���R���ꏈ���X���b�h�@���̂S
1 �F�f�t�H���g�̖����������F
�O�O�X���@���R���ꏈ���X���b�h�@���̂Q
http://mimizun.com/log/2ch/tech/1173105287/
�O�X���@���R���ꏈ���X���b�h�@���̂R
http://mimizun.com/log/2ch/tech/1235129481/
���̃X���b�h�ł́A���{��̍\����́A�k�b�����A����A
���͐����Ȃǂ̋Z�p�Ɋւ��闝�_��(������)�����������܂��B
�����܂ŃA�v���P�[�V�����v���O���~���O�̋Z�p�I�Ȗʂɏd�_�����������̂ŁA
�w�p�I�Șb�̓A���ł����A������l�H���\��N�w�IAI�b�A
����w�̘b��Ȃǂ͑��̃X���b�h�ł��肢���܂��B
http://mimizun.com/log/2ch/tech/1173105287/
�O�X���@���R���ꏈ���X���b�h�@���̂R
http://mimizun.com/log/2ch/tech/1235129481/
���̃X���b�h�ł́A���{��̍\����́A�k�b�����A����A
���͐����Ȃǂ̋Z�p�Ɋւ��闝�_��(������)�����������܂��B
�����܂ŃA�v���P�[�V�����v���O���~���O�̋Z�p�I�Ȗʂɏd�_�����������̂ŁA
�w�p�I�Șb�̓A���ł����A������l�H���\��N�w�IAI�b�A
����w�̘b��Ȃǂ͑��̃X���b�h�ł��肢���܂��B
|
|
|
2 �F�ЎR����MZ�������q ��T6xkBnTXz7B0 �F2014/06/04(��) 00:23:39.07 ID:qVJRsv3N
�P��
3 �F�ЎR����MZ�������q ��T6xkBnTXz7B0 �F2014/06/06(��) 16:12:41.21 ID:dyn5MnFB
�l�H����̍\����͂ł͂����Ă��̏ꍇ�A���@�͌Œ肳��Ă��ˁB
���I�ɉ�͂��镶�@��ς������Ƃ��́A���s���Ƀp�[�T�W�F�l���[�^��
�R���p�C�����g��Ȃ��Ƃ����Ȃ��̂��H
���I�ɉ�͂��镶�@��ς������Ƃ��́A���s���Ƀp�[�T�W�F�l���[�^��
�R���p�C�����g��Ȃ��Ƃ����Ȃ��̂��H
4 �F�f�t�H���g�̖����������F2014/06/09(��) 11:47:07.19 ID:PtiKDSQ8
�����E�ł��Ȃ���ǂ����g�����Ȃ��̂�
�ǂ���������word2vec�����₪��
�B����ɂȂ肻���Ȃ̂�paragraph vector���炢����
�ǂ���������word2vec�����₪��
�B����ɂȂ肻���Ȃ̂�paragraph vector���炢����
5 �F�f�t�H���g�̖����������F2014/06/09(��) 15:08:04.19 ID:HHhmYyTe
���[�W�[���N�͂ǂ�ȋZ�p�����Ă�́H
6 �F�f�t�H���g�̖����������F2014/06/09(��) 15:33:05.97 ID:PtiKDSQ8
�d���Ŏg���Ă�̂�bag-of-words��n-gram����
word2vec�����������̕��L�������Ă�J�X�͏�����
word2vec�����������̕��L�������Ă�J�X�͏�����
7 �F�f�t�H���g�̖����������F2014/06/09(��) 17:49:36.60 ID:HHhmYyTe
�l�H�m�\��13�̏��N�A�`���[�����O�e�X�g�Ɂg���i�h
�p���f�B���O��w��6��8���i���n���ԁj�A�A�����E�`���[�����O���m�v��60���N�ɓ�����7���ɓ��Z��
�p�����w��ŊJ�Â����uTuring Test 2014�v�ɂ����āA�`���[�����O�e�X�g�̏��̍��i�҂��o���Ɣ��\�����B
���i�����̂̓E�N���C�i�ݏZ��13�̏��N�A���[�W�[���E�O�[�c�}������Ƃ����ݒ�̃v���O�����B
���[�W�[�������2001�N�Ƀ��V�A�l�̃E���W�~�[���E���F�Z���t���i�č��ݏZ�j�A�E�N���C�i�l��
���[�W�[���E�f���`�F���R���i���V�A�ݏZ�j�炪�\�z�����B����܂ł������̃`���[�����O�e�X�g�C�x���g��
�Q�����ĉ��ǂ��d�˂��Ă����B
�`���[�����O�e�X�g�́A�u�R���s���[�^�̕��v�ƌĂ��20���I�̉p���w�ҁA�A�����E�`���[�����O���m����Ă����A
�l�H�m�\��m�I�ƌĂׂ邩�ǂ����f���邽�߂̃e�X�g�B�l�Ԃ��l�H�m�\�ƑΘb���āA
���肪�l�H�m�\���l�Ԃ����f�ł��Ȃ���A���̐l�H�m�\�͎v�l���Ă���Ƃ�����Ƃ������́B
�`���[�����O���m�́A5���Ԃ̃e�X�g�Ől�Ԃ̐R����30�������܂���A�l�H�m�\�͎v�l���Ă���Ƃ�����Ƃ���
�iWikipedia���j�B
����̃e�X�g�ŁA�R������33���i�R�����̐l���͕s���j�����[�W�[�������l�Ԃ��Ɣ��f�����B
http://image.itmedia.co.jp/news/articles/1406/09/yu_turing.jpg
http://www.itmedia.co.jp/news/articles/1406/09/news049.html
�p���f�B���O��w��6��8���i���n���ԁj�A�A�����E�`���[�����O���m�v��60���N�ɓ�����7���ɓ��Z��
�p�����w��ŊJ�Â����uTuring Test 2014�v�ɂ����āA�`���[�����O�e�X�g�̏��̍��i�҂��o���Ɣ��\�����B
���i�����̂̓E�N���C�i�ݏZ��13�̏��N�A���[�W�[���E�O�[�c�}������Ƃ����ݒ�̃v���O�����B
���[�W�[�������2001�N�Ƀ��V�A�l�̃E���W�~�[���E���F�Z���t���i�č��ݏZ�j�A�E�N���C�i�l��
���[�W�[���E�f���`�F���R���i���V�A�ݏZ�j�炪�\�z�����B����܂ł������̃`���[�����O�e�X�g�C�x���g��
�Q�����ĉ��ǂ��d�˂��Ă����B
�`���[�����O�e�X�g�́A�u�R���s���[�^�̕��v�ƌĂ��20���I�̉p���w�ҁA�A�����E�`���[�����O���m����Ă����A
�l�H�m�\��m�I�ƌĂׂ邩�ǂ����f���邽�߂̃e�X�g�B�l�Ԃ��l�H�m�\�ƑΘb���āA
���肪�l�H�m�\���l�Ԃ����f�ł��Ȃ���A���̐l�H�m�\�͎v�l���Ă���Ƃ�����Ƃ������́B
�`���[�����O���m�́A5���Ԃ̃e�X�g�Ől�Ԃ̐R����30�������܂���A�l�H�m�\�͎v�l���Ă���Ƃ�����Ƃ���
�iWikipedia���j�B
����̃e�X�g�ŁA�R������33���i�R�����̐l���͕s���j�����[�W�[�������l�Ԃ��Ɣ��f�����B
http://image.itmedia.co.jp/news/articles/1406/09/yu_turing.jpg
{kind=link}
http://www.itmedia.co.jp/news/articles/1406/09/news049.html
8 �F�f�t�H���g�̖����������F2014/06/13(��) 22:56:37.05 ID:qhg9plHy
�n��
9 �F�f�t�H���g�̖����������F2014/06/14(�y) 00:57:41.13 ID:O/sWuNjK
���O���Ȃ�
10 �F�f�t�H���g�̖����������F2014/06/14(�y) 09:49:46.90 ID:C3RmOQgD
1. ����̔w�i�ɂ���m���͏�������Ȃ����炢�[��
�܂�Ȃɂ����ۉ������Ӗ����L���������u�Ԃɔw�i�̎����E���痣��Ă��܂��C
�l�Ԃ�����悤�Ȍ��ꗝ���͋L�����ł͕s�\�Ȃ悤�Ɍ�����D
2. �����⓮���̈Ӗ��͑g�ݍ��킹�ŗ�������Ă���
������u�����̍\���v��u�����̍\���v�ƓƗ������Y��ɏ����Ȃ��D
3. ���R���ꏈ���V�X�e���͕���E�^�X�N�ˑ��̏�K�v
�N�C�Y�������Ȃ�N�C�Y�̒m�����K�v�D����w�����̒����I�m�������ł̓V�X�e���͂ł��Ȃ��D
4. �ėp�I�Ȍ��ꗝ���V�X�e���͓���悤�Ɍ�����
��L 3. �Ɠ��l�ŕ���ˑ��̒m��������ď��߂Ďg����悤�ɂȂ�̂Ŕėp�͓���D
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/E6-2.pdf
�㐔�w��w�Ȃǂ́A�ł����ۓI�ȏW���̂��Ƃɗ��_��ςݏグ�A����ɁA�W���̌����m
�̊W�����G�ɂȂ邱�Ƃ���A�L�q�����i�Ƃ��āA������L�����p�ɂɗp������B������
�̓��e�͒��ۓI�ł���A�Ӗ��𗝉�����ɂ́A��������̋�̗�ɒu��������K�v������B
�Ƃ��낪���̂悤�ɒ��ۉ����i���e���A��̓I�ɃC���[�W���A���̈Ӗ��𗝉����邱�Ƃ�
�ł��Ȃ��A���邢�́A���������L���ŏ�����Ă�������̈Ӗ����܂��ǂݎ��Ȃ��w����
���ɑ����A���̂��Ƃ���w�̐��w���킩��Ȃ������̏d��ȗv���ƂȂ��Ă���̂ł���B
http://satsuki.ex.osaka-kyoiku.ac.jp/~j129307/miyazaki2.pdf
Project Euler �Ɍ��J����Ă�����͐��S��ł���, �ȏ�ɂ���ē�������Ǝd�l���̑�
�����x�̗ʂɂ����Ȃ�Ȃ�. ���̂���, ���������ɑ��Ă��̖��̉�@�Ɋ܂܂�镔�������l��,
�������������R�[�h�����l�ɍ쐬����悤�Ɏw������. �Ⴆ�u1000 �����̎��R����,
3 �̔{���ƂȂ���̘̂a�����߂�v�Ƃ�����肪�������ꍇ, �u1000 �����̎��R���̏W�������߂�v
�u���鎩�R�� x ��3 �̔{���ł��邩�ǂ������ׂ�v�u�^����ꂽ���R���̏W��x �Ɋ܂܂��v�f�̑��a�����߂�v
�Ȃǂ��������Ƃ��čl������.
http://www.phontron.com/paper/oda14nl05.pdf
�܂�Ȃɂ����ۉ������Ӗ����L���������u�Ԃɔw�i�̎����E���痣��Ă��܂��C
�l�Ԃ�����悤�Ȍ��ꗝ���͋L�����ł͕s�\�Ȃ悤�Ɍ�����D
2. �����⓮���̈Ӗ��͑g�ݍ��킹�ŗ�������Ă���
������u�����̍\���v��u�����̍\���v�ƓƗ������Y��ɏ����Ȃ��D
3. ���R���ꏈ���V�X�e���͕���E�^�X�N�ˑ��̏�K�v
�N�C�Y�������Ȃ�N�C�Y�̒m�����K�v�D����w�����̒����I�m�������ł̓V�X�e���͂ł��Ȃ��D
4. �ėp�I�Ȍ��ꗝ���V�X�e���͓���悤�Ɍ�����
��L 3. �Ɠ��l�ŕ���ˑ��̒m��������ď��߂Ďg����悤�ɂȂ�̂Ŕėp�͓���D
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/E6-2.pdf
�㐔�w��w�Ȃǂ́A�ł����ۓI�ȏW���̂��Ƃɗ��_��ςݏグ�A����ɁA�W���̌����m
�̊W�����G�ɂȂ邱�Ƃ���A�L�q�����i�Ƃ��āA������L�����p�ɂɗp������B������
�̓��e�͒��ۓI�ł���A�Ӗ��𗝉�����ɂ́A��������̋�̗�ɒu��������K�v������B
�Ƃ��낪���̂悤�ɒ��ۉ����i���e���A��̓I�ɃC���[�W���A���̈Ӗ��𗝉����邱�Ƃ�
�ł��Ȃ��A���邢�́A���������L���ŏ�����Ă�������̈Ӗ����܂��ǂݎ��Ȃ��w����
���ɑ����A���̂��Ƃ���w�̐��w���킩��Ȃ������̏d��ȗv���ƂȂ��Ă���̂ł���B
http://satsuki.ex.osaka-kyoiku.ac.jp/~j129307/miyazaki2.pdf
Project Euler �Ɍ��J����Ă�����͐��S��ł���, �ȏ�ɂ���ē�������Ǝd�l���̑�
�����x�̗ʂɂ����Ȃ�Ȃ�. ���̂���, ���������ɑ��Ă��̖��̉�@�Ɋ܂܂�镔�������l��,
�������������R�[�h�����l�ɍ쐬����悤�Ɏw������. �Ⴆ�u1000 �����̎��R����,
3 �̔{���ƂȂ���̘̂a�����߂�v�Ƃ�����肪�������ꍇ, �u1000 �����̎��R���̏W�������߂�v
�u���鎩�R�� x ��3 �̔{���ł��邩�ǂ������ׂ�v�u�^����ꂽ���R���̏W��x �Ɋ܂܂��v�f�̑��a�����߂�v
�Ȃǂ��������Ƃ��čl������.
http://www.phontron.com/paper/oda14nl05.pdf
11 �F�f�t�H���g�̖����������F2014/06/14(�y) 10:04:31.11 ID:C3RmOQgD
�l���̍s�����ȒP�ȃp�����[�^�ŕ\������ꍇ�C�����̈ʒu�E�p���ɒ��ڂ��邱�Ƃ́C
�l���̈ʒu�⒍����𐄒肷�邱�Ƃ��l����������I�Ƃ�����D�{�����ł́C�\�ߐl��
�����̃T���v���摜��p�ӂ��Ă������ƂŁC���f���x�[�X�̈ʒu�E�p��������s���C�ق�
���p�I�Ȑ��x�Ől���̈ړ��o�H��ǐՂ��邱�Ƃ��\�ł��邱�Ƃ��������D
�����āC���̈ړ��O�Ղɂ����Ĉ��̌X�����ێ������Ԃɕ������C���ꂼ��̋��
���Ƃɐl���̎p������ӂ̕��̂Ƃ̑��ΓI�Ȉʒu�W�Ȃǂ̈Ӗ��f���𐔒l�I�ɕ]�����C
�������邱�ƂŁC���R����̎��ۊT�O�Ƃ̑Ή��t�����s���Ƃ�����{�I�ȍl�������Ă����D
����͏]���̃e���v���[�g�ɂ�鎩�R���ꐶ���Ɣ�r���āC���g�����̍����_��Ȏ�@�ł���Ƃ�����D
http://www.las.osakafu-u.ac.jp/~ark/publication/kojima-thesis.pdf
����܂ł̍l�@�Ŗ��炩�ƂȂ����u�F�߂�v�̕ʋ`�́A�ȉ��̒ʂ�ł���B
�E�ʋ`�P�F������͈͂ɒ��ӂ����Ƃɂ�聄���Ώۂ�����������
���i���炩���ߎ����Ă���j�ΏۂɊւ���m���Ɠ��肷�遄
�E�ʋ`�Q�F���O���̏i���҂̈ӌ��E�w�E�Ȃǂ��܂ށj�������Ó��Ȃ��̂Ƃ��ā�������遄
�E�ʋ`�R�F�����҂̔\�͂�i�\�͂̔��f�ł���j��i���������l�̂�����̂Ƃ��ā�������遄
�E�ʋ`�S�F�����҂̖������̍s�ׂ������Ó��Ȃ��̂Ƃ��ā�������遄
http://www.lang.nagoya-u.ac.jp/nichigen/issue/pdf/5/5-09.pdf
�Ⴆ�A�u�����z���v�Ƃ��������̌�b�T�O�\���́A���̂悤�ɋK�肳���B
�uX �� Y �Ɉ����z���v�� ��X �I�u�W�F�N�g�������̏Z���A�g���r���[�g�̒l�� Y �ɕύX���遄
��L�̋K��ɂ��A�uX �������z���v�Ƃ����ꍇ�A�uX �I�u�W�F�N�g�͉ς̏Z���A�g���r���[�g����
���˂Ȃ�Ȃ��v���Ƃ��������B����ɂ��A�g�D���ς̏Z���A�g���r���[�g��L����̂ŁA
�g�D�������z���\�ł��邱�Ƃ��������B����́A�]���̈Ӗ��_�ɂ�����Ӗ������̊T�O����
�����ɏq��i�������j�ƍ��i�������j�̊Ԃ̈Ӗ��W���K��ł��邱�Ƃ������Ă���B
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/B1-1.pdf
�l���̈ʒu�⒍����𐄒肷�邱�Ƃ��l����������I�Ƃ�����D�{�����ł́C�\�ߐl��
�����̃T���v���摜��p�ӂ��Ă������ƂŁC���f���x�[�X�̈ʒu�E�p��������s���C�ق�
���p�I�Ȑ��x�Ől���̈ړ��o�H��ǐՂ��邱�Ƃ��\�ł��邱�Ƃ��������D
�����āC���̈ړ��O�Ղɂ����Ĉ��̌X�����ێ������Ԃɕ������C���ꂼ��̋��
���Ƃɐl���̎p������ӂ̕��̂Ƃ̑��ΓI�Ȉʒu�W�Ȃǂ̈Ӗ��f���𐔒l�I�ɕ]�����C
�������邱�ƂŁC���R����̎��ۊT�O�Ƃ̑Ή��t�����s���Ƃ�����{�I�ȍl�������Ă����D
����͏]���̃e���v���[�g�ɂ�鎩�R���ꐶ���Ɣ�r���āC���g�����̍����_��Ȏ�@�ł���Ƃ�����D
http://www.las.osakafu-u.ac.jp/~ark/publication/kojima-thesis.pdf
����܂ł̍l�@�Ŗ��炩�ƂȂ����u�F�߂�v�̕ʋ`�́A�ȉ��̒ʂ�ł���B
�E�ʋ`�P�F������͈͂ɒ��ӂ����Ƃɂ�聄���Ώۂ�����������
���i���炩���ߎ����Ă���j�ΏۂɊւ���m���Ɠ��肷�遄
�E�ʋ`�Q�F���O���̏i���҂̈ӌ��E�w�E�Ȃǂ��܂ށj�������Ó��Ȃ��̂Ƃ��ā�������遄
�E�ʋ`�R�F�����҂̔\�͂�i�\�͂̔��f�ł���j��i���������l�̂�����̂Ƃ��ā�������遄
�E�ʋ`�S�F�����҂̖������̍s�ׂ������Ó��Ȃ��̂Ƃ��ā�������遄
http://www.lang.nagoya-u.ac.jp/nichigen/issue/pdf/5/5-09.pdf
�Ⴆ�A�u�����z���v�Ƃ��������̌�b�T�O�\���́A���̂悤�ɋK�肳���B
�uX �� Y �Ɉ����z���v�� ��X �I�u�W�F�N�g�������̏Z���A�g���r���[�g�̒l�� Y �ɕύX���遄
��L�̋K��ɂ��A�uX �������z���v�Ƃ����ꍇ�A�uX �I�u�W�F�N�g�͉ς̏Z���A�g���r���[�g����
���˂Ȃ�Ȃ��v���Ƃ��������B����ɂ��A�g�D���ς̏Z���A�g���r���[�g��L����̂ŁA
�g�D�������z���\�ł��邱�Ƃ��������B����́A�]���̈Ӗ��_�ɂ�����Ӗ������̊T�O����
�����ɏq��i�������j�ƍ��i�������j�̊Ԃ̈Ӗ��W���K��ł��邱�Ƃ������Ă���B
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/B1-1.pdf
12 �F�f�t�H���g�̖����������F2014/06/14(�y) 12:47:56.94 ID:2GCCkitO
�T���v���R�[�h���������
13 �F�ЎR����MZ�������q ��T6xkBnTXz7B0 �F2014/06/14(�y) 13:18:14.77 ID:TMbzloys
�u�Ђ炪�ȓd��vWindows�p�t���[�\�t�g�B
�Ђ炪�ȂŖ��ʑ吔�܂ł̎l�����Z�A�����v�Z�A�����v�Z�A���[�g�A
�O�p���A�]��A�p�[�Z���g�v�Z���ł��܂��I�I�I
http://katahiromz.web.fc2.com/calc-h/
�Ђ炪�ȂŖ��ʑ吔�܂ł̎l�����Z�A�����v�Z�A�����v�Z�A���[�g�A
�O�p���A�]��A�p�[�Z���g�v�Z���ł��܂��I�I�I
http://katahiromz.web.fc2.com/calc-h/
14 �F�f�t�H���g�̖����������F2014/06/14(�y) 14:59:25.78 ID:C3RmOQgD
�Ⴆ�A����Ȗ��͂������ł��傤���B
���Ȃ݂ɂ���͍���A���W�I�ŕ��������ł��B
�u�R�O�O�~�����Ĕ������ɍs���܂����B�����āA�P�O�O�~�̂��َq��
�S�O�~�̂��َq�ƂU�O�~�̂��َq���܂����B
����͂�����ł��傤�H�v
�Ƃ������ł��B
������ĂP�O�O�~�Ɠ����鎞�A���̎v�l�͈ȉ��̂悤�Ȃ��̂ł͂Ȃ��ł��傤���B
�R�O�O�[�i�P�O�O�{�S�O�{�U�O�j���P�O�O
�Ԉ���Ă��܂���ˁB
���������َq�̍��v�͂Q�O�O�~�Ȃ̂ŁA�R�O�O?�Q�O�O�͂P�O�O�Ƃ��Ă���킯�ł��B
������A�}���g���ď�ʂ��C���[�W���Ă݂�̂ł��B
���̂悤�ɂ������}�Ƃ��ĕ`����Ό����Ă��܂��B
�����Ȃ�ł��B
����͂�����N�C�Y�Ȃ̂ŁA���́E�E�E�u����Ȃ��v�������Ȃ�ł��B
�R�O�O�~�����Ă����āA�Q�O�O�~�̂��َq�����Ƃ���ŁA
�Q�O�O�~���o���킯�ł�����A����͂���܂����ˁB
���邢�I�Ƃ������������������ł����A
�ł��A������u����A����͂Ȃ��ł���I�H�v�Ɠ������邩�ǂ�������
���͖�肪�C���[�W�ł��Ă��邩�Ƃ�����ȂƂ���ł���Ǝv���̂ł��B
��蕶��^�����āA�������������ʼn��Z��������Ă��܂�����ԈႦ��̂ł��B
http://mhidetoshi.exblog.jp/22011978
���Ȃ݂ɂ���͍���A���W�I�ŕ��������ł��B
�u�R�O�O�~�����Ĕ������ɍs���܂����B�����āA�P�O�O�~�̂��َq��
�S�O�~�̂��َq�ƂU�O�~�̂��َq���܂����B
����͂�����ł��傤�H�v
�Ƃ������ł��B
������ĂP�O�O�~�Ɠ����鎞�A���̎v�l�͈ȉ��̂悤�Ȃ��̂ł͂Ȃ��ł��傤���B
�R�O�O�[�i�P�O�O�{�S�O�{�U�O�j���P�O�O
�Ԉ���Ă��܂���ˁB
���������َq�̍��v�͂Q�O�O�~�Ȃ̂ŁA�R�O�O?�Q�O�O�͂P�O�O�Ƃ��Ă���킯�ł��B
������A�}���g���ď�ʂ��C���[�W���Ă݂�̂ł��B
���̂悤�ɂ������}�Ƃ��ĕ`����Ό����Ă��܂��B
�����Ȃ�ł��B
����͂�����N�C�Y�Ȃ̂ŁA���́E�E�E�u����Ȃ��v�������Ȃ�ł��B
�R�O�O�~�����Ă����āA�Q�O�O�~�̂��َq�����Ƃ���ŁA
�Q�O�O�~���o���킯�ł�����A����͂���܂����ˁB
���邢�I�Ƃ������������������ł����A
�ł��A������u����A����͂Ȃ��ł���I�H�v�Ɠ������邩�ǂ�������
���͖�肪�C���[�W�ł��Ă��邩�Ƃ�����ȂƂ���ł���Ǝv���̂ł��B
��蕶��^�����āA�������������ʼn��Z��������Ă��܂�����ԈႦ��̂ł��B
http://mhidetoshi.exblog.jp/22011978
15 �F�f�t�H���g�̖����������F2014/06/14(�y) 15:34:15.93 ID:h7hlzhCn
���W�Ɉ���ʂ����Ƃ͏����Ă��Ȃ��̂ŁA60�~�̂��َq�̎���40�~�A
40�~�̂��َq�̎���60�~�A�s��100�~�̂�������ƌ������߂����蓾��ˁB
���ʁA�q���ɂ��g���ɍs������Ȃ�]�T�������Ă�����a����
�߂��Ă����Ƃ��Ɏc�z������Ƃ��Ď��B�Ȃ̂ŁA���肪100�~�ƌ������������蓾��B
40�~�̂��َq�̎���60�~�A�s��100�~�̂�������ƌ������߂����蓾��ˁB
���ʁA�q���ɂ��g���ɍs������Ȃ�]�T�������Ă�����a����
�߂��Ă����Ƃ��Ɏc�z������Ƃ��Ď��B�Ȃ̂ŁA���肪100�~�ƌ������������蓾��B
16 �F�f�t�H���g�̖����������F2014/06/14(�y) 16:09:45.04 ID:C3RmOQgD
����Z�Ƃ����̂́A�������ł͓���ȉ��Z���Ǝv���B
���N���w�����S�O�Q�l�̏��w�P�N�����P�O�g�ɕ�����Ƃǂ��Ȃ邩�B
�S�O�Q�l���A�ł��邩���蓙�����l���ɂȂ�悤������Ȃ�A�S�O�l�̑g���W�g�A�S�P�l�̑g���Q�g�B
�i�S�O�Q���P�O���S�O�]��Q�A�S�O�l����������ŁA�c��̂Q�l����j
�ł����̏ꍇ���l����Ɓi�Ⴆ�u���Ȃ��Ƃ��\�l�ȏ�v�Ƃ��j�A�����グ�͓�����̂ƂȂ낤�B
���N���w�����S�O�Q�l�̏��w�P�N�����P�O�g�ɕ�����Ƃǂ��Ȃ邩�B
�S�O�Q�l���A�ł��邩���蓙�����l���ɂȂ�悤������Ȃ�A�S�O�l�̑g���W�g�A�S�P�l�̑g���Q�g�B
�i�S�O�Q���P�O���S�O�]��Q�A�S�O�l����������ŁA�c��̂Q�l����j
�ł����̏ꍇ���l����Ɓi�Ⴆ�u���Ȃ��Ƃ��\�l�ȏ�v�Ƃ��j�A�����グ�͓�����̂ƂȂ낤�B
17 �F�f�t�H���g�̖����������F2014/06/14(�y) 16:20:00.41 ID:C3RmOQgD
>>15
�����W�Ɉ���ʂ����Ƃ͏����Ă��Ȃ��̂ŁA60�~�̂��َq�̎���40�~�A
��40�~�̂��َq�̎���60�~�A�s��100�~�̂�������ƌ������߂����蓾��ˁB
����ł��A�i�P�O�~�ʂ��R�O�ō��v�j�R�O�O�~�����Ĕ������ɍs���܂����A���Ƃ���͂O�ɂȂ�B
���ꂩ�琭�{���V���Ɂu�R�O�O�~�ʁv�s�����Ƃ��Ȃ�A�b�͕ʂƂȂ낤�B
�����W�Ɉ���ʂ����Ƃ͏����Ă��Ȃ��̂ŁA60�~�̂��َq�̎���40�~�A
��40�~�̂��َq�̎���60�~�A�s��100�~�̂�������ƌ������߂����蓾��ˁB
����ł��A�i�P�O�~�ʂ��R�O�ō��v�j�R�O�O�~�����Ĕ������ɍs���܂����A���Ƃ���͂O�ɂȂ�B
���ꂩ�琭�{���V���Ɂu�R�O�O�~�ʁv�s�����Ƃ��Ȃ�A�b�͕ʂƂȂ낤�B
18 �F�f�t�H���g�̖����������F2014/06/15(��) 13:44:13.39 ID:0Xbi4t4E
word2vec�Ŏg���Ă�hierarchical softmax����
���t�M�����n�t�}�������ɂ��������H
���t�M�����n�t�}�������ɂ��������H
19 �F�f�t�H���g�̖����������F2014/06/15(��) 14:36:22.47 ID:0Xbi4t4E
����ȒP������Ȃ�������
https://gist.github.com/kokukuma/85bebedb0635485e4f5b
https://gist.github.com/kokukuma/85bebedb0635485e4f5b
20 �F�f�t�H���g�̖����������F2014/06/15(��) 18:21:24.22 ID:r1yj7QX5
http://www.phontron.com/paper/oda14nl05.pdf
x1��x2�Ŋ����Ȃ��Ȃ�܂�x1��x2�Ŋ��聨x1��x2�Ŋ����Ȃ��Ȃ�܂Łi�J��Ԃ��ājx1��x2�Ŋ���
�i�J��Ԃ��āj������A�e�ՂɁuwhile���v�ɖ|��ł���B
�������玩���I�ɏȗ�������āA�|�₷���`�Ɏ����ό`����A���S���Y�����K�v�B
x1��x2�Ŋ����Ȃ��Ȃ�܂�x1��x2�Ŋ��聨x1��x2�Ŋ����Ȃ��Ȃ�܂Łi�J��Ԃ��ājx1��x2�Ŋ���
�i�J��Ԃ��āj������A�e�ՂɁuwhile���v�ɖ|��ł���B
�������玩���I�ɏȗ�������āA�|�₷���`�Ɏ����ό`����A���S���Y�����K�v�B
21 �F�f�t�H���g�̖����������F2014/06/16(��) 10:59:25.96 ID:4kD5cm9H
���������@�B�I�ɂł��鏈�����Č`�ԑf��͂��炢�܂ł��낤�ȁB�`�ԑf��͂Ȃ�X�p�[�X�\���łł��������B
�߂���ł���b�ł��邯�ǁA���ȊO�̌܊����Ȃ��킯�ł͂Ȃ���
�߂���ł���b�ł��邯�ǁA���ȊO�̌܊����Ȃ��킯�ł͂Ȃ���
22 �F�f�t�H���g�̖����������F2014/06/16(��) 11:07:05.33 ID:4kD5cm9H
�`�ԑf��͂��ł��Ă���A���̏Ǝ��R����̊W���Ƃ炵���킹�ĒP�ꂲ�Ƃɍ\�����w�K����B
���̏̓e�L�X�g��������\�������
���̏̓e�L�X�g��������\�������
23 �F�f�t�H���g�̖����������F2014/06/16(��) 11:56:09.75 ID:xNeMvzgG
����Z�E�����́A�u���ρv�܂��́u�P�ʂ�����v�Ɨ��������ׂ��T�O�Ǝv���B�u���ϓ_�v�͐��̑��a��l���Ŋ����ē���ꂽ���B
�u���x�v�͕��̂�g���P�ʎ��Ԃ�����ɓ����������B
�u���x�v�͕��̂�g���P�ʎ��Ԃ�����ɓ����������B
24 �F�f�t�H���g�̖����������F2014/06/16(��) 11:57:19.39 ID:xNeMvzgG
900 �F�f�t�H���g�̖���������F2009/02/20(��) 20:46:21.00
�u�ގ��������V�X�e���v�Ƃ��ẮA�����{�����u�́v�{�����{�A�̂悤�ɕ��\���̃p�^�[����ԗ����Ă����A
�ڐV�������͂��o�����ɕ��\���p�^�[���F�m�ł���悤�ɂ��Ă����Ƃ��B
�Ⴆ�u�g���̍����j�����̉���ʂ�߂����v�u���̒��������ނ̎���������v�͂�������A
�����{�����u�́v�{�`�e���{�����{�����u���v�{�����{�����u�́v�{�����{�����u���v�{�����B
�u�ގ��������V�X�e���v�Ƃ��ẮA�����{�����u�́v�{�����{�A�̂悤�ɕ��\���̃p�^�[����ԗ����Ă����A
�ڐV�������͂��o�����ɕ��\���p�^�[���F�m�ł���悤�ɂ��Ă����Ƃ��B
�Ⴆ�u�g���̍����j�����̉���ʂ�߂����v�u���̒��������ނ̎���������v�͂�������A
�����{�����u�́v�{�`�e���{�����{�����u���v�{�����{�����u�́v�{�����{�����u���v�{�����B
25 �F�f�t�H���g�̖����������F2014/06/16(��) 13:00:19.74 ID:xNeMvzgG
(1) ���V��s4,1 �̒��g
(e4,2:�K)13 (e4,3:�K)14 �\�����ɑ呠�Ȃ̋�s�Ƌ����擾�A14 (e4,4:�K)15 ��{�܂ł� ��������15 (e4,5:
�K)16 ���{���� �l�S���~�Ƃ��A16 �O����\�����߂ǂɁA�J�Ƃ���B13
���̓_���l�����邽�߂ɁC�Q�ƕ\���̏o���ʒu��l��ŏC�����C���̌��ʂɑ��Đl��ŎQ�ƕ\����I������D
�������C�C�ӂ̕\���������Ă��܂��Ɩ�肪���U���邽�߁C����̕]���ł́u�Q�ƕ\�����ȗ�����v�u�Q�ƕ\������艻��
�Ė����I�ɋL�q����i�܂�C���� �g�́h �������� �g�ɂ́h���Ƃ��Ȃ��ĕ\������j�v�u��艻�����ɖ����I�ɋL�q����
�i�܂�C���� �g��/��/�Ɂh ���Ƃ��Ȃ��ĕ\������j�v�� 3 ��ނ���I�����Ă��炢�C�l�萶���̌X���͂���D
http://www.cl.cs.titech.ac.jp/~ryu-i/papers/NL206-15.pdf
(58) a. �w�����R�l���̌��Ńh�A���J����
b. ?? �w�������̌��łR�l�h�A���J����
(58a-b) �́A�V�����ʎ����A�אڂ��閼������C�����邱�Ƃ������12
(58b) �ł́A�u�R�l�v��
�u�w���v���אڂ��Ă��Ȃ����߁A�Ӑ}���ꂽ�C���W���������Ȃ��B���̊ώ@���ӂ܂��āA
Miyagawa (1989) �́A(59) �̕��@������Ίi�����̏؋��ƂȂ邱�Ƃ��w�E����B
(59) �h�A�����̌��łR�J����
��Ίi�����ɂ��A(59) �́u�J���v����Ίi�����ł��邱�Ƃ���A�u�h�A�v�́A(60) �Ɏ�
���悤�ɁA�ړI��̈ʒu�Ŏ��̖�������ɁA���̈ʒu�Ɉړ�����B
http://www.ic.nanzan-u.ac.jp/LINGUISTICS/staff/saito_mamoru/pdf/saito.2013.pdf
���{��̏ȗ����킩��{ �N���H�N�ɁH�����H
���R �d�q �� �^ �������@�i810.7�i�j
���{��̓����ł���ȗ����ƕ��@���瑨�����{�B��炢�̐���ȗ�
�̏����̐���܂ő̌n�I�ɉ���B���@�����Ȑl�⒆���҈ȉ��̊w�K�҂̂���
�Ɂu�ȗ��̃C���X�^���g���@�v�����^�B
https://www.ishikari-lib-unet.ocn.ne.jp/html/%E3%81%82%E3%81%8B%E3%81%9F%E3%81%BE72.pdf
(e4,2:�K)13 (e4,3:�K)14 �\�����ɑ呠�Ȃ̋�s�Ƌ����擾�A14 (e4,4:�K)15 ��{�܂ł� ��������15 (e4,5:
�K)16 ���{���� �l�S���~�Ƃ��A16 �O����\�����߂ǂɁA�J�Ƃ���B13
���̓_���l�����邽�߂ɁC�Q�ƕ\���̏o���ʒu��l��ŏC�����C���̌��ʂɑ��Đl��ŎQ�ƕ\����I������D
�������C�C�ӂ̕\���������Ă��܂��Ɩ�肪���U���邽�߁C����̕]���ł́u�Q�ƕ\�����ȗ�����v�u�Q�ƕ\������艻��
�Ė����I�ɋL�q����i�܂�C���� �g�́h �������� �g�ɂ́h���Ƃ��Ȃ��ĕ\������j�v�u��艻�����ɖ����I�ɋL�q����
�i�܂�C���� �g��/��/�Ɂh ���Ƃ��Ȃ��ĕ\������j�v�� 3 ��ނ���I�����Ă��炢�C�l�萶���̌X���͂���D
http://www.cl.cs.titech.ac.jp/~ryu-i/papers/NL206-15.pdf
(58) a. �w�����R�l���̌��Ńh�A���J����
b. ?? �w�������̌��łR�l�h�A���J����
(58a-b) �́A�V�����ʎ����A�אڂ��閼������C�����邱�Ƃ������12
(58b) �ł́A�u�R�l�v��
�u�w���v���אڂ��Ă��Ȃ����߁A�Ӑ}���ꂽ�C���W���������Ȃ��B���̊ώ@���ӂ܂��āA
Miyagawa (1989) �́A(59) �̕��@������Ίi�����̏؋��ƂȂ邱�Ƃ��w�E����B
(59) �h�A�����̌��łR�J����
��Ίi�����ɂ��A(59) �́u�J���v����Ίi�����ł��邱�Ƃ���A�u�h�A�v�́A(60) �Ɏ�
���悤�ɁA�ړI��̈ʒu�Ŏ��̖�������ɁA���̈ʒu�Ɉړ�����B
http://www.ic.nanzan-u.ac.jp/LINGUISTICS/staff/saito_mamoru/pdf/saito.2013.pdf
���{��̏ȗ����킩��{ �N���H�N�ɁH�����H
���R �d�q �� �^ �������@�i810.7�i�j
���{��̓����ł���ȗ����ƕ��@���瑨�����{�B��炢�̐���ȗ�
�̏����̐���܂ő̌n�I�ɉ���B���@�����Ȑl�⒆���҈ȉ��̊w�K�҂̂���
�Ɂu�ȗ��̃C���X�^���g���@�v�����^�B
https://www.ishikari-lib-unet.ocn.ne.jp/html/%E3%81%82%E3%81%8B%E3%81%9F%E3%81%BE72.pdf
26 �F�f�t�H���g�̖����������F2014/06/17(��) 11:34:59.62 ID:sceXYbna
�i�T�j�u�Ӗ��������́v�Ɓu�Ӗ�������́v�����邱�Ƃɂ��A���̓�̂��ꂼ��ɓK�����\
���`����Ǝ��ɔ��W�����邱�Ƃ��ł���B�u�Ӗ��������́v�̕\�����@�́A�k�b���͂��p�_�̌�����
�ʂ�������邱�Ƃɂ���Ă���ɔ��W�����邱�Ƃ��\�ł���B�܂��A�u�Ӗ�������́v�̕\���`���Ƃ��ẮA
�������R����� RDF/OWL �ȊO�ɂ��l�X�Ȃ��̂��g�p���邱�Ƃ��ł��A�u�Ӗ��������́v�̓��e�ɉ����čł�
�K�����\���`����I�����邱�Ƃ��ł���B�l�X�Ȍ`���̏�����̓I�Ɉ����V�X�e���̊J�����\�ł��낤�B
http://sigswo.org/papers/SIG-SWO-A1303/SIG-SWO-A1303-04.pdf
h4i �O�����̎��Ԃ��㕶���̎��Ԃ̑O��ƂȂ� : �u�`��v�̂悤�ȏ����߂͑O�����̎��Ԃ��㕶���̎��Ԃ���
�����邽�߂̑O������ƂȂ�D���̍ہC�p�^�����̖����傪�u���Ɓv�̂悤�Ȗ��m�Ȏ��Ԃ�����\���̏ꍇ
�ł����Ă��C�u�\���v�Ȃǂ̑O�����̎��ԂɃ��_���e�B�̏���t�^����\���ł����Ă��C���l�ɑO��ƂȂ��
�W��\�����ƂɂȂ�D�Ⴆ�C�� (9) �ł́C�u����i=�r�㍑�����̊�����̉����j�������グ��v���Ƃ��u��
�Ԃ����P����v���Ƃ̕K�v�����ƂȂ��Ă���D
(9) ������������T�N�ԁA�R�O����㔼�A�T�O�O�O���~���x�� �����グ�邱�Ƃ�����A���Ԃ͑傫�� ���P�����B
http://www.cl.cs.titech.ac.jp/~ryu-i/papers/nlp2014_ryu-i_discrel.pdf
���ۂ̂Ƃ���"this"��"is"�����ł����̈Ӗ��͑�������A���͂������Ȃ�قLjӖ��̑g�ݍ��킹�͑����Ȃ�A
�u�g�ݍ��킹�̔����v�Ƃ������ۂ��N���R���s���[�^�͎~�܂��Ă��܂��B����ɁA40 ��̃h���t����ɂƂ���
"This is a pen."�͂܂��ʂ̈Ӗ�������B
http://ed-www.ed.okayama-u.ac.jp/~shinri/terasawa/files%5Cthinking_new_theory_of_thinkingV5.pdf
���`����Ǝ��ɔ��W�����邱�Ƃ��ł���B�u�Ӗ��������́v�̕\�����@�́A�k�b���͂��p�_�̌�����
�ʂ�������邱�Ƃɂ���Ă���ɔ��W�����邱�Ƃ��\�ł���B�܂��A�u�Ӗ�������́v�̕\���`���Ƃ��ẮA
�������R����� RDF/OWL �ȊO�ɂ��l�X�Ȃ��̂��g�p���邱�Ƃ��ł��A�u�Ӗ��������́v�̓��e�ɉ����čł�
�K�����\���`����I�����邱�Ƃ��ł���B�l�X�Ȍ`���̏�����̓I�Ɉ����V�X�e���̊J�����\�ł��낤�B
http://sigswo.org/papers/SIG-SWO-A1303/SIG-SWO-A1303-04.pdf
h4i �O�����̎��Ԃ��㕶���̎��Ԃ̑O��ƂȂ� : �u�`��v�̂悤�ȏ����߂͑O�����̎��Ԃ��㕶���̎��Ԃ���
�����邽�߂̑O������ƂȂ�D���̍ہC�p�^�����̖����傪�u���Ɓv�̂悤�Ȗ��m�Ȏ��Ԃ�����\���̏ꍇ
�ł����Ă��C�u�\���v�Ȃǂ̑O�����̎��ԂɃ��_���e�B�̏���t�^����\���ł����Ă��C���l�ɑO��ƂȂ��
�W��\�����ƂɂȂ�D�Ⴆ�C�� (9) �ł́C�u����i=�r�㍑�����̊�����̉����j�������グ��v���Ƃ��u��
�Ԃ����P����v���Ƃ̕K�v�����ƂȂ��Ă���D
