AMD�̎�����APU/CPU/SoC�ɂ��Č�낤 205����©2ch.net
�_.�Q�@ | �r�炵�E����E�~�[�͕��u����ԁB
�^|�Q|�@| �ނ�ꂸ�ɃX���[���܂��傤�B
|�Q�^�_! sage�i�s�Ń}�^�[�������܂���
�r�炵��W�Ȃ��R�s�y�Ȑl��NG�ɓ���Ė������܂��傤�B
�����AMD�n�X���b�h�ߋ����O�ۑ��T�C�g
http://amd.jisakuita.net/
�O�X��
AMD�̎�����APU/CPU/SoC�ɂ��Č�낤 204���� [�]�ڋ֎~](c)2ch.net
http://anago.2ch.net/test/read.cgi/jisaku/1415452208/
�^|�Q|�@| �ނ�ꂸ�ɃX���[���܂��傤�B
|�Q�^�_! sage�i�s�Ń}�^�[�������܂���
�r�炵��W�Ȃ��R�s�y�Ȑl��NG�ɓ���Ė������܂��傤�B
�����AMD�n�X���b�h�ߋ����O�ۑ��T�C�g
http://amd.jisakuita.net/
�O�X��
AMD�̎�����APU/CPU/SoC�ɂ��Č�낤 204���� [�]�ڋ֎~](c)2ch.net
http://anago.2ch.net/test/read.cgi/jisaku/1415452208/
|
|
|
Llano�o��̋łɂ�
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
�T���`�����P���A���h�s�v��
���{�l�Ȃ�A����ς�C���e���Q�t�H������˂�
���{�l�Ȃ�A����ς�C���e���Q�t�H������˂�
�I����Ă�ȃA���h�����̃X����ww
���̂܂ܗ��Ƃ����܂���
���̂܂ܗ��Ƃ����܂���
5 �FSocket774�F2014/12/21(��) 12:36:03.07 ID:hFt05d43
�Y�ꋎ���䂭AMD
6 �FSocket774�F2014/12/21(��) 12:39:53.83 ID:uk4ocio8
����ȁ[�������[�Ȃ�
Nolan��Amur�̏�����Ɨ��Ȃ�����
5W�ȉ��̃��o�C�������̓N�A���R���ɔ����Ĉȗ������ւ��Ȃ��Ǝv���Ă�����
�Q���Ƀ^�C�~���O�Ƃ��Ă͂��Ȃ�x����łǂ������헪�œW�J���Ă����̂����C�ɂȂ�
5W�ȉ��̃��o�C�������̓N�A���R���ɔ����Ĉȗ������ւ��Ȃ��Ǝv���Ă�����
�Q���Ƀ^�C�~���O�Ƃ��Ă͂��Ȃ�x����łǂ������헪�œW�J���Ă����̂����C�ɂȂ�
����Tegra���݂ɂ͍̗p��͏o��������
���̊��܂킵��Meopad���オ������
���̊��܂킵��Meopad���オ������
NOPLAN
AMD��APU�͗ǂ��ł�����������ł���B
�����Intel��CPU+�f�B�X�N���[�gGPU�͂�����Ƃ�������Ƃ��Đ������郌�x���ł��B
�������CPU��GPU�̃����N����ł����B
���̐E��ł͊w�p�v�Z�������̂ł����AAMD��APU�̓R�[�h���H�v������R���p�C����ς��Ă݂���w�p�v�Z�p�̃��C�u�������g���Ă݂��肵�Ă�����ς�x���ł��BGPU���Z�����Ă��x���B
AMD��Opteron��ς�32�R�A�̃��[�N�X�e�[�V�������A�����̃R�A���ŃN���b�N�����Xeon���ڂ̃��[�N�X�e�[�V�������_�u���X�R�A�ň��|���Ă���ł��B
AMD���������ꂽ���R�͂�����A�l�i����������ł��B�ƌ����Ă��A��L���[�N�X�e�[�V�����̉��i���͂�������2����������ł����B
AMD�͐^�̃}���`�R�A�Ƃ����Ƃ������Ă���悤�ł����A�����܂ň��|�I�Ȑ��\�����o��Ƙb�ɂȂ�܂���B
���̐E��ł͍���AAMD��APU�͓������Ȃ����ƂɂȂ��Ă��܂��B�\�����������ۂ̐��\���������Ȃ̂ŁB
����A�x���`�}�[�N�̂悤�ȃ`�[�g�����ő����R�[�h���͂��o���D�G�ȃR���p�C�����o��APU��Intel��CPU�𗽉킷�鎞�オ����ēx�������������邱�ƂɂȂ�ł��傤���A
10�N�͂Ȃ��ł��傤�ˁB
�����Intel��CPU+�f�B�X�N���[�gGPU�͂�����Ƃ�������Ƃ��Đ������郌�x���ł��B
�������CPU��GPU�̃����N����ł����B
���̐E��ł͊w�p�v�Z�������̂ł����AAMD��APU�̓R�[�h���H�v������R���p�C����ς��Ă݂���w�p�v�Z�p�̃��C�u�������g���Ă݂��肵�Ă�����ς�x���ł��BGPU���Z�����Ă��x���B
AMD��Opteron��ς�32�R�A�̃��[�N�X�e�[�V�������A�����̃R�A���ŃN���b�N�����Xeon���ڂ̃��[�N�X�e�[�V�������_�u���X�R�A�ň��|���Ă���ł��B
AMD���������ꂽ���R�͂�����A�l�i����������ł��B�ƌ����Ă��A��L���[�N�X�e�[�V�����̉��i���͂�������2����������ł����B
AMD�͐^�̃}���`�R�A�Ƃ����Ƃ������Ă���悤�ł����A�����܂ň��|�I�Ȑ��\�����o��Ƙb�ɂȂ�܂���B
���̐E��ł͍���AAMD��APU�͓������Ȃ����ƂɂȂ��Ă��܂��B�\�����������ۂ̐��\���������Ȃ̂ŁB
����A�x���`�}�[�N�̂悤�ȃ`�[�g�����ő����R�[�h���͂��o���D�G�ȃR���p�C�����o��APU��Intel��CPU�𗽉킷�鎞�オ����ēx�������������邱�ƂɂȂ�ł��傤���A
10�N�͂Ȃ��ł��傤�ˁB
���ꂾ�����Ƃ���Ȃ̂ŕ⑫���B���͉Ƃł�AMD��APU���g���Ă��܂��B
����͒P���Ɉ�������ƌ����̂ƁA������������ł���Ȃ�CPU�p���[������悤�Ȃ��Ƃ����Ȃ�����ł��B
����ł��Ă���������GPU���\�����҂ł���̂ŁA�V�тɎg�����ɂ͈����Ȃ��ł���B�������A�����{�i�I�ȂRD�Q�[������肽���Ƃ������o���ƕs���ł��傤����ǁB
��������Ƃ��Ă͖{���ɗǂ��ł��Ă܂��B
����͒P���Ɉ�������ƌ����̂ƁA������������ł���Ȃ�CPU�p���[������悤�Ȃ��Ƃ����Ȃ�����ł��B
����ł��Ă���������GPU���\�����҂ł���̂ŁA�V�тɎg�����ɂ͈����Ȃ��ł���B�������A�����{�i�I�ȂRD�Q�[������肽���Ƃ������o���ƕs���ł��傤����ǁB
��������Ƃ��Ă͖{���ɗǂ��ł��Ă܂��B
�Ă������Ԃ����Ⴏ�{�i�I��3D�Q�[�����v���C���鎞�Ԃ��Ƃ�Ȃ���ȁB
���Ԃ��R�����܂��Ă�j�[�g�△�E�Ȃ�Ƃ������B
���Ԃ��R�����܂��Ă�j�[�g�△�E�Ȃ�Ƃ������B
���Ԃ͍����̂���
�Ƃ���������O�̂��Ƃ͒u���Ƃ��āA�p�v���C����̂̓j�[�g�△�E����Ȃ��Ɩ���������
�v���C���邾���Ȃ�T�x1���ł��\���Ǝv����
�Ƃ���������O�̂��Ƃ͒u���Ƃ��āA�p�v���C����̂̓j�[�g�△�E����Ȃ��Ɩ���������
�v���C���邾���Ȃ�T�x1���ł��\���Ǝv����
���Ԕ��ŗV�Ԃ�Ȃ�Q�[���\�t�g��PC���v��Ȃ������
�ۈ��̂��߂ɑ��ɓS�i�q�͗v�邯��
�ۈ��̂��߂ɑ��ɓS�i�q�͗v�邯��
�N��Carrizo�͂Ȃ������ˁB
FM2�̓I���{NIC�������Ă悢
:473 ���O�FSocket774[sage] ���e���F2014/06/08(��) 02:14:14.40 ID:KXR8ESOI
��:774 ���O�F,,�E�L�́M�E,,�j��-������[sage] ���e���F2014/05/31(�y) 21:20:40.57
���uAMD�}�V��������LAN�Ɍq���ȁv���Č����邵��
��:778 ���O�F,,�E�L�́M�E,,�j��-������[sage] ���e���F2014/05/31(�y) 21:32:54.97
���u���m�ȗ��R���Ȃ�����AMD�̃}�V�����Г��ɓ����ȁv����B
��:780 ���O�F,,�E�L�́M�E,,�j��-������[sage] ���e���F2014/05/31(�y) 21:41:14.97 ID:+WKxBJ8a [11/36]
�����������̖��Ƃ���NEC���x�m�ʂ��@�l����PC��AMD�̃��f���Ȃ����ǂ�
��:801 ���O�FSocket774[sage] ���e���F2014/05/31(�y) 22:28:13.21
����Ƃ���Ȃ����A���I�@�ւ̑���PC�ŁA2�R�A2�X���b�h�`4�X���b�h��
���}�V�����g���ĂĂ��B�@�d�����ɃE�C���X�`�F�b�N�����ő���ƁA�Ȃ�ƁA
���Ɩ��p�V�X�e���̓��삪���f�`�j�������炵����
��:802 ���O�F,,�E�L�́M�E,,�j��-������[sage] ���e���F2014/05/31(�y) 22:34:21.61 ID:+WKxBJ8a [18/36]
������͒P���ɐ��\����ĂȂ�������
��AMD��Intel���Ȃ�đS���W�Ȃ������̘b����
���V�X�e�������ŔѐH���Ă�l�Ԃ��炷������Ԃ�t�قȘb����
��:808 ���O�FSocket774[sage] ���e���F2014/05/31(�y) 22:50:46.66
������@���@�@�L�����[�J��PC��������A�V�X�e���x���_�l��
�������炪�I������ꂽ�Ƃ���́A���[�J�l���̃v���Z�b�T�̐��\��
���n��ő���ĂȂ��E�E�E��
���ŁA���������Ƃ���ɂ́AAMD���i�͂Ȃ��c��
�����\����Ȃ����̂ŃV�X�e����g��ŁA���C�Ŕ[������̂͗c�t����
��:774 ���O�F,,�E�L�́M�E,,�j��-������[sage] ���e���F2014/05/31(�y) 21:20:40.57
���uAMD�}�V��������LAN�Ɍq���ȁv���Č����邵��
��:778 ���O�F,,�E�L�́M�E,,�j��-������[sage] ���e���F2014/05/31(�y) 21:32:54.97
���u���m�ȗ��R���Ȃ�����AMD�̃}�V�����Г��ɓ����ȁv����B
��:780 ���O�F,,�E�L�́M�E,,�j��-������[sage] ���e���F2014/05/31(�y) 21:41:14.97 ID:+WKxBJ8a [11/36]
�����������̖��Ƃ���NEC���x�m�ʂ��@�l����PC��AMD�̃��f���Ȃ����ǂ�
��:801 ���O�FSocket774[sage] ���e���F2014/05/31(�y) 22:28:13.21
����Ƃ���Ȃ����A���I�@�ւ̑���PC�ŁA2�R�A2�X���b�h�`4�X���b�h��
���}�V�����g���ĂĂ��B�@�d�����ɃE�C���X�`�F�b�N�����ő���ƁA�Ȃ�ƁA
���Ɩ��p�V�X�e���̓��삪���f�`�j�������炵����
��:802 ���O�F,,�E�L�́M�E,,�j��-������[sage] ���e���F2014/05/31(�y) 22:34:21.61 ID:+WKxBJ8a [18/36]
������͒P���ɐ��\����ĂȂ�������
��AMD��Intel���Ȃ�đS���W�Ȃ������̘b����
���V�X�e�������ŔѐH���Ă�l�Ԃ��炷������Ԃ�t�قȘb����
��:808 ���O�FSocket774[sage] ���e���F2014/05/31(�y) 22:50:46.66
������@���@�@�L�����[�J��PC��������A�V�X�e���x���_�l��
�������炪�I������ꂽ�Ƃ���́A���[�J�l���̃v���Z�b�T�̐��\��
���n��ő���ĂȂ��E�E�E��
���ŁA���������Ƃ���ɂ́AAMD���i�͂Ȃ��c��
�����\����Ȃ����̂ŃV�X�e����g��ŁA���C�Ŕ[������̂͗c�t����
:474 ���O�FSocket774[sage] ���e���F2014/06/08(��) 02:16:51.88 ID:KXR8ESOI
��:802 ���O�F,,�E�L�́M�E,,�j��-������[sage] ���e���F2014/05/31(�y) 22:34:21.61
������͒P���ɐ��\����ĂȂ�������
��:809 ���O�F,,�E�L�́M�E,,�j��-������[sage] ���e���F2014/05/31(�y) 22:54:30.30
�������������[�����ꂽ�V�X�e���ɃP�`�����Ă�n�R��z�{�{�b�^�N��
��:811 ���O�FSocket774[sage] ���e���F2014/05/31(�y) 22:58:05.62
�����I�Ȋ����Ƒϗp5�N���炢����Ȃ��́H
������Ȃ��Ƃ��m��Ȃ��́H
��:819 ���O�FSocket774[sage] ���e���F2014/05/31(�y) 23:04:25.11
���c�t�Ă�肵���̂�
�����\����ĂȂ����Ė��L�����̂�
���ϗp�E���p�N�����ƌ������̂����Ȃ��ǁH
�������̌��I�@�ւ��A���������ł�������ȂǂƎv���Ă�Ȃ�
�������͊e�Ȓ�������̏��Z�L�����e�B�|���V�[�ł��ǂ�ł���
��:827 ���O�F,,�E�L�́M�E,,�j��-������[sage] ���e���F2014/05/31(�y) 23:14:54.20
���}�V���̃X�y�b�N�����ׂ���
�����\�s�����ȂƂ�߂���
�����ł�߂��Ă����āA���l���Ȃ��ăg�����炵�����ǂ�
��:802 ���O�F,,�E�L�́M�E,,�j��-������[sage] ���e���F2014/05/31(�y) 22:34:21.61
������͒P���ɐ��\����ĂȂ�������
��AMD��Intel���Ȃ�đS���W�Ȃ������̘b����
���V�X�e�������ŔѐH���Ă�l�Ԃ��炷������Ԃ�t�قȘb����
���́A�P���ɐ��\�̑���ĂȂ������̗c�t�Șb�@���Ēf���̏ڍׂ������Ă�
���m�ȓ��A�܂�����?�@�����O�F,,�E�L�́M�E,,�j��-������
��:802 ���O�F,,�E�L�́M�E,,�j��-������[sage] ���e���F2014/05/31(�y) 22:34:21.61
������͒P���ɐ��\����ĂȂ�������
��:809 ���O�F,,�E�L�́M�E,,�j��-������[sage] ���e���F2014/05/31(�y) 22:54:30.30
�������������[�����ꂽ�V�X�e���ɃP�`�����Ă�n�R��z�{�{�b�^�N��
��:811 ���O�FSocket774[sage] ���e���F2014/05/31(�y) 22:58:05.62
�����I�Ȋ����Ƒϗp5�N���炢����Ȃ��́H
������Ȃ��Ƃ��m��Ȃ��́H
��:819 ���O�FSocket774[sage] ���e���F2014/05/31(�y) 23:04:25.11
���c�t�Ă�肵���̂�
�����\����ĂȂ����Ė��L�����̂�
���ϗp�E���p�N�����ƌ������̂����Ȃ��ǁH
�������̌��I�@�ւ��A���������ł�������ȂǂƎv���Ă�Ȃ�
�������͊e�Ȓ�������̏��Z�L�����e�B�|���V�[�ł��ǂ�ł���
��:827 ���O�F,,�E�L�́M�E,,�j��-������[sage] ���e���F2014/05/31(�y) 23:14:54.20
���}�V���̃X�y�b�N�����ׂ���
�����\�s�����ȂƂ�߂���
�����ł�߂��Ă����āA���l���Ȃ��ăg�����炵�����ǂ�
��:802 ���O�F,,�E�L�́M�E,,�j��-������[sage] ���e���F2014/05/31(�y) 22:34:21.61
������͒P���ɐ��\����ĂȂ�������
��AMD��Intel���Ȃ�đS���W�Ȃ������̘b����
���V�X�e�������ŔѐH���Ă�l�Ԃ��炷������Ԃ�t�قȘb����
���́A�P���ɐ��\�̑���ĂȂ������̗c�t�Șb�@���Ēf���̏ڍׂ������Ă�
���m�ȓ��A�܂�����?�@�����O�F,,�E�L�́M�E,,�j��-������
�m��Ƃ킴�킴�Θb���悤�Ƃ��Ă�z���ُ�
�M�҂͐��\���ǂ����ĐM���Ă邩��@�c�q�݂�����
����Ƃ���Ȃ����A���I�@�ւ̑���PC�ŁA2�R�A2�X���b�h�`4�X���b�h��
���}�V�����g���ĂĂ��B�@�d�����ɃE�C���X�`�F�b�N�����ő���ƁA�Ȃ�ƁA
���Ɩ��p�V�X�e���̓��삪���f�`�j�������炵����
���̘b�̏ڍׂ������Ă�
���m�ȓ��A�܂�����?�@�����OGPU�œd�͏����y��E�i�M��̓��[�v�d��
���}�V�����g���ĂĂ��B�@�d�����ɃE�C���X�`�F�b�N�����ő���ƁA�Ȃ�ƁA
���Ɩ��p�V�X�e���̓��삪���f�`�j�������炵����
���̘b�̏ڍׂ������Ă�
���m�ȓ��A�܂�����?�@�����OGPU�œd�͏����y��E�i�M��̓��[�v�d��
�Â��A�v�����ƍŐV�S�R�A�̂�����2�R�A��15�����炢�ł��������Ȃ�����Â�CPU�ł�����
�܂��J���̖͂����̌����Ă�B
�{���ɈӖ��̂��鐫�\�]����--PC�̃x���`�}�[�N���čl����
ttp://japan.zdnet.com/article/35058483/
�{���ɈӖ��̂��鐫�\�]����--PC�̃x���`�}�[�N���čl����
ttp://japan.zdnet.com/article/35058483/
