"The duct tape of the Internet" こと、Perlについての質問箱です。
"There's more than one way to do it" ということで、Perlの奥深さについて皆で語り合い、追求してまいりましょう。
CGIについての質問は板違いです。WEBプログラミング板でどうぞ。
CGIとPerlの区別がつかない人もWEBプログラミング板に行ってください。
(WEBプログラミング板
http://pc8.2ch.net/php/ )
CGIの質問は答えがPerlと全然関係ない話に帰着する場合が多かったりするのでWEBプログラミング板に行って聞いたほうが得ですよ。
このスレでは(CGI以外の)純粋にPerlのみに関係する質問を取り扱っていこうと思います。
http://www.perl.org/get.html ● 2006/04/26現在の最新版: 5.8.8
● 2006/04/26現在の開発版: 5.9.3
リンク集は
>>2-3 過去スレは
>>4 こんな時間に乙!
乙~
Perlで2つのプロセスを動かして同時に同じファイルを参照したり書き込むとき
ある変数 $kekka に、20バイト分のバイナリデータを代入した場合、
久々にエロ小説埋めきたな
@list = unpack('C*', $kekka);
>>8 flock とか fcntl の F_SETLKW とか。
ロックファイルとかセマフォとか。
15 :
デフォルトの名無しさん :2006/04/26(水) 16:15:07
あげ
17 :
デフォルトの名無しさん :2006/04/26(水) 21:34:40
>>970 環境変数?の変更ですか?
ご教授ください。
Encode::JP::H2Zを使って半角->全角変換しようとしたけどうまくいきませんでした。
スクリプト自体の文字コードが分らないからなんとも言えないけど
>>17 環境変数とは違うものなんだけど…作業ディレクトリ=カレントディレクトリといえば分かる?
もし分からないなら、自分で調べれ。Perl以前の基本中の基本だから。
# 時々知らない香具師が現れる…
$FindBin::Binのほう、起動されたスクリプトが配置されているディレクトリの絶対パスが入っている。
そもそもそのスクリプトは、スクリプトのあるディレクトリにあるファイルを操作する、
つまり作業ディレクトリがスクリプトのある場所になっていることを前提に作ってあるわけだ。
だから、その前提に合うように作業ディレクトリを変えてやれば望んだとおりに動作する、と。
windowsへのコンパイルってどれ使えばいいの?
PARとか
サンスコ!わかった。
え?でも変だな、、、。
29 :
デフォルトの名無しさん :2006/04/27(木) 16:41:12
>>27 ||はスカラーコンテキストで評価される
だから@valにはstatの戻り値としてリストは格納されていない
試しにprint $val[0];とやってみ1って出るから
つまりstatが成功したことを示すスカラーが返却されている
つぅか||なんて使うな
orにしとけ
>>27 read <perldoc> or die;
Type of arg 1 to read must be HANDLE (not <HANDLE>) at
>>33 line 2, near "<perldoc> or"
Not enough arguments for read at
>>33 line 2, near "<perldoc> or"
>>33 had compilation errors.
perldoc -f read
>>21 PerlAppオススメ。有料だけど起動時間は最速だと思う。
36 :
18 :2006/04/27(木) 21:20:48
>>19 あり。
Encode::JP::H2Z使う時はencodingプラグマは使えないという仕様なんですかね~
37 :
デフォルトの名無しさん :2006/04/27(木) 23:13:01
また知らない香具師が現れたな・・・
39 :
デフォルトの名無しさん :2006/04/27(木) 23:23:43
ごめんなさい。わかりません。
カレントディレクトリの意味はわかるけど
>>20 のいうようなカレントディレクトリの変更方法がわからんw
40 :
20 :2006/04/27(木) 23:32:11 BE:750910278-
>>37 そうか、スマソ
「環境変数」で意味が解る香具師がいるなら漏れの勘違いなんだろうな。
漏れには話のつながりが解らんから質問に対する答え頼んだ。
41 :
デフォルトの名無しさん :2006/04/27(木) 23:32:57
pathのこと?
43 :
デフォルトの名無しさん :2006/04/27(木) 23:36:41
>>40 ごめん、、、ヒントをくれ・・・カレントディレクトリの意味しかわからんよ。
俺も白根
>>43 | use FindBin;
| chdir $FindBin::Bin;
のchdirについて訊いているのかと思って解説しただけ…
ってもしかして
>>37 氏ageてるって事は質問者さんだったか・・・
そうだったら重ねてスマソ。普通の回答者だと思って回答頼んじまった
46 :
デフォルトの名無しさん :2006/04/27(木) 23:45:50
>>45 970 名前:デフォルトの名無しさん[sage] 投稿日:2006/04/26(水) 01:01:29 ?
>>969 原因は分からんが関連付けから起動したときに、
作業ディレクトリが別のところに行くようになっちゃってるようで。
根本的な原因はこのスレの範疇外だと思う。スクリプトの頭で、
use FindBin;
chdir $FindBin::Bin;
とでもやっておきなされ。これで作業ディレクトリがスクリプトのある場所に行く。
>作業ディレクトリが別のところへ行くようになっちゃってるようで
これの設定変更ってできる?
47 :
20 :2006/04/27(木) 23:57:54 BE:107273524-
>>46 そっちのことだったのかorz それについては知らん。
というかその問題はPerlと関係ないと伝えたつもりだったから、
Perlに関連する部分か前提になっている作業ディレクトリという単語に対しての
レスだろうと思ってあんな勘違いしたレスになった。いや申し訳ない。
もう、win から再インストールしなされ
こういうときに何で馬鹿がわくのか・・・
cperl-modeで
またエラー内容隠蔽者か。
52 :
デフォルトの名無しさん :2006/04/28(金) 02:03:08
>>51 エラーつってもcperl-modeのエラーだから、
cperl-mode使えるやつなら試してみれるかなと思って。
End of `/ ... /' string/RE not found: (scan-error Unbalanced parentheses 1 13)
これがミニバッファにしつこく表示される。
Emacs 21.3 で試したけど問題無いみたい。
>>53 >Emacs 21.3 で試したけど問題無いみたい。
試していただきどうもです。
時間があるときにEmacsのアップデートするのが良さそうですね。
>>46 思ったんだけどショートカットから起動してたりと化しない?
56 :
デフォルトの名無しさん :2006/04/28(金) 08:32:47
すいません、ActivePerlなんですが、
>>56 だろうけど
動かないモジュールがでるかもね
58 :
デフォルトの名無しさん :2006/04/28(金) 16:27:53
>>57 ありがとうございます。
バージョン違いで動かないものが出てくることはある、ということですよね。
それはしょうがないですね。
ふと思ったのですが、ハッシュのキーに使えるものにはどんな制限あるのでしょうか?
>>59 え? スカラにさえなるなら何でも使えると思うけど?
$val{$x}{$y} のようにキーが2つあるハッシュを値でソートして $x,$y,$val{$x}{$y} を出力するには
>>62 一回でやろうとするからこんがらがる。$xと$yを別々に決定するんだ
foreach my $x (sort keys %val) {
foreach my $y (sort keys %{$val{$x}}) {
print $x, $y, $val{$x}{$y};
}
}
64 :
62 :2006/04/28(金) 22:12:17
>>63 それではハッシュのキーでのソートになってしまいます。
ハッシュを値でソートしてと言う意味は
$val{ a }{ A } = 1;
$val{ a }{ B } = 4;
$val{ b }{ A } = 3;
$val{ b }{ B } = 2;
の場合
a,A,1
b,B,2
b,A,3
a,B,4
のように出力させたいのです。
65 :
 ̄ ̄∨ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ :2006/04/28(金) 22:34:42
___ ミ
sub main {
ぁ cmpじゃなくって<=>だった;
68 :
62 :2006/04/28(金) 23:21:32
>>66 やばい。ヒントだけもらって自分で解くつもりが答えを見てもよくわかんない...orz
でも、時間をかけて順々に追っかけていくと何とかわかったような気がしてきました
解読結果を書くので間違っていたら指摘してください( 用語とか間違ってるかも )
$fkは$x成分を一時的に入れている。
外側のmapでキーの要素$x,$yの組み合わせに対して
無名配列[$x,$y]を要素としたリストをつくっている。
@xy_list = map{...} keys(%val)
できた@xy_listに対して、以下のsort
(自分の場合やりたいのはcmpでなくて、<=> なので少し変えてます)
sort {
$val{ $aのx成分 }{ $aのy成分 }
<=>
$val{ $bのx成分 }{ $bのy成分 }
}@xy_list
この、値順に並んだ[$x,$y]に対してこれを$khとしてforeachで回している。
一度[$x,$y]の組み合わせのリストをmapで作るのがポイント。
自分一人では絶対に思いつかない方法でした。
ありがとうございました。
そもそもの構造が、あはぁんな悪寒。
>>68 あってると思う。
でもこんなことやるより最初にハッシュキーの組み合わせのリストだけ作ってsortしたほうが読みやすいし、
>>69 の人が言ってるようにそもそもデータ構造を変えたほうが正解かもしれない
71 :
62 :2006/04/28(金) 23:34:45
>69 のヒントに従って書くと、
憧れのDANさんが最近の記事で書いていたんですが
>>66 を1行で書けばこんな感じ。
print map { "$_->[0],$_->[1],$_->[2]\n" }
sort { $a->[2] <=> $b->[2] }
map {
my $x = $_;
map { [$x, $_, $val{$x}{$_}] } keys %{$val{$x}}
} keys %val;
おれはこの手の書き方をよく使うけど、複雑になりそうなら
>>71 のような素直な書き方の方がいいかもね。
>>72 > 憧れのDANさんが最近の記事で書いていたんですが
その憧れのDANさんに訊けばいいだろ。
>>72 優先順位
open $fh, '<', "$file" or croak "failed to open: $file: $!";
と書ける。どちらが可読性が高いかという話だ
正規表現で最後の前にマッチした値を知るにはどうしたらいいですか?
>>76 @x = m/pattern/;
print ((grep {defined $_} @x)[-2]);
78 :
76 :2006/04/29(土) 08:14:40
>>77 おー、なるほど。
いわれてみれば、あーそうだとわかるのに、思いつかんかった。
ありがとうございます。
patternの中身が可変長でもない限り目で数えて$nでいんじゃね?
それか嫌ならマッチを2行にして
最後のマッチにだけ(?>pattern)を使う
→次のマッチから()を使ってそれの$+とか?
>>77 みたいなperlらしすぎるコードも嫌いじゃないけどさ
txtファイルを読み込んで、改行コードを外してから連結していく処理を作ろうとして、
>>81 そのtxtファイルの改行コードが壊れてCR CR LFになってる悪寒。
先頭に出るのはコンソール上でカーソルを行頭に戻す制御コードCRが
一個以上消え残ってしまっているからだと思われる。
- $line =~ s/\r//;
+ $line =~ s/\r//g;
でどう?
>>81 さすがにperlの.=がバグっているとは考えにくいので思い違いの
可能性が高いな。
$all_line .= $line;
の前後で$all_lineの値を表示してみると問題はそこではないことが
わかりそうな気がする。
異プラットホームのテキスト扱ってて行末以外にも改行コードがあるってこと?
>>83 その場合、確認すべき事を理解して無いと
>>82 の現象を見逃してしまうけどね。
$all_line = "abcdef\rXYZ"; になっている場合。
>>81 原因は82で間違いなさそう。
CRCRLFが出力されるのはWindows上でPerlを動かしてるときに
print FH "abcdef\r\n";
といったことをしたんだと思う。
元々\nを(環境に合わせて)CRLFにする機能があるから自分でCRを出力する必要は無いんだよね。
えーと、まとめてレスさせていただきますが、状況としては、
あ、あと、
>>82 さんの方法ですが、会社でないと試せないので、
月曜日にやってみます。
でも、試しに今、自宅で上記の再現コードを書いても発生しないから、
どこかで自分が改行コードを壊して、やらかしている予感・・・・
ファイルのバイナリをみればいいじゃない
プログラムは、あなたの「思えない」を考慮しない。
@in = (
青ラクダ本って日本語訳されたperldocが本になってるだけと思ってたんですが、
当たり前のことだが perldelta や CPAN から入れたモジュールに関しては,逆に perldoc を読むしかない.
sql文を一行読み込み、
97 :
96 :2006/05/01(月) 16:37:39
抜けが有りそうだけど、結局手作業で簡単なものを作りました。
threads使いたくてベースの5.6に、5.8を追加して共存させたいんですが
99 :
98 :2006/05/01(月) 17:59:43
環境書き忘れましたが、WindowsXPでPerlはActivePerlです。
HASHへのリファレンスを一つ引数に取る関数で、
&hoge({a => 1, b => 2});
下の書き方に拘るならこうだが・・・
きんもーっ☆
next unless $t->[0] eq 'T' or $t->[0] eq 'S' and $t->[1] eq 'a';
>>105 小学校の算数の教科書を復習するとわかるよ。
>>105 next if !( $t->[0] eq 'T' or $t->[0] eq 'S' and $t->[1] eq 'a' );
next if $t->[0] ne 'T' and !($t->[0] eq 'S' and $t->[1] eq 'a');
next if $t->[0] ne 'T' and ($t->[0] ne 'S' or $t->[1] ne 'a);
でも元のunless使ったのが一番読みやすいと思う。
>>106 ド・モリマンの法則ですか?わかりません!><
クックブックvol1,526ページに
>>109 逆スラッシュ演算子はデリファレンスでなく作る方。
my で map ブロック内のスコープを持つレキシカル変数 $aton を宣言し、
そのリファレンスを返している。演算子の優先順位が分かるよう括弧を
付けるなら map { \(my $aton) } 0..3;
111 :
109 :2006/05/02(火) 14:52:05
>>110 ありがとうございます
\がmy $aton全体にかかってるんですね
逆スラッシュ演算子については完全に勘違いでした
あほでした失礼します
>>108 ド・モリマンの法則ってのがあるんだ
へぇ~
やっぱこのスレ勉強になるわ
>>105 next if (! ($t->[0] eq 'T' or $t->[0] eq 'S' and $t->[1] eq 'a'));
>>105 next if $t->[0] ne 'T' and "$t->[0]$t->[1]" ne 'Sa';
または
next if "$t->[0]$t->[1]" !~ /^T|^Sa/;
よく使う自作関数を別ファイルにしてrequireで呼び出すようにしたんですが
.pl かな
while (1) {
>>118 > last if ()の時点でループを抜けてしまい
そうだな。
> $flag=1は評価されないような気がするのですが、
なぜ?
