F2009/10/08(��) 02:21:40 ID:Xhw3gY36
���̔����Đl�A���Ȃ́H
http://www.itmedia.co.jp/enterprise/articles/0910/07/news011.html
http://www.itmedia.co.jp/enterprise/articles/0910/07/news011.html
726 �F�s���ȃf�o�C�X�����F2009/10/08(��) 05:26:39 ID:SJheXxFq
Web�Ŗ����ŋL�����ǂ߂�͉̂��̂��A������ƍl���Ă݂�A�킩��ł���B
727 �F�s���ȃf�o�C�X�����F2009/10/08(��) 06:55:19 ID:sVBM2l27
�܂����_��IMF�̌���
728 �F�s���ȃf�o�C�X�����F2009/10/08(��) 14:45:30 ID:xhqFNoNl
�Ȋw�Z�p�v�Z�������Z�\�͂������グ��ꂽGPU�A�[�L�e�N�`���uFermi�v
http://journal.mycom.co.jp/articles/2009/10/07/nvidia_fermi/index.html
http://journal.mycom.co.jp/articles/2009/10/07/nvidia_fermi/index.html
729 �F�s���ȃf�o�C�X�����F2009/10/08(��) 18:13:00 ID:wTBF5FTF
SPARC�̋������ߴۂ݂��������
�ł��R�A�̋K�͂Ő��\�҂��̂��Ďד������
�ł��R�A�̋K�͂Ő��\�҂��̂��Ďד������
730 �F�s���ȃf�o�C�X�����F2009/10/08(��) 18:45:33 ID:SJheXxFq
����A�����ł��傤�B
�W�ω�H�̗��j���̂��̂����B
�W�ω�H�̗��j���̂��̂����B
731 �F�s���ȃf�o�C�X�����F2009/10/08(��) 19:01:21 ID:49vnmICW
Socket G34�ɑ}���̂��HHyperTransport�z��������Ǝ��\�P�b�g�H
732 �F�s���ȃf�o�C�X�����F2009/10/08(��) 20:01:54 ID:SJheXxFq
G34����DDR3��4�`���l������ˁB
Fermi��GDDR5��6�`���l���Ȃ킯�ŁAG34�̓{�g���l�b�N�ɂȂ肻���B
Opteron��12�R�A��DDR3��4�`���l���Ƃ����̂��A�����P�`�Șb���Ǝv���B
Fermi��GDDR5��6�`���l���Ȃ킯�ŁAG34�̓{�g���l�b�N�ɂȂ肻���B
Opteron��12�R�A��DDR3��4�`���l���Ƃ����̂��A�����P�`�Șb���Ǝv���B
733 �F�s���ȃf�o�C�X�����F2009/10/08(��) 20:13:28 ID:HhXKV9cm
>>728
>���̔�r�\�ł͒P���x�̐��\�Ƃ��ď�����Ă��Ȃ����AGT200�Ɠ��l�ɁA
>Fermi��CUDA�R�A�ɂ�FMUL������Ƃ���A�P���x�̃s�[�N���\��2.3TFLOPS
>�ƂȂ�AHD5870�ɂ͋y�Ȃ����̂́A�܂��A�R�ł��郌�x���̐����ɂȂ�B
���̌v�Z���������Ȃ��HGT200�ɂ���ׂāAFermi�ł́ASFU�̊�����SP�ɔ�ׂČ����Ă������A
FMUL����300GFLOPS���x�ŁASP��1.6TFLOPS�Ƃ����Ă�2TFLOPS�ɂ��y�Ȃ��Ȃ��H
>���̔�r�\�ł͒P���x�̐��\�Ƃ��ď�����Ă��Ȃ����AGT200�Ɠ��l�ɁA
>Fermi��CUDA�R�A�ɂ�FMUL������Ƃ���A�P���x�̃s�[�N���\��2.3TFLOPS
>�ƂȂ�AHD5870�ɂ͋y�Ȃ����̂́A�܂��A�R�ł��郌�x���̐����ɂȂ�B
���̌v�Z���������Ȃ��HGT200�ɂ���ׂāAFermi�ł́ASFU�̊�����SP�ɔ�ׂČ����Ă������A
FMUL����300GFLOPS���x�ŁASP��1.6TFLOPS�Ƃ����Ă�2TFLOPS�ɂ��y�Ȃ��Ȃ��H
734 �F�s���ȃf�o�C�X�����F2009/10/08(��) 22:02:45 ID:9jWnZ+kf
�A�N�Z�����[�^�J�[�h�p�Ƀs���ӂ�5.2Gbps��HTX3�����邩��A
HT��Fermi���Ƃ�����AHTX3���̗p�����̂ɂȂ��Ȃ��́H
HT��Fermi���Ƃ�����AHTX3���̗p�����̂ɂȂ��Ȃ��́H
735 �F�s���ȃf�o�C�X�����F2009/10/08(��) 22:07:09 ID:imjvTZGb
Socket G34���C�Z���X������Opteron�̃V�F�A�H�����Ⴄ�����m��疳�������
736 �F�s���ȃf�o�C�X�����F2009/10/08(��) 23:19:08 ID:3qUCYKRG
�ŁA���낻��SPARC�`�b�v�͓����悤�ɂȂ����̂��H
737 �F�s���ȃf�o�C�X�����F2009/10/08(��) 23:36:33 ID:bgortpwE
ttp://journal.mycom.co.jp/articles/2009/10/07/nvidia_fermi/002.html
>�܂��AFermi�̖ڋʂ�ECC�ł��邪�A���W�X�^�t�@�C����L���b�V���̓G���[�`�F�b�N�ɕK�v�ȃr�b�g����lj����Ă��Ηǂ��̂ł��邪�A
>GDDR5�������`�b�v��32�r�b�g�C���^�t�F�[�X���������Ă��炸�AECC�̃`�F�b�N�r�b�g��t������]�T���Ȃ��̂ł��邪�B
>NVIDIA���ǂ��Ƀ`�F�b�N�r�b�g���i�[���Ă��邩�͌��\����Ă��Ȃ��B
>�M�҂Ƃ��ẮA�������C���^�t�F�[�X��384�r�b�g�ł͂Ȃ��A�����I�ɂ̓`�F�b�N�r�b�g���݂�432�r�b�g�ł���A
>�O���t�B�b�N�X�p�ł�ECC�����Ŏg�p���AECC���g���ꍇ�́AECC�p��GDDR5��������lj�����̂ł͂Ȃ����ƍl���Ă���B
RWT�ɂ���
ttp://www.realworldtech.com/page.cfm?ArticleID=RWT093009110932&p=10
>However, they did say that when using ECC they observed an application performance drop of 5-20%, with some applications suffering even more.
>This probably corresponds to a drop of 25-30% in memory bandwidth.
320bit(ECC���݂�360bit)�ł��o���Ȃ���
>�܂��AFermi�̖ڋʂ�ECC�ł��邪�A���W�X�^�t�@�C����L���b�V���̓G���[�`�F�b�N�ɕK�v�ȃr�b�g����lj����Ă��Ηǂ��̂ł��邪�A
>GDDR5�������`�b�v��32�r�b�g�C���^�t�F�[�X���������Ă��炸�AECC�̃`�F�b�N�r�b�g��t������]�T���Ȃ��̂ł��邪�B
>NVIDIA���ǂ��Ƀ`�F�b�N�r�b�g���i�[���Ă��邩�͌��\����Ă��Ȃ��B
>�M�҂Ƃ��ẮA�������C���^�t�F�[�X��384�r�b�g�ł͂Ȃ��A�����I�ɂ̓`�F�b�N�r�b�g���݂�432�r�b�g�ł���A
>�O���t�B�b�N�X�p�ł�ECC�����Ŏg�p���AECC���g���ꍇ�́AECC�p��GDDR5��������lj�����̂ł͂Ȃ����ƍl���Ă���B
RWT�ɂ���
ttp://www.realworldtech.com/page.cfm?ArticleID=RWT093009110932&p=10
>However, they did say that when using ECC they observed an application performance drop of 5-20%, with some applications suffering even more.
>This probably corresponds to a drop of 25-30% in memory bandwidth.
320bit(ECC���݂�360bit)�ł��o���Ȃ���
738 �F�s���ȃf�o�C�X�����F2009/10/09(��) 00:13:40 ID:vfu9kQcA
�F�����̃G���[���ǂ��Ƃ������Ă邪�A����Ȃ̔��ɓ���Ă��h���邾��B
�d�b�b���������蔠���ق����������āB
�d�b�b���������蔠���ق����������āB
739 �F�s���ȃf�o�C�X�����F2009/10/09(��) 00:21:50 ID:n7yWqPwF
>>738
�����q���̎Օ������锠�B�ǂ�Ȕ��ɂȂ�낤�Ȃ��B
�����q���̎Օ������锠�B�ǂ�Ȕ��ɂȂ�낤�Ȃ��B
740 �F�s���ȃf�o�C�X�����F2009/10/09(��) 00:30:07 ID:UsN9n/tx
741 �F�s���ȃf�o�C�X�����F2009/10/09(��) 00:32:44 ID:/aMWuf76
>>738
���ɉF���������ׂĎՒf�ł����Ƃ��Ă��A
���ː����ʌ��f�����R���ďo�����ː��͂ǁ[����̂��B
���́u���v�����ԂƂƂ��ɉF�����𗁂тāA���ː����ʌ��f�ɉ����Ă������B
���ɉF���������ׂĎՒf�ł����Ƃ��Ă��A
���ː����ʌ��f�����R���ďo�����ː��͂ǁ[����̂��B
���́u���v�����ԂƂƂ��ɉF�����𗁂тāA���ː����ʌ��f�ɉ����Ă������B
742 �F�s���ȃf�o�C�X�����F2009/10/09(��) 00:42:35 ID:/aMWuf76
���ۂɊϑ�����Ă���F�����̃G�l���M�[�́A�l�ނ̍ő�ŋ��̗��q�������1000���{�����Ă��B
743 �F�s���ȃf�o�C�X�����F2009/10/09(��) 17:26:19 ID:hMa7yAmZ
>>733
SFU�ł̏�Z���܂߂����_���\���]�X���āAGeForce9�ł��Ă���GT200�ł܂��܂߂�悤�ɂȂ����o�܂�����B
GeForce8�`GT200���ă��W�X�^��[�J���������̋K�͈ȊO�قƂ�Ǖς���ĂȂ��̂ɂȁB
�������Ƃ���GPU��FLOPS�����č��\����B
FLOPS�͖{��1�b�Ԃɔ��s�ł��镂���������Z������B
�������Ȃ���V�F�[�_��1.3GFLOPS�Ƃ���2 issue�̃p�C�v���C���ŐϘa�Z�{��Z�̗�����13���T�C�N���̊�
�A���Ŏ��s�������邱�Ƃ͌������Ƃ��Ă��肦�Ȃ��킯�ŁB
���������牉�Z�Ώۂ̃f�[�^��ǂݏ������Ȃ��Ƃ����Ȃ�����A���[�h�E�X�g�A���s���邾��B
����ɂ��̃A�h���X�̎Z�o�̂��߂̐������Z�����s����B
�ǂ��l���Ă��R���X�^���g��SP��SFU�ɖ��ߋ���������P�[�X�����肦�Ȃ��B
FP�Ɛ����������s�ł���悤�ɂ����̂́A�Ϙa�Z�ƃ��[�h�E�X�g�A�A�h���X�̎Z�o��
������s�ł���悤�ɂ������Ă��ƂŁA�s�[�N���\�̌�������������\�Ƃ̃M���b�v�߂邱�Ƃ�
��₵���Ƃ�����̂ł́B
���ƁA2�̖��߃t�����g�G���h�Ń��\�[�X���L����N���X�^�^�}���`�X���b�h�\���Ȃ���
�Е��̃A�N�e�B�u���[�v�����[�h�X�g�A���s���Ă�ԁA�����Е��̃��[�v��16SP�~2���t���Ɏg����悤��
�g�����������ق��������B
�ƂȂ��SFU�Ŕėp��Z�ł��邱�Ƃɑ傫�ȈӖ��͐����Ȃ��B�Ƃ������A���s�ł��Ȃ��Ȃ��Ă�\��������B
���������낢��I�y���[�V�������܂��Ă�FLOPS���̒ቺ�����Ȃ����ĈӖ��ł́A�X�g���[���v���Z�b�T�Ƃ��Ă�
Larrabee�̂ق����D�G�Ɍ�����B
�Ϙa�Z�Ƀ������A�h���X�Z�o�ƃ��[�h�ƃV���b�t����ɏ�݂���Ńp�C�v���C�����s�ł��A
����ɃX�J�����߂�}�X�N���W�X�^�̃r�b�g���Z���߂������s�o���邩���
Larrabee��32�R�A16�����SIMD�����瓯��512SP�����B�\��ʂ�2GHz�ŏo���Ă�����s�[�NFLOPS���ł��畉����B
SFU�ł̏�Z���܂߂����_���\���]�X���āAGeForce9�ł��Ă���GT200�ł܂��܂߂�悤�ɂȂ����o�܂�����B
GeForce8�`GT200���ă��W�X�^��[�J���������̋K�͈ȊO�قƂ�Ǖς���ĂȂ��̂ɂȁB
�������Ƃ���GPU��FLOPS�����č��\����B
FLOPS�͖{��1�b�Ԃɔ��s�ł��镂���������Z������B
�������Ȃ���V�F�[�_��1.3GFLOPS�Ƃ���2 issue�̃p�C�v���C���ŐϘa�Z�{��Z�̗�����13���T�C�N���̊�
�A���Ŏ��s�������邱�Ƃ͌������Ƃ��Ă��肦�Ȃ��킯�ŁB
���������牉�Z�Ώۂ̃f�[�^��ǂݏ������Ȃ��Ƃ����Ȃ�����A���[�h�E�X�g�A���s���邾��B
����ɂ��̃A�h���X�̎Z�o�̂��߂̐������Z�����s����B
�ǂ��l���Ă��R���X�^���g��SP��SFU�ɖ��ߋ���������P�[�X�����肦�Ȃ��B
FP�Ɛ����������s�ł���悤�ɂ����̂́A�Ϙa�Z�ƃ��[�h�E�X�g�A�A�h���X�̎Z�o��
������s�ł���悤�ɂ������Ă��ƂŁA�s�[�N���\�̌�������������\�Ƃ̃M���b�v�߂邱�Ƃ�
��₵���Ƃ�����̂ł́B
���ƁA2�̖��߃t�����g�G���h�Ń��\�[�X���L����N���X�^�^�}���`�X���b�h�\���Ȃ���
�Е��̃A�N�e�B�u���[�v�����[�h�X�g�A���s���Ă�ԁA�����Е��̃��[�v��16SP�~2���t���Ɏg����悤��
�g�����������ق��������B
�ƂȂ��SFU�Ŕėp��Z�ł��邱�Ƃɑ傫�ȈӖ��͐����Ȃ��B�Ƃ������A���s�ł��Ȃ��Ȃ��Ă�\��������B
���������낢��I�y���[�V�������܂��Ă�FLOPS���̒ቺ�����Ȃ����ĈӖ��ł́A�X�g���[���v���Z�b�T�Ƃ��Ă�
Larrabee�̂ق����D�G�Ɍ�����B
�Ϙa�Z�Ƀ������A�h���X�Z�o�ƃ��[�h�ƃV���b�t����ɏ�݂���Ńp�C�v���C�����s�ł��A
����ɃX�J�����߂�}�X�N���W�X�^�̃r�b�g���Z���߂������s�o���邩���
Larrabee��32�R�A16�����SIMD�����瓯��512SP�����B�\��ʂ�2GHz�ŏo���Ă�����s�[�NFLOPS���ł��畉����B
744 �F�s���ȃf�o�C�X�����F2009/10/09(��) 17:27:06 ID:tVinwEG4
>>736
�ǂ����낤���@�Ŏ��ۂɓ����悤�ɂȂ����Ƃ��͂܂��ꐢ��x��ŁA
�ᔻ���ł�ƁA2009�N4�����\�̂��̂Ƃ���ׂ�Ȃ悗���Č����o����ł��ˁB
�킩��܂��B
�ǂ����낤���@�Ŏ��ۂɓ����悤�ɂȂ����Ƃ��͂܂��ꐢ��x��ŁA
�ᔻ���ł�ƁA2009�N4�����\�̂��̂Ƃ���ׂ�Ȃ悗���Č����o����ł��ˁB
�킩��܂��B
745 �F�s���ȃf�o�C�X�����F2009/10/09(��) 17:31:08 ID:hMa7yAmZ
��F1.3GFLOPS�Ƃ���
���F1.3GHz�Ƃ���
���F1.3GHz�Ƃ���
746 �F�s���ȃf�o�C�X�����F2009/10/09(��) 21:13:38 ID:/aMWuf76
>>743
�R���s���[�^�́u���_�l�v�Ƃ��u���_�s�[�N���\�v�Ƃ����̂́A
���\�������o����D�����𑵂����ꍇ�̎����\�Ȑ��\�̏���Ƃ����Ӗ��ł͂Ȃ��A
�P���Ƀt�H�[�J�X����������(���ۂɂ͂��肦�Ȃ��Ƃ��Ă�)�t���ғ������ꍇ�̒l�ł��B
�����Ɏg�����Ƃ��ł��Ȃ����Z��ł����Ă��A�����Ɏg������̂Ƃ��Čv�Z���܂��B
�܂�A���_�s�[�N���\�̐����ɂ��܂�Ӗ��͂Ȃ��̂ł��B
������A���̗��_�s�[�N���\�ɑ�����ۂ̐��\���ׂĎ��s�������]�X�Ƃ����̂��A���܂�Ӗ����Ȃ��̂ł��B
�R���s���[�^�́u���_�l�v�Ƃ��u���_�s�[�N���\�v�Ƃ����̂́A
���\�������o����D�����𑵂����ꍇ�̎����\�Ȑ��\�̏���Ƃ����Ӗ��ł͂Ȃ��A
�P���Ƀt�H�[�J�X����������(���ۂɂ͂��肦�Ȃ��Ƃ��Ă�)�t���ғ������ꍇ�̒l�ł��B
�����Ɏg�����Ƃ��ł��Ȃ����Z��ł����Ă��A�����Ɏg������̂Ƃ��Čv�Z���܂��B
�܂�A���_�s�[�N���\�̐����ɂ��܂�Ӗ��͂Ȃ��̂ł��B
������A���̗��_�s�[�N���\�ɑ�����ۂ̐��\���ׂĎ��s�������]�X�Ƃ����̂��A���܂�Ӗ����Ȃ��̂ł��B
747 �F�s���ȃf�o�C�X�����F2009/10/09(��) 22:19:17 ID:9H6qKXdY
���с[���ė��N�o��Ƃ��Ă��x��ɒx�ꂽ�̂Ƀg�b�v�N���X�̃X�y�b�N������̂���
�Ƃ����venus���Ԃɍ���Ȃ�������amd�̐V����������Ƃ��A��ֈĂčl���Ă���́H
�Ƃ����venus���Ԃɍ���Ȃ�������amd�̐V����������Ƃ��A��ֈĂčl���Ă���́H
748 �F�s���ȃf�o�C�X�����F2009/10/09(��) 22:26:28 ID:/aMWuf76
�����Ƃ킩��₷�������ƁA
���_�I�ɁA�����܂Ő��\���ł�͂����E�E�E�Ƃ����l�́A�Ȃ����u���_�l�v�Ƃ͌ĂȂ��̂�����B
���_�I�ɁA�����܂Ő��\���ł�͂����E�E�E�Ƃ����l�́A�Ȃ����u���_�l�v�Ƃ͌ĂȂ��̂�����B
749 �F�s���ȃf�o�C�X�����F2009/10/09(��) 23:40:11 ID:anRWB2jn
���с[�͂ȂӎU�L���c
750 �F�s���ȃf�o�C�X�����F2009/10/09(��) 23:47:46 ID:NjVkaOfy
751 �F�s���ȃf�o�C�X�����F2009/10/09(��) 23:48:39 ID:NjVkaOfy
���с[���ċؓ������т̋Ȃ݂���
752 �F�s���ȃf�o�C�X�����F2009/10/09(��) 23:53:12 ID:rZUmEhCJ
>>747
�x�ꂽ����������������R�A���₵���肵�Ă邩���
�x�ꂽ����������������R�A���₵���肵�Ă邩���
753 �F�s���ȃf�o�C�X�����F2009/10/09(��) 23:54:30 ID:Jkp7zXDv
Larrabee�̏�o�Ă���3�N���炢�������H
��̃x�[���ɕ�܂ꂽ�܂܁u�Ȃɂ�琦�����ȁv�������o����
�R��ׂ��̋���������������̂���ړI�̃u�c����������A
���������������܂����͎̂��s�����������ȁB
�u���҂��Ă������������`���`���ŃK�b�N�V�v
��̃x�[���ɕ�܂ꂽ�܂܁u�Ȃɂ�琦�����ȁv�������o����
�R��ׂ��̋���������������̂���ړI�̃u�c����������A
���������������܂����͎̂��s�����������ȁB
�u���҂��Ă������������`���`���ŃK�b�N�V�v
754 �F�s���ȃf�o�C�X�����F2009/10/09(��) 23:56:26 ID:/aMWuf76
�x�m�ʂ�Venus�ȏ�ɁA
�����̌��s���i�ɑ��ėD��Ă��邱�Ƃ��A�s�[�������Ƃ���ŁA
���ۂɐ��i���o�鍠�ɂ́A�����̐��\���オ���Ă��Ēǂ���������Ă���
���Ă����\�����傾��ˁALarrabee�́B
�C���e���ʼn��x����������Ă郂�m�́A�������ĂȂ��Ǝv���B
����Itanium�Ƃ��A�U�X���т����ʁA����x��̐��\���������B
(���܂�ɒx�ꂽ���̂�����A���N�̓��ڂ�McKinley�Ƃ̐��\�����A���炢���Ƃ�)
���Ԃ�A���ꂩ��o��Tukwila�����x���������āA���x�I�ɂ͎���x��ɂȂ邾�낤�B
(���͂�A���x�����ɂȂ�Ȃ��p�r�ł����i���͂��Ȃ��E�E�E���x������Ȃ��Ȃ�A���̃A�[�L�e�N�`���ł���K�v���Ȃ��̂ɁE�E�E)
��������ʎY���čL���̔����ăX�P�[�������b�g�����p���Ȃ��Ǝ������Ȃ��K�͂ɂȂ��Ă��܂����ȏ�A
�A�[�L�e�N�`���̑P�����������A�^�C�����[�Ɏs��ɓ������Ĕ���Ƃ����r�W�l�X�I�Ȗʂ̂ق����d�v�Ȃ̂ˁB
Larrabee���o���ɂ��݂����A16�R�A���炢�ŃX���[�X�^�[�g���Ă�AN��A��GPGPU�̓���������`�����X�͂����������B
�����̌��s���i�ɑ��ėD��Ă��邱�Ƃ��A�s�[�������Ƃ���ŁA
���ۂɐ��i���o�鍠�ɂ́A�����̐��\���オ���Ă��Ēǂ���������Ă���
���Ă����\�����傾��ˁALarrabee�́B
�C���e���ʼn��x����������Ă郂�m�́A�������ĂȂ��Ǝv���B
����Itanium�Ƃ��A�U�X���т����ʁA����x��̐��\���������B
(���܂�ɒx�ꂽ���̂�����A���N�̓��ڂ�McKinley�Ƃ̐��\�����A���炢���Ƃ�)
���Ԃ�A���ꂩ��o��Tukwila�����x���������āA���x�I�ɂ͎���x��ɂȂ邾�낤�B
(���͂�A���x�����ɂȂ�Ȃ��p�r�ł����i���͂��Ȃ��E�E�E���x������Ȃ��Ȃ�A���̃A�[�L�e�N�`���ł���K�v���Ȃ��̂ɁE�E�E)
��������ʎY���čL���̔����ăX�P�[�������b�g�����p���Ȃ��Ǝ������Ȃ��K�͂ɂȂ��Ă��܂����ȏ�A
�A�[�L�e�N�`���̑P�����������A�^�C�����[�Ɏs��ɓ������Ĕ���Ƃ����r�W�l�X�I�Ȗʂ̂ق����d�v�Ȃ̂ˁB
Larrabee���o���ɂ��݂����A16�R�A���炢�ŃX���[�X�^�[�g���Ă�AN��A��GPGPU�̓���������`�����X�͂����������B
755 �F�s���ȃf�o�C�X�����F2009/10/09(��) 23:56:45 ID:NjVkaOfy
Merced�Ƃ�Itanium�Ƃ�����ȋC��
756 �F�s���ȃf�o�C�X�����F2009/10/09(��) 23:57:53 ID:NjVkaOfy
���łł��������烊���[�X���邱�Ƃ��d�v��
�n�[�h�E�F�A�ł��K���ł���̂�����
�n�[�h�E�F�A�ł��K���ł���̂�����
757 �F�s���ȃf�o�C�X�����F2009/10/09(��) 23:57:56 ID:8J9hww0m
>>753
http://www.4gamer.net/games/098/G009883/20091007054/SS/019.jpg
�傫���ĔM���ăr�N���r�N�����Ă闧�h�ȃC�`���c��YO!
http://www.4gamer.net/games/098/G009883/20091007054/SS/019.jpg
{kind=link}
�傫���ĔM���ăr�N���r�N�����Ă闧�h�ȃC�`���c��YO!
