Intel�̎�����Z�p�ɂ��Č�낤 80©2ch.net
Intel�̎����㐻�i��A����Ɋ֘A����Z�p�ɂ��ẴX���b�h�ł�
���O�X��
Intel�̎�����Z�p�ɂ��Č�낤 79
http://anago.2ch.net/test/read.cgi/jisaku/1414134650/
���O�X��
Intel�̎�����Z�p�ɂ��Č�낤 79
http://anago.2ch.net/test/read.cgi/jisaku/1414134650/
|
|
|
����
Linux�ł��ŐV���~�������Windows�݂������O�Ń\�[�X���o�C�i����web����T���Ⴂ���̂ɂˁB
Linux�łȂ���MS�ɂ͖߂��B
Linux�łȂ���MS�ɂ͖߂��B
���������Ӗ���Windows�X�g�A�Ɋ��҂��Ă����Ǎ���Ƃ��_�����ۂ��B
�o�^���͂���ς������
�o�^���͂���ς������
�X�g�A�A�v����
Win8����Ȃ̂��ɂ�����
Win8����Ȃ̂��ɂ�����
Intel's 14nm Broadwell-U HD 5500 iGPU Performance Numbers Revealed - 32% Increase over Intel HD 4400
http://wccftech.com/broadwellu-intel-hd-5500-igpu-performance-numbers-revealed/
http://wccftech.com/broadwellu-intel-hd-5500-igpu-performance-numbers-revealed/
7 �FSocket774�F2014/12/31(��) 18:58:23.44 ID:88Gwk2O7
Intel�l�������l�ނ̖������J����B��_
�S�l�ނ�Intel�l�̉��ɕ�����Intel�l�����𐒔q��
Intel�l�ɑS�Ă������ׂ��ł���
Intel�l���I�I�I�I�I
�S�l�ނ�Intel�l�̉��ɕ�����Intel�l�����𐒔q��
Intel�l�ɑS�Ă������ׂ��ł���
Intel�l���I�I�I�I�I
PC�e�N�m���W�[�g�����h 2015 - ����CPU/GPU����e��`�b�v�܂�
(1) Intel CPU - Broadwell��Skylake
http://s.news.mynavi.jp/special/2015/trendspring/
�������Ȃ̂��Ƃ�����Intel��14nm�v���Z�X���̂��̂����܂��ɐ��n�ł��Ă��Ȃ����Ƃł���B
����1��Intel��14nm�v���Z�X������قǓ�����g�����オ�肻���ɖ������Ƃ��B
(1) Intel CPU - Broadwell��Skylake
http://s.news.mynavi.jp/special/2015/trendspring/
�������Ȃ̂��Ƃ�����Intel��14nm�v���Z�X���̂��̂����܂��ɐ��n�ł��Ă��Ȃ����Ƃł���B
����1��Intel��14nm�v���Z�X������قǓ�����g�����オ�肻���ɖ������Ƃ��B
Intel Process - 14nm�ɂ�������̗v���Ƃ�
http://s.news.mynavi.jp/special/2015/trendspring/006.html
Yield�������ɉ��P���Ă���A��v�Ȑ����p�����[�^��22nm�Ɠ������x���܂ʼn��P����A
�M�����Ɋւ��Ă��S�Ă̍��ڂ�Low Risk�ɂȂ��Ă���B
�ł͉���Broadwell�̏o�ׂ��i�܂��A����ǂ��납Respin���d�˂Ă���̂��Ƃ������Ƃ��B
���͂���Ɋւ��Ă�Intel�̒��ł��g�b�v�V�[�N���b�g�ɋ߂��b�炵���A���Ȃ��Ƃ�
����ł͈�ؐ����Șb�͂킩��Ȃ��B�����A�������̏������킹����Ŕ��f����ƁA
���E���\�̂Ԃꂪ���܂�Ȃ��Ƃ����b�ŁA���̕����̃R���g���[���ɑ�����V���Ă���炵���B
������Ƙb����Ԃ��A2�N�قǑO�ɓ��������̋v�{�厁��FinFET�̂��b���f�������ɁA
�uFin������Ă݂����ɁAFin�̕���10nm�ȉ��ɂ��čs���ƁAVt�̂������l���ʎq���ʂł�����ł���ˁv
�Ƃ����b���������B�ǂ���Intel�����ʂ��Ă�����́A�܂��������������b�ɋ߂��炵���B
�v�{���̘b�͂����܂�R&D�̃��x���̘b������10nm���肬��܂ł�����(10nm������ɕ~��������)
�Ƃ����b���������A���ۂɗʎY���C���ł�14nm������Ō��E�ɋ߂Â��Ă���̂ł͂Ȃ���
http://s.news.mynavi.jp/special/2015/trendspring/006.html
Yield�������ɉ��P���Ă���A��v�Ȑ����p�����[�^��22nm�Ɠ������x���܂ʼn��P����A
�M�����Ɋւ��Ă��S�Ă̍��ڂ�Low Risk�ɂȂ��Ă���B
�ł͉���Broadwell�̏o�ׂ��i�܂��A����ǂ��납Respin���d�˂Ă���̂��Ƃ������Ƃ��B
���͂���Ɋւ��Ă�Intel�̒��ł��g�b�v�V�[�N���b�g�ɋ߂��b�炵���A���Ȃ��Ƃ�
����ł͈�ؐ����Șb�͂킩��Ȃ��B�����A�������̏������킹����Ŕ��f����ƁA
���E���\�̂Ԃꂪ���܂�Ȃ��Ƃ����b�ŁA���̕����̃R���g���[���ɑ�����V���Ă���炵���B
������Ƙb����Ԃ��A2�N�قǑO�ɓ��������̋v�{�厁��FinFET�̂��b���f�������ɁA
�uFin������Ă݂����ɁAFin�̕���10nm�ȉ��ɂ��čs���ƁAVt�̂������l���ʎq���ʂł�����ł���ˁv
�Ƃ����b���������B�ǂ���Intel�����ʂ��Ă�����́A�܂��������������b�ɋ߂��炵���B
�v�{���̘b�͂����܂�R&D�̃��x���̘b������10nm���肬��܂ł�����(10nm������ɕ~��������)
�Ƃ����b���������A���ۂɗʎY���C���ł�14nm������Ō��E�ɋ߂Â��Ă���̂ł͂Ȃ���
news.mynavi.jp���s.news.mynavi.jp�����Ă�l�̕��������̂���
>�����ăf�X�N�g�b�v������Skylake��2016�N�ɓ��鎖�͂قڕs���ƌ����Ă���B
�_(^o^)�^���
�_(^o^)�^���
�x��Ă�����قNjꋫ�ɂȂ�Ȃ����炢�������ア
�N���b�N���Ⴍ�Ă��d�͓�����̐��\�������Ȃ�o�c�I�ɂ͖��Ȃ��ȁB
�܂��N���b�N�Ⴂ���Ă̂͑匴�̖ϑz���Ǝv������
�㓡�E�R�c�E�}����3���ƐU��Ԃ�2014�N�̃j���[�X
http://m.pc.watch.impress.co.jp/docs/topic/feature/20141231_682301.html
�y�㓡�zIntel��14nm�͔��ɉ���I�Ȃ��̂ŋƊE�ł������ł����B
�N���������܂Ńt�B���s�b�`�ƃ��^���s�b�`�����߂�Ǝv���ĂȂ������̂ŁB
�����A���߂������ʃg���u�����������킯��(��)�B
�y�}���zIntel�͑傫�����i����Ɛ�������ɕ�����Ă����ł����A8���Ɏ�ނ������A
��������̐l�ɕ����Ɓu14nm�͔��ɐ������Ă��ė����オ��͖��Ȃ��v�ƌ������ǁA
���i����̐l�����̓����͈Ⴄ��(��)�B���̃M���b�v�͒[���猩�Ă��Ėʔ����ł�(��)�B
�ŁA���ǂ̓_�C�ɖ�肪���������A�v���Z�X�ɂ���肪�������炵���B
http://m.pc.watch.impress.co.jp/docs/topic/feature/20141231_682301.html
�y�㓡�zIntel��14nm�͔��ɉ���I�Ȃ��̂ŋƊE�ł������ł����B
�N���������܂Ńt�B���s�b�`�ƃ��^���s�b�`�����߂�Ǝv���ĂȂ������̂ŁB
�����A���߂������ʃg���u�����������킯��(��)�B
�y�}���zIntel�͑傫�����i����Ɛ�������ɕ�����Ă����ł����A8���Ɏ�ނ������A
��������̐l�ɕ����Ɓu14nm�͔��ɐ������Ă��ė����オ��͖��Ȃ��v�ƌ������ǁA
���i����̐l�����̓����͈Ⴄ��(��)�B���̃M���b�v�͒[���猩�Ă��Ėʔ����ł�(��)�B
�ŁA���ǂ̓_�C�ɖ�肪���������A�v���Z�X�ɂ���肪�������炵���B
�N���b�N���Ⴂ�Ƃ����̂̓g���u�������������珟��ɐ��������ϑz����
���ۂ̃g���u���͂Ȃ낤�Ȃ��E�E�E
���ۂ̃g���u���͂Ȃ낤�Ȃ��E�E�E
ES�̃N���b�N���Ⴂ���Ęb�ł���
���ۂ̃����[�X���ɂ͘@�Ɠ������x���̃N���b�N�͏o���Ă���Ǝv������
���ۂ̃����[�X���ɂ͘@�Ɠ������x���̃N���b�N�͏o���Ă���Ǝv������
2015�N��PC�͂ǂ��ς�邩�H�\�\Intel�v���b�g�t�H�[���̐i������l����
http://www.itmedia.co.jp/pcuser/spv/1501/03/news007.html
http://www.itmedia.co.jp/pcuser/spv/1501/03/news007.html
�㓡�O��Weekly�C�O�j���[�X
�t�@�E���_���ڋq��Atom CPU�R�A�����Intel
http://pc.watch.impress.co.jp/docs/column/kaigai/20150105_682366.html
�t�@�E���_���ڋq��Atom CPU�R�A�����Intel
http://pc.watch.impress.co.jp/docs/column/kaigai/20150105_682366.html
���N������ƊE�ɂ́A��������N�ɂȂ肻�����Ȃ�
�N���b�N�オ��Ȃ��̂͂��Ȃ����ԈႢ����Ȃ���?
tsmc��20nm���A���o�C���ł̒���d���͂Ƃ�����
�N���b�N�グ���Ȃ���Ԃŋꂵ��ł邵
�N���b�N�オ��Ȃ��̂͂��Ȃ����ԈႢ����Ȃ���?
tsmc��20nm���A���o�C���ł̒���d���͂Ƃ�����
�N���b�N�グ���Ȃ���Ԃŋꂵ��ł邵
���܂�オ��Ȃ��A�Ƃ����̂͂܂��T�ː������Ƃ���
���Ȃ��Ƃ�Intel��14nm�Ɋւ��Ă�22nm���N���b�N��Ⴍ�ݒ肵�Ă���A�Ƃ������Ƃ͂Ȃ�
�Ⴆ��Broadwell-U i7/i5�̍ʼn��ʃ��f��(5500U/5200U)�̓x�[�X�����ꂼ��2.4/2.2GHz��
Haswell-U�̓���SKU(4500U/4200U)��1.8/1.6GHz����傫�����サ�Ă���
���Ȃ��Ƃ�Intel��14nm�Ɋւ��Ă�22nm���N���b�N��Ⴍ�ݒ肵�Ă���A�Ƃ������Ƃ͂Ȃ�
�Ⴆ��Broadwell-U i7/i5�̍ʼn��ʃ��f��(5500U/5200U)�̓x�[�X�����ꂼ��2.4/2.2GHz��
Haswell-U�̓���SKU(4500U/4200U)��1.8/1.6GHz����傫�����サ�Ă���
���쎩�̂��I���R���ȋC������B
����Linux�����玩�삵�Ă邯�ǁAWindows�Ȃ烁�[�J�[�i�̕����������A
����Linux�����玩�삵�Ă邯�ǁAWindows�Ȃ烁�[�J�[�i�̕����������A
���[�J�[�i�͂ȂI�i�j�[�����t�����Ă�悤�ł���܂�D������Ȃ��ȁB
�X�J�C���[�N�͋�\���BTO���悤�Ǝv���Ă���B
�X�J�C���[�N�͋�\���BTO���悤�Ǝv���Ă���B
>>21
���̓f�X�N�����̍��N���b�N�E���N���b�N�i�B
AVX���p���̃_�E���N���b�N�͍���8�R�A�݂̂�����
14nm�ł�6�R�A�������Ȃ邩������Ȃ��B
���̓f�X�N�����̍��N���b�N�E���N���b�N�i�B
AVX���p���̃_�E���N���b�N�͍���8�R�A�݂̂�����
14nm�ł�6�R�A�������Ȃ邩������Ȃ��B
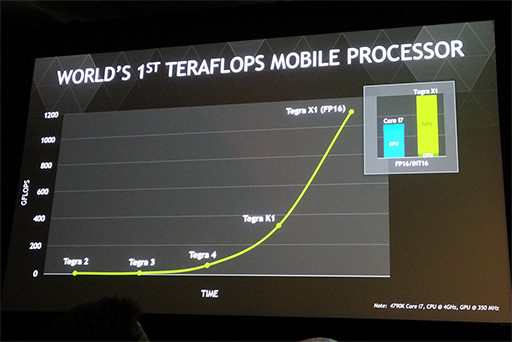
Tegra X1 ���Ăǂ������1TFLOPS������́H
FP16�̔����x��1TFLOPS��������Ă����ł����Ă�H
http://www.4gamer.net/games/049/G004964/20150105001/
http://www.4gamer.net/games/049/G004964/20150105001/TN/019.jpg
http://www.4gamer.net/games/049/G004964/20150105001/
http://www.4gamer.net/games/049/G004964/20150105001/TN/019.jpg
{kind=link}
�����
����kepler�ł�32bit���W�X�^�g����1cuda core��16bit x2,8bit x4��simd�������\�Ȃ���
�ԍڂȂ̉摜�Z���T�[�����Ȃ�16bit�ŏ\�����Ă��ƂȂ����
�܂��̓O���[�X�P�[���Ńf�B�[�v���[�j���O���Ƃ�����
����kepler�ł�32bit���W�X�^�g����1cuda core��16bit x2,8bit x4��simd�������\�Ȃ���
�ԍڂȂ̉摜�Z���T�[�����Ȃ�16bit�ŏ\�����Ă��ƂȂ����
�܂��̓O���[�X�P�[���Ńf�B�[�v���[�j���O���Ƃ�����
���ɕ����P���x1TFLOPS�ɂȂ�邩�Ǝv�����̂� (�Q�[�~���O�m�[�g�ł��Ȃ�邩���j
����32bit�ł�500gflops�����Ă邵
�Œ�@�\��k1����tmu��8����16��rop��4����16�ɑ啝�ɑ����Ă�̂�
�Q�[���������I�ɉ��K�ɂȂ�
�Œ�@�\��k1����tmu��8����16��rop��4����16�ɑ啝�ɑ����Ă�̂�
�Q�[���������I�ɉ��K�ɂȂ�
30 �FSocket774�F2015/01/06(��) 00:40:03.19 ID:10klxQXM
Intel�C�uBroadwell-U�v���ƃm�[�gPC������5����Core�v���Z�b�T14���i�\ - 4Gamer.net
http://www.4gamer.net/games/235/G023503/20141230001/
http://www.4gamer.net/games/235/G023503/20141230001/
31 �FSocket774�F2015/01/06(��) 02:47:59.59 ID:fSpAlzbf
iGPU�̑��x�Ȃ�Ăǂ��ł���������A
CPU�����̑��x�グ��敳�C���e��
Sandy�ȍ~�J���݂����ȃy�[�X�ł���CPU�����̐��\���オ���ĂȂ�
CPU�����̑��x�グ��敳�C���e��
Sandy�ȍ~�J���݂����ȃy�[�X�ł���CPU�����̐��\���オ���ĂȂ�
FMA3�Ƃ�AVX2�ŗ����{�ɂȂ��Ă邶���
>>30
4�T�͐V���i��Pentium/Celeron�V���[�Y��Haswell���ゾ���ď����Ă��邯��
Intel�̃f�[�^�⑼�̃T�C�g��Broadwell�x�[�X�����ď����Ă��邵�ǂ��炪�{���ȂE�E�E
4�T�͐V���i��Pentium/Celeron�V���[�Y��Haswell���ゾ���ď����Ă��邯��
Intel�̃f�[�^�⑼�̃T�C�g��Broadwell�x�[�X�����ď����Ă��邵�ǂ��炪�{���ȂE�E�E
ark.intel.com��Pentium 3805U�ACeleron 3755U/3205U ��
AVX�i128�j ��enable �ɂȂ��Ă��
AVX�i128�j ��enable �ɂȂ��Ă��
>>30
����HcoreiM�́HU�Ƃ�����Ȃ����ǁE�E�E
����HcoreiM�́HU�Ƃ�����Ȃ����ǁE�E�E
i3��23EU�ȂˁA�����܂��
�C���e���y�����z ?@IntelJapan
�C���e���͎������14nm�v���Z�X�Z�p���̗p�����^�u���b�g�����v���Z�b�T�[(�J���R�[�h��: Cherry Trail)�̏o�ׂ��n�߂܂����B
��荂���\�ȃO���t�B�b�N�X�ƃ��[�U�[�̌����^�u���b�g�ł��y���݂��������܂��B http://intel.ly/1D0TU7A #CES2015
�C���e���͎������14nm�v���Z�X�Z�p���̗p�����^�u���b�g�����v���Z�b�T�[(�J���R�[�h��: Cherry Trail)�̏o�ׂ��n�߂܂����B
��荂���\�ȃO���t�B�b�N�X�ƃ��[�U�[�̌����^�u���b�g�ł��y���݂��������܂��B http://intel.ly/1D0TU7A #CES2015
38 �FSocket774�F2015/01/06(��) 16:48:38.33 ID:2fmjEQ9Q
����ƃu��������
CES 2015 : Lenovo�A�ƊE�� Intel��64bit�v���Z�b�T�� LTE-Advanced�Ή����f���𓋍ڂ����V�^Android�X�}�[�g�t�H���uLenovo P90�v�𐳎����\
http://getnews.jp/archives/756206
�y����zIntel�AHDMI�X�e�B�b�N�^PC��3������
�`149�h����Windows��100�h��������Linux���f��
http://pc.watch.impress.co.jp/docs/news/event/20150106_682502.html
http://getnews.jp/archives/756206
�y����zIntel�AHDMI�X�e�B�b�N�^PC��3������
�`149�h����Windows��100�h��������Linux���f��
http://pc.watch.impress.co.jp/docs/news/event/20150106_682502.html
>>37
�x�[�X�o���h�v���Z�b�T�܂�ł�̂��ȁB����ŃX�}�z�s��U�߂���ł����ȁB
�x�[�X�o���h�v���Z�b�T�܂�ł�̂��ȁB����ŃX�}�z�s��U�߂���ł����ȁB
>>34
128?
128?
Cherry Trail�o�ׂƂ������ǃA�[�L�e�N�`���̏ڍׂ͂��납
�X�y�b�N�����S���o�Ă��Ȃ��͉̂��Ȃ�
�X�y�b�N�����S���o�Ă��Ȃ��͉̂��Ȃ�
�y�C�x���g���|�[�g�z�y����zIntel�ABroadwell����NUC��1������ �`�g�����W���[���𓋍ڂł��锖�^�̐V➑� - PC Watch
http://pc.watch.impress.co.jp/docs/news/event/20150106_682503.html
http://pc.watch.impress.co.jp/docs/news/event/20150106_682503.html
>>45
����H���������������Airmont�H�H
����H���������������Airmont�H�H
>>45
Windows10�Ȃ�X�}�z���f�X�N�Ƌ���OS�ɂȂ�炵������A
CherryTrail�@��WindowsPhone10���}�C�i�[���[�J�[�o����Ȃ����ȁB
BayTrail�@�ł�SIM���h����z�����邵�B
Windows10�Ȃ�X�}�z���f�X�N�Ƌ���OS�ɂȂ�炵������A
CherryTrail�@��WindowsPhone10���}�C�i�[���[�J�[�o����Ȃ����ȁB
BayTrail�@�ł�SIM���h����z�����邵�B
49 �F,,�E�L�́M�E,,�j��-�������F2015/01/06(��) 22:49:54.23 ID:wDEred6F
Haswell�����iGPU���ڂ邭�炢����
�ڋʂ�SHA-1/2�g����MPX��Goldmont����ł�
�ڋʂ�SHA-1/2�g����MPX��Goldmont����ł�
Atom���{����C2D���̐��\�ɂȂ�̂͂��Ȃ낤�ˁB
�R�A���\�ŗ��킵�Ă���Ȃ��Ɖ��ɂ��Ӗ��Ȃ���B
�R�A���\�ŗ��킵�Ă���Ȃ��Ɖ��ɂ��Ӗ��Ȃ���B
OS���������ɂȂ��ĂĎh���Ɠ�����ɂȂ�����N������������
>>25
CPU��1TFlops�ƁA�ق�GPU�̐��\��1TFlops�����Ƃ����̂͂Ȃ��������錾�����ɕ��������
CPU��1TFlops�ƁA�ق�GPU�̐��\��1TFlops�����Ƃ����̂͂Ȃ��������錾�����ɕ��������
>>16,21
http://news.mynavi.jp/special/2015/trendspring/006.html
��������Ƙb����Ԃ��A2�N�قǑO�ɓ��������̋v�{�厁��FinFET�̂��b���f�������ɁA
���uFin������Ă݂����ɁAFin�̕���10nm�ȉ��ɂ��čs���ƁAVt�̂������l���ʎq���ʂł�����ł���ˁv�Ƃ����b���������B
����̓N���b�N���グ�ɂ����v���ɂȂ��Ȃ���
���ʂƂ��ă��o�C�������̂ƃn�C�p�t�H�[�}���X�E�f�X�N�g�b�v�ł̓C�[���h�ɑ傫�ȍ����o���������A
��d���ł����N���b�N�ł��Ȃ��_�C����ʂɂł��Ă����ꂵ���Ȃ����낤���Ȃ�
http://news.mynavi.jp/special/2015/trendspring/006.html
��������Ƙb����Ԃ��A2�N�قǑO�ɓ��������̋v�{�厁��FinFET�̂��b���f�������ɁA
���uFin������Ă݂����ɁAFin�̕���10nm�ȉ��ɂ��čs���ƁAVt�̂������l���ʎq���ʂł�����ł���ˁv�Ƃ����b���������B
����̓N���b�N���グ�ɂ����v���ɂȂ��Ȃ���
���ʂƂ��ă��o�C�������̂ƃn�C�p�t�H�[�}���X�E�f�X�N�g�b�v�ł̓C�[���h�ɑ傫�ȍ����o���������A
��d���ł����N���b�N�ł��Ȃ��_�C����ʂɂł��Ă����ꂵ���Ȃ����낤���Ȃ�
�y����zIntel�A�{�^���T�C�Y�̃E�F�A���u���������W���[���uCurie�v
�`Quark SE SoC�A384KB�t���b�V���ABluetooth LE��
http://pc.watch.impress.co.jp/docs/news/event/20150107_682716.html
����Ȃ�r���v��K�l����������
�`Quark SE SoC�A384KB�t���b�V���ABluetooth LE��
http://pc.watch.impress.co.jp/docs/news/event/20150107_682716.html
����Ȃ�r���v��K�l����������
{kind=link}
>>57
�ɂ����ȉ��䂾�ȥ����
�ɂ����ȉ��䂾�ȥ����
59 �F,,�E�L�́M�E,,�j��-�������F2015/01/07(��) 22:11:04.96 ID:atR9gTKn
�ܔ�����Ă��
�N���U�j�b�`CEO�̎w��{�I�ɂ����ɂ��������
�����ۂЂǂ������ɍr��Ă邯��
�����ۂЂǂ������ɍr��Ă邯��
��Ńv���Z�b�T����Ă�낤�������
��������Y�o�g�������Ȃ�
��������Y�o�g�������Ȃ�
�d�q�������{�ŏ��H���V���R�������グ�Ă�݂̂�
>>57
CPU�N�[���[�O�����ɂ�����܂��Ƃ����Ȃ��
CPU�N�[���[�O�����ɂ�����܂��Ƃ����Ȃ��
�X�}�z�퍑�j�̎��̔e�҂͒����V���I�~���H
AP(�A�v���P�[�V�����v���Z�b�T)�𐧂�����̂��X�}�z�𐧂���
http://bylines.news.yahoo.co.jp/yunogamitakashi/20150106-00042021/
�C���e���̎���Ƌ��v�̗����T���X���d�q
�X�}�z��AP�̐v�Ɠ��l�ɐ������d�v�ł���B�������A�A�b�v���͔����̗̂ʎY�H��������Ă��Ȃ��B
�����ŃA�b�v���́A����iPhone �p AP�̐������C���e���ɑŐf�����B�Ƃ��낪�C���e���́A�u1��10�h���ł̓r�W�l�X�ɂȂ�Ȃ��v�ƒf���Ă��܂��B
����́A�u�C���e���j��ő�̃~�X�W���b�W�v�ƌ����A����CEO�������|�[���E�I�b�e���[�j��2013�N�Ɉ��ӎ��C��]�V�Ȃ�������ꂽ�B
�V���I�~�̖��i�Ǝv��ʓW�J
�����āA�V���I�~�́A�����̐v����Ѓ��[�h�R�A�Ƒg��ŁAAP�̓��������n�߂�Ɣ��\�����B����ɂ͋������I
�V���I�~���A�A�b�v���̃W���u�Y�Ɠ����悤�ɁA�uAP�𐧂�����̂��X�}�z�𐧂���v�Ƃ������_�Ɏ������킯���B
2015�N�ɂ�1����ȏ�̃X�}�z���o�ׂ���v��ł���BAP�̓���������������A1���ȏ�̃V���I�~��AP�����ɏo�邱�ƂɂȂ�B
����A�X�}�z�pAP�̎���́A���f�B�A�e�b�N����V���I�~�Ɍ�シ��̂�������Ȃ��B
AP(�A�v���P�[�V�����v���Z�b�T)�𐧂�����̂��X�}�z�𐧂���
http://bylines.news.yahoo.co.jp/yunogamitakashi/20150106-00042021/
�C���e���̎���Ƌ��v�̗����T���X���d�q
�X�}�z��AP�̐v�Ɠ��l�ɐ������d�v�ł���B�������A�A�b�v���͔����̗̂ʎY�H��������Ă��Ȃ��B
�����ŃA�b�v���́A����iPhone �p AP�̐������C���e���ɑŐf�����B�Ƃ��낪�C���e���́A�u1��10�h���ł̓r�W�l�X�ɂȂ�Ȃ��v�ƒf���Ă��܂��B
����́A�u�C���e���j��ő�̃~�X�W���b�W�v�ƌ����A����CEO�������|�[���E�I�b�e���[�j��2013�N�Ɉ��ӎ��C��]�V�Ȃ�������ꂽ�B
�V���I�~�̖��i�Ǝv��ʓW�J
�����āA�V���I�~�́A�����̐v����Ѓ��[�h�R�A�Ƒg��ŁAAP�̓��������n�߂�Ɣ��\�����B����ɂ͋������I
�V���I�~���A�A�b�v���̃W���u�Y�Ɠ����悤�ɁA�uAP�𐧂�����̂��X�}�z�𐧂���v�Ƃ������_�Ɏ������킯���B
2015�N�ɂ�1����ȏ�̃X�}�z���o�ׂ���v��ł���BAP�̓���������������A1���ȏ�̃V���I�~��AP�����ɏo�邱�ƂɂȂ�B
����A�X�}�z�pAP�̎���́A���f�B�A�e�b�N����V���I�~�Ɍ�シ��̂�������Ȃ��B
1��10�h���̒�����f������CPU���^�_�Ŕz��H�ڂɁc
�ꐡ��͈ł���
�ꐡ��͈ł���
AP�Ȃ�ڍׂɐ����H���B���Ă�����Ȃ��̂�
>>64
��t���L���Ȃ���
��t���L���Ȃ���
69 �F,,�E�L�́M�E,,�j��-�������F2015/01/10(�y) 10:15:39.53 ID:Lla2Inxv
���ӎ��C����Ȃ��āA���ނ�錾�������Ƃłڂ����ƌ�������Ƃ������Ǝv���B
���d�튯�� ���������v���Z�T�𑁂����
�]�ɖ��ߍ��݂���
�]�ɖ��ߍ��݂���
�f����Ă��Ƃ������B���ʘ_�����݂���������邯�ǁA
�v�����ǂ�ǂ�オ���Ă����Č��ǂׂ͖���O�ɕʂ̉�ЂɂȂ�ꍇ������B
�ł���ł��Ȃ��ł͂Ȃ��āA���݂���Г����\�[�X�ɑ��Ĉ�Ԍ����I��
���v���グ����̂ɐl�ނ�z������̂���B
�C�O���[�J�[�̗��v��20�`30%�ɑ��āA���{���[�J�[�͌o�c�헪���l����̂�
��ς�������ė����d�����Ă��܂����v������P�^��Ƃ��ɂȂ��Ă�B
�v�����ǂ�ǂ�オ���Ă����Č��ǂׂ͖���O�ɕʂ̉�ЂɂȂ�ꍇ������B
�ł���ł��Ȃ��ł͂Ȃ��āA���݂���Г����\�[�X�ɑ��Ĉ�Ԍ����I��
���v���グ����̂ɐl�ނ�z������̂���B
�C�O���[�J�[�̗��v��20�`30%�ɑ��āA���{���[�J�[�͌o�c�헪���l����̂�
��ς�������ė����d�����Ă��܂����v������P�^��Ƃ��ɂȂ��Ă�B
�����Pentium/66MHz���o�Ă������͏���d�͂�9W�����邩��m�[�g�p�\�R��
�Ɏg���Ȃ���A�Ȃ�Ęb�����������̂�
�Ɏg���Ȃ���A�Ȃ�Ęb�����������̂�
�M������
74 �FSocket774�F2015/01/11(��) 15:45:32.02 ID:uQP6yB9z
���܂��Ƀo�b�e���[���j�b�P�����f�Ȃ�ꂵ�����낤��
���`�E���C�I���o�b�e���[�̏o�������ׂĂ�ς���
���`�E���C�I���o�b�e���[�̏o�������ׂĂ�ς���
�̂�Intel�͖{���ɋZ�p�͂��Ȃ�������
Intel���m�[�g�p150MHz Pentium�𓊓�
�m�[�g�p�\�R���̍����\���͂��낻�듪�ł���?
�@��Intel�Ђ��m�[�g�p�\�R���pPentium��150MHz�ł\����ƁA�e�j���[�X�T�C�g����Ăɕn�߂��B
���݂̃m�[�g�p�ō���133MHz�ł\���Ă����5�����A���낻�덂���ł��o�ꂵ�Ă����̕s�v�c���Ȃ��B
�܂��A���łȂǂ́A133MHz��荂����Pentium�ɑΉ����鏀���͂ł��Ă���Ɨ\�����Ă���A�قڂ��̓W�J���B
���C������w
Intel���m�[�g�p150MHz Pentium�𓊓�
�m�[�g�p�\�R���̍����\���͂��낻�듪�ł���?
�@��Intel�Ђ��m�[�g�p�\�R���pPentium��150MHz�ł\����ƁA�e�j���[�X�T�C�g����Ăɕn�߂��B
���݂̃m�[�g�p�ō���133MHz�ł\���Ă����5�����A���낻�덂���ł��o�ꂵ�Ă����̕s�v�c���Ȃ��B
�܂��A���łȂǂ́A133MHz��荂����Pentium�ɑΉ����鏀���͂ł��Ă���Ɨ\�����Ă���A�قڂ��̓W�J���B
���C������w
�g����L���b�V�����g���Ȃ����Đ��\���Ƃ��Ĕ���̂�������`�Ȃ�ł����H
�ނ�����Intel�́A���{���[�J�[�̌݊��i�̂ق��������\�����������
���܂�Intel�Ƃ͈Ⴄ
���܂�Intel�Ƃ͈Ⴄ
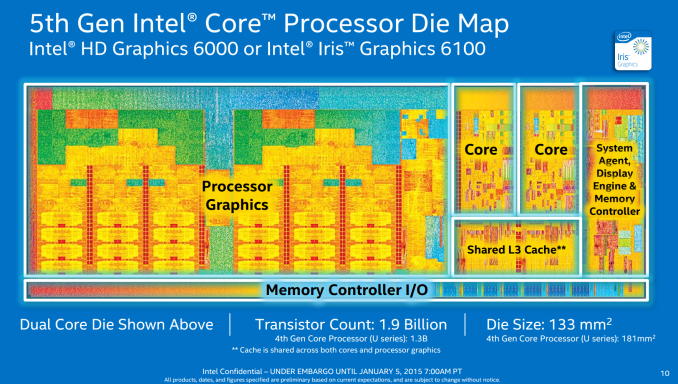
�_�C�T�C�Y��2/3���̂��Ă�S�~GPU�ɋ������Ă�Intel�M�҃��S��������������
http://images.anandtech.com/doci/8814/Slide%2010%20-%20Iris%206100%20Die%20Labelled_678x452.png
http://images.anandtech.com/doci/8814/Slide%2010%20-%20Iris%206100%20Die%20Labelled_678x452.png
{kind=link}
���o�C����soc����cpu�ʐς͑S�̂�1/4����1/6���x�����H
���ꂪ�Ȃɂ��H
���ꂪ�Ȃɂ��H
����ł��A���h��葬�����炵��[�ˁ[�킗
�A���h��Phenom�U�͗ǂ���������
�����܂��܂��J���Ĕ߂�����
�����܂��܂��J���Ĕ߂�����
���̃��o�C��GPU��8800GT���鐫�\������킯������
��ʗp�r�Ȃ�\���������
��ʗp�r�Ȃ�\���������
���Ă������AIntel���ŐV�v���Z�X�Ń~�h�������WGPU�𓋍ڂ��č����グ������
�m�[�gPC���̌^PC�ɊO�t��GPU�Ȃ�ĕK�v�Ȃ��Ȃ��
�ނ��낻�������ړI�̂��̂���
�m�[�gPC���̌^PC�ɊO�t��GPU�Ȃ�ĕK�v�Ȃ��Ȃ��
�ނ��낻�������ړI�̂��̂���
����8800GT�̐��\�ɓ��B���B
���܂����ȁB
���܂����ȁB
���̑O�܂ŃI���{�[�h��HD3200���Ă̂��g���Ă�
>>65
����i810
����i810
�I��NeoMagic
�ƊE�Ő�[��簐i����Intel�̃X���b�h�̏Z�l�Ƃ͎v���Ȃ�������
MDA����
�O���t�B�b�N�H
����Ȃ̒m��ˁ[�����ēz�͂������ɂ��Ȃ���
�O���t�B�b�N�H
����Ȃ̒m��ˁ[�����ēz�͂������ɂ��Ȃ���
���F�I���_�C��GPU�����Ȃ��c
��������GPU�ɎアIntel�̂������I���_�C�����猾���ɋy�����낗
����ł��A��T�̃Q�[���͗V�ׂ��Ⴄ��ˁB�B�B
��������GPU�ɎアIntel�̂������I���_�C�����猾���ɋy�����낗
����ł��A��T�̃Q�[���͗V�ׂ��Ⴄ��ˁB�B�B
1740
GMA950�̎��ォ�炵���璷���̐i������
8800GT 57.6GB/s�A4core i7 (25.6-��)GB/s
iGPU�̐��\�������̐l�ɂƂ��ď\�������鐫�\�ɂȂ����̂͂킩���Ă邯�ljߋ��̐��i�Ɣ�ׂĂ��ꂪ�����\�ȂƎ����Ɍ����������Ă�悤�ɂ��������Ȃ�
8800GT 57.6GB/s 256�`1024MB
GT3e (51.2+51.2)GB/s 128MB�A (25.6-��)GB/s
GT3e (51.2+51.2)GB/s 128MB�A (25.6-��)GB/s
���炽�߂Ă݂�Ƒш���������ɂȂ��Ă�Ȃ�
GT3e�̃L���b�V����1�`�b�v�ł����܂ł̐��\���Ă��Ƃ���
GT3e�̃L���b�V����1�`�b�v�ł����܂ł̐��\���Ă��Ƃ���
>>94
���ǂ��A�ŐV�O�t��GPU���K�v�Ȋ����ĂȂɂ�H���ĂȂ�킯��
����GPU������ݗ��̂RD�Q�[�������ʂɗV�ׂĂ��܂��Ƃ����Ƃ��낪�܂������Ƃ�������
���̂�����̉��b�̓m�[�gPC�g���̂ق����͂�����̊��ł����łȂ�����
���ǂ��A�ŐV�O�t��GPU���K�v�Ȋ����ĂȂɂ�H���ĂȂ�킯��
����GPU������ݗ��̂RD�Q�[�������ʂɗV�ׂĂ��܂��Ƃ����Ƃ��낪�܂������Ƃ�������
���̂�����̉��b�̓m�[�gPC�g���̂ق����͂�����̊��ł����łȂ�����
���Ȃ�>>78�����Ċ������邯�ǂȂ�
����Intel���w�e���W�j�A�X�R���s���[�e�B���O����˓�����
����Intel���w�e���W�j�A�X�R���s���[�e�B���O����˓�����
CPU�J�����ǂ�l�܂�Ȃ�����GPU���t�����e�B�A�Ƃ����̂܂ł͗����ł���
��𐧌䂷��r�b�O�R�A�Ǝ��s�����̃X���[���R�A�B
�r�b�O�R�A�͐������~�܂����̂Ŏ��s����������Ă銴�����ȁB
���Z���C�u���������낦�X���[���R�A�ł��\���킦��B
�������ϑԃA�[�L�͏����B
�r�b�O�R�A�͐������~�܂����̂Ŏ��s����������Ă銴�����ȁB
���Z���C�u���������낦�X���[���R�A�ł��\���킦��B
�������ϑԃA�[�L�͏����B
iGPU���\�́Aweb�E�I�t�B�X�E����Ȃ�Sandy�����ŏ\�������A
�{�i3D�Q�[���ɂ�Haswell�����ł�����Ȃ��A
�ǂ��ɂ����r���[�Ȑ��\�����Ȃ����
�{�i3D�Q�[���ɂ�Haswell�����ł�����Ȃ��A
�ǂ��ɂ����r���[�Ȑ��\�����Ȃ����
GPU�̓I���R���B
��������FPGA�ڂ���B
��������FPGA�ڂ���B
�ϑԃA�[�L��NG
Intel�̓V�������N�������ʐς��ǂ�ǂ�iGPU�ɓ˂�����ł邯��
���낻��iGPU�̃A�[�L�e�N�`�������V���Ă���̂���
���낻��iGPU�̃A�[�L�e�N�`�������V���Ă���̂���
�l�I�ɂ̓O���t�B�b�N�������ł���Atom�ɂȂ��Ăق����BPhi�̃~�j�ł݂����ȁB
�ŋ�72�R�A�˂����ނ��Ƃɐ������������ŁA16�R�A���x�悹��I�t�B�X�ɂ͖��Ȃ����x���ɂȂ��Ăق����B
�ŋ�72�R�A�˂����ނ��Ƃɐ������������ŁA16�R�A���x�悹��I�t�B�X�ɂ͖��Ȃ����x���ɂȂ��Ăق����B
Phi�̃\�P�ň������肢
�������̓������܂߂�all���t���}�U�[
�������̓������܂߂�all���t���}�U�[
>>102
�t���[�\�t�g�Ȃ�ʁA�t���[�R���t�B�O�f�[�^���z�z����鎞�ォ�B
�����M���ȁB
��`���A��������A�������RTL�������Ⴄ���`�B
�t���[�\�t�g�Ȃ�ʁA�t���[�R���t�B�O�f�[�^���z�z����鎞�ォ�B
�����M���ȁB
��`���A��������A�������RTL�������Ⴄ���`�B
���ۂ̂Ƃ���ЂƂ̃I���_�CFPGA�̈�ňÍ������E�n�b�V�������E�摜���批��CODEC�c
���X�S���܂��Ȃ��A�V�K�p�r���A���S���Y���̓R���t�B�O�f�[�^�A�b�v�f�[�g���Ă����̂͂��蓾�Ȃ��̂��˂�
���X�S���܂��Ȃ��A�V�K�p�r���A���S���Y���̓R���t�B�O�f�[�^�A�b�v�f�[�g���Ă����̂͂��蓾�Ȃ��̂��˂�
�Í��E�n�b�V����CPU�ɐ�p���߂̂������ق�������
����CODEC�Ȃ��GPU�ɂ��̋@�\�̂������ق�������
����CODEC�Ȃ�Ă��܂�CPU�Ȃ�\�t�g�E�F�A�ŗ]�T�ŏ�������̂ŗ]�v�Ȃ̂ɗ���K�v�Ȃ�
�L�����y���Ă���̂��g������AFPGA�Ōv�Z�Ƃ��͕s�v�Ȃ�H
�ނ���FPGA�́A�C���^�t�F�[�X�����Ɏg���̂�������ˁH
�g���J�[�h�ɂ����ȏ����̐�p�`�b�v����邪�A������PC�̃C���^�t�F�[�X������
FPGA�ō���Ă��Ƃ���
����CODEC�Ȃ��GPU�ɂ��̋@�\�̂������ق�������
����CODEC�Ȃ�Ă��܂�CPU�Ȃ�\�t�g�E�F�A�ŗ]�T�ŏ�������̂ŗ]�v�Ȃ̂ɗ���K�v�Ȃ�
�L�����y���Ă���̂��g������AFPGA�Ōv�Z�Ƃ��͕s�v�Ȃ�H
�ނ���FPGA�́A�C���^�t�F�[�X�����Ɏg���̂�������ˁH
�g���J�[�h�ɂ����ȏ����̐�p�`�b�v����邪�A������PC�̃C���^�t�F�[�X������
FPGA�ō���Ă��Ƃ���
�v�Z�������܂��Ă鏈����ASIC�̕��������I������˂��B
�ʐM�n�͏���d�͂̊W��ASIC����B
FPGA��GPGPU��H���Ă��܂��\���͂����Ă�ASIC�Ƃ͎s�ꂪ�Ⴄ�B
�ʐM�n�͏���d�͂̊W��ASIC����B
FPGA��GPGPU��H���Ă��܂��\���͂����Ă�ASIC�Ƃ͎s�ꂪ�Ⴄ�B
�Z��������SSD�Ԃ�����OS�C���X�R�o�N��
�}�U�[�Ɠ������ė~������
���̃}�U�[�̓f�U�C�����Â���
���̃}�U�[�̓f�U�C�����Â���
CPU������͂����}�U�[���t���ł�����B
�}�U�[���t���Ȃ�A���C����������GDDR5�Ƃ����ш惁��������Ȃ���
���������}�U�[���t���ŁADDR3�Ƃ��Ӗ����Ȃ�������
���������}�U�[���t���ŁADDR3�Ƃ��Ӗ����Ȃ�������
���C���[�h���W�b�N�̐�p���߂���h265�Ή���opus���V�K�i�Ή���1-2����ȏ�x���킯��
���A���ڂ��Ă��ė~�����̂�2����x���Ƃ��c�Ɛ헪�Ƃ��Ă������蓾�Ȃ�����ɂȂ�
������CPU�ŏ\���Ƃ����ӌ��́ACPU�̃A�N�e�B�u���Ԃ�1%��L����̂�0.01%��L���Ă����Q��̂��A
�Ńo�b�e���[�������Ԃ��傫���ς���Ă��܂��̂ŏ\���Ȃ�Ă������͖���
���A���ڂ��Ă��ė~�����̂�2����x���Ƃ��c�Ɛ헪�Ƃ��Ă������蓾�Ȃ�����ɂȂ�
������CPU�ŏ\���Ƃ����ӌ��́ACPU�̃A�N�e�B�u���Ԃ�1%��L����̂�0.01%��L���Ă����Q��̂��A
�Ńo�b�e���[�������Ԃ��傫���ς���Ă��܂��̂ŏ\���Ȃ�Ă������͖���
�_�C�i�~�b�N���R���t�B�M�����u����H�Z�p�@VME(Virtual�@Mobile�@Engine)�@SONY
�i�L��2005�N�@���p��2002�N�`�j
ttp://pc.watch.impress.co.jp/docs/2005/0506/gyokai122.htm
�i�L��2005�N�@���p��2002�N�`�j
ttp://pc.watch.impress.co.jp/docs/2005/0506/gyokai122.htm
Nintendo64���o�ꂵ�����냊�A���e�B�G���W���Ƃ�����p��H��CPU�����ڂ����R���Z�v�g��
�`�b�v���������ł���
����ɋߕt�������
�`�b�v���������ł���
����ɋߕt�������
>>115
�V�K�i�͂���Ȃɂ����ɕ��y���Ȃ�
H265�����y����̂́A�̔�����Ă�PC�E�X�}�z���S��H265�̃n�[�h�E�F�A�Đ��ɑΉ���������ł��傤
�V�K�i�͂���Ȃɂ����ɕ��y���Ȃ�
H265�����y����̂́A�̔�����Ă�PC�E�X�}�z���S��H265�̃n�[�h�E�F�A�Đ��ɑΉ���������ł��傤
��Intel�A10-12�����͏����v39%���APC�s��͂������Ɖ�
http://news.mynavi.jp/news/2015/01/16/108/
http://news.mynavi.jp/news/2015/01/16/108/
����4000���o�ׂ̖ڕW�͒B�������̂�
���[�J�[�����㍂147���h���ŏ����v37���h�����āc�c
�قړƐ�ɂȂ��ĉ��炪�ǂ��{����Ă邩���Ă悭�����鐔������
�قړƐ�ɂȂ��ĉ��炪�ǂ��{����Ă邩���Ă悭�����鐔������
�^�u���b�g�����{����Ȃ���
�ڂ��������Ă�̂������Ȃ�Aatom�X�}�z�Ƃ�atom�^�u�������������
Intel���g�K����Ĕ����Ă邩���
Intel���g�K����Ĕ����Ă邩���
�Ƃ肠�����������p�b�h�̈�̓s���ō팸�ł��Ȃ��ׂɁA�c��ڂ͑�ʂɗ]���Ă�̂�
���\�����o�b�e���[�쓮���Ԃɒ�������悤�ȃw�r�[���[�N�ɐ�p�V���R��������
�]�T�����͂�����Ă��Ƃ���
���\�����o�b�e���[�쓮���Ԃɒ�������悤�ȃw�r�[���[�N�ɐ�p�V���R��������
�]�T�����͂�����Ă��Ƃ���
���Ђ�GPGPU�ŒB�����悤�Ƃ��Ă鐫�\��MMX�`AVX2�̗���̉�������ŒB���ł���Ȃ�iGPU�͕`��ɐ�O�ł���A�[�L�e�N�`���ɂł���Ǝv��
�����������āA�݂͖݉��Ȃ�ˁB
>>126
�i256bit�ȁjAVX���p�Ń_�E���N���b�N����d�l���炷��ƁA���̂܂܊g���ł���̂��ȁH���ĐS�z�͂��邯��
�R�A�͍��ȏ�ɑ��������ɂȂ�������ɂ͂Ȃ�Ȃ��̂��ȁB
�ǂ��Ȃ�낤���B
�i256bit�ȁjAVX���p�Ń_�E���N���b�N����d�l���炷��ƁA���̂܂܊g���ł���̂��ȁH���ĐS�z�͂��邯��
�R�A�͍��ȏ�ɑ��������ɂȂ�������ɂ͂Ȃ�Ȃ��̂��ȁB
�ǂ��Ȃ�낤���B
129 �FSocket774�F2015/01/16(��) 22:18:08.33 ID:XicG24j4
skl��knl�ł�avx512�ɂȂ�
gpgpu?�Ȃɂ��ꂨ�������́H
gpgpu?�Ȃɂ��ꂨ�������́H
���Ԃ�A���܂���������Ȃ���
���������Ȃ��Ȃ�_�C�T�C�Y�̔������炢�g�������eDRAM�t����iGPU�̋����Ƃ����Ȃ���
GPGPU���������Ȃ��Ǝ��ʂ���ǂ����悤���Ȃ�
GPGPU���������Ȃ��Ǝ��ʂ���ǂ����悤���Ȃ�
�ʂ�GPGPU�̐��\���~�����������Ă��Ȃ���
�����ʐς������Ă郉�b�v�g�b�v�Ƃ��ȃX�y�[�X�f�X�N�g�b�v��dGPU��邽�߂ɂ���Ă��ł���
�����ʐς������Ă郉�b�v�g�b�v�Ƃ��ȃX�y�[�X�f�X�N�g�b�v��dGPU��邽�߂ɂ���Ă��ł���
�Q�t�H�ς�łȂ�Intel�Ƃ�APU�ɎE����邾������
���͗ǂ��Ă��A�Q�t�H�r������ق�iGPU��������A����O��ŃQ�[���⓮��n��OpenCL�\�t�g����Ă�����
�������爳�|�I�ɋ��͂�Radeon�ς�APU�ɑR�ł���킯���Ȃ�
���͗ǂ��Ă��A�Q�t�H�r������ق�iGPU��������A����O��ŃQ�[���⓮��n��OpenCL�\�t�g����Ă�����
�������爳�|�I�ɋ��͂�Radeon�ς�APU�ɑR�ł���킯���Ȃ�
�u���X���ł��
�g�ݗ��Ă₷����APU�̕����ゾ��
i7�͔{���炢�Ⴄ
i7�͔{���炢�Ⴄ
�ނ���ėp�v���Z�T�̎���͏I���C���ꂩ��͖ړI���Ƃɂ�������p�v���Z�T���g�������鎞��ɂ܂�����̂��낤�B
����������p�Ƃ�
����������p�Ƃ�
�ėpCPU���n�C�y�[�X�Ő��\���サ�Ă�ΐ�p���W�b�N�̏o�Ԃ�
���Ȃ��̂����A�݂��Ă��邩��ȁ[
���Ȃ��̂����A�݂��Ă��邩��ȁ[
Latest Intel Graphics Drivers Enhanced for 4th gen and 5th gen Core Processors | techPowerUp
http://www.techpowerup.com/208950/latest-intel-graphics-drivers-enhanced-for-4th-gen-and-5th-gen-core-processors.html
Benefits of updating to this driver include addition of partial hardware acceleration for the VP9 video format, GPU accelerated decode of HEVC video format
http://www.techpowerup.com/208950/latest-intel-graphics-drivers-enhanced-for-4th-gen-and-5th-gen-core-processors.html
Benefits of updating to this driver include addition of partial hardware acceleration for the VP9 video format, GPU accelerated decode of HEVC video format
�f�X�N�g�b�v�pCPU��iGPU���\�Ȃ�đ��₷�Ӗ������ł����ˁH
>>136
���������Ȃ�avx�����肪�ȊO�Ƃ������C�������
���������Ȃ�avx�����肪�ȊO�Ƃ������C�������
�Ȃ���ˁB
�ł�CPU�R�A������ɑ��₵���猸�炷���Ƃ��ł��Ȃ����炵�Ȃ��낤�ˁB
Phi�̓����Ƃ����v�����̈�Ƃ��Ďc���Ă邩������Ȃ����B
�ł�CPU�R�A������ɑ��₵���猸�炷���Ƃ��ł��Ȃ����炵�Ȃ��낤�ˁB
Phi�̓����Ƃ����v�����̈�Ƃ��Ďc���Ă邩������Ȃ����B
�ނ��뒲��������Ƃ����������Ȃ�
�ĊO�t�@�u�ғ�����ɁAiGPU�ł������Ė��ʂɃr�b�O�_�C�ɂ��Ă��ˁH���ċC�������
�{���A��ʃf�X�N�g�b�v�p�r����iGPU���x���₵�Ă�����s���ӂ���킯����Ȃ��̂ŁA
iGPU�Ɋ����ʐς����������Đ��Y�R�X�g���������ق�������
�Ƃ��낪�A��v�I�ɂ͂������ăt�@�u�ғ�����������ƁA
�������������߂��āA�{�����Y�R�X�g�����ăR�X�g�����͏オ�����̂ɁA
��v��͑������o�����肷�邩���
�{���A��ʃf�X�N�g�b�v�p�r����iGPU���x���₵�Ă�����s���ӂ���킯����Ȃ��̂ŁA
iGPU�Ɋ����ʐς����������Đ��Y�R�X�g���������ق�������
�Ƃ��낪�A��v�I�ɂ͂������ăt�@�u�ғ�����������ƁA
�������������߂��āA�{�����Y�R�X�g�����ăR�X�g�����͏オ�����̂ɁA
��v��͑������o�����肷�邩���
�Ȃ�����iGPU���������p�r�𑝂₷�ׂ����Ǝv�����ǁA
Intel�͑S�RGPGPU�ɗ͓���ĂȂ���ȁB
Intel�͑S�RGPGPU�ɗ͓���ĂȂ���ȁB
GPU�ӂ���x86�v���Z�b�T��Phi�����Ă�I
GPGPU�Ƃ��Ďg���������ǁAOpenCL�Ή����i��ł���̂ł���ŏ\�����Ȃ�
HSA�����̋@�\�����N���ɐ��荞�ނ��Ęb�����������ǁA
�������͏o����g�����炢�ōl���Ă�ΊԂɍ�����
HSA�����̋@�\�����N���ɐ��荞�ނ��Ęb�����������ǁA
�������͏o����g�����炢�ōl���Ă�ΊԂɍ�����
GPGPU�Ɋւ��Ă͊��ɗL���ȕ���ł͏\�Ɋ��p����Ă�킯�ł���(CUDA���o�Ă����������8�N��)
�҂ĂǕ�点�ǃR���V���[�}�����A�v���̑唼��GPGPU�Ō��I�ɍ����������悤�Ȏ���͗��Ȃ�
������R���V���[�}������CPU��GPGPU���\���C���Z���e�B�u�ɂȂ邱�Ƃ͐�ɂȂ�
����Ɏ��s�ł��Ȃ��������A����Ɏ��s����邱�Ƃ́A�i���ɂȂ��̂��B
�҂ĂǕ�点�ǃR���V���[�}�����A�v���̑唼��GPGPU�Ō��I�ɍ����������悤�Ȏ���͗��Ȃ�
������R���V���[�}������CPU��GPGPU���\���C���Z���e�B�u�ɂȂ邱�Ƃ͐�ɂȂ�
����Ɏ��s�ł��Ȃ��������A����Ɏ��s����邱�Ƃ́A�i���ɂȂ��̂��B
>>148
�܁A�����������Ƃ��낤�ˁB
8�N���o���āA�ǂ������p�r�Ŋ��p�ł��邩�Ƃ��������͂���s�����A
��ʌ����ɂ͌��ǃO���t�B�b�N�X�p�r���قƂ�ǂƂ����I�`�ɁB
�܁A�����������Ƃ��낤�ˁB
8�N���o���āA�ǂ������p�r�Ŋ��p�ł��邩�Ƃ��������͂���s�����A
��ʌ����ɂ͌��ǃO���t�B�b�N�X�p�r���قƂ�ǂƂ����I�`�ɁB
CUDA�̓������ш悪�l�b�N�Ȃ��������
�������o�E���h�͑�����ǂ��܂ł�
152 �FSocket774�F2015/01/17(�y) 17:37:09.23 ID:1vcCaUPW
avx�ł���قƂ�ǎg���ĂȂ��̂ɂ�
gpgpu�Ƃ�����
gpgpu�Ƃ�����
Linux�Ȃ��{���C�u�����ł��傱���傱avx�R�[�h�����Ă邩��A
���[�U�[�̃v���O������avx����Ȃ��Ă��A
�ӂ��Ƀ��C�u�����Ăяo������avx�œ������肷���
���[�U�[�̃v���O������avx����Ȃ��Ă��A
�ӂ��Ƀ��C�u�����Ăяo������avx�œ������肷���
���������Ӗ��ł�HSA�͊��҂��Ă��܂��B
glibc�Ŏg���Ă�AVX����memcpy�Ƃ�strcmp�Ƃ�GPGPU�Ƃ͑S�����W�̗̈�ł���
AVX�̃\�t�g�J���i�߂���GPGPU�Ή����i��ł��܂���APU�̐�`�Ɍq���邩���
���ꂶ��}�Y�C����Intel�Ƃ��Ă�AVX��iGPU�̃\�t�g�J����i�߂����͂Ȃ����낤��
���������������Z��̂ŃI�}�P��AVX�g�����炢���낤
iGPU���ă������g�p�ʂ�1G�Ƃ������Ȃ��āACPU�Ƃ̘A�g���������A�h���X���ʂŖʓ|�����牉�Z�����Ƃ��ăC�}�C�`������
HSA��OpenCL2.0���ƁA�A�h���X�����L�ɂȂ��ă��C���������S�̂��g���ĘA�g���ł��邩��A�y���Ɏg���₷���Ȃ�
����������A�摜��������_�����O�Ƃ���GPGPU�Ή����₷���Ȃ��Ă���
Photoshop��CINEBENCH�̃G���W���Ƃ��͑Ή����₷����
���ꂶ��}�Y�C����Intel�Ƃ��Ă�AVX��iGPU�̃\�t�g�J����i�߂����͂Ȃ����낤��
���������������Z��̂ŃI�}�P��AVX�g�����炢���낤
iGPU���ă������g�p�ʂ�1G�Ƃ������Ȃ��āACPU�Ƃ̘A�g���������A�h���X���ʂŖʓ|�����牉�Z�����Ƃ��ăC�}�C�`������
HSA��OpenCL2.0���ƁA�A�h���X�����L�ɂȂ��ă��C���������S�̂��g���ĘA�g���ł��邩��A�y���Ɏg���₷���Ȃ�
����������A�摜��������_�����O�Ƃ���GPGPU�Ή����₷���Ȃ��Ă���
Photoshop��CINEBENCH�̃G���W���Ƃ��͑Ή����₷����
157 �FSocket774�F2015/01/18(��) 04:44:45.01 ID:LwN7fQCY
�����Ȃ��܂�
�z���g�o�J��SIMD��GPGPU�̈Ⴂ��������Ȃ��ȁB
GPGPU��MIMD������i�k����
mimd����ˁ[��
1�v�f���X���b�h�Ƃ������Ă邯��
���Ǘ��x�ł�����simd
1�v�f���X���b�h�Ƃ������Ă邯��
���Ǘ��x�ł�����simd
4�N�Ԃ�CPU�̐i��
�� Pen2 233MHz��Pen3 1GHz
�� 2600K��4790K
�����i�т�CPU���ƁA2600K��4690K
�����CPU�����ւ�����Ă����Ă��ǂ�����H
�ނ����Ȃ�P�N�̐��\����̃��x����4�N�������ĒB�����Ă�
�� Pen2 233MHz��Pen3 1GHz
�� 2600K��4790K
�����i�т�CPU���ƁA2600K��4690K
�����CPU�����ւ�����Ă����Ă��ǂ�����H
�ނ����Ȃ�P�N�̐��\����̃��x����4�N�������ĒB�����Ă�
�v���O���}�ɂ��Ă݂���CPU�������g����GPU���g��Ȃ̂���Ԋy�ȂB
�ł�AMD��CPU�͐��\���Ⴂ����GPU���g���ĕ���Ăق������ǁA�g���ɂ�������
�撣���ă��������L���������Ęb��CPU�̐��\��������Ώd�v�ł͂Ȃ��B
�����������p�������L���Ă���CPU��GPU�̐�ւ��x�������邩�琫�\�I�ɂ�
�����܂�ς��Ȃ���Ȃ��́B
�ł�AMD��CPU�͐��\���Ⴂ����GPU���g���ĕ���Ăق������ǁA�g���ɂ�������
�撣���ă��������L���������Ęb��CPU�̐��\��������Ώd�v�ł͂Ȃ��B
�����������p�������L���Ă���CPU��GPU�̐�ւ��x�������邩�琫�\�I�ɂ�
�����܂�ς��Ȃ���Ȃ��́B
�������W�X�^���t���Ɏg���R���p�C�����Ƃ����g��Ȃ��ƃt���p���͏o�Ȃ�
�ǂ݂̂��قƂ�ǂ̃v���O���}�[�͂��������̈ӎ������ɂ��ă��C�u�����[�g�����炻�̒��ŏ���ɑ����Ȃ���Č`�Ȃ��ǁA���C�u�����[����鑤���炷��Ƃ��ꂪ�ǂꂾ������Ėׂ��邩���d�v������ŏ����猋�_�͂͂����肵�Ă��ˁB
�ʏ�g�p���̏���d�͂����Ȃ茸���Ă�̂́@�m�������ǁA
������A�t���E���[�h���̏���d�͂͂��܂茸���ĂȂ������
���ꂪ�l�b�N�ŁA���\�グ���Ȃ���
���M�Ŕj�]����B
������A�t���E���[�h���̏���d�͂͂��܂茸���ĂȂ������
���ꂪ�l�b�N�ŁA���\�グ���Ȃ���
���M�Ŕj�]����B
�펞�x���`�Ă��ł�����܂�
>>162
���C���������S�̂��g���āACPU�Ƌ��ʂ̃|�C���^���g���āA�ш��C�e���V�����{����q�g�����炢�����\�ɂȂ��GPGPU���g���₷���Ȃ邾��
GPU�ɂ��V���v�������ǃX�J�����j�b�g�t���Ă邩��A�Œ���̕��������Z�Ȃ�GPU�������ŏ����ł���
��������CPU�����Ŏ������Ȃ�GPGPU�g�����Ȃ�ĒN������Ȃ����A�ꂪ�m��Ă�Ȃ璼���ɘb��ɂȂ�Ȃ��Ȃ邾��
�\���ɂ�������炸10�N�ȏ�GPGPU�Ɋ��҂���GPU���[�J�[�S���������������Ă�̂́A���ꂾ���̉��l�����邩��ł�
����Intel�������t����Ă�����ǁA�A�h���X���L�̎d�g�݂�J�����͉��P����Ă�������A���̂����ǂ��ɂ��Ȃ�Ȃ��Ȃ肻��������
���C���������S�̂��g���āACPU�Ƌ��ʂ̃|�C���^���g���āA�ш��C�e���V�����{����q�g�����炢�����\�ɂȂ��GPGPU���g���₷���Ȃ邾��
GPU�ɂ��V���v�������ǃX�J�����j�b�g�t���Ă邩��A�Œ���̕��������Z�Ȃ�GPU�������ŏ����ł���
��������CPU�����Ŏ������Ȃ�GPGPU�g�����Ȃ�ĒN������Ȃ����A�ꂪ�m��Ă�Ȃ璼���ɘb��ɂȂ�Ȃ��Ȃ邾��
�\���ɂ�������炸10�N�ȏ�GPGPU�Ɋ��҂���GPU���[�J�[�S���������������Ă�̂́A���ꂾ���̉��l�����邩��ł�
����Intel�������t����Ă�����ǁA�A�h���X���L�̎d�g�݂�J�����͉��P����Ă�������A���̂����ǂ��ɂ��Ȃ�Ȃ��Ȃ肻��������
�t����ĂȂ��ł���B
�w�e���������̃�������Ԃ̋��L�Ƃ��L���b�V���R�[�q�[�Ȃ����ċ@�\���������Ă邵
�g���̂�Phi��iGPU�̈Ⴂ������
�w�e���������̃�������Ԃ̋��L�Ƃ��L���b�V���R�[�q�[�Ȃ����ċ@�\���������Ă邵
�g���̂�Phi��iGPU�̈Ⴂ������
�g���������肻���Ȃ̂�hpc���炢�Ȃ����
����ȊO�͂���܂ł�8�N��nv��gtc�Ŕ��\����悤�Ȃ��̂����Ȃ�
phi��gpu����Ȃ��đ�^simd�Ή���cpu
�ʔ����̂�nv�����Ȃ��Ƃ����ۂ̏����i�K�ł̗��x������܂ł�32����4�ɂ��悤�Ƃ��Ă��邱��
����ȊO�͂���܂ł�8�N��nv��gtc�Ŕ��\����悤�Ȃ��̂����Ȃ�
phi��gpu����Ȃ��đ�^simd�Ή���cpu
�ʔ����̂�nv�����Ȃ��Ƃ����ۂ̏����i�K�ł̗��x������܂ł�32����4�ɂ��悤�Ƃ��Ă��邱��
Phi�͌���x86������R�q�[�����g���͑��݂��Ȃ�
iGPU�������Ċ��p���镗���ɂȂ�����A����ɏ���AMD�q�Â����邱�ƂɂȂ�
���ꂪ���邩��intel�́A�\�����������Ă�悤�Ɍ��������āA�h���C�o�Ƃ��������Ȃ���iGPU���p�̑������������Ă���
iGPU�������Ċ��p���镗���ɂȂ�����A����ɏ���AMD�q�Â����邱�ƂɂȂ�
���ꂪ���邩��intel�́A�\�����������Ă�悤�Ɍ��������āA�h���C�o�Ƃ��������Ȃ���iGPU���p�̑������������Ă���
172 �FSocket774�F2015/01/18(��) 21:59:48.66 ID:LwN7fQCY
ivy�ȍ~��igpu��h.265�̃f�R�[�h�����܂����H
���[�U�[��CPU��GPU���g�������Ă���Intel�ɖ]��ł���̂�iGPU�̋�������CPU�̋����ł���B
GPU������Ȃɑf���炵���Ȃ牽��XEON�̏�ʃ��f����OPTERON�ɂ�GPU�t���ĂȂ��B
GPU������Ȃɑf���炵���Ȃ牽��XEON�̏�ʃ��f����OPTERON�ɂ�GPU�t���ĂȂ��B
���߂����玀��ł܂�����������Ȃ�����˂�
Intel�������\�����������AMD������
�Ƃ��낪�A���\�グ�Ȃ����甃���ւ����v�����܂�Ȃ�
���܂܂ł́APC��2�`3�N�Œ�X�y�b�N�ɂȂ蔃���ւ���Ȃ�MB/CPU�����̂�������O���������A
���܂�Sandy�ȍ~��PC�����Ă�X�y�b�N���Ŕ����ւ���K�v������
�̏Ⴗ��܂Ŏg������
�Ƃ��낪�A���\�グ�Ȃ����甃���ւ����v�����܂�Ȃ�
���܂܂ł́APC��2�`3�N�Œ�X�y�b�N�ɂȂ蔃���ւ���Ȃ�MB/CPU�����̂�������O���������A
���܂�Sandy�ȍ~��PC�����Ă�X�y�b�N���Ŕ����ւ���K�v������
�̏Ⴗ��܂Ŏg������
�ƂĂ�����Ȃ�����8K���j�^6�ʍ\���������ł���̂�AMD�����ł���
�V���R�������]���Ă�C���e�����ł��Ȃ��������Ȃ��B
Intel Confirms Skylake in 2H 2015 - 10nm Still Far Off
http://wccftech.com/intel-confirms-skylake-2h-2015-10nm/
http://wccftech.com/intel-confirms-skylake-2h-2015-10nm/
Intel�̓���GPU��PS4����͉̂��N�ォ�HPart3
http://anago.2ch.net/test/read.cgi/jisaku/1421128423/
http://anago.2ch.net/test/read.cgi/jisaku/1421128423/
����x�������
182 �FSocket774�F2015/01/20(��) 08:23:46.04 ID:ggrHpzI9
>>170
���N�̃G�N�T�X�P�[���Ɍ����Ă̖��_�����Ă��Ƃ��ɂ���������
32�v�f���Ɩ��ʂȃp�X�iwarp���ɕʂ̌v�Z������v����X���b�h�i�v�f�j�����荞�ޏꍇ�j����������
�d�͓I�ɂ��܂��낵���Ȃ��Ƃ̂���
���ƃ��W�X�^�t�@�C���̊K�w�����Ă̂�������
�����̓r���E�_���[�̌������e�ɉ��������\���낤
https://research.nvidia.com/publication/hierarchical-thread-scheduler-and-register-file-energy-efficient-throughput-processors
A Hierarchical Thread Scheduler and Register File for Energy-Efficient Throughput Processors
���N�̃G�N�T�X�P�[���Ɍ����Ă̖��_�����Ă��Ƃ��ɂ���������
32�v�f���Ɩ��ʂȃp�X�iwarp���ɕʂ̌v�Z������v����X���b�h�i�v�f�j�����荞�ޏꍇ�j����������
�d�͓I�ɂ��܂��낵���Ȃ��Ƃ̂���
���ƃ��W�X�^�t�@�C���̊K�w�����Ă̂�������
�����̓r���E�_���[�̌������e�ɉ��������\���낤
https://research.nvidia.com/publication/hierarchical-thread-scheduler-and-register-file-energy-efficient-throughput-processors
A Hierarchical Thread Scheduler and Register File for Energy-Efficient Throughput Processors
����d�͂�����̐��\���g�����h�ɂȂ��IPC���Ȃ�������ɂ���鎞�オ����������
�����ł��������͌��E�ɂ��Ă邵
�����ł��������͌��E�ɂ��Ă邵
�f�ޓI�Ɍ��E������˂��B�����Ƀu���[�N�X���[�������ƌ���ێ�����ȁB
CNT��V���Z���͂ǂ��܂Ŏg����̂��Ȃ�
186 �F,,�E�L�́M�E,,�j��-�������F2015/01/20(��) 23:03:40.42 ID:dzC45vre
�g�����W�X�^�A���Ȃ킿�^��ǂ���f�q����邵���ȁ[��
>>186
���ꂩ��̓v���O���}�[�������Č������Ƃ��������A��ւ��ăV�X�e���J�����邵�����\����͌����߂Ȃ��킯���B
���ꂩ��̓v���O���}�[�������Č������Ƃ��������A��ւ��ăV�X�e���J�����邵�����\����͌����߂Ȃ��킯���B
189 �F,,�E�L�́M�E,,�j��-�������F2015/01/21(��) 00:06:52.51 ID:VYIs1nCh
�܂��Y���Ă�Ȃ��̂��������
�x���\�t�g�̐l�����Ȃł���
���R�Ȕ��z����ł����C�m�x�[�V�����͐��܂�Ȃ�
�����ϔO�ł��a�Ŏ��߂Ă����܂�
�x���\�t�g�̐l�����Ȃł���
���R�Ȕ��z����ł����C�m�x�[�V�����͐��܂�Ȃ�
�����ϔO�ł��a�Ŏ��߂Ă����܂�
>>189
�ނ�Ƀ}�W���X(�L�E�ցE`)
�ނ�Ƀ}�W���X(�L�E�ցE`)
���������͗ʎq�����o�C�I�R���s���[�^�̗̈悶��Ȃ��̂�
���{�̏ꍇ�v���O���}�̑ҋ��������D�G�Ȑl��SE�Ƃ��ɂȂ�̂ŁA
�D�G�ȃv���O���}�̊m�ۂ����
�D�G�ȃv���O���}�̊m�ۂ����
�n�[�h�͑傫���A�\�t�g�͏������B
��Ԃ̃C�m�x�[�V�����͓��{�ŊJ�����Ȃ�������ˁH
�C�m�x�[�V�����͋��炩��B
���܂���IT�ł��Ȃ���҂���������B
���܂���IT�ł��Ȃ���҂���������B
>>195
���ʂ��̂悤�� ,,�E�L�́M�E,,�j��-��������n�O�����܂ꂽ�̂��c
���ʂ��̂悤�� ,,�E�L�́M�E,,�j��-��������n�O�����܂ꂽ�̂��c
�c�q����͂ł��������B
198 �F,,�E�L�́M�E,,�j��-�������F2015/01/21(��) 01:27:37.85 ID:VYIs1nCh
GPGPU�i�j�Ȃ�Ă����F���ꂾ��
�\�t�g�J�����l�C��p�łǂ��ɂł��Ȃ�Ǝv���Ă��Ӄo�JSIer�̔��z�Ɠ���
��l���w���o���đS�������������������Ȃ��āA�X�ɍl���ē�����
CPU�I�ȃv���O���}���K�v�Ȃ�
�\�t�g�J�����l�C��p�łǂ��ɂł��Ȃ�Ǝv���Ă��Ӄo�JSIer�̔��z�Ɠ���
��l���w���o���đS�������������������Ȃ��āA�X�ɍl���ē�����
CPU�I�ȃv���O���}���K�v�Ȃ�
phi������������ƃV�������N�����Ȃ��B
200 �F,,�E�L�́M�E,,�j��-�������F2015/01/21(��) 02:07:46.06 ID:VYIs1nCh
���������X���b�h���Ƃ̕����Ȃ�ĂقƂ�ǔ��������Ȃ�LINPACK�X�R�A��
�P���ɏ���d�͂Ŋ�����������GREEN500�i�j�Ȃ���{���̃X�p�R����
�d�͌������킩��킯���ȁ[��
����nv�̘_���Ă�̂��A�����Ǝ��p�I�ŕ��G�Ȍv�Z�̘b�Ȃ�ˁB
Phi�͏��Ȃ��Ƃ�LINPACK�̌����̍ő剻��ڎw���ĂȂ����炠��͂���ł����Ǝv���B
���Ȃ݂Ƀr�b�g�}�X�N�ɂ���ĉ��Z���j�b�g�̌X�̃��[���̓d�͐���ł����ˁH�Ƃ��v��������
����̂��˂��BAVX512�ɃX�J��, 128bit, 256bit�̃��[�h�lj������̂������������ƂȂ̂��ȁB
�i�}�X�N���W�X�^�̏�Ԃł͂Ȃ��f�R�[�h�i�K�Ŏg�p���[�������킩��j
�P���ɏ���d�͂Ŋ�����������GREEN500�i�j�Ȃ���{���̃X�p�R����
�d�͌������킩��킯���ȁ[��
����nv�̘_���Ă�̂��A�����Ǝ��p�I�ŕ��G�Ȍv�Z�̘b�Ȃ�ˁB
Phi�͏��Ȃ��Ƃ�LINPACK�̌����̍ő剻��ڎw���ĂȂ����炠��͂���ł����Ǝv���B
���Ȃ݂Ƀr�b�g�}�X�N�ɂ���ĉ��Z���j�b�g�̌X�̃��[���̓d�͐���ł����ˁH�Ƃ��v��������
����̂��˂��BAVX512�ɃX�J��, 128bit, 256bit�̃��[�h�lj������̂������������ƂȂ̂��ȁB
�i�}�X�N���W�X�^�̏�Ԃł͂Ȃ��f�R�[�h�i�K�Ŏg�p���[�������킩��j
PHI�͓d�͂������X�^�[������팸�͑��}�̉ۑ肾�낤���ǁA�C���e���ɂ���Ȋ�p�Ȃ��Ƃ��\���낤���B
202 �F,,�E�L�́M�E,,�j��-�������F2015/01/21(��) 02:40:01.57 ID:VYIs1nCh
����PCIe���K�i��300W�܂łƂ����炻���ɂ͍��킹�Ă���ł��傤
���͓d�͑����̐��\�����邩�ǂ����B
LINPACK�̃X�R�A�������ɉz�������Ƃ͂Ȃ����AGPU�Ɍ��K�����͉̂����Ȃ��B
���͓d�͑����̐��\�����邩�ǂ����B
LINPACK�̃X�R�A�������ɉz�������Ƃ͂Ȃ����AGPU�Ɍ��K�����͉̂����Ȃ��B
�}�X�N�ʼn��Z���j�b�g�̈ꕔ�����~�߂�̂���
�Ⴆ�}�X�N����������ALU�ւ̓��͂�S��0�ɂ���Ƃ�����
ALU�ŐV����0����͂Ƃ��Čv�Z�������ƂɂȂ��������
��H�̏�Ԃ��ς�����Ⴄ�Ƃ�
�Ȃ�ƂȂ�������
�Ⴆ�}�X�N����������ALU�ւ̓��͂�S��0�ɂ���Ƃ�����
ALU�ŐV����0����͂Ƃ��Čv�Z�������ƂɂȂ��������
��H�̏�Ԃ��ς�����Ⴄ�Ƃ�
�Ȃ�ƂȂ�������
�悭�}�X�R�~�ɏo�Ă��镶�n�́u�L���ҁv�Ƃ��́ATOP500�Ƃ�GREEN500�݂�����
Linpack�X�R�A�������ĂȂ��悤�����ǂ�
Linpack�X�R�A�������Ĕ������Ƃ��������Ƃ������ł�
����Linpack������`�Ҍ����ɁALinpack��pASIC�J�������ق�����������
TOP500�ł�GREEN500�ł����E�g�b�v�ŃI�i�j�[�ł����ă}�X�R�~�Ɏ����グ���Ă����
Linpack�X�R�A�������ĂȂ��悤�����ǂ�
Linpack�X�R�A�������Ĕ������Ƃ��������Ƃ������ł�
����Linpack������`�Ҍ����ɁALinpack��pASIC�J�������ق�����������
TOP500�ł�GREEN500�ł����E�g�b�v�ŃI�i�j�[�ł����ă}�X�R�~�Ɏ����グ���Ă����
205 �F,,�E�L�́M�E,,�j��-�������F2015/01/21(��) 02:49:34.58 ID:VYIs1nCh
Knights Landing��Silvermont�R�A���x�[�X�ɂ��邱�Ƃ�
CPU�R�A�̃N���b�N���]���̔{�ȏ�ɂȂ�iSIMD���j�b�g�͔����~2�j
�R�A������̐��\�͂��������O����̂Q�{���~�܂肾��
�P���ȃX���[�v�b�g�����X�J�����\�̌��オ�d�v�ƌ��Ă���悤���B
CPU�R�A�̃N���b�N���]���̔{�ȏ�ɂȂ�iSIMD���j�b�g�͔����~2�j
�R�A������̐��\�͂��������O����̂Q�{���~�܂肾��
�P���ȃX���[�v�b�g�����X�J�����\�̌��オ�d�v�ƌ��Ă���悤���B
���ʂ�CPU����ALU�ŖړI�̉��Z�̎�ވȊO�̉�H�͓��삵�Ȃ��悤�ɂ���̂��Ăǂ�����Ă�
ALU�̒��O��FF���������烌�C�e���V�������邩�炱��͂Ȃ��Ƃ����
ALU�̒��O�Ƀf�[�^�Z���N�^�������Ďg��Ȃ�����ALU�ɖ���0����͂��Ă�Ƃ����
GPU�݂����ɖ��T�C�N������ALU���g����ł�
1�����̃T�C�N���Ńf�[�^�Z���N�^��0�̓��͂ɐ�ւ����Ƃ��Ă�
ALU�̑g�ݍ��킹��H�̏�Ԃ��ς���������
�}�X�N���W�X�^�̃r�b�g�����T�C�N����ւ��Ƃ���Ɠ��͂�0�ɂ�������ɂ܂��L���ȃf�[�^�̓��͂ɐ�ւ�����肷�邱�Ƃ�
�d�͂��팸�ł��Ȃ��̂���
ALU�̒��O��FF���������烌�C�e���V�������邩�炱��͂Ȃ��Ƃ����
ALU�̒��O�Ƀf�[�^�Z���N�^�������Ďg��Ȃ�����ALU�ɖ���0����͂��Ă�Ƃ����
GPU�݂����ɖ��T�C�N������ALU���g����ł�
1�����̃T�C�N���Ńf�[�^�Z���N�^��0�̓��͂ɐ�ւ����Ƃ��Ă�
ALU�̑g�ݍ��킹��H�̏�Ԃ��ς���������
�}�X�N���W�X�^�̃r�b�g�����T�C�N����ւ��Ƃ���Ɠ��͂�0�ɂ�������ɂ܂��L���ȃf�[�^�̓��͂ɐ�ւ�����肷�邱�Ƃ�
�d�͂��팸�ł��Ȃ��̂���
�u�������ǂ�����ēd�͍팸���Ă邩�Ƃ����ƁA�C���o�[�^�Ō����ɓ_�ł����Ă���B
���̌����łł��邩������Ȃ����ł��Ȃ���������Ȃ��B
���̌����łł��邩������Ȃ����ł��Ȃ���������Ȃ��B
208 �FSocket774�F2015/01/21(��) 04:17:56.80 ID:1hooODzG
nv�̂͂����炭�\�ʏ�i���Ȃ��Ƃ��\�t�g�E�G�A��j��warp��32�v�f�̂܂܂�
gpu����4�v�f�ŏ���������Ă͂Ȃ��ɂȂ�Ǝv���܂�
�X�P�W���[���ƃ��W�X�^�t�@�C���̊K�w���̐���̓R���p�C���ōs���Ƃ��Ă���̂�
gpu�����ŊO��������warp������ɍăX�P�W���[���i�����炭�����œ����߃X���b�h��I�яo���j����
4�v�f���ɏ�������悤�ɂȂ�̂ł��傤
����linpak�ȊO����{���x���܂�g��Ȃ����Ă̂�
�������낢�Ȃ�
gpu����4�v�f�ŏ���������Ă͂Ȃ��ɂȂ�Ǝv���܂�
�X�P�W���[���ƃ��W�X�^�t�@�C���̊K�w���̐���̓R���p�C���ōs���Ƃ��Ă���̂�
gpu�����ŊO��������warp������ɍăX�P�W���[���i�����炭�����œ����߃X���b�h��I�яo���j����
4�v�f���ɏ�������悤�ɂȂ�̂ł��傤
����linpak�ȊO����{���x���܂�g��Ȃ����Ă̂�
�������낢�Ȃ�
209 �FSocket774�F2015/01/21(��) 04:30:20.37 ID:1hooODzG
���Ȃ݂ɂ����̋L����
SC14 - NVIDIA�̎���ExaScale�ւ̓�
http://news.mynavi.jp/articles/2014/12/16/sc14_exascale/
�������߂�Warp�Ɋ܂܂��ꍇ�́A����X���b�h�ł͕���Ŕ�щz����閽�߂�����s���邱�ƂɂȂ�A���_�ȃG�l���M�[�������B
���̂悤�Ɏ��s�̗��ꂪ������Ă��܂����Ƃ��uDivergence�v�ƌĂԁB
�E�̐}�̖_�O���t�̂悤�ɁADivergence���N���������ɂǂꂾ���̃X���b�h���L���Ɏ��s����邩�̓A�v���P�[�V������Warp�T�C�Y�Ɉˑ�����B
NVIDIA�̌����ł́A�����Warp�T�C�Y��32�̏ꍇ��41%�̖��߂����L���ɗ��p�ł��Ȃ����A
Warp�T�C�Y��4�ɒZ�k�����65%�L���ɗ��p�ł���悤�ɂȂ�Ƃ����B
Warp�̊e�X���b�h�͂��ׂē������߂����s���邪�A���̃I�y�����h���X���b�h���ƂɈقȂ�ꍇ�͂��ꂼ��̖��߂̎��s�͈Ӗ������邪�A
�܂����������I�y�����h���g���A�����v�Z������ꍇ������B
��҂̏ꍇ��1�J���ʼn��Z����Ηǂ��A���̑��̃X���b�h�ł̃��W�X�^�t�@�C���̓ǂݏ����≉�Z�̃G�l���M�[�̓��_�Ɏg���Ă���B
��2�̉��P���́A���̂悤�ȃ��_�ȃP�[�X���R���p�C���Ō��o���āA
1�̉��Z���j�b�g�����Ōv�Z����悤�ɂ��邱�ƂŃG�l���M�[����̃��_���Ȃ��B
SC14 - NVIDIA�̎���ExaScale�ւ̓�
http://news.mynavi.jp/articles/2014/12/16/sc14_exascale/
�������߂�Warp�Ɋ܂܂��ꍇ�́A����X���b�h�ł͕���Ŕ�щz����閽�߂�����s���邱�ƂɂȂ�A���_�ȃG�l���M�[�������B
���̂悤�Ɏ��s�̗��ꂪ������Ă��܂����Ƃ��uDivergence�v�ƌĂԁB
�E�̐}�̖_�O���t�̂悤�ɁADivergence���N���������ɂǂꂾ���̃X���b�h���L���Ɏ��s����邩�̓A�v���P�[�V������Warp�T�C�Y�Ɉˑ�����B
NVIDIA�̌����ł́A�����Warp�T�C�Y��32�̏ꍇ��41%�̖��߂����L���ɗ��p�ł��Ȃ����A
Warp�T�C�Y��4�ɒZ�k�����65%�L���ɗ��p�ł���悤�ɂȂ�Ƃ����B
Warp�̊e�X���b�h�͂��ׂē������߂����s���邪�A���̃I�y�����h���X���b�h���ƂɈقȂ�ꍇ�͂��ꂼ��̖��߂̎��s�͈Ӗ������邪�A
�܂����������I�y�����h���g���A�����v�Z������ꍇ������B
��҂̏ꍇ��1�J���ʼn��Z����Ηǂ��A���̑��̃X���b�h�ł̃��W�X�^�t�@�C���̓ǂݏ����≉�Z�̃G�l���M�[�̓��_�Ɏg���Ă���B
��2�̉��P���́A���̂悤�ȃ��_�ȃP�[�X���R���p�C���Ō��o���āA
1�̉��Z���j�b�g�����Ōv�Z����悤�ɂ��邱�ƂŃG�l���M�[����̃��_���Ȃ��B
�uCurie�v�������яオ�点��Intel��IoT�헪
http://pc.watch.impress.co.jp/docs/column/kaigai/20150121_684534.html
http://pc.watch.impress.co.jp/docs/column/kaigai/20150121_684534.html
���̃������T�C�Y����Linux�������Ȃ�����A���܂���Intel�ɂ���Ӗ����킩��Ȃ���
�{���ɂ����̃����`�b�v�}�C�R�����Ċ��������
�{���ɂ����̃����`�b�v�}�C�R�����Ċ��������
>>206
�p�C�v���C���Ȃ�FF�͓����Ă邵
�Z���N�^�g���Ȃ�0�ł͂Ȃ��đO��̓��͒l���g��
�Z���N�^��芷����ۂɃZ���N�^�ȍ~���������Ⴄ���ǂ�
�p�C�v���C���Ȃ�FF�͓����Ă邵
�Z���N�^�g���Ȃ�0�ł͂Ȃ��đO��̓��͒l���g��
�Z���N�^��芷����ۂɃZ���N�^�ȍ~���������Ⴄ���ǂ�
>>211
�����Č����Ȃ�A�����������邩�A�ڐA�������邩�B���ĂƂ�����ˁH
�����Č����Ȃ�A�����������邩�A�ڐA�������邩�B���ĂƂ�����ˁH
>>211
�z��OS��VxWorks����Ȃ�����?
http://www.windriver.com/japan/products/vxworks.html
Wind River�́AIntel�ɔ�������Ă邵�B
�z��OS��VxWorks����Ȃ�����?
http://www.windriver.com/japan/products/vxworks.html
Wind River�́AIntel�ɔ�������Ă邵�B
�C�[�T�[�l�b�g�EUSB���ŁALinux��TCP/IP�A�v���P�[�V���������������ȃ����`�b�v�}�C�R����������̂�
USB���̈����ȃ����`�b�v�}�C�R���Ȃ�ŋ߂͂������邪�A�C�[�T�[�l�b�g������Linux���ڂ�Ȃ�
USB���̈����ȃ����`�b�v�}�C�R���Ȃ�ŋ߂͂������邪�A�C�[�T�[�l�b�g������Linux���ڂ�Ȃ�
�C�[�T�l�b�g�R�l�N�^�AUSB�R�l�N�^�A��������̂ň����ɂȂ�Ȃ��A�ȓd�͂ɂȂ�Ȃ�
broadwell-k�͂�
Intel��CES 2015�ŃA�s�[�������̂́C�ŐVCPU�ł͂Ȃ�RealSense�ƃE�F�A���u���@����������^�R���s���[�^������
http://www.4gamer.net/games/047/G004743/20150121122/
http://www.4gamer.net/games/047/G004743/20150121122/
Microsoft's HoloLens uses unreleased Intel Atom chip
The holographic headset computer has the Cherry Trail chip, which will also be in tablets and low-end PCs
http://www.cio.co.nz/article/564585/microsoft-hololens-uses-unreleased-intel-atom-chip/
The holographic headset computer has the Cherry Trail chip, which will also be in tablets and low-end PCs
http://www.cio.co.nz/article/564585/microsoft-hololens-uses-unreleased-intel-atom-chip/
>>219
�����[�A�߂�����~���[�B
�����[�A�߂�����~���[�B
�C���e���s����1�ʁA���㍂�����L���O
http://eetimes.jp/ee/spv/1501/19/news123.html
Intel�������̃g�b�v�̍����犊�藎�����
http://m.pc.watch.impress.co.jp/docs/column/semicon/20150123_685107.html
http://eetimes.jp/ee/spv/1501/19/news123.html
Intel�������̃g�b�v�̍����犊�藎�����
http://m.pc.watch.impress.co.jp/docs/column/semicon/20150123_685107.html
�C���e���͈�̂��ɂȂ�����N��30���h���ȏ�̂�܂�����߂����ł��傤��
��AMD�̂悤�ȐԎ��O����Ƃ̐M��҂̃A�z�ɂ͕K�v�o������ł��Ȃ��炵��
���q�����x�@�����v�o�Ȃ�����ׂ����Ă������z
���q�����x�@�����v�o�Ȃ�����ׂ����Ă������z
�C�X���G���Ɏ��������C�X�������̂悤�ȘA����
�K�v�ȂƂ���œ��X�ƐԎ����o�����Ƃ��g�[�^���������o����A���ꂾ���̂��Ƃ���B
�[�Z���̐V����Ƃ̍����v�\�͂ɂ͐��E�̑����̃��[�J�[����Ƃ����ڂ��Ă�B
Intel��Android��Windows������➑̂Ŏ����ł��邩��ƁAAtom�̓^�_���R
�����PC�A�[�L�e�N�`���̒�R�X�g���ɂ��Ȃ��邵�A➑̂ɍ��ꂽIntel���S���̂�
��`���ʂ�����B
���ܐԎ����o�����Ƃ���߂��珫���̐H���т��Ȃ��Ȃ邩������Ȃ�
���������}�N���I���_�����@���Ă邩��AMD�͍��؋��܂݂�Ŏ��]�ԑ��ƂȂ�
�킩��H
�[�Z���̐V����Ƃ̍����v�\�͂ɂ͐��E�̑����̃��[�J�[����Ƃ����ڂ��Ă�B
Intel��Android��Windows������➑̂Ŏ����ł��邩��ƁAAtom�̓^�_���R
�����PC�A�[�L�e�N�`���̒�R�X�g���ɂ��Ȃ��邵�A➑̂ɍ��ꂽIntel���S���̂�
��`���ʂ�����B
���ܐԎ����o�����Ƃ���߂��珫���̐H���т��Ȃ��Ȃ邩������Ȃ�
���������}�N���I���_�����@���Ă邩��AMD�͍��؋��܂݂�Ŏ��]�ԑ��ƂȂ�
�킩��H
227 �FSocket774�F2015/01/23(��) 22:03:09.50 ID:S6mOcqar
���p�b�h��dual os�̐^������ł���
AMD�����Ă��낢�듊�����Ă���̂ɁA
���������ʂ����Ă������Ȃ��̂��낤���˂�
���������ʂ����Ă������Ȃ��̂��낤���˂�
AMD�̓w�e���W�j�A�X�R���s���[�e�B���O�̃��[�f�B���O�J���p�j�[���C����Ă͂��邪
����GPU�ł����邱�Ƃ���邱�Ƃɂ�������Č��ʓI�ɉ��������ł��ĂȂ����肩
���ăA�N�Z�����[�^���������闧��ɂ������p�[�g�i�[���玸���������Ƃ����ˁB
NVIDIA�͂��납Xilinx��Altera������t���Ȃ��Ȃ�قǔr���I�ȃ��[�J�[�ɐ��艺�������B
���������w�e���W�j�A�X�R���s���[�e�B���O�̍\�z�Ƃ��Ă�Intel�̒���QuickAssist�̂ق��������B
QPI�ڑ���FPGA�����łȂ�Denverton�̃I���_�C�������ꂽ�Í��A�N�Z�����[�^��
QuickAssist�̋��ʊ�ՂŃA�N�Z�X�ł���B
����GPU�ł����邱�Ƃ���邱�Ƃɂ�������Č��ʓI�ɉ��������ł��ĂȂ����肩
���ăA�N�Z�����[�^���������闧��ɂ������p�[�g�i�[���玸���������Ƃ����ˁB
NVIDIA�͂��납Xilinx��Altera������t���Ȃ��Ȃ�قǔr���I�ȃ��[�J�[�ɐ��艺�������B
���������w�e���W�j�A�X�R���s���[�e�B���O�̍\�z�Ƃ��Ă�Intel�̒���QuickAssist�̂ق��������B
QPI�ڑ���FPGA�����łȂ�Denverton�̃I���_�C�������ꂽ�Í��A�N�Z�����[�^��
QuickAssist�̋��ʊ�ՂŃA�N�Z�X�ł���B
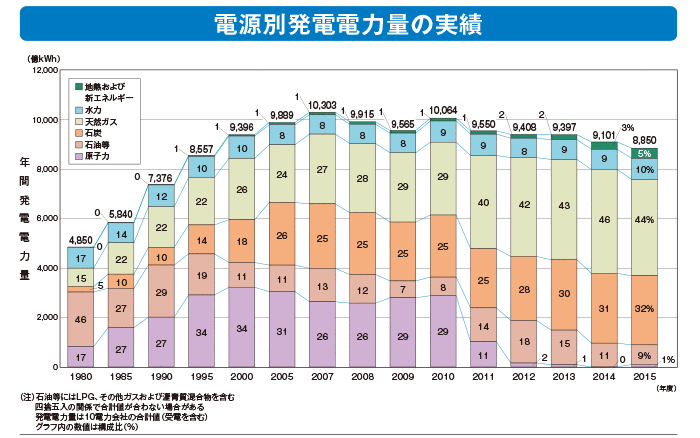
�v���X�R�����{�̓d�͎�����������Ă��Ƃ�������������
http://www.fepc.or.jp/resource_sw/pres_jigy_japa_inde01_l.gif
http://www.fepc.or.jp/resource_sw/env_war_co2h_co2b_inde01_l.gif
http://www.fepc.or.jp/resource_sw/pres_jigy_japa_inde03_l.gif
http://www.fepc.or.jp/resource_sw/pres_jigy_japa_inde04_l.gif
http://www.fepc.or.jp/resource_sw/pres_jigy_japa_inde05_l.gif
http://www.fepc.or.jp/resource_sw/pres_jigy_japa_inde06_l.gif
���{�̓d�͏��� �| �d�͎���ɂ��� �b �d�C���ƘA����
http://www.fepc.or.jp/enterprise/jigyou/japan/
�������܂����������ɕs�s���Ȏ����ɂ͂܂������G��ĂȂ���
http://www.fepc.or.jp/resource_sw/pres_jigy_japa_inde01_l.gif
{kind=link}
http://www.fepc.or.jp/resource_sw/env_war_co2h_co2b_inde01_l.gif
{kind=link}
http://www.fepc.or.jp/resource_sw/pres_jigy_japa_inde03_l.gif
{kind=link}
http://www.fepc.or.jp/resource_sw/pres_jigy_japa_inde04_l.gif
{kind=link}
http://www.fepc.or.jp/resource_sw/pres_jigy_japa_inde05_l.gif
{kind=link}
http://www.fepc.or.jp/resource_sw/pres_jigy_japa_inde06_l.gif
{kind=link}
���{�̓d�͏��� �| �d�͎���ɂ��� �b �d�C���ƘA����
http://www.fepc.or.jp/enterprise/jigyou/japan/
�������܂����������ɕs�s���Ȏ����ɂ͂܂������G��ĂȂ���
���{�̓Z��������������Ă����Intel�������u�[����Ă����ǁA
����ł����M�̓G�N�X�g���[���������H
����ł����M�̓G�N�X�g���[���������H
�ǂ��ɂ�����ȋ�̓I�ȃf�[�^���������lj�����
> �������܂����������ɕs�s���Ȏ����ɂ͂܂������G��ĂȂ���
�������肻�̂܂܂��Ȃ����
����AMD��Bulldozer/Piledriver�Ȃ�Ă��̃v���X�R���X�ɓd�͐H������
���Ȃ��Ƃ���i����d��200W����悤��CPU�͏o�������Ƃ͂Ȃ�
�h���C���[�Ɲ��������悤�ȑ����d�͂̃r�f�I�J�[�h���o�n�߂��̂�2004�N�O�ゾ��
200W�������U����CPU���͂邩�ɍ�����d�͂��B
> �������܂����������ɕs�s���Ȏ����ɂ͂܂������G��ĂȂ���
�������肻�̂܂܂��Ȃ����
����AMD��Bulldozer/Piledriver�Ȃ�Ă��̃v���X�R���X�ɓd�͐H������
���Ȃ��Ƃ���i����d��200W����悤��CPU�͏o�������Ƃ͂Ȃ�
�h���C���[�Ɲ��������悤�ȑ����d�͂̃r�f�I�J�[�h���o�n�߂��̂�2004�N�O�ゾ��
200W�������U����CPU���͂邩�ɍ�����d�͂��B
2004�N�����Ɩ@�l�����̓f�X�N�g�b�vPC����m�[�gPC�A���邢��CRT�i�u���E���ǁj����
�t���f�B�X�v���C�ւ̎��v�̈ڍs�������݁A�g�[�^���Ō����PC1�䂠�����
����d�͂͂ނ��댸���X���ɂ������̂������B
�ނ���VIA��SiS�Ƀ`�b�v�Z�b�g�̋����𗊂܂���Ȃ����炢��PC���̂��̂�
�䐔�̎��v���}�g�債�Ă����̂����̎����B
�t���f�B�X�v���C�ւ̎��v�̈ڍs�������݁A�g�[�^���Ō����PC1�䂠�����
����d�͂͂ނ��댸���X���ɂ������̂������B
�ނ���VIA��SiS�Ƀ`�b�v�Z�b�g�̋����𗊂܂���Ȃ����炢��PC���̂��̂�
�䐔�̎��v���}�g�債�Ă����̂����̎����B
>>222
100���ȏ�̃��^�[�������邩��~�߂�킯�Ȃ�
100���ȏ�̃��^�[�������邩��~�߂�킯�Ȃ�
�i�C����}�W���X
����Ă邱�Ǝ��̂̓l�b�g�u�b�N����̔��W�r�㍑����ULCPC�̉���������ˁB
������P�̂Œ��낪����Ȃ��Ă����W�r�㍑�����ɍ����荞��ł������Ƃ́A10�N20�N��̂��߂ɂȂ�ƁB
��}�S�ݓX�̃\�[���C�X�ŃO�O��
��i���ł�Atom�^�u���b�g�����邩��h������Core��Xeon������Ȃ��Ȃ邩�Ƃ����ƁA�S������Ȃ��Ƃ͂Ȃ�
�^�u���b�g�������[�U�[�͌��ǃp�\�R���������Ă���B
�ł�AMD���ƃw�^����ƃJ�j�o���[�[�V�������N���肤�邩�瓯�����Ƃ͏o���Ȃ����낤�ȁB
������P�̂Œ��낪����Ȃ��Ă����W�r�㍑�����ɍ����荞��ł������Ƃ́A10�N20�N��̂��߂ɂȂ�ƁB
��}�S�ݓX�̃\�[���C�X�ŃO�O��
��i���ł�Atom�^�u���b�g�����邩��h������Core��Xeon������Ȃ��Ȃ邩�Ƃ����ƁA�S������Ȃ��Ƃ͂Ȃ�
�^�u���b�g�������[�U�[�͌��ǃp�\�R���������Ă���B
�ł�AMD���ƃw�^����ƃJ�j�o���[�[�V�������N���肤�邩�瓯�����Ƃ͏o���Ȃ����낤�ȁB
AMD��HSA�́ACPU��GPU�̃A�h���X���L�ł���A���Ȃ�̕���Ő��\����Əȓd�͉����_�����Ɏ��Г������ŊJ���ł��邩�����Ă��
FPGA�Ƃ��́A���R�X�g�ȎI����蕪����肾����A�������炢�͂��Ă邾�낤���Ǐd�v�����ĂȂ�����\�ɏo�Ȃ�����
��{�AAMD�AIntel�ANvidia�̌����J���̕���ɍ��͂Ȃ���
�P�ɁA�R�X�g�ƗD��x�̈Ⴂ�ŗ͂����Ă���̂��Ⴄ����
Intel��x86�����ANvidia�̓O���t�B�b�N��CUDA�AAMD��CPU��GPU�̘A�g
���́ACPU��GPU�͕ʕ��Ƃ��Ĉ������@�����Ȃ�����Intel��Nvidia�̕���������
���ǁASoc�����y���čX�Ɍ�������ȓd�͉���i�߂邽�߂ɂ�CPU��GPU�̘A�g�������K�v������A������AMD���]�ޗ���ɂȂ�
���ꂪ���N��5�N�ォ10�N�ォ�͒m��Ȃ����ǂ�
FPGA�Ƃ��́A���R�X�g�ȎI����蕪����肾����A�������炢�͂��Ă邾�낤���Ǐd�v�����ĂȂ�����\�ɏo�Ȃ�����
��{�AAMD�AIntel�ANvidia�̌����J���̕���ɍ��͂Ȃ���
�P�ɁA�R�X�g�ƗD��x�̈Ⴂ�ŗ͂����Ă���̂��Ⴄ����
Intel��x86�����ANvidia�̓O���t�B�b�N��CUDA�AAMD��CPU��GPU�̘A�g
���́ACPU��GPU�͕ʕ��Ƃ��Ĉ������@�����Ȃ�����Intel��Nvidia�̕���������
���ǁASoc�����y���čX�Ɍ�������ȓd�͉���i�߂邽�߂ɂ�CPU��GPU�̘A�g�������K�v������A������AMD���]�ޗ���ɂȂ�
���ꂪ���N��5�N�ォ10�N�ォ�͒m��Ȃ����ǂ�
239 �FSocket774�F2015/01/24(�y) 12:03:27.89 ID:R/oVyQtT
�A�g�Ȃ�Ă����Ă邤���͉����ς��Ȃ�
�������^��phi�������
nv��nv��phi�������r��
�������^��phi�������
nv��nv��phi�������r��
Phi�ƃ��C��CPU�Ƃ̘A�g�͕K�v�Ȃ�H
241 �FSocket774�F2015/01/24(�y) 12:15:57.20 ID:R/oVyQtT
����phi�iknl�j��qpi�ڑ��ɂȂ�̂�
�L���b�V���R�q�[�����g�Ȑڑ����ł��ACPU�Ƌ��ʂ̃�������Ԃ�������
������KNL�`�b�v���L���b�V���R�q�[�����g�ɐڑ��\
nv�͂����power��pascal,nvlink�ł��
�L���b�V���R�q�[�����g�Ȑڑ����ł��ACPU�Ƌ��ʂ̃�������Ԃ�������
������KNL�`�b�v���L���b�V���R�q�[�����g�ɐڑ��\
nv�͂����power��pascal,nvlink�ł��
AMD������ARM������AGPU�AGPU�A�g搂��Ă��Ђ͉������^���^���Ă�́H
�n����Γ݂�����Ă��������
NVIDIA��GPU���ł��邱�ƁA�ł��Ȃ����Ƃ̔��f�͂Ƃ����ɂ���
�����ԋƊE��r�b�O�f�[�^�E�G�ɂɔ��荞�݂������Ă�i�K
AMD�͖����ɓ������킩��Ȃ����牄�X�͍����Ă�i�K�B
�����Ȃ���ɑ��Ђ������Ă���炻���F�߂Ă������ƒǂ��������
�����烁�������L���悤���J�������\�t�g�����悤��
GPU�̑e���x�ŕs���R�ȃx�N�g���v���Z�b�T�̍\�����ς��킯����Ȃ��B
�����ԋƊE��r�b�O�f�[�^�E�G�ɂɔ��荞�݂������Ă�i�K
AMD�͖����ɓ������킩��Ȃ����牄�X�͍����Ă�i�K�B
�����Ȃ���ɑ��Ђ������Ă���炻���F�߂Ă������ƒǂ��������
�����烁�������L���悤���J�������\�t�g�����悤��
GPU�̑e���x�ŕs���R�ȃx�N�g���v���Z�b�T�̍\�����ς��킯����Ȃ��B
�����}�ȊO�̎x���҂́A�e�����X�g��X�p�C�ɖ������Ă鎖�ɋC�t���āI
�y�N��z�����}�u���@�̂����œ���̏@�������U�������Ȃ��v
http://www.log-channel.net/bbs/poverty/1386937136/
�����̃I�E�������U�������Ȃ����̎i�@�ƌ��@�͖��Ǝv���܂��H
���I�E���̃T���������̂Ƃ��ɁA�����}�������I�E���ɔj�h�@��K�p���悤�Ƃ��A
���d�߁i�e���𖢑R�ɖh���@���A�܂����̖@��������A���������d�҂Ƃ��ĎE�l�߂ɖ₦���B�j
�����肵�悤�Ƃ������A�����}�ȊO�����ŁA�{�c
���ꂪ�A�\�����̋U���Ƃ͗����ɁA�����}�ȊO�̐��}�E�c�����A�݂�Ȓ��Ԃǂ����i�ݓ��A���H�j
�ł��邱�Ƃ̏ł͂Ȃ��ł��傤���B�B
�������̘A���O�܂ŁA�n���̐�����v��ᔻ���Ă��͎̂����̂݁B
���݂̖���}�⋤�Y�}�ɂ��ᔻ�́A��������(�n���E�ݓ��^�u�[�̉���)��j�~���邽�߂�
�u�ނ�v�u�U���v�Ǝv����B
�@���{�A����閧�ی�@�ɂ���
�u�H�����e�����X�g�A�X�p�C������ŁA�����͑S���W�Ȃ��B�v
http://headlines.yahoo.co.jp/hl?a=20141119-00000002-mai-pol
�y�N��z�����}�u���@�̂����œ���̏@�������U�������Ȃ��v
http://www.log-channel.net/bbs/poverty/1386937136/
�����̃I�E�������U�������Ȃ����̎i�@�ƌ��@�͖��Ǝv���܂��H
���I�E���̃T���������̂Ƃ��ɁA�����}�������I�E���ɔj�h�@��K�p���悤�Ƃ��A
���d�߁i�e���𖢑R�ɖh���@���A�܂����̖@��������A���������d�҂Ƃ��ĎE�l�߂ɖ₦���B�j
�����肵�悤�Ƃ������A�����}�ȊO�����ŁA�{�c
���ꂪ�A�\�����̋U���Ƃ͗����ɁA�����}�ȊO�̐��}�E�c�����A�݂�Ȓ��Ԃǂ����i�ݓ��A���H�j
�ł��邱�Ƃ̏ł͂Ȃ��ł��傤���B�B
�������̘A���O�܂ŁA�n���̐�����v��ᔻ���Ă��͎̂����̂݁B
���݂̖���}�⋤�Y�}�ɂ��ᔻ�́A��������(�n���E�ݓ��^�u�[�̉���)��j�~���邽�߂�
�u�ނ�v�u�U���v�Ǝv����B
�@���{�A����閧�ی�@�ɂ���
�u�H�����e�����X�g�A�X�p�C������ŁA�����͑S���W�Ȃ��B�v
http://headlines.yahoo.co.jp/hl?a=20141119-00000002-mai-pol
http://www.stat.go.jp/data/jinsui/img/pop.gif
http://www.stat.go.jp/data/jinsui/pdf/201501.pdf
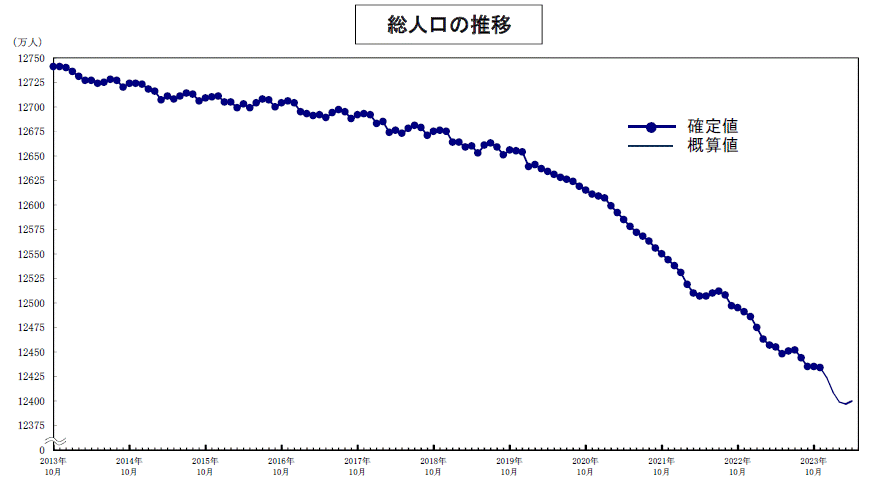
�l�����}���Ɍ��葱���Ă���̂ƁC�EPC�EIntel�̗��ꂪ�N���e�B�J���Ɍ����Ă��
ARM����ׂ��c�c����ׂ��c�c
{kind=link}
http://www.stat.go.jp/data/jinsui/pdf/201501.pdf
�l�����}���Ɍ��葱���Ă���̂ƁC�EPC�EIntel�̗��ꂪ�N���e�B�J���Ɍ����Ă��
ARM����ׂ��c�c����ׂ��c�c
>>242
�������ʓ|�Ȃ�
���̎d�g�݂́APCie�o�R�̕��x���ڑ��ƃ������A�h���X���f�₵�Ă���ʓ|�ȊJ�����������
����Ƃ̌݊����c���A�������A�h���X���L���Ȃ���Ȃ��
HSA�͂Ԃ����Ⴏ�Ax64�AOpenCL�ADirectX�ATrueAudio��UVD�Ƃ���DSP�S��������d�l�ɂȂ邩��A�����S�����ȏ�̃��\�[�X���K�v�ɂȂ�
������AAPI��������Ȃ��R���p�C����J�����A�Ή��f�o�C�X�Ƃ��̃��t�@�����X�Ƃ���
����Ȃ���A��邱�Ƃ���������AMD��������ǂ��ɂ��Ȃ��AHSA Foundation�����グ��ARM�Ƃ��F��ȏ��̋��͎��t���Ă�
�����܂��A���{�ɂȂ�APU�ʂȂ��Ɖ���������o���Ȃ�����Akaveri��Carrizo���ɍ���Ă���������T���Ă�
PS4�ɂ��̗p���ꂽ�̂͑傫���A����ŃQ�[������ł�HSA�Ή����������ꂽ
�������ʓ|�Ȃ�
���̎d�g�݂́APCie�o�R�̕��x���ڑ��ƃ������A�h���X���f�₵�Ă���ʓ|�ȊJ�����������
����Ƃ̌݊����c���A�������A�h���X���L���Ȃ���Ȃ��
HSA�͂Ԃ����Ⴏ�Ax64�AOpenCL�ADirectX�ATrueAudio��UVD�Ƃ���DSP�S��������d�l�ɂȂ邩��A�����S�����ȏ�̃��\�[�X���K�v�ɂȂ�
������AAPI��������Ȃ��R���p�C����J�����A�Ή��f�o�C�X�Ƃ��̃��t�@�����X�Ƃ���
����Ȃ���A��邱�Ƃ���������AMD��������ǂ��ɂ��Ȃ��AHSA Foundation�����グ��ARM�Ƃ��F��ȏ��̋��͎��t���Ă�
�����܂��A���{�ɂȂ�APU�ʂȂ��Ɖ���������o���Ȃ�����Akaveri��Carrizo���ɍ���Ă���������T���Ă�
PS4�ɂ��̗p���ꂽ�̂͑傫���A����ŃQ�[������ł�HSA�Ή����������ꂽ
nv��phi�̂悤��cpu�R�A�ƃx�N�^�[���Z��Z�b�g�ɂ���
�V�K�v���Z�b�T���o����
���̏ꍇ�x�N�^�[���Z��Ƃ���sm��������
phi�Ƃ̈�Ԃ̈Ⴂ�͌Œ�@�\�������K�w�Ōq���邱��
gpu�̃t�����g�G���h�͂Ȃ��Ȃ�cpu���S�Ă��x�z����
�V�K�v���Z�b�T���o����
���̏ꍇ�x�N�^�[���Z��Ƃ���sm��������
phi�Ƃ̈�Ԃ̈Ⴂ�͌Œ�@�\�������K�w�Ōq���邱��
gpu�̃t�����g�G���h�͂Ȃ��Ȃ�cpu���S�Ă��x�z����
���������命���̊J���҂�APU�Ƀ\�t�g�J���҂������������ĂȂ�������
�V�F�A�R�`�S�����������Ȃ�܂��J���҂͈ӎ�����K�v����������
�uAMD�Ȃ�ĒN���g���ĂȂ����瓮�쌟���炢��Ȃ��ł���H�v�Ƃ����X�^���X�������
���܂ǂ��̋Ɩ��p�A�v���ł�Intel CPU�ȊO�͓���ۏ؊O�ɂ��Ă�\�t�g���U���ɂ���
�i�܂�AMD�ł������ɂ͓������ǁj
�V�F�A�R�`�S�����������Ȃ�܂��J���҂͈ӎ�����K�v����������
�uAMD�Ȃ�ĒN���g���ĂȂ����瓮�쌟���炢��Ȃ��ł���H�v�Ƃ����X�^���X�������
���܂ǂ��̋Ɩ��p�A�v���ł�Intel CPU�ȊO�͓���ۏ؊O�ɂ��Ă�\�t�g���U���ɂ���
�i�܂�AMD�ł������ɂ͓������ǁj
>>250
��鑤�ɂƂ��Ă͂��̂ق����y�ł����Ȃ�
������Intel��x86�����^�[�Q�b�g�ɂ��đg��ł邯�ǁA
ARM���䓪���Ă�����ŁA���i�ʂŖ����ł��Ȃ����݂Ɂi���j
��鑤�ɂƂ��Ă͂��̂ق����y�ł����Ȃ�
������Intel��x86�����^�[�Q�b�g�ɂ��đg��ł邯�ǁA
ARM���䓪���Ă�����ŁA���i�ʂŖ����ł��Ȃ����݂Ɂi���j
���ꂩ��\�t�g�����Ƃ��āA��ԃ��[�U�[�w���傫���Ƃ����_������B
�Ώۃn�[�h�����������V�F�A�������č�����API�p�ӂ��܂����Ƃ��Ȃ�
�t�����l�ɂȂ邯��APU����PC�S�̂̃V�F�A10%���Ȃ��B
�n�[�h�ɓ������ꂽ��p�\�t�g�Ńn�[�h�̎x�z�͂����܂�̂ł͂Ȃ�
�x�z�I�ȃn�[�h�̏�Ƀ\�t�g���o���B
�Ώۃn�[�h�����������V�F�A�������č�����API�p�ӂ��܂����Ƃ��Ȃ�
�t�����l�ɂȂ邯��APU����PC�S�̂̃V�F�A10%���Ȃ��B
�n�[�h�ɓ������ꂽ��p�\�t�g�Ńn�[�h�̎x�z�͂����܂�̂ł͂Ȃ�
�x�z�I�ȃn�[�h�̏�Ƀ\�t�g���o���B
��������
�Q�[���R���\�[������APU�ŁAHPC���ƃC���e���ŁA�X�}�z����ARM�������
�{����4�R�A�Z�������ő啪������邯�ǁACore-i7������Ƃ���������Ă��Ȃ��ƈ�ʌ���PC���ᗘ�v�ɂȂ�Ȃ���
�Q�[���R���\�[������APU�ŁAHPC���ƃC���e���ŁA�X�}�z����ARM�������
�{����4�R�A�Z�������ő啪������邯�ǁACore-i7������Ƃ���������Ă��Ȃ��ƈ�ʌ���PC���ᗘ�v�ɂȂ�Ȃ���
��������A���܂�PC�����\�t�g�͏d���������̓N���E�h�ŏ�������悤�ɐ蕪����
PC�̃n�[�h�E�F�A�v�����ɗ͏グ�Ȃ��悤�ɂ��Ă���B
���ꂱ�����y���i�т́A3���~���BayTrail Celeron�m�[�g�ł��\�������悤�ȂˁB
�X�}�z��^�u���b�g��PC�L���[�Ƃ݂Ȃ��ꂽ�̂�PC��萫�\����������ł͂Ȃ�
�P���Ɂu����Ă邩��v�ɑ��Ȃ�Ȃ��B
Intel��Quark�AMicrosoft�̃z�������Y������APC�Ŏx�z�͂�����Ђ����܁u��PC�v�����
�J��ɖ�N�Ȃ̂́APC�̔��̂Ȃ��ł̃C�m�x�[�V�����̌��E�ɓ��B�����邩��B
HSA�Ńs�[�N���\�A�b�v�͑_���邩������Ȃ����ǁA�Ȃ�̃C�m�x�[�V�������N������́H�Ƃ����b�B
PC�̃n�[�h�E�F�A�v�����ɗ͏グ�Ȃ��悤�ɂ��Ă���B
���ꂱ�����y���i�т́A3���~���BayTrail Celeron�m�[�g�ł��\�������悤�ȂˁB
�X�}�z��^�u���b�g��PC�L���[�Ƃ݂Ȃ��ꂽ�̂�PC��萫�\����������ł͂Ȃ�
�P���Ɂu����Ă邩��v�ɑ��Ȃ�Ȃ��B
Intel��Quark�AMicrosoft�̃z�������Y������APC�Ŏx�z�͂�����Ђ����܁u��PC�v�����
�J��ɖ�N�Ȃ̂́APC�̔��̂Ȃ��ł̃C�m�x�[�V�����̌��E�ɓ��B�����邩��B
HSA�Ńs�[�N���\�A�b�v�͑_���邩������Ȃ����ǁA�Ȃ�̃C�m�x�[�V�������N������́H�Ƃ����b�B
GPGPU�\�t�g�J�����Ă邯�ǖʓ|�ł���Ă��Ȃ�
GPGPU�ɋ����͂��邯�ǖʓ|�Ŏ肪�o���Ȃ�
GPGPU�̃{�g���l�b�N�����ł�����g���Ă�����
�����������J���҂̓S�}���Ƃ���
HSA�̃^�[�Q�b�g�̓R�C�c������
PS4�̃\�t�g�J���͊���HSA�I�ȕ����ɐ�ւ���Ă����Ă�
Java9���Ή��������Ă��Ƃ́A���Z����VM�W�͌�ǂ����邾�낤
OpenCL2.0���Ή��������獡��͑Ή��\�t�g�������Ă���
���W��MS�����낻��AMD64��DX12����̉����悤�Ƃ��l���Ă��Ȃ�����
��������ƁAOpenCL��OpenGL��MP����̉������Ă��邩����
�܂��A���ɓI�ɂ̓X�J���ƃx�N�g���ƃO���t�B�b�N�ꂵ�Ĉ�����������z����
�y�Ɍ����ǂ���R�X�g�ɑS������ł����炢���Ǝv����
GPGPU�ɋ����͂��邯�ǖʓ|�Ŏ肪�o���Ȃ�
GPGPU�̃{�g���l�b�N�����ł�����g���Ă�����
�����������J���҂̓S�}���Ƃ���
HSA�̃^�[�Q�b�g�̓R�C�c������
PS4�̃\�t�g�J���͊���HSA�I�ȕ����ɐ�ւ���Ă����Ă�
Java9���Ή��������Ă��Ƃ́A���Z����VM�W�͌�ǂ����邾�낤
OpenCL2.0���Ή��������獡��͑Ή��\�t�g�������Ă���
���W��MS�����낻��AMD64��DX12����̉����悤�Ƃ��l���Ă��Ȃ�����
��������ƁAOpenCL��OpenGL��MP����̉������Ă��邩����
�܂��A���ɓI�ɂ̓X�J���ƃx�N�g���ƃO���t�B�b�N�ꂵ�Ĉ�����������z����
�y�Ɍ����ǂ���R�X�g�ɑS������ł����炢���Ǝv����
> �����������J���҂̓S�}���Ƃ���
���Ȃ�
����͂����܂ŌN�́u����Ƃ����ȁv�Ƃ�����]�ɉ߂��Ȃ�
�����Ȃ��Ƃ�HSA�Ȃ�Ċ��҂���Ă��Ȃ���
https://github.com/HSA-Libraries/
������Ă�̃��[���h���C�h�ł�������145�l�A�t�H�����[19�l�A�R���g���r���[�^����������8�l
�i�ق�AMD�̒��̐l�j
�قƂ�ǂ̃\�t�g�J���҂͊S�������Ă��Ȃ����Ƃ��킩��B
���Ȃ�
����͂����܂ŌN�́u����Ƃ����ȁv�Ƃ�����]�ɉ߂��Ȃ�
�����Ȃ��Ƃ�HSA�Ȃ�Ċ��҂���Ă��Ȃ���
https://github.com/HSA-Libraries/
������Ă�̃��[���h���C�h�ł�������145�l�A�t�H�����[19�l�A�R���g���r���[�^����������8�l
�i�ق�AMD�̒��̐l�j
�قƂ�ǂ̃\�t�g�J���҂͊S�������Ă��Ȃ����Ƃ��킩��B
>>252
AMD��APU���čl����Ə��Ȃ���
CPU+GPU��Soc�Ȃ�s��̂ق�10������
�����āASoc�̎�����̓R�q�[�����g�o�X�����ƌ�����
������A�X�}�t�H��PC���I�ł���R�q�[�����g�o�X�����ɐ�ւ���Ă������낤��
�����ăR�q�[�����g�o�X����������A�A�h���X���L�o���邩�瓖�R����p�̊J�������K�v�ɂȂ�
���̂Ƃ���OpenCL2.0���������ǁA����������Ďg���₷�����̂��o�Ă��邾�낤��
�����āA�R�q�[�����g�o�X�����̗B���Soc��kaveri������A�Ή��\�t�g���l���Ă鏊�́A
HSA�͂��Ƃ�葼�̊J���҂��I�������Ȃ�����kaveri��Carrizo�g���ĊJ�����Ă�
AMD��APU���čl����Ə��Ȃ���
CPU+GPU��Soc�Ȃ�s��̂ق�10������
�����āASoc�̎�����̓R�q�[�����g�o�X�����ƌ�����
������A�X�}�t�H��PC���I�ł���R�q�[�����g�o�X�����ɐ�ւ���Ă������낤��
�����ăR�q�[�����g�o�X����������A�A�h���X���L�o���邩�瓖�R����p�̊J�������K�v�ɂȂ�
���̂Ƃ���OpenCL2.0���������ǁA����������Ďg���₷�����̂��o�Ă��邾�낤��
�����āA�R�q�[�����g�o�X�����̗B���Soc��kaveri������A�Ή��\�t�g���l���Ă鏊�́A
HSA�͂��Ƃ�葼�̊J���҂��I�������Ȃ�����kaveri��Carrizo�g���ĊJ�����Ă�
�ő�h����Web�n�Ɣ�ׂ�̂��������AGitHub�̊����ȃv���W�F�N�g���Ă̂̓t�@�{����
����2�Ⴄ����ȁB
https://github.com/angular/angular.js
����2�Ⴄ����ȁB
https://github.com/angular/angular.js
AMD����X�I�ɐ�`���Ă�HSA���C�u��������
Intel�����ł�������J�����Ă邨�V�уc�[���ɂ����Ȃ�ispc�̂ق���
���̐����{�ȏ㑽�����Ăǂ��������Ƃ��낤��
https://github.com/ispc/ispc
https://github.com/HSA-Libraries/
Intel�����ł�������J�����Ă邨�V�уc�[���ɂ����Ȃ�ispc�̂ق���
���̐����{�ȏ㑽�����Ăǂ��������Ƃ��낤��
https://github.com/ispc/ispc
https://github.com/HSA-Libraries/
>>256
https://github.com/HSAFoundation
HSA-Runtime-AMD
https://github.com/HSAFoundation/HSA-Runtime-AMD
HSA-Drivers-Linux-AMD
https://github.com/HSAFoundation/HSA-Drivers-Linux-AMD
https://github.com/HSAFoundation
HSA-Runtime-AMD
https://github.com/HSAFoundation/HSA-Runtime-AMD
HSA-Drivers-Linux-AMD
https://github.com/HSAFoundation/HSA-Drivers-Linux-AMD
>>261
�S����2������ˁ[����������
�S����2������ˁ[����������
HSA�ɍS�肷������
���ڂ��ׂ���GPGPU�̃{�g���l�b�N����
�R�������������AHSA���낤��OpenCL���낤���A�������ċ���������Ďg����
����������{�g���l�b�N�͍��₩�Ȃ�y������Ă�
�X�J����������聨�V���v���ȃX�J���R�A����
��������聨������CU�ŗ͋Z�ʼn���
�ʐM�������Ēx�����������Đ�p�o�X�Œ���
�|�C���^�g���Ȃ��A�R�q�[�����g���Ȃ����R�q�[�����g�o�X����
�R���e�N�X�g�X�C�b�`�o���Ȃ����R���e�L�X�g�X�C�b�`�Ή������z���ɗL��
VLIW��HD6000�̍����炷��ƁA�ő�CPU���h�L�ƌ����Ă������炢CPU���ۂ��\���ɂȂ��Ă�
�����������ǂ������Ă�������A���CPU�ɋ߂��Ȃ��Ă���
���ʓI�ɁACPU+GPU����ACPU+���Z�����ӂ�CPU���h�L�ɂȂ��Ă�������
�R���́AIntel��Core+Phi�����ɋ߂��\�z�ƌ����邩��
���������AIntel��Core+Phi�v����Ăǂ��Ȃ�������
���ڂ��ׂ���GPGPU�̃{�g���l�b�N����
�R�������������AHSA���낤��OpenCL���낤���A�������ċ���������Ďg����
����������{�g���l�b�N�͍��₩�Ȃ�y������Ă�
�X�J����������聨�V���v���ȃX�J���R�A����
��������聨������CU�ŗ͋Z�ʼn���
�ʐM�������Ēx�����������Đ�p�o�X�Œ���
�|�C���^�g���Ȃ��A�R�q�[�����g���Ȃ����R�q�[�����g�o�X����
�R���e�N�X�g�X�C�b�`�o���Ȃ����R���e�L�X�g�X�C�b�`�Ή������z���ɗL��
VLIW��HD6000�̍����炷��ƁA�ő�CPU���h�L�ƌ����Ă������炢CPU���ۂ��\���ɂȂ��Ă�
�����������ǂ������Ă�������A���CPU�ɋ߂��Ȃ��Ă���
���ʓI�ɁACPU+GPU����ACPU+���Z�����ӂ�CPU���h�L�ɂȂ��Ă�������
�R���́AIntel��Core+Phi�����ɋ߂��\�z�ƌ����邩��
���������AIntel��Core+Phi�v����Ăǂ��Ȃ�������
�l�ڂɂ����Ƃ������ė��ł����������Ă�v���W�F�N�g�����邵
���ꂪ���ׂĂƂ����킯����Ȃ����A
���̂�������GitHub�Ńz�X�e�B���O����Ă�v���W�F�N�g�̉��l�̎w�W
AMD����X�I�ɐ�`���Ă�����đ�������
���E���̃v���O���}��AMD�̎��݂ɊS�������ĂȂ����Ƃ�
�ڂɌ�����`�ŏؖ����ꂽ�킯��
�}�W����
���ꂪ���ׂĂƂ����킯����Ȃ����A
���̂�������GitHub�Ńz�X�e�B���O����Ă�v���W�F�N�g�̉��l�̎w�W
AMD����X�I�ɐ�`���Ă�����đ�������
���E���̃v���O���}��AMD�̎��݂ɊS�������ĂȂ����Ƃ�
�ڂɌ�����`�ŏؖ����ꂽ�킯��
�}�W����
>>263
���E���̃v���O���}�ɑ��X�J������Ă邱�Ƃ��������̐��ŏؖ�����Ă�̂ɓƉ�����˂�
�Ј����Ȃ��H
�������Ǝ���AMD�t�@���{�[�C�X�����ĂĂ������ł�肽�܂�
�c�O�Ȃ��炱�����ɕs�l�CAMD�̎x���҂͂��Ȃ�����
���E���̃v���O���}�ɑ��X�J������Ă邱�Ƃ��������̐��ŏؖ�����Ă�̂ɓƉ�����˂�
�Ј����Ȃ��H
�������Ǝ���AMD�t�@���{�[�C�X�����ĂĂ������ł�肽�܂�
�c�O�Ȃ��炱�����ɕs�l�CAMD�̎x���҂͂��Ȃ�����
nVIDIA��GPU��CPU�R�A�g�ݍ���ł邭���ɉ������Ă�
267 �FSocket774�F2015/01/24(�y) 23:48:50.09 ID:wI+XM2g6
>>257
��AMD��APU���čl����Ə��Ȃ���
���X�V�F�A�̏��Ȃ�APU�̒��ł����s���i��HSA�Ή��̕������Ȃ����ǂ�
��CPU+GPU��Soc�Ȃ�s��̂ق�10������
SoC�̈Ӗ��킩���ĂȂ�����
�f�X�N�g�b�v�̑命���ƃ~�h���ȏ�̃m�[�g�Ŏ嗬��CPU�ƃ`�b�v�Z�b�g��������Ă���\����System on Chip�Ƃ͌���Ȃ�
�������āASoc�̎�����̓R�q�[�����g�o�X�����ƌ�����
Carrizo-L�͔�Ή�������
�������āA�R�q�[�����g�o�X�����̗B���Soc��kaveri������A�Ή��\�t�g���l���Ă鏊�́A
Kaveri��SoC����Ȃ�����
��HSA�͂��Ƃ�葼�̊J���҂��I�������Ȃ�����kaveri��Carrizo�g���ĊJ�����Ă�
�܂����[���`����ĂȂ�Carrizo�̓}�U�[�{�[�h���[�J�[��ES�i�͍s���Ă邩������Ȃ����A�\�t�g�E�F�A�J���҂��g���Ă���킯�Ȃ�����
�˂����݂ǂ��낪���ڂ�
��AMD��APU���čl����Ə��Ȃ���
���X�V�F�A�̏��Ȃ�APU�̒��ł����s���i��HSA�Ή��̕������Ȃ����ǂ�
��CPU+GPU��Soc�Ȃ�s��̂ق�10������
SoC�̈Ӗ��킩���ĂȂ�����
�f�X�N�g�b�v�̑命���ƃ~�h���ȏ�̃m�[�g�Ŏ嗬��CPU�ƃ`�b�v�Z�b�g��������Ă���\����System on Chip�Ƃ͌���Ȃ�
�������āASoc�̎�����̓R�q�[�����g�o�X�����ƌ�����
Carrizo-L�͔�Ή�������
�������āA�R�q�[�����g�o�X�����̗B���Soc��kaveri������A�Ή��\�t�g���l���Ă鏊�́A
Kaveri��SoC����Ȃ�����
��HSA�͂��Ƃ�葼�̊J���҂��I�������Ȃ�����kaveri��Carrizo�g���ĊJ�����Ă�
�܂����[���`����ĂȂ�Carrizo�̓}�U�[�{�[�h���[�J�[��ES�i�͍s���Ă邩������Ȃ����A�\�t�g�E�F�A�J���҂��g���Ă���킯�Ȃ�����
�˂����݂ǂ��낪���ڂ�
ARM�w�c��i7�͂��납POWER11�ɑ������鋭�͂�SoC���\���Ă邶���
269 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 00:20:46.02 ID:9zfd46sr
CUDA��Python�o�C���f�B���O��PyCUDA�Ƃ����ӂ���150������Ƃ����Ȃ�
https://github.com/inducer/pycuda
���܂��炪�v���ق�GPGPU�v���O���}��A����ɂȂ肽����z�͑����Ȃ����
���������ƊE�̎��v���Ȃ��B
CUDA��OpenCL�Ȃ�Đ��w�Z�Ȃł������Ă�Ƃ��m��Ȃ���B
�K�v�Ȑ��͐��w�╨����U���đ�w�@��GPGPU�ʼn�̘͂_�������܂������炢�̐l�ނ�
�\������Ă��܂����A���ꂷ��命���͂��Ԃ�āAIT�ƊE�ɂ����݂����낱���
VB.NET���PHP����炳���̂��ւ̎R��B
https://github.com/inducer/pycuda
���܂��炪�v���ق�GPGPU�v���O���}��A����ɂȂ肽����z�͑����Ȃ����
���������ƊE�̎��v���Ȃ��B
CUDA��OpenCL�Ȃ�Đ��w�Z�Ȃł������Ă�Ƃ��m��Ȃ���B
�K�v�Ȑ��͐��w�╨����U���đ�w�@��GPGPU�ʼn�̘͂_�������܂������炢�̐l�ނ�
�\������Ă��܂����A���ꂷ��命���͂��Ԃ�āAIT�ƊE�ɂ����݂����낱���
VB.NET���PHP����炳���̂��ւ̎R��B
>>260�A>>262
AMD����er�ɂ̓v���O���~���O�X�L�������ɍ����z�������̂�
���������̂ɂ͍v�����悤�Ƃ��Ȃ��̂��B
AMD���[�U�[�ɑ���ȗ��v�����炷�̂ɁA�����̍��X�L�����[�U�[�͔͂���
AMD�A���ꂷ������
AMD����er�ɂ̓v���O���~���O�X�L�������ɍ����z�������̂�
���������̂ɂ͍v�����悤�Ƃ��Ȃ��̂��B
AMD���[�U�[�ɑ���ȗ��v�����炷�̂ɁA�����̍��X�L�����[�U�[�͔͂���
AMD�A���ꂷ������
>>271
��ЂƂ��ė]�T�����邩�炾��B�Ԏ���AMD����Ј��ɂ���Ȃ��Ƃ�����]�T�Ȃ����낤
��ЂƂ��ė]�T�����邩�炾��B�Ԏ���AMD����Ј��ɂ���Ȃ��Ƃ�����]�T�Ȃ����낤
HSA�t�@�E���f�[�V�����ɂ́A����ARM���������Ă�͂������ǁA
����ł�GItHub�́������Ȃ��̂͂ǂ��������ƂȂ낤�H�H
AMD�����Ȃ疳�S����������ǁi�j�AARM������łĊS�����Ȃ����āA
ARM�ɂƂ��Ă�GPGPU�̌䗘�v�͊��҂ł��Ȃ��낤���H
�Z�~�i�[��Mari�̍\���Ƃ������Ă�ƁA����GPGPU���ӎ����Ă���悤�Ɍ����邯�ǥ��
>>272
�߂����˥���B
����Intel��AMD�������������āAARM����l�������A
�D�ꂽ�w�e���W�j�A�X�v���Z�b�T���\�t�g�J���������܂�Ă�����������Ȃ��B
����ł�GItHub�́������Ȃ��̂͂ǂ��������ƂȂ낤�H�H
AMD�����Ȃ疳�S����������ǁi�j�AARM������łĊS�����Ȃ����āA
ARM�ɂƂ��Ă�GPGPU�̌䗘�v�͊��҂ł��Ȃ��낤���H
�Z�~�i�[��Mari�̍\���Ƃ������Ă�ƁA����GPGPU���ӎ����Ă���悤�Ɍ����邯�ǥ��
>>272
�߂����˥���B
����Intel��AMD�������������āAARM����l�������A
�D�ꂽ�w�e���W�j�A�X�v���Z�b�T���\�t�g�J���������܂�Ă�����������Ȃ��B
274 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 00:40:27.60 ID:9zfd46sr
AMD�͂����炭PC�ɂ�����GPGPU�̐��ݎ��v���������2�`3�����炢���߂Ɍ��ς����Ă�Ǝv���̂ł��B
���L�������Ƃ��^�X�N�L���[�Ƃ��ɂ���Ċg��ł���s����Ă����������̈ꌅ%���x���Ǝv���܂�
PC�\�t�g�Ɋւ��ẮA�ق����\�t�g�ɍ��킹�ď���҂��n�[�h�������邱�ƂȂ��
���҂����Ⴂ���Ȃ��ł���B����҂ɑI��Ă�n�[�h���^�[�Q�b�g�Ƀ\�t�g�J������B
PC���X�y�b�N�̐���̂���X�}�z��^�u���b�g�������ˁB
�������N��AMD�̃I�[�v���\�[�X�̐��ʕ��݂Ă��
�j�[�Y�Ƃ��l���������������g�킹�������̂�����Ă�Ƃ�����
�v���O���}���]��ł�J�������Ĉӎ��������Ɩ�����Ȃ����ƁE�E�E
���L�������Ƃ��^�X�N�L���[�Ƃ��ɂ���Ċg��ł���s����Ă����������̈ꌅ%���x���Ǝv���܂�
PC�\�t�g�Ɋւ��ẮA�ق����\�t�g�ɍ��킹�ď���҂��n�[�h�������邱�ƂȂ��
���҂����Ⴂ���Ȃ��ł���B����҂ɑI��Ă�n�[�h���^�[�Q�b�g�Ƀ\�t�g�J������B
PC���X�y�b�N�̐���̂���X�}�z��^�u���b�g�������ˁB
�������N��AMD�̃I�[�v���\�[�X�̐��ʕ��݂Ă��
�j�[�Y�Ƃ��l���������������g�킹�������̂�����Ă�Ƃ�����
�v���O���}���]��ł�J�������Ĉӎ��������Ɩ�����Ȃ����ƁE�E�E
275 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 00:54:18.91 ID:9zfd46sr
�ƊE��GPGPU���g���������ݎ��v�������Đl������Ȃ����猾���n�[�h�E�F�A��
�����₷��������Ă����̂Ȃ�܂��킩�邯�NJ��ɐl�ނ͋����ߑ��Ȃ�ˁB
NVIDIA�������ȑ�w�ɔ��荞���́B
�ł��ƊE�̎��v�͂���قǐL�тȂ��āA�l���]���Ă�Ƃ����B
����������w�����GPGPU����Ă�����܂�Ȃ��d���̟T�����炵��
�I�[�v���\�[�X�ŃI�����C���Ō��J���Ă���x�̃\�t�g�͂��邾�낤����
���ۂɏ��ƃx�[�X�ɍڂ��Ă�\�t�g����Ă�ƊE�͒N�����߂ĂȂ��ł�����Ă����B
�d�����ł���Ă�l����������̊֘A�c�[���͕K�R�I�ɂӂ��ڐ����L�т�킯�ł��B
JavaScript�W�͋���
�����₷��������Ă����̂Ȃ�܂��킩�邯�NJ��ɐl�ނ͋����ߑ��Ȃ�ˁB
NVIDIA�������ȑ�w�ɔ��荞���́B
�ł��ƊE�̎��v�͂���قǐL�тȂ��āA�l���]���Ă�Ƃ����B
����������w�����GPGPU����Ă�����܂�Ȃ��d���̟T�����炵��
�I�[�v���\�[�X�ŃI�����C���Ō��J���Ă���x�̃\�t�g�͂��邾�낤����
���ۂɏ��ƃx�[�X�ɍڂ��Ă�\�t�g����Ă�ƊE�͒N�����߂ĂȂ��ł�����Ă����B
�d�����ł���Ă�l����������̊֘A�c�[���͕K�R�I�ɂӂ��ڐ����L�т�킯�ł��B
JavaScript�W�͋���
������A�䍂���������Ƃ��B
�w�e���W�j�A�X�R���s���[�e�B���O�����قǕ��y���Ȃ��ƂȂ�ƁA
���悢��v���Z�b�V���O�\�͌���̏I���Ƃ������ƂɂȂ�܂��ȁB
���̌�́A���炭�v���O���}�����葱���āA�S�̓I�ȃ��x���̌����m�E�n�E�̒~�ςȂǂ�
���[�U�[�̌��̌���͈ێ��������̂́A����ɂ��̐�ɂȂ�Ǝ�l�܂�B
���̃v���Z�b�V���O�\�̘͂g���ŁA
�����̊T�O��j��a�V�ȃA�v���P�[�V�����ɂ��C�m�x�[�V������
�U���I�ɋN����Ƃ�������ɂȂ��Ȃ��낤���B
�w�e���W�j�A�X�R���s���[�e�B���O�����قǕ��y���Ȃ��ƂȂ�ƁA
���悢��v���Z�b�V���O�\�͌���̏I���Ƃ������ƂɂȂ�܂��ȁB
���̌�́A���炭�v���O���}�����葱���āA�S�̓I�ȃ��x���̌����m�E�n�E�̒~�ςȂǂ�
���[�U�[�̌��̌���͈ێ��������̂́A����ɂ��̐�ɂȂ�Ǝ�l�܂�B
���̃v���Z�b�V���O�\�̘͂g���ŁA
�����̊T�O��j��a�V�ȃA�v���P�[�V�����ɂ��C�m�x�[�V������
�U���I�ɋN����Ƃ�������ɂȂ��Ȃ��낤���B
>>273
ARM�����łȂ�Intel��GPU�͂�����犈�p���悤�Ƃ��Ă���Ǝv���B
AMD��GPGPU������ׂĂ�F�ɂ��炵���Ȃ�I�@
Intel�AARM��GPGPU�ŗ�������̂����邩��A����ɂ͎g���܂��傤���ĂȊ���
���Ǝv���BGPGPU��AVX�݂����Ȋ����Ⴉ�B�ŏI���[�U�[�ɑ傫����`���Ă��֑�L�����Ċ����ɂȂ�Ǝv��
ARM�����łȂ�Intel��GPU�͂�����犈�p���悤�Ƃ��Ă���Ǝv���B
AMD��GPGPU������ׂĂ�F�ɂ��炵���Ȃ�I�@
Intel�AARM��GPGPU�ŗ�������̂����邩��A����ɂ͎g���܂��傤���ĂȊ���
���Ǝv���BGPGPU��AVX�݂����Ȋ����Ⴉ�B�ŏI���[�U�[�ɑ傫����`���Ă��֑�L�����Ċ����ɂȂ�Ǝv��
278 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 01:27:19.14 ID:9zfd46sr
�ʂɌ���̑唼�̃v���O���}��JavaScript��PHP��Ruby���ɊS�������Ă鎖����
�����Ƃ͎v��Ȃ��̂����ǂ�
���ꂪ�\�t�g�Y�ƊE�̎��v�ł����āA�A�Z���u���ł�����œK������悤�ȃv���O���}��
�K�v�Ȃ��Ȃ����̂͂��ꂾ���n�[�h�̐��\�����n���ċq���������Ă����Ƃ������Ƃł�����킯�ŁB
���i���͋q�̖���������̂�����Ă�������̂�B
���i���q��g�ݗ��Ă�̂ł͂Ȃ��B�q�����i��I�Ԃ̂ł��B
AMD�֑̌�L���͂�����˂��B
�{�C�Ŏ��v��ǂ݊ԈႦ�Ă�̂��A���v���Ȃ��̂����m�ł킴�Ǝ��Ђ̏�A�q��
�x���Ă�̂��͒m��ǂ��B
�����Ƃ͎v��Ȃ��̂����ǂ�
���ꂪ�\�t�g�Y�ƊE�̎��v�ł����āA�A�Z���u���ł�����œK������悤�ȃv���O���}��
�K�v�Ȃ��Ȃ����̂͂��ꂾ���n�[�h�̐��\�����n���ċq���������Ă����Ƃ������Ƃł�����킯�ŁB
���i���͋q�̖���������̂�����Ă�������̂�B
���i���q��g�ݗ��Ă�̂ł͂Ȃ��B�q�����i��I�Ԃ̂ł��B
AMD�֑̌�L���͂�����˂��B
�{�C�Ŏ��v��ǂ݊ԈႦ�Ă�̂��A���v���Ȃ��̂����m�ł킴�Ǝ��Ђ̏�A�q��
�x���Ă�̂��͒m��ǂ��B
����ɏ풓���Ă鎩�̋Z�p�҂̏��N���̓G���h���[�U�[�����ĂȂ���
�G���h���[�U�[�Ƃ͂��������l����Ȃ��čŏI�I�ɗ��p����l�X����
������SIer�͋q�̊�F����f���ăG���h���[�U�[�̎��_���Ȃ�����ƊE�������Ă��܂�����
�����̃n�[�h���������悤�Ȃ���A�����ɂ�����肷���Ȃ�AUI��UX���l���Ă�PG�Ȃ�č����Ō������Ƃˁ[��
��������{�͂��ꂩ����\�t�g�E�F�A�ł͌�i���A�Z�p�͂���ˁ[��A�Z���X�Ȃ�
�G���h���[�U�[�Ƃ͂��������l����Ȃ��čŏI�I�ɗ��p����l�X����
������SIer�͋q�̊�F����f���ăG���h���[�U�[�̎��_���Ȃ�����ƊE�������Ă��܂�����
�����̃n�[�h���������悤�Ȃ���A�����ɂ�����肷���Ȃ�AUI��UX���l���Ă�PG�Ȃ�č����Ō������Ƃˁ[��
��������{�͂��ꂩ����\�t�g�E�F�A�ł͌�i���A�Z�p�͂���ˁ[��A�Z���X�Ȃ�
281 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 02:09:23.81 ID:9zfd46sr
�����̂��G���h���[�U�[�ł��B
�������p���I������p�b�P�[�W���J�X�^�}�C�Y���Ĉ�ʏ���҂ɔ������肷�邯��
�唼�̓T�|�[�g�R�X�g�̂ق��������Ȃ邩��唼�̃\�t�g�n�E�X�͈����グ�Ă��܂�����B
�u���ۏv���������ăt���[�Ŕz�z�����ق����܂������������x�B
MS��VisualStudio������Ă�悤�ɂˁB
UX�Ɋւ�镔���Ȃ�A���͎d����XAML��������Web�t�H�[���N�������������Ă��ł�����
�J���ɂ͈�ؐG�ꂸ���i�]�����ɂ܂���āATAB�Ńe�L�X�g�{�b�N�X�̈ړ����ł��Ȃ��Ƃ�
�^�u�I�[�_�[���ʖڂ��Ƃ��A�U�X�ʖڂ������Ă�邾���̍�Ƃ���������Ƃ�����܂���B
�������p���I������p�b�P�[�W���J�X�^�}�C�Y���Ĉ�ʏ���҂ɔ������肷�邯��
�唼�̓T�|�[�g�R�X�g�̂ق��������Ȃ邩��唼�̃\�t�g�n�E�X�͈����グ�Ă��܂�����B
�u���ۏv���������ăt���[�Ŕz�z�����ق����܂������������x�B
MS��VisualStudio������Ă�悤�ɂˁB
UX�Ɋւ�镔���Ȃ�A���͎d����XAML��������Web�t�H�[���N�������������Ă��ł�����
�J���ɂ͈�ؐG�ꂸ���i�]�����ɂ܂���āATAB�Ńe�L�X�g�{�b�N�X�̈ړ����ł��Ȃ��Ƃ�
�^�u�I�[�_�[���ʖڂ��Ƃ��A�U�X�ʖڂ������Ă�邾���̍�Ƃ���������Ƃ�����܂���B
282 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 03:12:06.96 ID:9zfd46sr
���̐��Ɋ�Â��čl����AHSA�c�[����200�{�ȏ�̃v���O���}�[��
AngularJS�ɊS�������Ă���
����͂܂�AJavaScript�������ɏ����ł���CPU���J�������ق����A
GPU�����p�]�X���200�{�̉\�����߂Ă���Ƃ������ƁB
AngularJS�ɊS�������Ă���
����͂܂�AJavaScript�������ɏ����ł���CPU���J�������ق����A
GPU�����p�]�X���200�{�̉\�����߂Ă���Ƃ������ƁB
283 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 03:20:24.11 ID:9zfd46sr
���[������JavaScript���̂��̂�OpenCL�ŏ�������Z�p���J�����Ă���Intel��������
WebCl�Ƃ�����Ȃ��ɁA�ʏ��JavaScript�̃R�[�h���̂��̂�OpenCL�ɕϊ�����Ƃ���
https://github.com/IntelLabs/RiverTrail
Firefox�ւ̃}�[�W����������Ă��݂���������
������������Firefox����HTML5�T�C�g�̓���ΏۊO�ɂ���Ă���
���Ȃ�����ȑ��݂Ȃ�ł����B�B�B
WebCl�Ƃ�����Ȃ��ɁA�ʏ��JavaScript�̃R�[�h���̂��̂�OpenCL�ɕϊ�����Ƃ���
https://github.com/IntelLabs/RiverTrail
Firefox�ւ̃}�[�W����������Ă��݂���������
������������Firefox����HTML5�T�C�g�̓���ΏۊO�ɂ���Ă���
���Ȃ�����ȑ��݂Ȃ�ł����B�B�B
�u���E�U�֘A�͂ǂ������������Ђǂ�
�Ђǂ�����
Bling��FireFox���Ȃ�ł���ȃ��������[�N��������
�ǂ������V�����u���E�U�G���W�����Ȃ����Ȃ�
�Ђǂ�����
Bling��FireFox���Ȃ�ł���ȃ��������[�N��������
�ǂ������V�����u���E�U�G���W�����Ȃ����Ȃ�
>>267
�˂����܂��ăX�}����
�܂��A�ǂ���14/16nm����̈�ʌ����̃v���Z�b�T�͖w��Soc�ɂȂ邾�낤����
AMD��Carrizo�ȍ~��AIntel���X�J�C���[�N�ȍ~��Xeon�ȊO�͑S������
> Carrizo-L�͔�Ή�������
Carrizo-L�͖��O�����̊����`�b�v���ǂ����玟���ザ��Ȃ�
> ��HSA�͂��Ƃ�葼�̊J���҂��I�������Ȃ�����kaveri��Carrizo�g���ĊJ�����Ă�
> �܂����[���`����ĂȂ�Carrizo�̓}�U�[�{�[�h���[�J�[��ES�i�͍s���Ă邩������Ȃ����A�\�t�g�E�F�A�J���҂��g���Ă���킯�Ȃ�����
hUMA��hQ����������Ă��������kaveri��PS4�ł��J���͂ł���
�˂����܂��ăX�}����
�܂��A�ǂ���14/16nm����̈�ʌ����̃v���Z�b�T�͖w��Soc�ɂȂ邾�낤����
AMD��Carrizo�ȍ~��AIntel���X�J�C���[�N�ȍ~��Xeon�ȊO�͑S������
> Carrizo-L�͔�Ή�������
Carrizo-L�͖��O�����̊����`�b�v���ǂ����玟���ザ��Ȃ�
> ��HSA�͂��Ƃ�葼�̊J���҂��I�������Ȃ�����kaveri��Carrizo�g���ĊJ�����Ă�
> �܂����[���`����ĂȂ�Carrizo�̓}�U�[�{�[�h���[�J�[��ES�i�͍s���Ă邩������Ȃ����A�\�t�g�E�F�A�J���҂��g���Ă���킯�Ȃ�����
hUMA��hQ����������Ă��������kaveri��PS4�ł��J���͂ł���
�c�q�������������Ƃ��킩��
�ǂ�ȂɗD�ꂽ�Z�p�ł��AIntel��Nvidia���Ή��ł��Ȃ��Ꮴ�p�ŊJ���ł��Ȃ������
�����A���v�����������܂��킯�Ȃ�
�܂��AIntel��DX12�Ή���R�q�[�����g�o�X�����Ƃ�AMD��3�T�ʒx��Ċ撣���ĂāA�w�e���R���s���[�e�B���O�̏d�v���c�����Ă邩��A���ʓI�ɂ�AMD�̎v�f�ʂ�Ɏ����i�݂���
���ƃO���t�B�b�N�ʂł̐��\������AMD��Intel�ɒx�����邱�Ƃ͂Ȃ�����AIntel���Ή����Ă��炪�z���g�̏�������
�܂��AAPU+RADEON���ADX12��OpenCL�ŁAAVX+iGPU+dGPU�̑S���Z�͂������ǂ���g����悤�ɂȂ�����A����Intel���Q�Ă邾��
�ǂ�ȂɗD�ꂽ�Z�p�ł��AIntel��Nvidia���Ή��ł��Ȃ��Ꮴ�p�ŊJ���ł��Ȃ������
�����A���v�����������܂��킯�Ȃ�
�܂��AIntel��DX12�Ή���R�q�[�����g�o�X�����Ƃ�AMD��3�T�ʒx��Ċ撣���ĂāA�w�e���R���s���[�e�B���O�̏d�v���c�����Ă邩��A���ʓI�ɂ�AMD�̎v�f�ʂ�Ɏ����i�݂���
���ƃO���t�B�b�N�ʂł̐��\������AMD��Intel�ɒx�����邱�Ƃ͂Ȃ�����AIntel���Ή����Ă��炪�z���g�̏�������
�܂��AAPU+RADEON���ADX12��OpenCL�ŁAAVX+iGPU+dGPU�̑S���Z�͂������ǂ���g����悤�ɂȂ�����A����Intel���Q�Ă邾��
287 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 05:06:24.53 ID:ZxI3P4mR
�̐��b�ɂȂ����E��̏�i���킭
70�`80�N��Ƀp�^�[���}�b�`�╄�����̃A���S���Y�����l�Ă��ē������������Ƃ�������
������CPU���\�ł͂������������ł��Ȃ������A�Ȃ�Ă��̂�90�N��ȍ~�̋}����
PC�ł̍����\���Ŏ��X�Ǝ�������Ă��������ȁB
���͂��������u�A�C�f�B�A�͂��邯�ǐ��\������Ȃ������Ď��p���ł��Ȃ��l�^�v�̃X�g�b�N��
���Ƃǂꂾ������́H�Ƃ������x������ˁH
�i�����Z�p�ő�p����������A�����������v�Ȃ��̂����O���������łˁj
�d�����X�N���v�g����ŗL��]��CPU���\��Q���Ȃ�Ă̂��ʂɈ����Ȃ���
�\�t�g�J����ێ�̃R�X�g��������Ȃ�\���L�v�Ȃ��ƁB
70�`80�N��Ƀp�^�[���}�b�`�╄�����̃A���S���Y�����l�Ă��ē������������Ƃ�������
������CPU���\�ł͂������������ł��Ȃ������A�Ȃ�Ă��̂�90�N��ȍ~�̋}����
PC�ł̍����\���Ŏ��X�Ǝ�������Ă��������ȁB
���͂��������u�A�C�f�B�A�͂��邯�ǐ��\������Ȃ������Ď��p���ł��Ȃ��l�^�v�̃X�g�b�N��
���Ƃǂꂾ������́H�Ƃ������x������ˁH
�i�����Z�p�ő�p����������A�����������v�Ȃ��̂����O���������łˁj
�d�����X�N���v�g����ŗL��]��CPU���\��Q���Ȃ�Ă̂��ʂɈ����Ȃ���
�\�t�g�J����ێ�̃R�X�g��������Ȃ�\���L�v�Ȃ��ƁB
AMD�͌������ċZ�p�L�߂�̂��d�����ۂ��̂��Ȃ�
FreeSync�݂����ɂ����Ȃ茈��ŏo���Ƃ������邯��
>>287
�X�}�z�^�u���b�g�ł͐��\�̘Q��͂���Ȃɋ�����Ȃ���
�d�r�̏���ƃg���[�h�I�t�������
FreeSync�݂����ɂ����Ȃ茈��ŏo���Ƃ������邯��
>>287
�X�}�z�^�u���b�g�ł͐��\�̘Q��͂���Ȃɋ�����Ȃ���
�d�r�̏���ƃg���[�h�I�t�������
289 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 05:17:51.36 ID:ZxI3P4mR
�A�C�f�B�A�̎������邽�߂ɂ͈��̃n�[�h�E�F�A���\�͕K�v�����A
�n�[�h�E�F�A�̐��\���オ�V���ȃA�C�f�B�A�ݏo���킯�ł͂Ȃ�
�����������̗v���ɑ��ăn�[�h����������̂ł�����
�n�[�h�̓s���ɂ��킹�Ă�荂�����\��K�v�Ƃ�V���ȗv�����v��������
����Ɩ{���]�|�Ȃ��Ƃ��Ǝv��
���i�������i���̓s���ŐV���ȗv�����l�����Ƃ���ŁA�����Ă�
�@�@�u����N���K�v�Ƃ��Ă�́H�v
�ƂȂ�̂��I�`�ł����Ȃ��B
Intel��3D Web�݂����Ȃ̎����グ�Ă��������������nj��nj���Ȃ��Ȃ�����ˁB
�n�[�h�E�F�A�̐��\���オ�V���ȃA�C�f�B�A�ݏo���킯�ł͂Ȃ�
�����������̗v���ɑ��ăn�[�h����������̂ł�����
�n�[�h�̓s���ɂ��킹�Ă�荂�����\��K�v�Ƃ�V���ȗv�����v��������
����Ɩ{���]�|�Ȃ��Ƃ��Ǝv��
���i�������i���̓s���ŐV���ȗv�����l�����Ƃ���ŁA�����Ă�
�@�@�u����N���K�v�Ƃ��Ă�́H�v
�ƂȂ�̂��I�`�ł����Ȃ��B
Intel��3D Web�݂����Ȃ̎����グ�Ă��������������nj��nj���Ȃ��Ȃ�����ˁB
290 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 05:39:03.45 ID:ZxI3P4mR
���܂���SIMD���g����Ȃ�ł������ł���Ǝv���Ă邾��
MMX���SSE�͂��Ƃ���MPEG2�̓���E�����R�[�f�b�N���̍�������z�肵
�A�v���P�[�V�����̗v���ɂ��킹�Ēlj����ꂽ�o�܂�����B
�R�[�f�b�N�̓n�[�h����Ɍ��߂��Ă��āA����ɍ��킹�ăn�[�h���v���ꂽ�B
�uGPU�R�A�����������L�Ŏg����悤�ɂ�������ق�Ȃ���Ă݂�v
�Ȃ�Č����Ď����ł���A�C�f�B�A�͂قډ����Ȃ��킯�ł���B
MMX���SSE�͂��Ƃ���MPEG2�̓���E�����R�[�f�b�N���̍�������z�肵
�A�v���P�[�V�����̗v���ɂ��킹�Ēlj����ꂽ�o�܂�����B
�R�[�f�b�N�̓n�[�h����Ɍ��߂��Ă��āA����ɍ��킹�ăn�[�h���v���ꂽ�B
�uGPU�R�A�����������L�Ŏg����悤�ɂ�������ق�Ȃ���Ă݂�v
�Ȃ�Č����Ď����ł���A�C�f�B�A�͂قډ����Ȃ��킯�ł���B
>>281
�������̂��G���h���[�U�[�ł��B
����A�Ⴄ��
�c�q�̎��_�̓G���h���[�U�[�����(�V�X�e���ɂ��������l)�Ȃ�
���̌����Ă�G���h���[�U�[�Ƃ́A�ŏI�I�ɗ��p���邱�ƂɂȂ�I�y���[�^�[���ʏ���҂���
������Sier�ɂ���Ȏ��_�Ȃ��ˁA������o�J������
��ʏ���҂����ăv���_�N�g�ݏo���Ă�̂�Apple�������ˁA����̃u���[�t�B���O��MS��������Windows 10��HoloLens�͗ǂ��Z���X���Ă��
��UX�Ɋւ�镔���Ȃ�A���͎d����XAML��������Web�t�H�[���N�������������Ă��ł�����
���������AWPF��ASP.NET��UI����������ŃZ���X����܂��Ƃ��킹��Ȃ悗
���Ȃ݂ɂ���̓f�U�C���̌o������́H���͂����A�ߋ��f�U�C�i�[����č���PG(SE���Č��t������)���B
�y����邪UX��UI�ǂ��m���Ă�A�����ō��ꂽ�܂Ƃ��ȃf�U�C���EUX�̃\�t�g�E�F�A�Ȃ�Č������Ɩ�������
���Ȃ݂�WPF�͉��̓��ӕ���Ȃ�ʼn���Ȃ��ƌ���Ȃ�������������
�������̂��G���h���[�U�[�ł��B
����A�Ⴄ��
�c�q�̎��_�̓G���h���[�U�[�����(�V�X�e���ɂ��������l)�Ȃ�
���̌����Ă�G���h���[�U�[�Ƃ́A�ŏI�I�ɗ��p���邱�ƂɂȂ�I�y���[�^�[���ʏ���҂���
������Sier�ɂ���Ȏ��_�Ȃ��ˁA������o�J������
��ʏ���҂����ăv���_�N�g�ݏo���Ă�̂�Apple�������ˁA����̃u���[�t�B���O��MS��������Windows 10��HoloLens�͗ǂ��Z���X���Ă��
��UX�Ɋւ�镔���Ȃ�A���͎d����XAML��������Web�t�H�[���N�������������Ă��ł�����
���������AWPF��ASP.NET��UI����������ŃZ���X����܂��Ƃ��킹��Ȃ悗
���Ȃ݂ɂ���̓f�U�C���̌o������́H���͂����A�ߋ��f�U�C�i�[����č���PG(SE���Č��t������)���B
�y����邪UX��UI�ǂ��m���Ă�A�����ō��ꂽ�܂Ƃ��ȃf�U�C���EUX�̃\�t�g�E�F�A�Ȃ�Č������Ɩ�������
���Ȃ݂�WPF�͉��̓��ӕ���Ȃ�ʼn���Ȃ��ƌ���Ȃ�������������
292 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 06:03:39.24 ID:ZxI3P4mR
�w�����ォ��Adobe InDesign�g���Ă����lj����H
�����҂Ɏw������邪�܂܂ɃR�[�h�����̂�SE�ǂ��납PG�ł���Ȃ���
�����̃R�[�_�[�B
���R��ƒS���҂̃��j�^�����O���炢�͓�����O�ɂ���
�����҂Ɏw������邪�܂܂ɃR�[�h�����̂�SE�ǂ��납PG�ł���Ȃ���
�����̃R�[�_�[�B
���R��ƒS���҂̃��j�^�����O���炢�͓�����O�ɂ���
InDesign�g�������lj����H������
�O���t�B�b�N�X�f�U�C��ꖂ��Ă�Ȃ�Adobe�̃\�t�g�E�F�A�Ȃ�ĒN�ł��g���܂��������H
�x�N�^�[�łǂꂾ���f�U�C���ł���́H�A�b�v���Ă݂��炢���Ǝv���܂��������H������
�������҂Ɏw������邪�܂܂ɃR�[�h�����̂�SE�ǂ��납PG�ł���Ȃ���
�������̃R�[�_�[�B
�����R��ƒS���҂̃��j�^�����O���炢�͓�����O�ɂ���
�����������̂��܂������킩��Ȃ���ł��������H
�O���t�B�b�N�X�f�U�C��ꖂ��Ă�Ȃ�Adobe�̃\�t�g�E�F�A�Ȃ�ĒN�ł��g���܂��������H
�x�N�^�[�łǂꂾ���f�U�C���ł���́H�A�b�v���Ă݂��炢���Ǝv���܂��������H������
�������҂Ɏw������邪�܂܂ɃR�[�h�����̂�SE�ǂ��납PG�ł���Ȃ���
�������̃R�[�_�[�B
�����R��ƒS���҂̃��j�^�����O���炢�͓�����O�ɂ���
�����������̂��܂������킩��Ȃ���ł��������H
294 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 06:21:58.21 ID:ZxI3P4mR
���[���ʂɏo�ŎЂŃo�C�g���Ă������ł���
295 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 06:31:00.76 ID:ZxI3P4mR
>>293
�N�A���܂��ɏ㗬�H����������ƂȂ��B���ꂶ��v���O���}�[�̈悾��
�v����`�͌����Ǝ҂̃q�A�����O�����Ȃ���K�v�Ȏd�l���ł߂Ă�����
����������������ƂȂ��Ȃ�A������Ɏw�����ꂽ�܂܂ɃR�[�h���������������
�����炭�G���h���[�U�[�ł͂Ȃ��N�̏�i�̎w�����B��i�����߁B
�N�A���܂��ɏ㗬�H����������ƂȂ��B���ꂶ��v���O���}�[�̈悾��
�v����`�͌����Ǝ҂̃q�A�����O�����Ȃ���K�v�Ȏd�l���ł߂Ă�����
����������������ƂȂ��Ȃ�A������Ɏw�����ꂽ�܂܂ɃR�[�h���������������
�����炭�G���h���[�U�[�ł͂Ȃ��N�̏�i�̎w�����B��i�����߁B
�G���h���[�U�[�̗��v�́A�����̑I�������痝�z�ɋ߂����̂�I�Ԃ��ƂȂ�
�R�X�g�����\���@�\���f�U�C�����̊����͐l���ꂼ��
�m�[�g��^�u���b�g�݂����ȁA�����`�b�v���\���d�v��PC�ɂ́A���f�B�A���\�ɗD�ꂽAPU���œK�Ȃ̂ɁA�����ɂ͉e���`���Ȃ����
����̂̓N�\���\��Intel HD���A���R�X�g�ȃQ�t�H���ڕi�̂�
�����ŃQ�[����������y���߂�APU���ڋ@���Ȃ��Ƃ��G���h���[�U�[�̕s���v�ɂ܂�Ȃ�
���ł�NEC�͊C�O�����ɂ͏o���Ă邯�ǁA�����ɂ͏o���ĂȂ������
�����ɏo���Ă�̂́AASUS��HP�Ƃ��̊O�����Ƃ����̂��炭
�R�X�g�����\���@�\���f�U�C�����̊����͐l���ꂼ��
�m�[�g��^�u���b�g�݂����ȁA�����`�b�v���\���d�v��PC�ɂ́A���f�B�A���\�ɗD�ꂽAPU���œK�Ȃ̂ɁA�����ɂ͉e���`���Ȃ����
����̂̓N�\���\��Intel HD���A���R�X�g�ȃQ�t�H���ڕi�̂�
�����ŃQ�[����������y���߂�APU���ڋ@���Ȃ��Ƃ��G���h���[�U�[�̕s���v�ɂ܂�Ȃ�
���ł�NEC�͊C�O�����ɂ͏o���Ă邯�ǁA�����ɂ͏o���ĂȂ������
�����ɏo���Ă�̂́AASUS��HP�Ƃ��̊O�����Ƃ����̂��炭
297 �FSocket774�F2015/01/25(��) 06:45:14.17 ID:gl/8vhKA
298 �FSocket774�F2015/01/25(��) 06:49:28.13 ID:gl/8vhKA
300 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 06:51:00.98 ID:ZxI3P4mR
�p�b�P�[�W�\�t�g�o���҂��猾�킹�Ă��炤����
������HSA�̊J���c�[���������[�X���ꂽ�Ƃ��Ă�������g���ĊJ�����邱�Ƃ͊�{�Ȃ��Ǝv����B
�ǂ�ȃp�b�P�[�W�\�t�g����{�@�l������s�����A�@�l���[�U�[��AMD����������q�Ȃ��
�͂��ꃁ�^�����ɋH������ȁB
Intel CPU�œ��삷��悤�ɐv���Ă����Ί�{�ԈႢ�Ȃ��B
AMD�ɓ������ꂽ�@�\������Ƃ��Ă�����Ȃ��̂ɕʓr�H���������Ȃ��B
��p�Ό��ʂ��l����Γ�����O�̂��ƁB
������HSA�̊J���c�[���������[�X���ꂽ�Ƃ��Ă�������g���ĊJ�����邱�Ƃ͊�{�Ȃ��Ǝv����B
�ǂ�ȃp�b�P�[�W�\�t�g����{�@�l������s�����A�@�l���[�U�[��AMD����������q�Ȃ��
�͂��ꃁ�^�����ɋH������ȁB
Intel CPU�œ��삷��悤�ɐv���Ă����Ί�{�ԈႢ�Ȃ��B
AMD�ɓ������ꂽ�@�\������Ƃ��Ă�����Ȃ��̂ɕʓr�H���������Ȃ��B
��p�Ό��ʂ��l����Γ�����O�̂��ƁB
301 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 06:52:13.60 ID:ZxI3P4mR
TMPEGEnc��QSV�����͑Ή����Ă邯��AMD�̂Ȃ�Ƃ��ɂ͂��܂��ɑΉ����ĂȂ�
���R�l�������Ƃ��邩���H���ꂪ�u��p�Ό��ʁv����B
���R�l�������Ƃ��邩���H���ꂪ�u��p�Ό��ʁv����B
���������A�₽��x���`���Ύ����āA�̊��n���ɂ��Ă邯��
�}�E�X��L�[�{�[�h�A�f�B�X�v���C�Ƃ��̃C���^�[�t�F�[�X�̑I���̌���ł͉����Ǝv���H
�d���␡�@��dpi�₻�̑����X�̐��l�����ꂽ�f�[�^���Ǝv���H
�Ⴄ����A���ڌ��ĐG���đ̊����Ď����Ƀt�B�b�g�����̂����낤
web�Ȃ�A�����Ђ̑��푽�l�Ȏ����̂�����������ׂĔ������낤
����͂��Ȃ킿�A���l������Ȃ������ɂ��d�v�ȗv�f���������炾��
CPU��GPU�������ȁA���N�ɒ��ׂȂ��Ńx���`�����Ō��߂��Ĕ�����̂�
�}�E�X��L�[�{�[�h�A�f�B�X�v���C�Ƃ��̃C���^�[�t�F�[�X�̑I���̌���ł͉����Ǝv���H
�d���␡�@��dpi�₻�̑����X�̐��l�����ꂽ�f�[�^���Ǝv���H
�Ⴄ����A���ڌ��ĐG���đ̊����Ď����Ƀt�B�b�g�����̂����낤
web�Ȃ�A�����Ђ̑��푽�l�Ȏ����̂�����������ׂĔ������낤
����͂��Ȃ킿�A���l������Ȃ������ɂ��d�v�ȗv�f���������炾��
CPU��GPU�������ȁA���N�ɒ��ׂȂ��Ńx���`�����Ō��߂��Ĕ�����̂�
303 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 06:56:07.42 ID:ZxI3P4mR
�\�����킩��Ȃ�PC�ł�AMD�̃V�[���\���Ă���Δ����Ɋ�������
�t�@���{�[�C�̑̊���ł��ˁA�킩��܂��B
�t�@���{�[�C�̑̊���ł��ˁA�킩��܂��B
304 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 07:01:11.05 ID:ZxI3P4mR
�����ɂقƂ�ǃ��[�U�[�̂��Ȃ�AMD�̃`�b�v�ɓ��������@�\�̂��߂̗]���ȊJ�����
�命����Intel CPU���[�U�[�ɕ��S������Ȃ�Ă��Ƃ͓����I�ɂ��肦�Ȃ�
�命����Intel CPU���[�U�[�ɕ��S������Ȃ�Ă��Ƃ͓����I�ɂ��肦�Ȃ�
>>297
���낻��AGPU��GPGPU����Ȃ��A�x�N�g���v���Z�b�T�ŃO���t�B�b�N�A�Ƃ������E�ɂȂ邩��d���Ȃ�
�܂�A�X�J���A�x�N�g���A�O���t�B�b�N���ǂ�����Č����ǂ��A�g�����邩������̃g�����h�ɂȂ��Ă�����Ȃ�����
Intel�̃A�v���[�`��x86�őS�����AHD�̓I�}�P
AMD��GPU��CPU���őΉ�����
Nvidia�̓X�J���͑��ЂɊۓ����ADenver��GPU����p
�Ⴆ�A4k��8k��3D�f�������H�ҏW�������悤�Ƃ�����A�ǂꂪ�������ƍl�����ꍇ
GPU���_����Intel�͐��\���f���i�����A�E�g
CPU���������������ᐫ�\��Nvidia�����
CPU��GPU���߂��č����\��AMD���ł��œK���낤
�����͍X��AR��VR�A����ʂ��ւ���Ă��邩��X�Ɍ������Ȃ��āAFreeSync��Eyefinity������AMD�̗D�ʂ͕���Ȃ�
���낻��AGPU��GPGPU����Ȃ��A�x�N�g���v���Z�b�T�ŃO���t�B�b�N�A�Ƃ������E�ɂȂ邩��d���Ȃ�
�܂�A�X�J���A�x�N�g���A�O���t�B�b�N���ǂ�����Č����ǂ��A�g�����邩������̃g�����h�ɂȂ��Ă�����Ȃ�����
Intel�̃A�v���[�`��x86�őS�����AHD�̓I�}�P
AMD��GPU��CPU���őΉ�����
Nvidia�̓X�J���͑��ЂɊۓ����ADenver��GPU����p
�Ⴆ�A4k��8k��3D�f�������H�ҏW�������悤�Ƃ�����A�ǂꂪ�������ƍl�����ꍇ
GPU���_����Intel�͐��\���f���i�����A�E�g
CPU���������������ᐫ�\��Nvidia�����
CPU��GPU���߂��č����\��AMD���ł��œK���낤
�����͍X��AR��VR�A����ʂ��ւ���Ă��邩��X�Ɍ������Ȃ��āAFreeSync��Eyefinity������AMD�̗D�ʂ͕���Ȃ�
306 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 07:09:59.85 ID:ZxI3P4mR
������Ă��߂ĂQ�`�R�����x�̖@�l���[�U�[��������O�Ɏg���悤�ɂȂ�Ȃ���
������֗��@�\�ς�ł��J���̌����Ώۂɂ��Ȃ�Ȃ�
������֗��@�\�ς�ł��J���̌����Ώۂɂ��Ȃ�Ȃ�
gpu��cpu���Ȃ�Ė��ʂɂ��قǂ������
308 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 07:28:03.07 ID:ZxI3P4mR
�@�l��9���ȏ��Intel�v���b�g�t�H�[�����[�U�[���g��Ȃ�AMD�����@�\�̂��߂�
�J����]���ɂ������Ă��܂����Ƃ����͐�ɔ����Ȃ���Ȃ�Ȃ��B
����Ȗ��ʂȋ@�\�ɋ������邭�炢�Ȃ�����ƈ�������Ƃ��ʂ̋@�\�[��������Ƃ�
�ᔻ�������Ă��܂��B
�ʗ����Ԃ����Ă����Ȃ�L���̃A�h�I���őΉ��ł����ł���B
���̋q�ɐl���H�������̂܂ܐ����B
����ȋ���������Ȃ�AMD�Ȃ�Ĉ����I�Ȃ����낤���ǂȁB
�J����]���ɂ������Ă��܂����Ƃ����͐�ɔ����Ȃ���Ȃ�Ȃ��B
����Ȗ��ʂȋ@�\�ɋ������邭�炢�Ȃ�����ƈ�������Ƃ��ʂ̋@�\�[��������Ƃ�
�ᔻ�������Ă��܂��B
�ʗ����Ԃ����Ă����Ȃ�L���̃A�h�I���őΉ��ł����ł���B
���̋q�ɐl���H�������̂܂ܐ����B
����ȋ���������Ȃ�AMD�Ȃ�Ĉ����I�Ȃ����낤���ǂȁB
>>295
���N�A���܂��ɏ㗬�H����������ƂȂ��B���ꂶ��v���O���}�[�̈悾��
�b���Ȃ�ł����ɔ�Ԃ̂������ł��Ȃ����Ęb�Ȃ��ǂ�
�㗬�������������[���ꉞ�o�c�҂Ȃ�ł��������H���v���C���O�}�l�[�W���[�Ȃ�ł����lj����H��
��������SIer���o�J�����[�b���Ȃ�ŏ㗬����Ă邯�lj����H���㗬�o���Ȃ��A�ɂȂ�悗
�c�q���Ă��ꂾ�ȁA�������Ȃ�Ƙ_�_���炵�ėL�떳��ɂ���J�X�ȂȁA�͂��A�������܂�����
���N�A���܂��ɏ㗬�H����������ƂȂ��B���ꂶ��v���O���}�[�̈悾��
�b���Ȃ�ł����ɔ�Ԃ̂������ł��Ȃ����Ęb�Ȃ��ǂ�
�㗬�������������[���ꉞ�o�c�҂Ȃ�ł��������H���v���C���O�}�l�[�W���[�Ȃ�ł����lj����H��
��������SIer���o�J�����[�b���Ȃ�ŏ㗬����Ă邯�lj����H���㗬�o���Ȃ��A�ɂȂ�悗
�c�q���Ă��ꂾ�ȁA�������Ȃ�Ƙ_�_���炵�ėL�떳��ɂ���J�X�ȂȁA�͂��A�������܂�����
��łǂ��Ńp�b�P�[�W����Ă悗
FIP�HHISOL�HNSOL�HRITS�H���ꂩ�ǂ����̌������E�E�E�ɂ͂���Ȃ���Ȃ��Ȃ�
FIP�HHISOL�HNSOL�HRITS�H���ꂩ�ǂ����̌������E�E�E�ɂ͂���Ȃ���Ȃ��Ȃ�
311 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 07:34:59.12 ID:ZxI3P4mR
��l�����̉�Ђ̎В�����Ȃ�ĕ��ʂɉ������ɂ����邩��ˁ[
�K�͂͂��@�����܂�
�K�͂͂��@�����܂�
312 �FSocket774�F2015/01/25(��) 07:36:19.96 ID:CuZ5bhdK
>>296
�ቿ�i�����m�[�g�ɂ�Beema�Ƃ����ǂ�APU���L�邯�ǁA�^�u���b�g�ɍœK��APU�Ȃ�Ăǂ��ɂ����B
>>301
TMGEnc�̍ŐV�ł�NVENC�ɑΉ�������B
VCE�ւ͑Ή����ĂȂ����ǁB
�ቿ�i�����m�[�g�ɂ�Beema�Ƃ����ǂ�APU���L�邯�ǁA�^�u���b�g�ɍœK��APU�Ȃ�Ăǂ��ɂ����B
>>301
TMGEnc�̍ŐV�ł�NVENC�ɑΉ�������B
VCE�ւ͑Ή����ĂȂ����ǁB
313 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 07:39:24.09 ID:ZxI3P4mR
314 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 07:44:05.60 ID:ZxI3P4mR
CUDA�t�����͖@�l���`�ǂ��납�l�J���̃\�t�g�ɂ܂Ŗ����Ŏx���Ƃ�����Ă�����ˁ[
>>292
���w�����ォ��Adobe InDesign�g���Ă����lj����H
>>294
�����[���ʂɏo�ŎЂŃo�C�g���Ă������ł���
�܂����ꂪ�c�q�̂��ׂĂ���
>>311
���߂�A�]�ƈ�8�l���܂����A�����H
�N��2000�������Ă܂����A�����H��
���w�����ォ��Adobe InDesign�g���Ă����lj����H
>>294
�����[���ʂɏo�ŎЂŃo�C�g���Ă������ł���
�܂����ꂪ�c�q�̂��ׂĂ���
>>311
���߂�A�]�ƈ�8�l���܂����A�����H
�N��2000�������Ă܂����A�����H��
316 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 07:48:04.83 ID:ZxI3P4mR
�ꉞ1�l�В����W�l�̂ق����̂��Ǝv���Ă�B�ց[�B��ׂɕς��Ȃ����B
�܂���ׂł��U���h�����ɐl�݂��̂��Ėׂ��邩��ˁB
�܂���ׂł��U���h�����ɐl�݂��̂��Ėׂ��邩��ˁB
317 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 08:08:58.01 ID:ZxI3P4mR
�V���̗p���Ĉ�Ă��邭�炢�̋K�͂ɂȂ����狹�����ĎВ��ł����Ă�����Ǝv����B
���̎�̋K�͂̎��̉�Ђ̐l���đ��肵�Ă������炳�A
���݉�Ƃ��̐ȂŕK���o�鎿�₪�u�V�l����ǂ�����Ă�́H�v
�����Ă��V�l����؎��Ȃ���ЂȂ��ǂ��i���Ȃ��̂Ƃ���������炭�����ł��傤�ˁj
�Ƃ����Ƃ��Ă��O���̎��Ȍ[���Z�~�i�[�ɍs�����邾�Ƃ��A�m�荇���̉�Ђɗa���邾�Ƃ�
�܂��A����Ȋ��ň�Ă�ꂽ�V�l�͂��낢�됫�i�c�݂������ȂƎv�����B
���̎�̋K�͂̎��̉�Ђ̐l���đ��肵�Ă������炳�A
���݉�Ƃ��̐ȂŕK���o�鎿�₪�u�V�l����ǂ�����Ă�́H�v
�����Ă��V�l����؎��Ȃ���ЂȂ��ǂ��i���Ȃ��̂Ƃ���������炭�����ł��傤�ˁj
�Ƃ����Ƃ��Ă��O���̎��Ȍ[���Z�~�i�[�ɍs�����邾�Ƃ��A�m�荇���̉�Ђɗa���邾�Ƃ�
�܂��A����Ȋ��ň�Ă�ꂽ�V�l�͂��낢�됫�i�c�݂������ȂƎv�����B
�����ς炩��(�L�E�ցE`)�n������˂��̃R�C�c��
�c�q��^���Ԃ�
�����������ꂽ�̂�����ۂlj����������ȁ[
�܂�2ch�ŃR�e���ĉ��N���R���{�����킩��Ȃ������ق����Ă邨�܂��Ɍ����Ă�����^���ԂɂȂ�Ȃ�����
���߂�˂�����
�����������ꂽ�̂�����ۂlj����������ȁ[
�܂�2ch�ŃR�e���ĉ��N���R���{�����킩��Ȃ������ق����Ă邨�܂��Ɍ����Ă�����^���ԂɂȂ�Ȃ�����
���߂�˂�����
320 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 08:25:21.73 ID:ZxI3P4mR
�c�O�����N�̎������x��
�傫������
��
��
��
��������̂͂܂������ˁB
�U���h���܂����̂��Ƃ���Ă�͔̂ے肵�Ȃ���
�傫������
��
��
��
��������̂͂܂������ˁB
�U���h���܂����̂��Ƃ���Ă�͔̂ے肵�Ȃ���
�������[���L��GPGPU�ȊO�ɃQ�[���ɂ��e�����Ă����Ȃ��́H
>>314
geforce����������
geforce����������
323 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 08:38:20.16 ID:ZxI3P4mR
>>317�͐����œ����Ă����Љ�l�P�N���{�l����������b�������
����܋�̓I�Ȃ��Ƃ͌���Ȃ����ǁA������Ƃ������Ђł̐V�l����������ĂȂ����Ƃ���
�{�l�͑����R���v���b�N�X�����Ă���B
�P�N�����Ȃ�����
����܋�̓I�Ȃ��Ƃ͌���Ȃ����ǁA������Ƃ������Ђł̐V�l����������ĂȂ����Ƃ���
�{�l�͑����R���v���b�N�X�����Ă���B
�P�N�����Ȃ�����
�� ageia��physx�{�[�h������Ƃ���58gflops�����Ȃ���������
cpu�ő���ˁ[�́H���Ďv������
cpu�ő���ˁ[�́H���Ďv������
325 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 08:42:17.72 ID:ZxI3P4mR
>>324
CPU���쎞��PhysX�͑�l�̎���ŃV���O���R�A��x87����ƂȂ��Ă���܂��B
Havok��Intel�P���ɓ��������Ƃ������Ă����Ԑ������ꂽ���ǁB
CPU���쎞��PhysX�͑�l�̎���ŃV���O���R�A��x87����ƂȂ��Ă���܂��B
Havok��Intel�P���ɓ��������Ƃ������Ă����Ԑ������ꂽ���ǁB
���_�l�Ō�����1.8ghz��4core�ŊԂɍ��������Ȃ��ǂ�
Skylake��҂��Ă�̂ɑS�R�b�肪�����c
�N��2000���Ƃ��������ȁB
����ϓƗ�������ׂ���ȁB
�����̋Z�p�͗v�邾�낤���ǁB
�ق��ŃN�\�ȎЈ��Ɗւ����A
�Ɨ����Đ��_�q���̗ǂ����ł����ق����[�����������B
�����A���ɂ͌��ȋq�����邾�낤���ǁA�����Ɗւ��킯�ł͂Ȃ�����ˁB
�܂��Ă�A�\�t�g�J���̉�ЂȂ�ău���b�N���炯�ł���H
�݂�Ȏ��߂ēƗ����ĂȂ��̂��ȁH
����ϓƗ�������ׂ���ȁB
�����̋Z�p�͗v�邾�낤���ǁB
�ق��ŃN�\�ȎЈ��Ɗւ����A
�Ɨ����Đ��_�q���̗ǂ����ł����ق����[�����������B
�����A���ɂ͌��ȋq�����邾�낤���ǁA�����Ɗւ��킯�ł͂Ȃ�����ˁB
�܂��Ă�A�\�t�g�J���̉�ЂȂ�ău���b�N���炯�ł���H
�݂�Ȏ��߂ēƗ����ĂȂ��̂��ȁH
�T�|�[�g�Ƃ��Ŋւ��Ȃ��́H
�R�e�n���������A���������ˁ[����
331 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 12:57:03.00 ID:ZxI3P4mR
> �܂��Ă�A�\�t�g�J���̉�ЂȂ�ău���b�N���炯�ł���H
> �݂�Ȏ��߂ēƗ����ĂȂ��̂��ȁH
��߂ēƗ������炻�̉��Ɍق��l���������݂����l�Ԃ�8�l�����Ă������Ęb�ł���B
���[�̐l�݂����C���̗��IT���Ȃ�Ă݂�Ȃ��̂��炢�̋K��
���ЂŃI���W�i���\�t�g����炸�A�l���P���������A�����Ȃ炻��Ԏ��o�Ȃ���ȁB
��̉�Ђ��瑽���s���n�l���ꂽ���z�����K�b�|���ł�����˂��Ⴟ��͂�́B
���ꂪ��80���ł����Ј�1�l������40�������Ă�����40���͎c��
��5���O��̂���ڂ��݂��I�t�B�X�Őݔ�������ĉ�Ђ̍Œ���̉^�c��c����
���̑S�������̋����݂����ȁB
> �݂�Ȏ��߂ēƗ����ĂȂ��̂��ȁH
��߂ēƗ������炻�̉��Ɍق��l���������݂����l�Ԃ�8�l�����Ă������Ęb�ł���B
���[�̐l�݂����C���̗��IT���Ȃ�Ă݂�Ȃ��̂��炢�̋K��
���ЂŃI���W�i���\�t�g����炸�A�l���P���������A�����Ȃ炻��Ԏ��o�Ȃ���ȁB
��̉�Ђ��瑽���s���n�l���ꂽ���z�����K�b�|���ł�����˂��Ⴟ��͂�́B
���ꂪ��80���ł����Ј�1�l������40�������Ă�����40���͎c��
��5���O��̂���ڂ��݂��I�t�B�X�Őݔ�������ĉ�Ђ̍Œ���̉^�c��c����
���̑S�������̋����݂����ȁB
332 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 13:08:46.78 ID:ZxI3P4mR
���̎�̗�ׂ̎��ۂ���Ă邱�Ƃ́u��ǔh����Ёv�ɂ������B
�����Ă��h���Ƌ����Ƃ��ĂȂ��āu�@�����ǂ��t���ĂȂ��v�ƌ�����̂���ԁB
�u�V�l�ق���悤�ɂȂ��Ă���ƎВ����v���Č������̂͂��������Ӗ���B
����͂̃x�e������������Ȃ���A�T�C���������Ȃ邵�A������ɏo������
�������ɂ͂قڐl���Ȃ����A�y�Ȃ���ł��傤�B
�l�ނ����Ђň�Ă邱�Ƃ��������А��\�t�g�ݏo���Ȃ��A
�l�݂����������߂邾���̎���IT��Ƃ̌o�c�͂����ׂ���܂���
���Ђł������A�����l�ނ���܂ŁA���邢�̓\�t�g����������܂ŁA
��Ђ�1�K������܂���ˁB
�����Ă��h���Ƌ����Ƃ��ĂȂ��āu�@�����ǂ��t���ĂȂ��v�ƌ�����̂���ԁB
�u�V�l�ق���悤�ɂȂ��Ă���ƎВ����v���Č������̂͂��������Ӗ���B
����͂̃x�e������������Ȃ���A�T�C���������Ȃ邵�A������ɏo������
�������ɂ͂قڐl���Ȃ����A�y�Ȃ���ł��傤�B
�l�ނ����Ђň�Ă邱�Ƃ��������А��\�t�g�ݏo���Ȃ��A
�l�݂����������߂邾���̎���IT��Ƃ̌o�c�͂����ׂ���܂���
���Ђł������A�����l�ނ���܂ŁA���邢�̓\�t�g����������܂ŁA
��Ђ�1�K������܂���ˁB
333 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 13:11:40.88 ID:ZxI3P4mR
���{�̃\�t�g�E�F�A���ɂ�2��ނ���B
�\�t�g���ЂƁA�l���Ђ��B
�\�t�g���ЂƁA�l���Ђ��B
334 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 13:23:17.85 ID:ZxI3P4mR
�Ј��̉҂��ł����������̋��������������z�����ɓ���āu�����̋������v�i��ԯ
������Ⴄ�В����������A�ꕔ�͐l�݂��ɏo�����ǂ�����^�]�����ɂʂ��ʂ����ЃI���W�i����
�\�t�g����肠���A���������݂�Ƃ������������ŁA��T�ɂЂƂ�����ɂł��Ȃ��̂����ǂˁB
������Ⴄ�В����������A�ꕔ�͐l�݂��ɏo�����ǂ�����^�]�����ɂʂ��ʂ����ЃI���W�i����
�\�t�g����肠���A���������݂�Ƃ������������ŁA��T�ɂЂƂ�����ɂł��Ȃ��̂����ǂˁB
�c�q����A������߂����Ă�[��
336 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 13:33:20.66 ID:ZxI3P4mR
�u�����̒P������200�����I�v���Ă����Ȃ�܂��ł���G���W�j�A�ȂȂƎv�����ǁA
�{����8�l�����ĔN��2000�����I�́A�o�c�҂Ƃ��Ă�����Ǝc�O�Ȋ��������܂��B
�{����8�l�����ĔN��2000�����I�́A�o�c�҂Ƃ��Ă�����Ǝc�O�Ȋ��������܂��B
���܂Œc�q�̏����Ă������X�̂ق�����含�������l�I�ɐM�p�ł���̂͒c�q����
���傹���f���Ȃ��猨�����ɕ����킹���Ȃ��ă��X�̓��e�ŏ������Ȃ����
���ɑ�����b��g���^�̎В���SMAP�̃L���^�N���������Ƃ��Ă�
�j�[�g�ɘ_�j���ꂽ��݂�Ȃ���v�M���[����Ă��܂��Ƃ����̂�2�����˂�ł���
���傹���f���Ȃ��猨�����ɕ����킹���Ȃ��ă��X�̓��e�ŏ������Ȃ����
���ɑ�����b��g���^�̎В���SMAP�̃L���^�N���������Ƃ��Ă�
�j�[�g�ɘ_�j���ꂽ��݂�Ȃ���v�M���[����Ă��܂��Ƃ����̂�2�����˂�ł���
338 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 14:15:08.37 ID:ZxI3P4mR
�����I�ɐl�s���ȃA�v���J������Ă���������ƕt�������͐����邵�A
����������Ђ̓�����Ă̂͂���ł��킩���Ă��܂�����ˁ[
UI�f�U�C���n�̃G���W�j�A�Ȃ�ĒP����������W�������Ȃ̂�
�N��2000��������Ȃ�Ă̂͂������������������炭�肪�����
�f�ŒP�����Z��200���Ȃ�Ă̂͋���N���X�̗��n�̉@�o�g�Ő��l��͂̃v���O����
�o���o�������郌�x���ł��낤���Ă�����x�B
���̃N���X�̐��s�Ȃ�Ɨ����Ă��p�C�v�̂����肩�璼�ڃI�t�@�[�������
���������̂܂܃K�b�|���ł���B
�܂��ق�ƂɎd���Ȃ��Ƃ��̓r���x���������Ƃ��ߎS�炵�����ǂˁB
����������Ђ̓�����Ă̂͂���ł��킩���Ă��܂�����ˁ[
UI�f�U�C���n�̃G���W�j�A�Ȃ�ĒP����������W�������Ȃ̂�
�N��2000��������Ȃ�Ă̂͂������������������炭�肪�����
�f�ŒP�����Z��200���Ȃ�Ă̂͋���N���X�̗��n�̉@�o�g�Ő��l��͂̃v���O����
�o���o�������郌�x���ł��낤���Ă�����x�B
���̃N���X�̐��s�Ȃ�Ɨ����Ă��p�C�v�̂����肩�璼�ڃI�t�@�[�������
���������̂܂܃K�b�|���ł���B
�܂��ق�ƂɎd���Ȃ��Ƃ��̓r���x���������Ƃ��ߎS�炵�����ǂˁB
�Ɨ�����Ȃ玩�Ѓ\�t�g��肽���Ȃ��B
�����A�M�����u���ȑ��ʂ��邵�A���ꂭ�炢����I����Ȃ��ጭ��b����Ȃ��ƂȂ�ƁA
������x�͐����d���ňێ�������Ƃ����C����������˥���B
�[�������l�����ē���Ȃ��B
�����A�M�����u���ȑ��ʂ��邵�A���ꂭ�炢����I����Ȃ��ጭ��b����Ȃ��ƂȂ�ƁA
������x�͐����d���ňێ�������Ƃ����C����������˥���B
�[�������l�����ē���Ȃ��B
�Ј��͊�������Ă낤��
341 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 15:00:03.18 ID:ZxI3P4mR
�����ʼn҂��ł��镪��400���A���Ɨ{���̃s���n�l200���~8�ō��v2000���݂����ȃC���[�W
342 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 15:13:05.65 ID:ZxI3P4mR
�������̉�Ђ��ƁA�В������͑��l�̉҂����������グ�Ċ������낤��
�{���̃��`�x�[�V�����͒Ⴛ����
����悭�ΐ�����̃v���p�[�ɓ]���ł���A���炢�̒W����]������Ă���x��
�ł��h���_��Ȃ��̂Ő������Ƃ͉��N�߂Ă����ڌٗp�`�����������Ȃ��Ƃ����B
���ڎw���l�Ԃ͊Ԉ���Ă�����ȉ�Ђɓ����Ă͂����Ȃ��B
�{���̃��`�x�[�V�����͒Ⴛ����
����悭�ΐ�����̃v���p�[�ɓ]���ł���A���炢�̒W����]������Ă���x��
�ł��h���_��Ȃ��̂Ő������Ƃ͉��N�߂Ă����ڌٗp�`�����������Ȃ��Ƃ����B
���ڎw���l�Ԃ͊Ԉ���Ă�����ȉ�Ђɓ����Ă͂����Ȃ��B
343 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 15:54:27.36 ID:ZxI3P4mR
������h���́u�ł����킹�v�Ə̂���������̖ʐځi������z���g�͈�@�Ȃ�ˁj�ł��A
�P�����̘b�ɂȂ�ƘJ���Җ{�l�͐ȊO���Ă��炤�ł���B
���ꂷ���[�����ȕ��K�B
�č��Ȃ��Ꭹ���̘J���҂Ƃ��Ă̎���P���͖{�l���m�錠����������̂Ƃ݂Ȃ���Ă�킯��B
�����ƊJ�������A�ł���Z�p�҂��s���ɍ�悳���悤�Ȃ��Ƃ͂Ȃ��Ȃ�Ǝv���B
���d���̍\�����g���ĊÂ��`���z���l�ԂȂA������IT�ƊE�̉��_���̂��̂ł��B
���̗���̐l�Ԃ����{��IT�����������������̂͏Ύ~
�P�����̘b�ɂȂ�ƘJ���Җ{�l�͐ȊO���Ă��炤�ł���B
���ꂷ���[�����ȕ��K�B
�č��Ȃ��Ꭹ���̘J���҂Ƃ��Ă̎���P���͖{�l���m�錠����������̂Ƃ݂Ȃ���Ă�킯��B
�����ƊJ�������A�ł���Z�p�҂��s���ɍ�悳���悤�Ȃ��Ƃ͂Ȃ��Ȃ�Ǝv���B
���d���̍\�����g���ĊÂ��`���z���l�ԂȂA������IT�ƊE�̉��_���̂��̂ł��B
���̗���̐l�Ԃ����{��IT�����������������̂͏Ύ~
�u�ԍő卂�����͒������Ȃ��B�����Ƒ�������ΗD�G
�c�q���ĕ��i��悳��Ă�̂�
346 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 19:39:38.71 ID:ZxI3P4mR
�n�C�p�[���f�B�A�t���[�^�[�Ȃ߂��
���{��IT��Ƃ̑����́A
�l���E���{��n��W�E���{�́i���j�E�m���x�����Ďd��������Ă���
�e�N�m���W�[�Ŏd��������Ă���킯����Ȃ��̂ŁA
�l�����ƂɂȂ�͓̂��R�����
����ł��A�����������l���⎑�{��m���x�Ŏd������Ă���㗬��SE�ɂȂ�A
����Ȃ�̋����͖Ⴆ��
�l���E���{��n��W�E���{�́i���j�E�m���x�����Ďd��������Ă���
�e�N�m���W�[�Ŏd��������Ă���킯����Ȃ��̂ŁA
�l�����ƂɂȂ�͓̂��R�����
����ł��A�����������l���⎑�{��m���x�Ŏd������Ă���㗬��SE�ɂȂ�A
����Ȃ�̋����͖Ⴆ��
�c�q����撣��߂���
�����X����B
�����X����B
349 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 20:00:41.93 ID:ZxI3P4mR
>>347
���ꂱ�����l���J���̃X�}�z�A�v����Web�T�[�r�X�Ŗ��������ă��[�f�B���O�J���p�j�[��
�x��o��V����Ƃ����Ă���ˁB
������������Ђ̊�b�̗͋����̂��߂ɗ��ۂ��Ă����ׂ����Y���A�����̉��ɓ��ꂿ�Ⴄ�̂͂ǂ����ˁH
�J���g���F���������IT�ƊE���āB�����}���В����\�����Â��Ă������Q����Ƃ��悭����B
���Ȃ������V800�����x�ʼn䖝���Ď��Ђ̐V�K�A�v���J���̂��߂ɏ]�ƈ�3�`4�l���₷�Ƃ�
�K�v�ɂ���Ă͌l�̎����Ă�s���Y���ɂ���Ăł����{��������Ǝv��
�܂����������ĂȂ����ǂ��B
���ꂱ�����l���J���̃X�}�z�A�v����Web�T�[�r�X�Ŗ��������ă��[�f�B���O�J���p�j�[��
�x��o��V����Ƃ����Ă���ˁB
������������Ђ̊�b�̗͋����̂��߂ɗ��ۂ��Ă����ׂ����Y���A�����̉��ɓ��ꂿ�Ⴄ�̂͂ǂ����ˁH
�J���g���F���������IT�ƊE���āB�����}���В����\�����Â��Ă������Q����Ƃ��悭����B
���Ȃ������V800�����x�ʼn䖝���Ď��Ђ̐V�K�A�v���J���̂��߂ɏ]�ƈ�3�`4�l���₷�Ƃ�
�K�v�ɂ���Ă͌l�̎����Ă�s���Y���ɂ���Ăł����{��������Ǝv��
�܂����������ĂȂ����ǂ��B
351 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 20:31:20.69 ID:ZxI3P4mR
�ʂɂ��܌o�c���ĂȂ���ł����ǂˁi�����̓y�n�ȊO�j
�����͂�����ƍH��Ńq�f���z���Ă����Ȃ����炵����
���_
,,�E�L�́M�E,,�j��-������ ���|�I�叟���I�I�I�I�I
,,�E�L�́M�E,,�j��-������ ���|�I�叟���I�I�I�I�I
�c�q������t���Ă���Ƒ��X�����r�炳��Ȃ��Ȃ邩��A�����ƃK���o��
356 �FSocket774�F2015/01/25(��) 22:34:09.46 ID:gl/8vhKA
���Y�Ƃ����珟���g�Ǝv��
357 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 22:43:36.87 ID:ZxI3P4mR
�����C����DAIGO���炢�̃o�����X��������ł��傤��
�Ȃɂ����ʔ������������Ǝv�킹�Ă����Ď��͂������ƌn�݂�����
�Ȃɂ����ʔ������������Ǝv�킹�Ă����Ď��͂������ƌn�݂�����
�c�q����̈ȊO�ȃv���t�B�[�������炩�ɂ�
>>287
�Q�[��������UBI�ɂȂ�������
�Q�[��������UBI�ɂȂ�������
�̂̐l�Ԃ͐[���D��T���^�B
���̐l�Ԃ͕��D��T���^�B
��Ƃ肪�I�������T�W�F�X�g���Ēc�r�ނ��Ă����̂��x�X�g�B
���̐l�Ԃ͕��D��T���^�B
��Ƃ肪�I�������T�W�F�X�g���Ēc�r�ނ��Ă����̂��x�X�g�B
�c�q�����AMD�̃X���ɗ��čr�炳�Ȃ������D�����Ă�
IT�͓y�����Ɠ����\��������ȁB
�����Z�p���͉p�ꂾ���A�I���C���[�̖�{��ނ��A���͂ʼnp���ǂނ��������B
���{�l�ɂƂ��āA�\�t�g�Ƃ͍����ǂ�
�����Z�p���͉p�ꂾ���A�I���C���[�̖�{��ނ��A���͂ʼnp���ǂނ��������B
���{�l�ɂƂ��āA�\�t�g�Ƃ͍����ǂ�
�O�����������ǁAAMD�M�҂̎����ɂƂ��ẮA
�S�̃R�s�y���c�q�̐��_�̂ق����d���B
�S�̃R�s�y���c�q�̐��_�̂ق����d���B
�K���ȃ��C�^�[�̋L�����A�c�q���������搶�݂����Ȍ���o���̂���l�̌��t�͉������d���ȁB
366 �F,,�E�L�́M�E,,�j��-�������F2015/01/26(��) 20:45:14.11 ID:LeFQQ2yV
�ʏ��Skylake��AVX512�����ASkylake Xeon�ł͗L��
http://anon42.hatenablog.com/entry/2015/01/18/184446
10nm�̘b�ɂȂ邪Canonlake Xeon��Canonlake�ɕ�����\�����ے�ł���
http://anon42.hatenablog.com/entry/2015/01/18/184446
10nm�̘b�ɂȂ邪Canonlake Xeon��Canonlake�ɕ�����\�����ے�ł���
��������Skylake���҂��Ă��̂�iGPU�����i�����Ȃ����Ă��ƁH
368 �F,,�E�L�́M�E,,�j��-�������F2015/01/26(��) 21:18:55.30 ID:LeFQQ2yV
�������Ă邯�ǖ����ɂ����ł���
�ڂ̑O�ɉa���Ԃ炳���Ƃ��āA�H�킹���Ɏ��グ�Ă��܂��B
�܂��ɋS�{������
�܂��ɋS�{������
Xeon�͗L���ɂ��Ă����ˁ[��
�����Ȃ����玩��h�݂͂��Xeon�ɂȂ�\��
�����Ȃ����玩��h�݂͂��Xeon�ɂȂ�\��
AVX512�g������������Xeon���A�A�A������
372 �F,,�E�L�́M�E,,�j��-�������F2015/01/26(��) 21:51:37.41 ID:LeFQQ2yV
Xeon E3�ł͗L���ɂȂ�Ȃ�A�Ȋw�Z�p���Z��肽���l��E3������˂��Ԃ�B
���̓m�[�gPC�ł��炾�珑���ē�������������m�[�g������Xeon���o���Ăق����ȁB
���̓m�[�gPC�ł��炾�珑���ē�������������m�[�g������Xeon���o���Ăق����ȁB
����ȁ`
AVX512���҂��Ă��̂Ɂ`
AVX512���҂��Ă��̂Ɂ`
���߂�Xeon�����������悤�����
�W�[�N Xeon !!
�Ȃɂ��̃X���c
��l�Ő萷�肵�Ă�̂���
��l�Ő萷�肵�Ă�̂���
�K���_���t�@���̑������̍��Ȃ�A�݂��Xeon�����Ǝv������A
���E�ōł�Celeron������鍑��������
���E�ōł�Celeron������鍑��������
>>366
���M�ɂȂ邩��xeon�̂ݗL�����Ă��Ƃ���
>>370
��ʗp�Ŏg���Ȃ����Ă��Ƃ́A���炪�g���悤�ȃ\�t�g�͂قƂ�ǑΉ����Ȃ���Ȃ���
�ł�����er�Ȃ�\�[�X�M����AVX512���g���悤�ɂ���z�������낤�����
>>260
ISPC��aobench�������ɂ���Ă݂����AISPC�����ł��������������Ȃ�ȁix6.5)
�����āAISPC + TASKS(�}���`�X���b�hISPC?)�Ƃ��Ƃ��炭�͂₭�Ȃ��ċ�����(x26.5).
SIMD�ƃ}���`�X���b�h�g������Ă��Ƃ���
���M�ɂȂ邩��xeon�̂ݗL�����Ă��Ƃ���
>>370
��ʗp�Ŏg���Ȃ����Ă��Ƃ́A���炪�g���悤�ȃ\�t�g�͂قƂ�ǑΉ����Ȃ���Ȃ���
�ł�����er�Ȃ�\�[�X�M����AVX512���g���悤�ɂ���z�������낤�����
>>260
ISPC��aobench�������ɂ���Ă݂����AISPC�����ł��������������Ȃ�ȁix6.5)
�����āAISPC + TASKS(�}���`�X���b�hISPC?)�Ƃ��Ƃ��炭�͂₭�Ȃ��ċ�����(x26.5).
SIMD�ƃ}���`�X���b�h�g������Ă��Ƃ���
�ǂ���256bit��SIMD���j�b�g��2���512bit�ɂ����B
���\�ʂŃ����b�g�Ȃ������B
���\�ʂŃ����b�g�Ȃ������B
64SP / 32 DP Flops/Cycle���Č����Ɍ����Ă���炻��͂Ȃ�
SIMD�̃x�N�g�����𑁋}�ɑ��₵�ċ������Ȃ��Ⴂ���Ȃ����C�o����
���Ȃ��Ƃ�PC�s��ɂ͂��Ȃ����炻���Ȃ�ł��傤��
GeForce�Ŕ{���x���j�b�g���E����Ă�̂Ɠ����悤��CPU���������̂ł���
�������Ȃ��̂����������ȁB
���Ȃ��Ƃ�PC�s��ɂ͂��Ȃ����炻���Ȃ�ł��傤��
GeForce�Ŕ{���x���j�b�g���E����Ă�̂Ɠ����悤��CPU���������̂ł���
�������Ȃ��̂����������ȁB
�����炵��Phi�ƃR�[�h���p���ł���悤�ɂ��Ċ������ȁH
Xeon�ŊJ������Phi�œ��������Ă��
Xeon�ŊJ������Phi�œ��������Ă��
8�r�b�g��64����ŏ����ł���Ȃ��������
AVX2�����āA�������������������Ȃ�Ȃ��I�ƌ����Ă邯�ǁA
���̃\�t�g�͕�����������Ȃ�ŁA�ӊO�ƌ��ʂ�������
AVX2�����āA�������������������Ȃ�Ȃ��I�ƌ����Ă邯�ǁA
���̃\�t�g�͕�����������Ȃ�ŁA�ӊO�ƌ��ʂ�������
384 �F,,�E�L�́M�E,,�j��-�������F2015/01/27(��) 19:52:22.70 ID:bt23XFwe
KNC���ゾ��4�o�C�g�~16�����g���Ȃ���������ˁ[
�킴�킴�O���R�v���ɓ����鉿�l���Ȃ������Ƃ������E�E�E
strlen��strstr�݂����Ȑ��`�ƍ����ƃ������ш日���ɂȂ邩�炻��قǎ|���͂Ȃ��̂�����
�S�������ɂ͂��Ȃ�L�����ˁB
�܂��A��ʌl���g���v���O�������Ɣ����Ȃ�ł����ǂˁB
�킴�킴�O���R�v���ɓ����鉿�l���Ȃ������Ƃ������E�E�E
strlen��strstr�݂����Ȑ��`�ƍ����ƃ������ш日���ɂȂ邩�炻��قǎ|���͂Ȃ��̂�����
�S�������ɂ͂��Ȃ�L�����ˁB
�܂��A��ʌl���g���v���O�������Ɣ����Ȃ�ł����ǂˁB
385 �F,,�E�L�́M�E,,�j��-�������F2015/01/27(��) 21:04:50.56 ID:bt23XFwe
https://downloadcenter.intel.com/Detail_Desc.aspx?DwnldID=24594&lang=eng&ProdId=3723
�Ă�Broadwell���Č��Ǒ�5����Ȃ́H��4�����Tick�������Ǝv���Ă��B
�Ă�Broadwell���Č��Ǒ�5����Ȃ́H��4�����Tick�������Ǝv���Ă��B
Ivy Bridge����3���ゾ�����
Apple��Mac��Intel��̂Ă������Ȃ�
Intel��߂Ăǂ��̎g���̂�
389 �F,,�E�L�́M�E,,�j��-�������F2015/01/28(��) 01:10:27.05 ID:4T8jg6g0
���������\�����͖��N�������ˁ[
A10X�̐���ł���i3�����Ȃ���܂���������Ȃ�������
�iMac����i5�ȏサ���̗p���ĂȂ��̒m���Ă�H�j
http://iphone-mania.jp/news-59060/
A10X�̐���ł���i3�����Ȃ���܂���������Ȃ�������
�iMac����i5�ȏサ���̗p���ĂȂ��̒m���Ă�H�j
http://iphone-mania.jp/news-59060/
390 �F,,�E�L�́M�E,,�j��-�������F2015/01/28(��) 01:17:54.31 ID:4T8jg6g0
Windows RT�̑�R�P���Ղ茩�Ă��A�\�t�g�������ĂȂ��̂ɉ��ʃ��f������
ARM�ɂ����ǂ�ȔߎS�Ȃ��ƂɂȂ邩�͒N�����ė����ł���ł��傤�B
�N�b�N�͂����܂Ŗ��\�Ȍo�c�҂��Ƃ͎v��Ȃ����ǂȂ�
ARM�ɂ����ǂ�ȔߎS�Ȃ��ƂɂȂ邩�͒N�����ė����ł���ł��傤�B
�N�b�N�͂����܂Ŗ��\�Ȍo�c�҂��Ƃ͎v��Ȃ����ǂȂ�
���g���[����PPC��Intel�Ƃ������A
�܂��ʂ̃A�[�L�e�N�`���Ɉڍs���Ă����������Ȃ�
�������A���܂̐��\��ARM�ȂɈڍs���ꂽ��A
�E�F�u�ƃ��[����itunes��������Ȃ���ʐl�͂Ƃ������A
�Ɩ��Ŏg���Ă�l�Ƃ��AMac/iOS�J���҂͑�ς���
�܂��ʂ̃A�[�L�e�N�`���Ɉڍs���Ă����������Ȃ�
�������A���܂̐��\��ARM�ȂɈڍs���ꂽ��A
�E�F�u�ƃ��[����itunes��������Ȃ���ʐl�͂Ƃ������A
�Ɩ��Ŏg���Ă�l�Ƃ��AMac/iOS�J���҂͑�ς���
��������Ȃ�ARM�{FPGA���낤�ˁB
FPGA�ɂ��Ȃ�̃u���C�N�X���[���K�v�����ǁB
FPGA�ɂ��Ȃ�̃u���C�N�X���[���K�v�����ǁB
FPGA�ɖ�����Ƃ��AGPGPU�Ɋ��҂�����ߏゾ��
�܂�GPGPU�ɖ������Ȃ�����d���Ȃ��B
�����o���オ���Ă����Ԃ̐��\�́@�ėp�@<�@FPGA�@<ASIC�@������ȁB
���������ړI����ASIC������Ă��Ȃ�����ėpCPU���g���Ă��邾����
���������ړI����ASIC������Ă��Ȃ�����ėpCPU���g���Ă��邾����
Web�T�[�o�֘A�̃A�N�Z�����[�^��ASIC/FPGA���嗬�ɂȂ�����
GPGPU��FPGA������d�͂�10�{�ȏ�ɂȂ��Ă��܂���ɂ܂Ƃ܂����f�[�^���Ȃ���
�y�C�ł��Ȃ��̂ŁA�w�^�����CPU�I�����[���d�͌��������Ȃ邩��g���Ȃ�
FPGA���v���O�����g�݂₷���Ƃ��Ă��A�ˁB
GPGPU��FPGA������d�͂�10�{�ȏ�ɂȂ��Ă��܂���ɂ܂Ƃ܂����f�[�^���Ȃ���
�y�C�ł��Ȃ��̂ŁA�w�^�����CPU�I�����[���d�͌��������Ȃ邩��g���Ȃ�
FPGA���v���O�����g�݂₷���Ƃ��Ă��A�ˁB
397 �F,,�E�L�́M�E,,�j��-�������F2015/01/28(��) 19:12:23.28 ID:FzEfD0B2
Windows�^�u���b�g�͂����ƕ]�������ׂ�
�}�E�X������ł̓S�~�����ǂ�
�}�E�X������ł̓S�~�����ǂ�
�����e�@�̑����̗~������
�uAndroid TV�v�����ڂ̉~�`STB�uNexus Player�v�A1��2800�~��2�����{�ɍ�������
http://internet.watch.impress.co.jp/docs/news/20150129_685962.html
http://internet.watch.impress.co.jp/docs/news/20150129_685962.html
400 �FSocket774�F2015/01/29(��) 13:54:47.51 ID:eV2YPJry
401 �FSocket774�F2015/01/29(��) 14:56:18.58 ID:hRJh83qn
2�Ђł����݊�����肠�����̂ɁA���������ƊJ�����ꂽ�炳���h���C�o�̊J���̂��b�オ���邾�낤�ˁB
404 �FSocket774�F2015/01/29(��) 18:52:57.59 ID:BO5xN5Iw
arm��A57�ȊO�͂��܂��s���Ă邶���
>>402
Apple���[���h����������
���̑O�G����Ȃ��u����ARM��OSX������Ă܂����`�v�ƕ��C�Ō����Ă̂�
���̓��ɂ́uARM�ŋ��v�Ə�����M�҂��W�܂�@���W�c��
�Ƃ��������̂���OSX����iOS����ʂɂ����ˁH
Apple���[���h����������
���̑O�G����Ȃ��u����ARM��OSX������Ă܂����`�v�ƕ��C�Ō����Ă̂�
���̓��ɂ́uARM�ŋ��v�Ə�����M�҂��W�܂�@���W�c��
�Ƃ��������̂���OSX����iOS����ʂɂ����ˁH
406 �FSocket774�F2015/01/29(��) 19:32:24.94 ID:4fCY4mqd
>>404
�Ƃ�킯denver�͋K�͂̊��ɍ����\������
�Ƃ�킯denver�͋K�͂̊��ɍ����\������
a57�͕s������
http://rbmen.blogspot.jp/2015/01/snapdragon-810.html
�N�A���R���ASnapdragon 810���u��v�X�}�z���[�J�[�ɋ��₳�ꂽ�v�ƔF�߂�
Qualcomm��2015�N�xQ1�Ɛє��\�̒��ŁASnapdragon 810���u��K�͌ڋq�̐V�^�t���O�V�b�v�ɓ��ڂ���Ȃ��v�ƔF�߂܂����B
��K�͌ڋq�̐V�^�t���O�V�b�v�X�}�[�g�t�H���Ƃ����̂́A���E�̃X�}�z�s��Ŗ�����1�ʂɌN�Ղ���T���X����3��1���ɔ��\�Ƃ݂���uGALAXY S6�v�Ɛ��肳��܂��B
GALAXY S6��Snapdragon 810�̑����14nm�v���Z�X�̓Ǝ��J�������I�N�^�R�A�v���Z�b�T Exynos 7420�𓋍ڂ��邱�ƂŒm���Ă��܂��B
http://browser.primatelabs.com/geekbench3/compare/1713791?baseline=1780313
http://browser.primatelabs.com/geekbench3/compare/1720602?baseline=1780313
http://rbmen.blogspot.jp/2015/01/snapdragon-810.html
�N�A���R���ASnapdragon 810���u��v�X�}�z���[�J�[�ɋ��₳�ꂽ�v�ƔF�߂�
Qualcomm��2015�N�xQ1�Ɛє��\�̒��ŁASnapdragon 810���u��K�͌ڋq�̐V�^�t���O�V�b�v�ɓ��ڂ���Ȃ��v�ƔF�߂܂����B
��K�͌ڋq�̐V�^�t���O�V�b�v�X�}�[�g�t�H���Ƃ����̂́A���E�̃X�}�z�s��Ŗ�����1�ʂɌN�Ղ���T���X����3��1���ɔ��\�Ƃ݂���uGALAXY S6�v�Ɛ��肳��܂��B
GALAXY S6��Snapdragon 810�̑����14nm�v���Z�X�̓Ǝ��J�������I�N�^�R�A�v���Z�b�T Exynos 7420�𓋍ڂ��邱�ƂŒm���Ă��܂��B
http://browser.primatelabs.com/geekbench3/compare/1713791?baseline=1780313
http://browser.primatelabs.com/geekbench3/compare/1720602?baseline=1780313
Xperia Z4�~����
�ǂ��������Ă�����GPU���\���C�ɂȂ�
�ǂ��������Ă�����GPU���\���C�ɂȂ�
�r�b�O�`�����X�Ȃ̂�Intel�ɂ��̋@��˂���R�}�������ĂȂ��̂����������Ȃ�
������14nm�Ȃ̂���
���arm��28nm�Ȃ̂�
���arm��28nm�Ȃ̂�
>>409
http://gfxbench.com/compare.jsp?benchmark=gfx30&D1=Qualcomm+MSM8994+for+arm64+%28Adreno+430%2C+development+board%29&os1=Android&api1=gl&D2=Google+Nexus+9&cols=2
�Œ�@�\�͑啝�i���{�j�ɏ����Ă邵
���Z��������Ȃ̂����A�h���C�o�[���E���R�߂���
���Ǖ����Ă�
http://gfxbench.com/compare.jsp?benchmark=gfx30&D1=Qualcomm+MSM8994+for+arm64+%28Adreno+430%2C+development+board%29&os1=Android&api1=gl&D2=NVIDIA+Tegra+X1+Reference+Platform+%28development+board%29&cols=2
���ꂾ��3�{������
http://gfxbench.com/compare.jsp?benchmark=gfx30&D1=Qualcomm+MSM8994+for+arm64+%28Adreno+430%2C+development+board%29&os1=Android&api1=gl&D2=Google+Nexus+9&cols=2
�Œ�@�\�͑啝�i���{�j�ɏ����Ă邵
���Z��������Ȃ̂����A�h���C�o�[���E���R�߂���
���Ǖ����Ă�
http://gfxbench.com/compare.jsp?benchmark=gfx30&D1=Qualcomm+MSM8994+for+arm64+%28Adreno+430%2C+development+board%29&os1=Android&api1=gl&D2=NVIDIA+Tegra+X1+Reference+Platform+%28development+board%29&cols=2
���ꂾ��3�{������
��ł���́AGCN�����GPU�Ɍ����ẮA
2013�N���납��h���C�o�i���͂܂Ƃ��ɂȂ��Ă�
�ł��A�ނ�����ł���Œɂ��ڂɂ������Q�[�}�[�ɂ�
���f�I���̃h���C�o�̓N�\���Ă����L�����]���ɐ��݂��Ă邩���
���̈�ۂ͓��ʂʂ��Ȃ��ł��傤
2013�N���납��h���C�o�i���͂܂Ƃ��ɂȂ��Ă�
�ł��A�ނ�����ł���Œɂ��ڂɂ������Q�[�}�[�ɂ�
���f�I���̃h���C�o�̓N�\���Ă����L�����]���ɐ��݂��Ă邩���
���̈�ۂ͓��ʂʂ��Ȃ��ł��傤
>>411
AMD���c
AMD���c
�h���C�o�[�i���[��
�h���C�o�[�������x����
�I�[�o�[�w�b�h�f�J�߂�
�h���C�o�[�������x����
�I�[�o�[�w�b�h�f�J�߂�
�h���C�o���d�����Ƃɂ��ẮAIntel�̏��CPU���g���Ƃ��Ȃ���P�����
���łǂ����h���C�o���Ȃ́H
���ꂾ���̋���L����ƂȂ̂ɁA�v���O���}�����\�Ȃ́H
���ꂾ���̋���L����ƂȂ̂ɁA�v���O���}�����\�Ȃ́H
GeForce���Q�[��
Radeon��������i��
Intel���H
Radeon��������i��
Intel���H
���x���K�v�Ƃ����s��ł͂Ȃ������̂�
���邢�͏�����cpu�̏������x���x�������Ȃ̂��������
�����X�i�h����x1��cpu�͓��������ǂ�
�I�[�o�[�w�b�h�͂����ĂȂ����番�����
���邢�͏�����cpu�̏������x���x�������Ȃ̂��������
�����X�i�h����x1��cpu�͓��������ǂ�
�I�[�o�[�w�b�h�͂����ĂȂ����番�����
�X�i�h������Ă�N�I���R���͑O����▭�Ƀh���C�o�[���Z�ʗ����Ȃ��ăN�\���Č���ꑽ�l�ȋC�����Ȃ��ł͂Ȃ�
Intel���������ƃn�C�G���h���f�����X�}�z�Ή����Ăق�������
Intel���������ƃn�C�G���h���f�����X�}�z�Ή����Ăق�������
Mali��Adreno��PowerVR���ǂ����悤���Ȃ��_�����Ǝv��
HDG�����i�ʂ����i���ƐS��v������x��
HDG�����i�ʂ����i���ƐS��v������x��
���������A�^�u���b�g���S���ȓd�͂ł���K�v�͂Ȃ��Ƃ�����
AC�쓮��O��ɂ����AIntel�̃��o�C���pcore i7�ς����^�u���b�g�������Ă������Ƃ�����
AC�쓮��O��ɂ����AIntel�̃��o�C���pcore i7�ς����^�u���b�g�������Ă������Ƃ�����
�m�[�p�\�ł��������
������������VAIO������Ă�炵��
�^�u���b�g�Ɂg�������\�h�Ƃ����V��āF�uVAIO Prototype Tablet PC�v��Z���Ƀ`�F�b�N���� ITmedia PC USER http://www.itmedia.co.jp/pcuser/spv/1410/08/news041.html
�^�u���b�g�Ɂg�������\�h�Ƃ����V��āF�uVAIO Prototype Tablet PC�v��Z���Ƀ`�F�b�N���� ITmedia PC USER http://www.itmedia.co.jp/pcuser/spv/1410/08/news041.html
426 �FSocket774�F2015/01/31(�y) 05:38:35.13 ID:01WvYgyA
surface�ł���
surface��android�����Ȃ������
N-trig��VAIO Duo13�Őh�_���r�߂�����ꂽ����A�����g���
Intel 2015-2016 Roadmap Reveals Skylake-S Unlocked Processors In Q3 2015 - 65W Broadwell K-Series in Q2, Broadwell-E Arrives In Q1 2016
http://wccftech.com/intel-2015-2016-roadmap-reveals-skylake-s-unlocked-processors-q3-2015-65w-broadwell-kseries-q2-broadwelle-arrives-q1-2016/
http://wccftech.com/intel-2015-2016-roadmap-reveals-skylake-s-unlocked-processors-q3-2015-65w-broadwell-kseries-q2-broadwelle-arrives-q1-2016/
�A�����b�N�o�[�W�������炢�n���_�ɂ����
�����̒J�̐V�^TIM�͎��s�삾��
�����̒J�̐V�^TIM�͎��s�삾��
431 �FSocket774�F2015/01/31(�y) 14:44:34.34 ID:9O1MzA9/
�킴�킴XEON�p�̃n���_�̃��C���ɗ����̂��ʓ|�Ȃ�B
�����\�O���X�Ȃ�O���X�̍ޗ��ς��邾���ŊȒP�ɑΉ��ł���킯���B
�����\�O���X�Ȃ�O���X�̍ޗ��ς��邾���ŊȒP�ɑΉ��ł���킯���B
������TIM��P�`���đ呹�Q��
�c�O�Ȏ��ɑ呹�Q���Ăقǂ̎��v�������ȁB
�l�I�ɂ�CPU�R�A���������ɗU�f�����
�@Z97�@ PCI-E Gen2 8 lanes
�@Z17x�@PCI-E Gen3 20 lanes�i14lane��SATA�AUSB�ALAN�Ƌ��L�j
���L���������ASATA��USB���S�����܂邱�Ƃ͂Ȃ���
�u���b�W�`�b�v�̒lj����v��Ȃ�����MB�̑I������������
ttp://wccftech.com/intel-skylake-s-platform-specifications-detailed-z170-100series-chipset-replace-z97-2h-2015/
�@Z97�@ PCI-E Gen2 8 lanes
�@Z17x�@PCI-E Gen3 20 lanes�i14lane��SATA�AUSB�ALAN�Ƌ��L�j
���L���������ASATA��USB���S�����܂邱�Ƃ͂Ȃ���
�u���b�W�`�b�v�̒lj����v��Ȃ�����MB�̑I������������
ttp://wccftech.com/intel-skylake-s-platform-specifications-detailed-z170-100series-chipset-replace-z97-2h-2015/
�呹�Q(�ߋ��ō��̔��㍂
436 �F,,�E�L�́M�E,,�j��-�������F2015/01/31(�y) 18:30:22.49 ID:e7zb0iU3
LGA2011��i7�����邩��킴�킴���ʐ��i�ɃR�X�g�����Ȃ���ł���
Intel�̃X�^���X���킩���Ă悩���������B
Intel�̃X�^���X���킩���Ă悩���������B
437 �F,,�E�L�́M�E,,�j��-�������F2015/01/31(�y) 18:33:37.79 ID:e7zb0iU3
>>434
�ǂ��ɂ������GPU3�`4���}���Ȃ�ďo���Ă��܂��ˁB
�ǂ��ɂ������GPU3�`4���}���Ȃ�ďo���Ă��܂��ˁB
AMD�����y���i�т�Intel���݂̏���d�͂����萫�\����OC�̗]�T�x�̍����R�A���o����
Intel���Q�Ăăn���_ver���o���Ă����
Intel���Q�Ăăn���_ver���o���Ă����
>434�̃u���b�W�v��Ȃ��Ƃ����̂͊��Ⴂ�����B
���I�ɋ��L�ł���̂ł͂Ȃ�MB�v���ɌŒ肳���̂�������Ȃ��B
�������Ƃ��Ă�Z97�ɔ�ׂ���[�����Ă��邪
���I�ɋ��L�ł���̂ł͂Ȃ�MB�v���ɌŒ肳���̂�������Ȃ��B
�������Ƃ��Ă�Z97�ɔ�ׂ���[�����Ă��邪
���\�������ɂ߂Ă������Ƃ������サ�Ȃ��Ȃ�A�ui�n���4-way�ł���}�U�[�{�[�h�v���uiGPU�̕�����S���ʏ�̉��Z��H�ɂ���i�n��v
���uOS����͒P�Ȃ�CPU�Ƃ��ĔF�������APCIE�ڑ���CPU��lj��ł���g���{�[�h�v���o���Ăق�����
i7�ŏ�ʈȏ�̐��\���ق����ƂȂ�ƁA�\�Z�������I�ɑ�����̂͂��������Ȃ�Ƃ����Ă���
���uOS����͒P�Ȃ�CPU�Ƃ��ĔF�������APCIE�ڑ���CPU��lj��ł���g���{�[�h�v���o���Ăق�����
i7�ŏ�ʈȏ�̐��\���ق����ƂȂ�ƁA�\�Z�������I�ɑ�����̂͂��������Ȃ�Ƃ����Ă���
�������Ɛ��\�����サ�Ȃ�����A�����Ă���ʃ��f�����Ă����͂Ȃ��B
�̂͂ǂ�ǂ\�����シ�鎞��Ɍl�pPC��30�`50�����炢�o���Ĕ��������̂���B
�����}����Ȃ畡��PC��LAN�Ōq���Ōv�Z������Ƃ��H�v�����Ȃ���B
�̂͂ǂ�ǂ\�����シ�鎞��Ɍl�pPC��30�`50�����炢�o���Ĕ��������̂���B
�����}����Ȃ畡��PC��LAN�Ōq���Ōv�Z������Ƃ��H�v�����Ȃ���B
����win tab��ds���₷��
���^�u���Ă��ꂼ��ǂ��ɂǂꂾ�������������
445 �F,,�E�L�́M�E,,�j��-�������F2015/02/01(��) 20:36:46.45 ID:lgt+ZAqg
MS��Intel��������^�_���R�Ŕz���Ă��Ԃ����ǒP�Ƃł̍̎Z�͍l���ĂȂ���B
MS�̓N���E�h�T�[�r�X�ŁAIntel�͂��̃N���E�h�Ŏg����Xeon�ʼn������Ƃ������j
MS�̓N���E�h�T�[�r�X�ŁAIntel�͂��̃N���E�h�Ŏg����Xeon�ʼn������Ƃ������j
446 �F,,�E�L�́M�E,,�j��-�������F2015/02/01(��) 21:02:05.50 ID:lgt+ZAqg
���m�{�E�W���p���uThinkPad X1 Carbon�v
�`6��̕����L�[�{�[�h�ɖ߂�����3����ThinkPad X1 Carbon
http://pc.watch.impress.co.jp/docs/column/hothot/20150131_686264.html
> ���������ύX�̓��[�U�[����̃t�B�[�h�o�b�N�f�������߂Ǝv���邪�A
> �蕨����œo�ꂵ��Adaptive�L�[�{�[�h����������Ǝ̂ċ��������Ƃ́A�^���ׂ��ł��낤�B
�^�b�`�p�b�h��3�{�^���ɖ߂�����
6��L�[�{�[�h�{�{�^���Ȃ��̃^�b�`�p�b�h��ThinkPad�g���Ă邯�NJ�������قǎg���ɂ����Ƃ�
�v��Ȃ����ǂȁB
�����������i�g���ł̓L�[�{�[�h���}�E�X���O�t�����Ă�Ƃ����̂͂��Ă���
�`6��̕����L�[�{�[�h�ɖ߂�����3����ThinkPad X1 Carbon
http://pc.watch.impress.co.jp/docs/column/hothot/20150131_686264.html
> ���������ύX�̓��[�U�[����̃t�B�[�h�o�b�N�f�������߂Ǝv���邪�A
> �蕨����œo�ꂵ��Adaptive�L�[�{�[�h����������Ǝ̂ċ��������Ƃ́A�^���ׂ��ł��낤�B
�^�b�`�p�b�h��3�{�^���ɖ߂�����
6��L�[�{�[�h�{�{�^���Ȃ��̃^�b�`�p�b�h��ThinkPad�g���Ă邯�NJ�������قǎg���ɂ����Ƃ�
�v��Ȃ����ǂȁB
�����������i�g���ł̓L�[�{�[�h���}�E�X���O�t�����Ă�Ƃ����̂͂��Ă���
����҂ɂ͗L����ˁA�����̂́B
Win�^�u��300g���Kindle���܂Ƃ��Ɏg����ƃX�g���[�W�����̂Ŏ��v�������B
�C�O�^�u��Kindle�͓��{�ł͎g���˂���
Win�^�u��300g���Kindle���܂Ƃ��Ɏg����ƃX�g���[�W�����̂Ŏ��v�������B
�C�O�^�u��Kindle�͓��{�ł͎g���˂���
448 �FSocket774�F2015/02/01(��) 21:12:59.50 ID:y0Oe0eWQ
kindle�̓��{��windows�ŏo����
http://www.amazon.co.jp/gp/feature.html?ie=UTF8&docId=3078592246
http://www.amazon.co.jp/gp/feature.html?ie=UTF8&docId=3078592246
449 �F,,�E�L�́M�E,,�j��-�������F2015/02/01(��) 21:15:04.16 ID:lgt+ZAqg
�uWindows�^�u���b�g�Łv�𗊂�
450 �F,,�E�L�́M�E,,�j��-�������F2015/02/01(��) 21:17:54.90 ID:lgt+ZAqg
�m�[�g�����ǁABroadwell�͂���������݂������ˁB
http://news.mynavi.jp/news/2015/01/14/157/
http://news.mynavi.jp/news/2015/01/14/157/
451 �F,,�E�L�́M�E,,�j��-�������F2015/02/01(��) 22:12:16.99 ID:lgt+ZAqg
�Ƃ肠����PC��Kindle�̓^�u���b�g����g�����ɂȂ�Ȃ�
��DPI�Ή����炢�܂Ƃ��ɂ��
https://twitter.com/unaginga/status/561874133533720577
��DPI�Ή����炢�܂Ƃ��ɂ��
https://twitter.com/unaginga/status/561874133533720577
Core-M Win�^�u���b�g��Kindle�g������
Intel�������`�b�v������Ă�Lantiq�Ƃ������h�C�c�̊�Ƃ�
http://www.zdnet.com/article/intel-buys-lantiq-for-connected-home-networking/
Infineon����Ɨ�������Ƃ炵���̂Ō��̏�Ɏ��܂���������
http://www.zdnet.com/article/intel-buys-lantiq-for-connected-home-networking/
Infineon����Ɨ�������Ƃ炵���̂Ō��̏�Ɏ��܂���������
454 �F,,�E�L�́M�E,,�j��-�������F2015/02/03(��) 02:15:48.09 ID:Q1sBTQhd
NEC��Core M���ڂ�ThinkPad 10�����̂܂܊g�債���悤��11.6�C���`�^�u���b�g����Ă��
Lenovo�ɂ��o�����f������̂��ȂƎv�����疳������
�����炭�h�b�N�͂܂�܌݊��B
Lenovo�ɂ��o�����f������̂��ȂƎv�����疳������
�����炭�h�b�N�͂܂�܌݊��B
�y�㓡�O��Weekly�C�O�j���[�X�z���L�ш惁�����̗̍p���\�ɂ���Intel�̐V�p�b�P�[�W���O�Z�p�uEMIB�v - PC Watch
http://pc.watch.impress.co.jp/docs/column/kaigai/20150203_686619.html?ref=rss
������Intel�̃n�C�G���hGPU�R�A����CPU�́A���݂�eDRAM�ł͂Ȃ��AHBM(High Bandwidth Memory)�𓋍ڂ���悤�ɂȂ�\��������B
���̏ꍇ�A�P�Ƀ������`�b�v���ς�邾���łȂ��A�������ʂƎg�������ς��B
128MB�ł͂Ȃ��A��GB�P�ʂ̃��������ڂ���悤�ɂȂ�A�L���b�V���ł͂Ȃ����C���������̈ꕔ�Ƃ��Ďg����悤�ɂȂ�\���������B
http://pc.watch.impress.co.jp/docs/column/kaigai/20150203_686619.html?ref=rss
������Intel�̃n�C�G���hGPU�R�A����CPU�́A���݂�eDRAM�ł͂Ȃ��AHBM(High Bandwidth Memory)�𓋍ڂ���悤�ɂȂ�\��������B
���̏ꍇ�A�P�Ƀ������`�b�v���ς�邾���łȂ��A�������ʂƎg�������ς��B
128MB�ł͂Ȃ��A��GB�P�ʂ̃��������ڂ���悤�ɂȂ�A�L���b�V���ł͂Ȃ����C���������̈ꕔ�Ƃ��Ďg����悤�ɂȂ�\���������B
456 �F,,�E�L�́M�E,,�j��-�������F2015/02/03(��) 20:06:09.52 ID:Q1sBTQhd
���ʂɍl�����Knights Landing��HMC��ڑ�����Z�p�ł���
����GPU����HBM���̂͂����̌㓡�߁B
����GPU����HBM���̂͂����̌㓡�߁B
HMC���낤��HBM���낤���A����CPU�_�C��DRAM�i���R���g���[���j�_�C�̊Ԃ��ǂ������Z����ʂɔz�����邩�A������
���������T�[�o�����E�Q�[���n�C�G���h�����Ɏg����Ȃ�CPU�ɂ��g���Ă��邾�낤
�c�������A�O��EMIB�̘b�肱���ł���������v���Ă����AIntel���Ď���TSV�����p���E�o�ϐ��Ō��āu������i�V�v�Ɣ��f���Ăˁ[���H��
���������T�[�o�����E�Q�[���n�C�G���h�����Ɏg����Ȃ�CPU�ɂ��g���Ă��邾�낤
�c�������A�O��EMIB�̘b�肱���ł���������v���Ă����AIntel���Ď���TSV�����p���E�o�ϐ��Ō��āu������i�V�v�Ɣ��f���Ăˁ[���H��
458 �F,,�E�L�́M�E,,�j��-�������F2015/02/03(��) 21:26:16.56 ID:Q1sBTQhd
�㓡����͂Ȃɂ䂦Intel���J���ɗ���ł�HMC���X���[����
�Ȃ�̖������Ȃ������K�i��HBM�ɂ��Č���Ă�̂������ς�킩���̂ł���
�Ȃ�̖������Ȃ������K�i��HBM�ɂ��Č���Ă�̂������ς�킩���̂ł���
Intel��EMIB�Ȃ�Ă��̂��J�������u�^�Ӂv�𑪂肩�˂Ă��Ȃ��́H
���͂����AHMC��HBM���̂Ă�CPU-EMIB-DRAM��DDR3/4�őS���s���A�Ƃ������f�������ƌ���
64GB����256GB���̑S�����L�ш�Őڑ�����Ӗ��ȂF���A��
���͂����AHMC��HBM���̂Ă�CPU-EMIB-DRAM��DDR3/4�őS���s���A�Ƃ������f�������ƌ���
64GB����256GB���̑S�����L�ш�Őڑ�����Ӗ��ȂF���A��
460 �F,,�E�L�́M�E,,�j��-�������F2015/02/03(��) 22:00:56.08 ID:Q1sBTQhd
http://www.anandtech.com/show/8217/intels-knights-landing-coprocessor-detailed
���N�̎��_�ō\���C���[�W�o�Ă������B
������Knights Landing�̃j���[�X�ǂ������Ă��l�Ԃ��炷����ׂđz����B
�����EIMB�̋L���͐�����������ł���B
����GPU�̘b�������Ƌ߂������ɕK�v�Ƃ������̂�����̂ɂȂ�ł���ɋC�Â��Ȃ��̂��B
�����㓡���낻�듪�{�P����������ȂƁB
Hisa Ando��������Ȃ�����Ƃ܂Ƃ��ȋL���ɂȂ邩�ȂƂ������ҁB
���N�̎��_�ō\���C���[�W�o�Ă������B
������Knights Landing�̃j���[�X�ǂ������Ă��l�Ԃ��炷����ׂđz����B
�����EIMB�̋L���͐�����������ł���B
����GPU�̘b�������Ƌ߂������ɕK�v�Ƃ������̂�����̂ɂȂ�ł���ɋC�Â��Ȃ��̂��B
�����㓡���낻�듪�{�P����������ȂƁB
Hisa Ando��������Ȃ�����Ƃ܂Ƃ��ȋL���ɂȂ邩�ȂƂ������ҁB
462 �F,,�E�L�́M�E,,�j��-�������F2015/02/03(��) 22:22:26.29 ID:Q1sBTQhd
Xeon Phi�݂����ȃ��W�b�N������150W���H���悤�ȃv���Z�b�T��
�M�ɎアDRAM���d�˂�̂͗�����͖����ł���
TSV�͂����ƒ����d�͂̃f�o�C�X�Ƀt�H�[�J�X�������̂��ƁB
�M�ɎアDRAM���d�˂�̂͗�����͖����ł���
TSV�͂����ƒ����d�͂̃f�o�C�X�Ƀt�H�[�J�X�������̂��ƁB
TSV�͂��炭�X�}�z�������Ȃ�
�����܂肪�т����肷��قLj���
�����܂肪�т����肷��قLj���
����������WIde I/O�Ɗ��Ⴂ���Ă�H
http://pc.watch.impress.co.jp/docs/column/kaigai/20141226_682075.html
���Ȃ݂ɁAIntel�̒���t�@�E���_���T�[�r�X����������I/O�ɂ�HBM���܂܂�Ă���A
EMIB�Z�p�Ƃ̑g�ݍ��킹��Intel�͈Ӑ}���Ă���ƌ�����BHBM�́A�C���^�|�[�U��
DRAM���[�J�[�ł͖������[�U�[��Ƃ��p�ӂ��邱�ƂɂȂ��Ă���BIntel��EMIB�ɂ���āA
��R�X�g��HBM�T�|�[�g���\�ɂ��悤�Ƃ��Ă��邱�ƂɂȂ�B
���Ȃ݂ɁAIntel�̒���t�@�E���_���T�[�r�X����������I/O�ɂ�HBM���܂܂�Ă���A
EMIB�Z�p�Ƃ̑g�ݍ��킹��Intel�͈Ӑ}���Ă���ƌ�����BHBM�́A�C���^�|�[�U��
DRAM���[�J�[�ł͖������[�U�[��Ƃ��p�ӂ��邱�ƂɂȂ��Ă���BIntel��EMIB�ɂ���āA
��R�X�g��HBM�T�|�[�g���\�ɂ��悤�Ƃ��Ă��邱�ƂɂȂ�B
466 �F,,�E�L�́M�E,,�j��-�������F2015/02/03(��) 23:01:26.47 ID:Q1sBTQhd
���̍�������HBM���������Ȃ�
�܂��HBM�������n�惁�����̑I�������Ȃ��݂�������Ȃ��ł���������
Intel��14nm�̌ڋq��P���̃A���e����Stratix 10���܂�Gen10��HMC��S�̓T�|�[�g���Ă邵
HBM�ɌX�|���闝�R�����o���Ȃ��̂ł���
�܂��HBM�������n�惁�����̑I�������Ȃ��݂�������Ȃ��ł���������
Intel��14nm�̌ڋq��P���̃A���e����Stratix 10���܂�Gen10��HMC��S�̓T�|�[�g���Ă邵
HBM�ɌX�|���闝�R�����o���Ȃ��̂ł���
467 �F,,�E�L�́M�E,,�j��-�������F2015/02/03(��) 23:02:02.12 ID:Q1sBTQhd
�L�ш��
http://pc.watch.impress.co.jp/img/pcw/docs/682/366/html/3.jpg.html
��IP��HBM�������Ă�悤��
{kind=link}
��IP��HBM�������Ă�悤��
Knights Landing��HMC���ǂ������ڑ��`�ԂɂȂ��Ă�̂��͒m���
HMC�͊�{�I�Ƀ������`�b�v���Ƀ��W�b�N�`�b�v��ϑw���ċ����r�b�g���̐M���ɕϊ�����
�]���̃s�b�`�̃o���v�Ŋ�ɐڑ��ł���悤�ɂ���ϑw�������Z�p�ł���
�������{�I�ɃC���^�[�|�[�U�[�Ƃ�EMIB�݂����Ȃ͎̂g���͂�
HBM�͎d�l�㋲�s�b�`�̃}�C�N���o���v�Ŋ�Ɛڑ����Ȃ��Ⴂ����t���L�V�u����ɒ��ڎ�������͓̂��
�C���^�[�|�[�U�[���K�v�ŁA���̑��肪EMIB�̂悤�Ȋ���ߍ��^�̃}�C�N���o���v�ȂƎv������
�����獡��̌㓡�L����HMC�Ɍ��y���ĂȂ��͕̂ʂɓI�O��ł͂Ȃ��Ǝv��
HMC�͊�{�I�Ƀ������`�b�v���Ƀ��W�b�N�`�b�v��ϑw���ċ����r�b�g���̐M���ɕϊ�����
�]���̃s�b�`�̃o���v�Ŋ�ɐڑ��ł���悤�ɂ���ϑw�������Z�p�ł���
�������{�I�ɃC���^�[�|�[�U�[�Ƃ�EMIB�݂����Ȃ͎̂g���͂�
HBM�͎d�l�㋲�s�b�`�̃}�C�N���o���v�Ŋ�Ɛڑ����Ȃ��Ⴂ����t���L�V�u����ɒ��ڎ�������͓̂��
�C���^�[�|�[�U�[���K�v�ŁA���̑��肪EMIB�̂悤�Ȋ���ߍ��^�̃}�C�N���o���v�ȂƎv������
�����獡��̌㓡�L����HMC�Ɍ��y���ĂȂ��͕̂ʂɓI�O��ł͂Ȃ��Ǝv��
HMC�͉����������
����ߋ������z�肵�Ă��
http://pc.watch.impress.co.jp/img/pcw/docs/472/122/04.jpg
http://pc.watch.impress.co.jp/img/pcw/docs/472/122/04.jpg
{kind=link}
472 �F,,�E�L�́M�E,,�j��-�������F2015/02/03(��) 23:23:54.53 ID:Q1sBTQhd
�[�����ꗝ�����CPU-CPU�̃C���^�[�R�l�N�g�ɂ��g������
�������Ƀj�R�C�`�_�C�͂������Ȃ��Ǝv������
�������Ƀj�R�C�`�_�C�͂������Ȃ��Ǝv������
HBM��JEDEC�̂��n�t������Ȃ����������H
TSV�Z�p�E�܂�V���R���Ɍ���Ȃ�Ă����N�\�Z�p�S�ʂ�����n�C�G���h�Ŏg���āA
�R�X�g�������Ă��ăR���V���[�}�ɁA�Ƃ��������AIntel�͕`���̂���߂���Ȃ����Ǝv���A
�Ȃ̂�HBM��HMC��WideI/O�����鎞�_�őS���邾�낤�A��
DRAM���ꖇ�ꖇ�����ɒu���Ē��Z������ʔz�����œK���ł���A��
�R�X�g�������Ă��ăR���V���[�}�ɁA�Ƃ��������AIntel�͕`���̂���߂���Ȃ����Ǝv���A
�Ȃ̂�HBM��HMC��WideI/O�����鎞�_�őS���邾�낤�A��
DRAM���ꖇ�ꖇ�����ɒu���Ē��Z������ʔz�����œK���ł���A��
477 �F,,�E�L�́M�E,,�j��-�������F2015/02/03(��) 23:37:33.51 ID:Q1sBTQhd
>>475
HMC�͊��ɓ������̂�������FPGA�Ƃ��Ƒg�ݍ��킹�Ď����f������Ă邩��ȁ[
�R���\�[�V�A���Q����Ƃ��������W���ɏ����鈵���ł����Ǝv��
HMC�͊��ɓ������̂�������FPGA�Ƃ��Ƒg�ݍ��킹�Ď����f������Ă邩��ȁ[
�R���\�[�V�A���Q����Ƃ��������W���ɏ����鈵���ł����Ǝv��
���₢��ύڃ������ł��傤���łȂ��ƃ������e�ʂƑ��x���E�E
>>474
����HBM���g�������Ȃ���Ȃ����H
�Ȃ��Ŏ��ЊJ���̎��А��Yonly�̃������K�i�ň͂����ق���
Intel�̗L���ɓ������B
>>474
����HBM���g�������Ȃ���Ȃ����H
�Ȃ��Ŏ��ЊJ���̎��А��Yonly�̃������K�i�ň͂����ق���
Intel�̗L���ɓ������B
>>476
Intel�炵��������炵���Ȃ�
���������Ƃ��D�����킗
>>477
FPGA����Ă邩��HMC�A�s�[�����ꂽ��B
HBM��WideI/O�́H�Ǝv�������ǁAHMC���s��������̂ˁB
Intel�炵��������炵���Ȃ�
���������Ƃ��D�����킗
>>477
FPGA����Ă邩��HMC�A�s�[�����ꂽ��B
HBM��WideI/O�́H�Ǝv�������ǁAHMC���s��������̂ˁB
intel�̓������̃I���p�b�P�[�W��������������DRAM�̎��А������ĊJ����̂ł͂Ȃ����Ɨ\�z���Ă�
�X�^�b�N�hDRAM��8�`32GB�ڂ�DRAM�X���b�g��p�~���Ď��А���CPU��DRAM���Z�b�g�Ŕ���
����Ȃ甄��������邵�ő�̖��ł������H��̉ғ��������P�o���邾�낤
�����܂ł��\�z�Ȃ̂Řb������
�X�^�b�N�hDRAM��8�`32GB�ڂ�DRAM�X���b�g��p�~���Ď��А���CPU��DRAM���Z�b�g�Ŕ���
����Ȃ甄��������邵�ő�̖��ł������H��̉ғ��������P�o���邾�낤
�����܂ł��\�z�Ȃ̂Řb������
481 �F,,�E�L�́M�E,,�j��-�������F2015/02/03(��) 23:43:52.85 ID:Q1sBTQhd
>>476
> DRAM���ꖇ�ꖇ�����ɒu���Ē��Z������ʔz�����œK���ł���A��
���₠����͂���Ńp�b�P�[�W���O����ςł��傤����A�X�^�b�L���O�������͕��p���邩��
> DRAM���ꖇ�ꖇ�����ɒu���Ē��Z������ʔz�����œK���ł���A��
���₠����͂���Ńp�b�P�[�W���O����ςł��傤����A�X�^�b�L���O�������͕��p���邩��
482 �F,,�E�L�́M�E,,�j��-�������F2015/02/03(��) 23:45:48.86 ID:Q1sBTQhd
>>480
Pentium 4�E�E�E�E����Ȃ�ł��Ȃ�
Pentium 4�E�E�E�E����Ȃ�ł��Ȃ�
>>478
HMC��Intel���[���ւ���Ă�Ƃ͌���Micron�哱�������Y��Micron�݂̂Ȃ̂ł�
HMC��Intel���[���ւ���Ă�Ƃ͌���Micron�哱�������Y��Micron�݂̂Ȃ̂ł�
>>481
���L�ш�̓��C����������1�`2GB�����x�Ŏc���DIMM��DDR3/4�ŗǂ��A�ƂȂ��
�I���p�b�P�[�WDRAM��2���Ƃ��ōςގ��ɂȂ�
OS�E�\�t�g�E�F�A���ʼn��z�E�����A�h���X�}�b�s���O�����ǂ��邩�ADIMM��DDR3/4��
�S�̂��X�g���[�W�����ăX���b�v�t�@�C���u����ɂ���Ƃ��őΉ��\���낤
���L�ш�̓��C����������1�`2GB�����x�Ŏc���DIMM��DDR3/4�ŗǂ��A�ƂȂ��
�I���p�b�P�[�WDRAM��2���Ƃ��ōςގ��ɂȂ�
OS�E�\�t�g�E�F�A���ʼn��z�E�����A�h���X�}�b�s���O�����ǂ��邩�ADIMM��DDR3/4��
�S�̂��X�g���[�W�����ăX���b�v�t�@�C���u����ɂ���Ƃ��őΉ��\���낤
intel��DRAM�̎��А����܂ł͂����Ȃ��Ă��������̃I���p�b�P�[�W����DRAM�X���b�g�p�~�͊m���ɂ��
�x�m�ʂ�HPC�p��HMC�g�����ɂȂ��Ă邯��
HBM�Ƃ̔�r�ł͂���ς�2.5D�������s�v�Ȃ��ƂɌ��y���Ă���
http://news.mynavi.jp/column/sc13/007/images/005l.jpg
HBM�Ƃ̔�r�ł͂���ς�2.5D�������s�v�Ȃ��ƂɌ��y���Ă���
http://news.mynavi.jp/column/sc13/007/images/005l.jpg
{kind=link}
>>484
�`�b�v�̈ꖇ���1GB�Ȃ�Ė�������H
�`�b�v�̈ꖇ���1GB�Ȃ�Ė�������H
>>487
���ɔ�JEDEC�����������̖ڂ����鎞�オ����̂����
���ɔ�JEDEC�����������̖ڂ����鎞�オ����̂����
490 �F,,�E�L�́M�E,,�j��-�������F2015/02/04(��) 00:16:43.90 ID:Oi4jnyDd
��ނ��@���@����������@�Ȃ��܂ɂȂ肽�����Ɂ@���������@�݂Ă���
������Ɨ���ɏ���Ă邯�ǁA>>456,458,460,466�Ƃ��炭�͐����Ă����
HMC�ɂ�2.5D��EMIB�Ȃ�ėv��Ȃ���Ȃ��̂Ƃ���>>469�̎w�E��
�c�q�͉����������ǂ��Ǝv����
HMC�ɂ�2.5D��EMIB�Ȃ�ėv��Ȃ���Ȃ��̂Ƃ���>>469�̎w�E��
�c�q�͉����������ǂ��Ǝv����
�s�^���ƃ��X���~�܂������
�c�q���Ă��������Ƃ��͂�����������
�c�q���Ă��������Ƃ��͂�����������
493 �F,,�E�L�́M�E,,�j��-�������F2015/02/04(��) 01:26:27.40 ID:Oi4jnyDd
HMC�̃C���^�[�t�F�[�X�m�F���Ă邯�Ǖ��ʂ�BGA����
����Knights Landing�̃������Ɋւ��ẮAMicron�̃T�C�g�ł��uHMC�̋Z�p��p�������́v�Ƃ���
�����������j���A���X�̕\�����Ȃ���Ă�̂��C�ɂȂ�B
����Knights Landing�̃������Ɋւ��ẮAMicron�̃T�C�g�ł��uHMC�̋Z�p��p�������́v�Ƃ���
�����������j���A���X�̕\�����Ȃ���Ă�̂��C�ɂȂ�B
�����̂��ƁB
495 �F,,�E�L�́M�E,,�j��-�������F2015/02/04(��) 01:52:32.62 ID:Oi4jnyDd
��������Intel, Micron���o���Ă鎑���ł�KNL��NearMemory�́uMCDRAM�v�Ƃ����\�������Ă��āA
HMC�̃C���^�[�t�F�[�X�d�l�ɂ��̂܂����������̂Ƃ͌����ĂȂ���B
�L���b�V�������˂�ȏ�A�ʏ�̃o���v�Ń��C���{���f�B���O�������C�e���V�ŒʐM�ł���
�Ȃ炻�̂ق��������ł��傤�B
�}�C�N���o���v��EMIB�Őڑ����邱�Ƃ�O��Ƃ����J�X�^���`�b�v���Ƃ�����H
�u����HBM����Ȃ��́H�v���Ă͔̂����łˁi�����͔�HBM�w�c��Micron�ł����j
HMC�̃C���^�[�t�F�[�X�d�l�ɂ��̂܂����������̂Ƃ͌����ĂȂ���B
�L���b�V�������˂�ȏ�A�ʏ�̃o���v�Ń��C���{���f�B���O�������C�e���V�ŒʐM�ł���
�Ȃ炻�̂ق��������ł��傤�B
�}�C�N���o���v��EMIB�Őڑ����邱�Ƃ�O��Ƃ����J�X�^���`�b�v���Ƃ�����H
�u����HBM����Ȃ��́H�v���Ă͔̂����łˁi�����͔�HBM�w�c��Micron�ł����j
496 �F,,�E�L�́M�E,,�j��-�������F2015/02/04(��) 02:02:41.93 ID:Oi4jnyDd
http://www.techenablement.com/intel-knights-landing-claimed-4x-an-nvidia-k40-on-some-applications/
����ˁB
HMC�x�[�X�Ȃ̂͂킩�邪�AHMC���̂��̂Ȃ�MCDRAM�Ȃ�Ė��O�̓ǂݑւ��͕K�v�Ȃ��͂����B
����ˁB
HMC�x�[�X�Ȃ̂͂킩�邪�AHMC���̂��̂Ȃ�MCDRAM�Ȃ�Ė��O�̓ǂݑւ��͕K�v�Ȃ��͂����B
�uTSV�Ƃ������̂́A����͖����������ɂ����v�Ƃ��������Ǝv��
�܂�GDDR5�Ɛڑ����������O���\���͓����A
DRAM�����\�����Ƃ����t���b�V���̍H�v�Ƃ��A���ꂪHMC���ł��ˁA��
�M�c���ŊȒP�ɃY���ăr�A��o���v����錻�ۂ́A�����s�A��
�܂�GDDR5�Ɛڑ����������O���\���͓����A
DRAM�����\�����Ƃ����t���b�V���̍H�v�Ƃ��A���ꂪHMC���ł��ˁA��
�M�c���ŊȒP�ɃY���ăr�A��o���v����錻�ۂ́A�����s�A��
2.5D�̏ꍇ�A�q�[�g�V���N�܂ł̍����̍����ǂ���������낤
�Ⴂ���ɓ����̃o�b�t�@�[�ł��\��t����?
