Intel uPs Info 4
1 ҒF–јҸМ–ўҗЭ’иҒF
Intelҗ»ғ}ғCғNғҚғvғҚғZғbғTӮМҸо•сӢЗғXғҢғbғhӮЕӮ·ҒB
Ҹо•с“ҠҚeӮжӮлӮөӮӯӮЕӮ·ҒBIntelғvғҚғZғbғTӮМҗМҳbӮаOKҒB
Һ©Қм”ВӮМIntelғXғҢӮЙ•үӮҜӮИӮўӮжӮӨӮЙӮөӮжӮӨҒB
ҒҰ–П‘zҒA’ҝҗаҒE’ҝҳ_ҒAҢЦ’Ј•\Ң»ӮНҚTӮҰӮЯӮЙҒB
ҒҰұСБӯ°ҒAУДБӯ°ҒAIBMБӯ°Ӯ©ӮзӮМҸ‘Ӯ«ҚһӮЭӮНӮІү“—¶ӮӯӮҫӮіӮўҒB
ҒҰБӯ°—¬“ь–hҺ~ӮМӮҪӮЯҒAҲУҗ}“IӮЙӮнӮ©ӮиӮЙӮӯӮўғ^ғCғgғӢӮЙӮөӮДӮўӮЬӮ·ҒBӮІ—№ҸіӮӯӮҫӮіӮўҒB
ҒҰПА°ШӮөӮЬӮөӮеӮӨҒB
‘OғXғҢ
Intel uPs Info 3
http://pc11.2ch.net/test/read.cgi/mac/1190013206/
‘OҒXғXғҢ
Intel uPs Info 2
http://pc11.2ch.net/test/read.cgi/mac/1159817811/
‘OҒXҒXғXғҢ
Intel uPs Info
http://pc7.2ch.net/test/read.cgi/mac/1121683774/
Ҹо•с“ҠҚeӮжӮлӮөӮӯӮЕӮ·ҒBIntelғvғҚғZғbғTӮМҗМҳbӮаOKҒB
Һ©Қм”ВӮМIntelғXғҢӮЙ•үӮҜӮИӮўӮжӮӨӮЙӮөӮжӮӨҒB
ҒҰ–П‘zҒA’ҝҗаҒE’ҝҳ_ҒAҢЦ’Ј•\Ң»ӮНҚTӮҰӮЯӮЙҒB
ҒҰұСБӯ°ҒAУДБӯ°ҒAIBMБӯ°Ӯ©ӮзӮМҸ‘Ӯ«ҚһӮЭӮНӮІү“—¶ӮӯӮҫӮіӮўҒB
ҒҰБӯ°—¬“ь–hҺ~ӮМӮҪӮЯҒAҲУҗ}“IӮЙӮнӮ©ӮиӮЙӮӯӮўғ^ғCғgғӢӮЙӮөӮДӮўӮЬӮ·ҒBӮІ—№ҸіӮӯӮҫӮіӮўҒB
ҒҰПА°ШӮөӮЬӮөӮеӮӨҒB
‘OғXғҢ
Intel uPs Info 3
http://pc11.2ch.net/test/read.cgi/mac/1190013206/
‘OҒXғXғҢ
Intel uPs Info 2
http://pc11.2ch.net/test/read.cgi/mac/1159817811/
‘OҒXҒXғXғҢ
Intel uPs Info
http://pc7.2ch.net/test/read.cgi/mac/1121683774/
|
|
|
2 ҒF–јҸМ–ўҗЭ’иҒF2008/06/26(–Ш) 15:29:51 ID:I3hfESaw0
ӮўӮҝӮЁӮВ
3 ҒF–јҸМ–ўҗЭ’иҒF2008/06/26(–Ш) 17:48:17 ID:3kddYdrL0
ӮӨӮБӮХӮ·ӮўӮсӮЩӮБӮДүҪҒH
4 ҒF–јҸМ–ўҗЭ’иҒF2008/06/27(Ӣа) 11:48:53 ID:TPhqu8PIO
үі
5 ҒF–јҸМ–ўҗЭ’иҒF2008/06/29(“ъ) 17:45:37 ID:6xhzC9U60
ho
6 ҒF–јҸМ–ўҗЭ’иҒF2008/07/02(җ…) 00:14:19 ID:rwYkpwLh0
su
7 ҒF–јҸМ–ўҗЭ’иҒF2008/07/04(Ӣа) 17:19:16 ID:fgLIt9p50
”N––ӮЙӮНNehalem“ӢҚЪMacProӮӘҸoӮйӮМӮ©ӮЛ
8 ҒF–јҸМ–ўҗЭ’иҒF2008/07/07(ҢҺ) 19:17:47 ID:6WIpDbt10
”N––ӮЙҸoӮйӮМӮН1sҢьӮҜӮМNehalemӮЕXeonӮН’xӮкӮйӮсӮ¶ӮбӮИӮўӮМӮ©ҒB
AppleӮМӮұӮЖӮҫӮ©ӮзғtғүғCғ“ғOӮЕӢҹӢӢӮөӮДӮаӮзӮӨӮ©ӮаӮөӮкӮсӮӘ
AppleӮМӮұӮЖӮҫӮ©ӮзғtғүғCғ“ғOӮЕӢҹӢӢӮөӮДӮаӮзӮӨӮ©ӮаӮөӮкӮсӮӘ
9 ҒF–јҸМ–ўҗЭ’иҒF2008/07/12(“y) 22:10:45 ID:X2NY0d4t0
ho
10 ҒF–јҸМ–ўҗЭ’иҒF2008/07/16(җ…) 21:37:41 ID:2tJDaSEC0
ze
Intel Roadmap indicates multiple Havendale incoming Q3ҒҢ09
http://en.expreview.com/2008/07/16/intel-roadmap-indicates-multiple-havendale-incoming-q309/#more-543
- Lynnfield/HavendaleӮаHyper-Threading—LӮи
- LynnfieldӮНTurbe Boost Technology—LӮиҒB
# LynnfieldӮН4 core + PCIeӮИӮМӮЕ200mmsqҗШӮйӮМӮНҢөӮөӮўӮ©??
# HavendaleӮа2 core + GMCHӮМMCMӮИӮМӮЕӮ ӮЬӮиV2, V1ӮН45nmӮЕӮН–і—қӮМ—\ҠҙҒB
# NehalemҢnӮМV2,V1ӮНWestmereҗў‘г‘ТӮҝӮ©ҒADC AtomӮ©ӮИӮ ҒB
# WestmereӮЦӮМҲИҚ~ҺһҠъӮӘӮ©ӮИӮи“дҒBTickTockӮНӮвӮБӮП“пӮөӮўӮМӮ©ҒcҒB
http://en.expreview.com/2008/07/16/intel-roadmap-indicates-multiple-havendale-incoming-q309/#more-543
- Lynnfield/HavendaleӮаHyper-Threading—LӮи
- LynnfieldӮНTurbe Boost Technology—LӮиҒB
# LynnfieldӮН4 core + PCIeӮИӮМӮЕ200mmsqҗШӮйӮМӮНҢөӮөӮўӮ©??
# HavendaleӮа2 core + GMCHӮМMCMӮИӮМӮЕӮ ӮЬӮиV2, V1ӮН45nmӮЕӮН–і—қӮМ—\ҠҙҒB
# NehalemҢnӮМV2,V1ӮНWestmereҗў‘г‘ТӮҝӮ©ҒADC AtomӮ©ӮИӮ ҒB
# WestmereӮЦӮМҲИҚ~ҺһҠъӮӘӮ©ӮИӮи“дҒBTickTockӮНӮвӮБӮП“пӮөӮўӮМӮ©ҒcҒB
ӮЖӮўӮӨӮнӮҜӮЕҒAҸ¬ӮіӮўғlғ^ӮМӮЭӮҫӮӘӮұӮМғXғҢ•ңҠҲҒB
ҲИ‘OӮжӮиҳRӮкӮМғҢғxғӢӮӘ—ҺӮҝӮДӮўӮйӮМӮЕҒA‘¶ҚЭүҝ’lӮН‘Ҫ•Ә”ч–ӯӮҫӮӘҒB
ҲИ‘OӮжӮиҳRӮкӮМғҢғxғӢӮӘ—ҺӮҝӮДӮўӮйӮМӮЕҒA‘¶ҚЭүҝ’lӮН‘Ҫ•Ә”ч–ӯӮҫӮӘҒB
Intel's Larrabee GPU based on secret Pentagon tech, sorta
http://arstechnica.com/news.ars/post/20080708-intels-larrabee-gpu-based-on-secret-pentagon-tech-sorta.html
Larrabee P54C-basedҗаӮЙӮВӮўӮДҒB
Ӯ©ӮИӮиҲИ‘OҒAIntelӮНP5җў‘гӮӘҲш‘ЮӮіӮ№ӮҪӮ ӮЖӮЙҒA•ДҚ‘Қ‘–h‘ҚҸИӮЙP54CӮМRTLғRҒ[ғhӮр’сӢҹӮөӮҪҒB
ӮЕҒAҚ‘–h‘ҚҸИӮНP54CӮрғxҒ[ғXӮЙ‘О•ъҺЛҗь”ЕӮМӮрҢRҺ–—p“rҢьӮҜP5ӮрҚмӮБӮҪҒB
җ””NҢгҒAӮ»ӮМPentagon”ЕP5ӮаҲш‘ЮӮөӮҪӮ ӮЖҒAҚЎ“xӮНIntelӮЙPentagon”ЕP5ӮМRTLӮӘ•ФӮіӮкӮҪҒB
Ӯ»ӮкӮрMany-CoreҢьӮҜӮЙҠg’ЈӮөӮҪӮаӮМӮӘLarrabeeӮМcoreӮБӮДӮұӮЖӮзӮөӮўҒB
# ӮҝӮИӮЭӮЙҳRӮкӮНӮұӮкӮр“ЗӮсӮЕӮаP5-basedӮҫӮЖӮНҺvӮБӮДӮИӮў”hҒB
http://arstechnica.com/news.ars/post/20080708-intels-larrabee-gpu-based-on-secret-pentagon-tech-sorta.html
Larrabee P54C-basedҗаӮЙӮВӮўӮДҒB
Ӯ©ӮИӮиҲИ‘OҒAIntelӮНP5җў‘гӮӘҲш‘ЮӮіӮ№ӮҪӮ ӮЖӮЙҒA•ДҚ‘Қ‘–h‘ҚҸИӮЙP54CӮМRTLғRҒ[ғhӮр’сӢҹӮөӮҪҒB
ӮЕҒAҚ‘–h‘ҚҸИӮНP54CӮрғxҒ[ғXӮЙ‘О•ъҺЛҗь”ЕӮМӮрҢRҺ–—p“rҢьӮҜP5ӮрҚмӮБӮҪҒB
җ””NҢгҒAӮ»ӮМPentagon”ЕP5ӮаҲш‘ЮӮөӮҪӮ ӮЖҒAҚЎ“xӮНIntelӮЙPentagon”ЕP5ӮМRTLӮӘ•ФӮіӮкӮҪҒB
Ӯ»ӮкӮрMany-CoreҢьӮҜӮЙҠg’ЈӮөӮҪӮаӮМӮӘLarrabeeӮМcoreӮБӮДӮұӮЖӮзӮөӮўҒB
# ӮҝӮИӮЭӮЙҳRӮкӮНӮұӮкӮр“ЗӮсӮЕӮаP5-basedӮҫӮЖӮНҺvӮБӮДӮИӮў”hҒB
14 ҒF–јҸМ–ўҗЭ’иҒF2008/07/19(“y) 17:14:12 ID:tdFjqt3o0
ҸЪҚЧӮӘ”ӯ•\ӮіӮкӮҪӮзӮіӮкӮҪӮЕҒA
ҠeҺ©ӮӘҺvӮӨӮЖӮұӮлӮМОЖ¬ЧЧНЮ°Ҫҳ_ӮЕ
ӮЬӮҪ•s–СӮИӢcҳ_ӮЙүФӮрҚзӮ©Ӯ№ӮжӮӨӮ¶ӮбӮИӮўӮ©ҒB
ҠeҺ©ӮӘҺvӮӨӮЖӮұӮлӮМОЖ¬ЧЧНЮ°Ҫҳ_ӮЕ
ӮЬӮҪ•s–СӮИӢcҳ_ӮЙүФӮрҚзӮ©Ӯ№ӮжӮӨӮ¶ӮбӮИӮўӮ©ҒB
Ӣcҳ_ӮН•\ғXғҢӮЕ(ӮИӮзҢВҗlӮМҢ©үрҸ‘ӮӯӮИӮЖӮ©ӮўӮнӮкӮ»ӮӨӮҫӮӘ)ҒB
ӮұӮұӮНӮЬӮБӮҪӮиӮўӮ«ӮҪӮўӮМӮЕӮ·ҒB
# 2-issue in-orderӮБӮДӮҫӮҜӮ¶ӮбAtomӮаӮ»ӮӨӮҫӮөҒAP5ӮҫӮЖӮНӮўӮнӮсҒB
# ӮвӮБӮПuop•ПҠ·ӮИӮөӮЕҒAU,VғpғCғvғxҒ[ғXӮ¶ӮбӮИӮўӮЖҒB
# ҚЕӢЯӮМx86ӮМFPU/SIMDӮЙҺgӮнӮкӮДӮўӮйғgғүғ“ғWғXғ^җ”ӮӘғIғҠғWғiғӢP5ӮжӮиӮа‘еӮ«Ӯў(ӮНӮёӮИ)ӮұӮЖҒA
# SMT, SIMDҠg’Ј, 64bitү», үј‘zү»ӮИӮЗӮИӮЗҒAP5ҲИҚ~ӮЙӮөӮИӮҜӮкӮОӮИӮзӮИӮўҠg’ЈӮӘӮ ӮЬӮиӮЙӮаӮ ӮиӮ·Ӯ¬ӮйӮұӮЖҒA
# ӮИӮЗӮ©ӮзӮИӮсӮЖӮИӮӯғoғүғ“ғXҲ«ӮўӮө–і—қӮ©ӮИӮ ӮЖҒBӮИӮЙӮөӮлuopӮаregister-renamingӮаӮИӮўӮсӮҫҒB
# Ҳк‘МӮЗӮӨӮвӮБӮДx86 decodeӮ·ӮйӮМ??ӮБӮДӮ©ӮсӮ¶ҒB
ӮұӮұӮНӮЬӮБӮҪӮиӮўӮ«ӮҪӮўӮМӮЕӮ·ҒB
# 2-issue in-orderӮБӮДӮҫӮҜӮ¶ӮбAtomӮаӮ»ӮӨӮҫӮөҒAP5ӮҫӮЖӮНӮўӮнӮсҒB
# ӮвӮБӮПuop•ПҠ·ӮИӮөӮЕҒAU,VғpғCғvғxҒ[ғXӮ¶ӮбӮИӮўӮЖҒB
# ҚЕӢЯӮМx86ӮМFPU/SIMDӮЙҺgӮнӮкӮДӮўӮйғgғүғ“ғWғXғ^җ”ӮӘғIғҠғWғiғӢP5ӮжӮиӮа‘еӮ«Ӯў(ӮНӮёӮИ)ӮұӮЖҒA
# SMT, SIMDҠg’Ј, 64bitү», үј‘zү»ӮИӮЗӮИӮЗҒAP5ҲИҚ~ӮЙӮөӮИӮҜӮкӮОӮИӮзӮИӮўҠg’ЈӮӘӮ ӮЬӮиӮЙӮаӮ ӮиӮ·Ӯ¬ӮйӮұӮЖҒA
# ӮИӮЗӮ©ӮзӮИӮсӮЖӮИӮӯғoғүғ“ғXҲ«ӮўӮө–і—қӮ©ӮИӮ ӮЖҒBӮИӮЙӮөӮлuopӮаregister-renamingӮаӮИӮўӮсӮҫҒB
# Ҳк‘МӮЗӮӨӮвӮБӮДx86 decodeӮ·ӮйӮМ??ӮБӮДӮ©ӮсӮ¶ҒB
Runtime Environment for Tera-scale Platforms
ftp://download.intel.com/technology/itj/2007/v11i3/4-environment/vol11-i3-art04.pdf
Intel VCGӮМҳ_•¶ҒB
# ӮұӮұӮЕғVғ~ғ…ғҢҒ[ғVғҮғ“ӮөӮДӮйTS-CMP processorӮБӮДӮМӮӘ”ч–ӯӮЙLarrabeeҺ—Ӯ©ӮаҒB
# SIGGRAPH 2008ӮЕҳ_•¶”ӯ•\Ӯ·ӮйҗlӮӘ’ҳҺТӮЙӮўӮйӮҫӮҜӮ ӮБӮДҒA
# ӮжӮӯ’mӮзӮсӮӘRun-TimeӮЕ“sҚҮӮӘҲ«ӮўӮЖӮұӮлӮНӢzҺыӮөӮДҒA‘Ҫҗ”ғRғA+HW MultiThreadingӮр•ӘүсӮ·ӮБӮДӮМӮа
# LarrabeeӮМ•ыҢьӮЙӮвӮНӮиӢЯӮўӢCӮӘҒB
TS-CMP processor
- 16 in-order core
- HW Multi-threading, round-robin each cycle
- 32KB L1D, 2MB shared L2, 4MB off-chip L3
- L1: 3 cycle, L2: 12 cycle, L3: 40 cycle
>We used a cycle-accurate simulator to evaluate McRTҒfs
>performance on a TS-CMP processor. The simulated
>platform consists of an array of up to 16 in-order cores,
>each of which has four threads. Each core will select a
>different thread each cycle, round-robin, unless the thread
>is stalled due to, for example, a cache miss, being in the
>sleep state. The memory system consists of a 32 KB L1
>data cache that is shared by all four threads in the core, a
>2MB L2 cache that is shared by all the cores, and an
>off-chip 4MB L3 cache. All caches were simulated with
>an 8-way set associative configuration. The L1 cache
>access time is 3 cycles, the L2 cache access time is 12
>cycles, and the L3 cache access time is 40 cycles.
Doug Carmean, Visual Computing Group, DEG
Eric Sprangle, Visual Computing Group, DEG
ftp://download.intel.com/technology/itj/2007/v11i3/4-environment/vol11-i3-art04.pdf
Intel VCGӮМҳ_•¶ҒB
# ӮұӮұӮЕғVғ~ғ…ғҢҒ[ғVғҮғ“ӮөӮДӮйTS-CMP processorӮБӮДӮМӮӘ”ч–ӯӮЙLarrabeeҺ—Ӯ©ӮаҒB
# SIGGRAPH 2008ӮЕҳ_•¶”ӯ•\Ӯ·ӮйҗlӮӘ’ҳҺТӮЙӮўӮйӮҫӮҜӮ ӮБӮДҒA
# ӮжӮӯ’mӮзӮсӮӘRun-TimeӮЕ“sҚҮӮӘҲ«ӮўӮЖӮұӮлӮНӢzҺыӮөӮДҒA‘Ҫҗ”ғRғA+HW MultiThreadingӮр•ӘүсӮ·ӮБӮДӮМӮа
# LarrabeeӮМ•ыҢьӮЙӮвӮНӮиӢЯӮўӢCӮӘҒB
TS-CMP processor
- 16 in-order core
- HW Multi-threading, round-robin each cycle
- 32KB L1D, 2MB shared L2, 4MB off-chip L3
- L1: 3 cycle, L2: 12 cycle, L3: 40 cycle
>We used a cycle-accurate simulator to evaluate McRTҒfs
>performance on a TS-CMP processor. The simulated
>platform consists of an array of up to 16 in-order cores,
>each of which has four threads. Each core will select a
>different thread each cycle, round-robin, unless the thread
>is stalled due to, for example, a cache miss, being in the
>sleep state. The memory system consists of a 32 KB L1
>data cache that is shared by all four threads in the core, a
>2MB L2 cache that is shared by all the cores, and an
>off-chip 4MB L3 cache. All caches were simulated with
>an 8-way set associative configuration. The L1 cache
>access time is 3 cycles, the L2 cache access time is 12
>cycles, and the L3 cache access time is 40 cycles.
Doug Carmean, Visual Computing Group, DEG
Eric Sprangle, Visual Computing Group, DEG
‘Оүһ•\(үј)
XE $999 ҒЁ Bloomfield-3.2G
P1 $530 ҒЁ Bloomfield-2.83G ҒЁ Lynnfield
MS3 $316 ҒЁ Bloomfield-2.66G($283) ҒЁ Lynnfield, Havendale
MS2 $266 ҒЁ Lynnfield, Havendale
MS1 $183 $224 ҒЁ Havendale
E2 $163 ҒЁ Havendale
E1 $133 ҒЁ Havendale
V3 $113 ҒЁ Havendale
V2 $64-$84
V1 $34-$53
# ҲкүһҚlӮҰӮҪӮӘҚЎӮўӮҝҗіҠmӮИ‘ОүһӮӘӮнӮ©ӮзӮИӮўҒB
# BloomfieldӮМүҝҠi=$284ӮНғVғXғeғҖӮЕҚӮүҝӮЙӮИӮйӮұӮЖӮЙ‘ОӮ·ӮйIntelӮМ•ҒӢyӮМӮҪӮЯӮМ”z—¶??
# 32nm WestmereӮӘӮўӮВҸoӮйӮМӮ©’mӮзӮИӮўӮӘҒA
# WestmereӮағTҒ[ғoҢьӮҜӮМ6 coreӮрҗжҚsӮөӮДҠJ”ӯӮөӮДӮўӮДӮўӮД
# ғfғXғNғgғbғvҢьӮҜӮМClarkdaleӮӘ’xӮкӮДӮўӮйӮЖӮ·ӮйӮЖҒA
# BloomfieldӮЖ“ҜӮ¶ҸуӢөӮЕӮЬӮҪӢҗ‘еӮИғ_ғCӮрғfғXғNғgғbғvҢьӮҜӮЙғoҒ[ғQғ“ӮөӮИӮ«ӮбӮўӮҜӮИӮӯӮИӮйҒB
# ғTҒ[ғo—pӮЙ4 core WestmereӮрҠJ”ӯӮөӮДӮўӮкӮОӮжӮўӮӘҒA
# Ӯ»ӮМҸкҚҮӮЕӮаQuickPathӮМғTҒ[ғo—pғ}ғUҒ[&socketӮрӮЬӮҪ“]—pӮ·ӮйӮұӮЖӮЙҒB
# ӮўӮёӮкӮЙӮөӮлsocketӮӘҲЩӮИӮйӮЕӮ ӮлӮӨLynnfieldӮЖDesktop WestmereӮЖӮМҠФӮМҲЪҚsҠЦҢWӮЙ–і—қӮӘӮ ӮйҒB
# ӢtӮЙClarkdaleӮӘ‘ҒҠъӮЙӮЕӮҪӮЖӮ·ӮйӮЖLynnfieldӮӘӢ°ӮлӮөӮӯ’Z–ҪӮЙҸIӮнӮБӮДӮөӮЬӮӨҒB
# LynnfieldӮНӮөӮОӮзӮӯ32nmӮЙҲЪҚsӮөӮИӮўӮЕ”SӮйӮұӮЖӮЙӮ·ӮйӮЖҒA
# ClarkdaleӮЖSandy Bridgeҗў‘гӮМҠЦҢWӮӘӮжӮӯӮнӮ©ӮзӮИӮӯӮИӮйӮИҒB
# ӮЖӮЙӮ©ӮӯLynnfield/HavendaleӮЖWestmereҗў‘гӮМҲЪҚsӮН–і—қӮӘӮ Ӯй—\ҠҙҒB
# ҺАӮНLynnfieldӮа4 coreӮИӮМӮЕӮ ӮЬӮиҲА”„ӮиӮЕӮ«ӮИӮўӮНӮёӮЕҒAғoҒ[ғQғ“Ҹу‘ФӮЙӢЯӮўҒB
# ӮВӮ©ҒA4 coreӮБӮД32nmӮЕӮаIntelӮМүЯӢҺӮМMainstreamӮЖ”дӮЧӮДӮЕӮ©ӮўӮсӮЕҒB
# ’ІҺqӮЙҸжӮБӮДcoreҗ”‘қӮвӮөӮ·Ӯ¬ӮИӮсӮ¶Ӯб??
# ҚЎӮМRoadmapӮН–і—қӮӘӮ ӮиӮ·Ӯ¬ӮИӢCӮӘӮ·ӮйӮМӮҫӮӘ‘ҒӮӯӮЙҚlӮҰүЯӮ¬Ӯ©ҒcҒB
XE $999 ҒЁ Bloomfield-3.2G
P1 $530 ҒЁ Bloomfield-2.83G ҒЁ Lynnfield
MS3 $316 ҒЁ Bloomfield-2.66G($283) ҒЁ Lynnfield, Havendale
MS2 $266 ҒЁ Lynnfield, Havendale
MS1 $183 $224 ҒЁ Havendale
E2 $163 ҒЁ Havendale
E1 $133 ҒЁ Havendale
V3 $113 ҒЁ Havendale
V2 $64-$84
V1 $34-$53
# ҲкүһҚlӮҰӮҪӮӘҚЎӮўӮҝҗіҠmӮИ‘ОүһӮӘӮнӮ©ӮзӮИӮўҒB
# BloomfieldӮМүҝҠi=$284ӮНғVғXғeғҖӮЕҚӮүҝӮЙӮИӮйӮұӮЖӮЙ‘ОӮ·ӮйIntelӮМ•ҒӢyӮМӮҪӮЯӮМ”z—¶??
# 32nm WestmereӮӘӮўӮВҸoӮйӮМӮ©’mӮзӮИӮўӮӘҒA
# WestmereӮағTҒ[ғoҢьӮҜӮМ6 coreӮрҗжҚsӮөӮДҠJ”ӯӮөӮДӮўӮДӮўӮД
# ғfғXғNғgғbғvҢьӮҜӮМClarkdaleӮӘ’xӮкӮДӮўӮйӮЖӮ·ӮйӮЖҒA
# BloomfieldӮЖ“ҜӮ¶ҸуӢөӮЕӮЬӮҪӢҗ‘еӮИғ_ғCӮрғfғXғNғgғbғvҢьӮҜӮЙғoҒ[ғQғ“ӮөӮИӮ«ӮбӮўӮҜӮИӮӯӮИӮйҒB
# ғTҒ[ғo—pӮЙ4 core WestmereӮрҠJ”ӯӮөӮДӮўӮкӮОӮжӮўӮӘҒA
# Ӯ»ӮМҸкҚҮӮЕӮаQuickPathӮМғTҒ[ғo—pғ}ғUҒ[&socketӮрӮЬӮҪ“]—pӮ·ӮйӮұӮЖӮЙҒB
# ӮўӮёӮкӮЙӮөӮлsocketӮӘҲЩӮИӮйӮЕӮ ӮлӮӨLynnfieldӮЖDesktop WestmereӮЖӮМҠФӮМҲЪҚsҠЦҢWӮЙ–і—қӮӘӮ ӮйҒB
# ӢtӮЙClarkdaleӮӘ‘ҒҠъӮЙӮЕӮҪӮЖӮ·ӮйӮЖLynnfieldӮӘӢ°ӮлӮөӮӯ’Z–ҪӮЙҸIӮнӮБӮДӮөӮЬӮӨҒB
# LynnfieldӮНӮөӮОӮзӮӯ32nmӮЙҲЪҚsӮөӮИӮўӮЕ”SӮйӮұӮЖӮЙӮ·ӮйӮЖҒA
# ClarkdaleӮЖSandy Bridgeҗў‘гӮМҠЦҢWӮӘӮжӮӯӮнӮ©ӮзӮИӮӯӮИӮйӮИҒB
# ӮЖӮЙӮ©ӮӯLynnfield/HavendaleӮЖWestmereҗў‘гӮМҲЪҚsӮН–і—қӮӘӮ Ӯй—\ҠҙҒB
# ҺАӮНLynnfieldӮа4 coreӮИӮМӮЕӮ ӮЬӮиҲА”„ӮиӮЕӮ«ӮИӮўӮНӮёӮЕҒAғoҒ[ғQғ“Ҹу‘ФӮЙӢЯӮўҒB
# ӮВӮ©ҒA4 coreӮБӮД32nmӮЕӮаIntelӮМүЯӢҺӮМMainstreamӮЖ”дӮЧӮДӮЕӮ©ӮўӮсӮЕҒB
# ’ІҺqӮЙҸжӮБӮДcoreҗ”‘қӮвӮөӮ·Ӯ¬ӮИӮсӮ¶Ӯб??
# ҚЎӮМRoadmapӮН–і—қӮӘӮ ӮиӮ·Ӯ¬ӮИӢCӮӘӮ·ӮйӮМӮҫӮӘ‘ҒӮӯӮЙҚlӮҰүЯӮ¬Ӯ©ҒcҒB
x Bloomfield-2.83G
o Bloomfield-2.93G
o Bloomfield-2.93G
Intel Bloomfield CPU pricing reveals pleasant surprise
http://www.digitimes.com/news/a20080717PD222.html
Bloomfield 3.20GHz $999
Bloomfield 2.93GHz $562
Bloomfield 2.66GHz $284
http://www.digitimes.com/news/a20080717PD222.html
Bloomfield 3.20GHz $999
Bloomfield 2.93GHz $562
Bloomfield 2.66GHz $284
32NM ATOM ON IDF 2008
http://xtreview.com/addcomment-id-5880-view-32nm-atom-on-idf-2008.html
8ҢҺӮМIDFӮЕӮНҒA32nm”ЕAtomӮрғfғӮҒB
Cell PhoneӮвiPhoneӮМғTғCғYӮӘүВ”\ӮЙҒB
# 32nm Atom = Lincroft
http://xtreview.com/addcomment-id-5880-view-32nm-atom-on-idf-2008.html
8ҢҺӮМIDFӮЕӮНҒA32nm”ЕAtomӮрғfғӮҒB
Cell PhoneӮвiPhoneӮМғTғCғYӮӘүВ”\ӮЙҒB
# 32nm Atom = Lincroft
Intel: Atom Will Not Substitute Celeron Processors.
http://www.xbitlabs.com/news/cpu/display/20080717121547_Intel_Atom_Will_Not_Substitute_Celeron_Processors.html
IntelӮНҢ»Һһ“_ӮЕAtomӮЕCeleronӮр’uӮ«Ҡ·ӮҰӮйӮВӮаӮиӮИӮөҒB
http://www.xbitlabs.com/news/cpu/display/20080717121547_Intel_Atom_Will_Not_Substitute_Celeron_Processors.html
IntelӮНҢ»Һһ“_ӮЕAtomӮЕCeleronӮр’uӮ«Ҡ·ӮҰӮйӮВӮаӮиӮИӮөҒB
Nehalem arrives in week 40 and 44, possibly
http://www.bit-tech.net/news/2008/07/14/nehalem-arrives-in-week-40-and-44/1
BloomfieldӮН10ҢҺ––ҒB # ҒcӮ©ӮаӮөӮкӮИӮў
X58ғ`ғbғvғZғbғgӮНӮ»ӮкӮҫӮҜӮЕ$70ӮМғRғXғgӮЕӮ ӮиҒAғ}ғUҒ[ғ{Ғ[ғhӮНӮ©ӮИӮиҚӮүҝӮЙӮИӮй
(nVIDIAӮМnForce 790i Ultra SLIӮН$100+ӮИӮМӮЕӮіӮ·ӮӘӮЙӮ»ӮұӮЬӮЕӮНӮўӮ©ӮИӮў)ҒB
>We've also been told that Intel's premium X58 chipset alone will cost $70,
>making the boards quite expensive, but this is not unexpected and by no means
> completely insane like Nvidia launching the nForce 790i Ultra SLI
> with a chipset that cost $100+.
http://www.bit-tech.net/news/2008/07/14/nehalem-arrives-in-week-40-and-44/1
BloomfieldӮН10ҢҺ––ҒB # ҒcӮ©ӮаӮөӮкӮИӮў
X58ғ`ғbғvғZғbғgӮНӮ»ӮкӮҫӮҜӮЕ$70ӮМғRғXғgӮЕӮ ӮиҒAғ}ғUҒ[ғ{Ғ[ғhӮНӮ©ӮИӮиҚӮүҝӮЙӮИӮй
(nVIDIAӮМnForce 790i Ultra SLIӮН$100+ӮИӮМӮЕӮіӮ·ӮӘӮЙӮ»ӮұӮЬӮЕӮНӮўӮ©ӮИӮў)ҒB
>We've also been told that Intel's premium X58 chipset alone will cost $70,
>making the boards quite expensive, but this is not unexpected and by no means
> completely insane like Nvidia launching the nForce 790i Ultra SLI
> with a chipset that cost $100+.
>>20 ’щҗі
More Details on the Intel Atom Emerge
http://www.anandtech.com/printarticle.aspx?i=3254
>Moorestown will allow IntelҒfs Atom CPU to exist in larger smart phones (4 - 5Ғh size),
>while its successor in 2010/2011 will use the magic of IntelҒfs 32nm process to finally
> get into something iPhone-sized.
•\ғXғҢӮЕӮўӮнӮкӮДӮўӮй’КӮиҒALincroftӮН45nmӮҫӮБӮҪҒB
AnandTechӮМүЯӢҺӮМӢLҺ–ӮЙӮжӮкӮО32nmӮНMoorestownӮМӮіӮзӮЙҢгҢpӮЖӮўӮӨӮұӮЖӮзӮөӮўҒB
# ӮЙӮөӮҝӮбӮвӮҪӮзғfғӮӮӘ‘ҒӮўӮсӮЕӮ·ӮӘҒcҒB
More Details on the Intel Atom Emerge
http://www.anandtech.com/printarticle.aspx?i=3254
>Moorestown will allow IntelҒfs Atom CPU to exist in larger smart phones (4 - 5Ғh size),
>while its successor in 2010/2011 will use the magic of IntelҒfs 32nm process to finally
> get into something iPhone-sized.
•\ғXғҢӮЕӮўӮнӮкӮДӮўӮй’КӮиҒALincroftӮН45nmӮҫӮБӮҪҒB
AnandTechӮМүЯӢҺӮМӢLҺ–ӮЙӮжӮкӮО32nmӮНMoorestownӮМӮіӮзӮЙҢгҢpӮЖӮўӮӨӮұӮЖӮзӮөӮўҒB
# ӮЙӮөӮҝӮбӮвӮҪӮзғfғӮӮӘ‘ҒӮўӮсӮЕӮ·ӮӘҒcҒB
# ӮҝӮеӮБӮЖ”ӯҢ©ҒB
# $530 ҒЁ $562 ($32ғAғbғv)
# $316 ҒЁ $284 ($32ғ_ғEғ“)
# 2.66GHzӮр•n–RҗlҢьӮҜӮЙҸ]—ҲӮжӮиҲАӮӯҗЭ’иӮөӮДӮўӮйӮ©ӮнӮиӮЙҒA
# 2.93GHzӮр“ҜӮ¶үҝҠiҚ·•ӘҸгҸёӮіӮ№ӮҪӮҫӮҜ??
# 2.66GHzӮр”ғӮӨҗlӮН2.93GHzӮр”ғӮӨҗlӮЙӮНҠҙҺУӮөӮИӮ«ӮбҒiҘҒНҘҒj
# $530 ҒЁ $562 ($32ғAғbғv)
# $316 ҒЁ $284 ($32ғ_ғEғ“)
# 2.66GHzӮр•n–RҗlҢьӮҜӮЙҸ]—ҲӮжӮиҲАӮӯҗЭ’иӮөӮДӮўӮйӮ©ӮнӮиӮЙҒA
# 2.93GHzӮр“ҜӮ¶үҝҠiҚ·•ӘҸгҸёӮіӮ№ӮҪӮҫӮҜ??
# 2.66GHzӮр”ғӮӨҗlӮН2.93GHzӮр”ғӮӨҗlӮЙӮНҠҙҺУӮөӮИӮ«ӮбҒiҘҒНҘҒj
25 ҒF–јҸМ–ўҗЭ’иҒF2008/07/23(җ…) 20:24:57 ID:w8379Ch40
ӮІӮЯӮсӮИӮіӮў
Ӯ»ӮкӮЕӮа”ғӮҰӮИӮў•n–RҗlӮЕ
ӮІӮЯӮсӮИӮіӮўҒAӮІӮЯӮсӮИӮіӮў
Ӯ»ӮкӮЕӮа”ғӮҰӮИӮў•n–RҗlӮЕ
ӮІӮЯӮсӮИӮіӮўҒAӮІӮЯӮсӮИӮіӮў
Nehalem-EP......BLOOMFIELD
ttp://www.xtremesystems.org/forums/showpost.php?p=3168831&postcount=816
xtremesystemsӮМҢfҺҰ”ВӮЙNehalemӮМES•iӮрғxғ“ғ`ӮөӮҪҢӢүКӮӘӮ»ӮұӮ»ӮұӮ ӮиҒB
# —бӮЙӮжӮБӮДғ}ғӢғ`ғXғҢғbғhӮаӮМӮӘ‘ҪӮўҒB
ttp://www.xtremesystems.org/forums/showpost.php?p=3168831&postcount=816
xtremesystemsӮМҢfҺҰ”ВӮЙNehalemӮМES•iӮрғxғ“ғ`ӮөӮҪҢӢүКӮӘӮ»ӮұӮ»ӮұӮ ӮиҒB
# —бӮЙӮжӮБӮДғ}ғӢғ`ғXғҢғbғhӮаӮМӮӘ‘ҪӮўҒB
ҲИүәҒAғVғ“ғOғӢғXғҢғbғhӮжӮиӮМҢӢүК(Yorkfield vs Bloomfield)Ӯр’ҠҸo
QX9650 = Yorkfield 3GHz
Bloomfield = Bloomfield 2.93GHz
ҒECinebench R10 Single Core # Ғ© Single ThreadӮМӮұӮЖӮИӮНӮё
- QX9650 3.263
- Bloomfield 3.396 (+6.6%)
ҒECinebench R10 Multi Core
- QX9650 11.437
- Bloomfield 14.299 (+28%)
ҒEWhestone
- QX9650 3.124
- Bloomfield-HTӮИӮө 3.152 (+3.3%)
- Bloomfield-HTӮ Ӯи 2.786 (-8.7%)
ҒEDhrystone
- QX9650 6.468
- Bloomfield-HTӮИӮө 7.652 (+21%)
- Bloomfield-HTӮ Ӯи 7.045 (+12%)
()“аӮН“ҜғNғҚғbғNҠ·ҺZӮЕӮМҗ«”\”д vs Yorkfield
# CinebenchӮНSingle ThreadӮЕ+6.6% YorkfieldӮжӮи‘ҒӮў
# Whestone(=FPU)ӮН+3.3%ӮЕҒAHT ONӮҫӮЖYorkfieldҲИүәӮЙӮЬӮЕ—ҺӮҝӮй
# Dhrystone(=ALU)ӮН+21%Ӯа‘¬ӮўҒBHT ONӮҫӮЖ–с-10%—ҺӮҝӮй
# DhrystoneӮЭӮҪӮўӮИ’PҸғғxғ“ғ`ӮҫӮЖBufferӮвӮзӮЙӮӨӮЬӮӯӮНӮЬӮсӮМӮ©ӮИ
# HTӮҫӮЖҗГ“I•ӘҠ„ӮЕ—e—КӮв‘СҲжӮӘҢёӮй•”•ӘӮ ӮйӮ©ӮзӮЁӮҝӮсӮМӮ©ӮИ
# Ӯ ӮЖӮЕ’NӮ©ӮӘҸЪӮөӮӯүрҗНӮөӮДӮӯӮкӮйӮҫӮлӮӨҒiҘҒНҘҒj
QX9650 = Yorkfield 3GHz
Bloomfield = Bloomfield 2.93GHz
ҒECinebench R10 Single Core # Ғ© Single ThreadӮМӮұӮЖӮИӮНӮё
- QX9650 3.263
- Bloomfield 3.396 (+6.6%)
ҒECinebench R10 Multi Core
- QX9650 11.437
- Bloomfield 14.299 (+28%)
ҒEWhestone
- QX9650 3.124
- Bloomfield-HTӮИӮө 3.152 (+3.3%)
- Bloomfield-HTӮ Ӯи 2.786 (-8.7%)
ҒEDhrystone
- QX9650 6.468
- Bloomfield-HTӮИӮө 7.652 (+21%)
- Bloomfield-HTӮ Ӯи 7.045 (+12%)
()“аӮН“ҜғNғҚғbғNҠ·ҺZӮЕӮМҗ«”\”д vs Yorkfield
# CinebenchӮНSingle ThreadӮЕ+6.6% YorkfieldӮжӮи‘ҒӮў
# Whestone(=FPU)ӮН+3.3%ӮЕҒAHT ONӮҫӮЖYorkfieldҲИүәӮЙӮЬӮЕ—ҺӮҝӮй
# Dhrystone(=ALU)ӮН+21%Ӯа‘¬ӮўҒBHT ONӮҫӮЖ–с-10%—ҺӮҝӮй
# DhrystoneӮЭӮҪӮўӮИ’PҸғғxғ“ғ`ӮҫӮЖBufferӮвӮзӮЙӮӨӮЬӮӯӮНӮЬӮсӮМӮ©ӮИ
# HTӮҫӮЖҗГ“I•ӘҠ„ӮЕ—e—КӮв‘СҲжӮӘҢёӮй•”•ӘӮ ӮйӮ©ӮзӮЁӮҝӮсӮМӮ©ӮИ
# Ӯ ӮЖӮЕ’NӮ©ӮӘҸЪӮөӮӯүрҗНӮөӮДӮӯӮкӮйӮҫӮлӮӨҒiҘҒНҘҒj
’щҗі
ӮәӮсӮәӮсҲбӮӨҒB
BOINC ManagerӮМWhestone/DhrystoneӮӘper CPUӮҫӮ©ӮзҒA
HT ONӮМҢӢүКӮӘҲ«ӮӯҢ©ӮҰӮйӮБӮДӮҫӮҜҒB
ӮЖӮўӮӨӮнӮҜӮЕҒA>>27ӮМғRғҒғ“ғgӮН–іӮ©ӮБӮҪӮұӮЖӮЕӮжӮлӮөӮӯҒB
ӮәӮсӮәӮсҲбӮӨҒB
BOINC ManagerӮМWhestone/DhrystoneӮӘper CPUӮҫӮ©ӮзҒA
HT ONӮМҢӢүКӮӘҲ«ӮӯҢ©ӮҰӮйӮБӮДӮҫӮҜҒB
ӮЖӮўӮӨӮнӮҜӮЕҒA>>27ӮМғRғҒғ“ғgӮН–іӮ©ӮБӮҪӮұӮЖӮЕӮжӮлӮөӮӯҒB
29 ҒF–јҸМ–ўҗЭ’иҒF2008/07/28(ҢҺ) 13:41:12 ID:oSKc0BSx0
CPUӮМ‘¬ӮіӮБӮД“Ә‘ЕӮҝӮИӮс?
ғҖҒ[ғAӮМ–@‘ҘӮНҸIӮнӮи?
ғҖҒ[ғAӮМ–@‘ҘӮНҸIӮнӮи?
30 ҒF–јҸМ–ўҗЭ’иҒF2008/07/28(ҢҺ) 18:37:31 ID:XAvBqRmv0
ғҖҒ[ғAӮМ–@‘ҘӮНCPUӮМҸҲ—қ‘¬“xӮЙӮВӮўӮДҢҫӢyӮөӮҪ•ЁӮЕӮНӮИӮўӮ©ӮзҒB
31 ҒF–јҸМ–ўҗЭ’иҒF2008/07/28(ҢҺ) 19:29:42 ID:Gu7w0ktk0
Ӯ¶ӮбӮ ғAғҖғ_Ғ[ғӢӮН?
Via's Nano L2100 takes on Intel's Atom 230
http://techreport.com/articles.x/15204/1
Low-end grudge match: Nano vs. Atom
http://arstechnica.com/reviews/hardware/atom-nano-review.ars/1
VIAӮМNano(Isaiah)ӮЖAtom 230(Diamondville)ӮМ”дҠrғxғ“ғ`ӢLҺ–ҒB
# җі’јҒAPentium MӮЖAtomӮМ’ҶҠФ’цӮМғNғҚғbғN“–ӮҪӮиҗ«”\
# (PC Mark2005 CPUӮЕAtom +33%)ӮЕӮөӮ©ӮИӮӯҺvӮБӮҪӮжӮ葬ӮӯӮИӮўҒB
# Performance per Watt ӮЕӮа90nm Pentium M(Dothan)ӮЙ•үӮҜӮДӮўӮйӮМӮЕCPUӮЖӮөӮДҺ|–ЎӮӘӮИӮўҒB
VIAғXғҢӮжӮиғRғsғyҒB
Atom
L1:3 cycles
L2:16 cycles
nano
L1:4 cycles
L2:24 Cycles
http://techreport.com/articles.x/15204/1
Low-end grudge match: Nano vs. Atom
http://arstechnica.com/reviews/hardware/atom-nano-review.ars/1
VIAӮМNano(Isaiah)ӮЖAtom 230(Diamondville)ӮМ”дҠrғxғ“ғ`ӢLҺ–ҒB
# җі’јҒAPentium MӮЖAtomӮМ’ҶҠФ’цӮМғNғҚғbғN“–ӮҪӮиҗ«”\
# (PC Mark2005 CPUӮЕAtom +33%)ӮЕӮөӮ©ӮИӮӯҺvӮБӮҪӮжӮ葬ӮӯӮИӮўҒB
# Performance per Watt ӮЕӮа90nm Pentium M(Dothan)ӮЙ•үӮҜӮДӮўӮйӮМӮЕCPUӮЖӮөӮДҺ|–ЎӮӘӮИӮўҒB
VIAғXғҢӮжӮиғRғsғyҒB
Atom
L1:3 cycles
L2:16 cycles
nano
L1:4 cycles
L2:24 Cycles
33 ҒF–јҸМ–ўҗЭ’иҒF2008/08/08(Ӣа) 00:39:39 ID:HHyF/lKu0
ho
34 ҒF–јҸМ–ўҗЭ’иҒF2008/08/13(җ…) 22:51:52 ID:8VyxyAHL0
ze
35 ҒF–јҸМ–ўҗЭ’иҒF2008/08/18(ҢҺ) 09:15:33 ID:AGnF5NVe0
m
36 ҒF–јҸМ–ўҗЭ’иҒF2008/08/25(ҢҺ) 22:35:02 ID:btW8gkhH0
tai
Ӯ ӮЬӮиӮЙӮаүЙӮӘ–іӮӯҒAIDFӮМҸо•сӮрҠm”FӮЕӮ«ӮйӮМӮаҚД—ҲҸTӮӯӮзӮўӮҫҒB
ҚKӮўҒAҚЎүсӮМIDFӮНҗVҸо•сӮӘӮ·ӮӯӮИӮўӮжӮӨӮҫӮҜӮЗҒB
>>29
ғҖҒ[ғAӮМ–@‘ҘӮЙӮВӮўӮДӮНҒAғҚғWғbғN•”ӮӘ1җў‘гӮМғVғ…ғҠғ“ғNӮЕӮа0.7”{ӮӯӮзӮўӮЙӮөӮ©
ҸkҸ¬ӮіӮкӮДӮИӮўӮБӮДӮЖӮұӮлӮӘ–Ў‘XҒB
http://www.chip-architect.com/news/2007_02_19_Various_Images.html
cacheӮИӮЗӮМSRAM•”ӮНғҚғWғbғN•”ӮжӮиӮағgғүғ“ғWғXғ^–§“xӮӘҚӮӮўӮМӮЕҒA
“ҜӮ¶–КҗПӮЕӮағgғүғ“ғWғXғ^җ”ӮӘ‘ҪӮўӮөҒAҸkҸ¬—ҰӮаӮўӮўҒB
ӮЕҒAIntelӮНғҖҒ[ғAӮМ–@‘ҘӮӘ‘ұӮўӮДӮўӮйӮұӮЖӮрSRAMӮӘ9Ҡ„Ӯр—TӮЙ’ҙӮҰӮйItaniumӮрҲшӮ«ҚҮӮўӮЙӮҫӮөӮД
җй“`ӮөӮДӮўӮйӮМ(Ӯ»ӮкӮЕӮа24ғ–ҢҺӮЕ2”{ӮӯӮзӮўӮӘҺАҚЫӮМ’lӮҫӮҜӮЗ)ҒB
http://ja.wikipedia.org/wiki/%E7%94%BB%E5%83%8F:Moores_law.svg
ҢВҗl“IӮЙӮНғ}ғCғNғҚғvғҚғZғbғTӮЙӮЁӮҜӮйғҖҒ[ғAӮМ–@‘ҘӮИӮсӮДҸӯӮИӮӯӮЖӮағVғ“ғOғӢғRғAӮЕҢ©ӮкӮО
ҠщӮЙ(P6Ғ`NetBurstӮ ӮҪӮиӮЕ)ҸIӮнӮБӮДӮўӮДӢvӮөӮўҒB
(logic•”•ӘӮМғgғүғ“ғWғXғ^”дӮМ•Ҫ•ыҚӘӮӘҺАҚЫӮМҗ«”\ҢьҸг—ҰӮЙӢЯӮўӮМӮЕL2 L3ӮвӮзӮМSRAM•”ӮНғJғEғ“ғgӮЙӮўӮкӮйҲУ–Ўҗ«ӮӘ”–ӮўҒB)
ҚKӮўҒAҚЎүсӮМIDFӮНҗVҸо•сӮӘӮ·ӮӯӮИӮўӮжӮӨӮҫӮҜӮЗҒB
>>29
ғҖҒ[ғAӮМ–@‘ҘӮЙӮВӮўӮДӮНҒAғҚғWғbғN•”ӮӘ1җў‘гӮМғVғ…ғҠғ“ғNӮЕӮа0.7”{ӮӯӮзӮўӮЙӮөӮ©
ҸkҸ¬ӮіӮкӮДӮИӮўӮБӮДӮЖӮұӮлӮӘ–Ў‘XҒB
http://www.chip-architect.com/news/2007_02_19_Various_Images.html
cacheӮИӮЗӮМSRAM•”ӮНғҚғWғbғN•”ӮжӮиӮағgғүғ“ғWғXғ^–§“xӮӘҚӮӮўӮМӮЕҒA
“ҜӮ¶–КҗПӮЕӮағgғүғ“ғWғXғ^җ”ӮӘ‘ҪӮўӮөҒAҸkҸ¬—ҰӮаӮўӮўҒB
ӮЕҒAIntelӮНғҖҒ[ғAӮМ–@‘ҘӮӘ‘ұӮўӮДӮўӮйӮұӮЖӮрSRAMӮӘ9Ҡ„Ӯр—TӮЙ’ҙӮҰӮйItaniumӮрҲшӮ«ҚҮӮўӮЙӮҫӮөӮД
җй“`ӮөӮДӮўӮйӮМ(Ӯ»ӮкӮЕӮа24ғ–ҢҺӮЕ2”{ӮӯӮзӮўӮӘҺАҚЫӮМ’lӮҫӮҜӮЗ)ҒB
http://ja.wikipedia.org/wiki/%E7%94%BB%E5%83%8F:Moores_law.svg
{kind=link}
ҢВҗl“IӮЙӮНғ}ғCғNғҚғvғҚғZғbғTӮЙӮЁӮҜӮйғҖҒ[ғAӮМ–@‘ҘӮИӮсӮДҸӯӮИӮӯӮЖӮағVғ“ғOғӢғRғAӮЕҢ©ӮкӮО
ҠщӮЙ(P6Ғ`NetBurstӮ ӮҪӮиӮЕ)ҸIӮнӮБӮДӮўӮДӢvӮөӮўҒB
(logic•”•ӘӮМғgғүғ“ғWғXғ^”дӮМ•Ҫ•ыҚӘӮӘҺАҚЫӮМҗ«”\ҢьҸг—ҰӮЙӢЯӮўӮМӮЕL2 L3ӮвӮзӮМSRAM•”ӮНғJғEғ“ғgӮЙӮўӮкӮйҲУ–Ўҗ«ӮӘ”–ӮўҒB)
—]’kӮҫӮӘҒA
ғҚғWғbғN•”ӮӘ1җў‘гӮМғVғ…ғҠғ“ғNӮЕӮа0.7”{ӮӯӮзӮўӮЙӮөӮ©ӮИӮзӮИӮўӮБӮДӮЖӮұӮлӮ©Ӯз
ӢtҺZӮ·ӮйӮЖҒAҢӢӢЗ1җў‘гӮМғVғ…ғҠғ“ғNӮЕ‘қӮвӮ№ӮйғRғAҗ”ӮНӮ№ӮўӮәӮў1.4”{ӮӯӮзӮўӮЙӮөӮ©ӮИӮзӮИӮўҒB
ӮөӮ©ӮаҒAғVғ“ғOғӢғRғAӮЕӮМҠg’ЈӮӘ‘SӮӯӮИӮўӮнӮҜӮЕӮНӮИӮўӮМӮЕӮЬӮ –{“–ӮНғRғAҗ”ӮИӮсӮД
ӮЮӮвӮЭӮвӮҪӮз‘қӮвӮ№ӮИӮўӮНӮёӮҫӮӘҒAIntelӮНӮвӮҪӮз‘қӮвӮөӮҪӮўӮЭӮҪӮўӮИӮсӮҫӮжӮЛҒB
ғlғCғeғBғu4 coreү»ӮөӮҪӮҪӮЯӮЙBloomfieldӮвLynnfieldӮНүҝҠiӮрүәӮ°ӮзӮкӮИӮўҒB
WestmereӮвSandy BridgeӮағRғ“ғVғ…Ғ[ғ}ӮЕӮН4 coreӮЕӢӯӢCӮМӮНӮёӮЕҒA
ҚЕӢЯӮЕӮДӮйғҚҒ[ғhғ}ғbғvӮНҗі’јӮ ӮЬӮиҗM—pӮЕӮ«ӮИӮўӮЖҺvӮБӮДӮйҒB
ғҚғWғbғN•”ӮӘ1җў‘гӮМғVғ…ғҠғ“ғNӮЕӮа0.7”{ӮӯӮзӮўӮЙӮөӮ©ӮИӮзӮИӮўӮБӮДӮЖӮұӮлӮ©Ӯз
ӢtҺZӮ·ӮйӮЖҒAҢӢӢЗ1җў‘гӮМғVғ…ғҠғ“ғNӮЕ‘қӮвӮ№ӮйғRғAҗ”ӮНӮ№ӮўӮәӮў1.4”{ӮӯӮзӮўӮЙӮөӮ©ӮИӮзӮИӮўҒB
ӮөӮ©ӮаҒAғVғ“ғOғӢғRғAӮЕӮМҠg’ЈӮӘ‘SӮӯӮИӮўӮнӮҜӮЕӮНӮИӮўӮМӮЕӮЬӮ –{“–ӮНғRғAҗ”ӮИӮсӮД
ӮЮӮвӮЭӮвӮҪӮз‘қӮвӮ№ӮИӮўӮНӮёӮҫӮӘҒAIntelӮНӮвӮҪӮз‘қӮвӮөӮҪӮўӮЭӮҪӮўӮИӮсӮҫӮжӮЛҒB
ғlғCғeғBғu4 coreү»ӮөӮҪӮҪӮЯӮЙBloomfieldӮвLynnfieldӮНүҝҠiӮрүәӮ°ӮзӮкӮИӮўҒB
WestmereӮвSandy BridgeӮағRғ“ғVғ…Ғ[ғ}ӮЕӮН4 coreӮЕӢӯӢCӮМӮНӮёӮЕҒA
ҚЕӢЯӮЕӮДӮйғҚҒ[ғhғ}ғbғvӮНҗі’јӮ ӮЬӮиҗM—pӮЕӮ«ӮИӮўӮЖҺvӮБӮДӮйҒB
39 ҒF–јҸМ–ўҗЭ’иҒF2008/08/27(җ…) 01:12:17 ID:8N+4VQn+0
CPUғAҒ[ғLғXғҢӮМ’cҺqӮЖToHeart(үј–ј)ӮЖғIғ^ӮМ–ҹҚЛӮр
’NӮ©ҺOҚsӮЕӮЬӮЖӮЯӮДӮӯӮк
’NӮ©ҺOҚsӮЕӮЬӮЖӮЯӮДӮӯӮк
40 ҒF–јҸМ–ўҗЭ’иҒF2008/08/27(җ…) 08:24:24 ID:XzDDiX1J0
ғҠ
ғb
ғ`ӮИүсҳHҒiҸОҒjҒiҸОҒj
ғb
ғ`ӮИүсҳHҒiҸОҒjҒiҸОҒj
41 ҒF–јҸМ–ўҗЭ’иҒF2008/08/27(җ…) 09:04:13 ID:1hzLwNu40
үҙ
ғCғRҒ[ғӢ
җіӢ`
ғCғRҒ[ғӢ
җіӢ`
42 ҒF–јҸМ–ўҗЭ’иҒF2008/08/27(җ…) 18:36:28 ID:HhyGN9g90
MACғIғ^
–ј–іӮөӮЖ’cҺq
ҺOҢZ’н
–ј–іӮөӮЖ’cҺq
ҺOҢZ’н
43 ҒF–јҸМ–ўҗЭ’иҒF2008/08/30(“y) 00:22:40 ID:db5LjGcM0
ӮВӮўӮЙҚrӮзӮөҺnӮЯӮҪӮжw
44 ҒF–јҸМ–ўҗЭ’иҒF2008/08/30(“y) 17:21:42 ID:H6XJQM9R0
MACғIғ^ӮӘ
ӮЬӮЖӮаӮЙ
Ң©ӮҰӮДӮөӮЬӮӨ
ӮЬӮЖӮаӮЙ
Ң©ӮҰӮДӮөӮЬӮӨ
>>44
“сҗlӮЖӮаҒw“пӮөӮўҢҫ—tӮр’mӮБӮДӮўӮй•ыӮӘҸҹӮҝҒxӮЖҺvӮБӮДӮўӮйғtғVӮӘӮ ӮБӮДҒAҺ©җgӮЕ—қүрӮЕӮ«ӮИӮў
ҠT”OӮрӮвӮиӮЖӮиӮөӮДӮўӮйӮМӮӘ•ҙӢҠӮ·ӮйҢіӮМӮжӮӨӮЙҢ©ӮҰӮйӮ·ӮЛҒBҒBҒB
’cҺqӮіӮсӮаҒwғ}ғjғ…ғAғӢӮЙӮаҚЪӮБӮДӮйҒ@Ғ@ҸнҒ@Ғ@ҺҜҒ@Ғ@ӮЕҒ@Ғ@Ӯ·ҒBҒxӮЖӮ©Ӣ©ӮсӮЕӮйҠ„ӮЙҒADeveloper Manual
3AӮЕҚ§җШ’ҡ”JӮЙғXғgғAғoғbғtғ@ӮМҗа–ҫӮӘӮ ӮйӮұӮЖӮр’mӮзӮИӮ©ӮБӮҪӮжӮӨӮҫӮөҒA—бӮМ”S’…–ј–іӮөӮіӮсӮнҒA
җіӮөӮў’mҺҜӮМ’ҶӮЙҒAӮЖӮұӮлӮЗӮұӮлғgғ“ғfғӮӮӘҚ¬ӮҙӮйӮЖӮўӮӨғ}ғbғh“Б—LӮМҳ_—қ“WҠJӮрҢ©Ӯ№ӮДӮӯӮкӮйӮ·ҒB
Ӯ»ӮкӮЙӮөӮДӮа“сҗlӮЖӮаҺРүпҗlӮЖӮ©ӮұӮМ“№20”NӮЖӮ©Һе’ЈӮөӮДӮўӮйӮМӮЙҒA•Ҫ“ъ’ӢҠФӮ©Ӯз”MӮӯӢcҳ_Ӯр
җнӮнӮ№ӮДӮўӮйӮМӮҫӮҜӮн•sҺvӢcӮЖӮөӮ©ҢҫӮў—lӮӘ–іӮўӮ·(ҸО)
“сҗlӮЖӮаҒw“пӮөӮўҢҫ—tӮр’mӮБӮДӮўӮй•ыӮӘҸҹӮҝҒxӮЖҺvӮБӮДӮўӮйғtғVӮӘӮ ӮБӮДҒAҺ©җgӮЕ—қүрӮЕӮ«ӮИӮў
ҠT”OӮрӮвӮиӮЖӮиӮөӮДӮўӮйӮМӮӘ•ҙӢҠӮ·ӮйҢіӮМӮжӮӨӮЙҢ©ӮҰӮйӮ·ӮЛҒBҒBҒB
’cҺqӮіӮсӮаҒwғ}ғjғ…ғAғӢӮЙӮаҚЪӮБӮДӮйҒ@Ғ@ҸнҒ@Ғ@ҺҜҒ@Ғ@ӮЕҒ@Ғ@Ӯ·ҒBҒxӮЖӮ©Ӣ©ӮсӮЕӮйҠ„ӮЙҒADeveloper Manual
3AӮЕҚ§җШ’ҡ”JӮЙғXғgғAғoғbғtғ@ӮМҗа–ҫӮӘӮ ӮйӮұӮЖӮр’mӮзӮИӮ©ӮБӮҪӮжӮӨӮҫӮөҒA—бӮМ”S’…–ј–іӮөӮіӮсӮнҒA
җіӮөӮў’mҺҜӮМ’ҶӮЙҒAӮЖӮұӮлӮЗӮұӮлғgғ“ғfғӮӮӘҚ¬ӮҙӮйӮЖӮўӮӨғ}ғbғh“Б—LӮМҳ_—қ“WҠJӮрҢ©Ӯ№ӮДӮӯӮкӮйӮ·ҒB
Ӯ»ӮкӮЙӮөӮДӮа“сҗlӮЖӮаҺРүпҗlӮЖӮ©ӮұӮМ“№20”NӮЖӮ©Һе’ЈӮөӮДӮўӮйӮМӮЙҒA•Ҫ“ъ’ӢҠФӮ©Ӯз”MӮӯӢcҳ_Ӯр
җнӮнӮ№ӮДӮўӮйӮМӮҫӮҜӮн•sҺvӢcӮЖӮөӮ©ҢҫӮў—lӮӘ–іӮўӮ·(ҸО)
http://www.spec.org/cpu2006/results/res2008q3/cpu2006-20080711-04753.html
SunғXғҢӮЕҢ©ӮВӮҜӮҪӮҜӮЗҒA•xҺm’КӮМSPARC64 VIIӮӘ
SPECfp2006(rateӮ¶ӮбӮИӮў•ы)ӮЕXeonӮрҗUӮиҗШӮБӮДҗўҠEҚЕҚӮғXғRғAӮрҸoӮөӮҪҒB
# NehalemӮЕ’ҙӮҰӮзӮкӮ»ӮӨӮИ”НҲНӮЕӮНӮ ӮйӮӘҒAӮұӮкӮЙӮНӮСӮБӮӯӮиҒB
SunғXғҢӮЕҢ©ӮВӮҜӮҪӮҜӮЗҒA•xҺm’КӮМSPARC64 VIIӮӘ
SPECfp2006(rateӮ¶ӮбӮИӮў•ы)ӮЕXeonӮрҗUӮиҗШӮБӮДҗўҠEҚЕҚӮғXғRғAӮрҸoӮөӮҪҒB
# NehalemӮЕ’ҙӮҰӮзӮкӮ»ӮӨӮИ”НҲНӮЕӮНӮ ӮйӮӘҒAӮұӮкӮЙӮНӮСӮБӮӯӮиҒB
http://www.spec.org/cpu2006/results/res2008q2/cpu2006-20080527-04430.html
# Wolfdale-DP 3.4GHz ӮЕӮұӮМғXғRғAӮ©ҒBӮвӮБӮПNehalemӮЕ’ҙӮҰӮзӮкӮйӮ©үцӮөӮўӮИҒB
# –іҳ_ҒAӮұӮкӮЕӮаPOWER6 5GHzӮЙӮНҸҹӮБӮДӮйҒB
# Wolfdale-DP 3.4GHz ӮЕӮұӮМғXғRғAӮ©ҒBӮвӮБӮПNehalemӮЕ’ҙӮҰӮзӮкӮйӮ©үцӮөӮўӮИҒB
# –іҳ_ҒAӮұӮкӮЕӮаPOWER6 5GHzӮЙӮНҸҹӮБӮДӮйҒB
48 ҒFMACғIғ^Ғ„u ӮіӮсҒF2008/08/30(“y) 23:21:04 ID:DJepu+s80
>>46-47
ӮұӮкӮнҒASPEC2000Һһ‘гӮМ"179.art trick"ӮМҚД—ҲӮ·(ҸО)
“–•ӘҗўҠФӮЕӮнҚЕ“Kү»ӮЖғ`Ғ[ғgӮМҲбӮўӮЙӮВӮўӮДӮМӢcҳ_ӮЕҢ–ӮөӮӯӮИӮйӮМӮЕӮнҒH
ӮұӮкӮнҒASPEC2000Һһ‘гӮМ"179.art trick"ӮМҚД—ҲӮ·(ҸО)
“–•ӘҗўҠФӮЕӮнҚЕ“Kү»ӮЖғ`Ғ[ғgӮМҲбӮўӮЙӮВӮўӮДӮМӢcҳ_ӮЕҢ–ӮөӮӯӮИӮйӮМӮЕӮнҒH
49 ҒFMACғIғ^Ғ—•в‘«ҒF2008/08/30(“y) 23:28:19 ID:DJepu+s80
SunӮМҲ«–јҚӮӮў"179.art trick"ӮЙҠЦӮ·ӮйӢLҺ–Ӯ·ҒB
http://www.theinquirer.net/gb/inquirer/news/2003/07/07/benchmarks-used-to-mislead-customers
http://www.theinquirer.net/gb/inquirer/news/2003/07/07/benchmarks-used-to-mislead-customers
http://www.spec.org/cpu2006/results/res2008q3/cpu2006-20080712-04768.html
ӮұӮБӮҝӮӘҗіүрӮҫӮИҒBSunӮМӮЖ‘S‘RӮҝӮӘӮӨҒB
BlogӮЖӮўӮўӮИӮсӮЖӮўӮўҒAӮіӮ·ӮӘSunӮН‘fҗ°ӮзӮөӮўҒB
ӮұӮБӮҝӮӘҗіүрӮҫӮИҒBSunӮМӮЖ‘S‘RӮҝӮӘӮӨҒB
BlogӮЖӮўӮўӮИӮсӮЖӮўӮўҒAӮіӮ·ӮӘSunӮН‘fҗ°ӮзӮөӮўҒB
ӮИӮсӮҫӮҪӮсӮИӮйҺ©“®•А—сӮ©ӮжҒBҳRӮкӮМӮНӮвӮЖӮҝӮиӮҫӮБӮҪҒcҒB
http://www.spec.org/cpu2006/results/res2008q3/cpu2006-20080711-04734.html
http://www.spec.org/cpu2006/results/res2008q3/cpu2006-20080711-04734.html
–ҫӮзӮ©ӮЙӮИӮйCore i7ӮМ”й–§Ғ`DDR3ғҒғӮғҠғTғ|Ғ[ғgӮЖTurbo ModeӮМғJғүғNғҠ
http://www.4gamer.net/games/043/G004345/20080825042/
>ӮұӮМ“_ӮЙӮВӮўӮДҒCIntelӮЕҒuOverclock GuruҒvӮЖӮөӮДӮа’mӮзӮкӮйDunfordҺҒӮНҒC
>ҒuSmackoverӮЕӮНҒCBIOSғҒғjғ…Ғ[ӮЙҒwTDP’lӮр”CҲУӮЙҺw’иӮ·ӮйҒxҗЭ’иҚҖ–ЪӮӘҗЭӮҜӮзӮкӮйҒB
>—бӮҰӮОҒCӮұӮМ’lӮр190WӮИӮЗӮЖҚӮӮЯӮЙҗЭ’иӮ·ӮкӮОҒCTurbo ModeӮЙӮжӮйү¶ҢbӮа‘еӮ«ӮӯӮИӮйҒv
>ӮЖҗа–ҫӮ·ӮйҒB
TGdailyӮЙӮаҸ‘ӮўӮДӮ ӮйӮӘҒA
NehalemӮЕӮНTDPӮрғfғtғHғӢғgӮМ’lӮ©Ӯз”CҲУӮЙBIOSҸгӮЕ•ПҚXӮЕӮ«ҒA
—вӢp”\—НҲЛ‘¶ӮЕTurbo ModeӮМү¶ҢbӮрҠg‘еӮЕӮ«ӮйҒB(—б:130WҒЁ190W)
http://www.4gamer.net/games/043/G004345/20080825042/
>ӮұӮМ“_ӮЙӮВӮўӮДҒCIntelӮЕҒuOverclock GuruҒvӮЖӮөӮДӮа’mӮзӮкӮйDunfordҺҒӮНҒC
>ҒuSmackoverӮЕӮНҒCBIOSғҒғjғ…Ғ[ӮЙҒwTDP’lӮр”CҲУӮЙҺw’иӮ·ӮйҒxҗЭ’иҚҖ–ЪӮӘҗЭӮҜӮзӮкӮйҒB
>—бӮҰӮОҒCӮұӮМ’lӮр190WӮИӮЗӮЖҚӮӮЯӮЙҗЭ’иӮ·ӮкӮОҒCTurbo ModeӮЙӮжӮйү¶ҢbӮа‘еӮ«ӮӯӮИӮйҒv
>ӮЖҗа–ҫӮ·ӮйҒB
TGdailyӮЙӮаҸ‘ӮўӮДӮ ӮйӮӘҒA
NehalemӮЕӮНTDPӮрғfғtғHғӢғgӮМ’lӮ©Ӯз”CҲУӮЙBIOSҸгӮЕ•ПҚXӮЕӮ«ҒA
—вӢp”\—НҲЛ‘¶ӮЕTurbo ModeӮМү¶ҢbӮрҠg‘еӮЕӮ«ӮйҒB(—б:130WҒЁ190W)
53 ҒF–јҸМ–ўҗЭ’иҒF2008/08/31(“ъ) 00:35:08 ID:RSd9rRSC0
>>52
MacӮ¶ӮбEFIӮЕӮМ•ПҚXӮН–і—қӮҫӮИ
PenrynӮМғ^Ғ[ғ{ғӮҒ[ғhӮН2ғRғAӮМӮӨӮҝ1ғRғAӮрғIғtӮЙӮ·ӮйӮ©ӮзҒAOS XӮ¶ӮбғTғ|Ғ[ғgӮөӮИӮўӮЖҺvӮБӮДӮўӮҪӮӘ
ҚЎүсӮМғfғXғNғgғbғvҒiӮНҚМ—pҗ»•iӮИӮўӮҜӮЗҒjӮвғTҒ[ғoҒ[ҢьӮҜӢ@”\ӮҫӮЖӮөӮДӮаҒAғAғbғvғӢӮНҺgӮнӮ№ӮИӮўӮҫӮлӮӨӮИ
MacӮ¶ӮбEFIӮЕӮМ•ПҚXӮН–і—қӮҫӮИ
PenrynӮМғ^Ғ[ғ{ғӮҒ[ғhӮН2ғRғAӮМӮӨӮҝ1ғRғAӮрғIғtӮЙӮ·ӮйӮ©ӮзҒAOS XӮ¶ӮбғTғ|Ғ[ғgӮөӮИӮўӮЖҺvӮБӮДӮўӮҪӮӘ
ҚЎүсӮМғfғXғNғgғbғvҒiӮНҚМ—pҗ»•iӮИӮўӮҜӮЗҒjӮвғTҒ[ғoҒ[ҢьӮҜӢ@”\ӮҫӮЖӮөӮДӮаҒAғAғbғvғӢӮНҺgӮнӮ№ӮИӮўӮҫӮлӮӨӮИ
55 ҒF–јҸМ–ўҗЭ’иҒF2008/09/05(Ӣа) 22:50:19 ID:VYtVW2Zg0
ho
56 ҒFMACғIғ^Ғ„u ӮіӮсҒF2008/09/06(“y) 20:18:39 ID:KVnsulHy0
>>54
SiggraphӮМҳ_•¶Ӯ»ӮМӮаӮМӮр“ЗӮсӮҫӮЩӮӨӮӘ100”{ӮҪӮЯӮЙӮИӮйӮЖҺvӮӨӮ·ӮҜӮЗҒBҒBҒB
ӮҝӮИӮЭӮЙғvғҢғ[ғ“Һ‘—ҝӮМӮЩӮӨӮағRғRӮЙӮЁӮўӮДӮ ӮйӮ·ҒB
http://s08.idav.ucdavis.edu/
SiggraphӮМҳ_•¶Ӯ»ӮМӮаӮМӮр“ЗӮсӮҫӮЩӮӨӮӘ100”{ӮҪӮЯӮЙӮИӮйӮЖҺvӮӨӮ·ӮҜӮЗҒBҒBҒB
ӮҝӮИӮЭӮЙғvғҢғ[ғ“Һ‘—ҝӮМӮЩӮӨӮағRғRӮЙӮЁӮўӮДӮ ӮйӮ·ҒB
http://s08.idav.ucdavis.edu/
57 ҒF–јҸМ–ўҗЭ’иҒF2008/09/13(“y) 20:11:54 ID:UC26C+RH0
shu
58 ҒF–јҸМ–ўҗЭ’иҒF2008/09/20(“y) 12:07:48 ID:XDJNTSsn0
Ҳк—¬‘еҠw‘ІӮМҗк–еүЖӮӘҗ”җlҸWӮЬӮйӮЖҚӮҸ®ӮИӢcҳ_ӮЦ”ӯ“WӮөӮДҒA
Ң©Ӯй•ыӮЖӮөӮДӮНӮ ӮиӮӘӮҪ ӮӯӮҹӮ—Ӯ№Ӯ„Ӯ’ӮҶӮ”ӮҮӮҷӮУӮ¶ӮұҒB
613 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ ҒF2008/09/20(“y) 10:16:37 ID:ALOSlSrK
ҺАҢұӮ©ӮзҚlҺ@ӮөӮДҢЕ’иҠП”OӮрҗШӮи•цӮөӮДӮўӮӯӮМӮӘүИҠwӮҫҒB
ҺАҢұӮ·ӮкӮОүрӮйҺ–ҺАӮ·Ӯз”FӮЯӮИӮўӮМӮҫӮ©ӮзҒAӮ»ӮсӮИӢіҲзӮ·ӮзҺуӮҜӮДӮИӮўӮсӮҫӮлӮӨӮИҒB
616 ҒFSocket774 ҒF2008/09/20(“y) 11:17:04 ID:zgYvllNz
’cҺqӮНғGғ“ғWғjғAӮҫӮҜӮЗғTғCғGғ“ғeғBғXғgӮ¶ӮбӮИӮўӮжӮИҒ[
ӮИӮсӮ©ӮіҒ[ҒAғTғCғGғ“ғXӮЙ‘ОӮ·ӮйғRғ“ғvғҢғbғNғXӮӘ‘КҒXҳRӮкӮЕӢCҺқӮҝҲ«ӮўӮҫӮжӮЛҒ[
617 ҒFSocket774 ҒF2008/09/20(“y) 11:51:32 ID:59KlAnFS
ӮЁӮкӮМҺw“EӮНҠ®‘SӮЙҗіӮөӮўӮМӮҫӮӘҒAҢN’BӮӘ—қүрӮЕӮ«ӮДӮўӮИӮўӮҫӮҜӮМӮұӮЖ
Ң©Ӯй•ыӮЖӮөӮДӮНӮ ӮиӮӘӮҪ ӮӯӮҹӮ—Ӯ№Ӯ„Ӯ’ӮҶӮ”ӮҮӮҷӮУӮ¶ӮұҒB
613 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ ҒF2008/09/20(“y) 10:16:37 ID:ALOSlSrK
ҺАҢұӮ©ӮзҚlҺ@ӮөӮДҢЕ’иҠП”OӮрҗШӮи•цӮөӮДӮўӮӯӮМӮӘүИҠwӮҫҒB
ҺАҢұӮ·ӮкӮОүрӮйҺ–ҺАӮ·Ӯз”FӮЯӮИӮўӮМӮҫӮ©ӮзҒAӮ»ӮсӮИӢіҲзӮ·ӮзҺуӮҜӮДӮИӮўӮсӮҫӮлӮӨӮИҒB
616 ҒFSocket774 ҒF2008/09/20(“y) 11:17:04 ID:zgYvllNz
’cҺqӮНғGғ“ғWғjғAӮҫӮҜӮЗғTғCғGғ“ғeғBғXғgӮ¶ӮбӮИӮўӮжӮИҒ[
ӮИӮсӮ©ӮіҒ[ҒAғTғCғGғ“ғXӮЙ‘ОӮ·ӮйғRғ“ғvғҢғbғNғXӮӘ‘КҒXҳRӮкӮЕӢCҺқӮҝҲ«ӮўӮҫӮжӮЛҒ[
617 ҒFSocket774 ҒF2008/09/20(“y) 11:51:32 ID:59KlAnFS
ӮЁӮкӮМҺw“EӮНҠ®‘SӮЙҗіӮөӮўӮМӮҫӮӘҒAҢN’BӮӘ—қүрӮЕӮ«ӮДӮўӮИӮўӮҫӮҜӮМӮұӮЖ
59 ҒF–јҸМ–ўҗЭ’иҒF2008/09/20(“y) 19:47:23 ID:M1fLWDhg0
’cҺqӮНҗшӮиӮ·Ӯ¬ҒB
‘јҗlӮЖғfғBғXғJғbғVғҮғ“Ҹo—ҲӮИӮўғ^ғCғvҒB
‘јҗlӮЖғfғBғXғJғbғVғҮғ“Ҹo—ҲӮИӮўғ^ғCғvҒB
60 ҒFMACғIғ^Ғ„58 ӮіӮсҒF2008/09/20(“y) 21:51:23 ID:sxMJGBgR0
>>58
Ғ@Ғ@--------------------
Ғ@Ғ@Ҳк—¬‘еҠw‘ІӮМҗк–еүЖӮӘҗ”җlҸWӮЬӮйӮЖҚӮҸ®ӮИӢcҳ_ӮЦ”ӯ“WӮөӮДҒA
Ғ@Ғ@--------------------
–{—ҲӮМӢZҸp•Ә–мӮМӢcҳ_ӮЖӮўӮӨӮМӮнҒAӮ Ӯ ӮўӮБӮҪғӮғmӮЕӮн–іӮўӮМӮЕҢлүрӮөӮИӮўӮЕ—~ӮөӮўӮ·ҒB
’cҺqӮіӮсӮнҒAҒuҺАҢұӮөӮҪҒvӮЖҸМӮ·ӮйӮИӮзҲў•рӮЕӮаҚДҢ»ӮЕӮ«ӮйӮжӮӨӮЙ“а—eӮрҸ‘ӮӯӮЧӮ«ӮҫӮөҒA
ғLғ`ғKғC”S’…ӮМғqғgӮнҒuүҙӮН’mӮБӮДӮўӮйҒvӮЕӮИӮӯҒAүҪӮр’mӮБӮДӮўӮйӮМӮ©ҸqӮЧӮйӮЧӮ«ӮИӮсӮ·ӮҜӮЗҒBҒBҒB
ӮўӮЬғAҒ[ғLғeғNғ`ғғғXғҢғbғhӮЕқҶӮЯӮДӮўӮйӮМӮнҒAӮЗӮҝӮзӮМғ`ғ“ғ`ғ“ӮӘғfғJӮўӮ©ҒHӮЖӮўӮӨҳb‘иӮЕӮөӮ©
–іӮўӮ·ҒB
Ғ@Ғ@--------------------
Ғ@Ғ@Ҳк—¬‘еҠw‘ІӮМҗк–еүЖӮӘҗ”җlҸWӮЬӮйӮЖҚӮҸ®ӮИӢcҳ_ӮЦ”ӯ“WӮөӮДҒA
Ғ@Ғ@--------------------
–{—ҲӮМӢZҸp•Ә–мӮМӢcҳ_ӮЖӮўӮӨӮМӮнҒAӮ Ӯ ӮўӮБӮҪғӮғmӮЕӮн–іӮўӮМӮЕҢлүрӮөӮИӮўӮЕ—~ӮөӮўӮ·ҒB
’cҺqӮіӮсӮнҒAҒuҺАҢұӮөӮҪҒvӮЖҸМӮ·ӮйӮИӮзҲў•рӮЕӮаҚДҢ»ӮЕӮ«ӮйӮжӮӨӮЙ“а—eӮрҸ‘ӮӯӮЧӮ«ӮҫӮөҒA
ғLғ`ғKғC”S’…ӮМғqғgӮнҒuүҙӮН’mӮБӮДӮўӮйҒvӮЕӮИӮӯҒAүҪӮр’mӮБӮДӮўӮйӮМӮ©ҸqӮЧӮйӮЧӮ«ӮИӮсӮ·ӮҜӮЗҒBҒBҒB
ӮўӮЬғAҒ[ғLғeғNғ`ғғғXғҢғbғhӮЕқҶӮЯӮДӮўӮйӮМӮнҒAӮЗӮҝӮзӮМғ`ғ“ғ`ғ“ӮӘғfғJӮўӮ©ҒHӮЖӮўӮӨҳb‘иӮЕӮөӮ©
–іӮўӮ·ҒB
61 ҒF–јҸМ–ўҗЭ’иҒF2008/09/23(үО) 01:47:24 ID:cTGfj3RS0
ӮўӮв”з“чӮ¶ӮбӮИӮўӮМӮ©Ӯ»ӮкӮНw
62 ҒF–јҸМ–ўҗЭ’иҒF2008/10/01(җ…) 20:16:13 ID:nFmMPbi70
ho
63 ҒF–јҸМ–ўҗЭ’иҒF2008/10/05(“ъ) 17:04:33 ID:aAZn0usH0
dngӮНҒAүҪӮЕӮўӮВӮаx86ӮМҺ‘ҺYӮОӮ©ӮиӮұӮҫӮнӮйӮМ?
64 ҒF–јҸМ–ўҗЭ’иҒF2008/10/06(ҢҺ) 02:16:15 ID:5c6LklUD0
x86ӮөӮ©ҺgӮБӮҪӮұӮЖӮИӮўӮ©ӮзӮ¶ӮбӮЛ
65 ҒFMACғIғ^Ғ„64 ӮіӮсҒF2008/10/06(ҢҺ) 02:39:50 ID:stVTHjWG0
>>64
ҲИ‘OҺdҺ–ӮЕItaniumӮрҲөӮБӮҪӮБӮДҺ©–қӮөӮДӮҪӮ·ҒB
CELL/B.EӮЙӮВӮўӮДӮнҒAӮұӮМ•УҒBҒ@http://tripper.kousaku.in/20070304.html
Ӯ»ӮМҸгҒA”ЮӮнPowerPC Mac-miniӮМғҶҒ[ғUҒ[Ӯ·ҒB
ҲИ‘OҺdҺ–ӮЕItaniumӮрҲөӮБӮҪӮБӮДҺ©–қӮөӮДӮҪӮ·ҒB
CELL/B.EӮЙӮВӮўӮДӮнҒAӮұӮМ•УҒBҒ@http://tripper.kousaku.in/20070304.html
Ӯ»ӮМҸгҒA”ЮӮнPowerPC Mac-miniӮМғҶҒ[ғUҒ[Ӯ·ҒB
66 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒқҒңҒF2008/10/12(“ъ) 13:28:13 ID:Om3rCJhu0
ӮжӮӨғJғXӮЗӮа
67 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒқҒңҒF2008/10/12(“ъ) 13:29:07 ID:Om3rCJhu0
ҢҹҸШӮаҢ“ӮЛӮДEeePCӮрӮнӮҙӮнӮҙҺ©• ӮЕ”ғӮБӮҪүҙ—lӮрдrӮЯӮсӮИҒB
68 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒқҒңҒF2008/10/12(“ъ) 13:36:19 ID:Om3rCJhu0
>>45Ғ@ӮВӮЬӮзӮс—gӮ°‘«ҺжӮиӮвӮБӮДӮйӮИҒB
ҒiғtғFғ“ғXҢNӮМҢҫӮӨғXғgғAғfҒ[ғ^ӮМ”jҠьӮр–Ъ“IӮЖӮөӮҪҒjғXғgғAғoғbғtғ@ғҠғ“ғOӢ@Қ\ӮН‘¶ҚЭӮөӮИӮў
ӮБӮДҲУ–ЎҚҮӮўӮҫӮжҒB
‘СҲжҠm•ЫҒE’бғҢғCғeғ“ғVү»Ҡm•ЫӮМӮҪӮЯӮМғoғbғtғ@ғҠғ“ғOӮМ‘¶ҚЭӮНүҙҺ©җgӮӘҺе’ЈӮөӮДӮйӮБӮВҒ[ӮМҒB
ӮҪӮЖӮҰӮОPrescottӮМL1ӮӘғҢғCғeғ“ғVӮМҠ„ӮЙ‘еӮөӮД’xӮӯӮИӮ©ӮБӮҪӮМӮҫӮБӮД
ғүғCғgғoғbғNғoғbғtғ@ӮӘҠФӮЙ‘¶ҚЭӮөӮҪӮ©ӮзӮҫҒB
ӮБӮДүщӮ©ӮөӮўғlғ^ӮҫӮИ
ҒiғtғFғ“ғXҢNӮМҢҫӮӨғXғgғAғfҒ[ғ^ӮМ”jҠьӮр–Ъ“IӮЖӮөӮҪҒjғXғgғAғoғbғtғ@ғҠғ“ғOӢ@Қ\ӮН‘¶ҚЭӮөӮИӮў
ӮБӮДҲУ–ЎҚҮӮўӮҫӮжҒB
‘СҲжҠm•ЫҒE’бғҢғCғeғ“ғVү»Ҡm•ЫӮМӮҪӮЯӮМғoғbғtғ@ғҠғ“ғOӮМ‘¶ҚЭӮНүҙҺ©җgӮӘҺе’ЈӮөӮДӮйӮБӮВҒ[ӮМҒB
ӮҪӮЖӮҰӮОPrescottӮМL1ӮӘғҢғCғeғ“ғVӮМҠ„ӮЙ‘еӮөӮД’xӮӯӮИӮ©ӮБӮҪӮМӮҫӮБӮД
ғүғCғgғoғbғNғoғbғtғ@ӮӘҠФӮЙ‘¶ҚЭӮөӮҪӮ©ӮзӮҫҒB
ӮБӮДүщӮ©ӮөӮўғlғ^ӮҫӮИ
69 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒқҒңҒF2008/10/12(“ъ) 21:48:16 ID:Om3rCJhu0
ӮЩӮзҒA’NӮ©җшӮкӮж
70 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒқҒңҒF2008/10/13(ҢҺ) 19:50:34 ID:JTqFA0Mr0
>>65ӮЙӮВӮўӮДӮҫӮҜӮЗҒAӮұӮИӮўӮҫғfғBғXғNҢрҠ·ӮөӮҪӮзDVDӮЙҸқӮӘ•tӮўӮДӮДҚДғCғ“ғXғgҒ[ғӢӮЕӮ«ӮИӮӯӮД
ҲИ—ҲLinuxғ}ғVғ“ӮЖӮөӮДҠҲ—pӮөӮДӮйӮБӮДӮМӮНҺQҚlӮЬӮЕӮЙҒB
ҲИ—ҲLinuxғ}ғVғ“ӮЖӮөӮДҠҲ—pӮөӮДӮйӮБӮДӮМӮНҺQҚlӮЬӮЕӮЙҒB
71 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒқҒңҒғӮЩӮзүҪӮ©ҢҫӮҰҒF2008/10/13(ҢҺ) 19:51:16 ID:JTqFA0Mr0
Ғ@
72 ҒF–јҸМ–ўҗЭ’иҒF2008/10/14(үО) 11:26:09 ID:ubBjcfrj0
ӮұӮұӮНu—lӮМҢВҗlғXғҢӮИӮМӮЕҒB
‘OғXғҢӮЙҸ‘ӮўӮҪPOWER7ӮЙҠЦӮ·ӮйҸо•сӮаҺQҚlӮЙҒB
http://pc11.2ch.net/test/read.cgi/jisaku/1219884494/950
Ғ@Ғ@=====================
Ғ@Ғ@ҠJ”ӯғOғӢҒ[ғvӮӘҲЩӮИӮйӮЖӮнҢҫӮҰҒAPOWER6ӮЕ“d—НҢш—ҰҢьҸгӮМӮҪӮЯӮЙҲк’UӮ Ӯ«ӮзӮЯӮҪOoOEӮр
Ғ@Ғ@ҚД“Ҡ“ьӮ·Ӯй ӢZҸp“I— •tӮҜӮн“дӮ·ҒB—вӢpӮЙҠЦӮөӮДӮнҗ…—вӢZҸpӮЕҗжҚsӮөӮДӮўӮйӮҪӮЯӮЙ–в‘иӮн
Ғ@Ғ@–іӮіӮ»ӮӨӮ·ҒB
Ғ@Ғ@=====================
ӮвӮБӮПӮиOOO•ңҠҲӮ©ҒB
ҳRӮк“IӮЙӮНOOO=“d—НҢш—ҰӮӘҲ«ӮўӮН”јҗM”јӢ^ӮҫӮБӮҪ
(ғAҒ[ғLӮЕӮНӮИӮӯ“ҜҺһ‘гӮМүсҳHӢZҸpӮӘҢҙҲцӮИӢCӮӘӮ·Ӯй)ӮМӮЕҒAӮ«ӮҪӮ«ӮҪӮБӮДҠҙӮ¶ҒB
ӮҝӮИӮЭӮЙӮвӮБӮПҳRӮкӮНӮаӮӨӮұӮұӮ©ӮзҲш‘ЮӮ·ӮйӮМӮЕҒAӮ ӮЖҺПӮйӮИӮиҸДӮӯӮИӮиӮжӮлӮөӮӯҒB
http://pc11.2ch.net/test/read.cgi/jisaku/1219884494/950
Ғ@Ғ@=====================
Ғ@Ғ@ҠJ”ӯғOғӢҒ[ғvӮӘҲЩӮИӮйӮЖӮнҢҫӮҰҒAPOWER6ӮЕ“d—НҢш—ҰҢьҸгӮМӮҪӮЯӮЙҲк’UӮ Ӯ«ӮзӮЯӮҪOoOEӮр
Ғ@Ғ@ҚД“Ҡ“ьӮ·Ӯй ӢZҸp“I— •tӮҜӮн“дӮ·ҒB—вӢpӮЙҠЦӮөӮДӮнҗ…—вӢZҸpӮЕҗжҚsӮөӮДӮўӮйӮҪӮЯӮЙ–в‘иӮн
Ғ@Ғ@–іӮіӮ»ӮӨӮ·ҒB
Ғ@Ғ@=====================
ӮвӮБӮПӮиOOO•ңҠҲӮ©ҒB
ҳRӮк“IӮЙӮНOOO=“d—НҢш—ҰӮӘҲ«ӮўӮН”јҗM”јӢ^ӮҫӮБӮҪ
(ғAҒ[ғLӮЕӮНӮИӮӯ“ҜҺһ‘гӮМүсҳHӢZҸpӮӘҢҙҲцӮИӢCӮӘӮ·Ӯй)ӮМӮЕҒAӮ«ӮҪӮ«ӮҪӮБӮДҠҙӮ¶ҒB
ӮҝӮИӮЭӮЙӮвӮБӮПҳRӮкӮНӮаӮӨӮұӮұӮ©ӮзҲш‘ЮӮ·ӮйӮМӮЕҒAӮ ӮЖҺПӮйӮИӮиҸДӮӯӮИӮиӮжӮлӮөӮӯҒB
ҲкүһӮҝӮеӮБӮЖҸ‘ӮўӮДӮЁӮӯӮЖҒA
LarrabeeӮЕ90W 10 coreӮҫӮБӮҪӮЖүјӮЙӮ·ӮйӮЖҒA1ғRғAӮ ӮҪӮиӮН’ҙ’PҸғҢvҺZӮЕ9WҒB
ClarksfieldӮЕӮН45WӮЕ4 coreӮҫӮБӮҪӮЖӮ·ӮйӮЖ1ғRғAӮ ӮҪӮиӮН11WҒB
OOOӮМғnғCғGғ“ғhғvғҚғZғbғTӮӘғpғtғHҒ[ғ}ғ“ғXҚЕ—DҗжӮЕүсҳHҗЭҢvӮіӮкӮДӮўӮҪҺһ‘гӮНӮіӮДӮЁӮ«ҒA
in-orderӮНҚЎ•ңҠҲӮөӮД–{“–ӮЙ“d—НҢш—ҰӮЕ—DӮкӮДӮўӮйӮЖӮўӮҰӮйӮҫӮлӮӨӮ©??
ӮаӮҝӮлӮсLarrabeeӮНP5-basedӮЖӮўӮнӮкӮДӮўӮйӮЖӮНӮўӮҰ512-bitӮМғxғNғgғӢҠg’ЈӮаӮ ӮйӮнӮҜӮҫӮӘҒA
Ӯ»ӮкӮЙӮөӮДӮа4 issue OOO + LNIӮЕӮаӮ»ӮұӮЬӮЕ“d—Н‘еӮ«ӮӯӮИӮйӢCӮӘӮөӮИӮўҒB
ҲИ‘OPart1Ӯ©2ӮЕEPIӮМҳbӮӘӮ ӮБӮҪӮӘҒAYonahӮЖi486ӮМEPIӮН–wӮЗӮ©ӮнӮзӮИӮўӮЖӮўӮӨҳ_•¶ӮаӮ ӮБӮҪҒB
Ӯ»ӮсӮИӮЖӮұӮлӮЕӮ·ҒB
LarrabeeӮЕ90W 10 coreӮҫӮБӮҪӮЖүјӮЙӮ·ӮйӮЖҒA1ғRғAӮ ӮҪӮиӮН’ҙ’PҸғҢvҺZӮЕ9WҒB
ClarksfieldӮЕӮН45WӮЕ4 coreӮҫӮБӮҪӮЖӮ·ӮйӮЖ1ғRғAӮ ӮҪӮиӮН11WҒB
OOOӮМғnғCғGғ“ғhғvғҚғZғbғTӮӘғpғtғHҒ[ғ}ғ“ғXҚЕ—DҗжӮЕүсҳHҗЭҢvӮіӮкӮДӮўӮҪҺһ‘гӮНӮіӮДӮЁӮ«ҒA
in-orderӮНҚЎ•ңҠҲӮөӮД–{“–ӮЙ“d—НҢш—ҰӮЕ—DӮкӮДӮўӮйӮЖӮўӮҰӮйӮҫӮлӮӨӮ©??
ӮаӮҝӮлӮсLarrabeeӮНP5-basedӮЖӮўӮнӮкӮДӮўӮйӮЖӮНӮўӮҰ512-bitӮМғxғNғgғӢҠg’ЈӮаӮ ӮйӮнӮҜӮҫӮӘҒA
Ӯ»ӮкӮЙӮөӮДӮа4 issue OOO + LNIӮЕӮаӮ»ӮұӮЬӮЕ“d—Н‘еӮ«ӮӯӮИӮйӢCӮӘӮөӮИӮўҒB
ҲИ‘OPart1Ӯ©2ӮЕEPIӮМҳbӮӘӮ ӮБӮҪӮӘҒAYonahӮЖi486ӮМEPIӮН–wӮЗӮ©ӮнӮзӮИӮўӮЖӮўӮӨҳ_•¶ӮаӮ ӮБӮҪҒB
Ӯ»ӮсӮИӮЖӮұӮлӮЕӮ·ҒB
75 ҒF–јҸМ–ўҗЭ’иҒF2008/10/14(үО) 21:19:59 ID:t9fgm6IC0
ӮЁӮўӮЁӮў
ӮQӮҝӮбӮсӮЙҢ»–рӮаҲш‘ЮӮаӮИӮў
ӮQӮҝӮбӮсӮЙҢ»–рӮаҲш‘ЮӮаӮИӮў
76 ҒF–јҸМ–ўҗЭ’иҒF2008/10/14(үО) 21:35:26 ID:jc15SCAm0
Ҳш‘ЮӮБӮДӮа2chӮЙ‘SӮӯҸ‘Ӯ«ҚһӮЭӮөӮИӮўӮЖӮўӮӨӮұӮЖӮЕӮНӮИӮўг©ҒB
җПӢЙ“IӮИғjғ…Ғ[ғX“\Ӯиғlғ^“\ӮиӮМҠҲ“®ӮНӮвӮЯӮйӮҜӮЗҒA
ӮҪӮЬӮЙүЙӮВӮФӮөӮЙҸ‘Ӯ«ҚһӮЮ&–ј–іӮөӮЙӮжӮйҠҲ“®ӮНҢp‘ұҒB
ӮаӮҝӮлӮс“ЗӮЮӮҫӮҜӮИӮзғlғbғgӮЙӮВӮИӮ°Ӯй“ъӮНҠmҺАӮЙҒA
ӮұӮкӮЬӮЕ’КӮиҺе—vӮИCPUҠЦҳAӮМғXғҢӮНңpңjӮ·ӮйӮМӮҫӮБӮҪҒB
җПӢЙ“IӮИғjғ…Ғ[ғX“\Ӯиғlғ^“\ӮиӮМҠҲ“®ӮНӮвӮЯӮйӮҜӮЗҒA
ӮҪӮЬӮЙүЙӮВӮФӮөӮЙҸ‘Ӯ«ҚһӮЮ&–ј–іӮөӮЙӮжӮйҠҲ“®ӮНҢp‘ұҒB
ӮаӮҝӮлӮс“ЗӮЮӮҫӮҜӮИӮзғlғbғgӮЙӮВӮИӮ°Ӯй“ъӮНҠmҺАӮЙҒA
ӮұӮкӮЬӮЕ’КӮиҺе—vӮИCPUҠЦҳAӮМғXғҢӮНңpңjӮ·ӮйӮМӮҫӮБӮҪҒB
77 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒқҒңҒF2008/10/18(“y) 23:50:27 ID:6v7IJN9B0
> LarrabeeӮЕ90W 10 coreӮҫӮБӮҪӮЖүјӮЙӮ·ӮйӮЖҒA1ғRғAӮ ӮҪӮиӮН’ҙ’PҸғҢvҺZӮЕ9WҒB
ӮӨҒ[ӮсҒA•sҗіүрҒBLarrabeeӮМғRғAҗ”ӮН8ӮМ”{җ”ӮЕӮ·ҒB
ӮўӮВӮјӮМSIGGRAPHӮМ10ғRғAӮЕү]ҒXӮНҠчҸгҳ_ӮМҳbҒB
ӮЕҒAҗ»•iӮН16ғRғAӮЕ150WӮМTDPҲИ“аӮЙӮЙҺыӮЬӮйӮҫӮЖӮ©ҢҫӮнӮкӮДӮйӮҜӮЗҒAGDDR3ғҒғӮғҠӮЖӮ©ӮаҠЬӮЯӮҪ
PCIeӮЙҺhӮіӮйғ{Ғ[ғh‘S‘МӮЕӮМҸБ”п“d—НӮЙӮИӮйӮМӮЕҒACPU’P‘МӮЖ”дӮЧӮйӮМӮНӮўӮіӮіӮ©ғAғ“ғtғFғAӮ©ӮЖ
ӮВҒ[Ӯ©ClarksfieldӮБӮД–{“–ӮЙҸoӮйӮМӮ©үцӮөӮӯӮИӮБӮДӮ«ӮҪҠҙӮӘӮ ӮйҒB
ҸoӮДӮа‘еҢ^ғmҒ[ғgҢьӮҜӮ¶ӮбӮИӮўӮМҒHғCғXғүғGғӢғ`Ғ[ғҖӮаҢҷӮўӮЖҢҫӮБӮДӮйӮӯӮзӮўӮҫӮө
ӮҪӮ©ӮҫӮ©DDR3ӮЙ‘ОүһӮөӮҪӮҫӮҜӮЕҒuCentrino 2ҒvӮр—§ӮҝҸгӮ°ӮҪҺһ“_ӮЕҒAIntel‘S‘МӮМҲУҺuӮЖӮөӮД
NehalemӮМғӮғoғCғӢ”ЕӮНҢ©‘—ӮйғӮғmӮЖҺvӮБӮДӮҪӮМӮҫӮӘҒB
PenrynӮМҸБ”п“d—НӮМ’бӮіӮН–Ј—НӮҫӮөӮИӮҹ
ӮӨҒ[ӮсҒA•sҗіүрҒBLarrabeeӮМғRғAҗ”ӮН8ӮМ”{җ”ӮЕӮ·ҒB
ӮўӮВӮјӮМSIGGRAPHӮМ10ғRғAӮЕү]ҒXӮНҠчҸгҳ_ӮМҳbҒB
ӮЕҒAҗ»•iӮН16ғRғAӮЕ150WӮМTDPҲИ“аӮЙӮЙҺыӮЬӮйӮҫӮЖӮ©ҢҫӮнӮкӮДӮйӮҜӮЗҒAGDDR3ғҒғӮғҠӮЖӮ©ӮаҠЬӮЯӮҪ
PCIeӮЙҺhӮіӮйғ{Ғ[ғh‘S‘МӮЕӮМҸБ”п“d—НӮЙӮИӮйӮМӮЕҒACPU’P‘МӮЖ”дӮЧӮйӮМӮНӮўӮіӮіӮ©ғAғ“ғtғFғAӮ©ӮЖ
ӮВҒ[Ӯ©ClarksfieldӮБӮД–{“–ӮЙҸoӮйӮМӮ©үцӮөӮӯӮИӮБӮДӮ«ӮҪҠҙӮӘӮ ӮйҒB
ҸoӮДӮа‘еҢ^ғmҒ[ғgҢьӮҜӮ¶ӮбӮИӮўӮМҒHғCғXғүғGғӢғ`Ғ[ғҖӮаҢҷӮўӮЖҢҫӮБӮДӮйӮӯӮзӮўӮҫӮө
ӮҪӮ©ӮҫӮ©DDR3ӮЙ‘ОүһӮөӮҪӮҫӮҜӮЕҒuCentrino 2ҒvӮр—§ӮҝҸгӮ°ӮҪҺһ“_ӮЕҒAIntel‘S‘МӮМҲУҺuӮЖӮөӮД
NehalemӮМғӮғoғCғӢ”ЕӮНҢ©‘—ӮйғӮғmӮЖҺvӮБӮДӮҪӮМӮҫӮӘҒB
PenrynӮМҸБ”п“d—НӮМ’бӮіӮН–Ј—НӮҫӮөӮИӮҹ
78 ҒF–јҸМ–ўҗЭ’иҒF2008/10/19(“ъ) 04:07:24 ID:P/3pgAzM0
’cҺqӮіӮсӮНҚЎ“ъӮаүsӮў•ӘҗНӮЕӢБӮўӮҪҒB
79 ҒF–јҸМ–ўҗЭ’иҒF2008/10/19(“ъ) 12:59:03 ID:C1xtvS4W0
100–ңҲИҸгӮМғgғүғ“ғWғXғ^Ӯр”пӮвӮөӮҪPCUӮЕҒAғvғҚғZғbғT‘S‘МӮрҠДҺӢӮөғNғҚғbғNӮв“dҢ№Ӯрҗ§ҢдҒB
ғRғA’P‘МӮЕӮМ“dҢ№ӮМON/OFFӮрүВ”\ӮЙӮ·ӮйPower GateӮМӮҪӮЯӮЙҒA‘е“d—¬ӮЙ‘ПӮҰӮй
7mmҢъӮМ“d—Н”zҗь‘wӮр’ЗүБӮЕ“\Ӯи•tӮҜҒAғXғCғbғ`ғ“ғOҗк—pӮМғgғүғ“ғWғXғ^ӮрҠJ”ӯҒB
“ҷҒXҒAӮ©ӮВӮДӮИӮўӮЩӮЗҸИ“d—НӮЙӢCҚҮӮӘ“ьӮБӮДӮўӮйӮнӮҜӮҫӮӘҒB
http://pc.watch.impress.co.jp/docs/2008/0825/kaigai462.htm
http://journal.mycom.co.jp/articles/2008/09/03/idf11/003.html
ӮЖӮНҢҫӮҰҒAAuburndaleҒiHavendaleҒj“Ҡ“ьӮӘӮёӮўӮФӮсҗжӮЙӮИӮБӮДӮөӮЬӮўҒA
ғmҒ[ғgғuғbғNҢьӮҜӮрClarksfiledҒiLynnfiledҒjӮҫӮҜӮЕ“WҠJӮ·ӮйӮнӮҜӮЙӮаӮўӮ©ӮёҒA
45nmҗў‘гӮНPenrynҢn—сӮМ‘§ӮӘ’·Ӯ»ӮӨӮИҠҙӮНӮ ӮйҒB
ғRғA’P‘МӮЕӮМ“dҢ№ӮМON/OFFӮрүВ”\ӮЙӮ·ӮйPower GateӮМӮҪӮЯӮЙҒA‘е“d—¬ӮЙ‘ПӮҰӮй
7mmҢъӮМ“d—Н”zҗь‘wӮр’ЗүБӮЕ“\Ӯи•tӮҜҒAғXғCғbғ`ғ“ғOҗк—pӮМғgғүғ“ғWғXғ^ӮрҠJ”ӯҒB
“ҷҒXҒAӮ©ӮВӮДӮИӮўӮЩӮЗҸИ“d—НӮЙӢCҚҮӮӘ“ьӮБӮДӮўӮйӮнӮҜӮҫӮӘҒB
http://pc.watch.impress.co.jp/docs/2008/0825/kaigai462.htm
http://journal.mycom.co.jp/articles/2008/09/03/idf11/003.html
ӮЖӮНҢҫӮҰҒAAuburndaleҒiHavendaleҒj“Ҡ“ьӮӘӮёӮўӮФӮсҗжӮЙӮИӮБӮДӮөӮЬӮўҒA
ғmҒ[ғgғuғbғNҢьӮҜӮрClarksfiledҒiLynnfiledҒjӮҫӮҜӮЕ“WҠJӮ·ӮйӮнӮҜӮЙӮаӮўӮ©ӮёҒA
45nmҗў‘гӮНPenrynҢn—сӮМ‘§ӮӘ’·Ӯ»ӮӨӮИҠҙӮНӮ ӮйҒB
80 ҒF–јҸМ–ўҗЭ’иҒF2008/10/19(“ъ) 13:08:12 ID:P/3pgAzM0
’cҺqӮіӮсӮӘ’бҸБ”п“d—НӮЖ”FӮЯӮйPenrynӮаҒAӮ»ӮөӮДӮЁӮ»ӮзӮӯSandyBridgeӮа4ғCғVғ…Ғ[ӮМғAғEғgғIғuғIҒ[ғ_Ғ[ӮИӮМӮҫӮӘҒB
’cҺqӮіӮс“IӮЙӮНғCғXғүғGғӢӮМSandyBridgeӮНғCғ“ғIҒ[ғ_Ғ[ӮЖӮМ—\‘zӮЕӮ·ӮЛҒB
’cҺqӮіӮс“IӮЙӮНғCғXғүғGғӢӮМSandyBridgeӮНғCғ“ғIҒ[ғ_Ғ[ӮЖӮМ—\‘zӮЕӮ·ӮЛҒB
81 ҒF–јҸМ–ўҗЭ’иҒF2008/10/19(“ъ) 14:20:43 ID:/3rKfTXs0
2009”NQ1ӮЙ2.93GHz’ЗүБӮМӮ ӮЖӮН2010”NӮЬӮЕҒAQuadҢnҠgҸ[ӮҫӮҜӮ©ӮЛ
82 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒқҒңҒF2008/10/19(“ъ) 14:22:02 ID:AQDPVDw20
>>80
ғCғXғүғGғӢғ`Ғ[ғҖӮМҚм•iӮМҗ«”\ӮӘҚӮӮўӮМӮНҒAҗ«”\ҢьҸгҢшүКӮМҚӮӮў•”•ӘӮрҸd“_“IӮЙҢьҸгӮіӮ№ӮД
ҸҲ—қӮрӮіӮБӮіӮЖҸIӮнӮзӮ№ӮД‘ТӢ@Ҹу‘ФӮЙӮИӮБӮҪӮЩӮӨӮӘҒAҢӢүК“IӮЙҸИ“d—НӮЙӮИӮйӮЖӮўӮӨҠП‘ӘӮЙҠоӮГӮўӮДӮйҒB
ғfғ…ғAғӢғRғAҒEғ}ғӢғ`ғRғAү»ӮаӮ»ӮМҲкҠВӮҫӮөҒACore 2ӮЕӮНSSEӮМүүҺZҗ«”\ӮӘҢҖ“IӮЙҢьҸгӮөӮДӮўӮйҒB
•K—vӮИӮаӮМӮИӮзҸБ”п“d—НӮӘҚӮӮӯӮИӮБӮДӮаҺуӮҜ“ьӮкӮйҒB
SandyBridgeӮН4 issueӮБӮДӮўӮӨ“ЗӮЭӮНҢNӮЖ“ҜӮ¶ӮЕӮ·ҒB
5issueҲИҸгӮМҗьӮаҚlӮҰӮҪӮӘ•КӮМ—қ—RӮЕӮ Ӯи“ҫӮИӮўӮұӮЖӮЙӢCӮГӮўӮҪҒB
ғCғXғүғGғӢғ`Ғ[ғҖӮӘ“БӮЙҢҷӮўӮЖҢҫӮБӮҪӮМӮНAuburndaleӮҫӮЛҒB
ғҒғӮғRғ“ҒEGPUҗк—pғ_ғCӮЖӮМMCMӮЕҒAQPIӮЙӮжӮБӮДҗЪ‘ұӮ·Ӯй•ыҺ®ӮрӮЖӮБӮДӮйӮӘ
ғӮғmғҠғVғbғNӮЕӮИӮўӮЖ“қҚҮӮЙ”әӮӨҸИ“d—Нү»ӮМү¶ҢbӮӘӮЩӮЖӮсӮЗӮИӮўӮ©ӮзӮЛҒB
Ӯ»ӮМ‘јҒAғTҒ[ғoҸdҺӢӮөӮ·Ӯ¬ӮЕӮЗӮұӮ»ӮұғӮғoғCғӢӮЙҢьӮўӮДӮИӮў•”•ӘӮӘ‘ҪӮ·Ӯ¬ӮйӮсӮҫӮЖҒB
ғCғXғүғGғӢғ`Ғ[ғҖӮМҚм•iӮМҗ«”\ӮӘҚӮӮўӮМӮНҒAҗ«”\ҢьҸгҢшүКӮМҚӮӮў•”•ӘӮрҸd“_“IӮЙҢьҸгӮіӮ№ӮД
ҸҲ—қӮрӮіӮБӮіӮЖҸIӮнӮзӮ№ӮД‘ТӢ@Ҹу‘ФӮЙӮИӮБӮҪӮЩӮӨӮӘҒAҢӢүК“IӮЙҸИ“d—НӮЙӮИӮйӮЖӮўӮӨҠП‘ӘӮЙҠоӮГӮўӮДӮйҒB
ғfғ…ғAғӢғRғAҒEғ}ғӢғ`ғRғAү»ӮаӮ»ӮМҲкҠВӮҫӮөҒACore 2ӮЕӮНSSEӮМүүҺZҗ«”\ӮӘҢҖ“IӮЙҢьҸгӮөӮДӮўӮйҒB
•K—vӮИӮаӮМӮИӮзҸБ”п“d—НӮӘҚӮӮӯӮИӮБӮДӮаҺуӮҜ“ьӮкӮйҒB
SandyBridgeӮН4 issueӮБӮДӮўӮӨ“ЗӮЭӮНҢNӮЖ“ҜӮ¶ӮЕӮ·ҒB
5issueҲИҸгӮМҗьӮаҚlӮҰӮҪӮӘ•КӮМ—қ—RӮЕӮ Ӯи“ҫӮИӮўӮұӮЖӮЙӢCӮГӮўӮҪҒB
ғCғXғүғGғӢғ`Ғ[ғҖӮӘ“БӮЙҢҷӮўӮЖҢҫӮБӮҪӮМӮНAuburndaleӮҫӮЛҒB
ғҒғӮғRғ“ҒEGPUҗк—pғ_ғCӮЖӮМMCMӮЕҒAQPIӮЙӮжӮБӮДҗЪ‘ұӮ·Ӯй•ыҺ®ӮрӮЖӮБӮДӮйӮӘ
ғӮғmғҠғVғbғNӮЕӮИӮўӮЖ“қҚҮӮЙ”әӮӨҸИ“d—Нү»ӮМү¶ҢbӮӘӮЩӮЖӮсӮЗӮИӮўӮ©ӮзӮЛҒB
Ӯ»ӮМ‘јҒAғTҒ[ғoҸdҺӢӮөӮ·Ӯ¬ӮЕӮЗӮұӮ»ӮұғӮғoғCғӢӮЙҢьӮўӮДӮИӮў•”•ӘӮӘ‘ҪӮ·Ӯ¬ӮйӮсӮҫӮЖҒB
83 ҒF–јҸМ–ўҗЭ’иҒF2008/10/19(“ъ) 15:12:50 ID:P/3pgAzM0
ClarksfieldӮМ45WӮНMCH•ӘҸгҸжӮ№ӮҫӮ©ӮзҒA
PenrynӮжӮиӮа–Ъ—§ӮБӮД“d—НҢш—ҰӮЕ—тӮБӮДӮўӮйӮнӮҜӮЕӮНӮИӮўӮЕӮөӮеӮӨҒB
SandyBridgeӮа“Ҝ’ц“xӮМ“d—НӮрҲЫҺқӮ·ӮйӮМӮЕӮНӮИӮўӮ©ӮЖҒB
ӮЕҒA’cҺqӮіӮс“IӮЙӮНSandyBridgeӮНғCғ“ғIҒ[ғ_Ғ[җF”ZҢъӮИӮсӮЕӮ·ӮжӮЛҒB
ӮЁӮкӮН‘SӮӯғAғEғgғIғuғIҒ[ғ_Ғ[ӮҫӮЖҺvӮӨӮсӮЕӮ·ӮӘӮЛҒB
PenrynӮжӮиӮа–Ъ—§ӮБӮД“d—НҢш—ҰӮЕ—тӮБӮДӮўӮйӮнӮҜӮЕӮНӮИӮўӮЕӮөӮеӮӨҒB
SandyBridgeӮа“Ҝ’ц“xӮМ“d—НӮрҲЫҺқӮ·ӮйӮМӮЕӮНӮИӮўӮ©ӮЖҒB
ӮЕҒA’cҺqӮіӮс“IӮЙӮНSandyBridgeӮНғCғ“ғIҒ[ғ_Ғ[җF”ZҢъӮИӮсӮЕӮ·ӮжӮЛҒB
ӮЁӮкӮН‘SӮӯғAғEғgғIғuғIҒ[ғ_Ғ[ӮҫӮЖҺvӮӨӮсӮЕӮ·ӮӘӮЛҒB
84 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒқҒӣҒF2008/10/19(“ъ) 15:17:53 ID:AQDPVDw20
> ӮЕҒA’cҺqӮіӮс“IӮЙӮНSandyBridgeӮНғCғ“ғIҒ[ғ_Ғ[җF”ZҢъӮИӮсӮЕӮ·ӮжӮЛҒB
ӮИӮсӮЕҢҫӮБӮДӮаӮИӮўӮұӮЖӮрҸҹҺиӮЙ‘z‘ңӮ·ӮйӮМҒH“ӘҲ«ӮўӮМҒH
ӮИӮсӮЕҢҫӮБӮДӮаӮИӮўӮұӮЖӮрҸҹҺиӮЙ‘z‘ңӮ·ӮйӮМҒH“ӘҲ«ӮўӮМҒH
85 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒқҒңҒF2008/10/19(“ъ) 15:29:36 ID:AQDPVDw20
Core 2 QX9300 TDP 35W
PM45 TDP 7W
Clarksfield TDP 55W
Core 2 P9000”Ф‘дҒ@TDP=25W
GM45 TDP=11W
Auburndale TDP45W
“ҜҲкғvғҚғZғXӮЕӮаӮұӮИӮкӮДӮӯӮйӮЖTDPӮН—ҺӮҝӮйғӮғ“ӮИӮсӮҫӮҜӮЗӮЛ•Ғ’КӮНҒB
Ӯ»ӮкӮЙҢ©ҚҮӮӨҗ«”\ҢьҸгӮӘӮ ӮйӮИӮзғgғҢҒ[ғhғIғtӮЙӮИӮйӮҫӮлӮӨӮҜӮЗ
ғmҒ[ғgӮНғoғbғeғҠҒ[ӮМҺқӮҝӮӘ‘еҺ–ӮҫӮ©ӮзӮЛӮҘҒiQXҗПӮЮӮжӮӨӮИғҢғ“ғWӮЙӮН•K—vӮИӮіӮ»ӮӨӮҫӮӘҒj
ӮҫӮ©ӮзғIғҢғSғ“ӮЙӮНҠъ‘ТӮ·ӮйӮИӮЖ
PM45 TDP 7W
Clarksfield TDP 55W
Core 2 P9000”Ф‘дҒ@TDP=25W
GM45 TDP=11W
Auburndale TDP45W
“ҜҲкғvғҚғZғXӮЕӮаӮұӮИӮкӮДӮӯӮйӮЖTDPӮН—ҺӮҝӮйғӮғ“ӮИӮсӮҫӮҜӮЗӮЛ•Ғ’КӮНҒB
Ӯ»ӮкӮЙҢ©ҚҮӮӨҗ«”\ҢьҸгӮӘӮ ӮйӮИӮзғgғҢҒ[ғhғIғtӮЙӮИӮйӮҫӮлӮӨӮҜӮЗ
ғmҒ[ғgӮНғoғbғeғҠҒ[ӮМҺқӮҝӮӘ‘еҺ–ӮҫӮ©ӮзӮЛӮҘҒiQXҗПӮЮӮжӮӨӮИғҢғ“ғWӮЙӮН•K—vӮИӮіӮ»ӮӨӮҫӮӘҒj
ӮҫӮ©ӮзғIғҢғSғ“ӮЙӮНҠъ‘ТӮ·ӮйӮИӮЖ
86 ҒF–јҸМ–ўҗЭ’иҒF2008/10/19(“ъ) 15:51:12 ID:P/3pgAzM0
ҒӘӮаӮҝӮлӮсҗ«”\ҢьҸг•ӘӮӘӮ ӮйӮсӮҫӮҜӮЗӮЛ
Ӯ»ӮкӮ©Ӯзғ`ғbғvғZғbғgӮӘ“d—Н‘қ‘еҢXҢьӮЙӮ Ӯй
Ӯ»ӮкӮ©Ӯзғ`ғbғvғZғbғgӮӘ“d—Н‘қ‘еҢXҢьӮЙӮ Ӯй
87 ҒF–јҸМ–ўҗЭ’иҒF2008/10/19(“ъ) 16:08:13 ID:P/3pgAzM0
>ӮҫӮ©ӮзғIғҢғSғ“ӮЙӮНҠъ‘ТӮ·ӮйӮИӮЖ
Ӯ»ӮӨӮҫLarrabeeӮЙӮН‘S‘RҠъ‘ТӮЕӮ«ӮИӮўӮЛ
Ӯ»ӮӨӮҫLarrabeeӮЙӮН‘S‘RҠъ‘ТӮЕӮ«ӮИӮўӮЛ
88 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒқҒңҒF2008/10/19(“ъ) 16:10:57 ID:AQDPVDw20
ӮЬӮ Ӯ»ӮӨӮҫӮИҒB
89 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒқҒңҒF2008/10/19(“ъ) 19:47:04 ID:AQDPVDw20
’EҗьӮ·ӮйӮә
EeePCӮӘ54800ү~ӮЕ”„ӮБӮДӮй“XӮӘҒA’l’iҗҳӮҰ’uӮ«ӮЕ16GBӮМUSBғҒғӮғҠӮрғTҒ[ғrғXӮөӮДӮӯӮкӮЬӮ·ҒB
ӮұӮМ“XӮЕӮНUSBғҒғӮғҠӮӘғ^ғ_ӮЕӮаӮзӮҰӮйӮЖҢ©ӮИӮөӮДӮжӮўӮ©ҒH
EeePCӮӘ54800ү~ӮЕ”„ӮБӮДӮй“XӮӘҒA’l’iҗҳӮҰ’uӮ«ӮЕ16GBӮМUSBғҒғӮғҠӮрғTҒ[ғrғXӮөӮДӮӯӮкӮЬӮ·ҒB
ӮұӮМ“XӮЕӮНUSBғҒғӮғҠӮӘғ^ғ_ӮЕӮаӮзӮҰӮйӮЖҢ©ӮИӮөӮДӮжӮўӮ©ҒH
90 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒқҒңҒF2008/10/19(“ъ) 19:48:43 ID:AQDPVDw20
үҙӮНҒAӮ»ӮкӮНғZғbғgӮҫӮ©ӮзӮЁ“ҫүҝҠiӮҫӮБӮДҢҫӮБӮДӮйӮсӮҫӮҜӮЗӮЛҒB
ӮұӮМ”ВӮМҸd’Б“IӮЙӮНғ^ғ_ӮзӮөӮўӮсӮҫӮжҒB
ӮұӮМ”ВӮМҸd’Б“IӮЙӮНғ^ғ_ӮзӮөӮўӮсӮҫӮжҒB
91 ҒF–јҸМ–ўҗЭ’иҒF2008/10/20(ҢҺ) 11:12:18 ID:99tCC+XJ0
USBғҒғӮғҠӮИӮсӮД—vӮзӮсӮө‘ҰҺМӮДӮйҒBҚЕҸүӮ©Ӯз•tӮўӮДӮұӮИӮўӮЙ“ҷӮөӮў
ӮВӮЬӮи\0ӮЕӮНӮИӮӯӮДnullӮҫ
ӮВӮЬӮи\0ӮЕӮНӮИӮӯӮДnullӮҫ
92 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБҒF2008/10/20(ҢҺ) 17:13:25 ID:q/HMxPLJO
Ӯ»ӮкӮНӮВӮЬӮиҗПҳaҺZ–Ҫ—ЯӮЙӮЁӮўӮДғAғLғ…ғҖғҢҒ[ғg’lӮЙ0ӮрҺw’иӮөӮДҸжҺZӮЖӮЭӮИӮ·ӮЖӮўӮӨӮұӮЖӮЕӮ·ӮЛҒBӮ ӮИӮҪӮНҢ«ӮўҒB
93 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБҒF2008/10/20(ҢҺ) 19:30:16 ID:q/HMxPLJO
Ӯ ҒAӮҝӮИӮЭӮЙEeePCӮЖUSBғҒғӮғҠӮМҳbӮНӮҪӮЖӮҰҳbӮЕӮ·ӮжҒB
94 ҒF–јҸМ–ўҗЭ’иҒF2008/10/23(–Ш) 00:37:53 ID:nnufksPm0
”ј“ұ‘Мҗ»‘ў‘•’uғIҒ[ғNғVғҮғ“ӮЙ‘е—КҸo•iӮМ“Ҫ–јҠйӢЖҒAҗі‘МӮНғCғ“ғeғӢҺРӮ©Ғi2008/10/22Ғj
http://eetimes.jp/article/22478/
Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@,'ҒЬ,°ӨҒ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@ _ ,,..Ғ@,
Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@ҒqҒЙҒЬ Ғ^Ғ___,,..Ғ@Ғ@-Ғ]Ғ@'' " _,,. Ғ]''ҒL
Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@ҒqҒ_Ғ@Ғ@ _,,r'" ҒrҒ@Ғ^/ /Ғ^Ғ@Ғ@Ғ@Ғ@Ғ@.Ғ@Ғ]''"
Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@ ,ҒTҒ@`Ӯӯ/Ғ@/Ғ@ ҒrҒ@/Ғ@ ҒИ_,.Ғ@r ''"
-Ғ@-Ғ@-Ғ@-_,,.. Ғ]''"Ғ@_,.ҒrҒ@/ /Ғ@ . {'ҒЬ) ҒЪ“с“сҒ„Ғ@-Ғ@ - - - - - -
Ғ@ _,..Ғ@Ғ]''"Ғ@Ғ@_,,,..Ғ@-{(ҒЬ)ӨҒ@Ғ@r'`°''Ғ]Ғ]^Ғ]'ҒS{}Ғ@+
Ғ@'-Ғ]Ғ@'' "Ғ@Ғ@_,,.Ғ@Ғ]''"`°Ғ]Нj^Ғ]'Ғ@Ғ@ ;;Ғ@Ғ@Ғ@Ғ@Ғ] -Ғ]Ғ@Ғ@Ғ@_-Ғ@ӮҝӮеӮБӮӯӮз“ьҺDӮөӮЙҚsӮБӮДӮӯӮй
Ғ@-Ғ@Ғ]_+Ғ@Ғ@ Ғ@Ғ@Ғ@;'"Ғ@Ғ@,;''Ғ@,''Ғ@Ғ@ ,;ЮҒ@Ғ]-Ғ@Ғ@°_-Ғ@Ғ]
ҒQҒQҒQҒQҒQҒQ,''ҒQ__,;;"ҒQ;;ҒQҒQ,,ҒQҒQҒQҒQҒQҒQҒQҒQҒQҒQҒQ
Ғ^Ғ^Ғ^Ғ^Ғ^Ғ^Ғ^Ғ^Ғ^Ғ^Ғ^Ғ^Ғ^Ғ^Ғ^Ғ^Ғ^Ғ^Ғ^Ғ^Ғ^Ғ^Ғ^
http://eetimes.jp/article/22478/
Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@,'ҒЬ,°ӨҒ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@ _ ,,..Ғ@,
Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@ҒqҒЙҒЬ Ғ^Ғ___,,..Ғ@Ғ@-Ғ]Ғ@'' " _,,. Ғ]''ҒL
Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@ҒqҒ_Ғ@Ғ@ _,,r'" ҒrҒ@Ғ^/ /Ғ^Ғ@Ғ@Ғ@Ғ@Ғ@.Ғ@Ғ]''"
Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@Ғ@ ,ҒTҒ@`Ӯӯ/Ғ@/Ғ@ ҒrҒ@/Ғ@ ҒИ_,.Ғ@r ''"
-Ғ@-Ғ@-Ғ@-_,,.. Ғ]''"Ғ@_,.ҒrҒ@/ /Ғ@ . {'ҒЬ) ҒЪ“с“сҒ„Ғ@-Ғ@ - - - - - -
Ғ@ _,..Ғ@Ғ]''"Ғ@Ғ@_,,,..Ғ@-{(ҒЬ)ӨҒ@Ғ@r'`°''Ғ]Ғ]^Ғ]'ҒS{}Ғ@+
Ғ@'-Ғ]Ғ@'' "Ғ@Ғ@_,,.Ғ@Ғ]''"`°Ғ]Нj^Ғ]'Ғ@Ғ@ ;;Ғ@Ғ@Ғ@Ғ@Ғ] -Ғ]Ғ@Ғ@Ғ@_-Ғ@ӮҝӮеӮБӮӯӮз“ьҺDӮөӮЙҚsӮБӮДӮӯӮй
Ғ@-Ғ@Ғ]_+Ғ@Ғ@ Ғ@Ғ@Ғ@;'"Ғ@Ғ@,;''Ғ@,''Ғ@Ғ@ ,;ЮҒ@Ғ]-Ғ@Ғ@°_-Ғ@Ғ]
ҒQҒQҒQҒQҒQҒQ,''ҒQ__,;;"ҒQ;;ҒQҒQ,,ҒQҒQҒQҒQҒQҒQҒQҒQҒQҒQҒQ
Ғ^Ғ^Ғ^Ғ^Ғ^Ғ^Ғ^Ғ^Ғ^Ғ^Ғ^Ғ^Ғ^Ғ^Ғ^Ғ^Ғ^Ғ^Ғ^Ғ^Ғ^Ғ^Ғ^
95 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒңҒқҒӣҒF2008/10/24(Ӣа) 01:42:23 ID:S/rLQ15J0
LarrabeeӮНғVғ…ғҠғ“ғNӮр‘ТӮҪӮёӮЙӮўӮ«ӮИӮи48ғRғAӮИӮсӮДү\•ӮҸг
http://northwood.blog60.fc2.com/blog-entry-2380.html
ӮұӮкӮӘ–{“–ӮИӮз32ғRғAӮЕ300WӮИӮсӮДғAғzӮЭӮҪӮўӮИү\ӮНүRӮҫӮБӮҪӮұӮЖӮЙӮИӮйӮИ
Ғi300WӮНPCIeӮМҸгҢАҒj
ӮаӮөӮӯӮНnVIDIA/ATIӮМ40nm GPUӮЙ‘ОҚRӮ·ӮйӮҪӮЯӮЙ32nmӮр‘O“|ӮөӮөӮДӮ«ӮҪӮМӮ©ҒH
ӮЬӮ ҒA40nmӮБӮДҢҫӮБӮДӮағoғӢғNӮ¶ӮбӮҪӮ©ӮӘ’mӮкӮДӮйӮӘҒB
http://northwood.blog60.fc2.com/blog-entry-2380.html
ӮұӮкӮӘ–{“–ӮИӮз32ғRғAӮЕ300WӮИӮсӮДғAғzӮЭӮҪӮўӮИү\ӮНүRӮҫӮБӮҪӮұӮЖӮЙӮИӮйӮИ
Ғi300WӮНPCIeӮМҸгҢАҒj
ӮаӮөӮӯӮНnVIDIA/ATIӮМ40nm GPUӮЙ‘ОҚRӮ·ӮйӮҪӮЯӮЙ32nmӮр‘O“|ӮөӮөӮДӮ«ӮҪӮМӮ©ҒH
ӮЬӮ ҒA40nmӮБӮДҢҫӮБӮДӮағoғӢғNӮ¶ӮбӮҪӮ©ӮӘ’mӮкӮДӮйӮӘҒB
96 ҒF–јҸМ–ўҗЭ’иҒF2008/10/24(Ӣа) 15:18:25 ID:iJHIvs/D0
♥
97 ҒF–јҸМ–ўҗЭ’иҒF2008/10/24(Ӣа) 19:56:24 ID:nPRTSrj+0
>>95
FUDzillaӮМҢіғ\Ғ[ғXӮрӮЭӮДӮЭӮлҒB
It looks like the first version of Larrabee is supposed to be a
graphics chip with 48 cores, and not with 80 cores as most originally expected.
ҚЎӮЬӮЕ80ғRғAӮҫӮЖ—\‘zӮіӮкӮДӮўӮҪӮӘҒA48ғRғAӮЕҺc”OӮҫӮБӮДw
“d”gӮЕӮ·ӮЛҒBӮўӮЬӮҫӮЙPolarisӮЖҠЁҲбӮўӮөӮДӮвӮӘӮйҒB
FUDzillaӮМҢіғ\Ғ[ғXӮрӮЭӮДӮЭӮлҒB
It looks like the first version of Larrabee is supposed to be a
graphics chip with 48 cores, and not with 80 cores as most originally expected.
ҚЎӮЬӮЕ80ғRғAӮҫӮЖ—\‘zӮіӮкӮДӮўӮҪӮӘҒA48ғRғAӮЕҺc”OӮҫӮБӮДw
“d”gӮЕӮ·ӮЛҒBӮўӮЬӮҫӮЙPolarisӮЖҠЁҲбӮўӮөӮДӮвӮӘӮйҒB
98 ҒFMACғIғ^Ғ„97 ӮіӮсҒF2008/10/24(Ӣа) 21:00:51 ID:30ap5gPo0
>>97
Ӯ»ӮкҲИ‘OӮЙҒA–ўӮҫӮЙ"FUD"zillaӮМ•…ӮкғӢҒ[ғ}Ғ[ӮрҗMӮ¶ӮйғqғgӮӘ‘¶ҚЭӮ·ӮйӮұӮЖҺ©‘МӮӘӢБӮ«Ӯ·(ҸО)
Ӯ»ӮкҲИ‘OӮЙҒA–ўӮҫӮЙ"FUD"zillaӮМ•…ӮкғӢҒ[ғ}Ғ[ӮрҗMӮ¶ӮйғqғgӮӘ‘¶ҚЭӮ·ӮйӮұӮЖҺ©‘МӮӘӢБӮ«Ӯ·(ҸО)
99 ҒF–јҸМ–ўҗЭ’иҒF2008/10/24(Ӣа) 21:03:28 ID:nPRTSrj+0
FUDzillaӮНӮЛҒAҢіғ\Ғ[ғXӮНӮўӮўӮЭӮҪӮўӮИӮсӮҫӮӘҒA
ғүғCғ^Ғ[ӮӘӮаӮМӮ·ӮІӮў”nҺӯӮЕҠЁҲбӮўӮӘ‘ҪӮўӮ©ӮзӮЗӮӨӮөӮжӮӨӮаӮИӮўҒBӮ№ӮБӮ©ӮӯӮМҸо•сӮӘ‘д–іӮөҒB
2chӮМ•Ҫ–}ӮИ–ј–іӮөҲИүәӮҫӮЛӮҘҒB
ғүғCғ^Ғ[ӮӘӮаӮМӮ·ӮІӮў”nҺӯӮЕҠЁҲбӮўӮӘ‘ҪӮўӮ©ӮзӮЗӮӨӮөӮжӮӨӮаӮИӮўҒBӮ№ӮБӮ©ӮӯӮМҸо•сӮӘ‘д–іӮөҒB
2chӮМ•Ҫ–}ӮИ–ј–іӮөҲИүәӮҫӮЛӮҘҒB
100 ҒFMACғIғ^Ғ„99 ӮіӮсҒF2008/10/24(Ӣа) 21:25:38 ID:30ap5gPo0
>>99
Ғ@Ғ@---------------
Ғ@Ғ@FUDzillaӮНӮЛҒAҢіғ\Ғ[ғXӮНӮўӮўӮЭӮҪӮўӮИӮсӮҫӮӘ
Ғ@Ғ@---------------
“ЖҺ©ғ\Ғ[ғXӮМӢLҺ–Ӯнқs‘ўӮ·(ҸО)
Ғ@Ғ@---------------
Ғ@Ғ@FUDzillaӮНӮЛҒAҢіғ\Ғ[ғXӮНӮўӮўӮЭӮҪӮўӮИӮсӮҫӮӘ
Ғ@Ғ@---------------
“ЖҺ©ғ\Ғ[ғXӮМӢLҺ–Ӯнқs‘ўӮ·(ҸО)
101 ҒF–јҸМ–ўҗЭ’иҒF2008/10/24(Ӣа) 21:31:59 ID:nPRTSrj+0
Ңіғ\Ғ[ғXӮЖӮўӮӨӮ©ғ\Ғ[ғXӮМӢЖҠE–¬ҒB
FUDzillaӮМғtғBғӢғ^”\—НӮӘӮИӮўӮ©ӮзӮЮӮҝӮбӮӯӮҝӮбӮЙӮИӮБӮДҸoӮДӮ«ӮДӮйӮҫӮҜҒB
FUDzillaӮМғtғBғӢғ^”\—НӮӘӮИӮўӮ©ӮзӮЮӮҝӮбӮӯӮҝӮбӮЙӮИӮБӮДҸoӮДӮ«ӮДӮйӮҫӮҜҒB
102 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒқҒңҒF2008/10/25(“y) 01:31:15 ID:fUrTbkVn0
>>97
Ӯ»ӮкӢCӮГӮўӮҪӮҜӮЗ•КғXғҢӮЙӮаҸ‘ӮўӮҪӮұӮЖӮҫӮ©Ӯз
http://pc11.2ch.net/test/read.cgi/jisaku/1217915128/247
–kҗXӮМҗlӮаүpҢкӮНҺгӮўӮБӮЫӮўӮМӮЕӮ ӮЬӮиӮ ӮДӮЙӮөӮДӮўӮИӮў
Ӯ»ӮкӢCӮГӮўӮҪӮҜӮЗ•КғXғҢӮЙӮаҸ‘ӮўӮҪӮұӮЖӮҫӮ©Ӯз
http://pc11.2ch.net/test/read.cgi/jisaku/1217915128/247
–kҗXӮМҗlӮаүpҢкӮНҺгӮўӮБӮЫӮўӮМӮЕӮ ӮЬӮиӮ ӮДӮЙӮөӮДӮўӮИӮў
103 ҒF–јҸМ–ўҗЭ’иҒF2008/10/25(“y) 01:32:47 ID:OOrGsk9c0
ӮВӮЬӮи48ғRғAӮИӮсӮДӮМӮНҗM—pӮЙӮ ӮҪӮўӮөӮИӮўӮБӮДӮұӮЖӮЛҒB
’cҺqӮНҗMӮ¶җШӮБӮДӮўӮйӮжӮӨӮҫӮӘҒB
’cҺqӮНҗMӮ¶җШӮБӮДӮўӮйӮжӮӨӮҫӮӘҒB
104 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒқҒңҒF2008/10/25(“y) 01:39:00 ID:fUrTbkVn0
Ӯ Ӯ ҒAӮЧӮВӮЙҠmҗMӮа”Ы’иӮаӮ·ӮйӢCӮНӮИӮўӮЛҒB
ӮҪӮҫӮЗӮБӮҝӮЙӮөӮл32nmӮЬӮЕӮНnVIDIAӮжӮиӮН•s—ҳӮЙӮИӮйӮБӮДҸо•сӮИӮзӮ ӮБӮҪҒB
җПҳaҺZӮМғNғҚғbғNҗ”ӮӘ4ғNғҚғbғNӮҫӮ©ӮзүБҺZӮМғҢғCғeғ“ғVӮН1ғNғҚғbғNӮҫӮИӮсӮДҢҫӮӨҗlҠФӮМӮўӮӨӮұӮЖӮЩӮЗ
җM—pӮЕӮ«ӮИӮўӮаӮМӮНӮИӮўӮжҒB
ӮҪӮҫӮЗӮБӮҝӮЙӮөӮл32nmӮЬӮЕӮНnVIDIAӮжӮиӮН•s—ҳӮЙӮИӮйӮБӮДҸо•сӮИӮзӮ ӮБӮҪҒB
җПҳaҺZӮМғNғҚғbғNҗ”ӮӘ4ғNғҚғbғNӮҫӮ©ӮзүБҺZӮМғҢғCғeғ“ғVӮН1ғNғҚғbғNӮҫӮИӮсӮДҢҫӮӨҗlҠФӮМӮўӮӨӮұӮЖӮЩӮЗ
җM—pӮЕӮ«ӮИӮўӮаӮМӮНӮИӮўӮжҒB
105 ҒF–јҸМ–ўҗЭ’иҒF2008/10/25(“y) 01:40:59 ID:OOrGsk9c0
>ӮўӮ«ӮИӮи48Ӯ©ӮжҒI
>16-32ғRғAӮЕҸҮ“–ӮЙҚUӮЯӮйӮЖҺvӮБӮДӮҪүҙ
ҚЕҸүӮНӮҝӮеӮБӮЖҗMӮ¶ӮҝӮбӮБӮДӮҪӮҫӮлwҒ@ӮұӮМғmғҠ
>16-32ғRғAӮЕҸҮ“–ӮЙҚUӮЯӮйӮЖҺvӮБӮДӮҪүҙ
ҚЕҸүӮНӮҝӮеӮБӮЖҗMӮ¶ӮҝӮбӮБӮДӮҪӮҫӮлwҒ@ӮұӮМғmғҠ
106 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒқҒңҒF2008/10/25(“y) 01:49:30 ID:fUrTbkVn0
ӮіӮ ҒAҸБ”п“d—НӮЙҢҫӢyӮөӮДӮйҺ‘—ҝӮ ӮБӮҪӮөӮИҒB
Ӯ»ӮкҲИҸгӮЙӮаӮ»ӮкҲИүәӮЙӮаӮИӮзӮИӮўӮсӮ¶ӮбӮИӮўҒH
32nmӮМWestmereӮӘҸoӮйӮжӮӨӮИҺһҠъӮЙ45nmғvғҚғZғXӮЕғXғ^Ғ[ғgӮЖҢҫӮнӮкӮДӮйҒB
ҢёүҝҸһӢpҸIӮнӮБӮДӮйӮ©ӮзҒAӮЕӮ©Ӯўғ_ғCӮЕҸoӮөӮДӮа–в‘иӮИӮўӮБӮДӮұӮЖӮҫӮлӮӨӮИ
ӮөӮ©ӮөCeleronҚмӮйӮМӮЖӮЗӮБӮҝӮӘ–ЧӮ©ӮйӮсӮҫӮлӮӨӮИҒH
Ӯ»ӮкҲИҸгӮЙӮаӮ»ӮкҲИүәӮЙӮаӮИӮзӮИӮўӮсӮ¶ӮбӮИӮўҒH
32nmӮМWestmereӮӘҸoӮйӮжӮӨӮИҺһҠъӮЙ45nmғvғҚғZғXӮЕғXғ^Ғ[ғgӮЖҢҫӮнӮкӮДӮйҒB
ҢёүҝҸһӢpҸIӮнӮБӮДӮйӮ©ӮзҒAӮЕӮ©Ӯўғ_ғCӮЕҸoӮөӮДӮа–в‘иӮИӮўӮБӮДӮұӮЖӮҫӮлӮӨӮИ
ӮөӮ©ӮөCeleronҚмӮйӮМӮЖӮЗӮБӮҝӮӘ–ЧӮ©ӮйӮсӮҫӮлӮӨӮИҒH
107 ҒF–јҸМ–ўҗЭ’иҒF2008/10/25(“y) 03:23:11 ID:a4obVWfZ0
1stғVғҠғRғ“ӮӘӮИӮўҸу‘ФӮЕ’NӮаӮ©ӮкӮаӮӘҚDӮ«ҸҹҺиҢҫӮБӮДӮ«ӮҪӮнӮҜӮЕҒAҗM—pӮ·ӮйӮЖӮ©ҲИ‘OӮМ–в‘иҒB
ғXғPҒ[ғүғuғӢӮИҗЭҢvӮИӮНӮёӮҫӮөҒAҺsҸк“®ҢьӮрбЙӮЭӮВӮВ’ҶӮМҗlӮӘ”CҲУӮЙҢҲ’иӮ·ӮйӮЖӮөӮ©ҢҫӮўӮжӮӨӮӘӮИӮўҒB
ғXғPҒ[ғүғuғӢӮИҗЭҢvӮИӮНӮёӮҫӮөҒAҺsҸк“®ҢьӮрбЙӮЭӮВӮВ’ҶӮМҗlӮӘ”CҲУӮЙҢҲ’иӮ·ӮйӮЖӮөӮ©ҢҫӮўӮжӮӨӮӘӮИӮўҒB
108 ҒF–јҸМ–ўҗЭ’иҒF2008/10/25(“y) 12:18:42 ID:OOrGsk9c0
>>106
ӮВӮЬӮи’cҺqӮіӮсӮН48ғRғAӮМүВ”\җ«”ZҢъӮЖӮЭӮДӮўӮйӮнӮҜӮЕӮ·ӮЛҒB
ӮЁӮк“IӮЙӮН—\‘zӮжӮиҸӯӮИӮўғRғAҗ”ӮЕӮЕӮДӮЭӮсӮИ”l“|ғӮҒ[ғhӮЙӮНӮўӮйӮЖӮЭӮДӮўӮЬӮ·ӮӘҒB
ӮВӮЬӮи’cҺqӮіӮсӮН48ғRғAӮМүВ”\җ«”ZҢъӮЖӮЭӮДӮўӮйӮнӮҜӮЕӮ·ӮЛҒB
ӮЁӮк“IӮЙӮН—\‘zӮжӮиҸӯӮИӮўғRғAҗ”ӮЕӮЕӮДӮЭӮсӮИ”l“|ғӮҒ[ғhӮЙӮНӮўӮйӮЖӮЭӮДӮўӮЬӮ·ӮӘҒB
109 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒңҒқҒӣҒF2008/10/25(“y) 15:02:12 ID:fUrTbkVn0
ӮўӮўӮвҒAүҙҢВҗlӮЖӮөӮДӮН45nm”ЕӮН32ғRғAӮЕҒA48ғRғAӮӘ”qӮЯӮйӮМӮН32nmӮ¶ӮбӮИӮўӮ©ӮЖҺvӮБӮДӮйҒB
ғҒғCғ“ғXғgғҠҒ[ғҖҗ»•iғRғAӮМ‘қүБ”д—Ұ“IӮЙҒB
45nmҒ@ӮЕҒ@4ғRғA
32nmҒ@ӮЕҒ@6ғRғA
22nmҒ@ӮЕҒ@8ғRғA
ӮаӮҝӮлӮсҒA45nmӮЕ48ғRғAҒA32nmӮЕ80ғRғAӮЕӮаӮЩӮЪ”д—ҰӮЗӮЁӮиӮИӮсӮҫӮҜӮЗӮаҒB
48Ғ~1.5ҒҒ72
ӮҪӮҫҒAҗ»•iӮМғүғCғ“ғiғbғvӮН‘ҪӮўӮЙүzӮөӮҪӮұӮЖӮН–іӮўӮ©Ӯз
ӮвӮкӮйӮИӮзӮвӮкӮОӮўӮўӮсӮ¶ӮбӮИӮўӮМҒH
ғҒғCғ“ғXғgғҠҒ[ғҖҗ»•iғRғAӮМ‘қүБ”д—Ұ“IӮЙҒB
45nmҒ@ӮЕҒ@4ғRғA
32nmҒ@ӮЕҒ@6ғRғA
22nmҒ@ӮЕҒ@8ғRғA
ӮаӮҝӮлӮсҒA45nmӮЕ48ғRғAҒA32nmӮЕ80ғRғAӮЕӮаӮЩӮЪ”д—ҰӮЗӮЁӮиӮИӮсӮҫӮҜӮЗӮаҒB
48Ғ~1.5ҒҒ72
ӮҪӮҫҒAҗ»•iӮМғүғCғ“ғiғbғvӮН‘ҪӮўӮЙүzӮөӮҪӮұӮЖӮН–іӮўӮ©Ӯз
ӮвӮкӮйӮИӮзӮвӮкӮОӮўӮўӮсӮ¶ӮбӮИӮўӮМҒH
110 ҒF–јҸМ–ўҗЭ’иҒF2008/10/25(“y) 17:41:28 ID:OOrGsk9c0
ӮЁӮкӮН‘f’јӮЙ10Ғ`16ғRғAӮҫӮЖҺvӮӨӮЛҒB
16ғRғAӮӘҢА“xҒB32ғRғAӮНӮЁүФ”ЁүЯӮ¬ӮйҒB
1”NҢгӮЙӮН”l“|ғӮҒ[ғhӮМ’cҺqӮіӮсӮӘӮЭӮзӮкӮЬӮ·ӮЛҒB
16ғRғAӮӘҢА“xҒB32ғRғAӮНӮЁүФ”ЁүЯӮ¬ӮйҒB
1”NҢгӮЙӮН”l“|ғӮҒ[ғhӮМ’cҺqӮіӮсӮӘӮЭӮзӮкӮЬӮ·ӮЛҒB
111 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒңҒқҒӣҒF2008/10/25(“y) 21:59:22 ID:fUrTbkVn0
ғRғAҗ”ӮҫӮЖӮ©ғsҒ[ғNFLOPSӮН–{ҺҝӮЕӮНӮИӮўӮИ
’[Ӯ©ӮзGPUӮҫӮЖӮНҺvӮБӮДӮИӮўӮөҒACPUӮЙ“қҚҮӮіӮкӮйӮЬӮЕӮНӮҪӮҫӮМҳI•ҘӮўҒB
Ңл“ҡҚG–ОӮМҢҫӮӨӮжӮӨӮЙLarrabeeӮМSIMD–Ҫ—ЯӮӘҒuҸ«—ҲӮМCPUӮЕҺgӮнӮкӮйҠg’ЈҒv
ӮЖӮўӮӨҲК’uӮГӮҜӮӘҗіӮөӮўӮЖӮөӮД
ӮўӮВӮЬӮЕ•sҺ©—RӮіӮ№ӮйӢCӮҫҒHӮБӮДӮМӮНӢCӮЙӮИӮйӮИ
ғrғbғg’PҲКӮМNOTӮЕ2ғIғyғҢҒ[ғVғҮғ“Ӯ©Ӯ©ӮйӮЖӮ©ӮіӮ—
ӮўӮўүБҢёNANDӮИӮиNORӮИӮиғTғ|Ғ[ғgӮөӮжӮӨӮжҒB
ғRғ“ғsғ…Ғ[ғ^ӮМҳ_—қ‘fҺqӮЕҲк”Ф’PҸғӮИӮаӮМӮр’HӮБӮДӮўӮӯӮЖNANDӮ©NORӮЙ
ӮҪӮЗӮи’…ӮӯӮұӮЖӮӯӮзӮў‘fҗlӮЕӮаӮнӮ©ӮйӮМӮЙҒAӮИӮсӮЕӮұӮМүпҺРӮНMMXӮӘҸoӮДӮ©Ӯз
10”NӮа•ъ’uӮө‘ұӮҜӮДӮйӮМӮ©ӮЛҒB”Д—pғҢғWғXғ^‘ӨӮЕӮНNOTӮвNEG–Ҫ—ЯҺgӮҰӮйӮМӮЙҒB
CellӮӘ‘К–ЪӮИӮМӮНҒAҠщӮЙOpcodeӢуҠФӮЙ—]—TӮӘ–іӮўӮ©ӮзҒB
”{җё“xӮрҚӮ‘¬ү»ӮөӮҪӮзӮ ӮЖүҪӮаӮвӮкӮйӮұӮЖӮИӮўӮҫӮлҒB
җ«”\ӮӘӮЁӮБӮВӮ©ӮИӮӯӮИӮБӮҪӮзҺgӮўҺМӮДӮйӢCҠЫҸoӮөҒB
MMX/SSEӮНҒAӮвӮкӮйӮМӮЙ•ъ’uӮөӮДӮйӮМӮӘӢCӮЙ“ьӮзӮИӮўҒB
•КӮЙpcmpeqb + pxorӮЕӮаӮўӮўӮсӮҫӮжҒB
ӮҪӮҫSIMDғҶғjғbғgӮӘӮPҠоӮөӮ©ӮИӮўғvғҚғZғbғTӮЕӮНӮвӮзӮ№ӮИӮўӮЕӮӯӮк
ӮЗӮӨӮҫҒAӮВӮЬӮсӮЛҒ[ӮҫӮл
’[Ӯ©ӮзGPUӮҫӮЖӮНҺvӮБӮДӮИӮўӮөҒACPUӮЙ“қҚҮӮіӮкӮйӮЬӮЕӮНӮҪӮҫӮМҳI•ҘӮўҒB
Ңл“ҡҚG–ОӮМҢҫӮӨӮжӮӨӮЙLarrabeeӮМSIMD–Ҫ—ЯӮӘҒuҸ«—ҲӮМCPUӮЕҺgӮнӮкӮйҠg’ЈҒv
ӮЖӮўӮӨҲК’uӮГӮҜӮӘҗіӮөӮўӮЖӮөӮД
ӮўӮВӮЬӮЕ•sҺ©—RӮіӮ№ӮйӢCӮҫҒHӮБӮДӮМӮНӢCӮЙӮИӮйӮИ
ғrғbғg’PҲКӮМNOTӮЕ2ғIғyғҢҒ[ғVғҮғ“Ӯ©Ӯ©ӮйӮЖӮ©ӮіӮ—
ӮўӮўүБҢёNANDӮИӮиNORӮИӮиғTғ|Ғ[ғgӮөӮжӮӨӮжҒB
ғRғ“ғsғ…Ғ[ғ^ӮМҳ_—қ‘fҺqӮЕҲк”Ф’PҸғӮИӮаӮМӮр’HӮБӮДӮўӮӯӮЖNANDӮ©NORӮЙ
ӮҪӮЗӮи’…ӮӯӮұӮЖӮӯӮзӮў‘fҗlӮЕӮаӮнӮ©ӮйӮМӮЙҒAӮИӮсӮЕӮұӮМүпҺРӮНMMXӮӘҸoӮДӮ©Ӯз
10”NӮа•ъ’uӮө‘ұӮҜӮДӮйӮМӮ©ӮЛҒB”Д—pғҢғWғXғ^‘ӨӮЕӮНNOTӮвNEG–Ҫ—ЯҺgӮҰӮйӮМӮЙҒB
CellӮӘ‘К–ЪӮИӮМӮНҒAҠщӮЙOpcodeӢуҠФӮЙ—]—TӮӘ–іӮўӮ©ӮзҒB
”{җё“xӮрҚӮ‘¬ү»ӮөӮҪӮзӮ ӮЖүҪӮаӮвӮкӮйӮұӮЖӮИӮўӮҫӮлҒB
җ«”\ӮӘӮЁӮБӮВӮ©ӮИӮӯӮИӮБӮҪӮзҺgӮўҺМӮДӮйӢCҠЫҸoӮөҒB
MMX/SSEӮНҒAӮвӮкӮйӮМӮЙ•ъ’uӮөӮДӮйӮМӮӘӢCӮЙ“ьӮзӮИӮўҒB
•КӮЙpcmpeqb + pxorӮЕӮаӮўӮўӮсӮҫӮжҒB
ӮҪӮҫSIMDғҶғjғbғgӮӘӮPҠоӮөӮ©ӮИӮўғvғҚғZғbғTӮЕӮНӮвӮзӮ№ӮИӮўӮЕӮӯӮк
ӮЗӮӨӮҫҒAӮВӮЬӮсӮЛҒ[ӮҫӮл
112 ҒF–јҸМ–ўҗЭ’иҒF2008/10/25(“y) 22:42:42 ID:OOrGsk9c0
’cҺqӮіӮсӮНLarrabeeӮЙҠъ‘ТӮөӮДӮўӮйӮМӮ©Ҡъ‘ТӮөӮДӮўӮИӮўӮМӮ©ӮжӮӯӮнӮ©ӮзӮИӮўӮЕӮ·ӮЛҒB
LarrabeeӮНLNIӮЖғҒғjҒ[ғRғAҺь•УӮМғeғXғgӮрIntelӮӘ‘ҒӮЯӮЙӮвӮиӮҪӮўӮБӮДӮҫӮҜӮБӮДӮМӮН“ҜҲУҒB
’PҸғӮЙGPUӮЖ”дҠrӮөӮДӮЗӮӨӮҪӮзӮМӢLҺ–ӮН–OӮ«ӮҪҒB
LarrabeeӮНLNIӮЖғҒғjҒ[ғRғAҺь•УӮМғeғXғgӮрIntelӮӘ‘ҒӮЯӮЙӮвӮиӮҪӮўӮБӮДӮҫӮҜӮБӮДӮМӮН“ҜҲУҒB
’PҸғӮЙGPUӮЖ”дҠrӮөӮДӮЗӮӨӮҪӮзӮМӢLҺ–ӮН–OӮ«ӮҪҒB
113 ҒF–јҸМ–ўҗЭ’иҒF2008/10/25(“y) 22:45:16 ID:OOrGsk9c0
ҚЕӢЯӮМҢл“ҡӮіӮсӮМӢLҺ–ӮНҒA
ҒEGPUӮМGPGPUү»ӮЖLarrabeeӮМ•ыҢьҗ«
ҒEҗVӮөӮў’бҸБ”п“d—НғRғAӮМ”й–§(ғCғ“ғIҒ[ғ_Ғ[ӮЖғ|ғүғbғNӮМ–@‘Ҙ)
ӮМ2ғlғ^ӮМ–іҢАғӢҒ[ғvӮҫӮөӮИҒB
ҒEGPUӮМGPGPUү»ӮЖLarrabeeӮМ•ыҢьҗ«
ҒEҗVӮөӮў’бҸБ”п“d—НғRғAӮМ”й–§(ғCғ“ғIҒ[ғ_Ғ[ӮЖғ|ғүғbғNӮМ–@‘Ҙ)
ӮМ2ғlғ^ӮМ–іҢАғӢҒ[ғvӮҫӮөӮИҒB
114 ҒF–јҸМ–ўҗЭ’иҒF2008/10/25(“y) 23:14:35 ID:OOrGsk9c0
http://www.geocities.jp/andosprocinfo/wadai08/20081025.htm
>ҸнҺҜ“IӮЙҢ©ӮДҒuҲк•ы“IӮЙ—ЈҚҘҒvӮЖ[ғAғoғ^Ғ[ҸБӮөҒvӮМӮЗӮБӮҝӮӘҲ«ӮўҚsҲЧӮИӮсӮЕӮөӮеӮӨӮ©ӮЛҒB
>Ӯ»ӮкӮЙҒCӮұӮсӮИғPҒ[ғXӮЙҗЕӢаҺgӮӨӮМӮа–Ь‘М–іӮўӮжӮӨӮИӢCӮӘӮөӮЬӮ·ҒB
ӮӯӮҫӮзӮИӮўҺ–ҢҸӮҫӮЖӮНҺvӮӨӮӘҒAғAғoғ^Ғ[ҸБӮөӮМ•ыӮӘҲ«ӮўӮЙҢҲӮЬӮБӮДӮйӮҫӮлӮБҒB
IDӮЖғpғXғҸҒ[ғhҺgӮБӮДҗi“ьӮөӮДҒAҢМҲУӮЙғfҒ[ғ^ҚнҸңӮЙӢЯӮўӮұӮЖӮвӮБӮДӮйӮсӮҫӮ©ӮзӮіӮ ҒB
>ҸнҺҜ“IӮЙҢ©ӮДҒuҲк•ы“IӮЙ—ЈҚҘҒvӮЖ[ғAғoғ^Ғ[ҸБӮөҒvӮМӮЗӮБӮҝӮӘҲ«ӮўҚsҲЧӮИӮсӮЕӮөӮеӮӨӮ©ӮЛҒB
>Ӯ»ӮкӮЙҒCӮұӮсӮИғPҒ[ғXӮЙҗЕӢаҺgӮӨӮМӮа–Ь‘М–іӮўӮжӮӨӮИӢCӮӘӮөӮЬӮ·ҒB
ӮӯӮҫӮзӮИӮўҺ–ҢҸӮҫӮЖӮНҺvӮӨӮӘҒAғAғoғ^Ғ[ҸБӮөӮМ•ыӮӘҲ«ӮўӮЙҢҲӮЬӮБӮДӮйӮҫӮлӮБҒB
IDӮЖғpғXғҸҒ[ғhҺgӮБӮДҗi“ьӮөӮДҒAҢМҲУӮЙғfҒ[ғ^ҚнҸңӮЙӢЯӮўӮұӮЖӮвӮБӮДӮйӮсӮҫӮ©ӮзӮіӮ ҒB
ҚЎӮЬӮЕSIMDӮМ•қӮӘ128-bit’ц“xӮЙ—ҜӮЬӮБӮДӮўӮҪ—қ—RӮнҒAӮҝӮбӮсӮЖғAғӢӮ·ҒB
Ғ@ҒEғxғNғgғӢ’·Ӯр‘қӮвӮөӮДӮа—p“rӮӘҚLӮӘӮзӮИӮў
Ғ@ҒEғ^ғXғNғXғCғbғ`ӮМғIҒ[ғoҒ[ғwғbғhӮӘ‘қӮҰӮй
”Д—pғvғҚғZғbғTӮЙLRB (intelӮнLNIӮЕӮн–іӮӯҒALarrabeeӮМISAӮрӮұӮӨҢДӮсӮЕӮўӮйӮ·)ӮӘҚМ—pӮіӮкӮйӮ©ӮнҒA
Ӣ^–вӮ·ҒBӮЬӮөӮД’PӮИӮйAVXӮМғҸғCғh”ЕӮҫӮЖӮ·ӮкӮОҒA•K—vҗ«Ӯ·ӮзҠF–іӮ©ӮаҒBҒBҒB
Ғ@ҒEғxғNғgғӢ’·Ӯр‘қӮвӮөӮДӮа—p“rӮӘҚLӮӘӮзӮИӮў
Ғ@ҒEғ^ғXғNғXғCғbғ`ӮМғIҒ[ғoҒ[ғwғbғhӮӘ‘қӮҰӮй
”Д—pғvғҚғZғbғTӮЙLRB (intelӮнLNIӮЕӮн–іӮӯҒALarrabeeӮМISAӮрӮұӮӨҢДӮсӮЕӮўӮйӮ·)ӮӘҚМ—pӮіӮкӮйӮ©ӮнҒA
Ӣ^–вӮ·ҒBӮЬӮөӮД’PӮИӮйAVXӮМғҸғCғh”ЕӮҫӮЖӮ·ӮкӮОҒA•K—vҗ«Ӯ·ӮзҠF–іӮ©ӮаҒBҒBҒB
116 ҒF–јҸМ–ўҗЭ’иҒF2008/10/25(“y) 23:22:02 ID:OOrGsk9c0
>”Д—pғvғҚғZғbғTӮЙLRB (intelӮнLNIӮЕӮн–іӮӯҒALarrabeeӮМISAӮрӮұӮӨҢДӮсӮЕӮўӮйӮ·)ӮӘҚМ—pӮіӮкӮйӮ©ӮнҒA
>Ӣ^–вӮ·ҒB
ӮЬӮұӮҪӮсӮнӮ©ӮБӮДӮИӮўӮЛҒBҠm’иӮЕӮНӮИӮўӮЖӮНӮўӮҰҒAIntel CPUӮӘӮЗӮӨӮўӮӨ•ыҢьӮЙҗiү»ӮөӮжӮӨӮЖӮўӮӨ
—¬ӮкӮИӮМӮ©—қүрӮЕӮ«ӮДӮИӮўҒB’cҺqҗжҗ¶ӮЙҗа–ҫӮөӮДӮаӮзӮнӮИӮўӮЖҒBҒBҒB
>Ғ@ҒEғxғNғgғӢ’·Ӯр‘қӮвӮөӮДӮа—p“rӮӘҚLӮӘӮзӮИӮў
>Ғ@ҒEғ^ғXғNғXғCғbғ`ӮМғIҒ[ғoҒ[ғwғbғhӮӘ‘қӮҰӮй
ӮұӮкӮНҲк”К“IӮ·Ӯ¬ӮйҒBIntel“Б—LӮМӮұӮҫӮнӮиӮЙӮНӮЭӮҰӮИӮўҒB
>Ӣ^–вӮ·ҒB
ӮЬӮұӮҪӮсӮнӮ©ӮБӮДӮИӮўӮЛҒBҠm’иӮЕӮНӮИӮўӮЖӮНӮўӮҰҒAIntel CPUӮӘӮЗӮӨӮўӮӨ•ыҢьӮЙҗiү»ӮөӮжӮӨӮЖӮўӮӨ
—¬ӮкӮИӮМӮ©—қүрӮЕӮ«ӮДӮИӮўҒB’cҺqҗжҗ¶ӮЙҗа–ҫӮөӮДӮаӮзӮнӮИӮўӮЖҒBҒBҒB
>Ғ@ҒEғxғNғgғӢ’·Ӯр‘қӮвӮөӮДӮа—p“rӮӘҚLӮӘӮзӮИӮў
>Ғ@ҒEғ^ғXғNғXғCғbғ`ӮМғIҒ[ғoҒ[ғwғbғhӮӘ‘қӮҰӮй
ӮұӮкӮНҲк”К“IӮ·Ӯ¬ӮйҒBIntel“Б—LӮМӮұӮҫӮнӮиӮЙӮНӮЭӮҰӮИӮўҒB
117 ҒF–јҸМ–ўҗЭ’иҒF2008/10/25(“y) 23:23:00 ID:OOrGsk9c0
>ӮЬӮөӮД’PӮИӮйAVXӮМғҸғCғh”ЕӮҫӮЖӮ·ӮкӮОҒA•K—vҗ«Ӯ·ӮзҠF–іӮ©ӮаҒBҒBҒB
ӮұӮБӮҝӮМ•ыӮЛҒBӮнӮ©ӮБӮДӮИӮўҒB
ӮұӮБӮҝӮМ•ыӮЛҒBӮнӮ©ӮБӮДӮИӮўҒB
118 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒңҒқҒӣҒF2008/10/25(“y) 23:46:56 ID:fUrTbkVn0
x86ӮНҳ_—қғҢғWғXғ^–{җ”ӮНҸӯӮИӮўӮЩӮӨӮИӮсӮҫӮҜӮЗӮЛҒB
ғRғAҗ”ӮӘ‘қӮҰӮДӮўӮӯӮИӮзғRғ“ғeғNғXғgғXғCғbғ`ӮМ•p“xӮН‘Ҡ‘О“IӮЙҢёӮйӮ©Ӯз
Ӯ»ӮұӮЙSIMDҠg’ЈӮЙ”пӮвӮ·—]’nӮӘҸoӮДӮӯӮйҒB
‘ҪғRғAү»Ӯрҗ„ӮөҗiӮЯӮйӮЩӮЗғVғ“ғOғӢғRғAҗ«”\ӮрҢьҸгӮіӮ№‘ұӮҜӮйӮұӮЖӮӘӮЕӮ«Ӯй
ӮБӮД–К”’ӮўҳbӮҫӮЖҺvӮнӮсӮ©ӮЛҒH
ғRғAҗ”ӮӘ‘қӮҰӮДӮўӮӯӮИӮзғRғ“ғeғNғXғgғXғCғbғ`ӮМ•p“xӮН‘Ҡ‘О“IӮЙҢёӮйӮ©Ӯз
Ӯ»ӮұӮЙSIMDҠg’ЈӮЙ”пӮвӮ·—]’nӮӘҸoӮДӮӯӮйҒB
‘ҪғRғAү»Ӯрҗ„ӮөҗiӮЯӮйӮЩӮЗғVғ“ғOғӢғRғAҗ«”\ӮрҢьҸгӮіӮ№‘ұӮҜӮйӮұӮЖӮӘӮЕӮ«Ӯй
ӮБӮД–К”’ӮўҳbӮҫӮЖҺvӮнӮсӮ©ӮЛҒH
119 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒңҒқҒӣҒF2008/10/25(“y) 23:54:10 ID:fUrTbkVn0
ӮВҒ[Ӯ©SIMDӮМ•қӮр‘қӮвӮ·ҸкҚҮҒALSUӮЕҲк“xӮЙғXғgғAӮЕӮ«Ӯйғrғbғgҗ”Ӯа‘қӮҰӮйӮұӮЖӮЙӮИӮйӮ©Ӯз
ғRғ“ғeғNғXғgғXғCғbғ`ӮМҺһҠФ“IӮЙ‘еӮ«ӮИ–в‘иӮЙӮИӮйӮЖӮНҺvӮҰӮсӮМӮҫӮӘӮИҒB
Ӯ»ӮкӮЖӮаүҪӮ©ҒH
Sandy BridgeӮМAVXӮӘғlғCғeғBғu256ғrғbғgӮЕӮНӮИӮӯӮД128ғrғbғgҒ~2ӮБӮДҺ–ҺАӮр”FӮЯӮйӢCӮЙӮИӮБӮҪӮМӮ©ӮИҒH
LoadӮН2–{ӮҫӮ©ӮзҲАҗSӮөӮлӮжҒB128ғrғbғg•қӮҫӮҜӮЗҒB
ғRғ“ғeғNғXғgғXғCғbғ`ӮМҺһҠФ“IӮЙ‘еӮ«ӮИ–в‘иӮЙӮИӮйӮЖӮНҺvӮҰӮсӮМӮҫӮӘӮИҒB
Ӯ»ӮкӮЖӮаүҪӮ©ҒH
Sandy BridgeӮМAVXӮӘғlғCғeғBғu256ғrғbғgӮЕӮНӮИӮӯӮД128ғrғbғgҒ~2ӮБӮДҺ–ҺАӮр”FӮЯӮйӢCӮЙӮИӮБӮҪӮМӮ©ӮИҒH
LoadӮН2–{ӮҫӮ©ӮзҲАҗSӮөӮлӮжҒB128ғrғbғg•қӮҫӮҜӮЗҒB
120 ҒF–јҸМ–ўҗЭ’иҒF2008/11/06(–Ш) 21:07:42 ID:oKRRJ3qZ0
ho
121 ҒF–јҸМ–ўҗЭ’иҒF2008/11/13(–Ш) 21:39:21 ID:uYgQ1Hzm0
ze
122 ҒF–јҸМ–ўҗЭ’иҒF2008/11/20(–Ш) 19:16:52 ID:O5PoN1Ej0
m
123 ҒF–јҸМ–ўҗЭ’иҒF2008/11/22(“y) 03:20:45 ID:nyf5uIV/0
ҳAӢxӮӘӢЯӮӯӮИӮйӮЖ,MACғIғ^ӮӘҢіӢCӮЙӮИӮйӢCӮӘӮ·ӮйӮМӮЕӮ·ӮӘ,ӮұӮкӮНӮЗ
124 ҒF–јҸМ–ўҗЭ’иҒF2008/11/28(Ӣа) 22:30:43 ID:clGGZJre0
“Ә”]•ъ’k ‘ж102үс ҒuCore i7ҒvӮМ–КӮрҢ©ӮкӮОҒcҒc
http://www.atmarkit.co.jp/fsys/zunouhoudan/102zunou/corei7.html
http://www.atmarkit.co.jp/fsys/zunouhoudan/102zunou/corei7.html
125 ҒF–јҸМ–ўҗЭ’иҒF2008/11/28(Ӣа) 23:56:53 ID:c4mbtITH0
MassaӮіӮсҒA–К”’ӮўҳbӮӘҸ‘ӮҜӮИӮӯӮИӮБӮДӮ«ӮҪӮИӮ
Һc”O
Һc”O
126 ҒF–јҸМ–ўҗЭ’иҒF2008/12/06(“y) 14:14:01 ID:Vjs45hM70
ho
127 ҒF–јҸМ–ўҗЭ’иҒF2008/12/14(“ъ) 21:21:03 ID:6aiL+7bg0
ze
128 ҒF–јҸМ–ўҗЭ’иҒF2008/12/22(ҢҺ) 21:46:55 ID:xpR/Ra7nO
Ӯс
129 ҒF–јҸМ–ўҗЭ’иҒF2008/12/23(үО) 12:27:54 ID:rOoYHhsJ0
ӮаӮӨ—ҺӮЖӮөӮДӮўӮсӮ¶ӮбӮЛҒH
130 ҒF–јҸМ–ўҗЭ’иҒF2008/12/28(“ъ) 19:07:59 ID:pRD9mmbq0
ho
ҲкүһҒAӮQӮҝӮбӮсӮЛӮйӮМҠЗ—қ“IӮЙӮнҒw•ЫҺзӮнҚrӮзӮөҒxӮ·ҒB
http://www.media-k.co.jp/jiten/wiki.cgi?%A1%E3%A4%DB%A1%E4#i32
ӮЕӮа•ЫҺзҚrӮзӮөӮМғqғgӮӘҒAӮ»ӮкӮЕ”ҪҸИӮөӮҪ—бӮа–іӮўӮ·Ӯ©Ӯз”ЮӮзӮӘ–OӮ«ӮйӮЬӮЕ•ъ’uӮ·ӮйӮөӮ©–іӮўӮ·(ҸО)
http://www.media-k.co.jp/jiten/wiki.cgi?%A1%E3%A4%DB%A1%E4#i32
ӮЕӮа•ЫҺзҚrӮзӮөӮМғqғgӮӘҒAӮ»ӮкӮЕ”ҪҸИӮөӮҪ—бӮа–іӮўӮ·Ӯ©Ӯз”ЮӮзӮӘ–OӮ«ӮйӮЬӮЕ•ъ’uӮ·ӮйӮөӮ©–іӮўӮ·(ҸО)
132 ҒF–јҸМ–ўҗЭ’иҒF2008/12/28(“ъ) 21:28:54 ID:IA+OxsQu0
—ЗӮўӮЁ”NӮр
133 ҒF–јҸМ–ўҗЭ’иҒF2009/01/06(үО) 01:39:02 ID:wgCWHbwp0
–ҫ–С”ц–Ъ
134 ҒF–јҸМ–ўҗЭ’иҒF2009/01/13(үО) 20:02:33 ID:jF9qZ7xe0
ho
135 ҒFӮұӮлӮөӮвӮЬӮс ҒҹsnOWCRs4I2 ҒF2009/01/13(үО) 21:48:34 ID:gAF8aAmZ0
136 ҒF,,ҒE ҒН ҒE,,ҒjӮБ-ҒӣҒқҒӣҒF2009/01/20(үО) 23:40:04 ID:wOuIW6B10
ӮұӮұӮӘү\ӮМMACғIғ^җжҗ¶ӮӘ•ъ’uҠ®‘SҗйҢҫҢҲӮЯҚһӮсӮҫғXғҢӮ©ҒB
ӮЮӮөӮлүЯӮІӮөӮвӮ·ӮӯҒAүх“KӮЙӮИӮБӮҪӮЖӮМӮЕӮНӮИӮўӮ©ӮЖҠъ‘ТӮөӮДӮЭӮйҺи‘f’ГҒB
ӮЮӮөӮлүЯӮІӮөӮвӮ·ӮӯҒAүх“KӮЙӮИӮБӮҪӮЖӮМӮЕӮНӮИӮўӮ©ӮЖҠъ‘ТӮөӮДӮЭӮйҺи‘f’ГҒB
137 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒңҒқҒӣҒF2009/01/22(–Ш) 02:50:50 ID:EcCWQxd/0
ӮlӮ`ӮbҰАӮМғRғsғyӮНғEғUғCӮМӮН“ҜҲУҒB
“ЗӮЭӮҪӮў“zӮЙ“ЗӮЬӮ№ӮҪӮўӮИӮзғuғҚғOӮЙӮЕӮаҸ‘Ӯ«ӮвӮӘӮкӮЕӮ·ҒB
ҸҠ‘FӮвӮБӮДӮйӮұӮЖӮНӮrӮoӮ`ӮlӮЖ“ҜӮ¶ҒB
“ЗӮЭӮҪӮў“zӮЙ“ЗӮЬӮ№ӮҪӮўӮИӮзғuғҚғOӮЙӮЕӮаҸ‘Ӯ«ӮвӮӘӮкӮЕӮ·ҒB
ҸҠ‘FӮвӮБӮДӮйӮұӮЖӮНӮrӮoӮ`ӮlӮЖ“ҜӮ¶ҒB
138 ҒF,,ҒE ҒН ҒE,,ҒjӮБ-ҒӣҒқҒӣҒF2009/01/25(“ъ) 14:48:16 ID:bJndmWs60
ҚЕ’·ҺхIntelғXғҢӮМ•\ғXғҢӮӘ—ҺӮҝӮҪӮЬӮЬӮҫӮИ
ӮЬӮ ҒAӮұӮМӮЬӮЬӮИӮӯӮИӮБӮДӮӯӮкӮДӮа‘S‘RӮ©ӮЬӮнӮсӮМӮҫӮӘ
ӮЬӮ ҒAӮұӮМӮЬӮЬӮИӮӯӮИӮБӮДӮӯӮкӮДӮа‘S‘RӮ©ӮЬӮнӮсӮМӮҫӮӘ
139 ҒF–јҸМ–ўҗЭ’иҒF2009/01/29(–Ш) 22:03:06 ID:Z+u7UWQO0
ho
140 ҒF–јҸМ–ўҗЭ’иҒF2009/02/06(Ӣа) 00:17:29 ID:9M1rglFp0
”ыӮИӮө’cҺqӮӘ•aӢCӮЙӮ©Ӯ©ӮБӮҪӮЭӮҪӮў
141 ҒF,,ҒE ҒН ҒE,,ҒjӮБ-ҒӣҒқҒӣҒF2009/02/06(Ӣа) 00:21:11 ID:uyuWahBF0
Ӯ©ӮИӮиӢкӮөӮўӮЕӮ·w
142 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒңҒқҒӣҒF2009/02/11(җ…) 14:19:17 ID:tSOMH7TM0
ӮўӮБӮШӮсҺҒӮсӮЕӮЭӮйҒH
143 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒңҒқҒӣҒF2009/02/11(җ…) 22:00:34 ID:tSOMH7TM0
Ғ„—бӮҰӮОx86 ISAӮнҒA•Ӯ“®Ҹ¬җ”“_ӮМҗПҳaүүҺZ–Ҫ—ЯӮрҺқӮҪӮИӮўӮ·ӮҜӮЗҒAӮұӮМҢӢүКHPC•Ә–мӮЕӮнLinpackӮЕӮМғsҒ[ғN
Ғ„җ«”\ӮӘ—тӮйӮЖӮўӮӨ—қ—RӮЕ‘I‘рӮ©ӮзҠOӮкӮҪӮиӮ·ӮйӮұӮЖӮӘӮ ӮйӮ·ҒB
Ғ„җ«”\ӮӘ—тӮйӮЖӮўӮӨ—қ—RӮЕ‘I‘рӮ©ӮзҠOӮкӮҪӮиӮ·ӮйӮұӮЖӮӘӮ ӮйӮ·ҒB
144 ҒF–јҸМ–ўҗЭ’иҒF2009/02/16(ҢҺ) 22:15:03 ID:5Z19wUSR0
ze
145 ҒF–јҸМ–ўҗЭ’иҒF2009/02/25(җ…) 00:41:29 ID:RAcNtJD20
m
146 ҒF–јҸМ–ўҗЭ’иҒF2009/02/25(җ…) 22:59:26 ID:VWV9mOc30
“Ә”]•ъ’k ‘ж105үс •sӢөӮМӮЖӮ«ӮұӮ»–ҫ“ъӮМӢZҸpӮЦ“ҠҺ‘Ӯ№Ӯж
http://www.atmarkit.co.jp/fsys/zunouhoudan/105zunou/sicrisis.html
http://www.atmarkit.co.jp/fsys/zunouhoudan/105zunou/sicrisis.html
147 ҒF–јҸМ–ўҗЭ’иҒF2009/03/07(“y) 20:38:56 ID:SbDAuR7k0
ho
148 ҒF–јҸМ–ўҗЭ’иҒF2009/03/09(ҢҺ) 20:18:15 ID:MMrppieI0
68. x86 ғvғҚғZғbғTӮМҸ«—Ҳ (2009/2/28)
http://jun.artcompsci.org/articles/future_sc/note069.html
ҺҖӮКӢCӮЕҺgӮҰӮйӮжӮӨӮЙӮ·ӮйӮМӮ©ҒH’ъӮЯӮйӮМӮ©ҒH
http://www.ne.jp/asahi/comp/tarusan/main204.htm
http://jun.artcompsci.org/articles/future_sc/note069.html
ҺҖӮКӢCӮЕҺgӮҰӮйӮжӮӨӮЙӮ·ӮйӮМӮ©ҒH’ъӮЯӮйӮМӮ©ҒH
http://www.ne.jp/asahi/comp/tarusan/main204.htm
149 ҒF–јҸМ–ўҗЭ’иҒF2009/03/14(“y) 15:36:05 ID:uz5RZgqm0
(2009 3/8 ҠФҲбӮўӮМҺw“EӮЖ’щҗіӮМ’ЗүБҒ@3/13)
150 ҒF–јҸМ–ўҗЭ’иҒF2009/03/21(“y) 09:05:22 ID:WrLlCy9u0
ze
151 ҒF–јҸМ–ўҗЭ’иҒF2009/03/30(ҢҺ) 21:28:48 ID:I/tR6wwZO
andoӮіӮс•ңҠҲӢFҠи
152 ҒF–јҸМ–ўҗЭ’иҒF2009/04/09(–Ш) 02:20:23 ID:3pK7bnE+0
m
153 ҒF–јҸМ–ўҗЭ’иҒF2009/04/14(үО) 13:13:55 ID:eBNB2p7K0
IntelҒA“ҜҺРҗ»MLC SSD—pӮМҗ«”\үь‘Pғtғ@Ғ[ғҖғEғFғA
http://pc.watch.impress.co.jp/docs/news/20090414_125340.html
http://pc.watch.impress.co.jp/docs/news/20090414_125340.html
154 ҒF ҒҹILoveinTcg ҒF2009/04/15(җ…) 03:01:43 ID:Oz70AZbE0
ғeғXғg
ҚЎҚX•\ғXғҢӮЙҸгӮӘӮБӮДӮҪҳ_•¶Ӯр“ЗӮсӮҫ....
DX9җў‘гӮМғQҒ[ғҖӮИӮз10ғRғA@1GHzӮЕҸ\•ӘҺА—p“IӮИҠҙӮ¶(7950GTҒ`X1950 XTXҲК?)ӮҫӮӘ.....
ҚЎӮМGPUӮҫӮЖӮЗӮМҲКӮИӮМӮ©ӮӘӮнӮ©ӮзӮЛҒ[Ӯ©ӮзҲУ–ЎӮИӮўӮИ
ӮЬӮ Ғ`LarrabeeӮӘGPUӮЖӮөӮД‘SӮӯҺgӮў•ЁӮЙӮИӮзӮИӮўӮЖӮўӮӨ”ЯҺSӮИҺ–‘ФӮЙӮНӮИӮзӮИӮіӮ°
DX9җў‘гӮМғQҒ[ғҖӮИӮз10ғRғA@1GHzӮЕҸ\•ӘҺА—p“IӮИҠҙӮ¶(7950GTҒ`X1950 XTXҲК?)ӮҫӮӘ.....