758 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 00:10:21 ID:kfSnR0Rj
>>750
����͓��ӁB
�ł��g�������炷��A���s�������Ⴂ�ق����y���Ƃ��������������B
���肳�ꂽ�������ł̂ݑS���Z����t���ғ���������A�Ƃ����͎̂g���ɂ����B
������Ƃł�����������o�Ă��܂��ƁA�r�[�ɃX�s�[�h���K�N���Ɨ����Ă��܂��̂ŁB
�S���Z����t���ғ��������Ȃ�����ɁA�����肵�ăX�s�[�h���x���Ȃ�A
�X�C�[�g�X�|�b�g�ɍ��킹�邽�߂ɘM��Ȃ��Ă��悢�̂�����B
���z�������A
�L���͈͂őS���Z�킪�t���ғ����āA��������Ă��X�s�[�h���o��̂������̂����ǂˁB
����͓��ӁB
�ł��g�������炷��A���s�������Ⴂ�ق����y���Ƃ��������������B
���肳�ꂽ�������ł̂ݑS���Z����t���ғ���������A�Ƃ����͎̂g���ɂ����B
������Ƃł�����������o�Ă��܂��ƁA�r�[�ɃX�s�[�h���K�N���Ɨ����Ă��܂��̂ŁB
�S���Z����t���ғ��������Ȃ�����ɁA�����肵�ăX�s�[�h���x���Ȃ�A
�X�C�[�g�X�|�b�g�ɍ��킹�邽�߂ɘM��Ȃ��Ă��悢�̂�����B
���z�������A
�L���͈͂őS���Z�킪�t���ғ����āA��������Ă��X�s�[�h���o��̂������̂����ǂˁB
759 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 00:15:13 ID:kfSnR0Rj
>>756
CPU���ƌ݊������d�v������A��x�o���Ă��܂��ƒ����Ȃ��Ƃ�����肪���邪�A
Larrabee��GPU�I�Ȃ��̂�����A���Ђ�GPU�̕ω��̑��x���l����ƁA
�ŏ��̐��i�Ǝ��̐��i�̊ԂɃn�[�h�E�F�A�I�Ȍ݊������Ȃ��Ă��A�������Ǝv���B
CPU���ƌ݊������d�v������A��x�o���Ă��܂��ƒ����Ȃ��Ƃ�����肪���邪�A
Larrabee��GPU�I�Ȃ��̂�����A���Ђ�GPU�̕ω��̑��x���l����ƁA
�ŏ��̐��i�Ǝ��̐��i�̊ԂɃn�[�h�E�F�A�I�Ȍ݊������Ȃ��Ă��A�������Ǝv���B
760 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 00:20:02 ID:JqlqztU7
>>758
�Ȃa������
�Ȃa������
761 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 00:43:53 ID:MyfXvdkT
>>747
�Ȃ���Intel��45nm-HKMG�̃g�����W�X�^���x�Ɛ��\�͉������B
TSMC��40nm(��SOI,��HKMG�j���Ƃ����ᑾ���ł��ł��Ȃ��B
����ł�Intel�ɂƂ��Ă͗��N�̐���o�ꎞ�_�ł�CPU�̈ꐢ��x��́u�͂ꂽ�v���Z�X�v�Ȃ�ȁB
����_�C����������܂�ƌ������p���l����ΑÓ����낤��
�Ȃ���Intel��45nm-HKMG�̃g�����W�X�^���x�Ɛ��\�͉������B
TSMC��40nm(��SOI,��HKMG�j���Ƃ����ᑾ���ł��ł��Ȃ��B
����ł�Intel�ɂƂ��Ă͗��N�̐���o�ꎞ�_�ł�CPU�̈ꐢ��x��́u�͂ꂽ�v���Z�X�v�Ȃ�ȁB
����_�C����������܂�ƌ������p���l����ΑÓ����낤��
762 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 00:47:45 ID:JqlqztU7
45nm�͂����܂ŃV�������N���ĂȂ�����
32nm�͐�������
32nm�͐�������
763 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 00:51:13 ID:1WPDLZjX
764 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 01:12:58 ID:MyfXvdkT
>>754
�܂��o���̈������b�N�A�b�v�����ł��ĂȂ��̂Ɏd�l�����͂������Ă�fermi�̂��Ƃł��ˁB�킩��܂��B
�ǂ��݂Ă�Larrabee����ɏo�邾�날��́B
�܂��o���̈������b�N�A�b�v�����ł��ĂȂ��̂Ɏd�l�����͂������Ă�fermi�̂��Ƃł��ˁB�킩��܂��B
�ǂ��݂Ă�Larrabee����ɏo�邾�날��́B
765 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 01:18:55 ID:3ibff/O9
�͂��H
766 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 01:22:32 ID:tPza6LS+
>>764
3�`6��������Č����Ă邩��Larrabee��葁����������Ȃ�
3�`6��������Č����Ă邩��Larrabee��葁����������Ȃ�
767 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 01:29:58 ID:MyfXvdkT
�X�e�b�r���O���d�˂Ă܂���Ȃ�ɂ��������̂��ł��Ă�Larrabee���
�������|���̃��b�N�A�b�v�����ł��ĂȂ�Fermi����ɏo��Ȃ�
�����_�̊�ՂƂ����̂��낤��
���ꂭ�炢���肦�Ȃ�
�Ȃɂ��NVIDIA�Ƃ�����Ђ����
�������|���̃��b�N�A�b�v�����ł��ĂȂ�Fermi����ɏo��Ȃ�
�����_�̊�ՂƂ����̂��낤��
���ꂭ�炢���肦�Ȃ�
�Ȃɂ��NVIDIA�Ƃ�����Ђ����
768 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 01:38:12 ID:tPza6LS+
Intel�͋H�ɗǂ���l�̎���ŏo�ׂ�x�点�邩��
�ŋ߂ł�Nehalem-EP�Ƃ�Wolfdale�Ƃ�
Larrabee�Ƌ����i�̍ɂƂ̌��ˍ�������������i�Ǝ����͗\�f�������Ȃ�
�ŋ߂ł�Nehalem-EP�Ƃ�Wolfdale�Ƃ�
Larrabee�Ƌ����i�̍ɂƂ̌��ˍ�������������i�Ǝ����͗\�f�������Ȃ�
769 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 01:41:32 ID:NtZKl7vs
����ۂ��� (*�e�ցe ) �i�����G�j(�e�ցe*) ����ۂ���
�gLarrabee�h�͑�3����Ȃ̂��H��4������H
http://northwood.blog60.fc2.com/blog-entry-3071.html
�ŏ���2����͑傫���M�������B�Ȃ̂ŁAIntel�̍l���Ă������̂Ƃ͍��v�����A
���s�ƂȂ����B�gLarrabee 3�h�����āgLarrabee 4�h�Ɉڍs�����ꍇ�A
�gLarrabee�h�̃����[�X��2010�N����2011�N���߂Ɍ��邱�ƂɂȂ�B
�f���Ɏg��ꂽLarrabee��A6�V���R��
http://northwood.blog60.fc2.com/blog-entry-3150.html
IDF�Ńf���Ɏg��ꂽ�̂̓o�O������A6(�H)�V���R���ŁA
�o�O����B0�́AIDF�ɂ͊Ԃɍ���Ȃ����������ȁB
��������Larrabee�v�� �S�e�͖������炩�ɂȂ炸
http://www.4gamer.net/games/098/G009883/20091007054/
Larrabee�̕]�����J�n���Ă���x���_�[�̊W�҂ɂ��C
�u�����_�ł͈�ʓI��GPU�Ƃ��ĕ]���ł���i�K�ɂȂ��v�������B
http://northwood.blog60.fc2.com/blog-entry-3172.html
�gFermi�h��A1 revision�̃`�b�v��2009�N��35�T�\8���㔼�ɍ��ꂽ�B
�ʏ�NVIDIA��A2 revision�̃`�b�v�i�łƂ��ē������Ă��܂��B
�gLarrabee�h�͑�3����Ȃ̂��H��4������H
http://northwood.blog60.fc2.com/blog-entry-3071.html
�ŏ���2����͑傫���M�������B�Ȃ̂ŁAIntel�̍l���Ă������̂Ƃ͍��v�����A
���s�ƂȂ����B�gLarrabee 3�h�����āgLarrabee 4�h�Ɉڍs�����ꍇ�A
�gLarrabee�h�̃����[�X��2010�N����2011�N���߂Ɍ��邱�ƂɂȂ�B
�f���Ɏg��ꂽLarrabee��A6�V���R��
http://northwood.blog60.fc2.com/blog-entry-3150.html
IDF�Ńf���Ɏg��ꂽ�̂̓o�O������A6(�H)�V���R���ŁA
�o�O����B0�́AIDF�ɂ͊Ԃɍ���Ȃ����������ȁB
��������Larrabee�v�� �S�e�͖������炩�ɂȂ炸
http://www.4gamer.net/games/098/G009883/20091007054/
Larrabee�̕]�����J�n���Ă���x���_�[�̊W�҂ɂ��C
�u�����_�ł͈�ʓI��GPU�Ƃ��ĕ]���ł���i�K�ɂȂ��v�������B
http://northwood.blog60.fc2.com/blog-entry-3172.html
�gFermi�h��A1 revision�̃`�b�v��2009�N��35�T�\8���㔼�ɍ��ꂽ�B
�ʏ�NVIDIA��A2 revision�̃`�b�v�i�łƂ��ē������Ă��܂��B
770 �F,,�E�L�́M�E,,�j��-�������F2009/10/10(�y) 02:06:00 ID:KB1kCPci
>>768
�����Cell�Ƃ�CUDA�Ƃ��X�p�R���s��ŃE���`�������Ă�V���A�[�L�Ƀ��L���ꂽ�납�A�Ƃ���
��l�̎���Ŏn�܂����v���W�F�N�g�����́B
�f�B�X�N���[�gGPU�s��͏k������GMA���J�������ď��Ƃ�������H���ɏ�������Ă�Intel��
�킴�킴PCIe�{�[�h�ɏ�����鋐��`�b�v��闝�R���A��GPU�Ƃ��Ă̋������i�̌����ɂ��邱�Ƃ��炢
�@�����t���B
�������ALarrabee���x��Ă邪�A�������Ђ̐��i���X�Ɋ������Ė��O�̊J���i���Ƃ������B
x86�̖��߃Z�b�g���x�[�X��Cell���݈ȏ�̔ėp���������Ȃ��烏���`�b�v��2TFLOPS����
�I�[�o�[�L�����ǂ��Ƃ��낾����ȁB
Xeon��HPC�ō̗p����Ă�̂�FLOPS�P�������ƈ������Ă̂����邩��
����x86�x�[�X�ł��������ėp���������čX�ɒP���������i����jLarrabee���o������
�����̎s���H�������̌��ʂɂȂ肩�˂Ȃ��B
�����Cell�Ƃ�CUDA�Ƃ��X�p�R���s��ŃE���`�������Ă�V���A�[�L�Ƀ��L���ꂽ�납�A�Ƃ���
��l�̎���Ŏn�܂����v���W�F�N�g�����́B
�f�B�X�N���[�gGPU�s��͏k������GMA���J�������ď��Ƃ�������H���ɏ�������Ă�Intel��
�킴�킴PCIe�{�[�h�ɏ�����鋐��`�b�v��闝�R���A��GPU�Ƃ��Ă̋������i�̌����ɂ��邱�Ƃ��炢
�@�����t���B
�������ALarrabee���x��Ă邪�A�������Ђ̐��i���X�Ɋ������Ė��O�̊J���i���Ƃ������B
x86�̖��߃Z�b�g���x�[�X��Cell���݈ȏ�̔ėp���������Ȃ��烏���`�b�v��2TFLOPS����
�I�[�o�[�L�����ǂ��Ƃ��낾����ȁB
Xeon��HPC�ō̗p����Ă�̂�FLOPS�P�������ƈ������Ă̂����邩��
����x86�x�[�X�ł��������ėp���������čX�ɒP���������i����jLarrabee���o������
�����̎s���H�������̌��ʂɂȂ肩�˂Ȃ��B
771 �F,,�E�L�́M�E,,�j��-�������F2009/10/10(�y) 02:07:39 ID:KB1kCPci
> �ʏ�NVIDIA��A2 revision�̃`�b�v�i�łƂ��ē������Ă��܂��B
�ʏ�ʂ�ɂ����ĂȂ����炠�̂��܂Ȃ܂��B
�����܂肪1�`2%�̏ŗʎY���C���ғ��Ƃ����肦�Ȃ��B
�ʏ�ʂ�ɂ����ĂȂ����炠�̂��܂Ȃ܂��B
�����܂肪1�`2%�̏ŗʎY���C���ғ��Ƃ����肦�Ȃ��B
772 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 02:14:11 ID:4lWS19ya
http://www.xbitlabs.com/news/video/display/20070919151611.html
> In 2010 Intel will release its code-named Larrabee processor, which is
> projected to deliver teraflops performance and also be able to process graphics.
http://www.xbitlabs.com/news/video/display/20080117222433_Intel_Promises_to_Sample_Larrabee_Processors_in_Late_2008.html
> �gLarrabee first silicon should be late this year in terms of samples
> and we�fll start playing with it and sampling it to developers and I
> still think we are on track for a product in late �f09, 2010 timeframe,�h
> said Paul Otellini, chief executive officer of Intel.
�܂������̗\��͈͓̔�����܂���
> In 2010 Intel will release its code-named Larrabee processor, which is
> projected to deliver teraflops performance and also be able to process graphics.
http://www.xbitlabs.com/news/video/display/20080117222433_Intel_Promises_to_Sample_Larrabee_Processors_in_Late_2008.html
> �gLarrabee first silicon should be late this year in terms of samples
> and we�fll start playing with it and sampling it to developers and I
> still think we are on track for a product in late �f09, 2010 timeframe,�h
> said Paul Otellini, chief executive officer of Intel.
�܂������̗\��͈͓̔�����܂���
773 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 02:20:06 ID:kfSnR0Rj
>>767
�������Ȃ�
Fermi��nVIDIA�́A���܂܂�GPU�Ŏ��т�ς�ł�������Ȃ����B
���Ԃ���͌����Ă��āA����������������A�����o���Ǝv���B
�C���e���̒P��GPU���i���A���܂܂łǂ����������B
i740����̒����̃u�����N�A�`�b�v�Z�b�g�����O���t�B�b�N�X�̃V�����{���������A
�������������т��炷��ƁA
����d�͂��傫�����邩��v���Z�X�̃V�������N��҂��Ă�A
�Ȃ�Ă����̂́A�{���Ȃ̂��ǂ������������B
Fermi�Ńl�b�N�ɂȂ��Ă���̂́A��S�I��nVIDIA�̐v�Ƃ������́A
���������TSMC��40nm�v���Z�X�̕����܂肪�������邱�Ƃ��낤�B
�\�ł�2%���Ƃ������������B
�����������܂�͐v�ɂ���Ă��ς��Ă���̂ł͂��邪�E�E�E�B
���Ȃ݂ɓ����v���Z�X(=�����������C���Ǝv���Ă�����)�Ő�������Ă�Radeon���A
40nm�̐��i�̗����オ�肪�����B�o�חʂ����Ȃ��đ��D��ɂȂ��Ă���B
���Ƃ��ƃn�C�G���h�̃r�f�I�J�[�h�Ȃ�āA�X���Ŕ����̂́A�ɂ߂Ă����ꕔ�̍D���Ƃ����ŁA
���Ƃ������ɐ��Y���Ă��Ă��A�X�������̏o�חʂ͔��X������̂ɂȂ�Ƃ͎v�����B
�������Ȃ�
Fermi��nVIDIA�́A���܂܂�GPU�Ŏ��т�ς�ł�������Ȃ����B
���Ԃ���͌����Ă��āA����������������A�����o���Ǝv���B
�C���e���̒P��GPU���i���A���܂܂łǂ����������B
i740����̒����̃u�����N�A�`�b�v�Z�b�g�����O���t�B�b�N�X�̃V�����{���������A
�������������т��炷��ƁA
����d�͂��傫�����邩��v���Z�X�̃V�������N��҂��Ă�A
�Ȃ�Ă����̂́A�{���Ȃ̂��ǂ������������B
Fermi�Ńl�b�N�ɂȂ��Ă���̂́A��S�I��nVIDIA�̐v�Ƃ������́A
���������TSMC��40nm�v���Z�X�̕����܂肪�������邱�Ƃ��낤�B
�\�ł�2%���Ƃ������������B
�����������܂�͐v�ɂ���Ă��ς��Ă���̂ł͂��邪�E�E�E�B
���Ȃ݂ɓ����v���Z�X(=�����������C���Ǝv���Ă�����)�Ő�������Ă�Radeon���A
40nm�̐��i�̗����オ�肪�����B�o�חʂ����Ȃ��đ��D��ɂȂ��Ă���B
���Ƃ��ƃn�C�G���h�̃r�f�I�J�[�h�Ȃ�āA�X���Ŕ����̂́A�ɂ߂Ă����ꕔ�̍D���Ƃ����ŁA
���Ƃ������ɐ��Y���Ă��Ă��A�X�������̏o�חʂ͔��X������̂ɂȂ�Ƃ͎v�����B
774 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 02:22:37 ID:AQzF83SN
http://www.google.co.jp/search?hl=ja&q=TSMC+40nm+%E6%AD%A9%E7%95%99%E3%81%BE%E3%82%8A
�ň��l���l���Ă�2���͂��肦�Ȃ�
�ň��l���l���Ă�2���͂��肦�Ȃ�
775 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 02:24:44 ID:r5PI6jSm
>>771
��G�c�ɏ����Ƃ���ȗ���
�e�X�g&�f�o�b�O(1����)��A2�e�[�v�A�E�g�A�V���R����(1����)���f�o�b�O(1����)�AOK�H��[yes]���ʎY
�@�@�@���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �@[no]
�@�@�@��������������������������������������������������������������������
������A���X�e�b�s���O��A1�Ȃ琻�i(A2�ȍ~)��3�`6������Ƃ����̂̓��A���Ȍ��ς���
��G�c�ɏ����Ƃ���ȗ���
�e�X�g&�f�o�b�O(1����)��A2�e�[�v�A�E�g�A�V���R����(1����)���f�o�b�O(1����)�AOK�H��[yes]���ʎY
�@�@�@���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �@[no]
�@�@�@��������������������������������������������������������������������
������A���X�e�b�s���O��A1�Ȃ琻�i(A2�ȍ~)��3�`6������Ƃ����̂̓��A���Ȍ��ς���
776 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 02:26:12 ID:r5PI6jSm
�Ȃ�ID�ς��������ID:tPza6LS+�ł�YO�I
777 �F,,�E�L�́M�E,,�j��-�������F2009/10/10(�y) 02:54:57 ID:KB1kCPci
>>773
Pentium Pro�����āAXeon���s������A���ꂱ��10�N�]�A������d�˂�ƂƂ���HPC�s��ł̃V�F�A���g�債�Ă����̂�Intel
���F���G������̂�GPU�̎��тȂ�ĉ��̖��ɗ��̂��B
Pentium Pro�����āAXeon���s������A���ꂱ��10�N�]�A������d�˂�ƂƂ���HPC�s��ł̃V�F�A���g�債�Ă����̂�Intel
���F���G������̂�GPU�̎��тȂ�ĉ��̖��ɗ��̂��B
778 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 03:04:41 ID:AQzF83SN
�������ˁA���ɗ����Ȃ����炳�����Ɛ�̂Ă�����������
http://software.intel.com/en-us/visual-computing/
http://software.intel.com/en-us/visual-computing/
779 �F,,�E�L�́M�E,,�j��-�������F2009/10/10(�y) 03:38:58 ID:KB1kCPci
�X�p�R���ƊW�Ȃ�����B
GPU�Ɍ����GMA��PC�pGPU�Ƃ��Ă̓g�b�v�V�F�A�����B