�Ⴂ���ɓ����̃o�b�t�@�[�ł��\��t����?
�c���A����d�͗�0.01pJ/b�����������ϑw�`�b�v�Ԗ����ʐM�Z�p���J��
ttp://news.mynavi.jp/news/2010/06/21/034/
ThruChip�̃��C�����X�ڑ����g��3D�X�^�b�N
ttp://news.mynavi.jp/articles/2014/09/02/hotchips26_hbm/001.html
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20140819_662558.html
4��m�̒����^DRAM
ttp://pc.watch.impress.co.jp/docs/news/event/20140619_654110.html
ttp://news.mynavi.jp/news/2014/06/05/369/
ttp://news.mynavi.jp/news/2010/06/21/034/
ThruChip�̃��C�����X�ڑ����g��3D�X�^�b�N
ttp://news.mynavi.jp/articles/2014/09/02/hotchips26_hbm/001.html
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20140819_662558.html
4��m�̒����^DRAM
ttp://pc.watch.impress.co.jp/docs/news/event/20140619_654110.html
ttp://news.mynavi.jp/news/2014/06/05/369/
�v�����Intel�̃I���_�CDRAM�͂��ꎩ�̂����C���������Ŏ������������A
OS���̈����ɂ����鉼�z��������DDR3/4�̊O�t��DRAM�Ɏ����Ă������Ƃ����n���Ȃ낤��
OS���̈����ɂ����鉼�z��������DDR3/4�̊O�t��DRAM�Ɏ����Ă������Ƃ����n���Ȃ낤��
>>501
����RAM�f�B�X�N����
����Ȃ�HDD��SSD�����z�������ɂ������̎���������C�ɉ���������
�ő僁�������啝�ɑ�������RAM�f�B�X�N���p�ꂽ�Ǝv�����炱���������@������̂�
�ƌ����Ă��A�����Ȃ�ƃ��C�����������I���_�C����ɂȂ�Ƒ啝�ȑ����͂��ɂ����Ȃ肻�����Ȃ�
����32GB������Ɩ��p�r�ł��\��������قǂ̐��\�ł͂��邪
����RAM�f�B�X�N����
����Ȃ�HDD��SSD�����z�������ɂ������̎���������C�ɉ���������
�ő僁�������啝�ɑ�������RAM�f�B�X�N���p�ꂽ�Ǝv�����炱���������@������̂�
�ƌ����Ă��A�����Ȃ�ƃ��C�����������I���_�C����ɂȂ�Ƒ啝�ȑ����͂��ɂ����Ȃ肻�����Ȃ�
����32GB������Ɩ��p�r�ł��\��������قǂ̐��\�ł͂��邪
�㓡���̋L���������HBM��DDR3/4���ǂ�������C�������������ŁA�\�t�g�E�F�A����
�H�v��HBM��DDR3/4�̂ǂ��瑤�Ƀf�[�^��u���������肷��Ƃ���
����͂�����ƃv���O���}�ɕ��S����������@�����A�������OS����
�S�����Ńf�[�^�̒u���ꏊ�����߂Ă����悤�ɂȂ邾�낤
�H�v��HBM��DDR3/4�̂ǂ��瑤�Ƀf�[�^��u���������肷��Ƃ���
����͂�����ƃv���O���}�ɕ��S����������@�����A�������OS����
�S�����Ńf�[�^�̒u���ꏊ�����߂Ă����悤�ɂȂ邾�낤
TSV���ăX�p�R���Ƃ��ł̃������ш�̖��Ƃ���C�ɕЕt���̂��Ǝv������@�����ł��Ȃ��́H
505 �FSocket774�F2015/02/04(��) 07:07:50.78 ID:lqH3GyrZ
�߂���₪���ʂ�
506 �FSocket774�F2015/02/04(��) 07:55:34.08 ID:8ThFYrS7
Sequoia
>>503
�y�[�W�e�[�u���ɂ�����ƃt���O�lj�����A�����̉��z�������̎d�g�݂�OS�����z�u�œK���ł��������B
�y�[�W�e�[�u���ɂ�����ƃt���O�lj�����A�����̉��z�������̎d�g�݂�OS�����z�u�œK���ł��������B
�}�C�N������intel�ɔ�������ACPU�̓������[���ڗʂŃu�����f�B���O����関����
SD�J�[�h��64GB��4,000�~���x����iPhone��64GB���f����128GB���f���̉��i����25,000�~
SD�J�[�h�X���b�g�͖����̂ő�e�ʃ��������g�������ꍇ��apple�ɍ������z�{��Ȃ��Ƃ����Ȃ�
���̂����p�\�R���̃������X���b�g�͔p�~����CPU��iphone�̂悤�Ȕ�����ɂȂ�
SD�J�[�h�X���b�g�͖����̂ő�e�ʃ��������g�������ꍇ��apple�ɍ������z�{��Ȃ��Ƃ����Ȃ�
���̂����p�\�R���̃������X���b�g�͔p�~����CPU��iphone�̂悤�Ȕ�����ɂȂ�
Intel���@>500�Ƃ���TSV�����܂荂���]�����ĂȂ���������
TSV�������Ă�̂͒N�Ȃ낤�ȁB�������u���[�J�[�H
TSV�������Ă�̂͒N�Ȃ낤�ȁB�������u���[�J�[�H
�\������ԒP��������ł́H��SI���g����2.5D TSV
���ƍ\���I�Ƀ������ȊO�ɂ��g����炵����
���ƍ\���I�Ƀ������ȊO�ɂ��g����炵����
�C���e����TSV�ɏ��ɓI�ʼn�������Ă邾�낤�Ƃ͗\�z�ł�����
�ǂ��Ȃ�낤�ˁB
�ǂ��Ȃ�낤�ˁB
�T�[�o�E�n�C�p�t�H�[�}���X�f�X�N�g�b�v�݂����ȁA
�����M��CPU��DRAM��ϑw����͖̂�������
������A�V���R���C���^�|�[�U�g���Đڑ����邩�AHMC���g����
�����M��CPU��DRAM��ϑw����͖̂�������
������A�V���R���C���^�|�[�U�g���Đڑ����邩�AHMC���g����
>>514
����͗�p�Z�p���̂��J�M�ɂȂ���Ă��ƂȂ�ł�
�T�[�o��f�X�N�g�b�v�Ƃ����ǂ��I���`�b�v�������C���������H���͂Ȃ������߂���
����͗�p�Z�p���̂��J�M�ɂȂ���Ă��ƂȂ�ł�
�T�[�o��f�X�N�g�b�v�Ƃ����ǂ��I���`�b�v�������C���������H���͂Ȃ������߂���
��Ώ̃f���A���R�A�Ƃ��A�h���X���ƂɃ��������x��������ꍇ��OS�̋����͂ǂ��Ȃ��Ă��
✕�f���A���R�A
���f���A���`�����l��
���f���A���`�����l��
�ᑬ�ɍ��킹�邩�A���̓s�x�A�N�Z�X�҂����ȁH�H
���̐�98��cpu�A�N�Z�����[�^�Œ��ڃ������ς߂�z��������
����v���X�{�̂̃������X���b�g��c bus�ɍ�����ƕ��p���Ă��L��������
�N�����̃������J�E���g�Ŗ��炩�ɃX�s�[�h����Ă��ȁ[
�������Ǘ��h���C�o�[�ŃA�h���X�Ŗ����I��disk cache�Ɏg�����悤�ȋC������
melware�Ƃ�
����v���X�{�̂̃������X���b�g��c bus�ɍ�����ƕ��p���Ă��L��������
�N�����̃������J�E���g�Ŗ��炩�ɃX�s�[�h����Ă��ȁ[
�������Ǘ��h���C�o�[�ŃA�h���X�Ŗ����I��disk cache�Ɏg�����悤�ȋC������
melware�Ƃ�
NUMA�ƈ���Ēx���������͂ǂ�CPU������x������Ȃ�
OS�łǂ��ɂ�����̂��A�n�[�h�E�F�A�ŊǗ�����̂��B
����Phi���y���݂�
OS�łǂ��ɂ�����̂��A�n�[�h�E�F�A�ŊǗ�����̂��B
����Phi���y���݂�
�Z�N�^�L���b�V���݂����Ȃ̂����邩���
HBM�e�ʂ��SGB-8GB���炢��������m�[�g��f�X�N���x���Ȃ�O�t��DRAM�������
��₱�����̖ʓ|�Ȃ�A�I���p�b�P�[�W1GB���L���b�V���ɂ��ăL���b�V�����C���T�C�Y��
4KBytes�ɂ���^�ORAM�Ȃ��Ȃ��Ȃ邼��
4KBytes�ɂ���^�ORAM�Ȃ��Ȃ��Ȃ邼��
�ւ��`�A�ʔ��`���B
�v���Z�b�T�̐i�����݉�����Ȃ�A���\��]�����ƂȂ������o���₷������v���O���~���O�p���_�C���Ɋ��҂��ˁB
>>523
�����ʂ�̃����`�b�v�R���s���[�e�B���O���\�ɂȂ�ˁB
�M�������Ȃ�B
�v���Z�b�T�̐i�����݉�����Ȃ�A���\��]�����ƂȂ������o���₷������v���O���~���O�p���_�C���Ɋ��҂��ˁB
>>523
�����ʂ�̃����`�b�v�R���s���[�e�B���O���\�ɂȂ�ˁB
�M�������Ȃ�B
>>525
DDR4���������x���Ȃ�\��4
DDR4���������x���Ȃ�\��4
528 �FSocket774�F2015/02/04(��) 21:48:03.65 ID:PyK/oG4Q
>>526
�������ʂ�̃����`�b�v�R���s���[�e�B���O���\�ɂȂ�ˁB
HBM�͓������ɕʃ`�b�v�œ��ڂ����̂����烏���`�b�v�ɂȂ�Ȃ���B
�������ʂ�̃����`�b�v�R���s���[�e�B���O���\�ɂȂ�ˁB
HBM�͓������ɕʃ`�b�v�œ��ڂ����̂����烏���`�b�v�ɂȂ�Ȃ���B
�����p�b�P�[�W���ȁH
>>526
���{�ł͕ێ�I�Ȑl����������A���I�ȃv���O���~���O�Z�p�ω��͂Ȃ���B
���{�ł͕ێ�I�Ȑl����������A���I�ȃv���O���~���O�Z�p�ω��͂Ȃ���B
��������̃��C�u�����Ƃ��Đ�`���Ȃ��Ɩ��������ˁB
>>530
�܂����������l���������b�ɂ��������̂�OS�Ȃ��ǂ�
�Q�[�����̓K���K���@�����Lj�ʓI�ȃv���O���}�͕ێ�I������p���[�v���C�劽�}
�܂����������l���������b�ɂ��������̂�OS�Ȃ��ǂ�
�Q�[�����̓K���K���@�����Lj�ʓI�ȃv���O���}�͕ێ�I������p���[�v���C�劽�}
cortex-A72���o���炵��
�Ƃ肠�����AHMC�̓I���R���Ă��Ƃ���
Intel�������W������Ȃ��Ǝ��K�i���đ��|�V���邩�}�C�i�[�ŏI�����
HBM����AMD���J�����݂����Ȃ�����A�ŏ��̂�����Radeon��APU�D��ɋ�����J�����i�ނ�Ȃ�����
Intel�������W������Ȃ��Ǝ��K�i���đ��|�V���邩�}�C�i�[�ŏI�����
HBM����AMD���J�����݂����Ȃ�����A�ŏ��̂�����Radeon��APU�D��ɋ�����J�����i�ނ�Ȃ�����
�������������ꂪ����ɉ���Ď����ɂ����b������B
�ŏI�I�ɂ͓Ǝ��ɂ�����炸�W���K�i���g�������������B
�ŏI�I�ɂ͓Ǝ��ɂ�����炸�W���K�i���g�������������B
AMD�͂ǂ����ċ��ɂ��Ȃ�Ȃ��W���K�i������Ă��܂��̂�
HSA�͋��ɂȂ����W�����B�R���V���[�}100%�����B
�{�Ƃ����߂Ȃ�Ȃ��B
�{�Ƃ����߂Ȃ�Ȃ��B
iGPU���p��PC���i��AAMD���y���ɗ��Intel�͍��邩�炻�������ʂ̋@���ׂ��Ă��
���[�J�[�̌���ꂽ�J���͂�C���i�b�v�����������͂�����ł����AAMD�̖{�Ƃ��U���Ȃ��̂͂ǂ����悤���Ȃ�
�܂��A�����悤�Ȃ��Ƃ��X�}�t�H��^�u���b�g��Qualcomm��Apple��Intel������Ă邯�ǂ�
���������AIntel+Nvidia����Ȃ���AMD�ɂ����ĂȂ��̂ɁA���o�C���ł͋t���Ԃ����Ă邩�珟���ڂƂ�����͂����Ȃ�
���[�J�[�̌���ꂽ�J���͂�C���i�b�v�����������͂�����ł����AAMD�̖{�Ƃ��U���Ȃ��̂͂ǂ����悤���Ȃ�
�܂��A�����悤�Ȃ��Ƃ��X�}�t�H��^�u���b�g��Qualcomm��Apple��Intel������Ă邯�ǂ�
���������AIntel+Nvidia����Ȃ���AMD�ɂ����ĂȂ��̂ɁA���o�C���ł͋t���Ԃ����Ă邩�珟���ڂƂ�����͂����Ȃ�
�u���h�[�U�[�v�����l�A�C���e���Ńl�g�o�v�����l�炵������l�I������̂����������ԈႢ�B
���o�C���̐v�̂ق����o�����������Ă����B
�l�ޗ������C���e������m���ȁB
���o�C���̐v�̂ق����o�����������Ă����B
�l�ޗ������C���e������m���ȁB
����l��
541 �F,,�E�L�́M�E,,�j��-�������F2015/02/05(��) 04:38:47.07 ID:+aTsRuER
ID:rg2FbfU+���|���Z�Q���Z�P��̖��E
�����������˂�
�����������˂�
HSA�̐����͐�����Ȃ�
�����̉\�����L�����Ă�
�����̉\�����L�����Ă�
>>527
�ŋ߂̃n�[�h�E�F�A�v���t�F�b�`�ُ̈�ȗD�G������ɁA�L���b�V�����C���f�J���낤��
DRAM���C�e���V���f�J���낤�����\�����Ȃ��C�����Ă��Ă�
���߂��Ă�̂͑�e�ʂŒ��L�ш�ȃ������ŁA���Ƃ�CPU�̃v���t�F�b�`�ɂ܂����Ƃ��݂�����
������DRAM-CPU�̑ш���đ��₹��Ȃ�ǂ��܂ő��₷�ׂ��Ȃ̂���
L3-L2�EL2-L1�EL1-���W�X�^��葾���Ӗ��͂��邩�ȁA�R�A�����K�v������1TB/s���炢�~������
�ŋ߂̃n�[�h�E�F�A�v���t�F�b�`�ُ̈�ȗD�G������ɁA�L���b�V�����C���f�J���낤��
DRAM���C�e���V���f�J���낤�����\�����Ȃ��C�����Ă��Ă�
���߂��Ă�̂͑�e�ʂŒ��L�ш�ȃ������ŁA���Ƃ�CPU�̃v���t�F�b�`�ɂ܂����Ƃ��݂�����
������DRAM-CPU�̑ш���đ��₹��Ȃ�ǂ��܂ő��₷�ׂ��Ȃ̂���
L3-L2�EL2-L1�EL1-���W�X�^��葾���Ӗ��͂��邩�ȁA�R�A�����K�v������1TB/s���炢�~������
���L1�Ɠ����ʂɂ������n�Y�B
��������Γ����Ńf�[�^�����ł���̂�CPU�̃X�g�[��������B
�{���ɏo���������L1���瑬�x���L�тĂ����̂Ō��Ǔ����B
��������Γ����Ńf�[�^�����ł���̂�CPU�̃X�g�[��������B
�{���ɏo���������L1���瑬�x���L�тĂ����̂Ō��Ǔ����B
�������[�̐ϑw�Ƃ����ΐ̂�������̂��ƌ|�B�G���s�[�_����ɓ��ꂽ�}�C�N������HMC�͊m���ɃA�h�o���e�[�W������܂��ȁB
���̓O���t�B�b�N�p�r�ȊO�ōL�ш惁������K�v�Ƃ��ĂȂ����ƂȂ��
HSA���L��������Ɗ��p�@������邩�������
HSA���L��������Ɗ��p�@������邩�������
HPC�ł����ш惁�������K�v
�g�ݍ��������ƁA���[�^�����̃������Ȃ����ш悪�K�v�����
�R�p���ƃ��[�_�[�����Ƃ��H
�g�ݍ��������ƁA���[�^�����̃������Ȃ����ш悪�K�v�����
�R�p���ƃ��[�_�[�����Ƃ��H
HSA����CUDA���D�G�Ȃ́H
�܂����ߌ���͗p�ӂł��ĂȂ��i�Ƃ������������͒��߂Ē��Ԃ̌������ɒ��͂��Ă�
>>546
���_�I�Ȑ��l����AVX���t���Ɏg����i7�ł��K�v�B
>>546
���_�I�Ȑ��l����AVX���t���Ɏg����i7�ł��K�v�B
����������ł���𗘗p����A�v�����o�Ă��邩�����Ă����đ����邱�Ƃ͂Ȃ��Ƃ�������
CPU�J�����ǂ�Â܂�łǂ�ǂ�V�������N���Ă����\�オ��Ȃ��Ȃ�
�J�����c��ڂL�����p���邩�Ƃ��������ɂ��Ȃ�
CPU�J�����ǂ�Â܂�łǂ�ǂ�V�������N���Ă����\�オ��Ȃ��Ȃ�
�J�����c��ڂL�����p���邩�Ƃ��������ɂ��Ȃ�
�Ƃ肠���������邱�Ƃ́A���o�C�������ƍ����Œ����M�������k������Ƃ����̂�
�ȓd�͂��猩��Ƒ����C���p�N�g�ł͂���
�ᑬ�œ��������������قǏȓd�͂����҂ł�����Ă��Ƃ������
�ȓd�͂��猩��Ƒ����C���p�N�g�ł͂���
�ᑬ�œ��������������قǏȓd�͂����҂ł�����Ă��Ƃ������
>>449
�������ш�͕K�v����
SSE*(128-bit)��AVX(256-bit)��AVX2(+FMA)
���C���X�g���[��CPU�������Ă��������ш悠����̗��_FLOPS����Nehalem�̂����悻4�{�ɂȂ��Ă�
����AFLOPS������̑ш�͍�NVIDIA�̃n�C�G���h�N���X��GPU��苷��
�������A�����牉�Z���j�b�g�̖��ʌ������Ƃ�����
GPU���y���ɒ�C�e���V����e�ʂ̃L���b�V�������������邩���T�ɂ͌����Ȃ�
�@
���Ƃ͓d�́E�M�̖�肾��
AVX1���炢�܂ł�OoO�̃X�P�W���[���̃R�X�g�̂ق������ΓI�ɑ傫����������SIMD�̋�����
�y�C�ł�����̂����������sXeon�ł�AVX���߂����m����ƃN���b�N�𗎂Ƃ��Ȃ��Ƃ����Ȃ����炢��
SIMD���Z�̓d�̓R�X�g�͑傫���Ȃ��Ă�B
�i�t���I�ɓd�͊Ǘ��@�\�̉��P�ŃX�J�����Z���̃N���b�N��L����悤�ɂȂ����Ƃ������߂��ł���j
�������ш�͕K�v����
SSE*(128-bit)��AVX(256-bit)��AVX2(+FMA)
���C���X�g���[��CPU�������Ă��������ш悠����̗��_FLOPS����Nehalem�̂����悻4�{�ɂȂ��Ă�
����AFLOPS������̑ш�͍�NVIDIA�̃n�C�G���h�N���X��GPU��苷��
�������A�����牉�Z���j�b�g�̖��ʌ������Ƃ�����
GPU���y���ɒ�C�e���V����e�ʂ̃L���b�V�������������邩���T�ɂ͌����Ȃ�
�@
���Ƃ͓d�́E�M�̖�肾��
AVX1���炢�܂ł�OoO�̃X�P�W���[���̃R�X�g�̂ق������ΓI�ɑ傫����������SIMD�̋�����
�y�C�ł�����̂����������sXeon�ł�AVX���߂����m����ƃN���b�N�𗎂Ƃ��Ȃ��Ƃ����Ȃ����炢��
SIMD���Z�̓d�̓R�X�g�͑傫���Ȃ��Ă�B
�i�t���I�ɓd�͊Ǘ��@�\�̉��P�ŃX�J�����Z���̃N���b�N��L����悤�ɂȂ����Ƃ������߂��ł���j
��ʌ����̗p�r��SIMD���Z�̉��b���Ă���́H
SIMD���Z����ނ�݂ɍL����̂͂ǂ��Ȃ̂��ȁB
���߃Z�b�g�̍��ɂ���邪PC�ŗL���Ȃ̂�512bit��3D��32bit�~4�~4�̍s�Z����x�ɍs�����܂ł��낤�ȁB����ȏ�̗��x�̉��Z�͎g�p�p�x���Ⴍ�đΉ����Ă���������Ȃ����B
�摜�̂悤�ȋ���z��f�[�^�����Ȃ畝�LSIMD���GPU��SIMT�̕����������ǂ����B
���߃Z�b�g�̍��ɂ���邪PC�ŗL���Ȃ̂�512bit��3D��32bit�~4�~4�̍s�Z����x�ɍs�����܂ł��낤�ȁB����ȏ�̗��x�̉��Z�͎g�p�p�x���Ⴍ�đΉ����Ă���������Ȃ����B
�摜�̂悤�ȋ���z��f�[�^�����Ȃ畝�LSIMD���GPU��SIMT�̕����������ǂ����B
LGA115���̃������ш悾��LINPACK�̃x���`/���_�l�̔䗦��
AVX2�ł����炩��AVX����������i��Βl�͂������͂₢�j�B
Xeon E3 v3��DDR3�ŏo��������E5 v3��DDR4�B������������̎����ł����������A
DDR4�ɂ��Ȃ���E5 ���[�U�[�̊��҂ɂ������鐫�\�ɂȂ�Ȃ��Ƃ����̂����������낤
AVX2�ł����炩��AVX����������i��Βl�͂������͂₢�j�B
Xeon E3 v3��DDR3�ŏo��������E5 v3��DDR4�B������������̎����ł����������A
DDR4�ɂ��Ȃ���E5 ���[�U�[�̊��҂ɂ������鐫�\�ɂȂ�Ȃ��Ƃ����̂����������낤
DDR4���Ō�̃��������W���[���K�i�ɂȂ肻���ȗ\��
GPU�̂悤��CPU�̎��͂ɃI���`�b�v���������̂������イ�ɂȂ��
GPU�̂悤��CPU�̎��͂ɃI���`�b�v���������̂������イ�ɂȂ��
>>556
DSP�ł��������
DSP�ł��������
�ӂ���DSP���core i7��SIMD�g���ق����͂邩�ɍ����\
���܂�CPU�̒��ɓ���Đ���Í��Ȃǂ̓���p�rDSP�������Ă�悤�ȏ�Ԃ����Ȃ�
>>557
�����čĂуX���b�g�^CPU�̎��オ����Ă���̂�
�����čĂуX���b�g�^CPU�̎��オ����Ă���̂�
>>558
�����ē�̉�f�������Ƃ����݂������ł��ˁA������܂��B
�����ē�̉�f�������Ƃ����݂������ł��ˁA������܂��B
>>543
�m���ɁA�ŋ߂̃n�[�h�E�F�A�v���t�F�b�`�̗D�G���ُ͈�B
�ǂ��������X�g�[���N������̂�������Ȃ����炢��
>>554
512bit�̓L���������ȁB
���̂�����ł��炭��������ȗ\���B
�m���ɁA�ŋ߂̃n�[�h�E�F�A�v���t�F�b�`�̗D�G���ُ͈�B
�ǂ��������X�g�[���N������̂�������Ȃ����炢��
>>554
512bit�̓L���������ȁB
���̂�����ł��炭��������ȗ\���B
564 �F,,�E�L�́M�E,,�j��-�������F2015/02/05(��) 22:53:48.82 ID:UC61hctc
�Ƃ����AVX-512����4x4�s��ς��Ăǁ[���H
���sXeon Phi����swizzle�����邩�炱�ꂾ���ł��ނ���AVX-512�ɂ͖������H
vmovdqa zmm0, [A]
vmovdqa zmm1, [B]
vmulps zmm2, zmm0, zmm1{aaaa}
vfmadd231ps zmm2, zmm0, zmm1{bbbb}
vfmadd231ps zmm2, zmm0, zmm1{cccc}
vfmadd231ps zmm2, zmm0, zmm1{dddd}
vmovdqa [D], zmm2
����ł��疽�ߊԃ��C�e���V�����邩��P�̂̍s��ς������߂�ɂ�
128�r�b�g��256�r�b�g��SIMD�Ɣ�ׂđ����킯�ł͂Ȃ��B
�������߂��C���^�[���[�u���āA��ʂ�4x4�s��ɓ����s��l��������g�����Ȃ�\���L���B
�����Ă��������g�����Ȃ�ʂ�1024�r�b�g�A2048�r�b�g�Ƒ����Ă������Ȃ�ȁB
���sXeon Phi����swizzle�����邩�炱�ꂾ���ł��ނ���AVX-512�ɂ͖������H
vmovdqa zmm0, [A]
vmovdqa zmm1, [B]
vmulps zmm2, zmm0, zmm1{aaaa}
vfmadd231ps zmm2, zmm0, zmm1{bbbb}
vfmadd231ps zmm2, zmm0, zmm1{cccc}
vfmadd231ps zmm2, zmm0, zmm1{dddd}
vmovdqa [D], zmm2
����ł��疽�ߊԃ��C�e���V�����邩��P�̂̍s��ς������߂�ɂ�
128�r�b�g��256�r�b�g��SIMD�Ɣ�ׂđ����킯�ł͂Ȃ��B
�������߂��C���^�[���[�u���āA��ʂ�4x4�s��ɓ����s��l��������g�����Ȃ�\���L���B
�����Ă��������g�����Ȃ�ʂ�1024�r�b�g�A2048�r�b�g�Ƒ����Ă������Ȃ�ȁB
�C���^�[���[�u���ă��C�e���V���B��������ăe�N�j�b�N���g���̂��B
������āA�C���g�����V�b�N�ł��\�H
������āA�C���g�����V�b�N�ł��\�H
Intel Expects to Launch 10nm Chips in 2017
http://wccftech.com/intel-expects-launch-10nm-2017/#ixzz3QsaDD1Mq
http://wccftech.com/intel-expects-launch-10nm-2017/#ixzz3QsaDD1Mq
567 �F,,�E�L�́M�E,,�j��-�������F2015/02/05(��) 23:17:03.52 ID:UC61hctc
�܂��A�����[���̓R���p�C���C���ɂ��邩�ȁB
���W�X�^���l�[�~���O�������_���ȃA�[�L�Ȃ炢������
Xeon Phi�̓C���I�[�_�����疽�߂̃��C�e���V�̌v�Z�����ɂ߂�ǂ��������B
Phi�͐Ϙa���߂̃��C�e���V��8�Ȃ̂ŁA8�̍s��̊|���Z���C���^�[���[�u����K�v������B
�A�Z���u���ŏ����Ƃ��������v�Z�����ɂ߂�ǂ������B
inline __m512 MatrixMultiply(__m512 a, __m512 b) { /* �ق��ق� */ }
for (int i = 0; i < N; i++) { c[i] = MatrixMultiply(a[i], b[i]); }
�݂����ȃR�[�h�����Ƃ��R���p�C��������ɃA�����[�����Ă�����
���W�X�^���l�[�~���O�������_���ȃA�[�L�Ȃ炢������
Xeon Phi�̓C���I�[�_�����疽�߂̃��C�e���V�̌v�Z�����ɂ߂�ǂ��������B
Phi�͐Ϙa���߂̃��C�e���V��8�Ȃ̂ŁA8�̍s��̊|���Z���C���^�[���[�u����K�v������B
�A�Z���u���ŏ����Ƃ��������v�Z�����ɂ߂�ǂ������B
inline __m512 MatrixMultiply(__m512 a, __m512 b) { /* �ق��ق� */ }
for (int i = 0; i < N; i++) { c[i] = MatrixMultiply(a[i], b[i]); }
�݂����ȃR�[�h�����Ƃ��R���p�C��������ɃA�����[�����Ă�����
>>566
����cGF�T���X��TMSC�ɕ������Ă��Ƃ����c
����cGF�T���X��TMSC�ɕ������Ă��Ƃ����c
>>567
���[�APhi�̓C���I�[�_�[���`�B
����Ⴛ������Ȃ���A����Ȃɐ��ς߂Ȃ�����Ȃ�
�����C�e���V�����肾�B
�R���p�C�����X��������Ă����Ȃ���Ȃ��ˁB
���`�AAVX512�������낻�����`�B
Skylake��Xeon���������ƁB
���[�APhi�̓C���I�[�_�[���`�B
����Ⴛ������Ȃ���A����Ȃɐ��ς߂Ȃ�����Ȃ�
�����C�e���V�����肾�B
�R���p�C�����X��������Ă����Ȃ���Ȃ��ˁB
���`�AAVX512�������낻�����`�B
Skylake��Xeon���������ƁB
570 �F,,�E�L�́M�E,,�j��-�������F2015/02/05(��) 23:33:09.28 ID:UC61hctc
>>568
���H
TSMC�͍Ő�[�v���Z�X�����グ�Ă�����ۂɌڋq���ʎY����܂Ń��O�����邩��
Intel�̂����ʎY�J�n�i�����i�̗ʎY�j�ƒ�`���Ⴄ�B
���H
TSMC�͍Ő�[�v���Z�X�����グ�Ă�����ۂɌڋq���ʎY����܂Ń��O�����邩��
Intel�̂����ʎY�J�n�i�����i�̗ʎY�j�ƒ�`���Ⴄ�B
571 �FSocket774�F2015/02/05(��) 23:36:24.84 ID:mkbmETf9
AVX2�ȍ~����AVX�ɑΉ����Ă�\�t�g�Ȃ瑁���Ȃ��Ă����́H
573 �FSocket774�F2015/02/05(��) 23:40:15.23 ID:WSCKXfoL
����Ivy�ł�����
�ǂ�������Ȑ��\�オ��Ȃ�����w
�ǂ�������Ȑ��\�オ��Ȃ�����w
GF���Ď��Ɛ��藧���Ă�̂�?
�I�C���}�l�[�����������̂̂����Ƃ��O���ɏ��Ȃ��C���[�W�Ȃ�
�I�C���}�l�[�����������̂̂����Ƃ��O���ɏ��Ȃ��C���[�W�Ȃ�
575 �F,,�E�L�́M�E,,�j��-�������F2015/02/05(��) 23:41:23.70 ID:UC61hctc
>>572
��Ȃ������Ȃ�
TSMC��GF�̎���14nm/16nm�͎���20nm + FinFET��Intel��14nm�Ɠ����ł͂Ȃ��B
22nm�ɖт����������x���B
Intel��32nm�̐��i���������̂���2010�N�����ǁA���̎����ɂ͊���TSMC��40nm�g����
���i�o�Ă��͂�����B
http://news.mynavi.jp/news/2008/03/24/019/
��Ȃ������Ȃ�
TSMC��GF�̎���14nm/16nm�͎���20nm + FinFET��Intel��14nm�Ɠ����ł͂Ȃ��B
22nm�ɖт����������x���B
Intel��32nm�̐��i���������̂���2010�N�����ǁA���̎����ɂ͊���TSMC��40nm�g����
���i�o�Ă��͂�����B
http://news.mynavi.jp/news/2008/03/24/019/
576 �F,,�E�L�́M�E,,�j��-�������F2015/02/05(��) 23:43:34.13 ID:UC61hctc
���ꂾ�ˁB�ނ���TSMC��1����ȏ㍷�����Ă��������Ă���H
http://pc.watch.impress.co.jp/docs/column/kaigai/20090617_294281.html
http://pc.watch.impress.co.jp/docs/column/kaigai/20090617_294281.html
TSMC��28nm��Intel��32nm���������ɍ̗p���i���o���ł���
���ꂪ20nm�����Intel��14nm�Ɠ������炢�ɂȂ��Ă��܂�
14nm(���^���s�b�`�������Ƒ����ɏk���������)�͂��o��́H�Ƃ����Ȃ̂ł�
���Ԃ��ƂȂ��ꐢ��ȏ�̍������� �Ȃ�Ă̂͂ނ���ߔN�����Ȃ����A�Ƃ�����������
���ꂪ20nm�����Intel��14nm�Ɠ������炢�ɂȂ��Ă��܂�
14nm(���^���s�b�`�������Ƒ����ɏk���������)�͂��o��́H�Ƃ����Ȃ̂ł�
���Ԃ��ƂȂ��ꐢ��ȏ�̍������� �Ȃ�Ă̂͂ނ���ߔN�����Ȃ����A�Ƃ�����������
578 �FSocket774�F2015/02/05(��) 23:48:08.45 ID:mkbmETf9
>>575
�C���e����22nm��FinFET�ɂ�鐫�\���㕪��������ŃT�C�Y���猾���ƃT�o�ǂ����ɂȂ��Ă��Ǝv���B
�[�����́���nm���ĉ�����ɂ��ċ���̂��������f�X��B
�C���e����22nm��FinFET�ɂ�鐫�\���㕪��������ŃT�C�Y���猾���ƃT�o�ǂ����ɂȂ��Ă��Ǝv���B
�[�����́���nm���ĉ�����ɂ��ċ���̂��������f�X��B
���̏�ԂŃv���Z�X���Ԃ�ARM�̍U����������ƂɂȂ肻��
14nm��8�w�ō�����Ƃ���1�w������̃I�[�o�[���C���x��2nm�ȉ�����
ASML�̑��u�����Ă݂�����
ASML�̑��u�����Ă݂�����
���܂ł�TSMC��Intel���x��Ȃ����Intel�������k�������v���Z�X��ł��Ă�����
16/14nm����Ɋւ��Ă�Intel���x���Intel���f�J�����̂���邱�ƂɂȂ��Ă��܂���
16/14nm����Ɋւ��Ă�Intel���x���Intel���f�J�����̂���邱�ƂɂȂ��Ă��܂���
>>581
�d�ˍ��킹���x�����̓j�R�����D��Ă��Ȃ����������H
�m���A�W��2nm�Ŋ撣���1nm���Ƃ�
�O�͔��X���炢�������ۂ����A����1st����3rd���炢���S��ASML�Ȃ̂��Ȃ�
�d�ˍ��킹���x�����̓j�R�����D��Ă��Ȃ����������H
�m���A�W��2nm�Ŋ撣���1nm���Ƃ�
�O�͔��X���炢�������ۂ����A����1st����3rd���炢���S��ASML�Ȃ̂��Ȃ�
2nm�Ƃ�2nm�Ƃ��A�l�ރ}�W���������륥�
�ʎ��ŕ������C���̐U�������ŃY�������Ȑ��x���
���ہA���ɐ����@�B���̂�������U���̉e���������ł��Ȃ����x�����Ǝv���̂����ǂ��Ă���̂��낤
�l�Ԃ̓f�������ɂ�鐅���C
�~�N�����x���̔畆�̔�U
�ǂ�����ĊǗ����Ă낤
�~�N�����x���̔畆�̔�U
�ǂ�����ĊǗ����Ă낤
�f�B�X�N�A���C�̑O�ő吺���o���ƃp�t�H�[�}���X���ቺ����������v���o����
TSMC�̗ʎY���Ă����Ă��A�P�P�O�O���~��FPGA��A
GPU���[�J�[�̎���`�b�v�̐��Y���ł��邠���肪�ʎY�J�n�ł���H
GPU���[�J�[�̎���`�b�v�̐��Y���ł��邠���肪�ʎY�J�n�ł���H
590 �FSocket774�F2015/02/06(��) 01:13:17.66 ID:to5vwjzE
Intel�l�������l�ނ̖������J����B��_
�S�l�ނ�Intel�l�̉��ɕ�����Intel�l�����𐒔q��
Intel�l�ɑS�Ă������ׂ��ł���
Intel�l���I�I�I�I�I
�S�l�ނ�Intel�l�̉��ɕ�����Intel�l�����𐒔q��
Intel�l�ɑS�Ă������ׂ��ł���
Intel�l���I�I�I�I�I
�U���u�����s�\�����������̑����g���l���������Ƃ�����ς������炵���ȁB
����闝�R��˂��~�߂��炠��Ȃɗ��ꂽ�ԓ��������A�Ƃ�
����闝�R��˂��~�߂��炠��Ȃɗ��ꂽ�ԓ��������A�Ƃ�
>>484
OS��\�t�g���ɕύX��������^�C�v�̊v�V�͕��y���Ȃ���
L3�L���b�V���Ƃ�L4�L���b�V������e�ʉ����邩
���C�����������ۂ��ƒu�������邩�̂ǂ���������
OS��\�t�g���ɕύX��������^�C�v�̊v�V�͕��y���Ȃ���
L3�L���b�V���Ƃ�L4�L���b�V������e�ʉ����邩
���C�����������ۂ��ƒu�������邩�̂ǂ���������
>>592
OS�̑Ή������ŏZ�ނȂ��C�ɕ��y�����B
���̏ꍇ���L�ш惁������GPU�̃��[�J����������CPU������L���b�V���s�̈�Ƃ��ăA�N�Z�X�\�ɂȂ邯�ǂ��̕��������Ǝv����B
�_���I�ɂ�dGPU��CPU�ƈ�̂ɂȂ��������ł������̊Ԃ��q���o�X��PCI-E����CPU�����o�X�ɕς���Č��I�ɑ����Ȃ邾���B
���L�ш�Ƃ����Ă�L3�ɂ͗���CPU���猩���炠�܂�����������̂ł͂Ȃ��B�Ȃ��GPU��CPU�̃������o�X�����ĕ����A�N�Z�X�\�ɂ��ăg�[�^���̃������ш���L������������I�Ȑ��\���P�ɂȂ�B
������GPU�ɋ��Ȃ��Ƃ�������̂ł͂Ȃ�GPU��CPU�����ꂼ��ɓ��ӂȕ���S���ĕ��s���ē����̂���Ԍ������ǂ��B
OS�̑Ή������ŏZ�ނȂ��C�ɕ��y�����B
���̏ꍇ���L�ш惁������GPU�̃��[�J����������CPU������L���b�V���s�̈�Ƃ��ăA�N�Z�X�\�ɂȂ邯�ǂ��̕��������Ǝv����B
�_���I�ɂ�dGPU��CPU�ƈ�̂ɂȂ��������ł������̊Ԃ��q���o�X��PCI-E����CPU�����o�X�ɕς���Č��I�ɑ����Ȃ邾���B
���L�ш�Ƃ����Ă�L3�ɂ͗���CPU���猩���炠�܂�����������̂ł͂Ȃ��B�Ȃ��GPU��CPU�̃������o�X�����ĕ����A�N�Z�X�\�ɂ��ăg�[�^���̃������ш���L������������I�Ȑ��\���P�ɂȂ�B
������GPU�ɋ��Ȃ��Ƃ�������̂ł͂Ȃ�GPU��CPU�����ꂼ��ɓ��ӂȕ���S���ĕ��s���ē����̂���Ԍ������ǂ��B
OS�̑Ή����K�v�Ȃ̂�CPU��GPU�̒ʐM�����C���������o�R�ōs���̂ł͂Ȃ�CPU������GPU�̃��[�J�����������A�N�Z�X����悤�ɕύX���邱�ƁB
�x�����C���������ւ̃A�N�Z�X���s�v�ƂȂ肱�ꂾ���Ő��{�����Ȃ�B
�x�����C���������ւ̃A�N�Z�X���s�v�ƂȂ肱�ꂾ���Ő��{�����Ȃ�B
���ł�2GB-DIMM��4GB-DIMM�̃f���A���h����4GB�f���A���ш�E2GB�V���O���ш��
�t���b�N�X���[�h�ɂȂ�킯�����A����OS�ł͂��̃A�h���X�͈͖��̑ш捷��F������
�y�[�W�̊��蓖�ĕ����œK�����Ă���͂��Ȃ��̂���
�t���b�N�X���[�h�ɂȂ�킯�����A����OS�ł͂��̃A�h���X�͈͖��̑ш捷��F������
�y�[�W�̊��蓖�ĕ����œK�����Ă���͂��Ȃ��̂���
>>595
����ȁB�X�Q�[�C�ɂȂ�
����ȁB�X�Q�[�C�ɂȂ�
>>595
OS�͉����ӎ����ĂȂ���B
�P�ɉ��ʔԒn���珇�ԂɎg���Ďg���I�������ė��p���n�߂邾���B
�N�����ɓǂݍ��܂��OS�Ə풓�T�[�r�X�A�g�p�p�x�̍����A�v���͌��ʂƂ��č����ȉ��ʔԒn�𗘗p���A���g�p��͒x�����ʔԒn�ɏW������B
����Ŗ��Ȃ�������ɑ�͂���Ȃ��B
���������V���O���`���l���Œx���������Ƃ����Ă����^�≺�ʋ@���CPU�̃������Ɣ�ׂ�Βx���ǂ��납�������炢�Ȃ̂ł�����ӎ����Ȃ��Ă�����Ɏx��͂Ȃ��B
OS�͉����ӎ����ĂȂ���B
�P�ɉ��ʔԒn���珇�ԂɎg���Ďg���I�������ė��p���n�߂邾���B
�N�����ɓǂݍ��܂��OS�Ə풓�T�[�r�X�A�g�p�p�x�̍����A�v���͌��ʂƂ��č����ȉ��ʔԒn�𗘗p���A���g�p��͒x�����ʔԒn�ɏW������B
����Ŗ��Ȃ�������ɑ�͂���Ȃ��B
���������V���O���`���l���Œx���������Ƃ����Ă����^�≺�ʋ@���CPU�̃������Ɣ�ׂ�Βx���ǂ��납�������炢�Ȃ̂ł�����ӎ����Ȃ��Ă�����Ɏx��͂Ȃ��B
�@�@�@�@�@�@�@�@�@�@ 2013�N�@�@�@2014�N
�@�@�@�m�[�gPC�@ 1.694����@ 1.755����
�@�@�@�^�u���b�g�@1.963����@ 1.920����
�X�}�[�g�t�H���@9.272����@11.669����
ttp://press.trendforce.com/press/20150128-1821.html
ttp://press.trendforce.com/press/20150203-1830.html
ttp://press.trendforce.com/press/20150120-1806.html
�L�[�{�[�h������Ή�ʂ��^�b�`�p�l���ł��m�[�gPC�H
�@�@�@�m�[�gPC�@ 1.694����@ 1.755����
�@�@�@�^�u���b�g�@1.963����@ 1.920����
�X�}�[�g�t�H���@9.272����@11.669����
ttp://press.trendforce.com/press/20150128-1821.html
ttp://press.trendforce.com/press/20150203-1830.html
ttp://press.trendforce.com/press/20150120-1806.html
�L�[�{�[�h������Ή�ʂ��^�b�`�p�l���ł��m�[�gPC�H
�R���p�N�V�������ɉ��ʃA�h���X�ɏW�߂�Ⴂ���̂�
>>593
GPU�قǐ��l�E�����ڂƂ�������₷���w�W���Ȃ������ŁACPU�ɂƂ��Ă����ʂɔ��������B
iGPU�ɁiHBM�I�ȁj�L�ш惁������Ɛ肳����Ȃ�AMD�Ɠ����Q�ނ��ƂɂȂ�B
GPU�قǐ��l�E�����ڂƂ�������₷���w�W���Ȃ������ŁACPU�ɂƂ��Ă����ʂɔ��������B
iGPU�ɁiHBM�I�ȁj�L�ш惁������Ɛ肳����Ȃ�AMD�Ɠ����Q�ނ��ƂɂȂ�B
���C�����������p����\��������̂�CPU�����ł͂Ȃ��̂ɁA���ʂ��珇�ԂɂȂ�ďo�����Ȃ�����B
�����R��������I/O�����DMA�v���ƒ��⓮�삵�Ȃ���n�[�h�I�Ɍ��肵�Ă���B
�_���A�h���X�ƕ����A�h���X�̑Ή���OS�͉���͂ł��Ȃ��B
�����R��������I/O�����DMA�v���ƒ��⓮�삵�Ȃ���n�[�h�I�Ɍ��肵�Ă���B
�_���A�h���X�ƕ����A�h���X�̑Ή���OS�͉���͂ł��Ȃ��B
>>601
MMU��OS���Ǘ����Ă����
MMU��OS���Ǘ����Ă����
Core i�n��MMU�̃e�[�u���A���P�[�V�����̃A���S���Y�����Č��J����Ă�������?
