AMD�̎�����APU/SoC���������悤201����
1 �FSocket774 �]�ڃ_���F
�_.�Q�@ | �r�炵�E����E�~�[�͕��u����ԁB
�^|�Q|�@| �ނ�ꂸ�ɃX���[���܂��傤�B
|�Q�^�_! sage�i�s�Ń}�^�[�������܂���
Intel�M�ҏ������֎~�B
,,�E�L�́M�E,,�j��-�������������֎~�B
�r�炵��W�Ȃ��R�s�y�Ȑl��NG�ɓ���Ė������܂��傤�B
�O�X��
AMD�̎�����APU/SoC���������悤202����
http://anago.2ch.net/test/read.cgi/jisaku/1422145337/
�^|�Q|�@| �ނ�ꂸ�ɃX���[���܂��傤�B
|�Q�^�_! sage�i�s�Ń}�^�[�������܂���
Intel�M�ҏ������֎~�B
,,�E�L�́M�E,,�j��-�������������֎~�B
�r�炵��W�Ȃ��R�s�y�Ȑl��NG�ɓ���Ė������܂��傤�B
�O�X��
AMD�̎�����APU/SoC���������悤202����
http://anago.2ch.net/test/read.cgi/jisaku/1422145337/
|
|
|
2 �FSocket774�F2015/02/12(��) 10:33:47.34 ID:nfNwESBg
���̃X���ł͎���֎~
Llano�o��̋łɂ�
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
�� 2014�N �����̔��ド���L���O
http://eetimes.jp/ee/articles/1412/25/news147.html
��AMD�A2014�N�x��4���h���̐Ԏ�
http://pc.watch.impress.co.jp/docs/news/20150121_684660.html
AMD�̏��ʂ������}�~���ЂƂ蕉���_(^o^)�^
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
�� 2014�N �����̔��ド���L���O
http://eetimes.jp/ee/articles/1412/25/news147.html
��AMD�A2014�N�x��4���h���̐Ԏ�
http://pc.watch.impress.co.jp/docs/news/20150121_684660.html
AMD�̏��ʂ������}�~���ЂƂ蕉���_(^o^)�^
4 �FSocket774�F2015/02/12(��) 10:44:15.49 ID:nfNwESBg
���ƁA��������C�������z���������֎~
�ʂ�AMD�M�҂̖ϑz����o���F�̖����͉������Ȃ��Ă�������ł��ˁH
�y�x���z�y�x���z�y�x���z
�R�R�͊�n�O�����Ă��㔭�d���X���ł��B
�^�X�����͉��L�ɂĐi�s�� (�E�ցE)�m
AMD�̎�����APU/CPU/SoC�ɂ��Č�낤 206����
http://anago.2ch.net/test/read.cgi/jisaku/1422600946/
�R�R�͊�n�O�����Ă��㔭�d���X���ł��B
�^�X�����͉��L�ɂĐi�s�� (�E�ցE)�m
AMD�̎�����APU/CPU/SoC�ɂ��Č�낤 206����
http://anago.2ch.net/test/read.cgi/jisaku/1422600946/
DirectX 12 Preview: Geforce GTX 980 with D3D12 Takes The Lead - Mantle Performs Better for Radeons
http://wccftech.com/directx-12-preview-gtx-980-d3d12-takes-lead-mantle-performs-radeons/
http://wccftech.com/directx-12-preview-gtx-980-d3d12-takes-lead-mantle-performs-radeons/
�V���f���uA8-7650K�v�iTDP95W/4�R�A/3.3GHz/TC3.9GHz�j���lj��B
�{���ɃN���b�N���L�тȂ���
�{���ɃN���b�N���L�тȂ���
10 �FSocket774 �]�ڃ_��©2ch.net�F2015/02/12(��) 17:20:21.54 ID:2Q8rFuST
>>5
�@���Ȃ���AMD����������C���Ȃ�����̔������̋֎~�����ǂˁB
�@���Ȃ���AMD����������C���Ȃ�����̔������̋֎~�����ǂˁB
���{�l�Ȃ�C���e���Q�t�H���
Berlin�͌��Ǐo�Ȃ��������lj�����肪�������̂��낤���H
NVIDIA�ߋ��ō��̔�����L�^
�����v�͑O�N��43%����6��3,059���h��
GeForce�ASHIELD�A�ԍڌ����v���b�g�t�H�[���AGRID�ATesla�ȂǑS���ʓI�ɍD��������
AMD��Ԏ�
��������4��300���h��
AMD�ɂ���2015�N��1�l������15%�̔��㌸��\�����Ă���
�@�@�@�@ ��
( ߄t�)��
�����v�͑O�N��43%����6��3,059���h��
GeForce�ASHIELD�A�ԍڌ����v���b�g�t�H�[���AGRID�ATesla�ȂǑS���ʓI�ɍD��������
AMD��Ԏ�
��������4��300���h��
AMD�ɂ���2015�N��1�l������15%�̔��㌸��\�����Ă���
�@�@�@�@ ��
( ߄t�)��
���{�Q�t�H84%�̎�����
���{�l�Ȃ�C���e���Q�t�H�����
���{�l�Ȃ�C���e���Q�t�H�����
���{�Q�t�H84%�̎�����
���{�l�Ȃ�C���e���Q�t�H�����
���{�l�Ȃ�C���e���Q�t�H�����
>>11
���_���z��̓��{�l�ɂ͂��̑I���������������
���_���z��̓��{�l�ɂ͂��̑I���������������
���{�l�Ȃ�C���e���Q�t�H���
���T�̍����̓��[�N���ꂽ�X���C�h�Ő���オ���Ă邩�ȁH
�f�X�N�����̒v���I�Ȓx���ƃ��W���[�����̕ύX�Ȃ��őO�]���͈�������
�V�������̂̏��J�����Ă̂͊y���݂ł͂���B
�f�X�N�����̒v���I�Ȓx���ƃ��W���[�����̕ύX�Ȃ��őO�]���͈�������
�V�������̂̏��J�����Ă̂͊y���݂ł͂���B
���{�l�Ȃ�C���e���Q�t�H���
ISSCC�͌��n���Ԃ�22�����炾������
AMD Kaveri Godavari Refresh Released mid-2015
AMD cancelled Carrizo-based FM2+ APUs
ttp://www.guru3d.com/news-story/amd-kaveri-refresh-released-mid-2015.html
�c�O�Ȃ��獡�N�̃l�^�́A�����I������悤���B
AMD cancelled Carrizo-based FM2+ APUs
ttp://www.guru3d.com/news-story/amd-kaveri-refresh-released-mid-2015.html
�c�O�Ȃ��獡�N�̃l�^�́A�����I������悤���B
8850K�͂܂��킸���ɐ��\���L�т邩�炢�����A
����8000�V���[�Y�̑�����7000��藎���邩��Ȃ�
����8000�V���[�Y�̑�����7000��藎���邩��Ȃ�
23 �FSocket774�F2015/02/15(��) 21:19:44.06 ID:CH82YBF7
������悤�Ɍ��������Ď��ۂ͐��\�オ���Ă��ȁB
�L�[���[�h�̓������ш�B
�L�[���[�h�̓������ш�B
>>23
���{��ł���
���{��ł���
25 �FSocket774�F2015/02/15(��) 21:35:48.17 ID:CH82YBF7
����͎t����B
���ׂ�Ε����邾��
���ׂ�Ε����邾��
26 �FSocket774�F2015/02/15(��) 21:37:58.45 ID:CH82YBF7
�t�Ɍ�����A10�̕��́A����قǐL�т��낪������ȁB
27 �FSocket774�F2015/02/15(��) 21:38:14.54 ID:QC+8JCsz
>>22-23�̓R�s�y�ɂ��Ă�����
22 ���O:Socket774 [sage] :2015/02/15(��) 20:49:44.70 ID:XWiKPvin
8850K�͂܂��킸���ɐ��\���L�т邩�炢�����A
����8000�V���[�Y�̑�����7000��藎���邩��Ȃ�
23 ���O:Socket774 :2015/02/15(��) 21:19:44.06 ID:CH82YBF7
������悤�Ɍ��������Ď��ۂ͐��\�オ���Ă��ȁB
�L�[���[�h�̓������ш�B
22 ���O:Socket774 [sage] :2015/02/15(��) 20:49:44.70 ID:XWiKPvin
8850K�͂܂��킸���ɐ��\���L�т邩�炢�����A
����8000�V���[�Y�̑�����7000��藎���邩��Ȃ�
23 ���O:Socket774 :2015/02/15(��) 21:19:44.06 ID:CH82YBF7
������悤�Ɍ��������Ď��ۂ͐��\�オ���Ă��ȁB
�L�[���[�h�̓������ш�B
���{�l�Ȃ�C���e���Q�t�H���
2016�N�ɂȂ��Ă���������HBM����Carrizo���o����Ώ\�������͂͏o����B
����2015�N�Ȃ��ǂ�
����2015�N�Ȃ��ǂ�
30 �FSocket774�F2015/02/15(��) 22:57:19.32 ID:CH82YBF7
2015�N��HSA�\�t�g���o����Intel���AMD�����ė�����ǂ��ɂ����č��o���邩�������낤�B
A10-7850K��270��IrisPro��200������3�������Ă邩��ˁB
A10-7850K��270��IrisPro��200������3�������Ă邩��ˁB
AMD��HSA�Ή��\�t�g����t����ĉ����y���܂����
���{�l�Ȃ�C���e���Q�t�H���
AMD�̊��Q�[���V���[�Y���e�I�@�n���O�A�b�v
AMD�@�ł��Q�[�����Ȃ���ł��̊��o���܂�
AMD�@�ȊO�ɂ͕s�v�ȃV�~�����[�^�[�ł�
AMD�@�ȊO�ɂ͕s�v�ȃV�~�����[�^�[�ł�
36 �FSocket774�F2015/02/16(��) 13:31:12.79 ID:2N3np9Pa
DirectX11���Ɗ��S��Intel��CPU�ɍœK������Ă邪
DirectX12�ɂȂ�Ƌt�]����AMD�̂������Ȃ�B
Xbox��APU���̗p���ꂽ���炩�H
Core i3-4330 ��i3.5GHz 2�R�A4�X���b�h
A8-7600 ��i3.1GHz 2���W���[��4�X���b�h
http://wccftech.com/wp-content/uploads/2015/02/DirectX-12_StarSwarm_CPU-Submission-Time.png
DirectX12�ɂȂ�Ƌt�]����AMD�̂������Ȃ�B
Xbox��APU���̗p���ꂽ���炩�H
Core i3-4330 ��i3.5GHz 2�R�A4�X���b�h
A8-7600 ��i3.1GHz 2���W���[��4�X���b�h
http://wccftech.com/wp-content/uploads/2015/02/DirectX-12_StarSwarm_CPU-Submission-Time.png
{kind=link}
���{�l�Ȃ�C���e���Q�t�H���
A8-7600��Turbo CORE���ő�3.8GHz
i3��TB����
i3��TB����
�œK���ł͂Ȃ�CPU���ׂ��y���Ȃ������Ƃ�iGPU�̐��\��������������������B
AMD�p��i�j���ƍ���APU�i�j�ł�12�R�A�i�j�ł����Ă�i�j
>>AMD�́AKaveri���g12�R���s���[�g�R�A�hAPU�Ə̂��� �i���j
>>����́ACPU�R�A4�ƁA�ėp���Z�ɗp����GPU�N���X�^8��̍��v12�̉��Z�R�A��L���Ă��邱�Ƃ����� �i���j
http://www.itmedia.co.jp/pcuser/spv/1401/14/news164.html
>>AMD�́AKaveri���g12�R���s���[�g�R�A�hAPU�Ə̂��� �i���j
>>����́ACPU�R�A4�ƁA�ėp���Z�ɗp����GPU�N���X�^8��̍��v12�̉��Z�R�A��L���Ă��邱�Ƃ����� �i���j
http://www.itmedia.co.jp/pcuser/spv/1401/14/news164.html
770�������W����
�܂�����GPU�g��Ȃ��Ȃ�TDP�̗]�蕪��CPU��OC�Ɏg������
�f�X�N�g�b�v������Haswell��TurboBoost�Ή���2�R�A4�X���b�h�ł��Ė�����ˁH
�Ǝv�����炠����
http://ark.intel.com/ja/products/75045/Intel-Core-i5-4570T-Processor-4M-Cache-up-to-3_60-GHz
�f�X�N�g�b�v������Haswell��TurboBoost�Ή���2�R�A4�X���b�h�ł��Ė�����ˁH
�Ǝv�����炠����
http://ark.intel.com/ja/products/75045/Intel-Core-i5-4570T-Processor-4M-Cache-up-to-3_60-GHz
>>36
�Ȃ��A10-7800����A8-7600�̕����X�R�A�������́H
�Ȃ��A10-7800����A8-7600�̕����X�R�A�������́H
>>45
�uLower is Better�v�ł�
�uLower is Better�v�ł�
The Big Interview: AMD�fs Robert Hallock On Mantle, DirectX 12, PS4/Xbox One, Free-Sync And More
http://gamingbolt.com/the-big-interview-amds-robert-hallock-on-mantle-directx-12-ps4xbox-one-free-sync-and-more
http://gamingbolt.com/the-big-interview-amds-robert-hallock-on-mantle-directx-12-ps4xbox-one-free-sync-and-more
http://images.anandtech.com/graphs/graph8968/71534.png
http://images.anandtech.com/graphs/graph8968/71580.png
�������A�Ȃ���iGPU�e�X�g��A10���A8�̕����ǃX�R�A�o�Ă�P�[�X���m���ɂ���
{kind=link}
http://images.anandtech.com/graphs/graph8968/71580.png
{kind=link}
�������A�Ȃ���iGPU�e�X�g��A10���A8�̕����ǃX�R�A�o�Ă�P�[�X���m���ɂ���
>>36
��DirectX12�ɂȂ�Ƌt�]����AMD�̂������Ȃ�B
>>36
��DirectX12�ɂȂ�Ƌt�]����AMD�̂������Ȃ�B
>>36
��DirectX12�ɂȂ�Ƌt�]����AMD�̂������Ȃ�B
���uLower is Better�v�i���j👀
��DirectX12�ɂȂ�Ƌt�]����AMD�̂������Ȃ�B
>>36
��DirectX12�ɂȂ�Ƌt�]����AMD�̂������Ȃ�B
>>36
��DirectX12�ɂȂ�Ƌt�]����AMD�̂������Ȃ�B
���uLower is Better�v�i���j👀
51 �FSocket774�F2015/02/16(��) 19:48:25.39 ID:x2tylqP0
����B�t�]����Ă邶���B
�O���t�̒��g���ĂȂ��́H
�O���t�̒��g���ĂȂ��́H
���{�l�Ȃ�C���e���Q�t�H���
�Ȃ��C���e����NVIDIA�ɍœK�����ꂽ�ꍇ�̓`�[�g�ƌ����炵��(�د
�~AMD�̂ق��������������R�A���������������낗
��Lower���Đ����������ق��̂��ƂȂ��ǁi���j
�ꉞ��ǂ��Ă݂�
��Lower���Đ����������ق��̂��ƂȂ��ǁi���j
�ꉞ��ǂ��Ă݂�
>>50
�����uLower is Better�v�i���j
>>50
�����uLower is Better�v�i���j
>>50
�����uLower is Better�v�i���j
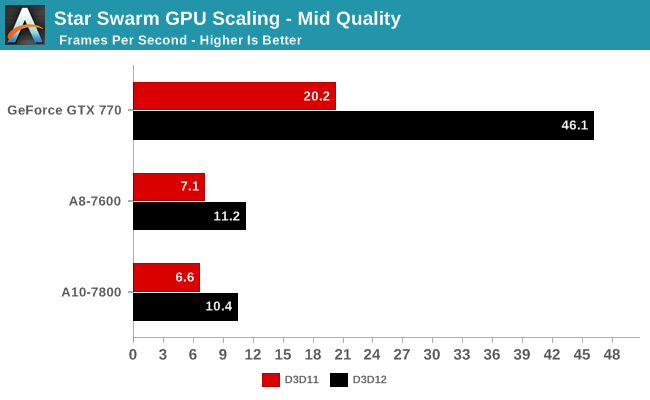
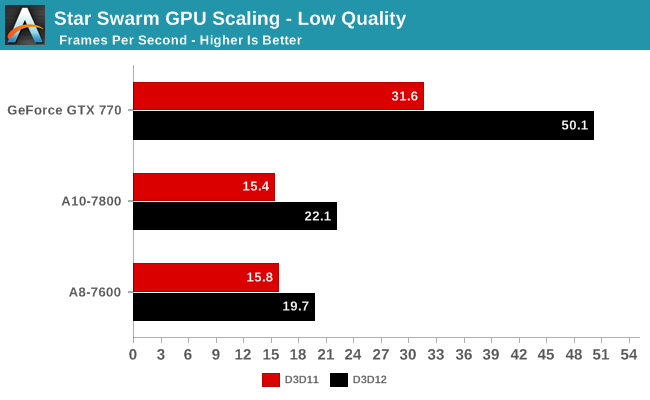
�@�@�@�@�@�@�@�@DX11 �� DX12
�@�@ i3-4330 �F 30.7 �� 6.4
�@ .A8-7600 �F 57.4 �� 6.1
�@A10-7800 �F 50.1 �� 5.9
���u6.4�v(����)👀
�����uLower is Better�v�i���j
>>50
�����uLower is Better�v�i���j
>>50
�����uLower is Better�v�i���j
�@�@�@�@�@�@�@�@DX11 �� DX12
�@�@ i3-4330 �F 30.7 �� 6.4
�@ .A8-7600 �F 57.4 �� 6.1
�@A10-7800 �F 50.1 �� 5.9
���u6.4�v(����)👀
AMD�fs 20nm Nolan APU Spotted in Update - The First 20nm APUs Coming Soon?
http://wccftech.com/amd-nolan-apu-spotted-update-20nm-apus-coming/
http://wccftech.com/amd-nolan-apu-spotted-update-20nm-apus-coming/
preliminary support for AMD Nolan APU
http://www.aida64.com/downloads/OWZjZDU4ZGI%3D
http://www.aida64.com/downloads/OWZjZDU4ZGI%3D
���������AMD�������IT�R�X�g�팸�{��
�f�[�^�Z���^�[��9�����AAMD�̑���v�v���W�F�N�g�̑S�e
http://techtarget.itmedia.co.jp/tt/news/1502/16/news15.html
�f�[�^�Z���^�[��9�����AAMD�̑���v�v���W�F�N�g�̑S�e
http://techtarget.itmedia.co.jp/tt/news/1502/16/news15.html
>>55
�Ȃ�ňꕔ�̉摜������o���Ċ��ł�́H
http://www.anandtech.com/show/8968/star-swarm-directx-12-amd-apu-performance
�Ȃ�ňꕔ�̉摜������o���Ċ��ł�́H
http://www.anandtech.com/show/8968/star-swarm-directx-12-amd-apu-performance
���{�l�Ȃ�C���e���Q�t�H���
Dental Assistance Device Adopts 3D Visualization with AMD Embedded G-Series APUs
http://www.amd.com/Documents/54942A-White-Lion-Dental-Case-Study.pdf
http://www.amd.com/Documents/54942A-White-Lion-Dental-Case-Study.pdf
AMD at GDC 2015
http://developer.amd.com/community/events/amd-gdc-2015/
Monday, March 2
.Getting the Most Out of DirectX12
.Visual Effects in Star Citizen
.Advancements in Tile-based Compute Rendering
Wednesday, March 4
.Low Latency and Stutter-Free Rendering in VR and Graphics Applications
.Optimizing Games for Graphics Core Next Architecture using AMD Graphics Tools
Thursday, March 5
.Augmented Hair in Deus Ex Universe projects: TressFX 3.0
.DirectX 12: A New Meaning for Efficiency and Performance
http://developer.amd.com/community/events/amd-gdc-2015/
Monday, March 2
.Getting the Most Out of DirectX12
.Visual Effects in Star Citizen
.Advancements in Tile-based Compute Rendering
Wednesday, March 4
.Low Latency and Stutter-Free Rendering in VR and Graphics Applications
.Optimizing Games for Graphics Core Next Architecture using AMD Graphics Tools
Thursday, March 5
.Augmented Hair in Deus Ex Universe projects: TressFX 3.0
.DirectX 12: A New Meaning for Efficiency and Performance
64 �FSocket774�F2015/02/17(��) 08:43:22.81 ID:SNs9z6cp
�}���g���͒��߂��A��_��(�_�
65 �FSocket774�F2015/02/17(��) 08:51:02.32 ID:eHDoVKeG
AMD
http://schedule.gdconf.com/search-sessions/AMD
NVIDIA
http://schedule.gdconf.com/search-sessions/NVIDIA
http://schedule.gdconf.com/search-sessions/AMD
NVIDIA
http://schedule.gdconf.com/search-sessions/NVIDIA
���{�l�Ȃ�C���e���Q�t�H�������
������ADx12�L�����Z����������MS�̐K�@�����߂ɏo��������
AMD��Mantle�����̗��p�ɂ͑S����������Ƃ��킗
AMD��Mantle�����̗��p�ɂ͑S����������Ƃ��킗
Mantle�̃A�[���[�A�_�v�^�[�ɂ���������������?
69 �FSocket774�F2015/02/18(��) 07:38:44.93 ID:az7YalVH
Enea Linux and System Management on the ARMv8-based AMD Embedded R-Series Processor
http://news.cision.com/enea-ab/r/enea-linux-and-system-management-on-the-armv8-based-amd-embedded-r-series-processor,c9725766
http://news.cision.com/enea-ab/r/enea-linux-and-system-management-on-the-armv8-based-amd-embedded-r-series-processor,c9725766
Chris Donahue join AMD
https://www.linkedin.com/pub/chris-donahue/0/2b/ba9
Manage the AMD corporate relationship with Microsoft,
including identifying and driving new partnership opportunities across Consumer/Commercial PC, Server/Cloud, and Embedded markets.
Scope spanning from technical engagement on new product features to product launch and field alignment.
https://www.linkedin.com/pub/chris-donahue/0/2b/ba9
Manage the AMD corporate relationship with Microsoft,
including identifying and driving new partnership opportunities across Consumer/Commercial PC, Server/Cloud, and Embedded markets.
Scope spanning from technical engagement on new product features to product launch and field alignment.
���ނ̓Ǝ��d�l�ɐ�s����������
�����h�u�Ɏ̂Ă�o�債�Ă�
�����h�u�Ɏ̂Ă�o�債�Ă�
73 �FSocket774�F2015/02/18(��) 17:48:20.37 ID:b88hrZ+e
�C���e����k�r�̍��\���}�V
�����h�u�Ɏ̂Ă�ꂽ�����}�V�Ȃ̂�
�悭�킩���Ȃ�
�悭�킩���Ȃ�
�C���e���k�r�̓��A�����\��Ђ�����ȁA�h�u�Ɏ̂Ă�悤�Ȃ����A���R���\�s�ׂɂ��g���邩��ň�����
�Ƃ������Ƃɂ�����
���{�Q�t�H84%�̎���
���{�l�Ȃ�C���e���Q�t�H���
���{�Q�t�H84%�̎���
���{�l�Ȃ�C���e���Q�t�H���
>>76
�s�̎Z���Ƃɖ��ʂɓ�������ꍇ������킯��
�s�̎Z���Ƃɖ��ʂɓ�������ꍇ������킯��
AMD�̎����㍼�\���������悤
80 �FSocket774�F2015/02/19(��) 07:36:56.91 ID:iBVYG6Da
��������C���Ȃ��Ȃ珑�����ނȃo�J
AMD Showcases Jagex Gaming Studios Big Data Implementation
http://www.amd.com/en-us/press-releases/Pages/amd-showcases-jagex-2015feb18.aspx
http://www.amd.com/en-us/press-releases/Pages/amd-showcases-jagex-2015feb18.aspx
���{�l�Ȃ�C���e���Q�t�H�������
83 �FSocket774�F2015/02/19(��) 12:20:54.92 ID:kF6NUApQ
AMD��ǂ��e�N�m���W�[�����I
2000�N �f���A���R�APOWER4
��
2005�N�̓f���A���R�A���N�I���E���f���A���R�AAthlon64 X2�I
2003�N �N�A�b�h�R�APOWER5�A1�R�A2�X���b�hSMT
��
2007�N�A���ɃN�A�b�h�R�ACPU���o��IPhenom X4�I
2010�N2�� TurboCore���[�h�������POWER7�A1�R�A������4�X���b�hSMT
��
���N Turbo CORE��������Phenom II X6
2007�N �I�[�o�[5GHz POWER6
��
2013�N ���E����5GHz�AFX-9590�I(��i4.7GHz)
2014�N 12�R�A96�X���b�hSMT�APOWER8
��
2016�N(AMD����) ���E���ISMT����CPU�I�Ȃ�ƁI1�R�A������2�X���b�h�������Ă��܂��I���ꂩ���SMT�̎���IIntel�����ǂ��Ă��邩�ȁH
2000�N �f���A���R�APOWER4
��
2005�N�̓f���A���R�A���N�I���E���f���A���R�AAthlon64 X2�I
2003�N �N�A�b�h�R�APOWER5�A1�R�A2�X���b�hSMT
��
2007�N�A���ɃN�A�b�h�R�ACPU���o��IPhenom X4�I
2010�N2�� TurboCore���[�h�������POWER7�A1�R�A������4�X���b�hSMT
��
���N Turbo CORE��������Phenom II X6
2007�N �I�[�o�[5GHz POWER6
��
2013�N ���E����5GHz�AFX-9590�I(��i4.7GHz)
2014�N 12�R�A96�X���b�hSMT�APOWER8
��
2016�N(AMD����) ���E���ISMT����CPU�I�Ȃ�ƁI1�R�A������2�X���b�h�������Ă��܂��I���ꂩ���SMT�̎���IIntel�����ǂ��Ă��邩�ȁH
intel�p�N��������킵�����O�ŏ�����x������
���W���[�����\�Ƃ�GPU������CPU�Ɠ��l��
�����邩�̂悤�Ɍ֑��12�R�A�Ƃ��ق���
���\���
���W���[�����\�Ƃ�GPU������CPU�Ɠ��l��
�����邩�̂悤�Ɍ֑��12�R�A�Ƃ��ق���
���\���
>>84
�n�C�G���h�T�[�o�[��������Ă�IBM�Ƃ��̕����V�Z�p���ڂ��������
AMD�Aintel�̓��C����PC�Ȃ̂ŁA���т���Z�p����ǂ��Ŏ���������Ċ�����
�ŋ߂�XeonEX���ǂ����n�߂�������̂ŁA���܂�intel��IBM����Ɏ�������̂����邯��
�N���b�N�Ɠd�͂I�ɐ��䂷��Z�p�́Aintel�̒��̐l��AMD�Ɉڂ��Ď������Ă���̂ŁA
TurboCore�Ɋւ��Ă�AMD�̕�����ǂ��Ȃ̂͊m��
�n�C�G���h�T�[�o�[��������Ă�IBM�Ƃ��̕����V�Z�p���ڂ��������
AMD�Aintel�̓��C����PC�Ȃ̂ŁA���т���Z�p����ǂ��Ŏ���������Ċ�����
�ŋ߂�XeonEX���ǂ����n�߂�������̂ŁA���܂�intel��IBM����Ɏ�������̂����邯��
�N���b�N�Ɠd�͂I�ɐ��䂷��Z�p�́Aintel�̒��̐l��AMD�Ɉڂ��Ď������Ă���̂ŁA
TurboCore�Ɋւ��Ă�AMD�̕�����ǂ��Ȃ̂͊m��
���{�l�Ȃ�C���e���Q�t�H�������
>>84
�G���^�[�v���C�Y�����ƃR���V���}�[�������r���Ă鎞�_�Ń_���_������B
�G���^�[�v���C�Y�����ƃR���V���}�[�������r���Ă鎞�_�Ń_���_������B
�Ex86��SIMD������Intel��s����
������Intel��IA64�����ނ�AMD��ARM��GPU�ł�����
������Intel��IA64�����ނ�AMD��ARM��GPU�ł�����
�m���Ă�BXScale���ēz����H
���{�l�Ȃ�C���e���Q�t�H������˂�
92 �FSocket774�F2015/02/19(��) 17:43:51.01 ID:mGF5v5rW
http://www.fudzilla.com/news/notebooks/37040-mobile-braswell-pentium-coming-in-q3-15
Pentium N3700 1.6GHz SDP4W 14nm
Pentium N3540 2.16GHz SDP3.5W 22nm
Atom Z3795 1.6GHz SDP 2W 22nm
CPU�N���b�N�啝�_�E��Intel14nm�͎��s���H
Pentium N3700 1.6GHz SDP4W 14nm
Pentium N3540 2.16GHz SDP3.5W 22nm
Atom Z3795 1.6GHz SDP 2W 22nm
CPU�N���b�N�啝�_�E��Intel14nm�͎��s���H
N3700 CPU1.6GHz/2.4GHz GPU16EU?/400MHz/700MHz TDP6W/SDP4W 14nm
N3540 CPU2.16GHz/2.66GHz GPU4EU/313MHz/896MHz TDP7.5W/SDP4.5W 22nm
�ʂɎ��s����Ȃ���Ȃ��H
N3540 CPU2.16GHz/2.66GHz GPU4EU/313MHz/896MHz TDP7.5W/SDP4.5W 22nm
�ʂɎ��s����Ȃ���Ȃ��H
�N���b�N�_�E�����Ă̂�K8���r�W����G�݂����Ȃ̂�������
Fudzilla��SDP�~�X���R�s�y�l�^�Ƃ��Ă͒ɂ���
�N���b�N�������Ă����\������Εʂɂ�����
97 �FSocket774�F2015/02/19(��) 18:46:20.58 ID:oJpngAkN
���s����Ă̂͂���������
http://www.cnbeta.com/articles/371527.htm
http://it-eproducts.com/images/810geek3.png
http://it-eproducts.com/images/2geek3.png
http://it-eproducts.com/images/810805.png
http://www.cnbeta.com/articles/371527.htm
http://it-eproducts.com/images/810geek3.png
{kind=link}
http://it-eproducts.com/images/2geek3.png
{kind=link}
http://it-eproducts.com/images/810805.png
{kind=link}
98 �FSocket774�F2015/02/19(��) 19:33:54.52 ID:mGF5v5rW
�{���Ȃ�22nm����14nm�ɂȂ�Γ����R�A���Ȃ��3.5GHz�ʂ͍s���ē��O�Ȃ̂�1.6GHz�Ƌt�ɉ������Ă�B
Atom Z3795�Ɠ����N���b�N�ł�����SDP��2�{�ɑ����Ă�B
Atom�̕������b�g�p�t�H�[�}���X���ǂ��Ƃ����s��Ƃ��������Ȃ��B
Atom Z3795�Ɠ����N���b�N�ł�����SDP��2�{�ɑ����Ă�B
Atom�̕������b�g�p�t�H�[�}���X���ǂ��Ƃ����s��Ƃ��������Ȃ��B
99 �FSocket774�F2015/02/19(��) 19:38:15.03 ID:mGF5v5rW
>>92
AtomZ3795 2.4GHz GPU780MHz SDP2W
AtomZ3795 2.4GHz GPU780MHz SDP2W
> �{���Ȃ�22nm����14nm�ɂȂ�Γ����R�A���Ȃ��3.5GHz�ʂ͍s���ē��O
�{�C�Ō����Ă�H
> Atom�̕������b�g�p�t�H�[�}���X���ǂ��Ƃ����s��Ƃ��������Ȃ��B
Bay Trail-T(Z3795)�Ɣ�ׂ�Ȃ�Braswell�ł͂Ȃ�Charry Trail����B
�{�C�Ō����Ă�H
> Atom�̕������b�g�p�t�H�[�}���X���ǂ��Ƃ����s��Ƃ��������Ȃ��B
Bay Trail-T(Z3795)�Ɣ�ׂ�Ȃ�Braswell�ł͂Ȃ�Charry Trail����B
101 �FSocket774�F2015/02/19(��) 19:46:16.48 ID:mGF5v5rW
�����H
22nm����20nm�ɂ������x�̔�������Ȃ���H
�܂��Ă�16nm�ł��Ȃ��B
��C��14nm�v���Z�X�ɃW�����v������H
����ł��̑̂��炭�͊��҂͂���
22nm����20nm�ɂ������x�̔�������Ȃ���H
�܂��Ă�16nm�ł��Ȃ��B
��C��14nm�v���Z�X�ɃW�����v������H
����ł��̑̂��炭�͊��҂͂���
102 �FSocket774�F2015/02/19(��) 19:50:09.59 ID:mGF5v5rW
���߂�CPU��8�R�A�ɑ����ăN���b�N�������Ă�����}�V�B
Core M��15W����4.5W�܂ʼn����Đ��\�����������܂����͂ɂ��炤��B
Core M��15W����4.5W�܂ʼn����Đ��\�����������܂����͂ɂ��炤��B
103 �FSocket774�F2015/02/19(��) 19:53:53.82 ID:mGF5v5rW
����32nm����22nm��Atom�Ő��Z�グ���������A�������Ȃ肭��ꂽ����킴�ƃNCPU���b�N�����Đ��\�����Ē������Ă�̂����ȁB
�v���~�A���u�����h�Ȃ�Ƃ�����Pentium������
22nm�̐��Y���C���𑱓�����ȏ�͌̈ӂɃN���b�N�������邾���̗��R������
22nm�̐��Y���C���𑱓�����ȏ�͌̈ӂɃN���b�N�������邾���̗��R������
��������CPU�R�A���ƃN���b�N�����Ō��̂͂ǂ����Ǝv���B
��������BayTrail�ł�Pentium/Celeron��Atom��艺�ʃu�����h�ł���
107 �FSocket774�F2015/02/19(��) 20:09:52.63 ID:mGF5v5rW
�\����Carrizo��Llano�Ɠ��T�C�Y��3�{�̃g�����W�X�^�����ւ�炵���B
Llano 11���g�����W�X�^ 32nm
Kaveri 24���g�����W�X�^ 28nm
Carrizo 31���g�����W�X�^ 28nm
Kaveri��28nm�ƌ�������22nn
Carrizo��28nm�ƌ�������20nm
�ƁA�����Ă������x���������낤�B
Llano 11���g�����W�X�^ 32nm
Kaveri 24���g�����W�X�^ 28nm
Carrizo 31���g�����W�X�^ 28nm
Kaveri��28nm�ƌ�������22nn
Carrizo��28nm�ƌ�������20nm
�ƁA�����Ă������x���������낤�B
�Ȃ��amd�M�҂͓��{���s���R�Ȃ�
���̂����z���͎͂��R�߂�
>>108�@>>���{���s���R
�܂����Ă��A���ȏЉ�ł�����
�R�s�y�̑f�����ǂ������鏑�����݉��B
>>107
Godavari�̃��t���b�V��Kaveri�A�܂�܂ł��ς��鉿�l������̂��y���݂��˂��B
�܂����Ă��A���ȏЉ�ł�����
�R�s�y�̑f�����ǂ������鏑�����݉��B
>>107
Godavari�̃��t���b�V��Kaveri�A�܂�܂ł��ς��鉿�l������̂��y���݂��˂��B
��������GPU�R�A��CPU����N���b�N���삾����g�����W�X�^���x�����̓�����O�Ȃ��ǂ�
��������Carrizo�ő������g�����W�X�^���ǂ��Ŏg���Ă�̂��䂷����
CPU����L2�L���b�V���T�C�Y���������Ƃ邵�AGPU�̃V�F�[�_���͕ς�炸�ŁA�啝�ɑ�����悤�v�f���l���t���Ȃ�
ISSCC�����̂��݂��
CPU����L2�L���b�V���T�C�Y���������Ƃ邵�AGPU�̃V�F�[�_���͕ς�炸�ŁA�啝�ɑ�����悤�v�f���l���t���Ȃ�
ISSCC�����̂��݂��
�N������JaneStyle�ɏ�芷����2ch.net�ɂ̂���́H
114 �FSocket774�F2015/02/19(��) 21:32:04.98 ID:YbRU8F6A
SoC
>>107
> Kaveri 24���g�����W�X�^ 28nm
> Carrizo 31���g�����W�X�^ 28nm
����2�́ACPU��GPU�̐��\�͂Ƃ������K�͎��͈̂ꏏ�炵������A7���g�����W�X�^�͕ʂ̉����Ɏg���Ă�炵�����
����L3�L���b�V���lj����Ǝv������
> Kaveri��28nm�ƌ�������22nn
> Carrizo��28nm�ƌ�������20nm
> �ƁA�����Ă������x���������낤�B
�m���ɂ��ꂭ�炢���ᖳ���Ɛ������Ȃ���
> Kaveri 24���g�����W�X�^ 28nm
> Carrizo 31���g�����W�X�^ 28nm
����2�́ACPU��GPU�̐��\�͂Ƃ������K�͎��͈̂ꏏ�炵������A7���g�����W�X�^�͕ʂ̉����Ɏg���Ă�炵�����
����L3�L���b�V���lj����Ǝv������
> Kaveri��28nm�ƌ�������22nn
> Carrizo��28nm�ƌ�������20nm
> �ƁA�����Ă������x���������낤�B
�m���ɂ��ꂭ�炢���ᖳ���Ɛ������Ȃ���
L3�L���b�V�����ڂ��Ó����낤��
�e�ʓI�ɂ�8MB����
CPU�̐��\�A�b�v�AGPU�̐��\�A�b�v�ACPU��GPU�Ńf�[�^�̋��L�A�����̃}���`�v���Z�b�T�ł̃f�[�^���L��X�k�[�v�t�B���^�Ƃ��A�����b�g����������
�e�ʓI�ɂ�8MB����
CPU�̐��\�A�b�v�AGPU�̐��\�A�b�v�ACPU��GPU�Ńf�[�^�̋��L�A�����̃}���`�v���Z�b�T�ł̃f�[�^���L��X�k�[�v�t�B���^�Ƃ��A�����b�g����������
Nolan��GF��20nmLPM�BBhavani�Ƃ͂Ȃ�
https://www.linkedin.com/pub/srinivas-choudary/6/417/397?trk=pub-pbmap
>Involved in 3 very successful projects: Kabini (TSMC28HP), Bhavani (GF28A) and Nolan (GF20LPM).
https://www.linkedin.com/pub/srinivas-choudary/6/417/397?trk=pub-pbmap
>Involved in 3 very successful projects: Kabini (TSMC28HP), Bhavani (GF28A) and Nolan (GF20LPM).
>>115
I/O�������������Ă��g�����W�X�^�Ȃ��5�疜�������Ȃ����x���Ǝv������
�T�E�X�Ƃ̐ڑ��Ɏg���Ă�UMI�̕���PCIePHY�͍팸���ꂻ������
I/O�������������Ă��g�����W�X�^�Ȃ��5�疜�������Ȃ����x���Ǝv������
�T�E�X�Ƃ̐ڑ��Ɏg���Ă�UMI�̕���PCIePHY�͍팸���ꂻ������
>>116
���@����L3�L���b�V���lj�
���ꂾ�Ǝd�l�̕ύX�Ƃ��ē`������Ă���悤�ȁE�E
�����ԑO��FPU��GPU�̐v���C�u�����ōĐv����Ȃ�Ęb������������
�����I�ȍœK���̌��ʂ��ăI�`�ȋC������B
http://northwood.blog60.fc2.com/blog-entry-7849.html
���ƁAAMD�̎�����APU/SoC���������悤200�����400�ԑ䂩�炪�ʔ�����
���@����L3�L���b�V���lj�
���ꂾ�Ǝd�l�̕ύX�Ƃ��ē`������Ă���悤�ȁE�E
�����ԑO��FPU��GPU�̐v���C�u�����ōĐv����Ȃ�Ęb������������
�����I�ȍœK���̌��ʂ��ăI�`�ȋC������B
http://northwood.blog60.fc2.com/blog-entry-7849.html
���ƁAAMD�̎�����APU/SoC���������悤200�����400�ԑ䂩�炪�ʔ�����
HSA2.0�̓s����ARM�R�A�����剻&�}���`�R�A���Ƃ����E���g��C�����邩�H
����͂�����2ch����₱�������ƂɂȂ��Ă�݂��������ǁA�w��̂���22��������܂ł͑��v�H
����͂�����2ch����₱�������ƂɂȂ��Ă�݂��������ǁA�w��̂���22��������܂ł͑��v�H
>>121
3��2���������ĎR��Jane�ȊO�̂قڑS�Ă̐�u�������ځ[����ۂ��B
3��2���������ĎR��Jane�ȊO�̂قڑS�Ă̐�u�������ځ[����ۂ��B
>>119
SATA�AUSB3���Ă����������ƂȂ���
>>120
�����炭GPU�̐��\�グ�邽�߂ɂ�GPU�ɂ�������̃g�����W�X�^���g���悤��
�����Ǝv���B
SATA�AUSB3���Ă����������ƂȂ���
>>120
�����炭GPU�̐��\�グ�邽�߂ɂ�GPU�ɂ�������̃g�����W�X�^���g���悤��
�����Ǝv���B
���{�l�Ȃ�C���e���Q�t�H�������
GE and AMD: Making the Industrial Internet Real
https://www.youtube.com/watch?v=aRs0pcLSTeA
https://www.youtube.com/watch?v=aRs0pcLSTeA
AMD Godavri APU (Kaveri Refresh) Coming in June 2015 ? Carrizo Desktop APU Might Arrive by 1H 2016
http://wccftech.com/amd-godavri-apu-kaveri-refresh-coming-june-2015-carrizo-desktop-apu-arrive-1h-2016/
http://wccftech.com/amd-godavri-apu-kaveri-refresh-coming-june-2015-carrizo-desktop-apu-arrive-1h-2016/
http://www.geocities.jp/andosprocinfo/wadai15/20150221.htm
�Q�DAMD��HPC������APU�̊J���ɂ��Ĕ��\
�@�@2015�N2��20���ɑ��ŊJ�Â��ꂽPC Cluster Consortium�̃��[�N�V���b�v
�ɂ����āCAMD�̗ю����u���̒��ŁCAMD���n�C�G���h��GPU���W�ς���HPC
������APU�̊J������Ɣ��\���܂����B���݂�APU�́C�f�X�N�g�b�v�����̍ō�
���\�̂��̂ł�����d�͂�100W���x�ŁC200W����n�C�G���h��GPU�͏W��
�ł��܂���B
����ɑ��āC�n�C�G���h��GPU���W�ς����C200�`300W�̏���d�͂�HPC����
��APU���J������Ƃ̂��Ƃł��B
�@���݂�Hawaii GPU�̎������GPU��2016�N�ɏo���C������W�ς���n�C�G���h
APU��2017�N�ɏo���v��ł��B����APU�ɂ�FirePro���̃n�C�G���hGPU�Ǝ�����
Opteron�̃T�[�o�p�����\CPU���W�ς��܂��B
�@���������C2018�N�ɂ͂��̎��̐����GPU�C2019�N�ɂ͂�����W�ς���n�C�G��
�hAPU���J������v��ŁC2019�N��APU�̓}���`TFlops�̐��\�����Ƃ̂��Ƃł��B
�R�DAMD��32�R�A�C64�X���b�h��ARM��x86�v���Z�T�i������v��
�@�@2015�N2��20���ɑ��ŊJ�Â��ꂽPC Cluster Consortium�̃��[�N�V���b�v��
�����āCAMD�̗ю����C�u���̒��ŁCAMD��2016�N�ɂ�Cortex-A57�̉��{����
���\������ARM v8�A�[�L�e�N�`����K12�R�A��Ǝ��J�����C�T�[�o�p�v���Z�T�Ƃ���
���i������Ƃ����v��\���܂����B
�@�@����K12�Ɠ������x86�v���Z�T�Ƃ̓s���݊��ƂȂ�Ƃ̂��Ƃł��B�܂��C������
�v���Z�T��32�R�A���W�ς��C����܂�AMD�ł͍̗p���Ă��Ȃ������}���`�X���b�h��
�T�|�[�g����Ƃ̂��ƂŁC64�X���b�h�������s����v���Z�T�ƂȂ�Ƃ̂��Ƃł��B
�Q�DAMD��HPC������APU�̊J���ɂ��Ĕ��\
�@�@2015�N2��20���ɑ��ŊJ�Â��ꂽPC Cluster Consortium�̃��[�N�V���b�v
�ɂ����āCAMD�̗ю����u���̒��ŁCAMD���n�C�G���h��GPU���W�ς���HPC
������APU�̊J������Ɣ��\���܂����B���݂�APU�́C�f�X�N�g�b�v�����̍ō�
���\�̂��̂ł�����d�͂�100W���x�ŁC200W����n�C�G���h��GPU�͏W��
�ł��܂���B
����ɑ��āC�n�C�G���h��GPU���W�ς����C200�`300W�̏���d�͂�HPC����
��APU���J������Ƃ̂��Ƃł��B
�@���݂�Hawaii GPU�̎������GPU��2016�N�ɏo���C������W�ς���n�C�G���h
APU��2017�N�ɏo���v��ł��B����APU�ɂ�FirePro���̃n�C�G���hGPU�Ǝ�����
Opteron�̃T�[�o�p�����\CPU���W�ς��܂��B
�@���������C2018�N�ɂ͂��̎��̐����GPU�C2019�N�ɂ͂�����W�ς���n�C�G��
�hAPU���J������v��ŁC2019�N��APU�̓}���`TFlops�̐��\�����Ƃ̂��Ƃł��B
�R�DAMD��32�R�A�C64�X���b�h��ARM��x86�v���Z�T�i������v��
�@�@2015�N2��20���ɑ��ŊJ�Â��ꂽPC Cluster Consortium�̃��[�N�V���b�v��
�����āCAMD�̗ю����C�u���̒��ŁCAMD��2016�N�ɂ�Cortex-A57�̉��{����
���\������ARM v8�A�[�L�e�N�`����K12�R�A��Ǝ��J�����C�T�[�o�p�v���Z�T�Ƃ���
���i������Ƃ����v��\���܂����B
�@�@����K12�Ɠ������x86�v���Z�T�Ƃ̓s���݊��ƂȂ�Ƃ̂��Ƃł��B�܂��C������
�v���Z�T��32�R�A���W�ς��C����܂�AMD�ł͍̗p���Ă��Ȃ������}���`�X���b�h��
�T�|�[�g����Ƃ̂��ƂŁC64�X���b�h�������s����v���Z�T�ƂȂ�Ƃ̂��Ƃł��B
���Ƀ}���`�X���b�h�Ɏ���o������
�܂����傤���Ȃ���
�ŋ߂�CPU�͗V�ю��ԑ���������
�܂����傤���Ȃ���
�ŋ߂�CPU�͗V�ю��ԑ���������
130 �FSocket774�F2015/02/21(�y) 15:01:08.95 ID:cMOR0EAh
���ɐ��E����SMT����CP���邩�I
2000�N �f���A���R�APOWER4
��
2005�N�̓f���A���R�A���N�I���E���f���A���R�AAthlon64 X2�I
2003�N �N�A�b�h�R�APOWER5�A1�R�A2�X���b�hSMT
��
2007�N�A���ɃN�A�b�h�R�ACPU���o��IPhenom X4�I
2010�N2�� TurboCore���[�h�������POWER7�A1�R�A������4�X���b�hSMT
��
���N Turbo CORE��������Phenom II X6
2007�N �I�[�o�[5GHz POWER6
��
2013�N ���E����5GHz�AFX-9590�I(��i4.7GHz)
2014�N 12�R�A96�X���b�hSMT�APOWER8
��
2016�N(AMD����) ���E���ISMT����CPU�I�Ȃ�ƁI1�R�A������2�X���b�h�������Ă��܂��I���ꂩ���SMT�̎���IIntel�����ǂ��Ă��邩�ȁH
2000�N �f���A���R�APOWER4
��
2005�N�̓f���A���R�A���N�I���E���f���A���R�AAthlon64 X2�I
2003�N �N�A�b�h�R�APOWER5�A1�R�A2�X���b�hSMT
��
2007�N�A���ɃN�A�b�h�R�ACPU���o��IPhenom X4�I
2010�N2�� TurboCore���[�h�������POWER7�A1�R�A������4�X���b�hSMT
��
���N Turbo CORE��������Phenom II X6
2007�N �I�[�o�[5GHz POWER6
��
2013�N ���E����5GHz�AFX-9590�I(��i4.7GHz)
2014�N 12�R�A96�X���b�hSMT�APOWER8
��
2016�N(AMD����) ���E���ISMT����CPU�I�Ȃ�ƁI1�R�A������2�X���b�h�������Ă��܂��I���ꂩ���SMT�̎���IIntel�����ǂ��Ă��邩�ȁH
�\�N�O���ƃT�[�o�[������300�`400mm2����������
�����32�R�A���܂�悤�ȃR�A���ƁE�E�H
�����32�R�A���܂�悤�ȃR�A���ƁE�E�H
����ɂł�����GPU������������A600mm2���炢����
��������32�R�A��GPU�Ȃ��Ȃ�ˁH
14nm�Ȃ�R�A������̃g�����W�X�^���͌��s�Ƒ債�ĕς��Ȃ��������B
14nm�Ȃ�R�A������̃g�����W�X�^���͌��s�Ƒ債�ĕς��Ȃ��������B
134 �FSocket774�F2015/02/21(�y) 16:52:27.03 ID:gvFND6ZZ
14nm�ƌ����Ă�28nm��4�{�ɂ͂Ȃ��B
20nm��FINFET���ƁB
20nm��FINFET���ƁB
APU��ϑw�����
>>134
�I�p�͌��s16�R�A�Ȃ̂�GPU�ς܂Ȃ��̂ł����2�{���炢�����邾��B
4�{�ł͂Ȃ��B
�X���b�h����4�{�ɂȂ�ȁB
�x�m�ʂ�HPC�pSPARC�͓������炢�̃X���b�h���������H�@�����Ƒ����H
�I�p�͌��s16�R�A�Ȃ̂�GPU�ς܂Ȃ��̂ł����2�{���炢�����邾��B
4�{�ł͂Ȃ��B
�X���b�h����4�{�ɂȂ�ȁB
�x�m�ʂ�HPC�pSPARC�͓������炢�̃X���b�h���������H�@�����Ƒ����H
Zen�㖢��
Sun��Niagara�Ɠ����������̃T�[�o�[�����v���Z�b�T���낤
���XArm�͒ᕉ�ׂł�������̃��N�G�X�g����������悤�ȗp�r�Ɋ��҂���Ă�����
�������������̃v���Z�b�T��1�`�b�v�ɏW�ς����`�b�v�����͓̂���
���܂ł�64it�����ׂ���Ă��Ȃ��������瓋�ڃ������ʂ����Ȃ��ė��s���ĂȂ���������
���ꂩ��͂������������R�A�̃T�[�o�[�pArm�v���Z�b�T���e�Ђ���o�Ă���̂ł�
���XArm�͒ᕉ�ׂł�������̃��N�G�X�g����������悤�ȗp�r�Ɋ��҂���Ă�����
�������������̃v���Z�b�T��1�`�b�v�ɏW�ς����`�b�v�����͓̂���
���܂ł�64it�����ׂ���Ă��Ȃ��������瓋�ڃ������ʂ����Ȃ��ė��s���ĂȂ���������
���ꂩ��͂������������R�A�̃T�[�o�[�pArm�v���Z�b�T���e�Ђ���o�Ă���̂ł�
2017�̃��C���i�b�v�͂���������
�E500mm2��HPC�����n�C�G���hAPU
����16�R�A32�X���b�h+4096sp�� + HBM 8GB + DDR4 64GB
HBM�������Ƒ����������e�ʂ�����Ȃ�����ADDR4�ŗe�ʉ҂�����
�������Ǘ�������������ǁA�܂����Ƃ����邾�낤
�E32�R�A64�X���b�h�̃n�C�G���hCPU
�����AZen��K12��2��ނ����݂���
�����ċ��炭���̃��j�[�R�ACPU�Ƒ��Ȃ��n�C�G���hGPU�����݂��邾�낤
����8096sp+HBM 16GB
������������4�R�A���炢CPU�悹�Ă��邩��
���܂�500mm2���̃n�C�G���h�`�b�v�s�݂ŃC���e���Q�t�H�Ƀn�C�G���h�ł���Ă�������A�R���ŋt�P�������Ȃ낤��
�E500mm2��HPC�����n�C�G���hAPU
����16�R�A32�X���b�h+4096sp�� + HBM 8GB + DDR4 64GB
HBM�������Ƒ����������e�ʂ�����Ȃ�����ADDR4�ŗe�ʉ҂�����
�������Ǘ�������������ǁA�܂����Ƃ����邾�낤
�E32�R�A64�X���b�h�̃n�C�G���hCPU
�����AZen��K12��2��ނ����݂���
�����ċ��炭���̃��j�[�R�ACPU�Ƒ��Ȃ��n�C�G���hGPU�����݂��邾�낤
����8096sp+HBM 16GB
������������4�R�A���炢CPU�悹�Ă��邩��
���܂�500mm2���̃n�C�G���h�`�b�v�s�݂ŃC���e���Q�t�H�Ƀn�C�G���h�ł���Ă�������A�R���ŋt�P�������Ȃ낤��
>>133
APU�ƌ��������Ă邪
APU�ƌ��������Ă邪
>>141
133�ł�>>128���b��ɂȂ��Ă�킯�����A����������Ƃ悭�ǂ�ł݂Ă���B
HPC�pAPU�Ǝ�����Opteron32�R�A���o��Ə�����Ă��邪�A
���҂��C�R�[���Ƃ�>>128��ǂތ���ǂ��ɂ������ĂȂ��B
APU��2017�N�Ŏ�����Opteron��2016�N�Ə�����Ă���B
>>128�̈��p�ȊO��32�R�AAPU���o��Ƃ�������������Ȃ�
�����N�����Ă����Ƃ��肪�����B�������Ƃ�����V���Ȃ̂ł��Ȃ����I���B
133�ł�>>128���b��ɂȂ��Ă�킯�����A����������Ƃ悭�ǂ�ł݂Ă���B
HPC�pAPU�Ǝ�����Opteron32�R�A���o��Ə�����Ă��邪�A
���҂��C�R�[���Ƃ�>>128��ǂތ���ǂ��ɂ������ĂȂ��B
APU��2017�N�Ŏ�����Opteron��2016�N�Ə�����Ă���B
>>128�̈��p�ȊO��32�R�AAPU���o��Ƃ�������������Ȃ�
�����N�����Ă����Ƃ��肪�����B�������Ƃ�����V���Ȃ̂ł��Ȃ����I���B
�����\���������ǂ��C�����Ă���
����
����������Intel����^���ł��Ȃ������\GPU�����v���Z�b�T�Ŏ��v���Ă��邩��A��������C�ɑ�����Trinity�ŃV�F�A�𑝂₷�̂͊m��Ȃ�
Trinity���_���Ƃ�������̂͂�߂���H
���N�́A�o�����Ăŕ����܂舫��AMD��32nm SOI vs ���肵�ĕ����܂荂�� Intel 32nm�ň��|�I�ɕ����������������ŁA����ێ��ł����̂͂킩���ˁH
���N�́A���肵�ĕ����܂荂�� AMD 32nm vs �o�����Ăŕ����܂舫�� Intel 22nm�̏����ŁA��N��肩�Ȃ�͗ǂ��Ȃ��Ă�
�o�חʂł��Ȃ荷���l�߂邩�獡�N�̓V�F�A�������A���Ƀ��o�C����������
2012/02/28(��) 00:20 | URL | LGA774 #-[ �ҏW]
����
����3�N�Ȃ�
���肦�Ȃ��V�F�A�������ϑz�͂܂��܂�������I
����
����������Intel����^���ł��Ȃ������\GPU�����v���Z�b�T�Ŏ��v���Ă��邩��A��������C�ɑ�����Trinity�ŃV�F�A�𑝂₷�̂͊m��Ȃ�
Trinity���_���Ƃ�������̂͂�߂���H
���N�́A�o�����Ăŕ����܂舫��AMD��32nm SOI vs ���肵�ĕ����܂荂�� Intel 32nm�ň��|�I�ɕ����������������ŁA����ێ��ł����̂͂킩���ˁH
���N�́A���肵�ĕ����܂荂�� AMD 32nm vs �o�����Ăŕ����܂舫�� Intel 22nm�̏����ŁA��N��肩�Ȃ�͗ǂ��Ȃ��Ă�
�o�חʂł��Ȃ荷���l�߂邩�獡�N�̓V�F�A�������A���Ƀ��o�C����������
2012/02/28(��) 00:20 | URL | LGA774 #-[ �ҏW]
����
����3�N�Ȃ�
���肦�Ȃ��V�F�A�������ϑz�͂܂��܂�������I
���������O
����ȏ������݂��O�N����ɕۊǂ��Ă����̂�
����͂��������ˁI
����͂��������ˁI
146 �FSocket774�F2015/02/22(��) 16:53:19.52 ID:XQ0rBBDm
������X���Ȃ̂�Trinity�Ƃ��ߋ��̐��i�̂��Ǝ��グ�Ă����傤���Ȃ�����
�����\���������ǂ�����
2015�N�̈ӋC����
AMD�̏ꍇ
��2015�N�̈ӋC���݂������ĉ�����
�@���o�C�������ɏȓd�͐���啝�ɍ��߂����o�C��APU�t�@�~���[�uCarrizo�v���n�߂Ƃ��鎟����APU��A
���s��GPU���\���X�ɍ��߂����i�Ȃǂ̓����ɒ��͂��Ă����܂��B
�d�͌�������O���t�B�b�N�X���\���啝�Ɍ��シ��AMD���i��OEM���[�J�[���̗p���₷�����邱�ƂŁA
���L�����\�Ɖ��i�|�C���g���J�o�[����ŏI���i���F�l�ɂ��͂��������Ǝv���܂��B
���ǎ҂Ɉꌾ�ǂ���
�@���N��Mantle��TrueAudio�A�є������_�����O�Z�p��TressFX Hair�Ƃ������ŐV�Z�p�ւ̃Q�[���̍œK�����܂��܂��i�݁AAMD���i�����p�����Q�[���̌�������Ƀp���[�A�b�v���܂��I
�l�X�ȍŐV�Q�[�����o���h������uNever Settle�v��A�l�X�ȃL�����y�[���A�H�t���ł̃C�x���g�ȂǁA�F�l�Ɋ��Œ�����������{���Ă��������Ǝv���܂��B
�ŐV����AMD��Facebook�y�[�W�Ő������ē����܂��̂ł��Ѓ`�F�b�N���Ă݂Ă��������B
�Q�t�H�~�[�̏ꍇ
��2015�N�̈ӋC���݂������ĉ�����
�@�V�F�A100%��ڎw���Ĉ��������撣��܂��i�j�B
���N���F�l�Ɉ������NVIDIA�ƂȂ�悤�ɐ��i���Ă܂���܂��̂ŁA�X�������肢�܂��B
���ǎ҂Ɉꌾ�ǂ���
�@2015�N���F�l�̂����҂ɂ������ł���GeForce���i�����ĐV���ȋZ�p�����͂��ł���悤�ɓw�͂��Ă��������ł��B���N�����[�U�[�̊F�l�Ƃ̐G�ꍇ�����厖�ɂ��Ă��������Ǝv���܂��B
�\�[�X
http://akiba-pc.watch.impress.co.jp/docs/sp/20150101_682313.html
�����\���������ǂ�����
2015�N�̈ӋC����
AMD�̏ꍇ
��2015�N�̈ӋC���݂������ĉ�����
�@���o�C�������ɏȓd�͐���啝�ɍ��߂����o�C��APU�t�@�~���[�uCarrizo�v���n�߂Ƃ��鎟����APU��A
���s��GPU���\���X�ɍ��߂����i�Ȃǂ̓����ɒ��͂��Ă����܂��B
�d�͌�������O���t�B�b�N�X���\���啝�Ɍ��シ��AMD���i��OEM���[�J�[���̗p���₷�����邱�ƂŁA
���L�����\�Ɖ��i�|�C���g���J�o�[����ŏI���i���F�l�ɂ��͂��������Ǝv���܂��B
���ǎ҂Ɉꌾ�ǂ���
�@���N��Mantle��TrueAudio�A�є������_�����O�Z�p��TressFX Hair�Ƃ������ŐV�Z�p�ւ̃Q�[���̍œK�����܂��܂��i�݁AAMD���i�����p�����Q�[���̌�������Ƀp���[�A�b�v���܂��I
�l�X�ȍŐV�Q�[�����o���h������uNever Settle�v��A�l�X�ȃL�����y�[���A�H�t���ł̃C�x���g�ȂǁA�F�l�Ɋ��Œ�����������{���Ă��������Ǝv���܂��B
�ŐV����AMD��Facebook�y�[�W�Ő������ē����܂��̂ł��Ѓ`�F�b�N���Ă݂Ă��������B
�Q�t�H�~�[�̏ꍇ
��2015�N�̈ӋC���݂������ĉ�����
�@�V�F�A100%��ڎw���Ĉ��������撣��܂��i�j�B
���N���F�l�Ɉ������NVIDIA�ƂȂ�悤�ɐ��i���Ă܂���܂��̂ŁA�X�������肢�܂��B
���ǎ҂Ɉꌾ�ǂ���
�@2015�N���F�l�̂����҂ɂ������ł���GeForce���i�����ĐV���ȋZ�p�����͂��ł���悤�ɓw�͂��Ă��������ł��B���N�����[�U�[�̊F�l�Ƃ̐G�ꍇ�����厖�ɂ��Ă��������Ǝv���܂��B
�\�[�X
http://akiba-pc.watch.impress.co.jp/docs/sp/20150101_682313.html
148 �FSocket774�F2015/02/22(��) 16:58:38.17 ID:XQ0rBBDm
�V�F�A�����y���Ă�̂̓Q�t�H�~�[�̂݁B
�������������Ă�ƕ����B
�����������������V�F�A100%(��)�Ƃ������Ă�o�J�d�������ă}�C�N�����Ă��B
�����F��ȃX���ŃR�s�y�J��Ԃ��Ă钣�{�l����H
�������������Ă�ƕ����B
�����������������V�F�A100%(��)�Ƃ������Ă�o�J�d�������ă}�C�N�����Ă��B
�����F��ȃX���ŃR�s�y�J��Ԃ��Ă钣�{�l����H
amd�͖{�����悾����
150 �FSocket774�F2015/02/22(��) 17:05:38.67 ID:XQ0rBBDm
�Q�t�H�~�[�́A�����炩�Ƀ��^�{�̌^�B
�}�X���f�B�A�Ɍf�ڂ����̈ӎ����Ă�NVIDIA�̃��S����̃J�b�^�[�V���c�𒅂Ă�w
�}�W�ŋC�����������炱�����݂�ȁB
�}�X���f�B�A�Ɍf�ڂ����̈ӎ����Ă�NVIDIA�̃��S����̃J�b�^�[�V���c�𒅂Ă�w
�}�W�ŋC�����������炱�����݂�ȁB
����[�������˂�
http://www.itbusiness.ca/images/cdn_20thAnniversary/Ho-%20KY.jpg
http://www.nag.co.za/wp-content/uploads/2012/08/AMD-Rory_Reed.jpg
http://www.legitreviews.com/wp-content/uploads/2014/10/lisa-su-amd-ceo-645x803.jpg
http://www.itbusiness.ca/images/cdn_20thAnniversary/Ho-%20KY.jpg
{kind=link}
http://www.nag.co.za/wp-content/uploads/2012/08/AMD-Rory_Reed.jpg
{kind=link}
http://www.legitreviews.com/wp-content/uploads/2014/10/lisa-su-amd-ceo-645x803.jpg
{kind=link}
���N��32�R�A64�X���b�h�A�ė��N�̓n�C�G���hGPU���ڂ̃n�C�G���hAPU���o���Ƃ������Ă邩��
����Ə��F�n�C�G���h�𐧂��Ȃ��ƁA�~�h����[�G���h�ł��V�F�A���Ȃ����ċC�t���������
�����A�Г��̑啝�ȉ��v�ł�����āA�~�h�������W��̂���A�n�C�G���h��̂ɊJ���̐�����ւ�����낤
�܂��ASkyBridge���邩��A�ȓd�͌������d�v���͂��Ă邾�낤����
���Ƃ́A��������邾���̐�`�L����c�Ƃ��o���邩���ĂƂ��낾�낤
����Ə��F�n�C�G���h�𐧂��Ȃ��ƁA�~�h����[�G���h�ł��V�F�A���Ȃ����ċC�t���������
�����A�Г��̑啝�ȉ��v�ł�����āA�~�h�������W��̂���A�n�C�G���h��̂ɊJ���̐�����ւ�����낤
�܂��ASkyBridge���邩��A�ȓd�͌������d�v���͂��Ă邾�낤����
���Ƃ́A��������邾���̐�`�L����c�Ƃ��o���邩���ĂƂ��낾�낤
�ǂ����R�A�����₵�Ă����\�����u������
���\�iIPC�j�オ����Č����Ă邵�A�オ��Ǝv���B
������Intel�̓g�����W�X�^������݂Ă����̗y������s���Ă�̂ŁA
��͂�Zen�̓R�A�����݂̃A�[�L�e�N�`���[�Ȃ�Ȃ����B
�R�A�����݂Ƃ������j���ԈႢ�������̂��ABulldozer���_�������������Ȃ̂��B
������Intel�̓g�����W�X�^������݂Ă����̗y������s���Ă�̂ŁA
��͂�Zen�̓R�A�����݂̃A�[�L�e�N�`���[�Ȃ�Ȃ����B
�R�A�����݂Ƃ������j���ԈႢ�������̂��ABulldozer���_�������������Ȃ̂��B
������MIPS�nx86�݊��Ƃ��Ă͑Ó��Ȑ��\�Ƃ���������
����ő���Ȃ���A�ق��Ă��������������Ηǂ������Ȃ���A�C�ɂ���K�v�Ȃ��B
����ő���Ȃ���A�ق��Ă��������������Ηǂ������Ȃ���A�C�ɂ���K�v�Ȃ��B
>>155
AMD��MIPS���Ɣ��p�ς݂Ȃ�ł����A���������Ă�̂�������Ƃ킩��܂���ˁB
AMD��MIPS���Ɣ��p�ς݂Ȃ�ł����A���������Ă�̂�������Ƃ킩��܂���ˁB
Bulldozer���R�A���\��������Intel���ȓd�͂Ȃ��̎���B
�ǂ����A���ł��Ȃ�����ė��R�ŁA���j�[�R�A�ɍs�������Ȃ�������
�_�������Ă킩���Ă��Ȃ�A�킴�킴�`�l�c�Ȃ�ċC�ɂ��Ă���Ȃ��Ă�������ł���H
�_�������Ă킩���Ă��Ȃ�A�킴�킴�`�l�c�Ȃ�ċC�ɂ��Ă���Ȃ��Ă�������ł���H
AMD�֘A�̃X���ŋC�ɂ���Ȃƌ�����AMD�̑��݂��āc�c
AMD�̎�����X���Ȃ���AMD�̕��j�����������_���Ȃ��Ǝn�܂�Ȃ��ł���B
�����㐻�i�Ȃ���x���`��鎖���ł��Ȃ����B
AMD�̎�����X���Ȃ���AMD�̕��j�����������_���Ȃ��Ǝn�܂�Ȃ��ł���B
�����㐻�i�Ȃ���x���`��鎖���ł��Ȃ����B
28nm�͌�����
20nm�͖w�ǃX�L�b�v�Ő��i���݂��Ȃ�
����16/14nm���炪�����ゾ��
�Ƃ肠�����A�n�C�G���hCPU�AAPU�̘b�͏o��
32�R�ACPU��n�C�G���hGPU����APU�Ƃ��ϑz��������������wktk���~�܂��
�����ē��R�n�C�G���hGPU��������o�Ă��邾�낤
�ȓd�͌����ɂ�SkyBridge�̍����x�T�[�o�[��g���������o�Ă���
�\�t�g�ʂ��ƁADX12�AGLnext�AOpenCL2.0�AHSA�AMantle�Ajava9�ӂ肩��
�b��͑������ǁA���ꂼ��̏���Ȃ�����p�����Đ���オ��Ȃ����
20nm�͖w�ǃX�L�b�v�Ő��i���݂��Ȃ�
����16/14nm���炪�����ゾ��
�Ƃ肠�����A�n�C�G���hCPU�AAPU�̘b�͏o��
32�R�ACPU��n�C�G���hGPU����APU�Ƃ��ϑz��������������wktk���~�܂��
�����ē��R�n�C�G���hGPU��������o�Ă��邾�낤
�ȓd�͌����ɂ�SkyBridge�̍����x�T�[�o�[��g���������o�Ă���
�\�t�g�ʂ��ƁADX12�AGLnext�AOpenCL2.0�AHSA�AMantle�Ajava9�ӂ肩��
�b��͑������ǁA���ꂼ��̏���Ȃ�����p�����Đ���オ��Ȃ����
162 �FSocket774 �]�ڃ_��©2ch.net�F2015/02/23(��) 10:45:32.77 ID:A+7iwUU/
>>159
�@�_����̂͑����ł���Ă���B�����͉�������X���B
�@�_����̂͑����ł���Ă���B�����͉�������X���B
Llano�o��̋łɂ�
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
�� 2014�N �����̔��ド���L���O
http://eetimes.jp/ee/articles/1412/25/news147.html
��AMD�A2014�N�x��4���h���̐Ԏ�
http://pc.watch.impress.co.jp/docs/news/20150121_684660.html
AMD�̏��ʂ������}�~���ЂƂ蕉���_(^o^)�^
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
�� 2014�N �����̔��ド���L���O
http://eetimes.jp/ee/articles/1412/25/news147.html
��AMD�A2014�N�x��4���h���̐Ԏ�
http://pc.watch.impress.co.jp/docs/news/20150121_684660.html
AMD�̏��ʂ������}�~���ЂƂ蕉���_(^o^)�^
AMD�͏����Ȃ�ARM�ƃ\�P�b�g�݊����o��
���̎���x86��ARM�������_�C�ɍڂ�
hQ��hUMA��GPU����3�̖��ߌ`����CPU�ɂȂ�
3��ނ�CPU�R�A������_�C�ɍ��ڂ����킯��
���Intel��x86�R�A�Ƃ����SIMD�������Ă���ȊO����̉�������
�悤��2��̃R�A���L�߂悤�Ƃ��Ă���
NVIDIA�͐���pARM�R�A�͑S��GPU�ʼn��Z����Ƃ����Ƃ��E�E�E
���O��ǂ�x������H
���̎���x86��ARM�������_�C�ɍڂ�
hQ��hUMA��GPU����3�̖��ߌ`����CPU�ɂȂ�
3��ނ�CPU�R�A������_�C�ɍ��ڂ����킯��
���Intel��x86�R�A�Ƃ����SIMD�������Ă���ȊO����̉�������
�悤��2��̃R�A���L�߂悤�Ƃ��Ă���
NVIDIA�͐���pARM�R�A�͑S��GPU�ʼn��Z����Ƃ����Ƃ��E�E�E
���O��ǂ�x������H
>>151
AMD�̏ꍇ
��2015�N�̈ӋC���݂������ĉ�����
�@���o�C�������ɏȓd�͐���啝�ɍ��߂����o�C��APU�t�@�~���[�uCarrizo�v���n�߂Ƃ��鎟����APU��A
���s��GPU���\���X�ɍ��߂����i�Ȃǂ̓����ɒ��͂��Ă����܂��B
�d�͌�������O���t�B�b�N�X���\���啝�Ɍ��シ��AMD���i��OEM���[�J�[���̗p���₷�����邱�ƂŁA
���L�����\�Ɖ��i�|�C���g���J�o�[����ŏI���i���F�l�ɂ��͂��������Ǝv���܂��B
���ǎ҂Ɉꌾ�ǂ���
�@���N��Mantle��TrueAudio�A�є������_�����O�Z�p��TressFX Hair�Ƃ������ŐV�Z�p�ւ̃Q�[���̍œK�����܂��܂��i�݁AAMD���i�����p�����Q�[���̌�������Ƀp���[�A�b�v���܂��I
�l�X�ȍŐV�Q�[�����o���h������uNever Settle�v��A�l�X�ȃL�����y�[���A�H�t���ł̃C�x���g�ȂǁA�F�l�Ɋ��Œ�����������{���Ă��������Ǝv���܂��B
�ŐV����AMD��Facebook�y�[�W�Ő������ē����܂��̂ł��Ѓ`�F�b�N���Ă݂Ă��������B
�Q�t�H�~�[�̏ꍇ
��2015�N�̈ӋC���݂������ĉ�����
�@�V�F�A100%��ڎw���Ĉ��������撣��܂��i�j�B
���N���F�l�Ɉ������NVIDIA�ƂȂ�悤�ɐ��i���Ă܂���܂��̂ŁA�X�������肢�܂��B
���ǎ҂Ɉꌾ�ǂ���
�@2015�N���F�l�̂����҂ɂ������ł���GeForce���i�����ĐV���ȋZ�p�����͂��ł���悤�ɓw�͂��Ă��������ł��B���N�����[�U�[�̊F�l�Ƃ̐G�ꍇ�����厖�ɂ��Ă��������Ǝv���܂��B
�\�[�X
http://akiba-pc.watch.impress.co.jp/docs/sp/20150101_682313.html
AMD�̏ꍇ
��2015�N�̈ӋC���݂������ĉ�����
�@���o�C�������ɏȓd�͐���啝�ɍ��߂����o�C��APU�t�@�~���[�uCarrizo�v���n�߂Ƃ��鎟����APU��A
���s��GPU���\���X�ɍ��߂����i�Ȃǂ̓����ɒ��͂��Ă����܂��B
�d�͌�������O���t�B�b�N�X���\���啝�Ɍ��シ��AMD���i��OEM���[�J�[���̗p���₷�����邱�ƂŁA
���L�����\�Ɖ��i�|�C���g���J�o�[����ŏI���i���F�l�ɂ��͂��������Ǝv���܂��B
���ǎ҂Ɉꌾ�ǂ���
�@���N��Mantle��TrueAudio�A�є������_�����O�Z�p��TressFX Hair�Ƃ������ŐV�Z�p�ւ̃Q�[���̍œK�����܂��܂��i�݁AAMD���i�����p�����Q�[���̌�������Ƀp���[�A�b�v���܂��I
�l�X�ȍŐV�Q�[�����o���h������uNever Settle�v��A�l�X�ȃL�����y�[���A�H�t���ł̃C�x���g�ȂǁA�F�l�Ɋ��Œ�����������{���Ă��������Ǝv���܂��B
�ŐV����AMD��Facebook�y�[�W�Ő������ē����܂��̂ł��Ѓ`�F�b�N���Ă݂Ă��������B
�Q�t�H�~�[�̏ꍇ
��2015�N�̈ӋC���݂������ĉ�����
�@�V�F�A100%��ڎw���Ĉ��������撣��܂��i�j�B
���N���F�l�Ɉ������NVIDIA�ƂȂ�悤�ɐ��i���Ă܂���܂��̂ŁA�X�������肢�܂��B
���ǎ҂Ɉꌾ�ǂ���
�@2015�N���F�l�̂����҂ɂ������ł���GeForce���i�����ĐV���ȋZ�p�����͂��ł���悤�ɓw�͂��Ă��������ł��B���N�����[�U�[�̊F�l�Ƃ̐G�ꍇ�����厖�ɂ��Ă��������Ǝv���܂��B
�\�[�X
http://akiba-pc.watch.impress.co.jp/docs/sp/20150101_682313.html
>>164
> ���̎���x86��ARM�������_�C�ɍڂ�
����Șb�͕��������Ƃ��Ȃ�
> hQ��hUMA��GPU����3�̖��ߌ`����CPU�ɂȂ�
�����烁������Ԃ����ăn�[�h�E�F�A�Ǘ��̃^�X�N�L���[������Ă�
GPU��CPU���炨�V���Ă��Ă����Ȃ��Ɠ����Ȃ����Ƃɂ͕ς��Ȃ�
�R�v���Z�b�T�̓R�v���Z�b�T�ACentral Processing Unit�ɂ͂Ȃ蓾�Ȃ�
�܂����_���肫�ŁA�����̐���ے肳����C���Ȃ�����
�܂����ׂ傤���ďo�Ȃ���
> ���̎���x86��ARM�������_�C�ɍڂ�
����Șb�͕��������Ƃ��Ȃ�
> hQ��hUMA��GPU����3�̖��ߌ`����CPU�ɂȂ�
�����烁������Ԃ����ăn�[�h�E�F�A�Ǘ��̃^�X�N�L���[������Ă�
GPU��CPU���炨�V���Ă��Ă����Ȃ��Ɠ����Ȃ����Ƃɂ͕ς��Ȃ�
�R�v���Z�b�T�̓R�v���Z�b�T�ACentral Processing Unit�ɂ͂Ȃ蓾�Ȃ�
�܂����_���肫�ŁA�����̐���ے肳����C���Ȃ�����
�܂����ׂ傤���ďo�Ȃ���
167 �FSocket774�F2015/02/23(��) 17:03:55.60 ID:RuFSp/SL
������5�N��ɂ͍�����25�{��HSA���\�ɂȂ�̂�
�������z���Đv���Ȃ�����ł���H
Intel�ɂ���CPU���\�͓��ł��ŐL�тȂ�����
�������z���Đv���Ȃ�����ł���H
Intel�ɂ���CPU���\�͓��ł��ŐL�тȂ�����
> ������5�N��ɂ͍�����25�{��HSA���\�ɂȂ�̂�
> �������z���Đv���Ȃ�����ł���H
> Intel�ɂ���CPU���\�͓��ł��ŐL�тȂ�����
�d�͂�����̐��\��25�{�ɂ���i�w�͖ڕW�j�Ƃ͌����Ă���
���\��25�{�ɂȂ�Ȃ�Ă��Ƃ͌����ĂȂ������Ǝv�����ǂ�
�ɒ[�Șb�A�N���b�N�����ŏ���d��1/4�ɉ����Ă�2�{�̓d�͌�����B���������ƂɂȂ�
�i���Ȃ݂�Carrizo��28nm�̂܂ܓd�͌��������߂���@������j
> �������z���Đv���Ȃ�����ł���H
> Intel�ɂ���CPU���\�͓��ł��ŐL�тȂ�����
�d�͂�����̐��\��25�{�ɂ���i�w�͖ڕW�j�Ƃ͌����Ă���
���\��25�{�ɂȂ�Ȃ�Ă��Ƃ͌����ĂȂ������Ǝv�����ǂ�
�ɒ[�Șb�A�N���b�N�����ŏ���d��1/4�ɉ����Ă�2�{�̓d�͌�����B���������ƂɂȂ�
�i���Ȃ݂�Carrizo��28nm�̂܂ܓd�͌��������߂���@������j
169 �FSocket774�F2015/02/23(��) 17:18:31.33 ID:RuFSp/SL
�����H
�m�[�gAPU��Carrizo���f�X�N�g�b�v�n�C�G���hA10-7850K��2�{��GPGPU�X�R�A�@���o���Ă��ł��傤��
�m�[�gAPU��Carrizo���f�X�N�g�b�v�n�C�G���hA10-7850K��2�{��GPGPU�X�R�A�@���o���Ă��ł��傤��
170 �FSocket774�F2015/02/23(��) 17:20:11.66 ID:RuFSp/SL
����ł��f�X�N�g�b�v��Iris Pro��3�{�����I
���̌X����5�N�ԑ����Ă�����
���̌X����5�N�ԑ����Ă�����
> A10-7850K��2�{��GPGPU�X�R�A�@���o���Ă��ł��傤��
Kaveri��GPU���āA�{���x���������キ��7850K�ł����_�l50GFLOPS���x�����Ȃ����
Kaveri��GPU���āA�{���x���������キ��7850K�ł����_�l50GFLOPS���x�����Ȃ����
Intel��x86�}���Z�[�����AVX�ɂ��R�A����
�ϑz��債���M�҂Ƌ��ɓ˂��i��ōs��
AMD�Ƃ��Ă͔���AVX�ɂ�������x�Ή����Ȃ��Ƃ����Ȃ��̂�
GPU��NV�̂悤�ȃX�J���������L���b�V������̋�������
AVX�̏�ʃ��j�b�g�Ƃ����ʒu�t������D�ʂ��m����
ARM�R�A�ƍ��킹��x86�E�p��}���čs��
Intel�͈�x�y�X�������̂Ă�x86�ɂ����ƃx�b�^���ł�
�Ǝv�����牽���Ⴑ��Ⴀ�I
ttp://www.4gamer.net/games/235/G023503/20141230001/TN/008.jpg
�ϑz��債���M�҂Ƌ��ɓ˂��i��ōs��
AMD�Ƃ��Ă͔���AVX�ɂ�������x�Ή����Ȃ��Ƃ����Ȃ��̂�
GPU��NV�̂悤�ȃX�J���������L���b�V������̋�������
AVX�̏�ʃ��j�b�g�Ƃ����ʒu�t������D�ʂ��m����
ARM�R�A�ƍ��킹��x86�E�p��}���čs��
Intel�͈�x�y�X�������̂Ă�x86�ɂ����ƃx�b�^���ł�
�Ǝv�����牽���Ⴑ��Ⴀ�I
ttp://www.4gamer.net/games/235/G023503/20141230001/TN/008.jpg
{kind=link}
���ɋƖ��֘A�̃\�t�g�ƊE����VB6.0����̃\�t�g���Y�����܂��Ɏg���Ă邭�炢�ɕێ�I������
����5�N���x�ł͉����͕ς���ł���B
http://pc.watch.impress.co.jp/img/pcw/docs/630/739/html/g6.jpg.html
������GPGPU��HSA���Ƌ��Ƃ����CPU���\���グ�����邱�Ƃ�������߂���
���z�s������ăQ�[���I�[�o�[
����5�N���x�ł͉����͕ς���ł���B
http://pc.watch.impress.co.jp/img/pcw/docs/630/739/html/g6.jpg.html
{kind=link}
������GPGPU��HSA���Ƌ��Ƃ����CPU���\���グ�����邱�Ƃ�������߂���
���z�s������ăQ�[���I�[�o�[
�n�[�h�������\�t�g�Ƃ͈Ⴄ�����ɓƂ�����A���ꂪAMD�̖���
VB6.0����̃\�t�g���Y�ŊԂɍ����Ɩ���
VB6.0����̃\�t�g���Y�̂܂܂Ƃ���������
AVX�ŋ������悤�ɃR�A��傳����Intel���}���Z�[����̂͗��ΐM�҂ƌ������Ƃ��납
���g�̓���d�g�ŋ��Ԃ�VB6.0�A�v����AVX�x���`�ł�������낤��
VB6.0����̃\�t�g���Y�̂܂܂Ƃ���������
AVX�ŋ������悤�ɃR�A��傳����Intel���}���Z�[����̂͗��ΐM�҂ƌ������Ƃ��납
���g�̓���d�g�ŋ��Ԃ�VB6.0�A�v����AVX�x���`�ł�������낤��
����IHSA�\�t�g�E�F�A�̈��|�I�ȃt�H�����[�����I
https://github.com/HSAFoundation
���Intel�́E�E�E
https://github.com/IntelLabs/
https://github.com/HSAFoundation
���Intel�́E�E�E
https://github.com/IntelLabs/
>>166
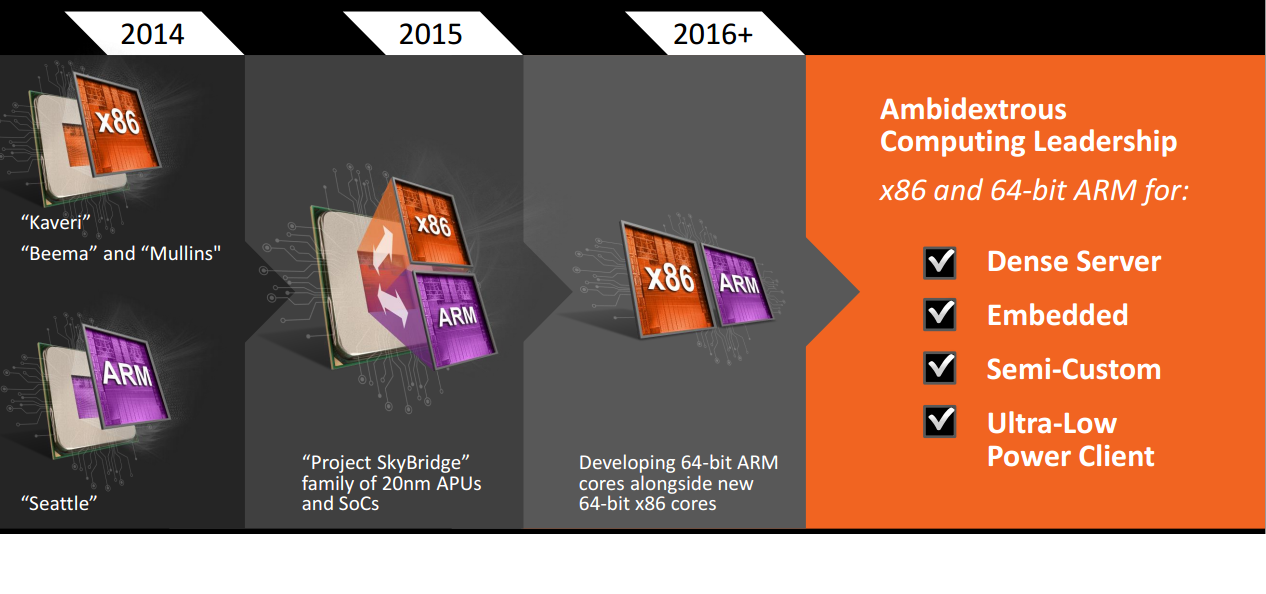
Developing 64bit ARM cores alongside new 64bit x86 cores
http://core0.staticworld.net/images/article/2014/05/amd-skybridge-roadmap-2-100266192-orig.png
Developing 64bit ARM cores alongside new 64bit x86 cores
http://core0.staticworld.net/images/article/2014/05/amd-skybridge-roadmap-2-100266192-orig.png
{kind=link}
�@�͈�()
Intel��AVX��SIMD���\���ǂ�ǂ�グ�����Ă邯��SSE�ȑO�̌Â��v���O������
���������p�����Ă���Ă邵�V�������̂����ɗ����ĂȂ������
�ǂ�Ȃ�ARM�������グ�悤���ǂ�Ȃ�HSA���K�N�F�̖�������낤��
�\�t�g�J���҂ɋ�����������Ă��Ȃ��Ƃ�������������Ȃ�����
AMD�̏����͈Â�
���������p�����Ă���Ă邵�V�������̂����ɗ����ĂȂ������
�ǂ�Ȃ�ARM�������グ�悤���ǂ�Ȃ�HSA���K�N�F�̖�������낤��
�\�t�g�J���҂ɋ�����������Ă��Ȃ��Ƃ�������������Ȃ�����
AMD�̏����͈Â�
VB6�A�v���Ƃ����̂͂��̂���̃R���p�C���ŋ@�B��ɖ|�ꂽ�܂܂Ȃ̂�
����VBNET���Ԍ��ꂪ.NET Framework�ŃR���p�C�����ꂽ���̂��x�����炢�Ȃ�
ttp://www.atmarkit.co.jp/fdotnet/vbcheer/vbcheer08/vbcheer08.html
2004�̍��ł������Ă�
�Ɩ��p���đ�̎����n��Excel���Ɩ����������悤�Ȃ��̂��낤����
�S�R�p���[�v��Ȃ����
VB�ŏ[�����Ă��炻�����낤
�uCPU���ώg�p����2%����1%�ɂȂ����I�L���IIntel�͐_�I�v
������Ƃ���q�킶��Ȃ����
�E���ނ�GPU��SIMT�œ���������u���ނ�GPU��SIMT�œ����v�Ƃ������Ă�z�͂[��
�E�f�[�^�����߁i�u���ߕ����̏����͂����ς�ł����f�[�^�]�����x���킯�������I
�����Z1��|���Z2�f�[�^�]���v�]�X�j
�E���j�b�g������ƒ����d��
���������q�킶��Ȃ����l�ς����̒n����ŕ��R�ƂЂ��炩���Ă邩�炻��Ⴛ���Ȃ낤����
����ς�q�킶��Ȃ�
����VBNET���Ԍ��ꂪ.NET Framework�ŃR���p�C�����ꂽ���̂��x�����炢�Ȃ�
ttp://www.atmarkit.co.jp/fdotnet/vbcheer/vbcheer08/vbcheer08.html
2004�̍��ł������Ă�
�Ɩ��p���đ�̎����n��Excel���Ɩ����������悤�Ȃ��̂��낤����
�S�R�p���[�v��Ȃ����
VB�ŏ[�����Ă��炻�����낤
�uCPU���ώg�p����2%����1%�ɂȂ����I�L���IIntel�͐_�I�v
������Ƃ���q�킶��Ȃ����
�E���ނ�GPU��SIMT�œ���������u���ނ�GPU��SIMT�œ����v�Ƃ������Ă�z�͂[��
�E�f�[�^�����߁i�u���ߕ����̏����͂����ς�ł����f�[�^�]�����x���킯�������I
�����Z1��|���Z2�f�[�^�]���v�]�X�j
�E���j�b�g������ƒ����d��
���������q�킶��Ȃ����l�ς����̒n����ŕ��R�ƂЂ��炩���Ă邩�炻��Ⴛ���Ȃ낤����
����ς�q�킶��Ȃ�
182 �FSocket774�F2015/02/23(��) 19:52:27.99 ID:RuFSp/SL
CPU���\���Č��Ȃ�18������2�{���������鎞��͂Ƃ����̐̂Ƀn�^���V�e����
���̑O����������L�o���ĂȂ��Ƙb�͐i�܂Ȃ���H
���̑O����������L�o���ĂȂ��Ƙb�͐i�܂Ȃ���H
Excel��VBA���d�����炻��Ȃ�ɑ����Ȃ��Ă����N���C�A���g��PC�X�V���g�c���ʂ�₷���Ȃ��Ă��肪�����B
184 �F,,�E�L�́M�E,,�j��-�������F2015/02/23(��) 20:06:12.85 ID:Mne6GXgt
>>181
�悤�@�͈�()
��Ђɖ��߂����Ƃ̂Ȃ����E�p���T�C�g�͔����ɏd�݂������
>>182
����Ȃ��ƒN�ł��킩���Ă邩��
�N1�`2���̃y�[�X�ł��V���O���X���b�h���\�̉��P�����݂��Ђ�
��������肵�Đ��\�������悤�Ƃ��Ȃ���ЂƂɂ�
�ǂ����Ă��������Ă��܂���ˁH
���̌��ʂ��T�[�o�V�F�A2%�Ƃ��������B
�悤�@�͈�()
��Ђɖ��߂����Ƃ̂Ȃ����E�p���T�C�g�͔����ɏd�݂������
>>182
����Ȃ��ƒN�ł��킩���Ă邩��
�N1�`2���̃y�[�X�ł��V���O���X���b�h���\�̉��P�����݂��Ђ�
��������肵�Đ��\�������悤�Ƃ��Ȃ���ЂƂɂ�
�ǂ����Ă��������Ă��܂���ˁH
���̌��ʂ��T�[�o�V�F�A2%�Ƃ��������B
185 �F,,�E�L�́M�E,,�j��-�������F2015/02/23(��) 20:11:32.29 ID:Mne6GXgt
01-10�N��AMD�̃T�[�o�V�F�A�̎����݂�������\���Ă����ˁB
���[��A�����ȃW�F�b�g�R�[�X�^�[��
http://notablecalls.blogspot.jp/2011/02/advanced-micro-devices-nyseamd-upgrade.html
���[��A�����ȃW�F�b�g�R�[�X�^�[��
http://notablecalls.blogspot.jp/2011/02/advanced-micro-devices-nyseamd-upgrade.html
���ς�炸�A�X���^�C���ǂ߂Ȃ��l�܂��z���Ȃ�
187 �F,,�E�L�́M�E,,�j��-�������F2015/02/23(��) 20:20:11.40 ID:Mne6GXgt
�ǂދC�Ȃ�Ăˁ[���炗����
188 �F,,�E�L�́M�E,,�j��-�������F2015/02/23(��) 20:26:34.01 ID:Mne6GXgt
���ƁAIntel��AMD�̌����J���\�Z�̐��ڂ炵���B
http://www.fool.com/investing/general/2013/12/30/can-amd-make-gains-against-intel-in-2014.aspx
�X�J�����\���L�тȂ��Ȃ��Ă��Ă邩�炱���~�h���E�F�A�E�t���[�����[�N�Ȃǂ̊�Ր������K�v�Ȃ̂�
Intel��������Ȃ���Qualcomm��Apple��NVIDIA�������J�����N�X���z���Ă���
�Ȃ�AMD����������H
http://www.fool.com/investing/general/2013/12/30/can-amd-make-gains-against-intel-in-2014.aspx
�X�J�����\���L�тȂ��Ȃ��Ă��Ă邩�炱���~�h���E�F�A�E�t���[�����[�N�Ȃǂ̊�Ր������K�v�Ȃ̂�
Intel��������Ȃ���Qualcomm��Apple��NVIDIA�������J�����N�X���z���Ă���
�Ȃ�AMD����������H
>>1
Intel�M�ҏ������֎~�B
,,�E�L�́M�E,,�j��-�������������֎~�B
�r�炵��W�Ȃ��R�s�y�Ȑl��NG�ɓ���Ė������܂��傤�B
Intel�M�ҏ������֎~�B
,,�E�L�́M�E,,�j��-�������������֎~�B
�r�炵��W�Ȃ��R�s�y�Ȑl��NG�ɓ���Ė������܂��傤�B
190 �F,,�E�L�́M�E,,�j��-�������F2015/02/23(��) 20:36:28.12 ID:Mne6GXgt
����ȃ��[���m�������Ƃ���Ȃ�
����Ƃ����O�����̊Ǘ��l��JIM�ɋ��[�߂Ă�H
����Ƃ����O�����̊Ǘ��l��JIM�ɋ��[�߂Ă�H
191 �F,,�E�L�́M�E,,�j��-�������F2015/02/23(��) 20:45:53.89 ID:Mne6GXgt
AMD��CPU���\���L�тȂ����R�ƌ����J����̐��ڂƂ̈��ʊW
����Ȃ̒��w���ł��킩�邺
>>167
AMD���ڎw��x86�s��V�F�A50%�̐헪
http://pc.watch.impress.co.jp/docs/2008/1210/kaigai480.htm
�u2008�N��2014�N�̊Ԃ�x86�̃V�F�A50%��ڎw���v
AMD�̌��5�`6�N��̌v��Ȃ�Ă̂͂��̒��x�̂��̂��B
�K���B���ł���Ȃ�Ă��̂͑��݂��Ȃ��B
����Ȃ̒��w���ł��킩�邺
>>167
AMD���ڎw��x86�s��V�F�A50%�̐헪
http://pc.watch.impress.co.jp/docs/2008/1210/kaigai480.htm
�u2008�N��2014�N�̊Ԃ�x86�̃V�F�A50%��ڎw���v
AMD�̌��5�`6�N��̌v��Ȃ�Ă̂͂��̒��x�̂��̂��B
�K���B���ł���Ȃ�Ă��̂͑��݂��Ȃ��B
192 �FSocket774�F2015/02/23(��) 20:57:51.26 ID:RuFSp/SL
���̔N��GF�Ƃ͓r���Ō��ܕʂ�݂����Ȃ̂����̒m��Ȃ��̂��H
AMD��GF�g���̌�������GF�ɂ������đ��z�̔����������Ƃ��B
����ȓ��֝��߂��Ă���V�F�A�ǂ��낶��Ȃ���ȁB
AMD��GF�g���̌�������GF�ɂ������đ��z�̔����������Ƃ��B
����ȓ��֝��߂��Ă���V�F�A�ǂ��낶��Ȃ���ȁB
193 �FSocket774�F2015/02/23(��) 21:01:00.11 ID:RuFSp/SL
����ȉߋ��̘b�������Ƃ���ǂ��ł������B
CPU���\��intel��AMD��ARM�����̐�L�тȂ��B
�������ł����B
�ǂ������̐�͓���GPU�̋��������C�����B
CPU���\��intel��AMD��ARM�����̐�L�тȂ��B
�������ł����B
�ǂ������̐�͓���GPU�̋��������C�����B
���������Ă��~�h���E�F�A�J�����o���Ȃ�AMD�ɂ͐V�Z�p���K�N�F�����ɂ͂Ȃ���
�Ƃ���ʼn���~�h���E�F�A���ĕ����ƃn���}�L���v���o���B
�Ȃ�ł��ȁH
�Ȃ�ł��ȁH
197 �F,,�E�L�́M�E,,�j��-�������F2015/02/23(��) 21:17:32.50 ID:Mne6GXgt
�L�тĂȂ��̂�AMD�����ł����B
4�R�A�T�[�o�APRIMERGY TX140�V���[�Y��CPU2006�̗��X�R�A��SPEC�ɓo�^����Ă���B
Xeon E3-1280(Sandy Bridge)
SPECint?2006 = 50.1
SPECint_base2006 = 47.4
https://www.spec.org/cpu2006/results/res2011q2/cpu2006-20110509-16150.html
Xeon E3-1280 v2(Ivy Bridge)
SPECint?2006 = 58.0
SPECint_base2006 = 54.5
https://www.spec.org/cpu2006/results/res2012q2/cpu2006-20120522-22359.html
Xeon E3-1280 v3(Haswell)
SPECint?2006 = 62.8
SPECint_base2006 = 60.9
https://www.spec.org/cpu2006/results/res2013q4/cpu2006-20131007-26606.html
Rate�͌��킸�����ȁB
�����R�A���E�����O���[�h�ŔN10%���̐��\�����B�����Ă���̂��B
�m���ɑO���͐L�тȂ���������Ȃ����A�ł����Ȃ���ǂ�ǂ����B
���ꂱ�����Ԃ������Ȃ��قǂɂˁB
4�R�A�T�[�o�APRIMERGY TX140�V���[�Y��CPU2006�̗��X�R�A��SPEC�ɓo�^����Ă���B
Xeon E3-1280(Sandy Bridge)
SPECint?2006 = 50.1
SPECint_base2006 = 47.4
https://www.spec.org/cpu2006/results/res2011q2/cpu2006-20110509-16150.html
Xeon E3-1280 v2(Ivy Bridge)
SPECint?2006 = 58.0
SPECint_base2006 = 54.5
https://www.spec.org/cpu2006/results/res2012q2/cpu2006-20120522-22359.html
Xeon E3-1280 v3(Haswell)
SPECint?2006 = 62.8
SPECint_base2006 = 60.9
https://www.spec.org/cpu2006/results/res2013q4/cpu2006-20131007-26606.html
Rate�͌��킸�����ȁB
�����R�A���E�����O���[�h�ŔN10%���̐��\�����B�����Ă���̂��B
�m���ɑO���͐L�тȂ���������Ȃ����A�ł����Ȃ���ǂ�ǂ����B
���ꂱ�����Ԃ������Ȃ��قǂɂˁB
198 �F,,�E�L�́M�E,,�j��-�������F2015/02/23(��) 21:21:22.59 ID:Mne6GXgt
���Ƃ��łɂ����
ASUSTeK Computer Inc. (Test Sponsor: Intel Corporation)
ASUS A88X-PRO motherboard (AMD A10-7850K APU with Radeon R7 Graphics)
SPECint?2006 = 31.2
SPECint_base2006 = 29.6
https://www.spec.org/cpu2006/results/res2014q3/cpu2006-20140630-30113.html
ASUSTeK Computer Inc. (Test Sponsor: Intel Corporation)
ASUS A88X-PRO motherboard (AMD A10-7850K APU with Radeon R7 Graphics)
SPECint?2006 = 31.2
SPECint_base2006 = 29.6
https://www.spec.org/cpu2006/results/res2014q3/cpu2006-20140630-30113.html
199 �FSocket774�F2015/02/23(��) 21:24:50.16 ID:RuFSp/SL
>>196
�������Đ̂̓N���b�N�������̂悤�ɏオ���Ă�����B
100MHz�A2������ɂ�110MHz�A�A�A18�����Ŕ{�ʂ̃y�[�X�ŁB
����d�͂�����ɂƂ��Ȃ��ďオ���Ă������A�N�[���[�������\�����Ă��̂��ł��B
�������Đ̂̓N���b�N�������̂悤�ɏオ���Ă�����B
100MHz�A2������ɂ�110MHz�A�A�A18�����Ŕ{�ʂ̃y�[�X�ŁB
����d�͂�����ɂƂ��Ȃ��ďオ���Ă������A�N�[���[�������\�����Ă��̂��ł��B
Mantle���o���āAMS�̐K��@�������炱����Dx11��5�{�`��ł���DX12�o��B
�����Ă����AMS�̓L�����Z���̂��肾�����̂�����
�`��t�@���N�V�����̖��O��ς��Ă邾���̐�p�Q�[���Ƃ�
���łɂ���@�\���A��p�{�[�h����Ă܂Ŏg�킹��Ƃ�
�������킹���@�A�X�y�b�N���̂̃��[�J�[�ɔ�ׂ���A���[�U�[�̗��v�ɂ͍v�����Ă��Ȃ�
�����Ă����AMS�̓L�����Z���̂��肾�����̂�����
�`��t�@���N�V�����̖��O��ς��Ă邾���̐�p�Q�[���Ƃ�
���łɂ���@�\���A��p�{�[�h����Ă܂Ŏg�킹��Ƃ�
�������킹���@�A�X�y�b�N���̂̃��[�J�[�ɔ�ׂ���A���[�U�[�̗��v�ɂ͍v�����Ă��Ȃ�
201 �F,,�E�L�́M�E,,�j��-�������F2015/02/23(��) 21:29:46.21 ID:Mne6GXgt
���[�A�̖@���͔����̂̏W�ϓx�̐L�ї��̂��Ƃ��������̂ł�����
�N���b�N���g���Ƃ����\�͂܂��ʂ̘b�B
����d�͂��グ�Ă�����������E�ɂԂ�������������
���̏���d�͔͈͓��ł̐��\�����ڎw���܂��傤�A�Ƃ������ƂɂȂ��Ă邾��
�ʂ�CPU�̐��\��������߂��킯�ł͂Ȃ��iAMD�������j
�N���b�N���g���Ƃ����\�͂܂��ʂ̘b�B
����d�͂��グ�Ă�����������E�ɂԂ�������������
���̏���d�͔͈͓��ł̐��\�����ڎw���܂��傤�A�Ƃ������ƂɂȂ��Ă邾��
�ʂ�CPU�̐��\��������߂��킯�ł͂Ȃ��iAMD�������j
202 �FSocket774�F2015/02/23(��) 21:37:15.74 ID:KA4QqN66
>>199
�̂͏㏸���Ă������g�����L�тȂ��Ȃ����̂�GPU�������B
�P�W�����]�X�ƌ����Ă��邱�Ƃ��烀�[�A�̖@���̏I�������������̂��낤���A���[�A�̖@���͔����̂̏W�ϓx���P�W�����łQ�{�Ƃ��������́B
�W�ϓx���オ��Ȃ����GPU�̐��\�������̂����A�ǂ������GPU����������̂��H
�̂͏㏸���Ă������g�����L�тȂ��Ȃ����̂�GPU�������B
�P�W�����]�X�ƌ����Ă��邱�Ƃ��烀�[�A�̖@���̏I�������������̂��낤���A���[�A�̖@���͔����̂̏W�ϓx���P�W�����łQ�{�Ƃ��������́B
�W�ϓx���オ��Ȃ����GPU�̐��\�������̂����A�ǂ������GPU����������̂��H
203 �FSocket774�F2015/02/23(��) 21:39:24.80 ID:RuFSp/SL
���[�A�̖@����2�N��2�{
CPU�̐��\��18������2�{
���ꂪ���藧���Ă���
CPU�̐��\��18������2�{
���ꂪ���藧���Ă���
204 �FSocket774�F2015/02/23(��) 21:43:28.59 ID:RuFSp/SL
28nm�ő��Ă�W�ϓx��2�{�ɂȂ�Ȃ��Ă�
�A�[�L�e�N�`�����X�V������
���b�g�p�t�H�[�}���X��2�{�ɂȂ��Ă��̂�������H
���b�g�p�t�H�[�}���X��25�{�ɂ���ɂ́A�A�[�L�e�N�`���̈�V���܂܂�Ă�B
�A�[�L�e�N�`�����X�V������
���b�g�p�t�H�[�}���X��2�{�ɂȂ��Ă��̂�������H
���b�g�p�t�H�[�}���X��25�{�ɂ���ɂ́A�A�[�L�e�N�`���̈�V���܂܂�Ă�B
Carizzo��AMD�̃p�l���ɂ��ƁA�d�͌�����Kaveri�̎O�{�炵���ˁB
�f�X�N�g�b�v�̓L�����Z��������(;�L��֥)
�f�X�N�g�b�v�̓L�����Z��������(;�L��֥)
206 �F,,�E�L�́M�E,,�j��-�������F2015/02/23(��) 21:45:45.77 ID:Mne6GXgt
>>202
80nm��55nm��40nm�ƒ��q�悭�V�������N���Ă�������
NVIDIA���uGPU��CPU�ȏ�̃X�s�[�h�Ői������I�v
�Ƃ����q�����Ă����ǂ��̌�́E�E�E�ł����ˁB
���������Ƃ�GPU�̕��ϓI�ȖʐϒP����CPU���y���Ɉ����̂�
�_�u���p�^�[�j���O�����ȍ~�̃E�F�n�P���̍����̓V�r�A�Ɍ����Ă���B
�A�h�o���e�[�W�Ƃ����A�V�F�[�_�R�A�̍\�����P���ŏ璷�\�����Ƃ�邩��
�ʐς̊��ɕ����܂藦�͍������炢��
80nm��55nm��40nm�ƒ��q�悭�V�������N���Ă�������
NVIDIA���uGPU��CPU�ȏ�̃X�s�[�h�Ői������I�v
�Ƃ����q�����Ă����ǂ��̌�́E�E�E�ł����ˁB
���������Ƃ�GPU�̕��ϓI�ȖʐϒP����CPU���y���Ɉ����̂�
�_�u���p�^�[�j���O�����ȍ~�̃E�F�n�P���̍����̓V�r�A�Ɍ����Ă���B
�A�h�o���e�[�W�Ƃ����A�V�F�[�_�R�A�̍\�����P���ŏ璷�\�����Ƃ�邩��
�ʐς̊��ɕ����܂藦�͍������炢��
207 �FSocket774�F2015/02/23(��) 21:56:07.18 ID:RuFSp/SL
512SP��GCN��Mobile Kaveri����X�^�[�g���Ă邩��ˁB
�������̘b�́AKepler����Maxwell�̃A�[�L�e�N�`���X�V�ȁB
GCN�����b�g�p�t�H�[�}���X�I�Ɍ��������Ǝv���Ă邩��r���ŕς���ƌ��������������Ă�B
5�N��25�{�͖��N1.9�{�̃y�[�X�B
�A�[�L�e�N�`���̍X�V�^�C�~���O�́A�`�b�N�^�b�N�݂����ȃy�[�X�����m��Ȃ��ȁB
�������̘b�́AKepler����Maxwell�̃A�[�L�e�N�`���X�V�ȁB
GCN�����b�g�p�t�H�[�}���X�I�Ɍ��������Ǝv���Ă邩��r���ŕς���ƌ��������������Ă�B
5�N��25�{�͖��N1.9�{�̃y�[�X�B
�A�[�L�e�N�`���̍X�V�^�C�~���O�́A�`�b�N�^�b�N�݂����ȃy�[�X�����m��Ȃ��ȁB
208 �F,,�E�L�́M�E,,�j��-�������F2015/02/23(��) 22:01:52.42 ID:Mne6GXgt
�Z�p�I�ɉ\���Ȃ�Ă��Ƃ͌����ĂȂ��Ă����̓w�͖ڕW�����牽�Ƃł������邾��
Intel������Tejas�L�����Z���܂ł�10GHz��100GHz�������Ă����p���邱�Ƃ͂Ȃ��B
Intel������Tejas�L�����Z���܂ł�10GHz��100GHz�������Ă����p���邱�Ƃ͂Ȃ��B
>>205
�܂�2015�N��AMD�f�X�N�g�b�v�̓m�[�g�ɔ�ׂ�3�{�����������Ƃ�������
�܂�2015�N��AMD�f�X�N�g�b�v�̓m�[�g�ɔ�ׂ�3�{�����������Ƃ�������
210 �FSocket774�F2015/02/23(��) 22:18:36.15 ID:FeyJNJuL
NVIDIA��GTX 970�U�L���ɂ킽��i�ׂɒ��ʂ���
�^�f��GeForce GTX 970�U�L���ɂ킽��i�ׂɒ��ʂ����Nvidia
���Q���������߂��Ă�����̂̂��߂Ɏl��s��������܂��B�������܂߂�F
��1�s�����ȃr�W�l�X���s�B
��2�\�ԃr�W�l�X���s�B
��3�s�@�r�W�l�X���s�B
��4�L������������B
http://wccftech.com/nvidia-face-lawsuit-gtx-970-false-advertising/
�^�f��GeForce GTX 970�U�L���ɂ킽��i�ׂɒ��ʂ����Nvidia
���Q���������߂��Ă�����̂̂��߂Ɏl��s��������܂��B�������܂߂�F
��1�s�����ȃr�W�l�X���s�B
��2�\�ԃr�W�l�X���s�B
��3�s�@�r�W�l�X���s�B
��4�L������������B
http://wccftech.com/nvidia-face-lawsuit-gtx-970-false-advertising/
�̂̊�̓V���O���X���b�h
���̊�̓}���`�X���b�h
�R�A�̃g�����W�X�^�����ێ����āA�V�������N�Ŕ����T�C�Y�ɂȂ�����{�̃R�A��ςނ̂����̃��[�A���낤
���̂Ƃ���V�������N�Ŕ{�̃R�A��ς߂Ă͂����
��ʌ�������4�R�A8�X���b�h�œ��ł������瑝���Ȃ����ǁA�I������Xeon�⎟����Opteron�̓R�A�������\����������Ă���
���̊�̓}���`�X���b�h
�R�A�̃g�����W�X�^�����ێ����āA�V�������N�Ŕ����T�C�Y�ɂȂ�����{�̃R�A��ςނ̂����̃��[�A���낤
���̂Ƃ���V�������N�Ŕ{�̃R�A��ς߂Ă͂����
��ʌ�������4�R�A8�X���b�h�œ��ł������瑝���Ȃ����ǁA�I������Xeon�⎟����Opteron�̓R�A�������\����������Ă���
25�{�̉��P�̘b�̓s�[�N���\�ƈ���āA�`�b�v�ɍڂ����Z���T�[�g���āA
�N���b�N�Ɠd�͂̐������荂�x�ɂ��邱�Ƃɂ��A
�T�^�I�ȗ��p�`�Ԃł̓d�̖͂��ʂ��Ȃ����Ă̂�����̂ŁA
AMD�����ɓ��Ă͂܂�b����Ȃ��悤��
�N���b�N�Ɠd�͂̐������荂�x�ɂ��邱�Ƃɂ��A
�T�^�I�ȗ��p�`�Ԃł̓d�̖͂��ʂ��Ȃ����Ă̂�����̂ŁA
AMD�����ɓ��Ă͂܂�b����Ȃ��悤��
213 �FSocket774�F2015/02/23(��) 22:35:23.57 ID:KA4QqN66
>>203
���g���������Ɍ��サ�Ă���Pentium3�̎���ł���S�N�Ő��\�R�{���x�������̂����A�P�W�����Ő��\�Q�{�����藧���Ă����̂͂����������N�O�̘b���ˁH
>>204
����Maxwell��Tesla�͏o�Ȃ������̗��R���l���Ă݂���ǂ������B
�Ƃ����>>193�ŁuCPU���\��intel��AMD��ARM�����̐�L�тȂ��B�������ł����B�ǂ������̐�͓���GPU�̋��������C�����B�v�Ƃ������Ă����̂����̊ԂɃ��b�p�̘b�ɂȂ����H
���b�p�̘b�Ȃ�CPU�̓A�[�L�e�N�`���̕ύX�Ń��b�p���ǂ��Ȃ�Ȃ��̂��H
Temash(28nm)��Mullins(28nm)�Ń��b�p�Q�{�Ƃ������Ă����C������̂����B
���g���������Ɍ��サ�Ă���Pentium3�̎���ł���S�N�Ő��\�R�{���x�������̂����A�P�W�����Ő��\�Q�{�����藧���Ă����̂͂����������N�O�̘b���ˁH
>>204
����Maxwell��Tesla�͏o�Ȃ������̗��R���l���Ă݂���ǂ������B
�Ƃ����>>193�ŁuCPU���\��intel��AMD��ARM�����̐�L�тȂ��B�������ł����B�ǂ������̐�͓���GPU�̋��������C�����B�v�Ƃ������Ă����̂����̊ԂɃ��b�p�̘b�ɂȂ����H
���b�p�̘b�Ȃ�CPU�̓A�[�L�e�N�`���̕ύX�Ń��b�p���ǂ��Ȃ�Ȃ��̂��H
Temash(28nm)��Mullins(28nm)�Ń��b�p�Q�{�Ƃ������Ă����C������̂����B
>>213
> Temash(28nm)��Mullins(28nm)�Ń��b�p�Q�{�Ƃ������Ă����C������̂����B
������͈Ⴄ�v���Z�X�g���Ă��Ƃ����b
kaveri��Carrizo������28nm�Ƃ͎v���Ȃ����P������A����22nm��20nm��������Ȃ����Ƃ����b������
> Temash(28nm)��Mullins(28nm)�Ń��b�p�Q�{�Ƃ������Ă����C������̂����B
������͈Ⴄ�v���Z�X�g���Ă��Ƃ����b
kaveri��Carrizo������28nm�Ƃ͎v���Ȃ����P������A����22nm��20nm��������Ȃ����Ƃ����b������
���̂��郁���b�g�Ȃ������B
�t�@�E���_���́A�^�[�Q�b�g�ɂ��鐻�i�ɂ���ăg�����W�X�^�̓�����ς��Ă�
�܂������v���Z�X�ł����d�͍����x�A��d�͒ᑬ�x�A���x�������Ƃ��F�X�^�C�v������
������A������Ђ̓�������ł��v���Z�X��g�����W�X�^�̃^�C�v�̑I�����������肷���
���Ȃ萫�\���ς��
�܂������v���Z�X�ł����d�͍����x�A��d�͒ᑬ�x�A���x�������Ƃ��F�X�^�C�v������
������A������Ђ̓�������ł��v���Z�X��g�����W�X�^�̃^�C�v�̑I�����������肷���
���Ȃ萫�\���ς��
28nm�����̒������������ĂȂ��z����?
�����܂ł����Ȑ\���Ƃ͂����A���̂��郁���b�g�Ȃ����獼�̂���Ȃ���
�����܂ł����Ȑ\���Ƃ͂����A���̂��郁���b�g�Ȃ����獼�̂���Ȃ���
218 �FSocket774�F2015/02/23(��) 23:05:45.34 ID:FeyJNJuL
Carrizo��Jaguar��GPU�R�A�ȂǂŎg���Ă����v�t���[�ƍ�������������
Amur��CortexA57�ł������v��@��p���čœK������Ǝv����
�K�b�J��CPU�R�A�Ƃ������Ă邱����ǂ����܂�ς�邩�y���݂���
Amur��CortexA57�ł������v��@��p���čœK������Ǝv����
�K�b�J��CPU�R�A�Ƃ������Ă邱����ǂ����܂�ς�邩�y���݂���
>>218
gm204�̒i�K�ł��Ȃ�ł����̂�
1.5�{��3072sp���ڂƂ�����gm200�ł̓f�J���Ȃ肷���Ă��܂��̂�
dp���j�b�g�͏��Ȃ��ƌ����Ă���
�܂�
gm204�̒i�K�ł��Ȃ�ł����̂�
1.5�{��3072sp���ڂƂ�����gm200�ł̓f�J���Ȃ肷���Ă��܂��̂�
dp���j�b�g�͏��Ȃ��ƌ����Ă���
�܂�
>>219
Carrizo�̓v���Z�X�ύX�ƁA�v�c�[���̉��P�̌��ʂ炵��
Zen��k12�́Ax86��ARM�̊J����@�̗ǂ��Ƃ����ŊJ����������A�݂��ɐF�X�p���[�A�b�v�ł����炵��
�������߃f�R�[�_�ȊO�͂��Ȃ苤�ʂ��č���Ă邾�낤��
Carrizo�̓v���Z�X�ύX�ƁA�v�c�[���̉��P�̌��ʂ炵��
Zen��k12�́Ax86��ARM�̊J����@�̗ǂ��Ƃ����ŊJ����������A�݂��ɐF�X�p���[�A�b�v�ł����炵��
�������߃f�R�[�_�ȊO�͂��Ȃ苤�ʂ��č���Ă邾�낤��
AMD�̎��������c�[���͕�������ARM�̂ɕς����琦�܂��������ʐς�����낤�ȁB
D-wave�ƒ�g���Ă��炩��
Virtual, Immersive, Interactive: Performance Graphics and Processing for IoT Displays
http://eecatalog.com/caciufo/2015/02/20/
http://eecatalog.com/caciufo/2015/02/20/
http://www.4gamer.net/games/282/G028229/20150223061/
AMD�C����APU�uCarrizo�v�̏ڍ������J�BKaveri�Ɠ���28nm�v���Z�X�Z�p���̗p���Ȃ���g�����W�X�^����29�����ʂł����閧�Ƃ�
9���O�̂������ꂽ�Ă̋L���Ȃ�B
������7���g�����W�X�^��CU��6����8�ւ̑����Ƃ������Ƃ炵��
AMD�C����APU�uCarrizo�v�̏ڍ������J�BKaveri�Ɠ���28nm�v���Z�X�Z�p���̗p���Ȃ���g�����W�X�^����29�����ʂł����閧�Ƃ�
9���O�̂������ꂽ�Ă̋L���Ȃ�B
������7���g�����W�X�^��CU��6����8�ւ̑����Ƃ������Ƃ炵��
226 �FSocket774�F2015/02/24(��) 10:04:51.25 ID:endjnTMt
AMD�A�V�A�[�L�e�N�`���uCarrizo�v�̏ڍ׃A�[�L�e�N�`���\
��AMD��23��(���n����)�A�č��ŊJ�Â���Ă��锼���̂̍��ۉ�c�uInternational Solid State Circuits Conference�v(ISSCC)�ɂ����āA
����A�V���[�YAPU�ƂȂ�R�[�h�l�[���uCarrizo�v�̃A�[�L�e�N�`���ڍׂ\�����B
http://m.pc.watch.impress.co.jp/docs/news/20150224_689687.html
��AMD��23��(���n����)�A�č��ŊJ�Â���Ă��锼���̂̍��ۉ�c�uInternational Solid State Circuits Conference�v(ISSCC)�ɂ����āA
����A�V���[�YAPU�ƂȂ�R�[�h�l�[���uCarrizo�v�̃A�[�L�e�N�`���ڍׂ\�����B
http://m.pc.watch.impress.co.jp/docs/news/20150224_689687.html
227 �FSocket774�F2015/02/24(��) 10:09:53.22 ID:endjnTMt
>������7���g�����W�X�^��CU��6����8�ւ̑����Ƃ������Ƃ炵��
�Ȃ킯�Ȃ�w
1CU��64SP������AKaveri�Ŋ���8CU����
�Ȃ킯�Ȃ�w
1CU��64SP������AKaveri�Ŋ���8CU����
228 �FSocket774�F2015/02/24(��) 10:11:11.14 ID:RbnY+FDv
4core haswell��2�{�̃g�����W�X�^����
229 �FSocket774�F2015/02/24(��) 10:37:09.65 ID:endjnTMt
���傤���Ȃ�����I���l���f�ڏ��̊ԈႢ���˗����Ă����w
���₢���킹
4Gamer.net���q�l�̃��[���A�h���X���₢���킹��ʋL���ɂ��āi�f�ڏ��̊ԈႢ��C���˗��Ȃǁj
���w�E��URLhttp://www.4gamer.net/games/282/G028229/20150223061/
���₢���킹���e
���̋L���ɂ���??
>����ŁCGPU�R�A��GCN����̃R�A��8��ƁCKaveri�����6����1.3�{�ɑ��ʂ����BGPU�����̐��\����͂���Ȃ�Ɋ��҂ł��邾�낤�B??
���̕����̋L�ڂɊԈႢ������܂��B??
Kaveri�����GPU��6��ł͂Ȃ��A8���܂��BA10-7850K��A10-7800��512SP�ʼn��Z���j�b�g��8��Ƃ���ʂ�ł�??
�Q�l??
http://www.4gamer.net/games/147/G014731/20140703048/
���₢���킹
4Gamer.net���q�l�̃��[���A�h���X���₢���킹��ʋL���ɂ��āi�f�ڏ��̊ԈႢ��C���˗��Ȃǁj
���w�E��URLhttp://www.4gamer.net/games/282/G028229/20150223061/
���₢���킹���e
���̋L���ɂ���??
>����ŁCGPU�R�A��GCN����̃R�A��8��ƁCKaveri�����6����1.3�{�ɑ��ʂ����BGPU�����̐��\����͂���Ȃ�Ɋ��҂ł��邾�낤�B??
���̕����̋L�ڂɊԈႢ������܂��B??
Kaveri�����GPU��6��ł͂Ȃ��A8���܂��BA10-7850K��A10-7800��512SP�ʼn��Z���j�b�g��8��Ƃ���ʂ�ł�??
�Q�l??
http://www.4gamer.net/games/147/G014731/20140703048/
AMD�p��i�j���ƍ���APU�i�j�ł�12�R�A�i�j�ł����Ă�i�j
>>AMD�́AKaveri���g12�R���s���[�g�R�A�hAPU�Ə̂��� �i���j
>>����́ACPU�R�A4�ƁA�ėp���Z�ɗp����GPU�N���X�^8��̍��v12�̉��Z�R�A��L���Ă��邱�Ƃ����� �i���j
http://www.itmedia.co.jp/pcuser/spv/1401/14/news164.html
>>AMD�́AKaveri���g12�R���s���[�g�R�A�hAPU�Ə̂��� �i���j
>>����́ACPU�R�A4�ƁA�ėp���Z�ɗp����GPU�N���X�^8��̍��v12�̉��Z�R�A��L���Ă��邱�Ƃ����� �i���j
http://www.itmedia.co.jp/pcuser/spv/1401/14/news164.html
>Steamroller�R�A�ɑ��N���b�N������̐��\�iIPC�FInstructions per Clock�j��5�����サ�Ă��邻�����B
>IPC��5���Ƃ�������͂킸���Ȃ��̂Ȃ̂ŁC�P����CPU�R�A�̐��\�́C
>Kaveri����Ɣ�ׂĂ��܂�ς���Ă��Ȃ��Ƃ������ƂɂȂ�Ǝv����B
�c�O������E�E�E
Zen�̎��ɂ�50%�A�b�v���҂��Ă��I
>IPC��5���Ƃ�������͂킸���Ȃ��̂Ȃ̂ŁC�P����CPU�R�A�̐��\�́C
>Kaveri����Ɣ�ׂĂ��܂�ς���Ă��Ȃ��Ƃ������ƂɂȂ�Ǝv����B
�c�O������E�E�E
Zen�̎��ɂ�50%�A�b�v���҂��Ă��I
232 �FSocket774�F2015/02/24(��) 13:27:54.74 ID:vXw85BfU
���x�����킹��ȁB
CPU���\�͓��ł������āB
���Ⴀ���ꂩ��ǂ�������珈���������Ȃ�̂��H
CPU�ɂ܂Ƃ߂�GPGPU���g�����Ƃŏ]���̏�����荂������i�߂邱�Ƃ��\�ɂȂ�B
CPU���\�͓��ł������āB
���Ⴀ���ꂩ��ǂ�������珈���������Ȃ�̂��H
CPU�ɂ܂Ƃ߂�GPGPU���g�����Ƃŏ]���̏�����荂������i�߂邱�Ƃ��\�ɂȂ�B
233 �FSocket774�F2015/02/24(��) 13:35:42.57 ID:1Okz7MrX
CPU�͕ς�炸�����Ă��Ƃł��ˁA���̐���Ɋ��҂��܂�
234 �FSocket774�F2015/02/24(��) 13:52:03.17 ID:vXw85BfU
CPU�ɖ�������ȁA22nn����14nm�ɂȂ���Broadwell�Ɋ��҂��Ă��z���������Ǝv���Ă邩��ȁB
CPU�͓��ł����Č����Ă����݂�CPU�̐��\�ɂ͕�������킯�ŁA
���̕��̒��ŏ�̕��ɂ��邩�^���炢�ɂ��邩���̕��ɂ��邩�ɂ���ĈႤ�B
Intel�͘J�͂����Ă���̕��ɋ������鎖�ɉ��l������Ǝv���Ă�B
GPGPU�őR�Ƃ����Ȃ�Intel�̉��l��ے�ł��鐫�\���o���Ȃ��Ƃ����Ȃ��B
���̕��̒��ŏ�̕��ɂ��邩�^���炢�ɂ��邩���̕��ɂ��邩�ɂ���ĈႤ�B
Intel�͘J�͂����Ă���̕��ɋ������鎖�ɉ��l������Ǝv���Ă�B
GPGPU�őR�Ƃ����Ȃ�Intel�̉��l��ے�ł��鐫�\���o���Ȃ��Ƃ����Ȃ��B
���x�����킹���
CPU���\�����ł����Ȃ�ċ������͒ʗp���Ȃ�����
���Ⴀ���ꂩ��ǂ��������Intel�ɒǂ�����̂�
CPU���\�����サ�Ȃ��Ȃ�Ė�������ȁA���\�����サ�Ȃ��Ƃ���AMD�t�@���{�[�C�̊��҂��Ԃ���
���ꂪSkylake
876 �FSocket774 �F2015/02/24(��) 02:30:49.04 ID:WIYXI5+z
http://www.sisoftware.eu/rank2011d/show_system.php?q=cea598aa9fab99a99fb9dee3ceffd9ab96a680e9d4e5c3ab96a385fdc0f1d7b2d7eadafc8fb28a&l=jp
Skylake([email protected]?)
SIMD:170.25Mpix/�b
Multi-Media Integer 200.09Mpix/�b
Multi-Media Long-int 92.24Mpix/�b
Multi-Media Quad-int 1074kpix/�b
Multi-Media Single-float 193.00Mpix/�b
Multi-Media Double-float 127.78Mpix/�b
Multi-Media Quad-float 5181kpix/�b
ALU/FPU:67.72GOPS
Dhrystone 98.26GIPS
Whetstone Single-float 54.62GFLOPS
Whetstone Double-float 39.88GFLOPS
�Q�l�܂ł�i7-4770T([email protected]�Œ�)
SIMD:134.75Mpix/�b
Multi-Media Integer 151.81Mpix/�b
Multi-Media Long-int 65.33Mpix/�b
Multi-Media Quad-int 1020kpix/�b
Multi-Media Single-float 148.8Mpix/�b
Multi-Media Double-float 108.32Mpix/�b
Multi-Media Quad-float 4100kpix/�b
ALU/FPU:62.63GOPS
Dhrystone 86.78GIPS
Whetstone Single-float 54.46GFLOPS
Whetstone Double-float 37.52GFLOPS
CPU���\�����ł����Ȃ�ċ������͒ʗp���Ȃ�����
���Ⴀ���ꂩ��ǂ��������Intel�ɒǂ�����̂�
CPU���\�����サ�Ȃ��Ȃ�Ė�������ȁA���\�����サ�Ȃ��Ƃ���AMD�t�@���{�[�C�̊��҂��Ԃ���
���ꂪSkylake
876 �FSocket774 �F2015/02/24(��) 02:30:49.04 ID:WIYXI5+z
http://www.sisoftware.eu/rank2011d/show_system.php?q=cea598aa9fab99a99fb9dee3ceffd9ab96a680e9d4e5c3ab96a385fdc0f1d7b2d7eadafc8fb28a&l=jp
Skylake([email protected]?)
