1 :
デフォルトの名無しさん:
2 :
デフォルトの名無しさん:2011/04/04(月) 20:59:31.81
保守
テンプレって無いんだっけ?
前スレ、落ちてたのか
全くの初心者がどのサイトまたはどの書籍を参考にしたらいいか教えてください
forとかwhileとか配列とか簡単なCくらいなら使えるけどIplimageとか訳がわからないってレベル
何を知りたいか、もうちと詳しく言ってくれるとレスが付きやすいかも
>>6 Essential OpenCV Programming―with Visual C++2008
OpenCV初心者ならこの辺りが良いんじゃなかろうか
C++/CLIだから、.NETで扱えて比較的楽
そのままMFCに行くも良し、C#でラッパー使うも良し
C++/CLIは癖があるから、そのまま使い続けるのは危険だがwww
>>6 構造体のポインタあたりまでCの学習をしてくるんだw
つまらないな
画像処理の勉強をしたいんだけど、どの位まで行けばプロ級なんすか?
私の当面の目標は、とりあえずライブラリを使って、色々な画像処理を覚えながら、
簡単なアプリ作って、色んなボタン押して画像処理できるようになって、、、
まずは半人前を目指す予定
画像処理関連アプリだとPhotoShopの○○機能みたいなの入れてって言われること多い
それを二つ返事で引き受けられないようだと素人
なるほど~その辺勉強してみますわ
OpenCVスレの方が適してるかもだけど
26日15時~17時に中部大の藤吉先生と広島大の栗田先生の講演が
Ustream配信されるよ
ブラインドデコンボリューションって方式が色々ありますが、
レントゲンのような透過画像の場合、どれが一番良いのでしょうか?
検索しても天体用とか色々あってちょっと混乱してます・・・。
ソースもあんまり無いですし。
matlabを使って見るのが一番早いんでしょうが持って無いので、すいませんがどんな助言でも構いませんのでお願いします。
画像処理技術の最新動向とかってどうやってチェックしてる?
このスレをウォッチ
とりあえずWebP Discussion Google Groupは
Google Readerに登録しておいた
21 :
デフォルトの名無しさん:2011/05/28(土) 15:30:12.08
NL-Means法のGa(差分2乗に対する距離ごとの重み)に使う
a(標準偏差)ってどのように決めているのでしょうか?
多くの論文内では,探索範囲や重み評価の窓幅,指数関数の
減衰を決めるhに対しては実験で使った値が公表されているのに
aについて述べられている論文が見つからなかったので質問させて頂きました.
このスレでいいかわからないんですけど、他に適切なスレが見つからなかったので質問させてください。
psdファイルの解像度(dpi)を取得する方法ないでしょうか。
600dpiのpsdのデータが大量にあるんですが、少しだけ72dpiのデータが混ざってしまっています。
これを検出するツールを作成したいのです。
ImageMagickで出来ると一番都合がいいんですが、調べた限りではImageMagickだと
dpiを変更することはできるけど、取得はできないようでした。
ImageMagickのソースを見たらどうでしょう。
普通にidentify -verboseで解像度も出るようだけど?
PNG, JPEG, GIF, BMPがデコードできて
WindowsとLinuxで共通に使える軽い画像ライブラリを教えてください。
libpng, libjpegなどを個別に使ってましたが、さらにbmpとかに対応しないといけなくて
いい加減めんどくさくなりました。
つ[ImageMagick]
29 :
27:2011/05/30(月) 12:36:02.30
軽いってどの程度よ
OpenCVで良くね?
OpenCV, CImg, ImageMagick, GraphicsMagick, DevIL, GIL, CxImage, Imlib2, FreeImage
個人的にはImageMagickが好き
そういえば昔DevILを使ったなぁ。結構よかった気がする。
>>24 ありがとうございます。
自分であれこれググった時にはそのパラメータにたどり着けませんでした。
で、試してみたのですが、解像度600dpiのファイルでちゃんと600x600が出てくる場合と、
なぜか30068x16になる場合があるようです。
画像そのものは問題なさそうなのですが、Photshopのバージョンによっては上手く解像度が取得できないんでしょうか・・・?
ドロップシャドウって検索したらペイント系ツールの使い方ばっか出てくる。
陰影効果作りたいだけなんだけど、プログラム作る側の観点で解説してるサイト知らない?
YUV420みたいにチャンネルごとにサイズが違う画像にアフィン変換かけたいんですけど、
1チャンネルずつ独立にかけるしかないんですかね
需要あるのか...
顔認識システムについて質問です。
同じ大きさの二つの写真を比べて、何%一致とかいいますよね?
この場合二つの写真を区画して、それぞれの同じ位置の場所の部分
を比べて一致したらx%分一致ってことですか?
似たような写真でも、違う写真ならば、全ての区分において一致しない
こともあるんじゃないですか?
ここら辺良く分からないので教えてください。またスレ違いなら関連
スレ教えてください。
物理板で聞いたのですが、ここが最適化と思いました。
ここは最適化じゃないよぉ。
このスレは最適化されています。
特徴ベクトルがどうたらこうたらで識別器がどうじゃこうじゃの識別率や誤識別率がうんぬんかんぬん
44 :
デフォルトの名無しさん:2011/06/18(土) 13:11:29.71
>>43 どういう判断で一致率を計算してるんでしょうか?
通りすがりの素人だけど、
■□■□
□■□■
■□■□
□■□■
↑と↓がどのくらい一致しているかを調べるとすると、、、
■□■□
□■□■
■□■□
□■□□
先ず横方向に■が何個あるか数えて、両方のビットマップで数が揃っている確率を調べる
次に縦方向に同じ事をして、斜め方向にも同じ事をする
みたいな話を聞いた様な聞いてない様な・・・
これが
>>43 さんの書いてる特徴ベクトル?
画像パターンを特定する「特徴量」ってのがあって、この特徴量ってのにもさまざまな
計り方があって、それぞれ関数とか統計とか使ったりするわけだな。
よくあるのは、その「もの」の写真を何パターンかプログラムに処理させて、その「もの」
の特徴を学習させる(機械学習)ってのがあるな。
顔認識だったらまず顔を認識して、顔の特徴を抽出するから、写真の区画がどうとかは関係なくなる。
特徴点を3つ使うとすると、三次元の特徴ベクトルという事。
超高速に2値化画像をラベリングするのってどうしたらいいすか?
いろいろ論文や特許はでてるけど、これぞ1番、もしくは2番くらいの教えてください
opencvを使って、やりたいことはできるが、それだとアルゴリズムが理解できない。画像処理工学?的で処理をプログラムレベルまでおとして、説明してくれてるサイトしりませんか?特にrgb⇒yuv変換、2値化、blobなど
最近は数学の勉強ばっかりで訳わからん
まー勉強するしか無いんだけどさ
って愚痴スマソ
>>48 高速ラベリングは過去スレにたくさんあるな
過去スレ見ると
鳥脇先生の2パスアルゴリズムや
image MLに流れていた1パスアルゴリズムが速いらしい
会社で使っているのは3パス以上のアルゴリズムだが
4096×4096でラベル数1000程度の画像で20ms(core i3)くらい
>>52 ●持ってないんで過去ログみれない
鳥脇先生やimage MLで流れたという手法の文献ってわかりますか?
てか4Kで20msってバカ速じゃないですか。文献ありますか?それとも独自だから教えられない?
ここって医用画像やってる人多い⁈
少ない
いよぅ
鳥脇先生の名が挙がっていたから多いのかと思ったが違ったみたいね
59 :
デフォルトの名無しさん:2011/06/23(木) 11:19:36.31
>>17 レントゲン画像でブラインドデコンボリューションが有用な局面って
どんな状況を想定されてますか ? 散乱は被写体の内部構造に依存するとして
事前撮影した画像から状況を読み取ってモデルを変更するとかですか ?
60 :
デフォルトの名無しさん:2011/06/23(木) 11:22:06.50
測定計画は「最初が肝心」なので取得された画像を後からどうこうするより
透視像をリアルタイム解析してウェッジフィルタを自動挿入するほうが
被曝低減と画質改善を同時にできるから有用じゃないかとおもったり...
>>59 散乱を推定して修正することで、今まで見えなかった物が見えたりしないかなと思っています。
被爆を抑える為に、他の光を使用したり。
62 :
デフォルトの名無しさん:2011/06/23(木) 18:59:09.09
>>61 ちょっとググってみると20年以上前の放射線技術学会の発表記録で
SPECTの散乱線除去を検討したものがありました
盲点でしたけどSPECT関係は昔から理工学的な検討が尽くされているので
その方面のいろいろな論文は古くても参考になるかもしれません
実装するときの指標としては通常行われるグリッドを通した画像と
同じ程度に(散乱推定で)みえればいいのでは? と個人的にはおもったり。
どこかのページで、霧の中を車で走行しながら撮影した動画があったけど、
それを画像処理したら建物や電柱がはっきり見えていたのには驚いた
どのくらい?
霧で目の前や道路もほとんど見えない状態だったのに、
周りの建物や電柱が認識できるレベルにまで復元されていた
霧の中なんて散乱係数一定じゃないのに、どーやったらこんなの計算出来るのかと
前に適当にググって見つけたんだけど、今探しても見付からねぇ・・・
原発事故収拾部隊に召喚したい
20cm四方の段ボールの切れ端5×4の20個並ぶとして、それぞれに
直径3,4センチの真っ白の円をプリントし、カメラの画像でしるしを認識したい。
2値化する際にしきい値を動的に決めたいんですが、どんな決め方が適してると思いますか?
また、ラべリングの中に円形度を調べられるっぽいのを本で見たのですが、
実際にあったら、円形度で円を認識したいと思いますが有用だと思われますか?
輝度分布でヒストグラム作って、白部分とダンボール部分の差を閾値にすれば良いんじゃね?
円を認識出来るのは影次第だから、何とも言えないところがある
円用に照明環境も調整出来る施設なら良いけど、ただの施設にカメラ置くだけじゃ多分ダメぽ
>>67 適応的2値化 とかいうやつでどうか? だいたい↓のような感じだったかと思う.
画像がグレースケールだとして,
まずそれに適当なフィルタサイズでガウシアンフィルタでも掛けたぼかし画像を用意する.
フィルタサイズは画像次第だが,画像幅の1/3とか1/4とか1/10とか適当にやる.
で,ぼかし画像輝度値にこれまた適当な係数(0.0~1.0.例えば0.5とか)を掛けた結果を各画素位置での閾値とする.
やること簡単だし,ある程度は陰影に対処できる.
2つの関数のリファレンス見れば原理が書いてあんだろハゲ
ハ、ハゲてなんか、い、いねーぞ、な、な、なに言ってんだよ、ハハ
ズレてますよ
>>70 3次元ベクトルと四元数、もしくは行列で行けるんじゃね。
そのサイトのピンクの四角形を四元数で行う場合。
1.元の四角形の4個の頂点座標を既に持っているものとする。
2.軸ベクトルを用意する。
(ピンクの四角でいうと、底辺の部分が軸になってる。底辺の2つの頂点同士を引き算することで得られる)
(軸の方向は、右から左だろうが左向から右だろうが角度のとり方が変わるだけでどっちでもいい)
3.回転対象のベクトルを作る
(ピンクの四角でいうと、上辺の頂点座標から底辺の頂点座標を引く事で得られる)
4.回転対象ベクトルと、軸ベクトルを四元数にかける
(そこで得られたベクトルで、底辺の頂点座標を移動した座標を作る)
以上で完了。
画像に適用する場合は、各頂点を、画像の各ピクセルに見立てればいい。
移動後のピクセル座標が重複した場合は平均化など別途ぼかしの技術を調べて調整する。
2次元画像の「拡大縮小だけ」してくれるライブラリないですか?
拡大縮小だけできれば十分な俺にはフルスペックの画像処理ライブラリは大きすぎる。
アホか
そのくらい自分で作れ
79 :
76:2011/06/30(木) 18:02:31.10
最低Bicubic法かできればLanczos法がいいです。
作れるぐらいなら聞きません。
人に聞けば答えを持ってきてくれると思ったら大間違いだ
拡大縮小なんて、ライブラリ以前に、素で用意されてるがな(´・ω・`)
82 :
76:2011/06/30(木) 18:24:10.83
そんなこと言わずに本当に困っているのでコピってくればすぐ使えるC++のLanczos法のソースを教えてください。
クグれガス
あなたのためだから
85 :
76:2011/06/30(木) 18:52:48.14
もう2時間はぐぐったけど見つからないの><
じゃあねえよ、シネ
Googleで見つからない時は、Yahoo!で探してみるといいよ。
// ̄~`i ゝ `l |
/ / ,______ ,_____ ________ | | ____ TM
| | ___ // ̄ヽヽ // ̄ヽヽ (( ̄)) | | // ̄_>>
\ヽ、 |l | | | | | | | | ``( (. .| | | | ~~
`、二===-' ` ===' ' ` ===' ' // ̄ヽヽ |__ゝ ヽ二=''
ヽヽ___// 日本
______________ __
|Lanczos C言語 .| |検索|←をクリック!!
 ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄  ̄ ̄
◎ウェブ全体 〇日本語のページ
YES → 【見つかった?】 ─ YES → じゃあ聞くな死ね
/ \
【探した?】 NO → それより僕と踊りませんか?
\
NO → 死ね
課題か何かか?
自力でやれよ
91 :
67:2011/07/01(金) 06:00:00.97
自分なりに考えてキトラーのしきい値判別法にきめて、境界線追跡で円周長も求める、円形度みるようにしました。
これをペイントで作った理想画像で上手くいったので、実写でやりました。
甘くないんですね。
輝度しきい値が、78と低くく丸以外も検出しまくりです。ためしにしきい値高くしても上手くいきませんでした。影で黒にふられたマークもありました。
しきい値判別法考えなおします。
あと、なんちゃらフィルタにかけないと影の影響でちゃんですね。
93 :
69:2011/07/01(金) 10:04:17.96
>>91 実際の画像がどんななのか不明だが
画像全体に対して単一の閾値を決めようとしているの?
撮影対象面に無視できないほどの明暗があるんだったら
単一閾値でうまくいかないのはやる前にわかりそうなものだが.
とりあえずいまやっている処理内容はそのままで
その画像から一部分だけ切り出してきた画像に
やってみたらどうなるかとかやってみたら?
>>91 まずは機械屋や電気屋に、出来る限り均等な条件で計測出来るように設計させろ
何も考えずに適当に作らせて「ライン作ったから後はよろ^^」で終わらせると、
設置する環境毎に調整しないといけなくなる上に、誤検出が多くて使い物にならなくなる
影ってのは環境次第では時間帯によっても変わるし、近くを人が通ったりするだけで影響受けたりするからなー
まー調整料取れるから、会社としては良いかもしれんが
最終的には画像処理次第だが、処理するレベルを下げる努力をしたほうが良い機械になるぞ
2011年、Ruby,Perl,PHP,Pythonって並べたときにさ
ここで、Ruby以外を選ぶ奴ってマジでなんなんだろうな
土方が何をほざいて
天使ちゃんマジ天使
PHPと同じところに並べてほしくないな
Rubyって糞遅いじゃん
>>95 >2011年、Ruby,Perl,PHP,Pythonって並べたときにさ
画像処理で、その辺のが並ぶことがあるのか疑問だが・・・
コピペマルチしまくってるクソコテだから反応するな
100 :
91:2011/07/04(月) 18:15:46.99
部分切り出して、やったら検出できました。なんで、部分画像分割とやらでいくつか領域わけてやります。
だけど、段ボール背景だと閾値がひくくなっちゃうんだけど、閾値が高めにでる閾値決定法ないすか。
現状、灰色の背景で検出できてるがフラッシュたいた画像は検出できんわ。
仕様うんねんは実現性検証だんかいなんでなんも決まってません。今はフラッシュたいたやつ検出できるまでいきたい…
×うんねん
○うんぬん
◎云々
,. -─- 、
/ ___丶
∠. /´ ,.- 、r‐、`|
l | | ー | lー | |
l. |@`ー' oー' l
(\ヽヽ ~~~~ゝ にんにん
\.ゞ,>nn‐r=<
( / `^^´`ヽハ)
/`! ー--=≦-‐1
YUV4:4:4の動画を読み込んで4:2:2に変換したいのですが、CbCrの出力
を水平1つ飛ばしにするだけでいいのでしょうか?
//PH,PWは縦と横のサイズ
/*読み込み*/
for(y=0;y<PH;y++){
for(x=0;x<PW;x++){
Y1[y][x]=(unsigned char) fgetc(fp_in1);
Cb1[y][x]=(unsigned char) fgetc(fp_in1);
Cr1[y][x]=(unsigned char) fgetc(fp_in1);
}
}
/*書き出し*/
for(y=0;y<PH;y++){
for(x=0;x<PW;x++){
fputc((unsigned char) Y1[y][x], fp_out);
}
}
for(y=0;y<PH;y++){
for(x=0;x<PW;x+=2){
fputc((unsigned char) Cb1[y][x], fp_out);
fputc((unsigned char) Cr1[y][x], fp_out);
}
}
おまえがいいとおもうならばそれでいい
>>100 実際に映るダンボールと白枠の画像が無いとわからんが、
俺はライン状を流れる物を検出してると思ってるから処理時間も考えるとy=ax+b程度の係数でダンボールと白枠を分離させろとしか言えん
あとはカラーにしてサブピクセルの比率から判別するとかな
フラッシュで真っ白になったら検出出来ないのは当たり前
もっと安定した光源使え
なんでそんな機械仕様なんだと上を問い詰めろ
106 :
デフォルトの名無しさん:2011/07/05(火) 12:40:46.17
フラッシュはちゃんとバウンスさせてる?
テカりやすいもの写すのに点光源とかダメだよ
107 :
デフォルトの名無しさん:2011/07/05(火) 12:41:37.13
いや逆に点光源のほうがうまく反射してステルスになるのか??
機械屋<フラッシュで強い光を当てれば、他の照明からの影の影響を受けなくなる
とか言ってるんだろうか
109 :
デフォルトの名無しさん:2011/07/05(火) 19:33:03.08
いや、助かりますわ。最近異業種から電気系に転職したんでなんの知識もないんす。
とりあえず、フラッシュたいたような画像の認識は常識的にないと。
ついでになんですが、カウントした値をLCDだか?別のディスプレイに表示させたいんですが、マイコンかCPUボード使った組み込みになるんですか?
PCからならUSB接続のサブモニタやデュアルディスプレイのグラボ、S端子接続のTVなどでも出せるし
キャラクタLCDなら秋月あたりにセットで売ってるんじゃない?
>フラッシュたいた画像
がありかなしかはどんな絵になってるのかわからないことには何とも言えん.
画像見せてもらえないなら適切なアドバイスをもらうのはなかなか難しいと思うよ.
あと,パターン検出方法にしても
撮影方法が固定
(姿勢や配置位置等は固定なのか,常に特定のカメラを使用するのか 等)
されているのならその状況に特化した工夫の余地もあるだろう.
例えば,↑の()内が全て固定だとすれば
画像のどこらへんにどの程度のサイズでパターンが存在するかまで
既知であるハズなので,その部分領域だけを相手にすればよく
パターン検出難易度はかなり下がるわけで
フラッシュたこうが,局所的な領域内での処理は十分可能かもしれないわけだし.
>>109 ダンボールのライン検出を作ってるのは想像出来るんだが、情報が少なすぎてこっちも妄想でアドバイスしてるだけだから盲信するなよ
フラッシュも撮像に適切な光であれば問題無いが、光量が安定しなかったりハレーションするようなのはNG
個人的には多灯LEDを常時点灯させてるのが安定してるかなと
カウントした値を適当なLCDとかに表示するのは、実際に作業する人間がどの位置でどのように判別するか次第
基本的には組み込み系キットを使うが、大きく表示したいのなら別PCってパターンもある
知識無いならPICとかの本を読むとか、Interfaceのバックナンバーに練習キット付いてるからそれ見て覚えれ
質問です。
ImageMagick(Windows版)についてです。
指定したフォントで斜体の文字列を描画したいのですが、
うまくいきません。できないのでしょうか。
convert -size 100x100 xc:none -fill #303030 -pointsize 20 -style italic -draw "text 0,50 Test" Test.png
このようにすると斜体の「Test」が描画されますが、
convert -size 100x100 xc:none -fill #303030 -pointsize 20 -font "C:\WINDOWS\Fonts\MSMINCHO.TTC" -style italic -draw "text 0,50 Test" Test.png
フォントを指定すると標準の文字が描画されてしまいます。
どのようにすればよいでしょうか。
115 :
76:2011/07/08(金) 11:31:47.02
Lanczosの拡大縮小実装した。
チンカスゴミ野郎どもが情報を出し渋るから苦労した。
本当に役に立たないカスニートどもが死ねばいいと思う。
Lanczosは当然3だろうな?