>>118 コンマは演算子であって文の区切りでは無いよ。
> 一体何が起こっているのでしょうか?
if ((適当)) { $flag = 1, last }
ファイルをロックしてオープンするサブルーチンを作ろうと思い
flockならopenしてから
125 :
123 :2006/05/03(水) 11:25:13
NFSですのでロックはmkdirにしようと思っています。
>>123 open my $fh, ">> $file";
return $fh;
でいいんじゃね?
つか、ひょっとして
OUT = lock_open( 'filename');
とかやってない? だとしたら間違い。
日本でもPerl盛り上がっているように見えるけど、
>>128 >
>>127 >perldoc.jp にある HTML 化された POD ってアンカー消してあって不便だよね。
ものによるみたいだよ?
今読んでたperlfuncはアンカーあったし。
>>126 やってます。
あー違うんですかー。
>>127 よく理解できていませんが、これみたいです。
ちょっとがんばってみます。
ありがとうございました。
>>126 様のように my をつければ局所化はされていると理解しました。
OUT = lock_open('filename') という記述が誤っているとのことでしたが、
正しい書き方がわかりません。
イチイチで申し訳ないのですが、教えていただけないでしょうか。
あ、分かりました。
gzipを解凍したのですが、モジュールありますか?
Compress::Zlib
user1:password
一致しないときは
>>140 ファイルからロードしたデータ:70617373776f72640d0a
入力したデータ70617373776f7264
と出ました。0d0aを検索してみたら改行コードだということがわかりました。
chompしてみると70617373776f72640dと出ます。なので一致しません。
Perl 改行 削除で検索してみましたらこのページが出てきたので
ttp://www.nishishi.com/perltips/string2.html 書いてあるようにファイルを読み込むときに
$dataline=0;
foreach (@userdata){
$_=~ s/\r//;
$_=~ s/\n//;
($loadid[$dataline],$loadpass[$dataline])=split(/:/,$_);
$dataline++;
}
のように追加してみましたらうまくいきました。ありがとうございました。
可能ならセパレーターを変える方法もあるます。
143 :
デフォルトの名無しさん :2006/05/05(金) 23:07:19
すいません。ActivePerl5.8.4を使い続けていて、
perlスクリプトでHDDの空き容量を調べる方法を
>>144 WindowsならWin32::DriveInfoってモジュールを使ったことがある
>>143 馬 鹿 は encoding.pm を 使 う な (゚Д゚)
use encoding 'cp932', Filter=>1;
>>143 use encoding 'shift-jis';
use open 'encoding(shift-jis)';
でも同様のエラーになるから、cp932の問題じゃないんじゃないか?
つか、そのスクリプトなら use encoding だけでよくて use open いらないんじゃね?
>>147 今でも十分お手軽でしょ。副作用が大きいから分かんない奴は使うなって
作った人間が言ってるのに、なんで固執するのか理解に苦しむ。
>>145 素早いご回答をありがとうございます。
求めている機能を含むモジュールがあるので
すね。
Unix系でも動くperlスクリプトにしたいので、
別のモジュールも探してみます。
Perlで現時刻から10000分後の時間を得るにはどうすればいいですか?
むしろそれで何が不満なのか聞きたい
>>152 N分後ならtime()+60*n
N時間後ならtime()+60*60*n
N日後ならtime()+60*60*24*n
うるう秒みたいな特殊なケースを除けばこれは絶対に正しい?
>>153 「60*n」等の式が正しいとすれば(正しいだろう)
現在のエポック秒に求める秒数を足してるのだから明らかに正しい。
なんせ年月日時分の概念が無いんだから。
掛け算で閏秒はどうやって解決しているのか、ぜひ聞かせていただきたい物だ
>>156 本来の要求仕様がわからんから正確にはなんとも言えんが、
「n秒後」という要求では、逆にうるう秒は考えちゃいけないだろ。
「x月y日まであと何秒?」という場合なら考えなきゃいけないが。
どっちにしても、うるう病は地球の自転の観測結果から調整するもので、うるう年みたいな
162 :
デフォルトの名無しさん :2006/05/06(土) 22:10:13
次のPerlの仕様がどうたらこうたらってきいたのですが
つか、エポック秒なんだから、そもそも考える必要性がないだろ?
ていうか何がしたいねん
キチガイ君は放って置けよwww
エポック社といえば
ビッグエッグ野球盤
バーコードバトラー
おまいら責め杉だ
use CGI::Util qw( expire_calc );
>>171 >use CGI::Util qw( expire_calc );
いや、それ、31日ある月の計算すらしてないよ。
my(%mult) = ('s'=>1,
'm'=>60,
'h'=>60*60,
'd'=>60*60*24,
'M'=>60*60*24*30,
'y'=>60*60*24*365);
を掛けてるだけだから。
174 :
デフォルトの名無しさん :2006/05/07(日) 01:09:54
.exeっていうファイルもつくれるのか?この言語は
175 :
173 :2006/05/07(日) 01:11:30
>>172 閏年の計算してないんで、おそらく、2/29の有無によって、1年後の日付が1日ずれるって言いたいと思われ。
今からn秒後が閏年であろうがなかろうがn秒後であることには変わりがない。
>>174 反則技を使えばできないこともない。でも基本的にそういう言語ではない。
>>175 要するに任意の日付までの秒数を求めようとしている人がいるわけね…
日付は歴史と密接な関係があるからなぁ。
こうまとめたらいいかな?
スルー
182 :
デフォルトの名無しさん :2006/05/07(日) 01:56:54
>>177 ええええええ
俺がやりたいのは、市販のプログラム に乗っかって パケット解析しつつ
そのパケットをアルゴリズムで分析して(かなり原始的なアイデアはいくつかあるから実験したい)
命令出す ってのなんだけど この言語でいけるかな?
トップ企業では普通にやってるらしいが
その関係者がにちゃんでぼろっと言ってたのだと、そいつはむかしperlつかって組んだらしい
ネトゲでマクロやってて正規表現の基本とかはわかってる
ただ、ネックだったのはパケットとアルゴリズムでした。
らくだ本と、アルゴリズムの基礎を学校の図書館で借りてきた。パケットはあとまわし。
とりあえず自動ログインツールをつくることを目標にしてるけど、
exeで動かさないなら、いちいちperl login.plとか打って起動させなきゃならんの?
login.pl の末端に autorun.plを起動させる文かいたりして、
条件 しだいで buy.plとかを動かす、とかそんなふうに組んでくの?
リアルタイムでどんな処理してるかビジュアルで把握したかったら、
別のプログラムが必要なんかな?VBちょっとやったことあるけど、あれは窓をすぐにつくれるじゃん?
華麗にスルー
>>182 >exeで動かさないなら、いちいちperl login.plとか打って起動させなきゃならんの?
>login.pl の末端に autorun.plを起動させる文かいたりして、
>条件 しだいで buy.plとかを動かす、とかそんなふうに組んでくの?
そうだよ
閏秒や閏年に対応したけりゃ DateTime 使うか zic が leapsecond に対応した環境で
localtime() 使えばいいだけじゃないの?
>>180 「閏秒でずれる」という表現がおかしいでそ。
例えば「3分後」は 3 * 60 = 180秒後であって、間に閏秒を挟んでいても
それは変わらん。
x/x/x x:x:x から n 秒後を y/y/y y:y:y
たとえば「1分後」といったときに、60秒後のことを言っているのか、
過去の閏秒は分かっているからいいけど、未来だとどうしてもズレちゃうよね。
189 :
153 :2006/05/07(日) 12:08:48
とりあえずうるう秒以外に例外はないってことが分かっただけで十分です
しかしまじめに閏秒の設定して使ってる人っているのかね?
>>190 天文関係とか、年単位で正確な秒数が必要な科学技術計算では必須だよ。
で、実際にそんな人見たことあるわけ?
改行区切りの文字列("abc\ndef\nghi)を1行ずつ処理する方法ありますか?
@lines = split(/\n/, $string);
195 :
193 :2006/05/07(日) 21:06:03
>>194 ありがとう。
splitは改行使えないと思いこんでた・・・orz
よく天文学的な数字って言うけどPerlで桁足りるんだろうか。
use bignum 入れて速度保とうとすると面倒だしさ。
>>190 閏病を調整する人が使えば当然必要だーね。
>>196 crackmeのkeygen作るのに、Math::BigInt使って、Perlで16進数16桁の平方を求めるとかはやったことあるけどね。
s///ee
(それを書いた人にとっては)見た目が良いから。
>>198 式評価した結果を更に式評価したいから。
201 :
198 :2006/05/08(月) 09:14:16
203 :
デフォルトの名無しさん :2006/05/08(月) 11:00:38
>>146 ヽ(`Д´)ノ
>>147 ありがとうございます。結局こちらでは、
use encoding "cp932";
use open ":encoding(cp932)";
use open ":std";
と、最後に use open ":std"; を追加することで対応できました。
確かにencoding、馬鹿ではよく理解できない。。。
>>148 確かにcp932の問題ではなかったですね。失礼しました。
use openを付けたのは、実際の処理の際には、
テキストファイルを読み込む場合が多いので、
その状況も検証したかった、というのが理由です。
>>149 jperl時代のお手軽さに慣れてしまってたので。。。
204 :
201 :2006/05/08(月) 16:11:27
>>202 ありがとう。
とりあえずわかったけど
おっしゃる通り使い道が浮かばない
>>202 > まともなコーディングで二重評価する必要性のある例がなかなか思い浮かばないけど…何か良い例あるかね
う~む、具体的に思い出せないが、かつて「あれってこのためにあったのか!!」と
驚愕した記憶がある。
中に書く式で自分でevalすりゃいい話のような気がするのだが、
思い出せないんじゃしょうがない
>>202 > まともなコーディングで二重評価する必要性のある例がなかなか思い浮かばないけど…何か良い例あるかね
どっかのカスCGIで、HTMLテンプレート展開ルーチンに
そんなのが使われてたのを見た記憶が。
s/<\?php(.*?)\?>/$1/ee;
まぁ普通にURLデコードとか。
ワロス
>ヽ(´ー`)ノ ◆.ogCuANUcE
ee = Enterprise Edition
s/u//gee;
216 :
デフォルトの名無しさん :2006/05/09(火) 14:49:57
Perlってなんでこんなに楽しいの?
220,221=214
俺も思った
perlfaq7 に一つ、二重評価の例があるけど、あまり良い例じゃないな…。
>>202 /e の多重評価って確か、意図した仕様じゃなくて、開発側も当初は気づかなかったけど結果として可能になっちゃってた、というモノだったと思ふ。
「面白いからそのまま feature にしようぜ」、というノリが Perl 流か。w
winでホームディレクトリへ移動するにはどうすれば?
とあるディレクトリで
>>227 chdir($ENV{'USERPROFILE'});
>>228 readlineと同じでスカラコンテキストではイテレータになるから
ドキュメントではファイル名グロブ<>の方かな
>>229 さんくす!
でもこのUSERPROFILEっていう環境変数は誰が
セットしているの?
マイコンピュータ→環境変数とたどって一覧みたけど
USERPROFILEなんてなかったよ
win2000proですけど。
EffectivePerlに載ってたんだけど
>>227 chdir の引数を省略するとホームディレクトリに移動する。参考まで。
HOME が未設定の環境でどうなるかは知らん。
>>232 優先順位の問題。
print は引数にリストを取るので、連続したリストに見える後続の全てを引数として飲み込む。ひとつの文中で、print のようなリスト演算子モドキの後に何か別の処理を書く時にはこの動作に注意しなくてはいけない。
引数をそれぞれ () で括るのが最も万能の対策。() を使わずに何か後続させようとする場合は、より優先順位の低い not、and、or、xor のいずれか、あるいは制御構造修飾子を使うべし。
最初の && を用いた文は次のようにパースされる。
print( "hello, " && print( "goodbye.") );
perl はまず && の左辺 "hello, " を評価する。リテラル "hello, " は Perl の有効な真値であるため、次に右辺の print() が評価される。
print は出力に成功すると真値 '1' を返すのでこれも真と評価される。よって && の両辺が真となり、最後に評価された値である '1' が、最初の print の引数として渡され、それが出力される。
てな感じ。
>>232 >print "hello, " && print "goodbye.";
print ("hello, " && (print "goodbye."));
>print "hello, " and print "goodbye.";
(print "hello, ") && (print "goodbye.");
237 :
214 :2006/05/10(水) 12:44:50
>>233 C:\>perl -MCwd -echdir(); -eprint(Cwd::getcwd());
C:/Documents and Settings/Administrator
おーう、知らなかったぜ
>>233 なんだ単にchdirの引数省略すりゃよかったのか
どうもありがとうもー
eachで頭が壊れそうです
243 :
240 :2006/05/10(水) 16:20:51
perldoc -f each でサンプルプログラムまで出てくるというのに…
そもそもforeach (...)のカッコ内がスカラーコンテキストだと思っている時点で間違い
以前こんな風に書いてあるのを見たことがある。
>>245 pritn for 1
これが構文的にはOKだしね
プリトン
>>247 Unquoted string "pritn" may clash with future reserved word at - line 1.
Useless use of a constant in void context at - line 1.
- syntax OK
ほんとだ。syntax は OK らしい。
>>245 そっかforeach(...)のカッコ内はリストコンテキストだったんだね
コンテキスト以前に、foreachは()内を一回しか評価しないということ。
てか
>>252 Data::Dumper超便利だねありがとー
>>251 そっか単にハッシュをforeachでまわせばよかったのか
ありがとー
「each は while のオプション」くらいの認識でだいたいヨシ。
Perlのスレッドっていくらなんでも重過ぎない?