�r������ǂݔ����������قǂɓ��e���Ȃ��B
4gamer��bull�ւ̍œK�����`�̂ق����F�X�ȈӖ��Ŗʔ���
4gamer��bull�ւ̍œK�����`�̂ق����F�X�ȈӖ��Ŗʔ���
>>23
������O�̂��Ə����Ă邾���ł܂���
�ŋ߂�CPU�͐��\���K�v�\�������Ė��Ӗ��ȃx���`�}�[�N�ł����点�Đ��l���r���邱�Ƃł������\�̌�����Ղ���������邱�Ƃ͂ł��Ȃ�
�x���`�}�[�N�̂��߂�CPU�����Ă��ʂɂ�������Ȃ��B����er�Ȃ�Ă���Ȃ���
������O�̂��Ə����Ă邾���ł܂���
�ŋ߂�CPU�͐��\���K�v�\�������Ė��Ӗ��ȃx���`�}�[�N�ł����点�Đ��l���r���邱�Ƃł������\�̌�����Ղ���������邱�Ƃ͂ł��Ȃ�
�x���`�}�[�N�̂��߂�CPU�����Ă��ʂɂ�������Ȃ��B����er�Ȃ�Ă���Ȃ���
�Ō�̃I�`���v���H
�命���̃��[�U�[���I��Intel���D��Ă���Ƃ�����������Ă邼�B
�命���̃��[�U�[���I��Intel���D��Ă���Ƃ�����������Ă邼�B
�l��ɂƂ��āA�����A��ɂƂ��ẮAAMD����̓q�[���[��������ł��B
����Ȃ��Ƃ����킸�ɁA�uGPU�̋��Ђ�Phi�̂��e���U��ɖڂ�w����
x86�̃R�A����SIMD�ɗ������x���`�X�R�A�ŕ����オ�邱�ƂɈӖ��͂���̂��v�Ƃ��炢�����ĉ������I
����Ȃ��Ƃ����킸�ɁA�uGPU�̋��Ђ�Phi�̂��e���U��ɖڂ�w����
x86�̃R�A����SIMD�ɗ������x���`�X�R�A�ŕ����オ�邱�ƂɈӖ��͂���̂��v�Ƃ��炢�����ĉ������I
Zen�����APU�̃X�y�b�N���l���悤
�u�������5�X���b�h�ȏ�̂��o�Ă��Ȃ��������Azen����APU��4�X���b�h�ɂȂ肻�������
SMT���ĉ\���邩��APU��2�R�A4�X���b�h�AFX��4�R�A8�X���b�hGPU�������ȁH
HBM�������L3�L���b�V���͖������ȁH
HBM��GPU�̑ш�s���͂Ȃ��Ȃ邾�낤����AGPU�͌���̂܂܂ł����\���\�オ�肻�������ǂǂ�����
�ς���Ƃ�����ő�704�R�A(R9 290�̃V�F�[�_�G���W��1�)�ɂȂ邩�ȁH
�������Ă邱�ƂȂ��߂��Ėϑz���ł��Ȃ�
SMT���ĉ\���邩��APU��2�R�A4�X���b�h�AFX��4�R�A8�X���b�hGPU�������ȁH
HBM�������L3�L���b�V���͖������ȁH
HBM��GPU�̑ш�s���͂Ȃ��Ȃ邾�낤����AGPU�͌���̂܂܂ł����\���\�オ�肻�������ǂǂ�����
�ς���Ƃ�����ő�704�R�A(R9 290�̃V�F�[�_�G���W��1�)�ɂȂ邩�ȁH
�������Ă邱�ƂȂ��߂��Ėϑz���ł��Ȃ�
�ϑz�ł����Ȃ����AAPU��4�R�A8�X���͗���Ǝv���Ă�B
Jaguar�n8�R�A�͌v�悳��Ă�B�_�C�T�C�Y�̖����V�������N�̌��E�܂ŊԂ�����B
�����AK12�Ɖ��炩�̐v�̋��ʐ�����������ƂȂ��
Zen�������܂Ń_�C�T�C�Y���߂�Ƃ͎v���Ȃ��B
Jaguar�n8�R�A�͌v�悳��Ă�B�_�C�T�C�Y�̖����V�������N�̌��E�܂ŊԂ�����B
�����AK12�Ɖ��炩�̐v�̋��ʐ�����������ƂȂ��
Zen�������܂Ń_�C�T�C�Y���߂�Ƃ͎v���Ȃ��B
jaguar8�R�A�̓J�X�^��APU�p����Ȃ��́H
�����u���Q�[���@�̂���
�R�A�̑傫���C�ɂȂ������璲�ׂĂ݂�
jaguar(3.1mm2)
ARM A15(2.7mm2)
ARM A7(0.45mm2)
�X�`�[�����[���[(18.4mm2)
K10��28nm�ł���12mm2���炢
��������K10���̓f�J���Ȃ邾�낤���AK12��zen��1/4�̑傫���Ƃ��̕��������₷���Ǝv��
�b�͂�����ƕς�邯��
zen�͍����\���������ǁA�ȓd�͌�����K12�����H
jaguar�̌�p���H
ARM����windows�����Ȃ���ˁH���R�����
win�^�u�ǂ�����́H
���Ɠ���������Ȃ��Ȃ�Socket���ꂷ�闘�_������ǁA����������windows��������́H
�����u���Q�[���@�̂���
�R�A�̑傫���C�ɂȂ������璲�ׂĂ݂�
jaguar(3.1mm2)
ARM A15(2.7mm2)
ARM A7(0.45mm2)
�X�`�[�����[���[(18.4mm2)
K10��28nm�ł���12mm2���炢
��������K10���̓f�J���Ȃ邾�낤���AK12��zen��1/4�̑傫���Ƃ��̕��������₷���Ǝv��
�b�͂�����ƕς�邯��
zen�͍����\���������ǁA�ȓd�͌�����K12�����H
jaguar�̌�p���H
ARM����windows�����Ȃ���ˁH���R�����
win�^�u�ǂ�����́H
���Ɠ���������Ȃ��Ȃ�Socket���ꂷ�闘�_������ǁA����������windows��������́H
�Q�[���@�̃W���K�[���D��Č�����̂�OS��Windows���̗p���Ă��Ȃ����炾����B
��ARM����windows�����Ȃ���ˁH
���ʂ�PC�A�v�����Ή�����x86��x64�ɑΉ�����Windows���o����Ă邩��
���ʂ��ꂵ���ڂɂ��Ȃ�������
����PC98���FMTOWNS���
����ł�ARM��Itanium����
���ʂ�PC�A�v�����Ή�����x86��x64�ɑΉ�����Windows���o����Ă邩��
���ʂ��ꂵ���ڂɂ��Ȃ�������
����PC98���FMTOWNS���
����ł�ARM��Itanium����
windows�̓\�t�g������Ȃ��Ă�OS�P�̂ŗ]�v�ȕ��ׂƗ]�v��HDD���Ղȃg���b�v���̂��|���邩���
OS��HDD�̃N���[���\�t�g�̑唼�̓�������Ԃ�OS�C���[�W���œ���ł���Linux���g���Ă��肷�邵
OS��HDD�̃N���[���\�t�g�̑唼�̓�������Ԃ�OS�C���[�W���œ���ł���Linux���g���Ă��肷�邵
�����œ���ł���@-> �Ԃ�����œ���ł���
�������Ȋ����ϊ������������悤������������� IME������
�������Ȋ����ϊ������������悤������������� IME������
�Ԃ���Ł@�Ɓ@�Ԃ�����Ł@�ł͌�ϊ�����������\���͂Ȃ��悤�Ɍ�����
�^�C�v�~�X���\�t�g�E�F�A�̐ӔC�ɂ��Ă�Ȃ���
�^�C�v�~�X���\�t�g�E�F�A�̐ӔC�ɂ��Ă�Ȃ���
surface3�o���Ȃ��������_��windows rt�͂����
�����������g���A�v�����n���win tab�ł̓f�X�N�g�b�v�A�v��������
tab�̈Ӗ����S���Ȃ�
�����������g���A�v�����n���win tab�ł̓f�X�N�g�b�v�A�v��������
tab�̈Ӗ����S���Ȃ�
>>32
�v��Ƃ������\�z�i�K�̂悤�����ACheetah8�R�A���z�肳��Ă���B
http://northwood.blog60.fc2.com/blog-entry-7545.html
Zen��K12�̃`�b�v�v�̋��ʉ����l�����Ă���B
http://pc.watch.impress.co.jp/docs/column/kaigai/20140801_660442.html
�����m���ɂ��������ʂ�AK12��Zen��1��1�ɂȂ�ƒf���͂ł��Ȃ��B
1/4���K���͂킩��Ȃ����B
Windows�̃L���[�R���e���c��AD�Ȃ���RT���������ƑΉ�������
�Ɩ��p�^�u���b�g�Ƃ��Ĕ��荞�߂悩������B
pro-����-phone��3���i�̐����ˁBphone����߂Ă��Ȃ���̘b�����ǁB
�v��Ƃ������\�z�i�K�̂悤�����ACheetah8�R�A���z�肳��Ă���B
http://northwood.blog60.fc2.com/blog-entry-7545.html
Zen��K12�̃`�b�v�v�̋��ʉ����l�����Ă���B
http://pc.watch.impress.co.jp/docs/column/kaigai/20140801_660442.html
�����m���ɂ��������ʂ�AK12��Zen��1��1�ɂȂ�ƒf���͂ł��Ȃ��B
1/4���K���͂킩��Ȃ����B
Windows�̃L���[�R���e���c��AD�Ȃ���RT���������ƑΉ�������
�Ɩ��p�^�u���b�g�Ƃ��Ĕ��荞�߂悩������B
pro-����-phone��3���i�̐����ˁBphone����߂Ă��Ȃ���̘b�����ǁB
>>32
���@zen�͍����\���������ǁA�ȓd�͌�����K12�����H
�����������ݕ�������Ȃ��݂�������B
�����Ƃ��O������i�H�j�����₷���悤�ɐv�����ʉ����邾����
�ix86�AARM���ꂼ��Łj���[����n�C�܂ŃR�A���ƃN���b�N�Œ�������悤�ɂ�����肾�Ǝv���B
�����N�̕邮�炢�Ƀ��o�C������n�C�p�t�H�[�}���X�܂ł��J�o�[���A�ŏ�2�R�A+256sp�A�ő�8�R�A+1024sp��Cheetah�Ȃ����ꂽ���Ƃ�����B
���@zen�͍����\���������ǁA�ȓd�͌�����K12�����H
�����������ݕ�������Ȃ��݂�������B
�����Ƃ��O������i�H�j�����₷���悤�ɐv�����ʉ����邾����
�ix86�AARM���ꂼ��Łj���[����n�C�܂ŃR�A���ƃN���b�N�Œ�������悤�ɂ�����肾�Ǝv���B
�����N�̕邮�炢�Ƀ��o�C������n�C�p�t�H�[�}���X�܂ł��J�o�[���A�ŏ�2�R�A+256sp�A�ő�8�R�A+1024sp��Cheetah�Ȃ����ꂽ���Ƃ�����B
�Ȃ��e�������ɂ��Ԃ����B�B
RISC���ăR���p�C���ɗ����Ė��߂�P��������
���W�X�^������ɂ��邱�Ƃō��N���b�N������������ė������������
AMD�̓L���b�V�����ア����
���N���b�N���������牽�Ƃ������Ⴄ�̂��H
���W�X�^������ɂ��邱�Ƃō��N���b�N������������ė������������
AMD�̓L���b�V�����ア����
���N���b�N���������牽�Ƃ������Ⴄ�̂��H
���N���b�N��������RISC���Ƃ��p�C�v���C���̋����Ƃ��F�X�肪����B
A15�ɔ�ׂ�Apple��CPU�̓_�C�T�C�Y���傫���N���b�N���o�ɂ����������A
��IPC�������̂�2�R�A��4�R�A����ɐ��\�͕����ĂȂ������B
K12���iARM�ɂ��Ắj�����ȃr�b�O�R�A�ɂȂ��Ȃ����B
A15�ɔ�ׂ�Apple��CPU�̓_�C�T�C�Y���傫���N���b�N���o�ɂ����������A
��IPC�������̂�2�R�A��4�R�A����ɐ��\�͕����ĂȂ������B
K12���iARM�ɂ��Ắj�����ȃr�b�O�R�A�ɂȂ��Ȃ����B
a7��10��
a8��20��
a8x��30��
a8��20��
a8x��30��
Trinity 24��
http://www.4gamer.net/games/147/G014731/20140114055/
http://www.4gamer.net/games/147/G014731/20140114055/
>>43
����RISC����������N���b�N�オ�����Ƃ����Ȃ�
����͂܂�N���b�N�I�ɂ�x86=RISC�ł���
�X�Ɍ�����RISC�ł̓R���p�C����RISC���߉�����̂�
x86�̓f�R�[�_�������S���Ă���
�������ۛ��ڂɌ��Ă�x86<=RISC�ƂȂ�̂������Ȃ̂�
������x86>RISC�Ȃ�
����RISC����������N���b�N�オ�����Ƃ����Ȃ�
����͂܂�N���b�N�I�ɂ�x86=RISC�ł���
�X�Ɍ�����RISC�ł̓R���p�C����RISC���߉�����̂�
x86�̓f�R�[�_�������S���Ă���
�������ۛ��ڂɌ��Ă�x86<=RISC�ƂȂ�̂������Ȃ̂�
������x86>RISC�Ȃ�
�|���Ă�\�Z���n���p�Ȃ������
����RISC���Ŏ��ۂɖڎw���Ă邱�Ƃ̓x���`�}�[�N��������
�l�g�o�ȍ~�̃C���e���͂��������r�W�l�X���f��
����RISC���Ŏ��ۂɖڎw���Ă邱�Ƃ̓x���`�}�[�N��������
�l�g�o�ȍ~�̃C���e���͂��������r�W�l�X���f��
�ʃv���b�g�t�H�[�������グ�Ă���Ă���������8c4m���ė~�����Ȃ��E�E�E
AM3+�̂܂܂͗��ɍ���E�E�EPCI-E�̐ڑ��I��
AM3+�̂܂܂͗��ɍ���E�E�EPCI-E�̐ڑ��I��
>>49
�ǂ݂̂�4GHz��O�ő����ݏ�Ԃ�����A�N���b�N�I�ɂ�ARM��x86���ς��Ȃ��C������B
�Ƃ������A�[�L�e�N�`���▽�߃Z�b�g�ŃN���b�N��L���鎞�ザ��Ȃ��Ǝv���B
�ǂ݂̂�4GHz��O�ő����ݏ�Ԃ�����A�N���b�N�I�ɂ�ARM��x86���ς��Ȃ��C������B
�Ƃ������A�[�L�e�N�`���▽�߃Z�b�g�ŃN���b�N��L���鎞�ザ��Ȃ��Ǝv���B
�e���w���c�g�����W�X�^�����̗p���邩���ȁB
�������͌�CPU���J�[�{���i�m�`���[�u�B
�������͌�CPU���J�[�{���i�m�`���[�u�B
4core hswell���P�S��
amd�͖��ʂȃg�����W�X�^������������
gpu�K�͂��낤��
���ʂƂ͌���AGPU���g���Ă�g�����W�X�^�ʂقǏo���ĂȂ���Ȃ����B
�����HBM�Җ]���B
�����HBM�Җ]���B
�g�����W�X�^������̐��\�͂ǂ��ł��悭�āA���x�Ɠd�͌����D���
Intel�����o�C���ɂ�GT3�Ƃ��p�ӂ��Ă�̂Ɠ������R
Intel�����o�C���ɂ�GT3�Ƃ��p�ӂ��Ă�̂Ɠ������R
����͒P�Ƀx���`�����邽�߂�FUD�ړI��SKU�ł���
>>40
�����v��CPU�ς��邾���ŁA�D�^�u��win�^�u���v���̂܂g���܂킹��悤�ɂȂ�̂Ȃ�Awin�^�u(AMD APU)������H
����������̖��͕ʂƂ���
>>39-40
Cheetah�͂ǂ����������ʒu�Ȃ�
x86�����Ȃ͕̂����邯�ǁAzen�Ɣ���Ă邵
�����n�C�p�t�H�[�}���X�s����Ȃ�Е��ł������
zen������Cheetah�A�Ȃ�S���킩��₷���̂������
zenbook�Ƃ̋��͂�\�ɏo�����߂ɖ��O�ς����A�݂����Ȃ�
�����v��CPU�ς��邾���ŁA�D�^�u��win�^�u���v���̂܂g���܂킹��悤�ɂȂ�̂Ȃ�Awin�^�u(AMD APU)������H
����������̖��͕ʂƂ���
>>39-40
Cheetah�͂ǂ����������ʒu�Ȃ�
x86�����Ȃ͕̂����邯�ǁAzen�Ɣ���Ă邵
�����n�C�p�t�H�[�}���X�s����Ȃ�Е��ł������
zen������Cheetah�A�Ȃ�S���킩��₷���̂������
zenbook�Ƃ̋��͂�\�ɏo�����߂ɖ��O�ς����A�݂����Ȃ�
���D�^�u��win�^�u���v���̂܂g���܂킹��
BIOS���ς��Ȃ��ƃ_������B
Cheetah��Jaguar�n�ł��邱�Ƃ����m�Ȃ̂œ����ł͂Ȃ�����B
2015-2016���ĂȂ��Ă邩��Cheetah�̕�����ɏo��Ǝv���B
BIOS���ς��Ȃ��ƃ_������B
Cheetah��Jaguar�n�ł��邱�Ƃ����m�Ȃ̂œ����ł͂Ȃ�����B
2015-2016���ĂȂ��Ă邩��Cheetah�̕�����ɏo��Ǝv���B
�ŏ�����g���v�Ȃ�ύX�͕s�v
pc�iwindows)���ɂ��킹�č���Ă�����android��os���������boot�o����悤�ɂ��Ƃ�����
atom���ڂ̃`���E�J�p�b�h�����ɂ���Ă邱��
pc�iwindows)���ɂ��킹�č���Ă�����android��os���������boot�o����悤�ɂ��Ƃ�����
atom���ڂ̃`���E�J�p�b�h�����ɂ���Ă邱��
>>60
�����̂Ȃ��ł�Zen�v���Z�b�T���g����APU��Cheetah�B
��86��ARM��2����256sp�������Z�b�g�ɂȂ��Ă�APU�̃R�[�h�l�[����Cheetah�B
�ł���x86�v���Z�b�T��Zen��ARM��k12����Ȃ�ARM�B
�����܂Ōl�̖ϑz�����ǘb�̒���͂������ȂƁB
�����̂Ȃ��ł�Zen�v���Z�b�T���g����APU��Cheetah�B
��86��ARM��2����256sp�������Z�b�g�ɂȂ��Ă�APU�̃R�[�h�l�[����Cheetah�B
�ł���x86�v���Z�b�T��Zen��ARM��k12����Ȃ�ARM�B
�����܂Ōl�̖ϑz�����ǘb�̒���͂������ȂƁB
>>63
Cheetah��zen���R�A�̖��O�����炻��͂�����ƈႤ�悤��
�܂����o�Ă��Ȃ��Ɖ��ɂ�������Ȃ�����
>>61
jaguar�n��Cheetah�ɁAbull�n��zen�ɂ��Ċ����H
>>62
atom���ڃp�b�h�ł͂�������Ă邱�Ƃ������̂�
AMD�ł����҂��Ă܂���I
Cheetah��zen���R�A�̖��O�����炻��͂�����ƈႤ�悤��
�܂����o�Ă��Ȃ��Ɖ��ɂ�������Ȃ�����
>>61
jaguar�n��Cheetah�ɁAbull�n��zen�ɂ��Ċ����H