SIMD:170.25Mpix/�b
Multi-Media Integer 200.09Mpix/�b
Multi-Media Long-int 92.24Mpix/�b
Multi-Media Quad-int 1074kpix/�b
Multi-Media Single-float 193.00Mpix/�b
Multi-Media Double-float 127.78Mpix/�b
Multi-Media Quad-float 5181kpix/�b
ALU/FPU:67.72GOPS
Dhrystone 98.26GIPS
Whetstone Single-float 54.62GFLOPS
Whetstone Double-float 39.88GFLOPS
�Q�l�܂ł�i7-4770T([email protected]�Œ�)
SIMD:134.75Mpix/�b
Multi-Media Integer 151.81Mpix/�b
Multi-Media Long-int 65.33Mpix/�b
Multi-Media Quad-int 1020kpix/�b
Multi-Media Single-float 148.8Mpix/�b
Multi-Media Double-float 108.32Mpix/�b
Multi-Media Quad-float 4100kpix/�b
ALU/FPU:62.63GOPS
Dhrystone 86.78GIPS
Whetstone Single-float 54.46GFLOPS
Whetstone Double-float 37.52GFLOPS
�ǂ����č����t������ - ���S�A���̈Ⴂ
http://www.sisoftware.eu/rank2011d/show_system.php?q=cea598aa98af9ba391b7d0edc0f1d7a598a88ee7daebcda598ad8bf3ceffd9bcd9e4d4f281bc84&l=jp
�EGardenia Carrizo(2.5GHz)
Dhrystone 35.19GIPS
Whetstone Single-float 34.83GFLOPS
Whetstone Double-float 23.22GFLOPS
Multi-Media Integer 89.58Mpix/�b
Multi-Media Long-int 44.79Mpix/�b
Multi-Media Quad-int 11198kpix/�b
Multi-Media Single-float 66.17Mpix/�b
Multi-Media Double-float 35.02Mpix/�b
Multi-Media Quad-float 8755kpix/�b
http://www.sisoftware.eu/rank2011d/show_system.php?q=cea598aa9fab99a99fb9dee3ceffd9ab96a680e9d4e5c3ab96a385fdc0f1d7b2d7eadafc8fb28a&l=jp
�ESkylake(2.0GHz)
ALU/FPU:67.72GOPS
Dhrystone 98.26GIPS
Whetstone Single-float 54.62GFLOPS
Whetstone Double-float 39.88GFLOPS
Multi-Media Integer 200.09Mpix/�b
Multi-Media Long-int 92.24Mpix/�b
Multi-Media Quad-int 1074kpix/�b
Multi-Media Single-float 193.00Mpix/�b
Multi-Media Double-float 127.78Mpix/�b
Multi-Media Quad-float 5181kpix/�b
http://www.sisoftware.eu/rank2011d/show_system.php?q=cea598aa98af9ba391b7d0edc0f1d7a598a88ee7daebcda598ad8bf3ceffd9bcd9e4d4f281bc84&l=jp
�EGardenia Carrizo(2.5GHz)
Dhrystone 35.19GIPS
Whetstone Single-float 34.83GFLOPS
Whetstone Double-float 23.22GFLOPS
Multi-Media Integer 89.58Mpix/�b
Multi-Media Long-int 44.79Mpix/�b
Multi-Media Quad-int 11198kpix/�b
Multi-Media Single-float 66.17Mpix/�b
Multi-Media Double-float 35.02Mpix/�b
Multi-Media Quad-float 8755kpix/�b
http://www.sisoftware.eu/rank2011d/show_system.php?q=cea598aa9fab99a99fb9dee3ceffd9ab96a680e9d4e5c3ab96a385fdc0f1d7b2d7eadafc8fb28a&l=jp
�ESkylake(2.0GHz)
ALU/FPU:67.72GOPS
Dhrystone 98.26GIPS
Whetstone Single-float 54.62GFLOPS
Whetstone Double-float 39.88GFLOPS
Multi-Media Integer 200.09Mpix/�b
Multi-Media Long-int 92.24Mpix/�b
Multi-Media Quad-int 1074kpix/�b
Multi-Media Single-float 193.00Mpix/�b
Multi-Media Double-float 127.78Mpix/�b
Multi-Media Quad-float 5181kpix/�b
�������ACarrizo��15W��skylake��65W�ł���
>>238
http://northwood.blog60.fc2.com/blog-entry-7578.html
> U series��25W�܂���15W�ƂȂ�AGPU��GT3e�܂���GT2�ƂȂ�B
> Y series��TDP4.5W��2-core+GT2�̑g�ݍ��킹�ƂȂ�B
http://northwood.blog60.fc2.com/blog-entry-7578.html
> U series��25W�܂���15W�ƂȂ�AGPU��GT3e�܂���GT2�ƂȂ�B
> Y series��TDP4.5W��2-core+GT2�̑g�ݍ��킹�ƂȂ�B
�܂��A�������R�s�y�\��t���Ă�̂���
�}���`�|�X�g�E�U���킗
����p�r�ł͏\��������AMD�B
���������A�����܂ŗ��āA���L���@���𐁂������Ȃ��ł���܂����H
�}���`�|�X�g�E�U���킗
����p�r�ł͏\��������AMD�B
���������A�����܂ŗ��āA���L���@���𐁂������Ȃ��ł���܂����H
AMD���炵����A�J�͂��g�����ɂ͐��\����̊�����������CPU�ɗ͂��������A
GPU�ɗ͂����������s�����ǂ��낤��
���Ƃ�AMD�������悤��GPU�����p����A�v�����o��̂��A�o��܂�AMD�����̂��A����
GPU�ɗ͂����������s�����ǂ��낤��
���Ƃ�AMD�������悤��GPU�����p����A�v�����o��̂��A�o��܂�AMD�����̂��A����
GPU�̃V�F�[�_����6CU����8CU�ɂȂ�Ƃ��b�͊Ԉ���Ă�悤�ňꕔ�����Ă�݂���
��TDP��SKU�͂��܂܂�6CU�~�܂肾�������ǁACarrizo�ł�8CU�ɂȂ�炵����
��TDP��SKU�͂��܂܂�6CU�~�܂肾�������ǁACarrizo�ł�8CU�ɂȂ�炵����
>>227
��u�u��H�v�Ƃ͎v���������ǂ���ς肻�����������B
��u�u��H�v�Ƃ͎v���������ǂ���ς肻�����������B
http://www.hardware.fr/news/14085/amd-leve-voile-carrizo-cote-technique.html
CPU�R�A�̃y�A(L2$����)��86Million Tr����102Million Tr�֑���
L1D��16KB��32KB�֑���
GPU�ւ̋����d�����[����VddNB���痣���VddGFX�Ƃ��ēƗ�
�lj����ꂽ7���̃g�����W�X�^��GPU��(HSA�֘A�f�[�^�o�X��UVD/VCE?)�Ɏg����
�r�f�I�f�R�[�_�[�͊e�F10bit�̃t�H�[�}�b�g�ɑΉ�����炵��
CPU�R�A�̃y�A(L2$����)��86Million Tr����102Million Tr�֑���
L1D��16KB��32KB�֑���
GPU�ւ̋����d�����[����VddNB���痣���VddGFX�Ƃ��ēƗ�
�lj����ꂽ7���̃g�����W�X�^��GPU��(HSA�֘A�f�[�^�o�X��UVD/VCE?)�Ɏg����
�r�f�I�f�R�[�_�[�͊e�F10bit�̃t�H�[�}�b�g�ɑΉ�����炵��
http://wccftech.com/amd-carrizo-apu-isscc-2015-presentation-leaked-5-ipc-gain-x86-steamroller-die-consists-31-billion-transistors/
�N���b�N�������炩������Steamroller���d�͌��������Ȃ�͗l
�N���b�N�������炩������Steamroller���d�͌��������Ȃ�͗l
>>241
������g�b�v�ɂȂ�Ƃ͂����ĂȂ�
Intel��80%�`90%�̐��\�ň��������Ă��ꂗ
GPU��CPU�����ł���Ȃ���Ȃ����ǂ����܂Ń\�t�g�E�F�A�����Ă����ĂȂ���
������g�b�v�ɂȂ�Ƃ͂����ĂȂ�
Intel��80%�`90%�̐��\�ň��������Ă��ꂗ
GPU��CPU�����ł���Ȃ���Ȃ����ǂ����܂Ń\�t�g�E�F�A�����Ă����ĂȂ���
247 �FSocket774�F2015/02/24(��) 17:39:02.68 ID:endjnTMt
Carrizo�̓m�[�g�p��SoC�ȁB
�f�X�N�g�b�v�ɂ́AKaveri���t���b�V���������B
�f�X�N�g�b�v�ɂ́AKaveri���t���b�V���������B
������Haswell Refresh�Ƃ͈����SATAe��M.2�T�|�[�g�̐V�`�b�v�Z�b�g�͂Ȃ�
http://soramimifinland.blogspot.jp/2015/01/amdapuapukaveri.html
> �uKaveri�v�̓t�B�������h��Łu�F�B�v�A�u�_�`�v�Ƃ������Ӗ��̖����ł��B
> ���̏�APU�̐������̂��uKaveri Refresh�v�Ȃ�u�F�B���t���b�V���v�Ƃ������ɁB
> �u���̃_�`�A�Â��Ȃ�������V�����_�`�Ɠ���ւ��悤���v�Ƃł����������̂ł��傤���B
http://soramimifinland.blogspot.jp/2015/01/amdapuapukaveri.html
> �uKaveri�v�̓t�B�������h��Łu�F�B�v�A�u�_�`�v�Ƃ������Ӗ��̖����ł��B
> ���̏�APU�̐������̂��uKaveri Refresh�v�Ȃ�u�F�B���t���b�V���v�Ƃ������ɁB
> �u���̃_�`�A�Â��Ȃ�������V�����_�`�Ɠ���ւ��悤���v�Ƃł����������̂ł��傤���B
249 �FSocket774�F2015/02/24(��) 17:44:45.17 ID:Oo6xKD3O
�� CPU Hierarchy Chart 2015
AMD�ߎS�������
�܂�ŏ����ɂȂ��ĂȂ���
6�N�O�̐ɂ��畉���Ă��
������x��Ȃ���
http://www.tomshardware.com/reviews/gaming-cpu-review-overclock,3106-5.html
AMD�ߎS�������
�܂�ŏ����ɂȂ��ĂȂ���
6�N�O�̐ɂ��畉���Ă��
������x��Ȃ���
http://www.tomshardware.com/reviews/gaming-cpu-review-overclock,3106-5.html
Richland�݂����ɐV�R�[�h�l�[���ɂ��Ȃ������ǐS�I�Ƃ����悤
Kaveri��Godavari(Kaveri Refresh)���C���h�̐�̖��O
carrizo��HSA1.0�ɓ��B���Ă��Ƃ����ǁAkaveri�Ɣ�ׂĂǂ������@�\���lj�����āA
����͋�̓I�ɂǂ�������ʂŖ��ɗ��́H
����͋�̓I�ɂǂ�������ʂŖ��ɗ��́H
�ȒP�Ɍ�����
GPU��HSA�ɂ����
�P�Ȃ�A�N�Z�����[�^�iCPU�̃p�V���j����
CPU�ix86��ARM�Ɠ��i�j�ɂȂ�
GPU��HSA�ɂ����
�P�Ȃ�A�N�Z�����[�^�iCPU�̃p�V���j����
CPU�ix86��ARM�Ɠ��i�j�ɂȂ�
255 �F,,�E�L�́M�E,,�j��-�������F2015/02/24(��) 20:11:18.04 ID:/fcUNsIr
�n�[�h�E�F�A�Ǘ����ꂽ�^�X�N�L���[�Ȃ�Cell B.E.��mfcio�����ɂ���Ă邯��
���ꂪ�\�t�g�̐��Y�����グ���ŏ����ɂȂ������Ƃ����ƁE�E�E
���ԃR�[�h����n�[�h�E�F�A�l�C�e�B�u�̃R�[�h�ɕϊ�����̂Ƀz�X�gCPU�̏������K�v�Ȏ��_��
�u�悭�P�����ꂽ�R�v���Z�b�T�v�ł����Ă�CPU�ɂ͂Ȃ蓾�Ȃ��B
Cell��SPE�͂܂���Ȃ�ɂ��R�[�h�̎��ȓW�J���\�������B
��x�L�b�N���Ă��܂��z�X�g���������瓮�I�ɃR�[�h��ǂݏo������A�v���Z�b�T���
�R�[�h�������Ă��܂����Ƃ���ł����B
����͕ʂ�Cell��J�߂����͂Ȃ��AHSA�͂��̃X�^�[�g���C���ɂ��痧�ĂĂ��Ȃ��Ƃ������ƁB
���ꂪ�\�t�g�̐��Y�����グ���ŏ����ɂȂ������Ƃ����ƁE�E�E
���ԃR�[�h����n�[�h�E�F�A�l�C�e�B�u�̃R�[�h�ɕϊ�����̂Ƀz�X�gCPU�̏������K�v�Ȏ��_��
�u�悭�P�����ꂽ�R�v���Z�b�T�v�ł����Ă�CPU�ɂ͂Ȃ蓾�Ȃ��B
Cell��SPE�͂܂���Ȃ�ɂ��R�[�h�̎��ȓW�J���\�������B
��x�L�b�N���Ă��܂��z�X�g���������瓮�I�ɃR�[�h��ǂݏo������A�v���Z�b�T���
�R�[�h�������Ă��܂����Ƃ���ł����B
����͕ʂ�Cell��J�߂����͂Ȃ��AHSA�͂��̃X�^�[�g���C���ɂ��痧�ĂĂ��Ȃ��Ƃ������ƁB
256 �F,,�E�L�́M�E,,�j��-�������F2015/02/24(��) 20:15:20.83 ID:/fcUNsIr
����C#.NET�̃��t���N�V���������̋@�\��GPU�ł���
�s�xCPU�Ƀ^�X�N�����ăR�[�h���R���p�C�����Ă��炤�K�v���������
�s�xCPU�Ƀ^�X�N�����ăR�[�h���R���p�C�����Ă��炤�K�v���������
����B��̓I�ɂǂ������ނ��̃\�t�g�𑖂点�����Ƀp�t�H�[�}���X�ʂŗL���ɂȂ�́H
�{�^�����荞�݃n���h���ɔr��������������Ȃ��̂����R�Ȃ�
�z�X�gCPU���ǂ̃A�[�L�e�N�`���R�A�ɂ���̂��A�v���̎��R
����͍���AMDGPU���l�g�o�݂����Ȃ��Ƃ����Ƃ͕ʎ���
���̂R���CPU�������_�C�ɑ��݂��鎩�R��
�R���p�C���������̖��ߋK�i�ɑΉ������@�B��ɖ|��悤�ɂȂ邱�ƂŖ{�̂�����
GPGPU���}���`�X���b�h�Ƃ��ăR�[�h�������x���ň��ՂɂȂ�
GPGPU����A�v���̐�������I�ɐL�т�
�z�X�gCPU���ǂ̃A�[�L�e�N�`���R�A�ɂ���̂��A�v���̎��R
����͍���AMDGPU���l�g�o�݂����Ȃ��Ƃ����Ƃ͕ʎ���
���̂R���CPU�������_�C�ɑ��݂��鎩�R��
�R���p�C���������̖��ߋK�i�ɑΉ������@�B��ɖ|��悤�ɂȂ邱�ƂŖ{�̂�����
GPGPU���}���`�X���b�h�Ƃ��ăR�[�h�������x���ň��ՂɂȂ�
GPGPU����A�v���̐�������I�ɐL�т�
260 �F,,�E�L�́M�E,,�j��-�������F2015/02/24(��) 20:41:30.54 ID:/fcUNsIr
�����Ȃ��Ƃ������シ�����ܖ��ɗ��悤�Ȃ��Ƃ͂܂������B
Intel��NVIDIA����������ʂɒǏ]���錩��������Ȃ�܂������Ǝ��H���̈���o�Ȃ�����ˁB
�����^�[�Q�b�g�ł��\����������p�r�A���Ƃ��Η�̃n�C�G���hAPU���X�p�R���Ƃ�
�f�[�^�Z���^�[�ɍ̗p����āA���̐��ʂ̈ꕔ���p�\�R���ɂ���Ă��邩�ǂ���
�Ƃ������x���B������Ȃ��Ȃ��������Ƃ������B
���Ȃ��Ƃ�PC�̔̔����̈ꌅ%�̃f�o�C�X���^�[�Q�b�g�Ƀ\�t�g�J������Ȃ��
����Ȋ���ȃ\�t�g�J����Ђ���킯�Ȃ������B
�u�g�b�v�K���Ȃ����v�n�̃f�o�C�X�����s����̂�SpursEngine��������B
Qosmio�ɍ̗p����P�̂ł��������ꂽ���nj��lj��N��������������H
���Ƃ���HSA�̑O�g��Fusion�̌v���2014�N�܂ł�x86�V�F�A��50%����������Ƃ���
��Z�p��O��ɂ��Ă����B
�s��x�z�͂̂���n�[�h�ł���ɓ��������@�\�荞�ނ̂ƁA����ĂȂ�����
�{�C�o���ΐ������[�ł͑S�R�b���Ⴄ�B
Intel��NVIDIA����������ʂɒǏ]���錩��������Ȃ�܂������Ǝ��H���̈���o�Ȃ�����ˁB
�����^�[�Q�b�g�ł��\����������p�r�A���Ƃ��Η�̃n�C�G���hAPU���X�p�R���Ƃ�
�f�[�^�Z���^�[�ɍ̗p����āA���̐��ʂ̈ꕔ���p�\�R���ɂ���Ă��邩�ǂ���
�Ƃ������x���B������Ȃ��Ȃ��������Ƃ������B
���Ȃ��Ƃ�PC�̔̔����̈ꌅ%�̃f�o�C�X���^�[�Q�b�g�Ƀ\�t�g�J������Ȃ��
����Ȋ���ȃ\�t�g�J����Ђ���킯�Ȃ������B
�u�g�b�v�K���Ȃ����v�n�̃f�o�C�X�����s����̂�SpursEngine��������B
Qosmio�ɍ̗p����P�̂ł��������ꂽ���nj��lj��N��������������H
���Ƃ���HSA�̑O�g��Fusion�̌v���2014�N�܂ł�x86�V�F�A��50%����������Ƃ���
��Z�p��O��ɂ��Ă����B
�s��x�z�͂̂���n�[�h�ł���ɓ��������@�\�荞�ނ̂ƁA����ĂȂ�����
�{�C�o���ΐ������[�ł͑S�R�b���Ⴄ�B
���܂̂Ƃ���OpenCL�ɌX�|���Ă邵�V�F�A�]�X�͓��Ă͂܂�Ȃ���H
�����
���荞�݂Ƃ��͊W������
�u�t���O�ύX�ɔr�����䂗�����l��M��X���b�h���ɑ��݂��Ȃ��̂ɂ������v
������
���荞�݂Ƃ��͊W������
�u�t���O�ύX�ɔr�����䂗�����l��M��X���b�h���ɑ��݂��Ȃ��̂ɂ������v
������
263 �F,,�E�L�́M�E,,�j��-�������F2015/02/24(��) 20:50:51.33 ID:/fcUNsIr
264 �F,,�E�L�́M�E,,�j��-�������F2015/02/24(��) 20:52:05.90 ID:/fcUNsIr
��������OpenCL���̂��v���O���}�̊Ԃł͒��}�C�i�[����
pgi�Ƃ��������ׂ��������Ȃ�
�������c�q�����_�œ����Ă��
�c�q�͑��_����Ȃ����H
���Ԕ����_���܂���AMD�͏���I�Ƃ������Ă�l���������Ȃ�����
���Ԕ����_���܂���AMD�͏���I�Ƃ������Ă�l���������Ȃ�����
268 �F,,�E�L�́M�E,,�j��-�������F2015/02/24(��) 21:49:59.27 ID:/fcUNsIr
HSA��GPGPU�E��3DNow!�̗����ʒu����
�������A��������GPGPU�E���̂�����
�������A��������GPGPU�E���̂�����
sse5�����
270 �FSocket774�F2015/02/24(��) 22:04:51.61 ID:urZWmVv5
3DNow!/Enhanced 3DNow!��TMPGEnc�̌Â��o�[�W�����Ƃ��Ή��\�t�g�����������݂��邩��ȁB
HSA�ȂƓ���Ɉ����͎̂���Ƃ������̂��B
HSA�ȂƓ���Ɉ����͎̂���Ƃ������̂��B
271 �F,,�E�L�́M�E,,�j��-�������F2015/02/24(��) 22:06:21.42 ID:/fcUNsIr
�uMMX Pentium���Z���[�g�v�Ƃ������������3DNow!���Ēቿ�i�p�\�R���ł͈�吨�͂����������
x86���[�J�[���̂������������B
x86���[�J�[���̂������������B
�h���}�C�I
�r��������Ă̂͒P�Ɂu���Ԏ�点��v���Ċo���Ă��܂�����������
�E�P�̕ϐ���
�E�����X���b�h��
�E���Z�i�Q�Ɓ����l�ύX������j��
�J��Ԃ��ꍇ�ɕK�v�ɂȂ���̂�����
�t���O�ɏ��Ԃ������Ȃ����
�Ƃɂ��������Ȃ��Ă������ʂ�Ƀh���}�C�I
�r��������Ă̂͒P�Ɂu���Ԏ�点��v���Ċo���Ă��܂�����������
�E�P�̕ϐ���
�E�����X���b�h��
�E���Z�i�Q�Ɓ����l�ύX������j��
�J��Ԃ��ꍇ�ɕK�v�ɂȂ���̂�����
�t���O�ɏ��Ԃ������Ȃ����
�Ƃɂ��������Ȃ��Ă������ʂ�Ƀh���}�C�I
273 �FSocket774 �]�ڃ_��©2ch.net�F2015/02/24(��) 22:14:47.35 ID:uccH1lWT
>>267
�@��������C�������̂ɂ����ɏ������ގ��_�ʼn��̐��������������ǂˁB
�@��������C�������̂ɂ����ɏ������ގ��_�ʼn��̐��������������ǂˁB
274 �F,,�E�L�́M�E,,�j��-�������F2015/02/24(��) 22:18:43.57 ID:/fcUNsIr
�N���E�h����̃l�C�e�B�u�R�[�h��HTML5/JavaScript�ƌ�����悤�Ȏ����
C/C++����Փx�̍������ꏈ���n�����s��Ǝv���Ă鎞�_��AMD�̌o�c�w�̔]�݂��͉���
C/C++����Փx�̍������ꏈ���n�����s��Ǝv���Ă鎞�_��AMD�̌o�c�w�̔]�݂��͉���
�X���[�uGPU��`��≉�Z�ւ�炸�蓮�Ŏg�����߂�
�c��ȗʂ̃R�[�h���K�v�ɂȂ�Ƃ����
GPU��CPU�����邱�ƂŃ��W���[�Ȍ���ŃR���p�C�����Ă��炤�̂�HSA�̑_��������
����͂Ƃ������h���}�C�̒B�l�̓v���O�����̂��Ƃ����l���ĂȂ�����
��ʏ펯�Ŗ��N�h���}�C�������Ă���̂��Ǝv������
�v���O�����ł����R�̔@�������ɂ��Ȃ��{���̔@���h���}�C���J��o���Ă���̂ł�����
�c��ȗʂ̃R�[�h���K�v�ɂȂ�Ƃ����
GPU��CPU�����邱�ƂŃ��W���[�Ȍ���ŃR���p�C�����Ă��炤�̂�HSA�̑_��������
����͂Ƃ������h���}�C�̒B�l�̓v���O�����̂��Ƃ����l���ĂȂ�����
��ʏ펯�Ŗ��N�h���}�C�������Ă���̂��Ǝv������
�v���O�����ł����R�̔@�������ɂ��Ȃ��{���̔@���h���}�C���J��o���Ă���̂ł�����
276 �F,,�E�L�́M�E,,�j��-�������F2015/02/24(��) 22:29:16.40 ID:/fcUNsIr
Ruby on Rails �� 25,064
https://github.com/rails/rails
angular.js �� 35,563
https://github.com/angular/angular.js
HSA�@�u���Ȃɂ���H�݂�Ȓm���Ă�H�v
https://github.com/HSAFoundation
�V�F�A�����Ȃ����Ƃ́A�߂������ƂȂ̂ł��B
https://github.com/rails/rails
angular.js �� 35,563
https://github.com/angular/angular.js
HSA�@�u���Ȃɂ���H�݂�Ȓm���Ă�H�v
https://github.com/HSAFoundation
�V�F�A�����Ȃ����Ƃ́A�߂������ƂȂ̂ł��B
277 �F,,�E�L�́M�E,,�j��-�������F2015/02/24(��) 22:33:22.07 ID:/fcUNsIr
HSA�������������Ȃ�
�t�@���{�[�C����������GitHub�A�J�E���g�Ƃ��ā�����Ă�������Ǝv����
�N�����ڂ��ĂȂ��t���[�����[�N�Ƀ\�t�g�J���҂͌Q����Ȃ�
�t�@���{�[�C����������GitHub�A�J�E���g�Ƃ��ā�����Ă�������Ǝv����
�N�����ڂ��ĂȂ��t���[�����[�N�Ƀ\�t�g�J���҂͌Q����Ȃ�
openacc�ł���
http://www.planet3dnow.de/cms/14242-amd-praesentiert-excavator-und-carrizo-auf-der-isscc-2015/subpage-weitere-eckdaten-und-die-shot/
http://www.planet3dnow.de/cms/14242-amd-praesentiert-excavator-und-carrizo-auf-der-isscc-2015/subpage-schrumpfprozesse-und-layout-tricks/
�_�C�̉摜
�Ȃɂ���VCE��2��ɑ����Ă�̂�
http://www.planet3dnow.de/cms/14242-amd-praesentiert-excavator-und-carrizo-auf-der-isscc-2015/subpage-schrumpfprozesse-und-layout-tricks/
�_�C�̉摜
�Ȃɂ���VCE��2��ɑ����Ă�̂�
������c�q�͉����Ȃ��ĂȂ���A�P�ɃC���e���}���Z�[�̉Ԕ��X�e�}���Ă邾��
282 �F,,�E�L�́M�E,,�j��-�������F2015/02/25(��) 01:42:18.20 ID:7qe8aGsF
>>281
���Ȃ��͑��̕��Ƃ͈�����m�����������̂悤�Ȃ̂ł��f���������̂ł���
GitHub��HSA�̃R�[�h�́����Q�������Ȃ��͉̂��̂��Ǝv���܂����H
��5����̃\�t�g�E�F�A�͎����Ꭶ�����ȊO�ɂ���������̂ł����A
�����͂ǂ�Ȃ��̂��Ǝv���܂����H
���Ȃ��͑��̕��Ƃ͈�����m�����������̂悤�Ȃ̂ł��f���������̂ł���
GitHub��HSA�̃R�[�h�́����Q�������Ȃ��͉̂��̂��Ǝv���܂����H
��5����̃\�t�g�E�F�A�͎����Ꭶ�����ȊO�ɂ���������̂ł����A
�����͂ǂ�Ȃ��̂��Ǝv���܂����H
��r�Ώێ��̂���Ă���ǁB
�����ė���WEB�W�̃t���[�����[�N����ˁ[���B
�����ė���WEB�W�̃t���[�����[�N����ˁ[���B
�t���[�����[�N�̃v���W�F�N�g��
�h�L�������g���T���v�����̃v���W�F�N�g���r�Ƃ��ˁ[�킗
�h�L�������g���T���v�����̃v���W�F�N�g���r�Ƃ��ˁ[�킗
GCN can handle x86_64 threads providing
http://en.wikipedia.org/wiki/Graphics_Core_Next
http://en.wikipedia.org/wiki/Graphics_Core_Next
GCN uses a RISC SIMD not a VILW SIMD.
287 �F,,�E�L�́M�E,,�j��-�������F2015/02/25(��) 04:56:56.50 ID:7qe8aGsF
�����̃w�e���W�j�A�X��������t���[�����[�N�����\��Ȃ̂�
�h�L�������g��T���v�����x�����o���オ���ĂȂ��̂����O�炪�}���Z�[���Ă�
HSA�֘A�\�t�g�̎��ԂȂ�ł��������
���ł�ARM���Qualcomm���������Ă�Ƃ������ۓ����Ă�̂�AMD����
���ꂪAMD��HSA�ŋt�]���邱�Ƃ���Εs�\�ȏؖ������炾��B
JavaScript��Ruby�ɏ]�����Ă���v���O���}���唼�ŁA�ނ�͌�����GPU�����Ƀv���O�������������Ƃ͂Ȃ�
GPGPU���̂ɊS�������Ă�̂̓��[���h���C�h�ł�������قǂ����Ȃ��B
���ł����炱��watch���Ă�Ɩʔ�����
������������R�~�b�g�����
https://github.com/ispc/ispc/
�����Intel�̖T���v���W�F�N�g�ɂ��灚������AMD�̎�����t���[�����[�N���Ĉ�̂Ȃ�H
�h�L�������g��T���v�����x�����o���オ���ĂȂ��̂����O�炪�}���Z�[���Ă�
HSA�֘A�\�t�g�̎��ԂȂ�ł��������
���ł�ARM���Qualcomm���������Ă�Ƃ������ۓ����Ă�̂�AMD����
���ꂪAMD��HSA�ŋt�]���邱�Ƃ���Εs�\�ȏؖ������炾��B
JavaScript��Ruby�ɏ]�����Ă���v���O���}���唼�ŁA�ނ�͌�����GPU�����Ƀv���O�������������Ƃ͂Ȃ�
GPGPU���̂ɊS�������Ă�̂̓��[���h���C�h�ł�������قǂ����Ȃ��B
���ł����炱��watch���Ă�Ɩʔ�����
������������R�~�b�g�����
https://github.com/ispc/ispc/
�����Intel�̖T���v���W�F�N�g�ɂ��灚������AMD�̎�����t���[�����[�N���Ĉ�̂Ȃ�H
Cogent Computer Systems Announces Extended Temperature AMD G-Series SOC Quad-Core 1.1GHz
COM Express Type 10 With 4GB DDR3L Memory Supporting ECC
http://www.marketwired.com/press-release/-1994486.htm
COM Express Type 10 With 4GB DDR3L Memory Supporting ECC
http://www.marketwired.com/press-release/-1994486.htm
congatec extends availability of AMD processor-based Computer-on-Modules
http://www.congatec.com/en/congatec-ag/press-releases/article/congatec-extends-availability-of-amd-processor-based-computer-on-modules.html
http://www.congatec.com/en/congatec-ag/press-releases/article/congatec-extends-availability-of-amd-processor-based-computer-on-modules.html
290 �F,,�E�L�́M�E,,�j��-�������F2015/02/25(��) 05:15:11.27 ID:7qe8aGsF
HSA Foundation�{�Ɩ{�����烊���N����Ă�����J���c�[���Ȃ�ł����ǂ�
�Ȃ�ł��̂��܂Ȃ̂������o����l���܂����H
http://www.hsafoundation.com/hsa-developer-tools/
�Ȃ�ł��̂��܂Ȃ̂������o����l���܂����H
http://www.hsafoundation.com/hsa-developer-tools/
291 �F,,�E�L�́M�E,,�j��-�������F2015/02/25(��) 05:22:25.08 ID:7qe8aGsF
MS��AMD��Bolt�ł͂Ȃ�NVIDIA��Thrust���x�[�X��Parallel STL�̊J����
http://blogs.msdn.com/b/vcblog/archive/2014/04/16/parallel-stl-democratizing-parallelism-in-c.aspx
�J�����|�W�g���͂�����
https://parallelstl.codeplex.com
�܂�Bolt����Thrust�̗Ȗ͕탉�C�u�����ł͂���܂���
http://blogs.msdn.com/b/vcblog/archive/2014/04/16/parallel-stl-democratizing-parallelism-in-c.aspx
�J�����|�W�g���͂�����
https://parallelstl.codeplex.com
�܂�Bolt����Thrust�̗Ȗ͕탉�C�u�����ł͂���܂���
292 �F,,�E�L�́M�E,,�j��-�������F2015/02/25(��) 05:30:16.32 ID:7qe8aGsF
CUDA Thrust ��814
https://github.com/thrust/thrust
HSA Bolt ��153
https://github.com/HSA-Libraries/Bolt
�Ȃ�[���AGPGPU���̂����}�C�i�[���Ǝv����ł����
����Ȃ��̂ɗ\�Z��������A�����ƊJ���Ґl���̑���JavaScript��Ruby�̎��s���x��
�����Ȃ�悤��CPU�̉��ǂɃ��\�[�X�������ق���AMD�̏����̂��߂ɂȂ�̂�
�n���ł��킩���ȁH
https://github.com/thrust/thrust
HSA Bolt ��153
https://github.com/HSA-Libraries/Bolt
�Ȃ�[���AGPGPU���̂����}�C�i�[���Ǝv����ł����
����Ȃ��̂ɗ\�Z��������A�����ƊJ���Ґl���̑���JavaScript��Ruby�̎��s���x��
�����Ȃ�悤��CPU�̉��ǂɃ��\�[�X�������ق���AMD�̏����̂��߂ɂȂ�̂�
�n���ł��킩���ȁH
GCN is highly programmable.
Linux kernel: prefer graphics or HSA for VRAM.
http://lists.freedesktop.org/archives/dri-devel/2015-February/078078.html
http://lists.freedesktop.org/archives/dri-devel/2015-February/078078.html
295 �FSocket774�F2015/02/25(��) 06:04:27.15 ID:VAxPmYo+
���ǂ��悤�����ACPU���\��18������2�{�̎���͏I�������B
����6�N�O�̐��i�Ɠ���7�N���Ƃ���8�N���Ƃ����B
Intel��AMD�͓����������ł͂Ȃ���
���܂ł������y�U�ŋ����Ă����̍��̓��ł����Ŗ����O�_�O�_���������ȁB
Intel�ɃK�`�ōœK���Ȃ����v���O������Intel��荂���ɓ������͕̂s�\�B
AMD�ɃK�`�ōœK���Ȃ����v���O������AMD��荂���ɓ������͕̂s�\�B
Intel�̐��i�͊F���łɎ����Ă邩��AMD�̐��i����������B
���O�ɂ��ꉽ�S���Ă��������炵�����璼�ډ����AMD�X���ōr�炷�̂�߂�悤�������������ǁB
����6�N�O�̐��i�Ɠ���7�N���Ƃ���8�N���Ƃ����B
Intel��AMD�͓����������ł͂Ȃ���
���܂ł������y�U�ŋ����Ă����̍��̓��ł����Ŗ����O�_�O�_���������ȁB
Intel�ɃK�`�ōœK���Ȃ����v���O������Intel��荂���ɓ������͕̂s�\�B
AMD�ɃK�`�ōœK���Ȃ����v���O������AMD��荂���ɓ������͕̂s�\�B
Intel�̐��i�͊F���łɎ����Ă邩��AMD�̐��i����������B
���O�ɂ��ꉽ�S���Ă��������炵�����璼�ډ����AMD�X���ōr�炷�̂�߂�悤�������������ǁB
The iGPU will be an integral part of the processor just like the FPU.
GF 28nm process carrizo 12.4M transistors per mm^2
Intel 22nm process 8M transistors per mm^2
Intel 14nm process 16M transistors per mm^2
carrizo is somewhere inbetween Harwell and Broadwell in terms of transistor density.
Intel 22nm process 8M transistors per mm^2
Intel 14nm process 16M transistors per mm^2
carrizo is somewhere inbetween Harwell and Broadwell in terms of transistor density.
298 �FSocket774 �]�ڃ_��©2ch.net�F2015/02/25(��) 06:43:59.90 ID:lDJbGvOM
>>280
�@�ǂ����Ă��z�͈Ⴄ��B
�@�ǂ����Ă��z�͈Ⴄ��B
gpgpu��os��A�v���̊�������x�������Ȃ�킭����Ȃ�����
300 �F,,�E�L�́M�E,,�j��-�������F2015/02/25(��) 06:57:12.82 ID:7qe8aGsF
���܂ǂ��̗��s��̃C���^�v���^�����GPGPU�ɖ��炩�ɕs�����Ȃ��炳
���̓��������T�[�`���������ŁACPU�ɂ���ɓ��������g�����߂�g�ݍ����
�e���ꏈ���n�ɂ��̖��߂��g���悤�ɓ����������ق�������ۂnj��ݓI���Ǝv����
���̓��������T�[�`���������ŁACPU�ɂ���ɓ��������g�����߂�g�ݍ����
�e���ꏈ���n�ɂ��̖��߂��g���悤�ɓ����������ق�������ۂnj��ݓI���Ǝv����
301 �F,,�E�L�́M�E,,�j��-�������F2015/02/25(��) 07:01:25.51 ID:7qe8aGsF
CPU�̐������߂Ă邩��GPGPU�����̊J���c�[���ɑS�͂Ŏ��g��ł���Ă����Ȃ�܂��킩�邯��
�S�͏o���Ă��̂��܂��ĂȂ�Ȃ́H���Q�`�R�����ĂȂ�Ȃ́H
����A�_���e�N�m���W�[�̓T�^�B�n�܂�O�ɏI����Ă�B
�S�͏o���Ă��̂��܂��ĂȂ�Ȃ́H���Q�`�R�����ĂȂ�Ȃ́H
����A�_���e�N�m���W�[�̓T�^�B�n�܂�O�ɏI����Ă�B
���{�l�Ȃ�C���e���Q�t�H�����
Linux 3.19 kernel supports AMD's HSA kernel driver
http://community.amd.com/community/amd-blogs/amd-business/blog/2015/02/20/amd-innovations-move-upstream-in-the-linux-319-kernel
http://community.amd.com/community/amd-blogs/amd-business/blog/2015/02/20/amd-innovations-move-upstream-in-the-linux-319-kernel
AMD G-Series SoC Powers Fujitsu�fs Next Generation Mini-ITX System Design
http://community.amd.com/community/amd-blogs/amd-business/blog/2015/02/23/amd-g-series-soc-powers-fujitsu-s-next-generation-mini-itx-system-design
http://community.amd.com/community/amd-blogs/amd-business/blog/2015/02/23/amd-g-series-soc-powers-fujitsu-s-next-generation-mini-itx-system-design
�u���j�b�g������ƒ����d�́v�Ƃ���
���̐��̂��̂Ƃ͎v���Ȃ������@�������������ė��Ă���̂�����
ID�y�у��X�����𑝂₹�Α��₷�ق�
����������҂�HSA�M��������Ƃ��������Ȃ̂��낤
�ł��m��R�e�̓d�g�ŃX�����L�����Ȃ��Ď��Ă�
�����HSA�ւ̊��҂Ƃ͖��W�Ȃ��
���̐��̂��̂Ƃ͎v���Ȃ������@�������������ė��Ă���̂�����
ID�y�у��X�����𑝂₹�Α��₷�ق�
����������҂�HSA�M��������Ƃ��������Ȃ̂��낤
�ł��m��R�e�̓d�g�ŃX�����L�����Ȃ��Ď��Ă�
�����HSA�ւ̊��҂Ƃ͖��W�Ȃ��
306 �FSocket774�F2015/02/25(��) 07:52:30.59 ID:kwv2DzkD
���͂ނ�ɂ肩�����悤�Ƃ��Ȃ��Ă���
307 �FSocket774�F2015/02/25(��) 07:57:37.15 ID:VAxPmYo+
����pcwatch�̎�ނɊ����Ă��V�F�A100%(��)�ڎw���Ċ撣���Ă�
���Ă��̔��������}�C�N���������^�{�̃Q�t�H�~�[�݂����ȓz��������
�����ł������ɖ���������w
���Ă��̔��������}�C�N���������^�{�̃Q�t�H�~�[�݂����ȓz��������
�����ł������ɖ���������w
�c�q�͂킩���ĂȂ���
�^����������intel�ɏ��Ă�킯���Ȃ����낤
intel�ɏ��Ă�y�U�ŏ������Ă���AMD�Ɋ��H�������
intel�ɏ��Ă�y�U�͎��v�����Ȃ��H
����Ȃ��܂���������������
�^����������intel�ɏ��Ă�킯���Ȃ����낤
intel�ɏ��Ă�y�U�ŏ������Ă���AMD�Ɋ��H�������
intel�ɏ��Ă�y�U�͎��v�����Ȃ��H
����Ȃ��܂���������������
Tool&SDK�̒u���ꂪ�ς�����̂��m��Ȃ���
http://developer.amd.com/tools-and-sdks/
http://developer.amd.com/tools-and-sdks/
Khronos Updates OpenCL and SYCL Specifications for Heterogeneous Parallel Programming
Integration of developer feedback for improved application portability;Alignment with latest C++ developments
https://www.khronos.org/news/press/khronos-updates-opencl-and-sycl-specifications-for-heterogeneous-parallel-p
Integration of developer feedback for improved application portability;Alignment with latest C++ developments
https://www.khronos.org/news/press/khronos-updates-opencl-and-sycl-specifications-for-heterogeneous-parallel-p
>>305
���j�b�g���₷�����Ȃ����d�́i�Ɛ��\�j�͏オ�邯�ǁA
���j�b�g���₵�����N���b�N�Ɠd��������i���j�b�g���₷�O�Ɠ������\���Ɂj����d�͉����邾��B
���j�b�g���₷�����Ȃ����d�́i�Ɛ��\�j�͏オ�邯�ǁA
���j�b�g���₵�����N���b�N�Ɠd��������i���j�b�g���₷�O�Ɠ������\���Ɂj����d�͉����邾��B
312 �FSocket774�F2015/02/25(��) 08:38:30.57 ID:RotEqNik
�V�����������ɂ��Č�낤���ɂ��Ƃ���www
https://www.youtube.com/watch?v=IxGtV0CmsT0
https://www.youtube.com/watch?v=IxGtV0CmsT0
���̐��E�ł̓��j�b�g���₷�Ǝ����I�ɃN���b�N�Ɠd��������Ƃ����̂Ȃ�
����ɉ����čl����Ȃ�ID�ƃ��X�𑝂₳�����t���ȂɐT�d�Ɍ���Ă����
�]�̉�]�����܂茌�����㏸���ĉΕa�E�E�E����H
�r���܂ł͌����I�����Ǝv�������ǍŌオ��͂�َ�������
����ɉ����čl����Ȃ�ID�ƃ��X�𑝂₳�����t���ȂɐT�d�Ɍ���Ă����
�]�̉�]�����܂茌�����㏸���ĉΕa�E�E�E����H
�r���܂ł͌����I�����Ǝv�������ǍŌオ��͂�َ�������
>>313�����������Ă�̂��킩��Ȃ���
315 �FSocket774�F2015/02/25(��) 09:01:08.07 ID:kwv2DzkD
�����͓��{�ꂪ�I�J�V�C
�Ȃ̂ł���������
��������Ă͂����Ȃ�
�Ȃ̂ł���������
��������Ă͂����Ȃ�
����܂�邩�炩������Ă͂����Ȃ���������Ă͂����Ȃ��Ǝ����Ɍ�����������
�u����ȃ��[���m�������Ƃ���Ȃ�
����Ƃ����O�����̊Ǘ��l��JIM�ɋ��[�߂Ă�H�v
�ȂǂƊ����Ă킴�킴�֎~���ɐi�����ė���͎̂₵������Ȃ̂��H
�₵��Intel�X���ł��R�̑叫�������������Ă�X���ŃL��������ق���I�ԂƂ����̂�
�h���}�C
�u����ȃ��[���m�������Ƃ���Ȃ�
����Ƃ����O�����̊Ǘ��l��JIM�ɋ��[�߂Ă�H�v
�ȂǂƊ����Ă킴�킴�֎~���ɐi�����ė���͎̂₵������Ȃ̂��H
�₵��Intel�X���ł��R�̑叫�������������Ă�X���ŃL��������ق���I�ԂƂ����̂�
�h���}�C
New Module from GE Brings Benefits of COM Express Architecture to Harsh Environments
http://www.geautomation.com/news/new-module-ge-brings-benefits-com-express-architecture-harsh-environments-1
http://www.geautomation.com/news/new-module-ge-brings-benefits-com-express-architecture-harsh-environments-1
>>301
zen���J�������킯�����ǁB�B
zen���J�������킯�����ǁB�B
GCN Assembler for AMD GPUs
http://www.codeproject.com/Articles/872477/Assembler-for-AMD-s-GCN-GPU
http://www.codeproject.com/Articles/872477/Assembler-for-AMD-s-GCN-GPU
AMD�fS KAVERI HOLDS A SIGNIFICANT EDGE OVER INTEL IN ARRAYFIRE GPU BENCHMARKS
http://www.vrworld.com/2015/02/24/amds-kaveri-holds-significant-edge-intel-arrayfire-gpu-benchmarks/
http://www.vrworld.com/2015/02/24/amds-kaveri-holds-significant-edge-intel-arrayfire-gpu-benchmarks/
Nvidia���V�F�A76%���l���B 2014�N�̃r�f�I�J�[�h�s��
http://hibisaca.seesaa.net/article/414630595.html
http://hibisaca.seesaa.net/article/414630595.html
���{�Q�t�H84%�̎���
���{�l�Ȃ�C���e���Q�t�H�������
���{�l�Ȃ�C���e���Q�t�H�������
catalist�������H��������ƃX���[�v����̕��A���ł��Ȃ��Ȃ邩��O���{�������̂Ă�������B
�Q�t�H�����肵�Ă�
�Q�t�H�����肵�Ă�
�s�s���o�O�Ă���p�N����X�y���M�X�p�C�A���`�����͂Ȃ���
���{�l�Ȃ�C���e���Q�t�H���
���{�l�Ȃ�C���e���Q�t�H���
�N�A���R���ꊇ����
326 �FSocket774�F2015/02/25(��) 16:19:28.43 ID:lQ7ZMsaH
�P�O�N��́A�`�q�l�P�����Ǝv���ȁB
Voodoo���������悤�ɁARadeon��GeForce���ߋ��̂��̂ƂȂ�
Voodoo���������悤�ɁARadeon��GeForce���ߋ��̂��̂ƂȂ�
x86�Ƃ����̂̓R���V���[�}�[����T�[�o�AHPC�ւ�
�t�E�H�[�^�[�t�H�[���ŏ����Ă����A�[�L�e�N�`���[�Ȃ킯�����A
�����ւ���PC����^�u���b�g�ւƃE�H�[�^�[�t�H�[�����n�߂��킯���B
����ɑ���ARM�͋t�E�H�[�^�[�t�H�[����Intel�ɑR���Ȃ���Ȃ�Ȃ����A
ARM�R�A�͍ŏ����珬�����ă��o�C������PC�A�T�[�o�AHPC�ւƏオ���Ă���
�r�W�������S���`���Ȃ��B
��������BigLittle������̂�����ARM������ō�IPC�ȃR�A�����ׂ����B
�t�E�H�[�^�[�t�H�[���ŏ����Ă����A�[�L�e�N�`���[�Ȃ킯�����A
�����ւ���PC����^�u���b�g�ւƃE�H�[�^�[�t�H�[�����n�߂��킯���B
����ɑ���ARM�͋t�E�H�[�^�[�t�H�[����Intel�ɑR���Ȃ���Ȃ�Ȃ����A
ARM�R�A�͍ŏ����珬�����ă��o�C������PC�A�T�[�o�AHPC�ւƏオ���Ă���
�r�W�������S���`���Ȃ��B
��������BigLittle������̂�����ARM������ō�IPC�ȃR�A�����ׂ����B
328 �F,,�E�L�́M�E,,�j��-�������F2015/02/25(��) 16:46:35.52 ID:trFcfpxA
>>308
�����Ȃ��炻�̃��X�͉��̓����ɂ��Ȃ��Ă��Ȃ��ł���
���Ă�����Ɍ������Ă���Ƃ����̂Ȃ�킩�邯��
���́u���Ă�v�ƌ����ł���w�e���W�j�A�X�R���s���[�e�B���O�̕����ł���
GitHub�́��̐��������Intel���J�����Ă���ISPC��RiverTrail�Ȃǂ�
�l�C�������Ă���Ƃ������������͍ĎO�w�E���Ă��܂�
�܂����̌��������Ȃ��͐������F���ł��Ă��܂����H
ISPC�Ȃ�āAICC�Ȃǂ̐��n�����\�t�g�J���c�[��������Intel�ɂƂ��Ă�
�Ȃ�̖��ɗ������킩��Ȃ��T���v���W�F�N�g�ɉ߂��܂���
�����牽����`���Ă��Ȃ����A3�����x�́��������Ȃ�
����ł��قږ����̂悤�ɃR�~�b�g���O���d�Ȃ��Ă��܂�
AMD��HSA�͂����������������ƁA�v���O���~���O�����Ȃ��悤�Ȑl�ɂ܂�
�U�X��`���Ă���̂ɁAIntel�̖T���ɂ��牓���y�Ȃ����P�`�Q������
���|�W�g���̍X�V�p�x���y���ɏ��Ȃ��̂ł�
��̉�������Ȃ��̂ł����ˁH
�����A����l���Ȃ��Ă����ł���
�����݂̂Ȃ��Z�p�ɐH�����\�t�g�J���҂͂��Ȃ��Ƃ������ɓ�����O�̂��Ƃ�
������O�ɋN���Ă�̂����ɉ߂��Ȃ��̂ł�
������I���I�����_�ł����[�����[�Ǝ����グ���Ƃ����
�\�t�g�s�݂̃n�[�h�̓K���N�^�ɉ߂��܂���
�w�e���W�j�A�X�R���s���[�e�B���O�ŃC�j�V�A�e�B�u������Ƃ����̂ł����
�\�t�g�J���҂̎x���Ƃ������t�����K�v�Ȃ̂ł���
���̌���ɑ��锲�{�I�ȑŊJ�p�ӏo������Ŏ��̘b�����܂��傤�� 👀
�����Ȃ��炻�̃��X�͉��̓����ɂ��Ȃ��Ă��Ȃ��ł���
���Ă�����Ɍ������Ă���Ƃ����̂Ȃ�킩�邯��
���́u���Ă�v�ƌ����ł���w�e���W�j�A�X�R���s���[�e�B���O�̕����ł���
GitHub�́��̐��������Intel���J�����Ă���ISPC��RiverTrail�Ȃǂ�
�l�C�������Ă���Ƃ������������͍ĎO�w�E���Ă��܂�
�܂����̌��������Ȃ��͐������F���ł��Ă��܂����H
ISPC�Ȃ�āAICC�Ȃǂ̐��n�����\�t�g�J���c�[��������Intel�ɂƂ��Ă�
�Ȃ�̖��ɗ������킩��Ȃ��T���v���W�F�N�g�ɉ߂��܂���
�����牽����`���Ă��Ȃ����A3�����x�́��������Ȃ�
����ł��قږ����̂悤�ɃR�~�b�g���O���d�Ȃ��Ă��܂�
AMD��HSA�͂����������������ƁA�v���O���~���O�����Ȃ��悤�Ȑl�ɂ܂�
�U�X��`���Ă���̂ɁAIntel�̖T���ɂ��牓���y�Ȃ����P�`�Q������
���|�W�g���̍X�V�p�x���y���ɏ��Ȃ��̂ł�
��̉�������Ȃ��̂ł����ˁH
�����A����l���Ȃ��Ă����ł���
�����݂̂Ȃ��Z�p�ɐH�����\�t�g�J���҂͂��Ȃ��Ƃ������ɓ�����O�̂��Ƃ�
������O�ɋN���Ă�̂����ɉ߂��Ȃ��̂ł�
������I���I�����_�ł����[�����[�Ǝ����グ���Ƃ����
�\�t�g�s�݂̃n�[�h�̓K���N�^�ɉ߂��܂���
�w�e���W�j�A�X�R���s���[�e�B���O�ŃC�j�V�A�e�B�u������Ƃ����̂ł����
�\�t�g�J���҂̎x���Ƃ������t�����K�v�Ȃ̂ł���
���̌���ɑ��锲�{�I�ȑŊJ�p�ӏo������Ŏ��̘b�����܂��傤�� 👀
329 �FSocket774�F2015/02/25(��) 17:01:23.12 ID:4vhbBHvR
�X���[���肽�߂����
�܂��c�q�n�b�L����
331 �F,,�E�L�́M�E,,�j��-�������F2015/02/25(��) 17:51:27.09 ID:trFcfpxA
�����Ƃ����y�U�ŏ��ĂȂ�����ϑz�Ƃ����y�U�ŏ��̂ł��ˁA�킩��܂�
�m����
����Ȃ���
�͗{�؏�ɋA��
����Ȃ���
�͗{�؏�ɋA��
333 �F,,�E�L�́M�E,,�j��-�������F2015/02/25(��) 18:10:14.89 ID:trFcfpxA
�n�[�h���̃I�i�j�[���肫�Ŏ��Ђ̃\�t�g������čs���ĂȂ��̂�Cell�Ɠ����ł���
������Ђǂ��C�����܂���
������Ђǂ��C�����܂���
���l�̌��t���
����
����
335 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂����F2015/02/25(��) 18:43:08.40 ID:trFcfpxA
��ӂ�ӁiAMD�́j
��ӂ�Ӂi�Q�[���I�[�o�[�j
��ӂ�Ӂi�Q�[���I�[�o�[�j
GitHub����Git�i�v���O�����̍X�V�����Ǘ��j�̂��߂̃o�b�N�A�b�v��Web��ŏo����A�v���_
��SNS�Ƃ̂��Ƃ�
����ȃ��_�����ł܂����q���o�����̂��F�ڕs���Ȃ���
����͂Ƃ�����HSA���Ă̂̓v���O��������l�Ԃ��炷���
�K�����̂���Ȃ����̊Ԃɂ�����ƃR���p�C�����Ή����Ă���̂Ȃ��
����Ƃ����̂̓R���p�C������ŐF��Ȗ��߃Z�b�g�ɖ|���
C#�����Ċ�{�͒��Ԍ���ɑւ�邾��������
Itenium����Ax86����Ax64����A�̂悤�Ȋ����Ɏw����o����
GPU�͍����̓R�v���Z�b�T�ł���A�N�Z�����[�^�ł�����
OpenCL�Ȃǂ̓���ȒP��WAPI���g��Ȃ��Ǝ蓮�œ������Ȃ�����
VRAM���g���Ȃlj����牽�܂œ���Ŕ��ɂƂ����h��
���ꂪHSA�̒���hQ��GPU�̓R�v�����烁�C���Ɋi�グ���ꂽ
��̓R���p�C�������̖��߃Z�b�g�ɖ��ǂ����̖��ɂȂ����킯��
�uC#�̎g���������Ă��������I�v���Đl�͑������낤��
�uC#��Android�Ƀl�C�e�B�u�Ή���������@�����Ă��������I�v�Ƃ������l�͂܂����Ȃ�
����Ȃ��ƍl�������Ȃ����u�����MS�̎d�����v�Ɣ����Ă�l�Ԃ��̂ǂ��炩�����炾
��SNS�Ƃ̂��Ƃ�
����ȃ��_�����ł܂����q���o�����̂��F�ڕs���Ȃ���
����͂Ƃ�����HSA���Ă̂̓v���O��������l�Ԃ��炷���
�K�����̂���Ȃ����̊Ԃɂ�����ƃR���p�C�����Ή����Ă���̂Ȃ��
����Ƃ����̂̓R���p�C������ŐF��Ȗ��߃Z�b�g�ɖ|���
C#�����Ċ�{�͒��Ԍ���ɑւ�邾��������
Itenium����Ax86����Ax64����A�̂悤�Ȋ����Ɏw����o����
GPU�͍����̓R�v���Z�b�T�ł���A�N�Z�����[�^�ł�����
OpenCL�Ȃǂ̓���ȒP��WAPI���g��Ȃ��Ǝ蓮�œ������Ȃ�����
VRAM���g���Ȃlj����牽�܂œ���Ŕ��ɂƂ����h��
���ꂪHSA�̒���hQ��GPU�̓R�v�����烁�C���Ɋi�グ���ꂽ
��̓R���p�C�������̖��߃Z�b�g�ɖ��ǂ����̖��ɂȂ����킯��
�uC#�̎g���������Ă��������I�v���Đl�͑������낤��
�uC#��Android�Ƀl�C�e�B�u�Ή���������@�����Ă��������I�v�Ƃ������l�͂܂����Ȃ�
����Ȃ��ƍl�������Ȃ����u�����MS�̎d�����v�Ɣ����Ă�l�Ԃ��̂ǂ��炩�����炾
337 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂����F2015/02/25(��) 18:59:19.19 ID:NG5TN0mq
�܂����̕s���R�ȃ��i�r�[��40��j�[�g���i���Ă邪
VS2015�Ɏ����Ă�C#��Android�J������Xamarin�Ɋۓ����ł�
MS�͂����܂�Windows����
VS2015�Ɏ����Ă�C#��Android�J������Xamarin�Ɋۓ����ł�
MS�͂����܂�Windows����
�ؒc�q���܂��A���`AMD����L���Ă��
339 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂����F2015/02/25(��) 19:06:02.04 ID:NG5TN0mq
master���ʂɂ����ăo�b�N�A�b�v�ړI�ʼn^�p���Ă�Ȃ�Ȃ��l��clone���邾������
�����̊J���҂�GitHub���|�W�g����push���Ă邩��ˁB
������Ȃ�master�T�[�o�Ƃ��ĉ^�p���Ă��
�igit�Ǘ����ŊJ���������Ƃ���Ȃ�킩���ˁA���̈Ӗ��j
AMD��Stream SDK�Ɋ܂܂��Bolt�i���j���������GitHub�ɏオ���Ă���̂�Stable��
���E��������͕����l���ŊJ�������o���Ȃ�����킩��Ȃ����낤����
�������p�����������ƌ����Ă邾����������Ă����Ă�
�Ђ���Ƃ�����M���O�̂��肩������Ȃ���
�����̊J���҂�GitHub���|�W�g����push���Ă邩��ˁB
������Ȃ�master�T�[�o�Ƃ��ĉ^�p���Ă��
�igit�Ǘ����ŊJ���������Ƃ���Ȃ�킩���ˁA���̈Ӗ��j
AMD��Stream SDK�Ɋ܂܂��Bolt�i���j���������GitHub�ɏオ���Ă���̂�Stable��
���E��������͕����l���ŊJ�������o���Ȃ�����킩��Ȃ����낤����
�������p�����������ƌ����Ă邾����������Ă����Ă�
�Ђ���Ƃ�����M���O�̂��肩������Ȃ���
340 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂����F2015/02/25(��) 19:23:02.95 ID:NG5TN0mq
https://github.com/HSAFoundation/HSAIL-Tools/commits/master
��ӂ�Ӂicommit���O����ǂ������^�p���Ă邩�Ȃ�Ă����킩��̂Ɂj
��ӂ�Ӂi�����������R�Ő^������ڂ��B�����Ƃ���͈̂����ˁj
��ӂ�Ӂi�g�����ׂ�킩�邯�ǃR�~�b�^�͑S��AMD�Ј��j
��ӂ�Ӂicommit���O����ǂ������^�p���Ă邩�Ȃ�Ă����킩��̂Ɂj
��ӂ�Ӂi�����������R�Ő^������ڂ��B�����Ƃ���͈̂����ˁj
��ӂ�Ӂi�g�����ׂ�킩�邯�ǃR�~�b�^�͑S��AMD�Ј��j
341 �FSocket774�F2015/02/25(��) 19:24:57.47 ID:EP5mbbmL
������ŃX�����Ă邩�H
���̏������݂́A�����m���ɏ����Ă����B
���̏������݂́A�����m���ɏ����Ă����B
342 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂����F2015/02/25(��) 19:26:12.04 ID:NG5TN0mq
������AMD�Q����2ch����o�čs��
�u�ŋߓo�^�����v�Ƃ��������悤�ȋC�����邯��
�������̋L�����m���ł��̂�����
���n��⎞�c��ł��艿�l�ς�������Ԃ̂��̂������肷�邾�������
������
�u�A�Ԑ����A�v������҂ɒ�q���肵�ėL���V�ɂȂ��Ă���j�傳�ꂽ�v�Ƃ������Ⴊ
�u�����m�炸�̑���Ƀp�N���A�v������t���Ď���������Ԏ��������Č������I
��l�ŊJ���������Ǖ����ŊJ���������Ƃɂ��Ƃ��I�ȑf�ȃA�v�����l�b�g�ʼn�邾���̑���ƊJ���I�v
����Ȋ����ɕϊ����ꂿ�Ⴄ�ˑ���
�������̋L�����m���ł��̂�����
���n��⎞�c��ł��艿�l�ς�������Ԃ̂��̂������肷�邾�������
������
�u�A�Ԑ����A�v������҂ɒ�q���肵�ėL���V�ɂȂ��Ă���j�傳�ꂽ�v�Ƃ������Ⴊ
�u�����m�炸�̑���Ƀp�N���A�v������t���Ď���������Ԏ��������Č������I
��l�ŊJ���������Ǖ����ŊJ���������Ƃɂ��Ƃ��I�ȑf�ȃA�v�����l�b�g�ʼn�邾���̑���ƊJ���I�v
����Ȋ����ɕϊ����ꂿ�Ⴄ�ˑ���
�Ȃ��Ă�̂ɏ������ނƂ�
�����������Ǝv����
�����������Ǝv����
345 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂����F2015/02/25(��) 19:35:13.67 ID:NG5TN0mq
�܂���git���|�W�g����GitHub�����Ȃ��Ǝv���Ă�̂����̔n��
wiki=Wikipedia�Ȃ݂̔��z
wiki=Wikipedia�Ȃ݂̔��z
346 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂����F2015/02/25(��) 19:38:11.63 ID:NG5TN0mq
>>344
���̂Ƃ���Intel�X����HSA�}���Z�[�̓����������������݂������̂�
�����Ō����������Ă�邵���Ȃ��ł���
���܂���w���Ȃ�����
���̂Ƃ���Intel�X����HSA�}���Z�[�̓����������������݂������̂�
�����Ō����������Ă�邵���Ȃ��ł���
���܂���w���Ȃ�����
�����~���悤���Ȃ����x���œ������킗
>>292�Ƀ��X�BJavaScript�Ƃ����ău���E�U��œ������Ă킩���ˁH
���Ă��Ƃ́A�ǂ����������̓u���E�U����Ȃ�B
�܂�A�u���E�U���ł��̏�����GPGPU�g���悤�ɂ���Ȃ�Ή�����������삷���B
Ruby�����l�B���ɏo�Ă邯�ǃR���p�C�����őΉ�������́B
���̏�AGitHub���ǂ��������������ǁA�S���I�[�v���ł��Ǝv���Ă�́H
�s���̗ǂ�������͈͂łǂ������������ȑO�ɘ_���I�ɍl����B
���Ɩ��m�̂����ɒm�������ȃn�Q�B
Android��C#�ǂ������H
���XAndroid��Java�ł̊J�������Ή����ĂȂ����ǁB
�Ή�����Ȃ�MS����Ȃ���Google����B
>>292�Ƀ��X�BJavaScript�Ƃ����ău���E�U��œ������Ă킩���ˁH
���Ă��Ƃ́A�ǂ����������̓u���E�U����Ȃ�B
�܂�A�u���E�U���ł��̏�����GPGPU�g���悤�ɂ���Ȃ�Ή�����������삷���B
Ruby�����l�B���ɏo�Ă邯�ǃR���p�C�����őΉ�������́B
���̏�AGitHub���ǂ��������������ǁA�S���I�[�v���ł��Ǝv���Ă�́H
�s���̗ǂ�������͈͂łǂ������������ȑO�ɘ_���I�ɍl����B
���Ɩ��m�̂����ɒm�������ȃn�Q�B
Android��C#�ǂ������H
���XAndroid��Java�ł̊J�������Ή����ĂȂ����ǁB
�Ή�����Ȃ�MS����Ȃ���Google����B
�[���A,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂���
�E�E�E�E����������A�X���^�C�ǂ�
���ꂱ���A�w�������ƌ������肶��Ȃ�����
�E�E�E�E����������A�X���^�C�ǂ�
���ꂱ���A�w�������ƌ������肶��Ȃ�����
349 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂����F2015/02/25(��) 19:58:10.18 ID:NG5TN0mq
> ���̏�AGitHub���ǂ��������������ǁA�S���I�[�v���ł��Ǝv���Ă�́H
> �s���̗ǂ�������͈͂łǂ������������ȑO�ɘ_���I�ɍl����B
�����\�t�g�E�F�A�́u�N���[�Y�h�Łv���ʂɂ���Ƃł��H
�Ȃ�ł킴�킴����Ȏ��肭�ǂ����Ƃ���悗������
�_���I�ɍl������肦�Ȃ�
> Android��C#�ǂ������H
> ���XAndroid��Java�ł̊J�������Ή����ĂȂ����ǁB
> �Ή�����Ȃ�MS����Ȃ���Google����B
Mono for Android�J�����Ă�̂�MS�ł�Google�ł��Ȃ�Xamarin�����[��
> ���Ɩ��m�̂����ɒm�������ȃn�Q�B
�������g�Ɍ�������������
> �s���̗ǂ�������͈͂łǂ������������ȑO�ɘ_���I�ɍl����B
�����\�t�g�E�F�A�́u�N���[�Y�h�Łv���ʂɂ���Ƃł��H
�Ȃ�ł킴�킴����Ȏ��肭�ǂ����Ƃ���悗������
�_���I�ɍl������肦�Ȃ�
> Android��C#�ǂ������H
> ���XAndroid��Java�ł̊J�������Ή����ĂȂ����ǁB
> �Ή�����Ȃ�MS����Ȃ���Google����B
Mono for Android�J�����Ă�̂�MS�ł�Google�ł��Ȃ�Xamarin�����[��
> ���Ɩ��m�̂����ɒm�������ȃn�Q�B
�������g�Ɍ�������������
��́A>>276�̏����Č��݂����ƃ|�s�����[�ŐⒸ���ƌ����Ă������̂ŁAHSA�͂܂��t�����Ȃ��ǁB
���̕ӂ̈Ⴂ����킩��_�Œm���Ȃ����Č����Ă�悤�Ȃ����B
>>349
�����\�t�g�E�F�A����ˁ[���ǂ�����
���������Ⴂ�Ȃ��Ƃ�������Ȃ��̂�
���̕ӂ̈Ⴂ����킩��_�Œm���Ȃ����Č����Ă�悤�Ȃ����B
>>349
�����\�t�g�E�F�A����ˁ[���ǂ�����
���������Ⴂ�Ȃ��Ƃ�������Ȃ��̂�
�f�l��������ƌ������������ł�VS��Xamarin�̊ւ��͂łĂ���̂�
�S�R�b�����ݍ����ĂȂ���
�S�R�b�����ݍ����ĂȂ���
352 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂����F2015/02/25(��) 20:04:14.33 ID:NG5TN0mq
> �܂�A�u���E�U���ł��̏�����GPGPU�g���悤�ɂ���Ȃ�Ή�����������삷���B
> Ruby�����l�B���ɏo�Ă邯�ǃR���p�C�����őΉ�������́B
Ruby�̃��|�W�g���悭�ǂ��Ă邯��GPGPU�ɑΉ��Ȃ�ĕ��������Ƃ��Ȃ����ǂ�
AMD�����́H
�u�Ή�����ł���v�Ȃ�ĉ��ł�������B�N������ĂȂ��B
matz�Ƀ��N�G�X�g����H
JavaScript�G���W����IE�ȊO�̃u���E�U�̓I�[�v���\�[�X�ł���Ă邩��킩�邾��
GPGPU��G�̕������Ȃ��B
Node.js��Chrome�Ɏg���Ă�̂Ɠ���V8�x�[�X������悭�G���ˁA���̃R�[�h�B
Intel��RiverTrail��Firefox�́u�v���O�C���v�ɉ߂��Ȃ��B
��������Firefox��HTML5�Ή��T�C�g����n�u���ĂĂ����܂Ƃ��Ɏg���ĂȂ����
�i���Ƃ���Hotmail����܂Ƃ��ɊJ����j
> Ruby�����l�B���ɏo�Ă邯�ǃR���p�C�����őΉ�������́B
Ruby�̃��|�W�g���悭�ǂ��Ă邯��GPGPU�ɑΉ��Ȃ�ĕ��������Ƃ��Ȃ����ǂ�
AMD�����́H
�u�Ή�����ł���v�Ȃ�ĉ��ł�������B�N������ĂȂ��B
matz�Ƀ��N�G�X�g����H
JavaScript�G���W����IE�ȊO�̃u���E�U�̓I�[�v���\�[�X�ł���Ă邩��킩�邾��
GPGPU��G�̕������Ȃ��B
Node.js��Chrome�Ɏg���Ă�̂Ɠ���V8�x�[�X������悭�G���ˁA���̃R�[�h�B
Intel��RiverTrail��Firefox�́u�v���O�C���v�ɉ߂��Ȃ��B
��������Firefox��HTML5�Ή��T�C�g����n�u���ĂĂ����܂Ƃ��Ɏg���ĂȂ����
�i���Ƃ���Hotmail����܂Ƃ��ɊJ����j
353 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂����F2015/02/25(��) 20:05:16.72 ID:NG5TN0mq
354 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂����F2015/02/25(��) 20:09:04.25 ID:NG5TN0mq
AMD�������U�X��`���Ă�Bolt(��)������GitHub�ɏオ���Ă�ߎS�Ȃ���Ȃ��ǂ�
�ʂɉ����������̂����݂���́H
http://www.4gamer.net/games/147/G014731/20130827001/
�ʂɉ����������̂����݂���́H
http://www.4gamer.net/games/147/G014731/20130827001/
355 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂����F2015/02/25(��) 20:11:45.80 ID:NG5TN0mq
Aparapi�͂�������
https://code.google.com/p/aparapi/
https://code.google.com/p/aparapi/
356 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂����F2015/02/25(��) 20:14:49.10 ID:NG5TN0mq
�v���O������g�܂Ȃ����m�ȃG���h���[�U�[����Ƀz�������͓̂��ӂ����
�u���K�[�����̕���i�j�͊J�����NJJ���Ҍ����̃Z�~�i�[���J���Ȃ�
IT���e���V�̒Ⴂ�f�l�����܂����������n�b�^����ƁA���ꂪAMD
�u���K�[�����̕���i�j�͊J�����NJJ���Ҍ����̃Z�~�i�[���J���Ȃ�
IT���e���V�̒Ⴂ�f�l�����܂����������n�b�^����ƁA���ꂪAMD
>>351
Xamarin���Ă̂�iOS��Android�p�̃A�v�������R�[�h��C#�ł�����悤�ɂ�����́B
Xamarin�ł͊Ԃ�Mono����ē��삳���Ă�B
��������ۂ�iOS��Objective-C��Swift�AAndroid��Java�ł�����{�I�ɓ����Ȃ��B
������n�߂���Android��C#�������Ȃ�J�����Ă���Google��C#�œ����悤��VM���������Ȃ��Ƃ����Ȃ��B
���̕ӂ������ł��ĂȂ���B��b�m�����S���Ȃ��B
>>352-353
���ƑΉ����邩�ۂ��̓��|�W�g���̊J���ґ��Ȃ�ŁB�S�����킹�Ă����Ǝv���Ă�H
���ƁAWebCL���Ă����Ă�H�m���̂��낤�ȁBWeb���GPGPU�s���d�g�݂���B������܂��t�����őΉ����Ă�̂�FF���炢�B
angular.js�͂����S�����ō���͏��X�ɐ��ނ��邾���B���̎����VirtualDOM�Ȃ�ŁB
Xamarin���Ă̂�iOS��Android�p�̃A�v�������R�[�h��C#�ł�����悤�ɂ�����́B
Xamarin�ł͊Ԃ�Mono����ē��삳���Ă�B
��������ۂ�iOS��Objective-C��Swift�AAndroid��Java�ł�����{�I�ɓ����Ȃ��B
������n�߂���Android��C#�������Ȃ�J�����Ă���Google��C#�œ����悤��VM���������Ȃ��Ƃ����Ȃ��B
���̕ӂ������ł��ĂȂ���B��b�m�����S���Ȃ��B
>>352-353
���ƑΉ����邩�ۂ��̓��|�W�g���̊J���ґ��Ȃ�ŁB�S�����킹�Ă����Ǝv���Ă�H
���ƁAWebCL���Ă����Ă�H�m���̂��낤�ȁBWeb���GPGPU�s���d�g�݂���B������܂��t�����őΉ����Ă�̂�FF���炢�B
angular.js�͂����S�����ō���͏��X�ɐ��ނ��邾���B���̎����VirtualDOM�Ȃ�ŁB
�ŁH���Ă���
Intel�Ƃ̏����͉c�Ɨ͂̏����������
�Œ�ł�Intel�Ɠ����̋����g��Ȃ��Ə����ɂȂ�Ȃ�
���̍��͐��\�ŕ₦�邯�ǁA�����͂�10�{�Ⴄ�Ɛ��\�����{�ł��A�V�F�A����5�{�ɂȂ邾��
�Œ�ł�Intel�Ɠ����̋����g��Ȃ��Ə����ɂȂ�Ȃ�
���̍��͐��\�ŕ₦�邯�ǁA�����͂�10�{�Ⴄ�Ɛ��\�����{�ł��A�V�F�A����5�{�ɂȂ邾��
360 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂����F2015/02/25(��) 20:30:44.78 ID:NG5TN0mq
WebCL�͏����O�Ȃ�Android�ł��v���O�C���œ�������Google Play����r���ς�
�t�����ǂ��납�o�����ł���
���ꂩ�畁�y�Ƃ��������炗������
�t�����ǂ��납�o�����ł���
���ꂩ�畁�y�Ƃ��������炗������
iOS�ł�C�n�Ȃ瓮�����Ȃ����Ƃ��Ȃ����LjӖ����Ȃ��ˁB
����Ȃ�n�߂���Objective-C�g�������������B
>>359
����ȁB�Ƌ֖@�X���X���̍s���N�����ăV�F�A�L��������ȁB
INTEL�̎����W�߂Đ����v���Z�X�u�[�X�g��P4����ɓd���グ�Đ��\�������Ă��̂ƒʂ�����̂������B
AMD�͍��㎟��B�Q�[���@�͗���AMD�����B
���Ƀn�[�h�E�F�A�̐i���ɂ͍��掿�̃Q�[�����K�v�s��������ˁB
����Ȃ�n�߂���Objective-C�g�������������B
>>359
����ȁB�Ƌ֖@�X���X���̍s���N�����ăV�F�A�L��������ȁB
INTEL�̎����W�߂Đ����v���Z�X�u�[�X�g��P4����ɓd���グ�Đ��\�������Ă��̂ƒʂ�����̂������B
AMD�͍��㎟��B�Q�[���@�͗���AMD�����B
���Ƀn�[�h�E�F�A�̐i���ɂ͍��掿�̃Q�[�����K�v�s��������ˁB
�v�������ǒc�q���ăX�}�z�W���������B
�X�}�z�̑O��̘b�����B
�X�}�z�̑O��̘b�����B
363 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂����F2015/02/25(��) 20:35:39.27 ID:NG5TN0mq
���܂ǂ��p�\�R���\�t�g���\�t�g�J���̎嗬�Ƃ��������炗������
Web�J���l���̂ق������|�I�ɑ�����������킩�邾��
Web�J���l���̂ق������|�I�ɑ�����������킩�邾��
>>357
�ǂ��ł��������nj��X�̓l�C�e�B�u�̘b�Ȃ���
Android NDK��Google�̂��̂�����C#��.NETFramework��MS�̂��̂���
����̏��L�҂����߃Z�b�g�ɃR���p�C���Ή������Ă���
C#�l�C�e�B�u����Android�ɔ��W�������Ȃ�MS�̗̈悾�낤
�ǂ��ł��������nj��X�̓l�C�e�B�u�̘b�Ȃ���
Android NDK��Google�̂��̂�����C#��.NETFramework��MS�̂��̂���
����̏��L�҂����߃Z�b�g�ɃR���p�C���Ή������Ă���
C#�l�C�e�B�u����Android�ɔ��W�������Ȃ�MS�̗̈悾�낤
>>363
�n�[�h�̍őO����PC�̕��Ȃ̂ɂ����ے肵�Ă鎞�_�Ō�鎑�i�Ȃ��ˁB
�X�}�z���ǂ��������������A����̗���ɂ��Ă����ĂȂ��B
������angular.js���t�����Ƃ��ˁ[��B�o���̑啪�O����B
>>364
�J���v���W�F�N�g�ɎQ�����Ă�Ȃ炻�ꂪ�ʂ��邯�ǁA�Q�����ĂȂ��݂���������ʂ����B
MS�I�ɂ�Windows Mobile�����������肽�����낤���B��C�����ǁB
�n�[�h�̍őO����PC�̕��Ȃ̂ɂ����ے肵�Ă鎞�_�Ō�鎑�i�Ȃ��ˁB
�X�}�z���ǂ��������������A����̗���ɂ��Ă����ĂȂ��B
������angular.js���t�����Ƃ��ˁ[��B�o���̑啪�O����B
>>364
�J���v���W�F�N�g�ɎQ�����Ă�Ȃ炻�ꂪ�ʂ��邯�ǁA�Q�����ĂȂ��݂���������ʂ����B
MS�I�ɂ�Windows Mobile�����������肽�����낤���B��C�����ǁB
366 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂����F2015/02/25(��) 20:45:04.84 ID:NG5TN0mq
Android��C#��MS�Ƃ������o�����n���͒N���悗������
Mono��MS�Ƃ͊W�Ȃ��Ƃ���ŃI�[�v���\�[�X�ŏ���Ɏn�܂����v���W�F�N�g��
�����Android�ɈڐA�����̂�����܂�MS�Ƃ͑S���W�Ȃ����
Mono��MS�Ƃ͊W�Ȃ��Ƃ���ŃI�[�v���\�[�X�ŏ���Ɏn�܂����v���W�F�N�g��
�����Android�ɈڐA�����̂�����܂�MS�Ƃ͑S���W�Ȃ����
367 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂����F2015/02/25(��) 20:48:17.21 ID:NG5TN0mq
> �n�[�h�̍őO����PC�̕��Ȃ̂ɂ����ے肵�Ă鎞�_�Ō�鎑�i�Ȃ��ˁB
�c�O�Ȃ���\�t�g�̍őO���ł͂Ȃ�
���̃g�����h��IoT�ƃr�b�O�f�[�^
�R���V���[�}�ɐG���Ƃ���ł̓E�F�A���u���[����ԍڏ��[��
�T�[�o�T�C�h�ł͂�荂�x�ȃf�[�^��͂�
�p�\�R���̓X�}�z�ŎB�肽�߂��ʐ^�̓��ꕨ����
�ق��ł��Ȃ�PC���[�J�[�����������������]��ł�B
�c�O�Ȃ���\�t�g�̍őO���ł͂Ȃ�
���̃g�����h��IoT�ƃr�b�O�f�[�^
�R���V���[�}�ɐG���Ƃ���ł̓E�F�A���u���[����ԍڏ��[��
�T�[�o�T�C�h�ł͂�荂�x�ȃf�[�^��͂�
�p�\�R���̓X�}�z�ŎB�肽�߂��ʐ^�̓��ꕨ����
�ق��ł��Ȃ�PC���[�J�[�����������������]��ł�B
���߁��f�[�^�����p�����MS��Intel�ɂȂ邾�낤����
C#��Itanium�ɑΉ�����̂́uMS��Intel�����߃Z�b�g�ɑΉ����邩��v�ł͂Ȃ�
�uMS��Intel������v�Ƃ������_�ɂȂ��Ē�����
C#��Itanium�ɑΉ�����̂́uMS��Intel�����߃Z�b�g�ɑΉ����邩��v�ł͂Ȃ�
�uMS��Intel������v�Ƃ������_�ɂȂ��Ē�����
>>367
�I���͕��ʂɃ\�t�g�̍őO���ł���ƁB
Docker�Ƃ�OpenStack�Ƃ��������S���Ⴄ���ǂȁB
�Ƃ������őO������Ȃ��Ƃ���Ȃ�Ăˁ[���ǁB
�I���͕��ʂɃ\�t�g�̍őO���ł���ƁB
Docker�Ƃ�OpenStack�Ƃ��������S���Ⴄ���ǂȁB
�Ƃ������őO������Ȃ��Ƃ���Ȃ�Ăˁ[���ǁB
370 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂����F2015/02/25(��) 20:57:11.82 ID:NG5TN0mq
Windows Mobile�i�j
�Ƃ�����CE�J�[�l�����ł��Ă邼
�ǂ�����̊T�O�����Ă�
Angular�͐��������[�X����܂�2�N������Ƃ����o���ĂȂ���
MVC�t���[�����[�N�ǂ��납�܂�jQuery���o���o���g���Ă邭�炢��
Rails�v���W�F�N�g�Ŗ{�i�I�Ɏg����悤�ɂȂ����̂������ŋ߂̂���
VirtualDOM�i�j�Ȃ�Ă܂��e���`���Ȃ����炗
�Ƃ�����CE�J�[�l�����ł��Ă邼
�ǂ�����̊T�O�����Ă�
Angular�͐��������[�X����܂�2�N������Ƃ����o���ĂȂ���
MVC�t���[�����[�N�ǂ��납�܂�jQuery���o���o���g���Ă邭�炢��
Rails�v���W�F�N�g�Ŗ{�i�I�Ɏg����悤�ɂȂ����̂������ŋ߂̂���
VirtualDOM�i�j�Ȃ�Ă܂��e���`���Ȃ����炗
�V���O�����\���̒c�q����^���邭�炢������A�X�}�t�H�Ƃ���web�A�v����i7�̃V���O�����\����Ȃ��Ɩ����Ȃ��炢�d���낤��
����Ȃ��T�N�T�N����ARM���Ă̂͂ǂꂭ�炢�����\�Ȃ낤��
����������Power8�Ƃ����SnapDragon�̕��������\�Ȃ̂���
win7�̃\�t�g���T�N�T�N�����Ă邤����APU���Aweb�A�v���͏d������낤��
����Ȃ��T�N�T�N����ARM���Ă̂͂ǂꂭ�炢�����\�Ȃ낤��
����������Power8�Ƃ����SnapDragon�̕��������\�Ȃ̂���
win7�̃\�t�g���T�N�T�N�����Ă邤����APU���Aweb�A�v���͏d������낤��
>>370
WEB�n�͑�̎O�N�o������O�̋Z�p���g���Ȃ��Ȃ��Ă����ŁA�������ނ��邵���Ȃ������B
jQuery�͉��p�͈͍L�����AWEB�W�̋Z�p���������ꂽ���C�u�����������O�̕��ނɓ��邯�ǂ������X�ɐ��ނ��Ă��Ă�B
VirtualDOM�̃����b�g��DOM��������炵�ĕ����炷�_������m���ɍ���͂��̌n���Ɉڂ�B���͊����̃��C�u�����Ƒ����ň��ȓ_�����B
WEB�n�͑�̎O�N�o������O�̋Z�p���g���Ȃ��Ȃ��Ă����ŁA�������ނ��邵���Ȃ������B
jQuery�͉��p�͈͍L�����AWEB�W�̋Z�p���������ꂽ���C�u�����������O�̕��ނɓ��邯�ǂ������X�ɐ��ނ��Ă��Ă�B
VirtualDOM�̃����b�g��DOM��������炵�ĕ����炷�_������m���ɍ���͂��̌n���Ɉڂ�B���͊����̃��C�u�����Ƒ����ň��ȓ_�����B
�ԈႦ��
>>368�͓��ɔ���ɂȂ��ĂȂ���
����P�̂▽�߃A�[�L�e�N�`���͒N�̂��̂ł��Ȃ���
�����炱���N�ł��R���p�C���͍��邯��
C#�łقڑO�������.NETFramework�i���C�Z���X�j��MS�̂��̂��낤��
C#���炻�̂܂܋@�B��ɂ����̂�MS����
C#�R���p�C����MS����I�[�v���\�[�X�Ƃ��āu���J�v���ꂽ
�b�߂���HSA�͗Ⴆ��Ȃ炱�����������ł�����
�uHSA�ŃA�v���g�݂����v�Ǝv���Ă�
�uHSA�̍u�������́H���HOpenCL�݂����Ȃ���Ȃ��́H������H�v
�ȂǂƎv����悤�Ȃ��̂���
�M�ӂ���v���O���}�������C�g�w����荞�ނ��߂̂���
�u�}���`�X���b�h�݂����ɊȒP��GPGPU�o����炵������g���Ă݂邩�v
���ꂪ�_��
>>368�͓��ɔ���ɂȂ��ĂȂ���
����P�̂▽�߃A�[�L�e�N�`���͒N�̂��̂ł��Ȃ���
�����炱���N�ł��R���p�C���͍��邯��
C#�łقڑO�������.NETFramework�i���C�Z���X�j��MS�̂��̂��낤��
C#���炻�̂܂܋@�B��ɂ����̂�MS����
C#�R���p�C����MS����I�[�v���\�[�X�Ƃ��āu���J�v���ꂽ
�b�߂���HSA�͗Ⴆ��Ȃ炱�����������ł�����
�uHSA�ŃA�v���g�݂����v�Ǝv���Ă�
�uHSA�̍u�������́H���HOpenCL�݂����Ȃ���Ȃ��́H������H�v
�ȂǂƎv����悤�Ȃ��̂���
�M�ӂ���v���O���}�������C�g�w����荞�ނ��߂̂���
�u�}���`�X���b�h�݂����ɊȒP��GPGPU�o����炵������g���Ă݂邩�v
���ꂪ�_��
374 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂����F2015/02/25(��) 21:23:53.28 ID:NG5TN0mq
>>371
�����m��Ȃ���Kaveri��7850K�l�ł��̒��x������ȁA��@���͎������ق�������
�����AMD�X���̉ߋ����O�����p
> 801 �FSocket774�F2014/08/10(��) 18:10:18.38 ID:vSpEcDpT
> �u���E�U�̐��\��}��x���`��PC�̐��\��}�낤�Ƃ���s���̋^�₾���ǂ�
> �܂������A�N�̑�D����google�l���p�ӂ���JavaScript�x���` Octane�ł������Ă�������
> �N���G�C�^�[���ɗ����Ă���N��PC�Ȃ瓖�R���̐����͔�����킯�����琥����Ă݂Ă����
> http://i.imgur.com/6hYFKS9.png
�u�m�[�gPC�v�p��Core i3�ɂ�������AMD�t���O�V�b�v���Ēp������������
http://viploader.net/ippan/src/vlippan337251.png
�����m��Ȃ���Kaveri��7850K�l�ł��̒��x������ȁA��@���͎������ق�������
�����AMD�X���̉ߋ����O�����p
> 801 �FSocket774�F2014/08/10(��) 18:10:18.38 ID:vSpEcDpT
> �u���E�U�̐��\��}��x���`��PC�̐��\��}�낤�Ƃ���s���̋^�₾���ǂ�
> �܂������A�N�̑�D����google�l���p�ӂ���JavaScript�x���` Octane�ł������Ă�������
> �N���G�C�^�[���ɗ����Ă���N��PC�Ȃ瓖�R���̐����͔�����킯�����琥����Ă݂Ă����
> http://i.imgur.com/6hYFKS9.png
{kind=link}
�u�m�[�gPC�v�p��Core i3�ɂ�������AMD�t���O�V�b�v���Ēp������������
http://viploader.net/ippan/src/vlippan337251.png
{kind=link}
>>371
�C�ɂȂ��Ē��ׂĂ݂����ǎv������萫�\�������������B�Â�����f�[�^�����獡�Ȃ�C2D�����ȁH
http://dench.flatlib.jp/opengl/cpubench
>>374
�f�[�^�o���Ȃ炱�����o��HAGE
http://www.cpubenchmark.net/high_end_cpus.html
�C�ɂȂ��Ē��ׂĂ݂����ǎv������萫�\�������������B�Â�����f�[�^�����獡�Ȃ�C2D�����ȁH
http://dench.flatlib.jp/opengl/cpubench
>>374
�f�[�^�o���Ȃ炱�����o��HAGE
http://www.cpubenchmark.net/high_end_cpus.html
376 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂����F2015/02/25(��) 21:29:10.42 ID:NG5TN0mq
������CPU�\�����Ƃ���
http://imgur.com/PikO8Yh
http://imgur.com/PikO8Yh
>>376
http://cpuboss.com/cpus/Intel-Core-i7-4930K-vs-Intel-Core-i3-4000M
http://cpuboss.com/cpus/Intel-Core-i3-4000M-vs-AMD-FX-9590
http://cpuboss.com/cpus/Intel-Core-i7-4930K-vs-AMD-FX-9590
http://cpuboss.com/cpus/Intel-Core-i3-4000M-vs-AMD-A10-7850K
�{���������B�V���O���R�A�����Ȃ瑼��CPU�Ƃ����ĕς���ˁ[���B
FX�͌Â��A�[�L�e�N�`���̂܂܂����B
http://cpuboss.com/cpus/Intel-Core-i7-4930K-vs-Intel-Core-i3-4000M
http://cpuboss.com/cpus/Intel-Core-i3-4000M-vs-AMD-FX-9590
http://cpuboss.com/cpus/Intel-Core-i7-4930K-vs-AMD-FX-9590
http://cpuboss.com/cpus/Intel-Core-i3-4000M-vs-AMD-A10-7850K
�{���������B�V���O���R�A�����Ȃ瑼��CPU�Ƃ����ĕς���ˁ[���B
FX�͌Â��A�[�L�e�N�`���̂܂܂����B
378 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂����F2015/02/25(��) 21:39:26.76 ID:NG5TN0mq
PassMark���ĉ����v��������̂Ȃ́H
Octane��Web�A�v���Ŏ��ۂɎg���Ă�R�[�h���x�[�X�ɂ��Ă���B
Octane��Web�A�v���Ŏ��ۂɎg���Ă�R�[�h���x�[�X�ɂ��Ă���B
�Ó������Ȃ̂���r���Ă݂����ǁA������V���O���ȊO�����Ă�ˁ[��
http://cpuboss.com/cpus/Intel-Core-i5-4200M-vs-AMD-A10-7850K
>>378
http://www.passmark.com/products/pt.htm
�����ɂ����Ă���B
http://cpuboss.com/cpus/Intel-Core-i5-4200M-vs-AMD-A10-7850K
>>378
http://www.passmark.com/products/pt.htm
�����ɂ����Ă���B
380 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂����F2015/02/25(��) 21:46:59.13 ID:NG5TN0mq
���܂ǂ��̃A�v���̎嗬�ł��Ȃ�ł��Ȃ������B
�N���E�h��Office�Ƃ�AutoDesk360�Ȃ�Web�u���E�U�Ŏ��s����킯������
�u���E�U���\�����d�v����
�u���E�U��HSA�ɑΉ�����Α����Ȃ邾���H
�Ȃ�@������@���@���@���@�Ɓ@��@���@�ā@�݁@��@��
�m�[�gPC�ɕ�����f�X�N�g�b�vCPU�A���ꂪAMD�N�I���e�B
�N���E�h��Office�Ƃ�AutoDesk360�Ȃ�Web�u���E�U�Ŏ��s����킯������
�u���E�U���\�����d�v����
�u���E�U��HSA�ɑΉ�����Α����Ȃ邾���H
�Ȃ�@������@���@���@���@�Ɓ@��@���@�ā@�݁@��@��
�m�[�gPC�ɕ�����f�X�N�g�b�vCPU�A���ꂪAMD�N�I���e�B
��������
382 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂����F2015/02/25(��) 21:48:27.02 ID:NG5TN0mq
���O����
383 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂����F2015/02/25(��) 21:50:17.61 ID:NG5TN0mq
Google Chrome��
https://developers.google.com/octane/?hl=ja
�����s���Ă��O��̍ŋ�PC�̃X�R�A�\���Ă��������܂����H
�C���X�g�[�����Ȃ��������
�u���E�U�Ŏ��s�{�^�������Ă��Ă������ʑ҂����B
https://developers.google.com/octane/?hl=ja
�����s���Ă��O��̍ŋ�PC�̃X�R�A�\���Ă��������܂����H
�C���X�g�[�����Ȃ��������
�u���E�U�Ŏ��s�{�^�������Ă��Ă������ʑ҂����B
�@��i7�ł�IE11����i3�ǂ��납A10-7850K�ȉ��̃X�R�A��������
���ۂɎg���Ă�Chrome���IE11�̕������K�Ȋ�������������g���Ă����ǂ�
���͂₱�̃N���X��CPU����JavaScript�������\�������獂���Ă��덷���x���ɂȂ��Ă��܂��̂���
���ۂɎg���Ă�Chrome���IE11�̕������K�Ȋ�������������g���Ă����ǂ�
���͂₱�̃N���X��CPU����JavaScript�������\�������獂���Ă��덷���x���ɂȂ��Ă��܂��̂���
385 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂����F2015/02/25(��) 21:57:26.18 ID:NG5TN0mq
IE11��JS�G���W����SunSpider�ɓ��������œK�������Ă邯��Octane��Kraken���Ɖ�œI������ˁ[
SunSpider�������̃��[�N���[�h�ɑ����ĂȂ����Ă̂͂���B
���Ƃ���JavaScript��nbody�Ƃ����ʂ��Ȃ�����
SunSpider�������̃��[�N���[�h�ɑ����ĂȂ����Ă̂͂���B
���Ƃ���JavaScript��nbody�Ƃ����ʂ��Ȃ�����
>>384
��������IE11��Chrome����X�R�A����ׁ[��BIE�͑�̔��������łȂ��B
����Ȃ̂Ő��\�����Ƃ��ˁ[��B���C�̍�������ˁ[��
���ꂱ���u���E�U��HSA�ɍœK�������畳�����Ȃ�ؖ�����ˁ[���B
���S�Ƀu���E�U���̍œK����̍��ł��B�{���ɂ��肪�Ƃ��������܂����B
��������IE11��Chrome����X�R�A����ׁ[��BIE�͑�̔��������łȂ��B
����Ȃ̂Ő��\�����Ƃ��ˁ[��B���C�̍�������ˁ[��
���ꂱ���u���E�U��HSA�ɍœK�������畳�����Ȃ�ؖ�����ˁ[���B
���S�Ƀu���E�U���̍œK����̍��ł��B�{���ɂ��肪�Ƃ��������܂����B
387 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂����F2015/02/25(��) 22:03:15.57 ID:NG5TN0mq
> �u���E�U��HSA�œK��������
�����炻��Ȃ��肦�Ȃ�����̘b�������炫�肪�Ȃ�����
�����炻��Ȃ��肦�Ȃ�����̘b�������炫�肪�Ȃ�����
388 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂����F2015/02/25(��) 22:03:48.81 ID:NG5TN0mq
>>386
�ŁA�X�R�A�͂����炾�����́H�˂�������
�ŁA�X�R�A�͂����炾�����́H�˂�������
��Ђ�i5+HDD����������J�N�J�N�ŃX�g���X�����o�C
�����APU+SSD�͉�����Ă��T�N�T�N�y��
�܂�Intel�̓N�\���Ă��ƂŌ��_���o��
�����APU+SSD�͉�����Ă��T�N�T�N�y��
�܂�Intel�̓N�\���Ă��ƂŌ��_���o��
>>387-388
�����炻���ړI�ɊJ�����Ă���B�u���E�U���g���Ă�R���p�C�����Ή������炻����g���Ă���u���E�U�������I�ɍ����������B
http://cloud.watch.impress.co.jp/docs/column/virtual/20131227_629232.html
����͎蓮�ł��Ȃ��Ƃ��߂݂��������ǂȁB
���ɕ����o�����x���`���ʂ����_�̓V���O���R�A�̃X�R�A�͂ǂ��ł��������Ă��ƂɂȂ���B
�Ȃ�ŃR�A�����₷�������ɂȂ����Ǝv���Ă�H
���\�L�тȂ�����R�A���₷�����ɂ������낤�ɁB
���O���ĕ��������ɂȂ�Ƃ����������ˁB
�����炻���ړI�ɊJ�����Ă���B�u���E�U���g���Ă�R���p�C�����Ή������炻����g���Ă���u���E�U�������I�ɍ����������B
http://cloud.watch.impress.co.jp/docs/column/virtual/20131227_629232.html
����͎蓮�ł��Ȃ��Ƃ��߂݂��������ǂȁB
���ɕ����o�����x���`���ʂ����_�̓V���O���R�A�̃X�R�A�͂ǂ��ł��������Ă��ƂɂȂ���B
�Ȃ�ŃR�A�����₷�������ɂȂ����Ǝv���Ă�H
���\�L�тȂ�����R�A���₷�����ɂ������낤�ɁB
���O���ĕ��������ɂȂ�Ƃ����������ˁB
391 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂����F2015/02/25(��) 22:30:26.98 ID:NG5TN0mq
AMD���u���v�Ƃ��������Ƃ����܂łǂꂾ���B�����ꂽ��
�������Ƃ��x���ŗ��ĕ����C�ɂ��Ȃ��
�������Ƃ��x���ŗ��ĕ����C�ɂ��Ȃ��
�Ƃ肠���������Ƃ��܂��ˁO�O
�c�_�Łu�����v���^���t�����Ă���v�l���@30�p�^�[��
http://gigazine.net/news/20150213-logical-fallacy-collection/
�c�_�Łu�����v���^���t�����Ă���v�l���@30�p�^�[��
http://gigazine.net/news/20150213-logical-fallacy-collection/
> AMD��Analyst Day�̓x�ɁA�O�N��Analyst Day�Ŕ��\�����R�[�h�l�[���̔�����j���A
> �V���ɑ����̃R�[�h�l�[���\����B
http://pc.watch.impress.co.jp/docs/column/kaigai/20120203_509658.html
�E�\�A��U���A�}�M�����V�C
�n�i�V�����̍��\�t�A���h_��(�_�
> �V���ɑ����̃R�[�h�l�[���\����B
http://pc.watch.impress.co.jp/docs/column/kaigai/20120203_509658.html
�E�\�A��U���A�}�M�����V�C
�n�i�V�����̍��\�t�A���h_��(�_�
394 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂����F2015/02/25(��) 22:33:00.95 ID:NG5TN0mq
> ���������̌����Ă��Ȃ��o����l�I�Ȏ�����A�������l������̂̂悤�Ɏ�藧�Ăđi���邱�ƁB
������̓T�^��
�����炻���ړI�ɊJ�����Ă���B�u���E�U���g���Ă�R���p�C�����Ή������炻����g���Ă���u���E�U�������I�ɍ����������B
������̓T�^��
�����炻���ړI�ɊJ�����Ă���B�u���E�U���g���Ă�R���p�C�����Ή������炻����g���Ă���u���E�U�������I�ɍ����������B
7700k��20557
>>394
���O�Ɍ����Q������̂͂悭�킩����
���O�Ɍ����Q������̂͂悭�킩����
397 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂����F2015/02/25(��) 22:35:22.71 ID:NG5TN0mq
�������q�ϓI�Ɍ����Ȃ��c�O�Ȑl�̂悤��
398 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂����F2015/02/25(��) 22:39:30.42 ID:NG5TN0mq
���O���������ł���\�t�g�G���W�j�A���Ǝv���Ȃ�
AMD�̍ŋ��̐��Y�����ւ�Bolt�i�j���g���ĉ����\�t�g�J�����Ă݂Ă����
�Ȃ�Ȃ�Qiita�ɓ��e���Ă����
HSA��Mantle���܂�AMD�֘A�̋Z�p�͂܂��������e���Ȃ����H
AMD�̍ŋ��̐��Y�����ւ�Bolt�i�j���g���ĉ����\�t�g�J�����Ă݂Ă����
�Ȃ�Ȃ�Qiita�ɓ��e���Ă����
HSA��Mantle���܂�AMD�֘A�̋Z�p�͂܂��������e���Ȃ����H
�c�q�u�������q�ϓI�Ɍ����Ȃ��c�O�Ȑl�̂悤��(�د�v
>>375>>377>>379�����đS�͂œ����邗
���̋q�ϓI�Ɍ�����l����
Mantle�Ȃ�BF4�g���Ă邵�A���̏�DX12�ɓ���@�\���g�ݍ��܂�܂���������
>>375>>377>>379�����đS�͂œ����邗
���̋q�ϓI�Ɍ�����l����
Mantle�Ȃ�BF4�g���Ă邵�A���̏�DX12�ɓ���@�\���g�ݍ��܂�܂���������
400 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂����F2015/02/25(��) 22:46:11.64 ID:NG5TN0mq
����Web�A�v���̃l�^�U��ꂽ����Octane�̃X�R�A�\�������H
PassMark���ĉ��̖��ɗ��̂������ς�킩���̂����H
PassMark���ĉ��̖��ɗ��̂������ς�킩���̂����H
401 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂����F2015/02/25(��) 22:47:13.73 ID:NG5TN0mq
�Ȃ��AMD�̋Z�p��Qiita��GitHub�̂悤�ȋZ�p���L�T�C�g�Ől�C���Ȃ��̂�
402 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂����F2015/02/25(��) 22:50:28.54 ID:NG5TN0mq
�悵���߂�
Mantle API�ɂ���Qiita�ɉ���L���������Ă��Ă�
��������N�̖]�݂̃x���`�}�[�N�Ƃ��Ă�����
Mantle API�ɂ���Qiita�ɉ���L���������Ă��Ă�
��������N�̖]�݂̃x���`�}�[�N�Ƃ��Ă�����
���ɍ\���̂�
�܂��r��
�Ƃ������A���܂��ɍ\���l�����邱�Ƃ�����
�������Șb��
�܂��r��
�Ƃ������A���܂��ɍ\���l�����邱�Ƃ�����
�������Șb��
404 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂����F2015/02/25(��) 22:54:18.41 ID:NG5TN0mq
�uHSA�Ή�����Α����Ȃ�v�i�د
���Ă̂͌N�݂�����F�����N�o�g���u������Γ���Ɏ�v���Ă����悤�Ȃ��̂ł���
���Ă̂͌N�݂�����F�����N�o�g���u������Γ���Ɏ�v���Ă����悤�Ȃ��̂ł���
�A���`������Ӗ��t�@���̂���
�{���ɋ����̖����Ȃ����l�͋����Ă䂭�̂�
�{���ɋ����̖����Ȃ����l�͋����Ă䂭�̂�
406 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂����F2015/02/25(��) 22:59:56.36 ID:NG5TN0mq
�ǂ����uMS��Windows Mobile�肽�����Ă�v�Ƃ������Ԏ��̐l�Ƃ͘b�����ݍ���Ȃ��悤��
408 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂����F2015/02/25(��) 23:04:55.13 ID:NG5TN0mq
��������AMD�ɂ��̎�̃\�t�g�ւ̍����ł���Ȃ�
SSE5���XOP���͍L�����y���Ă�͂��Ȃ��
�����ςݏd�Ȃ茤���J����E��������ł��悢������������
���ꂩ��u�{�C�o���v���Ĕ��z���j�[�g���낗����
SSE5���XOP���͍L�����y���Ă�͂��Ȃ��
�����ςݏd�Ȃ茤���J����E��������ł��悢������������
���ꂩ��u�{�C�o���v���Ĕ��z���j�[�g���낗����
���{�l�Ȃ�C���e���Q�t�H�������
�Ȃ��ځ[�炯�Ȃ���
An interesting query now arises.
The c urrent design actually makes the CPU a bit more GPU like than tradition.
Apparently, the inverse could hold true for the GPU as well.
http://wccftech.com/amd-carrizo-apu-benchmark-skus-spotted/
�ق�Ƃ��ځ`�炯���
The c urrent design actually makes the CPU a bit more GPU like than tradition.
Apparently, the inverse could hold true for the GPU as well.
http://wccftech.com/amd-carrizo-apu-benchmark-skus-spotted/
�ق�Ƃ��ځ`�炯���
�h�h���A����I
413 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂����F2015/02/26(��) 02:28:34.40 ID:dBK/G9XF
��ӂ�Ӂi�����Ȃ����I�j
��ӂ�Ӂi���ꂢ�ȉԉł���I�j
��ӂ�Ӂi���ꂢ�ȉԉł���I�j
�����̒c�q����
415 �FSocket774�F2015/02/26(��) 04:11:36.58 ID:mruFzKS9
���̏ꍇ�������ځ[����
���̂܂ܔ��������Ă�
���̂܂ܔ��������Ă�
>>409
NVIDIA��GeForce GTX 970�́uVRAM3.5GB���v�ői������
http://gigazine.net/news/20150225-nvidia-lawsuit-gtx-970/
NVIDIA��GeForce GTX 970�́uVRAM3.5GB���v�ői������
http://gigazine.net/news/20150225-nvidia-lawsuit-gtx-970/
417 �FSocket774�F2015/02/26(��) 09:06:30.57 ID:yLY6qIxO
���܁[
�����970������������\�����o�Ă����킢
�����970������������\�����o�Ă����킢
�uGeForce GTX 970��VRAM 3.5GB���v�ɂ���NVIDIA������Jen-Hsun Huang���������\
http://www.4gamer.net/games/274/G027467/20150225053/
�u�R�������Ƃ͔F�߂��A�����������������̂f�o�t�͂����v�������낗�v
http://www.4gamer.net/games/274/G027467/20150225053/
�u�R�������Ƃ͔F�߂��A�����������������̂f�o�t�͂����v�������낗�v
�������Ƃ���
�E3GB�ȏチ�����ς݂���������3.5GB�{0.5GB
�E512MB�͂���܂�g��Ȃ��f�[�^�̈ꎞ�ۊǓI�ȏꏊ
���ۂ�
�E512MB�ɂ悭�g���f�[�^���z�u���ꂿ����Ă�
��
�E���撣���Ă��
����Ȋ�����
�E3GB�ȏチ�����ς݂���������3.5GB�{0.5GB
�E512MB�͂���܂�g��Ȃ��f�[�^�̈ꎞ�ۊǓI�ȏꏊ
���ۂ�
�E512MB�ɂ悭�g���f�[�^���z�u���ꂿ����Ă�
��
�E���撣���Ă��
����Ȋ�����
> �Ƃ��낪�A���̏ڍׂɂ��ĎГ��̃}�[�P�e�B���O�̃`�[���ɏ\���ɓ`����Ă��炸�A
> �ЊO�ɑ��Ă��A���i���\���A���i�����r���[���Ă����������X�ɂ�����Ɠ`����Ă��܂���ł����B
�`���ĂȂ��������h���C�o�ʼnB�����������[�U�[���C�t���܂ł̔��N�Ԉ�ؒ������Ȃ������̂ɂ��̌�������
�ق��970��(�����x���̂�)�����v����
> �ЊO�ɑ��Ă��A���i���\���A���i�����r���[���Ă����������X�ɂ�����Ɠ`����Ă��܂���ł����B
�`���ĂȂ��������h���C�o�ʼnB�����������[�U�[���C�t���܂ł̔��N�Ԉ�ؒ������Ȃ������̂ɂ��̌�������
�ق��970��(�����x���̂�)�����v����
good design��
>>408
�V�������̂���XOP�Ή��̂��̂�������ǁA����avx�̏㐟�ݐ�%���낤�ˁi����AVX��SSE�V���[�Y�̐�%�̏㐟�ݒ��x�j�B
���Ă�����SIMD�Ƃ��Ĕėp�I�Ɏg������̂�AVX�ɍ������āA���̎c�肾����
�V�������̂���XOP�Ή��̂��̂�������ǁA����avx�̏㐟�ݐ�%���낤�ˁi����AVX��SSE�V���[�Y�̐�%�̏㐟�ݒ��x�j�B
���Ă�����SIMD�Ƃ��Ĕėp�I�Ɏg������̂�AVX�ɍ������āA���̎c�肾����
���{�l�Ȃ�C���e���Q�t�H������˂�
425 �FSocket774�F2015/02/26(��) 15:07:14.29 ID:yLY6qIxO
�ł������Ȃ����甃�����Ⴄ���ǂ�
���{�l�Ȃ�C���e���Q�t�H�������
���{�Q�t�H84%�̎���
���{�Q�t�H84%�̎���
>>419
��h���C�o�̌��J�͒��~�B
����������̃R���|�[�l���g�Ɋւ���s��́A�d�l�ł��B
�ŁA�Ƃ����ɏI��������Ƃ��āA���{�ł͔̔����i�ւ̉e��0�������ȁB
��h���C�o�̌��J�͒��~�B
����������̃R���|�[�l���g�Ɋւ���s��́A�d�l�ł��B
�ŁA�Ƃ����ɏI��������Ƃ��āA���{�ł͔̔����i�ւ̉e��0�������ȁB
GeForce�̃X�y�b�N�Ɍ�L���������Ƃ��āA���ꂪ�̈ӂ������Ƃ��Ă��A
RADEON�̃��b�p��h���C�o���܂Ƃ��ɂȂ�킯�ł͂Ȃ��̂�
RADEON�̃��b�p��h���C�o���܂Ƃ��ɂȂ�킯�ł͂Ȃ��̂�
�D���Ȃ̔������������
�P�Ɍ����������邽�߂Ƀ��f�̓h���C�o���[���b�p���[���Ă����Ă邾������
�P�Ɍ����������邽�߂Ƀ��f�̓h���C�o���[���b�p���[���Ă����Ă邾������
�N�����Ԕ������ϑz�Ō��������g���b�v���Ă�AMD�t�@���{�[�C���悭������
���������������Ă����炵���Ȃ�����ǂ�����
���������������Ă����炵���Ȃ�����ǂ�����
���{�l�Ȃ�C���e���Q�t�H������˂�
�C���e���Q�t�H����Intel��GeForce���ĈӖ������
����Ȃ��̂��g���Ă�Ɠd�g���ɂȂ邼�I����
����͂��̎��H�����Ȃ낤����
��������Intel��GeForce���g���Ă�ƐM���Ă鎞�_�Ŗϑz�̊C�ɓۂ܂�Ă���
����Ȃ��̂��g���Ă�Ɠd�g���ɂȂ邼�I����
����͂��̎��H�����Ȃ낤����
��������Intel��GeForce���g���Ă�ƐM���Ă鎞�_�Ŗϑz�̊C�ɓۂ܂�Ă���
>>425
�}�X�R�~�ɂ˂�����ł�̂��A�S������Ȃ�����b���͒l���������Ȃ�ł�?
�܂����̂��o�Ă��čɏ����ΏۂɂȂ�Α����͒l��������邾�낤���ǁB
�}�X�R�~�ɂ˂�����ł�̂��A�S������Ȃ�����b���͒l���������Ȃ�ł�?
�܂����̂��o�Ă��čɏ����ΏۂɂȂ�Α����͒l��������邾�낤���ǁB
Nvidia���V�������\������݂�����
http://wccftech.com/nvidia-launching-gaming-platform-3rd-march-2015/
����Ȃ�Tegra�A����ɂ���Ȃ�Android�A�n�u��ꂽ�Q�[���v���b�g�t�H�[��
�R���S�����������Ƃɂ��Ď蒆�Ɏ��߂����݂�����
http://wccftech.com/nvidia-launching-gaming-platform-3rd-march-2015/
����Ȃ�Tegra�A����ɂ���Ȃ�Android�A�n�u��ꂽ�Q�[���v���b�g�t�H�[��
�R���S�����������Ƃɂ��Ď蒆�Ɏ��߂����݂�����
NVIDIA�ߋ��ō��̔�����L�^
�����v�͑O�N��43%����6��3,059���h��
GeForce�ASHIELD�A�ԍڌ����v���b�g�t�H�[���AGRID�ATesla�ȂǑS���ʓI�ɍD��������
AMD��Ԏ�
��������4��300���h��
AMD�ɂ���2015�N��1�l������15%�̔��㌸��\�����Ă���
�@�@�@�@ ��
( ߄t�)��
�����v�͑O�N��43%����6��3,059���h��
GeForce�ASHIELD�A�ԍڌ����v���b�g�t�H�[���AGRID�ATesla�ȂǑS���ʓI�ɍD��������
AMD��Ԏ�
��������4��300���h��
AMD�ɂ���2015�N��1�l������15%�̔��㌸��\�����Ă���
�@�@�@�@ ��
( ߄t�)��
�݂��AMD�D����������
���ꂾ���̈��������Intel�Ȃ�ēG����Ȃ��̂�
���ꂾ���̈��������Intel�Ȃ�ēG����Ȃ��̂�
>>436
���Ⴀ�N���܂��ŏ��Ƀh���h�������Ȃ�h���h���h��
���Ⴀ�N���܂��ŏ��Ƀh���h�������Ȃ�h���h���h��
���N�̍��\�̎�����
�@���Ε���قLj��s���o�Ă�������
�@���Ε���قLj��s���o�Ă�������
hsa���\
stream���\
mantle���\
stream���\
mantle���\
���䂦�ɐl�͋ꂵ�܂˂Ȃ�ʁI
970���\�AG�V���N���\�AGameWorks���\�ATegra���\
�܂�ō��\�̃o�[�Q���Z�[������
�܂�ō��\�̃o�[�Q���Z�[������
�ڂԂ��q�������P�Q�W�A�R�c�@�\�ڂf�e�R�̂��납�炎�u�͎��샆�[�U�[�ɍ������Ƃ����Ă�����ˁB
havok���\��
Physx���\�͍�������
�܂���SSE��AVX����Ȃ�x87�ʼn��Z����Ƃ�
�܂���SSE��AVX����Ȃ�x87�ʼn��Z����Ƃ�
���ɂȂ�����gpu�ŕ������������z���f�I����
Tegra�͎ԍڂɊ��H�����o�������Ȃ��B
APU�����p���������āE�E�E����Q�[��������ɓ����邩������Ȃ�����
�����̓J�o�[�ł��ĂȂ��̂���ۂ������ȁB
APU�����p���������āE�E�E����Q�[��������ɓ����邩������Ȃ�����
�����̓J�o�[�ł��ĂȂ��̂���ۂ������ȁB
���H�ɂ͑S�R�����Ȃ���
�Q�[������ǂ��o����āA�X�}�t�H���ᑊ��ɂ���Ȃ��A�d���Ȃ�����ԍڂɎg���Ă��炤
�i�X�ǂ��l�߂��Ă����Ă�悤�ɂ��������Ȃ�
�����ɗ��č����970���\�����������
�{�ۂ�PC�Q�[���ŕs�M��������Ă����オ�Ȃ��C
AMD�́A���v���낤�ƐԎ����낤�ƁA������̊J�����������肫���������Ă邩��A����ۂ͌��Ђ��Ȃ���
��Nvidia�ɂ̓n�C�G���h��390x�p�ӂ��Ă邵�A��Intel�ɂ�32�R�A��Opteron�p�ӂ��Ă邵�AHPC�����Ƀn�C�G���hAPU���J�����Ă�
�I�}�P��ARM�s������ɁAx86�Ƃ̃R���p�`��SkyBridge�����������o��
�S���ʂŁA�K�`�ŏ��Ă�z�w��p�ӂ��Ă��AMD��
��́ADX12���}���`GPU��iGPU�����p�ł���悤�ɂȂ�APC�Q�[���s����͂����ނ��Ƃ��o����
�Q�[������ǂ��o����āA�X�}�t�H���ᑊ��ɂ���Ȃ��A�d���Ȃ�����ԍڂɎg���Ă��炤
�i�X�ǂ��l�߂��Ă����Ă�悤�ɂ��������Ȃ�
�����ɗ��č����970���\�����������
�{�ۂ�PC�Q�[���ŕs�M��������Ă����オ�Ȃ��C
AMD�́A���v���낤�ƐԎ����낤�ƁA������̊J�����������肫���������Ă邩��A����ۂ͌��Ђ��Ȃ���
��Nvidia�ɂ̓n�C�G���h��390x�p�ӂ��Ă邵�A��Intel�ɂ�32�R�A��Opteron�p�ӂ��Ă邵�AHPC�����Ƀn�C�G���hAPU���J�����Ă�
�I�}�P��ARM�s������ɁAx86�Ƃ̃R���p�`��SkyBridge�����������o��
�S���ʂŁA�K�`�ŏ��Ă�z�w��p�ӂ��Ă��AMD��
��́ADX12���}���`GPU��iGPU�����p�ł���悤�ɂȂ�APC�Q�[���s����͂����ނ��Ƃ��o����
AMD����Geode�������ł�炩������NV��50000000000�{�}�V�������̂����ɑg�ݍ������ł��������Ă��邾�낤
����A�g�ݍ������͂������ɖ�������c
QNAP�AGE�A�x�m�ʂƋ}��Embedded�̗p�������Ă��Ă͂���
QNAP and AMD TVS-863+ Golden Cloud Turbo vNAS Launched
Read more at http://benchmarkreviews.com/24510/qnap-amd-tvs-863-golden-cloud-turbo-vnas-launched/
New Module from GE Brings Benefits of COM Express Architecture to Harsh Environments
http://www.geautomation.com/news/new-module-ge-brings-benefits-com-express-architecture-harsh-environments-1
AMD G-Series SoC Powers Fujitsu�fs Next Generation Mini-ITX System Design
http://community.amd.com/community/amd-blogs/amd-business/blog/2015/02/23/amd-g-series-soc-powers-fujitsu-s-next-generation-mini-itx-system-design
Dental Assistance Device Adopts 3D Visualization with AMD Embedded G-Series APUs
http://www.amd.com/Documents/54942A-White-Lion-Dental-Case-Study.pdf
Enea Linux and System Management on the ARMv8-based AMD Embedded R-Series Processor
http://news.cision.com/enea-ab/r/enea-linux-and-system-management-on-the-armv8-based-amd-embedded-r-series-processor,c9725766
congatec extends availability of AMD processor-based Computer-on-Modules
http://www.congatec.com/en/congatec-ag/press-releases/article/congatec-extends-availability-of-amd-processor-based-computer-on-modules.html
QNAP and AMD TVS-863+ Golden Cloud Turbo vNAS Launched
Read more at http://benchmarkreviews.com/24510/qnap-amd-tvs-863-golden-cloud-turbo-vnas-launched/
New Module from GE Brings Benefits of COM Express Architecture to Harsh Environments
http://www.geautomation.com/news/new-module-ge-brings-benefits-com-express-architecture-harsh-environments-1
AMD G-Series SoC Powers Fujitsu�fs Next Generation Mini-ITX System Design
http://community.amd.com/community/amd-blogs/amd-business/blog/2015/02/23/amd-g-series-soc-powers-fujitsu-s-next-generation-mini-itx-system-design
Dental Assistance Device Adopts 3D Visualization with AMD Embedded G-Series APUs
http://www.amd.com/Documents/54942A-White-Lion-Dental-Case-Study.pdf
Enea Linux and System Management on the ARMv8-based AMD Embedded R-Series Processor
http://news.cision.com/enea-ab/r/enea-linux-and-system-management-on-the-armv8-based-amd-embedded-r-series-processor,c9725766
congatec extends availability of AMD processor-based Computer-on-Modules
http://www.congatec.com/en/congatec-ag/press-releases/article/congatec-extends-availability-of-amd-processor-based-computer-on-modules.html
�̂�AMD�͐����ݔ�����ɍX�V���Ă�����Â����i����낤�Ǝv���Ă����Ȃ��������
���͐����͊O���Ȃ̂ł��ł��Â����i������
���������Ӗ��ł͐̂��g�ݍ������͔���₷��������
���Ƃ͐M�p
���͐����͊O���Ȃ̂ł��ł��Â����i������
���������Ӗ��ł͐̂��g�ݍ������͔���₷��������
���Ƃ͐M�p
�Q�[���@���g���݂���
�\�j�[��MS���ƊE�̎x�z�������ĕK��������ȁA�M�p�o���Ȃ��_���ȂƂ���Ȃ�̗p�����
���N�͍X�ɕʂ̃Q�[���@�Ɛ��N��10���h���̌_�炵����
����ɁAMatrox�ƒ�g���Ĉ�Õ���ɂ��i�o���Ă�
���܂ł�CPU�Ƃ��Ă���������AIntel��ARM�ɑ����ł��o���������������ŁA
GPU���Ȃ瑼�̒ǐ��������Ȃ�����A�ŋߍ̗p�������Ă����Ă�
�\�j�[��MS���ƊE�̎x�z�������ĕK��������ȁA�M�p�o���Ȃ��_���ȂƂ���Ȃ�̗p�����
���N�͍X�ɕʂ̃Q�[���@�Ɛ��N��10���h���̌_�炵����
����ɁAMatrox�ƒ�g���Ĉ�Õ���ɂ��i�o���Ă�
���܂ł�CPU�Ƃ��Ă���������AIntel��ARM�ɑ����ł��o���������������ŁA
GPU���Ȃ瑼�̒ǐ��������Ȃ�����A�ŋߍ̗p�������Ă����Ă�
>>452
CPU����Intel�̖W�Q��ז�������������ȁA�����Ɏs���ǂ��Ă��܂�
�����Ǎ���iGPU����ARM�����ł̗̍p�������Ă��Ă邩��A�����̒N���ז����邱�Ƃ��o���Ȃ�
�G�����Ȃ�����ł̗̍p������A���y�������قǃE�n�E�n�ɂȂ��Ă���
CPU����Intel�̖W�Q��ז�������������ȁA�����Ɏs���ǂ��Ă��܂�
�����Ǎ���iGPU����ARM�����ł̗̍p�������Ă��Ă邩��A�����̒N���ז����邱�Ƃ��o���Ȃ�
�G�����Ȃ�����ł̗̍p������A���y�������قǃE�n�E�n�ɂȂ��Ă���
�܂��A���ꂾ
x86�̎��Y�͖c��ŁA�ŋ߂̓O���t�B�b�N���ʂ̎��v�������Ă��ĂāAx86+Radeon��APU�̓h���s�V���͂܂���
�O���t�B�b�N���_����Intel��Ax86����Ȃ�Nvidia�͂��Ăт���Ȃ�
ARM���ʂ̎��v�������Ă��Ă邯�ǁA�I������Opteron�̃m�E�n�E���݂��낤���A
�����\�g���݂Ƃ��ł�SkyBridge��x86�̃m�E�n�E��ARM�Ɋ��p�������Ƃ����v�]�����肻��
x86�̎��Y�͖c��ŁA�ŋ߂̓O���t�B�b�N���ʂ̎��v�������Ă��ĂāAx86+Radeon��APU�̓h���s�V���͂܂���
�O���t�B�b�N���_����Intel��Ax86����Ȃ�Nvidia�͂��Ăт���Ȃ�
ARM���ʂ̎��v�������Ă��Ă邯�ǁA�I������Opteron�̃m�E�n�E���݂��낤���A
�����\�g���݂Ƃ��ł�SkyBridge��x86�̃m�E�n�E��ARM�Ɋ��p�������Ƃ����v�]�����肻��
�K�`�̑g�ݍ��ݐ�����͂܂��M������Ȃ����낤���ǁA
������������Intel�݊��ł���K�v�����܂�Ȃ��B
AMD���Ȃ��Ȃ��̗p����Ȃ��̂͒P��Atom�Ƃ̋��������邩��B
������������Intel�݊��ł���K�v�����܂�Ȃ��B
AMD���Ȃ��Ȃ��̗p����Ȃ��̂͒P��Atom�Ƃ̋��������邩��B
���������A�P�̎ICPU��Opteron�����C�Ȃ������
AMD�͎������x���Ă���郁�[�J�[�̋��ׂ����̂��ƍl���Ȃ���Ђ��Ċ����������
�����������łȂ��̂ɕ��y���i��3�̃\�P
Kaveri���t�łĂ��V�`�b�v�Z�b�g�Ȃ�����������A�����������v�������ĂȂ���MB����܂蔄��Ȃ�����
FX�ɂ������Ă͉��ŐV�KMB�w�����ď��Ȃ����낤��
TDP220W�T�|�[�g����
MB���[�J�[���
AMD�͎������x���Ă���郁�[�J�[�̋��ׂ����̂��ƍl���Ȃ���Ђ��Ċ����������
�����������łȂ��̂ɕ��y���i��3�̃\�P
Kaveri���t�łĂ��V�`�b�v�Z�b�g�Ȃ�����������A�����������v�������ĂȂ���MB����܂蔄��Ȃ�����
FX�ɂ������Ă͉��ŐV�KMB�w�����ď��Ȃ����낤��
TDP220W�T�|�[�g����
MB���[�J�[���
CPU�ł̋������C�����ƁA�u�����h�⎑���͂���ʂŕ�����
��������Intel�͏����߂Ȃ�A�^�_�Ńo���܂��ĔN�Ԑ��\���̐Ԏ��������Ȃ�����A�����関����������
�����A�O���t�B�b�N������ł���ƁA����ȃn���f���S�����Ӗ��ɂȂ邩��̗p�������Ă���
��������Intel�͏����߂Ȃ�A�^�_�Ńo���܂��ĔN�Ԑ��\���̐Ԏ��������Ȃ�����A�����関����������
�����A�O���t�B�b�N������ł���ƁA����ȃn���f���S�����Ӗ��ɂȂ邩��̗p�������Ă���
{kind=link}
>>367
���p�\�R���̓X�}�z�ŎB�肽�߂��ʐ^�̓��ꕨ����
���ق��ł��Ȃ�PC���[�J�[�����������������]��ł�B
�����甄��Ȃ���o�J����˂��̂���������������������������
�R���V���[�}�ł��}���`���f�B�A�Ɋւ��鐫�\�����߂Ă�l�����邵
����Ă�����Ђ�����A���{�̃S�~��Ƃ̌������ƕ����K�v�͂Ȃ����
TRON�������H���{��OS�ŃA�����J�ɒׂ��ꂽ��
BD�Ƃ����A���{�l��IT�Ɋւ��ƃ��N�Ȃ��ƂȂ�����ׂ��Ă���ėǂ�������
���p�\�R���̓X�}�z�ŎB�肽�߂��ʐ^�̓��ꕨ����
���ق��ł��Ȃ�PC���[�J�[�����������������]��ł�B
�����甄��Ȃ���o�J����˂��̂���������������������������
�R���V���[�}�ł��}���`���f�B�A�Ɋւ��鐫�\�����߂Ă�l�����邵
����Ă�����Ђ�����A���{�̃S�~��Ƃ̌������ƕ����K�v�͂Ȃ����
TRON�������H���{��OS�ŃA�����J�ɒׂ��ꂽ��
BD�Ƃ����A���{�l��IT�Ɋւ��ƃ��N�Ȃ��ƂȂ�����ׂ��Ă���ėǂ�������
461 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂����F2015/02/27(��) 05:03:02.14 ID:eKNrnP9T
�O��GPU��ς߂Ȃ����^�m�[�gPC�̂��߂�APU��������͂��Ȃ̂�
�m�[�gPC�ɍ̗p���Ă��炦�Ȃ�AMD���킢����
�m�[�gPC�ɍ̗p���Ă��炦�Ȃ�AMD���킢����
462 �FSocket774�F2015/02/27(��) 05:54:37.64 ID:RTMEoTMD
�́H�p�\�R����Ɠd�͊��ɂ݂�Ȃɍs���n�������甄��Ȃ���B
�N���������\�Ȃ�ċ��߂ĂȂ����B
���Ȃy���e�B�A��4�����Ǝg���Ă�B
�X�}�z��^�u���b�g���������ĂȂ��l�͂܂����邩�甄��Ă�́B
�F�ɍs���n������p�\�R����Ɠd�Ɠ����悤�ɂ�������Ȃ��Ȃ�B
����Ȃ�����������̂��H
�N���������\�Ȃ�ċ��߂ĂȂ����B
���Ȃy���e�B�A��4�����Ǝg���Ă�B
�X�}�z��^�u���b�g���������ĂȂ��l�͂܂����邩�甄��Ă�́B
�F�ɍs���n������p�\�R����Ɠd�Ɠ����悤�ɂ�������Ȃ��Ȃ�B
����Ȃ�����������̂��H
intel��pc�ł�����Ă邯��
pc������Ȃ��Ȃ���pc�����s�ꂪ�Ȃ�amd�͂����Ɗ撣��Ȃ���
pc������Ȃ��Ȃ���pc�����s�ꂪ�Ȃ�amd�͂����Ɗ撣��Ȃ���
�ƃQ��AMD�����e���������
���N���������\�Ȃ�ċ��߂ĂȂ���
���߂Ă�l����������ی�����Ă���Č����Ă��ł����H
����p�[�c�V���b�v�̃t��BTOPC�Ƃ������邵�A�����Ȃ�DELL�Ƃ��̒��ؐ�
���\�����߂�Ȃ���{�̃��[�J�[��PC�Ȃ�đI�����ɓ����
�����\���߂ĂȂ��Ă��y���S�Ă����ˁH�u���E�W���O����X�}�z�̕����������c�c
���߂Ă�l����������ی�����Ă���Č����Ă��ł����H
����p�[�c�V���b�v�̃t��BTOPC�Ƃ������邵�A�����Ȃ�DELL�Ƃ��̒��ؐ�
���\�����߂�Ȃ���{�̃��[�J�[��PC�Ȃ�đI�����ɓ����
�����\���߂ĂȂ��Ă��y���S�Ă����ˁH�u���E�W���O����X�}�z�̕����������c�c
466 �FSocket774�F2015/02/27(��) 06:56:25.61 ID:ZeMeJNKc
�N�ԂR���䔄���pc�ɂ������ăQ�[���@���ǂ�قǔ���Ă錾����
�\�t�g�x���_�͐����u�������̃Q�[������肽����܂�
�Ȃ��ł��傤�H
�Ȃ��ł��傤�H
CS���S���e�������APS4�Ńn�[�h�Z�p���������Ƃ��L�߂�ꂽ���AAMD�̖����͖��邢
469 �FSocket774�F2015/02/27(��) 07:07:30.96 ID:RTMEoTMD
>>466
���̔���Ă�p�\�R���ŃQ�[���@��萫�\�ǂ��̂Ȃ�Ĕ���ĂȂ�����H
���̔���Ă�p�\�R���ŃQ�[���@��萫�\�ǂ��̂Ȃ�Ĕ���ĂȂ�����H
A8-7650K�̔������ĉ����̊Ԃɂ������Ă����ď�Ԃł���
����Ȃ��̔����A�����Ĉꕔ�����Ȃ�
������[��̔����C�x���g�������Ђ�����Ɣ����Ă�
>>464
�ő����̒��x�̊ߋ�ɂ����g���Ă��炦�Ȃ���
����������łԂ���ꂻ�������ǂ�w
����Ȃ��̔����A�����Ĉꕔ�����Ȃ�
������[��̔����C�x���g�������Ђ�����Ɣ����Ă�
>>464
�ő����̒��x�̊ߋ�ɂ����g���Ă��炦�Ȃ���
����������łԂ���ꂻ�������ǂ�w
471 �FSocket774�F2015/02/27(��) 07:25:28.74 ID:RTMEoTMD
>>465
�Â����{�I�ƌ���������܂Ŏg���̂��B
�y���e�B�A��4�͓����͍Œ�ň���PC���B���������[�N�d���̑���90nm�v���Z�X�̃V���O���R�A�̒ʏ̃v���X�R�b�g�B
����11�N�O����PC�ɏڂ����X���Ƀ��l2���������PC�ł��肢���Ă�����ă`���C�X�����ꂪ�g�܂ꂽ�B
23���~���B
�Â����{�I�ƌ���������܂Ŏg���̂��B
�y���e�B�A��4�͓����͍Œ�ň���PC���B���������[�N�d���̑���90nm�v���Z�X�̃V���O���R�A�̒ʏ̃v���X�R�b�g�B
����11�N�O����PC�ɏڂ����X���Ƀ��l2���������PC�ł��肢���Ă�����ă`���C�X�����ꂪ�g�܂ꂽ�B
23���~���B
>>471
���ɂ���͍����i����w
���ɂ���͍����i����w
473 �FSocket774�F2015/02/27(��) 07:31:20.34 ID:RTMEoTMD
�Ȃ�AMD��I�Ԃ��H
�p�\�R���̎���F�X��������AMD���g�����������玩����AMD���w�����邵�����@���Ȃ��ƌ������ƂɋC�Â������炾�B
Intel����̔������������Ă邩�炩���͂������Ă�̂��m��A���\���������爫������Ƃ��W�Ȃ���Intel��PC�����I�ׂȂ�����~���������炵�傤���Ȃ��B