DirectX11�Ή��̃n�C�X�y�b�N�v������Q�[����肽���Ȃ�Radeon�����B
�n�C�G���hGPU�Ƃ��Ă��ėp�v���Z�b�T�Ƃ��Ă��A�тɒZ���������ɒ����Ȃ̂�NVIDIA
�I���{�[�hVGA�s��������ĔN200���~�̎������������̂�NVIDIA
�f�B�X�N���[�gGPU���邵���Ȃ��̂Ƀ_�C�T�C�Y���������R�X�g�A�Ԏ��o��Ŕ���Ȃ��Ⴂ���Ȃ��̂�NVIDIA
GPU�Ɍ����GMA��PC�pGPU�Ƃ��Ă̓g�b�v�V�F�A�����B
DirectX11�Ή��̃n�C�X�y�b�N�v������Q�[����肽���Ȃ�Radeon�����B
�n�C�G���hGPU�Ƃ��Ă��ėp�v���Z�b�T�Ƃ��Ă��A�тɒZ���������ɒ����Ȃ̂�NVIDIA
�I���{�[�hVGA�s��������ĔN200���~�̎������������̂�NVIDIA
�f�B�X�N���[�gGPU���邵���Ȃ��̂Ƀ_�C�T�C�Y���������R�X�g�A�Ԏ��o��Ŕ���Ȃ��Ⴂ���Ȃ��̂�NVIDIA
780 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 03:46:11 ID:kfSnR0Rj
>>777
Fermi��(1�O��Tesra����������)�Q�[���p��GPU�̃X�P�[�������b�g�ɏ�����������i�B
HPC�Ő������邩�ǂ����͂Ƃ������AGPU�Ƃ��Ă͎��т�����v�̉�������ɂ���B
���Larrabee�́ACPU�̃X�P�[�������b�g�ɏ���Ă���Ƃ����Ă��A�����v���Z�X�������B
�����v���Z�X�͐�s����CPU�Ŏ��т������Ă��A�R�A��x86�Ɏ��т������Ă��AGPU�Ƃ��Ă̎��т͊F�����B
�X�p�R�����A�X�P�[�������b�g�ɏ�����邽�߂�x86���̗p���Ă���悤�ɁA
���̃X�p�R���Ɏg����GPU�I�ȃA�N�Z�����[�^���܂��A�Q�[��������GPU�̃X�P�[�������b�g�ɏ������Ȃ��Ɛh���ł���B
Fermi��(1�O��Tesra����������)�Q�[���p��GPU�̃X�P�[�������b�g�ɏ�����������i�B
HPC�Ő������邩�ǂ����͂Ƃ������AGPU�Ƃ��Ă͎��т�����v�̉�������ɂ���B
���Larrabee�́ACPU�̃X�P�[�������b�g�ɏ���Ă���Ƃ����Ă��A�����v���Z�X�������B
�����v���Z�X�͐�s����CPU�Ŏ��т������Ă��A�R�A��x86�Ɏ��т������Ă��AGPU�Ƃ��Ă̎��т͊F�����B
�X�p�R�����A�X�P�[�������b�g�ɏ�����邽�߂�x86���̗p���Ă���悤�ɁA
���̃X�p�R���Ɏg����GPU�I�ȃA�N�Z�����[�^���܂��A�Q�[��������GPU�̃X�P�[�������b�g�ɏ������Ȃ��Ɛh���ł���B
781 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 03:54:11 ID:r5PI6jSm
�f�B�X�N���[�g�O���t�B�b�N�X�̕���ł�Intel�ɂ͏����ڂ�����Ǝv����
�������N�K�v�Ƃ���鐫�\�����ł��ɂȂ��č��ʉ�������Ȃ��Ă邩��Intel�̃u�����h�l�[�������Ȃ�e������Ɨ\�����Ă���
�������N�K�v�Ƃ���鐫�\�����ł��ɂȂ��č��ʉ�������Ȃ��Ă邩��Intel�̃u�����h�l�[�������Ȃ�e������Ɨ\�����Ă���
782 �F,,�E�L�́M�E,,�j��-�������F2009/10/10(�y) 03:54:59 ID:KB1kCPci
>>780
�X�P�[�������b�g�˂��E�E�E
����Ȃ��Ə�����Ă�ł悭���������̂�
Nvidia kills GTX285, GTX275, GTX260, abandons the mid and high end market
Full on retreat, can't compete with ATI
ttp://www.semiaccurate.com/2009/10/06/nvidia-kills-gtx285-gtx275-gtx260-abandons-mid-and-high-end-market/
285�͊���EOL�A260��11or12����EOL�A275��2�T�Ԉȓ���EOL�A295���I��肻���B
�n�C�G���h�A�~�h�������W����E������B
Fermi�̔h�����f���̓e�[�v�A�E�g���炵�Ă��Ȃ��̂ŁA���Ȃ��Ƃ�2Q�͊|����B
Fermi�̓_�C�T�C�Y������̐��\���Ⴍ�h�����f��������Ă��t�����C���i�b�v�ʼn��i�����͂ŗ��B
�n���_�̌��ז��AG212�̎��s�AG214�̑厸�s�AG215�̒x���AG216��G218�̉�ꂽGDDR5�R���g���[���B
�~����ƂȂ�`�b�v�͂Ȃ��A�v����B�͂Ȃ��A�S�Ď��s�����B
�Ԏ��̔��𑱂��邩�A�P�ނ��ď��Ȃ��Ԏ����o���������Ȃ��B
�������s����O�ɊJ���̖����C���������͂̂��鐻�i���o���邩�����B
1���ɂ̓��[�G���h������E������B
Nvidia�͑S�Ẵp�[�g�i�[���瑞�܂�Ă��菕���Ă����p�[�g�i�[�͂��Ȃ��B
Nvidia�ɕK�v�Ȃ̂͌o�c�w�̑�����ւ������A���̏o�čs���ׂ��z��͊���Ȃ̂ŋN���肻�����Ȃ��B
�Q�[���I�[�o�[�B
�W�F���Z���͔N��1�h���ł��Ⴂ�߂��ł���B
�ǂ��������
�X�P�[�������b�g�˂��E�E�E
����Ȃ��Ə�����Ă�ł悭���������̂�
Nvidia kills GTX285, GTX275, GTX260, abandons the mid and high end market
Full on retreat, can't compete with ATI
ttp://www.semiaccurate.com/2009/10/06/nvidia-kills-gtx285-gtx275-gtx260-abandons-mid-and-high-end-market/
285�͊���EOL�A260��11or12����EOL�A275��2�T�Ԉȓ���EOL�A295���I��肻���B
�n�C�G���h�A�~�h�������W����E������B
Fermi�̔h�����f���̓e�[�v�A�E�g���炵�Ă��Ȃ��̂ŁA���Ȃ��Ƃ�2Q�͊|����B
Fermi�̓_�C�T�C�Y������̐��\���Ⴍ�h�����f��������Ă��t�����C���i�b�v�ʼn��i�����͂ŗ��B
�n���_�̌��ז��AG212�̎��s�AG214�̑厸�s�AG215�̒x���AG216��G218�̉�ꂽGDDR5�R���g���[���B
�~����ƂȂ�`�b�v�͂Ȃ��A�v����B�͂Ȃ��A�S�Ď��s�����B
�Ԏ��̔��𑱂��邩�A�P�ނ��ď��Ȃ��Ԏ����o���������Ȃ��B
�������s����O�ɊJ���̖����C���������͂̂��鐻�i���o���邩�����B
1���ɂ̓��[�G���h������E������B
Nvidia�͑S�Ẵp�[�g�i�[���瑞�܂�Ă��菕���Ă����p�[�g�i�[�͂��Ȃ��B
Nvidia�ɕK�v�Ȃ̂͌o�c�w�̑�����ւ������A���̏o�čs���ׂ��z��͊���Ȃ̂ŋN���肻�����Ȃ��B
�Q�[���I�[�o�[�B
�W�F���Z���͔N��1�h���ł��Ⴂ�߂��ł���B
�ǂ��������
783 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 04:05:15 ID:e+By2sIH
���̋L����
By Charlie Demerjian
900 �F,,�E�L�́M�E,,�j��-�������F2009/02/17(��) 20:36:33 ID:x/bBLQwK
���Ȃ݂ɁuGPU�͐�Ŋ뜜��v�ƌ������̂��ނ�
��������ɓ��ӂ���Ă邯�ǁB
http://www.geocities.jp/andosprocinfo/wadai07/20071222.htm
�i�����j
���ɂ��f�}����̖����͖ʔ���
�E�uPlaystation 4��GPU��Intel�������v�ƃ\�[�X�s���Ȕ��\��R�炷
���\�j�[�͔ے�
81 �F,,�E�L�́M�E,,�j��-�������F2009/02/28(�y) 02:05:22 ID:aHJb2TRX
By Charlie Demerjian
�܂��R�������\�[�X�ł���������
859 �F,,�E�L�́M�E,,�j��-�������F2009/04/14(��) 20:21:46 ID:WBJWfhIq �@[age]
�f�}�j�������グ��s���I�^����
�ނ̉R�f���͎��m�̎����ł���
By Charlie Demerjian
900 �F,,�E�L�́M�E,,�j��-�������F2009/02/17(��) 20:36:33 ID:x/bBLQwK
���Ȃ݂ɁuGPU�͐�Ŋ뜜��v�ƌ������̂��ނ�
��������ɓ��ӂ���Ă邯�ǁB
http://www.geocities.jp/andosprocinfo/wadai07/20071222.htm
�i�����j
���ɂ��f�}����̖����͖ʔ���
�E�uPlaystation 4��GPU��Intel�������v�ƃ\�[�X�s���Ȕ��\��R�炷
���\�j�[�͔ے�
81 �F,,�E�L�́M�E,,�j��-�������F2009/02/28(�y) 02:05:22 ID:aHJb2TRX
By Charlie Demerjian
�܂��R�������\�[�X�ł���������
859 �F,,�E�L�́M�E,,�j��-�������F2009/04/14(��) 20:21:46 ID:WBJWfhIq �@[age]
�f�}�j�������グ��s���I�^����
�ނ̉R�f���͎��m�̎����ł���
784 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 04:06:03 ID:e+By2sIH
871 �F,,�E�L�́M�E,,�j��-�������F2009/04/14(��) 21:10:21 ID:WBJWfhIq
IDF�Ŏ��۔ނ����^�������Ă��Ƃ�����ؖ�����l�Ԃ͂���́H
�c�O�����ނ̐l���Ɋւ��āA�R�f���Ƃ����]�������o�Ă��Ȃ��Ȃ�
http://forums.vr-zone.com/news-around-the-web/374309-nvidia-occular-vi-llu-sion-sucks-you.html
> Charlie Demerjian.....lol
>
> This guy is a well known liar
http://extended64.com/blogs/news/archive/2008/08/28/one-more-time-with-nvidia-denial.aspx
> Although many had lambasted me and have called the Inq
> and Charlie Demerjian everything under the sun that means
> liar and FUD spreader.
873 �F,,�E�L�́M�E,,�j��-�������F2009/04/14(��) 21:24:12 ID:WBJWfhIq
http://forums.nvidia.com/index.php?showtopic=74800
> So the Inquirer is at it again with FUD poster Charlie at the helm.
���x���������A�f�}�����R�Ɨ����L�҂ȂǐM�p����ɒl���Ȃ�
IDF�Ŏ��۔ނ����^�������Ă��Ƃ�����ؖ�����l�Ԃ͂���́H
�c�O�����ނ̐l���Ɋւ��āA�R�f���Ƃ����]�������o�Ă��Ȃ��Ȃ�
http://forums.vr-zone.com/news-around-the-web/374309-nvidia-occular-vi-llu-sion-sucks-you.html
> Charlie Demerjian.....lol
>
> This guy is a well known liar
http://extended64.com/blogs/news/archive/2008/08/28/one-more-time-with-nvidia-denial.aspx
> Although many had lambasted me and have called the Inq
> and Charlie Demerjian everything under the sun that means
> liar and FUD spreader.
873 �F,,�E�L�́M�E,,�j��-�������F2009/04/14(��) 21:24:12 ID:WBJWfhIq
http://forums.nvidia.com/index.php?showtopic=74800
> So the Inquirer is at it again with FUD poster Charlie at the helm.
���x���������A�f�}�����R�Ɨ����L�҂ȂǐM�p����ɒl���Ȃ�
785 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 04:06:50 ID:e+By2sIH
87 �F,,�E�L�́M�E,,�j��-�������F2009/03/31(��) 07:20:32 ID:YbyWNvCs
���Ƃ����N�̃W�����v�Ɍf�ڂ��ꂽ�h���N�G�X�̔������Ő���オ��邩�H
���܂���̂���Ă�̂͂���ȉ��ŁA�uDQ5�ŃG�X�^�[�N�����ԂɂȂ�v���x���ȁB
������l�^�ł���ȑO�ɗ������ĂȂ��A�Ƃ������T���ĝs���B
MAC���^�̐M��f�}�j����͐̂��炱�����������ł���
> 801 �FSocket774[sage]�F2008/09/05(��) 04:37:50 ID:Kupns0iS
> �f�X�N�g�b�v�p��GPU�Ɋւ���L���������Ă�Charlie Demerjian�ēz��
> �L���ȓz�����u�F�l�ɂ��Ɓv�Ƃ��u���̍l���ł́v���ĂȖϑz�L���������z����
> �C�O�̃t�H�[�����T�C�g�ł͑���ɂ���Ȃ����x���̓z
�@~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
�M�����ʂ��R�m�U�}����
http://www.theinquirer.net/inquirer/news/419/1030419/penryn-to-have-ht
http://www.theinquirer.net/inquirer/news/724/1002724/penryn-does-not-have-ht
By Charlie Demerjian
���Ƃ����N�̃W�����v�Ɍf�ڂ��ꂽ�h���N�G�X�̔������Ő���オ��邩�H
���܂���̂���Ă�̂͂���ȉ��ŁA�uDQ5�ŃG�X�^�[�N�����ԂɂȂ�v���x���ȁB
������l�^�ł���ȑO�ɗ������ĂȂ��A�Ƃ������T���ĝs���B
MAC���^�̐M��f�}�j����͐̂��炱�����������ł���
> 801 �FSocket774[sage]�F2008/09/05(��) 04:37:50 ID:Kupns0iS
> �f�X�N�g�b�v�p��GPU�Ɋւ���L���������Ă�Charlie Demerjian�ēz��
> �L���ȓz�����u�F�l�ɂ��Ɓv�Ƃ��u���̍l���ł́v���ĂȖϑz�L���������z����
> �C�O�̃t�H�[�����T�C�g�ł͑���ɂ���Ȃ����x���̓z
�@~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
�M�����ʂ��R�m�U�}����
http://www.theinquirer.net/inquirer/news/419/1030419/penryn-to-have-ht
http://www.theinquirer.net/inquirer/news/724/1002724/penryn-does-not-have-ht
By Charlie Demerjian
786 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 04:13:19 ID:ns3ffaUg
�c�q�ν
787 �F,,�E�L�́M�E,,�j��-�������F2009/10/10(�y) 04:14:52 ID:KB1kCPci
�悭�C�Â����ˁB
����NVIDIA�̖����͂��Ȃ��悤��
http://www.nordichardware.com/news,9960.html
�n���ł����闝���Ƃ���
�m���Ȃ̂��܂�Radeon 5800�V���[�Y�̔{�ȏ�̃_�C�T�C�Y�ɂȂ���Ă���
����������TSMC��Fab�ł��B
NVIDIA���i��Fab������R�X�g�������n���Ȃ�Ė��@�͂Ȃ��B
Fermi��TMU/ROP��GTX280��1.5�{���x����A�P����RV770��2�{�ɂȂ��ăN���b�N���オ����870�n
���Ɏs��ɏo�Ă�̂�5870����B
Fermi�͏o�����_�Ŋ��ɋ����͂Ȃ������
GPU�Ƃ��Đ������Ȃ���HPC�ł̃X�P�[�������b�g�Ȃ�Č��ȑO�̖�肾
����NVIDIA�̖����͂��Ȃ��悤��
http://www.nordichardware.com/news,9960.html
�n���ł����闝���Ƃ���
�m���Ȃ̂��܂�Radeon 5800�V���[�Y�̔{�ȏ�̃_�C�T�C�Y�ɂȂ���Ă���
����������TSMC��Fab�ł��B
NVIDIA���i��Fab������R�X�g�������n���Ȃ�Ė��@�͂Ȃ��B
Fermi��TMU/ROP��GTX280��1.5�{���x����A�P����RV770��2�{�ɂȂ��ăN���b�N���オ����870�n
���Ɏs��ɏo�Ă�̂�5870����B
Fermi�͏o�����_�Ŋ��ɋ����͂Ȃ������
GPU�Ƃ��Đ������Ȃ���HPC�ł̃X�P�[�������b�g�Ȃ�Č��ȑO�̖�肾
788 �F,,�E�L�́M�E,,�j��-�������F2009/10/10(�y) 04:47:31 ID:KB1kCPci
������Ƃ������Ђł͂������낤��
����Fermi�x�[�X��512sp��Tesla��1��8000�h�����x���炢�̒P���ŏo����ǂ��Ȃ�Ǝv���H
����ł��P�@600�`700GFLOPS���B
�{���x���P���x��1/12����������Ƃ͂킯���Ⴄ�B
HPC�s��ɂ�����FLOPS������啝�����͕K���B
�܂��AXeon�������đ�����قǂ����܂ł̔ėp���͂Ȃ��Ǝv�����A
�u�A�N�Z�����[�^�v�ˑ��x�������Ȃ�\���͂���B
Larrabee��Intel�ɂƂ��Ă͌R����݂����Ȃ���B
����������Xeon���������ނ�������Ȃ��j���킾�B
���v�D��ōl����Ȃ�Ȃ�ׂ��Ȃ�s�g���Ȃ��ɉz�������Ƃ͂Ȃ��B
����Fermi�x�[�X��512sp��Tesla��1��8000�h�����x���炢�̒P���ŏo����ǂ��Ȃ�Ǝv���H
����ł��P�@600�`700GFLOPS���B
�{���x���P���x��1/12����������Ƃ͂킯���Ⴄ�B
HPC�s��ɂ�����FLOPS������啝�����͕K���B
�܂��AXeon�������đ�����قǂ����܂ł̔ėp���͂Ȃ��Ǝv�����A
�u�A�N�Z�����[�^�v�ˑ��x�������Ȃ�\���͂���B
Larrabee��Intel�ɂƂ��Ă͌R����݂����Ȃ���B
����������Xeon���������ނ�������Ȃ��j���킾�B
���v�D��ōl����Ȃ�Ȃ�ׂ��Ȃ�s�g���Ȃ��ɉz�������Ƃ͂Ȃ��B
789 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 06:20:55 ID:kfSnR0Rj
GPU�Ƃ��Đ������Ȃ���_���ł͂���̂����A
ttp://journal.mycom.co.jp/articles/2009/10/07/nvidia_fermi/003.html
������ō̗p����������Ă����ˁB
nVIDIA�������Ɏ���i�߂��Ȃ���AAMD(ATi)�Ɏ���đ�����̂��낤���B
ttp://journal.mycom.co.jp/articles/2009/10/07/nvidia_fermi/003.html
������ō̗p����������Ă����ˁB
nVIDIA�������Ɏ���i�߂��Ȃ���AAMD(ATi)�Ɏ���đ�����̂��낤���B
790 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 09:01:41 ID:1WPDLZjX
ORNL�i�̂悤�ȋ����������ޕ����Ă���@�ցj�ɂ�������Ȃ������肵��
791 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 09:46:52 ID:I/Q42ZMk
Colfax shows off octo-GPU NVIDIA Tesla server
http://www.hexus.net/content/item.php?item=20567
http://www.hexus.net/content/item.php?item=20567
792 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 11:58:58 ID:kfSnR0Rj
>>790
���ɁA�����Jaguar��CPU�̔�����Fermi�Ɍ�������Ƃ��Ă��A4���߂��ɂȂ�B
�n�C�G���hGPU���đS���E�łǂꂭ�炢������?
���ɁA�����Jaguar��CPU�̔�����Fermi�Ɍ�������Ƃ��Ă��A4���߂��ɂȂ�B
�n�C�G���hGPU���đS���E�łǂꂭ�炢������?