257 :
デフォルトの名無しさん :2006/05/11(木) 09:51:08
文字コードをEUCかSJISかを変数で切り替えるようにしたいんだけどうまく表示できません
HTMLの勉強しる
259 :
デフォルトの名無しさん :2006/05/11(木) 10:30:22
>>258 途中省略しただけ
これでもちゃんと表示できないんだけど
$mozi_code="euc-jp";
#$mozi_code="sjis";
$str="文字コードテスト";
print "<HTML>\n";
print "<HEAD>\n";
print "<META HTTP-EQUIV=\"Content-Type\" CONTENT=\"text/html; charset=$mozi_code\">";
print "<TITLE>$title</TITLE>\n";
print "<BODY>";
&jcode'convert (*str,$mozi_code);
print "文字列=$str";
print "</BODY></HTML>";
以下のサブルーチンが何やってるか意味不明です
>>258 print "文字列=$str";
とりあえずこの「文字列=」の部分も変換すれ
>>260 kill 0は汚染チェックされる物なら何でもよくて、特にkill 0でなければならないというわけではない。
たぶん実行しても他に影響なさそうなものということで選んだと思われる。
そしてなぜだかわからないがperlsec(1)の例にあるように、
$arg, `true`; # Insecure (although it isn't really)
汚染されたデータと危険な操作を,で並べたときも汚染チェックでNGになるので、is_taintedの
パラメタが汚染されていたときは実行時エラーの発生によりevalの戻り値がundefになる。
263 :
デフォルトの名無しさん :2006/05/11(木) 12:35:56
&jcode'convert (*str,euc);だとうまくいくのに
なぜperl4
>>263 jcode.plのconvertは文字コードの指定はeuc,jis,sjisのどれかしか受付けない。
euc-jpは結果的に空文字列になるがそのどれでもない。
素直にJcode.pm使った方が…
>>267 ありゃ、確認するために
print euc-jp;
としたら空文字列だったんだが、よくかんがえるとこれは
eucというファイルハンドルに-jpをprintしていたのか...
すまん。
269 :
260 :2006/05/11(木) 14:26:07
jcode.plの57-58行目読めよ
271 :
デフォルトの名無しさん :2006/05/11(木) 14:59:39
EUCコードに改行って含まれるんでしょうか?
272 :
デフォルトの名無しさん :2006/05/11(木) 15:07:16
&jcode'convertでEUCに変換するときソースコードの表示する文字列部分を一つずつ
なんか凄い奴がいるな……。
275 :
デフォルトの名無しさん :2006/05/11(木) 15:34:14
>>273 つまりフォームから送信されたデータをファイルに書き込んで保存する場合は
EUCに変換して保存するのはやめたほうがいいということですね?
( ゚д゚)ポカーン
>>269 kill がシグナル送信に成功したプロセス数を返すことを思い出したら、
kill 0; の戻り値を確認するといいよ。
>>262 は、この(一見)無意味なkill 0; の役割だね。
>>272 &jcode'convert (*all_str,euc);
>>275 どこをどう読むと(ry
280 :
269 :2006/05/11(木) 17:28:26
>>278 ありがとう。
でもごめん
もっとわからなくなった
>>279 データの保存方法ですが
1:フォームから送信されたデータをEUCに変換して保存してEUCとして読み込んで表示する
2:フォームから送信されたデータをSJISで保存して読み込むときEUCに変換するして表示する
のどっちがいいか知りたかっただけです
それでどっちがいいんでしょうか?
>>281 自分のすきな方でいいんじゃないかな。
保存より表示の回数が多いなら、保存時に変換しておくと変換回数を減らせる。
まぁ、効果は小さいものだろうけど。
個人的には、表示を EUC で行うなら EUC で保存しておくのが好みだけど。
板違いはしょうがないとしても指摘されたら改めろ。
>>283 指摘されたのが自分だと気づいてないんじゃないだろうか。
>>283 まぁもちつけ。
それから、もっとまともな指摘をしろよ。
perlで以下のようなpasswdファイル文字列の"Hoge"の部分だけ小文字にしたいと考えています。
>>286 splitのマニュアルを、良く読め。
3つ目のパラメータだ。
@MA = split(',',$5,-1);
(.*): より ([^:]*): の方が良くないか?
>>286 s/(.*?:.*?:.*?:.*?:)(.*?):/$1.lc($2)/e;
みなさんありがとうございます。
s/^((?:[^:]*:){4})([^,]*)/$1.lc($2)/e;
>>259 取り繕ってもダメ。大文字でタグを書く人間がHTMLを勉強しているはずがない。
>>294 昔は、本文と区別しやすくするためにHTMLは大文字で書くのが良いとされていたのになぁ
終戦直後はそうだったよなぁ
299 :
デフォルトの名無しさん :2006/05/12(金) 01:24:25
一行ごとに print文使うのは突っ込むところじゃないのか?
みんなマメだね。w
Perlを愛するみんな!! ありあまっているそのパワーを、フリーソフトウェアを作ることに向けようよ!!
>>301 Perlを愛してるなんて気持ちはないと断言できる!
>>303 以前 Win32::DDE 使ったことあるけど、おれもエラーが出た。
そのときソース(Win32::DDE のperl部分)もみたけどよく分からなかった。
Win::32::DDE::Callback には
TO DO
Test, debug, document; this hasn't been touched since the original version, and
doesn't seem to be used by Win32::DDE::Client, so no rush :)
と書かれてるけど、Win32::DDE::Client によって使われてるし。
2^15 や 2^16 回でエラーが発生してるということは、モジュール自体あたりのバグかも
しれないね。
Win32::DDE ではなく、Win32::API を使うという方法はどうかな。
PDFを読めるようなモジュールってないでしょうか。
307 :
305 :2006/05/13(土) 11:07:44
>>306 ありがとうございます。
実はすでにモジュールのサーチはしてたんですが、
作るためのモジュールと読み出すためのモジュールの区別も付かなかったんです。
英語力なさ過ぎです。
せめてサンプルプログラムでもあれば想像で何とかできるんですが…。
特定のコマンドラインオプションが指定されていた場合は
>>304 ありがとうございます。
XSの方のソースをちょっと眺めてみます。
9年前に作成されたモジュールでVer0.02だから多くを求めるのは無理なのかもしれませんねーー)
>>308 リダイレクトじゃだめなのかい
some_script.pl > foo.txt
>>308 select
open STDOUT,...
open $fh,'>&STDOUT' や $fh = *STDOUT
それはなんか美しくないなぁ
open FILE, ...
select FILE;
de ii jan.
むしろ
>>310 でいいじゃん。
315 :
308 :2006/05/13(土) 14:21:17
>>310 すみません、書き忘れていました
途中経過を標準出力したかったので
リダイレクトは使いたくなかったのです
>>311 でうまいこと実現できたのでこれを使わせていただきます
どうもありがとうございます
途中経過はSTDERRに出せばええやん…
それはなんか美しくないなぁ
use strict; しちゃうと、どうやってもtrue/false は使えなくなるの?
Perlにはtrue/falseのリテラルないよ
0と1でいいじゃん
use constant false => 0;
うわ、コピペミス
win2kのコマンドプロンプトでactiveperlを使っています
>>323 Term::ANSIColor
Win32::Console::ANSI
>>323 自前でエスケープコード送ったりする方法も使えるかも。一応。
モジュール使う方が断然いいけど。
エスケープコードは、cmd.exeが無視するので使えません
無視するので使えません
cmd.exe では使えないけど、command.com では使えるってことじゃまいか。
いやいや、cmd.exeで動いてる他のexeファイルで
Win32::Console::ANSI がそれを解決するのか
nmakeはなんとか落としてきたけど、
PerlはLinuxでは大体/usr/lib/perl5/にインストールされますが
>>333 みての通り、Perlのバージョンによってわけられてる。
perl5/VERSION/がバージョン別のコアライブラリ
perl5/site_perl/VERSIONがバージョン別の追加ライブラリ
vendor_perlとsite_perlの違いはよく分からん。
>>334 ありがとうございます。
/usr/lib/perl5/直下にコアライブラリがあって
site_perlとvender_perlは追加ライブラリって事なんですね。
いろんなバージョンが共存できるから、バージョン毎にディレクトリがあるのでしょうか?
FedoraCoreではrpmで入れるとvender_perlに入って、cpanから入れるとsite_perlに
入るらしいですけど、なんで2つに分かれてるんでしょうね。。。
>>336 できるかできないかじゃないだろ? 正真正銘のアホだな。
それがありならCGIの質問だってOKってことか?
>>330-331 ppm install Win32-Colsole-ANSI
でよくね?
>>337 Perlがかかわってるならなんでもいいよwww
>>335 まさかきみサーバ運用する気って訳じゃないよね?
>>340 ご安心ください。。。
外部に公開する気は今の所全くありません。
単にperlの勉強を始めようと思って、環境を作ろうとしているだけですので。
>>338 Error installing package 'Win32-Colsole-ANSI': Could not locate a PPD file for package Win32-Colsole-ANSI
となります
何か下準備が要る?
タイプミスですた
ということで、カラー表示できました
346 :
デフォルトの名無しさん :2006/05/14(日) 18:23:43
#!/usr/local/bin/perl
347 :
346 :2006/05/14(日) 18:28:57
ダブルクリックで起動させようとしました
348 :
346 :2006/05/14(日) 18:53:27
いつもperl command line interpreterで開いてます
多分、物凄い速さでウィンドウが
350 :
346 :2006/05/14(日) 20:22:07
そうです
【すいません演算子】
352 :
346 :2006/05/14(日) 21:35:00
ちがうすれいきます
cpanからモジュールをインストールするときはinstallでOKですが
rm
>>355 それはcpanからではなくて、直接削除しちゃえばいいっていうことですか?
1. CPANPLUS
358 :
デフォルトの名無しさん :2006/05/14(日) 22:48:24
コマンドプロンプトで普通
日本語でおk
360 :
違うスレからきました :2006/05/14(日) 23:17:51
すみません
>>358 C:\perl\ の下にもhello.plがある
に一票!
普通は実行したいスクリプトのあるところまで移動してから実行する
(c:\perlにはパスが通っていること)
363 :
358 :2006/05/14(日) 23:26:49
>>361 さん
C:\perlってPROGRAMFILESの中にありますよね?みたらないんですが…
364 :
358 :2006/05/14(日) 23:28:59
検索かけたらありました…なぜだ……orz
最後にsleep(5);でも入れとけ
>>363-364 Windowsの基本を勉強した方がいい気がします。
C:\perl\ は C:\perl\ です。
C:\Program Files\ は C:\Program Files\ です。
ぜんぜん別物です。
基本はコマンドプロンプトを開いてそこから実行すべきです。
どうしても直接実行してそのまま開いておきたい場合は、
BATファイルに記述してプロパティで継続オプションを有効にしてください。
367 :
デフォルトの名無しさん :2006/05/14(日) 23:38:37
ありがとうございます
もうね…
>oggdropXPd
あまりにプログラミング以前過ぎてワロタ
371 :
デフォルトの名無しさん :2006/05/15(月) 18:03:20
質問です。
>>371 ソースも何も無しでは、全く我々には分かりません。
WebProg板でどぞ
>>371 つまり君の書いたプログラムを想像しろと、こう言いたいわけですね。
あるいは君の書いたプログラムが保存されているコンピュータを
クラックしてソースを見ろと、こうおっしゃる。
>>371 PHPみたいに、変数に自動で設定はされませんよ。
>>375 やったけどスパゲッティだったんで萎えた
>>375 エスパーの俺にまかせろ!
%in = map{s/\+/ /g;s/%([\da-fA-F]{2})/chr hex$1/eg;$_}map{split/=/,$_,2}split/&/,$ENV{QUERY_STRING};
>>371 で <FORM> が無いってどういうことだ?!
みんなやさしいな
インストールに関する質問もこちらでよろしいでしょうか?
以前ここでwindowsで.plファイルをダブルクリックで実行
perl %1
>>380 RedHat または Linux 関係のスレで聞くべし。
つーかもはやPerlの質問じゃないだろ…
385 :
381 :2006/05/16(火) 11:46:27
>>384 ごめんなさい
>>382 そっか.batの拡張子は無視されちゃんだ
ありがとうございます
Benchmarkについて質問です
bignumじゃね?
>>387 use bignum;
いれたけど同じエラーになります
Benchmark.pmの方にも
>>389 bignumのマニュアルに以下のようにあるのでだめだね。
Please note the following does not work as expected (prints nothing),
since overloading of '..' is not yet possible in Perl (as of v5.8.0):
perl -Mbignum -le 'for (1..2) { print ref($_); }'
そこだけなら範囲演算子使わないように書き換えればなんとかなるんじゃね?
for($_ = 1; $_ <= 100000000000; $_++) { ... }
みたいに。隠れていた別の問題がでるだけかもしれんが。
[
>>392 単に頭に sigilが付けられないから
スカラなのか配列なのか、何なのかよく分からなくなるという意味では
>>393 あっそういう意味でしたか
どうもさんくすべりまっちゅ
395 :
389 :2006/05/16(火) 14:38:01
>>390 Benchmark.pmの635行あたりにあった
$subcode = "sub { for (1 .. $n) { local \$_; package $pack; &\$c; } }";
を
$subcode = "sub { for(my \$int = 1; \$int <= \$n;\$int++) { local \$_; package $pack; $c;} }";
にしたらとりあえず動いてるっぽい
でも
timetheseに10000000000000も指定しちゃうと
ベンチ終わんない..