�p�\�R���̎���F�X��������AMD���g�����������玩����AMD���w�����邵�����@���Ȃ��ƌ������ƂɋC�Â������炾�B
Intel����̔������������Ă邩�炩���͂������Ă�̂��m��A���\���������爫������Ƃ��W�Ȃ���Intel��PC�����I�ׂȂ�����~���������炵�傤���Ȃ��B
���H
�������ɂ��Ȃ邩�炾��Hw
https://www.youtube.com/watch?v=IxGtV0CmsT0
https://www.youtube.com/watch?v=FKo2JUtgkpw
�������ɂ��Ȃ邩�炾��Hw
https://www.youtube.com/watch?v=IxGtV0CmsT0
https://www.youtube.com/watch?v=FKo2JUtgkpw
475 �FSocket774�F2015/02/27(��) 07:38:11.99 ID:h6W+BLkm
1.�V�F�A��Ԃ͌���������AMD
��AMD PC��Windows(�V�F�A���)�C���X�R
1.5.�a�l�����͌���������AMD
��AMD PC�ɓa�lOS Windows�C���X�R
2.�C���e���ɍœK�����ꂽ�`�[�g�\�t�g�g����������
��Windows 8��AMD�ɍœK������Ă���`�[�gOS����������ׂ�
3.�C���e��CPU���Ƃ��Ő[��̔����Ă�
��Windows�[��̔��͌�����������
4.�l�Ɋ��߂�Ƃ���Intel(Windows)�����ǂ����삵�ĂĖʔ����̂�AMD(Windows)����
�ł��ǂ����Ă��Q�[���������������l������Ȃ�BTO��A10(Windows)��i�߂邯�ǂ�
5.�u1�ʂ���Ȃ���_���Ȃ�ł����H�v
���_���ł��BAMD�{1�� Windows�ł��B
6.AMD�g���͈Ⴂ�̕�������
��Windows���g����
7.Samsung��AMD�Ȃ�ďo����A�C���e���ɏ�芷�����AWindows�g���������
8.AMD64��Windows���g����ACPU�Ȃ�ĉ��ł�����
9.3�����o����i7�Ȃ�Ĕ����n���������
��Windows 7�͂킸��5���~�I
�C���e���M�҂�A���ꂪAMD�M�҂��x��Windows�M�҂̐��̂��I
No�I�`�[�g�h���C�o�I
No�I�`�[�g�x���`�I
No �`�[�gOS Windows, No Life�I
��AMD PC��Windows(�V�F�A���)�C���X�R
1.5.�a�l�����͌���������AMD
��AMD PC�ɓa�lOS Windows�C���X�R
2.�C���e���ɍœK�����ꂽ�`�[�g�\�t�g�g����������
��Windows 8��AMD�ɍœK������Ă���`�[�gOS����������ׂ�
3.�C���e��CPU���Ƃ��Ő[��̔����Ă�
��Windows�[��̔��͌�����������
4.�l�Ɋ��߂�Ƃ���Intel(Windows)�����ǂ����삵�ĂĖʔ����̂�AMD(Windows)����
�ł��ǂ����Ă��Q�[���������������l������Ȃ�BTO��A10(Windows)��i�߂邯�ǂ�
5.�u1�ʂ���Ȃ���_���Ȃ�ł����H�v
���_���ł��BAMD�{1�� Windows�ł��B
6.AMD�g���͈Ⴂ�̕�������
��Windows���g����
7.Samsung��AMD�Ȃ�ďo����A�C���e���ɏ�芷�����AWindows�g���������
8.AMD64��Windows���g����ACPU�Ȃ�ĉ��ł�����
9.3�����o����i7�Ȃ�Ĕ����n���������
��Windows 7�͂킸��5���~�I
�C���e���M�҂�A���ꂪAMD�M�҂��x��Windows�M�҂̐��̂��I
No�I�`�[�g�h���C�o�I
No�I�`�[�g�x���`�I
No �`�[�gOS Windows, No Life�I
>>471
�y���S�������������ǃ��l�Q�����������ȁA3�N�O�܂ł���Ă����ǂ�������
�S������ŁAAthron64��Sandyi7��Haswell Reflesh
�V�@�\�⍂�X�y�b�N�ɔ�т����ł��A�Â������ɂ���Ƃ����������������Ď̂Ă��Ȃ���
�撣���Ă������߂Ă���X��Ȃ���p�[�c�I��ŁA�J�[�e���߂ė��őg���
�g���u�������������ɂȂ�����A�܂��V�������Ƃ��o���Ȃ����ƐF�X��������A�������ĂȂ��̂ɉ��Ă݂���c�c
�v���o���l�܂肷���ĂĔ������肠��������ł��Ȃ���
�y���S�������������ǃ��l�Q�����������ȁA3�N�O�܂ł���Ă����ǂ�������
�S������ŁAAthron64��Sandyi7��Haswell Reflesh
�V�@�\�⍂�X�y�b�N�ɔ�т����ł��A�Â������ɂ���Ƃ����������������Ď̂Ă��Ȃ���
�撣���Ă������߂Ă���X��Ȃ���p�[�c�I��ŁA�J�[�e���߂ė��őg���
�g���u�������������ɂȂ�����A�܂��V�������Ƃ��o���Ȃ����ƐF�X��������A�������ĂȂ��̂ɉ��Ă݂���c�c
�v���o���l�܂肷���ĂĔ������肠��������ł��Ȃ���
AMD�͕�����������
Intel�͎��Y����������ɐ헪�͒m�Ⴞ��
��p�̓G���b�^���ڂŎg���Ă�Ƃ������܂Œm��ɂȂ肻��
MS�͑Ή��A�v���g���ɂ�Win�K�{����
����VisualStudio�����ɗL��
IDE�̋N���������r���h������
�t�@�C���敪�������牽�܂Ŏg���₷��C#��������
Intel�͎��Y����������ɐ헪�͒m�Ⴞ��
��p�̓G���b�^���ڂŎg���Ă�Ƃ������܂Œm��ɂȂ肻��
MS�͑Ή��A�v���g���ɂ�Win�K�{����
����VisualStudio�����ɗL��
IDE�̋N���������r���h������
�t�@�C���敪�������牽�܂Ŏg���₷��C#��������
479 �FSocket774�F2015/02/27(��) 07:51:14.02 ID:RTMEoTMD
>>475
���O�͉����킩���ĂȂ��B
�Ȃ���������AMD��I�Ԃ̂��H
�y���e�B�A��4��͂܂��ꂽ�������ׂ���AMD��Intel�ɐ��\�̗D��͖����B
�ǂ�����œK�����ꂽ���ǂ����Ő��\�̗D�킩��邾���B
AMD��ے肵�Ă�A���́AAMD�������ĂȂ��B
Intel��ے肵�Ă�A���́AIntel�����Ɏ����Ă�B
�����g���Ă݂�Intel��ے肵�Ă邩�炩�Ȃ�����͂���B
AMD�̕���Intel���i��舳�|�I�ɖ��͓I�����炾�B
���O�͉����킩���ĂȂ��B
�Ȃ���������AMD��I�Ԃ̂��H
�y���e�B�A��4��͂܂��ꂽ�������ׂ���AMD��Intel�ɐ��\�̗D��͖����B
�ǂ�����œK�����ꂽ���ǂ����Ő��\�̗D�킩��邾���B
AMD��ے肵�Ă�A���́AAMD�������ĂȂ��B
Intel��ے肵�Ă�A���́AIntel�����Ɏ����Ă�B
�����g���Ă݂�Intel��ے肵�Ă邩�炩�Ȃ�����͂���B
AMD�̕���Intel���i��舳�|�I�ɖ��͓I�����炾�B
P4�̓}�W����������B
���܂�ɏ���d�͂��Ƃ̐��\�Ⴗ�����A���o�C��������PenM�Ɍ����Ń{�������B
������̉ʂĂ�PenM��OC������Pen4�Ɠ����x���̐��\�ɂȂ���Č�������Ȃ���B
�ϊ��Q�^�Ƃ������Ă���ȁE�E�E
>>479
�ŋ߂܂�INTEL�����g���Ă����ǂ���͓��ӂ���B
�R�X�p�������A�݊����̖���INTEL��荓���Ȃ�����ȁB
���܂�ɏ���d�͂��Ƃ̐��\�Ⴗ�����A���o�C��������PenM�Ɍ����Ń{�������B
������̉ʂĂ�PenM��OC������Pen4�Ɠ����x���̐��\�ɂȂ���Č�������Ȃ���B
�ϊ��Q�^�Ƃ������Ă���ȁE�E�E
>>479
�ŋ߂܂�INTEL�����g���Ă����ǂ���͓��ӂ���B
�R�X�p�������A�݊����̖���INTEL��荓���Ȃ�����ȁB
���܂�Pen4�Ɛ���Ă��
>>477
���l�[�W���V�����̂ł�݂�������
���l�[�W���V�����̂ł�݂�������
����P4yori�ǂ������������������C2D����ɂȂ�����I���R�������Ă�����Ȃ�
Remote Graphics using AMD FirePro R5000 on BOXX XDI V8 for SOLIDWORKS
http://fireuser.com/blog/remote_graphics_using_r5000_on_boxx_xdi_v8_for_solidworks
http://fireuser.com/blog/remote_graphics_using_r5000_on_boxx_xdi_v8_for_solidworks
���{�l�Ȃ�C���e���Q�t�H������˂�
Getting Started With Gizmo 2
http://www.element14.com/community/community/designcenter/single-board-computers/blog/2014/12/27/gizmo-2-the-new-batch
http://www.element14.com/community/community/designcenter/single-board-computers/blog/2014/12/27/gizmo-2-the-new-batch
Llano�o��̋łɂ�
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
�� 2014�N �����̔��ド���L���O
http://eetimes.jp/ee/articles/1412/25/news147.html
��AMD�A2014�N�x��4���h���̐Ԏ�
http://pc.watch.impress.co.jp/docs/news/20150121_684660.html
AMD�̏��ʂ������}�~���ЂƂ蕉���_(^o^)�^
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
�� 2014�N �����̔��ド���L���O
http://eetimes.jp/ee/articles/1412/25/news147.html
��AMD�A2014�N�x��4���h���̐Ԏ�
http://pc.watch.impress.co.jp/docs/news/20150121_684660.html
AMD�̏��ʂ������}�~���ЂƂ蕉���_(^o^)�^
���{�l�Ȃ�C���e���Q�t�H�������
�����Q���
��{AMD/intel�Ō��݂ɔ����Ă邩��
����Hasi5������Kaveri Refreash��Carrizo�ōX�V���悤���ƌ�����
���\�I�ɂ�Pen3�Ŏ�����邵���p���Ȃ��p�[�c�I��łāA�g��łāA�g���ĂĊy����PC��ڎw���Ă�
����Hasi5������Kaveri Refreash��Carrizo�ōX�V���悤���ƌ�����
���\�I�ɂ�Pen3�Ŏ�����邵���p���Ȃ��p�[�c�I��łāA�g��łāA�g���ĂĊy����PC��ڎw���Ă�
2014�N10���ɁA2014�N���ɍ�����������Ɣ��\���Ă������A�����x���2���̔����ƂȂ����B
�����������_�ɂ����Ă��A��̓I�Ȕ������Ɣ̔��X�܂͖���ƂȂ��Ă���A�i�j
����z�[���y�[�W�ɂĈē�����Ƃ��Ă���B�i�j
�܂��A�X���\�z���i�������_�ł͕s�����B�i�j
http://m.pc.watch.impress.co.jp/docs/news/20150109_683098.html
2���͖����ŏI���܂���A�Ɓi�j
�����������_�ɂ����Ă��A��̓I�Ȕ������Ɣ̔��X�܂͖���ƂȂ��Ă���A�i�j
����z�[���y�[�W�ɂĈē�����Ƃ��Ă���B�i�j
�܂��A�X���\�z���i�������_�ł͕s�����B�i�j
http://m.pc.watch.impress.co.jp/docs/news/20150109_683098.html
2���͖����ŏI���܂���A�Ɓi�j
492 �FSocket774 �]�ڃ_��©2ch.net�F2015/02/27(��) 18:51:53.89 ID:wYl7qAZf
�@�f�X�N�g�b�v�p��(�I�����łȂ�)4C/4M�ȏ�Ȃ�āA����}�j�A������
�j�b�`���i�ł����Ȃ��킯�ŁA�Q�[���@�s��̂ق����y���ɏd�v����ȁB
�j�b�`���i�ł����Ȃ��킯�ŁA�Q�[���@�s��̂ق����y���ɏd�v����ȁB
493 �FSocket774�F2015/02/27(��) 18:54:53.41 ID:BfftHV+8
�����
�N�ԂR���䔄���pc�͂�����߂ĂP�疜�����Ȃ��Q�[���@�ɗ��邵���Ȃ���
�N�ԂR���䔄���pc�͂�����߂ĂP�疜�����Ȃ��Q�[���@�ɗ��邵���Ȃ���
�\�t�g�x���_�͐����u�������̃Q�[������肽����܂�
�Ȃ��ł��傤�H
�Ȃ��ł��傤�H
495 �FSocket774�F2015/02/27(��) 19:00:46.88 ID:BfftHV+8
�����amd���ׂ���́H��
�v���Z�X������L���b�V���Ȃǂ̐����Z�p�ł̑R�͒��߂�
CPU�̕������܂�GPGPU�ŏ������|����
�Q�[�����e�Ń\�t�g�ʂ���̃A�v���[�`���|��
�̗͂������̒m��Intel��HSA�ŏ�������
CPU�̕������܂�GPGPU�ŏ������|����
�Q�[�����e�Ń\�t�g�ʂ���̃A�v���[�`���|��
�̗͂������̒m��Intel��HSA�ŏ�������
�Q�[���Ȃ��IT�ƊE�S�̂Ō�����덷�݂����ȃV�F�A�����Ȃ����炶��ˁH
>>495
����Ɏ���ŕԂ��̂͗c�t�ł���
����Ɏ���ŕԂ��̂͗c�t�ł���
499 �FSocket774�F2015/02/27(��) 19:04:17.91 ID:BfftHV+8
�Q�[�����X�}�z�����ɏo���������Ă邗
500 �FSocket774�F2015/02/27(��) 19:09:03.49 ID:BfftHV+8
http://www.4gamer.net/games/117/G011794/20150225075/
���^�C�g����ps4���vita�����|����
���H
�����u���ɏo�������H��
�����傤������
�G���i�������Ȃ�
���^�C�g����ps4���vita�����|����
���H
�����u���ɏo�������H��
�����傤������
�G���i�������Ȃ�
�D�Ƃ��p�Y���Q�[�Ƃ����C�g�Q�[���������
502 �FSocket774�F2015/02/27(��) 19:13:17.13 ID:BfftHV+8
���C�g�����������̂����瓖�R��
�܂��C�V���ׂ͒�ĂȂ��˂�
504 �FSocket774�F2015/02/27(��) 19:28:26.12 ID:BfftHV+8
�C�V���͐l�C�Ǝ��^�C�g�����邩��Ԃ�Ȃ���
�X�}�z�ɂ��ڍs�ł��邵��
�Ԃꂻ���Ȃ͉̂������ĂȂ��̂ɃK���X�������X�}�z�������
�ᑬmicro sd�������������ƌ��������ĂT�|�U�{�̒l�i�Ŕ��낤�Ƃ��Ă�Ƃ��낾
�X�}�z�ɂ��ڍs�ł��邵��
�Ԃꂻ���Ȃ͉̂������ĂȂ��̂ɃK���X�������X�}�z�������
�ᑬmicro sd�������������ƌ��������ĂT�|�U�{�̒l�i�Ŕ��낤�Ƃ��Ă�Ƃ��낾
�|�P�b�g�ɓ��ꂽ�犄���K���X�̃X�}�z�����邩��
�O��������˂���
�O��������˂���
������PowerPC�͔���܂���̂Ƃ���ŃQ�[���@�ɍ̗p����A�]���݂����ȂƂ�����������
AMD�͂���ɖ����������Ă�
AMD�͂���ɖ����������Ă�
>>497
�Q�[���̓n�C�G���h�̐��\�w�W�ŏd�v�Ȃ�
i7+780ti��980���n�C�G���h�Ƃ��ČN�Ղ��邩��A�~�h���ȉ�������Ă���
�R��������āADX12��APU+390x���ŋ��ɂȂ�ƁAAMD������ăV�F�A�t�]����
�Ȃ�ł��Ƃ����ƁA�Q�[���ȏ�ɍ����ׂȏ�������ʂɂ͑��݂��Ȃ�����
�ł����ׂ����������ōł������\�ȃV�X�e���́A���̂ǂ�ȏ����ł������\�Ƃ������ƂɂȂ�
Nvidia��r������AMDvsIntel�ōl���Ă݂悤��
APU+290x���Q�[���ŋ��A�G���R��i7���ŋ�
�R�X�p�͓�����Q�[�����o����APU���ŋ�
��`�Ɛ��i���K�x�ɓ���������AMD�̕�������Ă������낤��
Intel�̃����b�g�Ȃ��i7���G���R�ő��������ɂȂ��Ă��܂�
�Q�[���̓n�C�G���h�̐��\�w�W�ŏd�v�Ȃ�
i7+780ti��980���n�C�G���h�Ƃ��ČN�Ղ��邩��A�~�h���ȉ�������Ă���
�R��������āADX12��APU+390x���ŋ��ɂȂ�ƁAAMD������ăV�F�A�t�]����
�Ȃ�ł��Ƃ����ƁA�Q�[���ȏ�ɍ����ׂȏ�������ʂɂ͑��݂��Ȃ�����
�ł����ׂ����������ōł������\�ȃV�X�e���́A���̂ǂ�ȏ����ł������\�Ƃ������ƂɂȂ�
Nvidia��r������AMDvsIntel�ōl���Ă݂悤��
APU+290x���Q�[���ŋ��A�G���R��i7���ŋ�
�R�X�p�͓�����Q�[�����o����APU���ŋ�
��`�Ɛ��i���K�x�ɓ���������AMD�̕�������Ă������낤��
Intel�̃����b�g�Ȃ��i7���G���R�ő��������ɂȂ��Ă��܂�
508 �FSocket774 �]�ڃ_��©2ch.net�F2015/02/27(��) 20:51:43.78 ID:wYl7qAZf
�@��`�i��CPU��Intel�ɔC���āA����PC�̃��C���X�g���[���ł���Ƃ����
�f�X�N�m�[�g�ӂ�̃����W�ɒ��͂�������Ǝv����B
�f�X�N�m�[�g�ӂ�̃����W�ɒ��͂�������Ǝv����B
Llano�o��̋łɂ�
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
�� 2014�N �����̔��ド���L���O
http://eetimes.jp/ee/articles/1412/25/news147.html
��AMD�A2014�N�x��4���h���̐Ԏ�
http://pc.watch.impress.co.jp/docs/news/20150121_684660.html
AMD�̏��ʂ������}�~���ЂƂ蕉���_(^o^)�^
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
�� 2014�N �����̔��ド���L���O
http://eetimes.jp/ee/articles/1412/25/news147.html
��AMD�A2014�N�x��4���h���̐Ԏ�
http://pc.watch.impress.co.jp/docs/news/20150121_684660.html
AMD�̏��ʂ������}�~���ЂƂ蕉���_(^o^)�^
AMD�D�������ǁA�C���e�������Ă�I�̃R�s�[�ŕ������Ǝv���B
AMD�D���̍��ł��V�F�A�������炢��������ł���H
INTEL�̃L���b�`�͂ł�������
INTEL�̃L���b�`�͂ł�������
512 �FSocket774�F2015/02/27(��) 21:58:23.36 ID:RTMEoTMD
����Ȃ�Ȃ��B
�X���ɂ����Ă��鐻�i��Intel���������ĂȂ�����B
�X���ɂ����Ă��鐻�i��Intel���������ĂȂ�����B
�����ƈ��l�ŏo���悩�����̂�
�a�l�������邩��_���Ȃ�
�a�l�������邩��_���Ȃ�
514 �F���@�Ɏ����ݓ��X�p�C�E�n���E���N�U�F2015/02/28(�y) 10:28:51.17 ID:qWUHl6DS
�}�X�R�~����ɐG��Ȃ�����
���j�����}�ȊO���ݓ�����A�������X�p�C�A�܂��͂��̉e�����ɂ���Ɖ��肵�Ă������������B
�悭������
����ꂽ�Q�O�N�@���@��Q�O�N�O�@���߂Ď����}���P�Ɖߔ���������i����̐V���}���^�}����j��
����ꂽ�P�T�N�@���@��P�T�N�O�@�����̘A���������n�܂�@�@�i�����}�̗^�}����j /
�����̂Ƃ��A���߂ĂW�O�~/�h���Ƃ������~���U������āA���{�̐����Ƃ͐��ށE��
�@�������E�؍����䓪���n�߂�B���{�̋Z�p�҂��A��ʂɊ؍��ȂǂɈ����������悤�ɂȂ�B
�@�C�I���i����}�E���c�Ɓj���^�p�`���R�X���A�n���o�ς⏤�X�X��H���Ԃ����߂́A
�@��X���n�@�������B�ݓ��p�`���R����CM�E�`���V�����ցE��^�`�F�[���W�J���n�܂�B
�@���{�̊w�͒ቺ���ړI�́u��Ƃ苳��v�̖{�i�����B�i���Q�́A�P�V�N�O�B�j
�����̂Ƃ��̉H�c�i�V���}�j�̊炪�����ɔ�����B
�����̂Ƃ��A����̐V���}��S�͂őI���x�������̂��A�n���w��Ƃ�����B
�����̂Ƃ��A�����u�P�Ɓv�����i���������̒P�ƂQ/�R�c�ȁj�̕����ɁA���|�I�s����
�@���I�����x�֖@������
2014���I���̔�ᓖ�I���@
���}�� �@�@�@�@�����@�@�����@�@����@�@�ېV�@�@���Y
����@�@�@�@�@�@68�@�@�@26�@�@�@�@35�@�@�@30�@�@�@20
���v���@�@�@�@�@ 291�@�@�@35�@�@�@�@73�@�@�@41�@�@�@21
��ᓖ�I���@�@23%�@�@�@74%�@�@�@48%�@�@73%�@�@�@95%�@�@����
���Y�E�����E�ېV�́A��ᐧ�x��p�~����Ώ��ł�
(�����̏��I����́A�I�����͂̌��Ԃ�Ƃ��āA�����}�͌��𗧂Ă��Ȃ���ɁA
�����}���͌����֓��[��������Ƃ����o�����[�X)�@�@
�Q�l�j
����}�́A���~���U���Ńp�i�\�j�b�N��V���[�v�A�\�j�[��ׂ��C�������H
http://www.youtube.com/watch?v=iG_oaqU0pEM
�A�����N�l���肪�����Ƃ�ڎw�����H���{
http://www.youtube.com/watch?v=CxIGOhFT4g8 �@����
���j�����}�ȊO���ݓ�����A�������X�p�C�A�܂��͂��̉e�����ɂ���Ɖ��肵�Ă������������B
�悭������
����ꂽ�Q�O�N�@���@��Q�O�N�O�@���߂Ď����}���P�Ɖߔ���������i����̐V���}���^�}����j��
����ꂽ�P�T�N�@���@��P�T�N�O�@�����̘A���������n�܂�@�@�i�����}�̗^�}����j /
�����̂Ƃ��A���߂ĂW�O�~/�h���Ƃ������~���U������āA���{�̐����Ƃ͐��ށE��
�@�������E�؍����䓪���n�߂�B���{�̋Z�p�҂��A��ʂɊ؍��ȂǂɈ����������悤�ɂȂ�B
�@�C�I���i����}�E���c�Ɓj���^�p�`���R�X���A�n���o�ς⏤�X�X��H���Ԃ����߂́A
�@��X���n�@�������B�ݓ��p�`���R����CM�E�`���V�����ցE��^�`�F�[���W�J���n�܂�B
�@���{�̊w�͒ቺ���ړI�́u��Ƃ苳��v�̖{�i�����B�i���Q�́A�P�V�N�O�B�j
�����̂Ƃ��̉H�c�i�V���}�j�̊炪�����ɔ�����B
�����̂Ƃ��A����̐V���}��S�͂őI���x�������̂��A�n���w��Ƃ�����B
�����̂Ƃ��A�����u�P�Ɓv�����i���������̒P�ƂQ/�R�c�ȁj�̕����ɁA���|�I�s����
�@���I�����x�֖@������
2014���I���̔�ᓖ�I���@
���}�� �@�@�@�@�����@�@�����@�@����@�@�ېV�@�@���Y
����@�@�@�@�@�@68�@�@�@26�@�@�@�@35�@�@�@30�@�@�@20
���v���@�@�@�@�@ 291�@�@�@35�@�@�@�@73�@�@�@41�@�@�@21
��ᓖ�I���@�@23%�@�@�@74%�@�@�@48%�@�@73%�@�@�@95%�@�@����
���Y�E�����E�ېV�́A��ᐧ�x��p�~����Ώ��ł�
(�����̏��I����́A�I�����͂̌��Ԃ�Ƃ��āA�����}�͌��𗧂Ă��Ȃ���ɁA
�����}���͌����֓��[��������Ƃ����o�����[�X)�@�@
�Q�l�j
����}�́A���~���U���Ńp�i�\�j�b�N��V���[�v�A�\�j�[��ׂ��C�������H
http://www.youtube.com/watch?v=iG_oaqU0pEM
�A�����N�l���肪�����Ƃ�ڎw�����H���{
http://www.youtube.com/watch?v=CxIGOhFT4g8 �@����
515 �F���@�Ɏ����ݓ��X�p�C�E�n���E���N�U�F2015/02/28(�y) 11:43:34.72 ID:qWUHl6DS
�����@���{�Ɏ؋���������܂����̂͏����Y�i���Ԃ�ݓ��A���j�B
���S�R�O���~
���R�i���Љ�}�F���̐l���A���H�j���t���v���X�Q�O�O���~�@
�g�[�^���U�R�O���~
�i�ڂ����͓��č\�����c�Ō����j
������؋��́A����Ƃ��̗����ł́H
����́A�����}����ɓ��{�ɔ��e�������������ɁA���̃o���}�L���������œ���
�x����Ղ��������莩���}������������i���Ԃ������A�ꗣ�}�j�A
������P�Ɖߔ�������ɒǂ����B
�����āA��R�ɐ��}�i�V���}�������}�j����������A�؍���ݓ��֗��v�U�����Ă����B
���{���؋��卑�ɂ����͎̂����}���I�ƁA�����Ŏd���Ύ���}������
�Nj����鎩�쎩�����ɂ���āA����}�ւ̐������ɂȂ����B
�������}�ȊO�̋c���́A���{���𖼏��A�����N�l���A���̉e�����ɂ���Ɖ���B
�Ƃ�������ł͂Ȃ��ł��傤���B
���S�R�O���~
���R�i���Љ�}�F���̐l���A���H�j���t���v���X�Q�O�O���~�@
�g�[�^���U�R�O���~
�i�ڂ����͓��č\�����c�Ō����j
������؋��́A����Ƃ��̗����ł́H
����́A�����}����ɓ��{�ɔ��e�������������ɁA���̃o���}�L���������œ���
�x����Ղ��������莩���}������������i���Ԃ������A�ꗣ�}�j�A
������P�Ɖߔ�������ɒǂ����B
�����āA��R�ɐ��}�i�V���}�������}�j����������A�؍���ݓ��֗��v�U�����Ă����B
���{���؋��卑�ɂ����͎̂����}���I�ƁA�����Ŏd���Ύ���}������
�Nj����鎩�쎩�����ɂ���āA����}�ւ̐������ɂȂ����B
�������}�ȊO�̋c���́A���{���𖼏��A�����N�l���A���̉e�����ɂ���Ɖ���B
�Ƃ�������ł͂Ȃ��ł��傤���B
Choice for today: coding office-software en web-services for the rest of your life, or start learning OpenCL today.
http://streamcomputing.eu/knowledge/for-developers/
http://streamcomputing.eu/knowledge/for-developers/
�ǂ����̊J���҂�DirectX12�ɂ��Ă̂��ꂱ��ɂ��ē����Ă��ꂽ�悤��
http://forums.anandtech.com/showthread.php?t=2422223
���ǁADX12���܂Ƃ��ɓ����̂�GCN��Maxwell(Gen2)�����Ȃ��݂�������
Gen2�����Maxwell�̂ݑΉ����Ă�Conservative Raster�̓W�I���g���V�F�[�_�[�ɂ��G�~���Ŏ�������Ƃ�����@������AGCN�ł͂��̎�@�ł��p�t�H�[�}���X�������o����Ƃ����b��
���R���s���[�g�g�p����ƒ�i�N���b�N�ł̓���ɂȂ�̂Ń^�[�{�ɂ����IntelGPU�ł͕s�����Ƃ�
http://forums.anandtech.com/showthread.php?t=2422223
���ǁADX12���܂Ƃ��ɓ����̂�GCN��Maxwell(Gen2)�����Ȃ��݂�������
Gen2�����Maxwell�̂ݑΉ����Ă�Conservative Raster�̓W�I���g���V�F�[�_�[�ɂ��G�~���Ŏ�������Ƃ�����@������AGCN�ł͂��̎�@�ł��p�t�H�[�}���X�������o����Ƃ����b��
���R���s���[�g�g�p����ƒ�i�N���b�N�ł̓���ɂȂ�̂Ń^�[�{�ɂ����IntelGPU�ł͕s�����Ƃ�
Most of the GPUs support the first tier or TIER1.
Maxwellv2 (GM206 and GM204) support the second tier or TIER2.
All GCN-based Radeons support the third tier or TIER3.
I'm expect that all future hardware will support TIER3.
http://s29.postimg.org/hsmlfnv7b/rbt.jpg
Maxwellv2 (GM206 and GM204) support the second tier or TIER2.
All GCN-based Radeons support the third tier or TIER3.
I'm expect that all future hardware will support TIER3.
http://s29.postimg.org/hsmlfnv7b/rbt.jpg
{kind=link}
AMD To Disclose 14/16nm CPU and GPU Roadmaps in May ? Zen, K12 and Arctic Islands
http://wccftech.com/amd-future-gpu-cpu-roadmap/
5����
http://wccftech.com/amd-future-gpu-cpu-roadmap/
5����
http://wccftech.com/
���̃T�C�g�͍ŐV���ׂ�̂ɐ����C�C��
�C�O�̃T�C�g�����������Ă݂����ǁA�����ق�AMD�n�������Ă�Ƃ���͂Ȃ����炢�b�肪�L�x��
�k�X��wccftech������AAMD�Ƃ�����PC�S�ʂ��̃J�o�[�o����Ǝv��
���{�̃T�C�g�̑唼���@���ɃC���e���k�r���肾�Ƃ������Ƃ��悭������
PCWatch��4�T�ł���1���Ԃ�1�ʂ����ǁAwccftech���Ƃقږ������������o�Ă���
���̃T�C�g�͍ŐV���ׂ�̂ɐ����C�C��
�C�O�̃T�C�g�����������Ă݂����ǁA�����ق�AMD�n�������Ă�Ƃ���͂Ȃ����炢�b�肪�L�x��
�k�X��wccftech������AAMD�Ƃ�����PC�S�ʂ��̃J�o�[�o����Ǝv��
���{�̃T�C�g�̑唼���@���ɃC���e���k�r���肾�Ƃ������Ƃ��悭������
PCWatch��4�T�ł���1���Ԃ�1�ʂ����ǁAwccftech���Ƃقږ������������o�Ă���
LINPACK �� LAPACK�ɕt���āE�E�E
http://dualsocketworld.blog134.fc2.com/blog-entry-396.html
Intel��CPU��LINPACK�����ł��邩�̗l��8087�̓����Ɏn�܂�
SMP -> MMX -> SSE -> �}���`�R�A�� -> NUMA -> AVX�Ɗg�����Ă��܂����B
���ہASSE��AVX�̉��Z�@�i���Z�@�Ə�Z�@�̐������ׂ̈̃p�C�v���C���\���Ȃǁj���ڂ������ׂ��
LINPACK�x���`�}�[�N�ׂ̈����ɑn��ꂽ���̗l�ɍœK������Ă��鎖������܂����A
LINPACK�x���`�}�[�N�����s�����SSE��AVX�̉��Z�@���ق�100���t���ғ����A
���R�AMP���ł��S�R�A100%�̕��ׂɐ���p�C�v���C�����t���ғ����܂�����A
�t�Ɍ�����LINPACK�x���`�}�[�N�����ɍœK������Ă��Ȃ����100%�߂����p���ɂ͐��蓾�Ȃ���ł��B
�X�p�R���ł̎��ۂ̗p�r�ł͑�������q��LAPACK�ɒu��������Ă���
http://dualsocketworld.blog134.fc2.com/blog-entry-396.html
Intel��CPU��LINPACK�����ł��邩�̗l��8087�̓����Ɏn�܂�
SMP -> MMX -> SSE -> �}���`�R�A�� -> NUMA -> AVX�Ɗg�����Ă��܂����B
���ہASSE��AVX�̉��Z�@�i���Z�@�Ə�Z�@�̐������ׂ̈̃p�C�v���C���\���Ȃǁj���ڂ������ׂ��
LINPACK�x���`�}�[�N�ׂ̈����ɑn��ꂽ���̗l�ɍœK������Ă��鎖������܂����A
LINPACK�x���`�}�[�N�����s�����SSE��AVX�̉��Z�@���ق�100���t���ғ����A
���R�AMP���ł��S�R�A100%�̕��ׂɐ���p�C�v���C�����t���ғ����܂�����A
�t�Ɍ�����LINPACK�x���`�}�[�N�����ɍœK������Ă��Ȃ����100%�߂����p���ɂ͐��蓾�Ȃ���ł��B
�X�p�R���ł̎��ۂ̗p�r�ł͑�������q��LAPACK�ɒu��������Ă���
LAPACK
������LAPACK�̉��Z���C�u�����͎��ۂ̗p�r�ł�LINPACK����������g���₷���A
���ł�LINPACK�͎g���Ă��炸LAPACK���g���Ă���
���Ȃ��Ƃ�Bulldozer�ɓ��ڂ��ꂽFMA4��LAPACK�����ɍœK������Ă���l��
LAPACK���g�����x���`�}�[�N�����s�����Bulldozer�͓������Intel�ɏ���
�x���`�pLINPACK�ɍœK������Intel
���pLAPACK�ɍœK������AMD
���̕����ƁAPhi��LINPACK�ɁAGCN��LAPACK�ɍœK�����Ă����
�����Intel��LINPACK���߂�����킯�Ȃ���
������LAPACK�̉��Z���C�u�����͎��ۂ̗p�r�ł�LINPACK����������g���₷���A
���ł�LINPACK�͎g���Ă��炸LAPACK���g���Ă���
���Ȃ��Ƃ�Bulldozer�ɓ��ڂ��ꂽFMA4��LAPACK�����ɍœK������Ă���l��
LAPACK���g�����x���`�}�[�N�����s�����Bulldozer�͓������Intel�ɏ���
�x���`�pLINPACK�ɍœK������Intel
���pLAPACK�ɍœK������AMD
���̕����ƁAPhi��LINPACK�ɁAGCN��LAPACK�ɍœK�����Ă����
�����Intel��LINPACK���߂�����킯�Ȃ���
linpack�œK����AMD��GPGPU����
Phi��Linpack�œK���ł͂Ȃ�Linpack�ȊO�������Ȃ�悤�ɍ���Ă�
Phi��Linpack�œK���ł͂Ȃ�Linpack�ȊO�������Ȃ�悤�ɍ���Ă�
>>523
> linpack�œK����AMD��GPGPU����
���ł����Ȃ�
GCN��AMD CPU�Ɠ��l�A�����Z������LAPACK�œK������Ă�
> Phi��Linpack�œK���ł͂Ȃ�Linpack�ȊO�������Ȃ�悤�ɍ���Ă�
���l�ɁAPhi�͌���Intel CPU��AVX������ALINPACK�œK������Ă�
> linpack�œK����AMD��GPGPU����
���ł����Ȃ�
GCN��AMD CPU�Ɠ��l�A�����Z������LAPACK�œK������Ă�
> Phi��Linpack�œK���ł͂Ȃ�Linpack�ȊO�������Ȃ�悤�ɍ���Ă�
���l�ɁAPhi�͌���Intel CPU��AVX������ALINPACK�œK������Ă�
GCN��DGEMM���s�����͂��܂荂���Ȃ��ق���
�ǂ��炩�Ƃ�����Linpack�Ԓ���Kepler����
�ǂ��炩�Ƃ�����Linpack�Ԓ���Kepler����
GCN��LINPACK�������̂�GREEN500�ŏؖ�����Ă��
Phi��LAPACK�ő����̂��͕s���A����LINPACK���x��
;��������ȗ͊W���낤
Phi LAPACK < Phi LINPACK << GCN LINPACK < GCN LAPACK
Phi��LAPACK�ő����̂��͕s���A����LINPACK���x��
;��������ȗ͊W���낤
Phi LAPACK < Phi LINPACK << GCN LINPACK < GCN LAPACK
527 �FSocket774�F2015/03/01(��) 06:31:46.78 ID:n3fPh9ps
�ؖ����ꂽ�̂�linpack�x���`�ɍœK�������V�X�e����
green�Ńg�b�v�Ƃ������Ă�����
green�Ńg�b�v�Ƃ������Ă�����
�܂��A���ꂾ���̘b������
���Ȃ��Ƃ�����̃x���`�ł�FirePro���ŋ��Ŋm�肵�Ă�
LAPACK�̔�r�̓O�O���Ă�������A�^���͒N�ɂ��������
������ALAPACK�ŋ��́A���ۂ�TOP500�ɍ̗p�����܂ŒN�ɂ�������Ȃ�
�܂��AHPC�������x�z���Ă�C���e���k�r��LAPACK�ɑS�����y���ĂȂ����炨�@�����낤����
���Ȃ��Ƃ�����̃x���`�ł�FirePro���ŋ��Ŋm�肵�Ă�
LAPACK�̔�r�̓O�O���Ă�������A�^���͒N�ɂ��������
������ALAPACK�ŋ��́A���ۂ�TOP500�ɍ̗p�����܂ŒN�ɂ�������Ȃ�
�܂��AHPC�������x�z���Ă�C���e���k�r��LAPACK�ɑS�����y���ĂȂ����炨�@�����낤����
529 �FSocket774�F2015/03/01(��) 06:54:13.44 ID:n3fPh9ps
�������x���`��͂��Ď��n���cpu,gpu�L���ȕ��ɐ�ւ���
hdd����ڂɂ��Ă���ƂƂ��Ȃ���
�x���`���[��Ƃ�������A�N�Z�����[�^�̕�����������
hdd����ڂɂ��Ă���ƂƂ��Ȃ���
�x���`���[��Ƃ�������A�N�Z�����[�^�̕�����������
x86�̎�ł���Intel�����틶�C��
AVX��LNI�ɂ�x86��SIMD�g�����܂����Ă錻��
����ƑɂȂ�SIMD�A
����V���O�����Ƃ����Ȃ����ߐ��ő����̕��Z������R�A����ׂ悤�Ƃ����
���܂�X�J�����o���Ȃ����
NV�̕������͑��̉��Z���u�Ɖ�����
�P�̂ʼn��ł����Ȃ��K�v������ꍇ�ł̂ݗL��
AVX��LNI�ɂ�x86��SIMD�g�����܂����Ă錻��
����ƑɂȂ�SIMD�A
����V���O�����Ƃ����Ȃ����ߐ��ő����̕��Z������R�A����ׂ悤�Ƃ����
���܂�X�J�����o���Ȃ����
NV�̕������͑��̉��Z���u�Ɖ�����
�P�̂ʼn��ł����Ȃ��K�v������ꍇ�ł̂ݗL��
�����Ȃ��Ƃ��č��G�l���M�[�Ȃ̕]���\�t�g�ł�
cpu�g�p���͂���߂ĒႢ
http://news.mynavi.jp/articles/2014/12/16/sc14_exascale/001.html
cpu�g�p���͂���߂ĒႢ
http://news.mynavi.jp/articles/2014/12/16/sc14_exascale/001.html
532 �FSocket774�F2015/03/01(��) 08:40:05.64 ID:4nsO90+e
2020�N�Ɍ��݂�28nm�v���Z�X��7nm�ɃV�������N�ł���Ɨ\�z����A
�e�N�m���W�I�ɂ�4�{�̐��\���P���ł���ƌ����܂��B
����ɉ����āA��H�v�ƃA�[�L�e�N�`����6�{�̉��P�������ł���AKaveri��25�{��50GFlops/W�������ł���v�Z�ɂȂ�B
�����Ȃ�A50�{�̐��\�ł���1000PFlops���A2�{��20MW�̏���d�͂Ŏ����ł��邱�ƂɂȂ�B
�e�N�m���W�I�ɂ�4�{�̐��\���P���ł���ƌ����܂��B
����ɉ����āA��H�v�ƃA�[�L�e�N�`����6�{�̉��P�������ł���AKaveri��25�{��50GFlops/W�������ł���v�Z�ɂȂ�B
�����Ȃ�A50�{�̐��\�ł���1000PFlops���A2�{��20MW�̏���d�͂Ŏ����ł��邱�ƂɂȂ�B
�ϑz�ɖϑz���d�˂Ĉ��ꂾ��
�u���C���X�g�[�~���O��4����
���f�E���_���o���Ȃ��i���_���ցj
�e��ȍl�������}����i���R�z���j
�ʂ��d������i�����ʁj
�A�C�f�B�A�����������W������i�������P�j
���f�E���_���o���Ȃ��i���_���ցj
�e��ȍl�������}����i���R�z���j
�ʂ��d������i�����ʁj
�A�C�f�B�A�����������W������i�������P�j
����͕��n���c�Ƃ̂��V��
�m���ɍH�w�n�ŃE�H�[�Y�}�����_��NG���Ȃ�
537 �FSocket774�F2015/03/01(��) 09:34:58.81 ID:4nsO90+e
�\�[�X�͂��ꂾ���ǂ�
http://s.news.mynavi.jp/articles/2014/12/16/sc14_exascale/index.html
http://s.news.mynavi.jp/articles/2014/12/16/sc14_exascale/index.html
�[��
�Z�p�I�����̂Ȃ��ϑz�ƈꏏ�ɂ���Ȃ�
�Z�p�I�����̂Ȃ��ϑz�ƈꏏ�ɂ���Ȃ�
539 �FSocket774�F2015/03/01(��) 09:46:37.29 ID:4nsO90+e
�^���ԂɂȂ�Ȃ�w
540 �FSocket774�F2015/03/01(��) 09:50:05.59 ID:F9kNOzGF
�S���ŒB���ł���ƌ����Ă��Ȃ��̂���������
warp����4�ɂȂ��sse2���x�̗��x��
warp����4�ɂȂ��sse2���x�̗��x��
AMD�͒�������ł�NTT�h�R���ɔ����ꂽ
�h�R��
https://www.youtube.com/watch?v=4ViwSeuWVfE
AMD
https://www.youtube.com/watch?v=IxGtV0CmsT0
�h�R��
https://www.youtube.com/watch?v=4ViwSeuWVfE
AMD
https://www.youtube.com/watch?v=IxGtV0CmsT0
�}�g���ɃR�s�y���ςł��ĂȂ��̂͂��Ă����A
>��H�v�ƃA�[�L�e�N�`����6�{�̉��P�������ł����
���������݂Ă����܂��������B
���ꂪ�{���Ȃ琻���v���Z�X�����ł�6�{���\�グ������Ęb�ɂȂ肻���B
�ߔN��CPU�ł̓A�[�L�e�N�`���ύX�ɂ�鐫�\�����10%���x���Ȃ̂ɁE�E�E
>��H�v�ƃA�[�L�e�N�`����6�{�̉��P�������ł����
���������݂Ă����܂��������B
���ꂪ�{���Ȃ琻���v���Z�X�����ł�6�{���\�グ������Ęb�ɂȂ肻���B
�ߔN��CPU�ł̓A�[�L�e�N�`���ύX�ɂ�鐫�\�����10%���x���Ȃ̂ɁE�E�E
543 �FSocket774�F2015/03/01(��) 09:54:54.14 ID:F9kNOzGF
cpu�̃A�[�L�e�N�`�����ĂقƂ�Ǖς���ĂȂ�����
�t�Ɍ������x����CPU(Kaveri)�̃A�[�L�e�N�`����ς����6�{�ɏo����̂��H���Ęb���ȁB
�Ԃ����ႯCPU�Ɋւ��Ă͂��������ς����Ȃ��̂������Ȃ낤��
6�{�Ƃ����X�܂߂�50�{�Ƃ��M���O����H
6�{�Ƃ����X�܂߂�50�{�Ƃ��M���O����H
546 �FSocket774�F2015/03/01(��) 10:09:58.83 ID:F9kNOzGF
cpu�͉�����Ă��������낗
���ꂱ��dynamic code optimization�Ƃ�trace cache�g��Ȃ�����
������A�N�Z�����[�^�̕K�v�����o�Ă���
����PEZY�x�[�X��gpu������炗�H
���ꂱ��dynamic code optimization�Ƃ�trace cache�g��Ȃ�����
������A�N�Z�����[�^�̕K�v�����o�Ă���
����PEZY�x�[�X��gpu������炗�H
���\6�{�ł͂Ȃ�����d�͑ΐ��\�䂾����6�{�͗]�T����B
�X�[�p�[�X�J�����X�[�p�[�p�C�v���C������߂Đ��\��1/100�ɂ�����ł��B���ł���B
�X�[�p�[�X�J�����X�[�p�[�p�C�v���C������߂Đ��\��1/100�ɂ�����ł��B���ł���B
��ΐ��\�������グ��������ƃ������ш悪�K���l�b�N�ɂȂ��Ă��܂������
�������͂Ȃ�炩�̃u���C�N�X���[���N����܂ő҂��Ȃ��Ƃ�����
�������͂Ȃ�炩�̃u���C�N�X���[���N����܂ő҂��Ȃ��Ƃ�����
>>542
�����܂őO�����̐��\����Ȃ�Llano����̃G�l���M�[���P���ˁB
����28nm��kaveri����Carrizo�ł͂��Ȃ�̉��P��z�肵�Ă邩��A���̒��q�ł����Η]�T�B
http://www.fudzilla.com/news/processors/37088-amd-carrizo-specs-revealed-at-isscc
�����܂őO�����̐��\����Ȃ�Llano����̃G�l���M�[���P���ˁB
����28nm��kaveri����Carrizo�ł͂��Ȃ�̉��P��z�肵�Ă邩��A���̒��q�ł����Η]�T�B
http://www.fudzilla.com/news/processors/37088-amd-carrizo-specs-revealed-at-isscc
����CPU6�R�A�{���̕�iGPU���炷�����邾���ŁA���\�킦��Ǝv�����ǁc�B
FX�̃��[�G���h���낻����Ă����Ǝv�����B
FX�̃��[�G���h���낻����Ă����Ǝv�����B
GPGPU���\�Ƃ̃o�����X���Ƃ�Ȃ��Ƃ����Ȃ�����ˁB
���������_�ł�3M,2CU���炢���~�������ǁB
�����炱�������䗦�̂܂܃R�A����������i�ł��낤�jzen����APU�Ɋ��ҁB
���������_�ł�3M,2CU���炢���~�������ǁB
�����炱�������䗦�̂܂܃R�A����������i�ł��낤�jzen����APU�Ɋ��ҁB
Bull�n�̃R�A�̓��W���[������������ق�L2���x���Ȃ�̂�3M�ȏ�Ń}���`�X���b�h���\���ێ����悤�Ƃ����L3���K�v�ɂȂ�
���̏�L3��GPU���`�b�v�Z�b�g�����Ă̂͏��������Ȃ�����
6�R�A�ȏ��Zen�Ɋ��҂��邵���Ȃ�
���̏�L3��GPU���`�b�v�Z�b�g�����Ă̂͏��������Ȃ�����
6�R�A�ȏ��Zen�Ɋ��҂��邵���Ȃ�
��ΐ��\�̘b����Ȃ����ǂ̓��b�g�p�t�H�[�}���X��50�{�Ƃ������b�ȂˁB
���\1/100�Ȃ炢�ł��B���\���Ă̂́A���W�R���Ȃ�X�P�[���X�s�[�h300km/h�ȏ�Ƃ��A�m�~�Ȃ�W�����v�͂��l�Ԃ�200�{�����݂����ȃl�^���B
���\1/100�Ȃ炢�ł��B���\���Ă̂́A���W�R���Ȃ�X�P�[���X�s�[�h300km/h�ȏ�Ƃ��A�m�~�Ȃ�W�����v�͂��l�Ԃ�200�{�����݂����ȃl�^���B
554 �FSocket774�F2015/03/01(��) 18:38:20.37 ID:pZ8DAORz
���₢��A�G�N�T�t���b�v�X�Ƃ����̂͐�ΐ��\�̎�����B
���b�g�p�t�H�[�}���X�����Ă����̎��B�G�N�T�t���b�v�X�B������̂ɍ����50�{�ȏ����d�͐H���Ă���_�O����ȁB
���b�g�p�t�H�[�}���X�����Ă����̎��B�G�N�T�t���b�v�X�B������̂ɍ����50�{�ȏ����d�͐H���Ă���_�O����ȁB
�x���`�̐������グ��ɂ̓x���`�œd�͌����̈���CPU��ᐫ�\�����ăx���`�����͗ǂ�GPU����������̂���ԁB
����Intel��AMD�̌��ǂ���CPU�̋�����f�O����GPU�̋����ɑ����Ă���B
����x64�̐��\��ARM���ɂ��邱�Ƃ����肵�Ă���AMD�͍Ő�[�𑖂��Ă���B
����Intel��AMD�̌��ǂ���CPU�̋�����f�O����GPU�̋����ɑ����Ă���B
����x64�̐��\��ARM���ɂ��邱�Ƃ����肵�Ă���AMD�͍Ő�[�𑖂��Ă���B
intel�͂��łɊ����^��phi�����p�����Ă�̂�
hsa�Ȃ�ăz���ƌ��悾���ōŌ�����ǂ��Ƃ�����
hsa�Ȃ�ăz���ƌ��悾���ōŌ�����ǂ��Ƃ�����
�t�@�C�Ƃ��O���{�̂ł������Ȃ��̃l�^�{�[�h���낗
�o�����Ȃ�����hsa���̂͂��������J�x���H���������H
>>471
�Ȃe�ߊ��킭�ȁ[
�����É�PC���ɔ��āi����̑g�ݗ��Ă��A�É��\�z�̃g���C���G���[���ɔ��j
���������������������������BTO�V���b�v�����PC������
4�`5�N�O�ɃI���I�X�y�b�N��AMD PC�i���쉹18db�j���Ė����Ɏg���Ă�B
CPU��Phenom�U 945�A��������8G�ŁA�}�U�[�Ɠd�������͉����~�����̂��I�����ڂɖ��������̂�
����Ń`���C�X���Ă�������B
���̌�A�O���{�����̓t�@�����XHD7750���đ��݂������A���Ƃ͂��̂܂�܁B
���낻��V����PC���~�����Ȃ�APU�@���~�����̂���
���A�I���I�X�y�b�N��M-ATX��AMD�@��̔����ĂȂ���ȁB
AMD�}�V�����̔����Ă����A���͔������炳�B
�Ȃe�ߊ��킭�ȁ[
�����É�PC���ɔ��āi����̑g�ݗ��Ă��A�É��\�z�̃g���C���G���[���ɔ��j
���������������������������BTO�V���b�v�����PC������
4�`5�N�O�ɃI���I�X�y�b�N��AMD PC�i���쉹18db�j���Ė����Ɏg���Ă�B
CPU��Phenom�U 945�A��������8G�ŁA�}�U�[�Ɠd�������͉����~�����̂��I�����ڂɖ��������̂�
����Ń`���C�X���Ă�������B
���̌�A�O���{�����̓t�@�����XHD7750���đ��݂������A���Ƃ͂��̂܂�܁B
���낻��V����PC���~�����Ȃ�APU�@���~�����̂���
���A�I���I�X�y�b�N��M-ATX��AMD�@��̔����ĂȂ���ȁB
AMD�}�V�����̔����Ă����A���͔������炳�B
AVX�Ȃ�炢���������₵�Ă����ȊO�̌|�͂˂��́H��
>>559
�I���I�ɗ���Ńt���X�N���b�`�Ő��삵�Ă��炦�H
�I���I�ɗ���Ńt���X�N���b�`�Ő��삵�Ă��炦�H
opencl��intel��50�{�ȏ㑬���Ƃ������Ă��̂�
>>561
�܂��A�m���ɁB
��{����PC�Ȃ��M-ATX��Intel�@�̃}�U�[��CPU��AMD�ɕς��Ă���Ɨ���
����Ă��ꂻ���ł͂����
���łɓd���̓V�[�\�j�b�N�M�҂Ȃ�ŁA����ɕς��Ă��炤��
�܂��A�m���ɁB
��{����PC�Ȃ��M-ATX��Intel�@�̃}�U�[��CPU��AMD�ɕς��Ă���Ɨ���
����Ă��ꂻ���ł͂����
���łɓd���̓V�[�\�j�b�N�M�҂Ȃ�ŁA����ɕς��Ă��炤��
Sandy Bridge���Č���GPU��OpenCL���炸CPU�G�~���̂܂I������́H��
>>563
�V�k�S�Ȃ���I���{�[�h�ł̃A�i���O�����̕i���������Ƃ����}�U�[��I����������
�V�k�S�Ȃ���I���{�[�h�ł̃A�i���O�����̕i���������Ƃ����}�U�[��I����������
���݂
�킩���ā[�ȁ[
�킩���ā[�ȁ[
�掿���@�\���ň��Ƃ����̕�HD�O�������Ƃ��Ȃ����˂�
�~�h���N���X�ōŊ��̔��cCPU�������̂�
�~�h���N���X�ōŊ��̔��cCPU�������̂�
���̗ǂ��Ƃ��Ȃ��Ɍ���I�_���[�W�����Ă�
��������T�|�[�g�����I��肾����Ȃ�
�ǂ�����GTX970�݂Ă��ɂ�
�ǂ�����GTX970�݂Ă��ɂ�
���H��
kaveri��hsahsa������
���Ǔ������ςȂ����������
havok��opencl�Ή��͂ǂ��Ȃ����̂��H
kaveri��hsahsa������
���Ǔ������ςȂ����������
havok��opencl�Ή��͂ǂ��Ȃ����̂��H
>>571
���肪�Ƃ��A�����Œ��ׂĂ݂��
�܂��A�m�C�Y�����悤�Ȃ�ASE-90PCI���N���[�[�b�g�ɂ����ꖇ�]�����Ă�͂�������
����}����
���肪�Ƃ��A�����Œ��ׂĂ݂��
�܂��A�m�C�Y�����悤�Ȃ�ASE-90PCI���N���[�[�b�g�ɂ����ꖇ�]�����Ă�͂�������
����}����
havok�̓C���e���̎q��Ђł���
OpenCL�Ή���邩�ǂ����̓C���e�����悶��˂�����
�Ȃ�Ȃ悻�̃u�[������
OpenCL�Ή���邩�ǂ����̓C���e�����悶��˂�����
�Ȃ�Ȃ悻�̃u�[������
hd5000����cpu���x���Ȃ�havok cloth��
�������E�X�O�ł܂������demo����
������Ă��̂�
�������E�X�O�ł܂������demo����
������Ă��̂�
�C���e����CPU��Ђ������
�\�t�g�E�F�A�ɑ��Ă͗�W����
���̕��O���̃h���C�o���ĂĂ������邾��
�ŋ߂�GbE�h���C�o�点�Ă������
�\�t�g�E�F�A�ɑ��Ă͗�W����
���̕��O���̃h���C�o���ĂĂ������邾��
�ŋ߂�GbE�h���C�o�点�Ă������
havok���������̂͒P��AMD�ւ̌����点�Ǝv����
�����炻�̂��ƍw���������Y�ւ̓����Ŏ�����ėǂ�����Ƃ��F��
�k�r��ATi�ւ̌����点�̂��߂�ULi�������̂Ɠ��l
����2�Ђ͗��p�҃K�`�����ł��������L�`�K�C�݂����ȍs�����Ƃ�
�����炻�̂��ƍw���������Y�ւ̓����Ŏ�����ėǂ�����Ƃ��F��
�k�r��ATi�ւ̌����点�̂��߂�ULi�������̂Ɠ��l
����2�Ђ͗��p�҃K�`�����ł��������L�`�K�C�݂����ȍs�����Ƃ�
intel�@Atom���Q�[���@�̗p�֔��荞�ނ��߂�
�n�[�h�E�F�A������Z�T�|�[�g����A���^�C�������_�����O�\����
����Ȃ��ƌ����Ă����̘b���������Ȃ��A�A�A
���̎��́APVR�p�̃h���C�o������Ȃ����l�Ȋ�Ƃ������ˁB
���܂ł������[�X�ł��Ȃ�����C�}�W�l�[�V�����������M�o������R�������
�h���C�o�J���`�[�����U�������A�A�A
�n�[�h�E�F�A������Z�T�|�[�g����A���^�C�������_�����O�\����
����Ȃ��ƌ����Ă����̘b���������Ȃ��A�A�A
���̎��́APVR�p�̃h���C�o������Ȃ����l�Ȋ�Ƃ������ˁB
���܂ł������[�X�ł��Ȃ�����C�}�W�l�[�V�����������M�o������R�������
�h���C�o�J���`�[�����U�������A�A�A
>>573
�T�E���h�̕i���Ɋւ��Ă͓X���Ƒ��k���Ă����ߕ����Ă݂Ă�
�T�E���h�̕i���Ɋւ��Ă͓X���Ƒ��k���Ă����ߕ����Ă݂Ă�
>>578
����atom��PVR��߂��̂��Ǝv������Medfield�Ƃ�Moorefield�ł͐�������Ȃ��̗p���Ă�̂�
�Ȃ̂Ƀh���C�o�J���`�[�����U�Ƃ��C�}�W�l�[�V�����̓D�h���C�o���p�Ƃ�����������
����atom��PVR��߂��̂��Ǝv������Medfield�Ƃ�Moorefield�ł͐�������Ȃ��̗p���Ă�̂�
�Ȃ̂Ƀh���C�o�J���`�[�����U�Ƃ��C�}�W�l�[�V�����̓D�h���C�o���p�Ƃ�����������
�[���Ȃ̂�
�Ȃ��intel��powevr�̃h���C�o�[���Ȃ���Ȃ�ˁ[�̂��H����
�Ȃ��intel��powevr�̃h���C�o�[���Ȃ���Ȃ�ˁ[�̂��H����
����CPU���i��PVR��IP�R�A��g�ݍ��߂h���C�o�J���͕K�{���낤��
�C�}�W�l�[�V�����͌���dGPU�������[�X���ĂȂ�����win�p�h���C�o�͕ʓr�J������K�v������
�����̓}�W�Ńo�J����
�C�}�W�l�[�V�����͌���dGPU�������[�X���ĂȂ�����win�p�h���C�o�͕ʓr�J������K�v������
�����̓}�W�Ńo�J����
�[����
�R�C�c�߂�����o�J��
�o�J�����Ęb�ɂȂ���
���A�����E�ő���ɂ���Ȃ�����Q�����ɏo�Ă��Ă�낤��
�R�R�ɂ����O�̋��ꏊ�͂˂���
�ǂ�������
�o�J�����Ęb�ɂȂ���
���A�����E�ő���ɂ���Ȃ�����Q�����ɏo�Ă��Ă�낤��
�R�R�ɂ����O�̋��ꏊ�͂˂���
�ǂ�������
586 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂����F2015/03/01(��) 20:09:53.68 ID:gefCpGvU
�R
�@�J
�@�@��
�@�@�@��
�@�@�@�@��
�H
�@�J
�@�@��
�@�@�@��
�@�@�@�@��
�H
mediatek��T���`�������Ǝ��Ńh���C�o�[����Ă�Ǝv���Ă[��������
588 �F,,�E�L�́M�E,,�j��-�������F2015/03/01(��) 20:40:44.33 ID:gefCpGvU
CiscoUCS��Opteron�ő叟���Ȕ]���X�Ȑl�ł���
���Ђ̋Z�p�x���ȂǕK�v�Ȃ�
��C���e���͖��T�ł���I�i�L��
��C���e���͖��T�ł���I�i�L��
�����[�X�m�[�g����ߋ��̃o�O�t�h���C�o��ver��������Ƃ�
591 �FSocket774�F2015/03/02(��) 07:49:04.87 ID:1rLSlriC
http://web.stanford.edu/class/ee380/Abstracts/150304.html
Dynamic Code Optimization and the NVIDIA Denver Processor
Nathan Tuck
NVIDIA
Dynamic Code Optimization and the NVIDIA Denver Processor
Nathan Tuck
NVIDIA
592 �FSocket774�F2015/03/02(��) 13:10:52.23 ID:VXnIE2NN
���O��
594 �FSocket774�F2015/03/02(��) 21:10:29.69 ID:isuEKpN7
�嗬�̃C���e��Core�v���Z�b�T�[��Skylake����AVX 512���T�|�[�g���Ă��܂��� - �݂̂�Xeon
���|�[�g�t�H�[���̂ŁA����͂��Ƃ���AVX 512�́A���ׂĂ�Skylake�v���Z�b�T��ŗ��p�ł���悤�ɂȂ�ƍl�����Ă������A
����doesnt�̂́A�P�[�X�̂悤�Ɍ�����B���Xeon�x�[�X�̃v���Z�b�T��������T�|�[�g���邱�Ƃ����悤�Ƃ��Ă��邱�Ƃ����炩�ɂȂ���-
���Ȃ킿���C���X�g���[���T�|�[�g��SIMD������閳���B�ł��AXeon�v���Z�b�T�̃v���Z�b�T�͊��S�ȋ@�\�Z�b�g���y���ނ���Cannonlake��҂K�v������܂��B
http://wccftech.com/mainstream-intel-core-processors-support-avx-512-skylake-xeon/
���|�[�g�t�H�[���̂ŁA����͂��Ƃ���AVX 512�́A���ׂĂ�Skylake�v���Z�b�T��ŗ��p�ł���悤�ɂȂ�ƍl�����Ă������A
����doesnt�̂́A�P�[�X�̂悤�Ɍ�����B���Xeon�x�[�X�̃v���Z�b�T��������T�|�[�g���邱�Ƃ����悤�Ƃ��Ă��邱�Ƃ����炩�ɂȂ���-
���Ȃ킿���C���X�g���[���T�|�[�g��SIMD������閳���B�ł��AXeon�v���Z�b�T�̃v���Z�b�T�͊��S�ȋ@�\�Z�b�g���y���ނ���Cannonlake��҂K�v������܂��B
http://wccftech.com/mainstream-intel-core-processors-support-avx-512-skylake-xeon/
�O����\�z����Ă��ʂ肾��
On APIs and the future of Mantle
http://community.amd.com/community/amd-blogs/amd-gaming/blog/2015/03/02/on-apis-and-the-future-of-mantle
http://community.amd.com/community/amd-blogs/amd-gaming/blog/2015/03/02/on-apis-and-the-future-of-mantle
Mantle was destined to follow suit, and it does so today as we proudly announce that the 450-page programming guide
and API reference for Mantle will be available this month (March, 2015) at www.amd.com/mantle
http://www.amd.com/en-us/innovations/software-technologies/technologies-gaming/mantle#overview
and API reference for Mantle will be available this month (March, 2015) at www.amd.com/mantle
http://www.amd.com/en-us/innovations/software-technologies/technologies-gaming/mantle#overview
AMD, HP Join Forces to Accelerate Server Graphics
http://www.enterprisetech.com/2015/02/27/amd-hp-join-forces-to-accelerate-server-graphics/
http://www.enterprisetech.com/2015/02/27/amd-hp-join-forces-to-accelerate-server-graphics/
599 �FSocket774�F2015/03/03(��) 12:39:55.36 ID:NYtBFKN6
�mGDC 2015�nAMD�Ǝ�API�uMantle�g1.0�h�v��������̏I���BAMD��DirectX 12�Ǝ�����OpenGL�̗��p���Ăт���
http://www.4gamer.net/games/234/G023477/20150303015/
http://www.4gamer.net/games/234/G023477/20150303015/
���W�I���������牽�����Ȃ���
AMD�̖ړI�̓n�[�h�邱�ƂŃ\�t�g�邱�Ƃ���Ȃ�
����͂����܂ł��n�[�h�̔��̃T�|�[�g
������MS���u����œG�͋��˂��I�v�Ɩ��f���ĉ������Ȃ��Ȃ�����Mantle2���o�ė���
�iGPU�p�r�g��̂��ߎd���Ȃ����\�[�X�����āj
����͂����܂ł��n�[�h�̔��̃T�|�[�g
������MS���u����œG�͋��˂��I�v�Ɩ��f���ĉ������Ȃ��Ȃ�����Mantle2���o�ė���
�iGPU�p�r�g��̂��ߎd���Ȃ����\�[�X�����āj
603 �FSocket774�F2015/03/03(��) 14:25:45.79 ID:XUbUd2uV
���ɂ�IGPU��DGPU�̗Z���B
���N�o�ꂪ�\�肳��Ă�APU��1024SP��1GHz
���\�I�ɂ�GTX580�AGTX660�����B
���̋��͂�APU�ɂ���ɋ��͂�DGPU���������ꍇ�Ɉ�C�ɐ��\���オ��悤�Ɏ�����Mantle���\�肳��Ă���B
���N�o�ꂪ�\�肳��Ă�APU��1024SP��1GHz
���\�I�ɂ�GTX580�AGTX660�����B
���̋��͂�APU�ɂ���ɋ��͂�DGPU���������ꍇ�Ɉ�C�ɐ��\���オ��悤�Ɏ�����Mantle���\�肳��Ă���B
Mantle2.0�͂��낤���Ǎ��������ʂ�Ȃ��������玟���ʂ�킯�Ȃ��ˁH
�ƁA�v���̂����B
AMD���炷���}���`�R�A�ł̐��\���オ��Ԏ��������������������낤���A
���Ȃ��̂�������Ȃ����ǁB
�ƁA�v���̂����B
AMD���炷���}���`�R�A�ł̐��\���オ��Ԏ��������������������낤���A
���Ȃ��̂�������Ȃ����ǁB
>>600
�������uMantle�g1.0�h�v�̋@�\�ɋ���������Ȃ�CAMD�Ƃ��Ă�DirectX 12����ю�����OpenGL�Ƀt�H�[�J�X���邱�Ƃ����߂�
DX12��GLnext��Mantle1.0�x�[�X�����Č���������Ă�悤�Ȃ��Ȃ����
������5����GDC��Mantle2.0�̂���I�ڂ������
�������uMantle�g1.0�h�v�̋@�\�ɋ���������Ȃ�CAMD�Ƃ��Ă�DirectX 12����ю�����OpenGL�Ƀt�H�[�J�X���邱�Ƃ����߂�
DX12��GLnext��Mantle1.0�x�[�X�����Č���������Ă�悤�Ȃ��Ȃ����
������5����GDC��Mantle2.0�̂���I�ڂ������
>>596
1. AMD will continue to support our trusted partners that have committed to Mantle in future projects, like Battlefield Hardline, with all the resources at our disposal.
2. Mantle�fs definition of �gopen�h must widen. It already has, in fact. This vital effort has replaced our intention to release a public Mantle SDK, and you will learn the facts on Thursday, March 5 at GDC 2015.