793 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 12:56:28 ID:1WPDLZjX
�n�C�G���hGPU�̋敪�͂ǂ�Ȃ���Ȃ낤�Ǝv���Ƃ���ł͂��邯�ǁA
���Ƃ���AMD��HD4800�V���[�Y��2008/6���{����2008/11���{�܂ł�
200�����o�Ă���炵���̂ł���Ȃ��̂Ȃ̂��ȁB
���Ƃ���AMD��HD4800�V���[�Y��2008/6���{����2008/11���{�܂ł�
200�����o�Ă���炵���̂ł���Ȃ��̂Ȃ̂��ȁB
794 �F,,�E�L�́M�E,,�j��-�������F2009/10/10(�y) 12:56:42 ID:KB1kCPci
��v�������ׂĂ݂�
http://www.nvidia.co.jp/object/io_1249982404004.html
�C�ɂȂ����̂�
> NVIDIA CUDA?�A�[�L�e�N�`���́A���E����6���l���郆�[�U������
�����Ă��B�j�b�`�}�[�P�b�g�ɂ���������B
http://www.nvidia.co.jp/object/io_1249982404004.html
�C�ɂȂ����̂�
> NVIDIA CUDA?�A�[�L�e�N�`���́A���E����6���l���郆�[�U������
�����Ă��B�j�b�`�}�[�P�b�g�ɂ���������B
795 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 12:58:19 ID:1WPDLZjX
�܂�CUDA�Ȃ炻��Ȃ��̂���
796 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 13:06:26 ID:p0jGj/fw
http://jonpeddie.com/press-releases/details/the-workstation-market-finds-a-bottom-in-q209-reports-jon-peddie-research/
Tesla���܂܂�Ă��邩�킩��Ȃ����A�Ɩ��p�Ƃ��č��l�Ŕ��������s�ꂾ�ƁA
�N��400�����s���Ȃ��悤���B
Tesla���܂܂�Ă��邩�킩��Ȃ����A�Ɩ��p�Ƃ��č��l�Ŕ��������s�ꂾ�ƁA
�N��400�����s���Ȃ��悤���B
797 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 13:37:42 ID:kfSnR0Rj
�݂�ȁA���肪�Ƃ��B
4������A�{���ɔ��X������̂Ȃ̂ˁB
���v�Ȃ̂��S�z���ˁB
�Ƃ���ŋ������A
128GFlops��SPARC64VIIIfx�Ńs�[�N10PFlops�Ȃ�8���A20PFlops�Ȃ�16����
����ȃj�b�`��CPU������āA�x�m�ʂ͑��v�Ȃ̂��낤���B
4������A�{���ɔ��X������̂Ȃ̂ˁB
���v�Ȃ̂��S�z���ˁB
�Ƃ���ŋ������A
128GFlops��SPARC64VIIIfx�Ńs�[�N10PFlops�Ȃ�8���A20PFlops�Ȃ�16����
����ȃj�b�`��CPU������āA�x�m�ʂ͑��v�Ȃ̂��낤���B
798 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 14:07:21 ID:MHetB6fL
z10�Ƃ����͑S�R��������
799 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 14:14:44 ID:EUonxfsR
fermi�͏��FGPU�B
sparc�̐\���q�ł���venus�ɂ́A�T�[�o��N���E�h�ɕK�v�Ȃ����̑����̖��߂�������Ă���B
�G�ł͂Ȃ�
sparc�̐\���q�ł���venus�ɂ́A�T�[�o��N���E�h�ɕK�v�Ȃ����̑����̖��߂�������Ă���B
�G�ł͂Ȃ�
800 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 14:17:40 ID:kTcLQuIb
��������Ȃ�
�ɒB�␌����F
���ꂩ�牺�肽N
���肪�Ƃ��������܂�����
�ɒB�␌����F
���ꂩ�牺�肽N
���肪�Ƃ��������܂�����
801 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 14:18:05 ID:nTJp+b5t
�N���E�h�i�j
802 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 14:40:42 ID:kfSnR0Rj
803 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 15:10:52 ID:JZ0mjPTK
������ɂ̓R�X�g�ȊO�ŕ�����v�f���Ȃ�
POWER7�ɂ͏��ĂȂ�
POWER7�ɂ͏��ĂȂ�
804 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 15:50:31 ID:r5PI6jSm
�R�X�g�ŕ�������ʖڂ���
���Ƃ��Ĕ�ԂƂ����I���Ď�������悤�Ȃ���
���Ƃ��Ĕ�ԂƂ����I���Ď�������悤�Ȃ���
805 �F,,�E�L�́M�E,,�j��-�������F2009/10/10(�y) 15:52:57 ID:KB1kCPci
�����Ƃ��Ĕ�ԂƂ����I���Ď�������悤�Ȃ���
�I���`�b�vGPU�̎s���GMA�ɖ����n���Ă��܂�NVIDIA��g����Ȃ�
�u�����Ȃ������͕��������v�ł���
�I���`�b�vGPU�̎s���GMA�ɖ����n���Ă��܂�NVIDIA��g����Ȃ�
�u�����Ȃ������͕��������v�ł���
806 �F,,�E�L�́M�E,,�j��-�������F2009/10/10(�y) 16:12:06 ID:KB1kCPci
2012�N����̎��_�ł͍ŋ���Xeon�́A256bit SIMD���ڂ�IvyBridge�ɂȂ�낤��
6�R�A�Ȃ�2.66GHz�ȏ�o����1�`�b�v������̐��\��Venus�̕����m��B
8�R�A�Ȃ�2GHz�ȏ�ŏ[���B
�������\���ƍX��Venus�̕��������B
SIMD�p�Ƀ��W�X�^��ʂɓ��ڂ����Ӗ��͓������ߔ��s���l����킩��B
128�r�b�gFMA��2���߂Ńs�[�N���\�o����킯����
�܂胍�[�h�E�X�g�A���s���Ă�ԕ����������Z���i����
�[���A�_�˂̃X�p�R���ǂ�����낤�ˁB
NEC�S����̃x�N�g���v���Z�b�T�̌����߂͂ǂ������̂��B
GPGPU��Larrabee�̂ق��ɑI�����������C���B
6�R�A�Ȃ�2.66GHz�ȏ�o����1�`�b�v������̐��\��Venus�̕����m��B
8�R�A�Ȃ�2GHz�ȏ�ŏ[���B
�������\���ƍX��Venus�̕��������B
SIMD�p�Ƀ��W�X�^��ʂɓ��ڂ����Ӗ��͓������ߔ��s���l����킩��B
128�r�b�gFMA��2���߂Ńs�[�N���\�o����킯����
�܂胍�[�h�E�X�g�A���s���Ă�ԕ����������Z���i����
�[���A�_�˂̃X�p�R���ǂ�����낤�ˁB
NEC�S����̃x�N�g���v���Z�b�T�̌����߂͂ǂ������̂��B
GPGPU��Larrabee�̂ق��ɑI�����������C���B
807 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 16:50:29 ID:2tqra70j
���܂��A�����̃��_������
808 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 16:57:28 ID:1WPDLZjX
�o�ĂȂ��v���_�N�g���m������ׂ��Ű
�Ƃ����C��
�Ƃ����C��
809 �F,,�E�L�́M�E,,�j��-�������F2009/10/10(�y) 17:04:07 ID:KB1kCPci
AVX��CPU�G�~�����[�^���邵�R���p�C���͂����Ή����Ă邩����ɃR�[�h�����n�߂Ă邼
810 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 17:53:10 ID:r5PI6jSm
811 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 19:07:33 ID:2tqra70j
>>714
�듚���ł͂��邪
> Larrabee�͐V�݂�Visual Computing Group�̊NJ������A�J�����s�Ȃ����̂�
> Digital Enterprise Group�̉��ɂ���I���S���B�q���Y�{���̊J���Z���^�[���ƌ����Ă���B
�듚���ł͂��邪
> Larrabee�͐V�݂�Visual Computing Group�̊NJ������A�J�����s�Ȃ����̂�
> Digital Enterprise Group�̉��ɂ���I���S���B�q���Y�{���̊J���Z���^�[���ƌ����Ă���B
812 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 21:48:17 ID:JZ0mjPTK
�c�q�������Ă����̂̓z�E�_�_���S����
813 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 22:03:08 ID:kfSnR0Rj
>>806
������NEC���������́A�x�m�ʂ̃X�J���̋K�͊g��ŁA���ߍ��킹��B
���Ȃ�O�ɕ���Ă���B
>>808
�J�����̂��̂ƗʎY�o�ׂ���Ă�����̂��r������̓}�V�B
SPARC64VIIIfx(venus)�̐��E�ő��錾�͒p�������������B
venus�͖�������f������ĂȂ��Ǝv��(���������ꂪ�Ȃ���������)���A
�C���e����SandyBridge�͓���f�������łɂ���Ă���B
�C���e���̂ق���CPU�̗ʎY�o�J�n�Ƃقړ����ɁA���ڃT�[�o�����\�����(�J�n����)
�x�m�ʂ�x86�T�[�o����Ă���̂�����A�C���e������SandyBridge�̃T���v��������Ă�͂��B
�����オ��͑����A�����Ɏg���͂��߂�B
venus�͌������ˁE�E�E�B
������NEC���������́A�x�m�ʂ̃X�J���̋K�͊g��ŁA���ߍ��킹��B
���Ȃ�O�ɕ���Ă���B
>>808
�J�����̂��̂ƗʎY�o�ׂ���Ă�����̂��r������̓}�V�B
SPARC64VIIIfx(venus)�̐��E�ő��錾�͒p�������������B
venus�͖�������f������ĂȂ��Ǝv��(���������ꂪ�Ȃ���������)���A
�C���e����SandyBridge�͓���f�������łɂ���Ă���B
�C���e���̂ق���CPU�̗ʎY�o�J�n�Ƃقړ����ɁA���ڃT�[�o�����\�����(�J�n����)
�x�m�ʂ�x86�T�[�o����Ă���̂�����A�C���e������SandyBridge�̃T���v��������Ă�͂��B
�����オ��͑����A�����Ɏg���͂��߂�B
venus�͌������ˁE�E�E�B
814 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 22:19:19 ID:CGvzFPFs
�f���܂ŋC���ɑ҂��Ă���͂�
http://blog.livedoor.jp/itlifehack/archives/342756.html
�����݂��܂��܂ȕ]�����i�߂��Ă���i�K�������B
http://blog.livedoor.jp/itlifehack/archives/342756.html
�����݂��܂��܂ȕ]�����i�߂��Ă���i�K�������B
815 �F,,�E�L�́M�E,,�j��-�������F2009/10/10(�y) 22:24:32 ID:KB1kCPci
>>812
����ɂ��Ԃ���̂̓S�L�u���ȕ��ł���
����ɂ��Ԃ���̂̓S�L�u���ȕ��ł���
816 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 22:24:34 ID:JZ0mjPTK
>2012�N�ȍ~�̐��i����ڏ���
���Ă��H���N�ɂ͋��������ғ�����˂��́H
���Ă��H���N�ɂ͋��������ғ�����˂��́H
817 �F,,�E�L�́M�E,,�j��-�������F2009/10/10(�y) 22:28:24 ID:KB1kCPci
NEC���E�ނ������ƂŃV�X�e���S�̂���������Ă邩��
�X�J��������Venus�ƌ��܂����킯����Ȃ�
�x�m�ʂ͗�����Nehalem��ʔ[�����т��邵
�܂������������Ƃ�
�X�J��������Venus�ƌ��܂����킯����Ȃ�
�x�m�ʂ͗�����Nehalem��ʔ[�����т��邵
�܂������������Ƃ�
818 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 22:34:44 ID:JZ0mjPTK
���Y������߂�Ȃ�A�����v�����ă��C����GPU�ɂ��Ăق�����
819 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 22:35:02 ID:CGvzFPFs
820 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 22:37:48 ID:h1swkXRP
���������s����91.2%���ł�������������炨��������SPARC�Ȃ�Ă����Ȃ���Ȃ�
SGI�ɗ��߂�93.9%�Ȃ�či��o�������SX�����v��Nehalem�ŋ���������������
SGI�ɗ��߂�93.9%�Ȃ�či��o�������SX�����v��Nehalem�ŋ���������������
821 �F,,�E�L�́M�E,,�j��-�������F2009/10/10(�y) 22:49:05 ID:KB1kCPci
>>819
�����Ă邾��A�V�X�e���C���e�O���[�^�Ƃ��āB
�����̐����̗��v�Ȃ�đ��ǂ�����Ă邵�B
�X�p�R�������ɂ����g���Ȃ��v���Z�b�T�Ȃ�ĕ��ł����Ȃ��B
�����Ă邾��A�V�X�e���C���e�O���[�^�Ƃ��āB
�����̐����̗��v�Ȃ�đ��ǂ�����Ă邵�B
�X�p�R�������ɂ����g���Ȃ��v���Z�b�T�Ȃ�ĕ��ł����Ȃ��B
822 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 22:53:20 ID:r5PI6jSm
>>815
�i�L�G�ցG�M�j��
�i�L�G�ցG�M�j��
823 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 23:14:20 ID:6ZF9AK19
824 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 23:22:21 ID:n6m8GTKC
>>808
ieta
ieta
825 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 23:24:07 ID:kfSnR0Rj
>>819
�����́A����P�̂ł̓��[�J�[�ɂƂ��Ă͐Ԏ�����B����Ȃ��B
�����̃��[�U�[�ɑ��ē������̂邱�Ƃō��������Ă���A���Ă����ςȃv���W�F�N�g�B
NEC�Ȃ�SX�̃��[�U�[�������̋������p�ɏW�ꂿ�Ⴄ�ƁASX������Ȃ��Ȃ�̂œP�ނ����̂��낤�B
�����́A����P�̂ł̓��[�J�[�ɂƂ��Ă͐Ԏ�����B����Ȃ��B
�����̃��[�U�[�ɑ��ē������̂邱�Ƃō��������Ă���A���Ă����ςȃv���W�F�N�g�B
NEC�Ȃ�SX�̃��[�U�[�������̋������p�ɏW�ꂿ�Ⴄ�ƁASX������Ȃ��Ȃ�̂œP�ނ����̂��낤�B
826 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 23:26:35 ID:JZ0mjPTK
�Q�����J���āA�\�������Ƃ��Ăǂ�ȕ��ɗ\��H
827 �F,,�E�L�́M�E,,�j��-�������F2009/10/10(�y) 23:38:52 ID:KB1kCPci
Top500���肵�Ă�x�m�ʂ̃V�X�e�����Ă���3����
28 JAXA Japan
40 Institute of Physical and Chemical Res. (RIKEN) Japan ��Nehalem����
78 Kyoto University Japan
http://www.top500.org/list/2009/06/100
28 JAXA Japan
40 Institute of Physical and Chemical Res. (RIKEN) Japan ��Nehalem����
78 Kyoto University Japan
http://www.top500.org/list/2009/06/100
828 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 23:39:22 ID:kfSnR0Rj
>>826
������Ȃ��A�L���b�`�[�ȃZ�[���X�g�[�N�ł��傤�B
�n���V�~�����[�^�̂Ƃ����傰���Ȃ��Ƃ������Ă����ˁB
�Ƃ���ŁA�����͌����������Ă���Ă���Ƃ͎v�����ǁA�ӂƋ^��Ɏv�����Ƃ��B
�W�ω�H�͔����������قǁA�g�����W�X�^1�̒l�i�������Ȃ邵�A
1�̃`�b�v�ɁA��������W�ς���قnj����ǂ����\��L�����Ƃ��ł���
�Ƃ����̂́A���܂܂ł̗��j�������Ă��邱�Ƃ����ǁA���ꂩ��������Ȃ̂��ȁB
��ʂɐ��Y����悤�ȏꍇ�ɂ́A������������Ȃ�����ǂ��A
�����̃I�[�_�[�ł������Ȃ����̂ł́A���낻�������Ă��܂��B
������Ȃ��A�L���b�`�[�ȃZ�[���X�g�[�N�ł��傤�B
�n���V�~�����[�^�̂Ƃ����傰���Ȃ��Ƃ������Ă����ˁB
�Ƃ���ŁA�����͌����������Ă���Ă���Ƃ͎v�����ǁA�ӂƋ^��Ɏv�����Ƃ��B
�W�ω�H�͔����������قǁA�g�����W�X�^1�̒l�i�������Ȃ邵�A
1�̃`�b�v�ɁA��������W�ς���قnj����ǂ����\��L�����Ƃ��ł���
�Ƃ����̂́A���܂܂ł̗��j�������Ă��邱�Ƃ����ǁA���ꂩ��������Ȃ̂��ȁB
��ʂɐ��Y����悤�ȏꍇ�ɂ́A������������Ȃ�����ǂ��A
�����̃I�[�_�[�ł������Ȃ����̂ł́A���낻�������Ă��܂��B
829 �F�s���ȃf�o�C�X�����F2009/10/10(�y) 23:48:56 ID:CdX13FAJ
�����C�j�V�����R�X�g����ɖ߂肽����(�L��֥�M)
http://jun.artcompsci.org/articles/future_sc/note045.html
15�N�O�܂łȂ�A1000���~������Ό��\�傫�ȃ}�C�N���v���Z�b�T������Ă݂邱�Ƃ��ł��܂���
http://jun.artcompsci.org/articles/future_sc/note034.html
�����̊J��������Ă��������G���N�g�����Ɏ�������ŁA��p�Ƃ��̌��ς���������̂ł��B
����łłĂ����������A GRAPE-1 �̐��x���������������炢�̂��̂��Ƃ܂��J���
1500���~�ʂƂ��������ł����B�v�����g����ɂ�������������̂ŁA 2000�����炢���邱�ƂɂȂ�܂��B
http://jun.artcompsci.org/articles/future_sc/note036.html
������ɂ��Ă����� LSI ����܂ł̔�p������ɂȂ��Ă����Ƃ������Ƃł��B�܂�A
1���~���x�܂łȂ當���Ȃ̉Ȋw�Z�p������⏕���Ƃ����A�����҂������Ȋw�Ȃ�
�\�������ނ̂����łȂ�Ƃ��Ȃ�܂��B GRAPE-4 �͂�������������ł��܂����B
GRAPE-6 �ł́A���ɏq�ׂ��悤�ɉ^�ǂ�����������Ƒ傫�Ȋz�̗\�Z���g�����Ƃ��ł��܂����B
�������A���̎��ɂ͂����Ƒ傫�ȗ\�Z���K�v�ɂȂ�܂��B�`�b�v����邾����5���~�Ƃ���Ȃ�A
10���~���炢�g��Ȃ��ƑS�̂Ƃ��Ẳ��i���\�䂪���܂�ǂ��Ȃ�Ȃ�����ł��B
http://jun.artcompsci.org/articles/future_sc/note045.html
15�N�O�܂łȂ�A1000���~������Ό��\�傫�ȃ}�C�N���v���Z�b�T������Ă݂邱�Ƃ��ł��܂���
http://jun.artcompsci.org/articles/future_sc/note034.html
�����̊J��������Ă��������G���N�g�����Ɏ�������ŁA��p�Ƃ��̌��ς���������̂ł��B
����łłĂ����������A GRAPE-1 �̐��x���������������炢�̂��̂��Ƃ܂��J���
1500���~�ʂƂ��������ł����B�v�����g����ɂ�������������̂ŁA 2000�����炢���邱�ƂɂȂ�܂��B
http://jun.artcompsci.org/articles/future_sc/note036.html
������ɂ��Ă����� LSI ����܂ł̔�p������ɂȂ��Ă����Ƃ������Ƃł��B�܂�A
1���~���x�܂łȂ當���Ȃ̉Ȋw�Z�p������⏕���Ƃ����A�����҂������Ȋw�Ȃ�
�\�������ނ̂����łȂ�Ƃ��Ȃ�܂��B GRAPE-4 �͂�������������ł��܂����B
GRAPE-6 �ł́A���ɏq�ׂ��悤�ɉ^�ǂ�����������Ƒ傫�Ȋz�̗\�Z���g�����Ƃ��ł��܂����B
�������A���̎��ɂ͂����Ƒ傫�ȗ\�Z���K�v�ɂȂ�܂��B�`�b�v����邾����5���~�Ƃ���Ȃ�A
10���~���炢�g��Ȃ��ƑS�̂Ƃ��Ẳ��i���\�䂪���܂�ǂ��Ȃ�Ȃ�����ł��B
830 �F�s���ȃf�o�C�X�����F2009/10/11(��) 00:19:27 ID:iwKDFw4d
������FPGA
831 �F�s���ȃf�o�C�X�����F2009/10/11(��) 00:22:07 ID:ZaYPOE8k
�̃m�E�n�E������܂���
832 �F�s���ȃf�o�C�X�����F2009/10/11(��) 00:30:10 ID:IJs9Jiwv
�����^
833 �F�s���ȃf�o�C�X�����F2009/10/11(��) 00:30:42 ID:TDTP04aK
>>817
������X�[�p�[�R���s���[�^�̐V�V�X�e���\��������
http://www.riken.jp/r-world/info/release/press/2009/090717/index.html
��CPU�ɂ́A�x�m�ʂ��v����45nm�����̃v���Z�X�Z�p�ɂ��CPU
���iSPARC64 VIIIfx�A8�R�A�A128�M�KFLOPS�j���̗p���܂��B
������X�[�p�[�R���s���[�^�̐V�V�X�e���\��������
http://www.riken.jp/r-world/info/release/press/2009/090717/index.html
��CPU�ɂ́A�x�m�ʂ��v����45nm�����̃v���Z�X�Z�p�ɂ��CPU
���iSPARC64 VIIIfx�A8�R�A�A128�M�KFLOPS�j���̗p���܂��B
834 �F�s���ȃf�o�C�X�����F2009/10/11(��) 00:49:43 ID:ZaYPOE8k
�c�q�ϑz�۽
835 �F,,�E�L�́M�E,,�j��-�������F2009/10/11(��) 01:49:29 ID:bpOc/3SE
>>833
�����l����Ɗ��S�ɗD�ʐ��ˁ[��
�Ő�[�v���Z�X�Ŏs����㑦�����ł���̂�x86�̋��݂�����ȁB
������Nehalem�N���X�^�͓����v��̃X�y�b�N��������������ǁB
�����l����Ɗ��S�ɗD�ʐ��ˁ[��
�Ő�[�v���Z�X�Ŏs����㑦�����ł���̂�x86�̋��݂�����ȁB
������Nehalem�N���X�^�͓����v��̃X�y�b�N��������������ǁB
836 �F�s���ȃf�o�C�X�����F2009/10/11(��) 02:57:02 ID:/cm7GXK8
�q��搶��grape�ȃ`�b�v��100�����邩�Ȃ��Ă����
837 �F�s���ȃf�o�C�X�����F2009/10/11(��) 03:13:40 ID:6xhZT9wZ
�A�����J��ORNL��CPU�������ւ��ăA�b�v�O���[�h�Ƃ�����Ă邯�ǁA���{�ł͂��Ȃ���?
���Ƃ��A�X�p�R�������āA�����̂�5�N���g��������Ƃ��A�Ȃ��ʂ��ۂ���B
2�N�̓X�p�R���Ƃ��Ďg���A�c��3�N��Web�z�X�e�B���O�Ɏg���Ƃ�������A�����̂ɁB
���Ƃ��A�X�p�R�������āA�����̂�5�N���g��������Ƃ��A�Ȃ��ʂ��ۂ���B
2�N�̓X�p�R���Ƃ��Ďg���A�c��3�N��Web�z�X�e�B���O�Ɏg���Ƃ�������A�����̂ɁB
838 �F�s���ȃf�o�C�X�����F2009/10/11(��) 03:18:27 ID:r2d6BTyI
Web�Ƃ��Ɏg���̂�x86��Niagara
839 �F�s���ȃf�o�C�X�����F2009/10/11(��) 03:28:03 ID:6xhZT9wZ
������ė��p���l������x86�N���X�^�ŃX�p�R�������ׂ�����Ȃ����ƁB
840 �F�s���ȃf�o�C�X�����F2009/10/11(��) 03:34:39 ID:6TCFKUpE
>>837
�܂��A�_�˂̂͂��낢����ł���B�Ђ���Ƃ�����GPU�����ꂽ��Ƃ��B
�܂��A�_�˂̂͂��낢����ł���B�Ђ���Ƃ�����GPU�����ꂽ��Ƃ��B
841 �F�s���ȃf�o�C�X�����F2009/10/11(��) 04:24:27 ID:6xhZT9wZ
>>840
���܂܂łɔ�₵���J����p�́A���������ǂ��ɏ�������?
���܂܂łɔ�₵���J����p�́A���������ǂ��ɏ�������?