>>62
atom���ڃp�b�h�ł͂�������Ă邱�Ƃ������̂�
AMD�ł����҂��Ă܂���I
>>64
Bulldozer�R�A�𓋍ڂ���APU�̃R�[�h�l�[����Trinity�Ƃ�Richland����
�����R�A�ɕʁX�̖��O�����͕̂s�v�c�ł͂Ȃ��C������B
�A�[�L�e�N�`�����Bull�̌�p�͂Ȃ��A���̗̈���J�o�[�ł���悤�ɂ���Jaguar�i�̌�p�j��Cheetah/Zen���Ɩϑz���Ă�
Bulldozer�R�A�𓋍ڂ���APU�̃R�[�h�l�[����Trinity�Ƃ�Richland����
�����R�A�ɕʁX�̖��O�����͕̂s�v�c�ł͂Ȃ��C������B
�A�[�L�e�N�`�����Bull�̌�p�͂Ȃ��A���̗̈���J�o�[�ł���悤�ɂ���Jaguar�i�̌�p�j��Cheetah/Zen���Ɩϑz���Ă�
>>65
���̖ϑz�����C����������ے肷��C���Ȃ��̂����A
��̕��ŏo�Ă����R�A�T�C�Y�̔�r�������Jaguar�n�͏���������B
Apple��CPU��K12�͓����ł͂Ȃ����A�g�ь������i�����
��̃Z�O�����g������ɓ��ꂽK12��Apple���V���v���ɂȂ�Ǝv���Ȃ��B
Apple�̃��c��A15�̔{�߂��ʐϋ���Ă����������Ȃ��킯�ŁA
�R�A�̃t�b�g�v�����g���߂Â�����Ă̂��l����ƕʃR�A���Ǝv���B
���̖ϑz�����C����������ے肷��C���Ȃ��̂����A
��̕��ŏo�Ă����R�A�T�C�Y�̔�r�������Jaguar�n�͏���������B
Apple��CPU��K12�͓����ł͂Ȃ����A�g�ь������i�����
��̃Z�O�����g������ɓ��ꂽK12��Apple���V���v���ɂȂ�Ǝv���Ȃ��B
Apple�̃��c��A15�̔{�߂��ʐϋ���Ă����������Ȃ��킯�ŁA
�R�A�̃t�b�g�v�����g���߂Â�����Ă̂��l����ƕʃR�A���Ǝv���B
>>66
�ڂ��̂Ȃ��ł́A�N���X�^�[�h�E�A�[�L�e�N�`������Ȃ���Jaguar��p�A�Ƃ����v�l��H���Ă�B
�����14nm�ɂȂ����瓯���傫���Ŕ{���炢�̋K�͂ɂł��邵��
�ڂ��̂Ȃ��ł́A�N���X�^�[�h�E�A�[�L�e�N�`������Ȃ���Jaguar��p�A�Ƃ����v�l��H���Ă�B
�����14nm�ɂȂ����瓯���傫���Ŕ{���炢�̋K�͂ɂł��邵��
������Jaguar�̌�p��Jaguar�n�R�A�Ƃ����̂ł͈Ӗ����Ⴄ�B
Cheetah�͊m��ł����Ȃ����AJaguar�n�R�A�̃R�[�h�l�[�����^�����A
Jaguar�n�R�A�ł���Ƃ�����o�Ă���B
Zen��Jaguar��p�ł��邩������Ȃ����A
Jaguar�n�R�A�ł���Ƃ������͏o�Ă��Ȃ��B
Cheetah�͊m��ł����Ȃ����AJaguar�n�R�A�̃R�[�h�l�[�����^�����A
Jaguar�n�R�A�ł���Ƃ�����o�Ă���B
Zen��Jaguar��p�ł��邩������Ȃ����A
Jaguar�n�R�A�ł���Ƃ������͏o�Ă��Ȃ��B
����CPU�R�A�̐��\�͍��Ƒ債�ĕς��Ȃ��Ǝv�����ǂ�
�V�������N�œ�����ȓd�͈ȏ�̂��̂͂Ȃ��Ǝv��
����ɍŋ߂̃{�g���l�b�N��CPU���\����Ȃ���������X�g���[�W�̕����傫��
jaguar�̃l�b�N�̓V���O���`���l���ŁAkaveri�̃l�b�N��DDR3�̋����ш悾����
�V�������N�œ�����ȓd�͈ȏ�̂��̂͂Ȃ��Ǝv��
����ɍŋ߂̃{�g���l�b�N��CPU���\����Ȃ���������X�g���[�W�̕����傫��
jaguar�̃l�b�N�̓V���O���`���l���ŁAkaveri�̃l�b�N��DDR3�̋����ш悾����
����Bulldozer�ł��V�������N�Ń��W���[�������{�ɂȂ��
�}���`�X���b�h���L���ȏ����ł͔{�̐��\�ɂȂ�̂�
�G���R����ړI�̂킽���͔��ɂ��ꂵ���i�̂�Bull�ł������̂ő��R�A���~�����j�B
�}���`�X���b�h���L���ȏ����ł͔{�̐��\�ɂȂ�̂�
�G���R����ړI�̂킽���͔��ɂ��ꂵ���i�̂�Bull�ł������̂ő��R�A���~�����j�B
AMD GPU�̐����v���Z�X��GlobalFoundries 28nmSHP�Ɉڍs����H
http://northwood.blog60.fc2.com/blog-entry-7887.html
�i�v���GPU��kaveri�Ɠ���28nm SHP�ցA������CPU���i��TSMC��16nm finfet�ւƂ����b�j
�������㓡���̋L����GF��Apple�ւ̋��������܂��Ă��āATSMC��Apple�����������߂邽�߂�
�ϋɓI�ɃA�v���[�`���Ă���Ęb���������̂ł��̗��ꂩ�ȁH
http://northwood.blog60.fc2.com/blog-entry-7887.html
�i�v���GPU��kaveri�Ɠ���28nm SHP�ցA������CPU���i��TSMC��16nm finfet�ւƂ����b�j
�������㓡���̋L����GF��Apple�ւ̋��������܂��Ă��āATSMC��Apple�����������߂邽�߂�
�ϋɓI�ɃA�v���[�`���Ă���Ęb���������̂ł��̗��ꂩ�ȁH
Intel������X������匴���̋L���B
���Ԃ�X�}�z�����̂悤�ȃf�U�C�������nj��₷�������̂ł��̂܂ܓ\���Ă܂�
PC�e�N�m���W�[�g�����h 2015 - ����CPU/GPU����e��`�b�v�܂� (2) AMD APU - Carrizo/Carrizo-L
http://s.news.mynavi.jp/special/2015/trendspring/001.html
PC�e�N�m���W�[�g�����h 2015 - ����CPU/GPU����e��`�b�v�܂� (5) AMD GPU - 20nm�œ�������鎟����GPU
http://s.news.mynavi.jp/special/2015/trendspring/004.html
PC�e�N�m���W�[�g�����h 2015 - ����CPU/GPU����e��`�b�v�܂� (8) TSMC Process - 20nm��16FF/16FF+�̌���Ƃ��̐�
http://s.news.mynavi.jp/special/2015/trendspring/007.html
PC�e�N�m���W�[�g�����h 2015 - ����CPU/GPU����e��`�b�v�܂� (9) Samsung/GlobalFoundries Process - 14nm�̌���������炢
http://s.news.mynavi.jp/special/2015/trendspring/008.html
���Ԃ�X�}�z�����̂悤�ȃf�U�C�������nj��₷�������̂ł��̂܂ܓ\���Ă܂�
PC�e�N�m���W�[�g�����h 2015 - ����CPU/GPU����e��`�b�v�܂� (2) AMD APU - Carrizo/Carrizo-L
http://s.news.mynavi.jp/special/2015/trendspring/001.html
PC�e�N�m���W�[�g�����h 2015 - ����CPU/GPU����e��`�b�v�܂� (5) AMD GPU - 20nm�œ�������鎟����GPU
http://s.news.mynavi.jp/special/2015/trendspring/004.html
PC�e�N�m���W�[�g�����h 2015 - ����CPU/GPU����e��`�b�v�܂� (8) TSMC Process - 20nm��16FF/16FF+�̌���Ƃ��̐�
http://s.news.mynavi.jp/special/2015/trendspring/007.html
PC�e�N�m���W�[�g�����h 2015 - ����CPU/GPU����e��`�b�v�܂� (9) Samsung/GlobalFoundries Process - 14nm�̌���������炢
http://s.news.mynavi.jp/special/2015/trendspring/008.html
�V�������N���i���HBM���������[���͂Ȃ̂ł���������
�������S��ް�H
http://s.news.mynavi.jp/special/2015/trendspring/001.html
GF��TSMC�̎�����v���Z�X�͎��g�����グ�ɂ������ď����Ă��邯��
���̑OIBM��������22/14nmSOI�v���Z�X�͎g��Ȃ��̂���
����̓T�[�o��C���t���[���p��4Ghz�I�[�o�[��CPU����邽�߂̃v���Z�X������
3Ghz���x�Ȃ�]�T���낤��eDRAM�Ƃ�����ѓ��������
HBM�ŃV���R���C���^�[�|�[�U�[���g���̂Ȃ�CPU�����N���b�N�ᖧ�x��14nmSOI�ō��
GPU�͒�N���b�N�����x��GF/TSMC�ō���ăV���R���C���^�[�|�[�U�[�ō����ڑ�����Ƃ������@������
GF��TSMC�̎�����v���Z�X�͎��g�����グ�ɂ������ď����Ă��邯��
���̑OIBM��������22/14nmSOI�v���Z�X�͎g��Ȃ��̂���
����̓T�[�o��C���t���[���p��4Ghz�I�[�o�[��CPU����邽�߂̃v���Z�X������
3Ghz���x�Ȃ�]�T���낤��eDRAM�Ƃ�����ѓ��������
HBM�ŃV���R���C���^�[�|�[�U�[���g���̂Ȃ�CPU�����N���b�N�ᖧ�x��14nmSOI�ō��
GPU�͒�N���b�N�����x��GF/TSMC�ō���ăV���R���C���^�[�|�[�U�[�ō����ڑ�����Ƃ������@������
�����p�ɂ͎g���Ȃ����炢
�X���[�v�b�g�������Ƃ������Ƃ�����̂����
�X���[�v�b�g�������Ƃ������Ƃ�����̂����
IBM��FAB��XBOX360��WiiU�̃`�b�v������Ă邩�炻���܂ō��R�X�g�̎��ł͂Ȃ��Ǝv��
�܂����͓d���Ǘ��}���Z�[�̎���Ȃ̂�
�����d�͉����čő�N���b�N�œ�����������APU����
�ő�N���b�N���オ��Ȃ��̂����ɂȂ�Ȃ��̂�������Ȃ��B
�����d�͉����čő�N���b�N�œ�����������APU����
�ő�N���b�N���オ��Ȃ��̂����ɂȂ�Ȃ��̂�������Ȃ��B
>>77
�����Ȃ́H
���ꂶ�Ⴀ�Z�~�E�J�X�^�����Ƃŗ��p�ł��Ȃ�����Ƃ����ȁB
�n�C�p�t�H�[�}���X����14nm�����������グ����������ǂ�
�����Ȃ́H
���ꂶ�Ⴀ�Z�~�E�J�X�^�����Ƃŗ��p�ł��Ȃ�����Ƃ����ȁB
�n�C�p�t�H�[�}���X����14nm�����������グ����������ǂ�
>>78
����������Carrizo ES 1.4-2.5GHz��Kaveri 1.9-3.2GHz�̃X�R�A���������Ęb����������
����������Carrizo ES 1.4-2.5GHz��Kaveri 1.9-3.2GHz�̃X�R�A���������Ęb����������
45nm���Q�[���@�̃`�b�v���Ȃ�������A�X�p�R�����������Ȃ������Ƃ������Ƃł́H
Llano�o��̋łɂ�
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
���{�l�Ȃ�C���e���Q�t�H�Ō��܂肗
�ቿ�iSIM�t���[�X�}�zASUS Zenfone2
5.5�C���` 1920�~1080�@Gorilla Glass 3
Android 5.0 Lollipop
intel Atom Z3560/Z3580 64bit �N�A�b�h�R�A
ROM 16/32/64GB
RAM 2GB/4GB
�o�b�e���[ 3000mAh
�J���� 13MP(���A) 5MP(�t�����g)
WiFi 11AC
199�h���`
5.5�C���` 1920�~1080�@Gorilla Glass 3
Android 5.0 Lollipop
intel Atom Z3560/Z3580 64bit �N�A�b�h�R�A
ROM 16/32/64GB
RAM 2GB/4GB
�o�b�e���[ 3000mAh
�J���� 13MP(���A) 5MP(�t�����g)
WiFi 11AC
199�h���`
Radeon290�~���ڂ����ꍇ
i5-4670k 61.3fps�@�@�@�@�@�@�@�@�@�@�@passmark����7785
FX-8350 44.9fps �@�@�@�@�@�@�@�@�@�@�@�@ passmark����9051
i3-4330 43.5fps �@ �@�@�@passmark����5100
G3420�@�@�@35.2fps �@�@�@�@passmark����3467
G3220�@�@�@33.1fps �@�@�@passmark����3186
A10-7850k 31.9fps�@�@�@ passmark����5680
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_radeon_dx.png
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�Q,_,,, �Q
�@ �@ �@ �������� �@ �@���� �@�@�@�@�@�@�@�@�@�@�@�@�@_ _(_)�^ �@ �@ �@�@�_�@�v�M���[�I�I
�������������������������� �@�@�@�@�@�@�@�@�@l_j_j_j^���ցA �@ , �ց@�R
�������������@ ������������ �@ �@���� �@�@�@�@�R�@| �@ �@ |�P|�@�@�@�K�@| (_) _ _
�@ �@ �@ �����@ �@ ������������������������ �@�@�R�R�@�@�m�Q���@�@�@ ��_�@l_j_j_j
���������� �@ �@�������������������������@�@ /�@�@�@�[�\�\ �@�^�@ �m�P
�����������@ �@ �������������������@ �����@ /�@�@�@�@�@�@�@�@�^�[
���� �@ �@ �@ �@ �@�������������� ���@�@�� ����������������������������������
�����������@ �@ �������� �@ �@��������������������������������������������
���������� �@ �@���������@ �@ �@ �@ ����������������������������������������
i5-4670k 61.3fps�@�@�@�@�@�@�@�@�@�@�@passmark����7785
FX-8350 44.9fps �@�@�@�@�@�@�@�@�@�@�@�@ passmark����9051
i3-4330 43.5fps �@ �@�@�@passmark����5100
G3420�@�@�@35.2fps �@�@�@�@passmark����3467
G3220�@�@�@33.1fps �@�@�@passmark����3186
A10-7850k 31.9fps�@�@�@ passmark����5680
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_radeon_dx.png
{kind=link}
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�Q,_,,, �Q
�@ �@ �@ �������� �@ �@���� �@�@�@�@�@�@�@�@�@�@�@�@�@_ _(_)�^ �@ �@ �@�@�_�@�v�M���[�I�I
�������������������������� �@�@�@�@�@�@�@�@�@l_j_j_j^���ցA �@ , �ց@�R
�������������@ ������������ �@ �@���� �@�@�@�@�R�@| �@ �@ |�P|�@�@�@�K�@| (_) _ _
�@ �@ �@ �����@ �@ ������������������������ �@�@�R�R�@�@�m�Q���@�@�@ ��_�@l_j_j_j
���������� �@ �@�������������������������@�@ /�@�@�@�[�\�\ �@�^�@ �m�P
�����������@ �@ �������������������@ �����@ /�@�@�@�@�@�@�@�@�^�[
���� �@ �@ �@ �@ �@�������������� ���@�@�� ����������������������������������
�����������@ �@ �������� �@ �@��������������������������������������������
���������� �@ �@���������@ �@ �@ �@ ����������������������������������������
�@�@�@�@�@�@�@�@�@�@�@�@�@�@��
Intel��Mantle�Q�[���킴�킴DX�œ��������肵�Ȃ��Ə��Ă��A�����x���`�ł̓{������
Intel���܂���������
�Ƃ����Ӗ��ł�
Intel��Mantle�Q�[���킴�킴DX�œ��������肵�Ȃ��Ə��Ă��A�����x���`�ł̓{������
Intel���܂���������
�Ƃ����Ӗ��ł�
>>87
Radeon290�~���ڂ����ꍇ��CPU�ʃQ�[�����\�ifps�j
i5-4670k 61.3fps�@�@�@�@�@�@�@�@�@�@�@passmark����7785
FX-8350 44.9fps �@�@�@�@�@�@�@�@�@�@�@�@ passmark����9051
i3-4340(i3-4160) 44.6fps �@ �@�@�@passmark����5200
G3420�iG3258��i�j�@�@�@35.2fps �@�@�@�@passmark����3467
G3220�@�@�@33.1fps �@�@�@passmark����3186
A10-7850k 31.9fps�@�@�@ passmark����5680
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_radeon_dx.png