3. Mantle must take on new capabilities and evolve beyond mastery of the draw call. It will continue to serve AMD as a graphics innovation platform available to select partners with custom needs.
The Mantle SDK also remains available to partners who register in this co-development and evaluation program.
However, if you are a developer interested in Mantle "1.0" functionality, we suggest that you focus your attention on DirectX 12 or GLnext.
1. AMD will continue to support our trusted partners that have committed to Mantle in future projects, like Battlefield Hardline, with all the resources at our disposal.
2. Mantle�fs definition of �gopen�h must widen. It already has, in fact. This vital effort has replaced our intention to release a public Mantle SDK, and you will learn the facts on Thursday, March 5 at GDC 2015.
3. Mantle must take on new capabilities and evolve beyond mastery of the draw call. It will continue to serve AMD as a graphics innovation platform available to select partners with custom needs.
The Mantle SDK also remains available to partners who register in this co-development and evaluation program.
However, if you are a developer interested in Mantle "1.0" functionality, we suggest that you focus your attention on DirectX 12 or GLnext.
mantle�͓���n�[�h�Ɉˑ����Ă���API������A�[�L�e�N�`���ύX�̂��тɌÂ��\�t�g�͓����Ȃ��Ȃ��
�����mantle�̎d�l�Ƃ������h���Ȃ̂ʼn���ł��Ȃ�
�݊������d������Ȃ瑽���p�t�H�[�}���X�͗����邯��directx���g���Ă˂Ƃ����̂�AMD�̍l��
�����mantle�̎d�l�Ƃ������h���Ȃ̂ʼn���ł��Ȃ�
�݊������d������Ȃ瑽���p�t�H�[�}���X�͗����邯��directx���g���Ă˂Ƃ����̂�AMD�̍l��
�Ȃ�ق�
DX12��AMD�哱�������Ă��悤�Ȃ���
MS�������������Ă���mantle2.0�ŃP�c�@����
DX12��AMD�哱�������Ă��悤�Ȃ���
MS�������������Ă���mantle2.0�ŃP�c�@����
DX12��MS���d�|�����I����mantle�ׂ��Ȃ�ł����ǁc
5����NDA���ւɂȂ�݂���������5���܂ő҂ĂH
>>609
����Ȃ�AMD���uDirectX 12���g���āI�v�Ȃ�Č����킯�Ȃ��ł���
MS���炵����Xbox one�̎������邵�J���҂���̗v�]������B
AMD�͏���ver. Mantle�̊�b�I�v�f��MS�Ɍ����肳�����킯��win=win�ł���B
Mantle 2.0��DIrectx12�̓Ǝ��g���݂����Ȉʒu�ɔ[�܂��Ȃ����H
����Ȃ�AMD���uDirectX 12���g���āI�v�Ȃ�Č����킯�Ȃ��ł���
MS���炵����Xbox one�̎������邵�J���҂���̗v�]������B
AMD�͏���ver. Mantle�̊�b�I�v�f��MS�Ɍ����肳�����킯��win=win�ł���B
Mantle 2.0��DIrectx12�̓Ǝ��g���݂����Ȉʒu�ɔ[�܂��Ȃ����H
Vulkan Is The Next-Gen Graphics API
http://www.phoronix.com/scan.php?page=news_item&px=Khronos-Vulkan-Graphics-API
GLnext�̖��O��Vulkan�ɂȂ����悤����
http://www.phoronix.com/scan.php?page=news_item&px=Khronos-Vulkan-Graphics-API
GLnext�̖��O��Vulkan�ɂȂ����悤����
AMD also says Mantle's definition of "open" will widen this year.
Mantle isn't being killed off but will be "a graphics innovation platform available to select partners with custom needs."
http://www.phoronix.com/scan.php?page=news_item&px=AMD-Mantle-Docs-Coming
Mantle isn't being killed off but will be "a graphics innovation platform available to select partners with custom needs."
http://www.phoronix.com/scan.php?page=news_item&px=AMD-Mantle-Docs-Coming
UE4��������
https://www.unrealengine.com/blog/ue4-is-free
https://www.unrealengine.com/blog/ue4-is-free
���ꂩ���DirectX�̎���I
AMD�u���������I�v
AMD�����g���Ȃ��Z�p���A�EI�EN���̑��ɑS�Ďg����DX12�̂ق������������
AMD�����������ĊJ��������Ȃ�ʂ���
AMD�����������ĊJ��������Ȃ�ʂ���
618 �FSocket774�F2015/03/03(��) 18:18:24.64 ID:QE0qNHg/
���ł����Ȃ�AMD�����R�ɂȂ�Ȃ��B
���͓I�ȓƎ��Z�p�ō��ʉ����ĂȂ��Ƃ��������������N���肤��B
���͓I�ȓƎ��Z�p�ō��ʉ����ĂȂ��Ƃ��������������N���肤��B
Maxwell��tier2�܂�GCN��tier3�܂łƂȂ��Ă邾��
DX12�̃T�|�[�g���x�����Ⴄ�Ƃ����͖̂��͓I�ȓƎ��Z�p�ō��ʉ����Ă���̂�����AMD�����R�ɂȂ�
DX12�̃T�|�[�g���x�����Ⴄ�Ƃ����͖̂��͓I�ȓƎ��Z�p�ō��ʉ����Ă���̂�����AMD�����R�ɂȂ�
Vulkan is making it happen.
https://www.khronos.org/vulkan
https://www.khronos.org/vulkan
Mantle�Ƃ͈�̂Ȃ����̂�
Vulkan�̃v���[����Johan Andersson��Dan Baker
http://schedule.gdconf.com/session/glnext-the-future-of-high-performance-graphics-presented-by-valve
Mantle��Linux�Ŏg����悤�ɂ������ƌ����Ă���2�l����
http://schedule.gdconf.com/session/glnext-the-future-of-high-performance-graphics-presented-by-valve
Mantle��Linux�Ŏg����悤�ɂ������ƌ����Ă���2�l����
Khronos Releases OpenCL 2.1 Provisional Specification for Public Review
https://www.khronos.org/news/press/khronos-releases-opencl-2.1-provisional-specification-for-public-review
OpenCL 2.1 is a significant evolution of the open,
royalty-free standard for heterogeneous parallel programming that defines a new kernel language based on a subset of C++ for significantly enhanced programmer productivity,
and support for the new Khronos SPIR-V cross-API shader program intermediate language now used by both OpenCL and the new Vulkan graphics API.
https://www.khronos.org/news/press/khronos-releases-opencl-2.1-provisional-specification-for-public-review
OpenCL 2.1 is a significant evolution of the open,
royalty-free standard for heterogeneous parallel programming that defines a new kernel language based on a subset of C++ for significantly enhanced programmer productivity,
and support for the new Khronos SPIR-V cross-API shader program intermediate language now used by both OpenCL and the new Vulkan graphics API.
624 �FSocket774�F2015/03/03(��) 18:43:50.26 ID:QE0qNHg/
32bit��64bit�����̂܂܍����ɓ�������I�ȓƎ��Z�p�������B
���̓V�ˊJ���҂�Apple�Ɉ���������AAMD��������̂͂��̋Z�p�����C�o����Ƃɗ����Ă��܂����B
�S�ɋ��_�Ƃ͂܂��ɂ��̎��ŁA���̌�ǂ��Ȃ������͍��ɂ�����B
����Ɠ��l�Ȏ����N���Ȃ����S�z���ȁB
���̓V�ˊJ���҂�Apple�Ɉ���������AAMD��������̂͂��̋Z�p�����C�o����Ƃɗ����Ă��܂����B
�S�ɋ��_�Ƃ͂܂��ɂ��̎��ŁA���̌�ǂ��Ȃ������͍��ɂ�����B
����Ɠ��l�Ȏ����N���Ȃ����S�z���ȁB
MS��AMD�����u�@�J����64bit�̉��b�͎�����
�Ƀj�E���Ƃ̕��ꉏ���ꂽ
�Ƀj�E���Ƃ̕��ꉏ���ꂽ
626 �FSocket774�F2015/03/03(��) 19:01:59.29 ID:QE0qNHg/
��������
64bit�ł��������Ȃ��A��������32bit�͉��z���Œ��X���[�ł������삵�Ȃ��悤�Ȃ̂������C�o����Ƃ͍��Ȃ������B
���ꂪ���X�Ƒ����Ă��Ǝv����ł���ˁB
�����Ȃ��AMD�����I�ׂȂ��ƌ����ʂȏ����o�����Ǝv���B
�V�F�A�́ACPU�����\�͂Ɍ��������ʂ܂Ŏ����Ă��ꂽ�ƁB
��K12��ZEN������Ă�J���҂��O�ɍ����AMD64�ƌ����Z�p�B
���炭�AK12��ZEN���������@�\�����ڂ���Ă���B
���̋Z�p�̑ǎ��Ŗ��Â��킩���قǁB
64bit�ł��������Ȃ��A��������32bit�͉��z���Œ��X���[�ł������삵�Ȃ��悤�Ȃ̂������C�o����Ƃ͍��Ȃ������B
���ꂪ���X�Ƒ����Ă��Ǝv����ł���ˁB
�����Ȃ��AMD�����I�ׂȂ��ƌ����ʂȏ����o�����Ǝv���B
�V�F�A�́ACPU�����\�͂Ɍ��������ʂ܂Ŏ����Ă��ꂽ�ƁB
��K12��ZEN������Ă�J���҂��O�ɍ����AMD64�ƌ����Z�p�B
���炭�AK12��ZEN���������@�\�����ڂ���Ă���B
���̋Z�p�̑ǎ��Ŗ��Â��킩���قǁB
Mantle1.0��DX12�ɈڐA���ꖳ���Ƀ����[�X�o�������Ȃ�ŁADX13������Mantle2.0������Ă܂�
���Ă��Ƃ��낤��
���Ă��Ƃ��낤��
628 �FSocket774�F2015/03/03(��) 19:06:28.86 ID:FcmdwI6Q
Mantle1.0�{����DX12
�@ �@DX12�{����������Mantle
�Ƃ��������ɂȂ�̂��B
�@ �@DX12�{����������Mantle
�Ƃ��������ɂȂ�̂��B
���zDX12�Ƃ���Mantle�����GCN�����
Mantle��DX12�̑��ĂƂ���MS�ɒ�Ă���
GCN��DX12�t���T�|�[�g������
����ADX12��GLnext�̔��\����������
Mantle1.0�͖�ڂ��I�����̂Ŏ��߂�
Mantle1.2��2.0�\���邩����
Mantle��DX12�̑��ĂƂ���MS�ɒ�Ă���
GCN��DX12�t���T�|�[�g������
����ADX12��GLnext�̔��\����������
Mantle1.0�͖�ڂ��I�����̂Ŏ��߂�
Mantle1.2��2.0�\���邩����
Mantle1.0�ɑΉ�����GCN1.0��DX12���S�Ή�
290x��GCN1.1�A285��GCN1.2�A390x��GCN1.3
���̕ӂ�DX12.1�����̉\����������
16nm���ƍX�ɐi������GCN1.4��2.0�ɂȂ邯�ǁA�ǂ�قǐ��������ŊJ�����Ă��
����DX13�ɂ��ē����Ă��炢��Ǝv����
290x��GCN1.1�A285��GCN1.2�A390x��GCN1.3
���̕ӂ�DX12.1�����̉\����������
16nm���ƍX�ɐi������GCN1.4��2.0�ɂȂ邯�ǁA�ǂ�قǐ��������ŊJ�����Ă��
����DX13�ɂ��ē����Ă��炢��Ǝv����
AMD64�����߂���Intel�����܂Ƃ��Ȑ��\��CPU�����Ȃ��Ƃ��������B
DX12��MS��Mantle�̃_���ȏ������ǂ��Ă���Ƃ͎v����Nv�������\���o���Ȃ��Ƃ��Ȃ肻���B
DX12��MS��Mantle�̃_���ȏ������ǂ��Ă���Ƃ͎v����Nv�������\���o���Ȃ��Ƃ��Ȃ肻���B
AMD�Ǝ�API�uMantle�g1.0�h�v��������̏I���BAMD��DirectX 12�Ǝ�����OpenGL�̗��p���Ăт���
http://fox.2ch.net/test/read.cgi/poverty/1425362606/
��ꕔ�A���i�j
http://fox.2ch.net/test/read.cgi/poverty/1425362606/
��ꕔ�A���i�j
>>631
�͂��͂��A���������̂͂܂�NV��DX12���t���T�|�[�g���Ă���ɂ��Ă�
�͂��͂��A���������̂͂܂�NV��DX12���t���T�|�[�g���Ă���ɂ��Ă�
>>633
�t���T�|�[�g���ĂȂ��Ă�Nv�̕��������炵������Ȃ��ł����B
�t���T�|�[�g���ĂȂ��Ă�Nv�̕��������炵������Ȃ��ł����B
���Ƃ���nvidia��dx12��10%�ɂ����Ή����ĂȂ��Ă�
�Q�[�����[�J�[��nvidia�ɍœK������悗
���Ƃ���nv���Ǝ�api�o�����Ƃ��Ă��Q�[�����[�J�[�͑Ή�����悗��
�Q�[�����[�J�[��nvidia�ɍœK������悗
���Ƃ���nv���Ǝ�api�o�����Ƃ��Ă��Q�[�����[�J�[�͑Ή�����悗��
Nvidia��MS���g���AMD�͊��S�Ƀn�u���Ă�DX12���A���_�[�������グ��s�v�c
AMD�uGPU�ł����������Əo����悤�Ȃ̍���Ă���v
MS�u��������������́H�v
MS�uDirectX�ŏo���邱�Ƃ����Ȃ��Ȃ��ė����ȁ`�ꉞ�p�����邯��XNA�ׂ͒����v
AMD�u�d�����������ō�邩�v
�\�t�g���u�����ꐦ���I�����g����I�v
MS�u�����ꐦ���I�����^�����I�v
MS�u��������������́H�v
MS�uDirectX�ŏo���邱�Ƃ����Ȃ��Ȃ��ė����ȁ`�ꉞ�p�����邯��XNA�ׂ͒����v
AMD�u�d�����������ō�邩�v
�\�t�g���u�����ꐦ���I�����g����I�v
MS�u�����ꐦ���I�����^�����I�v
mantle1.0�̋@�\��DirectX12�ɓ����ꂽ�Ƃ������Ƃ�
mantle�œ�����DirectX12�̐^�����o�����
AMD�͂���ł������������
Linux�̕��ʂ��ǂ��̂����̂́A�ǂ������H
mantle��linux�Ŏg���Ă�����mantle�Ȃ̂�
�������Ȃ��ƁAmantle�͒P�Ȃ�directX�̂Ȃ�����
�}�W�ň��Ȗ������Ƃ����������[�U�[�ł��B�͂�
mantle�œ�����DirectX12�̐^�����o�����
AMD�͂���ł������������
Linux�̕��ʂ��ǂ��̂����̂́A�ǂ������H
mantle��linux�Ŏg���Ă�����mantle�Ȃ̂�
�������Ȃ��ƁAmantle�͒P�Ȃ�directX�̂Ȃ�����
�}�W�ň��Ȗ������Ƃ����������[�U�[�ł��B�͂�
639 �FSocket774�F2015/03/03(��) 21:12:16.54 ID:KdHpqYKP
>>626
�������@�\�HSMT���邩�I
2000�N �f���A���R�APOWER4
��
2005�N�̓f���A���R�A���N�I���E���f���A���R�AAthlon64 X2�I
2003�N �N�A�b�h�R�APOWER5�A1�R�A2�X���b�hSMT
��
2007�N�A���ɃN�A�b�h�R�ACPU���o��IPhenom X4�I
2010�N2�� TurboCore���[�h�������POWER7�A1�R�A������4�X���b�hSMT
��
���N Turbo CORE��������Phenom II X6
2007�N �I�[�o�[5GHz POWER6
��
2013�N ���E����5GHz�AFX-9590�I(��i4.7GHz)
2014�N 12�R�A96�X���b�hSMT�APOWER8
��
2016�N(AMD����) ���E���ISMT����CPU�I�Ȃ�ƁI1�R�A������2�X���b�h�������Ă��܂��I���ꂩ���SMT�̎���IIntel�����ǂ��Ă��邩�ȁH
�������@�\�HSMT���邩�I
2000�N �f���A���R�APOWER4
��
2005�N�̓f���A���R�A���N�I���E���f���A���R�AAthlon64 X2�I
2003�N �N�A�b�h�R�APOWER5�A1�R�A2�X���b�hSMT
��
2007�N�A���ɃN�A�b�h�R�ACPU���o��IPhenom X4�I
2010�N2�� TurboCore���[�h�������POWER7�A1�R�A������4�X���b�hSMT
��
���N Turbo CORE��������Phenom II X6
2007�N �I�[�o�[5GHz POWER6
��
2013�N ���E����5GHz�AFX-9590�I(��i4.7GHz)
2014�N 12�R�A96�X���b�hSMT�APOWER8
��
2016�N(AMD����) ���E���ISMT����CPU�I�Ȃ�ƁI1�R�A������2�X���b�h�������Ă��܂��I���ꂩ���SMT�̎���IIntel�����ǂ��Ă��邩�ȁH
����Ƃ�����5���`windows10�ȍ~�ɔ��������V�^GPU(���l�[���͂Ȃ���)��DX12�Ή��ɂȂ邩��
���͕ʂɃt���Ή��łȂ��Ă��W�Ȃ���낤��
634���w�E���Ă�悤��nVidia�̂ق������������肷�邵
DX12�ł���Mantle2.0�͗]���������@�\���t���Ȃ��Ɠ�����낤��
AMD�͔��\�ł͑�X�I�ɃA�s�[�����邪�����̓��[�J�[���܂���Ă��Ă���ĂȂ������
���͕ʂɃt���Ή��łȂ��Ă��W�Ȃ���낤��
634���w�E���Ă�悤��nVidia�̂ق������������肷�邵
DX12�ł���Mantle2.0�͗]���������@�\���t���Ȃ��Ɠ�����낤��
AMD�͔��\�ł͑�X�I�ɃA�s�[�����邪�����̓��[�J�[���܂���Ă��Ă���ĂȂ������
>>639
����ǂނƈ�̒��̊^��C��m�炸��̂�
����ǂނƈ�̒��̊^��C��m�炸��̂�
Mantle�T�|�[�g��AMD�����I�叟���I
DX12Tier3�t���T�|�[�g��AMD�����I�叟���I
�������ƌJ��Ԃ��ĂĂق����肷��
DX12Tier3�t���T�|�[�g��AMD�����I�叟���I
�������ƌJ��Ԃ��ĂĂق����肷��
�ȕ����Ă鑊��`�[���̉����Ȃ�
���x�A�����ŖK��A�����b���U��l�ԂƂ�
�ǂ������l�ԂȂ̂�
���x�A�����ŖK��A�����b���U��l�ԂƂ�
�ǂ������l�ԂȂ̂�
�r�炵�͒m�Ⴖ��Ȃ��ƒp�������ďo���Ȃ�
�l�ԐS���I�ɍl����
�l�ԐS���I�ɍl����
646 �FSocket774�F2015/03/03(��) 21:31:08.16 ID:QE0qNHg/
������Η��ĂĈړ����邩�H
�c�q�̃J�L�R�~�͑S�ĉ����폜���čs����B
�c�q�̃J�L�R�~�͑S�ĉ����폜���čs����B
�ݺقő叟���̗\�肪gpu��s���Ƃ���
����w
�ݺقƂ͂Ȃ����̂�w
����w
�ݺقƂ͂Ȃ����̂�w
���ް���������őS�RRadeon��Mantle�Ή��Q�[��������Ȃ�����
Mantle�ͱ��ް�ɍ�����܂����Ƃ�
HSA�͂����ƌ���������Ȃ��Ď��ɂȂ�`�ʼn���������
Mantle�ͱ��ް�ɍ�����܂����Ƃ�
HSA�͂����ƌ���������Ȃ��Ď��ɂȂ�`�ʼn���������
649 �FSocket774 �]�ڃ_��©2ch.net�F2015/03/04(��) 00:21:23.84 ID:0uvYJ0r8
�@NV���������ŋ����̂́AGeForce256����̋ƊE�����[�h���Ă���
���т����邩��ł���B
�@Mantle���Ԃ��������W�I�����Ƃ����`�Ŏ����I�ɃX�^���_�[�h��������
���Ƃ�AMD�̑傫�Ȏ��тƂ����邾�낤�ˁB�Ӌ`���F�߂�ꂽ���炱��
������������ɂȂ����킯�ŁBFreeSync�Ȃ���肭��������ˁB
���т����邩��ł���B
�@Mantle���Ԃ��������W�I�����Ƃ����`�Ŏ����I�ɃX�^���_�[�h��������
���Ƃ�AMD�̑傫�Ȏ��тƂ����邾�낤�ˁB�Ӌ`���F�߂�ꂽ���炱��
������������ɂȂ����킯�ŁBFreeSync�Ȃ���肭��������ˁB
>>648
AMD��APU���[�U�[��GPGPU�EHSA���g�����t���[�\�t�g��F�X�o���Ă���邱�Ƃ����҂��Ă���낤��
�J���c�[���͂����Ȃ�
AMD��APU���[�U�[��GPGPU�EHSA���g�����t���[�\�t�g��F�X�o���Ă���邱�Ƃ����҂��Ă���낤��
�J���c�[���͂����Ȃ�
�v���O���~���O���ł���X�L��������l��AMD��I�Ȃ�
����AMD�ɋ������Mantle�Ή�����ꕔ���[�J�[�ȊO�́A
Mantle�Ή����������Đ�����������
Mantle�Ή����������Đ�����������
>>651
GPGPU���g�����炢�̃v���O���~���O�X�L��������z��AMD����Ȃ�
�����\Intel+GPGPU�p��Nv���ĂȂ�낤�ȁB
HSA�@APU�ł�CPU,iGPU���ɐ��\�Ⴗ���Ȃ낤
GPGPU���g�����炢�̃v���O���~���O�X�L��������z��AMD����Ȃ�
�����\Intel+GPGPU�p��Nv���ĂȂ�낤�ȁB
HSA�@APU�ł�CPU,iGPU���ɐ��\�Ⴗ���Ȃ낤
>>653
���\����蒷���̎��т���������A�p�����ɐM���������Ďg���Ȃ��̂�����
�\�t�g�J���҂͒P�̐��\���������̑Ή��ƌp�������d������
�o�[�W�����A�b�v���Ƃɍ�蒼���Ȃ��Ⴂ����悤�ȃ��m�Ȃg�����
�����炱��intel��CPU���������
�v���O�����ς����Ƀn�[�h��V�������������������Ȃ�
����̓����e�i���X�R�X�g���܂��Ĕ��ɏd�v�Ȃ���
���\����蒷���̎��т���������A�p�����ɐM���������Ďg���Ȃ��̂�����
�\�t�g�J���҂͒P�̐��\���������̑Ή��ƌp�������d������
�o�[�W�����A�b�v���Ƃɍ�蒼���Ȃ��Ⴂ����悤�ȃ��m�Ȃg�����
�����炱��intel��CPU���������
�v���O�����ς����Ƀn�[�h��V�������������������Ȃ�
����̓����e�i���X�R�X�g���܂��Ĕ��ɏd�v�Ȃ���
Mantle�Ŏ��O���K�ł����Ƃ���ƁA�Ԃ�����DX12�Ή�����Ƃ���ŁA�����x������Ă���낤��
Mantle�g���Ă��Ƃ��́A���̓}���`GPU��Ǝ������_�����O�ACPU�Ƃ̔����Z�Ƃ��A�����s���J�������Ă���Ƃ���
Mantle�g���Ă��Ƃ��́A���̓}���`GPU��Ǝ������_�����O�ACPU�Ƃ̔����Z�Ƃ��A�����s���J�������Ă���Ƃ���
>>654
>�����̑Ή��ƌp�������d��
�Ɩ��p�͂���厖�Ȃ��ǁA�u��Opteron�ł����Ƃ����ԂɌp���i�����̂Ă��Ƃ����ĂȂ��������
HSA�̏ꍇ��AMD�̂݃T�|�[�g��Intel�ֈڍs�ł��Ȃ������Ƃ͂������T�d�ɂȂ���
�����炱���A�l��AMD���[�U�[��HSA�̕��y�̎��x����낵�����낤
>�����̑Ή��ƌp�������d��
�Ɩ��p�͂���厖�Ȃ��ǁA�u��Opteron�ł����Ƃ����ԂɌp���i�����̂Ă��Ƃ����ĂȂ��������
HSA�̏ꍇ��AMD�̂݃T�|�[�g��Intel�ֈڍs�ł��Ȃ������Ƃ͂������T�d�ɂȂ���
�����炱���A�l��AMD���[�U�[��HSA�̕��y�̎��x����낵�����낤
�{����GPGPU��CPU�ƃA�h���X���L���ă|�C���^�̂��Ƃ�ŊȒP�ɘA�g�ł��Ȃ��Ƃ����Ȃ����ǁA�C���e���ƃQ�t�H����i���ɕs�\��������߂��ق�������
�����A�Q�[�����R���s���[�e�B���O��AMD���x�z������
�����A�Q�[�����R���s���[�e�B���O��AMD���x�z������
HSA�͂܂��n�[�h�������[�X����ĂȂ�������Č����ă\�t�g�����L���Ă邯��
Intel��NVIDIA�͐V�n�[�h���o��1�`2�N�O�ɂ̓A�[�L�e�N�`���V�~�����[�^���Ă��
AVX-512�Ȃ܂��n�[�h����o�ĂȂ��̂ɗL�u�̃\�t�g�E�F�A��GitHub�ɏオ���Ă�
���AMD�̋Z�p�ɂ͂܂��������������̂��Ȃ�
�T�[�o�EWS�Ŏg���Ă�Xeon�ƃA�[�L�e�N�`���݊��Ƃ��������ł�Core i*�̍œK���Z�p��
���v�������炷���AAPU�͈�PC�����~�܂�B
i3�`i5�Ɣ�ׂĐ��ݔ\�͂��ǂ��������������A�܂��G���W�j�A�������ɋ����������ĂȂ�
APU�ł�����œK���撣���Ă�DDR4 4ch�ς�Xeon�ɏ��Ă�킯����Ȃ�����ˁB
Intel��NVIDIA�͐V�n�[�h���o��1�`2�N�O�ɂ̓A�[�L�e�N�`���V�~�����[�^���Ă��
AVX-512�Ȃ܂��n�[�h����o�ĂȂ��̂ɗL�u�̃\�t�g�E�F�A��GitHub�ɏオ���Ă�
���AMD�̋Z�p�ɂ͂܂��������������̂��Ȃ�
�T�[�o�EWS�Ŏg���Ă�Xeon�ƃA�[�L�e�N�`���݊��Ƃ��������ł�Core i*�̍œK���Z�p��
���v�������炷���AAPU�͈�PC�����~�܂�B
i3�`i5�Ɣ�ׂĐ��ݔ\�͂��ǂ��������������A�܂��G���W�j�A�������ɋ����������ĂȂ�
APU�ł�����œK���撣���Ă�DDR4 4ch�ς�Xeon�ɏ��Ă�킯����Ȃ�����ˁB
�T�[�o�EWS��
�T�[�o�[�AWS�pAPU���F�X�Ȃ����āA�{�C�x�������������ƂȂ����Ă��Ƃ����
A10��WS���f�����炢�o���悢���Ďv���B
HSA1.0�Ή��̂̓m�[�g�݂̂Ńf�X�N�g�b�v�����B
���ł͋��̓A�s�[�����Ă���HSA�͎��s���ł͖{�C��x�������Ȃ������
�T�[�o�[�AWS�pAPU���F�X�Ȃ����āA�{�C�x�������������ƂȂ����Ă��Ƃ����
A10��WS���f�����炢�o���悢���Ďv���B
HSA1.0�Ή��̂̓m�[�g�݂̂Ńf�X�N�g�b�v�����B
���ł͋��̓A�s�[�����Ă���HSA�͎��s���ł͖{�C��x�������Ȃ������
CPU�ɂ��Ă�Intel��10nm��Cannonlake�܂ł̖��߃Z�b�g�����J���Ă���
�Ȃ����V���߂���������s�������Ă���i�l�ł������ŗ��p�\�j
AMD�͒��߂̃��W���[�A�b�v�f�[�g�ƂȂ�Zen�A�[�L�e�N�`������
�����ɏ������J���Ă��Ȃ��BGPU�����������ǂˁB
�Ȃ����V���߂���������s�������Ă���i�l�ł������ŗ��p�\�j
AMD�͒��߂̃��W���[�A�b�v�f�[�g�ƂȂ�Zen�A�[�L�e�N�`������
�����ɏ������J���Ă��Ȃ��BGPU�����������ǂˁB
'Liquid VR' is AMD's push into virtual reality with software
http://www.engadget.com/2015/03/03/amd-liquid-vr/?ncid=rss_truncated
http://www.engadget.com/2015/03/03/amd-liquid-vr/?ncid=rss_truncated
����Ȃ��Ƃ��^�u���b�g������Nolan��Amur�܂��[
����GCN�Ń��o�C���������Ă߂����ዻ������()
����GCN�Ń��o�C���������Ă߂����ዻ������()
>>656
>�u��Opteron�ł����Ƃ����ԂɌp���i�����̂Ă��Ƃ����ĂȂ��������
��̓I�ɂǂ̕ӂ��H
warsaw�Ƃ��čX�V�ł��o�������t�H���[���Ă���Ǝv���܂���
>�u��Opteron�ł����Ƃ����ԂɌp���i�����̂Ă��Ƃ����ĂȂ��������
��̓I�ɂǂ̕ӂ��H
warsaw�Ƃ��čX�V�ł��o�������t�H���[���Ă���Ǝv���܂���
>>658
>�T�[�o�EWS�Ŏg���Ă�Xeon�ƃA�[�L�e�N�`���݊��Ƃ��������ł�Core i*�̍œK���Z�p��
>���v�������炷���AAPU�͈�PC�����~�܂�B
APU�̓Q�[���ƊE�p�������u�n�A�[�L�e�N�`���̃R���Z�v�g�v���[�t���f���ł���
����AMD���[�U�[�͂���������i�I�ȋZ�p����肵�Ċy���߂���Ęb
>�T�[�o�EWS�Ŏg���Ă�Xeon�ƃA�[�L�e�N�`���݊��Ƃ��������ł�Core i*�̍œK���Z�p��
>���v�������炷���AAPU�͈�PC�����~�܂�B
APU�̓Q�[���ƊE�p�������u�n�A�[�L�e�N�`���̃R���Z�v�g�v���[�t���f���ł���
����AMD���[�U�[�͂���������i�I�ȋZ�p����肵�Ċy���߂���Ęb
�܂��҂��Ă�
���N32�R�A64�X���b�hOpteron�A�ė��N��390x�N���X�̃n�C�G���hGPU���������n�C�G���hAPU��AMD���o��
�R�C�c���ŁAHPC�A�N���E�h�A�I�AWS�ɉ��肱�݂����ɍs������
2�N�O�̃n�C�G���hGPU���đ債�����Ɩ������������ǁA���Ō�����HD7970�̂��Ƃ������
���AHD7970��280x����APU�o���Ă�����Intel��Nvidia���ʂ�
����ȏ�2�N��ɂȂ肻����
���N32�R�A64�X���b�hOpteron�A�ė��N��390x�N���X�̃n�C�G���hGPU���������n�C�G���hAPU��AMD���o��
�R�C�c���ŁAHPC�A�N���E�h�A�I�AWS�ɉ��肱�݂����ɍs������
2�N�O�̃n�C�G���hGPU���đ債�����Ɩ������������ǁA���Ō�����HD7970�̂��Ƃ������
���AHD7970��280x����APU�o���Ă�����Intel��Nvidia���ʂ�
����ȏ�2�N��ɂȂ肻����
AMD Simplified: Virtual Reality
https://www.youtube.com/watch?v=nJLbv8LmDnE
https://www.youtube.com/watch?v=nJLbv8LmDnE
����A�f�X�N�g�b�v�ȏ�̓����`�b�v�Ȃ�Ċ�{�S�~������ˁH�I�AWS�͌����܂ł��Ȃ�
iGPU����Ȃ���CPU�ǂ��ɂ����Ă��������}�W�ł�����HW�G���R�[�_��
���AGPGPU��CPU���\�[�X����˂����Ďn�܂������Ȃ̂�CPU����ăh�[�X���m��
�������A�f�X�N�g�b�v�ł������`�b�v�̕����ǂ��ꍇ�͂���A�ȓd��PC�Ȃ�����������
AC�A�_�v�^��PC����OC�����N�ɂł��Ȃ����烏�b�p���S�āAHTPC�����APU�キ�͂Ȃ�����
�G���R�[�h�V���{�C�̂̓L�c�C�A�f�R�[�h��肢�����Ȃ�X�}�[�gTV�ł�������
�I�[�f�B�IPC����GPU�Ȃ�ăN�\�̖��ɂ������Ȃ����A�����Q�[�~���OPC���Q�[���������Ȃ��Ȃ�Q�[���@�ł���
���f��HW�f�R�[�_�[�͈����Ȃ�����A���HW�G���R�[�_�[���Ȃ�Ƃ�����CPU��14nm����ɑ����������\�ɂ����
�܂���������������łȂ������H
iGPU����Ȃ���CPU�ǂ��ɂ����Ă��������}�W�ł�����HW�G���R�[�_��
���AGPGPU��CPU���\�[�X����˂����Ďn�܂������Ȃ̂�CPU����ăh�[�X���m��
�������A�f�X�N�g�b�v�ł������`�b�v�̕����ǂ��ꍇ�͂���A�ȓd��PC�Ȃ�����������
AC�A�_�v�^��PC����OC�����N�ɂł��Ȃ����烏�b�p���S�āAHTPC�����APU�キ�͂Ȃ�����
�G���R�[�h�V���{�C�̂̓L�c�C�A�f�R�[�h��肢�����Ȃ�X�}�[�gTV�ł�������
�I�[�f�B�IPC����GPU�Ȃ�ăN�\�̖��ɂ������Ȃ����A�����Q�[�~���OPC���Q�[���������Ȃ��Ȃ�Q�[���@�ł���
���f��HW�f�R�[�_�[�͈����Ȃ�����A���HW�G���R�[�_�[���Ȃ�Ƃ�����CPU��14nm����ɑ����������\�ɂ����
�܂���������������łȂ������H
One of Mantle's Futures: Vulkan
http://community.amd.com/community/amd-blogs/amd-gaming/blog/2015/03/03/one-of-mantles-futures-vulkan
http://community.amd.com/community/amd-blogs/amd-gaming/blog/2015/03/03/one-of-mantles-futures-vulkan
�E���m�}�l�j�_�[
671 �FSocket774�F2015/03/04(��) 07:24:59.28 ID:mPkXYnOk
2chmate��������I
��Ȃ������[�I
��Ȃ������[�I
hp���炨�Ƃ����
>>669
The cross-vendor Khronos Group has chosen the best and brightest parts of Mantle
to serve as the foundation for �gVulkan,�h the exciting next version of the storied OpenGL API.
The cross-vendor Khronos Group has chosen the best and brightest parts of Mantle
to serve as the foundation for �gVulkan,�h the exciting next version of the storied OpenGL API.
GDC 15: Khronos Acknowledges Mantle's Start of Vulkan
http://www.pcper.com/news/General-Tech/GDC-15-Khronos-Acknowledges-Mantles-Start-Vulkan
http://www.pcper.com/news/General-Tech/GDC-15-Khronos-Acknowledges-Mantles-Start-Vulkan
Imagination Already Has A Vulkan Driver In The Works For PowerVR GPUs
http://www.phoronix.com/scan.php?page=news_item&px=PowerVR-Vulkan-Drivers-Demo
http://www.phoronix.com/scan.php?page=news_item&px=PowerVR-Vulkan-Drivers-Demo
Valkan��OpenCL�Ƌ��ʎd�l��SPIR-V���J�M��
�O���t�B�b�N�X�����ɂ����Ăَ̈퍬���}���`�R�A�̎��オ������
�O���t�B�b�N�X�����ɂ����Ăَ̈퍬���}���`�R�A�̎��オ������
There's also some Vulkan source code:
vkCmdBindDescriptorSet(cmdBuffer, VK_PIPELINE_BIND_POINT_GRAPHICS,
textureDescriptorSet[0], 0);
vkQueueSubmit(graphicsQueue, 1, &cmdBuffer, 0, 0, fence);
vkMapMemory(staticUniformBufferMemory, 0, (void **)&data);
// ...
vkUnmapMemory(staticUniformBufferMemory);
Now let's check some Mantle64.dll code:
grCmdBindDescriptorSet(cmdBuffer, VK_PIPELINE_BIND_POINT_GRAPHICS,
textureDescriptorSet[0], 0);
grQueueSubmit(graphicsQueue, 1, &cmdBuffer, 0, 0, fence);
grMapMemory(staticUniformBufferMemory, 0, (void **)&data);
// ...
grUnmapMemory(staticUniformBufferMemory);
Vulkan is 100% similar to Mantle
vkCmdBindDescriptorSet(cmdBuffer, VK_PIPELINE_BIND_POINT_GRAPHICS,
textureDescriptorSet[0], 0);
vkQueueSubmit(graphicsQueue, 1, &cmdBuffer, 0, 0, fence);
vkMapMemory(staticUniformBufferMemory, 0, (void **)&data);
// ...
vkUnmapMemory(staticUniformBufferMemory);
Now let's check some Mantle64.dll code:
grCmdBindDescriptorSet(cmdBuffer, VK_PIPELINE_BIND_POINT_GRAPHICS,
textureDescriptorSet[0], 0);
grQueueSubmit(graphicsQueue, 1, &cmdBuffer, 0, 0, fence);
grMapMemory(staticUniformBufferMemory, 0, (void **)&data);
// ...
grUnmapMemory(staticUniformBufferMemory);
Vulkan is 100% similar to Mantle
���A�Ӗ����������B
���Mantle��Vulkan�H
���Mantle��Vulkan�H
Directx12�R�̎�����OpenGL�̎����B
�̓ǂ�OpenCL��OpenGL�̗Z���I�Ȃ��Ə����Ă邯��
Directx12�ɂ�hQ�Ƃ�HSA�̗v�f���ē����Ă�́H
�̓ǂ�OpenCL��OpenGL�̗Z���I�Ȃ��Ə����Ă邯��
Directx12�ɂ�hQ�Ƃ�HSA�̗v�f���ē����Ă�́H
>>679
DirectX��CPU�ȊO�̃n�[�h�E�F�A�p��API�i�_�C���N�g�ɑ��삷��j
hQ��GPU��CPU�ɂ������
HSA�iIL�j�̓\�t�g�ƃn�[�h���݊����钇�������������
DirectX��hQ�͂قڐ^�t�łǂ����������݂����GPU�͎g����
2���v��Ȃ�
DirectX��CPU�ȊO�̃n�[�h�E�F�A�p��API�i�_�C���N�g�ɑ��삷��j
hQ��GPU��CPU�ɂ������
HSA�iIL�j�̓\�t�g�ƃn�[�h���݊����钇�������������
DirectX��hQ�͂قڐ^�t�łǂ����������݂����GPU�͎g����
2���v��Ȃ�
x86�R�A��ARM�R�A�̓����[�h�}�b�v�Ő����s����d�_�I�ɍU�߂�AMD
http://news.mynavi.jp/articles/2015/03/04/amd_pccluster/
>2016�N�ɂ�AMD�̓Ǝ��v��K12�Ƃ���ARM�A�[�L�e�N�`���̃R�A���J������B���̃R�A��A57�Ɣ�r����ƁA���{���̐��\�����Ƃ����B
>����K12�R�A�̎���ɂ́Ax86�R�A�̃`�b�v��K12�R�A��ARM�`�b�v��32�R�A��1�`�b�v�ɏW�ς��A�e�R�A��2�X���b�h�̃}���`�X���b�h���T�|�[�g���A�n�[�h�E�F�A�I�ɁA���v64�X���b�h�������s����`�b�v�ɂȂ�Ƃ̂��Ƃł������B
http://news.mynavi.jp/articles/2015/03/04/amd_pccluster/
>2016�N�ɂ�AMD�̓Ǝ��v��K12�Ƃ���ARM�A�[�L�e�N�`���̃R�A���J������B���̃R�A��A57�Ɣ�r����ƁA���{���̐��\�����Ƃ����B
>����K12�R�A�̎���ɂ́Ax86�R�A�̃`�b�v��K12�R�A��ARM�`�b�v��32�R�A��1�`�b�v�ɏW�ς��A�e�R�A��2�X���b�h�̃}���`�X���b�h���T�|�[�g���A�n�[�h�E�F�A�I�ɁA���v64�X���b�h�������s����`�b�v�ɂȂ�Ƃ̂��Ƃł������B
Intel�̑f�������i�W�J��ARM�T�[�o�̖ڂ͂قڂȂ��Ȃ���
���܂��璆�~����킯�ɂ������Ȃ��̂�AMD�̐h���Ƃ���
���܂��璆�~����킯�ɂ������Ȃ��̂�AMD�̐h���Ƃ���
683 �FSocket774�F2015/03/04(��) 10:58:07.91 ID:knqtW0jt
14nm��Atom�����҂͂��ꂾ���������w
���ς�炸4�R�A�A4�X���b�h�A���܂���CPU�̃N���b�N���g�����ς���ĂȂ��B
GPU���\�Ƀg�����W�X�^���蓖�Ă��������A3D Mark�̃X�R�A��50�������オ���Ė����Ƃ����A22nm�Ńg���C�Q�[�g�������Ă����瑽���D�ʐ����������ǁA���Ђ�FinFET�g���Ɗ��S�ɗD�ʐ������ăS�~�Ɖ��������߂��̂ł́H
���ς�炸4�R�A�A4�X���b�h�A���܂���CPU�̃N���b�N���g�����ς���ĂȂ��B
GPU���\�Ƀg�����W�X�^���蓖�Ă��������A3D Mark�̃X�R�A��50�������オ���Ė����Ƃ����A22nm�Ńg���C�Q�[�g�������Ă����瑽���D�ʐ����������ǁA���Ђ�FinFET�g���Ɗ��S�ɗD�ʐ������ăS�~�Ɖ��������߂��̂ł́H
>>680
�Ƃ������Ƃ̓h���[�R���g���[���Ƃ��̍팸�ɓ������������H��directx12
�Ƃ������Ƃ̓h���[�R���g���[���Ƃ��̍팸�ɓ������������H��directx12
685 �FSocket774�F2015/03/04(��) 11:10:17.86 ID:knqtW0jt
32�R�A64�X���b�h��1�`�b�v�Ŏ�������̂�
�C���e���Ƃ̕��������S���Ⴄ�̂��ʔ����B
����200�`300W�̂��̃L�`�K�C���݂�APU���}�W�œo�ꂷ��Ȃ甃�������H
�C���e���Ƃ̕��������S���Ⴄ�̂��ʔ����B
����200�`300W�̂��̃L�`�K�C���݂�APU���}�W�œo�ꂷ��Ȃ甃�������H
686 �FSocket774�F2015/03/04(��) 11:10:37.46 ID:IoHaRO5h
���T�E�X�[���ĉ����������O����
PS3��CELL���������CELL�܂�Ŏʐ^�B���Ă��̂͂��̐l������
IBM����ڂ�����
PS3��CELL���������CELL�܂�Ŏʐ^�B���Ă��̂͂��̐l������
IBM����ڂ�����
>>685
intel��Atom�n�̎I�`�b�v�œ�������������Ă���
AMD�͍����x�I�Œx��Ă���̂ŁA��C�ɔ҉�̂��_������Ȃ�����
�V���O���X���b�h���\�d���̏]���^�I���Ƃǂ����V�F�A���������AAMD�I�ɂ͂���Ȃ낤
intel��Atom�n�̎I�`�b�v�œ�������������Ă���
AMD�͍����x�I�Œx��Ă���̂ŁA��C�ɔ҉�̂��_������Ȃ�����
�V���O���X���b�h���\�d���̏]���^�I���Ƃǂ����V�F�A���������AAMD�I�ɂ͂���Ȃ낤
>>684
�h���[����Draw�H
�ڂ������Ƃ̓E�B�L�yDirectX�̗��j�̍��ɏ����Ă����
OpenGL�͊ȑf�����d���ă��C�u���������Ȃ�
Direct3D�͓�������y��
Mantle�͍X�ɓ�������㔭��Direct3D12�ȏ�ɐ��\���o��
�e���̉����f�[�^�܂Ƃ߂�Ƃ���Ȋ���
�h���[����Draw�H
�ڂ������Ƃ̓E�B�L�yDirectX�̗��j�̍��ɏ����Ă����
OpenGL�͊ȑf�����d���ă��C�u���������Ȃ�
Direct3D�͓�������y��
Mantle�͍X�ɓ�������㔭��Direct3D12�ȏ�ɐ��\���o��
�e���̉����f�[�^�܂Ƃ߂�Ƃ���Ȋ���
689 �FSocket774�F2015/03/04(��) 11:26:58.05 ID:knqtW0jt
�mGDC 2015�nKhronos�C������OpenGL�uVulkan�v��AMD�́uMantle�v���̗p
Mantle���̂��͎̂���ł��Ȃ������B
AMD�́C�o�[�W����1.0�ƈʒu�Â����]����Mantle�Ɋւ���Blog�|�X�g�̗����ƂȂ�k�Ď���2015�N3��3���C
AMD�ŃO���[�o���e�N�j�J���}�[�P�e�B���O����𗦂���Robert Hallock�i���o�[�g�E�n���b�N�j���́C
AMD����Blog�ɂ����āCKhronos Group�i�N���m�X�O���[�v�j�̎�����OpenGL API�uVulkan�v�i���@���J���j���C���̏d�v�ȗv�f�Z�p��1�Ƃ���Mantle���̗p����Ɣ��\�����B
�܂�C���[���x���ȃO���t�B�b�N�XAPI�Ƃ��Ă�Mantle�͏I������̂ł͂Ȃ��C���O��ς��āC�ƊE�W���̈ꕔ�ƂȂ�킯�ł���B
�@��̋L����4Gamer�́C���s��Mantle�̕�������_�Ƃ��āC�Q�[���f�x���b�p���ʑΉ����Ȃ���Ȃ�Ȃ����Ƃ����������C
���̖��̂��Ȃ�̕����́CVulkan�̓o��ɂ���ĉ�������\���������B
AMD�̋����ł���NVIDIA��GPU�ł����p�\�ɂȂ�Ƃ����g������₷���h�b�����ł͂Ȃ��C
����CPlayStation 4��Vulkan�̃T�|�[�g���n�܂�C�Q�[���f�x���b�p�͌��s��Mantle�Ŕ|�����o������������悤�ɂȂ�\��������
�\�[�X
http://www.4gamer.net/games/107/G010729/20150304002/
Mantle���̂��͎̂���ł��Ȃ������B
AMD�́C�o�[�W����1.0�ƈʒu�Â����]����Mantle�Ɋւ���Blog�|�X�g�̗����ƂȂ�k�Ď���2015�N3��3���C
AMD�ŃO���[�o���e�N�j�J���}�[�P�e�B���O����𗦂���Robert Hallock�i���o�[�g�E�n���b�N�j���́C
AMD����Blog�ɂ����āCKhronos Group�i�N���m�X�O���[�v�j�̎�����OpenGL API�uVulkan�v�i���@���J���j���C���̏d�v�ȗv�f�Z�p��1�Ƃ���Mantle���̗p����Ɣ��\�����B
�܂�C���[���x���ȃO���t�B�b�N�XAPI�Ƃ��Ă�Mantle�͏I������̂ł͂Ȃ��C���O��ς��āC�ƊE�W���̈ꕔ�ƂȂ�킯�ł���B
�@��̋L����4Gamer�́C���s��Mantle�̕�������_�Ƃ��āC�Q�[���f�x���b�p���ʑΉ����Ȃ���Ȃ�Ȃ����Ƃ����������C
���̖��̂��Ȃ�̕����́CVulkan�̓o��ɂ���ĉ�������\���������B
AMD�̋����ł���NVIDIA��GPU�ł����p�\�ɂȂ�Ƃ����g������₷���h�b�����ł͂Ȃ��C
����CPlayStation 4��Vulkan�̃T�|�[�g���n�܂�C�Q�[���f�x���b�p�͌��s��Mantle�Ŕ|�����o������������悤�ɂȂ�\��������
�\�[�X
http://www.4gamer.net/games/107/G010729/20150304002/
��������PS4�͂��łɓƎ��̃��[���x��API�����ς݂������
Mantle���ǂ��Ή�����K�v��������
Mantle���ǂ��Ή�����K�v��������
691 �FSocket774�F2015/03/04(��) 11:48:07.17 ID:rX6UUTBJ
PS4�̑S���E�v�����䐔��2020�����B���B
��������PlayStation�V���[�Y�ɂ�����ő��̕��y�g��y�[�X
�\�[�X
http://www.4gamer.net/games/990/G999024/20150304004/
��������PlayStation�V���[�Y�ɂ�����ő��̕��y�g��y�[�X
�\�[�X
http://www.4gamer.net/games/990/G999024/20150304004/
692 �FSocket774�F2015/03/04(��) 11:59:13.72 ID:IoHaRO5h
>>690
��ۑ��삾��
�Q�[���@��BTO�Ƃ��S���l����K�v���Ȃ�����A�Ƃ��Ƃ[���x��API��Njy�ł���
�����PS4��������ꏏ
������������ƂɕK���ɂȂ���MANTLE�W�����̓����h�N�T�C�ADX12��MANTLE�͎��A
�����AMD���ӂ̓��Q�b�p���n�܂����ƌ��������Ďd���Ȃ��悤��
4�T��AMD�̂�낤�Ƃ��Ă邱�Ƃ��Ӗ������Ǝv�킹�����Ďd���Ȃ��݂�������
GCN�ŃR���V���[�}�@�ꂵ������ׂ������Ȃǂ��ł�������A�J���҂͂���ɏ]��������
��ۑ��삾��
�Q�[���@��BTO�Ƃ��S���l����K�v���Ȃ�����A�Ƃ��Ƃ[���x��API��Njy�ł���
�����PS4��������ꏏ
������������ƂɕK���ɂȂ���MANTLE�W�����̓����h�N�T�C�ADX12��MANTLE�͎��A
�����AMD���ӂ̓��Q�b�p���n�܂����ƌ��������Ďd���Ȃ��悤��
4�T��AMD�̂�낤�Ƃ��Ă邱�Ƃ��Ӗ������Ǝv�킹�����Ďd���Ȃ��݂�������
GCN�ŃR���V���[�}�@�ꂵ������ׂ������Ȃǂ��ł�������A�J���҂͂���ɏ]��������
�ėp�I��API�ł̓`�b�v�̐��\�ő傫�����AMD��NV�ɏ��ĂȂ��B
AMD�̓���ȃA�[�L�e�N�`���ɓ����������̂�����Ă����A�v���ł͂܂�NV�̔ėpAPI�łɏ��ĂȂ����A����̃x���`�Ɍ��肷��ΑΉ����ڂ̗L���A��Ή���NV��0�_�Ƃ��邱�Ƃō���t���邱�Ƃ��ł���B
AMD�̓���ȃA�[�L�e�N�`���ɓ����������̂�����Ă����A�v���ł͂܂�NV�̔ėpAPI�łɏ��ĂȂ����A����̃x���`�Ɍ��肷��ΑΉ����ڂ̗L���A��Ή���NV��0�_�Ƃ��邱�Ƃō���t���邱�Ƃ��ł���B
���Ƀ��f�̃`�b�v���\�͗���Ă��܂���
���ꂱ����ۑ��삾��
���ꂱ����ۑ��삾��
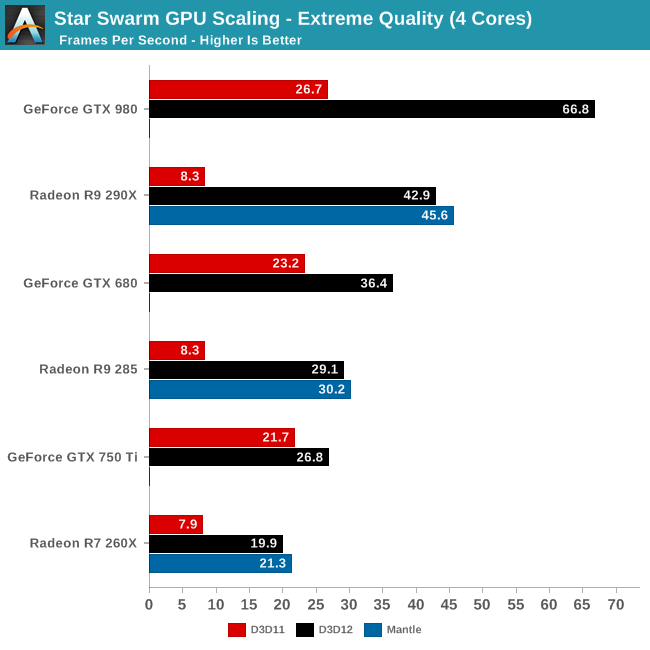{kind=link}
Nitrous engine���Ď��Q�[���ł̗̍p�Ⴀ��́H
������ĒP�Ȃ�ׂɂ���x���`�����
������ĒP�Ȃ�ׂɂ���x���`�����
����Ȉ�N�O��amd�Ɍ����Ă���ₗ
NVIDIA�ߋ��ō��̔�����L�^
�����v�͑O�N��43%����6��3,059���h��
GeForce�ASHIELD�A�ԍڌ����v���b�g�t�H�[���AGRID�ATesla�ȂǑS���ʓI�ɍD��������
AMD��Ԏ�
��������4��300���h��
AMD�ɂ���2015�N��1�l������15%�̔��㌸��\�����Ă���
�@�@�@�@ ��
( ߄t�)��
�����v�͑O�N��43%����6��3,059���h��
GeForce�ASHIELD�A�ԍڌ����v���b�g�t�H�[���AGRID�ATesla�ȂǑS���ʓI�ɍD��������
AMD��Ԏ�
��������4��300���h��
AMD�ɂ���2015�N��1�l������15%�̔��㌸��\�����Ă���
�@�@�@�@ ��
( ߄t�)��
http://www.4gamer.net/games/198/G019883/20150304003/
x1��android tv console
a57������7w�߂����s��Ń^�u���b�g�������Ǝv���Ă���
����������
x1��android tv console
a57������7w�߂����s��Ń^�u���b�g�������Ǝv���Ă���
����������
�����m��R�e���uIntel������X���r�炳��Ă邩�炨�Ԃ����I�v�Ƃ������Ă�
���ꂾ���ł����ɂ�����ǂ���͂��Ă���
�������Y���X�����ɍs�������NJՎU�Ƃ��������ʂƂ����������ɉ^�s���Ă�
Mantle�ŃX���������Ă��Ă̒�q�b�g�͖���
����ϒP�Ȃ�m��̂�����枖ς�
�R�e�Ɠ����x���Ȗ��������܂߂�
AMD�ɂ���Ƃ������@�����������̂ɖ���������r�点��قǂ�
���O�����Ă�z�Ȃ�Ă����������Ȃ������
���̔S�苭�������ł����Ə��Ɏg���Ȃ������I
���ꂾ���ł����ɂ�����ǂ���͂��Ă���
�������Y���X�����ɍs�������NJՎU�Ƃ��������ʂƂ����������ɉ^�s���Ă�
Mantle�ŃX���������Ă��Ă̒�q�b�g�͖���
����ϒP�Ȃ�m��̂�����枖ς�
�R�e�Ɠ����x���Ȗ��������܂߂�
AMD�ɂ���Ƃ������@�����������̂ɖ���������r�点��قǂ�
���O�����Ă�z�Ȃ�Ă����������Ȃ������
���̔S�苭�������ł����Ə��Ɏg���Ȃ������I
AMD Radeon TM R9 A360 (512SP 8C 725MHz, 2GB DDR5 4.5GHz 128-bit) (OpenCL)
http://www.sisoftware.eu/rank2011d/show_run.php?q=c2ffcdf4d2b3d2efdceddbe2d0e7c1b38ebe98fd98a595b3c0fdc5&l=jp
HP����Skylake�f�X�NPC�ɍڂ��Ă����GPU
http://www.sisoftware.eu/rank2011d/show_run.php?q=c2ffcdf4d2b3d2efdceddbe2d0e7c1b38ebe98fd98a595b3c0fdc5&l=jp
HP����Skylake�f�X�NPC�ɍڂ��Ă����GPU
AMD�Ǝ�API�uMantle�g1.0�h�v��������̏I���BAMD��DirectX 12�Ǝ�����OpenGL�̗��p���Ăт���
http://fox.2ch.net/test/read.cgi/poverty/1425362606/
��ꕔ�A���i�j
http://fox.2ch.net/test/read.cgi/poverty/1425362606/
��ꕔ�A���i�j
�c�q��HSA�Ƃ͌����Ă邪Mantle�Ƃ͌����ĂȂ���
> 346 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂��� [��] �F2015/02/25(��) 19:38:11.63 ID:NG5TN0mq (6/36)
> >>344
>
> ���̂Ƃ���Intel�X����HSA�}���Z�[�̓����������������݂������̂�
> �����Ō����������Ă�邵���Ȃ��ł���
> ���܂���w���Ȃ�����
> 346 �F,,�E�L�́M�E,,�j��-��������Na Na Na Na Na�Ȃ߂��� [��] �F2015/02/25(��) 19:38:11.63 ID:NG5TN0mq (6/36)
> >>344
>
> ���̂Ƃ���Intel�X����HSA�}���Z�[�̓����������������݂������̂�
> �����Ō����������Ă�邵���Ȃ��ł���
> ���܂���w���Ȃ�����
705 �FSocket774�F2015/03/04(��) 14:19:44.86 ID:rX6UUTBJ
Mantle�͏I���������R����B
�o�[�W����1�̊J���I��������Ă��Ƃ́A�o�O���c���ĂĂ����u������Ă��Ƃ���H
���Ƀo�[�W����2������Ă������悤��DX���X�V���ꂽ����u�����Ƃ킩���Ă���
�킴�킴Mantle�Ȃg��ˁ[���ẮB
DX�����ǂ��Ă�Ώ\�����Ă��Ƃ�����ȁB
�o�[�W����1�̊J���I��������Ă��Ƃ́A�o�O���c���ĂĂ����u������Ă��Ƃ���H
���Ƀo�[�W����2������Ă������悤��DX���X�V���ꂽ����u�����Ƃ킩���Ă���
�킴�킴Mantle�Ȃg��ˁ[���ẮB
DX�����ǂ��Ă�Ώ\�����Ă��Ƃ�����ȁB
707 �FSocket774�F2015/03/04(��) 14:41:40.56 ID:rX6UUTBJ
�I������Ȃ�ĒN�������ĂȂ���
�����ɂȂ��ďI������ǂ��납���l�[�����ċƊE�W���ɂȂ��Ă��܂����ƂÂ��Ă��邶���
�����ɂȂ��ďI������ǂ��납���l�[�����ċƊE�W���ɂȂ��Ă��܂����ƂÂ��Ă��邶���
�����ˁ[�A���E��W�Ԃ��Ă���ƊE�W���ɂȂ��Ă���[