842 �F�s���ȃf�o�C�X�����F2009/10/11(��) 04:54:49 ID:VXO5PEFC
>>825
�l���畷�������x�̘b�����A�����̃x�N�g���v���Z�b�T�͔�SX�݊��炵���B
���ۃv���X�����[�X���Ă�SX�Ƃ��������͖��������͂��B�i�Ԉ���Ă��炲�߂�j
���������̂������ASX�V���[�Y�Ƃ͕ʂȃX�p�R�������v���Z�b�T�V���[�Y�͖̒������Ɣ��f���āA
SX�V���[�Y�P�{�ɍi�������ʂ炵���B
�l���畷�������x�̘b�����A�����̃x�N�g���v���Z�b�T�͔�SX�݊��炵���B
���ۃv���X�����[�X���Ă�SX�Ƃ��������͖��������͂��B�i�Ԉ���Ă��炲�߂�j
���������̂������ASX�V���[�Y�Ƃ͕ʂȃX�p�R�������v���Z�b�T�V���[�Y�͖̒������Ɣ��f���āA
SX�V���[�Y�P�{�ɍi�������ʂ炵���B
843 �F�s���ȃf�o�C�X�����F2009/10/11(��) 07:30:03 ID:UrYJ6nqy
844 �F�s���ȃf�o�C�X�����F2009/10/11(��) 07:37:11 ID:6xhZT9wZ
>>843
������ƒ��ׂĂ݂��B
�����́A�ŏ���VIIIfx�ŁA�ғ��J�n����2�N(����������)���炢��CPU���A�b�v�O���[�h����v��炵���B
������ƒ��ׂĂ݂��B
�����́A�ŏ���VIIIfx�ŁA�ғ��J�n����2�N(����������)���炢��CPU���A�b�v�O���[�h����v��炵���B
845 �F�s���ȃf�o�C�X�����F2009/10/11(��) 10:32:20 ID:wjh0ZksT
�\�[�X����H
846 �F,,�E�L�́M�E,,�j��-�������F2009/10/11(��) 10:49:19 ID:bpOc/3SE
>>836
GRAPE���ă��[�J�����������Ŗw�ǂ̉��Z�������ł��邩�烁�����ш�͕K�v�Ȃ����Ă���
��������v�Ȃ��
���ꂶ�ᑼ�̗p�r�ɂ͎g���Ȃ��B
GRAPE���ă��[�J�����������Ŗw�ǂ̉��Z�������ł��邩�烁�����ш�͕K�v�Ȃ����Ă���
��������v�Ȃ��
���ꂶ�ᑼ�̗p�r�ɂ͎g���Ȃ��B
848 �F�s���ȃf�o�C�X�����F2009/10/11(��) 12:58:03 ID:4izbrYYD
�c�q�������߁B
�������Љ�Ɉ��܂ꂽ���Ǝv���Ă��B
�������Љ�Ɉ��܂ꂽ���Ǝv���Ă��B
849 �F�s���ȃf�o�C�X�����F2009/10/11(��) 14:38:50 ID:lLq9is9k
850 �F�s���ȃf�o�C�X�����F2009/10/11(��) 23:22:03 ID:sufs1MwC
851 �F�s���ȃf�o�C�X�����F2009/10/11(��) 23:24:49 ID:/cm7GXK8
>>850
���₻�������̂ł�����ˁH
���₻�������̂ł�����ˁH
852 �F�s���ȃf�o�C�X�����F2009/10/11(��) 23:53:06 ID:ZKBkLu9f
���ꂾ�����畁�ʂ�GPGPU�ł�������Ȃ����c�B
853 �F�s���ȃf�o�C�X�����F2009/10/12(��) 00:01:44 ID:s7CTlk5B
����Ƃ��ă`�b�v�����Ęb����
���̂�������Q���t�H�[�X�Ƃ����f�`�����Ƃ����e���������Ęb�ɂȂ��
���̂�������Q���t�H�[�X�Ƃ����f�`�����Ƃ����e���������Ęb�ɂȂ��
854 �F�s���ȃf�o�C�X�����F2009/10/12(��) 00:55:48 ID:G3VUl8Ap
GPU�𗬗p����Ȃ�Ƃ������AGPU�ɗ��p����̂́A�Ȃ����낤�B
�C�V���N���X�̒���ʐ��Y������̂Ɏg��GPU�������v����Ƃ��Ă��A
������GRAPE�n�̓��荞�ޗ]�n�͂Ȃ��ł��傤�B
���̋@�\�̓Q�[���ɕK�v�Ȃ��ƂȂ�A�ǂ�ǂ������B
��ʐ��Y����邪�䂦�ɁA�͂��Ȗ��ʂ��A�ς���ς����Ă��܂�����B
���łɑO�Ⴊ����v���X�e3��CELLBE�Ɠ��l�ɁA
�܂����ɃQ�[���@�ɓ����������̂ɂȂ�ł��傤�B
�C�V���N���X�̒���ʐ��Y������̂Ɏg��GPU�������v����Ƃ��Ă��A
������GRAPE�n�̓��荞�ޗ]�n�͂Ȃ��ł��傤�B
���̋@�\�̓Q�[���ɕK�v�Ȃ��ƂȂ�A�ǂ�ǂ������B
��ʐ��Y����邪�䂦�ɁA�͂��Ȗ��ʂ��A�ς���ς����Ă��܂�����B
���łɑO�Ⴊ����v���X�e3��CELLBE�Ɠ��l�ɁA
�܂����ɃQ�[���@�ɓ����������̂ɂȂ�ł��傤�B
855 �F�s���ȃf�o�C�X�����F2009/10/12(��) 02:41:28 ID:dEGUbCOr
���Ⴀ�A���{�A���Ƃ������ƂŁA�C�V���Asony�ŃR���\�[����CPU�AGPU�����ʉ����čڂ��Ă��炢�܂��傤�B
�J���͕x�m�ʂ�NEC�Ɠ���ŁACPU��venus�AGPU��SX-9�APPU��GRAPE�Ƃ������Ƃɂ��܂��傤�B
�������̓G���s�[�_�ŁATSV�Őϑw���Ă��炢�܂��傤�B
���ł�SSD���ڂ��܂��傤�B
�R���\�[���́A���C���^�[�R�l�N�g�łȂ��܂��B
�����10000�䂭�炢�N���X�^�����O����A�����ł��傤�B
�J���͕x�m�ʂ�NEC�Ɠ���ŁACPU��venus�AGPU��SX-9�APPU��GRAPE�Ƃ������Ƃɂ��܂��傤�B
�������̓G���s�[�_�ŁATSV�Őϑw���Ă��炢�܂��傤�B
���ł�SSD���ڂ��܂��傤�B
�R���\�[���́A���C���^�[�R�l�N�g�łȂ��܂��B
�����10000�䂭�炢�N���X�^�����O����A�����ł��傤�B
856 �F�s���ȃf�o�C�X�����F2009/10/12(��) 02:44:45 ID:G3VUl8Ap
GRAPE�M�҃E�U�C
857 �F�s���ȃf�o�C�X�����F2009/10/12(��) 02:49:44 ID:vROIp1QT
>>855
�b�̂킩���n����
�b�̂킩���n����
�Ȃ��X���t���Ă邗�@���ꂵ���Ȃ�������
�i����V850���Ȕԍ��őf�G�������j
���Ⴀ�A������Q�[���@��PC-FX2010�Ƃ���OK�ł���
NEC�z�[���G���N�g���j�N�X�ސ�
�����GRAPE����
���RNEC40nm�v���Z�X
�A�j����p�@
�����OK�ł��ˁ���
�i����V850���Ȕԍ��őf�G�������j
���Ⴀ�A������Q�[���@��PC-FX2010�Ƃ���OK�ł���
NEC�z�[���G���N�g���j�N�X�ސ�
�����GRAPE����
���RNEC40nm�v���Z�X
�A�j����p�@
�����OK�ł��ˁ���
859 �F�s���ȃf�o�C�X�����F2009/10/12(��) 07:14:36 ID:G3VUl8Ap
>>858
���[���[��[
�Q�[���@�̂�������ŃX�p�R������邱�Ƃ͂����Ă��A
�X�p�R���̂�������ŃQ�[���@����邱�Ƃ͂Ȃ��̂�B
��鐔�̌����������Ⴄ�̂�����B
���[���[��[
�Q�[���@�̂�������ŃX�p�R������邱�Ƃ͂����Ă��A
�X�p�R���̂�������ŃQ�[���@����邱�Ƃ͂Ȃ��̂�B
��鐔�̌����������Ⴄ�̂�����B
860 �F,,�E�L�́M�E,,�j��-�������F2009/10/12(��) 11:08:35 ID:q+NZ9A3B
�Q�[���@����{���x����Ȃ��Ƃ������ďI���ł���
861 �F�s���ȃf�o�C�X�����F2009/10/12(��) 11:16:54 ID:sA1XLiQm
�Ƃ����킋�Ŕ{���x�䂦�ɖʔ����Ĕ����Q�[��������ƂɁi����
862 �F�s���ȃf�o�C�X�����F2009/10/12(��) 11:32:31 ID:G3VUl8Ap
�{���]�|����B
863 �F�s���ȃf�o�C�X�����F2009/10/12(��) 11:57:46 ID:sA1XLiQm
�{���]�|�ƌ�����Ȃ��̂�
�Q�[���@��GUGPU���{���x�Ő��\���o��悤�ɂȂ�����
GRAPE���K�v�Ȃ��Ȃ�̂ł������ɏ��������������Ƃ��B
��G�c�Șb�B
�Q�[���@��GUGPU���{���x�Ő��\���o��悤�ɂȂ�����
GRAPE���K�v�Ȃ��Ȃ�̂ł������ɏ��������������Ƃ��B
��G�c�Șb�B
864 �F�s���ȃf�o�C�X�����F2009/10/12(��) 13:10:57 ID:VcwcJoY/
�����N���X�^�ł���邩��
865 �F�s���ȃf�o�C�X�����F2009/10/12(��) 14:38:44 ID:E+eicr2M
�Ȃł����A���ꂾ���Q�[���Y�ƌn��Cell�Ƃ�GPGPU��HPC�ŏo�Ă��Ă���̂ɁA
�����S���g��Ȃ����Ă����̂͂ǂ��Ȃ낤�B
���{�͓��Ƀv���b�g�t�H�[������Ă��郁�[�J�[��2�������Ă��āA�Q�[���Y�Ƃł�
���E�̒��œˏo�������݂������Ă��鍑�Ƃ�����ł��傤�H
���������ƊE�̋��݂𗘗p���Ȃ���͂Ȃ���Ȃ����낤���B�������A�Q�[���Y�Ƃɂ�
������悤�Ȓ�Ă��Ȃ��Ă͂����Ȃ����ǁB
���̋��݂��Ă̂̓n�[�h��������Ȃ��āA�ނ���J�����Ƃ��l�ނ̕����̕���
�d�v�Ȃ̂�������Ȃ��B�}���`�R�A�̕����̍œK�������I�ɂ���Ă���
�s��Ƃ��l���̋K�͂�����قǑ傫�ȋƊE���Ăق��ɂȂ��ł��傤�H
�����S���g��Ȃ����Ă����̂͂ǂ��Ȃ낤�B
���{�͓��Ƀv���b�g�t�H�[������Ă��郁�[�J�[��2�������Ă��āA�Q�[���Y�Ƃł�
���E�̒��œˏo�������݂������Ă��鍑�Ƃ�����ł��傤�H
���������ƊE�̋��݂𗘗p���Ȃ���͂Ȃ���Ȃ����낤���B�������A�Q�[���Y�Ƃɂ�
������悤�Ȓ�Ă��Ȃ��Ă͂����Ȃ����ǁB
���̋��݂��Ă̂̓n�[�h��������Ȃ��āA�ނ���J�����Ƃ��l�ނ̕����̕���
�d�v�Ȃ̂�������Ȃ��B�}���`�R�A�̕����̍œK�������I�ɂ���Ă���
�s��Ƃ��l���̋K�͂�����قǑ傫�ȋƊE���Ăق��ɂȂ��ł��傤�H
866 �F�s���ȃf�o�C�X�����F2009/10/12(��) 14:39:26 ID:A6+V1ewU
�ׂ���Ȃ����
867 �F�s���ȃf�o�C�X�����F2009/10/12(��) 14:56:13 ID:CS1EUk6Q
�ׂ����Ȃ��A���ȁB���̌��ʂ�����
http://www.top500.org/stats/list/33/vendors
http://www.top500.org/stats/list/33/vendors
868 �F�s���ȃf�o�C�X�����F2009/10/12(��) 15:00:15 ID:sA1XLiQm
�����Ō����Ƃ���́h���{�́h�̓������l���Ă݂�ׂ�����
869 �F�s���ȃf�o�C�X�����F2009/10/12(��) 15:02:18 ID:A6+V1ewU
���@��9���̂����ɂ���͎̂~�߂�
870 �F�s���ȃf�o�C�X�����F2009/10/12(��) 15:23:36 ID:G3VUl8Ap
>>863
���ł�IBM��CellBE��DP����������PowerXCell 8i�ŃX�p�R������Ă邶���B
>>865
�����Ⴂ������B
NEC��x�m�ʂł͂Ȃ��A�\�j�[�Ⓦ�łɍ�点��̂́A�����̐l�̃v���C�h�������Ȃ��ł��傤�B
���ł�IBM��CellBE��DP����������PowerXCell 8i�ŃX�p�R������Ă邶���B
>>865
�����Ⴂ������B
NEC��x�m�ʂł͂Ȃ��A�\�j�[�Ⓦ�łɍ�点��̂́A�����̐l�̃v���C�h�������Ȃ��ł��傤�B
871 �F�s���ȃf�o�C�X�����F2009/10/12(��) 15:33:03 ID:d1hKViFL
���̃X���ɂȂ�ăQ�n�~������́H
872 �F�s���ȃf�o�C�X�����F2009/10/12(��) 15:44:48 ID:E+eicr2M
>>870
�ł����A������ӂ̔����̕���͂��̂�������������Ă����b�������ˁB
�v���C�h�Ȃ�Ă����Ă������Ȃ��Ȃ�܂ł����A�b���ς���Ă��邩�ȁB
�ł����A������ӂ̔����̕���͂��̂�������������Ă����b�������ˁB
�v���C�h�Ȃ�Ă����Ă������Ȃ��Ȃ�܂ł����A�b���ς���Ă��邩�ȁB
873 �F�s���ȃf�o�C�X�����F2009/10/12(��) 15:52:25 ID:sA1XLiQm
>>870
�Q�[���@�̃X�P�[�������b�g�����Ă�悤�ɂ������Ȃ����ǂ�
�Q�[���@�̃X�P�[�������b�g�����Ă�悤�ɂ������Ȃ����ǂ�
874 �F�s���ȃf�o�C�X�����F2009/10/12(��) 15:58:31 ID:NPiiMXj/
PowerXCell 8i��PS3�ɍڂ��Ă���Cell�͕ʃ`�b�v������ˁB
�J����͍팸�ł������낤���ǁB
�J����͍팸�ł������낤���ǁB
875 �F�s���ȃf�o�C�X�����F2009/10/12(��) 16:03:10 ID:A6+V1ewU
cell8i��384GFLOPS�������H
���Ȃ�ϑ��I�ȃ`�b�v������Ȃ��Blinux��������pentium3�N���X����
���Ȃ�ϑ��I�ȃ`�b�v������Ȃ��Blinux��������pentium3�N���X����
876 �F�s���ȃf�o�C�X�����F2009/10/12(��) 17:21:02 ID:G3VUl8Ap
>>872
���┼���̕���ł͂Ȃ��A�X�p�R������Ă������ƕ����E�E�E
>>875
IBM Roadrunner�ł́A
Opteron�~2�̃}�V����PCI Express�X���b�g�ɁAPowerXCell 8i��2�ςA�N�Z�����[�^��2������
�Ƃ����\���ɂȂ��Ă��邩��B
���┼���̕���ł͂Ȃ��A�X�p�R������Ă������ƕ����E�E�E
>>875
IBM Roadrunner�ł́A
Opteron�~2�̃}�V����PCI Express�X���b�g�ɁAPowerXCell 8i��2�ςA�N�Z�����[�^��2������
�Ƃ����\���ɂȂ��Ă��邩��B
877 �F�s���ȃf�o�C�X�����F2009/10/12(��) 19:35:32 ID:VWHMZ9yG
�ŁA���ǔ\�V���̌����Ă��AGRAPE�v���W�F�N�g�͐ŋ��̖��ʁA���Ă����w�E�͐����������́H
GRAPE�̔��\���āA���ǂ������킯�H
GRAPE�̔��\���āA���ǂ������킯�H
878 �F�s���ȃf�o�C�X�����F2009/10/12(��) 19:51:11 ID:VcwcJoY/
879 �F�s���ȃf�o�C�X�����F2009/10/12(��) 20:25:34 ID:obP2H17U
>>875
�����Ȃ�ϑ��I�ȃ`�b�v������Ȃ��Blinux��������pentium3�N���X����
Roadrunner��PowerXCell 8i�ȊO�ɂ킴�킴Opteron�����ڂ���K�v��������
���R�̈�͂��ꂾ�낤�ˁB
�����Ȃ�ϑ��I�ȃ`�b�v������Ȃ��Blinux��������pentium3�N���X����
Roadrunner��PowerXCell 8i�ȊO�ɂ킴�킴Opteron�����ڂ���K�v��������
���R�̈�͂��ꂾ�낤�ˁB
880 �F,,�E�L�́M�E,,�j��-�������F2009/10/12(��) 21:41:54 ID:q+NZ9A3B
GRAPE���ėp�r�I��Larrabee���o�Ă���Ώ\����p�ł���Ǝv���Ă��
���j�[�R�A�v���Z�b�T�����������̂Ȃ�e���p�A���̂�������
�킴�킴��p�`�b�v��邾���̉��l������悤�ɂ͎v����
���j�[�R�A�v���Z�b�T�����������̂Ȃ�e���p�A���̂�������
�킴�킴��p�`�b�v��邾���̉��l������悤�ɂ͎v����
881 �F�s���ȃf�o�C�X�����F2009/10/12(��) 21:51:08 ID:WIaUhgzb
PowerXCell��������A�N�Z�����[�^�[���Ăǂ������s�̂��Ă��ˁB
�N�������ėV��ł݂��l���Ȃ��H
�N�������ėV��ł݂��l���Ȃ��H
882 �F,,�E�L�́M�E,,�j��-�������F2009/10/12(��) 22:10:05 ID:q+NZ9A3B
Fixstars�̂��Ƃ��[
���ꔄ��ĂȂ��炵����B
�{���x100GFLOPS�Ȃ��Xeon DP�ŏo���邩��ˁB
�킴�킴Cell��p�̃v���O��������Ȃ��ɕ��ʂ�x86�R�[�h�ŁB
�������l�ȊO�A100�����o���Ĕ���Ȃ���B
���ꔄ��ĂȂ��炵����B
�{���x100GFLOPS�Ȃ��Xeon DP�ŏo���邩��ˁB
�킴�킴Cell��p�̃v���O��������Ȃ��ɕ��ʂ�x86�R�[�h�ŁB
�������l�ȊO�A100�����o���Ĕ���Ȃ���B
883 �F�s���ȃf�o�C�X�����F2009/10/12(��) 22:16:48 ID:zeLWAzQI
���낢��ȃn�[�h�E�F�A�������Ă݂�A�Ƃ����ړI�Ȃ�A���ł́H
���͔���ǁB
���͔���ǁB
884 �F,,�E�L�́M�E,,�j��-�������F2009/10/12(��) 22:26:32 ID:q+NZ9A3B
http://www.fixstars.com/products/gigaaccel180/system.html
���[�N�X�e�[�V�����Ƃ������h�X�p��������̃V���b�v�u�����h���x����������
���łɃV���O���\�P�b�g���Ă̂����炵���d�l
Xeon�f���A�����ƈӖ����Ȃ������
�n���ɂ��Ă�ɂ���������
���[�N�X�e�[�V�����Ƃ������h�X�p��������̃V���b�v�u�����h���x����������
���łɃV���O���\�P�b�g���Ă̂����炵���d�l
Xeon�f���A�����ƈӖ����Ȃ������
�n���ɂ��Ă�ɂ���������
885 �F�s���ȃf�o�C�X�����F2009/10/12(��) 22:31:11 ID:zeLWAzQI
���ՂՁA�������B�Ȃ�قǁB
886 �F�s���ȃf�o�C�X�����F2009/10/12(��) 23:44:25 ID:WIaUhgzb
����I����100���߂�����̂�
��������ɂ���ɂ͂��ƍ�����
��������ɂ���ɂ͂��ƍ�����
887 �F�s���ȃf�o�C�X�����F2009/10/13(��) 00:11:05 ID:OH5XJFUR
Larrabee���ď����Ƃ��Ă����Ɖ��̂�����
�Ƃ����n�[�h�����z�����邩�ǂ����B
�Ƃ����n�[�h�����z�����邩�ǂ����B
888 �F,,�E�L�́M�E,,�j��-�������F2009/10/13(��) 00:15:02 ID:bd/YLJht
�������Ƃ���Fermi�Ɣ�邩��ANVIDIA�ׂ��̑O�ȁB
�f�B�X�N���[�g�J�[�h�̎s�ꎩ�̂��k�����Ăăp�C�����Ȃ��Ȃ��Ă�̂�GMA�̃V�F�A��^�g�咆��Intel���g��
��ԔF�����Ă���B
�f�B�X�N���[�g�J�[�h�̎s�ꎩ�̂��k�����Ăăp�C�����Ȃ��Ȃ��Ă�̂�GMA�̃V�F�A��^�g�咆��Intel���g��
��ԔF�����Ă���B
889 �F�s���ȃf�o�C�X�����F2009/10/13(��) 00:33:19 ID:rIy1qFSO