ҚЎӮМGPUӮҫӮЖӮЗӮМҲКӮИӮМӮ©ӮӘӮнӮ©ӮзӮЛҒ[Ӯ©ӮзҲУ–ЎӮИӮўӮИ
ӮЬӮ Ғ`LarrabeeӮӘGPUӮЖӮөӮД‘SӮӯҺgӮў•ЁӮЙӮИӮзӮИӮўӮЖӮўӮӨ”ЯҺSӮИҺ–‘ФӮЙӮНӮИӮзӮИӮіӮ°
156 ҒFғ`ғүғVӮМ— 2ҒF2009/04/17(Ӣа) 02:32:49 ID:n0Oo2o+40
ӮсӮЕӮЬӮ LarrabeeӮМҗ«”\ӮрӮаӮҝӮБӮЖӮнӮ©ӮиӮвӮ·ӮӯҢ©җПӮаӮиӮҪӮўӮМӮҫӮӘ
ӮнӮ©ӮБӮДӮйӮМӮН
http://en.wikipedia.org/wiki/Larrabee_(GPU)
>Graphs show how many 1 GHz Larrabee cores are required to maintain 60 FPS at 1600x1200 resolution in several popular games.
>Roughly 25 cores are required for Gears of War with no antialiasing, 25 cores for F.E.A.R with 4x antialiasing, and 10 cores for Half-Life 2: Episode 2 with 4x antialiasing.
ӮжӮӨӮ·ӮйӮЙ
hogeӮЖӮўӮӨғQҒ[ғҖӮр1600x1200 4xAAӮЕ—VӮФҸкҚҮ
xxғRғA@1GHzӮЕҚЕ’бғtғҢҒ[ғҖғҢҒ[ғgӮӘ60ӮЙӮИӮиӮЬӮ·Ӯж
ӮБӮДӮұӮЖ
ӮҫӮӘғrғfғIғJҒ[ғhӮМғҢғrғ…Ғ[ӮЕӮН‘еҠTҚЕ’бғtғҢҒ[ғҖғҢҒ[ғgӮИӮсӮ©‘Ә’иӮөӮДӮИӮў
ҚўӮБӮҪ
Һd•ыӮӘ–іӮўӮ©ӮзғOғүғtӮЙ’иӢKӮр“–ӮДӮД•ҪӢПғtғҢҒ[ғҖғҢҒ[ғgӮрҸoӮөӮДӮЭӮҪ...
//ҚӮҚZӮМ•Ё—қӮЕӮвӮйӮ Ӯк....
ӮЯӮсӮЗӮўӮМӮЕӮвӮйӮМӮНF.E.A.R.ӮҫӮҜӮЙӮөӮжӮӨ....
•ҪӢПғtғҢҒ[ғҖғҢҒ[ғgӮН...114Ӯ®ӮзӮў....Ӯ©?
ӮұӮМ•УӮиӮЖ”дҠrӮөӮДӮЭӮй....
http://pc.watch.impress.co.jp/docs/2008/0707/graph07.htm
Larrabee-25C@1GHzӮНGeforce 9800 GTX+Ӯр–ҫҠmӮЙҸгүсӮйӮҜӮЗGeforce GTX 260ӮЖ”дҠrӮ·ӮйӮЖҸӯӮө—тӮй?
ӮнӮ©ӮБӮДӮйӮМӮН
http://en.wikipedia.org/wiki/Larrabee_(GPU)
>Graphs show how many 1 GHz Larrabee cores are required to maintain 60 FPS at 1600x1200 resolution in several popular games.
>Roughly 25 cores are required for Gears of War with no antialiasing, 25 cores for F.E.A.R with 4x antialiasing, and 10 cores for Half-Life 2: Episode 2 with 4x antialiasing.
ӮжӮӨӮ·ӮйӮЙ
hogeӮЖӮўӮӨғQҒ[ғҖӮр1600x1200 4xAAӮЕ—VӮФҸкҚҮ
xxғRғA@1GHzӮЕҚЕ’бғtғҢҒ[ғҖғҢҒ[ғgӮӘ60ӮЙӮИӮиӮЬӮ·Ӯж
ӮБӮДӮұӮЖ
ӮҫӮӘғrғfғIғJҒ[ғhӮМғҢғrғ…Ғ[ӮЕӮН‘еҠTҚЕ’бғtғҢҒ[ғҖғҢҒ[ғgӮИӮсӮ©‘Ә’иӮөӮДӮИӮў
ҚўӮБӮҪ
Һd•ыӮӘ–іӮўӮ©ӮзғOғүғtӮЙ’иӢKӮр“–ӮДӮД•ҪӢПғtғҢҒ[ғҖғҢҒ[ғgӮрҸoӮөӮДӮЭӮҪ...
//ҚӮҚZӮМ•Ё—қӮЕӮвӮйӮ Ӯк....
ӮЯӮсӮЗӮўӮМӮЕӮвӮйӮМӮНF.E.A.R.ӮҫӮҜӮЙӮөӮжӮӨ....
•ҪӢПғtғҢҒ[ғҖғҢҒ[ғgӮН...114Ӯ®ӮзӮў....Ӯ©?
ӮұӮМ•УӮиӮЖ”дҠrӮөӮДӮЭӮй....
http://pc.watch.impress.co.jp/docs/2008/0707/graph07.htm
Larrabee-25C@1GHzӮНGeforce 9800 GTX+Ӯр–ҫҠmӮЙҸгүсӮйӮҜӮЗGeforce GTX 260ӮЖ”дҠrӮ·ӮйӮЖҸӯӮө—тӮй?
157 ҒF–јҸМ–ўҗЭ’иҒF2009/04/17(Ӣа) 17:47:05 ID:Ar5MVeP50
LarrabeeӮНҗ«”\ӮЕӮИӮӯҒCӮ»ӮМ•\Ң»—НӮЕӢЈӮӨ•ЁӮЙӮИӮйӮҫӮлӮӨҒB
158 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/04/17(Ӣа) 20:28:57 ID:/hlmiwyC0
ҚЕӢЯӮМҺ©Қм”ВӮМ—¬ӮкӮрӮЭӮДӮўӮйӮЖҒA”Ҫ“fӮӘӮЕӮйӮжӮЛҒB
LRBӮМғҠғҠҒ[ғXҲк”NҲИҸг‘OӮМ‘е–{үcғlғ^ӮрҠg‘еүрҺЯӮөӮДҺқӮҝҸгӮ°үЯӮ¬ҒB
–ўӮҫӮЙғ^Ғ[ғQғbғgғNғҚғbғNӮвғRғAҗ”ӮМ‘S–eӮаӮЭӮҰӮИӮўҒB
IDFӮМғEғGғnӮаҺҺҚмҢӨӢҶғ`ғbғvғҢғxғӢӮЕӮІӮЬӮ©ӮөӮДӮДӮа‘S‘RӮЁӮ©ӮөӮ©ӮИӮўӮӘҒB
—бӮМғXғPҒ[ғүғrғҠғeғBӮМғOғүғtӮа–ўӮҫӮЙғVғ~ғ…ғҢҒ[ғVғҮғ“ӮБӮДүәӮЙ’ҚҺЯҸ‘ӮўӮДӮ ӮйӮсӮҫӮҫӮнҒB
ҚЎӮЬӮЕӮіӮсӮҙӮсIntelӮЙ’ЮӮзӮкӮДӮ«ӮҪӮМӮЙ‘SӮӯ”ҪҸИӮӘӮИӮўӮИҒB
ӮЪӮ©ӮөӮД’ЮӮБӮДӮйӮҫӮҜӮМLarrabeeғlғ^ӮН—LҠQӮҫӮЖҺvӮўӮЬӮ·ҒB
GPGPUӮМ‘ОҚR”nӮҫӮБӮДҳb‘иҗ«ӮЖӮиӮҪӮўӮҫӮҜӮҫӮБӮДӮМҒB
HPCӮИӮзӮ»ӮұӮ»ӮұҺgӮҰӮйӮ©ӮаӮөӮкӮсӮӘҒB
LRBӮМғҠғҠҒ[ғXҲк”NҲИҸг‘OӮМ‘е–{үcғlғ^ӮрҠg‘еүрҺЯӮөӮДҺқӮҝҸгӮ°үЯӮ¬ҒB
–ўӮҫӮЙғ^Ғ[ғQғbғgғNғҚғbғNӮвғRғAҗ”ӮМ‘S–eӮаӮЭӮҰӮИӮўҒB
IDFӮМғEғGғnӮаҺҺҚмҢӨӢҶғ`ғbғvғҢғxғӢӮЕӮІӮЬӮ©ӮөӮДӮДӮа‘S‘RӮЁӮ©ӮөӮ©ӮИӮўӮӘҒB
—бӮМғXғPҒ[ғүғrғҠғeғBӮМғOғүғtӮа–ўӮҫӮЙғVғ~ғ…ғҢҒ[ғVғҮғ“ӮБӮДүәӮЙ’ҚҺЯҸ‘ӮўӮДӮ ӮйӮсӮҫӮҫӮнҒB
ҚЎӮЬӮЕӮіӮсӮҙӮсIntelӮЙ’ЮӮзӮкӮДӮ«ӮҪӮМӮЙ‘SӮӯ”ҪҸИӮӘӮИӮўӮИҒB
ӮЪӮ©ӮөӮД’ЮӮБӮДӮйӮҫӮҜӮМLarrabeeғlғ^ӮН—LҠQӮҫӮЖҺvӮўӮЬӮ·ҒB
GPGPUӮМ‘ОҚR”nӮҫӮБӮДҳb‘иҗ«ӮЖӮиӮҪӮўӮҫӮҜӮҫӮБӮДӮМҒB
HPCӮИӮзӮ»ӮұӮ»ӮұҺgӮҰӮйӮ©ӮаӮөӮкӮсӮӘҒB
159 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/04/17(Ӣа) 20:32:09 ID:/hlmiwyC0
ғVғҠғRғ“ӮБӮДӮҫӮҜӮИӮзPolarisӮаӮЖӮБӮӯӮЙғEғGғn“WҺҰӮіӮкӮДӮҪг©ҒB
IDFӮМғEғGғnҒA‘ОҸЫ”z’uӮМPolarisx2ӮвҒABecktonӮЖҸcүЎӮМғ_ғCҢВҗ”ӮӘ“ҜӮ¶ӮИӮМӮаӢCӮЙӮИӮйӮнҒB
IDFӮМғEғGғnҒA‘ОҸЫ”z’uӮМPolarisx2ӮвҒABecktonӮЖҸcүЎӮМғ_ғCҢВҗ”ӮӘ“ҜӮ¶ӮИӮМӮаӢCӮЙӮИӮйӮнҒB
160 ҒF–јҸМ–ўҗЭ’иҒF2009/04/17(Ӣа) 21:00:03 ID:owdxAf6k0
>–ўӮҫӮЙғ^Ғ[ғQғbғgғNғҚғbғNӮвғRғAҗ”ӮМ‘S–eӮаӮЭӮҰӮИӮўҒB
IntelӮӘғ_ғ“ғ}ғҠҢҲӮЯҚһӮсӮЕӮўӮйӮМӮҫӮ©Ӯз“–ӮҪӮи‘OҒB
>IDFӮМғEғGғnӮаҺҺҚмҢӨӢҶғ`ғbғvғҢғxғӢӮЕӮІӮЬӮ©ӮөӮДӮДӮа‘S‘RӮЁӮ©ӮөӮ©ӮИӮўӮӘҒB
IDFӮЕғEғFғnӮЖ—КҺYҠJҺnҺһҠъӮӘҸoӮй‘OӮНӮұӮсӮИӮұӮЖҢҫӮБӮДӮйӮМӮЙҒB
668 –ј‘OҒF---Ғј(ҒLҒНҒM’UҒјҒҷж|Қк[sage] “ҠҚe“ъҒF2009/03/27(Ӣа) 21:18:08 ID:N+VRP1rM
http://game.watch.impress.co.jp/docs/series/3dcg/20090325_79920.html
Ңг“ЎӮ¶ӮбӮИӮўӮҜӮЗҒALarrabeeӮБӮДӮЬӮҫғҠғҠҒ[ғXҺһҠъ–ў’иӮвӮБӮДӮсӮМ?
Һё”sҚмӮМ—\ҠҙӮӘӮөӮДӮ«ӮҪҒB
>Ҡъ‘ТӮіӮкӮДӮўӮйҒAҒuGPUғLғүҒ[ҒvӮМҲЩ–јӮрҺжӮйIntelӮМCPU/GPUғnғCғuғҠғbғhғvғҚғZғbғT
>ҒuLarrabeeҒvӮаDirectX 11ӮЙ‘ОүһӮ·ӮйӮЖҢ©ӮзӮкӮйӮӘҒAӮұӮҝӮзӮағҠғҠҒ[ғXҺһҠъӮН•s“§–ҫӮҫҒB
>ӮИӮЁҒALarrabeeӮЙӮВӮўӮДӮНҒAGDC2009үпҠъ’ҶӮЙҠЦҳAғZғbғVғҮғ“ӮЙӮВӮўӮДғҢғ|Ғ[ғgӮ·Ӯй—\’иӮИӮМӮЕҒA
>‘ұ•сӮЙҠъ‘ТӮөӮДӮўӮҪӮҫӮ«ӮҪӮўҒB
>—бӮМғXғPҒ[ғүғrғҠғeғBӮМғOғүғtӮа–ўӮҫӮЙғVғ~ғ…ғҢҒ[ғVғҮғ“ӮБӮДүәӮЙ’ҚҺЯҸ‘ӮўӮДӮ ӮйӮсӮҫӮҫӮнҒB
ғXғүғCғhҺgӮўүсӮөӮИӮсӮД“БӮЙ’ҝӮөӮӯӮаүҪӮЖӮа–іӮўҒB
>ғVғҠғRғ“ӮБӮДӮҫӮҜӮИӮзPolarisӮаӮЖӮБӮӯӮЙғEғGғn“WҺҰӮіӮкӮДӮҪг©ҒB
x86ӮЕӮНӮИӮў”сҸӨ—pӮМғ`ғbғvӮӘүҪӮ©ҒH
>IDFӮМғEғGғnҒA‘ОҸЫ”z’uӮМPolarisx2ӮвҒABecktonӮЖҸcүЎӮМғ_ғCҢВҗ”ӮӘ“ҜӮ¶ӮИӮМӮаӢCӮЙӮИӮйӮнҒB
•aү@җАӮҜҒB
IntelӮӘғ_ғ“ғ}ғҠҢҲӮЯҚһӮсӮЕӮўӮйӮМӮҫӮ©Ӯз“–ӮҪӮи‘OҒB
>IDFӮМғEғGғnӮаҺҺҚмҢӨӢҶғ`ғbғvғҢғxғӢӮЕӮІӮЬӮ©ӮөӮДӮДӮа‘S‘RӮЁӮ©ӮөӮ©ӮИӮўӮӘҒB
IDFӮЕғEғFғnӮЖ—КҺYҠJҺnҺһҠъӮӘҸoӮй‘OӮНӮұӮсӮИӮұӮЖҢҫӮБӮДӮйӮМӮЙҒB
668 –ј‘OҒF---Ғј(ҒLҒНҒM’UҒјҒҷж|Қк[sage] “ҠҚe“ъҒF2009/03/27(Ӣа) 21:18:08 ID:N+VRP1rM
http://game.watch.impress.co.jp/docs/series/3dcg/20090325_79920.html
Ңг“ЎӮ¶ӮбӮИӮўӮҜӮЗҒALarrabeeӮБӮДӮЬӮҫғҠғҠҒ[ғXҺһҠъ–ў’иӮвӮБӮДӮсӮМ?
Һё”sҚмӮМ—\ҠҙӮӘӮөӮДӮ«ӮҪҒB
>Ҡъ‘ТӮіӮкӮДӮўӮйҒAҒuGPUғLғүҒ[ҒvӮМҲЩ–јӮрҺжӮйIntelӮМCPU/GPUғnғCғuғҠғbғhғvғҚғZғbғT
>ҒuLarrabeeҒvӮаDirectX 11ӮЙ‘ОүһӮ·ӮйӮЖҢ©ӮзӮкӮйӮӘҒAӮұӮҝӮзӮағҠғҠҒ[ғXҺһҠъӮН•s“§–ҫӮҫҒB
>ӮИӮЁҒALarrabeeӮЙӮВӮўӮДӮНҒAGDC2009үпҠъ’ҶӮЙҠЦҳAғZғbғVғҮғ“ӮЙӮВӮўӮДғҢғ|Ғ[ғgӮ·Ӯй—\’иӮИӮМӮЕҒA
>‘ұ•сӮЙҠъ‘ТӮөӮДӮўӮҪӮҫӮ«ӮҪӮўҒB
>—бӮМғXғPҒ[ғүғrғҠғeғBӮМғOғүғtӮа–ўӮҫӮЙғVғ~ғ…ғҢҒ[ғVғҮғ“ӮБӮДүәӮЙ’ҚҺЯҸ‘ӮўӮДӮ ӮйӮсӮҫӮҫӮнҒB
ғXғүғCғhҺgӮўүсӮөӮИӮсӮД“БӮЙ’ҝӮөӮӯӮаүҪӮЖӮа–іӮўҒB
>ғVғҠғRғ“ӮБӮДӮҫӮҜӮИӮзPolarisӮаӮЖӮБӮӯӮЙғEғGғn“WҺҰӮіӮкӮДӮҪг©ҒB
x86ӮЕӮНӮИӮў”сҸӨ—pӮМғ`ғbғvӮӘүҪӮ©ҒH
>IDFӮМғEғGғnҒA‘ОҸЫ”z’uӮМPolarisx2ӮвҒABecktonӮЖҸcүЎӮМғ_ғCҢВҗ”ӮӘ“ҜӮ¶ӮИӮМӮаӢCӮЙӮИӮйӮнҒB
•aү@җАӮҜҒB
161 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/04/17(Ӣа) 21:06:30 ID:/hlmiwyC0
>ғ_ғ“ғ}ғҠҢҲӮЯҚһӮсӮЕӮўӮйӮМӮҫӮ©Ӯз“–ӮҪӮи‘OҒB
IntelӮНҗ«”\Ӯрҗ„‘ӘӮіӮкӮйӮЖ•s–ЎӮўӮ©ӮзӮнӮҙӮЖҗ«”\ӮӘ—Юҗ„ӮіӮкӮйӮжӮӨӮИҸо•сӮН
‘SӮДүB•БӮөӮДӮўӮйӮМӮҫӮжҒBғRғAҗ”ӮвғNғҚғbғNӮҫӮҜӮ¶ӮбӮИӮӯӮДӮЛҒB
>IDFӮЕғEғFғnӮЖ—КҺYҠJҺnҺһҠъӮӘҸoӮй‘OӮНӮұӮсӮИӮұӮЖҢҫӮБӮДӮйӮМӮЙҒB
Ӯ»ӮМҸ‘Ӯ«ҚһӮЭӮӘӮЗӮӨӮ©ӮөӮҪӮ©?
ғҠғҠҒ[ғXҺһҠъӮЙҢҲ’и“IӮИҸо•сӮН–ўӮҫӮЙҸoӮДӮИӮўӮјҒB
2009”N––Ӯ©Ӯз2010”N“ӘӮИӮсӮДӮЖӮиӮ ӮҰӮё“ҰӮ°ҢыҗчӮБӮДӮЭӮҪӮҫӮҜӮМғҢғxғӢӮҫҒB
ҢіӮН2008”NҒ`2009“ӘӮЖӮ©Ӯ»ӮсӮИӮаӮсӮҫӮБӮҪӮӘҒBғӢҒ[ғ}Ғ[ҸүҗSҺТҢNӮжҒB
GPUӮМҗўҠEӮЕ1”NӮа’xӮкӮҪӮзҺҖӮсӮҫӮа“Ҝ‘RӮМ•іғ`ғbғvӮЕӮ·ӮжҒB
>ғVғҠғRғ“ӮБӮДӮҫӮҜӮИӮзPolarisӮаӮЖӮБӮӯӮЙғEғGғn“WҺҰӮіӮкӮДӮҪг©ҒB
>x86ӮЕӮНӮИӮў”сҸӨ—pӮМғ`ғbғvӮӘүҪӮ©ҒH
ҲУ–ЎӮнӮ©ӮБӮДӮЛҒ[ӮМӮЙғҢғXӮВӮҜӮсӮИҒB
ҺҺҚмҢӨӢҶғҢғxғӢӮЕӮағEғGғAӢNӮұӮ·ӮсӮҫӮ©ӮзҒA‘гӮнӮиӮЙLRBӮМҢӨӢҶӮЖҸМӮөӮД
ғEғGғAӮЭӮ№ӮйӮӯӮзӮўӮН•Ғ’КӮЙӮ ӮиӮӨӮйҒB
>IDFӮМғEғGғnҒA‘ОҸЫ”z’uӮМPolarisx2ӮвҒABecktonӮЖҸcүЎӮМғ_ғCҢВҗ”ӮӘ“ҜӮ¶ӮИӮМӮаӢCӮЙӮИӮйӮнҒB
>•aү@җАӮҜ
–і’mӮНҸБӮҰӮл(ӮнӮзӮЎ
IntelӮНҗ«”\Ӯрҗ„‘ӘӮіӮкӮйӮЖ•s–ЎӮўӮ©ӮзӮнӮҙӮЖҗ«”\ӮӘ—Юҗ„ӮіӮкӮйӮжӮӨӮИҸо•сӮН
‘SӮДүB•БӮөӮДӮўӮйӮМӮҫӮжҒBғRғAҗ”ӮвғNғҚғbғNӮҫӮҜӮ¶ӮбӮИӮӯӮДӮЛҒB
>IDFӮЕғEғFғnӮЖ—КҺYҠJҺnҺһҠъӮӘҸoӮй‘OӮНӮұӮсӮИӮұӮЖҢҫӮБӮДӮйӮМӮЙҒB
Ӯ»ӮМҸ‘Ӯ«ҚһӮЭӮӘӮЗӮӨӮ©ӮөӮҪӮ©?
ғҠғҠҒ[ғXҺһҠъӮЙҢҲ’и“IӮИҸо•сӮН–ўӮҫӮЙҸoӮДӮИӮўӮјҒB
2009”N––Ӯ©Ӯз2010”N“ӘӮИӮсӮДӮЖӮиӮ ӮҰӮё“ҰӮ°ҢыҗчӮБӮДӮЭӮҪӮҫӮҜӮМғҢғxғӢӮҫҒB
ҢіӮН2008”NҒ`2009“ӘӮЖӮ©Ӯ»ӮсӮИӮаӮсӮҫӮБӮҪӮӘҒBғӢҒ[ғ}Ғ[ҸүҗSҺТҢNӮжҒB
GPUӮМҗўҠEӮЕ1”NӮа’xӮкӮҪӮзҺҖӮсӮҫӮа“Ҝ‘RӮМ•іғ`ғbғvӮЕӮ·ӮжҒB
>ғVғҠғRғ“ӮБӮДӮҫӮҜӮИӮзPolarisӮаӮЖӮБӮӯӮЙғEғGғn“WҺҰӮіӮкӮДӮҪг©ҒB
>x86ӮЕӮНӮИӮў”сҸӨ—pӮМғ`ғbғvӮӘүҪӮ©ҒH
ҲУ–ЎӮнӮ©ӮБӮДӮЛҒ[ӮМӮЙғҢғXӮВӮҜӮсӮИҒB
ҺҺҚмҢӨӢҶғҢғxғӢӮЕӮағEғGғAӢNӮұӮ·ӮсӮҫӮ©ӮзҒA‘гӮнӮиӮЙLRBӮМҢӨӢҶӮЖҸМӮөӮД
ғEғGғAӮЭӮ№ӮйӮӯӮзӮўӮН•Ғ’КӮЙӮ ӮиӮӨӮйҒB
>IDFӮМғEғGғnҒA‘ОҸЫ”z’uӮМPolarisx2ӮвҒABecktonӮЖҸcүЎӮМғ_ғCҢВҗ”ӮӘ“ҜӮ¶ӮИӮМӮаӢCӮЙӮИӮйӮнҒB
>•aү@җАӮҜ
–і’mӮНҸБӮҰӮл(ӮнӮзӮЎ
162 ҒF–јҸМ–ўҗЭ’иҒF2009/04/17(Ӣа) 21:18:20 ID:owdxAf6k0
>ғҠғҠҒ[ғXҺһҠъӮЙҢҲ’и“IӮИҸо•сӮН–ўӮҫӮЙҸoӮДӮИӮўӮјҒB
>2009”N––Ӯ©Ӯз2010”N“ӘӮИӮсӮДӮЖӮиӮ ӮҰӮё“ҰӮ°ҢыҗчӮБӮДӮЭӮҪӮҫӮҜӮМғҢғxғӢӮҫҒB
ҠъҠФӮЙ’јӮ№ӮО3ғ–ҢҺ’ц“xҒBӮұӮкҲИҸгҚЧӮ©Ӯў—ұ“xӮЕҺһҠъӮрҺw’иӮ·ӮйӮЖӮ©Ӯ»ӮӨӮ»ӮӨ–іӮўӮ©ӮзҒB
>ҢіӮН2008”NҒ`2009“ӘӮЖӮ©Ӯ»ӮсӮИӮаӮсӮҫӮБӮҪӮӘҒBғӢҒ[ғ}Ғ[ҸүҗSҺТҢNӮжҒB
>GPUӮМҗўҠEӮЕ1”NӮа’xӮкӮҪӮзҺҖӮсӮҫӮа“Ҝ‘RӮМ•іғ`ғbғvӮЕӮ·ӮжҒB
ғӢҒ[ғ}Ғ[ҸгӢүҺТӮМ•ыӮНLarrabeeӮМғRғAҗ”ӮЙҠЦӮ·Ӯйү\ӮӘҒA
16Ғ`24, 24Ғ`32, 48ӮЖ(ҲҪӮўӮНӮаӮБӮЖ‘Ҫ—lӮЙ)•Пү»ӮөӮДӮўӮйӮұӮЖӮр’mӮзӮИӮўӮМӮЕӮ·ӮЛҒB
2008”NҒ`2009“ӘӮЙ—\’иӮөӮДӮўӮҪҺd—lӮЕ“oҸкӮ·ӮйӮЖҺvӮБӮДӮўӮйӮМӮЕӮ·ӮЛҒB
>ҺҺҚмҢӨӢҶғҢғxғӢӮЕӮағEғGғAӢNӮұӮ·ӮсӮҫӮ©ӮзҒA‘гӮнӮиӮЙLRBӮМҢӨӢҶӮЖҸМӮөӮД
>ғEғGғAӮЭӮ№ӮйӮӯӮзӮўӮН•Ғ’КӮЙӮ ӮиӮӨӮйҒB
ғnғCғGғ“ғhҢьӮҜҗ»•iӮМғEғFғnӮҫӮЖCEOӮӘ–ҫӮ©ӮөӮҪӮОӮ©ӮиҒB
ғӢҒ[ғ}Ғ[ӮОӮБӮ©Ӯ¶ӮбӮИӮӯӮДӮҪӮЬӮЙӮНҚа–ұӮМӢLҺ–Ӯа“ЗӮЯҒB
>2009”N––Ӯ©Ӯз2010”N“ӘӮИӮсӮДӮЖӮиӮ ӮҰӮё“ҰӮ°ҢыҗчӮБӮДӮЭӮҪӮҫӮҜӮМғҢғxғӢӮҫҒB
ҠъҠФӮЙ’јӮ№ӮО3ғ–ҢҺ’ц“xҒBӮұӮкҲИҸгҚЧӮ©Ӯў—ұ“xӮЕҺһҠъӮрҺw’иӮ·ӮйӮЖӮ©Ӯ»ӮӨӮ»ӮӨ–іӮўӮ©ӮзҒB
>ҢіӮН2008”NҒ`2009“ӘӮЖӮ©Ӯ»ӮсӮИӮаӮсӮҫӮБӮҪӮӘҒBғӢҒ[ғ}Ғ[ҸүҗSҺТҢNӮжҒB
>GPUӮМҗўҠEӮЕ1”NӮа’xӮкӮҪӮзҺҖӮсӮҫӮа“Ҝ‘RӮМ•іғ`ғbғvӮЕӮ·ӮжҒB
ғӢҒ[ғ}Ғ[ҸгӢүҺТӮМ•ыӮНLarrabeeӮМғRғAҗ”ӮЙҠЦӮ·Ӯйү\ӮӘҒA
16Ғ`24, 24Ғ`32, 48ӮЖ(ҲҪӮўӮНӮаӮБӮЖ‘Ҫ—lӮЙ)•Пү»ӮөӮДӮўӮйӮұӮЖӮр’mӮзӮИӮўӮМӮЕӮ·ӮЛҒB
2008”NҒ`2009“ӘӮЙ—\’иӮөӮДӮўӮҪҺd—lӮЕ“oҸкӮ·ӮйӮЖҺvӮБӮДӮўӮйӮМӮЕӮ·ӮЛҒB
>ҺҺҚмҢӨӢҶғҢғxғӢӮЕӮағEғGғAӢNӮұӮ·ӮсӮҫӮ©ӮзҒA‘гӮнӮиӮЙLRBӮМҢӨӢҶӮЖҸМӮөӮД
>ғEғGғAӮЭӮ№ӮйӮӯӮзӮўӮН•Ғ’КӮЙӮ ӮиӮӨӮйҒB
ғnғCғGғ“ғhҢьӮҜҗ»•iӮМғEғFғnӮҫӮЖCEOӮӘ–ҫӮ©ӮөӮҪӮОӮ©ӮиҒB
ғӢҒ[ғ}Ғ[ӮОӮБӮ©Ӯ¶ӮбӮИӮӯӮДӮҪӮЬӮЙӮНҚа–ұӮМӢLҺ–Ӯа“ЗӮЯҒB
163 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/04/17(Ӣа) 21:22:46 ID:/hlmiwyC0
ӮЬӮ ҒAӮЁӮкӮНҢӢүКҸҹ•үӮҫӮ©Ӯз•КӮЙ1–ј–іӮөӮЖӮМӢcҳ_ӮМҚsӮӯ––ӮИӮсӮДӮЗӮӨӮЕӮаӮўӮўӮӘӮЛҒB
ғӮғmӮӘҸoӮДӮЭӮДӮ©ӮзҚДӮСҲУҢ©ӮИӮиҠҙ‘zӮИӮиӮрҸ‘Ӯ«ҚһӮсӮЕӮӯӮкӮвҒB
IntelҺҹҗў‘гCPUғXғҢӮНPrescottҲИ‘OӮМ–П‘zғӮҒ[ғhӮЙ–ЯӮиӮВӮВӮ ӮйӮ©ӮИҒB
ғӮғmӮӘҸoӮДӮЭӮДӮ©ӮзҚДӮСҲУҢ©ӮИӮиҠҙ‘zӮИӮиӮрҸ‘Ӯ«ҚһӮсӮЕӮӯӮкӮвҒB
IntelҺҹҗў‘гCPUғXғҢӮНPrescottҲИ‘OӮМ–П‘zғӮҒ[ғhӮЙ–ЯӮиӮВӮВӮ ӮйӮ©ӮИҒB
164 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/04/17(Ӣа) 21:25:27 ID:/hlmiwyC0
ӮЖӮ©ӮўӮБӮДӮйӮЖғӮғmӮӘӮЕӮДӮұӮИӮўӮЬӮЬҒAғvғҚғWғFғNғgӮӘӮ ӮЪҒ`ӮсӮөӮДӮЭӮҪӮиҒB
165 ҒF–јҸМ–ўҗЭ’иҒF2009/04/17(Ӣа) 23:54:29 ID:AKJLBmHI0
LarrabeeӮЙҚЕ“Kү»ӮөӮҪҒiPixomaticҒ{ҒjQuakeӮЕ
Ҹ]—ҲӮМx86CPUҒiC2QҒAi7“ҷҒjӮЕ‘–ӮзӮ№ӮҪҺһӮЖ”дҠrӮөӮДLarrabeeӮНӮұӮсӮИӮЙ‘¬ӮўҒI
ӮЖӮўӮӨғfғӮғ“ғXғgғҢҒ[ғVғҮғ“ӮрҺҹӮМIDFӮЕӮ©ӮЬӮөӮДҚJӮМҺёҸОӮр”ғӮӨ—\’и
Ҹ]—ҲӮМx86CPUҒiC2QҒAi7“ҷҒjӮЕ‘–ӮзӮ№ӮҪҺһӮЖ”дҠrӮөӮДLarrabeeӮНӮұӮсӮИӮЙ‘¬ӮўҒI
ӮЖӮўӮӨғfғӮғ“ғXғgғҢҒ[ғVғҮғ“ӮрҺҹӮМIDFӮЕӮ©ӮЬӮөӮДҚJӮМҺёҸОӮр”ғӮӨ—\’и
166 ҒFғ`ғүғVӮМ— 3 >>155-156ҒF2009/04/18(“y) 00:40:37 ID:biOfv1gm0
F.E.A.R.ӮҫӮҜӮБӮДӮМӮа–ЎӢCӮИӮўӮМӮЕӮвӮБӮПӮиHalf Life 2 episode 2Ӯа’иӢKӮЕ‘ӘӮБӮДӮЭӮй....
•ҪӢПғtғҢҒ[ғҖғҢҒ[ғgӮН78Ӯ®ӮзӮў....?
ӮұӮМ•УӮиӮЖ”дҠrӮөӮДӮЭӮй....
http://pc.watch.impress.co.jp/docs/2008/0910/graph11.gif
Larrabee-10C@1GHzӮНRadeon HD 4670ӮЖӮНӮўӮўҸҹ•үӮҫӮҜӮЗGeforce 9600 GTӮЖӮНӢЈҚҮӮЕӮ«ӮИӮў?
//’NӮаӢҸӮИӮўӮЖҺvӮБӮДӮўӮҪӮзӮИӮсӮ©җLӮСӮДӮДӢБӮўӮҪ...
//
//—L–јӮИҢЕ’иӮіӮсӮӘӮ«ӮДӮҪӮМӮ©ӮөӮз.....
•ҪӢПғtғҢҒ[ғҖғҢҒ[ғgӮН78Ӯ®ӮзӮў....?
ӮұӮМ•УӮиӮЖ”дҠrӮөӮДӮЭӮй....
http://pc.watch.impress.co.jp/docs/2008/0910/graph11.gif
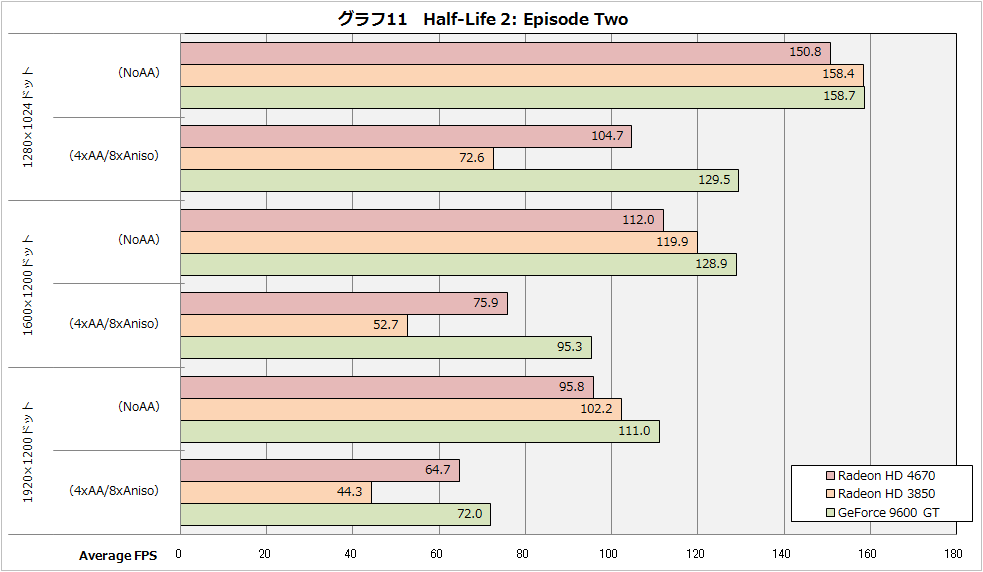{kind=link}
Larrabee-10C@1GHzӮНRadeon HD 4670ӮЖӮНӮўӮўҸҹ•үӮҫӮҜӮЗGeforce 9600 GTӮЖӮНӢЈҚҮӮЕӮ«ӮИӮў?
//’NӮаӢҸӮИӮўӮЖҺvӮБӮДӮўӮҪӮзӮИӮсӮ©җLӮСӮДӮДӢБӮўӮҪ...
//
//—L–јӮИҢЕ’иӮіӮсӮӘӮ«ӮДӮҪӮМӮ©ӮөӮз.....
167 ҒFғ`ғүғVӮМ— 4ҒF2009/04/18(“y) 00:49:36 ID:biOfv1gm0
ӮЬӮЖӮЯӮДӮЭӮй
//җ«”\ӮӘҚӮӮўҸҮӮЙғ\Ғ[ғg
F.E.A.R.
Geforce GTX 260 Ғ@ Ғ@ Ғ@715 GFlops
Radeon HD 4870 Ғ@ Ғ@ Ғ@ 1200 GFlops
Larrebee-25C@1GHzҒ@Ғ@800 GFlops
ҒӘ–ҫҠmӮИҚ·ҲЩҒ«
Geforce 9800 GTX +Ғ@ Ғ@705 GFlops
Radeon HD 4850Ғ@Ғ@Ғ@ Ғ@ 1000 GFlops
Half Life 2 episode 2
Geforce 9600 GTҒ@Ғ@Ғ@Ғ@ 208 GFlops
ҒӘ–ҫҠmӮИҚ·ҲЩҒ«
Larrebee-10C@1GHzҒ@Ғ@320 GFlops
Radeon HD 4670 Ғ@ Ғ@ Ғ@ 480 GFlops
GPUӮМҗ«”\ӮӘ2”NӮЕ3”{ӮЙӮИӮйӮЖүј’иӮөӮҪҸкҚҮ...
ғnғCғGғ“ғh Larrebee-40C@2GHzҒ@Ғ@ғ~ғbғhғҢғ“ғW Larrebee-16C@2GHz
ӮұӮМӮ®ӮзӮўӮЕҸoӮ№ӮОx86 many-coreӮНGPUӮЖӮөӮДӮа•Ғ’КӮЙӢЈ‘Ҳ—НӮрҺқӮДӮйӮНӮё.....
//җ«”\ӮӘҚӮӮўҸҮӮЙғ\Ғ[ғg
F.E.A.R.
Geforce GTX 260 Ғ@ Ғ@ Ғ@715 GFlops
Radeon HD 4870 Ғ@ Ғ@ Ғ@ 1200 GFlops
Larrebee-25C@1GHzҒ@Ғ@800 GFlops
ҒӘ–ҫҠmӮИҚ·ҲЩҒ«
Geforce 9800 GTX +Ғ@ Ғ@705 GFlops
Radeon HD 4850Ғ@Ғ@Ғ@ Ғ@ 1000 GFlops
Half Life 2 episode 2
Geforce 9600 GTҒ@Ғ@Ғ@Ғ@ 208 GFlops
ҒӘ–ҫҠmӮИҚ·ҲЩҒ«
Larrebee-10C@1GHzҒ@Ғ@320 GFlops
Radeon HD 4670 Ғ@ Ғ@ Ғ@ 480 GFlops
GPUӮМҗ«”\ӮӘ2”NӮЕ3”{ӮЙӮИӮйӮЖүј’иӮөӮҪҸкҚҮ...
ғnғCғGғ“ғh Larrebee-40C@2GHzҒ@Ғ@ғ~ғbғhғҢғ“ғW Larrebee-16C@2GHz
ӮұӮМӮ®ӮзӮўӮЕҸoӮ№ӮОx86 many-coreӮНGPUӮЖӮөӮДӮа•Ғ’КӮЙӢЈ‘Ҳ—НӮрҺқӮДӮйӮНӮё.....
168 ҒF–јҸМ–ўҗЭ’иҒF2009/04/18(“y) 01:10:42 ID:biOfv1gm0
x Larrebee
Ғӣ Larrabee
Ғӣ Larrabee
169 ҒFғ`ғүғVӮМ— 5ҒF2009/04/19(“ъ) 01:55:39 ID:PYj8khDY0
ҚXӮЙҚЎҚXӮМҳbӮр‘ұӮҜӮй...
ӮЗӮӨӮвӮзLarrabeeӮМғOғүғtғBғbғNғXғpғCғvғүғCғ“ӮН“Б’иӮМAPIӮЙҲЛӢ’ӮөӮИӮўӮзӮөӮў....
DirectXӮЕӮаOpenGLӮЕӮаҸ‘ӮҜӮйӮӘ•Ғ’КӮМC++ӮЕҸ‘ӮҜӮйӮжӮӨӮҫ....
–еҠOҠҝӮИӮМӮЕDirectXӮвOpenGLӮ¶ӮбӮИӮӯӮДC++ӮҫӮЖӢп‘М“IӮЙүҪӮӘҠрӮөӮўӮМӮ©ӮнӮ©ӮзӮИӮўӮӘ•\Ң»—НӮӘ‘қӮ·ӮзӮөӮў....
•Ё—қүүҺZӮвғҠғAғӢғ^ғCғҖғҢғCғgғҢҒ[ғVғ“ғOӮрҠЬӮЮҺҹҗў‘гӮМғQҒ[ғҖғGғ“ғWғ“....
ӮВӮЬӮи”Д—pғvғҚғZғbғVғ“ғOӮЖӢҢ—Ҳ“IӮИғOғүғtғBғbғNғXғvғҚғZғbғVғ“ғOӮЖғVҒ[ғҖғҢғXӮИҠJ”ӯҠВӢ«....?
ӮжӮӯӮнӮ©ӮзӮсӮұӮЖӮНүЎӮЙ’uӮўӮДҚlӮҰӮй....ӮЖӮиӮ ӮҰӮёIntelғcҒ[ғӢӮН–Ј—Н“IӮЙҢ©ӮҰӮй
“БӮЙThreading Building BlocksӮЙӮжӮйғXғPҒ[ғүғrғҠғeғBӮМҠm•ЫӮНғRҒ[ғhӮМҺ‘ҺYүҝ’lӮрҲшӮ«ҸгӮ°ӮйӮҫӮлӮӨ....
ӮұӮкӮЖCtӮМҸo—ҲӮНIntelӮМҸ«—ҲӮрҚ¶үEӮ·ӮйӮЖҺvӮБӮДӮўӮй....ҢВҗl“IӮЙ
ӮИӮсӮҫӮ©ӮұӮМӢLҺ–ӮЭӮҪӮўӮИ“а—eӮЙӮИӮБӮДӮөӮЬӮБӮҪ...
http://pc.watch.impress.co.jp/docs/2008/1225/kaigai482.htm
ӮЗӮӨӮвӮзLarrabeeӮМғOғүғtғBғbғNғXғpғCғvғүғCғ“ӮН“Б’иӮМAPIӮЙҲЛӢ’ӮөӮИӮўӮзӮөӮў....
DirectXӮЕӮаOpenGLӮЕӮаҸ‘ӮҜӮйӮӘ•Ғ’КӮМC++ӮЕҸ‘ӮҜӮйӮжӮӨӮҫ....
–еҠOҠҝӮИӮМӮЕDirectXӮвOpenGLӮ¶ӮбӮИӮӯӮДC++ӮҫӮЖӢп‘М“IӮЙүҪӮӘҠрӮөӮўӮМӮ©ӮнӮ©ӮзӮИӮўӮӘ•\Ң»—НӮӘ‘қӮ·ӮзӮөӮў....
•Ё—қүүҺZӮвғҠғAғӢғ^ғCғҖғҢғCғgғҢҒ[ғVғ“ғOӮрҠЬӮЮҺҹҗў‘гӮМғQҒ[ғҖғGғ“ғWғ“....
ӮВӮЬӮи”Д—pғvғҚғZғbғVғ“ғOӮЖӢҢ—Ҳ“IӮИғOғүғtғBғbғNғXғvғҚғZғbғVғ“ғOӮЖғVҒ[ғҖғҢғXӮИҠJ”ӯҠВӢ«....?
ӮжӮӯӮнӮ©ӮзӮсӮұӮЖӮНүЎӮЙ’uӮўӮДҚlӮҰӮй....ӮЖӮиӮ ӮҰӮёIntelғcҒ[ғӢӮН–Ј—Н“IӮЙҢ©ӮҰӮй
“БӮЙThreading Building BlocksӮЙӮжӮйғXғPҒ[ғүғrғҠғeғBӮМҠm•ЫӮНғRҒ[ғhӮМҺ‘ҺYүҝ’lӮрҲшӮ«ҸгӮ°ӮйӮҫӮлӮӨ....
ӮұӮкӮЖCtӮМҸo—ҲӮНIntelӮМҸ«—ҲӮрҚ¶үEӮ·ӮйӮЖҺvӮБӮДӮўӮй....ҢВҗl“IӮЙ
ӮИӮсӮҫӮ©ӮұӮМӢLҺ–ӮЭӮҪӮўӮИ“а—eӮЙӮИӮБӮДӮөӮЬӮБӮҪ...
http://pc.watch.impress.co.jp/docs/2008/1225/kaigai482.htm
170 ҒF–јҸМ–ўҗЭ’иҒF2009/04/19(“ъ) 02:29:00 ID:6UwP81XE0
P54CӮМ•\Ң»—НӮЙӮІҠъ‘Т
171 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/04/21(үО) 05:34:45 ID:K7yh5+Kd0
P54CӮМҢ»–рҺһ‘гӮЙӮНҠщӮЙҺ––ұҸҲ—қҒiҗ®җ”үүҺZҒjӮМPentiumҒA
ғAҒ[ғgҒi•Ӯ“®Ҹ¬җ”ҒjӮМPowerPCҒiMacҒjӮИӮсӮДҢҫӮнӮкӮДӮҪӮӘӮИҒB
җӮ’ј•ыҢьӮМүүҺZ–§“xӮМҚӮӮіӮНCISCӮМҒyҗ«”\–КӮЕӮМҒzғAғhғoғ“ғeҒ[ғWӮЕӮ·ӮжҒB
Ҳк•ыҒA•Ӯ“®Ҹ¬җ”ӮӘӮУӮйӮнӮИӮ©ӮБӮҪӮМӮНӮ»ӮкӮұӮ»ғXғ^ғbғNғ}ғVғ“ғxҒ[ғXӮМISAӮҫӮБӮҪӮ©ӮзҒA
ӮұӮкӮЙҗsӮ«ӮйӮМӮҫӮӘҒALarrabeeӮЕӮН512ғrғbғgӮМSIMDғҢғWғXғ^32–{ӮЖҒAғCғ“ғIҒ[ғ_ҒE2issueӮМғRғAӮЖӮөӮДӮН
ғpғҸҒ[ғoғүғ“ғX•цүуӢүӮМҗ~җ«”\ӮрҢЦӮиӮЬӮ·ҒB
ӮДӮ©ҒAӮұӮкGPUӮҫӮЖҺvӮӨҒH
GPUӮЕ‘Ҫ”{’·үүҺZӮЖӮ©‘Ҫ—pӮ·ӮйӮжӮӨӮИ•Ә–мӮН’mӮзӮИӮўӮжҒB
ӮұӮкӮНӮЬӮҝӮӘӮўӮИӮӯGPUӮЕӮ ӮйҲИ‘OӮЙғXғpғRғ“ҢьӮҜғAғNғZғүғҢҒ[ғ^ҒB
ғgғbғv500үЗҗиҸу‘ФӮрҠ®җ¬ӮіӮ№Ӯй–м–]ӮМӮҪӮЯӮЙӮ ӮйӮжӮӨӮИғvғҚғZғbғTҒB
ғAҒ[ғgҒi•Ӯ“®Ҹ¬җ”ҒjӮМPowerPCҒiMacҒjӮИӮсӮДҢҫӮнӮкӮДӮҪӮӘӮИҒB
җӮ’ј•ыҢьӮМүүҺZ–§“xӮМҚӮӮіӮНCISCӮМҒyҗ«”\–КӮЕӮМҒzғAғhғoғ“ғeҒ[ғWӮЕӮ·ӮжҒB
Ҳк•ыҒA•Ӯ“®Ҹ¬җ”ӮӘӮУӮйӮнӮИӮ©ӮБӮҪӮМӮНӮ»ӮкӮұӮ»ғXғ^ғbғNғ}ғVғ“ғxҒ[ғXӮМISAӮҫӮБӮҪӮ©ӮзҒA
ӮұӮкӮЙҗsӮ«ӮйӮМӮҫӮӘҒALarrabeeӮЕӮН512ғrғbғgӮМSIMDғҢғWғXғ^32–{ӮЖҒAғCғ“ғIҒ[ғ_ҒE2issueӮМғRғAӮЖӮөӮДӮН
ғpғҸҒ[ғoғүғ“ғX•цүуӢүӮМҗ~җ«”\ӮрҢЦӮиӮЬӮ·ҒB
ӮДӮ©ҒAӮұӮкGPUӮҫӮЖҺvӮӨҒH
GPUӮЕ‘Ҫ”{’·үүҺZӮЖӮ©‘Ҫ—pӮ·ӮйӮжӮӨӮИ•Ә–мӮН’mӮзӮИӮўӮжҒB
ӮұӮкӮНӮЬӮҝӮӘӮўӮИӮӯGPUӮЕӮ ӮйҲИ‘OӮЙғXғpғRғ“ҢьӮҜғAғNғZғүғҢҒ[ғ^ҒB
ғgғbғv500үЗҗиҸу‘ФӮрҠ®җ¬ӮіӮ№Ӯй–м–]ӮМӮҪӮЯӮЙӮ ӮйӮжӮӨӮИғvғҚғZғbғTҒB
172 ҒF–јҸМ–ўҗЭ’иҒF2009/04/21(үО) 06:26:47 ID:IEmHD7lr0
ҚЕҸүӮМLarrabeeӮНGDDRӮзӮөӮўӮ¶ӮбӮсҒBHPCҢьӮҜӮӘ–{–ҪӮИӮзECCғҒғӮғҠҲКҺgӮӨӮҫӮлҒB
ғGғ~ғ…ғҢҒ[ғgӮ©Ӯ»ӮМ•УӮЕҚПӮЬӮ№ӮжӮӨӮИӮсӮДӢCҚҮ“ьӮБӮДӮИӮўҸШӢ’ҒB
Ғ„ӮДӮ©ҒAӮұӮкGPUӮҫӮЖҺvӮӨҒH
GPUӮЕӮНӮИӮўҒBGPUӮр”Ы’иӮ·ӮйүҪӮ©ҒB
ғGғ~ғ…ғҢҒ[ғgӮ©Ӯ»ӮМ•УӮЕҚПӮЬӮ№ӮжӮӨӮИӮсӮДӢCҚҮ“ьӮБӮДӮИӮўҸШӢ’ҒB
Ғ„ӮДӮ©ҒAӮұӮкGPUӮҫӮЖҺvӮӨҒH
GPUӮЕӮНӮИӮўҒBGPUӮр”Ы’иӮ·ӮйүҪӮ©ҒB
173 ҒF–јҸМ–ўҗЭ’иҒF2009/04/21(үО) 07:36:52 ID:aedcnRSx0
P54CӮНGPUӮҫӮжҒB
ӮҫӮ©ӮзҲИҚ~ӮМP6ҒAnetburstҒAmeromҒAnehalemӮаGPUӮҫӮжҒB
http://www.radgametools.com/jp/pixofeat.htm
ӮҫӮ©ӮзҲИҚ~ӮМP6ҒAnetburstҒAmeromҒAnehalemӮаGPUӮҫӮжҒB
http://www.radgametools.com/jp/pixofeat.htm
174 ҒFғ`ғүғVӮМ— 6ҒF2009/04/21(үО) 21:05:04 ID:45frk9qZ0
ҚЎҚXNehalemҚДҚl....
NehalemӮЕӮН‘O‘гӮМPenrynӮЙ—lҒXӮИүь—ЗӮӘүБӮҰӮзӮкӮДӮўӮйӮнӮҜӮҫӮӘ...
ҒEғtғҚғҖғXғNғүғbғ`ӮЕ‘S–КStatic Circuitү»
ӮБӮДӮМӮМҲУ–ЎӮӘҺАӮНӮжӮӯӮнӮ©ӮБӮДӮўӮИӮ©ӮБӮҪ....
ӮУӮЖҗіүрӮЙӢЯӮ»ӮӨӮИ—қ—RӮрҺvӮўӮВӮўӮҪӮМӮЕғҒғӮ....
Ғ@Ӯ»ӮМ—қ—RӮНҒAҒu”чҚЧү»ӮМү¶ҢbӮрҺуӮҜӮйӮҪӮЯҒv.....?
ҺАӮНIntelӮМҸкҚҮMerom(65nm)Ӯ©ӮзPenryn(45nm)ӮЦӮМҢхҠwғVғ…ғҠғ“ғNӮЕӮНғvғҚғZғTғRғA•”ӮМ–КҗПӮН30%’ц“xӮөӮ©ҢёӮБӮДӮўӮИӮў....
ҠщӮЙCMOSӮЕӮНҒA”M–§“xӮМӮҪӮЯӮЙҒAҗь•қӮр30%ҢёӮзӮ№ӮОғ`ғbғv–КҗПӮӘ50%ҢёӮйҺһ‘гӮНҸIӮнӮБӮДӮўӮй....?
IntelӮӘӮұӮкӮр–в‘иҺӢӮөӮИӮ©ӮБӮҪӮЖӮНҺvӮҰӮИӮў....
ӢкҳJӮөӮД”чҚЧү»ӮөӮДӮаҢoҚП“IӮИғ_ғCғTғCғYӮЕӮНғRғAҗ”ӮН1.5”{ӮЙӮөӮ©ӮИӮзӮИӮўӮИӮсӮД....
Ӯ»ӮсӮИӮнӮҜӮЕ”M–§“xӮр—}ӮҰӮйӮҪӮЯӮЙ‘S–КStatic Circuitү»ӮЖӮўӮӨ‘еҚHҺ–ӮрӮвӮБӮҪӮсӮ¶ӮбӮИӮўӮ©ӮЖ...
Nehalem(45nm)Ӯ©ӮзWestmere(32nm)ӮЦӮМҢхҠwғVғ…ғҠғ“ғNӮЕғvғҚғZғTғRғA•”ӮМ–КҗПӮӘ50%ҢёӮйӮИӮзӮОҒA
SandyBridgeӮН8ғRғAӮЕӮаҲДҠOғ_ғCғTғCғYӮНBloomfieldӮЖ•ПӮнӮзӮИӮўӮМӮЕӮНӮИӮўӮ©?
1D-TorusӮИӮзXbarӮЖҲбӮБӮД–КҗПӮрӢтӮнӮИӮў....
ӮҝӮИӮЭӮЙPOWER6ӮаҚӮғNғҚғbғNӮЕӮФӮсүсӮ·ӮҪӮЯӮЙ”M–§“xӮМ’бӮўStatic CircuitӮрҚМ—pӮөӮДӮҪӮи....
Ӯ»ӮӨӮўӮҰӮОNehalemӮЕғvғҚғZғTғRғA•”ӮЙ”z’uӮіӮкӮҪL2$ӮН8T-SRAMӮҫӮБӮҪ...
ttp://www.sijapan.com/content/0508vol2/industry/industry_0508_1.html
>Ғ@“ҜӮ¶ӮӯIBMӮНҒA32nmҲИҚ~ӮЙҢьӮҜӮДSRAMғZғӢӮМҲА’иҗ«Ӯр6T-SRAMӮЖ8T-SRAMӮЕ”дҠrҢҹҸШӮөҒA
>ғgғүғ“ғWғXғ^җ”ӮӘ2ҢВ‘қӮҰӮйӮӘ8T-SRAMӮМ•ыӮӘҒAҲА’иҗ«ӮӘӮжӮӯ”чҚЧү»ӮЙ—LҢшӮЕӮ ӮйӮЖ”ӯ•\ӮөӮҪҒBҒi8A-2Ғj
NehalemӮЕӮН‘O‘гӮМPenrynӮЙ—lҒXӮИүь—ЗӮӘүБӮҰӮзӮкӮДӮўӮйӮнӮҜӮҫӮӘ...
ҒEғtғҚғҖғXғNғүғbғ`ӮЕ‘S–КStatic Circuitү»
ӮБӮДӮМӮМҲУ–ЎӮӘҺАӮНӮжӮӯӮнӮ©ӮБӮДӮўӮИӮ©ӮБӮҪ....
ӮУӮЖҗіүрӮЙӢЯӮ»ӮӨӮИ—қ—RӮрҺvӮўӮВӮўӮҪӮМӮЕғҒғӮ....
Ғ@Ӯ»ӮМ—қ—RӮНҒAҒu”чҚЧү»ӮМү¶ҢbӮрҺуӮҜӮйӮҪӮЯҒv.....?
ҺАӮНIntelӮМҸкҚҮMerom(65nm)Ӯ©ӮзPenryn(45nm)ӮЦӮМҢхҠwғVғ…ғҠғ“ғNӮЕӮНғvғҚғZғTғRғA•”ӮМ–КҗПӮН30%’ц“xӮөӮ©ҢёӮБӮДӮўӮИӮў....
ҠщӮЙCMOSӮЕӮНҒA”M–§“xӮМӮҪӮЯӮЙҒAҗь•қӮр30%ҢёӮзӮ№ӮОғ`ғbғv–КҗПӮӘ50%ҢёӮйҺһ‘гӮНҸIӮнӮБӮДӮўӮй....?
IntelӮӘӮұӮкӮр–в‘иҺӢӮөӮИӮ©ӮБӮҪӮЖӮНҺvӮҰӮИӮў....
ӢкҳJӮөӮД”чҚЧү»ӮөӮДӮаҢoҚП“IӮИғ_ғCғTғCғYӮЕӮНғRғAҗ”ӮН1.5”{ӮЙӮөӮ©ӮИӮзӮИӮўӮИӮсӮД....
Ӯ»ӮсӮИӮнӮҜӮЕ”M–§“xӮр—}ӮҰӮйӮҪӮЯӮЙ‘S–КStatic Circuitү»ӮЖӮўӮӨ‘еҚHҺ–ӮрӮвӮБӮҪӮсӮ¶ӮбӮИӮўӮ©ӮЖ...
Nehalem(45nm)Ӯ©ӮзWestmere(32nm)ӮЦӮМҢхҠwғVғ…ғҠғ“ғNӮЕғvғҚғZғTғRғA•”ӮМ–КҗПӮӘ50%ҢёӮйӮИӮзӮОҒA
SandyBridgeӮН8ғRғAӮЕӮаҲДҠOғ_ғCғTғCғYӮНBloomfieldӮЖ•ПӮнӮзӮИӮўӮМӮЕӮНӮИӮўӮ©?
1D-TorusӮИӮзXbarӮЖҲбӮБӮД–КҗПӮрӢтӮнӮИӮў....
ӮҝӮИӮЭӮЙPOWER6ӮаҚӮғNғҚғbғNӮЕӮФӮсүсӮ·ӮҪӮЯӮЙ”M–§“xӮМ’бӮўStatic CircuitӮрҚМ—pӮөӮДӮҪӮи....
Ӯ»ӮӨӮўӮҰӮОNehalemӮЕғvғҚғZғTғRғA•”ӮЙ”z’uӮіӮкӮҪL2$ӮН8T-SRAMӮҫӮБӮҪ...
ttp://www.sijapan.com/content/0508vol2/industry/industry_0508_1.html
>Ғ@“ҜӮ¶ӮӯIBMӮНҒA32nmҲИҚ~ӮЙҢьӮҜӮДSRAMғZғӢӮМҲА’иҗ«Ӯр6T-SRAMӮЖ8T-SRAMӮЕ”дҠrҢҹҸШӮөҒA
>ғgғүғ“ғWғXғ^җ”ӮӘ2ҢВ‘қӮҰӮйӮӘ8T-SRAMӮМ•ыӮӘҒAҲА’иҗ«ӮӘӮжӮӯ”чҚЧү»ӮЙ—LҢшӮЕӮ ӮйӮЖ”ӯ•\ӮөӮҪҒBҒi8A-2Ғj
175 ҒFғ`ғүғVӮМ— 7ҒF2009/04/21(үО) 21:07:11 ID:45frk9qZ0
ӮұӮкӮЙ”әӮБӮД—\‘zғ_ғCғTғCғYӮаӮ©ӮИӮиҸ¬ӮіӮӯӮИӮй....
WestmereӮМ250sqmm‘OҢг Ӯр 200sqmm‘OҢгӮЙүә•ыҸCҗі
SandyBridgeӮМ300sqmm‘OҢг Ӯр 250sqmm‘OҢгӮЙүә•ыҸCҗі
NehalemӮНPenryn”дӮҫӮЖғvғҚғZғTғRғAӮӘӮ©ӮИӮи‘еӮ«Ӯӯҗ¬ӮБӮДӮўӮй.... ӮөӮ©ӮөӢ@”\Ҡg’ЈӮН‘еҗlӮөӮЯ....
ӮвӮНӮиStatic Circuitү»ӮЖL2$(8T-SRAM)“қҚҮӮЙӢNҲц....?
ҸгҸqӮөӮҪ“сӮВӮЙүБӮҰҒAQPI, IMC, ATA, Turbo Boost, ғӮғWғ…ғүҒ[җЭҢv, Power Gate.......
NehalemӮЕҺ{ӮіӮкӮҪҠg’ЈӮНҢгӮМҗў‘гӮЕ–рӮЙ—§ӮҝӮ»ӮӨӮИӮаӮМӮОӮ©Ӯи....
ӮвӮНӮиӮ»ӮӨӮўӮӨӮұӮЖӮ©...?
үҪӮкӮЙӮ№ӮжIntelӮНғvғҚғZғbғTӮМҠJ”ӯӢЈ‘ҲӮЕ‘еӮ«ӮӯғҠҒ[ғhӮөӮДӮўӮйӮжӮӨӮЙҢ©ӮҰӮй.....
Ӯ»ӮкӮЩӮЗӮЙNehalemӮЕ’ҷӮҰӮҪҺ‘ҺYӮН‘еӮ«Ӯў....
WestmereӮМ250sqmm‘OҢг Ӯр 200sqmm‘OҢгӮЙүә•ыҸCҗі
SandyBridgeӮМ300sqmm‘OҢг Ӯр 250sqmm‘OҢгӮЙүә•ыҸCҗі
NehalemӮНPenryn”дӮҫӮЖғvғҚғZғTғRғAӮӘӮ©ӮИӮи‘еӮ«Ӯӯҗ¬ӮБӮДӮўӮй.... ӮөӮ©ӮөӢ@”\Ҡg’ЈӮН‘еҗlӮөӮЯ....
ӮвӮНӮиStatic Circuitү»ӮЖL2$(8T-SRAM)“қҚҮӮЙӢNҲц....?
ҸгҸqӮөӮҪ“сӮВӮЙүБӮҰҒAQPI, IMC, ATA, Turbo Boost, ғӮғWғ…ғүҒ[җЭҢv, Power Gate.......
NehalemӮЕҺ{ӮіӮкӮҪҠg’ЈӮНҢгӮМҗў‘гӮЕ–рӮЙ—§ӮҝӮ»ӮӨӮИӮаӮМӮОӮ©Ӯи....
ӮвӮНӮиӮ»ӮӨӮўӮӨӮұӮЖӮ©...?
үҪӮкӮЙӮ№ӮжIntelӮНғvғҚғZғbғTӮМҠJ”ӯӢЈ‘ҲӮЕ‘еӮ«ӮӯғҠҒ[ғhӮөӮДӮўӮйӮжӮӨӮЙҢ©ӮҰӮй.....
Ӯ»ӮкӮЩӮЗӮЙNehalemӮЕ’ҷӮҰӮҪҺ‘ҺYӮН‘еӮ«Ӯў....
176 ҒF–јҸМ–ўҗЭ’иҒF2009/04/21(үО) 22:20:40 ID:VEr0K0S50
NehalemӮӘ‘еӮ«ӮИҺdҺ–ӮЕӮ ӮйӮұӮЖӮНҠФҲбӮўӮИӮў
ӮЕӮаҒuNehalemӮЕ’ҷӮҰӮҪҺ‘ҺYҒvӮЖӮўӮӨҢҫӮў•ыӮНӮҝӮеӮБӮЖҒc
ҒE‘еҗМӮ©ӮзғVғҠғAғӢғoғXӮвCSIӮМҢӨӢҶӮөӮДӮҪӮБӮөӮе
ҒEIMCӮНTimnaӮЕҢoҢұӮөӮДӮйӮЕӮөӮе
ҒETurbo BoostӮНҢіFoxtonӮЕӮөӮеҒAғnғCғtғ@ӮМEDATӮаүә•~Ӯ«
ӮЕӮаҒuNehalemӮЕ’ҷӮҰӮҪҺ‘ҺYҒvӮЖӮўӮӨҢҫӮў•ыӮНӮҝӮеӮБӮЖҒc
ҒE‘еҗМӮ©ӮзғVғҠғAғӢғoғXӮвCSIӮМҢӨӢҶӮөӮДӮҪӮБӮөӮе
ҒEIMCӮНTimnaӮЕҢoҢұӮөӮДӮйӮЕӮөӮе
ҒETurbo BoostӮНҢіFoxtonӮЕӮөӮеҒAғnғCғtғ@ӮМEDATӮаүә•~Ӯ«
177 ҒF–јҸМ–ўҗЭ’иҒF2009/04/22(җ…) 01:39:06 ID:fJKnxz5U0
8T-SRAMӮЖStatic CircuitӮНӮ»ӮкӮрҚМ—pӮ№ӮҙӮйӮр“ҫӮИӮўӮЩӮЗ
ҸБ”п“d—НӮӘ‘еӮ«Ӯ©ӮБӮҪӮМӮ©ӮБӮДӮўӮӨҠҙӮ¶ӮрҺуӮҜӮйӮИҒB
Power GateӮНғvғҚғZғX–КӮ©ӮзҢ©ӮДӮаӮ©ӮИӮиҠж’ЈӮБӮДӮйӮИҒB
Ҹ«—Ҳ—L–]ҒB
ҸБ”п“d—НӮӘ‘еӮ«Ӯ©ӮБӮҪӮМӮ©ӮБӮДӮўӮӨҠҙӮ¶ӮрҺуӮҜӮйӮИҒB
Power GateӮНғvғҚғZғX–КӮ©ӮзҢ©ӮДӮаӮ©ӮИӮиҠж’ЈӮБӮДӮйӮИҒB
Ҹ«—Ҳ—L–]ҒB
178 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/04/26(“ъ) 13:56:47 ID:9jBPBAqE0
Merom(Core2)ӮӘ‘е“d—НӮЖ”ҡ”Mү»ӮМҺһ‘гӮЙӮӨӮЬӮӯғtғBғbғgӮөӮҪӮБӮДӮМӮН
ҠmӮ©ӮЙӮ ӮйӮМӮҫӮӘҒAӮўӮ©ӮсӮ№ӮсPCғIғ^ғNӮМҗўҠEӮЕIsraelӮНүЯ‘е•]үҝӮіӮкӮ·Ӯ¬ӮДӮўӮйҒB
>>176ӮМҢҫӮӨӮЖӮЁӮиҒACSIӮНTukwilaӮҫӮөTurbo BoostӮНIsraelӮМӢZҸpӮҫӮӘҒA
TimnaӮМIMCӮЖҒAIntelӮМҺе—Нҗ»•iӮЕӮ ӮйXeon/ӢҢPentiumҢnҒAғmҒ[ғgӮрҲкӢCӮЙ
IMC/CSIү»Ӯ·Ӯй‘еҺdҺ–ӮНIsraelӮМҠJ”ӯ—НӮЕӮН‘ОүһӮЕӮ«ӮҪӮ©Ӯ ӮвӮөӮўӮәҒB
ғIғҢғSғ“ӮМP6, NetBurst, Nehalem
ғCғXғүғGғӢҒAMMX, Tillamook, Timna, PenM/Merom
Ӯр”дҠrӮ·ӮйӮЖғIғҢғSғ“ӮМ•ыӮӘ–ҫӮзӮ©ӮЙ‘еҺdҺ–ӮөӮДӮўӮйӮМӮҫӮӘҒB
NehalemӮвNetBurstӮМ•ыӮӘ‘еҗәӮЕӮНӮўӮҰӮИӮўӮӘҒA
ӢZҸp“IӮЙ‘OҗiӮөӮДӮўӮй•”•ӘӮӘӮЁӮЁӮӯҒA’ҶҗgӮвҸ«—Ҳҗ«ӮжӮиӮаҸoӮҪӮЖӮ«ӮМғxғ“ғ`ғҢғrғ…Ғ[ӮМғXғRғAӮЕ
•]үҝӮМ—D—тӮӘӮ«ӮЬӮйPCғIғ^ғNҠEӮЙӮН•]үҝӮіӮкӮЙӮӯӮ©ӮБӮҪӮЖӮаӮўӮҰӮйҒB
ҠmӮ©ӮЙӮ ӮйӮМӮҫӮӘҒAӮўӮ©ӮсӮ№ӮсPCғIғ^ғNӮМҗўҠEӮЕIsraelӮНүЯ‘е•]үҝӮіӮкӮ·Ӯ¬ӮДӮўӮйҒB
>>176ӮМҢҫӮӨӮЖӮЁӮиҒACSIӮНTukwilaӮҫӮөTurbo BoostӮНIsraelӮМӢZҸpӮҫӮӘҒA
TimnaӮМIMCӮЖҒAIntelӮМҺе—Нҗ»•iӮЕӮ ӮйXeon/ӢҢPentiumҢnҒAғmҒ[ғgӮрҲкӢCӮЙ
IMC/CSIү»Ӯ·Ӯй‘еҺdҺ–ӮНIsraelӮМҠJ”ӯ—НӮЕӮН‘ОүһӮЕӮ«ӮҪӮ©Ӯ ӮвӮөӮўӮәҒB
ғIғҢғSғ“ӮМP6, NetBurst, Nehalem
ғCғXғүғGғӢҒAMMX, Tillamook, Timna, PenM/Merom
Ӯр”дҠrӮ·ӮйӮЖғIғҢғSғ“ӮМ•ыӮӘ–ҫӮзӮ©ӮЙ‘еҺdҺ–ӮөӮДӮўӮйӮМӮҫӮӘҒB
NehalemӮвNetBurstӮМ•ыӮӘ‘еҗәӮЕӮНӮўӮҰӮИӮўӮӘҒA
ӢZҸp“IӮЙ‘OҗiӮөӮДӮўӮй•”•ӘӮӘӮЁӮЁӮӯҒA’ҶҗgӮвҸ«—Ҳҗ«ӮжӮиӮаҸoӮҪӮЖӮ«ӮМғxғ“ғ`ғҢғrғ…Ғ[ӮМғXғRғAӮЕ
•]үҝӮМ—D—тӮӘӮ«ӮЬӮйPCғIғ^ғNҠEӮЙӮН•]үҝӮіӮкӮЙӮӯӮ©ӮБӮҪӮЖӮаӮўӮҰӮйҒB
179 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/04/26(“ъ) 13:58:17 ID:9jBPBAqE0
TimnaӮІӮЖӮ«ӮМIMCү»ӮЖ”дҠrӮіӮкӮДӮаӮұӮЬӮйӮБӮДӮұӮЖӮҫӮИҒB
TimnaӮНAtomӮӘIMCү»Ӯ·ӮйӮМӮЖ“ҜғҢғxғӢӮМҳbӮҫӮнҒB
Һё”sӮөӮДӮаӮ ӮЬӮи’ЙӮӯӮИӮўӮөӮЛҒBNehalemӮМCSI/IMCӮНҺё”sӮӘӢ–ӮіӮкӮсӮжҒB
TimnaӮНAtomӮӘIMCү»Ӯ·ӮйӮМӮЖ“ҜғҢғxғӢӮМҳbӮҫӮнҒB
Һё”sӮөӮДӮаӮ ӮЬӮи’ЙӮӯӮИӮўӮөӮЛҒBNehalemӮМCSI/IMCӮНҺё”sӮӘӢ–ӮіӮкӮсӮжҒB
180 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/04/26(“ъ) 14:00:30 ID:9jBPBAqE0
ӮҝӮИӮЭӮЙFoxtonӮЖTurbo BoostӮНҠmӮ©ӮЙҲкҢ©Һ—ӮДӮўӮйӮӘҲЩӮИӮйӢZҸpӮҫӮЛҒB
181 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/04/26(“ъ) 14:10:12 ID:9jBPBAqE0
ғCғXғүғGғӢӮМҺА—НӮНSandy BridgeӮЕӮЗӮкӮҫӮҜҗVӮөӮўӢZҸpӮр“Ҡ“ьӮЕӮ«ӮйӮ©Ӯр
ӮЭӮИӮўӮЖүҪӮЖӮаӮўӮҰӮИӮўӮИҒB
MeromӮЬӮЕӮНҗжҚsӮ·ӮйғIғҢғSғ“ӮМҗ»•iӮЙP4ғoғXӮвӮзSSE2/3ӮрӮНӮ¶ӮЯҒA
Һd—lӮрҚҮӮнӮ№ӮйҠҙӮ¶ӮМҠJ”ӯӮҫӮБӮҪӮӘҒASandy BridgeӮНҗVӮөӮўӮаӮМӮрӮВӮӯӮзӮўӮИӮўӮЖӮўӮҜӮИӮўӮсӮЕҒB
AVXҲИҠOӮЙ‘OҗiӮНӮ ӮйӮМӮҫӮлӮӨӮ©?
“БӮЙ“dӢC“IӮИҳbӮЙӮИӮйӮЖ•ДҚ‘ғ`Ғ[ғҖӮЙӮН‘S‘RӢyӮсӮЕӮИӮўӢCӮӘӮ·ӮйӮМӮҫӮӘҒB
ӮЬӮ ғIғ^ҺуӮҜӮЛӮзӮӨӮИӮз“dӢCӮжӮиӮағAҒ[ғLӮЕӮ·ӮӘҒB
ӮЭӮИӮўӮЖүҪӮЖӮаӮўӮҰӮИӮўӮИҒB
MeromӮЬӮЕӮНҗжҚsӮ·ӮйғIғҢғSғ“ӮМҗ»•iӮЙP4ғoғXӮвӮзSSE2/3ӮрӮНӮ¶ӮЯҒA
Һd—lӮрҚҮӮнӮ№ӮйҠҙӮ¶ӮМҠJ”ӯӮҫӮБӮҪӮӘҒASandy BridgeӮНҗVӮөӮўӮаӮМӮрӮВӮӯӮзӮўӮИӮўӮЖӮўӮҜӮИӮўӮсӮЕҒB
AVXҲИҠOӮЙ‘OҗiӮНӮ ӮйӮМӮҫӮлӮӨӮ©?
“БӮЙ“dӢC“IӮИҳbӮЙӮИӮйӮЖ•ДҚ‘ғ`Ғ[ғҖӮЙӮН‘S‘RӢyӮсӮЕӮИӮўӢCӮӘӮ·ӮйӮМӮҫӮӘҒB
ӮЬӮ ғIғ^ҺуӮҜӮЛӮзӮӨӮИӮз“dӢCӮжӮиӮағAҒ[ғLӮЕӮ·ӮӘҒB
182 ҒF–јҸМ–ўҗЭ’иҒF2009/04/26(“ъ) 14:13:44 ID:78wxbtxr0
ӮНӮўӮНӮў
NetburstӮНӢZҸp“IӮЙ‘OҗiӮөӮДҸ«—Ҳҗ«ӮӘ—LӮиӮЬӮӯӮиӮЕӮөӮҪӮжӮЛ
NetburstӮНӢZҸp“IӮЙ‘OҗiӮөӮДҸ«—Ҳҗ«ӮӘ—LӮиӮЬӮӯӮиӮЕӮөӮҪӮжӮЛ
183 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/04/26(“ъ) 14:15:28 ID:9jBPBAqE0
ӮаӮҝӮлӮс“d—НӮв”ӯ”MӮрҸңӮҜӮОӮЛҒB
Ӯ ӮЬӮиӮЙӮағCғXғүғGғӢғ}ғ“ғZҒ[ӮЕҒAғIғҢғSғ“ӮӘ•іӮҫӮЖӮЁӮаӮБӮДӮўӮй
җ~–[ӮӘ‘қӮҰӮ·Ӯ¬ӮҪӮМӮЕӮВӮўӢр’sӮБӮДӮөӮЬӮБӮҪӮнҒB
Ӯ ӮЬӮиӮЙӮағCғXғүғGғӢғ}ғ“ғZҒ[ӮЕҒAғIғҢғSғ“ӮӘ•іӮҫӮЖӮЁӮаӮБӮДӮўӮй
җ~–[ӮӘ‘қӮҰӮ·Ӯ¬ӮҪӮМӮЕӮВӮўӢр’sӮБӮДӮөӮЬӮБӮҪӮнҒB
184 ҒF–јҸМ–ўҗЭ’иҒF2009/04/26(“ъ) 14:23:52 ID:78wxbtxr0
4”NӮЩӮЗCore2ӮМғ^Ғ[ғ“ӮҫӮБӮҪӮ©ӮзӮ»ӮӨӮўӮӨҗ~–[ӮӘ‘қӮҰӮйӮМӮНӮөӮеӮӨӮӘӮИӮў
ҲАӮўii5Ӯвi3ӮӘ•ҒӢyӮөӮДӮӯӮкӮОӮЬӮҪ•ПӮнӮБӮДӮӯӮйӮі
ҲАӮўii5Ӯвi3ӮӘ•ҒӢyӮөӮДӮӯӮкӮОӮЬӮҪ•ПӮнӮБӮДӮӯӮйӮі
185 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/04/26(“ъ) 14:40:52 ID:9jBPBAqE0
ғIғҢғSғ“ӮНғCғXғүғGғӢӮжӮиӮа‘еҺdҺ–ӮрӮөӮДӮўӮй•ӘҒAҺё”sӮөӮҪӮЖӮ«ӮМҸХҢӮӮа‘еӮ«ӮўҒB
ғTғүғ“ғ^ғNғүғү/HPӮМIA64ғ`Ғ[ғҖӮаӮ»ӮӨӮҫӮөҒAӮұӮиӮб“–ӮҪӮи‘OӮМӮұӮЖҒB
Ӯ»ӮкӮӘҸБ”пҺТйxӮөӮЕҢЦ‘е–П‘zӮМҠg’ЈӮрӮвӮБӮДҺ©”ҡIntelӮрғsғ“ғ`ӮЙ’ЗӮўҚһӮсӮҫ
ғIғҢғSғ“ғ`Ғ[ғҖҒAӮЖӮўӮӨӮдӮӘӮсӮҫүрҺЯӮЙӮВӮИӮӘӮБӮҪҒBӮ»ӮкӮҫӮҜӮҫӮИҒB
Ӯ»ӮМҢгҒAҢӢӢЗTukwilaӮжӮиҗжӮЙQPIӮрҺА‘•ӮіӮ№ӮД“oҸкӮөӮҪNehalemӮМҸo—ҲӮрҢ©ӮДӮа
ғIғҢғSғ“ӮӘIntelӮМ’ҶҠjғ`Ғ[ғҖӮЕӮ ӮйӮұӮЖӮЙҠФҲбӮўӮНӮИӮўҒB
ғTғүғ“ғ^ғNғүғү/HPӮМIA64ғ`Ғ[ғҖӮаӮ»ӮӨӮҫӮөҒAӮұӮиӮб“–ӮҪӮи‘OӮМӮұӮЖҒB
Ӯ»ӮкӮӘҸБ”пҺТйxӮөӮЕҢЦ‘е–П‘zӮМҠg’ЈӮрӮвӮБӮДҺ©”ҡIntelӮрғsғ“ғ`ӮЙ’ЗӮўҚһӮсӮҫ
ғIғҢғSғ“ғ`Ғ[ғҖҒAӮЖӮўӮӨӮдӮӘӮсӮҫүрҺЯӮЙӮВӮИӮӘӮБӮҪҒBӮ»ӮкӮҫӮҜӮҫӮИҒB
Ӯ»ӮМҢгҒAҢӢӢЗTukwilaӮжӮиҗжӮЙQPIӮрҺА‘•ӮіӮ№ӮД“oҸкӮөӮҪNehalemӮМҸo—ҲӮрҢ©ӮДӮа
ғIғҢғSғ“ӮӘIntelӮМ’ҶҠjғ`Ғ[ғҖӮЕӮ ӮйӮұӮЖӮЙҠФҲбӮўӮНӮИӮўҒB
186 ҒF–јҸМ–ўҗЭ’иҒF2009/04/26(“ъ) 14:59:26 ID:U2fyDKvj0
>>184
3”NҲКӮ¶ӮбӮЛҒH
3”NҲКӮ¶ӮбӮЛҒH
187 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/04/26(“ъ) 15:07:34 ID:9jBPBAqE0
Core 2Ӯ©ӮзӮЬӮҫ3”NӮҪӮБӮДӮИӮўӮсӮҫӮИҒB
NetBurstӮМ”ҡ”MғtғBҒ[ғoҒ[ӮӘү“ӮўүЯӢҺӮМҸo—ҲҺ–ӮМӮжӮӨӮЙӮЁӮаӮҰӮйӮнҒB
ӮЖӮНӮўӮҰҒAҗўӮМ’ҶӮЕӮНNetBurstғ}ғVғ“ӮӘӮЬӮҫӮЬӮҫ•…ӮйӮЩӮЗҢ»–рӮЕҺgӮнӮкӮДӮўӮйӮМӮҫӮӘҒB
MeromӮМҗ¬Ңч•]үҝӮНMCMӮМҸ•ӮҜӮӘӮ ӮБӮҪӮМӮа‘еӮ«ӮўӮИҒB
ғNғAғbғhҲИҸгӮМғRғAӮНMP—pҲИҠO—pҲУӮөӮДӮўӮИӮ©ӮБӮҪӮМӮЕҒA
MCMӮӘ–іӮҜӮкӮО4ғRғAҲИҸгӮНAMDӮЙ’xӮкӮрӮЖӮБӮДӮўӮҪӮ©ӮаӮөӮкӮИӮўҒB
ӢtӮЙMCMӮӘӮ ӮБӮҪӮ№ӮўӮЕBloomfieldӮрӮНӮ¶ӮЯӮЖӮ·ӮйғlғCғeғBғu4ғRғAҗ»•iӮӘ
ӢZҸp“IӮЙҠж’ЈӮБӮҪӮнӮиӮЙҒAӮўӮЬӮўӮҝғCғ“ғpғNғgӮр—^ӮҰӮзӮкӮИӮўҸуӢөӮЙӮИӮБӮДӮөӮЬӮБӮҪӮнӮҜӮҫӮӘҒB
NetBurstӮМ”ҡ”MғtғBҒ[ғoҒ[ӮӘү“ӮўүЯӢҺӮМҸo—ҲҺ–ӮМӮжӮӨӮЙӮЁӮаӮҰӮйӮнҒB
ӮЖӮНӮўӮҰҒAҗўӮМ’ҶӮЕӮНNetBurstғ}ғVғ“ӮӘӮЬӮҫӮЬӮҫ•…ӮйӮЩӮЗҢ»–рӮЕҺgӮнӮкӮДӮўӮйӮМӮҫӮӘҒB
MeromӮМҗ¬Ңч•]үҝӮНMCMӮМҸ•ӮҜӮӘӮ ӮБӮҪӮМӮа‘еӮ«ӮўӮИҒB
ғNғAғbғhҲИҸгӮМғRғAӮНMP—pҲИҠO—pҲУӮөӮДӮўӮИӮ©ӮБӮҪӮМӮЕҒA
MCMӮӘ–іӮҜӮкӮО4ғRғAҲИҸгӮНAMDӮЙ’xӮкӮрӮЖӮБӮДӮўӮҪӮ©ӮаӮөӮкӮИӮўҒB
ӢtӮЙMCMӮӘӮ ӮБӮҪӮ№ӮўӮЕBloomfieldӮрӮНӮ¶ӮЯӮЖӮ·ӮйғlғCғeғBғu4ғRғAҗ»•iӮӘ
ӢZҸp“IӮЙҠж’ЈӮБӮҪӮнӮиӮЙҒAӮўӮЬӮўӮҝғCғ“ғpғNғgӮр—^ӮҰӮзӮкӮИӮўҸуӢөӮЙӮИӮБӮДӮөӮЬӮБӮҪӮнӮҜӮҫӮӘҒB
188 ҒF–јҸМ–ўҗЭ’иҒF2009/04/26(“ъ) 15:13:39 ID:U2fyDKvj0
ӮўӮЬӮМIntelӮНҺи”ІӮ«ғtғFғCғYӮҫӮӘAMDӮӘMCM12ғRғAӮЙDDR3-4chӮЖӮўӮӨҺ©”ҡғeғҚӮЙҸoӮҪӮМӮЕ—Ҳ”NӮНҸӯӮөӮН–{ӢCӮЙӮИӮйӮҫӮл
Beckton-DPӮМ“Ҡ“ьӮр—\‘ӘӮөӮДӮЁӮӯ
Beckton-DPӮМ“Ҡ“ьӮр—\‘ӘӮөӮДӮЁӮӯ
189 ҒF–јҸМ–ўҗЭ’иҒF2009/04/26(“ъ) 16:15:49 ID:7sweYQHn0
HT/QPIӮвIMCӮҫӮЖMCMӮ·ӮйӮЖ‘е•ПӮ»ӮӨ
ғzғbғvҗ”ӮаӮвӮвӮұӮөӮӯӮИӮйӮө
AMDӮНG34ӮЕ—НӢЖӮ·ӮйӮЭӮҪӮўӮҫӮӘIntelӮаMCMӮвӮйӮ©ӮИӮ
ғzғbғvҗ”ӮаӮвӮвӮұӮөӮӯӮИӮйӮө
AMDӮНG34ӮЕ—НӢЖӮ·ӮйӮЭӮҪӮўӮҫӮӘIntelӮаMCMӮвӮйӮ©ӮИӮ
190 ҒF–јҸМ–ўҗЭ’иҒF2009/04/27(ҢҺ) 02:20:09 ID:SPeq9uPe0
Ӣу—вҢАҠEӮМTDPӮН—јҺРӮЖӮаӮ»ӮӨ•ПӮнӮзӮИӮўӮсӮҫӮөҒA
ғRғAӮМ“d—НҢш—ҰӮӘ—тӮБӮДӮйӮМӮЙҒAӢЈҚҮ‘јҺРӮжӮиғRғA‘ҪӮӯҗПӮсӮҫӮз
TDPӮМҸгҢАӮрӮ©ӮИӮиҸгӮ°ӮИӮўҢАӮиҒA
“d—НӮЖ”MӮЕғNғҚғbғNҸгҸёӮр–WӮ°ӮзӮкҒAғVғ“ғOғӢғXғҢғbғhҗ«”\ӮӘҚ“ӮӯҺc”OӮИ
ғnғCғGғ“ғhCPUӮӘҸo—ҲҸгӮӘӮБӮДӮөӮЬӮӨӮМӮЕӮН?ҒAӮЖӮўӮӨҠлңңҒB
32nmӮЕintelӮӘзTӮҜӮО(AMDӮНзTӮ©ӮИӮўӮЖӮўӮӨ‘O’с)–К”’ӮӯӮИӮйӮМӮ©ӮЛҒB
ғRғAӮМ“d—НҢш—ҰӮӘ—тӮБӮДӮйӮМӮЙҒAӢЈҚҮ‘јҺРӮжӮиғRғA‘ҪӮӯҗПӮсӮҫӮз
TDPӮМҸгҢАӮрӮ©ӮИӮиҸгӮ°ӮИӮўҢАӮиҒA
“d—НӮЖ”MӮЕғNғҚғbғNҸгҸёӮр–WӮ°ӮзӮкҒAғVғ“ғOғӢғXғҢғbғhҗ«”\ӮӘҚ“ӮӯҺc”OӮИ
ғnғCғGғ“ғhCPUӮӘҸo—ҲҸгӮӘӮБӮДӮөӮЬӮӨӮМӮЕӮН?ҒAӮЖӮўӮӨҠлңңҒB
32nmӮЕintelӮӘзTӮҜӮО(AMDӮНзTӮ©ӮИӮўӮЖӮўӮӨ‘O’с)–К”’ӮӯӮИӮйӮМӮ©ӮЛҒB
191 ҒF–јҸМ–ўҗЭ’иҒF2009/04/27(ҢҺ) 02:29:18 ID:x7hZ3DEe0
ӮЗӮӨӮ№ғnғCғGғ“ғhғTҒ[ғoҒ[ҢьӮҜӮЕӮөӮ©ҸoӮИӮў
ғVғ“ғOғӢғXғҢғbғhҗ«”\ӮНүәӮӘӮйӮөғRғXғgӮаҸгӮӘӮйӮМӮЕ
Ӯ»ӮұӮНNehalem-EX(Beckton)ӮӘҢЕӮЯӮДӮйӮҫӮлӮӨӮө
Ӯ»ӮаӮ»ӮағRғXғgӢЈ‘ҲӮЙӮИӮБӮҪӮзAMDӮЙҸҹӮҝ–ЪӮӘ–іӮўӮБӮДӮМӮН‘е•Ә‘OӮЙҺw“EӮөӮҪ’КӮи
ӮЬӮҪҒAAMDӮН‘Ғ”У’E—ҺӮ·ӮйӮЖӮөӮДӮа
IntelӮНAtomӮвLarrabeeӮЕҺ©җgӮМҸ«—ҲӮрҗШӮиҠJӮўӮДҚsӮ©ӮЛӮОӮИӮзӮИӮў
ғVғ“ғOғӢғXғҢғbғhҗ«”\ӮНүәӮӘӮйӮөғRғXғgӮаҸгӮӘӮйӮМӮЕ
Ӯ»ӮұӮНNehalem-EX(Beckton)ӮӘҢЕӮЯӮДӮйӮҫӮлӮӨӮө
Ӯ»ӮаӮ»ӮағRғXғgӢЈ‘ҲӮЙӮИӮБӮҪӮзAMDӮЙҸҹӮҝ–ЪӮӘ–іӮўӮБӮДӮМӮН‘е•Ә‘OӮЙҺw“EӮөӮҪ’КӮи
ӮЬӮҪҒAAMDӮН‘Ғ”У’E—ҺӮ·ӮйӮЖӮөӮДӮа
IntelӮНAtomӮвLarrabeeӮЕҺ©җgӮМҸ«—ҲӮрҗШӮиҠJӮўӮДҚsӮ©ӮЛӮОӮИӮзӮИӮў
192 ҒF–јҸМ–ўҗЭ’иҒF2009/04/28(үО) 01:41:57 ID:E1cfOhSB0
WindowsӮМ”„ҸгҚӮӮӘҢёҸӯӮөӮҪҢҙҲцӮНғlғbғgғuғbғNҒ\Ғ\ғ}ғCғNғҚғ\ғtғgҠІ•”ӮӘ”FӮЯӮй
ttp://www.computerworld.jp/topics/netbook/144209.html
ttp://www.computerworld.jp/topics/netbook/144209.html
193 ҒFҢл“ҡҒF2009/04/30(–Ш) 01:57:25 ID:Ta7q+mG10
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20090430_167815.html
> Ғ@IntelӮМ8ғRғAғnғCғGғ“ғhCPUҒuNehalem-EX(Beckton:ғxғbғNғgғ“)ҒvӮНFB-DIMMғCғ“ғ^Ғ[ғtғFғCғXӮр
> ғIғ“ғ}ғUҒ[ғ{Ғ[ғhӮМғoғbғtғ@ғ`ғbғvӮрүоӮөӮДDDR3 DIMMӮрғTғ|Ғ[ғgӮ·ӮйҒBғRғXғg–КӮЕӮНAMDӮЙ—ҳӮӘӮ ӮйҒB
> Ғ@IntelӮМ8ғRғAғnғCғGғ“ғhCPUҒuNehalem-EX(Beckton:ғxғbғNғgғ“)ҒvӮНFB-DIMMғCғ“ғ^Ғ[ғtғFғCғXӮр
> ғIғ“ғ}ғUҒ[ғ{Ғ[ғhӮМғoғbғtғ@ғ`ғbғvӮрүоӮөӮДDDR3 DIMMӮрғTғ|Ғ[ғgӮ·ӮйҒBғRғXғg–КӮЕӮНAMDӮЙ—ҳӮӘӮ ӮйҒB
194 ҒF–јҸМ–ўҗЭ’иҒF2009/05/02(“y) 06:59:31 ID:ubub/qtZ0
ҒuNehalemҒvғvғҚғZғbғTӮМҺА—НӮр“O’кҢҹҸШӮ·Ӯй
ӢБҲЩ“IӮИҗ«”\ӮрҺҰӮ·җVҢ^XeonғvғҚғZғbғTӮМ–Ј—НӮЙ”—Ӯй
http://www.computerworld.jp/topics/srv/144829.html
ӢБҲЩ“IӮИҗ«”\ӮрҺҰӮ·җVҢ^XeonғvғҚғZғbғTӮМ–Ј—НӮЙ”—Ӯй
http://www.computerworld.jp/topics/srv/144829.html
195 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/05/04(ҢҺ) 18:21:16 ID:8HMR4CZP0
>>188
Ӯ»ӮӨӮаҺvӮҰӮИӮўӮӘӮИҒB
Many-CoreҒAӮ¶ӮбӮИӮӯӮДMagny-CoursӮНғүғCғ“ғiғbғvӮМӢу”’Ӯр–„ӮЯӮйӮҪӮЯӮҫӮлӮӨҒB
AMDӮЖӮөӮДӮНWestmere–і‘oҸу‘ФӮНғTҒ[ғoҺsҸкӮҫӮҜӮНҗHӮўҺ~ӮЯӮҪӮўҒB
Ӯ»ӮӨӮаҺvӮҰӮИӮўӮӘӮИҒB
Many-CoreҒAӮ¶ӮбӮИӮӯӮДMagny-CoursӮНғүғCғ“ғiғbғvӮМӢу”’Ӯр–„ӮЯӮйӮҪӮЯӮҫӮлӮӨҒB
AMDӮЖӮөӮДӮНWestmere–і‘oҸу‘ФӮНғTҒ[ғoҺsҸкӮҫӮҜӮНҗHӮўҺ~ӮЯӮҪӮўҒB
196 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/05/04(ҢҺ) 18:39:03 ID:8HMR4CZP0
Nehalem 1ғ\ғPғbғg4ғRғAӮЕHTҺgӮҰӮОShanghai 2ғ\ғPғbғg8ғRғA•ӘӮМҗ«”\ӮИӮсӮДҢҫӮнӮкӮйҺ–‘ФӮҫӮ©ӮзӮИ
ҚXӮЙWestmereӮЕ6ғRғAӮЙӮИӮиҢv24ғXғҢғbғhӮЙӮИӮйҒB
ғXғҢғbғhҗ”ӮҫӮҜӮН’ЗӮўӮВӮ©ӮИӮўӮЖ‘К–ЪӮҫӮлҒB
ҚXӮЙWestmereӮЕ6ғRғAӮЙӮИӮиҢv24ғXғҢғbғhӮЙӮИӮйҒB
ғXғҢғbғhҗ”ӮҫӮҜӮН’ЗӮўӮВӮ©ӮИӮўӮЖ‘К–ЪӮҫӮлҒB
197 ҒF–јҸМ–ўҗЭ’иҒF2009/05/05(үО) 06:37:04 ID:qFAa82aS0
ғXғҢғbғhҗ”ҸгӮ°ӮйӮМӮа—ЗӮўӮҜӮЗҒAғRғAҗПӮЭүЯӮ¬ӮДғNғҚғbғNҸгӮ°ӮзӮкӮИӮӯӮИӮйӮсӮҫӮ©Ӯз
ӮЗӮБӮҝӮЙӮөӮлғ„ғ”ғ@ӮўӮМӮЕӮ ?
ӮЗӮБӮҝӮЙӮөӮлғ„ғ”ғ@ӮўӮМӮЕӮ ?
198 ҒF–јҸМ–ўҗЭ’иҒF2009/05/05(үО) 08:10:36 ID:sZYe1Gl90
NiagaraӮаӮ»ӮұӮ»Ӯұ”„ӮкӮДӮйӮөғTҒ[ғoҒ[ӮНӮ»ӮкӮЕӮаӮўӮўӮсӮ¶ӮбӮЛҒ[ҒH
ӮөӮ©ӮөӮ»ӮМNiagaraӮрҸгүсӮйғXғӢҒ[ғvғbғgӮЕTurbo BoostӮЬӮЕ”хӮҰӮҪNehalemӮНҠ®ашӮЖӮөӮ©ҢҫӮў—lӮӘӮИӮўӮИ
ӮөӮ©ӮөӮ»ӮМNiagaraӮрҸгүсӮйғXғӢҒ[ғvғbғgӮЕTurbo BoostӮЬӮЕ”хӮҰӮҪNehalemӮНҠ®ашӮЖӮөӮ©ҢҫӮў—lӮӘӮИӮўӮИ
199 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/05/05(үО) 17:52:05 ID:EvzAltmX0
TDP”ӣӮиӮӘӮ ӮйӮ©ӮзғRғAҗ”ӮрҗПӮсӮҫӮФӮсғNғҚғbғNӮӘҸгӮ°ӮзӮкӮИӮўӮБӮДӮМӮНҗіӮөӮўӮӘ
ғNғҚғbғNҒ•“dҲіӮр7Ҡ„’ц“xӮЙ—}ӮҰӮкӮОҒA—қӢьӮМҸгӮЕӮНҸБ”п“d—НӮН1/3’ц“xӮЙӮИӮи
“ҜӮ¶TDPҳgӮЕ3”{ӮМғRғAӮрҚЪӮ№ӮйӮұӮЖӮӘӮЕӮ«ӮйӮжӮӨӮЙӮИӮйҒB
ғXғҢғbғhҗ”ӮЕүТӮ®ӮБӮДӮМӮНҗн—ӘӮЖӮөӮДӮНҸ\•ӘғAғҠӮҫӮжҒB
4ғRғAӮНҚӮғNғҚғbғNү»ӮЕғүғCғ“ғiғbғvӮрҸ[ҺАӮіӮ№ӮкӮОӮўӮўҒB
ӮөӮ©ӮөҒA•үӮҜӮйӮМӮӘүрӮБӮДӮДӮаҸoӮіӮИӮ«ӮбӮўӮҜӮИӮўӮұӮЖӮНӮ ӮйӮсӮҫӮЛҒB
PaxvilleӮрҸoӮөӮҪӮЖӮ«ӮМIntelӮӘӮұӮсӮИҠҙӮ¶ӮҫҒB
ғNғҚғbғNҒ•“dҲіӮр7Ҡ„’ц“xӮЙ—}ӮҰӮкӮОҒA—қӢьӮМҸгӮЕӮНҸБ”п“d—НӮН1/3’ц“xӮЙӮИӮи
“ҜӮ¶TDPҳgӮЕ3”{ӮМғRғAӮрҚЪӮ№ӮйӮұӮЖӮӘӮЕӮ«ӮйӮжӮӨӮЙӮИӮйҒB
ғXғҢғbғhҗ”ӮЕүТӮ®ӮБӮДӮМӮНҗн—ӘӮЖӮөӮДӮНҸ\•ӘғAғҠӮҫӮжҒB
4ғRғAӮНҚӮғNғҚғbғNү»ӮЕғүғCғ“ғiғbғvӮрҸ[ҺАӮіӮ№ӮкӮОӮўӮўҒB
ӮөӮ©ӮөҒA•үӮҜӮйӮМӮӘүрӮБӮДӮДӮаҸoӮіӮИӮ«ӮбӮўӮҜӮИӮўӮұӮЖӮНӮ ӮйӮсӮҫӮЛҒB
PaxvilleӮрҸoӮөӮҪӮЖӮ«ӮМIntelӮӘӮұӮсӮИҠҙӮ¶ӮҫҒB
200 ҒF–јҸМ–ўҗЭ’иҒF2009/05/05(үО) 19:05:00 ID:poX4wJ0s0
300•Ҫ•ыmmӮрҗШӮйNehalem-EPӮЙҒA400•Ҫ•ыmmӢЯӮўIstanbulӮЕҗнӮнӮҙӮйӮр“ҫӮИӮўӮБӮДӮұӮЖӮұӮлӮӘ
AMDӮМӢкӮөӮўӮЖӮұӮлӮҫӮлӮӨӮИҒB
ҚЕҲ«Magny-CoursӮЕӮ·ӮзҒAGulftownӮЙ‘ОӮөӮД‘еӮ«Ӯӯҗ«”\ӮрҸгүсӮкӮИӮўӮБӮДӮұӮЖӮЙӮИӮиӮ©ӮЛӮИӮўӮөҒB
AMDӮМӢкӮөӮўӮЖӮұӮлӮҫӮлӮӨӮИҒB
ҚЕҲ«Magny-CoursӮЕӮ·ӮзҒAGulftownӮЙ‘ОӮөӮД‘еӮ«Ӯӯҗ«”\ӮрҸгүсӮкӮИӮўӮБӮДӮұӮЖӮЙӮИӮиӮ©ӮЛӮИӮўӮөҒB
201 ҒF–јҸМ–ўҗЭ’иҒF2009/05/05(үО) 19:33:40 ID:T/MjLTGc0
>ҚЕҲ«Magny-CoursӮЕӮ·ӮзҒAGulftownӮЙ‘ОӮөӮД‘еӮ«Ӯӯҗ«”\ӮрҸгүсӮкӮИӮў
‘еӮ«ӮӯҸгүсӮйӮЗӮұӮлӮ©“Ҝ“ҷӮИӮз–ЧӮҜӮаӮсҒB
6ғRғAӮЕ2.4GHzӮИӮз12ғRғAӮН2.0GHz’ц“xҒB
—қҳ_үүҺZҗ«”\ӮЕӮа66%ӮөӮ©ҸгӮӘӮзӮИӮўҒB
Istanbul 2.4GHzӮМSPECint_rate_base2006ӮН184
ttp://finance.yahoo.com/news/AMD-Offers-Glimpse-of-the-bw-15002136.html
Nehalem-EP 2.93GHzӮМSPECint_rate_base2006ӮН240
ttp://www.spec.org/cpu2006/results/res2009q1/cpu2006-20090313-06653.htm
GulftownӮН32nmғvғҚғZғXӮҫӮӘIstanbul“Ҝ—lғNғҚғbғNӮӘүәӮӘӮБӮД30%ӮөӮ©җ«”\ӮӘҢьҸгӮөӮИӮ©ӮБӮҪ(җ»‘ўғvғҚғZғXӮЖӮөӮДӮН90nm PrescottӢүӮМҺё”s)ӮЖүј’иӮөӮДӮаҒA
184 * 1.7 = 312.8 (‘ҪӮЯӮЙҢ©җПӮаӮБӮҪMagny-CoursӮМҗ«”\)
240 * 1.3 = 312 (ӢЙӮЯӮД”ЯҠП“IӮЙҢ©җПӮаӮБӮҪWestmere-EPӮМҗ«”\)
FB-DIMM2@4chӮЙ24MBӮМL3ғLғғғbғVғ…Ӯр”хӮҰӮйBecktonӮӘ‘ҠҺиӮҫӮЖӮЁҳbӮЙӮИӮзӮИӮўӮЕӮ ӮлӮӨӮұӮЖӮНүОӮрҢ©ӮйӮжӮи–ҫӮзӮ©ҒB
‘еӮ«ӮӯҸгүсӮйӮЗӮұӮлӮ©“Ҝ“ҷӮИӮз–ЧӮҜӮаӮсҒB
6ғRғAӮЕ2.4GHzӮИӮз12ғRғAӮН2.0GHz’ц“xҒB
—қҳ_үүҺZҗ«”\ӮЕӮа66%ӮөӮ©ҸгӮӘӮзӮИӮўҒB
Istanbul 2.4GHzӮМSPECint_rate_base2006ӮН184
ttp://finance.yahoo.com/news/AMD-Offers-Glimpse-of-the-bw-15002136.html
Nehalem-EP 2.93GHzӮМSPECint_rate_base2006ӮН240
ttp://www.spec.org/cpu2006/results/res2009q1/cpu2006-20090313-06653.htm
GulftownӮН32nmғvғҚғZғXӮҫӮӘIstanbul“Ҝ—lғNғҚғbғNӮӘүәӮӘӮБӮД30%ӮөӮ©җ«”\ӮӘҢьҸгӮөӮИӮ©ӮБӮҪ(җ»‘ўғvғҚғZғXӮЖӮөӮДӮН90nm PrescottӢүӮМҺё”s)ӮЖүј’иӮөӮДӮаҒA
184 * 1.7 = 312.8 (‘ҪӮЯӮЙҢ©җПӮаӮБӮҪMagny-CoursӮМҗ«”\)
240 * 1.3 = 312 (ӢЙӮЯӮД”ЯҠП“IӮЙҢ©җПӮаӮБӮҪWestmere-EPӮМҗ«”\)
FB-DIMM2@4chӮЙ24MBӮМL3ғLғғғbғVғ…Ӯр”хӮҰӮйBecktonӮӘ‘ҠҺиӮҫӮЖӮЁҳbӮЙӮИӮзӮИӮўӮЕӮ ӮлӮӨӮұӮЖӮНүОӮрҢ©ӮйӮжӮи–ҫӮзӮ©ҒB
202 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/05/05(үО) 20:15:01 ID:EvzAltmX0
ӮЖӮұӮлӮЕҺ©Қм”ВӮЙӮўӮйMACғIғҸғ^(ғyғjғXҒjҢNӮМ—тү»ӢпҚҮӮӘӮ©ӮИӮиҚ“ӮўӮсӮҫӮӘҒB
ӢZҸp“IӮИҳb‘иӮЙӮИӮйӮЖғ{ғҚӮӘҸoӮЬӮӯӮйӮМӮНҗМӮ©ӮзӮИӮМӮ©ҒH
ӢZҸp“IӮИҳb‘иӮЙӮИӮйӮЖғ{ғҚӮӘҸoӮЬӮӯӮйӮМӮНҗМӮ©ӮзӮИӮМӮ©ҒH
203 ҒF–јҸМ–ўҗЭ’иҒF2009/05/06(җ…) 00:42:34 ID:OUVy38h00
>>199
> ғNғҚғbғNҒ•“dҲіӮр7Ҡ„’ц“xӮЙ—}ӮҰӮкӮО
ҚЎҺһ“dҲіӮНӮ»ӮсӮИӮЙүәӮ°ӮзӮкӮИӮўӮж
үәӮ°ӮйӮЖғҠҒ[ғN“d—¬ӮӘӮҰӮзӮўӮұӮЖӮЙӮИӮй
> ғNғҚғbғNҒ•“dҲіӮр7Ҡ„’ц“xӮЙ—}ӮҰӮкӮО
ҚЎҺһ“dҲіӮНӮ»ӮсӮИӮЙүәӮ°ӮзӮкӮИӮўӮж
үәӮ°ӮйӮЖғҠҒ[ғN“d—¬ӮӘӮҰӮзӮўӮұӮЖӮЙӮИӮй
204 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/05/06(җ…) 00:44:42 ID:NKsKejrK0
Ӯ¶ӮбӮ “dҲіӮр9Ҡ„ӢӯҒAғNғҚғbғN6Ҡ„ӮӯӮзӮўӮ©ӮИҒB
ӮЬӮ ҒAӮРӮЗӮўӮұӮЖӮЙӮИӮйӮИҒB
ӮЬӮ ҒAӮРӮЗӮўӮұӮЖӮЙӮИӮйӮИҒB
205 ҒF–јҸМ–ўҗЭ’иҒF2009/05/06(җ…) 01:07:06 ID:ytJd2eQd0
>ӮЬӮ ҒAӮРӮЗӮўӮұӮЖӮЙӮИӮйӮИҒB
ғҸғҚғ^
ҸОӮҰӮйҸуӢөӮ¶ӮбӮИӮўӮсӮҫӮӘҒAӮИӮәӮ©ғҸғҚғ^
ғҸғҚғ^
ҸОӮҰӮйҸуӢөӮ¶ӮбӮИӮўӮсӮҫӮӘҒAӮИӮәӮ©ғҸғҚғ^
206 ҒF–јҸМ–ўҗЭ’иҒF2009/05/06(җ…) 01:13:27 ID:Kjx6YeSY0
Ғb695 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/05/06(җ…) 00:01:31 ID:YebxnnTm
ҒbғQҒ[ғҖү®•—ҸоӮӘҲМӮ»ӮӨӮЙ
Ӯ Ӯ ҒAӮ»ӮӨӮҫӮИҒB
Ғi‘еҠйӢЖiӮМҒjғQҒ[ғҖү®•—ҸоҒi•”–еҒjӮӘҲМӮ»ӮӨӮЙӮ·ӮйӮМӮаӢCӮЙҸбӮйӮжӮИҒB
http://software.intel.com/sites/billboard/index.php
http://software.intel.com/en-us/articles/michael-abrash-biography/
http://software.intel.com/en-us/articles/tom-forsyth-bio/
http://software.intel.com/en-us/articles/quake-wars-gets-ray-traced/
http://www.projectoffset.com/
ҒbғQҒ[ғҖү®•—ҸоӮӘҲМӮ»ӮӨӮЙ
Ӯ Ӯ ҒAӮ»ӮӨӮҫӮИҒB
Ғi‘еҠйӢЖiӮМҒjғQҒ[ғҖү®•—ҸоҒi•”–еҒjӮӘҲМӮ»ӮӨӮЙӮ·ӮйӮМӮаӢCӮЙҸбӮйӮжӮИҒB
http://software.intel.com/sites/billboard/index.php
http://software.intel.com/en-us/articles/michael-abrash-biography/
http://software.intel.com/en-us/articles/tom-forsyth-bio/
http://software.intel.com/en-us/articles/quake-wars-gets-ray-traced/
http://www.projectoffset.com/
207 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/05/06(җ…) 03:30:54 ID:NKsKejrK0
ӮЗӮұӮЕIntelӮӘҸoӮДӮӯӮйӮсӮҫҒHӮ—Ӯ—
208 ҒF–јҸМ–ўҗЭ’иҒF2009/05/06(җ…) 03:34:28 ID:7ZIGg+XY0
Intel—lӮЙғPғ“ғJӮр”„Ӯй’cҺq
209 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/05/06(җ…) 03:34:36 ID:NKsKejrK0
> 650 –ј‘OҒFSocket774[sage] “ҠҚe“ъҒF2009/05/05(үО) 02:07:09 ID:DxOnYt1N
> >>642
> WWSӮМ“аҸоӮЙӮВӮўӮД’mӮзӮИӮўӮМӮӘӮНӮБӮ«ӮиӮөӮҪҒB—ЗӮ©ӮБӮҪҒB
>
> 652 –ј‘OҒFSocket774[sage] “ҠҚe“ъҒF2009/05/05(үО) 02:19:37 ID:DxOnYt1N
> Ӯ»ӮӨӮҫӮЛҒBGDC—ҲӮкӮОӮжӮ©ӮБӮҪӮМӮЙӮЛҒB
>
> 694 –ј‘OҒFSocket774[sage] “ҠҚe“ъҒF2009/05/05(үО) 23:59:56 ID:DxOnYt1N
> ӮЩӮсӮЖ’ҙҲкӢүӮМ—gӮ°‘«ҺжӮиӮҫӮИ
ӮұӮўӮВӮҫӮл
IntelӮЙWWSӮИӮсӮД•”–еӮНӮИӮўӮжҒBғ\ғjҒ[ӮМPS•”–еӮЙӮНӮ ӮйӮҜӮЗ
> >>642
> WWSӮМ“аҸоӮЙӮВӮўӮД’mӮзӮИӮўӮМӮӘӮНӮБӮ«ӮиӮөӮҪҒB—ЗӮ©ӮБӮҪҒB
>
> 652 –ј‘OҒFSocket774[sage] “ҠҚe“ъҒF2009/05/05(үО) 02:19:37 ID:DxOnYt1N
> Ӯ»ӮӨӮҫӮЛҒBGDC—ҲӮкӮОӮжӮ©ӮБӮҪӮМӮЙӮЛҒB
>
> 694 –ј‘OҒFSocket774[sage] “ҠҚe“ъҒF2009/05/05(үО) 23:59:56 ID:DxOnYt1N
> ӮЩӮсӮЖ’ҙҲкӢүӮМ—gӮ°‘«ҺжӮиӮҫӮИ
ӮұӮўӮВӮҫӮл
IntelӮЙWWSӮИӮсӮД•”–еӮНӮИӮўӮжҒBғ\ғjҒ[ӮМPS•”–еӮЙӮНӮ ӮйӮҜӮЗ
210 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/05/06(җ…) 03:41:02 ID:NKsKejrK0
–{җlӮҪӮҝӮЙӮөӮ©ӮнӮ©ӮзӮИӮўғAғiғOғүғҖӮрҺdҚһӮсӮЕүһҸVӮрҢJӮиҚLӮ°ӮДӮйӮМӮЕ
ҲкүоӮМMacҺgӮўӮЙӮ·Ӯ¬ӮИӮўӮЁӮЬӮўӮзӮЙӮвӮиҺжӮиӮМҲУ–ЎӮӘӮнӮ©ӮйӮнӮҜӮӘӮЛӮҘ
ҲкүоӮМMacҺgӮўӮЙӮ·Ӯ¬ӮИӮўӮЁӮЬӮўӮзӮЙӮвӮиҺжӮиӮМҲУ–ЎӮӘӮнӮ©ӮйӮнӮҜӮӘӮЛӮҘ
211 ҒF–јҸМ–ўҗЭ’иҒF2009/05/06(җ…) 06:53:20 ID:sEHrBwfw0
Intel buys into chip tool firm
http://www.theinquirer.net/inquirer/news/1052013/intel-buys-chip-tool-firm
GT300 delayed till 2010
http://www.theinquirer.net/inquirer/news/1052025/gt300-delayed-till-2010
Itanium Aims for the Mainstream
http://www.internetnews.com/hardware/article.php/3818676/Itanium%20Aims%20for%20the%20Mainstream.htm
http://www.theinquirer.net/inquirer/news/1052013/intel-buys-chip-tool-firm
GT300 delayed till 2010
http://www.theinquirer.net/inquirer/news/1052025/gt300-delayed-till-2010
Itanium Aims for the Mainstream
http://www.internetnews.com/hardware/article.php/3818676/Itanium%20Aims%20for%20the%20Mainstream.htm
212 ҒF–јҸМ–ўҗЭ’иҒF2009/05/08(Ӣа) 03:01:42 ID:ONjcgzm+0
http://aceshardware.freeforums.org/itanium-aims-for-the-mainstream-t822.html
The real story of Tukwila is how it well it scales up in performance
at 8, 16, 32, and 64 sockets. A 4s Tukwila box may only be 2.5x-3x
better than a 4s Montvale box but a 64s Tukwila Superdome may
outperform the 64s Montvale Superdome by 4x-5x or more.
Itanium 9150M 1.66 GHz x16
1,354,086tpmC
http://www.tpc.org/tpcc/results/tpcc_result_detail.asp?id=108112401
Itanium 9150M 1.66 GHz x32
2,382,032tpmC
http://www.tpc.org/tpcc/results/tpcc_result_detail.asp?id=108120401
Itanium 9050 1.60 GHz x64
4,092,799tpmC
http://www.tpc.org/tpcc/results/tpcc_result_detail.asp?id=107022701
POWER6 5.0 GHz x32
6,085,166tpmC
http://www.tpc.org/tpcc/results/tpcc_result_detail.asp?id=108061001
The real story of Tukwila is how it well it scales up in performance
at 8, 16, 32, and 64 sockets. A 4s Tukwila box may only be 2.5x-3x
better than a 4s Montvale box but a 64s Tukwila Superdome may
outperform the 64s Montvale Superdome by 4x-5x or more.
Itanium 9150M 1.66 GHz x16
1,354,086tpmC
http://www.tpc.org/tpcc/results/tpcc_result_detail.asp?id=108112401
Itanium 9150M 1.66 GHz x32
2,382,032tpmC
http://www.tpc.org/tpcc/results/tpcc_result_detail.asp?id=108120401
Itanium 9050 1.60 GHz x64
4,092,799tpmC
http://www.tpc.org/tpcc/results/tpcc_result_detail.asp?id=107022701
POWER6 5.0 GHz x32
6,085,166tpmC
http://www.tpc.org/tpcc/results/tpcc_result_detail.asp?id=108061001
213 ҒF–јҸМ–ўҗЭ’иҒF2009/05/08(Ӣа) 23:12:40 ID:b96YzYYX0
The Core 2 Quad Q8400: Intel's $183 Phenom II 940 Competitor
http://www.anandtech.com/cpuchipsets/intel/showdoc.aspx?i=3559&p=1
ғCғ“ғeғӢӮЖғmғxғӢҒAғӮғoғCғӢӢ@ҠнҢьӮҜOSҒuMoblinҒvӮМҗ„җiӮЕӢҰ—Н
http://japan.cnet.com/mobile/story/0,3800078151,20392798,00.htm
http://www.anandtech.com/cpuchipsets/intel/showdoc.aspx?i=3559&p=1
ғCғ“ғeғӢӮЖғmғxғӢҒAғӮғoғCғӢӢ@ҠнҢьӮҜOSҒuMoblinҒvӮМҗ„җiӮЕӢҰ—Н
http://japan.cnet.com/mobile/story/0,3800078151,20392798,00.htm
214 ҒF–јҸМ–ўҗЭ’иҒF2009/05/09(“y) 13:15:05 ID:J0Xs5Dm50
x86ӮЕӮМIntegrated Memory ControllerӮНғ}ғWӮЕIntelӮӘҢі‘cӮҫӮБӮҪӮзӮөӮўҒEҒEҒE
ttp://www.cpu-world.com/CPUs/80386/
>80386SL - low-power microprocessor with power management features, with
>16-bit external data bus and 24-bit external address bus.
>The processor included ISA bus controller, memory controller and cache controller.
ttp://www.cpu-world.com/CPUs/80386/
>80386SL - low-power microprocessor with power management features, with
>16-bit external data bus and 24-bit external address bus.
>The processor included ISA bus controller, memory controller and cache controller.
215 ҒF–јҸМ–ўҗЭ’иҒF2009/05/11(ҢҺ) 01:26:58 ID:MzhiD89l0
216 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/05/13(җ…) 21:46:07 ID:fQy4e05I0
“дӮМҗVx86ғ`ғbғvҒAXcore86ҒB
—dӮөӮўӮМ‘еҚDӮ«ҒB
713 ҒF[Fn]Ғ{[–ј–іӮөӮіӮс] [ҒӘ] ҒF2009/05/13(җ…) 21:13:56 ID:CsL/jUtu
Gecko EduBookӮЙҸжӮБӮДӮйXcore86ӮБӮДӮвӮВӮНҒA
ttp://xcore.weebly.com/technology.html
ttp://www.vortex86dx.com/
IntelӮвAMDӮЙ‘ОҚRӮ·ӮйӮаӮсӮ¶ӮбӮИӮўӮЖӮНҸ‘ӮўӮДӮ ӮйӮӘҒA
ӮұӮкӮБӮДҺАҚЫҺА—НӮНӮЗӮсӮИғӮғ“ӮҫӮлӮӨӮЛҒB
‘јӮЙҚМ—pғmҒ[ғgӮӘҢ©ӮВӮ©ӮзӮИӮўӮөҒB
—dӮөӮўӮМ‘еҚDӮ«ҒB
713 ҒF[Fn]Ғ{[–ј–іӮөӮіӮс] [ҒӘ] ҒF2009/05/13(җ…) 21:13:56 ID:CsL/jUtu
Gecko EduBookӮЙҸжӮБӮДӮйXcore86ӮБӮДӮвӮВӮНҒA
ttp://xcore.weebly.com/technology.html
ttp://www.vortex86dx.com/
IntelӮвAMDӮЙ‘ОҚRӮ·ӮйӮаӮсӮ¶ӮбӮИӮўӮЖӮНҸ‘ӮўӮДӮ ӮйӮӘҒA
ӮұӮкӮБӮДҺАҚЫҺА—НӮНӮЗӮсӮИғӮғ“ӮҫӮлӮӨӮЛҒB
‘јӮЙҚМ—pғmҒ[ғgӮӘҢ©ӮВӮ©ӮзӮИӮўӮөҒB
217 ҒF–јҸМ–ўҗЭ’иҒF2009/05/13(җ…) 21:49:04 ID:fsZZzXwq0
{kind=link}
218 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/05/13(җ…) 21:56:29 ID:fQy4e05I0
>>217
ӮИӮсӮҫmP6ӮМҢn•ҲӮ©ҒB
ӮИӮсӮҫmP6ӮМҢn•ҲӮ©ҒB
219 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/05/13(җ…) 22:05:41 ID:fQy4e05I0
http://www.legitreviews.com/images/reviews/726/die_overlay.jpg
GTX280ӮМғ_ғCӮрүьӮЯӮДӮЭӮДҺvӮБӮҪҒB
ғeғNғXғ`ғғғҶғjғbғgӮМ–КҗП”дӮӘӢЙ’[ӮЙҸ¬ӮіӮўӮ ӮўӮВӮН
RGPӮЖӮөӮДӮМҗ«”\ӮНҚlӮҰӮҝӮбӮўӮИӮўӮсӮҫӮЖҒB
{kind=link}
GTX280ӮМғ_ғCӮрүьӮЯӮДӮЭӮДҺvӮБӮҪҒB
ғeғNғXғ`ғғғҶғjғbғgӮМ–КҗП”дӮӘӢЙ’[ӮЙҸ¬ӮіӮўӮ ӮўӮВӮН
RGPӮЖӮөӮДӮМҗ«”\ӮНҚlӮҰӮҝӮбӮўӮИӮўӮсӮҫӮЖҒB
220 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/05/13(җ…) 22:18:27 ID:fQy4e05I0
’КҸнҒAGPUӮМҚ\җ¬ӮНғҢғ“ғ_ғҠғ“ғOғpғCғvӮМҸҲ—қӮр‘ШӮиӮИӮӯҚsӮӨӮҪӮЯҒA
Ҳк”К“IӮИғQҒ[ғҖғOғүғtғBғbғNғXғAғvғҠӮЕғlғbғNӮӘ”ӯҗ¶ӮөӮИӮўӮжӮӨӮЙғҠғ\Ғ[ғXӮӘғoғүғ“ғX
ӮіӮкӮДӮўӮйҒB
Ҹ]ӮБӮДҒAғeғNғXғ`ғғғҶғjғbғgӮМғXғӢҒ[ғvғbғgӮӘ–ҫӮзӮ©ӮЙӮИӮкӮО
Ӯ»ӮМӮЬӮЬRGPӮЖӮөӮДӮМҗ«”\ӮрӮЩӮЪҗ„Ӯө—КӮйӮұӮЖӮӘӮЕӮ«ӮйҒB
LarrabeeӮНҚЕӢЯӮМIntelғ`ғbғvӮЙӮөӮДӮНҒAI/O—ЮӮвғLғғғbғVғ…Ӯа–Ъ—§ӮҪӮИӮўҒB
–{җSӮНHPCҢьӮҜӮМҗЭҢvӮИӮМӮ©ҒAүүҺZҠнҲЩҸн“Бү»ӮЕTflopsӢүӮрүҪӮӘүҪӮЕӮаҸoӮөӮҪӮўӮҫӮҜӮҫӮБӮҪӮМӮ©ҒB
ӮўӮвҒAӮЁӮкӮМ—\‘zӮӘ—ЗӮў•ыҢьӮЙҢ©Һ–ӮЙӮНӮёӮкӮйӮұӮЖӮЙҠъ‘ТӮөӮДӮўӮЬӮ·ӮӘӮЛҒB
Ҳк”К“IӮИғQҒ[ғҖғOғүғtғBғbғNғXғAғvғҠӮЕғlғbғNӮӘ”ӯҗ¶ӮөӮИӮўӮжӮӨӮЙғҠғ\Ғ[ғXӮӘғoғүғ“ғX
ӮіӮкӮДӮўӮйҒB
Ҹ]ӮБӮДҒAғeғNғXғ`ғғғҶғjғbғgӮМғXғӢҒ[ғvғbғgӮӘ–ҫӮзӮ©ӮЙӮИӮкӮО
Ӯ»ӮМӮЬӮЬRGPӮЖӮөӮДӮМҗ«”\ӮрӮЩӮЪҗ„Ӯө—КӮйӮұӮЖӮӘӮЕӮ«ӮйҒB
LarrabeeӮНҚЕӢЯӮМIntelғ`ғbғvӮЙӮөӮДӮНҒAI/O—ЮӮвғLғғғbғVғ…Ӯа–Ъ—§ӮҪӮИӮўҒB
–{җSӮНHPCҢьӮҜӮМҗЭҢvӮИӮМӮ©ҒAүүҺZҠнҲЩҸн“Бү»ӮЕTflopsӢүӮрүҪӮӘүҪӮЕӮаҸoӮөӮҪӮўӮҫӮҜӮҫӮБӮҪӮМӮ©ҒB
ӮўӮвҒAӮЁӮкӮМ—\‘zӮӘ—ЗӮў•ыҢьӮЙҢ©Һ–ӮЙӮНӮёӮкӮйӮұӮЖӮЙҠъ‘ТӮөӮДӮўӮЬӮ·ӮӘӮЛҒB
221 ҒF–јҸМ–ўҗЭ’иҒF2009/05/15(Ӣа) 00:13:04 ID:8Hv+adcI0
69. GRAPE-DR ӮМ HPL ҺАҢшҗ«”\ (2009/5/9Ҹ‘Ӯ«Ӯ©ӮҜ)
70. Һҹҗў‘гғXҒ[ғpҒ[ғRғ“ғsғ…Ғ[ғ^Ғ[ҢvүжҢ©’јӮө (2009/5/14)
70. Һҹҗў‘гғXҒ[ғpҒ[ғRғ“ғsғ…Ғ[ғ^Ғ[ҢvүжҢ©’јӮө (2009/5/14)
222 ҒF–јҸМ–ўҗЭ’иҒF2009/05/16(“y) 09:51:16 ID:l8wOeGFa0
>>220
>’КҸнҒAGPUӮМҚ\җ¬ӮНғҢғ“ғ_ғҠғ“ғOғpғCғvӮМҸҲ—қӮр‘ШӮиӮИӮӯҚsӮӨӮҪӮЯҒA
>Ҳк”К“IӮИғQҒ[ғҖғOғүғtғBғbғNғXғAғvғҠӮЕғlғbғNӮӘ”ӯҗ¶ӮөӮИӮўӮжӮӨӮЙғҠғ\Ғ[ғXӮӘғoғүғ“ғX
>ӮіӮкӮДӮўӮйҒB
ҺАӮНӮұӮкӮНғ}ғ„ғJғVӮҫӮЖӮўӮӨӮМӮӘLarrabee: A Many-Core x86 Architecture for Visual ComputingӮЕҺw“EӮіӮкӮДӮўӮйӮнӮҜӮҫӮӘ
>’КҸнҒAGPUӮМҚ\җ¬ӮНғҢғ“ғ_ғҠғ“ғOғpғCғvӮМҸҲ—қӮр‘ШӮиӮИӮӯҚsӮӨӮҪӮЯҒA
>Ҳк”К“IӮИғQҒ[ғҖғOғүғtғBғbғNғXғAғvғҠӮЕғlғbғNӮӘ”ӯҗ¶ӮөӮИӮўӮжӮӨӮЙғҠғ\Ғ[ғXӮӘғoғүғ“ғX
>ӮіӮкӮДӮўӮйҒB
ҺАӮНӮұӮкӮНғ}ғ„ғJғVӮҫӮЖӮўӮӨӮМӮӘLarrabee: A Many-Core x86 Architecture for Visual ComputingӮЕҺw“EӮіӮкӮДӮўӮйӮнӮҜӮҫӮӘ
223 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/05/16(“y) 14:17:12 ID:dC0nnAgF0
ӮЬӮвӮ©ӮөӮИӮсӮДҸ‘ӮўӮДӮИӮўӮҫӮлҒB
Ӯ»ӮкӮЖӮН•КӮЙLarrabeeӮНҠeғҢғ“ғ_ғҠғ“ғOғpғCғvҸгӮМҸҲ—қӮрғ\ғtғgғEғGғAӮЖғvғҚғOғүғҖҗ«ӮМҚӮӮўғRғAӮЕ
“®“IғҚҒ[ғhғoғүғ“ғVғ“ғOӮөӮИӮӘӮзҸҲ—қҸo—ҲӮйӮМӮ©ӮзҒAғҠғ\Ғ[ғXӮМғoғүғ“ғXӮ©Ӯз‘е•”•Ә
үр•ъӮіӮкӮДӮўӮйӮМӮӘ”„Ӯ蕶ӢеӮМӮжӮӨӮҫӮӘҒAғeғNғXғ`ғғғҶғjғbғgӮНҢЕ’иӢ@”\ӮЕӮ»ӮМ—бҠOӮИӮсӮҫӮжҒB
ӮВӮЬӮиҒAGPUӮаLRBӮаҢЕ’иӮЕҺқӮБӮДӮўӮйғeғNғXғ`ғғғҶғjғbғg•Ә—КӮМ”дҠrӮЕ
ӮЁӮжӮ»ӮМҗ«”\ӮӘҗ„‘ӘӮЕӮ«ӮйӮМӮұӮЖӮН•ПӮнӮзӮИӮўҒB
Ӯ»ӮкӮЖӮН•КӮЙLarrabeeӮНҠeғҢғ“ғ_ғҠғ“ғOғpғCғvҸгӮМҸҲ—қӮрғ\ғtғgғEғGғAӮЖғvғҚғOғүғҖҗ«ӮМҚӮӮўғRғAӮЕ
“®“IғҚҒ[ғhғoғүғ“ғVғ“ғOӮөӮИӮӘӮзҸҲ—қҸo—ҲӮйӮМӮ©ӮзҒAғҠғ\Ғ[ғXӮМғoғүғ“ғXӮ©Ӯз‘е•”•Ә
үр•ъӮіӮкӮДӮўӮйӮМӮӘ”„Ӯ蕶ӢеӮМӮжӮӨӮҫӮӘҒAғeғNғXғ`ғғғҶғjғbғgӮНҢЕ’иӢ@”\ӮЕӮ»ӮМ—бҠOӮИӮсӮҫӮжҒB
ӮВӮЬӮиҒAGPUӮаLRBӮаҢЕ’иӮЕҺқӮБӮДӮўӮйғeғNғXғ`ғғғҶғjғbғg•Ә—КӮМ”дҠrӮЕ
ӮЁӮжӮ»ӮМҗ«”\ӮӘҗ„‘ӘӮЕӮ«ӮйӮМӮұӮЖӮН•ПӮнӮзӮИӮўҒB
224 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/05/16(“y) 14:30:26 ID:dC0nnAgF0
LRBӮНҒAҸ]—ҲӮМGPUӮМғvғҚғZғbғTғRғAӮжӮиӮа”Д—pҗ«ӮӘҚӮӮӯӮДҒA
ғ\ғtғgӮЕӮаӮБӮЖҸ_“оӮЙ“®“IҺgӮў•ӘӮҜӮӘӮЕӮ«ӮйӮсӮҫӮҜӮЗҒA
ғ_ғCӮрӮЭӮйӮЖҒALRBӮМғvғҚғZғbғTғRғAӮМ–КҗП”дӮӘҲЩҸнӮЙӮЁӮЁӮ«ӮӯҒA
ғeғNғXғ`ғғғҶғjғbғgӮМ–КҗПӮӘ”сҸнӮЙҸ¬ӮіӮўҒB
Ҹ_“оҗ«ӮӘӮ ӮБӮДӮа–КҗПӮӘҸ¬ӮіӮӯӮЕӮ«ӮИӮҜӮиӮбҢӢүКӮНҲУ–ЎӮИӮўӮжӮЛҒB
ғeғNғXғ`ғғғҶғjғbғgӮМ–КҗП”дӮМҸ¬ӮіӮіӮНҒAғ_ғCӮМ‘е•”•ӘӮрҗиӮЯӮйғvғҚғZғbғTғRғA
ӮМ–КҗПӮ ӮҪӮиӮМғXғӢҒ[ғvғbғgӮӘRGP“IҸҲ—қӮрӮөӮДӮўӮйҺһӮЙ‘еӮөӮҪӮұӮЖӮӘӮИӮў
ӮЖӮўӮӨӮұӮЖӮМҸШ–ҫӮИӮсӮҫӮжҒB
ӮұӮМҢӢүКӮрҚDҲУ“IӮЙүрҺЯӮөӮҪҢӢүКӮӘҒA—қҳ_flopsӮрҸdҺӢӮөӮҪғ}Ғ[ғPғ`ғ“ғOҢьӮҜҗ»•iӮ©ҒA
RGPӮЖӮөӮДӮМ—p“rӮИӮсӮДҚЕҸүӮ©ӮзҚlӮҰӮДӮИӮўӮБӮДӮұӮЖӮҫҒB
ғ\ғtғgӮЕӮаӮБӮЖҸ_“оӮЙ“®“IҺgӮў•ӘӮҜӮӘӮЕӮ«ӮйӮсӮҫӮҜӮЗҒA
ғ_ғCӮрӮЭӮйӮЖҒALRBӮМғvғҚғZғbғTғRғAӮМ–КҗП”дӮӘҲЩҸнӮЙӮЁӮЁӮ«ӮӯҒA
ғeғNғXғ`ғғғҶғjғbғgӮМ–КҗПӮӘ”сҸнӮЙҸ¬ӮіӮўҒB
Ҹ_“оҗ«ӮӘӮ ӮБӮДӮа–КҗПӮӘҸ¬ӮіӮӯӮЕӮ«ӮИӮҜӮиӮбҢӢүКӮНҲУ–ЎӮИӮўӮжӮЛҒB
ғeғNғXғ`ғғғҶғjғbғgӮМ–КҗП”дӮМҸ¬ӮіӮіӮНҒAғ_ғCӮМ‘е•”•ӘӮрҗиӮЯӮйғvғҚғZғbғTғRғA
ӮМ–КҗПӮ ӮҪӮиӮМғXғӢҒ[ғvғbғgӮӘRGP“IҸҲ—қӮрӮөӮДӮўӮйҺһӮЙ‘еӮөӮҪӮұӮЖӮӘӮИӮў
ӮЖӮўӮӨӮұӮЖӮМҸШ–ҫӮИӮсӮҫӮжҒB
ӮұӮМҢӢүКӮрҚDҲУ“IӮЙүрҺЯӮөӮҪҢӢүКӮӘҒA—қҳ_flopsӮрҸdҺӢӮөӮҪғ}Ғ[ғPғ`ғ“ғOҢьӮҜҗ»•iӮ©ҒA
RGPӮЖӮөӮДӮМ—p“rӮИӮсӮДҚЕҸүӮ©ӮзҚlӮҰӮДӮИӮўӮБӮДӮұӮЖӮҫҒB
225 ҒF–јҸМ–ўҗЭ’иҒF2009/05/16(“y) 15:17:12 ID:l8wOeGFa0
>ӮЬӮвӮ©ӮөӮИӮсӮДҸ‘ӮўӮДӮИӮўӮҫӮлҒB
ғZғbғVғҮғ“5ӮМ4
"Our conclusion is that application dependent resource balancing is not sufficient."
>ғ_ғCӮрӮЭӮйӮЖҒALRBӮМғvғҚғZғbғTғRғAӮМ–КҗП”дӮӘҲЩҸнӮЙӮЁӮЁӮ«ӮӯҒA
>ғeғNғXғ`ғғғҶғjғbғgӮМ–КҗПӮӘ”сҸнӮЙҸ¬ӮіӮўҒB
ttp://i41.tinypic.com/2hcdzja.png
ӮұӮМҺКҗ^ӮрҢ©ӮДҢҫӮБӮДӮўӮйӮМӮҫӮлӮӨӮӘ32KBӮөӮ©ғLғғғbғVғ…ӮрҺқӮҪӮИӮўӮНӮёӮМғeғNғXғ`ғғғҶғjғbғgӮЙ
ғvғҚғZғTғRғA(ӮЖ•ӘҗНӮіӮкӮДӮўӮй)•”•ӘӮжӮи–КҗПӮӘҚLӮўSRAMӮМ—lӮИғpғ^Ғ[ғ“ӮӘӮ ӮйӮсӮҫӮә
Ӯ ӮЬӮи“–ӮДӮЙӮИӮзӮИӮўӮЖҚlӮҰӮй
ғZғbғVғҮғ“3ӮМ5“ЗӮЯӮОӮнӮ©ӮйӮЖҺvӮӨӮӘғvғҚғZғTғRғAӮЖ•Ё—қ“IӮИӢ——ЈӮрӮ ӮҜӮҪӮӯӮИӮўӮҫӮлӮӨӮө
ғeғNғXғ`ғғғҶғjғbғgӮНғvғҚғZғTғRғA(ӮЖ•ӘҗНӮіӮкӮДӮўӮй)•”•ӘӮЙҠЬӮЬӮкӮДӮўӮйӮЖ—\‘z
ӮҝӮИӮЭӮЙRadeonӮЖӮ©GeforceӮМғҢғCғAғEғgӮаӮ»ӮсӮИҠҙӮ¶
ғZғbғVғҮғ“5ӮМ4
"Our conclusion is that application dependent resource balancing is not sufficient."
>ғ_ғCӮрӮЭӮйӮЖҒALRBӮМғvғҚғZғbғTғRғAӮМ–КҗП”дӮӘҲЩҸнӮЙӮЁӮЁӮ«ӮӯҒA
>ғeғNғXғ`ғғғҶғjғbғgӮМ–КҗПӮӘ”сҸнӮЙҸ¬ӮіӮўҒB
ttp://i41.tinypic.com/2hcdzja.png
{kind=link}
ӮұӮМҺКҗ^ӮрҢ©ӮДҢҫӮБӮДӮўӮйӮМӮҫӮлӮӨӮӘ32KBӮөӮ©ғLғғғbғVғ…ӮрҺқӮҪӮИӮўӮНӮёӮМғeғNғXғ`ғғғҶғjғbғgӮЙ
ғvғҚғZғTғRғA(ӮЖ•ӘҗНӮіӮкӮДӮўӮй)•”•ӘӮжӮи–КҗПӮӘҚLӮўSRAMӮМ—lӮИғpғ^Ғ[ғ“ӮӘӮ ӮйӮсӮҫӮә
Ӯ ӮЬӮи“–ӮДӮЙӮИӮзӮИӮўӮЖҚlӮҰӮй
ғZғbғVғҮғ“3ӮМ5“ЗӮЯӮОӮнӮ©ӮйӮЖҺvӮӨӮӘғvғҚғZғTғRғAӮЖ•Ё—қ“IӮИӢ——ЈӮрӮ ӮҜӮҪӮӯӮИӮўӮҫӮлӮӨӮө
ғeғNғXғ`ғғғҶғjғbғgӮНғvғҚғZғTғRғA(ӮЖ•ӘҗНӮіӮкӮДӮўӮй)•”•ӘӮЙҠЬӮЬӮкӮДӮўӮйӮЖ—\‘z
ӮҝӮИӮЭӮЙRadeonӮЖӮ©GeforceӮМғҢғCғAғEғgӮаӮ»ӮсӮИҠҙӮ¶
226 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/05/16(“y) 15:26:40 ID:dC0nnAgF0
>Our conclusion is that application dependent resource balancing is not sufficient.
ӮвӮБӮПӮұӮұӮ©ҒBӮұӮкӢҢ—ҲӮМGPUӮЙ‘ОӮөӮДӮўӮБӮДӮйӮсӮ¶ӮбӮИӮўӮәҒB
Ңҹ“ў’ҶӮМLRBӮЙ‘ОӮөӮДҢҫӮБӮДӮйӮсӮҫӮӘҒBӮЕҒA•sҸ\•ӘӮҫӮ©ӮзҸ_“оӮЙғҚҒ[ғhғoғүғ“ғXӮЕӮ«ӮйӮжӮӨӮЙscatter/gatherӮвӮз
bit-scanӮр’ЗүБӮөӮДӮўӮйӮБӮД—¬ӮкӮҫӮјҒB
>SRAMӮМ—lӮИғpғ^Ғ[ғ“ӮӘӮ ӮйӮсӮҫӮә
Ӯ»ӮМүж‘ңӮМ•ӘҗНӮӘӮЗӮұӮЬӮЕӮ ӮДӮЙӮИӮйӮ©ӮНҠmӮ©ӮЙӮ ӮвӮөӮўӮӘҒA
ӮЁӮкӮЙӮНSRAMӮМ—lӮИғpғ^Ғ[ғ“ӮЙӮНҢ©ӮҰӮИӮўӮЛҒB
ӮвӮБӮПӮұӮұӮ©ҒBӮұӮкӢҢ—ҲӮМGPUӮЙ‘ОӮөӮДӮўӮБӮДӮйӮсӮ¶ӮбӮИӮўӮәҒB
Ңҹ“ў’ҶӮМLRBӮЙ‘ОӮөӮДҢҫӮБӮДӮйӮсӮҫӮӘҒBӮЕҒA•sҸ\•ӘӮҫӮ©ӮзҸ_“оӮЙғҚҒ[ғhғoғүғ“ғXӮЕӮ«ӮйӮжӮӨӮЙscatter/gatherӮвӮз
bit-scanӮр’ЗүБӮөӮДӮўӮйӮБӮД—¬ӮкӮҫӮјҒB
>SRAMӮМ—lӮИғpғ^Ғ[ғ“ӮӘӮ ӮйӮсӮҫӮә
Ӯ»ӮМүж‘ңӮМ•ӘҗНӮӘӮЗӮұӮЬӮЕӮ ӮДӮЙӮИӮйӮ©ӮНҠmӮ©ӮЙӮ ӮвӮөӮўӮӘҒA
ӮЁӮкӮЙӮНSRAMӮМ—lӮИғpғ^Ғ[ғ“ӮЙӮНҢ©ӮҰӮИӮўӮЛҒB
227 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/05/16(“y) 15:31:30 ID:dC0nnAgF0
>ғZғbғVғҮғ“3ӮМ5“ЗӮЯӮОӮнӮ©ӮйӮЖҺvӮӨӮӘғvғҚғZғTғRғAӮЖ•Ё—қ“IӮИӢ——ЈӮрӮ ӮҜӮҪӮӯӮИӮўӮҫӮлӮӨӮө
ӮұӮкғ\ғtғgӮМғuғҚғbғNҗ}ӮҫӮј(ӮнӮзӮЎ ғnҒ[ғhӮМ•Ё—қ“IғҢғCғAғEғgӮЖӮНүҪӮМҠЦҢWӮаӮИӮўҒB
ӮВӮўӮЕӮЙғuғҚғbғNҗ}ӮБӮДӮМӮНғnҒ[ғhӮЙӮөӮлҗЪ‘ұӮӘҺҰӮөӮДӮ ӮйӮҫӮҜӮЕҒA•Ё—қ“IӮИ”z’uӮЖӮНҠЦҢWӮИӮўӮәҒB
ҠЦҢWӮИӮўӮ©ӮзӮұӮ»җ}ӮМҲУ–ЎӮӘӮ ӮйҒB
ӮұӮкғ\ғtғgӮМғuғҚғbғNҗ}ӮҫӮј(ӮнӮзӮЎ ғnҒ[ғhӮМ•Ё—қ“IғҢғCғAғEғgӮЖӮНүҪӮМҠЦҢWӮаӮИӮўҒB
ӮВӮўӮЕӮЙғuғҚғbғNҗ}ӮБӮДӮМӮНғnҒ[ғhӮЙӮөӮлҗЪ‘ұӮӘҺҰӮөӮДӮ ӮйӮҫӮҜӮЕҒA•Ё—қ“IӮИ”z’uӮЖӮНҠЦҢWӮИӮўӮәҒB
ҠЦҢWӮИӮўӮ©ӮзӮұӮ»җ}ӮМҲУ–ЎӮӘӮ ӮйҒB
228 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/05/16(“y) 15:42:11 ID:dC0nnAgF0
>ӮҝӮИӮЭӮЙRadeonӮЖӮ©GeforceӮМғҢғCғAғEғgӮаӮ»ӮсӮИҠҙӮ¶
>>219
http://img.hexus.net/v2/graphics_cards/ati/4850X/Die.png
>>219
http://img.hexus.net/v2/graphics_cards/ati/4850X/Die.png
{kind=link}
229 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/05/16(“y) 15:45:51 ID:dC0nnAgF0
Ӯ Ӯ ҒAӮИӮсӮҫҗ}ӮМ•ыӮ¶ӮбӮИӮўӮМӮ©ҒB
ӮЬӮ ҒAҗ}1ӮрӮЭӮкӮОғeғNғXғ`ғғғҶғjғbғgӮӘRingғoғXҸгӮЙӮФӮзӮіӮӘӮБӮДӮйӮМӮӘӮнӮ©ӮйӮЛҒB
ӮЬӮ ҒAҗ}1ӮрӮЭӮкӮОғeғNғXғ`ғғғҶғjғbғgӮӘRingғoғXҸгӮЙӮФӮзӮіӮӘӮБӮДӮйӮМӮӘӮнӮ©ӮйӮЛҒB
230 ҒF–јҸМ–ўҗЭ’иҒF2009/05/16(“y) 16:51:31 ID:l8wOeGFa0
>>Our conclusion is that application dependent resource balancing is not sufficient.
>ӮвӮБӮПӮұӮұӮ©ҒBӮұӮкӢҢ—ҲӮМGPUӮЙ‘ОӮөӮДӮўӮБӮДӮйӮсӮ¶ӮбӮИӮўӮәҒB
>Ңҹ“ў’ҶӮМLRBӮЙ‘ОӮөӮДҢҫӮБӮДӮйӮсӮҫӮӘҒBӮЕҒA•sҸ\•ӘӮҫӮ©ӮзҸ_“оӮЙғҚҒ[ғhғoғүғ“ғXӮЕӮ«ӮйӮжӮӨӮЙscatter/gatherӮвӮз
>bit-scanӮр’ЗүБӮөӮДӮўӮйӮБӮД—¬ӮкӮҫӮјҒB
ӮҰҒH
>>ӮҝӮИӮЭӮЙRadeonӮЖӮ©GeforceӮМғҢғCғAғEғgӮаӮ»ӮсӮИҠҙӮ¶
>>>219
>http://img.hexus.net/v2/graphics_cards/ati/4850X/Die.png
Ӯ Ӯ ӮӨӮс
ӮұӮкӮНҠФҲбӮБӮДӮўӮҪӮ©Ӯа
>Ӯ»ӮМүж‘ңӮМ•ӘҗНӮӘӮЗӮұӮЬӮЕӮ ӮДӮЙӮИӮйӮ©ӮНҠmӮ©ӮЙӮ ӮвӮөӮўӮӘҒA
ӮЖӮұӮлӮЕҒALarrabeeӮМғeғNғXғ`ғғғҶғjғbғgӮМ–КҗПӮНӮЗӮМ’ц“xӮӘҚЕ“KӮИӮМӮҫӮлӮӨӮ©
RV770ӮЖGT200ӮрҢ©ӮДӮўӮйӮЖӮ ӮЬӮи–КҗПӮрҠ„ӮўӮДӮИӮўRV770ӮЕӮаҗнӮҰӮДӮўӮйӮжӮӨӮҫӮӘ
>ӮвӮБӮПӮұӮұӮ©ҒBӮұӮкӢҢ—ҲӮМGPUӮЙ‘ОӮөӮДӮўӮБӮДӮйӮсӮ¶ӮбӮИӮўӮәҒB
>Ңҹ“ў’ҶӮМLRBӮЙ‘ОӮөӮДҢҫӮБӮДӮйӮсӮҫӮӘҒBӮЕҒA•sҸ\•ӘӮҫӮ©ӮзҸ_“оӮЙғҚҒ[ғhғoғүғ“ғXӮЕӮ«ӮйӮжӮӨӮЙscatter/gatherӮвӮз
>bit-scanӮр’ЗүБӮөӮДӮўӮйӮБӮД—¬ӮкӮҫӮјҒB
ӮҰҒH
>>ӮҝӮИӮЭӮЙRadeonӮЖӮ©GeforceӮМғҢғCғAғEғgӮаӮ»ӮсӮИҠҙӮ¶
>>>219
>http://img.hexus.net/v2/graphics_cards/ati/4850X/Die.png
Ӯ Ӯ ӮӨӮс
ӮұӮкӮНҠФҲбӮБӮДӮўӮҪӮ©Ӯа
>Ӯ»ӮМүж‘ңӮМ•ӘҗНӮӘӮЗӮұӮЬӮЕӮ ӮДӮЙӮИӮйӮ©ӮНҠmӮ©ӮЙӮ ӮвӮөӮўӮӘҒA
ӮЖӮұӮлӮЕҒALarrabeeӮМғeғNғXғ`ғғғҶғjғbғgӮМ–КҗПӮНӮЗӮМ’ц“xӮӘҚЕ“KӮИӮМӮҫӮлӮӨӮ©
RV770ӮЖGT200ӮрҢ©ӮДӮўӮйӮЖӮ ӮЬӮи–КҗПӮрҠ„ӮўӮДӮИӮўRV770ӮЕӮаҗнӮҰӮДӮўӮйӮжӮӨӮҫӮӘ
231 ҒF–јҸМ–ўҗЭ’иҒF2009/05/17(“ъ) 11:19:40 ID:zVHpXr4Z0
AMD shrugs off Intel cross-licensing threat
ttp://news.cnet.com/8301-1001_3-10242421-92.html
ӮаӮӨӮЩӮЖӮсӮЗ–YӮкӮДӮўӮҪҳbӮҫӮӘҠъҢАӮНҚЎ“ъӮЬӮЕӮҫӮБӮҪӮзӮөӮўҒB
ӢЯ“ъ’ҶӮЙҸoӮйӮЕӮ ӮлӮӨIntelӮМғvғҢғXғҠғҠҒ[ғXӮЙ’Қ–ЪӮӘҸWӮЬӮйҒB
ttp://news.cnet.com/8301-1001_3-10242421-92.html
ӮаӮӨӮЩӮЖӮсӮЗ–YӮкӮДӮўӮҪҳbӮҫӮӘҠъҢАӮНҚЎ“ъӮЬӮЕӮҫӮБӮҪӮзӮөӮўҒB
ӢЯ“ъ’ҶӮЙҸoӮйӮЕӮ ӮлӮӨIntelӮМғvғҢғXғҠғҠҒ[ғXӮЙ’Қ–ЪӮӘҸWӮЬӮйҒB
232 ҒF–јҸМ–ўҗЭ’иҒF2009/05/17(“ъ) 12:10:53 ID:fSxqUSJD0
EU“ЖӢЦ–@Ҳб”ҪӮЕӮ»ӮкӮЗӮұӮлӮ¶ӮбӮИӮўӮЁҒI
233 ҒF–јҸМ–ўҗЭ’иҒF2009/05/17(“ъ) 12:31:27 ID:zVHpXr4Z0
ғCғ“ғeғӢCEOҒAҗ§ҚЩӢа14үӯ4,000–ңғhғӢӮЙӢӯӮӯ”Ҫҳ_
ttp://www.computerworld.jp/topics/legal/145570.html
ttp://www.computerworld.com/action/article.do?command=viewArticleBasic&articleId=9133060
ӮұӮкӮ©ҒB
/.jӮМғRғҒғ“ғgҒBҸОӮБӮҪҒB
ttp://slashdot.jp/articles/09/05/14/0456224.shtml
>ӮИӮйӮЩӮЗӮұӮкӮӘEUӮМҢiӢC‘ОҚфӮЕӮ·Ӯ©
ttp://www.computerworld.jp/topics/legal/145570.html
ttp://www.computerworld.com/action/article.do?command=viewArticleBasic&articleId=9133060
ӮұӮкӮ©ҒB
/.jӮМғRғҒғ“ғgҒBҸОӮБӮҪҒB
ttp://slashdot.jp/articles/09/05/14/0456224.shtml
>ӮИӮйӮЩӮЗӮұӮкӮӘEUӮМҢiӢC‘ОҚфӮЕӮ·Ӯ©
234 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/05/18(ҢҺ) 00:02:10 ID:sslgF7jt0
ӮЬӮ ӮЁӮҝӮВӮҜғNғ\ӢӨ
ғXғJғү”ЕӮЖғxғNғgғӢ”Е—ј•ыӮӘ—pҲУӮіӮкӮДӮйғrғbғgғCғ“ғ^Ғ[ғҠҒ[ғuӮвғtғBҒ[ғӢғh‘}“ьӮИӮсӮ©ӮМүүҺZӮН
Ҡо–{“IӮЙғAғhғҢғXҒEғIғtғZғbғgҗ¶җ¬—pӮҫӮИ
ғXғJғү”ЕӮЖғxғNғgғӢ”Е—ј•ыӮӘ—pҲУӮіӮкӮДӮйғrғbғgғCғ“ғ^Ғ[ғҠҒ[ғuӮвғtғBҒ[ғӢғh‘}“ьӮИӮсӮ©ӮМүүҺZӮН
Ҡо–{“IӮЙғAғhғҢғXҒEғIғtғZғbғgҗ¶җ¬—pӮҫӮИ
235 ҒF–јҸМ–ўҗЭ’иҒF2009/05/18(ҢҺ) 00:25:05 ID:HtL6ETbHO
ӮжӮӨҒAғNғ\
236 ҒF–јҸМ–ўҗЭ’иҒF2009/05/18(ҢҺ) 01:14:42 ID:z+Ltl92o0
EUӮМғ^ғJғҠҸӨ”„
237 ҒF–јҸМ–ўҗЭ’иҒF2009/05/18(ҢҺ) 01:26:56 ID:tewePpJv0
“ъ–{ӮЙӮаҢҫӮўӮҪӮўӮӘғAғҒҠйӢЖӮӘӢCӮЙ“ьӮзӮИӮўӮИӮзҚ‘“аҠйӢЖӮЙӮҝӮбӮсӮЖһҢ“ьӮкӮөӮл
Ӣһ‘¬ӮЖӮ©җ§ҚЩӢаӮЖӮ©‘ОүһӮӘ”ј’[Ӯ·Ӯ®Ӯй
Ӣһ‘¬ӮЖӮ©җ§ҚЩӢаӮЖӮ©‘ОүһӮӘ”ј’[Ӯ·Ӯ®Ӯй
238 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/05/18(ҢҺ) 01:59:35 ID:nCvsfnBM0
Ӣһ‘¬ӮБӮДҗ_ҢЛӮҫӮБӮҪӮжӮИ
җ_ҢЛ‘еӮвҚг‘еӮ ӮҪӮиӮаӮөӮОӮзӮӯӢxҚZӮзӮөӮўӮЛҒB
җ_ҢЛ‘еӮвҚг‘еӮ ӮҪӮиӮаӮөӮОӮзӮӯӢxҚZӮзӮөӮўӮЛҒB
239 ҒF–јҸМ–ўҗЭ’иҒF2009/05/20(җ…) 06:31:22 ID:urVaIXEQ0
Nikon: EUV program alive and well
ttp://www.eetimes.com/news/latest/showArticle.jhtml;jsessionid=FC2ROOIRAWU5YQSNDLPCKH0CJUNN2JVN?articleID=217500676
EUVӮМ“ұ“ьӮН22nmҲИҚ~ҒAҺе—¬ӮЙӮИӮйӮМӮН16nmҲИҚ~
Intel's eight-core Nehalem-EX out next week
ttp://www.theinquirer.net/inquirer/news/1137401/intel-core-nehalem-ex
IstanbulӮЙ‘ОҚRӮөӮДPaper LaunchӮ©?
IstanbulӮаPaper LaunchҸLӮўӮӘ
Intel previews Atom 'Pineview' chip, Linux OS
ttp://news.cnet.com/8301-13924_3-10244721-64.html
Intel "Medfield" Platform Targets Smartphone Market
ttp://www.dailytech.com/Intel+Medfield+Platform+Targets+Smartphone+Market/article15160.htm
ttp://www.eetimes.com/news/latest/showArticle.jhtml;jsessionid=FC2ROOIRAWU5YQSNDLPCKH0CJUNN2JVN?articleID=217500676
EUVӮМ“ұ“ьӮН22nmҲИҚ~ҒAҺе—¬ӮЙӮИӮйӮМӮН16nmҲИҚ~
Intel's eight-core Nehalem-EX out next week
ttp://www.theinquirer.net/inquirer/news/1137401/intel-core-nehalem-ex
IstanbulӮЙ‘ОҚRӮөӮДPaper LaunchӮ©?
IstanbulӮаPaper LaunchҸLӮўӮӘ
Intel previews Atom 'Pineview' chip, Linux OS
ttp://news.cnet.com/8301-13924_3-10244721-64.html
Intel "Medfield" Platform Targets Smartphone Market
ttp://www.dailytech.com/Intel+Medfield+Platform+Targets+Smartphone+Market/article15160.htm
240 ҒF–јҸМ–ўҗЭ’иҒF2009/05/20(җ…) 20:25:26 ID:Vw7FNX+z0
ғCғ“ғeғӢҒAғlғbғgғuғbғNҢьӮҜLinuxҒuMoblin 2.0ҒvӮМғxҒ[ғ^”ЕӮрҢцҠJ
http://www.computerworld.jp/topics/netbook/146289.html
ғCғ“ғeғӢҒAҺҹҗў‘гAtomғvғүғbғgғtғHҒ[ғҖҒuPine TrailҒvӮМҠT—vӮр”ӯ•\
http://www.computerworld.jp/topics/netbook/146229.html
ҒyғҢғ|Ғ[ғgҒzғgғүғ“ғWғXғ^ҠJ”ӯӮНIntelӮМғnҒ[ғg - ғCғ“ғeғӢӢyҗмҺҒӮӘҢкӮйCPUӮМғgғҢғ“ғh
http://journal.mycom.co.jp/articles/2009/05/19/esec2009_intel/index.html
ү“ӮҙӮ©ӮйғXғpғRғ“җўҠEҲкӮМҚА
http://www.itmedia.co.jp/enterprise/articles/0905/20/news009.html
ҲкҺРҗ»‘ў‘Мҗ§ӮЕҒAӮжӮиӢӯү»ӮіӮкӮҪӮМӮ©ӮаӮөӮкӮИӮў“ъ–{ӮМҺҹҗў‘гғXғpғRғ“ҠJ”ӯ
http://hpc.livedoor.biz/archives/51440600.html
Ҹҹ•үӮМҚs•ыӮНҗ«”\ӮЕӮНӮИӮӯүҝҠiӮЕҢҲӮЬӮБӮҪҒB(Nano vs Atom330)
http://www.ne.jp/asahi/comp/tarusan/main207.htm
http://www.computerworld.jp/topics/netbook/146289.html
ғCғ“ғeғӢҒAҺҹҗў‘гAtomғvғүғbғgғtғHҒ[ғҖҒuPine TrailҒvӮМҠT—vӮр”ӯ•\
http://www.computerworld.jp/topics/netbook/146229.html
ҒyғҢғ|Ғ[ғgҒzғgғүғ“ғWғXғ^ҠJ”ӯӮНIntelӮМғnҒ[ғg - ғCғ“ғeғӢӢyҗмҺҒӮӘҢкӮйCPUӮМғgғҢғ“ғh
http://journal.mycom.co.jp/articles/2009/05/19/esec2009_intel/index.html
ү“ӮҙӮ©ӮйғXғpғRғ“җўҠEҲкӮМҚА
http://www.itmedia.co.jp/enterprise/articles/0905/20/news009.html
ҲкҺРҗ»‘ў‘Мҗ§ӮЕҒAӮжӮиӢӯү»ӮіӮкӮҪӮМӮ©ӮаӮөӮкӮИӮў“ъ–{ӮМҺҹҗў‘гғXғpғRғ“ҠJ”ӯ
http://hpc.livedoor.biz/archives/51440600.html
Ҹҹ•үӮМҚs•ыӮНҗ«”\ӮЕӮНӮИӮӯүҝҠiӮЕҢҲӮЬӮБӮҪҒB(Nano vs Atom330)
http://www.ne.jp/asahi/comp/tarusan/main207.htm
241 ҒF–јҸМ–ўҗЭ’иҒF2009/05/20(җ…) 21:51:03 ID:9VrFbvmR0
>>240
>ҒyғҢғ|Ғ[ғgҒzғgғүғ“ғWғXғ^ҠJ”ӯӮНIntelӮМғnҒ[ғg - ғCғ“ғeғӢӢyҗмҺҒӮӘҢкӮйCPUӮМғgғҢғ“ғh
>http://journal.mycom.co.jp/articles/2009/05/19/esec2009_intel/index.html
ӮұӮМӢLҺ–ӮЙLarrabeeӮН16ғRғAҲИҸгӮЖҸ‘ӮўӮДӮ ӮйҒB
45nmӮҫӮЖ32ғRғAӮЕӮа600sqmmӮр’ҙӮҰӮ»ӮӨӮИӮМӮЕғҒғCғ“ғXғgғҠҒ[ғҖҒ`ғҚҒ[ғGғ“ғhӮН32nmӮҫӮЖҺvӮнӮкҒB
ӮЬӮйӮБӮ«ӮиXeonӮЖXeonMPӮЕӮ·ӮИҒB
Intel and AMD begin server war dance
ttp://www.theregister.co.uk/2009/05/19/amd_intel_highend_server/
>>239ӮМNehalem-EXӮӘ—ҲҸT“oҸкӮЖӮўӮӨӢLҺ–ӮНINQӢLҺТӮМ—\‘zӮЙүЯӮ¬ӮИӮўӮжӮӨӮҫҒB
IntelӮӘғvғҢғXӮЦ‘—ӮБӮҪғҒҒ[ғӢӮ©ӮзӮНғnғCғGғ“ғhғTҒ[ғoҒ[ӮЙҠЦӮ·ӮйүҪӮзӮ©ӮМ”ӯ•\ӮрҚsӮӨӮұӮЖӮөӮ©“ЗӮЭҺжӮкӮИӮўӮзӮөӮўҒB
The RegisterӮНғXғPғWғ…Ғ[ғӢӮӘҺбҠұ‘ҒӮЯӮДTukwilaӮМ”ӯ•\ӮрӮ·ӮйӮМӮЕӮНӮИӮўӮ©ӮЖ—\‘zӮөӮДӮўӮйҒB
ӮЬӮҪҒAҺ©ҺРӮМғuғҢҒ[ғhӮЙNehalem-EXӮр“ӢҚЪӮ·ӮйӮМӮН2010”NӮМ‘ж1Һl”јҠъӮЙӮИӮйӮЖӮўӮӨүс“ҡӮр•xҺm’КӮЦӮМғCғ“ғ^ғrғ…Ғ[Ӯ©Ӯз“ҫӮҪӮзӮөӮўҒB
ӮұӮкӮрҲИӮБӮДNehalem-EXӮ»ӮМӮаӮМӮ©•xҺm’КӮМ‘ОүһӮМӮЗӮҝӮзӮ©ӮӘ’xӮкӮДӮўӮйӮНӮёӮҫӮЖҸ‘ӮўӮДӮўӮйҒB
үҪӮкӮЙӮ№ӮжIntelӮӘ”ј”NҲИҸгҗжӮМҗ»•iӮМ”ӯ•\ӮрҚsӮӨӮЖӮНҚlӮҰ“пӮўӮМӮЕTukwilaӮМ”ӯ•\ӮНҸҮ“–ӮИ—\‘zӮҫӮЖҺvӮӨҒB
ӮҪӮҫӮөҒAҗж“ъғGғ“ғvғү•”–еӮМғgғbғvӮЕӮ ӮйғpғbғgҒEғQғӢғVғ“ғKҒ[ӮӘ—Ҳ“ъӮөӮҪҺһӮЙ
Nehalem-EXӮН‘ҒӮҜӮкӮОүДҚ “oҸкӮЖҢҫӮБӮДӮўӮйӮМӮЕ‘O“|ӮөӮіӮкӮҪүВ”\җ«ӮаӮ»ӮкӮИӮиӮЙӮ ӮйҒB
ttp://journal.mycom.co.jp/news/2009/04/07/012/index.html
ӮЬӮЖӮЯӮйӮЖӮұӮсӮИҠҙӮ¶ҒB
–{–Ҫ TukwilaӮМӮЭ”ӯ•\ҒB
‘ОҚR TukwilaӮЖNehalem-EX—ј•ы”ӯ•\ҒB
‘еҢҠ Nehalem-EXӮМӮЭ”ӯ•\ҒB
>ҒyғҢғ|Ғ[ғgҒzғgғүғ“ғWғXғ^ҠJ”ӯӮНIntelӮМғnҒ[ғg - ғCғ“ғeғӢӢyҗмҺҒӮӘҢкӮйCPUӮМғgғҢғ“ғh
>http://journal.mycom.co.jp/articles/2009/05/19/esec2009_intel/index.html
ӮұӮМӢLҺ–ӮЙLarrabeeӮН16ғRғAҲИҸгӮЖҸ‘ӮўӮДӮ ӮйҒB
45nmӮҫӮЖ32ғRғAӮЕӮа600sqmmӮр’ҙӮҰӮ»ӮӨӮИӮМӮЕғҒғCғ“ғXғgғҠҒ[ғҖҒ`ғҚҒ[ғGғ“ғhӮН32nmӮҫӮЖҺvӮнӮкҒB
ӮЬӮйӮБӮ«ӮиXeonӮЖXeonMPӮЕӮ·ӮИҒB
Intel and AMD begin server war dance
ttp://www.theregister.co.uk/2009/05/19/amd_intel_highend_server/
>>239ӮМNehalem-EXӮӘ—ҲҸT“oҸкӮЖӮўӮӨӢLҺ–ӮНINQӢLҺТӮМ—\‘zӮЙүЯӮ¬ӮИӮўӮжӮӨӮҫҒB
IntelӮӘғvғҢғXӮЦ‘—ӮБӮҪғҒҒ[ғӢӮ©ӮзӮНғnғCғGғ“ғhғTҒ[ғoҒ[ӮЙҠЦӮ·ӮйүҪӮзӮ©ӮМ”ӯ•\ӮрҚsӮӨӮұӮЖӮөӮ©“ЗӮЭҺжӮкӮИӮўӮзӮөӮўҒB
The RegisterӮНғXғPғWғ…Ғ[ғӢӮӘҺбҠұ‘ҒӮЯӮДTukwilaӮМ”ӯ•\ӮрӮ·ӮйӮМӮЕӮНӮИӮўӮ©ӮЖ—\‘zӮөӮДӮўӮйҒB
ӮЬӮҪҒAҺ©ҺРӮМғuғҢҒ[ғhӮЙNehalem-EXӮр“ӢҚЪӮ·ӮйӮМӮН2010”NӮМ‘ж1Һl”јҠъӮЙӮИӮйӮЖӮўӮӨүс“ҡӮр•xҺm’КӮЦӮМғCғ“ғ^ғrғ…Ғ[Ӯ©Ӯз“ҫӮҪӮзӮөӮўҒB
ӮұӮкӮрҲИӮБӮДNehalem-EXӮ»ӮМӮаӮМӮ©•xҺm’КӮМ‘ОүһӮМӮЗӮҝӮзӮ©ӮӘ’xӮкӮДӮўӮйӮНӮёӮҫӮЖҸ‘ӮўӮДӮўӮйҒB
үҪӮкӮЙӮ№ӮжIntelӮӘ”ј”NҲИҸгҗжӮМҗ»•iӮМ”ӯ•\ӮрҚsӮӨӮЖӮНҚlӮҰ“пӮўӮМӮЕTukwilaӮМ”ӯ•\ӮНҸҮ“–ӮИ—\‘zӮҫӮЖҺvӮӨҒB
ӮҪӮҫӮөҒAҗж“ъғGғ“ғvғү•”–еӮМғgғbғvӮЕӮ ӮйғpғbғgҒEғQғӢғVғ“ғKҒ[ӮӘ—Ҳ“ъӮөӮҪҺһӮЙ
Nehalem-EXӮН‘ҒӮҜӮкӮОүДҚ “oҸкӮЖҢҫӮБӮДӮўӮйӮМӮЕ‘O“|ӮөӮіӮкӮҪүВ”\җ«ӮаӮ»ӮкӮИӮиӮЙӮ ӮйҒB
ttp://journal.mycom.co.jp/news/2009/04/07/012/index.html
ӮЬӮЖӮЯӮйӮЖӮұӮсӮИҠҙӮ¶ҒB
–{–Ҫ TukwilaӮМӮЭ”ӯ•\ҒB
‘ОҚR TukwilaӮЖNehalem-EX—ј•ы”ӯ•\ҒB
‘еҢҠ Nehalem-EXӮМӮЭ”ӯ•\ҒB
242 ҒF–јҸМ–ўҗЭ’иҒF2009/05/22(Ӣа) 22:07:42 ID:tJJhp+Cf0
Intel drags feet on Itanium quad-core (again)
ttp://www.theregister.co.uk/2009/05/21/intel_delays_tukwila_again/
>you would infer from Intel's terse invitation to the press that Tukwila was at least one of the topics it would discuss ahead of a product launch
ӮДӮұӮЖӮЕ>>241ӮаҠФҲбӮўӮҫӮБӮҪӮжӮӨӮЕӮ ӮйҒB
ӮұӮМӢLҺ–ҒAүҪӢCӮЙItaniumӮМ”„ӮиҸгӮ°ӮЖҸoүЧҗ”(җ„’и)ӮӘҚЪӮБӮДӮЬӮ·ҒB
ғCғ“ғeғӢҒAҺҹҠъҒuItaniumҒvӮМҸoүЧҺһҠъӮрҒgӮЬӮҪӮаӮвҒhү„Ҡъ
ttp://www.computerworld.jp/topics/mcore/146851.html
ttp://www.theregister.co.uk/2009/05/21/intel_delays_tukwila_again/
>you would infer from Intel's terse invitation to the press that Tukwila was at least one of the topics it would discuss ahead of a product launch
ӮДӮұӮЖӮЕ>>241ӮаҠФҲбӮўӮҫӮБӮҪӮжӮӨӮЕӮ ӮйҒB
ӮұӮМӢLҺ–ҒAүҪӢCӮЙItaniumӮМ”„ӮиҸгӮ°ӮЖҸoүЧҗ”(җ„’и)ӮӘҚЪӮБӮДӮЬӮ·ҒB
ғCғ“ғeғӢҒAҺҹҠъҒuItaniumҒvӮМҸoүЧҺһҠъӮрҒgӮЬӮҪӮаӮвҒhү„Ҡъ
ttp://www.computerworld.jp/topics/mcore/146851.html
243 ҒF–јҸМ–ўҗЭ’иҒF2009/05/22(Ӣа) 22:36:31 ID:tJJhp+Cf0
Unity SemiconductorӮМҗV•sҠц”ӯғҒғӮғҠӢZҸp
ttp://pc.watch.impress.co.jp/docs/column/hot/20090522_169760.html
IM Flash is possible partner for Unity's RRAM manufacture
ttp://www.eetimes.com/news/latest/showArticle.jhtml;jsessionid=CR5KG12UAFULIQSNDLPCKH0CJUNN2JVN?articleID=217600580
ttp://pc.watch.impress.co.jp/docs/column/hot/20090522_169760.html
IM Flash is possible partner for Unity's RRAM manufacture
ttp://www.eetimes.com/news/latest/showArticle.jhtml;jsessionid=CR5KG12UAFULIQSNDLPCKH0CJUNN2JVN?articleID=217600580
244 ҒF–јҸМ–ўҗЭ’иҒF2009/05/24(“ъ) 19:05:36 ID:i970n95q0
IntelӮ©ӮзInvestor MeetingӮМғvғҢғ[ғ“Һ‘—ҝӮӘғ_ғEғ“ғҚҒ[ғhӮЕӮ«ӮйҒB
ttp://intelstudios.edgesuite.net/im/home.htm
Ҳк’КӮи–ЪӮр’КӮөӮҪӮӘҒA’·ӮўӮМӮЕӮўӮӯӮВӮ©ӢCӮЙӮИӮБӮҪ“_ӮҫӮҜғҒғӮҒB
Stacy SmithӮМғvғҢғ[ғ“Һ‘—ҝ 27p
ҒE45nmғvғҚғZғXӮЙ‘ОүһӮөӮҪFabӮр32nmғvғҚғZғXӮЙ‘ОүһӮ·ӮйFabӮЦ“]Ҡ·Ӯ·ӮйҚЫӮЙӮНҗЭ”хӮМ9Ҡ„ӢЯӮӯӮр—¬—pӮЕӮ«Ӯй
ҒE32nmғvғҚғZғXӮЙ‘ОүһӮөӮҪFabӮр22nmғvғҚғZғXӮЙ‘ОүһӮ·ӮйFabӮЦ“]Ҡ·Ӯ·ӮйҚЫӮЙӮНҗЭ”хӮМ8Ҡ„ӢЯӮӯӮр—¬—pӮЕӮ«Ӯй
ҒЁ‘Ҫ•ӘҒAӢаҠzғxҒ[ғXӮМҒA—бӮҰӮО4BӮМFabӮӘ400MӮЕҚПӮЮӮЖӮўӮБӮҪӮжӮӨӮИҒAҳbӮЕӮНӮИӮў
ttp://intelstudios.edgesuite.net/im/home.htm
Ҳк’КӮи–ЪӮр’КӮөӮҪӮӘҒA’·ӮўӮМӮЕӮўӮӯӮВӮ©ӢCӮЙӮИӮБӮҪ“_ӮҫӮҜғҒғӮҒB
Stacy SmithӮМғvғҢғ[ғ“Һ‘—ҝ 27p
ҒE45nmғvғҚғZғXӮЙ‘ОүһӮөӮҪFabӮр32nmғvғҚғZғXӮЙ‘ОүһӮ·ӮйFabӮЦ“]Ҡ·Ӯ·ӮйҚЫӮЙӮНҗЭ”хӮМ9Ҡ„ӢЯӮӯӮр—¬—pӮЕӮ«Ӯй
ҒE32nmғvғҚғZғXӮЙ‘ОүһӮөӮҪFabӮр22nmғvғҚғZғXӮЙ‘ОүһӮ·ӮйFabӮЦ“]Ҡ·Ӯ·ӮйҚЫӮЙӮНҗЭ”хӮМ8Ҡ„ӢЯӮӯӮр—¬—pӮЕӮ«Ӯй
ҒЁ‘Ҫ•ӘҒAӢаҠzғxҒ[ғXӮМҒA—бӮҰӮО4BӮМFabӮӘ400MӮЕҚПӮЮӮЖӮўӮБӮҪӮжӮӨӮИҒAҳbӮЕӮНӮИӮў
245 ҒF–јҸМ–ўҗЭ’иҒF2009/05/24(“ъ) 19:06:18 ID:i970n95q0
Dadi Perlmutter & Renee JamesӮМғvғҢғ[ғ“Һ‘—ҝ 11p
ҒESmall ComputingӮЕӮаӮЬӮҫӮЬӮҫҗ«”\ӮӘ‘«ӮиӮИӮў
“Ҝ 18p
ҒEWestmere CoreӮНNehalem CoreӮЙ‘ОӮөӮД–КҗПӮӘ”ј•ӘӮЙӮИӮй
ҒЁ8Core/L3-16MBӮЕNehalem-EPӮЖ“ҜӮ¶ғ_ғCғTғCғY
“Ҝ 20p
ҒEҚӮӮўҗ«”\ӮЖ’·ӮўғoғbғeғҠҒ[ӮМҺқ‘ұҺһҠФӮрҺАҢ»ӮЕӮ«ӮйLarrabeeӮНDiscrete GraphicsӮЖӮөӮДӮНҚЕӮа—DӮкӮҪғ\ғҠғ…Ғ[ғVғҮғ“
ҒЁLarrabeeӮНғӮғoғCғӢ”ЕӮа“Ҡ“ьӮіӮкӮй–Н—l
Ғ@Ҡщ‘¶ӮМҗ»•i“ҜҺmӮЕ”дҠrӮ·ӮйӮЖNehalemӮвAtom(Intel Architecture)ӮМ“d—НҠЗ—қӮНGeforceӮвRadeonӮжӮиҲі“|“IӮЙӢӯ—Н
Ғ@CalpellaӮМҺһ“_ӮЕClarksfieldӮЙGPUӮӘ–іӮӯӮДғvғүғbғgғtғHҒ[ғҖӮЙҢҠӮӘҠJӮўӮДӮўӮйӮМӮЕ“Ҡ“ьӮНӮ©ӮИӮи‘ҒӮўӮМӮЕӮНӮИӮўӮ©
Ғ@Clarksfield(or later) + Larrabee, Arrandale + GMA, Atom + GMA, Atom + PowerVR
Ғ@җ””N‘OӮНPentiumMӮЖGMAӮМӮЭӮҫӮБӮҪғӮғoғCғӢҗ»•iӮЙ”сҸнӮЙ•қӮӘҸoӮДӮ«ӮҪ
“Ҝ 23p
ҒEMoorestownӮМғAғCғhғӢҺһӮМҸБ”п“d—НӮНҚЕӮа—ЗӮўғPҒ[ғXӮЕMenlowӮМ50•ӘӮМ1ӮЙӮИӮй
ҒЁMenlowӮӘ500mWҲКӮҫӮБӮҪӮЖҺvӮӨӮМӮЕ10mWҒ`ӮМғҢғ“ғWӮӘMoorestownӮЕ’Bҗ¬ӮЕӮ«ӮйҒH
“Ҝ 27p
ҒEBonnellӮМғfғUғCғ“ӮЙҸ]Һ–ӮөӮҪғGғ“ғWғjғAӮН220җlҲИүә
ҒE”hҗ¶•iӮМғfғUғCғ“ӮЙҸ]Һ–ӮөӮҪғGғ“ғWғjғAӮН150җlҲИүә
“Ҝ 43p
ҒEWindows 7ӮНIntel ArchitectureӮЙҚЕ“Kү»ӮіӮкӮДӮўӮй
“Ҝ 56p
ҒEAtomӮЖMoblin2.0ӮЙӮжӮБӮДSmall ComputingӮМҗўҠEӮЕӮаҢЭҠ·җ«ӮӘҗ¶ӮЬӮкӮй
ҒЁSmall Computing = MIDs, CE, Embedded
ҒESmall ComputingӮЕӮаӮЬӮҫӮЬӮҫҗ«”\ӮӘ‘«ӮиӮИӮў
“Ҝ 18p
ҒEWestmere CoreӮНNehalem CoreӮЙ‘ОӮөӮД–КҗПӮӘ”ј•ӘӮЙӮИӮй
ҒЁ8Core/L3-16MBӮЕNehalem-EPӮЖ“ҜӮ¶ғ_ғCғTғCғY
“Ҝ 20p
ҒEҚӮӮўҗ«”\ӮЖ’·ӮўғoғbғeғҠҒ[ӮМҺқ‘ұҺһҠФӮрҺАҢ»ӮЕӮ«ӮйLarrabeeӮНDiscrete GraphicsӮЖӮөӮДӮНҚЕӮа—DӮкӮҪғ\ғҠғ…Ғ[ғVғҮғ“
ҒЁLarrabeeӮНғӮғoғCғӢ”ЕӮа“Ҡ“ьӮіӮкӮй–Н—l
Ғ@Ҡщ‘¶ӮМҗ»•i“ҜҺmӮЕ”дҠrӮ·ӮйӮЖNehalemӮвAtom(Intel Architecture)ӮМ“d—НҠЗ—қӮНGeforceӮвRadeonӮжӮиҲі“|“IӮЙӢӯ—Н
Ғ@CalpellaӮМҺһ“_ӮЕClarksfieldӮЙGPUӮӘ–іӮӯӮДғvғүғbғgғtғHҒ[ғҖӮЙҢҠӮӘҠJӮўӮДӮўӮйӮМӮЕ“Ҡ“ьӮНӮ©ӮИӮи‘ҒӮўӮМӮЕӮНӮИӮўӮ©
Ғ@Clarksfield(or later) + Larrabee, Arrandale + GMA, Atom + GMA, Atom + PowerVR
Ғ@җ””N‘OӮНPentiumMӮЖGMAӮМӮЭӮҫӮБӮҪғӮғoғCғӢҗ»•iӮЙ”сҸнӮЙ•қӮӘҸoӮДӮ«ӮҪ
“Ҝ 23p
ҒEMoorestownӮМғAғCғhғӢҺһӮМҸБ”п“d—НӮНҚЕӮа—ЗӮўғPҒ[ғXӮЕMenlowӮМ50•ӘӮМ1ӮЙӮИӮй
ҒЁMenlowӮӘ500mWҲКӮҫӮБӮҪӮЖҺvӮӨӮМӮЕ10mWҒ`ӮМғҢғ“ғWӮӘMoorestownӮЕ’Bҗ¬ӮЕӮ«ӮйҒH
“Ҝ 27p
ҒEBonnellӮМғfғUғCғ“ӮЙҸ]Һ–ӮөӮҪғGғ“ғWғjғAӮН220җlҲИүә
ҒE”hҗ¶•iӮМғfғUғCғ“ӮЙҸ]Һ–ӮөӮҪғGғ“ғWғjғAӮН150җlҲИүә
“Ҝ 43p
ҒEWindows 7ӮНIntel ArchitectureӮЙҚЕ“Kү»ӮіӮкӮДӮўӮй
“Ҝ 56p
ҒEAtomӮЖMoblin2.0ӮЙӮжӮБӮДSmall ComputingӮМҗўҠEӮЕӮаҢЭҠ·җ«ӮӘҗ¶ӮЬӮкӮй
ҒЁSmall Computing = MIDs, CE, Embedded
246 ҒF–јҸМ–ўҗЭ’иҒF2009/05/24(“ъ) 19:07:32 ID:i970n95q0
Paul OtelliniӮМғvғҢғ[ғ“Һ‘—ҝ 6p
ҒE32nmғvғҚғZғXӮН45nmғvғҚғZғXӮжӮ葬ӮўғyҒ[ғXӮЕ•а—ҜӮиӮӘҸгӮӘӮБӮДӮўӮй
“Ҝ 9p
ҒE2011”NӮЙӮНEmbeddedӮЕ10BҲИҸгӮМ”„ӮиҸгӮ°ӮрҢ©ҚһӮЮ
“Ҝ 20p
ҒE7BӮМ“ҠҺ‘ӮЕ4ӮВӮМFabӮр32nmғvғҚғZғX‘ОүһӮМFabӮЙ
ҒЁ•КӮМғXғүғCғhӮЕӮН32nmғvғҚғZғXӮМFabғRғXғgӮр4BӮЖҢ©җПӮаӮБӮДӮўӮҪӮМӮЕҗЭ”хӮМ—¬—pӮМҢшүКӮӘӮ©ӮИӮиӮ Ӯй
“Ҝ 21p
ҒE22nmғvғҚғZғXӮЙ‘ОүһҸo—ҲӮйIDMӮНIntel, Samsung, ST MicroӮМӮЭ(IBM, ToshibaӮӘ’E—Һ)
ҒE32nmғvғҚғZғXӮН45nmғvғҚғZғXӮжӮ葬ӮўғyҒ[ғXӮЕ•а—ҜӮиӮӘҸгӮӘӮБӮДӮўӮй
“Ҝ 9p
ҒE2011”NӮЙӮНEmbeddedӮЕ10BҲИҸгӮМ”„ӮиҸгӮ°ӮрҢ©ҚһӮЮ
“Ҝ 20p
ҒE7BӮМ“ҠҺ‘ӮЕ4ӮВӮМFabӮр32nmғvғҚғZғX‘ОүһӮМFabӮЙ
ҒЁ•КӮМғXғүғCғhӮЕӮН32nmғvғҚғZғXӮМFabғRғXғgӮр4BӮЖҢ©җПӮаӮБӮДӮўӮҪӮМӮЕҗЭ”хӮМ—¬—pӮМҢшүКӮӘӮ©ӮИӮиӮ Ӯй
“Ҝ 21p
ҒE22nmғvғҚғZғXӮЙ‘ОүһҸo—ҲӮйIDMӮНIntel, Samsung, ST MicroӮМӮЭ(IBM, ToshibaӮӘ’E—Һ)
247 ҒF–јҸМ–ўҗЭ’иҒF2009/05/24(“ъ) 20:11:27 ID:5dSFORsX0
248 ҒF–јҸМ–ўҗЭ’иҒF2009/05/24(“ъ) 20:42:59 ID:i970n95q0
–Ьҳ_Ӯ»ӮӨӮўӮӨғlғKғeғBғuӮИҢҫӮў•ыӮаҸo—ҲӮйӮҜӮкӮЗӮа
Ңш—Ұ“IӮИ“ҠҺ‘ӮрҚsӮӨӮұӮЖӮЕӮұӮкӮ©ӮзӮа”чҚЧү»ӮМғyҒ[ғXӮрҲЫҺқӮЕӮ«Ӯй
ӮБӮДӮМӮӘIntelӮМҺе’ЈӮөӮҪӮўӮұӮЖӮҫӮЖҺvӮўӮЬӮ·ӮҪ
ӮҝӮИӮЭӮЙӮұӮМҺ‘—ҝӮНҢг“ЎӢLҺ–ӮЕ“xҒXҲш—pӮіӮкӮйӮұӮЖӮЙӮИӮйӮЖҺvӮӨӮМӮЕ
ҺһҠФӮӘӮ ӮБӮҪӮзҲк“x‘SӮДӮЙ–ЪӮр’КӮөӮДӮЁӮӯӮЖғCғCҠҙӮ¶Ӯ©Ӯа’mӮкӮИӮў
Ңш—Ұ“IӮИ“ҠҺ‘ӮрҚsӮӨӮұӮЖӮЕӮұӮкӮ©ӮзӮа”чҚЧү»ӮМғyҒ[ғXӮрҲЫҺқӮЕӮ«Ӯй
ӮБӮДӮМӮӘIntelӮМҺе’ЈӮөӮҪӮўӮұӮЖӮҫӮЖҺvӮўӮЬӮ·ӮҪ
ӮҝӮИӮЭӮЙӮұӮМҺ‘—ҝӮНҢг“ЎӢLҺ–ӮЕ“xҒXҲш—pӮіӮкӮйӮұӮЖӮЙӮИӮйӮЖҺvӮӨӮМӮЕ
ҺһҠФӮӘӮ ӮБӮҪӮзҲк“x‘SӮДӮЙ–ЪӮр’КӮөӮДӮЁӮӯӮЖғCғCҠҙӮ¶Ӯ©Ӯа’mӮкӮИӮў
249 ҒF–јҸМ–ўҗЭ’иҒF2009/05/30(“y) 00:51:30 ID:+wjxzd2o0
ғCғ“ғeғӢҺРҒAғrғWғ…ғAғӢҒEғRғ“ғsғ…Ғ[ғeғBғ“ғOӮМҢӨӢҶҺ{җЭӮрғhғCғcӮЙҠJҗЭ
http://eetimes.jp/article/23044/
Intel says EU fine won't lead to dividend cut
http://www.eetimes.com/news/latest/showArticle.jhtml;jsessionid=C0YBHLD4PMADGQSNDLPCKH0CJUNN2JVN?articleID=217700488
Intel Ships Parallel Studio Development Toolkit
http://www.hpcwire.com/features/Intel-Ships-Parallel-Studio-Development-Toolkit-46401262.html
Intel Previews Intel Xeon 'Nehalem-EX' Processor
http://www.intel.com/pressroom/archive/releases/20090526comp.htm?iid=pr1_releasepri_20090526m
http://download.intel.com/pressroom/pdf/nehalem-ex.pdf
Worldwide Server Market Revenues Decline 25% in First Quarter as Market Contraction Accelerates, According to IDC
http://www.idc.com/getdoc.jsp;jsessionid=ZQXUN325QHFCQCQJAFDCFFAKBEAVAIWD?containerId=prUS21856409
http://eetimes.jp/article/23044/
Intel says EU fine won't lead to dividend cut
http://www.eetimes.com/news/latest/showArticle.jhtml;jsessionid=C0YBHLD4PMADGQSNDLPCKH0CJUNN2JVN?articleID=217700488
Intel Ships Parallel Studio Development Toolkit
http://www.hpcwire.com/features/Intel-Ships-Parallel-Studio-Development-Toolkit-46401262.html
Intel Previews Intel Xeon 'Nehalem-EX' Processor
http://www.intel.com/pressroom/archive/releases/20090526comp.htm?iid=pr1_releasepri_20090526m
http://download.intel.com/pressroom/pdf/nehalem-ex.pdf
Worldwide Server Market Revenues Decline 25% in First Quarter as Market Contraction Accelerates, According to IDC
http://www.idc.com/getdoc.jsp;jsessionid=ZQXUN325QHFCQCQJAFDCFFAKBEAVAIWD?containerId=prUS21856409
250 ҒF–јҸМ–ўҗЭ’иҒF2009/05/30(“y) 03:10:40 ID:+wjxzd2o0
LynnfieldӮН‘fҗ°ӮзӮөӮў
The Lynnfield Preview: Rumblings of Revenge
ttp://www.anandtech.com/cpuchipsets/showdoc.aspx?i=3570
The Lynnfield Preview: Rumblings of Revenge
ttp://www.anandtech.com/cpuchipsets/showdoc.aspx?i=3570
251 ҒF–јҸМ–ўҗЭ’иҒF2009/06/02(үО) 01:20:15 ID:s4JkS7pR0
Һҹҗў‘гAtomҒuMoorestownҒvӮӘCOMPUTEXӮЕӮЁ”вҳI–ЪӮ©
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20090601_211977.html
ғXғ}Ғ[ғgғtғHғ“ӮМӢ@”\Ӯр“қҚҮӮ·ӮйҺҹҒXҗў‘гAtomҒuMedfieldҒv
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20090602_212014.html
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20090601_211977.html
ғXғ}Ғ[ғgғtғHғ“ӮМӢ@”\Ӯр“қҚҮӮ·ӮйҺҹҒXҗў‘гAtomҒuMedfieldҒv
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20090602_212014.html
252 ҒF–јҸМ–ўҗЭ’иҒF2009/06/02(үО) 22:09:08 ID:/bbi5IsR0
AMDӮӘ6ғRғAOpteronӮМIstanbulӮрҗіҺ®”ӯ•\
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20090602_212130.html
AMD's Six-Core Opteron 2435
ttp://it.anandtech.com/IT/showdoc.aspx?i=3571
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20090602_212130.html
AMD's Six-Core Opteron 2435
ttp://it.anandtech.com/IT/showdoc.aspx?i=3571
253 ҒF–јҸМ–ўҗЭ’иҒF2009/06/03(җ…) 21:26:33 ID:2FyuTKJL0
IntelҒfs Core i7-975 & 950: Preparing for Lynnfield
ttp://www.anandtech.com/cpuchipsets/showdoc.aspx?i=3574&p=1
Core i7ӮМҚЕҚӮғNғҚғbғNӮрҚXҗVҒuCore i7-975 Extreme EditionҒv
ttp://pc.watch.impress.co.jp/docs/column/tawada/20090603_170331.html
ҒyCOMPUTEX 2009ғҢғ|Ғ[ғgҒz CLEVOҒAғӮғoғCғӢғNғAғbғhғRғAўClarksfieldЈ“ӢҚЪғmҒ[ғgӮр“WҺҰ
ttp://pc.watch.impress.co.jp/docs/news/event/20090603_212241.html
ҒyCOMPUTEX 2009ғҢғ|Ғ[ғgҒz ECSҒAҡвҢ^PCӮв“қҚҮҢ^Atom“ӢҚЪғxғAғ{Ғ[ғ“Ӯр“WҺҰ
ttp://pc.watch.impress.co.jp/docs/news/event/20090603_212258.html
ҒyCOMPUTEX 2009ғҢғ|Ғ[ғgҒz IntelҠо’ІҚuүү Intel 5ғVғҠҒ[ғYғ`ғbғvғZғbғgӮвҒuMoblin 2ҒvӮӘ“®ҚмӮ·ӮйғlғbғgғuғbғNӮИӮЗӮрҢцҠJ
ttp://pc.watch.impress.co.jp/docs/news/event/20090603_212238.html
ҒyCOMPUTEX 2009ғҢғ|Ғ[ғgҒz Intel Montevina PlusӮрҗіҺ®”ӯ•\
ttp://pc.watch.impress.co.jp/docs/news/event/20090603_212267.html
ttp://www.anandtech.com/cpuchipsets/showdoc.aspx?i=3574&p=1
Core i7ӮМҚЕҚӮғNғҚғbғNӮрҚXҗVҒuCore i7-975 Extreme EditionҒv
ttp://pc.watch.impress.co.jp/docs/column/tawada/20090603_170331.html
ҒyCOMPUTEX 2009ғҢғ|Ғ[ғgҒz CLEVOҒAғӮғoғCғӢғNғAғbғhғRғAўClarksfieldЈ“ӢҚЪғmҒ[ғgӮр“WҺҰ
ttp://pc.watch.impress.co.jp/docs/news/event/20090603_212241.html
ҒyCOMPUTEX 2009ғҢғ|Ғ[ғgҒz ECSҒAҡвҢ^PCӮв“қҚҮҢ^Atom“ӢҚЪғxғAғ{Ғ[ғ“Ӯр“WҺҰ
ttp://pc.watch.impress.co.jp/docs/news/event/20090603_212258.html
ҒyCOMPUTEX 2009ғҢғ|Ғ[ғgҒz IntelҠо’ІҚuүү Intel 5ғVғҠҒ[ғYғ`ғbғvғZғbғgӮвҒuMoblin 2ҒvӮӘ“®ҚмӮ·ӮйғlғbғgғuғbғNӮИӮЗӮрҢцҠJ
ttp://pc.watch.impress.co.jp/docs/news/event/20090603_212238.html
ҒyCOMPUTEX 2009ғҢғ|Ғ[ғgҒz Intel Montevina PlusӮрҗіҺ®”ӯ•\
ttp://pc.watch.impress.co.jp/docs/news/event/20090603_212267.html
254 ҒF–јҸМ–ўҗЭ’иҒF2009/06/04(–Ш) 22:10:42 ID:DHGOz+Fn0
Intel Larrabee samples said to perform like GeForce GTX 285
ttp://www.tcmagazine.com/comments.php?id=26976&catid=6
ӮЖӮНҢҫӮҰӮұӮМҺһҠъӮЙҸoӮДӮӯӮйғTғ“ғvғӢӮНғNғҚғbғNӮӘҗ»•i”ЕӮЖ”дӮЧӮДӮ©ӮИӮи’бӮ©ӮБӮҪӮиғoғOӮЕIPCӮӘ’бӮ©ӮБӮҪӮиӮ·ӮйӮНӮёӮЕӮөӮДҒBҒBҒB
Intel VP deems Ion is overkill
ttp://www.theinquirer.net/inquirer/news/1184505/intel-vp-deems-ion-overkill
Mooly Eden
Intel's Maloney kicks off Computex keynotes
ttp://www.theinquirer.net/inquirer/news/1184502/intel-maloney-kicks-computex-keynotes
>Intel, said Maloney, will go on to deliver "Lynnfield" and "Clarksfield" processors in the second half of 2009
> and ship 32nm "Westmere" chips using a second-generation Hafnium-based high-k metal gate transistor design "soon after".
ttp://www.tcmagazine.com/comments.php?id=26976&catid=6
ӮЖӮНҢҫӮҰӮұӮМҺһҠъӮЙҸoӮДӮӯӮйғTғ“ғvғӢӮНғNғҚғbғNӮӘҗ»•i”ЕӮЖ”дӮЧӮДӮ©ӮИӮи’бӮ©ӮБӮҪӮиғoғOӮЕIPCӮӘ’бӮ©ӮБӮҪӮиӮ·ӮйӮНӮёӮЕӮөӮДҒBҒBҒB
Intel VP deems Ion is overkill
ttp://www.theinquirer.net/inquirer/news/1184505/intel-vp-deems-ion-overkill
Mooly Eden
Intel's Maloney kicks off Computex keynotes
ttp://www.theinquirer.net/inquirer/news/1184502/intel-maloney-kicks-computex-keynotes
>Intel, said Maloney, will go on to deliver "Lynnfield" and "Clarksfield" processors in the second half of 2009
> and ship 32nm "Westmere" chips using a second-generation Hafnium-based high-k metal gate transistor design "soon after".