>>386 sub test1 { ...}
を
sub test1 { for ( 0...9999 ) { ... } }
という風にするとかは。
test1を10000回繰り返す関数を作るとか。
ベンチマーク用に遅いマシンを確保しておくという方法。
401 :
デフォルトの名無しさん :2006/05/16(火) 19:24:43
$#LIST、これが要素数を変えなさいのって言語の設計的なミス?
foreach my $i (0 .. $#LIST) {
>>401 配列はスカラコンテキストで要素数を返す。
for (my $i; $i<@LIST; $i++) {
$LIST[$i] = ...
my @LIST = ( A..Z );
>>404 >$#LIST = 5;
これだけど、0を代入しても先頭の要素が残るのってあんまり直感的じゃないような・・・
406 :
389 :2006/05/16(火) 21:31:25
>>396 なるほど!!!全然思いつかなかった
>>397 全然知らなかった。次からはそれ使います
>>398 実用Perlって本に変数をサブルーチンに渡すときに
普通にsub1(@list)って渡すと配列のコピーのオーバヘッドが
出ちゃうからそれを回避する策としてリファレンス渡しと
型グロブ渡しの二つがあって、型グロブ渡しの方が1.5倍速い
って書いてあったのでBenchmark使って
timethese(1000,ほにゃらら)って実験してみたら
warning: too few iterations for a reliable count
てなってループ少なすぎて速度差出ませんってなったから
もっと増やしてやろうとしたのでした
407 :
404 :2006/05/16(火) 22:08:30
>>405 それは仕方ない
配列のクリアは
@list = ();
undef @list;
好きな方を選べ
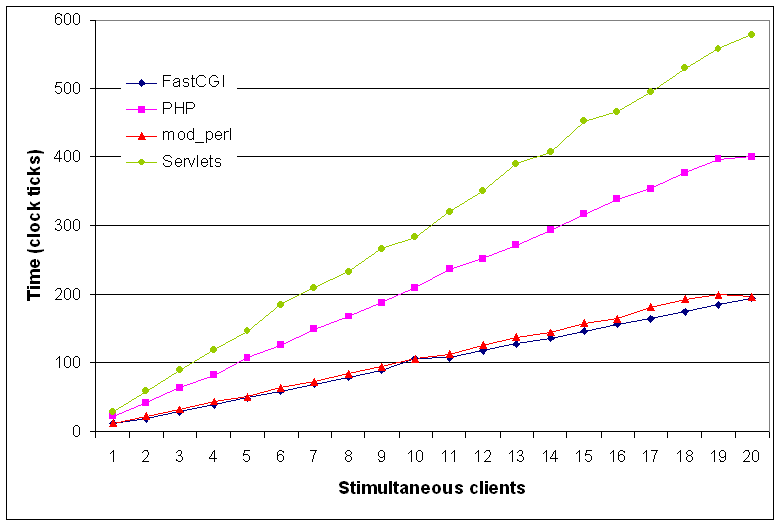
どうせ↓で配列クリアできたとしても↑と比べて感覚的に理解しづらいだろ。
$#LIST = 0;
$#は最後の添え字、それで十分
@list = qw(10 20 30);
410 :
408 :2006/05/17(水) 04:21:05
>>409 11 21 31
になりましたありがとうございます
でもどうしてカッコで括るだけでうまくいったの?
どういう原理なの?
sub a {
sub a {
414 :
411 :2006/05/17(水) 07:45:55
ばかでした失礼しました
Perl一本で仕事ありますか?
416 :
408 :2006/05/17(水) 07:53:23
>>408 なんだけどいくら考えてもわかりません
例えば*copyが型グロブじゃなくてスカラーだったら
@_ = qw(a);
$copy = @_;
としちゃうと$copyにはaじゃなくて1が入ってしまうから
($copy) = @_;
としなきゃいけないってのはわかるんだけど
@_ = *list;
*copy = @_;
がうまくいかないのに
(*copy) = @_;
がうまくいくのはなんでなんだろう
たすけてください
>>416 デバッガでシングルステップ実行してみるといいよ。
>>416 *copyがスカラーだから。$copyと理由は一緒。
てか、型グロブってきんもー☆だから極力避けたくね?
>>419 避ける。
こんな変態行為覚えちゃったら、Perlから離れられなくなっちゃうと
思ってる。
今時型グロブて…
BEログインして書き込んでいる人が煽ってばっかりのクソレスばっかりでうざいんですけど
そうですか。
>>421 いいじゃないか型グロブ
「もっとエレガントな方法があるじゃないか」と言いたいだろうけど、
そのエレガントな方法を生み出すためには型グロブが必要なんだぜ?
425 :
デフォルトの名無しさん :2006/05/17(水) 13:12:29
バッドノウハウの極地だな。
個人的には嫌いで使ってないけど、ありだと思う型グロブ。
PerlのtieはC#のプロパティとほぼ同義と考えてよいでしょうか?
428 :
デフォルトの名無しさん :2006/05/17(水) 17:51:45
libwww-perl(LWP)モジュールのインストールについて質問です。
多分インストールしなくても最初から入ってると思うんですけど、
HTTPアクセス関連の動作がおかしい(※)ようなので
関連モジュールをもう一度インストールしようとやってみましたがうまくいきません。
perl Makefile.PL
make
make test
までは普通に進み、「All tests successful.」と出るのですが
make install
とすると、lwp-requestのところで
Can't find string terminator "@" anywhere before EOF at -e line 1.
というエラーが出て終わってしまいます。
ppmもcpanシェルも、それぞれ別のエラーで失敗するので諦めました。
環境は以下の通りです。どうしようもなくて困っています。どうか助けて下さい。
OS…WinMe
Perl…ActivePer5.8.8.817
LWP…libwww-perl-5.805
Cコンパイラ…Borland C++ Compiler
(※動作がおかしいというのは以下のリンク先の質問のような症状です。
基本となるURLみたいなものがブラウザにちゃんと渡されていないようです。)
http://oshiete1.goo.ne.jp/kotaeru.php3?q=2143752 よろしくお願いします。
お前らRubyスレ荒らすなよ
Rubyスレ荒れてんの?
>>429 見てきたが、あれでPerlスレの住人を疑うって凄い被害妄想だな。
Perl6ならともかくPerl5はRubyとほぼ棲み分けされてるだろう。
そんなんだから荒らしを退治できないんじゃない?
>>430 py厨乙
型グロブでprint関数のデフォルト出力先を変えられる?
>>433 open my $fh,">foo.txt";
*STDOUT=$fh;
print "aaa";
これでいけました。どうもありがとう。
>>434 それをやるなら、普通は
open my $fh,">foo.txt";
select $fh;
print "aaa";
だが。
>>435 ほうほう、selectってそういう関数だったのか。
勉強になりました
局所化した関数を再帰処理させるってできますか?
438 :
303 :2006/05/17(水) 22:56:17
Win32::DDEを諦めWin32::APIを利用してUser32.dll経由でDDEを利用しようとしたのですが
sub foo(){
$varは、無名サブルーチンからグローバルに見えるはずなので動きそうだけどね
無名関数を定義するまえに変数$varを存在させとけばいい
442 :
437 :2006/05/18(木) 00:04:07
やりたいことをちゃんと書いてる間に解決策が・・・
>>442 解決乙
>$var =~ /(¥d+)(.*)/;
>
>my $first = $1;
>my $rest = $2;
どうでも良いけど↑の部分
my($first, $rest) = ($var =~ /(¥d+)(.*)/);
こんな書き方が俺は好き。1行で書けるから
444 :
437 :2006/05/18(木) 00:26:18
>443
445 :
428 :2006/05/18(木) 00:26:29
ここには分かる方おられませんでしょうか?
>>428 >libwww-perl(LWP)モジュールのインストールについて質問です。
プロキシーやウィルス・ソフトが動いていると、
接続できないことがあるが...
447 :
428 :2006/05/18(木) 00:40:12
>>442 わざわざそんなめんどくさいことしなくても。
$aaa = '1234aaaa5678bbb9876ccc';
print join ',', $aaa =~ /(\d+)(?{ print $', "\n" })/g;
スルーしろや。
>>447 以下のコードが動かないなら、ActivePerl を再インストールすべし。
アンインストール後、ActivePerl のフォルダも全部消してから。
use LWP::Simple;
print get( '
http://www.yahoo.co.jp/ ' );
また、socket での通信もできないとのことなので、ネットワークあたりの問題の
可能性も高い。
Windows のネットワークのプロパティを見てみるべし。
キチガイ相手にするなや。増えるぞ。
なんつーか、
ファイル名の取得についてです。
globとか?
>455
457 :
デフォルトの名無しさん :2006/05/18(木) 14:23:45
458 :
428 :2006/05/18(木) 20:22:27
>>458 > 皆さんありがとうございます。
> おっしゃるようにActivePerlを再インストールしました。
> でも同じです…。
>
>
>>451 のコードは動くのですが、ブラウザ上でちゃんと表示されないんです。
意味不明。
> 相対指定の基準とするURLをブラウザにちゃんと渡せていないせいかと思うんですが…。
> これって他の方も同じなんですか?
意味不明。
461 :
428 :2006/05/18(木) 21:17:31
意味不明ですか? じゃあ言い方を変えます。
お時間のある方にお願いしますが、次のコードで@niftyのトップページを取得してみたら
どうなるか教えていただけませんでしょうか?
print "Content-Type: text/html\n";
print "\n";
use LWP::Simple;
print get( '
http://www.nifty.com/ ' );
私のところだと、ブラウザ上での表示がぐちゃぐちゃになります。
(トップページのHTMLファイル自体は正常に取得できているのですが、
相対指定でリンクされている画像やスタイルシートやJavaScriptのファイルが取得できないため、
表示がぐちゃぐちゃになってしまうんだと思います)
ACTIVEPERLをダウンロードしようとしたら、
>>462 セキュリティソフト切る。
それでも無理なら、他のPCでdownloadすべし。
468 :
デフォルトの名無しさん :2006/05/18(木) 21:26:32
パールで出力したデータを隠したいんですが、どうやったらいいでしょうね??
470 :
428 :2006/05/18(木) 21:31:01
>>464 「そういうもの」とは…?
皆さんは、正常に表示させたい場合は
>>466 のタグを挿入して返してるんですか?
それだと元のページをそっくりそのまま取得できたことにならないと思うんですけど…。
HTTPヘッダにそういう情報があるのかと思ったんですが違うんでしょうか。
>>467 ノートンきりました。そしたらなんだか、パソコンがかってに再起動するように鳴ったんですが(泣)。
他のパソコンはありません。携帯なら歩けどできない。
おかしい質問だけじゃなく、それに対する返答も含めて巧妙な荒らしに見えるのだが。。。
>>470 HTTPヘッダにそんな情報はねえし
ヘッダ保存してないだろ
474 :
428 :2006/05/18(木) 21:44:36
>>473 そんなこと聞いてるんじゃないんですが(苦笑)
>>474 は偽物です。何が目的なんですか?
一時的にトリップつけさせていただきます。
>>473 じゃあ相対指定のリンクを含むページを取得する方法って
どうやるのか教えてください。
>>475 は偽物です。何が目的なんですか?
一時的にトリップつけさせていただきます。
少しは自分で考えろ
で、結局私の質問に答えられる方はおられないのでしょうか。
>>477 申し訳ありません。ですが自分で考えてわからないからこうして質問しているのです。
>>461 >(トップページのHTMLファイル自体は正常に取得できているのですが、
>相対指定でリンクされている画像やスタイルシートやJavaScriptのファイルが取得できないため、
>表示がぐちゃぐちゃになってしまうんだと思います)
そう思うんなら全部ダウンロードすればいいじゃん。
そうすりゃ表示されるよ。
482 :
デフォルトの名無しさん :2006/05/18(木) 22:01:41
471です。パソコンに詳しい友人によると、ブラスターだとかいうのに感染したらしく、修理しなければ直らないそうです。
>>480 127.0.0.1に指定しているフォルダに、ディレクトリ構造ごとそっくりそのまま
持ってくるということですか?
私がやりたいのはオフラインで閲覧できるようにページを丸ごと取得することではなく、
普通にどこかのページをブラウザに返すということです。
>>483 すれ違いだ。消えろ。行き場所は自分で探せ。
ん~、なんだぁ?
>>479 考えるな。調査せよ。行き来するデータをインスペクトせよ。
処理の各段階でのデータをインスペクトせよ。
>>486 それは偽物です。
428 ◆AOxf8.Tmck←これが私(
>>428 )です。
アドバイス頂いた方ありがとうございました。
これ以上ここでは聞けないと判断しましたのでもう移動させていただきました。
>>483 > 私がやりたいのはオフラインで閲覧できるようにページを丸ごと取得することではなく、
> 普通にどこかのページをブラウザに返すということです。
やっと一番最初に書いておかないと質問の体をなさない事項を書いたよ(嘲笑
依然として意味不明だけどな。
構うなよおまえら・・・
491 :
デフォルトの名無しさん :2006/05/18(木) 22:28:36
Cryptをもっと安全にするにはどうすればいい?
話に入れなくて悔しい約1名が必死に荒らしているスレはここですか?
>>489 質問に答えられないからってそういうこと言わないでくださいよ。
>>491 > Cryptをもっと安全にするにはどうすればいい?
意味不明
496 :
491 :2006/05/18(木) 22:36:52
>>495 質問に答えられない厨房君は帰ってね(^^;
貴方のほうが意味不明です。答えられないなら答えるな。
変な奴が…2名くらい?
>>497 いるな。ここは何でも質問箱だってのにぐだぐだ言う奴が。
>>437 普通にやるなら既に解決しているけれど、面白そうだから先に変数を宣言しないようにやってみた。
sub Y {
my $f = shift;
my $m = sub {
my $proc = shift;
$f->(sub { $proc->($proc)->(@_) });
};
$m->($m);
}
my $var = Y sub { my $f = shift; sub { $f->() } };
$fact->();
Y Combinatorってやつ。
質問です。
Windows 2000 ActivePerl 5.6を使っています。
ファイルが存在しているかどうかを確かめたくて、
ファイルテスト演算子を使おうとしたのですが、うまくいきません。
ttp://www.site-cooler.com/kwl/perl/7.htm#7-5 こちらのサイトに、
ファイルテスト演算子はWindowsではうまくいかないこともあると書かれていたのですが、
Windowsでは使えないものなのでしょうか。
この方法以外にテストできるやり方があったら教えてください。
>>501 いい加減この手の質問になってない質問に答えるのやめようよ。
さっきのみたいのがまた増えるよ?