�A���`���đ��ς�炸�Ȃ�w
MS��@����Dx12�𑁂��o�������ڂƂ��Ă�Mantle�͏I�������
������GL�����̘b�́A�܂��ʂ̘b�B
�����ȃn�[�h�킹�邽�߂ɁA���Ӗ��ɏd�����K�V�[API������DirectX���ς���������ŏ\���B
���ׂ������l���ĂȂ��Ƃ���Ƃ͈Ⴄ�̂�AMD�̗ǂ��Ƃ���B
MS��@����Dx12�𑁂��o�������ڂƂ��Ă�Mantle�͏I�������
������GL�����̘b�́A�܂��ʂ̘b�B
�����ȃn�[�h�킹�邽�߂ɁA���Ӗ��ɏd�����K�V�[API������DirectX���ς���������ŏ\���B
���ׂ������l���ĂȂ��Ƃ���Ƃ͈Ⴄ�̂�AMD�̗ǂ��Ƃ���B
���ꂾ���ƊE�K�i����Đ�s�ł��Ĉ��|�I�L���Ȃ̂�
�R���肪�����@�\������Ă��܂��ƒǂ��z����Ă��܂��̂���Ȃ�
�R���肪�����@�\������Ă��܂��ƒǂ��z����Ă��܂��̂���Ȃ�
GPU���͂�����Ă�̂ɂȂ�
�u���n�̂ĂĐV�����A�[�L��APU���łĂ���2017�N�������̔N��
�u���n�̂ĂĐV�����A�[�L��APU���łĂ���2017�N�������̔N��
712 �FSocket774�F2015/03/04(��) 15:38:59.89 ID:z1vKXjEA
����2016�N�ɗ��邩�炻��
2016�N��2��CPU�̖�������������
FX�̌�p��2016�N���Ղ���㔼��GPU������APU��2017�N�O�����Ɨ\�z���Ă���
FX�̌�p��2016�N���Ղ���㔼��GPU������APU��2017�N�O�����Ɨ\�z���Ă���
770 ���O�FSocket774[sage] ���e���F2015/03/04(��) 11:46:40.31 ID:iywXDq97
Vulkan�̔���́A
�@Mantle��AMD GPU�����A
�@DX12��Windows�����A
�@Metal��iOS�����A
�@�ł�Vulkan�͑S���T�|�[�g�I
�Ƃ������Ƃ炵��
����ƁAVulkan�Ɏg����V�F�[�_�[����́A�]����GLSL�ł͂Ȃ�SPIR-V(SPIR-V2�̂���)�B
SPIR�ŏ����Ď��O�ɒ��ԃR�[�h�ɃR���p�C�����Ă����ƁA�h���C�o�����ԃR�[�h�����߂���
�O���t�B�b�N���`�����
�X�ɍ������\�����OpenCL2.1�ł�SPIR-V���̗p�����̂ŁA
�h���C�o�����猩����O���t�B�b�N�Ɖ��Z�̋�ʂ������Ȃ邻�����B
Java�AJavascrtipt�AC++�APython�ȂǂȂǗl�X�Ȍ���ŏ����Ă��A���ԃR�[�h�ɂȂ��Ă�Ζ��Ȃ��B
LLVM�̍l������ˁB
Vulkan�̔���́A
�@Mantle��AMD GPU�����A
�@DX12��Windows�����A
�@Metal��iOS�����A
�@�ł�Vulkan�͑S���T�|�[�g�I
�Ƃ������Ƃ炵��
����ƁAVulkan�Ɏg����V�F�[�_�[����́A�]����GLSL�ł͂Ȃ�SPIR-V(SPIR-V2�̂���)�B
SPIR�ŏ����Ď��O�ɒ��ԃR�[�h�ɃR���p�C�����Ă����ƁA�h���C�o�����ԃR�[�h�����߂���
�O���t�B�b�N���`�����
�X�ɍ������\�����OpenCL2.1�ł�SPIR-V���̗p�����̂ŁA
�h���C�o�����猩����O���t�B�b�N�Ɖ��Z�̋�ʂ������Ȃ邻�����B
Java�AJavascrtipt�AC++�APython�ȂǂȂǗl�X�Ȍ���ŏ����Ă��A���ԃR�[�h�ɂȂ��Ă�Ζ��Ȃ��B
LLVM�̍l������ˁB
>>704
HSA�Ō������Ă��o�Ȃ���
�����������������Ȃ蔭���n�߂����̃^�[�Q�b�g��Mantle����
HSA���낤��Mantle���낤���������̃X���ł���������o���Ė\��Ă�z�����݂��炵�ĂȂ�
�P�ꌟ���Ƃ���ȊO�ł̓��X���Ɠ��t�ŃX���̐L�т𐔉���������������
�Ă��킴�킴�؋��o���Ă���Ă��肪��
HSA�Ō������Ă��o�Ȃ���
�����������������Ȃ蔭���n�߂����̃^�[�Q�b�g��Mantle����
HSA���낤��Mantle���낤���������̃X���ł���������o���Ė\��Ă�z�����݂��炵�ĂȂ�
�P�ꌟ���Ƃ���ȊO�ł̓��X���Ɠ��t�ŃX���̐L�т𐔉���������������
�Ă��킴�킴�؋��o���Ă���Ă��肪��
Llano�o��̋łɂ�
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
�� 2014�N �����̔��ド���L���O
http://eetimes.jp/ee/articles/1412/25/news147.html
��AMD�A2014�N�x��4���h���̐Ԏ�
http://pc.watch.impress.co.jp/docs/news/20150121_684660.html
AMD�̏��ʂ������}�~���ЂƂ蕉���_(^o^)�^
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
�� 2014�N �����̔��ド���L���O
http://eetimes.jp/ee/articles/1412/25/news147.html
��AMD�A2014�N�x��4���h���̐Ԏ�
http://pc.watch.impress.co.jp/docs/news/20150121_684660.html
AMD�̏��ʂ������}�~���ЂƂ蕉���_(^o^)�^
HSA Foundation announced a C++ AMP compiler that outputs to OpenCL,
Standard Portable Intermediate Representation (SPIR), and HSA Intermediate Language (HSAIL) supporting the current C++ AMP specification
Standard Portable Intermediate Representation (SPIR), and HSA Intermediate Language (HSAIL) supporting the current C++ AMP specification
C++ AMP to target Khronos SPIR and HSAIL
http://blogs.msdn.com/b/vcblog/archive/2013/11/21/c-amp-to-target-khronos-spir-and-hsail.aspx
http://blogs.msdn.com/b/vcblog/archive/2013/11/21/c-amp-to-target-khronos-spir-and-hsail.aspx
Khronos Releases OpenCL 2.1 Provisional Specification for Public Review
http://videocardz.com/54912/khronos-releases-opencl-2-1-provisional-specification-for-public-review
http://videocardz.com/54912/khronos-releases-opencl-2-1-provisional-specification-for-public-review
����������
Mantle��Valkan
OpenCL2.1��Valkan�̓O���t�B�b�N�Ɖ��Z�ŘA�g�\
OpenCL2.0�͉��z��������hUMA�Ή���HSA���h�L����������A2.1�����l���낤
�܂�AAMD�̗��z�ł���Mantle+HSA�̘A�g���N���m�X���W�����������Ă��Ƃ���
�R�����Ȃ萦�����AAPU��Radeon�̘A�g���W��API�őΉ��\���Ă��Ƃ������
�����AhUMA��XDMA��g�����ĐF�X�o����낤
Mantle��Valkan
OpenCL2.1��Valkan�̓O���t�B�b�N�Ɖ��Z�ŘA�g�\
OpenCL2.0�͉��z��������hUMA�Ή���HSA���h�L����������A2.1�����l���낤
�܂�AAMD�̗��z�ł���Mantle+HSA�̘A�g���N���m�X���W�����������Ă��Ƃ���
�R�����Ȃ萦�����AAPU��Radeon�̘A�g���W��API�őΉ��\���Ă��Ƃ������
�����AhUMA��XDMA��g�����ĐF�X�o����낤
�܁A����Ŗׂ���̂�nv�Ȃ��ǂ˂�
722 �FSocket774�F2015/03/04(��) 19:13:25.70 ID:e0zvDY3L
Mantle��Vulkan�ɂȂ����Ɗ��Ⴂ���Ă�z����
Mantle���n�k�܂ŏオ���ă}�O�}�ɂȂ�
�X�ɒn�\�ɕ��o����Vulkan�i�h�C�c��ʼnΎR�j�ɂȂ����Ɗ��Ⴂ���Ă�z����
�X�ɒn�\�ɕ��o����Vulkan�i�h�C�c��ʼnΎR�j�ɂȂ����Ɗ��Ⴂ���Ă�z����
724 �FSocket774�F2015/03/04(��) 19:25:54.19 ID:z1vKXjEA
�܂����O���H
valcun�Ȃ�R�i�~���ق�����
�f�W���u���Ȃ��B�Z�p�Ő�s���āA���Y���̍����J�����p�ӏo�����ɃY���Y����ށB
�D�G�ȃR���p�C�����������Ƌ��o���Čق��������ǂ���B
�Ȃ������ɋ������Ȃ��Ams google nv�͌����ɋy���A�X�p�R������Ă�
���{�̃��[�J�[�����͂��Ă�̂ɁB
�D�G�ȃR���p�C�����������Ƌ��o���Čق��������ǂ���B
�Ȃ������ɋ������Ȃ��Ams google nv�͌����ɋy���A�X�p�R������Ă�
���{�̃��[�J�[�����͂��Ă�̂ɁB
Volcanic island�͎�����GCN�������H
�N���m�X�̎��̈����\�z�ł����
���Ԍ���œ��ꂵ���ȏ�A�{�̂�OpenCL��Vulkan���������邾�낤
���������āAAMD��APU�̍\��������ɍ��킹�Ă�荂�����ō����\�Ȃ��̂Ɏd�グ�Ă���
���Ԍ���œ��ꂵ���ȏ�A�{�̂�OpenCL��Vulkan���������邾�낤
���������āAAMD��APU�̍\��������ɍ��킹�Ă�荂�����ō����\�Ȃ��̂Ɏd�グ�Ă���
shield�̂���vulkan�����肪�Ƃ�
nv�̓K�b�|���ׂ��邩��S�����Ȃ������
nv�̓K�b�|���ׂ��邩��S�����Ȃ������
����Ȃ̂Ȃ�����
SHIELD��
���ꂪ�����Ƃ��A���G�����[w
Nvidia�̍���B��̃l�^��sheild�炵���������_������
���ꂪ�����Ƃ��A���G�����[w
Nvidia�̍���B��̃l�^��sheild�炵���������_������
������shield��hsa���C�N��GPU��CPU�̃������A�h���X�����͂ł��Ă�́H��
>>733
�o���Ă����X�I�ɐ�`����
���ĂȂ������y���Ȃ��Ƃ������Ƃ͂�����������
GPU�̐��\�����Ŕ����Ɗ��Ⴂ���Ă邩��A�ŋ߂͎��s���肵�Ă�����NjC�t���ĂȂ�
��������s���A�����ď킹�Ă���邾�낤
���Ȃ݂ɂ��������̂�����
�mGTC 2014�nNVIDIA��HMD�uNear-Eye LFD�v�ɒ��ڏW�܂�GTC
http://www.4gamer.net/games/999/G999902/20140330002/
2015.02.25
3���ANVIDIA���Ǝ���VR�f�o�C�X�uTitan VR�v�\��
http://www.moguravr.com/titanvrgdc/
���x���s���Ă����������Ǝ��K�i�S����������k�r�����̖����͂ǂ�����
�o���Ă����X�I�ɐ�`����
���ĂȂ������y���Ȃ��Ƃ������Ƃ͂�����������
GPU�̐��\�����Ŕ����Ɗ��Ⴂ���Ă邩��A�ŋ߂͎��s���肵�Ă�����NjC�t���ĂȂ�
��������s���A�����ď킹�Ă���邾�낤
���Ȃ݂ɂ��������̂�����
�mGTC 2014�nNVIDIA��HMD�uNear-Eye LFD�v�ɒ��ڏW�܂�GTC
http://www.4gamer.net/games/999/G999902/20140330002/
2015.02.25
3���ANVIDIA���Ǝ���VR�f�o�C�X�uTitan VR�v�\��
http://www.moguravr.com/titanvrgdc/
���x���s���Ă����������Ǝ��K�i�S����������k�r�����̖����͂ǂ�����
>>734
���X�d
shield��GPU��CPU�̓I���_�C�œ������Ă�
�@�\�I�ɂ͂��܂���dGPU+CPU�̍\�����甲���o���ĂȂ����Ă��Ƃ���
���X�d
shield��GPU��CPU�̓I���_�C�œ������Ă�
�@�\�I�ɂ͂��܂���dGPU+CPU�̍\�����甲���o���ĂȂ����Ă��Ƃ���
736 �F,,�E�L�́M�E,,�j��-�������F2015/03/04(��) 20:52:23.36 ID:CX1+E4U6
> �o���Ă����X�I�ɐ�`����
�ʂɑ�X�I�Ɍ��Ȃ��ł���
�����ċ��N��K1�Ŋ��ɓ�������Ă邵
http://on-demand.gputechconf.com/gtc/2014/presentations/S4906-mobile-compute-tegra-K1.pdf
�ʂɑ�X�I�Ɍ��Ȃ��ł���
�����ċ��N��K1�Ŋ��ɓ�������Ă邵
http://on-demand.gputechconf.com/gtc/2014/presentations/S4906-mobile-compute-tegra-K1.pdf
Cortex-A15������32bit CPU�̂܂܂��c
IP�R�A�𑼎В��B����ƐF�X��ς���
IP�R�A�𑼎В��B����ƐF�X��ς���
738 �F,,�E�L�́M�E,,�j��-�������F2015/03/04(��) 20:54:56.79 ID:CX1+E4U6
������
> SHARING DATA BETWEEN HOST AND DEVICE
> ? Pageable + Memory Copy
> ? Page-locked/Pinned + Memory Copy
> ? Zero Copy
> SHARING DATA BETWEEN HOST AND DEVICE
> ? Pageable + Memory Copy
> ? Page-locked/Pinned + Memory Copy
> ? Zero Copy
AMD�uHSA�ł��炩��AVulkan�ł��炩��v
�\�t�g��ЁuAMD���������Ȃ�Ή����Ă�������iμ�μށv
����Ȋ����ł���H
�\�t�g��ЁuAMD���������Ȃ�Ή����Ă�������iμ�μށv
����Ȋ����ł���H
�Ǝ��H�����Č������ǎԍڌ�����Tegra���荞�ނ��Ƃɐ������Ă邵
VMware�Ƒg���zGPU���f�[�^�Z���^�[�ւ̓������т����ł���
�܂��傫�Ȕ��グ��܂łɂ͒B���ĂȂ��悤������
�h��Ȃ悤�ł���NVIDIA�̕�������Ă邱�ƒn�������
VMware�Ƒg���zGPU���f�[�^�Z���^�[�ւ̓������т����ł���
�܂��傫�Ȕ��グ��܂łɂ͒B���ĂȂ��悤������
�h��Ȃ悤�ł���NVIDIA�̕�������Ă邱�ƒn�������
>>739
���u��HSA�}�V�����̗p���ꂽ�ꍇ����
�\�t�g�x���_�͂�����ŗ��p�\�ȃn�[�h�E�F�A�����Ƃ��ė��p���邾��
�N�����Ή�����点��Ƃ����؍����̂��̂���Ȃ�
���u��HSA�}�V�����̗p���ꂽ�ꍇ����
�\�t�g�x���_�͂�����ŗ��p�\�ȃn�[�h�E�F�A�����Ƃ��ė��p���邾��
�N�����Ή�����点��Ƃ����؍����̂��̂���Ȃ�
>>734
������f�J�C����ˁB
����ō��҂����ɂȂ��Ă�GRID�y�����Ă��܂���
����҂�GPU��I�Ԏ����Ȃ��Ȃ�̂�API�̗L���s���Ȃǂǂ��ł��悭�Ȃ�Ɩژ_��ł���̂��ȁB
�����I�ɂ͐���AMD����������ׂ�����B
������f�J�C����ˁB
����ō��҂����ɂȂ��Ă�GRID�y�����Ă��܂���
����҂�GPU��I�Ԏ����Ȃ��Ȃ�̂�API�̗L���s���Ȃǂǂ��ł��悭�Ȃ�Ɩژ_��ł���̂��ȁB
�����I�ɂ͐���AMD����������ׂ�����B
DX12���PS4�̃��[���x��API��AMD���傫���v�����Ă�͎̂������낤���A
���ꂪAMD��GPU���v���Ƃ͂Ȃ�Ȃ����
nvidia�͂ǂ����Ă�DirectX�̈ꕔ�@�\�̎�����AMD���x���͂Ȃ邪�A
���́A�\�t�g���[�J�[��nvidia�ł������ƃp�t�H�[�}���X�o��悤�ɂ����������@�\�͎g��Ȃ����߂ɁA
���̓���@�\���g���x���`�ȊO�ł�AMD�ɑ��x�I�ȃ����b�g���o�Ȃ����
���ꂪAMD��GPU���v���Ƃ͂Ȃ�Ȃ����
nvidia�͂ǂ����Ă�DirectX�̈ꕔ�@�\�̎�����AMD���x���͂Ȃ邪�A
���́A�\�t�g���[�J�[��nvidia�ł������ƃp�t�H�[�}���X�o��悤�ɂ����������@�\�͎g��Ȃ����߂ɁA
���̓���@�\���g���x���`�ȊO�ł�AMD�ɑ��x�I�ȃ����b�g���o�Ȃ����
���ʐ���CEO�ɃP���J�������r�߂��Ă�̂�
�Q�t�H��������I�������c�����Đ����z�ꍪ�����ȂƎv���܂���
�Q�t�H��������I�������c�����Đ����z�ꍪ�����ȂƎv���܂���
745 �F,,�E�L�́M�E,,�j��-�������F2015/03/04(��) 21:09:25.25 ID:CX1+E4U6
�Y�p8370E�i���j�g���̒{�����Ȃ����Ă��
8370E��GTX970(��)�ƈ���ăX�y�b�N���\�͂��ĂȂ��Ǝv���܂����H��
3���ڍs��sc���ǂ���������Ȃ������́H�܂�����̃I�}�G
3���ڍs��sc���ǂ���������Ȃ������́H�܂�����̃I�}�G
�A�h���X��������Ȃ�hQ�݂����Ȏd�g�݂̂ق����d�v�ł́H
OpenCL�ɍ̗p���ꂽ�̂�hQ�̂͂������B
OpenCL�ɍ̗p���ꂽ�̂�hQ�̂͂������B
748 �F,,�E�L�́M�E,,�j��-�������F2015/03/04(��) 21:18:19.98 ID:CX1+E4U6
�܂�OpenCL�͕ʂɓ���GPU����̃t���[�����[�N����Ȃ������
�f�B�X�N���[�gGPU������GPU�������CUDA�Ɣ�ׂ��
���Ђ̃f�B�X�N���[�gGPU����J�o�[�ł��Ȃ�HSA�͌��d�l
�f�B�X�N���[�gGPU������GPU�������CUDA�Ɣ�ׂ��
���Ђ̃f�B�X�N���[�gGPU����J�o�[�ł��Ȃ�HSA�͌��d�l
����o�[�W�������d�˂ē������Ă�����ł���
�����܂�����̂���I�}�G��
�����܂�����̂���I�}�G��
�����I�ɂ��_���I�ɂ���������Ă���̂����ɓK���Ă���Ƃ����ȒP�Șb
���Ђ̕Ў藎���̎����X�ƌ��̂̓X���Ⴂ
���Ђ̕Ў藎���̎����X�ƌ��̂̓X���Ⴂ
751 �F,,�E�L�́M�E,,�j��-�������F2015/03/04(��) 22:19:32.80 ID:CX1+E4U6
����͖ϑz
�����ɂ̓z�X�g�������ƓƗ����������������̂ق����n�C�p�t�H�[�}���X�A�v���P�[�V�����ɂ�
���ɂ��Ȃ��Ă�킯�Ȃ̂ł��B
�u�}���`GPGPU�v�@�\��CUDA6����̋@�\����
HSA�͕����I�ɂ��_���I�ɂ�����GPU1�f�o�C�X�����g���Ȃ�
�������}���`�v���Z�b�T�\�����T�|�[�g���Ȃ��B
�����ɂ̓z�X�g�������ƓƗ����������������̂ق����n�C�p�t�H�[�}���X�A�v���P�[�V�����ɂ�
���ɂ��Ȃ��Ă�킯�Ȃ̂ł��B
�u�}���`GPGPU�v�@�\��CUDA6����̋@�\����
HSA�͕����I�ɂ��_���I�ɂ�����GPU1�f�o�C�X�����g���Ȃ�
�������}���`�v���Z�b�T�\�����T�|�[�g���Ȃ��B
����͒P�Ɍ������ł���Ƃ��������̂��Ƃ���
753 �F,,�E�L�́M�E,,�j��-�������F2015/03/04(��) 22:31:04.22 ID:CX1+E4U6
�����ς��邽�߂̃v��������ł��ĂȂ�����
>>740
AMD�͒n���ɂ���Ă����悤�ȑ̗͖������炵�Ⴀ�Ȃ�
�����̓r�W�����u���b�N�̖��\���������A�Z�p�҂��ǂ�ȂɊ撣���Ė����������Ă���Ă�
�������������ł����A���x���x�t�@���{�[�C�N�������K�N�F�����叟���ϑz�Ƃ͋t��
�ǂ�ǂ����čs��AMD�A����ጋ�ʏo��O�ɑ���@�����炢�����y���݂悤�Ȃ���Ȃ�
�ق�Ƃ��킢�������Ǝv����
AMD�͒n���ɂ���Ă����悤�ȑ̗͖������炵�Ⴀ�Ȃ�
�����̓r�W�����u���b�N�̖��\���������A�Z�p�҂��ǂ�ȂɊ撣���Ė����������Ă���Ă�
�������������ł����A���x���x�t�@���{�[�C�N�������K�N�F�����叟���ϑz�Ƃ͋t��
�ǂ�ǂ����čs��AMD�A����ጋ�ʏo��O�ɑ���@�����炢�����y���݂悤�Ȃ���Ȃ�
�ق�Ƃ��킢�������Ǝv����
>>753
���̐l�͑i�׃��X�N���ǂ������邩�c�_���Ă鑼�Ђ���
�]�����ݓI�ȋc�_�����Ă邾�낤��
>>754
DX12�̓}���g�����ۓۂ�
Maxwell v2�ł���tier2�T�|�[�g
GCN�̓t���T�|�[�g
����ȏ�Ȃ����炢�ɗǂ�����Ă�Ǝv���܂���
�X�y�b�N���\�ŏ���x�����c�ƕ���̎蕿�̂ǂ����Ƃ͉_�D�̍�����
���̐l�͑i�׃��X�N���ǂ������邩�c�_���Ă鑼�Ђ���
�]�����ݓI�ȋc�_�����Ă邾�낤��
>>754
DX12�̓}���g�����ۓۂ�
Maxwell v2�ł���tier2�T�|�[�g
GCN�̓t���T�|�[�g
����ȏ�Ȃ����炢�ɗǂ�����Ă�Ǝv���܂���
�X�y�b�N���\�ŏ���x�����c�ƕ���̎蕿�̂ǂ����Ƃ͉_�D�̍�����
756 �F,,�E�L�́M�E,,�j��-�������F2015/03/04(��) 22:48:19.12 ID:CX1+E4U6
���̏������CPU��8370E�i�j�����Ă�ᐢ�b�Ȃ���
�I���͊�{�R�X�p�d���Ȃ�ł�
�T�[�Z��������
�T�[�Z��������
>>753
OpenCL2.0����_���Ȃ́H
OpenCL2.0����_���Ȃ́H
759 �F,,�E�L�́M�E,,�j��-�������F2015/03/04(��) 22:58:57.12 ID:CX1+E4U6
OpenCL 2.0��SPIR��CUDA PTX�̃R�s�[����
HSAIL�̃R�s�[���Ǝv�����H�Ȃ�Ŋ������ĂȂ����̂�^�����
HSAIL�̃R�s�[���Ǝv�����H�Ȃ�Ŋ������ĂȂ����̂�^�����
>>755
���ꂪ�Z�p�҂��������Ă���Ă閲�Ȃ�
�����͐������ꂸAMD���叟�����鎖�͖����̂�
���N�O��GPU�V�F�A�AAMD 25% NVIDIA15%��NV�o�J�ɂ��Ă���H
���ǂ��Ȃ����HdGPU�I�����[��NVIDIA�ȉ�����ȍ���AMD
�t�@���{�[�C�͖ܘ_�AAMD���g���N����U�X�������Ƃ��Ă���
���l�ɂ����������Ȃ�
���N�O��AMD�̔���16���h�����������
���̍���NVIDIA�Ȃ��9���h���Ƃ�������
���ǂ��Ȃ��Ă�HCS���e���ĕ��������i�|�[�g�t�H���I�����Ȃ���
�܂��������Ă�Ƃ������͍X�ɕ��������L����Ƃ��Ȃ���ȁH��
������߂�A���O�炪�l�����ŋ��̖����Ȃ��Ȃ�����
���ꂪ�Z�p�҂��������Ă���Ă閲�Ȃ�
�����͐������ꂸAMD���叟�����鎖�͖����̂�
���N�O��GPU�V�F�A�AAMD 25% NVIDIA15%��NV�o�J�ɂ��Ă���H
���ǂ��Ȃ����HdGPU�I�����[��NVIDIA�ȉ�����ȍ���AMD
�t�@���{�[�C�͖ܘ_�AAMD���g���N����U�X�������Ƃ��Ă���
���l�ɂ����������Ȃ�
���N�O��AMD�̔���16���h�����������
���̍���NVIDIA�Ȃ��9���h���Ƃ�������
���ǂ��Ȃ��Ă�HCS���e���ĕ��������i�|�[�g�t�H���I�����Ȃ���
�܂��������Ă�Ƃ������͍X�ɕ��������L����Ƃ��Ȃ���ȁH��
������߂�A���O�炪�l�����ŋ��̖����Ȃ��Ȃ�����
>>759
��������Ȃ���OpenCL2.0�ɂ́AhQ�Ƃ��������������f���Ƃ�HSA�̈ꕔ����荞�܂��킯������
HSA��dGPU�̊g��Ƃ����Ӗ��ł͋y��_���グ����Ȃ��H���Ă���
��������Ȃ���OpenCL2.0�ɂ́AhQ�Ƃ��������������f���Ƃ�HSA�̈ꕔ����荞�܂��킯������
HSA��dGPU�̊g��Ƃ����Ӗ��ł͋y��_���グ����Ȃ��H���Ă���
>>760
�������ɍŋ��̖����͗��Ă邶���
���ǔ���ȂG���h���[�U�[�ǂ��ł��悭�Ď������ǂꂾ���i�Z�p�������ʂ��ċ���ł��邩����
�ʂɂ��O���k�r��CEO�Ƀo�J�ɂ���Ȃ���GTX970�g�������悤�Ǝ~�߂˂��悗
�Ⴆ���O�̓��j�N�����ׂ��Ă邩�烆�j�N���̕��͍ŋ��Ƃ��Ē��Ă�E�I�^(�ł��ĂȂ�����)��������ǂ�����H
����ȃ_�T�������ė{������o�J���ȂƎv������
�������ɍŋ��̖����͗��Ă邶���
���ǔ���ȂG���h���[�U�[�ǂ��ł��悭�Ď������ǂꂾ���i�Z�p�������ʂ��ċ���ł��邩����
�ʂɂ��O���k�r��CEO�Ƀo�J�ɂ���Ȃ���GTX970�g�������悤�Ǝ~�߂˂��悗
�Ⴆ���O�̓��j�N�����ׂ��Ă邩�烆�j�N���̕��͍ŋ��Ƃ��Ē��Ă�E�I�^(�ł��ĂȂ�����)��������ǂ�����H
����ȃ_�T�������ė{������o�J���ȂƎv������
AMD���{�I �Ԃ�������o�g���W�T�b�J�[�Y
��ϖ������W���[���R�A���A���`�ƗE�C�Ńp���`���b�v��
CEO���q���o�J�ɂ��ĉc�ƕ��傪�q���y�e���ɂ����悤�Ǝl�ꔪ�ꂵ�Ă郁�[�J�[�̊W�҂��猩���
AMD�̂���Ă邱�Ƃ͗V�тɌ�����̂���
AMD�̂���Ă邱�Ƃ͗V�тɌ�����̂���
�悤���������֗V�ڂ���p���_�C�X
�`�p���_�C�X���ȋ�́`
�`�p���_�C�X���ȋ�́`
�{�C�ŃI���B���|����Ώ��̂��O��Ȃ��ň�Ђ˂肾�b�I�݂����ȁH��
�s���S�ȋƊE���ˁ`
�s���S�ȋƊE���ˁ`
>>766
�V�тł���Ă��邩��Ԏ������ʂō����͒��������ĉ�ЂɂȂ��
�V�тł���Ă��邩��Ԏ������ʂō����͒��������ĉ�ЂɂȂ��
>>768
���l�[�������ʂ��Ċ����������
���l�[�������ʂ��Ċ����������
�@�@�@�@�@�ȁQ��
�@�@�@�@�@( ߃�߁@)�@�������i�̔j��CM�͔C����[
�@�����b��l��l��
�@�@�@�@�@/�@�@(�@�@ )�@��߂āI
�@�@�@�@ �i�m�P�ƁA�@��
�@�@�@�@�@�@�@�@���[J
�@�@�@�@�@( ߃�߁@)�@�������i�̔j��CM�͔C����[
�@�����b��l��l��
�@�@�@�@�@/�@�@(�@�@ )�@��߂āI
�@�@�@�@ �i�m�P�ƁA�@��
�@�@�@�@�@�@�@�@���[J
>>766
�G���^�[�v���C�Y�ƊE�ɂ͑S���e���͂Ȃ�
�p�����̖����ɂ��ƊE���ł̐M���������ȏ�A���ނ͂����Ă����͖���
�܂�����OpenGL��DX12��mantle�������邱�ƂɂȂ������A���ꂪAMD�ɂƂ��ċN���ɂȂ�v�f�͖���
�����AMD����Ȃ���Ƃ����V�`���G�[�V��������������
����AMD64�Ŏ����Ă�
�G���^�[�v���C�Y�ƊE�ɂ͑S���e���͂Ȃ�
�p�����̖����ɂ��ƊE���ł̐M���������ȏ�A���ނ͂����Ă����͖���
�܂�����OpenGL��DX12��mantle�������邱�ƂɂȂ������A���ꂪAMD�ɂƂ��ċN���ɂȂ�v�f�͖���
�����AMD����Ȃ���Ƃ����V�`���G�[�V��������������
����AMD64�Ŏ����Ă�
AMD�u�V�����̍������`������`�v
AMD�t�@���{�[�C�u����͐����IAMD�叟�����I�I���k�r�I���^�������v
�ڋq�uAMD�ȊO�Ŏg����́H�v
AMD�uAMD�ł����g���܂��v
�ڋq�u���Ⴀ������v
AMD�uAMD�ȊO�ł��g���܂��v
�ڋq�u�������IAMD�ȊO�Ŏg�킹�Ă��炤�ŁI�v
AMD���t�@���{�[�C�u�v
�b������
AMD�u�V�����̍������`������`�v
AMD�t�@���{�[�C�u����͐����IAMD�叟�����I�I���k�r�I���^�������v
�ڋq�uAMD�ȊO�ł����v
�����Ƃ���Ȋ������
AMD�������Ԃ��グ�遨�t�@���{�[�C�������錾��AMD����ŏ�����or�]���ɉ�����ĕ�����
�̌J��Ԃ��A��������������������錾�ł���t�@���{�[�C�̍����Ƃ������M�S�ɂ�
�ق�Ɗ��S���� 👀
AMD�t�@���{�[�C�u����͐����IAMD�叟�����I�I���k�r�I���^�������v
�ڋq�uAMD�ȊO�Ŏg����́H�v
AMD�uAMD�ł����g���܂��v
�ڋq�u���Ⴀ������v
AMD�uAMD�ȊO�ł��g���܂��v
�ڋq�u�������IAMD�ȊO�Ŏg�킹�Ă��炤�ŁI�v
AMD���t�@���{�[�C�u�v
�b������
AMD�u�V�����̍������`������`�v
AMD�t�@���{�[�C�u����͐����IAMD�叟�����I�I���k�r�I���^�������v
�ڋq�uAMD�ȊO�ł����v
�����Ƃ���Ȋ������
AMD�������Ԃ��グ�遨�t�@���{�[�C�������錾��AMD����ŏ�����or�]���ɉ�����ĕ�����
�̌J��Ԃ��A��������������������錾�ł���t�@���{�[�C�̍����Ƃ������M�S�ɂ�
�ق�Ɗ��S���� 👀
�������r�����������܂���
�Ƃ������A2,3�ɂ�̂���������Ԃ�
���A���Ȃ�A�����܂��������
�b��������낤
�Ƃ������A2,3�ɂ�̂���������Ԃ�
���A���Ȃ�A�����܂��������
�b��������낤
�������A�O���t�B�b�N�X�Z�p�ł͂Ƃ肠����AMD�ɕt���Ă����ΊԈႢ�Ȃ��ƌ�������т���ꂽ�̂͑傫����
������Mantle�ʼn���������ɂ��Ă��p�[�g�i�[��t���₷���Ȃ�Ǝv����
������Mantle�ʼn���������ɂ��Ă��p�[�g�i�[��t���₷���Ȃ�Ǝv����
DX12���A�V�炵��OpenGL���AAMD���ϋɊ֗^���Ă邪�A
�ǂ���AMD�ƐS���͂������Ȃ�����A
AMD�ł����g���Ȃ��Z�p�͍̗p�����ɁA
���Ђ�GPU�ł��ėp�I�Ɏg����Z�p���̗p����
������A�����͂₭�Ή�����̂�AMD�ł��A������nvidia�����ǂ����Ă���
�܂��A�����������V�K�i���ł��Ă����ɑΉ�����\�t�g�͏��Ȃ��A
�{�i�I�Ƀ\�t�g���g���Ă��邱��ɂ́Anvidia���{�i�Ή����Ă�̂ŁA
���قǍ��͏o�Ȃ��Ȃ�
AMD�͎킾���T���Ċ�����̂�nvidia���Ă̂��ADX12��VOpenGL�ł��傤
�ǂ���AMD�ƐS���͂������Ȃ�����A
AMD�ł����g���Ȃ��Z�p�͍̗p�����ɁA
���Ђ�GPU�ł��ėp�I�Ɏg����Z�p���̗p����
������A�����͂₭�Ή�����̂�AMD�ł��A������nvidia�����ǂ����Ă���
�܂��A�����������V�K�i���ł��Ă����ɑΉ�����\�t�g�͏��Ȃ��A
�{�i�I�Ƀ\�t�g���g���Ă��邱��ɂ́Anvidia���{�i�Ή����Ă�̂ŁA
���قǍ��͏o�Ȃ��Ȃ�
AMD�͎킾���T���Ċ�����̂�nvidia���Ă̂��ADX12��VOpenGL�ł��傤
AMD Nolan and Amur (SkyBridge) will use the BGA Socket FF1
http://www.bitsandchips.it/52-english-news/5334-amd-nolan-and-amur-skybridge-will-use-the-unique-socket-bga-ff1
http://www.bitsandchips.it/52-english-news/5334-amd-nolan-and-amur-skybridge-will-use-the-unique-socket-bga-ff1
>>776
�Q�[���ƊE�Ƃ�AMD����n�[�h�E�F�A�����Ă邵�Y�u�Y�u�ł����
AMD64�̎��ƈ���Ă�������APU�ň͂�����ł��邩�瑦�E�o�͂ł��Ȃ���
���[�A�̖@�����l���ƂȂ��Ă̓v���Z�X�V�������N�ɂ��GPU�̐L�т�����Ȃ��Ȃ�
���[�h�}�b�v�ʂ�ɂ̓k�r���`�b�v���X�V���Ă����Ȃ���
�Q�[���ƊE�Ƃ�AMD����n�[�h�E�F�A�����Ă邵�Y�u�Y�u�ł����
AMD64�̎��ƈ���Ă�������APU�ň͂�����ł��邩�瑦�E�o�͂ł��Ȃ���
���[�A�̖@�����l���ƂȂ��Ă̓v���Z�X�V�������N�ɂ��GPU�̐L�т�����Ȃ��Ȃ�
���[�h�}�b�v�ʂ�ɂ̓k�r���`�b�v���X�V���Ă����Ȃ���
NV��Fermi�ӂ��GPGPU�ɖ����ĂĖ���
�����J�[�h��GPGPU�̖��͎��������Ă邯�nj������Ă�
AMD�͌���HSA�̖����Ă�GPU��CPU�ɂ�����ǂ���
���������������Ƃ������J�[�h�̂ق������悤�Ƃ����
�J�����\�[�X���₵�ĕʃA�[�L�e�N�`����邩
����Ƃ�����GPU���߂邩���Ȃ��Ƃ����Ȃ����猵����
NV�̂悤�ɖ�����o�߂邾���ő��v�Ƃ����킯�ł͂Ȃ�����
�����J�[�h��GPGPU�̖��͎��������Ă邯�nj������Ă�
AMD�͌���HSA�̖����Ă�GPU��CPU�ɂ�����ǂ���
���������������Ƃ������J�[�h�̂ق������悤�Ƃ����
�J�����\�[�X���₵�ĕʃA�[�L�e�N�`����邩
����Ƃ�����GPU���߂邩���Ȃ��Ƃ����Ȃ����猵����
NV�̂悤�ɖ�����o�߂邾���ő��v�Ƃ����킯�ł͂Ȃ�����
OpenCL2.1��glNext��SPIR-V�̗p
glNext�͉�����Mantle���̗p
�O�x�������薄�߂Ă��Ă�Ǝv������
glNext�͉�����Mantle���̗p
�O�x�������薄�߂Ă��Ă�Ǝv������
�����������[
>>779�@�Ƃ�����HW�A�N�Z�����[�^�̗̍p�������āA���ʂ̗p�r�ł�GPU�������K�{�ɂȂ��Ă�̂�
����Google���u���ׂĂ̗p�r���N���E�h�ōς܂���Β[���Ȃǂ��ł��悭�Ȃ�v�I�Ȃ��ƌ����Ă�����
Web�A�v���̃��X�|���X�グ��ɂ͐�p�̃N���C�A���g�p�ӂ��邩HW�A�N�Z�����[�^�g��Ȃ��ƃn�C�X�yPC�ł��L�c�C�����
MS�̃��j�o�[�T���A�v�����́A�u�[���Ɉˑ����Ȃ��i�د�v�n���͑S�����̎�̍������Z�p���Ȃ��Ƙb�ɂȂ�Ȃ�
PC��PC��OS���g�̍�������N���E�h��G�R�V�X�e���Ńo�b�N�O���E���h�����������Ă邩��݂̂�����
��̃\�t�g��CPU�t�����[�h������悤�Ȏg�����͂����ł��Ȃ��A������ӂ̎����Intel��AMD������
�ł��A�Q�[���Ȃ蓮��ҏW�Ȃ�RD�v�Ȃ�ł�GPU�K�v�Ƃ��Ă�w���炵���炻��Ȃ��Ƃ���]�T����Ȃ�
�����ł�CPU�̃��\�[�X���₵�Ă�����ĂȂ�킯�ŁA���ႠiGPU�g���܂��傤���Ă̂��ŋ߂̗���
����Google���u���ׂĂ̗p�r���N���E�h�ōς܂���Β[���Ȃǂ��ł��悭�Ȃ�v�I�Ȃ��ƌ����Ă�����
Web�A�v���̃��X�|���X�グ��ɂ͐�p�̃N���C�A���g�p�ӂ��邩HW�A�N�Z�����[�^�g��Ȃ��ƃn�C�X�yPC�ł��L�c�C�����
MS�̃��j�o�[�T���A�v�����́A�u�[���Ɉˑ����Ȃ��i�د�v�n���͑S�����̎�̍������Z�p���Ȃ��Ƙb�ɂȂ�Ȃ�
PC��PC��OS���g�̍�������N���E�h��G�R�V�X�e���Ńo�b�N�O���E���h�����������Ă邩��݂̂�����
��̃\�t�g��CPU�t�����[�h������悤�Ȏg�����͂����ł��Ȃ��A������ӂ̎����Intel��AMD������
�ł��A�Q�[���Ȃ蓮��ҏW�Ȃ�RD�v�Ȃ�ł�GPU�K�v�Ƃ��Ă�w���炵���炻��Ȃ��Ƃ���]�T����Ȃ�
�����ł�CPU�̃��\�[�X���₵�Ă�����ĂȂ�킯�ŁA���ႠiGPU�g���܂��傤���Ă̂��ŋ߂̗���
�܂�������č����ɂȂ��Ă悗
784 �FSocket774�F2015/03/05(��) 07:48:45.32 ID:9T++OZ0P
AMD64�ő叟���̂͂����E�E�E
785 �FSocket774�F2015/03/05(��) 07:55:31.24 ID:qRQ81A5q
AMD�ƃQ�t�H�~�[�Ƃ͖ڎw���Ă���������S���Ⴄ��B
AMD�̏ꍇ
��2015�N�̈ӋC���݂������ĉ�����
�@���o�C�������ɏȓd�͐���啝�ɍ��߂����o�C��APU�t�@�~���[�uCarrizo�v���n�߂Ƃ��鎟����APU��A
���s��GPU���\���X�ɍ��߂����i�Ȃǂ̓����ɒ��͂��Ă����܂��B
�d�͌�������O���t�B�b�N�X���\���啝�Ɍ��シ��AMD���i��OEM���[�J�[���̗p���₷�����邱�ƂŁA
���L�����\�Ɖ��i�|�C���g���J�o�[����ŏI���i���F�l�ɂ��͂��������Ǝv���܂��B
���ǎ҂Ɉꌾ�ǂ���
�@���N��Mantle��TrueAudio�A�є������_�����O�Z�p��TressFX Hair�Ƃ������ŐV�Z�p�ւ̃Q�[���̍œK�����܂��܂��i�݁AAMD���i�����p�����Q�[���̌�������Ƀp���[�A�b�v���܂��I
�l�X�ȍŐV�Q�[�����o���h������uNever Settle�v��A�l�X�ȃL�����y�[���A�H�t���ł̃C�x���g�ȂǁA�F�l�Ɋ��Œ�����������{���Ă��������Ǝv���܂��B
�ŐV����AMD��Facebook�y�[�W�Ő������ē����܂��̂ł��Ѓ`�F�b�N���Ă݂Ă��������B
�Q�t�H�~�[�̏ꍇ
��2015�N�̈ӋC���݂������ĉ�����
�@�V�F�A100%��ڎw���Ĉ��������撣��܂��i�j�B
���N���F�l�Ɉ������NVIDIA�ƂȂ�悤�ɐ��i���Ă܂���܂��̂ŁA�X�������肢�܂��B
���ǎ҂Ɉꌾ�ǂ���
�@2015�N���F�l�̂����҂ɂ������ł���GeForce���i�����ĐV���ȋZ�p�����͂��ł���悤�ɓw�͂��Ă��������ł��B���N�����[�U�[�̊F�l�Ƃ̐G�ꍇ�����厖�ɂ��Ă��������Ǝv���܂��B
�\�[�X
http://akiba-pc.watch.impress.co.jp/docs/sp/20150101_682313.html
AMD�̏ꍇ
��2015�N�̈ӋC���݂������ĉ�����
�@���o�C�������ɏȓd�͐���啝�ɍ��߂����o�C��APU�t�@�~���[�uCarrizo�v���n�߂Ƃ��鎟����APU��A
���s��GPU���\���X�ɍ��߂����i�Ȃǂ̓����ɒ��͂��Ă����܂��B
�d�͌�������O���t�B�b�N�X���\���啝�Ɍ��シ��AMD���i��OEM���[�J�[���̗p���₷�����邱�ƂŁA
���L�����\�Ɖ��i�|�C���g���J�o�[����ŏI���i���F�l�ɂ��͂��������Ǝv���܂��B
���ǎ҂Ɉꌾ�ǂ���
�@���N��Mantle��TrueAudio�A�є������_�����O�Z�p��TressFX Hair�Ƃ������ŐV�Z�p�ւ̃Q�[���̍œK�����܂��܂��i�݁AAMD���i�����p�����Q�[���̌�������Ƀp���[�A�b�v���܂��I
�l�X�ȍŐV�Q�[�����o���h������uNever Settle�v��A�l�X�ȃL�����y�[���A�H�t���ł̃C�x���g�ȂǁA�F�l�Ɋ��Œ�����������{���Ă��������Ǝv���܂��B
�ŐV����AMD��Facebook�y�[�W�Ő������ē����܂��̂ł��Ѓ`�F�b�N���Ă݂Ă��������B
�Q�t�H�~�[�̏ꍇ
��2015�N�̈ӋC���݂������ĉ�����
�@�V�F�A100%��ڎw���Ĉ��������撣��܂��i�j�B
���N���F�l�Ɉ������NVIDIA�ƂȂ�悤�ɐ��i���Ă܂���܂��̂ŁA�X�������肢�܂��B
���ǎ҂Ɉꌾ�ǂ���
�@2015�N���F�l�̂����҂ɂ������ł���GeForce���i�����ĐV���ȋZ�p�����͂��ł���悤�ɓw�͂��Ă��������ł��B���N�����[�U�[�̊F�l�Ƃ̐G�ꍇ�����厖�ɂ��Ă��������Ǝv���܂��B
�\�[�X
http://akiba-pc.watch.impress.co.jp/docs/sp/20150101_682313.html
786 �FSocket774�F2015/03/05(��) 07:58:42.72 ID:qRQ81A5q
�Q�t�H�~�[�̊炪�C���������B
�����̓��e���c�t�ŋ�̐��������B
�����Ă�A�炪�f�J�C�̂͑ԓx���f�J�C�؋��B
�l�b�g��AMD�̔��オ�A�V�F�A�����Č����Ă�̂������R�C�c�Ȃ�ˁI
���f�ł����Ȃ�
�����̓��e���c�t�ŋ�̐��������B
�����Ă�A�炪�f�J�C�̂͑ԓx���f�J�C�؋��B
�l�b�g��AMD�̔��オ�A�V�F�A�����Č����Ă�̂������R�C�c�Ȃ�ˁI
���f�ł����Ȃ�
Llano�o��̋łɂ�
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
�� 2014�N �����̔��ド���L���O
http://eetimes.jp/ee/articles/1412/25/news147.html
��AMD�A2014�N�x��4���h���̐Ԏ�
http://pc.watch.impress.co.jp/docs/news/20150121_684660.html
AMD�̏��ʂ������}�~���ЂƂ蕉���_(^o^)�^
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
�� 2014�N �����̔��ド���L���O
http://eetimes.jp/ee/articles/1412/25/news147.html
��AMD�A2014�N�x��4���h���̐Ԏ�
http://pc.watch.impress.co.jp/docs/news/20150121_684660.html
AMD�̏��ʂ������}�~���ЂƂ蕉���_(^o^)�^
788 �FSocket774�F2015/03/05(��) 08:23:16.45 ID:9T++OZ0P
AMD64�ő叟��
dx10.1�ő叟��
DX11�ő叟��
DX11.1�ő叟��
DX11.2�ő叟��
mantle�ő叟��
DX12�ő叟��
vulkan�ő叟��
dx10.1�ő叟��
DX11�ő叟��
DX11.1�ő叟��
DX11.2�ő叟��
mantle�ő叟��
DX12�ő叟��
vulkan�ő叟��
�Ƃ肠����PS4�݂�����GDDR���ڂł���}�U�{���o�Ă��邱�Ƃɂ͊��҂��Ă�B
�����Ƃ��AHBM�Ɉڍs����̂��������
�����Ƃ��AHBM�Ɉڍs����̂��������
http://www.tomshardware.co.uk/amd-radeon-r9-oculus-rift,news-49857.html
GDC�Ŏ�����R9�̍ŏ��GPU���ڂ����}�V����Oculus Rift�̃f������Ă����ăT
GDC�Ŏ�����R9�̍ŏ��GPU���ڂ����}�V����Oculus Rift�̃f������Ă����ăT
>>780
�O�x���߂Ă�Ǝv���H
�c�O�Ȃ���S���Ⴄ
mantle�̋Z�p�A�v���[�`���ǂ��̂͊m�������ǁA
AMD�Ɏs�ꂩ��̐M������������ėpAPI����ꂿ���������
�ŁA�ėpAPI�ɓ�������Ă��Ƃ�
�AMD����Ȃ��Ƃ����Ȃ��Ƃ�����J�������
���Ă��Ƃ̓��[�U�[����AMD���g���K�v�������Ȃ�
�������̐V�Z�p�`�A�������̐V�Z�p�`���ăt���t�����Ė��m�ɂȂ�Ȃ��r�W������AMD�����̂܂܃t���t�������Ƃ���
������AMD�ɂ͗L���ɂȂ邱�Ɩ�����
�O�x���߂Ă�Ǝv���H
�c�O�Ȃ���S���Ⴄ
mantle�̋Z�p�A�v���[�`���ǂ��̂͊m�������ǁA
AMD�Ɏs�ꂩ��̐M������������ėpAPI����ꂿ���������
�ŁA�ėpAPI�ɓ�������Ă��Ƃ�
�AMD����Ȃ��Ƃ����Ȃ��Ƃ�����J�������
���Ă��Ƃ̓��[�U�[����AMD���g���K�v�������Ȃ�
�������̐V�Z�p�`�A�������̐V�Z�p�`���ăt���t�����Ė��m�ɂȂ�Ȃ��r�W������AMD�����̂܂܃t���t�������Ƃ���
������AMD�ɂ͗L���ɂȂ邱�Ɩ�����
�����ƒ��ۓI�ȕ\������
AMD���Ⴂ���Ȃ����R�͎g���������߂�
�v���_�N�g�A�E�g�ƃ}�[�P�b�g�C���̈Ⴂ
AMD���Ⴂ���Ȃ����R�͎g���������߂�
�v���_�N�g�A�E�g�ƃ}�[�P�b�g�C���̈Ⴂ
>>791
���O�s�̕\���͂Ƃ�����AMD���i�ł����Ă����i���Ƀv���O�����̍�蒼�����K�v��Mantle�Ƀ\�t�g�n�E�X�����̖��͂������Ă��Ȃ��Ƃ����v���I���ׂ�������DX12��DX12�ɑΉ�����AMD�ȊO�̐��i�ɂ���ĐV���オ�J�����̂͊ԈႢ�Ȃ��ȁB
���O�s�̕\���͂Ƃ�����AMD���i�ł����Ă����i���Ƀv���O�����̍�蒼�����K�v��Mantle�Ƀ\�t�g�n�E�X�����̖��͂������Ă��Ȃ��Ƃ����v���I���ׂ�������DX12��DX12�ɑΉ�����AMD�ȊO�̐��i�ɂ���ĐV���オ�J�����̂͊ԈႢ�Ȃ��ȁB
�M���������̂����i�j
�������_���j�]
�������_���j�]
We're likely to get our first glimpse of the R9 390X graphics card in action tomorrow during the TressFX 3.0 / Deus Ex Universe demo.
http://wccftech.com/amd-reveals-radeon-r9-390x-gdc-wip/
Augmented Hair in Deus Ex Universe projects: TressFX 3.0
Thursday, March 5, 10 - 11 a.m.
http://wccftech.com/amd-reveals-radeon-r9-390x-gdc-wip/
Augmented Hair in Deus Ex Universe projects: TressFX 3.0
Thursday, March 5, 10 - 11 a.m.
796 �FSocket774�F2015/03/05(��) 11:49:23.95 ID:chNowuCM
�M���i�j���������̗p���炳��Ȃ�
Weta, Epic Games Create 'The Hobbit' CG Virtual Reality Experience
http://www.hollywoodreporter.com/behind-screen/weta-epic-games-create-hobbit-779143
http://www.hollywoodreporter.com/behind-screen/weta-epic-games-create-hobbit-779143
>>794
�A�C�f�A�͈����Ȃ�����A�C�f�A�������������Ď����̓t���X�N���b�`�ō�蒼���Ă��B�łȂ��ƌ��ׂ܂ň����p���ł��܂�����B
�A�C�f�A�͈����Ȃ�����A�C�f�A�������������Ď����̓t���X�N���b�`�ō�蒼���Ă��B�łȂ��ƌ��ׂ܂ň����p���ł��܂�����B
Vulkan source code:
vkCmdBindDescriptorSet(cmdBuffer, VK_PIPELINE_BIND_POINT_GRAPHICS,
textureDescriptorSet[0], 0);
vkQueueSubmit(graphicsQueue, 1, &cmdBuffer, 0, 0, fence);
vkMapMemory(staticUniformBufferMemory, 0, (void **)&data);
// ...
vkUnmapMemory(staticUniformBufferMemory);
Mantle64.dll code:
grCmdBindDescriptorSet(cmdBuffer, VK_PIPELINE_BIND_POINT_GRAPHICS,
textureDescriptorSet[0], 0);
grQueueSubmit(graphicsQueue, 1, &cmdBuffer, 0, 0, fence);
grMapMemory(staticUniformBufferMemory, 0, (void **)&data);
// ...
grUnmapMemory(staticUniformBufferMemory);
����̂ǂ����t���X�N���b�`��
vkCmdBindDescriptorSet(cmdBuffer, VK_PIPELINE_BIND_POINT_GRAPHICS,
textureDescriptorSet[0], 0);
vkQueueSubmit(graphicsQueue, 1, &cmdBuffer, 0, 0, fence);
vkMapMemory(staticUniformBufferMemory, 0, (void **)&data);
// ...
vkUnmapMemory(staticUniformBufferMemory);
Mantle64.dll code:
grCmdBindDescriptorSet(cmdBuffer, VK_PIPELINE_BIND_POINT_GRAPHICS,
textureDescriptorSet[0], 0);
grQueueSubmit(graphicsQueue, 1, &cmdBuffer, 0, 0, fence);
grMapMemory(staticUniformBufferMemory, 0, (void **)&data);
// ...
grUnmapMemory(staticUniformBufferMemory);
����̂ǂ����t���X�N���b�`��
>>791
���[�Ȃ�قǂˁ[
DX���C�u������XNA������̂�MS�Ɏs�ꂩ��̐M������������Ȃˁ[
���x�����]���ɂƂ����Ղ�����Ȃ�
�l�C�e�B�u�}�C�N���\�t�g1���ɐM������������}�l�[�W�h�}�C�N���\�t�g2������^�����ˁ[
����[�A���`MS�̈ӌ��͎Q�l�ɂȂ�ȁ[
���[�Ȃ�قǂˁ[
DX���C�u������XNA������̂�MS�Ɏs�ꂩ��̐M������������Ȃˁ[
���x�����]���ɂƂ����Ղ�����Ȃ�
�l�C�e�B�u�}�C�N���\�t�g1���ɐM������������}�l�[�W�h�}�C�N���\�t�g2������^�����ˁ[
����[�A���`MS�̈ӌ��͎Q�l�ɂȂ�ȁ[
(�L �E�ցE�M)nvidia troll�A�����I��
�����AMD
�������܂��܂��^���Â�
�������܂��܂��^���Â�
AMD������������������������������������������
nvidia troll �����������Ƃ�����
>>794>>796
>>798�Ɍ���ꂽ���A������������
�A�C�f�A�͗ǂ������荞��ł݂�
�ėp�����炠�Ƃ͎s�ꂪ�����߂�
���Ďs�ꂪAMD�Ɉڍs���邱�Ƃ͖���
�܂��AMD64�̎��Ɠ���
PS4�┠1�o�Ă���1�N�ȏ�o���Ă邪�APC�Q�[���̏ς�������H
dGPU�̏ς�������HCPU(APU)�̏ς�������H
����ς���ĂȂ�����
���ς�炸Intel�̃V�X�e����dGPU��NVIDIA�̂܂܂�
1�N�ȏ���o���ĉe���������̂�
����Ɂy�@�ā@�p�@�z�@A�@P�@I�@�Ɂ@�A�@�C�@�f�@�A�@��@��@���@�܁@��@��
���炢���낤��
AMD�Ώd�������Ă邩�炻��Ȃ��Ƃ������ł��Ȃ����������Ȃ�
>>798�Ɍ���ꂽ���A������������
�A�C�f�A�͗ǂ������荞��ł݂�
�ėp�����炠�Ƃ͎s�ꂪ�����߂�
���Ďs�ꂪAMD�Ɉڍs���邱�Ƃ͖���
�܂��AMD64�̎��Ɠ���
PS4�┠1�o�Ă���1�N�ȏ�o���Ă邪�APC�Q�[���̏ς�������H
dGPU�̏ς�������HCPU(APU)�̏ς�������H
����ς���ĂȂ�����
���ς�炸Intel�̃V�X�e����dGPU��NVIDIA�̂܂܂�
1�N�ȏ���o���ĉe���������̂�
����Ɂy�@�ā@�p�@�z�@A�@P�@I�@�Ɂ@�A�@�C�@�f�@�A�@��@��@���@�܁@��@��
���炢���낤��
AMD�Ώd�������Ă邩�炻��Ȃ��Ƃ������ł��Ȃ����������Ȃ�
�r�����\���̂�
AMD�����܂������Ă�Ƃ�
�����ɂ�amd�́A���܂������ĂȂ��悤�Ɏv���邪
�ނ�ɂ́A�������A�����������ʂ�����AMD�͋��قȂ̂��낤
VR������������
�Q���͒x���������͂Ȃ�
AMD�����܂������Ă�Ƃ�
�����ɂ�amd�́A���܂������ĂȂ��悤�Ɏv���邪
�ނ�ɂ́A�������A�����������ʂ�����AMD�͋��قȂ̂��낤
VR������������
�Q���͒x���������͂Ȃ�
���̌��ł�AMD���P��������NV�����ʂ킯����Ȃ���
GPU�S�̂��P������
���ʂ̂�x86SIMD�ɂ����݂��Ă�Intel
�ƌ��������Ƃ�������
IA64�ɂ����݂���x86�ɂ����݂��Ď��ɂ͂���
ttp://www.4gamer.net/games/235/G023503/20141230001/TN/008.jpg
��Intel���ő��Ȃ��ƂŎ��ʂ킯�Ȃ�����
GPU�S�̂��P������
���ʂ̂�x86SIMD�ɂ����݂��Ă�Intel
�ƌ��������Ƃ�������
IA64�ɂ����݂���x86�ɂ����݂��Ď��ɂ͂���
ttp://www.4gamer.net/games/235/G023503/20141230001/TN/008.jpg
��Intel���ő��Ȃ��ƂŎ��ʂ킯�Ȃ�����
>>807
�����s�[�N�͏I�������B
�����s�[�N�͏I�������B
�N���[�Y�h����I�[�v����
�ƊE���ǂ������փV�t�g������Ƃ����b��
�ƊE���ǂ������փV�t�g������Ƃ����b��
>>799
�o�J����B
API�̎d�l���A�C�f�A
�����̃R�[�h���������B
UNIX�Ƃ��݊�OS����������Ǝv���Ă�B
����ɋ@��ˑ��������߂Ɉ����̃f�[�^��v���O�����R�[�h�̒�`���ς���Ă���B
�v���O������鑤���炷��Ƃ��������{�̂�����Mantle��DX12�͍l�����͎��Ă邪�ʕ�����B
�}�C�N���v���Z�b�T�Ƃ��݂��64bit��32���W�X�^3�I�y�����h��SIMD�T�|�[�g�Ƃ����`�ɏW�Ăčŋߍ��ꂽARM-V8��AVX512�Ȃ������Ȃ�����������ǂǂ�ł������Ƃ�����Ȃ�����B
�o�J����B
API�̎d�l���A�C�f�A
�����̃R�[�h���������B
UNIX�Ƃ��݊�OS����������Ǝv���Ă�B
����ɋ@��ˑ��������߂Ɉ����̃f�[�^��v���O�����R�[�h�̒�`���ς���Ă���B
�v���O������鑤���炷��Ƃ��������{�̂�����Mantle��DX12�͍l�����͎��Ă邪�ʕ�����B
�}�C�N���v���Z�b�T�Ƃ��݂��64bit��32���W�X�^3�I�y�����h��SIMD�T�|�[�g�Ƃ����`�ɏW�Ăčŋߍ��ꂽARM-V8��AVX512�Ȃ������Ȃ�����������ǂǂ�ł������Ƃ�����Ȃ�����B
����̓t���X�N���b�`�̐����ɂȂ��ĂȂ�����
Vulkan largely utilizes Mantle API.
The Khronos Group is a significant part of the functions taken over unchanged, however, they changed the name.
The difference is searched there, in the case of these functions Mantle "gr" -rel start, while the API at Vulkan "VK" with,
but the rest of the function names are not changed in the interests of simplicity.
In addition to the functions available Mantle was more than 90% of male subjects must be exactly the same code Vulkan API,
which makes it easy for developers to work because of an existing API Vulkan Mantle code you'll need to port it will be very simple.
The Khronos Group is a significant part of the functions taken over unchanged, however, they changed the name.
The difference is searched there, in the case of these functions Mantle "gr" -rel start, while the API at Vulkan "VK" with,
but the rest of the function names are not changed in the interests of simplicity.
In addition to the functions available Mantle was more than 90% of male subjects must be exactly the same code Vulkan API,
which makes it easy for developers to work because of an existing API Vulkan Mantle code you'll need to port it will be very simple.