255 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/06/04(–Ш) 23:41:49 ID:amuWwOox0
GTX285•АӮМҗ«”\ӮӘ–{“–ӮЙӮЕӮйӮМӮИӮзӮОLRBғvғҚғWғFғNғgӮЖӮөӮДӮНҸ\•Әҗ¬ҢчӮИӮМӮҫӮӘҒA
Ӯ Ӯи“ҫӮИӮўҠъ‘ТӮрӮөӮДӮўӮҪҗ~–[ӢӨӮӘӮұӮМҗжҸӯӮөӮЕӮаҠҰӮўҸо•сӮӘҸoӮйӮҪӮСӮЙ
–\ӮкүсӮБӮҪӮиӮөӮИӮўӮұӮЖӮрӢFӮйӮнҒB
Ӯ Ӯи“ҫӮИӮўҠъ‘ТӮрӮөӮДӮўӮҪҗ~–[ӢӨӮӘӮұӮМҗжҸӯӮөӮЕӮаҠҰӮўҸо•сӮӘҸoӮйӮҪӮСӮЙ
–\ӮкүсӮБӮҪӮиӮөӮИӮўӮұӮЖӮрӢFӮйӮнҒB
256 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/06/04(–Ш) 23:43:44 ID:amuWwOox0
685 ҒF---Ғј(ҒLҒНҒM’UҒјҒҷж|Қк [Ғ«] ҒF2009/03/31(үО) 19:42:12 ID:l/vZRUst (2/7)
>>684
Һ©Қм”ВӮБӮДҗМӮ©ӮзҢ»ҺА”hӮӘӮҪӮЬӮЙғoғүғ“ғXӮр’Іҗ®ӮөӮДӮвӮзӮИӮўӮЖҒA
ҢдүФ”Ё”hӮӘ–і—НӮИ–ј–іӮөӮрҠӘӮ«ҚһӮсӮЕ–\‘–ӮөӮҪӮ Ӯ°ӮӯҒA
Ң»ҺАӮМғӮғmӮрӮЭӮДӮ©ӮзғAғ“ғ`ӮЙҠиӮҰӮБӮДӮіӮзӮЙ–\ӮкҸoӮ·ӮсӮҫӮжҒB
ӮЁӮкӮНӢcҳ_ӮжӮиӮаҢӢүКҸҹ•үӮрӮҰӮзӮсӮҫҒB
>>684
Һ©Қм”ВӮБӮДҗМӮ©ӮзҢ»ҺА”hӮӘӮҪӮЬӮЙғoғүғ“ғXӮр’Іҗ®ӮөӮДӮвӮзӮИӮўӮЖҒA
ҢдүФ”Ё”hӮӘ–і—НӮИ–ј–іӮөӮрҠӘӮ«ҚһӮсӮЕ–\‘–ӮөӮҪӮ Ӯ°ӮӯҒA
Ң»ҺАӮМғӮғmӮрӮЭӮДӮ©ӮзғAғ“ғ`ӮЙҠиӮҰӮБӮДӮіӮзӮЙ–\ӮкҸoӮ·ӮсӮҫӮжҒB
ӮЁӮкӮНӢcҳ_ӮжӮиӮаҢӢүКҸҹ•үӮрӮҰӮзӮсӮҫҒB
257 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/06/04(–Ш) 23:44:39 ID:amuWwOox0
699+1 ҒF---Ғј(ҒLҒНҒM’UҒјҒҷж|Қк [Ғ«] ҒF2009/04/04(“y) 20:23:55 ID:WkDXM8VE (3/9)
Ңл“ҡҗжҗ¶ӮрҠЬӮЯ”ч–ӯӮЙҺІӮӘӮёӮкӮДӮўӮйҠЁҲбӮўҢNӮӘ‘ҪӮўӮжӮӨӮҫӮӘҒA
CPUғҒҒ[ғJҒ[ӮӘғXғgғҠҒ[ғҖғRғAӮМ“қҚҮӮИӮиҒA–Ҫ—ЯғZғbғgҠg’ЈӮИӮиӮрӮ·ӮйӮұӮЖӮЙӮжӮБӮД
GPUӮӘ•s—vӮЙӮИӮйӮЩӮЗCPUӮМүүҺZ”\—НӮӘӮ ӮӘӮйҒB
Ӯ»ӮкӮЕҒAGPUӮӘҚЎӮвӮБӮДӮўӮйӮұӮЖӮӘ–і‘КӮЙӮИӮйӮ©ӮаӮөӮкӮИӮўӮБӮДӮҫӮҜӮМӮұӮЖӮҫҒB
‘Ҫ•ӘҒAғvғҚғOғүғ}ғuғӢғVғFҒ[ғ_ӮМ‘еӢK–НGPUӮН–ЕӮСӮйӮ©ӮаӮөӮкӮИӮўӮҜӮЗҒA
Ҡ®‘SӮЙҢЕ’иӢ@”\Ӯр”pӮөӮДҒAғ\ғtғgӮҫӮҜӮЙӮИӮйӮЬӮЕӮНӮўӮ©ӮИӮўӮжҒB
GPUӮМҢЁ‘гӮнӮиӮМӮҪӮЯӮЙ•А—сүүҺZ”\—НӮрӮҪӮ©ӮЯӮДӮўӮйӮнӮҜӮ¶ӮбӮИӮӯӮДҒA
•А—сүүҺZ”\—НӮрҚӮӮЯӮҪҢӢүКӮМүһ—pӮМҲкӮВӮЖӮөӮДҒA
GPUӮМҸҲ—қӮМ‘ҪӮӯӮӘӮўӮзӮИӮӯӮИӮйӮ©ӮаӮөӮкӮИӮўӮБӮДӮҫӮҜӮҫҒB
ҚЕҸүӮЙүeӢҝӮрӮӨӮҜӮйӮМӮНғnғCғGғ“ғhӮЕӮНӮИӮӯӮДҒAӮЮӮөӮлғ`ғbғvғZғbғgӮЙ“қҚҮӮіӮкӮДӮўӮйӮжӮӨӮИғҚҒ[ғGғ“ғhӮМ
GPU&MediaEncoderӢ@”\ӮМ•ыҒB
700+1 ҒF---Ғј(ҒLҒНҒM’UҒјҒҷж|Қк [Ғ«] ҒF2009/04/04(“y) 20:27:14 ID:WkDXM8VE (4/9)
ӮаӮҝӮлӮсӮ»ӮМҢЕ’иӢ@”\ӮМҺcӮиғJғXӮаCPUӮЙ“қҚҮӮөӮДӮөӮЬӮӨӮМӮӘ“sҚҮӮӘ—ЗӮўӮ©ӮзҒA
ҢӢӢЗӮМӮЖӮұӮл“қҚҮҳHҗьӮЕҒAӮ»ӮМҢгӮМҚӮ‘¬ү»ӮЙӮжӮБӮДҒA”Д—pҗ«ӮМҚӮӮіҒAғRғXғgҒA“d—НӮМҠП“_Ӯ©ӮзҒA
ғjғbғ`ӮИғnғCғGғ“ғhGPUҺsҸкӮӘҸkҸ¬ӮөӮДӮўӮӯҒB
Ңл“ҡҗжҗ¶ӮрҠЬӮЯ”ч–ӯӮЙҺІӮӘӮёӮкӮДӮўӮйҠЁҲбӮўҢNӮӘ‘ҪӮўӮжӮӨӮҫӮӘҒA
CPUғҒҒ[ғJҒ[ӮӘғXғgғҠҒ[ғҖғRғAӮМ“қҚҮӮИӮиҒA–Ҫ—ЯғZғbғgҠg’ЈӮИӮиӮрӮ·ӮйӮұӮЖӮЙӮжӮБӮД
GPUӮӘ•s—vӮЙӮИӮйӮЩӮЗCPUӮМүүҺZ”\—НӮӘӮ ӮӘӮйҒB
Ӯ»ӮкӮЕҒAGPUӮӘҚЎӮвӮБӮДӮўӮйӮұӮЖӮӘ–і‘КӮЙӮИӮйӮ©ӮаӮөӮкӮИӮўӮБӮДӮҫӮҜӮМӮұӮЖӮҫҒB
‘Ҫ•ӘҒAғvғҚғOғүғ}ғuғӢғVғFҒ[ғ_ӮМ‘еӢK–НGPUӮН–ЕӮСӮйӮ©ӮаӮөӮкӮИӮўӮҜӮЗҒA
Ҡ®‘SӮЙҢЕ’иӢ@”\Ӯр”pӮөӮДҒAғ\ғtғgӮҫӮҜӮЙӮИӮйӮЬӮЕӮНӮўӮ©ӮИӮўӮжҒB
GPUӮМҢЁ‘гӮнӮиӮМӮҪӮЯӮЙ•А—сүүҺZ”\—НӮрӮҪӮ©ӮЯӮДӮўӮйӮнӮҜӮ¶ӮбӮИӮӯӮДҒA
•А—сүүҺZ”\—НӮрҚӮӮЯӮҪҢӢүКӮМүһ—pӮМҲкӮВӮЖӮөӮДҒA
GPUӮМҸҲ—қӮМ‘ҪӮӯӮӘӮўӮзӮИӮӯӮИӮйӮ©ӮаӮөӮкӮИӮўӮБӮДӮҫӮҜӮҫҒB
ҚЕҸүӮЙүeӢҝӮрӮӨӮҜӮйӮМӮНғnғCғGғ“ғhӮЕӮНӮИӮӯӮДҒAӮЮӮөӮлғ`ғbғvғZғbғgӮЙ“қҚҮӮіӮкӮДӮўӮйӮжӮӨӮИғҚҒ[ғGғ“ғhӮМ
GPU&MediaEncoderӢ@”\ӮМ•ыҒB
700+1 ҒF---Ғј(ҒLҒНҒM’UҒјҒҷж|Қк [Ғ«] ҒF2009/04/04(“y) 20:27:14 ID:WkDXM8VE (4/9)
ӮаӮҝӮлӮсӮ»ӮМҢЕ’иӢ@”\ӮМҺcӮиғJғXӮаCPUӮЙ“қҚҮӮөӮДӮөӮЬӮӨӮМӮӘ“sҚҮӮӘ—ЗӮўӮ©ӮзҒA
ҢӢӢЗӮМӮЖӮұӮл“қҚҮҳHҗьӮЕҒAӮ»ӮМҢгӮМҚӮ‘¬ү»ӮЙӮжӮБӮДҒA”Д—pҗ«ӮМҚӮӮіҒAғRғXғgҒA“d—НӮМҠП“_Ӯ©ӮзҒA
ғjғbғ`ӮИғnғCғGғ“ғhGPUҺsҸкӮӘҸkҸ¬ӮөӮДӮўӮӯҒB
258 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/06/04(–Ш) 23:49:55 ID:amuWwOox0
ӮЬӮ ҒALRBӮЙӮВӮўӮДӮНӮұӮсӮИӮЖӮұӮлӮҫӮлҒB
Ӯ ӮЖӮНҒA—бӮМғ_ғCӮМғeғNғXғ`ғғғҶғjғbғgӮМ–КҗПӮр“ҜҲкғvғҚғZғXҠ·ҺZӮЕҒA
nVIDIA, AMDATIӮЖ”дҠrӮөӮДӮ Ӯй’ц“xҗ«”\Ң©җПӮаӮиӮөӮДҒA>>254ӮМҳbӮӘҗMңЯҗ«Ӯ ӮйӮ©ӮЗӮЁӮ©ӮНӮЕӮ«Ӯ»ӮӨӮҫӮИҒB
LRBӮН–КҗПӮӘ•іӮЕӮ©ӮўӮМӮЖҒAғvғҚғZғbғTғRғAӮӘӮжӮи”Д—p“IӮҫӮ©ӮзғeғNғXғ`ғғғҶғjғbғgӮМ–КҗП”дӮӘҸ¬ӮіӮӯӮИӮйӮМӮН
–і—қӮНӮИӮўҒBҢ»ҺАӮМҗ«”\ӮНҗ»•iӮӘӮЕӮйӮЬӮЕӮНӮнӮ©ӮзӮсӮ©Ӯзҗж‘–ӮиӢcҳ_ӮНӮвӮиӮҪӮӯӮИӮўӮЛҒB
“БӮЙғ\ғtғgҺьӮиӮМҸo—ҲҺҹ‘жӮЕӮ¶ӮНӮзӮӯҗ”Ҡ„ӮМҗ«”\ӮН“–ӮҪӮи‘OӮЙ•П“®ӮөӮ»ӮӨӮҫҒB
Ӯ ӮЖӮНҒA—бӮМғ_ғCӮМғeғNғXғ`ғғғҶғjғbғgӮМ–КҗПӮр“ҜҲкғvғҚғZғXҠ·ҺZӮЕҒA
nVIDIA, AMDATIӮЖ”дҠrӮөӮДӮ Ӯй’ц“xҗ«”\Ң©җПӮаӮиӮөӮДҒA>>254ӮМҳbӮӘҗMңЯҗ«Ӯ ӮйӮ©ӮЗӮЁӮ©ӮНӮЕӮ«Ӯ»ӮӨӮҫӮИҒB
LRBӮН–КҗПӮӘ•іӮЕӮ©ӮўӮМӮЖҒAғvғҚғZғbғTғRғAӮӘӮжӮи”Д—p“IӮҫӮ©ӮзғeғNғXғ`ғғғҶғjғbғgӮМ–КҗП”дӮӘҸ¬ӮіӮӯӮИӮйӮМӮН
–і—қӮНӮИӮўҒBҢ»ҺАӮМҗ«”\ӮНҗ»•iӮӘӮЕӮйӮЬӮЕӮНӮнӮ©ӮзӮсӮ©Ӯзҗж‘–ӮиӢcҳ_ӮНӮвӮиӮҪӮӯӮИӮўӮЛҒB
“БӮЙғ\ғtғgҺьӮиӮМҸo—ҲҺҹ‘жӮЕӮ¶ӮНӮзӮӯҗ”Ҡ„ӮМҗ«”\ӮН“–ӮҪӮи‘OӮЙ•П“®ӮөӮ»ӮӨӮҫҒB
259 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/06/05(Ӣа) 00:01:00 ID:j38oaozK0
ӮФӮБӮҝӮбӮҜҒAIntelӮӘӮЬӮ¶ӮЯӮЙSandyBridgeӮМҢгҢpӮЖӮ©
CPUӮЦӮМ“қҚҮӮрҚlӮҰӮДӮйӮИӮзҒALRBӮЭӮҪӮўӮИ”ј•ӘҺҺҚмӮМҸҲҸ—ҚмғfғBғXғNғҠҒ[ғgҗ»•iӮН
1/2Ғ`1/3ӮМҗ«”\ӮЕӮДӮўӮкӮОӮўӮўӮсӮ¶ӮбӮЛӮӯӮзӮўӮМҗЁӮўҒB
Ӯ ӮЖӮНIntel x86ӮӘҗМӮ©ӮзӮвӮБӮДӮўӮйӮжӮӨӮЙ—НӢЖӮМҚӮ‘¬ү»ӮЖ“қҚҮү»ӮөӮДӮиӮбҸҹӮДӮҪӮиҒB
x86ӮрҢГӮўӮЖҗйӮӨ‘ОҚRӢZҸpӮӘӮұӮЖӮІӮЖӮӯx86ӮМӢ@”\ҺжӮиҚһӮЭӮЙӮжӮБӮДӢм’ҖӮіӮкӮй—рҺjӮЙ
ӮЬӮҪҲк•Е’ЗүБӮіӮкӮйӮМӮ©ҒB
RISC <- P6
Itanium <- AMD64
GPGPU <- LNI
CPUӮЦӮМ“қҚҮӮрҚlӮҰӮДӮйӮИӮзҒALRBӮЭӮҪӮўӮИ”ј•ӘҺҺҚмӮМҸҲҸ—ҚмғfғBғXғNғҠҒ[ғgҗ»•iӮН
1/2Ғ`1/3ӮМҗ«”\ӮЕӮДӮўӮкӮОӮўӮўӮсӮ¶ӮбӮЛӮӯӮзӮўӮМҗЁӮўҒB
Ӯ ӮЖӮНIntel x86ӮӘҗМӮ©ӮзӮвӮБӮДӮўӮйӮжӮӨӮЙ—НӢЖӮМҚӮ‘¬ү»ӮЖ“қҚҮү»ӮөӮДӮиӮбҸҹӮДӮҪӮиҒB
x86ӮрҢГӮўӮЖҗйӮӨ‘ОҚRӢZҸpӮӘӮұӮЖӮІӮЖӮӯx86ӮМӢ@”\ҺжӮиҚһӮЭӮЙӮжӮБӮДӢм’ҖӮіӮкӮй—рҺjӮЙ
ӮЬӮҪҲк•Е’ЗүБӮіӮкӮйӮМӮ©ҒB
RISC <- P6
Itanium <- AMD64
GPGPU <- LNI
260 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/06/05(Ӣа) 00:06:09 ID:j38oaozK0
ӮИҒ[ӮсӮДүRҒBLRBӮЭӮҪӮўӮИ’ЮӮиғvғҚғZғbғTӮӘҗ¬ҢчӮ·ӮйӮнӮҜӮИӮ©ӮҪҒB
LRBӮМӮжӮӨӮИҗ»•iӮНғӢҒ[ғ}Ғ[ӮМҺҝӮа’бӮӯӮИӮиӮӘӮҝҒBӮНӮБӮ«ӮиӮўӮБӮДҺАғxғ“ғ`ӮӘ
ӮЕӮйӮЬӮЕҗ«”\Ҹо•сӮНҗM—pӮЕӮ«ӮсҒB
LRBӮМӮжӮӨӮИҗ»•iӮНғӢҒ[ғ}Ғ[ӮМҺҝӮа’бӮӯӮИӮиӮӘӮҝҒBӮНӮБӮ«ӮиӮўӮБӮДҺАғxғ“ғ`ӮӘ
ӮЕӮйӮЬӮЕҗ«”\Ҹо•сӮНҗM—pӮЕӮ«ӮсҒB
261 ҒF–јҸМ–ўҗЭ’иҒF2009/06/05(Ӣа) 00:10:54 ID:p/h2Dm2b0
LarrabeeӮӘSoCү»ӮЖӮ©ғҒғjҒ[ғRғAү»ӮМҗж•ЪӮЖӮўӮӨӮМӮН“–ғXғҢӮМ“аҠOӮЕҺUҒXҢкӮзӮкӮДӮ«ӮҪӮұӮЖӮИӮМӮЕүЯӢҺғҚғO“\ӮБӮҪӮиӮөӮД’·ҒXҢJӮи•ФӮ·•K—vӮНӮИӮўӮЕӮ·ҒBӮНӮўҒB
Ӯ»ӮкӮЙӮұӮМҺиӮМӢcҳ_ӮМ•ыӮӘӮжӮБӮЫӮЗҗж‘–ӮБӮДӮўӮйӮЖӮўӮӨӮ©ғ}ғNғҚү»ӮөӮ·Ӯ¬ӮЕғAғҢӮИҠҙӮ¶ҒB
Ӯ»ӮкӮЙӮұӮМҺиӮМӢcҳ_ӮМ•ыӮӘӮжӮБӮЫӮЗҗж‘–ӮБӮДӮўӮйӮЖӮўӮӨӮ©ғ}ғNғҚү»ӮөӮ·Ӯ¬ӮЕғAғҢӮИҠҙӮ¶ҒB
262 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/06/05(Ӣа) 00:15:17 ID:j38oaozK0
Ӯ»ӮӨӮўӮнӮиӮкӮиӮбӮ»ӮӨӮҫӮИҒB
LRBӮНҺАғxғ“ғ`ӮӘӮЕӮйӮЬӮЕҗ«”\ӮнӮ©ӮзӮсӮЖӮ©ӮўӮўӮИӮӘӮзҒA
•№ҚsӮөӮДҲк”Фҗж‘–Ӯиғlғ^ӮвӮБӮДӮсӮМӮЁӮкӮ¶ӮбӮсӮ©(ӮнӮзӮЎ
ӮұӮМғXғҢӮЕӮНҺ©җ§ӮөӮЬӮ·ӮжҒBҒBҒB
LRBӮНҺАғxғ“ғ`ӮӘӮЕӮйӮЬӮЕҗ«”\ӮнӮ©ӮзӮсӮЖӮ©ӮўӮўӮИӮӘӮзҒA
•№ҚsӮөӮДҲк”Фҗж‘–Ӯиғlғ^ӮвӮБӮДӮсӮМӮЁӮкӮ¶ӮбӮсӮ©(ӮнӮзӮЎ
ӮұӮМғXғҢӮЕӮНҺ©җ§ӮөӮЬӮ·ӮжҒBҒBҒB
263 ҒF–јҸМ–ўҗЭ’иҒF2009/06/05(Ӣа) 20:49:06 ID:6JYxVtV20
ҒyCOMPUTEX 2009ғҢғ|Ғ[ғgҒz IntelғfғXғNғgғbғv•Т
ttp://pc.watch.impress.co.jp/docs/news/event/20090604_212402.html
Intel to Acquire Wind River Systems for Approximately $884 Million
ttp://www.intel.com/pressroom/archive/releases/20090604corp.htm?iid=pr1_releasepri_20090604r
‘gӮЭҚһӮЭOS‘еҺиӮМWind RiverҺРӮрIntelҺРӮӘ”ғҺы
ttp://eetimes.jp/article/23068/
Analysis: Intel eyes embedded apps with Wind River deal
ttp://www.eetimes.com/news/latest/showArticle.jhtml;jsessionid=OHZUVORS1JTDAQSNDLPCKH0CJUNN2JVN?articleID=217701869
ҒyCOMPUTEX 2009ғҢғ|Ғ[ғgҒz IntelғEғӢғgғүғӮғrғҠғeғBҠо’ІҚuүү ҺҹҠъAtomғvғүғbғgғtғHҒ[ғҖ“ӢҚЪӮМMIDӮр‘Ҫҗ”ғfғӮ
ttp://pc.watch.impress.co.jp/docs/news/event/20090605_212525.html
ӮұӮкӮӘIntelӮМҺҹҗў‘гAtomҒuLincroftҒvӮМҺАғ`ғbғvӮҫ
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20090605_212608.html
ttp://pc.watch.impress.co.jp/docs/news/event/20090604_212402.html
Intel to Acquire Wind River Systems for Approximately $884 Million
ttp://www.intel.com/pressroom/archive/releases/20090604corp.htm?iid=pr1_releasepri_20090604r
‘gӮЭҚһӮЭOS‘еҺиӮМWind RiverҺРӮрIntelҺРӮӘ”ғҺы
ttp://eetimes.jp/article/23068/
Analysis: Intel eyes embedded apps with Wind River deal
ttp://www.eetimes.com/news/latest/showArticle.jhtml;jsessionid=OHZUVORS1JTDAQSNDLPCKH0CJUNN2JVN?articleID=217701869
ҒyCOMPUTEX 2009ғҢғ|Ғ[ғgҒz IntelғEғӢғgғүғӮғrғҠғeғBҠо’ІҚuүү ҺҹҠъAtomғvғүғbғgғtғHҒ[ғҖ“ӢҚЪӮМMIDӮр‘Ҫҗ”ғfғӮ
ttp://pc.watch.impress.co.jp/docs/news/event/20090605_212525.html
ӮұӮкӮӘIntelӮМҺҹҗў‘гAtomҒuLincroftҒvӮМҺАғ`ғbғvӮҫ
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20090605_212608.html
264 ҒF–јҸМ–ўҗЭ’иҒF2009/06/11(–Ш) 03:02:36 ID:OCYoeEqN0
Dirk Meyer talks up Atom-competitor
ttp://www.theinquirer.net/inquirer/news/1184676/dirk-meyer-talks-atom-competitor
“ЗӮсӮҫҠҙӮ¶ӮҫӮЖ5WҲИүәӮМx86ӮНӮұӮМӮЬӮЬIntelӮМ“ЖҗиӮ©ӮЛҒ[ҒB
2011-12•УӮиӮЕ—јҺРӮМrevenueӮНҸОӮҰӮйҲКҠJӮӯӮЖ—\‘ӘҒB
Hot Chips 21 has a stellar lineup
ttp://www.semiaccurate.com./2009/06/09/hot-chips-21-has-stellar-lineup/
Hot ChipsӮМAPӮӘҸoӮДӮ«ӮҪҒBӮұӮМ•УӮН•Ғ’КӮЙwktkҒB“БӮЙ“сҺҹ‘кӮ—
>* QuickPath: Bob Safranek (Intel)
>* Moorestown:The Innovation Platform for Next Generation MIDs (Intel)
>* Understanding the Intel Microarchitectures (Nehalem and Westmere): Transitioning into the Mainstream (Intel)
>* Sun's Next-Generation Multi-threaded Processor-Rainbow Falls (Sun)
Intel Atom N450ӢKҠiҺс“x”ҳҢх
җ®й“•Ҫ‘дҢч–ХҢё”ј Netbookӣ’ҚXгҷ”–
ttp://global.hkepc.com/3210
PineviewӮЕ“қҚҮӮіӮкӮйGPUӮНPowerVRӮҫӮЖӮ©ҒBғfғ…ғAғӢғRғA”ЕӮаӮ ӮйӮжҒAӮЖӮ©ҒB‘јҗFҒXҒB
ttp://www.theinquirer.net/inquirer/news/1184676/dirk-meyer-talks-atom-competitor
“ЗӮсӮҫҠҙӮ¶ӮҫӮЖ5WҲИүәӮМx86ӮНӮұӮМӮЬӮЬIntelӮМ“ЖҗиӮ©ӮЛҒ[ҒB
2011-12•УӮиӮЕ—јҺРӮМrevenueӮНҸОӮҰӮйҲКҠJӮӯӮЖ—\‘ӘҒB
Hot Chips 21 has a stellar lineup
ttp://www.semiaccurate.com./2009/06/09/hot-chips-21-has-stellar-lineup/
Hot ChipsӮМAPӮӘҸoӮДӮ«ӮҪҒBӮұӮМ•УӮН•Ғ’КӮЙwktkҒB“БӮЙ“сҺҹ‘кӮ—
>* QuickPath: Bob Safranek (Intel)
>* Moorestown:The Innovation Platform for Next Generation MIDs (Intel)
>* Understanding the Intel Microarchitectures (Nehalem and Westmere): Transitioning into the Mainstream (Intel)
>* Sun's Next-Generation Multi-threaded Processor-Rainbow Falls (Sun)
Intel Atom N450ӢKҠiҺс“x”ҳҢх
җ®й“•Ҫ‘дҢч–ХҢё”ј Netbookӣ’ҚXгҷ”–
ttp://global.hkepc.com/3210
PineviewӮЕ“қҚҮӮіӮкӮйGPUӮНPowerVRӮҫӮЖӮ©ҒBғfғ…ғAғӢғRғA”ЕӮаӮ ӮйӮжҒAӮЖӮ©ҒB‘јҗFҒXҒB
265 ҒF–јҸМ–ўҗЭ’иҒF2009/06/12(Ӣа) 21:30:50 ID:AGYsQvE80
Dell plans to buy something big
ttp://www.theinquirer.net/inquirer/news/1271190/dell-plans
Һҹҗў‘гAtomӮНҒAғlғbғgғuғbғNӢЈ‘ҲӮрҗнӮў”ІӮӯӮҪӮЯӮМIntelӮМ–ө
ttp://www.computerworld.jp/news/plf/150409.html
Web servers get 'leccy bill
SPECweb2009 fights the power
ttp://www.theregister.co.uk/2009/06/11/spec_web_power_test/
ttp://www.spec.org/web2009/results/web2009.html
Hot papers at 2009 VLSI Technology Symposium
ttp://www.eetimes.com/news/latest/showArticle.jhtml;jsessionid=2TLOJ0BZBIPSAQSNDLPCKH0CJUNN2JVN?articleID=217800771
IntelӮН2009 VLSIӮЕ16nmғvғҚғZғXӮЬӮЕӮрҺӢ–мӮЙ“ьӮкӮҪғQҒ[ғgҗвүҸ–ҢӮМҢ`җ¬ӮЙӮВӮўӮДҸqӮЧӮйҒB
Ҹ]—ҲӮМғvғҚғZғXӮЕӮНғ`ғғғlғӢӮЖHigh-kҗвүҸ–ҢӮМҠФӮЙ”–ӮўSiOx(Low-k)ӮМ‘wӮӘӮ ӮБӮҪӮҪӮЯӮЙ
EOTӮрӮ Ӯй’ц“xӮЬӮЕӮөӮ©’бӮӯӮ·ӮйӮұӮЖӮӘҸo—ҲӮИӮ©ӮБӮҪ
Ӯ»ӮкӮрӮЩӮЪҠ®‘SӮЙ”rҸңӮ·ӮйӮұӮЖӮЙҗ¬ҢчӮөӮҪӮЖӮ©Ӯ»ӮсӮИҳbҒH
ҚЎҢгӮағҖҒ[ғAӮМ–@‘ҘӮрҲЫҺқӮЕӮ«ӮйӮЖӮўӮӨғAғsҒ[ғӢӮМҲУ–ЎӮӘӢӯӮўӮЖҺvӮнӮкӮйҒB
ttp://www.theinquirer.net/inquirer/news/1271190/dell-plans
Һҹҗў‘гAtomӮНҒAғlғbғgғuғbғNӢЈ‘ҲӮрҗнӮў”ІӮӯӮҪӮЯӮМIntelӮМ–ө
ttp://www.computerworld.jp/news/plf/150409.html
Web servers get 'leccy bill
SPECweb2009 fights the power
ttp://www.theregister.co.uk/2009/06/11/spec_web_power_test/
ttp://www.spec.org/web2009/results/web2009.html
Hot papers at 2009 VLSI Technology Symposium
ttp://www.eetimes.com/news/latest/showArticle.jhtml;jsessionid=2TLOJ0BZBIPSAQSNDLPCKH0CJUNN2JVN?articleID=217800771
IntelӮН2009 VLSIӮЕ16nmғvғҚғZғXӮЬӮЕӮрҺӢ–мӮЙ“ьӮкӮҪғQҒ[ғgҗвүҸ–ҢӮМҢ`җ¬ӮЙӮВӮўӮДҸqӮЧӮйҒB
Ҹ]—ҲӮМғvғҚғZғXӮЕӮНғ`ғғғlғӢӮЖHigh-kҗвүҸ–ҢӮМҠФӮЙ”–ӮўSiOx(Low-k)ӮМ‘wӮӘӮ ӮБӮҪӮҪӮЯӮЙ
EOTӮрӮ Ӯй’ц“xӮЬӮЕӮөӮ©’бӮӯӮ·ӮйӮұӮЖӮӘҸo—ҲӮИӮ©ӮБӮҪ
Ӯ»ӮкӮрӮЩӮЪҠ®‘SӮЙ”rҸңӮ·ӮйӮұӮЖӮЙҗ¬ҢчӮөӮҪӮЖӮ©Ӯ»ӮсӮИҳbҒH
ҚЎҢгӮағҖҒ[ғAӮМ–@‘ҘӮрҲЫҺқӮЕӮ«ӮйӮЖӮўӮӨғAғsҒ[ғӢӮМҲУ–ЎӮӘӢӯӮўӮЖҺvӮнӮкӮйҒB
266 ҒF–јҸМ–ўҗЭ’иҒF2009/06/15(ҢҺ) 22:53:23 ID:KsOAMBZq0
ғRғXғgҚнҢёӮЖ’бҸБ”п“d—НӮрҚЕ—DҗжӮЙӮөӮҪҺҹҗў‘гAtomҒgPineviewҒhӮМҸҹҺZ
ғpғtғHҒ[ғ}ғ“ғXӮН“сӮМҺҹӮЕӮаҺщ—vӮНӮ ӮйӮ©
ttp://www.computerworld.jp/topics/netbook/150609.html
WebғTҒ[ғoӮМҗVғxғ“ғ`ғ}Ғ[ғNҒuSPECweb2009ҒvҒA•]үҝҠоҸҖӮЙҸБ”п“d—НӮр’ЗүБ
ғGғlғӢғMҒ[ҸБ”пӮЙ‘ОӮ·ӮйҠЦҗSӮМҚӮӮЬӮиӮр”Ҫүf
ttp://www.computerworld.jp/topics/srv/150509.html
ғpғtғHҒ[ғ}ғ“ғXӮН“сӮМҺҹӮЕӮаҺщ—vӮНӮ ӮйӮ©
ttp://www.computerworld.jp/topics/netbook/150609.html
WebғTҒ[ғoӮМҗVғxғ“ғ`ғ}Ғ[ғNҒuSPECweb2009ҒvҒA•]үҝҠоҸҖӮЙҸБ”п“d—НӮр’ЗүБ
ғGғlғӢғMҒ[ҸБ”пӮЙ‘ОӮ·ӮйҠЦҗSӮМҚӮӮЬӮиӮр”Ҫүf
ttp://www.computerworld.jp/topics/srv/150509.html
267 ҒF–јҸМ–ўҗЭ’иҒF2009/06/19(Ӣа) 00:51:50 ID:fa3+D4lD0
‘еҢҙ—YүоӮМҚЕҗVғCғ“ғ^Ғ[ғtғFғCғX“®ҢьҒ@Serial ATA 3.0•ТӮ»ӮМ1
ttp://pc.watch.impress.co.jp/docs/column/interface/20090616_294113.html
ҒyVLSI 2009ғҢғ|Ғ[ғgҒz“ҢҺЕҒASSDӮМ‘е•қӮИғRғXғgҚнҢёӮрүВ”\ӮЙӮ·ӮйNANDғtғүғbғVғ…ӮрҺҺҚм
ttp://pc.watch.impress.co.jp/docs/news/event/20090617_294364.html
ҒyVLSI 2009ғҢғ|Ғ[ғgҒz”ј“ұ‘Мғ`ғbғvӮМ“®Қм’ҶӮЙҗ«”\•Пү»Ӯр”cҲ¬Ӯ·Ӯй
ttp://pc.watch.impress.co.jp/docs/news/event/20090618_294587.html
NVIDIAӮӘ40nmғvғҚғZғXӮМGPUӮрҲкӢCӮЙ3ғtғ@ғ~ғҠ“Ҡ“ь
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20090617_294281.html
Core i5ӮӘ•b“ЗӮЭӮЙ“ьӮБӮҪIntel CPUғҚҒ[ғhғ}ғbғv
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20090619_294653.html
IntelҒAғvғҚғZғbғTғuғүғ“ғhӮрCoreғtғ@ғ~ғҠӮЦ“қҚҮ
ttp://pc.watch.impress.co.jp/docs/news/20090618_294634.html
ҠЦҢWҺТӮМ•\ҸоӮӘҺҰӮ·ғӮғoғCғӢWiMAXӮМ–ҫӮйӮў–ў—Ҳ
ttp://pc.watch.impress.co.jp/docs/column/mobile/20090618_294462.html
ttp://pc.watch.impress.co.jp/docs/column/interface/20090616_294113.html
ҒyVLSI 2009ғҢғ|Ғ[ғgҒz“ҢҺЕҒASSDӮМ‘е•қӮИғRғXғgҚнҢёӮрүВ”\ӮЙӮ·ӮйNANDғtғүғbғVғ…ӮрҺҺҚм
ttp://pc.watch.impress.co.jp/docs/news/event/20090617_294364.html
ҒyVLSI 2009ғҢғ|Ғ[ғgҒz”ј“ұ‘Мғ`ғbғvӮМ“®Қм’ҶӮЙҗ«”\•Пү»Ӯр”cҲ¬Ӯ·Ӯй
ttp://pc.watch.impress.co.jp/docs/news/event/20090618_294587.html
NVIDIAӮӘ40nmғvғҚғZғXӮМGPUӮрҲкӢCӮЙ3ғtғ@ғ~ғҠ“Ҡ“ь
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20090617_294281.html
Core i5ӮӘ•b“ЗӮЭӮЙ“ьӮБӮҪIntel CPUғҚҒ[ғhғ}ғbғv
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20090619_294653.html
IntelҒAғvғҚғZғbғTғuғүғ“ғhӮрCoreғtғ@ғ~ғҠӮЦ“қҚҮ
ttp://pc.watch.impress.co.jp/docs/news/20090618_294634.html
ҠЦҢWҺТӮМ•\ҸоӮӘҺҰӮ·ғӮғoғCғӢWiMAXӮМ–ҫӮйӮў–ў—Ҳ
ttp://pc.watch.impress.co.jp/docs/column/mobile/20090618_294462.html
268 ҒF–јҸМ–ўҗЭ’иҒF2009/06/20(“y) 21:46:35 ID:clL/B9RW0
IntelӮӘSSDӮрҺиӮӘӮҜӮй—қ—R
ttp://pc.watch.impress.co.jp/docs/column/hot/20090619_294419.html
җЭ”х“ҠҺ‘ӮМ‘қүБӮЕҒA”ј“ұ‘Мҗ»‘ў‘•’uӢЖҠEӮМҢ©’КӮөӮӘүь‘P
ttp://www.ednjapan.com/content/l_news/2009/06/u0o686000002ch3i.html
TSMC to boost capex, says report
http://www.eetimes.com/news/latest/showArticle.jhtml;jsessionid=UGMLWUB2LFHCGQSNDLPCKH0CJUNN2JVN?articleID=218100087
Metrology firm gains order for 450-mm work
http://www.eetimes.com/news/latest/showArticle.jhtml;jsessionid=UGMLWUB2LFHCGQSNDLPCKH0CJUNN2JVN?articleID=218100387
Analysis: Intel, AMD take battle to new ultra-thin laptops
ttp://www.eetimes.com/news/latest/showArticle.jhtml;jsessionid=UGMLWUB2LFHCGQSNDLPCKH0CJUNN2JVN?articleID=218100397
Intel pushes 193-nm litho down to 15-nm
ttp://www.eetimes.com/news/latest/showArticle.jhtml;jsessionid=UGMLWUB2LFHCGQSNDLPCKH0CJUNN2JVN?articleID=218100243
ttp://pc.watch.impress.co.jp/docs/column/hot/20090619_294419.html
җЭ”х“ҠҺ‘ӮМ‘қүБӮЕҒA”ј“ұ‘Мҗ»‘ў‘•’uӢЖҠEӮМҢ©’КӮөӮӘүь‘P
ttp://www.ednjapan.com/content/l_news/2009/06/u0o686000002ch3i.html
TSMC to boost capex, says report
http://www.eetimes.com/news/latest/showArticle.jhtml;jsessionid=UGMLWUB2LFHCGQSNDLPCKH0CJUNN2JVN?articleID=218100087
Metrology firm gains order for 450-mm work
http://www.eetimes.com/news/latest/showArticle.jhtml;jsessionid=UGMLWUB2LFHCGQSNDLPCKH0CJUNN2JVN?articleID=218100387
Analysis: Intel, AMD take battle to new ultra-thin laptops
ttp://www.eetimes.com/news/latest/showArticle.jhtml;jsessionid=UGMLWUB2LFHCGQSNDLPCKH0CJUNN2JVN?articleID=218100397
Intel pushes 193-nm litho down to 15-nm
ttp://www.eetimes.com/news/latest/showArticle.jhtml;jsessionid=UGMLWUB2LFHCGQSNDLPCKH0CJUNN2JVN?articleID=218100243
269 ҒF–јҸМ–ўҗЭ’иҒF2009/07/01(җ…) 21:17:12 ID:IvcvOPN60
ҸүҺuҠС“OӮ©ғjҒ[ғYғ}ғbғ`Ӯ©ҒH(i7Ӯ©i5Ӯ©ҒAҠyӮөӮӯ”YӮЮ“ъҒXҒB) Ғ@Ғ@
http://www.ne.jp/asahi/comp/tarusan/main209.htm
http://www.ne.jp/asahi/comp/tarusan/main209.htm
270 ҒF–јҸМ–ўҗЭ’иҒF2009/07/12(“ъ) 00:57:22 ID:Kf3nS6QN0
ho
271 ҒF–јҸМ–ўҗЭ’иҒF2009/07/19(“ъ) 00:09:27 ID:JLYP5xgj0
ҚЕӢЯӮМҳb‘и 2009”N7ҢҺ18“ъ
http://www.geocities.jp/andosprocinfo/wadai09/20090718.htm
http://www.geocities.jp/andosprocinfo/wadai09/20090718.htm
272 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/07/28(үО) 20:08:12 ID:KYthl2Av0
ҸБӮҰҚsӮӯLGA1366ғpғbғPҒ[ғWӮМCore i7
http://pc.watch.impress.co.jp/docs/column/kaigai/20090727_304653.html
Ңл“ҡҗжҗ¶ӮМҢл“ҡ—ҲӮҪӮИҒB
BloomfieldӮНҒAӮаӮЖӮаӮЖXeon UPӮрғfғXғNғgғbғvPCӮМғnғCғGғ“ғhӮЙ“]—pӮөӮҪӮҫӮҜӮМҗ»•iӮҫҒB
ҚЎӮЬӮЕBloomfieldӮӘ$200Ғ`500ӮМLynnfieldҢ—ӮМғfғXғNғgғbғvүҝҠi‘СӮЙ“Ҡ“ьӮіӮкӮДӮўӮҪӮМӮНҒA
LynnfieldӮӘ’PҸғӮЙ’xӮкӮҪӮҪӮЯӮЙҒAҺd•ыӮИӮӯҠJ”ӯӮӘҗжҚsӮөӮДӮўӮҪғTҒ[ғo—pӮр’ҶҢpӮ¬ӮЖӮөӮДүсӮөӮҪӮ©ӮзӮЙӮ·Ӯ¬ӮёҒA
LynnfieldӮӘӮЕӮҪӮзXEӮМүҝҠi‘СҲИҠOӮН–{—ҲXeon“]—p=XEӮЕӮ ӮйBloomfieldӮӘҸБӮҰӮйӮМӮНҺ©‘RӮИӮұӮЖӮЕ
•КӮЙӢБӮӯӮжӮӨӮИҺ–ҺАӮЕӮаӮИӮўҒB
LGA1366ӮӘXeonҗк—pӮЖӮөӮД–{—ҲӮМ–р–ЪӮр‘SӮӨӮө‘ұӮҜӮйӮҫӮҜӮИӮМӮЙҒA
ӮҪӮҫLGA1366Ӯр”Ы’иҳ_’ІӮЕӮ©Ӯ©ӮкӮДӮаҚўӮйҒB
ӮөӮ©ӮаҒAGulftownҲИҚ~QPIӮвғҒғӮғҠҺн—ЮӮЖғ`ғғғlғӢҗ”ӮӘSandy BridgeӮМғTҒ[ғo—pӮЕӮа‘қӮҰӮИӮўӮұӮЖӮвҒA
LGA1155ӮИӮЗӮӘӮ ӮйӮұӮЖӮрҚlӮҰӮйӮЖӮЮӮөӮлғ\ғPғbғgӮЖӮөӮД’·җ¶Ӯ«ӮИӮМӮНLGA1366ӮМ•ыӮЕӮ ӮйӮұӮЖӮН
—eҲХӮЙ‘z‘ңӮЕӮ«ӮйҒB
LynnfieldӮЖHavendaleӮӘ’xӮкӮҪӮМӮНғӮғWғ…ғүҒ[җЭҢvӮМҚ·•Кү»ӮӘҺvӮБӮҪӮжӮиӮа•ү’SӮҫӮБӮҪӮ©ӮзӮЕҒA
ғӮғWғ…ғүҒ[җЭҢvӮрҢp‘ұӮ·ӮйSandy BridgeӮЕӮаҚЕҸүӮМ4CPU+1GPUғRғAӮжӮиӮаҢгӮМҗ»•iӮН
ӮЬӮҫғVғҠғRғ“ӮӘӮИӮўӮЖҢҫӮнӮкӮДӮўӮйҒB
http://pc.watch.impress.co.jp/docs/column/kaigai/20090727_304653.html
Ңл“ҡҗжҗ¶ӮМҢл“ҡ—ҲӮҪӮИҒB
BloomfieldӮНҒAӮаӮЖӮаӮЖXeon UPӮрғfғXғNғgғbғvPCӮМғnғCғGғ“ғhӮЙ“]—pӮөӮҪӮҫӮҜӮМҗ»•iӮҫҒB
ҚЎӮЬӮЕBloomfieldӮӘ$200Ғ`500ӮМLynnfieldҢ—ӮМғfғXғNғgғbғvүҝҠi‘СӮЙ“Ҡ“ьӮіӮкӮДӮўӮҪӮМӮНҒA
LynnfieldӮӘ’PҸғӮЙ’xӮкӮҪӮҪӮЯӮЙҒAҺd•ыӮИӮӯҠJ”ӯӮӘҗжҚsӮөӮДӮўӮҪғTҒ[ғo—pӮр’ҶҢpӮ¬ӮЖӮөӮДүсӮөӮҪӮ©ӮзӮЙӮ·Ӯ¬ӮёҒA
LynnfieldӮӘӮЕӮҪӮзXEӮМүҝҠi‘СҲИҠOӮН–{—ҲXeon“]—p=XEӮЕӮ ӮйBloomfieldӮӘҸБӮҰӮйӮМӮНҺ©‘RӮИӮұӮЖӮЕ
•КӮЙӢБӮӯӮжӮӨӮИҺ–ҺАӮЕӮаӮИӮўҒB
LGA1366ӮӘXeonҗк—pӮЖӮөӮД–{—ҲӮМ–р–ЪӮр‘SӮӨӮө‘ұӮҜӮйӮҫӮҜӮИӮМӮЙҒA
ӮҪӮҫLGA1366Ӯр”Ы’иҳ_’ІӮЕӮ©Ӯ©ӮкӮДӮаҚўӮйҒB
ӮөӮ©ӮаҒAGulftownҲИҚ~QPIӮвғҒғӮғҠҺн—ЮӮЖғ`ғғғlғӢҗ”ӮӘSandy BridgeӮМғTҒ[ғo—pӮЕӮа‘қӮҰӮИӮўӮұӮЖӮвҒA
LGA1155ӮИӮЗӮӘӮ ӮйӮұӮЖӮрҚlӮҰӮйӮЖӮЮӮөӮлғ\ғPғbғgӮЖӮөӮД’·җ¶Ӯ«ӮИӮМӮНLGA1366ӮМ•ыӮЕӮ ӮйӮұӮЖӮН
—eҲХӮЙ‘z‘ңӮЕӮ«ӮйҒB
LynnfieldӮЖHavendaleӮӘ’xӮкӮҪӮМӮНғӮғWғ…ғүҒ[җЭҢvӮМҚ·•Кү»ӮӘҺvӮБӮҪӮжӮиӮа•ү’SӮҫӮБӮҪӮ©ӮзӮЕҒA
ғӮғWғ…ғүҒ[җЭҢvӮрҢp‘ұӮ·ӮйSandy BridgeӮЕӮаҚЕҸүӮМ4CPU+1GPUғRғAӮжӮиӮаҢгӮМҗ»•iӮН
ӮЬӮҫғVғҠғRғ“ӮӘӮИӮўӮЖҢҫӮнӮкӮДӮўӮйҒB
273 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/07/28(үО) 20:09:24 ID:KYthl2Av0
NehalemӮЕӮНҒAӮвӮҪӮзӮЖғ\ғPғbғgӮӘ—җ—§ӮөӮДӮўӮйӮжӮӨӮҫӮӘҒA
ҢіҒXXeon MPӮЖXeon DP/UPҒAғfғXғNғgғbғvӮЕӮНӮ»ӮкӮјӮкҲбӮӨғ\ғPғbғgӮЕӮ ӮиҒA
—бӮҰӮОCore 2/PenDҢnӮЕӮаLGA775, 771, 604ӮЖғӮғoғCғӢӮрҸңӮўӮДӮа3Һн—ЮӮ ӮйҒB
ӮұӮкӮНNehalemӮЕӮа(ӮЁӮ»ӮзӮӯSandy BridgeӮЕӮа)“ҜӮ¶ӮЕҒA
LGA1156, 1366, 1567ӮЖ3Һн—ЮӮ ӮйҒB
–в‘иӮИӮМӮН1155ӮҫӮҜӮҫҒBҢл“ҡҗжҗ¶ӮМ’ҶӮЕӮН1155ӮНSandy Bridge—pӮіӮкӮДӮўӮДҒA
1155ӮМҲИҚ~—\‘ӘӮрғxҒ[ғXӮЙSandy BridgeӮМҲЪҚsӮМғVғFғA—\‘zӮЬӮЕҸҹҺиӮЙҗ„‘ӘӮөӮҪӢLҺ–
ӮӘ‘OүсӮ©Ӯ©ӮкӮДӮўӮйӮӘҒA1155ӮНHavendaleӮМ‘ОҚф”Еғ\ғPғbғgӮЕVRDӮМҺd—lӮӘ
VerUPӮөӮҪҒAӮөӮўӮДӮўӮҰӮОWestmere—pғ\ғPғbғgӮЕӮ ӮиҒASandy Bridge—pӮЕӮНӮИӮўӮұӮЖӮр
•tӮҜүБӮҰӮДӮЁӮӯҒB
(Ңл“ҡҗжҗ¶ӮӘ‘S‘М“IӮЙSandy BridgeӮЙҠъ‘ТӮөӮДNehalemӮНғnғYғҢӮЭӮҪӮўӮИҳ_’ІӮЕӮ ӮйӮӘҒA
ҢлүрӮрғxҒ[ғXӮЙ•ОӮБӮҪ—\‘zӮрӮөӮДӮўӮйӮМӮЕ’ҚҲУӮөӮД“ЗӮсӮЕӮЩӮөӮў)
274 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/07/28(үО) 20:16:21 ID:KYthl2Av0
ӮЬӮ ӮжӮӨӮ·ӮйӮЙүҪӮӘҢҫӮўӮҪӮўӮМӮ©ӮЖӮўӮӨӮЖҒA
Lynnfield/HavendaleӮӘ’xӮкӮҪ(ӮаӮөӮӯӮНғLғғғ“ғZғӢӮіӮкӮҪ)ӮМӮӘҲ«ӮўӮсӮЕҒA
LGA1366ӮрNehalemҸүҠъҢ^ӮМҺё”sҚмӮЕӮ ӮйӮ©ӮМӮжӮӨӮИ—қүрӮрӮөӮДӮўӮйҗlӮӘ
‘ј”ВӮЕӮаҚЕӢЯ‘қӮҰӮДӮ«ӮДҢл•сҚLӮЯӮйӮИӮжӮЖӮўӮўӮҪӮўӮҫӮҜӮҫӮИҒB
Lynnfield/HavendaleӮӘ’xӮкӮҪ(ӮаӮөӮӯӮНғLғғғ“ғZғӢӮіӮкӮҪ)ӮМӮӘҲ«ӮўӮсӮЕҒA
LGA1366ӮрNehalemҸүҠъҢ^ӮМҺё”sҚмӮЕӮ ӮйӮ©ӮМӮжӮӨӮИ—қүрӮрӮөӮДӮўӮйҗlӮӘ
‘ј”ВӮЕӮаҚЕӢЯ‘қӮҰӮДӮ«ӮДҢл•сҚLӮЯӮйӮИӮжӮЖӮўӮўӮҪӮўӮҫӮҜӮҫӮИҒB
275 ҒF–јҸМ–ўҗЭ’иҒF2009/07/29(җ…) 00:35:25 ID:LH1FbcF10
ғTҒ[ғoҒ[—p“rӮЕ–^AҺРӮЙӮ ӮкӮҫӮҜҚ·ӮрӮВӮҜӮҪғAҒ[ғLғeғNғ`ғғӮрғnғYғҢҢДӮОӮнӮиӮЖӮНҒc
Ӯ»ӮМғnғYғҢӮЙ•үӮҜӮҝӮбӮӨҳA’ҶӮНӮЗӮӨӮ·ӮкӮОӮўӮўӮМӮі
Ӯ»ӮМғnғYғҢӮЙ•үӮҜӮҝӮбӮӨҳA’ҶӮНӮЗӮӨӮ·ӮкӮОӮўӮўӮМӮі
276 ҒF–јҸМ–ўҗЭ’иҒF2009/07/29(җ…) 00:49:48 ID:4Bbr85+y0
>>492
4-2-3-1ӮМ–{“cғVғXғeғҖӮ©ҒB
–{“cӮіӮсӮНғVғ…Ғ[ғg—НӮ ӮйӮөҒAғJғүғuғҚӮЖӮМғzғbғgғүғCғ“Ӯағoғbғ`ғҠӮҫӮөҒAӮ©ӮИӮиӮ—ӮӢӮ”ӮӢӮҫӮИҒB
4-2-3-1ӮМ–{“cғVғXғeғҖӮ©ҒB
–{“cӮіӮсӮНғVғ…Ғ[ғg—НӮ ӮйӮөҒAғJғүғuғҚӮЖӮМғzғbғgғүғCғ“Ӯағoғbғ`ғҠӮҫӮөҒAӮ©ӮИӮиӮ—ӮӢӮ”ӮӢӮҫӮИҒB
277 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/07/30(–Ш) 19:46:34 ID:ec/NMCEm0
http://kishinkan.jugem.jp/?eid=2746
http://xtreview.com/addcomment-id-7780-view-intel-socket-H2-LGA-1155.html
LGA1155ӮНҒAҚЎ”NӮМ2ҢҺӮЙIntelӮӘҠJ”ӯҺТҢьӮҜӮМғyҒ[ғWӮЕҢцҠJҒA”М”„ӮөӮДӮўӮҪӮаӮМӮЕҒA
Ӯ»ӮМҺd—lӮЙӮжӮйӮЖҒAVRD11.1Ӯ©ӮзVRD12ӮЙVerUPӮөӮҪӮұӮЖӮЙӮӯӮнӮҰӮДҒA
LGA1156ӮЖ”дӮЧӮД“d—¬’lӮӘҸӯӮИӮўҺd—lӮЙӮИӮБӮДӮўӮйҒB
ӮЁӮкӮӘLGA1155 = Sandy Bridge—pӮЕӮНӮИӮўӮЖӮўӮБӮДӮўӮй—қ—RӮН3ӮВӮ ӮйҒB
(1)
ғҒғJғjғJғӢӮИғ\ғPғbғgӮМ•]үҝ•”ҚЮӮрҒA2”NӮа‘OӮ©Ӯз”М”„ӮөӮДӮўӮйӮМӮНҺһҠъ“IӮЙӮЁӮ©ӮөӮўҒB
(2)
Socket [P]enryn = mPGA478
Socket [B]loomfield = LGA1366
Socket [T]ejas = LGA775
Socket [G]ilo = mPGA989
IntelӮНSocketӮМғRҒ[ғhғlҒ[ғҖӮЙӮНҒAҚЕҸүӮМғ^Ғ[ғQғbғgӮҫӮБӮҪCPUӮМғRҒ[ғhғlҒ[ғҖӮМ“Ә•¶ҺҡӮрӮаӮБӮДӮӯӮйӮМӮЕ
ӮИӮЗӮМӮжӮӨӮЙҸ]ӮҰӮОҒASocket H1 / H2ӮМ[H]ӮНHavendaleӮрҺwӮөӮДӮўӮйӮМӮҫӮлӮӨҒB
(3)
Nehalem/Westmereҗў‘гӮЕӮНҒA1156/1155ӮӘ•№‘¶Ӯ·ӮйӮЖӮўӮӨғ\Ғ[ғXӮНҚЎӮЬӮЕӮЙӮаӮҝӮзӮЩӮзӮЖ
ӮЕӮДӮ«ӮДӮўӮйӮӘҒALGA 1155 = Sandy Bridge—pӮЖӮўӮӨӮжӮӨӮИғ\Ғ[ғXӮНҒA
ҚЎӮМӮЖӮұӮлҢл“ҡӢLҺ–ӮЖҒAҢл“ҡӢLҺ–ӮрӮЬӮсӮЬүL“ЫӮЭӮЙҸРүоӮЙӮөӮДӮўӮйғTғCғgӮМӮЭӮЕӮ ӮйҒB
http://xtreview.com/addcomment-id-7780-view-intel-socket-H2-LGA-1155.html
LGA1155ӮНҒAҚЎ”NӮМ2ҢҺӮЙIntelӮӘҠJ”ӯҺТҢьӮҜӮМғyҒ[ғWӮЕҢцҠJҒA”М”„ӮөӮДӮўӮҪӮаӮМӮЕҒA
Ӯ»ӮМҺd—lӮЙӮжӮйӮЖҒAVRD11.1Ӯ©ӮзVRD12ӮЙVerUPӮөӮҪӮұӮЖӮЙӮӯӮнӮҰӮДҒA
LGA1156ӮЖ”дӮЧӮД“d—¬’lӮӘҸӯӮИӮўҺd—lӮЙӮИӮБӮДӮўӮйҒB
ӮЁӮкӮӘLGA1155 = Sandy Bridge—pӮЕӮНӮИӮўӮЖӮўӮБӮДӮўӮй—қ—RӮН3ӮВӮ ӮйҒB
(1)
ғҒғJғjғJғӢӮИғ\ғPғbғgӮМ•]үҝ•”ҚЮӮрҒA2”NӮа‘OӮ©Ӯз”М”„ӮөӮДӮўӮйӮМӮНҺһҠъ“IӮЙӮЁӮ©ӮөӮўҒB
(2)
Socket [P]enryn = mPGA478
Socket [B]loomfield = LGA1366
Socket [T]ejas = LGA775
Socket [G]ilo = mPGA989
IntelӮНSocketӮМғRҒ[ғhғlҒ[ғҖӮЙӮНҒAҚЕҸүӮМғ^Ғ[ғQғbғgӮҫӮБӮҪCPUӮМғRҒ[ғhғlҒ[ғҖӮМ“Ә•¶ҺҡӮрӮаӮБӮДӮӯӮйӮМӮЕ
ӮИӮЗӮМӮжӮӨӮЙҸ]ӮҰӮОҒASocket H1 / H2ӮМ[H]ӮНHavendaleӮрҺwӮөӮДӮўӮйӮМӮҫӮлӮӨҒB
(3)
Nehalem/Westmereҗў‘гӮЕӮНҒA1156/1155ӮӘ•№‘¶Ӯ·ӮйӮЖӮўӮӨғ\Ғ[ғXӮНҚЎӮЬӮЕӮЙӮаӮҝӮзӮЩӮзӮЖ
ӮЕӮДӮ«ӮДӮўӮйӮӘҒALGA 1155 = Sandy Bridge—pӮЖӮўӮӨӮжӮӨӮИғ\Ғ[ғXӮНҒA
ҚЎӮМӮЖӮұӮлҢл“ҡӢLҺ–ӮЖҒAҢл“ҡӢLҺ–ӮрӮЬӮсӮЬүL“ЫӮЭӮЙҸРүоӮЙӮөӮДӮўӮйғTғCғgӮМӮЭӮЕӮ ӮйҒB
278 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/07/30(–Ш) 19:53:50 ID:ec/NMCEm0
’PҸғӮЙVRDӮМVerUpӮӘӮ Ӯи(VRD12ӮЕӮНҚЎӮнӮ©ӮБӮДӮўӮйӮҫӮҜӮЕғTҒ[ғo—pCPUӮИӮЗӮЙӮа•ПҚXӮӘӮ Ӯй–Н—l)ҒA
LGA1155ӮӘ’ЗүБӮіӮкӮйӮжӮӨӮҫӮӘҒA“d—¬—e—КӮӘ—}ӮҰӮзӮкӮДӮўӮйӮұӮЖӮвҒA
ҲИ‘OӮЙӮа1156—pӮМғ}ғUҒ[ӮЕӮН1155CPUӮӘҺgӮҰӮйӮИӮЗӮМҸгҲКҢЭҠ·ӮМҸо•сӮаӮЕӮДӮўӮйӮұӮЖӮ©ӮзҒA
’PҸғӮЙ“dҢ№Һd—lӮр—}ӮҰӮДҒAғvғүғbғgғtғHҒ[ғҖғRғXғgӮр—}ӮҰӮйӮҪӮЯӮМҒA
—хүҝ”ЕҺd—lӮӘ1155ӮЖӮўӮӨӮМӮӘҚЕӮа‘Г“–ӮИүрҺЯӮЙҺvӮҰӮДӮ«ӮҪҒB
IntelӮНғ}ғӢғ`ғRғAӮЙҲЪҚsӮөӮДӮ©Ӯз“БӮЙNehalemҲИҚ~ӮЕҒA
ғpғtғHҒ[ғ}ғ“ғX/ғҒғCғ“ғXғgғҠҒ[ғҖүҝҠi‘СӮМCPUӮМғ_ғCғTғCғYӮӘӮұӮкӮЬӮЕӮжӮиӢҗ‘еү»ӮөӮДӮўӮД
”дҠr“Iғ_ғCӮМҸ¬ӮіӮИClarkdaleӮЕӮаMCMӮЕӮ ӮйҒBғ{Ғ[ғh‘ӨӮЕғvғүғbғgғtғHҒ[ғҖғRғXғgӮр—}ӮҰӮҪ
Һd—lӮаҗVҗЭӮөӮҪӮўӮМӮ©ӮаӮөӮкӮИӮўҒBSandy BridgeӮЕӮаӮұӮМ‘OӮМғӢҒ[ғ}Ғ[ӢLҺ–ӮрүL“ЫӮЭӮЙӮ·ӮйӮИӮз
225mm^2Ӯағ_ғCғTғCғYӮӘӮ ӮиҒAғҒғCғ“ғXғgғҠҒ[ғҖ—pӮЖӮөӮДӮНӮ©ӮИӮиӢкӮөӮўғTғCғYӮЙӮИӮБӮДӮўӮй
ӮМӮЕҒA“sҚҮӮӘӮўӮўҒB
LGA1155ӮӘ’ЗүБӮіӮкӮйӮжӮӨӮҫӮӘҒA“d—¬—e—КӮӘ—}ӮҰӮзӮкӮДӮўӮйӮұӮЖӮвҒA
ҲИ‘OӮЙӮа1156—pӮМғ}ғUҒ[ӮЕӮН1155CPUӮӘҺgӮҰӮйӮИӮЗӮМҸгҲКҢЭҠ·ӮМҸо•сӮаӮЕӮДӮўӮйӮұӮЖӮ©ӮзҒA
’PҸғӮЙ“dҢ№Һd—lӮр—}ӮҰӮДҒAғvғүғbғgғtғHҒ[ғҖғRғXғgӮр—}ӮҰӮйӮҪӮЯӮМҒA
—хүҝ”ЕҺd—lӮӘ1155ӮЖӮўӮӨӮМӮӘҚЕӮа‘Г“–ӮИүрҺЯӮЙҺvӮҰӮДӮ«ӮҪҒB
IntelӮНғ}ғӢғ`ғRғAӮЙҲЪҚsӮөӮДӮ©Ӯз“БӮЙNehalemҲИҚ~ӮЕҒA
ғpғtғHҒ[ғ}ғ“ғX/ғҒғCғ“ғXғgғҠҒ[ғҖүҝҠi‘СӮМCPUӮМғ_ғCғTғCғYӮӘӮұӮкӮЬӮЕӮжӮиӢҗ‘еү»ӮөӮДӮўӮД
”дҠr“Iғ_ғCӮМҸ¬ӮіӮИClarkdaleӮЕӮаMCMӮЕӮ ӮйҒBғ{Ғ[ғh‘ӨӮЕғvғүғbғgғtғHҒ[ғҖғRғXғgӮр—}ӮҰӮҪ
Һd—lӮаҗVҗЭӮөӮҪӮўӮМӮ©ӮаӮөӮкӮИӮўҒBSandy BridgeӮЕӮаӮұӮМ‘OӮМғӢҒ[ғ}Ғ[ӢLҺ–ӮрүL“ЫӮЭӮЙӮ·ӮйӮИӮз
225mm^2Ӯағ_ғCғTғCғYӮӘӮ ӮиҒAғҒғCғ“ғXғgғҠҒ[ғҖ—pӮЖӮөӮДӮНӮ©ӮИӮиӢкӮөӮўғTғCғYӮЙӮИӮБӮДӮўӮй
ӮМӮЕҒA“sҚҮӮӘӮўӮўҒB
279 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/07/30(–Ш) 19:59:52 ID:ec/NMCEm0
ӮЬӮ ҒAҗ[“ЗӮЭӮөӮ·Ӯ¬ӮН—ЗӮӯӮИӮўӮҜӮЗҒA
LGA1155—pӮМCPUӮИӮзҒACPUҺ©‘МӮрҚӮӮӯӮӨӮБӮҪӮЖӮөӮДӮаҒA
ғ}ғUҒ[ғ{Ғ[ғh‘ӨӮМғRғXғgӮӘ’бӮўӮМӮЕҢӢүК“IӮЙPC‘S‘МӮЕӮНӮжӮи—хүҝӮЙ
Ӯ·ӮйӮұӮЖӮӘҸo—ҲӮйҒBҢӢүК“IӮЙ—хүҝ”ЕӮМғOғҢҒ[ғhӮМCPUӮЖӮөӮД”„ӮкӮйҒB
ӮВӮЬӮиIntelӮӘғ_ғCӮМӮЕӮ©ӮўҗОӮрҠж’ЈӮБӮДҲАӮӯ”„ӮзӮИӮӯӮДӮа
IntelӮМ–ЧӮҜӮрҸo—ҲӮйӮҫӮҜҠm•ЫӮЕӮ«ӮйӮөӮӯӮЭӮЖӮўӮӨӮнӮҜӮҫҒB
(–іҳ_ҚЕҸI–Ъ•WӮНғ}ғUҒ[ғ{Ғ[ғhғxғ“ғ_Ғ[ӮМӮҪӮЯӮЕӮНӮИӮўӮЖӮұӮлӮӘ–Ў‘X)
LGA1155—pӮМCPUӮИӮзҒACPUҺ©‘МӮрҚӮӮӯӮӨӮБӮҪӮЖӮөӮДӮаҒA
ғ}ғUҒ[ғ{Ғ[ғh‘ӨӮМғRғXғgӮӘ’бӮўӮМӮЕҢӢүК“IӮЙPC‘S‘МӮЕӮНӮжӮи—хүҝӮЙ
Ӯ·ӮйӮұӮЖӮӘҸo—ҲӮйҒBҢӢүК“IӮЙ—хүҝ”ЕӮМғOғҢҒ[ғhӮМCPUӮЖӮөӮД”„ӮкӮйҒB
ӮВӮЬӮиIntelӮӘғ_ғCӮМӮЕӮ©ӮўҗОӮрҠж’ЈӮБӮДҲАӮӯ”„ӮзӮИӮӯӮДӮа
IntelӮМ–ЧӮҜӮрҸo—ҲӮйӮҫӮҜҠm•ЫӮЕӮ«ӮйӮөӮӯӮЭӮЖӮўӮӨӮнӮҜӮҫҒB
(–іҳ_ҚЕҸI–Ъ•WӮНғ}ғUҒ[ғ{Ғ[ғhғxғ“ғ_Ғ[ӮМӮҪӮЯӮЕӮНӮИӮўӮЖӮұӮлӮӘ–Ў‘X)
280 ҒF–јҸМ–ўҗЭ’иҒF2009/07/30(–Ш) 20:06:16 ID:ZsHCgQAW0
ғ`ғbғvғZғbғgӮМүҝҠiӮрҸгҸжӮ№ӮөӮД”„ӮйӮБӮЫӮўҳbӮН•·ӮўӮҪ
Ҹ]—ҲӮМ‘МҢn
CPUӮӘ$50, MCHӮӘ$30, ICHӮӘ$10ӮМҢv$90
җV‘МҢn
CPUӮӘ$80, ICHӮӘ$10ӮМҢv$90
–Ў‘XӮНSoCҢ^CPU(MCH“қҚҮ)ӮНCPUӮЖMCHӮр•КҒXӮЙҗ»‘ўӮөӮД”„ӮйӮжӮиғRғXғgӮӘ’бӮўӮЖӮўӮӨӮұӮЖ
ӮұӮкӮНғҖҒ[ғAӮМ–@‘ҘӮМҲР—НӮЕӮаӮ ӮиCPUғRғAӮр’PҸғӮЙ‘қӮвӮөӮДӮағEғPӮИӮў(ӮЖIntelӮӘ”»’fӮөӮҪ)ӮЖӮўӮӨӮұӮЖӮЕӮаӮ Ӯй
Ҹ]—ҲӮМ‘МҢn
CPUӮӘ$50, MCHӮӘ$30, ICHӮӘ$10ӮМҢv$90
җV‘МҢn
CPUӮӘ$80, ICHӮӘ$10ӮМҢv$90
–Ў‘XӮНSoCҢ^CPU(MCH“қҚҮ)ӮНCPUӮЖMCHӮр•КҒXӮЙҗ»‘ўӮөӮД”„ӮйӮжӮиғRғXғgӮӘ’бӮўӮЖӮўӮӨӮұӮЖ
ӮұӮкӮНғҖҒ[ғAӮМ–@‘ҘӮМҲР—НӮЕӮаӮ ӮиCPUғRғAӮр’PҸғӮЙ‘қӮвӮөӮДӮағEғPӮИӮў(ӮЖIntelӮӘ”»’fӮөӮҪ)ӮЖӮўӮӨӮұӮЖӮЕӮаӮ Ӯй
281 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/07/30(–Ш) 20:07:48 ID:ec/NMCEm0
>>280
Ӯ ӮкҗVӮөӮўICHүьӮЯPCHӮНүҝҠiҸгҸжӮ№ӮөӮДӮйӮсӮ¶ӮбӮИӮ©ӮБӮҪӮҜ?
ӮВӮЬӮиӮұӮұӮЕӮағ{ғbӮБӮДӮўӮйҒAӮЖӮЁӮкӮН”FҺҜӮөӮДӮҪӮӘҒB
Ӯ ӮкҗVӮөӮўICHүьӮЯPCHӮНүҝҠiҸгҸжӮ№ӮөӮДӮйӮсӮ¶ӮбӮИӮ©ӮБӮҪӮҜ?
ӮВӮЬӮиӮұӮұӮЕӮағ{ғbӮБӮДӮўӮйҒAӮЖӮЁӮкӮН”FҺҜӮөӮДӮҪӮӘҒB
282 ҒF–јҸМ–ўҗЭ’иҒF2009/08/02(“ъ) 04:47:51 ID:CSO5OsLr0
ҚЕӢЯӮМҳb‘и 2009”N8ҢҺ1“ъ
ttp://www.geocities.jp/andosprocinfo/wadai09/20090801.htm
ttp://www.geocities.jp/andosprocinfo/wadai09/20090801.htm
283 ҒF–јҸМ–ўҗЭ’иҒF2009/08/11(үО) 05:54:52 ID:dJkoMT7B0
ho
284 ҒF–јҸМ–ўҗЭ’иҒF2009/08/19(җ…) 22:29:44 ID:s85m/ZDV0
ze
285 ҒF–јҸМ–ўҗЭ’иҒF2009/08/21(Ӣа) 00:13:54 ID:vFJF79T20
ғCғ“ғeғӢҒA32nmғvғҚғZғXӮМҸҮ’ІӮИ—§ӮҝҸгӮӘӮиӮрғAғsҒ[ғӢ
http://pc.watch.impress.co.jp/docs/news/20090821_309731.html
http://pc.watch.impress.co.jp/docs/news/20090821_309731.html
286 ҒF–јҸМ–ўҗЭ’иҒF2009/08/21(Ӣа) 06:01:32 ID:MySVE3Sa0
Intel to use Larrabee graphics on CPUs
http://www.semiaccurate.com/2009/08/19/intel-use-larrabee-graphics-cpus/
The Case for ECC Memory in NvidiaҒfs Next GPU
http://www.realworldtech.com/page.cfm?ArticleID=RWT081909212132
http://www.semiaccurate.com/2009/08/19/intel-use-larrabee-graphics-cpus/
The Case for ECC Memory in NvidiaҒfs Next GPU
http://www.realworldtech.com/page.cfm?ArticleID=RWT081909212132
287 ҒF–јҸМ–ўҗЭ’иҒF2009/08/21(Ӣа) 21:58:17 ID:29Nm8+Ay0
>>286
ӮвӮБӮПHaswellӮ©ӮзӮӘ”ZҢъӮ©ҒB2”N‘OӮМ–П‘zӮЗӮЁӮиӮЕӮ«ӮҪӮБӮДҠҙӮ¶ӮвӮЛҒB
756 ҒFuҒF2007/10/14(“ъ) 15:14:50 ID:Vcf5EqG/
>>755
Ӯ¶ӮбҒAx86ғxҒ[ғXӮЕSSEӮӘ512bitӮЙҠg’ЈӮіӮкӮйӮЖӮЕӮа–П‘zӮөӮДӮЭӮйғeғXғgҒB
ҳRӮкӮН10ғ–ҢҺ‘OӮЙx86ғxҒ[ғXӮЕ512bitҸ‘ӮўӮДӮҪӮжҒ`ҒB
Һ©–қӮөӮДӮЭӮйғeғXғc(ғ\Ғ[ғXӮ ӮБӮҪӮҫӮҜӮҫӮӘ)ҒB
ғlғbғgӮЙӢvҒXӮЙӮВӮИӮўӮҫӮМӮЕLarrabeeӮМҳ_•¶ӮЭӮйӮМӮНӮұӮкӮ©ӮзӮҫӮӘҒA
Tera Tera TeraӮМҺ‘—ҝӮН“–ҺһӮЖӮөӮДӮНҢӢүК“IӮЙӮНҢӢҚ\“–ӮҪӮБӮДӮй•ыӮ©ӮЖҒB
ҸгҠCIDFӮМҺ‘—ҝӮЕӮНHPC—p“rӮаҸ‘ӮўӮДӮ ӮйӮөҒALarrabeeӮН”hҗ¶ӮМҢvүжӮаӮ ӮйӮ©ӮЖҒB
LarrabeeӮЖSandy BridgeӮН“ҜӮ¶ring busӮрҚМ—pӮөӮДӮйҒB
Sandy BridgeӮМAVXӮрLarrabeeӮжӮиӮаҗжӮЙIDFӮЕҸoӮөӮҪӮЖӮ«ӮН
•sҺ©‘RӮҫӮБӮҪҒBӮЬӮҫҒANehalemӮМғAҒ[ғLӮМҸЪҚЧӮрӮҫӮөӮҪӮЖӮұӮлӮҫӮБӮҪӮМӮЙ
үҪҢМSandy BridgeӮМAVXӮӘӮұӮМғ^ғCғ~ғ“ғOӮЕ??
Nehalem/TukwilaӮНCSIӮМ“ұ“ьҒA
Sandy Bridge/PoulsonӮНchip“аring busӮМ“ұ“ь
ӮЖ—ҲӮДҒAҗ[“ЗӮЭӮ·ӮйӮЖLarrabeeӮМ512bit SIMDӮӘ
“ҜӮ¶OregonӮМHaswellғAҒ[ғLӮМ–Ҫ—ЯӮМғeғXғgӮЕҒA“ҜӮ¶ring busӮҫӮ©Ӯз
LarrabeeҒ@+Ғ@Sandy Bridge = Haswell
ӮБӮДӮўӮӨ“WҠJӮӘӮ ӮиӮ©ӮИӮ ӮЖҒB
ӮЕҒAAVXӮМ•ыӮӘҗжӮЙҢцҠJӮөӮИӮўӮЖHaswellӮЕ512bitӮИLarrabeeӮЖҸҮ”ФӮӘ
“ьӮк‘ЦӮнӮБӮДҢ©—тӮиӮ·ӮйӮ©ӮзӮ©ӮЖҺvӮБӮДӮЭӮҪӮиҒB
–П‘zӮҫӮҜӮЗҒB
ӮвӮБӮПHaswellӮ©ӮзӮӘ”ZҢъӮ©ҒB2”N‘OӮМ–П‘zӮЗӮЁӮиӮЕӮ«ӮҪӮБӮДҠҙӮ¶ӮвӮЛҒB
756 ҒFuҒF2007/10/14(“ъ) 15:14:50 ID:Vcf5EqG/
>>755
Ӯ¶ӮбҒAx86ғxҒ[ғXӮЕSSEӮӘ512bitӮЙҠg’ЈӮіӮкӮйӮЖӮЕӮа–П‘zӮөӮДӮЭӮйғeғXғgҒB
ҳRӮкӮН10ғ–ҢҺ‘OӮЙx86ғxҒ[ғXӮЕ512bitҸ‘ӮўӮДӮҪӮжҒ`ҒB
Һ©–қӮөӮДӮЭӮйғeғXғc(ғ\Ғ[ғXӮ ӮБӮҪӮҫӮҜӮҫӮӘ)ҒB
ғlғbғgӮЙӢvҒXӮЙӮВӮИӮўӮҫӮМӮЕLarrabeeӮМҳ_•¶ӮЭӮйӮМӮНӮұӮкӮ©ӮзӮҫӮӘҒA
Tera Tera TeraӮМҺ‘—ҝӮН“–ҺһӮЖӮөӮДӮНҢӢүК“IӮЙӮНҢӢҚ\“–ӮҪӮБӮДӮй•ыӮ©ӮЖҒB
ҸгҠCIDFӮМҺ‘—ҝӮЕӮНHPC—p“rӮаҸ‘ӮўӮДӮ ӮйӮөҒALarrabeeӮН”hҗ¶ӮМҢvүжӮаӮ ӮйӮ©ӮЖҒB
LarrabeeӮЖSandy BridgeӮН“ҜӮ¶ring busӮрҚМ—pӮөӮДӮйҒB
Sandy BridgeӮМAVXӮрLarrabeeӮжӮиӮаҗжӮЙIDFӮЕҸoӮөӮҪӮЖӮ«ӮН
•sҺ©‘RӮҫӮБӮҪҒBӮЬӮҫҒANehalemӮМғAҒ[ғLӮМҸЪҚЧӮрӮҫӮөӮҪӮЖӮұӮлӮҫӮБӮҪӮМӮЙ
үҪҢМSandy BridgeӮМAVXӮӘӮұӮМғ^ғCғ~ғ“ғOӮЕ??
Nehalem/TukwilaӮНCSIӮМ“ұ“ьҒA
Sandy Bridge/PoulsonӮНchip“аring busӮМ“ұ“ь
ӮЖ—ҲӮДҒAҗ[“ЗӮЭӮ·ӮйӮЖLarrabeeӮМ512bit SIMDӮӘ
“ҜӮ¶OregonӮМHaswellғAҒ[ғLӮМ–Ҫ—ЯӮМғeғXғgӮЕҒA“ҜӮ¶ring busӮҫӮ©Ӯз
LarrabeeҒ@+Ғ@Sandy Bridge = Haswell
ӮБӮДӮўӮӨ“WҠJӮӘӮ ӮиӮ©ӮИӮ ӮЖҒB
ӮЕҒAAVXӮМ•ыӮӘҗжӮЙҢцҠJӮөӮИӮўӮЖHaswellӮЕ512bitӮИLarrabeeӮЖҸҮ”ФӮӘ
“ьӮк‘ЦӮнӮБӮДҢ©—тӮиӮ·ӮйӮ©ӮзӮ©ӮЖҺvӮБӮДӮЭӮҪӮиҒB
–П‘zӮҫӮҜӮЗҒB
288 ҒF–јҸМ–ўҗЭ’иҒF2009/08/21(Ӣа) 22:19:45 ID:29Nm8+Ay0
2”N‘OӮ¶ӮбӮИӮўӮвҒA1”N‘OӮҫҒB
289 ҒF–јҸМ–ўҗЭ’иҒF2009/08/22(“y) 00:05:56 ID:1DcMiGI10
Ғu11nmғvғҚғZғXӮЬӮЕӮНҺ©ҺРӮҫӮҜӮЕҺАҢ»ӮЕӮ«ӮйҒvҒB
ғCғ“ғeғӢҒCҗ»‘ўҠJ”ӯ•”–еӮМғҚҒ[ғhғ}ғbғvӮр”вҳIҒB
’}”g–{ҺРӮМғүғ{ӮаҲк•”ҢцҠJӮЙ
http://www.4gamer.net/games/043/G004345/20090821001/
ғCғ“ғeғӢҒCҗ»‘ўҠJ”ӯ•”–еӮМғҚҒ[ғhғ}ғbғvӮр”вҳIҒB
’}”g–{ҺРӮМғүғ{ӮаҲк•”ҢцҠJӮЙ
http://www.4gamer.net/games/043/G004345/20090821001/
290 ҒF–јҸМ–ўҗЭ’иҒF2009/08/22(“y) 02:30:15 ID:zKW0R84t0
2018”N•УӮиӮЙӮНIII-VӮӘӮаӮМӮЙӮИӮйӮҫӮлӮӨҒBӮЬӮҫӮЬӮҫӮўӮҜӮйӮИҒB
291 ҒF–јҸМ–ўҗЭ’иҒF2009/08/22(“y) 02:32:06 ID:LZbIW79K0
ҒӘғҖғҠw
292 ҒF–јҸМ–ўҗЭ’иҒF2009/08/23(“ъ) 02:37:28 ID:WA5wUPbz0
ҚЕӢЯӮМҳb‘и 2009”N8 ҢҺ22“ъ
ttp://www.geocities.jp/andosprocinfo/wadai09/20090822.htm
ttp://www.geocities.jp/andosprocinfo/wadai09/20090822.htm
293 ҒF–ј–іӮөӮіӮсҒ—Ӯ»ӮӨӮҫ‘IӢ“ӮЙҚsӮұӮӨҒF2009/08/30(“ъ) 05:12:14 ID:o5UBAe320
ttp://www.pcworld.com/article/170629/intel_to_focus_on_next_generation_of_chips.html
"This will probably be the last IDF till Larrabee launches," McCarron said.
ҚЕӢЯӮМҳb‘и 2009”N8ҢҺ29“ъ
ttp://www.geocities.jp/andosprocinfo/wadai09/20090829.htm
"This will probably be the last IDF till Larrabee launches," McCarron said.
ҚЕӢЯӮМҳb‘и 2009”N8ҢҺ29“ъ
ttp://www.geocities.jp/andosprocinfo/wadai09/20090829.htm
294 ҒF–јҸМ–ўҗЭ’иҒF2009/09/07(ҢҺ) 18:06:36 ID:qb/koWiSO
ҒyғҢғ|Ғ[ғgҒzHot Chips 21 - ғӮғoғCғӢғvғүғbғgғtғHҒ[ғҖҢьӮҜғ`ғbғvӢZҸpӮМ“®ҢьӮр“ЗӮЭүрӮӯ
http://journal.mycom.co.jp/articles/2009/09/07/hot_chips21_client/index.html
http://journal.mycom.co.jp/articles/2009/09/07/hot_chips21_client/index.html
295 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/09/15(үО) 23:02:41 ID:TzDSxMKU0
245 ҒF[Fn]Ғ{[–ј–іӮөӮіӮс] [Ғ«] ҒF2009/09/15(үО) 12:49:08 ID:S/Bfp91A
ғCғXғүғGғӢ‘gӮМҠ®‘SҸҹ—ҳ
IntelғAҒ[ғLғeғNғ`ғғ•”–еҒiIAGҒjӮМҸгӢү•ӣҺР’·ӮЙDadi PerlmutterҺҒӮӘҸA”C
http://japan.cnet.com/news/biz/story/0,2000056020,20399998,00.htm
-----------
LynnfieldӮНҢВҗl“IӮИ‘z‘ңӮжӮиӮаҠ®җ¬“xӮӘҚӮӮ©ӮБӮҪӮҜӮЗҒA
LarrabeeӮӘӮвӮОӮ©ӮБӮҪӮзӮЗӮӨӮөӮжӮӨӮ©ӮЖ•sҲАӮЙӮИӮйҗlҺ–ӮЕӮ·ӮЛҒB
ғCғXғүғGғӢ‘gӮМҠ®‘SҸҹ—ҳ
IntelғAҒ[ғLғeғNғ`ғғ•”–еҒiIAGҒjӮМҸгӢү•ӣҺР’·ӮЙDadi PerlmutterҺҒӮӘҸA”C
http://japan.cnet.com/news/biz/story/0,2000056020,20399998,00.htm
-----------
LynnfieldӮНҢВҗl“IӮИ‘z‘ңӮжӮиӮаҠ®җ¬“xӮӘҚӮӮ©ӮБӮҪӮҜӮЗҒA
LarrabeeӮӘӮвӮОӮ©ӮБӮҪӮзӮЗӮӨӮөӮжӮӨӮ©ӮЖ•sҲАӮЙӮИӮйҗlҺ–ӮЕӮ·ӮЛҒB
296 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/09/15(үО) 23:07:38 ID:TzDSxMKU0
ҚЎүсҒAPCғNғүғCғAғ“ғgӮЕҒAҸ]—ҲғӮғoғCғӢӮЖғTҒ[ғoӮМ—¬—pӮМҢрҢЭӮИғAҒ[ғLғeғNғ`ғғғ`ғFғ“ғWӮҫӮБӮҪӮМӮӘ
ҺsҸкӢK–НӮӘҺе—НӮЖӮўӮҰӮй’цӮЙ‘еӮ«ӮӯӮИӮБӮҪғӮғoғCғӢӮжӮиӮМғ`ғbғvӮЕ
ғCғXғүғGғӢӮҫӮҜӮЕӮИӮӯғIғҢғSғ“ӮаҠJ”ӯӮөӮДӮўӮӯӮМӮЕӮНӮИӮўӮ©ӮЖҠъ‘ТҒB
ғIғҢғSғ“ӮМ—DӮкӮҪҠJ”ӯ—НӮӘғӮғoғCғӢҒ`ғfғXғNғgғbғvӮЙӮжӮиҗ¶Ӯ©ӮіӮкӮйӮМӮЕӮНӮИӮўӮ©ӮЖҚlӮҰӮйӮЖҠъ‘ТӮЕӮ«ӮйӮИҒB
ҺsҸкӢK–НӮӘҺе—НӮЖӮўӮҰӮй’цӮЙ‘еӮ«ӮӯӮИӮБӮҪғӮғoғCғӢӮжӮиӮМғ`ғbғvӮЕ
ғCғXғүғGғӢӮҫӮҜӮЕӮИӮӯғIғҢғSғ“ӮаҠJ”ӯӮөӮДӮўӮӯӮМӮЕӮНӮИӮўӮ©ӮЖҠъ‘ТҒB
ғIғҢғSғ“ӮМ—DӮкӮҪҠJ”ӯ—НӮӘғӮғoғCғӢҒ`ғfғXғNғgғbғvӮЙӮжӮиҗ¶Ӯ©ӮіӮкӮйӮМӮЕӮНӮИӮўӮ©ӮЖҚlӮҰӮйӮЖҠъ‘ТӮЕӮ«ӮйӮИҒB
297 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/09/15(үО) 23:10:37 ID:TzDSxMKU0
“ъ–{ҢкӮЙӮИӮБӮДӮИӮўӮИҒB
ӮұӮкӮ©ӮзӮНҒAғӮғoғCғӢ’ҶҗSӮЙҗЭҢvӮөӮҪ•ыӮӘҒAғXғҖҒ[ғYӮЙғfғXғNғgғbғvҒAӮРӮўӮДӮНғTҒ[ғoӮЦӮМ“]—pӮӘӮ«Ӯ«ӮвӮ·ӮўҒB
ӮНӮБӮ«ӮиӮўӮБӮДҢ»Һһ“_ӮЕӮ·ӮЕӮЙӮ»ӮӨӮҫӮБӮҪҒBӮЬӮіӮ©Sandy BridgeӮМҢгҢpӮЕғTҒ[ғo—pӮЙҗЭҢvӮөӮҪ3ғ`ғbғv—¬—pӮИӮсӮД‘z‘ңӮЕӮ«ӮИӮўӮөӮИҒB
ӮұӮкӮ©ӮзӮНҒAғӮғoғCғӢ’ҶҗSӮЙҗЭҢvӮөӮҪ•ыӮӘҒAғXғҖҒ[ғYӮЙғfғXғNғgғbғvҒAӮРӮўӮДӮНғTҒ[ғoӮЦӮМ“]—pӮӘӮ«Ӯ«ӮвӮ·ӮўҒB
ӮНӮБӮ«ӮиӮўӮБӮДҢ»Һһ“_ӮЕӮ·ӮЕӮЙӮ»ӮӨӮҫӮБӮҪҒBӮЬӮіӮ©Sandy BridgeӮМҢгҢpӮЕғTҒ[ғo—pӮЙҗЭҢvӮөӮҪ3ғ`ғbғv—¬—pӮИӮсӮД‘z‘ңӮЕӮ«ӮИӮўӮөӮИҒB
298 ҒF–јҸМ–ўҗЭ’иҒF2009/09/17(–Ш) 17:06:04 ID:cAbT1BN3O
IntelӮМғQғӢғVғ“ғKҒ[ҺҒҺ«”CӮЙҺvӮӨӮұӮЖ
http://pc.watch.impress.co.jp/docs/column/hot/20090917_316184.html
http://pc.watch.impress.co.jp/docs/column/hot/20090917_316184.html
299 ҒF–јҸМ–ўҗЭ’иҒF2009/09/21(ҢҺ) 21:59:45 ID:9fovQ+mc0
җ^ӮМҸҹ—ҳҗйҢҫӮНғӮғgғҚҒ[ғү‘gӮӘғCғ“ғeғӢӮрҸжӮБҺжӮБӮҪҺһӮ¶ӮбӮИӮўӮ©
300 ҒF–јҸМ–ўҗЭ’иҒF2009/09/23(җ…) 12:44:50 ID:2VKkKhHx0
Ӣ@”\’ЗүБӮвҗ«”\ғAғbғvӮрӮ·Ӯй•ӘҒA“ҜӮ¶32nmӮЕӮНғgғүғ“ғWғXғ^ӮӘ‘қӮҰӮДӮіӮзӮЙҚӮғRғXғgӮЙӮИӮйӮНӮёӮҫӮӘҒA
Nehalem 4ғRғAӮӘ32nmӮЙӮИӮзӮ©ӮИӮБӮҪ•ӘҒAӮ»ӮМҚ·ӮЕ45nmӮМ4ғRғAӮжӮи’бғRғXғg’бҸБ”п“d—НӮЙӮИӮйӮсӮҫӮлӮӨӮ©
ӮаӮөNehalem 32nm 4ғRғAӮӘҸoӮДӮҪӮзҒASandy Bridge 4ғRғAӮ¶Ӯб“ҜӮ¶ғvғҚғZғXӮҫӮ©ӮзғRғXғg‘қӮҰӮҝӮбӮӨӮ©ӮзӮИ
Nehalem 4ғRғAӮӘ32nmӮЙӮИӮзӮ©ӮИӮБӮҪ•ӘҒAӮ»ӮМҚ·ӮЕ45nmӮМ4ғRғAӮжӮи’бғRғXғg’бҸБ”п“d—НӮЙӮИӮйӮсӮҫӮлӮӨӮ©
ӮаӮөNehalem 32nm 4ғRғAӮӘҸoӮДӮҪӮзҒASandy Bridge 4ғRғAӮ¶Ӯб“ҜӮ¶ғvғҚғZғXӮҫӮ©ӮзғRғXғg‘қӮҰӮҝӮбӮӨӮ©ӮзӮИ
301 ҒF–јҸМ–ўҗЭ’иҒF2009/09/23(җ…) 12:47:46 ID:2VKkKhHx0
•ӘӮ©ӮиӮГӮзӮўҢҫӮў•ыӮЙӮИӮБӮДғXғ}ғ“
ҺАҚЫҒAYonahӮ©ӮзMeromӮЙӮИӮБӮҪӮЖӮ«ӮНҸБ”п“d—НӮағRғXғgӮаҸгӮӘӮБӮҪ
MPC74xxӮ©ӮзӮЭӮкӮОҒAӮЗӮҝӮзӮа3-4”{ӮМҸБ”п“d—НӮИӮМӮЕPowerBookвһ‘МӮЕӮМ”p”MӮМҗhӮіӮЕӮНҢлҚ·ӮЭӮҪӮўӮИӮаӮсӮҫӮӘӮ—
MeromӮНғҸғbғg•УӮиӮМҗ«”\ҢьҸгӮЕӮЭӮкӮОӮ©ӮИӮиӮМӮаӮМӮҫӮҜӮЗҒA
Sandy BridgeӮМғmҒ[ғgҢьӮҜӮНTDP45W/55WҲЫҺқӮЕҗ«”\ғAғbғvҒAӮЖӮ©ӮвӮБӮД—~ӮөӮӯӮИӮўӮЛ
ҺАҚЫҒAYonahӮ©ӮзMeromӮЙӮИӮБӮҪӮЖӮ«ӮНҸБ”п“d—НӮағRғXғgӮаҸгӮӘӮБӮҪ
MPC74xxӮ©ӮзӮЭӮкӮОҒAӮЗӮҝӮзӮа3-4”{ӮМҸБ”п“d—НӮИӮМӮЕPowerBookвһ‘МӮЕӮМ”p”MӮМҗhӮіӮЕӮНҢлҚ·ӮЭӮҪӮўӮИӮаӮсӮҫӮӘӮ—
MeromӮНғҸғbғg•УӮиӮМҗ«”\ҢьҸгӮЕӮЭӮкӮОӮ©ӮИӮиӮМӮаӮМӮҫӮҜӮЗҒA
Sandy BridgeӮМғmҒ[ғgҢьӮҜӮНTDP45W/55WҲЫҺқӮЕҗ«”\ғAғbғvҒAӮЖӮ©ӮвӮБӮД—~ӮөӮӯӮИӮўӮЛ
302 ҒF–јҸМ–ўҗЭ’иҒF2009/09/23(җ…) 12:55:18 ID:SLtWhjxf0
SandyBridgeӮНGPU•”•ӘӮіӮҰӮИӮҜӮкӮОҒA32nm”ЕLynnfieldӮжӮиғ_ғCғTғCғYӮӘҸ¬ӮіӮўүВ”\җ«Ӯ ӮйӮжҒB
ғ_ғCҺКҗ^Ң©ӮйӮЖҒAғRғAҠФ’КҗMӮӘғNғҚғXғoҒ[Ӯ©ӮзғҠғ“ғOғoғXӮИӮБӮҪӮ©ӮзҒA
Ӯ»ӮМ•Әғ_ғCғTғCғYҗЯ–сӮЕӮ«ӮДӮўӮйӮжӮӨӮҫӮөҒB
ғ_ғCҺКҗ^Ң©ӮйӮЖҒAғRғAҠФ’КҗMӮӘғNғҚғXғoҒ[Ӯ©ӮзғҠғ“ғOғoғXӮИӮБӮҪӮ©ӮзҒA
Ӯ»ӮМ•Әғ_ғCғTғCғYҗЯ–сӮЕӮ«ӮДӮўӮйӮжӮӨӮҫӮөҒB
303 ҒF–јҸМ–ўҗЭ’иҒF2009/09/23(җ…) 13:06:02 ID:2VKkKhHx0
>>302
ӮИӮйӮЩӮЗҒAӮ»ӮӨӮўӮӨӮұӮЖӮ©
ӮҪӮөӮ©ӮЙҒANehalemӮЙғvғүғXӮ·ӮйӮҫӮҜҒAӮБӮДӮнӮҜӮ¶ӮбӮИӮўӮаӮсӮИ
ғAҒ[ғLғeғNғ`ғғӮБӮДӮ ӮЬӮиҸЪӮөӮӯӮИӮўӮсӮҫӮҜӮЗҒAғҠғ“ғOғoғXӮБӮДRadeon HD 4000Ӯ©Ӯз”pҺ~ӮЙӮИӮБӮҪӮсӮ¶ӮбӮИӮ©ӮБӮҪӮБӮҜҒH
ғgғүғ“ғWғXғ^җHӮӨӮ©Ӯз
ӮИӮйӮЩӮЗҒAӮ»ӮӨӮўӮӨӮұӮЖӮ©
ӮҪӮөӮ©ӮЙҒANehalemӮЙғvғүғXӮ·ӮйӮҫӮҜҒAӮБӮДӮнӮҜӮ¶ӮбӮИӮўӮаӮсӮИ
ғAҒ[ғLғeғNғ`ғғӮБӮДӮ ӮЬӮиҸЪӮөӮӯӮИӮўӮсӮҫӮҜӮЗҒAғҠғ“ғOғoғXӮБӮДRadeon HD 4000Ӯ©Ӯз”pҺ~ӮЙӮИӮБӮҪӮсӮ¶ӮбӮИӮ©ӮБӮҪӮБӮҜҒH
ғgғүғ“ғWғXғ^җHӮӨӮ©Ӯз
304 ҒF–јҸМ–ўҗЭ’иҒF2009/09/23(җ…) 14:29:54 ID:G+b7FxvJ0
Fritz KrugerҺҒӮӘҢҫӮӨӮЖӮұӮлӮМӮ»ӮкӮаӮ ӮйӮҜӮЗҒAӮұӮұ2~3”NӮЕ
RadeonӮМғpғtғHҒ[ғ}ғ“ғXҒҖғ_ғCғTғCғYӮӘ—ЗӮӯӮИӮБӮДӮ«ӮҪӮМӮНҒA
ғfғUғCғ“ғcҒ[ғӢӮМ•ПҚXӮӘ‘еӮ«ӮўӮМӮЕӮНӮИӮўӮ©ӮЖҸҹҺиӮЙ“ҘӮсӮЕӮйҒB
RadeonӮМғpғtғHҒ[ғ}ғ“ғXҒҖғ_ғCғTғCғYӮӘ—ЗӮӯӮИӮБӮДӮ«ӮҪӮМӮНҒA
ғfғUғCғ“ғcҒ[ғӢӮМ•ПҚXӮӘ‘еӮ«ӮўӮМӮЕӮНӮИӮўӮ©ӮЖҸҹҺиӮЙ“ҘӮсӮЕӮйҒB
305 ҒF–јҸМ–ўҗЭ’иҒF2009/09/23(җ…) 14:40:43 ID:SLtWhjxf0
>>309
intelӮНҚЕӢЯғҠғ“ғOғoғXӮрҚМ—pӮөӮДӮўӮйӮМӮӘ‘қӮҰӮДӮўӮйӮжҒB
LarrabeeӮаӮ»ӮӨӮҫӮҜӮЗҒANehalem-EXӮМL3ӮЕӮаҒAғҚҒ[ғJғӢӮМ3MBӮЖ‘јӮМғRғAӮМL3Ӯр
ғҠғ“ғOғoғXӮЕҗЪ‘ұӮөӮДӮўӮйӮөҒB
RadeonӮЕӮНҢш—ҰӮӘҲ«Ӯ©ӮБӮҪӮЖӮөӮДӮаҒAintelӮЙӮЖӮБӮДҢш—ҰӮӘҲ«ӮўӮЖӮНҢАӮзӮИӮўӮсӮ¶ӮбӮИӮўӮ©ӮИҒB
intelӮНҚЕӢЯғҠғ“ғOғoғXӮрҚМ—pӮөӮДӮўӮйӮМӮӘ‘қӮҰӮДӮўӮйӮжҒB
LarrabeeӮаӮ»ӮӨӮҫӮҜӮЗҒANehalem-EXӮМL3ӮЕӮаҒAғҚҒ[ғJғӢӮМ3MBӮЖ‘јӮМғRғAӮМL3Ӯр
ғҠғ“ғOғoғXӮЕҗЪ‘ұӮөӮДӮўӮйӮөҒB
RadeonӮЕӮНҢш—ҰӮӘҲ«Ӯ©ӮБӮҪӮЖӮөӮДӮаҒAintelӮЙӮЖӮБӮДҢш—ҰӮӘҲ«ӮўӮЖӮНҢАӮзӮИӮўӮсӮ¶ӮбӮИӮўӮ©ӮИҒB
ӮҝӮеӮЖҒA‘ТӮБ
307 ҒF–јҸМ–ўҗЭ’иҒF2009/09/23(җ…) 14:56:10 ID:SLtWhjxf0
Ӯ ҒAғAғ“ғJҒ[ҠФҲбӮҰӮДӮўӮйҒB
>>303ӮМӮВӮаӮиӮӘҒAӮИӮәӮЙ309ӮЙorz
>>303ӮМӮВӮаӮиӮӘҒAӮИӮәӮЙ309ӮЙorz
308 ҒF–јҸМ–ўҗЭ’иҒF2009/09/23(җ…) 23:39:53 ID:q2228yZQ0
ҒyIDF 2009ғҢғ|Ғ[ғgҒzғ|Ғ[ғӢҒEғIғbғeғҠҒ[ғjҺР’·Ң“CEOҠо’ІҚuүү
22nmғvғҚғZғXғӢҒ[ғӢғEғFғnӮЖҒAҺА“ӯӮ·ӮйSandy BridgeӮрҸүҢцҠJ
http://pc.watch.impress.co.jp/docs/news/event/20090923_317302.html
22nmғvғҚғZғXғӢҒ[ғӢғEғFғnӮЖҒAҺА“ӯӮ·ӮйSandy BridgeӮрҸүҢцҠJ
http://pc.watch.impress.co.jp/docs/news/event/20090923_317302.html
309 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/09/24(–Ш) 21:57:03 ID:poMMhYda0
>>302
ӮВӮ©ҒAӮ»ӮкӮрүБ–ЎӮөӮДӮаSandy BridgeӮНғRғAӮӘҸ¬ӮіӮўӢCӮӘӮ·ӮйҒB
ӮЬӮЖӮаӮЙҺКҗ^Ӯ©Ӯз‘ӘӮБӮДӮИӮўӮ©ӮзSRAM–КҗПӮ©ӮзӮМ–Ъ‘ӘӮҫӮҜӮЗҒB
Ӯ ӮЖҒAғNғҚғXғoҒ[ӮжӮиӮағҠғ“ғOғoғXӮМ•ыӮӘҗ«”\ӮЕӮйӮЖӮНӮЁӮаӮҰӮсӮЛҒB
“БӮЙSandy BridgeӮМҸкҚҮҒAL3ӮағҠғ“ғOӮҫӮ©ӮзғҸҒ[ғXғgғPҒ[ғXӮЕӮН
ғҢғCғeғ“ғVӮӘӮ©ӮИӮиӮнӮйӮӯӮИӮйӮЖҢ©ӮзӮкӮйҒB
L1ӮаҠЬӮЯӮДғLғғғbғVғ…ғҢғCғeғ“ғVӮЙҠЦӮөӮДӮН‘S‘М“IӮЙ•sӢцӮМ—\ҠҙҒB
ӮЬӮ ҒASandy BridgeӮЕӮ©ӮҜӮйӮұӮЖӮНӮЁӮкӮаӮҪӮӯӮіӮсӮ ӮйӮМӮҫӮӘҒAӮЬӮҫ”й–§ӮҫҒB
ӮВӮ©ҒAӮ»ӮкӮрүБ–ЎӮөӮДӮаSandy BridgeӮНғRғAӮӘҸ¬ӮіӮўӢCӮӘӮ·ӮйҒB
ӮЬӮЖӮаӮЙҺКҗ^Ӯ©Ӯз‘ӘӮБӮДӮИӮўӮ©ӮзSRAM–КҗПӮ©ӮзӮМ–Ъ‘ӘӮҫӮҜӮЗҒB
Ӯ ӮЖҒAғNғҚғXғoҒ[ӮжӮиӮағҠғ“ғOғoғXӮМ•ыӮӘҗ«”\ӮЕӮйӮЖӮНӮЁӮаӮҰӮсӮЛҒB
“БӮЙSandy BridgeӮМҸкҚҮҒAL3ӮағҠғ“ғOӮҫӮ©ӮзғҸҒ[ғXғgғPҒ[ғXӮЕӮН
ғҢғCғeғ“ғVӮӘӮ©ӮИӮиӮнӮйӮӯӮИӮйӮЖҢ©ӮзӮкӮйҒB
L1ӮаҠЬӮЯӮДғLғғғbғVғ…ғҢғCғeғ“ғVӮЙҠЦӮөӮДӮН‘S‘М“IӮЙ•sӢцӮМ—\ҠҙҒB
ӮЬӮ ҒASandy BridgeӮЕӮ©ӮҜӮйӮұӮЖӮНӮЁӮкӮаӮҪӮӯӮіӮсӮ ӮйӮМӮҫӮӘҒAӮЬӮҫ”й–§ӮҫҒB
310 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/09/24(–Ш) 22:02:08 ID:poMMhYda0
Nehalem, Sandy Bridge, HaswellӮМ3ӮВӮН
“ҜӮ¶ғүғCғ“ӮМү„’·җьҸгӮЙӮ ӮйҢZ’нӮЭӮҪӮўӮИӮаӮМӮ©ӮаҒB
ҢВҗl“IӮЙӮНҚЎүсӮМ‘gҗDүь•ТӮЕHaswellӮӘSNB+LRBӮЭӮҪӮўӮИ
Қ\җ¬ӮЙӮИӮзӮИӮўӮұӮЖӮрӮЮӮөӮлӮўӮМӮБӮДӮЬӮ·(ӮнӮзӮЎ
җі’јҒAғ|Ғ[ғӢҒEғIғbғeғҠҒ[ғjҲИ‘OӮМIntelӮӘӮжӮ©ӮБӮҪҒB
Ҹt’jҗжҗ¶ӮаҗМӮЙҸ‘ӮўӮДӮўӮҪӮӘҒAIntelӮӘӮЗӮсӮЗӮсIntelӮзӮөӮӯӮИӮӯӮИӮБӮДӮйӢCӮӘӮ·ӮйӮәҒB
“ҜӮ¶ғүғCғ“ӮМү„’·җьҸгӮЙӮ ӮйҢZ’нӮЭӮҪӮўӮИӮаӮМӮ©ӮаҒB
ҢВҗl“IӮЙӮНҚЎүсӮМ‘gҗDүь•ТӮЕHaswellӮӘSNB+LRBӮЭӮҪӮўӮИ
Қ\җ¬ӮЙӮИӮзӮИӮўӮұӮЖӮрӮЮӮөӮлӮўӮМӮБӮДӮЬӮ·(ӮнӮзӮЎ
җі’јҒAғ|Ғ[ғӢҒEғIғbғeғҠҒ[ғjҲИ‘OӮМIntelӮӘӮжӮ©ӮБӮҪҒB
Ҹt’jҗжҗ¶ӮаҗМӮЙҸ‘ӮўӮДӮўӮҪӮӘҒAIntelӮӘӮЗӮсӮЗӮсIntelӮзӮөӮӯӮИӮӯӮИӮБӮДӮйӢCӮӘӮ·ӮйӮәҒB
311 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/09/24(–Ш) 22:07:28 ID:poMMhYda0
ҚЕӢЯӮМCPUӮН“d—Нҗ§ҢдҒEҠЗ—қӢZҸpӮЙҲЛ‘¶ӮөӮДҚЕҸI“IӮИҗ«”\ӮӘ‘еӮ«ӮӯҚ¶үEӮіӮкӮйӮ©ӮзҒA
Һ–‘O—\‘zӮНҲИ‘OӮжӮиӮаӮНӮйӮ©ӮЙҚў“пӮЙӮИӮБӮҪҒB
ҺАҚsғҶғjғbғg—ЮӮМ‘қүБӮаӮ ӮйӮҫӮлӮӨӮӘҒAӮ»ӮкӮжӮиӮаSandy BridgeӮН“d—НӮр—}ӮҰӮҪҢӢүКӮЕ
җ«”\(ғ}ғӢғ`ғXғҢғbғh/SIMD)ӮрүТӮІӮӨӮЖӮўӮӨ•ы–КӮМҗiү»Ӯр‘I‘рӮөӮДӮўӮйӮжӮӨӮЙҢ©ӮҰӮйҒB
ӮИӮЙӮөӮлӮЖӮиӮ ӮҰӮё“d—НӮіӮҰӮЁӮіӮҰӮкӮОғRғAӮМғXғӢҒ[ғvғbғgӮН‘SӮӯҠg’ЈӮөӮИӮӯӮДӮа
ғNғҚғbғNӮЕҗ«”\Ӯ ӮӘӮйӮ©ӮзӮЛҒBӮ ӮйҲУ–ЎӮ»ӮӨӮҫӮЖӮөӮҪӮзӮаӮМӮ·ӮІӮӯҢ»ҺА“IҒB
ҢВҗl“IҠи–]ӮЕӮН”Д—pғXғJғү&ғVғ“ғOғӢғXғҢғbғhӮЙ—НӮўӮкӮДӮЩӮөӮўӮсӮҫӮҜӮЗҒA
ӮЗӮЁӮвӮзӮ»ӮкӮНӮИӮўӮіӮ»ӮӨӮҫӮәҒB
Һ–‘O—\‘zӮНҲИ‘OӮжӮиӮаӮНӮйӮ©ӮЙҚў“пӮЙӮИӮБӮҪҒB
ҺАҚsғҶғjғbғg—ЮӮМ‘қүБӮаӮ ӮйӮҫӮлӮӨӮӘҒAӮ»ӮкӮжӮиӮаSandy BridgeӮН“d—НӮр—}ӮҰӮҪҢӢүКӮЕ
җ«”\(ғ}ғӢғ`ғXғҢғbғh/SIMD)ӮрүТӮІӮӨӮЖӮўӮӨ•ы–КӮМҗiү»Ӯр‘I‘рӮөӮДӮўӮйӮжӮӨӮЙҢ©ӮҰӮйҒB
ӮИӮЙӮөӮлӮЖӮиӮ ӮҰӮё“d—НӮіӮҰӮЁӮіӮҰӮкӮОғRғAӮМғXғӢҒ[ғvғbғgӮН‘SӮӯҠg’ЈӮөӮИӮӯӮДӮа
ғNғҚғbғNӮЕҗ«”\Ӯ ӮӘӮйӮ©ӮзӮЛҒBӮ ӮйҲУ–ЎӮ»ӮӨӮҫӮЖӮөӮҪӮзӮаӮМӮ·ӮІӮӯҢ»ҺА“IҒB
ҢВҗl“IҠи–]ӮЕӮН”Д—pғXғJғү&ғVғ“ғOғӢғXғҢғbғhӮЙ—НӮўӮкӮДӮЩӮөӮўӮсӮҫӮҜӮЗҒA
ӮЗӮЁӮвӮзӮ»ӮкӮНӮИӮўӮіӮ»ӮӨӮҫӮәҒB
312 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/09/24(–Ш) 22:21:20 ID:poMMhYda0
Ӯ ӮЖҒALynnfieldӮМ32nmғoҒ[ғWғҮғ“ӮН”ј”NҲИҸг‘OӮМҸо•сӮЕ‘¶ҚЭӮөӮИӮўӮұӮЖӮӘ–ҫӮзӮ©ӮЙӮИӮБӮДӮўӮйӮӘҒA
ӮҪӮФӮсҺАҚЫӮЙӮНHavendaleӮЖ“ҜҺһӮ©Ӯ»ӮкӮжӮиӮа‘OӮЙғLғғғ“ғZғӢӮіӮкӮҪӮсӮ¶ӮбӮИӮўӮ©ӮЖҒB
HavendaleӮНғҚҒ[ғhғ}ғbғvӮЙ“°ҒXӮЖҚЪӮБӮДӮҪӮ©Ӯз‘ӣӮ¬ӮЙӮИӮБӮҪӮӘҒA
LynnfieldӮМ32nm”ЕӮН‘¶ҚЭӮрҢц•\ӮаӮөӮДӮИӮ©ӮБӮҪӮ©ӮзҒAӮРӮБӮ»ӮиҸБӮҰӮзӮкӮҪӮМӮ©ӮаӮЛҒB
Lynnfield/HavendaleӮМ’xӮкӮЖҒASandy BridgeӮӘӮўӮЬӮЬӮЕӮМӮЖӮұӮлӮ©ӮИӮиҸҮ’ІӮИӮұӮЖӮ©ӮзӮўӮӯӮЖҒA
32nmӮЙғVғ…ғҠғ“ғNӮөӮДҒASandy BridgeӮЬӮЕӮВӮИӮ®ғҒғҠғbғgӮН–wӮЗӮИӮ©ӮБӮҪӮМӮҫӮлӮӨҒB
ҢВҗl“IӮЙӮНҒALynnfieldӮаClarksfieldӮаҺvӮБӮҪӮжӮиҠ®җ¬“xӮӘҚӮӮӯӮДҚDҲуҸЫӮИӮсӮҫӮӘҒA
2”NӮЕғAҒ[ғLғeғNғ`ғғҗШӮи‘ЦӮҰӮҫӮЖҒA”ј”NӮЕӮа’xӮкӮҪӮзӮ©ӮИӮи’ЙӮўӮ©ӮзӮИӮ ҒB
Ғ«Clarksfieldғxғ“ғ`
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=3647&p=1
ӮҪӮФӮсҺАҚЫӮЙӮНHavendaleӮЖ“ҜҺһӮ©Ӯ»ӮкӮжӮиӮа‘OӮЙғLғғғ“ғZғӢӮіӮкӮҪӮсӮ¶ӮбӮИӮўӮ©ӮЖҒB
HavendaleӮНғҚҒ[ғhғ}ғbғvӮЙ“°ҒXӮЖҚЪӮБӮДӮҪӮ©Ӯз‘ӣӮ¬ӮЙӮИӮБӮҪӮӘҒA
LynnfieldӮМ32nm”ЕӮН‘¶ҚЭӮрҢц•\ӮаӮөӮДӮИӮ©ӮБӮҪӮ©ӮзҒAӮРӮБӮ»ӮиҸБӮҰӮзӮкӮҪӮМӮ©ӮаӮЛҒB
Lynnfield/HavendaleӮМ’xӮкӮЖҒASandy BridgeӮӘӮўӮЬӮЬӮЕӮМӮЖӮұӮлӮ©ӮИӮиҸҮ’ІӮИӮұӮЖӮ©ӮзӮўӮӯӮЖҒA
32nmӮЙғVғ…ғҠғ“ғNӮөӮДҒASandy BridgeӮЬӮЕӮВӮИӮ®ғҒғҠғbғgӮН–wӮЗӮИӮ©ӮБӮҪӮМӮҫӮлӮӨҒB
ҢВҗl“IӮЙӮНҒALynnfieldӮаClarksfieldӮаҺvӮБӮҪӮжӮиҠ®җ¬“xӮӘҚӮӮӯӮДҚDҲуҸЫӮИӮсӮҫӮӘҒA
2”NӮЕғAҒ[ғLғeғNғ`ғғҗШӮи‘ЦӮҰӮҫӮЖҒA”ј”NӮЕӮа’xӮкӮҪӮзӮ©ӮИӮи’ЙӮўӮ©ӮзӮИӮ ҒB
Ғ«Clarksfieldғxғ“ғ`
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=3647&p=1
313 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/09/24(–Ш) 22:42:43 ID:poMMhYda0
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=3645
>The demo was nothing more than proof of functionality, but Sean Maloney did officially
> confirm that Larrabee's architecture would eventually be integrated into a desktop
> CPU at some point in the future.
>The CPU is called Haswell and will be built using 22nm transistors. It's about 3 years away.
ӮИӮсӮ©ҒAҚЎүсӮМIDFӮЕ“қҚҮӮӘҢцҺ®ӮЙ”FӮЯӮзӮкӮҝӮбӮБӮҪӮЭӮҪӮўӮҫӮИҒB
ӮЬӮ ӮЬӮҫ•ПҚXӮМүВ”\җ«ӮНӮ ӮйӮҜӮЗҒBӮўӮёӮкӮЙӮөӮлdiscreteӮМRGPӮЖӮөӮДӮМLarrabeeӮЙҠъ‘ТӮөӮДӮўӮйҗlӮН
ӮІӢкҳJӮіӮсӮЖӮөӮ©ӮўӮўӮжӮӨӮӘӮИӮўҒBҚЕҸүӮНӮөӮзӮсӮӘҒAӮвӮНӮиғnғCғGғ“ғhGPUӮЛӮзӮўӮМғvғҚғWғFғNғgӮ¶ӮбӮИӮўҒB
>The demo was nothing more than proof of functionality, but Sean Maloney did officially
> confirm that Larrabee's architecture would eventually be integrated into a desktop
> CPU at some point in the future.
>The CPU is called Haswell and will be built using 22nm transistors. It's about 3 years away.
ӮИӮсӮ©ҒAҚЎүсӮМIDFӮЕ“қҚҮӮӘҢцҺ®ӮЙ”FӮЯӮзӮкӮҝӮбӮБӮҪӮЭӮҪӮўӮҫӮИҒB
ӮЬӮ ӮЬӮҫ•ПҚXӮМүВ”\җ«ӮНӮ ӮйӮҜӮЗҒBӮўӮёӮкӮЙӮөӮлdiscreteӮМRGPӮЖӮөӮДӮМLarrabeeӮЙҠъ‘ТӮөӮДӮўӮйҗlӮН
ӮІӢкҳJӮіӮсӮЖӮөӮ©ӮўӮўӮжӮӨӮӘӮИӮўҒBҚЕҸүӮНӮөӮзӮсӮӘҒAӮвӮНӮиғnғCғGғ“ғhGPUӮЛӮзӮўӮМғvғҚғWғFғNғgӮ¶ӮбӮИӮўҒB
314 ҒF–јҸМ–ўҗЭ’иҒF2009/09/24(–Ш) 22:51:12 ID:2O/J6wuk0
ҒEI/OғpғbғhҺьӮиӮЕҲк’иӮМғ_ғCӮМғGғbғW’·ӮрҠm•ЫӮөӮИӮўӮЖӮўӮҜӮИӮў
ҒE”чҚЧү»Ӯр‘ұӮҜӮИӮ«ӮбӮўӮҜӮИӮў
ӮУӮВҒ[ӮЙ”чҚЧү»Ӯр‘ұӮҜӮйӮЖӢу”’•”•ӘӮӘҸo—ҲӮДӮөӮЬӮӨ
—бҒFhttp://pc.watch.impress.co.jp/img/pcw/docs/310/373/kaigai-06.jpg
ҒЁ Ӯ¶ӮбӮ ӢуӮ«’nӮЙҒAӮұӮкӮЬӮЕCPUӮМӢЯӮӯӮЙӮ ӮБӮҪүҪӮ©Ӯрғuғ`ҚһӮсӮЕҚsӮ«ӮЬӮөӮе
ӮИӮсӮ©ӮВӮЬӮсӮЛSoCғҖҒ[ғuғҒғ“ғg
ҒE”чҚЧү»Ӯр‘ұӮҜӮИӮ«ӮбӮўӮҜӮИӮў
ӮУӮВҒ[ӮЙ”чҚЧү»Ӯр‘ұӮҜӮйӮЖӢу”’•”•ӘӮӘҸo—ҲӮДӮөӮЬӮӨ
—бҒFhttp://pc.watch.impress.co.jp/img/pcw/docs/310/373/kaigai-06.jpg
{kind=link}
ҒЁ Ӯ¶ӮбӮ ӢуӮ«’nӮЙҒAӮұӮкӮЬӮЕCPUӮМӢЯӮӯӮЙӮ ӮБӮҪүҪӮ©Ӯрғuғ`ҚһӮсӮЕҚsӮ«ӮЬӮөӮе
ӮИӮсӮ©ӮВӮЬӮсӮЛSoCғҖҒ[ғuғҒғ“ғg
315 ҒF–јҸМ–ўҗЭ’иҒF2009/09/25(Ӣа) 21:28:09 ID:Ia7GjA+V0
>>312
ғfғXғNғgғbғv”ЕӮа’иҠiӮ©ӮзҸгӮӘӮйӮ©Ӯз“ҜӮ¶ӮҫӮҜӮЗҒAғmҒ[ғgӮМ2GHzӮЕӮа4ғRғAӮМӮЬӮЬ2.26GHzӮЬӮЕҸгӮӘӮйӮсӮҫӮжӮЛ
ӮұӮкӮӘӮ»ӮМӮЬӮЬ32nmӮЙӮИӮБӮДӮӯӮкӮҪӮзҒA’иҠi2.26GHzӮӘҸoӮ№ӮйӮсӮҫӮлӮӨӮҜӮЗӮИ
ғfғXғNғgғbғv”ЕӮа’иҠiӮ©ӮзҸгӮӘӮйӮ©Ӯз“ҜӮ¶ӮҫӮҜӮЗҒAғmҒ[ғgӮМ2GHzӮЕӮа4ғRғAӮМӮЬӮЬ2.26GHzӮЬӮЕҸгӮӘӮйӮсӮҫӮжӮЛ
ӮұӮкӮӘӮ»ӮМӮЬӮЬ32nmӮЙӮИӮБӮДӮӯӮкӮҪӮзҒA’иҠi2.26GHzӮӘҸoӮ№ӮйӮсӮҫӮлӮӨӮҜӮЗӮИ
316 ҒF–јҸМ–ўҗЭ’иҒF2009/09/25(Ӣа) 21:29:38 ID:Ia7GjA+V0
•ҙӮзӮнӮөӮӯӮДғXғ}ғ“ҒAғ^Ғ[ғ{ғuҒ[ғXғgӮЕ4ғRғAҺһ2.26GHzӮЬӮЕҸгӮӘӮйҒAӮЖӮўӮӨҲУ–ЎӮЕӮ·ҒB
2ғRғAӮЕ3.06GHzҒA1ғRғAӮЕ3.2GHz
1ғRғA“®ҚмӮНOS XӮЕӮаWindowsӮЕӮаӮЩӮЪ–іӮіӮ»ӮӨӮҫӮҜӮЗҒA2ғRғAӮИӮзӮӨӮЬӮў
ғfғXғNғgғbғvӮа4ғRғAӮМӮЬӮЬҒA133MHzӮёӮВҸгӮӘӮйӮжӮӨӮЙӮИӮБӮДӮй
2ғRғAӮЕ3.06GHzҒA1ғRғAӮЕ3.2GHz
1ғRғA“®ҚмӮНOS XӮЕӮаWindowsӮЕӮаӮЩӮЪ–іӮіӮ»ӮӨӮҫӮҜӮЗҒA2ғRғAӮИӮзӮӨӮЬӮў
ғfғXғNғgғbғvӮа4ғRғAӮМӮЬӮЬҒA133MHzӮёӮВҸгӮӘӮйӮжӮӨӮЙӮИӮБӮДӮй
317 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/09/25(Ӣа) 22:49:59 ID:gYgZTphd0
ғ^Ғ[ғ{ғuҒ[ғXғgӮНOS“§үЯӮИӮсӮЕӮөӮеҒB
ӮҝӮИӮЭӮЙIntelӮМғfҒ[ғ^ғVҒ[ғgӮЕӮНғ^Ғ[ғ{ғuҒ[ғXғgӮНҠо”ВҗЭҢvҠ®‘S“§үЯӮӘғEғҠӮМӮжӮӨӮҫӮәҒB
ғ}ғUҒ[ғ{Ғ[ғhӮМҠо”ВҗЭҢvҺТӮ©Ӯзғ^Ғ[ғ{ғuҒ[ғXғgӮМ‘¶ҚЭӮН‘SӮӯӮЭӮҰӮИӮўӮөҒAҚlӮҰӮИӮӯӮДӮаӮўӮўӮұӮЖӮЙӮИӮБӮДӮйҒB
ӮаӮҝӮлӮсҠФҗЪ“IӮЙ“dҢ№ҺьӮиӮМҗЭҢvӮЙүeӢҝӮНӮ ӮйӮҫӮлӮӨӮҜӮЗҒB
ӮҝӮИӮЭӮЙIntelӮМғfҒ[ғ^ғVҒ[ғgӮЕӮНғ^Ғ[ғ{ғuҒ[ғXғgӮНҠо”ВҗЭҢvҠ®‘S“§үЯӮӘғEғҠӮМӮжӮӨӮҫӮәҒB
ғ}ғUҒ[ғ{Ғ[ғhӮМҠо”ВҗЭҢvҺТӮ©Ӯзғ^Ғ[ғ{ғuҒ[ғXғgӮМ‘¶ҚЭӮН‘SӮӯӮЭӮҰӮИӮўӮөҒAҚlӮҰӮИӮӯӮДӮаӮўӮўӮұӮЖӮЙӮИӮБӮДӮйҒB
ӮаӮҝӮлӮсҠФҗЪ“IӮЙ“dҢ№ҺьӮиӮМҗЭҢvӮЙүeӢҝӮНӮ ӮйӮҫӮлӮӨӮҜӮЗҒB
318 ҒF–јҸМ–ўҗЭ’иҒF2009/09/26(“y) 00:01:07 ID:GYy20nyO0
ҚЎҢгғVғ“ғOғӢғXғҢғbғhӮМғXғsҒ[ғhҢьҸгӮНғ^Ғ[ғ{ғuҒ[ғXғgӮЙӮ©ӮИӮиҲЛ‘¶ӮөӮ»ӮӨӮҫӮө
ӮЗӮсӮЗӮс–ҒӮўӮДӮӯӮйӮЕӮөӮеӮӨӮЛ
ӮЗӮсӮЗӮс–ҒӮўӮДӮӯӮйӮЕӮөӮеӮӨӮЛ
319 ҒF–јҸМ–ўҗЭ’иҒF2009/09/26(“y) 10:23:24 ID:2OzYZX0E0
ӮЕӮаTurboBoostӮМҚЕҚӮғNғҚғbғNӮЕғiғ“ғoғҠғ“ғOӮ·ӮйӮМӮНҺ~ӮЯӮД—~ӮөӮў
•ҙӮзӮнӮөӮ·Ӯ¬Ӯй
•ҙӮзӮнӮөӮ·Ӯ¬Ӯй
320 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/09/27(“ъ) 01:16:38 ID:WkYek+C10
IDFҠЦҳAӮМғjғ…Ғ[ғXҒAҺ‘—ҝӮЁӮЁӮҙӮБӮПӮЙӮҫӮӘҢ©ӮҪҒB
ӮВҒ[Ӯ©ҒASandy BridgeӮұӮМҺһҠъӮЙҺА“ӯғfғӮӮБӮДҗв‘О‘O“|ӮөӮөӮДӮӯӮйӮҫӮлӮұӮкҒB
ӮўӮВӮаӮИӮз—Ҳ”N6Ғ`7ҢҺӮӯӮзӮўӮЙӮҫӮ№ӮйғyҒ[ғXӮҫҒB
Nehalem/WestmereҠЦҢWӮМҗ»•iӮӘӮЕӮ»ӮлӮБӮДӮИӮўӮ©ӮзҚw“ьҲУ—~ӮрҢё‘ЮӮіӮ№ӮИӮўӮжӮӨӮЙ
ӮРӮ©ӮҰӮДӮйӮҫӮҜӮЕClarkdaleӮ©GulftownӮӘӮЕӮҪ“–ӮҪӮиӮЕ‘O“|ӮөғXғPғWғ…Ғ[ғӢӮҫӮ·ӮсӮ¶ӮбӮИӮўӮ©ӮЖҒB
ҚЎ2011”NӮБӮДӮўӮнӮкӮДӮйӮҜӮЗҒAӮ·ӮӯӮИӮӯӮЖӮа—Ҳ”N’ҶӮЙ“oҸкӮ·ӮйӮЙ10000ғyғҠғJ“qӮҜӮДӮаӮўӮўӮЛҒB
ӮВҒ[Ӯ©ҒASandy BridgeӮұӮМҺһҠъӮЙҺА“ӯғfғӮӮБӮДҗв‘О‘O“|ӮөӮөӮДӮӯӮйӮҫӮлӮұӮкҒB
ӮўӮВӮаӮИӮз—Ҳ”N6Ғ`7ҢҺӮӯӮзӮўӮЙӮҫӮ№ӮйғyҒ[ғXӮҫҒB
Nehalem/WestmereҠЦҢWӮМҗ»•iӮӘӮЕӮ»ӮлӮБӮДӮИӮўӮ©ӮзҚw“ьҲУ—~ӮрҢё‘ЮӮіӮ№ӮИӮўӮжӮӨӮЙ
ӮРӮ©ӮҰӮДӮйӮҫӮҜӮЕClarkdaleӮ©GulftownӮӘӮЕӮҪ“–ӮҪӮиӮЕ‘O“|ӮөғXғPғWғ…Ғ[ғӢӮҫӮ·ӮсӮ¶ӮбӮИӮўӮ©ӮЖҒB
ҚЎ2011”NӮБӮДӮўӮнӮкӮДӮйӮҜӮЗҒAӮ·ӮӯӮИӮӯӮЖӮа—Ҳ”N’ҶӮЙ“oҸкӮ·ӮйӮЙ10000ғyғҠғJ“qӮҜӮДӮаӮўӮўӮЛҒB
321 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/09/27(“ъ) 01:24:39 ID:WkYek+C10
ӮЖӮўӮӨӮМӮрүҪғ–ҢҺӮ©‘OӮ©ӮзӮЁӮаӮБӮДӮўӮҪӮӘҚЎүьӮЯӮДҸ‘ӮўӮДӮЭӮҪӮиҒB
ғRғXғgғҒғҠғbғgӮЕӮН2ғRғA”ЕӮМSandy BridgeӮӘӮЕӮйӮЬӮЕӮНClarkdaleӮЙ•ӘӮӘӮ ӮйӮ©ӮзҒA
ҸгҲКSandyBridge 4ғRғA, үәҲКClarkdaleӮЕӮөӮОӮзӮӯӮНӮВӮИӮ®ӮсӮҫӮлӮӨӮИҒB
ғRғXғgғҒғҠғbғgӮЕӮН2ғRғA”ЕӮМSandy BridgeӮӘӮЕӮйӮЬӮЕӮНClarkdaleӮЙ•ӘӮӘӮ ӮйӮ©ӮзҒA
ҸгҲКSandyBridge 4ғRғA, үәҲКClarkdaleӮЕӮөӮОӮзӮӯӮНӮВӮИӮ®ӮсӮҫӮлӮӨӮИҒB
322 ҒF–јҸМ–ўҗЭ’иҒF2009/09/27(“ъ) 02:16:59 ID:G4+ZHiHE0
AMDӮӘӮөӮсӮ¶ӮбӮӨӮ©ӮзӮ ӮҰӮДү„ӮОӮ·ӮсӮ¶ӮбӮИӮўӮМ
323 ҒF–јҸМ–ўҗЭ’иҒF2009/09/28(ҢҺ) 09:15:20 ID:xlZIFoaD0
http://pc.watch.impress.co.jp/docs/2007/0919/idf01.htm
NehalemӮМӮЖӮ«Ӯа“Ҡ“ьҲк”NӮӯӮзӮў‘OӮЙ“®ҚмғfғӮӮөӮДӮйӮө
NehalemӮМӮЖӮ«Ӯа“Ҡ“ьҲк”NӮӯӮзӮў‘OӮЙ“®ҚмғfғӮӮөӮДӮйӮө
324 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/09/28(ҢҺ) 23:18:51 ID:fj44U9V00
>>323
http://www.theinquirer.net/inquirer/news/1034123/intels-merom-misses-tape-out-by-a-month
ӮұӮМӢLҺ–ӮЙӮжӮйӮЖMeromӮМӮЖӮ«ӮН2005”N6ҢҺғeҒ[ғvғAғEғgӮЕҒA12ғ–ҢҺӮЕWoodcrestғҠғҠҒ[ғXӮЬӮЕӮўӮБӮДӮйӮҜӮЗҒA
NehalemӮНA0ғVғҠғRғ“ӮМҚЕҸүӮМғfғӮӮ©Ӯз14ғ–ҢҺӮаӮ©Ӯ©ӮБӮДӮҪӮсӮҫӮЛҒB
ӮұӮкӮНӮ©ӮИӮи’xӮў•ыӮЕӮ·ҒBQPI&IMCӮМ‘еӮӘӮ©ӮиӮИғVғXғeғҖғAҒ[ғLғeғNғ`ғғ•ПҚXӮӘӮ ӮБӮҪӮ©ӮзӮ©ӮЛҒB
http://www.theinquirer.net/inquirer/news/1034123/intels-merom-misses-tape-out-by-a-month
ӮұӮМӢLҺ–ӮЙӮжӮйӮЖMeromӮМӮЖӮ«ӮН2005”N6ҢҺғeҒ[ғvғAғEғgӮЕҒA12ғ–ҢҺӮЕWoodcrestғҠғҠҒ[ғXӮЬӮЕӮўӮБӮДӮйӮҜӮЗҒA
NehalemӮНA0ғVғҠғRғ“ӮМҚЕҸүӮМғfғӮӮ©Ӯз14ғ–ҢҺӮаӮ©Ӯ©ӮБӮДӮҪӮсӮҫӮЛҒB
ӮұӮкӮНӮ©ӮИӮи’xӮў•ыӮЕӮ·ҒBQPI&IMCӮМ‘еӮӘӮ©ӮиӮИғVғXғeғҖғAҒ[ғLғeғNғ`ғғ•ПҚXӮӘӮ ӮБӮҪӮ©ӮзӮ©ӮЛҒB
325 ҒF–јҸМ–ўҗЭ’иҒF2009/09/29(үО) 02:24:38 ID:JYI+HcMi0
ӮаӮӨӮіҒCӢуӮ«ғXғyҒ[ғXӮН—вӢp—pӮМҗ…ӮЕӮа“ьӮкӮЖӮҜӮБӮДҠҙӮ¶ӮЕ
326 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/09/29(үО) 21:50:47 ID:EC0KZRzc0
ҒЎҢг“ЎҚO–ОӮМWeeklyҠCҠOғjғ…Ғ[ғXҒЎ
IntelӮМҺҹҗў‘гCPUҒuSandy BridgeҒvӮМҗі‘М
http://pc.watch.impress.co.jp/docs/column/kaigai/20090929_318033.html
IntelӮМҺҹҗў‘гCPUҒuSandy BridgeҒvӮМҗі‘М
http://pc.watch.impress.co.jp/docs/column/kaigai/20090929_318033.html
327 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/09/29(үО) 22:14:27 ID:EC0KZRzc0
Ңг“ЎӢLҺ–ӮрӮЭӮДҒAӮЬӮ —\‘zӮЗӮЁӮиӮИ“WҠJӮҫӮИ>Sandy BridgeҒB
ӮВҒ[Ӯ©ҒAҢг“Ўҗжҗ¶ӮжӮиҺ©•ӘӮМӮЩӮӨӮӘҢ»Һһ“_ӮЕӮН’f‘RҸ‘ӮҜӮйӮИҒAҸ‘Ӯ©ӮИӮўӮҜӮЗ(ӮнӮзӮЎ
ӮВҒ[Ӯ©ҒAҢг“Ўҗжҗ¶ӮжӮиҺ©•ӘӮМӮЩӮӨӮӘҢ»Һһ“_ӮЕӮН’f‘RҸ‘ӮҜӮйӮИҒAҸ‘Ӯ©ӮИӮўӮҜӮЗ(ӮнӮзӮЎ
328 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/09/29(үО) 23:29:15 ID:EC0KZRzc0
“қҚҮү»ӮӘҢ»ҺАӮЙҚLӮӯ”FҺҜӮіӮкӮйӮжӮӨӮЙӮИӮБӮДӮ«ӮҪӮжӮӨӮҫӮӘҒA
ӮИӮсӮ©ҺбҠұҒA“қҚҮү»ӮМҲУ–ЎӮвғҒғҠғbғgӮӘҠЁҲбӮўӮіӮкӮДӮўӮйӮИҒB
“қҚҮү»ӮНҒAүЯӢҺӮМғRғAӮМҠg’ЈӮМ•ы–@Ӯвғ}ғӢғ`ғRғAӮЖӮ©ӮМҚӮ‘¬ү»•ы–КӮМҠg’ЈӮЕғlғ^ӮӘӮВӮ«ӮҪӮ©ӮзӮвӮБӮДӮйӮЖӮўӮӨӮМӮН
“–ӮҪӮБӮДӮўӮйӮӘҒA•K—vҲ«ӮИӮсӮҫӮ©ӮзҺd•ыӮӘӮИӮўҒB
ӮҪӮөӮ©ӮЙҒAҚЎӮЬӮЕӮМCPUӮМҗiү»ӮМғyҒ[ғX(”N—Ұ–с+50%)ӮЙҠөӮкӮДӮөӮЬӮБӮҪҗlӮЙӮН
”б”»ӮаӮөӮҪӮӯӮИӮйӢCҺқӮҝӮаӮнӮ©ӮйӮӘҒAҗ«”\ҢьҸгӮМ“Эү»ӮНCPUӮМҸ«—ҲӮЙҗв–]ӮрҠҙӮ¶ӮВӮВӮаҺуӮҜ“ьӮкӮҙӮйӮр“ҫӮИӮўӮаӮМӮҫҒB
ғVғ…ғҠғ“ғNӮЕӮ ӮўӮҪғXғyҒ[ғXӮр–„ӮЯӮйӮЖӮўӮӨӮМӮа‘SӮӯӮНӮёӮкӮИӮўӮөҒA
ғRғXғgғҒғҠғbғgӮаӮ ӮйӮӘҒAӮ»ӮаӮ»Ӯаҗ«”\ҢьҸгӮМ‘«Ӯ©Ӯ№ӮЙӮИӮБӮДӮўӮй—v‘fӮЕҚЕӮаӮЕӮ©ӮўӮМӮӘ“d—НӮҫӮ©Ӯз
“қҚҮӮөӮҪ•ыӮӘ“d—НҚнҢёӮЕӮ«ӮДҒAҠФҗЪ“IӮЙҗ«”\ҢьҸгӮМғ}Ғ[ғWғ“ӮрҠm•ЫӮЕӮ«ӮйӮБӮДӮМӮӘӮЕӮ©ӮўҒB
Sandy BridgeӮЕӮаTBӮӘCPU-GPUҠФӮЙӮЬӮЕҠg’ЈӮіӮкӮйӮМӮӘ–ҫӮзӮ©ҒB
ғҒғjҒ[ғRғAӮЖҺь•У•”•iӮМ“қҚҮӮН–{—Ҳ‘О—§Ӯ·ӮйӮаӮМӮҫӮӘҒAӮИӮЙӮвӮз“ҜӮ¶ғӮғmӮМӮжӮӨӮЙ
ҚЕӢЯӮНӮӨӮЬӮӯӮІӮЬӮ©ӮіӮкӮДӮўӮйҠҙӮӘӮ ӮйӮЛҒB
ӮаӮБӮЖӮаҢ»ҚЭӮЬӮЕӮМҳbӮЕӮНҒAHaswellӮН–і–dӮЙӮа“ҜӮ¶ғҠғ“ғOғoғXҸгӮЙғXғgғҠҒ[ғҖғRғAӮр
‘Ҫҗ”ҸWҗПӮөӮДҠж’ЈӮйӮВӮаӮиӮЙӮЭӮҰӮйӮ©ӮзҒAғҒғjҒ[ғRғAӮаӮЬӮҫӮ Ӯ«ӮзӮЯӮҪӮнӮҜӮЕӮНӮИӮўӮжӮӨӮҫӮӘҒB
ӮЬӮҪҒA“қҚҮү»ӮаҺеӢLүҜӮЬӮЕӮ·Ӯ·ӮЮӮЖҗ«”\–КӮЕӮа‘SӮӯҲЩӮИӮйҲУ–ЎӮрӮаӮВӮсӮҫӮӘҒA
Ӯ»ӮкӮЬӮЕӮМүЯ“nҠъӮЖҺvӮБӮДӮ ӮЬӮиҠъ‘ТӮ№ӮёӮЙҠъ‘ТӮ·ӮйӮЖӮўӮӨҺиӮаӮ ӮйҒB
ӮИӮсӮ©ҺбҠұҒA“қҚҮү»ӮМҲУ–ЎӮвғҒғҠғbғgӮӘҠЁҲбӮўӮіӮкӮДӮўӮйӮИҒB
“қҚҮү»ӮНҒAүЯӢҺӮМғRғAӮМҠg’ЈӮМ•ы–@Ӯвғ}ғӢғ`ғRғAӮЖӮ©ӮМҚӮ‘¬ү»•ы–КӮМҠg’ЈӮЕғlғ^ӮӘӮВӮ«ӮҪӮ©ӮзӮвӮБӮДӮйӮЖӮўӮӨӮМӮН
“–ӮҪӮБӮДӮўӮйӮӘҒA•K—vҲ«ӮИӮсӮҫӮ©ӮзҺd•ыӮӘӮИӮўҒB
ӮҪӮөӮ©ӮЙҒAҚЎӮЬӮЕӮМCPUӮМҗiү»ӮМғyҒ[ғX(”N—Ұ–с+50%)ӮЙҠөӮкӮДӮөӮЬӮБӮҪҗlӮЙӮН
”б”»ӮаӮөӮҪӮӯӮИӮйӢCҺқӮҝӮаӮнӮ©ӮйӮӘҒAҗ«”\ҢьҸгӮМ“Эү»ӮНCPUӮМҸ«—ҲӮЙҗв–]ӮрҠҙӮ¶ӮВӮВӮаҺуӮҜ“ьӮкӮҙӮйӮр“ҫӮИӮўӮаӮМӮҫҒB
ғVғ…ғҠғ“ғNӮЕӮ ӮўӮҪғXғyҒ[ғXӮр–„ӮЯӮйӮЖӮўӮӨӮМӮа‘SӮӯӮНӮёӮкӮИӮўӮөҒA
ғRғXғgғҒғҠғbғgӮаӮ ӮйӮӘҒAӮ»ӮаӮ»Ӯаҗ«”\ҢьҸгӮМ‘«Ӯ©Ӯ№ӮЙӮИӮБӮДӮўӮй—v‘fӮЕҚЕӮаӮЕӮ©ӮўӮМӮӘ“d—НӮҫӮ©Ӯз
“қҚҮӮөӮҪ•ыӮӘ“d—НҚнҢёӮЕӮ«ӮДҒAҠФҗЪ“IӮЙҗ«”\ҢьҸгӮМғ}Ғ[ғWғ“ӮрҠm•ЫӮЕӮ«ӮйӮБӮДӮМӮӘӮЕӮ©ӮўҒB
Sandy BridgeӮЕӮаTBӮӘCPU-GPUҠФӮЙӮЬӮЕҠg’ЈӮіӮкӮйӮМӮӘ–ҫӮзӮ©ҒB
ғҒғjҒ[ғRғAӮЖҺь•У•”•iӮМ“қҚҮӮН–{—Ҳ‘О—§Ӯ·ӮйӮаӮМӮҫӮӘҒAӮИӮЙӮвӮз“ҜӮ¶ғӮғmӮМӮжӮӨӮЙ
ҚЕӢЯӮНӮӨӮЬӮӯӮІӮЬӮ©ӮіӮкӮДӮўӮйҠҙӮӘӮ ӮйӮЛҒB
ӮаӮБӮЖӮаҢ»ҚЭӮЬӮЕӮМҳbӮЕӮНҒAHaswellӮН–і–dӮЙӮа“ҜӮ¶ғҠғ“ғOғoғXҸгӮЙғXғgғҠҒ[ғҖғRғAӮр
‘Ҫҗ”ҸWҗПӮөӮДҠж’ЈӮйӮВӮаӮиӮЙӮЭӮҰӮйӮ©ӮзҒAғҒғjҒ[ғRғAӮаӮЬӮҫӮ Ӯ«ӮзӮЯӮҪӮнӮҜӮЕӮНӮИӮўӮжӮӨӮҫӮӘҒB
ӮЬӮҪҒA“қҚҮү»ӮаҺеӢLүҜӮЬӮЕӮ·Ӯ·ӮЮӮЖҗ«”\–КӮЕӮа‘SӮӯҲЩӮИӮйҲУ–ЎӮрӮаӮВӮсӮҫӮӘҒA
Ӯ»ӮкӮЬӮЕӮМүЯ“nҠъӮЖҺvӮБӮДӮ ӮЬӮиҠъ‘ТӮ№ӮёӮЙҠъ‘ТӮ·ӮйӮЖӮўӮӨҺиӮаӮ ӮйҒB
329 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/09/30(җ…) 00:10:25 ID:J8ZSa7k90
IntelӮМEdenҺҒӮЙ•·ӮӯSandy BridgeӮМҺp
http://pc.watch.impress.co.jp/docs/column/kaigai/20090930_318199.html
EdenҺҒҒBӮұӮМҗlӮМ”ӯҢҫӮНӮўӮВӮа–К”’ӮўӮИӮ ҒBӮ·Ӯ°Ғ[Ң»ҺА”hҒB
http://pc.watch.impress.co.jp/docs/column/kaigai/20090930_318199.html
EdenҺҒҒBӮұӮМҗlӮМ”ӯҢҫӮНӮўӮВӮа–К”’ӮўӮИӮ ҒBӮ·Ӯ°Ғ[Ң»ҺА”hҒB
330 ҒF–јҸМ–ўҗЭ’иҒF2009/10/01(–Ш) 21:01:00 ID:HQtghgjz0
ӮўӮЬӮіӮзӮИӮӘӮзҗжҸTӮМIDFӢLҺ–ӮжӮи
> MoorestownӮНҢіҒXӮН2009”NӮМ––ӮЙғҠғҠҒ[ғXӮіӮкӮй—\’иӮҫӮБӮҪ
> җ»•iӮҫӮӘҒA—\’иӮжӮиӮа’xӮкӮДӮЁӮиҒAҸү“ъӮЙҚsӮИӮнӮкӮҪғ|Ғ[ғӢҒE
> ғIғbғeғҠҒ[ғjҺР’·Ң“CEOӮМҠо’ІҚuүүӮМ’ҶӮЕҒA2010”NӮМ”јӮОӮЙ
> ғXғPғWғ…Ғ[ғӢӮӘ•ПҚXӮіӮкӮҪӮұӮЖӮӘӮіӮиӮ°ӮИӮӯ–ҫӮзӮ©ӮЙӮіӮкӮҪҒB
('A`)
> MoorestownӮНҢіҒXӮН2009”NӮМ––ӮЙғҠғҠҒ[ғXӮіӮкӮй—\’иӮҫӮБӮҪ
> җ»•iӮҫӮӘҒA—\’иӮжӮиӮа’xӮкӮДӮЁӮиҒAҸү“ъӮЙҚsӮИӮнӮкӮҪғ|Ғ[ғӢҒE
> ғIғbғeғҠҒ[ғjҺР’·Ң“CEOӮМҠо’ІҚuүүӮМ’ҶӮЕҒA2010”NӮМ”јӮОӮЙ
> ғXғPғWғ…Ғ[ғӢӮӘ•ПҚXӮіӮкӮҪӮұӮЖӮӘӮіӮиӮ°ӮИӮӯ–ҫӮзӮ©ӮЙӮіӮкӮҪҒB
('A`)
331 ҒF–јҸМ–ўҗЭ’иҒF2009/10/02(Ӣа) 20:05:20 ID:Mmpx0Jn/0
PPCғRғA“қҚҮӮөӮДӮӯӮк
332 ҒF–јҸМ–ўҗЭ’иҒF2009/10/03(“y) 01:09:33 ID:AXzQMdZm0
>>331
CoreӮвPhenomӮвAtomӮЕӮН‘е‘ӣӮ¬ӮөӮДӮйӮҜӮЗҒAPPCӮНӮаӮҝӮлӮсҒACPUӮЕ“қҚҮӮіӮкӮДӮйҗ»•iӮН•КӮЙ’ҝӮөӮӯӮИӮў
x86ӮН“БҲЩӮИӮсӮҫӮжӮИ
ғCғ“ғeғӢӮЖAMDӮЕ‘ҲӮБӮДӮйҗMҺТ“ҜҺmӮрҢ©ӮйӮЖҒAӮЛҒc
ғuҒ[ғrҒ[ҸЬӮМғtғ@ғ“ӮӘғrғҠӮрҸОӮӨӮЖӮ©ҒAғuҒ[ғrҒ[ҸЬӮМғtғ@ғ“ӮӘҒuҗўҠEҸүҒIҒvӮЖӮ©Һ©–қӮ°ӮЙҳbӮөӮДӮйӮМӮНҺ©Қм”ВӮЖӮ©ӮЕӮжӮӯӮЭӮй
CoreӮвPhenomӮвAtomӮЕӮН‘е‘ӣӮ¬ӮөӮДӮйӮҜӮЗҒAPPCӮНӮаӮҝӮлӮсҒACPUӮЕ“қҚҮӮіӮкӮДӮйҗ»•iӮН•КӮЙ’ҝӮөӮӯӮИӮў
x86ӮН“БҲЩӮИӮсӮҫӮжӮИ
ғCғ“ғeғӢӮЖAMDӮЕ‘ҲӮБӮДӮйҗMҺТ“ҜҺmӮрҢ©ӮйӮЖҒAӮЛҒc
ғuҒ[ғrҒ[ҸЬӮМғtғ@ғ“ӮӘғrғҠӮрҸОӮӨӮЖӮ©ҒAғuҒ[ғrҒ[ҸЬӮМғtғ@ғ“ӮӘҒuҗўҠEҸүҒIҒvӮЖӮ©Һ©–қӮ°ӮЙҳbӮөӮДӮйӮМӮНҺ©Қм”ВӮЖӮ©ӮЕӮжӮӯӮЭӮй
333 ҒF–јҸМ–ўҗЭ’иҒF2009/10/03(“y) 01:18:07 ID:J919hvp90
ӮіӮ·ӮӘӮЙӮаӮӨӮжӮӯҢ©ӮИӮўӮҫӮлҒB
җ””N‘OӮ©Ӯзғ^ғCғҖғXғҠғbғvӮөӮДӮ«ӮҪӮМӮ©ҒB
җ””N‘OӮ©Ӯзғ^ғCғҖғXғҠғbғvӮөӮДӮ«ӮҪӮМӮ©ҒB
334 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/10/03(“y) 01:29:19 ID:irtqZmH10
MoorestownӮвPPCӮЙӮЁӮҜӮй‘gӮЭҚһӮЭ•Ә–мӮЕӮМ“қҚҮү»ӮЖ
Intel Core, Phenom, POWER“ҷӮМғnғCғGғ“ғhғ`ғbғvӮӘ“қҚҮү»ӮрӮ·ӮйӮМӮЖӮН
(ҸӯӮИӮӯӮЖӮаҢ»Һһ“_ӮЕӮН)ӮжӮӯӮнӮ©ӮзӮИӮўҗlӮН•К•ЁӮЖӮЁҚlӮҰӮӯӮҫӮіӮўҒB
Ӯ»ӮұӮӘӢж•КӮЕӮ«ӮДӮўӮИӮўӮжӮӨӮЕӮНҚЕӢЯӮМCPUҺ–ҸоӮН”ј•ӘӮа—қүрӮЕӮ«ӮсӮМӮЕҒB
Intel Core, Phenom, POWER“ҷӮМғnғCғGғ“ғhғ`ғbғvӮӘ“қҚҮү»ӮрӮ·ӮйӮМӮЖӮН
(ҸӯӮИӮӯӮЖӮаҢ»Һһ“_ӮЕӮН)ӮжӮӯӮнӮ©ӮзӮИӮўҗlӮН•К•ЁӮЖӮЁҚlӮҰӮӯӮҫӮіӮўҒB
Ӯ»ӮұӮӘӢж•КӮЕӮ«ӮДӮўӮИӮўӮжӮӨӮЕӮНҚЕӢЯӮМCPUҺ–ҸоӮН”ј•ӘӮа—қүрӮЕӮ«ӮсӮМӮЕҒB
335 ҒF–јҸМ–ўҗЭ’иҒF2009/10/05(ҢҺ) 22:25:01 ID:taZUFkiJ0
SuperMicro shows 4 and 7 GPU boards
ttp://www.semiaccurate.com./2009/10/04/supermicro-shows-4-and-7-gpu-boards/
LRBҢьӮҜӮЙҚмӮзӮ№ӮДӮҪӮсӮҫӮлӮӨӮ©
8ҢҺӮМҗўҠE”ј“ұ‘М”„ҸгҚӮҒA‘OҢҺ”дӮЕ5Ғ“‘қҒ\Ғ\үс•ңҠо’ІӮрҲЫҺқ
ғlғbғgғuғbғNӮӘҺsҸкӮрҢЎҲш
ttp://www.computerworld.jp/topics/mp/163909.html
ttp://www.semiaccurate.com./2009/10/04/supermicro-shows-4-and-7-gpu-boards/
LRBҢьӮҜӮЙҚмӮзӮ№ӮДӮҪӮсӮҫӮлӮӨӮ©
8ҢҺӮМҗўҠE”ј“ұ‘М”„ҸгҚӮҒA‘OҢҺ”дӮЕ5Ғ“‘қҒ\Ғ\үс•ңҠо’ІӮрҲЫҺқ
ғlғbғgғuғbғNӮӘҺsҸкӮрҢЎҲш
ttp://www.computerworld.jp/topics/mp/163909.html
336 ҒF–јҸМ–ўҗЭ’иҒF2009/10/10(“y) 20:56:26 ID:6fu55yKf0
>>332-333
ӮЖӮұӮлӮӘӮЗӮБӮұӮўҒAҚЎӮЕӮаӮұӮМ—L—l
352 ҒFSocket774 [sage] ҒF2009/10/09(Ӣа) 20:06:09 ID:uqVW6qtj
AMDӮНCPU+GPUӮвӮзӮИӮўӮМӮ©ӮЛ
357 ҒFSocket774ҒF2009/10/09(Ӣа) 22:22:56 ID:sIbUQAlq
>>352
IntelӮМғpғNғҠӮЕ1”NҢгӮ®ӮзӮўӮЙҸoӮйӮсӮ¶ӮбӮИӮўӮМҒH
359 ҒFSocket774ҒF2009/10/09(Ӣа) 23:56:00 ID:O5LAnWm4
>357
GPUӮЖCPUӮМ“қҚҮӮНAMDӮМFusionҚ\‘zӮМӮӘ”ӯ•\җжӮҫӮӘҒB
ӮЖӮұӮлӮӘӮЗӮБӮұӮўҒAҚЎӮЕӮаӮұӮМ—L—l
352 ҒFSocket774 [sage] ҒF2009/10/09(Ӣа) 20:06:09 ID:uqVW6qtj
AMDӮНCPU+GPUӮвӮзӮИӮўӮМӮ©ӮЛ
357 ҒFSocket774ҒF2009/10/09(Ӣа) 22:22:56 ID:sIbUQAlq
>>352
IntelӮМғpғNғҠӮЕ1”NҢгӮ®ӮзӮўӮЙҸoӮйӮсӮ¶ӮбӮИӮўӮМҒH
359 ҒFSocket774ҒF2009/10/09(Ӣа) 23:56:00 ID:O5LAnWm4
>357
GPUӮЖCPUӮМ“қҚҮӮНAMDӮМFusionҚ\‘zӮМӮӘ”ӯ•\җжӮҫӮӘҒB
337 ҒF–јҸМ–ўҗЭ’иҒF2009/10/10(“y) 23:21:34 ID:CZknqYi50
—бӮМAMDӮМғgғҢғ“ғhҒAғeғ“ғvғҢӮЙ“ьӮкӮДӮЁӮўӮҪ•ыӮӘ—ЗӮўӮМ?
338 ҒF–јҸМ–ўҗЭ’иҒF2009/10/10(“y) 23:33:08 ID:xruqybeg0
ғCғүғl
339 ҒF–јҸМ–ўҗЭ’иҒF2009/10/17(“y) 09:22:54 ID:iSkDRKZu0
341 –ј‘OҒFSocket774[] “ҠҚe“ъҒF2009/10/17(“y) 07:33:31 ID:WOYbKCgb
Innovation@Intel
ttp://www.intel.com/pressroom/innovation/innovation.htm#101609a
ttp://techresearch.intel.com/UserFiles/en-us/File/terascale/Mayo_IEEE_VIS2009_FINAL.PDF
342 –ј‘OҒFSocket774[sage] “ҠҚe“ъҒF2009/10/17(“y) 07:51:06 ID:5sBlP9Av
64coreӮЖӮИ
343 –ј‘OҒFSocket774[sage] “ҠҚe“ъҒF2009/10/17(“y) 08:58:08 ID:b1GwOcaa
>>341
ҒEӮЬӮҫғVғ~ғ…ғҢҒ[ғ^Ғ[ӮЕӮМҢ©җПӮаӮиҒ@ӮҪӮҫӮөcycleҒ@accurateӮИӮМӮЕ‘еүRӮЕӮНӮИӮўӮ©Ӯа
ҒE“]‘—ӮӘғ{ғgғӢғlғbғNҒB—ј‘ӨӮЕҲіҸk“WҠJӮ·ӮкӮОӮНӮвӮўҒAӮЖҺе’Ј
ҒEӮ»ӮаӮ»ӮаLarrabeeҢьӮ«ғAғӢғSғҠғYғҖӮМ’сҲДӮЖғZғbғgҒB
Ғ@HPCӮЕӮМ•pҸoӮ·ӮйӮжӮӯ’mӮзӮкӮҪүЫ‘иӮМғeғXғgӮН”рӮҜӮДӮўӮйҒH
345 –ј‘OҒFSocket774[sage] “ҠҚe“ъҒF2009/10/17(“y) 09:10:32 ID:duVcaP5F
ӮЩӮЪCONCLUSIONSӮҫӮҜ“ЗӮсӮҫ
ҒELarrabeeӮМғpғtғHҒ[ғ}ғ“ғXӮНҚӮҗё“xӮМғVғ~ғ…ғҢҒ[ғ^Ғ[ӮЙӮжӮйӮаӮМҒB
ҒE“®ҚмғNғҚғbғNӮН1GHzӮЕ16, 32, 64ғRғAӮЕғVғ~ғ…ғҢҒ[ғVғҮғ“ӮөӮДӮўӮйҒB
ҒE16ғRғA@1GHzӮМLarrabeeӮЕGTX 280ӮжӮи•ҪӢП1.5”{‘¬ӮӯҒAғVғ“ғOғӢғRғAӮМHarpertownӮМ10”{‘¬ӮўҒB
ҒE32ғRғAӮЖ64ғRғAӮЕӮНCPU-LarrabeeҠФӮЕӮМғfҒ[ғ^“]‘—ӮӘғ{ғgғӢғlғbғNӮЙӮИӮйҒB
Ғ@ӮаӮөҒAӮұӮМғfҒ[ғ^“]‘—ӮМғRғXғgӮӘ0ӮИӮзӮО32ғRғAӮЕӮН(CPUӮМ)24”{‘¬ӮӯӮИӮиҒA64ғRғAӮЕӮН42”{‘¬ӮӯӮИӮйҒB
ҒEӮөӮ©ӮөӮұӮМғ{ғgғӢғlғbғNӮр•ъ’uӮ·ӮйӮЖ32ғRғAӮЕӮа64ғRғAӮЕӮа11”{ӮөӮ©‘¬ӮӯӮИӮзӮИӮўҒB
ҒEӮұӮМ–в‘иӮрүрҢҲӮ·ӮйӮҪӮЯӮЙғfҒ[ғ^ғZғbғgӮрүВӢtҲіҸkӮ·ӮйSIMDӮЖҗeҳaҗ«ӮМҚӮӮўғAғӢғSғҠғYғҖӮрҺА‘•ӮөӮҪҒB
Ғ@ӮұӮкӮЙӮжӮБӮДғfҒ[ғ^ӮрҺO•ӘӮМҲкҲИүәӮЙҲіҸkӮЕӮ«ӮйҒBӮЬӮҪҒAүр“ҖӮМғIҒ[ғoҒ[ғwғbғhӮа30ғpҒ[ғZғ“ғg–ў–һӮЕӮ ӮйҒB
ҒEғfҒ[ғ^ғZғbғgӮМҲіҸkӮЙӮжӮБӮД“]‘—ӮЙ—vӮ·ӮйҺһҠФӮр•ҪӢПӮөӮД20-30ғpҒ[ғZғ“ғgӮЙҚнҢёӮөӮҪҒB
ҒEӮ»ӮкӮЙӮжӮБӮДҒA32ғRғAӮЕӮН19”{җ«”\ӮӘҢьҸгҒA64ғRғAӮЕӮН31”{җ«”\ӮӘҢьҸгӮ·ӮйӮЖӮўӮӨҺАҢұҢӢүКӮӘ“ҫӮзӮкӮҪҒB
346 –ј‘OҒFSocket774[sage] “ҠҚe“ъҒF2009/10/17(“y) 09:15:39 ID:duVcaP5F
>16ғRғA@1GHzӮМLarrabeeӮЕGTX 280ӮжӮи•ҪӢП1.5”{‘¬ӮӯҒ`
ӮҝӮеӮБӮЖҗіҠmӮ¶ӮбӮИӮ©ӮБӮҪҒBҗіӮөӮӯӮНӮұӮӨҒB
16ғRғA@1GHzӮМLarrabeeӮН—қҳ_үүҺZҗ«”\ӮӘGTX 280ӮМ”ј•ӘӮҫӮӘҒAӮ»ӮкӮЕӮаGTX 280ӮжӮи•ҪӢП1.5”{‘¬ӮӯҒ`
Innovation@Intel
ttp://www.intel.com/pressroom/innovation/innovation.htm#101609a
ttp://techresearch.intel.com/UserFiles/en-us/File/terascale/Mayo_IEEE_VIS2009_FINAL.PDF
342 –ј‘OҒFSocket774[sage] “ҠҚe“ъҒF2009/10/17(“y) 07:51:06 ID:5sBlP9Av
64coreӮЖӮИ
343 –ј‘OҒFSocket774[sage] “ҠҚe“ъҒF2009/10/17(“y) 08:58:08 ID:b1GwOcaa
>>341
ҒEӮЬӮҫғVғ~ғ…ғҢҒ[ғ^Ғ[ӮЕӮМҢ©җПӮаӮиҒ@ӮҪӮҫӮөcycleҒ@accurateӮИӮМӮЕ‘еүRӮЕӮНӮИӮўӮ©Ӯа
ҒE“]‘—ӮӘғ{ғgғӢғlғbғNҒB—ј‘ӨӮЕҲіҸk“WҠJӮ·ӮкӮОӮНӮвӮўҒAӮЖҺе’Ј
ҒEӮ»ӮаӮ»ӮаLarrabeeҢьӮ«ғAғӢғSғҠғYғҖӮМ’сҲДӮЖғZғbғgҒB
Ғ@HPCӮЕӮМ•pҸoӮ·ӮйӮжӮӯ’mӮзӮкӮҪүЫ‘иӮМғeғXғgӮН”рӮҜӮДӮўӮйҒH
345 –ј‘OҒFSocket774[sage] “ҠҚe“ъҒF2009/10/17(“y) 09:10:32 ID:duVcaP5F
ӮЩӮЪCONCLUSIONSӮҫӮҜ“ЗӮсӮҫ
ҒELarrabeeӮМғpғtғHҒ[ғ}ғ“ғXӮНҚӮҗё“xӮМғVғ~ғ…ғҢҒ[ғ^Ғ[ӮЙӮжӮйӮаӮМҒB
ҒE“®ҚмғNғҚғbғNӮН1GHzӮЕ16, 32, 64ғRғAӮЕғVғ~ғ…ғҢҒ[ғVғҮғ“ӮөӮДӮўӮйҒB
ҒE16ғRғA@1GHzӮМLarrabeeӮЕGTX 280ӮжӮи•ҪӢП1.5”{‘¬ӮӯҒAғVғ“ғOғӢғRғAӮМHarpertownӮМ10”{‘¬ӮўҒB
ҒE32ғRғAӮЖ64ғRғAӮЕӮНCPU-LarrabeeҠФӮЕӮМғfҒ[ғ^“]‘—ӮӘғ{ғgғӢғlғbғNӮЙӮИӮйҒB
Ғ@ӮаӮөҒAӮұӮМғfҒ[ғ^“]‘—ӮМғRғXғgӮӘ0ӮИӮзӮО32ғRғAӮЕӮН(CPUӮМ)24”{‘¬ӮӯӮИӮиҒA64ғRғAӮЕӮН42”{‘¬ӮӯӮИӮйҒB
ҒEӮөӮ©ӮөӮұӮМғ{ғgғӢғlғbғNӮр•ъ’uӮ·ӮйӮЖ32ғRғAӮЕӮа64ғRғAӮЕӮа11”{ӮөӮ©‘¬ӮӯӮИӮзӮИӮўҒB
ҒEӮұӮМ–в‘иӮрүрҢҲӮ·ӮйӮҪӮЯӮЙғfҒ[ғ^ғZғbғgӮрүВӢtҲіҸkӮ·ӮйSIMDӮЖҗeҳaҗ«ӮМҚӮӮўғAғӢғSғҠғYғҖӮрҺА‘•ӮөӮҪҒB
Ғ@ӮұӮкӮЙӮжӮБӮДғfҒ[ғ^ӮрҺO•ӘӮМҲкҲИүәӮЙҲіҸkӮЕӮ«ӮйҒBӮЬӮҪҒAүр“ҖӮМғIҒ[ғoҒ[ғwғbғhӮа30ғpҒ[ғZғ“ғg–ў–һӮЕӮ ӮйҒB
ҒEғfҒ[ғ^ғZғbғgӮМҲіҸkӮЙӮжӮБӮД“]‘—ӮЙ—vӮ·ӮйҺһҠФӮр•ҪӢПӮөӮД20-30ғpҒ[ғZғ“ғgӮЙҚнҢёӮөӮҪҒB
ҒEӮ»ӮкӮЙӮжӮБӮДҒA32ғRғAӮЕӮН19”{җ«”\ӮӘҢьҸгҒA64ғRғAӮЕӮН31”{җ«”\ӮӘҢьҸгӮ·ӮйӮЖӮўӮӨҺАҢұҢӢүКӮӘ“ҫӮзӮкӮҪҒB
346 –ј‘OҒFSocket774[sage] “ҠҚe“ъҒF2009/10/17(“y) 09:15:39 ID:duVcaP5F
>16ғRғA@1GHzӮМLarrabeeӮЕGTX 280ӮжӮи•ҪӢП1.5”{‘¬ӮӯҒ`
ӮҝӮеӮБӮЖҗіҠmӮ¶ӮбӮИӮ©ӮБӮҪҒBҗіӮөӮӯӮНӮұӮӨҒB
16ғRғA@1GHzӮМLarrabeeӮН—қҳ_үүҺZҗ«”\ӮӘGTX 280ӮМ”ј•ӘӮҫӮӘҒAӮ»ӮкӮЕӮаGTX 280ӮжӮи•ҪӢП1.5”{‘¬ӮӯҒ`
340 ҒF–јҸМ–ўҗЭ’иҒF2009/10/17(“y) 12:40:43 ID:xOb4j0sQ0 BE:83624832-PLT(12022)

x86ҸүӮМGPU“қҚҮғvғҚғZғbғTӮБӮДCyrix MediaGXӮ©ҒH
IntelӮҫӮЖҒAҠ®җ¬ӮЬӮЕӮөӮДӮҪӮӘRDRAMӮӘғAғҢӮИӮұӮЖӮЙӮИӮБӮД
ҸoүЧӮЙҺҠӮзӮИӮ©ӮБӮҪTimnaӮЙӮИӮйӮсӮҫӮлӮӨӮӘ
341 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/10/17(“y) 13:15:48 ID:dXGbEjSJ0
>>339
ӮұӮМҢгӮЙӢyӮсӮЕғ{ғҠғ…Ғ[ғҖғҠғ“ғ_ғҠғ“ғOӮМғVғ~ғ…ғҢҒ[ғVғҮғ“”дҠrӮ©ӮжҒB
Discrete GPUүrӮӨӮИӮзӮЬӮёӮНғQҒ[ғҖӮМғүғXғ^ғOғүғtғBғbғNӮЕҸҹ•үӮөӮл(ӮнӮзӮЎ
ӮұӮМҢгӮЙӢyӮсӮЕғ{ғҠғ…Ғ[ғҖғҠғ“ғ_ғҠғ“ғOӮМғVғ~ғ…ғҢҒ[ғVғҮғ“”дҠrӮ©ӮжҒB
Discrete GPUүrӮӨӮИӮзӮЬӮёӮНғQҒ[ғҖӮМғүғXғ^ғOғүғtғBғbғNӮЕҸҹ•үӮөӮл(ӮнӮзӮЎ
342 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/10/17(“y) 13:17:04 ID:dXGbEjSJ0
ғҢғ“ғ_ғҠғ“ғOӮЛw
343 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/10/17(“y) 14:10:04 ID:dXGbEjSJ0
683 ҒF---Ғј(ҒLҒНҒM’UҒјҒҷж|Қк ҒF2009/03/31(үО) 19:28:37 ID:l/vZRUst
Cell(ҸО)
Larrabee(ҸО)
GPGPU(ҸО)
3‘е’ЮӮиғvғҚғZғbғTҒBӮұӮкӮзӮрҺқӮҝҸгӮ°ӮДӮўӮйӢLҺ–ӮН—v’ҚҲУӮҫҒB
Cell(ҸО)
Larrabee(ҸО)
GPGPU(ҸО)
3‘е’ЮӮиғvғҚғZғbғTҒBӮұӮкӮзӮрҺқӮҝҸгӮ°ӮДӮўӮйӢLҺ–ӮН—v’ҚҲУӮҫҒB
344 ҒF–јҸМ–ўҗЭ’иҒF2009/10/17(“y) 14:11:27 ID:7jpzBZ5T0
”Д—pӮЖҗк—pӮМӮўӮўӮЖӮұҺжӮиӮЕӮ«Ӯй–Ӯ–@ӮНӮИӮўӮБӮДӮұӮЖӮҫӮжӮЛ
345 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/10/17(“y) 14:16:54 ID:dXGbEjSJ0
3‘е’ЮӮиғvғҚғZғbғTӮМ’ҶӮЕӮНGPGPUӮӘӢZҸpӮИ•ыҢьҗ«ӮӘҲк”ФӮЬӮЖӮаӮЕӮ·ҒB
ӮҪӮҫҒAҚЎҢгLRBӮЗӮӨӮұӮӨӮЙҠЦӮнӮзӮёҒADiscrete GPUҺsҸкӮН—ҺӮҝҚһӮсӮЕӮўӮӯүВ”\җ«ӮӘҚӮӮўҒB
Ӯ»ӮМӮжӮӨӮИ’ҶӮЕHPCҢьӮҜӮМҠg’ЈӮрҚsӮӨӮЖӮЬӮ·ӮЬӮ·RGPӮЖӮөӮДӮМӢЈ‘Ҳ—НӮрӮӨӮөӮИӮӨӮөҒA
HPCҢnӮМҗк—pғvғҚғZғbғTӮН90”N‘гҲИҚ~ҒAӮ»ӮкӮҫӮҜӮЕӮН“ҠҺ‘ҒEүсҺыӮМғTғCғNғӢӮрҲЫҺқӮЕӮ«ӮйғWғғғ“ғӢӮЕӮНӮИӮўӮұӮЖӮӘ
ҸШ–ҫӮіӮкӮДӮўӮй(ҚЕӢЯӮЕӮНClearSpeedӮИӮсӮДӮМӮаӮ ӮБӮҪӮӘӮ·Ӯ®ҸБӮҰӮҪ)ҒB
ӮҪӮҫҒAҚЎҢгLRBӮЗӮӨӮұӮӨӮЙҠЦӮнӮзӮёҒADiscrete GPUҺsҸкӮН—ҺӮҝҚһӮсӮЕӮўӮӯүВ”\җ«ӮӘҚӮӮўҒB
Ӯ»ӮМӮжӮӨӮИ’ҶӮЕHPCҢьӮҜӮМҠg’ЈӮрҚsӮӨӮЖӮЬӮ·ӮЬӮ·RGPӮЖӮөӮДӮМӢЈ‘Ҳ—НӮрӮӨӮөӮИӮӨӮөҒA
HPCҢnӮМҗк—pғvғҚғZғbғTӮН90”N‘гҲИҚ~ҒAӮ»ӮкӮҫӮҜӮЕӮН“ҠҺ‘ҒEүсҺыӮМғTғCғNғӢӮрҲЫҺқӮЕӮ«ӮйғWғғғ“ғӢӮЕӮНӮИӮўӮұӮЖӮӘ
ҸШ–ҫӮіӮкӮДӮўӮй(ҚЕӢЯӮЕӮНClearSpeedӮИӮсӮДӮМӮаӮ ӮБӮҪӮӘӮ·Ӯ®ҸБӮҰӮҪ)ҒB
346 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/10/17(“y) 14:19:14 ID:dXGbEjSJ0
ҸБӮҰӮҪӮИӮсӮДӮўӮБӮҪӮз“{ӮзӮкӮйӮ©ҒB
347 ҒF–јҸМ–ўҗЭ’иҒF2009/10/17(“y) 14:49:56 ID:p9YOWB8y0
ӮИӮәӮұӮсӮИҺһҠъӮЙҗ«”\ӮрҺNӮіӮИӮўӮЖӮўӮҜӮИӮўӮсӮҫҒH
ғVғ~ғ…ғҢҒ[ғ^Ғ[ӮӘӮ ӮйӮИӮз“oҸкҺһҠъӮЖӮ»ӮМҺһӮЙӢЈҚҮӮ·Ӯйҗ»•iӮМ—\‘zғXғyғbғNӮ©ӮзӢtҺZӮөӮДғRғAҗ”ӮИӮиғҒғӮғҠ‘СҲжӮИӮиҢҲӮЯӮДӮўӮйӮҫӮлӮӨӮЙ
ӮұӮМ•іғRғeӮНӮ»ӮсӮИӮұӮЖӮаӮнӮ©ӮзӮсӮМӮ©
ғVғ~ғ…ғҢҒ[ғ^Ғ[ӮӘӮ ӮйӮИӮз“oҸкҺһҠъӮЖӮ»ӮМҺһӮЙӢЈҚҮӮ·Ӯйҗ»•iӮМ—\‘zғXғyғbғNӮ©ӮзӢtҺZӮөӮДғRғAҗ”ӮИӮиғҒғӮғҠ‘СҲжӮИӮиҢҲӮЯӮДӮўӮйӮҫӮлӮӨӮЙ
ӮұӮМ•іғRғeӮНӮ»ӮсӮИӮұӮЖӮаӮнӮ©ӮзӮсӮМӮ©
348 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/10/17(“y) 14:58:03 ID:dXGbEjSJ0
ӮИӮәӮұӮсӮИҺһҠъӮЙҗ«”\ӮрҺNӮіӮИӮўӮЖӮўӮҜӮИӮўӮсӮҫҒH
http://pc.watch.impress.co.jp/docs/news/20091016_322120.html
ӮұӮӨӮўӮӨ’ЮӮиӢLҺ–ӮӘҺ–‘OӮЙӮ ӮБӮҪӮ©ӮзӮЁӮкӮНҸ‘ӮўӮДӮўӮйӮнӮҜӮҫӮӘҒB
>ӮЬӮҪҒA“ҜҺРӮӘҠJ”ӯғRҒ[ғhғlҒ[ғҖҒgLarrabeeҒh(ғүғүғrҒ[)ӮЕҠJ”ӯӮрҗiӮЯӮДӮўӮй
>ғfғBғXғNғҠҒ[ғgGPUӮЙӮВӮўӮДҗGӮкҒA“ъ–{ҺһҠФӮМ17“ъӮЙҒA
>LarrabeeӮМҗ«”\ғfҒ[ғ^ӮрҸүӮЯӮДҢцҠJӮ·ӮйӮұӮЖӮр–ҫӮзӮ©ӮЙӮөӮҪҒB
ӮұӮӨӮўӮӨ’ЮӮиӢLҺ–ӮӘҺ–‘OӮЙӮ ӮБӮҪӮнӮҜӮҫӮӘҒB
Ӯ ӮЖҒA"ғVғ~ғ…ғҢҒ[ғ^Ғ["ӮЖ•·ӮўӮҪӮҫӮҜӮЕҒAҢ»ҺАӮМғvғҚғZғbғTӮЖүҪӮ©ӮзүҪӮЬӮЕҲк’vӮ·Ӯй–Ӯ–@ӮМғcҒ[ғӢ
ӮЭӮҪӮўӮИ”FҺҜӮНӮвӮЯӮжӮӨҒB
http://pc.watch.impress.co.jp/docs/news/20091016_322120.html
ӮұӮӨӮўӮӨ’ЮӮиӢLҺ–ӮӘҺ–‘OӮЙӮ ӮБӮҪӮ©ӮзӮЁӮкӮНҸ‘ӮўӮДӮўӮйӮнӮҜӮҫӮӘҒB
>ӮЬӮҪҒA“ҜҺРӮӘҠJ”ӯғRҒ[ғhғlҒ[ғҖҒgLarrabeeҒh(ғүғүғrҒ[)ӮЕҠJ”ӯӮрҗiӮЯӮДӮўӮй
>ғfғBғXғNғҠҒ[ғgGPUӮЙӮВӮўӮДҗGӮкҒA“ъ–{ҺһҠФӮМ17“ъӮЙҒA
>LarrabeeӮМҗ«”\ғfҒ[ғ^ӮрҸүӮЯӮДҢцҠJӮ·ӮйӮұӮЖӮр–ҫӮзӮ©ӮЙӮөӮҪҒB
ӮұӮӨӮўӮӨ’ЮӮиӢLҺ–ӮӘҺ–‘OӮЙӮ ӮБӮҪӮнӮҜӮҫӮӘҒB
Ӯ ӮЖҒA"ғVғ~ғ…ғҢҒ[ғ^Ғ["ӮЖ•·ӮўӮҪӮҫӮҜӮЕҒAҢ»ҺАӮМғvғҚғZғbғTӮЖүҪӮ©ӮзүҪӮЬӮЕҲк’vӮ·Ӯй–Ӯ–@ӮМғcҒ[ғӢ
ӮЭӮҪӮўӮИ”FҺҜӮНӮвӮЯӮжӮӨҒB
349 ҒF–јҸМ–ўҗЭ’иҒF2009/10/17(“y) 15:01:29 ID:uS+3FzvZ0
>>347
6ғ–ҢҺ‘OӮМү~”ХӮНүҪӮҫӮБӮҪӮсҒH
758 ҒFSocket774ҒF2009/04/10(Ӣа) 17:28:09 ID:9R26seby
ttp://www.hardware.fr/articles/757-4/idf-printemps-2009-pekin.html
LRBғEғFғnҢцҠJҒB
ғEғFғnӮМғ_ғCғTғCғYӮН600•Ҫ•ыmmӢүӮМӢҗ‘еӮіҒB
45nmӮИӮз48ғRғA? 32nmӮИӮз64ғRғA?