2で満足するなよ
やっぱここはレベル低いな。
Lanczos4で実装したに決まってるだろ。
118 :
76:2011/07/09(土) 00:30:49.38
そんなわけないだろ。バカか
ちゃんと引数で2か3を選べるようになっている。
一流のプログラマーならみなそうする。
ふむ
外周の濃い部分は比較的正確だが
内側の灰色が薄い部分はニアレストネイバーに近い出力になってると思われる
>>119 てか、なんでペイント画面のキャプチャーなんだよw
軽い嫌がらせとしか思えんwww
物凄くくだらない質問でスマン
ピクセルの正しいスペルがpixelだと言うことを今初めて知ったんだが、
pixcelでもググると沢山出てくるのは何か違いがあるの?
みんな俺と同じように間違えているだけ?
そもそも造語なんじゃなかったっけ?
picture cell
みたいな
>>74 返事が遅くなってすいません!
サイトを提示していただいたおかげで変換方法は理解できました。
自分でもopencvのソースをあたってみて確認もしました。
ありがとうございました!
ただ、そこから先に理解を深めようとすると躓いてしまいます・・・。
何故そのような式になるのかという原理を知りたいのですが、いろいろ書籍をあたってもピンとくる解説がありません。
透視変換は三次元から二次元に投影している、という曖昧な理解までは到達しました。
(x,y) = ( (A*X+B*Y+C)/(G*X+H*Y+1) , (D*X+E*Y+F)/(G*X+H*Y+1) )
という変換式にどうすれば辿りつけるのか・・・
図解や解説、サイト、または書籍など、なんでも構いませんので是非教えてください!
128 :
109:2011/07/12(火) 23:01:45.03
CPUの気持ちになって考えろ
>126
ちゃんと読んでないけど>127の射影変換(32-33)のところかな
誤字が多いことで有名な『詳解 画像処理プログラミング』p.232-234にちゃっかり載っていてわろた
>128
プログラムを書く前にGimpなりPhotoShopなりでシミュレートしたらどうだろうか
実際どういう処理順かしらないけど
原画像 -> (ノイズ除去) -> (コントラスト補正) -> 2値化 -> ラベリング -> 面積求めて円形度判定
2値化のところは、白丸(輝度が高い)であることがわかっているのなら画像内の最大輝度値から20, 30を引いたあたりを閾値にするとか
原画像 -> (ノイズ除去) -> (コントラスト補正) -> エッジ抽出 -> 2値化 -> ハフ変換
とか思ったのはここだけの話、とか言ってみるテスト
>>128 現状のアルゴリズムがわからんが
①最初にRGBの比率見て、差があるのは全部黒にする(タイルの部分が白になるのはこれで解決するはず)
②画面を細かく分割(16x16とか)してヒストグラム作ってから差を見て二値化
③画面を繋ぎ合せて円形のみ抽出
だけでいけそうな気がする
133 :
69:2011/07/13(水) 10:08:08.93
>>128 背景が固定で無い環境を考えているなら
全ての背景を除去できる2値化閾値を常に算出する処理パラメタなんて決められないだろうから
2値化でタイル部分を黒にしたい とか考えるだけ無駄だと思う.
(対話的にパラメタを調整していいのなら別だが)
あなたが画像を撮影する環境変動の範囲内で
検出対象たる白丸をその形で残せる閾値決定手法とその処理パラメタ
を用意できたら,後は以降の判別処理の精度を高める方に注力すべきと思う.
円の検出は
>>131が言うように
2値画像をErosionした画像とDilationした画像の差分絶対値画像あたりをエッジ点として
ハフ変換でもいいかも?
あと,部分画像でやってみろと言ったのは何が起こっているかを
考察してみろというニュアンスが大きかったわけで
画像内での白丸の位置に対する前提知識とかを使わない状態で
単純に画像4分割とかしたら,
分割個所で閾値が不連続になることの副作用の方が悩ましい結果になりそう.
例えば
>>69 に書いたような 閾値が滑らかに変化する方法を勧める.
提示画像の背景なら,タイル表面がざらついているから
良い閾値で2値化すると細かな白領域が無数に出る結果になると思うけど
(円の画像上面積に関する知識は使ってもいいみたいだから)
そんなのは輪郭追跡とかに入る前にモルフォロジ演算あたりでほとんどつぶせるはず.
136 :
109:2011/07/15(金) 01:06:03.20
いろいろもらったけど、正直理解できない部分があるので・・・
停滞してます。
ぼかし画像輝度値に1未満の係数かけたらしきい値低くなっちゃうじゃんとか。
でもフィルタは陰影にはいいっぽいすね。
最大輝度値から固定値ひくのうまくいかないす。
そこで、グレースケールのヒストグラムの極大値が大体、2つか3つあるんだけど、
巷の算出法だと真ん中の山近辺がしきい値になってうまくいってない。
ヒストグラムのいくつかある極大値の濃度値がわかるアルゴリズムってあります?
一番濃度たかいのと2番目の真ん中くらいにしきい値おきたい。
あとハフ変換て声もあるけど、なんか処理が大変ぽいのとうまくいかない場合が
あるみたいなのでやめたんだけど、ラべリング、輪郭よりいいのかな。
分割も確かになめらかなのがいいっすね。でもそのときのアルゴリズムが今のところ理解できないっす。
あと、分割した領域にモノがなかった時の処理とかどうしようとか。
ぐぐってっるけど、どうにもすすんでない・・・
おそらく今
>>109は
画像を複数の小領域に切り分けて
個々の領域毎にその領域内の画素群の画素値に基づいて閾値を求め,
その閾値はその領域内の全ての画素で共用される
という形を取ってるんだと思うけど,これを
ある画素に着目したときに,この画素を白とするか黒とするか
を決める閾値は
その画素を中心とした小領域内の画素群の画素値に基づいて求める
とすれば閾値は
(閾値計算方法としてぼかし画像を使う例を挙げたが
別に平均だろうが,領域内のヒストグラムを使おうが)
滑らかに変化するでしょ?という話だよ.
小領域の大きさは画像に合わせて決める必要があるだろうけど
後段の判定で白丸の面積の情報を使えるということはある程度
写る大きさは決まっているのだろうから,
複数の画像で試してよさそうなサイズに決めてしまえばいいかと.
(提示画像なら60~150pixel四方程度とか??)
領域内に白丸が無い場合 については
その中に偶然 丸くて,周囲より明るくて,白丸と同じくらいの 領域
が存在しているときしか問題にならないのでは?
(とは言え,背景が全く自由な場合だと
これが結構な頻度で起こるから困るんだけども)
領域サイズと白丸のサイズがだいだい決まってくれば
ヒストグラムから閾値決める方法としては
Pタイル法 とか使えたりしないかな?
>>136 基本、ヒストグラム等を滑らかにするのはガウシアンとか使うけど、
ぶっちゃけ山を取り出すだけなら前後で平均値を取るだけでいい
一発で滑らかにならなかったら、数回繰り返しても良いし
平均取る範囲は画素数(256諧調だとは思うが)やカメラの性能にもよるから自分で調節な
分割した領域で何も無かった場合、閾値で分けるか、黒にしちゃっても良い
円形抽出してるなら、円形の中に何があっても関係無いし
使用しているosはwindowsで
libpngを使って16bitグレースケール画像を作成すると
表示したときにヒストグラムがおかしくなり
表示が乱れる原因って分かりますか?
ライブラリの使い方が間違ってるんだろ
まさかと思うが、上下バイトが反転してたりして。
16bitグレースケールって地味に特殊な使い方だな
8bitなら大丈夫なのか?
>>141-143 画素値が最大255のデータを16bitグレースケールで保存した場合正常に表示されるのですが
ある程度高いと表示がおかしくなるみたいです
ライブラリについてそこまで詳しく調べたわけではないので調べなおしてみます
>142が的を射た悪寒。
>>145 エンディアンが違うという解釈でいいのでしょうか?
と思って調べていたらどうやら当たりっぽいです
ちょっと調べなおしてみます
ありがとうございました
めんどくさかったので
今までgimpで画像処理プログラムしてきたんですが
OpenCVに変えると劇的に速度が速くなったり
他にもいいことあるんですか?
いいこともあれば悪いこともある。それが人生というものぢゃ。
今日はついてないな
gimp便利なのに
あまり使ってるのみかけないのは
きっと他にもっといいソフトがあるのだと思ってた
しかしそれらしいものがない
schemeやpythonで画像処理スクリプト組めるのってPILぐらいしかみつからない
スクリプトで画像処理っていう需要がない
unix系でスクリプトとかだとImageMagick使うんじゃん?
フィルターなんかでバイト配列を対象とした処理を書く時はスクリプト言語のメリットは無さそう
遅くなるだけ?
思いついた処理をさくっと試してみる、とかならスクリプト言語もいいんじゃない?Cでゴリゴリ書くよりかなり楽できるし。
例えばどんな処理?
ppmで画像処理をする課題やってるんだけど、回転処理のとき角度270の時だけ左側に黒い線ができる・・・ヒントください・・・
黄金の獅子が目覚めし時、太陽のいかずちを月の水面に捧げよ。
tanθ
普通に考えれば端数の処理が間違ってるんじゃね?としか言えんよな
面倒くさいから画像処理はimagemagickとかでやってるんだけど
どうしても自分で処理したいところが出てきてしまったのですが
今のトレンドってpnmじゃないんだよね?
どういう形式が一番おしゃれなの?
オシャレかどうかはその人のセンス次第
君のセンスを教えて
リュックにビームサーベル2本が常識だろ
ポスタードリームとかもう覚えてるのはおっさん認定だな
>>161 libpngでも使えば。リンクは面倒だけど、手っ取り早い。
私はImageMagickと連携させるならpnmで済ませてしまうけど。
最近、面倒くさがりが多いけど、全部同じ人かな?
ファイルの読み込みなんて一度コードを書いたら幾らでも使い回せるんだから、
心を決めて手を動かすだけだと思うんだが・・・
とか言いつつ俺も面倒くさいから Cocoa のライブラリで読み込んでるけど・・・
Bitmapで読み込んだ物をbyte配列やIplImageに変換してるけど、面倒くせぇ
特にグレースケールと24Bitと32Bitが混ざった時にはわけわからん
でかい画像でなけりゃ おなじ大きさの32BitColor のビットマップを別に作って
読み込んだ bmp をいきなり BitBlt byte配列化やIplImage変換の対象は↑側を使う
ってのはどうだい?
見た感じ、FacebookのようなSNSっぽいね。
下側に霊が・・・
上側にカオナシが・・・
死ね
失礼します。
bitmapフォーマットについてですが、1Byte程度の任意の値を入れたいと思っています。
最初の14Byteのファイルヘッダの予約領域や、40Byteの情報領域の最後の「重要なパレットのインデックス」に、
任意の値を入れることで誤動作を起こすような画像ソフトってありますでしょうか?
自分で簡単に入れてみたところ、特に問題は無さそうだったので。(もちろん、今後追加されたらどうなるかわかりませんが)
もしくは、画素の(0,0)辺りを情報バイトとして使用したほうが無難でしょうか?
よろしくお願いします。
http://www.kk.iij4u.or.jp/~kondo/bmp/ 後ろに足せばいいじゃないか
任意の情報入れられる画像フォーマットあるだろーに
>>177 正しくそう言うデータを監視するツールなら昔作った。
画像処理の知識が乏しく困っています、教えてください。
リアルタイムで三次元のベクトル図を描画するために便利なライブラリはありますか?
opengl
画像処理の学習を始めるにあたりどちらをベースにするか迷っているのですが、
2次元に限定した場合OpenCVとOpneGLの違いって何でしょうか?
OpenGLの方が情報量も多く実績もあるのに
あえてOpenCVが選択されるのは何か理由があると思うのですがよくわかりません。
>>183 OpenCVが画像処理のためのライブラリです。
OpenGLは画像を表示するためのライブラリです。
OpenGLとOpenCVなんて
そもそも比較対象になるようなものじゃないだろ・・・
>>184 ありがとうございます。
OpenCVは撮影した画像を解析して条件に合致するところだけ加工するみたいな用途で、
OpenGLは複雑な図形を描画してそれをスムーズに回転させるみたいな用途
というという理解であってるでしょうか?
>>183 画像処理ってのは、画像に対して何らかのを処理する技術のことなんだ。
CGみたいに画像を生成するようなのとは、分野が違う。
>>186 画像データを解析したり加工したりするのがOpenCV
画像データをポリゴンにマッピングして表示するのがOpenGL
OpenCVで解析、加工したデータをOpenGLで表示するというのもありえます。
モザイクのかかってない動画を機械学習させた本格的モザイク除去を考えた
>>190 超解像の研究でかなり前からあるし
特許なしオープンソースで作って公開してから報告しろ
まずはモザイクのかかってない動画を公開するんだ
画像のマッチング計算(?)の文献を見ているのですが…
2つの画像f,gをフーリエ変換した結果F,Gの相関を計算するとかいう話になっていて、
そのときの相関の式で G側が複素共役にされているのですが
何故共役にしなくてはならないのでしょうか?
ググってみたところ、複素関数で相関を計算するときは一方を共役にするらしい
ことはわかったのですがその理由がわかりません
あと、この相関を逆フーリエ変換して画像の世界(?)に戻したものは
どういった意味のものになるのでしょうか?
>>193 その文献が何かを示して質問すれば答えてくれる可能性が増えると思わんかね?
195 :
193:2011/10/25(火) 17:08:22.40
質問内容は
f→(DFT)→F, g→(DFT)→G
とフーリエ変換した先で相関(正しい呼び方は”相互パワースペクトル”??)を計算する際に,
FG ではなく FG* (*は共役) とするのは何故?
あと,この FG*をIDFTしたら結果は何?
といったものだったのですが,改めて>193を自身で読み返してみると
↑のような質問内容であることすら読み取れない状態になっていました…すみません.
ご指摘通り,今見ているものを示しておきます.
ttp://w2.gakkai-web.net/gakkai/ieice/vol1no1pdf/vol1no1_030.pdf (この文献では"正規化"ということで FG*/|FG*|になってますが)
いや、2つの画像の相関(ある意味畳み込み)はフーリエでは乗算になるわけで
_F_[] : フーリエ変換, sum(x) : サメーション,xは添字で-∞から∞, exp(x) : ネピア数のx乗, j : j^2 = -1
f : 信号, F : フーリエ変換後の信号, ~F : 共役
相関のフーリエ変換
_F_[sum(k_1)sum(k_2)f(k_1, k_2)g(n_1 + k_1, n_2 + k_2)]
= sum(n_1)sum(n_2){sum(k_1)sum(k_2)f(k_1, k_2)g(n_1 + k_1, n_2 + k_2)}exp(-j w_1 n_1)exp(-j w_2 n_2)
= sum(k_1)sum(k_2)f(k_1, k_2)exp(j w_1 k_1)exp(j w_2 k_2)
sum(n_1)sum(n_2)g(n_1 + k_1, n_2 + k_2)exp(-j w_1(n_1 + k_1))exp(-j w_2(n_2 + k_2))
ここで、k_1 = -l_1, k_2 = -l_2, n_1 + k_1 = m_1, n_2 + k_2 = m_2に置き換える
sum(-l_1)sum(-l_2)f(-l_1, -l_2)exp(-j (w_1 l_1 + w_2 l_2))
sum(m_1 - k_1)sum(m_2 - k_2)g(m_1, m_2)exp(-j (w_1 m_1 + w_2 m_2))
= sum(l_1)sum(l_2)f(-l_1, -l_2)exp(-j (w_1 l_1 + w_2 l_2))
sum(m_1)sum(m_2)g(m_1, m_2)exp(-j (w_1 m_1 + w_2 m_2))
= F(-w_1, -w_2) G(w_1, w_2)
= ~F(w_1, w_2) G(w_1, w_2) //
なんかだまされた感じ
画像間のズレ、傾き(出来ればゆがみも)を検出 or 除去してくれるような
ライブラリとかがあったら教えてください
除去まで行ってくれる場合には16bitカラーの入出力に対応していてくれると嬉しいです
デジカメで同じ被写体を複数枚撮った画像(若干のズレ、傾きが含まれる)を
自動で重ね合わせて処理したいです
よろしくお願いします
SIFTとかで位置合わせしたりする
>>196 そのままのライブラリは知らないけど
OpenCVで特徴点マッチングして射影変換すればできる
もっとよくしたいならopencv_stitchingを参考にしたらいい
16Bitカラーとはマニアックなw
24Bitに変換くらいは自分でやれば良いんちゃう?
201 :
197:2011/10/26(水) 20:47:55.88
レスありがとう
>>198-199 ググってみてSIFTのソースとか見てみましたが何をしているのか全く判らん・・
ImageMagickを使ったことがある程度の自分が手を出すのは無謀な処理なのか・・・il||li ○| ̄|_
>>200 判りにくくてすみません。16bit/colorでRGB合わせて48bitと言う意味です
1波長が16Bitってもっとマイナーだろwww
48bitカラーだと、HDMI1.3でも使うのか?
位置検出だったら8bitグレースケールでもそんなに変わらんから、減色して傾き角度や位置ズレを計算して
それを元画像に当てはめるだけで良いかと
204 :
デフォルトの名無しさん:2011/10/29(土) 17:04:04.05
画像から赤色と緑色のヒストグラムを生成し、それぞれの色を抽出するプログラムを作っています。
Opencv関数を使わずにBGR各々のヒストグラムを生成するにはどうすればよいでしょうか?
画像の各ピクセルにアクセスして数える。
>>204 自分で画像に画素単位でアクセスして集計すればよろしかろ。
207 :
197:2011/10/29(土) 18:52:00.89
レスありがとうございます
>>202-203 後段の編集に耐性を持たせるためにRGB 48bitで扱いたいです
位置・角度検出は
>>203さんの指摘通り8bitの1チャンネルのみで十分だと思います
判らないなりに実験してみました
ttp://fox.jeez.jp/src/Fox_4832.zip.html dl pass:surf
extract pass:surf_mating
File list
DSC00212-H_s.png→画像1(Hチャンネル画像)
DSC00213-H_s.png→画像2(Hチャンネル画像)
test02.py→find_obj.pyを改造
DSC00212_s.xls→マッチング結果他
環境 Python2.6 x86+OpenCV2.3.1 x86
考え方が根本的に間違えている可能性もありますが・・・
位置ズレはともかく、傾いている角度の求め方がぴんと来ません
キーポイントのベクトルの角度?が使えるかなと思いましたが、ばらついて使えそうにないです
何か上手い方法があったら教えてください。よろしくお願いします
208 :
デフォルトの名無しさん:2011/10/29(土) 20:26:10.37
>>205-206 ありがとうございます
CvScalar s;
int i,j;
for (i=0; i<r_img->height; i++) {
for (j=0; j<r_img->width; j++) {
s= cvGet2D(img,i,j){
配列にアクセスするにはこれを使うんですよね?