(9) ������������T�N�ԁA�R�O����㔼�A�T�O�O�O���~���x�� �����グ�邱�Ƃ�����A���Ԃ͑傫�� ���P�����B
http://www.cl.cs.titech.ac.jp/~ryu-i/papers/nlp2014_ryu-i_discrel.pdf
���ۂ̂Ƃ���"this"��"is"�����ł����̈Ӗ��͑�������A���͂������Ȃ�قLjӖ��̑g�ݍ��킹�͑����Ȃ�A
�u�g�ݍ��킹�̔����v�Ƃ������ۂ��N���R���s���[�^�͎~�܂��Ă��܂��B����ɁA40 ��̃h���t����ɂƂ���
"This is a pen."�͂܂��ʂ̈Ӗ�������B
http://ed-www.ed.okayama-u.ac.jp/~shinri/terasawa/files%5Cthinking_new_theory_of_thinkingV5.pdf
27 �F�f�t�H���g�̖����������F2014/06/19(��) 03:03:30.38 ID:xTtna/5L
�u�܂��܂���A����͉��v
�u �n���͉��A�N���悹�� �v
��̓�́u���v�́A�����Ӗ��ł����H
�u �n���͉��A�N���悹�� �v
��̓�́u���v�́A�����Ӗ��ł����H
28 �F�f�t�H���g�̖����������F2014/06/19(��) 07:49:02.24 ID:66eAVPNK
>>27
���܂��܂���A����͉��
�u��������͉h�����������A���a����͈Í��������v�i�i�n�ɑ��Y�j�Ƃ����ӂ��ɁA����͉��Ƃ����Ӗ��B
���n���͉��A�N���悹��
�u�n���v�𒆐S�ɂ��ĉ�]���Ă���A�Ƃ����Ӗ��B
���܂��܂���A����͉��
�u��������͉h�����������A���a����͈Í��������v�i�i�n�ɑ��Y�j�Ƃ����ӂ��ɁA����͉��Ƃ����Ӗ��B
���n���͉��A�N���悹��
�u�n���v�𒆐S�ɂ��ĉ�]���Ă���A�Ƃ����Ӗ��B
29 �F�f�t�H���g�̖����������F2014/06/19(��) 11:47:01.23 ID:7DkBqMX+
30 �F�f�t�H���g�̖����������F2014/06/20(��) 05:49:29.43 ID:408WaNYH
4.1.1 �� 1 ��
�㔼�̖₢�ɑ��āC�_ P ���̂� (x, y) �Ƃ��ĉ������Ƃ͂ł��Ȃ��������߁C
�_ P �̑��� (x, y) �Ƃ��Ė�����L�q�����D�ϐ��̓������@�ɂ́C���s���낪�K�v�ł���D
4.1.2 �� 2 ��
�m�� (e) �����w�Ŋw�Ԃ��Ƃ͂Ȃ��Ǝv���邪�CMaxValue[] �� MinValue[] �𗘗p���邽�߂ɂ́C
���̂悤�ȁC�v���O�����ł͂Ȃ������ŕ\�����邽�߂̒m�����L�p�ł��낤�D
�m�� (f) ��p�����ɁC�ʐς��O�p���ŋL�q�����܂܂ł́CMaxValue[] �� MinValue[] �ōő�l��ŏ��l��
���߂邱�Ƃ͂ł��Ȃ������D�O�p�����܂ގ��Ɋւ�����ł́C���̂悤�ȕϐ��ϊ����L�͂ȃe�N�j�b�N�ł���D
�@���Ƃ��ėL���Ȗ{�₾���C���������V�X�e���𗘗p����C��r�I�ȒP�ɉ�����D���������̉�@�́C
���� [���� 89]�ȂǂɌf�ڂ���Ă���悤�ȁC�l�Ԃ���ʼn������@�Ƃ͑傫���قȂ��Ă���D
4.1.3 �� 3 ��
a �ɂ��Ă� 3 ���������ɂȂ邱�Ƃ��킩���ď��߂Ēm��(b) �����p�ł���D���̂悤�ɁC��̓I�ȕ��j�����O�Ɍ��߂�
�̂�����ꍇ������D�{��@�ɂ������ 3 ��̌��_�͐} 1(a) �����C�͔͉͐}1(b) �̂悤�ɁC�Ȑ��̎����_�̍��W�C
�Ȑ����̂�_���̂��܂ނ��ǂ������`�������̂ɂȂ�D
4.1.4 �� 4 ��
Mathematica �ł́C��n i=1 x i−1 �̂悤�ȊȒP�Ȍv�Z���C����ȉ���i���̏ꍇ�� x ̸= 1�j�̉��ɍs����댯�����邱��
��m���Ă����Ȃ���Ȃ�Ȃ��DReduce[] �̈����� {a, s, b} �� {a, b, s} �ɂ���Ɖ����Ȃ��D�ϐ��̏��Ԃ���ł���D
4.1.5 �� 5 ��
�ڕ��ʂ� (x − 1) + ay + b(z − 1) = 0 �̌`�ŋL�q����ƁC�v�Z���Ԃ� 68 �b���� 3300 �b�ɁC���p�L���e�ʂ� 21 MB ����
230 MB �ɑ�������D���̂悤�ɁC�����錋�ʂ͓����ł��C�ϐ��̓������@�ɂ���Čv�Z���Ԃ͑傫���قȂ�ꍇ������D
4.1.6 �� 6 ��
�������̂܂ܒ莮�����Ă��C�����I�Ȏ��Ԃł͉����Ȃ��D(a)�C(b) �̂悤�Ȓm���ɂ���āC�v�Z�ʂ����炷�K�v������D
�̐� f ���Ct �̊��� u �� v �̊��ɕ������ɁCMaxValue[]�ōő�l�����߂邱�Ƃ͂ł��Ȃ������Df �� 2 �̕����ɕ�
�����邱�Ƃ́C�����Ă���r���ŏ��߂Ă킩�邱�Ƃł���D
https://kaigi.org/jsai/webprogram/2014/pdf/768.pdf
�㔼�̖₢�ɑ��āC�_ P ���̂� (x, y) �Ƃ��ĉ������Ƃ͂ł��Ȃ��������߁C
�_ P �̑��� (x, y) �Ƃ��Ė�����L�q�����D�ϐ��̓������@�ɂ́C���s���낪�K�v�ł���D
4.1.2 �� 2 ��
�m�� (e) �����w�Ŋw�Ԃ��Ƃ͂Ȃ��Ǝv���邪�CMaxValue[] �� MinValue[] �𗘗p���邽�߂ɂ́C
���̂悤�ȁC�v���O�����ł͂Ȃ������ŕ\�����邽�߂̒m�����L�p�ł��낤�D
�m�� (f) ��p�����ɁC�ʐς��O�p���ŋL�q�����܂܂ł́CMaxValue[] �� MinValue[] �ōő�l��ŏ��l��
���߂邱�Ƃ͂ł��Ȃ������D�O�p�����܂ގ��Ɋւ�����ł́C���̂悤�ȕϐ��ϊ����L�͂ȃe�N�j�b�N�ł���D
�@���Ƃ��ėL���Ȗ{�₾���C���������V�X�e���𗘗p����C��r�I�ȒP�ɉ�����D���������̉�@�́C
���� [���� 89]�ȂǂɌf�ڂ���Ă���悤�ȁC�l�Ԃ���ʼn������@�Ƃ͑傫���قȂ��Ă���D
4.1.3 �� 3 ��
a �ɂ��Ă� 3 ���������ɂȂ邱�Ƃ��킩���ď��߂Ēm��(b) �����p�ł���D���̂悤�ɁC��̓I�ȕ��j�����O�Ɍ��߂�
�̂�����ꍇ������D�{��@�ɂ������ 3 ��̌��_�͐} 1(a) �����C�͔͉͐}1(b) �̂悤�ɁC�Ȑ��̎����_�̍��W�C
�Ȑ����̂�_���̂��܂ނ��ǂ������`�������̂ɂȂ�D
4.1.4 �� 4 ��
Mathematica �ł́C��n i=1 x i−1 �̂悤�ȊȒP�Ȍv�Z���C����ȉ���i���̏ꍇ�� x ̸= 1�j�̉��ɍs����댯�����邱��
��m���Ă����Ȃ���Ȃ�Ȃ��DReduce[] �̈����� {a, s, b} �� {a, b, s} �ɂ���Ɖ����Ȃ��D�ϐ��̏��Ԃ���ł���D
4.1.5 �� 5 ��
�ڕ��ʂ� (x − 1) + ay + b(z − 1) = 0 �̌`�ŋL�q����ƁC�v�Z���Ԃ� 68 �b���� 3300 �b�ɁC���p�L���e�ʂ� 21 MB ����
230 MB �ɑ�������D���̂悤�ɁC�����錋�ʂ͓����ł��C�ϐ��̓������@�ɂ���Čv�Z���Ԃ͑傫���قȂ�ꍇ������D
4.1.6 �� 6 ��
�������̂܂ܒ莮�����Ă��C�����I�Ȏ��Ԃł͉����Ȃ��D(a)�C(b) �̂悤�Ȓm���ɂ���āC�v�Z�ʂ����炷�K�v������D
�̐� f ���Ct �̊��� u �� v �̊��ɕ������ɁCMaxValue[]�ōő�l�����߂邱�Ƃ͂ł��Ȃ������Df �� 2 �̕����ɕ�
�����邱�Ƃ́C�����Ă���r���ŏ��߂Ă킩�邱�Ƃł���D
https://kaigi.org/jsai/webprogram/2014/pdf/768.pdf
31 �F�f�t�H���g�̖����������F2014/06/20(��) 16:45:06.34 ID:Egd9IXkN
�V�D�R�@���w���f���͌������E�Ƙ_�����E�����ԉ˂����̈��
�@���͊�ƂɋΖ����Ă������A���낢��ȕ���̃v�����g�̐���V�X�e���̊J���⓮�����V�~�����[�V����
�ɏ]�����Ă��܂������A�����Ő��w���f���̗L������Ɋ����܂����B
�@����́A�������w���f�����쐬�ł���ΐ��E���܂������ς���Ă��܂����Ƃł��B�������E�ł́A
�Ώۂ̋����͍\���A�ޗ��A�`��⓮����Ȃǂ��낢��ȏ����ɍ��E����A�����傫���ς��邱�Ƃ�
�����I�ɓ�����Ƃ������A��X�̎v�l������ɔ����邱�Ƃ������̂������ł��B
�@���w���f���������ł���A�_�����E�ɓ��邱�Ƃ��ł��A�����ł͋֎~����Ă���̂͘_���I�Ȗ��������ł��B
���w���_�͂������A�֘A�������l��́A�R���s���[�^�E�O���t�B�b�N���X�̌v��@�����p�ł��܂��B
����ɂ��A�������E�ɂƂǂ܂��Ă�����蓾���Ȃ��V�����A�C�f�A���o�Ă���\��������܂��B
���w���f���͌������E�Ƙ_�����E�����ԉ˂����ƂȂ�܂��B�������ʉ�����ƁA�u���f���͌������E
�Ɖ��z���E�����ԉ˂����v�ƌ����邩������܂���B
�@�����A�_�����E�œ���ꂽ���ʂ��������E�Ŏ������邽�߂ɂ́A���ꂪ�������E�ŗL�����܂������\
�Ȃ��̂Ȃ̂��ׂ�K�v������܂��B�������A����͘_�����E�̒��ł͕s�\�ł��B�������E�ɖ߂����߂ɂ́A
�ʂ̕��@���K�v�ł��B���ꂪ�V�~�����[�V�����ł��B���w���f���ƃV�~�����[�V�����ɂ��A���H�Ɨ��_�̌������}���̂ł��B
http://www.wind.sannet.ne.jp/masa-t/semioeng/modeling/modelasim/mas07/mas07.html
�@���͊�ƂɋΖ����Ă������A���낢��ȕ���̃v�����g�̐���V�X�e���̊J���⓮�����V�~�����[�V����
�ɏ]�����Ă��܂������A�����Ő��w���f���̗L������Ɋ����܂����B
�@����́A�������w���f�����쐬�ł���ΐ��E���܂������ς���Ă��܂����Ƃł��B�������E�ł́A
�Ώۂ̋����͍\���A�ޗ��A�`��⓮����Ȃǂ��낢��ȏ����ɍ��E����A�����傫���ς��邱�Ƃ�
�����I�ɓ�����Ƃ������A��X�̎v�l������ɔ����邱�Ƃ������̂������ł��B
�@���w���f���������ł���A�_�����E�ɓ��邱�Ƃ��ł��A�����ł͋֎~����Ă���̂͘_���I�Ȗ��������ł��B
���w���_�͂������A�֘A�������l��́A�R���s���[�^�E�O���t�B�b�N���X�̌v��@�����p�ł��܂��B
����ɂ��A�������E�ɂƂǂ܂��Ă�����蓾���Ȃ��V�����A�C�f�A���o�Ă���\��������܂��B
���w���f���͌������E�Ƙ_�����E�����ԉ˂����ƂȂ�܂��B�������ʉ�����ƁA�u���f���͌������E
�Ɖ��z���E�����ԉ˂����v�ƌ����邩������܂���B
�@�����A�_�����E�œ���ꂽ���ʂ��������E�Ŏ������邽�߂ɂ́A���ꂪ�������E�ŗL�����܂������\
�Ȃ��̂Ȃ̂��ׂ�K�v������܂��B�������A����͘_�����E�̒��ł͕s�\�ł��B�������E�ɖ߂����߂ɂ́A
�ʂ̕��@���K�v�ł��B���ꂪ�V�~�����[�V�����ł��B���w���f���ƃV�~�����[�V�����ɂ��A���H�Ɨ��_�̌������}���̂ł��B
http://www.wind.sannet.ne.jp/masa-t/semioeng/modeling/modelasim/mas07/mas07.html
32 �F�f�t�H���g�̖����������F2014/06/23(��) 11:54:56.02 ID:wCGes4Or
(1) John,fired Dave,because he had too many absesces.(he=dave)
(1) John,fired Dave,because he had too many employees.(he=dave)
����� 2 ���́C����̕��\���ł���C�Ⴂ�� absences ���C
employees �݂̂ł���Dhe �ɂ� John �� Dave �����肤�邽�߁C
����I�ȓ�������шӖ��I�ȓ����͖��ɗ����Ȃ��D
�����ŏd�v�Ȏ肪����ƂȂ�̂́C�ufire ���鑤�͏]�ƈ�������闧��v
�u���������l�� fired �����v�Ƃ������C���ۊԂ̊W�m���ł���D
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/A5-2.pdf
(1) John,fired Dave,because he had too many employees.(he=dave)
����� 2 ���́C����̕��\���ł���C�Ⴂ�� absences ���C
employees �݂̂ł���Dhe �ɂ� John �� Dave �����肤�邽�߁C
����I�ȓ�������шӖ��I�ȓ����͖��ɗ����Ȃ��D
�����ŏd�v�Ȏ肪����ƂȂ�̂́C�ufire ���鑤�͏]�ƈ�������闧��v
�u���������l�� fired �����v�Ƃ������C���ۊԂ̊W�m���ł���D
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/A5-2.pdf
33 �F�f�t�H���g�̖����������F2014/06/23(��) 17:07:41.81 ID:Z0nKY4vk
���S�Ɍ`�ԑf��͂��������ǂł��Ȃ��B
���� ����,�ŗL����,�l��,��,*,*,����,�I�m,�I�m
�� ����,���,*,*,*,*,��,�C���E�g,�C���[�g
�q ����,�ڔ�,������,*,*,*,�q,�V,�V
�� ����,�W����,*,*,*,*,��,�n,��
�� ����,����,*,*,�ܒi�E���s,�̌��ڑ�����Q,����,��,��
�@ ����,���,*,*,*,*,�@,�Y�C,�Y�C
�g ����,�ڔ�,���,*,*,*,�g,�V,�V
�ł� ������,*,*,*,����E�f�X,��{�`,�ł�,�f�X,�f�X
EOS
�ɂȂ�Bmecab�Ŏ����p�����[�^�ŏ��l�ɂ������ǁB
�ǂ���������̂��낤��
���� ����,�ŗL����,�l��,��,*,*,����,�I�m,�I�m
�� ����,���,*,*,*,*,��,�C���E�g,�C���[�g
�q ����,�ڔ�,������,*,*,*,�q,�V,�V
�� ����,�W����,*,*,*,*,��,�n,��
�� ����,����,*,*,�ܒi�E���s,�̌��ڑ�����Q,����,��,��
�@ ����,���,*,*,*,*,�@,�Y�C,�Y�C
�g ����,�ڔ�,���,*,*,*,�g,�V,�V
�ł� ������,*,*,*,����E�f�X,��{�`,�ł�,�f�X,�f�X
EOS
�ɂȂ�Bmecab�Ŏ����p�����[�^�ŏ��l�ɂ������ǁB
�ǂ���������̂��낤��
34 �F�f�t�H���g�̖����������F2014/06/23(��) 18:01:02.28 ID:qZVVaTos
���얅�q�A
���q�A
���@�g
�̂R���o�^����
���q�A
���@�g
�̂R���o�^����
35 �F�f�t�H���g�̖����������F2014/06/24(��) 00:30:04.82 ID:13L7pvDP
�ł��Ȃ�
36 �F�f�t�H���g�̖����������F2014/06/24(��) 00:45:44.58 ID:13L7pvDP
�ǂ����Ă������o�^���F�����Ă���Ȃ��B����ƍN�͂ł���Γ���{�ƍN�łȂ�����ƍN�ƔF��
���Ăق����̂����m���ɂł���肾�Ă͂Ȃ��̂��낤���H
���Ăق����̂����m���ɂł���肾�Ă͂Ȃ��̂��낤���H
37 �F�f�t�H���g�̖����������F2014/06/24(��) 01:30:56.05 ID:1OnpMhpf
�Œ���v�@
38 �F�f�t�H���g�̖����������F2014/06/24(��) 01:36:52.54 ID:13L7pvDP
mecab�łǂ�����̂���m�肽���B
39 �F�f�t�H���g�̖����������F2014/06/24(��) 08:21:43.05 ID:+csYm/QE
mecab���D�G����Ȃ��āA���������Ȃǂ̓��{�ꕶ�@���@�B�I�ȉ�͂Ɍ����Ă����������B
40 �F�f�t�H���g�̖����������F2014/06/24(��) 11:28:06.49 ID:AfD6RzLL
�����ĂȂ������ĂȂ��B
�킩�������̂悤�ȓ���ȏ����������ĂȂ�����A�P��̋�肪�s���ĂƂ��B
�킩�������̂悤�ȓ���ȏ����������ĂȂ�����A�P��̋�肪�s���ĂƂ��B
41 �F�f�t�H���g�̖����������F2014/06/24(��) 17:41:46.27 ID:FbF3Qsch
���ꎫ���o�^����̂͌��E�������ˁB
Google������Wikipedia�̃f�[�^�����������Ă��ėp�������Ȃ�Ă��Ƃ��K�v�ɂȂ肻���B
Google������Wikipedia�̃f�[�^�����������Ă��ėp�������Ȃ�Ă��Ƃ��K�v�ɂȂ肻���B
42 �F�f�t�H���g�̖����������F2014/06/24(��) 18:02:41.00 ID:1OnpMhpf
�����F���ɓK�����`�ԑf��͂��Ė������낤���H
43 �F�f�t�H���g�̖����������F2014/06/25(��) 01:28:47.07 ID:A+D1SfZu
>>Google������Wikipedia�̃f�[�^�����������Ă��ėp�������Ȃ�Ă��Ƃ��K�v�ɂȂ肻���B
���ꂪ�ł��Ȃ��BWikiPedia��DL���ăA���J�[�����o���ėp��W����Ă�
�R�X�g�̒l�߂��Ȃ��Ɛ������ł��Ȃ�.
mecab�͑����������H
���ꂪ�ł��Ȃ��BWikiPedia��DL���ăA���J�[�����o���ėp��W����Ă�
�R�X�g�̒l�߂��Ȃ��Ɛ������ł��Ȃ�.
mecab�͑����������H
44 �F�f�t�H���g�̖����������F2014/06/25(��) 01:32:05.16 ID:A+D1SfZu
Juman��kytea�������̂��H
mecab�͔����Ɍ`�ԑf���ւ�BWe���̋L���Ȃ�ƂĂ�99%������������Ƃ͎v���Ȃ�
�V���L���ł����₵��
mecab�͔����Ɍ`�ԑf���ւ�BWe���̋L���Ȃ�ƂĂ�99%������������Ƃ͎v���Ȃ�
�V���L���ł����₵��
45 �F�f�t�H���g�̖����������F2014/06/25(��) 07:47:26.06 ID:UMucURAO
99%�������������瑼�ɂ͉�������Ȃ��Ƃ������x���̐��x�����
46 �F�f�t�H���g�̖����������F2014/06/26(��) 09:41:16.59 ID:S6b66RTi
�q���̌���\�����͂����ƂɁC�u������`���v�C�u�p�ꑮ���v�C�u���z�ގ��x�v�C�u�@�\�\���v�Ƃ��������̌���m����p���C
������f���Ƃ������ʊw�K�œ��`������s���D
https://www.jstage.jst.go.jp/article/jnlp/20/4/20_539/_pdf
�@�܂�A�u�䏊�v�Ƃ����\���������Ƃ�����ʁ������t���[�������N����g���K�[�Ƃ��ē����A����
�悤�ȃt���[���̂Ȃ��ŁA�����l�⒲����ƁA��������A����ɗ����ɂ������p���A�����Ɋւ��
���l�ȗv�f���w�������킯�ł���B���L�́A���̂悤�Ȍ��ꌻ�ۂ𑽖ʓI���`�ƌĂсA���̑��ɂ�
�u�w�Z�v�u�a�@�v�u��s�v�Ƃ������T�O���A������g�D�A�����ʼnc�܂�銈�����A���l�Ȍ��ۂ̏W���Ƃ�
�ĕ��͂����Ǝw�E���Ă���B
http://opac.lib.yamanashi.ac.jp/metadb/up/honkan/13_302-320.pdf
�i�P�j���`��F�����Ӗ������P��ł���A�e�L�X�g���ł̒u���������\�ł���P��̃y�A�B�u�R���s���[�^�v�Ɓu�d�q�v�Z�@�v�ȂǁB
�i�Q�j��ʁ^���ʌ�F����������̏�ʊT�O�ł���悤�ȒP��y�A�B�u�R���s���[�^�v�Ɓu�T�[�o�v�ȂǁB
�i�R�j�����^�S�̌�F����������̈ꕔ�ł���悤�ȒP��y�A�B�u�X�q�v�Ɓu�v�ȂǁB
�i�S�j�`��F�ƂȂ�T�O�������P��y�A�B�u�j�v�Ɓu���v�ȂǁB
�i�T�j�Z���F���`�ł͂Ȃ����A���ʂ̏�ʊT�O�����P��y�A�B�u���[�^�v�Ɓu�T�[�o�v�ȂǁB
�i�U�j�֘A��F�ގ����Ă��炸�A�K�w�I�ł��Ȃ����A�T�O�I�ɘA�z�����P��y�A�B�u�זE�v�Ɓu�זE�w�v�ȂǁB
http://www.google.com/patents/WO2014033799A1?cl=ja
��(2)�̓����u������v�́A�ȉ��̂悤�ȈӖ��������Ă��邱�Ƃ���A�������̂��������������Ă��邱�Ƃ��f����B
�E�s����g���������Ȃǂɂ��Ē��ӂ�^���ē����B���܂��߂�B���Ƃ��B
�E�m���Ă��鎖�⎩���̋C���A�v���Ȃǂ𑼂̐l�ɍ����m�点��B
�E�m���A�Z�|�Ȃǂ�g�ɂ���悤�ɂ�����B��������B
�E�����Ă��肵�āA������������悤�ɂ��ނ���B
http://www.ninjal.ac.jp/event/specialists/project-meeting/files/JCLWorkshop_no5_papers/JCLWorkshop_No5_04.pdf
������f���Ƃ������ʊw�K�œ��`������s���D
https://www.jstage.jst.go.jp/article/jnlp/20/4/20_539/_pdf
�@�܂�A�u�䏊�v�Ƃ����\���������Ƃ�����ʁ������t���[�������N����g���K�[�Ƃ��ē����A����
�悤�ȃt���[���̂Ȃ��ŁA�����l�⒲����ƁA��������A����ɗ����ɂ������p���A�����Ɋւ��
���l�ȗv�f���w�������킯�ł���B���L�́A���̂悤�Ȍ��ꌻ�ۂ𑽖ʓI���`�ƌĂсA���̑��ɂ�
�u�w�Z�v�u�a�@�v�u��s�v�Ƃ������T�O���A������g�D�A�����ʼnc�܂�銈�����A���l�Ȍ��ۂ̏W���Ƃ�
�ĕ��͂����Ǝw�E���Ă���B
http://opac.lib.yamanashi.ac.jp/metadb/up/honkan/13_302-320.pdf
�i�P�j���`��F�����Ӗ������P��ł���A�e�L�X�g���ł̒u���������\�ł���P��̃y�A�B�u�R���s���[�^�v�Ɓu�d�q�v�Z�@�v�ȂǁB
�i�Q�j��ʁ^���ʌ�F����������̏�ʊT�O�ł���悤�ȒP��y�A�B�u�R���s���[�^�v�Ɓu�T�[�o�v�ȂǁB
�i�R�j�����^�S�̌�F����������̈ꕔ�ł���悤�ȒP��y�A�B�u�X�q�v�Ɓu�v�ȂǁB
�i�S�j�`��F�ƂȂ�T�O�������P��y�A�B�u�j�v�Ɓu���v�ȂǁB
�i�T�j�Z���F���`�ł͂Ȃ����A���ʂ̏�ʊT�O�����P��y�A�B�u���[�^�v�Ɓu�T�[�o�v�ȂǁB
�i�U�j�֘A��F�ގ����Ă��炸�A�K�w�I�ł��Ȃ����A�T�O�I�ɘA�z�����P��y�A�B�u�זE�v�Ɓu�זE�w�v�ȂǁB
http://www.google.com/patents/WO2014033799A1?cl=ja
��(2)�̓����u������v�́A�ȉ��̂悤�ȈӖ��������Ă��邱�Ƃ���A�������̂��������������Ă��邱�Ƃ��f����B
�E�s����g���������Ȃǂɂ��Ē��ӂ�^���ē����B���܂��߂�B���Ƃ��B
�E�m���Ă��鎖�⎩���̋C���A�v���Ȃǂ𑼂̐l�ɍ����m�点��B
�E�m���A�Z�|�Ȃǂ�g�ɂ���悤�ɂ�����B��������B
�E�����Ă��肵�āA������������悤�ɂ��ނ���B
http://www.ninjal.ac.jp/event/specialists/project-meeting/files/JCLWorkshop_no5_papers/JCLWorkshop_No5_04.pdf
47 �F�f�t�H���g�̖����������F2014/06/27(��) 04:03:33.62 ID:MjVrnFmf
�V���Ƃ��̃f�[�^���炩��u����+����+�����v�̑g�ݍ��킹���Ђ���Ă��������ǁA�\����͂���K�v����܂����H��Ⴂ�������炷�݂܂���
48 �F�f�t�H���g�̖����������F2014/06/28(�y) 06:42:58.08 ID:gMf17FhW
��2ch�X���b�h���������L���O�T�C�g���X�g��
��+�j���[�X��
�E 2NN (�����T�C�g)
�E 2chTimes
��+�j���[�X�V��
�E 2NN�V��
�E Headline BBY
�E unker Headline
��+�j���[�X���̑�
�E Desktop2ch
�E �L�ҕʈꗗ
���S��
�E �S�c�f���������L���O (�����T�C�g)
�E �X���b�h�����L���O���������L���O
�E ���O��
���S��������
�E 2�� (�����T�C�g)
�E READ2CH
�E i-ikioi
�� �v�^�C�g������
�� 2ch�u���E�U���p����
��+�j���[�X��
�E 2NN (�����T�C�g)
�E 2chTimes
��+�j���[�X�V��
�E 2NN�V��
�E Headline BBY
�E unker Headline
��+�j���[�X���̑�
�E Desktop2ch
�E �L�ҕʈꗗ
���S��
�E �S�c�f���������L���O (�����T�C�g)
�E �X���b�h�����L���O���������L���O
�E ���O��
���S��������
�E 2�� (�����T�C�g)
�E READ2CH
�E i-ikioi
�� �v�^�C�g������
�� 2ch�u���E�U���p����
49 �F�f�t�H���g�̖����������F2014/06/28(�y) 13:20:04.17 ID:pYYcNfOX
�Ⴆ�A�u��`�ւ̃A�N�Z�X�ׂ�v�Ƃ������͕��ɑ��āA�u�A�N�Z�X�v�������������ꍇ�A
�u��`�ւ́����v�Ƃ����O�����Ɓu�����ׂ�v�Ƃ����㕶���ɕ����ăR�[�p�X��T�����A
�����ɊY�����閼���̂������ʂ��閼���𒊏o����B�} 1 �̗�ł́A�O�����ƌ㕶���ŋ��ʂ���
�p������u��芷���v�u�����v�u�s�����v�� 3 �P�ꂪ���o�����B
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/D5-1.pdf
�Ӗ���Ԃ͂P�����ł͂Ȃ��������ł���. �ǂ̑����ɒ��ڂ��āi�ϓ_�Łj���ނ��邩�ɂ���āA���낢��ȕ��ނ̎d�����l������.
�g�߂ȗ�Łu�����v�ɂ��čl���Ă݂�D�Í������̗����̎�ނ͑����Ȑ��ɂȂ�A���ނ̎d�����l�ɂ���ĈقȂ�D
�����Œ����@�A�ޗ��A�n���3 �̊ϓ_�ŕ��ނ���Ƃ��̂悤�ɂȂ�D
�����@�̊ϓ_�ŕ��ނ���Ɓ@�����́A�ϕ��A�Ă���
�ޗ��̊ϓ_�ŕ��ނ���Ɓ@�@�������A�������A��ؗ���
�n��̊ϓ_�ŕ��ނ���Ɓ@�@�a�H�A���A�m�H
�Ⴆ�u�h���g�v�́A�������R�̊ϓ_�ɂ���ĕ��ނ������ʁA�A�z���ꂽ�p��u�������v�u�����́v�u�a�H�v�̋��`��ł���.
�t�Ɂu�h���g�v�̍L�`�ꂪ�u�����́v�u�������v�u�a�H�v�̂R���邱�ƂɂȂ�D���̌��ʁA�ԍ\���ɂȂ�B�����}�ɂ���ƁA�}�P�̂悤�ɂȂ�.
http://www.asahi-net.or.jp/~wd2y-kkb/t.pdf
�u��`�ւ́����v�Ƃ����O�����Ɓu�����ׂ�v�Ƃ����㕶���ɕ����ăR�[�p�X��T�����A
�����ɊY�����閼���̂������ʂ��閼���𒊏o����B�} 1 �̗�ł́A�O�����ƌ㕶���ŋ��ʂ���
�p������u��芷���v�u�����v�u�s�����v�� 3 �P�ꂪ���o�����B
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/D5-1.pdf
�Ӗ���Ԃ͂P�����ł͂Ȃ��������ł���. �ǂ̑����ɒ��ڂ��āi�ϓ_�Łj���ނ��邩�ɂ���āA���낢��ȕ��ނ̎d�����l������.
�g�߂ȗ�Łu�����v�ɂ��čl���Ă݂�D�Í������̗����̎�ނ͑����Ȑ��ɂȂ�A���ނ̎d�����l�ɂ���ĈقȂ�D
�����Œ����@�A�ޗ��A�n���3 �̊ϓ_�ŕ��ނ���Ƃ��̂悤�ɂȂ�D
�����@�̊ϓ_�ŕ��ނ���Ɓ@�����́A�ϕ��A�Ă���
�ޗ��̊ϓ_�ŕ��ނ���Ɓ@�@�������A�������A��ؗ���
�n��̊ϓ_�ŕ��ނ���Ɓ@�@�a�H�A���A�m�H
�Ⴆ�u�h���g�v�́A�������R�̊ϓ_�ɂ���ĕ��ނ������ʁA�A�z���ꂽ�p��u�������v�u�����́v�u�a�H�v�̋��`��ł���.
�t�Ɂu�h���g�v�̍L�`�ꂪ�u�����́v�u�������v�u�a�H�v�̂R���邱�ƂɂȂ�D���̌��ʁA�ԍ\���ɂȂ�B�����}�ɂ���ƁA�}�P�̂悤�ɂȂ�.
http://www.asahi-net.or.jp/~wd2y-kkb/t.pdf
50 �F�f�t�H���g�̖����������F2014/06/28(�y) 13:47:07.22 ID:mTJgjjdL
>>47
�\����͕͂K�v�Ȃ����`�ԑf��͂͂���
�\����͕͂K�v�Ȃ����`�ԑf��͂͂���
51 �F�f�t�H���g�̖����������F2014/06/28(�y) 13:54:17.48 ID:la3VBp+u
52 �F�f�t�H���g�̖����������F2014/06/28(�y) 14:49:34.97 ID:Wnh+uZwR
�\����͂܂Ŋ܂߂�Ȃ�
���̐������x�̍�����͂��K�v�ɂȂ�b�ł͂Ȃ���
���̐������x�̍�����͂��K�v�ɂȂ�b�ł͂Ȃ���
53 �F�f�t�H���g�̖����������F2014/06/28(�y) 18:38:56.18 ID:ago1EUHo
>>51 ���˃J�X�B���˂���Ȃ��Ď��ˁB
54 �F�f�t�H���g�̖����������F2014/06/29(��) 19:17:16.27 ID:8NVTS3/J
�}��C���X�g�̗���
�Z���^�[�����̉p��̖��ł́A�}��C���X�g�����p����܂��B�l�Ԃł������ł������ł���悤�ȊȒP�Ȑ}�ł����A
����𗝉����邱�Ƃ̓R���s���[�^�ɂƂ��Ă͎���̋Ƃł��B�摜�F���̌����͂�����ɍs���Ă��܂����A�قƂ�ǂ�
�����͎ʐ^��ΏۂƂ��Ă���A�}��C���X�g�𗝉����錤���͂قƂ�Ǎs���Ă��܂���B����́A�f�t�H�������ꂽ�C���[�W
�𗝉����邽�߂ɂ͂��܂��܂ȏ펯���K�v�ł���A���̂Ƃ���L���ȃA�v���[�`���S����������Ȃ����߂ƍl�����܂��B
�l�ԂɂƂ��Ă͐}��C���X�g�̗����͎�������������ŏd�v�ȃ|�C���g�ł͂Ȃ��ł����A�l�ԂɂƂ��ē�����O�����邩�炱���A
�t�ɃR���s���[�^�ɂƂ��Ă͔��ɓ���ƌ����܂��B
http://21robot.org/research_activities/english/
�@�����V�~�����[�^���g�����Ƃ̏������ɂ��āA���쎁�́A�u�Ⴆ�A�e�[�u���̏��]������̂������Ƃ��A
�l�͂Ƃ����Ɏ���o���ăe�[�u�����痎���Ȃ��悤�ɂ��܂��B�Ƃ��낪�A���̃��{�b�g�́A�]�����Ă�����̂�F���ł��Ă��A
�����̖@���ɏ]���Ă��ꂪ�e�[�u�����痎���邱�Ƃ܂ł͗\���ł��܂���B�l�H���]���i�W����A�����E�̏𗝉����A
�����@���ɏ]���ĕω����鎖�ۂ��V�~�����[�V�����ɂ���ă��f�������A������\�����邱�Ƃ��ł���ł��傤�v�ƌ��B
http://21robot.org/%E3%83%9B%E3%83%BC%E3%83%A0/introduce/NII-Special-2/
�Z���^�[�����̉p��̖��ł́A�}��C���X�g�����p����܂��B�l�Ԃł������ł������ł���悤�ȊȒP�Ȑ}�ł����A
����𗝉����邱�Ƃ̓R���s���[�^�ɂƂ��Ă͎���̋Ƃł��B�摜�F���̌����͂�����ɍs���Ă��܂����A�قƂ�ǂ�
�����͎ʐ^��ΏۂƂ��Ă���A�}��C���X�g�𗝉����錤���͂قƂ�Ǎs���Ă��܂���B����́A�f�t�H�������ꂽ�C���[�W
�𗝉����邽�߂ɂ͂��܂��܂ȏ펯���K�v�ł���A���̂Ƃ���L���ȃA�v���[�`���S����������Ȃ����߂ƍl�����܂��B
�l�ԂɂƂ��Ă͐}��C���X�g�̗����͎�������������ŏd�v�ȃ|�C���g�ł͂Ȃ��ł����A�l�ԂɂƂ��ē�����O�����邩�炱���A
�t�ɃR���s���[�^�ɂƂ��Ă͔��ɓ���ƌ����܂��B
http://21robot.org/research_activities/english/
�@�����V�~�����[�^���g�����Ƃ̏������ɂ��āA���쎁�́A�u�Ⴆ�A�e�[�u���̏��]������̂������Ƃ��A
�l�͂Ƃ����Ɏ���o���ăe�[�u�����痎���Ȃ��悤�ɂ��܂��B�Ƃ��낪�A���̃��{�b�g�́A�]�����Ă�����̂�F���ł��Ă��A
�����̖@���ɏ]���Ă��ꂪ�e�[�u�����痎���邱�Ƃ܂ł͗\���ł��܂���B�l�H���]���i�W����A�����E�̏𗝉����A
�����@���ɏ]���ĕω����鎖�ۂ��V�~�����[�V�����ɂ���ă��f�������A������\�����邱�Ƃ��ł���ł��傤�v�ƌ��B
http://21robot.org/%E3%83%9B%E3%83%BC%E3%83%A0/introduce/NII-Special-2/
55 �F�f�t�H���g�̖����������F2014/06/30(��) 11:11:53.76 ID:yTE03nVF
�ꎟ���o��͂قډ𖾂���Ă�
�ʐ^�ƃC���X�g�͂�����ʂ��Ȃ�
�ʐ^�ƃC���X�g�͂�����ʂ��Ȃ�
56 �F�f�t�H���g�̖����������F2014/06/30(��) 11:48:04.73 ID:9KK/EJtO
���W���[�����_�Ƃ��A���\�N�̊Ԃɂ����Ԑi���
57 �F�f�t�H���g�̖����������F2014/06/30(��) 13:42:52.23 ID:tZCwK3PP
>>55
���ꎟ���o��͂قډ𖾂���Ă�
���ʐ^�ƃC���X�g�͂�����ʂ��Ȃ�
�@�����炭�ŏ��Ƃ͈قȂ锻�f�ɂȂ����̂ł͂Ȃ��ł��傤���B���̂悤�ɁA�������͌o���₱��܂ł̏����Â��ɂ���āA
���ӎ��̂����Ɂu���߂��v���s�������ł��B���̊G�̂悤�ɁA�킸�����b���������ł��傫�Ȍ��_�̈Ⴂ�ނ��Ƃ�
����킯�ł�����A����܂Œ����l���̒��Ŕ|���Ă����u���߂��v�́A���Ȃ��̂��܂��܂Ȕ��f�ɑ傫�ȉe�����y�ڂ��܂��B
�����āA���������ς��ۂɂ�錈�߂��͔��Ɋ댯�Ȃ��̂Ƃ��킴��܂���B
���̊G�A���Ɍ����܂����H�\�\���Ȃ��́g�v�����݁h���e�X�g����
http://bizmakoto.jp/bizid/articles/0905/29/news009.html
���ꎟ���o��͂قډ𖾂���Ă�
���ʐ^�ƃC���X�g�͂�����ʂ��Ȃ�
�@�����炭�ŏ��Ƃ͈قȂ锻�f�ɂȂ����̂ł͂Ȃ��ł��傤���B���̂悤�ɁA�������͌o���₱��܂ł̏����Â��ɂ���āA
���ӎ��̂����Ɂu���߂��v���s�������ł��B���̊G�̂悤�ɁA�킸�����b���������ł��傫�Ȍ��_�̈Ⴂ�ނ��Ƃ�
����킯�ł�����A����܂Œ����l���̒��Ŕ|���Ă����u���߂��v�́A���Ȃ��̂��܂��܂Ȕ��f�ɑ傫�ȉe�����y�ڂ��܂��B
�����āA���������ς��ۂɂ�錈�߂��͔��Ɋ댯�Ȃ��̂Ƃ��킴��܂���B
���̊G�A���Ɍ����܂����H�\�\���Ȃ��́g�v�����݁h���e�X�g����
http://bizmakoto.jp/bizid/articles/0905/29/news009.html
58 �F�f�t�H���g�̖����������F2014/06/30(��) 16:33:45.79 ID:yTE03nVF
>>57
����͓��o��ȏ�̘b��
����͓��o��ȏ�̘b��
59 �F�f�t�H���g�̖����������F2014/06/30(��) 17:46:07.82 ID:ULkK/oEi
>>57
�l�Ɍ�������I�b�T���Ɍ�������E�E�E�l�Ԃ��C���X�g����ǂ��郁�J�j�Y���͂悭�킩��Ȃ��B
�l�Ɍ�������I�b�T���Ɍ�������E�E�E�l�Ԃ��C���X�g����ǂ��郁�J�j�Y���͂悭�킩��Ȃ��B
60 �F�f�t�H���g�̖����������F2014/06/30(��) 18:56:54.14 ID:OP+eMRFG
�R�͈Ⴄ�G������A�l�Y�~�Ɍ�����̂���������Ɍ�����̂�
���̒��ԂɌ�����̂��Ӑ}�ʂ�Ƃ��������Ȃ�
���̒��ԂɌ�����̂��Ӑ}�ʂ�Ƃ��������Ȃ�
61 �F�f�t�H���g�̖����������F2014/06/30(��) 20:02:41.31 ID:bnSHXbvL
����ԉ摜�����Ői��ł�̂̓R���{�����[�V�����j���[�����l�b�g
��ݍ��݂����ĂāA���o��ɋ߂��Ƃ͌����Ă�
��ݍ��݂����ĂāA���o��ɋ߂��Ƃ͌����Ă�
62 �F�f�t�H���g�̖����������F2014/06/30(��) 20:49:30.42 ID:CGk8SAom
IBM�̃��g�\���N�͉��̖��ɗ����Ă�́H
63 �F�f�t�H���g�̖����������F2014/06/30(��) 21:02:54.51 ID:CGk8SAom
��ƂɂP�䃏�g�\���N
64 �F�f�t�H���g�̖����������F2014/06/30(��) 21:03:06.40 ID:9KK/EJtO
�Z�p�́A��ʂ̃e�L�X�g�Ƀ^�O��t���ăR�[�p�X��������Ƃ��A�������������ɉ��p����Ă�
���낤�Ǝv�����ǁB
���낤�Ǝv�����ǁB
65 �F�f�t�H���g�̖����������F2014/06/30(��) 21:07:00.10 ID:CGk8SAom
�݂�ȂŃ��g�\���N���ǂ�����Ċ��p���邩�l���悤!!