6ғ–ҢҺ‘OӮМү~”ХӮНүҪӮҫӮБӮҪӮсҒH
758 ҒFSocket774ҒF2009/04/10(Ӣа) 17:28:09 ID:9R26seby
ttp://www.hardware.fr/articles/757-4/idf-printemps-2009-pekin.html
LRBғEғFғnҢцҠJҒB
ғEғFғnӮМғ_ғCғTғCғYӮН600•Ҫ•ыmmӢүӮМӢҗ‘еӮіҒB
45nmӮИӮз48ғRғA? 32nmӮИӮз64ғRғA?
350 ҒF–јҸМ–ўҗЭ’иҒF2009/10/17(“y) 15:02:27 ID:p9YOWB8y0
>>348
”nҺӯғjғҸғJүіӮЖӮөӮ©ҢҫӮў—lӮӘ–іӮўӮИ
ғVғ~ғ…ғҢҒ[ғ^Ғ[ӮМҗё“xӮӘҸҹ”sӮрҢҲӮЯӮйҗўҠEӮИӮМӮЙ
ӢLҺ–ӮаӮҝӮбӮсӮЖ“ЗӮсӮЕӮИӮўӮөҒBҒBҒBҒBҒB
>Ғ@ӮИӮЁҒA“ҜҺҒӮжӮкӮОIntelӮӘ•ДҚ‘ӮМғҒғCғҲҒ[•aү@ӮЖӢӨ“ҜӮЕҠJ”ӯӮөӮҪ
>ғҒғfғBғJғӢ—pӮМғAғvғҠғPҒ[ғVғҮғ“Ӯр—ҳ—pӮөӮҪLarrabeeӮМҗ«”\ғfҒ[ғ^ӮрҒA
>“ъ–{ҺһҠФӮМ17“ъӮМ’©ӮЙҢцҠJӮ·ӮйӮұӮЖӮр–ҫӮзӮ©ӮЙӮөӮҪҒB
>>349
ӮЁ‘OӮМҳ_Һ|ӮӘ•s–ҫҠm
”nҺӯғjғҸғJүіӮЖӮөӮ©ҢҫӮў—lӮӘ–іӮўӮИ
ғVғ~ғ…ғҢҒ[ғ^Ғ[ӮМҗё“xӮӘҸҹ”sӮрҢҲӮЯӮйҗўҠEӮИӮМӮЙ
ӢLҺ–ӮаӮҝӮбӮсӮЖ“ЗӮсӮЕӮИӮўӮөҒBҒBҒBҒBҒB
>Ғ@ӮИӮЁҒA“ҜҺҒӮжӮкӮОIntelӮӘ•ДҚ‘ӮМғҒғCғҲҒ[•aү@ӮЖӢӨ“ҜӮЕҠJ”ӯӮөӮҪ
>ғҒғfғBғJғӢ—pӮМғAғvғҠғPҒ[ғVғҮғ“Ӯр—ҳ—pӮөӮҪLarrabeeӮМҗ«”\ғfҒ[ғ^ӮрҒA
>“ъ–{ҺһҠФӮМ17“ъӮМ’©ӮЙҢцҠJӮ·ӮйӮұӮЖӮр–ҫӮзӮ©ӮЙӮөӮҪҒB
>>349
ӮЁ‘OӮМҳ_Һ|ӮӘ•s–ҫҠm
351 ҒF–јҸМ–ўҗЭ’иҒF2009/10/17(“y) 15:06:22 ID:uS+3FzvZ0
352 ҒF–јҸМ–ўҗЭ’иҒF2009/10/17(“y) 15:08:33 ID:p9YOWB8y0
>>351
Ӯ»ӮкӮӘҒH
Ӯ»ӮкӮӘҒH
353 ҒF–јҸМ–ўҗЭ’иҒF2009/10/17(“y) 15:10:37 ID:otMV1LSv0
“®ҚмӮ·ӮйғVғҠғRғ“ӮрҺgӮнӮ№ӮДӮаӮзӮҰӮИӮўғүғgғiҒ[ӮӘ•sӢцӮ·Ӯ¬Ӯй
354 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/10/17(“y) 15:15:20 ID:dXGbEjSJ0
ғVғ~ғ…ғҢҒ[ғ^ӮМҗё“xӮӘҸҹ”sӮрҢҲӮЯӮйҗўҠEӮБӮДҒA
ҳ_•¶’ҶӮМғVғ~ғ…ғҢҒ[ғ^ӮМ“а—eӮвҗё“xӮрӮЁ‘OӮНӮўӮВ•]үҝӮөӮҪӮМӮ©ӮЖw
ӮЬӮ LRBҗ~ӮНҢp‘ұ“IӮЙ—\‘zӮМҺАҗСӮрӮҫӮөӮДӮ©Ӯз”Ҫҳ_ӮөӮДӮЩӮөӮўӮнҒB
LRBҗ~ӮМҲУҢ©ӮН“sҚҮӮМҲ«Ӯў•”•ӘӮӘӮұӮЖӮІӮЖӮӯҚDҲУ“IӮИ–П‘zӮЕ•вҠ®ӮіӮкӮ·Ӯ¬ҒB
ҳ_•¶’ҶӮМғVғ~ғ…ғҢҒ[ғ^ӮМ“а—eӮвҗё“xӮрӮЁ‘OӮНӮўӮВ•]үҝӮөӮҪӮМӮ©ӮЖw
ӮЬӮ LRBҗ~ӮНҢp‘ұ“IӮЙ—\‘zӮМҺАҗСӮрӮҫӮөӮДӮ©Ӯз”Ҫҳ_ӮөӮДӮЩӮөӮўӮнҒB
LRBҗ~ӮМҲУҢ©ӮН“sҚҮӮМҲ«Ӯў•”•ӘӮӘӮұӮЖӮІӮЖӮӯҚDҲУ“IӮИ–П‘zӮЕ•вҠ®ӮіӮкӮ·Ӯ¬ҒB
355 ҒF–јҸМ–ўҗЭ’иҒF2009/10/17(“y) 15:18:41 ID:kf8p5ik50
’NӮӘҢ©ӮДӮаҳ_Һ|ӮӘ•s–ҫҠmӮИӮМӮН>>347
356 ҒF–јҸМ–ўҗЭ’иҒF2009/10/17(“y) 15:23:30 ID:p9YOWB8y0
>>354
ӮУӮӨҒAҒAҒAүҪӮрҚЎҚXҒBҒBҒB
IntelӮМҸнҸҹӮМ—рҺj Ға ғVғ~ғ…ғҢҒ[ғ^Ғ[ӮМҗё“xӮҫӮл
ӮЩӮЖӮсӮЗӮМғPҒ[ғXӮЕIntelӮНӢЈҚҮҗ»•iӮрӢНӮ©ӮЙҸгүсӮйҗ«”\ӮЕ–\—ҳӮржГӮи‘ұӮҜӮД—ҲӮҪӮнӮҜӮИӮсӮҫӮӘӮ—
ӮұӮсӮИҠо‘b“IӮИ”FҺҜӮ·ӮзҲк’vӮөӮДӮИӮўӮсӮ¶ӮбӮИҒ[
ӮУӮӨҒAҒAҒAүҪӮрҚЎҚXҒBҒBҒB
IntelӮМҸнҸҹӮМ—рҺj Ға ғVғ~ғ…ғҢҒ[ғ^Ғ[ӮМҗё“xӮҫӮл
ӮЩӮЖӮсӮЗӮМғPҒ[ғXӮЕIntelӮНӢЈҚҮҗ»•iӮрӢНӮ©ӮЙҸгүсӮйҗ«”\ӮЕ–\—ҳӮржГӮи‘ұӮҜӮД—ҲӮҪӮнӮҜӮИӮсӮҫӮӘӮ—
ӮұӮсӮИҠо‘b“IӮИ”FҺҜӮ·ӮзҲк’vӮөӮДӮИӮўӮсӮ¶ӮбӮИҒ[
357 ҒF–јҸМ–ўҗЭ’иҒF2009/10/17(“y) 15:36:54 ID:bpqPYLI80
ӮұӮұ10”NӮЕӮЭӮДҒuӢНӮ©ӮЙҸгүсӮйҒvҸу‘ФӮБӮДӮ ӮБӮҪӮБӮҜҒH
‘еӮЬӮ©ӮЙӢПҚtҒE•үӮҜҒEҠ®ҸҹӮБӮД—¬ӮкӮҫӮЖҺvӮӨӮӘ Ғi’ҚҒFүcӢЖҗ¬җС“IӮЙӮНҸнҸҹҒj
‘еӮЬӮ©ӮЙӢПҚtҒE•үӮҜҒEҠ®ҸҹӮБӮД—¬ӮкӮҫӮЖҺvӮӨӮӘ Ғi’ҚҒFүcӢЖҗ¬җС“IӮЙӮНҸнҸҹҒj
358 ҒF–јҸМ–ўҗЭ’иҒF2009/10/17(“y) 16:00:36 ID:bpqPYLI80
>>304
ғcҒ[ғӢӮМ•ПҚXӮЕӮ»ӮсӮИӮЙ—ЗӮӯӮИӮйӮаӮсӮ©ҒH
ҒuCADғcҒ[ғӢӮМ‘е•қүь—ЗӮЙӮжӮиҢш—ҰӮМ—ЗӮўғҢғCғAғEғgӮӘҚмҗ¬ӮЕӮ«ӮйӮжӮӨӮЙӮИӮБӮҪҒvӮЖӮіӮкӮйғvғҚғZғbғTӮМҲк—б
http://journal.mycom.co.jp/news/2003/02/21/30.html
http://pc.watch.impress.co.jp/docs/2003/0220/kaigai01.htm
ғcҒ[ғӢӮМ•ПҚXӮЕӮ»ӮсӮИӮЙ—ЗӮӯӮИӮйӮаӮсӮ©ҒH
ҒuCADғcҒ[ғӢӮМ‘е•қүь—ЗӮЙӮжӮиҢш—ҰӮМ—ЗӮўғҢғCғAғEғgӮӘҚмҗ¬ӮЕӮ«ӮйӮжӮӨӮЙӮИӮБӮҪҒvӮЖӮіӮкӮйғvғҚғZғbғTӮМҲк—б
http://journal.mycom.co.jp/news/2003/02/21/30.html
http://pc.watch.impress.co.jp/docs/2003/0220/kaigai01.htm
359 ҒF–јҸМ–ўҗЭ’иҒF2009/10/17(“y) 16:17:03 ID:83YBDSSC0
ҚмҲЧ“IӮҫӮИӮҹw
—ЗӮӯӮИӮиӮНӮөӮДӮаҲ«ӮӯӮИӮйҺ–ӮН–іӮўӮсӮ¶ӮбӮИӮў?
ғfғUғCғ“ғcҒ[ғӢӮЕғҠҒ[ғNӮН–hӮ°ӮИӮўӮЖҺvӮӨӮҜӮЗӮЛӮ—
—ЗӮӯӮИӮиӮНӮөӮДӮаҲ«ӮӯӮИӮйҺ–ӮН–іӮўӮсӮ¶ӮбӮИӮў?
ғfғUғCғ“ғcҒ[ғӢӮЕғҠҒ[ғNӮН–hӮ°ӮИӮўӮЖҺvӮӨӮҜӮЗӮЛӮ—
360 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/10/17(“y) 17:07:16 ID:xOb4j0sQ0
IntelғAҒ[ғLӮМғVғ~ғ…ғҢҒ[ғ^ӮЕ—VӮсӮЕӮйӮҜӮЗҗё“xӮМҚӮӮіӮСӮБӮӯӮиӮ·ӮйӮн
Ӯ Ӯ ҒAҲкӮВҢҫӮБӮДӮЁӮӯӮӘIntelӮНVTuneҚмӮБӮДӮйүпҺРӮҫӮә
Ӯ»ӮМҳ_•¶ӮӘGTX285Ӯ¶ӮбӮИӮӯӮД280ӮЖ”дҠrӮөӮДӮйӮМӮНҺdҚһӮЭӮМҠJҺnҺһҠъӮӘӮ»ӮМӮЦӮсӮБӮДӮұӮЖӮҫӮ©Ӯз
ӮЬӮ ҺАӢ@Ӯ¶ӮбӮИӮўӮМӮНҠЁ•ЩӮөӮДӮвӮБӮДӮЩӮөӮў
Ӯ Ӯ ҒAҲкӮВҢҫӮБӮДӮЁӮӯӮӘIntelӮНVTuneҚмӮБӮДӮйүпҺРӮҫӮә
Ӯ»ӮМҳ_•¶ӮӘGTX285Ӯ¶ӮбӮИӮӯӮД280ӮЖ”дҠrӮөӮДӮйӮМӮНҺdҚһӮЭӮМҠJҺnҺһҠъӮӘӮ»ӮМӮЦӮсӮБӮДӮұӮЖӮҫӮ©Ӯз
ӮЬӮ ҺАӢ@Ӯ¶ӮбӮИӮўӮМӮНҠЁ•ЩӮөӮДӮвӮБӮДӮЩӮөӮў
361 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/10/17(“y) 17:16:54 ID:xOb4j0sQ0
ӮВӮ©ҒAҠРҚиӮНLarrabeeҠJ”ӯӮМҲУҗ}ӮӘӮўӮЬӮҫӮЙӮнӮ©ӮзӮсӮМӮ©ҒB
IntelӮӘXeonӮЕҠl“ҫӮөӮДӮ«ӮҪHPCӮЙӮЁӮҜӮйҺsҸкӮрҲЫҺқӮ·ӮйӮҪӮЯӢЈҚҮғ`ғbғvӮр”rҸңӮ·ӮйӮҪӮЯӮМ
ҚЕҸIҢҲҗн•әҠнӮЕӮ ӮБӮДҒAGPUӮЖӮөӮДӮМҗ«”\ӮН“сӮМҺҹҒB
Ҡщ‘¶ӮМғQҒ[ғҖӮЙ‘ОӮ·Ӯйҗ«”\—vӢҒӮИӮЗӮИӮўҒB
VRAM-ғ`ғbғvҠФӮМ–і‘КӮИғfҒ[ғ^ғgғүғtғBғbғNӮрҚнҢёӮөҚЕ“Kү»Ӯ·ӮйӮұӮЖӮЕ
Ӯ©ӮлӮӨӮ¶ӮДGPUӮЖӮөӮДӮаӮЬӮЖӮаӮИҗ«”\ӮЙӮИӮйӮ©ӮИӮБӮДҠҙӮ¶ҒB
RadeonӮӘғVғFғAӮрҗLӮОӮөӮДӮйӮМӮНҒAғQҒ[ғҖҗ«”\ӮрӢҒӮЯӮДӮйғҶҒ[ғUҒ[ӮН–ўӮҫ‘ҪӮӯӮўӮД
GPGPUҗ«”\ӮИӮЗӢҒӮЯӮДӮўӮИӮўӮЖҢҫӮӨӮұӮЖӮҫҒB
FermiӮМҗЭҢvӮЙҠЦӮөӮДӮНҒALarrabeeӮЖRadeonӮр“ҜҺһӮЙ‘ҠҺиӮЙӮөӮДӮЗӮБӮҝӮЙӮаӢyӮОӮИӮў
’Ҷ“r”ј’[ӮИӮаӮМҚмӮБӮДӮөӮЬӮБӮҪӮИҒBNVIDIAӮМҗн—Әғ~ғXӮЖӮөӮ©ҺvӮҰӮИӮў
IntelӮӘXeonӮЕҠl“ҫӮөӮДӮ«ӮҪHPCӮЙӮЁӮҜӮйҺsҸкӮрҲЫҺқӮ·ӮйӮҪӮЯӢЈҚҮғ`ғbғvӮр”rҸңӮ·ӮйӮҪӮЯӮМ
ҚЕҸIҢҲҗн•әҠнӮЕӮ ӮБӮДҒAGPUӮЖӮөӮДӮМҗ«”\ӮН“сӮМҺҹҒB
Ҡщ‘¶ӮМғQҒ[ғҖӮЙ‘ОӮ·Ӯйҗ«”\—vӢҒӮИӮЗӮИӮўҒB
VRAM-ғ`ғbғvҠФӮМ–і‘КӮИғfҒ[ғ^ғgғүғtғBғbғNӮрҚнҢёӮөҚЕ“Kү»Ӯ·ӮйӮұӮЖӮЕ
Ӯ©ӮлӮӨӮ¶ӮДGPUӮЖӮөӮДӮаӮЬӮЖӮаӮИҗ«”\ӮЙӮИӮйӮ©ӮИӮБӮДҠҙӮ¶ҒB
RadeonӮӘғVғFғAӮрҗLӮОӮөӮДӮйӮМӮНҒAғQҒ[ғҖҗ«”\ӮрӢҒӮЯӮДӮйғҶҒ[ғUҒ[ӮН–ўӮҫ‘ҪӮӯӮўӮД
GPGPUҗ«”\ӮИӮЗӢҒӮЯӮДӮўӮИӮўӮЖҢҫӮӨӮұӮЖӮҫҒB
FermiӮМҗЭҢvӮЙҠЦӮөӮДӮНҒALarrabeeӮЖRadeonӮр“ҜҺһӮЙ‘ҠҺиӮЙӮөӮДӮЗӮБӮҝӮЙӮаӢyӮОӮИӮў
’Ҷ“r”ј’[ӮИӮаӮМҚмӮБӮДӮөӮЬӮБӮҪӮИҒBNVIDIAӮМҗн—Әғ~ғXӮЖӮөӮ©ҺvӮҰӮИӮў
362 ҒF–јҸМ–ўҗЭ’иҒF2009/10/17(“y) 17:50:59 ID:83YBDSSC0
ӮЕӮаҚЕҸI“IӮИ‘ЗӮМ•ыҢьӮНintelӮЖ“ҜӮ¶•ыҢьӮИӮсӮҫӮө
үЯ“n“IӮИҗ»•iӮаӮ ӮйӮМӮНҺd•ыӮМӮИӮўҺ–ӮИӮсӮ¶ӮбӮИӮўӮМ?
үЯ“n“IӮИҗ»•iӮаӮ ӮйӮМӮНҺd•ыӮМӮИӮўҺ–ӮИӮсӮ¶ӮбӮИӮўӮМ?
363 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/10/17(“y) 18:12:53 ID:xOb4j0sQ0
NVIDIAӮНCUDAӮМҺsҸкүҝ’lӮрүЯ“–•]үҝӮөӮДӮйӮЖӮөӮ©ҺvӮҰӮсҒB
ӮҝӮИӮЭӮЙCUDAғҶҒ[ғUҒ[җlҢыӮНҗўҠE6–ңҗlҒiNVIDIA’ІӮЧҒj
ӮҝӮИӮЭӮЙCUDAғҶҒ[ғUҒ[җlҢыӮНҗўҠE6–ңҗlҒiNVIDIA’ІӮЧҒj
364 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/10/18(“ъ) 02:39:59 ID:x9npZpn30
LRBӮН‘SӮӯҸҮ’ІӮЙҒA
CPUӮМ—ЗӮөҲ«ӮөӮвӢZҸp“®ҢьӮр—\‘ӘӮ·ӮйӮұӮЖӮМ“пӮөӮіӮрLRBҗ~ӮЙ’mӮзӮөӮЯӮДӮӯӮкӮ»ӮӨӮҫӮИҒB
IntelӮМҲУҗ}Ӯ·ӮйӮЖӮұӮлӮЕӮН–іӮўӮҫӮлӮӨӮҜӮЗҒB
CPUӮМ—ЗӮөҲ«ӮөӮвӢZҸp“®ҢьӮр—\‘ӘӮ·ӮйӮұӮЖӮМ“пӮөӮіӮрLRBҗ~ӮЙ’mӮзӮөӮЯӮДӮӯӮкӮ»ӮӨӮҫӮИҒB
IntelӮМҲУҗ}Ӯ·ӮйӮЖӮұӮлӮЕӮН–іӮўӮҫӮлӮӨӮҜӮЗҒB
365 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/10/18(“ъ) 02:46:45 ID:ynoD0Hzq0
ӮсғIғҢӮЙӮНҠъ‘ТҲИҸгӮҫ
FermiӮӘҺc”OҺd—lӮИӮМӮЕ“БӮЙӮ»ӮӨҢ©ӮҰӮйӮМӮ©Ӯа
FermiӮӘҺc”OҺd—lӮИӮМӮЕ“БӮЙӮ»ӮӨҢ©ӮҰӮйӮМӮ©Ӯа
366 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/10/18(“ъ) 03:11:52 ID:x9npZpn30
FermiҠЦҢWӮвӮҪӮзӮіӮнӮӘӮкӮДӮйӮҜӮЗҒA
GTX280ҒЁFermiӮБӮДҚЕӢЯӮМGPUҗi•аӮМ’ҶӮЕӮНҒA
ҠvҗV“IӮИӮаӮМӮНӮИӮўӮөҒAҗі’ј•Ё—КҲИҠOӮ ӮЬӮиӮ©ӮнӮБӮДӮИӮўҲуҸЫӮИӮсӮҫӮӘҒA
ӮўӮ©ӮЙGTX280ӮЬӮЕӮМGPUӮӘҚ‘“аӮЕ—қүрӮіӮкӮДӮўӮИӮўӮ©•ӮӮ«’ӨӮиӮЙӮИӮБӮҪӮЛҒB
ӮЁӮкӮаGPUӮНӮ ӮЬӮиӢ»–ЎӮӘӮИӮўӮ©Ӯз•Ғ’iӮИӮзӮЗӮӨӮЕӮаӮўӮўӮсӮҫӮӘҚ“Ӯ·Ӯ¬ӮйҒB
GTX280ҒЁFermiӮБӮДҚЕӢЯӮМGPUҗi•аӮМ’ҶӮЕӮНҒA
ҠvҗV“IӮИӮаӮМӮНӮИӮўӮөҒAҗі’ј•Ё—КҲИҠOӮ ӮЬӮиӮ©ӮнӮБӮДӮИӮўҲуҸЫӮИӮсӮҫӮӘҒA
ӮўӮ©ӮЙGTX280ӮЬӮЕӮМGPUӮӘҚ‘“аӮЕ—қүрӮіӮкӮДӮўӮИӮўӮ©•ӮӮ«’ӨӮиӮЙӮИӮБӮҪӮЛҒB
ӮЁӮкӮаGPUӮНӮ ӮЬӮиӢ»–ЎӮӘӮИӮўӮ©Ӯз•Ғ’iӮИӮзӮЗӮӨӮЕӮаӮўӮўӮсӮҫӮӘҚ“Ӯ·Ӯ¬ӮйҒB
367 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/10/18(“ъ) 03:13:20 ID:x9npZpn30
ӮЖӮўӮӨӮ©FermiӮИӮсӮЕӮ»ӮсӮИ‘ӣӮ¬ӮИӮМ?
ӢtӮЙGPUҗ~ӮЙӢіӮҰӮДӮаӮзӮўӮҪӮўҒB
”{җё“xғҶғjғbғg‘қӮҰӮйӮМӮа—\‘zӮМ”НҲНӮҫӮөҒAӮИӮсӮ©ӮөӮҪӮМӮ©?
ӢtӮЙGPUҗ~ӮЙӢіӮҰӮДӮаӮзӮўӮҪӮўҒB
”{җё“xғҶғjғbғg‘қӮҰӮйӮМӮа—\‘zӮМ”НҲНӮҫӮөҒAӮИӮсӮ©ӮөӮҪӮМӮ©?
368 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/10/18(“ъ) 03:17:52 ID:x9npZpn30
>IntelӮӘXeonӮЕҠl“ҫӮөӮДӮ«ӮҪHPCӮЙӮЁӮҜӮйҺsҸкӮрҲЫҺқӮ·ӮйӮҪӮЯӢЈҚҮғ`ғbғvӮр”rҸңӮ·ӮйӮҪӮЯӮМ
>ҚЕҸIҢҲҗн•әҠнӮЕӮ ӮБӮДҒAGPUӮЖӮөӮДӮМҗ«”\ӮН“сӮМҺҹҒB
HPCӮИӮсӮДҢіҒX•үӮҜ‘gғvғҚғZғbғTӮМҗўҠEҒAXeonӮҫӮҜӮЕҸ\•ӘӮИӮсӮҫӮжҒB
LRBӮӘҠJ”ӯӮіӮкӮҪҲУҗ}ӮНӮЁӮкӮМүЯӢҺӮМҸ‘Ӯ«ҚһӮЭӮр“ЗӮЯӮОӮнӮ©ӮйӮЛҒB
HPCӮНҢіҒXPC/ғTҒ[ғoҺsҸкӮЕ‘еӮаӮӨӮҜӮөӮДӮўӮйIntelӮЙӮЖӮБӮДӮНҸd—vӮИғ}Ғ[ғPғbғgӮ¶ӮбӮ ӮиӮЬӮ№ӮсҒB
LRBӮаGPGPUӮа•КӮМғ}Ғ[ғPғbғgӮрғoғbғNғOғүғEғ“ғhӮЖӮөӮДҺқӮБӮДӮўӮйӮ©Ӯз
HPC—p“rӮЖӮөӮДҠJ”ӯғTғCғNғӢӮрҲЫҺқӮЕӮ«ӮйӮЖӮўӮӨӮМӮӘ‘е‘O’сҒB
>ҚЕҸIҢҲҗн•әҠнӮЕӮ ӮБӮДҒAGPUӮЖӮөӮДӮМҗ«”\ӮН“сӮМҺҹҒB
HPCӮИӮсӮДҢіҒX•үӮҜ‘gғvғҚғZғbғTӮМҗўҠEҒAXeonӮҫӮҜӮЕҸ\•ӘӮИӮсӮҫӮжҒB
LRBӮӘҠJ”ӯӮіӮкӮҪҲУҗ}ӮНӮЁӮкӮМүЯӢҺӮМҸ‘Ӯ«ҚһӮЭӮр“ЗӮЯӮОӮнӮ©ӮйӮЛҒB
HPCӮНҢіҒXPC/ғTҒ[ғoҺsҸкӮЕ‘еӮаӮӨӮҜӮөӮДӮўӮйIntelӮЙӮЖӮБӮДӮНҸd—vӮИғ}Ғ[ғPғbғgӮ¶ӮбӮ ӮиӮЬӮ№ӮсҒB
LRBӮаGPGPUӮа•КӮМғ}Ғ[ғPғbғgӮрғoғbғNғOғүғEғ“ғhӮЖӮөӮДҺқӮБӮДӮўӮйӮ©Ӯз
HPC—p“rӮЖӮөӮДҠJ”ӯғTғCғNғӢӮрҲЫҺқӮЕӮ«ӮйӮЖӮўӮӨӮМӮӘ‘е‘O’сҒB
369 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/10/18(“ъ) 03:27:03 ID:x9npZpn30
GT200Ӯ©Ӯз”{җё“xғҶғjғbғgӮӘ‘қӮҰӮҪӮнӮҜӮ¶ӮбӮИӮўӮМӮ©ҒB
Ӯ ӮЖғeғNғXғ`ғғҠЦҢWӮағtғүғbғgӮЙӮИӮБӮДӮйӮсӮҫӮЛҒB
ӮЬӮ ӮЗӮМӮЭӮҝҚЎӮЬӮЕӮМGPUҗi•аӮМ—¬ӮкӮ©ӮзӮЭӮДӮаҚЎҚX‘ӣӮ®ӮжӮӨӮИ•Пү»Ӯ¶ӮбӮИӮўӮЖҺvӮӨӮӘҒB
Ӯ ӮЖғeғNғXғ`ғғҠЦҢWӮағtғүғbғgӮЙӮИӮБӮДӮйӮсӮҫӮЛҒB
ӮЬӮ ӮЗӮМӮЭӮҝҚЎӮЬӮЕӮМGPUҗi•аӮМ—¬ӮкӮ©ӮзӮЭӮДӮаҚЎҚX‘ӣӮ®ӮжӮӨӮИ•Пү»Ӯ¶ӮбӮИӮўӮЖҺvӮӨӮӘҒB
370 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/10/18(“ъ) 13:36:03 ID:ynoD0Hzq0
HPCӮНҗ¬’·ҺsҸкӮҫӮј
Ӯ ӮЖҒAғNғүғEғhҒiҸОҒjӮЙ‘ОүһӮөӮҪҚӮ–§“xғuғҢҒ[ғhғTҒ[ғo
ӮұӮБӮҝӮНӮЗӮБӮҝӮ©ӮЖӮўӮӨӮЖAtomӮМғҒғjҒ[ғRғA“Ҡ“ьӮӘӢ}ӮӘӮкӮйҒB
Ӯ ӮЖҒAғNғүғEғhҒiҸОҒjӮЙ‘ОүһӮөӮҪҚӮ–§“xғuғҢҒ[ғhғTҒ[ғo
ӮұӮБӮҝӮНӮЗӮБӮҝӮ©ӮЖӮўӮӨӮЖAtomӮМғҒғjҒ[ғRғA“Ҡ“ьӮӘӢ}ӮӘӮкӮйҒB
371 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/10/18(“ъ) 13:39:20 ID:ynoD0Hzq0
җ¬’·’ҳӮөӮўHPCҺsҸкҒA2010”NӮЙӮН143үӯғhғӢ
2006”N11ҢҺ20“ъ 06:04PM
http://sourceforge.jp/magazine/06/11/20/098246
2007”NQ3ӮМHPCғTҒ[ғoҒ[ҺsҸкӮН30үӯғhғӢӢK–НҒC2011”NӮЙӮН5”{ӮЙҠg‘е
http://itpro.nikkeibp.co.jp/article/Research/20071204/288674/
ӮЬӮ ғCғ“ғeғOғҢҒ[ғ^ӮЕӮИӮўIntelӮЙӮЖӮБӮДӮНҺжӮи•ӘӮНғ^ғJӮӘӮөӮкӮДӮйӮӘ
2006”N11ҢҺ20“ъ 06:04PM
http://sourceforge.jp/magazine/06/11/20/098246
2007”NQ3ӮМHPCғTҒ[ғoҒ[ҺsҸкӮН30үӯғhғӢӢK–НҒC2011”NӮЙӮН5”{ӮЙҠg‘е
http://itpro.nikkeibp.co.jp/article/Research/20071204/288674/
ӮЬӮ ғCғ“ғeғOғҢҒ[ғ^ӮЕӮИӮўIntelӮЙӮЖӮБӮДӮНҺжӮи•ӘӮНғ^ғJӮӘӮөӮкӮДӮйӮӘ
372 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/10/18(“ъ) 15:08:24 ID:x9npZpn30
HPCӮӘҗ¬’·ҺsҸкӮИӮМӮНӮаӮҝӮлӮс’mӮБӮДӮўӮйӮӘҒA–в‘иӮНғvғҚғZғbғTү®Ӯ©ӮзӮЭӮҪҺsҸкӮЖӮөӮДӮЗӮӨӮ©ӮҫӮ©ӮзӮИҒB
373 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/10/18(“ъ) 15:13:24 ID:x9npZpn30
җк—pғvғҚғZғbғT–wӮЗӮИӮӯӮИӮБӮДҒA
ҲАүҝӮИ”Д—pғvғҚғZғbғTӮМғNғүғXғ^ӮӘ’бүҝҠiү»ӮЖHPCӮМ•ҒӢyӮрҢгүҹӮөӮөӮДӮўӮйӮМӮӘӮЕӮ©ӮўҒB
ғXҒ[ғpҒ[ғRғ“ғsғ…Ғ[ғ^ӮНғAҒ[ғLғeғNғ`ғғӮЖӮөӮДӮНҸIӮнӮБӮҪғWғғғ“ғӢӮЕҢӢӢЗҺА‘ФӮНҚЎӮвғTҒ[ғoӮвPCӮИӮсӮҫӮжҒB
”Д—pғvғҚғZғbғTӮМSIMDӮрҠg’ЈӮөҒA—¬—pӮ·ӮйӮЖӮўӮӨ•ыҢьӮИӮзӮОҺ^“ҜӮЕӮ«ӮйӮӘҒA
HPCҢьӮҜӮМҗк—pғvғҚғZғbғTӮНҺһ‘гӮМ—¬ӮкӮЙӢtҚsӮөӮДӮўӮйүЯӢҺӮМғ{ғҠ•ФӮөӮЙӮ·Ӯ¬ӮИӮўҒB
ҲАүҝӮИ”Д—pғvғҚғZғbғTӮМғNғүғXғ^ӮӘ’бүҝҠiү»ӮЖHPCӮМ•ҒӢyӮрҢгүҹӮөӮөӮДӮўӮйӮМӮӘӮЕӮ©ӮўҒB
ғXҒ[ғpҒ[ғRғ“ғsғ…Ғ[ғ^ӮНғAҒ[ғLғeғNғ`ғғӮЖӮөӮДӮНҸIӮнӮБӮҪғWғғғ“ғӢӮЕҢӢӢЗҺА‘ФӮНҚЎӮвғTҒ[ғoӮвPCӮИӮсӮҫӮжҒB
”Д—pғvғҚғZғbғTӮМSIMDӮрҠg’ЈӮөҒA—¬—pӮ·ӮйӮЖӮўӮӨ•ыҢьӮИӮзӮОҺ^“ҜӮЕӮ«ӮйӮӘҒA
HPCҢьӮҜӮМҗк—pғvғҚғZғbғTӮНҺһ‘гӮМ—¬ӮкӮЙӢtҚsӮөӮДӮўӮйүЯӢҺӮМғ{ғҠ•ФӮөӮЙӮ·Ӯ¬ӮИӮўҒB
374 ҒF–јҸМ–ўҗЭ’иҒF2009/10/18(“ъ) 15:20:43 ID:rQ2rnlqQ0
’jҺqӮӘӮжӮӯңлӮиӮвӮ·ӮўӮМӮӘ
HPCҺҠҸгҺеӢ`ӮЖӮўӮӨ•a
HPCҺҠҸгҺеӢ`ӮЖӮўӮӨ•a
375 ҒF–јҸМ–ўҗЭ’иҒF2009/10/18(“ъ) 16:40:16 ID:bPPm8EN+0
HaswellӮ©Ӯ»ӮМ•УӮиӮЕLRB‘gӮЭҚһӮЮ‘OӮМҒAҺАҢұӮ¶ӮбӮИӮўӮМҒHLarrabeeӮБӮДҒB
376 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/10/18(“ъ) 18:02:16 ID:ynoD0Hzq0
ҺАҢұӮЖҢҫӮӨӮ©ҒAғfғBғXғNғҠҒ[ғg”ЕӮрғJғbғgғ_ғEғ“ӮөӮҪӮаӮМӮ»ӮМӮаӮМӮӘҚЪӮйӮБӮДҢҫӮБӮДӮЛҒH
Windows 7/Server 2008 R2ӮМVirtual ServerӮЖӮ©ҒALinuxӮМXenӮЖӮ©ӮЕ
ғnҒ[ғhғEғFғAүј‘zү»ҺxүҮӢZҸpӮЖ‘gӮЭҚҮӮнӮ№ӮҪғnғCғpҒ[ғoғCғUҸгӮЙҸжӮБӮҜӮйҢ`ӮЕ
ғQғXғgӮМLarrabeeғRғAӮМҠЗ—қ—pOSӮр“®Ӯ©Ӯ·Ӯ©ӮзҒAӮ»ӮМҗў‘гӮЙӮИӮйӮЖCeleronӮаҠЬӮЯ
‘S•”VTӮЙ‘ОүһӮөӮДӮӯӮйҒB
ӮіӮДҒAMacOSӮҫӮӘҒALarrabeeғRғAӮр“®Ӯ©Ӯ·ӮМӮЙ•K—vӮЙӮИӮзӮЛҒH
Windows 7/Server 2008 R2ӮМVirtual ServerӮЖӮ©ҒALinuxӮМXenӮЖӮ©ӮЕ
ғnҒ[ғhғEғFғAүј‘zү»ҺxүҮӢZҸpӮЖ‘gӮЭҚҮӮнӮ№ӮҪғnғCғpҒ[ғoғCғUҸгӮЙҸжӮБӮҜӮйҢ`ӮЕ
ғQғXғgӮМLarrabeeғRғAӮМҠЗ—қ—pOSӮр“®Ӯ©Ӯ·Ӯ©ӮзҒAӮ»ӮМҗў‘гӮЙӮИӮйӮЖCeleronӮаҠЬӮЯ
‘S•”VTӮЙ‘ОүһӮөӮДӮӯӮйҒB
ӮіӮДҒAMacOSӮҫӮӘҒALarrabeeғRғAӮр“®Ӯ©Ӯ·ӮМӮЙ•K—vӮЙӮИӮзӮЛҒH
377 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/10/18(“ъ) 18:03:31 ID:ynoD0Hzq0
MacOSҺ©җgӮЙғnғCғpҒ[ғoғCғUӢ@”\ӮӘҒB
378 ҒF–јҸМ–ўҗЭ’иҒF2009/10/19(ҢҺ) 00:05:00 ID:bGqNhypb0
1TBӮМғҒғӮғҠӮӘ—ҳ—pүВ”\Ғ|ғҒғCғ“ғtғҢҒ[ғҖ•АӮЭӮМҗM—Ҡҗ«ӮрҺқӮВҒuNehalem-EXҒv
http://enterprise.watch.impress.co.jp/docs/series/virtual/20091019_321274.html
http://enterprise.watch.impress.co.jp/docs/series/virtual/20091019_321274.html
379 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/10/19(ҢҺ) 00:47:16 ID:oMh6evTi0
Magny-CoursӮБӮДӮұӮўӮВӮМ‘ОҚRӮИӮсӮҫӮжӮИ
‘еҸд•vӮ©AMDӮН
‘еҸд•vӮ©AMDӮН
380 ҒF–јҸМ–ўҗЭ’иҒF2009/10/19(ҢҺ) 04:18:34 ID:rWGerDEy0
Magny-CoursӮЖNehalem-EXӮЕӮНүҝҠiӮаҲК’uӮГӮҜӮаҲбӮӨӮЖҺvӮўӮЬӮ·ҒB
Magny-CoursӮН2ғ\ғPғbғgӮӘғҒғCғ“ӮЙӮИӮйӮЖҺvӮнӮкӮйӮМӮЕҒA
ҚЎӮЬӮЕӮМ8000”Ф‘дӮжӮиӮНҲАӮӯӮИӮйӮМӮЕӮНӮИӮўӮЕӮөӮеӮӨӮ©ҒB
Nehalem-EXӮНғXғүғCғhӮЙ2ғ\ғPғbғgӮМ—бӮаӮ ӮиӮЬӮ·ӮӘҒA
ӮSғ\ғPғbғgҲИҸгӮЕҗM—Ҡҗ«Ӯр•K—vӮЖӮ·ӮйӮЖӮұӮлӮӘғҒғCғ“ӮЙӮИӮйӮМӮЕӮНҒB
—vӮ·ӮйӮЙAMDӮНNehalem-EXӮЙ‘ОҚRӮЕӮ«ӮйӮаӮМӮӘӮИӮўӮөҒAӮ·ӮйӢCӮаӮИӮўҒB
Magny-CoursӮН2ғ\ғPғbғgӮӘғҒғCғ“ӮЙӮИӮйӮЖҺvӮнӮкӮйӮМӮЕҒA
ҚЎӮЬӮЕӮМ8000”Ф‘дӮжӮиӮНҲАӮӯӮИӮйӮМӮЕӮНӮИӮўӮЕӮөӮеӮӨӮ©ҒB
Nehalem-EXӮНғXғүғCғhӮЙ2ғ\ғPғbғgӮМ—бӮаӮ ӮиӮЬӮ·ӮӘҒA
ӮSғ\ғPғbғgҲИҸгӮЕҗM—Ҡҗ«Ӯр•K—vӮЖӮ·ӮйӮЖӮұӮлӮӘғҒғCғ“ӮЙӮИӮйӮМӮЕӮНҒB
—vӮ·ӮйӮЙAMDӮНNehalem-EXӮЙ‘ОҚRӮЕӮ«ӮйӮаӮМӮӘӮИӮўӮөҒAӮ·ӮйӢCӮаӮИӮўҒB
381 ҒF–јҸМ–ўҗЭ’иҒF2009/10/19(ҢҺ) 07:37:25 ID:9omDrcN40
AMDӮаӮ»ӮӨӮҫӮҜӮЗItaniumӮМҸ«—ҲӮаҗS”zӮіӮкӮЬӮ·ҒB
җі’јӮаӮӨӮўӮзӮИӮӯӮЛҒH
җі’јӮаӮӨӮўӮзӮИӮӯӮЛҒH
382 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/10/20(үО) 20:51:41 ID:RJanAian0
ItaniumӮЬӮҫҗS”zӮЕӮ«Ӯй“zӮўӮҪӮсӮҫҒB
ӮЁӮкӮа5,6”NҲК‘OӮЬӮЕӮИӮзҗS”zӮөӮДӮҪӮӘҚЎӮНҗS”zӮөӮДӮИӮўӮәҒB
ӮЁӮкӮа5,6”NҲК‘OӮЬӮЕӮИӮзҗS”zӮөӮДӮҪӮӘҚЎӮНҗS”zӮөӮДӮИӮўӮәҒB
383 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/10/20(үО) 20:54:44 ID:RJanAian0
5,6”N‘OӮЬӮЕӮНӮўӮ©ӮИӮўӮ©ҒB
MontecitoӮ ӮҪӮиӮЕӮаӮӨҗS”zӮМ•K—vӮаӮИӮўӮИӮЖҒB
MontecitoӮ ӮҪӮиӮЕӮаӮӨҗS”zӮМ•K—vӮаӮИӮўӮИӮЖҒB
384 ҒF–јҸМ–ўҗЭ’иҒF2009/10/22(–Ш) 02:47:16 ID:/+lGNwVP0
>>380
Magny-CoursӮНNehalem-EX“Ҝ—lғRғXғgӮӘҚӮӮ·Ӯ¬ӮДғXғCҒ[ғgғXғ|ғbғgӮЙӮНӮаӮБӮД—ҲӮкӮИӮўӮ©Ӯз–і—қҒB
2S—pӮМғvғүғbғgғtғHҒ[ғҖӮӘ2Һн—ЮӮ ӮйҺһ“_ӮЕҺ@ӮөӮДӮвӮкҒB
ғRғA“–ӮҪӮиӮМҗ«”\ӮӘ1.5”{ҲИҸгҲбӮӨҺһ“_ӮЕҸҹ•үӮЙӮИӮзӮИӮўӮБӮДӮұӮБӮҪҒB
Magny-CoursӮНNehalem-EX“Ҝ—lғRғXғgӮӘҚӮӮ·Ӯ¬ӮДғXғCҒ[ғgғXғ|ғbғgӮЙӮНӮаӮБӮД—ҲӮкӮИӮўӮ©Ӯз–і—қҒB
2S—pӮМғvғүғbғgғtғHҒ[ғҖӮӘ2Һн—ЮӮ ӮйҺһ“_ӮЕҺ@ӮөӮДӮвӮкҒB
ғRғA“–ӮҪӮиӮМҗ«”\ӮӘ1.5”{ҲИҸгҲбӮӨҺһ“_ӮЕҸҹ•үӮЙӮИӮзӮИӮўӮБӮДӮұӮБӮҪҒB
385 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/10/22(–Ш) 08:18:32 ID:R/hKP3f40
HT-XӮМүеҸйӮр•цӮіӮ№ӮйӮнӮҜӮЙӮаӮўӮ©ӮсӮ©ӮзҒAAMDӮМҢoүcҗн—ӘҸгҸoӮіӮИӮўӮжӮиӮНғ}ғV
386 ҒF–јҸМ–ўҗЭ’иҒF2009/10/22(–Ш) 13:09:36 ID:B7ZXdSfp0
>>384
Ӯ»ӮӨӮЕӮ·Ӯ©ӮЛҒB
Opteron 2425 HEӮӘ523ғhғӢӮИӮМӮЕҒA
2ӮВӮЕ1000ғhғӢӮрҸӯӮөҸгүсӮйӮӯӮзӮўӮЕӮ·ӮжӮЛҒB
’PҸғӮЙ2”{ӮЙӮНӮИӮзӮИӮўӮЙӮөӮДӮаҚӮӮ·Ӯ¬ӮйӮЖӮўӮӨӮЩӮЗӮЙӮНӮИӮзӮИӮўӮЖҺvӮўӮЬӮ·ӮҜӮЗҒB
Ӯ»ӮкӮЙ12ғRғAӮЕӮа2.1GHzӮӯӮзӮўӮЕӮНWestmere-EPӮЙ‘ОӮөӮД—DҲКӮЙӮИӮзӮИӮўӮМӮЕҒA
Ӯ»ӮкӮЩӮЗҚӮӮӯӮНӮЕӮ«ӮИӮўӮЖҺvӮўӮЬӮ·ҒB
Ӯ»ӮӨӮЕӮ·Ӯ©ӮЛҒB
Opteron 2425 HEӮӘ523ғhғӢӮИӮМӮЕҒA
2ӮВӮЕ1000ғhғӢӮрҸӯӮөҸгүсӮйӮӯӮзӮўӮЕӮ·ӮжӮЛҒB
’PҸғӮЙ2”{ӮЙӮНӮИӮзӮИӮўӮЙӮөӮДӮаҚӮӮ·Ӯ¬ӮйӮЖӮўӮӨӮЩӮЗӮЙӮНӮИӮзӮИӮўӮЖҺvӮўӮЬӮ·ӮҜӮЗҒB
Ӯ»ӮкӮЙ12ғRғAӮЕӮа2.1GHzӮӯӮзӮўӮЕӮНWestmere-EPӮЙ‘ОӮөӮД—DҲКӮЙӮИӮзӮИӮўӮМӮЕҒA
Ӯ»ӮкӮЩӮЗҚӮӮӯӮНӮЕӮ«ӮИӮўӮЖҺvӮўӮЬӮ·ҒB
387 ҒF–јҸМ–ўҗЭ’иҒF2009/10/22(–Ш) 16:16:12 ID:oo36fMed0
ӮИӮсӮ©ӮЁӮ©ӮөӮўӮИӮЖҺvӮБӮДӮўӮҪӮз
Ғ„ҒyӮЁҳlӮСӮЖ’щҗіҒzҸүҸoҺһҒAҺҹҗў‘гItaniumӮЖғ\ғPғbғgҢЭҠ·ӮӘӮ ӮйҺ|ҒA
Ғ„ӢLҚЪӮөӮДӮЁӮиӮЬӮөӮҪӮӘҒAҺ–ҺАӮЖҲЩӮИӮиӮЬӮөӮҪҒBӮЁҳlӮСӮөӮД’щҗіӮөӮЬӮ·ҒB
Ғ„ҒyӮЁҳlӮСӮЖ’щҗіҒzҸүҸoҺһҒAҺҹҗў‘гItaniumӮЖғ\ғPғbғgҢЭҠ·ӮӘӮ ӮйҺ|ҒA
Ғ„ӢLҚЪӮөӮДӮЁӮиӮЬӮөӮҪӮӘҒAҺ–ҺАӮЖҲЩӮИӮиӮЬӮөӮҪҒBӮЁҳlӮСӮөӮД’щҗіӮөӮЬӮ·ҒB
388 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/10/22(–Ш) 22:36:06 ID:R/hKP3f40
М¶јӢLҺ–‘ҪӮ·Ӯ¬ӮйӮјҺR–{
390 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/10/25(“ъ) 12:42:11 ID:M0/5hHwu0
ӮұӮұ”ЮҸҲӮМ— ғXғҢӮҫӮБӮҪӮМӮ©
391 ҒF–јҸМ–ўҗЭ’иҒF2009/10/29(–Ш) 11:07:54 ID:iFYsovRy0
үӘ“cҠO–ұ‘еҗb·А„Ә„Ә„Ә„Ә„Ә„Ә(ЯҒНЯ)„Ә„Ә„Ә„Ә„Ә„Ә !!!!!
http://qb5.2ch.net/test/read.cgi/saku2ch/1256630318/1
‘ҒӮӯӢL”OғJғLғRӮөӮИӮўӮЖ–„ӮЬӮБӮҝӮбӮӨӮ—Ӯ—Ӯ—
392 ҒF–јҸМ–ўҗЭ’иҒF2009/11/01(“ъ) 18:29:30 ID:1YT33BKcO
HPCҠEҢGӮМblogҒE“ъӢLӮҙӮБӮЖҢ©ӮДӮ«ӮҪӮҜӮЗҢ¬•АӮЭ—бӮМҳ_•¶(>>339)ӮНғXғӢҒ[ҒB
ӮЭӮсӮИӢ»–ЎӮИӮӯӮөӮҝӮбӮБӮҪӮМӮ©ӮИҒB
ӮЭӮсӮИӢ»–ЎӮИӮӯӮөӮҝӮбӮБӮҪӮМӮ©ӮИҒB
393 ҒF–јҸМ–ўҗЭ’иҒF2009/11/01(“ъ) 19:40:59 ID:yMUg45BW0
CELLӮМҺһӮаҳ_•¶‘S•”’ЗӮБӮДӮҪӮМӮНғQғn–ҜӮ®ӮзӮўӮҫӮБӮҪӮҜӮЗӮИ
394 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/11/01(“ъ) 20:17:24 ID:ApiZUIQu0
LarrabeeҠЦҳA“БӢ–•¶Ҹ‘ӮЕӮа“ЗӮЯӮОӮўӮўӮЖҺvӮӨӮж
җПҳaҺZҒEғvғҢғfғBғPҒ[ғgҺьӮи
Ғ@http://www.freepatentsonline.com/20090171994.pdf
Gather/SvatterҺьӮи
Ғ@http://www.freepatentsonline.com/20090172364.pdf
ӮИӮЙӮ°ӮЙҺА‘•ғlғ^ғoғҢӮөӮДӮй
җПҳaҺZҒEғvғҢғfғBғPҒ[ғgҺьӮи
Ғ@http://www.freepatentsonline.com/20090171994.pdf
Gather/SvatterҺьӮи
Ғ@http://www.freepatentsonline.com/20090172364.pdf
ӮИӮЙӮ°ӮЙҺА‘•ғlғ^ғoғҢӮөӮДӮй
395 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/11/03(үО) 15:05:40 ID:IQCKSZs+0
–Ҫ—ЯғZғbғgӮӘҠ®‘SҢцҠJӮіӮкӮДӮДғҶҒ[ғUҒ[ӮӘҗGӮкӮйҺ‘—ҝӮӘҗFҒXҸoӮДӮҪCellӮЖӮНҲбӮБӮД
LarrabeeӮН”й–§ҺеӢ`ӮҫӮ©ӮзӮИҒB
–ЪӮЙҢ©ӮҰӮйӮБӮДҲУ–ЎӮЕӮНAVXӮМӮЩӮӨӮӘ–К”’ӮўӮ©ӮаӮЛ
LarrabeeӮН”й–§ҺеӢ`ӮҫӮ©ӮзӮИҒB
–ЪӮЙҢ©ӮҰӮйӮБӮДҲУ–ЎӮЕӮНAVXӮМӮЩӮӨӮӘ–К”’ӮўӮ©ӮаӮЛ
396 ҒF–јҸМ–ўҗЭ’иҒF2009/11/04(җ…) 23:47:21 ID:g1YOxLco0
New microarchitectureӮЖҢҫӮнӮкӮйMedfieldӮНLarrabeeғRғAӮӘғxҒ[ғXӮЙӮИӮйӮЖ—\‘zӮөӮДӮўӮй
ғRғAӮ»ӮМӮаӮМӮӘ—¬—pӮіӮкӮИӮӯӮДӮаLRBniӮӘenableӮіӮкӮДGPUӮЖCPUӮӘҢ“—pӮЙӮИӮйүВ”\җ«ӮӘҚӮӮўӮЖ—\‘Ә
ғRғAӮ»ӮМӮаӮМӮӘ—¬—pӮіӮкӮИӮӯӮДӮаLRBniӮӘenableӮіӮкӮДGPUӮЖCPUӮӘҢ“—pӮЙӮИӮйүВ”\җ«ӮӘҚӮӮўӮЖ—\‘Ә
397 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/11/04(җ…) 23:59:56 ID:r9SGJsla0
ӮИӮўӮИӮў
ӮҝӮИӮЭӮЙӮ»ӮМҺҹӮМҗў‘гӮӯӮзӮўӮЕAVXӮӘҺgӮҰӮйӮжӮӨӮЙӮИӮй–Н—l
ӮҝӮИӮЭӮЙӮ»ӮМҺҹӮМҗў‘гӮӯӮзӮўӮЕAVXӮӘҺgӮҰӮйӮжӮӨӮЙӮИӮй–Н—l
398 ҒF–јҸМ–ўҗЭ’иҒF2009/11/05(–Ш) 00:07:32 ID:2QyothRw0
{kind=link}
399 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/11/05(–Ш) 00:14:00 ID:JQjZeHoq0
ӮЖӮўӮӨӮ©ӮЛҒAAtomӮМҺsҸкҗiҸoӮМғXғgғүғeғWҒ[ӮНҒAARMӮЖ“ҜӮ¶ӮӯҒuғRғ“ғgғҚҒ[ғүҒvӮЙ“OӮ·ӮйӮұӮЖҒB
ғAғNғZғүғҢҒ[ғ^ӮЕӮ Ӯй•K—vӮНӮИӮўҒB
ғlғbғgғuғbғNӮИӮсӮДSoCғrғWғlғXӮӘ–{Ҡi“IӮЙ—§ӮҝҸгӮӘӮйӮЬӮЕӮМҢqӮ¬ӮИӮсӮЕӮ·ҒB
үҪӮМҲЧӮЙӮнӮҙӮнӮҙTSMCӮМҗ»‘ўғүғCғ“ӮЬӮйӮЬӮйAtom—pӮЙ”ғӮўҸгӮ°ӮҪӮЖҺvӮӨӮж
ғAғNғZғүғҢҒ[ғ^ӮЕӮ Ӯй•K—vӮНӮИӮўҒB
ғlғbғgғuғbғNӮИӮсӮДSoCғrғWғlғXӮӘ–{Ҡi“IӮЙ—§ӮҝҸгӮӘӮйӮЬӮЕӮМҢqӮ¬ӮИӮсӮЕӮ·ҒB
үҪӮМҲЧӮЙӮнӮҙӮнӮҙTSMCӮМҗ»‘ўғүғCғ“ӮЬӮйӮЬӮйAtom—pӮЙ”ғӮўҸгӮ°ӮҪӮЖҺvӮӨӮж
400 ҒF–јҸМ–ўҗЭ’иҒF2009/11/05(–Ш) 00:57:24 ID:JtuV1Db/0
’PӮИӮйҗ»‘ўҲП‘хӮЕӮаIntelӮӘӮвӮйӮЖғүғCғ“ӮМ”ғӮўҸгӮ°ӮЙӮИӮйӮМӮ©
401 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/11/05(–Ш) 01:53:41 ID:JQjZeHoq0
Ӯ»ӮиӮбTSMCҚЕҗж’[ӮМ40nm FabӮМҲкӮВӮӘӮЬӮйӮЬӮйAtomҗ»‘ў—pӮҫӮөҒB
402 ҒF–јҸМ–ўҗЭ’иҒF2009/11/05(–Ш) 02:12:37 ID:TpAftpO50
TSMC Fab14 40nmӮЕҚмӮйAtomӮБӮДүҪӮжҒH
LangwellӮНTSMC 65nmӮМӮНӮё
IntelӮМSoCҢьӮҜғvғҚғZғXғҚҒ[ғhғ}ғbғvӮНӮ ӮйӮө 45nmҒЁ32nmҒЁ22nm
http://pc.watch.impress.co.jp/img/pcw/docs/212/014/kaigai7.jpg
http://pc.watch.impress.co.jp/img/pcw/docs/212/014/kaigai8.jpg
LangwellӮНTSMC 65nmӮМӮНӮё
IntelӮМSoCҢьӮҜғvғҚғZғXғҚҒ[ғhғ}ғbғvӮНӮ ӮйӮө 45nmҒЁ32nmҒЁ22nm
http://pc.watch.impress.co.jp/img/pcw/docs/212/014/kaigai7.jpg
{kind=link}
http://pc.watch.impress.co.jp/img/pcw/docs/212/014/kaigai8.jpg
{kind=link}
403 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/11/05(–Ш) 02:15:42 ID:JQjZeHoq0
IntelӮӘҺ©ҺРFabӮЕҚмӮйSoCӮНӮ»ӮМғҚҒ[ғhғ}ғbғvӮМ’КӮиӮҫӮлҒB
ARMӮӘӮ»ӮӨӮЕӮ ӮйӮМӮжӮӨӮЙҒAAtomӮрғRғ“ғgғҚҒ[ғүӮЖӮөӮДҺgӮўӮҪӮў‘јӮМҠйӢЖӮЙӮаүр•ъӮ·ӮйҒB
ӮҫӮ©ӮзғҚҒ[ғhғ}ғbғvӮИӮсӮД–іӮўҒBҢЪӢqӮӘ•tӮ«Һҹ‘жҒB
ARMӮӘӮ»ӮӨӮЕӮ ӮйӮМӮжӮӨӮЙҒAAtomӮрғRғ“ғgғҚҒ[ғүӮЖӮөӮДҺgӮўӮҪӮў‘јӮМҠйӢЖӮЙӮаүр•ъӮ·ӮйҒB
ӮҫӮ©ӮзғҚҒ[ғhғ}ғbғvӮИӮсӮД–іӮўҒBҢЪӢqӮӘ•tӮ«Һҹ‘жҒB
404 ҒF–јҸМ–ўҗЭ’иҒF2009/11/05(–Ш) 06:43:52 ID:JtuV1Db/0
405 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/11/05(–Ш) 09:46:46 ID:JQjZeHoq0
ғlғ^ҢіӮӘ”нҠQ–П‘zӮМNVIDIA–ЧӮҫӮБӮҪӮ©ӮаӮЛ
җ¶ҺYғLғғғpӮрҺEӮўӮЕFermiӮМ—КҺYӮр‘jҺ~Ӯ·ӮйӮВӮаӮиӮҫӮЖӮ©ү]ҒX
‘ҠҺиӮЙӮ·ӮйӮҫӮҜ–і‘КӮ©
җ¶ҺYғLғғғpӮрҺEӮўӮЕFermiӮМ—КҺYӮр‘jҺ~Ӯ·ӮйӮВӮаӮиӮҫӮЖӮ©ү]ҒX
‘ҠҺиӮЙӮ·ӮйӮҫӮҜ–і‘КӮ©
406 ҒF–јҸМ–ўҗЭ’иҒF2009/11/05(–Ш) 20:34:49 ID:+pcBtANq0
ғMғғғOӮЕӮвӮБӮДӮсӮМӮұӮкҒH
ӮЬӮБӮҪӮӯҸОӮҰӮИӮў
399 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/11/05(–Ш) 00:14:00 ID:JQjZeHoq0
үҪӮМҲЧӮЙӮнӮҙӮнӮҙTSMCӮМҗ»‘ўғүғCғ“ӮЬӮйӮЬӮйAtom—pӮЙ”ғӮўҸгӮ°ӮҪӮЖҺvӮӨӮж
403 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣ [sage] ҒF2009/11/05(–Ш) 02:15:42 ID:JQjZeHoq0
ARMӮӘӮ»ӮӨӮЕӮ ӮйӮМӮжӮӨӮЙҒAAtomӮрғRғ“ғgғҚҒ[ғүӮЖӮөӮДҺgӮўӮҪӮў‘јӮМҠйӢЖӮЙӮаүр•ъӮ·ӮйҒB
405 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/11/05(–Ш) 09:46:46 ID:JQjZeHoq0
ғlғ^ҢіӮӘ”нҠQ–П‘zӮМNVIDIA–ЧӮҫӮБӮҪӮ©ӮаӮЛ
ӮЬӮБӮҪӮӯҸОӮҰӮИӮў
399 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/11/05(–Ш) 00:14:00 ID:JQjZeHoq0
үҪӮМҲЧӮЙӮнӮҙӮнӮҙTSMCӮМҗ»‘ўғүғCғ“ӮЬӮйӮЬӮйAtom—pӮЙ”ғӮўҸгӮ°ӮҪӮЖҺvӮӨӮж
403 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣ [sage] ҒF2009/11/05(–Ш) 02:15:42 ID:JQjZeHoq0
ARMӮӘӮ»ӮӨӮЕӮ ӮйӮМӮжӮӨӮЙҒAAtomӮрғRғ“ғgғҚҒ[ғүӮЖӮөӮДҺgӮўӮҪӮў‘јӮМҠйӢЖӮЙӮаүр•ъӮ·ӮйҒB
405 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/11/05(–Ш) 09:46:46 ID:JQjZeHoq0
ғlғ^ҢіӮӘ”нҠQ–П‘zӮМNVIDIA–ЧӮҫӮБӮҪӮ©ӮаӮЛ
407 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/11/05(–Ш) 22:52:25 ID:JQjZeHoq0
ӮҫӮсӮІӮ Ӯ°ӮйӮ©ӮзӢ–Ӯ№
TSMCӮН32nmӮЕӮаһҢҺqҗ ӮБӮДӮўӮй
ttp://www.semiaccurate.com./2009/11/09/tsmc-slips-their-32nm-process/
җ«”\
Intel 32nmҒ„TSMC 28nmҒ„TSMC32nm
–§“x
Intel 32nmҒ„TSMC 28nmҒ„TSMC32nm
“Ҡ“ьҺһҠъ
Intel 32nmҒ„TSMC 32nmҒ„TSMC28nm
ttp://www.semiaccurate.com./2009/11/09/tsmc-slips-their-32nm-process/
җ«”\
Intel 32nmҒ„TSMC 28nmҒ„TSMC32nm
–§“x
Intel 32nmҒ„TSMC 28nmҒ„TSMC32nm
“Ҡ“ьҺһҠъ
Intel 32nmҒ„TSMC 32nmҒ„TSMC28nm
409 ҒF–јҸМ–ўҗЭ’иҒF2009/11/10(үО) 08:50:50 ID:c8iHgPi90
үҪӮ©ҺcӮБӮДӮҪӮн
410 ҒF–јҸМ–ўҗЭ’иҒF2009/11/10(үО) 09:13:52 ID:P8aJS9x00
TSMCӮН28nmӮрғtғӢғmҒ[ғhӮЙӮ·ӮйӮБӮДҢҫӮБӮДӮйӮ©ӮзӮИ
ӢtӮЙҢҫӮҰӮО32nmӮНҠъ‘ТӮ·ӮйӮИӮБӮДӮұӮЖӮҫ
ӢtӮЙҢҫӮҰӮО32nmӮНҠъ‘ТӮ·ӮйӮИӮБӮДӮұӮЖӮҫ
411 ҒF–јҸМ–ўҗЭ’иҒF2009/11/12(–Ш) 23:32:57 ID:ml7u56XC0
ғCғ“ғeғӢҒAҗVҢ^SSDӮрӢЯ“ъ“Ҡ“ьҒ\Ғ\HDD•АӮЭӮМ—e—КӮрҺқӮВҠйӢЖҢьӮҜҗ»•iӮа
ttp://www.computerworld.jp/topics/storage/167389.html
ғCғ“ғeғӢҒA2.3/2.5/3.5GHz‘С‘ОүһӮМWiMAXғӮғWғ…Ғ[ғӢҒuKilmer PeakҒvӮрҗ»‘ўҠJҺn
ttp://www.computerworld.jp/topics/uw/167111.html
ғCғ“ғeғӢҒAvProғeғNғmғҚғWҒ[ӮМҢҳ’ІӮИ“ұ“ьҺАҗСӮрғAғsҒ[ғӢ
ttp://www.computerworld.jp/topics/mp/167349.html
ttp://www.computerworld.jp/topics/storage/167389.html
ғCғ“ғeғӢҒA2.3/2.5/3.5GHz‘С‘ОүһӮМWiMAXғӮғWғ…Ғ[ғӢҒuKilmer PeakҒvӮрҗ»‘ўҠJҺn
ttp://www.computerworld.jp/topics/uw/167111.html
ғCғ“ғeғӢҒAvProғeғNғmғҚғWҒ[ӮМҢҳ’ІӮИ“ұ“ьҺАҗСӮрғAғsҒ[ғӢ
ttp://www.computerworld.jp/topics/mp/167349.html
412 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/11/13(Ӣа) 22:40:08 ID:hK88L6Cj0
ҒЎҢг“ЎҚO–ОӮМWeeklyҠCҠOғjғ…Ғ[ғXҒЎ
AMDӮӘҺҹҠъғAҒ[ғLғeғNғ`ғғҒuBulldozerҒvӮЖҒuBobcatҒvӮМҠT—vӮр–ҫӮзӮ©ӮЙ
http://pc.watch.impress.co.jp/docs/column/kaigai/20091112_328392.html
AMDғlғ^ӮНӮ·ӮБӮ©ӮиғXғӢҒ[ғӮҒ[ғhӮҫӮӘҒAӮҜӮБӮұӮӨ–К”’ӮўҸо•сӮӘӮЕӮДӮ«ӮҪӮИҒB
BulldozerӮНғAҒ[ғLғeғNғ`ғғӮ©ӮзӮЭӮДӮЗӮӨҢ©ӮДӮағTҒ[ғoҢьӮҜҒB
ҚЎҚXҠҙӮНӮ ӮйӮӘҠJ”ӯҠJҺn“–ҺһғXғӢҒ[ғvғbғgғRғ“ғsғ…Ғ[ғeғBғ“ғOҺuҢьӮМ—¬ӮкӮрӮЭӮҪAMDӮИӮиӮМүс“ҡӮЕӮөӮеӮӨҒB
ҺАҚЫӮМӮЖӮұӮлPCҢьӮҜӮЕӮНBarcelonaҢnӮӘӮөӮОӮзӮӯCPUғRғAӮЖӮөӮДӮВӮГӮ«Ӯ»ӮӨӮЕҒAӮ»ӮМҢгҢpӮЖӮНӮИӮзӮИӮ»ӮӨӮҫӮЛҒB
Sandy Bridge“ҷӮЖҺsҸкӮӘӢЈҚҮӮ·ӮйӮМӮНҢvүж’КӮиӮўӮБӮҪӮЖӮөӮДLlanoҢnӮЙӮИӮиӮ»ӮӨӮЕӮ·ҒB
—јҺРӮНӮвӮНӮиҢӢӢЗӮМӮЖӮұӮлӢЯӮў•ыҢьҗ«ӮрҗiӮсӮЕӮўӮйӮжӮӨӮЙӮЭӮҰӮйҒB
AMDӮӘҺҹҠъғAҒ[ғLғeғNғ`ғғҒuBulldozerҒvӮЖҒuBobcatҒvӮМҠT—vӮр–ҫӮзӮ©ӮЙ
http://pc.watch.impress.co.jp/docs/column/kaigai/20091112_328392.html
AMDғlғ^ӮНӮ·ӮБӮ©ӮиғXғӢҒ[ғӮҒ[ғhӮҫӮӘҒAӮҜӮБӮұӮӨ–К”’ӮўҸо•сӮӘӮЕӮДӮ«ӮҪӮИҒB
BulldozerӮНғAҒ[ғLғeғNғ`ғғӮ©ӮзӮЭӮДӮЗӮӨҢ©ӮДӮағTҒ[ғoҢьӮҜҒB
ҚЎҚXҠҙӮНӮ ӮйӮӘҠJ”ӯҠJҺn“–ҺһғXғӢҒ[ғvғbғgғRғ“ғsғ…Ғ[ғeғBғ“ғOҺuҢьӮМ—¬ӮкӮрӮЭӮҪAMDӮИӮиӮМүс“ҡӮЕӮөӮеӮӨҒB
ҺАҚЫӮМӮЖӮұӮлPCҢьӮҜӮЕӮНBarcelonaҢnӮӘӮөӮОӮзӮӯCPUғRғAӮЖӮөӮДӮВӮГӮ«Ӯ»ӮӨӮЕҒAӮ»ӮМҢгҢpӮЖӮНӮИӮзӮИӮ»ӮӨӮҫӮЛҒB
Sandy Bridge“ҷӮЖҺsҸкӮӘӢЈҚҮӮ·ӮйӮМӮНҢvүж’КӮиӮўӮБӮҪӮЖӮөӮДLlanoҢnӮЙӮИӮиӮ»ӮӨӮЕӮ·ҒB
—јҺРӮНӮвӮНӮиҢӢӢЗӮМӮЖӮұӮлӢЯӮў•ыҢьҗ«ӮрҗiӮсӮЕӮўӮйӮжӮӨӮЙӮЭӮҰӮйҒB
413 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/11/14(“y) 01:19:00 ID:Ep6Chbf+0
LlanoӮНAVXғTғ|Ғ[ғgӮөӮИӮўӮМӮ©ӮЛ
414 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/11/15(“ъ) 14:29:41 ID:UyxcQfZa0
ӮаӮөLlanoӮЕAVXғTғ|Ғ[ғgӮЖӮөӮДӮўӮҪӮзҒA
ҚЎӮ©Ӯзҗй“`ӮөӮДҚўӮй—қ—RӮНӮИӮўӮҫӮлӮӨӮ©Ӯз–іӮўӮЙүҙ“IӮЙӮН1•[ӮҫӮИҒB
Ӯ ӮЖBulldozerӮМInteger CoreӮНҢг“ЎӮвDresdenboyӮМӮжӮӨӮЙ
ALU(+AGU)+ld+stӮӘ“S”В—\‘zҒBҗ«”\—\‘zӮМғOғүғtӮрӮЭӮДӮаӮ»ӮӨӮҫӮӘ
ғRғAӮ ӮҪӮиӮМҗ«”\ӮНӮЁӮҝӮйӮөҒAғXғӢҒ[ғvғbғgҺuҢьӮМғTҒ[ғoҢьӮҜҗ»•iӮЕӮ ӮБӮДҒA
ӮЖӮДӮаK10ҢnғRғAӮМ‘S–К’uӮ«Ҡ·ӮҰӮЙӮНӮИӮзӮИӮўҒB
BobcatӮНғ_ғCғTғCғY”ј•ӘӮЕӮағZғIғҠҒ[ӮЗӮЁӮиӮўӮҜӮО70%ҲКӮМҗ«”\ӮНҲЫҺқӮЕӮ«ӮйӮ©ӮзҒA
Ӯ ӮЖӮНғvғҚғZғXӮӘҗiӮсӮҫ•ӘӮЖ“d—Нғ}Ғ[ғWғ“ӮӘҸo—ҲӮҪӮМӮрғNғҚғbғNӮЙ20%-30%ӮУӮкӮзӮкӮкӮО2issue OOOӮЕӮа
ҚӮ“d—Н”ЕӮНҢ»Қs•iӮМ90%ӮӯӮзӮўӮМҗ«”\ӮНӮЕӮДӮаӮЁӮ©ӮөӮӯӮИӮўҒB
ҚЎӮ©Ӯзҗй“`ӮөӮДҚўӮй—қ—RӮНӮИӮўӮҫӮлӮӨӮ©Ӯз–іӮўӮЙүҙ“IӮЙӮН1•[ӮҫӮИҒB
Ӯ ӮЖBulldozerӮМInteger CoreӮНҢг“ЎӮвDresdenboyӮМӮжӮӨӮЙ
ALU(+AGU)+ld+stӮӘ“S”В—\‘zҒBҗ«”\—\‘zӮМғOғүғtӮрӮЭӮДӮаӮ»ӮӨӮҫӮӘ
ғRғAӮ ӮҪӮиӮМҗ«”\ӮНӮЁӮҝӮйӮөҒAғXғӢҒ[ғvғbғgҺuҢьӮМғTҒ[ғoҢьӮҜҗ»•iӮЕӮ ӮБӮДҒA
ӮЖӮДӮаK10ҢnғRғAӮМ‘S–К’uӮ«Ҡ·ӮҰӮЙӮНӮИӮзӮИӮўҒB
BobcatӮНғ_ғCғTғCғY”ј•ӘӮЕӮағZғIғҠҒ[ӮЗӮЁӮиӮўӮҜӮО70%ҲКӮМҗ«”\ӮНҲЫҺқӮЕӮ«ӮйӮ©ӮзҒA
Ӯ ӮЖӮНғvғҚғZғXӮӘҗiӮсӮҫ•ӘӮЖ“d—Нғ}Ғ[ғWғ“ӮӘҸo—ҲӮҪӮМӮрғNғҚғbғNӮЙ20%-30%ӮУӮкӮзӮкӮкӮО2issue OOOӮЕӮа
ҚӮ“d—Н”ЕӮНҢ»Қs•iӮМ90%ӮӯӮзӮўӮМҗ«”\ӮНӮЕӮДӮаӮЁӮ©ӮөӮӯӮИӮўҒB
415 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/11/15(“ъ) 14:30:50 ID:UyxcQfZa0
ӮЬӮҝӮӘӮҰӮҪ2 ALUӮҫҒB
ALU(AGU)+ALU(AGU)+ld+st
ALU(AGU)+ALU(AGU)+ld+st
416 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/11/15(“ъ) 18:20:25 ID:p8griTW90
ӮўӮвӮ»ӮкӮНӮЁӮ©ӮөӮўҒB
AGUӮНғAғhғҢғXӮрүрҢҲӮөӮДLoad/StoreғҶғjғbғgӮр“®Ӯ©Ӯ·ӮҪӮЯӮМӮаӮМӮҫ
Load/StoreӮМӮЭӮЕ“Ж—§ӮөӮҪғҠғUғxҒ[ғVғҮғ“ғpғCғvӮрҺқӮВӮМӮҫӮЖӮөӮҪӮз
AGUӮНLoad/Store‘ӨӮӘҺқӮВӮұӮЖӮЙӮИӮйӮҫӮлҒB
AGUӮНғAғhғҢғXӮрүрҢҲӮөӮДLoad/StoreғҶғjғbғgӮр“®Ӯ©Ӯ·ӮҪӮЯӮМӮаӮМӮҫ
Load/StoreӮМӮЭӮЕ“Ж—§ӮөӮҪғҠғUғxҒ[ғVғҮғ“ғpғCғvӮрҺқӮВӮМӮҫӮЖӮөӮҪӮз
AGUӮНLoad/Store‘ӨӮӘҺқӮВӮұӮЖӮЙӮИӮйӮҫӮлҒB
417 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/11/15(“ъ) 21:45:05 ID:UyxcQfZa0
җ®җ”ғҶғjғbғgӮЙLSUӮрӮФӮзүәӮ°ӮйӮМӮБӮДAlphaӮМ“`“қӮИӮсӮҫӮжӮИҒB
BobcatӮЭӮйӮИӮиҒAӮ»ӮМ“`“қӮвӮЯӮйӮМӮ©ӮаӮЛҒB
ALU+ALU+ld(AGU)+st(AGU)
Ӯ©ӮИҒB
AGUӮЖld/stӮрӮнӮҙӮЖ•ӘӮҜӮй•ыҺ®ӮаӮ ӮйҒBIntelӮМSTAғҶғjғbғgӮаӮ»ӮӨҒB
‘ҒӮЯӮЙҺАҢшғAғhғҢғXӮрҗ¶җ¬ӮөӮДStoreғoғbғtғ@ӮЙҸ‘Ӯ«ҚһӮЭӮөӮДӮўӮӯӮҫӮҜӮрӮвӮйӮЖ
ҲЛ‘¶җ«үрҗНӮЙҺgӮҰӮйҒB
BobcatӮЭӮйӮИӮиҒAӮ»ӮМ“`“қӮвӮЯӮйӮМӮ©ӮаӮЛҒB
ALU+ALU+ld(AGU)+st(AGU)
Ӯ©ӮИҒB
AGUӮЖld/stӮрӮнӮҙӮЖ•ӘӮҜӮй•ыҺ®ӮаӮ ӮйҒBIntelӮМSTAғҶғjғbғgӮаӮ»ӮӨҒB
‘ҒӮЯӮЙҺАҢшғAғhғҢғXӮрҗ¶җ¬ӮөӮДStoreғoғbғtғ@ӮЙҸ‘Ӯ«ҚһӮЭӮөӮДӮўӮӯӮҫӮҜӮрӮвӮйӮЖ
ҲЛ‘¶җ«үрҗНӮЙҺgӮҰӮйҒB
418 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/11/15(“ъ) 22:17:44 ID:UyxcQfZa0
BulldozerӮЙӮЁӮҜӮйClusterd-ArchitectureӮЖӮНҒAҚ\‘ў“IӮЙӮНӮЁӮЁӮҙӮБӮПӮЙҢҫӮҰӮОҒA
җ®җ”•”ӮӘCMP•—–ЎҒAFP•”ӮӘFGMT•—–ЎӮМғAғvғҚҒ[ғ`ӮЕӮ ӮиҒA•Ғ’КӮМғ}ғӢғ`ғRғAӮжӮиӮағҠғ\Ғ[ғXӮрҗЯ–сӮөӮҪӮаӮМӮҫҒB
ӮЕӮаҒAӮұӮМҺ–ҺАӮН‘еӮөӮДҸd—vӮ¶ӮбӮИӮ©ӮҪҒB
ҺАӮНҲУҠOӮвҲУҠOҒAClustered-ArchitectureӮМ–ЪҺwӮөӮДӮўӮҪ–Ъ•WӮНҒAIntelӮЕӮўӮӨӮЖӮұӮлӮМTurbo BoostӮИӮМӮҫҒB
җ®җ”•”ӮӘCMP•—–ЎҒAFP•”ӮӘFGMT•—–ЎӮМғAғvғҚҒ[ғ`ӮЕӮ ӮиҒA•Ғ’КӮМғ}ғӢғ`ғRғAӮжӮиӮағҠғ\Ғ[ғXӮрҗЯ–сӮөӮҪӮаӮМӮҫҒB
ӮЕӮаҒAӮұӮМҺ–ҺАӮН‘еӮөӮДҸd—vӮ¶ӮбӮИӮ©ӮҪҒB
ҺАӮНҲУҠOӮвҲУҠOҒAClustered-ArchitectureӮМ–ЪҺwӮөӮДӮўӮҪ–Ъ•WӮНҒAIntelӮЕӮўӮӨӮЖӮұӮлӮМTurbo BoostӮИӮМӮҫҒB
419 ҒF–јҸМ–ўҗЭ’иҒF2009/11/15(“ъ) 23:21:55 ID:qId6j8vh0
FPүүҺZӮНINTӮЙ”дӮЧӮДҸБ”п“d—НӮӘ‘еӮ«ӮўӮ©ӮзҺАҚsғҶғjғbғgӮМүТ“®ҸуӢөӮрғҠғAғӢғ^ғCғҖӮЕҢv‘ӘӮөӮД
ғҸҒ[ғNғҚҒ[ғhӮӘINT’ҶҗSӮМҸкҚҮӮНӮ»ӮМ’ц“xӮЙүһӮ¶ӮДғNғҚғbғNӮрҸгӮ°ӮйӮЖӮўӮӨӮМӮӘTukwilaӮМFoxtonӮҫӮӘ
ғNғүғXғ^ӮИӮсӮҝӮбӮзӮЕFPӮМүүҺZғҠғ\Ғ[ғXӮрINTӮЙ‘ОӮөӮДҸӯӮИӮӯ”zӮ·ӮкӮОғ^Ғ[ғQғbғgғNғҚғbғNӮНҚӮӮӯӮЕӮ«Ӯй(ғwғbғhғӢҒ[ғҖӮрҠm•Ы)
ӮБӮДҳbҒH >>418
ғҸҒ[ғNғҚҒ[ғhӮӘINT’ҶҗSӮМҸкҚҮӮНӮ»ӮМ’ц“xӮЙүһӮ¶ӮДғNғҚғbғNӮрҸгӮ°ӮйӮЖӮўӮӨӮМӮӘTukwilaӮМFoxtonӮҫӮӘ
ғNғүғXғ^ӮИӮсӮҝӮбӮзӮЕFPӮМүүҺZғҠғ\Ғ[ғXӮрINTӮЙ‘ОӮөӮДҸӯӮИӮӯ”zӮ·ӮкӮОғ^Ғ[ғQғbғgғNғҚғbғNӮНҚӮӮӯӮЕӮ«Ӯй(ғwғbғhғӢҒ[ғҖӮрҠm•Ы)
ӮБӮДҳbҒH >>418
420 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/11/15(“ъ) 23:23:32 ID:UyxcQfZa0
IntelӮМTBӮНғRғAӮӘ‘Ҫҗ”“ҜҺһүТ“ӯӮөӮДӮўӮйҸуӢөӮЕӮН’бғNғҚғbғNӮЕүсӮйӮжӮӨӮЙӮИӮБӮДӮўӮйҒB
TBӮНҒAғVғ“ғOғӢғXғҢғbғhҗ«”\ӮЖғXғӢҒ[ғvғbғgҗ«”\ӮМғoғүғ“ғXӮМ–в‘иӮЙ‘ОӮөӮДҸ_“оӮИӢҙ“nӮөӮрҺАҢ»ӮөҒA
ғ}ғӢғ`ғRғACPUӮМ”Д—pҗ«ӮрҚӮӮЯӮйӢZҸpӮЕӮаӮ ӮйҒB
AMDӮН“ҜӮ¶ғoғүғ“ғXӮМ–в‘иӮр‘SӮӯғ\ғҠғbғhӮИ•ы–@ӮЕ‘ОҸҲӮөӮжӮӨӮЖӮөӮҪӮсӮҫӮлҒB
ғvғҚғZғbғTӮМҗЭҢvӮЙӮН4,5”NӮ©Ӯ©ӮйӮМӮЕҒAҠJ”ӯҠJҺnӮ©ӮзғҠғҠҒ[ғXӮЬӮЕӮЙҗўӮМ”FҺҜӮӘ•ПӮнӮБӮДӮўӮйӮұӮЖӮНӮжӮӯӮ ӮйҒB
ғ}ғӢғ`ғRғAӮЦӮМӢ@ү^ӮӘҚӮӮЬӮБӮДӮўӮҪ“–ҺһҒATBӮНӮИӮўҒB
TBӮНҒAғVғ“ғOғӢғXғҢғbғhҗ«”\ӮЖғXғӢҒ[ғvғbғgҗ«”\ӮМғoғүғ“ғXӮМ–в‘иӮЙ‘ОӮөӮДҸ_“оӮИӢҙ“nӮөӮрҺАҢ»ӮөҒA
ғ}ғӢғ`ғRғACPUӮМ”Д—pҗ«ӮрҚӮӮЯӮйӢZҸpӮЕӮаӮ ӮйҒB
AMDӮН“ҜӮ¶ғoғүғ“ғXӮМ–в‘иӮр‘SӮӯғ\ғҠғbғhӮИ•ы–@ӮЕ‘ОҸҲӮөӮжӮӨӮЖӮөӮҪӮсӮҫӮлҒB
ғvғҚғZғbғTӮМҗЭҢvӮЙӮН4,5”NӮ©Ӯ©ӮйӮМӮЕҒAҠJ”ӯҠJҺnӮ©ӮзғҠғҠҒ[ғXӮЬӮЕӮЙҗўӮМ”FҺҜӮӘ•ПӮнӮБӮДӮўӮйӮұӮЖӮНӮжӮӯӮ ӮйҒB
ғ}ғӢғ`ғRғAӮЦӮМӢ@ү^ӮӘҚӮӮЬӮБӮДӮўӮҪ“–ҺһҒATBӮНӮИӮўҒB
421 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/11/15(“ъ) 23:30:06 ID:p8griTW90
ӮўӮвҒAҢӢүК“IӮЙӮНҚЕ‘е2”{ӮМғXғӢҒ[ғvғbғgӮр“ҫӮйӮұӮЖӮӘӮЕӮ«ӮйFPUӮЦӮМғfҒ[ғ^ӢҹӢӢӮМӮҪӮЯӮҫӮжҒB
8DP/16SPӮрҺJӮӯӮҪӮЯӮЙӮН“Ҝҗ”ӮМDPӮрғҚҒ[ғhӮ·ӮйӮМӮӘAMDӮМ”ьҠwӮМӮжӮӨӮЕҒB
Ӯ©ӮЖӮўӮБӮД1ӮВӮМL1ғLғғғbғVғ…ӮМ‘СҲжӮр2”{ҒAғҚҒ[ғhғҶғjғbғgӮр4–{ӮЙӮ·ӮйӮМӮНҢ»ҺА“IӮЕӮНӮИӮўҒB
җ®җ”ғpғCғvӮІӮЖӮЙ32byte/clkӮМ‘СҲжҒA2WayӮМLoadӮИӮзҸ\•ӘӮЙӢҹӢӢӮЕӮ«ӮйҒB
2ғXғҢғbғhҺgӮӨ•K—vӮӘӮ ӮйӮӘҒAӢtӮЙFPүүҺZӮМғҢғCғeғ“ғVӮрүB•БӮ·ӮйӮЙӮНғXғҢғbғhҗ”Ӯр‘қӮвӮөӮҪ•ыӮӘ—LҢшӮҫӮлӮӨҒB
ӮЬӮ ҒAӮұӮӨӮўӮӨғAғvғҚҒ[ғ`ӮНHPCҲИҠOӮЙӮаҺgӮў“№ӮНӮ ӮйӮсӮҫӮҜӮЗҒB
IntelӮМSandy BridgeӮН32byte Load + 16byte StoreӮЕҒAғҚҒ[ғhғҶғjғbғgӮН2–{ӮЙ‘қӮҰӮҪӮҫӮҜӮЕӮөӮ©ӮИӮўҒB
YMMғҢғWғXғ^ӮЕғҢғWғXғ^ӢуҠФӮӘ”{ӮЙ‘қӮҰӮйӮұӮЖҒAғuғҚҒ[ғhғLғғғXғgӮр—LҢшӮЙҠҲ—pӮ·ӮйӮұӮЖӮЕ
ҺАҢшғҚҒ[ғh‘СҲжӮрғZҒ[ғuӮ·Ӯй•ыҺ®ӮЕGEMMӮвFFTӮНҳdӮҰӮйӮЖ”»’fӮөӮҪӮжӮӨӮҫҒB
ҢӢүКӮЖӮөӮДSandy BridgeӮМ1ғRғAӮЖBulldozerӮМ1ғӮғWғ…Ғ[ғӢҒi2җ®җ”ғRғAҒ{•Ӯ“®Ҹ¬җ”ғҶғjғbғgҒjӮН
“ҜӮ¶’ц“xӮМҺА‘•–КҗПӮЙӮИӮиӮ»ӮӨӮҫӮӘҒAӮИӮ©ӮИӮ©–К”’Ӯ»ӮӨӮ¶ӮбӮИӮўӮ©ҒB
8DP/16SPӮрҺJӮӯӮҪӮЯӮЙӮН“Ҝҗ”ӮМDPӮрғҚҒ[ғhӮ·ӮйӮМӮӘAMDӮМ”ьҠwӮМӮжӮӨӮЕҒB
Ӯ©ӮЖӮўӮБӮД1ӮВӮМL1ғLғғғbғVғ…ӮМ‘СҲжӮр2”{ҒAғҚҒ[ғhғҶғjғbғgӮр4–{ӮЙӮ·ӮйӮМӮНҢ»ҺА“IӮЕӮНӮИӮўҒB
җ®җ”ғpғCғvӮІӮЖӮЙ32byte/clkӮМ‘СҲжҒA2WayӮМLoadӮИӮзҸ\•ӘӮЙӢҹӢӢӮЕӮ«ӮйҒB
2ғXғҢғbғhҺgӮӨ•K—vӮӘӮ ӮйӮӘҒAӢtӮЙFPүүҺZӮМғҢғCғeғ“ғVӮрүB•БӮ·ӮйӮЙӮНғXғҢғbғhҗ”Ӯр‘қӮвӮөӮҪ•ыӮӘ—LҢшӮҫӮлӮӨҒB
ӮЬӮ ҒAӮұӮӨӮўӮӨғAғvғҚҒ[ғ`ӮНHPCҲИҠOӮЙӮаҺgӮў“№ӮНӮ ӮйӮсӮҫӮҜӮЗҒB
IntelӮМSandy BridgeӮН32byte Load + 16byte StoreӮЕҒAғҚҒ[ғhғҶғjғbғgӮН2–{ӮЙ‘қӮҰӮҪӮҫӮҜӮЕӮөӮ©ӮИӮўҒB
YMMғҢғWғXғ^ӮЕғҢғWғXғ^ӢуҠФӮӘ”{ӮЙ‘қӮҰӮйӮұӮЖҒAғuғҚҒ[ғhғLғғғXғgӮр—LҢшӮЙҠҲ—pӮ·ӮйӮұӮЖӮЕ
ҺАҢшғҚҒ[ғh‘СҲжӮрғZҒ[ғuӮ·Ӯй•ыҺ®ӮЕGEMMӮвFFTӮНҳdӮҰӮйӮЖ”»’fӮөӮҪӮжӮӨӮҫҒB
ҢӢүКӮЖӮөӮДSandy BridgeӮМ1ғRғAӮЖBulldozerӮМ1ғӮғWғ…Ғ[ғӢҒi2җ®җ”ғRғAҒ{•Ӯ“®Ҹ¬җ”ғҶғjғbғgҒjӮН
“ҜӮ¶’ц“xӮМҺА‘•–КҗПӮЙӮИӮиӮ»ӮӨӮҫӮӘҒAӮИӮ©ӮИӮ©–К”’Ӯ»ӮӨӮ¶ӮбӮИӮўӮ©ҒB
422 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/11/15(“ъ) 23:47:34 ID:UyxcQfZa0
’cҺqҗжҗ¶ӮНӮвӮҪӮзҚЧ•”ӮЙҠЦҗSӮӘӮ ӮйӮжӮӨӮҫӮӘҒA’PӮЙҢӢүКӮрҸdҺӢӮөӮИӮўӢcҳ_ӮрӮөӮҪӮўӮИӮзӮЖӮаӮ©ӮӯҒA
ғvғҚғZғbғTӮМ“®Ңь—\‘ӘӮЖӮўӮӨ–Ъ“IӮМ’ҶӮЕӮНҒAӮЁӮкӮМҢoҢұӮ©ӮзӮўӮБӮДӮаӮ»ӮсӮИӮМӮН–wӮЗ–і‘КӮЖӮөӮ©ӮўӮўӮжӮӨӮӘӮИӮўҒB
FPүүҺZӮвHPC—p“rӮрӮвӮҪӮз’Қ–ЪӮөӮДӮўӮйӮжӮӨӮҫӮӘҒA
Ҡо–{“IӮЙ”Д—pғvғҚғZғbғTӮЕFPӮвSIMDӮБӮДғIғ}ғPҒB
җ®җ”Ӯр‘е’_ӮЙӢ]җөӮЙӮөӮДғAҒ[ғLғeғNғ`ғғӮр—ыӮйӮұӮЖӮНӮИӮўҒB
ҠmӮ©ӮЙҚЕӢЯӮМғTҒ[ғo—pCPUӮЕӮНFP/SIMDӮрӢӯү»Ӯ·ӮйҳHҗьӮӘ—¬ҚsӮБӮДӮ«ӮДӮўӮйӮаӮМӮМҒA
BulldozerӮМIntegerӮНғXғӢҒ[ғvғbғgӮрҸdҺӢӮөӮҪӮҫӮҜҒB
ғTҒ[ғoҺsҸкғҒғCғ“ӮМCPUӮЕFPӮр•Ўҗ”“ҜҺһӮЙ‘–ӮзӮ·‘z’иӮН–і‘КӮҫӮөҒA
FPӢӨ—Lү»ӮЕ8DP/16SPҸdҺӢӮБӮДӮМӮНҲ«Ӯ©ӮИӮўӮҫӮлҒB
ғvғҚғZғbғTӮМ“®Ңь—\‘ӘӮЖӮўӮӨ–Ъ“IӮМ’ҶӮЕӮНҒAӮЁӮкӮМҢoҢұӮ©ӮзӮўӮБӮДӮаӮ»ӮсӮИӮМӮН–wӮЗ–і‘КӮЖӮөӮ©ӮўӮўӮжӮӨӮӘӮИӮўҒB
FPүүҺZӮвHPC—p“rӮрӮвӮҪӮз’Қ–ЪӮөӮДӮўӮйӮжӮӨӮҫӮӘҒA
Ҡо–{“IӮЙ”Д—pғvғҚғZғbғTӮЕFPӮвSIMDӮБӮДғIғ}ғPҒB
җ®җ”Ӯр‘е’_ӮЙӢ]җөӮЙӮөӮДғAҒ[ғLғeғNғ`ғғӮр—ыӮйӮұӮЖӮНӮИӮўҒB
ҠmӮ©ӮЙҚЕӢЯӮМғTҒ[ғo—pCPUӮЕӮНFP/SIMDӮрӢӯү»Ӯ·ӮйҳHҗьӮӘ—¬ҚsӮБӮДӮ«ӮДӮўӮйӮаӮМӮМҒA
BulldozerӮМIntegerӮНғXғӢҒ[ғvғbғgӮрҸdҺӢӮөӮҪӮҫӮҜҒB
ғTҒ[ғoҺsҸкғҒғCғ“ӮМCPUӮЕFPӮр•Ўҗ”“ҜҺһӮЙ‘–ӮзӮ·‘z’иӮН–і‘КӮҫӮөҒA
FPӢӨ—Lү»ӮЕ8DP/16SPҸdҺӢӮБӮДӮМӮНҲ«Ӯ©ӮИӮўӮҫӮлҒB
423 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/11/15(“ъ) 23:51:49 ID:p8griTW90
ғ}ғgғҠғNғXүүҺZӮНHPCӮЕӮИӮӯӮЖӮаҠ„ӮЖ”Д—pҗ«Ӯ ӮйӮсӮҫӮҜӮЗӮИҒB
4x4’ц“xӮИӮзүс“]ӮЖӮ©ӮЕғQҒ[ғҖӮЕӮаӮжӮӯҺgӮӨӮө
4x4’ц“xӮИӮзүс“]ӮЖӮ©ӮЕғQҒ[ғҖӮЕӮаӮжӮӯҺgӮӨӮө
424 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/11/15(“ъ) 23:54:38 ID:UyxcQfZa0
ғAғtғBғ“•ПҠ·ӮЕӮ»ҒB
3DғQҒ[ӮӘӮИӮҜӮкӮОҒAFPӮаPCҺsҸкӮЕӮұӮӨӮЬӮЕғҒғWғғҒ[ӮЙӮИӮзӮИӮ©ӮБӮҪӮҫӮлӮӨӮИҒB
FPӮН–{“–ӮНғ}ғCғmғҠғeғBӮИӮсӮҫҒB
3DғQҒ[ӮӘӮИӮҜӮкӮОҒAFPӮаPCҺsҸкӮЕӮұӮӨӮЬӮЕғҒғWғғҒ[ӮЙӮИӮзӮИӮ©ӮБӮҪӮҫӮлӮӨӮИҒB
FPӮН–{“–ӮНғ}ғCғmғҠғeғBӮИӮсӮҫҒB
425 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/11/16(ҢҺ) 00:09:17 ID:hDiD8W7T0
AMDӮЭӮҪӮўӮИҢ`Һ®ӮҫӮЖ1ғRғAHTӮжӮиӮН—қӢьҸгҗ«”\ӮНҸoӮ№ӮйӮӘ2ғRғAӮжӮиӮН’бҗ«”\ӮИғAғvғҚҒ[ғ`
426 ҒF–јҸМ–ўҗЭ’иҒF2009/11/16(ҢҺ) 10:54:52 ID:Bsa8n4vG0
ғgғүғ“ғWғXғ^Ӯ ӮҪӮиӮМҸБ”п“d—НҚнҢёӮӘҚsӮ«ӢlӮБӮДғ_ғCӮ ӮҪӮиӮМҗ«”\ӮЙҲЪҚsӮ·ӮйӮ©
Ҹ«—ҲӮНғ_ғCӮМ‘еӮ«ӮіӮЕҸҹ•үӮ·ӮйӮұӮЖӮЙӮИӮйӮМ?
Ҹ«—ҲӮНғ_ғCӮМ‘еӮ«ӮіӮЕҸҹ•үӮ·ӮйӮұӮЖӮЙӮИӮйӮМ?
427 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/11/16(ҢҺ) 20:23:22 ID:itr1dYjW0
http://arstechnica.com/hardware/news/2009/11/amd-bobcat-bulldozer.ars
>As you can see in the diagram above, there are two integer schedulers, each of which feeds four pipelines:
> two integer pipes and two memory pipes (load and store).
> Right now, AMD is referring to each integer scheduler and the pipelines associated with it as a "core,"
>making each Bulldozer module "dual-core."
arsӮЙBulldozerӮМҗ®җ”ғRғAӮМғҶғjғbғgҚ\җ¬ӮӘҠщӮЙ
>two integer pipes and two memory pipes (load and store)
ӮБӮДҸ‘ӮўӮДӮ ӮйӮМӮҫӮӘҒAӮұӮкӮНAMDӮ©Ӯз•·ӮўӮҪӮМӮ©ҒAӮ»ӮкӮЖӮаarsӮМ’ҶӮМҗlӮМ–П‘zӮИӮМӮҫӮлӮӨӮ©?
>As you can see in the diagram above, there are two integer schedulers, each of which feeds four pipelines:
> two integer pipes and two memory pipes (load and store).
> Right now, AMD is referring to each integer scheduler and the pipelines associated with it as a "core,"
>making each Bulldozer module "dual-core."
arsӮЙBulldozerӮМҗ®җ”ғRғAӮМғҶғjғbғgҚ\җ¬ӮӘҠщӮЙ
>two integer pipes and two memory pipes (load and store)
ӮБӮДҸ‘ӮўӮДӮ ӮйӮМӮҫӮӘҒAӮұӮкӮНAMDӮ©Ӯз•·ӮўӮҪӮМӮ©ҒAӮ»ӮкӮЖӮаarsӮМ’ҶӮМҗlӮМ–П‘zӮИӮМӮҫӮлӮӨӮ©?
428 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/11/16(ҢҺ) 20:45:53 ID:itr1dYjW0
ӮЬӮ ’·•¶ӮИӮсӮДҸ‘ӮўӮДӮўӮДӮОӮ©ӮОӮ©ӮөӮӯӮИӮйӮЖӮұӮлӮЕӮ ӮйӮӘҒA
ҲкүһӮаӮӨҲк“x“ҜӮ¶ӮұӮЖӮрҸ‘ӮўӮДӮЁӮұӮӨҒB
ғ}ғӢғ`ғRғAӮМҸүҠъӮ©ӮзӮМ–в‘иӮЖӮөӮДҒAғRғAӮр‘қӮвӮөӮДӮўӮӯӮМӮЙӮНNiagaraӮМӮжӮӨӮЙҸ¬ӢK–НӮИғRғAӮр‘Ҫҗ”ҸWҗПӮөӮД
ғXғӢҒ[ғvғbғgӮрҸdҺӢӮөӮДҗЭҢvӮөӮҪ•ыӮӘӮжӮўӮМӮ©ҒAӮ»ӮкӮЖӮаӢҢ—ҲӮ©ӮзӮ Ӯй‘еӢK–НғRғAӮрҸWҗПӮөӮД
ғVғ“ғOғӢғXғҢғbғhҗ«”\ӮрӢЙ—НҲЫҺқӮөӮДӮўӮБӮҪҚsӮБӮҪ•ыӮӘӮжӮўӮМӮ©ҒAӮЖӮўӮӨ•ыҢьҗ«ӮМҢ©’иӮЯӮӘӮ ӮБӮҪҒB
‘еӢK–НғRғAӮр‘Ҫҗ”ҸWҗПӮөҒA“ҜҺһӮЙғRғAӮрүТ“ӯӮіӮ№ӮҪҸкҚҮӮНҒA“d—НӮМҸгҢАӮ©Ӯз’бғNғҚғbғN“®ҚмӮр—]ӢVӮИӮӯӮіӮкӮйҒB
ӮөӮҪӮӘӮБӮДҒATBӮМӮжӮӨӮИ“®“IӮИҗ«”\/“d—Нҗ§ҢдӮр‘z’иӮөӮДӮўӮИӮўҸкҚҮҒAҸүӮЯӮ©Ӯз’бӮўғNғҚғbғNӮЕӮМ“®ҚмӮрҢ©ҚһӮЬӮИӮҜӮкӮОӮИӮзӮёҒA
Ӯ»ӮсӮИӮұӮЖӮИӮзҸүӮЯӮ©Ӯз‘SғRғAӮӘ“d—НӮЕүТ“ӯӮөӮДӮа“d—НӮМҸгҢАӮЙ“һ’BӮөӮИӮўҸ¬ӢK–НӮМғRғAӮрҸWҗПӮөӮҪ•ыӮӘғgҒ[ғ^ғӢғXғӢҒ[ғvғbғgӮӘӮжӮўӮЖӮўӮӨӮұӮЖӮЙӮИӮйҒB
ӮұӮМӮжӮӨӮИ‘еӢK–НғRғAӮрҸ¬ӢK–НғRғAӮрӮҪӮҫ•АӮЧӮДӮўӮӯӮЖӮўӮӨғAғvғҚҒ[ғ`ӮМ–і‘КӮЙҗіҚU–@ӮЕғnҒ[ғh“IӮЙ‘ОҸҲӮөӮжӮӨӮЖӮөӮҪӮзҒA
ғ}ғӢғ`ғRғAӮЕҸз’·ӮИғҠғ\Ғ[ғXӮНӢӨ—LҒE“қҚҮү»ӮөҒAғXғӢҒ[ғvғbғgӮрүТӮ®ҸгӮЕ“sҚҮӮӘӮжӮўғҠғ\Ғ[ғXӮН‘ҪҸdү»ӮөӮДҒA
Ҹ¬ӢK–НғRғAӮЖ‘еӢK–НғRғAӮМҠФӮЙ‘¶ҚЭӮ·ӮйҒAғXғӢҒ[ғvғbғgҗ«”\ӮЖғVғ“ғOғӢғXғҢғbғhҗ«”\ӮМғgғҢҒ[ғhғIғtӮМҠЦҢWӮрӮҝӮеӮӨӮЗ—ЗӮўӮЖӮұӮлӮЕҗЬ”јӮөҒA
Ҳк’иӮМ“d—НӮМ”НҲНӮЕғxғXғgӮИғpғtғHҒ[ғ}ғ“ғXӮр’сӢҹӮ·ӮйӮЖӮўӮӨғAғvғҚҒ[ғ`ӮЙӮўӮҪӮйӮнӮҜӮЕҒA
Ӯ»ӮкӮӘғNғүғXғ^Ғ[ғhғAҒ[ғLғeғNғ`ғғӮЕӮ ӮйҒB
BobcatӮЕӮаҚЎ“ъӮМғҒғCғ“ғXғgғҠҒ[ғҖӮМ90%ӮМҗ«”\ӮЖӮўӮнӮкӮДӮўӮйӮЖӮЁӮиҒA2-issue OOO‘Ҡ“–ӮМғRғAӮЕӮа
Ӯ»ӮұӮЬӮЕӢЙ’[ӮЙғVғ“ғOғӢғXғҢғbғhҗ«”\ӮӘ—ҺӮҝӮйӮнӮҜӮЕӮНӮИӮўҒB
BulldozerӮМҸкҚҮҒAғtғҚғ“ғgғGғ“ғhӮНғҸғCғhӮҫӮ©ӮзҒA2-issue OOOӮМҗ®җ”ҺАҚsғRғAӮЕӮа3-issueӮЙӢЯӮўҗ«”\ӮӘҸoӮДӮаӮЁӮ©ӮөӮӯӮИӮўҒB
“БӮЙOOOғvғҚғZғbғTӮМҸкҚҮӮ»ӮкӮӯӮзӮўғtғҚғ“ғgғGғ“ғhӮМ‘СҲжӮНҸd—vӮҫҒB
ҲкүһӮаӮӨҲк“x“ҜӮ¶ӮұӮЖӮрҸ‘ӮўӮДӮЁӮұӮӨҒB
ғ}ғӢғ`ғRғAӮМҸүҠъӮ©ӮзӮМ–в‘иӮЖӮөӮДҒAғRғAӮр‘қӮвӮөӮДӮўӮӯӮМӮЙӮНNiagaraӮМӮжӮӨӮЙҸ¬ӢK–НӮИғRғAӮр‘Ҫҗ”ҸWҗПӮөӮД
ғXғӢҒ[ғvғbғgӮрҸdҺӢӮөӮДҗЭҢvӮөӮҪ•ыӮӘӮжӮўӮМӮ©ҒAӮ»ӮкӮЖӮаӢҢ—ҲӮ©ӮзӮ Ӯй‘еӢK–НғRғAӮрҸWҗПӮөӮД
ғVғ“ғOғӢғXғҢғbғhҗ«”\ӮрӢЙ—НҲЫҺқӮөӮДӮўӮБӮҪҚsӮБӮҪ•ыӮӘӮжӮўӮМӮ©ҒAӮЖӮўӮӨ•ыҢьҗ«ӮМҢ©’иӮЯӮӘӮ ӮБӮҪҒB
‘еӢK–НғRғAӮр‘Ҫҗ”ҸWҗПӮөҒA“ҜҺһӮЙғRғAӮрүТ“ӯӮіӮ№ӮҪҸкҚҮӮНҒA“d—НӮМҸгҢАӮ©Ӯз’бғNғҚғbғN“®ҚмӮр—]ӢVӮИӮӯӮіӮкӮйҒB
ӮөӮҪӮӘӮБӮДҒATBӮМӮжӮӨӮИ“®“IӮИҗ«”\/“d—Нҗ§ҢдӮр‘z’иӮөӮДӮўӮИӮўҸкҚҮҒAҸүӮЯӮ©Ӯз’бӮўғNғҚғbғNӮЕӮМ“®ҚмӮрҢ©ҚһӮЬӮИӮҜӮкӮОӮИӮзӮёҒA
Ӯ»ӮсӮИӮұӮЖӮИӮзҸүӮЯӮ©Ӯз‘SғRғAӮӘ“d—НӮЕүТ“ӯӮөӮДӮа“d—НӮМҸгҢАӮЙ“һ’BӮөӮИӮўҸ¬ӢK–НӮМғRғAӮрҸWҗПӮөӮҪ•ыӮӘғgҒ[ғ^ғӢғXғӢҒ[ғvғbғgӮӘӮжӮўӮЖӮўӮӨӮұӮЖӮЙӮИӮйҒB
ӮұӮМӮжӮӨӮИ‘еӢK–НғRғAӮрҸ¬ӢK–НғRғAӮрӮҪӮҫ•АӮЧӮДӮўӮӯӮЖӮўӮӨғAғvғҚҒ[ғ`ӮМ–і‘КӮЙҗіҚU–@ӮЕғnҒ[ғh“IӮЙ‘ОҸҲӮөӮжӮӨӮЖӮөӮҪӮзҒA
ғ}ғӢғ`ғRғAӮЕҸз’·ӮИғҠғ\Ғ[ғXӮНӢӨ—LҒE“қҚҮү»ӮөҒAғXғӢҒ[ғvғbғgӮрүТӮ®ҸгӮЕ“sҚҮӮӘӮжӮўғҠғ\Ғ[ғXӮН‘ҪҸdү»ӮөӮДҒA
Ҹ¬ӢK–НғRғAӮЖ‘еӢK–НғRғAӮМҠФӮЙ‘¶ҚЭӮ·ӮйҒAғXғӢҒ[ғvғbғgҗ«”\ӮЖғVғ“ғOғӢғXғҢғbғhҗ«”\ӮМғgғҢҒ[ғhғIғtӮМҠЦҢWӮрӮҝӮеӮӨӮЗ—ЗӮўӮЖӮұӮлӮЕҗЬ”јӮөҒA
Ҳк’иӮМ“d—НӮМ”НҲНӮЕғxғXғgӮИғpғtғHҒ[ғ}ғ“ғXӮр’сӢҹӮ·ӮйӮЖӮўӮӨғAғvғҚҒ[ғ`ӮЙӮўӮҪӮйӮнӮҜӮЕҒA
Ӯ»ӮкӮӘғNғүғXғ^Ғ[ғhғAҒ[ғLғeғNғ`ғғӮЕӮ ӮйҒB
BobcatӮЕӮаҚЎ“ъӮМғҒғCғ“ғXғgғҠҒ[ғҖӮМ90%ӮМҗ«”\ӮЖӮўӮнӮкӮДӮўӮйӮЖӮЁӮиҒA2-issue OOO‘Ҡ“–ӮМғRғAӮЕӮа
Ӯ»ӮұӮЬӮЕӢЙ’[ӮЙғVғ“ғOғӢғXғҢғbғhҗ«”\ӮӘ—ҺӮҝӮйӮнӮҜӮЕӮНӮИӮўҒB
BulldozerӮМҸкҚҮҒAғtғҚғ“ғgғGғ“ғhӮНғҸғCғhӮҫӮ©ӮзҒA2-issue OOOӮМҗ®җ”ҺАҚsғRғAӮЕӮа3-issueӮЙӢЯӮўҗ«”\ӮӘҸoӮДӮаӮЁӮ©ӮөӮӯӮИӮўҒB
“БӮЙOOOғvғҚғZғbғTӮМҸкҚҮӮ»ӮкӮӯӮзӮўғtғҚғ“ғgғGғ“ғhӮМ‘СҲжӮНҸd—vӮҫҒB
429 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/11/16(ҢҺ) 21:02:11 ID:itr1dYjW0
ӮнӮ©ӮиӮЙӮӯӮўӮұӮЖӮЙҒA
–в‘иӮИӮМӮНӮұӮұҚЕӢЯӮМIntelҢnӮМғ}ғӢғ`ғRғAӮӘ’n–ЎӮЙӮаӮ©ӮИӮи‘еӮ«ӮИҠvҗVӮрүКӮҪӮөӮДӮўӮйӮұӮЖӮИӮМӮЕӮ·ҒB
Turbo BoostӮНҒA“ҜҺһӮЙ“ұ“ьӮіӮкӮҪPower GatingӮМҢшүКӮаӮ ӮБӮДҒA
ғVғ“ғOғӢғXғҢғbғh“®ҚмҺһӮЙӮНҒA’PҲкғRғAӮр‘S—НӮЕӮЬӮнӮөӮИӮӘӮзӮа‘јӮМғRғAӮМ“d—НӮНӮЬӮйӮЕ–іҺӢӮЕӮ«ӮйӮЖӮұӮлӮЬӮЕҚ~үәӮ·ӮйӮөҒA
ғXғӢҒ[ғvғbғgҺuҢьӮМғvғҚғOғүғҖӮЕӮН•Ўҗ”ғRғAӮрӮжӮи’бғNғҚғbғNӮЕӮЬӮнӮ·ӮұӮЖӮЕҲк’иӮМ“d—НӮМ”НҲНӮрҺзӮиӮИӮӘӮзҸнҺһғxғXғgӮИғpғtғHҒ[ғ}ғ“ғXӮр
”ӯҠцӮ·ӮйӮжӮӨӮЙ“®ҚмӮ·ӮйҒB
ҠщӮЙLynnfieldӮвClarksfieldӮМҺһ“_ӮЕTBҺһӮЖ‘SғRғAүТ“ӯҺһӮМғNғҚғbғNӮМҠiҚ·ӮН—р‘RӮҪӮйӮаӮМӮЙӮИӮБӮДӮўӮйӮөҒA
ҚЕӢЯҳb‘иӮМSandy BridgeӮЕӮМғOғүғtғBғbғNғXӮМ“қҚҮү»ӮвҒAHaswellӮЕӮ ӮйӮ©ӮаӮөӮкӮИӮўғXғgғҠҒ[ғҖғRғAӮМ“қҚҮү»
ӮИӮЗӮМ“W–]ӮаTBӮЙӮжӮБӮДғVғ“ғOғӢғXғҢғbғhҗ«”\ӮЙ•ЫҢҜӮӘӮ©ӮҜӮзӮкӮДӮўӮйӮЖӮұӮлӮЕҗа“ҫ—НӮр‘қӮөӮДӮўӮйӮнӮҜӮҫҒB
ӮұӮкӮзӮМӢcҳ_ӮНӮұӮұҲк”N—]ӮиӮЕ“oҸкӮөӮҪҗVӮөӮўҳb‘иӮЕҒABulldozerӮМғAҒ[ғLғeғNғ`ғғӮЙӮН–wӮЗүeӢҝӮр—^ӮҰӮДӮўӮИӮўҒB
ӮЬӮҪӮұӮұҗ””NӮЕҚ‘“аӮМCPUҠЦҳAӮМҸо•сӮМ‘¬•сҗ«ӮвӢcҳ_ӮМ‘ҒӮіӮН’ҳӮөӮӯҗi•аӮөӮДӮўӮйҒB
Core 2ӮМғҠғҠҒ[ғXӮӯӮзӮўӮМӮЖӮ«ӮНӮұӮМғXғҢӮӘҚ‘“аҚЕ‘¬ӮҫӮБӮҪӮӯӮзӮўғVғҮғ{ӮўӮаӮМӮҫӮБӮҪӮ©ӮзӮИҒB
ӮөӮҪӮӘӮБӮДҒAIntelӮМҚ\‘zӮМү\ӮЙҠөӮзӮіӮкӮДҒAҺ©•ӘӮҪӮҝӮӘ–іҲУҺҜӮМӮӨӮҝӮЙҗiӮсӮҫ”FҺҜӮрӮаӮБӮДӮўӮйҺАҠҙӮМӮИӮўPCғIғ^ӮМ–ЪӮЙӮН
ғNғүғXғ^Ғ[ғhғAҒ[ғLғeғNғ`ғғӮНҒAHTӮЖӮаCMPӮЖӮаӮВӮ©ӮИӮў’Ҷ“r”ј’[ӮЕ•sүВүрӮИғAҒ[ғLғeғNғ`ғғӮЙӮЭӮҰӮйӮМӮЕӮ ӮйҒB
–{“–ӮНӮЮӮөӮлTurbo BoostӮЕғNғҚғbғN’Іҗ®ӮЕӮ«ӮйӮ©ӮзғRғA‘қӮвӮөӮДӮаӮўӮўӮҫӮлӮБӮДғAғvғҚҒ[ғ`ӮМ•ыӮӘ
IntelӮМ‘s‘еӮИ“ЖҺ©ҳHҗьӮИӮМӮ©ӮаӮөӮкӮИӮўӮМӮЙӮЛҒB
–в‘иӮИӮМӮНӮұӮұҚЕӢЯӮМIntelҢnӮМғ}ғӢғ`ғRғAӮӘ’n–ЎӮЙӮаӮ©ӮИӮи‘еӮ«ӮИҠvҗVӮрүКӮҪӮөӮДӮўӮйӮұӮЖӮИӮМӮЕӮ·ҒB
Turbo BoostӮНҒA“ҜҺһӮЙ“ұ“ьӮіӮкӮҪPower GatingӮМҢшүКӮаӮ ӮБӮДҒA
ғVғ“ғOғӢғXғҢғbғh“®ҚмҺһӮЙӮНҒA’PҲкғRғAӮр‘S—НӮЕӮЬӮнӮөӮИӮӘӮзӮа‘јӮМғRғAӮМ“d—НӮНӮЬӮйӮЕ–іҺӢӮЕӮ«ӮйӮЖӮұӮлӮЬӮЕҚ~үәӮ·ӮйӮөҒA
ғXғӢҒ[ғvғbғgҺuҢьӮМғvғҚғOғүғҖӮЕӮН•Ўҗ”ғRғAӮрӮжӮи’бғNғҚғbғNӮЕӮЬӮнӮ·ӮұӮЖӮЕҲк’иӮМ“d—НӮМ”НҲНӮрҺзӮиӮИӮӘӮзҸнҺһғxғXғgӮИғpғtғHҒ[ғ}ғ“ғXӮр
”ӯҠцӮ·ӮйӮжӮӨӮЙ“®ҚмӮ·ӮйҒB
ҠщӮЙLynnfieldӮвClarksfieldӮМҺһ“_ӮЕTBҺһӮЖ‘SғRғAүТ“ӯҺһӮМғNғҚғbғNӮМҠiҚ·ӮН—р‘RӮҪӮйӮаӮМӮЙӮИӮБӮДӮўӮйӮөҒA
ҚЕӢЯҳb‘иӮМSandy BridgeӮЕӮМғOғүғtғBғbғNғXӮМ“қҚҮү»ӮвҒAHaswellӮЕӮ ӮйӮ©ӮаӮөӮкӮИӮўғXғgғҠҒ[ғҖғRғAӮМ“қҚҮү»
ӮИӮЗӮМ“W–]ӮаTBӮЙӮжӮБӮДғVғ“ғOғӢғXғҢғbғhҗ«”\ӮЙ•ЫҢҜӮӘӮ©ӮҜӮзӮкӮДӮўӮйӮЖӮұӮлӮЕҗа“ҫ—НӮр‘қӮөӮДӮўӮйӮнӮҜӮҫҒB
ӮұӮкӮзӮМӢcҳ_ӮНӮұӮұҲк”N—]ӮиӮЕ“oҸкӮөӮҪҗVӮөӮўҳb‘иӮЕҒABulldozerӮМғAҒ[ғLғeғNғ`ғғӮЙӮН–wӮЗүeӢҝӮр—^ӮҰӮДӮўӮИӮўҒB
ӮЬӮҪӮұӮұҗ””NӮЕҚ‘“аӮМCPUҠЦҳAӮМҸо•сӮМ‘¬•сҗ«ӮвӢcҳ_ӮМ‘ҒӮіӮН’ҳӮөӮӯҗi•аӮөӮДӮўӮйҒB
Core 2ӮМғҠғҠҒ[ғXӮӯӮзӮўӮМӮЖӮ«ӮНӮұӮМғXғҢӮӘҚ‘“аҚЕ‘¬ӮҫӮБӮҪӮӯӮзӮўғVғҮғ{ӮўӮаӮМӮҫӮБӮҪӮ©ӮзӮИҒB
ӮөӮҪӮӘӮБӮДҒAIntelӮМҚ\‘zӮМү\ӮЙҠөӮзӮіӮкӮДҒAҺ©•ӘӮҪӮҝӮӘ–іҲУҺҜӮМӮӨӮҝӮЙҗiӮсӮҫ”FҺҜӮрӮаӮБӮДӮўӮйҺАҠҙӮМӮИӮўPCғIғ^ӮМ–ЪӮЙӮН
ғNғүғXғ^Ғ[ғhғAҒ[ғLғeғNғ`ғғӮНҒAHTӮЖӮаCMPӮЖӮаӮВӮ©ӮИӮў’Ҷ“r”ј’[ӮЕ•sүВүрӮИғAҒ[ғLғeғNғ`ғғӮЙӮЭӮҰӮйӮМӮЕӮ ӮйҒB
–{“–ӮНӮЮӮөӮлTurbo BoostӮЕғNғҚғbғN’Іҗ®ӮЕӮ«ӮйӮ©ӮзғRғA‘қӮвӮөӮДӮаӮўӮўӮҫӮлӮБӮДғAғvғҚҒ[ғ`ӮМ•ыӮӘ
IntelӮМ‘s‘еӮИ“ЖҺ©ҳHҗьӮИӮМӮ©ӮаӮөӮкӮИӮўӮМӮЙӮЛҒB
430 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/11/16(ҢҺ) 21:05:44 ID:itr1dYjW0
ӮЬӮ ӮЖӮўӮБӮДӮаҠщӮЙIBMӮМPower 7ӮН“®“IғNғҚғbғNҗ§ҢдӮЕ10%ҲКӮН’Іҗ®Ӯ©Ӯ©ӮйӮұӮЖӮӘӮнӮ©ӮБӮДӮўӮйӮМӮҫӮӘҒB
ҚЕӢЯӮНғnғCғGғ“ғhғvғҚғZғbғTӮрҚмӮБӮДӮўӮйүпҺРӮаӮЦӮБӮҪӮ©ӮзӮИӮЙӮӘғҶғjҒ[ғNӮИӮМӮ©”»’fӮӘӮВӮ«ӮЙӮӯӮӯӮИӮБӮДӮөӮЬӮБӮҪӮИҒB
ҚЕӢЯӮНғnғCғGғ“ғhғvғҚғZғbғTӮрҚмӮБӮДӮўӮйүпҺРӮаӮЦӮБӮҪӮ©ӮзӮИӮЙӮӘғҶғjҒ[ғNӮИӮМӮ©”»’fӮӘӮВӮ«ӮЙӮӯӮӯӮИӮБӮДӮөӮЬӮБӮҪӮИҒB
431 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/11/16(ҢҺ) 23:52:11 ID:hDiD8W7T0
> two memory pipes (load and store)
ӮвӮБӮПӮө1ғӮғWғ…Ғ[ғӢ“аӮМFPUӮӘ—ҳ—pӮЕӮ«ӮйғҚҒ[ғhҒEғXғgғA‘СҲжӮНҚҮҢv64byte/clkӮИӮнӮҜӮҫӮИ
ӮвӮБӮПӮө1ғӮғWғ…Ғ[ғӢ“аӮМFPUӮӘ—ҳ—pӮЕӮ«ӮйғҚҒ[ғhҒEғXғgғA‘СҲжӮНҚҮҢv64byte/clkӮИӮнӮҜӮҫӮИ
432 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/11/17(үО) 00:18:10 ID:in64F/m50
ӮвӮБӮП4ALU / Int.CoreӮзӮөӮўӮж
433 ҒF–јҸМ–ўҗЭ’иҒF2009/11/17(үО) 01:14:46 ID:m2gsTluy0
ғfғRҒ[ғ_ӮМ‘СҲж‘«ӮиӮйӮМӮ©ӮИ
Trace CacheӮБӮЫӮўӮМӮӘӮ ӮйӮсӮҫӮБӮҜӮ©
Power GatingӮМ“ұ“ьӮНҗҘ”сӮЖӮаҺАҢ»ӮөӮДӮаӮзӮўӮҪӮўӮҜӮЗIntelӮМ
“БҺкғvғҚғZғXӮБӮХӮиӮрҢ©ӮйӮЖ•ӘҺРү»ӮөӮҪAMDӮЙӮЖӮБӮДӮНҢөӮөӮўӮ©ӮИӮ
Trace CacheӮБӮЫӮўӮМӮӘӮ ӮйӮсӮҫӮБӮҜӮ©
Power GatingӮМ“ұ“ьӮНҗҘ”сӮЖӮаҺАҢ»ӮөӮДӮаӮзӮўӮҪӮўӮҜӮЗIntelӮМ
“БҺкғvғҚғZғXӮБӮХӮиӮрҢ©ӮйӮЖ•ӘҺРү»ӮөӮҪAMDӮЙӮЖӮБӮДӮНҢөӮөӮўӮ©ӮИӮ
434 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/11/17(үО) 02:17:06 ID:in64F/m50
Ғ„ғfғRҒ[ғ_ӮМ‘СҲж‘«ӮиӮйӮМӮ©ӮИ
–Ҫ—ЯғtғFғbғ`‘СҲжӮИӮзҸ\•ӘӮЕӮөӮеҒB32byte/clkӮ ӮкӮОҒB
ғfғRҒ[ғhӮН4–Ҫ—Я/clkӮҫӮҜӮЗӮНӮИӮ©Ӯз‘S•”“®Ӯ©Ӯ·ӢCӮНӮИӮўӮЕӮөӮеҒB
•Р•ыӮМғXғҢғbғhӮӘғXғgҒ[ғӢӮөӮҪӮзӮаӮӨ•Р•ыӮӘ‘S—НӮЕҺgӮҰӮй’ц“xӮЙ—]Ҹиҗ«”\ӮӘ•K—vӮИӮсӮЕӮөӮеҒB
NehalemӮМ–Ҫ—Я‘СҲжӮН16byte/clkӮЖҒA4issueӮЙӮөӮДӮН’v–Ҫ“IӮЙ‘«ӮиӮДӮИӮіүЯӮ¬ӮйӮсӮҫӮӘ
ҺАҚЫӮМғҸҒ[ғNғҚҒ[ғhӮЕӮН–Ҫ—ЯӢҹӢӢҲИҸгӮЙғҒғӮғҠӮӘғlғbғNӮИӮсӮЕӮөӮеҒB
–Ҫ—ЯғtғFғbғ`‘СҲжӮИӮзҸ\•ӘӮЕӮөӮеҒB32byte/clkӮ ӮкӮОҒB
ғfғRҒ[ғhӮН4–Ҫ—Я/clkӮҫӮҜӮЗӮНӮИӮ©Ӯз‘S•”“®Ӯ©Ӯ·ӢCӮНӮИӮўӮЕӮөӮеҒB
•Р•ыӮМғXғҢғbғhӮӘғXғgҒ[ғӢӮөӮҪӮзӮаӮӨ•Р•ыӮӘ‘S—НӮЕҺgӮҰӮй’ц“xӮЙ—]Ҹиҗ«”\ӮӘ•K—vӮИӮсӮЕӮөӮеҒB
NehalemӮМ–Ҫ—Я‘СҲжӮН16byte/clkӮЖҒA4issueӮЙӮөӮДӮН’v–Ҫ“IӮЙ‘«ӮиӮДӮИӮіүЯӮ¬ӮйӮсӮҫӮӘ
ҺАҚЫӮМғҸҒ[ғNғҚҒ[ғhӮЕӮН–Ҫ—ЯӢҹӢӢҲИҸгӮЙғҒғӮғҠӮӘғlғbғNӮИӮсӮЕӮөӮеҒB
435 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/11/17(үО) 19:48:24 ID:xvZTyT3r0
>>432
Ңіғ\Ғ[ғXӮЭӮҪӮӘӮҪӮФӮсғKғZӮҫӮлӮӨӮЛҒB
ӮЖӮўӮӨӮ©4 ALU + 4 ALUӮЖӮўӮӨҚ\җ¬ӮҫӮБӮҪӮЖӮөӮҪӮз
Ӯ»ӮкӮұӮ»BulldozerӮНҠъ‘ТӮЕӮ«ӮИӮўӮМӮҫӮлӮӨӮЙҒB
BarcelonaӮЕҺUҒX’xү„ӮөӮҪӮ Ӯ°ӮӯҒA‘е“d—НӮЕҗ«”\ӮӘӮЕӮИӮ©ӮБӮҪӮМӮ©Ӯз
үҪӮаҠҙӮ¶ӮИӮ©ӮБӮҪӮМӮҫӮлӮӨӮ©ҒB
Ңіғ\Ғ[ғXӮЭӮҪӮӘӮҪӮФӮсғKғZӮҫӮлӮӨӮЛҒB
ӮЖӮўӮӨӮ©4 ALU + 4 ALUӮЖӮўӮӨҚ\җ¬ӮҫӮБӮҪӮЖӮөӮҪӮз
Ӯ»ӮкӮұӮ»BulldozerӮНҠъ‘ТӮЕӮ«ӮИӮўӮМӮҫӮлӮӨӮЙҒB
BarcelonaӮЕҺUҒX’xү„ӮөӮҪӮ Ӯ°ӮӯҒA‘е“d—НӮЕҗ«”\ӮӘӮЕӮИӮ©ӮБӮҪӮМӮ©Ӯз
үҪӮаҠҙӮ¶ӮИӮ©ӮБӮҪӮМӮҫӮлӮӨӮ©ҒB
436 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/11/17(үО) 19:49:43 ID:xvZTyT3r0
ӮҝӮИӮЭӮЙ–ңӮӘҲк–і–dӮЙӮа4-issueӮҫӮБӮҪӮзҒAAlphaғүғCғNӮЙ
ALU +ALU/AGU + ALU + ALU/AGU
ӮЕ2 LoadӮҫӮЖӮЭӮҪҒB
ALU +ALU/AGU + ALU + ALU/AGU
ӮЕ2 LoadӮҫӮЖӮЭӮҪҒB
437 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/11/17(үО) 19:51:33 ID:xvZTyT3r0
ҢВҗl“IӮЙӮН2-issue OOOӮБӮДӮўӮӨғoғүғ“ғXӮНҠщӮЙBobcatӮЕӮНҠm’иӮөӮДӮўӮйӮнӮҜӮҫӮӘҒA
2011”NҺһ“_ӮМ“d—Нҗ«”\”д“IӮЙӮНӮҜӮБӮұӮӨӮЁӮўӮөӮўғ]Ғ[ғ“ӮҫӮЖӮЁӮаӮБӮДӮўӮйӮМӮҫӮӘҒB
2011”NҺһ“_ӮМ“d—Нҗ«”\”д“IӮЙӮНӮҜӮБӮұӮӨӮЁӮўӮөӮўғ]Ғ[ғ“ӮҫӮЖӮЁӮаӮБӮДӮўӮйӮМӮҫӮӘҒB
438 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/11/17(үО) 20:21:32 ID:xvZTyT3r0
http://www.ospn.jp/osc2009-shimane/amd.pdf
ӮұӮұӮМғXғүғCғhӮМ14 pageӮЙInterlagos 16 coreӮЬӮЕӮМғpғtғHҒ[ғ}ғ“ғX—\‘ӘӮӘҸ‘ӮўӮДӮ ӮйҒB
ӮұӮкӮЙӮжӮкӮОҗ®җ”ғXғӢҒ[ғvғbғgҗ«”\ӮН
Istanbul 6 coreӮӘ–с17ӮЕ
Interlagos 16 coreӮӘ–с33ӮЕӮ Ӯи
Istanbul vs InterlagosӮЕӮН2”{ҺгӮЕӮ ӮйӮұӮЖӮӘӮнӮ©ӮйҒB
(Magny CoursӮНMCMӮЙүҹӮөҚһӮсӮҫӮҫӮҜӮМҗЭҢvӮМӮҪӮЯҒA’PҸғӮЙғNғҚғbғNӮӘ’бӮўӮЖӮЭӮҰӮйҒB)
IstanbulӮЖInterlagosӮӘ•ЦӢXҸгӮЩӮЪ“ҜғNғҚғbғNӮЕӮ ӮйӮЖ‘z’иӮөӮДҚlӮҰӮйӮЖҒAҗ®җ”—қҳ_үүҺZ”\—НӮЖӮөӮДӮНҒA
Istanbul = 3 ALU x 6 core = 18 ALU
Interlagos 2 ALUҗаҒ@= ( 2 ALU x 16 core ) = 32 ALU
Interlagos 4 ALUҗаҒ@= ( 4 ALU x 16 core ) = 64 ALU
ӮЕӮ ӮиҒA2 ALUҗаӮЕӮНInterlagosӮНIstanbulӮМ2”{ҺгӮЕӮ ӮйӮ©ӮзALUӮМүТ“ӯ—Ұ”дӮЖӮөӮДӮНҒAIstanbulӮЖInterlagosӮЕӮЩӮЪ“ҜғҢғxғӢӮЕҒA
ӮнӮёӮ©ӮЙInterlagosӮӘӮжӮўӮЖӮўӮӨ’ц“xҒB
ӮөӮ©ӮөҒA4 ALUҗаӮЕӮНIstanbul”дӮЕӮЕ50Ғ`60%’ц“xӮМALUӮМүТ“ӯ—ҰӮЕӮ ӮиҒAӮ№ӮБӮ©ӮӯғNғүғXғ^ү»ӮөӮДғtғҚғ“ғgғGғ“ғhӮрӢӨ—LӮөӮДӮа
Ҹ]—ҲӮжӮиӮа—VӮсӮЕӮўӮйҸкҚҮӮӘ‘ҪӮӯҒA”сҢш—ҰӮЕӮ ӮйӮЖӮўӮӨүрҺЯӮЙӮИӮБӮДӮөӮЬӮӨҒB
ӮЬӮҪҒAAMDӮМӮўӮӨ+50%ӮМ“ҠҺ‘ӮЕҒA+80%ӮМғXғӢҒ[ғvғbғgӮЖӮўӮӨ”ӯҢҫӮЖӮаӮ©ӮҜ—ЈӮкӮДӮўӮДҗ®ҚҮҗ«ӮӘӮЖӮкӮИӮўҒB
ӮұӮұӮМғXғүғCғhӮМ14 pageӮЙInterlagos 16 coreӮЬӮЕӮМғpғtғHҒ[ғ}ғ“ғX—\‘ӘӮӘҸ‘ӮўӮДӮ ӮйҒB
ӮұӮкӮЙӮжӮкӮОҗ®җ”ғXғӢҒ[ғvғbғgҗ«”\ӮН
Istanbul 6 coreӮӘ–с17ӮЕ
Interlagos 16 coreӮӘ–с33ӮЕӮ Ӯи
Istanbul vs InterlagosӮЕӮН2”{ҺгӮЕӮ ӮйӮұӮЖӮӘӮнӮ©ӮйҒB
(Magny CoursӮНMCMӮЙүҹӮөҚһӮсӮҫӮҫӮҜӮМҗЭҢvӮМӮҪӮЯҒA’PҸғӮЙғNғҚғbғNӮӘ’бӮўӮЖӮЭӮҰӮйҒB)
IstanbulӮЖInterlagosӮӘ•ЦӢXҸгӮЩӮЪ“ҜғNғҚғbғNӮЕӮ ӮйӮЖ‘z’иӮөӮДҚlӮҰӮйӮЖҒAҗ®җ”—қҳ_үүҺZ”\—НӮЖӮөӮДӮНҒA
Istanbul = 3 ALU x 6 core = 18 ALU
Interlagos 2 ALUҗаҒ@= ( 2 ALU x 16 core ) = 32 ALU
Interlagos 4 ALUҗаҒ@= ( 4 ALU x 16 core ) = 64 ALU
ӮЕӮ ӮиҒA2 ALUҗаӮЕӮНInterlagosӮНIstanbulӮМ2”{ҺгӮЕӮ ӮйӮ©ӮзALUӮМүТ“ӯ—Ұ”дӮЖӮөӮДӮНҒAIstanbulӮЖInterlagosӮЕӮЩӮЪ“ҜғҢғxғӢӮЕҒA
ӮнӮёӮ©ӮЙInterlagosӮӘӮжӮўӮЖӮўӮӨ’ц“xҒB
ӮөӮ©ӮөҒA4 ALUҗаӮЕӮНIstanbul”дӮЕӮЕ50Ғ`60%’ц“xӮМALUӮМүТ“ӯ—ҰӮЕӮ ӮиҒAӮ№ӮБӮ©ӮӯғNғүғXғ^ү»ӮөӮДғtғҚғ“ғgғGғ“ғhӮрӢӨ—LӮөӮДӮа
Ҹ]—ҲӮжӮиӮа—VӮсӮЕӮўӮйҸкҚҮӮӘ‘ҪӮӯҒA”сҢш—ҰӮЕӮ ӮйӮЖӮўӮӨүрҺЯӮЙӮИӮБӮДӮөӮЬӮӨҒB
ӮЬӮҪҒAAMDӮМӮўӮӨ+50%ӮМ“ҠҺ‘ӮЕҒA+80%ӮМғXғӢҒ[ғvғbғgӮЖӮўӮӨ”ӯҢҫӮЖӮаӮ©ӮҜ—ЈӮкӮДӮўӮДҗ®ҚҮҗ«ӮӘӮЖӮкӮИӮўҒB
439 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/11/17(үО) 21:01:18 ID:xvZTyT3r0
>>431
BulldozerӮМFPUӮНҒAL1ӮрүоӮіӮёӮЙҒAL2ӮЖ’јҗЪғfҒ[ғ^ӮМӮвӮиӮЖӮиӮрӮ·ӮйӮЖӮўӮӨҗаӮрҸҘӮҰӮйҗlӮаӮўӮЬӮ·ӮжҒB
ӮВӮЬӮиғuғҚғbғNҗ}ӮЕӮНүBӮіӮкӮҪ“ЖҺ©ғҶғjғbғgӮ©ӮзғAғNғZғXӮөӮДӮўӮйӮМӮ©ӮаӮөӮкӮИӮўӮМӮҫҒB
BulldozerӮМFPғNғүғXғ^ӮМғ^Ғ[ғQғbғgғvғҚғOғүғҖӮӘӮжӮиғҒғӮғҠғCғ“ғeғ“ғVғ”ӮИӮзӮОӮ»ӮБӮҝӮМ•ыӮӘӮжӮўӮ©ӮаӮөӮкӮИӮўҒB
җПҳaӮЙ—НӮрӮўӮкӮДӮўӮйӮИӮзӮ ӮиӮ»ӮӨҒB
BulldozerӮМFPUӮНҒAL1ӮрүоӮіӮёӮЙҒAL2ӮЖ’јҗЪғfҒ[ғ^ӮМӮвӮиӮЖӮиӮрӮ·ӮйӮЖӮўӮӨҗаӮрҸҘӮҰӮйҗlӮаӮўӮЬӮ·ӮжҒB
ӮВӮЬӮиғuғҚғbғNҗ}ӮЕӮНүBӮіӮкӮҪ“ЖҺ©ғҶғjғbғgӮ©ӮзғAғNғZғXӮөӮДӮўӮйӮМӮ©ӮаӮөӮкӮИӮўӮМӮҫҒB
BulldozerӮМFPғNғүғXғ^ӮМғ^Ғ[ғQғbғgғvғҚғOғүғҖӮӘӮжӮиғҒғӮғҠғCғ“ғeғ“ғVғ”ӮИӮзӮОӮ»ӮБӮҝӮМ•ыӮӘӮжӮўӮ©ӮаӮөӮкӮИӮўҒB
җПҳaӮЙ—НӮрӮўӮкӮДӮўӮйӮИӮзӮ ӮиӮ»ӮӨҒB
440 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/11/18(җ…) 01:22:50 ID:GoxzWJsL0
ӮИӮўӮИӮў
”r‘јғLғғғbғVғ…ӮҫӮЖҺҖӮКӮйҒB
Ӯ»ӮкӮЖӮаInclusiveӮЙӮ·ӮйӮМӮ©ҒH
”r‘јғLғғғbғVғ…ӮҫӮЖҺҖӮКӮйҒB
Ӯ»ӮкӮЖӮаInclusiveӮЙӮ·ӮйӮМӮ©ҒH
441 ҒF–јҸМ–ўҗЭ’иҒF2009/11/18(җ…) 18:52:34 ID:EopSiN2r0
җM—Ҡ“x’бӮЯӮМ“ъ–{Ңк–у
ttp://www.heise.de/newsticker/meldung/SC09-Intel-demonstriert-Larrabee-mit-ueber-1-Teraflops-862305.html
SC09ӮЕғVғ“ғOғӢғJҒ[ғhӮМLarrabeeӮӘSGEMMӮЕ1TFoverӮЖӮўӮӨғfғӮӮӘҚsӮнӮкӮҪҒBҢ»ҚsҚЕ‘¬ӮМTesla C1060ӮН320GFҒB
1TFӮМғfғӮӮНҺҺҚм•iӮМOCӮЙӮжӮБӮДҚsӮнӮкӮҪҒB(‘Ҫ•Ә2006”NӮМ80ғRғAӮЖ“ҜӮ¶Һи–@)
OCӮөӮИӮўҸкҚҮӮН—қҳ_җ«”\712GFӮЕSGEMMӮН417GFҒH
ҢҳҢЕӮИҸо•с“қҗ§ӮМҚsӮнӮкӮДӮўӮҪLarrabeeӮҫӮӘҒAҒu’xү„ӮН–іӮ©ӮБӮҪ(by ғүғgғiҒ[)ҒvҒB
GPGPUӮНCPUӮЖӮМғfҒ[ғ^ӮМӮвӮиҺжӮиӮӘғ{ғgғӢғlғbғNҒB
IntelӮНQPIӮЕCPUӮЖLarrabeeӮр’јҢӢӮөғҒғӮғҠӢуҠФӮрӢӨ—L(M-Y-O)Ӯ·ӮйғӮғfғӢӮрҸoӮ·ҒB
Nehalem-EX 'Ӯа' 2010”N‘O”јӮЙҸoӮ·ҒBHPCҢьӮҜӮЙ6ғRғAӮМҚӮғNғҚғbғN”ЕӮрҸoӮ·ҒB
ttp://www.heise.de/newsticker/meldung/SC09-Intel-demonstriert-Larrabee-mit-ueber-1-Teraflops-862305.html
SC09ӮЕғVғ“ғOғӢғJҒ[ғhӮМLarrabeeӮӘSGEMMӮЕ1TFoverӮЖӮўӮӨғfғӮӮӘҚsӮнӮкӮҪҒBҢ»ҚsҚЕ‘¬ӮМTesla C1060ӮН320GFҒB
1TFӮМғfғӮӮНҺҺҚм•iӮМOCӮЙӮжӮБӮДҚsӮнӮкӮҪҒB(‘Ҫ•Ә2006”NӮМ80ғRғAӮЖ“ҜӮ¶Һи–@)
OCӮөӮИӮўҸкҚҮӮН—қҳ_җ«”\712GFӮЕSGEMMӮН417GFҒH
ҢҳҢЕӮИҸо•с“қҗ§ӮМҚsӮнӮкӮДӮўӮҪLarrabeeӮҫӮӘҒAҒu’xү„ӮН–іӮ©ӮБӮҪ(by ғүғgғiҒ[)ҒvҒB
GPGPUӮНCPUӮЖӮМғfҒ[ғ^ӮМӮвӮиҺжӮиӮӘғ{ғgғӢғlғbғNҒB
IntelӮНQPIӮЕCPUӮЖLarrabeeӮр’јҢӢӮөғҒғӮғҠӢуҠФӮрӢӨ—L(M-Y-O)Ӯ·ӮйғӮғfғӢӮрҸoӮ·ҒB
Nehalem-EX 'Ӯа' 2010”N‘O”јӮЙҸoӮ·ҒBHPCҢьӮҜӮЙ6ғRғAӮМҚӮғNғҚғbғN”ЕӮрҸoӮ·ҒB
442 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/11/18(җ…) 20:52:42 ID:Jlv2m8O/0
>>440
Ҡо–{“IӮЙӮНӮЁӮкӮаӮ»ӮсӮИӮЙҗMӮ¶ӮДӮўӮйӮнӮҜӮ¶ӮбӮИӮўӮӘҒA
BobcatӮрӮЭӮДӮаӮ»ӮӨӮҫӮӘҒABulldozerӮвBobcatӮНҸ]—ҲӮМK7ҲИҚ~ӮМAMD x86ӮМ“`“қӮр“ҘҸPӮөӮИӮўүВ”\җ«ӮаҚӮӮўӮҫӮлҒB
Ҡо–{“IӮЙӮНӮЁӮкӮаӮ»ӮсӮИӮЙҗMӮ¶ӮДӮўӮйӮнӮҜӮ¶ӮбӮИӮўӮӘҒA
BobcatӮрӮЭӮДӮаӮ»ӮӨӮҫӮӘҒABulldozerӮвBobcatӮНҸ]—ҲӮМK7ҲИҚ~ӮМAMD x86ӮМ“`“қӮр“ҘҸPӮөӮИӮўүВ”\җ«ӮаҚӮӮўӮҫӮлҒB
443 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/11/18(җ…) 22:10:05 ID:GoxzWJsL0
ҺАӮНInclusiveӮЕӮа–К“|ӮИӮұӮЖӮЙ•ПӮнӮиӮИӮў
“ҜӮ¶ғLғғғbғVғ…ғүғCғ“Ӯрҗ®җ”ғpғCғvӮЖ•Ӯ“®Ҹ¬җ”ғpғCғvӮЕ“ЗӮЭҸ‘Ӯ«ӮвӮБӮДӮҪӮЖӮөӮДӮЭҒH
ғLғғғbғVғ…ғүғCғ“ӮМinvalidateӮөӮЬӮӯӮБӮДҗ«”\ӮЕӮИӮўҒB
“ҜӮ¶ғLғғғbғVғ…ғүғCғ“Ӯрҗ®җ”ғpғCғvӮЖ•Ӯ“®Ҹ¬җ”ғpғCғvӮЕ“ЗӮЭҸ‘Ӯ«ӮвӮБӮДӮҪӮЖӮөӮДӮЭҒH
ғLғғғbғVғ…ғүғCғ“ӮМinvalidateӮөӮЬӮӯӮБӮДҗ«”\ӮЕӮИӮўҒB
444 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/11/18(җ…) 22:18:12 ID:GoxzWJsL0
ӮаӮөӮвӮйӮЖӮөӮДnon-temporal load/storeҗк—pӮҫӮИҒB
write-allocateӮИ–Ҫ—ЯӮрғ_ғCғҢғNғgӮЙL2ӮЙғXғgғAӮвӮлӮӨӮБӮДӮМӮНӮўӮлӮўӮл•s“sҚҮӮӘҗ¶Ӯ¶ӮйҒB
L1ғLғғғbғVғ…ӮӘ”j’]Ӯ·ӮйҒB
write-allocateӮИ–Ҫ—ЯӮрғ_ғCғҢғNғgӮЙL2ӮЙғXғgғAӮвӮлӮӨӮБӮДӮМӮНӮўӮлӮўӮл•s“sҚҮӮӘҗ¶Ӯ¶ӮйҒB
L1ғLғғғbғVғ…ӮӘ”j’]Ӯ·ӮйҒB
445 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/11/18(җ…) 22:36:02 ID:Jlv2m8O/0
’cҺqҗжҗ¶ӮМ”]“ағVғ~ғ…ӮМҗі“–җ«ӮНӮЖӮаӮ©ӮӯҒAFPӮНL2Ӯ©Ӯз’јҗЪ“ЗӮЮғAҒ[ғLғeғNғ`ғғӮӘҺАҚЫӮЯӮёӮзӮөӮӯӮаӮИӮўӮҜӮЗӮЛҒB
446 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/11/18(җ…) 22:40:43 ID:Jlv2m8O/0
ӮұӮкҲИҸгӮМӢcҳ_ӮНғAҒ[ғLғeғNғ`ғғӮрҢкӮйғXғҢғbғhӮвӢZҸp’kӢ`ӮрҠyӮөӮЮӮЖӮўӮӨ–Ъ“IӮМғXғҢғbғhӮЕӮНӮИӮўӮМӮЕҒA
Һ©Қм”ВӮЙӮҪӮӯӮіӮсӮ Ӯй“ҜҺнӮМ’kӢ`ғXғҢӮЕӮвӮБӮДӮЩӮөӮўӮИҒB
Ӣcҳ_ӮМӮҪӮЯӮМӢcҳ_ӮЙӮИӮБӮДӮөӮЬӮБӮДҒAҗ^ҺАӮЙӢЯӮГӮўӮДӮўӮйҠҙӮ¶ӮөӮИӮўӮаӮсҒB
Һ©Қм”ВӮЙӮҪӮӯӮіӮсӮ Ӯй“ҜҺнӮМ’kӢ`ғXғҢӮЕӮвӮБӮДӮЩӮөӮўӮИҒB
Ӣcҳ_ӮМӮҪӮЯӮМӢcҳ_ӮЙӮИӮБӮДӮөӮЬӮБӮДҒAҗ^ҺАӮЙӢЯӮГӮўӮДӮўӮйҠҙӮ¶ӮөӮИӮўӮаӮсҒB
447 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/11/18(җ…) 22:45:10 ID:Jlv2m8O/0
>>445
ӮЖӮўӮӨҸ‘Ӯ«ҚһӮЭӮрӮЗӮБӮ©ӮЕҚЕӢЯӮЭӮҪӮЖӮЁӮаӮБӮҪӮз—бӮЙӮжӮБӮДҲА“ЎҺҒӮМғTғCғgӮҫӮБӮҪӮ©ҒB
ӮЬӮ ҒAӮ ӮМғuғҚғbғNҗ}ӮрӮЭӮДL2ӮЙ’јҗЪӮВӮИӮӘӮБӮДӮўӮйӮЖ”»’fӮ·ӮйӮМӮН”т–фӮөӮ·Ӯ¬ӮЕӮ ӮйӮӘҒB
ӮЖӮўӮӨҸ‘Ӯ«ҚһӮЭӮрӮЗӮБӮ©ӮЕҚЕӢЯӮЭӮҪӮЖӮЁӮаӮБӮҪӮз—бӮЙӮжӮБӮДҲА“ЎҺҒӮМғTғCғgӮҫӮБӮҪӮ©ҒB
ӮЬӮ ҒAӮ ӮМғuғҚғbғNҗ}ӮрӮЭӮДL2ӮЙ’јҗЪӮВӮИӮӘӮБӮДӮўӮйӮЖ”»’fӮ·ӮйӮМӮН”т–фӮөӮ·Ӯ¬ӮЕӮ ӮйӮӘҒB
448 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/11/18(җ…) 22:46:07 ID:GoxzWJsL0
>>445
x86Ӯ¶ӮбӮИӮўӮҫӮлӮ»ӮкҒB
ғXғJғүӮЕғXғgғAӮөӮҪғfҒ[ғ^ӮрSIMDғfҒ[ғ^ӮЖӮөӮД“ЗӮЭҸoӮөӮҪӮиӮ»ӮМӢtӮрӮвӮБӮҪӮиӮБӮДғRҒ[ғhӮНғAғzӮЭӮҪӮўӮЙӮ ӮйҒB
Ң¬•АӮЭҗ«”\“IӮЙҺҖӮКӮй
x86Ӯ¶ӮбӮИӮўӮҫӮлӮ»ӮкҒB
ғXғJғүӮЕғXғgғAӮөӮҪғfҒ[ғ^ӮрSIMDғfҒ[ғ^ӮЖӮөӮД“ЗӮЭҸoӮөӮҪӮиӮ»ӮМӢtӮрӮвӮБӮҪӮиӮБӮДғRҒ[ғhӮНғAғzӮЭӮҪӮўӮЙӮ ӮйҒB
Ң¬•АӮЭҗ«”\“IӮЙҺҖӮКӮй
449 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/11/18(җ…) 22:51:29 ID:Jlv2m8O/0
ӮЬӮ ӮЁӮкӮаҺАҚЫ–в‘иL2ғ_ғCғҢғNғgҗаӮНӮ ӮЬӮиҺ^“ҜӮөӮДӮИӮўӮ©ӮзӮўӮўӮсӮҫӮӘҒB
Ӯ»ӮкӮНӮ»ӮӨӮЖҒAҢВҗl“IӮЙӮНBobcatӮӘҺАӮНӮўӮҝӮОӮсҺ©Қм“IӮЙӮН—¬ҚsӮөӮ»ӮӨӮҫӮЖҺvӮБӮДӮўӮйӮМӮҫӮӘҒA
Һ©Қм”ВӮЕӮН•]үҝғCғ}ғCғ`ӮИӮсӮҫӮЛҒB
Ӯ»ӮкӮНӮ»ӮӨӮЖҒAҢВҗl“IӮЙӮНBobcatӮӘҺАӮНӮўӮҝӮОӮсҺ©Қм“IӮЙӮН—¬ҚsӮөӮ»ӮӨӮҫӮЖҺvӮБӮДӮўӮйӮМӮҫӮӘҒA
Һ©Қм”ВӮЕӮН•]үҝғCғ}ғCғ`ӮИӮсӮҫӮЛҒB
450 ҒF–јҸМ–ўҗЭ’иҒF2009/11/18(җ…) 23:03:48 ID:EopSiN2r0
Ӯ»ӮзӮ»ӮӨӮҫ
AtomӮЙҸҹӮДӮ»ӮӨӮИӢC”zӮӘӮЛӮҰӮаӮс
AtomӮЙҸҹӮДӮ»ӮӨӮИӢC”zӮӘӮЛӮҰӮаӮс
451 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/11/18(җ…) 23:07:52 ID:Jlv2m8O/0
AtomӮНMIDӮвӮзғXғ}Ғ[ғgғtғHғ“ӮвӮзӮӘӮ ӮӯӮЬӮЕӮаIntelӮМҠб’ҶӮҫӮ©Ӯз
ғRғAӮрҠg’ЈӮөӮДҗ«”\ӮрӮ Ӯ°ӮжӮӨӮЖӮўӮӨҳbӮНҸӯӮИӮӯӮЖӮаҢ»’iҠKӮМғҚҒ[ғhғ}ғbғvӮЕӮНӮЕӮДӮўӮИӮўҒB
ғRғXғg–КӮЕULV CoreҒAҗ«”\–КӮЕAtomӮЙҸҹӮйӮИӮзҒAPCҺsҸкӮЕӮНIntelӮМҺи”–ӮИӮЖӮұӮлӮЙҸгҺиӮӯӮНӮЬӮйӮЖҺvӮӨҒB
32nm, 2-issue OOOӮӘӮ»ӮұӮ»ӮұӮМғNғҚғbғNӮЕӮЬӮнӮкӮО‘е’пӮМPCӮМ—p“rӮЙӮНҺ–‘«ӮиӮйӮөӮИҒB
ӮВҒ[Ӯ©ҒAҲк”ФBulldozerӮӘ”ч–ӯӮҫӮлҚЎүсӮМӮНҒB
ғRғAӮрҠg’ЈӮөӮДҗ«”\ӮрӮ Ӯ°ӮжӮӨӮЖӮўӮӨҳbӮНҸӯӮИӮӯӮЖӮаҢ»’iҠKӮМғҚҒ[ғhғ}ғbғvӮЕӮНӮЕӮДӮўӮИӮўҒB
ғRғXғg–КӮЕULV CoreҒAҗ«”\–КӮЕAtomӮЙҸҹӮйӮИӮзҒAPCҺsҸкӮЕӮНIntelӮМҺи”–ӮИӮЖӮұӮлӮЙҸгҺиӮӯӮНӮЬӮйӮЖҺvӮӨҒB
32nm, 2-issue OOOӮӘӮ»ӮұӮ»ӮұӮМғNғҚғbғNӮЕӮЬӮнӮкӮО‘е’пӮМPCӮМ—p“rӮЙӮНҺ–‘«ӮиӮйӮөӮИҒB
ӮВҒ[Ӯ©ҒAҲк”ФBulldozerӮӘ”ч–ӯӮҫӮлҚЎүсӮМӮНҒB
452 ҒF–јҸМ–ўҗЭ’иҒF2009/11/18(җ…) 23:27:06 ID:EopSiN2r0
ӮұӮМ•УӮ©ӮзҠ„Ӯ©ӮкӮйғҠғ\Ғ[ғX(ӮвӮйӢC)ӮМҸӯӮИӮіӮрҠҙӮ¶ӮДӮўӮйҒBҚЎӮЕӮаIntelӮН”hҗ¶•iӮЦӮ«ӮБӮҝӮиғҠғ\Ғ[ғXӮВӮ¬ҚһӮсӮЕҗЭҢvӮөӮДӮйӮөҒB
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20091112_328392.html
>Ғ@BobcatӮаBulldozerӮЖ“ҜӮ¶Ӯӯ2011”NӮЙ“oҸкӮ·Ӯй—\’иӮҫҒB
>ҚЕҸүӮМҗ»•iӮНOntarioӮЕғmҒ[ғgPCҢьӮҜӮЖӮИӮйҒB
>ӮЬӮҪҒABobcatӮНғJғXғ^ғҖүсҳHӮрҺgӮнӮёӮЙҒAҚД—ҳ—pӮөӮвӮ·ӮўӮжӮӨӮЙҚӮғҢғxғӢҢҫҢкӮЕҸ‘Ӯ©ӮкӮДӮўӮйҒB
>Ӯ»ӮМӮҪӮЯҒAғoғҠғGҒ[ғVғҮғ“ӮӘ‘Ҫҗ”“oҸкӮ·ӮйӮұӮЖӮӘ—\‘zӮіӮкӮйҒB
ӮВҒ[Ӯ©ҒAӮаӮЖӮаӮЖBobcatҺ©‘М2009”NӮҫӮ©ӮЙ“oҸкӮ·Ӯй—\’иӮҫӮБӮҪӮМӮӘBulldozerӮӘ’xӮкӮДҒAӮ»ӮБӮҝӮЙғҠғ\Ғ[ғXӮрүсӮ·Ң`ӮЕ’xү„ӮөӮДӮўӮйӮнӮҜӮЕҒBҒBҒB
AMDӮМ’ҶӮЕӮағvғүғCғIғҠғeғBӮаҠ_ҠФҢ©ӮҰӮйҒB
ӮсӮЕҒAӮ©ӮИӮи”ЯҠП“IӮЙҢ©җПӮаӮБӮДӮа2011”NӮЙӮНIntelӮНҚЕ’бҢАӮМ’n•аӮрҢЕӮЯӮДӮўӮй(AtomӮМR&DӮрAtomҺ©җgӮМ”„ӮиҸгӮ°Ӯ©Ӯз”PҸoӮ·ӮйӮұӮЖӮӘҸo—ҲӮй)ӮҫӮлҒB
AMDӮНӮ»ӮӨӮўӮӨҺиӮІӮнӮўҗжҚsҺТӮр’ЗҢӮӮ·Ӯй‘Мҗ§ӮЙ–іӮўӮЖҚlӮҰӮйҒB
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20091112_328392.html
>Ғ@BobcatӮаBulldozerӮЖ“ҜӮ¶Ӯӯ2011”NӮЙ“oҸкӮ·Ӯй—\’иӮҫҒB
>ҚЕҸүӮМҗ»•iӮНOntarioӮЕғmҒ[ғgPCҢьӮҜӮЖӮИӮйҒB
>ӮЬӮҪҒABobcatӮНғJғXғ^ғҖүсҳHӮрҺgӮнӮёӮЙҒAҚД—ҳ—pӮөӮвӮ·ӮўӮжӮӨӮЙҚӮғҢғxғӢҢҫҢкӮЕҸ‘Ӯ©ӮкӮДӮўӮйҒB
>Ӯ»ӮМӮҪӮЯҒAғoғҠғGҒ[ғVғҮғ“ӮӘ‘Ҫҗ”“oҸкӮ·ӮйӮұӮЖӮӘ—\‘zӮіӮкӮйҒB
ӮВҒ[Ӯ©ҒAӮаӮЖӮаӮЖBobcatҺ©‘М2009”NӮҫӮ©ӮЙ“oҸкӮ·Ӯй—\’иӮҫӮБӮҪӮМӮӘBulldozerӮӘ’xӮкӮДҒAӮ»ӮБӮҝӮЙғҠғ\Ғ[ғXӮрүсӮ·Ң`ӮЕ’xү„ӮөӮДӮўӮйӮнӮҜӮЕҒBҒBҒB
AMDӮМ’ҶӮЕӮағvғүғCғIғҠғeғBӮаҠ_ҠФҢ©ӮҰӮйҒB
ӮсӮЕҒAӮ©ӮИӮи”ЯҠП“IӮЙҢ©җПӮаӮБӮДӮа2011”NӮЙӮНIntelӮНҚЕ’бҢАӮМ’n•аӮрҢЕӮЯӮДӮўӮй(AtomӮМR&DӮрAtomҺ©җgӮМ”„ӮиҸгӮ°Ӯ©Ӯз”PҸoӮ·ӮйӮұӮЖӮӘҸo—ҲӮй)ӮҫӮлҒB
AMDӮНӮ»ӮӨӮўӮӨҺиӮІӮнӮўҗжҚsҺТӮр’ЗҢӮӮ·Ӯй‘Мҗ§ӮЙ–іӮўӮЖҚlӮҰӮйҒB
453 ҒF–јҸМ–ўҗЭ’иҒF2009/11/18(җ…) 23:27:54 ID:EopSiN2r0
Ғ~AMDӮМ’ҶӮЕӮа
ҒӣAMDӮМ’ҶӮЕӮМ
ҒӣAMDӮМ’ҶӮЕӮМ
454 ҒF–јҸМ–ўҗЭ’иҒF2009/11/25(җ…) 20:08:38 ID:66MSSZ3u0
ӮЬӮ –і”\ӮМҲУҢ©ӮНӢ¶ӮБӮДӮйӮ©ӮзӮЛҒB
Һ©•ӘӮӘ‘К–ЪӮИӮМӮЬӮЕҚ‘ӮМӮ№ӮўӮЙӮөӮҪӮӘӮйӮөҒB
—L”\ҒE–і”\ӮЙҚ‘Ӣ«ӮНӮИӮўҒB
—L”\ӮИҗlҠФӮН‘е‘МӮЗӮұӮМҚ‘ӮЕӮа’К—pӮ·ӮйӮөҒA—L”\ӮЕӮ ӮкӮОӮ ӮйӮЩӮЗҚ‘ӮНҠЦҢWӮИӮўҒB
–і”\ӮН•кҚ‘ӮЕ‘јҗlӮМ‘«ӮрҲшӮБ’ЈӮиӮИӮӘӮз•йӮзӮ·ӮМӮҫӮҜӮЕҗёҲк”tӮИӮсӮҫӮжҒB
ҚЕӢЯӮЙӮИӮБӮДҢіҒX–і”\ӮҫӮБӮҪҗlҠФӮҪӮҝӮӘҒAӮўӮЬӮЬӮЕӮМ•йӮзӮөӮрҲЫҺқӮЕӮ«ӮйӮ©•sҲАӮЙӮИӮБӮДӮ«ӮД
ғEғ_ғEғ_ӮўӮБӮДӮйӮҫӮҜҒB
–і”\ӮЙӮНӮЗӮМӮЭӮҝҚ‘Ӯрүь‘PӮ·Ӯй”\—НӮИӮЗҚЕҸүӮ©ӮзӮИӮўӮМӮҫӮ©Ӯз
ӮўӮВүь‘PӮ·ӮйӮ©ӮаӮнӮ©ӮзӮИӮўҚ‘ӮЙ•¶ӢеӮрӮҪӮкӮДӮўӮйүЙӮӘӮ ӮйӮМӮИӮзҒA
Һ©•ӘӮМҢ»ҸуӮрҺ©—НӮЕ‘ЕҠJӮ·ӮйҚфӮрҺ©•ӘҺ©җgӮЕҚlӮҰӮДӮўӮҪ•ыӮӘ‘SӮӯӮЁ—ҳҢыӮіӮсӮ¶ӮбӮИӮўӮ©ҒB
—L”\ӮИҗlҠФӮНӮ»ӮкӮӘҺ©‘RӮЙҚЕҸүӮБӮ©ӮзӮЕӮ«ӮДӮўӮйӮ©ӮзҲбӮӨӮсӮҫӮжҒB
Һ©•ӘӮМ”СӮН‘јҗlӮИӮЗҗM—pӮ№ӮёӮЙҺ©•ӘӮЕ’І’BӮ·ӮйҒBӮ»ӮкӮӘӮЕӮ«ӮИӮўӮвӮВӮЙӮНҺҖӮЙӢЯӮГӮўӮДӮўӮӯҒB
—LҺjҲИ‘OӮ©Ӯз“–ӮҪӮи‘OӮМҢ»ҺАӮрӮИӮәғEғ_ғEғ_ӮўӮБӮДҸі•ҡӮөӮИӮўӮсӮҫ?
Һ©•ӘӮӘ‘К–ЪӮИӮМӮЬӮЕҚ‘ӮМӮ№ӮўӮЙӮөӮҪӮӘӮйӮөҒB
—L”\ҒE–і”\ӮЙҚ‘Ӣ«ӮНӮИӮўҒB
—L”\ӮИҗlҠФӮН‘е‘МӮЗӮұӮМҚ‘ӮЕӮа’К—pӮ·ӮйӮөҒA—L”\ӮЕӮ ӮкӮОӮ ӮйӮЩӮЗҚ‘ӮНҠЦҢWӮИӮўҒB
–і”\ӮН•кҚ‘ӮЕ‘јҗlӮМ‘«ӮрҲшӮБ’ЈӮиӮИӮӘӮз•йӮзӮ·ӮМӮҫӮҜӮЕҗёҲк”tӮИӮсӮҫӮжҒB
ҚЕӢЯӮЙӮИӮБӮДҢіҒX–і”\ӮҫӮБӮҪҗlҠФӮҪӮҝӮӘҒAӮўӮЬӮЬӮЕӮМ•йӮзӮөӮрҲЫҺқӮЕӮ«ӮйӮ©•sҲАӮЙӮИӮБӮДӮ«ӮД
ғEғ_ғEғ_ӮўӮБӮДӮйӮҫӮҜҒB
–і”\ӮЙӮНӮЗӮМӮЭӮҝҚ‘Ӯрүь‘PӮ·Ӯй”\—НӮИӮЗҚЕҸүӮ©ӮзӮИӮўӮМӮҫӮ©Ӯз
ӮўӮВүь‘PӮ·ӮйӮ©ӮаӮнӮ©ӮзӮИӮўҚ‘ӮЙ•¶ӢеӮрӮҪӮкӮДӮўӮйүЙӮӘӮ ӮйӮМӮИӮзҒA
Һ©•ӘӮМҢ»ҸуӮрҺ©—НӮЕ‘ЕҠJӮ·ӮйҚфӮрҺ©•ӘҺ©җgӮЕҚlӮҰӮДӮўӮҪ•ыӮӘ‘SӮӯӮЁ—ҳҢыӮіӮсӮ¶ӮбӮИӮўӮ©ҒB
—L”\ӮИҗlҠФӮНӮ»ӮкӮӘҺ©‘RӮЙҚЕҸүӮБӮ©ӮзӮЕӮ«ӮДӮўӮйӮ©ӮзҲбӮӨӮсӮҫӮжҒB
Һ©•ӘӮМ”СӮН‘јҗlӮИӮЗҗM—pӮ№ӮёӮЙҺ©•ӘӮЕ’І’BӮ·ӮйҒBӮ»ӮкӮӘӮЕӮ«ӮИӮўӮвӮВӮЙӮНҺҖӮЙӢЯӮГӮўӮДӮўӮӯҒB
—LҺjҲИ‘OӮ©Ӯз“–ӮҪӮи‘OӮМҢ»ҺАӮрӮИӮәғEғ_ғEғ_ӮўӮБӮДҸі•ҡӮөӮИӮўӮсӮҫ?