�{�C��NV�ׂ��Ȃ�$50�`$100���炢�̗����ł��ŏ��ɏo���ă��[�J�[PC�ɓ��ڂ������̘_���ʼn����Ԃ��ׂ����Ǝv���̂���
$999(�\�z)�̃G�N�X�g���[���ł���X�^�[�g�Ȃ��Larrabee��
32nm��100sqmm���炢�̗����ł����s���č���Ă�̂����m��Ȃ��P�h
$999(�\�z)�̃G�N�X�g���[���ł���X�^�[�g�Ȃ��Larrabee��
32nm��100sqmm���炢�̗����ł����s���č���Ă�̂����m��Ȃ��P�h
890 �F,,�E�L�́M�E,,�j��-�������F2009/10/13(��) 00:34:17 ID:bd/YLJht
HPC�p�r�ōŏI�I�ɖ��Â���̂͏���d�͂��Ǝv���B
GDDR5���d�͔n���H���Ȃ̂͂킩���ĂĂ��Ƃ͂���ɑ��Ăǂ������邩
L2�L���b�V����8MB�Ȃ̂�Larrabee
������768KB�Ȃ̂�Fermi
�^�C�������_�Ɗe�R�A�̃��[�h�E�X�g�A���j�b�g���Ƀp�b�N�h�f�[�^�̈��k�W�J�@�\�����
�K�v�ȃf�[�^�]���ш���팸��������ɐU�����̂�Larrabee
���������@�\�͔����ĂȂ��̂�Fermi
���₳�AFermi����ɂȂ��Ă����܂�ɏ��Ȃ����邾�냍�[�J�����������B
GDDR5���d�͔n���H���Ȃ̂͂킩���ĂĂ��Ƃ͂���ɑ��Ăǂ������邩
L2�L���b�V����8MB�Ȃ̂�Larrabee
������768KB�Ȃ̂�Fermi
�^�C�������_�Ɗe�R�A�̃��[�h�E�X�g�A���j�b�g���Ƀp�b�N�h�f�[�^�̈��k�W�J�@�\�����
�K�v�ȃf�[�^�]���ш���팸��������ɐU�����̂�Larrabee
���������@�\�͔����ĂȂ��̂�Fermi
���₳�AFermi����ɂȂ��Ă����܂�ɏ��Ȃ����邾�냍�[�J�����������B
891 �F�s���ȃf�o�C�X�����F2009/10/13(��) 00:37:21 ID:4GBfZ58F
�c�q������悤�ɂȂ��ăX���̕��͋C�ς������
���X����Itanium�X���ɖ߂�����
���X����Itanium�X���ɖ߂�����
892 �F,,�E�L�́M�E,,�j��-�������F2009/10/13(��) 00:40:07 ID:bd/YLJht
>>889
�����������ŏ��̍�24�R�A�̗����ł��o����ď��Ȃ��������H
�Œ��H�����ĂȂ������̂������璷�������邩�炳
8�R�A����ł�OK���Ă��ƂɂȂ���̂����������藦�ɂȂ肻������
NVIDIA�͂Ԃ����Ⴏ�`�b�v�Z�b�g�P�ނł��Ȃ藘�v���k����Ă邩�烄�o�C
�����ł���ATI�̒ቿ�i�H���Ŏ��ɑ̂����B
GT200���~�b�h�����W�ɂ��낵�Ă��邱�Ƃ���ł��Ȃ�����A��r�I�_�C�T�C�Y�̑傫���Ȃ�
���N���b�N�ʼn��GeForce8800GTS�̃��l�[�������x���J��Ԃ��Ă�̒m���Ă邾��B
�S�N���XDX11�Ή��\���ATI�Ɩ��Â������ꂻ��
�����������ŏ��̍�24�R�A�̗����ł��o����ď��Ȃ��������H
�Œ��H�����ĂȂ������̂������璷�������邩�炳
8�R�A����ł�OK���Ă��ƂɂȂ���̂����������藦�ɂȂ肻������
NVIDIA�͂Ԃ����Ⴏ�`�b�v�Z�b�g�P�ނł��Ȃ藘�v���k����Ă邩�烄�o�C
�����ł���ATI�̒ቿ�i�H���Ŏ��ɑ̂����B
GT200���~�b�h�����W�ɂ��낵�Ă��邱�Ƃ���ł��Ȃ�����A��r�I�_�C�T�C�Y�̑傫���Ȃ�
���N���b�N�ʼn��GeForce8800GTS�̃��l�[�������x���J��Ԃ��Ă�̒m���Ă邾��B
�S�N���XDX11�Ή��\���ATI�Ɩ��Â������ꂻ��
893 �F�s���ȃf�o�C�X�����F2009/10/13(��) 00:54:18 ID:rIy1qFSO
�����肪100%�ł��_�C��300sqmm����100sqmm�̏ꍇ��1/3�����̂�Ȃ�
���̎��_�ł̃R�X�g��3�{�ɂȂ�
���̎��_�ł̃R�X�g��3�{�ɂȂ�
894 �F,,�E�L�́M�E,,�j��-�������F2009/10/13(��) 01:09:07 ID:bd/YLJht
�ܘ_���̒ʂ�B
�����A100mm²��GPU�R�A�Ȃ�Ăǂ݂̂�������ς����B
Westmere�ɍڂ�����GMCH�̃O���t�B�b�N�R�A���������x���̂��炢�̃T�C�Y����ˁ[�́H
���N��TSMC��40nm�͐�[�v���Z�X����Intel�ɂƂ���45nm�͋ƊE�ō������̍��}�[�W���̐��i�ݏo�������
�������p�ς݂̋�����v���Z�X������A�R�X�g�̒P����r�͂ł��Ȃ��B
�����A100mm²��GPU�R�A�Ȃ�Ăǂ݂̂�������ς����B
Westmere�ɍڂ�����GMCH�̃O���t�B�b�N�R�A���������x���̂��炢�̃T�C�Y����ˁ[�́H
���N��TSMC��40nm�͐�[�v���Z�X����Intel�ɂƂ���45nm�͋ƊE�ō������̍��}�[�W���̐��i�ݏo�������
�������p�ς݂̋�����v���Z�X������A�R�X�g�̒P����r�͂ł��Ȃ��B
895 �F�s���ȃf�o�C�X�����F2009/10/13(��) 02:37:07 ID:VlMpUJWy
>>877
���s��������ŋ��̖��ʂƂ����͈̂Ⴄ�Ǝv���Ȃ��B
�����E���s�ƁA�ŋ��̖��ʂ��ǂ����́A�ʂ̕]�������Ǝv���B
�����������Ă���ΐŋ��̖��ʂł͂Ȃ��������Ƃ����ƁA����Ȃ��Ƃ͂Ȃ��킯�ŁB
>>879
PowerXCell��PPE��Opteron���ɋ��͂ȃR�A�ɂ�������A
�o��������Opteron���O�t�������ق��������I�Ȃ̂ł��傤�B
PPE�́ASPE�̂��߂̐���v���Z�b�T���Ɗ�����Ă����Ǝv����B
>>880
�d�͌�����GRAPE-DR�̂ق����D��Ă���炵���B
GRAPE-DR����邱�Ƃł͂Ȃ��g�����ƂŃt���ғ����鍠�ɂ́A�t�]���Ă邩������Ȃ����B
>>884
�ς��ƌ���IBM�̒ቿ�iPC�T�[�o���ۂ����B�������B
>>890
�d�C�n���H���Ȃ̂̓��~�b�^�[�������ĂȂ�����A���Ǝv���B
DDR3�͏���d�͂𐧌����邽�߂ɁA�A�N�Z�X�p�^�[���Ƀ��~�b�^�[���������Ă���B�������A���\�����������B
DIMM�Ɏ������邱�Ƃ�O��ɂ��Ă��邩��A�����Ԋu�ŕ��Ԃ̂Ŕ��M�ʂɐ��������邵�A����ւ̓d�������ɂ�������B
GDDR�n�̓t�@���t���q�[�g�V���N�ŗ�₹�邵�A�r�f�I�J�[�h��ɒ��Ɏ��������̂œd�������̐������ɂ��B
���s��������ŋ��̖��ʂƂ����͈̂Ⴄ�Ǝv���Ȃ��B
�����E���s�ƁA�ŋ��̖��ʂ��ǂ����́A�ʂ̕]�������Ǝv���B
�����������Ă���ΐŋ��̖��ʂł͂Ȃ��������Ƃ����ƁA����Ȃ��Ƃ͂Ȃ��킯�ŁB
>>879
PowerXCell��PPE��Opteron���ɋ��͂ȃR�A�ɂ�������A
�o��������Opteron���O�t�������ق��������I�Ȃ̂ł��傤�B
PPE�́ASPE�̂��߂̐���v���Z�b�T���Ɗ�����Ă����Ǝv����B
>>880
�d�͌�����GRAPE-DR�̂ق����D��Ă���炵���B
GRAPE-DR����邱�Ƃł͂Ȃ��g�����ƂŃt���ғ����鍠�ɂ́A�t�]���Ă邩������Ȃ����B
>>884
�ς��ƌ���IBM�̒ቿ�iPC�T�[�o���ۂ����B�������B
>>890
�d�C�n���H���Ȃ̂̓��~�b�^�[�������ĂȂ�����A���Ǝv���B
DDR3�͏���d�͂𐧌����邽�߂ɁA�A�N�Z�X�p�^�[���Ƀ��~�b�^�[���������Ă���B�������A���\�����������B
DIMM�Ɏ������邱�Ƃ�O��ɂ��Ă��邩��A�����Ԋu�ŕ��Ԃ̂Ŕ��M�ʂɐ��������邵�A����ւ̓d�������ɂ�������B
GDDR�n�̓t�@���t���q�[�g�V���N�ŗ�₹�邵�A�r�f�I�J�[�h��ɒ��Ɏ��������̂œd�������̐������ɂ��B
896 �F�s���ȃf�o�C�X�����F2009/10/13(��) 03:17:17 ID:rhi9G3US
>>894
�����N��TSMC��40nm�͐�[�v���Z�X����Intel�ɂƂ���45nm�͋ƊE�ō������̍��}�[�W���̐��i�ݏo�������
���������p�ς݂̋�����v���Z�X������A�R�X�g�̒P����r�͂ł��Ȃ��B
���R����R�����g������
�����TSMC���͂ꂽ0.35/0.25um���オ�����t�@���h���T�[�r�X
�ŗ��v�グ�����Ă���A�Ƃ�����ʂ��l�����Ȃ��ƂˁB
TSMC�̓g�R�g���v���Z�X�g���|�����܂ŃV���u���헪�ł���B
�����猸�����p�̃X�p���͒��߂����ˁB
�i���Ȃ݂�0.5/0.6������������C�����邪�A�Y�ꂽ�j
�����N��TSMC��40nm�͐�[�v���Z�X����Intel�ɂƂ���45nm�͋ƊE�ō������̍��}�[�W���̐��i�ݏo�������
���������p�ς݂̋�����v���Z�X������A�R�X�g�̒P����r�͂ł��Ȃ��B
���R����R�����g������
�����TSMC���͂ꂽ0.35/0.25um���オ�����t�@���h���T�[�r�X
�ŗ��v�グ�����Ă���A�Ƃ�����ʂ��l�����Ȃ��ƂˁB
TSMC�̓g�R�g���v���Z�X�g���|�����܂ŃV���u���헪�ł���B
�����猸�����p�̃X�p���͒��߂����ˁB
�i���Ȃ݂�0.5/0.6������������C�����邪�A�Y�ꂽ�j
897 �F�s���ȃf�o�C�X�����F2009/10/13(��) 03:56:51 ID:KIhWSP91
>>877
�v���_�N�g�Ƃ��ẮA�������̂��ł������ɂ�GPU�ɔ�ׂĂ��Ȃ�����ȑ��݂ɂȂ��Ă��܂����B
�p�r�͌��肳��邯�ǁA�����v���Z�X�Ȃ�GPU�������Z�햧�x�����ƂP����������
�Ƃ������Ƃ��f�����X�g���[�g�����A�Ƃ����Ƃ��납�ˁB
�ėp���Ɖ��Z��̂ǂ����D�悷�邩�A�������o���h�ɂǂ��܂ł����������邩�A
���_�_�Ȃ킯�ˁB
�v���_�N�g�Ƃ��ẮA�������̂��ł������ɂ�GPU�ɔ�ׂĂ��Ȃ�����ȑ��݂ɂȂ��Ă��܂����B
�p�r�͌��肳��邯�ǁA�����v���Z�X�Ȃ�GPU�������Z�햧�x�����ƂP����������
�Ƃ������Ƃ��f�����X�g���[�g�����A�Ƃ����Ƃ��납�ˁB
�ėp���Ɖ��Z��̂ǂ����D�悷�邩�A�������o���h�ɂǂ��܂ł����������邩�A
���_�_�Ȃ킯�ˁB
898 �F,,�E�L�́M�E,,�j��-�������F2009/10/13(��) 08:11:58 ID:bd/YLJht
>>896
�t����B
�R�X�g���オ�肷���čŐV�v���Z�X�Ɍڋq�����Ȃ��Ȃ��Ă���̂������B
GRAPE�̖��݂�킩��Ǝv�����A�}�X�N�����̔�p�͐�����d�˂邲�Ƃɏオ���Ă���B
�����J��̖������邩��A�ǂ��̔����̃t�@�E���_�����N���v���قǗI���ɂ͍l���Ė�����B
�P��100�~�����̃`�b�v�����͂���グ���B
���̕��AGPU�Ȃǂ̍Ő�[�v���Z�X��p����L����x���t�����l�̕t�����i�ɏd���̂�������\�}���B
GPU������킩��B1�N���Ɓi�t���m�[�h�E�n�[�t�m�[�h�j�Ƀ}�X�N����Ă��̂��A55nm�ȍ~40nm, 28nm�Ɗu�N�ɂȂ����B
�t����B
�R�X�g���オ�肷���čŐV�v���Z�X�Ɍڋq�����Ȃ��Ȃ��Ă���̂������B
GRAPE�̖��݂�킩��Ǝv�����A�}�X�N�����̔�p�͐�����d�˂邲�Ƃɏオ���Ă���B
�����J��̖������邩��A�ǂ��̔����̃t�@�E���_�����N���v���قǗI���ɂ͍l���Ė�����B
�P��100�~�����̃`�b�v�����͂���グ���B
���̕��AGPU�Ȃǂ̍Ő�[�v���Z�X��p����L����x���t�����l�̕t�����i�ɏd���̂�������\�}���B
GPU������킩��B1�N���Ɓi�t���m�[�h�E�n�[�t�m�[�h�j�Ƀ}�X�N����Ă��̂��A55nm�ȍ~40nm, 28nm�Ɗu�N�ɂȂ����B
899 �F�s���ȃf�o�C�X�����F2009/10/13(��) 09:31:58 ID:g4Swstzf
�͂ꂽ������̃v���Z�X�ŗ��v�o�Ă�Ƃ����̂�
���̂Ԃ��ڋq�͐V����Ɉڍs���ĂȂ��Ƃ������Ƃ�����ȁB
�ŐV�v���Z�X�Ō������p���Ȃ��܂��̃v���Z�X�̓���������̂͏��X���X�N�v���ɂȂ�B
���̂Ԃ��ڋq�͐V����Ɉڍs���ĂȂ��Ƃ������Ƃ�����ȁB
�ŐV�v���Z�X�Ō������p���Ȃ��܂��̃v���Z�X�̓���������̂͏��X���X�N�v���ɂȂ�B
900 �F�s���ȃf�o�C�X�����F2009/10/13(��) 09:39:08 ID:VlMpUJWy
>>897
���Ȍ�������l����̂��A��w����(�̗ނ�)�̗\�Z�l���̎d������ˁB
�����o���������A���s�ł͂Ȃ��L�Ӌ`�Ȃ��������������Ƃ��������~�������B
���ԂȂ猟���ŝ��߂Ȃ��悤�ɁA�����E���s�̃��C���͎��O�ɃL�b�`�������Ă����B
�����Ď��s�Ȃ����Ȃ��B
������˂���w�́B�����I�Ɏ��s���Ă����Ő������Ă��Ƃɂ��ċ������炦��B
�������㕥���ł͂Ȃ��敥���A�ł���B
�~�N���ɂ݂�ΐ敥�������A
�}�N���Ɍ���A���łɏo�����ʂɑ��ė\�Z��t����Ƃ����㕥��������������邪�B
GRAPE-DR�̍ő�̔s���́A�v���W�F�N�g�Ǘ��ł��傤�B
���\�͐����̂�����A1���ł��������x�ꂽ��A���Ȃ�̑�����B
(�܂����Ԃ���Ȃ���ŁA���̂�����̊�@�����Ȃ��낤�ȁB)
���Ȍ�������l����̂��A��w����(�̗ނ�)�̗\�Z�l���̎d������ˁB
�����o���������A���s�ł͂Ȃ��L�Ӌ`�Ȃ��������������Ƃ��������~�������B
���ԂȂ猟���ŝ��߂Ȃ��悤�ɁA�����E���s�̃��C���͎��O�ɃL�b�`�������Ă����B
�����Ď��s�Ȃ����Ȃ��B
������˂���w�́B�����I�Ɏ��s���Ă����Ő������Ă��Ƃɂ��ċ������炦��B
�������㕥���ł͂Ȃ��敥���A�ł���B
�~�N���ɂ݂�ΐ敥�������A
�}�N���Ɍ���A���łɏo�����ʂɑ��ė\�Z��t����Ƃ����㕥��������������邪�B
GRAPE-DR�̍ő�̔s���́A�v���W�F�N�g�Ǘ��ł��傤�B
���\�͐����̂�����A1���ł��������x�ꂽ��A���Ȃ�̑�����B
(�܂����Ԃ���Ȃ���ŁA���̂�����̊�@�����Ȃ��낤�ȁB)
901 �F�s���ȃf�o�C�X�����F2009/10/13(��) 09:56:36 ID:5/2P6BoF
�@�@�@�@�@�@�@�@�@�@_,, �@---�� �[-�@,,,_
�@�@�@�A�Q,,,,�@�Q,, -.'"�@�@�@�@�@�@�@�@�@�@�@`�@�A
�@�~�OЎO�~�OЃ~�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�R_,
-=���O�~�c�O�~Ё@�@�@�@ ,,=-��=�@�@�@�@�@==�A�@i�=-�A�Q
�Q,,���~�~�OЎO�~�]�@�@-�c-�� �[-�A�@r�� �[�~�A|�~ЎO�=-'
_, -=���c�~�c�~Ѓ~|�@ ��|�@,=��)>�@(|�[|�@,��)>�A�@||�O�~�c��=-'
�Q,�c�c�O�~�O�~Ѓ�'~�@.|. '�@�@�@�@�@|�@ �R�@�@�@`�@ |�~�O�c�O=-�A
�i�Q�c�O�~�c�~�~�'�@�@�@�R�A�@�@�@ �m�@�@�@�_�Q�Q�i�~�c�~�O=�[
�[-=��O���[Ѓ~Ё@�@�@�@ `�[ /(�Qr-�Ar-_�j�@�@�@.|�c�~�O��-�A
�j�i�Q�~�c�| i' �R�R�~�@�@�@�@�@�@ | : : : __ : :__: :i�@�@�@.|�c�~�O=-�A_
�Ɯc�~�c�~�R�R<�R�Ё@�@�@�@�@�@|: ݁�-�j-�R�A�@�@ .|�c�~�O��=-
�@�c�~�c�~�~�R �@)�@`�@�@�@ �A�@.' <=������ |�@�@�@ |�c��=-��
�@-=���c�O� `�[�R : : : : : :i: :�@�@`�[--��''�@�@: : Ƀ~�O��=''
�@''�@�ăm���~�c�O�`i : : : : : :�R: : : .�@�@�@�@�@�@.:, :/�~�O=-�A
�@�@ ''�@�O�~���O�O�|�S�A: : : : :�R: : : : : : : : :_�m:./�O=-'
�@�@�@�@�@-=��''�P��.|�@�@: : : : : ::::::�P�P�P:::::::::|�c `
902 �F�s���ȃf�o�C�X�����F2009/10/13(��) 11:37:57 ID:BkHoD+An
> GRAPE-DR�̍ő�̔s���́A�v���W�F�N�g�Ǘ��ł��傤�B
���낤�ˁB�D����2�l����������?
���낤�ˁB�D����2�l����������?
903 �F�s���ȃf�o�C�X�����F2009/10/13(��) 11:54:49 ID:VlMpUJWy
>>902
2�l�Ƃ����̂́A���ؐ搶�Ɩq��搶�̂���? ����Ȃ�Ⴄ�ł��傤�B
����͒m��܂��A�q��搶�̓����Ȃǂ���z������ɁA
�E���\��̍H�������ׂĈ꒼����ɕ���ł��āA�������x���ƑS�Ă��x���
�E�H����ʂ̐l�ɒS���ւ����邱�Ƃ��ł��Ȃ�
�܂�A���ł�����ł�������l�ł��悤�ȁA���������Ă����̂ł͂Ȃ����ƁB
FPGA��ArriaGX�̓���\���x�ꂽ�͎̂d���Ȃ��Ƃ��Ă��A����͉����ł��傤���B
GRAPE-DR��2PFlops�B���̖ڕW�����牽���o�߂����ł��傤���B
��҂̂ق��������̂ł���A�v���W�F�N�g�Ǘ��͎��s���Ă��܂��B
2�l�Ƃ����̂́A���ؐ搶�Ɩq��搶�̂���? ����Ȃ�Ⴄ�ł��傤�B
����͒m��܂��A�q��搶�̓����Ȃǂ���z������ɁA
�E���\��̍H�������ׂĈ꒼����ɕ���ł��āA�������x���ƑS�Ă��x���
�E�H����ʂ̐l�ɒS���ւ����邱�Ƃ��ł��Ȃ�
�܂�A���ł�����ł�������l�ł��悤�ȁA���������Ă����̂ł͂Ȃ����ƁB
FPGA��ArriaGX�̓���\���x�ꂽ�͎̂d���Ȃ��Ƃ��Ă��A����͉����ł��傤���B
GRAPE-DR��2PFlops�B���̖ڕW�����牽���o�߂����ł��傤���B
��҂̂ق��������̂ł���A�v���W�F�N�g�Ǘ��͎��s���Ă��܂��B
904 �F�s���ȃf�o�C�X�����F2009/10/13(��) 12:11:41 ID:BkHoD+An
�ł͊Ǘ�����ʂ�ȑO�ɁA�l�����A�l���ق���������Ă��Ȃ��ƁB
������v���W�F�N�g�Ǘ��̔��e�Ƃ����������B
������v���W�F�N�g�Ǘ��̔��e�Ƃ����������B
905 �F�s���ȃf�o�C�X�����F2009/10/13(��) 12:27:42 ID:VlMpUJWy