PAR-0.92
同じような欠落質問が連続してきてるのってどういう現象?
505 :
500 :2006/05/18(木) 23:24:12
>501
>>505 $file = <STDIN> ;
chomp $file; # ファイル名に改行が含まれるかもしれないのでちょん切る♪
>>504 1.変な質問が出る
2.変な質問に答える奴が出る
3.変な質問をしてもいいんだと誤解した奴等が寄ってくる
4.変な質問に答える奴はまだいる
5.3.に戻る
>>509 何が楽しくて荒らすの? やめようよもう…
511 :
500 :2006/05/18(木) 23:37:00
>506
>>511 まあ、木に病むな。
わからんことがあったらどんどん質問しなされ。
暇人の俺らが答えるから。
>>512 荒らしさん勝手に自分の行為正当化しないでください。
Ruby スレを荒らしたら今度は Perl かね。
>>468 ベッドの下に入れる。
それでも無理なら貸し金庫を借りる。
>>471 hint: ネットカフェ
>>503 PAR と ActivePerl を最新版にしてみたらどうかな。
PAR は、配布されてるパッケージによっては動かないことがあるので(相性問題がある)
ppm の配布サイトを変えて試してみるといいかも。
517 :
503 :2006/05/19(金) 01:05:48
レスTHX。
518 :
デフォルトの名無しさん :2006/05/19(金) 02:19:36
perl のプログラムで、あるファイルを他のファイルにコピーする処理を行うサブルーチン
テンポラリファイルに書いてからrenameするのがいいんじゃない
>>518 どうなるもなにも書き込めなかった方がエラーになるだけでしょう
>>519 リネームできなかったら残っちゃうじゃん
522 :
デフォルトの名無しさん :2006/05/19(金) 11:32:53
スンマセン教えてください。
? 全部消せばいいんじゃねーの?
>>499 Y Combinator スゴス
1時間ネットをさまよって理解できた。かもしれん
528 :
527 :2006/05/19(金) 16:28:07
これYにプロトタイプ宣言しとくと、シンタクスシュガー的にかっこいいと思う
sub Y(&) { #
>>499 にプロトタイプを追加
my $f = shift;
my $m = sub { my $p = shift; $f->(sub { $p->($p)->(@_) }); };
$m->($m);
}
my $factorial = Y { # Yの後ろのsubが省略できる
my $label = shift;
sub { my $n = shift; ($n > 1) ? $n * $label->($n-1) : 1; }
};
print $factorial->(10);
529 :
デフォルトの名無しさん :2006/05/19(金) 16:32:36
utf8で、Latin Extended とかを Basic Latin に変換するようなスクリプトって、
PerlでMD5を使う方法を手取り足取り教えてくれ
use Digest::MD5;
532 :
デフォルトの名無しさん :2006/05/19(金) 18:39:12
12chスクリプトを使ってます。
533 :
532 :2006/05/19(金) 18:41:27
すいません。板違いみたいです。
>>528 確かに。
print Y { ... }->(10);
こういう風に使ったときに優先順位の関係で嵌らないかと思ったけど、
実際やってみると望んだとおりに解釈してくれるのね。
流石Do What I Mean戦略といったところか
sub rec(&) {
rec()自身を再帰するのは反則…とかなんとか404 Blog Not Foundに書かれていたような
>>535 もともとお遊びだったしY Combinatorそのまま移植してみたけど、
確かに先に変数を宣言しないように、というだけならrecの中での直接的な再帰を許してそれで良いわな…
538 :
535 :2006/05/19(金) 21:13:50
すまんどうやら流れ読めてなかった。
>>528 こう言うのってどういうときに便利なんですか?
前にそんなのが必要だった記憶があるんだけど思い出せない。
確かその時は引数にしてごまかした記憶が。こんな感じで。
my $f = sub { my ($f, $n) = @_; $n < 1 ? 1 : $n * $f->($f, $n - 1) };
print $f->($f, 10);
レキシカル変数使うなら
>>540 myのスコープはその右辺に適用されないからそれじゃ動かん。
>>441 >>539 便利とかそういう実用性の話をするなら
>>441 で十分だね。
Y Combinator等を使った方法は単に(関数的なのが好きな人には)面白いというだけだから。
無名関数を引数に取るようなサブルーチン(sortとかgrepとか)に渡すときとか。
>>541 嘘つくな!
名前まで付いてるくらいなんだからそんなはずはない。
ほんとはすげーかっこいい使い方知ってんだろ。
教えろこのやろう。。。
>>542 もう一声。
使い方とは存在するのではなく
ま、諸賢はくれぐれも技に溺れないようにね。
200万円の日本刀で鉛筆削る人生も乙なものです。
>>203 にsjisのencodingによる処理の仕方が書いてあったけど、euc-jpで
やってみたが、うまくない。「中」とか「薫」とかが出てこない。
use encoding 'euc-jp';
use open ':euc-jp';
use open ':std';
print "Test 1:\n";
open(IN, "euc.txt") or die;
while(<>) {
while(/[亜-腕]/g){ # [弌-龠] 堯槇遙瑤凜熙
print $&, "\n";
}
}
close IN;
いったい、文字クラスの正規表現[ ]はマルチバイト文字をサポート
してないのか。うまく行った人、教えてください。
文字クラスは多分ユニコードの文字コード順なので
>>548 あー、そうだったんですね。内部の処理はutfでやってると。
jperl相当のことができるって喜んでたら、あの不可解な
出来事で、悩んでいたんですが、これで目から鱗です。
ありがとうございました。
550 :
デフォルトの名無しさん :2006/05/20(土) 16:09:57
コンビネーターのコードがまったく読めないんだが・・・
>>552 無内容の上さりげなく多言語使いを煽ってるのはたしかに荒らしだろうな。
数日前なんか酷いことあって過敏なんだよ。
少し考えて書き込んでくれ。
色々浮気するが結局perlに戻ってくる俺がいる
>>549 漢字やひらがな等を指定したいときは文字クラスを指定するのが良いですよ。
# \p{Han}/ とか /\p{Hiragana}/ とかだったかな?
perldoc perlunicode に色々かかれてたはず。
>>556 ありがとうございます。かなり量があって全部読むのは大変ですが
ぼちぼち見てみます。
559 :
558 :2006/05/21(日) 17:36:13
すみません。
cryptの暗号化は簡単に解析されてしまいますか?
>>560 簡単の基準やどのcryptか言わない(言えない)なら回答は「NO」で問題ないだろう
ああ解析しようと思えば出来てしまうレベルの暗号化なんですね。
逆に総当りでも解読出来ない暗号ってあるのかと聞きたい
解析できない暗号など無い
>>563 安全性を追求するなら、今専門家が勧めているのはSHA256
# 解ってるとは思うけれど、暗号化方式がどんなに安全でも、元のパスワードの質が悪ければ辞書攻撃ですぐだから注意な
>567
569 :
改善派 :2006/05/21(日) 22:14:31
総当りしても解けない暗号はあるよ
>569
有名なのはワンタイムパッド暗号。あらかじめ乱数表を配っておいて
総当りすりゃ解けるじゃん
解けるの定義が食い違ってそうだ。
「何をしても絶対解けない」暗号方式なら3分で作れるなwww
>>572 例えば「バナナ」を暗号化して「ABCDEF」という文字列を作ったとする。
これを総当りするうちに「バナナ」という文字列は現れるが、
途中に「リンゴ」「イチゴ」などの文字列もあらわれるため、
「バナナ」が元の文字列だと断定することができない。
よって、「元の文字列を得る」という意味での「解読」は絶対に出来ない。
これがワンタイムパッド暗号。
>>576 そういう暗号化方式がWEBサービスとかで実際に使われているんですか?
>571
>>577 576じゃないけど、使い捨てる暗号なら普通に使われているのでは。
元の文字列が分からなくなれば良いんだから。
MD5とかって違うの?
乱数列が入った HDD の運び屋も大変だよな。
質問があります。
>>583 Jcode って utf8 フラグ立てるんだっけ?
Encode で utf8 文字列にしたらどうよ。
>>576 だから、『解読』自体は出来るでしょ?
お前本当の馬鹿だな
>>586 暗号無知は黙ってた方がいいよ?wwww
無知は言い負けてからがしつこいんだよねえ。
>>587 いや…この暗号方式はシーザー暗号並に単純だと思うんだけど…
辞書で解読の意味でも調べたら?
勝手に負かされても困るんですけど
勝手に言葉の意味を俺流に脳内変換しといて勝ったとか言われるのも困り物ですよね
(・∀・)ニヤニヤ
595 :
デフォルトの名無しさん :2006/05/22(月) 10:33:56
>>594 彼は落雷に遭ってから不思議な能力を身に付けたのです
もう通信記録とか全部見えちゃうんですよ
>>576 の理論で行けば共通鍵の暗号でも偶然で文章になる可能性があるよね。
>>576 の言ってる事はおかしいよね。変だよね。
逆に貴方が必死になってるんじゃないですかぁ?
webprogでやりなよ~(・∀・)
webprog板に来られても迷惑。
君が勉強しなよw
質問の内容が内容だし、反応した奴は全部まとめてアホでいいよ。
べつに匿名で勘違いとか物を知らないことがバレても
BAKAだから
だから勝手に勝ち逃げしないでよ
反論もせずに悪口ばっか垂れてても何も始まりませんよー
608 :
583 :2006/05/22(月) 11:35:04
>>585 アドバイスありがとうございます。
# $feed = {}; $feedには元XMLから取得したutf8文字列が入っている。
use XML::RSS;
my $rss = XML::RSS->new(Version=>'1.0');
my $label = '形態:';
from_to ( $label, 'euc-jp'=>'utf8' );
$rss->add_item(
title=>$feed->{title},
link=>$feed->{link},
description=>$label.$feed->{description}
);
このようにしてみましたが、結果は同じでした。
色々考えた挙句に、utf8で書いてuse utf8;したモジュールを作り、
そこから文字列を返してXML::RSSに食わせると望む結果が得られました。
ちなみに大元のスクリプトをutf8にすると、
鯖が何故かCGIとして認めてくれずにエラーを起こしたので、
このような事態になりました。
あんまりすっきりしませんが、ありがとうございました。
僕の言ってる事が正し過ぎて言い返せないのかなぁ
最近はCGIであることを隠して質問するのか。
↑これが自演しまくりで煽ってる奴。
Perl使いってこんなキモイ奴ばっかなの?
ウフフフ・・・
>>614 まあ Perl そのものがキモイ言語ですから。
この荒らし方はPHP厨ぽいな。
あのシメジ野郎…ッ!!
619 :
583 :2006/05/22(月) 18:08:49
>>609 原因かどうかはわかりませんが、確かにUTF-8Nで保存するとちゃんと実行してくれました。
なんだこりゃ?
次からは、UTF-8Nでスクリプト書いてuse utf8;しようと思います。
ありがとうございました。
すごい初歩的な質問なんですけど…
>>620 my $str = "うん";
print '$strちがいっぱいでたよ!\n'; #出血
print "$strちがいっぱいでたよ!\n"; #脱糞
shift_jisで書くならとりあえずシングル使っとけ
623 :
620 :2006/05/22(月) 19:13:53
>>620 どっち使ってもいい場面なら
基本シングル
シングルクォート含んでてダブルの方がすっきり書けるときはダブル
>>620 ちなみにベンチしてみればはっきりわかるが、
シングルのほうが早い
>>625 だと思ってベンチしたらダブルの方が速かった件について…
>>626 あ・・・・れ・・・・?もう一回やってみよう
初歩的な質問ですが…
windowsならいらんよ
>>629 書かなくても
perl 目的のスクリプト
で実行できるよ。
>>632 そういう事をするための pl2bat じゃないの?
cygwinでならc:\…でも動くよ。
>>629 儀礼的に書くようにしてる。
あと、winとかでもPerlがその文を読み取ってスイッチとか判断してる。
だから、基本的に書はいとけ、ってコトだと思う。
637 :
629 :2006/05/22(月) 22:49:21
>630-636
>>638 コンパイル時点でシングルとダブルを解釈するから速度差には影響しにくいという話を聞いたことがある。
それはあるバージョンからそのようになったとかなんとか。
このスレか?
ようわからんが、「ダブルだったら展開出来そうな文字列を探せ」みたいな解釈をしてないってことだろ。
>>637 >なくても動くんですね
>でも、あった方がいい、と。
「あったほうがいい」だけの理解だとすっきりしないと思うので。
#!/usr/bin/perl とかコマンドへのパス書くのは元々UNIXのシェルが
ファイルとプログラムを関連付けるルール。
Windowsではファイルの拡張子がその役割を担っているのでいらん。
でも、ApacheでCGIとして動かすなら、Apacheがファイルの一行目を
解析するのでWindowsでもUNIXでも必要だおy。
>>639 そうなのか。なんかダブルのほうが速いのがちょっと不可解だけど。
642 :
デフォルトの名無しさん :2006/05/23(火) 00:30:38
a.pl と b.pl の両方で、同じ変数 $name を参照したいのですが、設定は一カ所でしたいのです。
643 :
642 :2006/05/23(火) 00:32:00
ちなみに、これらのプログラムはcgiとして動かそうと思っています。
>>642 設定ファイルを c.pl にしてそこで$nameを定義。
a.pl と b.pl で c.pl を読み込む。
>>640 なるほどね
ってことはシングルで . でつなげたほうがコンパイルは速いのか
確か2,3ヶ月前にベンチしたときはシングルのほうが速かった気がした。
早いことは早いが、0.1%以下の差を気にしても意味ないと思うけどな。
ましてやコンパイル時のことはねえ。
読みやすい方が重要
>>646 > ってことはシングルで . でつなげたほうがコンパイルは速いのか
そりゃないでしょ。
スクリプトレベルでそういう風に書くと、明示的に処理が入っちゃうから
返って遅くなるはず。
速度が気になるならインタープリタの言語を使うのは間違いのような気がするが…。
>>651 言語のインタプリタなら分かるがインタプリタの言語というのは聞いたことがない
インタプリタ型言語だな
>641
シングルクォート vs ダブルクォートでいくつかベンチを取ってみたけど、同一ベンチでも結構ばらつくね。
同意。
>>658 勝手に人の話を妙な風に解釈するなよwww
リファレンスについて
破棄
663 :
660 :2006/05/24(水) 15:50:34
わかったーーありがとうございましたーー
ぶっちゃけperlって手続き型言語の中じゃ
>>664 安く上げることも出来ると思うが。
本を買わないで perldoc とウェブ検索で済ますんだよ。
リファレンスついでに前から聞きたかったこと
コストって、値段のことじゃないんじゃない?時間とか。
またブログで見かけたネタ持ってくるのかよ
こんなことができたりする。
>>667 リファレンスにしなくても配列のコピーは無料ですよ?