455 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/11/27(Ӣа) 00:12:45 ID:pIO1ytjl0
Sandy BridgeӮМғTҒ[ғo”ЕӮӘӮЁӮк“IӮЙӮҜӮБӮұӮӨ—\‘zҠOӮҫӮБӮҪҢҸӮЙӮВӮўӮДҒB
ӮдӮӯӮдӮӯӮН“қҚҮӮ·ӮйӮЖҺvӮБӮДӮҪӮҜӮЗҒA2ғ`ғbғvӮЕӮўӮ«ӮИӮиӮӯӮйӮЖӮНӮЛҒBӮЬӮ ӮўӮўӮҜӮЗҒB
ӮдӮӯӮдӮӯӮН“қҚҮӮ·ӮйӮЖҺvӮБӮДӮҪӮҜӮЗҒA2ғ`ғbғvӮЕӮўӮ«ӮИӮиӮӯӮйӮЖӮНӮЛҒBӮЬӮ ӮўӮўӮҜӮЗҒB
456 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/11/27(Ӣа) 00:15:14 ID:pIO1ytjl0
ӮИӮсӮ©NehalemӮ©ӮзLGA136x”ЕӮМSNBӮЦҲЪҚs‘_ӮБӮҪӮЩӮӨӮӘҗўүәӮ°ӮЙҺvӮҰӮДӮ«ӮҪӮИҒB
Ӯ ӮЖҒAҢг“Ўҗжҗ¶ӮМӢLҺ–ӮМAMDӮМ’ҶӮМҗlӮМҳbӮӘӮұӮБӮҝӮН‘z‘ң’КӮиүЯӮ¬ӮДғҸғүғ^ҒB
Ӯ ӮЖҒAҢг“Ўҗжҗ¶ӮМӢLҺ–ӮМAMDӮМ’ҶӮМҗlӮМҳbӮӘӮұӮБӮҝӮН‘z‘ң’КӮиүЯӮ¬ӮДғҸғүғ^ҒB
457 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/11/27(Ӣа) 00:48:25 ID:pIO1ytjl0
Sandy BridgeӮМғTҒ[ғo”ЕӮӘ2ғ`ғbғvӮЕӮ ӮйӮұӮЖӮӘ”ӯҠoӮөӮДSoCү»ҳHҗьҗFӮӘӮіӮзӮЙ”ZҢъӮИҲуҸЫӮЙӮИӮБӮҪҒB
>>328ӮЙҸ‘ӮўӮҪӮЖӮЁӮиҒA“қҚҮү»ӮЙӮжӮй“d—НҚнҢёӮМҢшүКӮНTB“ҷӮМҢшүК”НҲНӮаҚLӮӘӮйӮұӮЖӮа‘ҠҸжӮөӮДҒA
җв‘Оҗ«”\ӮМҠl“ҫӮЙӮВӮИӮӘӮБӮДӮўӮӯӮ©ӮзғTҒ[ғoӮЕӮаSoCҗFӮӘҸҷҒXӮЙӢӯӮӯӮИӮБӮДӮўӮӯӮұӮЖӮН•sҺvӢcӮЕӮНӮИӮўӮөҒA
ӮНӮвӮЯӮЙ“қҚҮӮөӮЖӮўӮҪӮЩӮӨӮӘ—ЗӮўӮЖӮўӮӨ”»’fӮаӮ ӮБӮҪӮМӮ©ӮаӮөӮкӮИӮўҒB
>>328ӮЙҸ‘ӮўӮҪӮЖӮЁӮиҒA“қҚҮү»ӮЙӮжӮй“d—НҚнҢёӮМҢшүКӮНTB“ҷӮМҢшүК”НҲНӮаҚLӮӘӮйӮұӮЖӮа‘ҠҸжӮөӮДҒA
җв‘Оҗ«”\ӮМҠl“ҫӮЙӮВӮИӮӘӮБӮДӮўӮӯӮ©ӮзғTҒ[ғoӮЕӮаSoCҗFӮӘҸҷҒXӮЙӢӯӮӯӮИӮБӮДӮўӮӯӮұӮЖӮН•sҺvӢcӮЕӮНӮИӮўӮөҒA
ӮНӮвӮЯӮЙ“қҚҮӮөӮЖӮўӮҪӮЩӮӨӮӘ—ЗӮўӮЖӮўӮӨ”»’fӮаӮ ӮБӮҪӮМӮ©ӮаӮөӮкӮИӮўҒB
458 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/11/27(Ӣа) 00:49:51 ID:pIO1ytjl0
ҳbӮНӮ©ӮнӮБӮДғRғXғgӮМҳbӮНӮнӮҙӮЖҸ‘Ӯ©ӮИӮўӮЕӮўӮҪӮнӮҜӮҫӮӘҚЎӮМӮӨӮҝӮЙӮҝӮеӮБӮЖӮ©ӮўӮЖӮ«ӮЬӮ·ҒB
ғRғXғg–КӮЙӮВӮўӮДӮНҒA‘S”КAMDӮМӮвӮВӮНҢ»ҸуӮжӮиӮаҚUҗЁӮ©ӮҜӮвӮ·ӮӯӮИӮйӮ©ӮаҒB
IntelӮНҚЎӮМӮЖӮұӮл’P‘МӮМҸу‘ФӮМғRғAӮрӢЙ—НӮўӮ¶ӮзӮИӮўӮЕғҠғ“ғOӮЕӮВӮИӮ®ӮҫӮҜӮМ•ыҢьӮЕҲкҠСӮөӮДӮўӮйҒB
ғ}ғӢғ`ғRғAӮМ”hҗ¶•i“WҠJӮЙ•K—vӮИҠJ”ӯҠъҠФӮр“O’к“IӮЙ’ZҸkӮ·Ӯй•ыҗjӮЙҢ©ӮҰӮйҒB
ӮұӮкӮЬӮЕӮМӮЖӮұӮл”Д—pғRғAӮҫӮҜӮ¶ӮбӮИӮӯLRBӮвGMAӮМӮжӮӨӮИғRғAӮа–wӮЗ’P‘МӮМҸу‘ФӮ©Ӯз
ғ}ғӢғ`ғRғAӮМӮҪӮЯӮЙӮВӮБӮұӮсӮҫҚЕ“Kү»ӮНӮөӮДӮИӮўӮЖӮўӮӨҲкҠСӮБӮХӮиҒB
ӮұӮМғAғvғҚҒ[ғ`ӮҫӮЖҸз’·•”•ӘӮӘӮ ӮйӮ©Ӯзҗ»‘ўғRғXғg–КӮЕ•s—ҳӮЙӮИӮйӮӘҒA
ҢГӮӯӮ©ӮзӢ@”\ӮМ–іҢшү»ӮЙҗПӢЙ“IӮИIntelӮНҒA”hҗ¶•iӮЙ‘ОӮөӮДҗ»‘ўҺһ“_ӮЕӮМҸз’·•”•ӘӮрӮВӮФӮ·ӮұӮЖӮЙӮНҸБӢЙ“IӮҫӮБӮҪҒB
ӮұӮМIntelӮМӮвӮи•ыӮНҒAӮӨӮЬӮӯҠJ”ӯҠъҠФӮрӮЁӮіӮҰӮзӮкӮкӮОҢӢүК“IӮЙӮНҗVӮөӮўCPUӮӘ‘¬ӮӯҺиӮЙ“ьӮйӮұӮЖӮЙӮИӮиҒA
ҢӢүК“IӮЙҗ«”\ӮрҚӮӮӯӮрҲЫҺқӮЕӮ«ӮйӮ©ӮзҒA“ҜҺһ‘гӮЕӮжӮиҚӮ‘¬ӮИCPUӮрғҠғҠҒ[ғXӮЕӮ«ӮйӮұӮЖӮЖ“ҜӢ`ӮЙӮИӮйҒB
ӮЬӮҪ—бӮҰӮО”с‘ОҸМӮЕ‘е—КӮЙLNIғRғAӮрҸWҗПӮөӮҪӮвӮВӮӘӮұӮҜӮДӮаӮ·Ӯ®ӮЙ•ЫҢҜғvғүғ“ӮМ”hҗ¶•iӮЕҠӘӮ«•ФӮ№ӮйӮҪӮЯҒAғҠғXғNӮӘӮ»ӮаӮ»ӮаҸӯӮИӮўҒB
AMDӮМғNғүғXғ^ғAҒ[ғLӮЕӮНҗ»‘ў–КӮЕӮМғRғXғgӮН—}ӮҰӮзӮкӮйӮӘҠJ”ӯҠъҠФ/ҠJ”ӯғRғXғgӮӘӢtӮЙ‘еӮ«ӮӯӮИӮйҒB
“d—НӮЕӮНҚЎӮМӮЖӮұӮлLynnfieldҺһ“_ӮЕIntelӮМTBӮМҠ®җ¬“xӮОӮЁӮкӮЖӮөӮДӮа—\‘zҲИҸгҒB
ӮЬӮ ‘ҚӮ¶ӮДҢҫӮӨӮЖIntelӮӨӮЬӮӯӮўӮ«Ӯ·Ӯ¬ӮИӮсӮҫӮжӮИҒB
AMDӮаTBғүғCғNӮИӮаӮМӮН“ұ“ьӮ·Ӯй—\’иӮНӮ ӮйӮжӮӨӮҫӮӘҒAғNғҚғbғNӮИӮиҒA–Ҫ—ЯӮ ӮҪӮиӮМ“d—НғRғXғgӮИӮиӮр“®“IӮЙ’Іҗ®ӮөӮД
ҸжӮиҗШӮлӮӨӮБӮДӮМӮНIntelӮМӮӘҲк”Фҗ«ҠiӮӘӢӯӮӯӮЕӮДӮўӮйӮМӮНҠФҲбӮў–іӮўӮЖҺvӮӨҒB
ғRғXғg–КӮЙӮВӮўӮДӮНҒA‘S”КAMDӮМӮвӮВӮНҢ»ҸуӮжӮиӮаҚUҗЁӮ©ӮҜӮвӮ·ӮӯӮИӮйӮ©ӮаҒB
IntelӮНҚЎӮМӮЖӮұӮл’P‘МӮМҸу‘ФӮМғRғAӮрӢЙ—НӮўӮ¶ӮзӮИӮўӮЕғҠғ“ғOӮЕӮВӮИӮ®ӮҫӮҜӮМ•ыҢьӮЕҲкҠСӮөӮДӮўӮйҒB
ғ}ғӢғ`ғRғAӮМ”hҗ¶•i“WҠJӮЙ•K—vӮИҠJ”ӯҠъҠФӮр“O’к“IӮЙ’ZҸkӮ·Ӯй•ыҗjӮЙҢ©ӮҰӮйҒB
ӮұӮкӮЬӮЕӮМӮЖӮұӮл”Д—pғRғAӮҫӮҜӮ¶ӮбӮИӮӯLRBӮвGMAӮМӮжӮӨӮИғRғAӮа–wӮЗ’P‘МӮМҸу‘ФӮ©Ӯз
ғ}ғӢғ`ғRғAӮМӮҪӮЯӮЙӮВӮБӮұӮсӮҫҚЕ“Kү»ӮНӮөӮДӮИӮўӮЖӮўӮӨҲкҠСӮБӮХӮиҒB
ӮұӮМғAғvғҚҒ[ғ`ӮҫӮЖҸз’·•”•ӘӮӘӮ ӮйӮ©Ӯзҗ»‘ўғRғXғg–КӮЕ•s—ҳӮЙӮИӮйӮӘҒA
ҢГӮӯӮ©ӮзӢ@”\ӮМ–іҢшү»ӮЙҗПӢЙ“IӮИIntelӮНҒA”hҗ¶•iӮЙ‘ОӮөӮДҗ»‘ўҺһ“_ӮЕӮМҸз’·•”•ӘӮрӮВӮФӮ·ӮұӮЖӮЙӮНҸБӢЙ“IӮҫӮБӮҪҒB
ӮұӮМIntelӮМӮвӮи•ыӮНҒAӮӨӮЬӮӯҠJ”ӯҠъҠФӮрӮЁӮіӮҰӮзӮкӮкӮОҢӢүК“IӮЙӮНҗVӮөӮўCPUӮӘ‘¬ӮӯҺиӮЙ“ьӮйӮұӮЖӮЙӮИӮиҒA
ҢӢүК“IӮЙҗ«”\ӮрҚӮӮӯӮрҲЫҺқӮЕӮ«ӮйӮ©ӮзҒA“ҜҺһ‘гӮЕӮжӮиҚӮ‘¬ӮИCPUӮрғҠғҠҒ[ғXӮЕӮ«ӮйӮұӮЖӮЖ“ҜӢ`ӮЙӮИӮйҒB
ӮЬӮҪ—бӮҰӮО”с‘ОҸМӮЕ‘е—КӮЙLNIғRғAӮрҸWҗПӮөӮҪӮвӮВӮӘӮұӮҜӮДӮаӮ·Ӯ®ӮЙ•ЫҢҜғvғүғ“ӮМ”hҗ¶•iӮЕҠӘӮ«•ФӮ№ӮйӮҪӮЯҒAғҠғXғNӮӘӮ»ӮаӮ»ӮаҸӯӮИӮўҒB
AMDӮМғNғүғXғ^ғAҒ[ғLӮЕӮНҗ»‘ў–КӮЕӮМғRғXғgӮН—}ӮҰӮзӮкӮйӮӘҠJ”ӯҠъҠФ/ҠJ”ӯғRғXғgӮӘӢtӮЙ‘еӮ«ӮӯӮИӮйҒB
“d—НӮЕӮНҚЎӮМӮЖӮұӮлLynnfieldҺһ“_ӮЕIntelӮМTBӮМҠ®җ¬“xӮОӮЁӮкӮЖӮөӮДӮа—\‘zҲИҸгҒB
ӮЬӮ ‘ҚӮ¶ӮДҢҫӮӨӮЖIntelӮӨӮЬӮӯӮўӮ«Ӯ·Ӯ¬ӮИӮсӮҫӮжӮИҒB
AMDӮаTBғүғCғNӮИӮаӮМӮН“ұ“ьӮ·Ӯй—\’иӮНӮ ӮйӮжӮӨӮҫӮӘҒAғNғҚғbғNӮИӮиҒA–Ҫ—ЯӮ ӮҪӮиӮМ“d—НғRғXғgӮИӮиӮр“®“IӮЙ’Іҗ®ӮөӮД
ҸжӮиҗШӮлӮӨӮБӮДӮМӮНIntelӮМӮӘҲк”Фҗ«ҠiӮӘӢӯӮӯӮЕӮДӮўӮйӮМӮНҠФҲбӮў–іӮўӮЖҺvӮӨҒB
459 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/11/27(Ӣа) 02:42:01 ID:kakEWK6S0
>>458
>>458
IntelӮӘӮЬӮҪғlғ^ғvғҚғZғbғTӮМ”ӯ•\Ӯ·ӮйӮБӮДӮіҒB
461 –ј‘OҒFSocket774[sage] “ҠҚe“ъҒF2009/11/27(Ӣа) 00:51:52 ID:D7mBF9pc
http://www.isscc.org/isscc/2010/ISSCCAP2010.pdf
ISSCC2010ӮМғvғҚғOғүғҖӮӘӮ ӮБӮҪҒB
intelӮМ”ӯ•\ӮНҗFҒXӮ ӮйӮжӮӨӮҫӮҜӮЗҒA48ҢВӮМIA32ғRғAӮЖ4chӮМDDR3ӮрғҒғbғVғ…ӮЕӮВӮИӮ°ӮҪӮаӮМӮр
45nmӮЕҚмӮБӮҪғ`ғbғvӮМ”ӯ•\ӮӘ—\’иӮіӮкӮДӮўӮйҒB
ӮөӮОӮзӮӯӮНғRғAҠФҗЪ‘ұӮНғҠғ“ғOғoғXӮЙӮИӮиӮ»ӮӨӮҫӮҜӮЗҒAӮіӮзӮЙ‘Ҫҗ”ӮМғRғAӮрҚЪӮ№ӮйӮЖӮ«ӮН
ғҒғbғVғ…ӮМ•ыӮӘ—L—НӮЖҚlӮҰӮДӮўӮйӮМӮҫӮлӮӨӮ©ҒB
“ъ–{ӮӘӢһ‘¬ӮвӮйӮҫӮМӮвӮзӮИӮўӮҫӮМқҶӮЯӮДӮйӮЖӮ«ӮЙҗ»•iү»—\’иӮаӮИӮўғvғҚғZғbғTҠJ”ӯӮөӮДӮЭӮҪӮиӮЖӮ©
Ӯ»ӮӨӮўӮӨӮұӮЖӮЙғ|ғ“ӮЖ“ҠҺ‘ӮЕӮ«Ӯй—]—TӮӘҒAҗўҠEҚЕӢӯӮМ”ј“ұ‘МғҒҒ[ғJҒ[ӮрҺxӮҰӮДӮйӮсӮҫӮә
Қ‘ҺYғXғpғRғ“•ңҢ ӮИӮсӮДүiӢvӮЙӮ Ӯи“ҫӮИӮўӮЖҢеӮБӮҪӮж
>>458
IntelӮӘӮЬӮҪғlғ^ғvғҚғZғbғTӮМ”ӯ•\Ӯ·ӮйӮБӮДӮіҒB
461 –ј‘OҒFSocket774[sage] “ҠҚe“ъҒF2009/11/27(Ӣа) 00:51:52 ID:D7mBF9pc
http://www.isscc.org/isscc/2010/ISSCCAP2010.pdf
ISSCC2010ӮМғvғҚғOғүғҖӮӘӮ ӮБӮҪҒB
intelӮМ”ӯ•\ӮНҗFҒXӮ ӮйӮжӮӨӮҫӮҜӮЗҒA48ҢВӮМIA32ғRғAӮЖ4chӮМDDR3ӮрғҒғbғVғ…ӮЕӮВӮИӮ°ӮҪӮаӮМӮр
45nmӮЕҚмӮБӮҪғ`ғbғvӮМ”ӯ•\ӮӘ—\’иӮіӮкӮДӮўӮйҒB
ӮөӮОӮзӮӯӮНғRғAҠФҗЪ‘ұӮНғҠғ“ғOғoғXӮЙӮИӮиӮ»ӮӨӮҫӮҜӮЗҒAӮіӮзӮЙ‘Ҫҗ”ӮМғRғAӮрҚЪӮ№ӮйӮЖӮ«ӮН
ғҒғbғVғ…ӮМ•ыӮӘ—L—НӮЖҚlӮҰӮДӮўӮйӮМӮҫӮлӮӨӮ©ҒB
“ъ–{ӮӘӢһ‘¬ӮвӮйӮҫӮМӮвӮзӮИӮўӮҫӮМқҶӮЯӮДӮйӮЖӮ«ӮЙҗ»•iү»—\’иӮаӮИӮўғvғҚғZғbғTҠJ”ӯӮөӮДӮЭӮҪӮиӮЖӮ©
Ӯ»ӮӨӮўӮӨӮұӮЖӮЙғ|ғ“ӮЖ“ҠҺ‘ӮЕӮ«Ӯй—]—TӮӘҒAҗўҠEҚЕӢӯӮМ”ј“ұ‘МғҒҒ[ғJҒ[ӮрҺxӮҰӮДӮйӮсӮҫӮә
Қ‘ҺYғXғpғRғ“•ңҢ ӮИӮсӮДүiӢvӮЙӮ Ӯи“ҫӮИӮўӮЖҢеӮБӮҪӮж
460 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/11/27(Ӣа) 03:06:07 ID:kakEWK6S0
Ӯ»ӮкӮЖҒABulldozerӮН50%ӮМ–КҗП‘қӮЕ80%ӮМғXғӢҒ[ғvғbғgҢьҸгӮрӮӨӮҪӮБӮДӮйӮӘ
Ӯ»ӮкӮБӮДҢӢӢЗ–КҗПҢш—ҰӮН1.2”{’ц“xӮИӮнӮҜӮЕҒAHTӮжӮи—DҲКӮИӢZҸpӮЖӮўӮӨӮнӮҜӮЕӮНӮИӮўҒB
Ӯ»ӮкӮБӮДҢӢӢЗ–КҗПҢш—ҰӮН1.2”{’ц“xӮИӮнӮҜӮЕҒAHTӮжӮи—DҲКӮИӢZҸpӮЖӮўӮӨӮнӮҜӮЕӮНӮИӮўҒB
461 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/11/27(Ӣа) 03:15:56 ID:pIO1ytjl0
ҲИ‘OҢг“ЎғXғҢӮЕӮаӮЙӮЁӮнӮ№ӮҪӮӘҒAӮЬӮ¶ӮЯӮИҳbҒAIntelӮӘCtӮМ“y‘дӮЙӮМӮ№ӮжӮӨӮЖӮөӮДӮўӮй
•А—сҺuҢьӮМғAҒ[ғLғeғNғ`ғғӮН•Ўҗ”Ӯ ӮйҒBIntelӮМҳ_•¶ӮИӮиҺ‘—ҝӮрӮЭӮйӮИӮиӮ»ӮӨҚlӮҰӮЖӮўӮҪ
•ыӮӘғxғ^Ғ[ҒBӮҫӮ©ӮзҺАӮНLRBӮНӮ»ӮМҢу•вӮМ’ҶӮМҲкӮВӮЙӮ·Ӯ¬ӮИӮўӮсӮҫӮжӮИҒB
ӮөӮ©ӮөӮЬӮҫӮЁӮкӮҪӮҝӮЙӮНӮұӮМӢcҳ_ӮН‘ҒӮ·Ӯ¬ӮйҒB“ӘӮЙ“ьӮкӮДӮЁӮӯӮҫӮҜӮЕӮўӮўҒB
SoC–іҗьҪКЯәЭПАЮ°??
•А—сҺuҢьӮМғAҒ[ғLғeғNғ`ғғӮН•Ўҗ”Ӯ ӮйҒBIntelӮМҳ_•¶ӮИӮиҺ‘—ҝӮрӮЭӮйӮИӮиӮ»ӮӨҚlӮҰӮЖӮўӮҪ
•ыӮӘғxғ^Ғ[ҒBӮҫӮ©ӮзҺАӮНLRBӮНӮ»ӮМҢу•вӮМ’ҶӮМҲкӮВӮЙӮ·Ӯ¬ӮИӮўӮсӮҫӮжӮИҒB
ӮөӮ©ӮөӮЬӮҫӮЁӮкӮҪӮҝӮЙӮНӮұӮМӢcҳ_ӮН‘ҒӮ·Ӯ¬ӮйҒB“ӘӮЙ“ьӮкӮДӮЁӮӯӮҫӮҜӮЕӮўӮўҒB
SoC–іҗьҪКЯәЭПАЮ°??
462 ҒF–јҸМ–ўҗЭ’иҒF2009/11/27(Ӣа) 10:57:13 ID:Io+tY/4/0
–КҗПҢш—ҰӮҫӮҜӮрҢкӮйӮИӮзғfғ…ғAғӢғRғAӮИӮсӮ©ӮЁ‘e––ӮИӢZҸpӮЙӮИӮБӮДӮөӮЬӮӨ
CBMTӮМ—ҳ“_ӮНHTӮжӮиҗв‘О“IӮИҗ«”\ӮӘҸгӮӘӮй“_ӮЕӮөӮеӮӨ
HTӮНҗ«”\—ҺӮҝӮйҸкҚҮӮҫӮБӮДӮ ӮйӮө
CBMTӮМ—ҳ“_ӮНHTӮжӮиҗв‘О“IӮИҗ«”\ӮӘҸгӮӘӮй“_ӮЕӮөӮеӮӨ
HTӮНҗ«”\—ҺӮҝӮйҸкҚҮӮҫӮБӮДӮ ӮйӮө
463 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/11/27(Ӣа) 19:38:56 ID:2Ui1ib200
ӮЬӮ Ӯ»ӮМҲкҢ©SMTӮЖ”дҠrӮөӮҪӮӯӮИӮйӮЕӮ ӮлӮӨҗlӮҪӮҝӮМӮҪӮЯӮЙ
ӮЁӮкӮНҸ‘ӮўӮДӮйӮнӮҜӮҫӮӘҒAӮнӮ©ӮБӮДӮӯӮкӮДӮИӮӯӮДҺc”OҒB
SMTӮБӮДӮМӮНCMPӮЖӮаӮЖӮаӮЖӮ ӮЬӮиӢЈҚҮӮ·ӮйӢZҸpӮЕӮНӮИӮўӮөҒA
ғNғүғXғ^ғhғAҒ[ғLӮНAMDӮаӮўӮБӮДӮйӮЖӮЁӮиҚЕ“Kү»ӮөӮҪғfғ…ғAғӢғRғAӮЕӮ ӮБӮД
ғ}ғӢғ`ғRғAӮМӮұӮкӮ©ӮзӮЙ‘ОӮ·ӮйAMDӮМүс“ҡӮИӮсӮҫӮжҒB
SMTӮНӮФӮБӮҝӮбӮҜӮЩӮЖӮсӮЗҠЦҢWӮИӮўҒB
“d—НӮв–КҗПӮрҚЕ“Kү»Ӯ·ӮйӮұӮЖӮӘӮұӮкӮ©ӮзӮМғ}ғӢғ`ғRғA“ҜҺmӮМ‘ОҢҲӮМ’ҶӮЕ—DҲКҗ«Ӯр“ҫӮйӮұӮЖӮЙӮВӮИӮӘӮйӮнӮҜӮЕҒA
Ӯ·Ӯ®ӮЙPCӮМғCғҒҒ[ғWӮЕҒAHTӮНғҠғ\Ғ[ғXӮӘӮЖӮўӮӨӮвӮВӮНҚЕӢЯӮМCPUҺ–ҸоӮӘ‘SӮӯӮнӮ©ӮБӮДӮИӮўӮЕӮ·ҒB
>ӮЬӮёүдҒXӮНҒACPUғAҒ[ғLғeғNғ`ғғӮЙғXғӢҒ[ғvғbғgҺһ‘гӮӘ—ҲӮйӮЖ—\‘ӘӮөӮҪҒB
>Ӯ»ӮөӮДҒAӮ»ӮМҺһ‘гӮЙҢьӮҜӮДҒAҚЕӮағpғҸҒ[Ңш—ҰӮӘҚӮӮӯҒAҚЕӮа–§“xӮМҚӮӮўғXғӢҒ[ғvғbғgғGғ“ғWғ“ӮрҠJ”ӯӮ·ӮйӮұӮЖӮЙӮөӮҪҒB
AMDӮаӮ ӮБӮіӮиӮЖӮўӮБӮДӮӯӮкӮҪӮжҒB
ӮЁӮкӮНҸ‘ӮўӮДӮйӮнӮҜӮҫӮӘҒAӮнӮ©ӮБӮДӮӯӮкӮДӮИӮӯӮДҺc”OҒB
SMTӮБӮДӮМӮНCMPӮЖӮаӮЖӮаӮЖӮ ӮЬӮиӢЈҚҮӮ·ӮйӢZҸpӮЕӮНӮИӮўӮөҒA
ғNғүғXғ^ғhғAҒ[ғLӮНAMDӮаӮўӮБӮДӮйӮЖӮЁӮиҚЕ“Kү»ӮөӮҪғfғ…ғAғӢғRғAӮЕӮ ӮБӮД
ғ}ғӢғ`ғRғAӮМӮұӮкӮ©ӮзӮЙ‘ОӮ·ӮйAMDӮМүс“ҡӮИӮсӮҫӮжҒB
SMTӮНӮФӮБӮҝӮбӮҜӮЩӮЖӮсӮЗҠЦҢWӮИӮўҒB
“d—НӮв–КҗПӮрҚЕ“Kү»Ӯ·ӮйӮұӮЖӮӘӮұӮкӮ©ӮзӮМғ}ғӢғ`ғRғA“ҜҺmӮМ‘ОҢҲӮМ’ҶӮЕ—DҲКҗ«Ӯр“ҫӮйӮұӮЖӮЙӮВӮИӮӘӮйӮнӮҜӮЕҒA
Ӯ·Ӯ®ӮЙPCӮМғCғҒҒ[ғWӮЕҒAHTӮНғҠғ\Ғ[ғXӮӘӮЖӮўӮӨӮвӮВӮНҚЕӢЯӮМCPUҺ–ҸоӮӘ‘SӮӯӮнӮ©ӮБӮДӮИӮўӮЕӮ·ҒB
>ӮЬӮёүдҒXӮНҒACPUғAҒ[ғLғeғNғ`ғғӮЙғXғӢҒ[ғvғbғgҺһ‘гӮӘ—ҲӮйӮЖ—\‘ӘӮөӮҪҒB
>Ӯ»ӮөӮДҒAӮ»ӮМҺһ‘гӮЙҢьӮҜӮДҒAҚЕӮағpғҸҒ[Ңш—ҰӮӘҚӮӮӯҒAҚЕӮа–§“xӮМҚӮӮўғXғӢҒ[ғvғbғgғGғ“ғWғ“ӮрҠJ”ӯӮ·ӮйӮұӮЖӮЙӮөӮҪҒB
AMDӮаӮ ӮБӮіӮиӮЖӮўӮБӮДӮӯӮкӮҪӮжҒB
464 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/11/27(Ӣа) 19:52:19 ID:2Ui1ib200
>Ӯ»ӮкӮаҒAғVғ“ғOғӢғXғҢғbғhғpғtғHҒ[ғ}ғ“ғXӮЙӮВӮўӮД‘ГӢҰӮ№ӮёӮЙҒB
>Ӯ»ӮМӮҪӮЯӮЙҒACPUӮМғҸҒ[ғNғҚҒ[ғhӮрҢӨӢҶӮөҒAҠeғҸҒ[ғNғҚҒ[ғhӮӘғVғXғeғҖӮМ’ҶӮЕӮЗӮМӮжӮӨӮЙҗUӮй•‘ӮӨӮ©ӮрҢӨӢҶӮөӮҪ
ғVғ“ғOғӢғXғҢғbғhҗ«”\ӮЙ‘ОӮ·Ӯй‘ГӢҰӮБӮДӮМӮНNiagaraӮМӮжӮӨ’PӮЙ“d—НӮр—}ӮҰӮҪӮўҒA
‘тҺRғRғAӮр•АӮЧӮзӮкӮйӮжӮӨӮЙӮөӮҪӮўӮБӮДӮўӮӨҸkҸ¬ҳHҗьӮМ‘ГӢҰӮЕӮ ӮБӮДҒA
SMTӮИӮЗӮЖ”дҠrӮөӮДҗ®җ”ӮМғҠғ\Ғ[ғXӮМӢӨ—LӮӘӮЗӮӨӮұӮӨӮМҳbӮ¶ӮбӮИӮўҒB
Ңг“ЎӮМӮұӮМ•”•ӘӮМүрҗаӮН‘SӮӯ“IӮр“ҫӮДӮўӮИӮўҒB
AMDӮМҗlӮН’PӮЙҗ®җ”ӮНҺg—p•p“xӮӘҚӮӮӯҒAFPӮНҸӯӮИӮўӮЖӮўӮБӮДӮўӮйӮҫӮҜӮҫӮлӮӨӮЙҒBӮ»ӮкӮӘӮИӮсӮЕHTӮЙӮИӮйӮМӮҫ?
ғXғӢҒ[ғvғbғgӮв“d—НӮЖӮўӮӨҢҫ—tӮӘҸd—vӮИӮсӮҫӮжҒB
>Ӯ»ӮМӮҪӮЯӮЙҒACPUӮМғҸҒ[ғNғҚҒ[ғhӮрҢӨӢҶӮөҒAҠeғҸҒ[ғNғҚҒ[ғhӮӘғVғXғeғҖӮМ’ҶӮЕӮЗӮМӮжӮӨӮЙҗUӮй•‘ӮӨӮ©ӮрҢӨӢҶӮөӮҪ
ғVғ“ғOғӢғXғҢғbғhҗ«”\ӮЙ‘ОӮ·Ӯй‘ГӢҰӮБӮДӮМӮНNiagaraӮМӮжӮӨ’PӮЙ“d—НӮр—}ӮҰӮҪӮўҒA
‘тҺRғRғAӮр•АӮЧӮзӮкӮйӮжӮӨӮЙӮөӮҪӮўӮБӮДӮўӮӨҸkҸ¬ҳHҗьӮМ‘ГӢҰӮЕӮ ӮБӮДҒA
SMTӮИӮЗӮЖ”дҠrӮөӮДҗ®җ”ӮМғҠғ\Ғ[ғXӮМӢӨ—LӮӘӮЗӮӨӮұӮӨӮМҳbӮ¶ӮбӮИӮўҒB
Ңг“ЎӮМӮұӮМ•”•ӘӮМүрҗаӮН‘SӮӯ“IӮр“ҫӮДӮўӮИӮўҒB
AMDӮМҗlӮН’PӮЙҗ®җ”ӮНҺg—p•p“xӮӘҚӮӮӯҒAFPӮНҸӯӮИӮўӮЖӮўӮБӮДӮўӮйӮҫӮҜӮҫӮлӮӨӮЙҒBӮ»ӮкӮӘӮИӮсӮЕHTӮЙӮИӮйӮМӮҫ?
ғXғӢҒ[ғvғbғgӮв“d—НӮЖӮўӮӨҢҫ—tӮӘҸd—vӮИӮсӮҫӮжҒB
465 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/11/27(Ӣа) 19:55:35 ID:2Ui1ib200
NiagaraӮНFPӮНӮўӮзӮсӮЖӮОӮ©ӮиӮЙӮ ӮБӮіӮиӮДҺМӮДӢҺӮиҒA“d—НҢш—ҰӮр‘қӮ·ӮҪӮЯӮЙғRғAӮрӢЙ—НғRғ“ғpғNғgӮЙӮөӮҪҒB
AMDӮМӮН‘ГӢҰӮНҚЕҸ¬ҢАӮЙӮөӮжӮӨӮЖӮөӮДӮўӮйҒBAMDӮӘӮўӮўӮҪӮўӮМӮНӮ»ӮӨӮўӮӨҳbҒBPCғIғ^ӮМ‘еҚDӮ«ӮИHTӮНҠЦҢWӮИӮўҒB
AMDӮМӮН‘ГӢҰӮНҚЕҸ¬ҢАӮЙӮөӮжӮӨӮЖӮөӮДӮўӮйҒBAMDӮӘӮўӮўӮҪӮўӮМӮНӮ»ӮӨӮўӮӨҳbҒBPCғIғ^ӮМ‘еҚDӮ«ӮИHTӮНҠЦҢWӮИӮўҒB
466 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/11/27(Ӣа) 21:25:46 ID:2Ui1ib200
http://pc.watch.impress.co.jp/docs/column/kaigai/20091127_331818.html
ArrandaleӮ©ӮзғpғbғPҒ[ғWғ^Ғ[ғ{ӮвӮйӮМӮ©ҒBNehalem—\‘zҠOӮЙҗFҒXӮвӮБӮДӮӯӮкӮйӮИҒB
ArrandaleӮ©ӮзғpғbғPҒ[ғWғ^Ғ[ғ{ӮвӮйӮМӮ©ҒBNehalem—\‘zҠOӮЙҗFҒXӮвӮБӮДӮӯӮкӮйӮИҒB
467 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/11/28(“y) 01:39:58 ID:J1/fezTO0
BulldozerӮБӮДNehalemӮМLSD“Ҝ“ҷӮМҺd‘gӮЭҺgӮБӮДҸ¬ӮіӮўғӢҒ[ғvӮЙҢАӮБӮДӮҫӮҜ
ғLғғғbғVғ…ӮіӮкӮҪғКOPsӮрҚД—ҳ—pӮіӮкӮД2ғXғҢғbғhҚҮҢvӮЕҚЕ‘е8–Ҫ—Я“ҜҺһ”ӯҚsӮЕӮ«ӮйҺd‘gӮЭӮзӮөӮўҒB
ӮұӮкӮБӮД•КӮЙҺАҢшҗ«”\ӮӘҸгӮӘӮйӢZҸpӮ¶ӮбӮИӮўӮжӮИҒB
ӮҝӮИӮЭӮЙNehalemӮН•КӮЙ“ҜҺһ–Ҫ—Я”ӯҚsҗ”ӮрҸгӮ°ӮйӮҪӮЯӮЙLSDҚМ—pӮөӮДӮйӮнӮҜӮ¶ӮбӮИӮўӮ©ӮзӮИҒB
ғLғғғbғVғ…ӮіӮкӮҪғКOPsӮрҚД—ҳ—pӮіӮкӮД2ғXғҢғbғhҚҮҢvӮЕҚЕ‘е8–Ҫ—Я“ҜҺһ”ӯҚsӮЕӮ«ӮйҺd‘gӮЭӮзӮөӮўҒB
ӮұӮкӮБӮД•КӮЙҺАҢшҗ«”\ӮӘҸгӮӘӮйӢZҸpӮ¶ӮбӮИӮўӮжӮИҒB
ӮҝӮИӮЭӮЙNehalemӮН•КӮЙ“ҜҺһ–Ҫ—Я”ӯҚsҗ”ӮрҸгӮ°ӮйӮҪӮЯӮЙLSDҚМ—pӮөӮДӮйӮнӮҜӮ¶ӮбӮИӮўӮ©ӮзӮИҒB
468 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/11/28(“y) 01:49:47 ID:J1/fezTO0
>>462
Bulldozer 8ғXғҢғbғhӮНCoreMAӮМ4ғRғA8ғXғҢғbғhӮжӮиӮНғXғӢҒ[ғvғbғgӮӘҸoӮйӮ©ӮаӮөӮкӮИӮўӮӘ
Core MAӮМ–{•ЁӮМ8ғRғAӮжӮиӮНҺгӮўӮЖҺvӮӨӮсӮҫҒB
–КҗПҢш—ҰҢкӮйӮЙӮНӮ»ӮӨӮўӮӨғҢғxғӢӮЕҢ©ӮИӮўӮЖӮўӮҜӮИӮўҒB
Bulldozer 8ғXғҢғbғhӮНCoreMAӮМ4ғRғA8ғXғҢғbғhӮжӮиӮНғXғӢҒ[ғvғbғgӮӘҸoӮйӮ©ӮаӮөӮкӮИӮўӮӘ
Core MAӮМ–{•ЁӮМ8ғRғAӮжӮиӮНҺгӮўӮЖҺvӮӨӮсӮҫҒB
–КҗПҢш—ҰҢкӮйӮЙӮНӮ»ӮӨӮўӮӨғҢғxғӢӮЕҢ©ӮИӮўӮЖӮўӮҜӮИӮўҒB
469 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/11/28(“y) 02:01:38 ID:J1/fezTO0
–{“–ӮНBulldozerӮа•Ӯ“®Ҹ¬җ”ҸdҺӢӮҫӮӘSandy BridgeӮМFPҗ«”\ӮӘү»ӮҜ•ЁӮЖ”»–ҫӮөӮД
GPGPUӮӘӮ ӮйӮ©Ӯзҗ®җ”ӮҫӮҜӮЕҸ\•ӘӮЖӢӯӮӘӮйҗн—ӘӮЙҸoӮҪӮҫӮҜӮҫӮЖҺvӮӨӮМӮЕӮ·ҒB
ҒiRadeonҢьӮҜӮМGPGPUҠJ”ӯҠВӢ«ӮНӮ ӮЬӮиӮЙӮЁ‘e––Ӯ·Ӯ¬ӮйӮӘҒj
LAMPғTҒ[ғoӮЖӮ©ӮИӮзҠmӮ©ӮЙ•Ӯ“®Ҹ¬җ”ӮН—vӮзӮсӮӘҒAӮ ӮӯӮЬӮЕPCӮЖӮөӮД‘ҪғRғA•K—vӮИҚҒӢпҺtӮБӮД
“®үжҸҲ—қҒAғQҒ[ғҖӮЙӮ№ӮжҒA•Ӯ“®Ҹ¬җ”җ«”\ӮНӮўӮӯӮзӮ ӮБӮДӮа‘«ӮиӮИӮўӮӯӮзӮў—~ӮөӮўӮЖҺvӮӨӮсӮҫӮӘҒEҒEҒEҒE
GPGPUӮӘӮ ӮйӮ©Ӯзҗ®җ”ӮҫӮҜӮЕҸ\•ӘӮЖӢӯӮӘӮйҗн—ӘӮЙҸoӮҪӮҫӮҜӮҫӮЖҺvӮӨӮМӮЕӮ·ҒB
ҒiRadeonҢьӮҜӮМGPGPUҠJ”ӯҠВӢ«ӮНӮ ӮЬӮиӮЙӮЁ‘e––Ӯ·Ӯ¬ӮйӮӘҒj
LAMPғTҒ[ғoӮЖӮ©ӮИӮзҠmӮ©ӮЙ•Ӯ“®Ҹ¬җ”ӮН—vӮзӮсӮӘҒAӮ ӮӯӮЬӮЕPCӮЖӮөӮД‘ҪғRғA•K—vӮИҚҒӢпҺtӮБӮД
“®үжҸҲ—қҒAғQҒ[ғҖӮЙӮ№ӮжҒA•Ӯ“®Ҹ¬җ”җ«”\ӮНӮўӮӯӮзӮ ӮБӮДӮа‘«ӮиӮИӮўӮӯӮзӮў—~ӮөӮўӮЖҺvӮӨӮсӮҫӮӘҒEҒEҒEҒE
470 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/11/28(“y) 22:44:15 ID:l/yEkxTt0
ӮЬӮ Ңг“Ўҗжҗ¶ӮМӢLҺ–ӮҫӮҜ“ЗӮЮӮЖӮіӮаFPӮрӢ]җөӮЙӮөӮҪӮ©ӮМӮжӮӨӮИҲуҸЫӮрӮӨӮҜӮйӮӘҒA
FPӮрӢӨ—Lү»ӮөӮДғҠғ\Ғ[ғXҸW’ҶӮБӮДӮМӮН•КӮЙҗ«”\үТӮ®Һи’iӮЖӮөӮДӮаҲ«ӮӯӮИӮўг©ҒB
ҺАҚЫӮЙAMDҢцҠJӮөӮДӮўӮйҗ«”\—\‘zӮМғOғүғtӮЕInterlagos FP‘Ҡ‘О“IӮЙҲ«ӮӯӮИӮўӮөӮЛҒB
SIMD”{ү»ӮМҢшүКӮӘӮЕӮ©ӮўӮҜӮЗҒB
FPӮрӢӨ—Lү»ӮөӮДғҠғ\Ғ[ғXҸW’ҶӮБӮДӮМӮН•КӮЙҗ«”\үТӮ®Һи’iӮЖӮөӮДӮаҲ«ӮӯӮИӮўг©ҒB
ҺАҚЫӮЙAMDҢцҠJӮөӮДӮўӮйҗ«”\—\‘zӮМғOғүғtӮЕInterlagos FP‘Ҡ‘О“IӮЙҲ«ӮӯӮИӮўӮөӮЛҒB
SIMD”{ү»ӮМҢшүКӮӘӮЕӮ©ӮўӮҜӮЗҒB
471 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/11/29(“ъ) 15:01:47 ID:WWPxkK630
ӮўӮвҒAҢг“ЎӮіӮсӮМҗ}ҒiAMDҺ‘—ҝӮМғfғbғhғRғsҒ[ҒjӮНӮ Ӯ©ӮзӮіӮЬӮЙғҶғjғbғgҗ”ӮӘҢёӮБӮҪӮжӮӨӮЙҢ©ӮҰӮйӮсӮҫӮӘҒB
FMISCӮЖӮ©үҪҸҲҚsӮБӮҪӮМҒHӮБӮДҠҙӮ¶ҒB
3ғҶғjғbғgӮ ӮБӮҪӮаӮМӮӘ2ғҶғjғbғgӮЙӮИӮБӮДӮҪӮз•Ӯ“®Ҹ¬җ”җ«”\—ҺӮҝӮйӮБӮДҺvӮӨӮ¶ӮбӮИӮўҒH
FMISCӮЖӮ©үҪҸҲҚsӮБӮҪӮМҒHӮБӮДҠҙӮ¶ҒB
3ғҶғjғbғgӮ ӮБӮҪӮаӮМӮӘ2ғҶғjғbғgӮЙӮИӮБӮДӮҪӮз•Ӯ“®Ҹ¬җ”җ«”\—ҺӮҝӮйӮБӮДҺvӮӨӮ¶ӮбӮИӮўҒH
472 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/11/29(“ъ) 15:04:32 ID:WWPxkK630
’ҶӮМҗlӮӘ•sҗіҠmӮҫӮБӮДҢҫӮБӮДӮйҗ}ӮрӮ»ӮМӮЬӮсӮЬҢ©ӮДӮЗӮӨӮұӮӨӮЖӮ©
473 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/11/29(“ъ) 18:28:53 ID:Xk0knOdJ0
Ӯ ӮкӮНҠИ—Әү»ӮіӮкӮҪҗ}ӮҫӮөҒAFMACӮөӮ©ӮИӮўӮЖӮ©ҺАҚЫӮ Ӯи“ҫӮИӮўӮ©ӮзӮИҒB
’PӮЙҗVӮөӮўFMACӮрҗа–ҫӮЕӢӯ’ІӮөӮҪӮ©ӮБӮҪӮҫӮҜӮҫӮлҒB
ғOғүғtӮЕҺҰӮіӮкӮДӮўӮйӮЖӮЁӮиҒAFPҺМӮДӮҪӮЖӮўӮӨӮнӮҜӮ¶ӮбӮИӮўҒB
FPүүҺZӮОӮ©Ӯиү„ҒXҺАҚsӮөӮДӮўӮйӮжӮӨӮИғҸҒ[ғNғҚҒ[ғhӮНҺАҚЫғTҒ[ғoӮЕӮН’ҙғҢғAӮИӮнӮҜӮЕҒA
FPғNғүғXғ^•”ӮНӮЗӮҝӮзӮМғXғҢғbғhӮ©ӮзӮағnҒ[ғhғEғGғAғ}ғӢғ`ғXғҢғbғfғBғ“ғOӮЕҗШӮи‘ЦӮҰӮД
ҺАҚsӮЕӮ«ӮйӮжӮӨӮЕӮ ӮйӮөҒA‘SӮӯ“ҜӮ¶ҺһҠФӮЙFPүүҺZӮӘӮ©ӮҝҚҮӮўӮВӮГӮҜӮй‘z’иӮНӮ ӮЬӮиҲУ–Ў–іӮўӮБӮДӮұӮЖӮҫӮИҒB
Ӯ»ӮкӮжӮиӮұӮМ“Б’Ҙ“IӮИINT/FPӮМҚ\җ¬ӮМғAҒ[ғLӮЙҚЕ“Kү»ӮөӮҪғRғ“ғpғCғүӮрҚмӮБӮДӮӯӮкӮй
ғxғ“ғ_Ғ[ӮНӮ ӮйӮМӮҫӮлӮӨӮ©?•Ғ’КӮЙCore 2ҢnӮЙҚЕ“Kү»ӮөӮҪӮҫӮҜӮ¶ӮбҺА—НӮЕӮИӮіӮ»ӮӨӮҫӮИҒB
’PӮЙҗVӮөӮўFMACӮрҗа–ҫӮЕӢӯ’ІӮөӮҪӮ©ӮБӮҪӮҫӮҜӮҫӮлҒB
ғOғүғtӮЕҺҰӮіӮкӮДӮўӮйӮЖӮЁӮиҒAFPҺМӮДӮҪӮЖӮўӮӨӮнӮҜӮ¶ӮбӮИӮўҒB
FPүүҺZӮОӮ©Ӯиү„ҒXҺАҚsӮөӮДӮўӮйӮжӮӨӮИғҸҒ[ғNғҚҒ[ғhӮНҺАҚЫғTҒ[ғoӮЕӮН’ҙғҢғAӮИӮнӮҜӮЕҒA
FPғNғүғXғ^•”ӮНӮЗӮҝӮзӮМғXғҢғbғhӮ©ӮзӮағnҒ[ғhғEғGғAғ}ғӢғ`ғXғҢғbғfғBғ“ғOӮЕҗШӮи‘ЦӮҰӮД
ҺАҚsӮЕӮ«ӮйӮжӮӨӮЕӮ ӮйӮөҒA‘SӮӯ“ҜӮ¶ҺһҠФӮЙFPүүҺZӮӘӮ©ӮҝҚҮӮўӮВӮГӮҜӮй‘z’иӮНӮ ӮЬӮиҲУ–Ў–іӮўӮБӮДӮұӮЖӮҫӮИҒB
Ӯ»ӮкӮжӮиӮұӮМ“Б’Ҙ“IӮИINT/FPӮМҚ\җ¬ӮМғAҒ[ғLӮЙҚЕ“Kү»ӮөӮҪғRғ“ғpғCғүӮрҚмӮБӮДӮӯӮкӮй
ғxғ“ғ_Ғ[ӮНӮ ӮйӮМӮҫӮлӮӨӮ©?•Ғ’КӮЙCore 2ҢnӮЙҚЕ“Kү»ӮөӮҪӮҫӮҜӮ¶ӮбҺА—НӮЕӮИӮіӮ»ӮӨӮҫӮИҒB
474 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/11/29(“ъ) 22:37:02 ID:WWPxkK630
Ӯ»ӮкӮНӮ»ӮкӮЕSandy BridgeӮЕ256bitӮМFADD+FMULӮЖBulldozerӮМ128bitӮМFMAC*2
ӮЗӮБӮҝӮӘ—ЗӮўӮ©ӮБӮДӮўӮӨӮЖ”»’fӮөӮ©ӮЛӮй
ӮЬӮ BulldozerӮМҗЭҢv’iҠKӮЕ256bitӮЖӮўӮӨ‘I‘рҺҲӮН–іӮ©ӮБӮҪӮнӮҜӮҫӮлӮӨӮӘ
ӮЗӮБӮҝӮӘ—ЗӮўӮ©ӮБӮДӮўӮӨӮЖ”»’fӮөӮ©ӮЛӮй
ӮЬӮ BulldozerӮМҗЭҢv’iҠKӮЕ256bitӮЖӮўӮӨ‘I‘рҺҲӮН–іӮ©ӮБӮҪӮнӮҜӮҫӮлӮӨӮӘ
475 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷж|ҚкҒF2009/12/05(“y) 14:38:48 ID:PWoPvAcf0
ҚЎ“ъӮ©ӮзӮұӮұӮН3”N‘OӮрүщӮ©ӮөӮсӮЕӮўӮӯғXғҢӮЙӮИӮиӮЬӮөӮҪҒB
476 ҒF–јҸМ–ўҗЭ’иҒF2009/12/05(“y) 14:41:26 ID:QyROQi480
No Thank You
477 ҒF–јҸМ–ўҗЭ’иҒF2009/12/05(“y) 15:26:05 ID:3dYt2kZj0
Ғј(ҒLҒНҒM’UҒјҺҒӮМ—\‘Әҗё“xӮМҚӮӮіӮЙҠҙ•һӮўӮҪӮөӮЬӮ·ӮҪҒI
478 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/12/05(“y) 15:42:21 ID:E+7NrUPd0
>>475ӮНүҙӮМүЕ
479 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/12/05(“y) 15:48:08 ID:E+7NrUPd0
Ӯ»ӮкӮНӮ»ӮӨӮЖҒAӮЗӮӨӮаBulldozerӮМFMISCӮН1–{ӮЫӮўӮИ
AMDӮМXOPӮМҺd—lҸ‘ӮЙIntel AVXӮЕғ|ғVғғӮБӮҪvpermil2ps/vpermil2pdӮМӢLҸqӮӘ’ЗүБ
ӮаӮБӮЖӮаҒAӮаӮЖӮаӮЖpermps/permpdӮМҢ`ӮЕ“ьӮБӮДӮҪғӮғmӮМ“ЗӮЭ‘ЦӮҰӮҫӮҜӮЗӮЛҒB
ӮұӮўӮВӮрҠҲ—pӮ·ӮйҸкҚҮҒA“]’uҚs—сҗПӮрӢҒӮЯӮДӮ©Ӯз“]’uҚs—сӮрҚмӮйҢ`ӮЙӮИӮй
4x4Қs—сҗПӮМҸкҚҮҒA16үсӮМSIMDҗПҳaҺZӮЙ‘ОӮөӮД8үсӮМPermuteӮЕҚПӮЮҒB
vbroadcast*ҒЁvmul*ҒЁvadd* ӮМIntelӮЖӮН‘ОҸМ“IӮҫӮЛҒB
AMDӮМXOPӮМҺd—lҸ‘ӮЙIntel AVXӮЕғ|ғVғғӮБӮҪvpermil2ps/vpermil2pdӮМӢLҸqӮӘ’ЗүБ
ӮаӮБӮЖӮаҒAӮаӮЖӮаӮЖpermps/permpdӮМҢ`ӮЕ“ьӮБӮДӮҪғӮғmӮМ“ЗӮЭ‘ЦӮҰӮҫӮҜӮЗӮЛҒB
ӮұӮўӮВӮрҠҲ—pӮ·ӮйҸкҚҮҒA“]’uҚs—сҗПӮрӢҒӮЯӮДӮ©Ӯз“]’uҚs—сӮрҚмӮйҢ`ӮЙӮИӮй
4x4Қs—сҗПӮМҸкҚҮҒA16үсӮМSIMDҗПҳaҺZӮЙ‘ОӮөӮД8үсӮМPermuteӮЕҚПӮЮҒB
vbroadcast*ҒЁvmul*ҒЁvadd* ӮМIntelӮЖӮН‘ОҸМ“IӮҫӮЛҒB
480 ҒFOOO-Ғј(ҒLҒНҒM’UҒјҒҷғКҒF2009/12/05(“y) 22:52:25 ID:PWoPvAcf0
ғvғҚғZғbғTӮН“d—Н(Power)ӮҫӮәҒI
481 ҒFҒОҒОҒОҒОҒј(ҒEҒНҒE,,ҒҷuҒF2009/12/05(“y) 23:17:36 ID:PWoPvAcf0
ӮИӮсӮЖLarrabeeeӮНҺё”sҚмӮҫӮБӮҪӮәҒI
612 ҒF,,ҒE ҒН ҒE,,ҒjӮБ-ҒӣҒқҒӣ [Ғ«] ҒF2008/10/25(“y) 18:01:54 ID:L+S6Bhz8 (2/2)
LarrabeeӮНҺё”sҚмӮЕӮ·ӮБ!!
624 ҒF,,ҒE ҒН ҒE,,ҒjӮБ-ҒӣҒқҒӣ [Ғ«] ҒF2008/10/27(ҢҺ) 20:53:06 ID:Awv+woA0
>>613
ӮЕӮ«Ӯ ӮӘӮБӮДӮўӮИӮўӮаӮМӮрҒA
ӮұӮкӮЬӮЕӮМҸо•сӮ©Ӯз”»’fӮөӮДҺё”sӮЖӮўӮБӮДӮўӮйӮМӮҫҒB
Ӯ«ӮЭӮМӮжӮӨӮИ’б”\ӮӯӮсӮМ—\‘zӮЖӮЁӮИӮ¶Ӯ¶Ӯ°ӮсӮЕҢкӮзӮИӮўӮЕ—~ӮөӮўҒB
ӮЁӮкӮН’cҺqӮҫӮјҒB
734 ҒF,,ҒE ҒН ҒE,,ҒjӮБ-ҒӣҒқҒӣ [Ғ«] ҒF2008/11/05(җ…) 23:28:06 ID:9Sl/DSog (8/8)
ӮДҒ[Ӯ©ҒAӮжӮӯӮ»ӮұӮЬӮЕҠъ‘ТӮЕӮ«ӮйӮжӮИҒB
SIGGRAPHӮМҳ_•¶ӮӘӮЕӮҪҺһ“_ӮЕҒA
ҒuӮ ҒAӮұӮкӮҫӮЯӮҫӮЛҒv
ӮБӮДӮМӮӘLarrabee’ЗӮўӮ©ӮҜӮДӮ«ӮҪӮаӮМӮМҗі’јӮИҠҙ‘zӮҫӮлӮӨҒB
Ӯ»ӮМҢгӮаҠъ‘ТӮЕӮ«Ӯйҳb‘иӮНӮИӮўӮИҒB
Ҹ«—ҲӮМ“қҚҮҳbӮН•КӮЖӮөӮДҒB
612 ҒF,,ҒE ҒН ҒE,,ҒjӮБ-ҒӣҒқҒӣ [Ғ«] ҒF2008/10/25(“y) 18:01:54 ID:L+S6Bhz8 (2/2)
LarrabeeӮНҺё”sҚмӮЕӮ·ӮБ!!
624 ҒF,,ҒE ҒН ҒE,,ҒjӮБ-ҒӣҒқҒӣ [Ғ«] ҒF2008/10/27(ҢҺ) 20:53:06 ID:Awv+woA0
>>613
ӮЕӮ«Ӯ ӮӘӮБӮДӮўӮИӮўӮаӮМӮрҒA
ӮұӮкӮЬӮЕӮМҸо•сӮ©Ӯз”»’fӮөӮДҺё”sӮЖӮўӮБӮДӮўӮйӮМӮҫҒB
Ӯ«ӮЭӮМӮжӮӨӮИ’б”\ӮӯӮсӮМ—\‘zӮЖӮЁӮИӮ¶Ӯ¶Ӯ°ӮсӮЕҢкӮзӮИӮўӮЕ—~ӮөӮўҒB
ӮЁӮкӮН’cҺqӮҫӮјҒB
734 ҒF,,ҒE ҒН ҒE,,ҒjӮБ-ҒӣҒқҒӣ [Ғ«] ҒF2008/11/05(җ…) 23:28:06 ID:9Sl/DSog (8/8)
ӮДҒ[Ӯ©ҒAӮжӮӯӮ»ӮұӮЬӮЕҠъ‘ТӮЕӮ«ӮйӮжӮИҒB
SIGGRAPHӮМҳ_•¶ӮӘӮЕӮҪҺһ“_ӮЕҒA
ҒuӮ ҒAӮұӮкӮҫӮЯӮҫӮЛҒv
ӮБӮДӮМӮӘLarrabee’ЗӮўӮ©ӮҜӮДӮ«ӮҪӮаӮМӮМҗі’јӮИҠҙ‘zӮҫӮлӮӨҒB
Ӯ»ӮМҢгӮаҠъ‘ТӮЕӮ«Ӯйҳb‘иӮНӮИӮўӮИҒB
Ҹ«—ҲӮМ“қҚҮҳbӮН•КӮЖӮөӮДҒB
482 ҒF–јҸМ–ўҗЭ’иҒF2009/12/05(“y) 23:22:48 ID:PWoPvAcf0
#үрҗа#
HavendaleӮМғLғғғ“ғZғӢ—\‘zӮЙ‘ұӮ«ҒALRBӮрҺё”sҚмӮЕӮ ӮйӮЖӮ®ӮӨӮәӮс“–ӮДӮДӮөӮЬӮБӮҪ”ЮӮН
”\—НӮӘ’ҙ(ғXҒ[ғpҒ[)ү»ӮөӮДӮ©ӮВӮДӮМғXғҢҺеӮМӮжӮӨӮЙ•ПҗgӮөӮДӮөӮЬӮБӮҪӮМӮҫӮБӮҪҒc(ҒEҒНҒE)
HavendaleӮМғLғғғ“ғZғӢ—\‘zӮЙ‘ұӮ«ҒALRBӮрҺё”sҚмӮЕӮ ӮйӮЖӮ®ӮӨӮәӮс“–ӮДӮДӮөӮЬӮБӮҪ”ЮӮН
”\—НӮӘ’ҙ(ғXҒ[ғpҒ[)ү»ӮөӮДӮ©ӮВӮДӮМғXғҢҺеӮМӮжӮӨӮЙ•ПҗgӮөӮДӮөӮЬӮБӮҪӮМӮҫӮБӮҪҒc(ҒEҒНҒE)
483 ҒFҒОҒОҒОҒОҒј(ҒEҒНҒE,,ҒҷuҒF2009/12/05(“y) 23:25:41 ID:PWoPvAcf0
ӮЖӮўӮӨҸз’kӮНӮіӮДӮЁӮ«
HaswellӮМү^–ҪӮӘӮЗӮӨӮИӮйӮ©ҠyӮөӮЭӮЙӮИӮБӮДӮ«ӮҪӮИҒB
ҢВҗl“IӮЙӮНҲк“xғLғғғ“ғZғӢӮөӮДSoCү»ӮМ•ыҢьӮрҠъ‘ТӮөӮДӮўӮйӮнӮҜӮЕӮ ӮйӮӘҒB
HaswellӮМү^–ҪӮӘӮЗӮӨӮИӮйӮ©ҠyӮөӮЭӮЙӮИӮБӮДӮ«ӮҪӮИҒB
ҢВҗl“IӮЙӮНҲк“xғLғғғ“ғZғӢӮөӮДSoCү»ӮМ•ыҢьӮрҠъ‘ТӮөӮДӮўӮйӮнӮҜӮЕӮ ӮйӮӘҒB
484 ҒFҒОҒОҒОҒОҒј(ҒEҒНҒE,,ҒҷuҒF2009/12/05(“y) 23:49:46 ID:PWoPvAcf0
Part1 >>702-
http://itl.jisakuita.net/intel_ups_info/1121683774.html#R702
KeiferӮН32nmғvғҚғZғXӮЕҒA4coreӮр1ғmҒ[ғhӮЕ32coreҸWҗПӮБӮДҳbӮЕҒA
ҚЎҺvӮҰӮОIntel”ЕӮМBulldozerӮЭӮҪӮўӮИҢvүжӮҫӮБӮҪӮИҒB
Part1ӮН1җў‘гӮМғVғ…ғҠғ“ғNӮЕғRғA–КҗПӮӘ”ј•ӘӮЙӮИӮйӮЖӮўӮӨҠФҲбӮБӮҪҗ„‘ӘӮрӮөӮД
WestmereӮМ”hҗ¶•iӮЕӮ ӮйӮЖӮ©ӮКӮ©ӮөӮДӮўӮйӮӘҒAMini CoreҢnҒB
KeiferӮНҗ®җ”ҸdҺӢӮҫӮБӮҪӮсӮҫӮлӮӨӮҜӮЗҒB
http://itl.jisakuita.net/intel_ups_info/1121683774.html#R702
KeiferӮН32nmғvғҚғZғXӮЕҒA4coreӮр1ғmҒ[ғhӮЕ32coreҸWҗПӮБӮДҳbӮЕҒA
ҚЎҺvӮҰӮОIntel”ЕӮМBulldozerӮЭӮҪӮўӮИҢvүжӮҫӮБӮҪӮИҒB
Part1ӮН1җў‘гӮМғVғ…ғҠғ“ғNӮЕғRғA–КҗПӮӘ”ј•ӘӮЙӮИӮйӮЖӮўӮӨҠФҲбӮБӮҪҗ„‘ӘӮрӮөӮД
WestmereӮМ”hҗ¶•iӮЕӮ ӮйӮЖӮ©ӮКӮ©ӮөӮДӮўӮйӮӘҒAMini CoreҢnҒB
KeiferӮНҗ®җ”ҸdҺӢӮҫӮБӮҪӮсӮҫӮлӮӨӮҜӮЗҒB
485 ҒFҒОҒОҒОҒОҒј(ҒEҒНҒE,,ҒҷuҒF2009/12/05(“y) 23:51:30 ID:PWoPvAcf0
>ӮұӮМғTғCғYӮҫӮЖXeon MP/IPFғNғүғXӮМғnғCғGғ“ғh“Бү»ғ`ғbғvӮИӮзsingle dieӮаӮ ӮиӮҰӮИӮӯӮаӮИӮўӮИҚЕӢЯӮМғgғҢғ“ғhӮҫӮЖҒB
>ғҠғ“ғOӮЕ’Ҷ“r”ј’[ӮИmcmҚ\җ¬ӮаӮвӮҫӮөҒAӮұӮЖMany CoreӮЙҠЦӮөӮДӮНҸз’·Қ\җ¬ӮЕғRғAӮрҗПӢЙ“IӮЙҺEӮ·•ыҗjӮЕӮВӮӯӮкӮО•а—ҜӮЬӮиӮа‘е•Әүь‘PӮіӮкӮйӮнӮҜӮҫӮөҒB
>ҲУҠOӮЖsingle dieӮЕӮўӮҜӮйӮ©ӮаӮөӮкӮИӮўҗа•ӮҸгҒB
BecktonӮӘ8coreӮЗӮЬӮиӮИӮЖӮұӮлӮ©ӮзӮөӮДҒA32nmӮЕWestmere 32 coreҸWҗПӮИӮсӮД
ҚЎӮМҸнҺҜӮ©ӮзҚlӮҰӮД“һ’к–і—қӮҫӮј(ӮнӮзӮЎ
>ғҠғ“ғOӮЕ’Ҷ“r”ј’[ӮИmcmҚ\җ¬ӮаӮвӮҫӮөҒAӮұӮЖMany CoreӮЙҠЦӮөӮДӮНҸз’·Қ\җ¬ӮЕғRғAӮрҗПӢЙ“IӮЙҺEӮ·•ыҗjӮЕӮВӮӯӮкӮО•а—ҜӮЬӮиӮа‘е•Әүь‘PӮіӮкӮйӮнӮҜӮҫӮөҒB
>ҲУҠOӮЖsingle dieӮЕӮўӮҜӮйӮ©ӮаӮөӮкӮИӮўҗа•ӮҸгҒB
BecktonӮӘ8coreӮЗӮЬӮиӮИӮЖӮұӮлӮ©ӮзӮөӮДҒA32nmӮЕWestmere 32 coreҸWҗПӮИӮсӮД
ҚЎӮМҸнҺҜӮ©ӮзҚlӮҰӮД“һ’к–і—қӮҫӮј(ӮнӮзӮЎ
486 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/12/05(“y) 23:56:13 ID:E+7NrUPd0
KeiferӮН•Ғ’КӮЙBonnelӮЭӮҪӮўӮИLPIAӮҫӮЖҺvӮБӮДӮҪӮж
487 ҒFҒОҒОҒОҒОҒј(ҒEҒНҒE,,ҒҷuҒF2009/12/05(“y) 23:57:09 ID:PWoPvAcf0
Part1 >>647-
http://itl.jisakuita.net/intel_ups_info/1121683774.html#R702
647 –ј‘OҒF–јҸМ–ўҗЭ’и ҒF2006/06/25(“ъ) 22:41:27 ID:wVCZoCKm0
intelerӮНғRғҢӮЗӮӨҺvӮӨҒH
ғQғeғӮғmғeғNғmғҚғWӮӘӮ«ӮЬӮөӮҪӮж
>"Reverse(Anti)-Hyper-Threading"ӢZҸpӮБӮДҒA
>X2ӮМ2ҢВӮМғRғAӮрҢӢҚҮӮө6IPC(3IPCx2ҢВ•Ә)ӮМғVғ“ғOғӢғRғAӮрғGғ~ғ…ғҢҒ[ғgӮ·ӮйӢZҸpӮЖӮМӮұӮЖ(CONROEӮН4IPC)ҒB
329 –ј‘OҒFSocket774[sage] “ҠҚe“ъҒF2006/06/24(“y) 23:36:08 ID:GbdsoFH3
http://nueda.main.jp/blog/archives/002203.html
ғpғtғHҒ[ғ}ғ“ғXҺҹ‘жӮЕAM2ү»ӮҜӮйӮИӮұӮкҒB
939ӮЕҸo—ҲӮкӮОҗ_ӮИӮМӮЙӮ—
336 –ј‘OҒFSocket774[sage] “ҠҚe“ъҒF2006/06/25(“ъ) 00:38:21 ID:W3KCOSqT
IntelӮа“ҜӮ¶ӮұӮЖӮвӮйӮ»ӮӨӮЕӮ·Ӯ—
ғPғ“ғcӮЕ4ғRғAӮр1CPUӮЙӮ—
98 –ј‘OҒFSocket774[sage] “ҠҚe“ъҒF2006/06/25(“ъ) 00:33:05 ID:Utko172H
ӮИӮсӮ©Һ—ӮҪӮжӮӨӮИӮМӮӘҒc
CMT (Core Multiplexing Technology)
http://www.xtremesystems.org/forums/showthread.php?t=104178
http://itl.jisakuita.net/intel_ups_info/1121683774.html#R702
647 –ј‘OҒF–јҸМ–ўҗЭ’и ҒF2006/06/25(“ъ) 22:41:27 ID:wVCZoCKm0
intelerӮНғRғҢӮЗӮӨҺvӮӨҒH
ғQғeғӮғmғeғNғmғҚғWӮӘӮ«ӮЬӮөӮҪӮж
>"Reverse(Anti)-Hyper-Threading"ӢZҸpӮБӮДҒA
>X2ӮМ2ҢВӮМғRғAӮрҢӢҚҮӮө6IPC(3IPCx2ҢВ•Ә)ӮМғVғ“ғOғӢғRғAӮрғGғ~ғ…ғҢҒ[ғgӮ·ӮйӢZҸpӮЖӮМӮұӮЖ(CONROEӮН4IPC)ҒB
329 –ј‘OҒFSocket774[sage] “ҠҚe“ъҒF2006/06/24(“y) 23:36:08 ID:GbdsoFH3
http://nueda.main.jp/blog/archives/002203.html
ғpғtғHҒ[ғ}ғ“ғXҺҹ‘жӮЕAM2ү»ӮҜӮйӮИӮұӮкҒB
939ӮЕҸo—ҲӮкӮОҗ_ӮИӮМӮЙӮ—
336 –ј‘OҒFSocket774[sage] “ҠҚe“ъҒF2006/06/25(“ъ) 00:38:21 ID:W3KCOSqT
IntelӮа“ҜӮ¶ӮұӮЖӮвӮйӮ»ӮӨӮЕӮ·Ӯ—
ғPғ“ғcӮЕ4ғRғAӮр1CPUӮЙӮ—
98 –ј‘OҒFSocket774[sage] “ҠҚe“ъҒF2006/06/25(“ъ) 00:33:05 ID:Utko172H
ӮИӮсӮ©Һ—ӮҪӮжӮӨӮИӮМӮӘҒc
CMT (Core Multiplexing Technology)
http://www.xtremesystems.org/forums/showthread.php?t=104178
488 ҒFҒОҒОҒОҒОҒј(ҒEҒНҒE,,ҒҷuҒF2009/12/05(“y) 23:58:26 ID:PWoPvAcf0
ttp://itl.jisakuita.net/intel_ups_info/1121683774.html#R647
ҚЎҺvӮҰӮО
Ҹг“cҗV•·ӮрӮЭӮйӮИӮиҒA"Reverse HT"ӮБӮДғNғүғXғ^ғhғAҒ[ғLҸүҠъҚ\‘zӮӘ
•ПҢ`ӮөӮД•…ӮкғӢҒ[ғ}Ғ[ү»ӮөӮҪӮЬӮМӮҫӮБӮҪӮсӮ¶ӮбӮЛ?
ҚЎҺvӮҰӮО
Ҹг“cҗV•·ӮрӮЭӮйӮИӮиҒA"Reverse HT"ӮБӮДғNғүғXғ^ғhғAҒ[ғLҸүҠъҚ\‘zӮӘ
•ПҢ`ӮөӮД•…ӮкғӢҒ[ғ}Ғ[ү»ӮөӮҪӮЬӮМӮҫӮБӮҪӮсӮ¶ӮбӮЛ?
489 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/12/05(“y) 23:59:17 ID:E+7NrUPd0
ғVғ“ғOғӢғXғҢғbғhҗ«”\Ӯр4issueҲИҸгӮЙҲшӮ«ҸгӮ°ӮйӮҪӮЯӮМғAғvғҚҒ[ғ`ӮЕӮНӮИӮ©ӮБӮҪӮаӮМӮМ
ӮвӮБӮПӮиCPUӮМҚЕҗж’[ӢZҸpӮЙӮНүҪӮзӮ©ӮМ•ҡҗьӮНӮ ӮйӮсӮҫӮИ
ӮвӮБӮПӮиCPUӮМҚЕҗж’[ӢZҸpӮЙӮНүҪӮзӮ©ӮМ•ҡҗьӮНӮ ӮйӮсӮҫӮИ
490 ҒFҒОҒОҒОҒОҒј(ҒEҒНҒE,,ҒҷuҒF2009/12/05(“y) 23:59:30 ID:PWoPvAcf0
652 –ј‘OҒF–јҸМ–ўҗЭ’и ҒF2006/06/25(“ъ) 23:00:43 ID:B3WpK4hv0
>>651
ӮҫӮ©ӮзҒAғ}ғӢғ`ғXғҢғbғhӮЙ•ӘүрӮ·ӮйӢZҸpӮЕӮНӮИӮ©ӮҪҒB
•”•Ә“IӮЙ2ғRғA•ӘӮМғҠғ\Ғ[ғXӮр1ғRғAӮЙүсӮ·ӮҫӮҜҒB
Ӯ»ӮкӮаҢ»ҚsғRғAӮЕӮН“пӮөӮўӮЖҺvӮӨӮҜӮЗӮИҒB
663 –ј‘OҒFinteler ҒF2006/07/01(“y) 12:53:35 ID:EoOwVEaJ0
“БӮЙ‘¬“xҢьҸгҺеҠбӮЕӮНӮИӮў—қ—RӮЕғ}ғӢғ`ғXғҢғbғhӮр—pӮўӮйҸуӢөӮНӮҪӮӯӮіӮсӮ ӮйӮнӮҜӮЕҒA
Ӯ»ӮМӮжӮӨӮИғAғvғҠӮЕӮНҒA•Ўҗ”ғRғAӮӘ—LҢшӮЙӮИӮБӮҪҸкҚҮҒAӢtӮЙҗ«”\ӮӘ’бүәӮөӮДӮөӮЬӮӨғPҒ[ғXӮаӮЕӮйӮнӮҜҒB
(Ӯ ӮйғXғҢғbғhӮӘӮКӮйӮўҸҲ—қӮөӮ©ӮөӮДӮўӮИӮӯӮД–wӮЗ—VӮсӮЕӮўӮҪӮиӮ·ӮйҸкҚҮӮИӮЗ)
OSӮНCPUӮЙ‘ОӮөӮД‘S’m‘S”\ӮИӮнӮҜӮНӮИӮўӮМӮЕҒA
ғAғvғҠ‘ӨӮМ—vӢҒӮЕҒA“®“IӮЙӮўӮзӮИӮўғRғAӮрҺEӮөӮДҗ«”\ӮрҲЫҺқӮөӮҪӮўCore MultiplexingӮМӮжӮӨӮИӢZҸpӮӘ—LҢшӮИӮБӮДӮӯӮйӮнӮҜҒB
•Р•ыӮМғRғAӮЙ•Ўҗ”•ӘӮМғRғAӮМғҠғ\Ғ[ғXӮрүсӮ·ӮЖӮўӮӨӮМӮНҒAғnҒ[ғhҗЭҢvӮМ–в‘иӮӘӮ ӮйӮМӮЕҒA
Ң»Қsҗ»•iӮЕӮНӮұӮМӮжӮӨӮИӢ@”\ӮМӮҪӮЯӮМ“ҠҺ‘ӮН–wӮЗӮөӮДӮИӮўӮҫӮлӮӨӮ©Ӯз“пӮөӮўҒB
"Core"ӮМҸкҚҮҒAshared L2ӮЖL1-to-L1ӮМғҠғ“ғNӮНҗ¶Ӯ©ӮіӮкӮ»ӮӨҒB
(ӮөӮ©ӮөҒAӮұӮкӮзӮМӢ@”\ӮНӮўӮҝӮўӮҝӮўӮзӮсғRғAӮрҺEӮіӮИӮӯӮДӮаSingle ThreadӮЙӮИӮкӮОҸҹҺиӮЙ“ӯӮўӮДӮӯӮкӮйӮнӮҜӮҫӮӘ)
ҚЎҢгӮМ“WҠJӮЕӮаҒAҺАҚsғҶғjғbғgҒAғXғPғWғ…Ғ[ғүӮМғҠғ\Ғ[ғXҺgӮўүсӮөӮНӮНӮБӮ«ӮиӮўӮБӮД•sүВ”\ӮҫӮЖҺvӮнӮкӮйҒB
Ҡж’ЈӮБӮДӮаFetch, DecodeӮИӮЗӮМғtғҚғ“ғgғGғ“ғhӮӘҢА“xӮ©ӮЖҒBӮ»ӮкӮЕӮа‘СҲж‘қӮвӮөӮИӮӘӮз’xү„ӮрҲк’иӮЙүҹӮіӮҰӮйӮМӮН
—eҲХӮЕӮНӮИӮўӮМӮЕғ^ғ_ӮЕ‘¬ӮӯӮНӮИӮиӮЬӮ№ӮсҒB
“d—НҒE”ӯ”MӮМ“sҚҮӮ©ӮзҚlӮҰӮДҒAӮўӮзӮсғRғAӮрҺEӮөӮДғIҒ[ғoҒ[ғNғҚғbғNӮЖӮўӮӨFoxtonҢnӮМ“WҠJӮНҚЎҢгҚlӮҰӮзӮкӮйҒB
ӮВҒ[Ӯ©ҒAғҠғ\Ғ[ғXүсӮ·ӮжӮиҒAғIҒ[ғoҒ[ғNғҚғbғNӮЕҗ«”\үТӮўӮҫ•ыӮӘҒAҲАҸгӮӘӮиӮЕҢшүКӮа‘еӮ«ӮўӮсӮ¶ӮбӮИӮўӮ©ӮЖҒB
>>651
ӮҫӮ©ӮзҒAғ}ғӢғ`ғXғҢғbғhӮЙ•ӘүрӮ·ӮйӢZҸpӮЕӮНӮИӮ©ӮҪҒB
•”•Ә“IӮЙ2ғRғA•ӘӮМғҠғ\Ғ[ғXӮр1ғRғAӮЙүсӮ·ӮҫӮҜҒB
Ӯ»ӮкӮаҢ»ҚsғRғAӮЕӮН“пӮөӮўӮЖҺvӮӨӮҜӮЗӮИҒB
663 –ј‘OҒFinteler ҒF2006/07/01(“y) 12:53:35 ID:EoOwVEaJ0
“БӮЙ‘¬“xҢьҸгҺеҠбӮЕӮНӮИӮў—қ—RӮЕғ}ғӢғ`ғXғҢғbғhӮр—pӮўӮйҸуӢөӮНӮҪӮӯӮіӮсӮ ӮйӮнӮҜӮЕҒA
Ӯ»ӮМӮжӮӨӮИғAғvғҠӮЕӮНҒA•Ўҗ”ғRғAӮӘ—LҢшӮЙӮИӮБӮҪҸкҚҮҒAӢtӮЙҗ«”\ӮӘ’бүәӮөӮДӮөӮЬӮӨғPҒ[ғXӮаӮЕӮйӮнӮҜҒB
(Ӯ ӮйғXғҢғbғhӮӘӮКӮйӮўҸҲ—қӮөӮ©ӮөӮДӮўӮИӮӯӮД–wӮЗ—VӮсӮЕӮўӮҪӮиӮ·ӮйҸкҚҮӮИӮЗ)
OSӮНCPUӮЙ‘ОӮөӮД‘S’m‘S”\ӮИӮнӮҜӮНӮИӮўӮМӮЕҒA
ғAғvғҠ‘ӨӮМ—vӢҒӮЕҒA“®“IӮЙӮўӮзӮИӮўғRғAӮрҺEӮөӮДҗ«”\ӮрҲЫҺқӮөӮҪӮўCore MultiplexingӮМӮжӮӨӮИӢZҸpӮӘ—LҢшӮИӮБӮДӮӯӮйӮнӮҜҒB
•Р•ыӮМғRғAӮЙ•Ўҗ”•ӘӮМғRғAӮМғҠғ\Ғ[ғXӮрүсӮ·ӮЖӮўӮӨӮМӮНҒAғnҒ[ғhҗЭҢvӮМ–в‘иӮӘӮ ӮйӮМӮЕҒA
Ң»Қsҗ»•iӮЕӮНӮұӮМӮжӮӨӮИӢ@”\ӮМӮҪӮЯӮМ“ҠҺ‘ӮН–wӮЗӮөӮДӮИӮўӮҫӮлӮӨӮ©Ӯз“пӮөӮўҒB
"Core"ӮМҸкҚҮҒAshared L2ӮЖL1-to-L1ӮМғҠғ“ғNӮНҗ¶Ӯ©ӮіӮкӮ»ӮӨҒB
(ӮөӮ©ӮөҒAӮұӮкӮзӮМӢ@”\ӮНӮўӮҝӮўӮҝӮўӮзӮсғRғAӮрҺEӮіӮИӮӯӮДӮаSingle ThreadӮЙӮИӮкӮОҸҹҺиӮЙ“ӯӮўӮДӮӯӮкӮйӮнӮҜӮҫӮӘ)
ҚЎҢгӮМ“WҠJӮЕӮаҒAҺАҚsғҶғjғbғgҒAғXғPғWғ…Ғ[ғүӮМғҠғ\Ғ[ғXҺgӮўүсӮөӮНӮНӮБӮ«ӮиӮўӮБӮД•sүВ”\ӮҫӮЖҺvӮнӮкӮйҒB
Ҡж’ЈӮБӮДӮаFetch, DecodeӮИӮЗӮМғtғҚғ“ғgғGғ“ғhӮӘҢА“xӮ©ӮЖҒBӮ»ӮкӮЕӮа‘СҲж‘қӮвӮөӮИӮӘӮз’xү„ӮрҲк’иӮЙүҹӮіӮҰӮйӮМӮН
—eҲХӮЕӮНӮИӮўӮМӮЕғ^ғ_ӮЕ‘¬ӮӯӮНӮИӮиӮЬӮ№ӮсҒB
“d—НҒE”ӯ”MӮМ“sҚҮӮ©ӮзҚlӮҰӮДҒAӮўӮзӮсғRғAӮрҺEӮөӮДғIҒ[ғoҒ[ғNғҚғbғNӮЖӮўӮӨFoxtonҢnӮМ“WҠJӮНҚЎҢгҚlӮҰӮзӮкӮйҒB
ӮВҒ[Ӯ©ҒAғҠғ\Ғ[ғXүсӮ·ӮжӮиҒAғIҒ[ғoҒ[ғNғҚғbғNӮЕҗ«”\үТӮўӮҫ•ыӮӘҒAҲАҸгӮӘӮиӮЕҢшүКӮа‘еӮ«ӮўӮсӮ¶ӮбӮИӮўӮ©ӮЖҒB
491 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/12/06(“ъ) 00:00:16 ID:E+7NrUPd0
IntelerүsӮўӮИ
492 ҒFҒОҒОҒОҒОҒј(ҒEҒНҒE,,ҒҷuҒF2009/12/06(“ъ) 00:01:26 ID:S8MnQmbp0
•”•Ә“IӮЙ2ғRғA•ӘӮМғҠғ\Ғ[ғXӮр1ғRғAӮЙүсӮ·ӮҫӮҜҒB
>ҚЎҢгӮМ“WҠJӮЕӮаҒAҺАҚsғҶғjғbғgҒAғXғPғWғ…Ғ[ғүӮМғҠғ\Ғ[ғXҺgӮўүсӮөӮНӮНӮБӮ«ӮиӮўӮБӮД•sүВ”\ӮҫӮЖҺvӮнӮкӮйҒB
>Ҡж’ЈӮБӮДӮаFetch, DecodeӮИӮЗӮМғtғҚғ“ғgғGғ“ғhӮӘҢА“xӮ©ӮЖҒBӮ»ӮкӮЕӮа‘СҲж‘қӮвӮөӮИӮӘӮз’xү„ӮрҲк’иӮЙүҹӮіӮҰӮйӮМӮН
> —eҲХӮЕӮНӮИӮўӮМӮЕғ^ғ_ӮЕ‘¬ӮӯӮНӮИӮиӮЬӮ№ӮсҒB
ҺАҚЫӮЙBulldozerӮНҠж’ЈӮБӮДFetch, Decode“қҚҮӮөӮҪӮ©ӮзӮӨӮҜӮйҒB
>ҚЎҢгӮМ“WҠJӮЕӮаҒAҺАҚsғҶғjғbғgҒAғXғPғWғ…Ғ[ғүӮМғҠғ\Ғ[ғXҺgӮўүсӮөӮНӮНӮБӮ«ӮиӮўӮБӮД•sүВ”\ӮҫӮЖҺvӮнӮкӮйҒB
>Ҡж’ЈӮБӮДӮаFetch, DecodeӮИӮЗӮМғtғҚғ“ғgғGғ“ғhӮӘҢА“xӮ©ӮЖҒBӮ»ӮкӮЕӮа‘СҲж‘қӮвӮөӮИӮӘӮз’xү„ӮрҲк’иӮЙүҹӮіӮҰӮйӮМӮН
> —eҲХӮЕӮНӮИӮўӮМӮЕғ^ғ_ӮЕ‘¬ӮӯӮНӮИӮиӮЬӮ№ӮсҒB
ҺАҚЫӮЙBulldozerӮНҠж’ЈӮБӮДFetch, Decode“қҚҮӮөӮҪӮ©ӮзӮӨӮҜӮйҒB
493 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/12/06(“ъ) 00:02:09 ID:BIG5ygr20
> L1-to-L1ӮМғҠғ“ғN
Ӯ»Ғ[ӮўӮвӮұӮсӮИӮМү\Ӯ ӮБӮҪӮҜӮЗ–ўӮҫӮЙҺА—pү»ӮіӮкӮДӮИӮўӮжӮИ
BulldozerӮЕ“ьӮйӮМӮ©ӮөӮзҒH
Ӯ»Ғ[ӮўӮвӮұӮсӮИӮМү\Ӯ ӮБӮҪӮҜӮЗ–ўӮҫӮЙҺА—pү»ӮіӮкӮДӮИӮўӮжӮИ
BulldozerӮЕ“ьӮйӮМӮ©ӮөӮзҒH
494 ҒFҒОҒОҒОҒОҒј(ҒEҒНҒE,,ҒҷuҒF2009/12/06(“ъ) 00:04:11 ID:S8MnQmbp0
Core MultiplexingӮМ“БӢ–ӮНӮ»ӮМӮЬӮЬTurbo BoostӮЙӮВӮИӮӘӮБӮДӮўӮйӮ©Ӯз–К”’ӮўҒB
ӮҫӮЖӮ·ӮйӮЖҒAӮўӮзӮИӮўғRғAӮрҺEӮөӮДғIҒ[ғoҒ[ғNғҚғbғNӮЬӮЕӮНҢ»ҚЭӮМӮЖӮұӮлҺАҢ»ӮөӮДӮйӮҜӮЗҒA
ғVғ“ғOғӢғXғҢғbғhҺһӮЙҺgӮӨғRғAӮр“®“IӮЙҗШӮи‘ЦӮҰӮДӮўӮБӮДҒA
ү·“xҸгҸёӮр—}ӮҰӮйӮБӮД“WҠJӮНҚЎҢгӮ ӮиӮҰӮјӮӨӮҫӮИҒBӮ»ӮӨ“БӢ–ӮЙӮ©ӮўӮДӮ ӮБӮҪӮнӮҜӮЕҒB
“®“IҗШӮи‘ЦӮҰӮЕү·“x—}ӮҰӮзӮкӮкӮОҒAҚXӮИӮйғIҒ[ғoҒ[ғNғҚғbғNӮЙӮаӮВӮИӮӘӮйҒB
ӮҫӮЖӮ·ӮйӮЖҒAӮўӮзӮИӮўғRғAӮрҺEӮөӮДғIҒ[ғoҒ[ғNғҚғbғNӮЬӮЕӮНҢ»ҚЭӮМӮЖӮұӮлҺАҢ»ӮөӮДӮйӮҜӮЗҒA
ғVғ“ғOғӢғXғҢғbғhҺһӮЙҺgӮӨғRғAӮр“®“IӮЙҗШӮи‘ЦӮҰӮДӮўӮБӮДҒA
ү·“xҸгҸёӮр—}ӮҰӮйӮБӮД“WҠJӮНҚЎҢгӮ ӮиӮҰӮјӮӨӮҫӮИҒBӮ»ӮӨ“БӢ–ӮЙӮ©ӮўӮДӮ ӮБӮҪӮнӮҜӮЕҒB
“®“IҗШӮи‘ЦӮҰӮЕү·“x—}ӮҰӮзӮкӮкӮОҒAҚXӮИӮйғIҒ[ғoҒ[ғNғҚғbғNӮЙӮаӮВӮИӮӘӮйҒB
495 ҒFҒОҒОҒОҒОҒј(ҒEҒНҒE,,ҒҷuҒF2009/12/06(“ъ) 00:06:11 ID:S8MnQmbp0
L1 to L1ӮМғҠғ“ғNӮНҢӢүКӮ©ӮзӮўӮӨӮЖғKғZҸо•сӮҫӮБӮҪӮсӮҫӮлҒBҚЎӮНӮ»ӮӨӮўӮӨ”FҺҜҒB
Core 2ҠЦҳAӮМү\Ӯа“–ҺһӮНҗё“xӮнӮйӮ©ӮБӮҪӮ©ӮзӮЛҒB20B-24BӮМғtғFғbғ`‘СҲжӮБӮДӮМӮаҢӢӢЗғKғZӮҫӮБӮҪҒB
Core 2ҠЦҳAӮМү\Ӯа“–ҺһӮНҗё“xӮнӮйӮ©ӮБӮҪӮ©ӮзӮЛҒB20B-24BӮМғtғFғbғ`‘СҲжӮБӮДӮМӮаҢӢӢЗғKғZӮҫӮБӮҪҒB
496 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/12/06(“ъ) 00:08:59 ID:BIG5ygr20
ӮӨӮЮҒAAVXҗў‘гӮЕӮағtғFғbғ`‘СҲжӮМ”ӣӮиӮ ӮйӮМӮНҗі’јӮ«ӮВӮў
497 ҒFҒОҒОҒОҒОҒј(ҒEҒНҒE,,ҒҷuҒF2009/12/06(“ъ) 00:11:00 ID:S8MnQmbp0
ӮұӮкӮӘTurbo BoostӮҫӮБӮҪӮнӮҜӮЛҒB
784 –ј‘OҒF–јҸМ–ўҗЭ’и ҒF2006/07/30(“ъ) 16:10:59 ID:htVIKc7F0
HotSpot‘ОҚфӮЖӮўӮӨ•\Ң»ӮӘ“KҗШӮ©ӮЗӮӨӮ©ӮНӮЁӮўӮДӮЁӮӯӮЖӮөӮДҒA
Core 2ӮЕӮНҒA>>750ӮЙҺҰӮіӮкӮДӮўӮйӮжӮӨӮЙҒAҲк’иӮМү·“xӮЙ’BӮ·ӮйӮЖҠИ’PӮЙғXғҚғbғgғҠғ“ғOӮӘ
“ӯӮўӮДғpғtғHҒ[ғ}ғ“ғXӮӘ—ҺӮҝӮДӮөӮЬӮӨӮМӮЕҒA”ӯ”MӮр•ӘҺUӮіӮ№ӮйӮМӮНғpғtғHҒ[ғ}ғ“ғXӮрҲЫҺқӮ·ӮйҸгӮЕӮа—LҢшӮИӮнӮҜҒB
ӮЬӮҪҒAҗГү№ү»ӮЙӮаҢшүКӮӘӮ ӮйӮ©ӮЖҒB
“–‘RҒA>>783ӮаӮўӮБӮДӮй’КӮиҸнӮЙ2coreӮӘғtғӢүТ“ӯӮөӮДӮўӮйӮнӮҜӮ¶ӮбӮИӮўӮ©ӮзҒA>>779ӮМӮжӮӨӮИҗ§ҢдӮӘҲУ–ЎӮрҺқӮБӮДӮӯӮйӮнӮҜҒB
“БӢ–ӮЙӮаӮ©ӮўӮДӮ ӮйӮҜӮЗҒAҠeғRғAӮМ”ӯ”MӮӘmax’lҲИҸгӮЙ’BӮ·ӮйӮЖӮвӮНӮиҚЕҸIҺи’iӮЖӮөӮДӮНғXғҚғbғgғҠғ“ғOӮӘ“ӯӮӯҒB
desktopӮжӮи”ӯ”MӮМҗ§–сӮӘҢөӮөӮўMeromӮЕӮНӮаӮБӮЖ—LҢшӮ©ӮаҒB
Ҹ«—ҲӮМғvғҚғZғbғTӮЕӮНӮіӮзӮЙҠщ’иӮЗӮЁӮиӮМғNғҚғbғN‘¬“xӮЕҸнӮЙ“®ҚмӮөӮДӮўӮйҸуӢөӮНӮЗӮсӮЗӮсҢёӮБӮДҒA
ғ}ғӢғ`ғXғҢғbғhҲИ‘OӮЙғNғҚғbғNӮ©ӮзғpғtғHҒ[ғ}ғ“ғXӮрҗ„‘ӘӮ·ӮйӮМӮН“пӮөӮӯӮИӮБӮДӮӯӮйӮсӮҫӮлӮИҒB
784 –ј‘OҒF–јҸМ–ўҗЭ’и ҒF2006/07/30(“ъ) 16:10:59 ID:htVIKc7F0
HotSpot‘ОҚфӮЖӮўӮӨ•\Ң»ӮӘ“KҗШӮ©ӮЗӮӨӮ©ӮНӮЁӮўӮДӮЁӮӯӮЖӮөӮДҒA
Core 2ӮЕӮНҒA>>750ӮЙҺҰӮіӮкӮДӮўӮйӮжӮӨӮЙҒAҲк’иӮМү·“xӮЙ’BӮ·ӮйӮЖҠИ’PӮЙғXғҚғbғgғҠғ“ғOӮӘ
“ӯӮўӮДғpғtғHҒ[ғ}ғ“ғXӮӘ—ҺӮҝӮДӮөӮЬӮӨӮМӮЕҒA”ӯ”MӮр•ӘҺUӮіӮ№ӮйӮМӮНғpғtғHҒ[ғ}ғ“ғXӮрҲЫҺқӮ·ӮйҸгӮЕӮа—LҢшӮИӮнӮҜҒB
ӮЬӮҪҒAҗГү№ү»ӮЙӮаҢшүКӮӘӮ ӮйӮ©ӮЖҒB
“–‘RҒA>>783ӮаӮўӮБӮДӮй’КӮиҸнӮЙ2coreӮӘғtғӢүТ“ӯӮөӮДӮўӮйӮнӮҜӮ¶ӮбӮИӮўӮ©ӮзҒA>>779ӮМӮжӮӨӮИҗ§ҢдӮӘҲУ–ЎӮрҺқӮБӮДӮӯӮйӮнӮҜҒB
“БӢ–ӮЙӮаӮ©ӮўӮДӮ ӮйӮҜӮЗҒAҠeғRғAӮМ”ӯ”MӮӘmax’lҲИҸгӮЙ’BӮ·ӮйӮЖӮвӮНӮиҚЕҸIҺи’iӮЖӮөӮДӮНғXғҚғbғgғҠғ“ғOӮӘ“ӯӮӯҒB
desktopӮжӮи”ӯ”MӮМҗ§–сӮӘҢөӮөӮўMeromӮЕӮНӮаӮБӮЖ—LҢшӮ©ӮаҒB
Ҹ«—ҲӮМғvғҚғZғbғTӮЕӮНӮіӮзӮЙҠщ’иӮЗӮЁӮиӮМғNғҚғbғN‘¬“xӮЕҸнӮЙ“®ҚмӮөӮДӮўӮйҸуӢөӮНӮЗӮсӮЗӮсҢёӮБӮДҒA
ғ}ғӢғ`ғXғҢғbғhҲИ‘OӮЙғNғҚғbғNӮ©ӮзғpғtғHҒ[ғ}ғ“ғXӮрҗ„‘ӘӮ·ӮйӮМӮН“пӮөӮӯӮИӮБӮДӮӯӮйӮсӮҫӮлӮИҒB
498 ҒFҒОҒОҒОҒОҒј(ҒEҒНҒE,,ҒҷuҒF2009/12/06(“ъ) 00:12:59 ID:S8MnQmbp0
Ӯ»ӮӨӮ»ӮӨcore hopping == Turbo Boost
ӮҫӮБӮҪӮсӮҫҒBIsraelӮМ“БӢ–ҒB
>core hopping = ҠeғRғAӮМҸБ”п“d—НӮв”MӮрғӮғjғ^ӮөӮДҒAғNҒ[ғӢӮИғRғAӮЙғvғҚғZғXӮрҠ„Ӯи“–ӮДӮйӮжӮӨӮЙӮөӮҪӮиҒA
>>>668ӮМӮжӮӨӮЙҒA”MӮӯӮИӮБӮҪӮзғRғAӮрғXғҸғbғvӮөӮҪӮиҒAғNҒ[ғӢӮИғRғAӮНҸёҲіӮЕғNғҚғbғNӮ Ӯ°ӮҪӮиӮИӮЗӮМ
>җ§ҢдӮрғnҒ[ғhғEғGғAғxҒ[ғXӮЕҚsӮўҠҲҗ«ү»—ҰӮр•ӘҺUү»ҒBOSӮ©Ӯз’PҲкғRғAӮЙӮЭӮҰӮйӮБӮДҳbӮНӮИӮөӮ©ӮИҒB
ӮҫӮБӮҪӮсӮҫҒBIsraelӮМ“БӢ–ҒB
>core hopping = ҠeғRғAӮМҸБ”п“d—НӮв”MӮрғӮғjғ^ӮөӮДҒAғNҒ[ғӢӮИғRғAӮЙғvғҚғZғXӮрҠ„Ӯи“–ӮДӮйӮжӮӨӮЙӮөӮҪӮиҒA
>>>668ӮМӮжӮӨӮЙҒA”MӮӯӮИӮБӮҪӮзғRғAӮрғXғҸғbғvӮөӮҪӮиҒAғNҒ[ғӢӮИғRғAӮНҸёҲіӮЕғNғҚғbғNӮ Ӯ°ӮҪӮиӮИӮЗӮМ
>җ§ҢдӮрғnҒ[ғhғEғGғAғxҒ[ғXӮЕҚsӮўҠҲҗ«ү»—ҰӮр•ӘҺUү»ҒBOSӮ©Ӯз’PҲкғRғAӮЙӮЭӮҰӮйӮБӮДҳbӮНӮИӮөӮ©ӮИҒB
499 ҒFҒОҒОҒОҒОҒј(ҒEҒНҒE,,ҒҷuҒF2009/12/06(“ъ) 00:14:07 ID:S8MnQmbp0
ӮўӮвҒAӮвӮБӮПӮ»ӮӨӮЕӮаӮИӮўӮ©ҒB
ғnҒ[ғhғEғGғAғxҒ[ғXӮЙғXғҢғbғhӮМ“®“IғRғAҠ„Ӯи“–ӮДӮБӮДӮМӮН–ўӮҫӮЙҺАҢ»ӮЕӮ«ӮДӮИӮўӮИҒB
Hypercore(ҸО)ӮНҺ—ӮДӮйӮӘҒB
ғnҒ[ғhғEғGғAғxҒ[ғXӮЙғXғҢғbғhӮМ“®“IғRғAҠ„Ӯи“–ӮДӮБӮДӮМӮН–ўӮҫӮЙҺАҢ»ӮЕӮ«ӮДӮИӮўӮИҒB
Hypercore(ҸО)ӮНҺ—ӮДӮйӮӘҒB
500 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/12/06(“ъ) 00:17:51 ID:BIG5ygr20
HypercoreӮБӮДғCғXғүғGғӢҠйӢЖӮҫӮЛҒBIntelӮМҳшҷSҠйӢЖӮЖӮўӮӨӮнӮҜӮЕӮаӮИӮіӮ»ӮӨӮҫӮҜӮЗҒB
501 ҒFҒОҒОҒОҒОҒј(ҒEҒНҒE,,ҒҷuҒF2009/12/06(“ъ) 00:18:13 ID:S8MnQmbp0
>"Reverse(Anti)-Hyper-Threading"ӢZҸpӮБӮДҒA
>X2ӮМ2ҢВӮМғRғAӮрҢӢҚҮӮө6IPC(3IPCx2ҢВ•Ә)ӮМғVғ“ғOғӢғRғAӮрғGғ~ғ…ғҢҒ[ғgӮ·ӮйӢZҸpӮЖӮМӮұӮЖ(CONROEӮН4IPC)ҒB
ӮұӮМҸүҠъҚ\‘zӮЗӮЁӮиӮИӮзBulldozerӮНҒA3 issueӮҫӮБӮҪӮсӮҫӮлӮӨӮЛҒB
ҚЎҳRӮкӮН’f‘R2issueҗаӮЕӮ ӮйӮӘҒB
>X2ӮМ2ҢВӮМғRғAӮрҢӢҚҮӮө6IPC(3IPCx2ҢВ•Ә)ӮМғVғ“ғOғӢғRғAӮрғGғ~ғ…ғҢҒ[ғgӮ·ӮйӢZҸpӮЖӮМӮұӮЖ(CONROEӮН4IPC)ҒB
ӮұӮМҸүҠъҚ\‘zӮЗӮЁӮиӮИӮзBulldozerӮНҒA3 issueӮҫӮБӮҪӮсӮҫӮлӮӨӮЛҒB
ҚЎҳRӮкӮН’f‘R2issueҗаӮЕӮ ӮйӮӘҒB
502 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/12/06(“ъ) 00:21:17 ID:BIG5ygr20
4+4ӮЕӮаӮўӮҜӮйӮсӮ¶ӮбӮИӮўӮМҒH
‘еҢҙӮіӮсӮМ—\‘zӮЖ”нӮйӮҜӮЗ
‘еҢҙӮіӮсӮМ—\‘zӮЖ”нӮйӮҜӮЗ
503 ҒFҒОҒОҒОҒОҒј(ҒEҒНҒE,,ҒҷuҒF2009/12/06(“ъ) 00:23:45 ID:S8MnQmbp0
–і—қӮҫӮлӮӨҒBӮЖӮўӮӨӮ©Ӯ»ӮМҳbӮНҸ‘Ӯ«Ӯ«ӮБӮҪӮМӮЕғ{ғҠ•ФӮөӮНӮИӮөӮҫӮИҒB
ғ{ғҠ•ФӮөҺnӮЯӮҪӮМӮНҳRӮкӮҫӮӘҒB
ғ{ғҠ•ФӮөҺnӮЯӮҪӮМӮНҳRӮкӮҫӮӘҒB
504 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/12/06(“ъ) 00:26:32 ID:BIG5ygr20
BarcelonaӮМғ_ғCғҢғCғAғEғgҢ©ӮйӮЙҗ®җ”ғpғCғvғүғCғ“ӮНӮ»ӮсӮИӮЙ–КҗПҗHӮБӮДӮИӮўҒB
ӮЮӮөӮлL1ғfҒ[ғ^ғLғғғbғVғ…ӮЖLSUӮӘ‘еҸд•vӮ©ӮЖ
ӮЮӮөӮлL1ғfҒ[ғ^ғLғғғbғVғ…ӮЖLSUӮӘ‘еҸд•vӮ©ӮЖ
505 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/12/06(“ъ) 00:39:48 ID:BIG5ygr20
ӮЖӮұӮлӮЕүҙӮМIDӮӘBIG5Ӯҫ
506 ҒF–јҸМ–ўҗЭ’иҒF2009/12/06(“ъ) 01:33:39 ID:paDtyVj20
“ҢҚH‘еӮМҸјүӘҗжҗ¶Ҹо•с
http://twitter.com/ProfMatsuoka/status/5643167774
>ӮQ”NҲИҸг‘OӮЙChuck MooreӮ©Ӯз(ӮаӮҝӮлӮсNDAӮЕ)җа–ҫӮрҺуӮҜӮҪӮаӮМӮЖӮН
>‘еӮЬӮ©ӮЙӮН•Пү»ӮөӮДӮўӮИӮўҒBҸd—vӮИӮұӮЖӮМҲкӮВӮНCore/NealemӮЖ
>“Ҝ“ҷӮЙ4-issueӮИӮұӮЖӮҫҒB
Ӯ»ӮаӮ»ӮаSandy Bridgeҗў‘гӮЕӮН8ғRғAӮӘҸoӮйӮжӮӨӮИӮМӮЙҒC
җ®җ”үүҺZғҶғjғbғg8ғRғAӮМBulldozerӮӘ4*(ALU+AGU)
ӮрҚМ—pӮөӮГӮзӮўӮЩӮЗғTғCғYӮӘ‘еӮ«ӮӯӮИӮйӮЖӮНҺvӮҰӮИӮўҒD
BulldozerӮНғzғbғgғXғ|ғbғgӮЙӮИӮйғfғRҒ[ғ_ӮМҗ”ӮӘ”ј•ӘӮЙӮИӮйӮ©ӮзҒC
ҚӮғNғҚғbғNӮЙӮЕӮ«ӮйӮМӮ©ӮИӮЖҺvӮБӮДӮўӮҪӮҜӮЗҒCӮ»ӮсӮИӮұӮЖӮНӮИӮўӮМӮ©ҒD
http://twitter.com/ProfMatsuoka/status/5643167774
>ӮQ”NҲИҸг‘OӮЙChuck MooreӮ©Ӯз(ӮаӮҝӮлӮсNDAӮЕ)җа–ҫӮрҺуӮҜӮҪӮаӮМӮЖӮН
>‘еӮЬӮ©ӮЙӮН•Пү»ӮөӮДӮўӮИӮўҒBҸd—vӮИӮұӮЖӮМҲкӮВӮНCore/NealemӮЖ
>“Ҝ“ҷӮЙ4-issueӮИӮұӮЖӮҫҒB
Ӯ»ӮаӮ»ӮаSandy Bridgeҗў‘гӮЕӮН8ғRғAӮӘҸoӮйӮжӮӨӮИӮМӮЙҒC
җ®җ”үүҺZғҶғjғbғg8ғRғAӮМBulldozerӮӘ4*(ALU+AGU)
ӮрҚМ—pӮөӮГӮзӮўӮЩӮЗғTғCғYӮӘ‘еӮ«ӮӯӮИӮйӮЖӮНҺvӮҰӮИӮўҒD
BulldozerӮНғzғbғgғXғ|ғbғgӮЙӮИӮйғfғRҒ[ғ_ӮМҗ”ӮӘ”ј•ӘӮЙӮИӮйӮ©ӮзҒC
ҚӮғNғҚғbғNӮЙӮЕӮ«ӮйӮМӮ©ӮИӮЖҺvӮБӮДӮўӮҪӮҜӮЗҒCӮ»ӮсӮИӮұӮЖӮНӮИӮўӮМӮ©ҒD
507 ҒF–јҸМ–ўҗЭ’иҒF2009/12/07(ҢҺ) 02:09:33 ID:oLx/lgG10
ғCғXғүғGғӢӮМ“БӢ–ӮМғRғAӮМ“®“Iҗ§ҢдӮЕ
HyperthreadingӮаҗ§ҢдӮЕӮ«ӮИӮўӮ©ӮИ?
HTonӮҫӮЖҺАҚsҗ«”\ӮӘ—ҺӮҝӮйҸҲ—қӮӘӮ ӮйҲИҸг
Ӯ»ӮӨӮўӮӨҢXҢьӮӯӮзӮўӮНintelӮаҸі’mӮөӮДӮйӮҫӮлӮӨӮө
HTӮӘӮ ӮйӮЖӮЬӮёӮўҸҲ—қӮрӮөӮДӮйғRғAӮМHTӮНҗШӮБӮҝӮбӮӨ“IӮИ
HyperthreadingӮаҗ§ҢдӮЕӮ«ӮИӮўӮ©ӮИ?
HTonӮҫӮЖҺАҚsҗ«”\ӮӘ—ҺӮҝӮйҸҲ—қӮӘӮ ӮйҲИҸг
Ӯ»ӮӨӮўӮӨҢXҢьӮӯӮзӮўӮНintelӮаҸі’mӮөӮДӮйӮҫӮлӮӨӮө
HTӮӘӮ ӮйӮЖӮЬӮёӮўҸҲ—қӮрӮөӮДӮйғRғAӮМHTӮНҗШӮБӮҝӮбӮӨ“IӮИ
508 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/12/07(ҢҺ) 23:54:03 ID:DYByEWQO0
ӮЁӮўүҙӮМ•ӘҗgӮЕӮДӮұӮўӮв
Core/NealemӮЖ“Ҝ“ҷӮЙ4-issue = —ҘӢVӮЙ 4ALU+4AGU ӮЖӮ©ӮЙӮ·ӮсӮМӮНӮаӮӨӮвӮЯӮЬӮөӮҪ
ӮБӮДӮұӮЖӮ¶ӮбӮИӮўӮМ?
ӮБӮДӮұӮЖӮ¶ӮбӮИӮўӮМ?
510 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/12/09(җ…) 20:07:19 ID:OuPLqOl50
ж|ҚкӮНғKғ\ғҠғ“Ӯ©ӮФӮБӮДүОӮМ’ҶӮЙ”тӮСҚһӮЮӮжӮӨӮИӮЬӮЛӮӘҚDӮ«ӮИӮсӮҫӮИ
Ңл“ҡғXғҢӮЙҳAғҢғXӮЖӮ©Ӯ—Ӯ—Ӯ—
ӮЬӮ GPUӮНӮЖӮаӮ©ӮӯҒAHPCӮЕӮИӮзҒA45nmӮМӮ ӮМҺd—lӮМӮЬӮЬҸoӮөӮДӮаLarrabeeӮН
Ҹ\•ӘӮИғpғҸҒ[ӮНӮ ӮйӮЖҺvӮӨӮҜӮЗӮЛҒBGPUӮЖӮөӮДӮМғoғүғ“ғXӮЖӮиӮЙҺё”sӮөӮҪӮҫӮҜӮЕҒB
ӮЖӮўӮӨӮжӮиҒASandy Bridge 6ғRғAӮЕ”{җё“xҺАҢш100GFLOPS‘_ӮҰӮйҺһ‘гӮӘ
ҠФӢЯӮИӮМӮЙҒAӮлӮӯӮЙғҚҒ[ғJғӢғҒғӮғҠӮаҗПӮсӮЕӮИӮўGPUӮЕҚs—сҗПӮМҗ«”\Ӯр
ӢЈӮӨӮұӮЖӮӘӮЗӮұӮЬӮЕ’КӮ¶ӮйӮ©ӮЖӮўӮӨ–в‘иӮаӮ ӮйҒB
1TFLOPSӮрҺ©ҸМӮөӮДӮҪTesla 1060ӮӘSGEMMӮЕ300GFLOPS, DGEMMӮЕ70GFLOPS’ц“xӮҫӮәҒB
Ӯ»ӮиӮбFermiӮЕӮН‘ҪҸӯӮ ӮӘӮйӮҫӮлӮӨӮӘҒAӮ ӮМғҶғjғbғgҚ\җ¬ҒAӮўӮЬӮҫӮЙLU•ӘүрӮЖӮ©
ҚЕ“Kү»ӮіӮкӮДӮИӮўӮҫӮлҒB
SFUӮрҸжҺZғҶғjғbғgӮЖӮөӮДҺgӮҰӮИӮӯӮИӮБӮҪӮұӮЖӮЕҺ©“®“IӮЙGEMMӮЕӮНҺgӮў•ЁӮЙ
ӮИӮзӮИӮў•ӘӮМ—қҳ_җ«”\ӮӘ—ҺӮҝӮҪӮМӮЕҒAҺ©“®“IӮЙҺАҢшҗ«”\”дӮН1.5”{’ц“xӮ ӮӘӮйҒiҸОҒj
ҢvҺZӮЙӮНӮИӮйӮҫӮлӮӨӮӘҒB
Ңл“ҡғXғҢӮЙҳAғҢғXӮЖӮ©Ӯ—Ӯ—Ӯ—
ӮЬӮ GPUӮНӮЖӮаӮ©ӮӯҒAHPCӮЕӮИӮзҒA45nmӮМӮ ӮМҺd—lӮМӮЬӮЬҸoӮөӮДӮаLarrabeeӮН
Ҹ\•ӘӮИғpғҸҒ[ӮНӮ ӮйӮЖҺvӮӨӮҜӮЗӮЛҒBGPUӮЖӮөӮДӮМғoғүғ“ғXӮЖӮиӮЙҺё”sӮөӮҪӮҫӮҜӮЕҒB
ӮЖӮўӮӨӮжӮиҒASandy Bridge 6ғRғAӮЕ”{җё“xҺАҢш100GFLOPS‘_ӮҰӮйҺһ‘гӮӘ
ҠФӢЯӮИӮМӮЙҒAӮлӮӯӮЙғҚҒ[ғJғӢғҒғӮғҠӮаҗПӮсӮЕӮИӮўGPUӮЕҚs—сҗПӮМҗ«”\Ӯр
ӢЈӮӨӮұӮЖӮӘӮЗӮұӮЬӮЕ’КӮ¶ӮйӮ©ӮЖӮўӮӨ–в‘иӮаӮ ӮйҒB
1TFLOPSӮрҺ©ҸМӮөӮДӮҪTesla 1060ӮӘSGEMMӮЕ300GFLOPS, DGEMMӮЕ70GFLOPS’ц“xӮҫӮәҒB
Ӯ»ӮиӮбFermiӮЕӮН‘ҪҸӯӮ ӮӘӮйӮҫӮлӮӨӮӘҒAӮ ӮМғҶғjғbғgҚ\җ¬ҒAӮўӮЬӮҫӮЙLU•ӘүрӮЖӮ©
ҚЕ“Kү»ӮіӮкӮДӮИӮўӮҫӮлҒB
SFUӮрҸжҺZғҶғjғbғgӮЖӮөӮДҺgӮҰӮИӮӯӮИӮБӮҪӮұӮЖӮЕҺ©“®“IӮЙGEMMӮЕӮНҺgӮў•ЁӮЙ
ӮИӮзӮИӮў•ӘӮМ—қҳ_җ«”\ӮӘ—ҺӮҝӮҪӮМӮЕҒAҺ©“®“IӮЙҺАҢшҗ«”\”дӮН1.5”{’ц“xӮ ӮӘӮйҒiҸОҒj
ҢvҺZӮЙӮНӮИӮйӮҫӮлӮӨӮӘҒB
511 ҒFҒОҒОҒОҒОҒј(ҒEҒНҒE,,ҒҷuҒF2009/12/09(җ…) 20:18:35 ID:4o1T9QKx0
ӮЬӮ LRBӮӘғLғғғ“ғZғӢӮіӮкӮҪ—қ—RӮМҲк”ФӮНҗ«”\ӮБӮДӮМӮНҗіүрӮҫӮлӮӨӮИҒB
ғxғNғgғӢ“Бү»ӮМғRғAӮрғҠғ“ғO1–{ӮЕӮҪӮӯӮіӮсӮВӮИӮўӮЕҒA’P‘МҸӨ•iӮЕ”„ӮйӮЭӮҪӮўӮИӮМӮН–ў—ҲүiҚ…Ң©ӮзӮкӮИӮўӮЕӮөӮеӮӨҒB
ӮЖӮўӮӨӮ©LRBғLғғғ“ғZғӢӮНҒA•ПӮЙ’Қ–ЪӮөӮДӮўӮҪGPUҗ~ӮвHPCҗ~ӮЙӮЖӮБӮДӮН‘еӮ«ӮИҳb‘иӮИӮМӮ©ӮаӮөӮкӮИӮўӮҜӮЗҒA
ӮФӮБӮҝӮбӮҜҒAӮ ӮЬӮиҸd—vӮИғjғ…Ғ[ғXӮ¶ӮбӮИӮўӮсӮҫӮжҒB
ӮаӮЖӮаӮЖҺҺҚм’iҠKӮЙӮ ӮйӮжӮИӮаӮМӮрҒAғҒғjғBғRғAӮМҸҮ’ІӮіӮрҸӯӮөӮЕӮа‘ҒӮӯғAғsҒ[ғӢӮөӮҪӮўӮӘӮҪӮЯӮЙҒA
–і—қӮЙҗ»•iү»ӮрҢцҢҫӮөӮДҺ–‘OӮЙҸо•сҢцҠJӮөӮДӮўӮҪӮҫӮҜӮЕҒA
ҳbӮӘӮЁӮЁӮ«ӮӯӮИӮБӮДӮўӮйӮӘҒAӮаӮЖӮаӮЖIntelӮМ–{ӢC“xӮЖӮөӮДӮаItanicӮЖ”дҠrӮЕӮ«ӮйӮжӮӨӮИ‘г•ЁӮ¶ӮбӮИӮўӮсӮЕҒB
Ӣcҳ_Ӯ·ӮйӮҫӮҜҺһҠФӮМ–і‘КӮҫӮЛҒB
ғxғNғgғӢ“Бү»ӮМғRғAӮрғҠғ“ғO1–{ӮЕӮҪӮӯӮіӮсӮВӮИӮўӮЕҒA’P‘МҸӨ•iӮЕ”„ӮйӮЭӮҪӮўӮИӮМӮН–ў—ҲүiҚ…Ң©ӮзӮкӮИӮўӮЕӮөӮеӮӨҒB
ӮЖӮўӮӨӮ©LRBғLғғғ“ғZғӢӮНҒA•ПӮЙ’Қ–ЪӮөӮДӮўӮҪGPUҗ~ӮвHPCҗ~ӮЙӮЖӮБӮДӮН‘еӮ«ӮИҳb‘иӮИӮМӮ©ӮаӮөӮкӮИӮўӮҜӮЗҒA
ӮФӮБӮҝӮбӮҜҒAӮ ӮЬӮиҸd—vӮИғjғ…Ғ[ғXӮ¶ӮбӮИӮўӮсӮҫӮжҒB
ӮаӮЖӮаӮЖҺҺҚм’iҠKӮЙӮ ӮйӮжӮИӮаӮМӮрҒAғҒғjғBғRғAӮМҸҮ’ІӮіӮрҸӯӮөӮЕӮа‘ҒӮӯғAғsҒ[ғӢӮөӮҪӮўӮӘӮҪӮЯӮЙҒA
–і—қӮЙҗ»•iү»ӮрҢцҢҫӮөӮДҺ–‘OӮЙҸо•сҢцҠJӮөӮДӮўӮҪӮҫӮҜӮЕҒA
ҳbӮӘӮЁӮЁӮ«ӮӯӮИӮБӮДӮўӮйӮӘҒAӮаӮЖӮаӮЖIntelӮМ–{ӢC“xӮЖӮөӮДӮаItanicӮЖ”дҠrӮЕӮ«ӮйӮжӮӨӮИ‘г•ЁӮ¶ӮбӮИӮўӮсӮЕҒB
Ӣcҳ_Ӯ·ӮйӮҫӮҜҺһҠФӮМ–і‘КӮҫӮЛҒB
512 ҒFҒОҒОҒОҒОҒј(ҒEҒНҒE,,ҒҷuҒF2009/12/09(җ…) 20:27:29 ID:4o1T9QKx0
Ҡ®‘SӮИ–П‘zӮЕӮ ӮйӮӘҒA
Intel“а•”ӮЙӮНҒAғҒғjғBғRғAӮжӮиӮа
—бӮҰӮОSoCү»Ӯрҗ„ӮөҗiӮЯӮДҺеӢLүҜӮр“қҚҮӮөӮҪӮиӮөӮИӮҜӮкӮО
’ҶҠъ“IӮЙҺА—p“IӮИҗ«”\ҢьҸгӮНӮЩӮЪ•sүВ”\ӮҫӮЖҠҙӮ¶ӮДӮўӮйғGғ“ғWғjғAӮНӮҪӮӯӮіӮсӮўӮйӮЖҺvӮӨҒB
ӮөӮ©ӮөғҒғjғBғRғAӮӘ‘SӮДҺё”sӮ·ӮкӮОҗ«”\ҢьҸгӮМғyҒ[ғXӮӘ’бүәӮөӮДҒA
ғ}ғCғNғҚғvғҚғZғbғTӮМүҝ’lӮӘ’бүәӮөӮДӮўӮ«ҒAIntelӮНҚЎӮМ—ҳүv‘МҗЁӮрҲЫҺқӮЕӮ«ӮИӮӯӮИӮйҒB
ӮҫӮ©ӮзҠИ’PӮЙ‘ЗӮрӮ«ӮкӮИӮўӮсӮҫӮлӮӨӮЖҒBӮЁӮкӮНӮ»ӮӨҺvӮБӮДӮўӮйҒB
‘Ҫ•ӘӮ ӮЖҗ””NӮНғҒғjғBғRғAӮрӮ Ӯ«ӮзӮЯӮёӮЙҢӨӢҶӮөӮВӮГӮҜӮйҒB
–і—қӮҫӮЖӮнӮ©ӮБӮҪӮзӢ}ҢғӮЙ‘ЗӮрӮЖӮБӮДӢt•ыҢьӮЙҗiӮЮӮҫӮлӮӨҒB
IntelӮМғҒғjғBғRғA/ғeғүғXғPҒ[ғӢғvғҚғWғFғNғgӮНҗ”‘ЕӮҝӮбӮ ӮҪӮйҸу‘ФӮЕҗiӮсӮЕӮ«ӮДӮўӮДҒA
ӮўӮЬӮЬӮЕӮЙғLғғғ“ғZғӢӮіӮкӮҪҢvүжӮН‘јӮЙӮаӮнӮ©ӮБӮДӮўӮйӮҫӮҜӮЕ•Ўҗ”Ӯ ӮйҒB
Intel“а•”ӮЙӮНҒAғҒғjғBғRғAӮжӮиӮа
—бӮҰӮОSoCү»Ӯрҗ„ӮөҗiӮЯӮДҺеӢLүҜӮр“қҚҮӮөӮҪӮиӮөӮИӮҜӮкӮО
’ҶҠъ“IӮЙҺА—p“IӮИҗ«”\ҢьҸгӮНӮЩӮЪ•sүВ”\ӮҫӮЖҠҙӮ¶ӮДӮўӮйғGғ“ғWғjғAӮНӮҪӮӯӮіӮсӮўӮйӮЖҺvӮӨҒB
ӮөӮ©ӮөғҒғjғBғRғAӮӘ‘SӮДҺё”sӮ·ӮкӮОҗ«”\ҢьҸгӮМғyҒ[ғXӮӘ’бүәӮөӮДҒA
ғ}ғCғNғҚғvғҚғZғbғTӮМүҝ’lӮӘ’бүәӮөӮДӮўӮ«ҒAIntelӮНҚЎӮМ—ҳүv‘МҗЁӮрҲЫҺқӮЕӮ«ӮИӮӯӮИӮйҒB
ӮҫӮ©ӮзҠИ’PӮЙ‘ЗӮрӮ«ӮкӮИӮўӮсӮҫӮлӮӨӮЖҒBӮЁӮкӮНӮ»ӮӨҺvӮБӮДӮўӮйҒB
‘Ҫ•ӘӮ ӮЖҗ””NӮНғҒғjғBғRғAӮрӮ Ӯ«ӮзӮЯӮёӮЙҢӨӢҶӮөӮВӮГӮҜӮйҒB
–і—қӮҫӮЖӮнӮ©ӮБӮҪӮзӢ}ҢғӮЙ‘ЗӮрӮЖӮБӮДӢt•ыҢьӮЙҗiӮЮӮҫӮлӮӨҒB
IntelӮМғҒғjғBғRғA/ғeғүғXғPҒ[ғӢғvғҚғWғFғNғgӮНҗ”‘ЕӮҝӮбӮ ӮҪӮйҸу‘ФӮЕҗiӮсӮЕӮ«ӮДӮўӮДҒA
ӮўӮЬӮЬӮЕӮЙғLғғғ“ғZғӢӮіӮкӮҪҢvүжӮН‘јӮЙӮаӮнӮ©ӮБӮДӮўӮйӮҫӮҜӮЕ•Ўҗ”Ӯ ӮйҒB
513 ҒFҒОҒОҒОҒОҒј(ҒEҒНҒE,,ҒҷuҒF2009/12/09(җ…) 20:31:06 ID:4o1T9QKx0
IDFӮМҺ‘—ҝӮрӮЭӮкӮОӮнӮ©ӮйӮӘҒAғRғAӮМҗ”ӮӘ‘қӮҰӮҪӮз
ғҠғ“ғOҲИҠOӮМғCғ“ғ^Ғ[ғRғlғNғgӮр“ұ“ьӮ·ӮйӮЖӮўӮӨҳbӮН‘OӮ©ӮзӮ ӮБӮДҒA
ӮЬӮ ҚЎӮМӮЖӮұӮлғҠғ“ғOӮМүВ”\җ«ӮӘҚӮӮўӮМӮНSNBҒ`HaswellӮЬӮЕӮЕӮ»ӮМӮ ӮЖӮНӮЗӮӨӮИӮйӮ©ӮнӮ©ӮзӮсҒB
NehalemҒ`HaswellӮӘ‘OӮЙ“ҜӮ¶ү„’·җьҸгӮЙӮ ӮйҢZ’нӮЖӮўӮБӮҪӮМӮНҒAӮЖӮиӮ ӮҰӮёғҒғjғBғRғAӮМ‘O’iҠKӮЖӮөӮД
ҚЕҸI“IӮЙӮ ӮЬӮиҚЕ“Kү»ӮөӮДӮўӮИӮўғRғAӮрӮЖӮиӮ ӮҰӮё”с‘ОҸМӮЕҸ_“оӮЙҗЪ‘ұӮөӮДғXғPҒ[ғӢӮ·ӮйӮЖӮўӮӨӮМӮӘ
–Ъ•WӮМҗў‘гӮМӮжӮӨӮЙҢ©ҺуӮҜӮзӮкӮйӮ©ӮзӮЕӮ ӮйҒB
ғҠғ“ғOҲИҠOӮМғCғ“ғ^Ғ[ғRғlғNғgӮр“ұ“ьӮ·ӮйӮЖӮўӮӨҳbӮН‘OӮ©ӮзӮ ӮБӮДҒA
ӮЬӮ ҚЎӮМӮЖӮұӮлғҠғ“ғOӮМүВ”\җ«ӮӘҚӮӮўӮМӮНSNBҒ`HaswellӮЬӮЕӮЕӮ»ӮМӮ ӮЖӮНӮЗӮӨӮИӮйӮ©ӮнӮ©ӮзӮсҒB
NehalemҒ`HaswellӮӘ‘OӮЙ“ҜӮ¶ү„’·җьҸгӮЙӮ ӮйҢZ’нӮЖӮўӮБӮҪӮМӮНҒAӮЖӮиӮ ӮҰӮёғҒғjғBғRғAӮМ‘O’iҠKӮЖӮөӮД
ҚЕҸI“IӮЙӮ ӮЬӮиҚЕ“Kү»ӮөӮДӮўӮИӮўғRғAӮрӮЖӮиӮ ӮҰӮё”с‘ОҸМӮЕҸ_“оӮЙҗЪ‘ұӮөӮДғXғPҒ[ғӢӮ·ӮйӮЖӮўӮӨӮМӮӘ
–Ъ•WӮМҗў‘гӮМӮжӮӨӮЙҢ©ҺуӮҜӮзӮкӮйӮ©ӮзӮЕӮ ӮйҒB
514 ҒFҒОҒОҒОҒОҒј(ҒEҒНҒE,,ҒҷuҒF2009/12/09(җ…) 20:35:36 ID:4o1T9QKx0
Ӯ»ӮӨӮўӮӨҲУ–ЎӮЕHaswellӮНӮ©ӮИӮи”ч–ӯӮИғ|ғWғVғҮғ“ӮЙӮўӮйӮнӮҜӮЕӮ·ҒB
ғLғғғ“ғZғӢӮіӮкӮД•КӮМӮаӮМӮЙ“ьӮк‘ЦӮнӮйӮ©ҒA
ӮұӮМӮЬӮЬ”с‘ОҸМӮЕғXғgғҠҒ[ғҖғRғAӮИӮиӮрҸWҗПӮөӮДғҠғҠҒ[ғXӮіӮкӮйӮ©ҒAҺһҠъ“IӮЙ”ч–ӯҒB
ғLғғғ“ғZғӢӮіӮкӮД•КӮМӮаӮМӮЙ“ьӮк‘ЦӮнӮйӮ©ҒA
ӮұӮМӮЬӮЬ”с‘ОҸМӮЕғXғgғҠҒ[ғҖғRғAӮИӮиӮрҸWҗПӮөӮДғҠғҠҒ[ғXӮіӮкӮйӮ©ҒAҺһҠъ“IӮЙ”ч–ӯҒB
515 ҒFҒОҒОҒОҒОҒј(ҒEҒНҒE,,ҒҷuҒF2009/12/09(җ…) 20:53:46 ID:4o1T9QKx0
ғҒғjғBғRғAӮрӮаӮМӮЙӮЕӮ«ӮйӮ©ӮЕӮ«ӮИӮўӮ©ӮМӢ«ҠEӮЖ“¬ӮБӮДӮўӮйӮИӮ©ӮЕ•KҺҖӮЙҸҮ’ІӮіӮрғAғsҒ[ғӢӮөӮҪӮўIntelҒB
ғҒғjғBғRғAӮМҺҺҚм•iӮрғ\ғtғgҠJ”ӯҺТӮЙ’сӢҹӮөӮДӮЕӮ«ӮйӮҫӮҜғҒғjғBғRғAӮрҗ¶Ӯ©ӮөӮДӮӯӮкӮйғ\ғtғgӮаҚмӮБӮД—~ӮөӮўҒB
IntelӮӘғҒғjғBғRғAӮрғ}ғ“ғZҒ[ӮөӮДҗй“`ӮөӮЬӮӯӮБӮДӮўӮйӮМӮНҒA
IntelӮӘҢ»‘гӮМғ}ғCғNғҚғvғҚғZғbғTӮМҗ«”\ҢьҸгӮМ•ЗӮЖ“¬ӮБӮДӮўӮйҢөӮөӮўҢ»ҺАӮМ— •ФӮөӮИӮМӮЕӮ ӮйҒB
ҸБ”пҺТӮЖӮөӮДӮаӮ»ӮкӮрҺ@ӮөӮДҸо•сӮрҺуӮҜҺ~ӮЯӮйӮЧӮ«ӮЕҒAҢ»ҺА“IӮИ—\‘zӮНIntelӮӘ‘ОҠO“IӮЙғAғsҒ[ғӢӮ·Ӯй—қ‘zӮМ•ыҢьҗ«ӮЖӮН
ҳbӮӘҲЩӮИӮБӮДӮЁӮ©ӮөӮӯӮНӮИӮўӮсӮҫҒB
ғҒғjғBғRғAӮМҺҺҚм•iӮрғ\ғtғgҠJ”ӯҺТӮЙ’сӢҹӮөӮДӮЕӮ«ӮйӮҫӮҜғҒғjғBғRғAӮрҗ¶Ӯ©ӮөӮДӮӯӮкӮйғ\ғtғgӮаҚмӮБӮД—~ӮөӮўҒB
IntelӮӘғҒғjғBғRғAӮрғ}ғ“ғZҒ[ӮөӮДҗй“`ӮөӮЬӮӯӮБӮДӮўӮйӮМӮНҒA
IntelӮӘҢ»‘гӮМғ}ғCғNғҚғvғҚғZғbғTӮМҗ«”\ҢьҸгӮМ•ЗӮЖ“¬ӮБӮДӮўӮйҢөӮөӮўҢ»ҺАӮМ— •ФӮөӮИӮМӮЕӮ ӮйҒB
ҸБ”пҺТӮЖӮөӮДӮаӮ»ӮкӮрҺ@ӮөӮДҸо•сӮрҺуӮҜҺ~ӮЯӮйӮЧӮ«ӮЕҒAҢ»ҺА“IӮИ—\‘zӮНIntelӮӘ‘ОҠO“IӮЙғAғsҒ[ғӢӮ·Ӯй—қ‘zӮМ•ыҢьҗ«ӮЖӮН
ҳbӮӘҲЩӮИӮБӮДӮЁӮ©ӮөӮӯӮНӮИӮўӮсӮҫҒB
516 ҒF–јҸМ–ўҗЭ’иҒF2009/12/09(җ…) 21:13:34 ID:iP9dIDZf0
’cҺqүЕғ}ғWӮЕҢг“ЎғXғҢҸZ–ҜӮМ‘ҠҺиӮөӮДӮДғҸғҚғXӮ—Ӯ—Ӯ—
517 ҒFҒОҒОҒОҒОҒј(ҒEҒНҒE,,ҒҷuҒF2009/12/09(җ…) 21:19:33 ID:4o1T9QKx0
ӮЬӮ ҚЕҸүӮЙҸ‘ӮұӮӨӮЖӮЁӮаӮБӮДӮўӮҪӮұӮЖӮЖҳbӮӘӮёӮкӮДӮөӮЬӮБӮҪӮӘҒA
IntelӮН‘јӮЙӮағҒғjғBғRғAӮМғvғҚғWғFғNғgӮрӮаӮБӮДӮўӮД
LRBӮаӮ»ӮМ’ҶӮМҲкӮВӮЕҒAғҒғjғBғRғA‘жҲк’eӮЖӮөӮДӮЖӮиӮ ӮҰӮёҗ»•iү»ӮрҢцҢҫӮөӮДҒA
Ӯ»ӮкӮИӮиӮМҸо•сӮр–ҫӮ©ӮөӮДӮөӮЬӮБӮҪғvғҚғWғFғNғgӮИӮнӮҜҒB
ӢZҸp“IӮЙҺё”sӮөӮҪғvғҚғWғFғNғgӮН‘јӮЙӮаӮ ӮйӮөҒALRBӮаӮ»ӮМҲкӮВӮЙӮёӮ«ӮИӮўӮМӮЕӮ ӮЬӮиӢZҸpӮЙӮВӮўӮЗӮӨӮұӮӨӮНӮЗӮӨӮЕӮаӮўӮўӮсӮҫҒB
ӮҪӮҫҒAҠ®җ¬“xӮМ’бӮўӮаӮМӮрҺ–‘OӮЙҗ»•iү»ӮрҢцҢҫӮөӮДҒAӮ»ӮкӮИӮиӮМҸЪҚЧӮрҢцҠJӮөӮДӮөӮЬӮБӮҪҸо•сҗн—ӘӮӘ‘еӮ«ӮИҺё”sӮҫӮБӮҪӮнӮҜӮЕ
ӮЬӮ ғQғӢӮаӮўӮИӮӯӮИӮБӮҪӮұӮЖӮҫӮөҚЎҢгӮНӮЗӮӨӮИӮйӮвӮзҒBӮаӮБӮЖӮРӮБӮ»ӮиӮЖғҒғjғBғRғAӮрҗiӮЯӮйүВ”\җ«ӮаӮ ӮйӮҫӮлӮӨҒB
ӮөӮ©ӮөӮИӮӘӮзӮўӮ«ӮИӮиLRBғLғғғ“ғZғӢӮМғCғҒҒ[ғW’бүәӮрӮвӮнӮзӮ°ӮйӮҪӮЯӮЙҒA
ӮұӮиӮёӮЙ48ғRғAӮМ”z•zӮМӮЯӮЗӮӘҢoӮБӮҪӮЖӮұӮлӮЕғLғғғ“ғZғӢ”ӯ•\ӮҫӮБӮҪӮ©ӮзӮИҒB
ҺҹӮН“ҜӮ¶‘е•—ҳC•~ӮНҚLӮ°ӮИӮўӮЕӮРӮБӮ»ӮиӮвӮБӮД—~ӮөӮўғӮғmӮҫӮӘҒB
IntelӮН‘јӮЙӮағҒғjғBғRғAӮМғvғҚғWғFғNғgӮрӮаӮБӮДӮўӮД
LRBӮаӮ»ӮМ’ҶӮМҲкӮВӮЕҒAғҒғjғBғRғA‘жҲк’eӮЖӮөӮДӮЖӮиӮ ӮҰӮёҗ»•iү»ӮрҢцҢҫӮөӮДҒA
Ӯ»ӮкӮИӮиӮМҸо•сӮр–ҫӮ©ӮөӮДӮөӮЬӮБӮҪғvғҚғWғFғNғgӮИӮнӮҜҒB
ӢZҸp“IӮЙҺё”sӮөӮҪғvғҚғWғFғNғgӮН‘јӮЙӮаӮ ӮйӮөҒALRBӮаӮ»ӮМҲкӮВӮЙӮёӮ«ӮИӮўӮМӮЕӮ ӮЬӮиӢZҸpӮЙӮВӮўӮЗӮӨӮұӮӨӮНӮЗӮӨӮЕӮаӮўӮўӮсӮҫҒB
ӮҪӮҫҒAҠ®җ¬“xӮМ’бӮўӮаӮМӮрҺ–‘OӮЙҗ»•iү»ӮрҢцҢҫӮөӮДҒAӮ»ӮкӮИӮиӮМҸЪҚЧӮрҢцҠJӮөӮДӮөӮЬӮБӮҪҸо•сҗн—ӘӮӘ‘еӮ«ӮИҺё”sӮҫӮБӮҪӮнӮҜӮЕ
ӮЬӮ ғQғӢӮаӮўӮИӮӯӮИӮБӮҪӮұӮЖӮҫӮөҚЎҢгӮНӮЗӮӨӮИӮйӮвӮзҒBӮаӮБӮЖӮРӮБӮ»ӮиӮЖғҒғjғBғRғAӮрҗiӮЯӮйүВ”\җ«ӮаӮ ӮйӮҫӮлӮӨҒB
ӮөӮ©ӮөӮИӮӘӮзӮўӮ«ӮИӮиLRBғLғғғ“ғZғӢӮМғCғҒҒ[ғW’бүәӮрӮвӮнӮзӮ°ӮйӮҪӮЯӮЙҒA
ӮұӮиӮёӮЙ48ғRғAӮМ”z•zӮМӮЯӮЗӮӘҢoӮБӮҪӮЖӮұӮлӮЕғLғғғ“ғZғӢ”ӯ•\ӮҫӮБӮҪӮ©ӮзӮИҒB
ҺҹӮН“ҜӮ¶‘е•—ҳC•~ӮНҚLӮ°ӮИӮўӮЕӮРӮБӮ»ӮиӮвӮБӮД—~ӮөӮўғӮғmӮҫӮӘҒB
518 ҒFҒОҒОҒОҒОҒј(ҒEҒНҒE,,ҒҷuҒF2009/12/09(җ…) 21:41:25 ID:4o1T9QKx0
Part1 >>692
http://itl.jisakuita.net/intel_ups_info/1121683774.html#R692
TejasӮМҗЭҢvғ`Ғ[ғҖ@ғeғLғTғXҸBғIҒ[ғXғeғBғ“ӮӘ
Һҹҗў‘гXscaleӮЙҚ¶‘JӮіӮкӮҪғjғ…Ғ[ғXҒB
ӮұӮМҺҹҗў‘гXscaleӮӘӮЬӮіӮ©XscaleӮМҢгҢpӮЖӮНӮўӮҰx86ӮМBonnellӮҫӮБӮҪӮЖӮНӮЛӮҘҒB
ӮаӮЖӮНMotorolaӮМ’бҸБ”п“d—Нғ`ғbғvӮМҠJ”ӯғ`Ғ[ғҖӮҫӮБӮҪғҒғ“ғoҒ[ӮМӮжӮӨӮҫӮӘҒB
692 –ј‘OҒFinteler ҒF2006/07/09(“ъ) 11:59:26 ID:euVMFGdC0
----
454 –ј‘OҒFSocket774[sage] “ҠҚe“ъҒF2006/07/09(“ъ) 05:42:10 ID:tZypqzus
>>419
ttp://www.eetimes.com/news/latest/showArticle.jhtml;jsessionid=W4YJQATP0HKDMQSNDLRCKHSCJUNN2JVN?articleID=188703330&pgno=3
>The Tejas design team, led by Brad Beavers, site director for Intel in Austin,
>was put to work on the ultramobile-PC processor.
>Intel's work force in Austin has increased from 500 to 800,
>including design teams working on the next-generation Xscale, an Intel Austin engineer said.
TejasӮМ’ҶӮМҗlӮНXscaleӮЙҚ¶‘JӮіӮкӮҪӮзӮөӮўӮжӮ—
----
•\ғXғҢӮМҸ‘Ӯ«ҚһӮЭӮр“ЗӮсӮЕҸd‘еӮИӮұӮЖӮЙӢCӮГӮўӮҪҒB
http://itl.jisakuita.net/intel_ups_info/1121683774.html#R692
TejasӮМҗЭҢvғ`Ғ[ғҖ@ғeғLғTғXҸBғIҒ[ғXғeғBғ“ӮӘ
Һҹҗў‘гXscaleӮЙҚ¶‘JӮіӮкӮҪғjғ…Ғ[ғXҒB
ӮұӮМҺҹҗў‘гXscaleӮӘӮЬӮіӮ©XscaleӮМҢгҢpӮЖӮНӮўӮҰx86ӮМBonnellӮҫӮБӮҪӮЖӮНӮЛӮҘҒB
ӮаӮЖӮНMotorolaӮМ’бҸБ”п“d—Нғ`ғbғvӮМҠJ”ӯғ`Ғ[ғҖӮҫӮБӮҪғҒғ“ғoҒ[ӮМӮжӮӨӮҫӮӘҒB
692 –ј‘OҒFinteler ҒF2006/07/09(“ъ) 11:59:26 ID:euVMFGdC0
----
454 –ј‘OҒFSocket774[sage] “ҠҚe“ъҒF2006/07/09(“ъ) 05:42:10 ID:tZypqzus
>>419
ttp://www.eetimes.com/news/latest/showArticle.jhtml;jsessionid=W4YJQATP0HKDMQSNDLRCKHSCJUNN2JVN?articleID=188703330&pgno=3
>The Tejas design team, led by Brad Beavers, site director for Intel in Austin,
>was put to work on the ultramobile-PC processor.
>Intel's work force in Austin has increased from 500 to 800,
>including design teams working on the next-generation Xscale, an Intel Austin engineer said.
TejasӮМ’ҶӮМҗlӮНXscaleӮЙҚ¶‘JӮіӮкӮҪӮзӮөӮўӮжӮ—
----
•\ғXғҢӮМҸ‘Ӯ«ҚһӮЭӮр“ЗӮсӮЕҸd‘еӮИӮұӮЖӮЙӢCӮГӮўӮҪҒB
519 ҒFҒОҒОҒОҒОҒј(ҒEҒНҒE,,ҒҷuҒF2009/12/09(җ…) 21:44:13 ID:4o1T9QKx0
Ӯ ҒAӮИӮсӮ©“–ҺһӢLҺ–“ЗӮЭҠФҲбӮҰӮДӮўӮйӮжӮӨӮҫӮИҒB
•Ғ’КӮЙx86 UMPCӮМғvғҚғZғbғTҠJ”ӯӮ·ӮйҒB
XscaleӮМҠJ”ӯғ`Ғ[ғҖӮаҲкҸҸӮЙӮИӮйӮЭӮҪӮўӮИ“а—eӮ¶ӮбӮИӮўӮ©ҒB
•Ғ’КӮЙx86 UMPCӮМғvғҚғZғbғTҠJ”ӯӮ·ӮйҒB
XscaleӮМҠJ”ӯғ`Ғ[ғҖӮаҲкҸҸӮЙӮИӮйӮЭӮҪӮўӮИ“а—eӮ¶ӮбӮИӮўӮ©ҒB
520 ҒFҒОҒОҒОҒОҒј(ҒEҒНҒE,,ҒҷuҒF2009/12/09(җ…) 21:47:08 ID:4o1T9QKx0
ӮҝӮИӮЭӮЙ"UMPC"ӮЖӮўӮӨҢҫ—tӮрҸүӮЯӮДҺжӮиҸгӮ°ӮҪӮМӮН“ъ–{ӮМғTғCғgӮЕӮұӮМҸ‘ҚһӮӘҚЕҚӮ‘¬ӮЖҺvӮнӮкӮйҒB
ӮұӮМҺһӮН‘SӮӯӮЖӮўӮБӮДӮўӮўӮЩӮЗ’Қ–ЪӮіӮкӮДӮЁӮиӮЬӮ№ӮсӮЕӮөӮҪҒB
322 –ј‘OҒFinteler ҒF2006/02/07(үО) 20:43:15 ID:6yKKLJCo0
>>321
Q3
Intel's Ultra Mobile PC on track for Q1 release
http://www.tgdaily.com/2006/02/06/intel_umpc/
UMPC(Ultra Mobile PC)ӮЙӮВӮўӮДҒB
ҸЪӮөӮӯӮНғ\Ғ[ғXҺQҸЖҒB
ӮҙӮБӮіӮЭӮҪӮ©ӮсӮ¶ҒA
IntelӮӘғnғ“ғhғgғbғvӮИPCӮрҚЎҺl”јҠъ’ҶӮЙ—\’иҒBQ2Ӯ ӮҪӮиӮ©Ӯзҗ”ӮӘҸoӮйҒB
“–ҸүӮН0.5WӮМҸБ”п“d—НӮМҗVӮөӮўғJғeғSғҠӮМғvғҚғZғbғTӮр“ӢҚЪӮ·Ӯй—\’иӮҫӮБӮҪӮжӮӨӮҫӮӘҒA
ҸӯӮИӮӯӮЖӮаҚЕҸүӮМғoҒ[ғWғҮғ“ӮН90nm ULV DothanӮЕҸoӮйҒB
ӮҝӮИӮЭӮЙӮұӮМғ\Ғ[ғXӮЙӮжӮйӮЖҗVғ}ғCғNғҚғAҒ[ғLӮМCPUӮН9ҢҺҒB
ӮұӮМҺһӮН‘SӮӯӮЖӮўӮБӮДӮўӮўӮЩӮЗ’Қ–ЪӮіӮкӮДӮЁӮиӮЬӮ№ӮсӮЕӮөӮҪҒB
322 –ј‘OҒFinteler ҒF2006/02/07(үО) 20:43:15 ID:6yKKLJCo0
>>321
Q3
Intel's Ultra Mobile PC on track for Q1 release
http://www.tgdaily.com/2006/02/06/intel_umpc/
UMPC(Ultra Mobile PC)ӮЙӮВӮўӮДҒB
ҸЪӮөӮӯӮНғ\Ғ[ғXҺQҸЖҒB
ӮҙӮБӮіӮЭӮҪӮ©ӮсӮ¶ҒA
IntelӮӘғnғ“ғhғgғbғvӮИPCӮрҚЎҺl”јҠъ’ҶӮЙ—\’иҒBQ2Ӯ ӮҪӮиӮ©Ӯзҗ”ӮӘҸoӮйҒB
“–ҸүӮН0.5WӮМҸБ”п“d—НӮМҗVӮөӮўғJғeғSғҠӮМғvғҚғZғbғTӮр“ӢҚЪӮ·Ӯй—\’иӮҫӮБӮҪӮжӮӨӮҫӮӘҒA
ҸӯӮИӮӯӮЖӮаҚЕҸүӮМғoҒ[ғWғҮғ“ӮН90nm ULV DothanӮЕҸoӮйҒB
ӮҝӮИӮЭӮЙӮұӮМғ\Ғ[ғXӮЙӮжӮйӮЖҗVғ}ғCғNғҚғAҒ[ғLӮМCPUӮН9ҢҺҒB
521 ҒF–јҸМ–ўҗЭ’иҒF2009/12/09(җ…) 22:12:25 ID:Dr7V1f8I0
XScaleӮвӮБӮДӮҪғ`Ғ[ғҖӮаAtomҠJ”ӯӮЙүБӮнӮБӮДӮўӮҪӮМӮ©ҒB
522 ҒFҒОҒОҒОҒОҒј(ҒEҒНҒE,,ҒҷuҒF2009/12/09(җ…) 22:27:10 ID:4o1T9QKx0
Һҹҗў‘гXscaleӮвӮБӮДӮйӮБӮДӮҫӮҜӮЕҲкҸҸӮЙAtomҠJ”ӯӮөӮҪӮБӮДӮнӮҜӮ¶ӮбӮИӮўӮМӮ©ҒB
523 ҒF–јҸМ–ўҗЭ’иҒF2009/12/10(–Ш) 01:41:38 ID:jmMKh6Q50
>>517
‘јӮМҺё”sӮөӮҪMany-CoreӮЖLarrabeeӮр“Ҝ—сӮЙҗҳӮҰӮжӮӨӮЖӮ·ӮйӮМӮНӮҝӮЖҲбҳaҠҙӮӘӮ ӮйӮИ
җ»•iү»ӮӘҢцҢҫӮіӮкӮДӮҪӮҫӮҜӮ¶ӮбӮИӮӯҒAx86ӮрҠg’ЈӮөӮДӮўӮӯ•ыҢьҗ«ӮӘ“ьӮБӮДӮйҺһ“_ӮЕ‘јӮМMany-CoreӮЖӮНҸdӮЭӮӘҲбӮӨӮЕӮөӮе
‘јӮМғvғҚғWғFғNғgӮНғRғAӮМ•АӮЧ•ыӮЙҠЦӮөӮДӮМғҠғTҒ[ғ`ӮБӮДҠҙӮ¶ӮӘӮ·Ӯй
Ӯ»ӮМғRғAӮӘӮҪӮЬӮҪӮЬx86ӮИӮҫӮҜӮЕҒAx86ӮЕӮ Ӯй•K‘Rҗ«ӮӘӮ ӮсӮЬӮИӮў
Ӯ»ӮкӮЖӮа’cҺqӮЙ“ЕӮіӮкӮ·Ӯ¬Ӯ©ҒHӮ—
‘јӮМҺё”sӮөӮҪMany-CoreӮЖLarrabeeӮр“Ҝ—сӮЙҗҳӮҰӮжӮӨӮЖӮ·ӮйӮМӮНӮҝӮЖҲбҳaҠҙӮӘӮ ӮйӮИ
җ»•iү»ӮӘҢцҢҫӮіӮкӮДӮҪӮҫӮҜӮ¶ӮбӮИӮӯҒAx86ӮрҠg’ЈӮөӮДӮўӮӯ•ыҢьҗ«ӮӘ“ьӮБӮДӮйҺһ“_ӮЕ‘јӮМMany-CoreӮЖӮНҸdӮЭӮӘҲбӮӨӮЕӮөӮе
‘јӮМғvғҚғWғFғNғgӮНғRғAӮМ•АӮЧ•ыӮЙҠЦӮөӮДӮМғҠғTҒ[ғ`ӮБӮДҠҙӮ¶ӮӘӮ·Ӯй
Ӯ»ӮМғRғAӮӘӮҪӮЬӮҪӮЬx86ӮИӮҫӮҜӮЕҒAx86ӮЕӮ Ӯй•K‘Rҗ«ӮӘӮ ӮсӮЬӮИӮў
Ӯ»ӮкӮЖӮа’cҺqӮЙ“ЕӮіӮкӮ·Ӯ¬Ӯ©ҒHӮ—
524 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/12/10(–Ш) 03:40:36 ID:/M5QA7t50
ҢӢӢЗӮЭӮсӮИPentium*ӮМғRҒ[ғhҺ‘ҺYҺgӮўӮҪӮўӮсӮЕӮ·Ӯж
525 ҒF–јҸМ–ўҗЭ’иҒF2009/12/10(–Ш) 09:48:31 ID:sa8rBxOy0
Қ¬ҚЪ—pӮМғRғAҠJ”ӯӮӘ–{—ҲӮМ–Ъ“IӮИӮсӮҫӮ©Ӯз
ғfғBғXғNғҠҒ[ғgӮӘӮўӮӯӮзҢг‘ЮӮөӮжӮӨӮЖintel“IӮЙӮН–в‘иӮИӮўӮМӮЕӮН?
ғQҒ[ғҖҠJ”ӯүпҺРӮЙӮНӮЁӢаӮЖҲкҸҸӮЙ“nӮөӮДӮЁӮӯӮЧӮ«ӮҫӮЖҺvӮӨӮҜӮЗӮ—
ғfғBғXғNғҠҒ[ғgӮӘӮўӮӯӮзҢг‘ЮӮөӮжӮӨӮЖintel“IӮЙӮН–в‘иӮИӮўӮМӮЕӮН?