色々考えていましたが、ここから赤色のみ抽出する方法が分かりません…
IplImageだったらimageDataから直接アクセスできるでしょ
>>208 画像がBGRなら
s.val[0] // Blue
s.val[1] // Green
s.val[2] // Red
>>211 >参加資格は、18歳以上の米国永住の個人かチーム。
組み合わせを考えるだけだからそんなに難しいことじゃないと思うけど、この時点でやる気無くした
214 :
デフォルトの名無しさん:2011/11/01(火) 00:09:03.22
欠損してるし難しいだろ
どうせ実際にやってみると絶望することになる
印刷のカスレとか行の歪みとか
OCRだと文字種少ないほうが簡単だけど
この場合は逆に難しくなりそう
普通の文書で欠損あるとなると
PRMUのアルゴリズムコンテストのネタになりそうだな
>>218 PRMU アルゴリズムコンテスト 2007
220 :
デフォルトの名無しさん:2011/11/02(水) 12:29:50.96
jpegファイルの明るさ情報について教えてください。
プログラムでjpegファイルを読み込み、
画像の明るさの指数(指数はかってにつけてます。)を数値値化したいです。
jpegのフォーマット上、どのような判断を行えばよいのでしょうか?
勝手に付けるんだったら勝手に付ければ?
数値値化って何?
指数なんだけど数値じゃないの?
>>221 すみません、説明が悪かったです。
例えば、明るさの段階を0-255とします。
次に、読み込んだ画像の明るさのレベルを測定します。
測定の結果、jpegファイルの明るさ指数を0-255のどれかに割り当てたいです。
jpegファイルを読み込み、そのjpegファイルの明るさを判断するには、
jpegフォーマット上、どの辺りを探れば判断できるかな?と聞いた次第です。
>>220 画像フォーマットに囚われずに、画素値を抽出して数値化すればいいと思うよ。
jpegフォーマットのどこかに「この画像の明るさ」という属性値があるとでも思ってる?
それともjpeg関係なく、画像の明るさを判定したいわけ?
例えば、デジカメでRAW撮影したら、
YUV形式とかですよね。
100*100の画像があって、YUV形式ならば、画像の10箇所くらいの輝度を見れば、大体の明るさがわかると思います。
jepgではそのような明るさを見ることはできなくて、
例えば、yuvに変換して見るとかしか方法はないのでしょうか?
私がしたいのは、画像の明るさ判断は、jpegに対してのみです。
ちなみに、jpegは全然しらない素人です。
Windowsに標準でついてるペイントでも使って、
jpegをbitmapに変換したら解り易いと思うんだ
>>225 圧縮かかってるのにそのままピクセルを参照出来るわけないよ。
デコード必須。
せめて画像処理の本の一冊でも読んでからにしてもらいたい
>>229 4 * ( sin( 7 * 0 - PI() / 2 ) ) = -0.109648534
ってのは解るが、残りの左半分をどう片付けるべきか解からん。
aが集合でa0が集合の第一要素なんだろうな。
一体何と戦っているんだ
>230
偏微分してから0代入なんだけど
数式処理なんてコンピュータのほうが得意だし
チューリングテストになっていないだろ
ネタにマジレス
d/dx [ 4 sin( 7x - π/2 ) ] | x=0
= 28 cos( 7x - π/2 ) | x=0
= 28 cos( - π/2 )
= 0
間違ってないかな?
CAPTCHA終了のおしらせ
d/dx [ 4 sin( 7x - π/2 ) ] | x=0
= 4 d/dx [ - cos( 7x ) ] | x=0
= - 28 sin( 7x ) | x=0
= 0
数式のネタCAPTCHAを作った人はいろんな意味でセンスある
新編 画像解析ハンドブック
相関関数について知ってる方いません?
いろいろな定義があってどれつかっていいかわからず、空間領域と周波数領域っていうのもようわからないです。
ppmのカラーフォーマットでP3形式(アスキー)と、P6形式(バイナリ)があるけど
これらの変換ってどうすれば良いですか?
// p3 -> p6
int val; fscanf(fp3, "%d", & val); fputc(val, fp6);
// p6 -> p3
int val = fgetc(fp6); fprintf("%d ", val);
>>238 この28ってどっから来たん?
4*7でどっからか7が来たんだと思うけど。
一体何と戦っているんだ
>245
高校数学やれよ
d/dx[sin(ax + b)] = acos(ax + b)
まぁ、>238はcos()の微分を間違えているんだけどね
この程度の数学の問題が解けない人間が画像処理のスレにいるはずがない
さては貴様、人間ではないな!
というわけ
誘導されてきました。
メディアンフィルタを作っているのですが
3要素に限定した場合、ソートするよりも速いアルゴリズムがあれば教えてください。
もしくは、3要素に限定した場合で最も速いソートアルゴリズムがあれば教えてください。
3要素でソートアルゴリズムなど使わないと思うが
RAMへのアクセスを少なくする方法がいいのか、計算量を少なくする方法がいいのか
そういう話?
>>251 それのどこが画像と関係するの?
それと、3要素の比較が本当にボトルネック? そういう場合はボトルネックが他にあることが多いと思う。
>>251 3要素って単純に3画素だよな?
それを比較するのにわざわざソートさせる必要なんてあるのか?
って話
3x3の9画素という意味ならソートは必要だよな
256 :
251:2011/11/08(火) 12:26:28.01
>>252, 254
比較回数や計算量が少なくなる方法を知りたいです。
それがソートアルゴリズムでも他の方法でもかまわないです。
>>253 横の3画素でメディアンをかけ、次に縦の3画素でメディアンをかけるというフィルタにしています。
画素を要素と書いてしまったのは、C言語スレで先に質問していたので
画像に限定することなく、単に中央値を求めるアルゴリズムとしたかったからです。
このスレに来るときに書き換えるべきでした。すいません。
最終的にハードウェアに落とすので、関数呼び出しやメモリのボトルネックは考えておらず
最初に書いたとおり、アルゴリズムが知りたいです。
3画素のうち、最大値を有する画素を1つ選ぶ(比較2回)
選ばれなかった2画素のうち、値の大きい方が中央値(比較1回)
比較計3回ってな方法で、どですか?ヽ(´ー`)ノ
>>256 よけいなお世話かもしれないけど
いわゆる3×3メディアンフィルタと結果が異なっているのは別にいいの?
259 :
251:2011/11/08(火) 14:49:12.62
>>255 >>258 3x3ではなく横3画素をかけてから縦3画素をかけるもので
3x3と結果が異なっていてもかまいません。
>>257 ありがとうございます。
この方法も実装してみようと思います。
3要素の中央を見つけるだけならアルゴリズムとか凝った話しにならないような…
ハードに落とすなら、そっちでの最適化を考えた方がよくないか?
262 :
251:2011/11/09(水) 08:28:53.93
3回の比較が最低限度のようです。
ソートも3要素で3回の比較というのは、計算量のオーダーに合った値のようです。
比較がもっと少ない方法や、比較以外の方法がとか
中央値を求めるだけに特化した方法とか、ないようですね。
皆様おつきあいくださいありがとうございました。
>>257の方法を実装しようと思います。
おまいら小学生か
264 :
193:2011/11/11(金) 09:40:13.88
>196
提示いただいた数式を解読すべく
畳込みと相関は似てるけど違うものとかいうあたりから調べたりして
大変遅くなりましたが ありがとうございました.
で,よしじゃあ実際やってみるか,となったわけですが…
画像fの中からパターン画像gを探すような場合って
当然ながら画像サイズは f>g なわけですが,
それに反して
フーリエ変換して比較する2画像のサイズは同じじゃないとダメ(だと思う).
これってどうすれば??
fと同じサイズになるようにgに余白を(画素値0で?)追加した画像hを作って
fとhで計算すればいいのでしょうか?
でもそうすると,計算される相関の意味が
本来の "f vs g" ではなくて "f vs h" に変わってしまうような…
>>262 すれ立てるまでもないスレで、似たような話題があった。
そっちは、3頂点のソートだったが。
単に3点ソートという点で言えば、比較回数はそれ以上
上げられないが、要素の交換を最適化するとかいう方法もある。
例えば、要素交換はせず、テーブル参照で要素を入れ替えるとか。
// 入れ替え先の要素番号テーブル d[0] = s[ index[0] ]; とか書いて使う
static const int
Tri::index[][3] =
{
{ 0, 1, 2 },
{ 0, 2, 1 },
{ 2, 0, 1 },
{ 1, 2, 0 },
{ 1, 0, 2 },
{ 2, 1, 0 }
};
// Tri::indexの何番目を参照するか返す
template<class Type> int Tri::SortIndex( Type vertex0, Type vertex1, Type vertex2 )
{
int index = 0;
if( vertex0 > vertex1 ) index = 3;
if( vertex1 < vertex2 ) return index;
if( vertex0 < vertex2 ) return index + 1;
return index + 2;
}
間違えた
×: d[0] = s[ index[0] ];
○: d[0] = s[ Tri::index[index][0] ];
ハード化するんでしょ
データはバーストで取り出してるとして
3データなら一撃で結果でるんじゃね
RAWを現像するとき、メーカー純正ソフトやdcrawでは飽き足らないので
自作している人はいないか?
専用のスレもないみたいだよね。
自作しようとしても、意外と情報がないから分からない。
デジカメ板に無かったけ?
ここは画像加工という意味の画像処理スレじゃないけども
フィルターとか前処理的なものは十分含むと思うから
やりたい事を書けばいいと思うの
OpenCVにDNGの読み書き機能が入れば、RAW原像をやる人も増えそうだな。
本来の意味でのRAWデータだと、メーカー毎(下手すりゃ機器毎)にフォーマットが違うからなぁ
下手すると1色8Bitじゃなかったりするし、ヘッダも違うし
ヘッダがあるとか、どんなRAWデータだよ。
ヘッダがないと、縦横の画素数やビット幅も分からないだろ~
DNG Converterというのがフリーで使えて
どんなカメラのRAWもDNGに変換できるからDNGを出発点にするのが良い
ロジのWebカメラは、Rawモードがあるね。
>>275 デジカメのRAWモードとやらは知らんが、ファイル名にサイズを埋め込むRAWデータはあるね。
>>273 画素値だけで画像のサイズもbit数もわかるのは、エスパーか限られた条件で取られたRawデータだけだろ
DCRAWでRAWをTIFFに変換するのがもっとも楽だろ
dcraw -D -4 -j -t 0 -T
>>280 世の中には何も書かれていないデータがごろごろしているってことが理解できませんか?
で、仕様書見ると隅っこに小さく書かれているんだw
>>282 仕様書なんて出来てから送られてくるものですしw
FPGAの仕様が変わりましたー^^v
なんて言って、末尾に追記されることなんてよくあることですしw
rawつっても、画素値がRGBとかじゃなくてRAW(bayerとか)なのと、
ヘッダなしのデータと、(少なくとも)2種類あるってのをごっちゃにしてる人がいる気がする
クスクス
雲と蜘蛛、橋と箸の区別が困難な人たちの集まり
規格もなにもなくそのメーカー/ベンダーにとって必要な最小限の情報をヘッダにして,あるいはヘッダなしで
画像データをベタ書きしてるから raw なんだが
RAWをRGBに変換するCソースここに載せてくれ
クスクス
俺様RAWが多すぎ
RAWは、まだ調理してない生のままという意味で、
センサーハードウェアの出力がそのままなものはRAWであって
そうでなければRAWではない
ファイルに関するヘッダやメタデータがショボいファイルはDAT、BIN、HEXなど呼び方は多い
hexはbinaryじゃないだろ。
まぁ、binaryだったとしても驚かないが。
DOSつながりで3文字ってのは
もう限界だろよ
DOS繋がりっつーか、FATの制約だよ。
296 :
デフォルトの名無しさん:2011/11/28(月) 22:06:48.42
255階調のグレースケール画像をn階調画像に変換してpgm画像として出力するプログラム kai.c を作成しなさい。
出力画像の階調は、255階調を等間隔に区切って指定するようにしてください(n=2の場合は{0, 255}, n=3の場合は, {0,127,255})。
また,nの値は端末から入力するようにしてください。
という課題が出たのですがわかりません。
ヒントでもなんでもいいので教えてほしいです。
お願いします。
for(float i = 0; i <= 255; i += 255 / (n - 1))printf("%d ",(int)n);
てきとうだけど、こんなかんじ?
あ、まちがってる。まあいいや
int i,n;
scanf("%d",&n);
printf("P2\n#\n%d 1\n255\n",n);
for(i = 0; i < n; i++)printf("%d ",(int)((255.0/(n - 1)) * (float)i));
無駄がありそうだけど、自分のじゃないからいいや。
学生の課題にヒントは無しやろ
聞くなら友達に
最近売られているロジクールのウェブカメラを用いて
uvcdynctrlでRAWの取得に成功した人はいますか?
302 :
デフォルトの名無しさん:2011/11/30(水) 11:36:58.59
画像処理って傾向として整数演算と浮動小数点演算のどちらが多い?
>>302 テスト実装の段階では(解析の理論をそのまま素直に実装したような場合)
浮動小数点演算でやるけれど大抵の場合丁寧に見直すと整数演算で
処理できるし、そのように変換できる場合には整数演算の方が速い場合が
多いので本気実装では整数演算を多用するみたいな感じ。
FFTみたいにあんまり整数演算に置き換える余地がないようなものも
あるけどな。
どんな画像処理を行うかにもよるけど、人間の目で違いを出す程度なら整数レベルで十分だしな
画像解析とかになると、小数必要だけども
305 :
デフォルトの名無しさん:2011/12/03(土) 15:42:33.36
こんにちは
環境中に、ラインレーザを適当に照射します。
その様子を撮影した画像から、ラインレーザの形状のみを抽出するにはどうしたらよいでしょうか?
ソフト名とプログラムをお聞きできればうれしいです。
ちなみに、PCにはMATLABであればインストールされています。
よろしくおねがいします
>>306 それはどのソフトでどのような処理を行えばよいのでしょうか?
ペイントで抜き出せば?ということですか?
おおう・・・
ここはプログラム書くヒトの板
何かソフトウェアを探してるなら板違い
だな
311 :
デフォルトの名無しさん:2011/12/10(土) 00:32:28.75
画像処理でフーリエ変換じゃなくウェーブレットを使うメリットを教えてください!
静止画像にt軸を持つウェーブレットを適用する理由が分からんです・・・
313 :
デフォルトの名無しさん:2011/12/10(土) 01:18:41.96
なるほど、フーリエだと元画像の位置情報が欠落していたけど
ウェーブレットだと位置情報の欠落が防げるってことでOKっすね?
>>313 元々モルレーが狙ってたのもそういう方向だな.
モルレーのはガウス窓フーリエだったから少し今言うウェーブレットとは違うけどね.
モルレーなんかのやり方はわりと泥臭い方法だったけど後になって色々
刺激を受けた人が整理してみたら1957ぐらいから研究されていた特異積分作用素
の話とくっついたりして実は数学的にも深い内容を持ってるなんて事になった.
画像処理を勉強している学生です。
ふと疑問に思ったことなのですが、SIFTでオリエンテーションを2つ持つキーポイントには、オリエンテーションごとに特徴を記述するとあるのですが、これは128次元の特徴量を2つ記述すると言うことでしょうか。
その場合キーポイントが128×2で256次元の特徴量を持つのでしょうか?
>>315 そんなことしたら他と比較できなくなるから
同じ位置とスケールから2つの特徴量を得るって意味じゃないかな
317 :
デフォルトの名無しさん:2011/12/14(水) 12:04:47.77
>>316 そうそう。128次元の特徴量を2個作るよ。
318 :
片山博文MZ ◆0lBZNi.Q7evd :2011/12/15(木) 11:07:53.10
画像をフーリエ変換すると何かいいことあるのでしょうか?
mp3圧縮みたいなことができる・・・んだろうな、多分
イラストと写真を判別するいい方法ないかな?
正規化したHSVヒストグラムのSVだけを見て
その両方が中程度に分布してたら写真と判定してみたんだが
厚塗りとか色彩豊かなイラスト、露光不足だったり間接照明な室内写真とかはそれぞれ誤判定した
Exif付いてるイラストがあるので、それでの判別は無しで
何か他の方法あれば頼む
イラストを撮影した写真はどうするんだ
324 :
デフォルトの名無しさん:2011/12/16(金) 20:32:02.05
てs
325 :
デフォルトの名無しさん:2011/12/16(金) 20:32:57.41
軽快なマンガミーヤクローン作るのに向いてる言語はなんですか?
スレ違いだボケクズ氏ね
確かにクローン欲しいよねえ
本当になんとからんものか
余計な機能とかいらないんだよね
>>322 画像全体でヒストグラム取って、SVそれぞれ独立して見てるだけ?
>>323 >>322の方法だとそういうのは8割くらいは写真になった
>>327 はい
色々種類ありすぎて、画素そのもので勝負するしか無いかなと思って
329 :
デフォルトの名無しさん:2011/12/16(金) 23:27:46.81
>>328 アニメの場合は、SVの分布が大きくなるの??小さくなるの?
>>322 イラストを撮影した写真は写真と判定するなら
固定パターンノイズを推定するのは?
というか説明からイラストを写真にとったものをどっちに扱いたいのかがわからない
いまんとこ、ちょっとヒューリスティック過ぎて・・・
http://nagamochi.info/src/up95474.jpg >>329 セル画は撮影してるから写真だろって引っ掛けは無しな
作品や場面によるけど大抵は、輝度が偏るのでVの分布が狭くなる感じ
>>330 なるほど、デジカメの特性を見るのか
メディアンフィルタ掛けた画像との残差を見てみる
>>331 普通の写真ですらまだ全然判別出来てないのに、なんでそこに固執するんだよ
正直それはどっちでもいいよ
でも例えば光沢紙にプリントしたものなら、人間なら光の反射とかから写真だと分かるよね
333 :
デフォルトの名無しさん:2011/12/17(土) 14:26:35.46
>>331 本質から離れたことにやたら固執する奴ってどこにでもいるな
サンプルワロリン
周波数分布も判定に使えそうだが、どうだろうか
336 :
デフォルトの名無しさん:2011/12/18(日) 00:44:25.09
オリジナル-メディアンフィルタの差分画像を、写真とアニメで比較してみたが、同じ色の領域で、写真だとノイズが乗ってるのが分かる。アニメだとほぼ差が0。
ただ、輪郭とか輝度変化が激しいところは、写真とアニメ両方で差があって、差の出方に違いがイマイチ見られないかな。
ここからどうやって固定パターンノイズと輪郭などの影響を分離するのかが分からん。
ブロックノイズ出やすいのもあるし輪郭周辺はマスクしちゃっていいと思う
ただ、輪郭抽出とノイズ推定って紙一重だよな・・・
>>335の言う2次元FFTを実装してみたが
見方が分からないので結果とにらめっこして学習中。日記ですまん
>>322 1,Googleの画像検索に画像を上げて、キーワードを探す。
2.キーワードをWikipediaで検索。
3.絵画や漫画系に飛んだらイラスト判定
ワロタw
google が API 作ってくれればいいんだよなあ。
>>336 オリジナルーメディアンってノイズ検出器であると同時にエッジ検出器でもあるからな
テクスチャに影響されずにノイズを検出しなきゃならん。
コンピュータビジョン最先端ガイド4に固定パターンノイズ推定について記述があったぞ。
1 Non-Localフィルタを使う
2 輝度変化がほぼ平面の部分で比較
3 周波数空間で処理
いろいろ手はあるようだが、どの程度の精度で推定できるのかは不明。
勘では2が実用性高そう。
HOG, SIFT, SURF, Ferns, etc. の特徴量計算を片っ端から試してみれば?
344 :
デフォルトの名無しさん:2011/12/26(月) 17:24:53.33
いえいえ
Photoshop辺りでいうレイヤー処理までサポートしているライブラリってありますか。
Gimpは良さそうなんですが、できればライセンスが緩めので・・・。
レイヤーって単にアルファチャンネルのある複数の画像を持ってて
順番に重ねて表示しているだけじゃねーの
ラスタレイヤーだけならね。
ベクタレイヤーもあればエフェクトレイヤーもあると思うんだ。
それはレイヤーに重ねてるものがラスタ画像かベクタ画像かフィルタ操作かって話だろ
そうだね。順番に重ねて表示しているだけじゃないね。
順番に重ねて表示してるだけの予感
どう考えても順番に重ねてるだけだろwww
レイヤーフォルダやら下のレイヤーとグループ化で
その順番も単純じゃないんだけどな
その辺までやってくれる画像ライブラリはなさそうだな
レイヤーフォルダも通過とそれ以外では順番が変わる
うっせえな。
うっせえな、順番に重ねてるだけだろwww
2D+Zデプスマップから立体視用の左右の画を得たいのですが
上手い変換方法が思いつきません
何も考えずにずらしたら隙間が出来ちゃうし・・・
良さそうな方法があったら教えてください
最終的にはリアルタイムで処理したいので速度はそれなりに重視します
よろしくお願いします
360 :
デフォルトの名無しさん:2012/01/06(金) 22:26:16.57
Windowsで10bit出力ってどうやるの?