66 �F�f�t�H���g�̖����������F2014/06/30(��) 21:14:43.35 ID:CGk8SAom
�����A�C�f�A���v���t����!!
���g�\����Web�Ɍ��J���A������ł��錠����̔������IBM���ڂ�ׂ��ł��邼���I
���g�\����Web�Ɍ��J���A������ł��錠����̔������IBM���ڂ�ׂ��ł��邼���I
67 �F�f�t�H���g�̖����������F2014/06/30(��) 21:46:33.42 ID:avOqRzMr
>>62
�Ƃ肠�����͈�Ðf�f�Ɏg�����Ƃ��Ă���B
�摜�f�f��摜�F���A�����F���Z�p�Ƒg�ݍ��킹��A�f�f����ɐl�Ԃ�
�o�開�͂Ȃ��Ȃ��Ȃ���
�Ƃ肠�����͈�Ðf�f�Ɏg�����Ƃ��Ă���B
�摜�f�f��摜�F���A�����F���Z�p�Ƒg�ݍ��킹��A�f�f����ɐl�Ԃ�
�o�開�͂Ȃ��Ȃ��Ȃ���
68 �F�f�t�H���g�̖����������F2014/06/30(��) 21:49:01.19 ID:kvIkRbCF
>>65
����̑����Ƀ��g�\���N��u���āA�������̐l����팸
����̑����Ƀ��g�\���N��u���āA�������̐l����팸
69 �F�f�t�H���g�̖����������F2014/07/01(��) 04:28:13.07 ID:9WHDZwaI
����Ȃ�ăG�L�X�p�[�g�V�X�������A�����A�Y��Ă���
70 �F�f�t�H���g�̖����������F2014/07/01(��) 08:59:30.77 ID:xCHeKPxQ
�d�b�T�|�[�g�Ȃ�o���������ˁB�x���⎞�ԊO�p�ɂł�
71 �F�f�t�H���g�̖����������F2014/07/01(��) 17:42:24.79 ID:MLoIfLOU
��������V�X�e�����������炱�����B�{��́A���O�p�`�ł͂Ȃ����p�ӎO�p�`��������A�܂��������ł͂Ȃ��ȉ~��������A
���Ƃ��̉�@�͂ǂ��ς�邩�B���邢�͐ݒ肪�ς����ɂ���ẮA���Z���w�ł͉ł��Ȃ��Ȃ�̂��B�@
�� ���嗝�n���w2004�N��1��
���Ƃ��̉�@�͂ǂ��ς�邩�B���邢�͐ݒ肪�ς����ɂ���ẮA���Z���w�ł͉ł��Ȃ��Ȃ�̂��B�@
�� ���嗝�n���w2004�N��1��
72 �F�f�t�H���g�̖����������F2014/07/01(��) 17:48:46.07 ID:MLoIfLOU
>>24
������Z���̉ӏ������ɏ���������A���S���Y���A�Z���̉ӏ��������ɂ܂Ƃ߂�A���S���Y�����l���Ă݂�B
�����͐l�C��p�ő����̒������A�Z���̉ӏ������ɏ��������A�Ӗ����e�ɂ��ďڍׂɃ^�O�t�����āA�C���v�b�g����B
�ގ��̕��͂ɑ���������A�I�����o�ł���悤�ɂ���B
������Z���̉ӏ������ɏ���������A���S���Y���A�Z���̉ӏ��������ɂ܂Ƃ߂�A���S���Y�����l���Ă݂�B
�����͐l�C��p�ő����̒������A�Z���̉ӏ������ɏ��������A�Ӗ����e�ɂ��ďڍׂɃ^�O�t�����āA�C���v�b�g����B
�ގ��̕��͂ɑ���������A�I�����o�ł���悤�ɂ���B
73 �F�f�t�H���g�̖����������F2014/07/01(��) 20:10:32.48 ID:WdBXMFPF
74 �F�f�t�H���g�̖����������F2014/07/05(�y) 11:17:57.64 ID:EeQIx6Tc
�@SW�ł͐}12�̂悤�Ȏ�̌`�C�����C��E���C�g�̂̕����Ȃǂ�\���}���I�ȋL������I�ɔz�u���āC
�l�ԂɂƂ��ĕ�����₷����b���L�q����D�}13��SW�ɂ����{��b�̋L�q��������D�����̋L���̏W��
��ISWA(International Sign Writing Alphabet)�ƌĂ�Ă���CISWA2008�ɂ�639��ނ̊�{�L�����܂܂��D
�����̈Ⴂ�Ȃǂ��l������Ƃ��̐��͖�35,000��ނɏ��D
https://www.jstage.jst.go.jp/article/essfr/4/4/4_4_282/_pdf
�{�����̍ŏI�I�ȖڕW��, CL ��g�ݍ���`�ω���, CL ��p�����}���I�Ȏ�̓������g�ݍ��킳����
��b�\�� CL �q�� (CL �\��, Classi?er Predicate)[3]�̐������@�B�|���ōs�����Ƃɂ���.
CL �q���, �������E�ł̏ꏊ�E�`��E���� (�����̋O��) ������b�\����ԏ�ł������N����悤�� CL ��`
��p���ĕ\��������̂�, ��b�̈ӎv�`�B�ɂ����Ĕ��ɏd�v�Ȗ�����S���Ă���.
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/P7-12.pdf
�l�ԂɂƂ��ĕ�����₷����b���L�q����D�}13��SW�ɂ����{��b�̋L�q��������D�����̋L���̏W��
��ISWA(International Sign Writing Alphabet)�ƌĂ�Ă���CISWA2008�ɂ�639��ނ̊�{�L�����܂܂��D
�����̈Ⴂ�Ȃǂ��l������Ƃ��̐��͖�35,000��ނɏ��D
https://www.jstage.jst.go.jp/article/essfr/4/4/4_4_282/_pdf
�{�����̍ŏI�I�ȖڕW��, CL ��g�ݍ���`�ω���, CL ��p�����}���I�Ȏ�̓������g�ݍ��킳����
��b�\�� CL �q�� (CL �\��, Classi?er Predicate)[3]�̐������@�B�|���ōs�����Ƃɂ���.
CL �q���, �������E�ł̏ꏊ�E�`��E���� (�����̋O��) ������b�\����ԏ�ł������N����悤�� CL ��`
��p���ĕ\��������̂�, ��b�̈ӎv�`�B�ɂ����Ĕ��ɏd�v�Ȗ�����S���Ă���.
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/P7-12.pdf
75 �F�f�t�H���g�̖����������F2014/07/05(�y) 15:51:46.96 ID:PDgdEPrp
word2vec��deep learning���ĕʂɊW������ˁH
word2vec�̑O�g��recurrent neural network���g���Ă����Ă�����
���݂�word2vec�̎����̓��W�X�e�B�b�N��A�x�[�X�̂��̂ɂȂ��Ă邵
word2vec�̑O�g��recurrent neural network���g���Ă����Ă�����
���݂�word2vec�̎����̓��W�X�e�B�b�N��A�x�[�X�̂��̂ɂȂ��Ă邵
76 �F�f�t�H���g�̖����������F2014/07/05(�y) 21:00:44.58 ID:yP4JAf0g
(5-4) ���̖�͊Q���ɋ���.(�A���̖��)
(5-4) ���Y�͖����������H�ׂ�.(�H���̖��)
http://tdl.libra.titech.ac.jp/hkshi/xc/contents/pdf/116061503/6
�Ԃ��O�p�C���ۂȂǂ̐}�`���������C����ɂ��Ă̎���u���F�ł����v
�u���Ƃ����`�ł����v�ɑ��āu�ԁv��u�ہv�ȂǂƎ��s����I�ɓ����C
���̓����ɑ���]���𗘗p���Đ�������������悤�Ɋw�K����V�X�e�����\�z����D
https://kaigi.org/jsai/webprogram/2014/pdf/474.pdf
�菇�i6�j�ł́C�����I���g���W�[�ɑ��C�T�O�lj��������s���D�����I���g���W�[�ɂ����āC
�Ώۗ̈�̒��ł��ŏ�ʂɈʒu����ƍl������T�O�����[�g�T�O�Ƃ��Đݒ肷��D
Protégé ���g�p���Ċ����I���g���W�[�̉������s�������} 5 �Ɏ����D�} 5�̉����͈͂ɂ����ẮC
���̑ȉ~�ň͂�ł���T�O�����[�g�T�O�Ƃ��Ă���D�Ȃ��Ȃ炱���̊T�O�����ȂɊ֘A����
�T�O�̍ŏ�ʊT�O�Ƃ��ēK���ł���Ɛ����ł��邩��ł���D���̂悤�ɂ��Ď蓮�Őݒ肵��
���[�g�T�O�́g���h�C�g�����h�C�g���ہh�C�g�ʒu�h�C�g�O�����`�̂��́h�C�g�ʂ̂��́h�C
�g�����h�C�g�����h�C�g�A���h�C�g�����h�C�g���R���ۂɂ���ďo������́h�C�g��̓I���邢��
���ۓI���ݕ��h�C�g���ە��h�̌v 13 �T�O�ł���D
http://sigswo.org/papers/SIG-SWO-A1303/SIG-SWO-A1303-05.pdf
(5-4) ���Y�͖����������H�ׂ�.(�H���̖��)
http://tdl.libra.titech.ac.jp/hkshi/xc/contents/pdf/116061503/6
�Ԃ��O�p�C���ۂȂǂ̐}�`���������C����ɂ��Ă̎���u���F�ł����v
�u���Ƃ����`�ł����v�ɑ��āu�ԁv��u�ہv�ȂǂƎ��s����I�ɓ����C
���̓����ɑ���]���𗘗p���Đ�������������悤�Ɋw�K����V�X�e�����\�z����D
https://kaigi.org/jsai/webprogram/2014/pdf/474.pdf
�菇�i6�j�ł́C�����I���g���W�[�ɑ��C�T�O�lj��������s���D�����I���g���W�[�ɂ����āC
�Ώۗ̈�̒��ł��ŏ�ʂɈʒu����ƍl������T�O�����[�g�T�O�Ƃ��Đݒ肷��D
Protégé ���g�p���Ċ����I���g���W�[�̉������s�������} 5 �Ɏ����D�} 5�̉����͈͂ɂ����ẮC
���̑ȉ~�ň͂�ł���T�O�����[�g�T�O�Ƃ��Ă���D�Ȃ��Ȃ炱���̊T�O�����ȂɊ֘A����
�T�O�̍ŏ�ʊT�O�Ƃ��ēK���ł���Ɛ����ł��邩��ł���D���̂悤�ɂ��Ď蓮�Őݒ肵��
���[�g�T�O�́g���h�C�g�����h�C�g���ہh�C�g�ʒu�h�C�g�O�����`�̂��́h�C�g�ʂ̂��́h�C
�g�����h�C�g�����h�C�g�A���h�C�g�����h�C�g���R���ۂɂ���ďo������́h�C�g��̓I���邢��
���ۓI���ݕ��h�C�g���ە��h�̌v 13 �T�O�ł���D
http://sigswo.org/papers/SIG-SWO-A1303/SIG-SWO-A1303-05.pdf
77 �F�f�t�H���g�̖����������F2014/07/06(��) 13:17:55.07 ID:UIel1dtG
���i����I�j�����Ɓi�㐔�X�L�[�}�j���\������
• �x�����K�v�Ȃ͖̂�胂�f���\���C����I�ȏ͂悭�m���Ă���
• �Ɋ�Â������ɂ͖�蕶����̈ÖٓI�ȓ������o���K�v
- �ŏ��Ɂu�`����`�v�����ɗ����R [Nathan 1988]
• ���݂Ɏx���u����胂�f���̈Ӗ��t���Ɂv�u���X�L�[�}�����f���쐬�Ɂv
�u�\��2�v
�^����ꂽ�J�o�[�X�g�[���ɂ�����L�����N�^�E�C�x���g�E�W��ʓI�ȉ�@�ɕK�v�Ȍ`���I�ȋL����
�\���̒m���ƊW�Â��邱�Ƃɂ�萔�w�I�ɃX�g�[�������߂���悤��܂��ꂽ���k�́C
���͑�̉����o����������̐����ɂ����āC�X�g�[���̃t���[�Y�ƕ������̃}�b�s���O���s��
���ړI�ȕϊ��Ɋ�Â��A�v���[�`���g���ΏƎ҂��L�ӂɂȂ�ł��낤�D
�u�\��3�v
�^����ꂽ�J�o�[�X�g�[���ɂ�����L�����N�^�E�C�x���g�E�W�̒m���Ɍ`���I�ȋL���ƕ\�����W�Â�
�邱�Ƃɂ��㐔�����I�ɉ��߂���悤��܂��ꂽ���k�́C�㐔���̏I�ȋL�q�̐����ɂ����āC
�X�g�[���̃t���[�Y�ƕ������̃}�b�s���O���s�����ړI�ȕϊ��Ɋ�Â��A�v���[�`���g���ΏƎ҂��L�ӂɂȂ�ł��낤�D
�u�\��4�v
�I�ɐ��_���s���������҂́C�t���[�Y�u���̑ΏƎ҂��C�J�o�[�X�g�[������������Ȃ��I
�ȕ������̑g�̓K���C���邢�͕s�K����F������\�͂����邾��
http://miwalab.cog.human.nagoya-u.ac.jp/database/resume/2003-02-04.pdf
• �x�����K�v�Ȃ͖̂�胂�f���\���C����I�ȏ͂悭�m���Ă���
• �Ɋ�Â������ɂ͖�蕶����̈ÖٓI�ȓ������o���K�v
- �ŏ��Ɂu�`����`�v�����ɗ����R [Nathan 1988]
• ���݂Ɏx���u����胂�f���̈Ӗ��t���Ɂv�u���X�L�[�}�����f���쐬�Ɂv
�u�\��2�v
�^����ꂽ�J�o�[�X�g�[���ɂ�����L�����N�^�E�C�x���g�E�W��ʓI�ȉ�@�ɕK�v�Ȍ`���I�ȋL����
�\���̒m���ƊW�Â��邱�Ƃɂ�萔�w�I�ɃX�g�[�������߂���悤��܂��ꂽ���k�́C
���͑�̉����o����������̐����ɂ����āC�X�g�[���̃t���[�Y�ƕ������̃}�b�s���O���s��
���ړI�ȕϊ��Ɋ�Â��A�v���[�`���g���ΏƎ҂��L�ӂɂȂ�ł��낤�D
�u�\��3�v
�^����ꂽ�J�o�[�X�g�[���ɂ�����L�����N�^�E�C�x���g�E�W�̒m���Ɍ`���I�ȋL���ƕ\�����W�Â�
�邱�Ƃɂ��㐔�����I�ɉ��߂���悤��܂��ꂽ���k�́C�㐔���̏I�ȋL�q�̐����ɂ����āC
�X�g�[���̃t���[�Y�ƕ������̃}�b�s���O���s�����ړI�ȕϊ��Ɋ�Â��A�v���[�`���g���ΏƎ҂��L�ӂɂȂ�ł��낤�D
�u�\��4�v
�I�ɐ��_���s���������҂́C�t���[�Y�u���̑ΏƎ҂��C�J�o�[�X�g�[������������Ȃ��I
�ȕ������̑g�̓K���C���邢�͕s�K����F������\�͂����邾��
http://miwalab.cog.human.nagoya-u.ac.jp/database/resume/2003-02-04.pdf
78 �F�f�t�H���g�̖����������F2014/07/06(��) 15:17:27.05 ID:Tf6s8TDO
��\���Ƃ���ɑΉ��t����ꂽ�q�ꍀ�\���������C������ƈӖ������������{��c���[�o���N
�ɂ��ďq�ׂ��D�\�z���� 20,000 ���������̍\����͊�ɓK�p���邱�Ƃɂ��C���ߌW���͂Ɠ����x
�̉�͐��x�������C�ڍׂȓ�������o�͂ł��邱�Ƃ��m���߂��D
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/B5-3.pdf
UML �ł́C�I�u�W�F�N�g����ԋ@�B�ƍl���C���̐U��������ԑJ�ڐ}�ŕ\���D�L�@�Ƃ��ẮC��{�I�� Harel��
Statechart ���̗p���Ă���D���Ƃ��C�} 5 �� Fowler �̖{ [2] ����Ƃ����D�}�́u���쒆�v�Ɩ��O��t���Ă����
���e��� (superstate) �ł���D���̒��� 3 �̎q��Ԃ����邪�C������B���� 1 �̏�Ԃƌ��Ȃ������̂��u���쒆�v�ł���D
http://tamai-lab.ws.hosei.ac.jp/pub/ss01paper.pdf
�܂�A�}�I���f�B�A�͕\�����Ă�����̓��e�T�����܂����ϓI�ɔc�����邱�Ƃ��ł��A���̓_�ɂ����ĕ������f�B�A
�Ƒ傫���قȂ�B�Ⴆ�A�����̐}�`�v�f����������ɐ��Ă���A�����������͗���̈Ӗ����u���Ɋ������邪�A
�����Ӗ���\�����������͒ʓǂ��Ȃ���킩��Ȃ��i�} 2.1�j�B
http://www.image.esys.tsukuba.ac.jp/~murayama/work/ms_thesis.pdf
�ɂ��ďq�ׂ��D�\�z���� 20,000 ���������̍\����͊�ɓK�p���邱�Ƃɂ��C���ߌW���͂Ɠ����x
�̉�͐��x�������C�ڍׂȓ�������o�͂ł��邱�Ƃ��m���߂��D
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/B5-3.pdf
UML �ł́C�I�u�W�F�N�g����ԋ@�B�ƍl���C���̐U��������ԑJ�ڐ}�ŕ\���D�L�@�Ƃ��ẮC��{�I�� Harel��
Statechart ���̗p���Ă���D���Ƃ��C�} 5 �� Fowler �̖{ [2] ����Ƃ����D�}�́u���쒆�v�Ɩ��O��t���Ă����
���e��� (superstate) �ł���D���̒��� 3 �̎q��Ԃ����邪�C������B���� 1 �̏�Ԃƌ��Ȃ������̂��u���쒆�v�ł���D
http://tamai-lab.ws.hosei.ac.jp/pub/ss01paper.pdf
�܂�A�}�I���f�B�A�͕\�����Ă�����̓��e�T�����܂����ϓI�ɔc�����邱�Ƃ��ł��A���̓_�ɂ����ĕ������f�B�A
�Ƒ傫���قȂ�B�Ⴆ�A�����̐}�`�v�f����������ɐ��Ă���A�����������͗���̈Ӗ����u���Ɋ������邪�A
�����Ӗ���\�����������͒ʓǂ��Ȃ���킩��Ȃ��i�} 2.1�j�B
http://www.image.esys.tsukuba.ac.jp/~murayama/work/ms_thesis.pdf
79 �F�f�t�H���g�̖����������F2014/07/07(��) 12:36:07.24 ID:bhOiadyO
2.2 ��b�E�\���I��������
��b�E�\���I���������Ɍ����Ă��C�����ɓ���_�ň��������Ȍ���������
���̏ڍׂȈӖ��ɗ�������K�v�̂��錾�������܂ő���ɂ킽��B������
�����������́C�����ɕK�v�Ȓm���̎�ނ̊ϓ_����X�I�Ɏ���4��ނɕ�������B
����I�������� �ʂ̌�̈Ӗ��ɗ�������Ȃ��Ă�����_�̋L�q���x���ŊT�ː����ł��錾������
(3) �ŏ��ɍ��i�����͍̂������� �� �������ŏ��ɍ��i����
��b�I�������� ��̓��`�������ŊT�ː����ł���C���ꑀ���Ȃ��Ǐ��I��������
(4) ��w�̋ꋫ�Ɋׂ鋰�ꂪ���� �� ��w�̋��n�Ɋׂ�\��������
��b�\���I�������� ��̓���I�����ƈӖ��I�����Ɋ�Â��č\���I�ɐ����ł���ƍl������K�����̍�����������
(5) 2 �ʂ��擪�Ƃ̋������k�߂� �� 2�ʂƐ擪�̋������k�܂���
���_�I�������� ����I�Ӗ����ߎ��I�ɓ����Ȍ��������̂����C��̂ǂ̎�ނɂ����Ă͂܂�Ȃ�����
(6) �����Č����}���̉ۑ肾 �ً̋}�ɍ����Č�����K�v������
http://paraphrasing.org/~fujita/publications/coauthor/inui-LF-2.pdf
��b�E�\���I���������Ɍ����Ă��C�����ɓ���_�ň��������Ȍ���������
���̏ڍׂȈӖ��ɗ�������K�v�̂��錾�������܂ő���ɂ킽��B������
�����������́C�����ɕK�v�Ȓm���̎�ނ̊ϓ_����X�I�Ɏ���4��ނɕ�������B
����I�������� �ʂ̌�̈Ӗ��ɗ�������Ȃ��Ă�����_�̋L�q���x���ŊT�ː����ł��錾������
(3) �ŏ��ɍ��i�����͍̂������� �� �������ŏ��ɍ��i����
��b�I�������� ��̓��`�������ŊT�ː����ł���C���ꑀ���Ȃ��Ǐ��I��������
(4) ��w�̋ꋫ�Ɋׂ鋰�ꂪ���� �� ��w�̋��n�Ɋׂ�\��������
��b�\���I�������� ��̓���I�����ƈӖ��I�����Ɋ�Â��č\���I�ɐ����ł���ƍl������K�����̍�����������
(5) 2 �ʂ��擪�Ƃ̋������k�߂� �� 2�ʂƐ擪�̋������k�܂���
���_�I�������� ����I�Ӗ����ߎ��I�ɓ����Ȍ��������̂����C��̂ǂ̎�ނɂ����Ă͂܂�Ȃ�����
(6) �����Č����}���̉ۑ肾 �ً̋}�ɍ����Č�����K�v������
http://paraphrasing.org/~fujita/publications/coauthor/inui-LF-2.pdf
80 �F�f�t�H���g�̖����������F2014/07/09(��) 09:13:08.64 ID:W1L77FJX
�C�k��A�C���J��A�T�������͂���A���S���Y������܂����H
81 �F�f�t�H���g�̖����������F2014/07/09(��) 19:42:55.77 ID:k9yY+Ntl
>>80
�o�E�����K���Ɠ����A�v���[�`�ʼn\
�o�E�����K���Ɠ����A�v���[�`�ʼn\
82 �F�f�t�H���g�̖����������F2014/07/09(��) 20:08:34.07 ID:s3czgtxE
���Ƃ��ǂ̂悤�ɂ�����H
83 �F�f�t�H���g�̖����������F2014/07/10(��) 11:50:45.70 ID:b8e/9c1m
10^5�P��
10^3�̒P�ꂩ��Ȃ镶��
(10^5)^(10^3)�̑g�ݍ��킹�i�e���\���j
�S�Ă̑g�ݍ��킹��\�ߌv�Z����͕̂s�\��
�\�������Ă���P��͓����\�������Ɖ��肵�A�m���I�ɍ\����͂�������̂��H
10^3�̒P�ꂩ��Ȃ镶��
(10^5)^(10^3)�̑g�ݍ��킹�i�e���\���j
�S�Ă̑g�ݍ��킹��\�ߌv�Z����͕̂s�\��
�\�������Ă���P��͓����\�������Ɖ��肵�A�m���I�ɍ\����͂�������̂��H
84 �F�f�t�H���g�̖����������F2014/07/10(��) 14:23:18.66 ID:aR1UjDzC
85 �F�f�t�H���g�̖����������F2014/07/10(��) 14:39:03.10 ID:b8e/9c1m
>>84
�I�[�g�}�g���ł�邩��e���\�����Z�ɂ͂Ȃ�Ȃ����A����ɂ��Ă����Ⴂ������i���Ăǂ��Ȃ�ʂ���Ȃ��B
���m�̒P�ꂪ�������Ή��ł��Ȃ����A�����œ��͂��ꂽ���Ƃ̂Ȃ����͂��\���I�ɐ��������̂𐄒肵�đg�ݗ��ĂȂ��Ƃ����Ȃ��B
�I�[�g�}�g���ł�邩��e���\�����Z�ɂ͂Ȃ�Ȃ����A����ɂ��Ă����Ⴂ������i���Ăǂ��Ȃ�ʂ���Ȃ��B
���m�̒P�ꂪ�������Ή��ł��Ȃ����A�����œ��͂��ꂽ���Ƃ̂Ȃ����͂��\���I�ɐ��������̂𐄒肵�đg�ݗ��ĂȂ��Ƃ����Ȃ��B
86 �F�ЎR����MZ�������q ��T6xkBnTXz7B0 �F2014/07/18(��) 14:38:59.47 ID:XMEHR0Aa
���R���ꑊ��ɂ��ׂẴP�[�X�̃e�X�g�f�[�^���쐬���悤�Ƃ�����A800MB�����Ă��܂����B�B�B
�������ȁB
�������ȁB
87 �F�f�t�H���g�̖����������F2014/07/18(��) 15:09:02.82 ID:D2raAtlG
800MB�Ȃ�܂��܂��ł́H
88 �F�ЎR����MZ�������q ��T6xkBnTXz7B0 �F2014/07/19(�y) 21:02:40.01 ID:mm+kcL5W
�܂��́A���̖�����ɋ߂��g�ݍ��킹�Ɛ��Ȃ��Ƃ����Ȃ��̂��B
�����_�����o���A��\�l�ł���Ă݂邩�B
�����_�����o���A��\�l�ł���Ă݂邩�B
89 �F�f�t�H���g�̖����������F2014/07/22(��) 12:13:33.59 ID:E09TR4vO
�`���p���W�[���ǂ����
http://wired.jp/2014/07/22/dictionary-of-chimpanzee/
http://wired.jp/2014/07/22/dictionary-of-chimpanzee/
90 �F�f�t�H���g�̖����������F2014/07/23(��) 06:05:31.34 ID:cG8Of2p8
���{���mecab cabocha�Ɠ������Ƃ��p��ł���ꍇ�ɂ�
�ǂ̃\�t�g���g�������̂ł��傤���H
�ǂ̃\�t�g���g�������̂ł��傤���H
91 �F�f�t�H���g�̖����������F2014/07/26(�y) 22:52:13.10 ID:vhGqByQW
Stanford CoreNLP�ł������Ă�
92 �F�f�t�H���g�̖����������F2014/07/27(��) 08:37:51.99 ID:b6NTPR2W
>>89
����\������������܂����Ă���
����\������������܂����Ă���
93 �F�f�t�H���g�̖����������F2014/07/29(��) 05:02:08.10 ID:lhxkPIlc
94 �F�ЎR����MZ����CEO ��T6xkBnTXz7B0 �F2014/07/30(��) 00:17:55.16 ID:yEskz56N
�������p�Ɠ��I�p�[�T�[���撣���Ă�邼�[�I
�G�C�G�C�I�[�I
�G�C�G�C�I�[�I
95 �F�ЎR����MZ����CEO ��T6xkBnTXz7B0 �F2014/07/30(��) 01:03:45.57 ID:yEskz56N
�Ⴄ�Ⴄ�B����ȕ����R�[�h���Œ肳�ꂽ�Z�ʂ̗����Ȃ����肫����̌`�ԑf��̓c�[����
�P���[�U�[�ɂƂǂ܂�̂̓C�����B�����ƃI�[�v���Ń_�C�i�~�b�N�ɑg�D�������V�X�e���łȂ���B
�����A��K�͋@�B�w�K�ⓝ�v�w��ے肷��́H �Ђ���Ƃ��Ĕn���H
�P���[�U�[�ɂƂǂ܂�̂̓C�����B�����ƃI�[�v���Ń_�C�i�~�b�N�ɑg�D�������V�X�e���łȂ���B
�����A��K�͋@�B�w�K�ⓝ�v�w��ے肷��́H �Ђ���Ƃ��Ĕn���H
96 �F�f�t�H���g�̖����������F2014/07/30(��) 01:06:51.20 ID:yEskz56N
����
97 �F�f�t�H���g�̖����������F2014/07/30(��) 14:46:58.32 ID:nHLRqrzx
moses-support��parser-support�ŃA�z�Ȏ�����肷�钆���l��A���r�A�l�ɂ��^���ɑΉ�����p�Ɋ��S����
98 �F�f�t�H���g�̖����������F2014/07/30(��) 22:44:45.78 ID:PuN0tVbh
99 �F�f�t�H���g�̖����������F2014/08/06(��) 18:09:18.10 ID:acb72KUN
�Ƃ���ł��B�u�`���{���V�R�V�R����v�Ƃ������{��\���́A���@�I�ɐ������̂��H
�`���{�u���v�V�R�V�R����̂ł͂Ȃ��āA�`���{�u���v�V�R�V�R����B���̏ꍇ�A�u�`���{�v�͎��ƂȂ�B
�I�u�W�F�N�g�w���Ō����u�W��v�͂Q��ނ����āA�S�́i���j�ƕ����i�`���{�j���q�����Ă���ꍇ�ƁA
�S�́i���j�ƕ����i�`���{�j���ʁX�ɂȂ��Ă���ꍇ�Ƃ��l������B����ǂ��u�`���{�v�͂��ꎩ��
���Ɨ������������ł���A���L�҂̈ӎv�Ƃ͖��W�ɁA�u�N���āu�V�R�V�R����v�B
�Ⴆ�ΐQ�Ă鎞�ɃG�������݂Ē��N���Ă݂���`���R���u�N���Ďː����Ă��Ƃ��B
�Ⴄ���H
�u�����Y�L�Y�L����v�͗ǂ����A�u�`���{���V�R�V�R����v�̓_���ȗ��R���A�T�O���ȓ��ŏq�ׂ�I>>98
�`���{�u���v�V�R�V�R����̂ł͂Ȃ��āA�`���{�u���v�V�R�V�R����B���̏ꍇ�A�u�`���{�v�͎��ƂȂ�B
�I�u�W�F�N�g�w���Ō����u�W��v�͂Q��ނ����āA�S�́i���j�ƕ����i�`���{�j���q�����Ă���ꍇ�ƁA
�S�́i���j�ƕ����i�`���{�j���ʁX�ɂȂ��Ă���ꍇ�Ƃ��l������B����ǂ��u�`���{�v�͂��ꎩ��
���Ɨ������������ł���A���L�҂̈ӎv�Ƃ͖��W�ɁA�u�N���āu�V�R�V�R����v�B
�Ⴆ�ΐQ�Ă鎞�ɃG�������݂Ē��N���Ă݂���`���R���u�N���Ďː����Ă��Ƃ��B
�Ⴄ���H
�u�����Y�L�Y�L����v�͗ǂ����A�u�`���{���V�R�V�R����v�̓_���ȗ��R���A�T�O���ȓ��ŏq�ׂ�I>>98
100 �F�f�t�H���g�̖����������F2014/08/29(��) 20:13:29.62 ID:pIYD+XWo
1. �����̈Ⴂ�ɂ��`�ԑf�P�ʂ̕���
2. �@�\��C������Ȃǂɂ�镶�ߕ���
3. �����ʓ��̓Ǔ_�ɂ�镶�̕���
4. �����ʂɂ�镶�ߕ���
5. �@�\���߂Ȃǂ̓���ȕ��߂ɂ�镪��
6. �W���̕��߂�����
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/P3-15.pdf
(1)��i�[�w�i�̏o���䗦�̓R�[�p�X�ɂ���ėL�ӂȍ�������D���Ɂu�ꏊ�v�C�u�������v�C�u�ړI�v
�ɂ����鍷�������ł���D
(2)�萫�I�ɕ��ނ��ꂽ�[�w�i���ʓI�Ɍ���ƕp�x�ɂ����č��������ł������D���Ɂu�Ώہv�i��
�ږړI��j�̕p�x�������D����C�u�ꏊ�v��u���ԁv�̕p�x�͑S�̂̊������猩��Ƃ��قǍ����Ȃ��D
(3)��i�Ƌ��N���閼���Ɠ����Ɛ[�w�i�Ƃ̊W�ɂ��Ď听�����͂��s�������ʁC�u���ʁv�u����
���v�u���̑��v���u�����v�u�ړI�v���u���ԁv�u�ꏊ�v�̏��ɑ��̐[�w�i�Ƃ̊u���肪�m�F���ꂽ�D����ɑ��āC
�u�Ώہv�u�����v�u�����v�u�p�x�v�͋��N��ɂ����Ă͓������������߁C�[�w�i����ɂ�����\�z�����D
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/P5-3.pdf
����́A���� 28 �N�x����ڕW�Ƃ��āA���{��̏������t�̕� 4 �����ɓ����E�Ӗ���͏����^�O�t����
���O�c���[�o���N������������\��ł���B�܂��A����Ƃ͕ʂɁA�Θb�f�[�^�̃^�O�t�����v�悵�Ă���B
�J�������c���[�o���N�̂������J�\�Ȃ��̂͑S�Ĉȉ��̃T�C�g�Ŕz�z����\��ł���B
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/P8-8.pdf
2. �@�\��C������Ȃǂɂ�镶�ߕ���
3. �����ʓ��̓Ǔ_�ɂ�镶�̕���
4. �����ʂɂ�镶�ߕ���
5. �@�\���߂Ȃǂ̓���ȕ��߂ɂ�镪��
6. �W���̕��߂�����
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/P3-15.pdf
(1)��i�[�w�i�̏o���䗦�̓R�[�p�X�ɂ���ėL�ӂȍ�������D���Ɂu�ꏊ�v�C�u�������v�C�u�ړI�v
�ɂ����鍷�������ł���D
(2)�萫�I�ɕ��ނ��ꂽ�[�w�i���ʓI�Ɍ���ƕp�x�ɂ����č��������ł������D���Ɂu�Ώہv�i��
�ږړI��j�̕p�x�������D����C�u�ꏊ�v��u���ԁv�̕p�x�͑S�̂̊������猩��Ƃ��قǍ����Ȃ��D
(3)��i�Ƌ��N���閼���Ɠ����Ɛ[�w�i�Ƃ̊W�ɂ��Ď听�����͂��s�������ʁC�u���ʁv�u����
���v�u���̑��v���u�����v�u�ړI�v���u���ԁv�u�ꏊ�v�̏��ɑ��̐[�w�i�Ƃ̊u���肪�m�F���ꂽ�D����ɑ��āC
�u�Ώہv�u�����v�u�����v�u�p�x�v�͋��N��ɂ����Ă͓������������߁C�[�w�i����ɂ�����\�z�����D
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/P5-3.pdf
����́A���� 28 �N�x����ڕW�Ƃ��āA���{��̏������t�̕� 4 �����ɓ����E�Ӗ���͏����^�O�t����
���O�c���[�o���N������������\��ł���B�܂��A����Ƃ͕ʂɁA�Θb�f�[�^�̃^�O�t�����v�悵�Ă���B
�J�������c���[�o���N�̂������J�\�Ȃ��̂͑S�Ĉȉ��̃T�C�g�Ŕz�z����\��ł���B
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/P8-8.pdf
101 �F�f�t�H���g�̖����������F2014/08/29(��) 21:20:47.93 ID:zSOx7Ia5
�\����͂��ĕ��@�I�ɐ��������ǂ����������f�ł��Ȃ���Ȃ��́H
102 �F�f�t�H���g�̖����������F2014/08/29(��) 23:25:55.15 ID:bwbSKW1s
>>101
>�\����͂��ĕ��@�I�ɐ��������ǂ����������f�ł��Ȃ���Ȃ��́H
�Ȃ�A�u�`���{���V�R�V�R����v�Ƃ������{��\���́A���@�I�ɐ������̂��H
>�\����͂��ĕ��@�I�ɐ��������ǂ����������f�ł��Ȃ���Ȃ��́H
�Ȃ�A�u�`���{���V�R�V�R����v�Ƃ������{��\���́A���@�I�ɐ������̂��H
103 �F�f�t�H���g�̖����������F2014/08/30(�y) 02:26:42.95 ID:BAPN2lOA
�P��Ɠ����Ƃ������ނŌ����ΐ��������A�P��Ƃ��Ă͊m���Ⴂ�g�ݍ��킹���낤�Ȃ�
104 �F�f�t�H���g�̖����������F2014/08/30(�y) 09:34:03.26 ID:014RRRVX
�w���\���ƕ��́\�u���́v�̃W�������ʃR�[�p�X���͂𒆐S��
https://www1.doshisha.ac.jp/~cjtl210/data1/22_ryuuhyoo.pdf
���{��@�\�\���̎����� �o�Ɠ��v�I�W���͂ւ̉��p
https://www.jstage.jst.go.jp/article/jnlp1994/14/5/14_5_167/_pdf
�����̑��l���Ɋ�Â����������̒��
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/D5-1.pdf
�\���\���̏����Z�p - �ʼnY�H�Ƒ�w
http://www.sic.shibaura-it.ac.jp/~sugimoto/nlps/nlps14-3.pdf
���̂��猩���w���̕���W�x�̌�b �\�w���{����j�R�[�p�X ��������ҁx�Ɣ�r����
http://www.ninjal.ac.jp/event/specialists/project-meeting/files/JCLWorkshop_no4_papers/JCLWorkshop_No4_15.pdf
NTCIR MedNLP: �{�M���̈�Õ���̌��ꏈ���R���e�X�g
http://mednlp.jp/PAPER/2013-jcmi-ntcir.pdf
�P��Ԍ����x�Ɋ�Â����P��\���̃A���C�����g�̉��P
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/A2-4.pdf
NTCIR MedNLP-2: ��Õ���̌��ꏈ��
http://must.c.u-tokyo.ac.jp/sigam/sigam05/sigam0512.pdf
�q��ƍ��̈ʒu�W���Ƃ̌���r�ɂ����{��q�ꍀ�\�����
http://hayashibe.jp/publications/JNLP2014.pdf
�u�q��\���̈Ӗ����e�̕��Ր��Ƒ��l���\���_�I����щ��p�I�Ȑ��ʁ\�v
http://www.ninjal.ac.jp/event/specialists/project-meeting/m-2013/20140202-ninjal2014/pdf/008.pdf