mantle�ł�i3���R�X�p�ŋ��IA10�͕����Ă邯��
mantle
i3-4340(i3-4160�j78.8fps
FX-8350 77.4fps
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_radeon_mantle.png
i3��i7�ɍ����F���ɁIA10�͕����Ă邯��
http://www.extremetech.com/wp-content/uploads/2014/02/BF4-Mantle-Overall.png
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�Q,_,,, �Q
�@ �@ �@ �������� �@ �@���� �@�@�@�@�@�@�@�@�@�@�@�@�@_ _(_)�^ �@ �@ �@�@�_�@�v�M���[�I�I
�������������������������� �@�@�@�@�@�@�@�@�@l_j_j_j^���ցA �@ , �ց@�R
�������������@ ������������ �@ �@���� �@�@�@�@�R�@| �@ �@ |�P|�@�@�@�K�@| (_) _ _
�@ �@ �@ �����@ �@ ������������������������ �@�@�R�R�@�@�m�Q���@�@�@ ��_�@l_j_j_j
���������� �@ �@�������������������������@�@ /�@�@�@�[�\�\ �@�^�@ �m�P
�����������@ �@ �������������������@ �����@ /�@�@�@�@�@�@�@�@�^�[
���� �@ �@ �@ �@ �@�������������� ���@�@�� ����������������������������������
�����������@ �@ �������� �@ �@��������������������������������������������
���������� �@ �@���������@ �@ �@ �@ ����������������������������������������
Radeon290�~���ڂ����ꍇ��CPU�ʃQ�[�����\�ifps�j
i5-4670k 61.3fps�@�@�@�@�@�@�@�@�@�@�@passmark����7785
FX-8350 44.9fps �@�@�@�@�@�@�@�@�@�@�@�@ passmark����9051
i3-4340(i3-4160) 44.6fps �@ �@�@�@passmark����5200
G3420�iG3258��i�j�@�@�@35.2fps �@�@�@�@passmark����3467
G3220�@�@�@33.1fps �@�@�@passmark����3186
A10-7850k 31.9fps�@�@�@ passmark����5680
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_radeon_dx.png
mantle�ł�i3���R�X�p�ŋ��IA10�͕����Ă邯��
mantle
i3-4340(i3-4160�j78.8fps
FX-8350 77.4fps
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_radeon_mantle.png
{kind=link}
i3��i7�ɍ����F���ɁIA10�͕����Ă邯��
http://www.extremetech.com/wp-content/uploads/2014/02/BF4-Mantle-Overall.png
{kind=link}
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�Q,_,,, �Q
�@ �@ �@ �������� �@ �@���� �@�@�@�@�@�@�@�@�@�@�@�@�@_ _(_)�^ �@ �@ �@�@�_�@�v�M���[�I�I
�������������������������� �@�@�@�@�@�@�@�@�@l_j_j_j^���ցA �@ , �ց@�R
�������������@ ������������ �@ �@���� �@�@�@�@�R�@| �@ �@ |�P|�@�@�@�K�@| (_) _ _
�@ �@ �@ �����@ �@ ������������������������ �@�@�R�R�@�@�m�Q���@�@�@ ��_�@l_j_j_j
���������� �@ �@�������������������������@�@ /�@�@�@�[�\�\ �@�^�@ �m�P
�����������@ �@ �������������������@ �����@ /�@�@�@�@�@�@�@�@�^�[
���� �@ �@ �@ �@ �@�������������� ���@�@�� ����������������������������������
�����������@ �@ �������� �@ �@��������������������������������������������
���������� �@ �@���������@ �@ �@ �@ ����������������������������������������
89 �FSocket774�F2015/01/07(��) 18:37:52.46 ID:wqaGIHGo
�����x���`����Ȃ���GPU�x���x���`�ł���
����I�ɂ������ʔ������Ȃ��̂ɂ��������S�ʂŎg���Ă邩�̂悤��
�~�X���[�h����AMD�̂����̔ڋ��Ȏ�i����
����I�ɂ������ʔ������Ȃ��̂ɂ��������S�ʂŎg���Ă邩�̂悤��
�~�X���[�h����AMD�̂����̔ڋ��Ȏ�i����
������N�ɂȂ�̂�
GPU�x���Ő��\���オ��͔̂ڋ��Ȃ́H
���[�J���Ƃɓǔە��삪����͓̂�����O�ŁA�ڋ��ł����ł��Ȃ�
�����Ă����́AAMD�֘A���X��
�X���^�C���ǂ߂Ȃ��悤�Ȕ]���X�悹�ď������݂ɗ����Ȃ�����
�]���ڋ��Ȃ����̂����ł����
���ꂷ��킫�܂���Ƃ��A�ǂ�ȎЉ�Ȃ�>ID:wqaGIHGo
���[�J���Ƃɓǔە��삪����͓̂�����O�ŁA�ڋ��ł����ł��Ȃ�
�����Ă����́AAMD�֘A���X��
�X���^�C���ǂ߂Ȃ��悤�Ȕ]���X�悹�ď������݂ɗ����Ȃ�����
�]���ڋ��Ȃ����̂����ł����
���ꂷ��킫�܂���Ƃ��A�ǂ�ȎЉ�Ȃ�>ID:wqaGIHGo
�������ꂵ���x���`�ɂ��݂͂Ȃ�
�g�ݍ��݂ɍ̗p���ꂿ�������
QNAP to Premier AMD-based Turbo NAS Models at CES 2015
http://www.storagereview.com/qnap_to_premier_amdbased_turbo_nas_models_at_ces_2015
QNAP to Premier AMD-based Turbo NAS Models at CES 2015
http://www.storagereview.com/qnap_to_premier_amdbased_turbo_nas_models_at_ces_2015
>>91
�X���^�C�́wAMD��GPU���\��CPU���\�����x��X���x����Ȃ���
�X���^�C�́wAMD��GPU���\��CPU���\�����x��X���x����Ȃ���
�T���`�����P���A���h�t�@���{�[�C������
�x���`�����������Ń��b�T���Ȃ̂͑����Ă���CPU��
�L���h�R���̑����̃u���E�U�ł��g���Ă�GPU�x���ʼn��K��APU�̓C���`�L�炵��
�L���h�R���̑����̃u���E�U�ł��g���Ă�GPU�x���ʼn��K��APU�̓C���`�L�炵��
>>97
CPU��CPU�����ŋ����I�O���{�͑��݂ł���Ƃ����͎̂������Ȍ����������
�܂��APU��iGPU�͈ٕ������̂悤�Ȉ���
��̃O���{�h�����Ƃ���ł�������͉������Ȃ��̂�
CPU��CPU�����ŋ����I�O���{�͑��݂ł���Ƃ����͎̂������Ȍ����������
�܂��APU��iGPU�͈ٕ������̂悤�Ȉ���
��̃O���{�h�����Ƃ���ł�������͉������Ȃ��̂�
�l�g�o���n�̂�������APU��
���������V�X�e���̕]���Ȃ�gpu���x���`���Ӗ�������
http://car.watch.impress.co.jp/docs/event_repo/ces2015/20150108_682914.html
�i�C�g���C�_�[��
http://car.watch.impress.co.jp/docs/event_repo/ces2015/20150108_683011.html
Tegra X1�Ɠ����ɔ��\���ꂽAUTO - VALET PIPLINE�ł́A���Ԃő��s���邱�ƂȂ��A�f�X�N�g�b�v�Ŏ������Ԃ̃V�X�e�����J���ł���悤�ɂȂ�B
���̎d�g�݂́AGeForce GTX980�𓋍ڂ���PC�ŃQ�[���G���W���Ƃ��Ēm����uUnreal Engine 4�v���삳���A�f�������o���Ƃ������̂��B
�V���s�[�����́A�����GeForce GTX980����PC�����グ�����z���E���V�i���I�ƌĂсA�u�V�i���I����ł͎����^�]�̃V�~�����[�V�������ł��܂��B�������邱�ƂŎ����^�]�̎������ł��Ȃ��悤�ȓ��H�ł̊J�����i�߂��܂��v�Ƃ����B
���Ƃ���Unreal Engine 4�p�̎�s���̃f�[�^��l�����ӂ��a�J�Z���^�[�X�Ȃǂ̃f�[�^�����A�����̒n���ADAS�⎩���^�]�̎��������z�I�ɂł��邱�ƂɂȂ�B
�������A�����Ƃ̂���Ȃǂ͓��R�������邽�߁A���̕����ɂ��Ă̓`���[�j���O���K�v�ɂȂ��Ă��邾�낤�B
����܂�ADAS�Ȃǂ̃V�X�e���J���ɂ́A�ԍڃV�X�e���̃v���O���~���O�\�͂���������B����͍�����ς��Ȃ����̂́A���z���E�̃V�i���I�����o���\�͂��v������Ă��邾�낤�B
���z���E�̓���NVIDA DRIVE PX���ڎԂ����葱���邱�ƂŁA���܂��܂Ȓm�����~�ς���AADAS�⎩���^�]�Ɋւ���CUDA���C�u�����͉����x�I�ɏ[�����Ă������̂Ǝv����B
NVIDIA�͋���ȃr�W���A���R���s���[�e�B���O�p���[�����i����邱�ƂŁA�����ԊJ���̍őO���ɖ��o�悤�Ƃ��Ă���B
http://car.watch.impress.co.jp/docs/event_repo/ces2015/20150108_682914.html
�i�C�g���C�_�[��
http://car.watch.impress.co.jp/docs/event_repo/ces2015/20150108_683011.html
Tegra X1�Ɠ����ɔ��\���ꂽAUTO - VALET PIPLINE�ł́A���Ԃő��s���邱�ƂȂ��A�f�X�N�g�b�v�Ŏ������Ԃ̃V�X�e�����J���ł���悤�ɂȂ�B
���̎d�g�݂́AGeForce GTX980�𓋍ڂ���PC�ŃQ�[���G���W���Ƃ��Ēm����uUnreal Engine 4�v���삳���A�f�������o���Ƃ������̂��B
�V���s�[�����́A�����GeForce GTX980����PC�����グ�����z���E���V�i���I�ƌĂсA�u�V�i���I����ł͎����^�]�̃V�~�����[�V�������ł��܂��B�������邱�ƂŎ����^�]�̎������ł��Ȃ��悤�ȓ��H�ł̊J�����i�߂��܂��v�Ƃ����B
���Ƃ���Unreal Engine 4�p�̎�s���̃f�[�^��l�����ӂ��a�J�Z���^�[�X�Ȃǂ̃f�[�^�����A�����̒n���ADAS�⎩���^�]�̎��������z�I�ɂł��邱�ƂɂȂ�B
�������A�����Ƃ̂���Ȃǂ͓��R�������邽�߁A���̕����ɂ��Ă̓`���[�j���O���K�v�ɂȂ��Ă��邾�낤�B
����܂�ADAS�Ȃǂ̃V�X�e���J���ɂ́A�ԍڃV�X�e���̃v���O���~���O�\�͂���������B����͍�����ς��Ȃ����̂́A���z���E�̃V�i���I�����o���\�͂��v������Ă��邾�낤�B
���z���E�̓���NVIDA DRIVE PX���ڎԂ����葱���邱�ƂŁA���܂��܂Ȓm�����~�ς���AADAS�⎩���^�]�Ɋւ���CUDA���C�u�����͉����x�I�ɏ[�����Ă������̂Ǝv����B
NVIDIA�͋���ȃr�W���A���R���s���[�e�B���O�p���[�����i����邱�ƂŁA�����ԊJ���̍őO���ɖ��o�悤�Ƃ��Ă���B
�ǂꂾ���������̂��˂�
��������
Unreal Engine 4�ŏa�J���s�����Ȃ�Q�[���Ɏg���Ă����
�ŋ߂̑��ʋZ�p���ƁA�Ԃ�gps��3d�X�L�����@�\�t���Ē����݃g���[�X�o���邩��
�R�[�X�V�~�����[�V�����͂͂��ǂ邩������Ȃ�
�R�[�X�V�~�����[�V�����͂͂��ǂ邩������Ȃ�
�܂��Ƃ��ɋZ�p�I��GPU�ɓK�������p��L�͊�ƂƐi�߂�n�Ђ�
�S��GPU�Ɍ����Ȃ����p���������ď��Ă���A��
���Ƃ��Ɩ�O���ł���Ȃ��獂���\�ȓƎ�CPU���J������Ɏ�����n�Ђ�
�{�Ƃł���Ȃ���IP���Ă��Ď�����CPU����邱�ƂɂȂ���A��
�ǂ��ō����t�����B
�S��GPU�Ɍ����Ȃ����p���������ď��Ă���A��
���Ƃ��Ɩ�O���ł���Ȃ��獂���\�ȓƎ�CPU���J������Ɏ�����n�Ђ�
�{�Ƃł���Ȃ���IP���Ă��Ď�����CPU����邱�ƂɂȂ���A��
�ǂ��ō����t�����B
��Amd���i�t���[�����[�g���̋^�f
��NVIDIA�̌f�����^�`
�uRadeon���ڊ��C�Ƃ���CrossFire�\���̊��ł́CFraps�̃X�R�A�������ۂɂ͒Ⴂ�t���[�����[�g���������Ȃ��\��������v
�uRadeon��CrossFire���ł́C�t���[���\���Ɉُ킪����̂ł͂Ȃ����v
NVIDIA���w�E����\���ُ�Ƃ����̂́C4Gamer�ł���Ɍf�ڂ����e�X�g�L���Ŋm�F�ł��Ă���
www.4gamer.net/games/032/G003251/20130528026/
www.4gamer.net/games/022/G002212/20130802001/
www.4gamer.net/games/022/G002212/20130807092/
������ɂ��Ă��CCrossFire�\�����ƁCFraps�œ����镽�σt���[�����[�g��Native FPS�̈Ⴂ���ɂ߂đ傫���B
CrossFire����Fraps�̃X�R�A��93.32fps�̂Ƃ���C
Native FPS�͂Ȃ��45.05fps�B
��48.3�������o�Ă��Ȃ��̂ł���B
���ہCCrossFire�ł͋ɒ[�ɍ����t���[�����[�g���v�������ȂǁC�o���c�L�����ɑ傫���B
����ɋ^��[������������Ȃ�CAMD�̃O���t�B�b�N�X�h���C�o�������I�ɃV�[���̕`���[�܂��Ă���Ƃ������Ƃ����蓾�Ȃ��͂Ȃ��B
���uAMD������̉𑜓x�ɑ��ċ����ȍœK�����s���Ă���v�ƒf���ł���
���u�𑜓x��ς���Ƃ����Ȃ��肪�Ȃ��Ȃ�v�Ƃ����̂��s���R
��NVIDIA�̌f�����^�`
�uRadeon���ڊ��C�Ƃ���CrossFire�\���̊��ł́CFraps�̃X�R�A�������ۂɂ͒Ⴂ�t���[�����[�g���������Ȃ��\��������v
�uRadeon��CrossFire���ł́C�t���[���\���Ɉُ킪����̂ł͂Ȃ����v
NVIDIA���w�E����\���ُ�Ƃ����̂́C4Gamer�ł���Ɍf�ڂ����e�X�g�L���Ŋm�F�ł��Ă���
www.4gamer.net/games/032/G003251/20130528026/
www.4gamer.net/games/022/G002212/20130802001/
www.4gamer.net/games/022/G002212/20130807092/
������ɂ��Ă��CCrossFire�\�����ƁCFraps�œ����镽�σt���[�����[�g��Native FPS�̈Ⴂ���ɂ߂đ傫���B
CrossFire����Fraps�̃X�R�A��93.32fps�̂Ƃ���C
Native FPS�͂Ȃ��45.05fps�B
��48.3�������o�Ă��Ȃ��̂ł���B
���ہCCrossFire�ł͋ɒ[�ɍ����t���[�����[�g���v�������ȂǁC�o���c�L�����ɑ傫���B
����ɋ^��[������������Ȃ�CAMD�̃O���t�B�b�N�X�h���C�o�������I�ɃV�[���̕`���[�܂��Ă���Ƃ������Ƃ����蓾�Ȃ��͂Ȃ��B
���uAMD������̉𑜓x�ɑ��ċ����ȍœK�����s���Ă���v�ƒf���ł���
���u�𑜓x��ς���Ƃ����Ȃ��肪�Ȃ��Ȃ�v�Ƃ����̂��s���R
AMD����������
�T�[�o�����ȊO��ECC�g���邩��d�Ă��̂�
�V���O���X���b�h���\���Ⴗ���đI�����ɓ���Ȃ��E�E�E
���̔{�ɂȂ��AMD�������ȁ[
�T�[�o�����ȊO��ECC�g���邩��d�Ă��̂�
�V���O���X���b�h���\���Ⴗ���đI�����ɓ���Ȃ��E�E�E
���̔{�ɂȂ��AMD�������ȁ[
>>106
>���Ƃ��Ɩ�O���ł���Ȃ��獂���\�ȓƎ�CPU���J������Ɏ�����n��
�������ˁAX1��IP����(����)
http://pc.watch.impress.co.jp/docs/news/event/20150106_682499.html
>���Ƃ��Ɩ�O���ł���Ȃ��獂���\�ȓƎ�CPU���J������Ɏ�����n��
�������ˁAX1��IP����(����)
http://pc.watch.impress.co.jp/docs/news/event/20150106_682499.html
111 �FSocket774�F2015/01/09(��) 14:54:13.22 ID:op8W4HHf
Q5:Denver���̗p����64bitTegra K1�ƁATegra X1�Ƃǂ������n�C�G���h�Ȃ�?