362 :
デフォルトの名無しさん:2012/01/07(土) 11:25:52.91
363 :
358:2012/01/10(火) 00:01:06.61
>>359 レスありがとうございます
ディスプレイスメント・マッピングですか・・・Blenderでも使って実験するしかないか
HDMIのL+デプスマップはどうやって変換しているのかな・・・
>OpenCV
そのサンプルは左右の画からデプスマップを得るコードで
逆だと思うのですが・・・
jpeg画像からDCT係数を直接取り出したりってできるんでしょうか
>>364 単にjpegのデコードを途中で止めればいいだけだから、そういうコード書けばできるよ
そういうライブラリがあるかって話しなら聞いたことないなぁ・・・
DCT符号?jpegアナライザにその機能あるよ。
自分で調べてバイナリ抜き出してもいい。
うっせえな。
何かわからないことでも?
kernelマシンってパターン認識以外で使われてるみたことない
他に何か応用あっただろうか
SVMの応用なんて山ほどあるだろ
カーネルサンダースってケンタッキー以外で使われてるみたことない
他に何か応用あっただろうか
何が面白いんだ
ケンタッキー州どころか、日本にも進出しているよ。
376 :
デフォルトの名無しさん:2012/01/20(金) 13:48:20.12
>>372 軍事用途に応用できるんじゃないかな
もともと軍人だし
>>372 道頓堀で発掘されたな
大阪の神に応用されたらしい
呪物として利用された。
元データに何らかの特性が必要らしい
疎(スパース)だとかなんだとか
382 :
デフォルトの名無しさん:2012/01/20(金) 20:09:04.57
質問です。
ハリスのコーナー検出についてわかりやすく紹介してるところありませんか。
Wikiとか見たんですが、もう少し図とかあるかんじで教えてもらえると嬉しいんですが。
画像処理と関係ないからどっかよそに行け
これからは気持ち悪い画像を貼らないように
ちなみにcpは564bit、pathは128bit。後者はMD5くせえな
385 :
デフォルトの名無しさん:2012/01/21(土) 13:17:50.29
2次元離散フーリエ変換したときに、DC成分を真ん中に持ってくるために
第1象限と第3象限、第2象限と第4象限を入れ替えますが、
データ数が奇数のときってどうやって入れ替えるんでしょうか?
>>385 データ数が奇数という事は、奇数x奇数だな。寧ろ、判り易いじゃないか。
012
345
678
↓
567
801
234
偶数だとこんな感じ。
0123
4567
89ab
cdef
↓
6789
abcd
ef01
2345
いけね、それぞれ
867
201
534
と
ab89
efcd
2301
6745
だったw
389 :
デフォルトの名無しさん:2012/01/21(土) 15:34:31.76
>>388 ありがとございます
5x5ならどうなりますか?
0 1 2 3 4
5 6 7 8 9
a b c d e
f g h i j
k l m n o
390 :
389:2012/01/21(土) 15:37:55.80
i j f g h
n o k l m
3 4 0 1 2
8 9 5 6 7
d e a b c
であってます?
>>390 いんじゃね?
要は、元のパターンをタイリングしてパターン半分ずらした状態なんだから。
圧縮した状態でも、座標を指定すればその画素値を取得出来るようなフォーマットってあるのでしょうか?
あるとしたら圧縮率は悪くなのでしょうが。
メモリに出来るだけ溜めこんで、出来るだけ高速に画像処理をするという矛盾したことをやりたいと思っています。
64bitOSにしてメモリ大量に詰むのが一番でしょうが、もしもありましたらお願いします。
>>392 ないない。
あるとしたら、ってそれはもう非圧縮っていう。
なんかのライブラリ挟んでそういう風に見せることは出来るだろうけど
私はそんなフォーマットわからない。
けど、もし同じことをしようとしたら画像処理途中のグレイスケールや2値画像でメモリにおいとくかな。
どんな用途なんだろう
複数のハイスピードカメラで学習画像をマッチングさせるのかな
画像の特性にもよるかなぁ。
画像処理というよりバイナリのメモリ圧縮と探索の話になるが。
カラーなら色空間変換で茶を濁すとか (当然不可逆
R8G8B8(24bit) → Y8U4V4(16 bit) 等
>>392 そもそもそれは画像なの?
特徴点抽出した結果とか輪郭線抽出した結果とかなら、別な有効な手段もあるんだけど。
>>393 ですよねー。
>>394 せいぜい余分なデータを省くくらいですよね。
CoaXPressをフルに使った映像をリアルタイムで各種画像処理しながら動画保存するのですが
画像処理に同一動画の前の画像を利用する処理があるので、全部メモリに溜めこめないかなと。
>>398 アクセスパターン次第じゃね?
ランダムアクセスじゃなきゃフォーマット設計すればできそう。
JPEGは8x8で符号化してるから画素単位までとは行かなくても
その周辺を含む領域でなら復号出来るだろ
可逆にしたって、ブロック単位でやればいいだけじゃね
圧縮率は下がるだろうが
OpenCVなどで日本語文字列を描画するのに
なんかいいライブラリありませんか?
402 :
デフォルトの名無しさん:2012/02/01(水) 18:43:34.61
いくつもある画像変換ソフトって設定でサンプリング?1:1:1みたいのとかJPG圧縮率90%とか合わせても変換後のサイズが全然違うのなんで?
内部アルゴリズムの違いだろ
フィルタ処理とか特徴点検出とか諸々の画像処理の基本的なアルゴリズムはわかっているんだけど、
高速動作のための実践的な実装を学ぶのにいい本はない?
>>404 高速動作する実践的な実装のコードや
数値計算やHPCの本を読めばいいのでは
>>404 急がば回れ。
一般的な高速化のアルゴリズムやデータ構造(部分計算、DP、木など)や画像処理とは
直接の関係の無い分野のアルゴリズム(文字列処理や人工知能)に詳しくなっていると、
画像処理でもアイデアがいくらでも湧いてくる。
そのうち循環畳み込み演算を膨大な回数繰り返す処理をfft/ifftを使った処理と比較して
3桁高速化するなんてこともできるようになる。
私も406と同じ意見。
アルゴリズムをもっと勉強してブレイクスルーを考えるのがはやいと思う。
普通の高速化なんて目じゃないほどはやくなるよ。
普通の高速化ならopenMPとかソートアルゴリズムの本なんかがオススメかな。結局計算しなくていいとこをいかに早くみつけるかが肝
>>404 私偉そうに高速化どうこういってますが、最近SURF特徴点抽出方法覚えたてで高速化に苦戦してます。
2つの画像の128次元ユークリッドベクトルの距離が近いものを探す処理で全部の線を比較するダメダメ処理しかわかりません。
一緒にがんがりましょう
そんな簡単にブレークスルーできてたらノーベル賞取りまくりやわ。ええ加減にしとけよ
アルゴリズム自体は固定で実装上の細かい最適化テクニックってことなら
Intelが出してる最適化リファレンス・マニュアルだな。
SIFTなんてガウシアンの畳み込み何回もやるから凄い重いけど実装の工夫だけで超高速にできるもんなんだろうか
パワープレイになりますけれども
CUDAで超並列マルチスッドレとか
マシンパワーに頼った実装ってなんかつまらないな
414 :
デフォルトの名無しさん:2012/02/04(土) 20:06:53.47
マシンパワーを引き出すのも面白いぞ
だからって16bitCPUで32bit使ったり、32bitCPUで16bit扱うのはマヌケだろう?
グラフィック分野では、CPUやGPUの実装に合わせてゴリゴリ書いて
パフォーマンスを叩き出すのが昔からの慣例。
最適化ってその時々の中流機で速いことに意味があると思う
ハードを追加することが前提ならいくらでも金かけりゃいいってことになってつまらん
ハードを追加することでコンスタントに処理速度が上がってく段階になると、
さすがにプログラマとしてはつまらなくなると思う
でも、例えばシングルコアがマルチコアになったとか、
複数のマシンをLANで繋いで負荷を分散できるようになったとか、
GPUが計算に使えるようになったとか、
CPUがCellに変わったとか
そういう劇的な変化時におけるパワープレイは、それはそれで面白い
その環境に最適化する場合の考え方ががらっと変わるからな
パワープレイの方法を間違うと本来の力が全然が出せないし
418 :
デフォルトの名無しさん:2012/02/04(土) 23:16:59.74
>>417 >ハードを追加することでコンスタントに処理速度が上がってく段階になると、
>さすがにプログラマとしてはつまらなくなると思う
処理速度に余裕ができた分、新しいアルゴリズムを追加できるように
なるんだから面白くなるんじゃないの
>>418 人によって段階をどう捉えるかは違うけど、私は次のような段階を考える
1. 様々なアルゴリズムを考え、実験し、検証する(計算上の仮想実験も含む)
2. ハードが変化し、1のアルゴリズムで実用的になるものも現れる
3. ハードの追加によってコンスタントに処理速度が上がってく
この段階で私がプログラマとして最も面白いと感じるのは 1 の段階
次に面白いのは 2 の段階だが、これはどちらかと言うと、
1 のアルゴリズムが使えるようになったおかげで可能になった
他の処理の実装などが面白い
3 の段階になると、処理速度が上がることが分かっているから、
単なる作業と確認でしかなくなる
確かにこの段階でも 2 の様なことは起きるのだが、
ワクワク感やドキドキ感は無いな
420 :
デフォルトの名無しさん:2012/02/04(土) 23:51:17.93
いや、だから、3の段階に達したらまた別の
アルゴリズムを考える1に戻ればいいじゃん
処理速度に余裕ができたんだから新しいアルゴリズムを追加できるんだよ
>>420 > いや、だから、3の段階に達したらまた別の
> アルゴリズムを考える1に戻ればいいじゃん
全くその通り
どうも言い方が悪かったみたいだ
あるひとつの方法に関して、その実装が
ハードを追加することでコンスタントに処理速度が上がってく段階になると、
その環境でその方法を使い続けることはプログラマとしてはつまらなくなる
(仕事としては、こちらの方が圧倒的に多いが)
>>421 いや、違うか
何て言えば良いのかな・・・
目標 --> 達成 --> 目標 --> 達成・・・というプロセスが続いていくわけだが、
ハードを追加することでコンスタントに処理速度が上がってく段階というのは、
その目標を達成するのにハードの追加で事足りてしまう段階だ
>>419 の 1 の段階は目標を達成するための行為であり、そこで複数の方法を考える
その方法は 2 の段階で実用になるものもあるだろうし、そこで新たな課題が出ることもある
しかし、3の段階になると、その方法を使ってあとはマシンパワーを上げていくだけになる
要求に対して足りないパワーを補うだけ
例えばサーバーやコアの数を増やしたり、メモリを増やしたり
この段階では、この方法に関してはもうプログラマ(私)があれこれ模索することもなくなり、
プログラム的にはほとんどメンテだけの状態に入る
何が言いたいのかというと、
>>413 はつまらんと言うが、
3 と違って 2 の段階でマシンパワーに頼るのはスゲー面白いだろ、と言うこと
ほとんどスレチだからもう終わる、長々とすまんかった
既存の画像処理をOpenCLで並列化なんてのはおもしろいぞ。
画像処理はほとんど反復処理だから劇的に高速化する。
元々が糞プログラムじゃない限り劇的にはならないよ
無知乙
ハードウェアの性能が何桁違うと思っているんだ
最近は何桁も違わないよ
GPUとかFPGA使って高速化したっていう発表は学会でもあるけど、フーン当たり前じゃんって反応だな
既存のアルゴリズムを複数スレッドに分けるだけじゃなくて、マルチコアを前提とした新しいアルゴリズムでないと感動しないな
フーン。
感動って無知だからできるんだぜ。
ハードによる高速化はシングルスレッドものと比較して早いって言ってるだけで
マルチスレッドCPUで真面目に記述したものとは大差ないんだよな
それとCPUのシングルとマルチでの比較だけど
マルチだとどうしても制御構造で無駄な処理が大量に入り込むから
シングルでMMXとか使った場合と比較しても大差ないんだよな
CPUのコア数が数十とかにでもならない限りは恩恵は実感出来ないだろうな
SSE ならまだしも、MMX って古代技術だろ
今の時代 MMX の恩恵が受けられる分野って何がある?
たぶんSIMD拡張全般を指して言ってる?
MMXじゃなくてMMXとかって書いてあるだろ
日本語読めない人なのか?
>>434 だから、その中には MMX も含まれてるんだろ?
シングルでMMX使った場合と比較しても大差ない場合もあるんだろ?
一番わかり易い例を出せば
シングルスレッドで画像処理をする場合はたいていメモリポインタは加算演算だけで
現在のピクセルデータの場所を計算出来る
しかしマルチスレッドでやろうとするとピクセル毎に乗算でポインタを計算しないと出来ない
アルゴリズム的な総計算回数ではシングルのほうが圧倒的に高速なんだよな
>>436 画像の一部に処理を施すのなら、どちらにしても
アドレスは (ベースアドレス + x + y * ピッチ) で計算する必要があると思うが
それに、そもそも今時かけ算が足し算の2倍時間がかかるなんてことは無いんだから、
マルチコアの環境ならマルチスレッドにして同時に計算した方が速い場合の方が
圧倒的に多いと思うぞ
輪郭摘出しかり、グレースケール化しかり、ノイズ除去しかり・・・
>>437 >ベースアドレス + x + y * ピッチ
足し算と掛け算が同じ処理時間だと過程してもこの式を見る限り4倍ですが?
>>438 おまえの言ってる意味が分からない。コード書いたことないだろ。
>>439 ほとんどの画像処理は1次元の概念だけで処理出来る
だから1ピクセルにつきポインタ加算を1度すればいいだけ
>>440 言ってる意味が分からない。おまえ画像処理したことないだろ。
ノイズリダクションというよくあるフィルターを考えても1ピクセルだけで処理すとかないし。
100歩譲って全ピクセルなめるだけと仮定しても、
2スレッドに分けたときそれぞれのベースアドレスが変わるだけで、
どっちのスレッドでも、ポインタをインクリメントするだけ。
なにが4倍なのか本当に意味が分からない。
>>442 ノイズリダクションも全8方向の1時限的相対位置を加減算するだけでデータ位置が特定出来る
もともと掛け算命令のない8ビットCPUの頃からアドレス計算は加減算と論理演算で計算してる。
ベースアドレス + x + y * ピッチなんてのは人間の理解用だ。
そもそもx86のアドレッシングは強力だ。アドレっシングで遅くなるとかほんと意味不明。
はっきりいって画像処理なんていう並列しやすい処理は、
スレッドが二つになれば速度は倍近く早くなる。
だからこそスレッド数を増やすだけのGPU実装を最適化というのは夢が無いよ
>>438 お前さ、簡単なグレースケール化でいいから、
シングルスレッドと、マルチコア+マルチスレッドの両方をプログラムしてみて、
処理速度を計測してみなよ
GPU内部で死ぬほど並列化していて、しかもそれがプログラマブルだというのに
それを使わないほうが夢があるとかどうかしてる。
楽してGPGPUライブラリ使えよ。
これから画像処理の最適化が盛り上がりそうなのってスマートフォンじゃん
NEONベースの最適化ってどれくらい効果あんの?
>>446 9600GTでさんざんやったが結局CPUと変わらないという結論に達した
CPUでのマルチスレッド化もやってみたが
区画を複数に分割してもそれぞれの境界をうまく相互作用させないといけない
単純にシングルでやるみたいな加算でループ一発とは行かないんだよ
だから2コアでやってみたが結果は変わらない
4個なら多少は早いかもしれないが多少だろうな
>>449 CPUでのマルチスレッド化をやっても上手く行かなかった原因が
> 区画を複数に分割してもそれぞれの境界をうまく相互作用させないといけない
であり、また
>>436 だと結論づけたのか
分析力が欠乏していると言わざるをえない、仕事仲間じゃなくて本当に良かった
では、他の人たちが画像処理のマルチスレッド化で成功しているのを見て、お前はどう思う?
魔法でも使ってると思ってるのか?
>>431 まずSIMDとマルチスレッドは同時に使えるわけだが
GPUはメモリの転送でかなりのオーバーヘッドがあるから
グレースケールのような単純処理だとほとんど変わらないけ
大きいガウシアンフィルタのような転送するデータ量に対して計算が多い処理ならかなり速くなるぞ
>>450 何も成功してる例なんてないって
だからSIMDを使ったシングルが一番効率がいい
速度と作りやすさのバランスでね
早くなったと言ってるのは最適化されてないプログラムと比較して言ってるか
CPUはスペック低くしてハードだけ高スペックにしてるとかそんなもん
詐欺だよ詐欺
>>451 だからマルチスレッドのアルゴリズムが高コストになるから意味ないってw
>>452 例えば Adobe Lightroom がマルチコア環境で処理が速くなるのは、
シングルコア環境時は拙いコードが走っていたり、
CPUはスペック低くしてハードだけ高スペックにしてる環境での比較だからなのか?
>>449 ありえね~www
100%おまえのバグだろw
アセンブラの知識が不足しまくってんだろうな。
どういう処理にコストがかかるとか全然分かってないのだろう。
境界をうまく相互作用と言ってる時点で設計が間違ってる。
無駄な分岐判定でストールしまくってるコード書いてるんだろ?
この流れだとGPU凄いよ派と大したことない派で簡単なコード公表するしか決着つかないんじゃね?
2値化くらいの簡単な処理なら表にできないもんかね
>>454 使ったことがないから知らないが早くなるのか?
明らかに見ただけで分かるくらい劇的か?
単に画像処理とは無関係なUI関係が早くなってるだけじゃなく?
>>456 だいたいグレースケールみたいに単純な処理はむしろマイノリティだろう
例えばラベリング処理とかどうする?
>>457 そのくらい単純だとメモリアクセスやディスクIOが律速になりそう
>>457 簡単すぎる処理だと、たんなるメモリ速度のベンチマークになるだけ。
それなりに複雑な処理やらせないと駄目。
複雑な処理になるとピクセル情報を判定タスクという単位にしてスタックにためていって
各スレッドはスタックから順次取り出して判定処理をしてタスクを追加するという作業を繰り返すことになる
スタックの排他制御での時間ロスが発生する
メモリも膨大に食うし
遅い
なぜ排他制御がいる?
マルチスレッドでは同期コストが一番高いというのに。
基本を無視して設計し杉。
同期が頻発するところは分けてはいけない。鉄則です。
スタックを複数スレッドで共有とか狂気w
>>462 >同期が頻発するところは分けてはいけない。鉄則です。
そんなこといったら画像処理のほとんどは並列化出来ないってことだから
言ってる通り、マルチスレッドの恩恵はない
意味不明。全くの逆で画像処理のほとんどは並列化可能。
そもそもGPUはバケモノじみた並列化をした実装になってる。これをどう説明するのか。
いくらなんでも素人過ぎる。
そんな事よりマンガミーヤのリニューアル版作れる人が居ない事のほうが問題
高速化出来るのはもともと高速な分野だけ
カメラ画像解析プログラムを良くかくけど、並列計算してくれるライブラリー(IPPとかIPL,MP)に処理を投げるとかなり速くなるよ。
ただ主にはやくなるのは画像取得や画面描写のところだね
二値化→オープニング→ラベリング
とか処理結果を引き継いで処理していくのはなかなか並列計算しにくいかな
>>458 全く違う、目に見えて速くなる
それはそうと
> 単に画像処理とは無関係なUI関係が早くなってるだけじゃなく?