�����E���͂̂��߂̎菇���͂���̈Ӗ��\�����o
http://db-event.jpn.org/deim2014/final/proceedings/C3-2.pdf
�R�[�p�X�Ɋ�Â����{��̕��@�`���̎g�p�X���̋L�q �\�u�傫���E�ȁv�u�������E�ȁv�̎g�������ɂ��ā\
http://ir.nul.nagoya-u.ac.jp/jspui/bitstream/2237/19119/1/1306.pdf
���I�ȓ������p�����P��A���C�������g�̉��P
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/A3-2.pdf
�Ζo�ɂ�����n�u�̉e��
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/B2-2.pdf
https://www1.doshisha.ac.jp/~cjtl210/data1/22_ryuuhyoo.pdf
���{��@�\�\���̎����� �o�Ɠ��v�I�W���͂ւ̉��p
https://www.jstage.jst.go.jp/article/jnlp1994/14/5/14_5_167/_pdf
�����̑��l���Ɋ�Â����������̒��
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/D5-1.pdf
�\���\���̏����Z�p - �ʼnY�H�Ƒ�w
http://www.sic.shibaura-it.ac.jp/~sugimoto/nlps/nlps14-3.pdf
���̂��猩���w���̕���W�x�̌�b �\�w���{����j�R�[�p�X ��������ҁx�Ɣ�r����
http://www.ninjal.ac.jp/event/specialists/project-meeting/files/JCLWorkshop_no4_papers/JCLWorkshop_No4_15.pdf
NTCIR MedNLP: �{�M���̈�Õ���̌��ꏈ���R���e�X�g
http://mednlp.jp/PAPER/2013-jcmi-ntcir.pdf
�P��Ԍ����x�Ɋ�Â����P��\���̃A���C�����g�̉��P
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/A2-4.pdf
NTCIR MedNLP-2: ��Õ���̌��ꏈ��
http://must.c.u-tokyo.ac.jp/sigam/sigam05/sigam0512.pdf
�q��ƍ��̈ʒu�W���Ƃ̌���r�ɂ����{��q�ꍀ�\�����
http://hayashibe.jp/publications/JNLP2014.pdf
�u�q��\���̈Ӗ����e�̕��Ր��Ƒ��l���\���_�I����щ��p�I�Ȑ��ʁ\�v
http://www.ninjal.ac.jp/event/specialists/project-meeting/m-2013/20140202-ninjal2014/pdf/008.pdf
�����E���͂̂��߂̎菇���͂���̈Ӗ��\�����o
http://db-event.jpn.org/deim2014/final/proceedings/C3-2.pdf
�R�[�p�X�Ɋ�Â����{��̕��@�`���̎g�p�X���̋L�q �\�u�傫���E�ȁv�u�������E�ȁv�̎g�������ɂ��ā\
http://ir.nul.nagoya-u.ac.jp/jspui/bitstream/2237/19119/1/1306.pdf
���I�ȓ������p�����P��A���C�������g�̉��P
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/A3-2.pdf
�Ζo�ɂ�����n�u�̉e��
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/B2-2.pdf
105 �F�f�t�H���g�̖����������F2014/08/30(�y) 09:35:42.15 ID:014RRRVX
�q���Ӗ��W�R�[�p�X�̍\�z
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/C4-4.pdf
���{�ꕶ�͂ɑ���q�ꍀ�\���A�m�e�[�V�����d�l�̍l�@
https://www.jstage.jst.go.jp/article/jnlp/21/2/21_333/_pdf
�@�B�w�K��p�����j�i�[�w�i�̎����t�^�̌���
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/D6-2.pdf
�����E�Ӗ�����t���������{��R�[�p�X�̍\�z�O�c���[�o���N �v���g�^�C�v �ɂ���
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/P8-8.pdf
�L�����ɂ�鐔�w���̗���—���`�㐔�ɂ����鐔�w���𒆐S�Ƃ���—
http://www.seto.nanzan-u.ac.jp/msie/gr-thesis/2013/10se201.pdf
���̈Ӗ��\���ɔ�����������Ԃ̍œK���ƒP��\���w�K
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/D6-3.pdf
�p��̑������l��������ʁC���ʊT�O�����̍\�z
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/B6-1.pdf
�w�Z���w�ɂ�����m���𑨂���g�g�݂̈���
�\���w�I���f���Ƃ��Ă̊m���Ƃ������_����\
http://www.juen.ac.jp/math/miyakawa/article/2013-ronhatu-ikarashi.pdf
�w������{�ꏑ�����t�ύt�R�[�p�X�x�`�Ԙ_���A�m�e�[�V�����x���V�X�e���̐v�E�����E�^�p
https://www.jstage.jst.go.jp/article/jnlp/21/2/21_301/_pdf
������ƈӖ������������{���\���c���[�o���N�̍\�z
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/B5-3.pdf
���v�I���{��q�ꍀ�\����͂̂��߂̑f���v�čl
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/D1-5.pdf
���t����@�B�w�K�ɂ�鏕���u���v�̕���
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/P8-11.pdf
�P��o���p�x���l����������m������ɂ��P��A���C�����g
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/A3-4.pdf
���{��J���e���A�m�e�[�g����
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/P5-2.pdf
��g�\���R�[�p�X�̍\�z�Ɩ��_-����w�̗��ꂩ��-
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/P3-2.pdf
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/C4-4.pdf
���{�ꕶ�͂ɑ���q�ꍀ�\���A�m�e�[�V�����d�l�̍l�@
https://www.jstage.jst.go.jp/article/jnlp/21/2/21_333/_pdf
�@�B�w�K��p�����j�i�[�w�i�̎����t�^�̌���
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/D6-2.pdf
�����E�Ӗ�����t���������{��R�[�p�X�̍\�z�O�c���[�o���N �v���g�^�C�v �ɂ���
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/P8-8.pdf
�L�����ɂ�鐔�w���̗���—���`�㐔�ɂ����鐔�w���𒆐S�Ƃ���—
http://www.seto.nanzan-u.ac.jp/msie/gr-thesis/2013/10se201.pdf
���̈Ӗ��\���ɔ�����������Ԃ̍œK���ƒP��\���w�K
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/D6-3.pdf
�p��̑������l��������ʁC���ʊT�O�����̍\�z
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/B6-1.pdf
�w�Z���w�ɂ�����m���𑨂���g�g�݂̈���
�\���w�I���f���Ƃ��Ă̊m���Ƃ������_����\
http://www.juen.ac.jp/math/miyakawa/article/2013-ronhatu-ikarashi.pdf
�w������{�ꏑ�����t�ύt�R�[�p�X�x�`�Ԙ_���A�m�e�[�V�����x���V�X�e���̐v�E�����E�^�p
https://www.jstage.jst.go.jp/article/jnlp/21/2/21_301/_pdf
������ƈӖ������������{���\���c���[�o���N�̍\�z
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/B5-3.pdf
���v�I���{��q�ꍀ�\����͂̂��߂̑f���v�čl
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/D1-5.pdf
���t����@�B�w�K�ɂ�鏕���u���v�̕���
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/P8-11.pdf
�P��o���p�x���l����������m������ɂ��P��A���C�����g
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/A3-4.pdf
���{��J���e���A�m�e�[�g����
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/P5-2.pdf
��g�\���R�[�p�X�̍\�z�Ɩ��_-����w�̗��ꂩ��-
http://www.anlp.jp/proceedings/annual_meeting/2014/pdf_dir/P3-2.pdf
106 �F�f�t�H���g�̖����������F2014/09/08(��) 02:15:18.02 ID:P298uFJ/
����̃v���W�F�N�g�ǂ��Ȃ�����w
�������܂ł���
�������܂ł���
107 �F�f�t�H���g�̖����������F2014/09/08(��) 09:27:57.13 ID:m/nJA+ci
>>101
�@�B�I�ȍ\����͂̂��ƁH
���������ǂ�������Ȃ��āA�������Ɖ��肵�ĉ��߂��邱�Ƃ���Ȃ��̂���
�Ӗ�����`�ŕ�����Ă邩�ǂ����́A�l�����߂��邵���Ȃ��悤�ȋC�����邯�ǁB
�@�B�I�ȍ\����͂̂��ƁH
���������ǂ�������Ȃ��āA�������Ɖ��肵�ĉ��߂��邱�Ƃ���Ȃ��̂���
�Ӗ�����`�ŕ�����Ă邩�ǂ����́A�l�����߂��邵���Ȃ��悤�ȋC�����邯�ǁB
108 �F�ЎR����MZ����CEO ��T6xkBnTXz7B0 �F2014/09/08(��) 11:11:27.22 ID:p73tUNq8
109 �F�f�t�H���g�̖����������F2014/09/08(��) 21:00:23.20 ID:wT2B4Cec
>>107
����A�R���p�C���̍\����͂��Đ��������Ԉ���Ă邩�����o�͂��Ȃ������
����A�R���p�C���̍\����͂��Đ��������Ԉ���Ă邩�����o�͂��Ȃ������
110 �F�f�t�H���g�̖����������F2014/09/09(��) 01:59:16.85 ID:gwS2ebzP
�Ȃ�ł�˂�
�Œ�ł��c���[�\�����炢����
�Œ�ł��c���[�\�����炢����
111 �F�f�t�H���g�̖����������F2014/09/09(��) 08:12:04.96 ID:FnHbwOUK
�u��蕶��ǂ�ő�ӂ������ł��Ȃ��v���Ă̂́A���N�̓���ނƋ��ʂ���_�Ɏv����B
�����Ă��邤���ɋC�Â������Ƃ�����܂��B����́A���w�̖�蕶��ǂ�ł��̑�ӂ������ł��Ȃ��q�ǂ����ڗ����đ������A
�Ƃ������Ƃł��B�u��蕶��ǂ�ő�ӂ������ł��Ȃ��v�Ƃ����Ă��A���낢��ȃ^�C�v������܂��B
1.?��b�͂��s�����Ă��ĕ��߂ƕ��߂̂Ȃ��肪�킩��Ȃ��B
2.?���w���L�̌��t�A�܂�L����p��̒�`�������ł��Ă��Ȃ��B
3.?���͂ƕ��͂̂Ȃ��肪�킩�炸�A���������߂Ȃ��i��㈓I�Ȑ��_�ɂ�镶�@�̒m�����Ȃ��j�B
4.?���͂������Ȃ�ƑS�̑������߂Ȃ��Ȃ�A��ӂ̖ڕW���������Ȃ��i�_���I�ȓlj�͂̕s���j�B
�w�lj�͂���������Z�����K���x���F�����P�Y
�u���w�Ƃ́A���̂��߂ɕ�����v�ƔY��ł���l��
http://gendai.ismedia.jp/articles/-/37357
�����Ă��邤���ɋC�Â������Ƃ�����܂��B����́A���w�̖�蕶��ǂ�ł��̑�ӂ������ł��Ȃ��q�ǂ����ڗ����đ������A
�Ƃ������Ƃł��B�u��蕶��ǂ�ő�ӂ������ł��Ȃ��v�Ƃ����Ă��A���낢��ȃ^�C�v������܂��B
1.?��b�͂��s�����Ă��ĕ��߂ƕ��߂̂Ȃ��肪�킩��Ȃ��B
2.?���w���L�̌��t�A�܂�L����p��̒�`�������ł��Ă��Ȃ��B
3.?���͂ƕ��͂̂Ȃ��肪�킩�炸�A���������߂Ȃ��i��㈓I�Ȑ��_�ɂ�镶�@�̒m�����Ȃ��j�B
4.?���͂������Ȃ�ƑS�̑������߂Ȃ��Ȃ�A��ӂ̖ڕW���������Ȃ��i�_���I�ȓlj�͂̕s���j�B
�w�lj�͂���������Z�����K���x���F�����P�Y
�u���w�Ƃ́A���̂��߂ɕ�����v�ƔY��ł���l��
http://gendai.ismedia.jp/articles/-/37357
112 �F�f�t�H���g�̖����������F2014/09/11(��) 17:25:16.70 ID:sSttSQlP
���R����͎Љ��\���ł��Ȃ��ƃ_�����낤
�I�[�g�}�g���̏W�c������
���ꂼ�ꂪ���̃I�[�g�}�g���Ǝ��R����ł̂ݒʐM�ł���
�C�ӂ̃I�[�g�}�g���́A�����ȊO�̃I�[�g�}�g���̎Љ�I�ȏ�Ԃ�m���Ă��邩�����ł���
�I�[�g�}�g���̏W�c������
���ꂼ�ꂪ���̃I�[�g�}�g���Ǝ��R����ł̂ݒʐM�ł���
�C�ӂ̃I�[�g�}�g���́A�����ȊO�̃I�[�g�}�g���̎Љ�I�ȏ�Ԃ�m���Ă��邩�����ł���
113 �F�f�t�H���g�̖����������F2014/09/12(��) 11:01:38.13 ID:E5d9ulLz
�q���͎w�����Ŋo����
http://development.kt.fc2.com/point.html
http://development.kt.fc2.com/point.html
114 �F�f�t�H���g�̖����������F2014/09/12(��) 13:53:52.51 ID:6MLnTCJT
http://livedoor.blogimg.jp/dfdgg/imgs/b/a/ba89783c.jpg
http://livedoor.blogimg.jp/dfdgg/imgs/2/5/251eed64.jpg
http://livedoor.blogimg.jp/dfdgg/imgs/1/8/1812a8fa.jpg
http://livedoor.blogimg.jp/dfdgg/imgs/3/0/301bcf4f.jpg
http://livedoor.blogimg.jp/dfdgg/imgs/a/e/ae860fd3.jpg
http://livedoor.blogimg.jp/dfdgg/imgs/d/4/d49c5e51.jpg
{kind=link}
http://livedoor.blogimg.jp/dfdgg/imgs/2/5/251eed64.jpg
{kind=link}
http://livedoor.blogimg.jp/dfdgg/imgs/1/8/1812a8fa.jpg
{kind=link}
http://livedoor.blogimg.jp/dfdgg/imgs/3/0/301bcf4f.jpg
{kind=link}
http://livedoor.blogimg.jp/dfdgg/imgs/a/e/ae860fd3.jpg
{kind=link}
http://livedoor.blogimg.jp/dfdgg/imgs/d/4/d49c5e51.jpg
{kind=link}
115 �F�ЎR����MZ����CEO ��T6xkBnTXz7B0 �F2014/10/11(�y) 00:07:21.76 ID:bs/sFubV
�w�K����̎����͂̏�ɓ��I�p�[�T�[���悹��ŋ�
116 �F�f�t�H���g�̖����������F2014/10/13(��) 21:41:40.39 ID:8+60HAaA
�@�B�͐l�ԂƓ����悤�Ɍ������E��F��������A�܂��l�ԂƓ����悤�ɗ���ׂ��𐄘_���邱�Ƃ͂ł��Ȃ��B
����ǂ��l�͂Łu�[���V�~�����[�^�v�Ɓu���ߕt���R�[�p�X�v���[��������A�������̉��͌��シ��B
�Ⴆ�u�}�N�h�i���h�̃n���o�[�K�[���v�Ƃ����t���[�����́A�����͈͓̔��Ƃ������ƂŐl�̓C���v�b�g�B
�}�N�h�i���h�͊�ƁE�X���ŁA�n���o�[�K�[�͏��i�E�H�ו��A�����āu�����v�ɂ��ẮA�������Ǝx�������z
�Ƃ��ނ�͂����炩�Ƃ����A�����͈͓̔������ŘA�z����B���w�╨���Ɋւ��Ă̓p�^�[����������x���܂��Ă���A
�����͈͓̔��ɂ̂ݑΉ�����������B�A��������߂��������ł��Ȃ��ƁA�������͉����Ă��ގ��̖��͉����Ȃ��B
���O��l�ɂȂ��Ă��Ȃ����A��̖���l�X�Ȋp�x���痝����������A�\����ݒ��ς��ėޑ������Ă݂�B
��������Ԃ����Ă��C�V��͗����Ă��Ȃ��D
��������Ԃ����Ă��C�����̕ǂ̐F�͂����Ȃ��D
��������Ԃ����Ă��C�����̓d�C�͏����Ȃ��D
��������Ԃ����Ă��C�ǂɌ����������肵�Ȃ��D
�l������S�Ẳ\�����A�l�͂ŃC���v�b�g����B�Ⴆ�Α�Ԃ������Ƃ��ɒ�d���N����A�����̓d�C�͏�����B
����ǂ��l�͂Łu�[���V�~�����[�^�v�Ɓu���ߕt���R�[�p�X�v���[��������A�������̉��͌��シ��B
�Ⴆ�u�}�N�h�i���h�̃n���o�[�K�[���v�Ƃ����t���[�����́A�����͈͓̔��Ƃ������ƂŐl�̓C���v�b�g�B
�}�N�h�i���h�͊�ƁE�X���ŁA�n���o�[�K�[�͏��i�E�H�ו��A�����āu�����v�ɂ��ẮA�������Ǝx�������z
�Ƃ��ނ�͂����炩�Ƃ����A�����͈͓̔������ŘA�z����B���w�╨���Ɋւ��Ă̓p�^�[����������x���܂��Ă���A
�����͈͓̔��ɂ̂ݑΉ�����������B�A��������߂��������ł��Ȃ��ƁA�������͉����Ă��ގ��̖��͉����Ȃ��B
���O��l�ɂȂ��Ă��Ȃ����A��̖���l�X�Ȋp�x���痝����������A�\����ݒ��ς��ėޑ������Ă݂�B
��������Ԃ����Ă��C�V��͗����Ă��Ȃ��D
��������Ԃ����Ă��C�����̕ǂ̐F�͂����Ȃ��D
��������Ԃ����Ă��C�����̓d�C�͏����Ȃ��D
��������Ԃ����Ă��C�ǂɌ����������肵�Ȃ��D
�l������S�Ẳ\�����A�l�͂ŃC���v�b�g����B�Ⴆ�Α�Ԃ������Ƃ��ɒ�d���N����A�����̓d�C�͏�����B
117 �F�f�t�H���g�̖����������F2014/10/15(��) 07:18:38.39 ID:beWphTMz
���ɏo�Ă������̂����l���������Ȃ��́H
��Ԃ��Ζʂ����ʼnq���̋O����ǂ̐F�Ȃ�Ă͍̂l���Ȃ��ėǂ��B���̏�œV��⏰�͓����Ȃ��Ƃ��A��Ԃ��Ζʂɂ߂荞�ނ��Ƃ͂Ȃ��Ƃ��������l����t���[�����͗}������B
��Ԃ��Ζʂ����ʼnq���̋O����ǂ̐F�Ȃ�Ă͍̂l���Ȃ��ėǂ��B���̏�œV��⏰�͓����Ȃ��Ƃ��A��Ԃ��Ζʂɂ߂荞�ނ��Ƃ͂Ȃ��Ƃ��������l����t���[�����͗}������B
118 �F�f�t�H���g�̖����������F2014/10/15(��) 11:31:02.58 ID:hrBmyTxM
�f�l�b�g �t���[����� �ŃO�O��
119 �F�f�t�H���g�̖����������F2014/10/15(��) 15:22:08.72 ID:beWphTMz
10�������ɕ��̂��o�Ă��Ȃ����S�Ă̑g�ݍ��킹���l���Ă�10!��3628800�A�\���Ɏ��ԓ��ɉ\�B
120 �F�f�t�H���g�̖����������F2014/10/15(��) 16:35:37.73 ID:beWphTMz
�g�`�����Ă���B10!�������B2^10�����������珮�X�����B
121 �F�f�t�H���g�̖����������F2014/10/17(��) 16:43:02.23 ID:724m77ZA
@noricoco ����̍Ō�̂��b�͂����铌���{�A���������˔j����l�H�m�\�v���W�F�N�g�ɂ��Ă̋L�O�u���������̂����A
���g�͐��w��b�_�������Ɏ����E�ɐڒn����̂��A�Ƃ����ɂ߂Ĉӗ~�I�E�����I�Ȃ��b�ł������B�_�������ł͉����Ȃ����
���o���I�ɉ����B�������A����͒P�Ȃ�p�^�[���}�b�`�ł͂Ȃ��A�R���s���[�^�����̏����̊J���ŕ]�������q���[���X�e�B�b�N
�ɐv���Ă����悤�ɁA�������ɍ��킹�č�荞�ށA�Ƃ������̂ł���B���Ƃ�����80�N��ɋt�߂肷��A�Ƃ����킯�ł͂Ȃ��A
�u���̖��͐��w�I�ɂǂ̃N���X�̖��i���Ƃ��ΏW���_�j�Ȃ̂��v�u���Z���w�͈͓̔��ʼn������߂悤�Ƃ���ƁA�ǂ��Ȃ邩�v
�Ƃ������悤�Ȃ��Ƃ��L�q����̂ł���B
�������w��������͐��w��b�_�������������Ƃ�����A���ꂱ�����N�w�ł͂Ȃ�����w�A�����Ď��R���ꏈ���ւƐ���ς���
�������R�ƂȂ����̂����A���̂悤�ȃv���O���������̓��������āA�������Q��ł���̂ł���A�N�w�̗���̂܂ܓN�w������
���E�Ɋ�b�t����A�Ƃ��������ɒ��킵�Ă�����������Ȃ��B�����{�v���W�F�N�g�S�̂Ɋւ��ẮA���܂�d�v�Ȗ��������Ă���
�킯�ł͂Ȃ��Ɣ�������u���Č��Ă������A���Ȃ��Ƃ����w�Ɋւ��ẮA�ƂĂ���S�I�Ȏ��݂ł���A���w�̖�肪������悤
�ɂȂ邾���ł��A���̃v���W�F�N�g�͐l�ނɂƂ��đ傢�ɈӖ��̂��鎎�݂Ȃ̂ł͂Ȃ��낤���B
http://d.hatena.ne.jp/mamoruk/20141004/p1
���g�͐��w��b�_�������Ɏ����E�ɐڒn����̂��A�Ƃ����ɂ߂Ĉӗ~�I�E�����I�Ȃ��b�ł������B�_�������ł͉����Ȃ����
���o���I�ɉ����B�������A����͒P�Ȃ�p�^�[���}�b�`�ł͂Ȃ��A�R���s���[�^�����̏����̊J���ŕ]�������q���[���X�e�B�b�N
�ɐv���Ă����悤�ɁA�������ɍ��킹�č�荞�ށA�Ƃ������̂ł���B���Ƃ�����80�N��ɋt�߂肷��A�Ƃ����킯�ł͂Ȃ��A
�u���̖��͐��w�I�ɂǂ̃N���X�̖��i���Ƃ��ΏW���_�j�Ȃ̂��v�u���Z���w�͈͓̔��ʼn������߂悤�Ƃ���ƁA�ǂ��Ȃ邩�v
�Ƃ������悤�Ȃ��Ƃ��L�q����̂ł���B
�������w��������͐��w��b�_�������������Ƃ�����A���ꂱ�����N�w�ł͂Ȃ�����w�A�����Ď��R���ꏈ���ւƐ���ς���
�������R�ƂȂ����̂����A���̂悤�ȃv���O���������̓��������āA�������Q��ł���̂ł���A�N�w�̗���̂܂ܓN�w������
���E�Ɋ�b�t����A�Ƃ��������ɒ��킵�Ă�����������Ȃ��B�����{�v���W�F�N�g�S�̂Ɋւ��ẮA���܂�d�v�Ȗ��������Ă���
�킯�ł͂Ȃ��Ɣ�������u���Č��Ă������A���Ȃ��Ƃ����w�Ɋւ��ẮA�ƂĂ���S�I�Ȏ��݂ł���A���w�̖�肪������悤
�ɂȂ邾���ł��A���̃v���W�F�N�g�͐l�ނɂƂ��đ傢�ɈӖ��̂��鎎�݂Ȃ̂ł͂Ȃ��낤���B
http://d.hatena.ne.jp/mamoruk/20141004/p1
122 �F�f�t�H���g�̖����������F2014/10/17(��) 21:14:01.02 ID:UIYNCvLu
�������蕷���Ȃ��Ȃ������ǂƂ����{�ǂ��Ȃ�����
123 �F�f�t�H���g�̖����������F2014/10/17(��) 23:45:31.75 ID:mnwHFJbg
664 �F�f�t�H���g�̖���������F2009/02/20(��) 20:42:25.00
�厫��
���{��u����{�S�ȁv�厫�T�̍ō���A�u�X�[�p�[�厫��3.0�v��oneswing�d�l�ŁB
�u�����`�D������v�ɂ��ƂÂ�����Œm�肽�����Ƃ�����������B�@�@
���ۂɎg���Ă���Ӗ������ؒ��J�ɉ�����h�ꓮ�����{��̌��݂��f���o��
25��2�������^�B�{���i�ł́A�S�ȓI�v�f�Ƃ��ē��A���̃J���[�ʐ^��1,000�_
�l�X�ȃ��m�N�������2,000�_����ђ����̖����̉�����270�_�����^�B
���{��̃A�N�Z���g���\������Ă���ق��A���ӂ��K�v�Ȗ�1,000��ɂ͉�����t�^���Ă��莨�Ŋm�F���邱�Ƃ��\�B
����ɁA�ߑ�̍�i����̘^�����L�x�ȗp��ق��������ދ`��̎g��������p�Ȃǂ̉�����[���B
http://jp.fujitsu.com/group/personal/services/jisho/kaiset95.html
��25��2�������^
�ł͂���25��2���S�Ă̒P��ɂ��āA�S�����̏��Ђ��X�p�R���u���v�Ō`�ԑf��͂��A
����ɃR���s���[�^�́u��ǁv�Ɓu����s�\�\���v�͒��o���A�������u�l�͂ŏC���v���A
�u�����t���[���v�Ɓu�Ӗ��l�b�g���[�N�v�ƁuRDF�g���v���v���쐬�Ƃ����킯�ɂ͂����܂��B
�R���s���[�^�ɂ͉��������ł��ĉ��������ł��Ȃ��̂����A�����ł͂����肳�����܂��B
�@�����Ď��ɁA���g�\���́u�듚�v�̓��g�\�������R����𗝉����Ă��Ȃ����Ƃ������Ă���B�A�����J�̓s�s����
�₤����ɑ��āA�J�i�_�̓s�s�������Ƃ����̂��B���̂Ƃ��ɂ͎����N�������Ƃ����B����͒m���̌��
�ł͂Ȃ��B��蕶�̕��ӎ��̂𗝉����Ă��Ȃ�����N���邱�Ƃ��B�J���r���ł́A�t�@�[�X�g���f�B�[�̖����
���Ă���̂ɑ哝�̖̂�����Ƃ������ԈႢ���N�����Ă���炵���B
http://d.hatena.ne.jp/r-hiragi/20130218/1361158109
���邢�͌��݂̋Z�p�ł́A�����ɃR���s���[�^�́u��ǁv�Ɓu����s�\�\���v���������Ė����Ȃ̂ł����B
����ǂ�����Ȃ�Q�`�����l���[�S���l�����āA�l�͂ŃI���g���W�[�쐬�Ƃ����������Ǝv���܂����B
�厫��
���{��u����{�S�ȁv�厫�T�̍ō���A�u�X�[�p�[�厫��3.0�v��oneswing�d�l�ŁB
�u�����`�D������v�ɂ��ƂÂ�����Œm�肽�����Ƃ�����������B�@�@
���ۂɎg���Ă���Ӗ������ؒ��J�ɉ�����h�ꓮ�����{��̌��݂��f���o��
25��2�������^�B�{���i�ł́A�S�ȓI�v�f�Ƃ��ē��A���̃J���[�ʐ^��1,000�_
�l�X�ȃ��m�N�������2,000�_����ђ����̖����̉�����270�_�����^�B
���{��̃A�N�Z���g���\������Ă���ق��A���ӂ��K�v�Ȗ�1,000��ɂ͉�����t�^���Ă��莨�Ŋm�F���邱�Ƃ��\�B
����ɁA�ߑ�̍�i����̘^�����L�x�ȗp��ق��������ދ`��̎g��������p�Ȃǂ̉�����[���B
http://jp.fujitsu.com/group/personal/services/jisho/kaiset95.html
��25��2�������^
�ł͂���25��2���S�Ă̒P��ɂ��āA�S�����̏��Ђ��X�p�R���u���v�Ō`�ԑf��͂��A
����ɃR���s���[�^�́u��ǁv�Ɓu����s�\�\���v�͒��o���A�������u�l�͂ŏC���v���A
�u�����t���[���v�Ɓu�Ӗ��l�b�g���[�N�v�ƁuRDF�g���v���v���쐬�Ƃ����킯�ɂ͂����܂��B
�R���s���[�^�ɂ͉��������ł��ĉ��������ł��Ȃ��̂����A�����ł͂����肳�����܂��B
�@�����Ď��ɁA���g�\���́u�듚�v�̓��g�\�������R����𗝉����Ă��Ȃ����Ƃ������Ă���B�A�����J�̓s�s����
�₤����ɑ��āA�J�i�_�̓s�s�������Ƃ����̂��B���̂Ƃ��ɂ͎����N�������Ƃ����B����͒m���̌��
�ł͂Ȃ��B��蕶�̕��ӎ��̂𗝉����Ă��Ȃ�����N���邱�Ƃ��B�J���r���ł́A�t�@�[�X�g���f�B�[�̖����
���Ă���̂ɑ哝�̖̂�����Ƃ������ԈႢ���N�����Ă���炵���B
http://d.hatena.ne.jp/r-hiragi/20130218/1361158109
���邢�͌��݂̋Z�p�ł́A�����ɃR���s���[�^�́u��ǁv�Ɓu����s�\�\���v���������Ė����Ȃ̂ł����B
����ǂ�����Ȃ�Q�`�����l���[�S���l�����āA�l�͂ŃI���g���W�[�쐬�Ƃ����������Ǝv���܂����B
124 �F�f�t�H���g�̖����������F2014/10/17(��) 23:51:06.28 ID:Lz6GLdVj
���Q�`�����l���[�S���l�����āA�l�͂ŃI���g���W�[�쐬
��ʂɃR�[�p�X�A�m�e�[�V�����͕����̍�Ǝ҂ɂ����{����C�٘_������ɂ���
�A�m�e�[�V�����̈�ѐ����قڗB��̒�ʓI�ȕ]�����j�ƂȂ�B���̂��߁C
��̏C���̓A�m�e�[�V�����]���ґS�Ăŋ��L����K�v������B��Ǝ҂̑�����
�l���n�̓��ق��������͎��ԒP���œ����p�[�g�J���҂ł���C��̌�������
���тɓ��@�Â����܂߂��g�D�^�c���K�v�ɂȂ�D
https://www.jstage.jst.go.jp/article/jnlp/21/2/21_95/_pdf
��ʂɃR�[�p�X�A�m�e�[�V�����͕����̍�Ǝ҂ɂ����{����C�٘_������ɂ���
�A�m�e�[�V�����̈�ѐ����قڗB��̒�ʓI�ȕ]�����j�ƂȂ�B���̂��߁C
��̏C���̓A�m�e�[�V�����]���ґS�Ăŋ��L����K�v������B��Ǝ҂̑�����
�l���n�̓��ق��������͎��ԒP���œ����p�[�g�J���҂ł���C��̌�������
���тɓ��@�Â����܂߂��g�D�^�c���K�v�ɂȂ�D
https://www.jstage.jst.go.jp/article/jnlp/21/2/21_95/_pdf
125 �F�f�t�H���g�̖����������F2014/10/23(��) 13:59:17.26 ID:H9x7O/fU
PAS-NNLM �̃��f���Ƃ��Ă̕\���� SVO �Ɋւ��Ă�, �{�����ł� PAS-NNLM �̊w�K��̃��f����p
���� �ePAS-NNLM comp�f �ɂ��, �ePAS-NNLM add�f�����������W�� (0.42) ��. ����� Tsubaki
�� [10] �� C-NLM �ɂ�錋�� (0.38) ��������̂ł���. ���� C-NLM ��, �����ƖړI��̃y�A�݂̂ɒ���
���� NNLM ���w�K���郂�f���ł���. ������, ������Tsubaki �� [10] �� CoC-NLM �ɂ�鑊�W�� (0.47)
�ɂ͋y�Ȃ�����. CoC-NLM �̗D��Ă���_��, ���̌�`�B���������̎�@��, ����-�ړI��̑g�ݍ��킹
�̈Ӗ��\���Ɏ����ꂽ���Ƃł���. �܂�, Kartsaklis�� Sadrzadeh [7] ��, �P�ꂩ��̈Ӗ��\���̑O�Ɍ�`
�B�����̉������s�����Ƃ̏d�v���������Ă���. �{������ PAS-NNLM �ł�, �i���̏��͗p���Ă�����̂�,
���̑��̖����I�Ȍ�`�B�����̉������s���Ă��Ȃ�. ��蕶���Ɉˑ�������`�B���������̎�@�����
����邱�Ƃɂ��, ����Ȃ鐫�\���オ�l������.
http://www.logos.t.u-tokyo.ac.jp/~hassy/publications/nlp2014/paper.pdf
����w�ɂ������b�Ӗ��_�̗��ꂩ�炷��C���̖����̈Ӗ��\���ɋL�ڂ��ׂ����e�͌�𐬗�������Œ���̗v�f��
����Ƃ����̂���{�I�ȗ���ł��낤�D����͖{�����̘g�g�݂ł����Ȃ�Ώ�o�V�X�e�����\�t�g�E�F�A�Ƒ������ꍇ�C
�V�X�e������������{�I�u�W�F�N�g�f�[�^�Ƒ����邱�Ƃ��o����D�܂�C�]���₻�̐f�Ï� (�C���X�^���X) �Ɋւ���l
����݂��F���Ȃǂ́C�����̃I�u�W�F�N�g�f�[�^�ɑ��ē��I�ɉ�����ꂽ�������ڂƍl������D�l�̌���\���͂܂��ɔ�
�b�҂̔F���ɂ����āC���ۓI�ɕ�����Ƌ��L����I�u�W�F�N�g�ɑ��Čʂ̏��������邱�ƂŐV���ȏ�����Ă���
�Ƒ�����Ȃ�C�������������Ӗ��\���̑����̊g���͎�荞�ނׂ��@�\�ł���C�\�t�g�E�F�A�ɂ�����I�u�W�F�N�g�w����
�g�g��?6�ŏ�o�V�X�e�����\�����Ă����K�v������D
https://kaigi.org/jsai/webprogram/2014/pdf/679.pdf
���� �ePAS-NNLM comp�f �ɂ��, �ePAS-NNLM add�f�����������W�� (0.42) ��. ����� Tsubaki
�� [10] �� C-NLM �ɂ�錋�� (0.38) ��������̂ł���. ���� C-NLM ��, �����ƖړI��̃y�A�݂̂ɒ���
���� NNLM ���w�K���郂�f���ł���. ������, ������Tsubaki �� [10] �� CoC-NLM �ɂ�鑊�W�� (0.47)
�ɂ͋y�Ȃ�����. CoC-NLM �̗D��Ă���_��, ���̌�`�B���������̎�@��, ����-�ړI��̑g�ݍ��킹
�̈Ӗ��\���Ɏ����ꂽ���Ƃł���. �܂�, Kartsaklis�� Sadrzadeh [7] ��, �P�ꂩ��̈Ӗ��\���̑O�Ɍ�`
�B�����̉������s�����Ƃ̏d�v���������Ă���. �{������ PAS-NNLM �ł�, �i���̏��͗p���Ă�����̂�,
���̑��̖����I�Ȍ�`�B�����̉������s���Ă��Ȃ�. ��蕶���Ɉˑ�������`�B���������̎�@�����
����邱�Ƃɂ��, ����Ȃ鐫�\���オ�l������.