815 �FSocket774�F2015/03/05(��) 13:38:04.84 ID:9T++OZ0P
����܂ł�dx��amd��ms�Ō��߂Ă���
�ŁA���̏�ԂȂ�
�ŁA���̏�ԂȂ�
>>814
�������Ƃ��̂�10�����Ⴄ���Ă��Ƃ͑傫�����B
�������Ƃ��̂�10�����Ⴄ���Ă��Ƃ͑傫�����B
�͂��H�Z�~�X�N���b�`�ƃt���X�N���b�`�̋�ʂ��ł��Ȃ��̂�
818 �FSocket774�F2015/03/05(��) 13:56:17.62 ID:9T++OZ0P
arm�����߂�64bit���߂Ȃ̂�
arm��a57�����������̂Ǝ��Ă��
arm��a57�����������̂Ǝ��Ă��
����܂�Tegra X1�̂��ƈ��������Ȃ�
820 �FSocket774�F2015/03/05(��) 14:06:28.83 ID:9T++OZ0P
samsung 20nm��A57��1.9GHz��4core�ғ���7W����
�b�ɂȂ��
�b�ɂȂ��
7W�Ƃ����M����
822 �FSocket774�F2015/03/05(��) 14:24:57.75 ID:9T++OZ0P
(CPU������)7W�ق�Ƙb�ɂȂ��
http://images.anandtech.com/doci/8718/A57-power-curve.png
http://images.anandtech.com/doci/8718/A57-power-curve.png
{kind=link}
AMD�M�҂ɂƂ��Ă����̂��Ƃ��Ȕ]���ϊ��œG��@����ɗL���ɂȂ�悤�Ȕ��z�����Ȃ�
���ߋ����O�݂�ƒp���������������݂���Ј��ł��Ȃ��̂ɕK������
���ߋ����O�݂�ƒp���������������݂���Ј��ł��Ȃ��̂ɕK������
����������ƂɗV�ꑱ����
�M�҂Ɋw�K�\�͂��Ȃ�����i���Ɨ��ꂪ�ς��Ȃ�
�M�҂Ɋw�K�\�͂��Ȃ�����i���Ɨ��ꂪ�ς��Ȃ�
�����ɈႤ�Ƃ����̂͂܂�h��Ă���Ƃ�������
�U��Ă���Ƃ�������
�X�N���b�`���Ђ������@����
�X�N���b�`����X�N���b�`��ƂȂ��
�Ђ��������߂ɓt���̂悤�Ȃ��̂�����Ƃ����Ӗ��ɂȂ�
���ꂪ�t���X�N���b�`
�d�g���U���Ƃ����̂�����܂�t���ł���
�R�s�y�œt�����Ȃ���d�g������ꂷ�Ȃ킿�t���X�N���b�`
�U��Ă���Ƃ�������
�X�N���b�`���Ђ������@����
�X�N���b�`����X�N���b�`��ƂȂ��
�Ђ��������߂ɓt���̂悤�Ȃ��̂�����Ƃ����Ӗ��ɂȂ�
���ꂪ�t���X�N���b�`
�d�g���U���Ƃ����̂�����܂�t���ł���
�R�s�y�œt�����Ȃ���d�g������ꂷ�Ȃ킿�t���X�N���b�`
�D���Ȃ��������錾
���܂��s���Ȃ��Ƒ��Ђ̖W�Q�̂���()
�����̃p�^�[��
���܂��s���Ȃ��Ƒ��Ђ̖W�Q�̂���()
�����̃p�^�[��
>>779
Fermi�����܂�ɔ��M�Ȃ̂ŁA���b�p���ǂ�AMD�ɈڏZ
���Ƃ��낪������AMD���ƃh���C�o�̕i�����������Ēn���A
�@AMD���������Ƃ�������Ă��Ƃ����M�ł������nvidia
�Ȑl���������Ǝv����
AMD�̓����̐��i�����܂�AMD�Ȃ݂̃h���C�o�i������A
������AMD�����s�������낤��
Fermi�����܂�ɔ��M�Ȃ̂ŁA���b�p���ǂ�AMD�ɈڏZ
���Ƃ��낪������AMD���ƃh���C�o�̕i�����������Ēn���A
�@AMD���������Ƃ�������Ă��Ƃ����M�ł������nvidia
�Ȑl���������Ǝv����
AMD�̓����̐��i�����܂�AMD�Ȃ݂̃h���C�o�i������A
������AMD�����s�������낤��
GPU�̃f�t�@�N�g�X�^���_�[�h�̍���NV����AMD�Ɉڂ������Ă��Ƃ�ˁB
830 �FSocket774�F2015/03/05(��) 15:27:47.27 ID:9T++OZ0P
http://jonpeddie.com/images/uploads/news/aibchart.JPG
http://jonpeddie.com/images/uploads/news/Capture4(1).JPG
����ŁH��
{kind=link}
http://jonpeddie.com/images/uploads/news/Capture4(1).JPG
����ŁH��
���{�Q�t�H84%�̎���
Mantle�̎d�l���̂�RADEON�ɍœK������Ă�Ǝv��Ȃ��̂��ˁH
�����������ɂł���̂��m��ǁB
>>829
������Q�[���@������AMD�Ȏ��_�ł����m�肵���H��
�����������ɂł���̂��m��ǁB
>>829
������Q�[���@������AMD�Ȏ��_�ł����m�肵���H��
Llano�o��̋łɂ�
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
�� 2014�N �����̔��ド���L���O
http://eetimes.jp/ee/articles/1412/25/news147.html
��AMD�A2014�N�x��4���h���̐Ԏ�
http://pc.watch.impress.co.jp/docs/news/20150121_684660.html
AMD�̏��ʂ������}�~���ЂƂ蕉���_(^o^)�^
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
�� 2014�N �����̔��ド���L���O
http://eetimes.jp/ee/articles/1412/25/news147.html
��AMD�A2014�N�x��4���h���̐Ԏ�
http://pc.watch.impress.co.jp/docs/news/20150121_684660.html
AMD�̏��ʂ������}�~���ЂƂ蕉���_(^o^)�^
834 �FSocket774�F2015/03/05(��) 16:08:46.84 ID:8N8LFftp
>>830
���ꂾ��Nvidia troll���r�炵����A���f�B�A���삵�ă}���Z�[�����̂�24%���D���Ă���đ����ł����ǁB
���ꂾ��Nvidia troll���r�炵����A���f�B�A���삵�ă}���Z�[�����̂�24%���D���Ă���đ����ł����ǁB
836 �FSocket774�F2015/03/05(��) 16:24:16.35 ID:9T++OZ0P
amd64��AMD�ɍœK������Ă�͂������ǂ˂�
838 �FSocket774�F2015/03/05(��) 16:28:44.47 ID:8N8LFftp
�܂�����Ȃ��ƌ����Ă�o�J������̂��H
AMD�́A����ȌƑ��Ȏ�i�͎��˂���
AMD�́A����ȌƑ��Ȏ�i�͎��˂���
�e�X�g���͎��А����낤����K�R�I�ɂȂ邩�ƁB
�܂�Nvidia�̏ꍇ�A���S�ɍœK�������ēƎ��d�l�ɂ��Ĕ���o����ł����ǁB
�܂�Nvidia�̏ꍇ�A���S�ɍœK�������ēƎ��d�l�ɂ��Ĕ���o����ł����ǁB
840 �FSocket774�F2015/03/05(��) 16:38:56.74 ID:9T++OZ0P
>>835
CPU�͈ꌅ�������
CPU�͈ꌅ�������
>>835
���ꂾ���A���t�@���{�[�C���r�炵����ACS�@���e���ď����錾�����̂�76%���D������đ����ł���ˁB
���ꂾ���A���t�@���{�[�C���r�炵����ACS�@���e���ď����錾�����̂�76%���D������đ����ł���ˁB
>>841
AMD�̏ꍇ�Ў��̂������̃J�[�h�j��CM���A�C�x���g���C���^�r���[�Œ������܂�������ł��̌��ʂ�����
�M�ғ��m�̐��荇������������Ă�̂�ˁAIntel����ɂ͂������������Ȃ��̂������������ς�
�����ɂ͉��������ˁ[�����ɓ��{�ɂ̓M���A�M���A�ς��ǂ����݂���
AMD�̏ꍇ�Ў��̂������̃J�[�h�j��CM���A�C�x���g���C���^�r���[�Œ������܂�������ł��̌��ʂ�����
�M�ғ��m�̐��荇������������Ă�̂�ˁAIntel����ɂ͂������������Ȃ��̂������������ς�
�����ɂ͉��������ˁ[�����ɓ��{�ɂ̓M���A�M���A�ς��ǂ����݂���
>>741
> ���u��HSA�}�V�����̗p���ꂽ�ꍇ����
> �\�t�g�x���_�͂�����ŗ��p�\�ȃn�[�h�E�F�A�����Ƃ��ė��p���邾��
> �N�����Ή�����点��Ƃ����؍����̂��̂���Ȃ�
hUMA�Ή����Ă�PS4�̂��Ƃ���
> ���u��HSA�}�V�����̗p���ꂽ�ꍇ����
> �\�t�g�x���_�͂�����ŗ��p�\�ȃn�[�h�E�F�A�����Ƃ��ė��p���邾��
> �N�����Ή�����点��Ƃ����؍����̂��̂���Ȃ�
hUMA�Ή����Ă�PS4�̂��Ƃ���
�����A�؍��A���{�̊W
�����͗��j�����邵�K�͂����{��10�{�ʂł����A���{����ɖ\�͓I�ō��ۖ@�ᔽ�܂����̈����ȍs�ׂ��悭����
�����l�̈ꕔ�͍��������ŁA�f���Ƃ��ł悭�����X�e�}�◒������
�؍��͗��j�����{��菬�����A�X�ɍ��\���x�������C�ł��
�؍��l�̈ꕔ�͍��������ŁA�f���Ƃ��ł悭�����X�e�}�◒������
���{�͐̒�������F�X�w��ő��h�͂��Ă���
�ŋ߂͓Ǝ��ɋZ�p�J�����āA�����Ƃ͕ʂ̓��ɐi��ł���
���̔����X�e�}�ɖ������炳��Ė��f���Ă�
�����͗��j�����邵�K�͂����{��10�{�ʂł����A���{����ɖ\�͓I�ō��ۖ@�ᔽ�܂����̈����ȍs�ׂ��悭����
�����l�̈ꕔ�͍��������ŁA�f���Ƃ��ł悭�����X�e�}�◒������
�؍��͗��j�����{��菬�����A�X�ɍ��\���x�������C�ł��
�؍��l�̈ꕔ�͍��������ŁA�f���Ƃ��ł悭�����X�e�}�◒������
���{�͐̒�������F�X�w��ő��h�͂��Ă���
�ŋ߂͓Ǝ��ɋZ�p�J�����āA�����Ƃ͕ʂ̓��ɐi��ł���
���̔����X�e�}�ɖ������炳��Ė��f���Ă�
nvidia troll �����������Ƃ�����
�C���e���ANvidia�AAMD�̊W
�C���e���͗��j�����邵�K�͂�AMD��10�{�ʂł����AAMD����ɖ\�͓I�ō��ۖ@�ᔽ�܂����̈����ȍs�ׂ��悭����
�C���e���M�҂̈ꕔ�͍�����AMD�ŁA�f���Ƃ��ł悭��AMD�X�e�}�◒������
Nvidia�͗��j����AMD��菬�����A�X�ɍ��\���x�������C�ł��
Nvidia�M�҂̈ꕔ�͍�����AMD�ŁA�f���Ƃ��ł悭�����X�e�}�◒������
AMD�͐̃C���e������F�X�w��ő��h�͂��Ă���
�ŋ߂͓Ǝ��ɋZ�p�J�����āA�C���e���Ƃ͕ʂ̓��ɐi��ł���
AMD�g���̓C���e���k�r�M�҂̔�AMD�X�e�}�ɖ������炳��Ė��f���Ă�
�C���e���͗��j�����邵�K�͂�AMD��10�{�ʂł����AAMD����ɖ\�͓I�ō��ۖ@�ᔽ�܂����̈����ȍs�ׂ��悭����
�C���e���M�҂̈ꕔ�͍�����AMD�ŁA�f���Ƃ��ł悭��AMD�X�e�}�◒������
Nvidia�͗��j����AMD��菬�����A�X�ɍ��\���x�������C�ł��
Nvidia�M�҂̈ꕔ�͍�����AMD�ŁA�f���Ƃ��ł悭�����X�e�}�◒������
AMD�͐̃C���e������F�X�w��ő��h�͂��Ă���
�ŋ߂͓Ǝ��ɋZ�p�J�����āA�C���e���Ƃ͕ʂ̓��ɐi��ł���
AMD�g���̓C���e���k�r�M�҂̔�AMD�X�e�}�ɖ������炳��Ė��f���Ă�
Intel=����
Nvidia=�؍�
AMD=���{
�ɕϊ�����ƐF�X���v���Ėʔ�����
Intel�ƒ����̓f�J�C���ǔƍߏ㓙�A��{�\�͓I
Nvidia�Ɗ؍��͊�{���\�W�c�A���Ƒԓx���ł���
AMD�Ɠ��{�́A�܂��߂ɊJ�����Ă������̍�邯�ǁA�}�[�P�e�B���O��c�Ɖ���ŁA������2�ɏo���������http://wktk.2ch.net/test/read.cgi/ghard/1425116032/36
Nvidia=�؍�
AMD=���{
�ɕϊ�����ƐF�X���v���Ėʔ�����
Intel�ƒ����̓f�J�C���ǔƍߏ㓙�A��{�\�͓I
Nvidia�Ɗ؍��͊�{���\�W�c�A���Ƒԓx���ł���
AMD�Ɠ��{�́A�܂��߂ɊJ�����Ă������̍�邯�ǁA�}�[�P�e�B���O��c�Ɖ���ŁA������2�ɏo���������http://wktk.2ch.net/test/read.cgi/ghard/1425116032/36
848 �FSocket774�F2015/03/05(��) 19:13:33.50 ID:9T++OZ0P
pupupu
http://www.4gamer.net/games/234/G023455/20131006001/SS/002.jpg
http://www.4gamer.net/games/234/G023455/20131006001/TN/004.jpg
http://www.4gamer.net/games/234/G023455/20131006001/SS/003.jpg
http://www.4gamer.net/games/234/G023455/20131006001/TN/005.jpg
http://www.4gamer.net/games/234/G023455/20131006001/SS/002.jpg
{kind=link}
http://www.4gamer.net/games/234/G023455/20131006001/TN/004.jpg
{kind=link}
http://www.4gamer.net/games/234/G023455/20131006001/SS/003.jpg
{kind=link}
http://www.4gamer.net/games/234/G023455/20131006001/TN/005.jpg
{kind=link}
849 �FSocket774�F2015/03/05(��) 19:14:20.93 ID:9T++OZ0P
850 �FSocket774�F2015/03/05(��) 19:36:19.16 ID:ADE84TcA
{kind=link}
>>832
�Ƃ��������f��mantle�ɍœK���ł��邩�炢����ˁH �������nV�����������ǁA��s���Ă����f���L���ł���ȁB
�Ƃ��������f��mantle�ɍœK���ł��邩�炢����ˁH �������nV�����������ǁA��s���Ă����f���L���ł���ȁB
>>801�ȍ~�q�[�g�A�b�v���Ă邶��˂���������������������
�ق�ˁA�����Ɣ�AMD�͎��Ă���
���ƃC���e���k�r�M�҂͒����Ƀt�@�r���邵�����r�炷
�܂��A���܂ɓ��{��AMD��TOP�͕ςȍs�����邯�ǁA��ɋ����Ă钆�ƃC���e���k�r�ɔ�ׂ�Ή�������
���ƃC���e���k�r�M�҂͒����Ƀt�@�r���邵�����r�炷
�܂��A���܂ɓ��{��AMD��TOP�͕ςȍs�����邯�ǁA��ɋ����Ă钆�ƃC���e���k�r�ɔ�ׂ�Ή�������
http://www.4gamer.net/games/234/G023455/20131006001/TN/004.jpg
����͍��ɗႦ��Ƒ����̍����݂��Ă�悤�Ȃ�����
���{�l�ŒႾ��
����͍��ɗႦ��Ƒ����̍����݂��Ă�悤�Ȃ�����
���{�l�ŒႾ��
855 �F,,�E�L�́M�E,,�j��-�������F2015/03/05(��) 21:04:51.16 ID:/Cv5vy8y
�������Ȃ��ŕ����闝�R��K���ɍl����
�����鎖�������ȊO�ɓ]�ł���������
�{�C���o���Ή�������
�]������Ȃ��͎̂��肪����
�����A���h�ȓ��{�l����
�����鎖�������ȊO�ɓ]�ł���������
�{�C���o���Ή�������
�]������Ȃ��͎̂��肪����
�����A���h�ȓ��{�l����
���������A�������Ƃł����А��i�Ɏ��M������̂ł����
�ǂ����̗p���Ȃ����Ƃ�Q�������A���Ђō���Ĕ�������̂�
����via�ł����A�������Ĕ��荞��ł����̂�
��������Ȃ��̂́A1mm�����M���Ȃ����ꂾ
���肪�������͐�����
�ꐶ���������ď����������
�ǂ����̗p���Ȃ����Ƃ�Q�������A���Ђō���Ĕ�������̂�
����via�ł����A�������Ĕ��荞��ł����̂�
��������Ȃ��̂́A1mm�����M���Ȃ����ꂾ
���肪�������͐�����
�ꐶ���������ď����������
���ǁA�L���[�A�v���������ŗp�ӏo���Ȃ����_�ŁA���V�����Z�p�Ŕ��荞��ł��A
�����ɂ͌q����Ȃ����Ď�����H
���肪���R�Ǝg���Ă����Intel�̗l�ȁA�C���X�g�[���x�[�X�̐��͖����B
���W��������悤���A����ꂽ���ł����g���Ȃ�����
���ʂ̃\�t�g���[�J�[�͎g����A����ɂȂ��B
�����炱���A�����Ń\�t�g����āA���ʂ������Ȃ���Ȃ��Ȃ̂ɁA
��������Ȃ��ŁA���l�C���B
���l�ɔC����Ȃ�C����ŁA����Ȃ�̂���������͂��Ȃ̂ɁA
��������Ȃ��B�Ԃ����Ⴏ�A�ۓ����B
NVIDIA�͂����ƕ������ĂāA�����ł�CUDA���g���ĖႦ��悤�ɁA
�Z�~�i�[�Ƃ��J���āA�Z�p�ґ��₵�Ă邶���H
AMD�������������Ƃ���Ă�́A�������Ɩ������ǁB
�{���Ɏg���Ă��炤�C����̂��ƁB
����ȏ�Ԃ���A��ʂ��猩����A�アCPU�ɂ�����Ɨǂ�GPU���t����"����"�̕��ł����Ȃ��B
���i����ɂȂ�_�������A����Ŕ����킯�ˁ[��B�B�B
�����ɂ͌q����Ȃ����Ď�����H
���肪���R�Ǝg���Ă����Intel�̗l�ȁA�C���X�g�[���x�[�X�̐��͖����B
���W��������悤���A����ꂽ���ł����g���Ȃ�����
���ʂ̃\�t�g���[�J�[�͎g����A����ɂȂ��B
�����炱���A�����Ń\�t�g����āA���ʂ������Ȃ���Ȃ��Ȃ̂ɁA
��������Ȃ��ŁA���l�C���B
���l�ɔC����Ȃ�C����ŁA����Ȃ�̂���������͂��Ȃ̂ɁA
��������Ȃ��B�Ԃ����Ⴏ�A�ۓ����B
NVIDIA�͂����ƕ������ĂāA�����ł�CUDA���g���ĖႦ��悤�ɁA
�Z�~�i�[�Ƃ��J���āA�Z�p�ґ��₵�Ă邶���H
AMD�������������Ƃ���Ă�́A�������Ɩ������ǁB
�{���Ɏg���Ă��炤�C����̂��ƁB
����ȏ�Ԃ���A��ʂ��猩����A�アCPU�ɂ�����Ɨǂ�GPU���t����"����"�̕��ł����Ȃ��B
���i����ɂȂ�_�������A����Ŕ����킯�ˁ[��B�B�B
>>832
�ėp����AMD���g�����R�������Ȃ�̂��������̂��ȁH
���̃Q�[���@���o�Ă��܂��\�}�ɕω��������A
�m�肵�Ă�̂�AMD�k����������
�ėp����AMD���g�����R�������Ȃ�̂��������̂��ȁH
���̃Q�[���@���o�Ă��܂��\�}�ɕω��������A
�m�肵�Ă�̂�AMD�k����������
860 �F,,�E�L�́M�E,,�j��-�������F2015/03/05(��) 21:32:21.52 ID:/Cv5vy8y
>>858
> �Z�~�i�[�Ƃ��J���āA�Z�p�ґ��₵�Ă邶���H
> AMD�������������Ƃ���Ă�́A�������Ɩ������ǁB
AMD��y�̓u���K�[����APU����J���Ă邾��I
�v���O��������g�߂Ȃ��t�@���{�[�C���������ǂ�
> �Z�~�i�[�Ƃ��J���āA�Z�p�ґ��₵�Ă邶���H
> AMD�������������Ƃ���Ă�́A�������Ɩ������ǁB
AMD��y�̓u���K�[����APU����J���Ă邾��I
�v���O��������g�߂Ȃ��t�@���{�[�C���������ǂ�
861 �FSocket774�F2015/03/05(��) 21:34:03.35 ID:ADE84TcA
���������A������������C�����Ȃ�o�Ă��Ă���B
���܂Ȃ��A�z���ȊO�͋A���Ă���Ȃ���
863 �F,,�E�L�́M�E,,�j��-�������F2015/03/05(��) 21:37:52.79 ID:/Cv5vy8y
864 �FSocket774�F2015/03/05(��) 21:40:35.94 ID:ADE84TcA
�Q�t�H�~�[�̊炪�����B
���̑��t��I���V�F�A100���ڎw���Ċ撣���Ă܂����Č����Ȃ�S�͂Ŏx�����鏗�̎q�����邩���m��A
���̃Q�t�H�~�[�̊�ł̓h���������邾���B
������x�Ɨ���ȁB
���̑��t��I���V�F�A100���ڎw���Ċ撣���Ă܂����Č����Ȃ�S�͂Ŏx�����鏗�̎q�����邩���m��A
���̃Q�t�H�~�[�̊�ł̓h���������邾���B
������x�Ɨ���ȁB
�܂��Ɂe���炵�f�I������
850 ���O�FSocket774[] ���e���F2015/03/05(��) 19:36:19.16 ID:ADE84TcA
�Q�t�H�~�[
http://m.akiba-pc.watch.impress.co.jp/img/ah/docs/682/313/nv1_s.jpg
861 ���O�FSocket774[] ���e���F2015/03/05(��) 21:34:03.35 ID:ADE84TcA
���������A������������C�����Ȃ�o�Ă��Ă���B
����͂Ђǂ�
�Q�t�H�~�[
http://m.akiba-pc.watch.impress.co.jp/img/ah/docs/682/313/nv1_s.jpg
861 ���O�FSocket774[] ���e���F2015/03/05(��) 21:34:03.35 ID:ADE84TcA
���������A������������C�����Ȃ�o�Ă��Ă���B
����͂Ђǂ�
867 �F,,�E�L�́M�E,,�j��-�������F2015/03/05(��) 21:49:53.28 ID:/Cv5vy8y
�ʖڐ��[�J�[�X���͂��ꂩ�炨�����h�X���ɂȂ�܂���
869 �FSocket774�F2015/03/05(��) 21:53:07.98 ID:2mGcsGhl
>>860
����d�́����M�ʂ��Ɩ{�C�Ŏv���Ă��c�q���[����
����d�́����M�ʂ��Ɩ{�C�Ŏv���Ă��c�q���[����
����
http://livedoor.blogimg.jp/geinoumatome-manga/imgs/b/1/b123378b-s.jpg�@
http://livedoor.blogimg.jp/geinoumatome-manga/imgs/3/d/3d8f24f0-s.jpg
http://livedoor.blogimg.jp/geinoumatome-manga/imgs/f/4/f422d096-s.jpg
http://livedoor.blogimg.jp/geinoumatome-manga/imgs/6/6/660f255e-s.jpg
http://livedoor.blogimg.jp/geinoumatome-manga/imgs/2/9/29592c4c-s.jpg
http://livedoor.blogimg.jp/geinoumatome-manga/imgs/6/2/6277b334-s.jpg
http://livedoor.blogimg.jp/geinoumatome-manga/imgs/9/3/934f23a8-s.jpg
http://livedoor.blogimg.jp/nana_news/imgs/5/e/5eea3cec.jpg
http://livedoor.blogimg.jp/geinoumatome-manga/imgs/b/1/b123378b-s.jpg�@
{kind=link}
http://livedoor.blogimg.jp/geinoumatome-manga/imgs/3/d/3d8f24f0-s.jpg
{kind=link}
http://livedoor.blogimg.jp/geinoumatome-manga/imgs/f/4/f422d096-s.jpg
{kind=link}
http://livedoor.blogimg.jp/geinoumatome-manga/imgs/6/6/660f255e-s.jpg
{kind=link}
http://livedoor.blogimg.jp/geinoumatome-manga/imgs/2/9/29592c4c-s.jpg
{kind=link}
http://livedoor.blogimg.jp/geinoumatome-manga/imgs/6/2/6277b334-s.jpg
{kind=link}
http://livedoor.blogimg.jp/geinoumatome-manga/imgs/9/3/934f23a8-s.jpg
{kind=link}
http://livedoor.blogimg.jp/nana_news/imgs/5/e/5eea3cec.jpg
{kind=link}
amd���ꂩ
872 �F,,�E�L�́M�E,,�j��-�������F2015/03/05(��) 22:13:28.25 ID:/Cv5vy8y
�F�È䁁 ID:8HW1LU5Z�i�p���T�C�g���E�j ���B
>>831
���܂��m�[�g�ł���������Ȃ�
���܂��m�[�g�ł���������Ȃ�
875 �F,,�E�L�́M�E,,�j��-�������F2015/03/05(��) 22:29:09.69 ID:/Cv5vy8y
���܂�Twitter�ł���
https://twitter.com/7_eq/status/568802853910810625
https://twitter.com/7_eq/status/568802853910810625
>>858
�����A�S�����̒ʂ�
�V�����Z�p����Ă��A������p�����Ċ���������ʐ��i���o������A��`�L�����o���Ȃ��ƈӖ�������
AMD�����{������Ĉ��S���āA��`��i�J����a���ɂ��Ă���
Intel��Nvidia���̂��̂́A�V�Z�p�ƑΉ����i���������ŁA��ɐ�`�L�����o���Ă�Ƃ���
�����A�S�����̒ʂ�
�V�����Z�p����Ă��A������p�����Ċ���������ʐ��i���o������A��`�L�����o���Ȃ��ƈӖ�������
AMD�����{������Ĉ��S���āA��`��i�J����a���ɂ��Ă���
Intel��Nvidia���̂��̂́A�V�Z�p�ƑΉ����i���������ŁA��ɐ�`�L�����o���Ă�Ƃ���
Intel��x86�ȊO�唼���|�V�����Ă邯�ǂ�
>>859
Mantle�̏d�v�Z�p�̓O���t�B�b�N���Y�킳�Ƃ�����Ȃ��A���Z������Ǘ��̎��R�x�̍����ɂ�鍂�x�ȃ����_�����O�Ȃ�
DMA�Ɖ��z�������g�����}���`GPU�̓O���t�B�b�N���������t���b�g�Ɏg���āA�A���o�����X�Ȑ��\�ł��g�����Ȃ��Ă����
�܂�AXDMA�ς�ł郉�f��CF�̌����͍����Ȃ邵�AAPU��iGPU�����ʂȂ��g���Đ��\����ɖ𗧂�
�����邩�ȁA�ėp�����邱�Ƃ�APU+Radeon�̂ݗL���ȍ����\���@�\����葽���g����Ƃ������ƂȂ�
Mantle�̏d�v�Z�p�̓O���t�B�b�N���Y�킳�Ƃ�����Ȃ��A���Z������Ǘ��̎��R�x�̍����ɂ�鍂�x�ȃ����_�����O�Ȃ�
DMA�Ɖ��z�������g�����}���`GPU�̓O���t�B�b�N���������t���b�g�Ɏg���āA�A���o�����X�Ȑ��\�ł��g�����Ȃ��Ă����
�܂�AXDMA�ς�ł郉�f��CF�̌����͍����Ȃ邵�AAPU��iGPU�����ʂȂ��g���Đ��\����ɖ𗧂�
�����邩�ȁA�ėp�����邱�Ƃ�APU+Radeon�̂ݗL���ȍ����\���@�\����葽���g����Ƃ������ƂȂ�
�@�����ANV�ɂ�����GeForce256�ȗ��̎��т�����킯�ŁA�����}��
180���ς��킯����Ȃ��B
�@����ǁACS�E���e�ɑ���FreeSync�AMantle�̕W���K�i���Ɨ����
���炩��AMD�ɌX���Ă����ˁB�����āAAMD64��Intel�Ɉ��܂������Ƃ�
x86CPU�����Ɋւ���_�����ƗL���ɂȂ��Ă��Ȃ���AAPU��
�������邱�Ƃ����ڂ��Ȃ������킯�ŁA�ǂ���S�R���Ӗ�����Ȃ��B
180���ς��킯����Ȃ��B
�@����ǁACS�E���e�ɑ���FreeSync�AMantle�̕W���K�i���Ɨ����
���炩��AMD�ɌX���Ă����ˁB�����āAAMD64��Intel�Ɉ��܂������Ƃ�
x86CPU�����Ɋւ���_�����ƗL���ɂȂ��Ă��Ȃ���AAPU��
�������邱�Ƃ����ڂ��Ȃ������킯�ŁA�ǂ���S�R���Ӗ�����Ȃ��B
>>864
�ǂ��ł��������ǂ��̐l���XAMD�̐l�Ȃ�
���N�����N�ɓ]�E���Ă�������̂͂�
����������NVIDIA�ɓ]�E����(������)�̂������Ȃ��Ƃ���
�������e�p�Ȃ��Ă�́H�������������ł���Ă���
���̐l�̗e�p�@����
�ǂ��ł��������ǂ��̐l���XAMD�̐l�Ȃ�
���N�����N�ɓ]�E���Ă�������̂͂�
����������NVIDIA�ɓ]�E����(������)�̂������Ȃ��Ƃ���
�������e�p�Ȃ��Ă�́H�������������ł���Ă���
���̐l�̗e�p�@����
�uMantle 1.0�v�AKhronos Group�̋ƊE�W���I�[�v��API�uVulkan�v�Ɋ��S������
http://ggsoku.com/2015/03/mantle-1-0-khronos-group-vulkan/
����Vulkan�ɂ����ẮA�}���`�R�ACPU�̗��p�����̌����A�}���`GPU�ɂ��SFR�iSplit Frame Rendering�j�Ȃǂ��n�߂Ƃ���A
Mantle 1.0 API�Ŏ����E�������ꂽ�������̋@�\��\���P�����̂܂܈����p����邱�ƂɂȂ�͗l�B
����ɂ́A�ƊE�W���̃I�[�v��API�ƂȂ邱�ƂŁAAMD�݂̂Ȃ炸NVIDIA�AIntel�AARM�AQualcomm����GPU���i��A
Linux�Ȃǂ́uWindows�ȊO��OS�v�Ȃǂɂ����Ă��AMantle API�̉��b�ɗ^�邱�Ƃ��\�ɂȂ�܂����B
http://ggsoku.com/2015/03/mantle-1-0-khronos-group-vulkan/
����Vulkan�ɂ����ẮA�}���`�R�ACPU�̗��p�����̌����A�}���`GPU�ɂ��SFR�iSplit Frame Rendering�j�Ȃǂ��n�߂Ƃ���A
Mantle 1.0 API�Ŏ����E�������ꂽ�������̋@�\��\���P�����̂܂܈����p����邱�ƂɂȂ�͗l�B
����ɂ́A�ƊE�W���̃I�[�v��API�ƂȂ邱�ƂŁAAMD�݂̂Ȃ炸NVIDIA�AIntel�AARM�AQualcomm����GPU���i��A
Linux�Ȃǂ́uWindows�ȊO��OS�v�Ȃǂɂ����Ă��AMantle API�̉��b�ɗ^�邱�Ƃ��\�ɂȂ�܂����B
�}���`GPU�̏����i�K���A�����\GPU�̃}���`�ƃt���b�g�Ɏg���Ȃ��O���t�B�b�N������
���̒i�K���A�t���b�g�Ƀ��������g����
���̎����A�A���o�����X�Ȑ��\�ł��}���`�o����A���̌��ʁAAPU������GPU���}���`�Ŏg����悤�ɂȂ�
�X�ɂ��̎����ACPU�ƃA�h���X���L���āA�������Z��AI�ȂǂS���ď����ł���
���̏��ȒP�ɂł���̂��A�N���m�X��OpenCL2.1+Vulkan��SPIR V
http://sourceforge.jp/magazine/15/03/05/065900
Vulkan��OpenCL 2.1�̗����̃\�[�X����ƂȂ�B
�V�F�[�_�[�ƃJ�[�l���̋@�\���l�C�e�B�u�ŃT�|�[�g���A�R���p�C���`�F�[���������B
����ɂ�����ŃO���t�B�b�N�X�ƌv�Z�������\�ɂȂ�Ƃ��Ă���B
�ŏI�i�K�܂ōs���ƁACPU�Ŗʓ|�ȕ����≉�Z�����AiGPU�ŕ��ʂ̃O���t�B�b�N���Z�AdGPU�͂Ђ�����`��ƃN���e�B�J���ȉ��Z�Ƃɕ����ď����ł���
�N���m�X��SPIR�ɑR���āAMS�������悤�Ȃ̏o����Ȃ��H
���邢�͂��ꂪDX12.1��DX13�ɂȂ邩��
���̒i�K���A�t���b�g�Ƀ��������g����
���̎����A�A���o�����X�Ȑ��\�ł��}���`�o����A���̌��ʁAAPU������GPU���}���`�Ŏg����悤�ɂȂ�
�X�ɂ��̎����ACPU�ƃA�h���X���L���āA�������Z��AI�ȂǂS���ď����ł���
���̏��ȒP�ɂł���̂��A�N���m�X��OpenCL2.1+Vulkan��SPIR V
http://sourceforge.jp/magazine/15/03/05/065900
Vulkan��OpenCL 2.1�̗����̃\�[�X����ƂȂ�B
�V�F�[�_�[�ƃJ�[�l���̋@�\���l�C�e�B�u�ŃT�|�[�g���A�R���p�C���`�F�[���������B
����ɂ�����ŃO���t�B�b�N�X�ƌv�Z�������\�ɂȂ�Ƃ��Ă���B
�ŏI�i�K�܂ōs���ƁACPU�Ŗʓ|�ȕ����≉�Z�����AiGPU�ŕ��ʂ̃O���t�B�b�N���Z�AdGPU�͂Ђ�����`��ƃN���e�B�J���ȉ��Z�Ƃɕ����ď����ł���
�N���m�X��SPIR�ɑR���āAMS�������悤�Ȃ̏o����Ȃ��H
���邢�͂��ꂪDX12.1��DX13�ɂȂ邩��
�@�^���邱�Ƃ͎�邱�Ƃł���B�����̌̎��͑f���炵���B
�@�W���K�i���ɂ��AMD�̒��ړI�ȗ��v�͏��Ȃ��̂�������Ȃ��B
����ǁA�ƊE�̔��W�ɍv�����邱�Ƃɂ���č��܂����e���͂��X��
�傫�ȗ��v���ŏI�I�ɂ͂����炷�킯����B
�@�W���K�i���ɂ��AMD�̒��ړI�ȗ��v�͏��Ȃ��̂�������Ȃ��B
����ǁA�ƊE�̔��W�ɍv�����邱�Ƃɂ���č��܂����e���͂��X��
�傫�ȗ��v���ŏI�I�ɂ͂����炷�킯����B
amd64�̉��b�̓V�F�A�ꌅ�ł���
����Ƃ�x86���Ă�arm�ɓ����悤�Ƃ�������
a57���Ƃ�ł��Ȃ��n���ł��������ɂ��Ă���Ȃ����ł���
����Ƃ�x86���Ă�arm�ɓ����悤�Ƃ�������
a57���Ƃ�ł��Ȃ��n���ł��������ɂ��Ă���Ȃ����ł���
D3D12: the feature levels 12_0 and 12_1
http://www.hardware.fr/news/14118/gdc-d3d12-feature-levels-12-0-12-1.html
http://www.hardware.fr/news/14118/gdc-d3d12-feature-levels-12-0-12-1.html
gtx980��12.1��
>>869
����d�́����M�ʂō����Ă邶���
����d�́����M�ʂō����Ă邶���
�v���O��������g�߂Ȃ��������Ă��܂����f�l�ɖт����������x����ˁ[��������
�S�V�S�V�ɂ����[�o�J�ɂ���Ă���Ȃ�������
�S�V�S�V�ɂ����[�o�J�ɂ���Ă���Ȃ�������
889 �FSocket774�F2015/03/06(��) 06:50:19.51 ID:5y/w7Owg
>>887
�����Ă�ƌ��������́H
�����Ă�ƌ��������́H
890 �F,,�E�L�́M�E,,�j��-�������F2015/03/06(��) 06:53:41.50 ID:d4RUBhyB
>>890
���F���Y�ƂŔѐH���Ă邯��GPGPU���܂��܂�H��͎ԍڃJ�[�i�r�����GPGPU�ł��܂��܂ɂȂ낤�Ƃ��Ă��B
�v�͓����v���O���}�ł�����őS�����������Ⴄ�̂ɁA�ꊇ��ɂ���GPGPU�ɖ����͂Ȃ����������Ⴄ�l����w
���F���Y�ƂŔѐH���Ă邯��GPGPU���܂��܂�H��͎ԍڃJ�[�i�r�����GPGPU�ł��܂��܂ɂȂ낤�Ƃ��Ă��B
�v�͓����v���O���}�ł�����őS�����������Ⴄ�̂ɁA�ꊇ��ɂ���GPGPU�ɖ����͂Ȃ����������Ⴄ�l����w
892 �F,,�E�L�́M�E,,�j��-�������F2015/03/06(��) 07:05:25.16 ID:d4RUBhyB
�ǂ�����AMD����łȂ�
>>888
�v���O�����̓A���S���Y���ƌ���iAPI�j�ɕ�����Ă�
���Z�n�̖��߂�������肭�g�ݍ��킹��A���S���Y���͌���Βm�b
����ɑ���API�͎g�����Ƃ������̂����肻��͒m���Ȃ��ƂȂ�Ȃ�
�m�b�ƒm���͎��Ă�悤�őS�R�Ⴄ����
�m�������̃I�^�N�����đf�l�Ƃ͑S�R�Ⴄ
�܂������g���b�v�����A�v���݂̂̏��ʂ��Ă��ƂɂȂ�ƒm��Ă邯�ǁE�E�E
�ł�����悠�̔M��
1��100���X���炢�͓�����O�Ȃ��̎��O
���炩�ɑf�l�Ƃ͈�����悷��
�v���O�����̓A���S���Y���ƌ���iAPI�j�ɕ�����Ă�
���Z�n�̖��߂�������肭�g�ݍ��킹��A���S���Y���͌���Βm�b
����ɑ���API�͎g�����Ƃ������̂����肻��͒m���Ȃ��ƂȂ�Ȃ�
�m�b�ƒm���͎��Ă�悤�őS�R�Ⴄ����
�m�������̃I�^�N�����đf�l�Ƃ͑S�R�Ⴄ
�܂������g���b�v�����A�v���݂̂̏��ʂ��Ă��ƂɂȂ�ƒm��Ă邯�ǁE�E�E
�ł�����悠�̔M��
1��100���X���炢�͓�����O�Ȃ��̎��O
���炩�ɑf�l�Ƃ͈�����悷��
>>889
�M�ȊO�̉��ɂȂ�Ǝv���Ă�́H
�M�ȊO�̉��ɂȂ�Ǝv���Ă�́H
895 �FSocket774�F2015/03/06(��) 07:26:46.57 ID:5y/w7Owg
�����������������
�c�q���x���̑f�lPG���S���S�����鐢�E�Ȃ�V�l����ɋ�J���邱�Ƃ��Ȃ��̂ɂȂ�
897 �F,,�E�L�́M�E,,�j��-�������F2015/03/06(��) 07:37:54.38 ID:d4RUBhyB
>>893
10�N�G���ĂȂ��iSSE2�̃R�[�h��MMX�̃R�[�h���@�B�I�ɏ��������������j���̂�
�����������ꂾ��������Ă����̂悤�Ɍ����Ă�����܂����H
�^�����̐l�ɗ��܂��nbody�̃R�[�h�Ƃ��������܂������H
rsqrt��11�r�b�g���x�����Ȃ�����ł킴�킴�j���[�g���@�ŕ⊮��������
�����x�ŏ\�����Č���ꂽ
10�N�G���ĂȂ��iSSE2�̃R�[�h��MMX�̃R�[�h���@�B�I�ɏ��������������j���̂�
�����������ꂾ��������Ă����̂悤�Ɍ����Ă�����܂����H
�^�����̐l�ɗ��܂��nbody�̃R�[�h�Ƃ��������܂������H
rsqrt��11�r�b�g���x�����Ȃ�����ł킴�킴�j���[�g���@�ŕ⊮��������
�����x�ŏ\�����Č���ꂽ
>>897
�����I
�A���S���Y����g�ނ̂͐������̑̑����]�̒b�B�o���邯��
�@�B�I�ɖ���100���X�i�S�����ɂ�1�X�����̂݁j�̃R�s�y���J��Ԃ�
����ȏh���ɂ���͉̂��z����
���ꂩ������̔ȊO�Ŋ撣���Ă�
�����I
�A���S���Y����g�ނ̂͐������̑̑����]�̒b�B�o���邯��
�@�B�I�ɖ���100���X�i�S�����ɂ�1�X�����̂݁j�̃R�s�y���J��Ԃ�
����ȏh���ɂ���͉̂��z����
���ꂩ������̔ȊO�Ŋ撣���Ă�
899 �F,,�E�L�́M�E,,�j��-�������F2015/03/06(��) 07:49:37.59 ID:d4RUBhyB
�����API�o���邾���̃R�[�_�[�Ȃ���w�Z���ŏ\���Ȃ�
���w�╨���̐����𗝉��ł��Ę_�������������������l�Ԃ������̉��ɂ͗v��Ȃ�
���w�╨���̐����𗝉��ł��Ę_�������������������l�Ԃ������̉��ɂ͗v��Ȃ�
Behind the scorching beauty of Oxide�fs Ashes of the Singularity!
https://www.youtube.com/watch?v=t9UACXikdR0
https://www.youtube.com/watch?v=t9UACXikdR0
Debug tool for the Vulkan API
https://www.youtube.com/watch?v=miZmas6sGqM
https://www.youtube.com/watch?v=miZmas6sGqM
N-body performance of various platforms (log scale). big winner is FirePro W9100.
http://www.arl.army.mil/opencampus/sites/default/files/CS20_PARK-ParallelProgrammabilityEmergingArchitectures.pdf
http://www.arl.army.mil/opencampus/sites/default/files/CS20_PARK-ParallelProgrammabilityEmergingArchitectures.pdf
905 �FSocket774�F2015/03/06(��) 09:31:13.05 ID:5y/w7Owg
Ivy���o��O��Sandy������d�͂��Ⴂ����M���Ȃ�Ȃ��Ƃ��v���Ă��A����
����d�͂ƔM����������ɂ��čl���Ă��B
���̃T�C�g���T�^�I�ȗႾ��
����d�͂ƔM����������ɂ��čl���Ă��B
���̃T�C�g���T�^�I�ȗႾ��
>>905�����M�Ɖ��x����������ɂ��Ă��ˁ[�́H
907 �FSocket774�F2015/03/06(��) 09:33:57.24 ID:5y/w7Owg
���{��ł�k
����d��(���M)�������Ă����M���ǂ����CPU�̉��x�͉�����
����d��(���M)�����Ȃ��Ă����M���������CPU�̉��x�͏オ��
����d��(���M)�����Ȃ��Ă����M���������CPU�̉��x�͏オ��
909 �FSocket774�F2015/03/06(��) 10:00:14.93 ID:5y/w7Owg
Core i7 3970X TDP150W 32nm Sandy
Core i7 4960X TDP130W 22nm Ivy
����d��
http://www.4gamer.net/games/142/G014271/20130902038/TN/037.gif
Core i7 4960X TDP130W 22nm Ivy
����d��
http://www.4gamer.net/games/142/G014271/20130902038/TN/037.gif
{kind=link}
910 �FSocket774�F2015/03/06(��) 10:03:30.44 ID:E2ah+1IQ
TDP�ƍő����d�͂͊W�Ȃ����Ă�
911 �FSocket774�F2015/03/06(��) 10:09:38.63 ID:hMsVirYX
>>905
��������AMD��Intel��TDP�̒�`���Ⴄ����m��Ȃ��z�������Ƃ����ˁc�c
��������AMD��Intel��TDP�̒�`���Ⴄ����m��Ȃ��z�������Ƃ����ˁc�c
TDP�̓��[�J�[�ɂ���Ē�`��������肷�邪�A
��{�I�ɂ͍ő����d�́�TDP�ɂ����
�������A�ő����d�͂��o�����Ԃ��Z���ꍇ�́A
�ő����d�͂�菬�����l�ɂ��邱�Ƃ�����
��{�I�ɂ͍ő����d�́�TDP�ɂ����
�������A�ő����d�͂��o�����Ԃ��Z���ꍇ�́A
�ő����d�͂�菬�����l�ɂ��邱�Ƃ�����
Intel�͂���������ł��āc�c
�yAM3+�zAMD FX���� 54��ځyZambezi Vishera�z
http://anago.2ch.net/test/read.cgi/jisaku/1414167888/l50
972 ���O�F Socket774 [sage] ���e���F 2014/11/28(��) 12:45:21.06 ID:gA7INU9/
�������炱��ł�����BIntel��HP�ŁuTDP�͕��ϓd�͂����b�g�P�ʂɕ\�����v�Ə����Ă邼�B
http://i.imgur.com/FqDLf4x.png
http://ark.intel.com/ja/products/75121/Intel-Core-i7-4765T-Processor-8M-Cache-up-to-3_00-GHz
�yAM3+�zAMD FX���� 54��ځyZambezi Vishera�z
http://anago.2ch.net/test/read.cgi/jisaku/1414167888/l50
972 ���O�F Socket774 [sage] ���e���F 2014/11/28(��) 12:45:21.06 ID:gA7INU9/
�������炱��ł�����BIntel��HP�ŁuTDP�͕��ϓd�͂����b�g�P�ʂɕ\�����v�Ə����Ă邼�B
http://i.imgur.com/FqDLf4x.png
{kind=link}
http://ark.intel.com/ja/products/75121/Intel-Core-i7-4765T-Processor-8M-Cache-up-to-3_00-GHz
TDP���ď���d�͂ƌ��т����ꍇ�A���\�A�o�E�g�ȃp�����[�^����ȁB
����TDP�������i�V���[�Y�̍ŏ�ʕi�ƍʼn��ʕi����������d�͂Ƃ͐����킯�����B
����TDP�������i�V���[�Y�̍ŏ�ʕi�ƍʼn��ʕi����������d�͂Ƃ͐����킯�����B
TDP�̓N�[���[�̐v���鑤�̎w�W�݂����Ȃ���
���[�U�[���ɂ�������x�̏���d�͂�������₷��SDP�݂����Ȑ��l�����J���Ăق����Ƃ��낾��
���[�U�[���ɂ�������x�̏���d�͂�������₷��SDP�݂����Ȑ��l�����J���Ăق����Ƃ��낾��
�ڂ��̂������ӂ����ȃ��[�N���[�h
�Ȃ��AAVX���g����Ə���d�͂�TDP�Ɏ��܂��͗l
�Ȃ��AAVX���g����Ə���d�͂�TDP�Ɏ��܂��͗l
���A����ȃX�[�p�[�v���O���}�[��2ch�ɒ���t���ɂ���̂�
918 �FSocket774�F2015/03/06(��) 13:02:25.98 ID:Zrq4caqn
������Intel�X����
AMD�̘b��o���Ă�z�A�X���^�C�ǂ߂�H
AMD�̘b��o���Ă�z�A�X���^�C�ǂ߂�H
�����������낱��ȃ��[�J�[
���PC�ł�Intel��������O����
�̗p����Ă��������f���ł����������o���悤�ȃ`���`�Ȃ̂����Ȃ�
�Ђ�����Q�[���@���[�J�[�ɛZ�є����Đ����c�邾�����낤��
���PC�ł�Intel��������O����
�̗p����Ă��������f���ł����������o���悤�ȃ`���`�Ȃ̂����Ȃ�
�Ђ�����Q�[���@���[�J�[�ɛZ�є����Đ����c�邾�����낤��
�Q�[���@�s��ł�����
>>920
�l����125���h���N��500���h���O�㔄�グ��Intel���炷��Ώ���ŕ��ɂ��Ȃ��
�Q�[���@���������Ă�AMD��PC���嗎���߂��ĂƂ��Ƃ�NVIDIA�ɔ��㔲���ꂽ����
Intel+NVIDIA+AMD�̔�Q�[���@�����Ă݂��A�s��K�͂̌����Ⴄ
�l����125���h���N��500���h���O�㔄�グ��Intel���炷��Ώ���ŕ��ɂ��Ȃ��
�Q�[���@���������Ă�AMD��PC���嗎���߂��ĂƂ��Ƃ�NVIDIA�ɔ��㔲���ꂽ����
Intel+NVIDIA+AMD�̔�Q�[���@�����Ă݂��A�s��K�͂̌����Ⴄ
922 �FSocket774�F2015/03/06(��) 13:56:10.44 ID:E2ah+1IQ
���Ŗ���ID�ς���H
Vulkan
https://www.khronos.org/assets/uploads/developers/library/2015-gdc/Khronos-Vulkan-GDC-Mar15.pdf
OpenCL2.1/SPIR-V
https://www.khronos.org/assets/uploads/developers/library/2015-gdc/OpenCL-GDC_Mar15.pdf
https://www.khronos.org/assets/uploads/developers/library/2015-gdc/Khronos-Vulkan-GDC-Mar15.pdf
OpenCL2.1/SPIR-V
https://www.khronos.org/assets/uploads/developers/library/2015-gdc/OpenCL-GDC_Mar15.pdf
{kind=link}
925 �FSocket774�F2015/03/06(��) 14:04:46.16 ID:zMsDLFwX
and goodbye
����H����AMD��Graham Sellers���������H
Hi! I�fm Graham Sellers
�E AMD�fs OpenGL and Vulkan architect
�E Represent AMD at OpenGL ARB
�E Contributor of many OpenGL features and extensions
�E Author of OpenGL SuperBible
�E Spent the last year or so working on Vulkan
�E I�fm going to whip through a complete Vulkan application from startup to tear down
This is pseudo-code, not final API
We are still finalizing some details
Hi! I�fm Graham Sellers
�E AMD�fs OpenGL and Vulkan architect
�E Represent AMD at OpenGL ARB
�E Contributor of many OpenGL features and extensions
�E Author of OpenGL SuperBible
�E Spent the last year or so working on Vulkan
�E I�fm going to whip through a complete Vulkan application from startup to tear down
This is pseudo-code, not final API
We are still finalizing some details
The new Vulkan and SPIR-V specifications
http://youtu.be/EUNMrU8uU5M?t=13m
http://youtu.be/EUNMrU8uU5M?t=13m
GFXBench 5.0 for Vulkan - Preview
https://www.youtube.com/watch?v=kzdwmba-gN0
https://www.youtube.com/watch?v=kzdwmba-gN0
AMD openCL triSYCL
https://github.com/amd/triSYCL
https://github.com/amd/triSYCL
Low Overhead OpenGL
http://developer.amd.com/community/blog/2014/07/09/low-overhead-opengl/
Graham Sellers is the architect for AMD OpenGL drivers and the author of several books on OpenGL.
http://developer.amd.com/community/blog/2014/07/09/low-overhead-opengl/
Graham Sellers is the architect for AMD OpenGL drivers and the author of several books on OpenGL.
Microsoft detailed the new features in DirectX 12
http://prohardver.hu/hir/microsoft_reszletezte_directx_12_uj_funkcio.html
http://prohardver.hu/hir/microsoft_reszletezte_directx_12_uj_funkcio.html
Sounds fishy. Why is AMD so generous?
Vulkan standardizes & replaces Mantle. "Best possible starting point we could have had, although I am really biased."
Vulkan standardizes & replaces Mantle. "Best possible starting point we could have had, although I am really biased."
>>903
> ����: GPU �A�N�Z�����[�^�̃X�s�[�h�͌������E�̃A�v���P�[�V�����ɒʗp���Ȃ�
> �u���Ƃ��A�I�[�N���b�W���������� �� Titan �V�X�e���ɂ� 18,688 �̃m�[�h������A
> ���ꂼ�ꂪ 16 �R�A 32GB AMD Opteron �v���Z�b�T�� 6GB Nvidia K20 GPU ��
> ���ڂ��Ă��܂��B2012 �N 11 ���ATitan �� HPL (Linpack) ���g�p�����x���`�}�[�N��
> �g�b�v�Ƀ����L���O����܂����B�������A���� Titan �ɂ����� HPL �̌��ʂ�̂�
> Opteron �v���Z�b�T�͕⏕�I�Ȗ��������ʂ����Ă��܂���B���ׂĂ̕��������_
> �v�Z�Ə����f�[�^�� GPU �ɏ풓���Ă��܂����B����A�����̃A�v���P�[�V������
> Titan �ɈڐA�����ƁA�ʏ�� CPU �����Ŏ��s����A�������������邽�߂Ɉꕔ��
> �v�Z���������� GPU �ɃI�t���[�h����܂��B�v
https://jp.linux.com/news/linuxcom-exclusive/410954-lco2013120201
���ENo.2�̃X�p�R���ł��炱�̌���
N-Body���Ȃ�GRAPE�݂����Ȑ�pASIC��FPGA�̂ق����������ł���
> ����: GPU �A�N�Z�����[�^�̃X�s�[�h�͌������E�̃A�v���P�[�V�����ɒʗp���Ȃ�
> �u���Ƃ��A�I�[�N���b�W���������� �� Titan �V�X�e���ɂ� 18,688 �̃m�[�h������A
> ���ꂼ�ꂪ 16 �R�A 32GB AMD Opteron �v���Z�b�T�� 6GB Nvidia K20 GPU ��
> ���ڂ��Ă��܂��B2012 �N 11 ���ATitan �� HPL (Linpack) ���g�p�����x���`�}�[�N��
> �g�b�v�Ƀ����L���O����܂����B�������A���� Titan �ɂ����� HPL �̌��ʂ�̂�
> Opteron �v���Z�b�T�͕⏕�I�Ȗ��������ʂ����Ă��܂���B���ׂĂ̕��������_
> �v�Z�Ə����f�[�^�� GPU �ɏ풓���Ă��܂����B����A�����̃A�v���P�[�V������
> Titan �ɈڐA�����ƁA�ʏ�� CPU �����Ŏ��s����A�������������邽�߂Ɉꕔ��
> �v�Z���������� GPU �ɃI�t���[�h����܂��B�v
https://jp.linux.com/news/linuxcom-exclusive/410954-lco2013120201
���ENo.2�̃X�p�R���ł��炱�̌���
N-Body���Ȃ�GRAPE�݂����Ȑ�pASIC��FPGA�̂ق����������ł���
OpenGL�g����AMD�͑傫�ȍv�����������A
�ׂ�AMD��GPU�ɗL���ȋK�i���Ă킯�ł��Ȃ��̂ŁA
���������Ή�����̂�AMD�Œx��đΉ�����̂�nvidia���x�̈Ⴂ��������
�ׂ�AMD��GPU�ɗL���ȋK�i���Ă킯�ł��Ȃ��̂ŁA
���������Ή�����̂�AMD�Œx��đΉ�����̂�nvidia���x�̈Ⴂ��������
936 �FSocket774�F2015/03/06(��) 17:28:45.31 ID:p10LnFkh
��������AMD��(�E�́E)���ެ�-�!!
�`�ł������Ă̂͂��łɃV�F�A�����Ă�Ƃ��ŗL���ȑ����g���闝���Ȃ̂��
������API�̑Ή�����������ۏ���Ă�̓_�͈��S����
����GCN��Tahiti�Ƃ�GPU�̗��j�ɖ����c�����x���̒���GPU�ɂȂ����Ǝv����
����GCN��Tahiti�Ƃ�GPU�̗��j�ɖ����c�����x���̒���GPU�ɂȂ����Ǝv����
939 �FSocket774�F2015/03/06(��) 18:12:23.11 ID:p10LnFkh
>>937
���O�͉��Ŗ���ID���ς���Ă�́H
�ʂ�AMD��������C�����Ȃ�W�Ȃ������H
2015�N�ŃV�F�A���ǂ����������Ă�o�J�Ȕ����̓Q�t�H�~�[�����Ȃ�
������100���ڎw���Ċ撣���Ă���Ĕ������Ă�B
�I���͂��������o�J�Ȕ���������Z�p����AMD�̕�����������C�Ȃ̂���B
AMD�ƃQ�t�H�~�[�Ƃ͖ڎw���Ă���������S���Ⴄ��B
AMD�̏ꍇ
��2015�N�̈ӋC���݂������ĉ�����
�@���o�C�������ɏȓd�͐���啝�ɍ��߂����o�C��APU�t�@�~���[�uCarrizo�v���n�߂Ƃ��鎟����APU��A
���s��GPU���\���X�ɍ��߂����i�Ȃǂ̓����ɒ��͂��Ă����܂��B
�d�͌�������O���t�B�b�N�X���\���啝�Ɍ��シ��AMD���i��OEM���[�J�[���̗p���₷�����邱�ƂŁA
���L�����\�Ɖ��i�|�C���g���J�o�[����ŏI���i���F�l�ɂ��͂��������Ǝv���܂��B
���ǎ҂Ɉꌾ�ǂ���
�@���N��Mantle��TrueAudio�A�є������_�����O�Z�p��TressFX Hair�Ƃ������ŐV�Z�p�ւ̃Q�[���̍œK�����܂��܂��i�݁AAMD���i�����p�����Q�[���̌�������Ƀp���[�A�b�v���܂��I
�l�X�ȍŐV�Q�[�����o���h������uNever Settle�v��A�l�X�ȃL�����y�[���A�H�t���ł̃C�x���g�ȂǁA�F�l�Ɋ��Œ�����������{���Ă��������Ǝv���܂��B
�ŐV����AMD��Facebook�y�[�W�Ő������ē����܂��̂ł��Ѓ`�F�b�N���Ă݂Ă��������B
�Q�t�H�~�[�̏ꍇ
��2015�N�̈ӋC���݂������ĉ�����
�@�V�F�A100%��ڎw���Ĉ��������撣��܂��i�j�B
���N���F�l�Ɉ������NVIDIA�ƂȂ�悤�ɐ��i���Ă܂���܂��̂ŁA�X�������肢�܂��B
���ǎ҂Ɉꌾ�ǂ���
�@2015�N���F�l�̂����҂ɂ������ł���GeForce���i�����ĐV���ȋZ�p�����͂��ł���悤�ɓw�͂��Ă��������ł��B���N�����[�U�[�̊F�l�Ƃ̐G�ꍇ�����厖�ɂ��Ă��������Ǝv���܂��B
�\�[�X
http://akiba-pc.watch.impress.co.jp/docs/sp/20150101_682313.html
���O�͉��Ŗ���ID���ς���Ă�́H
�ʂ�AMD��������C�����Ȃ�W�Ȃ������H
2015�N�ŃV�F�A���ǂ����������Ă�o�J�Ȕ����̓Q�t�H�~�[�����Ȃ�
������100���ڎw���Ċ撣���Ă���Ĕ������Ă�B
�I���͂��������o�J�Ȕ���������Z�p����AMD�̕�����������C�Ȃ̂���B
AMD�ƃQ�t�H�~�[�Ƃ͖ڎw���Ă���������S���Ⴄ��B
AMD�̏ꍇ
��2015�N�̈ӋC���݂������ĉ�����
�@���o�C�������ɏȓd�͐���啝�ɍ��߂����o�C��APU�t�@�~���[�uCarrizo�v���n�߂Ƃ��鎟����APU��A
���s��GPU���\���X�ɍ��߂����i�Ȃǂ̓����ɒ��͂��Ă����܂��B
�d�͌�������O���t�B�b�N�X���\���啝�Ɍ��シ��AMD���i��OEM���[�J�[���̗p���₷�����邱�ƂŁA
���L�����\�Ɖ��i�|�C���g���J�o�[����ŏI���i���F�l�ɂ��͂��������Ǝv���܂��B
���ǎ҂Ɉꌾ�ǂ���
�@���N��Mantle��TrueAudio�A�є������_�����O�Z�p��TressFX Hair�Ƃ������ŐV�Z�p�ւ̃Q�[���̍œK�����܂��܂��i�݁AAMD���i�����p�����Q�[���̌�������Ƀp���[�A�b�v���܂��I
�l�X�ȍŐV�Q�[�����o���h������uNever Settle�v��A�l�X�ȃL�����y�[���A�H�t���ł̃C�x���g�ȂǁA�F�l�Ɋ��Œ�����������{���Ă��������Ǝv���܂��B
�ŐV����AMD��Facebook�y�[�W�Ő������ē����܂��̂ł��Ѓ`�F�b�N���Ă݂Ă��������B
�Q�t�H�~�[�̏ꍇ
��2015�N�̈ӋC���݂������ĉ�����
�@�V�F�A100%��ڎw���Ĉ��������撣��܂��i�j�B
���N���F�l�Ɉ������NVIDIA�ƂȂ�悤�ɐ��i���Ă܂���܂��̂ŁA�X�������肢�܂��B
���ǎ҂Ɉꌾ�ǂ���
�@2015�N���F�l�̂����҂ɂ������ł���GeForce���i�����ĐV���ȋZ�p�����͂��ł���悤�ɓw�͂��Ă��������ł��B���N�����[�U�[�̊F�l�Ƃ̐G�ꍇ�����厖�ɂ��Ă��������Ǝv���܂��B
�\�[�X
http://akiba-pc.watch.impress.co.jp/docs/sp/20150101_682313.html
940 �FSocket774�F2015/03/06(��) 18:18:02.39 ID:p10LnFkh
�Q�t�H�~�̃J�L�R�~���Ă݂��B
�����Ɏ��Ђ́�5�Ń��C�o���Ɂ�1�̓��e���J��Ԃ��B
�������������ɘA���B
http://s.kakaku.com/auth/profile/profile.aspx/reviewhistory/?NickName=%81%99%83Q%83t%83H%90%7e%81%99
�����Ɏ��Ђ́�5�Ń��C�o���Ɂ�1�̓��e���J��Ԃ��B
�������������ɘA���B
http://s.kakaku.com/auth/profile/profile.aspx/reviewhistory/?NickName=%81%99%83Q%83t%83H%90%7e%81%99
�ǂ������Ƃ����ƃA���`��Mantle�I���I���Ċ|�����ɉߏ�ɔ������Ă邾���ȋC������
290x��12_0�܂�
gtx980��12_1
gtx980��12_1
943 �FSocket774�F2015/03/06(��) 19:22:25.09 ID:J3jhI6J/
Mantle2.0�͌��Ǐ�������̂�
AMD���Z�p���H
������H
������H
945 �FSocket774�F2015/03/06(��) 20:43:04.78 ID:p10LnFkh
12.1���ĉ���
11.3���ς�������̂��H
11.3���ς�������̂��H
947 �F,,�E�L�́M�E,,�j��-�������F2015/03/06(��) 20:56:44.23 ID:58OG1vP9
AMD�͋Z�p���i����o�����Ёj
�����J�����
'11 1,453(M�h��)
'12 1,354
'13 1,199
'14 1,072
�����J�����
'11 1,453(M�h��)
'12 1,354
'13 1,199
'14 1,072
>>947
�ƂȂ�ƁANvidia��(���\��)�Z�p�����B
�ƂȂ�ƁANvidia��(���\��)�Z�p�����B
���\���Ă��������Ɏ������ԋC�z�̂Ȃ�
���̋��������c�̂ɗU���ĔN����邱�Ƃł���
���̋��������c�̂ɗU���ĔN����邱�Ƃł���
TDP�͔�r�I���ׂ̍����A�v����I��Ō��߂Ă�BOCCT�݂����ȕ��ׂ��|����ړI�ȊO�Ɏ��p���̖����̂�Thermal virus�Ƃ����ď��O�ˁB
CPU�ɓ���d�͔͂M�ȊO�ɓd���g�Ƃ��Ă����˂���B�G�l���M�[�ۑ����I�ɂ͂��ꂾ���B
CPU�ɓ���d�͔͂M�ȊO�ɓd���g�Ƃ��Ă����˂���B�G�l���M�[�ۑ����I�ɂ͂��ꂾ���B
�����CPU�́A�����Ă����d�͂�99%�ȏ��M�Ƃ��ĕ��o����
����āA����d�́����M�Ŗ��Ȃ�
����āA����d�́����M�Ŗ��Ȃ�
952 �FSocket774�F2015/03/07(�y) 05:14:28.96 ID:gBJN1vo0
�����́H
953 �F,,�E�L�́M�E,,�j��-�������F2015/03/07(�y) 05:32:30.24 ID:0z2JZqdM
�R���M���H
���傱��ł��܂�
����̂Ȃ����傱��
TDP�����Ԃ�\���Ȃ����͉������Ȃ���ˁH
>>921
����ȃQ�[���s��ɎЉ^������Ă錳�Ɠd���[�J�[�������
����ȃQ�[���s��ɎЉ^������Ă錳�Ɠd���[�J�[�������
Congratulations to Chris Donahue on joining our team
https://www.linkedin.com/pub/chris-donahue/0/2b/ba9
https://www.linkedin.com/pub/chris-donahue/0/2b/ba9
Not dead yet: AMD�fs Mantle powers new Vulkan API, VR efforts
http://www.extremetech.com/extreme/200286-not-dead-yet-amds-mantle-powers-new-vulkan-api-vr-efforts
http://www.extremetech.com/extreme/200286-not-dead-yet-amds-mantle-powers-new-vulkan-api-vr-efforts
AMD_gcn_shader
https://www.opengl.org/registry/specs/AMD/gcn_shader.txt
AMD_gpu_shader_int64
https://www.opengl.org/registry/specs/AMD/gpu_shader_int64.txt
https://www.opengl.org/registry/specs/AMD/gcn_shader.txt
AMD_gpu_shader_int64
https://www.opengl.org/registry/specs/AMD/gpu_shader_int64.txt
http://www.sisoftware.eu/rank2011d/show_run.php?q=c2ffcfe988e9d4e3d2ebd9ecd8fe8cb181a7c2a79aaa8cffc2fa&l=jp
AMD A10-8850K(?)
�^�Ԃ��炷��ƒ�i3.9GHz�̃u�[�X�g��4.1GHz���ۂ������邯��
AMD A10-8850K(?)
�^�Ԃ��炷��ƒ�i3.9GHz�̃u�[�X�g��4.1GHz���ۂ������邯��
>>961
SAPPHIRE��M/B�g���Ă�̂��A������
SAPPHIRE��M/B�g���Ă�̂��A������
Evolution of SPIR
http://i.imgur.com/eKMtLG5.png
http://i.imgur.com/eKMtLG5.png
{kind=link}
>>963
����2.0�̎��������Ȃ�V�Ȃ�w
����2.0�̎��������Ȃ�V�Ȃ�w
>>964
8.1����10�ɃW�����v����OS�������Ă���
8.1����10�ɃW�����v����OS�������Ă���
�X�y�[�X�K���_��V
�e�R��V
�e�R��V
V��˂��V��
>>964
LLVM�g��Ȃ������ɕύX���邩��A�o�[�W�����d�蒼���ɂ����������Ƃ��H
LLVM�g��Ȃ������ɕύX���邩��A�o�[�W�����d�蒼���ɂ����������Ƃ��H
���@���J����V�����
972 �F,,�E�L�́M�E,,�j��-�������F2015/03/07(�y) 18:47:27.22 ID:drs6HM/1
���H���H�b�^��V
�{���ɕ���Ղ�
����
�{���ɕ���Ղ�
����
�u���H���H�b�^�v���ĂȂɁH
�T���o���J��
Llano�o��̋łɂ�
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
�� 2014�N �����̔��ド���L���O
http://eetimes.jp/ee/articles/1412/25/news147.html
��AMD�A2014�N�x��4���h���̐Ԏ�
http://pc.watch.impress.co.jp/docs/news/20150121_684660.html
AMD�̏��ʂ������}�~���ЂƂ蕉���_(^o^)�^
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
�� 2014�N �����̔��ド���L���O
http://eetimes.jp/ee/articles/1412/25/news147.html
��AMD�A2014�N�x��4���h���̐Ԏ�
http://pc.watch.impress.co.jp/docs/news/20150121_684660.html
AMD�̏��ʂ������}�~���ЂƂ蕉���_(^o^)�^
�n�[�h�E�F�A�E��SEGA�I�ȗ����ʒu������AMD�ɂ��Ɏ��オ�ǂ����Ă��������
977 �F,,�E�L�́M�E,,�j��-�������F2015/03/07(�y) 20:02:12.30 ID:drs6HM/1
�Z�K�Ō����ƃh���L���X�����O����
>>965
�O���A8850K�̓x�[�X�N���b�N�����̂܂܂�������
������͏オ���Ă���
����ȉ��̃��f����Kaveri���N���b�N�������āA���̂��߂̐V���i���s��
�O���A8850K�̓x�[�X�N���b�N�����̂܂܂�������
������͏オ���Ă���
����ȉ��̃��f����Kaveri���N���b�N�������āA���̂��߂̐V���i���s��
lllllllllllllllllll!�@�@�@�@�@�@,;;�@.;;''�@�@�@�@�@�@,:,:,:,:,:�@�@illllllll�m ��
llllllllllllllllll!,,,,,�@�@�@i�@ ;; i/ ;;;,,�@�@�@�@�@�@�@,,,,,,,�@ illlll���@��
lllllllllllllll'l!iil||||||||||l�U�@�@�i(||||||||||||||||llllllliiiiii'''�@ ;illllll�R�@ ��
lllllllllllll'l!�@_,,,,,��,, �R�@�@``..:::�@ �m^==- ..,_�@�@�@illllllllɁ@ ��
llllllllllll'l!�',...,�i�]'..;�j�R >�@ .:::::�@��@�@�@�i`'" `i�ʤ 'illllll�R�@�F
lllllllllll'l!' `'--�]`��' �m�@�@�@�S�A�ʁ]-Ɠ��.�t'' ` 'illlllɁ@! !
llllllllll'l!##;; ''�@�@ �m�@�@�@�@�@�@`�@�@�@�@�@�@�@�@�@�@ 'illlll�R,.-�,.-
�@�@�@�@�� �K �h �� �� �e �g �� �X ���@�E�@�E�@�E�@���@���@���@�Ł@���@�E�@�E�@�E
llllllllllllllllll!,,,,,�@�@�@i�@ ;; i/ ;;;,,�@�@�@�@�@�@�@,,,,,,,�@ illlll���@��
lllllllllllllll'l!iil||||||||||l�U�@�@�i(||||||||||||||||llllllliiiiii'''�@ ;illllll�R�@ ��
lllllllllllll'l!�@_,,,,,��,, �R�@�@``..:::�@ �m^==- ..,_�@�@�@illllllllɁ@ ��
llllllllllll'l!�',...,�i�]'..;�j�R >�@ .:::::�@��@�@�@�i`'" `i�ʤ 'illllll�R�@�F
lllllllllll'l!' `'--�]`��' �m�@�@�@�S�A�ʁ]-Ɠ��.�t'' ` 'illlllɁ@! !
llllllllll'l!##;; ''�@�@ �m�@�@�@�@�@�@`�@�@�@�@�@�@�@�@�@�@ 'illlll�R,.-�,.-
�@�@�@�@�� �K �h �� �� �e �g �� �X ���@�E�@�E�@�E�@���@���@���@�Ł@���@�E�@�E�@�E
980 �F,,�E�L�́M�E,,�j��-�������F2015/03/07(�y) 20:39:54.67 ID:drs6HM/1
�����َ͈����̖@�������o���Ď�����Ă�̂�
���l�ɂ͂������i��HDD�̃^�C�v�~�Xby�������z�����c�̃^�C�v�~�X�j�݂����Ȃ̂ʼn��X���Ɏ����Ă�̂�
������
���l�ɂ͂������i��HDD�̃^�C�v�~�Xby�������z�����c�̃^�C�v�~�X�j�݂����Ȃ̂ʼn��X���Ɏ����Ă�̂�
������
�{�{�������Ăǂ��̌��t���낤��
983 �F,,�E�L�́M�E,,�j��-�������F2015/03/07(�y) 21:07:44.92 ID:drs6HM/1
�u�F�{�ف@�{�{��v�Ō���
�E�������i���ȓ��͂ł�HDD�̃^�C�v�~�X�Ǝv�킹�Ď��̓v���N�V�g������Ƃ����J�~���O�A�E�g�j
�E�e�w�i�������X�y�N�g�Ǝv�킹�Ď��̓w�e�������e�w�����e�w�܂�w�e���̋t�̃z���J�~���O�A�E�g�j
�E�x�[�W�i�y�[�W�̃^�C�v�~�X�Ǝv�킹�Ď��̓K�x�[�W���S�~�A���͂ǂ����悤���Ȃ��S�~���Ƃ����T���猩�Č��킸�����ȂȃJ�~���O�A�E�g�j
�܂�^�C�v�~�X�Ǝv�킹���I���ȃL���z���A�s�[���̎g���肾���炱�����l�̒P�Ȃ�^�C�v�~�X�������Ȃ��̂��H
�E�e�w�i�������X�y�N�g�Ǝv�킹�Ď��̓w�e�������e�w�����e�w�܂�w�e���̋t�̃z���J�~���O�A�E�g�j
�E�x�[�W�i�y�[�W�̃^�C�v�~�X�Ǝv�킹�Ď��̓K�x�[�W���S�~�A���͂ǂ����悤���Ȃ��S�~���Ƃ����T���猩�Č��킸�����ȂȃJ�~���O�A�E�g�j
�܂�^�C�v�~�X�Ǝv�킹���I���ȃL���z���A�s�[���̎g���肾���炱�����l�̒P�Ȃ�^�C�v�~�X�������Ȃ��̂��H
>>983
�c�q�́w�X�P�x���悤��x���Č���ꂽ�̂��E�E�E
�c�q�́w�X�P�x���悤��x���Č���ꂽ�̂��E�E�E
tp://ameblo.jp/nirenoya/entry-10076586250.html
������u�{�{�v�̈Ӗ��̒��ŌF�{�ق�I�̂͂܂肻���������ƂȂ�
���肪���܂�C�t���Ȃ������ł�������Ă������z���A�s�[�����Ă�
�z���R�A���iIntel�̐M�҂��P�Ȃ�z�����A���
������u�{�{�v�̈Ӗ��̒��ŌF�{�ق�I�̂͂܂肻���������ƂȂ�
���肪���܂�C�t���Ȃ������ł�������Ă������z���A�s�[�����Ă�
�z���R�A���iIntel�̐M�҂��P�Ȃ�z�����A���
�ڂځ@�����ł�����Ƃ��ꂪ�����o�Ă��邵��
http://ja.wikipedia.org/wiki/%E3%83%9C%E3%83%9C
��˒n���͖̂{���ڂڂ��݂�������
���i���K���ɂ���(�L�E�ցE�M)
http://ja.wikipedia.org/wiki/%E3%83%9C%E3%83%9C
��˒n���͖̂{���ڂڂ��݂�������
���i���K���ɂ���(�L�E�ցE�M)
APU�̏��^PC�Ƃ��ǂ������Ȃ��ǂȂ