>>671 667じゃないですが横から失礼します。Perl勉強中の者です。
> 配列のコピーは無料ですよ?
ラクダ本には、関数の引数は参照渡し(@_ に入っているのはエイリアス)と書いてありますが
これはつまり $_[0]++; などと書けば、第一引数として渡した左辺値がインクリメントされる、
という理解でいいんでしょうか。この場合、左辺値になれない値を渡すとエラーになるんですよね?
その前提でいくと、配列を渡した場合も、個々の要素(スカラー値)のエイリアスが @_ に入るだけで
コピーは発生しないはずでは? それとも、@_ にエイリアスが入る事を「コピー」と呼ぶのでしょうか?
673 :
デフォルトの名無しさん :2006/05/24(水) 20:42:23
例えば
$foo = "hoge[test]hoge";
676 :
デフォルトの名無しさん :2006/05/24(水) 21:17:52
レス有難うございます。
>>672 @array = (1..1000);
&func(@array); # scalar @_ == 1000
&func(\@array); # scalar @_ == 1
@array[0..9] という風に、配列の範囲を指定出来るようになったのは
>>678 4? もっと前かなぁ。まぁ、配列スライスの実装はかなり前だ。
680 :
デフォルトの名無しさん :2006/05/24(水) 23:51:30
C言語のヘッダファイルのように、
>>680 sub PI () { 3.14 }
1;
な pi.pl を用意しておいて、
BEGIN { require 'pi.pl' }
した上で、
print PI;
なんてやり方もあるけど、どう?
>>671 そうじゃなくて
sub subroutine {
my @list2 = sfhit;
}
subroutine(@list);
ってするときに
subroutine(\@list);
とした方がコピーのコストが省けるでしょって意味
>>683 subroutine(\@list);と渡したら
sub subroutine {
my $ref = shift;
my @list2 = @$ref;
....
}
などとする必要があるぞ。
例示として適当なのは
sub my_sort { map{ undef $_ } @_; }
@list = my_sort(@list);
としたときに、
@listで受け取る以前にsub my_sortが@_に対する直接の操作をしているので
my_sort(@list);
と等価になると言う辺りか。
参照渡しでメモリの節約だとかスピードアップだとか言われるけど
本当の意味が分からんやつはしなくてよろしい。
array を渡すと、各要素のコピーが発生するの?
うぉ、サブルーチン名間違ってるなw
687 :
672 :2006/05/25(木) 01:27:39
どうも、「コピー」と「エイリアス」という使い分けは一般的ではないのでしょうか?
「コピー」は「値は同じでも実体が異なるもの」
「エイリアス」は「別名だが実体は同じもの」という意味ですよね?
手元の「第2版 プログラミングPerl VOL.2」の P1193 にある「エイリアス」の定義では、
> サブルーチン呼び出しの実引数が入る @_ の各要素に対して、それぞれ暗黙の
> 一時的なエイリアスが作られる。
となっています。
>>671 や
>>683 では「コピー」と書いていますが、「エイリアスを作る事」を「コピー」と呼ぶのですか?
と
>>672 でお聞きしたつもりでした。書き方が悪かったようで申し訳ありません。
688 :
672 :2006/05/25(木) 01:30:37
失礼。間違えました。
>>687 =~ s/第2版/第3版/;
689 :
672 :2006/05/25(木) 02:05:17
連続カキコ&スレを止めてしまったようで、すいません。
エイリアスはコピーではない。
>>687 >>683 じゃないけど
確かに@_はエイリアスだけど
my @a = @_;
ってやった時点でコピー。
@aに何しても元の配列に影響なし
配列のコピーが無料なのは
my @a = @_;
をやらない場合
だとおもう
いやだから
693 :
692 :2006/05/25(木) 03:33:55
>>691 と全く同じことをいっている・・うつだもうねるぽ
>>692 > サブルーチン内で@_を直接操作するなんてのは
> トラブルのもと
どの辺がトラブルのもとになるのか詳しく教えてください><
>>694 > どの辺が
「サブルーチン内で@_を直接操作する」辺りが。
ドキュメントで明示化すればよろしい。
再帰処理でコピーなんか多用したらあっという間に
>>694 perlのサブルーチンはCなんかの
int subroutine (int x, int y) {
return x * y;
}
とは違って"基本的に"引数の型や戻り値の型を指定できない
sub subroutine {
return $_[0] * $_[1];
}
こんなサブルーチンがあったら何をやっているか激しく意味不明だろ?
数字同士を掛けてるのかそれとも文字列同士を掛けてるのかもしれない
qmailの作者のコードじゃないんだから意味不明さは避けなきゃ
それが
$xと$yだったら面積の計算だとわかるだおうが!
(゚д゚)ハァ?
置換系のサブルーチンとか、渡す値自体がコピーだったりする場合が@_を直接弄っても大丈夫な例か?
好みの問題というか、宗教の問題というか。
正解はないが、そこまで毛嫌いする処理じゃないと思うぞ。
よほどでかい配列を扱うか、使用頻度の高いサブルーチンでも無い限り
速度どうのこうの言うのは馬鹿げてると思うぞ。
なぁ
>>692 サブルーチンへの引数の参照渡しの利点は
変数の値をサブルーチンの名前として指定する方法ってありますか?
&{$name};
あと、そのサブルーチンが処理しようとしてる
708 :
デフォルトの名無しさん :2006/05/25(木) 13:11:28
@pairs = split(/&/,$buffer);
709 :
デフォルトの名無しさん :2006/05/25(木) 13:15:44
@pairs = split(/&/,$buffer);
コンストラクタでblessする変数は$thisじゃなくて$dickにしてもいいですか?
日本語でおk
712 :
デフォルトの名無しさん :2006/05/25(木) 13:53:40
#!/usr/bin/perl
お前は何がしたいんだ
配列の一番最初は1じゃなく0だから。つかしね。
@pairs = split(/&/,$buffer);
すごいのがきたな
何がしたいんだろう。難解だな。
使用するモジュールを引数によって変更したいのですが書き方がわかりません。
>>720 autouseを使ってなんとかならんか?
724 :
720 :2006/05/25(木) 19:53:46
ありがとうございます。
なんのモジュールだかは知らんけど、useをrequireにするとタイミングが変になるからBEGINだといいよ。
ほんの数日前にPerlを始めたものですが質問をさせてください。
>>726 Windows の方は Cygwin 使えばいいんじゃないか?
多分そのままじゃ漢字使えないけど。
ああ、でも、Linux側に ftp で put して動かすという場合は
改行コードは ftp が変換してくれるよ。ascii モードで送れば
いいの。漢字のコードについては Windows では MKEditor とか
使えばいいんじゃないのかな。
Perlについての質問なのか?
>>726 何もしなくていい。改行コードの違いなんて問題にならない。
>>729 #! の行の改行コード違うとちょっと困りそう。
-- で回避するのめんどくさい。
>>726 >改行コードの一括返還の行えるソフトや
perl -i.bak -pe "binmode(select);s/\r//g;" *.pl
とか?
>>730 最初からLFで書いておけ、って話じゃないの?
734 :
デフォルトの名無しさん :2006/05/25(木) 22:38:46
引数の@_はエイリアスなんだけど、戻り値については必ず値のコピーが発生するよね?
2chのトリップ生成のperlのソースコードってありませんか
>>734 戻り値を何かに保存するなら、という条件付。
その場合は間違いなく値のコピーが発生するぞ。
たとえ戻り値が巨大な配列のリファレンスだったとしても、ちゃんと一つの「配列リファレンス」という値が、な。
C言語でUnixを作ったように、
叶?
♀?
>>738 どうだろね。 perlは何らかのソフト環境上で
動作してる様だし、原則無理ではないかな。
エミュレーターぐらいならなんとか。
>>737 grepやmapは内部でどういう処理してるんだろう?
Perlの組み込み関数はさすがにやってないよね?
>>743 ということは Perl machine を開発すれば解決ということか。
ネットワーク基盤とかミドルウェアなら作れそうですか?
747 :
737 :2006/05/25(木) 23:54:25
>>744 文意はいまひとつ取れないけれど、興味があるなら調べてレポートよろしく。
>>746 可能かどうかなら、可能なのかもね。
しかしそれを使うソフトは、どうすることもできない
パフォーマンスの頭打ちに悩まされる。
そこでparrotですよ!!
ああそうか、その上で動かすソフトがある門ね。
コンパイル出来るんだからその気になれば作れるし速度の問題もそれなりになるんじゃね?
>>731 入力時に既にCRは消えてるからARGVOUTをbinmodeにするだけでLF出力になるよ
>>750 そういうレベルの話なら
ImageMagick あたりの画像加工モジュールとか試して
みたら?(ピュアパールではないが)
PerlでDOS画面に同じ文字を繰り返したら指定されたコマンドを動かすときどうすればいいんでしょうか('A`)
唯一相手にまともに伝わってるのが顔文字による感情表現ってのが
>>738 perl -e 'for(;;){print"a:\\> ";$s=<>;chomp($s);if($s eq"dir"){system"ls"}}'
>>757 妙にPerl使いっぽくない書き方だな。いや別にだからどうしたってこともないけど。
まーたはじまった
↑
761 :
デフォルトの名無しさん :2006/05/26(金) 17:47:05
特殊変数 $/ を、特定のファイルハンドラについてのみ変更したいのですが、可能でしょうか?
local とか
>>757 何を言いたいか全くわからないがOSのつもり....なのか?
OSとか、shellとかが何なのかわかってる?
そういえばperlのネイティブコンパイラってどうなったの?
OSよりさきにブラウザから始めれば?
767 :
デフォルトの名無しさん :2006/05/26(金) 22:05:45
perlで計算科学のプログラムを書きたいんだけど,
769 :
デフォルトの名無しさん :2006/05/26(金) 22:47:10
言われなくてもしってるよ。 疲れる
今はその辺りはHuskel
Haskell じゃ?
HuskelとHaskellは違うぞ。
ハッスル!ハッスル!
774 :
かえる :2006/05/27(土) 00:27:03
最近 perlを勉強し始めたんですが 構文エラーで
おそらくShift_JISの全角スペース文字(0x8140)の1バイト目だと思う
>>772 Huskel ってどういう意味ですか><
Huskel の検索結果 約 480 件中 1 - 10 件目 (0.06 秒)
Haskell の検索結果 約 18,200,000 件中 1 - 10 件目 (0.16 秒)
見た感じ特別な意味はなくてただのtypoか人名っぽいんだけど・・・
なんだろ。Haskell の親戚かなにか?
親戚っていうか俺
Huskelさんは算数が得意な日系コロンビア人です。
parrot のこと?じゃないよなあ…
まさかperlcc
typoで盛り上がってるのは自演ですか?
全角スペースを入れてしまうような阿呆にマジレスするような奴にか?
>>784 \81から始まるのは、別に全角スペースに限らんだろうが。
use encodings を宣言せず、sjisの全角文字を入れたことが原因と思われ。
質問です。
>>788 あると云えばあるしないと云えば無い。
という回答を所望なのかしら?
具体的にソースを晒した方がより具体的な回答が得られるかと。
>>789 りょうかいしました。
ちょっと可読性あげと個人情報保護対策しますので
少々おまちを・・・
791 :
788 :2006/05/27(土) 18:06:14
#ソースです。
792 :
788 :2006/05/27(土) 18:07:27
#続き
793 :
788 :2006/05/27(土) 18:08:05
#続き
794 :
788 :2006/05/27(土) 18:09:14
#続き
sub search の中で @main::pkgs が更新されるって事?
$_ がパッケージ(グローバル)変数だからやね。
797 :
788 :2006/05/27(土) 18:57:04
ちょっくら試してみます。
へーなるほど。知らなかった・・・。これはハマリやすそうな罠。勉強になるなぁ。
あ、
>>798 の実行結果はこうだった。ちなみに僕は
>>788 とは別人です><
**1 2 3 4**
AAA
BBB
** **
>>788 while は $_ を破壊してしまうから foreach を使うべし。
>>800 ネタだと思うけど一応。
while (my $hage = <>) {}
と書け。
{
local $_;
while () {}
}
って解決策もあるけど、こんなんだったら my 使ったほうがいいべ。
802 :
デフォルトの名無しさん :2006/05/27(土) 21:40:54
>>800 ネタなんだろうけど、そんなことくらい気にするなよ。
$_は自分で使うときは必ずlocal $_する。
何かの関数を呼び出したら$_が破壊されていると考える。
それで充分。
>>802 ネタ……だよね?