ғQҒ[ғҖҠJ”ӯүпҺРӮЙӮНӮЁӢаӮЖҲкҸҸӮЙ“nӮөӮДӮЁӮӯӮЧӮ«ӮҫӮЖҺvӮӨӮҜӮЗӮ—
526 ҒFҒОҒОҒОҒОҒј(ҒEҒНҒE,,ҒҷuҒF2009/12/10(–Ш) 18:47:25 ID:THg85MlJ0
ӮвӮБӮПҺ–ҢгүрҺЯӮМӢcҳ_ӮНӮҫӮҫҠҠӮиӮҫӮИҒB
–ў—ҲӮМҳbӮНҒAӮ»ӮМҢгӮМҢoүЯӮрӮЭӮйӮұӮЖӮЕ—қҳ_ӮЙҺАҸШҗ«ӮрӮўӮкӮзӮкӮйӮҜӮЗҒA
үЯӮ¬ӮҪҳbӮрӮұӮӨӮҫӮлӮӨӮЖӮўӮБӮДӮаӮИӮЙӮӘҗіӮөӮ©ӮБӮҪӮМӮ©ҸШ–ҫӮ·ӮйӮМӮӘ“пӮөӮўҒB
ӮЖӮўӮӨӮнӮҜӮЕӮЁӮкӮН–ў—ҲӮМҳbҗкӢЖӮЙ“OӮ·ӮйӮұӮЖӮЙӮөӮҪҒB
–ў—ҲӮМҳbӮНҒAӮ»ӮМҢгӮМҢoүЯӮрӮЭӮйӮұӮЖӮЕ—қҳ_ӮЙҺАҸШҗ«ӮрӮўӮкӮзӮкӮйӮҜӮЗҒA
үЯӮ¬ӮҪҳbӮрӮұӮӨӮҫӮлӮӨӮЖӮўӮБӮДӮаӮИӮЙӮӘҗіӮөӮ©ӮБӮҪӮМӮ©ҸШ–ҫӮ·ӮйӮМӮӘ“пӮөӮўҒB
ӮЖӮўӮӨӮнӮҜӮЕӮЁӮкӮН–ў—ҲӮМҳbҗкӢЖӮЙ“OӮ·ӮйӮұӮЖӮЙӮөӮҪҒB
527 ҒFҒОҒОҒОҒОҒј(ҒEҒНҒE,,ҒҷuҒF2009/12/10(–Ш) 18:49:07 ID:THg85MlJ0
ӮаӮҝӮлӮсүЯӢҺғXғҢӮМҳb‘иӮӘӮЗӮМ’ц“xҗіӮөӮ©ӮБӮҪӮМӮ©ӮНӮЕӮ«ӮкӮОӮвӮБӮДӮЁӮ«ӮҪӮўӮЖӮұӮлӮҫҒB
528 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2009/12/10(–Ш) 18:57:03 ID:THg85MlJ0
CPUҠЦҳAӮМғjғ…Ғ[ғXӮвғӢҒ[ғ}Ғ[ӮЙүEүқҚ¶үқӮөӮДӮўӮйӮЖҒA
ӮЬӮ ӮұӮкӮҫӮҜҸо•сӮӘ—¬’КӮ·ӮйҺһ‘гӮЙӮЁӮўӮД”MҗSӮЙҸо•сӮрӮ ӮВӮЯӮДӮўӮйӮВӮаӮиӮЕӮаҒA
ӮнӮёӮ©җ””NӮМҺһҠФӮЙ‘ОӮөӮДӮўӮ©ӮЙҗ^ҺАӮр—рҺjӮЖӮөӮДӢLүҜӮөӮДӮўӮӯӮұӮЖӮӘ“пӮөӮўӮ©ӮӘӮнӮ©ӮйӮИҒB
җПӢЙ“IӮЙ–ў—ҲӮр—\‘zӮөӮДҒAғZғIғҠҒ[ӮЗӮЁӮиӮЙҗiӮсӮҫӮ©ӮЗӮӨӮ©ӮМҢӢүКӮрғtғBҒ[ғhғoғbғNӮ·ӮйӮұӮЖӮЕҒA
—рҺjӮЙ‘ОӮөӮДӮ Ӯй’ц“xӮМҺАҸШҗ«ӮМҠT”OӮрҺжӮи“ьӮкӮзӮкӮйҒB
ӮұӮкӮЕӮжӮиҗ^ҺАӮЙӢЯӮГӮӯӮұӮЖӮӘӮЁӮкӮМҲкӮВӮМ–Ъ•WӮЕӮ ӮйҸo—ҲӮйӮМӮҫҒB
ӮЬӮ —рҺjҠwҺТӮЙӮНӮнӮйӮўӮӘҒAӮЗӮсӮИ“VҚЛӮЕӮ ӮБӮДӮа
җl—ЮӮЙӮН100”N‘OӮМҗ^ҺАӮрӮЬӮЖӮа’mӮйӮұӮЖӮН•sүВ”\ӮҫӮЖҺАҠҙӮөӮДӮөӮЬӮӨҒB
—рҺjӮНүRӮОӮ©ӮиӮИӮМӮҫӮлӮӨҒB
ӮЬӮ ӮұӮкӮҫӮҜҸо•сӮӘ—¬’КӮ·ӮйҺһ‘гӮЙӮЁӮўӮД”MҗSӮЙҸо•сӮрӮ ӮВӮЯӮДӮўӮйӮВӮаӮиӮЕӮаҒA
ӮнӮёӮ©җ””NӮМҺһҠФӮЙ‘ОӮөӮДӮўӮ©ӮЙҗ^ҺАӮр—рҺjӮЖӮөӮДӢLүҜӮөӮДӮўӮӯӮұӮЖӮӘ“пӮөӮўӮ©ӮӘӮнӮ©ӮйӮИҒB
җПӢЙ“IӮЙ–ў—ҲӮр—\‘zӮөӮДҒAғZғIғҠҒ[ӮЗӮЁӮиӮЙҗiӮсӮҫӮ©ӮЗӮӨӮ©ӮМҢӢүКӮрғtғBҒ[ғhғoғbғNӮ·ӮйӮұӮЖӮЕҒA
—рҺjӮЙ‘ОӮөӮДӮ Ӯй’ц“xӮМҺАҸШҗ«ӮМҠT”OӮрҺжӮи“ьӮкӮзӮкӮйҒB
ӮұӮкӮЕӮжӮиҗ^ҺАӮЙӢЯӮГӮӯӮұӮЖӮӘӮЁӮкӮМҲкӮВӮМ–Ъ•WӮЕӮ ӮйҸo—ҲӮйӮМӮҫҒB
ӮЬӮ —рҺjҠwҺТӮЙӮНӮнӮйӮўӮӘҒAӮЗӮсӮИ“VҚЛӮЕӮ ӮБӮДӮа
җl—ЮӮЙӮН100”N‘OӮМҗ^ҺАӮрӮЬӮЖӮа’mӮйӮұӮЖӮН•sүВ”\ӮҫӮЖҺАҠҙӮөӮДӮөӮЬӮӨҒB
—рҺjӮНүRӮОӮ©ӮиӮИӮМӮҫӮлӮӨҒB
529 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2009/12/10(–Ш) 20:27:03 ID:THg85MlJ0
Ӯ»ӮкӮЙӮөӮДӮаҢг“Ўҗжҗ¶ӮЮӮ©ӮВӮӯӮИ(ӮнӮзӮЎ
ӮЁӮкӮӘLRBӮӘҺё”sӮөӮҪ—қ—RӮН
ғҠғAғӢғ^ғCғҖҗ«ӮМҚӮӮўҸҲ—қӮӘ1ғ^Ғ[ғQғbғgӮЕӮ ӮйӮМӮЙҒAғҸҒ[ғNғҚҒ[ғhӮр•ӘҗНӮаӮлӮӯӮЙӮИӮўӮЬӮЬ
–wӮЗғ\ғtғgӮЙҠЫ“ҠӮ°(=ғQҒ[ғҖ’ҶӮЕӮМ“ҫҲУҒE•s“ҫҲУӮИҸҲ—қӮМҚ·ӮӘ‘еӮ«ӮӯӮИӮйҒB
ғQҒ[ғҖӮН60fpsҲИҸгӮрҸнӮЙғLҒ[ғvӮөӮИӮўӮЖӮўӮҜӮИӮўӮМӮЕғTҒ[ғoӮМғgғүғ“ғUғNғVғҮғ“ӮИӮЗӮЖҲЩӮИӮиүәҢАӮМҗ«”\ӮӘӮ«ӮнӮЯӮДҸd—vҒB
LRBӮЙӮЖӮБӮДғxғXғgӮЙӢЯӮўғfҒ[ғ^ӮМҳ_•¶”ӯ•\ӮИӮсӮДҺQҚlӮЙӮИӮзӮИӮў)ӮөӮҪӮ Ӯ°ӮӯҒA
1–{ӮМғҠғ“ғOӮЕ10ҲИҸгӮМғRғAӮрҲөӮӨӮМӮН’xү„ӮӘҲА’иӮөӮИӮўӮ©Ӯз–і–dӮҫӮөҒAғeғNғXғ`ғғӮЕ‘СҲжӮаӢтӮнӮкӮД
үәҢАӮМҗ«”\ӮӘӮЕӮИӮўҒB”с‘ОҸМӮЙӮ·ӮйӮЙӮа—p“rӮМ‘SӮӯҲЩӮИӮйғRғAӮНғoғXӮр•Ә—ЈӮ·ӮЧӮ«ҒB
ӮЖӮўӮӨӮМӮрҸ‘ӮұӮӨӮЖӮөӮҪӮзҺ—ӮҪӮжӮӨӮИӮұӮЖӮрҗжӮЙӮ©Ӯ©ӮкӮҪҒB
ӮЬӮ >>328ӮЕӮа—p“r“IӮЙғҠғ“ғOӮӘ–і–dӮЕӮ ӮйӮЖӮрғLғғғ“ғZғӢӮіӮкӮйӮжӮиӮаҗжӮ©ӮўӮДӮўӮҪ
ӮЁӮкӮМҸҹ—ҳӮИӮнӮҜӮҫӮӘҒB
ӮЁӮкӮӘLRBӮӘҺё”sӮөӮҪ—қ—RӮН
ғҠғAғӢғ^ғCғҖҗ«ӮМҚӮӮўҸҲ—қӮӘ1ғ^Ғ[ғQғbғgӮЕӮ ӮйӮМӮЙҒAғҸҒ[ғNғҚҒ[ғhӮр•ӘҗНӮаӮлӮӯӮЙӮИӮўӮЬӮЬ
–wӮЗғ\ғtғgӮЙҠЫ“ҠӮ°(=ғQҒ[ғҖ’ҶӮЕӮМ“ҫҲУҒE•s“ҫҲУӮИҸҲ—қӮМҚ·ӮӘ‘еӮ«ӮӯӮИӮйҒB
ғQҒ[ғҖӮН60fpsҲИҸгӮрҸнӮЙғLҒ[ғvӮөӮИӮўӮЖӮўӮҜӮИӮўӮМӮЕғTҒ[ғoӮМғgғүғ“ғUғNғVғҮғ“ӮИӮЗӮЖҲЩӮИӮиүәҢАӮМҗ«”\ӮӘӮ«ӮнӮЯӮДҸd—vҒB
LRBӮЙӮЖӮБӮДғxғXғgӮЙӢЯӮўғfҒ[ғ^ӮМҳ_•¶”ӯ•\ӮИӮсӮДҺQҚlӮЙӮИӮзӮИӮў)ӮөӮҪӮ Ӯ°ӮӯҒA
1–{ӮМғҠғ“ғOӮЕ10ҲИҸгӮМғRғAӮрҲөӮӨӮМӮН’xү„ӮӘҲА’иӮөӮИӮўӮ©Ӯз–і–dӮҫӮөҒAғeғNғXғ`ғғӮЕ‘СҲжӮаӢтӮнӮкӮД
үәҢАӮМҗ«”\ӮӘӮЕӮИӮўҒB”с‘ОҸМӮЙӮ·ӮйӮЙӮа—p“rӮМ‘SӮӯҲЩӮИӮйғRғAӮНғoғXӮр•Ә—ЈӮ·ӮЧӮ«ҒB
ӮЖӮўӮӨӮМӮрҸ‘ӮұӮӨӮЖӮөӮҪӮзҺ—ӮҪӮжӮӨӮИӮұӮЖӮрҗжӮЙӮ©Ӯ©ӮкӮҪҒB
ӮЬӮ >>328ӮЕӮа—p“r“IӮЙғҠғ“ғOӮӘ–і–dӮЕӮ ӮйӮЖӮрғLғғғ“ғZғӢӮіӮкӮйӮжӮиӮаҗжӮ©ӮўӮДӮўӮҪ
ӮЁӮкӮМҸҹ—ҳӮИӮнӮҜӮҫӮӘҒB
530 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2009/12/10(–Ш) 20:30:21 ID:THg85MlJ0
GMAӮМ“қҚҮӮЖLRB“қҚҮӮМҚЕӮа‘еӮ«ӮИҲбӮўӮНҒA
LRBғRғAӮН”Д—pғRғA“ҜӮ¶ғҠғ“ғOӮЙ‘ОӮөӮДғtғүғbғgӮЙҸWҗПӮ·ӮйӮұӮЖӮӘ—\‘zӮіӮкӮҪӮМӮЙӮҪӮўӮөҒA
GMAӮНғXғgғҠҒ[ғҖҸҲ—қӮЙҠЦӮөӮДGMA“а•”ӮЕғfҒ[ғ^ӮМӮвӮиӮЖӮиӮр–wӮЗҠ®ҢӢӮЕӮ«ӮйӮұӮЖӮЙӮ ӮйҒB
ҢВҗl“IӮЙӮНIntelӮМҳ_•¶ӮрӮЭӮДӮаGMAӮЖLRBғRғAӮНӮЮӮөӮлӢӨ‘¶ӮөӮДӮЬӮ¶ӮБӮҪҗ»•iӮӘӮ ӮБӮДӮаӮЁӮ©ӮөӮӯӮНӮИӮўӮЖҺvӮБӮДӮўӮҪҒB
LRBғRғAӮН”Д—pғRғA“ҜӮ¶ғҠғ“ғOӮЙ‘ОӮөӮДғtғүғbғgӮЙҸWҗПӮ·ӮйӮұӮЖӮӘ—\‘zӮіӮкӮҪӮМӮЙӮҪӮўӮөҒA
GMAӮНғXғgғҠҒ[ғҖҸҲ—қӮЙҠЦӮөӮДGMA“а•”ӮЕғfҒ[ғ^ӮМӮвӮиӮЖӮиӮр–wӮЗҠ®ҢӢӮЕӮ«ӮйӮұӮЖӮЙӮ ӮйҒB
ҢВҗl“IӮЙӮНIntelӮМҳ_•¶ӮрӮЭӮДӮаGMAӮЖLRBғRғAӮНӮЮӮөӮлӢӨ‘¶ӮөӮДӮЬӮ¶ӮБӮҪҗ»•iӮӘӮ ӮБӮДӮаӮЁӮ©ӮөӮӯӮНӮИӮўӮЖҺvӮБӮДӮўӮҪҒB
531 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2009/12/10(–Ш) 20:36:44 ID:THg85MlJ0
GPGPUӮНӮ ӮӯӮЬӮЕӮағ\ғtғgү»үВ”\ӮИ•”•ӘӮр’iҠK“IӮЙӮ»Ӯ¬—ҺӮЖӮөӮД”Д—pү»ӮөӮДӮўӮйӮЖӮұӮлӮӘLRBӮЖҲЩӮИӮйҒB
•Ғ’КӮНғҸҒ[ғNғҚҒ[ғhӮр•ӘҗНӮөӮДҒA•K—vӮИӮЖӮұӮлӮЙғҠғ\Ғ[ғXӮрӮіӮўӮДӮўӮзӮИӮўӮЖӮұӮлӮрғJғbғgӮ·ӮйӮӘҒA
LRBӮМҸкҚҮҒA”Д—pCPUӮЦӮМ—eҲХӮИ“қҚҮү»ӮМғXғ^ғ“ғXӮӘӮаӮлӮЙҢ»ӮкӮДӮўӮДҒA
ӮҪӮҫғҠғ“ғOӮЕӮВӮИӮўӮҫӮҫӮҜӮЕҒAӮЖӮиӮ ӮҰӮёҗжӮЙғnҒ[ғhӮМғAҒ[ғLғeғNғ`ғғӮр—pҲУӮөӮҪҒB
Ӯ»ӮМҢгӮЕҒAӮұӮӨӮөӮҪӮзӮұӮМғAҒ[ғLӮНӮӨӮЬӮӯӮВӮ©ӮҰӮйӮјӮ§ҒAӮЭӮҪӮўӮИғ\ғtғgҢnӮМҳ_•¶ӮӘӮ ӮЖӮ©ӮзӮЕӮДӮӯӮйӮЖӮўӮӨ
ӮЬӮ Һё”s“xӮМҚӮӮў“WҠJӮҫӮБӮҪӮнӮҜӮЕҒBӮұӮӨӮўӮӨӮЖӮұӮлӮН–^ҒӣELLӮЙҺ—ӮДӮўӮҪӮИҒB
•Ғ’КӮНғҸҒ[ғNғҚҒ[ғhӮр•ӘҗНӮөӮДҒA•K—vӮИӮЖӮұӮлӮЙғҠғ\Ғ[ғXӮрӮіӮўӮДӮўӮзӮИӮўӮЖӮұӮлӮрғJғbғgӮ·ӮйӮӘҒA
LRBӮМҸкҚҮҒA”Д—pCPUӮЦӮМ—eҲХӮИ“қҚҮү»ӮМғXғ^ғ“ғXӮӘӮаӮлӮЙҢ»ӮкӮДӮўӮДҒA
ӮҪӮҫғҠғ“ғOӮЕӮВӮИӮўӮҫӮҫӮҜӮЕҒAӮЖӮиӮ ӮҰӮёҗжӮЙғnҒ[ғhӮМғAҒ[ғLғeғNғ`ғғӮр—pҲУӮөӮҪҒB
Ӯ»ӮМҢгӮЕҒAӮұӮӨӮөӮҪӮзӮұӮМғAҒ[ғLӮНӮӨӮЬӮӯӮВӮ©ӮҰӮйӮјӮ§ҒAӮЭӮҪӮўӮИғ\ғtғgҢnӮМҳ_•¶ӮӘӮ ӮЖӮ©ӮзӮЕӮДӮӯӮйӮЖӮўӮӨ
ӮЬӮ Һё”s“xӮМҚӮӮў“WҠJӮҫӮБӮҪӮнӮҜӮЕҒBӮұӮӨӮўӮӨӮЖӮұӮлӮН–^ҒӣELLӮЙҺ—ӮДӮўӮҪӮИҒB
532 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2009/12/10(–Ш) 20:38:22 ID:THg85MlJ0
ӮЬӮёғҸҒ[ғNғҚҒ[ғhҒAғ^Ғ[ғQғbғgғ\ғtғgӮМҢӨӢҶҒE•ӘҗНӮ©ӮзӮНӮ¶ӮЬӮзӮИӮўӮЖӮИҒB
‘Ҫ•ӘҺҹӮМғҒғjғBғRғAӮаҠъ‘ТӮЕӮ«ӮИӮўҒBғҠғ“ғOӮНӮвӮЯӮйӮ©ӮаӮөӮкӮИӮўӮҜӮЗҒAӮ»ӮкӮҫӮҜӮЕӮН
”І–{“IӮИүь‘PӮЙӮНӮИӮзӮИӮўӮҫӮлӮӨӮИҒB
‘Ҫ•ӘҺҹӮМғҒғjғBғRғAӮаҠъ‘ТӮЕӮ«ӮИӮўҒBғҠғ“ғOӮНӮвӮЯӮйӮ©ӮаӮөӮкӮИӮўӮҜӮЗҒAӮ»ӮкӮҫӮҜӮЕӮН
”І–{“IӮИүь‘PӮЙӮНӮИӮзӮИӮўӮҫӮлӮӨӮИҒB
533 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2009/12/10(–Ш) 21:03:05 ID:THg85MlJ0
ӮұӮӨӮөӮДӮ ӮзӮҪӮЯӮДҚlӮҰӮДӮЭӮйӮЖ
”Д—pғRғAӮМSIMDӮрӮ»ӮМӮЬӮЬҠg’ЈӮ·ӮйӮ©ҒA
җк—pғRғAӮр“қҚҮӮ·ӮйӮЙӮөӮДӮаҗк—pғRғA“аӮМғoғXӮЕӢЙ—НғfҒ[ғ^ӮМ—¬ӮкӮрҠ®ҢӢӮіӮ№ӮйҒA
ӮЖӮўӮӨSoC“IғAғvғҚҒ[ғ`ӮМ•ыӮӘҒA
Fabric, Ring, Mech“ҷӮЕ”Д—pғRғAӮаӮлӮЖӮаҒAғtғүғbғgӮЙғRғAӮр‘Ҫҗ”ҸWҗПӮЖӮўӮӨ
ғҒғjғBғRғA“IғAғvғҚҒ[ғ`ӮжӮиӮаҢ»ҺА“IӮЕ—LҢшӮИғAғvғҚҒ[ғ`ӮМӮжӮӨӮЙҺvӮҰӮДҒA
ҚЎIntelӮМӮвӮБӮДӮўӮйӮұӮЖӮӘ–і‘КӮЙӮЁӮаӮҰӮДҺd•ыӮӘӮИӮўҒB
“d—НӮМҳbӮрӮУӮӯӮЯӮДӮИӮәғҒғjғBғRғAӮӘӮҫӮЯӮИӮМӮ©ӮЖӮўӮӨӮұӮЖӮрӮЁӮіӮзӮўӮ·ӮйӮЖ
10-20’·•¶ғҢғXӮМ’·•ТӮЙӮИӮБӮДӮөӮЬӮӨӮөҒAӮЯӮсӮЗӮӨӮИӮМӮЕҸ‘Ӯ©ӮИӮўӮӘҒB
”Д—pғRғAӮМSIMDӮрӮ»ӮМӮЬӮЬҠg’ЈӮ·ӮйӮ©ҒA
җк—pғRғAӮр“қҚҮӮ·ӮйӮЙӮөӮДӮаҗк—pғRғA“аӮМғoғXӮЕӢЙ—НғfҒ[ғ^ӮМ—¬ӮкӮрҠ®ҢӢӮіӮ№ӮйҒA
ӮЖӮўӮӨSoC“IғAғvғҚҒ[ғ`ӮМ•ыӮӘҒA
Fabric, Ring, Mech“ҷӮЕ”Д—pғRғAӮаӮлӮЖӮаҒAғtғүғbғgӮЙғRғAӮр‘Ҫҗ”ҸWҗПӮЖӮўӮӨ
ғҒғjғBғRғA“IғAғvғҚҒ[ғ`ӮжӮиӮаҢ»ҺА“IӮЕ—LҢшӮИғAғvғҚҒ[ғ`ӮМӮжӮӨӮЙҺvӮҰӮДҒA
ҚЎIntelӮМӮвӮБӮДӮўӮйӮұӮЖӮӘ–і‘КӮЙӮЁӮаӮҰӮДҺd•ыӮӘӮИӮўҒB
“d—НӮМҳbӮрӮУӮӯӮЯӮДӮИӮәғҒғjғBғRғAӮӘӮҫӮЯӮИӮМӮ©ӮЖӮўӮӨӮұӮЖӮрӮЁӮіӮзӮўӮ·ӮйӮЖ
10-20’·•¶ғҢғXӮМ’·•ТӮЙӮИӮБӮДӮөӮЬӮӨӮөҒAӮЯӮсӮЗӮӨӮИӮМӮЕҸ‘Ӯ©ӮИӮўӮӘҒB
534 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2009/12/10(–Ш) 21:04:20 ID:THg85MlJ0
mesh
535 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2009/12/10(–Ш) 21:10:16 ID:THg85MlJ0
ғCғ“ғ^Ғ[ғRғlғNғgӮМ–в‘иӮН2”ФӮҫӮЛҒB
ғҒғjғBғRғAӮӘ‘К–ЪӮИ1”ФӮМ—қ—RӮНӮвӮНӮи“d—НҒB
–{“–ӮН“d—НӮӘӮжӮўӮ©ӮзғRғAӮр‘қӮвӮөӮҪӮВӮаӮиӮИӮсӮҫӮҜӮЗӮаҒB
ӮвӮБӮПCPUӮН“d—НӮҫӮәҒAӮБӮДӮұӮЖӮҫҒB
ғҒғjғBғRғAӮӘ‘К–ЪӮИ1”ФӮМ—қ—RӮНӮвӮНӮи“d—НҒB
–{“–ӮН“d—НӮӘӮжӮўӮ©ӮзғRғAӮр‘қӮвӮөӮҪӮВӮаӮиӮИӮсӮҫӮҜӮЗӮаҒB
ӮвӮБӮПCPUӮН“d—НӮҫӮәҒAӮБӮДӮұӮЖӮҫҒB
536 ҒF–јҸМ–ўҗЭ’иҒF2009/12/11(Ӣа) 11:00:23 ID:MUr77cKd0
> ӮЬӮёғҸҒ[ғNғҚҒ[ғhҒAғ^Ғ[ғQғbғgғ\ғtғgӮМҢӨӢҶҒE•ӘҗНӮ©ӮзӮНӮ¶ӮЬӮзӮИӮўӮЖӮИҒB
ӮөӮДӮҪӮлҒBҺАҚЫӮМғQҒ[ғҖғ^ғCғgғӢӮЕӮЗӮұӮМҸҲ—қӮӘҚӮ•үүЧӮ©ҒAӮИӮЗҒB
Ӯ»ӮкӮЕӮ ӮМ–Ҫ—ЯғZғbғgӮЙҺыӮЬӮБӮҪӮсӮҫӮлҒB
–в‘иӮНӮ»ӮМ–Ҫ—ЯғZғbғgӮрҺАҢ»Ӯ·ӮйӮҪӮЯӮМғ}ғCғNғҚғAҒ[ғLғeғNғ`ғғӮМҗЭҢvӮЕӮ ӮБӮД
ӮЗӮБӮҝӮ©ӮЖӮўӮӨӮЖғnҒ[ғhӮЖғ\ғtғgӮМ—ј–КӮ©ӮзҒAғXғCҒ[ғgғXғ|ғbғgӮӘӮЗӮұӮ©
’TӮиӮр“ьӮкӮй•K—vӮӘӮ ӮйҒB
512ғrғbғgӮМSIMDӮИӮсӮДIntelӮЖӮөӮДӮаҸүӮМҺҺӮЭҒB
ҚЎӮЕӮұӮ»Ң»ҚsCore MAӮМ‘bӮЖӮөӮД‘гҒXҺуӮҜҢpӮӘӮкӮДӮўӮйPentium ProӮЙӮөӮДӮа
PC—pӮЖӮөӮДҚЕҸүӮ©ӮзҚӮӮў•]үҝӮӘ“ҫӮзӮкӮҪӮнӮҜӮЕӮНӮИӮўҒB
ӮЬӮБӮҪӮӯҗVӢKӮМғvғҚғZғbғTӮӘҲк”ӯOKӮИӮсӮДӮ ӮиӮҰӮИӮўӮұӮЖҒB
ӮөӮДӮҪӮлҒBҺАҚЫӮМғQҒ[ғҖғ^ғCғgғӢӮЕӮЗӮұӮМҸҲ—қӮӘҚӮ•үүЧӮ©ҒAӮИӮЗҒB
Ӯ»ӮкӮЕӮ ӮМ–Ҫ—ЯғZғbғgӮЙҺыӮЬӮБӮҪӮсӮҫӮлҒB
–в‘иӮНӮ»ӮМ–Ҫ—ЯғZғbғgӮрҺАҢ»Ӯ·ӮйӮҪӮЯӮМғ}ғCғNғҚғAҒ[ғLғeғNғ`ғғӮМҗЭҢvӮЕӮ ӮБӮД
ӮЗӮБӮҝӮ©ӮЖӮўӮӨӮЖғnҒ[ғhӮЖғ\ғtғgӮМ—ј–КӮ©ӮзҒAғXғCҒ[ғgғXғ|ғbғgӮӘӮЗӮұӮ©
’TӮиӮр“ьӮкӮй•K—vӮӘӮ ӮйҒB
512ғrғbғgӮМSIMDӮИӮсӮДIntelӮЖӮөӮДӮаҸүӮМҺҺӮЭҒB
ҚЎӮЕӮұӮ»Ң»ҚsCore MAӮМ‘bӮЖӮөӮД‘гҒXҺуӮҜҢpӮӘӮкӮДӮўӮйPentium ProӮЙӮөӮДӮа
PC—pӮЖӮөӮДҚЕҸүӮ©ӮзҚӮӮў•]үҝӮӘ“ҫӮзӮкӮҪӮнӮҜӮЕӮНӮИӮўҒB
ӮЬӮБӮҪӮӯҗVӢKӮМғvғҚғZғbғTӮӘҲк”ӯOKӮИӮсӮДӮ ӮиӮҰӮИӮўӮұӮЖҒB
537 ҒF–јҸМ–ўҗЭ’иҒF2009/12/12(“y) 08:02:46 ID:ngGqOhUt0
HPCҺsҸкӮЖӮўӮӨ–ҫҠmӮИ–Ъ•WӮӘӮ ӮкӮОғҸҒ[ғNғҚҒ[ғhӮМҢӨӢҶ•ӘҗНӮН—eҲХӮўӮҫӮлӮӨӮҜӮЗҒA
IntelӮМҺеҗнҸкӮЕӮ ӮйғRғ“ғVғ…Ғ[ғ}ӮЕ•А—сғRғ“ғsғ…Ғ[ғeғBғ“ғOӮЖҢҫӮБӮҪӮзӮвӮБӮП
ғOғүғtғBғbғNғXӮөӮ©ӮИӮўӮ©ӮзӮИӮ ҒAҢ»ҸуӮЕӮНҒB
RTRTӮЖӮ©RMSӮЖӮ©ӮўӮВӮЙӮИӮБӮҪӮзӮвӮйӮМҒHӮБӮДҠҙӮ¶ӮҫӮөҒB
Ӯ»ӮкӮЕғҒғCғ“ғ^Ғ[ғQғbғgӮрҢҲӮЯӮзӮкӮёӮЗӮБӮҝӮВӮ©ӮёӮЙӮИӮБӮД–А‘–ӮөӮҪӮЖҒB
IntelӮМҺеҗнҸкӮНHPCӮЕӮНӮИӮӯғRғ“ғVғ…Ғ[ғ}ӮЕӮ ӮБӮДҒAӮ»ӮұӮЕҗ»•iӮрҚӮӮӯ”„Ӯи‘ұӮҜӮйӮҪӮЯ
ӮЙӮНүҪӮзӮ©ӮМҗVӮөӮўүҝ’lӮр’сҲДӮөӮИӮҜӮиӮбӮўӮҜӮИӮўҒB
ӮЖӮұӮлӮӘӮ»ӮМүҝ’lӮр’сҲДҸo—ҲӮИӮўӮЬӮЬҒAғҒғjҒ[ғRғAӮр”„ӮлӮӨӮЖӮөӮҝӮбӮБӮҪӮМӮӘҚЎүсӮМ
LarrabeeғLғғғ“ғZғӢӮЙҢqӮӘӮБӮҪӮБӮДӮұӮЖӮ¶ӮбӮИӮ©ӮлӮӨӮ©ҒB
ғnҒ[ғhӮЖғ\ғtғgҒA—‘ӮЖҢ{ӮМҠЦҢWӮЖӮаҢҫӮҰӮйӮҜӮЗҒB
Ӯ»ӮӨҚlӮҰӮйӮЖӮ·ӮЕӮЙ‘«ҸкӮӘӮ ӮйGPUӮМ•ыӮӘҗVүҝ’lӮН’сҲДӮөӮвӮ·ӮўҲК’uӮЙӮўӮйӮМӮ©ӮаҒB
IntelӮМҺеҗнҸкӮЕӮ ӮйғRғ“ғVғ…Ғ[ғ}ӮЕ•А—сғRғ“ғsғ…Ғ[ғeғBғ“ғOӮЖҢҫӮБӮҪӮзӮвӮБӮП
ғOғүғtғBғbғNғXӮөӮ©ӮИӮўӮ©ӮзӮИӮ ҒAҢ»ҸуӮЕӮНҒB
RTRTӮЖӮ©RMSӮЖӮ©ӮўӮВӮЙӮИӮБӮҪӮзӮвӮйӮМҒHӮБӮДҠҙӮ¶ӮҫӮөҒB
Ӯ»ӮкӮЕғҒғCғ“ғ^Ғ[ғQғbғgӮрҢҲӮЯӮзӮкӮёӮЗӮБӮҝӮВӮ©ӮёӮЙӮИӮБӮД–А‘–ӮөӮҪӮЖҒB
IntelӮМҺеҗнҸкӮНHPCӮЕӮНӮИӮӯғRғ“ғVғ…Ғ[ғ}ӮЕӮ ӮБӮДҒAӮ»ӮұӮЕҗ»•iӮрҚӮӮӯ”„Ӯи‘ұӮҜӮйӮҪӮЯ
ӮЙӮНүҪӮзӮ©ӮМҗVӮөӮўүҝ’lӮр’сҲДӮөӮИӮҜӮиӮбӮўӮҜӮИӮўҒB
ӮЖӮұӮлӮӘӮ»ӮМүҝ’lӮр’сҲДҸo—ҲӮИӮўӮЬӮЬҒAғҒғjҒ[ғRғAӮр”„ӮлӮӨӮЖӮөӮҝӮбӮБӮҪӮМӮӘҚЎүсӮМ
LarrabeeғLғғғ“ғZғӢӮЙҢqӮӘӮБӮҪӮБӮДӮұӮЖӮ¶ӮбӮИӮ©ӮлӮӨӮ©ҒB
ғnҒ[ғhӮЖғ\ғtғgҒA—‘ӮЖҢ{ӮМҠЦҢWӮЖӮаҢҫӮҰӮйӮҜӮЗҒB
Ӯ»ӮӨҚlӮҰӮйӮЖӮ·ӮЕӮЙ‘«ҸкӮӘӮ ӮйGPUӮМ•ыӮӘҗVүҝ’lӮН’сҲДӮөӮвӮ·ӮўҲК’uӮЙӮўӮйӮМӮ©ӮаҒB
538 ҒF–јҸМ–ўҗЭ’иҒF2009/12/12(“y) 11:01:33 ID:89Hacmni0
http://pc.watch.impress.co.jp/docs/2003/0901/kaigai015.htm
[Q] Ӯ»ӮМ’iҠKӮМCellғRғ“ғsғ…Ғ[ғeғBғ“ғOӮЕҒAғGғ“ғ^ғeғCғ“ғҒғ“ғgӮНүҪӮӘҺАҢ»ӮЕӮ«ӮйӮМӮ©ҒB
[Ӣvҡк—З–ШҺҒ] Ғ@ҸҲ—қ”\—НӮНҒAғGғ“ғ^ғeғCғ“ғҒғ“ғgӮрҚlӮҰӮйӮҫӮҜӮЕӮаӢЙ’[ӮИ—v–]ӮӘӮ ӮйҒB
ғGғ“ғ^ғeғCғ“ғҒғ“ғgӮрүzӮҰӮҪҒAҠҙҗ«ӮМҲжӮЬӮЕӮўӮБӮҪӮзҗз”{ӮЙӮИӮБӮДӮа‘«ӮиӮИӮўҒB
ғLғAғkҒEғҠҒ[ғuғXӮӘүfүжҒuғ}ғgғҠғbғNғXҒvӮМ’ҶӮЕҒAӮ»Ӯұ(ғ}ғgғҠғbғNғXӮМүј‘zҗўҠE)ӮЙӮўӮй
ӮЖҠҙӮ¶ӮйҒA–{•ЁӮ©ӮЗӮӨӮ©Ң©•ӘӮҜӮӘӮВӮ©ӮИӮў(ӮЖҠҙӮ¶Ӯй)ҒAӮўӮВӮ©ӮНҒAӮ Ӯ»ӮұӮЬӮЕӮдӮӯӮНӮёҒB
ӮЖӮаӮ©ӮӯҒA(CellғRғ“ғsғ…Ғ[ғeғBғ“ғOӮМ)җLӮСӮН–іҢАӮҫӮ©ӮзҒB(CellӮӘ)ғlғbғgғҸҒ[ғNӮЙҢqӮӘӮкӮО
ҢqӮӘӮйӮЩӮЗҗ”ӮӘ‘қӮҰӮйҒBҗl—ЮӮНӮЖӮсӮЕӮаӮИӮўӮаӮМӮрҺиӮЙӮ·ӮйӮсӮ¶ӮбӮИӮўӮ©ӮЖҺvӮБӮДӮўӮйӮЩӮЗҒB
http://journal.mycom.co.jp/articles/2009/12/10/sc09_algore/
IntelӮМCTOӮЕӮ ӮйJustin RattnerҺҒӮНHPC(High Performance Computing)ӮМғ}Ғ[ғPғbғg
ӮМҗLӮСӮНҸ¬ӮіӮӯҒA‘еӮ«ӮӯҗLӮСӮйӮҪӮЯӮЙӮНғLғүҒ[ғAғvғҠғPҒ[ғVғҮғ“ӮӘ•K—vӮЕӮ ӮйҸqӮЧҒA
Ӯ»ӮМүВ”\җ«ӮЖӮөӮДҒu3D WebҒvӮрӢ“Ӯ°ӮҪҒB3D WebӮНҳA‘ұ“IӮЙғVғ~ғ…ғҢҒ[ғVғҮғ“ӮрҚsӮўҒA
Ӯ»ӮМҢӢүКӮр3DғAғjғҒҒ[ғVғҮғ“ӮЕ•\ҺҰӮөҒAӮ ӮҪӮ©ӮаӮ»ӮМ’ҶӮЙҗZӮйӮжӮӨӮИҢoҢұӮр—^ӮҰҒA
Ӯ»ӮМ’ҶӮЕ‘јӮМҗlӮЖӮаӢҰ’ІӮөӮД“®ӮҜӮйӮжӮӨӮИҠВӢ«ӮЕӮ ӮйӮЖӮўӮӨҒB
Ғi Я„tЯҒj
ҒiЯ„tЯ Ғj
Ғi Я„tЯҒjҒEҒEҒE
Ғi Я„tЯ Ғj
[Q] Ӯ»ӮМ’iҠKӮМCellғRғ“ғsғ…Ғ[ғeғBғ“ғOӮЕҒAғGғ“ғ^ғeғCғ“ғҒғ“ғgӮНүҪӮӘҺАҢ»ӮЕӮ«ӮйӮМӮ©ҒB
[Ӣvҡк—З–ШҺҒ] Ғ@ҸҲ—қ”\—НӮНҒAғGғ“ғ^ғeғCғ“ғҒғ“ғgӮрҚlӮҰӮйӮҫӮҜӮЕӮаӢЙ’[ӮИ—v–]ӮӘӮ ӮйҒB
ғGғ“ғ^ғeғCғ“ғҒғ“ғgӮрүzӮҰӮҪҒAҠҙҗ«ӮМҲжӮЬӮЕӮўӮБӮҪӮзҗз”{ӮЙӮИӮБӮДӮа‘«ӮиӮИӮўҒB
ғLғAғkҒEғҠҒ[ғuғXӮӘүfүжҒuғ}ғgғҠғbғNғXҒvӮМ’ҶӮЕҒAӮ»Ӯұ(ғ}ғgғҠғbғNғXӮМүј‘zҗўҠE)ӮЙӮўӮй
ӮЖҠҙӮ¶ӮйҒA–{•ЁӮ©ӮЗӮӨӮ©Ң©•ӘӮҜӮӘӮВӮ©ӮИӮў(ӮЖҠҙӮ¶Ӯй)ҒAӮўӮВӮ©ӮНҒAӮ Ӯ»ӮұӮЬӮЕӮдӮӯӮНӮёҒB
ӮЖӮаӮ©ӮӯҒA(CellғRғ“ғsғ…Ғ[ғeғBғ“ғOӮМ)җLӮСӮН–іҢАӮҫӮ©ӮзҒB(CellӮӘ)ғlғbғgғҸҒ[ғNӮЙҢqӮӘӮкӮО
ҢqӮӘӮйӮЩӮЗҗ”ӮӘ‘қӮҰӮйҒBҗl—ЮӮНӮЖӮсӮЕӮаӮИӮўӮаӮМӮрҺиӮЙӮ·ӮйӮсӮ¶ӮбӮИӮўӮ©ӮЖҺvӮБӮДӮўӮйӮЩӮЗҒB
http://journal.mycom.co.jp/articles/2009/12/10/sc09_algore/
IntelӮМCTOӮЕӮ ӮйJustin RattnerҺҒӮНHPC(High Performance Computing)ӮМғ}Ғ[ғPғbғg
ӮМҗLӮСӮНҸ¬ӮіӮӯҒA‘еӮ«ӮӯҗLӮСӮйӮҪӮЯӮЙӮНғLғүҒ[ғAғvғҠғPҒ[ғVғҮғ“ӮӘ•K—vӮЕӮ ӮйҸqӮЧҒA
Ӯ»ӮМүВ”\җ«ӮЖӮөӮДҒu3D WebҒvӮрӢ“Ӯ°ӮҪҒB3D WebӮНҳA‘ұ“IӮЙғVғ~ғ…ғҢҒ[ғVғҮғ“ӮрҚsӮўҒA
Ӯ»ӮМҢӢүКӮр3DғAғjғҒҒ[ғVғҮғ“ӮЕ•\ҺҰӮөҒAӮ ӮҪӮ©ӮаӮ»ӮМ’ҶӮЙҗZӮйӮжӮӨӮИҢoҢұӮр—^ӮҰҒA
Ӯ»ӮМ’ҶӮЕ‘јӮМҗlӮЖӮаӢҰ’ІӮөӮД“®ӮҜӮйӮжӮӨӮИҠВӢ«ӮЕӮ ӮйӮЖӮўӮӨҒB
Ғi Я„tЯҒj
ҒiЯ„tЯ Ғj
Ғi Я„tЯҒjҒEҒEҒE
Ғi Я„tЯ Ғj
539 ҒF–јҸМ–ўҗЭ’иҒF2009/12/12(“y) 17:36:10 ID:EdMDAEnt0
VRML2.0‘ОүһғuғүғEғU Cosmo PlayerӮр”ӯ•\
Netscape Navigator 2.01ҲИҚ~ӮЙғvғүғOғCғ“
http://www.sgi.co.jp/newsroom/press_releases/1996/May/CosmoPlayer.html
Netscape Navigator 2.01ҲИҚ~ӮЙғvғүғOғCғ“
http://www.sgi.co.jp/newsroom/press_releases/1996/May/CosmoPlayer.html
540 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/12/12(“y) 22:19:57 ID:ZuadSBSX0
VRMLӮБӮДӮўӮВӮМҠФӮЙӮ©ҸБӮҰӮДӮҪӮжӮИҒB
Ӯ»ӮӨӮўӮҰӮОHTML5ӮБӮДӮЗӮӨӮжҒH
Ӯ»ӮӨӮўӮҰӮОHTML5ӮБӮДӮЗӮӨӮжҒH
541 ҒF–јҸМ–ўҗЭ’иҒF2009/12/12(“y) 22:37:50 ID:DdsqfCXW0
ғүғgғiҒ[ӮНӮ»ӮлӮ»Ӯл‘ЮҸкӮҫӮИ
542 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/12/12(“y) 22:40:17 ID:ZuadSBSX0
ғpғӢғpғeғBҒ[ғ“Қc’йӮЙҺ—ӮДӮйӮжӮЛ
543 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2009/12/13(“ъ) 01:27:25 ID:WQrIL6ry0
ӮЬӮ ӮұӮұӮН‘јҗlӮЙ”Ҫҳ_Ӯ·ӮйӮжӮиӮаҒA
Һ©•ӘӮМ—\‘zӮМҗё“xӮр’bҳBӮ·ӮйӮҪӮЯӮМғXғҢӮИӮМӮЕҒAӮЁӮкӮМҸ‘Ӯ«ҚһӮЭӮМ“а—eӮЙҚ\ӮнӮё
Һ©•ӘӮМ—\‘zӮрӢLҳ^ӮЖӮөӮД“Ж—§ӮөӮДҸ‘Ӯ«ҚһӮЭ—~ӮөӮўғӮғmӮҫҒB
ӮЁӮкӮНӮ ӮӯӮЬӮЕҺ©•ӘӮМ—\‘zӮМӢLҳ^ӮЖӮөӮДҸ‘ӮўӮДӮўӮйӮМӮЕғҢғXӮНҢӢҚ\ӮЕӮ·ӮМӮЕҒB
ҢӢүКӮЕӮаӮМӮрӮўӮўӮЬӮөӮеӮӨҒBҺ^“ҜӮЕӮ«ӮИӮўҗlӮН•\ғXғҢӮЕҒB
Һ©•ӘӮМ—\‘zӮМҗё“xӮр’bҳBӮ·ӮйӮҪӮЯӮМғXғҢӮИӮМӮЕҒAӮЁӮкӮМҸ‘Ӯ«ҚһӮЭӮМ“а—eӮЙҚ\ӮнӮё
Һ©•ӘӮМ—\‘zӮрӢLҳ^ӮЖӮөӮД“Ж—§ӮөӮДҸ‘Ӯ«ҚһӮЭ—~ӮөӮўғӮғmӮҫҒB
ӮЁӮкӮНӮ ӮӯӮЬӮЕҺ©•ӘӮМ—\‘zӮМӢLҳ^ӮЖӮөӮДҸ‘ӮўӮДӮўӮйӮМӮЕғҢғXӮНҢӢҚ\ӮЕӮ·ӮМӮЕҒB
ҢӢүКӮЕӮаӮМӮрӮўӮўӮЬӮөӮеӮӨҒBҺ^“ҜӮЕӮ«ӮИӮўҗlӮН•\ғXғҢӮЕҒB
544 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2009/12/13(“ъ) 14:02:14 ID:WQrIL6ry0
Intel“аӮЙӮНCtӮМ“y‘дӮЙGMAғAҒ[ғLӮаҸжӮ№ӮйҢvүжӮӘӮ ӮйӮҫӮлӮӨҒB
LRBӮағLғғғ“ғZғӢӮіӮкӮҪӮұӮЖӮҫӮө—Ҳ”NӮ ӮҪӮиӮЙӮаӮБӮЖӢп‘М“IӮИҢvүжӮӘӮ Ӯ«ӮзӮ©ӮЙӮіӮкӮйӮҫӮлӮӨҒB
ӮИӮсӮЖӮИӮӯӮ»ӮӨӮўӮӨ—\ҠҙӮӘӮ·ӮйҒB
ҚЎ“xӮНGMAӮН•іӮҫӮ©ӮзӮЗӮӨӮМӮМ‘ҠҺиӮөӮИӮ«ӮбӮўӮҜӮИӮӯӮИӮйӮ©ӮЖҺvӮӨӮЖӮўӮвӮҫӮИӮ ҒB
LRBӮағLғғғ“ғZғӢӮіӮкӮҪӮұӮЖӮҫӮө—Ҳ”NӮ ӮҪӮиӮЙӮаӮБӮЖӢп‘М“IӮИҢvүжӮӘӮ Ӯ«ӮзӮ©ӮЙӮіӮкӮйӮҫӮлӮӨҒB
ӮИӮсӮЖӮИӮӯӮ»ӮӨӮўӮӨ—\ҠҙӮӘӮ·ӮйҒB
ҚЎ“xӮНGMAӮН•іӮҫӮ©ӮзӮЗӮӨӮМӮМ‘ҠҺиӮөӮИӮ«ӮбӮўӮҜӮИӮӯӮИӮйӮ©ӮЖҺvӮӨӮЖӮўӮвӮҫӮИӮ ҒB
545 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/12/13(“ъ) 14:45:06 ID:XQl4FFJy0
ӮИӮўӮИӮўӮ—Ӯ—Ӯ—
WestmereӮЕӮжӮӨӮвӮӯ12WayӮМҗПҳaғҶғjғbғgӮҫӮәҒBCPU 1ғRғAӮМӮЩӮӨӮӘ‘¬ӮўҒB
Sandy Bridgeҗў‘гӮҫӮЖCPUӮМӢуӮ«ӮіӮҰӮ ӮкӮОғVғFҒ[ғ_ҸҲ—қӮрCPUӮЙ“ҠӮ°ӮҪ•ыӮӘ‘¬Ӯ©ӮлӮӨ
ҒiL3ғLғғғbғVғ…ӮрCPUӮЖGMAӮЕӢӨ—LӮөӮДӮй—қ—RӮНӮұӮкӮ¶ӮбӮИӮўӮ©ӮЖҺvӮӨҒj
WestmereӮЕӮжӮӨӮвӮӯ12WayӮМҗПҳaғҶғjғbғgӮҫӮәҒBCPU 1ғRғAӮМӮЩӮӨӮӘ‘¬ӮўҒB
Sandy Bridgeҗў‘гӮҫӮЖCPUӮМӢуӮ«ӮіӮҰӮ ӮкӮОғVғFҒ[ғ_ҸҲ—қӮрCPUӮЙ“ҠӮ°ӮҪ•ыӮӘ‘¬Ӯ©ӮлӮӨ
ҒiL3ғLғғғbғVғ…ӮрCPUӮЖGMAӮЕӢӨ—LӮөӮДӮй—қ—RӮНӮұӮкӮ¶ӮбӮИӮўӮ©ӮЖҺvӮӨҒj
546 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2009/12/13(“ъ) 14:50:55 ID:WQrIL6ry0
ӮЬӮҪ’cҺqҗжҗ¶ӮЖ‘О—§Ӯ·Ӯй—\‘zӮЙӮўӮҪӮБӮДӮөӮЬӮБӮҪӮжӮӨӮҫӮИҒB
CPU1ғRғAӮМ•ыӮӘӮНӮвӮўӮЖӮ©ӮжӮиӮаIntelӮМ•ыҢьҗ«ӮМ–в‘иӮҫӮлҒB
CPU1ғRғAӮМ•ыӮӘӮНӮвӮўӮЖӮ©ӮжӮиӮаIntelӮМ•ыҢьҗ«ӮМ–в‘иӮҫӮлҒB
547 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2009/12/13(“ъ) 14:52:38 ID:WQrIL6ry0
BonnellӮМҢгҢpғAҒ[ғLӮНOOOҺАҚsӮрҚМ—pӮ·ӮйӮҫӮлӮӨҒB
548 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2009/12/13(“ъ) 14:53:43 ID:WQrIL6ry0
ӮЖӮиӮ ӮҰӮёҢӢҳ_ӮҫӮҜҗжӮЙӮ©ӮўӮЖӮҜӮОҢг“Ўҗжҗ¶“ҷӮЙ“Ӯ“ЛӮЙҸoӮө”ІӮ©ӮкӮй
ӮұӮЖӮНӮИӮўӮМӮЕҲАҗSҒBӮЁӮкӮБӮД“ӘӮўӮўӮИҒ[ҒB
ӮұӮЖӮНӮИӮўӮМӮЕҲАҗSҒBӮЁӮкӮБӮД“ӘӮўӮўӮИҒ[ҒB
549 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/12/13(“ъ) 18:52:06 ID:XQl4FFJy0
> BonnellӮМҢгҢpғAҒ[ғLӮНOOOҺАҚsӮрҚМ—pӮ·ӮйӮҫӮлӮӨҒB
ҢҢ–АӮБӮҪӮ©
ҚЎӮМғlғbғgғuғbғNӮМғ|ғWғVғҮғ“ӮНCore MAғxҒ[ғXӮМCULVӮЕAtomӮМҸгҲКғҢғ“ғWӮН’uӮ«Ҡ·ӮҰӮйӮҫӮлӮӨӮӘ
AtomӮНӮ ӮМӮЬӮЬғVғ…ғҠғ“ғNӮр‘ұӮҜӮйӮЖҺvӮӨӮӘӮИҒB
OoOӮН“d—НҢш—Ұ–КӮЕҺгӮўҒB
ӮЗӮӨӮ№BobcatӮЖӮМ‘ОҚRӮЖӮ©ӮўӮӨӮсӮҫӮлҒH
Ӯ ӮкӮЙ‘еӮөӮҪ—DҲКҗ«ӮН–іӮўҒB
ҢҢ–АӮБӮҪӮ©
ҚЎӮМғlғbғgғuғbғNӮМғ|ғWғVғҮғ“ӮНCore MAғxҒ[ғXӮМCULVӮЕAtomӮМҸгҲКғҢғ“ғWӮН’uӮ«Ҡ·ӮҰӮйӮҫӮлӮӨӮӘ
AtomӮНӮ ӮМӮЬӮЬғVғ…ғҠғ“ғNӮр‘ұӮҜӮйӮЖҺvӮӨӮӘӮИҒB
OoOӮН“d—НҢш—Ұ–КӮЕҺгӮўҒB
ӮЗӮӨӮ№BobcatӮЖӮМ‘ОҚRӮЖӮ©ӮўӮӨӮсӮҫӮлҒH
Ӯ ӮкӮЙ‘еӮөӮҪ—DҲКҗ«ӮН–іӮўҒB
550 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2009/12/13(“ъ) 21:39:34 ID:WQrIL6ry0
Һҹҗў‘гAtomӮ¶ӮбӮИӮӯӮДBonnellғAҒ[ғLҺ©‘МӮМҢгҢpӮМҳbӮрӮөӮДӮўӮйӮсӮҫӮӘҒBӮ©ӮИӮиҗжӮМҳbӮҫҒB
551 ҒF–јҸМ–ўҗЭ’иҒF2009/12/13(“ъ) 23:44:42 ID:V0tuNtWm0
җlҚH“Ә”]ӮЕӮНӮИӮӯ,җlӮНӮ»ӮұӮЙҒCғVғҠғRғ“ӮМҗ_Ӯрҗ¶ӮЭҸoӮ»ӮӨӮЖӮөӮҪӮсӮҫӮж
552 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/12/14(ҢҺ) 01:05:06 ID:CbnVM1uG0
ғTғүғRғiҒ[ҒEғNғҚғjғNғӢғYӮЕғWғҮғ“–рӮӘIntelӮМҳbӮрӮөӮДӮҪӮИ
553 ҒF–јҸМ–ўҗЭ’иҒF2009/12/16(җ…) 00:16:45 ID:UV0jyaYj0
җ®җ”ғpғtғHҒ[ғ}ғ“ғXӮрӢ]җөӮЙӮ·Ӯй? AMDӮМҒuBulldozerҒv
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20091216_335956.html
FPғVғҮғ{ӮўғVғ“ғOғӢӮ·ӮБӮЗӮкғVғҮғ{ӮўӮДҠ®‘SӮЙNiagaraӮҫӮИ
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20091216_335956.html
FPғVғҮғ{ӮўғVғ“ғOғӢӮ·ӮБӮЗӮкғVғҮғ{ӮўӮДҠ®‘SӮЙNiagaraӮҫӮИ
554 ҒF–јҸМ–ўҗЭ’иҒF2009/12/16(җ…) 01:12:52 ID:F04lni+p0
ғVғ“ғOғӢғRғA“–ӮиӮМ•Ӯ“®Ҹ¬җ”“_үүҺZҗ«”\ӮНғvғҢғXғR5GHz‘Ҡ“–ӮЙ
—ҜӮЯӮДӮЁӮўӮДҒCҗ®җ”үүҺZҗ«”\ӮрӮРӮҪӮ·ӮзҲшӮ«ҸгӮ°ӮДӮўӮӯ•ыӮӘӮұӮМ
җжӮ ӮБӮДӮўӮйӮжӮӨӮИӢCӮӘӮөӮИӮўӮЕӮаӮИӮў
—ҜӮЯӮДӮЁӮўӮДҒCҗ®җ”үүҺZҗ«”\ӮрӮРӮҪӮ·ӮзҲшӮ«ҸгӮ°ӮДӮўӮӯ•ыӮӘӮұӮМ
җжӮ ӮБӮДӮўӮйӮжӮӨӮИӢCӮӘӮөӮИӮўӮЕӮаӮИӮў
555 ҒF–јҸМ–ўҗЭ’иҒF2009/12/16(җ…) 13:44:07 ID:shBuhR1o0
>ғvғҢғXғR5GHz
үҪӮЕӮ»ӮМӮ ӮЖcedermillӮӘҸoӮДӮйӮМӮЙүҪҺһӮЬӮЕӮағvғҢғXғRғvғҢғXғRҢҫӮӨӮМӮ©ӮЛҒc
үҪӮЕӮ»ӮМӮ ӮЖcedermillӮӘҸoӮДӮйӮМӮЙүҪҺһӮЬӮЕӮағvғҢғXғRғvғҢғXғRҢҫӮӨӮМӮ©ӮЛҒc
556 ҒF–јҸМ–ўҗЭ’иҒF2009/12/16(җ…) 16:12:32 ID:CrL5rxoN0
ғAғҖҗ~ӮҫӮ©Ӯз
557 ҒF–јҸМ–ўҗЭ’иҒF2009/12/17(–Ш) 03:58:47 ID:H+wtN4nt0
ғXғPғWғ…Ғ[ғүӮвғfғRҒ[ғ_“ҷҒAҚӮ‘¬ғgғүғ“ғWғXғ^ӮӘӢҒӮЯӮзӮкӮй•”•ӘӮМ”м‘еү»Ӯр—}җ§ӮөҒAғҠҒ[ғN“d—¬ӮрҚнҢёҒB
Ӯ»ӮкӮЙӮжӮи—]ӮБӮҪTDPҳgӮрғNғҚғbғNҢьҸгӮЙҗUӮиҢьӮҜғVғ“ғOғӢғXғҢғbғhҗ«”\ӮрҠm•ЫӮЖӮўӮӨҺZ’iҒH
ғVғ“ғOғӢғRғA”дӮЕғXғӢҒ[ғvғbғgӮН80%ҢьҸгӮЖҢҫӮБӮДӮйӮсӮҫӮ©ӮзҢ»ҚsӮМ9Ҡ„ӮӯӮзӮўӮМҗ«”\ӮНҠm•ЫҸo—ҲӮйӮсӮҫӮлӮӨӮ©ҒB
K8’ц“xӮМғVғ“ғOғӢғXғҢғbғhҗ«”\ӮӘӮ ӮкӮО“БӮЙ–в‘иӮЙӮаӮИӮзӮсӢCӮаӮ·ӮйҒB
Ӯ»ӮкӮЙӮжӮи—]ӮБӮҪTDPҳgӮрғNғҚғbғNҢьҸгӮЙҗUӮиҢьӮҜғVғ“ғOғӢғXғҢғbғhҗ«”\ӮрҠm•ЫӮЖӮўӮӨҺZ’iҒH
ғVғ“ғOғӢғRғA”дӮЕғXғӢҒ[ғvғbғgӮН80%ҢьҸгӮЖҢҫӮБӮДӮйӮсӮҫӮ©ӮзҢ»ҚsӮМ9Ҡ„ӮӯӮзӮўӮМҗ«”\ӮНҠm•ЫҸo—ҲӮйӮсӮҫӮлӮӨӮ©ҒB
K8’ц“xӮМғVғ“ғOғӢғXғҢғbғhҗ«”\ӮӘӮ ӮкӮО“БӮЙ–в‘иӮЙӮаӮИӮзӮсӢCӮаӮ·ӮйҒB
558 ҒF–јҸМ–ўҗЭ’иҒF2009/12/17(–Ш) 04:22:57 ID:rKIMFlFm0
Ӯ»ӮМҚӮғNғҚғbғNү»ӮЙӮН“dӢCҗHӮўӮИүсҳHӮӘ•K—vӮИг©
559 ҒF–јҸМ–ўҗЭ’иҒF2009/12/17(–Ш) 04:45:19 ID:H+wtN4nt0
32nmSOIӮН45nmSOI”дӮЕ50%ӮЬӮЕ‘¬ӮӯӮЕӮ«ӮйӮзӮөӮў
ғgғүғ“ғWғXғ^ӮМҗ«”\ҢьҸг•ӘӮЕғNғҚғbғNҢьҸгӮМғwғbғhғӢҒ[ғҖӮНҗ¶ӮЬӮкӮйӮсӮ¶ӮбӮИӮ©ӮлӮӨӮ©
ғgғүғ“ғWғXғ^ӮМҗ«”\ҢьҸг•ӘӮЕғNғҚғbғNҢьҸгӮМғwғbғhғӢҒ[ғҖӮНҗ¶ӮЬӮкӮйӮсӮ¶ӮбӮИӮ©ӮлӮӨӮ©
560 ҒF–јҸМ–ўҗЭ’иҒF2009/12/17(–Ш) 04:48:46 ID:BEtigqMo0
ӮНӮўӮНӮў
561 ҒF–јҸМ–ўҗЭ’иҒF2009/12/18(Ӣа) 00:09:19 ID:OLbC1nG5O
4GHz“Л”jӮНӮўӮВӮ©ӮИӮ
562 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2009/12/18(Ӣа) 19:27:35 ID:2/yBjFMZ0
ӮіӮ·ӮӘҢг“Ўҗжҗ¶(ӮнӮзӮЎ
үҪҺ–ӮаӮИӮ©ӮБӮҪӮ©ӮМӮжӮӨӮЙҲк“]ӮөӮДҗ®җ”ҸdҺӢӮ©Ӯзҗ®җ”Ӣ]җөӮЙҳ_’І•ПҚXӮөӮДӮ«ӮҪӮЛҒB
BulldozerӮНint/fpӮМҗ«”\ғoғүғ“ғXӮН‘ҚҚҮ“IӮЙӮЭӮДӮұӮкӮЬӮЕӮМ—¬ӮкӮ©ӮзӮ ӮЬӮи•ПӮнӮБӮДӮИӮўҒB
Ҹ]—ҲӮжӮиӮаҲкүһfpӮМ•ыӮӘҸdҺӢӮіӮкӮДӮйӮЖӮўӮӨҠҙӮ¶ӮҫӮӘҒA
IntelӮМSNBӮНӮаӮБӮЖfp/SIMDҸdҺӢӮИӮМӮЕҺАҚЫӮМӮаӮМӮӘӮЕӮйҚ ӮМ”дҠrҳbӮЕӮНҚЎӮМҠҙҠoӮЖӮНҲЩӮИӮйҒB
ӮҪӮҫ’PӮЙ2ғRғAӮЕFPӢӨ—LӮЖӮўӮӨӮҫӮҜӮЕҗ«”\ӮӘӮӘӮҪӮЁӮҝӮЙӮИӮйӮЖӮ©ӮўӮӨӮвӮВӮНғvғҚғZғbғTӮЖӮўӮӨӮаӮМӮӘӮнӮ©ӮБӮДӮИӮўҒB
intӮЕғXғӢҒ[ғvғbғgҸdҺӢӮИӮМӮНғTҒ[ғoӮЙӮНӮЮӮўӮДӮўӮйҒB
intӮЙӮВӮўӮДӮа2 issue OOOӮЕғtғҚғ“ғgғGғ“ғhӮӘҚLӮҜӮкӮО
Ӯ»ӮұӮЬӮЕҗ«”\ӮНӮЁӮҝӮИӮўҒBӮаӮҝӮлӮсIntelӮвҠщ‘¶ӮМK10ӮИӮЗӮЙӮӯӮзӮЧӮҪӮзӮЁӮҝӮйӮӘӮЛҒB
>ӮӨӮЬӮӯҚsӮҜӮОҒABulldozerӮӘ2011”NӮ©ӮзӮМ’·ҠъӮЙ“nӮБӮДӮМAMDӮМғAҒ[ғLғeғNғ`ғғӮМҠо–{ӮЙӮИӮйӮҫӮлӮӨҒB
ӮөӮ©ӮөӮұӮМҢӢҳ_ӮЙӮНҺ^“ҜӮЕӮ«ӮИӮўӮИҒB
ғҚҒ[ғhғ}ғbғvҸгӮЕӮНҲкүһғnғCғGғ“ғhPCҢьӮҜӮЙӮаBulldozerҢnӮЖӮўӮӨӮұӮЖӮЙӮИӮБӮДӮўӮйӮӘҒA
Ң»ҺА–в‘иӮЖӮөӮДPC—p“rӮЕӮНBulldozerӮНPCҢьӮҜSandy BridgeӮИӮЗӮЖӮНӮЬӮЖӮаӮЙӮвӮиҚҮӮӨӮМӮН“пӮөӮўӮөҒA
K10ӮМғҠғvғҢҒ[ғXӮЖҚlӮҰӮйӮМӮНҠлҢҜӮ·Ӯ¬ӮйҒB
ҠWӮрҠJӮҜӮДӮЭӮкӮОAMDӮН“–•ӘK10ӮМ”hҗ¶ҒEҠg’ЈӮрPCҢьӮҜӮЕӮНҺе—НӮЖӮөӮДҺgӮБӮДӮўӮӯӮұӮЖӮЙӮИӮйӮЖҺvӮнӮкӮйҒB
ӮЬӮ >>412ӮЕҚЕҸүӮЙҸ‘ӮўӮҪӮЖӮЁӮиӮҫӮЛҒB
Ӯ»ӮкӮ©ӮзfpӮНGPUӮр“қҚҮӮ·ӮйӮ©ӮзӮЗӮӨӮМӮЖӮўӮӨҳbӮНҢ»’iҠKӮЕӮНҢҫӮў–у“IҺЦ‘«ӮҫӮжҒB
ҺАҚЫFPUӮМ‘гӮнӮиӮЙGPUҢ^ӮМғRғAӮр“қҚҮӮ·ӮйӮЖӮөӮД‘S—НӮЕӮаFPUӮӘҠ®‘SӮЙӮўӮзӮИӮӯӮИӮйӮЬӮЕӮНҗ”җў‘гӮаӮ©Ӯ©ӮйҳbӮЕҒA
Һ©Қм”ВӮЕӮаҳb‘иӮМӮжӮӨӮҫӮӘҒABulldozerӮ·ӮзҚЎӮЬӮЕӮжӮӯ—қүрӮЕӮ«ӮИӮўӮЕӮўӮйӮжӮӨӮИҳA’ҶӮӘҚЎӮ©ӮзӮЗӮӨӮұӮӨҢкӮБӮД—\‘zӮЕӮ«ӮйҳbӮ¶ӮбӮИӮўҒB
үҪҺ–ӮаӮИӮ©ӮБӮҪӮ©ӮМӮжӮӨӮЙҲк“]ӮөӮДҗ®җ”ҸdҺӢӮ©Ӯзҗ®җ”Ӣ]җөӮЙҳ_’І•ПҚXӮөӮДӮ«ӮҪӮЛҒB
BulldozerӮНint/fpӮМҗ«”\ғoғүғ“ғXӮН‘ҚҚҮ“IӮЙӮЭӮДӮұӮкӮЬӮЕӮМ—¬ӮкӮ©ӮзӮ ӮЬӮи•ПӮнӮБӮДӮИӮўҒB
Ҹ]—ҲӮжӮиӮаҲкүһfpӮМ•ыӮӘҸdҺӢӮіӮкӮДӮйӮЖӮўӮӨҠҙӮ¶ӮҫӮӘҒA
IntelӮМSNBӮНӮаӮБӮЖfp/SIMDҸdҺӢӮИӮМӮЕҺАҚЫӮМӮаӮМӮӘӮЕӮйҚ ӮМ”дҠrҳbӮЕӮНҚЎӮМҠҙҠoӮЖӮНҲЩӮИӮйҒB
ӮҪӮҫ’PӮЙ2ғRғAӮЕFPӢӨ—LӮЖӮўӮӨӮҫӮҜӮЕҗ«”\ӮӘӮӘӮҪӮЁӮҝӮЙӮИӮйӮЖӮ©ӮўӮӨӮвӮВӮНғvғҚғZғbғTӮЖӮўӮӨӮаӮМӮӘӮнӮ©ӮБӮДӮИӮўҒB
intӮЕғXғӢҒ[ғvғbғgҸdҺӢӮИӮМӮНғTҒ[ғoӮЙӮНӮЮӮўӮДӮўӮйҒB
intӮЙӮВӮўӮДӮа2 issue OOOӮЕғtғҚғ“ғgғGғ“ғhӮӘҚLӮҜӮкӮО
Ӯ»ӮұӮЬӮЕҗ«”\ӮНӮЁӮҝӮИӮўҒBӮаӮҝӮлӮсIntelӮвҠщ‘¶ӮМK10ӮИӮЗӮЙӮӯӮзӮЧӮҪӮзӮЁӮҝӮйӮӘӮЛҒB
>ӮӨӮЬӮӯҚsӮҜӮОҒABulldozerӮӘ2011”NӮ©ӮзӮМ’·ҠъӮЙ“nӮБӮДӮМAMDӮМғAҒ[ғLғeғNғ`ғғӮМҠо–{ӮЙӮИӮйӮҫӮлӮӨҒB
ӮөӮ©ӮөӮұӮМҢӢҳ_ӮЙӮНҺ^“ҜӮЕӮ«ӮИӮўӮИҒB
ғҚҒ[ғhғ}ғbғvҸгӮЕӮНҲкүһғnғCғGғ“ғhPCҢьӮҜӮЙӮаBulldozerҢnӮЖӮўӮӨӮұӮЖӮЙӮИӮБӮДӮўӮйӮӘҒA
Ң»ҺА–в‘иӮЖӮөӮДPC—p“rӮЕӮНBulldozerӮНPCҢьӮҜSandy BridgeӮИӮЗӮЖӮНӮЬӮЖӮаӮЙӮвӮиҚҮӮӨӮМӮН“пӮөӮўӮөҒA
K10ӮМғҠғvғҢҒ[ғXӮЖҚlӮҰӮйӮМӮНҠлҢҜӮ·Ӯ¬ӮйҒB
ҠWӮрҠJӮҜӮДӮЭӮкӮОAMDӮН“–•ӘK10ӮМ”hҗ¶ҒEҠg’ЈӮрPCҢьӮҜӮЕӮНҺе—НӮЖӮөӮДҺgӮБӮДӮўӮӯӮұӮЖӮЙӮИӮйӮЖҺvӮнӮкӮйҒB
ӮЬӮ >>412ӮЕҚЕҸүӮЙҸ‘ӮўӮҪӮЖӮЁӮиӮҫӮЛҒB
Ӯ»ӮкӮ©ӮзfpӮНGPUӮр“қҚҮӮ·ӮйӮ©ӮзӮЗӮӨӮМӮЖӮўӮӨҳbӮНҢ»’iҠKӮЕӮНҢҫӮў–у“IҺЦ‘«ӮҫӮжҒB
ҺАҚЫFPUӮМ‘гӮнӮиӮЙGPUҢ^ӮМғRғAӮр“қҚҮӮ·ӮйӮЖӮөӮД‘S—НӮЕӮаFPUӮӘҠ®‘SӮЙӮўӮзӮИӮӯӮИӮйӮЬӮЕӮНҗ”җў‘гӮаӮ©Ӯ©ӮйҳbӮЕҒA
Һ©Қм”ВӮЕӮаҳb‘иӮМӮжӮӨӮҫӮӘҒABulldozerӮ·ӮзҚЎӮЬӮЕӮжӮӯ—қүрӮЕӮ«ӮИӮўӮЕӮўӮйӮжӮӨӮИҳA’ҶӮӘҚЎӮ©ӮзӮЗӮӨӮұӮӨҢкӮБӮД—\‘zӮЕӮ«ӮйҳbӮ¶ӮбӮИӮўҒB
563 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2009/12/18(Ӣа) 19:29:39 ID:2/yBjFMZ0
ӮіӮ·ӮӘӮЙ—\‘zӮМғXғҢӮҫӮЖ2ӮҝӮбӮсӮЛӮйӮМ—¬ӢVӮЙ”ҪӮөӮД
ғRғeӮӘҗ„Ҹ§
ӮіӮкӮйӮЛҒBӮЖӮўӮӨӮнӮҜӮЕ—\‘zӮрҸ‘ӮӯҗlӮнғRғeӮрҸo—ҲӮйӮҫӮҜ–јҸжӮБӮД—~ӮөӮўӮ·ҒB
ғRғeӮӘҗ„Ҹ§
ӮіӮкӮйӮЛҒBӮЖӮўӮӨӮнӮҜӮЕ—\‘zӮрҸ‘ӮӯҗlӮнғRғeӮрҸo—ҲӮйӮҫӮҜ–јҸжӮБӮД—~ӮөӮўӮ·ҒB
564 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2009/12/18(Ӣа) 19:34:48 ID:2/yBjFMZ0
IntelҒA2010”N1ҢҺ7“ъӮЙҗVCPUӮр”ӯ•\
http://itpro.nikkeibp.co.jp/article/NEWS/20091218/342246/
IntelӮМҗVҚмӮЕӮйӮсӮҫӮЛҒB
ӮЗӮсӮИғNғsғ…ӮЙӮИӮйӮМӮ©ҠyӮөӮЭӮҫӮнҒB
http://itpro.nikkeibp.co.jp/article/NEWS/20091218/342246/
IntelӮМҗVҚмӮЕӮйӮсӮҫӮЛҒB
ӮЗӮсӮИғNғsғ…ӮЙӮИӮйӮМӮ©ҠyӮөӮЭӮҫӮнҒB
565 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2009/12/18(Ӣа) 19:45:09 ID:2/yBjFMZ0
–П‘zӮЕӮ ӮйӮӘҒAҢВҗl“IӮЙӮНҗ®җ”ғRғAӮаҚЕҸ¬ҢАӮМFPUӮҫӮҜӮН—pҲУӮөӮДӮЁӮўӮДҒAӮҪӮЬӮЙӮ Ӯй•Ӯ“®Ҹ¬җ”“_үүҺZӮЙ‘ОҸҲҒB
ӮұӮкӮјӮЖӮўӮӨFPӮЬӮӯӮиӮМҸҲ—қӮЙӮИӮБӮҪӮзFPUғNғүғXғ^ӮМғRғAӮр“dҢ№ONӮөӮДҺАҚsӮЖӮ©ӮҫӮБӮҪӮзӮ©ӮБӮұӮжӮ©ӮБӮҪӮМӮЙӮИӮ ҒB
ӮЕӮаFPUӮМғNғүғXғ^ӮНӮжӮЩӮЗFPӮжӮиӮМҸҲ—қӮЕӮИӮўҢАӮи“dҲіӮЖғNғҚғbғNӮрүәӮ°ӮДӮЁӮӯӮЖӮ©ӮӯӮзӮўӮН•Ғ’КӮЙҸo—ҲӮ»ӮӨӮЕӮ ӮйҒB
FPUӮЙ“d—НҸнӮЙӮӯӮнӮкӮДӮйӮМ–і‘КӮҫӮ©ӮзӮИҒBӮ»ӮӨҚlӮҰӮйӮЖ”ӯ“WӮіӮкӮкӮОҢӢҚ\ӮЁӮўӮөӮўҚ\‘ўӮ©ӮаӮөӮкӮсҒB
Ӯ ӮЖӮжӮӯӮўӮнӮкӮДӮйӮўӮйӮЖӮЁӮиғfғRҒ[ғhҚПӮЭӮМғLғғғbғVғ…ӮИӮўӮөғoғbғtғ@ӮНҚ\‘ў“IӮЙ•Kҗ{ӮҫӮлӮӨҒB
ӮұӮкӮјӮЖӮўӮӨFPӮЬӮӯӮиӮМҸҲ—қӮЙӮИӮБӮҪӮзFPUғNғүғXғ^ӮМғRғAӮр“dҢ№ONӮөӮДҺАҚsӮЖӮ©ӮҫӮБӮҪӮзӮ©ӮБӮұӮжӮ©ӮБӮҪӮМӮЙӮИӮ ҒB
ӮЕӮаFPUӮМғNғүғXғ^ӮНӮжӮЩӮЗFPӮжӮиӮМҸҲ—қӮЕӮИӮўҢАӮи“dҲіӮЖғNғҚғbғNӮрүәӮ°ӮДӮЁӮӯӮЖӮ©ӮӯӮзӮўӮН•Ғ’КӮЙҸo—ҲӮ»ӮӨӮЕӮ ӮйҒB
FPUӮЙ“d—НҸнӮЙӮӯӮнӮкӮДӮйӮМ–і‘КӮҫӮ©ӮзӮИҒBӮ»ӮӨҚlӮҰӮйӮЖ”ӯ“WӮіӮкӮкӮОҢӢҚ\ӮЁӮўӮөӮўҚ\‘ўӮ©ӮаӮөӮкӮсҒB
Ӯ ӮЖӮжӮӯӮўӮнӮкӮДӮйӮўӮйӮЖӮЁӮиғfғRҒ[ғhҚПӮЭӮМғLғғғbғVғ…ӮИӮўӮөғoғbғtғ@ӮНҚ\‘ў“IӮЙ•Kҗ{ӮҫӮлӮӨҒB
566 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/12/19(“y) 00:06:22 ID:Vehkdehy0
WestmereӮ©
567 ҒF–јҸМ–ўҗЭ’иҒF2009/12/21(ҢҺ) 23:40:13 ID:zFINOD1r0
PineviewҒ^Atom N450ӮМғ_ғCҺКҗ^
http://ascii.jp/elem/000/000/484/484568/p_n450die_o_.jpg
http://ascii.jp/elem/000/000/484/484568/p_n450die_o_.jpg
{kind=link}
568 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2009/12/24(–Ш) 04:36:06 ID:dqF7/nOX0
ғӮғUғCғNӮЕӮаӮ©Ӯ©ӮБӮДӮйӮМӮ©ҒH
569 ҒF–јҸМ–ўҗЭ’иҒF2009/12/28(ҢҺ) 11:37:11 ID:h26t4FwT0
77. Larrabee, Fermi (2009/12/26)
http://jun.artcompsci.org/articles/future_sc/note078.html
http://jun.artcompsci.org/articles/future_sc/note078.html
570 ҒF–јҸМ–ўҗЭ’иҒF2010/01/09(“y) 16:29:11 ID:jmVWXJ+90
ҚЕӢЯӮМҳb‘и 2010”N1ҢҺ9“ъ
http://www.geocities.jp/andosprocinfo/wadai10/20100109.htm
http://www.geocities.jp/andosprocinfo/wadai10/20100109.htm
571 ҒF–јҸМ–ўҗЭ’иҒF2010/01/19(үО) 19:39:04 ID:PN077uEr0
ho
572 ҒF–јҸМ–ўҗЭ’иҒF2010/01/26(үО) 19:47:03 ID:H7Wjv3Ge0
ze
573 ҒF–јҸМ–ўҗЭ’иҒF2010/02/09(үО) 00:10:06 ID:oArgawsG0
n
574 ҒF–јҸМ–ўҗЭ’иҒF2010/02/13(“y) 21:12:17 ID:C2gXLoSz0
ta
575 ҒF–јҸМ–ўҗЭ’иҒF2010/02/20(“y) 04:25:11 ID:Z+8SjM9a0
Ӯ·Ӯ°Ғ[ҚЎҚXӮИғRҒ[ғhғlҒ[ғҖӮМғlғ^ӮҫӮҜӮЗCedarviewӮБӮДCedarmillӮЙҺ—ӮДӮйӮИ
үҪӮ©ҠЦҢWӮ ӮйӮМӮ©ӮЛ
үҪӮ©ҠЦҢWӮ ӮйӮМӮ©ӮЛ
576 ҒF–јҸМ–ўҗЭ’иҒF2010/02/27(“y) 15:45:21 ID:jiJXPmeJ0
ho
577 ҒF–јҸМ–ўҗЭ’иҒF2010/03/01(ҢҺ) 01:57:35 ID:jxyPWreL0
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20100301_351592.html
>Ғ@ӮҪӮҫӮөҒAӮұӮМLlanoӮМғ_ғCҺКҗ^ӮНҒAҠ®‘SӮИӮаӮМӮЕӮНӮИӮўүВ”\җ«ӮӘҚӮӮўҒB
‘Ҫ•ӘӮұӮұ“ЗӮсӮЕЖЦЖЦҒiҒEҒНҒEҒjӮөӮДӮөӮЬӮБӮҪҗl‘Ҫҗ”Ӯ—
>Ғ@ӮҪӮҫӮөҒAӮұӮМLlanoӮМғ_ғCҺКҗ^ӮНҒAҠ®‘SӮИӮаӮМӮЕӮНӮИӮўүВ”\җ«ӮӘҚӮӮўҒB
‘Ҫ•ӘӮұӮұ“ЗӮсӮЕЖЦЖЦҒiҒEҒНҒEҒjӮөӮДӮөӮЬӮБӮҪҗl‘Ҫҗ”Ӯ—
578 ҒF–јҸМ–ўҗЭ’иҒF2010/03/08(ҢҺ) 22:40:30 ID:dlb1Woa+0
ze
579 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/03/11(–Ш) 18:44:38 ID:0YhVyy+V0
ғRғ“ғsғ…Ғ[ғ^ғTғCғGғ“ғXҺjҸгҚЕ‘еӮМүЫ‘иҒu•А—сҸҲ—қӮЙӮжӮйҗ«”\ҢьҸг
Ғ`Ҹо•сҸҲ—қҠwүп‘n—§50Һь”NӢL”O‘SҚ‘‘еүпӮМҸө‘ТҚuүү
http://www.publickey.jp/blog/10/50.html
Ғ`Ҹо•сҸҲ—қҠwүп‘n—§50Һь”NӢL”O‘SҚ‘‘еүпӮМҸө‘ТҚuүү
http://www.publickey.jp/blog/10/50.html
580 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/03/11(–Ш) 19:05:24 ID:0YhVyy+V0
ӮЁӮЁӮЮӮЛ“ҜҲУӮЕӮ«ӮйӮӘҒAғ}ғӢғ`ғRғAӮМ•А—сү»ӮМ–в‘иӮНҒA
ҢВҗl“IӮЙӮНҢҫҢкӮжӮиӮіӮзӮЙүәҲКғҢғxғӢӮМ‘еӮ«ӮИ–в‘иӮҫӮЖҺvӮӨӮӘӮИҒB
ҺG‘ҪӮИғVғXғeғҖ/ғAғvғҠӮЕҒAғmғCғ}ғ“Ң^ғRғ“ғsғ…Ғ[ғ^ӮӘ’·ӮзӮӯ‘ұӮҜӮДӮ«ӮҪҒA
ғvғҚғOғүғ}ӮМғAғhғҠғ”ҺvҚlӮЙӮжӮйғvғҚғOғүғ~ғ“ғOӮМ•¶ү»ӮрҺМӮДӢҺӮйӮЖӮұӮлӮЬӮЕӮўӮ©ӮИӮўӮЖүрҢҲӮөӮИӮўӮМӮ©ӮаҒB
Ҹ\•Әҗ”Ҡw“IӮЙҢҹ“ўӮіӮк—қҳ_ү»ӮіӮкӮҪ•А—сү»ғAғӢғSғҠғYғҖӮМ•”•iӮрҗк–еүЖӮӘҠJ”ӯӮөҒA
Ҳк”КӮМғvғҚғOғүғ}ӮНӢЙ—НӮ»ӮМ•А—сӮИ•”•iӮҫӮҜӮрҢР•tӮҜӮөӮДғ\ғtғgғEғGғAӮрҚмҗ¬Ӯ·ӮйҒA
ӮаӮҝӮлӮс’ҖҺҹӮЕӮөӮ©ҸҲ—қӮЕӮ«ӮИӮўӮаӮМӮНҚӮ‘¬ү»ӮЕӮ«ӮИӮў–в‘иӮЖӮөӮД”F’mӮіӮ№ӮҪҸгӮЕӮ Ӯ«ӮзӮЯӮйҒB
ҚЕ’бӮ»ӮұӮЬӮЕӮўӮ©ӮИӮўӮЖҢҫҢкҒAғRғ“ғpғCғүӮМҸ¬ҺиҗжӮИҢӨӢҶӮЕӮНғSҒ[ғӢӮНӮұӮИӮўӮҫӮлӮӨҒB
HPCӮН—қҳ_ҒAғAғӢғSғҠғYғҖӮӘ–ҫҠmӮЕҒAӮ Ӯй’ц“xӮ»ӮкӮӘӮЕӮ«ӮДӮўӮйӮ©Ӯз•А—сү»ӮӘҲк’иӮМҗ¬ҢчӮрҺыӮЯӮДӮўӮйӮнӮҜӮЕҒB
ӮЬӮ Ӯ»ӮұӮЬӮЕӮЕӮ«ӮйӮИӮзғmғCғ}ғ“Ң^ӮЙӮұӮҫӮнӮй—қ—RӮаӮаӮӨӮИӮўӮИҒB
ҢВҗl“IӮЙӮНҢҫҢкӮжӮиӮіӮзӮЙүәҲКғҢғxғӢӮМ‘еӮ«ӮИ–в‘иӮҫӮЖҺvӮӨӮӘӮИҒB
ҺG‘ҪӮИғVғXғeғҖ/ғAғvғҠӮЕҒAғmғCғ}ғ“Ң^ғRғ“ғsғ…Ғ[ғ^ӮӘ’·ӮзӮӯ‘ұӮҜӮДӮ«ӮҪҒA
ғvғҚғOғүғ}ӮМғAғhғҠғ”ҺvҚlӮЙӮжӮйғvғҚғOғүғ~ғ“ғOӮМ•¶ү»ӮрҺМӮДӢҺӮйӮЖӮұӮлӮЬӮЕӮўӮ©ӮИӮўӮЖүрҢҲӮөӮИӮўӮМӮ©ӮаҒB
Ҹ\•Әҗ”Ҡw“IӮЙҢҹ“ўӮіӮк—қҳ_ү»ӮіӮкӮҪ•А—сү»ғAғӢғSғҠғYғҖӮМ•”•iӮрҗк–еүЖӮӘҠJ”ӯӮөҒA
Ҳк”КӮМғvғҚғOғүғ}ӮНӢЙ—НӮ»ӮМ•А—сӮИ•”•iӮҫӮҜӮрҢР•tӮҜӮөӮДғ\ғtғgғEғGғAӮрҚмҗ¬Ӯ·ӮйҒA
ӮаӮҝӮлӮс’ҖҺҹӮЕӮөӮ©ҸҲ—қӮЕӮ«ӮИӮўӮаӮМӮНҚӮ‘¬ү»ӮЕӮ«ӮИӮў–в‘иӮЖӮөӮД”F’mӮіӮ№ӮҪҸгӮЕӮ Ӯ«ӮзӮЯӮйҒB
ҚЕ’бӮ»ӮұӮЬӮЕӮўӮ©ӮИӮўӮЖҢҫҢкҒAғRғ“ғpғCғүӮМҸ¬ҺиҗжӮИҢӨӢҶӮЕӮНғSҒ[ғӢӮНӮұӮИӮўӮҫӮлӮӨҒB
HPCӮН—қҳ_ҒAғAғӢғSғҠғYғҖӮӘ–ҫҠmӮЕҒAӮ Ӯй’ц“xӮ»ӮкӮӘӮЕӮ«ӮДӮўӮйӮ©Ӯз•А—сү»ӮӘҲк’иӮМҗ¬ҢчӮрҺыӮЯӮДӮўӮйӮнӮҜӮЕҒB
ӮЬӮ Ӯ»ӮұӮЬӮЕӮЕӮ«ӮйӮИӮзғmғCғ}ғ“Ң^ӮЙӮұӮҫӮнӮй—қ—RӮаӮаӮӨӮИӮўӮИҒB
581 ҒF–јҸМ–ўҗЭ’иҒF2010/03/11(–Ш) 20:19:51 ID:GwSHDvbO0
—қ‘zҳ_ӮҫӮИ
582 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/03/11(–Ш) 20:22:42 ID:0YhVyy+V0
ӮЬӮ ’PӮИӮйҢВҗl“IӮИ–П‘zҲДӮМӮРӮЖӮВӮҫӮ©ӮзӮИҒB
583 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/03/11(–Ш) 20:34:15 ID:0YhVyy+V0
ғ}ғӢғ`ғvғҚғZғbғTӮБӮД‘еҺG”cӮЙӮЭӮД•Ўҗ”ӮМғmғCғ}ғ“Ң^ғRғ“ғsғ…Ғ[ғ^ӮӘ
ғҒғӮғҠӮрүоӮөӮД’КҗMӮөӮИӮӘӮзҠeҺ©ӮМҸҲ—қӮрӮөӮДӮўӮйӮҫӮҜӮИӮМӮЕҒA
ғVғXғeғҖ‘S‘МӮЖӮөӮДӮЭӮкӮОӮ·ӮЕӮЙғmғCғ}ғ“Ң^ӮМҳg‘gӮЭӮ©ӮзҠOӮкӮДӮўӮйӮЖӮаӮўӮҰӮжӮӨҒB
ӮдӮҰӮЙӮ Ӯ©ӮзӮіӮЬӮЙ’PҲкӮМғmғCғ}ғ“Ң^ғnҒ[ғhӮЧӮБӮҪӮиӮИCҢҫҢкӮвӮ»ӮкҢnӮМ•¶–@Қ\‘ўӮЕӮНҲөӮўӮЙӮӯӮўӮЖӮўӮҰӮйҒB
ӮЖӮўӮӨӮ©ҚЕӢЯӮМғXғNғҠғvғgҢҫҢкӮЙӮЖӮлүҪӮЙӮөӮлҺА—p“IӮИғvғҚғOғүғ~ғ“ғOҢҫҢкӮН
җVӮөӮўғvғҚғOғүғ~ғ“ғOӮМғpғүғ_ғCғҖӮрӮӨӮҪӮБӮДӮўӮДҒAӮўӮӯӮз”зӮрӮ©ӮФӮ№ӮДӮўӮДӮаҒA
ҸҠ‘FғmғCғ}ғ“Ң^ӮЕҢш—ҰӮжӮӯҸҲ—қӮЕӮ«Ӯй”НбeӮМ•¶–@Қ\‘ўӮөӮ©ӮаӮБӮДӮИӮўӮҫӮжӮИҒB
ғҒғӮғҠӮрүоӮөӮД’КҗMӮөӮИӮӘӮзҠeҺ©ӮМҸҲ—қӮрӮөӮДӮўӮйӮҫӮҜӮИӮМӮЕҒA
ғVғXғeғҖ‘S‘МӮЖӮөӮДӮЭӮкӮОӮ·ӮЕӮЙғmғCғ}ғ“Ң^ӮМҳg‘gӮЭӮ©ӮзҠOӮкӮДӮўӮйӮЖӮаӮўӮҰӮжӮӨҒB
ӮдӮҰӮЙӮ Ӯ©ӮзӮіӮЬӮЙ’PҲкӮМғmғCғ}ғ“Ң^ғnҒ[ғhӮЧӮБӮҪӮиӮИCҢҫҢкӮвӮ»ӮкҢnӮМ•¶–@Қ\‘ўӮЕӮНҲөӮўӮЙӮӯӮўӮЖӮўӮҰӮйҒB
ӮЖӮўӮӨӮ©ҚЕӢЯӮМғXғNғҠғvғgҢҫҢкӮЙӮЖӮлүҪӮЙӮөӮлҺА—p“IӮИғvғҚғOғүғ~ғ“ғOҢҫҢкӮН
җVӮөӮўғvғҚғOғүғ~ғ“ғOӮМғpғүғ_ғCғҖӮрӮӨӮҪӮБӮДӮўӮДҒAӮўӮӯӮз”зӮрӮ©ӮФӮ№ӮДӮўӮДӮаҒA
ҸҠ‘FғmғCғ}ғ“Ң^ӮЕҢш—ҰӮжӮӯҸҲ—қӮЕӮ«Ӯй”НбeӮМ•¶–@Қ\‘ўӮөӮ©ӮаӮБӮДӮИӮўӮҫӮжӮИҒB
584 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/03/11(–Ш) 20:46:26 ID:0YhVyy+V0
>QPIӮМ“dҲіҗU•қӮНҒAғTҒ[ғoҒ[ҢьӮҜCPUӮМ500mVӮЙ‘ОӮөӮДҒA
>ғNғүғCғAғ“ғgCPUӮМClarkdale/ArrandaleӮЕӮН150mVӮЕҒAҗU•қӮМғXғPҒ[ғүғrғҠғeғBӮН–с3”{ӮЙӮИӮйӮЖӮўӮӨҒB
җU•қӮМғXғPҒ[ғүғrғҠғeғB!!
Sandy Bridgeҗў‘гӮЕӮНQPIӮН1.1ӮЙӮИӮиӮЬӮ·ҒB
(ҚЕҸгҲКӮМWestmere-EXӮНҠ®‘S’uӮ«Ҡ·ӮҰӮЕӮНӮИӮўүВ”\җ«Ӯ ӮиҒB)
http://ch.bechtle.com/_rsc/content/download//bechtledirecthp200911_schaffner.pdf;jsessionid=DF2334E07DF177ECD1DD61EA7C76152B
>ғNғүғCғAғ“ғgCPUӮМClarkdale/ArrandaleӮЕӮН150mVӮЕҒAҗU•қӮМғXғPҒ[ғүғrғҠғeғBӮН–с3”{ӮЙӮИӮйӮЖӮўӮӨҒB
җU•қӮМғXғPҒ[ғүғrғҠғeғB!!
Sandy Bridgeҗў‘гӮЕӮНQPIӮН1.1ӮЙӮИӮиӮЬӮ·ҒB
(ҚЕҸгҲКӮМWestmere-EXӮНҠ®‘S’uӮ«Ҡ·ӮҰӮЕӮНӮИӮўүВ”\җ«Ӯ ӮиҒB)
http://ch.bechtle.com/_rsc/content/download//bechtledirecthp200911_schaffner.pdf;jsessionid=DF2334E07DF177ECD1DD61EA7C76152B
585 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/03/11(–Ш) 20:56:06 ID:0YhVyy+V0
ttp://lalsie.ist.hokudai.ac.jp/publication/dlcenter.php?fn=paper/ap_2009_amemiya.pdf
>Ӯ»ӮМҢгҒAӮұӮМғҒғӮғҠғXғ^ӮрҺАҢ»ӮөӮҪӮЖӮўӮӨ”ӯ•\ӮӘHP ҺРӮМ
>ҢӨӢҶғOғӢҒ[ғvӮ©ӮзҸoӮіӮкӮҪ[3-5]ҒBҗіҠmӮЙҢҫӮӨӮЖ, “ҜғOғӢҒ[
>ғvӮӘҲИ‘OӮ©ӮзҠJ”ӯӮрҗiӮЯӮДӮ«ӮҪ cross-point switch ӮЖӮў
>ӮӨғfғoғCғXӮӘғҒғӮғҠғXғ^ӮЙ‘Ҡ“–Ӯ·ӮйҒAӮЖӮўӮӨ”ӯ•\ӮЕӮ ӮйҒB
>ӮөӮ©ӮөҒAӮұӮМғfғoғCғXӮНҠщ‘¶ӮМReRAMҒi’пҚR•Пү»Ң^ӮМ•sҠц
>”ӯғҒғӮғҠ‘fҺqҒjӮв“dӢCү»Ҡw“IҗП•Ә‘fҺqӮЖ“ҜӮ¶ӮжӮӨӮИғqғXғe
>ғҠғVғX’пҚR‘fҺqӮЕӮ ӮиҒAғҒғӮғҠғXғ^ӮЖӮўӮӨӮЙӮН–в‘иӮӘӮ ӮйҒB
>ҺҘ‘©-“dүЧӮМ•Ё—қҢ»ҸЫӮӘҚӘ’кӮЙӮИӮўӮМӮЕҒAӮұӮкӮрғҒғӮғҠғXғ^
>ӮЖҢДӮФӮұӮЖӮНӮЕӮ«ӮИӮўҒB
>Ӯ»ӮМҢгҒAӮұӮМғҒғӮғҠғXғ^ӮрҺАҢ»ӮөӮҪӮЖӮўӮӨ”ӯ•\ӮӘHP ҺРӮМ
>ҢӨӢҶғOғӢҒ[ғvӮ©ӮзҸoӮіӮкӮҪ[3-5]ҒBҗіҠmӮЙҢҫӮӨӮЖ, “ҜғOғӢҒ[
>ғvӮӘҲИ‘OӮ©ӮзҠJ”ӯӮрҗiӮЯӮДӮ«ӮҪ cross-point switch ӮЖӮў
>ӮӨғfғoғCғXӮӘғҒғӮғҠғXғ^ӮЙ‘Ҡ“–Ӯ·ӮйҒAӮЖӮўӮӨ”ӯ•\ӮЕӮ ӮйҒB
>ӮөӮ©ӮөҒAӮұӮМғfғoғCғXӮНҠщ‘¶ӮМReRAMҒi’пҚR•Пү»Ң^ӮМ•sҠц
>”ӯғҒғӮғҠ‘fҺqҒjӮв“dӢCү»Ҡw“IҗП•Ә‘fҺqӮЖ“ҜӮ¶ӮжӮӨӮИғqғXғe
>ғҠғVғX’пҚR‘fҺqӮЕӮ ӮиҒAғҒғӮғҠғXғ^ӮЖӮўӮӨӮЙӮН–в‘иӮӘӮ ӮйҒB
>ҺҘ‘©-“dүЧӮМ•Ё—қҢ»ҸЫӮӘҚӘ’кӮЙӮИӮўӮМӮЕҒAӮұӮкӮрғҒғӮғҠғXғ^
>ӮЖҢДӮФӮұӮЖӮНӮЕӮ«ӮИӮўҒB
586 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/03/11(–Ш) 21:01:47 ID:0YhVyy+V0
Ӯ ӮзҒAғ^ғCғRғGғҢғNғgғҚғjғNғXҺРӮМғTғCғgӮЙ
Intel/AMDӮМғ\ғPғbғgғҚҒ[ғhғ}ғbғvӮӘӮ ӮБӮҪӮМӮҫӮӘҒA
ӮўӮЬӮ®Ӯ®ӮБӮҪӮзӮЕӮИӮӯӮИӮБӮҪӮИҒB
ғTҒ[ғoӮНSandy Bridgeҗў‘гӮЕ
Socket [R]omley (2011pin)
Socket BӮМҢгҢpӮЖӮөӮДSocket B1/B2(1356pin)
ӮӘӮ ӮйҒBӮЬӮ Ҡщ•сӮҫӮҜӮЗҒB
Ӯ»ӮМҢгғTҒ[ғoӮМSocketӮНғ}ғCғNғҚғRғ“ғ^ғNғgғ\ғPғbғgӮЦӮЖҗiӮЮҒB
ttp://www.asjp.co.jp/ja/topics/ele2005.07.pdf
Intel/AMDӮМғ\ғPғbғgғҚҒ[ғhғ}ғbғvӮӘӮ ӮБӮҪӮМӮҫӮӘҒA
ӮўӮЬӮ®Ӯ®ӮБӮҪӮзӮЕӮИӮӯӮИӮБӮҪӮИҒB
ғTҒ[ғoӮНSandy Bridgeҗў‘гӮЕ
Socket [R]omley (2011pin)
Socket BӮМҢгҢpӮЖӮөӮДSocket B1/B2(1356pin)
ӮӘӮ ӮйҒBӮЬӮ Ҡщ•сӮҫӮҜӮЗҒB
Ӯ»ӮМҢгғTҒ[ғoӮМSocketӮНғ}ғCғNғҚғRғ“ғ^ғNғgғ\ғPғbғgӮЦӮЖҗiӮЮҒB
ttp://www.asjp.co.jp/ja/topics/ele2005.07.pdf
587 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/03/11(–Ш) 21:25:37 ID:0YhVyy+V0
ғmҒ[ғgӮН
rPGA989,rPGA988AӮМҢгҢpӮЖӮөӮДҒA
2011”NӮЙ
rPGA988B
ӮіӮзӮЙ2012”N‘OҢгӮЕ
rPGA988C
2013”NӮЙ
rPGA II
ӮЖӮИӮБӮДӮўӮЬӮ·ҒB
ғfғXғNғgғbғvӮНLGA1155ҲИҚ~ҒAҸЪҚЧ’иӮ©ӮЕӮНӮИӮўӮӘҒAӮЬӮ “қҚҮү»ӮМ‘гҸһӮЖӮөӮД
ғӮғoғCғӢ•АӮЭӮМ•Пү»ӮНҚЎӮ©ӮзҠoҢеӮөӮЖӮўӮДӮаӮўӮўӮ©ӮаӮИҒB
rPGA989,rPGA988AӮМҢгҢpӮЖӮөӮДҒA
2011”NӮЙ
rPGA988B
ӮіӮзӮЙ2012”N‘OҢгӮЕ
rPGA988C
2013”NӮЙ
rPGA II
ӮЖӮИӮБӮДӮўӮЬӮ·ҒB
ғfғXғNғgғbғvӮНLGA1155ҲИҚ~ҒAҸЪҚЧ’иӮ©ӮЕӮНӮИӮўӮӘҒAӮЬӮ “қҚҮү»ӮМ‘гҸһӮЖӮөӮД
ғӮғoғCғӢ•АӮЭӮМ•Пү»ӮНҚЎӮ©ӮзҠoҢеӮөӮЖӮўӮДӮаӮўӮўӮ©ӮаӮИҒB
588 ҒF–јҸМ–ўҗЭ’иҒF2010/03/13(“y) 03:59:49 ID:2124ySIU0
җlҠФ’ҙӮҰӮкӮОүрҢҲӮөӮ»ӮӨӮҫ
589 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/03/16(үО) 19:26:22 ID:RswqaCWb0
ӮвӮБӮПLRBӮвӮЯӮҪӮсӮ©ӮЛӮҘҒc?
698 ҒFSocket774 [Ғ«] ҒF2010/03/16(үО) 11:02:25 ID:pImm+kO9
HaswellӮМғVғ…ғҠғ“ғN”ЕӮМRockwellӮМIGPӮЙӮіӮҰӮаLarrabeeӮӘҚЪӮзӮИӮўӮМӮҫӮЖӮ·ӮйӮЖҒEҒEҒE
Haswell has a sucessor
http://www.semiaccurate.com/2010/03/15/haswell-has-sucessor/
698 ҒFSocket774 [Ғ«] ҒF2010/03/16(үО) 11:02:25 ID:pImm+kO9
HaswellӮМғVғ…ғҠғ“ғN”ЕӮМRockwellӮМIGPӮЙӮіӮҰӮаLarrabeeӮӘҚЪӮзӮИӮўӮМӮҫӮЖӮ·ӮйӮЖҒEҒEҒE
Haswell has a sucessor
http://www.semiaccurate.com/2010/03/15/haswell-has-sucessor/
590 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/03/16(үО) 19:27:33 ID:RswqaCWb0
>>588
җўӮМ’ҶӮЙӮНҗlҠФӮвӮЯӮЬӮөӮҪӢүӮМ“ӘӮМҺқӮҝҺеӮӘӮҪӮӯӮіӮсӮўӮйӮҫӮлӮӨӮ©ӮзҒA
”ЮӮзӮЙҠъ‘ТӮ·ӮйӮөӮ©ӮИӮўӮЖӮўӮӨҳHҗьӮҫӮИҒB
җўӮМ’ҶӮЙӮНҗlҠФӮвӮЯӮЬӮөӮҪӢүӮМ“ӘӮМҺқӮҝҺеӮӘӮҪӮӯӮіӮсӮўӮйӮҫӮлӮӨӮ©ӮзҒA
”ЮӮзӮЙҠъ‘ТӮ·ӮйӮөӮ©ӮИӮўӮЖӮўӮӨҳHҗьӮҫӮИҒB
591 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/03/16(үО) 19:45:58 ID:RswqaCWb0
үКӮҪӮөӮДғNғүғEғhғRғ“ғsғ…Ғ[ғeғBғ“ғO(ҸО)ӮНҒA
ғRғ“ғVғ…Ғ[ғ}ҺsҸкӮЕ“ҫӮҪ”„ҸгӮ°ӮЙӮжӮБӮДҠJ”ӯӮіӮкӮҪCPU/GPUӮрӮНӮ¶ӮЯӮЖӮ·ӮйғnҒ[ғhғEғGғAҒA
җ»‘ўғvғҚғZғXӮрҲкҗШӮВӮ©ӮнӮИӮўӮЕҚӮҗ«”\ӮИғNғүғEғhғTҒ[ғoӮрҲкӮ©ӮзҠJ”ӯӮөӮҪӮЖүЯ’цӮөӮҪҸкҚҮҒA
ғrғWғlғXғTғCғNғӢӮрҲЫҺқӮЕӮ«ӮйӮМӮҫӮлӮӨӮ©?
Ӯ»ӮкӮӘӮЕӮ«ӮИӮҜӮкӮОғNғүғEғhӮӘғNғүғCғAғ“ғgғnҒ[ғhӮр–•ҺEӮ·ӮйӮұӮЖӮНҢҙ—қ“IӮЙ•sүВ”\ӮҫҒB
ҺАҚЫӮЙӮНғRғ“ғsғ…Ғ[ғ^ӮНӮжӮиҸ¬Ң^ҒA’бүҝҠiҒA•ӘҺUү»ӮМ•ыҢьӮЦҗi•аӮөӮДӮўӮЬӮ·ҒB
ғRғ“ғVғ…Ғ[ғ}ҺsҸкӮЕ“ҫӮҪ”„ҸгӮ°ӮЙӮжӮБӮДҠJ”ӯӮіӮкӮҪCPU/GPUӮрӮНӮ¶ӮЯӮЖӮ·ӮйғnҒ[ғhғEғGғAҒA
җ»‘ўғvғҚғZғXӮрҲкҗШӮВӮ©ӮнӮИӮўӮЕҚӮҗ«”\ӮИғNғүғEғhғTҒ[ғoӮрҲкӮ©ӮзҠJ”ӯӮөӮҪӮЖүЯ’цӮөӮҪҸкҚҮҒA
ғrғWғlғXғTғCғNғӢӮрҲЫҺқӮЕӮ«ӮйӮМӮҫӮлӮӨӮ©?
Ӯ»ӮкӮӘӮЕӮ«ӮИӮҜӮкӮОғNғүғEғhӮӘғNғүғCғAғ“ғgғnҒ[ғhӮр–•ҺEӮ·ӮйӮұӮЖӮНҢҙ—қ“IӮЙ•sүВ”\ӮҫҒB
ҺАҚЫӮЙӮНғRғ“ғsғ…Ғ[ғ^ӮНӮжӮиҸ¬Ң^ҒA’бүҝҠiҒA•ӘҺUү»ӮМ•ыҢьӮЦҗi•аӮөӮДӮўӮЬӮ·ҒB
592 ҒF–јҸМ–ўҗЭ’иҒF2010/03/16(үО) 23:15:40 ID:9XsxKj000
Westmere-EP”ӯ•\ӮЖ“ҜҺһӮЙғxғ“ғ`ғ}Ғ[ғNӮаӮўӮӯӮВӮ©ҸoӮДӮ«ӮҪ
ttp://www.intel.com/pressroom/archive/releases/2010/20100316comp_sm.htm
ӮЬӮ ‘е‘М—\‘z’КӮиҒi“–ӮҪӮи‘OӮ©
ttp://www.intel.com/pressroom/archive/releases/2010/20100316comp_sm.htm
ӮЬӮ ‘е‘М—\‘z’КӮиҒi“–ӮҪӮи‘OӮ©
593 ҒF–јҸМ–ўҗЭ’иҒF2010/03/22(ҢҺ) 12:13:32 ID:9FBVdyWn0
ho
594 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/03/27(“y) 17:09:57 ID:5hrh/s/s0
NVIDIAҒfs GeForce GTX 480 and GTX 470: 6 Months Late, Was It Worth the Wait?
http://www.anandtech.com/printarticle.aspx?i=3783
FermiӮ«ӮҪӮЛ!
“БӮЙҢҫӮӨӮұӮЖӮаӮИӮўӮӘҒAҚЎҢгӮМGPUӮӘӮЗӮұӮЦӮЮӮ©ӮБӮДӮЗӮӨӮӨӮИӮБӮДӮўӮӯӮ©ҠyӮөӮЭҒB
http://www.anandtech.com/printarticle.aspx?i=3783
FermiӮ«ӮҪӮЛ!
“БӮЙҢҫӮӨӮұӮЖӮаӮИӮўӮӘҒAҚЎҢгӮМGPUӮӘӮЗӮұӮЦӮЮӮ©ӮБӮДӮЗӮӨӮӨӮИӮБӮДӮўӮӯӮ©ҠyӮөӮЭҒB
595 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/03/27(“y) 17:18:41 ID:5hrh/s/s0
GeForceӮБӮДҸd—НүБ‘¬“x(G forces)ӮЖғWғIғҒғgғҠӮрӮ©ӮҜӮҪӮМӮ©ӮИ?
ӮЖӮўӮӨӮМӮрӮўӮЬӮіӮзҺvӮўӮВӮўӮҪҒB
ӮЖӮўӮӨӮМӮрӮўӮЬӮіӮзҺvӮўӮВӮўӮҪҒB
596 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/03/31(җ…) 19:14:07 ID:FsLm+5Y70
Nehalem-EX
http://ark.intel.com/Product.aspx?id=46499&processor=X7560&spec-codes=SLBRD
TurboӮНMax. 2.66GHzӮБӮЫӮўӮИҒB
http://ark.intel.com/Product.aspx?id=46499&processor=X7560&spec-codes=SLBRD
TurboӮНMax. 2.66GHzӮБӮЫӮўӮИҒB
597 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/03/31(җ…) 19:17:50 ID:FsLm+5Y70
Nehalem-EX vs. AMD 12-Core-Opteron 6100
Intel Xeon X7560 - Neue 8-Core-CPU im Test
http://www.tecchannel.de/server/prozessoren/2026908/test_review_benchmarks_intel_xeon_7500_octa_core/
ҲИүә RWTӮМҢfҺҰ”ВӮжӮиғRғsғy
First up SAP 2-tier.
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
IBM System x3850 X5, 4 Processors / 32 Cores / 64 Threads, Intel Xeon Processor X7560, 2.26 Ghz, 64 KB L1 cache and 256 KB L2 cache per core, 24 MB L3 cache per processor
= 57120 SAPS
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
Fujitsu PRIMEQUEST 1800E, 8 Processors / 64 Cores / 128 Threads, Intel Xeon Processor X7560, 2.26 Ghz, 64 KB L1 cache and 256 KB L2 cache per core, 24 MB L3 cache per processor
= 87550 SAPS
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
Compared to:
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
Fujitsu PRIMERGY BX922 S2, 2 Processors / 12 Cores / 24 Threads, Intel Xeon Processor X5680, 3.33 Ghz, 64 KB L1 cache and 256 KB L2 cache per core, 12 MB L3 cache per processor
= 26800 SAPS
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
IBM Power System 750, 4 Processors / 32 Cores / 128 Threads, POWER7, 3.55 Ghz, 32 KB(I) + 32 KB(D) L1 cache and 256 KB L2 cache per core, 4 MB L3 cache per core
= 85220 SAPS
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
Dell PowerEdge M905, 4 Processors / 24 Cores / 24 Threads, Six-Core AMD Opteron Processor 8431, 2.4 Ghz, 128 KB L1 cache and 512 KB L2 cache per core, 6 MB L3 cache per processor
= 19730 SAPS
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
SAPS per core:
Xeon 7560 ~1785(4s)1367(8s) (scaling doesn't look too hot?)
Xeon 5680 ~2233
Power7 ~2663
Opteron ~822
Intel Xeon X7560 - Neue 8-Core-CPU im Test
http://www.tecchannel.de/server/prozessoren/2026908/test_review_benchmarks_intel_xeon_7500_octa_core/
ҲИүә RWTӮМҢfҺҰ”ВӮжӮиғRғsғy
First up SAP 2-tier.
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
IBM System x3850 X5, 4 Processors / 32 Cores / 64 Threads, Intel Xeon Processor X7560, 2.26 Ghz, 64 KB L1 cache and 256 KB L2 cache per core, 24 MB L3 cache per processor
= 57120 SAPS
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
Fujitsu PRIMEQUEST 1800E, 8 Processors / 64 Cores / 128 Threads, Intel Xeon Processor X7560, 2.26 Ghz, 64 KB L1 cache and 256 KB L2 cache per core, 24 MB L3 cache per processor
= 87550 SAPS
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
Compared to:
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
Fujitsu PRIMERGY BX922 S2, 2 Processors / 12 Cores / 24 Threads, Intel Xeon Processor X5680, 3.33 Ghz, 64 KB L1 cache and 256 KB L2 cache per core, 12 MB L3 cache per processor
= 26800 SAPS
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
IBM Power System 750, 4 Processors / 32 Cores / 128 Threads, POWER7, 3.55 Ghz, 32 KB(I) + 32 KB(D) L1 cache and 256 KB L2 cache per core, 4 MB L3 cache per core
= 85220 SAPS
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
Dell PowerEdge M905, 4 Processors / 24 Cores / 24 Threads, Six-Core AMD Opteron Processor 8431, 2.4 Ghz, 128 KB L1 cache and 512 KB L2 cache per core, 6 MB L3 cache per processor
= 19730 SAPS
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
SAPS per core:
Xeon 7560 ~1785(4s)1367(8s) (scaling doesn't look too hot?)
Xeon 5680 ~2233
Power7 ~2663
Opteron ~822
598 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/03/31(җ…) 19:33:17 ID:FsLm+5Y70
ӮұӮМҢӢүКӮҫӮҜӮЕӮўӮӨӮЖҒA4SҒЁ8SӮЕӮМғXғPҒ[ғӢӮӘӮўӮЬӮўӮҝӮЖӮўӮӨӮұӮЖӮМӮжӮӨӮҫӮЛҒB
Ӯ»ӮкӮЙӮөӮДӮа8ғRғAӮЕӮаҚӮғNғҚғbғNӮЕӮЬӮнӮБӮДӮйPower 7ӮМҸo—ҲӮӘӮРӮ©ӮйӮИҒB
Nehalem-EXӮМӮЁӮіӮзӮў
http://www.hotchips.org/archives/hc21/2_mon/HC21.24.100.ServerSystemsI-Epub/HC21.24.122-Kottapalli-Intel-NHM-EX.pdf
Ӯ»ӮкӮЙӮөӮДӮа8ғRғAӮЕӮаҚӮғNғҚғbғNӮЕӮЬӮнӮБӮДӮйPower 7ӮМҸo—ҲӮӘӮРӮ©ӮйӮИҒB
Nehalem-EXӮМӮЁӮіӮзӮў
http://www.hotchips.org/archives/hc21/2_mon/HC21.24.100.ServerSystemsI-Epub/HC21.24.122-Kottapalli-Intel-NHM-EX.pdf
599 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/03/31(җ…) 20:20:56 ID:FsLm+5Y70
ӮӯӮТӮгғtғFғ`ҢьӮҜ“®үж
New POWER7 workload optimizing systems
http://www.youtube.com/watch?v=CmXfZmplxUA
IBM launches eight-core Power7 processor, servers
http://www.youtube.com/watch?v=lAKIdKi0Zpw
New POWER7 workload optimizing systems
http://www.youtube.com/watch?v=CmXfZmplxUA
IBM launches eight-core Power7 processor, servers
http://www.youtube.com/watch?v=lAKIdKi0Zpw
600 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2010/03/31(җ…) 20:33:28 ID:i3mJceSX0
>>598
> Ӯ»ӮкӮЙӮөӮДӮа8ғRғAӮЕӮаҚӮғNғҚғbғNӮЕӮЬӮнӮБӮДӮйPower 7ӮМҸo—ҲӮӘӮРӮ©ӮйӮИҒB
TDPҳgӮӘ“ҜӮ¶130WӮИӮзPOWER7ӮҫӮБӮДҚӮғNғҚғbғNӮЕүсӮйӮнӮҜӮӘӮИӮўӮж
> Ӯ»ӮкӮЙӮөӮДӮа8ғRғAӮЕӮаҚӮғNғҚғbғNӮЕӮЬӮнӮБӮДӮйPower 7ӮМҸo—ҲӮӘӮРӮ©ӮйӮИҒB
TDPҳgӮӘ“ҜӮ¶130WӮИӮзPOWER7ӮҫӮБӮДҚӮғNғҚғbғNӮЕүсӮйӮнӮҜӮӘӮИӮўӮж
601 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/03/31(җ…) 20:41:37 ID:FsLm+5Y70
200WӮҫӮЖNehalemӮӘ3.5GHzӮЕӮЬӮнӮйӮЖӮ©Ӯ ӮиӮҰӮИӮўӮИҒB
602 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/03/31(җ…) 20:59:01 ID:FsLm+5Y70
ғҸҒ[ғӢғhғҸғCғhӮМғTҒ[ғoғVғFғAҒAIBMӮӘҺсҲКҒAHPҒADellӮӘ‘ұӮӯҒBғTҒ[ғoӮМ96Ғ“ӮӘx86ғTҒ[ғo
http://www.publickey1.jp/blog/10/ibmhpdell96x86.html
>ғTҒ[ғoӮМҺн—ЮӮЖӮөӮДӮН”„ҸгӮ°ӮМ55Ғ“ҒAҸoүЧ‘дҗ”ӮМ96Ғ“ӮӘx86ғTҒ[ғoӮЕӮ ӮиҒA
>x86ғTҒ[ғoӮНүЯӢҺ5”NҒAҢp‘ұ“IӮЙғVғFғAӮрҸгҸёӮіӮ№‘ұӮҜӮДӮўӮйӮЖӮМӮұӮЖҒB
ӮӨҒ`ӮсҒAғVғFғA96%ӮЕ”„ҸгҚӮӮМ55%ӮИӮсӮҫӮжӮИx86ғTҒ[ғoӮБӮДҒB
IntelӮӘIA64ӮЙғ}ғWӮҫӮБӮҪӮМӮаӮӨӮИӮёӮҜӮйҗ”ҺҡӮҫҒB
ӮЬӮ ҒAӢtӮЙӮўӮҰӮОRISCғVғXғeғҖӮӘ–і‘КӮЙҚӮӮ·Ӯ¬ӮИӮнӮҜӮЕ
ғvғҚғZғbғTӮМ”„ҸгҚӮӮМ”дӮЕӮўӮҰӮОӮЬӮҪҗ”ҺҡӮӘҲбӮӨӮнӮҜӮЕӮ ӮйӮӘҒB
http://www.publickey1.jp/blog/10/ibmhpdell96x86.html
>ғTҒ[ғoӮМҺн—ЮӮЖӮөӮДӮН”„ҸгӮ°ӮМ55Ғ“ҒAҸoүЧ‘дҗ”ӮМ96Ғ“ӮӘx86ғTҒ[ғoӮЕӮ ӮиҒA
>x86ғTҒ[ғoӮНүЯӢҺ5”NҒAҢp‘ұ“IӮЙғVғFғAӮрҸгҸёӮіӮ№‘ұӮҜӮДӮўӮйӮЖӮМӮұӮЖҒB
ӮӨҒ`ӮсҒAғVғFғA96%ӮЕ”„ҸгҚӮӮМ55%ӮИӮсӮҫӮжӮИx86ғTҒ[ғoӮБӮДҒB
IntelӮӘIA64ӮЙғ}ғWӮҫӮБӮҪӮМӮаӮӨӮИӮёӮҜӮйҗ”ҺҡӮҫҒB
ӮЬӮ ҒAӢtӮЙӮўӮҰӮОRISCғVғXғeғҖӮӘ–і‘КӮЙҚӮӮ·Ӯ¬ӮИӮнӮҜӮЕ
ғvғҚғZғbғTӮМ”„ҸгҚӮӮМ”дӮЕӮўӮҰӮОӮЬӮҪҗ”ҺҡӮӘҲбӮӨӮнӮҜӮЕӮ ӮйӮӘҒB
603 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/03/31(җ…) 21:10:03 ID:FsLm+5Y70
http://www.ospn.jp/osc2010-kobe/pdf/OSC2010Kobe_HP.pdf
TOP500ӮБӮДHPӮӘғVғFғA1ҲКӮҫӮБӮҪӮМӮ©ҒB
TOP500ӮБӮДHPӮӘғVғFғA1ҲКӮҫӮБӮҪӮМӮ©ҒB
604 ҒF–јҸМ–ўҗЭ’иҒF2010/03/31(җ…) 21:45:30 ID:vqk/j4hd0
>>597
ҺQҚlӮЙӮИӮБӮҪӮ”ӮҲӮҳ
ҺQҚlӮЙӮИӮБӮҪӮ”ӮҲӮҳ
605 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2010/03/31(җ…) 21:54:47 ID:i3mJceSX0
>>601
ӮЬӮ Ӯ»ӮӨӮҫӮӘ
Ӯ»ӮаӮ»ӮаPOWERӮНғNғҚғbғNӮ ӮҪӮиӮМҗ®җ”үүҺZҗ«”\ӮӘCoreғtғ@ғ~ғҠӮжӮиӮёӮБӮЖ’бӮўӮМӮЕ
‘О“ҷӮИ”дҠrӮЕӮНӮИӮўӮҫӮлӮӨ
L3ӮаeDRAMӮҫӮөӮИ
ӮЬӮ Ӯ»ӮӨӮҫӮӘ
Ӯ»ӮаӮ»ӮаPOWERӮНғNғҚғbғNӮ ӮҪӮиӮМҗ®җ”үүҺZҗ«”\ӮӘCoreғtғ@ғ~ғҠӮжӮиӮёӮБӮЖ’бӮўӮМӮЕ
‘О“ҷӮИ”дҠrӮЕӮНӮИӮўӮҫӮлӮӨ
L3ӮаeDRAMӮҫӮөӮИ
606 ҒF–јҸМ–ўҗЭ’иҒF2010/03/31(җ…) 22:21:32 ID:3A+KXygZ0
>>598
ӮӨӮЙӮөӮ·ӮӘҗк—pӮМғ`ғvғZғgҺgӮБӮҪҺIҸoӮ·ӮҫӮлӮӨӮ©ӮзӮ»ӮкӮЬӮЕ‘ТӮДӮОҒH
ӮӨӮЙӮөӮ·ӮӘҗк—pӮМғ`ғvғZғgҺgӮБӮҪҺIҸoӮ·ӮҫӮлӮӨӮ©ӮзӮ»ӮкӮЬӮЕ‘ТӮДӮОҒH
607 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2010/04/01(–Ш) 20:39:13 ID:e/JBYppB0
http://www.amdzone.com/joomla/index.php?option=com_content&view=article&id=12578:amd-bulldozer-exclusive&catid=60&Itemid=92
ӮЬӮ ғlғ^ӮЖӮөӮДӮН–К”’Ӯў
ӮЬӮ ғlғ^ӮЖӮөӮДӮН–К”’Ӯў
608 ҒF–јҸМ–ўҗЭ’иҒF2010/04/01(–Ш) 21:05:01 ID:AndNcD/20
609 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/04/01(–Ш) 21:09:26 ID:AndNcD/20
ҺАӮНҚЕӢЯӮ ӮОӮкӮДӮўӮйӮҰӮйӮҰӮйӮМҗі‘МӮНҒA
ӮЁӮкӮҫӮБӮҪӮМӮЕӮ ӮйҒB
ӮЁӮкӮҫӮБӮҪӮМӮЕӮ ӮйҒB
610 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/04/01(–Ш) 21:20:00 ID:AndNcD/20
ӮЖӮўӮӨӮ©ӮЁӮкӮағGғCғvғҠғӢғtҒ[ғӢӮМ‘еғlғ^ҺdҚһӮсӮЕҠyӮөӮЭӮөӮДӮ«ӮҪӮМӮЙ
>>607ӮЕӮіӮ«ӮұӮіӮкӮДӮ·Ӯ®ӮОӮкӮйӮ©ӮзҢцҠJӮЕӮ«ӮИӮ©ӮБӮҪӮЖӮўӮӨҺ–ҺАҒB
>>607ӮЕӮіӮ«ӮұӮіӮкӮДӮ·Ӯ®ӮОӮкӮйӮ©ӮзҢцҠJӮЕӮ«ӮИӮ©ӮБӮҪӮЖӮўӮӨҺ–ҺАҒB
611 ҒF–јҸМ–ўҗЭ’иҒF2010/04/06(үО) 21:43:32 ID:exI81skj0
ho
612 ҒF–јҸМ–ўҗЭ’иҒF2010/04/07(җ…) 14:40:48 ID:bRIelQPF0
POWER7ҚӮҗҷӮҫӮл
POWERMac•ңҠҲӮН–ІӮМӮЬӮҪ–ІӮ©
POWERMac•ңҠҲӮН–ІӮМӮЬӮҪ–ІӮ©
613 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2010/04/07(җ…) 19:51:51 ID:LLVLYsL20
AppleӮӘғRғ“ғVғ…Ғ[ғ}ҢьӮҜғnғCғGғ“ғhPPCӮМғRғXғgғҒғҠғbғgҒEғXғPҒ[ғӢғҒғҠғbғgӮрҺxӮҰӮй‘ӨӮЙӮўӮИӮўӮ©Ӯз“–‘RӮҫӮИ
614 ҒF–јҸМ–ўҗЭ’иҒF2010/04/09(Ӣа) 21:55:26 ID:oSoFsai50
>>538
ғ°(ҒL„DҒMҒG Ғj
ғCғ“ғeғӢӮМғeғNғmғҚғWҒ[ҒEғҠҒ[ғ_Ғ[ҒAҒg3DғCғ“ғ^Ғ[ғlғbғgҒhӮМ–ў—ҲӮрҢкӮй
Ғu5”NҢгӮЙӮН’NӮаӮӘғIғ“ғүғCғ“3DғRғ“ғeғ“ғcӮрҠyӮөӮЯӮйӮжӮӨӮЙӮИӮйҒv
http://www.computerworld.jp/news/trd/178869.html
ғ°(ҒL„DҒMҒG Ғj
ғCғ“ғeғӢӮМғeғNғmғҚғWҒ[ҒEғҠҒ[ғ_Ғ[ҒAҒg3DғCғ“ғ^Ғ[ғlғbғgҒhӮМ–ў—ҲӮрҢкӮй
Ғu5”NҢгӮЙӮН’NӮаӮӘғIғ“ғүғCғ“3DғRғ“ғeғ“ғcӮрҠyӮөӮЯӮйӮжӮӨӮЙӮИӮйҒv
http://www.computerworld.jp/news/trd/178869.html
615 ҒF–јҸМ–ўҗЭ’иҒF2010/04/10(“y) 23:06:42 ID:LrzdKpKB0
ҚЎүсӮМҢг“ЎӢLҺ–ӮЁӮаӮлӮўӮИ
IntelҢӢҚ\ҸЕӮБӮДӮйӮ©ӮаӮИ
IntelҢӢҚ\ҸЕӮБӮДӮйӮ©ӮаӮИ
616 ҒF–јҸМ–ўҗЭ’иҒF2010/04/16(Ӣа) 18:30:29 ID:rtBDaLIZ0
617 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2010/04/17(“y) 16:09:14 ID:NVjGvv+E0
> Sandy BridgeӮМҗ«”\ӮНҗVTBӮМҺА—НӮЖcacheҺь•УӮМlatencyӮЙ‘еӮ«ӮӯҲЛ‘¶ӮөӮДӮўӮйӮҪӮЯҒA—\‘zӮӘ“пӮөӮўҒB
> memory/cache accessӮӘprocessorӮМҗ«”\ҢьҸгӮМ‘«Ӯ©Ӯ№ӮЙӮИӮБӮДӮўӮйҚрҚЎҒAҢВҗl“IӮЙӮНҒAL1DӮМlatencyӮӘ
> 3 cyclesӮ©Ҳ«ӮӯӮДNehalemӮЖ“Ҝ“ҷӮМ4 cyclesӮЕӮ ӮкӮОҒAload portӮМ‘қӮҰӮҪSNBӮНIPC–КӮЕӮ»ӮкӮИӮиӮЙ
> Ҡъ‘ТӮЕӮ«ӮйӮЖҺvӮўӮЬӮ·ӮӘҒAҢ»ҚЭӮМӮЖӮұӮл5 cyclesҲИҸгӮМҗаӮӘ—L—НӮЕӮ·ӮЛҒB
ғҚҒ[ғhғҶғjғbғgӮӘ‘қӮҰӮҪ•ӘӮҫӮҜғҚҒ[ғhӮрҗжҚsҺАҚsӮЕӮ«Ӯйғ`ғғғ“ғXӮӘ‘қӮҰӮйӮМӮЕҒA
‘е‘МӮМғҢғCғeғ“ғVӮМ‘қүБӮНғJғoҒ[ӮЕӮ«ӮйӮМӮЕӮНӮИӮўӮ©ӮЖ—\‘zҒB
Ҳк•ығҚҒ[ғhӮЙdependency chainӮӘӮ ӮйҸкҚҮҒAӮҪӮЖӮҰӮОӮ Ӯй’lӮрғҚҒ[ғhӮөӮДҚXӮЙӮ»ӮМ’lӮрғAғhғҢғXӮМғIғtғZғbғg’lӮЖӮөӮД
•]үҝӮөӮДғҚҒ[ғhӮ·ӮйӮжӮӨӮИғPҒ[ғXӮҫӮЖҒAғҢғCғeғ“ғVӮӘ‘қүБӮөӮҪ•ӘӮҫӮҜҗ«”\ӮН’бүәӮ·ӮйҒB
ӮЬӮ ҒAӮҪӮҫӮұӮМӮЦӮсӮМғpғCғvғүғCғ“ӮЙӢуӮ«ӮӘҸo—ҲӮйӮМӮНHTӮ Ӯй’ц“xӮНҠЙҳaӮіӮкӮйҒB
> ҸгӮМlinkҗжӮЙӮ ӮйSandy BridgeӮМҢцҺ®blockҗ}ӮЕӮНҒAAllocate/Rename/RetireӮМӮЖӮұӮлӮЙҒAZeroing Idioms(ғ[ғҚү»Ҡө—pӢе)ӮЖӮўӮӨӮМӮӘ
ӮұӮк‘OӮ©ӮзӮ ӮйӮҜӮЗӮИ
XOR*ӮҫӮҜӮҫӮБӮҪӮМӮӘSUB*ӮЖӮ©PCMPGT*ӮЙӮа“K—pӮіӮкӮйӮжӮӨӮЙӮИӮБӮҪӮҫӮҜ
> memory/cache accessӮӘprocessorӮМҗ«”\ҢьҸгӮМ‘«Ӯ©Ӯ№ӮЙӮИӮБӮДӮўӮйҚрҚЎҒAҢВҗl“IӮЙӮНҒAL1DӮМlatencyӮӘ
> 3 cyclesӮ©Ҳ«ӮӯӮДNehalemӮЖ“Ҝ“ҷӮМ4 cyclesӮЕӮ ӮкӮОҒAload portӮМ‘қӮҰӮҪSNBӮНIPC–КӮЕӮ»ӮкӮИӮиӮЙ
> Ҡъ‘ТӮЕӮ«ӮйӮЖҺvӮўӮЬӮ·ӮӘҒAҢ»ҚЭӮМӮЖӮұӮл5 cyclesҲИҸгӮМҗаӮӘ—L—НӮЕӮ·ӮЛҒB
ғҚҒ[ғhғҶғjғbғgӮӘ‘қӮҰӮҪ•ӘӮҫӮҜғҚҒ[ғhӮрҗжҚsҺАҚsӮЕӮ«Ӯйғ`ғғғ“ғXӮӘ‘қӮҰӮйӮМӮЕҒA
‘е‘МӮМғҢғCғeғ“ғVӮМ‘қүБӮНғJғoҒ[ӮЕӮ«ӮйӮМӮЕӮНӮИӮўӮ©ӮЖ—\‘zҒB
Ҳк•ығҚҒ[ғhӮЙdependency chainӮӘӮ ӮйҸкҚҮҒAӮҪӮЖӮҰӮОӮ Ӯй’lӮрғҚҒ[ғhӮөӮДҚXӮЙӮ»ӮМ’lӮрғAғhғҢғXӮМғIғtғZғbғg’lӮЖӮөӮД
•]үҝӮөӮДғҚҒ[ғhӮ·ӮйӮжӮӨӮИғPҒ[ғXӮҫӮЖҒAғҢғCғeғ“ғVӮӘ‘қүБӮөӮҪ•ӘӮҫӮҜҗ«”\ӮН’бүәӮ·ӮйҒB
ӮЬӮ ҒAӮҪӮҫӮұӮМӮЦӮсӮМғpғCғvғүғCғ“ӮЙӢуӮ«ӮӘҸo—ҲӮйӮМӮНHTӮ Ӯй’ц“xӮНҠЙҳaӮіӮкӮйҒB
> ҸгӮМlinkҗжӮЙӮ ӮйSandy BridgeӮМҢцҺ®blockҗ}ӮЕӮНҒAAllocate/Rename/RetireӮМӮЖӮұӮлӮЙҒAZeroing Idioms(ғ[ғҚү»Ҡө—pӢе)ӮЖӮўӮӨӮМӮӘ
ӮұӮк‘OӮ©ӮзӮ ӮйӮҜӮЗӮИ
XOR*ӮҫӮҜӮҫӮБӮҪӮМӮӘSUB*ӮЖӮ©PCMPGT*ӮЙӮа“K—pӮіӮкӮйӮжӮӨӮЙӮИӮБӮҪӮҫӮҜ
618 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/04/17(“y) 19:43:39 ID:zrwbqXB10
Sandy BirdgeӮНAVXӮвLd/StӢӯү»ӮӘӮ ӮйӮМӮЙҒA
WestmereӮЖ”дҠrӮөӮДӮИӮәғRғA–КҗПӮӘӮ ӮЬӮи‘еӮ«ӮӯӮИӮБӮДӮўӮИӮўӮ©
Ӯ ӮФӮИӮў’ҙүрҺЯӮМғeғXғcҒB
1.Nehlalem”дӮЕғpғCғvғүғCғ“ӮӘ’ZӮӯӮИӮБӮҪҗа
NehalemӮНғfҒ[ғ^ғpғXӮНallғXғ^ғeғBғbғNүсҳHӮЙғҚҒ[ғeғNүсӢAӮөӮДӮўӮйӮӯӮзӮўӮИҸгӮЙ
Sandy BridgeӮЕӮН32nmғvғҚғZғXҸҖӢ’ӮЙӮИӮБӮДӮіӮзӮЙғgғүғ“ғWғXғ^ӮМSW‘¬“xӮНүь‘PӮөӮДӮўӮйӮӯӮзӮўӮИӮМӮЕҒA
ғXғ^ғeғBғbғNүсҳHӮҫӮҜӮЕӮН–OӮ«‘«ӮзӮёҒAғpғCғvғүғCғ“ғsғbғ`ӮрҚrӮӯӮөӮДӮа“d—НҢёӮзӮөӮДғNғҚғbғNӮ©Ӯ№Ӯ°ӮйӮ¶ӮбӮсӮЖӮўӮӨӮұӮЖ
ӮЕғpғCғvғүғCғ“ӮМғXғeҒ[ғWҗ”ӮрҢёӮзӮөӮҪҒBӮ»ӮМӮЁӮ©Ӯ°ӮЕғRғAӮӘ‘S‘М“IӮЙғRғ“ғpғNғgӮЙӮИӮБӮҪҒB
2.OregonҗЭҢvӮМNehalemӮЖҒAIsraelҗЭҢvӮМSNBӮЖӮЕҳ_—қҚҮҗ¬ҒA”z’u”zҗьғcҒ[ғӢӮИӮЗӮӘҲЩӮИӮйҗа
ҺАӮНҠJ”ӯҠВӢ«ӮМ–в‘иӮҫӮБӮҪҒB
3.AVX‘ОүһӮаӮ ӮйӮұӮЖӮҫӮөҒAuopӮрҚXӮИӮйҸБ”п“d—Нү»ӮМӮҪӮЯӮЙ‘е•қӮЙҚД’иӢ`ӮөӮДҢ©’јӮөӮҪҗа
uopӮМғGғ“ғRҒ[ғhӮНҗ§ҢдғҚғWғbғNӮМҚЕҸ¬ү»ӮЙӮаүeӢҝӮ·ӮйҒB
SNBӮНҠж’ЈӮБӮДuopӮМ’иӢ`ӮрAVX‘ОүһӮИӮЗӮМӮВӮўӮЕӮЙ’ҙҚЕ“Kү»ӮөӮҪҒB
4.ү·“xғZғ“ғTӮрҢёӮзӮөӮҪҗа
ү·“xғZғ“ғTӮрӮЭӮй•p“xӮНҢёӮБӮҪӮМӮЕҒANehalemӮжӮиӮаҢёӮзӮөӮҪҒB
Ӯ»ӮаӮ»Ӯаү·“xғZғ“ғT”@Ӯ«ӮӘғ_ғC–КҗПӮрҗHӮБӮДӮўӮҪӮМӮ©ӮН“дӮЕӮ ӮйҒB
5.Israelғ`Ғ[ғҖӮӘҚЕ“Kү»ӮрҠж’ЈӮБӮҪҗа
NehalemӮНӢ}ӮўӮЕҗЭҢvӮөӮҪӮаӮМӮИӮМӮЕӮ»ӮаӮ»ӮаҚЕ“Kү»ӮӘҠГӮ©ӮБӮҪҒB
Ҳк•ыSNBӮНӮ¶ӮБӮӯӮиӮвӮкӮйҺһҠФӮӘӮ ӮБӮҪҒB’PӮИӮйҺһҠФӮЖҗlӮМ–в‘иҒB
WestmereӮЖ”дҠrӮөӮДӮИӮәғRғA–КҗПӮӘӮ ӮЬӮи‘еӮ«ӮӯӮИӮБӮДӮўӮИӮўӮ©
Ӯ ӮФӮИӮў’ҙүрҺЯӮМғeғXғcҒB
1.Nehlalem”дӮЕғpғCғvғүғCғ“ӮӘ’ZӮӯӮИӮБӮҪҗа
NehalemӮНғfҒ[ғ^ғpғXӮНallғXғ^ғeғBғbғNүсҳHӮЙғҚҒ[ғeғNүсӢAӮөӮДӮўӮйӮӯӮзӮўӮИҸгӮЙ
Sandy BridgeӮЕӮН32nmғvғҚғZғXҸҖӢ’ӮЙӮИӮБӮДӮіӮзӮЙғgғүғ“ғWғXғ^ӮМSW‘¬“xӮНүь‘PӮөӮДӮўӮйӮӯӮзӮўӮИӮМӮЕҒA
ғXғ^ғeғBғbғNүсҳHӮҫӮҜӮЕӮН–OӮ«‘«ӮзӮёҒAғpғCғvғүғCғ“ғsғbғ`ӮрҚrӮӯӮөӮДӮа“d—НҢёӮзӮөӮДғNғҚғbғNӮ©Ӯ№Ӯ°ӮйӮ¶ӮбӮсӮЖӮўӮӨӮұӮЖ
ӮЕғpғCғvғүғCғ“ӮМғXғeҒ[ғWҗ”ӮрҢёӮзӮөӮҪҒBӮ»ӮМӮЁӮ©Ӯ°ӮЕғRғAӮӘ‘S‘М“IӮЙғRғ“ғpғNғgӮЙӮИӮБӮҪҒB
2.OregonҗЭҢvӮМNehalemӮЖҒAIsraelҗЭҢvӮМSNBӮЖӮЕҳ_—қҚҮҗ¬ҒA”z’u”zҗьғcҒ[ғӢӮИӮЗӮӘҲЩӮИӮйҗа
ҺАӮНҠJ”ӯҠВӢ«ӮМ–в‘иӮҫӮБӮҪҒB
3.AVX‘ОүһӮаӮ ӮйӮұӮЖӮҫӮөҒAuopӮрҚXӮИӮйҸБ”п“d—Нү»ӮМӮҪӮЯӮЙ‘е•қӮЙҚД’иӢ`ӮөӮДҢ©’јӮөӮҪҗа
uopӮМғGғ“ғRҒ[ғhӮНҗ§ҢдғҚғWғbғNӮМҚЕҸ¬ү»ӮЙӮаүeӢҝӮ·ӮйҒB
SNBӮНҠж’ЈӮБӮДuopӮМ’иӢ`ӮрAVX‘ОүһӮИӮЗӮМӮВӮўӮЕӮЙ’ҙҚЕ“Kү»ӮөӮҪҒB
4.ү·“xғZғ“ғTӮрҢёӮзӮөӮҪҗа
ү·“xғZғ“ғTӮрӮЭӮй•p“xӮНҢёӮБӮҪӮМӮЕҒANehalemӮжӮиӮаҢёӮзӮөӮҪҒB
Ӯ»ӮаӮ»Ӯаү·“xғZғ“ғT”@Ӯ«ӮӘғ_ғC–КҗПӮрҗHӮБӮДӮўӮҪӮМӮ©ӮН“дӮЕӮ ӮйҒB
5.Israelғ`Ғ[ғҖӮӘҚЕ“Kү»ӮрҠж’ЈӮБӮҪҗа
NehalemӮНӢ}ӮўӮЕҗЭҢvӮөӮҪӮаӮМӮИӮМӮЕӮ»ӮаӮ»ӮаҚЕ“Kү»ӮӘҠГӮ©ӮБӮҪҒB
Ҳк•ыSNBӮНӮ¶ӮБӮӯӮиӮвӮкӮйҺһҠФӮӘӮ ӮБӮҪҒB’PӮИӮйҺһҠФӮЖҗlӮМ–в‘иҒB
619 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/04/17(“y) 19:46:51 ID:zrwbqXB10
Ӯ»ӮкӮЙӮөӮДӮаҚЎүсӮМIDFӮНғCғ“ғpғNғgӮИӮ©ӮБӮҪӮИҒB
Ӯ»ӮаӮ»ӮаҺ‘—ҝӮӘӮЁӮЖӮ№ӮИӮўӮаӮсӮИҒB
https://intel.wingateweb.com/bj10/scheduler/catalog/catalog.jsp
ғCғ\ғeғӢӮНIDFӮМҺ‘—ҝӮрҲк”КӮЙҢцҠJӮ·ӮйӢCӮИӮўӮМӮҫӮлӮӨӮ©ҒBҲЮӮҰӮй“WҠJӮҫӮЛҒB
Ӯ»ӮаӮ»ӮаҺ‘—ҝӮӘӮЁӮЖӮ№ӮИӮўӮаӮсӮИҒB
https://intel.wingateweb.com/bj10/scheduler/catalog/catalog.jsp
ғCғ\ғeғӢӮНIDFӮМҺ‘—ҝӮрҲк”КӮЙҢцҠJӮ·ӮйӢCӮИӮўӮМӮҫӮлӮӨӮ©ҒBҲЮӮҰӮй“WҠJӮҫӮЛҒB
620 ҒF–јҸМ–ўҗЭ’иҒF2010/04/17(“y) 19:54:57 ID:RLtF1pfp0
Ҹ\•ӘӮЕӮ©ӮӯӮИӮБӮДӮйӢCӮӘӮ·Ӯй
621 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/04/17(“y) 19:56:38 ID:zrwbqXB10
YonahҒЁMerom, PenrynҒЁNehalem
ӮМҺАҗСӮ©ӮзӮўӮӯӮЖӮвӮҜӮЙғRғ“ғpғNғgӮҫӮжҒB
ӮМҺАҗСӮ©ӮзӮўӮӯӮЖӮвӮҜӮЙғRғ“ғpғNғgӮҫӮжҒB
622 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/04/17(“y) 20:17:31 ID:zrwbqXB10
623 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2010/04/17(“y) 20:32:35 ID:NVjGvv+E0
>>618
5.ӮЙ1•[ҒB
Pentium IIIҒЁPentium MӮЕӮаӮҫӮўӮФҸ¬ӮіӮӯӮИӮБӮДӮйӮ©ӮзӮИ
Ӯ»ӮаӮ»ӮаPenrynҒЁNehalemӮЕ‘еӮ«ӮӯӮИӮиӮ·Ӯ¬ӮҪӮсӮҫӮжҒB
ғgғүғ“ғWғXғ^–§“xӮрҲшӮ«ҸгӮ°ӮйӢZҸpӮНғCғXғүғGғӢӮМ•ыӮӘ—DӮкӮДӮйӮсӮҫӮлӮӨӮжҒB
> HaswellӮЕL0D
L0ғLғғғbғVғ…ӮЖӮўӮӨӮЧӮ«ӮаӮМӮИӮз‘еҗМӮЙҒuStore to Load Forwarding BufferҒvӮМҢ`ӮЕҺА‘•ӮіӮкӮДӮИӮўӮ©ҒH
“ҜӮ¶ғAғhғҢғXӮЙғXғgғAҢгӮ·Ӯ®ӮЙғҚҒ[ғhӮ·ӮйӮжӮӨӮИғPҒ[ғXӮЕҺАҢшғҢғCғeғ“ғVӮӘ‘е•қ’ZҸkӮіӮкӮйҒB
5.ӮЙ1•[ҒB
Pentium IIIҒЁPentium MӮЕӮаӮҫӮўӮФҸ¬ӮіӮӯӮИӮБӮДӮйӮ©ӮзӮИ
Ӯ»ӮаӮ»ӮаPenrynҒЁNehalemӮЕ‘еӮ«ӮӯӮИӮиӮ·Ӯ¬ӮҪӮсӮҫӮжҒB
ғgғүғ“ғWғXғ^–§“xӮрҲшӮ«ҸгӮ°ӮйӢZҸpӮНғCғXғүғGғӢӮМ•ыӮӘ—DӮкӮДӮйӮсӮҫӮлӮӨӮжҒB
> HaswellӮЕL0D
L0ғLғғғbғVғ…ӮЖӮўӮӨӮЧӮ«ӮаӮМӮИӮз‘еҗМӮЙҒuStore to Load Forwarding BufferҒvӮМҢ`ӮЕҺА‘•ӮіӮкӮДӮИӮўӮ©ҒH
“ҜӮ¶ғAғhғҢғXӮЙғXғgғAҢгӮ·Ӯ®ӮЙғҚҒ[ғhӮ·ӮйӮжӮӨӮИғPҒ[ғXӮЕҺАҢшғҢғCғeғ“ғVӮӘ‘е•қ’ZҸkӮіӮкӮйҒB
624 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/04/17(“y) 20:39:20 ID:zrwbqXB10
>>623
Store BufferӮҫӮҜӮЕӮН‘«ӮиӮИӮў•”•ӘӮЙӮіӮзӮЙL0ӮрӮНӮіӮЯӮйӮсӮҫӮжҒB
L1ӮНӮіӮзӮЙғҢғCғeғ“ғVӮӘҲ«ү»ӮөӮДӮўӮӯүВ”\җ«Ӯ ӮйӮөӮИҒB
ғXғgғAғtғHғtғHғҸҒ[ғfғBғ“ғOӮМӢӯү»ӮЖӮ©Memory DisambiguationӮЖӮ©ҒAIsraelӮН
ғLғғғbғVғ…ҒAғҒғӮғҠғAғNғZғXҺьӮиӮНӮ©ӮИӮи–в‘иҺӢӮөӮДӮўӮД—НӮр“ьӮкӮй•ыҢьҗ«ӮИӮМӮ©ӮаӮЛҒB
Store BufferӮҫӮҜӮЕӮН‘«ӮиӮИӮў•”•ӘӮЙӮіӮзӮЙL0ӮрӮНӮіӮЯӮйӮсӮҫӮжҒB
L1ӮНӮіӮзӮЙғҢғCғeғ“ғVӮӘҲ«ү»ӮөӮДӮўӮӯүВ”\җ«Ӯ ӮйӮөӮИҒB
ғXғgғAғtғHғtғHғҸҒ[ғfғBғ“ғOӮМӢӯү»ӮЖӮ©Memory DisambiguationӮЖӮ©ҒAIsraelӮН
ғLғғғbғVғ…ҒAғҒғӮғҠғAғNғZғXҺьӮиӮНӮ©ӮИӮи–в‘иҺӢӮөӮДӮўӮД—НӮр“ьӮкӮй•ыҢьҗ«ӮИӮМӮ©ӮаӮЛҒB
625 ҒF–јҸМ–ўҗЭ’иҒF2010/04/17(“y) 20:43:35 ID:RLtF1pfp0
626 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/04/17(“y) 20:45:45 ID:zrwbqXB10
ғTҒ[ғoӮЕғXғӢҒ[ғvғbғg(ғ}ғӢғ`ғXғҢғbғh)җ«”\ӮӘҸdҺӢӮіӮкӮй—қ—RӮН’PҸғӮИҳbҒA
ғTҒ[ғoӮНӢӨ—pӮМғRғ“ғsғ…Ғ[ғ^ӮИӮМӮЕҒA“ҜҺһ—ҳ—pҺТҗ”ӮЙӢӯӮӯҲЛ‘¶ӮөӮД•Ўҗ”ӮМғ^ғXғNӮрҺАҚsӮ·ӮйӮ©ӮзӮҫӮлӮӨҒB
ӮұӮкӮНPC/WSҢьӮҜӮМғ}ғӢғ`ғXғҢғbғhғAғvғҠӮвHPCӮИӮЗӮЕғ}ғӢғ`ғRғAҒAғ}ғӢғ`ғvғҚғZғbғTӮӘ–рӮЙ—§ӮВӮМӮЖӮНҲЩӮИӮйҺ–ҸоӮҫҒB
ғTҒ[ғoӮҫӮлӮӨӮӘғfғXғNғgғbғvPCӮҫӮлӮӨӮӘғVғ“ғOғӢғXғҢғbғhҗ«”\ӮӘӮМӮСӮДӮӯӮкӮИӮўӮЖ
ҢӢӢЗӮМӮЖӮұӮлҗVӮөӮўғTҒ[ғrғXӮӘүВ”\ӮЙӮИӮБӮДӮўӮӯӮЖӮўӮӨ”ӯ“WӮНҺc”OӮИӮӘӮз“пӮөӮўҒB
ӮөӮҪӮӘӮБӮДҒAғTҒ[ғoғvғҚғZғbғTӮМҚӮ‘¬ү»ғgғҢғ“ғhӮЕҒAғVғ“ғOғӢғXғҢғbғhҗ«”\ӮрҗLӮОӮіӮёӮЙ
ғXғӢҒ[ғvғbғgҺuҢьӮЙ’Қ—НӮөӮДӮўӮБӮҪҸкҚҮҒAҠщ‘¶ӮМғTҒ[ғrғXӮрғxҒ[ғXӮЙ“ҜҺһ—ҳ—pҺТҗ”(ғNғүғCғAғ“ғgҗ”)ӮӘ‘қӮҰӮйҲк•ыӮЙӮИӮиҒA
ҢӢүКҒAғTҒ[ғoӮМ“қҚҮҸW–сү»/ғҚҒ[ғRғXү»ӮЖӮўӮӨҺgӮнӮк•ыӮЙӮИӮБӮДӮөӮЬӮӨҒB
Ӯ ӮйғlғbғgғҸҒ[ғNҸгӮЕӮМғTҒ[ғoӮЖғNғүғCғAғ“ғgғnҒ[ғhғEғGғAӮМғRғXғg”дӮрҚlӮҰӮкӮНҒA
ғTҒ[ғo > ғNғүғCғAғ“ғgҒ@ҒЁҒ@ғTҒ[ғo < ғNғүғCғAғ“ғg ҒЁ ғTҒ[ғo << ғNғүғCғAғ“ғg
ӮЖ•П‘JӮөӮДӮўӮӯӮМӮӘTSSӮМҺһ‘гӮ©ӮзҲшӮ«ҢpӮўӮҫү^–ҪӮИӮМӮҫӮлӮӨҒB
ӮаӮҝӮлӮсғlғbғgғҸҒ[ғNҸгӮЕӢӨ—LӮ№ӮҙӮйӮр“ҫӮИӮў•”•ӘӮН‘¶ҚЭӮ·ӮйӮ©ӮзғTҒ[ғoӮӘӮЬӮБӮҪӮӯӮИӮӯӮИӮйӮұӮЖӮНӮИӮўӮӘҒA
ғTҒ[ғoӮНғXғӢҒ[ғvғbғgӮӘӮ ӮӘӮкӮОӮжӮўӮ©ӮзҒA‘ҪғRғAү»ӮӘғTҒ[ғoҺuҢьӮрүБ‘¬Ӯ·ӮйӮЖӮўӮӨҢ©•ыӮНӢ^ӮнӮөӮўӮҫӮлӮӨҒB
ҚЎҢгғRғXғgҚ\‘ў“IӮЙӮЭӮДғTҒ[ғoӮНӮЗӮсӮЗӮсғlғbғgғҸҒ[ғNҸгӮЕӮНӮЗӮсӮЗӮсҸ¬ӮіӮӯӮИӮБӮДӮўӮӯ•ыҢьӮҫӮлӮӨҒB
ғTҒ[ғoӮНӢӨ—pӮМғRғ“ғsғ…Ғ[ғ^ӮИӮМӮЕҒA“ҜҺһ—ҳ—pҺТҗ”ӮЙӢӯӮӯҲЛ‘¶ӮөӮД•Ўҗ”ӮМғ^ғXғNӮрҺАҚsӮ·ӮйӮ©ӮзӮҫӮлӮӨҒB
ӮұӮкӮНPC/WSҢьӮҜӮМғ}ғӢғ`ғXғҢғbғhғAғvғҠӮвHPCӮИӮЗӮЕғ}ғӢғ`ғRғAҒAғ}ғӢғ`ғvғҚғZғbғTӮӘ–рӮЙ—§ӮВӮМӮЖӮНҲЩӮИӮйҺ–ҸоӮҫҒB
ғTҒ[ғoӮҫӮлӮӨӮӘғfғXғNғgғbғvPCӮҫӮлӮӨӮӘғVғ“ғOғӢғXғҢғbғhҗ«”\ӮӘӮМӮСӮДӮӯӮкӮИӮўӮЖ
ҢӢӢЗӮМӮЖӮұӮлҗVӮөӮўғTҒ[ғrғXӮӘүВ”\ӮЙӮИӮБӮДӮўӮӯӮЖӮўӮӨ”ӯ“WӮНҺc”OӮИӮӘӮз“пӮөӮўҒB
ӮөӮҪӮӘӮБӮДҒAғTҒ[ғoғvғҚғZғbғTӮМҚӮ‘¬ү»ғgғҢғ“ғhӮЕҒAғVғ“ғOғӢғXғҢғbғhҗ«”\ӮрҗLӮОӮіӮёӮЙ
ғXғӢҒ[ғvғbғgҺuҢьӮЙ’Қ—НӮөӮДӮўӮБӮҪҸкҚҮҒAҠщ‘¶ӮМғTҒ[ғrғXӮрғxҒ[ғXӮЙ“ҜҺһ—ҳ—pҺТҗ”(ғNғүғCғAғ“ғgҗ”)ӮӘ‘қӮҰӮйҲк•ыӮЙӮИӮиҒA
ҢӢүКҒAғTҒ[ғoӮМ“қҚҮҸW–сү»/ғҚҒ[ғRғXү»ӮЖӮўӮӨҺgӮнӮк•ыӮЙӮИӮБӮДӮөӮЬӮӨҒB
Ӯ ӮйғlғbғgғҸҒ[ғNҸгӮЕӮМғTҒ[ғoӮЖғNғүғCғAғ“ғgғnҒ[ғhғEғGғAӮМғRғXғg”дӮрҚlӮҰӮкӮНҒA
ғTҒ[ғo > ғNғүғCғAғ“ғgҒ@ҒЁҒ@ғTҒ[ғo < ғNғүғCғAғ“ғg ҒЁ ғTҒ[ғo << ғNғүғCғAғ“ғg
ӮЖ•П‘JӮөӮДӮўӮӯӮМӮӘTSSӮМҺһ‘гӮ©ӮзҲшӮ«ҢpӮўӮҫү^–ҪӮИӮМӮҫӮлӮӨҒB
ӮаӮҝӮлӮсғlғbғgғҸҒ[ғNҸгӮЕӢӨ—LӮ№ӮҙӮйӮр“ҫӮИӮў•”•ӘӮН‘¶ҚЭӮ·ӮйӮ©ӮзғTҒ[ғoӮӘӮЬӮБӮҪӮӯӮИӮӯӮИӮйӮұӮЖӮНӮИӮўӮӘҒA
ғTҒ[ғoӮНғXғӢҒ[ғvғbғgӮӘӮ ӮӘӮкӮОӮжӮўӮ©ӮзҒA‘ҪғRғAү»ӮӘғTҒ[ғoҺuҢьӮрүБ‘¬Ӯ·ӮйӮЖӮўӮӨҢ©•ыӮНӢ^ӮнӮөӮўӮҫӮлӮӨҒB
ҚЎҢгғRғXғgҚ\‘ў“IӮЙӮЭӮДғTҒ[ғoӮНӮЗӮсӮЗӮсғlғbғgғҸҒ[ғNҸгӮЕӮНӮЗӮсӮЗӮсҸ¬ӮіӮӯӮИӮБӮДӮўӮӯ•ыҢьӮҫӮлӮӨҒB
627 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2010/04/17(“y) 20:46:51 ID:NVjGvv+E0
ӢtӮМ”ӯ‘zӮНӮИӮўӮМӮ©
ӮЮӮөӮлғoғbғtғ@ӮӘҗ[ӮӯӮИӮБӮДӮйӮ©ӮзғҢғCғeғ“ғVӮӘ‘қӮҰӮДӮйӮЖ
ӮЮӮөӮлғoғbғtғ@ӮӘҗ[ӮӯӮИӮБӮДӮйӮ©ӮзғҢғCғeғ“ғVӮӘ‘қӮҰӮДӮйӮЖ
628 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/04/17(“y) 20:51:37 ID:zrwbqXB10
Store BufferӮНғXғgғAғtғHғҸҒ[ғfғBғ“ғOӮМӮҪӮЯӮҫӮҜӮЙӮ ӮйӮМӮЕӮНӮИӮўӮөҒA
ҢҹҚхӮН—]—TӮЕ1ғTғCғNғӢӮ«ӮБӮДӮйҗЭҢvӮЕӮИӮўӮЖғҒғӮғҠғIҒ[ғ_ғҠғ“ғOӮМҗ«”\‘S”КӮЙ–в‘иӮӘӮЕӮйӮҫӮлӮӨҒB
ҢҹҚхӮН—]—TӮЕ1ғTғCғNғӢӮ«ӮБӮДӮйҗЭҢvӮЕӮИӮўӮЖғҒғӮғҠғIҒ[ғ_ғҠғ“ғOӮМҗ«”\‘S”КӮЙ–в‘иӮӘӮЕӮйӮҫӮлӮӨҒB
629 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/04/17(“y) 21:54:19 ID:zrwbqXB10
ӮЬӮ ALUӮМ’ЗүБӮЙ”дӮЧӮйӮЖLoadғҶғjғbғgӮМ’ЗүБӮНғCғ“ғpғNғgӮӘҸ¬ӮіӮӯҢ©ӮҰӮйҗlӮӘ‘ҪӮўӮсӮҫӮлӮӨӮИҒB
STAғҶғjғbғgӮМ’ЗүБӮЕҺАҚsғAғhғҢғXҢvҺZҒAғGғCғҠғAғXүрҗНӮӘ‘ҒӮӯҺJӮҜӮйӮжӮӨӮЙӮИӮБӮҪӮиҒA
LoadғҶғjғbғgӮМ‘қүБӮЕLoad–Ҫ—ЯӮр‘ҒӮӯҺJӮҜӮйӮжӮӨӮЙӮИӮБӮҪӮиӮМүҝ’lӮр—қүрӮөӮДӮўӮйҗlӮНғRҒ[ғhғIғ^ҲИҠOӮЕӮН
Ӯ ӮЬӮи‘ҪӮӯӮИӮўӮМӮН–і—қӮа–іӮўӮҫӮлӮӨҒB
STAғҶғjғbғgӮМ’ЗүБӮЕҺАҚsғAғhғҢғXҢvҺZҒAғGғCғҠғAғXүрҗНӮӘ‘ҒӮӯҺJӮҜӮйӮжӮӨӮЙӮИӮБӮҪӮиҒA
LoadғҶғjғbғgӮМ‘қүБӮЕLoad–Ҫ—ЯӮр‘ҒӮӯҺJӮҜӮйӮжӮӨӮЙӮИӮБӮҪӮиӮМүҝ’lӮр—қүрӮөӮДӮўӮйҗlӮНғRҒ[ғhғIғ^ҲИҠOӮЕӮН
Ӯ ӮЬӮи‘ҪӮӯӮИӮўӮМӮН–і—қӮа–іӮўӮҫӮлӮӨҒB
630 ҒF–јҸМ–ўҗЭ’иҒF2010/04/17(“y) 22:10:05 ID:wILUVDCK0
Loop Stream Detectorүь—ЗӮіӮкӮДL1 5cyclesӮЕӮаOK
ҒEҒEҒEӮЖӮўӮӨӮұӮЖӮЙӮөӮДӮЁӮұӮӨ
ҒEҒEҒEӮЖӮўӮӨӮұӮЖӮЙӮөӮДӮЁӮұӮӨ
631 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2010/04/17(“y) 23:34:10 ID:NVjGvv+E0
LSDҠЦҢWӮЛӮҰӮҫӮлӮ»ӮұӮН
632 ҒF–јҸМ–ўҗЭ’иҒF2010/04/18(“ъ) 00:24:37 ID:ax+pEsnc0
NetBurstӮЕӮН12KҢк•ӘӮМғLғғғbғVғ…ӮҫӮБӮҪӮ©ӮзҒAӮұӮкӮЙ”дӮЧӮкӮО—yӮ©ӮЙҸ¬ӮіӮў
ӮЖӮНӮўӮҰҒAӮӨӮЬӮӯLoopҚ\‘ўӮЙ“ьӮйӮЖ‘SӮӯ“ҜӮ¶“®ҚмӮрӮ·ӮйҺ–ӮЙӮИӮйҒBҢ©•ыӮр•ПӮҰӮкӮОҒA
ӮұӮкӮұӮ»ӮӘL1–Ҫ—ЯғLғғғbғVғ…ӮЕӮ ӮиҒAPhoto05ӮЙҸoӮДӮӯӮй32KB Instruction Cache
ӮЖӮўӮӨӮМӮНL2–Ҫ—ЯғLғғғbғVғ…ӮЖӮа‘ЁӮҰӮзӮкӮй–уӮҫҒBStream Loop DetectorӮНҒA
ғvғҚғOғүғҖӮМ”сLoopҚ\‘ў•”•ӘӮМҺАҚs’ҶӮН’PӮЙFIFOӮЖӮөӮД“®ҚмӮ·ӮйӮұӮЖӮЙӮИӮйӮ©ӮзҒA
ӮұӮкӮНғLғғғbғVғ…Ӯ»ӮМӮаӮМӮЖҢ©ӮйӮМӮӘҗіӮөӮўӮЖ•MҺТӮНҚlӮҰӮйҒB
ӮЖӮНӮўӮҰҒAӮӨӮЬӮӯLoopҚ\‘ўӮЙ“ьӮйӮЖ‘SӮӯ“ҜӮ¶“®ҚмӮрӮ·ӮйҺ–ӮЙӮИӮйҒBҢ©•ыӮр•ПӮҰӮкӮОҒA
ӮұӮкӮұӮ»ӮӘL1–Ҫ—ЯғLғғғbғVғ…ӮЕӮ ӮиҒAPhoto05ӮЙҸoӮДӮӯӮй32KB Instruction Cache
ӮЖӮўӮӨӮМӮНL2–Ҫ—ЯғLғғғbғVғ…ӮЖӮа‘ЁӮҰӮзӮкӮй–уӮҫҒBStream Loop DetectorӮНҒA
ғvғҚғOғүғҖӮМ”сLoopҚ\‘ў•”•ӘӮМҺАҚs’ҶӮН’PӮЙFIFOӮЖӮөӮД“®ҚмӮ·ӮйӮұӮЖӮЙӮИӮйӮ©ӮзҒA
ӮұӮкӮНғLғғғbғVғ…Ӯ»ӮМӮаӮМӮЖҢ©ӮйӮМӮӘҗіӮөӮўӮЖ•MҺТӮНҚlӮҰӮйҒB
633 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2010/04/18(“ъ) 09:40:19 ID:/03Pvdnl0
ғҢғCғeғ“ғV5ӮИӮМӮНData CacheӮМӮЩӮӨӮҫӮј
634 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2010/04/18(“ъ) 09:58:42 ID:/03Pvdnl0
ӮҝӮИӮЭӮЙғAғҢӮН—vӮ·ӮйӮЙғӢҒ[ғvӮөӮДӮйғRҒ[ғhғVҒ[ғPғ“ғXӮрҢҹҸoӮөӮДғҠғIҒ[ғ_ғoғbғtғ@ҸгӮМғКOPsӮрғҠғ^ғCғ„Ӯ№ӮёӮЙ
ҚД—ҳ—pӮ·ӮйӢZҸpӮЕҒAҗVҗЭӮіӮкӮҪӮМӮНӮ ӮӯӮЬӮЕӮ»ӮМ–јӮМ’КӮиҒuҢҹҸoҠнҒvҒB
ҢҲӮөӮДҗк—pӮМғLғғғbғVғ…ӮрҗVҗЭӮөӮҪӮнӮҜӮЕӮНӮИӮўҒB
ҚД—ҳ—pӮ·ӮйӢZҸpӮЕҒAҗVҗЭӮіӮкӮҪӮМӮНӮ ӮӯӮЬӮЕӮ»ӮМ–јӮМ’КӮиҒuҢҹҸoҠнҒvҒB
ҢҲӮөӮДҗк—pӮМғLғғғbғVғ…ӮрҗVҗЭӮөӮҪӮнӮҜӮЕӮНӮИӮўҒB
635 ҒF–јҸМ–ўҗЭ’иҒF2010/04/20(үО) 21:13:21 ID:Qj2i6b3W0
ҒyғҢғ|Ғ[ғgҒzIDF Beijing 2010 - Sandy Bridge/Light Peak/Tunnel CreekӮрӮЬӮЖӮЯӮй - ‘еҢҙ—YүоӮМIDFӮЁ—ҜҺз”ФғҢғ|Ғ[ғg
http://journal.mycom.co.jp/articles/2010/04/20/idf02/menu.html
http://journal.mycom.co.jp/articles/2010/04/20/idf02/menu.html
636 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/04/22(–Ш) 19:21:38 ID:eBx/FkKH0
Sandy Bridge rumors
http://www.semiaccurate.com/2010/04/21/sandy-bridge-rumors/
NehalemӮЖ”дҠrӮ·ӮйӮЖ
L1IӮМҳA‘z“xӮӘ4wayҒЁ8wayӮЙ‘қӮҰӮҪ
L3ӮМҳA‘z“xӮН16wayҒЁ12way(4MBҒЁ3MB)ӮЙҢёӮБӮҪ
http://www.semiaccurate.com/2010/04/21/sandy-bridge-rumors/
NehalemӮЖ”дҠrӮ·ӮйӮЖ
L1IӮМҳA‘z“xӮӘ4wayҒЁ8wayӮЙ‘қӮҰӮҪ
L3ӮМҳA‘z“xӮН16wayҒЁ12way(4MBҒЁ3MB)ӮЙҢёӮБӮҪ
637 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/04/22(–Ш) 19:26:28 ID:eBx/FkKH0
>>630
L1DӮМҳbӮИӮМӮЕLSDӮНҚЎӮМҳbӮЙӮНҠЦҢWӮИӮўӮЕӮ·ҒB
>>634
LSDӮНғfғRҒ[ғ_ӮЖRSӮМҠФӮЙӮ ӮйҒBROBӮНҠЦҢWӮИӮўҒBӮЖӮўӮӨӮ©ROBӮЙӮН–Ҫ—ЯӮМғAғhғҢғXӮНӮўӮБӮДӮа–Ҫ—ЯӮН“ьӮзӮИӮўҒB
L1DӮМҳbӮИӮМӮЕLSDӮНҚЎӮМҳbӮЙӮНҠЦҢWӮИӮўӮЕӮ·ҒB
>>634
LSDӮНғfғRҒ[ғ_ӮЖRSӮМҠФӮЙӮ ӮйҒBROBӮНҠЦҢWӮИӮўҒBӮЖӮўӮӨӮ©ROBӮЙӮН–Ҫ—ЯӮМғAғhғҢғXӮНӮўӮБӮДӮа–Ҫ—ЯӮН“ьӮзӮИӮўҒB
638 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/04/22(–Ш) 19:30:24 ID:eBx/FkKH0
ӮўӮвғXғeҒ[ғW“IӮЙӮўӮӨӮЖDecodeӮЖRenameӮМ’ҶҠФӮ©ҒBROBӮНҠЦҢWӮИӮўӮҜӮЗҒB
639 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/04/22(–Ш) 19:31:47 ID:eBx/FkKH0
ӮЖӮўӮӨӮнӮҜӮЕӮўӮҝӮЁӮӨLSDӮМ“ӯӮӯғoғbғtғ@ӮНҒAӢЙҸ¬ғTғCғYuopғLғғғbғVғ…ӮМӮжӮӨӮЙ“ӯӮӯӮҫӮлҒB
640 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2010/04/22(–Ш) 21:02:46 ID:nO+O7nf10
ҳA‘zҢ^Қ\җ¬ӮҫӮБӮҪӮМӮр–YӮкӮДӮҪ
641 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/04/22(–Ш) 22:18:50 ID:eBx/FkKH0
L1IӮНҒA
Core 2 - 8 way
Nehalem - 4 way
Sandy Bridge - 8 way
ӮзӮөӮўӮМӮЕ–ЯӮБӮҪӮжӮӨӮҫӮЛҒB
Core 2 - 8 way
Nehalem - 4 way
Sandy Bridge - 8 way
ӮзӮөӮўӮМӮЕ–ЯӮБӮҪӮжӮӨӮҫӮЛҒB
642 ҒF–јҸМ–ўҗЭ’иҒF2010/04/28(җ…) 01:08:27 ID://Rer9DH0
PCI Express Gen3ӮЖDDR3-1600ӮрғTғ|Ғ[ғgӮ·ӮйSandy Bridge
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20100428_364200.html
ғ\ғPғbғgӮЖӮ©ғ_ғCӮМғoғҠғGҒ[ғVғҮғ“‘қӮвӮөӮДӮағRғXғgӮӘ”ҡ”ӯӮөӮИӮӯӮИӮБӮҪӮЭӮҪӮўӮҫӮИ
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20100428_364200.html
ғ\ғPғbғgӮЖӮ©ғ_ғCӮМғoғҠғGҒ[ғVғҮғ“‘қӮвӮөӮДӮағRғXғgӮӘ”ҡ”ӯӮөӮИӮӯӮИӮБӮҪӮЭӮҪӮўӮҫӮИ
643 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/04/28(җ…) 19:27:30 ID:wr2eoBUu0
ғoғҠғGҒ[ғVғҮғ“ӮНғӮғWғ…ғүҒ[ү»ӮЖғҠғ“ғOү»ӮЕӮвӮиӮвӮ·ӮӯӮИӮБӮҪ
(ӮЖӮўӮӨӮ©Ӯ»ӮкӮӘSNBӮМҚЕ‘еӮМҗ¬үКӮЖӮаӮўӮҰӮй)ӮЖҺvӮӨӮҜӮЗҒA
ғRғXғgӮНӮЬӮҫӢкӮөӮўӮЖҺvӮӨӮжҒB>>281ӮЕӮаҸ‘ӮўӮҪӮЖӮЁӮиPCHӮЕӮа2ҸdӮЙӮЪӮБӮДӮйӮөӮЛҒB
4ғRғAӮЕғGғ“ғgғҠҒ[ғҢғxғӢӮЬӮЕүВ”\ӮЙӮИӮйӮМӮНӮвӮНӮи22nmӮ©ӮзӮҫӮЖҺvӮӨҒB
(ӮЖӮўӮӨӮ©Ӯ»ӮкӮӘSNBӮМҚЕ‘еӮМҗ¬үКӮЖӮаӮўӮҰӮй)ӮЖҺvӮӨӮҜӮЗҒA
ғRғXғgӮНӮЬӮҫӢкӮөӮўӮЖҺvӮӨӮжҒB>>281ӮЕӮаҸ‘ӮўӮҪӮЖӮЁӮиPCHӮЕӮа2ҸdӮЙӮЪӮБӮДӮйӮөӮЛҒB
4ғRғAӮЕғGғ“ғgғҠҒ[ғҢғxғӢӮЬӮЕүВ”\ӮЙӮИӮйӮМӮНӮвӮНӮи22nmӮ©ӮзӮҫӮЖҺvӮӨҒB
644 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/04/28(җ…) 19:33:59 ID:wr2eoBUu0
>Ғ@Ivy Bridge-EX-AӮНҒAӮЁӮ»ӮзӮӯQPIӮр3ғҠғ“ғN”хӮҰҒA4ғ\ғPғbғgҚ\җ¬ӮЕӮа‘SӮДӮМCPUӮЙ1ғzғbғvӮЕ
>ғAғNғZғXӮЕӮ«ӮйӮжӮӨӮЙӮИӮйӮЖҗ„’иӮіӮкӮйҒB“–‘RҒA CPUғ\ғPғbғgӮНSocket R(LGA2011)ӮЖҲЩӮИӮйӮаӮМӮЖӮИӮйҒB
>ғҒғӮғҠүсӮиӮаҲЩӮИӮйүВ”\җ«ӮӘҚӮӮўӮӘҒA4ғ`ғғғlғӢҲИҸгӮЖӮИӮйӮЖғҒғӮғҠғuғҠғbғWғ`ғbғvӮрҺgӮӨӮұӮЖӮЙӮИӮй
Ivy Bridge-EX-AӮН>>616“IӮЙӮЭӮДӮаLGA1567Ңp‘ұӮ©ҒAӮ»ӮкӮЙӢЯӮўғsғ“җ”ӮҫӮлӮӨӮЛҒB
ғnғCғGғ“ғhӮНSMIҢo—RӮЕӮИӮўӮЖ—e—КӮЖ‘СҲжӮМ—ј—§ӮӘ“пӮөӮўӮҫӮлӮӨҒB
(Socket RӮНDDR3 4ch•ӘӮМI/FӮӘ’јҗЪ“ьӮйҚ\җ¬ӮҫӮ©ӮзӮЗӮӨӮөӮДӮағsғ“җ”ӮӘ‘ҪӮӯӮИӮБӮДӮөӮЬӮӨҒB)
>ғAғNғZғXӮЕӮ«ӮйӮжӮӨӮЙӮИӮйӮЖҗ„’иӮіӮкӮйҒB“–‘RҒA CPUғ\ғPғbғgӮНSocket R(LGA2011)ӮЖҲЩӮИӮйӮаӮМӮЖӮИӮйҒB
>ғҒғӮғҠүсӮиӮаҲЩӮИӮйүВ”\җ«ӮӘҚӮӮўӮӘҒA4ғ`ғғғlғӢҲИҸгӮЖӮИӮйӮЖғҒғӮғҠғuғҠғbғWғ`ғbғvӮрҺgӮӨӮұӮЖӮЙӮИӮй
Ivy Bridge-EX-AӮН>>616“IӮЙӮЭӮДӮаLGA1567Ңp‘ұӮ©ҒAӮ»ӮкӮЙӢЯӮўғsғ“җ”ӮҫӮлӮӨӮЛҒB
ғnғCғGғ“ғhӮНSMIҢo—RӮЕӮИӮўӮЖ—e—КӮЖ‘СҲжӮМ—ј—§ӮӘ“пӮөӮўӮҫӮлӮӨҒB
(Socket RӮНDDR3 4ch•ӘӮМI/FӮӘ’јҗЪ“ьӮйҚ\җ¬ӮҫӮ©ӮзӮЗӮӨӮөӮДӮағsғ“җ”ӮӘ‘ҪӮӯӮИӮБӮДӮөӮЬӮӨҒB)
645 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/04/28(җ…) 19:42:40 ID:wr2eoBUu0
>>635
‘еҢҙҗжҗ¶ӮМӢLҺ–ӮжӮЮӮЬӮЕӢCӮӘӮВӮ©ӮИӮ©ӮБӮҪӮҜӮЗҒA
LS PortӮ©ӮзBufferӮЬӮЕӮН256bx2/clock•ӘӮМғXғӢҒ[ғvғbғgӮӘӮ ӮйүВ”\җ«Ӯ ӮйӮсӮҫӮИҒB
ӮвӮвӮЁүФ”ЁӮҫӮҜӮЗҒA256bӮМғXғgғAғtғHғҸҒ[ғfғBғ“ғOӮӘүВ”\ӮҫӮБӮҪӮиӮЖӮ©Ӯ·ӮкӮО“а•”“IӮЙӮНCore2”д4”{ӮМ256bx2Ӣү
ӮЕүсӮйӮұӮЖӮр‘z’иӮөӮДӮўӮйүВ”\җ«ӮӘӮ ӮйӮИҒBSandyӮЕӮИӮӯӮДӮаIvyҲИҚ~ӮЕӢӯү»ӮЖӮўӮӨүВ”\җ«ӮаӮ ӮйҒB
‘еҢҙҗжҗ¶ӮМӢLҺ–ӮжӮЮӮЬӮЕӢCӮӘӮВӮ©ӮИӮ©ӮБӮҪӮҜӮЗҒA
LS PortӮ©ӮзBufferӮЬӮЕӮН256bx2/clock•ӘӮМғXғӢҒ[ғvғbғgӮӘӮ ӮйүВ”\җ«Ӯ ӮйӮсӮҫӮИҒB
ӮвӮвӮЁүФ”ЁӮҫӮҜӮЗҒA256bӮМғXғgғAғtғHғҸҒ[ғfғBғ“ғOӮӘүВ”\ӮҫӮБӮҪӮиӮЖӮ©Ӯ·ӮкӮО“а•”“IӮЙӮНCore2”д4”{ӮМ256bx2Ӣү
ӮЕүсӮйӮұӮЖӮр‘z’иӮөӮДӮўӮйүВ”\җ«ӮӘӮ ӮйӮИҒBSandyӮЕӮИӮӯӮДӮаIvyҲИҚ~ӮЕӢӯү»ӮЖӮўӮӨүВ”\җ«ӮаӮ ӮйҒB
646 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/04/28(җ…) 19:44:54 ID:wr2eoBUu0
ӮЬӮ ӮЕӮаҸo—ҲӮДӮаL1DӮЙҸ‘Ӯ«ҚһӮЬӮкӮйӮЬӮЕӮМҠФӮҫӮ©ӮзҸuҠФ“IӮИҳbӮ©ӮИӮ ҒB
647 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/04/28(җ…) 19:58:01 ID:wr2eoBUu0
>>645->>646ӮН“а—eӮӘ”ч–ӯӮИӮМӮЕ”]“аҚнҸңӮжӮлӮөӮӯҒB
ARM Cortex-A8 vs Atom“ҷӮМғxғ“ғ`ғ}Ғ[ғN”ӯҢ©
http://www.brightsideofnews.com/news/2010/4/7/the-coming-war-arm-versus-x86.aspx?pageid=0
ARM Cortex-A8 vs Atom“ҷӮМғxғ“ғ`ғ}Ғ[ғN”ӯҢ©
http://www.brightsideofnews.com/news/2010/4/7/the-coming-war-arm-versus-x86.aspx?pageid=0
648 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/04/28(җ…) 20:00:21 ID:wr2eoBUu0
http://www.brightsideofnews.com/print/2010/4/7/the-coming-war-arm-versus-x86.aspx
ӮұӮМӮЩӮӨӮЭӮвӮ·ӮўӮ©ӮИҒB
ӮұӮМӮЩӮӨӮЭӮвӮ·ӮўӮ©ӮИҒB
649 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2010/04/28(җ…) 20:28:52 ID:eFV2QoW40
>>645
ӮИӮўӮИӮўҒB
ӮҝӮИӮЭӮЙҳA‘ұӮөӮҪ256ғrғbғgӮМғfҒ[ғ^ӮМғҚҒ[ғhӮН2ғTғCғNғӢ•ӘӮ©Ӯ©ӮйҒB
ҒE128b Load Data (+ AGU)Ғ~2
ҒE128b Store Data Ғ~1
ӮМҚҮҢv48byte/clk
256bӮМғҚҒ[ғhҒEғXғgғAӮаҒAAGUӮН1ғTғCғNғӢӮЕүрҢҲӮЕӮ«ӮйҒBӮөӮҪӮӘӮБӮДҒAӮҪӮЖӮҰӮО
ӮҪӮЖӮҰӮО256b LoadӮЖ128b StoreӮМғAғhғҢғXүрҢҲӮрҠeLoad PortӮЕҢрҢЭӮЙҚsӮӨӮұӮЖӮаӮЕӮ«ӮйӮМӮҫҒB
ӮўӮёӮкӮЙӮөӮДӮа48byte/clk(ҸгӮи32үәӮи16)ӮМ‘СҲжӮрғtғӢӮЙҺgӮӨӮЙӮН
> Ӣ°ӮзӮӯ“–ҸүӮНAVXӮМLoad/StoreӮМғXғӢҒ[ғvғbғgӮӘ’бӮӯӮДӮаӮ»ӮкӮЩӮЗ–в‘иӮЕӮНӮИӮӯҒA
> ӮЮӮөӮлSSEӮМғXғӢҒ[ғvғbғgӮр’кҸгӮ°Ӯ·ӮйҺ–ӮрҸdҺӢӮөӮҪӮМӮЖҒAӮұӮұӮЕAVXӮЙӮ ӮнӮ№ӮД
> 96Bytes/cycleӮМ‘СҲжӮрҗЭӮҜӮйӮМӮНҺА‘•Ҹг•sүВ”\ӮҫӮБӮҪҺ–ӮМ—ј•ыӮӘ—қ—RӮЕӮНӮИӮўӮ©ҒA
> ӮЖ‘z‘ңӮіӮкӮйҒB
Қs—сҗПӮвN-BodyӮЭӮҪӮўӮИ“ҜӮ¶’lӮрғuғҚҒ[ғhғLғғғXғgӮөӮД”Ҫ•ңӮ·Ӯй–в‘иӮҫӮЖӮұӮкӮЕҸ\•ӘӮИӮсӮҫӮҜӮЗӮЛҒB
256ғrғbғgSIMDӮҫӮЖҳ_—қғҢғWғXғ^ӮӘ”ј•ӘӮЙҢёӮйҒAӮЭӮҪӮўӮИӮөӮеӮБӮПӮўғAҒ[ғLғeғNғ`ғғӮЖӮНҲбӮБӮД
YMMҸгҲКӮрҺgӮӨӮұӮЖӮЕғҢғWғXғ^ӢуҠФӮа”{ӮЙӮИӮйӮМӮЕҢӢүК“IӮЙғҚҒ[ғhҒEғXғgғA‘СҲжӮағZҒ[ғuӮЕӮ«ӮйҒB
ӮИӮўӮИӮўҒB
ӮҝӮИӮЭӮЙҳA‘ұӮөӮҪ256ғrғbғgӮМғfҒ[ғ^ӮМғҚҒ[ғhӮН2ғTғCғNғӢ•ӘӮ©Ӯ©ӮйҒB
ҒE128b Load Data (+ AGU)Ғ~2
ҒE128b Store Data Ғ~1
ӮМҚҮҢv48byte/clk
256bӮМғҚҒ[ғhҒEғXғgғAӮаҒAAGUӮН1ғTғCғNғӢӮЕүрҢҲӮЕӮ«ӮйҒBӮөӮҪӮӘӮБӮДҒAӮҪӮЖӮҰӮО
ӮҪӮЖӮҰӮО256b LoadӮЖ128b StoreӮМғAғhғҢғXүрҢҲӮрҠeLoad PortӮЕҢрҢЭӮЙҚsӮӨӮұӮЖӮаӮЕӮ«ӮйӮМӮҫҒB
ӮўӮёӮкӮЙӮөӮДӮа48byte/clk(ҸгӮи32үәӮи16)ӮМ‘СҲжӮрғtғӢӮЙҺgӮӨӮЙӮН
> Ӣ°ӮзӮӯ“–ҸүӮНAVXӮМLoad/StoreӮМғXғӢҒ[ғvғbғgӮӘ’бӮӯӮДӮаӮ»ӮкӮЩӮЗ–в‘иӮЕӮНӮИӮӯҒA
> ӮЮӮөӮлSSEӮМғXғӢҒ[ғvғbғgӮр’кҸгӮ°Ӯ·ӮйҺ–ӮрҸdҺӢӮөӮҪӮМӮЖҒAӮұӮұӮЕAVXӮЙӮ ӮнӮ№ӮД
> 96Bytes/cycleӮМ‘СҲжӮрҗЭӮҜӮйӮМӮНҺА‘•Ҹг•sүВ”\ӮҫӮБӮҪҺ–ӮМ—ј•ыӮӘ—қ—RӮЕӮНӮИӮўӮ©ҒA
> ӮЖ‘z‘ңӮіӮкӮйҒB
Қs—сҗПӮвN-BodyӮЭӮҪӮўӮИ“ҜӮ¶’lӮрғuғҚҒ[ғhғLғғғXғgӮөӮД”Ҫ•ңӮ·Ӯй–в‘иӮҫӮЖӮұӮкӮЕҸ\•ӘӮИӮсӮҫӮҜӮЗӮЛҒB
256ғrғbғgSIMDӮҫӮЖҳ_—қғҢғWғXғ^ӮӘ”ј•ӘӮЙҢёӮйҒAӮЭӮҪӮўӮИӮөӮеӮБӮПӮўғAҒ[ғLғeғNғ`ғғӮЖӮНҲбӮБӮД
YMMҸгҲКӮрҺgӮӨӮұӮЖӮЕғҢғWғXғ^ӢуҠФӮа”{ӮЙӮИӮйӮМӮЕҢӢүК“IӮЙғҚҒ[ғhҒEғXғgғA‘СҲжӮағZҒ[ғuӮЕӮ«ӮйҒB
650 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/04/28(җ…) 20:32:58 ID:wr2eoBUu0
‘Ҡ•ПӮнӮзӮёҚЧ•”ӮМҳbӮЙӮИӮйӮЖҲЩ—lӮИӮНӮиӮ«ӮиӮБӮХӮиӮЕӮ·ӮЛҒB
ӮөӮ©ӮөҒAӮнӮ©ӮБӮДӮ©ӮўӮДӮўӮйӮМӮ©ӮаӮөӮкӮИӮўӮҜӮЗ>>645->>646ӮНL1DӮ©ӮзӮМloadӮЙӮВӮўӮДҸ‘ӮўӮҪӮаӮМӮЕӮН–іӮўӮәҒB
ӮЬӮ ӮаӮӨ”]“аҚнҸңӮіӮкӮДӮўӮйӮМӮЕ–іҢшӮЕӮ ӮйӮӘҒB
ӮөӮ©ӮөҒAӮнӮ©ӮБӮДӮ©ӮўӮДӮўӮйӮМӮ©ӮаӮөӮкӮИӮўӮҜӮЗ>>645->>646ӮНL1DӮ©ӮзӮМloadӮЙӮВӮўӮДҸ‘ӮўӮҪӮаӮМӮЕӮН–іӮўӮәҒB
ӮЬӮ ӮаӮӨ”]“аҚнҸңӮіӮкӮДӮўӮйӮМӮЕ–іҢшӮЕӮ ӮйӮӘҒB
651 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/04/28(җ…) 20:48:33 ID:wr2eoBUu0
IntelӮМғuғҚғbғNҗ}ӮН•қӮӘ‘Оүһbitҗ”ӮрӮ ӮзӮнӮөӮДӮўӮйӮМӮЕҒA
Store DataӮН128bӮҫӮҜӮЗҒA
Load PortӮН256bӮӘ2ӮВӮ ӮйӮжӮӨӮЙҸ‘Ӯ©ӮкӮДӮўӮйҒB
ӮаӮҝӮлӮсL1DӮН32BӮМғҚҒ[ғh‘СҲжӮөӮ©ӮИӮўӮ©ӮзL1DӮЙ‘СҲжӮӘҗ§–сӮіӮкӮйӮ©ӮзҺқ‘ұӮН–і—қӮҫӮҜӮЗ
ғҶғjғbғg“IӮЙӮН512b•ӘӮМғҠғ\Ғ[ғXӮӘӮ ӮйӮЖӮЖӮкӮйҒBӮЖӮўӮӨӮМӮ©Ӯз>>645ӮНӮ©ӮўӮҪӮсӮҫӮжҒB
ӮұӮМ•”•ӘӮаҠщӮЙғVғ~ғ…ғҢҒ[ғ^ӮЕүрҗНҚПӮЭӮЖӮўӮӨӮИӮ當ӢеӮН–іӮўӮҜӮЗӮЛҒB
Store DataӮН128bӮҫӮҜӮЗҒA
Load PortӮН256bӮӘ2ӮВӮ ӮйӮжӮӨӮЙҸ‘Ӯ©ӮкӮДӮўӮйҒB
ӮаӮҝӮлӮсL1DӮН32BӮМғҚҒ[ғh‘СҲжӮөӮ©ӮИӮўӮ©ӮзL1DӮЙ‘СҲжӮӘҗ§–сӮіӮкӮйӮ©ӮзҺқ‘ұӮН–і—қӮҫӮҜӮЗ
ғҶғjғbғg“IӮЙӮН512b•ӘӮМғҠғ\Ғ[ғXӮӘӮ ӮйӮЖӮЖӮкӮйҒBӮЖӮўӮӨӮМӮ©Ӯз>>645ӮНӮ©ӮўӮҪӮсӮҫӮжҒB
ӮұӮМ•”•ӘӮаҠщӮЙғVғ~ғ…ғҢҒ[ғ^ӮЕүрҗНҚПӮЭӮЖӮўӮӨӮИӮ當ӢеӮН–іӮўӮҜӮЗӮЛҒB
652 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2010/04/28(җ…) 21:32:39 ID:eFV2QoW40
>>651
ӮаӮҝӮлӮсӮ ӮМғVғ~ғ…ӮЕүрҗНҚПӮЭҒB
256bit Load–Ҫ—ЯӮН2ғTғCғNғӢӮ©Ӯ©ӮйӮҜӮЗ2ӮВӮМLoad PortӮЕҢрҢЭӮЙ”ӯҚsӮ·ӮкӮО
1ғTғCғNғӢӮ ӮҪӮи1үсӮЙӮИӮйӮнӮҜӮҫҒB
Ӯ ӮЖҒA256b LoadӮМғҢғCғeғ“ғVӮӘ128bӮМӮ»ӮкӮжӮи‘еӮ«Ӯў—қ—RӮаҗа–ҫӮЕӮ«ӮйӮЛҒB
ӮаӮҝӮлӮсӮ ӮМғVғ~ғ…ӮЕүрҗНҚПӮЭҒB
256bit Load–Ҫ—ЯӮН2ғTғCғNғӢӮ©Ӯ©ӮйӮҜӮЗ2ӮВӮМLoad PortӮЕҢрҢЭӮЙ”ӯҚsӮ·ӮкӮО
1ғTғCғNғӢӮ ӮҪӮи1үсӮЙӮИӮйӮнӮҜӮҫҒB
Ӯ ӮЖҒA256b LoadӮМғҢғCғeғ“ғVӮӘ128bӮМӮ»ӮкӮжӮи‘еӮ«Ӯў—қ—RӮаҗа–ҫӮЕӮ«ӮйӮЛҒB
653 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2010/04/28(җ…) 21:38:51 ID:eFV2QoW40
Ӯ ҒADestination BusҒiҒHҒjӮН256ғrғbғgү»ӮіӮкӮДӮйӮЖҺvӮнӮкӮйҒB
654 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/05/01(“y) 00:42:37 ID:G4KGRk6/0
’cҺqҗжҗ¶ӮНSNBӮЙӮЁӮҜӮйNehalemӮ©ӮзӮМҠщ‘¶ғAғvғҠӮМҺАҢшIPCғAғbғvӮН
үҪ%ӮӯӮзӮўӮҫӮЖҢ©җПӮаӮБӮДӮўӮйӮМӮЕӮөӮеӮӨӮ©?
үҪ%ӮӯӮзӮўӮҫӮЖҢ©җПӮаӮБӮДӮўӮйӮМӮЕӮөӮеӮӨӮ©?
655 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2010/05/01(“y) 07:43:12 ID:r+xUw7tB0
җіӢK•\Ң»ғ}ғbғ`ғ“ғOҒiNFAҒjӮЖӮ©ӮЩӮЖӮсӮЗ•ӘҠт—\‘ӘӮЖғLғғғbғVғ…ӮМғҢғCғeғ“ғVҲЛ‘¶ӮҫӮ©ӮзӮИӮ
ғVғ~ғ…ӮЙӮжӮйӮЖҸ]—ҲSSEӮЕӮ·Ӯз‘еӮөӮДҗ«”\Ӯ ӮӘӮзӮИӮўҒB
ӮҪӮҫӮөLoadғlғbғNӮМғRҒ[ғhӮЙҠЦӮөӮДӮНҒiLoadғҶғjғbғgӮӘ‘қӮҰӮҪ•ӘҒjҢҖ“IӮЙҗ«”\ҢьҸгӮ·ӮйүВ”\җ«ӮӘӮ ӮйҒB
ҒiӮҝӮИӮЭӮЙLoadғlғbғNӮҫӮЖӮЗӮМӮЭӮҝAVXӮЕҗ«”\ҢьҸгӮМ—]’n–wӮЗӮИӮўӮсӮҫӮжӮЛҒj
”сSSEӮЕӮа—LҢшӮ»ӮӨӮИӮЖӮұӮлӮЕӮНsub+jccӮЖӮ©dec+jccӮЕӮаMacro Ops FusionӮӘҺgӮҰӮйӮжӮӨӮЙӮИӮБӮҪӮұӮЖӮӯӮзӮўӮ©ҒB
ӮЗӮБӮҝӮЙӮөӮл”ч–ӯӮ·Ӯ¬ҒB
ғVғ~ғ…ӮЙӮжӮйӮЖҸ]—ҲSSEӮЕӮ·Ӯз‘еӮөӮДҗ«”\Ӯ ӮӘӮзӮИӮўҒB
ӮҪӮҫӮөLoadғlғbғNӮМғRҒ[ғhӮЙҠЦӮөӮДӮНҒiLoadғҶғjғbғgӮӘ‘қӮҰӮҪ•ӘҒjҢҖ“IӮЙҗ«”\ҢьҸгӮ·ӮйүВ”\җ«ӮӘӮ ӮйҒB
ҒiӮҝӮИӮЭӮЙLoadғlғbғNӮҫӮЖӮЗӮМӮЭӮҝAVXӮЕҗ«”\ҢьҸгӮМ—]’n–wӮЗӮИӮўӮсӮҫӮжӮЛҒj
”сSSEӮЕӮа—LҢшӮ»ӮӨӮИӮЖӮұӮлӮЕӮНsub+jccӮЖӮ©dec+jccӮЕӮаMacro Ops FusionӮӘҺgӮҰӮйӮжӮӨӮЙӮИӮБӮҪӮұӮЖӮӯӮзӮўӮ©ҒB
ӮЗӮБӮҝӮЙӮөӮл”ч–ӯӮ·Ӯ¬ҒB
656 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2010/05/01(“y) 07:45:08 ID:r+xUw7tB0
Ӯ ӮҰӮДҢҫӮӨҒB”сSIMD—p“rӮЕҒғ10%
657 ҒF–јҸМ–ўҗЭ’иҒF2010/05/01(“y) 12:04:13 ID:dFZm4cxB0
Ӯ»ӮсӮИӮЙғAғbғvӮөӮИӮўӮҫӮлҒB
5Ғ“ӮЕӮаҸ\•ӘӮЙӮ·ӮІӮўӮЖҺvӮӨӮӘҒB
5Ғ“ӮЕӮаҸ\•ӘӮЙӮ·ӮІӮўӮЖҺvӮӨӮӘҒB
658 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/05/01(“y) 12:29:03 ID:G4KGRk6/0
ӮИӮсӮҫӮЁӮкӮЖ“ҜӮ¶ӮӯӮзӮўӮҫӮИҒBCore 2Ӯа–{—ҲӮҪӮҫALU‘қӮвӮөӮҪӮҫӮҜӮЕӮНӮ ӮсӮИӮЙ
ӮНӮвӮӯӮИӮзӮИӮ©ӮБӮҪҒBOOOӮМld/stҺь•УӮН—қүрӮіӮкӮДӮИӮўӮөүЯҸ¬•]үҝӮҫӮлӮӨҒB
5%ҲИүәӮН–іӮўӮЖҺvӮӨӮжҒBӮЁӮкӮНӢӯӢCӮЕ10%‘OҢгӮЙӮөӮЖӮӯҒB
ӮНӮвӮӯӮИӮзӮИӮ©ӮБӮҪҒBOOOӮМld/stҺь•УӮН—қүрӮіӮкӮДӮИӮўӮөүЯҸ¬•]үҝӮҫӮлӮӨҒB
5%ҲИүәӮН–іӮўӮЖҺvӮӨӮжҒBӮЁӮкӮНӢӯӢCӮЕ10%‘OҢгӮЙӮөӮЖӮӯҒB
659 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/05/01(“y) 12:44:59 ID:G4KGRk6/0
SNBӮЕҗ«”\Ӯ ӮӘӮзӮИӮ©ӮБӮҪӮзIsrael“IӮЙӮНOregonӮӘNehalemӮЕ‘z’иҠOӮЙҠж’ЈӮиӮ·Ӯ¬ӮҝӮбӮБӮҪӮБӮДӮұӮЖӮҫӮлӮӨӮИҒB
ғAғOғҢғbғVғuғNғҚғbғNғQҒ[ғeғBғ“ғOӮНWillametteӮӘҚЕҸүӮҫӮөҒA
PenrynӮЕӮМҗVҸИ“d—НӮаүсҳHҺА‘•ӮНғTғ“ғ^ғNғүғүӮЙҠЫ“ҠӮ°ҒBTBӮаOregonӮМҺА‘•ӮӘҗжҚsҒB
үсҳHӢZҸpӮН•ДҚ‘’ҶҗSӮЕҒA’б“d—Нү»ӮМӢZҸpӮНҺАҚЫӮМӮЖӮұӮлғAҒ[ғLғeғNғ`ғғӮжӮиӮа
үсҳHӮвғfғoғCғXӮЙҲЛ‘¶ӮөӮДӮўӮй“xҚҮӮўӮӘҚӮӮўӮМӮЕҒAҗўҠФӮЕӮМ•]үҝӮЖӮН— • ӮЙ
ӮЮӮөӮлҸИ“d—НӢZҸpӮН•ДҚ‘ғ`Ғ[ғҖ’ҶҗSӮЕҚЎҢгӮНҢкӮйӮұӮЖӮЙӮИӮйүВ”\җ«Ӯ·ӮзӮ ӮйҒB
ҚӘӮБӮұӮЙӮ Ӯй—қӢьӮӘ“ҜӮ¶ӮИӮМӮЕҒAҚӮ‘¬ӮИүсҳHӮЕҲк—¬ӮМғAғCғfғAӮрӮҫӮ№ӮйҗЭҢvғ`Ғ[ғҖӮӘ
“d—¬—}ӮҰӮйӮұӮЖӮрҚlӮҰӮҪӮз“Л‘RҺO—¬ӮЙӮИӮйӮЖӮўӮӨӮұӮЖӮНҺАҚЫӮМӮЖӮұӮл–іӮўӮҫӮлӮӨҒB
җЭҢvҗlӮ©ӮзӮЭӮкӮО–Ъ•W’lӮӘӮ©ӮнӮйӮҫӮҜҒB
ғAғOғҢғbғVғuғNғҚғbғNғQҒ[ғeғBғ“ғOӮНWillametteӮӘҚЕҸүӮҫӮөҒA
PenrynӮЕӮМҗVҸИ“d—НӮаүсҳHҺА‘•ӮНғTғ“ғ^ғNғүғүӮЙҠЫ“ҠӮ°ҒBTBӮаOregonӮМҺА‘•ӮӘҗжҚsҒB
үсҳHӢZҸpӮН•ДҚ‘’ҶҗSӮЕҒA’б“d—Нү»ӮМӢZҸpӮНҺАҚЫӮМӮЖӮұӮлғAҒ[ғLғeғNғ`ғғӮжӮиӮа
үсҳHӮвғfғoғCғXӮЙҲЛ‘¶ӮөӮДӮўӮй“xҚҮӮўӮӘҚӮӮўӮМӮЕҒAҗўҠФӮЕӮМ•]үҝӮЖӮН— • ӮЙ
ӮЮӮөӮлҸИ“d—НӢZҸpӮН•ДҚ‘ғ`Ғ[ғҖ’ҶҗSӮЕҚЎҢгӮНҢкӮйӮұӮЖӮЙӮИӮйүВ”\җ«Ӯ·ӮзӮ ӮйҒB
ҚӘӮБӮұӮЙӮ Ӯй—қӢьӮӘ“ҜӮ¶ӮИӮМӮЕҒAҚӮ‘¬ӮИүсҳHӮЕҲк—¬ӮМғAғCғfғAӮрӮҫӮ№ӮйҗЭҢvғ`Ғ[ғҖӮӘ
“d—¬—}ӮҰӮйӮұӮЖӮрҚlӮҰӮҪӮз“Л‘RҺO—¬ӮЙӮИӮйӮЖӮўӮӨӮұӮЖӮНҺАҚЫӮМӮЖӮұӮл–іӮўӮҫӮлӮӨҒB
җЭҢvҗlӮ©ӮзӮЭӮкӮО–Ъ•W’lӮӘӮ©ӮнӮйӮҫӮҜҒB
660 ҒF–јҸМ–ўҗЭ’иҒF2010/05/01(“y) 12:53:23 ID:WiYAGZ1W0
“ҜғvғҚғZғXӮЕTDP25Ғ“ҢёҒ•IPC10Ғ“ғAғbғv
Ӯ»ӮсӮИ“sҚҮӮжӮӯӮўӮӯӮМӮ©ӮўӮИ
Ӯ»ӮсӮИ“sҚҮӮжӮӯӮўӮӯӮМӮ©ӮўӮИ
661 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/05/01(“y) 12:54:42 ID:G4KGRk6/0
Pentium 4ӮМӮЖӮ«ӮНӮЬӮҫӮЬӮҫCPUӮМҗ«”\ӮНӮ ӮӘӮБӮДӮўӮӯӮЖҒA
IntelӮМҸг‘w•”ӮрҠЬӮЯӮДҗMӮ¶ӮДӮўӮҪӮжӮӨӮЕҒAӮЬӮ Pentium 4ӮЭӮҪӮўӮИҚӮғNғҚғbғNҳHҗьӮӘ
җЭҢvғTғCғhӮҫӮҜӮЕӮИӮӯIntel‘S‘МӮМ•ыҗjӮЭӮҪӮўӮИӮаӮМӮҫӮБӮҪӮ©ӮзӮИҒB
IntelӮӘӮЬӮҫ“d—НӮв”ӯ”MӮӘҸd—vӮҫӮЖӮўӮӨӮұӮЖӮр–{ӢCӮЕҺуӮҜ“ьӮкҗШӮкӮДӮўӮИӮ©ӮБӮҪӮМӮҫӮлӮӨҒB
ӮЕӮаҚЎӮНIsrealғ`Ғ[ғҖӮМ•]үҝӮӘӮ ӮӘӮБӮДӮөӮЬӮБӮҪӮЖӮНӮўӮҰҒA
OregonӮа’бҸБ”п“d—Н•Kҗ{ӮМ•ыҗjүәӮЙӮ ӮйӮМӮЕӮЗӮӨӮИӮйӮ©ӮнӮ©ӮзӮИӮўӮЛҒB
ӮЕӮаLRBӮМӮ®ӮҫӮ®ӮҪӮӘӮ ӮйӮ©ӮзHaswellӮНӮ ӮЬӮиғRғAӮрҠg’ЈӮөӮД–іӮўҸгҠъ‘ТӮЕӮ«ӮИӮўӮ©ӮаӮөӮкӮИӮўҒB
ҲИҸгҒAGWӮМ–П‘zӮЕӮөӮҪҒB
IntelӮМҸг‘w•”ӮрҠЬӮЯӮДҗMӮ¶ӮДӮўӮҪӮжӮӨӮЕҒAӮЬӮ Pentium 4ӮЭӮҪӮўӮИҚӮғNғҚғbғNҳHҗьӮӘ
җЭҢvғTғCғhӮҫӮҜӮЕӮИӮӯIntel‘S‘МӮМ•ыҗjӮЭӮҪӮўӮИӮаӮМӮҫӮБӮҪӮ©ӮзӮИҒB
IntelӮӘӮЬӮҫ“d—НӮв”ӯ”MӮӘҸd—vӮҫӮЖӮўӮӨӮұӮЖӮр–{ӢCӮЕҺуӮҜ“ьӮкҗШӮкӮДӮўӮИӮ©ӮБӮҪӮМӮҫӮлӮӨҒB
ӮЕӮаҚЎӮНIsrealғ`Ғ[ғҖӮМ•]үҝӮӘӮ ӮӘӮБӮДӮөӮЬӮБӮҪӮЖӮНӮўӮҰҒA
OregonӮа’бҸБ”п“d—Н•Kҗ{ӮМ•ыҗjүәӮЙӮ ӮйӮМӮЕӮЗӮӨӮИӮйӮ©ӮнӮ©ӮзӮИӮўӮЛҒB
ӮЕӮаLRBӮМӮ®ӮҫӮ®ӮҪӮӘӮ ӮйӮ©ӮзHaswellӮНӮ ӮЬӮиғRғAӮрҠg’ЈӮөӮД–іӮўҸгҠъ‘ТӮЕӮ«ӮИӮўӮ©ӮаӮөӮкӮИӮўҒB
ҲИҸгҒAGWӮМ–П‘zӮЕӮөӮҪҒB
662 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/05/01(“y) 12:55:40 ID:G4KGRk6/0
663 ҒF–јҸМ–ўҗЭ’иҒF2010/05/01(“y) 13:14:49 ID:WiYAGZ1W0
Ӯ·ӮЬӮс>>662ӮМүрҺЯӮЕӮ ӮБӮДӮйӮжӮӨӮҫҒBӮУӮ¶ӮзӮ»Ғ[Ӯ·ҒB
http://www.fudzilla.com/content/view/18545/35/
http://www.fudzilla.com/content/view/18576/1/
http://www.fudzilla.com/content/view/18590/1/
http://www.fudzilla.com/content/view/18545/35/
http://www.fudzilla.com/content/view/18576/1/
http://www.fudzilla.com/content/view/18590/1/
664 ҒF–јҸМ–ўҗЭ’иҒF2010/05/01(“y) 13:24:50 ID:+qceu7oV0
FUD“\ӮсӮИ
665 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2010/05/01(“y) 17:22:05 ID:r+xUw7tB0
Ғғ10%ӮБӮДӮМӮНHTҚһӮЭӮЕӮМ—\‘z
3ӮВӮМALUӮЙ‘ОӮөӮДLoadғҶғjғbғgӮӘҸӯӮИӮӯӮДғlғbғNӮБӮДӮМӮНғXғJғүӮЕӮа“ҜӮ¶ӮҫӮөӮИ
3ӮВӮМALUӮЙ‘ОӮөӮДLoadғҶғjғbғgӮӘҸӯӮИӮӯӮДғlғbғNӮБӮДӮМӮНғXғJғүӮЕӮа“ҜӮ¶ӮҫӮөӮИ
666 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2010/05/02(“ъ) 23:55:49 ID:5hQw4TI00
ӮұӮБӮҝӮЙ“]ҚЪӮөӮДӮЁӮӯӮ©
Bulldozer will be Version 1 and other info
http://citavia.blog.de/2010/04/30/bulldozer-will-be-version-1-and-other-info-8484302/
721 –ј‘OҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣ[sage] “ҠҚe“ъҒF2010/05/02(“ъ) 20:10:58 ID:rgIg+qs9
> - Improve fetch bandwidth by reducing code size.
> This is accomplished by:
> Replacing "packed double (PD)" and "packed integer (DQ)" forms of some
> SSEx/AVX instructions with "packed single (PS)" forms, where the "PS" form
> of the instruction is 1 byte shorter than the "PD" or "DQ" form.
> This applies to
> - use movaps instead of movapd/movdqa.
> - use movups instead of movupd/movdqu.
> - use xorps/andps/orpd instead of xorpd/andpd/orpd.
–ўӮҫӮЙӮұӮсӮИғ`ғ…Ғ[ғ“•K—vӮИӮМӮ©Ӯж
үҪӮМӮҪӮЯӮМ32B/clkӮМ–Ҫ—ЯғtғFғbғ`ӮҫӮжӮ—Ӯ—Ӯ—
ӮҝӮИӮЭӮЙӮұӮкIntelғvғҚғZғbғTӮЕӮНҗ«”\’бүәӮ·ӮйғRҒ[ғhӮМ‘gӮЭ•ыӮМ“TҢ^ҒB
Ӯ Ӯ ҒAӢЈҚҮӮӘ’xӮӯӮИӮйӮ©ӮзӮ ӮйҲУ–ЎҒuҚЕ“Kү»ҒvӮИӮМӮ©ҒB
Bulldozer will be Version 1 and other info
http://citavia.blog.de/2010/04/30/bulldozer-will-be-version-1-and-other-info-8484302/
721 –ј‘OҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣ[sage] “ҠҚe“ъҒF2010/05/02(“ъ) 20:10:58 ID:rgIg+qs9
> - Improve fetch bandwidth by reducing code size.
> This is accomplished by:
> Replacing "packed double (PD)" and "packed integer (DQ)" forms of some
> SSEx/AVX instructions with "packed single (PS)" forms, where the "PS" form
> of the instruction is 1 byte shorter than the "PD" or "DQ" form.
> This applies to
> - use movaps instead of movapd/movdqa.
> - use movups instead of movupd/movdqu.
> - use xorps/andps/orpd instead of xorpd/andpd/orpd.