�܂����������Ƃ���ŁA���z�L���̎��ۂ̕����A�h���X�Ȃ�Ăǂ��ɂ��ł��Ȃ����c
�܂����������Ƃ���ŁA���z�L���̎��ۂ̕����A�h���X�Ȃ�Ăǂ��ɂ��ł��Ȃ����c
�`���I�ȃ������\���ɏ]���Ă�����A�v���P�[�V����������Ă�킯��
�X�p�R���Ƃ���p�Q�[���@����Ȃ�����`���I�ȃ������\���ɏ]�����ق����������
�X�p�R���Ƃ���p�Q�[���@����Ȃ�����`���I�ȃ������\���ɏ]�����ق����������
>598�@�⑫
PC�͂킩��Ȃ����ǁAPC�Ɗ֘A�������P�̃��j�^
�@2013�N 1.44����@�@2014�N 1.336����
�@ttp://press.trendforce.com/press/20150129-1825.html
PC�͂킩��Ȃ����ǁAPC�Ɗ֘A�������P�̃��j�^
�@2013�N 1.44����@�@2014�N 1.336����
�@ttp://press.trendforce.com/press/20150129-1825.html
>>602
OS���Ǘ����Ă���̂�MMU�̘_���A�h���X(�Z�O�����g�A�y�[�W���O�����Ȃǂ�����)�B
���ۂ̃������̕����A�h���X�Ƃ͕ʂ̂��́B
���z�L�����ł́A�X���b�v����������x�ɉ����Ɋ��蓖�Ă��邩�͕�����Ȃ��B
�Ή��y�[�W�e�[�u���̓n�[�h�E�F�A���x���Ő��䂳���B
OS���Ǘ����Ă���̂�MMU�̘_���A�h���X(�Z�O�����g�A�y�[�W���O�����Ȃǂ�����)�B
���ۂ̃������̕����A�h���X�Ƃ͕ʂ̂��́B
���z�L�����ł́A�X���b�v����������x�ɉ����Ɋ��蓖�Ă��邩�͕�����Ȃ��B
�Ή��y�[�W�e�[�u���̓n�[�h�E�F�A���x���Ő��䂳���B
�}���`�R�A��10�N�����Ă悤�₭�g�����Ȃ���悤�ɂȂ����킯��
�L�ш惁�������g�����Ȃ���̂�2025�N�����肩��
�L�ш惁�������g�����Ȃ���̂�2025�N�����肩��
>>608
�����̏�ł́A���z�L����OS(�\�t�g�E�F�A)�����ł������ł���B
�܂��A���z�L���ɕK�{�̊O���L����OS�Ȃ��ł͓��삳����͓̂���B
�����AMMU�Ƃ����n�[�h�E�F�A������CPU�ŁA�����A�h���X�̊Ǘ���OS(�\�t�g�E�F�A)�ōs�Ȃ����ƂɈӖ��͂Ȃ��B
�O��GPU��ς�ł��Ȃ���A�S�Ă̕`�揈����CPU�ōs�Ȃ��悤�Ȃ��̂Ńi���Z���X���낤�B
�����̏�ł́A���z�L����OS(�\�t�g�E�F�A)�����ł������ł���B
�܂��A���z�L���ɕK�{�̊O���L����OS�Ȃ��ł͓��삳����͓̂���B
�����AMMU�Ƃ����n�[�h�E�F�A������CPU�ŁA�����A�h���X�̊Ǘ���OS(�\�t�g�E�F�A)�ōs�Ȃ����ƂɈӖ��͂Ȃ��B
�O��GPU��ς�ł��Ȃ���A�S�Ă̕`�揈����CPU�ōs�Ȃ��悤�Ȃ��̂Ńi���Z���X���낤�B
���z�L���̓n�[�h�E�F�A�x���̉���OS���Ǘ����Ă�
�܂������Ǘ����Ċ�������
�܂������Ǘ����Ċ�������
���̃X���L�т��������^
>>595
iGPU�ɑш���g���Ă��g���Ȃ��Ă��A���܂�C�ɂȂ�Ȃ��悤��
���[�U�[�A�A�v���P�[�V�������唼���Ƃ�������l���āA
��������ɒl���郊�^�[���͖R������Ȃ����B
�Ɩ��p�ŏ������e�I�Ƀ��^�[�����\���ɂ���悤�ȏꍇ��
���������h�����͂��Ȃ����낤��
iGPU�ɑш���g���Ă��g���Ȃ��Ă��A���܂�C�ɂȂ�Ȃ��悤��
���[�U�[�A�A�v���P�[�V�������唼���Ƃ�������l���āA
��������ɒl���郊�^�[���͖R������Ȃ����B
�Ɩ��p�ŏ������e�I�Ƀ��^�[�����\���ɂ���悤�ȏꍇ��
���������h�����͂��Ȃ����낤��
>>595
Linux�̃\�[�X�R�[�h��K������A�ǂ��Ȃ��Ă邩�������Ȃ����B
���z�L�����ǂ�������Č�����Ȃ�A�I�[�v���\�[�X��Linux���ǂ�Ȃ��Ƃ����Ă��邩
���炢�͒��ׂĂ��邾��
Linux�̃\�[�X�R�[�h��K������A�ǂ��Ȃ��Ă邩�������Ȃ����B
���z�L�����ǂ�������Č�����Ȃ�A�I�[�v���\�[�X��Linux���ǂ�Ȃ��Ƃ����Ă��邩
���炢�͒��ׂĂ��邾��
�������R���s���[�^�a���̉\�����߂����q1���̋ɔ��V���R���n�ޗ��uSilicene�v - GIGAZINE
http://gigazine.net/news/20150206-silicene/
http://gigazine.net/news/20150206-silicene/
���܂���߂���ڂ����Ȃ�
����ĕt���Ă����Ȃ����ǁA
�v��GPU��L�ш惁������CPU����߂��Ȃ����i�A�N�Z�X���Ղ��Ȃ����H�j�Ƃ��Ă��A
OS�̐��\�ɍ��E�����\����������Ă��ƁH
�v���O���}��R���p�C�������̓w�͂ł͂Ȃ����Ă��ƂȂ̂��ȁH
����ĕt���Ă����Ȃ����ǁA
�v��GPU��L�ш惁������CPU����߂��Ȃ����i�A�N�Z�X���Ղ��Ȃ����H�j�Ƃ��Ă��A
OS�̐��\�ɍ��E�����\����������Ă��ƁH
�v���O���}��R���p�C�������̓w�͂ł͂Ȃ����Ă��ƂȂ̂��ȁH
���Ԃ�uMS�̂��d���v�ōςނ͂�
>>614
���A�Ȃ�ʼn��c �g�����ł����Ȃ���Ŋ��ق��Ă�
�������l���Ă݂�ɁA�Ⴆ���A���P�[�g����悤�Ƃ��Ă郁�����́A�ʂ�����
�ė��p�������̂��iCPU�L���b�V�������Ȃ̂Œᑬ�������ŗǂ��j�A
�X�g���[��������1���g�킸��e�ʂȂ̂��i�L�ш惁���������j�A
�����1��̃y�[�W���蓖�Ăōς܂��悤�ɃA���P�[�g���ɔ��f�ł��Ȃ��Ⴂ���Ȃ��킯��
�A�v�����Ō݊����ɖ��Ȃ����@�Ńq���g�����������A���P�[�g���ɉ�����A�Ƃ�������ɂȂ��Ă����̂���
���A�Ȃ�ʼn��c �g�����ł����Ȃ���Ŋ��ق��Ă�
�������l���Ă݂�ɁA�Ⴆ���A���P�[�g����悤�Ƃ��Ă郁�����́A�ʂ�����
�ė��p�������̂��iCPU�L���b�V�������Ȃ̂Œᑬ�������ŗǂ��j�A
�X�g���[��������1���g�킸��e�ʂȂ̂��i�L�ш惁���������j�A
�����1��̃y�[�W���蓖�Ăōς܂��悤�ɃA���P�[�g���ɔ��f�ł��Ȃ��Ⴂ���Ȃ��킯��
�A�v�����Ō݊����ɖ��Ȃ����@�Ńq���g�����������A���P�[�g���ɉ�����A�Ƃ�������ɂȂ��Ă����̂���
������L4�L���b�V���ɂȂ邩���C���������ۂ��ƒu�������邩�����Ȃ����Ă�
�����̃\�t�g�E�F�A�E�J��������̈ڍs���ȒP�Ȃ̂́A
����L4�������̓��C���������u����������
����L4�������̓��C���������u����������
�ʂɂǂ��ł��������
Haswell��128MB�̍�����e�ʃL���b�V���ڂ��Ă��AGPU�x���`�����������Ȃ��������ʼn��ɂ����b�������������
��������intel��L3�܂ł������\�߂��āA���ɉ����ڂ����Ƃ���ő債���e���Ȃ���
���Ȃ��Ƃ�CPU���\�ɂ͉��̉e�����Ȃ����낤��
Haswell��128MB�̍�����e�ʃL���b�V���ڂ��Ă��AGPU�x���`�����������Ȃ��������ʼn��ɂ����b�������������
��������intel��L3�܂ł������\�߂��āA���ɉ����ڂ����Ƃ���ő債���e���Ȃ���
���Ȃ��Ƃ�CPU���\�ɂ͉��̉e�����Ȃ����낤��
2�`3%���x�Ȃ�܂�����75%�������Ȃ����̂������Ƃ͌�����
624 �F,,�E�L�́M�E,,�j��-�������F2015/02/07(�y) 03:07:16.05 ID:sdijzNBq
Intel's SoFIA - Can It Bring Success In Phones?
http://seekingalpha.com/article/2893296-intels-sofia-can-it-bring-success-in-phones
3�y�[�W�ڈȍ~�͉���o�^���K�v�����ǂȂ��Ȃ��ǂ݉����̂���L��
http://seekingalpha.com/article/2893296-intels-sofia-can-it-bring-success-in-phones
3�y�[�W�ڈȍ~�͉���o�^���K�v�����ǂȂ��Ȃ��ǂ݉����̂���L��
625 �F,,�E�L�́M�E,,�j��-�������F2015/02/07(�y) 03:12:18.63 ID:sdijzNBq
����14nm CherryTrail�̃x���`�}�[�N�X�R�A�����[�N���ꂽ�Ƃ����L���B
http://www.fool.com/investing/general/2015/02/06/the-first-benchmarks-of-intel-corporations-14-nano.aspx
�܂��A���\�͂���Ȃɑ傫���͕ς��Ȃ��ˁB
���͏���d�͂��ǂ��܂ŗ����Ă邩�B
�X�^���o�C�Ȃ�d�C�H��Ȃ����ǂȂɂ����瓮�����Ă�Ƃ����o�b�e���[�s����B
http://www.fool.com/investing/general/2015/02/06/the-first-benchmarks-of-intel-corporations-14-nano.aspx
�܂��A���\�͂���Ȃɑ傫���͕ς��Ȃ��ˁB
���͏���d�͂��ǂ��܂ŗ����Ă邩�B
�X�^���o�C�Ȃ�d�C�H��Ȃ����ǂȂɂ����瓮�����Ă�Ƃ����o�b�e���[�s����B
phi�ɏ�邾�낤���A���\��萔���d�����Ă�̂��ȁ[�H�H
�����^�u��SoFIA�Ԃɍ��킸�܂��o��Airmont�ōs���낤��
Phi�G���Ă݂����Ȃ��B
���������ɗ����Ă��Ȃ����Ȃ��B
���������ɗ����Ă��Ȃ����Ȃ��B
phi�͍ŏ����疯���i�����
�ӂ��ɔ����Ă��
�ӂ��ɔ����Ă��
�ǂ��Ŕ����Ă�H�H
����ɍ�����`�B
20�����炢����ł���H
����ɍ�����`�B
20�����炢����ł���H
�@�l�����ɋ����V���b�v���A�K����IT���ЂŔ������
�������PC�V���b�v�Ŕ����邭�炢�ɐg�߂ɂȂ��Ăق����Ȃ��B
>>631
���A�����Ă���Ă��肪�Ƃ��B
���A�����Ă���Ă��肪�Ƃ��B
>>775
��������
2005�N3���̋L�������炾������10�N���炢�O�Ƃ������̋L���͓������Ă�
http://www.itmedia.co.jp/news/articles/0503/11/news084.html
�u2007�N�ɂ͈�C��3000��ɂ܂ŗ������ނƗ\�����Ă���v
��������
2005�N3���̋L�������炾������10�N���炢�O�Ƃ������̋L���͓������Ă�
http://www.itmedia.co.jp/news/articles/0503/11/news084.html
�u2007�N�ɂ͈�C��3000��ɂ܂ŗ������ނƗ\�����Ă���v
�딚����orz
636 �F���@�Ɏ����ݓ��X�p�C�E�n���E���N�U�F2015/02/07(�y) 13:29:19.22 ID:hY3wqcBx
�X�p�C������悤�Ƃ��鎩���}���A�ݓ��ɋ�������Ă܂��B
�閧�ی�@�����Δh�ɋ�������鎩���}�c���@�@�����ƌ���������̏��X�p�C�h�~�@
http://uni.2ch.net/test/read.cgi/newsplus/1386041789/
http://megalodon.jp/2014-0730-0837-15/ameblo.jp/okb-34/archive24-201312.html (�u���O)
�u�@�ĂɎ^�������炠�Ȃ��̂��q�l�̓^�_�ł͂����܂����v�@�@�@ ���@���@���I�I�I�I
�u����閧�ی�@�ĂɎ^�������Ȃ���Ȃ��́A����̑I���ŗ��I����ł��傤�v
�������炭�A�n�������I�����͂��Ȃ��Ƃ��������B
�u��N���c���ɂ�������قǂ̋���������Ƃ������Ƃ͊������͂��ߓ}�����̕��X��
���X�ǂ̂悤�Ȗڂɑ����Ă����邱�Ƃł��傤���B �v
�������Ă�͍̂ݓ���
��O���ȐE���ɂ͋A�������ݓ��؍�����N�l�������A����閧�ی�@�Ă͔ނ���̂Ă�l������
http://awabi.2ch.net/test/read.cgi/news4plus/1386159045/
�A�����N�l�X�p�C�ɂ��H���R�����̗�
�y����z��㍑�ŋǕ����Ŗ���������ߕ߁A���N���A�ɐŖ������������[�N�c���s�{�x
http://hayabusa3.2ch.net/test/read.cgi/news/1414066544/ �@�@
�@���{�A����閧�ی�@�ɂ���
�u�H�����e�����X�g�A�X�p�C������ŁA�����͑S���W�Ȃ��B�v
http://headlines.yahoo.co.jp/hl?a=20141119-00000002-mai-pol �@/
�閧�ی�@�����Δh�ɋ�������鎩���}�c���@�@�����ƌ���������̏��X�p�C�h�~�@
http://uni.2ch.net/test/read.cgi/newsplus/1386041789/
http://megalodon.jp/2014-0730-0837-15/ameblo.jp/okb-34/archive24-201312.html (�u���O)
�u�@�ĂɎ^�������炠�Ȃ��̂��q�l�̓^�_�ł͂����܂����v�@�@�@ ���@���@���I�I�I�I
�u����閧�ی�@�ĂɎ^�������Ȃ���Ȃ��́A����̑I���ŗ��I����ł��傤�v
�������炭�A�n�������I�����͂��Ȃ��Ƃ��������B
�u��N���c���ɂ�������قǂ̋���������Ƃ������Ƃ͊������͂��ߓ}�����̕��X��
���X�ǂ̂悤�Ȗڂɑ����Ă����邱�Ƃł��傤���B �v
�������Ă�͍̂ݓ���
��O���ȐE���ɂ͋A�������ݓ��؍�����N�l�������A����閧�ی�@�Ă͔ނ���̂Ă�l������
http://awabi.2ch.net/test/read.cgi/news4plus/1386159045/
�A�����N�l�X�p�C�ɂ��H���R�����̗�
�y����z��㍑�ŋǕ����Ŗ���������ߕ߁A���N���A�ɐŖ������������[�N�c���s�{�x
http://hayabusa3.2ch.net/test/read.cgi/news/1414066544/ �@�@
�@���{�A����閧�ی�@�ɂ���
�u�H�����e�����X�g�A�X�p�C������ŁA�����͑S���W�Ȃ��B�v
http://headlines.yahoo.co.jp/hl?a=20141119-00000002-mai-pol �@/
����L���b�V�����L���Ȃ̂�POWER�A�[�L�e�N�`�������Ƃ�������
�z�肵�Ă郏�[�N���[�h���Ⴄ�����B
�Ƃ茾�A�ĂŎ������邵���]���Ȃ�2ch�{�����e�B�A�S�~�K�L��������w
P2P�g���܂���̕n�R����K�L���������������̔ޏ�����L�������银�傗���������������n�R������32bit�����g���Ȃ��}�k�P��������������������
�ʃX���ŃG���Q500�{�ȏ㎝���Ă�Ƃ��ق����Ă����ȃR�C�c���������������������������C�����������邗��������������������������������
���O�̂悤�ȃS�~�ɗF�B�Ȃ�ďo�����ˁ[���낗��������������������Ȃ�G���Q��D��32bit��D�����m�}�l���N��������������������
�����̎��͉��������Ȃ��N�\�r�r���w�^�����S�Ґl���̈���ȃS�~�N�Y����������������������������
����ł����l�̐^�������o���Ȃ��r���̂����Ɏ����͂܂Ƃ��Ƃ��v������ł�n���������^��������������������������������������������������������������
2ch�̃L�`�K�C���l�����ނ������������̃A�z�����������������ꂾ�������������������������_�Z�F����������������Ȃ��S���X���C������������������������������������������������
P2P�g���܂���̕n�R����K�L���������������̔ޏ�����L�������银�傗���������������n�R������32bit�����g���Ȃ��}�k�P��������������������
�ʃX���ŃG���Q500�{�ȏ㎝���Ă�Ƃ��ق����Ă����ȃR�C�c���������������������������C�����������邗��������������������������������
���O�̂悤�ȃS�~�ɗF�B�Ȃ�ďo�����ˁ[���낗��������������������Ȃ�G���Q��D��32bit��D�����m�}�l���N��������������������
�����̎��͉��������Ȃ��N�\�r�r���w�^�����S�Ґl���̈���ȃS�~�N�Y����������������������������
����ł����l�̐^�������o���Ȃ��r���̂����Ɏ����͂܂Ƃ��Ƃ��v������ł�n���������^��������������������������������������������������������������
2ch�̃L�`�K�C���l�����ނ������������̃A�z�����������������ꂾ�������������������������_�Z�F����������������Ȃ��S���X���C������������������������������������������������
���Ȃ݂ɂ���,,�E�L�́M�E,,�j��-�������Ƃ��������E�S�~��2ch�{�����e�B�A�Ȍ���40���i�����̕����͎����Ŗ\�I�j�炵��������������������������������������
�L�`�K�C�S�~�K�L�S���̃X�����痣���ƌh��A�c�q�ɂ��h�ꂗ�����������������������������{�����e�B�A������Ȃ�����������������������������
���F2ch�ɒ���t���Ă�S�~���ጎ��������Ȃ���������������������������������������������
���É��œ����Ă�ݒ�Ȃ̂ɖ��É��ɏڂ����l���w�E���Ă݂�Ɖ��������Ԃ��������o�������悾���̃w�^��������������������������������
�{�E���v���O���}�[�̐l�Ɏw�E�����ƊԈ�����m���Ђ��炩���Č�����p�m�炸�̈�����������������������������������������������������������
���̃f�u�c�q���ۂɂ�2ch����Ŏ������܂����2ch�{�����e�B�A���Ă����Ȃ�������������������������������������
�N�����̎����S�~�c�q�������Ă�Ȃ�Ďv���ĂȂ�����������������������������������������������������
�����N����N������ɒ���t���Ă�2ch�{�����e�B�A����Ȃ�������ĂȂ��Ƃ��������炨�O�ǂ��₵���ڂ����S�~�Ȃ���Ęb�ɂȂ邵�Ȃ�������������������������������������������������������
���ꂵ����鎖�ˁ[�̂��悗�����������������������������l�������ꂗ�����������������m�������m��2ch�łЂ��炩���ėD�z���_�T��������������������������
���Ęb�ɂȂ��ȁH������������������������������������������������������
�L�`�K�C�S�~�K�L�S���̃X�����痣���ƌh��A�c�q�ɂ��h�ꂗ�����������������������������{�����e�B�A������Ȃ�����������������������������
���F2ch�ɒ���t���Ă�S�~���ጎ��������Ȃ���������������������������������������������
���É��œ����Ă�ݒ�Ȃ̂ɖ��É��ɏڂ����l���w�E���Ă݂�Ɖ��������Ԃ��������o�������悾���̃w�^��������������������������������
�{�E���v���O���}�[�̐l�Ɏw�E�����ƊԈ�����m���Ђ��炩���Č�����p�m�炸�̈�����������������������������������������������������������
���̃f�u�c�q���ۂɂ�2ch����Ŏ������܂����2ch�{�����e�B�A���Ă����Ȃ�������������������������������������
�N�����̎����S�~�c�q�������Ă�Ȃ�Ďv���ĂȂ�����������������������������������������������������
�����N����N������ɒ���t���Ă�2ch�{�����e�B�A����Ȃ�������ĂȂ��Ƃ��������炨�O�ǂ��₵���ڂ����S�~�Ȃ���Ęb�ɂȂ邵�Ȃ�������������������������������������������������������
���ꂵ����鎖�ˁ[�̂��悗�����������������������������l�������ꂗ�����������������m�������m��2ch�łЂ��炩���ėD�z���_�T��������������������������
���Ęb�ɂȂ��ȁH������������������������������������������������������
�[��
���܂�ɂ����˂����ă|�J�[���ĂȂ��
���������ƌ����������[�A�̖@���Ŕ����Ɖ��ǂ����ǂ��ꂪ�@��
�c�q���`�l�c�ɂ���
�c�q����AMD�ɏA�E�������Ă��ƁH
���������킫��ˁ[���낗
�����ēD�D�ɏ��킯�ˁ[�����
�A�C2�N�ڂ̃C���e���]�c�В���2015�N�̐헪��
http://pc.watch.impress.co.jp/docs/topic/feature/20150210_687606.html
http://pc.watch.impress.co.jp/docs/topic/feature/20150210_687606.html
���{�̃C���e���͂����̉c�Ƌ��_�ŁA
�헪�Ȃ�ăA�����J�{�Ђ̂���ꂽ�Ƃ���ɂ��邭�炢����������Ȃ��́H
�헪�Ȃ�ăA�����J�{�Ђ̂���ꂽ�Ƃ���ɂ��邭�炢����������Ȃ��́H
�̔��헪
Intel���炢���ꂪ�����Ă����[�J���q�i���{��Ɓj�̐������̂���B
�ǂ��������狭���Ƃ�������
�ǂ��������狭���Ƃ�������
652 �F,,�E�L�́M�E,,�j��-�������F2015/02/10(��) 19:46:18.66 ID:m74wgqJQ
���������}�g�Ɍ����J���Z���^�[���邱�Ƃ��炢�m���Ă����Ă�������
�J�V�I��V���[�v�̓d��p�v���Z�b�T�̊J������Intel��CPU�̗��j�͎n�܂����̂�����
���{���d������͓̂�����O�ł��傤
�J�V�I��V���[�v�̓d��p�v���Z�b�T�̊J������Intel��CPU�̗��j�͎n�܂����̂�����
���{���d������͓̂�����O�ł��傤
�����ĂȂ�����
CPU�����Đ��i��点�邾��
Intel���i���Ȃ��Ɛ����Ă����Ȃ�����]����������
CPU�����Đ��i��点�邾��
Intel���i���Ȃ��Ɛ����Ă����Ȃ�����]����������
�����̃f�X�N�g�b�v�̒��q����������A�����V����CPU�o���Ă��������B
amd�͊؍����ɓ��{���ꂽ����
���͂ǂ��Ȃ��Ă�̂��m���
���͂ǂ��Ȃ��Ă�̂��m���
PenM���o���N�ŗ�������s���ǂނ��Ƃɂ͒����Ă�B
���̎��ォ��u�ȓd�́I�ȓd�́I�v���Č����Ă��͓̂��{���炢���������B
���̎��ォ��u�ȓd�́I�ȓd�́I�v���Č����Ă��͓̂��{���炢���������B
�d�����ӂŋ��͂��Ă��鍑�����[�J�[�Ƃ����邩�瑽���e���������Ȃ���
658 �F,,�E�L�́M�E,,�j��-�������F2015/02/10(��) 20:30:25.94 ID:m74wgqJQ
>>656
����Centrino���ē��{�s����厲�ɂ����v���b�g�t�H�[����������
PenM�����͂��ɂ����Ȃ葽�������̂ł́B
�I���S�����Ђǂ����������Ƃ������邪�B
����Centrino���ē��{�s����厲�ɂ����v���b�g�t�H�[����������
PenM�����͂��ɂ����Ȃ葽�������̂ł́B
�I���S�����Ђǂ����������Ƃ������邪�B
����ȑO�Ɏ���PC�̃V�F�A���Ⴗ���ăo���N�ŗ����Ƃ������Ȃ��Ƃ��덷�͈̔�
>>659
AMD��Turion�iPenM�̑R�n�j���o���N�ɗ���Ă�̂ɃL������
AMD��Turion�iPenM�̑R�n�j���o���N�ɗ���Ă�̂ɃL������
�挩�̖�������������Ă����b
662 �F,,�E�L�́M�E,,�j��-�������F2015/02/10(��) 23:19:39.45 ID:m74wgqJQ
����
�����Socket754�g���Ă����狌��������̃f�X�N�g�b�v�}�U�[�œ����������
����Ŏ��̐��ォ��̓f�X�N�g�b�v�ƌ݊��̂Ȃ��\�P�b�g�ɂ��Ă��܂����B
�����Socket754�g���Ă����狌��������̃f�X�N�g�b�v�}�U�[�œ����������
����Ŏ��̐��ォ��̓f�X�N�g�b�v�ƌ݊��̂Ȃ��\�P�b�g�ɂ��Ă��܂����B
�ڂ��ڂ��v���Z�X���������E�������Ă��������邯�ǁA����5�N��C���e���͂ǂ��Ȃ��Ă�낤��
�V���ȃu���[�N�X���[�N����̂���
�V���ȃu���[�N�X���[�N����̂���
���������ΐ̂̓o���N��CPU�����Ă�̂����ʂ������ȁB
2015�N02��04��
��3.5�{�����ŏ���d��4����1�̐VCPU�uCortex-A72�v��ARM�����\
http://i.gzn.jp/img/2015/02/04/arm-cortex-a72/00-top_m.jpg
�����̃��[�J�[����ARM���A�O���f����3.5�{�̐��\��
����d�͂��ő�75�����ጸ������VCPU�uCortex-A72�v�\���܂���
Cortex-A72�̓o��ɂ��A�X�}�[�g�t�H����^�u���b�g�������
�����\�����A���ғ����Ԃ��A�b�v�������ł�
Cortex-A72��16nm�v���Z�X��ARMv8-A�A�[�L�e�N�`���̗p��
64�r�b�g�Ɋ��S�Ή����Ȃ���A������32�r�b�g�\�t�g�E�F�A�ւ�
���S�ȉ��ʌ݊������������Ă��܂�
�܂��AARMv8-A��4GB�ȏ�̃������ւ̑Ή���Í����Z�p��
�̗p���Ă���Ƃ̂���
Cortex-A72�͍ő���g��2.5GHz�Ō��s���f����Cortex-A15��
3.5�{�̐��\��B�����A����d�͂�75�����啝�ɒጸ�\�Ƃ̂���
Cortex-A53�Ƒg�ݍ�����������ubig.LITTLE�v�\���Ńp�t�H�[�}���X��
�ȓd�͐��𗼗������܂�
ARM��Cortex-A72�����łȂ����o�C���pGPU�uMali-T880�v�ɂ��Ă�
���\���Ă���A���s���f����Mali-T760�ɔ�ׂăO���t�B�b�N���\��1.8�{�A
40���̏���d�͒ጸ���������Ă���Ƃ̂���
�܂��AMali-T880��10�r�b�gYUV���T�|�[�g
���s��Mali-V550�EMali-DP550�����S�⊮���Ă���120fps��
4K���[�r�[�֑Ή����܂�
http://i.gzn.jp/img/2015/02/04/arm-cortex-a72/a01_m.jpg
ARM��Cortex-A72��Mali-T880�ŁuPremium Mobile Experience
(���i���ȃ��o�C���̌�)�v��ł���Ƃ��Ă���
Qualcomm��NVIDIA�AApple�Ȃǂ̃p�[�g�i�[��Ƃ�CPU�EGPU��
2015�N���ɒ\��
2016�N�ɂ͌��I�ȍ����\���E�ȓd�͉������������X�}�[�g�t�H����
�^�u���b�g�[�������X�Ɠo�ꂵ�Ă������ł�
��3.5�{�����ŏ���d��4����1�̐VCPU�uCortex-A72�v��ARM�����\
http://i.gzn.jp/img/2015/02/04/arm-cortex-a72/00-top_m.jpg
{kind=link}
�����̃��[�J�[����ARM���A�O���f����3.5�{�̐��\��
����d�͂��ő�75�����ጸ������VCPU�uCortex-A72�v�\���܂���
Cortex-A72�̓o��ɂ��A�X�}�[�g�t�H����^�u���b�g�������
�����\�����A���ғ����Ԃ��A�b�v�������ł�
Cortex-A72��16nm�v���Z�X��ARMv8-A�A�[�L�e�N�`���̗p��
64�r�b�g�Ɋ��S�Ή����Ȃ���A������32�r�b�g�\�t�g�E�F�A�ւ�
���S�ȉ��ʌ݊������������Ă��܂�
�܂��AARMv8-A��4GB�ȏ�̃������ւ̑Ή���Í����Z�p��
�̗p���Ă���Ƃ̂���
Cortex-A72�͍ő���g��2.5GHz�Ō��s���f����Cortex-A15��
3.5�{�̐��\��B�����A����d�͂�75�����啝�ɒጸ�\�Ƃ̂���
Cortex-A53�Ƒg�ݍ�����������ubig.LITTLE�v�\���Ńp�t�H�[�}���X��
�ȓd�͐��𗼗������܂�
ARM��Cortex-A72�����łȂ����o�C���pGPU�uMali-T880�v�ɂ��Ă�
���\���Ă���A���s���f����Mali-T760�ɔ�ׂăO���t�B�b�N���\��1.8�{�A
40���̏���d�͒ጸ���������Ă���Ƃ̂���
�܂��AMali-T880��10�r�b�gYUV���T�|�[�g
���s��Mali-V550�EMali-DP550�����S�⊮���Ă���120fps��
4K���[�r�[�֑Ή����܂�
http://i.gzn.jp/img/2015/02/04/arm-cortex-a72/a01_m.jpg
{kind=link}
ARM��Cortex-A72��Mali-T880�ŁuPremium Mobile Experience
(���i���ȃ��o�C���̌�)�v��ł���Ƃ��Ă���
Qualcomm��NVIDIA�AApple�Ȃǂ̃p�[�g�i�[��Ƃ�CPU�EGPU��
2015�N���ɒ\��
2016�N�ɂ͌��I�ȍ����\���E�ȓd�͉������������X�}�[�g�t�H����
�^�u���b�g�[�������X�Ɠo�ꂵ�Ă������ł�
�VOS�uTizen�v��Android�̗ȃR�s�[�Ƃ������|�[�g���o��
http://gigazine.net/news/20150209-samsung-z1-tizen-review/
http://gigazine.net/news/20150209-samsung-z1-tizen-review/
intel�̐i�����]��ɂ��x���̂�5�N�ȓ���arm�ɐ��\�Œǂ������ꂻ������
�����₃���͊��ɒǂ�������Ă��邩��
�����₃���͊��ɒǂ�������Ă��邩��
TSMC���悾���A���̃R�A���N�̘b�����B
�E�T�M�ƃJ�����ȁB
�E�T�M�ƃJ�����ȁB
>>664
�o���N�̔����قƂ�ǖ����Ȃ����̂́A
�������ӔC�@�ŁA�O���̐��i�͗A���҂��ӔC�����ƂɂȂ��������
������A���[�J�[�����ڗA�����邩�A���K�㗝�X���A�����āA
�̔��X�����ɗA�����邱�Ƃ��Ȃ��Ȃ���
�o���N�̔����قƂ�ǖ����Ȃ����̂́A
�������ӔC�@�ŁA�O���̐��i�͗A���҂��ӔC�����ƂɂȂ��������
������A���[�J�[�����ڗA�����邩�A���K�㗝�X���A�����āA
�̔��X�����ɗA�����邱�Ƃ��Ȃ��Ȃ���
Intel Skylake HD Graphics ULT GT2
http://www.sisoftware.eu/rank2011d/show_device.php?q=c9a598d1bfcbaec2e2b1daa3cfaec5a080c88caceb99f888e089ea99b9eca0f4d493c7f5d3b489a495b3c1fcccea83be8fa9c1fcc9ef97aa9bbdd8bd80b096e5d8e0&l=jp
http://www.sisoftware.eu/rank2011d/show_device.php?q=c9a598d1bfcbaec2e2b1daa3cfaec5a080c88caceb99f888e089ea99b9eca0f4d493c7f5d3b489a495b3c1fcccea83be8fa9c1fcc9ef97aa9bbdd8bd80b096e5d8e0&l=jp
384sp,24cu���Ă��Ƃ�16sp/eu���Ă��Ƃ�
����܂�Cortex��J�߂�ƒc�q���������邼
A9�܂ł̓X�}�[�g�f�o�C�X�̋}�g��ƃ��[�A�̖@���ɏ�������Đ����������ǁAA15�ȍ~�͐������������Ȃ��Ȃ���
�t��Atom�̗p�̃^�u���b�g����������悤�ɂȂ�����
�t��Atom�̗p�̃^�u���b�g����������悤�ɂȂ�����
x86�ŋ�
676 �FSocket774�F2015/02/13(��) 13:57:46.61 ID:eeIhKlu/
A15�ȍ~�͋K�͑傫���Ȃ��ēd�͌���������
���q���A���̏Ǝ˂ŃI��/�I�t���ւ��钴�`���X�C�b�`���J�� - PC Watch
http://pc.watch.impress.co.jp/docs/news/20150213_688173.html?ref=rss
http://pc.watch.impress.co.jp/docs/news/20150213_688173.html?ref=rss
���Ă�ARM�R�A�́A�{�Ƃ̂��g�ݍ������X���[���_�C���^�[�Q�b�g�ɂ��ĂĒx������A
apple��qualcomm�����������č��������Ă��̂��A
�ŋ߂͖{�Ƃ������̂�����悤�ɂȂ������Ă����ł���H
apple��qualcomm�����������č��������Ă��̂��A
�ŋ߂͖{�Ƃ������̂�����悤�ɂȂ������Ă����ł���H
��������
>>678
����ŒN���}�g����SoC�����Ȃ����M�R�A�ɂȂ����̂�Cortex-A15�Ȃ̂Łc�c�B
����ŒN���}�g����SoC�����Ȃ����M�R�A�ɂȂ����̂�Cortex-A15�Ȃ̂Łc�c�B
�ŋ�A57��PC�̃��b�v�g�b�v�����N���X�̔��M�����ăo�������
http://images.anandtech.com/doci/8718/big-cluster.png
����Core M��薾�炩�ɓd�͐H���Ă邾�낗
http://images.anandtech.com/doci/8718/big-cluster.png
{kind=link}
����Core M��薾�炩�ɓd�͐H���Ă邾�낗
big.LITTLE�����邶���
big.little�̓s�[�N�̓d�͌��炷����Ȃ������
����Intel���s���D�҂���Ƃ���������
686 �FSocket774�F2015/02/13(��) 19:19:21.73 ID:9oQpvLj8
http://www.anandtech.com/show/8718/the-samsung-galaxy-note-4-exynos-review/6
http://www.tomshardware.com/reviews/snapdragon-810-benchmarks,4053.html
http://www.tomshardware.com/reviews/snapdragon-810-benchmarks,4053.html
687 �FSocket774�F2015/02/13(��) 19:32:46.05 ID:9oQpvLj8
anand��exynos5433�͈ꉞsamsung��20nm�̂͂�
688 �FSocket774�F2015/02/13(��) 19:42:44.54 ID:V2w66GSW
tegra k1��5w
���Ԃ�denver�ł�
cpu�t���ғ��ŏ[�d�ǂ��������1.5a��
���Ԃ�denver�ł�
cpu�t���ғ��ŏ[�d�ǂ��������1.5a��
tegra����10W����Ȃ���������
��������Intel�X����Tegra�̐�`���ɗ��Ȃ��Ă�������
jetson�͍ŏ��\����5W�A�ő�\����33W���Ɠd�͐���̃J�[�l���h���C�o�����̃\�[�X�R�[�h�ɏ����Ă���
694 �F,,�E�L�́M�E,,�j��-�������F2015/02/13(��) 20:43:50.51 ID:FskOvHs4
JetsonTK1����A15�����
��������64�r�b�g�̓y�U�ɏオ��ĂȂ����炨�Ăт���Ȃ���
��������64�r�b�g�̓y�U�ɏオ��ĂȂ����炨�Ăт���Ȃ���
JetsonTK1�{�[�h����GFX�x���`�}�[�N���̃s�[�N����d�͂�SoC+DRAM��7W�߂��݂�����
DRAM�̏���d�͏�����������6W���ĂƂ��낾
TDP�̏�����͕̂�����Ȃ����A���̃��[�N���[�h����SoC�̓t�����[�h�ɂ͂Ȃ�Ȃ��Ƃ͎v����
SoC�P�̂ł̃s�[�N������d�͂�5W�Ɏ��܂��Ă�Ƃ͎v���Ȃ���
DRAM�̏���d�͏�����������6W���ĂƂ��낾
TDP�̏�����͕̂�����Ȃ����A���̃��[�N���[�h����SoC�̓t�����[�h�ɂ͂Ȃ�Ȃ��Ƃ͎v����
SoC�P�̂ł̃s�[�N������d�͂�5W�Ɏ��܂��Ă�Ƃ͎v���Ȃ���
���X�������Ԃ�Z�����邱�Ƃ��d�����Ă���Intel�̎v�z�Ɏ��オ�ǂ������ȁB
697 �F,,�E�L�́M�E,,�j��-�������F2015/02/13(��) 21:22:28.39 ID:FskOvHs4
�A�C�h�����̓d�͐��䂪���܂������Ȃ�����ȓd�͓���p�R�A��ʂɗp�ӂ���Ƃ�
����Ă邱�Ƃ��A�z�炵������
����Ă邱�Ƃ��A�z�炵������
nexus9�͋}���[�d�Ή����ĂȂ��ď[�d���1.5A
����ŃR�C���x�����Ă��[�d�͒ǂ����Ă�
a57�͑�K�͂���samsung��14nm�g�����Ƃʼn������ۂ�
�܂��Ȃ��ł�s6��14nm��exynos7420
a15��tsmc��20nm�������ň�����L���g��ꂽ������
����ŃR�C���x�����Ă��[�d�͒ǂ����Ă�
a57�͑�K�͂���samsung��14nm�g�����Ƃʼn������ۂ�
�܂��Ȃ��ł�s6��14nm��exynos7420
a15��tsmc��20nm�������ň�����L���g��ꂽ������
�r�b�O���g���̃A�C�f�B�A���̂̓C���e�����ł���͂������A�Ȃ����Ȃ��̂��˂��B
�_�[�N�V���R���Ŗʐώ��̂͗]���Ă����ˁB
�_�[�N�V���R���Ŗʐώ��̂͗]���Ă����ˁB
apple������ĂȂ���
���ʂɍl���ďȓd�͗p�̐�p�R�A��ʂɍ�邭�炢�Ȃ�A���̊J�����\�[�X�������\�R�A�̏ȓd�͉��ɓ��Ă�������������ł���
ARM�Ђ͊e�v���b�g�t�H�[���ɍ��킹�Ă�����CPU�R�A�̃o���G�[�V�����p�ӂ��Ă邩��big.LITTLE�̂悤�Ȏ�@���ȓd�͉��Ƀ}�b�`���Ă���Ƃ�������
ARM�Ђ͊e�v���b�g�t�H�[���ɍ��킹�Ă�����CPU�R�A�̃o���G�[�V�����p�ӂ��Ă邩��big.LITTLE�̂悤�Ȏ�@���ȓd�͉��Ƀ}�b�`���Ă���Ƃ�������
>>699
�㓡���H���AIntel�͎��Ђ̗D�ꂽfab�ŃI���_�CVRM�����邩��B
����ɑ債��ARM�́A����fab���Ȃ��I���_�CVRM������قǂ̋Z�p���������t�@�E���_�����Ȃ�����
Big,Little�헪���Ƃ炴������Ȃ��������Ă��B
�㓡���H���AIntel�͎��Ђ̗D�ꂽfab�ŃI���_�CVRM�����邩��B
����ɑ債��ARM�́A����fab���Ȃ��I���_�CVRM������قǂ̋Z�p���������t�@�E���_�����Ȃ�����
Big,Little�헪���Ƃ炴������Ȃ��������Ă��B
>>699
��i�ƃu�[�X�g�ŏ\�����S�ł��邩��ł́H
��i�ƃu�[�X�g�ŏ\�����S�ł��邩��ł́H
>434�@>440
8���[���A20���[���Ƃ����\���͕s�K�������B
DMI�@4GB/s ���@8GB/s �̕����킩��₷���B
Z87��18�|�[�g���f�o�C�X�Ɗg���X���b�g�ɐU�蕪���AZ170��26�|�[�g�B
�|�[�g����1�|�[�g�̍ő�ш�̗���������
Sandy Bridge ����n�܂�4����̂����������݂��Ă���DMI�ш��
����ɒ����Ԕ����𑱂��Ă����������ш�̖��ĂȌ���͊�����B
Skylake��CPU����PCIe ��20���[���ɖ߂邵�A���r��
�����A����������~������l�Ԃ͎���ł������Ȃ�����
8���[���A20���[���Ƃ����\���͕s�K�������B
DMI�@4GB/s ���@8GB/s �̕����킩��₷���B
Z87��18�|�[�g���f�o�C�X�Ɗg���X���b�g�ɐU�蕪���AZ170��26�|�[�g�B
�|�[�g����1�|�[�g�̍ő�ш�̗���������
Sandy Bridge ����n�܂�4����̂����������݂��Ă���DMI�ш��
����ɒ����Ԕ����𑱂��Ă����������ш�̖��ĂȌ���͊�����B
Skylake��CPU����PCIe ��20���[���ɖ߂邵�A���r��
�����A����������~������l�Ԃ͎���ł������Ȃ�����
Big,Little���Anvidia��4+1�݂����ȏȓd�̓R�A�̂ق����X�}�[�g���Ǝv����
�������A4+1��OS�̑Ή����K�{�����ALinux�J�[�l��/Android�͂��łɑΉ��ς�
Big,Little�̓R�A�����\���ł��ăJ�^���O�X�y�b�N�ň�ʐl�x���ɂ͗L�����ȁH
����4�R�A�ł��A����8�R�A�����邵
�������A4+1��OS�̑Ή����K�{�����ALinux�J�[�l��/Android�͂��łɑΉ��ς�
Big,Little�̓R�A�����\���ł��ăJ�^���O�X�y�b�N�ň�ʐl�x���ɂ͗L�����ȁH
����4�R�A�ł��A����8�R�A�����邵
Nvidia���g��Denver��4+1��20nm�Œ��߂Ă邯�ǂ�
�H���A�V�v���Z�X�Ȃ̂œƎ��R�A+�Ǝ����@�̃��X�N����������Ęb�����ǁA
���̗������ƁA�������16nm���V�v���Z�X������ADenver��4+1����߂�����
�H���A�V�v���Z�X�Ȃ̂œƎ��R�A+�Ǝ����@�̃��X�N����������Ęb�����ǁA
���̗������ƁA�������16nm���V�v���Z�X������ADenver��4+1����߂�����
�R�A���E�@�\�u���b�N���ɓd���E�N���b�N�ύX�ł�����APWM�I���삪�\�Ȃ�܂������s�K�v�ȋZ�p
Skylake�œd�����M�����[�^���܂��I���_�C�ł͂Ȃ��Ȃ�炵�����A�@�\�I�ɑމ��͖������낤��
���ƁA���̋Z�p��Atom�ł�Intel�H�ꐻ�Ȃ�g���邪SoFIA���Ǝg���Ȃ���Ȃ���
Skylake�œd�����M�����[�^���܂��I���_�C�ł͂Ȃ��Ȃ�炵�����A�@�\�I�ɑމ��͖������낤��
���ƁA���̋Z�p��Atom�ł�Intel�H�ꐻ�Ȃ�g���邪SoFIA���Ǝg���Ȃ���Ȃ���
{kind=link}
{kind=link}
Silvermont�̎���Intel�̎咣
http://regmedia.co.uk/2013/05/06/silvermont_dynamic_range1_large.jpg
Cortex-A15�̎���ARM�̎咣
http://pc.watch.impress.co.jp/img/pcw/docs/602/036/12.jpg
http://regmedia.co.uk/2013/05/06/silvermont_dynamic_range1_large.jpg
{kind=link}
Cortex-A15�̎���ARM�̎咣
http://pc.watch.impress.co.jp/img/pcw/docs/602/036/12.jpg
{kind=link}
>>711
NTV�͐�p�̉�H�v���K�v�����獂���\�R�A�ɂ܂œK�p���L����͓̂���ł���
>>712
�O���t�̉�����Performance��3����ĂȂ�������
NTV�͐�p�̉�H�v���K�v�����獂���\�R�A�ɂ܂œK�p���L����͓̂���ł���
>>712
�O���t�̉�����Performance��3����ĂȂ�������
�Ǝv������3�͒��ӏ���������
����Silvermont 4�R�A�̓D�^�u��A15 4�R�A�̓D�^�u�����Ȃ�o�������킯�����ǁA
�o�b�e���e�ʂɂ���邯�ǎ��g�p�̎������Ԃ͂ǂ�Ȃ�������
�o�b�e���e�ʂɂ���邯�ǎ��g�p�̎������Ԃ͂ǂ�Ȃ�������
716 �FSocket774�F2015/02/14(�y) 05:59:55.99 ID:9tJ+uIj+
2core�ł����̐��\�̂��̎̂Ă�킯�ˁ[�����
http://s30.postimg.org/depqioy4g/Screenshot_2015_02_13_21_55_23.jpg
samsun qualcomm a57
http://www.phonearena.com/news/Preliminary-Snapdragon-810-vs-Exynos-7420-benchmark-results-show-Samsung-made-the-faster-CPU_id65973
http://www.tomshardware.com/reviews/snapdragon-810-benchmarks,4053-4.html
http://www.anandtech.com/show/8718/the-samsung-galaxy-note-4-exynos-review/6
http://s30.postimg.org/depqioy4g/Screenshot_2015_02_13_21_55_23.jpg
{kind=link}
samsun qualcomm a57
http://www.phonearena.com/news/Preliminary-Snapdragon-810-vs-Exynos-7420-benchmark-results-show-Samsung-made-the-faster-CPU_id65973
http://www.tomshardware.com/reviews/snapdragon-810-benchmarks,4053-4.html
http://www.anandtech.com/show/8718/the-samsung-galaxy-note-4-exynos-review/6
Denver��Android5.0��ART�́A�����ɃC���X�R�䗦�����������Đ������s����������Ă�̂��A
���v�̃p�t�H���o�O�����o�Ă�̂��A�݊����͂ǂ�Ȃ��A���X�O�O���ɒ~�ς��Ȃ���Ȃ�
�������Ȃ������ĂĘb��ɂȂ�Ȃ���Ȃ炻��͂���Ő�����Ղ��Ǝv�����ǁA�����n�[�h��������
���v�̃p�t�H���o�O�����o�Ă�̂��A�݊����͂ǂ�Ȃ��A���X�O�O���ɒ~�ς��Ȃ���Ȃ�
�������Ȃ������ĂĘb��ɂȂ�Ȃ���Ȃ炻��͂���Ő�����Ղ��Ǝv�����ǁA�����n�[�h��������
720 �FSocket774�F2015/02/14(�y) 08:59:40.84 ID:NZC4apJZ
�����̏��i���Ŕ��낤�����АӔC�ŏ��肶��Ȃ��̂�
>>717
5.0.2�ȑO�̓��������[�N��������A�o�[�M�[�ő��X��5.1�ɂȂ�
5.0.2�ȑO�̓��������[�N��������A�o�[�M�[�ő��X��5.1�ɂȂ�
722 �F,,�E�L�́M�E,,�j��-�������F2015/02/14(�y) 12:41:39.43 ID:iTHmxoln
Z3735F�͒艿17�h�����B
�^�_���R�ƌ����Ă��鐻�i�ɂ́A���ۂɂ͖{�̂�➑̂ƍŏ��̋N����ʂ�
Intel���S�̕\�����s�����Ƃ��v�������B
���̗v���������ƂŁA���[�J�[�͍L����`�̋��̖͂��ڂŁAAtom�̒艿��
�قړ��z���̃L�b�N�o�b�N������B
�����s�������Ƃ������ǂ����͑��Ђ��ǂ�����Ă邩�݂�킩�邱��
���Ƃ��Ƃ̒ቿ�i�[�������D�҉��iOEM���i20�`30�h�����x�̂��̂��A��������
�f�t�H���g�̌����G���W����Bing�ɂ��������i���[�U�[�ɂ���ĕύX�\�j��
0�h���Œ���MS�Ƃǂ������l�����z���傫�����l���Ă݂������B
�^�_���R�ƌ����Ă��鐻�i�ɂ́A���ۂɂ͖{�̂�➑̂ƍŏ��̋N����ʂ�
Intel���S�̕\�����s�����Ƃ��v�������B
���̗v���������ƂŁA���[�J�[�͍L����`�̋��̖͂��ڂŁAAtom�̒艿��
�قړ��z���̃L�b�N�o�b�N������B
�����s�������Ƃ������ǂ����͑��Ђ��ǂ�����Ă邩�݂�킩�邱��
���Ƃ��Ƃ̒ቿ�i�[�������D�҉��iOEM���i20�`30�h�����x�̂��̂��A��������
�f�t�H���g�̌����G���W����Bing�ɂ��������i���[�U�[�ɂ���ĕύX�\�j��
0�h���Œ���MS�Ƃǂ������l�����z���傫�����l���Ă݂������B
���⎟��parker����
���Ƃ���K1(logan)�̎���denver�g����parker�������̂�
�Ԃ�X1(erista)�����Ă���
���Ƃ���K1(logan)�̎���denver�g����parker�������̂�
�Ԃ�X1(erista)�����Ă���
���X�N�����Denver��߂��̂ɁA���X�N����16nm��Denver�g���Ƃ͎v����
�܂��Aparker��20nm�Ȃ炠�肦�邩����
���̎��͋�����16nm�g���Ă邾�낤����
�܂��Aparker��20nm�Ȃ炠�肦�邩����
���̎��͋�����16nm�g���Ă邾�낤����
GPU�ɃZ�L�����e�B�����R���p�j�I��������ARM�����������Ƃ͌����ĂȂ����������HNV���āB
�����ɂ��Adenver��p��CPU�R�A�J���͌p���Ȃ̂�
�P��denver+maxwell���Ă킯����Ȃ��悤�ȋC�����邪
http://www.4gamer.net/games/049/G004964/20150105001/
�Ƃ���ŁCNVIDIA��64bit��Tegra K1�ŁC���ГƎ���64bit ARM�x�[�XCPU�R�A�uDenver�v���̗p���Ă����i�֘A�L���j�B
�����Tegra X1��ARM����CPU�R�A���̗p���ꂽ�ƕ����C�Ǝ��J��CPU�R�A�̘H������߂��̂��낤���Ǝv�����낤�B
�����C�u�����ł͂Ȃ��v��NVIDIA���S���҂͏q�ׂ�B
�@Denver�̌�p�ƂȂ�ARM�x�[�XCPU�R�A�̓Ǝ��J���͌p������Ă��邻�������C
Tegra X1�ł̓O���t�B�b�N�X���\�̌���ɏd�_��u�������߁CARM���R�A���̗p�����Ƃ������Ƃ��B
GPU�R�A�����̕ύX���傫�����߁CCPU�R�A�͈��S�������āC���т̂���ARM�����̗p�����Ƃ������ƂȂ̂��낤�B
�P��denver+maxwell���Ă킯����Ȃ��悤�ȋC�����邪
http://www.4gamer.net/games/049/G004964/20150105001/
�Ƃ���ŁCNVIDIA��64bit��Tegra K1�ŁC���ГƎ���64bit ARM�x�[�XCPU�R�A�uDenver�v���̗p���Ă����i�֘A�L���j�B
�����Tegra X1��ARM����CPU�R�A���̗p���ꂽ�ƕ����C�Ǝ��J��CPU�R�A�̘H������߂��̂��낤���Ǝv�����낤�B
�����C�u�����ł͂Ȃ��v��NVIDIA���S���҂͏q�ׂ�B
�@Denver�̌�p�ƂȂ�ARM�x�[�XCPU�R�A�̓Ǝ��J���͌p������Ă��邻�������C
Tegra X1�ł̓O���t�B�b�N�X���\�̌���ɏd�_��u�������߁CARM���R�A���̗p�����Ƃ������Ƃ��B
GPU�R�A�����̕ύX���傫�����߁CCPU�R�A�͈��S�������āC���т̂���ARM�����̗p�����Ƃ������ƂȂ̂��낤�B
>>726
maxwell��CPU�̂��ăX���b�h�Ǘ��Ȃ�点��\��ł�����
���Ԃ�20nm���X�x�����̂ŗ��ꂽ��Ȃ�����
�g�b�v�G���h��GM200��DP����̂��Ȃ��Ƃ����Ęb������
maxwell��CPU�̂��ăX���b�h�Ǘ��Ȃ�点��\��ł�����
���Ԃ�20nm���X�x�����̂ŗ��ꂽ��Ȃ�����
�g�b�v�G���h��GM200��DP����̂��Ȃ��Ƃ����Ęb������
NVIDIA��Tegra4�ȍ~�T�b�p���ŌՂ̎q��Denver�ł������Ԃ��ɂ͎����ĂȂ�
Qualcomm��64bit���ł܂����̂܂Â��A�{���̓Ǝ��A�[�LCPU�������ɉe���`��������
���{�R��ARM�͎���IoT���ƌ����Ȃ���A12�AA17�AA72�Ɩ�p�����Ƀp�t�H�[�}���X�d���̐VCPU�\���č̗p���i���o�Ă��Ȃ��������Ղ�
������Intel�����̍����ɏ悶��Airmont�AGoldmont�ƈ��������ɂ�����Ǝv��ꂽ����D��14nm���N�P�ʒx���ł��������̃`�����X������
����Apple�͌����ɓƎ��A�[�L�ւ̐芷����64bit�����ʂ����l�X�ƃ��[�A�̖@����˂��i��ō��N��14nm FinFET��
�Ō�Ƀ_�[�N�z�[�X��AMD���Љ^��q����K12�łǂ��܂Œ��ڂ��W�߂��邩�Ƃ������Ƃ���
Qualcomm��64bit���ł܂����̂܂Â��A�{���̓Ǝ��A�[�LCPU�������ɉe���`��������
���{�R��ARM�͎���IoT���ƌ����Ȃ���A12�AA17�AA72�Ɩ�p�����Ƀp�t�H�[�}���X�d���̐VCPU�\���č̗p���i���o�Ă��Ȃ��������Ղ�
������Intel�����̍����ɏ悶��Airmont�AGoldmont�ƈ��������ɂ�����Ǝv��ꂽ����D��14nm���N�P�ʒx���ł��������̃`�����X������
����Apple�͌����ɓƎ��A�[�L�ւ̐芷����64bit�����ʂ����l�X�ƃ��[�A�̖@����˂��i��ō��N��14nm FinFET��
�Ō�Ƀ_�[�N�z�[�X��AMD���Љ^��q����K12�łǂ��܂Œ��ڂ��W�߂��邩�Ƃ������Ƃ���
K12���X�}�z���^�[�Q�b�g�ɂ��Ă�Ƃ͎v���Ȃ�����
���p�t�H�[�}���X��ڎw�����Ƃ���ƋK�͂�傫�����邩�A�N���b�N���グ�邩
apple��intel�̓��b�`�R�A���N���b�N�ʼn^�p���邱�ƂŃ��o�C���̓d�́A�M�v�Ɏ��߂��p�t�H�[�}���X���������邪
���̎�@�͎����ʂł����b�`�Ȋ�Ƃɂ����o���Ȃ�
���K�͍��N���b�N�͔M�A�d�͖ʂŕs���ɂȂ邾�낤��
�����Č����Ahaswell��skylake���݂̃p�t�H�[�}���X�ɂȂ����Ƃ����
�_�C�T�C�Y���d�͂��M�������ɂȂ�Ȃ炠����arm�ɂ��闝�R���Ȃ�
apple��intel�̓��b�`�R�A���N���b�N�ʼn^�p���邱�ƂŃ��o�C���̓d�́A�M�v�Ɏ��߂��p�t�H�[�}���X���������邪
���̎�@�͎����ʂł����b�`�Ȋ�Ƃɂ����o���Ȃ�
���K�͍��N���b�N�͔M�A�d�͖ʂŕs���ɂȂ邾�낤��
�����Č����Ahaswell��skylake���݂̃p�t�H�[�}���X�ɂȂ����Ƃ����
�_�C�T�C�Y���d�͂��M�������ɂȂ�Ȃ炠����arm�ɂ��闝�R���Ȃ�
����qualcomm�̏ꍇ���f�������Ȃ�ł����悤�ł�
>>732
���@apple��intel�̓��b�`�R�A���N���b�N�ʼn^�p���邱�ƂŃ��o�C���̓d�́A�M�v�Ɏ��߂��p�t�H�[�}���X���������邪
���@���̎�@�͎����ʂł����b�`�Ȋ�Ƃɂ����o���Ȃ�
�����̘b���Ȃ����ĂȂ��C������B
���@apple��intel�̓��b�`�R�A���N���b�N�ʼn^�p���邱�ƂŃ��o�C���̓d�́A�M�v�Ɏ��߂��p�t�H�[�}���X���������邪
���@���̎�@�͎����ʂł����b�`�Ȋ�Ƃɂ����o���Ȃ�
�����̘b���Ȃ����ĂȂ��C������B
���b�`�R�A�͉�H�K�͂��傫�����J���Ɏ�Ԃ��|����B
������J�����鎑���͂�������Ă��Ƃ���B
������J�����鎑���͂�������Ă��Ƃ���B
736 �FSocket774�F2015/02/14(�y) 17:32:01.73 ID:ibS39Zis
���������i�����R�X�g
Apple�̓T���X���H��ɁAIntel��Intel�H��ɍ��킹���ގ��ŏo���鐫�\�E�d�͐��\�ł�����
A72��TSMC 16FF+�ɍ��킹���ƃA�s�[�����Ă�̂͂����������Ȃ̂��낤
A72��TSMC 16FF+�ɍ��킹���ƃA�s�[�����Ă�̂͂����������Ȃ̂��낤
Apple��A9�ł͗����ɍ��킹���ނƂ����������ɂ����ł��Ȃ��r�Ƃ����Ă�ȁB
�t�Z�I���@�����ł����ЂȂ�Č����Ă邵��
�ŁA���u���[�J�[���C���e���E�T���\���̈ӌ����ŏd�v�����Ă邵��
�z���g�A�������̉ǐ肾��
�ŁA���u���[�J�[���C���e���E�T���\���̈ӌ����ŏd�v�����Ă邵��
�z���g�A�������̉ǐ肾��
���{�̓d�@���[�J�[�̈ӌ����d�����ăX�e�b�p����Ă���A
�d�@���[�J�[���Ɩv������C�ЂƂ�N�Ђ����邪��
�d�@���[�J�[���Ɩv������C�ЂƂ�N�Ђ����邪��
N�Ђ���Intel�ƃT���̎q������Ȃ����H
�i�V���i���H
���Ă�C�Ђ��Ăǂ���
���Ă�C�Ђ��Ăǂ���
�ǂ��l���Ă�Canon��Nikon����
Nikon�͐����Ă邪
Nikon�͐����Ă邪
�E�F�n���Y�ʂ͐�[�v���Z�X������[�ȊO�̕����͂邩�ɑ�������
C��N�������e���Ă�䐔�͑������낤���ǁA�V�K�A���z�͐�[�v���Z�X�p�������
C��N�������e���Ă�䐔�͑������낤���ǁA�V�K�A���z�͐�[�v���Z�X�p�������
>>730
ARM�̎��s��64�r�b�g�̃X���[���R�A�̃����i�b�v���[����������
A12�AA17�Ƃ�����32�r�b�g�R�A�̉��ǔł�A���������Ƃ��Ǝv��
���̂�����64�r�b�g�ւ̈ڍs����Intel�ɃV�F�A��D��ꂽ
ARM�̎��s��64�r�b�g�̃X���[���R�A�̃����i�b�v���[����������
A12�AA17�Ƃ�����32�r�b�g�R�A�̉��ǔł�A���������Ƃ��Ǝv��
���̂�����64�r�b�g�ւ̈ڍs����Intel�ɃV�F�A��D��ꂽ
A12��64bit�ő�����A55�Ƃ��o���ׂ���������
A57�͔M�����邵A53�͔�͂�����B
A57�͔M�����邵A53�͔�͂�����B
A57�ĂȂ�ł���Ȃɔ��M�Ȃ̂�
Intel�̐V����CPU�uBroadwell�v���ڂ�NUC��17���ɔ���
http://akiba-pc.watch.impress.co.jp/docs/news/news/20150214_688345.html
http://akiba-pc.watch.impress.co.jp/docs/news/news/20150214_688345.html
A57�͂������Ȃ��炵��
Snapdragon 810�A���ۂɂ�Snapdragon 801�����ᔭ�M�ł��邱�Ƃ�����
http://ggsoku.com/2015/02/snapdragon-810-cooler/
Snapdragon 810�A���ۂɂ�Snapdragon 801�����ᔭ�M�ł��邱�Ƃ�����
http://ggsoku.com/2015/02/snapdragon-810-cooler/
751 �FSocket774�F2015/02/16(��) 19:05:51.05 ID:OShHBolj
�ŁA�t���[�����[�g�́H��
752 �FSocket774�F2015/02/16(��) 19:06:42.14 ID:OShHBolj
��������cpu�t������Ȃ�����
http://images.anandtech.com/doci/8718/gpu-core-scaling_575px.png
http://images.anandtech.com/doci/8718/big-cluster.png
exynos�̂�ł�gpu full�̕����ȓd��
{kind=link}
http://images.anandtech.com/doci/8718/big-cluster.png
exynos�̂�ł�gpu full�̕����ȓd��
754 �F,,�E�L�́M�E,,�j��-�������F2015/02/18(��) 01:05:17.07 ID:M7iqIVnw
�ȂЂǂ����ƂɂȂ��Ă�ȃW�������˂�
2�����˂�A��p�u���E�U��API�g�p���`���t���B�ᔽ�҂ɂ͖@�I�Ή����H
http://developers.slashdot.jp/story/15/02/16/088240/
2�����˂�A��p�u���E�U��API�g�p���`���t���B�ᔽ�҂ɂ͖@�I�Ή����H
http://developers.slashdot.jp/story/15/02/16/088240/
�gBroadwell-K�h�̃L�����Z������������Ă���E�E�E�炵���H
http://northwood.blog60.fc2.com/blog-entry-7947.html
�f�X�N�g�b�v�����uSkylake�v�A���N8�����ւƂ��ꍞ�ޖ͗l �\���o�C�������͑�4�l�����ȍ~
http://ggsoku.com/2015/02/skylake-coming-in-q4/
http://northwood.blog60.fc2.com/blog-entry-7947.html
�f�X�N�g�b�v�����uSkylake�v�A���N8�����ւƂ��ꍞ�ޖ͗l �\���o�C�������͑�4�l�����ȍ~
http://ggsoku.com/2015/02/skylake-coming-in-q4/
-K�͂͂ɂȂ�A����TDP�����Ă������̐l�������ł��傤
�����[���ƂȂ��Ă�̂Ȃ�
�yAPI�ɑ���e��u���̓��� (�\�[�X�t��)�z 2015/2/17 21:30 ����
�\�[�X�s���̂��̂́H�����Ă��܂��B
�y�Ή�(�����E�_��ς�)�z
�E�Ȃ�
�y�����炭�Ή��z�i�_��ς݂Ƃ̌������\�͂Ȃ����A�Ή���O�����Ɍ������Ă�����́j
�EJane Style�i�R����API�g�p�����̌�����ێ�: http://developer.2ch.net�j
�EBathyScaphe�i�����������A�K�v�Ȃ�N���[�Y�h�ɂ��Ă��Ή��\��: http://anago.2ch.net/test/read.cgi/mac/1409303728/333+351+362+368+373+383�j
�y�����炭��Ή��z�i�������\�͂Ȃ����A�����炭�Ή����Ȃ��E�ł��Ȃ����́j
�EJane Xeno�i�R���Ɍl����n�������Ȃ��H�j
�ETwintail�i�J�����͎҂̐��ʎ��u�����ǂ����ȁv: http://anago.2ch.net/test/read.cgi/software/1410688871/345�j
�E2chSharp�iPSM�͍L���\���s��: http://anago.2ch.net/test/read.cgi/software/1402028127/98�j
�E2chMate�isc�ɑΉ����Ă���Ƌ��������Ȃ�: http://qerozon.jp/browser.docx�j
�EJane�i�I�[�v���\�[�X�͋������o�Ȃ��H�j
�Eread.js�i�I�[�v���\�[�X�͋������o�Ȃ��H�j
�EThousand�i�I�[�v���\�[�X�͋������o�Ȃ��H�j
�EJD�i�I�[�v���\�[�X�͋������o�Ȃ��H�j
�Erep2�i�I�[�v���\�[�X�͋������o�Ȃ��H�j
�EFreeze Owata+1�i�I�[�v���\�[�X�͋������o�Ȃ��H�j
�EV2C�i��ҍs���s���j
�E�]�k�i�J����~�j
�E������`����i�J����~�j
�yAPI�ɑ���e��u���̓��� (�\�[�X�t��)�z 2015/2/17 21:30 ����
�\�[�X�s���̂��̂́H�����Ă��܂��B
�y�Ή�(�����E�_��ς�)�z
�E�Ȃ�
�y�����炭�Ή��z�i�_��ς݂Ƃ̌������\�͂Ȃ����A�Ή���O�����Ɍ������Ă�����́j
�EJane Style�i�R����API�g�p�����̌�����ێ�: http://developer.2ch.net�j
�EBathyScaphe�i�����������A�K�v�Ȃ�N���[�Y�h�ɂ��Ă��Ή��\��: http://anago.2ch.net/test/read.cgi/mac/1409303728/333+351+362+368+373+383�j
�y�����炭��Ή��z�i�������\�͂Ȃ����A�����炭�Ή����Ȃ��E�ł��Ȃ����́j
�EJane Xeno�i�R���Ɍl����n�������Ȃ��H�j
�ETwintail�i�J�����͎҂̐��ʎ��u�����ǂ����ȁv: http://anago.2ch.net/test/read.cgi/software/1410688871/345�j
�E2chSharp�iPSM�͍L���\���s��: http://anago.2ch.net/test/read.cgi/software/1402028127/98�j
�E2chMate�isc�ɑΉ����Ă���Ƌ��������Ȃ�: http://qerozon.jp/browser.docx�j
�EJane�i�I�[�v���\�[�X�͋������o�Ȃ��H�j
�Eread.js�i�I�[�v���\�[�X�͋������o�Ȃ��H�j
�EThousand�i�I�[�v���\�[�X�͋������o�Ȃ��H�j
�EJD�i�I�[�v���\�[�X�͋������o�Ȃ��H�j
�Erep2�i�I�[�v���\�[�X�͋������o�Ȃ��H�j
�EFreeze Owata+1�i�I�[�v���\�[�X�͋������o�Ȃ��H�j
�EV2C�i��ҍs���s���j
�E�]�k�i�J����~�j
�E������`����i�J����~�j
�y��Ή��E�J�����~�z�i�����ɑΉ����Ȃ��Ɣ��\�������́j
�EJane View�i�Ή��\��Ȃ��A�ėp�f���u���E�U��: http://peace.2ch.net/test/read.cgi/win/1408059545/458�j
�EJane Clone�i�_��: http://anago.2ch.net/test/read.cgi/software/1365071612/294�j
�E�M�R�i�r�i�{�ƊJ����~�ρA�h���ō�҂͌_��: http://anago.2ch.net/test/read.cgi/software/1420712317/947-949�j
�EWakamurasaki�i������ꂸ: https://twitter.com/kazuakix/status/567077182241906688�j
�EAndy�i������ꂸ: http://yomogi.2ch.net/test/read.cgi/chakumelo/1396104842/251�j
�ENavi2ch�i������ꂸ�Fhttp://peace.2ch.net/test/read.cgi/unix/1405127170/148+181�j
�Echaika�i������ꂸ�Fhttp://anago.2ch.net/test/read.cgi/software/1421229692/457+589�j
�EiMona�i������ꂸ: http://dahlia.ddo.jp/imona/�j
�E2Live�i������ꂸ�A���J��~��: http://qerozon.jp/archives/1725�j
�EW2Ch�i������ꂸ�A�T�[�r�X��~��: http://yomogi.2ch.net/test/read.cgi/chakumelo/1407232693/499�j
�E2ch Sanka�i������ꂸ: http://ikudev.blogspot.jp/2015/02/api.html�j
�Es2ch.net[�]�j���[]�i������ꂸ�H�j
�En2ch.net[�ʂ�]�i������ꂸ�H�j
�EJane View�i�Ή��\��Ȃ��A�ėp�f���u���E�U��: http://peace.2ch.net/test/read.cgi/win/1408059545/458�j
�EJane Clone�i�_��: http://anago.2ch.net/test/read.cgi/software/1365071612/294�j
�E�M�R�i�r�i�{�ƊJ����~�ρA�h���ō�҂͌_��: http://anago.2ch.net/test/read.cgi/software/1420712317/947-949�j
�EWakamurasaki�i������ꂸ: https://twitter.com/kazuakix/status/567077182241906688�j
�EAndy�i������ꂸ: http://yomogi.2ch.net/test/read.cgi/chakumelo/1396104842/251�j
�ENavi2ch�i������ꂸ�Fhttp://peace.2ch.net/test/read.cgi/unix/1405127170/148+181�j
�Echaika�i������ꂸ�Fhttp://anago.2ch.net/test/read.cgi/software/1421229692/457+589�j
�EiMona�i������ꂸ: http://dahlia.ddo.jp/imona/�j
�E2Live�i������ꂸ�A���J��~��: http://qerozon.jp/archives/1725�j
�EW2Ch�i������ꂸ�A�T�[�r�X��~��: http://yomogi.2ch.net/test/read.cgi/chakumelo/1407232693/499�j
�E2ch Sanka�i������ꂸ: http://ikudev.blogspot.jp/2015/02/api.html�j
�Es2ch.net[�]�j���[]�i������ꂸ�H�j
�En2ch.net[�ʂ�]�i������ꂸ�H�j
snapdragon810�͂��Ȃ�c�O�ȃR�g�ɂȂ��Ă�Ȃ�
http://www.cnbeta.com/articles/371527.htm
http://it-eproducts.com/images/810geek3.png
http://it-eproducts.com/images/2geek3.png
http://it-eproducts.com/images/810805.png
http://www.cnbeta.com/articles/371527.htm
http://it-eproducts.com/images/810geek3.png
{kind=link}
http://it-eproducts.com/images/2geek3.png
{kind=link}
http://it-eproducts.com/images/810805.png
{kind=link}
�Đ��œ��{���[�J�[�����邸��S�̗p���ăI�I�S�g�ɂȂ肻����
�������805��������Ă�Ƃ��������ł����̂��H
Krait��64bit���͂�
�x���`�J��Ԃ����ƂɔM���オ���Ă��ăN���b�N�����ăp�t�H�[�}���X��������
���V���O���������ȉ��ɂȂ��Ă����
���V���O���������ȉ��ɂȂ��Ă����
�t�@���t���̃X�}�[�g�t�H�����Ă������݂���̂���
�d�r�������\����������ł�����d�͂𑝂₹��킯�ł͂Ȃ����
�\�z�͂��Ă������ǁA���ꂩ��1�N��ł��������W�J�ɂȂ�Ƃ́E�E�E
���̎�����R����Jim���V�i���I�����Ă��̂��˂�
750 Socket774[sage] 2014/04/15(��) 01:09:52.54 ID:JnKHNjlp
������(Jim+Fox/N.T. Technology) vs p2����(�z�b�g�����N/���������u���W��)
���N�U���N�U�̐킢
�Ђ�䂫�̓A�������A���ׂ�]�ڋ֎~�~�𗘗p���Ď������₻���Ɗ��Jim�T�C�h���A��
���̎�����R����Jim���V�i���I�����Ă��̂��˂�
750 Socket774[sage] 2014/04/15(��) 01:09:52.54 ID:JnKHNjlp
������(Jim+Fox/N.T. Technology) vs p2����(�z�b�g�����N/���������u���W��)
���N�U���N�U�̐킢
�Ђ�䂫�̓A�������A���ׂ�]�ڋ֎~�~�𗘗p���Ď������₻���Ɗ��Jim�T�C�h���A��
>>754
���炱�����_��
Jim�����˂�_��
�ŁA���ǂ��s��������H
748 ,,�E�L�́M�E,,�j��-������[sage] 2014/04/15(��) 00:54:54.59 ID:O0WptWdm
���炱sc��T����Ă邱�Ƃ����������ȁB
�������̂��Ɠ��{���̗L���v���o�C�_�_�܂����ĕ��U�N���[�����������ˁH
���炱�����_��
Jim�����˂�_��
�ŁA���ǂ��s��������H
748 ,,�E�L�́M�E,,�j��-������[sage] 2014/04/15(��) 00:54:54.59 ID:O0WptWdm
���炱sc��T����Ă邱�Ƃ����������ȁB
�������̂��Ɠ��{���̗L���v���o�C�_�_�܂����ĕ��U�N���[�����������ˁH
768 �F,,�E�L�́M�E,,�j��-�������F2015/02/19(��) 00:54:29.98 ID:Ea7owr4Z
JaneStyle�Ȃ�Ďg���C���N���Ȃ�����A����3���ɂȂ�����V2C�̔��X�g��S��.sc�ɏ����������
�����ɋ�����݂�ȂƂ����ʂ�
�����ɋ�����݂�ȂƂ����ʂ�
�c�q����A�s���Ȃ���
Web�T�[�r�X������̂Ȃ�OAuth�����F�����p�[�\�i���C�Y�h�L�������z�M���炢�ŗǂ������̂�
�c�q�̂��܂ɏo��Ő�D�����������ǂȂ�
���Ȃ��Ȃ����Ⴄ�̂���
���Ȃ��Ȃ����Ⴄ�̂���
�S�V�S�V�N�̂������Ŏ���𗣂�Ajim�̂�������2ch�𑲋Ƃ��B���肪�Ƃ��B
>>770
�G�������Ō����ڂ�����
�G�������Ō����ڂ�����
�c�q�����Ȃ��Ȃ������ԍ���̂͒c�q����̃A���`
����͓���̊�Ƃ̃N���[�}�[���������肵�Ă����S���҂����Ȃ��Ȃ�ƃN���[��������Ȃ��Ȃ�@���Ɠ���
����͓���̊�Ƃ̃N���[�}�[���������肵�Ă����S���҂����Ȃ��Ȃ�ƃN���[��������Ȃ��Ȃ�@���Ɠ���
SC�͂ǂ����C�M���X�n�̖@���œ������ƂɂȂ肻�����ȁB�ƂӁ[����ǂ�Ŏv���B
�q�����L�o�������ȁB
�q�����L�o�������ȁB
2ch�̘b�͂ǂ��ł�������
777 �F,,�E�L�́M�E,,�j��-�������F2015/02/19(��) 21:01:11.66 ID:TPrE65Nl
.sc�̃R���e���c�ɑ��ă\�t�g�J���҂Ɉ��̎��R���^������Ȃ炻���ɍs���܂łł���
���Z�̒n���ƌ�������͂Ȃ����A�D���ȂƂ���ɎU������Ǝv���B
���Ȃ��Ƃ�.net�ɂ͋��ꏊ�͖����Ȃ����A���ꂾ���͊m���B
��������Ӱ�i�j�̉Εa���Ղ肪���[�Ȃ���
���O�炪���������ʂ���[��������
���Z�̒n���ƌ�������͂Ȃ����A�D���ȂƂ���ɎU������Ǝv���B
���Ȃ��Ƃ�.net�ɂ͋��ꏊ�͖����Ȃ����A���ꂾ���͊m���B
��������Ӱ�i�j�̉Εa���Ղ肪���[�Ȃ���
���O�炪���������ʂ���[��������
�P�����E���̍��Z�ł���a�g�����낤��
�v���N�V�J������ďI���
2ch.net�Ƃ����h���C����15�N2ch�Ƃ����T�[�r�X����Ă����A�Ƃ������j�͂ƂĂ��Ȃ��d��
�܂��x86�̂悤�ȃ��K�V�[�̏d��
2ch.net�Ƃ����h���C����15�N2ch�Ƃ����T�[�r�X����Ă����A�Ƃ������j�͂ƂĂ��Ȃ��d��
�܂��x86�̂悤�ȃ��K�V�[�̏d��
�v���N�V�Ȃ�2ch�ɂ͕��ׂ�����Ȃ��Ĉ����ς݂��������ǁB�����ƃL���b�V�������Ȃ�ˁB
781 �F,,�E�L�́M�E,,�j��-�������F2015/02/20(��) 20:29:59.57 ID:aPKsAu0m
>>779
�N���J������́H
�R���̂��B���ǂ�łȂ��́H
����Ȃ��̋������킯�Ȃ�����Ȃ����B
�҂��Ӑ}���Ȃ���i�Ńl�b�g�ɐڑ�����͕̂s���A�N�Z�X�֎~�@�ᔽ
��O�҂ɃR���e���c�ی�̉I���i����悤���̂Ȃ�s�������h�~�@�ᔽ
�ƍߍs�ׂ���N������v���ȂǂȂ��̂���
�V���ȃ��[������Ă����ȏ�A���̃��[���ɏ]�����A���p���̂��̂��~�߂邩��
2�������Ȃ��̂�B
���[�U�[�ɂł����R��i�́A3/3�ȍ~.net����ؗ��p�����A�����T�C�g�Ɉڍs���邱�Ƃ������B
�N���J������́H
�R���̂��B���ǂ�łȂ��́H
����Ȃ��̋������킯�Ȃ�����Ȃ����B
�҂��Ӑ}���Ȃ���i�Ńl�b�g�ɐڑ�����͕̂s���A�N�Z�X�֎~�@�ᔽ
��O�҂ɃR���e���c�ی�̉I���i����悤���̂Ȃ�s�������h�~�@�ᔽ
�ƍߍs�ׂ���N������v���ȂǂȂ��̂���
�V���ȃ��[������Ă����ȏ�A���̃��[���ɏ]�����A���p���̂��̂��~�߂邩��
2�������Ȃ��̂�B
���[�U�[�ɂł����R��i�́A3/3�ȍ~.net����ؗ��p�����A�����T�C�g�Ɉڍs���邱�Ƃ������B
Mac�ł��g���邩��V2C�g���Ă����ǎg���Ȃ��Ȃ�̂�
�܂��Aread.cgi�o�R��dat��f���悤�ȃv���N�V�Ȃ���Ȃ�����
784 �F,,�E�L�́M�E,,�j��-�������F2015/02/21(�y) 01:17:44.60 ID:qVwlS5W5
����Ȃ��̒N������ĒN�̌����Ŕz�z����H
�ǂꂾ���̃��[�U�[���c��H
���[�U�[���炵�Ă�open2ch��.sc �Ɉڍs����ق������|�I�Ɋy�����
����ȃA���O���Ȏ�@�O���.net�����̃u���E�U��ێ炷���u���J���҂͂��ˁ[����B
�J�����̂𓀌����邩�A���낤���Ďc���Ă�������dat�t�@�C����ǂ߂�݊��f������
�Ƃ��Ă̑�����}�邭�炢�����Ȃ��B
�����ƌ��������B
�ǂꂾ���̃��[�U�[���c��H
���[�U�[���炵�Ă�open2ch��.sc �Ɉڍs����ق������|�I�Ɋy�����
����ȃA���O���Ȏ�@�O���.net�����̃u���E�U��ێ炷���u���J���҂͂��ˁ[����B
�J�����̂𓀌����邩�A���낤���Ďc���Ă�������dat�t�@�C����ǂ߂�݊��f������
�Ƃ��Ă̑�����}�邭�炢�����Ȃ��B
�����ƌ��������B
���ꂪ����Ă��ꂪ�l�I�Ɏg���̂���
API�ɑΉ����Ȃ��u���E�U�ŁA.net���낤��.sc���낤��open2ch���낤��
�ǂ��ł��������Ԃ��L�[�v����̂��ړI
API�ɑΉ����Ȃ��u���E�U�ŁA.net���낤��.sc���낤��open2ch���낤��
�ǂ��ł��������Ԃ��L�[�v����̂��ړI
PHP�Ƃ��X�N���v�g�Ńu���b�W���邱�Ǝ��̂͌����ɋ֎~����ĂȂ���Ȃ��H
����ID�����Ă���邩�킩��ǁB
����ID�����Ă���邩�킩��ǁB
�I������spyle�ȊO�̊O���c�[���ɂ��G�~�����[�V����������������@�͂Ȃ������
����Ȃ�Ɏ��v����Ǝv�����������ʂ����Ȃ����ȂƂ͎v��
����Ȃ�Ɏ��v����Ǝv�����������ʂ����Ȃ����ȂƂ͎v��
�܂����̖@���̒m�����Ȃ��f�l�l��������
���̃A�v�����������������API�L�[�g����API�@���̂͂��ꂱ���s���A�N�Z�X��������ă}�Y����
���̃A�v�����������������API�L�[�g����API�@���̂͂��ꂱ���s���A�N�Z�X��������ă}�Y����
/.j�Ŗ@�I�Ȉ������������Ă�l������http://developers.slashdot.jp/comments.pl?sid=652012&cid=2763004
big.LITTLE�v���l�b�g
792 �F,,�E�L�́M�E,,�j��-�������F2015/02/21(�y) 02:39:16.22 ID:qVwlS5W5
������ƍl�����ɂ����i.net�j����S�����Ȃ��Ȃ��Ă��܂�����ł����Ǝv���܂����ǂ˂�
�Ȃ�ł��O�ɂ���Ȃ��Ǝw�����܂��������ɂႢ����́H
794 �F,,�E�L�́M�E,,�j��-�������F2015/02/21(�y) 03:49:38.07 ID:qVwlS5W5
2ch.net�ɑ吨�������葱���邱�Ƃ��S�̂ɂƂ��đ��������炾��B
����̌��ŊJ�������߂�ƌ����Ă�l�����������B
�����̃��[�U�[�����Ȃ��Ȃ��āAdat�`���݊��̑��̌f�����嗬�ɂȂ邱�Ƃ�
��u���J���҂̊J���p���ӗ~�����������邤���ł����Ƃ��L���Ȏ�i�Ȃ̂ł���B
��̂ɎR���͑���Jane�h���u���E�U���X�V�~�܂�����Style�̍X�V���ł��Ȃ��Ȃ邾�낗����
����̌��ŊJ�������߂�ƌ����Ă�l�����������B
�����̃��[�U�[�����Ȃ��Ȃ��āAdat�`���݊��̑��̌f�����嗬�ɂȂ邱�Ƃ�
��u���J���҂̊J���p���ӗ~�����������邤���ł����Ƃ��L���Ȏ�i�Ȃ̂ł���B
��̂ɎR���͑���Jane�h���u���E�U���X�V�~�܂�����Style�̍X�V���ł��Ȃ��Ȃ邾�낗����
�Z�����ڏZ���邩�ǂ����Ƒ���Jane�h���u���E�U�̊J������߂邩�ǂ����͒��ڂ̊W���Ȃ�
�R�����������߂�Jane�h���u���E�U�J���҂��������ĊJ����߂��Ƃ��Ă�
spyle�̊J�����̂��A�E�g�\�[�X���邱�Ƃ͉\
�R�����������߂�Jane�h���u���E�U�J���҂��������ĊJ����߂��Ƃ��Ă�
spyle�̊J�����̂��A�E�g�\�[�X���邱�Ƃ͉\
796 �F,,�E�L�́M�E,,�j��-�������F2015/02/21(�y) 05:04:04.80 ID:qVwlS5W5
�����Ƃ��W�Ȃ��ɁA2ch��p�̃u���E�U��2ch�Ŏg���Ȃ��Ȃ�����
�J������ӗ~�����Ȃ�Ɍ��܂��Ă邾��[���A�z��
������J�����p������Ӌ`���������邽�߂Ɍ݊��f���ɕ��U����K�v������̂��A��
�l�����Ă����̌f���ł��肻�̂��߂̃u���E�U������ˁB
�J������ӗ~�����Ȃ�Ɍ��܂��Ă邾��[���A�z��
������J�����p������Ӌ`���������邽�߂Ɍ݊��f���ɕ��U����K�v������̂��A��
�l�����Ă����̌f���ł��肻�̂��߂̃u���E�U������ˁB
chaika
���̃X���Ɍ�����܂łɂ��ځ[��ł��ĂȂ����_��
���ǂ̓X����グ�Ă�l���ړ�����Εt���Ă����
�������Ȃ��ł���
�ڂ�Ȃ�U���͂��Ă�
���ǂ̓X����グ�Ă�l���ړ�����Εt���Ă����
�������Ȃ��ł���
�ڂ�Ȃ�U���͂��Ă�
���낻��html2dat�v���L�V��kage.exe�I�ȃ��b�p�[���ۂ�ۂ�o�Ă��Ă鍠�Ȃ�Ȃ���
�K�v�͔����̕ꂾ��
�K�v�͔����̕ꂾ��
2��22������@ISSCC2015
�@�O��v���r���[�uISSCC2015�̕������v�i1�j�`�i13�j
�@ttp://eetimes.jp/ee/kw/ee_isscc2015.html
�@�O��v���r���[�uISSCC2015�̕������v�i1�j�`�i13�j
�@ttp://eetimes.jp/ee/kw/ee_isscc2015.html
801 �F,,�E�L�́M�E,,�j��-�������F2015/02/21(�y) 13:18:58.18 ID:qVwlS5W5
���[��A���͒��X����Ă邾���������
�Ă�����3/3�܂łɐ����^�p�ł���́H
�@�Ƃ����[���Ƃ��W�Ȃ��ɒN�������ȁ[�Ƃ͎v���Ă����ǂ�����͂Ƃ�����
API�g���Əd�����Ȃ�Ƃ��ǂ����悤���Ȃ��ˁH
�y�ߕ�z�ŋ߂�2ch���d�������������A�ǂ����VAPI�̎d�l�Ȃ̂ŐVAPI�Ή���u���g���̂�߂Ă�������
http://fox.2ch.net/test/read.cgi/poverty/1424469182
�Ă�����3/3�܂łɐ����^�p�ł���́H
�@�Ƃ����[���Ƃ��W�Ȃ��ɒN�������ȁ[�Ƃ͎v���Ă����ǂ�����͂Ƃ�����
API�g���Əd�����Ȃ�Ƃ��ǂ����悤���Ȃ��ˁH
�y�ߕ�z�ŋ߂�2ch���d�������������A�ǂ����VAPI�̎d�l�Ȃ̂ŐVAPI�Ή���u���g���̂�߂Ă�������
http://fox.2ch.net/test/read.cgi/poverty/1424469182
802 �F,,�E�L�́M�E,,�j��-�������F2015/02/21(�y) 13:21:01.00 ID:qVwlS5W5
JSON�g���Ƃ������Ă�����DAT�Ȍ�����������
�R������̃X�L���̂��s��������
�R������̃X�L���̂��s��������
�����̊W��SE���Ă��鎩��er�Ƃ��ẮA
�c�q���̏������݂�ǂނ̂��y����
twitter�ł������̂ŁA�ړ]��������Ă�
�c�q���̏������݂�ǂނ̂��y����
twitter�ł������̂ŁA�ړ]��������Ă�
>>794
dat�`������2ch�ȊO�ł����ՓI�Ȃ́H
���Ր��������Ƃ�����ʂɎ̂ĂĂ��\��Ȃ���
���Ր�������Ȃ�2ch���Ƃ�����߂Ă�dat�`���͎c��ł���
dat�`������2ch�ȊO�ł����ՓI�Ȃ́H
���Ր��������Ƃ�����ʂɎ̂ĂĂ��\��Ȃ���
���Ր�������Ȃ�2ch���Ƃ�����߂Ă�dat�`���͎c��ł���
�D��2ch�u���E�U����Ă鉴�ɂ͂����낢�b��
���l�͒m��A���͂��ǂ����̂���肽����������ȁB
2chmate�݂����ȑ��@�\�Ȃ��A�����g���₷���́B
���l�͒m��A���͂��ǂ����̂���肽����������ȁB
2chmate�݂����ȑ��@�\�Ȃ��A�����g���₷���́B
API�Ή��̘b���c
����sc��open2ch�Ɉڍs���邾�낤�Ȃ��B�B
����sc��open2ch�Ɉڍs���邾�낤�Ȃ��B�B
�N���[���Ƃ�IE�Ƃ����ʂ̃u���E�U�Ō����́H
�����͂�����B
����dat�t�@�C���ւ̒��A�N�Z�X���֎~�����
�R������d�����A��u���Ƃ��Ă͕�����
����dat�t�@�C���ւ̒��A�N�Z�X���֎~�����
�R������d�����A��u���Ƃ��Ă͕�����
809 �F,,�E�L�́M�E,,�j��-�������F2015/02/21(�y) 21:14:38.47 ID:qVwlS5W5
����́@�A�J��
http://sag.tank.jp/res/20150221/1424501082/911
http://sag.tank.jp/res/20150221/1424501082/911
>>809
�����
�����
��ЂŊJ���Ă��炷������
812 �F,,�E�L�́M�E,,�j��-�������F2015/02/22(��) 02:14:50.59 ID:/mEdeDGD
�˂������̓��Ȃ킯�����A�g��Ƃ��Ă������߂Ȃ����
0.8.6.x �y�d�v�z2ch.net �̐V�����d�l�ɂ��� (2015-02-21)
0.8.6.21 ��� 2ch.net �̐V�����d�l�ɑΉ����܂����B
����܂�2chMate�ł�Home��ʂƔ�ʂōL�����\������Ă���܂������A2015�N3��3���ȍ~�̓X���̉�ʂł��L�����\�������悤�ɂȂ�܂��B
�X���̉�ʂ̍L����Ronin���w�����邱�Ƃɂ���\���ɂ��邱�Ƃ��ł��܂��B
2chMate�̍L����\���I�v�V�����́AHome��ʂƔ�ʂł̂ݗL���ł��B
https://sites.google.com/site/nikenonomonooki/2chMate
0.8.6.21 ��� 2ch.net �̐V�����d�l�ɑΉ����܂����B
����܂�2chMate�ł�Home��ʂƔ�ʂōL�����\������Ă���܂������A2015�N3��3���ȍ~�̓X���̉�ʂł��L�����\�������悤�ɂȂ�܂��B
�X���̉�ʂ̍L����Ronin���w�����邱�Ƃɂ���\���ɂ��邱�Ƃ��ł��܂��B
2chMate�̍L����\���I�v�V�����́AHome��ʂƔ�ʂł̂ݗL���ł��B
https://sites.google.com/site/nikenonomonooki/2chMate
2ch�͂�����莞�Ԃ������Đ��ނ��Ă����Ǝv���Ă����ǂ����Ȃ蔚�j��̂���
html�X�N���C�s���O�ɂ��html�̍ė��p���R�邽�߂ɋ@�B���猩�ăm�C�Y���������@��
���낢�날�邩�炻�̎�̂���������ˁB
����PC���̂��������̃X���������Ĕp�ЂƉ����Ă�����ǂ��������ȁB
���낢�날�邩�炻�̎�̂���������ˁB
����PC���̂��������̃X���������Ĕp�ЂƉ����Ă�����ǂ��������ȁB
2ch����݂�Ȃ�����Ă������
�₵���悧���
�₵���悧���
�Q����.net�I���̂��m�点����c
818 �FSocket774�F2015/02/22(��) 17:34:57.45 ID:bium2EEP
Intel Preparing Something 'Big' and 'Disruptive' with Skylake Microarchitecture
http://wccftech.com/intel-preparing-dirsuptive-skylake-microarchitecture-morphcore/
http://wccftech.com/intel-preparing-dirsuptive-skylake-microarchitecture-morphcore/
MorphCore.�Ƃ����̂��V�����A�[�L�e�N�`���ɊW���Ă�݂��������ǁA
4�X���b�h��SMT��A�C���I�[�_�[�Ƃ������Ă��邯�ǁA�C�}�C�`�悭��������
4�X���b�h��SMT��A�C���I�[�_�[�Ƃ������Ă��邯�ǁA�C�}�C�`�悭��������
MorphyOne...
���낻�����Ă݂邩
�傫�ȕύX�����肻���ł���
823 �F,,�E�L�́M�E,,�j��-�������F2015/02/22(��) 19:19:55.68 ID:/mEdeDGD
MorphCore���Ă���ł���
http://ieeexplore.ieee.org/xpl/login.jsp?tp=&arnumber=6493629
�Ȃ����ꂪIntel�ƊW���H
�Ă�Edison���ʂɌl�ł���������A�Ȃɂ�����IoT���i�̊J���Ɏg����������
http://www.pc-koubou.jp/goods/1177390.html?dmai=a53f56c9732c77
http://ieeexplore.ieee.org/xpl/login.jsp?tp=&arnumber=6493629
�Ȃ����ꂪIntel�ƊW���H
�Ă�Edison���ʂɌl�ł���������A�Ȃɂ�����IoT���i�̊J���Ɏg����������
http://www.pc-koubou.jp/goods/1177390.html?dmai=a53f56c9732c77
"MorphCore: An Energy-Efficient Microarchitecture for High Performance ILP and High Throughput TLP"
�@Khubaib, K. ; Suleman, M.A. ; Hashemi, M. ; Wilkerson, C. ; Patt, Y.N.
abstract�@ttp://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=6493629
full text�@ttp://hps.ece.utexas.edu/people/khubaib/
Chris Wilkerson�Đl��Intel�ő��͑�w��
�M������Khubaib�͍��A�b�v���炵��
�@Khubaib, K. ; Suleman, M.A. ; Hashemi, M. ; Wilkerson, C. ; Patt, Y.N.
abstract�@ttp://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=6493629
full text�@ttp://hps.ece.utexas.edu/people/khubaib/
Chris Wilkerson�Đl��Intel�ő��͑�w��
�M������Khubaib�͍��A�b�v���炵��
�n�C�p�t�H�[�}���XOoO�R�A�ɋ͂��Ɏ�������邾���Łi�����ȃy�i���e�B�j
�ᕉ�ׂ̑��X���b�h�ł��������ɂ�����@�����邩��
�ʂ̃X���[���R�A��v���Ȃ��Ă�������A�Ƃ����b�݂�������
�ᕉ�ׂ̑��X���b�h�ł��������ɂ�����@�����邩��
�ʂ̃X���[���R�A��v���Ȃ��Ă�������A�Ƃ����b�݂�������
�Ȃ�قǁB
�����������������肩�B
�����������������肩�B
>>825
�����U�����ăX���b�h�Ƀv���C�I���e�B�^����������������\���낤���ǁA
�x�[�X�R�X�g�����������Ⴄ�̂ŃX���[���R�A��傫�����Ă����̂ɈӖ����Ȃ��Ƃ͎v��Ȃ��ȁB
Z�����ł��J�������H
�����U�����ăX���b�h�Ƀv���C�I���e�B�^����������������\���낤���ǁA
�x�[�X�R�X�g�����������Ⴄ�̂ŃX���[���R�A��傫�����Ă����̂ɈӖ����Ȃ��Ƃ͎v��Ȃ��ȁB
Z�����ł��J�������H
>>823
edison����������
ARM�}�C�R���Ȃ猋�\�����\�Ȃ̂����̔��z�ȉ��Ŕ����邵
�ǂ����Ă�windows�����������Ƃ�����Ȃ���A
ARM�ł����C�������
edison����������
ARM�}�C�R���Ȃ猋�\�����\�Ȃ̂����̔��z�ȉ��Ŕ����邵
�ǂ����Ă�windows�����������Ƃ�����Ȃ���A
ARM�ł����C�������
>>720
�_���s���O���Č��t���m��Ȃ��̂��悗
�_���s���O���Č��t���m��Ȃ��̂��悗
830 �FSocket774�F2015/02/23(��) 11:52:47.00 ID:HtyQVSCs
�x�m�ʁACPU�Ԃ̍����`�����]���̔����̓d�͂Ŏ������������M�Z�p - PC Watch
http://pc.watch.impress.co.jp/docs/news/20150223_689447.html?ref=rss
http://pc.watch.impress.co.jp/docs/news/20150223_689447.html?ref=rss
>830
SPARC64 XIfx��FX100�Ɏg���Ă�C���^�[�R�l�N�g��
25Gbpsx4 12.5GB/s 10���������{��Gbps�͓����B
�d�͂�ʐς��������Ȃ��x4 �������₷���Ƃ��o����Ƃ������Ƃ�
ttp://news.mynavi.jp/photo/articles/2014/12/05/sc14_fx100/images/014l.jpg
SPARC64 XIfx��FX100�Ɏg���Ă�C���^�[�R�l�N�g��
25Gbpsx4 12.5GB/s 10���������{��Gbps�͓����B
�d�͂�ʐς��������Ȃ��x4 �������₷���Ƃ��o����Ƃ������Ƃ�
ttp://news.mynavi.jp/photo/articles/2014/12/05/sc14_fx100/images/014l.jpg
{kind=link}
�x�m�ʂ̎���HPC�́A���C���������S��HMC�ɂȂ�̂��ȁH
>832
ttp://news.mynavi.jp/articles/2014/12/05/sc14_fx100/001.html
>831�Ɠ����L�������AJAXA��4���ɉғ��\���FX100��HMC���ȁB
�������ƃ��W�b�N��4+1���ϑw��HMC��1CPU������8�B
�|�X�gFX100�͂ǂ�����낤��
ttp://news.mynavi.jp/articles/2014/12/05/sc14_fx100/001.html
>831�Ɠ����L�������AJAXA��4���ɉғ��\���FX100��HMC���ȁB
�������ƃ��W�b�N��4+1���ϑw��HMC��1CPU������8�B
�|�X�gFX100�͂ǂ�����낤��
����̓��{���X�p�R���̃������Z�p�Ɋւ���v�V�͑����ˑ����Ă��Ƃ����
����������s���G���s�ׂ����̂�
����������s���G���s�ׂ����̂�
�G���s�[�_���}�C�N�����ɂȂ�������HBM�̗p���Ă��ł���B
���{��ƂɊ֘A�Ȃ������瑽���̗p����Ȃ��B
�G���s�[�_�̓R�X�g�x�Ԃ��Ő��\�҂��ł��ʂ�����̂ō��̎����������낤�B
���{��ƂɊ֘A�Ȃ������瑽���̗p����Ȃ��B
�G���s�[�_�̓R�X�g�x�Ԃ��Ő��\�҂��ł��ʂ�����̂ō��̎����������낤�B
���̃������̓`�������Ȃ��Ǔ��{�̊�Ƃ����\�O���t�B�W�̋Z�p��[�����Ă邩��W������ė����H��
���̃��������[�J�[�́ADRAM�s���̂Ƃ���Flash�ʼn҂��ł����A
�G���s�[�_�́AFlash�s��ɎQ�����ĂȂ������̂�DRAM�s���ł��̂܂ܒׂꂽ
�܂�DRAM�s�����̃G���s�[�_����C��܂��ɗʎY���܂������̂������̂ЂƂ��낤��
�G���s�[�_�́AFlash�s��ɎQ�����ĂȂ������̂�DRAM�s���ł��̂܂ܒׂꂽ
�܂�DRAM�s�����̃G���s�[�_����C��܂��ɗʎY���܂������̂������̂ЂƂ��낤��
�t���b�V���Q�����Ȃ����Ă������f�������G���s�[�_�o�c�w���A
�G���s�[�_�|�Y�̎�Ƃ݂����Ȃ���
�G���s�[�_�|�Y�̎�Ƃ݂����Ȃ���
>>836
�R�X�g�͂�����邪�A���ɍ��@�\�Ȃ��̂�I�肷��Ƃ��ɓ��{����������Ă��邩���Ă����͎̂����w�j�ɂȂ�B
>>837
�������ɋ�g������Ƃ���肽�����肾��������ȁB
�R�X�g�͂�����邪�A���ɍ��@�\�Ȃ��̂�I�肷��Ƃ��ɓ��{����������Ă��邩���Ă����͎̂����w�j�ɂȂ�B
>>837
�������ɋ�g������Ƃ���肽�����肾��������ȁB
>>838
���A�T���X���A�n�C�j�b�N�X�A�}�C�N������3�Ђł������荂����������ŊÂ��`�z���܂���Ȃ̂�����Ε����邾��
�t���b�V���Q���͖��Ӗ�
���A�T���X���A�n�C�j�b�N�X�A�}�C�N������3�Ђł������荂����������ŊÂ��`�z���܂���Ȃ̂�����Ε����邾��
�t���b�V���Q���͖��Ӗ�
���N��s�͏����Ă��G���s�[�_�͖���
>>840
�S���t���b�V������ĂȂ����H
�S���t���b�V������ĂȂ����H
���̃��[�J�[�@DRAM�H��̉ғ����������������������ADRAM�H��̃��C����Flash�ɓ]�p���ĉғ����ێ����悤
�G���s�[�_�@DRAM�H��̉ғ������������Ȃ������̂܂�DRAM�������ē������肵�悤
�G���s�[�_�@DRAM�H��̉ғ������������Ȃ������̂܂�DRAM�������ē������肵�悤
�����̃Z�J���h�\�[�X�Ƃ��Ă��̎��̓t���b�V���K�v�������̂͂���ȁ[�B
���Z�T�C�h�̔����͂������Ȃ��Ă��������ʂ������Ƃ��낭�Ɏc��Ȃ��Ȃ������̕č���p������
�A�����J�Ȃ�ČR���ȊO�̖������v�͑S���x�ߐ��Y���肾
�A�����J�Ȃ�ČR���ȊO�̖������v�͑S���x�ߐ��Y���肾
�ނ���A�����J�̓V�F�[���K�X�ɂ��G�l���M�[�R�X�g�ቺ�ŁA
�����Ƃ���������C�z������
�����Ƃ���������C�z������
>>846
�����̌������ŃV�F�[���K�X��Ƃ��|�Y���Ă�̂ɂ��H
���{�Ƃ��A�����J�Ő��Y���Ȃ��̂̓I�C���R�X�g��������˂���
�����̌������ŃV�F�[���K�X��Ƃ��|�Y���Ă�̂ɂ��H
���{�Ƃ��A�����J�Ő��Y���Ȃ��̂̓I�C���R�X�g��������˂���
>>843
PC����DRAM�����\�������ăG���s�[�_��s����ɂ����������͑�p
PC����DRAM�����\�������ăG���s�[�_��s����ɂ����������͑�p
2015�N1���̍���PC�o�ׂ͑O�N�䔼���������AJEITA����
http://m.pc.watch.impress.co.jp/docs/news/20150223_689586.html
����PC�̏o�ב䐔��51��7���ŁA�O�N�̔����ȉ��ƂȂ�48.7%�̑O�N��������тƂȂ����B
���Ƀf�X�N�g�b�vPC�̗������݂������ŁA�O�N��39.3%��14����B
�m�[�gPC�͑O�N��53.5%��37��7��䂾�����B
http://m.pc.watch.impress.co.jp/docs/news/20150223_689586.html
����PC�̏o�ב䐔��51��7���ŁA�O�N�̔����ȉ��ƂȂ�48.7%�̑O�N��������тƂȂ����B
���Ƀf�X�N�g�b�vPC�̗������݂������ŁA�O�N��39.3%��14����B
�m�[�gPC�͑O�N��53.5%��37��7��䂾�����B
����ł�14���������Ă��
����Ⴢ�o�C���̂悤�ɏȓd�͂����Ȃ��f�X�N�g�b�vPC�́A
Sandy�������炻��ȍ~����܂Ŕ����ւ���K�v�Ȃ������
Sandy Bridge�������l�������ւ������Ȃ�悤��PC��
���ɂȂ�Ώo��̂��낤��
Sandy�������炻��ȍ~����܂Ŕ����ւ���K�v�Ȃ������
Sandy Bridge�������l�������ւ������Ȃ�悤��PC��
���ɂȂ�Ώo��̂��낤��
853 �F,,�E�L�́M�E,,�j��-�������F2015/02/23(��) 20:31:51.68 ID:Mne6GXgt
���N��XP�����ւ�������ŗ��A�b�v�O�̋삯���ݎ��v�����������
���������Ďg�������Ă��B
SATA EXPRESS�Ή���������낤���Ƃ͎v���Ă邯��
SATA EXPRESS�Ή���������낤���Ƃ͎v���Ă邯��
855 �F,,�E�L�́M�E,,�j��-�������F2015/02/23(��) 21:57:26.31 ID:Mne6GXgt
�Ȃu���C�N�X���[�~�������
Pentium Pro�@3IPC + OoO + ���W�X�^���l�[�~���O
Pentium 4�@�@�@�n�C�p�[�p�C�v���C���ɂ�鍂�N���b�N�쓮�{���s�g���[�X�L���b�V��
Pentium M�@�@��OPs fusion + ��e��L2�L���b�V��
Core 2 �@�@�@�@4IPC��
1st. Core i*�@�@32�G���g����OPs buffer + �����R������ + �L���b�V��3�K�w��
2nd. Core i*�@��OPs buffer + �����R������ + �L���b�V��3�K�w��
3rd. Core i*�@mov�G���~�l�[�V����
Haswell��K8��K10�Ȃ݂̖}��
Pentium Pro�@3IPC + OoO + ���W�X�^���l�[�~���O
Pentium 4�@�@�@�n�C�p�[�p�C�v���C���ɂ�鍂�N���b�N�쓮�{���s�g���[�X�L���b�V��
Pentium M�@�@��OPs fusion + ��e��L2�L���b�V��
Core 2 �@�@�@�@4IPC��
1st. Core i*�@�@32�G���g����OPs buffer + �����R������ + �L���b�V��3�K�w��
2nd. Core i*�@��OPs buffer + �����R������ + �L���b�V��3�K�w��
3rd. Core i*�@mov�G���~�l�[�V����
Haswell��K8��K10�Ȃ݂̖}��
4gamer�̃X�e�}�H��Ɋ��������K8->K10��}��ƌ��������Ⴄ�̂̓A�z�Ǝv���܂���
���̋m����bull�͔��M�Ƌ���ł��낤��
���̃C���e��CPU�̓A�|�̕��������ĂȂ��}�N�I�^�����̕���
���̋m����bull�͔��M�Ƌ���ł��낤��
���̃C���e��CPU�̓A�|�̕��������ĂȂ��}�N�I�^�����̕���
�����f�X�N�g�b�v����PC�n�߂�̂Ȃ�ăQ�[�}�[���炢����
�����ړI�����ăf�X�N�g�b�v�~������l�͕��ʂɎ��삷��ł���
�Ƃ肠����QSV��Haswell�łȂ�Ƃ��g�����ɂȂ郌�x���ɂȂ��Ă�������
�������ш悪����ĂȂ��Ƃ��Ȃ�Ƃ��HSkylake��95W�łɂ�Ilis�ς�łق���
�����ړI�����ăf�X�N�g�b�v�~������l�͕��ʂɎ��삷��ł���
�Ƃ肠����QSV��Haswell�łȂ�Ƃ��g�����ɂȂ郌�x���ɂȂ��Ă�������
�������ш悪����ĂȂ��Ƃ��Ȃ�Ƃ��HSkylake��95W�łɂ�Ilis�ς�łق���
�@�͂���ȏ�ɂЂǂ������Ǝv���B
���Ғl���₽�獂����������A����Ɏc�O������
���Ғl���₽�獂����������A����Ɏc�O������
859 �F,,�E�L�́M�E,,�j��-�������F2015/02/23(��) 22:12:33.65 ID:Mne6GXgt
����K10�͖}��ł���B����SIMD��2�{�ɂȂ��������B
CPU�R�A�̐v�I��Ivy Bridge��Haswell�̗����ʒu�ƕς��Ȃ��B
Skylake�������ȈӖ��Ŋy���݂��ȁB
�P��Broadwell��SIMD��512�r�b�g�����������̑㕨�Ȃ�A���悢�攃�����̂Ȃ����H
�R���V���[�}�����͍X�ɂ���512�r�b�gSIMD�����������
CPU�R�A�̐v�I��Ivy Bridge��Haswell�̗����ʒu�ƕς��Ȃ��B
Skylake�������ȈӖ��Ŋy���݂��ȁB
�P��Broadwell��SIMD��512�r�b�g�����������̑㕨�Ȃ�A���悢�攃�����̂Ȃ����H
�R���V���[�}�����͍X�ɂ���512�r�b�gSIMD�����������
���z���ɂ��肪�����Ă邾��c
Ivy����@�R���͑��ς�炸��HD�O������4K�r�f�I�ɑΉ������Ƃ�
�A�|����CPU�Ƃ��Ă̖ʖږ��@
Ivy����@�R���͑��ς�炸��HD�O������4K�r�f�I�ɑΉ������Ƃ�
�A�|����CPU�Ƃ��Ă̖ʖږ��@
861 �F,,�E�L�́M�E,,�j��-�������F2015/02/23(��) 23:14:54.59 ID:Mne6GXgt
Apple�͌����I��Intel����̏�芷���悪�Ȃ��Ǝv���̂ł�
Haswell��AVX2���߂����������ŏ���CPU�ɂ��čŏ��Ƀt��256�r�b�g������CPU�ł�����
Pentium Pro�̂悤�ɂ��Ƃ���]���������Ȃ�^�C�v�̃`�b�v���Ǝv���Ă�B
Haswell��AVX2���߂����������ŏ���CPU�ɂ��čŏ��Ƀt��256�r�b�g������CPU�ł�����
Pentium Pro�̂悤�ɂ��Ƃ���]���������Ȃ�^�C�v�̃`�b�v���Ǝv���Ă�B
�t�ł���
���̃C���e���ɂ͑����CPU�����Ă����q���A�|���炢�������Ȃ�
���̃C���e���ɂ͑����CPU�����Ă����q���A�|���炢�������Ȃ�
863 �F,,�E�L�́M�E,,�j��-�������F2015/02/23(��) 23:25:16.42 ID:Mne6GXgt
2�N��1���V���f���o���Ȃ�Apple���E�E�E�ˁB
��������v��������c
���ێS�D��Ivy���@�R�����@���t���ǂ���̗p���Ă���Ă邾��
�T�C�����g�A�b�v�f�[�g�̏ꍇ�܂߂Ă�
���ێS�D��Ivy���@�R�����@���t���ǂ���̗p���Ă���Ă邾��
�T�C�����g�A�b�v�f�[�g�̏ꍇ�܂߂Ă�
865 �F,,�E�L�́M�E,,�j��-�������F2015/02/23(��) 23:40:29.64 ID:Mne6GXgt
����A�����炱��Intel���瓦����Ȃ��ƌ����Ă�B
�������Thunderbolt�Ή��`�b�v�Z�b�g���郁�[�J�[��Intel�ȊO�ɂȂ��B
USB3.1 type-C�ɓ��ꂷ��Ȃ�ĉ\������ɂ͂��邪�ǂ��Ȃ���
�������Thunderbolt�Ή��`�b�v�Z�b�g���郁�[�J�[��Intel�ȊO�ɂȂ��B
USB3.1 type-C�ɓ��ꂷ��Ȃ�ĉ\������ɂ͂��邪�ǂ��Ȃ���
�����͏�q�ɓ������Ȃ��悤�ɓƎ��Z�p�ň͂�����ł��邳
�����ʂ�������
Apple�̎��v��������̂�Intel����
AMD���Ƒ���Ȃ�����AHP�ADELL�̂ǂ��炩���Ȃ��Ɩ���
���邢�́APS4�Ɣ�1�~�߂�AApple�����炢�͉��Ƃ��Ȃ�
Apple�̎��v��������̂�Intel����
AMD���Ƒ���Ȃ�����AHP�ADELL�̂ǂ��炩���Ȃ��Ɩ���
���邢�́APS4�Ɣ�1�~�߂�AApple�����炢�͉��Ƃ��Ȃ�
868 �FSocket774�F2015/02/24(��) 00:25:32.68 ID:jt/qm8hk
�����A�ʎq�R���s���[�^�ɕC�G����CMOS�����̃R���s���[�^���J��
http://www.hitachi.co.jp/New/cnews/month/2015/02/0223b.html
http://pc.watch.impress.co.jp/docs/news/20150223_689576.html
�@�����65nm�v���Z�X�Ő������ꂽ�����̂�p�����R���s���[�^�̎���@���J���B���݂̗ʎq�R���s���[�^�̃p�����[�^��512��
���A20,480�p�����[�^�̑g�ݍ��킹�œK������msec�ʼn����A�]���̃R���s���[�^�Ɣ�r���ēd�͌�������1,800�{�ƂȂ邱�Ƃ�
�������B�܂��A�V�X�e�����퉷�œ��삷�邱�Ƃ��m�F����Ă���B���̎d�g�݂�14nm�v���Z�X�̔����̂Ŏ��������ꍇ�ɂ́A1,600���p�����[�^�ɑΉ����邱�Ƃ��ł���Ƃ����B
http://www.hitachi.co.jp/New/cnews/month/2015/02/0223b.html
http://pc.watch.impress.co.jp/docs/news/20150223_689576.html
�@�����65nm�v���Z�X�Ő������ꂽ�����̂�p�����R���s���[�^�̎���@���J���B���݂̗ʎq�R���s���[�^�̃p�����[�^��512��
���A20,480�p�����[�^�̑g�ݍ��킹�œK������msec�ʼn����A�]���̃R���s���[�^�Ɣ�r���ēd�͌�������1,800�{�ƂȂ邱�Ƃ�
�������B�܂��A�V�X�e�����퉷�œ��삷�邱�Ƃ��m�F����Ă���B���̎d�g�݂�14nm�v���Z�X�̔����̂Ŏ��������ꍇ�ɂ́A1,600���p�����[�^�ɑΉ����邱�Ƃ��ł���Ƃ����B
�A�|�̓E���g���n�C�G���h���f���ȊO�ł�GPU�̕`��i�����y������X��������̂�
AMD���`�b�v��{�i�̗p�͂��肦�Ȃ��Ǝv���܂�
���ېM�҂ǂ��͂���Ŗ������Ă���悤�Ȃ̂�
AMD���`�b�v��{�i�̗p�͂��肦�Ȃ��Ǝv���܂�
���ېM�҂ǂ��͂���Ŗ������Ă���悤�Ȃ̂�
870 �F,,�E�L�́M�E,,�j��-�������F2015/02/24(��) 00:40:05.24 ID:MMHemARs
�G���g���[���i��Mac mini�ł���i3�ȉ�����Ȃɍ̗p���Ȃ��̂�Apple
�܂��A�G���g���[���i��Celeron��BayTrail��������ʂɍ̗p���钆����p���[�J�[�Ɣ�ׂ��
�����q�ł͂��邩��
�܂��A�G���g���[���i��Celeron��BayTrail��������ʂɍ̗p���钆����p���[�J�[�Ɣ�ׂ��
�����q�ł͂��邩��
web�ƃ��[����itunes���OS�̂��܂��Ă��Ă���A�v�������g��Ȃ��݂����Ȑl�Ȃ�A
�ׂ�Mac��AMD�����Ă��������낤���ǁA
�N���G�C�^�[�n�E�Ƃ̐l�́AAMD�����ăp�t�H�[�}���X�������獢�邾��
�ׂ�Mac��AMD�����Ă��������낤���ǁA
�N���G�C�^�[�n�E�Ƃ̐l�́AAMD�����ăp�t�H�[�}���X�������獢�邾��
�v���O���}��PC��ATOM�ł������B
�G�W�\����Windows���������炻��ł������B
�G�W�\����Windows���������炻��ł������B
���肦�����[��Xeon��Mac Pro �g��������
��������Ȃ��z�́AAPU���炢�̐��\�ŏ\������
������Q�[����������Ƃ����ҏW��Ƃ��]�T�ł��Ȃ��邩���
��������Ȃ��z�́AAPU���炢�̐��\�ŏ\������
������Q�[����������Ƃ����ҏW��Ƃ��]�T�ł��Ȃ��邩���
APU���Ă��������������ʖڂ���
875 �F,,�E�L�́M�E,,�j��-�������F2015/02/24(��) 02:27:30.93 ID:MMHemARs
APU�������ٕʕ{��F�����N�����A�z�����邩����{�ł̓C���[�W�ǂ��Ȃ���
http://www.sisoftware.eu/rank2011d/show_system.php?q=cea598aa9fab99a99fb9dee3ceffd9ab96a680e9d4e5c3ab96a385fdc0f1d7b2d7eadafc8fb28a&l=jp
Skylake([email protected]?)
SIMD:170.25Mpix/�b
Multi-Media Integer 200.09Mpix/�b
Multi-Media Long-int 92.24Mpix/�b
Multi-Media Quad-int 1074kpix/�b
Multi-Media Single-float 193.00Mpix/�b
Multi-Media Double-float 127.78Mpix/�b
Multi-Media Quad-float 5181kpix/�b
ALU/FPU:67.72GOPS
Dhrystone 98.26GIPS
Whetstone Single-float 54.62GFLOPS
Whetstone Double-float 39.88GFLOPS
�Q�l�܂ł�i7-4770T([email protected]�Œ�)
SIMD:134.75Mpix/�b
Multi-Media Integer 151.81Mpix/�b
Multi-Media Long-int 65.33Mpix/�b
Multi-Media Quad-int 1020kpix/�b
Multi-Media Single-float 148.8Mpix/�b
Multi-Media Double-float 108.32Mpix/�b
Multi-Media Quad-float 4100kpix/�b
ALU/FPU:62.63GOPS
Dhrystone 86.78GIPS
Whetstone Single-float 54.46GFLOPS
Whetstone Double-float 37.52GFLOPS
Skylake([email protected]?)