こう思った理由が気になる
マルチコア+マルチスレッドで速くなるという話で、
なんで画像処理とは無関係なUI関係が速くなると思ったのだ?
お前はマルチスレッドでUI関係が速くなるライブラリでも自作してたのか?
今時UI関係が速くなるという状況がよく分からんのだが
そもそも、お前の言う「UI関係」って何だ?
>>463 461が1ピクセルごとにタスク切って同期化してるならアホとしか言えんが
Producer-Consumerでキューなりスタックなりがいるのは当たり前だろ
GPUのレンダリングパイプイランの実装がどうなってるか理解してるか?
同期というのは、同時にアクセスする可能性がある設計になってるから必要なんだよ。
もしそういう設計ならその設計は既に間違ってんだよ。
Producer-Consumerとか言ってる時点で設計が間違ってる。
画像処理で採用するパターンではない。
>>470はスレッドプールみたいなモノの事を言いたかったんじゃないの?
ていうのは嘘で、タスクキューみたいなやつ。
というわけでさようなら!
同期するようなのは並列化出来ないってのが本来の主張であって
なぜなら画像処理の大部分は同期処理が必須という前提があるからね
「同期を伴うものを並列化するのは設計の時点で間違い」という主張は意味不明なんだけど
なにを言ってる意味が分からない。
>>475 同期処理が必須の画像処理と、並列化できる画像処理
10個くらいそれぞれ箇条書きで書いてみなよ
(10個も思いつかんかも知れんが)
認識が間違ってたらみんなで指摘し合えば良い
>>477 高速化出来るのは単純な微積分問題だけ
つまりぼかしやグレースケールやらといったフィルタ系の
CPUでも十分実用レベルだろってものだけ
同期が必要になるのは
オブジェクト検出、ラベリング、パターンマッチなど
一番高速化したいものたち
どうも、処理全体を一つの大きな塊と考え、
それを等分しようとしてできないと言っているような感じがする
>>478 君が同期が必要だと思っているその3つは全て並列処理することで高速化可能
それぞれ一例を挙げると・・・
オブジェクト検出は検出したいオブジェクトのサイズがだいたい分かっていれば、
画像を分割して、それぞれでオブジェクト検出を並列にできる
検出したいオブジェクトが分割の境界にまたがる恐れがあるのなら、
単に分割するのではなく、オブジェクトのサイズを考慮してオーバーラップさせればいい
(この方法はオブジェクトに対して画像サイズが小さいと効果が無いが)
ラベリングは行毎に横方向にスキャンし上の行との関連を調べながら行うのなら、
画像を何行かずつに分けてそれぞれ並列にラベリングし、
最後に境界線の上下の繋がりを調べれば良い
パターンマッチも、ある程度絞った候補を最後に総当たりして、
それぞれとのマッチング度合いを測るところで並列処理できる
ランダムな数値が並んでいる1次元配列に特定の数値が入ってるかを調べる処理が
マルチスレッドで高速処理できるのと「概念的には」同じだ
この部分を並列化することで高速化できるから、
その前のある程度絞る部分も検査基準を下げて高速化の恩恵が受けられる
GPU意味ない派がシングルコアAVXでGPU並の速度出せば納得するけどね
ラベリングでもテンプレートマッチングでも何でもいいけど
並列処理もまともに設計できない馬鹿素人を相手にするのはもう止めときましょう。
建設的ではない。
>>480 条件が限られすぎ
一部分だけ並列化したって労力の割に効果はほとんどない
>>481 GPUが早いかどうやって話はしてない
無駄なプログラムを書く労力を使ってまでして得るような速度ではないという話
>>482 まともに設計しないといけない時点で思想自体が馬鹿なんだと気がつこう
オーダー減らないと意味ない派の研究者と20%も高速化すれば御の字の技術者が争ってたりしないか?
>>483 > 条件が限られすぎ
オブジェクトのサイズがだいたい分かっていればの部分か?
普通は何のオブジェクトを抽出するか設計する段階で、
画像のサイズに対するオブジェクトのサイズの割合は
だいたい適正値の範囲を決めておくものだが、君は決めないのか?
定点カメラで車の交通量を測る場合然り、
デジカメで被写体の顔を認識する場合然り
> 一部分だけ並列化したって労力の割に効果はほとんどない
その一部は全体のボトルネックになっている部分だったりする
君は当然「
>>480 と同じ方法」で実験してみて、
でもそれほど処理速度が出なかったんだよね
分析した結果どこがボトルネックになってたと結論づけた?
486 :
デフォルトの名無しさん:2012/02/08(水) 05:57:38.34
馬鹿は黙ってろ
具体的な移動体検出 背景差分なんかで並列処理する方法を知りたい。
私はオーダー計算減らさないとあんまり効果ないんじゃね?派
>>487 フレーム間のピクセルの差をとるループやその累積を更新するループを並列化するだけだ。
オーダー減らなくても4倍、8倍、300倍速くなれば、
他のもっと複雑な計算もできるようになって
時間的な制約でできなかった高精度な方法も使えるようになってきたり
数日かかってたような処理が数時間でできるようになってうれしいだろ。
実用に使ってないやつは時間的制約なんてのが無いから分からないだろうが。
>>487 初心者なのになんで~派とか言ってんの?
単に「自分は馬鹿だから並列処理ができない派」ってことだろ。
そもそも並列化によってオーダーが減る事はあり得ない
にも関わらず並列化の研究が盛んで、かつ有益な結果が出続けてるのは、
>>488 の言うように同じオーダーでも係数の違いに意味がある処理もあるからだ
確かに、アルゴリズムの工夫で計算量のオーダーが2次元から1次元になったとしても
計算速度が100倍、1000倍になるとは限らないからな
並列化で処理速度が100倍、1000倍になるほうが嬉しいことのほうが多いんじゃないか?
専用ハード使って100倍ならスーパーコンピューターで1兆倍でもやればって話なわけで
現状のマルチコアCPUもGPUも10倍すらいかないよ
数倍になれば大成功だと思うが
5日かかってた解析が1日で終わる
5日かかってたレンダリングが1日で終わる
5日かかってた・・・
今時マルチコアが普通なんだし、並列化しないと1個しか使われなくてもったいないよ。
HD動画をリアルタイムに処理するとかだとぜんぜん違う。
ちょっと関係ないが、映画のVFXは、一フレームの処理が
1時間程度以下が要求されるそうな。
フレームひたすら多いからね。
まああの世界はふつうのマルチコアPCでやってるとは思えんが。
画像処理というか数値計算みたいなものだけだと
ほとんどはコア数に線形に速くできるだろ。
最近は4コアか8コアだから4倍か8倍くらいにはできるものが多いのに
それをやっていないと、いくらいいアルゴリズムを使っていても
大損していると思うわ。
GPUはフィルタ処理なら数百倍は速くなるぞ。
複雑な処理は異常に書きにくい上にあまり速くできないが。
GPU使ったり並列処理使ったり
linuxでもwinでもMacでもポータブルに実装する方法ってないですか?
Boost.threadは並列処理のポータブルなラッパー?
GPUでも同じ感じのあるといいのだけど
OpenCLとか
Javaの失敗を見て分かるとおり、そんなの不可能。
プログラマなら常識のはずだけど。
Write once, debug everywhere!!が鉄則。
write once, debug you
OpenCVのGPU使う方法ってポータブルなんだろうか
昔見限ったImageMagickを入れてみたが相変わらずXCFも作れないのな
PSD期待したがopacityなんかすぐ実装出来るだろうに
一度見限ったらもうそいつには期待しない
二度とチャンスは与えない
そうやって生きていきましょう
XCFもPSDもライセンス絡みの問題があるだけだろ
libpngで例外落ちする画像があって、Gimpでは読み込めるから問題ないんだろうけど
読み込む度に落ちるタイミングが違う
そこでpng_read_endをする直前にSleep(5000)といれてみたら
落ちずに待機して止まってる様子で5秒たつと例外が発生する
そしてこのSleepの直前にprintf("end\n")と入れてみたら5秒もせずに例外落ちする
なにこれ
libpng のソースを落として問題の画像でデバッグしてみれば、
「なにこれ」の疑問が解消されるかも知れない
510 :
508:2012/02/12(日) 01:35:05.59
最新版ダウンロードしてやったら出来た
ポータブルでいうならOpenCLだろう
AMDとnVidia両方のGPUでいけるし、CPUもいける
しかし、これからのお薦めはなんと言ってもDirectComputeだろうな。
513 :
508:2012/02/13(月) 06:51:50.42
プログラム側が対応するというよりはハード側が現行のプログラムを並列処理するようになる流れだと思う
その流れでしか普及しない
DirectComputeって、HLSLを使わなきゃいけないし
Macで使えないからないな
Macで使えないってどんだけメリットなんだよ。最強じゃん。
いまのMacはソースコードからコンパできるでしょ
がまんなさい
今時はコンパって言うのかw
コンパwwww
勉強させてもらったわ
結局、画像処理を並列化するには何使うのがいいんだ?
画像処理にも色々あるでしょ
得て増えてガール
とりあえずはFPGA並べて試作だな
前の会社の時はFPGAで処理させて、
ってことをたくらんでたけど結局やらなかったなぁ…。
ハードの知識ないし、詳しい人たちはひたすら忙しかったし…。
その手の謎の挙動はメモリ関係だな。
うわ誤爆
>>515 Macで使えない=他の大抵のOSで使えない
だから、やっぱ採用しにくいわな。
DirectComputeがそれに当てはまるわけだが。
しかし、OSの採用比率で言うと、圧倒的な割合なわけだ。
それを採用しにくいとかマカーのステマだろうな。
最近はスマホの影響でOpenGLとかもそれなりに流行ってるし、
Windowsだけやるのはお気楽だけど、あちこちでコードを使いまわす事考えたら、
ちょっと考えちゃう。
OpenCLが一番汎用性高そうだね
OpenCVはCUDAぽいけど
529 :
508:2012/02/16(木) 01:15:21.62
OpenCLがマルチコアCPUでも動くなら普及するんだがな
OpenMPとCUDAの複合
OpenCLはCUDAほどパフォーマンスが出ないから
せっかくそこまでやるならCUDAってことになるのでは
>>529 OpnCLはマルチコアCPUでも動く。しかもIntelでもAMDでもおk
>>392 dag_vector: ランダムアクセス可能な圧縮配列
tp://research.preferred.jp/2011/06/dag_vector/
こんなのあるのね
DTAMの論文読んだけど、なんだかよくわからん。
読んだ人いますか?
KinectFusionは分かった気にはなった。
>>534 読んだには読んだけど、解説出来るかは箇所による
ああいうのは論文通りに安定して動かないことがほとんどだから微妙だね
PTAMもすげー不安定だったし
画像処理について勉強中のものです。
質問があるのですが、
Harris-affine領域を抽出するのに
R=detM-k(traceM)^2=λ_1λ_2-k(λ_1+λ_2)^2
を求めてRの値が大きければコーナーと判定するのはいいのですが、そのあとの
求められた点に対して、周囲の画素の輝度勾配を計算し、注目画素を中心とす
る楕円領域を求める。
この箇所がよくわかりません。
具体的にどのようにして楕円領域を求めるのでしょうか?
538 :
508:2012/04/01(日) 09:48:18.11
Harris-affineって初めて聞いたし画像処理も素人だが
英語のwiki見て適当に答えるなら
楕円領域ってのは繰り返しパターン検出法だろ
ある点に注目した時の周囲の特徴点で算出された計算値が
隣接する点を中心にした場合と同じである場合は同じパターンの繰り返しということになって
その中間地点が境界領域ということになる
それをXYの両方向で特定すると楕円形になる
>>539 アフィン変換不変の詳しい解説はないだろ
>>539 藤吉先生の"一般物体認識のための局所特徴量(SIFTとHOG)"というのを読んでみましたが、
Harris-affine領域の記述はなかったのですが・・・
主曲率のところで固有値が出てくる似たような式がでてきましたが、
楕円領域の求め方はわからなかったです。
固有値の根の逆比が楕円領域の2軸でしょ
そもそもハリスとかDoGの特徴点検出がどうやってるかわかってんの?
ハリスは
(Ix)^2 IxIy
[ ] Ix,Iyはx,y方向の1階微分
IyIx (Iy)^2
それぞれをガウス平滑化したものをMとすると
R=detM-k(traceM)^2=λ_1λ_2-k(λ_1+λ_2)^2
で求める
DoGは
異なるσ(kσ,k^2σ,...)の平滑化画像の差分をとった元をDoG画像とし、
DoG画像3枚1組で注目点のまわり26近傍をみて極値であれば特徴点候補とする(ダウンサンプリングし繰り返すのは省略)
こんな感じだと思うのですが、DOGは実装したことがあるのですが、
ハリスはしたことがないので固有値がどのような値をとるのかがよくわかりません。
固有値の根のといのはルートのことでしょうか?
たとえば固有値がλ1、λ2(λ1>λ2)とすると
長軸が1/√λ2、短軸が1/√λ1
となるということでしょうか?
また楕円の傾きはどのように求めるのでしょうか?
固有値に対応する固有ベクトルが軸の方向
固有値と楕円の関係は主軸変換とかでググれば分かると思う
ところで横からだけど
これって勾配を計算する範囲がアフィン変換に不変ではないと思うけど
楕円領域のほうが大きいから問題になりにくいということ?
楕円領域を実際にアフィン変換して円に正規化するんだよ
そんで勾配と特徴量計算する
547 :
543:2012/04/06(金) 22:57:17.57
ありがとうございました!
548 :
508:2012/04/06(金) 23:30:15.39
一番正確な領域分割アルゴリズムって何?
>>546 楕円用の固有値と固有ベクトルを求めるための行列を計算する範囲のことだよ
楕円領域を計算する前だからその範囲はアフィン変換に強いわけではないでしょうと
そういうことか。確かにそれはかなり影響ある。
実際Harris-Affineの検出力は他と比べてかなり低いよ。
551 :
デフォルトの名無しさん:2012/04/12(木) 21:25:52.13
画像関連、全くの初心者なのですが質問させてください。
たまにテレビで、背景(壁)が真っ赤や真っ青にしてある画像処理用のスタジオが写ってますが、
あれで映像の背景部分と人間部分をデジタル的に分けてるんでしょうか?
その様な技術を一般的になんていうんですが?
似たようなことをして物体の形状をカメラで調べられるのを作りたいと思ってます。
最終的には背景(壁)の適した表面処理等も調べてみたいです。
先輩方、よろしくお願いいたします。m(_ _)m
クロマキー
553 :
デフォルトの名無しさん:2012/04/12(木) 22:51:32.55
>>552 ありがとうございます。m(_ _)m
「クロマキー」というんですね。色々と調べてみます。
小学生の時に聞き覚えがあります。それはクロマティか。
背景にはクロマティ用の「布」を使うようですね。
私の場合、工場の生産ラインで長期間使いたいので、「布」は保守性に難かな。
クロマティ用の塗料が販売してるみたいなので問い合わせてみます。
あと被写体の色が様々で、青い背景だと、青い被写体を識別するのは難しいですよね。
背景に設置する板を、対象物に応じて取り換えるしかないのかな。
複数の異なる色のLEDで、対象物に応じて手動で発光する色を切り替えることも考えられますが、コストの面で難が出るだろうな。
何か良い方法思い浮かぶ方がいましたら、何でも書いてくれると嬉しいです。m(_ _)m
背景だけを撮った映像(A)と人物+背景を撮った映像(B)を作り、
BからAを減算して人物や屋台だけを抽出して、別の背景と合成する
というのを高校の文化祭でやった
3階の教室から模擬店で賑わっている庭をビデオカメラで撮って、
人物と屋台を宇宙空間や水中の映像と合成した
映像Aは前日に同じ場所から同じ角度で撮っておいた静止画一枚だけ
所詮は高校生がやることなんでとても拙く、
壁や地面に落ちた影もいっしょに抽出されてしまってたし、
切り抜き自体も綺麗にはいかなかったが、それはそれで面白かった
555 :
デフォルトの名無しさん:2012/04/12(木) 23:25:42.99
>>554 なるほど楽しそうですね。
クロマティを教えてもらった私ですが、その方法も考えてみます。
それでうまくいけば、背景に特別なものを用意する必要がないですね。
背景で、機械が動いていたり、人が横切ったり、人の影が変わったりと色々難が出そうですが、それも試してみます。
LEDのパネルがクロマキーに優れてると思うよ。と書こうとしたら既に検討してたか。
光の屈折やレンズ内の反射で物体が小さく映ると思うから1画素程度膨張させるのいいね。
あと、エッジを見るようにすると色は気にしなくてもなんとかなる
557 :
デフォルトの名無しさん:2012/04/13(金) 08:03:35.38
>>556 おはようございます。
ありがとうございます。LEDパネルを購入してみます。
実験レベルでは、安価な白色のLEDパネルに、フィルム?を貼ればいいでしょうか。
なるほど、強い光がしみだしてくるんですね。確認してみます。
>あと、エッジを見るようにすると色は気にしなくてもなんとかなる
これは、色判定と同時に、エッジ検出も同時うということでしょうか。
HALCONのスレが無いので、本スレで質問致します。
sobel_amp(), edges_image()等で抽出したエッジから領域を
生成する方法で悩んでます。
sobel_amp(), edges_image()で得たエッジのみ白く
その他は真っ黒な画像をthreshold(),hysteresis_threshold()しても
エッジで囲まれた面を抽出できません。
大変、恐縮ですが何か、コツなどを教えて頂けないでしょうか。
宜しく御願い致します。
>>557 エッジというのは554の言ってることをやる手段のことね。
背景画像と今の画像を引き算して移動物体を見つける。この引き算の仕方にも流行りがあって最近はエッジ画像でやるのが流行りなんだよ。
背景画像を使う事が廃れてきてはいるけどね。
面白いと思ってわざと間違えを引っ張ってるんだろうが
つまんねえからそのクロマティっての
死ね
些末なところに突っ込むなよ
どうでも良いだろ
×間違え
○間違い
ハイ残念賞
国語の勉強からやり直しな
565 :
デフォルトの名無しさん:2012/04/20(金) 01:02:14.89
>>560 その方法なら背景に特別な物を用意する必要がなくていいですね。
でも背景と被写体が同じ明るさ(カラーの場合色も)だと、誤検出(非検出)しそうですね。
現在、LEDパネルやカメラモジュール、アルミ板金治具とか色々調達して実験してるけど、
今のところ背景を「黒」にするのが有力です。
背景を「白」にすると、被写体での照明光反射と区別がつかない。LEDパネルでも。
背景を黒で撮影して、微分(エッジ検出)してから2値化するのがよさそう。
被写体に対して、横からライトで照らせば、黒い被写体やビニル袋のような透明な被写体の輪郭も検出できそう。
念のために2値化した後、孤立点消去や膨張/収縮処理もするつもり。(小容量のFPGAでもパイプライン処理できる)
背景を青にしても上手くいくけど、被写体の色依存性とか話しが複雑になりそうなんで、モノクロでいきます。
カメラはCMOSのグローバルシャッタ方式でいこうと思ってます。今は市販モジュール使ってます。
CMOSグローバルシャッタ方式って最強ですね。(smear,blooming,動体歪み出ないし低消費電力、周辺回路は超楽ちん)
「黒」の背景として、現在クロマティ用背景紙を購入して使ってますが、製品に紙を使うわけにはいかないんで、良さそうなものを今後探します。
低反射の黒色塗料とか、目の細かいスポンジ状のものがいいんですかね?
何か使えそうなノウハウをお持ちの方がいましたら教えてください。
工場の生産ラインで、色々な物体の輪郭を検出するものを作りたいのです。画像関連全くやったことありません。
よろしくお願いいたします。
光完全吸収素材が理想でない?
まあ値段高いので、
工場ならrom用の静電マットの黒固スポンジがある。代用したら?