�@����Maxwell�A�[�L�e�N�`����GPU���̗p�������ACPU��Cortex-A57/53�ɂȂ��Ă���Tegra X1���o�ꂵ�����ƂŁA
CPU��Denver����GPU��Kepler����Ƃ���Tegra K1��64bit�łƂǂ��炪�n�C�G���h�Ȑ��i�Ȃ̂��A
�ʒu�t�����B���ɂȂ��Ă���B���̓_�ɂ���NVIDIA�̃E�F�u�����O���́u�ڋq�̃j�[�Y�ɂ��B
GPU���K�v�Ȍڋq�ł����Tegra X1�����A
CPU�̕����d���������ڋq�ł����Tegra K1��64bit�ł��v�ƁA
�������������Ă����`�ɂȂ�Ƃ̔F�����������B
x1(A57+A53)
http://tctechcrunch2011.files.wordpress.com/2015/01/img_8312.jpg
http://tctechcrunch2011.files.wordpress.com/2015/01/img_8310.jpg
denver 2core
http://i.imgur.com/CG3HSUoh.jpg
http://i.imgur.com/B4T7bODh.jpg
���҂̃X�i�h��(X1�Ɠ���A57+A53)��denver
http://browser.primatelabs.com/geekbench3/compare/1639448?baseline=1655985
�@����Maxwell�A�[�L�e�N�`����GPU���̗p�������ACPU��Cortex-A57/53�ɂȂ��Ă���Tegra X1���o�ꂵ�����ƂŁA
CPU��Denver����GPU��Kepler����Ƃ���Tegra K1��64bit�łƂǂ��炪�n�C�G���h�Ȑ��i�Ȃ̂��A
�ʒu�t�����B���ɂȂ��Ă���B���̓_�ɂ���NVIDIA�̃E�F�u�����O���́u�ڋq�̃j�[�Y�ɂ��B
GPU���K�v�Ȍڋq�ł����Tegra X1�����A
CPU�̕����d���������ڋq�ł����Tegra K1��64bit�ł��v�ƁA
�������������Ă����`�ɂȂ�Ƃ̔F�����������B
x1(A57+A53)
http://tctechcrunch2011.files.wordpress.com/2015/01/img_8312.jpg
{kind=link}
http://tctechcrunch2011.files.wordpress.com/2015/01/img_8310.jpg
{kind=link}
denver 2core
http://i.imgur.com/CG3HSUoh.jpg
{kind=link}
http://i.imgur.com/B4T7bODh.jpg
{kind=link}
���҂̃X�i�h��(X1�Ɠ���A57+A53)��denver
http://browser.primatelabs.com/geekbench3/compare/1639448?baseline=1655985
>>109
���O�͏����t���邾���ʼni���ɔ���Ȃ��l�ł���
���O�͏����t���邾���ʼni���ɔ���Ȃ��l�ł���
113 �FSocket774�F2015/01/09(��) 15:53:29.82 ID:op8W4HHf
����o������̂�GPU�ɓ����Ă���Œ�@�\�œ��揈��������
CPU�Ɏc��͕̂��o���Ȃ��V���O���^�X�N�Ȃ킯��
CPU�Ɏc��͕̂��o���Ȃ��V���O���^�X�N�Ȃ킯��
x264�̂ǂ������ł��Ȃ��V���O���^�X�N�Ȃ�n�Q
115 �FSocket774�F2015/01/09(��) 16:00:01.15 ID:op8W4HHf
����hsa�ł�GPU������H
�Œ�n�[�h���Ɖ掿���A�Ƃ������Č��ǂ��育�����Ă邩��ȁB
�V���O���^�X�N�ł͂Ȃ����ǁB
���������w�ɂ́A�n�[�h�G���R��HSA���_���ł���B
�V���O���^�X�N�ł͂Ȃ����ǁB
���������w�ɂ́A�n�[�h�G���R��HSA���_���ł���B
���������̌����o������SIMD�iSSE,AVX�j���A�E�g������
�܁A�掿�̗Ƒ��x�̌����V���ɂ����Ȃ��Ⴂ���Ȃ��ˁB
�܁A�掿�̗Ƒ��x�̌����V���ɂ����Ȃ��Ⴂ���Ȃ��ˁB
�Ȃ��SIMD���A�E�g�Ȃ�
�d�g�����Ă�Ƒ�̑S���A�E�g
>>118
�������̉掿�̒ቺ������
�������̉掿�̒ቺ������
x264��SIMD�����Ă��������Z�Ȃ̂���
���肦�Ȃ��b����
���肦�Ȃ��b����
�Z�������R���@�����@�����z�����玝���Ă���
�������邽�߂�
����������̂��x�X�g�ȏ������Đ��l�v�Z�݂̂ō�Ƃ�����悤��
�h�v���O������ς���Ɓh���ʂ��ς��܂�掿��������
�X�J���������x�X�g�Ȃ̂�SIMD���p����悤�ɂ����͂蓯�l����
APU�ŏI�`�ԂȂ�Ƃ���������܂�CPU���牓���ɂ���GPU������
���������悤�ƃv���O������g��ł��掿�͗�����
����HSA��HSAIL���g���K�i�̂��Ƃ�VLIW�Ƃ�x86�Ƃ��Ɠ����悤�Ȃ���
������g���ăA�v�����Ƃ���Ƃ�����Ƃ������z�͂�����Ƃ�������
����������̂��x�X�g�ȏ������Đ��l�v�Z�݂̂ō�Ƃ�����悤��
�h�v���O������ς���Ɓh���ʂ��ς��܂�掿��������
�X�J���������x�X�g�Ȃ̂�SIMD���p����悤�ɂ����͂蓯�l����
APU�ŏI�`�ԂȂ�Ƃ���������܂�CPU���牓���ɂ���GPU������
���������悤�ƃv���O������g��ł��掿�͗�����
����HSA��HSAIL���g���K�i�̂��Ƃ�VLIW�Ƃ�x86�Ƃ��Ɠ����悤�Ȃ���
������g���ăA�v�����Ƃ���Ƃ�����Ƃ������z�͂�����Ƃ�������
�d���̑����z������������ׂ�
126 �FSocket774�F2015/01/09(��) 18:45:06.84 ID:op8W4HHf
>>121
�����g�������������Z���悻�������R�[�f�b�N������
�v�͎蔲�����Ă邩�ǂ���
�ނ��댈�܂肫�����A���S���Y���Ȃ炢���畡�G�ɂȂ��Ă�
�Œ�@�\�̂ق����悢
�����g�������������Z���悻�������R�[�f�b�N������
�v�͎蔲�����Ă邩�ǂ���
�ނ��댈�܂肫�����A���S���Y���Ȃ炢���畡�G�ɂȂ��Ă�
�Œ�@�\�̂ق����悢
http://rbmen.blogspot.jp/2015/01/snapdragon-810lghtc.html
JP�����K���،��̓N�A���R����Snapdragon 810�̔��M���ɐ旧���A
������S�������pTSMC�̋Ɛт�2015�N�Ɛт������C�����܂����B
AnTuTu�x���`�}�[�N�ł�LG G Flex 2�̃X�R�A��Cortex-A57/53 �I�N�^�R�A�̎��͂Ɍ�����Ȃ��قǒႭ
�œK�����ǂ����Ă��Ȃ����A�Ӑ}�I�ɃX�y�b�N���������Ă���\�������肻���ł��B
JP�����K���،��̓N�A���R����Snapdragon 810�̔��M���ɐ旧���A
������S�������pTSMC�̋Ɛт�2015�N�Ɛт������C�����܂����B
AnTuTu�x���`�}�[�N�ł�LG G Flex 2�̃X�R�A��Cortex-A57/53 �I�N�^�R�A�̎��͂Ɍ�����Ȃ��قǒႭ
�œK�����ǂ����Ă��Ȃ����A�Ӑ}�I�ɃX�y�b�N���������Ă���\�������肻���ł��B
http://lh4.ggpht.com/-KXSGQEtxaQE/VK-eG_eBS1I/AAAAAAABiOM/9TH5_gzr_m0/s1600-h/image%25255B4%25255D.png
http://i.imgur.com/UWNi1nxh.jpg
http://browser.primatelabs.com/geekbench3/compare/1639448?baseline=1655985
���Ȃǂ炗
{kind=link}
http://i.imgur.com/UWNi1nxh.jpg
{kind=link}
http://browser.primatelabs.com/geekbench3/compare/1639448?baseline=1655985
���Ȃǂ炗
Radeon290�~���ڂ����ꍇ��CPU�ʃQ�[�����\�ifps�j
i5-4670k 61.3fps�@�@�@�@�@�@�@�@�@�@�@passmark����7785
FX-8350 44.9fps �@�@�@�@�@�@�@�@�@�@�@�@ passmark����9051
i3-4340(i3-4160) 44.6fps �@ �@�@�@passmark����5200
G3420�iG3258��i�j�@�@�@35.2fps �@�@�@�@passmark����3467
G3220�@�@�@33.1fps �@�@�@passmark����3186
A10-7850k 31.9fps�@�@�@ passmark����5680
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_radeon_dx.png
mantle�ł�i3���R�X�p�ŋ��IA10�͕����Ă邯��
mantle
i3-4340(i3-4160�j78.8fps
FX-8350 77.4fps
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_radeon_mantle.png
i3��i7�ɍ����F���ɁIA10�͕����Ă邯��
http://www.extremetech.com/wp-content/uploads/2014/02/BF4-Mantle-Overall.png
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�Q,_,,, �Q
�@ �@ �@ �������� �@ �@���� �@�@�@�@�@�@�@�@�@�@�@�@�@_ _(_)�^ �@ �@ �@�@�_�@�v�M���[�I�I
�������������������������� �@�@�@�@�@�@�@�@�@l_j_j_j^���ցA �@ , �ց@�R
�������������@ ������������ �@ �@���� �@�@�@�@�R�@| �@ �@ |�P|�@�@�@�K�@| (_) _ _
�@ �@ �@ �����@ �@ ������������������������ �@�@�R�R�@�@�m�Q���@�@�@ ��_�@l_j_j_j
���������� �@ �@�������������������������@�@ /�@�@�@�[�\�\ �@�^�@ �m�P
�����������@ �@ �������������������@ �����@ /�@�@�@�@�@�@�@�@�^�[
���� �@ �@ �@ �@ �@�������������� ���@�@�� ����������������������������������
�����������@ �@ �������� �@ �@��������������������������������������������
���������� �@ �@���������@ �@ �@ �@ ����������������������������������������
i5-4670k 61.3fps�@�@�@�@�@�@�@�@�@�@�@passmark����7785
FX-8350 44.9fps �@�@�@�@�@�@�@�@�@�@�@�@ passmark����9051
i3-4340(i3-4160) 44.6fps �@ �@�@�@passmark����5200
G3420�iG3258��i�j�@�@�@35.2fps �@�@�@�@passmark����3467
G3220�@�@�@33.1fps �@�@�@passmark����3186
A10-7850k 31.9fps�@�@�@ passmark����5680
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_radeon_dx.png
mantle�ł�i3���R�X�p�ŋ��IA10�͕����Ă邯��
mantle
i3-4340(i3-4160�j78.8fps
FX-8350 77.4fps
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_radeon_mantle.png
i3��i7�ɍ����F���ɁIA10�͕����Ă邯��
http://www.extremetech.com/wp-content/uploads/2014/02/BF4-Mantle-Overall.png
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�Q,_,,, �Q
�@ �@ �@ �������� �@ �@���� �@�@�@�@�@�@�@�@�@�@�@�@�@_ _(_)�^ �@ �@ �@�@�_�@�v�M���[�I�I
�������������������������� �@�@�@�@�@�@�@�@�@l_j_j_j^���ցA �@ , �ց@�R
�������������@ ������������ �@ �@���� �@�@�@�@�R�@| �@ �@ |�P|�@�@�@�K�@| (_) _ _
�@ �@ �@ �����@ �@ ������������������������ �@�@�R�R�@�@�m�Q���@�@�@ ��_�@l_j_j_j
���������� �@ �@�������������������������@�@ /�@�@�@�[�\�\ �@�^�@ �m�P
�����������@ �@ �������������������@ �����@ /�@�@�@�@�@�@�@�@�^�[
���� �@ �@ �@ �@ �@�������������� ���@�@�� ����������������������������������
�����������@ �@ �������� �@ �@��������������������������������������������
���������� �@ �@���������@ �@ �@ �@ ����������������������������������������
131 �FSocket774�F2015/01/11(��) 19:54:15.21 ID:7fhnzTn+
>>130
�����L�`�K�C���܂�w
�����L�`�K�C���܂�w
��Amd���i�t���[�����[�g���̋^�f
��NVIDIA�̌f�����^�`
�uRadeon���ڊ��C�Ƃ���CrossFire�\���̊��ł́CFraps�̃X�R�A�������ۂɂ͒Ⴂ�t���[�����[�g���������Ȃ��\��������v
�uRadeon��CrossFire���ł́C�t���[���\���Ɉُ킪����̂ł͂Ȃ����v
NVIDIA���w�E����\���ُ�Ƃ����̂́C4Gamer�ł���Ɍf�ڂ����e�X�g�L���Ŋm�F�ł��Ă���
www.4gamer.net/games/032/G003251/20130528026/
www.4gamer.net/games/022/G002212/20130802001/
www.4gamer.net/games/022/G002212/20130807092/
������ɂ��Ă��CCrossFire�\�����ƁCFraps�œ����镽�σt���[�����[�g��Native FPS�̈Ⴂ���ɂ߂đ傫���B
CrossFire����Fraps�̃X�R�A��93.32fps�̂Ƃ���C
Native FPS�͂Ȃ��45.05fps�B
��48.3�������o�Ă��Ȃ��̂ł���B
���ہCCrossFire�ł͋ɒ[�ɍ����t���[�����[�g���v�������ȂǁC�o���c�L�����ɑ傫���B
����ɋ^��[������������Ȃ�CAMD�̃O���t�B�b�N�X�h���C�o�������I�ɃV�[���̕`���[�܂��Ă���Ƃ������Ƃ����蓾�Ȃ��͂Ȃ��B
���uAMD������̉𑜓x�ɑ��ċ����ȍœK�����s���Ă���v�ƒf���ł���
���u�𑜓x��ς���Ƃ����Ȃ��肪�Ȃ��Ȃ�v�Ƃ����̂��s���R
��NVIDIA�̌f�����^�`
�uRadeon���ڊ��C�Ƃ���CrossFire�\���̊��ł́CFraps�̃X�R�A�������ۂɂ͒Ⴂ�t���[�����[�g���������Ȃ��\��������v
�uRadeon��CrossFire���ł́C�t���[���\���Ɉُ킪����̂ł͂Ȃ����v
NVIDIA���w�E����\���ُ�Ƃ����̂́C4Gamer�ł���Ɍf�ڂ����e�X�g�L���Ŋm�F�ł��Ă���
www.4gamer.net/games/032/G003251/20130528026/
www.4gamer.net/games/022/G002212/20130802001/
www.4gamer.net/games/022/G002212/20130807092/
������ɂ��Ă��CCrossFire�\�����ƁCFraps�œ����镽�σt���[�����[�g��Native FPS�̈Ⴂ���ɂ߂đ傫���B
CrossFire����Fraps�̃X�R�A��93.32fps�̂Ƃ���C
Native FPS�͂Ȃ��45.05fps�B
��48.3�������o�Ă��Ȃ��̂ł���B
���ہCCrossFire�ł͋ɒ[�ɍ����t���[�����[�g���v�������ȂǁC�o���c�L�����ɑ傫���B