���ʂ́A�����������X�N�͎����ŕ������܂��A�O���ɉ����t�������B
GRAPE-DR�̏ꍇ�́AKFCR�ɁB
GRAPE-DR�̏ꍇ�́AKFCR�ɁB
>>898
������I���ɂƂ͂����ĂȂ����B
�m���ɁA�������p�̔�p�̏d�ݕt���A�o�����X�̖��͂���ˁB
��X�܂ł����������p���Ă����̂ł͖�肾�낤�B
�������A�Ő�[�������߂��Ă����邵�B
�����A�M��������GPU/FPGA�Ƃ���[�v���Z�X�p�r��������Ȃ����炾�낤�ˁB
MixedSignal/RF�p�r�ȂɃv���Z�X�Ă�̂�
�ꕔ�ւ���ĕʂ̑��ʌ��Ă��Ă邩��A�����͂����ł��Ȃ��Ǝv��������B
�i�P�E�F�n����R�O�O�O�`�b�v��o���łW�O�~���Ă�̂Ƃ��j
��[�v���Z�X�͔���グ�V�F�A�ɂ͍v�����邪�A
���v�͌ォ��B�@�悭����b���B
�����炱��������
�������猸�����p�̃X�p���͒��߂����ˁB
Intel�̃v���Z�X�W�J�Ɣ�r���Ă̘b����B
��Intel��0.18�ȑO�̉ғ����Ă�������H
������I���ɂƂ͂����ĂȂ����B
�m���ɁA�������p�̔�p�̏d�ݕt���A�o�����X�̖��͂���ˁB
��X�܂ł����������p���Ă����̂ł͖�肾�낤�B
�������A�Ő�[�������߂��Ă����邵�B
�����A�M��������GPU/FPGA�Ƃ���[�v���Z�X�p�r��������Ȃ����炾�낤�ˁB
MixedSignal/RF�p�r�ȂɃv���Z�X�Ă�̂�
�ꕔ�ւ���ĕʂ̑��ʌ��Ă��Ă邩��A�����͂����ł��Ȃ��Ǝv��������B
�i�P�E�F�n����R�O�O�O�`�b�v��o���łW�O�~���Ă�̂Ƃ��j
��[�v���Z�X�͔���グ�V�F�A�ɂ͍v�����邪�A
���v�͌ォ��B�@�悭����b���B
�����炱��������
�������猸�����p�̃X�p���͒��߂����ˁB
Intel�̃v���Z�X�W�J�Ɣ�r���Ă̘b����B
��Intel��0.18�ȑO�̉ғ����Ă�������H
907 �F�s���ȃf�o�C�X�����F2009/10/13(��) 13:53:30 ID:14I2LeMl
http://pc.watch.impress.co.jp/docs/2005/0805/hot379.htm
2005�N�̋L�������ǁA���̎��_��Fab8�������āA�Â��̂�130nm�܂ł����Ȃ����ۂ��B
2005�N�̋L�������ǁA���̎��_��Fab8�������āA�Â��̂�130nm�܂ł����Ȃ����ۂ��B
909 �F�s���ȃf�o�C�X�����F2009/10/13(��) 14:45:15 ID:VlMpUJWy
2007�N��2008�N���炢�܂ŁA(Marvell�ɔ�����)XScale��90nm�Ő������Ă����炵���B
910 �F�s���ȃf�o�C�X�����F2009/10/13(��) 15:04:50 ID:14I2LeMl
���������AAtom�̃`�b�v�Z�b�g��130nm�������͂�������A
��������ȗp�r�ȊO�ł�130nm����ԌÂ���Ȃ����ȁB
��������ȗp�r�ȊO�ł�130nm����ԌÂ���Ȃ����ȁB
911 �F�s���ȃf�o�C�X�����F2009/10/13(��) 15:28:07 ID:rIGbUkF/
NVIDIA�A������Intel CPU�����`�b�v�Z�b�g�̊J���𒆎~
http://www.itmedia.co.jp/news/articles/0910/13/news075.html
http://www.itmedia.co.jp/news/articles/0910/13/news075.html
912 �F�s���ȃf�o�C�X�����F2009/10/13(��) 18:25:43 ID:GBfAEwts
>>906
������A�L�`���ƌ������p�ς܂��ē�������������Ă邩��A
�P��100�~�����̏��K�͂ȃ`�b�v�̐��Y�ϑ����Ă��u���v�v���v��ł���킯�����H
TSMC����O�Ȃ���[�v���Z�X����[�ł��邤���Ɍ������p����̂ɂ͕ς��Ȃ��B
������A�L�`���ƌ������p�ς܂��ē�������������Ă邩��A
�P��100�~�����̏��K�͂ȃ`�b�v�̐��Y�ϑ����Ă��u���v�v���v��ł���킯�����H
TSMC����O�Ȃ���[�v���Z�X����[�ł��邤���Ɍ������p����̂ɂ͕ς��Ȃ��B
>>912
����A��Q�s�͊�{���̒ʂ�B
���ӂ����A����ɔ����邱�Ƃ����������肪�����B
�������ATSMC����[�����Ō������p���Ȃ�����@�ƌ����������������B
������TSMC�ł��{���ɐ�[���ゾ���Ō������p������̂��H���Ȃ�^��B
��[�̕����܂�U�O���t�߂Ƃ��i�����͂����ƒႢ�j�A���ŋ߂̘b��ł���������ˁB
���̃��X�g�A��p���S�ǂ������_��Ȃ̂��A���O�҂�����m��Ȃ����A
�܂��������ґ�����Ȃ���ˁB
TSMC�����S����Ƃ���傾��ˁB
������������p�܂߂āA�Ő�[����̂��������ŏ��X�̏����R�X�g�����p������Ȃ����낤�ƁB
���I�C���͒��̐l�Ԃł͂Ȃ�����A�{���̂��Ƃ�m��Ȃ����ˁB
�@�M���f���������ǁA���̐l�Ȃ̂��ȁH
���X�b
�����N��TSMC��40nm�͐�[�v���Z�X����Intel�ɂƂ���45nm�͋ƊE�ō������̍��}�[�W���̐��i�ݏo�������
���������p�ς݂̋�����v���Z�X������A�R�X�g�̒P����r�͂ł��Ȃ��B
�R�X�g��r�ł͒P����r�ł��Ȃ��A�ɑ��������̑��ʂ��R�����g�����̂�����ˁB
���̏���������Intel�L���Ȍ����ɕ��Ă�悤�Ɋ���������B
>>896�̎�|���悭�ǂݎ���ė~�����ȁB
����A��Q�s�͊�{���̒ʂ�B
���ӂ����A����ɔ����邱�Ƃ����������肪�����B
�������ATSMC����[�����Ō������p���Ȃ�����@�ƌ����������������B
������TSMC�ł��{���ɐ�[���ゾ���Ō������p������̂��H���Ȃ�^��B
��[�̕����܂�U�O���t�߂Ƃ��i�����͂����ƒႢ�j�A���ŋ߂̘b��ł���������ˁB
���̃��X�g�A��p���S�ǂ������_��Ȃ̂��A���O�҂�����m��Ȃ����A
�܂��������ґ�����Ȃ���ˁB
TSMC�����S����Ƃ���傾��ˁB
������������p�܂߂āA�Ő�[����̂��������ŏ��X�̏����R�X�g�����p������Ȃ����낤�ƁB
���I�C���͒��̐l�Ԃł͂Ȃ�����A�{���̂��Ƃ�m��Ȃ����ˁB
�@�M���f���������ǁA���̐l�Ȃ̂��ȁH
���X�b
�����N��TSMC��40nm�͐�[�v���Z�X����Intel�ɂƂ���45nm�͋ƊE�ō������̍��}�[�W���̐��i�ݏo�������
���������p�ς݂̋�����v���Z�X������A�R�X�g�̒P����r�͂ł��Ȃ��B
�R�X�g��r�ł͒P����r�ł��Ȃ��A�ɑ��������̑��ʂ��R�����g�����̂�����ˁB
���̏���������Intel�L���Ȍ����ɕ��Ă�悤�Ɋ���������B
>>896�̎�|���悭�ǂݎ���ė~�����ȁB
914 �F�s���ȃf�o�C�X�����F2009/10/13(��) 20:02:20 ID:GBfAEwts
�_�_����Ă邾��B
Intel�����Ђ�1����g���Â��v���Z�X��Intel���g��GPU�����̂�
NVIDIA��TSMC�̐�[�v���Z�X�Ō������p����}�[�W������������
�Ƃ��������Œ����GPU���̂Ƃ��ׂ�
NVIDIA�̂ق�����������Ȃ��Ȃ�Č�������A��n�O�ɂ��قǂ�����B
Intel�����Ђ�1����g���Â��v���Z�X��Intel���g��GPU�����̂�
NVIDIA��TSMC�̐�[�v���Z�X�Ō������p����}�[�W������������
�Ƃ��������Œ����GPU���̂Ƃ��ׂ�
NVIDIA�̂ق�����������Ȃ��Ȃ�Č�������A��n�O�ɂ��قǂ�����B
>>914
���̓����R�����g�̗L���͈͂�>>894�ŏI�Q�s�܂ł̂���B
�債���b�ł͂Ȃ��B
�����>>914��NVIDIA�̕�����������Ȃ��b�Ƃ��A
�����܂ŕs�K�v�ɔ��W��������肪�܂�Ŗ�����A�����́B
�_�_����Ă�A�Ƃ������A�_�_���炻���Ƃ��������ł��ˁA�킩��܂�����
����Ƀh�E�]�B
���̓����R�����g�̗L���͈͂�>>894�ŏI�Q�s�܂ł̂���B
�債���b�ł͂Ȃ��B
�����>>914��NVIDIA�̕�����������Ȃ��b�Ƃ��A
�����܂ŕs�K�v�ɔ��W��������肪�܂�Ŗ�����A�����́B
�_�_����Ă�A�Ƃ������A�_�_���炻���Ƃ��������ł��ˁA�킩��܂�����
����Ƀh�E�]�B
916 �F�s���ȃf�o�C�X�����F2009/10/13(��) 20:24:32 ID:GBfAEwts
����ϒ����N�͔n�����ȁA�܂œǂ�
917 �F�s���ȃf�o�C�X�����F2009/10/13(��) 20:31:00 ID:rr3wHhc5
�ł��@�C�^�`�̍Ō����
�Ȃ�ď������悪�ǂ߂�
�Ȃ�ď������悪�ǂ߂�
918 �F�s���ȃf�o�C�X�����F2009/10/13(��) 20:31:03 ID:GBfAEwts
> �����炱��������
> �������猸�����p�̃X�p���͒��߂����ˁB
> Intel�̃v���Z�X�W�J�Ɣ�r���Ă̘b����B
> ��Intel��0.18�ȑO�̉ғ����Ă�������H
����Ȏ����܂ŋ@�ޓ����̉������Ă�悤����o�c���肵�܂���B
�ނ��낻��ȌÂ�����܂Ŏ��v���c���Ă�̂́A
�g�ݍ��݂𒆐S�ɐ�[�v���Z�X���ꂪ�N���Ă邩��B
GPU�ȊO����n�C�G���hARM���炢�����Ȃ���B
�����炱��GPU�x���_�[�̕��S���傫���Ȃ��Ă�킯�����B
�n�������Ęb�ɂȂ�Ȃ�
> �������猸�����p�̃X�p���͒��߂����ˁB
> Intel�̃v���Z�X�W�J�Ɣ�r���Ă̘b����B
> ��Intel��0.18�ȑO�̉ғ����Ă�������H
����Ȏ����܂ŋ@�ޓ����̉������Ă�悤����o�c���肵�܂���B
�ނ��낻��ȌÂ�����܂Ŏ��v���c���Ă�̂́A
�g�ݍ��݂𒆐S�ɐ�[�v���Z�X���ꂪ�N���Ă邩��B
GPU�ȊO����n�C�G���hARM���炢�����Ȃ���B
�����炱��GPU�x���_�[�̕��S���傫���Ȃ��Ă�킯�����B
�n�������Ęb�ɂȂ�Ȃ�
919 �F�s���ȃf�o�C�X�����F2009/10/13(��) 21:54:43 ID:g4Swstzf
�Â�����̃v���Z�X���c���Ă�̂́A�P�Ƀ��[�N�d���ȂǏ��X�̖����܂߃V�������N����߂�����B
��130nm�ȑO�~�܂�̃}�C�R���̒���40nm�v���Z�X���̗p�ł���悤�ȑg�ݍ��݃}�C�R���Ȃ�Ă���͂��Ȃ��B
�����i���n�C�G���h�g�Ǝ��v���Ȃ��Ȃ�܂ŗ]���������������̃V�������N�E���g��
��ɉ����Ă�̂�����B
��130nm�ȑO�~�܂�̃}�C�R���̒���40nm�v���Z�X���̗p�ł���悤�ȑg�ݍ��݃}�C�R���Ȃ�Ă���͂��Ȃ��B
�����i���n�C�G���h�g�Ǝ��v���Ȃ��Ȃ�܂ŗ]���������������̃V�������N�E���g��
��ɉ����Ă�̂�����B
920 �F�s���ȃf�o�C�X�����F2009/10/13(��) 21:55:26 ID:gsQWGL3P
�܂��A�����ƃ}�^�|���s������B
http://journal.mycom.co.jp/column/sopinion/103/index.html
http://techon.nikkeibp.co.jp/article/LECTURE/20090205/165272/?P=6
5V�Ƃ�3.3V�Ƃ��������ł����A�����ł���
http://techon.nikkeibp.co.jp/article/LECTURE/20090205/165272/?P=6
5V�Ƃ�3.3V�Ƃ��������ł����A�����ł���
922 �F����� ��yanyan72E. �F2009/10/13(��) 23:48:26 ID:+TyDpQVP
74F�V���[�Y�Ƃ����܂ł������?
923 �F,,�E�L�́M�E,,�j��-�������F2009/10/14(��) 00:38:20 ID:fwAmDetG
90nm���z���邩�ǂ��������肪���E���Ǝv��
�z���ĂȂ��v���Z�b�T���z���\���͐�]�I�ɒႢ
�z���ĂȂ��v���Z�b�T���z���\���͐�]�I�ɒႢ
924 �F�s���ȃf�o�C�X�����F2009/10/14(��) 03:42:01 ID:csrU96yO
�v���Z�X�J����������E�����āA�������̂���葱���Ă����Ђ������
ttp://www.okisemi.com/jp/semicon/dram/5vsupply.htm
5V�Ƃ��AFastPageDRAM�Ƃ��A�a�ނˁ`�B
ttp://www.okisemi.com/jp/semicon/dram/5vsupply.htm
5V�Ƃ��AFastPageDRAM�Ƃ��A�a�ނˁ`�B
925 �F�s���ȃf�o�C�X�����F2009/10/14(��) 06:03:21 ID:71B6jMwL
>>913
������60%�̍s�͉��̎Q�l�ɂ��Ȃ�Ȃ��K���ȗႦ�b����
������60%�̍s�͉��̎Q�l�ɂ��Ȃ�Ȃ��K���ȗႦ�b����
926 �F,,�E�L�́M�E,,�j��-�������F2009/10/14(��) 07:21:25 ID:fwAmDetG
�܂��s����k�ق���
�����Ƃ���NVIDIA��ATI�����ʼnĂ��ł��B
����DRAM������Ă������B���ꂭ�炢����P�������̂́B
�Ő�[�v���Z�X�̂����Ɍ������p���邵���Ȃ���ł��B
���������v�Z�ł��Ȃ���TSMC�͂����܂���Ԏ��Ȃ�ł��B���ꂪ�����B
�����Ƃ���NVIDIA��ATI�����ʼnĂ��ł��B
����DRAM������Ă������B���ꂭ�炢����P�������̂́B
�Ő�[�v���Z�X�̂����Ɍ������p���邵���Ȃ���ł��B
���������v�Z�ł��Ȃ���TSMC�͂����܂���Ԏ��Ȃ�ł��B���ꂪ�����B
927 �F�s���ȃf�o�C�X�����F2009/10/14(��) 07:26:22 ID:csrU96yO
ATI��TSMC�g���̂�߂�GF��{�ɂ�����A���o����?
928 �F,,�E�L�́M�E,,�j��-�������F2009/10/14(��) 07:27:50 ID:fwAmDetG
Intel��Atom�̊O�̂͋~�ύ�ƌ��Ă�
������450mm�E�F�n�ڍs
������450mm�E�F�n�ڍs
929 �F,,�E�L�́M�E,,�j��-�������F2009/10/14(��) 07:31:37 ID:fwAmDetG
���ƁAFab�������Ƃ��������o�Ă����ł���ŐH���Ȃ��Ƃ��B
TI��\�j�[�������Intel�������炵����TSMC�ɉ���Ă��邩��
TI��\�j�[�������Intel�������炵����TSMC�ɉ���Ă��邩��
930 �F�s���ȃf�o�C�X�����F2009/10/14(��) 08:28:19 ID:EJqazYiH
�t�Ƀn�C�G���h�����Ō����Ƃ�Ȃ��Ȃ�Ɨ͂Ńn�C�G���h��郁���b�g���̂Ȃ��Ȃ�B
Intel���炨������̋Z�p�E�@�ޔ����Ă�NVIDIA��GPU�͌�������������Ȃ���
�g�ݍ��݂ɂ͏\��������ȁB
Intel���炨������̋Z�p�E�@�ޔ����Ă�NVIDIA��GPU�͌�������������Ȃ���
�g�ݍ��݂ɂ͏\��������ȁB
�܂����̘b�����̂�
>>925
��������60%�̍s�͉��̎Q�l�ɂ��Ȃ�Ȃ��K���ȗႦ�b����
�����͎�������B
��������Ĕ���ȃR�X�g���������Ă���킯���B
�K���Ȃ��Ƃ��b�A���̒ʂ肾�B�@�K���ē������Ă���Ƃ����B
>>926
�������Ƃ���NVIDIA��ATI�����ʼnĂ��ł��B
������DRAM������Ă������B���ꂭ�炢����P�������̂́B
���̎����F�������������邗����
����͂���܂肾�B
NVIDIA��ATI�����m��Ȃ��̂��A�������A
���@DRAM���P�������@DRAM���P�������@DRAM���P�������@DRAM���P������
���@DRAM���P�������@DRAM���P�������@DRAM���P�������@DRAM���P������
���@DRAM���P�������@DRAM���P�������@DRAM���P�������@DRAM���P������
�������A����̓h�������ł�����
�n�r���i����
�I�C�������������G�ł́A
�Q�`�R���ォ���Č������p���Ă��镗���������ǂˁB
�������Ȃ��H�@TSMC�c�Ƃ�����̐Ȃŕ��������ˁB
������Ⴀ180nm�t�߂͂����E�n�E�n���낤���B
>>925
��������60%�̍s�͉��̎Q�l�ɂ��Ȃ�Ȃ��K���ȗႦ�b����
�����͎�������B
��������Ĕ���ȃR�X�g���������Ă���킯���B
�K���Ȃ��Ƃ��b�A���̒ʂ肾�B�@�K���ē������Ă���Ƃ����B
>>926
�������Ƃ���NVIDIA��ATI�����ʼnĂ��ł��B
������DRAM������Ă������B���ꂭ�炢����P�������̂́B
���̎����F�������������邗����
����͂���܂肾�B
NVIDIA��ATI�����m��Ȃ��̂��A�������A
���@DRAM���P�������@DRAM���P�������@DRAM���P�������@DRAM���P������
���@DRAM���P�������@DRAM���P�������@DRAM���P�������@DRAM���P������
���@DRAM���P�������@DRAM���P�������@DRAM���P�������@DRAM���P������
�������A����̓h�������ł�����
�n�r���i����
�I�C�������������G�ł́A
�Q�`�R���ォ���Č������p���Ă��镗���������ǂˁB
�������Ȃ��H�@TSMC�c�Ƃ�����̐Ȃŕ��������ˁB
������Ⴀ180nm�t�߂͂����E�n�E�n���낤���B
�Ƃ肠�����c�q�Ƃ��A���̎�̘A���̃\�[�X��
ITmedia�Ƃ��������Ə\���ɕ�������
ITmedia�Ƃ��������Ə\���ɕ�������
933 �F�s���ȃf�o�C�X�����F2009/10/14(��) 16:20:06 ID:I54kJzpz
ITMedia�Ƃ��͂���������Ƃ����ׂ�
�Ƃ������Ƃł���
�Ƃ������Ƃł���
934 �F�s���ȃf�o�C�X�����F2009/10/14(��) 16:27:19 ID:YKOJPPvi
�͂��A�����ł��B
���Ɠ��l�͖��ʂɊ撣��Ȃ��Ƃ��ǂ��A�Ƃ������Ƃł�����܂��B
���Ɠ��l�͖��ʂɊ撣��Ȃ��Ƃ��ǂ��A�Ƃ������Ƃł�����܂��B
935 �F�s���ȃf�o�C�X�����F2009/10/14(��) 16:29:26 ID:csrU96yO
DRAM�������������ǂ��납�}�C�i�X�Ń`�L�����[�X��ԂȂ̂͗L���Ȃ̂�����A
���Ԃ㍂�ƊԈ������Ȃ�?
���Ԃ㍂�ƊԈ������Ȃ�?