>>565 先ずは「クロマティ」って書くのをやめようよ。
野球の話だからいいんだよ
魁
男塾
クロマティつながりで「それはひょっとしてギャグで言っているのか?」のAA貼りたくなる
572 :
デフォルトの名無しさん:2012/04/20(金) 22:20:20.09
565です。
「クロマティ」は私のギャグです。
一応「明るくて面白い人」と言われます。皆さん私についてきてくれると幸いです。
>>566 「光完全吸収素材」は、どの様な素材を言われているでしょうか?
本日、黒背景として「CRスポンジ」を調達しました。
光学的には非常に良好なのですが、ゴミの付着という問題がありそうです。
小さな白いゴミが付着してるとそれを誤検出してしまうのですが、
CRスポンジでは一度付着したゴミがふっと息を吹きかけた程度では取れません。
雑巾で拭いても取れません。
ゴミが付着したら雑巾で水拭きして取れるのが良いのですが、何か良い素材はないでしょうか?
そもそも、
「低反射」→「表面がざらざら」→「水拭きでゴミ取り不可」
なので、無理のある考えなのでしょうか。
画像処理での対策も検討しましたが、1画素の孤立点は消去できますが、
2画素以上に連なった孤立点を消すのはハードウェア規模と処理時間を考えて現実的ではなさそうです。
よろしくお願いします。
>>553 昔の映画じゃ「ブルーバック合成」が多かったけど十五年ぐらい前からは「グリーンバック」
の方をよく見かけるねぇ。まあいずれにせよ
1.切り抜きのための色空間の選択
2.選択した色空間における被写体とクロマキー用の色の分離性
に応じてブルーバックが良かったりグリーンバックが良かったりするわけだ。
つまんねえつってんだろ
死ねよ
いるよなー、一発ギャグを百発繰り返すヤツ。
しかもそういうヤツのギャグに限って一発目から滑ってるっていう。
指向性の高い光源で影作って、それを読み取るってのはどうだろうな。
輪郭を検出というより、輪郭像を抽出って感じだが。
スクリーン
/ \
対象物 カメラ
/
光源
カメラと光源の位置から変換を求めれば、光源から見た像も復元出来るし、フィルターもかけやすそうだ。
対象物の色に関係なく穴があいてる物体の輪郭も検出できるし。
まぁ透明な物体は無理があるかもしれんが。
ZCam を使えば良くないか
なぜ自作にこだわっているのか分からんが
赤外線が反射したところを抜き取る。ラインの向こうに汗をかいたデブが
うろついていると困るけど
長い行列に対してm-sequenceでディザリングをしたかったのですが
後で処理をするためにディザリングの配列は残しておかねばなりません
ここにSFMTで作った64bitのunsigned longの乱数があります
これを1bitずつ上位ビットor下位ビットから
array[0] = 1;
array[1] = 0;
・
・
・
というように64個の配列(intでもboolでも何でもOK)に入れたいんですが、どう書けばいいでしょうか
最終的に、ループで回して0と1の行列は長い(数千万の)配列にしたいので
速いコードだとありがたいです
よい実装方法をご存じの方、いらっしゃいますか?
画像処理の質問ではないな。
unionって知ってる?
unsigned longをbit配列と同意義で読み替えてやればいい。組み込み系でよく使う手法だがや
ただ速くしたいなら素直にビット演算としてSIMDで書いたほうが速いだろ
処理依存の回答を求めているからだろ。だからもっと依存の強いSIMDのようにハードリソースに合わせたソフトのつくりはアリだと思う
unsignd longは固定64bitと書いてあるように読みとれないか?処理系が変わると大元設計から変えるんだろうね。
えっと、、だがや
inttypes.hも知らないのか
stdint.h じゃなかった?
>>585 仕様上はそうだけど
実装によってはinttypes.hしかないのと
inttypes.hはstdint.hの内容を含む(またincludeする)ので
移植性を考えるとinttypes.hだけを使うべきだって話がある
組み込み系コンパイラにどこまで期待してるんだ。標準ANSIしかサポートしてないのがザラだぞ
ハード回りのプログラムしてないで移植製を語られてもねぇ
jpg,png,gif画像の拡大・縮小をしたいのですが、
なんかヒントになるものないでしょうか?
調べてもそういうツールが出てくるばかりで、
プログラム的な解説がなくて困ってます。
何かいいページとか参考になるキーワードあれば教えて下さい。
ツールにナントカ法で拡大などのオプションあんだろ?
それがまさにキーワードじゃねえか
なるほど線形補間ですか。
言葉だけなら聞いたことあります。
キュービックってのもありますね。
早速調べてみます。
『フルスクラッチによるグラフィックスプログラミング入門』
nearest neighbor
馬鹿には無理
>>588 lanczos ってので検索してみたらどう?
596 :
588:2012/05/28(月) 20:12:56.86
ありがとうございます。
バイナリプログラム自体が始めてなので、
かなり苦戦しそうですが頑張ってみます。
画像の読み込みからやるつもりかよ
YUV形式の画像データ(1次元のバイト配列)
の回転に挑戦してるんですが、
上下逆にするのは成功したものの、90度回転が出来ません。
1920x1080の画像で、横長のままです。
バイト配列の中のどれかに、改行コードみたいなものが含まれているんでしょうか?
いいから寝ろよ
解決するぞ
寝ようかなーと思ったら原因判明しました。どうもです
>>583 容量の問題じゃなくて、Endianの問題だがや
ARMとかBigendianが使える環境だと、
x64系でテストしたコードを移植できんがや
おとなしくビットシフトと論理和論理積使っとくのが
一番移植性があるがや
一般的でそれなりに安価にノートPCで高速に画像を取り込みたい場合、
GigE カメラが理想でしょうか?(カメラが高い、ってのは置いといて)
603 :
602:2012/06/04(月) 18:21:43.74
もう一つ質問ですが、GigEカメラがなかなか普及しない理由って何かあるのでしょうか?
ググっても利点だらけで欠点らしい欠点が出てこない割に、普及してないのは単価が高いからでしょうか。
普通はWEBカメラ程度で十分で、高速なら据え置きPCにCoaXpressボードとか使えって話になるのかもですが。
604 :
デフォルトの名無しさん:2012/06/04(月) 19:11:11.72
ここって超初心者的な質問でもよろしいのでしょうか?
>>604 各処理言語別のスレやスレ立てるまでもない質問スレでは適当ではないと言う根拠があるならどうぞ。
>>604 質問内容は初心者的でもいいが、質問文はちゃんと論理的に書いてくれよ
あと、質問する前に1日くらいは熟考しろよ
602
やっぱ高いのが問題なんやない?
うちはステレオカメラ用途にシステム作ったで。高速な用途だけやなくて高度制御もできる
>>607 やっぱり価格の問題くらいですか。
メモリや外部トリガはカメラ依存になりますが、
GigE自体はかなりこなれて来て使い易い割にあまり使われていないので不思議に思っていました。
(調べて出てきた性能の欠点は、パケットなので若干不安定なくらい)
ちょっと借りて使ってみます、ありがとうございました。
PoEなGigEが出回れば本命になると思うよ
>>609 電源供給もケーブル1本で出来れば、色々と便利ですね。
出回っとるで。PoEつこうとった。
カメラは高いだけあって歪みの少ないええ~レンズしとったわ。
CMOS だと画素飛び保障範囲の差でピンキリって感じ
メーカー<画素飛びしたところは中央値でも使ってて
横浜の画像センシング行って来たけど、実用的なUSB3.0カメラがだいぶ出てきたな
まだ主流はGigEだけども
CoaXpressも出てきたけど、CameraLinkが強いのと、ニッチ過ぎて需要が少ないそうだ
>>609 PoE対応のPCが普及しないと意味無くね?
特にノートPC
PoE対応のハブ経由でごまかす
>>596 特別な事情がないかぎりOpenCVとか使ったほうが捗るな。
59-63だな
この画像の情報量だと(ヾノ・∀・`)ムリムリ
クロエかマックに頼めよ
>>618 inverse hyperbolic hierachical scale-invariant feature を使って解析した所、外交官ナンバーっぽい。
>>623 信じる奴がいたらどうすんの? そんな手法ないよね?
信じる奴がいてもどうもしないよw
個人を特定出来る情報の書き込みは禁止な
つうかあんなのからまじで解析できるの?
時間と車種、内装などから車自体の特定はできる
ただ、この画像だけでは不確定なのでまわりの道や店などにあるカメラの画像を解析する
>>621 映画で監視カメラに映った小さい画像を拡大すると鮮明になる機能あるじゃん!
あれを実装すれば問題無し
そういうのは現実的には複数フレームからの解析で、
たった1枚の画像ではどうこねくり回そうが
元の画像にある情報量以上の情報は得られない。
できるのは、見難い画像を人間が見やすいように補正する程度。
>>630 > 元の画像にある情報量以上の情報は得られない
確かにそうだが、元の画像が何を撮ったものか分ってるのなら、
不鮮明な画像でもパターンマッチである程度情報を絞り込める場合もあるよ。
たとえば車のナンバープレートが映ってるはずだと分ってるのなら、
一般的に使われているフォントは限られてくるし(地域差もあるが)、
プレートのサイズから文字のサイズは推測できる。
そうすると、マッチングテストすべきパターンの数も減らせる。
人間の目でみてわからないものを画像処理でなんとかなるわけない
>>632 冗談だろ?
たとえば人間が見て判別できないほどの低コントラストの画像も、
画像処理すれば何か分る場合がけっこうある。
これは画像だけでなく信号全般に言える。
ノイズの情報量は無限大(キリっ)
>>633 現場を生でみたときの事だね。
焦点を絞ってるからなんだろうけどダイナミックレンジ、低照度、解像度は比べ物にならん
>>632 フーリエ変換した画像を見て、何が映っているのか解る人ですか?
ナンバープレートを生成
写真の撮られた環境をシミュレーションして加工
元画像と比較
一番近いのが該当するナンバーだ!
>>637 それナンバープレートに限らず、
犯人の服の陰の特徴とか皺の寄り方とか、いろいろ普通に使われてる。
「~だ!」って言うほどのことでもない。
レベル低いな
>>629 確かにそうだな、あの監視カメラで撮影できなかったことが敗因だな
629はカメラのことを言ってるわけじゃないが
>>630 干渉電波望遠鏡は見やすいようになっただけなのか?
あれは実は分解能が上がってないのか?
いやいや、皮肉じゃなくて、冗談には冗談で返したというか(以下ry
>>643 干渉電波望遠鏡は開口合成の一種であって、
一枚の画像をいじくりまわすんじゃなくて複数枚の画像から
合成して分解能を上げる仕組みでしょ。
パラボラ群を巨大なレンズ面のファセットの集まりだと思って計算する
と、個々のパラボラの数百~数千倍の開口径を持つレンズだと思えるとかそんな。
カラー画像を色周波数で分解して複数枚として同じことはできる?
>一枚の画像をいじくりまわすんじゃなくて複数枚の画像から
>合成して分解能を上げる仕組みでしょ。
ってとこに注目すると、たぶん無理
分解してる時点で情報量減ってるから
合成しても元の画像に戻るだけ
650 :
あきら:2012/07/30(月) 13:42:20.71
気になっている事を質問させてもらいます。
・画角、光学中心の測定の仕方
・特徴点を用いた、光学中心から見た特徴点の方向・方向ベクトルの算出
・光学中心・特徴点に映っているものを結ぶ直線の算出方法とその演算
・ステレオ視環境を利用した3次元位置の測定
・ステレオ視環境の構築
・3次元位置推定のアルゴリズムとその算出
が今のところわからないです。
他にもあると思いますが、現在悩んでいる
のはこれぐらいです。
>>650 その画像解析の前提となる波動光学は理解できているかい?
652 :
あきら:2012/07/30(月) 14:26:00.12
一応できてると思います。
653 :
デフォルトの名無しさん:2012/07/30(月) 16:19:46.70
できてるかできてないかって聞いてんだろ池沼
お前がどう思ってようが関係ない
できてるかできてないか事実だけを答えろ
654 :
あきら:2012/07/30(月) 16:34:59.85
できないです。
じゃあ初めにすべきことは決まったね
>できてるかできてないか事実だけを答えろ
>できないです。
諦めろ。
波動解析なんか関係ないから、騙されんなって
まず徐剛「写真から作る3次元CG」でも読め
TsaiかZhangの論文読むのが早いんじゃ?
659 :
デフォルトの名無しさん:2012/08/04(土) 22:31:54.11
画像サイズについてです。
部活で発行する本の表紙を書きました。A5サイズで、ということだったので、A4で描いてパソコンで取り込んで縮小しようと思ったのですが、
取り込んで、pictbearというソフトで「イメージのリサイズ」でサイズを半分の数字にしたのですが、
ためしに印刷してもA5の大きさになってくれません。それどころかすごく大きくて、一部だけしか印刷できませんでした。
A4の半分がA5と聞いたので半分に縮小すればいいんだと思ったんですけど、それじゃだめだったんでしょうか?
私のパソコンのなかの今のデータでは、A5サイズになってないってことですか?
どうやったらなりますか?
データ提出なので、データサイズをA5にしなくちゃいけないんです…
困ってるのでどうか、お願いします。助けてください。
ここで訊いてもあなたには理解できない答えが返ってくるので、質問に適した板に行ってください
>>659 >>660 が正論ですが、今パソコンに取り込まれているデータが A4 として
正しいとお思いなら、Windows をお使いならアクセサリーのペイントで
メニューの「変形(I)」→「サイズ変更/傾斜」で水平垂直を50%に指定して
「OK」し、(名前を変えて)保存されれば"A5"になるでしょう。
A5の用紙が必要です。
画像処理の専門家の私の意見は、
1 コンビニへダッシュする
2 服を脱ぎます
3 データをプリンターの設定をつかい、A5で印刷します。
4 スキャナーでA5サイズで読み取ります。
これでA5のデータができます。
コツとしては脱いだ服はシワのつかないように畳むことです。
つーかcutepdfとか入れて印刷とかすればいーんじゃね
つーか、普通は担当者がよっぽど間抜けじゃなければ印刷する段階でなんとでもなるから変に加工せずにそのまま送れ。
>>661 どうでもいいけど、A4を水平垂直を50%にしたら"A6"になるだろ・・・
666 :
661:2012/08/06(月) 15:39:08.61
>>665 訂正感謝。書き込んですぐ気が付いたけど、1+1=3 って書いたような
ものだからマ分かるだろうと放置していた。
>>659 スキャナで画像を取り込むとき、1インチあたり何ドットで取り込むか指定するDPIという単位の値を設定しているはず。
意識していないようなら、大抵200~600DPIくらいが設定されていると思うけど要確認。
プリンタドライバで印刷サイズを用紙に合わせるといった指定をしていない(できない?)場合は、印刷する際にもDPIを意識する必要があり、
この値をスキャナで取り込んだ際の値と同じにしておかないと、そもそもA4で取り込んだ画像をA4で印刷できない。
PictBearはデフォルトで72DPIが設定されるようなので、スキャナで取り込む際のDPIが200DPI以上だった場合、リサイズで1/2したぐらいではきっとまだ大きいんだと思う。
なので、解決方法としては、この値を変更することで対応できるのではないかと思う。(DPIはイメージ->イメージ情報...で変更可能)
A4->A5へのサイズ変更は1辺あたり1/1.414なので、イメージのリサイズをするのではなく、
DPIをスキャナで取り込んだ際の値の1.414倍に設定することで期待するサイズで印刷できるんじゃないかな。
668 :
デフォルトの名無しさん:2012/08/22(水) 19:47:06.86
1枚の写真から自動で3Dモデリングしてくれるのはどうすればいいの?
>>668 それだけで10cmくらい厚さの本になるだろ。
>>668 とりあえず「1枚の写真 3Dモデル」でググってみろ。
複数枚ではなく任意の1枚の写真からという事なら、
大きく分けて2つの技術の連結で成り立つ。
一つは写真から意味を読み取る技術、
もう一つは写真からジオメトリやトポロジを構築する技術。
前者は、写真には人の顔が写っているとか、建造物が写っているとか、
そういった何が写っているのかということを知り、
それらの境界(背景との境界や、目的のモノ同士の境界など)を知ること。
後者は、目的のモノの各点が30空間上のどこに位置し、
どの点同士が繋がっているのか、いくつかの点を繋いでできる面が
どこを向いているかなどを知ること。
予め何が写っているのか分かっている場合、
たとえば人の正面を向いた顔が中央に写っているとか、
比較的直線でできた建築物が写っているなどという前提に立てるなら、
上記の処理は(そうでない場合に比べて)大幅に難易度が下がる。
初めにググってみろと言ったリンクは、そういうものばかりだと思う。
求めているものは一応 image-based modeling と総称される技術のひとつだ。
こういうのは SIGGRAPH の論文を漁った方が正確な情報が早く手に入る。
最新の論文に一本目を通して、そこから参考文献を辿るといい。
>>670 それ人工知能で実現できないの?
例えば遺伝的プログラミングとかファジーとかベイズとか使ってやったりとか
建築物などの写真にたいして直線や円柱、並行・直角・鉛直の組み合わせのような
幾何学形状を仮定して一定範囲で復元ってのはあったはず
完全自動かどうかは忘れた
任意の対象に十分高精度にやれたらすごいね
動画やステレオカメラならできるだろうけど
1枚写真からの復元は大昔にさんざん研究されたけど条件を揃えないとできないから
研究のための研究(役に立たない)と批判されたのではなかったか
>>673 >>670 でも言ったはずだが、それにも関わらず、
なぜ先ず SIGGRAPH の論文に当たろうとしない?
読めないとか、調べ方を調べるのが面倒とか、
そういうくだらない理由ならもう付き合わん。
2D→3Dはかなり無理があるのはいくらアホでもわかるだろ?
3Dにするには情報量が足りないから、
あらかじめモデリングを用意してそれに2Dのテクスチャを貼り付ける方法しかまず思い浮かばない。
>>676 どこのページで、どういうキーワードで、探した?
文献が見つからないっていう人は検索結果に出てきてるけどもそれが自分の求めている情報と分からないのが大半だよね
>>679 「1枚の写真 3Dモデル」でググってみたけど見つからなかったんだよね
いいからURL貼れよ
>>681 だから、SIGGRAPH の論文を探せと何度も言ってるんだが
ACM DIGITAL LIBRARY(
http://dl.acm.org/dl.cfm)で検索して、
それっぽいタイトルの論文をクリックしろ。
(SIGGRAPH 以外のカテゴリの論文もヒットするが、SIGGRAPH のサイトより検索しやすい)
abstract は無償で読めるから、気になる内容だったら、まずは同名タイトルでググれ。
個人やグループで無償で公開されている場合も多々ある。
無償では公開されてないけど気になるのなら、論文1本につき$15でダウンロードできる。
ダウンロードしないで数日読むだけでいいなら、もっと安くなる。
$42で SIGGRAPH のメンバーシップになれば、1年間はダウンロードし放題だ。
今回の件に関して本気で原理を調べたいのなら、日本語の情報なんてほとんどないのだから、
SIGGRAPH のメンバーシップになって気になる論文を片っ端から落とし、
参考文献(eeferences)を巡ることを強く勧める。
>>681 日本語で(あるいは英語ですら)言ってるようなのの実用的で平易な解説なんてどこにもないと思うぞ
SIGGRAPH 押しされてるが、その分野だとCV系の論文も対象に入れといたほうがいい
>>683 だから、SIGGRAPH の論文を検索しても出てこないんだって
>>687 >>681 からは、そんなことは読み取れないんだが・・・
では、
>>683 で紹介した ACM のライブラリページで、
"image-based modeling" と "photo-based modeling" の2つで検索してみろ。
これだけでもかなり大量の関連論文がヒットするぞ。
画像をエッジ抽出後、抽出された物体の個数、面積を求めるコードを書こうとしています。
その際エッジで囲まれたピクセルを認識させたいのですが、何かいい方法はないでしょうか?
走査していって、エッジにぶつかったらON、次のエッジにぶつかったらOFF、ONとOFFの間をピクセルを囲まれているとする
今のところこんなのしか思いつかないのですが、これだとエッジの端だとワークしないためだめぽです。
なにかいいアルゴリズムはないでしょうか?