����ɋ^��[������������Ȃ�CAMD�̃O���t�B�b�N�X�h���C�o�������I�ɃV�[���̕`���[�܂��Ă���Ƃ������Ƃ����蓾�Ȃ��͂Ȃ��B
���uAMD������̉𑜓x�ɑ��ċ����ȍœK�����s���Ă���v�ƒf���ł���
���u�𑜓x��ς���Ƃ����Ȃ��肪�Ȃ��Ȃ�v�Ƃ����̂��s���R
http://techreport.com/news/27652/amd-carrizo-will-face-off-with-broadwell-u-wont-land-in-desktops
�f�X�N�g�b�v����Carrizo�͖���
�f�X�N�g�b�v����Carrizo�͖���
�ŋ߁ACarrizo���f�X�N�ɗ��Ȃ��̂�
Zen APU��2016�N�����ɏo�Ă���t���O���Ǝv���Ă����B
Zen APU��2016�N�����ɏo�Ă���t���O���Ǝv���Ă����B
�f�X�N�g�b�v�ł��鎖�̓m�[�g�ł��\�ɂȂ�������Ǝv���B
���̉�Ђ͂����x��邩��2016�N�ɏo��Ƃ͎v��Ȃ���������
���鏗�I���̂��m�点�����
�{�Ђ̕��j�Ƃ��s���͂Ƃ������z���g�ɂ���Ȃ��Ƃ������
�V���b�v�͂��Ă��Ȃ����M�p�Ȃ�����
�{�Ђ̕��j�Ƃ��s���͂Ƃ������z���g�ɂ���Ȃ��Ƃ������
�V���b�v�͂��Ă��Ȃ����M�p�Ȃ�����
�G���R�Ńt�����[�h�ɂ�������
>>134
����Zen�����o�C�������Ƃ����\�������ȁB
����Zen�����o�C�������Ƃ����\�������ȁB
LGA�p�~���Ęb��2012�N�ɂ��������ǂ悭�䖝���������Ǝv��
�܂��via���݂Ă�悤��
ttp://northwood.blog60.fc2.com/blog-entry-6405.html
AMD�͒����ɂ킽����DIY����уG���X�[�W�A�X�g�����f�X�N�g�b�v�s����T�|�[�g���Ă��Ă���A
Socket�p�b�P�[�W��CPU�����APU�͕��L���}�U�[�{�[�h���i�ɑΉ����Ă���B
������2013�N����2014�N�́gKaveri�h��VFX series�ł�����͑����B
���Ȃ��Ƃ�����͎����
���炭�C���e�������̐�̓m�[�v������Ԃ��낤��
�C���e�������}�U�[��߂�NUC�݂̂ɂ������������
AMD�͒����ɂ킽����DIY����уG���X�[�W�A�X�g�����f�X�N�g�b�v�s����T�|�[�g���Ă��Ă���A
Socket�p�b�P�[�W��CPU�����APU�͕��L���}�U�[�{�[�h���i�ɑΉ����Ă���B
������2013�N����2014�N�́gKaveri�h��VFX series�ł�����͑����B
���Ȃ��Ƃ�����͎����
���炭�C���e�������̐�̓m�[�v������Ԃ��낤��
�C���e�������}�U�[��߂�NUC�݂̂ɂ������������
�[���G���X�[������Intel�ɏ��ĂȂ�����ȁB
�n�C�G���h�m�[�g����CPU�Ƃ��o����
�f�X�N�g�b�v�s����J�o�[��������܂������B
�n�C�G���h�m�[�g����CPU�Ƃ��o����
�f�X�N�g�b�v�s����J�o�[��������܂������B
��������Ȃ���DX12�ŃQ�[���`�悪CPU���\�ɋɒ[�Ɉˑ����Ȃ����ɂȂ邩�炾��
����ōs�����肾�����̂ɍ����\�R�A���X�N���b�`���鎖�ɂȂ�����ˁB
�I�pCPU��ARM�ł��͎̂��v�Ƃ��ꗂ������Ė���������ƌ�����
ARM�V�t�g�Ƃ��ׂ���Ȃ����������Č����Ă��O�X��DEC�o�g��CEO������������
ARM�V�t�g�Ƃ��ׂ���Ȃ����������Č����Ă��O�X��DEC�o�g��CEO������������
���ꂩ��̍Ő�[�v���Z�X�̓N���b�N���グ�ɂ����d�l�ɂȂ�炵�����獂�p�t�H�[�}���XCPU��
�ᑬ�g�����W�X�^���ʂɎg������N���b�N��IPC�^�ɂȂ��Ȃ����ȁH
Apple A�V���[�Y�ɂ͂��̕З�������
�ᑬ�g�����W�X�^���ʂɎg������N���b�N��IPC�^�ɂȂ��Ȃ����ȁH
Apple A�V���[�Y�ɂ͂��̕З�������
�ǂ����낤�ȁB
Broadwell�ƍ�IPC��������Ă�AMD�ɂႨ�������Ȃ��悤�ȋC������B
���Y�Z�p�ŕ����Ă邩��B
IvyBridge���炢��IPC��ڎw���āA�~�h��IPC�A�R�A���ێ��Ƃ����H����������Ȃ����B
Broadwell�ƍ�IPC��������Ă�AMD�ɂႨ�������Ȃ��悤�ȋC������B
���Y�Z�p�ŕ����Ă邩��B
IvyBridge���炢��IPC��ڎw���āA�~�h��IPC�A�R�A���ێ��Ƃ����H����������Ȃ����B
���f�X�N�g�b�v������Carrizo�̌v��͌����_�ł͑��݂��Ȃ�
�_(^o^)�^
���N��AMD�̃��C���i�b�v
�E�m�[�g����Carrizo�@�i28nm�v���Z�X�̂܂܁A�ϑw�������Ȃ��ADDR4�Ȃ��j
�ECarrizo-L�@�iBeema�̃��l�[���݂����Ȃ��́j
�EMullinus�p���@�iAtom CherryTrail�Ƀ{�������j
�_(^o^)�^
���N��AMD�̃��C���i�b�v
�E�m�[�g����Carrizo�@�i28nm�v���Z�X�̂܂܁A�ϑw�������Ȃ��ADDR4�Ȃ��j
�ECarrizo-L�@�iBeema�̃��l�[���݂����Ȃ��́j
�EMullinus�p���@�iAtom CherryTrail�Ƀ{�������j
����ς���{�l�Ȃ�C���e���Q�t�H�Ō��܂肾�˂�
�T���`�����P���A���h��
�T���`�����P���A���h��
152 �FSocket774�F2015/01/12(��) 05:00:00.60 ID:0dKXw00U
1�N�O���番�����Ă�������H
���ō����̘b������グ�Ă�̂��B
zen��ASUS���Ɛ�_����2016�N�Ɏ�������ɏo�Ȃ��Ɨ͐����Ă����������ɗ��N�����������H
���ō����̘b������グ�Ă�̂��B
zen��ASUS���Ɛ�_����2016�N�Ɏ�������ɏo�Ȃ��Ɨ͐����Ă����������ɗ��N�����������H
�l�b�g�̏����ǂ��̓o�J�����牽�x�����Ă����N���x��Ō����ɋ��Ђ������Ă��瑛���o��
�G���s�̎�������
���{�Ńf�U�C���������������Ȃ��Ȃ�ƌ����Ă��N������݂��Ȃ�����
�C���e���̃n�C�v�ɂ̓R���b���x�����Ȃ�
�G���s�̎�������
���{�Ńf�U�C���������������Ȃ��Ȃ�ƌ����Ă��N������݂��Ȃ�����
�C���e���̃n�C�v�ɂ̓R���b���x�����Ȃ�
�N�����\�z���Ă������Ƃ������ɂ��Ċ����ŁA���܂�����͂Ȃ����c�O����
DX12�����[�X���Mantle���u�ɂȂ��Ă��������Ă����Ƃ��낢��������
AMD�̏ꍇ�����V�F�A�I�ɉ�����Ă������I�ȉe���Ȃ��̂��K�������ǂ�
AMD�̏ꍇ�����V�F�A�I�ɉ�����Ă������I�ȉe���Ȃ��̂��K�������ǂ�
>�����ɋ��Ђ������Ă��瑛���o��
AMD�t�@�������̓~�T���݂����ɋ������ĂȂ��ł����Ƒ������ق���������Ȃ��H
�܂��ɍ���̂Ă��Ď��삪�ł��Ȃ��Ȃ�Ƃ���Ȃ�
AMD�t�@�������̓~�T���݂����ɋ������ĂȂ��ł����Ƒ������ق���������Ȃ��H
�܂��ɍ���̂Ă��Ď��삪�ł��Ȃ��Ȃ�Ƃ���Ȃ�
�x�A�{�[���L�b�g�Ƃ��Ďc��\���͂��邯�ǃ��[�J�[���̍ɕ��S���傫���Ȃ邩��
AMD�n�̃{�����[���Ń��X�N�����Ă��Ƃ����邩�^�₾���
AMD�n�̃{�����[���Ń��X�N�����Ă��Ƃ����邩�^�₾���
>>152
�\�[�X���傤����
>>148
������������IPC�オ���ăN���b�N����������Ӗ��Ȃ��B
����3GHz�㔼�œ����f�X�Nor�T�[�o�[�����͗p�ӂ����Ǝv���B
�\�[�X���傤����
>>148
������������IPC�オ���ăN���b�N����������Ӗ��Ȃ��B
����3GHz�㔼�œ����f�X�Nor�T�[�o�[�����͗p�ӂ����Ǝv���B
�V�F�A15%�̏���ASUS�Ƃ̃p�[�g�i�[�V�b�v������30%��ڎw���炵������
ZEN���ґ�ɋ������Ă���
ZEN���ґ�ɋ������Ă���
���͎��v���Ȃ����ƂȂ�
GPU�̖��i��������HSA��Mantle������DirectX12�ɂ킭�킭����AMD�t�@�����v���O���}�┻���ۛ�
GPU�̐��i�܂ł����Ȃ�Mantle��DirectX12�ł����̑������ɂ��ď������������ŗL���V�Ȓm�ႪIntel�t�@��
����ł�������Ȃ���
GPU�̐��i�܂ł����Ȃ�Mantle��DirectX12�ł����̑������ɂ��ď������������ŗL���V�Ȓm�ႪIntel�t�@��
����ł�������Ȃ���
DX11.3�Ɍ��̂Ă�ꂽ�A���`������
���{�l�Ȃ�C���e���Q�t�H�Ō��܂肗
���{�l�Ȃ�C���e���Q�t�H�Ō��܂肗
�Ȃɂ����Ă{�P�B
�C���e���Q�t�H��Mantle�Ɍ��̂Ă�ꂽ�B
�C���e���Q�t�H��Mantle�Ɍ��̂Ă�ꂽ�B
�Ƃ��Ƃ�office��android�܂őΉ����������
AMD��APU�͗ǂ��ł�����������ł���B
�����Intel��CPU+�f�B�X�N���[�gGPU�͂�����Ƃ�������Ƃ��Đ������郌�x���ł��B
�������CPU��GPU�̃����N����ł����B
���̐E��ł͊w�p�v�Z�������̂ł����AAMD��APU�̓R�[�h���H�v������R���p�C����ς��Ă݂���w�p�v�Z�p�̃��C�u�������g���Ă݂��肵�Ă�����ς�x���ł��BGPU���Z�����Ă��x���B
AMD��Opteron��ς�32�R�A�̃��[�N�X�e�[�V�������A�����̃R�A���ŃN���b�N�����Xeon���ڂ̃��[�N�X�e�[�V�������_�u���X�R�A�ň��|���Ă���ł��B
AMD���������ꂽ���R�͂�����A�l�i����������ł��B�ƌ����Ă��A��L���[�N�X�e�[�V�����̉��i���͂�������2����������ł����BAMD�͐^�̃}���`�R�A�Ƃ����Ƃ������Ă���悤�ł����A�����܂ň��|�I�Ȑ��\�����o��Ƙb�ɂȂ�܂���B
���̐E��ł͍���AAMD��APU�͓������Ȃ����ƂɂȂ��Ă��܂��B�\�����������ۂ̐��\���������Ȃ̂ŁB
����A�x���`�}�[�N�̂悤�ȃ`�[�g�����ő����R�[�h���͂��o���D�G�ȃR���p�C�����o��APU��Intel��CPU�𗽉킷�鎞�オ����ēx�������������邱�ƂɂȂ�ł��傤���A10�N�͂Ȃ��ł��傤�ˁB
�����Intel��CPU+�f�B�X�N���[�gGPU�͂�����Ƃ�������Ƃ��Đ������郌�x���ł��B
�������CPU��GPU�̃����N����ł����B
���̐E��ł͊w�p�v�Z�������̂ł����AAMD��APU�̓R�[�h���H�v������R���p�C����ς��Ă݂���w�p�v�Z�p�̃��C�u�������g���Ă݂��肵�Ă�����ς�x���ł��BGPU���Z�����Ă��x���B
AMD��Opteron��ς�32�R�A�̃��[�N�X�e�[�V�������A�����̃R�A���ŃN���b�N�����Xeon���ڂ̃��[�N�X�e�[�V�������_�u���X�R�A�ň��|���Ă���ł��B
AMD���������ꂽ���R�͂�����A�l�i����������ł��B�ƌ����Ă��A��L���[�N�X�e�[�V�����̉��i���͂�������2����������ł����BAMD�͐^�̃}���`�R�A�Ƃ����Ƃ������Ă���悤�ł����A�����܂ň��|�I�Ȑ��\�����o��Ƙb�ɂȂ�܂���B
���̐E��ł͍���AAMD��APU�͓������Ȃ����ƂɂȂ��Ă��܂��B�\�����������ۂ̐��\���������Ȃ̂ŁB
����A�x���`�}�[�N�̂悤�ȃ`�[�g�����ő����R�[�h���͂��o���D�G�ȃR���p�C�����o��APU��Intel��CPU�𗽉킷�鎞�オ����ēx�������������邱�ƂɂȂ�ł��傤���A10�N�͂Ȃ��ł��傤�ˁB
���ӁB
���������_�v�Z����k���x����FXwww
���������_�v�Z����k���x����FXwww
�R�s�y�I�c
>>160
���ʂ́u����v�Ƃ����\�������Ȃ����H
���ʂ́u����v�Ƃ����\�������Ȃ����H
���̃R�s�y���吳�_�����炵��[�Ȃ����w
>>170
���̑吳�_�̑�����������
���ꂾ�����Ƃ���Ȃ̂ŕ⑫���B���͉Ƃł�AMD��APU���g���Ă��܂��B
����͒P���Ɉ�������ƌ����̂ƁA������������ł���Ȃ�CPU�p���[������悤�Ȃ��Ƃ����Ȃ�����ł��B
����ł��Ă���������GPU���\�����҂ł���̂ŁA�V�тɎg�����ɂ͈����Ȃ��ł���B�������A�����{�i�I�ȂRD�Q�[������肽���Ƃ������o���ƕs���ł��傤����ǁB
��������Ƃ��Ă͖{���ɗǂ��ł��Ă܂��B
Intel��CPU�p���[�͎����s�v���Ƃ���
���̑吳�_�̑�����������
���ꂾ�����Ƃ���Ȃ̂ŕ⑫���B���͉Ƃł�AMD��APU���g���Ă��܂��B
����͒P���Ɉ�������ƌ����̂ƁA������������ł���Ȃ�CPU�p���[������悤�Ȃ��Ƃ����Ȃ�����ł��B
����ł��Ă���������GPU���\�����҂ł���̂ŁA�V�тɎg�����ɂ͈����Ȃ��ł���B�������A�����{�i�I�ȂRD�Q�[������肽���Ƃ������o���ƕs���ł��傤����ǁB
��������Ƃ��Ă͖{���ɗǂ��ł��Ă܂��B
Intel��CPU�p���[�͎����s�v���Ƃ���
172 �FSocket774�F2015/01/15(��) 10:43:48.58 ID:GJEG5W1O
�܂������PC���̂��s�v�Ȃ��ǂ�
�C���e�������ꂸAMD������邮�炢�Ȃ�PC���̂��s�v���Ă��Ƃɂ��Ă��܂����Ċ���
174 �FSocket774�F2015/01/15(��) 14:34:18.02 ID:GJEG5W1O
�ǂ���AMD������Ă�w�H
http://anago.2ch.net/test/read.cgi/jisaku/1420417384/869
ttp://kakaku.com/pc/desktop-pc/
���i�R���ł�2��
ttp://kakaku.com/pc/desktop-pc/
���i�R���ł�2��
176 �FSocket774�F2015/01/15(��) 14:52:16.95 ID:GJEG5W1O
pos�J�E���g���Ă�BCN�ł͂��H
hp��ntt-x��bcn(��)�ɎQ�����ĂȂ�����W�Ȃ����
�����^�̕ȂɃh�f�l�Ɠ�����㕨�����~�����̂��H
�u�̒Ⴂ��߂�
�����^�̕ȂɃh�f�l�Ɠ�����㕨�����~�����̂��H
�u�̒Ⴂ��߂�
178 �FSocket774�F2015/01/15(��) 15:01:45.99 ID:GJEG5W1O
�N�����^�ȂL����
���^����Ȃ���Ύ��X�܂ł���PC�̔������m���V�l�Ɠ����悤��
�C���e���u�����h�̃p�`���R�������Ă���������
�킴�킴�g�ނ̂������i�����̂��͒m���
pos�J�E���g���Ă�BCN(��)�Q�l�ɂ��Ă���
���Ȃ݂�BCN(��)�ɂ̓c�N�����Q�����Ă܂���
�C���e���u�����h�̃p�`���R�������Ă���������
�킴�킴�g�ނ̂������i�����̂��͒m���
pos�J�E���g���Ă�BCN(��)�Q�l�ɂ��Ă���
���Ȃ݂�BCN(��)�ɂ̓c�N�����Q�����Ă܂���
180 �FSocket774�F2015/01/15(��) 15:13:55.77 ID:GJEG5W1O
�ق�ƃL���C
�H������Ĕ��_�ɍ������瑊���ے肷�郌�b�e���\�肵�����Ȃ���˂�
�}�j���A���ʂ���ă��P�ł�����
�}�j���A���ʂ���ă��P�ł�����
12�J�A����16�R�A�����̃n�C�G���h�o���b�ǂ��������H