–ўӮҫӮЙӮұӮсӮИғ`ғ…Ғ[ғ“•K—vӮИӮМӮ©Ӯж
үҪӮМӮҪӮЯӮМ32B/clkӮМ–Ҫ—ЯғtғFғbғ`ӮҫӮжӮ—Ӯ—Ӯ—
ӮҝӮИӮЭӮЙӮұӮкIntelғvғҚғZғbғTӮЕӮНҗ«”\’бүәӮ·ӮйғRҒ[ғhӮМ‘gӮЭ•ыӮМ“TҢ^ҒB
Ӯ Ӯ ҒAӢЈҚҮӮӘ’xӮӯӮИӮйӮ©ӮзӮ ӮйҲУ–ЎҒuҚЕ“Kү»ҒvӮИӮМӮ©ҒB
667 ҒF–јҸМ–ўҗЭ’иҒF2010/05/03(ҢҺ) 00:38:42 ID:rBEWYQP10
movapsҒAmovupsҒAxorps/andps/orpd
ӮЗӮкӮӘғ_ғҒӮИӮМҒH
‘fҗlӮЙӮнӮ©ӮйӮжӮӨӮЙүрҗаӮХӮиҒ[Ӯҡ
ӮЗӮкӮӘғ_ғҒӮИӮМҒH
‘fҗlӮЙӮнӮ©ӮйӮжӮӨӮЙүрҗаӮХӮиҒ[Ӯҡ
668 ҒF–јҸМ–ўҗЭ’иҒF2010/05/03(ҢҺ) 00:44:45 ID:4tskhm5H0
ӮўӮЬӮЬӮЕӮЗӮЁӮи
AMDӮМCPUӮНFPғpғCғvӮЕҒAҗ®җ”SIMDӮЖFPӮрӢж•КӮөӮИӮўӮЖӮӨӮұӮЖӮөӮ©ӮнӮ©ӮзӮИӮў
ҒiIntelӮМCPUӮМҸкҚҮҒAғfҒ[ғ^ғ^ғCғvӮЖ–Ҫ—ЯӮр“ҜӮ¶ӮЙӮөӮИӮўӮЖғyғiғӢғeғBӮрҺуӮҜӮйҒj
ғRҒ[ғhғTғCғYӮӘҸ¬ӮіӮўӮЩӮӨӮӘғLғғғbғVғ…ӮМғqғbғg—ҰӮӘҸгӮӘӮйӮМӮЕ
–Ҫ—ЯғtғFғbғ`‘СҲжӮЙӮ©Ӯ©ӮнӮзӮёҒA—LҢшӮИҚЕ“Kү»ӮҫӮЖҺvӮнӮкӮй
AMDӮМCPUӮНFPғpғCғvӮЕҒAҗ®җ”SIMDӮЖFPӮрӢж•КӮөӮИӮўӮЖӮӨӮұӮЖӮөӮ©ӮнӮ©ӮзӮИӮў
ҒiIntelӮМCPUӮМҸкҚҮҒAғfҒ[ғ^ғ^ғCғvӮЖ–Ҫ—ЯӮр“ҜӮ¶ӮЙӮөӮИӮўӮЖғyғiғӢғeғBӮрҺуӮҜӮйҒj
ғRҒ[ғhғTғCғYӮӘҸ¬ӮіӮўӮЩӮӨӮӘғLғғғbғVғ…ӮМғqғbғg—ҰӮӘҸгӮӘӮйӮМӮЕ
–Ҫ—ЯғtғFғbғ`‘СҲжӮЙӮ©Ӯ©ӮнӮзӮёҒA—LҢшӮИҚЕ“Kү»ӮҫӮЖҺvӮнӮкӮй
669 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2010/05/03(ҢҺ) 02:26:29 ID:QSiraSJF0
ҺАҚЫ–в‘иIntelӮМғvғҚғZғbғTӮЕӮаӮұӮсӮИӮұӮЖӮвӮБӮД‘¬ӮӯӮИӮБӮҪӮМӮНAtomӮӯӮзӮўӮҫӮӘ
ҺАҚЫӮЙ–Ҫ—ЯғtғFғbғ`‘СҲжӮӘӮ©ӮИӮиӢ·ӮўӮ©Ӯз5%’ц“xӮМҗ«”\ҢьҸгӮН“ҫӮзӮкӮҪӮұӮЖӮӘӮ ӮйҒB
ғRҒ[ғhғTғCғYӮМҚЕ“Kү»ҢҫӮӨӮИӮзӮаӮБӮЖ‘јӮЙӮвӮйӮұӮЖӮӘӮ ӮйӮәҒB
64ғrғbғgғӮҒ[ғhӮЕREXғvғҠғtғBғNғXӮӘ•tӮӯ–Ҫ—ЯӮрҢёӮзӮ·ӮЖӮ©ҒAӮ ӮйӮўӮНAVXӮҫӮЖ
vaddps xmm10, xmm7, xmm8ҒЁvaddps xmm10, xmm8, xmm7
ӮЖӮ©ӮЛҒB‘OҺТӮҫӮЖ5ғoғCғgӮҫӮӘҢгҺТӮН4ғoғCғgҒB
GCCӮНӮЬӮҫӮЬӮҫӮұӮМҺиӮМҚЕ“Kү»ҺгӮўӮ©ӮзҺи“®ӮЕӮвӮзӮсӮЖӮўӮ©ӮсҒB
ҺАҚЫӮЙ–Ҫ—ЯғtғFғbғ`‘СҲжӮӘӮ©ӮИӮиӢ·ӮўӮ©Ӯз5%’ц“xӮМҗ«”\ҢьҸгӮН“ҫӮзӮкӮҪӮұӮЖӮӘӮ ӮйҒB
ғRҒ[ғhғTғCғYӮМҚЕ“Kү»ҢҫӮӨӮИӮзӮаӮБӮЖ‘јӮЙӮвӮйӮұӮЖӮӘӮ ӮйӮәҒB
64ғrғbғgғӮҒ[ғhӮЕREXғvғҠғtғBғNғXӮӘ•tӮӯ–Ҫ—ЯӮрҢёӮзӮ·ӮЖӮ©ҒAӮ ӮйӮўӮНAVXӮҫӮЖ
vaddps xmm10, xmm7, xmm8ҒЁvaddps xmm10, xmm8, xmm7
ӮЖӮ©ӮЛҒB‘OҺТӮҫӮЖ5ғoғCғgӮҫӮӘҢгҺТӮН4ғoғCғgҒB
GCCӮНӮЬӮҫӮЬӮҫӮұӮМҺиӮМҚЕ“Kү»ҺгӮўӮ©ӮзҺи“®ӮЕӮвӮзӮсӮЖӮўӮ©ӮсҒB
670 ҒF–јҸМ–ўҗЭ’иҒF2010/05/03(ҢҺ) 04:23:00 ID:/j1Kz81m0
‘¬ӮӯӮИӮзӮсIntelӮМ•ыӮӘҲ«Ӯў
671 ҒF–јҸМ–ўҗЭ’иҒF2010/05/03(ҢҺ) 05:30:52 ID:XR1sEdTh0
ғJғGғҢҒiҒEҒНҒEҒj
672 ҒF–јҸМ–ўҗЭ’иҒF2010/05/06(–Ш) 17:17:28 ID:JJd8lpPp0
Moorestown·А„Ә„Ә„Ә„Ә(ЯҒНЯ)„Ә„Ә„Ә„Ә !!!!!
ttp://pc.watch.impress.co.jp/docs/news/20100506_365603.html
>Ғ@•ДIntelӮН4“ъҒAғXғ}Ғ[ғgғtғHғ“ҢьӮҜӮМIntelғAҒ[ғLғeғNғ`ғғSoC(System-on-Chip)ҒuAtom Z6xxҒvғVғҠҒ[ғYӮр”ӯ•\ҒA“Ҝ“ъ•tӮҜӮЕҸoүЧҠJҺnӮөӮҪҒB
>
>Ғ@ӮұӮкӮЬӮЕҒuLincroftҒvӮМғRҒ[ғhғlҒ[ғҖӮЕҢДӮОӮкӮДӮ«ӮҪғvғҚғZғbғTҒBHigh-k 45nm LP SoCғvғҚғZғXӮрҚМ—pҒB
>ғLғғғbғVғ…—e—КӮНL1ғfҒ[ғ^ӮӘ24KBҒAL1–Ҫ—ЯӮӘ32KBҒAL2ӮӘ512KBҒB
>ғNғҚғbғNӮНғnғ“ғhғwғӢғh/ғXғ}Ғ[ғgғtғHғ“ҢьӮҜӮӘҚЕ‘е1.5GHzҒAғ^ғuғҢғbғgҢьӮҜӮӘҚЕ‘е1.9GHzҒB
>
>Ғ@ӮЬӮҪҒACPUӮЙҒAғtғӢHDӮЕӮМH.264/WMV/VC1ӮЙӮжӮйғfғRҒ[ғhӮвҒA720pӮЕӮМH.264ӮЙӮжӮйғGғ“ғRҒ[ғhӢ@”\ӮвҒA
>OpenGL 2.1ӮЙ‘ОүһӮ·Ӯй2D/3DӢ@”\ӮИӮЗӮЙ‘ОүһӮөӮҪғrғfғIғRғAҒuGMA 600ҒvҒA
>32bitғVғ“ғOғӢғ`ғғғlғӢLPDDR-200(ҚЕ‘е1GB)/DDR2-400(ҚЕ‘е2GB)ӮЙ‘ОүһӮөӮҪғҒғӮғҠғRғ“ғgғҚҒ[ғүӮр“а‘ Ӯ·ӮйҒB
>
>Ғ@Ӣ@”\–КӮЕӮНҒAHyper-ThreadingғeғNғmғҚғWӮМӮЩӮ©ҒA’ZҺһҠФӮҫӮҜ“®“IӮЙғvғҚғZғbғTӮМҗ«”\ӮрҺқӮҝҸгӮ°ӮйBurst PerformanceғeғNғmғҚғWҒA
>OSӮӘғIғ“Ҹу‘Ф(S0)ӮЕӮаCPUғRғAӮвSoCӮрғIғtӮЙӮ·ӮйSmart IdleғeғNғmғҚғWӮИӮЗӮМҗVӢ@”\Ӯр“ӢҚЪӮ·ӮйҒB
>
>Ғ@ғ`ғbғvғZғbғgӮНғRҒ[ғhғlҒ[ғҖҒuLangwellҒvӮұӮЖҒuPlatform Controller Hub MP20ҒvҒBғIҒ[ғfғBғIӮвUSBӢ@”\ӮМӮЩӮ©ҒAҲГҚҶү»Ӣ@”\Ӯа“ӢҚЪӮ·ӮйҒB
>ӮЬӮҪҒAҒuMixed Signal IC (MSCI)ҒvӮЖҢДӮОӮкӮйҒAғoғbғeғҠӮМҸ[“dӮвҒAғIҒ[ғfғBғIҒAғ^ғbғ`ғXғNғҠҒ[ғ“ӮИӮЗҠeҺнғAғiғҚғO/ғfғWғ^ғӢҺьӮиӮр“қҗ§Ӯ·Ӯйғ`ғbғvӮр”әӮӨҒB
>
>Ғ@ғvғүғbғgғtғHҒ[ғҖ‘S‘МӮМҸБ”п“d—НӮНҒAҸ]—Ҳ•iӮЖ”дӮЧҒAғAғCғhғӢҺһӮМҸБ”п“d—НӮӘ1/50ҲИүәҒAғuғүғEғWғ“ғOӮвғrғfғIҚДҗ¶ҺһӮМҸБ”п“d—НӮӘ1/2Ғ`1/3ӮЙӮИӮиҒA
>‘ТӮҝҺуӮҜӮН10“ъҠФҲИҸгҒAү№ҠyҚДҗ¶ҺһӮЕҚЕ‘е2“ъҒAғuғүғEғWғ“ғOӮвғrғfғIҚДҗ¶ҺһӮЕ4Ғ`5ҺһҠФғoғbғeғҠӢм“®ӮЕӮ«ӮйӮЖӮўӮӨҒB
>
>Ғ@Ҹ]—ҲӮМAtom Z5xxғVғҠҒ[ғY(ғRҒ[ғhғlҒ[ғҖSilverthorne)ӮМ‘ҪӮӯӮӘҸ¬Ң^ӮМx86 PCӮЙҚМ—pӮіӮкӮҪӮМӮЖҲЩӮИӮиҒAAtom Z6xxғVғҠҒ[ғYӮН‘gӮЭҚһӮЭҢьӮҜӮЖӮИӮиҒA
>‘ОүһOSӮаAndroidҒAMoblinҒAMeeGoӮЖӮўӮБӮҪLinuxҢnӮЖӮИӮйҒBӮҪӮҫӮөҒAӮұӮкӮЖӮН•КӮЙWindows PCҢьӮҜӮМҒuOak TrailҒvӮЖӮўӮӨғvғүғbғgғtғHҒ[ғҖӮаҢvүжӮіӮкӮДӮўӮйҒB
ttp://pc.watch.impress.co.jp/docs/news/20100506_365603.html
>Ғ@•ДIntelӮН4“ъҒAғXғ}Ғ[ғgғtғHғ“ҢьӮҜӮМIntelғAҒ[ғLғeғNғ`ғғSoC(System-on-Chip)ҒuAtom Z6xxҒvғVғҠҒ[ғYӮр”ӯ•\ҒA“Ҝ“ъ•tӮҜӮЕҸoүЧҠJҺnӮөӮҪҒB
>
>Ғ@ӮұӮкӮЬӮЕҒuLincroftҒvӮМғRҒ[ғhғlҒ[ғҖӮЕҢДӮОӮкӮДӮ«ӮҪғvғҚғZғbғTҒBHigh-k 45nm LP SoCғvғҚғZғXӮрҚМ—pҒB
>ғLғғғbғVғ…—e—КӮНL1ғfҒ[ғ^ӮӘ24KBҒAL1–Ҫ—ЯӮӘ32KBҒAL2ӮӘ512KBҒB
>ғNғҚғbғNӮНғnғ“ғhғwғӢғh/ғXғ}Ғ[ғgғtғHғ“ҢьӮҜӮӘҚЕ‘е1.5GHzҒAғ^ғuғҢғbғgҢьӮҜӮӘҚЕ‘е1.9GHzҒB
>
>Ғ@ӮЬӮҪҒACPUӮЙҒAғtғӢHDӮЕӮМH.264/WMV/VC1ӮЙӮжӮйғfғRҒ[ғhӮвҒA720pӮЕӮМH.264ӮЙӮжӮйғGғ“ғRҒ[ғhӢ@”\ӮвҒA
>OpenGL 2.1ӮЙ‘ОүһӮ·Ӯй2D/3DӢ@”\ӮИӮЗӮЙ‘ОүһӮөӮҪғrғfғIғRғAҒuGMA 600ҒvҒA
>32bitғVғ“ғOғӢғ`ғғғlғӢLPDDR-200(ҚЕ‘е1GB)/DDR2-400(ҚЕ‘е2GB)ӮЙ‘ОүһӮөӮҪғҒғӮғҠғRғ“ғgғҚҒ[ғүӮр“а‘ Ӯ·ӮйҒB
>
>Ғ@Ӣ@”\–КӮЕӮНҒAHyper-ThreadingғeғNғmғҚғWӮМӮЩӮ©ҒA’ZҺһҠФӮҫӮҜ“®“IӮЙғvғҚғZғbғTӮМҗ«”\ӮрҺқӮҝҸгӮ°ӮйBurst PerformanceғeғNғmғҚғWҒA
>OSӮӘғIғ“Ҹу‘Ф(S0)ӮЕӮаCPUғRғAӮвSoCӮрғIғtӮЙӮ·ӮйSmart IdleғeғNғmғҚғWӮИӮЗӮМҗVӢ@”\Ӯр“ӢҚЪӮ·ӮйҒB
>
>Ғ@ғ`ғbғvғZғbғgӮНғRҒ[ғhғlҒ[ғҖҒuLangwellҒvӮұӮЖҒuPlatform Controller Hub MP20ҒvҒBғIҒ[ғfғBғIӮвUSBӢ@”\ӮМӮЩӮ©ҒAҲГҚҶү»Ӣ@”\Ӯа“ӢҚЪӮ·ӮйҒB
>ӮЬӮҪҒAҒuMixed Signal IC (MSCI)ҒvӮЖҢДӮОӮкӮйҒAғoғbғeғҠӮМҸ[“dӮвҒAғIҒ[ғfғBғIҒAғ^ғbғ`ғXғNғҠҒ[ғ“ӮИӮЗҠeҺнғAғiғҚғO/ғfғWғ^ғӢҺьӮиӮр“қҗ§Ӯ·Ӯйғ`ғbғvӮр”әӮӨҒB
>
>Ғ@ғvғүғbғgғtғHҒ[ғҖ‘S‘МӮМҸБ”п“d—НӮНҒAҸ]—Ҳ•iӮЖ”дӮЧҒAғAғCғhғӢҺһӮМҸБ”п“d—НӮӘ1/50ҲИүәҒAғuғүғEғWғ“ғOӮвғrғfғIҚДҗ¶ҺһӮМҸБ”п“d—НӮӘ1/2Ғ`1/3ӮЙӮИӮиҒA
>‘ТӮҝҺуӮҜӮН10“ъҠФҲИҸгҒAү№ҠyҚДҗ¶ҺһӮЕҚЕ‘е2“ъҒAғuғүғEғWғ“ғOӮвғrғfғIҚДҗ¶ҺһӮЕ4Ғ`5ҺһҠФғoғbғeғҠӢм“®ӮЕӮ«ӮйӮЖӮўӮӨҒB
>
>Ғ@Ҹ]—ҲӮМAtom Z5xxғVғҠҒ[ғY(ғRҒ[ғhғlҒ[ғҖSilverthorne)ӮМ‘ҪӮӯӮӘҸ¬Ң^ӮМx86 PCӮЙҚМ—pӮіӮкӮҪӮМӮЖҲЩӮИӮиҒAAtom Z6xxғVғҠҒ[ғYӮН‘gӮЭҚһӮЭҢьӮҜӮЖӮИӮиҒA
>‘ОүһOSӮаAndroidҒAMoblinҒAMeeGoӮЖӮўӮБӮҪLinuxҢnӮЖӮИӮйҒBӮҪӮҫӮөҒAӮұӮкӮЖӮН•КӮЙWindows PCҢьӮҜӮМҒuOak TrailҒvӮЖӮўӮӨғvғүғbғgғtғHҒ[ғҖӮаҢvүжӮіӮкӮДӮўӮйҒB
673 ҒF–јҸМ–ўҗЭ’иҒF2010/05/06(–Ш) 19:39:30 ID:sA0dgkcx0
‘S•¶Ҳш—pӮНӮөӮИӮӯӮДӮўӮў
674 ҒF–јҸМ–ўҗЭ’иҒF2010/05/06(–Ш) 22:36:18 ID:zXoOTmobP
ӮҰӮБҒAҒAҒAultra-low-power statesӮЕ100mWҒH ҒiSnapdragonӮН10mW–ў–һҒj
ҺА‘•–КҗПӮағ„ғoӮ»ӮӨҒEҒEҒEAtom Z6xxҒ{MP20Ғ{MSCIҒ{ӮЗӮұӮјӮвӮМғxҒ[ғXғoғ“ғhғ`ғbғvҒior Evans PeakҒjҒB
http://pc.watch.impress.co.jp/docs/column/kaigai/20090601_211977.html
Ғ„ҒuMoorestownӮЕӮНҒAғVғXғeғҖӮрҚ\җ¬Ӯ·Ӯй‘SӮДӮрҠЬӮЯӮҪғvғүғbғgғtғHҒ[ғҖ
Ғ„ӮЖӮөӮД1/50ӮМ20mWӮМғAғCғhғӢҺһ“d—НӮЖӮИӮБӮДӮўӮйҒv(ChandrasekherҺҒ)ҒB
іҝВ· ('A`)
ҺА‘•–КҗПӮағ„ғoӮ»ӮӨҒEҒEҒEAtom Z6xxҒ{MP20Ғ{MSCIҒ{ӮЗӮұӮјӮвӮМғxҒ[ғXғoғ“ғhғ`ғbғvҒior Evans PeakҒjҒB
http://pc.watch.impress.co.jp/docs/column/kaigai/20090601_211977.html
Ғ„ҒuMoorestownӮЕӮНҒAғVғXғeғҖӮрҚ\җ¬Ӯ·Ӯй‘SӮДӮрҠЬӮЯӮҪғvғүғbғgғtғHҒ[ғҖ
Ғ„ӮЖӮөӮД1/50ӮМ20mWӮМғAғCғhғӢҺһ“d—НӮЖӮИӮБӮДӮўӮйҒv(ChandrasekherҺҒ)ҒB
іҝВ· ('A`)
675 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2010/05/07(Ӣа) 07:19:20 ID:gZ0L5lu/0
>Ғ@ӮұӮкӮЬӮЕҒuLincroftҒvӮМғRҒ[ғhғlҒ[ғҖӮЕҢДӮОӮкӮДӮ«ӮҪғvғҚғZғbғTҒBHigh-k 45nm LP SoCғvғҚғZғXӮрҚМ—pҒB
>ғLғғғbғVғ…—e—КӮНL1ғfҒ[ғ^ӮӘ24KBҒAL1–Ҫ—ЯӮӘ32KBҒAL2ӮӘ512KBҒB
>ғNғҚғbғNӮНғnғ“ғhғwғӢғh/ғXғ}Ғ[ғgғtғHғ“ҢьӮҜӮӘҚЕ‘е1.5GHzҒAғ^ғuғҢғbғgҢьӮҜӮӘҚЕ‘е1.9GHzҒB
L1DӮӘ24KBӮЖӮИҒH
Ӯ»ӮӨӮўӮҰӮОAtomӮМL1DӮМ—e—КӮБӮДӢCӮЙӮөӮҪӮұӮЖӮИӮ©ӮБӮҪӮИҒi8Ӯs-SRAMӮҫӮБӮҪӮМӮНҠoӮҰӮДӮйӮӘҒj
>ғLғғғbғVғ…—e—КӮНL1ғfҒ[ғ^ӮӘ24KBҒAL1–Ҫ—ЯӮӘ32KBҒAL2ӮӘ512KBҒB
>ғNғҚғbғNӮНғnғ“ғhғwғӢғh/ғXғ}Ғ[ғgғtғHғ“ҢьӮҜӮӘҚЕ‘е1.5GHzҒAғ^ғuғҢғbғgҢьӮҜӮӘҚЕ‘е1.9GHzҒB
L1DӮӘ24KBӮЖӮИҒH
Ӯ»ӮӨӮўӮҰӮОAtomӮМL1DӮМ—e—КӮБӮДӢCӮЙӮөӮҪӮұӮЖӮИӮ©ӮБӮҪӮИҒi8Ӯs-SRAMӮҫӮБӮҪӮМӮНҠoӮҰӮДӮйӮӘҒj
676 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/05/07(Ӣа) 22:18:33 ID:sdIxt4vx0
AtomҸҹӮБӮҪӮИӮұӮиӮбҒB
677 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/05/07(Ӣа) 22:19:32 ID:sdIxt4vx0
“d—Нҗ«”\”дӮЕҚЕӢЯӮНӮвӮиӮМCortex-A8ҢnSoCӮұӮҰӮДӮйӮсӮ¶ӮбӮЛӮҘӮ©?
’NӮ©ҢҹҸШӮөӮДҒB
Intel Unveils Moorestown and the Atom Z600, The Fastest Smartphone Platform?
http://www.anandtech.com/print/3696
Moorestown Battery Life (Figures by Intel)
Total Phone Power Consumption
Idle 21 - 23 mW
Audio Playback 120 mW
1080p Video Playback 1.1W+
Web Browsing (WiFi) 1.1W
2G Phone Call 550 mW
3G Phone Call 1.2W
1.5 GHz SKU for smartphones
1.9 GHz SKU for tablets
’NӮ©ҢҹҸШӮөӮДҒB
Intel Unveils Moorestown and the Atom Z600, The Fastest Smartphone Platform?
http://www.anandtech.com/print/3696
Moorestown Battery Life (Figures by Intel)
Total Phone Power Consumption
Idle 21 - 23 mW
Audio Playback 120 mW
1080p Video Playback 1.1W+
Web Browsing (WiFi) 1.1W
2G Phone Call 550 mW
3G Phone Call 1.2W
1.5 GHz SKU for smartphones
1.9 GHz SKU for tablets
678 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/05/07(Ӣа) 22:21:13 ID:sdIxt4vx0
ARMӮ ӮЬӮиӮӯӮнӮөӮӯӮИӮўӮҜӮЗҒA
ARMӮМҚЕ‘еӮМҺг“_ӮНҸҠ‘FRTLғҢғxғӢӮМIPғRғAӮЙӮ·Ӯ¬ӮИӮўӮБӮДӮұӮЖӮр
ҚЕӢЯӮЬӮЕҢ©“ҰӮөӮДӮҪӮнҒBMedfieldӮЬӮЕӮўӮҜӮОӮ©ӮИӮиӮМҚ·ӮЕҸҹӮДӮйӮЖҺvӮӨӮжҒB
ARMӮМҚЕ‘еӮМҺг“_ӮНҸҠ‘FRTLғҢғxғӢӮМIPғRғAӮЙӮ·Ӯ¬ӮИӮўӮБӮДӮұӮЖӮр
ҚЕӢЯӮЬӮЕҢ©“ҰӮөӮДӮҪӮнҒBMedfieldӮЬӮЕӮўӮҜӮОӮ©ӮИӮиӮМҚ·ӮЕҸҹӮДӮйӮЖҺvӮӨӮжҒB
679 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/05/07(Ӣа) 22:22:48 ID:sdIxt4vx0
LevelғҢғxғӢӮЙӮИӮБӮДӮөӮЬӮБӮҪӮИҒB
>>639
uopғLғғғbғVғ…ӮЖӮўӮӨӮМӮНuopӮМғLғғғbғVғ…ӮҫҒB
ғgғҢҒ[ғXғLғғғbғVғ…ӮНuopӮрғLғғғbғVғ…ӮөӮДӮўӮйӮҫӮҜӮЕӮИӮӯғRҒ[ғhӮМҺАҚsғpғXӮағLғғғbғVғ…
Ӯ·ӮйӮҪӮЯҒAҗ§ҢдӮӘ•ЎҺGҒBuopӮН•ПҠ·ҚПӮЭӮМ–Ҫ—ЯӮрғLғғғbғVғ…ӮөӮДӮўӮйӮҫӮҜӮИӮМӮЕҗ§ҢдӮӘ’PҸғӮЕ
“d—НҢш—Ұ“IӮЙӮағEғ}Ғ[ӮЕӮ ӮйҒB
uop cacheӮЖL1I cacheӮрӮИӮзӮЖӮўӮД
uop cacheғ~ғXҺһӮЙӮНL1IӮрӮ»ӮМӮЬӮЬ“ЗӮсӮЕғfғRҒ[ғhҒA
ғqғbғgҺһӮНuopғLғғғbғVғ…Ӯ©Ӯз“ЗӮсӮЕғfғRҒ[ғhӮНӮөӮИӮўӮЖӮўӮӨҺА‘•ӮаӮ ӮиӮӨӮйҒB
>>639
uopғLғғғbғVғ…ӮЖӮўӮӨӮМӮНuopӮМғLғғғbғVғ…ӮҫҒB
ғgғҢҒ[ғXғLғғғbғVғ…ӮНuopӮрғLғғғbғVғ…ӮөӮДӮўӮйӮҫӮҜӮЕӮИӮӯғRҒ[ғhӮМҺАҚsғpғXӮағLғғғbғVғ…
Ӯ·ӮйӮҪӮЯҒAҗ§ҢдӮӘ•ЎҺGҒBuopӮН•ПҠ·ҚПӮЭӮМ–Ҫ—ЯӮрғLғғғbғVғ…ӮөӮДӮўӮйӮҫӮҜӮИӮМӮЕҗ§ҢдӮӘ’PҸғӮЕ
“d—НҢш—Ұ“IӮЙӮағEғ}Ғ[ӮЕӮ ӮйҒB
uop cacheӮЖL1I cacheӮрӮИӮзӮЖӮўӮД
uop cacheғ~ғXҺһӮЙӮНL1IӮрӮ»ӮМӮЬӮЬ“ЗӮсӮЕғfғRҒ[ғhҒA
ғqғbғgҺһӮНuopғLғғғbғVғ…Ӯ©Ӯз“ЗӮсӮЕғfғRҒ[ғhӮНӮөӮИӮўӮЖӮўӮӨҺА‘•ӮаӮ ӮиӮӨӮйҒB
680 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/05/07(Ӣа) 22:28:13 ID:sdIxt4vx0
ӮЬӮ ғxғ“ғ_Ғ[ӮЖӮөӮДӮНAtomӮрҚМ—pӮ·ӮйӮЖIntelӮМғvғүғ“ҒAғXғPғWғ…Ғ[ғӢӮЙҗUӮиүсӮіӮкӮйӮұӮЖӮЙӮИӮйӮ©Ӯз
ӮИӮ©ӮИӮ©ҚЎӮМҢg‘СғҒҒ[ғJҒ[ӮӘ‘ЗӮрӮ«ӮйӮМӮН“пӮөӮўӮМӮӘҢ»ҺАӮҫӮлӮӨӮҜӮЗҒB
AtomҢnӮМғXғ}Ғ[ғgғtғHғ“ӮН•КғWғғғ“ғӢӮЖӮўӮӨӮ©ҚЕҸI“IӮЙӮНAtomӮӘҸҹӮВҸкҚҮҒA
ӮвӮБӮПPCӮЖӮМҢЭҠ·җ«ӮрҸdҺӢӮөӮҪҗ»•iӮӘ•ҒӢyӮ·ӮйӮМӮЕӮНӮИӮ©ӮлӮӨӮ©ҒB
>>675
L1DӮН‘OӮ©Ӯз24KBӮҫӮәҒB–Ҫ—Я•ПҠ·ӮаӮөӮДӮйӮәҒB
ӮИӮ©ӮИӮ©ҚЎӮМҢg‘СғҒҒ[ғJҒ[ӮӘ‘ЗӮрӮ«ӮйӮМӮН“пӮөӮўӮМӮӘҢ»ҺАӮҫӮлӮӨӮҜӮЗҒB
AtomҢnӮМғXғ}Ғ[ғgғtғHғ“ӮН•КғWғғғ“ғӢӮЖӮўӮӨӮ©ҚЕҸI“IӮЙӮНAtomӮӘҸҹӮВҸкҚҮҒA
ӮвӮБӮПPCӮЖӮМҢЭҠ·җ«ӮрҸdҺӢӮөӮҪҗ»•iӮӘ•ҒӢyӮ·ӮйӮМӮЕӮНӮИӮ©ӮлӮӨӮ©ҒB
>>675
L1DӮН‘OӮ©Ӯз24KBӮҫӮәҒB–Ҫ—Я•ПҠ·ӮаӮөӮДӮйӮәҒB
681 ҒF–јҸМ–ўҗЭ’иҒF2010/05/07(Ӣа) 22:40:20 ID:0bImzWQ00
ARMӮМҚЕ‘еӮМҺг“_ӮНҸҠ‘FRTLғҢғxғӢӮМIPғRғAӮЙӮ·Ӯ¬ӮИӮўӮБӮДӮұӮЖӮр
ҚЕӢЯӮЬӮЕҢ©“ҰӮөӮДӮҪӮнҒB
ӮЁӮўӮ—Ӯ—Ӯ—Ӯ—Ӯ—Ӯ—Ӯ—Ӯ—
SilverthorneӮӘҸoӮй‘OӮ©Ӯз’cҺqӮНӮ¶ӮЯӮЖӮ·ӮйҲъҗ~ҒiARM”hӮўӮнӮӯҒjӮӘҺе’ЈӮөӮДӮҪӮҫӮлӮ—Ӯ—Ӯ—
ҚЕӢЯӮЬӮЕҢ©“ҰӮөӮДӮҪӮнҒB
ӮЁӮўӮ—Ӯ—Ӯ—Ӯ—Ӯ—Ӯ—Ӯ—Ӯ—
SilverthorneӮӘҸoӮй‘OӮ©Ӯз’cҺqӮНӮ¶ӮЯӮЖӮ·ӮйҲъҗ~ҒiARM”hӮўӮнӮӯҒjӮӘҺе’ЈӮөӮДӮҪӮҫӮлӮ—Ӯ—Ӯ—
682 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/05/07(Ӣа) 22:44:26 ID:sdIxt4vx0
ҲИҸгҒAӮЁӮкӮНӮөӮОӮзӮӯ2chӮрӢxӢЖӮ·ӮйӮұӮЖӮЙӮөӮҪӮМӮЕүіҒB
683 ҒF–јҸМ–ўҗЭ’иҒF2010/05/07(Ӣа) 23:00:52 ID:mC3k9eWQ0
k-tai.impressӮвmycomӮЙ100mWӮЖҸ‘ӮўӮДӮ ӮБӮҪӮҜӮЗҒA
ғIғtғBғVғғғӢғҠғҠҒ[ғX“ЗӮсӮҫӮз100Ү_ҮhӮ¶ӮбӮИӮӯӮД100ғКҮhӮМӮжӮӨӮҫҒB
ӮВӮЬӮи0.0001WҒH ғzғ“ғgӮҫӮЖӮөӮҪӮзҗҰӮўҒB
ғIғtғBғVғғғӢғҠғҠҒ[ғX“ЗӮсӮҫӮз100Ү_ҮhӮ¶ӮбӮИӮӯӮД100ғКҮhӮМӮжӮӨӮҫҒB
ӮВӮЬӮи0.0001WҒH ғzғ“ғgӮҫӮЖӮөӮҪӮзҗҰӮўҒB
684 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/05/07(Ӣа) 23:05:32 ID:sdIxt4vx0
>100 uW deep sleep power
>21 mW idle power
>300-400mW active power for video playback
>21 mW idle power
>300-400mW active power for video playback
685 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/05/07(Ӣа) 23:09:15 ID:sdIxt4vx0
IsraelӮНӮИӮсӮҫӮ©ӮсӮҫӮўӮБӮДҳ_—қҒ`ғAҒ[ғLҗЭҢvӮМүь—ЗӮӘ‘ҪӮўӮИҒB
“d—НӮЕӮНӮұӮкӮзӮНҳe–рҒBғAғiғҚғOҗFӮМӢӯӮў•”•ӘӮЕӢZҸpҺТӮМ‘wӮӘ”–ӮўӮМӮҫӮлӮӨӮ©ҒB
“d—НӮЕӮНӮұӮкӮзӮНҳe–рҒBғAғiғҚғOҗFӮМӢӯӮў•”•ӘӮЕӢZҸpҺТӮМ‘wӮӘ”–ӮўӮМӮҫӮлӮӨӮ©ҒB
686 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/05/07(Ӣа) 23:12:24 ID:sdIxt4vx0
AtomӮМҗЭҢvӮӘ‘е“d—НӮЕғLғғғ“ғZғӢӮіӮкӮҪTeҒӣasӮЖ“ҜӮ¶җЭҢvғ`Ғ[ғҖӮЖӮўӮӨҺ–ҺАӮӘҸОӮҰӮйҒB
687 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2010/05/08(“y) 05:52:57 ID:1IRkakSI0
AtomӮМӢӯӮЭӮНҗ¶ӮМLinuxӮвWindowsӮӘӮ»ӮМӮЬӮЬ“®ӮӯӮұӮЖӮҫӮлҒBPCӮМғnҒ[ғhҒEғ\ғtғgғCғ“ғtғүӮӘӮ»ӮМӮЬӮЬҺgӮҰӮйҒB
ARMӮНҚЕҗж’[ғvғҚғZғXӮЕҺА‘•ӮөӮҪIPғfғӮӮөӮДӮаӮ»ӮБӮ©ӮзSoCҚмӮБӮДғVғXғeғҖҠJ”ӯӮөӮДҒAӮҫӮ©ӮзҺАҚЫӮМҗ»•iӮӘҸoӮйӮМӮН2Ғ`3”NҢгӮҫӮ©ӮзӮИҒB
“ҜӮ¶ғVғғҒ[ғvӮЕӮаD4ӮНAtom ZғVғҠҒ[ғY”ӯ•\Ӯ©ӮзӮЬӮаӮИӮӯӮөӮДҸoӮҪӮӘҒAҢг”ӯӮМNetWalkerӮН–ўӮҫӮЙ90nmӮЕ800MHzӮМCortex A8ӮҫҒB
ARMӮНҚЕҗж’[ғvғҚғZғXӮЕҺА‘•ӮөӮҪIPғfғӮӮөӮДӮаӮ»ӮБӮ©ӮзSoCҚмӮБӮДғVғXғeғҖҠJ”ӯӮөӮДҒAӮҫӮ©ӮзҺАҚЫӮМҗ»•iӮӘҸoӮйӮМӮН2Ғ`3”NҢгӮҫӮ©ӮзӮИҒB
“ҜӮ¶ғVғғҒ[ғvӮЕӮаD4ӮНAtom ZғVғҠҒ[ғY”ӯ•\Ӯ©ӮзӮЬӮаӮИӮӯӮөӮДҸoӮҪӮӘҒAҢг”ӯӮМNetWalkerӮН–ўӮҫӮЙ90nmӮЕ800MHzӮМCortex A8ӮҫҒB
688 ҒF–јҸМ–ўҗЭ’иҒF2010/05/08(“y) 06:20:58 ID:CTea2poH0
ғOғOғbӮҪ”НҲНӮЕ
Snapdragon 1GHzҒ@Ғ@Ғ@Ғ@Ғ@Ғ@ҚЕ‘е500mW
Snapdragon(җVҢ^) 1.3GHzҒ@Ғ@‘ТӢ@Һһ10mWҲИүә
TegraҒ@Ғ@Ғ@Ҳк”К“IӮИ—ҳ—p50mWҒ@“®үжҚДҗ¶150mW
Tegra 2Ғ@Ғ@ ү№ҠyҚДҗ¶30mWҲИүәҒ@“®үжҚДҗ¶500mW
Ғ–“®үжҚДҗ¶ҺһӮМ“d—НӮӘTegra2ӮжӮи’бӮўҸү‘гTegraӮМҗ”’lӮНӢ^ӮнӮөӮўҒB
Ҳк”К“IӮИҢg‘С“dҳbӮМ1.3Ғ`2”{’ц“xӮМғoғbғeғҠ—e—КӮЙӮаӮ©Ӯ©ӮнӮзӮё
Snapdragon’[––ӮМғoғbғeғҠҺқӮҝӮНҲ«Ӯў
http://review.kakaku.com/review/K0000082257/
http://review.kakaku.com/review/K0000035612/
http://review.kakaku.com/review/K0000035598/
Z600ӮӘ>>677ӮҫӮЖӮ·ӮйӮЖҒAiPad•АӢҗ‘еғoғbғeғҠ’[––ӮЙҗ¬ӮзӮҙӮй“ҫӮИӮўҒH
Snapdragon 1GHzҒ@Ғ@Ғ@Ғ@Ғ@Ғ@ҚЕ‘е500mW
Snapdragon(җVҢ^) 1.3GHzҒ@Ғ@‘ТӢ@Һһ10mWҲИүә
TegraҒ@Ғ@Ғ@Ҳк”К“IӮИ—ҳ—p50mWҒ@“®үжҚДҗ¶150mW
Tegra 2Ғ@Ғ@ ү№ҠyҚДҗ¶30mWҲИүәҒ@“®үжҚДҗ¶500mW
Ғ–“®үжҚДҗ¶ҺһӮМ“d—НӮӘTegra2ӮжӮи’бӮўҸү‘гTegraӮМҗ”’lӮНӢ^ӮнӮөӮўҒB
Ҳк”К“IӮИҢg‘С“dҳbӮМ1.3Ғ`2”{’ц“xӮМғoғbғeғҠ—e—КӮЙӮаӮ©Ӯ©ӮнӮзӮё
Snapdragon’[––ӮМғoғbғeғҠҺқӮҝӮНҲ«Ӯў
http://review.kakaku.com/review/K0000082257/
http://review.kakaku.com/review/K0000035612/
http://review.kakaku.com/review/K0000035598/
Z600ӮӘ>>677ӮҫӮЖӮ·ӮйӮЖҒAiPad•АӢҗ‘еғoғbғeғҠ’[––ӮЙҗ¬ӮзӮҙӮй“ҫӮИӮўҒH
689 ҒF–јҸМ–ўҗЭ’иҒF2010/05/08(“y) 06:26:50 ID:qjHU8RLE0
Ӯ»ӮұӮЕғoғbғeғҠӮр‘еӮ«ӮӯӮ·ӮйӮ©җШӮкӮвӮ·ӮӯӮ·ӮйӮ©ӮНғKғҸҚмӮй‘ӨӮӘ”»’fӮ·ӮйӮҫӮлҒ[Ӯ©ӮзӮЙӮсӮЖӮаӮ©ӮсӮЖӮа
690 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2010/05/08(“y) 07:26:48 ID:1IRkakSI0
Һе”ЖӮНүtҸ»ғpғlғӢӮ¶ӮбӮЛҒH
ғXғ}Ғ[ғgғtғHғ“ғTғCғYӮЖғlғbғgғuғbғNғTғCғYӮ¶ӮбҸБ”п“d—НӮҫӮўӮФҲбӮӨӮҫӮлӮӨӮж
ғXғ}Ғ[ғgғtғHғ“ғTғCғYӮЖғlғbғgғuғbғNғTғCғYӮ¶ӮбҸБ”п“d—НӮҫӮўӮФҲбӮӨӮҫӮлӮӨӮж
691 ҒF–јҸМ–ўҗЭ’иҒF2010/05/08(“y) 07:49:12 ID:niuDmG410
Z600ӮН4Ң^үtҸ»ғXғ}ғtғHӮЙӮНүЯҸиӮИӢCӮӘӮ·ӮйӮЛӮҘ
692 ҒF–јҸМ–ўҗЭ’иҒF2010/05/08(“y) 07:58:17 ID:qjHU8RLE0
ӮФӮБӮҝӮбӮ°ғoғbғeғҠӮжӮи“ь—НғfғoғCғXӮЗӮӨӮ·ӮйӮ©ӮМ•ыӮӘӢCӮЙӮИӮй
ӮұӮұӮЬӮЕӮ«ӮҪӮзPCӮЖӮ©ӮнӮзӮсӮө
ӮұӮұӮЬӮЕӮ«ӮҪӮзPCӮЖӮ©ӮнӮзӮсӮө
693 ҒF–јҸМ–ўҗЭ’иҒF2010/05/08(“y) 07:59:19 ID:qjHU8RLE0
sageӮДӮөӮЬӮБӮҪageage
>>692
Ӯ»ӮұӮЕғfғBғXғvғҢғCғRғ“ғsғ…Ғ[ғeғBғ“ғOӮЕӮ·ӮжҒB
1. •Ғ’iӮНҢg‘С“dҳbӮМӮжӮӨӮИҺgӮў•ыӮрӮ·ӮйҒBӮЭӮсӮИӮӘӮ»ӮкӮрҺқӮҝ•аӮўӮДӮўӮй–ў—ҲҒB
2. ҠX’ҶӮМ—lҒXӮИүУҸҠӮвҒAҗEҸкӮМ‘мҸгӮЙғfғBғXғvғҢғCӮЖғLҒ[ғ{Ғ[ғh/ғ}ғEғXӮҫӮҜӮӘ
ӮӯӮБӮВӮўӮҪӮҫӮҜӮМӮжӮӨӮИӢӨ—p“ьҸo—НғvғүғbғgғtғHҒ[ғҖӮрҗЭ’uҒBғCғ“ғ^Ғ[ғtғFҒ[ғXӮНғfғBғXғvғҢғCӮрҠЬӮЯӮД
–іҗьӮМғҶғjғoҒ[ғTғӢӮИӮаӮМӮЙӮИӮБӮДӮўӮйҒB
3. ӢӨ—p“ьҸo—НғvғүғbғgғtғHҒ[ғҖӮМӢЯӮӯӮЙҢg‘СӢ@ҠнӮрӮЁӮӯӮЖ–іҗьӮЕҺ©“®“IӮЙӮВӮИӮӘӮиҒA
ғfғBғXғvғҢғCӮЖғLҒ[ғ{Ғ[ғh/ғ}ғEғXӮӘ”FҺҜӮіӮкӮДӮ»ӮҝӮзӮЙ“ьҸo—НӮМҗ§ҢдӮӘӮӨӮВӮйҒB
Ңg‘СӢ@ҠнӮНPCӮМ–{‘МӮМӮжӮӨӮИ–рҠ„ӮЙ‘ҰҚАӮЙҗШӮи‘ЦӮнӮйҒB
ғlғ^ӮҫӮӘғNғүғEғhӮжӮиӮНүВ”\җ«ӮӘӮ ӮйӮЖҺvӮӨӮјҒB
Ӯ»ӮұӮЕғfғBғXғvғҢғCғRғ“ғsғ…Ғ[ғeғBғ“ғOӮЕӮ·ӮжҒB
1. •Ғ’iӮНҢg‘С“dҳbӮМӮжӮӨӮИҺgӮў•ыӮрӮ·ӮйҒBӮЭӮсӮИӮӘӮ»ӮкӮрҺқӮҝ•аӮўӮДӮўӮй–ў—ҲҒB
2. ҠX’ҶӮМ—lҒXӮИүУҸҠӮвҒAҗEҸкӮМ‘мҸгӮЙғfғBғXғvғҢғCӮЖғLҒ[ғ{Ғ[ғh/ғ}ғEғXӮҫӮҜӮӘ
ӮӯӮБӮВӮўӮҪӮҫӮҜӮМӮжӮӨӮИӢӨ—p“ьҸo—НғvғүғbғgғtғHҒ[ғҖӮрҗЭ’uҒBғCғ“ғ^Ғ[ғtғFҒ[ғXӮНғfғBғXғvғҢғCӮрҠЬӮЯӮД
–іҗьӮМғҶғjғoҒ[ғTғӢӮИӮаӮМӮЙӮИӮБӮДӮўӮйҒB
3. ӢӨ—p“ьҸo—НғvғүғbғgғtғHҒ[ғҖӮМӢЯӮӯӮЙҢg‘СӢ@ҠнӮрӮЁӮӯӮЖ–іҗьӮЕҺ©“®“IӮЙӮВӮИӮӘӮиҒA
ғfғBғXғvғҢғCӮЖғLҒ[ғ{Ғ[ғh/ғ}ғEғXӮӘ”FҺҜӮіӮкӮДӮ»ӮҝӮзӮЙ“ьҸo—НӮМҗ§ҢдӮӘӮӨӮВӮйҒB
Ңg‘СӢ@ҠнӮНPCӮМ–{‘МӮМӮжӮӨӮИ–рҠ„ӮЙ‘ҰҚАӮЙҗШӮи‘ЦӮнӮйҒB
ғlғ^ӮҫӮӘғNғүғEғhӮжӮиӮНүВ”\җ«ӮӘӮ ӮйӮЖҺvӮӨӮјҒB
695 ҒF–јҸМ–ўҗЭ’иҒF2010/05/11(үО) 22:24:04 ID:glb1gcqj0
Ӯ»ӮаӮ»Ӯа‘gҚһҢnӮМғvғҚғZғbғTӮМҸЪҚЧӮИӮсӮДӮЗӮұӮаҢцҠJӮөӮДӮИӮўӮөҒC
ҢцҗіӮИ”дҠrҺ©‘М•sүВ”\Ӯ¶ӮбӮсҒB
ҢцҗіӮИ”дҠrҺ©‘М•sүВ”\Ӯ¶ӮбӮсҒB
696 ҒF–јҸМ–ўҗЭ’иҒF2010/05/12(җ…) 00:24:26 ID:ub3MBS6O0
ӮўӮёӮкӮЙӮ№ӮжUniPhier 4MBB+Ғ•SH-Mobile G4ӮӘ
ғҸғbғgғpғtғHҒ[ғ}ғ“ғXҚЕӢӯӮЕӮ ӮйӮұӮЖӮЙ•ПӮнӮиӮНӮИӮў
ғҸғbғgғpғtғHҒ[ғ}ғ“ғXҚЕӢӯӮЕӮ ӮйӮұӮЖӮЙ•ПӮнӮиӮНӮИӮў
697 ҒF–јҸМ–ўҗЭ’иҒF2010/05/26(җ…) 02:51:11 ID:lPo5TLVD0
ho
698 ҒF–јҸМ–ўҗЭ’иҒF2010/05/27(–Ш) 01:39:25 ID:YhCm224N0
•ДIntelҒAғfғBғXғNғҠҒ[ғgGPUҺsҸкӮЦӮМҺQ“ьӮНӮИӮўӮұӮЖӮрҚДҠm”F
http://journal.mycom.co.jp/news/2010/05/26/117/index.html
4”N‘OҒEҒEҒE
Ғb838 ҒF2006/09/03(“ъ) 01:58:34 ID:MD28wGH60
ҒbIntel puts beef into designing discrete graphics chip
Ғbhttp://www.theinquirer.net/default.aspx?article=33720
Ғb
ҒbIntelӮӘdiscreteӮИGPUӮЙҗ^–К–ЪӮЙҺжӮи‘gӮсӮЕӮўӮйӮзӮөӮўҒB
Ғb
Ғb434 ҒF2007/02/11(“ъ) 02:29:30 ID:7KPzS4wf0
Ғbhttp://www.theinquirer.net/default.aspx?article=32776
Ғb
ҒbүрҢЩҺТӮМӮЩӮӨӮӘ‘ҪӮўIntelӮМғRҒ[ғhғlҒ[ғҖҒAҺ–ҺАҸг3ӮВӮМӮӨӮҝ2ӮВӮӘҺҖӮЙӮЬӮ·ҒB
ҒbӢ»–Ўҗ[ӮўӮМӮНӮ»ӮкӮзӮМ‘¶ҚЭӮ»ӮМӮаӮМӮЕӮНӮИӮӯҒAӮ»ӮкӮзӮӘmini-coreӮЕӮ ӮйӮұӮЖӮЕӮ·ҒB
Ғb
Ғb”ЮӮзӮМ–ј‘OӮНKevetҒAKeiferҒALarrabee(Larabee?Laraby?Larraby?)ӮЕӮ·ҒB
Ғb”ЮӮзӮНҠFҒAҠmӮ©ӮЙҚЭӮиӮЬӮ·ҒAӮўӮҰҚЭӮиӮЬӮөӮҪҒBIntelӮМmini-coreҢvүжӮМҲкҠВӮЖӮөӮДҒB
ҒbKevetӮЖKeiferӮНүрҢЩӮіӮкӮЬӮөӮҪӮӘLarrabeeӮЙӮНғSҒ[ғTғCғ“ӮӘҸoӮЬӮөӮҪҒB
http://journal.mycom.co.jp/news/2010/05/26/117/index.html
4”N‘OҒEҒEҒE
Ғb838 ҒF2006/09/03(“ъ) 01:58:34 ID:MD28wGH60
ҒbIntel puts beef into designing discrete graphics chip
Ғbhttp://www.theinquirer.net/default.aspx?article=33720
Ғb
ҒbIntelӮӘdiscreteӮИGPUӮЙҗ^–К–ЪӮЙҺжӮи‘gӮсӮЕӮўӮйӮзӮөӮўҒB
Ғb
Ғb434 ҒF2007/02/11(“ъ) 02:29:30 ID:7KPzS4wf0
Ғbhttp://www.theinquirer.net/default.aspx?article=32776
Ғb
ҒbүрҢЩҺТӮМӮЩӮӨӮӘ‘ҪӮўIntelӮМғRҒ[ғhғlҒ[ғҖҒAҺ–ҺАҸг3ӮВӮМӮӨӮҝ2ӮВӮӘҺҖӮЙӮЬӮ·ҒB
ҒbӢ»–Ўҗ[ӮўӮМӮНӮ»ӮкӮзӮМ‘¶ҚЭӮ»ӮМӮаӮМӮЕӮНӮИӮӯҒAӮ»ӮкӮзӮӘmini-coreӮЕӮ ӮйӮұӮЖӮЕӮ·ҒB
Ғb
Ғb”ЮӮзӮМ–ј‘OӮНKevetҒAKeiferҒALarrabee(Larabee?Laraby?Larraby?)ӮЕӮ·ҒB
Ғb”ЮӮзӮНҠFҒAҠmӮ©ӮЙҚЭӮиӮЬӮ·ҒAӮўӮҰҚЭӮиӮЬӮөӮҪҒBIntelӮМmini-coreҢvүжӮМҲкҠВӮЖӮөӮДҒB
ҒbKevetӮЖKeiferӮНүрҢЩӮіӮкӮЬӮөӮҪӮӘLarrabeeӮЙӮНғSҒ[ғTғCғ“ӮӘҸoӮЬӮөӮҪҒB
699 ҒF–јҸМ–ўҗЭ’иҒF2010/05/27(–Ш) 07:39:18 ID:M1WLhPFf0
Larrabee 2ӮӘғLғғғ“ғZғӢӮіӮкӮДLarrabee 3ӮӘLarrabee 2ӮЙүь–јӮіӮкӮҪӮБӮДҳbӮЛ
ttp://www.semiaccurate.com/2010/05/17/larrabee-3-now-larrabee-2/
ttp://www.semiaccurate.com/2010/05/17/larrabee-3-now-larrabee-2/
700 ҒF–јҸМ–ўҗЭ’иҒF2010/05/27(–Ш) 08:34:04 ID:ZiiX71BD0
Ӯ»ӮкҗжҸTӮМғfғ}ҺӨҲБ
SCC Technical Information
http://techresearch.intel.com/articles/Tera-Scale/1836.htm
MPRӮМpdfӢvҒXӮЙӮЭӮҪӮәҒB
http://techresearch.intel.com/UserFiles/en-us/File/M17_Intel_CloudChip_reprint.pdf
http://techresearch.intel.com/articles/Tera-Scale/1836.htm
MPRӮМpdfӢvҒXӮЙӮЭӮҪӮәҒB
http://techresearch.intel.com/UserFiles/en-us/File/M17_Intel_CloudChip_reprint.pdf
”ј“ұ‘МIPғүғCғZғ“ғXӮЕ•ҒӢyӮөӮҪARMғAҒ[ғLғeғNғ`ғғ
http://www.gbrc.jp/journal/amr/free/dlranklog.cgi?dl=AMR5-5-4.pdf
ARMӮӘҢg‘СӮЕ•ҒӢyӮөӮҪ—қ—RӮНҢӢӢЗү^ӮИӮМӮ©ҒA
Ӯ»ӮкӮЖӮаIPғrғWғlғXғӮғfғӢӮМҗ¬ҢчӮЖҢ©ӮДӮжӮўӮМӮҫӮлӮӨӮ©ҒB
ӮЁӮкӮМ”]“аӮЕӮН‘gӮЭҚһӮЭӮЕӮНARMҲИҸгӮМ“d—Нҗ«”\”дӮМғvғҚғZғbғTӮН
ӮаӮБӮЖӮ ӮБӮҪӮНӮёӮҫӮӘҒA’бҸБ”п“d—НӮҫӮҜӮӘ•ҒӢyӮМҢ®ӮЕӮИӮўӮұӮЖӮНҠmӮ©ҒB
http://www.gbrc.jp/journal/amr/free/dlranklog.cgi?dl=AMR5-5-4.pdf
ARMӮӘҢg‘СӮЕ•ҒӢyӮөӮҪ—қ—RӮНҢӢӢЗү^ӮИӮМӮ©ҒA
Ӯ»ӮкӮЖӮаIPғrғWғlғXғӮғfғӢӮМҗ¬ҢчӮЖҢ©ӮДӮжӮўӮМӮҫӮлӮӨӮ©ҒB
ӮЁӮкӮМ”]“аӮЕӮН‘gӮЭҚһӮЭӮЕӮНARMҲИҸгӮМ“d—Нҗ«”\”дӮМғvғҚғZғbғTӮН
ӮаӮБӮЖӮ ӮБӮҪӮНӮёӮҫӮӘҒA’бҸБ”п“d—НӮҫӮҜӮӘ•ҒӢyӮМҢ®ӮЕӮИӮўӮұӮЖӮНҠmӮ©ҒB
–{“–ӮЙ“d—Нҗ«”\”дӮр’ЗӢҒӮ·ӮйӮИӮзғAҒ[ғLҒ`RTLҗЭҢvҲИүәӮМ—МҲжӮЕӮа
“d—НӮрҚЕ“Kү»ӮрӮөӮИӮҜӮкӮОӮИӮзӮИӮўҒB
(–{үЖ)ARMӮНҸҠ‘FRTLӮИIPғRғAӮЙӮ·Ӯ¬ӮИӮўӮМӮЕҒA
ҚЕҸI“IӮИҸБ”п“d—НӮНҢӢӢЗӮМӮЖӮұӮлғxғ“ғ_Ғ[‘ӨӮМҗЭҢvӮвҗ»‘ўғvғҚғZғXӮМ—Н—КӮЙӮаҲЛ‘¶ӮөӮДӮўӮйҒB
ӮұӮМ“_ҒAIntelӮМAtomӮНҠ®‘S“ЖҺ©җЭҢvӮЕҒAҗ»‘ўғvғҚғZғXӮаAtom SoC—pӮЙҚЕ“Kү»ӮіӮкӮДӮўӮйӮМӮЕҒA
ғ}ғCғNғҚғAҒ[ғLҒ`ғvғҚғZғXӮЙӮўӮҪӮйӮЬӮЕҲкҠСӮөӮД“d—Нҗ«”\”дӮЙғtғHҒ[ғJғXӮөӮДӮўӮй“_ӮЙғAғhғoғ“ғeҒ[ғWӮӘӮ ӮйҒB
ӮЖӮўӮӨӮнӮҜӮЕӢZҸp“IӮЙAtomӮӘARMӮр“d—Нҗ«”\”дӮЕҸгүсӮйӮМӮН•КӮЙӢБӮ«ӮЕӮНӮИӮўҒB
(үҪӮЕӮаӮ©ӮсӮЕӮаISAӮӘ—D—тӮрҢҲ’иӮ·ӮйӮ©ӮМӮжӮӨӮИ”ӯҢҫӮрӮ·ӮйҳA’ҶӮНҒARISCҳ_‘ҲӮӘҺcӮөӮҪ•үӮМҲвҺYӮҫӮЖҺvӮӨҒB)
http://ednjapan.rbi-j.com/issue/2009/12/49/5693
Ҳк•ыӮЕҒA“d—Нҗ«”\”дӮЕүјӮЙAtomӮӘARMӮЙ‘еӮ«ӮӯҸҹӮБӮҪӮЖӮөӮДҒA
‘ҰAtomӮӘ•ҒӢyӮӘҢҲ’иӮ·ӮйӮ©ӮЖӮўӮнӮкӮйӮЖҒAӮұӮкӮағRғ“ғsғ…Ғ[ғ^ӮМ—рҺjӮрҢЪӮЭӮкӮОӮнӮ©ӮйӮЖӮЁӮиҒA
Ӯ»ӮӨ’PҸғӮЙӮўӮӯӮжӮӨӮИӮаӮМӮЕӮНӮИӮўҒB
“d—НӮрҚЕ“Kү»ӮрӮөӮИӮҜӮкӮОӮИӮзӮИӮўҒB
(–{үЖ)ARMӮНҸҠ‘FRTLӮИIPғRғAӮЙӮ·Ӯ¬ӮИӮўӮМӮЕҒA
ҚЕҸI“IӮИҸБ”п“d—НӮНҢӢӢЗӮМӮЖӮұӮлғxғ“ғ_Ғ[‘ӨӮМҗЭҢvӮвҗ»‘ўғvғҚғZғXӮМ—Н—КӮЙӮаҲЛ‘¶ӮөӮДӮўӮйҒB
ӮұӮМ“_ҒAIntelӮМAtomӮНҠ®‘S“ЖҺ©җЭҢvӮЕҒAҗ»‘ўғvғҚғZғXӮаAtom SoC—pӮЙҚЕ“Kү»ӮіӮкӮДӮўӮйӮМӮЕҒA
ғ}ғCғNғҚғAҒ[ғLҒ`ғvғҚғZғXӮЙӮўӮҪӮйӮЬӮЕҲкҠСӮөӮД“d—Нҗ«”\”дӮЙғtғHҒ[ғJғXӮөӮДӮўӮй“_ӮЙғAғhғoғ“ғeҒ[ғWӮӘӮ ӮйҒB
ӮЖӮўӮӨӮнӮҜӮЕӢZҸp“IӮЙAtomӮӘARMӮр“d—Нҗ«”\”дӮЕҸгүсӮйӮМӮН•КӮЙӢБӮ«ӮЕӮНӮИӮўҒB
(үҪӮЕӮаӮ©ӮсӮЕӮаISAӮӘ—D—тӮрҢҲ’иӮ·ӮйӮ©ӮМӮжӮӨӮИ”ӯҢҫӮрӮ·ӮйҳA’ҶӮНҒARISCҳ_‘ҲӮӘҺcӮөӮҪ•үӮМҲвҺYӮҫӮЖҺvӮӨҒB)
http://ednjapan.rbi-j.com/issue/2009/12/49/5693
Ҳк•ыӮЕҒA“d—Нҗ«”\”дӮЕүјӮЙAtomӮӘARMӮЙ‘еӮ«ӮӯҸҹӮБӮҪӮЖӮөӮДҒA
‘ҰAtomӮӘ•ҒӢyӮӘҢҲ’иӮ·ӮйӮ©ӮЖӮўӮнӮкӮйӮЖҒAӮұӮкӮағRғ“ғsғ…Ғ[ғ^ӮМ—рҺjӮрҢЪӮЭӮкӮОӮнӮ©ӮйӮЖӮЁӮиҒA
Ӯ»ӮӨ’PҸғӮЙӮўӮӯӮжӮӨӮИӮаӮМӮЕӮНӮИӮўҒB
http://pc.watch.impress.co.jp/img/pcw/docs/367/786/html/11.jpg.html
ӮҝӮИӮЭӮЙӮұӮМҠGӮрӮЭӮкӮОӮнӮ©ӮйӮЖӮЁӮиҒA
32nmӮЕҺc”OӮИӮӘӮз
Bonnell ҒЁ Saltwell
ӮЙғ}ғCғNғҚғAҒ[ғLғeғNғ`ғғӮӘ•ПҚXӮіӮкӮй—\’иӮЙӮИӮБӮДӮўӮйҒB
ҢВҗl“IӮЙӮНӮаӮӨҸӯӮөӮұӮМӮЬӮЬҠg’ЈӮөӮИӮўӮЕ’б“d—Нү»Ӯр’ЗӢҒӮөӮДӮЩӮөӮўӮ©ӮБӮҪӮсӮҫӮҜӮЗӮИҒB
{kind=link}
ӮҝӮИӮЭӮЙӮұӮМҠGӮрӮЭӮкӮОӮнӮ©ӮйӮЖӮЁӮиҒA
32nmӮЕҺc”OӮИӮӘӮз
Bonnell ҒЁ Saltwell
ӮЙғ}ғCғNғҚғAҒ[ғLғeғNғ`ғғӮӘ•ПҚXӮіӮкӮй—\’иӮЙӮИӮБӮДӮўӮйҒB
ҢВҗl“IӮЙӮНӮаӮӨҸӯӮөӮұӮМӮЬӮЬҠg’ЈӮөӮИӮўӮЕ’б“d—Нү»Ӯр’ЗӢҒӮөӮДӮЩӮөӮўӮ©ӮБӮҪӮсӮҫӮҜӮЗӮИҒB
705 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2010/06/01(үО) 02:08:50 ID:oYz7PYiz0
Sandy BridgeӮМLoad UnitӮМҺА‘•
http://microboy.seesaa.net/article/148783139.html
>>704
ӮЬҒAӮжӮи“d—НҢш—ҰӮӘүь‘PӮ·Ӯйүь—ЗӮИӮз‘еҠҪҢ}ӮҫӮӘҒEҒEҒE
http://microboy.seesaa.net/article/148783139.html
>>704
ӮЬҒAӮжӮи“d—НҢш—ҰӮӘүь‘PӮ·Ӯйүь—ЗӮИӮз‘еҠҪҢ}ӮҫӮӘҒEҒEҒE
706 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2010/06/01(үО) 02:14:45 ID:oYz7PYiz0
>>702
Ӯ»ӮиӮбӮ»ӮӨӮҫӮл
“ЖҺ©–Ҫ—ЯғZғbғgғAҒ[ғLғeғNғ`ғғӮЕғRғ“ғpғCғүӮрӮНӮ¶ӮЯӮЖӮөӮҪғ\ғtғgғCғ“ғtғүӮрҲЫҺқӮ·ӮйӮМӮН
ӮЗӮұӮМғҒҒ[ғJҒ[Ӯа•ү’SӮӘ‘еӮ«ӮўҒB
Ӯ»ӮиӮбӮ»ӮӨӮҫӮл
“ЖҺ©–Ҫ—ЯғZғbғgғAҒ[ғLғeғNғ`ғғӮЕғRғ“ғpғCғүӮрӮНӮ¶ӮЯӮЖӮөӮҪғ\ғtғgғCғ“ғtғүӮрҲЫҺқӮ·ӮйӮМӮН
ӮЗӮұӮМғҒҒ[ғJҒ[Ӯа•ү’SӮӘ‘еӮ«ӮўҒB
707 ҒF–јҸМ–ўҗЭ’иҒF2010/06/03(–Ш) 23:16:19 ID:ZpNJ2ECp0
>>688-692
3.8ғCғ“ғ`үtҸ»ӮЕ—ҲӮҪӮжҒBғCғ“ғeғӢӮН–{ӢCӮҫӮжҒB
Moorestown“ӢҚЪғXғ}Ғ[ғgғtғHғ“ӮрғCғ“ғeғӢӮӘ”вҳI
http://ascii.jp/elem/000/000/526/526838/
3.8ғCғ“ғ`үtҸ»ӮЕ—ҲӮҪӮжҒBғCғ“ғeғӢӮН–{ӢCӮҫӮжҒB
Moorestown“ӢҚЪғXғ}Ғ[ғgғtғHғ“ӮрғCғ“ғeғӢӮӘ”вҳI
http://ascii.jp/elem/000/000/526/526838/
708 ҒF–јҸМ–ўҗЭ’иҒF2010/06/03(–Ш) 23:21:10 ID:ss1mAvp60
ӮұӮМ”ВӮЕҢҫӮӨӮМӮаӮИӮсӮҫӮӘӮвӮБӮПWindowsӮӘҺgӮўӮҪӮўӮжӮИӮ
709 ҒF–јҸМ–ўҗЭ’иҒF2010/06/03(–Ш) 23:39:44 ID:L58ABFRQ0
ӮҰӮБҒAWindowsҒH
VAIO Tyep PӮМ8Ң^ғҸғCғhӮЕӮіӮҰғLғcғLғcүж–КӮЕҢҷӢCӮӘӮіӮ·ӮМӮЙ3.8Ң^Ӯ¶ӮбҒEҒE
VAIO Tyep PӮМ8Ң^ғҸғCғhӮЕӮіӮҰғLғcғLғcүж–КӮЕҢҷӢCӮӘӮіӮ·ӮМӮЙ3.8Ң^Ӯ¶ӮбҒEҒE
710 ҒF–јҸМ–ўҗЭ’иҒF2010/06/04(Ӣа) 00:28:40 ID:h1aopu8m0
ӮўӮв—¬җОӮЙғ|ғ“ҚЪӮ№ӮНҢҷӮҫӮӘӮ—Ӯ—Ӯ—
GPUӮЖCPUӮӘҢҲ’и“IӮЙҲЩӮИӮй“_ӮЖӮөӮДҒA
ҸҲ—қ‘ОҸЫӮЙғҠғAғӢғ^ғCғҖҗ«ӮӘӢҒӮЯӮзӮДӮўӮйӮ©ӮЗӮӨӮ©ӮБӮДӮұӮЖӮӘӮ ӮйҒB
ӮұӮМӮұӮЖӮӘ”ғӮўҺиӮМҗн—ӘӮЙҢҲ’и“IӮИҲбӮўӮрӮаӮҪӮзӮ·ҒB
CPUӮМҸкҚҮҒA—бӮҰӮОPCҸгӮЕӮжӮӯ“®Ӯ©Ӯ·ғvғҚғOғүғҖӮЖӮўӮҰӮОҒA
OSӮМғTҒ[ғrғXӮҫӮБӮҪӮиӮвғIғtғBғXӮвӮзғuғүғEғUӮМҸҲ—қӮҫӮБӮҪӮиӮ·ӮйӮнӮҜӮҫӮӘҒA
Ӯ»ӮМ‘е•”•ӘӮӘғҠғAғӢғ^ғCғҖҗ«ӮрӢҒӮЯӮзӮкӮДӮЁӮзӮёҒA‘¬ӮҜӮкӮО‘¬ӮўӮЩӮЗүҝ’lӮМҚӮӮўӮаӮМӮЙӮИӮБӮДӮўӮйҒB
ӮөӮ©ӮөҒAGPU=ғүғXғ^ғOғүғtғBғbғNғvғҚғZғbғTӮМғ^Ғ[ғQғbғgӮНғQҒ[ғҖӮИӮМӮЕ
ҚЕҚӮүжҺҝӮМҗЭ’иӮЕ60fpsӮӘҸoӮкӮОҒAӮ»ӮкҲИҸгӮМҸҲ—қ”\—НӮНҲУ–ЎӮӘӮИӮӯӮИӮйҒB
Ӯ»ӮкӮЗӮұӮлӮ©Ҳк”КӮЙҚӮҗ«”\GPUӮН“d—НӮвүҝҠiӮӘҚӮӮӯӮИӮйӮМӮЕҒA
—\ҺZӮЙҗ§–сӮМӮИӮў”ғӮўҺиӮЙӮЖӮБӮДӮНҺ©•ӘӮМӮвӮйғQҒ[ғҖӮМүжҺҝӮЕ60fpsӮӘӮЕӮйҚЕ’бҢАӮМGPUӮр
ҸнӮЙ‘•’…ӮөӮДӮўӮйӮМӮӘҚ\җ¬ҸгӮМғxғXғgӮЖӮўӮӨӮұӮЖӮЙӮИӮБӮДӮөӮЬӮӨҒB
ҺАҚЫҒAPCӮЕғQҒ[ғҖӮр”дҠr“IӮвӮй‘wӮЕҒAӮИӮЁӮ©ӮВ—\ҺZӮНҸ\•ӘӮ ӮБӮДӮа
ӮнӮҙӮнӮҙғҚҒ[ғGғ“ғhӮвғ~ғhғӢӮМғJҒ[ғhӮрҚDӮсӮЕ”ғӮБӮДӮўӮйҗlӮН‘ҪӮўӮҫӮлӮӨҒB
ғnғCғGғ“ғhGPUӮМҚw“ьҺТӮНғQҒ[ғ}Ғ[ӮЕӮ ӮйҲИ‘OӮЙ’PӮИӮйғӮғmҚDӮ«ӮӘ‘ҪӮўҒB
(ӮұӮМӮжӮӨӮИ ғҠғAғӢғ^ғCғҖҗ« == үЯҸиҗ«”\ӮМ”Ы’и ӮНҒAGPUҲИҠOӮМғҠғAғӢғ^ғCғҖҸҲ—қӮИ•Ә–мӮЕӮаҗ¬Ӯи—§ӮБӮДӮўӮйҒB)
ҸҲ—қ‘ОҸЫӮЙғҠғAғӢғ^ғCғҖҗ«ӮӘӢҒӮЯӮзӮДӮўӮйӮ©ӮЗӮӨӮ©ӮБӮДӮұӮЖӮӘӮ ӮйҒB
ӮұӮМӮұӮЖӮӘ”ғӮўҺиӮМҗн—ӘӮЙҢҲ’и“IӮИҲбӮўӮрӮаӮҪӮзӮ·ҒB
CPUӮМҸкҚҮҒA—бӮҰӮОPCҸгӮЕӮжӮӯ“®Ӯ©Ӯ·ғvғҚғOғүғҖӮЖӮўӮҰӮОҒA
OSӮМғTҒ[ғrғXӮҫӮБӮҪӮиӮвғIғtғBғXӮвӮзғuғүғEғUӮМҸҲ—қӮҫӮБӮҪӮиӮ·ӮйӮнӮҜӮҫӮӘҒA
Ӯ»ӮМ‘е•”•ӘӮӘғҠғAғӢғ^ғCғҖҗ«ӮрӢҒӮЯӮзӮкӮДӮЁӮзӮёҒA‘¬ӮҜӮкӮО‘¬ӮўӮЩӮЗүҝ’lӮМҚӮӮўӮаӮМӮЙӮИӮБӮДӮўӮйҒB
ӮөӮ©ӮөҒAGPU=ғүғXғ^ғOғүғtғBғbғNғvғҚғZғbғTӮМғ^Ғ[ғQғbғgӮНғQҒ[ғҖӮИӮМӮЕ
ҚЕҚӮүжҺҝӮМҗЭ’иӮЕ60fpsӮӘҸoӮкӮОҒAӮ»ӮкҲИҸгӮМҸҲ—қ”\—НӮНҲУ–ЎӮӘӮИӮӯӮИӮйҒB
Ӯ»ӮкӮЗӮұӮлӮ©Ҳк”КӮЙҚӮҗ«”\GPUӮН“d—НӮвүҝҠiӮӘҚӮӮӯӮИӮйӮМӮЕҒA
—\ҺZӮЙҗ§–сӮМӮИӮў”ғӮўҺиӮЙӮЖӮБӮДӮНҺ©•ӘӮМӮвӮйғQҒ[ғҖӮМүжҺҝӮЕ60fpsӮӘӮЕӮйҚЕ’бҢАӮМGPUӮр
ҸнӮЙ‘•’…ӮөӮДӮўӮйӮМӮӘҚ\җ¬ҸгӮМғxғXғgӮЖӮўӮӨӮұӮЖӮЙӮИӮБӮДӮөӮЬӮӨҒB
ҺАҚЫҒAPCӮЕғQҒ[ғҖӮр”дҠr“IӮвӮй‘wӮЕҒAӮИӮЁӮ©ӮВ—\ҺZӮНҸ\•ӘӮ ӮБӮДӮа
ӮнӮҙӮнӮҙғҚҒ[ғGғ“ғhӮвғ~ғhғӢӮМғJҒ[ғhӮрҚDӮсӮЕ”ғӮБӮДӮўӮйҗlӮН‘ҪӮўӮҫӮлӮӨҒB
ғnғCғGғ“ғhGPUӮМҚw“ьҺТӮНғQҒ[ғ}Ғ[ӮЕӮ ӮйҲИ‘OӮЙ’PӮИӮйғӮғmҚDӮ«ӮӘ‘ҪӮўҒB
(ӮұӮМӮжӮӨӮИ ғҠғAғӢғ^ғCғҖҗ« == үЯҸиҗ«”\ӮМ”Ы’и ӮНҒAGPUҲИҠOӮМғҠғAғӢғ^ғCғҖҸҲ—қӮИ•Ә–мӮЕӮаҗ¬Ӯи—§ӮБӮДӮўӮйҒB)
>>705
‘Ҡ•ПӮнӮзӮёӮұӮМғXғҢӮМғӮғҚғpғNғlғ^ӮМ‘ҪӮўғTғCғgӮҫӮИҒBӮЬӮ ӮЁӮк“IӮЙӮНғpғNғҠҺ©‘МӮН•КӮЙӮўӮўӮҜӮЗӮіҒB
‘Ҡ•ПӮнӮзӮёӮұӮМғXғҢӮМғӮғҚғpғNғlғ^ӮМ‘ҪӮўғTғCғgӮҫӮИҒBӮЬӮ ӮЁӮк“IӮЙӮНғpғNғҠҺ©‘МӮН•КӮЙӮўӮўӮҜӮЗӮіҒB
713 ҒF–јҸМ–ўҗЭ’иҒF2010/06/07(ҢҺ) 20:10:06 ID:aInL02c80
җVҺQӮ©ҒB
ӮұӮМғXғҢӮМҸZҗlӮӘӮвӮБӮДӮйblogӮҫӮжҒB
ӮұӮМғXғҢӮМҸZҗlӮӘӮвӮБӮДӮйblogӮҫӮжҒB
ӮЙӮаӮ©Ӯ©ӮнӮзӮёPCҗўҠEӮЕGPUӮӘӮаӮДӮНӮвӮіӮкӮй—қ—RӮЖӮөӮД
ҒE•ДҚ‘ӮЕӮМFPSӮӘҒAPC•¶ү»ӮМ’ҶӮЕҲЩҸнӮИ’nҲКӮЕӮ ӮйӮұӮЖ
ҒE3DғQҒ[ӮаүЯӢҺӮМ2DғQҒ[ӮЖ“ҜӮ¶ӮӯҒAҸ\•ӘӮИӢZҸpғҢғxғӢӮМ’Bҗ¬ ҒЁ Ң|ҸpҒE•\Ң»–КӮМ–НҚх
ӮМ’iҠKӮЙ’BӮөӮДӮўӮйӮӘҒAҸБ”пҺТӮМ”FҺҜӮӘӮЬӮҫ’ЗӮўӮВӮўӮДӮИӮў
ӮМ2“_ӮӘ‘еӮ«ӮўӮҫӮлӮӨҒB
ҒE•ДҚ‘ӮЕӮМFPSӮӘҒAPC•¶ү»ӮМ’ҶӮЕҲЩҸнӮИ’nҲКӮЕӮ ӮйӮұӮЖ
ҒE3DғQҒ[ӮаүЯӢҺӮМ2DғQҒ[ӮЖ“ҜӮ¶ӮӯҒAҸ\•ӘӮИӢZҸpғҢғxғӢӮМ’Bҗ¬ ҒЁ Ң|ҸpҒE•\Ң»–КӮМ–НҚх
ӮМ’iҠKӮЙ’BӮөӮДӮўӮйӮӘҒAҸБ”пҺТӮМ”FҺҜӮӘӮЬӮҫ’ЗӮўӮВӮўӮДӮИӮў
ӮМ2“_ӮӘ‘еӮ«ӮўӮҫӮлӮӨҒB
715 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2010/06/08(үО) 02:38:53 ID:fD+35dOm0
716 ҒF–јҸМ–ўҗЭ’иҒF2010/06/08(үО) 04:04:25 ID:c1Uplqh40
IntelerӮМғuғҚғOӮҫӮл
“Ж’fӮЖ•ОҢ©ӮЙ–һӮҝӮ·Ӯ¬ӮҪPCӮМӢZҸpҠvҗVTOP100
ttp://labaq.com/archives/50853196.html
TOP10ӮЙDoom, Quake, Voodoo
ӮЖӮўӮӨ•іӮИғүғ“ғLғ“ғOҒB
ttp://labaq.com/archives/50853196.html
TOP10ӮЙDoom, Quake, Voodoo
ӮЖӮўӮӨ•іӮИғүғ“ғLғ“ғOҒB
718 ҒF–јҸМ–ўҗЭ’иҒF2010/06/27(“ъ) 12:58:30 ID:+CMu174E0
ho
719 ҒF–јҸМ–ўҗЭ’иҒF2010/07/24(“y) 01:06:18 ID:965BV2Xx0
IntelӮМғvғҚғZғXҠJ”ӯ’S“–ҺТӮЙ•·ӮўӮҪҒC15nmҗў‘гҲИҚ~ӮМCMOSӢZҸp
http://techon.nikkeibp.co.jp/article/NEWS/20100712/184141/
Nvidia: Intel Has No Particular Advantages in Heterogeneous Multi-Core Technologies.
http://www.xbitlabs.com/news/other/display/20100722132431_Nvidia_Intel_Has_No_Particular_Advantages_in_Heterogeneous_Multi_Core_Technologies.html
http://techon.nikkeibp.co.jp/article/NEWS/20100712/184141/
Nvidia: Intel Has No Particular Advantages in Heterogeneous Multi-Core Technologies.
http://www.xbitlabs.com/news/other/display/20100722132431_Nvidia_Intel_Has_No_Particular_Advantages_in_Heterogeneous_Multi_Core_Technologies.html
720 ҒF–јҸМ–ўҗЭ’иҒF2010/08/02(ҢҺ) 20:28:04 ID:le5RTAMdP
>җў‘г–ҲӮМүь‘PӮН‘е‘М 1.6 ”{ӮИӮМӮЕҒA22nm ӮЙӮИӮйӮЖ Intel ӮН 650 MF/W ’ц“xҒAAMD ӮН 800MF/W ’ц“xӮЖӮўӮӨӮұӮЖӮЙӮИӮиӮЬӮ·ҒB
>ӮұӮМ•УӮЬӮЕӮ«ӮДӮвӮБӮЖ 65nm ӮМ PowerXCell ӮЖ“Ҝ“ҷӮЕӮ ӮиҒA‘е‘М3җў‘гҒA4”{ӮМҢш—ҰҚ·ӮӘӮ ӮйҒAӮЖӮўӮӨӮұӮЖӮЙӮИӮиӮЬӮ·ҒB
җў‘гӮІӮЖӮМүь‘P1.6”{ӮЖӮМӮұӮЖӮҫӮӘҒAӮ»ӮМ’КӮиӮҫӮЖӮөӮДӮ»ӮкӮНҚЕӢЯӮМҳbӮЕӮНӮИӮўӮ©ҒB
үЯӢҺӮМғ}ғCғNғҚғvғҚғZғbғTӮН“d—НӮжӮиӮаҗ«”\ӮрҸdҺӢӮөӮҪҗЭҢvӮрӮөӮДӮўӮҪӮӘҒA
ҚЕӢЯӮНүь‘PӮіӮкӮДӮ»ӮМҗ¬үКӮӘҢ°’ҳӮЙӮЕӮДӮўӮйӮЖӮЖӮкӮйҒB
ӮұӮМӮЬӮЬӮаӮө1.6”{ғyҒ[ғXӮӘҲЫҺқӮЕӮ«ӮйӮИӮзӮ»ӮкӮНӢБҲЩ“IӮИӮұӮЖӮЕӮ ӮиҒA
•А—сүүҺZӮЙғtғHҒ[ғJғXӮөӮҪҗк—pғvғҚғZғbғTӮӘҒA1.6”{ҲИүәӮМүь‘PӮЕӮ ӮкӮОx86ӮЙӮўӮёӮк”ІӮ©ӮіӮкӮйӮЖӮўӮӨӮұӮЖӮЙӮИӮйҒB
Ң»ҚЭӮНҗМӮЖҲЩӮИӮиҗк—pғvғҚғZғbғTӮа”Д—pғ}ғCғNғҚғvғҚғZғbғTӮа“ҜҺнӮМ‘fҺqҒAғvғҚғZғXӮрҺg—pӮөӮДҗЭҢvӮіӮкӮДӮўӮйӮМӮЙҒA
җк—pғvғҚғZғbғTӮМ•ыӮӘүь‘P•қӮӘӮжӮўӮЖӮўӮӨӢп‘М“IҸШӢ’ӮӘҺҰӮіӮкӮўӮИӮўҒB
ӮНӮБӮ«ӮиӮўӮБӮДPowerXCellӮМӮжӮӨӮИ•А—сҺuҢьӮМғAҒ[ғLғeғNғ`ғғӮЙ‘ОӮөӮДӮаҒA
X86ӮӘ4”{ӮөӮ©Қ·ӮӘӮЕӮИӮўӮЖӮұӮлӮЬӮЕ“d—НӮӘҚЕ“Kү»ӮіӮкӮДӮўӮйӮұӮЖӮӘӮЮӮөӮлӢБӮ«ҒB
ӮұӮМӢLҺ–ӮН‘S‘М“IӮЙҢлӮБӮДӮўӮйӮЕӮөӮеӮӨҒBӮаӮБӮЖ’·ӮўҺһҠФӮМғXғPҒ[ғӢӮЕҒAүЯӢҺӮМHPC—pғvғҚғZғbғTӮЖ”Д—pғvғҚғZғbғTӮЖҒA
“d—Нүь‘PӮМ”д—ҰӮЖӮұӮкӮ©ӮзӮМ“W–]Ӯр”дҠrӮ·ӮЧӮ«ӮЕӮ·ҒB
>ӮұӮМ•УӮЬӮЕӮ«ӮДӮвӮБӮЖ 65nm ӮМ PowerXCell ӮЖ“Ҝ“ҷӮЕӮ ӮиҒA‘е‘М3җў‘гҒA4”{ӮМҢш—ҰҚ·ӮӘӮ ӮйҒAӮЖӮўӮӨӮұӮЖӮЙӮИӮиӮЬӮ·ҒB
җў‘гӮІӮЖӮМүь‘P1.6”{ӮЖӮМӮұӮЖӮҫӮӘҒAӮ»ӮМ’КӮиӮҫӮЖӮөӮДӮ»ӮкӮНҚЕӢЯӮМҳbӮЕӮНӮИӮўӮ©ҒB
үЯӢҺӮМғ}ғCғNғҚғvғҚғZғbғTӮН“d—НӮжӮиӮаҗ«”\ӮрҸdҺӢӮөӮҪҗЭҢvӮрӮөӮДӮўӮҪӮӘҒA
ҚЕӢЯӮНүь‘PӮіӮкӮДӮ»ӮМҗ¬үКӮӘҢ°’ҳӮЙӮЕӮДӮўӮйӮЖӮЖӮкӮйҒB
ӮұӮМӮЬӮЬӮаӮө1.6”{ғyҒ[ғXӮӘҲЫҺқӮЕӮ«ӮйӮИӮзӮ»ӮкӮНӢБҲЩ“IӮИӮұӮЖӮЕӮ ӮиҒA
•А—сүүҺZӮЙғtғHҒ[ғJғXӮөӮҪҗк—pғvғҚғZғbғTӮӘҒA1.6”{ҲИүәӮМүь‘PӮЕӮ ӮкӮОx86ӮЙӮўӮёӮк”ІӮ©ӮіӮкӮйӮЖӮўӮӨӮұӮЖӮЙӮИӮйҒB
Ң»ҚЭӮНҗМӮЖҲЩӮИӮиҗк—pғvғҚғZғbғTӮа”Д—pғ}ғCғNғҚғvғҚғZғbғTӮа“ҜҺнӮМ‘fҺqҒAғvғҚғZғXӮрҺg—pӮөӮДҗЭҢvӮіӮкӮДӮўӮйӮМӮЙҒA
җк—pғvғҚғZғbғTӮМ•ыӮӘүь‘P•қӮӘӮжӮўӮЖӮўӮӨӢп‘М“IҸШӢ’ӮӘҺҰӮіӮкӮўӮИӮўҒB
ӮНӮБӮ«ӮиӮўӮБӮДPowerXCellӮМӮжӮӨӮИ•А—сҺuҢьӮМғAҒ[ғLғeғNғ`ғғӮЙ‘ОӮөӮДӮаҒA
X86ӮӘ4”{ӮөӮ©Қ·ӮӘӮЕӮИӮўӮЖӮұӮлӮЬӮЕ“d—НӮӘҚЕ“Kү»ӮіӮкӮДӮўӮйӮұӮЖӮӘӮЮӮөӮлӢБӮ«ҒB
ӮұӮМӢLҺ–ӮН‘S‘М“IӮЙҢлӮБӮДӮўӮйӮЕӮөӮеӮӨҒBӮаӮБӮЖ’·ӮўҺһҠФӮМғXғPҒ[ғӢӮЕҒAүЯӢҺӮМHPC—pғvғҚғZғbғTӮЖ”Д—pғvғҚғZғbғTӮЖҒA
“d—Нүь‘PӮМ”д—ҰӮЖӮұӮкӮ©ӮзӮМ“W–]Ӯр”дҠrӮ·ӮЧӮ«ӮЕӮ·ҒB
721 ҒF–јҸМ–ўҗЭ’иҒF2010/08/02(ҢҺ) 20:29:02 ID:le5RTAMdP
>Ӯ»ӮМҢӢүКӮНGPUӮМ•ыӮӘ•ҪӢПӮЕ2.5”{ҒCҚЕ‘еӮЕ14.9”{‘¬ӮўӮЖӮўӮӨҢӢҳ_ӮЕӮ·ҒBҠmӮ©ӮЙ100”{‘¬ӮўӮЖӮўӮӨӮМӮНҗіӮөӮӯӮИӮўӮЖӮўӮӨӮұӮЖӮрҺҰӮөӮҪӮМӮЕӮ·ӮӘҒC
>•ҪӢП2.5”{ӮЕӮаҸ\•Ә‘¬ӮўӮМӮЕҒCҲк”КӮМҺуӮҜҺ~ӮЯ•ыӮНӮвӮБӮПӮиGPGPUӮМ•ыӮӘӮМӮ©ӮЖӮИӮБӮДӮөӮЬӮўҒC
>ӮұӮкӮНIntel ӮМғIғEғ“ғSҒ[ғӢӮЕӮНӮИӮўӮ©ӮЖӮўӮӨҢ©•ыӮӘҲк”К“IӮЕӮ·ҒB
ӮұӮМҢӢүКӮӘғIғEғ“ғSҒ[ғӢӮЖүрҺЯӮ·ӮйӮвӮВӮӘҲк”КӮЖӮўӮӨӮМӮИӮзҒA
үЯӢҺӮрҢЪӮЭӮИӮўor“sҚҮӮМӮжӮўӮұӮЖӮөӮ©ҺуӮҜ“ьӮкӮзӮкӮИӮўҗlӮӘҲк”Кү»ӮөӮҪӮМӮҫӮИҒAӮЖӮөӮ©ӮўӮўӮжӮӨӮӘӮИӮўҒB
GPUӮМӮжӮӨӮИғAҒ[ғLғeғNғ`ғғӮӘ”Д—pCPUӮЙ‘ОӮөӮДҒAIntelӮМҳ_•¶ӮӘ–{“–ӮЙғtғFғAӮЕ2.5”{ӮөӮ©Қ·ӮӘӮИӮўӮЖӮўӮӨӮИӮзӮОҒA
Ӯ»ӮкӮНӢБӮ«ӮЕӮ ӮиҒAHPCҢьӮҜӮЖӮөӮДӮН”s–kӮМғ{Ғ[ғ_Ғ[ғүғCғ“Ӯр—]—TӮЕӮнӮБӮДӮўӮйӮМӮЕӮНӮИӮўӮ©ӮЖҚlӮҰӮйӮМӮӘӮУӮВӮӨӮҫӮлӮӨӮЙҒB
җк—pӮН10”{Ғ`җ”Ҹ\”{’ц“xӮНғAғhғoғ“ғeҒ[ғWӮӘӮ ӮйҒBӮұӮкӮН’ҝӮөӮўӮұӮЖӮЕӮНӮИӮўӮөҒAӮЮӮөӮлӮ»ӮұӮ©ӮзҳbӮӘҺnӮЬӮйҒB
1,2Ҡ„ӮМҗ«”\Қ·ӮЕғuҒ[ғuҒ[ӮўӮҰӮйҺАүv“xҠOҺӢӮМғIғ^ғNҗўҠEӮ©ӮзӮЭӮкӮО2.5”{ӮН‘еҚ·ӮЖӮўӮӨҲуҸЫӮИӮМӮ©ӮаӮөӮкӮИӮўӮӘҒA
Ӯ»ӮМҚ·ӮЕӮұӮкӮ©ӮзғrғWғlғX“IӮЙӮа—¬ҚsӮйғ]ӮЖҺvӮБӮҪӮз•үӮҜ‘gғRҒ[ғXҒB
#ҚЕӢЯӮМҚ‘“аHPCғlғ^ӮНғzғүҸLӮМӮ·ӮйҳbӮӘ‘ҪӮў—\ҠҙҒBүeӢҝ—НӮМӮ ӮйҗlӮӘӮаӮөӮнӮ©ӮБӮДӮвӮБӮДӮйӮМӮИӮзӮОҸdҚЯҒB
#җ^ӮЙҺуӮҜӮйӮвӮВӮа‘ҪӮўӮөҠЁ•ЩӮөӮДӮЩӮөӮўҒB
>•ҪӢП2.5”{ӮЕӮаҸ\•Ә‘¬ӮўӮМӮЕҒCҲк”КӮМҺуӮҜҺ~ӮЯ•ыӮНӮвӮБӮПӮиGPGPUӮМ•ыӮӘӮМӮ©ӮЖӮИӮБӮДӮөӮЬӮўҒC
>ӮұӮкӮНIntel ӮМғIғEғ“ғSҒ[ғӢӮЕӮНӮИӮўӮ©ӮЖӮўӮӨҢ©•ыӮӘҲк”К“IӮЕӮ·ҒB
ӮұӮМҢӢүКӮӘғIғEғ“ғSҒ[ғӢӮЖүрҺЯӮ·ӮйӮвӮВӮӘҲк”КӮЖӮўӮӨӮМӮИӮзҒA
үЯӢҺӮрҢЪӮЭӮИӮўor“sҚҮӮМӮжӮўӮұӮЖӮөӮ©ҺуӮҜ“ьӮкӮзӮкӮИӮўҗlӮӘҲк”Кү»ӮөӮҪӮМӮҫӮИҒAӮЖӮөӮ©ӮўӮўӮжӮӨӮӘӮИӮўҒB
GPUӮМӮжӮӨӮИғAҒ[ғLғeғNғ`ғғӮӘ”Д—pCPUӮЙ‘ОӮөӮДҒAIntelӮМҳ_•¶ӮӘ–{“–ӮЙғtғFғAӮЕ2.5”{ӮөӮ©Қ·ӮӘӮИӮўӮЖӮўӮӨӮИӮзӮОҒA
Ӯ»ӮкӮНӢБӮ«ӮЕӮ ӮиҒAHPCҢьӮҜӮЖӮөӮДӮН”s–kӮМғ{Ғ[ғ_Ғ[ғүғCғ“Ӯр—]—TӮЕӮнӮБӮДӮўӮйӮМӮЕӮНӮИӮўӮ©ӮЖҚlӮҰӮйӮМӮӘӮУӮВӮӨӮҫӮлӮӨӮЙҒB
җк—pӮН10”{Ғ`җ”Ҹ\”{’ц“xӮНғAғhғoғ“ғeҒ[ғWӮӘӮ ӮйҒBӮұӮкӮН’ҝӮөӮўӮұӮЖӮЕӮНӮИӮўӮөҒAӮЮӮөӮлӮ»ӮұӮ©ӮзҳbӮӘҺnӮЬӮйҒB
1,2Ҡ„ӮМҗ«”\Қ·ӮЕғuҒ[ғuҒ[ӮўӮҰӮйҺАүv“xҠOҺӢӮМғIғ^ғNҗўҠEӮ©ӮзӮЭӮкӮО2.5”{ӮН‘еҚ·ӮЖӮўӮӨҲуҸЫӮИӮМӮ©ӮаӮөӮкӮИӮўӮӘҒA
Ӯ»ӮМҚ·ӮЕӮұӮкӮ©ӮзғrғWғlғX“IӮЙӮа—¬ҚsӮйғ]ӮЖҺvӮБӮҪӮз•үӮҜ‘gғRҒ[ғXҒB
#ҚЕӢЯӮМҚ‘“аHPCғlғ^ӮНғzғүҸLӮМӮ·ӮйҳbӮӘ‘ҪӮў—\ҠҙҒBүeӢҝ—НӮМӮ ӮйҗlӮӘӮаӮөӮнӮ©ӮБӮДӮвӮБӮДӮйӮМӮИӮзӮОҸdҚЯҒB
#җ^ӮЙҺуӮҜӮйӮвӮВӮа‘ҪӮўӮөҠЁ•ЩӮөӮДӮЩӮөӮўҒB
722 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/08/22(“ъ) 00:35:08 ID:nW3BuggLP
Intel Core i7 Q 720
http://browse.geekbench.ca/geekbench2/view/274637
Intel Corporation SandyBridge Platform - 1.60 GHz(ғNғҚғbғN•s–ҫ)
http://browse.geekbench.ca/geekbench2/view/273184
More Sandy Bridge performance numbers
http://citavia.blog.de/2010/08/05/more-sandy-bridge-performance-numbers-9128712/
SNB Core-i7-920 Difference
Integer 6224 5059 23.0
Floating Point 7193 5805 23.9
Memory 3217 3456 -6.9
Stream 3388 3275 3.5
Total 5678 4821 17.8
http://browse.geekbench.ca/geekbench2/view/274637
Intel Corporation SandyBridge Platform - 1.60 GHz(ғNғҚғbғN•s–ҫ)
http://browse.geekbench.ca/geekbench2/view/273184
More Sandy Bridge performance numbers
http://citavia.blog.de/2010/08/05/more-sandy-bridge-performance-numbers-9128712/
SNB Core-i7-920 Difference
Integer 6224 5059 23.0
Floating Point 7193 5805 23.9
Memory 3217 3456 -6.9
Stream 3388 3275 3.5
Total 5678 4821 17.8
723 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/08/22(“ъ) 00:54:24 ID:nW3BuggLP
ҒЎInteger Performance - Multithread
Sandy_Bridge Nehalem_i7-920 (%) Benchmark
-------------------------------------------------
8037 6905 16.4 Blowfish
9739 7245 34.4 Text Compress
11673 8281 41.0 Text Decompress
8966 7174 25.0 Image Compress
9147 6912 32.3 Image Decompress
14826 10899 36.0 Lua
-------------------------------------------------
10177 7792 30.6 GEOMEAN()
ҒЎInteger Performance - Singlethread
-------------------------------------------------
Sandy_Bridge Nehalem_i7-920 (%) Benchmark
1206 1442 -16.4 Blowfish
2022 1958 3.3 Text Compress
2197 2133 3.0 Text Decompress
1801 2035 -11.5 Image Compress
1757 2025 -13.2 Image Decompress
3325 3704 -10.2 Lua
-------------------------------------------------
1958 2124 -7.8 GEOMEAN()
Sandy_Bridge Nehalem_i7-920 (%) Benchmark
-------------------------------------------------
8037 6905 16.4 Blowfish
9739 7245 34.4 Text Compress
11673 8281 41.0 Text Decompress
8966 7174 25.0 Image Compress
9147 6912 32.3 Image Decompress
14826 10899 36.0 Lua
-------------------------------------------------
10177 7792 30.6 GEOMEAN()
ҒЎInteger Performance - Singlethread
-------------------------------------------------
Sandy_Bridge Nehalem_i7-920 (%) Benchmark
1206 1442 -16.4 Blowfish
2022 1958 3.3 Text Compress
2197 2133 3.0 Text Decompress
1801 2035 -11.5 Image Compress
1757 2025 -13.2 Image Decompress
3325 3704 -10.2 Lua
-------------------------------------------------
1958 2124 -7.8 GEOMEAN()
724 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/08/22(“ъ) 00:56:09 ID:nW3BuggLP
ҒЎFloating Point Performance - Multithread
-------------------------------------------------
Sandy_Bridge Nehalem_i7-920 (%) Benchmark
11728 8598 36.4 Mandelbrot
6720 5317 26.4 Dot Product
24322 17037 42.8 Dot Product
9404 6079 54.7 LU Decomposition
15814 10070 57.0 Primality Test
3581 4040 -11.4 Sharpen Image
13443 13663 -1.6 Blur Image
-------------------------------------------------
10462 8264 26.6 GEOMEAN()
ҒЎFloating Point Performance - Singlethread
Sandy_Bridge Nehalem_i7-920 (%) Benchmark
-------------------------------------------------
1591 1923 -17.3 Mandelbrot
902 992 -9.1 Dot Product
3585 4197 -14.6 Dot Product
2538 1526 66.3 LU Decomposition
4273 4015 6.4 Primality Test
562 840 -33.1 Sharpen Image
2246 2975 -24.5 Blur Image
--------------------------------------------------
1836 1988 -7.6 GEOMEAN()
-------------------------------------------------
Sandy_Bridge Nehalem_i7-920 (%) Benchmark
11728 8598 36.4 Mandelbrot
6720 5317 26.4 Dot Product
24322 17037 42.8 Dot Product
9404 6079 54.7 LU Decomposition
15814 10070 57.0 Primality Test
3581 4040 -11.4 Sharpen Image
13443 13663 -1.6 Blur Image
-------------------------------------------------
10462 8264 26.6 GEOMEAN()
ҒЎFloating Point Performance - Singlethread
Sandy_Bridge Nehalem_i7-920 (%) Benchmark
-------------------------------------------------
1591 1923 -17.3 Mandelbrot
902 992 -9.1 Dot Product
3585 4197 -14.6 Dot Product
2538 1526 66.3 LU Decomposition
4273 4015 6.4 Primality Test
562 840 -33.1 Sharpen Image
2246 2975 -24.5 Blur Image
--------------------------------------------------
1836 1988 -7.6 GEOMEAN()
725 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/08/22(“ъ) 00:57:26 ID:nW3BuggLP
ӮҝӮИӮЭӮЙӮұӮМғxғ“ғ`ҢӢүКӮ©ӮзӮН–wӮЗӮИӮЙӮаӮнӮ©ӮзӮИӮўӮИҒB
726 ҒF–јҸМ–ўҗЭ’иҒF2010/08/22(“ъ) 01:01:57 ID:Ce0WYfA20
ғVғ“ғOғӢғXғҢғbғhӮӘҲЩ—lӮЙ—ҺӮҝӮДӮйӮМӮНSNBӮЕӮНTBӮӘҢшӮўӮДӮИӮўҒH
727 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/08/22(“ъ) 01:02:19 ID:nW3BuggLP
http://plusd.itmedia.co.jp/pcuser/articles/1006/08/news089.html
>CINEBENCH R10ӮЕӮНҒACPUӮЙҒgSandy BridgeҒhӮр‘gӮЭҚһӮЭҒAGPUӮЙMobility Radeon HD 5000”Ф‘дҒi56xxӮ©ҒHҒjӮр“ӢҚЪӮөӮҪғVғXғeғҖӮЖҒA
>Core i7-920XMӮЖGeForce GTX280MӮр‘gӮЭҚһӮсӮҫӮЖӮіӮкӮйғVғXғeғҖӮр•АӮЧӮД”дҠrӮөӮҪӮӘҒA
>Sandy BridgeӮМғVғXғeғҖҸо•сӮЙӮНҒA“®ҚмғNғҚғbғNӮЖӮөӮДҒu2.20GHzҒvӮЖ•\ҺҰӮіӮкӮДӮўӮҪҒB
>ӮҪӮҫӮөҒAӮұӮМғNғҚғbғNӮНғfғӮӮМӮҪӮЯӮЙҗЭ’иӮіӮкӮДӮўӮДҗ»•i”ЕӮМғNғҚғbғNӮЖӮНҲЩӮИӮйүВ”\җ«ӮаҚӮӮўҒB
>ӮҝӮИӮЭӮЙҒAғүғCғuғfғӮӮЕҚsӮнӮкӮҪCINEBENCH R10ӮМҢӢүКӮНҒAҒgSandy BridgeҒh“ӢҚЪғVғXғeғҖӮӘҒu19843ҒvҒA
>Core i7-920Ғiҗ„’и2.00GHz“®ҚмҒj“ӢҚЪғVғXғeғҖӮӘҒu11961ҒvӮҫӮБӮҪҒB
ӮҝӮИӮЭӮЙӮұӮМғfғӮӮЕӮ ӮйӮӘҒACinebenchӮӘҚЕҗVӮМR11.5ӮЕӮИӮўӮЖӮұӮлӮ©ӮзӮөӮДҒA
R10ӮрAVXӮЙҚЕ“Kү»ӮөӮҪIntel“а•”ӮМ•]үҝ—pver.ӮЖӮўӮӨүрҺЯӮӘ‘Г“–ӮЕӮНӮИӮ©ӮлӮӨӮ©ҒB
>CINEBENCH R10ӮЕӮНҒACPUӮЙҒgSandy BridgeҒhӮр‘gӮЭҚһӮЭҒAGPUӮЙMobility Radeon HD 5000”Ф‘дҒi56xxӮ©ҒHҒjӮр“ӢҚЪӮөӮҪғVғXғeғҖӮЖҒA
>Core i7-920XMӮЖGeForce GTX280MӮр‘gӮЭҚһӮсӮҫӮЖӮіӮкӮйғVғXғeғҖӮр•АӮЧӮД”дҠrӮөӮҪӮӘҒA
>Sandy BridgeӮМғVғXғeғҖҸо•сӮЙӮНҒA“®ҚмғNғҚғbғNӮЖӮөӮДҒu2.20GHzҒvӮЖ•\ҺҰӮіӮкӮДӮўӮҪҒB
>ӮҪӮҫӮөҒAӮұӮМғNғҚғbғNӮНғfғӮӮМӮҪӮЯӮЙҗЭ’иӮіӮкӮДӮўӮДҗ»•i”ЕӮМғNғҚғbғNӮЖӮНҲЩӮИӮйүВ”\җ«ӮаҚӮӮўҒB
>ӮҝӮИӮЭӮЙҒAғүғCғuғfғӮӮЕҚsӮнӮкӮҪCINEBENCH R10ӮМҢӢүКӮНҒAҒgSandy BridgeҒh“ӢҚЪғVғXғeғҖӮӘҒu19843ҒvҒA
>Core i7-920Ғiҗ„’и2.00GHz“®ҚмҒj“ӢҚЪғVғXғeғҖӮӘҒu11961ҒvӮҫӮБӮҪҒB
ӮҝӮИӮЭӮЙӮұӮМғfғӮӮЕӮ ӮйӮӘҒACinebenchӮӘҚЕҗVӮМR11.5ӮЕӮИӮўӮЖӮұӮлӮ©ӮзӮөӮДҒA
R10ӮрAVXӮЙҚЕ“Kү»ӮөӮҪIntel“а•”ӮМ•]үҝ—pver.ӮЖӮўӮӨүрҺЯӮӘ‘Г“–ӮЕӮНӮИӮ©ӮлӮӨӮ©ҒB
728 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/08/22(“ъ) 01:05:06 ID:nW3BuggLP
>>726
Sandy Bridge‘ӨӮМғNғҚғbғNӮӘ•s–ҫӮИӮМӮЕҗв‘Оҗ«”\ӮвғNғҚғbғNӮ ӮҪӮиҗ«”\ӮМ”дҠrӮЙӮИӮБӮДӮИӮўҒB
ғ}ғӢғ`ғXғҢғbғhҺһӮЙӮНҚӮғXғRғAӮЙӮИӮБӮДӮўӮйӮМӮЕҒAғ}ғӢғ`ғXғҢғbғhӮӘ“ҫҲУӮЖӮўӮӨӮұӮЖӮНӮўӮҰӮйҒB
Sandy Bridge‘ӨӮМғNғҚғbғNӮӘ•s–ҫӮИӮМӮЕҗв‘Оҗ«”\ӮвғNғҚғbғNӮ ӮҪӮиҗ«”\ӮМ”дҠrӮЙӮИӮБӮДӮИӮўҒB
ғ}ғӢғ`ғXғҢғbғhҺһӮЙӮНҚӮғXғRғAӮЙӮИӮБӮДӮўӮйӮМӮЕҒAғ}ғӢғ`ғXғҢғbғhӮӘ“ҫҲУӮЖӮўӮӨӮұӮЖӮНӮўӮҰӮйҒB
729 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/08/22(“ъ) 01:14:06 ID:nW3BuggLP
Ӯ ҒAӮҝӮӘӮӨӮҝӮӘӮӨҒB
ӮЖӮўӮӨӮ©ӮұӮМғxғ“ғ`ӮМғTғCғgӮЕҢҹҚхӮ·ӮйӮЖ“ҜӮ¶CPUӮЕӮаҢӢүКӮӘғ}ғ`ғ}ғ`Ӯ·Ӯ¬ӮД”дҠrӮЙӮИӮБӮДӮИӮўӮЛҒB
ӮұӮиӮбӮВӮ©ӮҰӮЛӮҘӮИҒBӮНӮйӮсӮ¶ӮбӮИӮ©ӮБӮҪҒB
ӮЖӮўӮӨӮ©ӮұӮМғxғ“ғ`ӮМғTғCғgӮЕҢҹҚхӮ·ӮйӮЖ“ҜӮ¶CPUӮЕӮаҢӢүКӮӘғ}ғ`ғ}ғ`Ӯ·Ӯ¬ӮД”дҠrӮЙӮИӮБӮДӮИӮўӮЛҒB
ӮұӮиӮбӮВӮ©ӮҰӮЛӮҘӮИҒBӮНӮйӮсӮ¶ӮбӮИӮ©ӮБӮҪҒB
730 ҒF–јҸМ–ўҗЭ’иҒF2010/08/26(–Ш) 11:42:54 ID:VFD3TXL60
731 ҒF–јҸМ–ўҗЭ’иҒF2010/08/26(–Ш) 12:03:57 ID:VFD3TXL60
>>720
–q–мӮіӮсӮМӮЖӮұӮМӮҫӮЛҒBӮҝӮбӮсӮЖAVXӮЙӮжӮйҗ«”\ҢьҸгӮМүВ”\җ«ӮЙӮаҗGӮкӮДӮйӮж
> Ӯ ҒAӮЕӮаҒA AVX ӮЖӮўӮӨӮаӮМӮӘӮ ӮйӮМӮЕҒA Intel ӮЙҠЦӮөӮДӮНғ`ғbғvӮМ“d—НӮрӮ ӮЬӮиӮ Ӯ°ӮИӮўӮЕ•Ӯ“®Ҹ¬җ”“_җ«”\ӮӘ”{ӮЙӮИӮйүВ”\җ«ӮНӮ ӮиӮЬӮ·ҒB
> Ӯ»ӮӨӮ·ӮйӮЖ 32 nm ӮЕ 700-800MF/WҒA22 nm ӮЕӮН 1.2GF/W ’ц“xӮЙӮИӮиӮЬӮ·ҒB2012 ”NӮЙӮН 22nm ӮЙӮИ ӮйӮЕӮөӮеӮӨӮ©ӮзҒAӮИӮ©ӮИӮ©ҢөӮөӮўӮаӮМӮНӮ ӮиӮЬӮ·ҒB
ҢӢӢЗӮНMF/WӮБӮДSIMDүүҺZҗ«”\ӮҫӮҜӮ Ӯ°ӮДӮкӮОүь‘PӮ·ӮйӮ©ӮзҒA
SIMD“Бү»Ң^ӮМғAғNғZғүғҢҒ[ғ^ӮБӮДӮ»ӮсӮИӮЙ—DҲКҗ«ӮӘ–іӮӯӮИӮБӮДӮўӮӯ
> GPGPU ӮН Fermi ӮӘӮИӮ©ӮИӮ©“пӮөӮўҸу‘ФӮЙӮИӮБӮДӮўӮйӮМӮЕҚЎҢгӮӘ•s“§–ҫӮЕӮ·ӮӘҒA –ҫӮзӮ©ӮИӮМӮНӮұӮМӮЬӮЬӮЕӮН x86 ӮЙ”дӮЧӮДӮжӮўӮЖӮұӮлӮӘӮИӮўҒA
> ӮЖӮўӮӨӮұӮЖӮЕӮ·ҒB 84 ӮЕӮНҒAFermi ӮрҺgӮӨӮұӮЖӮЕ Xeon ӮҫӮҜӮЙ”дӮЧӮД 1.6 ”{’ц“xӮН “d—НҢш—ҰӮӘҸгӮӘӮБӮДӮўӮйӮМӮЕӮНҒHӮЖҸ‘ӮўӮҪӮМӮЕӮ·ӮӘҒA
> Ӯ»ӮсӮИ‘еӮ«ӮИҢшүКӮНӮИӮӯ ӮДҺАҚЫӮМҢьҸгӮН 14% ӮөӮ©ӮИӮ©ӮБӮҪӮнӮҜӮЕӮ·ҒBӮұӮкӮНҒAҸјүӘӮіӮсӮӘӮЗӮұӮ©ӮЕҺw“E ӮөӮДӮўӮҪӮжӮӨӮЙҒAҚs—сғTғCғYӮӘ
> –ӯӮЙҸ¬ӮіӮўӮҪӮЯӮЙҺАҚsҢш—ҰӮӘ’бӮўӮұӮЖӮӘҢҙҲцӮМ Ҳк•”ӮЕӮНӮ ӮиҒAӮ ӮЖ 2-3 Ҡ„ӮНҸгӮӘӮй—]’nӮӘӮ ӮйӮЖҺvӮўӮЬӮ·ҒB
> ӮөӮ©ӮөӮұӮкӮН”ј“ұ ‘МӢZҸp1җў‘г•ӘӮЙӮаӮИӮзӮИӮўӮнӮҜӮЕҒAҢ»ҸуӮМ Fermi ӮвҒAӮ»ӮұӮ©ӮзӢZҸpӮрҠO‘}Ӯө ӮҪӮаӮМӮЙӮНҸ«—Ҳҗ«ӮНӮИӮўҒAӮЖӮўӮӨӮұӮЖӮЙӮИӮйӮЕӮөӮеӮӨҒB
ӮЬӮ ҒAӮұӮМ•УӮН”[“ҫҒB
–q–мӮіӮсӮМӮЖӮұӮМӮҫӮЛҒBӮҝӮбӮсӮЖAVXӮЙӮжӮйҗ«”\ҢьҸгӮМүВ”\җ«ӮЙӮаҗGӮкӮДӮйӮж
> Ӯ ҒAӮЕӮаҒA AVX ӮЖӮўӮӨӮаӮМӮӘӮ ӮйӮМӮЕҒA Intel ӮЙҠЦӮөӮДӮНғ`ғbғvӮМ“d—НӮрӮ ӮЬӮиӮ Ӯ°ӮИӮўӮЕ•Ӯ“®Ҹ¬җ”“_җ«”\ӮӘ”{ӮЙӮИӮйүВ”\җ«ӮНӮ ӮиӮЬӮ·ҒB
> Ӯ»ӮӨӮ·ӮйӮЖ 32 nm ӮЕ 700-800MF/WҒA22 nm ӮЕӮН 1.2GF/W ’ц“xӮЙӮИӮиӮЬӮ·ҒB2012 ”NӮЙӮН 22nm ӮЙӮИ ӮйӮЕӮөӮеӮӨӮ©ӮзҒAӮИӮ©ӮИӮ©ҢөӮөӮўӮаӮМӮНӮ ӮиӮЬӮ·ҒB
ҢӢӢЗӮНMF/WӮБӮДSIMDүүҺZҗ«”\ӮҫӮҜӮ Ӯ°ӮДӮкӮОүь‘PӮ·ӮйӮ©ӮзҒA
SIMD“Бү»Ң^ӮМғAғNғZғүғҢҒ[ғ^ӮБӮДӮ»ӮсӮИӮЙ—DҲКҗ«ӮӘ–іӮӯӮИӮБӮДӮўӮӯ
> GPGPU ӮН Fermi ӮӘӮИӮ©ӮИӮ©“пӮөӮўҸу‘ФӮЙӮИӮБӮДӮўӮйӮМӮЕҚЎҢгӮӘ•s“§–ҫӮЕӮ·ӮӘҒA –ҫӮзӮ©ӮИӮМӮНӮұӮМӮЬӮЬӮЕӮН x86 ӮЙ”дӮЧӮДӮжӮўӮЖӮұӮлӮӘӮИӮўҒA
> ӮЖӮўӮӨӮұӮЖӮЕӮ·ҒB 84 ӮЕӮНҒAFermi ӮрҺgӮӨӮұӮЖӮЕ Xeon ӮҫӮҜӮЙ”дӮЧӮД 1.6 ”{’ц“xӮН “d—НҢш—ҰӮӘҸгӮӘӮБӮДӮўӮйӮМӮЕӮНҒHӮЖҸ‘ӮўӮҪӮМӮЕӮ·ӮӘҒA
> Ӯ»ӮсӮИ‘еӮ«ӮИҢшүКӮНӮИӮӯ ӮДҺАҚЫӮМҢьҸгӮН 14% ӮөӮ©ӮИӮ©ӮБӮҪӮнӮҜӮЕӮ·ҒBӮұӮкӮНҒAҸјүӘӮіӮсӮӘӮЗӮұӮ©ӮЕҺw“E ӮөӮДӮўӮҪӮжӮӨӮЙҒAҚs—сғTғCғYӮӘ
> –ӯӮЙҸ¬ӮіӮўӮҪӮЯӮЙҺАҚsҢш—ҰӮӘ’бӮўӮұӮЖӮӘҢҙҲцӮМ Ҳк•”ӮЕӮНӮ ӮиҒAӮ ӮЖ 2-3 Ҡ„ӮНҸгӮӘӮй—]’nӮӘӮ ӮйӮЖҺvӮўӮЬӮ·ҒB
> ӮөӮ©ӮөӮұӮкӮН”ј“ұ ‘МӢZҸp1җў‘г•ӘӮЙӮаӮИӮзӮИӮўӮнӮҜӮЕҒAҢ»ҸуӮМ Fermi ӮвҒAӮ»ӮұӮ©ӮзӢZҸpӮрҠO‘}Ӯө ӮҪӮаӮМӮЙӮНҸ«—Ҳҗ«ӮНӮИӮўҒAӮЖӮўӮӨӮұӮЖӮЙӮИӮйӮЕӮөӮеӮӨҒB
ӮЬӮ ҒAӮұӮМ•УӮН”[“ҫҒB
732 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2010/08/29(“ъ) 02:53:40 ID:Urxmzf5n0
ӮіӮДҒASandy BridgeӮМESӮМғxғ“ғ`ӮаҸoӮҪӮұӮЖӮҫӮөҒEҒEҒE
үҙӮМ—\‘zӮЗӮсӮТӮөӮбӮ¶ӮбӮИӮўӮ©>>656
үҙӮМ—\‘zӮЗӮсӮТӮөӮбӮ¶ӮбӮИӮўӮ©>>656
733 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/08/29(“ъ) 09:18:31 ID:MTTiKgI5P
”сSIMDӮМӮЬӮЖӮЬӮБӮҪғxғ“ғ`ӮИӮсӮДӮ ӮБӮҪӮ©?
ӮЖӮўӮӨӮ©ҢӢҳ_ӮўӮ»Ӯ¬Ӯ·Ӯ¬ҒBӮЬӮҫҢӢҳ_ӮҫӮ·ӮМӮЙӮН•sҸ\•ӘҒB
CacheҺь•УӮМ—e—КӮв‘СҲжҒAғҢғCғeғ“ғVӮИӮЗӮМҺd—lҒA
ҺАҚsғҶғjғbғgӮИӮЗӮМҺd—lӮа•ПӮнӮБӮДӮўӮйӮМӮЕҒA
ӮЬӮ ҺА—НӮН”сSIMDӮЙҠЦӮөӮДӮағRғ“ғpғCғүӮӘҚЕ“Kү»ӮіӮкӮДӮ©ӮзӮҫӮИҒB
ӮўӮВӮаӮМӮжӮӨӮЙSPECӮЖӮ©ӮЕҚЕ“Kү»ӮіӮкӮҪӮвӮВ“oҳ^ӮөӮДӮӯӮйӮ©ӮзӮИҒB
ӮЖӮўӮӨӮ©ҢӢҳ_ӮўӮ»Ӯ¬Ӯ·Ӯ¬ҒBӮЬӮҫҢӢҳ_ӮҫӮ·ӮМӮЙӮН•sҸ\•ӘҒB
CacheҺь•УӮМ—e—КӮв‘СҲжҒAғҢғCғeғ“ғVӮИӮЗӮМҺd—lҒA
ҺАҚsғҶғjғbғgӮИӮЗӮМҺd—lӮа•ПӮнӮБӮДӮўӮйӮМӮЕҒA
ӮЬӮ ҺА—НӮН”сSIMDӮЙҠЦӮөӮДӮағRғ“ғpғCғүӮӘҚЕ“Kү»ӮіӮкӮДӮ©ӮзӮҫӮИҒB
ӮўӮВӮаӮМӮжӮӨӮЙSPECӮЖӮ©ӮЕҚЕ“Kү»ӮіӮкӮҪӮвӮВ“oҳ^ӮөӮДӮӯӮйӮ©ӮзӮИҒB
734 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/08/29(“ъ) 10:02:04 ID:MTTiKgI5P
>>703
ARMӮаҚЕҸгҲКӮМA9ӮЙӮИӮйӮЖ–{–ҪӮНғnҒ[ғhғ}ғNғҚӮЕӮ Ӯй’ц“xҚЕ“Kү»ӮіӮкӮҪӮвӮВӮЭӮҪӮўӮҫӮЛҒB
typ.2GHzӮЕ1.9WӮБӮД”ч–ӯӮҫӮЖҺvӮӨӮҜӮЗӮЛҒB
# Advanced SIMD NEON? unit (Optional)
# Floating Point Unit (Optional)
ӮБӮДҸ‘ӮўӮДӮ ӮйӮөӮИҒB
http://www.arm.com/products/processors/cortex-a/index.php
http://www.arm.com/products/processors/cortex-a/cortex-a9.php
ARMӮаҚЕҸгҲКӮМA9ӮЙӮИӮйӮЖ–{–ҪӮНғnҒ[ғhғ}ғNғҚӮЕӮ Ӯй’ц“xҚЕ“Kү»ӮіӮкӮҪӮвӮВӮЭӮҪӮўӮҫӮЛҒB
typ.2GHzӮЕ1.9WӮБӮД”ч–ӯӮҫӮЖҺvӮӨӮҜӮЗӮЛҒB
# Advanced SIMD NEON? unit (Optional)
# Floating Point Unit (Optional)
ӮБӮДҸ‘ӮўӮДӮ ӮйӮөӮИҒB
http://www.arm.com/products/processors/cortex-a/index.php
http://www.arm.com/products/processors/cortex-a/cortex-a9.php
735 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2010/08/29(“ъ) 10:18:55 ID:Urxmzf5n0
ӮжӮӨӮНAVXӮрҺgӮнӮёӮЙӮЗӮұӮЬӮЕҗ«”\ӮӘӮ ӮӘӮйӮ©ӮБӮДӮұӮЖӮИӮсӮЕ
SSEӮрҠЬӮЯӮҪҠщ‘¶ғRҒ[ғhӮӘ1Ҡ„җ«”\ҸгӮӘӮкӮОҸ\•ӘӮҫӮлӮӨ
ӮўӮлӮўӮлҚЧӮ©Ӯў•”•ӘӮаӮ ӮйӮӘҒASandy BridgeӮМҗ«”\ҢьҸгӮМҲк”ФӮМғLғӮӮНLoad UnitӮМ”{‘қӮИӮсӮЕҒA
ӮұӮкӮНSSE, ғXғJғүҠЦҢWӮИӮӯғRҒ[ғhӮрҸ‘Ӯ«Ҡ·ӮҰӮйӮұӮЖӮИӮӯҺ©“®“IӮЙү¶ҢbӮрҺуӮҜӮзӮкӮйҒB
> ӮЬӮ ҺА—НӮН”сSIMDӮЙҠЦӮөӮДӮағRғ“ғpғCғүӮӘҚЕ“Kү»ӮіӮкӮДӮ©ӮзӮҫӮИҒB
Ӯ»ӮМҚЕ“Kү»ғXғCғbғ`ӮБӮД-mavxӮЖӮ©/QxAVXӮЖӮ©ҲИҠOӮЙӮ ӮйӮБӮДӮұӮЖӮЕӮ·Ӯ©ҒHӮ—
ҺАҚЫ–в‘иҒAAVXӮрҺgӮӨҲИҠOӮЕғRғ“ғpғCғүӮЕӮвӮкӮйҚЕ“Kү»ғeғNғjғbғNӮИӮсӮД–wӮЗ–іӮўӮжҒB
җМӮМPentium 4/Pentium Mҗў‘гӮҫӮЖҒAQxW, QxB, QxN, QxPӮЖӮ©•Ўҗ”ӮМҚЕ“Kү»ғXғCғbғ`ӮӘ‘¶ҚЭӮөӮҪӮҜӮЗ
ҚЎӮНӮИӮӯӮИӮБӮДӮйҒB
MSӮМғRғ“ғpғCғүӮЙӮ ӮБӮҪG5, G6, G7ӮИӮсӮД”pҺ~ӮіӮкӮДӢvӮөӮўҒB
IntelғRғ“ғpғCғүӮағXғJғүғRҒ[ғhӮЙҠЦӮ·Ӯй•”•ӘӮНCore MAғxҒ[ғXӮЕҒAӮ ӮЖӮН–Ҫ—ЯғZғbғgӮМғTғ|Ғ[ғgӮҫӮҜ
ғxҒ[ғXӮМғ}ғCғNғҚғAҒ[ғLғeғNғ`ғғӮӘ“ҜӮ¶ӮҫӮ©ӮзӮИҒB
AtomҲИҠOӮЙғAҒ[ғLҢЕ—LӮМҚЕ“Kү»ғXғCғbғ`ӮИӮсӮД‘¶ҚЭӮөӮИӮўӮжҒB
http://www.sofken.com/Documentation/compiler_c/main_cls/copts/common_options/option_x_lcase.htm
ӮўӮБӮШӮсIntelғRғ“ғpғCғүӮЕ/QaxSSE2 /QaxSSE3 /QaxSSSE3 /QaxSSE4.1 /QaxSSS4.2 /QxAVXӮЖӮ©ӮЕғRҒ[ғhҗ¶җ¬ӮвӮБӮДӮЭӮйӮЖӮўӮўӮжҒB
ғXғJғү•”•ӘӮМғRҒ[ғh•ӘӮҜӮИӮсӮДӮвӮзӮИӮўӮ©ӮзӮ—
IntelғRғ“ғpғCғүӮаGCCӮаSandy Bridge—pҚЕ“Kү»ӮН -march=core2 -mavx ӮЕҸ\•ӘӮЖҢҫӮБӮДӮйҸуӢө
ӮұӮкӮрүјӮЙ-march=opteronӮЙӮөӮДӮа1Ғ`2%Ӯа•ПӮнӮзӮсӮжҒB
ҚЎӮЖӮИӮБӮДӮНғRҒ[ғhӮМ•АӮЧ•ы•ПӮҰӮйӮұӮЖӮЕӮвӮкӮйҺ–ӮИӮсӮД–wӮЗүҪӮа–іӮўҒB
Ӯ»ӮкӮӘғAғEғgғIғuғIҒ[ғ_ҺАҚsӮҫӮ©ӮзҒB
SSEӮрҠЬӮЯӮҪҠщ‘¶ғRҒ[ғhӮӘ1Ҡ„җ«”\ҸгӮӘӮкӮОҸ\•ӘӮҫӮлӮӨ
ӮўӮлӮўӮлҚЧӮ©Ӯў•”•ӘӮаӮ ӮйӮӘҒASandy BridgeӮМҗ«”\ҢьҸгӮМҲк”ФӮМғLғӮӮНLoad UnitӮМ”{‘қӮИӮсӮЕҒA
ӮұӮкӮНSSE, ғXғJғүҠЦҢWӮИӮӯғRҒ[ғhӮрҸ‘Ӯ«Ҡ·ӮҰӮйӮұӮЖӮИӮӯҺ©“®“IӮЙү¶ҢbӮрҺуӮҜӮзӮкӮйҒB
> ӮЬӮ ҺА—НӮН”сSIMDӮЙҠЦӮөӮДӮағRғ“ғpғCғүӮӘҚЕ“Kү»ӮіӮкӮДӮ©ӮзӮҫӮИҒB
Ӯ»ӮМҚЕ“Kү»ғXғCғbғ`ӮБӮД-mavxӮЖӮ©/QxAVXӮЖӮ©ҲИҠOӮЙӮ ӮйӮБӮДӮұӮЖӮЕӮ·Ӯ©ҒHӮ—
ҺАҚЫ–в‘иҒAAVXӮрҺgӮӨҲИҠOӮЕғRғ“ғpғCғүӮЕӮвӮкӮйҚЕ“Kү»ғeғNғjғbғNӮИӮсӮД–wӮЗ–іӮўӮжҒB
җМӮМPentium 4/Pentium Mҗў‘гӮҫӮЖҒAQxW, QxB, QxN, QxPӮЖӮ©•Ўҗ”ӮМҚЕ“Kү»ғXғCғbғ`ӮӘ‘¶ҚЭӮөӮҪӮҜӮЗ
ҚЎӮНӮИӮӯӮИӮБӮДӮйҒB
MSӮМғRғ“ғpғCғүӮЙӮ ӮБӮҪG5, G6, G7ӮИӮсӮД”pҺ~ӮіӮкӮДӢvӮөӮўҒB
IntelғRғ“ғpғCғүӮағXғJғүғRҒ[ғhӮЙҠЦӮ·Ӯй•”•ӘӮНCore MAғxҒ[ғXӮЕҒAӮ ӮЖӮН–Ҫ—ЯғZғbғgӮМғTғ|Ғ[ғgӮҫӮҜ
ғxҒ[ғXӮМғ}ғCғNғҚғAҒ[ғLғeғNғ`ғғӮӘ“ҜӮ¶ӮҫӮ©ӮзӮИҒB
AtomҲИҠOӮЙғAҒ[ғLҢЕ—LӮМҚЕ“Kү»ғXғCғbғ`ӮИӮсӮД‘¶ҚЭӮөӮИӮўӮжҒB
http://www.sofken.com/Documentation/compiler_c/main_cls/copts/common_options/option_x_lcase.htm
ӮўӮБӮШӮсIntelғRғ“ғpғCғүӮЕ/QaxSSE2 /QaxSSE3 /QaxSSSE3 /QaxSSE4.1 /QaxSSS4.2 /QxAVXӮЖӮ©ӮЕғRҒ[ғhҗ¶җ¬ӮвӮБӮДӮЭӮйӮЖӮўӮўӮжҒB
ғXғJғү•”•ӘӮМғRҒ[ғh•ӘӮҜӮИӮсӮДӮвӮзӮИӮўӮ©ӮзӮ—
IntelғRғ“ғpғCғүӮаGCCӮаSandy Bridge—pҚЕ“Kү»ӮН -march=core2 -mavx ӮЕҸ\•ӘӮЖҢҫӮБӮДӮйҸуӢө
ӮұӮкӮрүјӮЙ-march=opteronӮЙӮөӮДӮа1Ғ`2%Ӯа•ПӮнӮзӮсӮжҒB
ҚЎӮЖӮИӮБӮДӮНғRҒ[ғhӮМ•АӮЧ•ы•ПӮҰӮйӮұӮЖӮЕӮвӮкӮйҺ–ӮИӮсӮД–wӮЗүҪӮа–іӮўҒB
Ӯ»ӮкӮӘғAғEғgғIғuғIҒ[ғ_ҺАҚsӮҫӮ©ӮзҒB
736 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/08/29(“ъ) 10:21:38 ID:MTTiKgI5P
Coremark(EEMBCғxғ“ғ`ғ}Ғ[ғN)
http://www.coremark.org/benchmark/index.php
Nvidia Tegra2 (dual-core ARM Cortex-A9) 1GHz
5866.39
Intel Atom N280 1.68 GHz
5353.79
Atom+HT 1.68GHz
ARM-A9+DualCore 1GHz
ӮЕ“ҜӮ¶ӮӯӮзӮўҒBӮЖӮўӮӨӮ©ғRғAҗ«”\ӮНҢЭҠpӮӯӮзӮўӮ©ӮИҒB
>>667ӮрӮЭӮйӮИӮиҒASoC‘S‘МӮЕ1.1WӮЖӮўӮӨMoorestownӮМҗў‘гӮЕҠщӮЙ
“d—Нҗ«”\”дӮЕARMӮЙғAғhғoғ“ғeҒ[ғWӮНӮИӮўүВ”\җ«ӮӘҚӮӮўҒB
http://www.coremark.org/benchmark/index.php
Nvidia Tegra2 (dual-core ARM Cortex-A9) 1GHz
5866.39
Intel Atom N280 1.68 GHz
5353.79
Atom+HT 1.68GHz
ARM-A9+DualCore 1GHz
ӮЕ“ҜӮ¶ӮӯӮзӮўҒBӮЖӮўӮӨӮ©ғRғAҗ«”\ӮНҢЭҠpӮӯӮзӮўӮ©ӮИҒB
>>667ӮрӮЭӮйӮИӮиҒASoC‘S‘МӮЕ1.1WӮЖӮўӮӨMoorestownӮМҗў‘гӮЕҠщӮЙ
“d—Нҗ«”\”дӮЕARMӮЙғAғhғoғ“ғeҒ[ғWӮНӮИӮўүВ”\җ«ӮӘҚӮӮўҒB
737 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/08/29(“ъ) 10:24:53 ID:MTTiKgI5P
ӮЬӮ ӮЁӮкӮНғRҒ[ғhғIғ^Ӯ¶ӮбӮИӮўӮөIntelғRғ“ғpғCғүҺ–ҸоӮИӮсӮД’ЗӮўӮ©ӮҜӮДӮИӮўӮ©Ӯз’mӮзӮсӮӘҒA
ҚЕ“Kү»ғXғCғbғ`ҲИҠOӮЕғRғ“ғpғCғүӮМүь—ЗӮНӮИӮўӮЖӮ©ҒA
’cҺqҗжҗ¶ӮМҳbӮНҺһҗЬӢӯҲшӮЙӮИӮйӮМӮНӮжӮӯӮнӮ©ӮБӮДӮўӮйӮ©Ӯз•·Ӯ«—¬ӮөӮДӮўӮйҒB
ҚЕ“Kү»ғXғCғbғ`ҲИҠOӮЕғRғ“ғpғCғүӮМүь—ЗӮНӮИӮўӮЖӮ©ҒA
’cҺqҗжҗ¶ӮМҳbӮНҺһҗЬӢӯҲшӮЙӮИӮйӮМӮНӮжӮӯӮнӮ©ӮБӮДӮўӮйӮ©Ӯз•·Ӯ«—¬ӮөӮДӮўӮйҒB
738 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/08/29(“ъ) 10:31:55 ID:MTTiKgI5P
ӮЖӮўӮӨӮнӮҜӮЕҢ»ҺАӮНҒA
- IPғrғWғlғXғӮғfғӢӮЕӮӨӮБӮДӮўӮӯӮМӮӘARM
- “d—НӮЖҗ«”\ӮМҚЕ“Kү»ӮЕғAғhғoғ“ғeҒ[ғWӮрӮӨӮБӮДӮўӮӯӮМӮӘҗVӢKҺQ“ьӮМIntel SoC
ӮЖӮўӮӨҗнӮў•ыӮЙӮИӮйӮМӮЕӮНӮИӮўӮ©ӮЖҒB
ҠҙҠoӮИҗ«”\ӮНғAғoғEғgӮИӮЖӮұӮлӮЕ
Coretex-A8 Ғc Deschutes-KatmaiғNғүғX
Coretex-A9 Ғc WillametteҒABonnellғNғүғX
җ«”\ӮЕPCғnғCғGғ“ғhӮМ–с8”N’xӮк
ғAҒ[ғLғeғNғ`ғғӮЕ–с10Ғ`15”N’xӮк
ӮЕҒAҗ»‘ўғvғҚғZғXӮНӮ ӮЬӮи•ПӮнӮзӮИӮўӮМӮЕӮ»ӮұӮЬӮЕғRғAҗ«”\Қ·ӮӘӮЕӮДӮИӮўӮЖӮўӮӨғCғҒҒ[ғWҒB
- IPғrғWғlғXғӮғfғӢӮЕӮӨӮБӮДӮўӮӯӮМӮӘARM
- “d—НӮЖҗ«”\ӮМҚЕ“Kү»ӮЕғAғhғoғ“ғeҒ[ғWӮрӮӨӮБӮДӮўӮӯӮМӮӘҗVӢKҺQ“ьӮМIntel SoC
ӮЖӮўӮӨҗнӮў•ыӮЙӮИӮйӮМӮЕӮНӮИӮўӮ©ӮЖҒB
ҠҙҠoӮИҗ«”\ӮНғAғoғEғgӮИӮЖӮұӮлӮЕ
Coretex-A8 Ғc Deschutes-KatmaiғNғүғX
Coretex-A9 Ғc WillametteҒABonnellғNғүғX
җ«”\ӮЕPCғnғCғGғ“ғhӮМ–с8”N’xӮк
ғAҒ[ғLғeғNғ`ғғӮЕ–с10Ғ`15”N’xӮк
ӮЕҒAҗ»‘ўғvғҚғZғXӮНӮ ӮЬӮи•ПӮнӮзӮИӮўӮМӮЕӮ»ӮұӮЬӮЕғRғAҗ«”\Қ·ӮӘӮЕӮДӮИӮўӮЖӮўӮӨғCғҒҒ[ғWҒB
739 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/08/29(“ъ) 10:35:25 ID:MTTiKgI5P
o Coretex
x Cortex
x Cortex
740 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/08/29(“ъ) 10:38:04 ID:MTTiKgI5P
ӮЬӮ AnandӮМғxғ“ғ`ӮҫӮҜӮЕӮаӮЁӮжӮ»ӮМӮұӮЖӮНӮнӮ©ӮБӮҪӮөҒA
ӮЩӮЪ—\‘z’КӮиӮЖӮўӮӨӮұӮЖӮаӮнӮ©ӮБӮҪӮЛҒB
Ӯ»ӮкӮЙӮөӮДӮа”ӯ”„ӮЬӮЕӮЬӮҫӮЬӮҫӮ ӮйӮМӮЙSandy BridgeӮМғxғ“ғ`үрӢЦ‘ҒӮ·Ӯ¬ӮйҒB
ӮаӮӨғeҒ[ғvғAғEғgӮ©Ӯз1”NҲИҸгҢoүЯӮөӮДӮўӮйӮ©ӮзӮИҒB
ӮаӮӨӮўӮўӮ©ӮзҒA‘ҒӮӯIntelӮҫӮ№ӮжӮЖҒB
ӮЩӮЪ—\‘z’КӮиӮЖӮўӮӨӮұӮЖӮаӮнӮ©ӮБӮҪӮЛҒB
Ӯ»ӮкӮЙӮөӮДӮа”ӯ”„ӮЬӮЕӮЬӮҫӮЬӮҫӮ ӮйӮМӮЙSandy BridgeӮМғxғ“ғ`үрӢЦ‘ҒӮ·Ӯ¬ӮйҒB
ӮаӮӨғeҒ[ғvғAғEғgӮ©Ӯз1”NҲИҸгҢoүЯӮөӮДӮўӮйӮ©ӮзӮИҒB
ӮаӮӨӮўӮўӮ©ӮзҒA‘ҒӮӯIntelӮҫӮ№ӮжӮЖҒB
741 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/08/29(“ъ) 10:39:31 ID:MTTiKgI5P
HaswellӮНҚЎӮМӮЖӮұӮлҸз’·ғ}ғӢғ`ғXғҢғbғhӮЖғlғbғgғҸҒ[ғNҗк—pғvғҚғZғbғTӮМ“қҚҮӮӘҢВҗl“IӮЙҚЎӮМӮЖӮұӮл—L—НӮ©ҒB
—бӮЙӮжӮБӮДғTҒ[ғoҗFӮМӢӯӮўүь—ЗӮӘ‘ҪӮ»ӮӨӮҫӮИҒB
—бӮЙӮжӮБӮДғTҒ[ғoҗFӮМӢӯӮўүь—ЗӮӘ‘ҪӮ»ӮӨӮҫӮИҒB
742 ҒF–јҸМ–ўҗЭ’иҒF2010/08/29(“ъ) 10:40:25 ID:viTFkRsHP
http://ednjapan.cancom-j.com/issue/2010/6/69/6784/2
CoreMarkӮБӮД8bitӮв16bitӮМҸҲ—қӮаӮвӮБӮДӮйӮ©ӮзҒA
ARMӮМғxғ“ғ`ҢӢүК—ЗӮўӮМӮБӮДThumbӮЕ8bitӮв16bitӮМҗ”ҺҡүТӮўӮЕӮйӮсӮ¶ӮбӮИӮўӮМҒH
CoreMarkӮБӮД8bitӮв16bitӮМҸҲ—қӮаӮвӮБӮДӮйӮ©ӮзҒA
ARMӮМғxғ“ғ`ҢӢүК—ЗӮўӮМӮБӮДThumbӮЕ8bitӮв16bitӮМҗ”ҺҡүТӮўӮЕӮйӮсӮ¶ӮбӮИӮўӮМҒH
743 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2010/08/29(“ъ) 11:17:42 ID:Urxmzf5n0
ғҚҒ[ғhғҶғjғbғgӮӘ‘қӮҰӮйӮұӮЖӮЕӮМҗ«”\ӮМү¶ҢbӮБӮДӮМӮН
ғҚҒ[ғh–Ҫ—ЯӮМ”д—ҰӮӘ‘қӮҰӮйӮЖӮұӮлҒAӮҫӮҜӮЕӮНӮИӮӯҒAғ~ғXғAғүғCғ“ғҒғ“ғgӮИғfҒ[ғ^ӮЙ‘ОӮ·ӮйғҚҒ[ғhӮрҚsӮБӮДӮа
җ«”\’бүәӮӘҸӯӮИӮўӮұӮЖҒB
ӮұӮкӮНAMDӮМ’ҶӮМҗlӮаҗа–ҫӮөӮДӮўӮҪҒB
ғҚҒ[ғh–Ҫ—ЯӮМ”д—ҰӮӘ‘қӮҰӮйӮЖӮұӮлҒAӮҫӮҜӮЕӮНӮИӮӯҒAғ~ғXғAғүғCғ“ғҒғ“ғgӮИғfҒ[ғ^ӮЙ‘ОӮ·ӮйғҚҒ[ғhӮрҚsӮБӮДӮа
җ«”\’бүәӮӘҸӯӮИӮўӮұӮЖҒB
ӮұӮкӮНAMDӮМ’ҶӮМҗlӮаҗа–ҫӮөӮДӮўӮҪҒB
744 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/08/29(“ъ) 17:40:11 ID:MTTiKgI5P
IGPӮМғXғRғAӮӘArrandale”дӮЕӮвӮҪӮзӮМӮСӮДӮўӮйӮжӮӨӮҫӮӘҒA
L3ӮМҢшүКӮӘӮўӮ©ӮЩӮЗӮ©ӢCӮЙӮИӮйӮИҒB
GPU“қҚҮӮНӮаӮЖӮаӮЖGPUӮЙӢ»–ЎӮИӮ©ӮБӮҪ‘wӮЙӮНҢкӮйӮЙ—]ҢvӮИӮаӮМӮӘӮӯӮБӮВӮўӮДӮ«ӮДӮ«ӮВӮў(ӮнӮзӮЎ
L3ӮМҢшүКӮӘӮўӮ©ӮЩӮЗӮ©ӢCӮЙӮИӮйӮИҒB
GPU“қҚҮӮНӮаӮЖӮаӮЖGPUӮЙӢ»–ЎӮИӮ©ӮБӮҪ‘wӮЙӮНҢкӮйӮЙ—]ҢvӮИӮаӮМӮӘӮӯӮБӮВӮўӮДӮ«ӮДӮ«ӮВӮў(ӮнӮзӮЎ
745 ҒF–јҸМ–ўҗЭ’иҒF2010/08/29(“ъ) 18:02:56 ID:MTTiKgI5P
>>714
ӮВӮЬӮиҒAғQҒ[ғҖ’ҶӮЕӮМғүғXғ^ғOғүғtғBғbғNғXӮМҺҝӮрүь‘PӮ·ӮйӮЙӮНҚЎӮв
ғVғFҒ[ғ_ғvғҚғOғүғ}ӮрӮҪӮӯӮіӮсҢЩӮБӮДҸҠ‘FғүғXғ^ғOғүғtғBғbғNӮЙӮ©ӮФӮ№ӮйғVғFҒ[ғ_ғvғҚғOғүғҖӮрғoғҠғoғҠҺgӮў“|Ӯ·ӮжӮиӮаҒA
ғOғүғtғBғbғNү®ӮвғZғ“ғXӮМӮжӮўүүҸoү®ӮрӮҪӮӯӮіӮсҢЩӮБӮҪӮиӮөӮДҒAҺҝӮМҚӮӮўғӮғfғӢӮЙҸ]—ҲӮЗӮЁӮиҚӮүжҺҝӮМғeғNғXғ`ғғӮрғoғҠғoғҠӮН
ӮБӮДӮўӮБӮҪӮЩӮӨӮӘӮёӮБӮЖҺӢҠoҢшүКӮӘҚӮӮўӮнӮҜӮЕҒBҺАҚЫӮМғQҒ[ғҖҗ»ҚмӮМҚHҗ”“IӮЙӮағOғүғtғBғbғNӮвүүҸoӮМ’Іҗ®ӮӘӮ©ӮИӮиӮМ”дҸdӮЙӮИӮБӮДӮўӮйҒB
2DғQҒ[ғҖӮаGPUҗ«”\ӮӘӮ ӮЬӮиҸd—vӮЕӮИӮӯӮИӮБӮДӮ©ӮзғOғүғtғBғbғJҒ[ӮИӮЗӮМҺҝӮӘғQҒ[ғҖӮМғrғWғ…ғAғӢ–КӮМ•iҺҝӮрҚ¶үEӮ·ӮйӮМӮӘ
Ң°’ҳӮЙӮИӮБӮҪӮӘӮ»ӮкӮЖ“ҜӮ¶—lӮИ—¬ӮкӮЕӮ ӮйҒB
ӮаӮЖӮаӮЖғvғҚғOғүғ}ғuғӢғVғFҒ[ғ_ӮИӮсӮДӮўӮӨӮМӮНGPUӮӘ‘еӢK–НӮЙӮИӮБӮДҚ·•Кү»ӮвғoғOӮВӮФӮөӮӘҚў“пӮЙӮИӮБӮДӮ«ӮҪ
GPUғҒҒ[ғJҒ[ӮвMSӮМҠJ”ӯӮМ“sҚҮӮ©ӮзӮ«ӮҪӮаӮМӮЙӮ·Ӯ¬ӮИӮўӮ©ӮаӮөӮкӮИӮўӮМӮЙҒAGPUӮӘғOғүғtғBғbғNӮМҺҝӮрҢьҸгӮ·ӮЧӮӯ”Д—pү»ӮрӮЁӮұӮИӮБӮД
ӮВӮўӮЙCPUӮМ’nҲКӮрӮЁӮСӮвӮ©Ӯ·ӮЖӮұӮлӮЬӮЕӮ«ӮҪӮЭӮҪӮўӮИ•¶–¬ӮЕҢкӮзӮкӮДӮйӮұӮЖӮӘӮНӮ¶ӮЯӮ©Ӯз”ј•ӘҢУҺUҸLӮўҳbӮЕӮНӮ ӮБӮҪҒB
nVIDIAӮЖӮөӮДӮа—бӮҰӮОғҢғCғgғҢҒ[ғVғ“ғOҗк—pғ`ғbғvӮИӮЗӮр‘ҒӮўӮӨӮҝӮЙҢӨӢҶӮөӮЖӮўӮДӮӯӮкӮкӮОҒA
HPCӮЖӮўӮӨӢ·ӮўҗўҠEӮр—ҠӮЭӮМҚjӮЙӮөӮИӮӯӮДӮа‘ҪҸӯү„–ҪӮЕӮ«ӮҪӮ©ӮаӮөӮкӮИӮўӮМӮЙҺc”OӮҫҒB
ғҢғCғgғҢҒ[ғVғ“ғOӢZҸpӮӘҲк”КҸБ”пҺТӮЙӮаҗZ“§Ӯ·ӮкӮОҒAғIғ^ғNҠEҢGӮЕ3D”ьҸӯҸ—ғӮғfғүҒ[ӮҪӮҝӮӘ‘ұҒXӮЖ“oҸкӮөӮДҒA
Һҹҗў‘гӮМғIғ^ғNғRғ“ғeғ“ғcӮЖӮөӮДғQҒ[ғҖӮИӮўӮөғQҒ[ғҖҲИҠOӮМғҒғfғBғAӮЙҗiҸoӮөӮДҗZ“§Ӯ·ӮйғVғiғҠғIӮӘӮВӮИӮӘӮБӮҪӮМӮЙ
“ъ–{ӮЖӮөӮДӮаҺc”OӮИӮұӮЖӮҫ(ӮнӮзӮЎ
ӮВӮЬӮиҒAғQҒ[ғҖ’ҶӮЕӮМғүғXғ^ғOғүғtғBғbғNғXӮМҺҝӮрүь‘PӮ·ӮйӮЙӮНҚЎӮв
ғVғFҒ[ғ_ғvғҚғOғүғ}ӮрӮҪӮӯӮіӮсҢЩӮБӮДҸҠ‘FғүғXғ^ғOғүғtғBғbғNӮЙӮ©ӮФӮ№ӮйғVғFҒ[ғ_ғvғҚғOғүғҖӮрғoғҠғoғҠҺgӮў“|Ӯ·ӮжӮиӮаҒA
ғOғүғtғBғbғNү®ӮвғZғ“ғXӮМӮжӮўүүҸoү®ӮрӮҪӮӯӮіӮсҢЩӮБӮҪӮиӮөӮДҒAҺҝӮМҚӮӮўғӮғfғӢӮЙҸ]—ҲӮЗӮЁӮиҚӮүжҺҝӮМғeғNғXғ`ғғӮрғoғҠғoғҠӮН
ӮБӮДӮўӮБӮҪӮЩӮӨӮӘӮёӮБӮЖҺӢҠoҢшүКӮӘҚӮӮўӮнӮҜӮЕҒBҺАҚЫӮМғQҒ[ғҖҗ»ҚмӮМҚHҗ”“IӮЙӮағOғүғtғBғbғNӮвүүҸoӮМ’Іҗ®ӮӘӮ©ӮИӮиӮМ”дҸdӮЙӮИӮБӮДӮўӮйҒB
2DғQҒ[ғҖӮаGPUҗ«”\ӮӘӮ ӮЬӮиҸd—vӮЕӮИӮӯӮИӮБӮДӮ©ӮзғOғүғtғBғbғJҒ[ӮИӮЗӮМҺҝӮӘғQҒ[ғҖӮМғrғWғ…ғAғӢ–КӮМ•iҺҝӮрҚ¶үEӮ·ӮйӮМӮӘ
Ң°’ҳӮЙӮИӮБӮҪӮӘӮ»ӮкӮЖ“ҜӮ¶—lӮИ—¬ӮкӮЕӮ ӮйҒB
ӮаӮЖӮаӮЖғvғҚғOғүғ}ғuғӢғVғFҒ[ғ_ӮИӮсӮДӮўӮӨӮМӮНGPUӮӘ‘еӢK–НӮЙӮИӮБӮДҚ·•Кү»ӮвғoғOӮВӮФӮөӮӘҚў“пӮЙӮИӮБӮДӮ«ӮҪ
GPUғҒҒ[ғJҒ[ӮвMSӮМҠJ”ӯӮМ“sҚҮӮ©ӮзӮ«ӮҪӮаӮМӮЙӮ·Ӯ¬ӮИӮўӮ©ӮаӮөӮкӮИӮўӮМӮЙҒAGPUӮӘғOғүғtғBғbғNӮМҺҝӮрҢьҸгӮ·ӮЧӮӯ”Д—pү»ӮрӮЁӮұӮИӮБӮД
ӮВӮўӮЙCPUӮМ’nҲКӮрӮЁӮСӮвӮ©Ӯ·ӮЖӮұӮлӮЬӮЕӮ«ӮҪӮЭӮҪӮўӮИ•¶–¬ӮЕҢкӮзӮкӮДӮйӮұӮЖӮӘӮНӮ¶ӮЯӮ©Ӯз”ј•ӘҢУҺUҸLӮўҳbӮЕӮНӮ ӮБӮҪҒB
nVIDIAӮЖӮөӮДӮа—бӮҰӮОғҢғCғgғҢҒ[ғVғ“ғOҗк—pғ`ғbғvӮИӮЗӮр‘ҒӮўӮӨӮҝӮЙҢӨӢҶӮөӮЖӮўӮДӮӯӮкӮкӮОҒA
HPCӮЖӮўӮӨӢ·ӮўҗўҠEӮр—ҠӮЭӮМҚjӮЙӮөӮИӮӯӮДӮа‘ҪҸӯү„–ҪӮЕӮ«ӮҪӮ©ӮаӮөӮкӮИӮўӮМӮЙҺc”OӮҫҒB
ғҢғCғgғҢҒ[ғVғ“ғOӢZҸpӮӘҲк”КҸБ”пҺТӮЙӮаҗZ“§Ӯ·ӮкӮОҒAғIғ^ғNҠEҢGӮЕ3D”ьҸӯҸ—ғӮғfғүҒ[ӮҪӮҝӮӘ‘ұҒXӮЖ“oҸкӮөӮДҒA
Һҹҗў‘гӮМғIғ^ғNғRғ“ғeғ“ғcӮЖӮөӮДғQҒ[ғҖӮИӮўӮөғQҒ[ғҖҲИҠOӮМғҒғfғBғAӮЙҗiҸoӮөӮДҗZ“§Ӯ·ӮйғVғiғҠғIӮӘӮВӮИӮӘӮБӮҪӮМӮЙ
“ъ–{ӮЖӮөӮДӮаҺc”OӮИӮұӮЖӮҫ(ӮнӮзӮЎ
746 ҒF–јҸМ–ўҗЭ’иҒF2010/08/29(“ъ) 19:58:29 ID:hYIILOih0
үҙӮаGPU•tӮҜӮйӮИӮзCPUғRғA‘қӮвӮ№ӮИӮсӮДҠҙӮ¶ӮҝӮбӮӨ
Һ©ҚмerӮБӮД”nҺӯӮЕ”ЯӮөӮўҗ¶Ӯ«•ЁӮҫӮжӮЛ
Һ©ҚмerӮБӮД”nҺӯӮЕ”ЯӮөӮўҗ¶Ӯ«•ЁӮҫӮжӮЛ
747 ҒF–јҸМ–ўҗЭ’иҒF2010/08/29(“ъ) 20:01:20 ID:hYIILOih0
ӮөӮ©Ӯө2005”NӮЙIntelӮӘ’сҸҘӮөӮДӮўӮҪMany-CoreӮЙӮЗӮсӮЗӮсӢЯӮГӮўӮДӮйӮЖӮўӮӨӮМӮНҠҙӮ¶Ӯй
LRBӮӘғLғғғ“ғZғӢӮіӮкӮИӮ©ӮБӮҪӮзғ}ғCғNғҚғJҒ[ғlғӢӮаҠщӮЙҺАҢ»ӮөӮДӮўӮҪӮНӮёӮЕ
LRBӮӘғLғғғ“ғZғӢӮіӮкӮИӮ©ӮБӮҪӮзғ}ғCғNғҚғJҒ[ғlғӢӮаҠщӮЙҺАҢ»ӮөӮДӮўӮҪӮНӮёӮЕ
748 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2010/08/31(үО) 00:02:15 ID:CFkt7Rae0
ғmҒ[ғgPC—pӮМCPUӮр‘I•КӮөӮДҸoӮ·ҲЧӮЙғfғXғNғgғbғvӮвғҚҒ[ғGғ“ғhғTҒ[ғoӮЙӮа“WҠJӮ·ӮйӮнӮҜӮЕ
“а‘ GPUҺgӮӨҺ–ӮИӮсӮДӢӯҗ§ӮіӮкӮДӮИӮўӮҫӮл
“а‘ GPUҺgӮӨҺ–ӮИӮсӮДӢӯҗ§ӮіӮкӮДӮИӮўӮҫӮл
749 ҒF–јҸМ–ўҗЭ’иҒF2010/08/31(үО) 09:51:46 ID:G+KH+kzj0
ӮвӮБӮПӮиғAғ|Ғ[ӮН10–ңү~‘дӮМPOWER7Mac”ӯ”„ӮЖӮ©ӮвӮБӮДӮӯӮкӮИӮўӮЖ–К”’–ЎӮИӮўӮжӮИ
750 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/08/31(үО) 20:19:55 ID:qxLqmzCnP
ғRғXғg“IӮЙ–і—қҒB
AppleӮӘ‘еҢы’Қ•¶ӮөӮДӮкӮОPOWERӮМүҝҠiӮа—КҺYҢшүКӮЕғ_ғEғ“Ӯ·ӮйӮНӮ·ӮйӮҫӮлӮӨӮӘҒA
Ӯ»ӮкӮЕӮаӮ ӮМҚӢүШҺd—lӮНPCғҢғxғӢӮМҗ»•iӮЙӮН–і—қӮИӮМӮЕӢ@”\Ӯрғ_ғEғ“ӮөӮДҗШӮи”„ӮиӮ·ӮйӮұӮЖӮЙӮИӮйҒB
ҢӢӢЗPPCӮЭӮҪӮўӮИӮМӮӘӮЕӮ«ӮйӮҫӮҜҒB
AppleӮӘ‘еҢы’Қ•¶ӮөӮДӮкӮОPOWERӮМүҝҠiӮа—КҺYҢшүКӮЕғ_ғEғ“Ӯ·ӮйӮНӮ·ӮйӮҫӮлӮӨӮӘҒA
Ӯ»ӮкӮЕӮаӮ ӮМҚӢүШҺd—lӮНPCғҢғxғӢӮМҗ»•iӮЙӮН–і—қӮИӮМӮЕӢ@”\Ӯрғ_ғEғ“ӮөӮДҗШӮи”„ӮиӮ·ӮйӮұӮЖӮЙӮИӮйҒB
ҢӢӢЗPPCӮЭӮҪӮўӮИӮМӮӘӮЕӮ«ӮйӮҫӮҜҒB
751 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/08/31(үО) 20:28:23 ID:qxLqmzCnP
ҢВҗl“IӮЙӮНMany-CoreӮЙӮНӮәӮсӮәӮсӢЯӮГӮўӮДӮўӮБӮДӮўӮйӮжӮӨӮЙҺvӮнӮИӮўӮҜӮЗӮИӮ ҒB
GPUӮЕӮўӮӨғRғAӮЖӮ©ғXғҢғbғhӮБӮДӮМӮНCPUӮМӮЖ’иӢ`ӮӘҲЩӮИӮйӮөҒA
GPUӮрғҒғjғBғRғAӮЖӮ©ӮўӮӨӮМӮН’PӮИӮйүcӢЖ•¶ӢеӮҫӮ©ӮзӮИҒB
>>38ӮЙҸ‘ӮўӮДӮ ӮйӮЖӮЁӮиҒAғ}ғӢғ`ғRғAӮНғvғҚғZғX1җў‘гӮЕ1.4”{ӮМғRғAӮөӮ©ҸWҗПӮЕӮ«ӮИӮў
–КҗПӮЖ“d—НӮМ—ј•ыӮЕҢш—ҰӮМҲ«ӮўӢZҸpӮҫӮжҒBӮ»ӮкӮЕ‘¬ӮӯӮИӮйӮМӮНҲк•”ӮМғAғvғҠӮҫӮҜҒB
2006”N11ҢҺӮЙQuad-CoreӮӘ“oҸкӮөӮҪӮӘҒA4”NҺгӮҪӮБӮДӮўӮйӮМӮЙӮўӮЬӮҫӮЙ4ғRғAӮНҲк”КӮЙҗZ“§ӮөӮДӮИӮўҒB
ӮұӮМӮЬӮЬҸҮ’ІӮЙғRғAҗ”ӮУӮвӮөӮДӮўӮБӮДӮа8ғRғAӮИӮсӮД“–•Ә•ҒӢyӮөӮИӮўӮәҒB
GPUӮЕӮўӮӨғRғAӮЖӮ©ғXғҢғbғhӮБӮДӮМӮНCPUӮМӮЖ’иӢ`ӮӘҲЩӮИӮйӮөҒA
GPUӮрғҒғjғBғRғAӮЖӮ©ӮўӮӨӮМӮН’PӮИӮйүcӢЖ•¶ӢеӮҫӮ©ӮзӮИҒB
>>38ӮЙҸ‘ӮўӮДӮ ӮйӮЖӮЁӮиҒAғ}ғӢғ`ғRғAӮНғvғҚғZғX1җў‘гӮЕ1.4”{ӮМғRғAӮөӮ©ҸWҗПӮЕӮ«ӮИӮў
–КҗПӮЖ“d—НӮМ—ј•ыӮЕҢш—ҰӮМҲ«ӮўӢZҸpӮҫӮжҒBӮ»ӮкӮЕ‘¬ӮӯӮИӮйӮМӮНҲк•”ӮМғAғvғҠӮҫӮҜҒB
2006”N11ҢҺӮЙQuad-CoreӮӘ“oҸкӮөӮҪӮӘҒA4”NҺгӮҪӮБӮДӮўӮйӮМӮЙӮўӮЬӮҫӮЙ4ғRғAӮНҲк”КӮЙҗZ“§ӮөӮДӮИӮўҒB
ӮұӮМӮЬӮЬҸҮ’ІӮЙғRғAҗ”ӮУӮвӮөӮДӮўӮБӮДӮа8ғRғAӮИӮсӮД“–•Ә•ҒӢyӮөӮИӮўӮәҒB
752 ҒFMACғIғ^Ғ„OOO-Ғј(ҒEҒНҒE,,ҒҷuҒ@ӮіӮсҒF2010/09/01(җ…) 17:53:59 ID:Jr3ElFqy0
>>750
Ғ@Ғ@---------------
Ғ@Ғ@ғRғXғg“IӮЙ–і—қҒB
Ғ@Ғ@---------------
IBMӮМғTҒ[ғoҒ[җ»•iӮНҗіӮЙҒwIBMүҝҠiҒxӮЖӮўӮӨғ„ғcӮИӮМӮЕҒAғRғXғgӮЕ’l’iӮӘҢҲӮЬӮБӮДӮўӮй–уӮ¶ӮбӮ ӮиӮЬӮ№ӮсҒB
ҺҺӮөӮЙӮ©ӮВӮД‘¶ҚЭӮөӮҪPPC970“ӢҚЪӮМIBMҗ»ғTҒ[ғoҒ[ӮМүҝҠiӮр’ІӮЧӮДӮЭӮйӮЖҒc
http://www-07.ibm.com/businesscenter/sg/pdf/IBM_Express_Portfolio.pdf (p.3ҺQҸЖ)
Ғ@Ғ@===============
Ғ@Ғ@IBM System p5 185 Express
Ғ@Ғ@Price starting from $6,099
Ғ@Ғ@===============
Ҳк•ыҒAPOWER7“ӢҚЪғTҒ[ғoҒ[ӮМҚЕ—хүҝ”Е Power 710 Express ӮМ•ДҚ‘үҝҠiӮНӮұӮҝӮзҒB
http://www-03.ibm.com/systems/power/hardware/710/browse_aix.html
Ғ@Ғ@===============
Ғ@Ғ@8231-E2B1
Ғ@Ғ@POWER7 / 3.0 GHz 4-core
Ғ@Ғ@$6,385.00 IBM Web price*
Ғ@Ғ@===============
Ӯ ӮЬӮи•ПӮнӮзӮИӮўӮЖӮўӮӨ(ҸО)
ҺАҚЫӮМӮЖӮұӮлҒAPOWER7ӮМғҚҒ[ғGғ“ғh”ЕӮНҠO•”L3ғ`ғbғvӮӘ•s—vӮЙӮИӮБӮҪӮұӮЖӮЙүБӮҰӮДҒAғvғүғXғ`ғbғN
җ»ӮЕғsғ“җ”ӮаҸӯӮИӮўғpғbғPҒ[ғWӮЙӮИӮБӮДӮўӮЬӮ·ҒBғuғҢҒ[ғhӮвғҚҒ[ғGғ“ғhғTҒ[ғoҒ[ӮЕ x86 җ»•iӮЖӮМ
үҝҠiӢЈ‘Ҳ—НӮрҚl—¶ӮөӮДҠJ”ӯӮіӮкӮДӮўӮЬӮ·Ӯ©ӮзҒAPower Mac G5ғҢғxғӢӮМғnғCғGғ“ғhғfғXғNғgғbғv/
ғҸҒ[ғNғXғeҒ[ғVғҮғ“ӮЙӮНӮ»ӮМӮЬӮЬ—¬—pӮЕӮ«ӮЬӮ·ӮөҒAҸгӮМүҝҠi”дҠrӮ©ӮзӮа”»ӮйӮжӮӨӮЙғVғXғeғҖүҝҠiӮа
Power Mac G5 ’ц“xӮЕҚПӮЭӮ»ӮӨӮЕӮ·ҒB
Ғ@Ғ@---------------
Ғ@Ғ@ғRғXғg“IӮЙ–і—қҒB
Ғ@Ғ@---------------
IBMӮМғTҒ[ғoҒ[җ»•iӮНҗіӮЙҒwIBMүҝҠiҒxӮЖӮўӮӨғ„ғcӮИӮМӮЕҒAғRғXғgӮЕ’l’iӮӘҢҲӮЬӮБӮДӮўӮй–уӮ¶ӮбӮ ӮиӮЬӮ№ӮсҒB
ҺҺӮөӮЙӮ©ӮВӮД‘¶ҚЭӮөӮҪPPC970“ӢҚЪӮМIBMҗ»ғTҒ[ғoҒ[ӮМүҝҠiӮр’ІӮЧӮДӮЭӮйӮЖҒc
http://www-07.ibm.com/businesscenter/sg/pdf/IBM_Express_Portfolio.pdf (p.3ҺQҸЖ)
Ғ@Ғ@===============
Ғ@Ғ@IBM System p5 185 Express
Ғ@Ғ@Price starting from $6,099
Ғ@Ғ@===============
Ҳк•ыҒAPOWER7“ӢҚЪғTҒ[ғoҒ[ӮМҚЕ—хүҝ”Е Power 710 Express ӮМ•ДҚ‘үҝҠiӮНӮұӮҝӮзҒB
http://www-03.ibm.com/systems/power/hardware/710/browse_aix.html
Ғ@Ғ@===============
Ғ@Ғ@8231-E2B1
Ғ@Ғ@POWER7 / 3.0 GHz 4-core
Ғ@Ғ@$6,385.00 IBM Web price*
Ғ@Ғ@===============
Ӯ ӮЬӮи•ПӮнӮзӮИӮўӮЖӮўӮӨ(ҸО)
ҺАҚЫӮМӮЖӮұӮлҒAPOWER7ӮМғҚҒ[ғGғ“ғh”ЕӮНҠO•”L3ғ`ғbғvӮӘ•s—vӮЙӮИӮБӮҪӮұӮЖӮЙүБӮҰӮДҒAғvғүғXғ`ғbғN
җ»ӮЕғsғ“җ”ӮаҸӯӮИӮўғpғbғPҒ[ғWӮЙӮИӮБӮДӮўӮЬӮ·ҒBғuғҢҒ[ғhӮвғҚҒ[ғGғ“ғhғTҒ[ғoҒ[ӮЕ x86 җ»•iӮЖӮМ
үҝҠiӢЈ‘Ҳ—НӮрҚl—¶ӮөӮДҠJ”ӯӮіӮкӮДӮўӮЬӮ·Ӯ©ӮзҒAPower Mac G5ғҢғxғӢӮМғnғCғGғ“ғhғfғXғNғgғbғv/
ғҸҒ[ғNғXғeҒ[ғVғҮғ“ӮЙӮНӮ»ӮМӮЬӮЬ—¬—pӮЕӮ«ӮЬӮ·ӮөҒAҸгӮМүҝҠi”дҠrӮ©ӮзӮа”»ӮйӮжӮӨӮЙғVғXғeғҖүҝҠiӮа
Power Mac G5 ’ц“xӮЕҚПӮЭӮ»ӮӨӮЕӮ·ҒB
753 ҒFMACғIғ^Ғ—’щҗіҒF2010/09/01(җ…) 18:36:10 ID:Jr3ElFqy0
ҸгӮЕҲш—pӮөӮҪIBMӮМG5ғTҒ[ғoҒ[ӮМүҝҠiӮН•ДғhғӢӮ¶ӮбӮИӮӯӮДҒAғVғ“ғKғ|Ғ[ғӢғhғӢӮЕӮөӮҪҒc
ӮЕҒA“–ҺһӮМӢLҺ–ӮжӮиӮҝӮеӮБӮЖ’щҗіҒBӮЁӮжӮ» $4,000 ӮЖӮМӮұӮЖҒB
http://www.osnews.com/story/13678/
Ғ@Ғ@--------------------
Ғ@Ғ@A 2-way 2.5GHz system with 2GB of RAM and two SCSI drives
Ғ@Ғ@will set you back $4000 [EUR 3360] without any OS licenses.
Ғ@Ғ@--------------------
ӮҝӮИӮЭӮЙӮұӮМҗ»•iҒAҢгҒXYDL ӮМ Terra Soft Solutions ӮӘ OEM ӮЕ”М”„ӮөӮДӮўӮЬӮ·ҒBӮұӮМҺһӮМүҝҠiӮНӮИӮсӮЖ $1,895 –зҒB
http://lwn.net/Articles/285538/
Ғ@Ғ@--------------------
Ғ@Ғ@The YDL PowerStation is available for just $1895 and will ship
Ғ@Ғ@by the close of June, 2008.
Ғ@Ғ@--------------------
Power 710 Ӯа•Ғ’КӮМғxғ“ғ_ӮӘ”М”„Ӯ·ӮкӮО 30-50–ңү~’ц“xӮМҗ»•iӮЙӮИӮиӮ»ӮӨҒcҒ@ӮЖӮўӮӨӮұӮЖӮЕҒB
ӮұӮкӮжӮиҲАӮӯӮ·ӮйӮЙӮН Power Mac ӮМӮжӮӨӮЙғfғXғNғgғbғvҗ»•iӮЖӮөӮДҗЭҢvӮөӮИӮЁӮ·•K—vӮӘӮ ӮйӮМӮЕӮөӮеӮӨҒB
ӮЕҒA“–ҺһӮМӢLҺ–ӮжӮиӮҝӮеӮБӮЖ’щҗіҒBӮЁӮжӮ» $4,000 ӮЖӮМӮұӮЖҒB
http://www.osnews.com/story/13678/
Ғ@Ғ@--------------------
Ғ@Ғ@A 2-way 2.5GHz system with 2GB of RAM and two SCSI drives
Ғ@Ғ@will set you back $4000 [EUR 3360] without any OS licenses.
Ғ@Ғ@--------------------
ӮҝӮИӮЭӮЙӮұӮМҗ»•iҒAҢгҒXYDL ӮМ Terra Soft Solutions ӮӘ OEM ӮЕ”М”„ӮөӮДӮўӮЬӮ·ҒBӮұӮМҺһӮМүҝҠiӮНӮИӮсӮЖ $1,895 –зҒB
http://lwn.net/Articles/285538/
Ғ@Ғ@--------------------
Ғ@Ғ@The YDL PowerStation is available for just $1895 and will ship
Ғ@Ғ@by the close of June, 2008.