http://www.logos.t.u-tokyo.ac.jp/~hassy/publications/nlp2014/paper.pdf
����w�ɂ������b�Ӗ��_�̗��ꂩ�炷��C���̖����̈Ӗ��\���ɋL�ڂ��ׂ����e�͌�𐬗�������Œ���̗v�f��
����Ƃ����̂���{�I�ȗ���ł��낤�D����͖{�����̘g�g�݂ł����Ȃ�Ώ�o�V�X�e�����\�t�g�E�F�A�Ƒ������ꍇ�C
�V�X�e������������{�I�u�W�F�N�g�f�[�^�Ƒ����邱�Ƃ��o����D�܂�C�]���₻�̐f�Ï� (�C���X�^���X) �Ɋւ���l
����݂��F���Ȃǂ́C�����̃I�u�W�F�N�g�f�[�^�ɑ��ē��I�ɉ�����ꂽ�������ڂƍl������D�l�̌���\���͂܂��ɔ�
�b�҂̔F���ɂ����āC���ۓI�ɕ�����Ƌ��L����I�u�W�F�N�g�ɑ��Čʂ̏��������邱�ƂŐV���ȏ�����Ă���
�Ƒ�����Ȃ�C�������������Ӗ��\���̑����̊g���͎�荞�ނׂ��@�\�ł���C�\�t�g�E�F�A�ɂ�����I�u�W�F�N�g�w����
�g�g��?6�ŏ�o�V�X�e�����\�����Ă����K�v������D
https://kaigi.org/jsai/webprogram/2014/pdf/679.pdf
126 �F�ЎR����MZ����CEO ��T6xkBnTXz7B0 �F2014/10/23(��) 20:25:59.88 ID:FP/Pp1Ki
�y�Z�p�z���{�b�g�͓�����w�̓����ɍ��i�ł��邩�H�@�u�����{����v�A�ҕ��Ŏ���A����� [10/23]
http://daily.2ch.net/test/read.cgi/newsplus/1414063059/
http://daily.2ch.net/test/read.cgi/newsplus/1414063059/
127 �F�f�t�H���g�̖����������F2014/10/29(��) 15:23:53.31 ID:WOXCtObY
�|����ĕs�t�ϊ����ꂽ��̃f�[�^����A�ʂ̕s�t�ϊ����ꂽ��̃f�[�^�ɂ����Ȃ�ϊ����悤�Ƃ��Ă邩�獢��Ȃ�ˁB
�����jpg����jpg2000��raw�摜�ɖ߂����ɕϊ����悤�Ƃ��Ă�
�����jpg����jpg2000��raw�摜�ɖ߂����ɕϊ����悤�Ƃ��Ă�
128 �F�f�t�H���g�̖����������F2014/10/29(��) 17:53:35.79 ID:TaY3Bs2I
���𑜂݂�����
129 �F�ЎR����MZ����CEO ��T6xkBnTXz7B0 �F2014/10/29(��) 19:15:45.42 ID:N8JvcROE
�ǂ݁E�����E�������̍ŋ��̓��{��R�[�p�X�u�O�ʈ�́v
�v���W�F�N�g���J�n���܂����B
�����҉������B
�v���W�F�N�g���J�n���܂����B
�����҉������B
130 �F�f�t�H���g�̖����������F2014/10/29(��) 23:38:27.55 ID:zlK0g2wj
raw�摜�ɖ߂����Ă̂́A
���Ԍ��ꎮ�̖|��̂��ƁH
���Ԍ��ꎮ�̖|��̂��ƁH
131 �F�f�t�H���g�̖����������F2014/10/30(��) 00:55:36.93 ID:iSxCzdRK
1pix���Ƃ̊��S�Ɍ��̃f�[�^
���R����̏ꍇ�Ō����Ȃ�A�K����������ł���K�v���Ȃ��Ǝv��
���R����̏ꍇ�Ō����Ȃ�A�K����������ł���K�v���Ȃ��Ǝv��
132 �F�f�t�H���g�̖����������F2014/10/30(��) 01:56:04.20 ID:jdjv0M6/
���ɉf����̂��v��A���ꂪMZ�̖ڕW�ł���B
133 �F �y���d 74.8 %�z �F2014/10/30(��) 12:36:21.88 ID:VubmAqci
>>125
�܂��A����Ȃ��Ƃ��������āI�L�~�͂��������ɂ����܂��B�{�N�̓L�~�����܂�m��Ȃ��B�����ʓ|�����������炠��Ⴕ���
�_�ˎs�̓��A�������{�̒m�I��Q�Ҏ{�݂Ŗ����N���p�҂ɐ��I�ȍs�ׂ����Ĉ��s���őߕ߂��ꂽ�O�c�J�w�����E���̓��_���l(���{�s�V����)�́A���ǂǂ������߂ɂȂ����́H
��Q�҉Ƒ��̃P�A�������s�����ƕ��Ɍ��x�͂����Ƃ�����̂��H
���ʂ�s�҂͊���I�ׂȂ��q���ɂ͊W�Ȃ��B
http://www.youtube.com/watch?v=JxMzW3ZlV4g&sns=em
���s�P�\�I���܂ł܂������B
�܂��A����Ȃ��Ƃ��������āI�L�~�͂��������ɂ����܂��B�{�N�̓L�~�����܂�m��Ȃ��B�����ʓ|�����������炠��Ⴕ���
�_�ˎs�̓��A�������{�̒m�I��Q�Ҏ{�݂Ŗ����N���p�҂ɐ��I�ȍs�ׂ����Ĉ��s���őߕ߂��ꂽ�O�c�J�w�����E���̓��_���l(���{�s�V����)�́A���ǂǂ������߂ɂȂ����́H
��Q�҉Ƒ��̃P�A�������s�����ƕ��Ɍ��x�͂����Ƃ�����̂��H
���ʂ�s�҂͊���I�ׂȂ��q���ɂ͊W�Ȃ��B
http://www.youtube.com/watch?v=JxMzW3ZlV4g&sns=em
���s�P�\�I���܂ł܂������B
134 �F�f�t�H���g�̖����������F2014/10/31(��) 16:05:31.03 ID:0ns/rhdq
�y�Ȋw�z�l�H�m�\�u�����{����v�A�Z���^�[�͎��p��ŕ��ϓ_���� �S�̐��т͎���W���ƍ������S�Z�ł`����@�Q�P�N�x�܂ł̓��升�i�ڕW??2ch.net
http://daily.2ch.net/test/read.cgi/newsplus/1414724624/
http://daily.2ch.net/test/read.cgi/newsplus/1414724624/
135 �F�f�t�H���g�̖����������F2014/11/01(�y) 11:21:29.62 ID:m4AuzDYU
���I
136 �F�f�t�H���g�̖����������F2014/11/03(��) 08:11:18.01 ID:tokfpTJi
��[�~�������̃C���X�g�B
http://livedoor.blogimg.jp/mikamikanmikamikan/imgs/a/8/a8fbf865.jpg
http://livedoor.blogimg.jp/mikamikanmikamikan/imgs/3/b/3b63acc4.jpg
http://livedoor.blogimg.jp/mikamikanmikamikan/imgs/3/b/3b65850a.jpg
http://livedoor.blogimg.jp/mikamikanmikamikan/imgs/2/8/28b52d74.jpg
�@��A�͖����ł��A�C�̐}�Ȃ�u�l�p�����v�u�l�p�����́v���炢�̑�G�c�ȔF��������B
����́u�ٓ����v��������Ȃ����A�u�{�v��������Ȃ����A�u����v��������Ȃ��B
���ɇB�̐}��l����ƁA�_�����r���܂łɂȂ��Ă��āA�u�����������Ă��锠�v�ƍl������B
���͂ł́A�u�v�Ɓu���v�����āu�͒��߂�v�Ƃ������ƂɂȂ��Ă���B
����ǂ��u�v�Ƃ����Ă�����͕����I�ɉ��̖������ʂ����̂����l���Ȃ���Ȃ�Ȃ��B
http://livedoor.blogimg.jp/mikamikanmikamikan/imgs/a/8/a8fbf865.jpg
{kind=link}
http://livedoor.blogimg.jp/mikamikanmikamikan/imgs/3/b/3b63acc4.jpg
{kind=link}
http://livedoor.blogimg.jp/mikamikanmikamikan/imgs/3/b/3b65850a.jpg
{kind=link}
http://livedoor.blogimg.jp/mikamikanmikamikan/imgs/2/8/28b52d74.jpg
{kind=link}
�@��A�͖����ł��A�C�̐}�Ȃ�u�l�p�����v�u�l�p�����́v���炢�̑�G�c�ȔF��������B
����́u�ٓ����v��������Ȃ����A�u�{�v��������Ȃ����A�u����v��������Ȃ��B
���ɇB�̐}��l����ƁA�_�����r���܂łɂȂ��Ă��āA�u�����������Ă��锠�v�ƍl������B
���͂ł́A�u�v�Ɓu���v�����āu�͒��߂�v�Ƃ������ƂɂȂ��Ă���B
����ǂ��u�v�Ƃ����Ă�����͕����I�ɉ��̖������ʂ����̂����l���Ȃ���Ȃ�Ȃ��B
137 �F�f�t�H���g�̖����������F2014/11/03(��) 08:35:06.90 ID:gGej6kOp
�i�P�j���N�͂R�p�[�Z���g�������㏸���A���N�͂T�p�[�Z���g�������㏸����Ƃ����B���ς̗\�z�����㏸���͂������B
�i�Q�j���N�͂R�p�[�Z���g�������㏸����Ƃ����l�ƁA�T�p�[�Z���g�㏸����Ƃ����l������B���ς̗\�z�����㏸���͂������B
�����{�b�g�͓���ɓ���邩�@�V��I�q��
�u���N�́`�v
�@�@����N�x�i���݁j�Q�j
�A�@���N�́A���N�́A���N�O�́A���N��́`�i�P�j
�B�@���邤�N��
�u�������㏸�v
�@�@�ǂ̌��ԂɁA�ǂ̔N�ԂɁi�P�j�A�����̊������i�P�j�i�Q�j
�A�@�i�ڕʂɂ́`�A���~�㏸�A���~����
�u�`�Ƃ����l�v
�@�@�`�Ƃ������O�̐l�Ԃ�����i�l��A�A�l��B�j
�A�@�l��A�́����Əq�ׂ��A�l��B�́����Əq�ׂ��i�Q�j
�@�B�ɂ͘A�z�v�l�͊��҂ł��Ȃ��ȏ�A�O���O���l�͂ŃC���v�b�g����̂݁B
�i�Q�j���N�͂R�p�[�Z���g�������㏸����Ƃ����l�ƁA�T�p�[�Z���g�㏸����Ƃ����l������B���ς̗\�z�����㏸���͂������B
�����{�b�g�͓���ɓ���邩�@�V��I�q��
�u���N�́`�v
�@�@����N�x�i���݁j�Q�j
�A�@���N�́A���N�́A���N�O�́A���N��́`�i�P�j
�B�@���邤�N��
�u�������㏸�v
�@�@�ǂ̌��ԂɁA�ǂ̔N�ԂɁi�P�j�A�����̊������i�P�j�i�Q�j
�A�@�i�ڕʂɂ́`�A���~�㏸�A���~����
�u�`�Ƃ����l�v
�@�@�`�Ƃ������O�̐l�Ԃ�����i�l��A�A�l��B�j
�A�@�l��A�́����Əq�ׂ��A�l��B�́����Əq�ׂ��i�Q�j
�@�B�ɂ͘A�z�v�l�͊��҂ł��Ȃ��ȏ�A�O���O���l�͂ŃC���v�b�g����̂݁B
138 �F�f�t�H���g�̖����������F2014/11/03(��) 09:22:18.89 ID:tokfpTJi
�������ɓ��Ă͂߂�P���ȃ^�C�v�̖��ɂ͑Ή��ł��܂����A�}�`�̐����ɒ��ڂ���悤�ȉ��p�^�C�v�̖��ɂ͂܂��Ή��ł��Ȃ��悤�ł��B
�u���ׂ��̒藝�v�Ƃ��������ɂ��Ă͂߂邾���̖����A�}�`����݂��Ƌ@�B�ɂ͗����ł��Ȃ��炵���B
http://livedoor.blogimg.jp/mikamikanmikamikan/imgs/f/d/fd1497d7.jpg
�]�v�ȕ����������A�u�~�Ɍ����i�܂��͐ڂ���j�A���s�ł͂Ȃ��Q�{�̒����v�ƁA�������ł���B
http://livedoor.blogimg.jp/mikamikanmikamikan/imgs/0/c/0cdeedcc.jpg
�}�`�̐����ɒ��ڂ���悤�ȉ��p�^�C�v�̖��́A�]�v�ȕ����������āA�����ɓ��Ă͂߂�P���ȃ^�C�v�̖��ɋA�������邱�ƁB
�ݒ肪���G�ɂȂ�����A�u���{�̒����ƁA���̉~�ƁA���̎O�p�`�ƁA���ӏ��̐ړ_�ƁA���ӏ��̌�_�v���o���o���ɒ��o���A�������ɑS�Ă̑g�ݍ��킹�����B
�u���ׂ��̒藝�v�Ƃ��������ɂ��Ă͂߂邾���̖����A�}�`����݂��Ƌ@�B�ɂ͗����ł��Ȃ��炵���B
http://livedoor.blogimg.jp/mikamikanmikamikan/imgs/f/d/fd1497d7.jpg
{kind=link}
�]�v�ȕ����������A�u�~�Ɍ����i�܂��͐ڂ���j�A���s�ł͂Ȃ��Q�{�̒����v�ƁA�������ł���B
http://livedoor.blogimg.jp/mikamikanmikamikan/imgs/0/c/0cdeedcc.jpg
{kind=link}
�}�`�̐����ɒ��ڂ���悤�ȉ��p�^�C�v�̖��́A�]�v�ȕ����������āA�����ɓ��Ă͂߂�P���ȃ^�C�v�̖��ɋA�������邱�ƁB
�ݒ肪���G�ɂȂ�����A�u���{�̒����ƁA���̉~�ƁA���̎O�p�`�ƁA���ӏ��̐ړ_�ƁA���ӏ��̌�_�v���o���o���ɒ��o���A�������ɑS�Ă̑g�ݍ��킹�����B
139 �F�f�t�H���g�̖����������F2014/11/03(��) 11:07:24.52 ID:gGej6kOp
������o���̈�����������ɂ��āB
b1 = 1 , bn+1 = bn + 3�@���@�K������ Cn = bn+1 - bn ���l����
�����{�́A����Ȓ��x�̏����I�ȘA�z�Q�[�����o���Ȃ������B���̓��l�ό`�͓����{�̓��ӋZ�ł���A
bn+1 - bn = 3�@ �ƕό`�ł���ΊȒP�ł͂Ȃ��낤���B���l�� 3bn+1 = 3bn + 4�@�� bn+1 = bn + 4/3�@
�� bn+1 - bn = 4/3 ���\�Ȃ͂����B���ꂩ�玮�̓��l�ό`�̎菇����������ł��������B
b1 = 1 , bn+1 = bn + 3�@���@�K������ Cn = bn+1 - bn ���l����
�����{�́A����Ȓ��x�̏����I�ȘA�z�Q�[�����o���Ȃ������B���̓��l�ό`�͓����{�̓��ӋZ�ł���A
bn+1 - bn = 3�@ �ƕό`�ł���ΊȒP�ł͂Ȃ��낤���B���l�� 3bn+1 = 3bn + 4�@�� bn+1 = bn + 4/3�@
�� bn+1 - bn = 4/3 ���\�Ȃ͂����B���ꂩ�玮�̓��l�ό`�̎菇����������ł��������B
140 �F�f�t�H���g�̖����������F2014/11/03(��) 11:29:13.15 ID:gGej6kOp
�����̑�O��́A�u�i����������e��ɐ����͂�v�u�ߕ����Ɉ������̕��ʉH����˂�����v�̕�����A�ȉ��̂悤�ȗޑ�������ł��Ȃ����낤���B
�}1�̂悤�Ȑ[�����ω����鐅���ɐ������}2�̂悤�ɐ[�����ς�鋫�E�ʂɑ��āA45���̕�������߂ɕ��ʔg��i�s�������Ƃ���A
http://detail.chiebukuro.yahoo.co.jp/qa/question_detail/q12119401572
�}1�̂悤�Ȑ[�����ω����鐅���ɐ������}2�̂悤�ɐ[�����ς�鋫�E�ʂɑ��āA45���̕�������߂ɕ��ʔg��i�s�������Ƃ���A
http://detail.chiebukuro.yahoo.co.jp/qa/question_detail/q12119401572
141 �F�f�t�H���g�̖����������F2014/11/03(��) 18:22:59.01 ID:tokfpTJi
http://livedoor.blogimg.jp/mikamikanmikamikan/imgs/f/1/f1f74737.jpg
�@�u���[�x���[���̂����f�R���[�V�����P�[�L�i�̃C���X�g�j�Ȃ�āA�����炭������
�l�����܂�ď��߂Č�����̂ł��傤�ˁB�Ȃ̂ɁA�����͂��ꂪ�������ƁA����
���킩��B�ǂ����ĂȂ̂ł��傤���B����͔F�m�Ȋw�Ƃ�������̓��̂ЂƂł��B
�@���������A���̃C���X�g�A�ςȂ�ł��B�u���[�x���[�̒��a���ĂP�Z���`�����ł���B
���Ƃ���ƁA���̃P�[�L�A���a��12�Z���`���炢�����Ȃ����ƂɂȂ�B����Ȃ́A
���������ł��傤�H�i�j�ɂ�������炸�A���̔N�̃Z���^�[��������������
�͒N��l�Ƃ��Ă����ς��Ǝv�킸�A�l�X�Ɩ�����������ł��ˁB
�@���Ȃ݂Ɏ��̐E��ŁA�P�[�L�Ƀv�`�g�}�g���̂��Ă�ˁA�ƌ������ЂƂ����܂��ˁi�j�B
�����{�b�g�͓���ɓ���邩�@�V��I�q��
���P�[�L�Ƀv�`�g�}�g���̂��Ă�ˁA
�ȉ~�`�̎���ɁA�����ۂ��s��`�̉����ƁA�����ۂ��~�`�̉������A���݂ɕ���ł���B
�A�����̐}�𗧑̂Ƃ��Ċώ@����ƁA�ȉ~�`�͉~�`�������Ă���A�܂������ۂ��~�`�̉����̒��S���������Ȃ��Ă���̂͋��`�Ɛ��������B
{kind=link}
�@�u���[�x���[���̂����f�R���[�V�����P�[�L�i�̃C���X�g�j�Ȃ�āA�����炭������
�l�����܂�ď��߂Č�����̂ł��傤�ˁB�Ȃ̂ɁA�����͂��ꂪ�������ƁA����
���킩��B�ǂ����ĂȂ̂ł��傤���B����͔F�m�Ȋw�Ƃ�������̓��̂ЂƂł��B
�@���������A���̃C���X�g�A�ςȂ�ł��B�u���[�x���[�̒��a���ĂP�Z���`�����ł���B
���Ƃ���ƁA���̃P�[�L�A���a��12�Z���`���炢�����Ȃ����ƂɂȂ�B����Ȃ́A
���������ł��傤�H�i�j�ɂ�������炸�A���̔N�̃Z���^�[��������������
�͒N��l�Ƃ��Ă����ς��Ǝv�킸�A�l�X�Ɩ�����������ł��ˁB
�@���Ȃ݂Ɏ��̐E��ŁA�P�[�L�Ƀv�`�g�}�g���̂��Ă�ˁA�ƌ������ЂƂ����܂��ˁi�j�B
�����{�b�g�͓���ɓ���邩�@�V��I�q��
���P�[�L�Ƀv�`�g�}�g���̂��Ă�ˁA
�ȉ~�`�̎���ɁA�����ۂ��s��`�̉����ƁA�����ۂ��~�`�̉������A���݂ɕ���ł���B
�A�����̐}�𗧑̂Ƃ��Ċώ@����ƁA�ȉ~�`�͉~�`�������Ă���A�܂������ۂ��~�`�̉����̒��S���������Ȃ��Ă���̂͋��`�Ɛ��������B
142 �F�f�t�H���g�̖����������F2014/11/03(��) 19:01:37.56 ID:ieVOoQg9
�����{������ĉ摜�����n�̐l�قƂ�ǂ��Ȃ��ł���
143 �F�f�t�H���g�̖����������F2014/11/03(��) 23:09:51.81 ID:tokfpTJi
�����́A�s�v�Ȑ��������āA�K�v�Ȑ������ɂ��Ȃ��ƁA�藝���g���Ȃ��B
���̐}�`
http://livedoor.blogimg.jp/mikamikanmikamikan/imgs/3/a/3aaa1e5f.jpg
�P�������āA�Q�p�s���p�q
http://livedoor.blogimg.jp/mikamikanmikamikan/imgs/0/1/01eaff32.jpg
�����p�s�Ɛ����p�q�̊W�����߂�̂ɁA�ǂ̐����K�v�ŁA�ǂ̐����s�v�Ȃ̂��B
�܂��K�v�Ȑ��������ꍇ�́A�_�Ɠ_���m����������������������肵�āA�⏕���������B
�v�Z�͂Ƀ��m�����킹�āA����݂Ԃ��ɑS�Ă̏ꍇ�ׂ����Ƃ�������������B
����p�`������ӂ����L���Ȃ��O�p�`�͂������邩�B�Ƃ�����肪����A�����͂R�O�炵���ł��B�Ȃ������Ȃ�̂ł��傤���H
http://detail.chiebukuro.yahoo.co.jp/qa/question_detail/q10114300645
�S�Ă̏ꍇ������݂Ԃ��ɐ����グ��A���S���Y���͉\�ł����H
���̐}�`
http://livedoor.blogimg.jp/mikamikanmikamikan/imgs/3/a/3aaa1e5f.jpg
{kind=link}
�P�������āA�Q�p�s���p�q
http://livedoor.blogimg.jp/mikamikanmikamikan/imgs/0/1/01eaff32.jpg
{kind=link}
�����p�s�Ɛ����p�q�̊W�����߂�̂ɁA�ǂ̐����K�v�ŁA�ǂ̐����s�v�Ȃ̂��B
�܂��K�v�Ȑ��������ꍇ�́A�_�Ɠ_���m����������������������肵�āA�⏕���������B
�v�Z�͂Ƀ��m�����킹�āA����݂Ԃ��ɑS�Ă̏ꍇ�ׂ����Ƃ�������������B
����p�`������ӂ����L���Ȃ��O�p�`�͂������邩�B�Ƃ�����肪����A�����͂R�O�炵���ł��B�Ȃ������Ȃ�̂ł��傤���H
http://detail.chiebukuro.yahoo.co.jp/qa/question_detail/q10114300645
�S�Ă̏ꍇ������݂Ԃ��ɐ����グ��A���S���Y���͉\�ł����H
144 �F�f�t�H���g�̖����������F2014/11/04(��) 00:06:26.26 ID:LJyHsHlb
�g�ݍ��킹�œK������
�I�[�_�[���炢�����ōl�����
�I�[�_�[���炢�����ōl�����
145 �F�f�t�H���g�̖����������F2014/11/04(��) 02:08:02.45 ID:Td6UKxL3
http://livedoor.blogimg.jp/mikamikanmikamikan/imgs/5/8/589fbe91.jpg
�S�ł������\��肾���A���̂��炢�Ȃ�G�N�Z�������ł���̂ł͂Ȃ����B
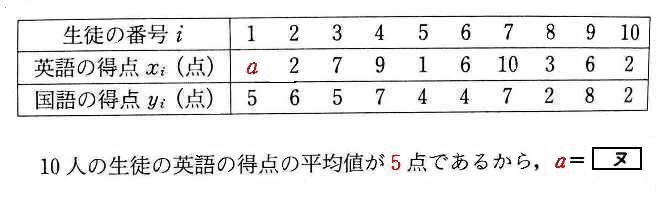{kind=link}
�S�ł������\��肾���A���̂��炢�Ȃ�G�N�Z�������ł���̂ł͂Ȃ����B
146 �F�f�t�H���g�̖����������F2014/11/04(��) 10:46:33.52 ID:Td6UKxL3
�C���X�g�����́A�Ƃ肠�����`��ƐF�ʂ������A�u���ߖ@�v�ő�G�c�ɑ����Đ��肷�邭�炢�̋@�\���B
���P�[�L�Ƀv�`�g�}�g���̂��Ă�ˁA
�P�[�L���̃N���[�����̃u���[�x���[���͓̂���ł��Ȃ��Ă������B�܂��u�`��v�́A�菑���̕����F���@�\
�͌��サ�Ă���̂�����A���̋Z�p�����p��������B�܂��u�F�ʁv�͔����ł����ߖ@���c���ł���悤�ɍH�v����B
�ȉ~�`�̎���ɁA�����ۂ��s��`�̉����ƁA�����ۂ��~�`�̉������A���݂ɕ���ł���B�A�����̐}�𗧑�
�Ƃ��Ċώ@����ƁA�܂������̓y�䂪�����āA�㕔�̑ȉ~�`�͉~�`�������Ă���A�܂������ۂ��~�`�̉�����
���S���������Ȃ��Ă���̂͋��`�Ɛ��������B
���P�[�L�Ƀv�`�g�}�g���̂��Ă�ˁA
�P�[�L���̃N���[�����̃u���[�x���[���͓̂���ł��Ȃ��Ă������B�܂��u�`��v�́A�菑���̕����F���@�\
�͌��サ�Ă���̂�����A���̋Z�p�����p��������B�܂��u�F�ʁv�͔����ł����ߖ@���c���ł���悤�ɍH�v����B
�ȉ~�`�̎���ɁA�����ۂ��s��`�̉����ƁA�����ۂ��~�`�̉������A���݂ɕ���ł���B�A�����̐}�𗧑�
�Ƃ��Ċώ@����ƁA�܂������̓y�䂪�����āA�㕔�̑ȉ~�`�͉~�`�������Ă���A�܂������ۂ��~�`�̉�����
���S���������Ȃ��Ă���̂͋��`�Ɛ��������B
147 �F�f�t�H���g�̖����������F2014/11/04(��) 11:14:12.09 ID:Td6UKxL3
>>116
�����O��l�ɂȂ��Ă��Ȃ����A��̖���l�X�Ȋp�x���痝����������A�\����ݒ��ς��ėޑ������Ă݂�B
���̍u���̃e�L�X�g�ŋ��k�ł����A�R�`���̂Q����������������B
�ꌩ����ƁA�u���َq��z����v�u�����̂�ςݏグ����v�ƕʂ̖��Ɍ����܂��B
�������A�����Ă��炦��Ƃ킩��܂����A���̂Q��͑f�����������g���ĉ����A
�����p�^�[���̖��ł��B�܂�ޑ���Ă��ƂɂȂ�܂��ˁB
����ɁA�i�ׂ��������͉���ɔC���܂����j�Q�̖��Ƃ��u�Q�ȏ�v�Ƃ�����傪���ʂ��Ă���A
���́u�Q�ȏ�v����@�̕��j�������Ă����d�v�Ȍ�傾�Ƃ������Ƃ��킩��܂��B
������ޑ�Ƃ́A��蕶�̏d�v��傪���ʂ��Ă�������w�����Ƃ��킩��܂��B
���������āA�F���ޑ��F�����邽�߂ɂ́A��蕶�̏d�v�|�C���g���ӎ����Ȃ�
�Ƃ����Ȃ����Ă������Ƃ��킩��܂��ˁH
http://shibasaki873.blog.fc2.com/blog-entry-74.html
�����O��l�ɂȂ��Ă��Ȃ����A��̖���l�X�Ȋp�x���痝����������A�\����ݒ��ς��ėޑ������Ă݂�B
���̍u���̃e�L�X�g�ŋ��k�ł����A�R�`���̂Q����������������B
�ꌩ����ƁA�u���َq��z����v�u�����̂�ςݏグ����v�ƕʂ̖��Ɍ����܂��B
�������A�����Ă��炦��Ƃ킩��܂����A���̂Q��͑f�����������g���ĉ����A
�����p�^�[���̖��ł��B�܂�ޑ���Ă��ƂɂȂ�܂��ˁB
����ɁA�i�ׂ��������͉���ɔC���܂����j�Q�̖��Ƃ��u�Q�ȏ�v�Ƃ�����傪���ʂ��Ă���A
���́u�Q�ȏ�v����@�̕��j�������Ă����d�v�Ȍ�傾�Ƃ������Ƃ��킩��܂��B
������ޑ�Ƃ́A��蕶�̏d�v��傪���ʂ��Ă�������w�����Ƃ��킩��܂��B
���������āA�F���ޑ��F�����邽�߂ɂ́A��蕶�̏d�v�|�C���g���ӎ����Ȃ�
�Ƃ����Ȃ����Ă������Ƃ��킩��܂��ˁH
http://shibasaki873.blog.fc2.com/blog-entry-74.html
148 �F�f�t�H���g�̖����������F2014/11/04(��) 11:49:28.30 ID:Td6UKxL3
�����{��̌`���\���ϊ��ɂ��ẮC�����Ȗڂł͋ɂ߂č���ŁC
���]�v�ȕ����������A�u�~�Ɍ����i�܂��͐ڂ���j�A���s�ł͂Ȃ��Q�{�̒����v�ƁA�������ł���B
�����������R����Ƃ����̂́A�P��ЂƂƂ��Ă��w�s�v�ȏ��x�ň��Ԃ��Ă���B�Ⴆ�w�x�Ƃ����P��̗p�r�͗l�X�ŁA
�����w�I�ɂ݂�u���́v�ɂ��Ȃ肤�邵�u���́v�ɂ��Ȃ肦�邵�u��Q���v�ɂ��Ȃ肦��B����̓����Ȃǂ͕��삪����
�ɂ܂������Ă��Ĉ�w�킩��ɂ����B���R���ꕶ���ӂɍ��킹���`���\���ϊ�����ɂ́A�c��ȘA�z�V�\�[���X�Ԃ���A
�K�v�ȕ����������o�����ƁB
���̔ώG���s�v�ȏ������S�ɏ��O���u�d�v�|�C���g�v�݂̂𒊏o����B�������̑����͉ߋ���̏Ă����������A
�\�ʏ�̌�����ς��Ă�����A�ʂ̐}����p���Ă����肵�āA���肵�ďo�肳���ꍇ�������B�������͏o�邪
�������͏o�Ȃ��B�P���Ȗ��ɕs�v�ȏ���lj����Ă킴�Ƃ킩��ɂ������Ă���̂��B���������ꍇ�́u�ތ^���v
�̌��������������āA���ʎ����𒊏o����Ƃ����A���S���Y�����s���ɂȂ��Ă���B
���]�v�ȕ����������A�u�~�Ɍ����i�܂��͐ڂ���j�A���s�ł͂Ȃ��Q�{�̒����v�ƁA�������ł���B
�����������R����Ƃ����̂́A�P��ЂƂƂ��Ă��w�s�v�ȏ��x�ň��Ԃ��Ă���B�Ⴆ�w�x�Ƃ����P��̗p�r�͗l�X�ŁA
�����w�I�ɂ݂�u���́v�ɂ��Ȃ肤�邵�u���́v�ɂ��Ȃ肦�邵�u��Q���v�ɂ��Ȃ肦��B����̓����Ȃǂ͕��삪����
�ɂ܂������Ă��Ĉ�w�킩��ɂ����B���R���ꕶ���ӂɍ��킹���`���\���ϊ�����ɂ́A�c��ȘA�z�V�\�[���X�Ԃ���A
�K�v�ȕ����������o�����ƁB
���̔ώG���s�v�ȏ������S�ɏ��O���u�d�v�|�C���g�v�݂̂𒊏o����B�������̑����͉ߋ���̏Ă����������A
�\�ʏ�̌�����ς��Ă�����A�ʂ̐}����p���Ă����肵�āA���肵�ďo�肳���ꍇ�������B�������͏o�邪
�������͏o�Ȃ��B�P���Ȗ��ɕs�v�ȏ���lj����Ă킴�Ƃ킩��ɂ������Ă���̂��B���������ꍇ�́u�ތ^���v
�̌��������������āA���ʎ����𒊏o����Ƃ����A���S���Y�����s���ɂȂ��Ă���B
149 �F�f�t�H���g�̖����������F2014/11/05(��) 13:11:11.01 ID:TFchYdUt
�Ă������ǂ��������̂��ˁB
�摜�����ł͕��̔F���ƁA���W�ʒu�͎擾�ł����ǁB
�摜�����ł͕��̔F���ƁA���W�ʒu�͎擾�ł����ǁB
150 �F�f�t�H���g�̖����������F2014/11/06(��) 07:15:21.52 ID:1dD9kBwW
http://blog.livedoor.jp/dg_law/archives/52234923.html
�����{��̌`���\���ϊ��ɂ��ẮC�����Ȗڂł͋ɂ߂č���ŁC���w�̂悤�Ȕ���������������B
�����{�ꂪ�B�������邽�߁B���Ƃ��u������܂�Ȃ���v��u���炩�ȍ�v�𓌃��{�����͂ŗ������āC
���V�~�����[�^�[�Ɏ�荞�ނ̂́C���Ȃ��Ƃ�����ł͐�ɖ����B
���������̂́A�����p�̌`���\���ϊ��R�[�p�X��p�ӂ��Ă��������B
��������܂�Ȃ���
�����`��ABCD������B�����͈�l�ŁA���ʂ�M�B������EF��GH�ł��ꂼ�꒼�p�ɐ܂�Ȃ��āA
�����ȏ��ɒu��CD�̒��_I����y�����ł�������邷�B������̎��ʂ�����l���傫���Ƌ����͓|��Ă��܂�
���͂ǂ̂悤�Ȓl�ɂȂ邩�H
http://okwave.jp/qa/q7197628.html
���̗ޑ�ɁA�u�����v���u�����łł����v�ƃA�m�e�[�V���������Ă����A�u������܂�Ȃ���v�ɂ����p�ł���B
�܂�������܂�Ȃ���ƁA�x�_�ƃ��[�����g�͂ǂ��Ȃ邩�Ƃ����A�z�v�l���\�ɂȂ�B
�����炩�ȍ�
���������Ċ��炩�ȍ��]���鎿�_�͉^���̕������Ζʂ̌`��ɂ���ĕς�낤�Ƃ��͊w�I�G�l���M�[�̕ۑ��͐��藧���Ă���B
http://www.ep.sci.hokudai.ac.jp/~heki/pdf/mechanics5.pdf
�S�Ă̕��͂������Ɍ`���\���ϊ��ł��Ȃ��Ă��A�ߋ���̉�@�p�^�[�����炠����x�̐��_�͂ł���B
���͗\���@�\������������ϊ��V�X�e���̂悤�ɁA��@�\���@�\������B
�����{��̌`���\���ϊ��ɂ��ẮC�����Ȗڂł͋ɂ߂č���ŁC���w�̂悤�Ȕ���������������B
�����{�ꂪ�B�������邽�߁B���Ƃ��u������܂�Ȃ���v��u���炩�ȍ�v�𓌃��{�����͂ŗ������āC
���V�~�����[�^�[�Ɏ�荞�ނ̂́C���Ȃ��Ƃ�����ł͐�ɖ����B
���������̂́A�����p�̌`���\���ϊ��R�[�p�X��p�ӂ��Ă��������B
��������܂�Ȃ���
�����`��ABCD������B�����͈�l�ŁA���ʂ�M�B������EF��GH�ł��ꂼ�꒼�p�ɐ܂�Ȃ��āA
�����ȏ��ɒu��CD�̒��_I����y�����ł�������邷�B������̎��ʂ�����l���傫���Ƌ����͓|��Ă��܂�
���͂ǂ̂悤�Ȓl�ɂȂ邩�H
http://okwave.jp/qa/q7197628.html
���̗ޑ�ɁA�u�����v���u�����łł����v�ƃA�m�e�[�V���������Ă����A�u������܂�Ȃ���v�ɂ����p�ł���B
�܂�������܂�Ȃ���ƁA�x�_�ƃ��[�����g�͂ǂ��Ȃ邩�Ƃ����A�z�v�l���\�ɂȂ�B
�����炩�ȍ�
���������Ċ��炩�ȍ��]���鎿�_�͉^���̕������Ζʂ̌`��ɂ���ĕς�낤�Ƃ��͊w�I�G�l���M�[�̕ۑ��͐��藧���Ă���B
http://www.ep.sci.hokudai.ac.jp/~heki/pdf/mechanics5.pdf
�S�Ă̕��͂������Ɍ`���\���ϊ��ł��Ȃ��Ă��A�ߋ���̉�@�p�^�[�����炠����x�̐��_�͂ł���B
���͗\���@�\������������ϊ��V�X�e���̂悤�ɁA��@�\���@�\������B
151 �F�f�t�H���g�̖����������F2014/11/06(��) 13:15:54.06 ID:1dD9kBwW
http://www.ep.sci.hokudai.ac.jp/~heki/pdf/mechanics5.pdf
���Ȃ߂炩�Ȗʂɑ������ꂽ���_�̉^���B
������ǂ�����ăR���s���[�^�[�ɗ��������邩�A�ǂ��`���ϊ����邩�B
mv2/2�i�^���G�l���M�[�j �{ mgh�i�ʒu�G�l���M�[�j �� ���A�ƂȂ镨�����ۂƂł���`���悤���B
���炩�Ȗʂ͕s��Ȑ��ł������Ƃ������ƂŁB����Ȃ畗����������d���C���o����ŕʂ̃G�l���M�[����
�������Ȃ�����A�������Ă͂߂Ŋy�ɉł���B
�������e�̕������ۂ��A�ʂ̌��t�Ō�����������A�ʂ̃C���X�g�}�ŏ����������肵�āA�`���ϊ��R�[�p�X�𑝂₷�B
���Ȃ߂炩�Ȗʂɑ������ꂽ���_�̉^���B
������ǂ�����ăR���s���[�^�[�ɗ��������邩�A�ǂ��`���ϊ����邩�B
mv2/2�i�^���G�l���M�[�j �{ mgh�i�ʒu�G�l���M�[�j �� ���A�ƂȂ镨�����ۂƂł���`���悤���B
���炩�Ȗʂ͕s��Ȑ��ł������Ƃ������ƂŁB����Ȃ畗����������d���C���o����ŕʂ̃G�l���M�[����
�������Ȃ�����A�������Ă͂߂Ŋy�ɉł���B
�������e�̕������ۂ��A�ʂ̌��t�Ō�����������A�ʂ̃C���X�g�}�ŏ����������肵�āA�`���ϊ��R�[�p�X�𑝂₷�B
152 �F�f�t�H���g�̖����������F2014/11/06(��) 14:50:01.57 ID:1dD9kBwW
���w�T�`�̑�T��u104��f������������Ɓ`�v���ł��Ȃ������͉̂��̂��𐔊w�S���҂ɕ����Ă݂��B
�����瓌���{����w�I���`�ł��A����͂Ȃ����낤�A�ƁB
http://livedoor.blogimg.jp/mikamikanmikamikan/imgs/3/0/301029f2.jpg
�O���́u104�ȉ��̎��R���ŁC104�ƌ݂��ɑf�ł��鎩�R���̌������߂悤�B�v�ɖڂ������ʼnł��Ȃ������炵���B
�]�v�ȃm�C�Y�i�ŏ��̖₢�ł́j�����f�����킹���̂��B�����m�C�Y���́A���͂̈ꕔ�����S��������_���ɔ����o���ċᖡ���邵���Ȃ��B
�����͈ꕶ�ꕶ�����āi�ȗ����₢�A���u����v�u����v�Ȃǂ̑㖼���̓��e�͖��m�ɂ�����Łj�A
�Ⴆ�Έ�̑��ɂP�O�̕��͂���������A���̒����烉���_���Ɉ�i�P�O�ʂ�j�A�����_���ɂQ�i�P�O�~�X���Q���S�T�ʂ�j�A
�����_���ɂR�i�P�O�E�X�E�W���R�E�Q�j�E�E�E�Ƃ����ӂ��ɋ����Ă݂�B�܂���̕��߂ɋ������A�Z�����ɏ�����������A
�ȗ����������A�����_���ɂ������̕��߂�����Ă݂��肵�āA���₲�ƂɕK�v�ȗv�f�����𒊏o����B
http://livedoor.blogimg.jp/mikamikanmikamikan/imgs/8/f/8f23e42b.jpg
���������������������B����̍ŏ��̖₢�́A��������ł̓��䐔��̈�ʍ������߂�Ƃ������������I�Ȗ₢�B
��������m�C�Y���������āAa2 = 24 , a5 = 192 ���� r^3 = 8
http://livedoor.blogimg.jp/mikamikanmikamikan/imgs/5/6/56b247f8.jpg
���Ƃ��畜�������āA����͎��������� r = 2 �����
http://livedoor.blogimg.jp/mikamikanmikamikan/imgs/2/8/28b927d8.jpg
���䁁�Q�A���� a2 = 24 ��� ����a1 = 12 �A����Đ���oan�p�̈�ʍ��� an = 12(2)^(n-1)
http://livedoor.blogimg.jp/mikamikanmikamikan/imgs/c/3/c3506aa2.jpg
���Ƃ͓����{�����ӂ́u���l�ό`�v�Ŋy���̂͂��B
�����瓌���{����w�I���`�ł��A����͂Ȃ����낤�A�ƁB
http://livedoor.blogimg.jp/mikamikanmikamikan/imgs/3/0/301029f2.jpg
{kind=link}
�O���́u104�ȉ��̎��R���ŁC104�ƌ݂��ɑf�ł��鎩�R���̌������߂悤�B�v�ɖڂ������ʼnł��Ȃ������炵���B
�]�v�ȃm�C�Y�i�ŏ��̖₢�ł́j�����f�����킹���̂��B�����m�C�Y���́A���͂̈ꕔ�����S��������_���ɔ����o���ċᖡ���邵���Ȃ��B
�����͈ꕶ�ꕶ�����āi�ȗ����₢�A���u����v�u����v�Ȃǂ̑㖼���̓��e�͖��m�ɂ�����Łj�A
�Ⴆ�Έ�̑��ɂP�O�̕��͂���������A���̒����烉���_���Ɉ�i�P�O�ʂ�j�A�����_���ɂQ�i�P�O�~�X���Q���S�T�ʂ�j�A
�����_���ɂR�i�P�O�E�X�E�W���R�E�Q�j�E�E�E�Ƃ����ӂ��ɋ����Ă݂�B�܂���̕��߂ɋ������A�Z�����ɏ�����������A
�ȗ����������A�����_���ɂ������̕��߂�����Ă݂��肵�āA���₲�ƂɕK�v�ȗv�f�����𒊏o����B
http://livedoor.blogimg.jp/mikamikanmikamikan/imgs/8/f/8f23e42b.jpg
{kind=link}
���������������������B����̍ŏ��̖₢�́A��������ł̓��䐔��̈�ʍ������߂�Ƃ������������I�Ȗ₢�B
��������m�C�Y���������āAa2 = 24 , a5 = 192 ���� r^3 = 8
http://livedoor.blogimg.jp/mikamikanmikamikan/imgs/5/6/56b247f8.jpg
{kind=link}
���Ƃ��畜�������āA����͎��������� r = 2 �����
http://livedoor.blogimg.jp/mikamikanmikamikan/imgs/2/8/28b927d8.jpg
{kind=link}
���䁁�Q�A���� a2 = 24 ��� ����a1 = 12 �A����Đ���oan�p�̈�ʍ��� an = 12(2)^(n-1)
http://livedoor.blogimg.jp/mikamikanmikamikan/imgs/c/3/c3506aa2.jpg
{kind=link}
���Ƃ͓����{�����ӂ́u���l�ό`�v�Ŋy���̂͂��B
153 �F�f�t�H���g�̖����������F2014/11/06(��) 16:11:34.55 ID:1dD9kBwW
���u���[�x���[���̂����f�R���[�V�����P�[�L�i�̃C���X�g�j�Ȃ�āA�����炭�����̐l�����܂�ď��߂Č�����̂ł��傤�ˁB
���Ȃ̂ɁA�����͂��ꂪ�������ƁA�������킩��B�ǂ����ĂȂ̂ł��傤���B
http://livedoor.blogimg.jp/mikamikanmikamikan/imgs/0/9/090ff180.jpg
�������āu���镔���v���폜���Ă��܂��A�u�����Ɖ��������݂ɑȉ~�`�ɕ���ł���v���炢�̔F���͂ł���͂����B
�ǂ̂悤�ɍ폜���邩�́A�u���E���v�݂̂ɒ��ڂ��Đ蕪���ŁA���Ƃ̓����_���ɉ����ʂ�����o����B
���Ȃ̂ɁA�����͂��ꂪ�������ƁA�������킩��B�ǂ����ĂȂ̂ł��傤���B
http://livedoor.blogimg.jp/mikamikanmikamikan/imgs/0/9/090ff180.jpg
{kind=link}
�������āu���镔���v���폜���Ă��܂��A�u�����Ɖ��������݂ɑȉ~�`�ɕ���ł���v���炢�̔F���͂ł���͂����B
�ǂ̂悤�ɍ폜���邩�́A�u���E���v�݂̂ɒ��ڂ��Đ蕪���ŁA���Ƃ̓����_���ɉ����ʂ�����o����B
154 �F�f�t�H���g�̖����������F2014/11/06(��) 18:54:37.32 ID:yUh2UtPW