�C���e���t�@���̐l�̓C���e��CPU������ID:GJEG5W1O�̃o�C�g��v���ł����Ă˂�
184 �FSocket774�F2015/01/15(��) 15:29:17.31 ID:GJEG5W1O
�L���I�^�͊撣����AMD�@CPU�����ăA�j�����悤����
4�R�A�ȏ��APU�͌v��ɖ�����B
�X���̋Y����^�Ɏ������ł���B
�X���̋Y����^�Ɏ������ł���B
�C���e��CPU���k�r�̃O���{���A�j���Đ���������Ȃ�����
���{�̃I�^�}�[�P�b�g�ŃV�F�A���Ⴂ�̂͂��傤���Ȃ����
���{�̃I�^�}�[�P�b�g�ŃV�F�A���Ⴂ�̂͂��傤���Ȃ����
�܂��N���b�N�����L���O�Ŕ���Ă�Ɗ��Ⴂ�����q������̂�
�N���b�N����ĂȂ��Ă��C���e���̃p�\�R��������Ă���b�I���Đ������M������
�̊��ł�AMD�͔���Ă���
���{�Ŕ̔����Ă�`���l���ŋq�ϕ]���ł��鐔�����o�Ă��Ȃ����Č����Ă�̂�
�V�F�A�Ƃ��ƐтƂ�POS�f�[�^�Ƃ��R�C�c�̓o�J�Ȃ̂��H��
�V�F�A�Ƃ��ƐтƂ�POS�f�[�^�Ƃ��R�C�c�̓o�J�Ȃ̂��H��
192 �FSocket774�F2015/01/15(��) 18:04:46.64 ID:GJEG5W1O
http://pc.watch.impress.co.jp/docs/column/ubiq/20141106_674536.html
����ɓ��{AMD������� �R���V���[�}�E�R�}�[�V�������ƕ� ���ƕ��� �я~��
�u���݂�1����ɗ��܂��Ă�����{�̊�ƌ���PC�s��ł̎s��V�F�A���A
���݂̔{�ȏ�̐�����ڕW�ɂ��Ĕ��荞�݂������Ă����v�Ɩ��炩�ɂ����B
���{AMD�̗я~�́u���{�ł̊�ƌ���PC�̎s��V�F�A��1����̔䗦�ɗ��܂��Ă���B
���{AMD�Ƃ��Ă��������e�R���ꂵ�����ƍl���Ă���A�܂���HP�l��Lenovo�l�Ƃ�����
�O���[�o���Ƀr�W�l�X��W�J���Ă���OEM���[�J�[�l�̊�����ƌ���PC����{�ł�
�̔����Ă��炦��悤�ɂ��肢���邱�Ƃ���n�߂Ă���B
���̎��т������āA�������[�J�[�l�ɂ��������������߂Ă��������v�Ɛ��������B
����ɓ��{AMD������� �R���V���[�}�E�R�}�[�V�������ƕ� ���ƕ��� �я~��
�u���݂�1����ɗ��܂��Ă�����{�̊�ƌ���PC�s��ł̎s��V�F�A���A
���݂̔{�ȏ�̐�����ڕW�ɂ��Ĕ��荞�݂������Ă����v�Ɩ��炩�ɂ����B
���{AMD�̗я~�́u���{�ł̊�ƌ���PC�̎s��V�F�A��1����̔䗦�ɗ��܂��Ă���B
���{AMD�Ƃ��Ă��������e�R���ꂵ�����ƍl���Ă���A�܂���HP�l��Lenovo�l�Ƃ�����
�O���[�o���Ƀr�W�l�X��W�J���Ă���OEM���[�J�[�l�̊�����ƌ���PC����{�ł�
�̔����Ă��炦��悤�ɂ��肢���邱�Ƃ���n�߂Ă���B
���̎��т������āA�������[�J�[�l�ɂ��������������߂Ă��������v�Ɛ��������B
>>192
184 ���O�F Socket774 ���e���F 2015/01/15(��) 15:29:17.31 ID:GJEG5W1O
�L���I�^�͊撣����AMD�@CPU�����ăA�j�����悤����
�����������Ə����l����ƌ����̃V�F�A()�Ƃ��C�ɂ���́H
184 ���O�F Socket774 ���e���F 2015/01/15(��) 15:29:17.31 ID:GJEG5W1O
�L���I�^�͊撣����AMD�@CPU�����ăA�j�����悤����
�����������Ə����l����ƌ����̃V�F�A()�Ƃ��C�ɂ���́H
194 �FSocket774�F2015/01/15(��) 18:11:56.85 ID:GJEG5W1O
�H
������L���I�^��AMD CPU�i�j�ŃL���I�^�A�j���݂ĂȂ悗
������L���I�^��AMD CPU�i�j�ŃL���I�^�A�j���݂ĂȂ悗
AMD�t�@���{�[�C�͔n�������ǁA�������ɉ��i�R�����N���b�N�����L���O���Ă��Ƃ��炢
�o���Ă邾��
�������낤��
�o���Ă邾��
�������낤��
AMD��BCN������X�Ńo�J���ꂵ�Ă����
�������V�F�A�ꊄ��́A�݊�CPU��@������A�������Ȃ߂邽�߂�
������X���ɒ���t���āA�����点���Ă��̐l�����ĉ����낤�Ȃ�
�����n�ɏ���đ�В���Ȃ�Č����̂́A�j���[�X�n������킾���A����PC�łƂ��������Ȃ��B
������X���ɒ���t���āA�����点���Ă��̐l�����ĉ����낤�Ȃ�
�����n�ɏ���đ�В���Ȃ�Č����̂́A�j���[�X�n������킾���A����PC�łƂ��������Ȃ��B
via�X��
����ł͑̊���AMD���V�F�A�����ȏゾ��
�}�Ȓl�����Ȃǔ̔��X�ɂ₳�����Ȃ������B�ɂ�AMD�͐_�̑���
�}�Ȓl�����Ȃǔ̔��X�ɂ₳�����Ȃ������B�ɂ�AMD�͐_�̑���
���{�l�Ȃ�C���e���Q�t�H�Ō��܂肾��
�m��͂h���������������̂Ɏ��犪�����܂�ɍs����
�����͂ŏ���������ŏ�����AVX�͒�������SIMD�͂����ƒ������đ���
�v���O���}��AMD������GPGPU�ɂ����Z�̏�����W�]����
���{�I�ɘb�����ݍ���Ȃ�
�����͂ŏ���������ŏ�����AVX�͒�������SIMD�͂����ƒ������đ���
�v���O���}��AMD������GPGPU�ɂ����Z�̏�����W�]����
���{�I�ɘb�����ݍ���Ȃ�
202 �FSocket774�F2015/01/16(��) 07:40:52.10 ID:3QI6ujAF
���v���O���}��AMD������GPGPU�ɂ����Z�̏�����W�]����
���v���O���}��AMD������GPGPU�ɂ����Z�̏�����W�]����
���v���O���}��AMD������GPGPU�ɂ����Z�̏�����W�]����
���[�͂炢�ā[
���v���O���}��AMD������GPGPU�ɂ����Z�̏�����W�]����
���v���O���}��AMD������GPGPU�ɂ����Z�̏�����W�]����
���[�͂炢�ā[
203 �FSocket774�F2015/01/16(��) 09:38:24.19 ID:iKqPMzdS
�g�C���s����H
��n�O�A���_�����͋�̒e�ۂ�M���Ă��
No Silver Bullet
http://www.itmedia.co.jp/im/spv/0706/25/news104.html
No Silver Bullet
http://www.itmedia.co.jp/im/spv/0706/25/news104.html
{kind=link}
>>200
���{�l�Ȃ�x�m�ʂ�NEC���낗
���{�l�Ȃ�x�m�ʂ�NEC���낗
�����ɓs���̂������������{�l�Ȃ�ǂ������Ƃ��Y�p�����Ă��Ȃ��łق�����
���{�l�Ƃ��Ẳ��b�Ȃ�ĂȂɂ��Ȃ�����
���{�l�Ƃ��Ẳ��b�Ȃ�ĂȂɂ��Ȃ�����
>>200
�S�{�Ē�͎���
�S�{�Ē�͎���
AMD�A�S�]�ƈ���7�����ꎞ���ق�
2014�N��4�l�����i10�`12�����j�̔��㍂�͂����13���������錩���݂��Ƃ����B
ttp://eetimes.jp/ee/articles/1410/22/news055.html
>> �����13���������錩���݂��Ƃ���
>> 13���������錩����
>> 13������
2014�N��4�l�����i10�`12�����j�̔��㍂�͂����13���������錩���݂��Ƃ����B
ttp://eetimes.jp/ee/articles/1410/22/news055.html
>> �����13���������錩���݂��Ƃ���
>> 13���������錩����
>> 13������
>>206
NEC��PC�͒������m�{�E�E�E
NEC��PC�͒������m�{�E�E�E
���オ�����Ă�A�Ԏ��ɂȂ��Ă�B
����҂Ƃ��Ă�Intel�̂�荂���\�Ȑ��i�����������Ă郆�[�U�[�ڐ���AMD���D�]���B
���オ�������v�������ۂ����ۏ��́A
AMD���ᐫ�\�Ȃ̂����܂��ă��f�B�A���x�z������҂��{�b�^�����Ă�BIntel�݂����Ȋ�Ƃ̓I���I�����\�݂����ȘA�����Ȃƌ�������B
����҂Ƃ��Ă�Intel�̂�荂���\�Ȑ��i�����������Ă郆�[�U�[�ڐ���AMD���D�]���B
���オ�������v�������ۂ����ۏ��́A
AMD���ᐫ�\�Ȃ̂����܂��ă��f�B�A���x�z������҂��{�b�^�����Ă�BIntel�݂����Ȋ�Ƃ̓I���I�����\�݂����ȘA�����Ȃƌ�������B
212 �FSocket774�F2015/01/17(�y) 10:27:04.87 ID:ymObnc3p
��Intel�̂�荂���\�Ȑ��i�����������Ă�
Llano��SandyBridge�̓��挩�����낤���H
214 �FSocket774�F2015/01/17(�y) 10:56:34.05 ID:ymObnc3p
��Intel�̂�荂���\�Ȑ��i�����������Ă�
�����͈̂����Ȃ��Ɣ���Ȃ�����A��������镨�͕��ʂɍ�������
���[�U�[�ڐ��ł����ł��Ȃ�
Llano��Sandy�݂����ȓ����780G��G35���ォ�炠�邯��
���̕����S�R����ĂȂ��̂������AnForce��������iGPU���͍L�������̂ɂ�
CPU�̊J�����s����iGPU���艟���Ō떂�������Ƃ�������������s
���[�U�[�ڐ��ł����ł��Ȃ�
Llano��Sandy�݂����ȓ����780G��G35���ォ�炠�邯��
���̕����S�R����ĂȂ��̂������AnForce��������iGPU���͍L�������̂ɂ�
CPU�̊J�����s����iGPU���艟���Ō떂�������Ƃ�������������s
Llano�o��̋łɂ�
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
����̗\��
��
ARM��APU�o��̋łɂ�
skybridge�o��̋łɂ�
��
ARM��APU�o��̋łɂ�
skybridge�o��̋łɂ�
>CPU�̊J�����s����iGPU���艟���Ō떂�������Ƃ�������������s
iGPU�܂�CPU�P�̂ŃQ�[�����\��ׂ���A10��i7��葬�������
iGPU�܂�CPU�P�̂ŃQ�[�����\��ׂ���A10��i7��葬�������
>CPU�P�̂ŃQ�[�����\��ׂ���A10��i7��葬��
���ꂪ�����V�F�A�ɂȂ����ĂȂ����玸�s�Ȃ�
���ꂪ�����V�F�A�ɂȂ����ĂȂ����玸�s�Ȃ�
�����������Ƃ����̉����o�Ȃ�
�킸���̓���Q�[���ł��������Ă������킯����
�Ƀj�E������r�Ȃ�Ƃ�����PenD����ł������킯����
���\�ƃV�F�A�͑S���W�������w
�I���I�����\�������ۂ����ׂۖ����Ă�B
���v�������[�Ȃ�w
�����ɂ��Ė��m�Ȑl������������グ�邩���낤�B
�I���I�����\�������ۂ����ׂۖ����Ă�B
���v�������[�Ȃ�w
�����ɂ��Ė��m�Ȑl������������グ�邩���낤�B
>>219
APU�ő̊�����グ�E�V�F�A�͑傫���L�т�
APU�ő̊�����グ�E�V�F�A�͑傫���L�т�
PC����CPU/GPU�ȊO�̎s��ň�ʎ��Ȃ��Ɛh���ˁB
��ʂł��h���s��ňꐶ��������Ă�����[�Ȃ��Ǝv�����ǁB
���������̐��i�����Ȃ����A�����~�߂�킯�ɂ��s���Ȃ��̂��ˁB
��ʂł��h���s��ňꐶ��������Ă�����[�Ȃ��Ǝv�����ǁB
���������̐��i�����Ȃ����A�����~�߂�킯�ɂ��s���Ȃ��̂��ˁB
>>215
���͂ނ���k�܂��Ă��Ă���
���͂ނ���k�܂��Ă��Ă���
>>223
�����
�����
Radeon290�~���ڂ����ꍇ��CPU�ʃQ�[�����\�ifps�j
i5-4670k 61.3fps�@�@�@�@�@�@�@�@�@�@�@passmark����7785
FX-8350 44.9fps �@�@�@�@�@�@�@�@�@�@�@�@ passmark����9051
i3-4340(i3-4160) 44.6fps �@ �@�@�@passmark����5200
G3420�iG3258��i�j�@�@�@35.2fps �@�@�@�@passmark����3467
G3220�@�@�@33.1fps �@�@�@passmark����3186
A10-7850k 31.9fps�@�@�@ passmark����5680
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_radeon_dx.png
mantle�ł�i3���R�X�p�ŋ��IA10�͕����Ă邯��
mantle
i3-4340(i3-4160�j78.8fps
FX-8350 77.4fps
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_radeon_mantle.png
i3��i7�ɍ����F���ɁIA10�͕����Ă邯��
http://www.extremetech.com/wp-content/uploads/2014/02/BF4-Mantle-Overall.png
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�Q,_,,, �Q
�@ �@ �@ �������� �@ �@���� �@�@�@�@�@�@�@�@�@�@�@�@�@_ _(_)�^ �@ �@ �@�@�_�@�v�M���[�I�I
�������������������������� �@�@�@�@�@�@�@�@�@l_j_j_j^���ցA �@ , �ց@�R
�������������@ ������������ �@ �@���� �@�@�@�@�R�@| �@ �@ |�P|�@�@�@�K�@| (_) _ _
�@ �@ �@ �����@ �@ ������������������������ �@�@�R�R�@�@�m�Q���@�@�@ ��_�@l_j_j_j
���������� �@ �@�������������������������@�@ /�@�@�@�[�\�\ �@�^�@ �m�P
�����������@ �@ �������������������@ �����@ /�@�@�@�@�@�@�@�@�^�[
���� �@ �@ �@ �@ �@�������������� ���@�@�� ����������������������������������
�����������@ �@ �������� �@ �@��������������������������������������������
���������� �@ �@���������@ �@ �@ �@ ����������������������������������������
i5-4670k 61.3fps�@�@�@�@�@�@�@�@�@�@�@passmark����7785
FX-8350 44.9fps �@�@�@�@�@�@�@�@�@�@�@�@ passmark����9051
i3-4340(i3-4160) 44.6fps �@ �@�@�@passmark����5200
G3420�iG3258��i�j�@�@�@35.2fps �@�@�@�@passmark����3467
G3220�@�@�@33.1fps �@�@�@passmark����3186
A10-7850k 31.9fps�@�@�@ passmark����5680
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_radeon_dx.png
mantle�ł�i3���R�X�p�ŋ��IA10�͕����Ă邯��
mantle
i3-4340(i3-4160�j78.8fps
FX-8350 77.4fps
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_radeon_mantle.png
i3��i7�ɍ����F���ɁIA10�͕����Ă邯��
http://www.extremetech.com/wp-content/uploads/2014/02/BF4-Mantle-Overall.png
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�Q,_,,, �Q
�@ �@ �@ �������� �@ �@���� �@�@�@�@�@�@�@�@�@�@�@�@�@_ _(_)�^ �@ �@ �@�@�_�@�v�M���[�I�I
�������������������������� �@�@�@�@�@�@�@�@�@l_j_j_j^���ցA �@ , �ց@�R