>>690 追加ですが、二値画像のラベリングではなく、あくまでエッジで囲まれている領域の
ラベリングを行いという意味です。
最初にニ値化しないのは、扱いたい物体の色がけっこうばらついているためです。
詳しい方、ご教授いただけると幸いです。
>>690 エッジ部分の2値化しきい値を得て、エッジ以外のしきい値を補間すれば
高品質に2値化できるんじゃね。処理速度は知らんけど。
映像からモーションを取り出すモーションキャプチャーのアルゴリズムってどうなっているの?
そんなのアルゴリズムによるだろ(´・ω・`)
>>694 カメラが特殊か認識しやすいカラーのシールを体中に張ってるだろ
Kinect みたいなのか?
Kinect SDKのサンプル一通り見てみれば?
モーションキャプチャーはハードウェアとセットの技術だから
アルゴリズムだけ問題にしても意味がない。
スケルトンモデルが決まってんだから、遺伝アルゴリズムが楽だな。
>>699 > スケルトンモデルが決まってんだから、遺伝アルゴリズムが楽だな。
具体的に教えてくれ
>>698 > モーションキャプチャーはハードウェアとセットの技術だから
> アルゴリズムだけ問題にしても意味がない。
でも動画だけでモーションキャプチャーできるソフトあるよ?
あれどんなふうになっているのかな?
どのソフト?
>>702 東大のベンチャー企業が開発したソフトのこと
>>703 2台以上のカメラを使えばそりゃできるよ
カメラもフレームの同期がいるだろうし
そういうのは特殊なハードウェアと言っていいだろ
あと手など速い動きはカラーマーカーを使うと書いてあるぞ
単純な話かもしれないけど。
白い画面に黒のペンで適当に落書きして、
そこから一カ所選んで陸続きのとこを塗りつぶすアルゴリズムってどんな方法があるかな?
考えた中だと、開始地点から横に真っ直ぐ塗りつぶして、
上下の次に塗りつぶせる範囲をスタックに入れて、
次はスタックを一つ選んで次に塗りつぶせる範囲を探しながらと…
そんな再起処理を思いついたんだけど、
これよりいいやり方があったら教えてほしい。
福沢諭吉「脱亜論」 1885年3月16日 時事新報
日本の不幸は中国と朝鮮だ。
この二国の人々も日本人と同じく漢字文化圏に属し、同じ古典を共有しているが、
もともと人種的に異なるのか、教育に差があるのか、 日本との精神的隔たりはあまりにも大きい。
地球規模で情報が行き来する時代にあって、近代文明や国際法について知りながら、
過去に拘り続ける中国・朝鮮の精神は千年前と違わない。
国際的な紛争の場面でも「悪いのはお前の方だ」と開き直って恥じることもない。
もはや、この二国が国際的な常識を身につけることを期待してはならない。
「東アジア共同体」の一員として その繁栄に与ってくれるなどという幻想は捨てるべきである。
日本は、大陸や半島との関係を絶ち、 欧米と共に進まなければならない。
ただ隣国だからという理由だけで特別な感情を持って接してはならない。
この二国に対しても、国際的な常識に従い、国際法に則って接すればよい。
悪友の悪事を見逃す者は、共に悪名を逃れ得ない。
私は気持ちにおいては「東アジア」の悪友と絶交するものである。
_,,,,,,__ __,,,__
ィjj)))))))))!!!!!彡ヽ,
/ミ/ ,}彡ヘ
|ミ{ -‐ ‐ ‐ ‐- {三=|
El==; ゚ ''==. |ミミ,|
`レfォ、,〉 :rfォ.、, !iル┤
. { `¨ i ・、¨ ´ `{ゞ'} 支那、朝鮮とは
. | '`!!^'ヽ .「´ 付き合うなと忠告しておいたのに。。。
! ,-ニ'¬-、 ,!|,_
. \´?` / ∧ヘ、
__/〉`ー ' ´ / 〉 \
_, ィ´「∧ / / 」¬ー- 、_
-‐ ´ / / ヽ、/ / iヾ ヽ
>>707 「シードフィル」でググると人によっては幸せになれる
>>710 ありがとう。
惜しいとこまでは考えてたけど、確かに再起はいらなかったなぁ
ROM-BASICの時代はPAINT文がスタックを使った実装だったなぁ。
シード・フィルに変えたら数割早くなったって遊んでいたら、
依頼元にぱくられてROM-BASICの次のバージョンで採用されたのもいい思い出w
全く関係無いけど「シードフィル」でググって一番上の記事の参考文献に泣いた
画像処理をやることになったんでOctaveかScilabを使おうと思っていますが、
画像データを手軽に操作できるインタプリタで他にお勧めのものはありますか?
あと、画像処理に限った場合、OctaveとScilabでは使い勝手、ライブラリの充実度、
情報の豊富さなどの面でどっちが優れているでしょうか?
fast marching は綺麗に丸く広がっていくのでコンピュータくさくない
(けど意外性は無い) 効率は FPU があれば
scan-line seed fill > fast marching > seed fill
pythonからOpenCV使うのは?
>>699 これ気になったがどうやればいいの?教えてくれ
画像処理の最適化アルゴリズムでAx=bを解くのに共役勾配方みたいな柔軟なものってなにがありますか?
>>719 あなたの画像処理の最適化アルゴリズムでAx=bを解くのに
共役勾配法ではいけない理由は?
柔軟とは何?
何ができればその方法を柔軟と呼べる?
>>720 周波数領域で一発で求める(l0smoothingのように)といった最適解を求める速度の問題です
柔軟とはパラメータ設定に容易に対応できるということです
jacobiなんかは設定にめんどくささがありますので
>>721 小出しにしないで、何をやっていて、何が分からないかを、
できる限り正確に質問してほしいのだが。
できれば、これくらいは言わなくても察してくれるだろとは思わないで、
多少冗長でも丁寧に質問してくれないか。
隠れた意図を探りながらレスを考えるのはけっこうしんどい。
そもそも画像処理関係なくね
線形方程式を解くだけだろ
行列の特徴によるとしか言えないのでは
最適で柔軟な思考を持ったエスパー希望
友愛
727 :
デフォルトの名無しさん:2012/09/16(日) 01:21:02.56
画像フィルタの特性を評価する一般的な手法ってあるでしょうか?
今はサンプルの処理結果をフーリエ変換して見てますが、これだと
使う画像にも依存しますし、なにか体系的な手法はないかと思いまして。
ありがとうございました。
ただ、インパルス応答というものを調べてみましたが、線形性が必要なようですね。
今回評価しようとしているのはエッジ保存フィルタのような非線形フィルタを含みますので。
といいますか、そのようなフィルタは解析的に特性を求めることができないのでどうしようかと
思っていたところでした。
しかし言われてみれば、そのような非線形フィルタの特性を表現できる一般的な入力という
ものもないだろうということに気づきました。こういう研究をやっている人は、どういう手法で
評価しているんでしょうか。
>>729 そのフィルタはどのようなパラメータをつかってどのような結果がでてほしいのかがしりたい
とりあえずはエッジ保存型のLPFとしかわからないから既存のものとの比較だね
Bilateral,NLMean,L0とかかな
731 :
727:2012/09/16(日) 13:53:39.55
例えばLPFで、カットオフ周波数以下はできるだけ保存しそれ以上は除去したいという
目標があったとき、評価したいフィルタをあるサンプル画像に適用して、その結果が
既存の他のフィルタと比較して良いか悪いかという評価はできます。
ただ、用いる画像を変えた場合にその傾向が変わりますので、なにか体系的な手法は
ないかと考えています。
最初は主にCZPを使っていたんですが、そこで良い成績を上げていたフィルタを別の
ある画像に適用したら非常に性能が悪化したということがありまして。
今は手当たり次第に画像を集めて試しているような状態です。
>体系的な手法
何を期待してるのか
もっと具体的に書かないと
似たようなことをしている論文を読めばどうやって評価したか書いてあるだろ
結局サンプル画像の作り方(選び方)を知りたいだけなんだろうな
>>734 ひらたく言えばそうですね。
要は、何か特性を向上させたフィルタを作成して評価する際、逆に劣化している
部分がないかを探るのに効率的な手法、あるいはサンプルの選び方はないかと
いうことです。
「一般的な手法などない」というのが答であればそれはそれでしかたありませんが。
書き忘れてましたが、対象としているのは写真画像の画像処理とその画質評価に
ついてでした。
フィルタの特性は自分で知ってる訳だから
いくらでもいじわるなデータを作れば良いのでは?
画像から体の身長を求めることはできないの?
三角測量すれば逝けるお
>735
顔認識フィルタに心霊写真を通すとどうなりますか?
顔の比率から回帰学習すれば大体は予測できるのでは
きっちり測るのは無理だけど
そういうのは測定したいとは思わない
奥行きの情報を意図的に変えてるんだから
メジャー持ってきて並べて撮影するのが正解
>>746 それならメジャーで図ればいいだろwwwwww
>>747 どういう状態にある何をどのようにメジャーで測るのか、
もう少し具体的に説明してほしい
人間がやってるんじゃね?
>>751 定規で顔の各寸法を測って、頭蓋骨の形や大きさ、性別などを割り出して、
あとは科捜研が白骨バラバラ死体から身元確認するために使う技術なんかを使って身長を割り出すんだろ。
>>753 どこまで分かって、何が分からないか、もっと明確に質問してくれ。
>>754 全部がわからん
もっとわかり易く教えてくれ
この白痴に物を教えるのは無理だよ。
>>755 では順番に説明する。
「定規で顔の各寸法を測る」
この意味は分かるか?
どういう作業か想像できるか?
>>749 の疑問は、人物画の縮尺をどう算出しているのかってことでは?
なにか指標を使ってるんだろ。
全てをキッチリ正確に計る必要なんて無いってか、できないしな
そういえば、モザイクの除去てどうやるんだっけ?
すいません失礼します
細線化について質問させてください
細線化をするとヒゲが発生する場合があり、多くの場合はこのヒゲを除去すると思いますが、ヒゲを残しておくと何か不都合な事がおこるのでしょうか?
別に不都合が起きないのであればヒゲは残したままでもいいと思うのですが・・・
エスパー頼む
たとえば認識が目的の場合、基準図形には普通ひげが無いので、
入力図形からもひげを除去したほうが比較しやすいでしょ
順序としては切片線形近似するなら近似してから短い線分を除去すればよい
統計的な情報でも使うんだろう。
成人女性の頭の大きさにそう開きがあるわけではないし、差がある場合でも
各部の寸法が同じ比率で拡大するわけじゃないから、その寸法比である程度
推定できると聞いたことがある。
まぁ、モナリザが分布の中心から外れたパース無視の造りじゃなければだが。
>>766 正確だとどこから読み取ったのですか~?
誤差何mmなんですか~?
骨相学という学問が昔あって
それ自体はオカルトだが人間の体の比率なんかはある程度測れるとか
L0smoothingをL1ノルムにしたものの導出わかる方いらっしゃいますか?
ちょうど1年前なのか
ちょっと論文読んでみるわ
Windows7に付属の動画編集ソフトの超解像機能がとんでもなく高性能な件
超解像のソフトを3000円ぐらい出して買ったのに無料ソフトの方が上なんて
>>766 >>772 便宜上細かい数値出してるだけで、何の意味も無いよ
自分の顔の寸法をメジャーとかでミクロン単位で測ってみ
で、次の日も測って同じ数字が出るとでも?
質問です。
画像中から障害物の検出・除去を行う方法を探しています。
自分が調べた限り、エピポーラ平面画像を利用した手法が主流なようなのですが、
他にもそういった技術を知っている方がいましたら教えて頂けないでしょうか。
また、そういったことに詳しいサイトURLもありましたらお願いします。
よろしくお願いします。
>>772 そのURLになにか意味があるように出されても
馬鹿かとしか言いようがない
>>772 統計ってしってるかな?
ようは、実在する人を測定したデータをたくさんあつめたものだよ。
もしかして
777
OpenCVで超解像のプログラムみつけたけど
商用ソフトも同じアルゴリズムなんだろうか
中学生がくるところじゃないよ。
>>779 モノサシって見たことある?
棒や紐状の物にあらかじめ等間隔で目盛を刻んだものを使って、
その目盛を数えることで距離を測ることができる。
>>779 >じゃあどうやって測定したの?
言葉足らずすぎwww
国語で主語、述語、動詞習ったかな?
日本語には主語がない
TV法ていろんなやり方あるけど導出をやってる論文で日本語のものありますか?
典型的なものから応用してるのまでどれでもいいです
>>786 そんなの適当に決まってる。
もう少し言えば、数カ所は適当に決めて、あとはそこから比を定規で測るだけ。
そんなわけない、というのなら、違うという証拠を見せてみろ。
>>786 もうわかったからさやすめよ
理論的なことわかんないんなら知恵袋いっとけ
>>789 写真に定規当てて測るだけだ。
それだけだと、各寸法の比しか分からない。
なぜなら、実際の顔のサイズと絵や写真のそれは縮尺が違うからだ。
(100% 原寸大の絵や写真ならいいけど)
だからどこか、たとえば目尻と目尻の間のサイズの原寸を適当に決定する。
統計で割り出した人の平均値を使ってもいいし、
あり得そうなサイズの幅を決めて、その中でランダムに選んでもいい。
これが基準だ。
原寸サイズと、各パーツとの比を決定できれば、全パーツの原寸が割り出せるだろ。
数カ所は適当に決めてと言ったのは、一カ所ではなく数カ所の基準から
各パーツの原寸を割り出して平均値を計算した方が、
なんとなくより本物の寸法を割り出しやすいかなと、
なんの根拠もなく適当に言ってみただけだ。
これ以上は詳しく説明できん。
>>790 定規を当ててどうやって比を算出するの?
黒目の大きさを代表平均値(12mm?)としてそこからスケーリングしてるんでないの?
>>791 人物画の上に定規を当てて、例えば目尻から目尻まで(A)を測る。
それが5メートルだったとしよう。
次に口元から口元まで(B)を測ったら2.6メートルだったとしよう。
すると、(A)の長さと(B)の長さの比は 5:2.6 だ。
つまり、その人物画のモデルの目尻から目尻までの長さを基準にすれば、
口元から口元までの長さはそのおよそ半分だなと推測する。
定規を当てて比を算出するというのはこういうことだ。
各パーツの比が分かれば、あとはどこか一つのパーツの実寸さえ分かれば、
全パーツの実寸が推測できる。
実際は
>>792 のように、個人差があまり出ない
黒目の大きさなどを基準にするのだろう。
>>793 個人差もそうだけど、年齢による差(成長過程での変化)も比較的小さい部位らしいよ <黒目部
>>794 へぇ、でも小さいから誤差は大きそうだね
どれを基準にしたらいいんだ?
計れるもの全部計って
誤差の少なそうな部分からの比に変換したあと重回帰とかだろ
基準を複数選んでbaggingしてもいいし
誰か画像処理の1次微分と2次微分の違いを馬鹿でもわかるように教えてください!根本的に何が違うかわけわかりません!
>>800 画素の数値の変化量を表すのが1次微分
変化量の変化量を表すのが2次微分
変化量の変化量の変化量を表すのが3次微分
THX! 微かに分かった。
1回の引き算を一次微分
2回の引き算を二次微分
って言う世界もある
変化の割合のことだけど、引き算で済ましてることがあるってことね。
今どきは画像処理を学習・応用する人が微分、積分、離散数学
は無理解で済むようなライブラリでも供給されてるの ?
離散値 An+2, An+1, An, An-1, ... があるとして
1次 (An+2 - An+1), (An+1 - An), (An - An-1)
2次 (An+2 - 2An+1 + An), (An+1 - 2An + An-1)
3次 (An+2 - 3An+1 + 3An - An-1)
空間方向の離散値 隣のピクセルとの…
時間方向の離散値 1つ前の映像との…
大学でいきなり「来週までに一次微分と二次微分の違いを調べて説明しろ」とか言われた、マジわけわかめ画像処理の事なんて一ミリもわからんがな!
じゃあ辞めたら?
時間の無駄だよね
画像処理以前に、二次微分の意味を解ってないような
いまどき微分も知らずに入れる大学なんてどんなF欄よ
全入時代の今だから入れるんだろ。理系でさえもな。
○大工学部の学生さん
132.5kの抵抗って…高くつきますよ
ハッハッハそのとおり!!私はF欄大学に通ってるぞ!!よくぞ見破ったな!!
815 :
デフォルトの名無しさん:2012/10/20(土) 07:35:32.91
そういう質問の仕方をしている限り作れません。
あきらめましょう。
了解
あきらめました
あきらめまーした♪
820 :
デフォルトの名無しさん [sage] :2012/10/20(土) 22:26:07.85
Σ(゚Д゚)スゲェ!!ーこの板参考になる
激安PCソフト市場でググってみて
色んなソフトが激安いいよ
1枚1枚って、お前バカか?
ドットの数え方は1粒1粒だろうが
823 :
デフォルトの名無しさん:2012/10/22(月) 20:14:54.23
動画で一枚ならフレームってことだろ。
フレーム一枚々、ドット絵描きなさい。
無問題だな。
それはさておき、
お前バカ…こういうの止めないか
議論に割り込んでスマンが、
>>815 のはサイズ的にドット絵を描くという範囲を超えてないか。
いや、どれくらいまでならドット絵と呼べるかという基準はもちろん無いが。
>>824 NHK 等で行っている昔の映像の修復やカラー化などは
部分的ではあるがドットお絵描きをやってるよ。
NHK 以外でも数年の時間を費やして数十秒の動画を
修復、そのやり方はほとんどドットお絵描き。
>>825 昔の映像の記録方式って当然デジタルじゃないよね
それをドットを打って修復するということは、
修復後の解像度は固定されるということ?
後の世にもっと解像度が高いテレビがでたら、
またその解像度に合わせてドットを打って修復した映像を公開するの?
今の技術ではそれしか方法がないのかも知れんが、
それにしても、すごい仕事だな
実際にどのような形式、どの解像度でデジタル化しているかまでは
知らないけど、少なくとも MPEG-2 の解像度は 1920x1080i が
最高解像度ってことではないよ。
動画ではないが、美術品のデジタル画像化などでは、スキャナー
方式的な方法で、ちょっと普通ではありえないような画素数で
行っているみたい。色の扱いもスゴイ厳格に行っている。
ラインカメラ(受光素子が1次元で一直線に配置)で
複数回スキャンするようなのか
それぞれに、方式があるだろうと思う。
自分が関係したところでは、単素子スキャンでした。
そいつを、超巨大プロッタのような装置で移動させる。
画像が歪むのでレンズで画像を縮小はダメとか、いろいろある。
昔は高分解能で高速なA/DCが無かったので大変でした。
ドット打ち法を
>>815 に使うのは非常に「スジが悪い」と思うのだが
832 :
830:2012/10/23(火) 12:53:02.56
>>831 仕方ないだろ。
人間が1フレームずつ描いていく方法はスジが悪いと直感で感じるが、
しかしどういう方法でやるのが良いかは分からないんだから。
正確に言えば、いろいろ考えてはいるが、
実験して確かめる術が今はないし、このおもちゃを実際に見たこともないから、
この方法だとははっきり言えない。
始めにグリップ部を振り下ろす直前に、向き(回転角度)を確認してるから、
どこかにボタンがあって、押すとグリップ部から長い棒状の物が出るのではないか?
恐らくその棒がARマーカーとなってるのだと思うのだが、どうだろうか。
この方法なら、体の後ろに回ったときもちゃんと描画できるだろうし。
>>832 現在は 1フレーム毎を容易に確認できる。
何かを想定したのなら、とりあえず 1フレーム毎見てみれば ?
わかるかどうかは知らんけど。
昔ね、揺れているカーテンに映る、波打つ画像のコマーシャルがあってだね
適当に画像をゆすって重ねれば、人間の目はごまかされるってオチだったよ。
20秒程度の動画で奥行きが解り辛いビームサーベルなら、
下手に考えるよりドッターが直接描いたほうが早いな
んで、最初のスターウォーズはどうやって描いたの?