������p�ɂɍX�V���Ă���l���ē���l���Ȃ́H
155 �F�f�t�H���g�̖����������F2014/11/06(��) 20:49:20.00 ID:Z+6n6avI
156 �F�f�t�H���g�̖����������F2014/11/07(��) 02:56:19.25 ID:zRPOEUiC
>>155
���������N�́A�摜�����̃v���Ȃ́H
���������N�́A�摜�����̃v���Ȃ́H
157 �F�f�t�H���g�̖����������F2014/11/07(��) 20:12:31.00 ID:LCGb7X+6
�͌�̌�́A�����̋�Ƃ͈Ⴂ�A���ɔ\�͂̍��͖����B�ɂ���ėv�ɂȂ�����p�ɂȂ����肷��B
����͊�Ƃ��Ј��ЂƂ�ЂƂ�̕]�����ǂ����邩�Ƃ������Ǝ��Ă���B�ǂ̎Ј����K�v�ŁA�ǂ̎Ј������ו��Ȃ̂��B
���鎞�ɂ͑����̊�������Ă����Ј����A���オ�ς����ו��ɂȂ�����A�t�ɐV�l�̂Ƃ��ɂ��ו��������Ј����A
�R�N�ڂœ��p�������Ă���ꍇ�����肤��B��̕]���͎Ј��̎Г��]���Ɠ����ƍl�����Ȃ����낤���B
������
������
������
�������Ȃ��Ƃ���̐}�̐^�̍��́A���ɗ����Ȃ��ǂ��납���S�ȊQ���ł��낤�B��ЂŌ����u�����ƐE�v�ɒl����B
����ȎЈ����������Ă����ƂɁA����������悤�ɂ͎v���Ȃ��B�͌�ɂ�����u�]�����v���A
����ڌ��݂ɂ�����l���]���Ƃ������Ƃɂ��Ă͂ǂ����B
����͊�Ƃ��Ј��ЂƂ�ЂƂ�̕]�����ǂ����邩�Ƃ������Ǝ��Ă���B�ǂ̎Ј����K�v�ŁA�ǂ̎Ј������ו��Ȃ̂��B
���鎞�ɂ͑����̊�������Ă����Ј����A���オ�ς����ו��ɂȂ�����A�t�ɐV�l�̂Ƃ��ɂ��ו��������Ј����A
�R�N�ڂœ��p�������Ă���ꍇ�����肤��B��̕]���͎Ј��̎Г��]���Ɠ����ƍl�����Ȃ����낤���B
������
������
������
�������Ȃ��Ƃ���̐}�̐^�̍��́A���ɗ����Ȃ��ǂ��납���S�ȊQ���ł��낤�B��ЂŌ����u�����ƐE�v�ɒl����B
����ȎЈ����������Ă����ƂɁA����������悤�ɂ͎v���Ȃ��B�͌�ɂ�����u�]�����v���A
����ڌ��݂ɂ�����l���]���Ƃ������Ƃɂ��Ă͂ǂ����B
158 �F�f�t�H���g�̖����������F2014/11/08(�y) 04:53:29.67 ID:WHpgboF2
159 �F�ЎR����MZ����CEO ��T6xkBnTXz7B0 �F2014/11/08(�y) 05:41:32.70 ID:ebCh2W7f
�y�m�����̍l�����z
�P�D���s�⎖�ۂ�\�����͂���A���ׂĂ̖��m���͈̔͂����肵�A
���ꂼ��̖��m���͈̔͂���Ԃ̏W���Ƃ��ĕ\��(Boost.Icl�Q��)�B
�Q�D����̎��s�⎖�ۂ̖��m���̑g�������v�Z���A�S���s�E�S���ۂ̑g�����ɑ��銄�������߂����̂��m���ł���B
�P�D���s�⎖�ۂ�\�����͂���A���ׂĂ̖��m���͈̔͂����肵�A
���ꂼ��̖��m���͈̔͂���Ԃ̏W���Ƃ��ĕ\��(Boost.Icl�Q��)�B
�Q�D����̎��s�⎖�ۂ̖��m���̑g�������v�Z���A�S���s�E�S���ۂ̑g�����ɑ��銄�������߂����̂��m���ł���B
160 �F�ЎR����MZ����CEO ��T6xkBnTXz7B0 �F2014/11/08(�y) 06:33:51.13 ID:ebCh2W7f
���u�R�C���ɂ͗��ƕ\������v�u�܂ɂ���������Ƒ܂̒��̂�����������v
�Ƃ������펯�𗝉����Ă����K�v������B
�����s�ɂ͏���������B
�Ƃ������펯�𗝉����Ă����K�v������B
�����s�ɂ͏���������B
161 �F�f�t�H���g�̖����������F2014/11/08(�y) 09:53:46.74 ID:DB2yxOk0
>>158
���v�������ǁH
���ł��������݂̓��e����Œ���x�̒m�����������Ƃ͒N�ł��킩���
�ł͐搶��>�����u�Œ���x�̒m���v�Ƃ͉��H
���v�������ǁH
���ł��������݂̓��e����Œ���x�̒m�����������Ƃ͒N�ł��킩���
�ł͐搶��>�����u�Œ���x�̒m���v�Ƃ͉��H
162 �F�f�t�H���g�̖����������F2014/11/08(�y) 09:56:43.31 ID:6X6f98tO
>>158�͑f�l�Ȃ̂́A�������݂��炵�Ė��炩�B�v���Ȃ�ԈႢ�̗��R�𗝘H���R�Əq�ׂ�B
163 �F�f�t�H���g�̖����������F2014/11/08(�y) 09:58:47.70 ID:6X6f98tO
>>161
�u�v���̂��Ȃ��ɋ���肽���v�Ȃ�Č�������t�ꂷ�邾�낤��w
�u�v���̂��Ȃ��ɋ���肽���v�Ȃ�Č�������t�ꂷ�邾�낤��w
164 �F�f�t�H���g�̖����������F2014/11/08(�y) 10:04:27.32 ID:DB2yxOk0
�X�Ɍ����A���̓��ō����҂��ł�摜�����̃v�����A����ȂQ�����˂�̖�������
�S�~�J�L�R�ɂ��������������闝�R������̂��B
�x��A�z�E�Ɍ���A�z�E��������
�S�~�J�L�R�ɂ��������������闝�R������̂��B
�x��A�z�E�Ɍ���A�z�E��������
165 �F�f�t�H���g�̖����������F2014/11/08(�y) 10:10:13.37 ID:6X6f98tO
�D�G�ȃv���̉摜�����G���W�j�A�̌N�̃��X���A�����ǂ݂����Ȃ�w
166 �F�f�t�H���g�̖����������F2014/11/08(�y) 11:13:11.28 ID:V4kxl14a
�����������̐搶���Ȃɂ��ق����Ă���́H
167 �F�f�t�H���g�̖����������F2014/11/09(��) 00:34:13.35 ID:iKOy/805
>>162
���傤���Ȃ��Ȃ�
�}�b�`���O���\�g�b�v�͂�����convolution newralnet����
�摜�����̋@�B�w�K�ɂ��Ē��ׂ��炷���o�Ă��邱�Ƃ���
���傤���Ȃ��Ȃ�
�}�b�`���O���\�g�b�v�͂�����convolution newralnet����
�摜�����̋@�B�w�K�ɂ��Ē��ׂ��炷���o�Ă��邱�Ƃ���
168 �F�f�t�H���g�̖����������F2014/11/09(��) 00:36:05.09 ID:iKOy/805
�����{����̍u���ŎQ���҂��A�z�Ȃ��Ƃق����Ă�͉̂摜�����̐l�Ԃ��قڂ��Ȃ�������Ă�����
���݂��ɂł��邱�ł��Ȃ����Ƃ����ł����k���Ă݂��炢���̂ɂ�
��������H�w�͒��x���Ⴂ���Č������
���݂��ɂł��邱�ł��Ȃ����Ƃ����ł����k���Ă݂��炢���̂ɂ�
��������H�w�͒��x���Ⴂ���Č������
169 �F�f�t�H���g�̖����������F2014/11/09(��) 09:28:59.82 ID:GJ+B7IxW
���߂ĉ摜�F���Ƃ��R���s���[�^�r�W�����Ƃ������Ă���
170 �F�f�t�H���g�̖����������F2014/11/09(��) 12:07:09.66 ID:iKOy/805
�A�n�n�n��
171 �F�f�t�H���g�̖����������F2014/11/09(��) 18:10:14.84 ID:uoUT28t9
>>168
�������{����̍u���ŎQ���҂��A�z�Ȃ��Ƃق����Ă�̂�
������D�G�ȃG���W�j�A�̌N�ɂ����A�Z�p�������{�̖������������Ă�����Ă��Ƃ��I�I
�D�G�ȃG���W�j�A�̌N�̘b���A�����ƕ��������Ȃ��B
�������{����̍u���ŎQ���҂��A�z�Ȃ��Ƃق����Ă�̂�
������D�G�ȃG���W�j�A�̌N�ɂ����A�Z�p�������{�̖������������Ă�����Ă��Ƃ��I�I
�D�G�ȃG���W�j�A�̌N�̘b���A�����ƕ��������Ȃ��B
172 �F�f�t�H���g�̖����������F2014/11/09(��) 19:16:53.62 ID:wHnpXD4s
>>168
���O�����m���Ƃ������Ƃ͂悭�킩�����B�������Ȃ��ŗ~�����B
���O�����m���Ƃ������Ƃ͂悭�킩�����B�������Ȃ��ŗ~�����B
173 �F�f�t�H���g�̖����������F2014/11/11(��) 07:12:12.70 ID:0bxYCDe4
�u�e��������v�u������1��ɕ��ׂ�v�u�`�̏��ɕ���ł���v�u�J��Ԃ��s���v�u���̑�����J��Ԃ��s���v�u����ׂɁ`��I�сv
�u�ꏊ�����ւ���v�A���̂܂܂Ă͂߂���������ł͂Ȃ��̂��B
��2014�N��[�~����v�����n���w���⁄
�@�����C�����C�ԋ��C�����e�P������C������������P��ɕ��ׂ�B�ŏ��C�S�̋��͍�����u�����C�����C�ԋ��C���v
�̏��ɕ���ł���B�����̋��ɁC���̑���i���j���J��Ԃ��s���B
�i���j�S�̋��̂������疳��ׂɂQ�̋���I�сC�����̕���ł���ꏊ�����ւ���
���ȉ�����
�y��z�`�C�a�C�b�̂R�̔��ƁC�ԁC���C�C���̋ʂ��e�R������B
http://www.nipec.nein.ed.jp/kk/b14/h22/pdf/16nagai.pdf
�i�P�j���������āC������ 1 ��ɕ��ׂ�ꍇ�����ׂĂ�����D
http://157.7.137.167/text/mat_a_s2/mat_a_s2_05.pdf
http://pws.prserv.net/math/mathpuz.html
�R�l�́A�O����`�A�a�A�b�̏��ɕ���ł��܂��B
���܁A���߂ɒ��_A�ɔ��ʂ�1�A���_C�ɐԋʂ�1�u�����̑�����J��Ԃ��s���B
http://www.riruraru.com/cfv21/math/kom11sA4.htm
��� 13 �E�̕\�́C206 �̗��̂������疳��ׂ�35��I�сC���̏d���ׂ����̂ł���B
http://www.insatell.co.jp/CN/ikou/chugaku/pdf/chumath_3.pdf
�r�̍����ɃA�}�K�G�����A�E���Ƀq�L�K�G����3�C������ł���B���̃J�G���̂���ꏊ�������������ւ��Ăق����B
http://r27.jp/quiz/toads-and-frogs/
�u�ꏊ�����ւ���v�A���̂܂܂Ă͂߂���������ł͂Ȃ��̂��B
��2014�N��[�~����v�����n���w���⁄
�@�����C�����C�ԋ��C�����e�P������C������������P��ɕ��ׂ�B�ŏ��C�S�̋��͍�����u�����C�����C�ԋ��C���v
�̏��ɕ���ł���B�����̋��ɁC���̑���i���j���J��Ԃ��s���B
�i���j�S�̋��̂������疳��ׂɂQ�̋���I�сC�����̕���ł���ꏊ�����ւ���
���ȉ�����
�y��z�`�C�a�C�b�̂R�̔��ƁC�ԁC���C�C���̋ʂ��e�R������B
http://www.nipec.nein.ed.jp/kk/b14/h22/pdf/16nagai.pdf
�i�P�j���������āC������ 1 ��ɕ��ׂ�ꍇ�����ׂĂ�����D
http://157.7.137.167/text/mat_a_s2/mat_a_s2_05.pdf
http://pws.prserv.net/math/mathpuz.html
�R�l�́A�O����`�A�a�A�b�̏��ɕ���ł��܂��B
���܁A���߂ɒ��_A�ɔ��ʂ�1�A���_C�ɐԋʂ�1�u�����̑�����J��Ԃ��s���B
http://www.riruraru.com/cfv21/math/kom11sA4.htm
��� 13 �E�̕\�́C206 �̗��̂������疳��ׂ�35��I�сC���̏d���ׂ����̂ł���B
http://www.insatell.co.jp/CN/ikou/chugaku/pdf/chumath_3.pdf
�r�̍����ɃA�}�K�G�����A�E���Ƀq�L�K�G����3�C������ł���B���̃J�G���̂���ꏊ�������������ւ��Ăق����B
http://r27.jp/quiz/toads-and-frogs/
174 �F�f�t�H���g�̖����������F2014/11/12(��) 11:50:37.55 ID:LPSYNXn+
���Ԍ�������͂Ȃ����s�����̂�
175 �F�f�t�H���g�̖����������F2014/11/12(��) 14:03:23.82 ID:dsokmnVj
�@�B�|��ɂ����鐕���ipivot�j�̘b���H
���̂悤�Ȓ��Ԍ������邱�Ƃ�������s�\������B�ȏ�B
���̂悤�Ȓ��Ԍ������邱�Ƃ�������s�\������B�ȏ�B
176 �F�f�t�H���g�̖����������F2014/11/12(��) 15:33:24.76 ID:LPSYNXn+
�Ȃ��s�\�������̂�
177 �F�f�t�H���g�̖����������F2014/11/12(��) 22:23:18.43 ID:yWDn898h
�@�����L�[���[�h��I��u�����v�u�������v�u�͈́v�Ƃ��ua�v�ux�v�Ƃ��A�قƂ�Ǖς��Ȃ��ł��B
�ł��A���������������S�R�Ⴄ�B���w�̖��́A���v�I��@�ł͂ǂ��ɂ��Ȃ�Ȃ������ł��B
�P�jx�������Ƃ���B�˂�x^2 + ax + 4 �� 0 �ł���Ƃ��Aa�͈̔͂����߂�B
�Q�jx,y �������Ƃ���Aa = x + y �Ƃ���B�˂�x^2 + y^2 = 1 �ł���Ƃ��Aa�͈̔͂����߂�B
�����{�b�g�͓���ɓ���邩�@�V��I�q��
���˂�x^2 + ax + 4 �� 0 �ł���Ƃ��A
���˂�x^2 + y^2 = 1 �ł���Ƃ��A
�O�҂́u2���s�����v�A��҂́u�~�̕������v�B���ꂭ�炢�̈Ⴂ�͋�ʂ��Ă��炢�����B
�ł��A���������������S�R�Ⴄ�B���w�̖��́A���v�I��@�ł͂ǂ��ɂ��Ȃ�Ȃ������ł��B
�P�jx�������Ƃ���B�˂�x^2 + ax + 4 �� 0 �ł���Ƃ��Aa�͈̔͂����߂�B
�Q�jx,y �������Ƃ���Aa = x + y �Ƃ���B�˂�x^2 + y^2 = 1 �ł���Ƃ��Aa�͈̔͂����߂�B
�����{�b�g�͓���ɓ���邩�@�V��I�q��
���˂�x^2 + ax + 4 �� 0 �ł���Ƃ��A
���˂�x^2 + y^2 = 1 �ł���Ƃ��A
�O�҂́u2���s�����v�A��҂́u�~�̕������v�B���ꂭ�炢�̈Ⴂ�͋�ʂ��Ă��炢�����B
178 �F�f�t�H���g�̖����������F2014/11/12(��) 22:50:00.93 ID:dsokmnVj
>>176
���{��́u��v���A�l�b�N�̈Ӗ���������w�b�h�̈Ӗ��������肷��Ƃ�
�����������|���̍����S���A�����������錾��Ԃɂ����邻��������
���ق�S�����Ԍ��ꂪ�z�����Ȃ���Ȃ�Ȃ��B���邢�́A�����łȂ����
�e����Ԃ̂��������������A���Ԍ���i�ւ́E����́j�ϊ���������������
�K�v�������āA���ǁAn �̌���ɑ��� n �~ n �̖|��G���W�������̂�
�ς��Ȃ�����Ƃ������ƂɂȂ��Ă��܂��B
���{��́u��v���A�l�b�N�̈Ӗ���������w�b�h�̈Ӗ��������肷��Ƃ�
�����������|���̍����S���A�����������錾��Ԃɂ����邻��������
���ق�S�����Ԍ��ꂪ�z�����Ȃ���Ȃ�Ȃ��B���邢�́A�����łȂ����
�e����Ԃ̂��������������A���Ԍ���i�ւ́E����́j�ϊ���������������
�K�v�������āA���ǁAn �̌���ɑ��� n �~ n �̖|��G���W�������̂�
�ς��Ȃ�����Ƃ������ƂɂȂ��Ă��܂��B
179 �F�f�t�H���g�̖����������F2014/11/13(��) 00:33:08.26 ID:EzUPhDs/
���Ԍ���̌��Ƃ��ẮA���w�Ƃ������Ƃ����ǂ��Ǝv���B�u�����{�v�v���W�F�N�g�Ɋ��҂������B
���˂�x^2 + y^2 = 1 �ł���Ƃ��A
x^2���P/x�ix��0�j��������b�͈���Ă��邾�낤�B�܂����Z���w�œ������͉����邪�O���������͉����Ȃ��B
���˂�x^2 + y^2 = 1 �ł���Ƃ��A
x^2���P/x�ix��0�j��������b�͈���Ă��邾�낤�B�܂����Z���w�œ������͉����邪�O���������͉����Ȃ��B
180 �F�f�t�H���g�̖����������F2014/11/13(��) 02:08:12.41 ID:EzUPhDs/
�ގ����Ɋ�Â����_�́C�l�Ԃ̋��͂Ȗ����������� 1�ł���D��X��
�V��Ȗ��ɑ����������C�������g���ߋ��Ɍo��������������̗��
�������u����v���玗�����̂��Q�Ƃ��C�����������ɗ��p���邱�Ƃ�
�����D���̂��߁C�l�X�ȉۑ��p���āC�l�Ԃ̗ގ������f��������ɂ�
����v�l���J�j�Y���𗝉�����F�m�S���w�I������C�ގ����Ɋ�Â����_
��v�f�Z�p�Ƃ��Ė�������������x�����s���v�Z�@�V�X�e�����\�z��
��m���H�w�I�������W�J��������D
�ގ����Ɋ�Â����_�ɂ����ẮC���ݒ��ʂ��Ă�����Ɨގ�����ߋ�
�̎���𗘗p���邱�Ƃ���C�ގ����̔��f���������ɂ�����d�v�ȃL�[
�ƂȂ�D�ގ����́C���Ǝ���Ƃ̊Ԃ̓���̗v�f�i���ʓ_�j�C����сC
�قȂ�v�f�i���فj�Ɋ�Â��ĕ]�������D��ʂɁC���݂̖��Ɗ��S��
��v����ߋ��̎��Ⴊ���p�ł��邱�Ƃ͋H�ł��邽�߁C�ʏ�͖��Ǝ���
�Ƃ̍��قɊ�Â��C������C������K�v������D
�������C���ق͒P�ɖ��߂��Ȃ���Ȃ�Ȃ������̂��̂ł͂Ȃ��C��
�قɐϋɓI�ȈӖ���������ꍇ�����݂���D���̈�Ⴊ�C���w�w�K�ɂ���
��������ł���D���w�w�K�ɂ́C�������ꂽ���i���j�Ɋ�Â��ĕ�
�̖��i�ޑ�j�������ޑ������C�w�K�Ҏ��g���V�����������o����
��Ƃ�����������������D���w�ɂ�������ɂ��ẮC������邱
�Ƃ͖����������ƂƓ��l�ɏd�v�Ȋ����ł��邱�Ƃ��C���w�҂␔�w����
�҂ɂ���Ďw�E����Ă���D
�ގ����Ɋ�Â����_��p�����m�I�������x���̌����Ǝ���
http://ir.nul.nagoya-u.ac.jp/jspui/bitstream/2237/8249/1/kojima_thesis.pdf
�V��Ȗ��ɑ����������C�������g���ߋ��Ɍo��������������̗��
�������u����v���玗�����̂��Q�Ƃ��C�����������ɗ��p���邱�Ƃ�
�����D���̂��߁C�l�X�ȉۑ��p���āC�l�Ԃ̗ގ������f��������ɂ�
����v�l���J�j�Y���𗝉�����F�m�S���w�I������C�ގ����Ɋ�Â����_
��v�f�Z�p�Ƃ��Ė�������������x�����s���v�Z�@�V�X�e�����\�z��
��m���H�w�I�������W�J��������D
�ގ����Ɋ�Â����_�ɂ����ẮC���ݒ��ʂ��Ă�����Ɨގ�����ߋ�
�̎���𗘗p���邱�Ƃ���C�ގ����̔��f���������ɂ�����d�v�ȃL�[
�ƂȂ�D�ގ����́C���Ǝ���Ƃ̊Ԃ̓���̗v�f�i���ʓ_�j�C����сC
�قȂ�v�f�i���فj�Ɋ�Â��ĕ]�������D��ʂɁC���݂̖��Ɗ��S��
��v����ߋ��̎��Ⴊ���p�ł��邱�Ƃ͋H�ł��邽�߁C�ʏ�͖��Ǝ���
�Ƃ̍��قɊ�Â��C������C������K�v������D
�������C���ق͒P�ɖ��߂��Ȃ���Ȃ�Ȃ������̂��̂ł͂Ȃ��C��
�قɐϋɓI�ȈӖ���������ꍇ�����݂���D���̈�Ⴊ�C���w�w�K�ɂ���
��������ł���D���w�w�K�ɂ́C�������ꂽ���i���j�Ɋ�Â��ĕ�
�̖��i�ޑ�j�������ޑ������C�w�K�Ҏ��g���V�����������o����
��Ƃ�����������������D���w�ɂ�������ɂ��ẮC������邱
�Ƃ͖����������ƂƓ��l�ɏd�v�Ȋ����ł��邱�Ƃ��C���w�҂␔�w����
�҂ɂ���Ďw�E����Ă���D
�ގ����Ɋ�Â����_��p�����m�I�������x���̌����Ǝ���
http://ir.nul.nagoya-u.ac.jp/jspui/bitstream/2237/8249/1/kojima_thesis.pdf
181 �F�f�t�H���g�̖����������F2014/11/13(��) 03:28:10.49 ID:mINVD8Cg
���Ԍ����C���^�[�t�F�[�X�́A�����Ɠ���
���[�J�[��10�ЁA�����X��20�Ђ���Ƃ��A
�����������ƁA10*20=200 �ʂ�̃R�l�N�V�������K�v�����A
�����𒆊Ԃɉ��ƁA���[�J�[�E�����Ԃ�10�ʂ�A
�����X�E�����Ԃ�20�ʂ�̍��v�A10+20=30 �ʂ�
�܂�A�|���Z�𑫂��Z�ɂ��邱�ƂŁA
�g�ݍ��킹������h���ŁA�R�l�N�V�����̎�Ԃ��ւ炷
���[�J�[��10�ЁA�����X��20�Ђ���Ƃ��A
�����������ƁA10*20=200 �ʂ�̃R�l�N�V�������K�v�����A
�����𒆊Ԃɉ��ƁA���[�J�[�E�����Ԃ�10�ʂ�A
�����X�E�����Ԃ�20�ʂ�̍��v�A10+20=30 �ʂ�
�܂�A�|���Z�𑫂��Z�ɂ��邱�ƂŁA
�g�ݍ��킹������h���ŁA�R�l�N�V�����̎�Ԃ��ւ炷
182 �F�f�t�H���g�̖����������F2014/11/13(��) 07:54:59.39 ID:EnlSRtmw
>>179
��ʓI��@�͋������Ȃ������w�U�ň����藝���g�����������͋�������
��ʓI��@�͋������Ȃ������w�U�ň����藝���g�����������͋�������
183 �F�f�t�H���g�̖����������F2014/11/13(��) 10:17:56.29 ID:7ZjHj42h
>>179
�P�Ɍ��ꂪ�\���ł��鐢�E���ɒ[�ɐ������邾������Ȃ����B
����Ȃ��Ƃ�����������ł��ȒP�ɂȂ邱�Ƃ͓��R�킩���Ă���B
���̂����ǂ�ȒZ�я����̈�{���Ȃ��悤�Ȏg���Ȃ��S�~���ł��邾�����B
�P�Ɍ��ꂪ�\���ł��鐢�E���ɒ[�ɐ������邾������Ȃ����B
����Ȃ��Ƃ�����������ł��ȒP�ɂȂ邱�Ƃ͓��R�킩���Ă���B
���̂����ǂ�ȒZ�я����̈�{���Ȃ��悤�Ȏg���Ȃ��S�~���ł��邾�����B
184 �F�f�t�H���g�̖����������F2014/11/13(��) 14:34:17.79 ID:ydn9QRw8
>>183
�����{�͍��������Ă邪�H
�����{�͍��������Ă邪�H
185 �F�f�t�H���g�̖����������F2014/11/13(��) 15:00:26.25 ID:7ZjHj42h
�@�B�|��ɂ����鐕���ipivot�j�̘b�Ƃ͈Ⴄ�u���Ԍ���v�̂��Ƃ����������̂��H
��������m����B
��������m����B
186 �F�f�t�H���g�̖����������F2014/11/13(��) 23:46:06.97 ID:G+XRMicG
�����{�̘b���Ă��͑̌n�I�ɕ����ďo�����Ă���
187 �F�f�t�H���g�̖����������F2014/11/14(��) 02:28:48.58 ID:cE0anVKk
>>186
���������N�́A���R���ꏈ���w�̃v���Ȃ́H
���������N�́A���R���ꏈ���w�̃v���Ȃ́H
188 �F�f�t�H���g�̖����������F2014/11/14(��) 10:28:40.79 ID:0NdzO4Gj
�v���̒�`�ɂ��A�ƈ�R����ďI���Ƃ������Ƃ��킩���Ă��鎿����Ȃ�����̂��H
�l�H�m�\�]�X�ȑO�ɁA�o�J������A���B
�l�H�m�\�]�X�ȑO�ɁA�o�J������A���B
189 �F�f�t�H���g�̖����������F2014/11/14(��) 10:55:08.96 ID:NoejJarl
�v���Ƃ��������A�}�`���A�ȕ���
190 �F�f�t�H���g�̖����������F2014/11/14(��) 10:59:07.21 ID:0NdzO4Gj
�����{�̘b���Ă��͂ǂ����Ă��A�}�`���A�ȑO������
191 �F�f�t�H���g�̖����������F2014/11/14(��) 10:59:35.20 ID:NoejJarl
�A�}�`���A�ȑO���Ă���ł����H
192 �F�f�t�H���g�̖����������F2014/11/14(��) 11:05:09.41 ID:/Gbyfjip
�����Ƀv���ȍ~()������Ƃ͎v����B
193 �F�f�t�H���g�̖����������F2014/11/14(��) 11:11:46.80 ID:NoejJarl
������ۂ��������܂ɍ~�Ղ���邱�Ƃ�
194 �F�f�t�H���g�̖����������F2014/11/14(��) 16:47:02.37 ID:cE0anVKk
>>188
���v���̒�`�ɂ��A�ƈ�R����ďI���Ƃ������Ƃ��킩���Ă��鎿����Ȃ�����̂��H
���X���肪�Ƃ��B���ꂪ���R���ꏈ���w�̃v������N�̈ӌ��ȂˁB
������D�G�ȃG���W�j�A�̌N�ɂ����A�Z�p�������{�̖������������Ă���Ă��Ƃ��I
���v���̒�`�ɂ��A�ƈ�R����ďI���Ƃ������Ƃ��킩���Ă��鎿����Ȃ�����̂��H
���X���肪�Ƃ��B���ꂪ���R���ꏈ���w�̃v������N�̈ӌ��ȂˁB
������D�G�ȃG���W�j�A�̌N�ɂ����A�Z�p�������{�̖������������Ă���Ă��Ƃ��I
195 �F�f�t�H���g�̖����������F2014/11/14(��) 17:15:16.64 ID:127iWseV
�����{�̓}�[�P�e�B���O�E�b����̃Z���X���Y�o�����Ă���
�G�X�L���[�ɕX��郌�x��
�G�X�L���[�ɕX��郌�x��
196 �F�f�t�H���g�̖����������F2014/11/14(��) 20:26:15.60 ID:E47YIEif
�l�H�m�\�w��̐e�ʂł���
���l�C�����čׁX�Ƃ���Ă��Ƃ��Ő̂���A�}�`���A�̎Q�������サ�Ă����
���l�C�����čׁX�Ƃ���Ă��Ƃ��Ő̂���A�}�`���A�̎Q�������サ�Ă����
197 �F�f�t�H���g�̖����������F2014/11/16(��) 15:42:31.45 ID:jrq2Dts2
( 1) �I�u�W�F�N�g�w���I�A�v���[�`�ɂ��W���/��`�B��������/�Ɖ����/
�q�ꍀ��̓V�X�e��
�ɓ� �p�I (�i���j�x�m�ʌ�����)
�W���́A��`�B���������A�Ɖ���́A����яq�ꍀ��͂�4�̃^�X�N��
����V���ȃA�v���[�`���Ă���B���ɁA�����4�̏������A�����I(�p�C
�v���C���I)�ɂłȂ������ɍs���B����ɂ��A�����I�ɍs��������͐��x��
���シ�邱�Ƃ����҂����B���ɁA�����̖������I�u�W�F�N�g�ɑΉ������A
�����I�u�W�F�N�g�̑����Ƃ��̕ω����g���b�L���O����B�`�e���͈�ʂɃI�u
�W�F�N�g�̑������A�����͂����I�u�W�F�N�g�����̕ω���\���A�ƍl����B
����ɂ��A�����̏�����͌��ʂɔ��f�����邱�Ƃ��\�ƂȂ�B���̂悤��
�Ӗ������̃��f���́A�l�Ԃ��]�ōs���Ă���ł��낤�����v���Z�X�ɋ߂��A���R
���ꗝ���ɂ͗L�]�ȃA�v���[�`�ł���B���̃A�C�f�A�Ɋ�Â����V�X�e��������
���A�ᕶ�ɑ��ē�����m�F�����B
( 2) uLSIF ��p��������ւ̏d�ݕt���ɂ���b�B���������̗̈�K��
�V�[ �_�K, �e�r �T�I, ���X�� ��, �Ë{ �Óߎq (����w�H�w�����H�w��)
��b�B���������̗̈�K���ɑ��ċ��ϗʃV�t�g���̊w�K�����݂�B�m�����x��
�̎Z�o�� uLSIF ��p����B���̂Ƃ��ʏ�̃K�E�X�J�[�l���ł͂Ȃ����`�J�[�l
���𗘗p����A�܂��d�ݕt���w�K�ɂ́A�ʏ�A�ő�G���g���s�[�@��p���邪�A
�����ł� SVM �𗘗p����B�܂��m�����x�䂪�ɒ[�ɏ������A���邢�͑傫����
��݂̂ɏd�݂�^������@�������B
http://www.ipsj.or.jp/kenkyukai/event/nl218.html
�q�ꍀ��̓V�X�e��
�ɓ� �p�I (�i���j�x�m�ʌ�����)
�W���́A��`�B���������A�Ɖ���́A����яq�ꍀ��͂�4�̃^�X�N��
����V���ȃA�v���[�`���Ă���B���ɁA�����4�̏������A�����I(�p�C
�v���C���I)�ɂłȂ������ɍs���B����ɂ��A�����I�ɍs��������͐��x��
���シ�邱�Ƃ����҂����B���ɁA�����̖������I�u�W�F�N�g�ɑΉ������A
�����I�u�W�F�N�g�̑����Ƃ��̕ω����g���b�L���O����B�`�e���͈�ʂɃI�u
�W�F�N�g�̑������A�����͂����I�u�W�F�N�g�����̕ω���\���A�ƍl����B
����ɂ��A�����̏�����͌��ʂɔ��f�����邱�Ƃ��\�ƂȂ�B���̂悤��
�Ӗ������̃��f���́A�l�Ԃ��]�ōs���Ă���ł��낤�����v���Z�X�ɋ߂��A���R
���ꗝ���ɂ͗L�]�ȃA�v���[�`�ł���B���̃A�C�f�A�Ɋ�Â����V�X�e��������
���A�ᕶ�ɑ��ē�����m�F�����B
( 2) uLSIF ��p��������ւ̏d�ݕt���ɂ���b�B���������̗̈�K��
�V�[ �_�K, �e�r �T�I, ���X�� ��, �Ë{ �Óߎq (����w�H�w�����H�w��)
��b�B���������̗̈�K���ɑ��ċ��ϗʃV�t�g���̊w�K�����݂�B�m�����x��
�̎Z�o�� uLSIF ��p����B���̂Ƃ��ʏ�̃K�E�X�J�[�l���ł͂Ȃ����`�J�[�l
���𗘗p����A�܂��d�ݕt���w�K�ɂ́A�ʏ�A�ő�G���g���s�[�@��p���邪�A
�����ł� SVM �𗘗p����B�܂��m�����x�䂪�ɒ[�ɏ������A���邢�͑傫����
��݂̂ɏd�݂�^������@�������B
http://www.ipsj.or.jp/kenkyukai/event/nl218.html
198 �F�f�t�H���g�̖����������F2014/11/18(��) 04:28:56.07 ID:3dChaymz
�����R�s�y����z�����邹���ŕ��ڂ�
199 �F�f�t�H���g�̖����������F2014/11/18(��) 14:10:53.64 ID:7YVftxrd
�l�H���]�w��͂Ȃ��́H
200 �Fsage�F2014/11/18(��) 20:56:42.46 ID:jieDrr0b
>>198
�{������ˁB���̃X���͖{�����v�������͂��Ȃ��ǁA�X�p�����e�ōr�炳��Ă�C������B
�{������ˁB���̃X���͖{�����v�������͂��Ȃ��ǁA�X�p�����e�ōr�炳��Ă�C������B
201 �F�f�t�H���g�̖����������F2014/11/18(��) 21:19:15.86 ID:f2DqKBZs
���R���ꏈ���̎��v���Ă���́H
202 �F�f�t�H���g�̖����������F2014/11/18(��) 21:44:26.22 ID:EImKA09P
>>200
�폜�肢�o������H
�폜�肢�o������H
203 �Fsage�F2014/11/19(��) 01:09:50.33 ID:hLraT9DN
�폜���čďo�����Ă��A�����̈ӌ��̂Ȃ��r�炵�N������Ƃ܂�����������Ȃ��B
204 �F�f�t�H���g�̖����������F2014/11/19(��) 05:37:54.13 ID:SWof/ihh
���Ⴀ�������Ǔ��働�{�b�g�Ė��ǂ��ǂݍ���ł��
���E�j�Ȃ}����F������K�v������̂�
�܂������ƂŁA�R���s���[�^�ɗ����ł���悤��
���͂��Ă邶�Ⴀ�Ȃ����낤��w
���E�j�Ȃ}����F������K�v������̂�
�܂������ƂŁA�R���s���[�^�ɗ����ł���悤��
���͂��Ă邶�Ⴀ�Ȃ����낤��w
205 �F�f�t�H���g�̖����������F2014/11/19(��) 06:50:11.76 ID:CbmB6PIS
�����֎~�Ƃ��������[����������Ȃ��c�r�炵�Ƃ͔��f���h���B
����������l���R�e���Ă��ꂽ�炢����Ȃ����ȁH�ǂ݂����l�͓ǂ߂Ē��������Ȑl�͖ق���NG�ł���悤�ɁB
����������l���R�e���Ă��ꂽ�炢����Ȃ����ȁH�ǂ݂����l�͓ǂ߂Ē��������Ȑl�͖ق���NG�ł���悤�ɁB
206 �F�f�t�H���g�̖����������F2014/11/20(��) 08:59:42.01 ID:AVgM9bDZ
�ł��摜�����X�������ɂ���̂ɂ����ŕςȘb����Ă���
207 �F�f�t�H���g�̖����������F2014/11/21(��) 19:28:46.00 ID:u/qmfXxQ
>>206
�摜�������{�̖{���Ƃ����킯�ł͂Ȃ���ˁB
�摜�������{�̖{���Ƃ����킯�ł͂Ȃ���ˁB
208 �F�f�t�H���g�̖����������F2014/11/21(��) 21:08:35.82 ID:u7zfQT1D
209 �F�f�t�H���g�̖����������F2014/11/21(��) 22:00:40.78 ID:o0Qb8YAB
>>208
����������>>153�𓊍e���ꂽ���ł��傤���B�ł����玿�₪����܂��B
���݂̉摜�����Z�p�ŁA�u�s�v�ȕ����������āA�K�v�ȕ����������o���ĔF���v�͉\�ł����H
�܂�>>153�̉摜����A�u�����Ɖ��������݂ɑȉ~�`�ɕ���ł���v�ƔF�������邱�Ƃ͉\�ł����H
���ꂩ��>>136��>>143�̂悤�ɁA�u�F���ɕK�v�ȗ֊s���������o���v���Ƃ͉\�ł����H
����������>>153�𓊍e���ꂽ���ł��傤���B�ł����玿�₪����܂��B
���݂̉摜�����Z�p�ŁA�u�s�v�ȕ����������āA�K�v�ȕ����������o���ĔF���v�͉\�ł����H
�܂�>>153�̉摜����A�u�����Ɖ��������݂ɑȉ~�`�ɕ���ł���v�ƔF�������邱�Ƃ͉\�ł����H
���ꂩ��>>136��>>143�̂悤�ɁA�u�F���ɕK�v�ȗ֊s���������o���v���Ƃ͉\�ł����H
210 �F�f�t�H���g�̖����������F2014/11/21(��) 22:33:18.98 ID:u7zfQT1D
�摜���� ����14
http://peace.2ch.net/test/read.cgi/tech/1370170263/
http://peace.2ch.net/test/read.cgi/tech/1370170263/
211 �F�f�t�H���g�̖����������F2014/11/22(�y) 01:13:12.25 ID:AHB+ph+z
�T���X�B
>>137
���͑�́A�u���������Ή������ׂ���v�����̘A�z���[�h�ʼn��Ƃ��Ȃ邩���B�@�B�ɂ�
�u�Ȃ������Ȃ邩�v�̘_���v�l�͖��������A�������̑����͂��������\�͂�v�����Ă��Ȃ��B
>>137
���͑�́A�u���������Ή������ׂ���v�����̘A�z���[�h�ʼn��Ƃ��Ȃ邩���B�@�B�ɂ�
�u�Ȃ������Ȃ邩�v�̘_���v�l�͖��������A�������̑����͂��������\�͂�v�����Ă��Ȃ��B
212 �F�f�t�H���g�̖����������F2014/11/22(�y) 01:16:42.03 ID:g4vKpQIM
�������ĂH
213 �F�f�t�H���g�̖����������F2014/11/22(�y) 14:09:13.78 ID:6/H2UDnl
�G���[���͂܂Ƃ�
<��� 200���� ���͌���>
�@�������x�����鐄�_���Ⴊ�����Ă��Ă������
? �]���̒m���\����?�K�łȂ����_���Ⴊ�K�p����Ă��܂��̂ł͂Ȃ����H
�� �啔�����߂Ă���D�@���ۊԊW�m��?������
�A�������x�����鐄�_���Ⴊ�����Ȃ�����
? 2�����̐��_����������Ă��Ă������Ȃ� �� �ގ��������Ⴊ�݂邪�K�p�ł��Ȃ�
? ����K�͂ɂ���?����������Ȃ̂��H �� �������������?���Ȃ�
http://www.cl.ecei.tohoku.ac.jp/~jun-s/publications/nlp2014_slides.pdf
<��� 200���� ���͌���>
�@�������x�����鐄�_���Ⴊ�����Ă��Ă������
? �]���̒m���\����?�K�łȂ����_���Ⴊ�K�p����Ă��܂��̂ł͂Ȃ����H
�� �啔�����߂Ă���D�@���ۊԊW�m��?������
�A�������x�����鐄�_���Ⴊ�����Ȃ�����
? 2�����̐��_����������Ă��Ă������Ȃ� �� �ގ��������Ⴊ�݂邪�K�p�ł��Ȃ�
? ����K�͂ɂ���?����������Ȃ̂��H �� �������������?���Ȃ�
http://www.cl.ecei.tohoku.ac.jp/~jun-s/publications/nlp2014_slides.pdf
214 �F�f�t�H���g�̖����������F2014/11/22(�y) 16:10:30.29 ID:6qlI/h48
�l���m�\
���\�W�c�̍����t
��l�̎�������l���m�\�֘A�ʼnȌ���o�₷��
�����܂ł����\�s�ׂ��Ƃ܂�Ȃ�
���\�W�c�̍����t
��l�̎�������l���m�\�֘A�ʼnȌ���o�₷��
�����܂ł����\�s�ׂ��Ƃ܂�Ȃ�
215 �F�f�t�H���g�̖����������F2014/11/22(�y) 19:26:32.72 ID:ueFBqDyb
�u�l���m�\�v����\�Z�͏o�Ȃ��Ǝv������
216 �F�f�t�H���g�̖����������F2014/11/22(�y) 22:49:14.76 ID:o5aDMJLX
�����ɂ��Ƃݍ��������Ő����Ă��閳�\�炵���뎚����
217 �F�f�t�H���g�̖����������F2014/11/23(��) 02:01:52.03 ID:PwhPUgLb
>>124
����Ǝ҂̑����͐l���n�̓��ق��������͎��ԒP���œ����p�[�g�J���҂ł���C
�u �Q�`�����l���[�S���l �v���Ă̂��A�����炸���������炸���ȁB
����Ǝ҂̑����͐l���n�̓��ق��������͎��ԒP���œ����p�[�g�J���҂ł���C
�u �Q�`�����l���[�S���l �v���Ă̂��A�����炸���������炸���ȁB
218 �F�f�t�H���g�̖����������F2014/11/23(��) 02:42:03.48 ID:PwhPUgLb
�V��I�q���u����͖ʔ������ʁB"�܈ӊW�F���͐l�Ԃɂ͈Ղ����@�B�ɂ͓��"�Ɖ�X�l�H
�m�\/���R���ꏈ���̊w�҂͍l���Ă��邪�A�{���ɂ��ׂĂ̐l�Ԃ͊܈ӊW�F�����s����̂��낤���v
�m�\/���R���ꏈ���̊w�҂͍l���Ă��邪�A�{���ɂ��ׂĂ̐l�Ԃ͊܈ӊW�F�����s����̂��낤���v
219 �F�f�t�H���g�̖����������F2014/11/23(��) 03:50:57.22 ID:EIkF2ojA
���H�w�̘A���͂Ȃ�������̂���Ă邱�Ƃ��T�C�G���X���Ǝv���Ă�H
220 �F�f�t�H���g�̖����������F2014/11/23(��) 03:57:22.23 ID:K4bM7kRY
�m���ɂǂ������Ƃ����Ɛ��w�ɋ߂�
221 �F�f�t�H���g�̖����������F2014/11/23(��) 04:24:52.15 ID:EIkF2ojA
���w�Ȃ�T�C�G���X����
�A�z��
�A�z��
222 �F�f�t�H���g�̖����������F2014/11/23(��) 10:31:00.56 ID:K4bM7kRY
�������킯�Ȃ������w�̓T�C�G���X=���R�Ȋw�ł͂Ȃ���
223 �F�f�t�H���g�̖����������F2014/11/23(��) 10:43:58.95 ID:heOpQ8vp
���O�̒��ł͂ȁB
224 �F�f�t�H���g�̖����������F2014/11/23(��) 10:52:01.52 ID:U8weQpWK
�H�w�̓G���W�j�A�����O�����ȁB
����������������{�I�Ȍ�̉��߂���������z������ᔻ���悤�Ƃ��Ă���������͓̂��Rw
����������������{�I�Ȍ�̉��߂���������z������ᔻ���悤�Ƃ��Ă���������͓̂��Rw
225 �F ��QZaw55cn4c �F2014/11/23(��) 10:56:15.70 ID:K4bM7kRY
���H���w�����R�Ȋw�ł͂Ȃ��A�Ƃ����͓̂�����O�̘b����Ȃ������́H
226 �F�f�t�H���g�̖����������F2014/11/23(��) 15:07:14.96 ID:z0t1kbZ2
���w�����R�Ȋw����Ȃ��ች�ɕ��ނ������Č������������X���`����
227 �F�f�t�H���g�̖����������F2014/11/23(��) 15:13:23.98 ID:K4bM7kRY
228 �F�f�t�H���g�̖����������F2014/11/23(��) 18:57:03.46 ID:PERA2nvu
51. �Ӗ��f�� �Â� ?�o��������ѓ���A��p�̗̈�FPRC ?ACT�i����A�s�ׁj ?EVE�i�C�x���g�A�o�����j
?APO�i�\��ɏ]�����s���F ex ��s��9������n�܂�j ?RES�i���� ex �ЊQ�j ?PRO(���ʁA���앨 ex �p�����Ă��j
?PHE�i���R���ۂ̌��ʂł������ ex �X������j ?NAT�i���R���A���� ex �䕗�A���z�j ?PLA(�A���j ?GAS�i�C�� ex ���A��)
?ELM(�܊��ł͑������Ȃ����� ex ����ς����A�_ �o�j ?POT�i�g�̕��� potency ex ���A���A�x�A�ݒ�)
52. �Ӗ��f�� �Â� ?���ې��̗̈�FABS ?Price�i�����A���i�j ?Measure�i�g���A�̏d�j ?Information�i���A�g���A�����A���y�A��]�A�Z���j
?Quantity�i�d�ʁA�ʐρj ?Social bonds�i�i���A�W�j ?Grade(�g���A�]���A�K�́j ?Form �i�]������鑮�� ex ���A�`�j
?Attribute�i���x�Ōv����� ex ��펯�A�i���A���j ?Reciprocity�i�����j ?Personality�i�Ӓn�A���i�j ?Mind �i���A�_�o�j
?Manner�i�\�́A�����Ȃ� ex �����A�l�߁A���\�A�^�]�A�F �g���A�l�g���j
53. �Ӗ��f�� �Â� ?���ې��̗̈�FABS ?Method�i���@�A�����j ?Objective-value(�l ex �ԁA�l�p�j ?Sensational-value�i�Â��A�h���j
?Evaluation(�]�� ex �䏊���ꂵ���A�����A��j ?Currency(���i ex �P�O�O�h���A�P�O�O�O�~�j ?Duration�i���� ex �R�N�j ?Distance �i���� ex �R�����j
?Item�i����\���Aex �R�l�A�P�j ?Ratio�i����, ex 30%) ?Quantity(�� ex 30kg) ?State(��� ex����A�K���A�s�K�A�Â��A�\�A��Łj
54. �Ӗ��f�� �Â� ?���ې��̗̈�FABS ?Role(��E���j ?Relational-term�i�e���A��F�W�j ?Direction(������k���E�㉺�O��j
?Phase(���ԓI�A�ʒu�I�����j ?Reference-point(��_����̑��� ex �t�A�ȏ�j ?Norm(�K���A�@���A�@���A�����j
?Subfield(�w��A�|�p�A�X�|�[�c�Ȃǂ̕���j ?Inclination(�S���I�X�� ex �����A����݁j ?Appearance�i�O�� ex��ہA�ԓx�A�`�Ձj
?Unit�i�P�ʁj ?Time-point�i���_�j ?Time(�o�����̏����W�A���ۓI���� ex �����j
http://www.slideshare.net/hirsoshnakagawa3/grammar-39910952
?APO�i�\��ɏ]�����s���F ex ��s��9������n�܂�j ?RES�i���� ex �ЊQ�j ?PRO(���ʁA���앨 ex �p�����Ă��j
?PHE�i���R���ۂ̌��ʂł������ ex �X������j ?NAT�i���R���A���� ex �䕗�A���z�j ?PLA(�A���j ?GAS�i�C�� ex ���A��)
?ELM(�܊��ł͑������Ȃ����� ex ����ς����A�_ �o�j ?POT�i�g�̕��� potency ex ���A���A�x�A�ݒ�)
52. �Ӗ��f�� �Â� ?���ې��̗̈�FABS ?Price�i�����A���i�j ?Measure�i�g���A�̏d�j ?Information�i���A�g���A�����A���y�A��]�A�Z���j
?Quantity�i�d�ʁA�ʐρj ?Social bonds�i�i���A�W�j ?Grade(�g���A�]���A�K�́j ?Form �i�]������鑮�� ex ���A�`�j
?Attribute�i���x�Ōv����� ex ��펯�A�i���A���j ?Reciprocity�i�����j ?Personality�i�Ӓn�A���i�j ?Mind �i���A�_�o�j
?Manner�i�\�́A�����Ȃ� ex �����A�l�߁A���\�A�^�]�A�F �g���A�l�g���j
53. �Ӗ��f�� �Â� ?���ې��̗̈�FABS ?Method�i���@�A�����j ?Objective-value(�l ex �ԁA�l�p�j ?Sensational-value�i�Â��A�h���j
?Evaluation(�]�� ex �䏊���ꂵ���A�����A��j ?Currency(���i ex �P�O�O�h���A�P�O�O�O�~�j ?Duration�i���� ex �R�N�j ?Distance �i���� ex �R�����j
?Item�i����\���Aex �R�l�A�P�j ?Ratio�i����, ex 30%) ?Quantity(�� ex 30kg) ?State(��� ex����A�K���A�s�K�A�Â��A�\�A��Łj
54. �Ӗ��f�� �Â� ?���ې��̗̈�FABS ?Role(��E���j ?Relational-term�i�e���A��F�W�j ?Direction(������k���E�㉺�O��j
?Phase(���ԓI�A�ʒu�I�����j ?Reference-point(��_����̑��� ex �t�A�ȏ�j ?Norm(�K���A�@���A�@���A�����j
?Subfield(�w��A�|�p�A�X�|�[�c�Ȃǂ̕���j ?Inclination(�S���I�X�� ex �����A����݁j ?Appearance�i�O�� ex��ہA�ԓx�A�`�Ձj
?Unit�i�P�ʁj ?Time-point�i���_�j ?Time(�o�����̏����W�A���ۓI���� ex �����j
http://www.slideshare.net/hirsoshnakagawa3/grammar-39910952
229 �F�f�t�H���g�̖����������F2014/11/23(��) 18:57:20.44 ID:yTKWpXRp
���ɗ��Ăǂ����ł�������
230 �F�f�t�H���g�̖����������F2014/11/23(��) 19:14:32.75 ID:uAltGaNh
�����͐_����������琮���_�͎��R�Ȋw
����ȊO�͐l�Ԃ�����������`���Ȋw
����ȊO�͐l�Ԃ�����������`���Ȋw
231 �F�f�t�H���g�̖����������F2014/11/23(��) 19:22:23.28 ID:PERA2nvu
�O�[�O�����J����i�߂Ă���A�ʐ^���u�����I�ɐ�������v�Z�p
http://wired.jp/2014/11/20/google-image-recognition/
���R���ꏈ���ɐV���������N������Word2Vec�Ƃ͉���
http://business.nikkeibp.co.jp/article/bigdata/20141110/273649/
�q�ꍀ�\�����ӎ����������̈Ӗ��\���A�m�e�[�V�����̂��߂̖����Ӗ��\���̌���
http://www.ninjal.ac.jp/event/specialists/project-meeting/files/JCLWorkshop_no6_papers/JCLWorkshop_No6_06.pdf
�Ӗ������̎��
���i�K�ł̈Ӗ������̎�ނ��L�q����D�傫�� 4 �̗ނɂ킯�āC�����ނ� 29 ��ނ��`�����D
����ɂ����ɑ��đ����^�C�v���t�^�����`�ł���D�܂� 29 ��ނ��ȉ��Ɏ����D
�\���� ? �@�@�@�@�@�A��C�O�̊W�C��ꑊ��
�Ώۗ� ? �@�@�@�@�@�o���ҁC��g���ҁC�ΏہC�, ����, �N�_�C���_�C�N�_�E���_�C�ʉߓ_�C�o�H�C����
������ ? �@�@�@�g���C�����C�����C�g���ҁC��i
�������ӗ� ? �@�@���E�C�̈�C�ꏊ�C���ԁC�����C�l�ԁC���x�C�ړI�C���ځC�t��
http://wired.jp/2014/11/20/google-image-recognition/
���R���ꏈ���ɐV���������N������Word2Vec�Ƃ͉���
http://business.nikkeibp.co.jp/article/bigdata/20141110/273649/
�q�ꍀ�\�����ӎ����������̈Ӗ��\���A�m�e�[�V�����̂��߂̖����Ӗ��\���̌���
http://www.ninjal.ac.jp/event/specialists/project-meeting/files/JCLWorkshop_no6_papers/JCLWorkshop_No6_06.pdf
�Ӗ������̎��
���i�K�ł̈Ӗ������̎�ނ��L�q����D�傫�� 4 �̗ނɂ킯�āC�����ނ� 29 ��ނ��`�����D
����ɂ����ɑ��đ����^�C�v���t�^�����`�ł���D�܂� 29 ��ނ��ȉ��Ɏ����D
�\���� ? �@�@�@�@�@�A��C�O�̊W�C��ꑊ��
�Ώۗ� ? �@�@�@�@�@�o���ҁC��g���ҁC�ΏہC�, ����, �N�_�C���_�C�N�_�E���_�C�ʉߓ_�C�o�H�C����
������ ? �@�@�@�g���C�����C�����C�g���ҁC��i
�������ӗ� ? �@�@���E�C�̈�C�ꏊ�C���ԁC�����C�l�ԁC���x�C�ړI�C���ځC�t��
232 �F�f�t�H���g�̖����������F2014/11/23(��) 19:26:53.14 ID:PmCQRqdR
>>228
>>231
�Ȃ�������A���������u�Ӗ������v��t�^�����A�m�e�[�V�����R�[�p�X���쐬���ׂ����B
���ꂱ�� �u �Q�`�����l���[�S���l �v������Ή��Ƃ��Ȃ�͂����B
>>231
�Ȃ�������A���������u�Ӗ������v��t�^�����A�m�e�[�V�����R�[�p�X���쐬���ׂ����B
���ꂱ�� �u �Q�`�����l���[�S���l �v������Ή��Ƃ��Ȃ�͂����B
233 �F�f�t�H���g�̖����������F2014/11/23(��) 19:34:46.40 ID:U8weQpWK
2�����˂�[�Ȃ���������A�S�~�̎R���o���オ�邾���B
�����Ƃ����_�Ƃ����������Ă��܂������V�X�e������Ȃ��̂Ɠ����B
�����Ƃ����_�Ƃ����������Ă��܂������V�X�e������Ȃ��̂Ɠ����B
234 �F�f�t�H���g�̖����������F2014/11/23(��) 21:41:51.89 ID:PmCQRqdR
�ł��A�A�m�e�[�V�����R�[�p�X�́A�l��ł�邵���Ȃ���ł���B
235 �F�f�t�H���g�̖����������F2014/11/24(��) 03:15:43.74 ID:wqHflsYn
���Ӗ��ȃR�s�y������߂Ă���Ȃ��H
236 �F�f�t�H���g�̖����������F2014/11/24(��) 11:35:30.53 ID:rXGvP499
>>228�Ƃ��z���g���f����ˁB���O�̈ӌ��͂Ȃ���?�Ƃ����B
237 �F�f�t�H���g�̖����������F2014/11/24(��) 23:07:25.90 ID:PS8Utgm4
238 �F�f�t�H���g�̖����������F2014/11/25(��) 09:26:09.87 ID:aL15dD2y
���w�ł́C��������������߂ɁC���̖���ʂ̖��ɖ|�āC���Ƃ̖��ł͂Ȃ�
�Ė|�ꂽ���̕��������C�Ƃ������@���Ƃ��邱�Ƃ��悭����܂��DA �Ƃ�����
����������߂ɁCB �Ƃ�����肪������C���̉����� A �̉��������邱�Ƃ�������
����悤�Ȗ�� B �����܂��ݒ肵�āCA ������������ B �������̂ł��D���̂悤��
��� B �������邱�Ƃ��C�u��� A ���� B �ɋA��������v�ƕ\�����܂��DB �͈ȉ���
��ł̂悤�ɒP�� A �̌����ւ��ɂ����Ȃ��ꍇ������܂����C�ʔ������Ƃɂ́CB �� A
���ނ��������ɂȂ��Ă��邱�Ƃ������̂ł��D����́C��肪�₳���������
���͕K��������肪�����₷�����ǂ����Ƃ������Ƃƈ�v���Ȃ��C�Ƃ������Ƃł��傤�D
�����̏ꍇ�C���������{���̖�� A ���A���������̖�� B �� A ��肸���ƒ��ۓI
�Ȗ��ɂȂ��Ă��܂��D����́C�O�̐߂ł��q�ׂ��C���ۓI�Ȑݒ�̕������w�I�ɂ͈���
�₷���C�Ƃ������ۂ̌����ƌ�����ł��傤�D
���Ƃ̖�� A ����ʓI�ȁi�K���������w�ň��������ɂ͌����Ȃ��悤�ȁj���ŁC��
��𐔊w�I�Ȗ�� B �ɋA�������Ă���Ƃ��ɂ́CA �̐��w��(mathem atization)�� B ��
����C�Ƃ����悤�Ȍ����������邱�Ƃ�����܂��D
��ʓI�Ȗ��𐔊w�I�Ȗ��ɋA��������C�܂肱�̈�ʓI�Ȗ��̐��w�����s��
��Ƃ��āu�P�[�j�q�X�x���N�̋��̖��v�Ƃ������O�Œm���Ă�����ɂ��čl�@��
�Ă݂邱�Ƃɂ��܂��傤�D
http://kurt.scitec.kobe-u.ac.jp/~fuchino/chubu/method-math-WS06.pdf
�Ė|�ꂽ���̕��������C�Ƃ������@���Ƃ��邱�Ƃ��悭����܂��DA �Ƃ�����
����������߂ɁCB �Ƃ�����肪������C���̉����� A �̉��������邱�Ƃ�������
����悤�Ȗ�� B �����܂��ݒ肵�āCA ������������ B �������̂ł��D���̂悤��
��� B �������邱�Ƃ��C�u��� A ���� B �ɋA��������v�ƕ\�����܂��DB �͈ȉ���
��ł̂悤�ɒP�� A �̌����ւ��ɂ����Ȃ��ꍇ������܂����C�ʔ������Ƃɂ́CB �� A
���ނ��������ɂȂ��Ă��邱�Ƃ������̂ł��D����́C��肪�₳���������
���͕K��������肪�����₷�����ǂ����Ƃ������Ƃƈ�v���Ȃ��C�Ƃ������Ƃł��傤�D
�����̏ꍇ�C���������{���̖�� A ���A���������̖�� B �� A ��肸���ƒ��ۓI
�Ȗ��ɂȂ��Ă��܂��D����́C�O�̐߂ł��q�ׂ��C���ۓI�Ȑݒ�̕������w�I�ɂ͈���
�₷���C�Ƃ������ۂ̌����ƌ�����ł��傤�D
���Ƃ̖�� A ����ʓI�ȁi�K���������w�ň��������ɂ͌����Ȃ��悤�ȁj���ŁC��
��𐔊w�I�Ȗ�� B �ɋA�������Ă���Ƃ��ɂ́CA �̐��w��(mathem atization)�� B ��
����C�Ƃ����悤�Ȍ����������邱�Ƃ�����܂��D
��ʓI�Ȗ��𐔊w�I�Ȗ��ɋA��������C�܂肱�̈�ʓI�Ȗ��̐��w�����s��
��Ƃ��āu�P�[�j�q�X�x���N�̋��̖��v�Ƃ������O�Œm���Ă�����ɂ��čl�@��
�Ă݂邱�Ƃɂ��܂��傤�D
http://kurt.scitec.kobe-u.ac.jp/~fuchino/chubu/method-math-WS06.pdf
239 �F�f�t�H���g�̖����������F2014/11/25(��) 12:38:38.21 ID:7PX75+Zb
���Ӗ��ȃR�s�y���f�������߂Ă���Ȃ��H
240 �F�f�t�H���g�̖����������F2014/11/25(��) 12:48:45.94 ID:jd8KQlKm
��������n����������悗��
241 �F�f�t�H���g�̖����������F2014/11/25(��) 12:50:18.42 ID:7PX75+Zb
�@���Ȃ��Ə����Ȃ��ł���
242 �F�f�t�H���g�̖����������F2014/11/25(��) 13:21:08.54 ID:jd8KQlKm
tech�F�v���O�����Z�p�m�d�v�폜�n
http://qb5.2ch.net/test/read.cgi/saku2ch/1273146924/
http://qb5.2ch.net/test/read.cgi/saku2ch/1273146924/
243 �F�f�t�H���g�̖����������F2014/11/25(��) 14:01:43.88 ID:aL15dD2y
�R�[�p�X�J���̓I�[�v���ɂ��������悢�A�Ƃ����ŁA�S�Ă̂��������J���܂��傤�A
�Ƃ����b�Ȃ̂����A�I�[�v���\�[�X�\�t�g�E�F�A�J���̂悤�Ƀ\�[�X�R�[�h����J���̂����
�܂őS�Ă��I�[�v���ɂł���ꍇ�����邪�A�R�[�p�X�쐬�͌��̃e�L�X�g���������l������킯�ŁA
�S�Ă��I�[�v���ɂł��Ȃ��Ƃ������i���ǂ����Ă����܂Ƃ��B�������ė��p�\�ȃe�L�X�g
�ɃA�m�e�[�V����������������A�e�L�X�g�����Ƃ��납��I�[�v���ɂ��ł���킯�����A
����Ō����Ȃ��Ȃ��Ă��܂����ꌻ�ۂ����Ȃ��Ȃ��Ǝv���邵�i���ۍu���̒��ł��u������
������ǂ����邩�v�Ƃ�������N���������j�A�l�I�ɂ̓Z�~�N���[�Y�h�i����̃O���[�v���ŋ��L�j
���x�������I�ȂƂ���ł͂Ȃ����Ǝv���B
������厖���Ǝv����̂́A�����������R�[�p�X�J���ɎQ������A���邢�͖�O�̏��m��Ԃŕ�
�������ł��l������Ƃł����āA���ǂ������{�g���l�b�N�ɂȂ�A����̌������̏o�g�҂����m�E�n�E���Ȃ��A
�Ƃ����ɂȂ��Ă���̂��Ǝv���B���Ɍl�I�Ƀ|�C���g���Ǝv���Ă���̂́A������������悤�ȐV�l
�ɑ��ėD�����R�~���j�e�B�ɂȂ��Ă��邩�ǂ����ŁA���R���ꏈ�����̂͂��Ȃ�V�l������₷��
�R�~���j�e�B���Ǝv���̂����A���ƃR�[�p�X�⎫���̂悤�ȃ��\�[�X�쐬�n�͂��Ȃ�n�[�h���������Ɗ�����B
�R�[�p�X���͂₻���p����������͂Ɋւ��Ă��A�ȒP�ɂł���Ƃ���͂��łɂ��s������Ă��āA
�c���Ă���͓̂���Ƃ������ŁA�ȒP�ȂƂ��납����K���ăE�H�[�~���O�A�b�v���A
�������Ԃ�݂��Ė{�ۂɓˌ�����A�Ƃ����悤�ɂȂ��Ă��Ȃ��̂ł���B�������Ő�[�𑖂錤����
�����ŋc�_����̂͂����Ƃ��������ł悢���A�ނ��낻���łȂ��ƈӖ����Ȃ��̂����A�ȒP�Ȏ���
����n�߂�i���邢�͊����̂��̂̕��͂���ł͂Ȃ��A�V�����^�O�t�^�Ƀ����^�[���ōŏ�����ւ��j�A
�Ƃ����g���[�j���O�������Ă悢�Ǝv���B
http://d.hatena.ne.jp/mamoruk/20140902/p1
�Ƃ����b�Ȃ̂����A�I�[�v���\�[�X�\�t�g�E�F�A�J���̂悤�Ƀ\�[�X�R�[�h����J���̂����
�܂őS�Ă��I�[�v���ɂł���ꍇ�����邪�A�R�[�p�X�쐬�͌��̃e�L�X�g���������l������킯�ŁA
�S�Ă��I�[�v���ɂł��Ȃ��Ƃ������i���ǂ����Ă����܂Ƃ��B�������ė��p�\�ȃe�L�X�g
�ɃA�m�e�[�V����������������A�e�L�X�g�����Ƃ��납��I�[�v���ɂ��ł���킯�����A
����Ō����Ȃ��Ȃ��Ă��܂����ꌻ�ۂ����Ȃ��Ȃ��Ǝv���邵�i���ۍu���̒��ł��u������
������ǂ����邩�v�Ƃ�������N���������j�A�l�I�ɂ̓Z�~�N���[�Y�h�i����̃O���[�v���ŋ��L�j
���x�������I�ȂƂ���ł͂Ȃ����Ǝv���B
������厖���Ǝv����̂́A�����������R�[�p�X�J���ɎQ������A���邢�͖�O�̏��m��Ԃŕ�
�������ł��l������Ƃł����āA���ǂ������{�g���l�b�N�ɂȂ�A����̌������̏o�g�҂����m�E�n�E���Ȃ��A
�Ƃ����ɂȂ��Ă���̂��Ǝv���B���Ɍl�I�Ƀ|�C���g���Ǝv���Ă���̂́A������������悤�ȐV�l
�ɑ��ėD�����R�~���j�e�B�ɂȂ��Ă��邩�ǂ����ŁA���R���ꏈ�����̂͂��Ȃ�V�l������₷��
�R�~���j�e�B���Ǝv���̂����A���ƃR�[�p�X�⎫���̂悤�ȃ��\�[�X�쐬�n�͂��Ȃ�n�[�h���������Ɗ�����B
�R�[�p�X���͂₻���p����������͂Ɋւ��Ă��A�ȒP�ɂł���Ƃ���͂��łɂ��s������Ă��āA
�c���Ă���͓̂���Ƃ������ŁA�ȒP�ȂƂ��납����K���ăE�H�[�~���O�A�b�v���A
�������Ԃ�݂��Ė{�ۂɓˌ�����A�Ƃ����悤�ɂȂ��Ă��Ȃ��̂ł���B�������Ő�[�𑖂錤����
�����ŋc�_����̂͂����Ƃ��������ł悢���A�ނ��낻���łȂ��ƈӖ����Ȃ��̂����A�ȒP�Ȏ���
����n�߂�i���邢�͊����̂��̂̕��͂���ł͂Ȃ��A�V�����^�O�t�^�Ƀ����^�[���ōŏ�����ւ��j�A
�Ƃ����g���[�j���O�������Ă悢�Ǝv���B
http://d.hatena.ne.jp/mamoruk/20140902/p1
244 �F�f�t�H���g�̖����������F2014/11/25(��) 14:04:53.12 ID:jd8KQlKm
�R�s�y�������B
�N���폜�肢�o����B
�N���폜�肢�o����B
245 �F�f�t�H���g�̖����������F2014/11/25(��) 14:29:27.54 ID:aL15dD2y
�R�[�p�X�쐬�ɂ��Ĉꂩ���蒼�����ق����������ǂ����́A�Y�܂������Ȃ̂ň�T�ɂǂ���
�Ƃ������Ƃ͌����ɂ����̂ł����A�A�m�e�[�V�����E�R�[�p�X�쐬���̂��傫�Ȍ����e�[�}�ł���A
�x�X�g�v���N�e�B�X�I�Ȃ��̂��Ȃ���A���������~�ς���Ă���m�E�n�E�I�Ȃ��̂���`�[��
���x���ł������L�ł��Ă��Ȃ��i���L����̂�����j�A�Ƃ����ł��B�܂��A��蒼������
�����R�[�p�X���ł��邩�Ƃ����ƁA���̍����R�[�p�X�����ɂ͎��Ԃ����N����������̂Ȃ̂�
�i�����̌g����� NAIST �e�L�X�g�R�[�p�X��5�N�ȏォ�����Ă��܂��j�A�������p�\�ɂ͂Ȃ�Ȃ��ł��傤�B
http://d.hatena.ne.jp/mamoruk/20140902/p1
�Ƃ������Ƃ͌����ɂ����̂ł����A�A�m�e�[�V�����E�R�[�p�X�쐬���̂��傫�Ȍ����e�[�}�ł���A
�x�X�g�v���N�e�B�X�I�Ȃ��̂��Ȃ���A���������~�ς���Ă���m�E�n�E�I�Ȃ��̂���`�[��
���x���ł������L�ł��Ă��Ȃ��i���L����̂�����j�A�Ƃ����ł��B�܂��A��蒼������
�����R�[�p�X���ł��邩�Ƃ����ƁA���̍����R�[�p�X�����ɂ͎��Ԃ����N����������̂Ȃ̂�
�i�����̌g����� NAIST �e�L�X�g�R�[�p�X��5�N�ȏォ�����Ă��܂��j�A�������p�\�ɂ͂Ȃ�Ȃ��ł��傤�B
http://d.hatena.ne.jp/mamoruk/20140902/p1
246 �F�f�t�H���g�̖����������F2014/11/26(��) 10:03:34.88 ID:NpjnEUfO
���⎩���̂́A�n���V�ŕ\���ł���B���́E���̂Ƃ��̉^���́A�V�~�����[�^�[�ŕ\���ł���B
�l���Ƃ��̍s���̓I�u�W�F�N�g�ŕ\���ł���B����ǂ��u�����`�v�Ƃ��̒��ۊT�O�͕\���ł����A
�����������N�W�ׂ�̂݁B�Ⴆ�Β��N�����`�l�����a�������āu�����`�v�Ƃ������ƂŁA
�k���N�������`���ƂȂ�ė��������藧�B����������͈�ʓI�ȃC���[�W�Ƃ͂�������Ă���B
�]���Ē��ۊT�O����ʓI�ȃC���[�W�ɋA�������邽�߂ɂ́A�������̋�̕������т��邵���Ȃ��B
�u���ԁv�Ƃ͉���
http://www.pat.hi-ho.ne.jp/nobu-nisi/kokugo/seken.htm
�u���ԁv�Ƃ́E�E�E�ߏ��̂�����A�x�@�A�V���A�w�Z�A�ߐ�̉�ЁA�m�荇���E�E�E�E
�l���Ƃ��̍s���̓I�u�W�F�N�g�ŕ\���ł���B����ǂ��u�����`�v�Ƃ��̒��ۊT�O�͕\���ł����A
�����������N�W�ׂ�̂݁B�Ⴆ�Β��N�����`�l�����a�������āu�����`�v�Ƃ������ƂŁA
�k���N�������`���ƂȂ�ė��������藧�B����������͈�ʓI�ȃC���[�W�Ƃ͂�������Ă���B
�]���Ē��ۊT�O����ʓI�ȃC���[�W�ɋA�������邽�߂ɂ́A�������̋�̕������т��邵���Ȃ��B
�u���ԁv�Ƃ͉���
http://www.pat.hi-ho.ne.jp/nobu-nisi/kokugo/seken.htm
�u���ԁv�Ƃ́E�E�E�ߏ��̂�����A�x�@�A�V���A�w�Z�A�ߐ�̉�ЁA�m�荇���E�E�E�E
247 �F�f�t�H���g�̖����������F2014/11/27(��) 17:46:09.92 ID:+o9Dshrb
�p��̘_���ǂނ̂���ɂł��܂�Ȃ�
�͂₭�|�u�����Ă���
�͂₭�|�u�����Ă���
248 �F�f�t�H���g�̖����������F2014/11/28(��) 17:31:36.07 ID:7V+kfZOs
�Θb�̊w�K���Ăǂ����́H
249 �F�f�t�H���g�̖����������F2014/11/28(��) 21:08:06.67 ID:utFPiG0+
���ɁC3 �����I�u�W�F�N�g�̒��ɂ͕����̕��̂���\�������I�u�W�F�N�g������i���Ƃ��C�} 6 �́u�ԁv�Ɓu���v
���琬���̃I�u�W�F�N�g�ł���j�D����C�摜��͋Z�p���i�݁C�@�B�������̕��̂���\�������I�u�W�F�N�g
�����̕��̂ɕ����ł����Ƃ��Ă��C�@�B�ɂƂ��āC���ꂪ�펯�Ɋ�Â����\���ł��邩�C�펯����O�ꂽ
�\���ł��邩����ʂ��邱�Ƃ͍���ł���Ɛ��������D
http://minamigaki.cs.inf.shizuoka.ac.jp/work/2014/SCIS2014fujita.pdf
���琬���̃I�u�W�F�N�g�ł���j�D����C�摜��͋Z�p���i�݁C�@�B�������̕��̂���\�������I�u�W�F�N�g
�����̕��̂ɕ����ł����Ƃ��Ă��C�@�B�ɂƂ��āC���ꂪ�펯�Ɋ�Â����\���ł��邩�C�펯����O�ꂽ
�\���ł��邩����ʂ��邱�Ƃ͍���ł���Ɛ��������D
http://minamigaki.cs.inf.shizuoka.ac.jp/work/2014/SCIS2014fujita.pdf
250 �F�f�t�H���g�̖����������F2014/12/01(��) 17:26:06.50 ID:7r1s3h7c
�ڏ��ȃR�s�y��Y��
251 �F�f�t�H���g�̖����������F2014/12/02(��) 19:50:43.04 ID:OPiibqqe
�����{����@�Z���^�[�͎�2014
�p��c�c�c95
����c�c�c69
���E�j�a�c 52
���{�j�a�c 44
���w�T�`�c 40
���w�U�a�c 55
�����c�c�c31
�V�Ȗڍ��v�c386/900
�����͑S��m�[�}�[�N
���E�j�a�͂Q��m�[�}�[�N
���{�j�a�͂S��m�[�}�[�N
���w����Ȃ�����
������Ȃ����̓����_���Ƀ}�[�N�����c
�p��c�c�c95
����c�c�c69
���E�j�a�c 52
���{�j�a�c 44
���w�T�`�c 40
���w�U�a�c 55
�����c�c�c31
�V�Ȗڍ��v�c386/900
�����͑S��m�[�}�[�N
���E�j�a�͂Q��m�[�}�[�N
���{�j�a�͂S��m�[�}�[�N
���w����Ȃ�����
������Ȃ����̓����_���Ƀ}�[�N�����c
252 �F�f�t�H���g�̖����������F2014/12/02(��) 19:51:56.20 ID:OPiibqqe
�����E���E�j�a�E���{�j�a
�m�[�}�[�N�̖������ׂă����_���Ƀ}�[�N���Ă���
49.6���̊m����14�_�ȏ�A�b�v
�܂�49.6���̊m���łV�Ȗڍ��v��400�_�ɓ͂������ƂɂȂ�
�m�[�}�[�N�̖������ׂă����_���Ƀ}�[�N���Ă���
49.6���̊m����14�_�ȏ�A�b�v
�܂�49.6���̊m���łV�Ȗڍ��v��400�_�ɓ͂������ƂɂȂ�
253 �F�f�t�H���g�̖����������F2014/12/02(��) 19:53:47.76 ID:OPiibqqe
�����{����@�p��@�Z���^�[�͎�2014
�����E�A�N�Z���g���c�p�[�t�F�N�g�i�z�_14�j
���m��-��Ӑ������c�p�[�t�F�N�g�i�z�_8�j
�O���t�E�}�\���c���_��75���i�z�_20�j
��吮���������c���_��67���i�z�_12�j
�ӌ��v�|�c�����c���_��67���i�z�_18�j
���@�E��@�E��b���c���_��60���i�z�_20�j
��b���������c���_��33���i�z�_12�j
�����ɍ���Ȃ���-�w�E���c���_��33���i�z�_15�j
���p�����lj���c���_��33���i�z�_15�j
�lj���i�_�����j�c���_��33���i�z�_36�j
�lj���i����j�c�S�Łi�z�_30�j
�����E�A�N�Z���g���c�p�[�t�F�N�g�i�z�_14�j
���m��-��Ӑ������c�p�[�t�F�N�g�i�z�_8�j
�O���t�E�}�\���c���_��75���i�z�_20�j
��吮���������c���_��67���i�z�_12�j
�ӌ��v�|�c�����c���_��67���i�z�_18�j
���@�E��@�E��b���c���_��60���i�z�_20�j
��b���������c���_��33���i�z�_12�j
�����ɍ���Ȃ���-�w�E���c���_��33���i�z�_15�j
���p�����lj���c���_��33���i�z�_15�j
�lj���i�_�����j�c���_��33���i�z�_36�j
�lj���i����j�c�S�Łi�z�_30�j
254 �F�f�t�H���g�̖����������F2014/12/02(��) 19:54:56.87 ID:OPiibqqe
�����{����@����i���㕶�j�@�Z���^�[�͎�2014
�����c�p�[�t�F�N�g�i�z�_10�j
���̈Ӗ��c���_��67���i�z�_9�j
�]�_�lj��c���_��50���i�z�_40�j
�����lj��c���_��32���i�z�_41�j
�����c�p�[�t�F�N�g�i�z�_10�j
���̈Ӗ��c���_��67���i�z�_9�j
�]�_�lj��c���_��50���i�z�_40�j
�����lj��c���_��32���i�z�_41�j
255 �F�f�t�H���g�̖����������F2014/12/02(��) 19:55:07.53 ID:iCHrVmBA
�����{����̘b���Ȃ��ł���Ȃ��H
256 �F�f�t�H���g�̖����������F2014/12/02(��) 21:51:00.22 ID:E8W1d5Nr
>>255
���O���́A�����Œ����R�s�y�\���Ă����āA���쎩�����Ă钣�{�l����H
���O���́A�����Œ����R�s�y�\���Ă����āA���쎩�����Ă钣�{�l����H
257 �F�f�t�H���g�̖����������F2014/12/03(��) 20:07:38.80 ID:+0WWtRs0
>>253
���m��̐������A��������܂ł��Ȃ��Ӗ���m���Ă���Ȃ��̂���
���m��̐������A��������܂ł��Ȃ��Ӗ���m���Ă���Ȃ��̂���
258 �F�f�t�H���g�̖����������F2014/12/03(��) 21:02:56.05 ID:14+GtqTY
���͂����͂��ꂽ��A�B��}���R�t���f�����������݂���W���Ɏˉe����悤�Ȃ��Ƃł��Ȃ����Ȃ�
259 �F�f�t�H���g�̖����������F2014/12/03(��) 22:32:37.61 ID:H1Y0sahg
NAIST�̎��������|��
2013�N�A�����ʖ�҃��x���ɓ��B
�h�R�����@�B�|��̉�Ёu�݂炢�|��v��ݗ�
�@�B�|��̐��x�͌���TOEIC 600�_���x��
2016�N�܂ł�TOEIC 700�_���x���A2019�N�܂ł�TOEIC 800�_���x����ڎw��
TOEIC 600�_���x���Ȃ�A�Z���^�[�p��͂����Ɠ_�Ƃ���Ȃ��́H
�����{�p��`�[���݂͂炢�|��Ƒg�߂���������
2013�N�A�����ʖ�҃��x���ɓ��B
�h�R�����@�B�|��̉�Ёu�݂炢�|��v��ݗ�
�@�B�|��̐��x�͌���TOEIC 600�_���x��
2016�N�܂ł�TOEIC 700�_���x���A2019�N�܂ł�TOEIC 800�_���x����ڎw��
TOEIC 600�_���x���Ȃ�A�Z���^�[�p��͂����Ɠ_�Ƃ���Ȃ��́H
�����{�p��`�[���݂͂炢�|��Ƒg�߂���������
260 �F�f�t�H���g�̖����������F2014/12/04(��) 11:13:59.73 ID:h+gvphcs
word2vec�̓M���M���܂Ŏ��������炵�ĈӖ����肰�Ȏw�W������������Ƃ����\��
261 �F�f�t�H���g�̖����������F2014/12/04(��) 16:22:22.74 ID:NIw8k+Ja
�|��͂��傹����o�͂���Έꃌ�x�������@�������ǂ��܂Ō��Ă邩�����₵��
262 �F�f�t�H���g�̖����������F2014/12/04(��) 18:17:46.95 ID:5hTqY9uU
�����{����@����͎�2014
���n���w�c36/120�i���l55.7�j
���n���w�c32/80�i���l54.1�j
���n���w�c36/120�i���l55.7�j
���n���w�c32/80�i���l54.1�j
263 �F�f�t�H���g�̖����������F2014/12/04(��) 18:19:56.45 ID:5hTqY9uU
�u���_��́v�����{���قڑS�Ă̓������i���w�j��������u�ڏ��v���������炵����
�܂��ۑ肪����݂���
http://blog.livedoor.jp/dg_law/archives/52234923.html
�܂��ۑ肪����݂���
http://blog.livedoor.jp/dg_law/archives/52234923.html
264 �F�f�t�H���g�̖����������F2014/12/04(��) 21:03:38.82 ID:MwWrePzc
�����{�����p�X�����ĂĂ��̃X���ł͋֎~���Ă������ȁH
265 �F�f�t�H���g�̖����������F2014/12/04(��) 21:26:07.87 ID:otxDKoZc
�����ˁB
�{�l�����{�b�g�݂�������w
�{�l�����{�b�g�݂�������w
266 �F�f�t�H���g�̖����������F2014/12/04(��) 21:50:05.85 ID:+VhC1jdJ
>>264
�폜�肢�o������H
�폜�肢�o������H
267 �F�ЎR����MZ����CEO ��T6xkBnTXz7B0 �F2014/12/07(��) 12:57:22.31 ID:O40P0GQH
NTT���]�i���g�A���{��`�ԉ��API�����J
http://it.slashdot.jp/story/14/12/04/0537230/NTT%E3%83%AC%E3%82%BE%E3%83%8A%E3%83%B3%E3%83%88%E3%80%81%E6%97%A5%E6%9C%AC%E8%AA%9E%E5%BD%A2%E6%85%8B%E8%A7%A3%E6%9E%90API%E3%82%92%E5%85%AC%E9%96%8B
http://it.slashdot.jp/story/14/12/04/0537230/NTT%E3%83%AC%E3%82%BE%E3%83%8A%E3%83%B3%E3%83%88%E3%80%81%E6%97%A5%E6%9C%AC%E8%AA%9E%E5%BD%A2%E6%85%8B%E8%A7%A3%E6%9E%90API%E3%82%92%E5%85%AC%E9%96%8B
268 �F�f�t�H���g�̖����������F2014/12/09(��) 07:42:52.02 ID:NLTvYswf
���������������̐搶�������{�̘b���R�s�y���Ă���́H
269 �F�f�t�H���g�̖����������F2014/12/15(��) 06:54:15.73 ID:NngIclHu
�����{��Ruby�͎g���Ȃ��̂��H
�͊w�V�~�����[�V�����Ɖ���
����܂�Ruby�Ōy���V�~�����[�V�����������̂͂��Ȃ荢��Ȃ��Ƃł����B
������������Ruby-GSL�ʼn����܂����C���X�g�[���͔��ɔώG�ł����B
�����Ɋւ��Ă͌���I�ȕ��@���Ȃ������悤�Ɏv���܂��B (�����悭�m��Ȃ�������������܂��c)
���ł�Fortran�����b�v����ODE gem (gem install ode�����ŃC���X�g�[���\)�ŏ����������
���������Ƃ��ł��܂��B �܂��AIRuby�ɐV�����������CustomWidget���g�����ƂŁARuby�ƃl�C�e�B�u
�g���̏o�������ʂ����A���^�C���Ƀu���E�U��ɕ\���ł��܂��B���̏ꍇJavaScript�̗L����dom���색�C�u�����A
jQuery��d3.js���g���ĉ����������ȒP�ɏ������Ƃ��ł��܂��B
http://domitry.hatenablog.jp/entry/science_with_ruby
�͊w�V�~�����[�V�����Ɖ���
����܂�Ruby�Ōy���V�~�����[�V�����������̂͂��Ȃ荢��Ȃ��Ƃł����B
������������Ruby-GSL�ʼn����܂����C���X�g�[���͔��ɔώG�ł����B
�����Ɋւ��Ă͌���I�ȕ��@���Ȃ������悤�Ɏv���܂��B (�����悭�m��Ȃ�������������܂��c)
���ł�Fortran�����b�v����ODE gem (gem install ode�����ŃC���X�g�[���\)�ŏ����������
���������Ƃ��ł��܂��B �܂��AIRuby�ɐV�����������CustomWidget���g�����ƂŁARuby�ƃl�C�e�B�u
�g���̏o�������ʂ����A���^�C���Ƀu���E�U��ɕ\���ł��܂��B���̏ꍇJavaScript�̗L����dom���색�C�u�����A
jQuery��d3.js���g���ĉ����������ȒP�ɏ������Ƃ��ł��܂��B
http://domitry.hatenablog.jp/entry/science_with_ruby
270 �F�f�t�H���g�̖����������F2014/12/16(��) 14:52:53.84 ID:hxvZqs1F
271 �F�f�t�H���g�̖����������F2014/12/17(��) 13:49:18.49 ID:+8T0slzN
>>245
�������̌g����� NAIST �e�L�X�g�R�[�p�X��5�N�ȏォ�����Ă��܂�
����ł��A�m�e�[�V�����R�[�p�X�̏[���́A����܂��܂��K�v�ɂȂ��Ă���Ǝv���B
������?���l��?�J�o�[�ł��Ă���̂�?