Ғ@Ғ@--------------------
Power 710 Ӯа•Ғ’КӮМғxғ“ғ_ӮӘ”М”„Ӯ·ӮкӮО 30-50–ңү~’ц“xӮМҗ»•iӮЙӮИӮиӮ»ӮӨҒcҒ@ӮЖӮўӮӨӮұӮЖӮЕҒB
ӮұӮкӮжӮиҲАӮӯӮ·ӮйӮЙӮН Power Mac ӮМӮжӮӨӮЙғfғXғNғgғbғvҗ»•iӮЖӮөӮДҗЭҢvӮөӮИӮЁӮ·•K—vӮӘӮ ӮйӮМӮЕӮөӮеӮӨҒB
754 ҒF–јҸМ–ўҗЭ’иҒF2010/09/02(–Ш) 09:57:19 ID:ZoXk0IcZ0
MACғIғ^ғAғzӮ©
ҢҫӮБӮДӮйӮМӮНҗк—pҗЭҢvӮ·ӮйӮұӮЖӮИӮӯӮ»ӮМ”јҠzӮЕ”„ӮкӮЖӮўӮӨӮұӮЖӮҫҒB
ҢҫӮБӮДӮйӮМӮНҗк—pҗЭҢvӮ·ӮйӮұӮЖӮИӮӯӮ»ӮМ”јҠzӮЕ”„ӮкӮЖӮўӮӨӮұӮЖӮҫҒB
755 ҒFMACғIғ^Ғ„754 ӮіӮсҒF2010/09/02(–Ш) 21:07:57 ID:bXSyxYHZ0
>>754
Ғ@Ғ@-------------------
Ғ@Ғ@җк—pҗЭҢvӮ·ӮйӮұӮЖӮИӮӯӮ»ӮМ”јҠzӮЕ”„ӮкӮЖӮўӮӨӮұӮЖӮҫҒB
Ғ@Ғ@-------------------
җк—pҗЭҢvӮМ Power Mac G5 ӮН“ҜӮ¶ғNғүғXӮЕ30-40–ңү~ӮМҗ»•iӮИӮМӮЕӮ·ӮӘҒHҢоҗHӮМғqғgӮЕӮ·Ӯ©(ҸО)
http://www.apple.com/jp/news/2005/oct/20powermac.html
Ғ@Ғ@========================
Ғ@Ғ@Power Mac G5 Dual 299,800ү~Ғ@Ғi–{‘МүҝҠi 285,524ү~Ғj
Ғ@Ғ@Ғ@- ғfғ…ғAғӢғRғA2.3 GHz PowerPC G5ғvғҚғZғbғT
Ғ@Ғ@Power Mac G5 Quad 399,800ү~ Ғi–{‘МүҝҠi 380,762ү~Ғj
Ғ@Ғ@Ғ@- ғfғ…ғAғӢғRғA2.5 GHz PowerPC G5ғvғҚғZғbғT
Ғ@Ғ@========================
Ғ@Ғ@-------------------
Ғ@Ғ@җк—pҗЭҢvӮ·ӮйӮұӮЖӮИӮӯӮ»ӮМ”јҠzӮЕ”„ӮкӮЖӮўӮӨӮұӮЖӮҫҒB
Ғ@Ғ@-------------------
җк—pҗЭҢvӮМ Power Mac G5 ӮН“ҜӮ¶ғNғүғXӮЕ30-40–ңү~ӮМҗ»•iӮИӮМӮЕӮ·ӮӘҒHҢоҗHӮМғqғgӮЕӮ·Ӯ©(ҸО)
http://www.apple.com/jp/news/2005/oct/20powermac.html
Ғ@Ғ@========================
Ғ@Ғ@Power Mac G5 Dual 299,800ү~Ғ@Ғi–{‘МүҝҠi 285,524ү~Ғj
Ғ@Ғ@Ғ@- ғfғ…ғAғӢғRғA2.3 GHz PowerPC G5ғvғҚғZғbғT
Ғ@Ғ@Power Mac G5 Quad 399,800ү~ Ғi–{‘МүҝҠi 380,762ү~Ғj
Ғ@Ғ@Ғ@- ғfғ…ғAғӢғRғA2.5 GHz PowerPC G5ғvғҚғZғbғT
Ғ@Ғ@========================
756 ҒF–јҸМ–ўҗЭ’иҒF2010/09/03(Ӣа) 02:49:31 ID:ugKmVNlu0
ғCғ“ғ^ғrғ…Ғ[ҒFғjғRғ“ҺР’·
http://jp.reuters.com/article/topNews/idJPJAPAN-17068220100902
> ӢЈҚҮӮ·ӮйғIғүғ“ғ_ӮМӮ`ӮrӮlӮkӮӘҺҹҗў‘гӢZҸpӮМҒuӮdӮtӮuҒvӮрҺgӮБӮҪҚЕҗVҢ^ӮМ
> ”ј“ұ‘МҳIҢх‘•’uӮМҠJ”ӯӮЙӮўӮҝ‘ҒӮӯ’…ҺиӮөӮДӮPӮQ”NӮЙ—КҺYӢ@ӮрҸoүЧӮ·Ӯй
> Ң©’КӮөӮЙӮИӮБӮДӮўӮйӮӘҒA–Ш‘әҺР’·ӮНҒuҢЪӢqӮӘӮdӮtӮuӮр–{Ҡi“IӮИ—КҺYӢ@ӮЖӮөӮД
> ҺgӮӨӮМӮНӮQӮOӮPӮO”N‘гӮМҚЕҢгӮМ•ыӮЙӮИӮйӮҫӮлӮӨҒvӮЖӮөҒAӮ»ӮкӮЬӮЕӮНҒuүtҗZҒvҢ^ӮМ
> ӢZҸpҠvҗVӮр‘ұӮҜӮйӮұӮЖӮЕӮ`ӮrӮlӮkӮМӮdӮtӮuӢZҸpӮЙ‘ОҚRӮөӮДӮўӮӯ•ыҗjӮрҺҰӮөӮҪҒB
http://jp.reuters.com/article/topNews/idJPJAPAN-17068220100902
> ӢЈҚҮӮ·ӮйғIғүғ“ғ_ӮМӮ`ӮrӮlӮkӮӘҺҹҗў‘гӢZҸpӮМҒuӮdӮtӮuҒvӮрҺgӮБӮҪҚЕҗVҢ^ӮМ
> ”ј“ұ‘МҳIҢх‘•’uӮМҠJ”ӯӮЙӮўӮҝ‘ҒӮӯ’…ҺиӮөӮДӮPӮQ”NӮЙ—КҺYӢ@ӮрҸoүЧӮ·Ӯй
> Ң©’КӮөӮЙӮИӮБӮДӮўӮйӮӘҒA–Ш‘әҺР’·ӮНҒuҢЪӢqӮӘӮdӮtӮuӮр–{Ҡi“IӮИ—КҺYӢ@ӮЖӮөӮД
> ҺgӮӨӮМӮНӮQӮOӮPӮO”N‘гӮМҚЕҢгӮМ•ыӮЙӮИӮйӮҫӮлӮӨҒvӮЖӮөҒAӮ»ӮкӮЬӮЕӮНҒuүtҗZҒvҢ^ӮМ
> ӢZҸpҠvҗVӮр‘ұӮҜӮйӮұӮЖӮЕӮ`ӮrӮlӮkӮМӮdӮtӮuӢZҸpӮЙ‘ОҚRӮөӮДӮўӮӯ•ыҗjӮрҺҰӮөӮҪҒB
757 ҒF–јҸМ–ўҗЭ’иҒF2010/09/03(Ӣа) 03:02:50 ID:827AzcaM0
2009”NӮЙҺА—pү»ӮЖӮ©ҢҫӮБӮДӮҪӮМӮӘүщӮ©ӮөӮўӮИӮ—Ӯ—Ӯ—
758 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2010/09/03(Ӣа) 23:55:55 ID:a4BVoU7i0
450mmғEғFғnӮ©ӮзӮИӮМӮ©ӮИҒH
759 ҒF–јҸМ–ўҗЭ’иҒF2010/09/04(“y) 00:45:55 ID:GecsTqw80
ӮжӮӨӮвӮБӮЖEUVӮ©
193nm ArFӮӘ’·Ӯ©ӮБӮҪӮИ
193nm ArFӮӘ’·Ӯ©ӮБӮҪӮИ
760 ҒF–јҸМ–ўҗЭ’иҒF2010/09/04(“y) 12:42:07 ID:fbqRKqmH0
761 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/09/04(“y) 18:32:42 ID:PWto0yVqP
ӢCҺқӮҝғ|ғWғeғBғ”–ЪӮЕ
BullӮМIPCӮӘSNB”дӮЕ0.6‘OҢгӮЖӮўӮӨҗ”ҺҡӮҫӮБӮҪҒB
BullӮМIPCӮӘSNB”дӮЕ0.6‘OҢгӮЖӮўӮӨҗ”ҺҡӮҫӮБӮҪҒB
762 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2010/09/04(“y) 19:03:40 ID:AXtKnU6k0
Ӯ»ӮкӮ¶ӮбAMDӮНҸҹӮДӮсӮҫӮлҒB
ғ_ғCғtғHғgҢ©ӮйҢАӮиӮҫӮЖBulldozer 8ғRғAӮНSandy Bridge 4ғRғAӮжӮиӮН‘еӮ«ӮӯӮИӮиӮ»ӮӨӮҫӮөҒi6ғRғAӮЖ“Ҝ’ц“xҒHҒj
ҢӢӢЗӮНғVғ“ғOғӢғXғҢғbғhҗ«”\ӮрҸгӮ°ӮйӮМӮЙIPCӮрҸгӮ°ӮйӮ©ғNғҚғbғNӮрӮ Ӯ°ӮйӮ©ҒAӮҫӮЖҺvӮӨӮМӮҫӮӘҒB
IPCӮрx”{ӮЙӮ·ӮйӮЙӮНӮЁӮЁӮжӮ»ғgғүғ“ғWғXғ^ӮНxӮМ2Ҹж”{•K—vӮЙӮИӮиҒAҸБ”п“d—НӮНӮ»ӮкӮЙ”д—бӮөӮД‘қӮҰӮйҒB
ғNғҚғbғNӮрx”{ӮЙӮ·ӮйӮЙӮНҒAxӮМ2ҸжӮжӮиҚXӮЙ‘ҪӮӯӮМ“d—НӮӘ•K—vӮЙӮИӮй
Turbo BoostӮМӮжӮӨӮЙғpғҸҒ[ғQҒ[ғeғBғ“ғOӮЕ1Ғ`2ғRғAӮЙ“d—НӢҹӢӢӮрҸW’ҶӮөӮД
ғNғҚғbғNӮрҲкҺһ“IӮЙҸгӮ°ӮйғAғvғҚҒ[ғ`ӮНҒAӮЬӮ Ӯ ӮиӮҫӮЖҺvӮӨӮӘ
‘SғRғAӮМ’иҠiғNғҚғbғNӮрҸгӮ°ӮйғAғvғҚҒ[ғ`ӮНӮИӮ©ӮИӮ©ӮӨӮЬӮӯӮўӮ©ӮИӮўӮЖҺvӮнӮкӮйҒB
ғ_ғCғtғHғgҢ©ӮйҢАӮиӮҫӮЖBulldozer 8ғRғAӮНSandy Bridge 4ғRғAӮжӮиӮН‘еӮ«ӮӯӮИӮиӮ»ӮӨӮҫӮөҒi6ғRғAӮЖ“Ҝ’ц“xҒHҒj
ҢӢӢЗӮНғVғ“ғOғӢғXғҢғbғhҗ«”\ӮрҸгӮ°ӮйӮМӮЙIPCӮрҸгӮ°ӮйӮ©ғNғҚғbғNӮрӮ Ӯ°ӮйӮ©ҒAӮҫӮЖҺvӮӨӮМӮҫӮӘҒB
IPCӮрx”{ӮЙӮ·ӮйӮЙӮНӮЁӮЁӮжӮ»ғgғүғ“ғWғXғ^ӮНxӮМ2Ҹж”{•K—vӮЙӮИӮиҒAҸБ”п“d—НӮНӮ»ӮкӮЙ”д—бӮөӮД‘қӮҰӮйҒB
ғNғҚғbғNӮрx”{ӮЙӮ·ӮйӮЙӮНҒAxӮМ2ҸжӮжӮиҚXӮЙ‘ҪӮӯӮМ“d—НӮӘ•K—vӮЙӮИӮй
Turbo BoostӮМӮжӮӨӮЙғpғҸҒ[ғQҒ[ғeғBғ“ғOӮЕ1Ғ`2ғRғAӮЙ“d—НӢҹӢӢӮрҸW’ҶӮөӮД
ғNғҚғbғNӮрҲкҺһ“IӮЙҸгӮ°ӮйғAғvғҚҒ[ғ`ӮНҒAӮЬӮ Ӯ ӮиӮҫӮЖҺvӮӨӮӘ
‘SғRғAӮМ’иҠiғNғҚғbғNӮрҸгӮ°ӮйғAғvғҚҒ[ғ`ӮНӮИӮ©ӮИӮ©ӮӨӮЬӮӯӮўӮ©ӮИӮўӮЖҺvӮнӮкӮйҒB
763 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/09/04(“y) 19:55:34 ID:PWto0yVqP
AMDӮаҺА—НӮр”FҺҜӮөӮДӮйӮҫӮлӮӨӮИҒBIvy-Bridge-EXӮЖӮ©ӮМғ]Ғ[ғ“ӮН‘_ӮБӮДӮИӮўӮҫӮлӮӨӮЛҒB
’бүҝҠi‘СӮМғTҒ[ғoӮвҒAғfғ^ғZғ“ӮЕ‘е—К”ғӮўӮөӮДӮӯӮкӮйҢЪӢqӮр“–ӮДӮЙӮөӮДӮўӮйӮМӮЕӮНӮИӮўӮ©ӮЖҒB
BulldozerӮЖӮўӮҰӮОғXғӢҒ[ғvғbғgӮИӮМӮҫӮӘғXғӢҒ[ғvғbғgҗ«”\ӮЕӮа‘еӢK–НғRғA‘ҠҺиӮЙӢкҗнӮ·ӮйӮЖҺvӮӨҒB
ҸҠ‘FғXғӢҒ[ғvғbғgҸdҺӢӮМғAҒ[ғLғeғNғ`ғғӮИӮсӮДӮ»ӮсӮИӮаӮсҒB
ғfғXғNғgғbғvӮНҺе—НӮЙӮНӮИӮзӮИӮўӮЖҺvӮӨӮжҒB
ҢВҗl“IӮЙӮНBulldozerӮМӮжӮӨӮИғAҒ[ғLғeғNғ`ғғӮӘPCӮЙҗiҸoӮөӮДӮӯӮкӮйӮЁӮ©ӮҜӮЕ
ӮвӮБӮПғ}ғӢғ`ғRғAӮвғXғӢҒ[ғvғbғgӮН“ҠҺ‘ӮЙҢ©ҚҮӮӨӮҫӮҜӮМҗ«”\ӮЕӮИӮўӮсӮҫӮИҒA
ӮЖӮўӮӨ”FҺҜӮӘҚLӮЬӮБӮДӢЖҠEӮМ—¬ӮкӮӘ•ПӮнӮБӮДӮӯӮкӮИӮўӮ©ӮЖӮўӮӨ“_ӮЕӮЮӮөӮлӮ©ӮИӮиҠъ‘ТӮөӮДӮўӮйҒB
Sandy BridgeӮНTurbo BoostӮМ‘¶ҚЭӮр‘O’сӮЙғAҒ[ғLғeғNғ`ғғӮр—ыӮБӮҪҗў‘гӮЖӮўӮӨҠҙӮ¶ӮӘӮ·ӮйӮӘҒA
җМӮаӮўӮБӮҪӮӘBulldozerӮНғAҒ[ғLғeғNғ`ғғҚ\‘z’iҠKӮЕӮНTBҚlӮҰӮДӮИӮ©ӮБӮҪӮҫӮлӮӨӮЛҒB
ӮҫӮ©ӮзӮ Ӯ ӮўӮӨғ\ғҠғbғhӮИғAғvғҚҒ[ғ`ӮЙӮИӮБӮҪӮсӮҫӮлӮӨҒB
ӮұӮМҺиӮМ“d—Н/ғNғҚғbғNҗ§ҢдӢZҸpӮЕӮНThubanҒALlanoӮЕғXғeғbғvғAғbғvӮөӮИӮӘӮзIntelӮЙӮИӮйӮҫӮҜ’ЗӮўӮВӮ©Ӯ№ӮжӮӨӮЖӮўӮӨӮ©ӮсӮ¶ҒB
’бүҝҠi‘СӮМғTҒ[ғoӮвҒAғfғ^ғZғ“ӮЕ‘е—К”ғӮўӮөӮДӮӯӮкӮйҢЪӢqӮр“–ӮДӮЙӮөӮДӮўӮйӮМӮЕӮНӮИӮўӮ©ӮЖҒB
BulldozerӮЖӮўӮҰӮОғXғӢҒ[ғvғbғgӮИӮМӮҫӮӘғXғӢҒ[ғvғbғgҗ«”\ӮЕӮа‘еӢK–НғRғA‘ҠҺиӮЙӢкҗнӮ·ӮйӮЖҺvӮӨҒB
ҸҠ‘FғXғӢҒ[ғvғbғgҸdҺӢӮМғAҒ[ғLғeғNғ`ғғӮИӮсӮДӮ»ӮсӮИӮаӮсҒB
ғfғXғNғgғbғvӮНҺе—НӮЙӮНӮИӮзӮИӮўӮЖҺvӮӨӮжҒB
ҢВҗl“IӮЙӮНBulldozerӮМӮжӮӨӮИғAҒ[ғLғeғNғ`ғғӮӘPCӮЙҗiҸoӮөӮДӮӯӮкӮйӮЁӮ©ӮҜӮЕ
ӮвӮБӮПғ}ғӢғ`ғRғAӮвғXғӢҒ[ғvғbғgӮН“ҠҺ‘ӮЙҢ©ҚҮӮӨӮҫӮҜӮМҗ«”\ӮЕӮИӮўӮсӮҫӮИҒA
ӮЖӮўӮӨ”FҺҜӮӘҚLӮЬӮБӮДӢЖҠEӮМ—¬ӮкӮӘ•ПӮнӮБӮДӮӯӮкӮИӮўӮ©ӮЖӮўӮӨ“_ӮЕӮЮӮөӮлӮ©ӮИӮиҠъ‘ТӮөӮДӮўӮйҒB
Sandy BridgeӮНTurbo BoostӮМ‘¶ҚЭӮр‘O’сӮЙғAҒ[ғLғeғNғ`ғғӮр—ыӮБӮҪҗў‘гӮЖӮўӮӨҠҙӮ¶ӮӘӮ·ӮйӮӘҒA
җМӮаӮўӮБӮҪӮӘBulldozerӮНғAҒ[ғLғeғNғ`ғғҚ\‘z’iҠKӮЕӮНTBҚlӮҰӮДӮИӮ©ӮБӮҪӮҫӮлӮӨӮЛҒB
ӮҫӮ©ӮзӮ Ӯ ӮўӮӨғ\ғҠғbғhӮИғAғvғҚҒ[ғ`ӮЙӮИӮБӮҪӮсӮҫӮлӮӨҒB
ӮұӮМҺиӮМ“d—Н/ғNғҚғbғNҗ§ҢдӢZҸpӮЕӮНThubanҒALlanoӮЕғXғeғbғvғAғbғvӮөӮИӮӘӮзIntelӮЙӮИӮйӮҫӮҜ’ЗӮўӮВӮ©Ӯ№ӮжӮӨӮЖӮўӮӨӮ©ӮсӮ¶ҒB
764 ҒF–јҸМ–ўҗЭ’иҒF2010/09/04(“y) 20:09:07 ID:Ujkes8tIP
ӮаӮЖӮаӮЖIntelӮНFoxtonӮЕғAғvғҠӮІӮЖӮЙҸБ”п“d—НӮӘҲбӮӨӮұӮЖӮЙ’…–ЪӮөӮДҒA
TDP”НҲН“аӮЕҚЕҚӮҗ«”\ӮрҸoӮ·ӮұӮЖӮр–ЪҺwӮөӮДӮўӮҪӮсӮҫӮ©ӮзҒA
ғRғA’PҲКӮМҗ§ҢдӮЙҺжӮиӮ©Ӯ©ӮБӮҪӮОӮ©ӮиӮМAMDӮЖӮН”NҠъӮӘҲбӮБӮД“–‘RӮИӮсӮ¶ӮбӮИӮўӮМҒH
TDP”НҲН“аӮЕҚЕҚӮҗ«”\ӮрҸoӮ·ӮұӮЖӮр–ЪҺwӮөӮДӮўӮҪӮсӮҫӮ©ӮзҒA
ғRғA’PҲКӮМҗ§ҢдӮЙҺжӮиӮ©Ӯ©ӮБӮҪӮОӮ©ӮиӮМAMDӮЖӮН”NҠъӮӘҲбӮБӮД“–‘RӮИӮсӮ¶ӮбӮИӮўӮМҒH
765 ҒF–јҸМ–ўҗЭ’иҒF2010/09/04(“y) 21:57:56 ID:0padwxkf0
үКӮҪӮөӮДBulldozerӮНIntelӮ©ӮзAtomғTҒ[ғoҒ[ӮрҲшӮ«ӮёӮиҸoӮ·ӮұӮЖӮӘӮЕӮ«ӮйӮМӮ©
766 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2010/09/04(“y) 22:41:08 ID:AXtKnU6k0
>>763
ӮФӮБӮҝӮбӮҜӮҪҳbҒASandy BridgeӮЖBulldozer(Orochi)ӮН“ҜӮ¶ғӮғWғ…Ғ[ғӢҒiғRғAҒjҗ”ӮЕ”дҠrӮөӮҪҸкҚҮ
“®ҚмғNғҚғbғN“IӮЙӮНӮ»ӮсӮИӮЙ•ПӮнӮзӮсӮМӮЕӮНӮИӮўӮ©ӮЖҺvӮӨӮсӮҫӮӘҒB
ҢӢӢЗӮНx86ӮМ•ЎҺGӮіӮМҚЕӮҪӮй•”•ӘӮЕӮ ӮйғfғRҒ[ғ_ӮЙ“®ҚмҢАҠEӮӘ”ӣӮзӮкӮйӮөӮИҒB
ӮұӮМ“_ӮЙҠЦӮөӮДӮНҒAӮЁӮИӮ¶4ғEғFғCӮЕComplex DecoderҒ~4ӮМOrochiӮМӮЩӮӨӮӘӮЮӮөӮл•s—ҳӮ©ӮЖҒB
ҒiCoreMAӮМҸкҚҮҒA–Ҫ—Я—сӮӘLSDӮЙҺыӮЬӮйҸкҚҮӮНғfғRҒ[ғ_ӮрҺ~ӮЯӮйӮұӮЖӮӘӮЕӮ«ӮйҒj
>>765
Atomғ}ғӢғ`ғRғAӮН–К”’ӮўӮИ
ҢіҒXғҒғjҒ[ғRғAҢьӮҜӮЙҗЭҢvӮөӮДӮҪҗОӮрҢg‘СӢ@ҠнҢьӮҜӮЙғJғbғgғ_ғEғ“ӮөӮҪ•ЁӮзӮөӮўӮөҒA
Nehalem-EXӮМӢZҸpүһ—pӮ·ӮкӮОӮ·Ӯ®ӮЙӮЕӮаӮЕӮ«ӮйӢCӮӘӮ·Ӯй
ӮФӮБӮҝӮбӮҜӮҪҳbҒASandy BridgeӮЖBulldozer(Orochi)ӮН“ҜӮ¶ғӮғWғ…Ғ[ғӢҒiғRғAҒjҗ”ӮЕ”дҠrӮөӮҪҸкҚҮ
“®ҚмғNғҚғbғN“IӮЙӮНӮ»ӮсӮИӮЙ•ПӮнӮзӮсӮМӮЕӮНӮИӮўӮ©ӮЖҺvӮӨӮсӮҫӮӘҒB
ҢӢӢЗӮНx86ӮМ•ЎҺGӮіӮМҚЕӮҪӮй•”•ӘӮЕӮ ӮйғfғRҒ[ғ_ӮЙ“®ҚмҢАҠEӮӘ”ӣӮзӮкӮйӮөӮИҒB
ӮұӮМ“_ӮЙҠЦӮөӮДӮНҒAӮЁӮИӮ¶4ғEғFғCӮЕComplex DecoderҒ~4ӮМOrochiӮМӮЩӮӨӮӘӮЮӮөӮл•s—ҳӮ©ӮЖҒB
ҒiCoreMAӮМҸкҚҮҒA–Ҫ—Я—сӮӘLSDӮЙҺыӮЬӮйҸкҚҮӮНғfғRҒ[ғ_ӮрҺ~ӮЯӮйӮұӮЖӮӘӮЕӮ«ӮйҒj
>>765
Atomғ}ғӢғ`ғRғAӮН–К”’ӮўӮИ
ҢіҒXғҒғjҒ[ғRғAҢьӮҜӮЙҗЭҢvӮөӮДӮҪҗОӮрҢg‘СӢ@ҠнҢьӮҜӮЙғJғbғgғ_ғEғ“ӮөӮҪ•ЁӮзӮөӮўӮөҒA
Nehalem-EXӮМӢZҸpүһ—pӮ·ӮкӮОӮ·Ӯ®ӮЙӮЕӮаӮЕӮ«ӮйӢCӮӘӮ·Ӯй
767 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/09/11(“y) 21:45:21 ID:UL7M3C3vP
768 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/09/11(“y) 22:06:45 ID:UL7M3C3vP
>>764
FoxtonҲИҠOӮЙӮа”с‘ОҸМғ}ғӢғ`ғRғAҢьӮҜӮЙEPIғXғҚғbғgғҠғ“ғOӮИӮсӮДҢӨӢҶӮаӮ ӮБӮҪӮИҒB
җ«”\/“d—НҒAғVғ“ғOғӢғXғҢғbғh/ғXғӢҒ[ғvғbғgӮМ“®“IӮИғXғPҒ[ғҠғ“ғOӮЖӮўӮӨӮМӮН
IntelӮМҚDӮ«•ЁӮИӮсӮҫӮлӮӨӮИҒB
http://itl.jisakuita.net/intel_ups_info/1159817811.html#R148
http://itl.jisakuita.net/intel_ups_info/1121683774.html#R232
http://download.intel.com/jp/developer/jpdoc/epi-throttling-1005_j.pdf
http://download.intel.com/jp/developer/jpdoc/power_efficiency-0206_j.pdf
FoxtonҲИҠOӮЙӮа”с‘ОҸМғ}ғӢғ`ғRғAҢьӮҜӮЙEPIғXғҚғbғgғҠғ“ғOӮИӮсӮДҢӨӢҶӮаӮ ӮБӮҪӮИҒB
җ«”\/“d—НҒAғVғ“ғOғӢғXғҢғbғh/ғXғӢҒ[ғvғbғgӮМ“®“IӮИғXғPҒ[ғҠғ“ғOӮЖӮўӮӨӮМӮН
IntelӮМҚDӮ«•ЁӮИӮсӮҫӮлӮӨӮИҒB
http://itl.jisakuita.net/intel_ups_info/1159817811.html#R148
http://itl.jisakuita.net/intel_ups_info/1121683774.html#R232
http://download.intel.com/jp/developer/jpdoc/epi-throttling-1005_j.pdf
http://download.intel.com/jp/developer/jpdoc/power_efficiency-0206_j.pdf
769 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/09/11(“y) 23:32:46 ID:UL7M3C3vP
>>766
TDPӮр”ІӮ«ӮЙӮөӮДҒA“ҜӮ¶ғRғAҗ”ӮЕӮМ”дҠrӮЖӮўӮӨӮМӮЙӮНӮ ӮЬӮиҲУ–ЎӮӘӮИӮўӮЕӮөӮеҒB
TDPӮЙ‘ОӮөӮДғRғAҗ”ӮрӮЗӮкӮҫӮҜ(’иҠi“IӮИ“®ҚмӮЕ)үҹӮөҚһӮЯӮйӮ©ӮӘҒABulldozerӮМ‘_ӮўҒB
•ЦӢXҸгҒANehalemӮЖӮМIPC”дӮНғWғғғ“ғӢӮЙӮжӮзӮё0.65ӮЕTBӮИӮө‘O’сӮЕӮМ”дҠrҒBӮұӮкӮНғeғLғgҒ[ӮЙҢҲӮЯӮҪҗ”ҺҡӮЕӮ·ҒB
(IntelӮМ’иҠiғNғҚғbғNӮНҢ»ҚЭҒA‘SғRғAүТ“®ҺһӮрҠоҸҖӮЙҗЭ’иӮіӮкӮДӮўӮйӮЖҢ©ӮзӮкӮйҒB)
- MPғTҒ[ғo (TDPӮЙ‘ОӮөӮДғRғAҗ”ӮӘ‘ҪӮӯҒAҗ§–сӮӘҢөӮөӮўҒB)
Nehalem-EX, 130W, 8ғRғA, 2.26GHz, TB 2.66GHz
2.26GHz / 0.65 = 3.47GHz
ҒЁ BulldozerӮН130WӮЕ8ғRғAӮӘ3.5GHz’ц“xӮЕүсӮБӮДӮӯӮкӮкӮОғRғAӮ ӮҪӮиӮМҗ«”\ӮЕӮа’К—pҒB
ғNғүғXғ^Ғ[ғhӮИӮМӮЕ–КҗПӮИӮЗӮЕғҒғҠғbғgӮӘӮ ӮйҒB
- ғҒғCғ“ғXғgғҠҒ[ғҖғfғXғNғgғbғv (TDPӮЙ‘ОӮөӮДғRғAҗ”ӮӘҸӯӮИӮўҒBTBӮМү¶ҢbӮӘӮЩӮЖӮсӮЗӮИӮӯӮИӮйҒB)
Clarkdale-620, 73W, 2ғRғA, 3.60GHz, TB 3.86GHz
3.33GHz / 0.65 = 5.54GHz
ҒЁ BulldozerӮНғRғAӮ ӮҪӮиҗ«”\ӮЕҸҹӮВӮЙӮН2ғRғAӮр5.6GHzӮаӮМҗўҠEҚЕҚӮғXғsҒ[ғhӮЕүсӮіӮИӮҜӮкӮОӮИӮзӮИӮўҒB
–і—қӮӘӮ ӮйӮМӮЕүҝҠiғҒғҠғbғgӮвҒAӮжӮи‘ҪӮӯӮМғRғAӮрҸWҗПӮ·ӮйӮИӮЗӮМ‘ОүһҒB
ӮЖӮўӮӨӮнӮҜӮЕҒATDP vs Coreҗ”ӮӘBulldozerӮМ—D—тӮрҢҲӮЯӮйҢ®ӮИӮсӮҫӮж(–{—ҲӮН)ҒB
’КҸнҒA’PҸғӮИ—қҳ_ӮЕ
- ғRғAҗЭҢvӮМҠg’ЈӮЙ‘ОӮ·Ӯйҗ«”\ҢьҸгӮЙ‘ОӮөӮДҒA“d—НӮН2ҸжӮӯӮзӮўӮЕ‘қӮҰӮй (Ғ©ғRғAӮр–{ӢCӮЕ“d—НӮЙҚЕ“Kү»ӮөӮДӮИӮ©ӮБӮҪҺһ‘г‘O’сӮМҳbӮҫӮӘ)
- “dҲіҲк’иӮЕғNғҚғbғNғAғbғvӮЙ‘ОӮөӮДҒA“d—НӮН1ҸжӮЕ‘қӮҰӮй
- ҚXӮИӮйғNғҚғbғNҢьҸгӮМӮМӮҪӮЯҸёҲіҚһӮЭӮЕғNғҚғbғNӮр–і—қӮЙӮ Ӯ°ӮйӮЖҒA“d—НӮН3ҸжӮЕ‘қӮҰӮй
ӮМӮЕҒA“d—НӮЙӢCӮрҺgӮБӮҪғAҒ[ғLғeғNғ`ғғӮЕӮаҒA“dҲіӮрӮ Ӯ°ӮДӮЬӮЕ–і—қӮЙҗ«”\ӮрӮ Ӯ°ӮйӮЖӮҪӮҝӮЬӮҝ“d—НӮЖ”ӯ”MӮӘ”ҡ”ӯӮөӮДӮөӮЬӮӨҒB
ӮөӮҪӮӘӮБӮДҒAҸ¬ӢK–НғRғAӮИӮзҗ«”\’бүәҲИҸгӮЙ“d—НӮрүәӮ°ӮйӮұӮЖӮН—eҲХӮҫӮӘҒA
Ҹ¬ӢK–НғRғAӮЕӮ ӮБӮДӮаҸёҲіӮөӮДӮМҗ«”\ғAғbғvӮөӮҪӮзҒA3ҸжӮЕ”ҡ”ӯӮ·ӮйӮ©ӮзӮвӮОӮўҒB
ғvғҚғZғX/ғfғoғCғXӮМ“Kҗі’lӮИ“dҲіӮЕҺgӮӨӮұӮЖӮр‘O’сӮИӮзҒABullӮМӮжӮӨӮИӢK–НӮр—}ӮҰӮҪғRғAӮИӮзTDPӮӘҢөӮөӮӯӮЕӮаӮ»ӮкӮИӮиӮЙүсӮйӮ©Ӯз—L—ҳҒB
ӮөӮ©ӮөҒA‘еғRғAӮӘӮжӮўӮ©Ҹ¬ғRғAӮӘӮжӮўӮ©ӮНҒAӮЗӮсӮИҺgӮў•ыӮрӮөӮДӮа“d—Нҗ«”\”дӮЕҸ¬ғRғAӮӘ—L—ҳӮЖӮўӮӨӮнӮҜӮЕӮаӮИӮўҒB
TDPӮр”ІӮ«ӮЙӮөӮДҒA“ҜӮ¶ғRғAҗ”ӮЕӮМ”дҠrӮЖӮўӮӨӮМӮЙӮНӮ ӮЬӮиҲУ–ЎӮӘӮИӮўӮЕӮөӮеҒB
TDPӮЙ‘ОӮөӮДғRғAҗ”ӮрӮЗӮкӮҫӮҜ(’иҠi“IӮИ“®ҚмӮЕ)үҹӮөҚһӮЯӮйӮ©ӮӘҒABulldozerӮМ‘_ӮўҒB
•ЦӢXҸгҒANehalemӮЖӮМIPC”дӮНғWғғғ“ғӢӮЙӮжӮзӮё0.65ӮЕTBӮИӮө‘O’сӮЕӮМ”дҠrҒBӮұӮкӮНғeғLғgҒ[ӮЙҢҲӮЯӮҪҗ”ҺҡӮЕӮ·ҒB
(IntelӮМ’иҠiғNғҚғbғNӮНҢ»ҚЭҒA‘SғRғAүТ“®ҺһӮрҠоҸҖӮЙҗЭ’иӮіӮкӮДӮўӮйӮЖҢ©ӮзӮкӮйҒB)
- MPғTҒ[ғo (TDPӮЙ‘ОӮөӮДғRғAҗ”ӮӘ‘ҪӮӯҒAҗ§–сӮӘҢөӮөӮўҒB)
Nehalem-EX, 130W, 8ғRғA, 2.26GHz, TB 2.66GHz
2.26GHz / 0.65 = 3.47GHz
ҒЁ BulldozerӮН130WӮЕ8ғRғAӮӘ3.5GHz’ц“xӮЕүсӮБӮДӮӯӮкӮкӮОғRғAӮ ӮҪӮиӮМҗ«”\ӮЕӮа’К—pҒB
ғNғүғXғ^Ғ[ғhӮИӮМӮЕ–КҗПӮИӮЗӮЕғҒғҠғbғgӮӘӮ ӮйҒB
- ғҒғCғ“ғXғgғҠҒ[ғҖғfғXғNғgғbғv (TDPӮЙ‘ОӮөӮДғRғAҗ”ӮӘҸӯӮИӮўҒBTBӮМү¶ҢbӮӘӮЩӮЖӮсӮЗӮИӮӯӮИӮйҒB)
Clarkdale-620, 73W, 2ғRғA, 3.60GHz, TB 3.86GHz
3.33GHz / 0.65 = 5.54GHz
ҒЁ BulldozerӮНғRғAӮ ӮҪӮиҗ«”\ӮЕҸҹӮВӮЙӮН2ғRғAӮр5.6GHzӮаӮМҗўҠEҚЕҚӮғXғsҒ[ғhӮЕүсӮіӮИӮҜӮкӮОӮИӮзӮИӮўҒB
–і—қӮӘӮ ӮйӮМӮЕүҝҠiғҒғҠғbғgӮвҒAӮжӮи‘ҪӮӯӮМғRғAӮрҸWҗПӮ·ӮйӮИӮЗӮМ‘ОүһҒB
ӮЖӮўӮӨӮнӮҜӮЕҒATDP vs Coreҗ”ӮӘBulldozerӮМ—D—тӮрҢҲӮЯӮйҢ®ӮИӮсӮҫӮж(–{—ҲӮН)ҒB
’КҸнҒA’PҸғӮИ—қҳ_ӮЕ
- ғRғAҗЭҢvӮМҠg’ЈӮЙ‘ОӮ·Ӯйҗ«”\ҢьҸгӮЙ‘ОӮөӮДҒA“d—НӮН2ҸжӮӯӮзӮўӮЕ‘қӮҰӮй (Ғ©ғRғAӮр–{ӢCӮЕ“d—НӮЙҚЕ“Kү»ӮөӮДӮИӮ©ӮБӮҪҺһ‘г‘O’сӮМҳbӮҫӮӘ)
- “dҲіҲк’иӮЕғNғҚғbғNғAғbғvӮЙ‘ОӮөӮДҒA“d—НӮН1ҸжӮЕ‘қӮҰӮй
- ҚXӮИӮйғNғҚғbғNҢьҸгӮМӮМӮҪӮЯҸёҲіҚһӮЭӮЕғNғҚғbғNӮр–і—қӮЙӮ Ӯ°ӮйӮЖҒA“d—НӮН3ҸжӮЕ‘қӮҰӮй
ӮМӮЕҒA“d—НӮЙӢCӮрҺgӮБӮҪғAҒ[ғLғeғNғ`ғғӮЕӮаҒA“dҲіӮрӮ Ӯ°ӮДӮЬӮЕ–і—қӮЙҗ«”\ӮрӮ Ӯ°ӮйӮЖӮҪӮҝӮЬӮҝ“d—НӮЖ”ӯ”MӮӘ”ҡ”ӯӮөӮДӮөӮЬӮӨҒB
ӮөӮҪӮӘӮБӮДҒAҸ¬ӢK–НғRғAӮИӮзҗ«”\’бүәҲИҸгӮЙ“d—НӮрүәӮ°ӮйӮұӮЖӮН—eҲХӮҫӮӘҒA
Ҹ¬ӢK–НғRғAӮЕӮ ӮБӮДӮаҸёҲіӮөӮДӮМҗ«”\ғAғbғvӮөӮҪӮзҒA3ҸжӮЕ”ҡ”ӯӮ·ӮйӮ©ӮзӮвӮОӮўҒB
ғvғҚғZғX/ғfғoғCғXӮМ“Kҗі’lӮИ“dҲіӮЕҺgӮӨӮұӮЖӮр‘O’сӮИӮзҒABullӮМӮжӮӨӮИӢK–НӮр—}ӮҰӮҪғRғAӮИӮзTDPӮӘҢөӮөӮӯӮЕӮаӮ»ӮкӮИӮиӮЙүсӮйӮ©Ӯз—L—ҳҒB
ӮөӮ©ӮөҒA‘еғRғAӮӘӮжӮўӮ©Ҹ¬ғRғAӮӘӮжӮўӮ©ӮНҒAӮЗӮсӮИҺgӮў•ыӮрӮөӮДӮа“d—Нҗ«”\”дӮЕҸ¬ғRғAӮӘ—L—ҳӮЖӮўӮӨӮнӮҜӮЕӮаӮИӮўҒB
770 ҒF–јҸМ–ўҗЭ’иҒF2010/09/12(“ъ) 01:22:02 ID:AxuRPBvE0
ғXғ^ғeғBғbғNӮИ“d—НӮӘ–іҺӢӮЕӮ«ӮИӮўҢ»ҚЭӮМ”ј“ұ‘МӮЕӮНҒAӮаӮНӮвӮ»ӮӨӮўӮӨ’PҸғӮИғӮғfғӢӮНҲУ–ЎӮӘ–іӮўӮ©ӮЖҒB
771 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/09/16(–Ш) 20:11:42 ID:+L9A3ktCP
>>769
ӮвӮЧӮҘҒABull—\‘z‘е•қӮЙғ~ғXӮБӮДӮйӮ©ӮаҒB
http://www.realworldtech.com/page.cfm?ArticleID=RWT082610181333
RWTӮМүрҗаӮЭӮҪӮз2 ALUӮЕӮНӮ ӮйӮаӮМӮМҒAҠeҗ®җ”ғRғA 4issueӮМғAҒ[ғLғeғNғ`ғғӮЕҒA
OOOҠЦҳAӮМBufferӮвQueueӮаҸ]—ҲӮжӮижТ‘тӮҫӮЛҒBӮЬӮ¶ӮИӮзIPCӮа•ҺӮкӮИӮўӮ©ӮаӮөӮкӮИӮўҒB
ӮвӮЧӮҘҒABull—\‘z‘е•қӮЙғ~ғXӮБӮДӮйӮ©ӮаҒB
http://www.realworldtech.com/page.cfm?ArticleID=RWT082610181333
RWTӮМүрҗаӮЭӮҪӮз2 ALUӮЕӮНӮ ӮйӮаӮМӮМҒAҠeҗ®җ”ғRғA 4issueӮМғAҒ[ғLғeғNғ`ғғӮЕҒA
OOOҠЦҳAӮМBufferӮвQueueӮаҸ]—ҲӮжӮижТ‘тӮҫӮЛҒBӮЬӮ¶ӮИӮзIPCӮа•ҺӮкӮИӮўӮ©ӮаӮөӮкӮИӮўҒB
772 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/09/16(–Ш) 20:13:05 ID:+L9A3ktCP
>>770
Ӯ»ӮкӮНӮнӮ©ӮБӮДӮўӮйӮӘ‘еӢШӮЕҢӢҳ_ӮӘ•ПӮнӮзӮИӮў’ц“xӮ©ӮзҸ‘ӮўӮҪҒB
Ӯ»ӮкӮНӮнӮ©ӮБӮДӮўӮйӮӘ‘еӢШӮЕҢӢҳ_ӮӘ•ПӮнӮзӮИӮў’ц“xӮ©ӮзҸ‘ӮўӮҪҒB
773 ҒF–јҸМ–ўҗЭ’иҒF2010/09/17(Ӣа) 01:15:36 ID:Kg0iP0E10
>>771
LlanoӮЕӮаROBӮМentryӮӘ72Ӯ©Ӯз84ӮЙ‘қӮҰӮйӮзӮөӮўӮҜӮЗ‘fҗl–ЪӮЙӮН
ӮЗӮкӮЩӮЗҢшүКӮӘӮ ӮйӮМӮ©ӮжӮӯӮнӮ©ӮзӮсӮИ
BulldozerӮМҚ\җ¬ӮӘ–ҫӮзӮ©ӮЙӮИӮБӮҪ“–ҸүӮНҸ«—Ҳ“IӮЙҗ®җ”ғRғAӮЕSMTӮа
ғAғҠӮ©ӮЖҺvӮБӮДӮҪӮҜӮЗҒAҗ®җ”ғRғAӮрӮ«ӮБӮҝӮиүсӮ·•ыҢьҗ«ӮБӮЫӮўӮИ
SMTӮМӮҪӮЯӮЙғtғҚғ“ғgғGғ“ғhӮрҠg’ЈӮ·ӮйӮЖӮ©ӮНӢpӮБӮДҢш—ҰҲ«ӮӯӮИӮиӮ»ӮӨӮИ—\Ҡҙ
ALUӮӘ‘қӮҰӮкӮО—ЗӮўӮМӮ©Ӯа’mӮкӮсӮӘ
LlanoӮЕӮаROBӮМentryӮӘ72Ӯ©Ӯз84ӮЙ‘қӮҰӮйӮзӮөӮўӮҜӮЗ‘fҗl–ЪӮЙӮН
ӮЗӮкӮЩӮЗҢшүКӮӘӮ ӮйӮМӮ©ӮжӮӯӮнӮ©ӮзӮсӮИ
BulldozerӮМҚ\җ¬ӮӘ–ҫӮзӮ©ӮЙӮИӮБӮҪ“–ҸүӮНҸ«—Ҳ“IӮЙҗ®җ”ғRғAӮЕSMTӮа
ғAғҠӮ©ӮЖҺvӮБӮДӮҪӮҜӮЗҒAҗ®җ”ғRғAӮрӮ«ӮБӮҝӮиүсӮ·•ыҢьҗ«ӮБӮЫӮўӮИ
SMTӮМӮҪӮЯӮЙғtғҚғ“ғgғGғ“ғhӮрҠg’ЈӮ·ӮйӮЖӮ©ӮНӢpӮБӮДҢш—ҰҲ«ӮӯӮИӮиӮ»ӮӨӮИ—\Ҡҙ
ALUӮӘ‘қӮҰӮкӮО—ЗӮўӮМӮ©Ӯа’mӮкӮсӮӘ
774 ҒF–јҸМ–ўҗЭ’иҒF2010/09/17(Ӣа) 17:42:54 ID:WPcpC8Mn0
ӮИӮәSandy BridgeӮНӮ»ӮсӮИӮЙғpғtғHҒ[ғ}ғ“ғXӮӘҚӮӮўӮМӮ©
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20100917_394622.html
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20100917_394622.html
775 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/09/17(Ӣа) 18:58:33 ID:+yqJbz12P
ҺАӮНӮіӮиӮ°ӮИӮӯ>>679ӮӘSNBӮМ—\‘zғlғ^ӮҫӮБӮҪӮсӮҫӮәҒBӮЁӮк‘Ҡ•ПӮнӮзӮёӮ·Ӯ°Ғ[ҒB
776 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/09/17(Ӣа) 19:05:41 ID:+yqJbz12P
ӮЕӮаuopғLғғғbғVғ…ӮжӮиӮаLoad UnitӮМ•ыӮӘҠщ‘¶ғRҒ[ғhӮМҚӮ‘¬ү»ӮЙӮаҢшӮўӮДӮйӮЖҺvӮӨӮсӮҫӮӘҒB
ғLғғғbғVғ…ӮМғҢғCғeғ“ғV‘қүБӮЕ‘е•Ә‘ҠҺEӮіӮкӮДӮйӮҫӮлӮӨӮҜӮЗҒB
Ӯ ӮЖҒAuopғLғғғbғVғ…ӮНғTғCғYӮМҠ„ӮЙҢш—ҰҲ«ӮўҒBӮ»ӮМӮӨӮҝHansӮМғ_ғC•ӘҗНӮЕӮДӮӯӮйӮҫӮлӮӨӮҜӮЗҒA
ҲУҠOӮИғTғCғYӮЙҚ¬—җӮ·ӮйӮҫӮлӮӨӮИҒB
ғLғғғbғVғ…ӮМғҢғCғeғ“ғV‘қүБӮЕ‘е•Ә‘ҠҺEӮіӮкӮДӮйӮҫӮлӮӨӮҜӮЗҒB
Ӯ ӮЖҒAuopғLғғғbғVғ…ӮНғTғCғYӮМҠ„ӮЙҢш—ҰҲ«ӮўҒBӮ»ӮМӮӨӮҝHansӮМғ_ғC•ӘҗНӮЕӮДӮӯӮйӮҫӮлӮӨӮҜӮЗҒA
ҲУҠOӮИғTғCғYӮЙҚ¬—җӮ·ӮйӮҫӮлӮӨӮИҒB
777 ҒF–јҸМ–ўҗЭ’иҒF2010/09/17(Ӣа) 19:29:05 ID:mlGFuKuVP
ҺgӮҰӮйғgғүғ“ғWғXғ^ӮӘ‘қӮҰӮДҒA‘ҪҸӯҢш—ҰҲ«ӮӯӮДӮағfғRҒ[ғ_Ғ[ӢxӮЯӮҪ•ыӮӘ
ҸИ“d—НӮҫӮ©ӮзғКopғLғғғbғVғ…•ңҠҲӮБӮДӮұӮЖҒH
ҸИ“d—НӮҫӮ©ӮзғКopғLғғғbғVғ…•ңҠҲӮБӮДӮұӮЖҒH
778 ҒF–јҸМ–ўҗЭ’иҒF2010/09/17(Ӣа) 22:09:17 ID:Yvdqo1IX0
>>776
ӮҝӮӨӮ©4ғRғA+GPU”ЕӮМғ_ғCғTғCғYӮӘ225•Ҫ•ыmmӮЕғRғA1ҢВӮӘ20•Ҫ•ыmmӮБӮД1”N‘OӮЙғҠҒ[ғNӮөӮДӮҪӮжӮИ
“–ҺһӮ©ӮзAVXӮр’ЗүБӮөӮҪӮҫӮҜӮЙӮөӮДӮНғRғAӮӘ‘еӮ«Ӯ·Ӯ¬ӮйӮБӮДҳb‘иӮЙӮИӮБӮДӮҪ
ӮҝӮИӮЭӮЙӮ»ӮМҺһғҠҒ[ғNӮөӮҪҸо•сӮЕ“®ҚмғNғҚғbғNӮӘҚЕ‘еӮЕ3.8GHzӮЙӮИӮйӮБӮДӮМӮа“–ӮҪӮБӮДӮйӮсӮҫӮжӮИ
ӮұӮМҸо•сғҠҒ[ғNӮөӮҪӮвӮВҸБӮіӮкӮҪӮсӮ¶ӮбӮЛҒ[Ӯ©Ӯ—Ӯ—Ӯ—Ӯ—Ӯ—Ӯ—
ӮҝӮӨӮ©4ғRғA+GPU”ЕӮМғ_ғCғTғCғYӮӘ225•Ҫ•ыmmӮЕғRғA1ҢВӮӘ20•Ҫ•ыmmӮБӮД1”N‘OӮЙғҠҒ[ғNӮөӮДӮҪӮжӮИ
“–ҺһӮ©ӮзAVXӮр’ЗүБӮөӮҪӮҫӮҜӮЙӮөӮДӮНғRғAӮӘ‘еӮ«Ӯ·Ӯ¬ӮйӮБӮДҳb‘иӮЙӮИӮБӮДӮҪ
ӮҝӮИӮЭӮЙӮ»ӮМҺһғҠҒ[ғNӮөӮҪҸо•сӮЕ“®ҚмғNғҚғbғNӮӘҚЕ‘еӮЕ3.8GHzӮЙӮИӮйӮБӮДӮМӮа“–ӮҪӮБӮДӮйӮсӮҫӮжӮИ
ӮұӮМҸо•сғҠҒ[ғNӮөӮҪӮвӮВҸБӮіӮкӮҪӮсӮ¶ӮбӮЛҒ[Ӯ©Ӯ—Ӯ—Ӯ—Ӯ—Ӯ—Ӯ—
779 ҒF–јҸМ–ўҗЭ’иҒF2010/09/17(Ӣа) 23:54:22 ID:mlGFuKuVP
http://www.heise.de/ct/artikel/Prozessorgefluester-796627.html
“–ӮҪӮБӮДӮҪӮЖӮўӮӨӮМӮҫӮЖҒAӮұӮМӢLҺ–ӮЙӮН1500ғКopsӮМғgғҢҒ[ғXғLғғғbғVғ…ӮБӮДғlғ^ӮӘӮ ӮБӮҪӮИҒB
“–ҺһӮНӮұӮкӮЖҒAғ\Ғ[ғX•s–ҫӮМүpҢкӮМWikipediaӮМSandyBridgeӮМҚҖ–ЪӮӯӮзӮўӮөӮ©
ғgғҢҒ[ғXғLғғғbғVғ…“ӢҚЪӮЙҗGӮкӮДӮИӮ©ӮБӮҪӮМӮЕҒA
–{“–ӮҫӮлӮӨӮ©ӮБӮД”јҗM”јӢ^ӮҫӮБӮҪӮМӮЙҒB
“–ӮҪӮБӮДӮҪӮЖӮўӮӨӮМӮҫӮЖҒAӮұӮМӢLҺ–ӮЙӮН1500ғКopsӮМғgғҢҒ[ғXғLғғғbғVғ…ӮБӮДғlғ^ӮӘӮ ӮБӮҪӮИҒB
“–ҺһӮНӮұӮкӮЖҒAғ\Ғ[ғX•s–ҫӮМүpҢкӮМWikipediaӮМSandyBridgeӮМҚҖ–ЪӮӯӮзӮўӮөӮ©
ғgғҢҒ[ғXғLғғғbғVғ…“ӢҚЪӮЙҗGӮкӮДӮИӮ©ӮБӮҪӮМӮЕҒA
–{“–ӮҫӮлӮӨӮ©ӮБӮД”јҗM”јӢ^ӮҫӮБӮҪӮМӮЙҒB
780 ҒF–јҸМ–ўҗЭ’иҒF2010/09/18(“y) 00:11:04 ID:yhV/62WkP
ӮЬӮ Ңіғlғ^ӮНIntelӮМ“БӢ–ӮҫӮҜӮЗӮЛҒB
781 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/09/18(“y) 00:13:13 ID:yhV/62WkP
—\‘zӮЖӮўӮӨӮМӮНҸз’kӮЕ40%ӮӯӮзӮўӮМӮВӮаӮиӮЕҸ‘ӮўӮҪҒB
782 ҒF–јҸМ–ўҗЭ’иҒF2010/09/18(“y) 00:14:36 ID:9+7ERCe90
Ӯ·Ӯ°Ғ[ӮИӮЁӮЬӮўӮз
783 ҒF–јҸМ–ўҗЭ’иҒF2010/09/18(“y) 14:57:59 ID:Sr5UEBIM0
ғVғ“ғOғӢғXғҢғbғhҗ«”\Ӯр‘ГӢҰӮөӮИӮўӮЖҢҫӮў‘ұӮҜӮДӮ«ӮҪғpҒ[ғӢғҖғbғ^Ғ[ӮіӮсҒB
—LҢАҺАҚsӮБӮДӮвӮВӮ©ҒB
—LҢАҺАҚsӮБӮДӮвӮВӮ©ҒB
784 ҒF–јҸМ–ўҗЭ’иҒF2010/09/18(“y) 20:30:43 ID:Vu0+qBbc0
—LҢАҺАҚsӮнӮлӮҪ
IntelӮМғRғXғgӮЙҢ©ҚҮӮӨ”НҲНӮЕӮөӮ©Ҡж’ЈӮзӮИӮўҢXҢьӮН‘јҺРӮжӮиҢ°’ҳӮҫӮ©ӮзӮИӮ—Ӯ—Ӯ—
IntelӮМғRғXғgӮЙҢ©ҚҮӮӨ”НҲНӮЕӮөӮ©Ҡж’ЈӮзӮИӮўҢXҢьӮН‘јҺРӮжӮиҢ°’ҳӮҫӮ©ӮзӮИӮ—Ӯ—Ӯ—
785 ҒF–јҸМ–ўҗЭ’иҒF2010/09/20(ҢҺ) 03:25:11 ID:O8uqpYK+0
SNBӮМҸ[ҺАӮӘ–ҫӮзӮ©ӮЙӮИӮБӮҪӮұӮЖӮЕҠyӮөӮЭӮЙӮИӮБӮДӮ«ӮҪӮМӮӘMedfield
ӮұӮБӮҝӮаӢCҚҮ“ьӮкӮДҠg’ЈӮөӮДӮ«Ӯ»ӮӨӮИ—\ҠҙӮӘӮ·Ӯй
BonnellӮМӮЬӮЬ32nmӮЙҚsӮӯӮЖғRғAӮӘҸ¬ӮіӮӯӮИӮиӮ·Ӯ¬Ӯй•i
ӮұӮБӮҝӮаӢCҚҮ“ьӮкӮДҠg’ЈӮөӮДӮ«Ӯ»ӮӨӮИ—\ҠҙӮӘӮ·Ӯй
BonnellӮМӮЬӮЬ32nmӮЙҚsӮӯӮЖғRғAӮӘҸ¬ӮіӮӯӮИӮиӮ·Ӯ¬Ӯй•i
786 ҒF–јҸМ–ўҗЭ’иҒF2010/09/20(ҢҺ) 13:51:58 ID:Ka6SJsCP0
Langwell‘Ҡ“–ӮӘҚҮ‘МӮ·ӮйӮ©ӮзBonnellғRғAӮрӮЮӮвӮЭӮЙӮЕӮ©ӮӯӮ·Ӯй—]—TӮИӮсӮДӮИӮўӮж
787 ҒF–јҸМ–ўҗЭ’иҒF2010/09/21(үО) 00:43:59 ID:wfQu39bY0
BonnellғRғAӮӘ•ПҚXӮіӮкӮйӮМӮН22nmӮМSaltwellғvғүғbғgғtғHҒ[ғҖӮ©ӮзҒ@by fudzilla
788 ҒF–јҸМ–ўҗЭ’иҒF2010/09/21(үО) 01:40:07 ID:l20FHvGy0
SaltwellӮН32nmӮМғRғAӮМ–ј‘OӮҫӮӘ...?
789 ҒF–јҸМ–ўҗЭ’иҒF2010/09/21(үО) 01:50:20 ID:TCk32FD2P
>>787
Ӯ»Ӯк–kҗXҢл–уӮ¶ӮбӮсҒBFudzillaӮНҚЎүсӮНҠФҲбӮБӮДӮИӮўӮжҒB
Ӯ»Ӯк–kҗXҢл–уӮ¶ӮбӮсҒBFudzillaӮНҚЎүсӮНҠФҲбӮБӮДӮИӮўӮжҒB
790 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/09/21(үО) 18:52:38 ID:tRKQOonEP
791 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/09/21(үО) 19:15:44 ID:tRKQOonEP
AtomӮН1”NӮёӮзӮөӮМғfғXғNғgғbғv/ғӮғoғCғӢӮЖҲЩӮИӮиҒA
ғvғҚғZғXӮМҗў‘гӮЖғ}ғCғNғҚғAҒ[ғLғeғNғ`ғғӮӘҲк‘ОҲкҒB
ҚЕӢЯӮНҢіӢLҺ–Ӯ ӮЬӮиҢ©ӮИӮӯӮИӮБӮҪӮӘҒAҚ‘“ағjғ…Ғ[ғXғTғCғgӮ»ӮлӮБӮДҢл–уӮЭӮҪӮўӮҫӮИҒB
ҢіӢLҺ–ӮН32nmӮӘSaltwellӮЕҒAғRғAӮўӮ¶ӮӯӮБӮҪҒB
ҚXӮЙSaltwellӮМҢгҢpӮМғRғAӮМ22nm AtomӮӘ2013”NӮӯӮзӮўӮЕҸҮ’ІҒB
ӮЭӮҪӮўӮИ“а—eҒB
ғvғҚғZғXӮМҗў‘гӮЖғ}ғCғNғҚғAҒ[ғLғeғNғ`ғғӮӘҲк‘ОҲкҒB
ҚЕӢЯӮНҢіӢLҺ–Ӯ ӮЬӮиҢ©ӮИӮӯӮИӮБӮҪӮӘҒAҚ‘“ағjғ…Ғ[ғXғTғCғgӮ»ӮлӮБӮДҢл–уӮЭӮҪӮўӮҫӮИҒB
ҢіӢLҺ–ӮН32nmӮӘSaltwellӮЕҒAғRғAӮўӮ¶ӮӯӮБӮҪҒB
ҚXӮЙSaltwellӮМҢгҢpӮМғRғAӮМ22nm AtomӮӘ2013”NӮӯӮзӮўӮЕҸҮ’ІҒB
ӮЭӮҪӮўӮИ“а—eҒB
792 ҒF–јҸМ–ўҗЭ’иҒF2010/09/21(үО) 20:13:04 ID:Kg75FcQY0
ӮДӮ©AtomӮӘ32nmӮЕғAҒ[ғL•ПӮнӮйӮБӮДӮМӮН1”N‘OӮЙӮНғpҒ[ғӢғҖғbғ^Ғ[ӮӘҢҫӮБӮДӮй >>244
ҢіӢLҺ–“ЗӮЬӮё“]ҚЪӮөӮҝӮбӮБӮДӮІӮЯӮсӮИӮіӮўҒ„Ғғ
794 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/09/23(–Ш) 21:11:15 ID:VTtnLfr+P
SPECint2006
Intel Xeon X5677 3467MHz Base 40.1 Peak 43.5
http://www.spec.org/cpu2006/results/res2010q3/cpu2006-20100706-12329.html
IBM POWER7 4140MHz Base 29.3 Peak 44.0
http://www.spec.org/cpu2006/results/res2010q2/cpu2006-20100426-10753.html
SPECfp2006
Intel Xeon X5677 3467MHz Base 45.5 Peak 48.9
http://www.spec.org/cpu2006/results/res2010q3/cpu2006-20100702-12044.html
POWER7 3860MHz Base 44.5 Peak 71.5
http://www.spec.org/cpu2006/results/res2010q2/cpu2006-20100426-10752.html
ҚЎӮЬӮЕBaseӮМғXғRғAӮөӮ©ӮЭӮДӮИӮ©ӮБӮҪӮ©ӮзӢCӮӘӮВӮ©ӮИӮ©ӮБӮҪӮҜӮЗҒA
PeakӮНPOWER7ӮӘҚЕҚӮғXғRғAӮМӮжӮӨӮҫӮИҒB“БӮЙfpӮӘғ_ғ“ғgғcӮЕӮвӮЧӮҘҒB
eDRAMӢ°ӮйӮЧӮөҒB
Intel Xeon X5677 3467MHz Base 40.1 Peak 43.5
http://www.spec.org/cpu2006/results/res2010q3/cpu2006-20100706-12329.html
IBM POWER7 4140MHz Base 29.3 Peak 44.0
http://www.spec.org/cpu2006/results/res2010q2/cpu2006-20100426-10753.html
SPECfp2006
Intel Xeon X5677 3467MHz Base 45.5 Peak 48.9
http://www.spec.org/cpu2006/results/res2010q3/cpu2006-20100702-12044.html
POWER7 3860MHz Base 44.5 Peak 71.5
http://www.spec.org/cpu2006/results/res2010q2/cpu2006-20100426-10752.html
ҚЎӮЬӮЕBaseӮМғXғRғAӮөӮ©ӮЭӮДӮИӮ©ӮБӮҪӮ©ӮзӢCӮӘӮВӮ©ӮИӮ©ӮБӮҪӮҜӮЗҒA
PeakӮНPOWER7ӮӘҚЕҚӮғXғRғAӮМӮжӮӨӮҫӮИҒB“БӮЙfpӮӘғ_ғ“ғgғcӮЕӮвӮЧӮҘҒB
eDRAMӢ°ӮйӮЧӮөҒB
795 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/09/23(–Ш) 21:40:31 ID:VTtnLfr+P
ҘGPGPU
GPGPUӮНҢ»ҚЭnVIDIAӮӘ’ҶҗSӮМ“WҠJӮЖӮЭӮзӮкӮДӮўӮйӮӘҒAӮөӮВӮұӮўӮжӮӨӮҫӮӘҒA
ғRғ“ғVғ…Ғ[ғ}ӮЕӮМDiscrete GPUӮМ”„ҸгӮӘҸkҸ¬ӮөӮДӮӯӮйӮЖҒA
HPCӮҫӮҜӮЕҚМҺZӮрӮЖӮзӮИӮҜӮкӮОӮИӮзӮИӮӯӮИӮйӮҪӮЯҒAGPGPUӮМҗжҚsӮ«ӮНӮ©ӮИӮиүцӮөӮўҒB
ӮаӮЖӮаӮЖғnғCғGғ“ғhGPUӮНғҚҒ[ғGғ“ғhӮЬӮЕғJғbғgғ_ғEғ“ӮЕ“WҠJӮ·ӮйӮұӮЖӮЕҗ¶ҠUӮЕҠJ”ӯ”пӮрүсҺыӮөӮДӮўӮҪӮҪӮЯҒA
ғ~ғhғӢҲИүәӮЕҠщӮЙҺё”sӮөӮДӮўӮйFermiӮМғRғ“ғVғ…Ғ[ғ}ҺsҸкӮЕӮМ—L—lӮрӮЭӮДӮаӮнӮ©ӮйӮЖӮЁӮиҒA
ғrғWғlғXғӮғfғӢ“IӮЙӢкӮөӮў—§ӮҝҲК’uӮҫӮЖҺvӮӨҒB
LRB(Kights Series)ӮЙӮВӮўӮДӮа“Ҝ—lӮМӮұӮЖӮӘҢҫӮҰӮйҒBӮұӮҝӮзӮНIntelӮМҺе—Нҗ»•iӮЕӮНӮИӮўӮ©ӮзҒA
үпҺРӮӘҢXӮӯӮұӮЖӮНӮИӮўӮЖҺvӮӨӮӘҒAGPUӮЖӮөӮДҺgӮҰӮИӮўӮЖӮўӮӨӮұӮЖӮЙӮИӮйӮЖӮвӮНӮиҒAGPGPUӢӨҒXҒAҚМҺZҗ«ӮӘӮИӮўҒB
HPCҺsҸкӮМӮЭӮМ”„ҸгӮЕӮНҒA2, 3җў‘гӮЕғvғҚғZғbғTӮНҸц”ӯӮ·ӮйҒB
Ҳк•ыҒAAMDӮМFusionӮвSandy BridgeӮМӮжӮӨӮИGPU“қҚҮғAғvғҚҒ[ғ`ӮН
CPUғ\ғPғbғgӮМ‘ҪӮўғVғXғeғҖӮЕӮНҺ©“®“IӮЙGPUӮӘ‘қӮҰӮйӮұӮЖӮЙӮИӮиҒAGPGPUӮЖӮөӮДӮН
ғnғCғGғ“ғhGPUҺuҢьӮжӮиӮаӮЮӮөӮлҗ¬ҢчӮ·ӮйүВ”\җ«ӮаӮ ӮйҒBӮұӮҝӮзӮНғRғ“ғVғ…Ғ[ғ}ӮМғҒғCғ“ғXғgғҠҒ[ғҖPCҺsҸкӮЕ
”„ӮкӮйӮұӮЖӮНӮЩӮЪҠФҲбӮўӮИӮўӮМӮЕҒAҚМҺZҗ«ӮӘӮЖӮкӮИӮўӮЖӮўӮӨӮұӮЖӮНӮЩӮЪ—LӮи“ҫӮИӮў•sҺҖҗgӮМ‘МӮрҺқӮВҒB
GPGPUӮНҢ»ҚЭnVIDIAӮӘ’ҶҗSӮМ“WҠJӮЖӮЭӮзӮкӮДӮўӮйӮӘҒAӮөӮВӮұӮўӮжӮӨӮҫӮӘҒA
ғRғ“ғVғ…Ғ[ғ}ӮЕӮМDiscrete GPUӮМ”„ҸгӮӘҸkҸ¬ӮөӮДӮӯӮйӮЖҒA
HPCӮҫӮҜӮЕҚМҺZӮрӮЖӮзӮИӮҜӮкӮОӮИӮзӮИӮӯӮИӮйӮҪӮЯҒAGPGPUӮМҗжҚsӮ«ӮНӮ©ӮИӮиүцӮөӮўҒB
ӮаӮЖӮаӮЖғnғCғGғ“ғhGPUӮНғҚҒ[ғGғ“ғhӮЬӮЕғJғbғgғ_ғEғ“ӮЕ“WҠJӮ·ӮйӮұӮЖӮЕҗ¶ҠUӮЕҠJ”ӯ”пӮрүсҺыӮөӮДӮўӮҪӮҪӮЯҒA
ғ~ғhғӢҲИүәӮЕҠщӮЙҺё”sӮөӮДӮўӮйFermiӮМғRғ“ғVғ…Ғ[ғ}ҺsҸкӮЕӮМ—L—lӮрӮЭӮДӮаӮнӮ©ӮйӮЖӮЁӮиҒA
ғrғWғlғXғӮғfғӢ“IӮЙӢкӮөӮў—§ӮҝҲК’uӮҫӮЖҺvӮӨҒB
LRB(Kights Series)ӮЙӮВӮўӮДӮа“Ҝ—lӮМӮұӮЖӮӘҢҫӮҰӮйҒBӮұӮҝӮзӮНIntelӮМҺе—Нҗ»•iӮЕӮНӮИӮўӮ©ӮзҒA
үпҺРӮӘҢXӮӯӮұӮЖӮНӮИӮўӮЖҺvӮӨӮӘҒAGPUӮЖӮөӮДҺgӮҰӮИӮўӮЖӮўӮӨӮұӮЖӮЙӮИӮйӮЖӮвӮНӮиҒAGPGPUӢӨҒXҒAҚМҺZҗ«ӮӘӮИӮўҒB
HPCҺsҸкӮМӮЭӮМ”„ҸгӮЕӮНҒA2, 3җў‘гӮЕғvғҚғZғbғTӮНҸц”ӯӮ·ӮйҒB
Ҳк•ыҒAAMDӮМFusionӮвSandy BridgeӮМӮжӮӨӮИGPU“қҚҮғAғvғҚҒ[ғ`ӮН
CPUғ\ғPғbғgӮМ‘ҪӮўғVғXғeғҖӮЕӮНҺ©“®“IӮЙGPUӮӘ‘қӮҰӮйӮұӮЖӮЙӮИӮиҒAGPGPUӮЖӮөӮДӮН
ғnғCғGғ“ғhGPUҺuҢьӮжӮиӮаӮЮӮөӮлҗ¬ҢчӮ·ӮйүВ”\җ«ӮаӮ ӮйҒBӮұӮҝӮзӮНғRғ“ғVғ…Ғ[ғ}ӮМғҒғCғ“ғXғgғҠҒ[ғҖPCҺsҸкӮЕ
”„ӮкӮйӮұӮЖӮНӮЩӮЪҠФҲбӮўӮИӮўӮМӮЕҒAҚМҺZҗ«ӮӘӮЖӮкӮИӮўӮЖӮўӮӨӮұӮЖӮНӮЩӮЪ—LӮи“ҫӮИӮў•sҺҖҗgӮМ‘МӮрҺқӮВҒB
796 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/09/23(–Ш) 21:42:02 ID:VTtnLfr+P
ҒEGPU+CPU
Sandy BridgeӮЕӮНGPUӮӘғIғ“ғ_ғCӮЕ“қҚҮӮіӮкӮҪҒBAMDӮаGPU“қҚҮҗ»•iӮр’…ҒXӮЖҸҖ”хӮөӮДӮўӮйҒB
AMDӮМҸкҚҮӮНDiscrete GPUӮӘӮ ӮйӮҪӮЯҒAӮұӮкӮЬӮЕӮЖ“Ҝ—lғnғCғGғ“ғhӮ©Ӯзғ~ғhғӢӮЙӮЁӮЖӮөҒA
ҢгӮ©ӮзCPUӮЙ“қҚҮӮ·ӮйӮЖӮўӮӨҢ`ӮЕ‘ОүһӮ·ӮйӮұӮЖӮӘӮЕӮ«ӮйӮҪӮЯҒAғҠғXғNӮНҸ¬ӮіӮўҒB
Ӯ»ӮкӮЙ‘ОӮөҒAIntelӮМGMAӮНDiscreteҺsҸкӮрӮаӮБӮДӮўӮИӮўӮҪӮЯҒAӮНӮ¶ӮЯӮ©ӮзҗVӢKғAҒ[ғLғeғNғ`ғғӮр
CPUӮЙ“қҚҮӮ·ӮйҢvүжӮЕҗiӮЮӮұӮЖӮЙӮИӮиҒAGPU‘ӨӮӘӮұӮҜӮйӮЖCPU‘ӨӮӘ“№ҳAӮкӮЙӮИӮйүВ”\җ«ӮаӮ ӮиҒAғҠғXғNӮН‘еӮ«ӮўҒB
IntelӮМӢӯӮЭӮЖӮөӮДӮНCPUӮМғVғFғAӮӘ8Ҡ„Ӯ ӮйӮҪӮЯҒAҚЎҢгӮМ“WҠJӮЕӮНҒAIntel GPUӮӘ•]үҝӮМҠоҸҖӮЙӮИӮиҒA
ғnғCғGғ“ғhғQҒ[ғҖӮрӮМӮјӮўӮДҒAIntel GPUғRғAӮЙҚЕ“Kү»ӮіӮкӮДӮӯӮйғQҒ[ғҖӮӘ‘қӮҰӮйүВ”\җ«ӮӘӮ ӮйҒB
AMDӮвnVIDIAӮНӮұӮМ“_ӮЙӮЁӮўӮДҢ»‘гӮМ•]үҝӮЖӮН— • ӮЙҒA•sӢпҚҮӮЖӮўӮӨҢ`ӮЕҗ”ӮМ•s—ҳӮр”нӮй“WҠJӮа—\‘zӮіӮкӮйҒB
“қҚҮҢ^GPUӮМҗнӮўӮНҸ]—ҲӮЖӮНҲЩӮИӮиҒAҢөӮөӮўғRғXғgӮЖ”M“IӮИҗ§–сүәӮЕӮМӢЈ‘ҲӮЙӮИӮйӮҪӮЯҒA
Discrete GPUӮЖӮН•ӘӮҜӮД“WҠJӮрҚlӮҰӮй•K—vӮӘӮ ӮйӮЖҢ©ӮДӮўӮйҒB
ҚЎҢгӮНCPUӮЖGPUӮМ“қҚҮ“xӮНҚXӮЙ‘қӮөӮДҚsӮӯӮ©ӮаӮөӮкӮИӮўӮӘҒA
- CPU‘ӨӮМ•А—с“xӮрҸгӮ°ӮДӮўӮӯғAғvғҚҒ[ғ`
- GPU‘ӨӮМғvғҚғOғүғ}ғrғҠғeғBӮрҸгӮ°ӮДӮўӮӯғAғvғҚҒ[ғ`
ӮМ2ӮВӮМ•ыҢьҗ«ӮМӮЗӮҝӮзӮЙҢXӮӯӮ©’Қ–ЪҒB
ҢВҗl“IӮЙӮНCPUӮМ•А—с“xӮрҸгӮ°ӮДӮўӮБӮДҒAGPUӮНҢЕ’иӢ@”\үсӢAӮӘҚDӮЭӮҫӮӘҒB
ӮЬӮ IDFӮрҢ©ӮйҢАӮиhalf floatӮЖӮ©ӮўӮБӮДӮйӮ©ӮзҒACPUӮӘӮжӮиGPU“IӮИҸҲ—қӮрӮ·Ӯй“WҠJӮр‘_ӮБӮДӮўӮй
ӮМӮ©ӮаӮөӮкӮИӮўҒB
Sandy BridgeӮЕӮНGPUӮӘғIғ“ғ_ғCӮЕ“қҚҮӮіӮкӮҪҒBAMDӮаGPU“қҚҮҗ»•iӮр’…ҒXӮЖҸҖ”хӮөӮДӮўӮйҒB
AMDӮМҸкҚҮӮНDiscrete GPUӮӘӮ ӮйӮҪӮЯҒAӮұӮкӮЬӮЕӮЖ“Ҝ—lғnғCғGғ“ғhӮ©Ӯзғ~ғhғӢӮЙӮЁӮЖӮөҒA
ҢгӮ©ӮзCPUӮЙ“қҚҮӮ·ӮйӮЖӮўӮӨҢ`ӮЕ‘ОүһӮ·ӮйӮұӮЖӮӘӮЕӮ«ӮйӮҪӮЯҒAғҠғXғNӮНҸ¬ӮіӮўҒB
Ӯ»ӮкӮЙ‘ОӮөҒAIntelӮМGMAӮНDiscreteҺsҸкӮрӮаӮБӮДӮўӮИӮўӮҪӮЯҒAӮНӮ¶ӮЯӮ©ӮзҗVӢKғAҒ[ғLғeғNғ`ғғӮр
CPUӮЙ“қҚҮӮ·ӮйҢvүжӮЕҗiӮЮӮұӮЖӮЙӮИӮиҒAGPU‘ӨӮӘӮұӮҜӮйӮЖCPU‘ӨӮӘ“№ҳAӮкӮЙӮИӮйүВ”\җ«ӮаӮ ӮиҒAғҠғXғNӮН‘еӮ«ӮўҒB
IntelӮМӢӯӮЭӮЖӮөӮДӮНCPUӮМғVғFғAӮӘ8Ҡ„Ӯ ӮйӮҪӮЯҒAҚЎҢгӮМ“WҠJӮЕӮНҒAIntel GPUӮӘ•]үҝӮМҠоҸҖӮЙӮИӮиҒA
ғnғCғGғ“ғhғQҒ[ғҖӮрӮМӮјӮўӮДҒAIntel GPUғRғAӮЙҚЕ“Kү»ӮіӮкӮДӮӯӮйғQҒ[ғҖӮӘ‘қӮҰӮйүВ”\җ«ӮӘӮ ӮйҒB
AMDӮвnVIDIAӮНӮұӮМ“_ӮЙӮЁӮўӮДҢ»‘гӮМ•]үҝӮЖӮН— • ӮЙҒA•sӢпҚҮӮЖӮўӮӨҢ`ӮЕҗ”ӮМ•s—ҳӮр”нӮй“WҠJӮа—\‘zӮіӮкӮйҒB
“қҚҮҢ^GPUӮМҗнӮўӮНҸ]—ҲӮЖӮНҲЩӮИӮиҒAҢөӮөӮўғRғXғgӮЖ”M“IӮИҗ§–сүәӮЕӮМӢЈ‘ҲӮЙӮИӮйӮҪӮЯҒA
Discrete GPUӮЖӮН•ӘӮҜӮД“WҠJӮрҚlӮҰӮй•K—vӮӘӮ ӮйӮЖҢ©ӮДӮўӮйҒB
ҚЎҢгӮНCPUӮЖGPUӮМ“қҚҮ“xӮНҚXӮЙ‘қӮөӮДҚsӮӯӮ©ӮаӮөӮкӮИӮўӮӘҒA
- CPU‘ӨӮМ•А—с“xӮрҸгӮ°ӮДӮўӮӯғAғvғҚҒ[ғ`
- GPU‘ӨӮМғvғҚғOғүғ}ғrғҠғeғBӮрҸгӮ°ӮДӮўӮӯғAғvғҚҒ[ғ`
ӮМ2ӮВӮМ•ыҢьҗ«ӮМӮЗӮҝӮзӮЙҢXӮӯӮ©’Қ–ЪҒB
ҢВҗl“IӮЙӮНCPUӮМ•А—с“xӮрҸгӮ°ӮДӮўӮБӮДҒAGPUӮНҢЕ’иӢ@”\үсӢAӮӘҚDӮЭӮҫӮӘҒB
ӮЬӮ IDFӮрҢ©ӮйҢАӮиhalf floatӮЖӮ©ӮўӮБӮДӮйӮ©ӮзҒACPUӮӘӮжӮиGPU“IӮИҸҲ—қӮрӮ·Ӯй“WҠJӮр‘_ӮБӮДӮўӮй
ӮМӮ©ӮаӮөӮкӮИӮўҒB
797 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/09/25(“y) 11:35:27 ID:BQT0FDxzP
>>771ӮМӢLҺ–ӮҫӮӘҒADKҺҒӮМ–П‘zӮБӮЫӮўҒB
ғRғAӮ ӮҪӮи4-issueӮМ–ҫҠmӮИҚӘӢ’ӮНҺқӮБӮДӮИӮўӮжӮӨӮИӮМӮЕҒAӮЁӮк“IӮЙӮН—\‘zӮЙҸCҗіӮИӮөҒB
ӮөӮ©ӮөҒABulldozerӮМғVғ“ғOғӢғXғҢғbғhҗ«”\ӮМҢ©җПӮиӮӘRWTӮМҢfҺҰ”ВӮаҠЬӮЯӮДҒAҗўҠE“IӮЙ
ҠГӮ·Ӯ¬ӮйҒBӮұӮкӮНҺА‘ӘғfҒ[ғ^ӮӘӮЕӮДӮ©Ӯз‘е‘ӣӮ¬ӮМ—\ҠҙҒB
ғRғAӮ ӮҪӮи4-issueӮМ–ҫҠmӮИҚӘӢ’ӮНҺқӮБӮДӮИӮўӮжӮӨӮИӮМӮЕҒAӮЁӮк“IӮЙӮН—\‘zӮЙҸCҗіӮИӮөҒB
ӮөӮ©ӮөҒABulldozerӮМғVғ“ғOғӢғXғҢғbғhҗ«”\ӮМҢ©җПӮиӮӘRWTӮМҢfҺҰ”ВӮаҠЬӮЯӮДҒAҗўҠE“IӮЙ
ҠГӮ·Ӯ¬ӮйҒBӮұӮкӮНҺА‘ӘғfҒ[ғ^ӮӘӮЕӮДӮ©Ӯз‘е‘ӣӮ¬ӮМ—\ҠҙҒB
798 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ[”„ӮиҗШӮк]ҒF2010/09/26(“ъ) 10:49:42 ID:ucQwjAvSO
ғҚҒ[ғhӮЖғҢғWғXғ^ҠФүүҺZӮЙ•ӘүрӮөӮД2ALUҒ{2AGUӮЕҢv4issueӮҫӮҜӮЗӮЛҒB
ҒuCRISCҒvүсӢAӮЖӮўӮӨӮ©ҒAӮЬӮ —LҢшҗ«ӮНӮнӮ©ӮзӮсӮИҒB
“ҜӮ¶3issueӮМP6ғxҒ[ғXӮЕӮаPen3ӮЖPenM’ц“xӮЙӮНғVғ“ғOғӢғXғҢғbғhҗ«”\ӮЙҚ·ӮӘӮ ӮБӮҪӮөҒB
ҒuCRISCҒvүсӢAӮЖӮўӮӨӮ©ҒAӮЬӮ —LҢшҗ«ӮНӮнӮ©ӮзӮсӮИҒB
“ҜӮ¶3issueӮМP6ғxҒ[ғXӮЕӮаPen3ӮЖPenM’ц“xӮЙӮНғVғ“ғOғӢғXғҢғbғhҗ«”\ӮЙҚ·ӮӘӮ ӮБӮҪӮөҒB
799 ҒF–јҸМ–ўҗЭ’иҒF2010/09/27(ҢҺ) 18:43:01 ID:3FtM0Kda0
Intel's Sandy Bridge Microarchitecture
http://www.realworldtech.com/page.cfm?ArticleID=RWT091810191937&p=10
ҺQҚl•¶ҢЈӮӘҠF–іӮИӮсӮҫӮҜӮЗҒAӮұӮкӮа–П‘zӮИӮМӮ©ӮИҒH
http://www.realworldtech.com/page.cfm?ArticleID=RWT091810191937&p=10
ҺQҚl•¶ҢЈӮӘҠF–іӮИӮсӮҫӮҜӮЗҒAӮұӮкӮа–П‘zӮИӮМӮ©ӮИҒH
800 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/09/27(ҢҺ) 20:41:50 ID:btzetW5f0
ғpғbӮЖӮЭӮҪӮҜӮЗҢлӮи‘ҪӮўӮЛҒBDKҺҒӮМ’mҺҜӮН”FӮЯӮДӮўӮйӮӘҒAӮўӮӯӮзӮИӮсӮЕӮа’ІҺqӮЙҸжӮиӮ·Ӯ¬ӮЕӮНӮИӮ©ӮлӮӨӮ©ҒB
LSDӮМ“ь—НӮЖӮ©Ӯ»ӮсӮИӮИ‘СҲжӮЛӮҘӮөҒAIDFғXғүғCғhҢл“ЗӮөӮДӮйҒB
Microcode ROMӮМ“ь—НӮМҸ‘Ӯ«•ыӮаҲИ‘OӮ©Ӯз–оҲуӮӘӮЁӮ©ӮөӮўҒB
LSDӮМ“ь—НӮЖӮ©Ӯ»ӮсӮИӮИ‘СҲжӮЛӮҘӮөҒAIDFғXғүғCғhҢл“ЗӮөӮДӮйҒB
Microcode ROMӮМ“ь—НӮМҸ‘Ӯ«•ыӮаҲИ‘OӮ©Ӯз–оҲуӮӘӮЁӮ©ӮөӮўҒB
801 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/09/27(ҢҺ) 21:00:30 ID:btzetW5f0
Ӯ»ӮӨӮўӮвӮ»ӮаӮ»ӮаSNBӮЙLSDӮНӮ ӮйӮМӮҫӮлӮӨӮ©ҒB
uopғLғғғbғVғ…ӮМӮЁӮ©Ӯ°ӮЕ–wӮЗ—vӮзӮИӮӯӮИӮБӮҪӮЖҺvӮӨӮМӮҫӮӘҒB
uopғLғғғbғVғ…ӮМӮЁӮ©Ӯ°ӮЕ–wӮЗ—vӮзӮИӮӯӮИӮБӮҪӮЖҺvӮӨӮМӮҫӮӘҒB
802 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/09/27(ҢҺ) 21:10:06 ID:btzetW5f0
All the uops from the traditional front-end and the uop cache are ultimately merged into the 32 uop Loop Stream Buffer.
The Loop Stream Buffer can still act as a cache for small loops like in Nehalem, and actually can bypass both
the instruction cache and uop cache. The Loop Stream Buffer also smoothes out uop delivery to the back-end.
Since uop cache hits can provide far more uops than the back-end can receive (18 vs. 4),
this decoupling can hide the pipeline bubbles introduced by taken branches and effectively Ғestitch across taken branchesҒf.
ӮЁӮкӮНҗMӮ¶ӮИӮўӮјҒ[ҒB
The Loop Stream Buffer can still act as a cache for small loops like in Nehalem, and actually can bypass both
the instruction cache and uop cache. The Loop Stream Buffer also smoothes out uop delivery to the back-end.
Since uop cache hits can provide far more uops than the back-end can receive (18 vs. 4),
this decoupling can hide the pipeline bubbles introduced by taken branches and effectively Ғestitch across taken branchesҒf.
ӮЁӮкӮНҗMӮ¶ӮИӮўӮјҒ[ҒB
803 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/09/27(ҢҺ) 21:22:51 ID:btzetW5f0
RWTӮаҸ‘ӮўӮДӮйӮҜӮЗҒASandy BridgeӮБӮДӮ ӮйҲУ–ЎNetBurstүсӢAӮИӮсӮҫӮжӮИҒB
ӮЬӮ үсӢAӮЖӮўӮӨӮжӮиҒAPenM/Core2ӮЕP6үсӢAӮөӮҪӮ ӮЖӮЕҒA
P6ҢnғRғAӮМҢГӮў•”•ӘӮрҲкҗVӮөӮҪҢӢүКҒANetBurstӮМ“Б’ҘӮЖҺ—ӮДӮ«ӮҪҒB
ӮЬӮ үсӢAӮЖӮўӮӨӮжӮиҒAPenM/Core2ӮЕP6үсӢAӮөӮҪӮ ӮЖӮЕҒA
P6ҢnғRғAӮМҢГӮў•”•ӘӮрҲкҗVӮөӮҪҢӢүКҒANetBurstӮМ“Б’ҘӮЖҺ—ӮДӮ«ӮҪҒB
804 ҒF–јҸМ–ўҗЭ’иҒF2010/09/27(ҢҺ) 22:29:01 ID:N1ahscyP0
>>802
Ӯ»ӮМ18ӮЖӮўӮӨҗ”’lӮН“БӢ–Ӯ©ӮзӮҫӮлӮӨӮҜӮЗҒA
ҒE1ғүғCғ“ӮЙ6uopsӮЬӮЕ
ҒEғ^ғOӮӘҲк’vӮ·ӮйғүғCғ“ӮМҢҹҸoӮНҸӯӮИӮӯӮЖӮа3ғүғCғ“ӮЬӮЕ“ҜҺһӮЙүВ”\
ӮЖӮ ӮйӮӘҒAҺАҚЫӮМғLғғғbғVғ…ғүғCғ“ӮЦӮМғAғNғZғXӮӘ3ғүғCғ““ҜҺһӮЙүВ”\ӮЖӮНҸ‘ӮўӮДӮИӮўӮИҒB
ӮЖӮўӮӨӮ©ғLғғғbғVғ…“ЗӮЭҸoӮөӮМ‘СҲжӮжӮиӮағ^ғOӮМҲк’vҢҹҸoӮМ‘СҲжӮМ•ыӮӘҚLӮўӮ©Ӯз
match queueӮЙuop“ЗӮЭҸoӮө‘ТӮҝӮМғAғhғҢғXӮӘ—ӯӮЬӮБӮДӮўӮйҢАӮи
ғ~ғXғqғbғgӮЕI$ғtғFғbғ`ғғ/ғfғRҒ[ғ_Ӯр“®Ӯ©Ӯ·ғҢғCғeғ“ғVӮрүB•БӮЕӮ«ӮД
ғoғbғNғGғ“ғhӮЦӮМ–Ҫ—ЯӢҹӢӢӮНҲЫҺқӮіӮкӮйӮйӮЖҸ‘ӮўӮДӮ ӮйҒB
Ӯ»ӮМ18ӮЖӮўӮӨҗ”’lӮН“БӢ–Ӯ©ӮзӮҫӮлӮӨӮҜӮЗҒA
ҒE1ғүғCғ“ӮЙ6uopsӮЬӮЕ
ҒEғ^ғOӮӘҲк’vӮ·ӮйғүғCғ“ӮМҢҹҸoӮНҸӯӮИӮӯӮЖӮа3ғүғCғ“ӮЬӮЕ“ҜҺһӮЙүВ”\
ӮЖӮ ӮйӮӘҒAҺАҚЫӮМғLғғғbғVғ…ғүғCғ“ӮЦӮМғAғNғZғXӮӘ3ғүғCғ““ҜҺһӮЙүВ”\ӮЖӮНҸ‘ӮўӮДӮИӮўӮИҒB
ӮЖӮўӮӨӮ©ғLғғғbғVғ…“ЗӮЭҸoӮөӮМ‘СҲжӮжӮиӮағ^ғOӮМҲк’vҢҹҸoӮМ‘СҲжӮМ•ыӮӘҚLӮўӮ©Ӯз
match queueӮЙuop“ЗӮЭҸoӮө‘ТӮҝӮМғAғhғҢғXӮӘ—ӯӮЬӮБӮДӮўӮйҢАӮи
ғ~ғXғqғbғgӮЕI$ғtғFғbғ`ғғ/ғfғRҒ[ғ_Ӯр“®Ӯ©Ӯ·ғҢғCғeғ“ғVӮрүB•БӮЕӮ«ӮД
ғoғbғNғGғ“ғhӮЦӮМ–Ҫ—ЯӢҹӢӢӮНҲЫҺқӮіӮкӮйӮйӮЖҸ‘ӮўӮДӮ ӮйҒB
805 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/09/27(ҢҺ) 22:47:37 ID:btzetW5f0
Ӯ»ӮаӮ»ӮаIDFӮМғXғүғCғhӮЕ
ғfғRҒ[ғ_ӮЖuopғLғғғbғVғ…ӮМҸo—НӮӘғ}ғӢғ`ғvғҢғNғTүоӮөӮДӮўӮйӮжӮӨӮЙҸ‘Ӯ©ӮкӮДӮўӮйӮМӮЙ
ӮИӮсӮЕRWTӮН•А—сӮЙҸ‘ӮӯӮсӮҫӮлӮӨӮЛҒB
ғfғRҒ[ғ_ӮЖuopғLғғғbғVғ…ӮМҸo—НӮӘғ}ғӢғ`ғvғҢғNғTүоӮөӮДӮўӮйӮжӮӨӮЙҸ‘Ӯ©ӮкӮДӮўӮйӮМӮЙ
ӮИӮсӮЕRWTӮН•А—сӮЙҸ‘ӮӯӮсӮҫӮлӮӨӮЛҒB
806 ҒF–јҸМ–ўҗЭ’иҒF2010/09/27(ҢҺ) 22:58:01 ID:N1ahscyP0
ultimately mergedӮБӮДӮ»ӮӨӮўӮӨҺ–ӮИӮМӮ©w
807 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/09/27(ҢҺ) 23:03:03 ID:btzetW5f0
’EҗьӮөӮДӮ«ӮҪӮИҒB
ӮұӮұӮНғAҒ[ғLғeғNғ`ғғӮрҢкӮй–Ъ“IӮМғXғҢӮЕӮНӮИӮ©ӮҪҒB
Sandy BridgeӮМҲУӢ`ӮНӮ ӮӯӮЬӮЕҒA
(1) ғҠғ“ғOғoғXӮЙӮжӮй”hҗ¶•iӮвҸ«—ҲӮЦӮМғXғPҒ[ғүғrғҠғeғB
(2) (1)ӮЖҠЦҳAӮөӮДӮўӮйӮӘҒAGPUӮМғIғ“ғ_ғC“қҚҮ
(3) 256bit SIMD‘Оүһ+Load PortӮМ‘қҗЭ
(4)ҲИүәҒAӮ»ӮМ‘јӮМҚЕӢЯ–ҫӮзӮ©ӮЙӮИӮБӮҪҚЧӮ©Ӯўҳb
ӮИӮМӮЕҒAӮ ӮөӮ©ӮзӮёҒB
ӮұӮұӮНғAҒ[ғLғeғNғ`ғғӮрҢкӮй–Ъ“IӮМғXғҢӮЕӮНӮИӮ©ӮҪҒB
Sandy BridgeӮМҲУӢ`ӮНӮ ӮӯӮЬӮЕҒA
(1) ғҠғ“ғOғoғXӮЙӮжӮй”hҗ¶•iӮвҸ«—ҲӮЦӮМғXғPҒ[ғүғrғҠғeғB
(2) (1)ӮЖҠЦҳAӮөӮДӮўӮйӮӘҒAGPUӮМғIғ“ғ_ғC“қҚҮ
(3) 256bit SIMD‘Оүһ+Load PortӮМ‘қҗЭ
(4)ҲИүәҒAӮ»ӮМ‘јӮМҚЕӢЯ–ҫӮзӮ©ӮЙӮИӮБӮҪҚЧӮ©Ӯўҳb
ӮИӮМӮЕҒAӮ ӮөӮ©ӮзӮёҒB
808 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ[”„ӮиҗШӮк]ҒF2010/09/28(үО) 06:46:48 ID:ur96O5hNO
Ӯ ӮЬӮиҗа–ҫӮНӮіӮкӮДӮИӮўӮӘҒAuopsғLғғғbғVғ…ӮН‘ҪғoғCғg–Ҫ—Я—ҳ—pҺһӮМ–Ҫ—ЯғtғFғbғ`‘СҲж•s‘«ӮаӮ Ӯй’ц“xүрҢҲӮЕӮ«ӮйҒB
Ң»ҸуӮМ16B/cycleӮМ‘СҲжӮМӮЬӮЬӮЕӮНҸ«—ҲӮМFMAӮрҺА‘•ӮөӮДӮа—LҢшҠҲ—pӮЕӮ«ӮИӮўӮұӮЖӮр—\Ң©ӮөӮДӮҪӮҜӮЗ
IntelӮНүрҢҲҚфӮр—pҲУӮөӮДӮ«ӮҪӮнӮҜӮҫӮнӮИҒB
1500uopsӮаӮ ӮкӮОӮ Ӯй’ц“xӮНғӢҒ[ғvғAғ“ғҚҒ[ғӢӮөӮДӮа”[ӮЬӮйҒB
Ң»ҸуӮМ16B/cycleӮМ‘СҲжӮМӮЬӮЬӮЕӮНҸ«—ҲӮМFMAӮрҺА‘•ӮөӮДӮа—LҢшҠҲ—pӮЕӮ«ӮИӮўӮұӮЖӮр—\Ң©ӮөӮДӮҪӮҜӮЗ
IntelӮНүрҢҲҚфӮр—pҲУӮөӮДӮ«ӮҪӮнӮҜӮҫӮнӮИҒB
1500uopsӮаӮ ӮкӮОӮ Ӯй’ц“xӮНғӢҒ[ғvғAғ“ғҚҒ[ғӢӮөӮДӮа”[ӮЬӮйҒB
809 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ[”„ӮиҗШӮк]ҒF2010/10/01(Ӣа) 14:59:17 ID:u3NM9wAMO
>>801
–wӮЗӮДӮ©‘SӮӯӮўӮзӮсӮҫӮлҒB
LSDӮНҳA‘ұӮөӮҪ–Ҫ—Я—сӮМ”Ҫ•ңӮЙӮөӮ©ҺgӮҰӮИӮўҒB
ғgғҢҒ[ғXғLғғғbғVғ…ӮН•p”ЙӮЙcallӮіӮкӮйҸ¬ӢK–НӮИҠЦҗ”ҒiӮаӮөӮӯӮНғvғҚғVҒ[ғWғғҒjӮИӮсӮ©ӮаҠi”[ӮЕӮ«Ӯй
–wӮЗӮДӮ©‘SӮӯӮўӮзӮсӮҫӮлҒB
LSDӮНҳA‘ұӮөӮҪ–Ҫ—Я—сӮМ”Ҫ•ңӮЙӮөӮ©ҺgӮҰӮИӮўҒB
ғgғҢҒ[ғXғLғғғbғVғ…ӮН•p”ЙӮЙcallӮіӮкӮйҸ¬ӢK–НӮИҠЦҗ”ҒiӮаӮөӮӯӮНғvғҚғVҒ[ғWғғҒjӮИӮсӮ©ӮаҠi”[ӮЕӮ«Ӯй
810 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/10/01(Ӣа) 21:13:30 ID:6OYRlSWf0
http://journal.mycom.co.jp/articles/2010/09/30/nvidia_gpu/002.html
>--үИҠwӢZҸpҢvҺZ—pGPUӮЙ“ҠҺ‘Ӯ·ӮйӮМӮНғyғCӮ·ӮйӮМӮ©?
>Dally:Ӯ»ӮкӮНғrғWғlғXғNғGғXғ`ғҮғ“ӮҫӮӘҒAҗжӮЙҸqӮЧӮҪӮжӮӨӮЙҒA
>Ӯ·ӮЧӮДӮӘғwғeғҚғWғjғAғXғRғ“ғsғ…Ғ[ғeғBғ“ғOӮЙӮИӮБӮДӮўӮӯӮЖҚlӮҰӮДӮўӮйҒB
>үИҠwӢZҸpҢvҺZҗк—pӮМGPUӮрҠJ”ӯӮ·ӮйӮМӮЕӮНҠJ”ӯ“ҠҺ‘ӮрүсҺыӮЕӮ«ӮИӮўӮӘҒA
>ғOғүғtғBғbғNғXӮМҺщ—vӮЙғAғhғIғ“ӮМҢ`ӮИӮз–в‘иӮИӮўҒB
ҲА“ЎҺҒғ}ғ“ғZҒ[ҒB’јӢ…ӮЕ•·Ӯ«ӮвӮӘӮБӮҪҒB
nVIDIAӮағRғ“ғVғ…Ғ[ғ}ӮМ”„ҸгӮИӮөӮЕӮНғyғCӮөӮИӮўӮЖ”FҺҜӮөӮДӮўӮйӮжӮӨӮҫӮЛҒB
>--үИҠwӢZҸpҢvҺZ—pGPUӮЙ“ҠҺ‘Ӯ·ӮйӮМӮНғyғCӮ·ӮйӮМӮ©?
>Dally:Ӯ»ӮкӮНғrғWғlғXғNғGғXғ`ғҮғ“ӮҫӮӘҒAҗжӮЙҸqӮЧӮҪӮжӮӨӮЙҒA
>Ӯ·ӮЧӮДӮӘғwғeғҚғWғjғAғXғRғ“ғsғ…Ғ[ғeғBғ“ғOӮЙӮИӮБӮДӮўӮӯӮЖҚlӮҰӮДӮўӮйҒB
>үИҠwӢZҸpҢvҺZҗк—pӮМGPUӮрҠJ”ӯӮ·ӮйӮМӮЕӮНҠJ”ӯ“ҠҺ‘ӮрүсҺыӮЕӮ«ӮИӮўӮӘҒA
>ғOғүғtғBғbғNғXӮМҺщ—vӮЙғAғhғIғ“ӮМҢ`ӮИӮз–в‘иӮИӮўҒB
ҲА“ЎҺҒғ}ғ“ғZҒ[ҒB’јӢ…ӮЕ•·Ӯ«ӮвӮӘӮБӮҪҒB
nVIDIAӮағRғ“ғVғ…Ғ[ғ}ӮМ”„ҸгӮИӮөӮЕӮНғyғCӮөӮИӮўӮЖ”FҺҜӮөӮДӮўӮйӮжӮӨӮҫӮЛҒB
811 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/10/01(Ӣа) 21:16:38 ID:6OYRlSWf0
nVIDIAӮӘARMӮрҺқӮҝҸгӮ°Ӯй—қ—RӮН–ҫ”’ӮҫӮИҒB
ӮЖӮўӮӨӮ©ҚЎӮЬӮЕnVIDIAӮМ”„ҸгӮрҺxӮҰӮДӮ«ӮҪғnғCғGғ“ғhҺuҢьӮМPCғҶҒ[ғUӮвPCғQҒ[ғ}Ғ[Ӯр
”Ы’иӮ·ӮйӮжӮӨӮИғRғҒғ“ғgӮр”ӯӮөӮДӮӯӮйӮ ӮҪӮиҒAӮ©ӮИӮи’ЗӮўӢlӮЯӮзӮкӮДӮйӮЖҺvӮӨӮӘҒB
ҚЕӢЯӮМGPGPU HPCҗ„җiҺТӮМ”ӯҢҫӮЙӮНӢ°ӮкӮўӮиӮЬӮ·ҒB
ӮЖӮўӮӨӮ©ҚЎӮЬӮЕnVIDIAӮМ”„ҸгӮрҺxӮҰӮДӮ«ӮҪғnғCғGғ“ғhҺuҢьӮМPCғҶҒ[ғUӮвPCғQҒ[ғ}Ғ[Ӯр
”Ы’иӮ·ӮйӮжӮӨӮИғRғҒғ“ғgӮр”ӯӮөӮДӮӯӮйӮ ӮҪӮиҒAӮ©ӮИӮи’ЗӮўӢlӮЯӮзӮкӮДӮйӮЖҺvӮӨӮӘҒB
ҚЕӢЯӮМGPGPU HPCҗ„җiҺТӮМ”ӯҢҫӮЙӮНӢ°ӮкӮўӮиӮЬӮ·ҒB
812 ҒF–јҸМ–ўҗЭ’иҒF2010/10/02(“y) 00:25:22 ID:DBEcP3tV0
NV’ЗӮўӢlӮЯӮзӮкӮДӮйӮИ
813 ҒF–јҸМ–ўҗЭ’иҒF2010/10/02(“y) 00:30:52 ID:+LhhEOzK0
ӮҫӮ©ӮзӮұӮ»Ҡъ‘ТӮөӮДӮўӮй
814 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ[”„ӮиҗШӮк]ҒF2010/10/02(“y) 07:24:55 ID:/FCzXwhVO
>>811
IntelӮН–{ӢCӮЕHPC“Бү»ӮМGPUӮаӮЖӮўғfғBғXғNғҠҒ[ғgғRғvғҚғZғbғTғJҒ[ғhӮрҚмӮБӮДӮЁӮи
NVIDIAӮаGPUӮЖӮөӮДӮМғRғXғgғoғүғ“ғXӮр’ЗӢҒӮ·ӮйҲИҸгӮНHPCӮЕӮН•s—ҳӮЙӮИӮйҒB
ҢvүжҸCҗіҢгӮМLarrabeeҢvүжӮМ—ҠӮЗӮұӮлӮНHPCӮЖғnғCғGғ“ғhғQҒ[ғҖӮМҗ«”\—vӢҒӮМғMғғғbғvҒB
GPUӮЖӮөӮДӮМҗ«”\ӮЙҗUӮй•K—vӮӘӮИӮӯӮИӮБӮҪMICӮЖҒAғIғ“ғRғAӮМғRғvғҚғZғbғTӮЖӮөӮД”{ҒXӮЕҗ«”\ҢьҸгӮр–ЪҺwӮ·AVXӮМ2ҳHҗьҒB
IntelӮН–{ӢCӮЕHPC“Бү»ӮМGPUӮаӮЖӮўғfғBғXғNғҠҒ[ғgғRғvғҚғZғbғTғJҒ[ғhӮрҚмӮБӮДӮЁӮи
NVIDIAӮаGPUӮЖӮөӮДӮМғRғXғgғoғүғ“ғXӮр’ЗӢҒӮ·ӮйҲИҸгӮНHPCӮЕӮН•s—ҳӮЙӮИӮйҒB
ҢvүжҸCҗіҢгӮМLarrabeeҢvүжӮМ—ҠӮЗӮұӮлӮНHPCӮЖғnғCғGғ“ғhғQҒ[ғҖӮМҗ«”\—vӢҒӮМғMғғғbғvҒB
GPUӮЖӮөӮДӮМҗ«”\ӮЙҗUӮй•K—vӮӘӮИӮӯӮИӮБӮҪMICӮЖҒAғIғ“ғRғAӮМғRғvғҚғZғbғTӮЖӮөӮД”{ҒXӮЕҗ«”\ҢьҸгӮр–ЪҺwӮ·AVXӮМ2ҳHҗьҒB
815 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ[”„ӮиҗШӮк]ҒF2010/10/02(“y) 10:57:02 ID:/FCzXwhVO
ӮДӮ©ӢіҺцӮМx86ҢҷӮўӮНҢіҒXӮЕӮөӮе
ARMӮӘҸИ“d—НӮӨӮсӮКӮсӮаҢЦ‘еҚLҚҗӢC–ЎӮИӮсӮҫӮҜӮЗӮИҒB
ғfҒ[ғ^“]‘—ӮЙ“d—НҗHӮӨӮМӮНCPUӮа“ҜӮ¶ҒB
ӮҪӮЖӮҰӮОCortexA9ӮМғnғCғGғ“ғhӮЕӮ·ӮзAtomӮМӮжӮӨӮЙ64bit DDR*‘ОүһӮөӮҪҺА‘•ӮНҠF–іҒB
ӮҫӮ©ӮзғҒғӮғҠ‘СҲжӮӘӮ ӮЬӮи•K—vӮМӮИӮўғxғ“ғ`ӮЕӮөӮ©AtomӮЖҸҹ•үӮөӮИӮўӮсӮҫӮжӮЛҒB
Ӯ ӮЖҒAғLғғғbғVғ…”nҺӯӮЭӮҪӮўӮЙҗПӮсӮҫғTғ“ғvғӢғ`ғbғvҺgӮБӮҪӮиӮЖӮ©ҒB
ARMӮӘҸИ“d—НӮӨӮсӮКӮсӮаҢЦ‘еҚLҚҗӢC–ЎӮИӮсӮҫӮҜӮЗӮИҒB
ғfҒ[ғ^“]‘—ӮЙ“d—НҗHӮӨӮМӮНCPUӮа“ҜӮ¶ҒB
ӮҪӮЖӮҰӮОCortexA9ӮМғnғCғGғ“ғhӮЕӮ·ӮзAtomӮМӮжӮӨӮЙ64bit DDR*‘ОүһӮөӮҪҺА‘•ӮНҠF–іҒB
ӮҫӮ©ӮзғҒғӮғҠ‘СҲжӮӘӮ ӮЬӮи•K—vӮМӮИӮўғxғ“ғ`ӮЕӮөӮ©AtomӮЖҸҹ•үӮөӮИӮўӮсӮҫӮжӮЛҒB
Ӯ ӮЖҒAғLғғғbғVғ…”nҺӯӮЭӮҪӮўӮЙҗПӮсӮҫғTғ“ғvғӢғ`ғbғvҺgӮБӮҪӮиӮЖӮ©ҒB
816 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/10/04(ҢҺ) 19:30:51 ID:CNhB6Y5S0
>>802
ӢLҺ–ҸCҗіӮіӮкӮҪӮЛҒBӮЬӮҫҠФҲбӮў‘ҪӮўӮҜӮЗҒB
ӢLҺ–ҸCҗіӮіӮкӮҪӮЛҒBӮЬӮҫҠФҲбӮў‘ҪӮўӮҜӮЗҒB
817 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ[”„ӮиҗШӮк]ҒF2010/10/08(Ӣа) 07:32:05 ID:15N8aOw/O
ҚЎүсӮМҢг“ЎӢLҺ–
NVIDIAӮНӮаӮӨҠ®‘SӮЙӢӯӮӘӮиӮМҗўҠEӮҫӮИҒB
•КӮЙARMӮНӮЩӮ©ӮМ‘gӮЭҚһӮЭRISCӮЖ”дӮЧӮД“d—НҢш—ҰӮўӮўӮнӮҜӮ¶ӮбӮИӮўӮөҒB
ҢӢӢЗӮНx86ӮМӮжӮӨӮИӢӯ—НӮЕҸ_“оӮИғҒғӮғҠғAғhғҢғbғVғ“ғOғӮҒ[ғhӮрҺқӮВүВ•П’·CISC ISAӮМ”ь“_ӮрҚД”FҺҜӮ·ӮйӮҫӮҜӮЙӮИӮиӮ»ӮӨӮИҒB
NVIDIAӮНӮаӮӨҠ®‘SӮЙӢӯӮӘӮиӮМҗўҠEӮҫӮИҒB
•КӮЙARMӮНӮЩӮ©ӮМ‘gӮЭҚһӮЭRISCӮЖ”дӮЧӮД“d—НҢш—ҰӮўӮўӮнӮҜӮ¶ӮбӮИӮўӮөҒB
ҢӢӢЗӮНx86ӮМӮжӮӨӮИӢӯ—НӮЕҸ_“оӮИғҒғӮғҠғAғhғҢғbғVғ“ғOғӮҒ[ғhӮрҺқӮВүВ•П’·CISC ISAӮМ”ь“_ӮрҚД”FҺҜӮ·ӮйӮҫӮҜӮЙӮИӮиӮ»ӮӨӮИҒB
818 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ[”„ӮиҗШӮк]ҒF2010/10/08(Ӣа) 07:46:23 ID:15N8aOw/O
ӮЬӮ үјӮЙғEғ“Ҹ\ғҸғbғgҸБ”пӮ·ӮйARMҚмӮБӮҪӮЖӮөӮДӮа
ӮіӮ·ӮӘӮЙx86ӮМӮЩӮӨӮӘҗ«”\Ңш—ҰӮӘӮўӮўӮҫӮлӮӨҒB
ӮіӮ·ӮӘӮЙx86ӮМӮЩӮӨӮӘҗ«”\Ңш—ҰӮӘӮўӮўӮҫӮлӮӨҒB
819 ҒF–јҸМ–ўҗЭ’иҒF2010/10/12(үО) 17:21:26 ID:UnY3q/nd0
Һҹҗў‘гғXғҢӮЙғLғ`ғKғC’cҺqӮӘӮўӮйӮМӮҫӮӘ
Ӯ ӮкӮН–{•ЁӮ©ҒHӮ»ӮкӮЖӮаҗ¬ӮиӮ·ӮЬӮөӮ©ҒH
Ӯ ӮкӮН–{•ЁӮ©ҒHӮ»ӮкӮЖӮаҗ¬ӮиӮ·ӮЬӮөӮ©ҒH
820 ҒF–јҸМ–ўҗЭ’иҒF2010/10/12(үО) 18:16:27 ID:XA1dVxiB0
RISCӮИӮсӮДҒAғNғҚғbғNӮӘғKғ“ғKғ“ҸгӮӘӮйӮЖӮўӮӨҢ¶‘zӮр•шӮўӮДӮўӮҪҺһ‘гӮМҺY•Ё
821 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ[”„ӮиҗШӮк]ҒF2010/10/13(җ…) 14:04:15 ID:hPw9KiHMO
>>819
”„ӮиҗШӮкӮДӮИӮўӮвӮВӮНӢU•Ё
”„ӮиҗШӮкӮДӮИӮўӮвӮВӮНӢU•Ё
822 ҒF–јҸМ–ўҗЭ’иҒF2010/10/13(җ…) 18:51:51 ID:hPw9KiHMO
Cortex-A15ӮҫӮҜӮЗҒA3decodeӮМ8issueӮБӮДӮИӮсӮМӮұӮБӮҝӮб
җ«”\ӮӘ”{ӮЙӮИӮйҚӘӢ’Ӯа•s–ҫӮҫӮөҒB
ӮЬӮіӮ©x86ӮЭӮҪӮўӮЙғҒғӮғҠғAғhғҢғbғVғ“ғOғӮҒ[ғhӮЕӮа’ЗүБӮ·ӮйӮМӮ©ҒHӮ—
җ«”\ӮӘ”{ӮЙӮИӮйҚӘӢ’Ӯа•s–ҫӮҫӮөҒB
ӮЬӮіӮ©x86ӮЭӮҪӮўӮЙғҒғӮғҠғAғhғҢғbғVғ“ғOғӮҒ[ғhӮЕӮа’ЗүБӮ·ӮйӮМӮ©ҒHӮ—
823 ҒF–јҸМ–ўҗЭ’иҒF2010/10/13(җ…) 19:37:01 ID:qkZd4h+u0
vaporwareӮЕӮ·
824 ҒFMACғIғ^Ғ„’cҺq ӮіӮсҒF2010/10/13(җ…) 21:40:57 ID:XHDG4YSU0
>>821
ӮұӮұ”ј”NӮЩӮЗӮМҺҹҗў‘гғXғҢғbғhӮМ•…ӮкӮБӮХӮиӮН’cҺqӮіӮсӮӘҒuӮаӮБӮіӮиҒvғXғҢӮЙ“ЛҢӮӮөӮДҒAғLғ`ғKғCӮМғqғgӮрҲшӮ«ӮёӮиҸoӮөӮДӮөӮЬӮБӮҪҸҠҲЧӮЕӮНҒH
‘ҪҸӯӮНҗУ”CӮрҠҙӮ¶ӮД—~ӮөӮўғӮғmӮЕӮ·ҒB
ӮұӮұ”ј”NӮЩӮЗӮМҺҹҗў‘гғXғҢғbғhӮМ•…ӮкӮБӮХӮиӮН’cҺqӮіӮсӮӘҒuӮаӮБӮіӮиҒvғXғҢӮЙ“ЛҢӮӮөӮДҒAғLғ`ғKғCӮМғqғgӮрҲшӮ«ӮёӮиҸoӮөӮДӮөӮЬӮБӮҪҸҠҲЧӮЕӮНҒH
‘ҪҸӯӮНҗУ”CӮрҠҙӮ¶ӮД—~ӮөӮўғӮғmӮЕӮ·ҒB
825 ҒF–јҸМ–ўҗЭ’иҒF2010/10/14(–Ш) 07:11:49 ID:/+hy9TLA0
ғLғ`ғKғCӮМ‘¶ҚЭӮЙҗУ”CӮрҠҙӮ¶Ӯй•K—vӮИӮсӮДӮИӮўӮЖҺvӮӨӮҜӮЗӮИҒB
826 ҒF–јҸМ–ўҗЭ’иҒF2010/10/14(–Ш) 07:38:16 ID:mEvL3xnB0
ӮДӮ©824ӮӘҠо’nҠOӮИӮсӮ¶ӮбӮЛҒH‘ҠҺиӮөӮД—~ӮөӮӯӮДӮұӮБӮҝӮЙ—ҲӮҪӮЖӮ©Ӯ—
827 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ[”„ӮиҗШӮк]ҒF2010/10/14(–Ш) 11:38:55 ID:BG7o1quSO
ӮіӮДCortex-A15ӮӘA9ӮМ”{ӮМҗ«”\Ӯр’Bҗ¬ӮЕӮ«Ӯй—қ—RӮрҗ^Ң•ӮЙҚlӮҰӮжӮӨӮ©ҒB
828 ҒF–јҸМ–ўҗЭ’иҒF2010/10/14(–Ш) 15:11:40 ID:suUfNffM0
Ӯ Ӯ»ӮұӮЕ“ШӮЖӮ©ғzғӮӮЖӮ©ҢҫӮБӮДӮйҠо’nҠOӮМ•ыӮӘ—]’цҠQҲ«ӮҫӮЖҺvӮӨӮМӮҫӮӘ
ғXғҢӮМҳA’ҶӮаҚ\ӮнӮИӮўҸҠӮрҢ©ӮйӮЖ‘Ҡ“–ғ„ғoӮў“zӮИӮсӮҫӮлӮӨӮИ
ғXғҢӮМҳA’ҶӮаҚ\ӮнӮИӮўҸҠӮрҢ©ӮйӮЖ‘Ҡ“–ғ„ғoӮў“zӮИӮсӮҫӮлӮӨӮИ
829 ҒFMACғIғ^Ғ„828 ӮіӮсҒF2010/10/14(–Ш) 20:36:20 ID:gsxsaOzn0
>>828
Ғ@Ғ@-----------------
Ғ@Ғ@Ӯ Ӯ»ӮұӮЕ“ШӮЖӮ©ғzғӮӮЖӮ©ҢҫӮБӮДӮйҠо’nҠO
Ғ@Ғ@-----------------
ғ\ғҢӮӘҒAӮаӮБӮіӮиғXғҢғbғhӮЙҠu—ЈӮіӮкӮДӮўӮҪғLғ`ғKғCӮМғqғgӮЕӮ·ҒB
Ҡu—ЈҗжӮЕӮН“K“–ӮЙ‘ҠҺиӮрӮ·Ӯйғqғg’BӮӘӮўӮДҒAӮ ӮЬӮи‘јғXғҢӮЙҸoӮДӮұӮИӮўҸу‘ФӮҫӮБӮҪӮМӮЕӮ·ӮӘҒA’cҺqӮіӮсӮӘ“ЛҢӮӮөӮҪӮОӮ©ӮиӮЙҒc
Ғ@Ғ@-----------------
Ғ@Ғ@Ӯ Ӯ»ӮұӮЕ“ШӮЖӮ©ғzғӮӮЖӮ©ҢҫӮБӮДӮйҠо’nҠO
Ғ@Ғ@-----------------
ғ\ғҢӮӘҒAӮаӮБӮіӮиғXғҢғbғhӮЙҠu—ЈӮіӮкӮДӮўӮҪғLғ`ғKғCӮМғqғgӮЕӮ·ҒB
Ҡu—ЈҗжӮЕӮН“K“–ӮЙ‘ҠҺиӮрӮ·Ӯйғqғg’BӮӘӮўӮДҒAӮ ӮЬӮи‘јғXғҢӮЙҸoӮДӮұӮИӮўҸу‘ФӮҫӮБӮҪӮМӮЕӮ·ӮӘҒA’cҺqӮіӮсӮӘ“ЛҢӮӮөӮҪӮОӮ©ӮиӮЙҒc
830 ҒF–јҸМ–ўҗЭ’иҒF2010/10/14(–Ш) 21:30:03 ID:eiVffp1u0
>>827
IntelӮӘҗ»‘ўӮ·Ӯй
IntelӮӘҗ»‘ўӮ·Ӯй
831 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ[”„ӮиҗШӮк]ҒF2010/10/14(–Ш) 23:08:45 ID:BG7o1quSO
A9ӮМ1.4”{’ц“xӮМғNғҚғbғNӮрҺАҢ»ӮөӮҪӮЖӮөӮДӮаҒAӮ ӮЖ1.4”{IPCӮрӮ Ӯ°ӮИӮўӮЖ2”{ӮЙӮН“НӮ©ӮИӮўҒB
832 ҒF–јҸМ–ўҗЭ’иҒF2010/10/14(–Ш) 23:37:41 ID:/+hy9TLA0
A9”д1.5”{ӮМIPCӮр’Bҗ¬Ӯ·ӮйӮБӮДҳbӮӘӮЗӮұӮ©ӮЙӮИӮ©ӮБӮҪӮБӮҜҒH
ӮҫӮЖӮөӮҪӮз—\’и’КӮиӮ¶ӮбӮИӮўӮМҒH
ӮҫӮЖӮөӮҪӮз—\’и’КӮиӮ¶ӮбӮИӮўӮМҒH
833 ҒF–јҸМ–ўҗЭ’иҒF2010/10/15(Ӣа) 11:08:28 ID:oQDXxb5/0
ӮЮӮөӮлӮ»ӮлӮОӮс•ңҢ ӮМҺһ‘гӮӘӢЯӮГӮ«ӮВӮВӮ Ӯй
834 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ[”„ӮиҗШӮк]ҒF2010/10/15(Ӣа) 17:55:02 ID:9Gg50vncO
>>832
ӮҫӮ©ӮзӮ»ӮМIPCҢьҸгӮМӮ©ӮзӮӯӮиӮӘғCғ~ғt
ӮҪӮЖӮҰӮО128ғrғbғgNEON/VFPӮӘ2ғTғCғNғӢӮ©Ӯз1ғTғCғNғӢӮЙӮИӮйӮЖӮ©ҒH
Ӯ»ӮсӮИӮсӮЕҢьҸгӮ·ӮйӮМӮНҲк•”ӮҫӮҜӮҫӮжӮЛҒB
ӮҫӮ©ӮзӮ»ӮМIPCҢьҸгӮМӮ©ӮзӮӯӮиӮӘғCғ~ғt
ӮҪӮЖӮҰӮО128ғrғbғgNEON/VFPӮӘ2ғTғCғNғӢӮ©Ӯз1ғTғCғNғӢӮЙӮИӮйӮЖӮ©ҒH
Ӯ»ӮсӮИӮсӮЕҢьҸгӮ·ӮйӮМӮНҲк•”ӮҫӮҜӮҫӮжӮЛҒB
835 ҒF–јҸМ–ўҗЭ’иҒF2010/11/03(җ…) 15:48:08 ID:es+d9W490
ho
836 ҒF–јҸМ–ўҗЭ’иҒF2010/11/10(җ…) 17:30:18 ID:dzJ6dMfv0
PCҢьӮҜӮЕӮаBulldozerӮӘK10Ӯр’uӮ«Ҡ·ӮҰӮҝӮбӮўӮЬӮ·ӮЛ
837 ҒF–јҸМ–ўҗЭ’иҒF2010/11/10(җ…) 21:31:55 ID:1XXvJmcV0
196 –ј‘OҒFҗ…җжҲД–ј–іӮўҗl[sage] “ҠҚe“ъҒF2010/11/10(җ…) 12:41:26 ID:Jm8WaIBv0
95 –ј‘OҒF–ј–іӮөӮіӮсҒ—ӮЁ• ӮўӮБӮПӮўҒBҒF2010/10/16(“y) 04:40:44
Һ©•ӘӮЕҠJӮҜӮҪғhғAӮЙҠз(Қ¶”ј•Ә)Ӯр”hҺиӮЙӮФӮВӮҜӮҪҒB
’ЙӮҰҒ[ҒIҒIғ{Ғ[ғbӮЖӮөӮДӮҪӮ©ӮзӮҫӮИӮҹҒ`ҒBӮаҒ`ӮЈҒIӮЖҺvӮўӮИӮӘӮзүҪҢМӮ©ғhғAӮр•ВӮЯҒA
ӮЬӮҪҠJӮҜӮДӮЬӮҪ“ҜӮ¶ҸҲӮрӮФӮВӮҜӮҪҒB
ҢгӮлӮЕҢ©ӮДӮўӮҪ“Ҝ—»ӮЙҒuӮЁӮЬӮ¶ӮИӮўӮ©үҪӮ©ӮЕӮ·Ӯ©ҒHҒvӮЖҢҫӮнӮкӮҪҒB
ӮсӮИғ}ғWғiғCӮН–іӮўҒB
197 –ј‘OҒFҗ…җжҲД–ј–іӮўҗl[sage] “ҠҚe“ъҒF2010/11/10(җ…) 17:23:44 ID:91S8VEqS0
ғ}ғW–іӮў
95 –ј‘OҒF–ј–іӮөӮіӮсҒ—ӮЁ• ӮўӮБӮПӮўҒBҒF2010/10/16(“y) 04:40:44
Һ©•ӘӮЕҠJӮҜӮҪғhғAӮЙҠз(Қ¶”ј•Ә)Ӯр”hҺиӮЙӮФӮВӮҜӮҪҒB
’ЙӮҰҒ[ҒIҒIғ{Ғ[ғbӮЖӮөӮДӮҪӮ©ӮзӮҫӮИӮҹҒ`ҒBӮаҒ`ӮЈҒIӮЖҺvӮўӮИӮӘӮзүҪҢМӮ©ғhғAӮр•ВӮЯҒA
ӮЬӮҪҠJӮҜӮДӮЬӮҪ“ҜӮ¶ҸҲӮрӮФӮВӮҜӮҪҒB
ҢгӮлӮЕҢ©ӮДӮўӮҪ“Ҝ—»ӮЙҒuӮЁӮЬӮ¶ӮИӮўӮ©үҪӮ©ӮЕӮ·Ӯ©ҒHҒvӮЖҢҫӮнӮкӮҪҒB
ӮсӮИғ}ғWғiғCӮН–іӮўҒB
197 –ј‘OҒFҗ…җжҲД–ј–іӮўҗl[sage] “ҠҚe“ъҒF2010/11/10(җ…) 17:23:44 ID:91S8VEqS0
ғ}ғW–іӮў
838 ҒF–јҸМ–ўҗЭ’иҒF2010/11/11(–Ш) 05:25:26 ID:uQgtZG5D0
http://blogs.amd.com/work/2010/11/09/server-highlights-from-financial-analyst-day/
Turbo CORE -
We have disclosed that we would include AMD Turbo CORE technology
in the past, so this should not be a surprise to anyone. But what is
news is the uplift ? up to 500MHz with all cores fully utilized. TodayҒfs
implementations of boost technology can push up the clock speed of
a couple of cores when the others are idle, but with our new version of
Turbo CORE youҒfll see full core boost, meaning an extra 500MHz
across all 16 threads for most workloads.
‘SғRғAүТ“ӯҺһӮЕӮаҚЕ‘еӮЕ500MHzғuҒ[ғXғgҸo—ҲӮйӮЖӮ·ӮйҒB
IntelӮМҸкҚҮҒA‘SғRғAғuҒ[ғXғgӮ·ӮйӮЖӮ«ӮНӮҫӮўӮҪӮў’иҠiғNғҚғbғNӮМ1Ҡ„‘қӮөҒB
ӮұӮМүј’иӮр“–ӮДӮНӮЯӮйӮЖBulldozerӮН’иҠiғNғҚғbғN5GHzҒB
‘SғRғAғuҒ[ғXғgӮЕ’иҠiӮМ1.5Ҡ„‘қӮөӮЖӮөӮҪҸкҚҮӮН3.33GHzҒB
ӮіӮДӮұӮМҚlӮҰ•ыӮНҚҮӮБӮДӮўӮйӮҫӮлӮӨӮ©Ғc
Turbo CORE -
We have disclosed that we would include AMD Turbo CORE technology
in the past, so this should not be a surprise to anyone. But what is
news is the uplift ? up to 500MHz with all cores fully utilized. TodayҒfs
implementations of boost technology can push up the clock speed of
a couple of cores when the others are idle, but with our new version of
Turbo CORE youҒfll see full core boost, meaning an extra 500MHz
across all 16 threads for most workloads.
‘SғRғAүТ“ӯҺһӮЕӮаҚЕ‘еӮЕ500MHzғuҒ[ғXғgҸo—ҲӮйӮЖӮ·ӮйҒB
IntelӮМҸкҚҮҒA‘SғRғAғuҒ[ғXғgӮ·ӮйӮЖӮ«ӮНӮҫӮўӮҪӮў’иҠiғNғҚғbғNӮМ1Ҡ„‘қӮөҒB
ӮұӮМүј’иӮр“–ӮДӮНӮЯӮйӮЖBulldozerӮН’иҠiғNғҚғbғN5GHzҒB
‘SғRғAғuҒ[ғXғgӮЕ’иҠiӮМ1.5Ҡ„‘қӮөӮЖӮөӮҪҸкҚҮӮН3.33GHzҒB
ӮіӮДӮұӮМҚlӮҰ•ыӮНҚҮӮБӮДӮўӮйӮҫӮлӮӨӮ©Ғc
839 ҒF–јҸМ–ўҗЭ’иҒF2010/11/11(–Ш) 20:50:14 ID:KWv6bj0VP
‘SғRғAүТ“®ҺһӮағuҒ[ғXғgӮөӮДӮйӮБӮДӮМӮНҒA
’PӮЙAMD’иҠiғNғҚғbғNӮМ’иӢ`ӮМ–в‘иӮҫӮлҒB
IntelӮМҸкҚҮӮН‘SғRғAүТ“®Һһ=’иҠiӮМ’иӢ`ӮМҸ”Ңі
ӮҫӮ©ӮзҒB
’PӮЙAMD’иҠiғNғҚғbғNӮМ’иӢ`ӮМ–в‘иӮҫӮлҒB
IntelӮМҸкҚҮӮН‘SғRғAүТ“®Һһ=’иҠiӮМ’иӢ`ӮМҸ”Ңі
ӮҫӮ©ӮзҒB
840 ҒF–јҸМ–ўҗЭ’иҒF2010/11/12(Ӣа) 19:55:14 ID:Kh/qKkJf0
ҠmӮ©ӮЙ
ӮЕӮаӮнӮҙӮЖ’иҠiғNғҚғbғNӮр’бӮЯӮЙҗЭ’иӮ·ӮйӮұӮЖӮНҢ»ҸуӮрҚlӮҰӮДӮа–іӮўӮсӮ¶ӮбӮИӮўӮМҒH
ғ}Ғ[ғPғeғBғ“ғO“IӮЙӮағNғҚғbғNҚӮӮў•ыӮӘҗв‘О—ЗӮўӮнӮҜӮҫӮө
ӮЕӮаӮнӮҙӮЖ’иҠiғNғҚғbғNӮр’бӮЯӮЙҗЭ’иӮ·ӮйӮұӮЖӮНҢ»ҸуӮрҚlӮҰӮДӮа–іӮўӮсӮ¶ӮбӮИӮўӮМҒH
ғ}Ғ[ғPғeғBғ“ғO“IӮЙӮағNғҚғbғNҚӮӮў•ыӮӘҗв‘О—ЗӮўӮнӮҜӮҫӮө
841 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/11/13(“y) 15:47:35 ID:4NlXVPv1P
ӮЬӮ ҒA2issue in-order ҒЁ 3issue OOO ӮИӮз•Ғ’КӮИ—\ҠҙӮҫӮИҒBғLғғғbғVғ…Ӯа‘е•қӮЙ‘қӮҰӮДӮйӮөҒB
Ӯ ӮЖӮНғvғҚғZғXӮҫӮИҒB
ARM Cortex-A15Ғ\does this processor IP core need a new categoryҒcSuperstar IP?
http://eda360insider.wordpress.com/2010/11/10/arm-cortex-a15%E2%80%94does-this-processor-ip-core-need-a-new-category%E2%80%A6superstar-ip/?goback=.gde_30219_member_34714657
Ӯ ӮЖӮНғvғҚғZғXӮҫӮИҒB
ARM Cortex-A15Ғ\does this processor IP core need a new categoryҒcSuperstar IP?
http://eda360insider.wordpress.com/2010/11/10/arm-cortex-a15%E2%80%94does-this-processor-ip-core-need-a-new-category%E2%80%A6superstar-ip/?goback=.gde_30219_member_34714657
842 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/11/13(“y) 16:02:38 ID:4NlXVPv1P
Ӯ ҒAӮ·ӮЬӮсA9Ӯ©ӮзOOOӮҫӮБӮҪӮнҒB
Decode / Rename / DispatchӮЙ7ғXғeҒ[ғWӮаҺgӮБӮДӮйӮ©ӮзҒAP6ӮжӮиӮа’б’xү„җЭҢvӮ©??
ғLғғғbғVғ…ӮМғҢғCғeғ“ғVӮНӮЗӮӨӮИӮсӮҫӮлӮӨҒcҒB
Decode / Rename / DispatchӮЙ7ғXғeҒ[ғWӮаҺgӮБӮДӮйӮ©ӮзҒAP6ӮжӮиӮа’б’xү„җЭҢvӮ©??
ғLғғғbғVғ…ӮМғҢғCғeғ“ғVӮНӮЗӮӨӮИӮсӮҫӮлӮӨҒcҒB
843 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/11/17(җ…) 20:04:19 ID:mWwOozrpP
4.8 A 32nm 3.1 Billion Transistor 12-Wide-Issue Itanium? Processor for Mission-Critical Servers, Intel
http://isscc.org/doc/2011/isscc2011.advanceprogramflyerfinal.pdf
Poulson 12-issue ·А----------!!
ӮұӮӨҢҫӮӨӮМӮЬӮБӮДӮҪӮсӮҫӮжҒAӮЁӮкӮНҒB
ҲЛ‘¶ғ`ғFғCғ“ҺАҚsғAҒ[ғLӮ©ӮИҒB
http://isscc.org/doc/2011/isscc2011.advanceprogramflyerfinal.pdf
Poulson 12-issue ·А----------!!
ӮұӮӨҢҫӮӨӮМӮЬӮБӮДӮҪӮсӮҫӮжҒAӮЁӮкӮНҒB
ҲЛ‘¶ғ`ғFғCғ“ҺАҚsғAҒ[ғLӮ©ӮИҒB
844 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/11/17(җ…) 20:50:04 ID:mWwOozrpP
4.6 40-Entry Unified Out-of-Order Scheduler and Integer Execution Unit for the AMD Bulldozer x86-64 Core, AMD
14.3 An 8MB Level-3 Cache in 32nm SOI with Column-Select Aliasing, AMD
14.3 An 8MB Level-3 Cache in 32nm SOI with Column-Select Aliasing, AMD
845 ҒF–јҸМ–ўҗЭ’иҒF2010/11/18(–Ш) 00:50:37 ID:zYpORpjD0
846 ҒF–јҸМ–ўҗЭ’иҒF2010/11/18(–Ш) 17:16:59 ID:XgNFzZmu0
Intel‘S‘МӮЕҢ©ӮйӮЖӮвӮйӢCӮИӮўӮҜӮЗҠJ”ӯ•”‘аӮЙӮНӮвӮйӢCӮӘӮ ӮйӮжӮӨӮҫӮИ
847 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/11/18(–Ш) 18:17:07 ID:BFZb8/ovP
21464ӮЖRockӮЭӮҪӮўӮЙ”ӯ•\ӮөӮҪӮҜӮЗҒA
ӮаӮӨӮ©ӮБӮДӮИӮўӮөҸIӮнӮиӮЬӮөӮҪҒAӮЭӮҪӮўӮЙӮИӮзӮИӮ«ӮбӮўӮўӮҜӮЗӮИҒB
ӮаӮӨӮ©ӮБӮДӮИӮўӮөҸIӮнӮиӮЬӮөӮҪҒAӮЭӮҪӮўӮЙӮИӮзӮИӮ«ӮбӮўӮўӮҜӮЗӮИҒB
848 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/11/18(–Ш) 18:31:30 ID:BFZb8/ovP
12-issueӮНҲк”К“IӮИҗ®җ”ғvғҚғOғүғҖӮӘ–{Һҝ“IӮЙ“аҚЭӮ·Ӯй•А—сҗ«ӮМҢАҠEӮрӮұӮҰӮДӮйӮНӮёӮИӮМӮЕҒA
ғ}ғӢғ`ғXғҢғbғhӮ©ҸӯӮИӮӯӮЖӮаҸ]—ҲSIMDӮӘҢшӮӯӮжӮӨӮИ“БҺкӮИғAғӢғSғҠғYғҖӮрӮЭӮұӮөӮДӮМҠg’ЈӮҫӮлӮӨҒB
ӮаӮҝӮлӮсғVғ“ғOғӢғXғҢғbғhӮЙӮ©ӮсӮөӮДӮаҸ]—ҲҲИҸгӮЙ—НӮрӮўӮкӮзӮкӮДӮўӮйӮҫӮлӮӨӮӘҒB
OOOӮрҺgӮнӮИӮўӮҜӮЗOOO“IӮИҢшүКӮӘ“ҫӮзӮкӮйӢZҸpӮӘ“ұ“ьӮіӮкӮй—\ҠҙҒB
ғ}ғӢғ`ғXғҢғbғhӮ©ҸӯӮИӮӯӮЖӮаҸ]—ҲSIMDӮӘҢшӮӯӮжӮӨӮИ“БҺкӮИғAғӢғSғҠғYғҖӮрӮЭӮұӮөӮДӮМҠg’ЈӮҫӮлӮӨҒB
ӮаӮҝӮлӮсғVғ“ғOғӢғXғҢғbғhӮЙӮ©ӮсӮөӮДӮаҸ]—ҲҲИҸгӮЙ—НӮрӮўӮкӮзӮкӮДӮўӮйӮҫӮлӮӨӮӘҒB
OOOӮрҺgӮнӮИӮўӮҜӮЗOOO“IӮИҢшүКӮӘ“ҫӮзӮкӮйӢZҸpӮӘ“ұ“ьӮіӮкӮй—\ҠҙҒB
849 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/11/18(–Ш) 18:33:37 ID:BFZb8/ovP
ӮаӮҝӮлӮсFPӮНSPECғxғ“ғ`ӮЕӮаҗ”Ҹ\–Ҫ—ЯӮН•А—с“xӮӘӮ ӮйӮНӮёӮҫӮБӮҪӮМӮЕ
(Ӯ»ӮаӮ»ӮаFP—p“rӮЕҗк—pғvғҚғZғbғTӮӘ‘¶ҚЭӮЕӮ«Ӯй—қ—RӮЕӮаӮ Ӯй)ҒA
ӮұӮМҢАӮиӮЕӮНӮИӮўҒB
(Ӯ»ӮаӮ»ӮаFP—p“rӮЕҗк—pғvғҚғZғbғTӮӘ‘¶ҚЭӮЕӮ«Ӯй—қ—RӮЕӮаӮ Ӯй)ҒA
ӮұӮМҢАӮиӮЕӮНӮИӮўҒB
850 ҒF–јҸМ–ўҗЭ’иҒF2010/11/22(ҢҺ) 21:00:52 ID:oAbWWNic0
Bulldozer
1 module
Ғ@3.5GHz+
Ғ@0.8-1.3V
Ғ@213M transistors
Ғ@30.9mm2
Llano
1 core
Ғ@35M transistors
1 core + 1MB L2 + Power-Gate Ring
Ғ@3GHz+
Ғ@0.8-1.3V
Ғ@
1 module
Ғ@3.5GHz+
Ғ@0.8-1.3V
Ғ@213M transistors
Ғ@30.9mm2
Llano
1 core
Ғ@35M transistors
1 core + 1MB L2 + Power-Gate Ring
Ғ@3GHz+
Ғ@0.8-1.3V
Ғ@
851 ҒF–јҸМ–ўҗЭ’иҒF2010/11/22(ҢҺ) 21:04:27 ID:oAbWWNic0
ғ~ғXӮ·ӮЬӮс
http://isscc.org/doc/2011/isscc2011.advanceprogrambooklet_abstracts.pdf
Bulldozer
1 module
Ғ@3.5GHz+
Ғ@0.8-1.3V
Ғ@213M transistors
Ғ@30.9mm2
L3
Ғ@[email protected]
”дҠr‘ОҸЫ
Llano
1 core
Ғ@35M transistors
Ғ@9.69mm2
1 core + 1MB L2 + Power-Gate Ring
Ғ@3GHz+
Ғ@0.8-1.3V
Ғ@110M transistors
Ғ@17.7mm2
ҠmӮ©ӮЙ–КҗПӮН•Ғ’КӮМ2ғRғAӮЙ”дӮЧӮкӮОҸ¬ӮіӮўӮӘҺvӮБӮҪӮЩӮЗӮЕӮаӮИӮўӮжӮӨӮИ
http://isscc.org/doc/2011/isscc2011.advanceprogrambooklet_abstracts.pdf
Bulldozer
1 module
Ғ@3.5GHz+
Ғ@0.8-1.3V
Ғ@213M transistors
Ғ@30.9mm2
L3
Ғ@[email protected]
”дҠr‘ОҸЫ
Llano
1 core
Ғ@35M transistors
Ғ@9.69mm2
1 core + 1MB L2 + Power-Gate Ring
Ғ@3GHz+
Ғ@0.8-1.3V
Ғ@110M transistors
Ғ@17.7mm2
ҠmӮ©ӮЙ–КҗПӮН•Ғ’КӮМ2ғRғAӮЙ”дӮЧӮкӮОҸ¬ӮіӮўӮӘҺvӮБӮҪӮЩӮЗӮЕӮаӮИӮўӮжӮӨӮИ
852 ҒF–јҸМ–ўҗЭ’иҒF2010/11/23(үО) 01:08:10 ID:VBcGkBUB0
Ӯ ӮсӮЬҸ¬ӮіӮӯӮИӮўӮЖӮМӮұӮЖӮҫӮӘҒAғ|ғүғbғNӮМ–@‘ҘӮрҚlӮҰӮкӮО
IPCӮЙӮаӮҝӮеӮБӮЖӮНҠъ‘ТӮЕӮ«ӮйӮЖӮўӮӨӮұӮЖӮЙӮИӮзӮИӮўӮ©ҒH
’PҸғӮЙ“–ӮДӮНӮЯӮйӮЖK10”дӮЕ93%ӮЙӮИӮйӮј
IPCӮЙӮаӮҝӮеӮБӮЖӮНҠъ‘ТӮЕӮ«ӮйӮЖӮўӮӨӮұӮЖӮЙӮИӮзӮИӮўӮ©ҒH
’PҸғӮЙ“–ӮДӮНӮЯӮйӮЖK10”дӮЕ93%ӮЙӮИӮйӮј
853 ҒF–јҸМ–ўҗЭ’иҒF2010/11/23(үО) 01:51:16 ID:e6e3ST/g0
ӮЖӮБӮӯӮЙ”j’]ӮөӮҪҢoҢұ‘ҘҺқӮҝҸoӮіӮкӮДӮа
854 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2010/11/23(үО) 16:17:59 ID:dVdQWVg90
ARMҒA64ғrғbғgҒEғvғҚғZғbғTҒEғRғAӮрӢЯӮӯ”ӯ•\ӮЦ
http://www.computerworld.jp/topics/move/189915.html
ҢӢӢЗA15ӮМғAғhғҢғXҠg’ЈӮНғxғ“ғ_Ғ[Ӯ©ӮзӮМғEғPӮӘҲ«Ӯ©ӮБӮҪӮМӮ©ӮИҒH
http://www.computerworld.jp/topics/move/189915.html
ҢӢӢЗA15ӮМғAғhғҢғXҠg’ЈӮНғxғ“ғ_Ғ[Ӯ©ӮзӮМғEғPӮӘҲ«Ӯ©ӮБӮҪӮМӮ©ӮИҒH
855 ҒF–јҸМ–ўҗЭ’иҒF2010/11/23(үО) 16:48:24 ID:V0GZrBuT0
ӮЬӮ ӢtӮЙӮўӮҰӮОӮ»ӮкӮИӮиӮЙҺщ—vӮ ӮйӮБӮДӮұӮЖӮҫӮлҒB
ҢӢҚ\”„ӮкӮйӮЖҺvӮӨҒB
ҢӢҚ\”„ӮкӮйӮЖҺvӮӨҒB
856 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/11/23(үО) 21:35:20 ID:nWnkG7y1P
Sandy BridgeӮНSIMDӮӘӮҝӮеӮБӮЖ‘¬ӮўӮӯӮзӮўӮҫӮИҒBӮЬӮ Ҡg’ЈҚlӮҰӮкӮОӮ»ӮӨӮҫӮлӮӨӮИӮИҒB
ӮЖӮўӮӨӮ©10%ӮЖӮ©ӮИӮўӮИҒBӮЁӮкӮНӮаӮӨҗ¶Ӯ«ӮўӮӯҺ©җMӮрӮИӮӯӮөӮҪӮМӮЕҺс’ЮӮБӮДӮӯӮйҒcҒB
329 ҒFSocket774 [Ғ«] ҒF2010/11/23(үО) 04:12:31 ID:7hVwa3vr
ttp://www.inpai.com.cn/doc/hard/138458.htm
SandyBridge Core i7 2600K preview(’ҶҚ‘Ңк)
ӮЖӮўӮӨӮ©10%ӮЖӮ©ӮИӮўӮИҒBӮЁӮкӮНӮаӮӨҗ¶Ӯ«ӮўӮӯҺ©җMӮрӮИӮӯӮөӮҪӮМӮЕҺс’ЮӮБӮДӮӯӮйҒcҒB
329 ҒFSocket774 [Ғ«] ҒF2010/11/23(үО) 04:12:31 ID:7hVwa3vr
ttp://www.inpai.com.cn/doc/hard/138458.htm
SandyBridge Core i7 2600K preview(’ҶҚ‘Ңк)
857 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2010/11/23(үО) 21:57:11 ID:dVdQWVg90
IPCҗҳӮҰ’uӮ«ӮЕӮағNғҚғbғNҸгӮӘӮкӮОҸ\•ӘӮЖӮўӮҰӮйӮҜӮЗӮИҒB
2ғRғAӮЕӮМWestmereӮЖӮМ”дҠrӮӘ—~ӮөӮўҒB
2ғRғAӮЕӮМWestmereӮЖӮМ”дҠrӮӘ—~ӮөӮўҒB
858 ҒF–јҸМ–ўҗЭ’иҒF2010/11/24(җ…) 01:29:01 ID:hMcL8A340
>>851
bullӮМL1ӮН96KBӮЕLlanoӮМ128KBӮжӮиҢёӮБӮДӮўӮйӮМӮЕҒAғpғCғvғүғCғ“ғgғүғ“ғWғXғ^җ”ӮЙҢАӮйӮЖҒAҗ”ҺҡҲИҸгӮЙ‘ҪӮўӮ©ӮаӮИҒB
bullӮМL1ӮН96KBӮЕLlanoӮМ128KBӮжӮиҢёӮБӮДӮўӮйӮМӮЕҒAғpғCғvғүғCғ“ғgғүғ“ғWғXғ^җ”ӮЙҢАӮйӮЖҒAҗ”ҺҡҲИҸгӮЙ‘ҪӮўӮ©ӮаӮИҒB
860 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/11/24(җ…) 21:42:23 ID:digwo+48P
“ъ–{ӮМғRғ“ғsғ…Ғ[ғ^ҠЦҢWӮМҚ‘үЖғvғҚғWғFғNғgӮН
ҚМ—pҸЬ10үӯү~ӮЕҒAҲк”КӮ©ӮзӮа•ыҢьҗ«Ңц•еӮ·ӮйӮжӮӨӮЙӮөӮДӮЩӮөӮўҒB
Ӯ»ӮөӮҪӮзғvғҚҠЬӮЭӮЕӮЭӮсӮИ•KҺҖӮЙҚlӮҰӮйӮәҒB
10үӯӮЕ•ыҢьҗ«ӮжӮӯӮИӮйӮИӮзҲАӮўӮаӮсӮҫӮлҒB
ҚМ—pҸЬ10үӯү~ӮЕҒAҲк”КӮ©ӮзӮа•ыҢьҗ«Ңц•еӮ·ӮйӮжӮӨӮЙӮөӮДӮЩӮөӮўҒB
Ӯ»ӮөӮҪӮзғvғҚҠЬӮЭӮЕӮЭӮсӮИ•KҺҖӮЙҚlӮҰӮйӮәҒB
10үӯӮЕ•ыҢьҗ«ӮжӮӯӮИӮйӮИӮзҲАӮўӮаӮсӮҫӮлҒB
861 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/11/24(җ…) 21:55:33 ID:digwo+48P
ӮұӮМҺиӮМҲУҺvҢҲ’иӮНҒAҠщӮЙҗlҗ¶Ӯ ӮӘӮиӮЭӮҪӮўӮИӮ·ӮІӮӯғGғүғCҗl’BӮӘ
ӮҝӮсӮҪӮзүпӢcӮөӮҪӮБӮДҗв‘О—ЗӮў•ыҢьӮЙҢҲӮЬӮиӮЬӮ№ӮсҒB
ӮаӮБӮЖҺ©—RӮИ”ӯ‘zӮМҢВҗlӢZҲк”ӯӮЕӮвӮБӮҪ•ыӮӘӮўӮўҒB
ӮҝӮсӮҪӮзүпӢcӮөӮҪӮБӮДҗв‘О—ЗӮў•ыҢьӮЙҢҲӮЬӮиӮЬӮ№ӮсҒB
ӮаӮБӮЖҺ©—RӮИ”ӯ‘zӮМҢВҗlӢZҲк”ӯӮЕӮвӮБӮҪ•ыӮӘӮўӮўҒB
862 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2010/11/24(җ…) 22:58:38 ID:0Dybfnl00
•¶•”үИҠwҸИӮЖҢoҚПҺYӢЖҸИӮМҸcҠ„ӮиӮӘ–і‘КӮҫӮИҒB
‘еӢK–НӮИӢЈ‘Ҳ“IҢӨӢҶ”пӮВӮҜӮД–ҜҠФӮЖ‘еҠwӮЕӢӨ“ҜҠJ”ӯӮіӮ№ӮҪӮЩӮӨӮӘӮўӮўҒB
‘еӢK–НӮИӢЈ‘Ҳ“IҢӨӢҶ”пӮВӮҜӮД–ҜҠФӮЖ‘еҠwӮЕӢӨ“ҜҠJ”ӯӮіӮ№ӮҪӮЩӮӨӮӘӮўӮўҒB
863 ҒF–јҸМ–ўҗЭ’иҒF2010/11/24(җ…) 23:12:47 ID:G3nbEGdc0
ӮЙӮҝӮбӮсӮЕӮўӮӨӮЖӮұӮлӮМҳVҠQӮБӮДӮ ӮИӮӘӮҝҠФҲбӮўӮЕӮНӮИӮўӮжӮИ
864 ҒF–јҸМ–ўҗЭ’иҒF2010/11/25(–Ш) 03:52:28 ID:8hPhKGFS0
ҚsҗӯҸcҠ„ӮиӮӘ–і‘КӮИӮМӮЖ
ӮаӮӨҚ‘’PҲКӮЕ‘ҲӮӨӮұӮЖ&ҲЫҺқҺ©‘МӮӘ–і‘КӮИӮМӮНӮЗӮӨӮөӮҪӮзӮўӮўӮМ?
—ЗӮў•ыҢьӮМғOғҚҒ[ғoғҠғ[ғCғVғҮғ“Ӯр”ӯҠцӮөӮвӮ·Ӯў•Ә–мӮҫӮЖҺvӮӨӮМӮҫӮҜӮЗӮИӮҹҒACERNӮЭӮҪӮўӮЙ
Ӯ»ӮӨӮИӮйӮЖҲкҚ‘ӮМ–ҜҠФӮЖ‘еҠwӢK–НӮ¶ӮбҚПӮЬӮИӮӯӮИӮйӮНӮёӮҫӮҜӮЗ
җl—Юҗ«Ҳ«җаӮЙҠоӮГӮӯӮЖӮ»ӮӨӮўӮӨғvғҚғWғFғNғgҺ©‘МӮӘӮӨӮЬӮӯӮўӮ«ӮЬӮ№ӮсӮ©?
ӮҪӮҫҺ©•ӘӮӘҗ¶Ӯ«ӮДӮўӮйӮӨӮҝӮЙҗl—ЮӮМҗжӮӘҢ©ӮҪӮўӮҫӮҜӮИӮсӮҫӮжҒc
ӮаӮӨҚ‘’PҲКӮЕ‘ҲӮӨӮұӮЖ&ҲЫҺқҺ©‘МӮӘ–і‘КӮИӮМӮНӮЗӮӨӮөӮҪӮзӮўӮўӮМ?
—ЗӮў•ыҢьӮМғOғҚҒ[ғoғҠғ[ғCғVғҮғ“Ӯр”ӯҠцӮөӮвӮ·Ӯў•Ә–мӮҫӮЖҺvӮӨӮМӮҫӮҜӮЗӮИӮҹҒACERNӮЭӮҪӮўӮЙ
Ӯ»ӮӨӮИӮйӮЖҲкҚ‘ӮМ–ҜҠФӮЖ‘еҠwӢK–НӮ¶ӮбҚПӮЬӮИӮӯӮИӮйӮНӮёӮҫӮҜӮЗ
җl—Юҗ«Ҳ«җаӮЙҠоӮГӮӯӮЖӮ»ӮӨӮўӮӨғvғҚғWғFғNғgҺ©‘МӮӘӮӨӮЬӮӯӮўӮ«ӮЬӮ№ӮсӮ©?
ӮҪӮҫҺ©•ӘӮӘҗ¶Ӯ«ӮДӮўӮйӮӨӮҝӮЙҗl—ЮӮМҗжӮӘҢ©ӮҪӮўӮҫӮҜӮИӮсӮҫӮжҒc
865 ҒF–јҸМ–ўҗЭ’иҒF2010/11/25(–Ш) 04:26:50 ID:b9SbVeJV0
җl—ЮӮЖӮ©ҢҫӮБӮДӮйҺһ“_ӮЕӮЁүФ”Ё
866 ҒF–јҸМ–ўҗЭ’иҒF2010/11/27(“y) 10:47:16 ID:Gg5Jhsgx0
җлҠtҸ”“ҮӮрҗШӮБҠ|ӮҜӮЙ“ъ•ДӮuӮr’ҶҚ‘ҒE–k’©‘Nҗн‘Ҳ
http://toki.2ch.net/test/read.cgi/occult/1284709704/
Ғ@Ғ@Ғ@Ғ@ғҚғVғA’ҶҚ‘ӮuӮr“ъ•ДҳAҚҮҒ@Ғ@Ғ@Ғ@
http://toki.2ch.net/test/read.cgi/occult/1285158552/
Ғy“ъҢҺҒzғҚғVғAҢRӮӘ“ъ–{ӮрҚUҢӮӮөӮДӮӯӮйҒIҒy‘е–{Ғz
http://toki.2ch.net/test/read.cgi/occult/1290585658/
Ғy‘е“»“ьҢыҒzҒ@“ъҢҺҗ_ҺҰҸҖ”хҗк—pҒ@ҒyҚm’и”hҗк—pҒz
http://toki.2ch.net/test/read.cgi/occult/1289575866/
http://toki.2ch.net/test/read.cgi/occult/1284709704/
Ғ@Ғ@Ғ@Ғ@ғҚғVғA’ҶҚ‘ӮuӮr“ъ•ДҳAҚҮҒ@Ғ@Ғ@Ғ@
http://toki.2ch.net/test/read.cgi/occult/1285158552/
Ғy“ъҢҺҒzғҚғVғAҢRӮӘ“ъ–{ӮрҚUҢӮӮөӮДӮӯӮйҒIҒy‘е–{Ғz
http://toki.2ch.net/test/read.cgi/occult/1290585658/
Ғy‘е“»“ьҢыҒzҒ@“ъҢҺҗ_ҺҰҸҖ”хҗк—pҒ@ҒyҚm’и”hҗк—pҒz
http://toki.2ch.net/test/read.cgi/occult/1289575866/
867 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/12/02(–Ш) 20:02:12 ID:HQX0/URQP
RomleyӮМҢгҢpӮМBricklandӮӘIvy Bridge-EXӮМғvғүғbғgғtғHҒ[ғҖӮМғRҒ[ғhғlҒ[ғҖӮзӮөӮўҒB
Ivy Bridge server code names leak
http://semiaccurate.com/2010/12/01/ivy-bridge-server-code-names-leak/
Ivy Bridge server code names leak
http://semiaccurate.com/2010/12/01/ivy-bridge-server-code-names-leak/
868 ҒF–јҸМ–ўҗЭ’иҒF2010/12/23(–Ш) 00:16:14 ID:ydavJBN60
ho
869 ҒF–јҸМ–ўҗЭ’иҒF2010/12/30(–Ш) 12:15:46 ID:X7P5BexmP
Ivy BridgeӮЕғ_ғCғXғ^ғbғNү»ғҒғӮғҠӮрғIғ“ғpғbғPҒ[ғWӮЕ“қҚҮӮЦҒB
CPU+GPUӮН”MӮўӮМӮЕ•Кғ_ғCҒB
http://semiaccurate.com/2010/12/29/intel-puts-gpu-memory-ivy-bridge/
CPU+GPUӮН”MӮўӮМӮЕ•Кғ_ғCҒB
http://semiaccurate.com/2010/12/29/intel-puts-gpu-memory-ivy-bridge/
870 ҒF–јҸМ–ўҗЭ’иҒF2010/12/30(–Ш) 14:28:59 ID:h2Ss7I7J0
–{—ҲӮНSNBӮЕӮвӮй—\’иӮҫӮБӮҪӮсӮҫӮӘHSWӮЬӮЕғXғҠғbғvӮөӮИӮ©ӮБӮҪӮҫӮҜӮЕӮаҸгҸo—ҲӮ©
871 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/12/31(Ӣа) 11:59:28 ID:DcnNsfkqP
>>769
http://isca2010.inria.fr/media/slides/Azizi-ISCA2010-EnergyEfficientProcessors-FinalDistributable.pdf
ӮЯӮҝӮбӮӯӮҝӮб—ЗӮўҺ‘—ҝғLғ^Ғ[!!
dMarginalCost / dVoltageScale == dMarginalCost / dArchCircuitScale
ӮӘғvғҚғZғX–ҲӮМҚЕ“K“_ӮИӮМӮЕҒAғAҒ[ғLғeғNғ`ғғҒEүсҳHҗЭҢvӮНӮ»ӮұӮр‘_ӮҰҒB
in-orderҗ~•®ҺҖӮҫӮИҒB
ӮвӮБӮПOOOӮӘӮўӮВӮа“d—Нҗ«”\”дҲ«ӮўӮНғ}ғӢғ`ғRғAҗ„җi”hӮМғfғ}ӮҫӮЖӮўӮӨӮұӮЖӮӘӮНӮБӮ«ӮиӮөӮҪӮ«ӮҪӮнҒB
http://isca2010.inria.fr/media/slides/Azizi-ISCA2010-EnergyEfficientProcessors-FinalDistributable.pdf
ӮЯӮҝӮбӮӯӮҝӮб—ЗӮўҺ‘—ҝғLғ^Ғ[!!
dMarginalCost / dVoltageScale == dMarginalCost / dArchCircuitScale
ӮӘғvғҚғZғX–ҲӮМҚЕ“K“_ӮИӮМӮЕҒAғAҒ[ғLғeғNғ`ғғҒEүсҳHҗЭҢvӮНӮ»ӮұӮр‘_ӮҰҒB
in-orderҗ~•®ҺҖӮҫӮИҒB
ӮвӮБӮПOOOӮӘӮўӮВӮа“d—Нҗ«”\”дҲ«ӮўӮНғ}ғӢғ`ғRғAҗ„җi”hӮМғfғ}ӮҫӮЖӮўӮӨӮұӮЖӮӘӮНӮБӮ«ӮиӮөӮҪӮ«ӮҪӮнҒB
872 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/12/31(Ӣа) 12:05:54 ID:DcnNsfkqP
ҚЕҗVӮМCore i7ӮӘҠщӮЙin-orderҲИ‘OӮМҗЭҢvӮЖ“Ҝ“ҷғNғүғXӮМ“d—Нҗ«”\”дӮИӮМӮНҢҫӮӨӮЬӮЕӮаӮИӮўҒB
ҠЁҲбӮўҢNӮӘҢгӮрҗвӮҪӮИӮўӮӘҒA“ҜҲкӢK–НӮЕғAҒ[ғLғeғNғ`ғғҗЭҢvӮӘ“d—НӮЙүeӢҝӮ·Ӯй“xҚҮӮўӮНүсҳHҗЭҢvӮЙ”дӮЧӮйӮЖӮёӮБӮЖҸ¬ӮіӮўӮөӮИҒB
ғRғAӮрҸ¬ӮіӮӯӮөӮД‘Ҫҗ”ғRғAӮЕғXғӢҒ[ғvғbғgӮрүТӮІӮӨӮБӮДӮўӮӨғAғvғҚҒ[ғ`ӮНӢ^ӮнӮөӮўҒB
LRBӮа“d—Нҗ«”\”дӮӘҚЕҗVӮМ”Д—pғRғAӮЖ”дӮЧӮДӮЖӮиӮнӮҜӮжӮў–уӮЕӮНӮИӮўҒB
ғҒғjғBғRғAӮНғ}ғCғNғҚғvғҚғZғbғTҺjӮӘҺnӮЬӮБӮДҲИ—ҲӮМ–А‘–ӮЖӮөӮДҸ«—ҲҗUӮи•ФӮйӮұӮЖӮЙӮИӮйӮ©ӮаӮөӮкӮИӮўҒB
ҠЁҲбӮўҢNӮӘҢгӮрҗвӮҪӮИӮўӮӘҒA“ҜҲкӢK–НӮЕғAҒ[ғLғeғNғ`ғғҗЭҢvӮӘ“d—НӮЙүeӢҝӮ·Ӯй“xҚҮӮўӮНүсҳHҗЭҢvӮЙ”дӮЧӮйӮЖӮёӮБӮЖҸ¬ӮіӮўӮөӮИҒB
ғRғAӮрҸ¬ӮіӮӯӮөӮД‘Ҫҗ”ғRғAӮЕғXғӢҒ[ғvғbғgӮрүТӮІӮӨӮБӮДӮўӮӨғAғvғҚҒ[ғ`ӮНӢ^ӮнӮөӮўҒB
LRBӮа“d—Нҗ«”\”дӮӘҚЕҗVӮМ”Д—pғRғAӮЖ”дӮЧӮДӮЖӮиӮнӮҜӮжӮў–уӮЕӮНӮИӮўҒB
ғҒғjғBғRғAӮНғ}ғCғNғҚғvғҚғZғbғTҺjӮӘҺnӮЬӮБӮДҲИ—ҲӮМ–А‘–ӮЖӮөӮДҸ«—ҲҗUӮи•ФӮйӮұӮЖӮЙӮИӮйӮ©ӮаӮөӮкӮИӮўҒB
873 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/12/31(Ӣа) 13:11:57 ID:DcnNsfkqP
>>871
Ӯ ҒAүьӮЯӮДҢ©ӮҪӮзӮИӮсӮ©ҲбӮӨӮӘӮЬӮ ӮўӮўӮвҒB
Ӯ ҒAүьӮЯӮДҢ©ӮҪӮзӮИӮсӮ©ҲбӮӨӮӘӮЬӮ ӮўӮўӮвҒB
874 ҒF–јҸМ–ўҗЭ’иҒF2010/12/31(Ӣа) 14:12:08 ID:7jUsZ8L90
2-issue OoOҒAӮВӮЬӮиBulldozer,BobcatӮӘҚЕӢӯӮЖӮўӮӨӮнӮҜӮЕӮ·ӮЛ
875 ҒFOOO-Ғј(ҒEҒНҒE,,ҒҷuҒF2010/12/31(Ӣа) 14:19:41 ID:DcnNsfkqP
>>437
ӮЙӮаҸ‘ӮўӮҪӮЖӮЁӮиҒA’P‘МғRғAӮЕ2-issue OOOӮН“d—Нҗ«”\”д“IӮЙ”ь–ЎӮөӮўӮЖӮўӮӨӮМӮНғ}ғWӮҫӮЖҺvӮӨҒB
ӮЙӮаҸ‘ӮўӮҪӮЖӮЁӮиҒA’P‘МғRғAӮЕ2-issue OOOӮН“d—Нҗ«”\”д“IӮЙ”ь–ЎӮөӮўӮЖӮўӮӨӮМӮНғ}ғWӮҫӮЖҺvӮӨҒB
876 ҒF–јҸМ–ўҗЭ’иҒF2010/12/31(Ӣа) 19:34:04 ID:V2/Snvda0
“d—Нҗ«”\”д"ӮҫӮҜ"Ӯ¶Ӯбғ_ғҒӮБӮДintelӮМҲМӮўҗlӮҫӮБӮҪӮ©ҒAғnғCғtғ@ӮМҲМӮўҗlӮҫӮБӮҪӮ©ӮӘҢҫӮБӮДӮҪӢCӮӘӮ·ӮйӮӘ
ӮҪӮөӮ©ҒA“ҜҺһ•]үҝӮЙғpғtғHҒ[ғ}ғ“ғXғҢғ“ғWӮӘӮЗӮМ’ц“xӮ©ӮаҸd—v“IӮИ”ӯҢҫӮҫӮБӮҪӮжӮӨӮИ
ӮҪӮөӮ©ҒA“ҜҺһ•]үҝӮЙғpғtғHҒ[ғ}ғ“ғXғҢғ“ғWӮӘӮЗӮМ’ц“xӮ©ӮаҸd—v“IӮИ”ӯҢҫӮҫӮБӮҪӮжӮӨӮИ
җV”NӮЁӮЯӮЕӮЖӮӨӮІӮҙӮўӮЬӮ·ҒB
>>871 ӮіӮс
ҸБ”п“d—Н’Іҗ®ӮМӮҪӮЯӮЙғTғCғNғӢӮ ӮҪӮиӮМ dispatch/issue –Ҫ—Яҗ”Ӯр‘қҢёӮ·ӮйӮМӮНҸӨ—pғvғҚғZғbғTӮЕӮа IBM POWER5/POWER6 Ӯ ӮҪӮиӮМҗў‘гӮ©ӮзҚsӮнӮкӮДӮўӮЬӮ·Ӯ©ӮзҒA“БӮЙҗV–ЎӮН–іӮўӮМӮЕӮНҒH
Power-Gating ӮӘҲк”Кү»ӮөӮҪӮұӮЖӮЙӮжӮиҒAҺАҢш“IӮЙғҶғjғbғgҗ”Ӯр“®“IӮЙ‘қҢёӮ·ӮйӮұӮЖӮаүВ”\ӮЙӮИӮБӮДӮўӮЬӮ·ҒB
Ӣ»–Ўҗ[ӮўӮМӮНҒAӮұӮМӮжӮӨӮИғvғҚғZғbғT“аӮМҺАҚsғҶғjғbғgӮМ“®“I—LҢшҒE–іҢшү»ӮМү„’·ӮЖӮөӮДҒAin-order/OoO ӮМҗШ‘ЦӮЬӮЕӮвӮйүҝ’lӮӘӮ ӮйӮ©ӮЗӮӨӮ©ӮЖӮўӮӨӮұӮЖӮ©ӮаӮөӮкӮЬӮ№ӮсҒB
>>871 ӮіӮс
ҸБ”п“d—Н’Іҗ®ӮМӮҪӮЯӮЙғTғCғNғӢӮ ӮҪӮиӮМ dispatch/issue –Ҫ—Яҗ”Ӯр‘қҢёӮ·ӮйӮМӮНҸӨ—pғvғҚғZғbғTӮЕӮа IBM POWER5/POWER6 Ӯ ӮҪӮиӮМҗў‘гӮ©ӮзҚsӮнӮкӮДӮўӮЬӮ·Ӯ©ӮзҒA“БӮЙҗV–ЎӮН–іӮўӮМӮЕӮНҒH
Power-Gating ӮӘҲк”Кү»ӮөӮҪӮұӮЖӮЙӮжӮиҒAҺАҢш“IӮЙғҶғjғbғgҗ”Ӯр“®“IӮЙ‘қҢёӮ·ӮйӮұӮЖӮаүВ”\ӮЙӮИӮБӮДӮўӮЬӮ·ҒB
Ӣ»–Ўҗ[ӮўӮМӮНҒAӮұӮМӮжӮӨӮИғvғҚғZғbғT“аӮМҺАҚsғҶғjғbғgӮМ“®“I—LҢшҒE–іҢшү»ӮМү„’·ӮЖӮөӮДҒAin-order/OoO ӮМҗШ‘ЦӮЬӮЕӮвӮйүҝ’lӮӘӮ ӮйӮ©ӮЗӮӨӮ©ӮЖӮўӮӨӮұӮЖӮ©ӮаӮөӮкӮЬӮ№ӮсҒB
878 ҒF–јҸМ–ўҗЭ’иҒF2011/01/01(“y) 06:39:01 ID:Dd3NicD40
Power-GatingӮЕӮНӮИӮӯClock-GatingӮМҠФҲбӮўӮЕӮН
879 ҒFMACғIғ^Ғ„878 ӮіӮсҒF2011/01/01(“y) 07:09:15 ID:ltZyH+9s0
>>878
ҠщӮЙғRғA’PҲКӮМPower-GatingӮНҲк”К“IӮЖҢҫӮБӮД—ЗӮўӢZҸpӮ©ӮЖҒB
ӮІҺw“EӮМӮжӮӨӮЙҒAҢ»җў‘гӮМғvғҚғZғbғTӮЕӮНҺАҚsғҶғjғbғg’PҲКӮЕӮН Clock-Gating ӮөӮ©ҚsӮнӮкӮДӮўӮИӮў”ӨӮЕӮ·ӮӘҒAҺАҢ»үВ”\ӮИ”НбeӮЙ“ьӮБӮДӮўӮйӮМӮЕӮНӮИӮўӮЕӮөӮеӮӨӮ©ҒH
ҠщӮЙғRғA’PҲКӮМPower-GatingӮНҲк”К“IӮЖҢҫӮБӮД—ЗӮўӢZҸpӮ©ӮЖҒB
ӮІҺw“EӮМӮжӮӨӮЙҒAҢ»җў‘гӮМғvғҚғZғbғTӮЕӮНҺАҚsғҶғjғbғg’PҲКӮЕӮН Clock-Gating ӮөӮ©ҚsӮнӮкӮДӮўӮИӮў”ӨӮЕӮ·ӮӘҒAҺАҢ»үВ”\ӮИ”НбeӮЙ“ьӮБӮДӮўӮйӮМӮЕӮНӮИӮўӮЕӮөӮеӮӨӮ©ҒH
880 ҒF–јҸМ–ўҗЭ’иҒF2011/01/01(“y) 09:16:28 ID:Dd3NicD40
ғXғCғbғ`on/offҺһӮМ“d—Н‘қ‘еӮЖ•ңӢAҺһҠФӮЖҢҫӮБӮҪғgғҢҒ[ғhғIғtӮрҚlӮҰӮйӮЖ
ҺАҢ»үВ”\ӮЕӮНӮ ӮБӮДӮаҢ»ҺА“IӮЙӮНӮИӮБӮДӮИӮўӮжӮӨӮИӢCӮӘӮ·Ӯй
ҺАҢ»үВ”\ӮЕӮНӮ ӮБӮДӮаҢ»ҺА“IӮЙӮНӮИӮБӮДӮИӮўӮжӮӨӮИӢCӮӘӮ·Ӯй
881 ҒFMACғIғ^Ғ„880 ӮіӮсҒF2011/01/01(“y) 11:05:53 ID:ltZyH+9s0
>>880
Ғ@---------------
Ғ@ғXғCғbғ`on/offҺһӮМ“d—Н‘қ‘е
Ғ@---------------
ӮұӮҝӮзӮНүҪӮ©ғ\Ғ[ғXҒ^Һ‘—ҝӮНӮ ӮиӮЬӮөӮҪӮБӮҜҒH
җШ‘ЦҺһҠФӮЙӮВӮўӮДҒAғRғA‘S‘МӮрOFFӮ·ӮйҸкҚҮӮЙӮН“а•”Ҹо•сӮрҸ‘Ӯ«ҸoӮ·•K—vӮӘӮ ӮйӮҪӮЯӮЙҺһҠФӮр—vӮөӮЬӮ·ӮӘҒAҺАҚsғpғCғvғүғCғ“ӮМҸо•сӮрғtғүғbғVғ…Ӯ·ӮйҺһҠФӮНҒA•ӘҠтғ~ғXӮЖ“Ҝ’ц“xӮЙӮөӮ©ӮИӮиӮЬӮ№ӮсҒBӮЬӮҪҒAON/OFFӮрҚsӮӨ’PҲКӮӘҸ¬ӮіӮӯӮИӮйӮЩӮЗҒA“dӢC“IӮИүeӢҝӮаҸ¬ӮіӮӯӮИӮБӮДӮўӮ«ӮЬӮ·ҒB
ҲкӮВӮМӢЙҢАӮЖӮөӮДӮМғҠғRғ“ғtғBғKғүғuғӢҒEғvғҚғZғbғTӮӘҺА—pү»ӮіӮкӮДӮўӮйҲИҸгҒAҒwҢ»ҺА“IӮЕӮНӮИӮўҒxӮЖӮўӮӨӮұӮЖӮН–іӮўӮМӮЕӮНҒH
Ғ@---------------
Ғ@ғXғCғbғ`on/offҺһӮМ“d—Н‘қ‘е
Ғ@---------------
ӮұӮҝӮзӮНүҪӮ©ғ\Ғ[ғXҒ^Һ‘—ҝӮНӮ ӮиӮЬӮөӮҪӮБӮҜҒH
җШ‘ЦҺһҠФӮЙӮВӮўӮДҒAғRғA‘S‘МӮрOFFӮ·ӮйҸкҚҮӮЙӮН“а•”Ҹо•сӮрҸ‘Ӯ«ҸoӮ·•K—vӮӘӮ ӮйӮҪӮЯӮЙҺһҠФӮр—vӮөӮЬӮ·ӮӘҒAҺАҚsғpғCғvғүғCғ“ӮМҸо•сӮрғtғүғbғVғ…Ӯ·ӮйҺһҠФӮНҒA•ӘҠтғ~ғXӮЖ“Ҝ’ц“xӮЙӮөӮ©ӮИӮиӮЬӮ№ӮсҒBӮЬӮҪҒAON/OFFӮрҚsӮӨ’PҲКӮӘҸ¬ӮіӮӯӮИӮйӮЩӮЗҒA“dӢC“IӮИүeӢҝӮаҸ¬ӮіӮӯӮИӮБӮДӮўӮ«ӮЬӮ·ҒB
ҲкӮВӮМӢЙҢАӮЖӮөӮДӮМғҠғRғ“ғtғBғKғүғuғӢҒEғvғҚғZғbғTӮӘҺА—pү»ӮіӮкӮДӮўӮйҲИҸгҒAҒwҢ»ҺА“IӮЕӮНӮИӮўҒxӮЖӮўӮӨӮұӮЖӮН–іӮўӮМӮЕӮНҒH
882 ҒF–јҸМ–ўҗЭ’иҒF2011/01/01(“y) 12:28:25 ID:Dd3NicD40
ӮұӮсӮИӮМӮЖӮ©
http://www.hal.ipc.i.u-tokyo.ac.jp/~matutani/papers/matsutani_sacsis2010.pptx
http://www.ulp.jst.go.jp/topics/pdf/101126_PDF/H18-4_nakamura.pdf
Ң»ҺА“IӮЕӮИӮўӮБӮДӮМӮНALUӮЭӮҪӮўӮИҚӮ•p“xӮЕҺg—pӮ·ӮйӮЖӮұӮлӮЙҠЦӮөӮДӮМҳb
ӮұӮӨӮўӮӨӮЖӮұӮлӮҫӮЖ•ңӢAӮН1cycleӮӯӮзӮўӮЕҸo—ҲӮИӮўӮЖҗ«”\ӮЙӮаүeӢҝҸoӮйӮЕӮөӮе
http://www.hal.ipc.i.u-tokyo.ac.jp/~matutani/papers/matsutani_sacsis2010.pptx
http://www.ulp.jst.go.jp/topics/pdf/101126_PDF/H18-4_nakamura.pdf
Ң»ҺА“IӮЕӮИӮўӮБӮДӮМӮНALUӮЭӮҪӮўӮИҚӮ•p“xӮЕҺg—pӮ·ӮйӮЖӮұӮлӮЙҠЦӮөӮДӮМҳb
ӮұӮӨӮўӮӨӮЖӮұӮлӮҫӮЖ•ңӢAӮН1cycleӮӯӮзӮўӮЕҸo—ҲӮИӮўӮЖҗ«”\ӮЙӮаүeӢҝҸoӮйӮЕӮөӮе
883 ҒFMACғIғ^Ғ„882 ӮіӮсҒF2011/01/01(“y) 13:10:47 ID:ltZyH+9s0
>>882
–К”’ӮўҺ‘—ҝӮ ӮиӮӘӮЖӮӨӮІӮҙӮўӮЬӮөӮҪҒB
ӮҪӮҫҒA‘OҺТӮМҺ‘—ҝӮЕӮМ power-gating ӮЙӮжӮй“d—Н“IӮИғIҒ[ғoҒ[ғwғbғhӮМ•]үҝӮНҒAғӮҒ[ғh‘JҲЪӮЙ”әӮӨ“Б—LӮМ“d—НҸБ”пӮӘӮ ӮйӮЖӮўӮБӮҪҳbӮЕӮН–іӮӯҒAҚЧ—ұ“x power-gating —pӮЙҗVӮҪӮЙ’ЗүБӮөӮҪғgғүғ“ғWғXғ^ӮМҸБ”п“d—НӮрҚl—¶ӮөӮДӮўӮйӮұӮЖӮМ—lӮЕӮ·ҒB
ҢӢүК“IӮЙӮНғӢҒ[ғ^Ғ[ӮМ—lӮИҚӮ“xӮИғҠғAғӢғ^ғCғҖҗ«ӮӘ•K—vӮИ•Ә–мӮЕӮ·Ӯз“K—pүВ”\ӮЕӮ ӮйӮЖӮўӮӨӮұӮЖӮНҒAғҠғAғӢғ^ғCғҖҗ«ӮМ’бӮў”Д—pғvғҚғZғbғT—p“rӮЕӮНҚXӮЙҢшүКӮӘҚӮӮўӮЖҚlӮҰӮД—ЗӮіӮ»ӮӨӮЕӮ·ҒB
ҢгҺТӮМҺ‘—ҝӮЙҺҠӮБӮДӮНMIPSғAҒ[ғLғeғNғ`ғғӮЙ“K—pӮөӮДҒA—LҢшӮИҢӢүКӮӘ“ҫӮзӮкӮДӮўӮйӮЖҢӢҳ_ӮөӮДӮўӮЬӮ·ҒB
Ғ@------------------
Ғ@ӮұӮӨӮўӮӨӮЖӮұӮлӮҫӮЖ•ңӢAӮН1cycleӮӯӮзӮўӮЕҸo—ҲӮИӮўӮЖҗ«”\ӮЙӮаүeӢҝҸoӮйӮЕӮөӮе
Ғ@------------------
ӮұӮкӮНҚЧ—ұ“x power-gating Ӯр“®ҚмғӮҒ[ғhӮМӮЗӮұӮМҠK‘wӮЙ’uӮӯӮ©Һҹ‘жӮЕӮНӮИӮўӮЕӮөӮеӮӨӮ©ҒHғpғҸҒ[ғ}ғlғWғҒғ“ғgӢ@”\ӮМүһ—pӮаҚLӮӘӮБӮДӮ«ӮДӮЁӮиҒAғRғA’PҲКӮЕӮМ ON/OFF Ӣ@”\Ӯрҗ»•iӮМғAғbғvғOғҢҒ[ғhӮЙ—ҳ—pӮөӮДӮўӮй IBM ӮМғTҒ[ғoҒ[җ»•iӮМ—lӮИҺgӮў•ыӮ·ӮзӮ ӮйӮМӮЕӮ·Ӯ©ӮзҒB
–К”’ӮўҺ‘—ҝӮ ӮиӮӘӮЖӮӨӮІӮҙӮўӮЬӮөӮҪҒB
ӮҪӮҫҒA‘OҺТӮМҺ‘—ҝӮЕӮМ power-gating ӮЙӮжӮй“d—Н“IӮИғIҒ[ғoҒ[ғwғbғhӮМ•]үҝӮНҒAғӮҒ[ғh‘JҲЪӮЙ”әӮӨ“Б—LӮМ“d—НҸБ”пӮӘӮ ӮйӮЖӮўӮБӮҪҳbӮЕӮН–іӮӯҒAҚЧ—ұ“x power-gating —pӮЙҗVӮҪӮЙ’ЗүБӮөӮҪғgғүғ“ғWғXғ^ӮМҸБ”п“d—НӮрҚl—¶ӮөӮДӮўӮйӮұӮЖӮМ—lӮЕӮ·ҒB
ҢӢүК“IӮЙӮНғӢҒ[ғ^Ғ[ӮМ—lӮИҚӮ“xӮИғҠғAғӢғ^ғCғҖҗ«ӮӘ•K—vӮИ•Ә–мӮЕӮ·Ӯз“K—pүВ”\ӮЕӮ ӮйӮЖӮўӮӨӮұӮЖӮНҒAғҠғAғӢғ^ғCғҖҗ«ӮМ’бӮў”Д—pғvғҚғZғbғT—p“rӮЕӮНҚXӮЙҢшүКӮӘҚӮӮўӮЖҚlӮҰӮД—ЗӮіӮ»ӮӨӮЕӮ·ҒB
ҢгҺТӮМҺ‘—ҝӮЙҺҠӮБӮДӮНMIPSғAҒ[ғLғeғNғ`ғғӮЙ“K—pӮөӮДҒA—LҢшӮИҢӢүКӮӘ“ҫӮзӮкӮДӮўӮйӮЖҢӢҳ_ӮөӮДӮўӮЬӮ·ҒB
Ғ@------------------
Ғ@ӮұӮӨӮўӮӨӮЖӮұӮлӮҫӮЖ•ңӢAӮН1cycleӮӯӮзӮўӮЕҸo—ҲӮИӮўӮЖҗ«”\ӮЙӮаүeӢҝҸoӮйӮЕӮөӮе
Ғ@------------------
ӮұӮкӮНҚЧ—ұ“x power-gating Ӯр“®ҚмғӮҒ[ғhӮМӮЗӮұӮМҠK‘wӮЙ’uӮӯӮ©Һҹ‘жӮЕӮНӮИӮўӮЕӮөӮеӮӨӮ©ҒHғpғҸҒ[ғ}ғlғWғҒғ“ғgӢ@”\ӮМүһ—pӮаҚLӮӘӮБӮДӮ«ӮДӮЁӮиҒAғRғA’PҲКӮЕӮМ ON/OFF Ӣ@”\Ӯрҗ»•iӮМғAғbғvғOғҢҒ[ғhӮЙ—ҳ—pӮөӮДӮўӮй IBM ӮМғTҒ[ғoҒ[җ»•iӮМ—lӮИҺgӮў•ыӮ·ӮзӮ ӮйӮМӮЕӮ·Ӯ©ӮзҒB
884 ҒF–јҸМ–ўҗЭ’иҒF2011/01/03(ҢҺ) 21:07:08 ID:T4Thyrd/P
>>871ӮН“®“IӮИғXғPҒ[ғҠғ“ғOӮМҳbӮ¶ӮбӮИӮўӮсӮҫӮӘҒB
885 ҒF–јҸМ–ўҗЭ’иҒF2011/01/03(ҢҺ) 21:37:57 ID:T4Thyrd/P
The Sandy Bridge Review: Intel Core i7-2600K, i5-2500K and Core i3-2100 Tested
http://www.anandtech.com/show/4083/the-sandy-bridge-review-intel-core-i5-2600k-i5-2500k-and-core-i3-2100-tested
http://www.anandtech.com/show/4083/the-sandy-bridge-review-intel-core-i5-2600k-i5-2500k-and-core-i3-2100-tested
886 ҒF–јҸМ–ўҗЭ’иҒF2011/01/04(үО) 00:49:17 ID:diWsZEVoP
Sandy Bridge i7 & i5 Reviews
Reviews
http://www.techreaction.net/2011/01/...n-p67-part-12/
http://www.anandtech.com/show/4083/t...i3-2100-tested
http://www.techspot.com/review/353-i...-corei7-2600k/
http://www.tomshardware.com/reviews/...500k,2833.html
http://pcper.com/article.php?aid=1057
http://www.legionhardware.com/articl..._bridge,1.html
http://www.legitreviews.com/article/1501/1/
http://www.pcper.com/article.php?aid=1057
http://www.techpowerup.com/reviews/I..._i5_2500K_GPU/
http://techreport.com/articles.x/20188
http://www.bit-tech.net/hardware/cpu...ridge-review/1
http://techgage.com/article/intels_s...600k_reviewed/
http://benchmarkreviews.com/index.ph...=664&Itemid=63
http://benchmarkreviews.com/index.ph...=622&Itemid=63
http://www.bjorn3d.com/articles/Inte...pset/1972.html
http://www.lostcircuits.com/mambo//i...id=98&Itemid=1
http://www.computerbase.de/artikel/p...-sandy-bridge/
http://www.hardwareheaven.com/reviews.php?reviewid=1091
http://www.guru3d.com/article/core-i...-2600k-review/
http://hothardware.com/Reviews/Intel...cessors-Debut/
http://www.pcper.com/article.php?aid=1057
http://www.neoseeker.com/Articles/Ha...600K_i5_2500K/
http://lanoc.org/review/energy-items...k-sandy-bridge
http://www.overclock3d.net/reviews/c...ridge_review/1
http://tbreak.com/tech/2011/01/intel...-2600k-review/
http://www.tweaktown.com/reviews/375...pus/index.html
Reviews
http://www.techreaction.net/2011/01/...n-p67-part-12/
http://www.anandtech.com/show/4083/t...i3-2100-tested
http://www.techspot.com/review/353-i...-corei7-2600k/
http://www.tomshardware.com/reviews/...500k,2833.html
http://pcper.com/article.php?aid=1057
http://www.legionhardware.com/articl..._bridge,1.html
http://www.legitreviews.com/article/1501/1/
http://www.pcper.com/article.php?aid=1057
http://www.techpowerup.com/reviews/I..._i5_2500K_GPU/
http://techreport.com/articles.x/20188
http://www.bit-tech.net/hardware/cpu...ridge-review/1
http://techgage.com/article/intels_s...600k_reviewed/
http://benchmarkreviews.com/index.ph...=664&Itemid=63
http://benchmarkreviews.com/index.ph...=622&Itemid=63
http://www.bjorn3d.com/articles/Inte...pset/1972.html
http://www.lostcircuits.com/mambo//i...id=98&Itemid=1
http://www.computerbase.de/artikel/p...-sandy-bridge/
http://www.hardwareheaven.com/reviews.php?reviewid=1091
http://www.guru3d.com/article/core-i...-2600k-review/
http://hothardware.com/Reviews/Intel...cessors-Debut/
http://www.pcper.com/article.php?aid=1057
http://www.neoseeker.com/Articles/Ha...600K_i5_2500K/
http://lanoc.org/review/energy-items...k-sandy-bridge
http://www.overclock3d.net/reviews/c...ridge_review/1
http://tbreak.com/tech/2011/01/intel...-2600k-review/
http://www.tweaktown.com/reviews/375...pus/index.html
887 ҒF–јҸМ–ўҗЭ’иҒF2011/01/04(үО) 02:11:09 ID:ZTL2vVFx0
>>883
ғAҒ[ғLғeғNғ`ғғ“IӮЙӮН—ЗӮӯӮДӮағҢғCғAғEғg“IӮЙӮНӮ ӮЬӮиӮвӮиӮҪӮӯӮИӮўӢCӮӘӮ·Ӯй
deep nwellӮЖӮ©ҺgӮБӮД•Ә—ЈӮөӮИӮ«ӮбӮўӮ©ӮсӮө
ғAҒ[ғLғeғNғ`ғғ“IӮЙӮН—ЗӮӯӮДӮағҢғCғAғEғg“IӮЙӮНӮ ӮЬӮиӮвӮиӮҪӮӯӮИӮўӢCӮӘӮ·Ӯй
deep nwellӮЖӮ©ҺgӮБӮД•Ә—ЈӮөӮИӮ«ӮбӮўӮ©ӮсӮө
888 ҒF–јҸМ–ўҗЭ’иҒF2011/01/06(–Ш) 20:25:50 ID:eR0hxCMY0
889 ҒF–јҸМ–ўҗЭ’иҒF2011/01/06(–Ш) 20:58:32 ID:QhqdeZe90
ғҢғCғeғ“ғVӮНҸжҺZ’ҶҗSӮЙҲ«ӮӯӮИӮБӮДӮйӮМӮӘ‘ҪӮў?
ғXғӢҒ[ғvғbғgӮН—ЗӮӯӮИӮБӮДӮйӮМӮӘ‘ҪӮў? load, zeroing idioms, Ӯ»ӮМ‘ј
ҸңҺZӮН‘S‘М“IӮЙ’xӮӯӮИӮБӮДӮй
ғXғӢҒ[ғvғbғgӮН—ЗӮӯӮИӮБӮДӮйӮМӮӘ‘ҪӮў? load, zeroing idioms, Ӯ»ӮМ‘ј
ҸңҺZӮН‘S‘М“IӮЙ’xӮӯӮИӮБӮДӮй
890 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2011/01/07(Ӣа) 00:13:33 ID:EvLfdELP0
ғNғҚғbғNҸгӮ°ӮйӮҪӮЯӮЙғpғCғvғүғCғ“Ӯрҗ[ӮӯӮ№ӮҙӮйӮр“ҫӮИӮ©ӮБӮҪӮсӮҫӮлӮӨӮЛӮҰҒB
SSE4.1ӮМ–Ҫ—ЯӮӘӮЩӮЖӮсӮЗғXғӢҒ[ғvғbғg1ӮИӮМӮЙӮНҠҙ“®ҒB
SSE4.1ӮМ–Ҫ—ЯӮӘӮЩӮЖӮсӮЗғXғӢҒ[ғvғbғg1ӮИӮМӮЙӮНҠҙ“®ҒB
891 ҒF,,ҒEҒLҒНҒMҒE,,ҒjӮБ-ҒӣҒӣҒӣҒF2011/01/15(“y) 14:50:20 ID:0ItXKs9q0
ӮЖӮиӮ ӮҰӮё‘«үсӮиӮМ‘СҲжӮӘ“Ҝ“ҷӮИӮз“d—НҢш—ҰӮНAtomҒаARMӮЖӮўӮӨҗаӮрҸҘӮҰӮДӮЭӮйҒB
> 256 ҒF,,ҒEҒLҒНҒMҒE,,ҒjҒғҲк”Ф—ЗӮў -ҒӣҒӣҒӣ Ӯр—ҠӮЮ [Ғ«] ҒF2011/01/13(–Ш) 05:57:04 ID:tXE0aH+g
> Ң»ҸуҚЕӢӯӮМARMӮӘӮұӮкҒB
> http://jp.advfn.com/news__45120396.html
>
> ӮжӮӨӮНIntelӮ©ӮзMarvellӮЙӮнӮҪӮБӮҪXScaleӮМ––ебӮЕӮ·ӮӘҒB
> Atom 1.6GHzӮЕ1ғRғAӮ ӮҪӮи4000MIPS’ц“xӮИӮМӮЕҒA10WҲИүәӮЕ16600 DMIPSӮБӮДҗ”ҺҡӮНӮ»ӮсӮИӮЙҗҰӮӯӮН–іӮўӮЕӮ·ҒB
> ғfғ…ғAғӢғRғAӮМCore i5 430UM’ц“xӮМҗ”ҺҡӮҫӮөҒAQuad-Core AtomӮрҚмӮБӮҪӮЖӮөӮДӮаӮұӮМ’ц“xӮНҢyӮӯ’Bҗ¬ӮЕӮ«ӮйӢCӮӘӮөӮЬӮ·ӮЕӮ·ӮжҒB
> 256 ҒF,,ҒEҒLҒНҒMҒE,,ҒjҒғҲк”Ф—ЗӮў -ҒӣҒӣҒӣ Ӯр—ҠӮЮ [Ғ«] ҒF2011/01/13(–Ш) 05:57:04 ID:tXE0aH+g
> Ң»ҸуҚЕӢӯӮМARMӮӘӮұӮкҒB
> http://jp.advfn.com/news__45120396.html
>
> ӮжӮӨӮНIntelӮ©ӮзMarvellӮЙӮнӮҪӮБӮҪXScaleӮМ––ебӮЕӮ·ӮӘҒB
> Atom 1.6GHzӮЕ1ғRғAӮ ӮҪӮи4000MIPS’ц“xӮИӮМӮЕҒA10WҲИүәӮЕ16600 DMIPSӮБӮДҗ”ҺҡӮНӮ»ӮсӮИӮЙҗҰӮӯӮН–іӮўӮЕӮ·ҒB
> ғfғ…ғAғӢғRғAӮМCore i5 430UM’ц“xӮМҗ”ҺҡӮҫӮөҒAQuad-Core AtomӮрҚмӮБӮҪӮЖӮөӮДӮаӮұӮМ’ц“xӮНҢyӮӯ’Bҗ¬ӮЕӮ«ӮйӢCӮӘӮөӮЬӮ·ӮЕӮ·ӮжҒB
892 ҒF–јҸМ–ўҗЭ’иҒF2011/01/16(“ъ) 10:17:37 ID:z9LBX0TU0
ғ}ғbғLғ“ғgғbғVғ…ӮМғҶҒ[ғUҒ[ӮЕҒASandybridgeӮНҒA
үҪғeғүғtғbғvғҚғXҒ[ӮӯӮзӮўҸoӮйӮМ?
ӮвӮБӮПҒAPS3ӮМ1.8ӮжӮиӮНҸгӮҫӮЖҺvӮӨӮМ?
үҪғeғүғtғbғvғҚғXҒ[ӮӯӮзӮўҸoӮйӮМ?
ӮвӮБӮПҒAPS3ӮМ1.8ӮжӮиӮНҸгӮҫӮЖҺvӮӨӮМ?
893 ҒF–јҸМ–ўҗЭ’иҒF2011/01/31(ҢҺ) 23:40:10 ID:RoWnrbeyi
ho
894 ҒF–јҸМ–ўҗЭ’иҒF2011/02/05(“y) 18:03:55 ID:Pfx5eIaBI
andoҺҒ
> ‘z‘ңӮЕӮ·ӮӘҒC“dҢ№”zҗьӮ©SATAҗMҚҶҗьӮ©
ҚЎүсӮМғoғOӮНҒA
ҒEPLL VoltageӮӘҚӮӮ·Ӯ¬ӮҪ
ҒEPLLӮрҗ§ҢдӮ·Ӯйғgғүғ“ғWғXғ^ӮМғQҒ[ғgҺ_ү»–ҢӮӘ”–Ӯ·Ӯ¬ӮҪ
ӮМӮЕӮ ӮБӮДҒAVccӮвRx/TxӮН–іҠЦҢWӮМӮНӮёӮҫӮӘҒEҒEҒE
> ‘z‘ңӮЕӮ·ӮӘҒC“dҢ№”zҗьӮ©SATAҗMҚҶҗьӮ©
ҚЎүсӮМғoғOӮНҒA
ҒEPLL VoltageӮӘҚӮӮ·Ӯ¬ӮҪ
ҒEPLLӮрҗ§ҢдӮ·Ӯйғgғүғ“ғWғXғ^ӮМғQҒ[ғgҺ_ү»–ҢӮӘ”–Ӯ·Ӯ¬ӮҪ
ӮМӮЕӮ ӮБӮДҒAVccӮвRx/TxӮН–іҠЦҢWӮМӮНӮёӮҫӮӘҒEҒEҒE
895 ҒF–јҸМ–ўҗЭ’иҒF2011/02/24(–Ш) 14:05:27.83 ID:hDuf7t760
ҢӢӢЗPoulsonӮНғ_ғCӮМҺКҗ^ӮЖғҢғCғAғEғgҢцҠJӮөӮҪӮӯӮзӮўӮ©
ғtғҚғ“ғgғGғ“ғhӮМ•ПҚXӮӘҲкҗШҗGӮкӮзӮкӮИӮӯӮДғҸғҚғX
ISSCCӮНӮұӮсӮИғRғ}Ғ[ғVғғғӢғyҒ[ғpҒ[ӮвӮзӮ№ӮйӮИӮж
ғtғҚғ“ғgғGғ“ғhӮМ•ПҚXӮӘҲкҗШҗGӮкӮзӮкӮИӮӯӮДғҸғҚғX
ISSCCӮНӮұӮсӮИғRғ}Ғ[ғVғғғӢғyҒ[ғpҒ[ӮвӮзӮ№ӮйӮИӮж
896 ҒF–јҸМ–ўҗЭ’иҒF2011/02/26(“y) 02:33:04.76 ID:siWR2r8M0
new MBPӮЙҚЪӮБӮДӮй10.6.6ӮНAVX‘ОүһҚПӮЭӮҫғҸғbғVғҮғC
897 ҒF–јҸМ–ўҗЭ’иҒF2011/03/29(үО) 17:04:40.29 ID:f83/Zr7S0
ӮЩ
898 ҒF–јҸМ–ўҗЭ’иҒF2011/04/17(“ъ) 04:17:47.34 ID:399AmIUM0
Ӯә
899 ҒF–јҸМ–ўҗЭ’иҒF2011/05/02(ҢҺ) 15:35:56.15 ID:ZnTpz2530
Ӯс
900 ҒF–јҸМ–ўҗЭ’иҒF2011/05/14(“y) 15:13:25.47 ID:FJZhhxnr0
‘а
901 ҒF–јҸМ–ўҗЭ’иҒF2011/06/02(–Ш) 21:12:21.75 ID:APtDNt2U0
‘а
902 ҒF–јҸМ–ўҗЭ’иҒF2011/06/17(Ӣа) 06:11:52.02 ID:pJK48oNS0
’·
903 ҒF–јҸМ–ўҗЭ’иҒF2011/06/18(“y) 11:32:50.18 ID:rYkNudwc0
•в
904 ҒF–јҸМ–ўҗЭ’иҒF2011/07/05(үО) 21:55:14.12 ID:7YM65+PU0
ҚІ
905 ҒF–јҸМ–ўҗЭ’иҒF2011/07/23(“y) 23:29:19.53 ID:aLyEY5LP0
ӮЖ
906 ҒF–јҸМ–ўҗЭ’иҒF2011/08/11(–Ш) 22:44:34.96 ID:++COJ9hp0
‘а
907 ҒF–јҸМ–ўҗЭ’иҒF2011/08/31(җ…) 23:45:18.47 ID:8kMh7RLf0
’·
908 ҒF–јҸМ–ўҗЭ’иҒF2011/09/23(Ӣа) 20:53:47.99 ID:2IxR/zaR0
ӮМ
909 ҒF–јҸМ–ўҗЭ’иҒF
ҠL