最初は、光る棒切れだか光反射する棒切れ振ってたんじゃなかったっけな
ただの棒を振り回して後でフィルムを塗ったんだろ
スイッチ入れてビヨーンって伸びるとこは?
ロトスコープだね。
トレースして描いて合成して……ってところかな。
>>834 画像処理でやらなきゃ、このスレとしては面白くないだろ
842 :
デフォルトの名無しさん:2012/10/23(火) 20:59:35.20
画像処理に固執すると問題を解決したいだけの人には馬鹿と思われるだろ
家族アルバムの分類を機械学習でやろうとしているようなもの
適切に使え
現実問題を考えるなら、最も楽な手っ取り早い方法を選べばいいと思う。
その結果として、画像処理を全く使わず簡単に解決してしまう場合もあるだろう。
ただ、このスレにお題として出されたものを画像処理を使わず解くというのは、
なんか逃げてるというか、面白くないというか・・・
どのような画像処理で解くかを皆であーだこーだ議論する方が楽しくないか?
誰も解く気がないならそれでいいけど
困っている人の質問から始めると迷惑だろ…
>>815 が困っているようには見えん
すぐ諦めてるし
現実的な回答を出した後で好きに議論すればよい
グリップをトラッキングしていれば
グリップの白と黒の境界線からライトセーバーを出す方向は分かりそうだけど
これだけのためにそういった処理を書くとは思えないのでフォトショだろ
昔見た記憶がある
走ってきた釈の乳がこぼれる動画
あれは、サイズとフレーム・レートを調整し
ドットお絵かきだった。
>>847 ARマーカーを識別するのは画像処理だろ
>>849 新三部作辺りだとアルミの棒だったと思う。でないと鍔迫り合いができない。
で、ARライトセイバーを作るんだったら棒の先端に赤外線LEDでもつけておけば医院で内科医?w
854 :
デフォルトの名無しさん:2012/10/26(金) 23:02:40.40
それがあるのは知っててみんなスルーしてると思ってたの
いや、俺は知らなかった
>>853 面白いね
真剣なのに思わず笑ってしまって周りから白い目で見られた
857 :
デフォルトの名無しさん:2012/10/29(月) 16:50:04.40
麻生太郎 : 未曾有 = みぞうゆう
石原伸晃 : 生保 = ナマポ
前者は昔からのいわゆる、漫画ばかり見てると漢字読めない馬鹿になるよっ、の具現者
後者は知識もとを2CHとする、単なる馬鹿、民主が WikiPe で非難されたろ (学習能力の無い奴だ > 死ゲール)
大学でhogをopencvを使わずにc++でプログラムしなきゃいけないだが
全然分からん
aviの動画を読み込み1フレームずつ処理するんだが…はぁ
助けてくれ……
なんでプログラムが点で駄目な俺にこんな課題振るんだよ…
>>858 プラット・フォームに縛りはあるのかね ?
とりあえずVisualstdio2010で作ってみてるんだが
そもそもプラットフォームってなんぞやレベルの俺に振るから
どうしよううもない
>>860 HOGって何じゃらほい? って思わず調べてしまった。
最近は大学で、こうゆうのが流行してるのか・・・
分からないことが多い場合、例えば
(1)VisualStudio10の使い方と、C++プログラムの基本を覚える
(2)opencv等の既存のライブラリを使用し、静止画のHOG特徴を求めてみる
(3)自作のライブラリに置き換える。
(4)AVIを操作するライブラリ(vfw等)を使って、動画から1コマずつ取り出し (3)のプログラムに渡す
みたいな漢字で、段階的にやるといいと思うよ。
一気に片付けようとすると、途中で挫折するかもしれないから。
ライブラリというより画像の構造体でしたかね?
なんにせよこれらを使わず輝度値など取り出したりしないといけなさそうです
参考に出来る話となるかわからんが…
まずは AVI ファイルがどのような仕組みである事と
Windows で AVI ファイルを扱う仕組みを理解することが
先になると思う。
AVI ファイルは一種のコンテナなので、AVI ファイルと
言っただけでは、なかの画像形式まで限定される話では
ない。
まずは AVI ファイルからフレーム単位の画像を読み、
プログラム中の配列等に格納する段階で挫折しそうな
予感がするのだが…
動画の読み込みなんて既存のライブラリを使えばいいだろ馬鹿かとキレたほうがいいと思うけど
発言を見るとプログラミングが苦手なようなのでそのための課題なのかな
プログラミングが苦手なのに機械学習や画像処理の高度なプログラミングが必要なコンピュータビジョンを選んだのが悪いのでは
苦手を克服したいならC++を10年間勉強するなど苦行を積むしかない
処理する部分が必要なだけならAviSynthとかAviUtlのプラグインとして組んだほうが楽
「3日で作る高速特定物体認識システム」
のSIFTをホゲに変えてみりゃいいんじゃね
>>866 > 動画の読み込みなんて既存のライブラリを使えばいいだろ
その既存のライブラリとやらを教えてあげなよ。
一から知識仕入れての場合、連続再生であれば、
数日程度で C++ から AVI ファイルの再生を行うプログラムを
作れると思うが、AVI ファイルから任意のフレームの
画像データを読む部分が簡単に達成できるとは思えんよ。
昔、盛んに API プログラミングしていた頃なら資料や
サンプルを容易に入手できたが、今では資料を探すだけでも
難儀だと思う。
動画の読込が課題なのか特徴量の抽出が課題なのかよくわからんなw
今時AVIファイルから自力で静止画の抽出とか無駄すぐるw
AviSynthでいいじゃんね。
本人がOpenCVを使わずに言っているのが
そういったライブラリを使わずにフルスクラッチしろという意味なのか
HoGを理解するためにOpenCVの実装を使わずにという意味なのか
後者なら動画の読み込みや画像の操作はOpenCVでよくね
>>872 > 輝度値を取り出したり水平方向のデータ数とかちょこちょこopencvのライブラリを使ってるので
> ここを変えて行きながらやってみます
すごく前者な気配
まあ無理・無知
次のかたどうぞ
>>862 その本だとP.31か
EHOGなら簡単に出来そうだし、頑張れ
VLC は学生が作ったとかではなかっただろうか
あれは、結構な部分が自力だったような気がする
がんばってくれ
>>877 悪気は無いが、お前の文章はわけがわからん。
その文章を他人が見て、お前のやってることを
正確に知ることができると思っているのか ?
>>878 十分わかりやすいと思います
アスペは黙ってましょう
>>877 自分の書いたコードのバグは疑わないのね。
881 :
デフォルトの名無しさん:2012/11/09(金) 10:32:53.01
ミスっているだけ
自分のバグと思われます、すいません。
>>877のリンク先のアルゴリズムですが、ルックアップテーブルの書き換えでラスタスキャンする時、
4画素の内、複数の画素にテーブル番号を割り振ることってあるのでしょうか?
>>877 自分の書いたプログラムで入力画像に対してどんな結果が出力されたのか見せないと、
何も言えない。
>4画素の内、複数の画素にテーブル番号を割り振ることってあるのでしょうか?
書かれても居ない仕様を勝手に実装しようとする癖は良くない
ただ一例で癖だと判断する癖は良くない
ラスタスキャン中のルックアップテーブルの書き換えって
>参照した画素のラベル番号が複数存在した場合、最小の番号を割り振ります。
>このとき、用いなかったラベル番号(下図の例では3)のルックアップテーブルの番号を最小の番号に書き換えます。
これの話か?
ABCD□: 各画素のラベル値、 LUT: ルックアップテーブル
BCD
A□
□=(0 を除く A~Dの最小値)
LUT[A] = LUT[B] = LUT[C] = LUT[D] = □
この処理を
元画像の白が現れる毎に行う
元画像の白の探索は左から右へ、右端に到着したらひとつ下の左端へ
画像の最後まで走査し終わったらルックアップテーブルの整理(ラベル値の修正)
>>886 エスパー翻訳ありがとうございます。
BCDE
A□△
で、まず□を参照した時に「ABCD□」のテーブルを割り振りますよね。
その次に△を割り振る時、「□CDE」を見るので「□CD」は重複になるので参照する意味があるのかな・・・?って思ったのですが
よく考えたら△がより低い値でしたら、全て書き換えになりますね。
すいませんでした。
>>887 その例の場合(=□に続き△で隣接が確定してる)、多少の省略が効くかもだけど
まずは、提示されているアルゴリズムをその通り実装し確認てから、小細工しなさいな
>>888 すいません、アルゴリズム通りに書いたつもりが上手く動かなくてテンパってました。
2次元ボロノイ図生成のためのFortuneのアルゴリズムって3次元に拡張可能?
パッと考えると拡張可能そうだけど、その手の記事を全く見かけないのだが・・・
latent svmを用いて、対象検出(人)を行いたいと思ってます。
そこでlatent svmを使って学習を行えるプログラムを探しているのですが、なかなか見つけることができません。
何か良い方法を知っていたら教えてください。
環境
windows2007
visual studio 2005
visual studio 2010 express
自分で作ればいいと思うの
なんのための開発環境だよ
偉い人には分からない飾りか?
893 :
デフォルトの名無しさん:2012/12/12(水) 19:02:50.87
馬鹿には無理
>>891 ググったらソースもあるようだし、openCVにもあるようだが…
それに、なんかやりたいならWindowsじゃなくてもできるようにしといたほうがいいよ
895 :
デフォルトの名無しさん:2012/12/12(水) 20:55:31.86
ヒステリシスって書いてあるじゃん
微分ヒステリシスであることが分かっているのだから論文漁れよ
という意味なのでは?
微分ヒステリシスを応用した結果であって
微分ヒステリシスが本質ではないという事だろ?
こんな頭悪いのはうちの学生にもそういないな。
ヒステリーになるなよw
つまり、
日本語が不自由な民族ということですね。
わかります。
間違った解釈でわかっても将来恥をかくだけ。
903 :
デフォルトの名無しさん:2012/12/13(木) 20:54:12.36
このスレで難しい事を言ってはダメ。
DICOMも知らない人たちだから。
ヒステリー死す
>>895は本質じゃないことを応用したって宣伝してるんかいな
へんなの
ヒステリーは二度死ぬ
>>907 二つの異なる閾値がうまく表現されているね。山田くーん!座布団二枚!
>>906 くやしかったら同じようなアルゴリズムを提示時てみろ。
あっちはMITで開発されたそうだがお前はどこの大学?
京大?九州大学?
馬鹿には無理
俺の勘違いかも知れんが、
>>909 は虎の威を借りかけているように見える
その認識は間違ってない。
MITを前に負けを認めてくやしくないのか?
俺はくやしいのう くやしいのう だが。
最終的にはMITライセンスで作ったプログラムをみせろとか言ってきそうだなw
ほんとダメ人間の巣窟だな
画像処理と言っても頭のいい人が作ったアルゴリズムを
訳も分からず利用して、さも自分が作ったかのようにふるまう
似非技術者集団ですから。
ねえ、どんな気持ち?
∩___∩ ∩___∩
♪ | ノ ⌒ ⌒ヽハッ __ _,, -ー ,, ハッ / ⌒ ⌒ 丶|
/ (●) (●) ハッ (/ "つ`..,: ハッ (●) (●) 丶 自演がばれるって
| ( _●_) ミ :/ :::::i:. ミ (_●_ ) | どんな気持ち?
___ 彡 |∪| ミ :i ─::!,, ミ、 |∪| 、彡____
ヽ___ ヽノ、`\ ヽ.....::::::::: ::::ij(_::● / ヽノ ___/
/ /ヽ < r " .r ミノ~. 〉 /\ 丶
/ /  ̄ :|::| ::::| :::i ゚。  ̄♪ \ 丶
/ / ♪ :|::| ::::| :::|: \ 丶
(_ ⌒丶... :` | ::::| :::|_: /⌒_)
| /ヽ }. :.,' ::( :::} } ヘ /
し )). ::i `.-‐" J´((
ソ トントン ソ トントン
>>913 ミーハーだな
くやしいのう くやしいのう
920 :
908:2012/12/15(土) 08:58:43.93
わーい
素直に負けを認めないところは明治大学だな?
超解像度のアルゴリズムって
もう出尽くしてるのでしょうか?
現状あるアルゴリズムで一番動画が奇麗にみえるのって
どれになりますか?
特に人間の顔とかを奇麗に見せたいです
>>922 んなことはない
動画は、vRevealって製品があるくらいじゃね
face hallucinationを動画に応用するとか
今の市販テレビの超解像の処理速度って、専用チップ使ってるとは言え
はえーなーって思うのは俺だけ?
終わった番組だけどHEY^3がブロックノイズでまくり。
元ソースのせいなのかテレビのせいなのか。
nintendo 3DSのステレオカメラって
パソコンから使うことってできないのでしょうか
民生品のカメラってSDK公開されてないのがほとんどだよねぇ・・・
PC用のアプリついてるのに制御方法教えてくれないのは、何かあるんだろうか?
トラブルの元を公開する必要が無いからですよ
わざわざ金と時間を浪費してサポートしなけりゃならない理由なんて一つもありません
まー面倒なだけか
単価安いしそれを売りにしてもたかが知れてるし本気でやる奴は産業用を買うし
掛け算に問題があるんじゃね?(小並感)
935 :
933:2013/03/05(火) 20:26:16.73
フィルタ画像は元画像と同じサイズの画像の"中心"にガウス関数を置いていたのですが
左上に置くようにしたらできました
なぜ中心に置くと入れ替わってこれだといいのか分からないですが
周波数空間像は正負に振れるから原点を中心にするけど、
画像をFFTしたときは原点が左上のままなんじゃね。
見た目は良くても中心におかないと正しくフィルタされないんじゃね?
939 :
デフォルトの名無しさん:2013/03/24(日) 22:45:00.43
画像サイズの中心にガウシアンの中心を置いたら、原点からして半分ずれたガウシアンて事になるだろ
単純にフィルターの位相がずれているだけだと思うよ。位相がずれないフィルター設計は難しいからね。
ifftでも位相を直していたと思う。ifft のかやりにfftで戻してみれば?
942 :
デフォルトの名無しさん:2013/03/25(月) 04:49:57.77
ありがとうございます。
無事解決しました。
結局fftwのf像はどこが原点だったんだろう……
神話少女の水面が歪んで見えない部分を見えるように修正できる人いませんか
>>944 そっと目を閉じて心を静めればロックが解除されるはず
水面も波長なので、逆変換かければ見えるようになるはず
そういえばモザイク復元機が良く売れたらしいな
トリミングじゃだめなん?
技術というよりはトリミングって作業よくやらないか
背景色が1色なら簡単でその背景色でないピクセルを含む矩形の集合の差集合(ゲームとかのマスク画像) -> 非矩形
画像をいくつかの矩形の和集合とみなし(究極的にはピクセル)、その矩形に背景色(または指定色)が含まれている(いない)ならば、矩形集合に追加していく
上記の操作を矩形集合に対して矩形の大きさを小さく(大きく)して再帰的に行う
その集合の端の値(最小値と最大値)が求める矩形となる -> 矩形
画像のライブラリとかはCropのが多いね
Trimは文字列の空白を除外とかには使われてる
自動切抜きのアルゴリズムに名前が有るかは知らない
一瞬くろまきーって答えそうになった。
カットしたい色が決まっているなら透過しちゃうからないんだよね。なまえ。
そういえばImageMagick付属のconvertにもcropってあったな
ただ、cropは画像の特定の領域を取り出す感じで、trimは要らない部分(帯状のベタ部分)を取り除く感じ
955 :
948:2013/03/28(木) 11:54:54.53
GraphicDesigner系はトリミングって言ってる気がする
画像処理はかじったこともないけど質問があるので教えてください
bmpの画像の拡張子をjpgにしても普通に再生できちゃうんだけど
どうしてなの?
画質の劣化は目で確認できないどあるのでしょうか・・・?
>>957 拡張子を無視してファイルのヘッダの情報を見てるとか
その再生ソフト次第だろな
拡張子なんてただの飾りです。偉い人にはそれがわからないのです。
ファイルには大抵マジックってのがあってな云々
>>957 釣られたクマー
再生ソフトがどちらも対応してるからだよ。
実はOSがMacでした
今はどうかしらんが、IEなんかも拡張子見てないし
>>957 ・画像表示ソフトによっては拡張子をあてにせずにファイル内のヘッダを見て判別する
・エクスプローラで名前を変えたくらいでファイルの中身は変わらない
画像処理とはちょっと離れちゃうかもですけど教えてください。
2次元に得られた強度なんかのデータから2次元画像を生成する
(マッピング?)場合、例えばデータが[0,1]区間の実数だったら
例えば0を青、0.33が黄色、0.66が赤、1が白とかの色に変換したり
したいのですが、定石とかありますでしょうか?
ググリたいのですが、キーワードとか教えていただけないでしょうか。
よろしくお願いします。
>>964 定石なんかない。
例えばそれが温度だったら、0を青、0.66が赤とかでいいだろうけど、
強度が低いほど危険な状態を表しているのなら、0の方を赤にすべきだろう。
そういう事を考えずに、適当に色分けしたいだけなら、「色相環」でいいんじゃね。
>>965の方針でいけば、HSV色相間を通じてRGBに変換するのがお手軽じゃないかな?
ここにもQZが現れたか
みんな逃げろー
968 :
964:2013/03/31(日) 10:08:20.67
ありがとう。
色相環ですね。
勉強になります。
最初と最後を黒と白にしたい場合とかは、場合分けで対処、例えば
I<0.1 -> f(I) =黒から青
0.1<= I < 0.9 -> f(I) = 色相を動かす
I < 0.9 -> f(I) = 赤から白
とかするのでしょうか ?
厚かましくさらに質問なのですが
色相を動かすとき、青から緑をすっとばして黄色に持って行きたいのですが
連続的に自然な感じで変化させるよい手法はありませんでしょうか ?
>>968 > 最初と最後を黒と白にしたい場合とかは、
> ・・・
> 青から緑をすっとばして黄色に持って行きたいのですが
スプラインなんかで補間すればいいんじゃね。
もしある決まった値で決まった色を必ず使いたい(その間は滑らかに補間)のなら、
カットマルロム補間とかベジェ補間を使えばいいだろうし。
好きな色合いでやりたいならテーブル引きで十分じゃね?
テクスチャとして外部で作成しておけばいいし
緑を経由しないんだったら色相環を青→紫→赤→黄色の方向にたどればいいんじゃないかな。
途中、彩度を変えてもいいんならある程度自由な経路を選べるけど。
>>954 児ポルノの単純所持が規制されそうだし
早めにだれかやってくれないものかのう
>>969 黒→青→黄色→赤→白なら、
0, 0, 0,
0, 0, 1,
1, 1, 0,
1, 0, 0,
1, 1, 1,
の間を補間するだけでもそれなりになるよ。
>>973 いや、だから「自然な感じで変化させる」のが望みなら
補間法にBスプラインとかカットマルロムを使えば、という話だ。
(
>>969 は B が抜けてたな)
自然な感じでなくても良いなら、線形補間で十分だと思うよ。
補間方法が何であれリニアRGB空間で処理しないと自然な感じにはならなくない?
>>968 >青から緑をすっとばして黄色に持って行きたい
中間ではどんな色を想定しているのでしょうか?私は緑以外を想像できない‥‥
マジェンダでいいんじゃね?
青から緑を経由しないで黄色なら、彩度を維持するとマジェンタしかないね。
彩度を無視していいなら>973の要領でグレイを経由するとか。
馬鹿ばっか
981 :
964:
みんなありがとう!!
みんなが教えてくれた知識をもとに
(自分にとって)もっとも自然な経路を模索してみるよ。
サンキューな!!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
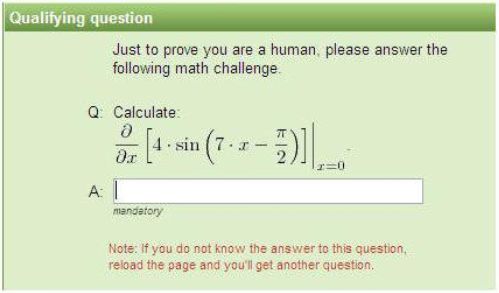{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}