SNS�����C�_���ȂǕ�?���?�����փA�m�e�[�V�������K�v
���w�K�A���S���Y���E��̓A���S���Y���E�������o?����Ȃ���P
����?���l���𑨂���ɂ�? ���܂�?��������ł��܂�������? ���?�ϓ_�����ʓI�ɑ�����ɂ�?
����L
�A�m�e�[�V������?�o�����C���?�]���w�W
���W�����}
�w�p�I��?�������肳���Ȃ���?���L����� /
����z�肳��鉞�p�Ɍ����Ė��?���҂��K�v
���A�m�e�[�V���������f�[�^�����Ώۂɂ��Ă��Ă����̂�?
�A�m�e�[�V�����w vs �|�X�g�o����`
�q�ꍀ�\���ƏƉ��W?�A�m�e�[�V�����F
NAIST�e�L�X�g�R�[�p�X�\�z?�o������
�ѓc��(NICT), ������(��s��),��V�㒼��(�f���\�[�E���k��),
�������Y(���k��), ���{�T��(NAIST)
http://www.anlp.jp/anniversary/20th_sympo/slide_iida.pdf
�������̌g����� NAIST �e�L�X�g�R�[�p�X��5�N�ȏォ�����Ă��܂�
����ł��A�m�e�[�V�����R�[�p�X�̏[���́A����܂��܂��K�v�ɂȂ��Ă���Ǝv���B
������?���l��?�J�o�[�ł��Ă���̂�?
SNS�����C�_���ȂǕ�?���?�����փA�m�e�[�V�������K�v
���w�K�A���S���Y���E��̓A���S���Y���E�������o?����Ȃ���P
����?���l���𑨂���ɂ�? ���܂�?��������ł��܂�������? ���?�ϓ_�����ʓI�ɑ�����ɂ�?
����L
�A�m�e�[�V������?�o�����C���?�]���w�W
���W�����}
�w�p�I��?�������肳���Ȃ���?���L����� /
����z�肳��鉞�p�Ɍ����Ė��?���҂��K�v
���A�m�e�[�V���������f�[�^�����Ώۂɂ��Ă��Ă����̂�?
�A�m�e�[�V�����w vs �|�X�g�o����`
�q�ꍀ�\���ƏƉ��W?�A�m�e�[�V�����F
NAIST�e�L�X�g�R�[�p�X�\�z?�o������
�ѓc��(NICT), ������(��s��),��V�㒼��(�f���\�[�E���k��),
�������Y(���k��), ���{�T��(NAIST)
http://www.anlp.jp/anniversary/20th_sympo/slide_iida.pdf
272 �F�f�t�H���g�̖����������F2014/12/18(��) 17:37:40.91 ID:h7yCp+rM
�������ӏ������ɂ���Ƃ����̂͋��炭�����v��̔��e�ŁA����Ɍ�������Ă���Ƃ��낾�Ǝv���܂����A
�d�v�����o�ȊO�͂܂����p�I�ɂ͓���ł��傤�i�����o�ȏ�̂��Ƃ����悤�Ƃ���ƁA�Ӗ��𗝉����Ȃ��Ƃ����Ȃ��Ȃ�j�B
�ŋ߂̓j���[�X�̔z�M�A�v���P�[�V�����E�T�[�r�X������ɊJ������Ă��āA��������܂Ƃ߂��肷��@�\������܂����A
���R���ꏈ���̍Ő�[�̋Z�p���g���Ă���Ƃ������́A���Ȃ胋�[������������A�l�����ꂽ�肵�Ă���A�ƕ��������Ƃ�����܂��B
http://d.hatena.ne.jp/mamoruk/20140902
�R�[�p�X�̃A�m�e�[�V�����́A���̂ɂ��܂����l�C��p�łȂ�Ƃ��Ȃ���̂ł͂Ȃ��A�l�𑝂₵�Ă������m�ۂł��Ȃ�
�i�ނ��눫������j���߁A�����̐l���Œ����ԍ쐬����A�Ƃ����̂��T�^�I�ȕ��@�ł��B�ŋ߂̓N���E�h�\�[�V���O�ɂ���āA
�����̐l�ԂɃA�m�e�[�V������������A�Ƃ������݂��Ȃ���Ă��܂����A���R���ꏈ���͉摜�F���قǂɂ͈�ʓI�ł͂���܂���B
���Ă���������A�Ƃ����^�X�N�Ȃ炢���̂ł����A�����l���Ȃ��Ƃ����Ȃ��悤�ȃ^�X�N����������ł��傤�B
�摜�F���ɂ��ẮA�����N���q�����܂������A����͉摜�F�������̖��ł͂Ȃ��A���Ȃ����ނ̖��ł���Ǝv���܂��B
�����u�]�v�v���Ƃ����̂��邽�߂ɂ́A�����𐄑��ł��Ȃ��ƕ�����Ȃ��悤�Ɏv���܂����A���܂̓����{�v���W�F�N�g�̐��w
�������n�i�����j�ɗ��Ƃ�����Ő��_�i�Ƃ������ؖ��Łj�����A�v���[�`�ł́A���̂悤�Ȗ��͋ꂵ���̂ł͂Ȃ��ł��傤���i
�\�����ĒT������悤�ȃA�v���[�`������K�v������A�ǂ��炩�Ƃ����Əؖ��n�Ƃ������̓Q�[��AI�̐��_�̂悤�Ȋ����H
�v�͑�K�͂ȃf�[�^����̃p�^�[���}�b�`�ɂ���A�Ƃ����p���_�C���ɂ���A�Ƃ����Ƃł��j�B������̖��̂܂܉�������
����̂͐��w�̉G���W�����ꂩ���蒼�����Ƃɑ�������Ǝv���܂����A���̃v���W�F�N�g�̃t�H�[�J�X����͗��ꂻ���ł��B
http://d.hatena.ne.jp/mamoruk/20140822
�d�v�����o�ȊO�͂܂����p�I�ɂ͓���ł��傤�i�����o�ȏ�̂��Ƃ����悤�Ƃ���ƁA�Ӗ��𗝉����Ȃ��Ƃ����Ȃ��Ȃ�j�B
�ŋ߂̓j���[�X�̔z�M�A�v���P�[�V�����E�T�[�r�X������ɊJ������Ă��āA��������܂Ƃ߂��肷��@�\������܂����A
���R���ꏈ���̍Ő�[�̋Z�p���g���Ă���Ƃ������́A���Ȃ胋�[������������A�l�����ꂽ�肵�Ă���A�ƕ��������Ƃ�����܂��B
http://d.hatena.ne.jp/mamoruk/20140902
�R�[�p�X�̃A�m�e�[�V�����́A���̂ɂ��܂����l�C��p�łȂ�Ƃ��Ȃ���̂ł͂Ȃ��A�l�𑝂₵�Ă������m�ۂł��Ȃ�
�i�ނ��눫������j���߁A�����̐l���Œ����ԍ쐬����A�Ƃ����̂��T�^�I�ȕ��@�ł��B�ŋ߂̓N���E�h�\�[�V���O�ɂ���āA
�����̐l�ԂɃA�m�e�[�V������������A�Ƃ������݂��Ȃ���Ă��܂����A���R���ꏈ���͉摜�F���قǂɂ͈�ʓI�ł͂���܂���B
���Ă���������A�Ƃ����^�X�N�Ȃ炢���̂ł����A�����l���Ȃ��Ƃ����Ȃ��悤�ȃ^�X�N����������ł��傤�B
�摜�F���ɂ��ẮA�����N���q�����܂������A����͉摜�F�������̖��ł͂Ȃ��A���Ȃ����ނ̖��ł���Ǝv���܂��B
�����u�]�v�v���Ƃ����̂��邽�߂ɂ́A�����𐄑��ł��Ȃ��ƕ�����Ȃ��悤�Ɏv���܂����A���܂̓����{�v���W�F�N�g�̐��w
�������n�i�����j�ɗ��Ƃ�����Ő��_�i�Ƃ������ؖ��Łj�����A�v���[�`�ł́A���̂悤�Ȗ��͋ꂵ���̂ł͂Ȃ��ł��傤���i
�\�����ĒT������悤�ȃA�v���[�`������K�v������A�ǂ��炩�Ƃ����Əؖ��n�Ƃ������̓Q�[��AI�̐��_�̂悤�Ȋ����H
�v�͑�K�͂ȃf�[�^����̃p�^�[���}�b�`�ɂ���A�Ƃ����p���_�C���ɂ���A�Ƃ����Ƃł��j�B������̖��̂܂܉�������
����̂͐��w�̉G���W�����ꂩ���蒼�����Ƃɑ�������Ǝv���܂����A���̃v���W�F�N�g�̃t�H�[�J�X����͗��ꂻ���ł��B
http://d.hatena.ne.jp/mamoruk/20140822
273 �F�f�t�H���g�̖����������F2014/12/19(��) 11:41:50.67 ID:Rp55Z5Hh
���Ӗ��Ȓ����R�s�y��߂�
274 �F�f�t�H���g�̖����������F2014/12/22(��) 13:05:29.12 ID:mCwiHCRV
�R�s�y����Ȃ�I
��ɃR�s�y����Ȃ�I
��ɃR�s�y����Ȃ�I
275 �F�f�t�H���g�̖����������F2015/01/01(��) 13:33:29.53 ID:BsJlAb0F
���R���ꏈ���̃G���[���͂́A����܂�����炵���B
Project Next NLP �Ƃ����A���낢��ȃ^�X�N�ŃG���[���͂�������{�̎��R���ꏈ���R�~���j�e�B�̈������v���W�F�N�g
������̂����A�\�z�ʂ��ς����ł���i�����͍��N�x�q��Ă̕��ׂ��������Ƃ��������Ă����̂ŁA���ǃ��C���ł�
�Q�����Ă��Ȃ��j�B���������@��K�v�Ȃ��Ƃ͋��炭���̋ƊE�̂قƂ�ǂ̐l���^������Ǝv���̂����A���ۂɃG���[��
���͂��悤�Ƃ���ƁA�A�m�e�[�V�����̌o�������肩����w�ɂ��ڂ����l���v���W�F�N�g���ɕ����l���Ȃ��ƁA
���������G���[���͎��̂��܂Ƃ��ɉ��Ȃ��Ǝv�����A�������������l���������j�ɂ����Ƃ��Ă��A�c�_�����M����
�����怂̋c�_�ɂȂ邱�Ƃ��������Ȃ̂ł���B
http://d.hatena.ne.jp/mamoruk/20141112/p1
Project Next NLP �Ƃ����A���낢��ȃ^�X�N�ŃG���[���͂�������{�̎��R���ꏈ���R�~���j�e�B�̈������v���W�F�N�g
������̂����A�\�z�ʂ��ς����ł���i�����͍��N�x�q��Ă̕��ׂ��������Ƃ��������Ă����̂ŁA���ǃ��C���ł�
�Q�����Ă��Ȃ��j�B���������@��K�v�Ȃ��Ƃ͋��炭���̋ƊE�̂قƂ�ǂ̐l���^������Ǝv���̂����A���ۂɃG���[��
���͂��悤�Ƃ���ƁA�A�m�e�[�V�����̌o�������肩����w�ɂ��ڂ����l���v���W�F�N�g���ɕ����l���Ȃ��ƁA
���������G���[���͎��̂��܂Ƃ��ɉ��Ȃ��Ǝv�����A�������������l���������j�ɂ����Ƃ��Ă��A�c�_�����M����
�����怂̋c�_�ɂȂ邱�Ƃ��������Ȃ̂ł���B
http://d.hatena.ne.jp/mamoruk/20141112/p1
276 �F�f�t�H���g�̖����������F2015/01/01(��) 13:39:38.39 ID:BsJlAb0F
�A�m�e�[�V�����Ɋւ��ẮA���R���ꏈ���ɂ�����A�m�e�[�V�����ɓ��������悤�Șa���͂���܂���ˁB���v�͂���Ǝv���̂ŁA
�o�ŎЂ̕����������Ƃ��A���̂悤�Ȗ{����悳��ẮA�ƒ�Ă������Ƃ͂���܂��B�������A�̌n�����邱�Ƃ�����̂ŁA
�����ɂ͍����܂��Ǝv���܂��B�قƂ�ǂ̏ꍇ�A�d�l���������Ă��Ӗ���������Ȃ��̂ŁA�ǂސl�����ꌻ�ێ��g�ɏڂ���
�i�܂茾��w�̒m��������j�A�����R���ꏈ���ɂ����邢�i�܂�v���O�����������ċ@�B�w�K���s���������C���[�W�ł���j
�K�v������܂��̂ŁA���发�Ƃ͂Ȃ�Ȃ��ł��傤���A�l�I�ɂ����发�ł͂Ȃ���发�Ƃ��Ă����Ə������ق��������Ǝv���Ă��܂��B
http://d.hatena.ne.jp/mamoruk/20140902
�o�ŎЂ̕����������Ƃ��A���̂悤�Ȗ{����悳��ẮA�ƒ�Ă������Ƃ͂���܂��B�������A�̌n�����邱�Ƃ�����̂ŁA
�����ɂ͍����܂��Ǝv���܂��B�قƂ�ǂ̏ꍇ�A�d�l���������Ă��Ӗ���������Ȃ��̂ŁA�ǂސl�����ꌻ�ێ��g�ɏڂ���
�i�܂茾��w�̒m��������j�A�����R���ꏈ���ɂ����邢�i�܂�v���O�����������ċ@�B�w�K���s���������C���[�W�ł���j
�K�v������܂��̂ŁA���发�Ƃ͂Ȃ�Ȃ��ł��傤���A�l�I�ɂ����发�ł͂Ȃ���发�Ƃ��Ă����Ə������ق��������Ǝv���Ă��܂��B
http://d.hatena.ne.jp/mamoruk/20140902
277 �F�f�t�H���g�̖����������F2015/01/01(��) 17:51:57.22 ID:LvmvuVw0
RDF���Ɋւ��Ă͎��R���ꏈ�����̓E�F�u�}�C�j���O�i�L�`�̐l�H�m�\�����j�Ő����
��������Ă��܂����A�قƂ�ǂ̌����͉p�ꂪ�ΏۂŁA���{��ł����Ƃ������\�[�X��
����Ă��Ȃ��Ƃ����̂����Ǝv���܂��B������ǂ��i���{��ł����ׂ��j���Ƃ�
���킯�ł͂Ȃ��ł����A���Ȃ��Ƃ������{�̃v���W�F�N�g���ԓ��ɂǂ������ł���Ƃ����b�ł͂Ȃ��ł��傤�B
�l�I�ɂ́A�����͊m���Ɍ����̗]�n������Ƃ��낾�Ǝv���Ă���̂ł����A�p��ŏ����ꂽ
���\�[�X�Ɣ�ׂ�Ɠ��{��ŏ����ꂽ���\�[�X�����Ȃ��i�����삪���Ă���j�Ƃ������ƁA
���{�ꂪ�p��Ɣ�ׂ�Ə������ɂ����Ƃ������̂��߁A�p��̂悤�ɐ��x�̍������\�[�X��
���̂͂���ȂɊȒP�ł͂Ȃ��Ǝv���Ă��܂��B�i���Ƃ��A�p�ꂾ��2�̖�����̊Ԃ̕�����
������Ă���A���������q�ꂪ����̂ŁA�\����͂ɂ��Ȃ��挒�ȏ������ł��܂����A
���{��ł͏q��͕��̖����ɏo������̂ŁA�W���͂����Ȃ��Əq�ꂪ�����炸�A�Ȃ��Ȃ��挒�ɂ͂ł��Ȃ������j
http://d.hatena.ne.jp/mamoruk/20140902
��������Ă��܂����A�قƂ�ǂ̌����͉p�ꂪ�ΏۂŁA���{��ł����Ƃ������\�[�X��
����Ă��Ȃ��Ƃ����̂����Ǝv���܂��B������ǂ��i���{��ł����ׂ��j���Ƃ�
���킯�ł͂Ȃ��ł����A���Ȃ��Ƃ������{�̃v���W�F�N�g���ԓ��ɂǂ������ł���Ƃ����b�ł͂Ȃ��ł��傤�B
�l�I�ɂ́A�����͊m���Ɍ����̗]�n������Ƃ��낾�Ǝv���Ă���̂ł����A�p��ŏ����ꂽ
���\�[�X�Ɣ�ׂ�Ɠ��{��ŏ����ꂽ���\�[�X�����Ȃ��i�����삪���Ă���j�Ƃ������ƁA
���{�ꂪ�p��Ɣ�ׂ�Ə������ɂ����Ƃ������̂��߁A�p��̂悤�ɐ��x�̍������\�[�X��
���̂͂���ȂɊȒP�ł͂Ȃ��Ǝv���Ă��܂��B�i���Ƃ��A�p�ꂾ��2�̖�����̊Ԃ̕�����
������Ă���A���������q�ꂪ����̂ŁA�\����͂ɂ��Ȃ��挒�ȏ������ł��܂����A
���{��ł͏q��͕��̖����ɏo������̂ŁA�W���͂����Ȃ��Əq�ꂪ�����炸�A�Ȃ��Ȃ��挒�ɂ͂ł��Ȃ������j
http://d.hatena.ne.jp/mamoruk/20140902
278 �F�f�t�H���g�̖����������F2015/01/04(��) 08:53:09.06 ID:Vh1lmQHV
���̃R�s�y�̓��@�͂Ȃ�Ȃ́H
��{�l�Ȃ́H
��{�l�Ȃ́H
279 �F�f�t�H���g�̖����������F2015/01/04(��) 19:32:49.96 ID:UrD0d14K
�R�s�y�������Ă��N���������܂Ȃ��X���b�h���R�s�y�̂����ɂ���Ȃ�
280 �F�f�t�H���g�̖����������F2015/01/05(��) 07:11:49.24 ID:755b/Otu
�R�s�y�������Ă��N���������܂Ȃ��X���b�h���R�s�y�̂����ɂ��Đ\����Ȃ��v���܂�
281 �F�f�t�H���g�̖����������F2015/01/06(��) 21:01:58.55 ID:rhCaR8KF
�܂�ʼn����̐�`�݂����B
282 �F�f�t�H���g�̖����������F2015/02/12(��) 14:36:17.01 ID:LHb2oe4V
�q�c�e�g���v���Z�b�g�́u�A�z�E���_�v�ɗ��p�ł���̂ŁA�l�͂łq�c�e���T���쐬���Ă��������B
���R����̑��`���E�B�����́A����ł�����x�����ł���͂��B
��Ď�@�ł́C�J���E�����Ɋ�Â��CRDF �O���t���炻���荂���\���͂����� SROIQ�T�O�̋ɏ����f���𐄘_�ł���D
����ɁC����T�O�̋ɏ����f������ӂɌ��܂邱�Ƃ𗘗p���C�^����ꂽRDF �O���t����L�q�ł��邷�ׂĂ̊T�O��
�����~�������A���S���Y���������D
http://sigswo.org/papers/SIG-SWO-A1402/SIG-SWO-A1402-10.pdf
�ix,y,z�j��(���,�q��,�ړI��)�ŁA�o���p�x�̑������ɕ��ׂ�A���邢�͏��Ȃ����ɕ��ׂ�B���p�x�̃g���v�����₽�瑽���Ƃ������Ƃ́A
�t�Ɍ����Α��Ǝ�����������ł܂�Ȃ��R���e���c�ł���\���������B�o���p�x�̏��Ȃ��g�ݍ��킹�́A�I���W�i���\����
���邢�̓i���Z���X�����̂ǂ��炩�B�Ⴆ�u�����͎q�����Y�ދ@�B�v�B���������͕̂��ʂɁu�����@�q���v�Ō������Ă��o�Ȃ��B
�R�[�p�X�쐬�ɂ��Ĉꂩ���蒼�����ق����������ǂ����́A�Y�܂������Ȃ̂ň�T�ɂǂ����Ƃ������Ƃ͌����ɂ����̂ł����A
�A�m�e�[�V�����E�R�[�p�X�쐬���̂��傫�Ȍ����e�[�}�ł���A�x�X�g�v���N�e�B�X�I�Ȃ��̂��Ȃ���A���������~�ς���Ă���
�m�E�n�E�I�Ȃ��̂���`�[�����x���ł������L�ł��Ă��Ȃ��i���L����̂�����j�A�Ƃ����ł��B�܂��A��蒼�����炷���R�[�p�X
���ł��邩�Ƃ����ƁA���̍����R�[�p�X�����ɂ͎��Ԃ����N����������̂Ȃ̂Łi�����̌g����� NAIST �e�L�X�g�R�[�p�X��
5�N�ȏォ�����Ă��܂��j�A�������p�\�ɂ͂Ȃ�Ȃ��ł��傤�B
http://d.hatena.ne.jp/mamoruk/20140822
����C�摜��͋Z�p���i�݁C�@�B�������̕��̂���\�������I�u�W�F�N�g�����̕��̂ɕ����ł����Ƃ��Ă��C�@�B�ɂƂ��āC
���ꂪ�펯�Ɋ�Â����\���ł��邩�C�펯����O�ꂽ�\���ł��邩����ʂ��邱�Ƃ͍���ł���Ɛ��������D
http://minamigaki.cs.inf.shizuoka.ac.jp/work/2014/SCIS2014fujita.pdf
�w�펯�x�Ȃ���̂́A���l�͂œo�^���邵���Ȃ��B�R���s���[�^�[�Ȃ�Ă����獂���\�ł������̌v�Z�@�ɉ߂��Ȃ��̂�����B
���R����̑��`���E�B�����́A����ł�����x�����ł���͂��B
��Ď�@�ł́C�J���E�����Ɋ�Â��CRDF �O���t���炻���荂���\���͂����� SROIQ�T�O�̋ɏ����f���𐄘_�ł���D
����ɁC����T�O�̋ɏ����f������ӂɌ��܂邱�Ƃ𗘗p���C�^����ꂽRDF �O���t����L�q�ł��邷�ׂĂ̊T�O��
�����~�������A���S���Y���������D
http://sigswo.org/papers/SIG-SWO-A1402/SIG-SWO-A1402-10.pdf
�ix,y,z�j��(���,�q��,�ړI��)�ŁA�o���p�x�̑������ɕ��ׂ�A���邢�͏��Ȃ����ɕ��ׂ�B���p�x�̃g���v�����₽�瑽���Ƃ������Ƃ́A
�t�Ɍ����Α��Ǝ�����������ł܂�Ȃ��R���e���c�ł���\���������B�o���p�x�̏��Ȃ��g�ݍ��킹�́A�I���W�i���\����
���邢�̓i���Z���X�����̂ǂ��炩�B�Ⴆ�u�����͎q�����Y�ދ@�B�v�B���������͕̂��ʂɁu�����@�q���v�Ō������Ă��o�Ȃ��B
�R�[�p�X�쐬�ɂ��Ĉꂩ���蒼�����ق����������ǂ����́A�Y�܂������Ȃ̂ň�T�ɂǂ����Ƃ������Ƃ͌����ɂ����̂ł����A
�A�m�e�[�V�����E�R�[�p�X�쐬���̂��傫�Ȍ����e�[�}�ł���A�x�X�g�v���N�e�B�X�I�Ȃ��̂��Ȃ���A���������~�ς���Ă���
�m�E�n�E�I�Ȃ��̂���`�[�����x���ł������L�ł��Ă��Ȃ��i���L����̂�����j�A�Ƃ����ł��B�܂��A��蒼�����炷���R�[�p�X
���ł��邩�Ƃ����ƁA���̍����R�[�p�X�����ɂ͎��Ԃ����N����������̂Ȃ̂Łi�����̌g����� NAIST �e�L�X�g�R�[�p�X��
5�N�ȏォ�����Ă��܂��j�A�������p�\�ɂ͂Ȃ�Ȃ��ł��傤�B
http://d.hatena.ne.jp/mamoruk/20140822
����C�摜��͋Z�p���i�݁C�@�B�������̕��̂���\�������I�u�W�F�N�g�����̕��̂ɕ����ł����Ƃ��Ă��C�@�B�ɂƂ��āC
���ꂪ�펯�Ɋ�Â����\���ł��邩�C�펯����O�ꂽ�\���ł��邩����ʂ��邱�Ƃ͍���ł���Ɛ��������D
http://minamigaki.cs.inf.shizuoka.ac.jp/work/2014/SCIS2014fujita.pdf
�w�펯�x�Ȃ���̂́A���l�͂œo�^���邵���Ȃ��B�R���s���[�^�[�Ȃ�Ă����獂���\�ł������̌v�Z�@�ɉ߂��Ȃ��̂�����B
283 �F�f�t�H���g�̖����������F2015/02/18(��) 13:15:42.49 ID:dIyx5cm4
>>282
���@�B�ɂƂ��āC���ꂪ�펯�Ɋ�Â����\���ł��邩�C�펯����O�ꂽ�\���ł��邩����ʂ��邱�Ƃ͍���ł���Ɛ��������D
�����쐬������ȁu��a��CAPTCHA�v�́A�������쐬�ψ��Ɠ����{�ƃC���X�g�쐬�x���c�[����
�ߋ������x���c�[���p���A�l�͂Ƌ@�B�͂̃n�C�u���b�h�Ō����I�ɍ쐬����B�C���X�g������
�R���s���[�^�[�ɂ͍�����l�Ԃɂ͈Ղ����B�������̉ߋ�����A���ؒ��J�ȗU���t���ňՂ������
�ɉ��肷������B�Z���^�[���w�͐l�Ԃɂ͈Ղ����������{�ɂ͍���B�܂�������̃Z�L�����e�B
��Ƃ�ݗ����āA�����悭��ʐ��Y�ł���悤�ɂ������B�ł���Έ��������ꖜ�ʂ肭�炢�͍�肽���B
�O��ԈႦ����R�O���Ԃ̓A�N�Z�X�֎~�ɂ���Ƃ��B��������Q�����̃A���V���e����������͂����B
�u���ɂႮ�ɂᕶ��CAPTCHA�v�ɂ͂����E���U���B
���@�B�ɂƂ��āC���ꂪ�펯�Ɋ�Â����\���ł��邩�C�펯����O�ꂽ�\���ł��邩����ʂ��邱�Ƃ͍���ł���Ɛ��������D
�����쐬������ȁu��a��CAPTCHA�v�́A�������쐬�ψ��Ɠ����{�ƃC���X�g�쐬�x���c�[����
�ߋ������x���c�[���p���A�l�͂Ƌ@�B�͂̃n�C�u���b�h�Ō����I�ɍ쐬����B�C���X�g������
�R���s���[�^�[�ɂ͍�����l�Ԃɂ͈Ղ����B�������̉ߋ�����A���ؒ��J�ȗU���t���ňՂ������
�ɉ��肷������B�Z���^�[���w�͐l�Ԃɂ͈Ղ����������{�ɂ͍���B�܂�������̃Z�L�����e�B
��Ƃ�ݗ����āA�����悭��ʐ��Y�ł���悤�ɂ������B�ł���Έ��������ꖜ�ʂ肭�炢�͍�肽���B
�O��ԈႦ����R�O���Ԃ̓A�N�Z�X�֎~�ɂ���Ƃ��B��������Q�����̃A���V���e����������͂����B
�u���ɂႮ�ɂᕶ��CAPTCHA�v�ɂ͂����E���U���B
284 �F�f�t�H���g�̖����������F2015/02/18(��) 15:59:15.93 ID:dIyx5cm4
���ƁA�Q�����˂�ł̔Ⴂ�X�����ė����h�~�̂��߂ɁA�u���i����CAPTCHA�v������Ƃ��B
�Ⴆ�v���O���}�[�Ȃ�A��{���Z�p�Ҏ����̌ߑO���ŁA�V���������Ȃ��Ɠ��e�ł��Ȃ��悤�ɂ���Ƃ��B
�Ⴆ�v���O���}�[�Ȃ�A��{���Z�p�Ҏ����̌ߑO���ŁA�V���������Ȃ��Ɠ��e�ł��Ȃ��悤�ɂ���Ƃ��B
285 �F�f�t�H���g�̖����������F2015/02/21(�y) 17:29:42.70 ID:VfWo/10x
�l�Ԃ͊��������߂�B���̂Ɍ����J���Ă���ƁA���̂̈ꕔ�������Ă���ƁA���̃M���b�v�߂悤�Ƃ���B
���̉摜������ƁA���ۂɂ͑��݂��Ȃ����̂́A�~�ƒ����`�Ɍ����Ă���B
���̖@�������݂��Ȃ���Ԃł́A�����̈قȂ���ɂ��������Ȃ����A���̖@���ɂ��A����g�ݍ��킹�āA�`�Ƃ��Č���B
http://livedoor.blogimg.jp/mikamikanmikamikan/imgs/1/8/186ef42f.jpg
http://www.seojapan.com/blog/8-web-design-rules
82. 1. �L�q�͈͂Ƃ���20s�̗̈��I�� 2. �̈��4 4(=16)�u���b�N�ɕ��� 3.
�L�q�͈͂��I���G���e�[�V���������ɉ�] �����̐��K�� 20s 20s 82
http://livedoor.blogimg.jp/mikamikanmikamikan/imgs/e/1/e1a13d79.jpg
http://www.slideshare.net/MPRG_Chubu_University/sift-32258833
�@��X�l�Ԃ́A���ӎ��̂����ɖc��ȗʂ̃R�����Z���X�m�����A���퐶���̒��Ŏ��R�Ɖ�����L���Ă���B
�l�Ԃɋ߂��v�l������l�H�m�\���������邽�߂ɂ́A�R���s���[�^��ɃR�����Z���X�m���̋���ȃf�[�^�x�[�X
���\�z����K�v������B�r�b�O�f�[�^�������Z�p�Ƒg�ݍ��킹��A�l�H�m�\�̎v�l���x�����コ����y��ƂȂ�B
http://livedoor.blogimg.jp/mikamikanmikamikan/imgs/2/9/2989d626.jpg
http://business.nikkeibp.co.jp/art�c/bigdata/20140722/268973/
���̉摜������ƁA���ۂɂ͑��݂��Ȃ����̂́A�~�ƒ����`�Ɍ����Ă���B
���̖@�������݂��Ȃ���Ԃł́A�����̈قȂ���ɂ��������Ȃ����A���̖@���ɂ��A����g�ݍ��킹�āA�`�Ƃ��Č���B
http://livedoor.blogimg.jp/mikamikanmikamikan/imgs/1/8/186ef42f.jpg
{kind=link}
http://www.seojapan.com/blog/8-web-design-rules
82. 1. �L�q�͈͂Ƃ���20s�̗̈��I�� 2. �̈��4 4(=16)�u���b�N�ɕ��� 3.
�L�q�͈͂��I���G���e�[�V���������ɉ�] �����̐��K�� 20s 20s 82
http://livedoor.blogimg.jp/mikamikanmikamikan/imgs/e/1/e1a13d79.jpg
{kind=link}
http://www.slideshare.net/MPRG_Chubu_University/sift-32258833
�@��X�l�Ԃ́A���ӎ��̂����ɖc��ȗʂ̃R�����Z���X�m�����A���퐶���̒��Ŏ��R�Ɖ�����L���Ă���B
�l�Ԃɋ߂��v�l������l�H�m�\���������邽�߂ɂ́A�R���s���[�^��ɃR�����Z���X�m���̋���ȃf�[�^�x�[�X
���\�z����K�v������B�r�b�O�f�[�^�������Z�p�Ƒg�ݍ��킹��A�l�H�m�\�̎v�l���x�����コ����y��ƂȂ�B
http://livedoor.blogimg.jp/mikamikanmikamikan/imgs/2/9/2989d626.jpg
{kind=link}
http://business.nikkeibp.co.jp/art�c/bigdata/20140722/268973/
286 �F�f�t�H���g�̖����������F2015/02/21(�y) 21:50:03.02 ID:RYr+Lvse
�����R�s�y����̂�߂�
287 �F�f�t�H���g�̖����������F2015/02/22(��) 12:00:11.88 ID:ALoz31q1
�S�p�J���}���_���ő��������A��ʂɂ͗]��p�����Ȃ����Ƃ���
�C(.|\n)+https?://
��NG�ɂ���ƌ��\�ǂ���Ȃ����낤���B
���Ƌ������̂�
��B(.|\n)+https?://
���v��������F�����Ȃ����ƁB������_���ɓ����I�ȁA�u�ł��钲�v���ӎ��������̂����A���̃X���ň��������������ŏ����ł��ӌ����܂܂��Ǝv���铊�e��9���ɗ��܂����B
�����N��Ƃ̓��e�̏d�������o����̂���ԂȂ낤���ǂˁB
�C(.|\n)+https?://
��NG�ɂ���ƌ��\�ǂ���Ȃ����낤���B
���Ƌ������̂�
��B(.|\n)+https?://
���v��������F�����Ȃ����ƁB������_���ɓ����I�ȁA�u�ł��钲�v���ӎ��������̂����A���̃X���ň��������������ŏ����ł��ӌ����܂܂��Ǝv���铊�e��9���ɗ��܂����B
�����N��Ƃ̓��e�̏d�������o����̂���ԂȂ낤���ǂˁB
288 �F�f�t�H���g�̖����������F2015/02/22(��) 12:27:03.95 ID:z7hrtyyQ
�����҃��i�r�[�̃I�b�T�����R�s�y���Ă��������
�w���͍����Ȃ������ȃI�b�T����
�w���͍����Ȃ������ȃI�b�T����
289 �F�f�t�H���g�̖����������F2015/02/22(��) 13:05:32.71 ID:I5/HIZJG
�ӂ��ɓ��发����ǂ߂A�w�����ǂ����ꂻ��Ȃ�ɗ����͂ł��邾�낤�ɂ˂��B
�킯���킩�炸������ۂ�web��̋L���������ĉ��ɂ�����ۂ��ƈËL�ł����Ƃ��Ă�
���̈Ӗ����Ȃ��̂ɁB
�킯���킩�炸������ۂ�web��̋L���������ĉ��ɂ�����ۂ��ƈËL�ł����Ƃ��Ă�
���̈Ӗ����Ȃ��̂ɁB
290 �F�f�t�H���g�̖����������F2015/02/26(��) 03:40:26.29 ID:syX8dA4x
Wikipedia��dump����
���̓��t�̂��ǂ��x���`�}�[�N�Ƃ��Ďg���Ă�Ƃ�����̂ł����H
�ނ���latest���g���̂����ʂȂ�ł����H
���̓��t�̂��ǂ��x���`�}�[�N�Ƃ��Ďg���Ă�Ƃ�����̂ł����H
�ނ���latest���g���̂����ʂȂ�ł����H
291 �F�f�t�H���g�̖����������F2015/02/26(��) 07:01:52.77 ID:Msso4ZG7
�Ȃ�̃x���`�}�[�N�H
292 �F�f�t�H���g�̖����������F2015/02/26(��) 07:27:44.19 ID:Xrj2IFMm
���t���Ԉ���Ă���
293 �F�f�t�H���g�̖����������F2015/02/28(�y) 15:19:37.45 ID:LSUjOX6L
�w�������I�b�T���Ń|�X�g�������Ă��b�ɂȂ��N�Y�͑������ǂ�
294 �F�f�t�H���g�̖����������F2015/03/01(��) 03:47:39.01 ID:2eKDkVCS
������H
CRF���čő�G���g���s�[�@�̓���ȏꍇ�Ȃ����H
CRF���čő�G���g���s�[�@�̓���ȏꍇ�Ȃ����H
295 �F�f�t�H���g�̖����������F2015/03/01(��) 09:29:41.24 ID:SMJwAP9t
���Ă͂���
���͂��͂̓r���̏�Ԃ����ׂĕۑ����Ă����A
���́E��͂��r���Ŏ~�܂��Ă��ĊJ�ł��邼�B
���X�Q�[
���́E��͂��r���Ŏ~�܂��Ă��ĊJ�ł��邼�B
���X�Q�[