「必ずlocal $_する」くらいなら、名前を付けてあげようよ。w
スコープについての心配が煩わしいなら、すでに $_ を使う理由がないということなのだから。
805 :
804 :2006/05/27(土) 22:14:08
806 :
804 :2006/05/27(土) 22:26:04
>>802 失礼のお詫びにサービス。
foreach はループ変数がグローバルである場合、自動的に変数の局所化を行う。対して while はそれをしない。
>>800 の「破壊」ってのはそれを指していると思われるけれど、うん、100% ネタということで。
808 :
デフォルトの名無しさん :2006/05/27(土) 23:55:11
809 :
808 :2006/05/27(土) 23:55:48
http://pc8.2ch.net/test/read.cgi/tech/1057329161/459-461 459 :stream ◆PNstream2s :2006/05/27(土) 16:31:16
新しい書き込みの仕様
レス
FROM= ←名前
mail= ←メール欄
MESSAGE= ←本文
bbs= ←板のディレクトリ名。operateとかtechとか
time= ←現在時刻より小さい値を適当に。1を送っておけばよい
key= ←スレッドキー
hana=mogera ←追加。常にmogeraを送っとけばいいのかな。
Cookieは不要。
460 :stream ◆PNstream2s :2006/05/27(土) 16:35:43
スレ立て
subject= ←スレッドのタイトル
FROM= ←名前
mail= ←メール欄
MESSAGE= ←本文
bbs= ←板のディレクトリ名。operateとかtechとか
time= ←現在時刻より小さい値を適当に。1を送っておけばよい
hana=mogera ←追加。常にmogeraを送っとけばいいのかな。
461 :stream ◆PNstream2s :2006/05/27(土) 16:36:37
Cookieは不要と書きましたが、sports2はCookie無しじゃ書けないので
Cookieも今までどおり必要ですね
810 :
デフォルトの名無しさん :2006/05/28(日) 00:05:46
Perlででかい何かを作りたいよぅ
foreach (<FH>) って、とても素敵。
呼び出した先での $_ の破損を調べるのに &hogehoge for 1; とか、
$_ を無駄に保護するのに &hogehoge for 1..1; とかどうですかね。
>>806 さん
重箱の隅ですが、foreach のループ変数局所化はmy変数にも有功ですだよ。
>>810 > Perlででかい何かを作りたいよぅ
Winnyノード
813 :
808 :2006/05/28(日) 00:56:01
華麗にスルーしないで下さい><
815 :
808 :2006/05/28(日) 01:08:51
816 :
デフォルトの名無しさん :2006/05/28(日) 01:09:51
結局、Perlってテキスト編集くらいしか役に立たんのか?
>>816 テキスト編集って言ってもイロイロあるんだぞ。
ISPなんかでは、アカウントの作成やらユーザの設定変更やらでPerl大活躍だ。
819 :
808 :2006/05/28(日) 01:38:17
ここでなんと神降臨!!!
821 :
sage :2006/05/28(日) 01:49:43 BE:41273524-
822 :
808 :2006/05/28(日) 01:51:18
823 :
806 :2006/05/28(日) 02:26:45
>>811 ツッコミさんきゅー。で (レキシカル|ダイナミック) スコープが継承される、と。
お返しに、
>呼び出した先での $_ の破損を調べるのに &hogehoge for 1; とか、
>$_ を無駄に保護するのに &hogehoge for 1..1; とかどうですかね。
デバッグ用としてはアリかと。でも可読性はイマイチ。
>>806 でもちょっと書いたけれど、「これってスコープどうなってんの」な心配が要る時には、$_ を使うべきじゃない。
呼び出し側で $_ を使っていなければサブルーチンが何やっててもその点での心配はしなくていい。
そんなところに神経使うのは無駄ざます。w
824 :
823 :2006/05/28(日) 02:31:27
ここで質問に答えている香具師どもはプログラミングPerlとかクックブックとかちゃんと読んでるんだろうな?
>>825 今度の荒らし君は少しは勉強してきたようですね。えらいえらあい。
>>816 つまり、
>>817 を要約すると、テキスト編集くらいしか役に立たんということだ。
あとは一応、コマンド実行できるから、シェルスクリプト(バッチファイル)の代わりとか、
ネットワーク周りも使えるから、ネットワークのクライアントとかサーバとかそんなもん。
でもやっぱり一番用途が多いのはテキスト編集で、テキストファイルの変換とか多いと気がするな。xxx2htmlとか。
>>822 ,.-─ ─-、─-、
, イ)ィ -─ ──- 、ミヽ
ノ /,.-‐'"´ `ヾj ii / Λ
,イ// ^ヽj(二フ'"´ ̄`ヾ、ノイ{
ノ/,/ミ三ニヲ´ ゙、ノi!
{V /ミ三二,イ , -─ Yソ
レ'/三二彡イ .:ィこラ ;:こラ j{
V;;;::. ;ヲヾ!V ー '′ i ー ' ソ
Vニミ( 入 、 r j ,′
ヾミ、`ゝ ` ー--‐'ゞニ<‐-イ
ヽ ヽ -''ニニ‐ /
| `、 ⌒ ,/
| > ---- r‐'´
ヽ_ |
ヽ _ _ 」
ググレカス [ Gugurecus ]
( 西暦一世紀前半 ~ 没年不明 )
ダガコトワル
831 :
デフォルトの名無しさん :2006/05/28(日) 15:05:43
質問お願いします
requireされたモジュールにおいて、自身のファイルのあるパスを取得するのはどうすればいいでしょうか?
834 :
デフォルトの名無しさん :2006/05/28(日) 15:08:25
835 :
833 :2006/05/28(日) 15:09:51
836 :
デフォルトの名無しさん :2006/05/28(日) 15:10:40
>>833 CGIからはどの言語からでも無理ということでしょうか?
こんな感じのはどうだい
#!/usr/bin/perl
use strict;
use LWP::UserAgent;
main();
sub getUA {
my $timeout = $_[0] ? $_[0] : 10;
my $ua = LWP::UserAgent->new();
$ua->agent('Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0)');
$ua->timeout($timeout);
return sub { # new($method, $url, $header)
my $res = $ua->request(
HTTP::Request- >new($_[0], $_[1], $_[2]));
return ($res->is_success) ? $res : 0;
}
}
sub main {
my $ua = getUA(10);
my $res= $ua->('GET', "$ARGV[0]");
$res or die "$ARGV[0] error\n";
print $res->content;
}
GETするだけならLWP::Simple使えよ…。そっちのが早いし。
840 :
デフォルトの名無しさん :2006/05/28(日) 15:29:40
PerlでGCA解凍出来る?
>840
Perlプログラムを起動すると、ターミナルの上部が常に同じ表示をしている状態にしたいのですが、
>>841 GCA形式とはまたマニアックな。
作ればできるが、今のところそういったモジュールはないと思われる。
>>845 できなくはないが…めんどくさいな。
使ったことはないがncursesとかのコンソール用のライブラリを
インストロールする必要があると思われる。
とりあえず、簡単にはできないかと。
インストロール
空気嫁
851 :
デフォルトの名無しさん :2006/05/28(日) 20:57:50
難問が出されたのでみんな黙ってしまった
どれが難問なの?
853 :
デフォルトの名無しさん :2006/05/28(日) 21:35:23
linuxのtopコマンドとかってどうやってるんだろう?
>>845 コマンドラインでの実行が必須の前提なのか?
見た目に拘るならuse Tk;
>>845 例によって環境が隠蔽されているでアレだが、
UNIX世界なら、Curses*のモジュールのどれかとか
あるいはTerm*に何かあるかも知れんね。
857 :
デフォルトの名無しさん :2006/05/28(日) 23:23:27
terminfoとか調べてみる必要あるね('A`)
858 :
デフォルトの名無しさん :2006/05/29(月) 01:00:04
>>844 あーやっぱりこれじゃだめですた。
ファイルの置かれてるパスが知りたいので
漢字だけ、ひらがなだけをマッチングさせたいのですが、わかりません。
860 :
デフォルトの名無しさん :2006/05/29(月) 01:21:26
mod_perlとサーブレットってどっちが速いの?
>>860 「速い」のはサーブレットかな。大抵の場合。
862 :
デフォルトの名無しさん :2006/05/29(月) 02:02:54
そうなんだ。残念だね('A`)
863 :
デフォルトの名無しさん :2006/05/29(月) 02:52:03
>>863 の図によると、mod_perlのほうがサーブレットより3倍くらい速いね。
っていうか、当たり前か。
866 :
デフォルトの名無しさん :2006/05/29(月) 14:20:45
>>859 PerlはPHPのようなローカルエンコーディング対応正規表現はないから、
昔のJPerlを引っ張り出してくるか、そうじゃなければutf8でやるしかないよ。
↓こんな感じ。
use encoding 'euc-jp', STDOUT => 'shift-jis';
use Encode;
$j = "ここが漢字です。abcここカタカナ。";
if ( $j =~ m/([\x{4e00}-\x{9fff}]+)/ ){
print "漢字 [$1]\n";
}else{
print "NOT 漢字\n";
}
if ( $j =~ m/([ぁ-ん]+)/ ){
print "ひらがな [$1]\n";
}else{
print "NOT ひらがな \n";
かぶった。
869 :
デフォルトの名無しさん :2006/05/29(月) 14:28:55
[S[NP [Det The][N man]][VP [V ate][N apples]]]
うお、2chて半角スペースは無視されちゃうんだ。もう一度。
>>869 NLPだね。
図にしてくれるのは見た事が無いな。というか図にしようと思わなかった。
Perlであるかどうかも分からないし、自分でぐぐるしか無いのでは。
>>869 perlでわざわざ作らんでもgraphvizで一発よ
わざわざコンピューター使わなくても紙と筆ペンで一発よ
T女の竹田を久しぶりに見た
876 :
844 :2006/05/29(月) 21:18:20
>>858 ん?「ファイルの置かれているパス」?相対パスでなくて絶対パスがいいってこと?
__FILE__が相対パスなら、カレントディレクトリ取ってきて__FILE__をくっつければ?
と適当な回答。
>>876 アナルほど。__FILE__はカレントディレクトリに対しての
ファイルの位置が得られるんですね。実行ファイルとしての
Perlのモジュールを別のモジュールからrequireしようとして、
そのモジュール内でのrequireに不都合があったんですが、
カレントを取るように書き換えるのがいいみたいですね。
ありがとうございました。
>>866 >>867 どうもありがとうございます。
なるほど、内部utf-8ですね。ちらっとその情報は見たことがあるのですが、
昔とかわらない感覚でいました。
日本語に問題あればEUCにすればいいだろ、みたいな。はは。
勉強になりました。
879 :
859 :2006/05/29(月) 21:44:01
これからはencodingが便利そうだ、というのはわかったのですが、ファイル出力のところがよく分かりません。
880 :
877 :2006/05/29(月) 21:59:19
use Cwd;
>>879 文字境界とかの問題のためにEUCを使うつもりだったけど
実際にはSJISが扱えればいい、ということであれば
use open ':encoding(shift-jis)';
use encoding 'shift-jis';
で、ソースの文字コードもファイルの読み書きも標準入出力もSJISで行けるよ。
あと、Windowsの話ならshift-jisよりcp932のほうが安全だと思う。
>>879 分かってないならuse encodingは使わないほうがいいよ。
#メンテナの人は非推奨だってさ
それはそれとしてサンプルでおかしいのは
open IN, '<:encoding(euc-jp)', $infile or die $!;
の部分かと。shiftjisのファイルを開くなら
open IN, '<:encoding(shiftjis)', $infile
でしょう。ついでに余計なお世話を言うと、
WindowsなファイルならCP932にしたほうが幸せになれるかもしれません。
perl 5.8以降で、UTF-8でスクリプトとデータを書いていいのなら、
884 :
879 :2006/05/29(月) 23:09:29
>>881-883 みなさん、ありがとうございます。
過去のレスにあった、
use encoding "cp932";
use open ":encoding(cp932)";
use open ":std";
でうまくいけそうです。それで、cp932とかたくさん書いてあったんですね。
今、基本的にWindowsなので、sjisで書こうと思っています。
でも、utf8のほうが問題が少なくなるとか、後が楽なら、それもよいと思うのですが、
みなさんはutf8は結構使っているのでしょうか?
どうもutf8とか慣れて無くて、、、
windowsで、parとThe Gui Loftで今遊んでいます。
>>885 使ったことないからわかんないけど、
use lib '../common';
とかじゃダメかな?
>>880 遅レスだが、
use FindBin;
$path=$FindBin::Bin . '/' . __FILE__;
の方が良くないか?
モジュールとスクリプトをどうしても別ディレクトリにしたい
ってのなら別だが。
>>887 foo.plというスクリプトがあって、それが同じディレクトリにあるjcode.plをrequireしてる。
bar.plというスクリプトはfoo.plをrequireしたい。bar.plの実行は任意のディレクトリで行われる。
/foo/foo.pl
/foo/jcode.pl
/bar/bar.pl
/test において実行
>>880 はfoo.plのことです。
カレントディレクトリがどこであろうと、foo.plがjcode.plをrequireできるようにしたい。
であるなら、モジュール内においてカレントディレクトリをチェックしなくてはならないかなと。
889 :
883 :2006/05/30(火) 01:39:40
>> 884
>>888 require 'foo.pl' したら$INC{'foo.pl'} にfoo.pl のabsolute path が格納されるので、それを元に調べればok
891 :
887 :2006/05/30(火) 08:13:35
>>888 __FILE__なんて書いたから真意が伝わらなかったか?
単に趣味の問題のお話しなんだ。
##/foo/foo.pl
#!/usr/local/bin/perl -w
use FindBin ;
#use lib $FindBin::Bin ;
#require 'jcode.pl' ;
require $FindBin::Bin . '/' . 'jcode.pl' ;
print 'foo.pl' .
print $FindBin::Bin . "\n" ;
893 :
885 :2006/05/30(火) 08:25:40
>>886 レスありがとう。
駄目でした。
今のところ、致命的なものではないので、バッチファイルを使って、
コピー、コンパイル、削除、という形にしようかなと思っています。
>>892 $ cat ~/foo/foo.pl
#!/usr/bin/perl
use FindBin;
print "---- foo.pl ----\n";
print "__FILE__ = ".__FILE__."\n";
print "FindBin::Bin = $FindBin::Bin\n";
print "FindBin::Script = $FindBin::Script\n";
print "FindBin::RealBin = $FindBin::RealBin\n";
print "FindBin::RealScript = $FindBin::RealScript\n";
$ cat ~/bar/bar.pl
require "$ENV{HOME}/foo/foo.pl";
$ perl ~/bar/bar.pl
---- foo.pl ----
__FILE__ = /home/Administrator/foo/foo.pl
FindBin::Bin = /home/Administrator/bar
FindBin::Script = bar.pl
FindBin::RealBin = /home/Administrator/bar
FindBin::RealScript = bar.pl
という具合にFindBinはrequireされた場合を考慮してくれません。使い方間違ってるかもしれませんが・・・
あるモジュールをrequireするには (1)絶対パス (2)カレントディレクトリに対する相対パス
のどちらかが必要ですよね。__FILE__なら、require時においてモジュール自身がどう指定されたのか、
そのパスが取得できます。
よく考えてみたら、カレントディレクトリを取得しなくても
require sub{$_=__FILE__;s/[^\/\\]+$//;$_}->()."jcode.pl";
foo.plにおいてこれで、絶対パス、相対パスのどちらにも対応できたっぽいです。
bar.plからfoo.plをrequireできているということはfoo.plのあるディレクトリをbar.plは
896 :
844 :2006/05/30(火) 11:14:38
>>895 まあ、ちょっと汎用的に作りたかったとかそういう理由じゃないかね。
毎回use lib→requireして使うライブラリより、require一発で取り込めるようにしたかった。今は反省している。とかそんな理由では。
~/foo/foo.pl で、require 'jcode.pl' ;すればいいだけの話では?