936 �F�s���ȃf�o�C�X�����F2009/10/14(��) 16:34:39 ID:YKOJPPvi
�܂��ˁA
�ł��P���@�Ƃ��������Ă��܂����Ƃ��낪���͂₱��܂Ŋ������Ղ�@�Ȃ�ł����B
���������ƁA�S�̎�Ƃ������̂��Ƃ������A
�����A�P���Ȃ��������炳��
�Ƃ������A
TSMC�Ƀo�J�o�JDRAM�����Ă����H
���ʂȂ炠�����̂����m��Ȃ����A
����ʂ��ꂩ���܂����H
�܂���XBOX��GPU�O�t���������̂��Ƃ�������
���ꂱ���k��
�ł��P���@�Ƃ��������Ă��܂����Ƃ��낪���͂₱��܂Ŋ������Ղ�@�Ȃ�ł����B
���������ƁA�S�̎�Ƃ������̂��Ƃ������A
�����A�P���Ȃ��������炳��
�Ƃ������A
TSMC�Ƀo�J�o�JDRAM�����Ă����H
���ʂȂ炠�����̂����m��Ȃ����A
����ʂ��ꂩ���܂����H
�܂���XBOX��GPU�O�t���������̂��Ƃ�������
���ꂱ���k��
937 �F�s���ȃf�o�C�X�����F2009/10/14(��) 16:46:53 ID:csrU96yO
TSMC��DRAM�Ƃ������獬�ڂ���˂��B
�ėp����Ȃ��B
�ėp����Ȃ��B
938 �F�s���ȃf�o�C�X�����F2009/10/14(��) 17:01:31 ID:DIUm7Rtz
ID:YKOJPPvi
�ɁX�����ł�
�ɁX�����ł�
939 �F�s���ȃf�o�C�X�����F2009/10/14(��) 17:02:30 ID:YKOJPPvi
����A
�����Ȃ�eDRAM�Ƃ��ׂ������A
����Ȃ炻��łˁB
�������P����グ���ƕS�������Ă�
�G���x�f�b�h���ꂽeDRAM�����P���������̒������o���Ă��ăJ�E���g����Ă��@�Ȃ��Ƃ��Ă�
�����Ȃ�eDRAM�Ƃ��ׂ������A
����Ȃ炻��łˁB
�������P����グ���ƕS�������Ă�
�G���x�f�b�h���ꂽeDRAM�����P���������̒������o���Ă��ăJ�E���g����Ă��@�Ȃ��Ƃ��Ă�
940 �F�s���ȃf�o�C�X�����F2009/10/14(��) 17:03:14 ID:YKOJPPvi
>>938�@��̓I��
941 �F�s���ȃf�o�C�X�����F2009/10/14(��) 19:30:49 ID:mVd7yFH5
>>923
�ǂ�����łĂ�����90nm���āB
�ǂ�����łĂ�����90nm���āB
942 �F�s���ȃf�o�C�X�����F2009/10/14(��) 19:43:36 ID:HORnpgVC
�c�q���v���Z�X�Z�p�ɑa���͎̂��m�̎�������Ȃ���
�ǂ��ł���������X�p�R���̘b�����Ȃ��Ȃ炻�낻���߂Ă���
�ǂ��ł���������X�p�R���̘b�����Ȃ��Ȃ炻�낻���߂Ă���
943 �F�s���ȃf�o�C�X�����F2009/10/14(��) 20:54:33 ID:EJqazYiH
TSMC���Đ�[�v���Z�X�ō���Ă�̂�DRAM��DRAM�ł�DDR2�݂�����
���݂����ȒP���̂��̂���Ȃ���XDR/XDR2�ł����
ID:YKOJPPvi���p�̏�h�肾��
���݂����ȒP���̂��̂���Ȃ���XDR/XDR2�ł����
ID:YKOJPPvi���p�̏�h�肾��
944 �F�s���ȃf�o�C�X�����F2009/10/14(��) 21:20:28 ID:EJqazYiH
�܂��ATSMC������Ă�̂͑f�q����Ȃ��ăR���g���[�������ǂȁB
eDRAM���f�q�͊O���i�k�o�ʁE�����j�������C��
���Ȃ݂ɋ����ߑ��Ƃ����ċv����DDR2�ł�ECC�t���͂���Ȃɒl���ꂵ�ĂȂ��B
Non-ECC�̋������������������ɏo���̂͏��F�X�p�R���ɑa���A���x���Ⴂ���B
�܂����̊ϓ_���炢����GeForce�Ȃ�Tesla(��)���܂߂���Ȃ��������������B
eDRAM���f�q�͊O���i�k�o�ʁE�����j�������C��
���Ȃ݂ɋ����ߑ��Ƃ����ċv����DDR2�ł�ECC�t���͂���Ȃɒl���ꂵ�ĂȂ��B
Non-ECC�̋������������������ɏo���̂͏��F�X�p�R���ɑa���A���x���Ⴂ���B
�܂����̊ϓ_���炢����GeForce�Ȃ�Tesla(��)���܂߂���Ȃ��������������B
945 �F�s���ȃf�o�C�X�����F2009/10/14(��) 21:41:03 ID:t62lfd4j
ECC�̃��������W���[���̓`�b�v��9�i�̔{���j�ڂ��Ă邯�ǁA
non-ECC�̂�8�i�̔{���j���ˁB
�Կ
non-ECC�̂�8�i�̔{���j���ˁB
�Կ
946 �F,,�E�L�́M�E,,�j��-�������F2009/10/14(��) 22:58:19 ID:fwAmDetG
���[�A�̖@������������O���̖A���`�b�v�ŏ���40nm�̌����Ƃ�������Ȃ�ł����蓾�Ȃ��ϑz�ł�����
947 �F�s���ȃf�o�C�X�����F2009/10/14(��) 23:30:00 ID:gPqWBriV
�y�X�p�R���z�X�[�p�[�R���s���[�^�֘A���3�yHPC�z
http://pc11.2ch.net/test/read.cgi/hard/1255529941/l50
http://pc11.2ch.net/test/read.cgi/hard/1255529941/l50
948 �F�s���ȃf�o�C�X�����F2009/10/14(��) 23:55:56 ID:nYCXxDcN
>>947�@���ł���܂�
949 �F�s���ȃf�o�C�X�����F2009/10/15(��) 04:25:00 ID:esvTbEO3
>>945���������������̂��킩��Ȃ��B
950 �F�s���ȃf�o�C�X�����F2009/10/15(��) 14:04:35 ID:esvTbEO3
951 �F�s���ȃf�o�C�X�����F2009/10/15(��) 14:13:36 ID:esvTbEO3
ttp://brightsideofnews.com/news/2009/10/13/nvidia-tegra-wins-contract-for-next-gen-nintendo-ds.aspx
���N��AnVIDIA�̔���̔�����Tegra�ɂȂ�E�E�E
���N��AnVIDIA�̔���̔�����Tegra�ɂȂ�E�E�E
952 �F�s���ȃf�o�C�X�����F2009/10/15(��) 15:52:48 ID:d0LFVWhv
tegra����̌g�ь^�Q�[���@���N2000���䔄�����̂��炢�ɂȂ邩��
953 �F�s���ȃf�o�C�X�����F2009/10/15(��) 21:17:46 ID:CwRGZj2u
954 �F�s���ȃf�o�C�X�����F2009/10/15(��) 22:23:10 ID:2ACjBWm5
>>951
��������ł�����
��������ł�����
955 �F�s���ȃf�o�C�X�����F2009/10/16(��) 01:26:20 ID:xi4cuWjs
>>953
�Ӗ������Ƃ��������Ⴄ���O���Ӗ������
http://www.necel.com/process/ja/edramoptions.html
> NEC�G���N�g���j�N�X90nm DRAM�̓Ǝ��̍ޗ��A�����H���ɂ��A���SCMOS�݊�����ۂ���
> �����\�E���[�p���[�������Ă��܂��B���́A�t�����^��eDRAM�Ə̂���\���ł��BeDRAM�f�q
> �̎�X�̕��ʂɃ��^���ޗ����g�p���A�i�����@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@~~~~~~~~~~~~~~~
�Ӗ������Ƃ��������Ⴄ���O���Ӗ������
http://www.necel.com/process/ja/edramoptions.html
> NEC�G���N�g���j�N�X90nm DRAM�̓Ǝ��̍ޗ��A�����H���ɂ��A���SCMOS�݊�����ۂ���
> �����\�E���[�p���[�������Ă��܂��B���́A�t�����^��eDRAM�Ə̂���\���ł��BeDRAM�f�q
> �̎�X�̕��ʂɃ��^���ޗ����g�p���A�i�����@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@~~~~~~~~~~~~~~~
956 �F�s���ȃf�o�C�X�����F2009/10/16(��) 01:48:55 ID:l8oZ3TwE
>>955
��������eDRAM���̂𗝉����ĂȂ�����
��������eDRAM���̂𗝉����ĂȂ�����
957 �F�s���ȃf�o�C�X�����F2009/10/16(��) 07:51:25 ID:yq54j+T5
tesla�Ƃ�fermi���Ă��������Ėׂ���Ǝv���ďo���Ă�킯�H
958 �F�s���ȃf�o�C�X�����F2009/10/16(��) 10:55:58 ID:tEjYpzUq
eDRAM����1�g�����W�X�^�ō\���ł��邩��e�ʖ��x�͍�����
SRAM���͗y���ɒx�����Ă��������ȃ\�����[�V���������
1T-SRAM�Ȃ�Ă̂�����܂���
SRAM���͗y���ɒx�����Ă��������ȃ\�����[�V���������
1T-SRAM�Ȃ�Ă̂�����܂���
959 �F�s���ȃf�o�C�X�����F2009/10/16(��) 11:45:26 ID:5RtHo667
SRAM�̑���ł͂Ȃ��A�O�t���̏��e��DRAM�̑���ɂȂ�A����ŏ\���ł��傤�B
960 �F�s���ȃf�o�C�X�����F2009/10/16(��) 21:33:28 ID:nKaM2KJ/
>>957
���A�w�C���o��
���A�w�C���o��
961 �F�s���ȃf�o�C�X�����F2009/10/16(��) 22:19:10 ID:tEjYpzUq
�����͂����邩�ǂ������悾��
Larrabee�̌����������Ȃ�HPC�s��ɂ�����Intel�̉�������邾�낤
������Ȃ�E�E�E
Larrabee�̌����������Ȃ�HPC�s��ɂ�����Intel�̉�������邾�낤
������Ȃ�E�E�E
962 �F�s���ȃf�o�C�X�����F2009/10/17(�y) 12:03:41 ID:IdMHkVqK
���v���̈Ⴂ�͂Ƃ������A���ʃx�[�X99.99���%��GPU�s����y�������炨���B
HP�ADell�AApple�����͌�����Radeon�̗p���𑝂₵�Ă���B
HP�ADell�AApple�����͌�����Radeon�̗p���𑝂₵�Ă���B
963 �F�s���ȃf�o�C�X�����F2009/10/17(�y) 14:34:15 ID:/z1CEwIT
Intel�l������O�Ƀ��[�U�[�͂����߂���
tesla��fermi�ւ̒��ړx���₽�獂�����̂����Ȃ��x����Ă���邩�������
��Ȃ菬�Ȃ�A�C���t���i�Ƃ����̂��낤���j����U���܂�Ǝv�l��~���Ă����ɂ͈ڂ��
tesla��fermi�ւ̒��ړx���₽�獂�����̂����Ȃ��x����Ă���邩�������
��Ȃ菬�Ȃ�A�C���t���i�Ƃ����̂��낤���j����U���܂�Ǝv�l��~���Ă����ɂ͈ڂ��
964 �F�s���ȃf�o�C�X�����F2009/10/17(�y) 15:40:48 ID:7swNV+bu
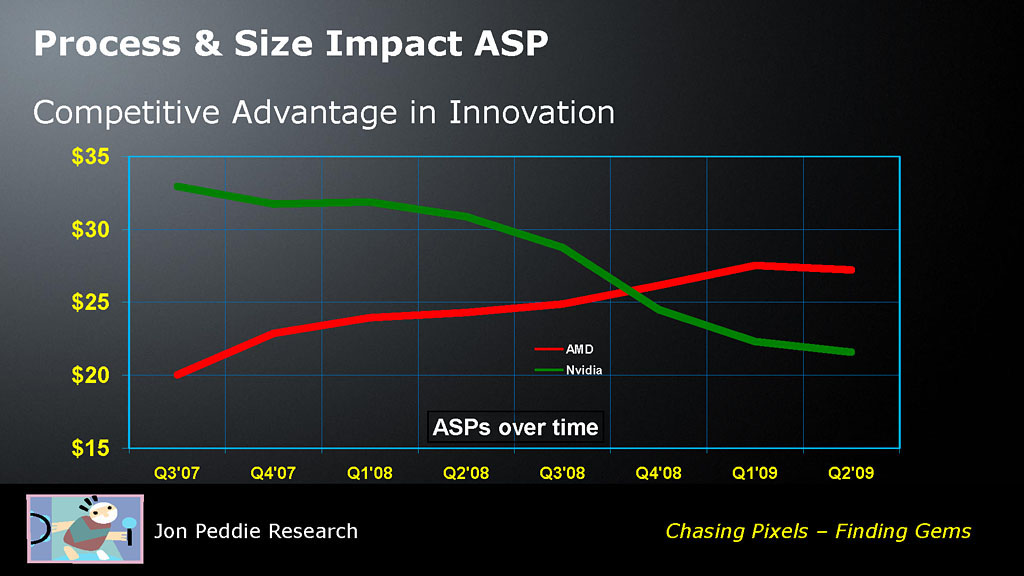{kind=link}
965 �F�s���ȃf�o�C�X�����F2009/10/17(�y) 15:46:55 ID:UrEOiVIZ
�̂́AATi�̓h���C�o���A���Ńg���u�������đI�����̊O�ɂ������̂ɂȂ��B
966 �F�s���ȃf�o�C�X�����F2009/10/17(�y) 22:43:51 ID:DilnuCe+
967 �F�s���ȃf�o�C�X�����F2009/10/17(�y) 22:46:44 ID:u6m1zI/t
DX11GPU
AMDATI�@�~�h���`�n�C ������
NVIDIA �@���b�N
Intel�@�@�@�V�~�����[�^�[
AMDATI�@�~�h���`�n�C ������
NVIDIA �@���b�N
Intel�@�@�@�V�~�����[�^�[
968 �F�s���ȃf�o�C�X�����F2009/10/19(��) 20:02:09 ID:egUUyMd7
tesla��fermi���Ƃ����Ō���intel�ɍŌ�̓V�F�A�����čs�����c�Ƃ������ƁH
969 �F�s���ȃf�o�C�X�����F2009/10/19(��) 21:09:34 ID:agpFJrLd
Fusion�ŃA�i���X�g�x���Ă�AMD�Ɠ�������
970 �F�s���ȃf�o�C�X�����F2009/10/19(��) 21:58:55 ID:R1LxX9Tn
http://www.donanimhaber.com/AMDden_Nvidia_Fermi_atagi_iste_detaylar-16160.htm
"Paper Dragon" ����������������
"Paper Dragon" ����������������
971 �F�s���ȃf�o�C�X�����F2009/10/20(��) 06:06:36 ID:vPBfEkhd
intel�͈��ׂȂ́H
NV���낤���Ȃ�ƁA�r�f�I�`�b�v�Z�b�g�ɂ����āAAMD���猩��intel�͐���x��Ȃ킯�����B
�ŁA�����Ȃ�Ƃ��̂�����AMD��CPU�����𗘂����Ă��������Ȃ��ǁH
NV�̋}�~�����A���̂܂�intel�ɂ��g�y���Ă����Ǝv������
NV���낤���Ȃ�ƁA�r�f�I�`�b�v�Z�b�g�ɂ����āAAMD���猩��intel�͐���x��Ȃ킯�����B
�ŁA�����Ȃ�Ƃ��̂�����AMD��CPU�����𗘂����Ă��������Ȃ��ǁH
NV�̋}�~�����A���̂܂�intel�ɂ��g�y���Ă����Ǝv������
972 �F�s���ȃf�o�C�X�����F2009/10/20(��) 07:06:19 ID:0e/yhSYi
�C�~�t
973 �F�s���ȃf�o�C�X�����F2009/10/20(��) 09:36:52 ID:0BB284KM
Intel�̃I���{�[�h������GPU�܂߂��V�F�A��50%�����ɐ�߂Ă���̂�m��Ȃ��낤�B
974 �F�s���ȃf�o�C�X�����F2009/10/20(��) 10:49:00 ID:cGBPcXNv
CUDA��PGI�A�N�Z�����[�^�[���Ƃ����ł��ďK�����Ă����ʂɂȂ邩�������
intel�̓R���p�C�����玩�O�Ő������Ă��܂���
intel�̓R���p�C�����玩�O�Ő������Ă��܂���
975 �F�s���ȃf�o�C�X�����F2009/10/20(��) 11:38:08 ID:ur3Rsqni
�K�����K�v�Ȑl�́u�����ĂȂ��v�ł�����A���̋ƊE�ɓ]�E���邱�Ƃ��I�X�X���B
976 �F�s���ȃf�o�C�X�����F2009/10/20(��) 18:44:23 ID:ucA7Fsuw
>>974
����Itanium�̂悤�ɂȂ�\���������ł���
����Itanium�̂悤�ɂȂ�\���������ł���
977 �F�s���ȃf�o�C�X�����F2009/10/20(��) 19:45:32 ID:JNnB04kF
Itanium�Ƃ�������VPP��VPPfortran�̑g�ݍ��킹�ɋ߂��Ȃ�̂ł́c
978 �F�s���ȃf�o�C�X�����F2009/10/20(��) 19:54:40 ID:Osz3EC4h
CUDA�K�����̉��Ɏӂ�
979 �F�s���ȃf�o�C�X�����F2009/10/20(��) 22:01:07 ID:pLp9q3w7
�܂������
980 �F�s���ȃf�o�C�X�����F2009/10/20(��) 22:03:29 ID:HwZOEJ5K
>>978
�Ȃ�Ɏg���́H
�Ȃ�Ɏg���́H
981 �F�s���ȃf�o�C�X�����F2009/10/20(��) 22:08:21 ID:pLp9q3w7
��ʂ����Ă������������Ƃ����b��
982 �F�s���ȃf�o�C�X�����F2009/10/21(��) 01:17:00 ID:8TX96NgB
����B�h�L�������g������Ă��邱�Ƃ̏K���͑債�đ�ς���Ȃ������B
���ǃA�v�����ƂɎ��s����Ő��\�o���̂���ρB
���ǃA�v�����ƂɎ��s����Ő��\�o���̂���ρB
983 �F�s���ȃf�o�C�X�����F2009/10/21(��) 07:46:50 ID:0iHYkIWx
���̎��s���낱���������ւ̓�������B
CUDA��Brook��OpenCL��Cell��SSE��AVX��OpenMP��MPI���S�����B
����ł��ꂼ��̂����̐��Y������E�A
���ɉB�ꂽ�A�[�L�e�N�`����v�z�������Ă���B
���炢�̐l�ނ����߂��Ă�C������Ȃ�
CUDA��Brook��OpenCL��Cell��SSE��AVX��OpenMP��MPI���S�����B
����ł��ꂼ��̂����̐��Y������E�A
���ɉB�ꂽ�A�[�L�e�N�`����v�z�������Ă���B
���炢�̐l�ނ����߂��Ă�C������Ȃ�
984 �F�s���ȃf�o�C�X�����F2009/10/21(��) 08:50:31 ID:0GB/sief
���s���낵�����Ȃ��悤�ɂˁB
���s�@��̃X�C�[�g�X�|�b�g�������Ċ��ł���A���̋@��ł͕ς��Ă����A�Ȃ�Ă��Ƃ��B
���s�@��̃X�C�[�g�X�|�b�g�������Ċ��ł���A���̋@��ł͕ς��Ă����A�Ȃ�Ă��Ƃ��B
985 �F�s���ȃf�o�C�X�����F2009/10/21(��) 09:00:00 ID:0iHYkIWx
0GB/s
���Ă������悷��
���Ă������悷��
986 �F�s���ȃf�o�C�X�����F2009/10/21(��) 10:17:36 ID:8TX96NgB
987 �F�s���ȃf�o�C�X�����F2009/10/21(��) 10:27:08 ID:0GB/sief
>>986
���������d���ɖZ�E����āA�����̖{���̎d�����a���ɂȂ郊�X�N�����邩��ˁB
�����ł��邯�ǎ����ł͂��Ȃ��A���ꂪ��ł���B
�v���ɗ��ނɂ��Ă��A����Ȃ�Ƀ��m��m��Ȃ��Ƃ����Ȃ��B
������A�����ł����Ȃ��Ƃ����Ȃ����A�Ō�܂ł���Ă͂����Ȃ��B
�����ł�����Ⴄ�ƁA����Ȃ����Ƃ�ʓ|�Ȃ��Ƃ܂ŁA�����Ŕw�������ނ��ƂɂȂ邩��B
���������̂́A�v���ɋ��ň����Ă��炤�̂��ǂ��B
���������d���ɖZ�E����āA�����̖{���̎d�����a���ɂȂ郊�X�N�����邩��ˁB
�����ł��邯�ǎ����ł͂��Ȃ��A���ꂪ��ł���B
�v���ɗ��ނɂ��Ă��A����Ȃ�Ƀ��m��m��Ȃ��Ƃ����Ȃ��B
������A�����ł����Ȃ��Ƃ����Ȃ����A�Ō�܂ł���Ă͂����Ȃ��B
�����ł�����Ⴄ�ƁA����Ȃ����Ƃ�ʓ|�Ȃ��Ƃ܂ŁA�����Ŕw�������ނ��ƂɂȂ邩��B
���������̂́A�v���ɋ��ň����Ă��炤�̂��ǂ��B
988 �F�s���ȃf�o�C�X�����F2009/10/21(��) 13:29:06 ID:27w+o9jP
���Ԃ������Ŕ����@�Ƃ������Ƃł��ˁB
���ԂƂ����A���ꂼ��Ŏ��x���ǂ��̂ł���Ύ�i�̈�B
���ԂƂ����A���ꂼ��Ŏ��x���ǂ��̂ł���Ύ�i�̈�B
989 �F�s���ȃf�o�C�X�����F2009/10/21(��) 15:35:42 ID:8TX96NgB
�݂�ȑ�l���Ȃ�
990 �F�s���ȃf�o�C�X�����F2009/10/21(��) 18:24:00 ID:OETd5HSB
�����𗝉�����A���Ă��Ƃɂ͎��ԂƘJ�͂�������B�����������邱�Ƃ�����B�ł��������������Ύ�ɓ�����̂ł��Ȃ��B
991 �F�s���ȃf�o�C�X�����F2009/10/21(��) 23:17:44 ID:0GB/sief
�ł����[�A�q��搶���f�o�b�O��ƂȂɎ��Ԃ��g���̂́A���{�̓��]�̖��ʂÂ�����?
992 �F�s���ȃf�o�C�X�����F2009/10/22(��) 06:59:29 ID:1BLU+hMJ
����Ⴓ�A�X�L���̒Ⴂ���l�̃R�[�h�̃f�o�b�O���E���Ƃ��ĐU���Ă�����A����͖{���ɖ��ʌ����B
�ł��o�����X�̈����n�[�h�E�F�A�ōs��������悭�����Ƃ����̂͂����Ƃ͂����Ȃ���B
�V���w��������ĂĂ��������Ƃ����̂Ȃ炻��͒P�Ȃ�꒣��ӎ��B
�ł��o�����X�̈����n�[�h�E�F�A�ōs��������悭�����Ƃ����̂͂����Ƃ͂����Ȃ���B
�V���w��������ĂĂ��������Ƃ����̂Ȃ炻��͒P�Ȃ�꒣��ӎ��B
993 �F�s���ȃf�o�C�X�����F2009/10/22(��) 08:05:38 ID:5pHDOCZn
994 �F�s���ȃf�o�C�X�����F2009/10/22(��) 10:22:16 ID:ItszE4UU
>>993
�����̃R�[�h�Ƃ��������A�ȉ���������� DR �p�� HPL ��
���������Ă���Ǝv�����ǁB
http://jun.artcompsci.org/articles/on_cs/note014.html#rdocsect18
http://jun.artcompsci.org/articles/on_cs/note015.html
http://jun.artcompsci.org/articles/on_cs/note016.html
�����̃R�[�h�Ƃ��������A�ȉ���������� DR �p�� HPL ��
���������Ă���Ǝv�����ǁB
http://jun.artcompsci.org/articles/on_cs/note014.html#rdocsect18
http://jun.artcompsci.org/articles/on_cs/note015.html
http://jun.artcompsci.org/articles/on_cs/note016.html
995 �F�s���ȃf�o�C�X�����F2009/10/22(��) 10:58:56 ID:5pHDOCZn
>>994
���͑��l�̃R�[�h�ł��A�����������ꂽ�u�ԂɁA�����̃R�[�h�ł���B
���쌠�̊ϓ_�ł͂Ȃ��A�R�[�f�B���O�Ƃ����ϓ_�ł́A�ˁB
�q��搶���炢�ɂȂ�A�A�C�f�A���������āA���Ƃ͊w���ɂ�点��Ⴂ���B
������A��w�Ɏc�炸�ɏA�E���Ă����悤�Ȋw���̎��Ԃ���悷��Ⴂ���B
����ɂ��Ă��A�Ȃ��[�e�N����B
CPU�ƃA�N�Z�����[�^�̃R���J�����g����Ƃ��A���������Ƃ�̂��A�ƁB
���͑��l�̃R�[�h�ł��A�����������ꂽ�u�ԂɁA�����̃R�[�h�ł���B
���쌠�̊ϓ_�ł͂Ȃ��A�R�[�f�B���O�Ƃ����ϓ_�ł́A�ˁB
�q��搶���炢�ɂȂ�A�A�C�f�A���������āA���Ƃ͊w���ɂ�点��Ⴂ���B
������A��w�Ɏc�炸�ɏA�E���Ă����悤�Ȋw���̎��Ԃ���悷��Ⴂ���B
����ɂ��Ă��A�Ȃ��[�e�N����B
CPU�ƃA�N�Z�����[�^�̃R���J�����g����Ƃ��A���������Ƃ�̂��A�ƁB
996 �F�s���ȃf�o�C�X�����F2009/10/22(��) 11:10:00 ID:5pHDOCZn
����ɂ��Ă��AFPGA�̏o�ׂ��x�ꂽ�E�E�E�����ł͂Ȃ������ˁB
����FPGA�̏o�ׂ��x��Ă��ʎY�n�[�h���@���x��邾���ŁA
�\�t�g�͍�����FPGA�Ŏ��삵���e�X�g�@��V�~�����[�^�ɂ���āA
�X�P�W���[���ʂ�ɊJ���ł���n�Y�ł��傤�ɁB
���\�͐����̂Ȃ���A
�n�[�h�������������"�`���[�j���O"�ɉ��N�������Ă���A
���������Ȃ��B
ArriaGX���o�ׂ���Ĕ��N��ɂ�2TFlops�B���̃v���X�����[�X�o���Ȃ���B
����FPGA�̏o�ׂ��x��Ă��ʎY�n�[�h���@���x��邾���ŁA
�\�t�g�͍�����FPGA�Ŏ��삵���e�X�g�@��V�~�����[�^�ɂ���āA
�X�P�W���[���ʂ�ɊJ���ł���n�Y�ł��傤�ɁB
���\�͐����̂Ȃ���A
�n�[�h�������������"�`���[�j���O"�ɉ��N�������Ă���A
���������Ȃ��B
ArriaGX���o�ׂ���Ĕ��N��ɂ�2TFlops�B���̃v���X�����[�X�o���Ȃ���B
997 �F�s���ȃf�o�C�X�����F2009/10/22(��) 12:28:53 ID:5DgSfyQf
FPGA�̖��͐�������ŏオ���Ă�150MHz�����o�ĂȂ��@�Ƃ�������ł����H
������ă��W�b�N�A�����z�u�z���A�{�[�h�A���������̕��i�I��@
�i�j�����Ȃ낤���H
������ă��W�b�N�A�����z�u�z���A�{�[�h�A���������̕��i�I��@
�i�j�����Ȃ낤���H
998 �F�s���ȃf�o�C�X�����F2009/10/22(��) 13:07:14 ID:5pHDOCZn
>>997
GRAPE-DR�v���W�F�N�g�̒x���̌����Ƃ���Ă�̂́A
ALTERA�Ђ������̗\��ǂ���̃X�P�W���[����ArriaGX�������[�X�ł��Ȃ��������ƁB
GRAPE-DR�v���W�F�N�g�̒x���̌����Ƃ���Ă�̂́A
ALTERA�Ђ������̗\��ǂ���̃X�P�W���[����ArriaGX�������[�X�ł��Ȃ��������ƁB
999 �F�s���ȃf�o�C�X�����F2009/10/22(��) 13:13:33 ID:5DgSfyQf
>>998
��������������낤���A���ꂾ���H�@�����c����薳���̂��ȁH
��������������낤���A���ꂾ���H�@�����c����薳���̂��ȁH
1000 �F�s���ȃf�o�C�X�����F2009/10/22(��) 13:40:22 ID:5pHDOCZn
>>999
�q��搶�̓������݂����A�x���̌����͂��ꂾ���A�炵����E�E�E�܁A�R���낤���ǁB
�q��搶�̓������݂����A�x���̌����͂��ꂾ���A�炵����E�E�E�܁A�R���낤���ǁB
1001 �F�P�O�O�P�F
���̃X���b�h�͂P�O�O�O���܂����B
���������Ȃ��̂ŁA�V�����X���b�h�𗧂ĂĂ��������ł��B�B�B
���������Ȃ��̂ŁA�V�����X���b�h�𗧂ĂĂ��������ł��B�B�B