SIMD:170.25Mpix/�b
Multi-Media Integer 200.09Mpix/�b
Multi-Media Long-int 92.24Mpix/�b
Multi-Media Quad-int 1074kpix/�b
Multi-Media Single-float 193.00Mpix/�b
Multi-Media Double-float 127.78Mpix/�b
Multi-Media Quad-float 5181kpix/�b
ALU/FPU:67.72GOPS
Dhrystone 98.26GIPS
Whetstone Single-float 54.62GFLOPS
Whetstone Double-float 39.88GFLOPS
�Q�l�܂ł�i7-4770T([email protected]�Œ�)
SIMD:134.75Mpix/�b
Multi-Media Integer 151.81Mpix/�b
Multi-Media Long-int 65.33Mpix/�b
Multi-Media Quad-int 1020kpix/�b
Multi-Media Single-float 148.8Mpix/�b
Multi-Media Double-float 108.32Mpix/�b
Multi-Media Quad-float 4100kpix/�b
ALU/FPU:62.63GOPS
Dhrystone 86.78GIPS
Whetstone Single-float 54.46GFLOPS
Whetstone Double-float 37.52GFLOPS
877 �F,,�E�L�́M�E,,�j��-�������F2015/02/24(��) 02:46:19.53 ID:MMHemARs
AVX-512����Ă銄��SIMD�̐L�т������[��
�܂���SIMD���j�b�g4�{�ɂȂ����Ƃ��H
�s�[�N5IPC�Ƃ��ˁA�܂�����
Whetstone�͑z����ˁBFMAC�~2�Ȃ炻��Ȃ���ł��傤�B
�܂���SIMD���j�b�g4�{�ɂȂ����Ƃ��H
�s�[�N5IPC�Ƃ��ˁA�܂�����
Whetstone�͑z����ˁBFMAC�~2�Ȃ炻��Ȃ���ł��傤�B
>>873�@�Q�[���Ő��\������邩�ǂ������߂�̂͂��O����Ȃ�
���łɁA����PC�g�ނɂ��Ă��G���R�ア�̂��L�c�C�A����Đ������Ȃ�PC�v���
�܁A�w�b�h�z���Ń��j�^�[�����z�Ɠ����ŁA���[�U�[���N���G�C�^�[�Ɠ����������������֗�����
����APU����Fluid�@motion��Mode�Q�g���Ȃ��̂��c�c
����ق�Ƃ����A�G���R��CPU�t�����[�h����̂����
���x��FHD�Ŏ����Ԃ��炢�ł���������A�����ƌ����掿�̃n�[�h�E�F�A�G���R�[�_�~����
4k��4k-BD��Ʈ��Ʈ�\�t�g���o��܂ł͂ǂ��ł�����
���łɁA����PC�g�ނɂ��Ă��G���R�ア�̂��L�c�C�A����Đ������Ȃ�PC�v���
�܁A�w�b�h�z���Ń��j�^�[�����z�Ɠ����ŁA���[�U�[���N���G�C�^�[�Ɠ����������������֗�����
����APU����Fluid�@motion��Mode�Q�g���Ȃ��̂��c�c
����ق�Ƃ����A�G���R��CPU�t�����[�h����̂����
���x��FHD�Ŏ����Ԃ��炢�ł���������A�����ƌ����掿�̃n�[�h�E�F�A�G���R�[�_�~����
4k��4k-BD��Ʈ��Ʈ�\�t�g���o��܂ł͂ǂ��ł�����
x264�ł���
8370E�g���ǂ���
8370E�g���ǂ���
880 �F,,�E�L�́M�E,,�j��-�������F2015/02/24(��) 03:25:33.73 ID:MMHemARs
8370E���Ăǂ̂ւ�H
���̃X���Ŋ��߂�悤�Ȑ��i����Ȃ��Ǝv����
http://www.anandtech.com/bench/CPU/54
Atom C2750���ڂ��Ă�̂��l�I�ɃE�P��
>>878
> �܁A�w�b�h�z���Ń��j�^�[�����z�Ɠ����ŁA���[�U�[���N���G�C�^�[�Ɠ����������������֗�����
�܂�����͍S��l�͂�������ˁB
�N���G�C�^�[�ƃ��[�U�[�̊W�ł͂Ȃ����ǁuAVX2���g����CPU�V�����Ȃ��Ɓv���Č����z��
Haswell��Xeon �o�Ă��瑝�����ˁB
�T�[�o�œ����v���O���������z�ɂ̓T�[�o�Ɠ������߃Z�b�g���T�|�[�g����CPU�͕K�{�B
���̃X���Ŋ��߂�悤�Ȑ��i����Ȃ��Ǝv����
http://www.anandtech.com/bench/CPU/54
Atom C2750���ڂ��Ă�̂��l�I�ɃE�P��
>>878
> �܁A�w�b�h�z���Ń��j�^�[�����z�Ɠ����ŁA���[�U�[���N���G�C�^�[�Ɠ����������������֗�����
�܂�����͍S��l�͂�������ˁB
�N���G�C�^�[�ƃ��[�U�[�̊W�ł͂Ȃ����ǁuAVX2���g����CPU�V�����Ȃ��Ɓv���Č����z��
Haswell��Xeon �o�Ă��瑝�����ˁB
�T�[�o�œ����v���O���������z�ɂ̓T�[�o�Ɠ������߃Z�b�g���T�|�[�g����CPU�͕K�{�B
�Ă��܂��AAndroid studio�g���Ă邪������SSD���Ă��A
�R���p�C���ɂ����鎞�Ԃ��l�����APU�͂��肦���
�R���p�C���ɂ����鎞�Ԃ��l�����APU�͂��肦���
882 �F,,�E�L�́M�E,,�j��-�������F2015/02/24(��) 04:24:34.60 ID:MMHemARs
���̃m�[�g��16GB��SSD�i�L���b�V���p�j + 7200rpm HDD500GB����
Visual Studio�Ŏg�����ƍl���Ă��̍\���ɂ���
���ۂɂ̓Q�[������Ă鎞�Ԃ̂ق��������Ƃ����ˁi����Ɖ��K�����j
Visual Studio�Ŏg�����ƍl���Ă��̍\���ɂ���
���ۂɂ̓Q�[������Ă鎞�Ԃ̂ق��������Ƃ����ˁi����Ɖ��K�����j
�����̐��\�ɓ��i�s�����Ȃ������낻����ւ������Ȃ��B�B
AVX�Ƃ��g���A�v���͑����g��Ȃ�����A�f�̐��\��������҂��邪�A
skylake�͂ǂ��Ȃ��ˁB
���G������GIMP�~�܂肾��B
SATA Express�Ή������邩������Ȃ��ˁB
AVX�Ƃ��g���A�v���͑����g��Ȃ�����A�f�̐��\��������҂��邪�A
skylake�͂ǂ��Ȃ��ˁB
���G������GIMP�~�܂肾��B
SATA Express�Ή������邩������Ȃ��ˁB
2500K����4770K�ɕς������A
VS�̃r���h���Ԃ������߂��ɂȂ�����
HTT�̌��ʂ��������A�P�R�A���\��2���ȏ����Ă�
VS�̃r���h���Ԃ������߂��ɂȂ�����
HTT�̌��ʂ��������A�P�R�A���\��2���ȏ����Ă�
�C���e���A�u���[�A�̖@���v��7nm�v���Z�X����ɂ܂œK�p����錩�ʂ��𖾂炩��
http://ggsoku.com/2015/02/intel-conference-call-isscc-2015/
http://ggsoku.com/2015/02/intel-conference-call-isscc-2015/
AMD�C����APU�uCarrizo�v�̏ڍ������J�BKaveri�Ɠ���28nm�v���Z�X�Z�p���̗p���Ȃ���g�����W�X�^����29�����ʂł����閧�Ƃ� - 4Gamer.net
http://www.4gamer.net/games/282/G028229/20150223061/
http://www.4gamer.net/games/282/G028229/20150223061/
���Ӗ��s��������
�Ȃ����Ƃ�肽���Ȃ�A�t�B�j�e�B�ݒ蒲������Ⴂ������
�Ȃ����Ƃ�肽���Ȃ�A�t�B�j�e�B�ݒ蒲������Ⴂ������
���������A�v�����Ƃ̗D��x�M��Ƃ��_����
���O�̔n���ۏo�����������������ځ[��̂��邢
�D��x�M��Ȃ�ăx���`�Ԓ��̃C���e��CPU���䖳�������
�������̓^�X�N��ւ����璴�҂�����邩�炻��ȂƂ���M�����Ƃ���ŏ��F�C�x�߂���
�������̓^�X�N��ւ����璴�҂�����邩�炻��ȂƂ���M�����Ƃ���ŏ��F�C�x�߂���
������^�X�N�����œ���������CPU�g�[�^���̉��Z���\��������킯�ł͂Ȃ�
�n�[�h�E�F�A�̃T�|�[�g����X���b�h�����ĂȂ����Ƃ�����̕�����
�������ŏ�������邩��X�̃^�X�N�̃p�t�H�[�}���X�͗�����
���ɗD�悷��^�X�N�������ăo�b�N�O���E���h�œ����������Ȃ�
8�X���b�h�S�����蓖�ĂȂ��Ă�1�R�A�������蓖�ĂƂ���������Ȃ���
���FAMD��AMD�A�ᐫ�\�͉��^�X�N�������Ă��ᐫ�\
�n�[�h�E�F�A�̃T�|�[�g����X���b�h�����ĂȂ����Ƃ�����̕�����
�������ŏ�������邩��X�̃^�X�N�̃p�t�H�[�}���X�͗�����
���ɗD�悷��^�X�N�������ăo�b�N�O���E���h�œ����������Ȃ�
8�X���b�h�S�����蓖�ĂȂ��Ă�1�R�A�������蓖�ĂƂ���������Ȃ���
���FAMD��AMD�A�ᐫ�\�͉��^�X�N�������Ă��ᐫ�\
�����������H��M���Ă��������x�͒��x���Ȃ邩��}���`�^�X�N�Ŏ��p�I�ɓ����Ȃ���
���ꂪ�V���O���^�X�N�̃x���`�̂݉Đ��\���ǂ�������������x���̎��
���ꂪ�V���O���^�X�N�̃x���`�̂݉Đ��\���ǂ�������������x���̎��
ID:jMfbNXxs
>>887
�}���`�^�X�N���ǂ��̂Ƃ��A2600��4,4Ghz��x264�G���R�Ńt�����[�h���Ȃ���285X�łS���A�v�R���{���z�S��
�{�掿����X�Ńk���k���A�j�����Ȃ���n�f�W�^�悵�Ȃ���LINE���Ȃ���PC�Ō��d�b��M������ł��邪��
�����A�G���R���ɃQ�[�������蓮��̃X�g���[�~���O�����肪�o���Ȃ��i�G���R�Ɋ���U��CPU���\�[�X������������ǒx���j
���Ă̂�������ƕs�ւɂ͊�����Ƃ�����CPU�t�����[�h���Ă��AMDCPU�ł�������ӈꏏ�ł��傗
������n�[�h�E�F�A�G���R�[�_�[�ɂ͊��҂��Ă�̂�A���ꂩ������̂W�R�AFX�ł���������
�o�邩�ǂ��������������
�}���`�^�X�N���ǂ��̂Ƃ��A2600��4,4Ghz��x264�G���R�Ńt�����[�h���Ȃ���285X�łS���A�v�R���{���z�S��
�{�掿����X�Ńk���k���A�j�����Ȃ���n�f�W�^�悵�Ȃ���LINE���Ȃ���PC�Ō��d�b��M������ł��邪��
�����A�G���R���ɃQ�[�������蓮��̃X�g���[�~���O�����肪�o���Ȃ��i�G���R�Ɋ���U��CPU���\�[�X������������ǒx���j
���Ă̂�������ƕs�ւɂ͊�����Ƃ�����CPU�t�����[�h���Ă��AMDCPU�ł�������ӈꏏ�ł��傗
������n�[�h�E�F�A�G���R�[�_�[�ɂ͊��҂��Ă�̂�A���ꂩ������̂W�R�AFX�ł���������
�o�邩�ǂ��������������
����ȂɃ}���`�^�X�N��肽���Ȃ�PC��䔃���ĕʁX�̎d���������ق���������
�G���R�[�_�[��AMD�ɍœK�����ĂȂ���CPU���Ă��Ȃ���
Microsoft�͂Ȃ��Android��Word/Excel/PowerPoint�o�����Ⴄ�́H
�����������ȁHWintel�̗D�ʐ������猸�炵�Ă����Ăǂ�����
�����������ȁHWintel�̗D�ʐ������猸�炵�Ă����Ăǂ�����
899 �F,,�E�L�́M�E,,�j��-�������F2015/02/24(��) 21:38:43.15 ID:/fcUNsIr
HTML�r���[��Office365���Ăяo���Ă邾���Ȃ̂ɂȂ������Ȃ�̂�
>>885
>7nm�v���Z�X�܂ł́A�v�V�I�ȋZ�p�̓�����K�v�Ƃ��邱�ƂȂ�
>7nm manufacturing (in 2018) can be done without moving to expensive, esoteric manufacturing methods
�u�v�V�I�v�ł̓j���A���X���`���Ȃ����낤�B
esoteric
1 ���`��; �[����, ����� (profound, recondite).
2 �q���@��ړI�Ȃǁr�閧�� (secret). �an esoteric motive.
3 �q���`�Ȃǁr�鋳�I��, (�I�ꂽ�����҂ɂ����`����)��`�� (��exoteric);
�@�q��q�Ȃǁr��`[���`]����. ���esoteric Buddhism.
�����АV�p�a�厫�T
>7nm�v���Z�X�܂ł́A�v�V�I�ȋZ�p�̓�����K�v�Ƃ��邱�ƂȂ�
>7nm manufacturing (in 2018) can be done without moving to expensive, esoteric manufacturing methods
�u�v�V�I�v�ł̓j���A���X���`���Ȃ����낤�B
esoteric
1 ���`��; �[����, ����� (profound, recondite).
2 �q���@��ړI�Ȃǁr�閧�� (secret). �an esoteric motive.
3 �q���`�Ȃǁr�鋳�I��, (�I�ꂽ�����҂ɂ����`����)��`�� (��exoteric);
�@�q��q�Ȃǁr��`[���`]����. ���esoteric Buddhism.
�����АV�p�a�厫�T
>>898�@�i�f����windows�̈�ʐl�i�j�̃V�F�A����߂Ă�Ƃ����\���c�c
Office�݊��A�v���͐F�X�ȏ������łɏo���Ă邵�AGoogle��Web�A�v����Office�݊��o���Ă邵��
�ǂ̓�����Office�̈͂����݂ŋ����͖̂����ł���A���x�ȋ@�\�~�����l�����f�X�N�g�b�v�A�v���Ŕ������Ċ����H
�n�C�G���hPC�g���Ă�p�\�R���I�^�N�ɂ������āA���̃n�C�G���hPC�����\�t�g�̓n�[�h�̋@�\�Ɉˑ�����̂�������
OpenCL�����邩�����ς�OS��A�v���K�i�����ň͂����ނ͖̂����Q�[
����ł�����ρA���[�U�[��x���_�[���D������ɑg�R���s���[�^��OS�œ�����������Ă͕̂֗������ǂ�
�����ɍœK������I���Ĉӌ��������邯�ǁA�[���̎�ނ��ו����������Ă邵�A�嗬�ɏ�������Ă邾������windows�ł���K�v���Ȃ���
�n�[�h������Ă�Apple�̂悤�ɂ͂����Ȃ���˂����
Office�݊��A�v���͐F�X�ȏ������łɏo���Ă邵�AGoogle��Web�A�v����Office�݊��o���Ă邵��
�ǂ̓�����Office�̈͂����݂ŋ����͖̂����ł���A���x�ȋ@�\�~�����l�����f�X�N�g�b�v�A�v���Ŕ������Ċ����H
�n�C�G���hPC�g���Ă�p�\�R���I�^�N�ɂ������āA���̃n�C�G���hPC�����\�t�g�̓n�[�h�̋@�\�Ɉˑ�����̂�������
OpenCL�����邩�����ς�OS��A�v���K�i�����ň͂����ނ͖̂����Q�[
����ł�����ρA���[�U�[��x���_�[���D������ɑg�R���s���[�^��OS�œ�����������Ă͕̂֗������ǂ�
�����ɍœK������I���Ĉӌ��������邯�ǁA�[���̎�ނ��ו����������Ă邵�A�嗬�ɏ�������Ă邾������windows�ł���K�v���Ȃ���
�n�[�h������Ă�Apple�̂悤�ɂ͂����Ȃ���˂����
Microsoft
�j���[�����l�b�g���[�N���Z�ɓ�������FPGA�A�N�Z�����[�^���J��(�p��)
http://research.microsoft.com/apps/pubs/default.aspx?id=240715
�j���[�����l�b�g���[�N���Z�ɓ�������FPGA�A�N�Z�����[�^���J��(�p��)
http://research.microsoft.com/apps/pubs/default.aspx?id=240715
904 �F,,�E�L�́M�E,,�j��-�������F2015/02/24(��) 22:37:33.18 ID:/fcUNsIr
iOS/Android��Office�i��Office365���Ăяo���Ă邾���j����Win32�̃v���O�C���͎g���Ȃ�
���R�ȒP�ȕҏW���x�����ł��Ȃ����A�v���O�C����V���ɍ�邱�Ƃ��ł��Ȃ�����
�V���ɃR�[�h���Y�̍��܂�邱�Ƃ��Ȃ�
���R�ȒP�ȕҏW���x�����ł��Ȃ����A�v���O�C����V���ɍ�邱�Ƃ��ł��Ȃ�����
�V���ɃR�[�h���Y�̍��܂�邱�Ƃ��Ȃ�
���z�A�v�����Ă��Ƃ��ȁH
HSA�ʼn��z�A�v���������Ȃ�ƕ�������
HSA�ʼn��z�A�v���������Ȃ�ƕ�������
906 �F,,�E�L�́M�E,,�j��-�������F2015/02/24(��) 23:06:52.91 ID:/fcUNsIr
�A�v����ʂ�Web�u���E�U�g�ݍ����HTML��JavaScript�x�[�X�ŕ\�����Ă邾���ł����H
JavaScript��GPU�Ŏ��s����́H�ł���́H
JavaScript��GPU�Ŏ��s����́H�ł���́H
HSA��Java�A�N�Z�����[�^�Ȃ���̂��J�������Ęb�͂����
�K�v���H���Ė����ƌ��\���邯��
>>905�@����OS�̃\�t�g�������Ă�̂͑�̌݊�API��������web�x�[�X�������肾��
��p�ɃG�~�����[�^�ς�ł�̂̓X�g�A�A�v���̉��ÃQ�[�Ƃ�����������Ȃ��������ȁH
HSA�ŕ�����OS�œ����A�v�����点���܂���`���Č����Ă�̂�HSA���n�[�h�E�F�A�Ɉˑ����鏈���������
���z���Z�p������ł͂Ȃ����
�K�v���H���Ė����ƌ��\���邯��
>>905�@����OS�̃\�t�g�������Ă�̂͑�̌݊�API��������web�x�[�X�������肾��
��p�ɃG�~�����[�^�ς�ł�̂̓X�g�A�A�v���̉��ÃQ�[�Ƃ�����������Ȃ��������ȁH
HSA�ŕ�����OS�œ����A�v�����点���܂���`���Č����Ă�̂�HSA���n�[�h�E�F�A�Ɉˑ����鏈���������
���z���Z�p������ł͂Ȃ����
>>903
���ꂪ��ʌ���CPU�ɓ��ڂ��ꂽ��madVR������낤��
���ꂪ��ʌ���CPU�ɓ��ڂ��ꂽ��madVR������낤��
909 �F,,�E�L�́M�E,,�j��-�������F2015/02/24(��) 23:29:10.49 ID:/fcUNsIr
JavaScript�R�[�h��OpenCL�ɃI�t���[�h����g���@�\�J�����Ă��Intel�����ǂ�
https://github.com/IntelLabs/RiverTrail
https://github.com/IntelLabs/RiverTrail
HSA�Ƃ�OpenCL�Ƃ��A���܂ЂƂp�b�Ƃ��Ȃ��˥��
>>909�@OpenCL�łƂ͕ʂ�HSA�ł����炵����
����AOpenCL�����ł悭�ˁH���Ďv�����A���ی�ɂ���Ă���ۂ�����
����ɂ��Ă�Intel��OpenCL���C�Ȃ̂��ςɊ�����Ƃ������A�Ӓn�ł�x86�ŃS�������Ă�邺�I
��x86�x�[�X�̃O���{�iXeon Phi�̃R���V���[�}�Łj�ł���邩�Ǝv���Ă����ǂ�
CUDA VS Xeon Phi���R���V���[�}�ł������ė~�����������ǂ���ς薳���Ȃ낤��
����AOpenCL�����ł悭�ˁH���Ďv�����A���ی�ɂ���Ă���ۂ�����
����ɂ��Ă�Intel��OpenCL���C�Ȃ̂��ςɊ�����Ƃ������A�Ӓn�ł�x86�ŃS�������Ă�邺�I
��x86�x�[�X�̃O���{�iXeon Phi�̃R���V���[�}�Łj�ł���邩�Ǝv���Ă����ǂ�
CUDA VS Xeon Phi���R���V���[�}�ł������ė~�����������ǂ���ς薳���Ȃ낤��
912 �F,,�E�L�́M�E,,�j��-�������F2015/02/24(��) 23:46:53.30 ID:/fcUNsIr
�Ă�PC�����̃l�C�e�B�u�A�v���i���Ɉ�ʃR���V���[�}�����j�J�����̂�����
�T�|�[�g�������t����s���R�s�[���s�����ŁAWeb�x�[�X�Ɉڍs�����ق��������b�g���傫������
CPU���\�̌�����d�����Ȃ��Ȃ������_��AMD�ɏ��@�͂Ȃ���
�T�|�[�g�������t����s���R�s�[���s�����ŁAWeb�x�[�X�Ɉڍs�����ق��������b�g���傫������
CPU���\�̌�����d�����Ȃ��Ȃ������_��AMD�ɏ��@�͂Ȃ���
913 �F,,�E�L�́M�E,,�j��-�������F2015/02/24(��) 23:49:13.92 ID:/fcUNsIr
OpenCL�͕ʂ�GPU�łȂ��Ă�CPU�ł����s�ł��邵�ˁB
Web�A�v�����ゾ���炱���A��ՂƂȂ�JavaScript�̍����������߂��Ă�Ƃ������ƁB
Web�A�v�����ゾ���炱���A��ՂƂȂ�JavaScript�̍����������߂��Ă�Ƃ������ƁB
>>912�@Zen�����Intel����Skylake�̋Z�p����č�邨�I����AMD�����\�����炵�����ǂ�
FX�AOpteron��14nm����ł��ő�W�R�A�ōs���炵������A���j�[�R�A�H������߂�������
CPU�J�����߂Ă�킯����Ȃ���Ȃ��H
APU��HSA���̃A�z�Ȃ��Ƃ��ɂႠCPU�������Ȃ��Ɓu�Ӗ����Ȃ��v�Ǝv������
�܂�������ɂ��덡��Ԃ̖��̓������ȋC������ADevils�@Canyon��Ilis�ςނ��ĉ\������������
�ǂ��Ȃ�HAPU������HBM�ς܂Ȃ�����
FX�AOpteron��14nm����ł��ő�W�R�A�ōs���炵������A���j�[�R�A�H������߂�������
CPU�J�����߂Ă�킯����Ȃ���Ȃ��H
APU��HSA���̃A�z�Ȃ��Ƃ��ɂႠCPU�������Ȃ��Ɓu�Ӗ����Ȃ��v�Ǝv������
�܂�������ɂ��덡��Ԃ̖��̓������ȋC������ADevils�@Canyon��Ilis�ςނ��ĉ\������������
�ǂ��Ȃ�HAPU������HBM�ς܂Ȃ�����
915 �F,,�E�L�́M�E,,�j��-�������F2015/02/25(��) 00:17:02.32 ID:7qe8aGsF
Google��Chrome�Ŗڎw���Ă�̂�Web�u���E�U�̃v���b�g�t�H�[����������ˁB
GUI��HTML�AJSON��XML�x�[�X�̃T�[�o�Ԃ̔��ʐM�A�Ђƒʂ�K�v�ȋ@�\�͔����Ă���
���[�J���X�g���[�W�̓L���b�V���p�ŁA��{�I�Ƀf�[�^�݂͂�ȃT�[�o�ɕۑ�����B
�v�����^�H�K�v�Ȃ�R���r�j����������p���������B
�l�C�e�B�u�̃R���V���[�}�A�v���̎��v�Ȃ�Ă����قƂ�ǂȂ��i�J���҂���肽�����Ă��Ȃ��j�̂�
�����ɂ����݂��Ă��Ӗ��Ȃ�����H
AVX2����AVX-512���̂��T�[�o�p�B
���܂ǂ��N���C�A���g�A�v���Ȃ�ĐϋɓI�ɍ��̂̓I�����C���\�t�g��҂̓��y���炢���B
����}�W�ŁB
> Skylake�̋Z�p����č�邨�I
����AVX-512�̂��Ƃ���ˁH���Č����Ă邯�ǂˁB�}�C�N���A�[�L�e�N�`���̐v�͎ЊO�邾��B
GUI��HTML�AJSON��XML�x�[�X�̃T�[�o�Ԃ̔��ʐM�A�Ђƒʂ�K�v�ȋ@�\�͔����Ă���
���[�J���X�g���[�W�̓L���b�V���p�ŁA��{�I�Ƀf�[�^�݂͂�ȃT�[�o�ɕۑ�����B
�v�����^�H�K�v�Ȃ�R���r�j����������p���������B
�l�C�e�B�u�̃R���V���[�}�A�v���̎��v�Ȃ�Ă����قƂ�ǂȂ��i�J���҂���肽�����Ă��Ȃ��j�̂�
�����ɂ����݂��Ă��Ӗ��Ȃ�����H
AVX2����AVX-512���̂��T�[�o�p�B
���܂ǂ��N���C�A���g�A�v���Ȃ�ĐϋɓI�ɍ��̂̓I�����C���\�t�g��҂̓��y���炢���B
����}�W�ŁB
> Skylake�̋Z�p����č�邨�I
����AVX-512�̂��Ƃ���ˁH���Č����Ă邯�ǂˁB�}�C�N���A�[�L�e�N�`���̐v�͎ЊO�邾��B
�S�Ẵf�[�^���N���E�h�ɗa����Ƃ��A�S���Y��Ԃ̑��l�ɗa���Ă�����`����
�p�u���b�N�N���E�h�����[�U�[��l������Ɋ��蓖�Ă���}�V�����\�[�X�����Č����Ă��
���������킴�킴���l�ɍ��Y���ׂĈ��点�邱�Ƃɂ�郁���b�g���ĂȂɂ�H
�����������N���E�h��Amazon��Microsoft�̂Q���������AOSBOX��onedrive�͎g���Ă邯�ǂ�
��̃X�}�z���炵�ăX�g���[�W128G�Ƃ��̐��E�Ȃ̂ɁA��ɏW���̃����b�g���������
�E�F�u�A�v���x�[�X���l�C�Ȃ̂��ăG���^�[�v���C�Y������H�������͂܂����������
�R���V���[�}�̖��P�ʂ̃\�t�g��G���v���̃N���G�C�^�[������web�x�[�X�Ɉڍs���邩�ȁH
�Ƃ�����Google���g�d����ubuntu�̃J�X�^���g���Ă���ĉ\����
�p�u���b�N�N���E�h�����[�U�[��l������Ɋ��蓖�Ă���}�V�����\�[�X�����Č����Ă��
���������킴�킴���l�ɍ��Y���ׂĈ��点�邱�Ƃɂ�郁���b�g���ĂȂɂ�H
�����������N���E�h��Amazon��Microsoft�̂Q���������AOSBOX��onedrive�͎g���Ă邯�ǂ�
��̃X�}�z���炵�ăX�g���[�W128G�Ƃ��̐��E�Ȃ̂ɁA��ɏW���̃����b�g���������
�E�F�u�A�v���x�[�X���l�C�Ȃ̂��ăG���^�[�v���C�Y������H�������͂܂����������
�R���V���[�}�̖��P�ʂ̃\�t�g��G���v���̃N���G�C�^�[������web�x�[�X�Ɉڍs���邩�ȁH
�Ƃ�����Google���g�d����ubuntu�̃J�X�^���g���Ă���ĉ\����
���A�N���E�h�T�[�r�X�����ǐ�p�A�v���Ŏg�����Ƃ��قƂ��
web�A�v���͊�Ƃ���p�̋Ɩ��V�X�e���g�ނ̂ɐl�C���Ă����A�Ǘ����y������
�l�b�g�ɂ�܂���Ă�web�A�v������{�͂������ƃ��o�C�������ŁA�ʂɃ��b�`�łƂ��ă��[�J���A�v����p�ӂ��Ă�ꍇ���w��
web�A�v���͊�Ƃ���p�̋Ɩ��V�X�e���g�ނ̂ɐl�C���Ă����A�Ǘ����y������
�l�b�g�ɂ�܂���Ă�web�A�v������{�͂������ƃ��o�C�������ŁA�ʂɃ��b�`�łƂ��ă��[�J���A�v����p�ӂ��Ă�ꍇ���w��
>CPU���\�̌�����d�����Ȃ��Ȃ������_��AMD�ɏ��@�͂Ȃ���
������Ƃ���ł����H
������Ƃ���ł����H
��s���ŏ��͂�������ꂽ�낤��
920 �FSocket774�F2015/02/25(��) 00:58:57.02 ID:z6dA3pb5
���ނ͒ᐫ�\�E���M�E�s����ڂ̎O�d�ꂻ������Y�p
���ݎ��̊Q���Ȃ̂ō������n�ォ���|���ׂ�
���ݎ��̊Q���Ȃ̂ō������n�ォ���|���ׂ�
��̋�s�ɑS���Y�a����͕̂n�R�l���]���̃o�J���������ǂ�w
��́Agoogle�ɑS���Y�a���邱�Ƃɋ�s���̃����b�g������킯�ł��Ȃ���
��́Agoogle�ɑS���Y�a���邱�Ƃɋ�s���̃����b�g������킯�ł��Ȃ���
��s��1�s����1�����Ɍ���1��}���܂ŗa���ی������邪
�O�[�O���̃f�[�^�ۏȂ�Ă˂����
�O�[�O���̃f�[�^�ۏȂ�Ă˂����
923 �F,,�E�L�́M�E,,�j��-�������F2015/02/25(��) 01:12:28.00 ID:7qe8aGsF
�c�O�Ȃ���s���R�s�[����Ă�T����郊�X�N�����Ă܂ň�ʃR���V���[�}�����̔������
�l�C�e�B�u�A�v�����Ȃ�Ă���ۂNjH������B
�Ɠd�ʔ̓X��PC�\�t�g�̃R�[�i�[�����ԏ������Ȃ�������H
�����Ă��̉�Ђ͖@�l�����ɓ���������Web�T�[�r�X�Ɉڍs���Ă�B
�܂��p�b�P�[�W�̔��Ŏc��̂̓Q�[�����炢���낤�ˁB
�������R��Ȃ�Steam�F���B
�@�l�����Ȃ�p�u���b�N�N���E�h�𗘗p�������Ȃ��q�����ɃT�u�Z�b�g�ł��T�[�o���Ɣ�����
�C���g���Ŕ���Ƃ����낢�뉞�p������������Web����Ԗ���Ƃ����B
�l�C�e�B�u�A�v�����Ȃ�Ă���ۂNjH������B
�Ɠd�ʔ̓X��PC�\�t�g�̃R�[�i�[�����ԏ������Ȃ�������H
�����Ă��̉�Ђ͖@�l�����ɓ���������Web�T�[�r�X�Ɉڍs���Ă�B
�܂��p�b�P�[�W�̔��Ŏc��̂̓Q�[�����炢���낤�ˁB
�������R��Ȃ�Steam�F���B
�@�l�����Ȃ�p�u���b�N�N���E�h�𗘗p�������Ȃ��q�����ɃT�u�Z�b�g�ł��T�[�o���Ɣ�����
�C���g���Ŕ���Ƃ����낢�뉞�p������������Web����Ԗ���Ƃ����B
924 �F,,�E�L�́M�E,,�j��-�������F2015/02/25(��) 01:14:53.73 ID:7qe8aGsF
>>918
��������B
2011�N�ȗ�������32nm�~�܂��Opteron���ǂ�ȔߎS�ȃV�F�A�ɂȂ��Ă邩
���������������ŏ���Ȃ�債�����̂���B
��������B
2011�N�ȗ�������32nm�~�܂��Opteron���ǂ�ȔߎS�ȃV�F�A�ɂȂ��Ă邩
���������������ŏ���Ȃ�債�����̂���B
>>923�@�l�b�g�F�ؕt����������Ă�Ȃ獡�̃R���V���[�}�����͑��l�b�g�F�ł���
�y�ʃA�v���Ȃ�Microsoft�����ăX�g�A�o���Ă���A�d�ʋ��A�v������悤�ȉ�Ђ̃\�t�g��
�N���b�N�ł��l�b�g�ɗ���Ă�́H���ǁA�l����p�\�R�����グ�����ł��ɂ����������Ȃ���
��́A���́u�H�v�Ƃ��ȃ\�t�g�ƃI�[�v���\�[�X�v���W�F�N�g��win�X�g�A�A�v���ő�̗̂p�r���������
�Ȃ�őS����web�x�[�X�Ɉڍs���Ȃ�����Ȃ��킯�H�����������Ƃ�������Ă邩��
�M�p�Ȃ����Ăǂ�ǂ�l������Ȃ��Ȃ��Ă���ĂȂ�ł킩���̂��Ȃ�
�y�ʃA�v���Ȃ�Microsoft�����ăX�g�A�o���Ă���A�d�ʋ��A�v������悤�ȉ�Ђ̃\�t�g��
�N���b�N�ł��l�b�g�ɗ���Ă�́H���ǁA�l����p�\�R�����グ�����ł��ɂ����������Ȃ���
��́A���́u�H�v�Ƃ��ȃ\�t�g�ƃI�[�v���\�[�X�v���W�F�N�g��win�X�g�A�A�v���ő�̗̂p�r���������
�Ȃ�őS����web�x�[�X�Ɉڍs���Ȃ�����Ȃ��킯�H�����������Ƃ�������Ă邩��
�M�p�Ȃ����Ăǂ�ǂ�l������Ȃ��Ȃ��Ă���ĂȂ�ł킩���̂��Ȃ�
>���ǁA�l����p�\�R�����グ�����ł�
�O�𑝂₷���߂̓D�^�u�����炵�傤���Ȃ�
�������Ƃ��Ă��炻�����ɉ������܂�Ă�
�O�𑝂₷���߂̓D�^�u�����炵�傤���Ȃ�
�������Ƃ��Ă��炻�����ɉ������܂�Ă�
927 �F,,�E�L�́M�E,,�j��-�������F2015/02/25(��) 02:03:47.85 ID:7qe8aGsF
�������X�g�A�A�v���Ȃ�č�邭�炢�Ȃ�iOS��Android�����ɍ�����ق����܂����������Ƃ���
���Ƃ��邲�Ƃɉۋ��̂��߂��Q�[���ƃo�i�[�L�����ꗬ���̕��A�v�������Ȃ�
���i���ꂪ�X�}�z���݂̂₷���P���A����MS�ɂ͂�������W�������B
�����܂őË����Ȃ�Web�ł����������Ă����B
���X�������Ƃł��Ȃ����ǃX�g�A�A�v���̃_���ȓ_�����Ă�����
�E�S��ʂ���{�ő��̃A�v���Ǝ��R�ɕ��ׂĕ\���ł��Ȃ�
�E�G�N�X�v���[������̃t�@�C���̃h���b�O���h���b�v����ł��Ȃ��iWeb�A�v���͉\�j
���Ƃ��邲�Ƃɉۋ��̂��߂��Q�[���ƃo�i�[�L�����ꗬ���̕��A�v�������Ȃ�
���i���ꂪ�X�}�z���݂̂₷���P���A����MS�ɂ͂�������W�������B
�����܂őË����Ȃ�Web�ł����������Ă����B
���X�������Ƃł��Ȃ����ǃX�g�A�A�v���̃_���ȓ_�����Ă�����
�E�S��ʂ���{�ő��̃A�v���Ǝ��R�ɕ��ׂĕ\���ł��Ȃ�
�E�G�N�X�v���[������̃t�@�C���̃h���b�O���h���b�v����ł��Ȃ��iWeb�A�v���͉\�j
928 �F,,�E�L�́M�E,,�j��-�������F2015/02/25(��) 02:16:51.63 ID:7qe8aGsF
>>925
����Ȃ�ōςႤ�قǁA��ʌl���p�\�R���ł���Ă����Ƃ�Web�A�v���Ɉڍs���Ă��H
00�N�䏉���܂Ōl�����A�v���ō����l�C���ւ��Ă����z�[���y�[�W�r���_�[����
Web�T�C�g�쐬�c�[���͂ǂ��ɏ������H
�u���O��Wiki�̕��y�ŁA�킴�킴HTML�������ăA�b�v���[�h����Õ��ȃT�C�g�Ǘ�����
���[�U�[�͂قƂ�ǂ��Ȃ��Ȃ�������B
�I�[�v���\�[�X��t���[�̃\�t�g�g���Ă�ᑫ�����āA�����l�̓s����
�\�t�g��Ђ͔ѐH��Ȃ���Ȃ��B
����Ȃ�ōςႤ�قǁA��ʌl���p�\�R���ł���Ă����Ƃ�Web�A�v���Ɉڍs���Ă��H
00�N�䏉���܂Ōl�����A�v���ō����l�C���ւ��Ă����z�[���y�[�W�r���_�[����
Web�T�C�g�쐬�c�[���͂ǂ��ɏ������H
�u���O��Wiki�̕��y�ŁA�킴�킴HTML�������ăA�b�v���[�h����Õ��ȃT�C�g�Ǘ�����
���[�U�[�͂قƂ�ǂ��Ȃ��Ȃ�������B
�I�[�v���\�[�X��t���[�̃\�t�g�g���Ă�ᑫ�����āA�����l�̓s����
�\�t�g��Ђ͔ѐH��Ȃ���Ȃ��B
>�S��ʂ���{�ő��̃A�v���Ǝ��R�ɕ��ׂĕ\���ł��Ȃ�
Win8.1�܂ł̐����Win10�ł͉��P����Ă���
Win8.1�܂ł̐����Win10�ł͉��P����Ă���
930 �F,,�E�L�́M�E,,�j��-�������F2015/02/25(��) 02:19:58.83 ID:7qe8aGsF
�܂��_���ȓ_���邯�ǂ킴�킴�����܂ł��Ȃ���ˁB
>�l�����A�v���ō����l�C���ւ��Ă����z�[���y�[�W�r���_�[����Web�T�C�g�쐬�c�[����
BiND for WebLiFE�g���܂��傤
BiND for WebLiFE�g���܂��傤
932 �F,,�E�L�́M�E,,�j��-�������F2015/02/25(��) 02:23:53.48 ID:7qe8aGsF
����Web�x�[�X�̃I�[�T�����O�c�[�����邵�i�Ƃ������̒��̐l����Ă����j
OCN�C�t���̃y�[�W�I���Ƃ��p�~���ꂿ�������
�����web�x�[�X�̃I�[�T�����O�c�[���̑��肾����
�����web�x�[�X�̃I�[�T�����O�c�[���̑��肾����
bind�ƕ�����DNS��z�N����͉̂���������Ȃ��͂���
����ɂ��Ă��p�b�P�[�W�\�t�g�Ƃ���ŏ�Ԃ���Ȃ��B
�n�}�n��GoogleMap�Ɋ��S�ɏR�U�炳��Ă�B�Ɩ��p�̒n�����͋@�\�Ƃ�
�n�}�ȊO�̕����ɕt�����l��p�ӂ��ĂȂ��~�߂Ă�̂�����t���B
�����l�I�ɒn�}�f�[�^�̓��[�J���ɒu���Ă��������h�Ȃ��ǂȁ[�X�V����Ԃ�����
����ɂ��Ă��p�b�P�[�W�\�t�g�Ƃ���ŏ�Ԃ���Ȃ��B
�n�}�n��GoogleMap�Ɋ��S�ɏR�U�炳��Ă�B�Ɩ��p�̒n�����͋@�\�Ƃ�
�n�}�ȊO�̕����ɕt�����l��p�ӂ��ĂȂ��~�߂Ă�̂�����t���B
�����l�I�ɒn�}�f�[�^�̓��[�J���ɒu���Ă��������h�Ȃ��ǂȁ[�X�V����Ԃ�����
�������X�g�A�A�v���̗ȕi���ُ͈�
�A�[�J�C�u�W�J�c�[�����畅���Ă�
�A�[�J�C�u�W�J�c�[�����畅���Ă�
>>927�@�F�X�t���[�\�t�g���[�����Ă�̂ɂ킴�킴web�ʂ��Ӗ����Ȃ��Ȃ��H
�����܂Ő��S�~�ł���肽���Ȃ�X�g�A�ʂ��H���Ă����̘b�����A��ʌ�����100�~�ł�����web�A�v��
�m��Ȃ����痘���Ȃ���Ă��c�c
�Ƃ肠�����X�}�z�E�^�u�Ŏg���Ȃ�\���ȗʑ����Ă邵�AHololens�ŗV�ԗp�\�t�g�F�X�T�����Ă邵
�L���\�t�g�Ȃ�Pico Viewer�Ƃ�PowerDVDMobile�����Ă邵�A�����Ȃ�j���[�X�A�v���n��People
��PC�ł��g���Ă邯�ǁi�ҏW�p��outlook2013�����������ǂ��j
�����r���[���[���p�̎I�@�\�ƘA�g�����邽�߂̃��o�C���p���f�B�A�v���C���[��[���[
�Ȃ�web�x�[�X�Ƃ��E�U������
����web�A�v���ł��X�g�A�A�v���ł��Ȃ����ǁA�y���\�t�g����itunes�Ƃ�handbreake�i����͏d�������j�Ƃ�LINE�Ƃ�
����v���C���[�Ȃ�MPC��VLC�����邵�iPowerDVD�����������ǁj�L���Ōy���\�t�g�Ȃ�Bria4����������
���ɂ��F�X�˂�����ł邵�A���v�Q�O�}�\�ȏ�L���\�t�g�ɓ˂�����ł邵�n�[�h������g���Ă�̂�����50�����炢���Ǝv��
�S�R��������Ȃ�����web�x�[�X�ŏ\�����Ă̂����Ɏv��������Ȃ���ł����ǁc�c
�����܂Ő��S�~�ł���肽���Ȃ�X�g�A�ʂ��H���Ă����̘b�����A��ʌ�����100�~�ł�����web�A�v��
�m��Ȃ����痘���Ȃ���Ă��c�c
�Ƃ肠�����X�}�z�E�^�u�Ŏg���Ȃ�\���ȗʑ����Ă邵�AHololens�ŗV�ԗp�\�t�g�F�X�T�����Ă邵
�L���\�t�g�Ȃ�Pico Viewer�Ƃ�PowerDVDMobile�����Ă邵�A�����Ȃ�j���[�X�A�v���n��People
��PC�ł��g���Ă邯�ǁi�ҏW�p��outlook2013�����������ǂ��j
�����r���[���[���p�̎I�@�\�ƘA�g�����邽�߂̃��o�C���p���f�B�A�v���C���[��[���[
�Ȃ�web�x�[�X�Ƃ��E�U������
����web�A�v���ł��X�g�A�A�v���ł��Ȃ����ǁA�y���\�t�g����itunes�Ƃ�handbreake�i����͏d�������j�Ƃ�LINE�Ƃ�
����v���C���[�Ȃ�MPC��VLC�����邵�iPowerDVD�����������ǁj�L���Ōy���\�t�g�Ȃ�Bria4����������
���ɂ��F�X�˂�����ł邵�A���v�Q�O�}�\�ȏ�L���\�t�g�ɓ˂�����ł邵�n�[�h������g���Ă�̂�����50�����炢���Ǝv��
�S�R��������Ȃ�����web�x�[�X�ŏ\�����Ă̂����Ɏv��������Ȃ���ł����ǁc�c
937 �F,,�E�L�́M�E,,�j��-�������F2015/02/25(��) 02:42:12.10 ID:7qe8aGsF
�摜���e�֘A�̃A�v���͕����Ă��
�}�C�s�N�`���Ƃ��̋K��t�H���_�O����摜�t�@�C���I�ׂȂ�����
�킴�킴�}�C�s�N�`���̉��ɃV���{���b�N�����N�쐬��������
�l�b�g���[�N�t�H���_����g�킹�Ȃ��C���ˁH
�}�C�s�N�`���Ƃ��̋K��t�H���_�O����摜�t�@�C���I�ׂȂ�����
�킴�킴�}�C�s�N�`���̉��ɃV���{���b�N�����N�쐬��������
�l�b�g���[�N�t�H���_����g�킹�Ȃ��C���ˁH
938 �F,,�E�L�́M�E,,�j��-�������F2015/02/25(��) 02:46:48.75 ID:7qe8aGsF
���Ȃ݂�Explorer�������u�t�H���_�̃V���[�g�J�b�g�v��
�V���{���b�N�����N�͕ʕ��ˁB�Ӗ���*NIX�̂���Ɠ����B
�V���{���b�N�����N�͕ʕ��ˁB�Ӗ���*NIX�̂���Ɠ����B
939 �F,,�E�L�́M�E,,�j��-�������F2015/02/25(��) 02:53:10.99 ID:7qe8aGsF
�ő��N���X�̃\�t�g�n�E�X�͂Ƃ������A�命���͖@�l�����̃p�b�P�[�W������J����
��ԃ��X�N�����Ȃ��ăR���V���[�}�����p�b�P�[�W�\�t�g�݂����ȃn�C���X�N���[���^�[���̂���
�n���炵���č���ƌ����Ă�킯���B
GPGPU�i�j�Ƃ�HSA�i�j�͘_�O���̘_�O�B
��ԃ��X�N�����Ȃ��ăR���V���[�}�����p�b�P�[�W�\�t�g�݂����ȃn�C���X�N���[���^�[���̂���
�n���炵���č���ƌ����Ă�킯���B
GPGPU�i�j�Ƃ�HSA�i�j�͘_�O���̘_�O�B
�܂��X�g�A�A�v���̓i�f������Ɋ��҂��Ă��Ƃłǂ��������s�N�A10�ŐF�X�d�l��������ۂ���
���Ȃ݂ɍ��g���Ă�L���A�v������ׂ�ƁA�t�H�g�V���A�A�N���o�b�g�Aoutlook�ABria�S�ADVD Fab�AScan snap
PowerDVD�ATMPGenc�}�X�^�����O�ƃX�}����
���ƃQ�[�����{�iskyrim�ƃM�����Q3�{�j�ƗL���N���E�h��AOSBOXcool��onedrive100G��itunes match
�Q�[������Ȃ���20���͂������ɒ����Ȃ��Ȃ��܂�
>>939�@GPGPU�A��ɏグ��������5�{���炢�Ή����Ă邯�ǁH���̓��f������CUDA�͎g���Ȃ�����
GPU���p���ĈӖ��Ȃ�QSV�����ĈꉞGPU���j�b�g���g���Ă��Ȃ����������H
��ł��O���m�肵�Ă�OpenCL������GPGPU�ł���HGPGPU�̈Ӗ��͂��Ⴆ�Ă���S����
���ƁA��肵���o���Ȃ����Č����Ȃ���̕���������Ȃ���������
�����낤�����낤�A�̂̓��{�l�̃u�����h�M�͂��������������Ǝv�����ǂ�
�u��������Ȃ��l�v��web�A�v���ֈڍs�ł�����Ȃ��H
���Ȃ݂ɍ��g���Ă�L���A�v������ׂ�ƁA�t�H�g�V���A�A�N���o�b�g�Aoutlook�ABria�S�ADVD Fab�AScan snap
PowerDVD�ATMPGenc�}�X�^�����O�ƃX�}����
���ƃQ�[�����{�iskyrim�ƃM�����Q3�{�j�ƗL���N���E�h��AOSBOXcool��onedrive100G��itunes match
�Q�[������Ȃ���20���͂������ɒ����Ȃ��Ȃ��܂�
>>939�@GPGPU�A��ɏグ��������5�{���炢�Ή����Ă邯�ǁH���̓��f������CUDA�͎g���Ȃ�����
GPU���p���ĈӖ��Ȃ�QSV�����ĈꉞGPU���j�b�g���g���Ă��Ȃ����������H
��ł��O���m�肵�Ă�OpenCL������GPGPU�ł���HGPGPU�̈Ӗ��͂��Ⴆ�Ă���S����
���ƁA��肵���o���Ȃ����Č����Ȃ���̕���������Ȃ���������
�����낤�����낤�A�̂̓��{�l�̃u�����h�M�͂��������������Ǝv�����ǂ�
�u��������Ȃ��l�v��web�A�v���ֈڍs�ł�����Ȃ��H
�摜up�n�̃A�v�����āA�����ȃ��[�U���g������A�t�H���_�����肷�邱�Ƃ�
�N�ɂł��킩��J���^��������������Ă��Ȃ��̂��ȁB
�����[���낢��M�����������̍D�݂����ǁA��������Ȃ����ӎ��̂���z��ɂ�
�g���Ă��炤�ɂ͍ő���̔��肪�t������B
�\�t�g���Ȃ�[���̂��炢�̎v���͂ł��Ă������Ǝv�����[
�N�ɂł��킩��J���^��������������Ă��Ȃ��̂��ȁB
�����[���낢��M�����������̍D�݂����ǁA��������Ȃ����ӎ��̂���z��ɂ�
�g���Ă��炤�ɂ͍ő���̔��肪�t������B
�\�t�g���Ȃ�[���̂��炢�̎v���͂ł��Ă������Ǝv�����[
942 �F,,�E�L�́M�E,,�j��-�������F2015/02/25(��) 03:13:50.27 ID:7qe8aGsF
�܂��ǂ���������Winny�̓\�t�g�Y�ƍ\����ς����킯��
�����I(�܂��������ǂ��[)
��PC�g���Ă��ʏ���҂����p�\�t�g���w�����邱�ƂɃ����b�g�������邱�Ƃ͂قƂ�ǂȂ���Ȃ�����
����Ȏ��PC�������Ă�Ȃ�Ƃ�������
����Ȏ��PC�������Ă�Ȃ�Ƃ�������
945 �F,,�E�L�́M�E,,�j��-�������F2015/02/25(��) 03:26:58.67 ID:7qe8aGsF
>>941
�R�����_�C�A���O�̍����A���[�U�[���C�ӂ̓o�^�t�H���_��lj��ł��邶���
���ꂱ�����[�U�r���e�B���l�������v���Ǝv���킯�扴��
�Ȃ�ŃX�g�A�A�v�����Ƃ����F�����Ȃ��̂������Ȃ��ˁB
MS���^�R�Ȃ����ł�����
�^�R����Ȃ���X�^�[�g���j���[�g���Ȃ�����悤�ȃA�z�Ȑ^�����Ȃ��ł��傤
���̓^�u���b�g�ȊO��8.1�}�V���ɂ͑S�ăX�^�[�g���j���[�����A�v������Ă�
�R�����_�C�A���O�̍����A���[�U�[���C�ӂ̓o�^�t�H���_��lj��ł��邶���
���ꂱ�����[�U�r���e�B���l�������v���Ǝv���킯�扴��
�Ȃ�ŃX�g�A�A�v�����Ƃ����F�����Ȃ��̂������Ȃ��ˁB
MS���^�R�Ȃ����ł�����
�^�R����Ȃ���X�^�[�g���j���[�g���Ȃ�����悤�ȃA�z�Ȑ^�����Ȃ��ł��傤
���̓^�u���b�g�ȊO��8.1�}�V���ɂ͑S�ăX�^�[�g���j���[�����A�v������Ă�
MS�Ƃ��ł�������Ƃ��Ɠ��K�Ń��[�U�r���e�B�W���Ƃ��K�肳��Ă�
����ɔ����ē����Ȃ��悤�ȋC�����邪�A�܂����͓����̐l�Ԃ���Ȃ����悭�킩��Ȃ��B
�Ƃ͂����lj��ł���]�X�ɂ͓��ӂȂ̂�
����ɔ����ē����Ȃ��悤�ȋC�����邪�A�܂����͓����̐l�Ԃ���Ȃ����悭�킩��Ȃ��B
�Ƃ͂����lj��ł���]�X�ɂ͓��ӂȂ̂�
MS�́A�������Ȃ��Ƃ�����Ƃ���_���o������l�����Ȃ��Ȃ����̂ł͂Ȃ����H
>>944�@
�ʂɕ��ʂɃA�j���݂��肽�܁[�ɃQ�[�������薟���m�x�ǂ�PC���Œ�d�b��
�����肵�Ă邾������H�I�^�������ƌ���ꂽ�炻��܂ł����ǂ�
�ł����ʂ̐l�ł��D�ŗL�����y�v���C���[�������肷�邶���A����̊g�唭�W�ł��Ă���
���ʂ̐l�͖����Q�[���ŏ\���I�Ƃ������Ȃ��瓯���Q�[���ɉ��S�����˂����ޓz������킯��
���������̂ɔ�ׂ���܂��펯�I�Ȕ͈͂��Ǝv�����ǂˁA�m���Ƃ����ϕi�����ʂɔ����Ă邵
���۔�����P�`�Q�����x�g���u��������v���x�ɂ̓I�^��ȊO�����ʂɊy����ł邵��
�ʂɕ��ʂɃA�j���݂��肽�܁[�ɃQ�[�������薟���m�x�ǂ�PC���Œ�d�b��
�����肵�Ă邾������H�I�^�������ƌ���ꂽ�炻��܂ł����ǂ�
�ł����ʂ̐l�ł��D�ŗL�����y�v���C���[�������肷�邶���A����̊g�唭�W�ł��Ă���
���ʂ̐l�͖����Q�[���ŏ\���I�Ƃ������Ȃ��瓯���Q�[���ɉ��S�����˂����ޓz������킯��
���������̂ɔ�ׂ���܂��펯�I�Ȕ͈͂��Ǝv�����ǂˁA�m���Ƃ����ϕi�����ʂɔ����Ă邵
���۔�����P�`�Q�����x�g���u��������v���x�ɂ̓I�^��ȊO�����ʂɊy����ł邵��
>>947�@�_���o�����ꂽ����o���}�[�N�r�ɂȂ������
����win8/8.1����������OS�Ƃ͎v���Ȃ����˃I���ɂ�
>>927
Win8.1�܂ł̃X�g�A�A�v����WinRT API�̍\�����l�����瓖����O�̋C�����邪�B
��{�I�ɑ��̃v���Z�X����u�����ꂽ�T���h�{�b�N�X�\���Ȃ���B
�܂�Win10�ł� �f�X�N�g�b�v���ƃX�g�A�A�v���̎��s�����A���Ȃ�ύX�����݂�����������Ɋ��҂��ȁB
Win8.1�܂ł̃X�g�A�A�v����WinRT API�̍\�����l�����瓖����O�̋C�����邪�B
��{�I�ɑ��̃v���Z�X����u�����ꂽ�T���h�{�b�N�X�\���Ȃ���B
�܂�Win10�ł� �f�X�N�g�b�v���ƃX�g�A�A�v���̎��s�����A���Ȃ�ύX�����݂�����������Ɋ��҂��ȁB
>>950�@�W�͂�����Ɓc�c8.1�ő啪�ǂ��Ȃ����Ǝv�����ǃX�g�A�A�v���̋K�i��
�E�B���h�E���ȊO�ł��A�F�X�@�\�lj����K�v�ɂȂ�Ǝv���AHololens�ł��g������
���ƁA�ʂɃ��_��UI���͕̂ʂɂ����Ǝv���A�^�b�`�œK���Ń}�E�X�Ń|�C���e�B���O����Ȃ�Ȃ�Ă��肦�Ȃ���
�����A�f�X�N�g�b�v��ʂƃX�^�[�g��ʂ̐�ւ��Ń`���z���s��N�������
���ƁA�E�B���h�E�ɉe�t����Ƃ�win�L�[�{Tab�Ȃ�Ƃ�����Ƃ��A�܂�������ӂ�10�ʼn��ǂ���Ă邯��
���Ƃ̓{�^�������̋��E���������Ƃ͂����肵�ė~�������Ă̂ƁA���z�f�X�N�g�b�v�����
�}�E�X�W�F�X�`���ς�ǂ���ƃ��Z�~�e��iPhone�݂����ȋ@�\�悱�����Ă��炢���Ȍl�I�ȗv�]�́A
�t�B�[�h�o�b�N�͏o���Ƃ�������
�E�B���h�E���ȊO�ł��A�F�X�@�\�lj����K�v�ɂȂ�Ǝv���AHololens�ł��g������
���ƁA�ʂɃ��_��UI���͕̂ʂɂ����Ǝv���A�^�b�`�œK���Ń}�E�X�Ń|�C���e�B���O����Ȃ�Ȃ�Ă��肦�Ȃ���
�����A�f�X�N�g�b�v��ʂƃX�^�[�g��ʂ̐�ւ��Ń`���z���s��N�������
���ƁA�E�B���h�E�ɉe�t����Ƃ�win�L�[�{Tab�Ȃ�Ƃ�����Ƃ��A�܂�������ӂ�10�ʼn��ǂ���Ă邯��
���Ƃ̓{�^�������̋��E���������Ƃ͂����肵�ė~�������Ă̂ƁA���z�f�X�N�g�b�v�����
�}�E�X�W�F�X�`���ς�ǂ���ƃ��Z�~�e��iPhone�݂����ȋ@�\�悱�����Ă��炢���Ȍl�I�ȗv�]�́A
�t�B�[�h�o�b�N�͏o���Ƃ�������
>>906
���ꉼ�z�����Ă����ˁH
���ꉼ�z�����Ă����ˁH
954 �F,,�E�L�́M�E,,�j��-�������F2015/02/25(��) 06:53:37.19 ID:7qe8aGsF
x86��Office�v���O�������u���E�U��ŃG�~�����[�V�������Ă�킯����Ȃ�
HTML�{JavaScript��0����g�܂ꂽ�S���ʂ̃A�v���Ȃ��B
HTML�{JavaScript��0����g�܂ꂽ�S���ʂ̃A�v���Ȃ��B
>>934
�N���\�t�g�̃��b�h�f�[�^�u�b�N������ė~�����B�ŋ߈ӎ������̂�
���[�J���ғ��̖|��\�t�g�B�܂������Ă邯�lj��ł͎~�܂��Ă�l�q
�N���\�t�g�̃��b�h�f�[�^�u�b�N������ė~�����B�ŋ߈ӎ������̂�
���[�J���ғ��̖|��\�t�g�B�܂������Ă邯�lj��ł͎~�܂��Ă�l�q
Intel��eDRAM����������Ȋ����Ŏg����̂��낤��
�y�C�x���g���|�[�g�zIBM�̎����チ�C���t���[���uSystem z13�v���x���鋐��ȃV���R�� - PC Watch
http://pc.watch.impress.co.jp/docs/news/event/20150225_689853.html?ref=rss
�y�C�x���g���|�[�g�zIBM�̎����チ�C���t���[���uSystem z13�v���x���鋐��ȃV���R�� - PC Watch
http://pc.watch.impress.co.jp/docs/news/event/20150225_689853.html?ref=rss
>>952
�^�b�`�œK���Ń}�E�X���g���ɂ����Ȃ邱�Ƃ͂Ȃ����Ă̂͊�{�I�ɂ͓��ӂ����ǁA
�X�^�[�g��ʂ����悤�Ǝv���ƁA�}�E�X���Ɩ��ʂɃJ�[�\���̈ړ���������ˁ[�B8.1�Ŏ�}�V�ɂȂ������ǁB
���������X�^�[�g���j���[�̍��͊K�w������Ă�����A����Ȃɐ�������K�v���Ȃ������B
�X�^�[�g��ʂ��t�H���_���炢�͗~�����B
�^�b�`�œK���Ń}�E�X���g���ɂ����Ȃ邱�Ƃ͂Ȃ����Ă̂͊�{�I�ɂ͓��ӂ����ǁA
�X�^�[�g��ʂ����悤�Ǝv���ƁA�}�E�X���Ɩ��ʂɃJ�[�\���̈ړ���������ˁ[�B8.1�Ŏ�}�V�ɂȂ������ǁB
���������X�^�[�g���j���[�̍��͊K�w������Ă�����A����Ȃɐ�������K�v���Ȃ������B
�X�^�[�g��ʂ��t�H���_���炢�͗~�����B
HSA�͐�����Ȃ�
�����̉\����������
Intel���p�N������̂�
�����̉\����������
Intel���p�N������̂�
959 �FSocket774�F2015/02/25(��) 18:26:09.18 ID:NXUx3Uk1
24V�d���������ė~����
CPU�d����H�́A�����������Ƌ@����p��UP�����ҏo����
��24V�d��
8�C���`FD�p�d���ŁA�����ɔp�~
1THz 32�R�A...����
CPU�d����H�́A�����������Ƌ@����p��UP�����ҏo����
��24V�d��
8�C���`FD�p�d���ŁA�����ɔp�~
1THz 32�R�A...����
>>955
PC�œ��������F���\�t�g�Ƃ�OCR�Ƃ��ǂ���
PC�œ��������F���\�t�g�Ƃ�OCR�Ƃ��ǂ���
>>957�@��win�L�[�t�}�E�X
�t�H���_���~�������Ă͓̂��ӁAwindowsPhone8.1�̃X�^�[�g��ʂ͊K�w���ɑΉ����Ă�̂�
�X�}�z��UI��������Ȃ炱��������Ă��Ăق������
�t�H���_���~�������Ă͓̂��ӁAwindowsPhone8.1�̃X�^�[�g��ʂ͊K�w���ɑΉ����Ă�̂�
�X�}�z��UI��������Ȃ炱��������Ă��Ăق������
�����̃z�[���y�[�W�A�e�L�X�g�G�f�B�^��HTML���K���K���ł��Ă�킗
������x�e���v���̐�\��ł��邯�ǁA���̌��n�I�Ƃ��������ړI�Ƃ������A���S���͑ウ����̂����邗
�v���O���~���O������AC++��C���g�����V�b�N���D���ł��B
�������A��H��VHDL�ŁB
������x�e���v���̐�\��ł��邯�ǁA���̌��n�I�Ƃ��������ړI�Ƃ������A���S���͑ウ����̂����邗
�v���O���~���O������AC++��C���g�����V�b�N���D���ł��B
�������A��H��VHDL�ŁB
963 �F,,�E�L�́M�E,,�j��-�������F2015/02/25(��) 20:50:33.56 ID:NG5TN0mq
�ւ�ݐ搶�ł���ŋߎ菑��HTML�̓��L����Ă邺
�t���[��CMS�����Ƃ�����
���Ă����Ă��킴�킴CMS�T�[�o�Ȃ�ė��Ă�̂��n���炵������A
web�T�[�o��80�Ƃ͈Ⴄ�|�[�g��CMS���ĂĂ���ł����������
���Ă����Ă��킴�킴CMS�T�[�o�Ȃ�ė��Ă�̂��n���炵������A
web�T�[�o��80�Ƃ͈Ⴄ�|�[�g��CMS���ĂĂ���ł����������
965 �F,,�E�L�́M�E,,�j��-�������F2015/02/25(��) 21:07:04.16 ID:NG5TN0mq
Rails�ŃI���I��CMS���ŋ�����
����PC�̓d�������܂ɂ�������Ȃ��Ȃ���
�X�}�[�g�t�H����HTML�������C�ɂ͂Ȃ��ȁ[
�Q���p�̃m�[�gPC�ł����������낤����
��x�r�ꂽ������ʖڂ���
�X�}�[�g�t�H����HTML�������C�ɂ͂Ȃ��ȁ[
�Q���p�̃m�[�gPC�ł����������낤����
��x�r�ꂽ������ʖڂ���
������Ƒ������A���X����
Intel�̎�����Z�p�ɂ��Č�낤 81
http://anago.2ch.net/test/read.cgi/jisaku/1424868826/
Intel�̎�����Z�p�ɂ��Č�낤 81
http://anago.2ch.net/test/read.cgi/jisaku/1424868826/
�ЂȍՂ�ڍs�����ɉ����b�肠��
���̂܂g����̂�? �ڂ����̓\�t�g�E�F�A��
���̂܂g����̂�? �ڂ����̓\�t�g�E�F�A��
���ł������̃X���͎��X�����Ă����肭���Ȃ�
�d�����Ă�̂���������Ɏg������
http://anago.2ch.net/test/read.cgi/jisaku/1419926683/l50
�d�����Ă�̂���������Ɏg������
http://anago.2ch.net/test/read.cgi/jisaku/1419926683/l50
http://www.pcworld.com/article/2888996/intel-to-rebrand-atom-chips-along-lines-of-core-processors.html
�V����Atom�̃��f���i���o�[�����K�����ς��
�V����Atom�̃��f���i���o�[�����K�����ς��
971 �F,,�E�L�́M�E,,�j��-�������F2015/02/26(��) 02:25:40.83 ID:dBK/G9XF
���ς�炸�̊�D������
���邢�͑f���Ȃ̂�
���邢�͑f���Ȃ̂�
CMOS�C���[�W�Z���T�[����������3�����ϑw�Z�p
ttp://eetimes.jp/ee/articles/1502/23/news063.html
> �܂����y���炵�Ă��Ȃ�TSV�Z�p���g����x��h�ɂȂ��Ă��܂��\��������
ttp://eetimes.jp/ee/articles/1502/23/news063_2.html
> �E�����u�n�C�u���b�h�ڍ��v�̍\���ł���B��-���ɂ��E�G�n�[�ڍ��ɂ��A
> �X�y�[�X�����TSV���̗p���Ȃ��Ă��悭�Ȃ�\��������
���X�������g���Ă�BSI�̓r�A��ʂ��܂ł��Ȃ����Ă��Ƃ��B
DRAM�͕\�����C�ɂȂ�Ȃ����炢�����o���邱�Ƃ��킩���Ă�B
�v���Z�b�T�͂ǂ����낤
ttp://eetimes.jp/ee/articles/1502/23/news063.html
> �܂����y���炵�Ă��Ȃ�TSV�Z�p���g����x��h�ɂȂ��Ă��܂��\��������
ttp://eetimes.jp/ee/articles/1502/23/news063_2.html
> �E�����u�n�C�u���b�h�ڍ��v�̍\���ł���B��-���ɂ��E�G�n�[�ڍ��ɂ��A
> �X�y�[�X�����TSV���̗p���Ȃ��Ă��悭�Ȃ�\��������
���X�������g���Ă�BSI�̓r�A��ʂ��܂ł��Ȃ����Ă��Ƃ��B
DRAM�͕\�����C�ɂȂ�Ȃ����炢�����o���邱�Ƃ��킩���Ă�B
�v���Z�b�T�͂ǂ����낤