>>897 >~/foo/foo.pl で、require 'jcode.pl' ;すればいいだけの話では?
それだと、
>>888 の問題を解決できないでしょ。
jcode.plは ~/foo/jcode.pl に存在してて、~/fooにはパスが通ってないから、
require 'jcode.pl'; ではファイルが見つからないエラーになるか、
/usr/local/lib/...../jcode.pl が取り込まれるはず。
899 :
897 :2006/05/30(火) 13:14:04
出来るんだけど?
>>899 /bar/bar.pl の中で use lib qw( /PATH/foo ) ; してない?
それしてるんだったら、897 は正しい。してなくて
require '/PATH/foo/foo.pl' ; だと 898 が正しい。
流れを読むと、質問者は「/bar/bar.pl の中で
use lib qw( /PATH/foo ) ;」はしない方向。で、答はでてる。
俺だったら、/bar/bar.pl の中で use lib qw( /PATH/foo ) ; する。
901 :
デフォルトの名無しさん :2006/05/30(火) 17:49:08
みんなおはよう
>>900 横入りごめん。
前から気になってたんだけど、なんでそういうところでqw使うの?
>>901 横レス
俺は癖…てのは冗談で lib を複数指定するときに
use lib ( '/foo', '/bar', '/piyo' ) ;
ってやるよりは
use lib qw( /foo /bar /piyo ) ;
ってやった方が可読性がいいから
ま、すきずき
s/901/902/ orz...
>>903 ,
>>904 Thx. その答えだとおかしい例がたまにあるけどそういうのはわかってないでやってる奴なんだろうな。。。
俺が理解できないのは、"$hoge" みたいに書いてる人。
>>893 そりゃ、駄目だろうね。
lib.pm の認識も間違っていそうだけど、parに関しても間違ってるみたいだから。
exe作成したものがモジュール読まないってのも認識違いで、885の場合だと
カレントディレクトリ相対で ..\common , アーカイブ内の順で捜してくれる。
とりあえず、par(むしろpp)を読む事を薦めとく。
perlコード部分だけでもね。
それが面倒なら、何も考えずに site/lib にでもモジュールを放りこめば?
(site/lib を使いたくないなら、perlrunでも読むといいよ)
>>907 文字列じゃないと嫌だったとかいう理由では?
my $hoge = \@_; # $hoge はリファレンス
&foo("$hoge"); # "$hoge" は文字列
みたいな。
あるいは未定義値を未定義ではない空文字列に変換したかったのかもしれん。
いや、ウォーニング出るし。
ウォーニング娘。
Perlのソースに自動的に着色(HTML等を使用)してくれるモジュールってありますか?
>>914 エディターとかじゃなくて、モジュールなのな?
>>915 はいそうです
エディタは着色機能のあるTeraPadを使っています
917 :
885 :2006/05/31(水) 00:33:35
>>908 レスTHANKSです。
今のところ、頻繁に書き換えているので、site/libには入れないつもりです。
でも、そういう考え方もあるのは考えていませんでした。
parを少し見てみました。すらすら読めないので時間がない。。。
見たエラーは書いて有りました。
やっている動作は想像つきそうだし、勉強ついでにあとで見てみることにします。
Perl::Tidy
WindowsでGDを利用したいのですが (5.8)
>>922 ありがとうございます
『CPANのppmレポジトリ』というのはどこにあるんでしょうか?
すみません…CPANの中を結構探してるんですが見つからなくて…
この二つってどう違うんですか?
ハッシュは対応するキーが存在しないときもundefを返すので、
5.6.0 → 5.6.1のperldeltaの和訳されたのって無いでしょうか?
>>921 インストール ○
インストロール 玄人
>>924 exists は$hashの中の$keyが存在するか調べる。
defined は$hash{$key}が返した結果がundefかどうか調べる。
内部処理的にはexistsのほうが無駄がなさそう。
928 :
927 :2006/05/31(水) 12:03:12
>>926 >definedだとキーが存在して値がundefなのかキーがそもそも
>存在しないのかが区別できない。
あっ、確かに。いい事しった。
929 :
928 :2006/05/31(水) 12:04:13
みなさまご苦労様です。
Text::CSV_XS とかは? TSVも扱えたはず
>>930 5000行程度ならまず平気でしょう。その判断は当然、レコード長と実行環境によります。
CPAN の Data::Table なんてのもありますけど、使ったことないんでなんとも。
933 :
930 :2006/06/01(木) 01:55:23
>>931-932 返事、ありがとうございます。
検索して、少し見てみました。
Text::CSV_XSは、MANUALを見た限り指定行を指定文字列で検索できなさそう。
でも、excelとかのデータを扱うときに便利そうですね。メモしておきます。
Data::Tableは複雑そう。検索するだけの、すぐ動かなくていいから簡単なサンプルだれか持ってないかな。
やりたいのは、ファイルを一括で読んでくれて、
タブで区切られたフィールドがあり(データにタブが入ることが無いデータ、"で囲むなども無し)、
f1f2f3
A001appleりんご
A002pineぱいなっぷる
こんなの(\t区切り)。一行目は、検索のために必要ならおいてもいいし、置かなくてもいい。
探しているのは、第一列のフィールドを検索(A002)して、その行の2,3のフィールドを取得できるもの、という簡単なものです。
第一列のフィールドからだけ検索出来ればOK。
1データ、だいたい、1KB - 6KBぐらいのファイルサイズ。
みんな自分で作るのかな。
キャッシュやインデックスのディレクトリなどを作成してもよいので、
簡単なインデックスを作成して読み込みが早くなるような物ってないものでしょうか。
まあ、無くてもどっちでもよいのですが、誰か作ってないのかな。
適当に書いてみるけど、
タイムスタンプ保持、その比較、なければインデックス作成、インデックスは、アルファベット順に並べた第一フィールド、
行番号があって、効率よい検索して行番取得、指定ファイル行だけを読み込み、って感じ。ここらへん専門じゃないので突っ込みは無しね。
でも、たいしてデータないときは速くならなくて、かえって遅くなるのかな~。
まあ、速度は重要じゃなくて、
簡単なのがないかなー、と。
殺意を覚えるのは俺だけ?
5000行程度で、タブ区切り、1列目が「A001」みたいなユニークなIDなら、
「りんごとぱいなっぷる大ちゅき♥」まで読んだ
最近は、100行を越えるコードを書くと、「スゲエ長いプログラム書いちゃった」
全てのプログラムは7行で書くべきだと
口数は多いが内容が実に馬鹿馬鹿しい。
941 :
932 :2006/06/01(木) 05:14:44
>>933 うんよしわかった、いいからまず書いて。
自前で実装しても全然大したコード量にはならないから練習がてら書いてみてくださいな。
それと、「突っ込みは無しね」なんてのは議論の上で重要な項目とそうでない項目が峻別できる水準にある人同士でのみ意味を持つんです。
「わからないので教えて」という人がそれを使った場合、
「ぼくのアイデアに対して否定的なことは言わずに、ぼくが気分良く採用できる実装だけをください」
と言っているに等しいので、どう見ても "回答者避け" にしか見えません。気をつけましょう。
あとね、とりあえず紹介したモジュールのドキュメントくらいは、役に立つかどうか判断できる程度に眼を通して欲しいなと思ったりする…orz
942 :
933 :2006/06/01(木) 06:02:48
たくさんの反感を買ってしまった。
943 :
933 :2006/06/01(木) 06:16:18
>>935 ありがとうございます。
perlって、こういうやり方が有効なんだとはっとさせられます。
もう少しperlの癖や常識みたいなのを身につけようと思います。
933です。
どーでもいい memo
Back スラッシュとエンマークが混じってもうた。。。。
>>945 勉強になったけど
>>933 は \S+\t\S+\t\S+ だから split じゃだめじゃね?
948 :
デフォルトの名無しさん :2006/06/01(木) 20:42:07
t\S
>>948 の見えているものが俺には見えない件について
t\ が翼で、 S が鳥の首~頭?
どーでもいい memo
my %hash;
>>951 を
>>952 の条件にして確認。
それだと、たしかに一番早かった。
行毎の処理なら、普通がー番って事だな。
>>953 検証あいがと。
正直なんつーかこう、巨大な一時リストを作業用に展開して丸ごとコピー、とか抵抗あんだよね。
貧乏性は治らないらしい。^^;
俺の対局にいる人かもw。
956 :
954 :2006/06/02(金) 02:53:27
>>955 たぶん上司殿じゃないと思ふが。上司殿によろしく。w
でもアロケートやらコピーってのは、ディスク I/O やサブプロセス起動ほどには高価じゃないけれど、単なる主記憶の読取ほどには安価じゃないわけで。
だから本質的に不要な場所でそういった操作が大量発生するコードってのは、やっぱり筋が悪く見えちゃうんだろう。
f1が連番でソートされてるんでしょ?
検索するのにいちいちハッシュに突っ込む時点で違和感を覚える貧乏性は俺だけか。
せっかくあるんだし、お手軽でいいんじゃないかな。
>>959 >一列目のkey名から2列、3列目を検索とさせるツールを探しています。
ごめんここ読み落としてたorz
忘れて。
検証不足スマソ。
これでこの件を引きずるのは終りにしますので、「判りきったこと書くな」
という先輩諸氏は御勘弁を。
夜中にやった(
>>593 )のは
- マシンが違う。
- @_ = split/\t/, $_ ; $_[0], [$_[1], $_[2]]
つーことで、マシンを同じにして
my ( $var, @arr) = split/\t/, $_ ; $var, \@arr
の条件にてもいっぺん検証。
1.
>>952 の while 及び for / map でもほぼ同じ結果。
4.33s user 0.27s system 91% cpu 5.051 total ( foreach, map も )
2. my %hash = map { chomp; my ( $var, @arr) = split/\t/, $_ ; $var, \@arr } <> ;
4.57s user 0.42s system 91% cpu 5.463 total
3. my %hash = map { chomp; @_ = split/\t/, $_ ; $_[0], [$_[1], $_[2]] } <> ;
5.91s user 0.44s system 94% cpu 6.713 total
4. my %hash = map { my ( $var, @arr ) = split /\t/, $_ ; $var, \@arr} split /\n/, do { local $/ ; <> } ;
2.54s user 0.26s system 93% cpu 2.983 total
5. my %hash = map { @_ = split /\t/, $_ ; $_[0], [$_[1], $_[2]]} split /\n/, do { local $/ ; <> } ;
5.32s user 0.35s system 94% cpu 6.012 total
カレントディレクトリの中にあるディレクトリのリストを得るにはどうすれば良い?
推奨はしない( glob 展開は非常にリスキー)が、
リスキー? じゃあ File::Glob は?
あと <*.c> のようなのも使えるな。
Perlの内部実装は新バージョンごとにどんどん変更が加えられている。
968 :
966 :2006/06/02(金) 17:45:51
リロードしてから書くんだった。。。
なるほど。
971 :
デフォルトの名無しさん :2006/06/02(金) 18:31:33
>>962 File::Slurpのread_dirとか。
>>962 はファイルの一覧じゃなくてディレクトリの一覧が知りたいってことじゃないの?
まあ、ひとつ筒-dすれ。
次スレまだぁ
ファイルのサイズをチェックして、ファイルサイズが小さいときに、
unko.log wwwww
最近のPerlは読み取り属性で開いても書き込めるのか
あら、間違えちった。まあその辺は適当に脳内修正頼む。
>>974 頭から全部読むのが問題なほど大きいのならFile::ReadBackwardsで後ろから読む手もある。
次スレか。テンプレについて提案。
過去ログのところhttpをttpに変えて一レスに纏めない?
>>979 >過去ログのところhttpをttpに変えて一レスに纏めない?
いいと思う。まあ、最終決定はスレ立てる人がどうぞ。
URLまだぁ~? チンチン (AA略)
983 :
デフォルトの名無しさん :2006/06/02(金) 23:23:32
There's more than one way to wait it.
985 :
979 :2006/06/02(金) 23:33:37
980じゃないけど立ててきちゃって良いかな
乙。
Template Toolkitで使用する
989 :
974 :2006/06/03(土) 00:40:31
>>975-979 ありがとーです。
全部試してみます。
1MB程度だから、975さんので問題ないのかな。
File::ReadBackwardsもよさげ、というか、こういうの標準でありそでないのかー。
990 :
デフォルトの名無しさん :2006/06/03(土) 02:16:33
991 :
デフォルトの名無しさん :2006/06/03(土) 02:17:05
992 :
デフォルトの名無しさん :2006/06/03(土) 02:26:24
ume
994 :
デフォルトの名無しさん :2006/06/03(土) 03:16:38
1000を取りたければ、私を越えて行くがよい。
別にこんなところで1000取ってもなぁ
そうは言いなら柄も人は乗り越えてゆくのだ
Rubyに完全に取って代わられちゃったね。
1000
1001 :
1001 :
Over 1000 Thread このスレッドは1000を超えました。
{kind=link}