�������������@ ������������ �@ �@���� �@�@�@�@�R�@| �@ �@ |�P|�@�@�@�K�@| (_) _ _
�@ �@ �@ �����@ �@ ������������������������ �@�@�R�R�@�@�m�Q���@�@�@ ��_�@l_j_j_j
���������� �@ �@�������������������������@�@ /�@�@�@�[�\�\ �@�^�@ �m�P
�����������@ �@ �������������������@ �����@ /�@�@�@�@�@�@�@�@�^�[
���� �@ �@ �@ �@ �@�������������� ���@�@�� ����������������������������������
�����������@ �@ �������� �@ �@��������������������������������������������
���������� �@ �@���������@ �@ �@ �@ ����������������������������������������
�����Z�p�̈��|�I�i�����ӂ݂���intel�Ɠ����y�U�ɏオ��Ȃ��̂͐����������Ƃ͎v��
CPU�A�[�L�e�N�`���ŕ��������������y�U�ɏオ��Ȃ����������ȋC�����邪
���o�C�������ɂ�蒍�͂���̂����ɂ��Ă݂�ΐ����������C�����邯�ǂ���͌�m�b����
CPU�A�[�L�e�N�`���ŕ��������������y�U�ɏオ��Ȃ����������ȋC�����邪
���o�C�������ɂ�蒍�͂���̂����ɂ��Ă݂�ΐ����������C�����邯�ǂ���͌�m�b����
�C���e�����Ȃ�ӂ�\�킸���o�C���ɒ��͂��Ă���炻�ꂱ���ԈႢ����
���g�ݎ��̒x���������������犪���Ԃ��̂͂ǂ��l���Ă��F�X�Ɩ�������˂��H��
232 �FSocket774�F2015/01/18(��) 05:20:10.82 ID:LwN7fQCY
���N�ȍ~����Ƃ����͂△��
intel��clover trail�o�����^�C�~���O�ŃM���M��
intel��clover trail�o�����^�C�~���O�ŃM���M��
intel�Ɛ^�������璣�荇���Ƃ����킯�ł͂Ȃ��A���߂�IPC��sandy���炢�����
�Ƃ����肢�ł��疳���Ȃ̂��˂��A��������
�Ƃ����肢�ł��疳���Ȃ̂��˂��A��������
���ނǂɂ͖����B
Intel��IBM�ȊO�̍�IPC�v���Z�b�T�݂͂�Ȓ�N���b�N����B
sandy��IPC�͈��|�I�ȕ��ʓ����̐��ʂł����Ă�����P�`��Ƃ����Ȃ�N���b�N�����Ƃ������ł��Ȃ�����ȁB
Intel��IBM�ȊO�̍�IPC�v���Z�b�T�݂͂�Ȓ�N���b�N����B
sandy��IPC�͈��|�I�ȕ��ʓ����̐��ʂł����Ă�����P�`��Ƃ����Ȃ�N���b�N�����Ƃ������ł��Ȃ�����ȁB
CPU��IPC�̓L���b�V���̉��b��������
�P�R�A�����AMD�̓f�[�^�T�C�Y�ӂ�̖ʐύL������đR���Ă���
����Ń_�C�T�C�Y���ȓd�͂���������
�}���`�R�A����ɂȂ��Ă��̐�@���X�ɓ���Ȃ�
�L���b�V�����\���߂����炻�ꂪ�����ɕ\��
�����Ɋ��H�����o�����ƂɂȂ���
�P�R�A�����AMD�̓f�[�^�T�C�Y�ӂ�̖ʐύL������đR���Ă���
����Ń_�C�T�C�Y���ȓd�͂���������
�}���`�R�A����ɂȂ��Ă��̐�@���X�ɓ���Ȃ�
�L���b�V�����\���߂����炻�ꂪ�����ɕ\��
�����Ɋ��H�����o�����ƂɂȂ���
�l���Ă݂�Ε����Ɍ�����GPU�������Ĕėp�Ƃ��Ďg������Ȃ���CPU�̓V���O�����\�Nj�����ׂ����������
���o�C�������ɑ������璍�͂��Ă������20nm�ŐV���i���o���Ă�����������Ȃ�
�܂�Fab��D��I�Ɏg���Ȃ��Ȃ��ď��ԑ҂�������Ȃ����_��intel�Ƌ������i��r�����Ă�C������
�܂�Fab��D��I�Ɏg���Ȃ��Ȃ��ď��ԑ҂�������Ȃ����_��intel�Ƌ������i��r�����Ă�C������
����ς���{�l�Ȃ�C���e���Q�t�H������˂�
>>236
ando���̃p�N�����B
���_�I�ɂ͂��������ǁA�i�������܂�APU��ȁj
�ik10 4�R�A�Ɂj�}���`�ŕ����ăV���O���ŏ���
�ik10 4�R�A�Ɓj�}���`�͓����ȏ�A�V���O���قړ���
�̓�������Ȃ�k10 4�R�A����g���g�����W�X�^�𑝂₳���ɐ��\��L�������đO�Ԉ���Ă�B
ando���̃p�N�����B
���_�I�ɂ͂��������ǁA�i�������܂�APU��ȁj
�ik10 4�R�A�Ɂj�}���`�ŕ����ăV���O���ŏ���
�ik10 4�R�A�Ɓj�}���`�͓����ȏ�A�V���O���قړ���
�̓�������Ȃ�k10 4�R�A����g���g�����W�X�^�𑝂₳���ɐ��\��L�������đO�Ԉ���Ă�B
240 �FSocket774�F2015/01/18(��) 11:04:29.40 ID:imQp7AbF
�P�R�A�������IPC���Ⴂ���͂���قǑ傫�Ȍ��_�ł͂Ȃ��̂����ȁB
Bulldozer�A�[�L�e�N�`���̒v���I�Ȍ��_�́w�_�C�T�C�Y���傫���x���Ƃ���B
ILP�𗎂Ƃ��Đ����R�A���������A���W���[�����łQ�R�A������̃T�C�Y�����������Đ���ςނƂ������Ă����̂ɁA���W���[�����͋t���ʂ���������Ȃ��B
���L�����������ȏ�ɔ�剻����������L���b�V���Ƃ����Ȃ��B
Bulldozer�A�[�L�e�N�`���̒v���I�Ȍ��_�́w�_�C�T�C�Y���傫���x���Ƃ���B
ILP�𗎂Ƃ��Đ����R�A���������A���W���[�����łQ�R�A������̃T�C�Y�����������Đ���ςނƂ������Ă����̂ɁA���W���[�����͋t���ʂ���������Ȃ��B
���L�����������ȏ�ɔ�剻����������L���b�V���Ƃ����Ȃ��B
>>240
���ł����Ȃ胂�W���[�����̂����ɂ��Ă�́H
ttp://www.chip-architect.com/news/2007_02_19_Various_Images.html
���ł����Ȃ胂�W���[�����̂����ɂ��Ă�́H
ttp://www.chip-architect.com/news/2007_02_19_Various_Images.html
�_�C�T�C�Y���傫���̂́A�f�����b�g�ł͖����B
�q�[�g�X�v���b�_�̐ݒu�ʐς�傫�����邩�炾�B
�M���x���������p���₷�������\�z�o����Ƃ������ƁB
�q�[�g�X�v���b�_�̐ݒu�ʐς�傫�����邩�炾�B
�M���x���������p���₷�������\�z�o����Ƃ������ƁB
243 �FSocket774�F2015/01/18(��) 13:26:17.93 ID:imQp7AbF
>>241
APU�ł�L3������Ă��邪�A�{��Bulldozer�ɂ�����Last Level Cashe��L3�B
Athlon64X2/Core2�ȑO��L2�Ɨe�ʔ�r����̂�FX�ɂ����Ă�L3�B
PhenomII�ł�L2=�e�R�A512KB�AL3=6MB(�ꕔ���f������)
Intel��Core i7�ł�L2=�e�R�A256KB�AL3=8MB(�S�R�A���f���̏ꍇ)
FX�ł�L2=�e���W���[��2MB�AL2=8MB
�_�C�̎ʐ^�Ƃ�����Ƃ킩��₷���̂����AFX��L2����߂�ʐϊ������ٗl�ɂł����B
>>242
�~�_�C�T�C�Y���傫���̂́A�f�����b�g�ł͖���
���_�C�T�C�Y���傫���ꍇ�̃����b�g�����݂���
�v���Z�X�̐���ڍs�������ɐi�߂Ζ��ɂȂ�Ȃ������̂�������Ȃ����A����ł̓_�C�̑傫�������\����̖��m�ȑ������ɂȂ��Ă���B
APU�ł�L3������Ă��邪�A�{��Bulldozer�ɂ�����Last Level Cashe��L3�B
Athlon64X2/Core2�ȑO��L2�Ɨe�ʔ�r����̂�FX�ɂ����Ă�L3�B
PhenomII�ł�L2=�e�R�A512KB�AL3=6MB(�ꕔ���f������)
Intel��Core i7�ł�L2=�e�R�A256KB�AL3=8MB(�S�R�A���f���̏ꍇ)
FX�ł�L2=�e���W���[��2MB�AL2=8MB
�_�C�̎ʐ^�Ƃ�����Ƃ킩��₷���̂����AFX��L2����߂�ʐϊ������ٗl�ɂł����B
>>242
�~�_�C�T�C�Y���傫���̂́A�f�����b�g�ł͖���
���_�C�T�C�Y���傫���ꍇ�̃����b�g�����݂���
�v���Z�X�̐���ڍs�������ɐi�߂Ζ��ɂȂ�Ȃ������̂�������Ȃ����A����ł̓_�C�̑傫�������\����̖��m�ȑ������ɂȂ��Ă���B
�́A�������i���Intel�r�b�O�R�A��8�R�A���ڂł���悤�ɂȂ邩��
�V���v���R�A�H���͊ԈႢ�Ȃ�Ȃ����A�Ƃǂ����̃X���ɏ�������
�r�b�O�R�A8�R�A�ς�GPU���ڂł��Ȃ��Ȃ�A�Ɣ��_���ꂽ�����ȁB
CPU���\�̌����GPU�ɗ���Ȃ���Ȃ��̂�AMD�����ŁA
����AMD��GPU����8�R�A����Intel�̃r�b�O�R�A8�R�A�̕�����ɏo�Ă��܂����B
�܂�GPU���ڂł��Ȃ��Ȃ���Ĕ��_�͐����������̂����B
�V���v���R�A�H���͊ԈႢ�Ȃ�Ȃ����A�Ƃǂ����̃X���ɏ�������
�r�b�O�R�A8�R�A�ς�GPU���ڂł��Ȃ��Ȃ�A�Ɣ��_���ꂽ�����ȁB
CPU���\�̌����GPU�ɗ���Ȃ���Ȃ��̂�AMD�����ŁA
����AMD��GPU����8�R�A����Intel�̃r�b�O�R�A8�R�A�̕�����ɏo�Ă��܂����B
�܂�GPU���ڂł��Ȃ��Ȃ���Ĕ��_�͐����������̂����B
>>243
������₷��������FX�̓R�X�g�_�E���̂��߂ɐ��\�ɏd�v��L2�L���b�V�����ȗ�������B�X�y�b�N�I�ɂ͈����ĊȒP�ɗe�ʂ̑��₹��L3���ڂ��������L��������B�x���L���b�V���������炠���Ă��Ӗ��Ȃ��̂ɁB
������₷��������FX�̓R�X�g�_�E���̂��߂ɐ��\�ɏd�v��L2�L���b�V�����ȗ�������B�X�y�b�N�I�ɂ͈����ĊȒP�ɗe�ʂ̑��₹��L3���ڂ��������L��������B�x���L���b�V���������炠���Ă��Ӗ��Ȃ��̂ɁB
�L���b�V���̒x���A�����Ō����ACPU�p�b�P�[�W���ōŊO���̃L���b�V����
�������̒x����₤���x�̈Ӗ�����B
�����K�v���Ȃ���ȁB�ʂɒ�C�e���V�ȃL���b�V���͕K�v�����ǁB
�������̒x����₤���x�̈Ӗ�����B
�����K�v���Ȃ���ȁB�ʂɒ�C�e���V�ȃL���b�V���͕K�v�����ǁB
>>243
http://pc.watch.impress.co.jp/img/pcw/docs/430/044/9.jpg
FX�̃L���b�V�����s���ɑ傫���Ƃ������Ƃ͂Ȃ������ȁi�e�ʂȂ�́j�傫���ł́H
�i������ƌ��L���ւ�URL��������Ȃ������̂ʼn摜�����B�}�i�[�ᔽ�����ǁj
http://pc.watch.impress.co.jp/img/pcw/docs/430/044/9.jpg
{kind=link}
FX�̃L���b�V�����s���ɑ傫���Ƃ������Ƃ͂Ȃ������ȁi�e�ʂȂ�́j�傫���ł́H
�i������ƌ��L���ւ�URL��������Ȃ������̂ʼn摜�����B�}�i�[�ᔽ�����ǁj
�������ɕЃR�A��1M��L�Ȃ�č\���͂��ĂȂ��Ƃ͎v������
L1��������������ȁiBulldozer = 2way 64KB, steamroller = 3way 96KB�j�B
>>246
�Â��l�Ԃ��炵���烁�����A�N�Z�X�̃o�b�e�B���O�\�h�ȋC�����遁�������₷�����R�A�ł̂ݕK�v
L1��������������ȁiBulldozer = 2way 64KB, steamroller = 3way 96KB�j�B
>>246
�Â��l�Ԃ��炵���烁�����A�N�Z�X�̃o�b�e�B���O�\�h�ȋC�����遁�������₷�����R�A�ł̂ݕK�v
250 �FSocket774�F2015/01/18(��) 16:12:24.89 ID:imQp7AbF
>>244
Intel�̂W�R�A�_�C�͂W�R�AAPU�ǂ��납GPU�����̂W�R�ABulldozer����ɓo�ꂵ�Ă܂����ȁB
>>247
�ŏI�L���b�V�������̃T�C�Y�Ȃ��薳����B
Llano��Kaveri��L2�͍ŏI�L���b�V����FX��L2�͒��ԃL���b�V���B
���L����R�A������������A�L���b�V���e�ʂ�������قǃI�[�o�[�w�b�h���傫���Ȃ�̂ŁA�W�R�AFX��8MB��L3�ɒ��ԃL���b�V�����������ɒ��ڃA�N�Z�X����Ɣ��ɒx���B
Intel�̂W�R�A�_�C�͂W�R�AAPU�ǂ��납GPU�����̂W�R�ABulldozer����ɓo�ꂵ�Ă܂����ȁB
>>247
�ŏI�L���b�V�������̃T�C�Y�Ȃ��薳����B
Llano��Kaveri��L2�͍ŏI�L���b�V����FX��L2�͒��ԃL���b�V���B
���L����R�A������������A�L���b�V���e�ʂ�������قǃI�[�o�[�w�b�h���傫���Ȃ�̂ŁA�W�R�AFX��8MB��L3�ɒ��ԃL���b�V�����������ɒ��ڃA�N�Z�X����Ɣ��ɒx���B
���̃N���X��PowerPC�Ȃ��Mac�����g��Ȃ�����蔲���Ă���
�b�o�t����Ɋւ��ẮA�f�X�N�g�b�v���p�ŁA�قƂ�Ǖς���̂�
��86�݊��l�h�o�r�̌��E�ɓ��B���Ă邩��A��86�o�[�X�g�ŋ��������������ʁB
�r�h�l�c�g���̈��i�Ƃ��Ă̂`�o�t�Ȃ��A�Ƃɂ����Ȃ߂�A�l�K��������Ȃ�
�����Ⴂ�ߏ�̘A����ɂ���Ӗ��Ȃ�Ė����Ǝv�����Ȃ�
��86�݊��l�h�o�r�̌��E�ɓ��B���Ă邩��A��86�o�[�X�g�ŋ��������������ʁB
�r�h�l�c�g���̈��i�Ƃ��Ă̂`�o�t�Ȃ��A�Ƃɂ����Ȃ߂�A�l�K��������Ȃ�
�����Ⴂ�ߏ�̘A����ɂ���Ӗ��Ȃ�Ė����Ǝv�����Ȃ�
254 �FSocket774�F2015/01/18(��) 22:04:38.96 ID:LwN7fQCY
simd�����Ȃ��Ă�
os��A�v���̋@�֕����������������킯����Ȃ���
os��A�v���̋@�֕����������������킯����Ȃ���
������C���e��CPU�̓x���`�͕����Ă��������肩�������
256 �FSocket774�F2015/01/18(��) 22:16:56.19 ID:LwN7fQCY
amd����
�`�o�t�̐헪���́A�\���ȗ̈�ɒB�������n�����b�o�t�ɑ���
�g���@�\�̃\�t�g������������ړI�ł̂`�o�t�Ƃ����͎̂��������킯�łȁB
����ŁA����Ȃ��A���͂`�l�c����Ȃ���Ηǂ����������A�h���������`�������c�ł��琫�\�\���Ȃ���
�j�b�`�Ȏ���s��ł̃n�C�G���h�n�D�Ȃ�āA�����瑊��ɂ��Ė���㩁B
�g���@�\�̃\�t�g������������ړI�ł̂`�o�t�Ƃ����͎̂��������킯�łȁB
����ŁA����Ȃ��A���͂`�l�c����Ȃ���Ηǂ����������A�h���������`�������c�ł��琫�\�\���Ȃ���
�j�b�`�Ȏ���s��ł̃n�C�G���h�n�D�Ȃ�āA�����瑊��ɂ��Ė���㩁B
AMD��APU�͗ǂ��ł�����������ł���B
�����Intel��CPU+�f�B�X�N���[�gGPU�͂�����Ƃ�������Ƃ��Đ������郌�x���ł��B
�������CPU��GPU�̃����N����ł����B
���̐E��ł͊w�p�v�Z�������̂ł����AAMD��APU�̓R�[�h���H�v������R���p�C����ς��Ă݂���w�p�v�Z�p�̃��C�u�������g���Ă݂��肵�Ă�����ς�x���ł��BGPU���Z�����Ă��x���B
AMD��Opteron��ς�32�R�A�̃��[�N�X�e�[�V�������A�����̃R�A���ŃN���b�N�����Xeon���ڂ̃��[�N�X�e�[�V�������_�u���X�R�A�ň��|���Ă���ł��B
AMD���������ꂽ���R�͂�����A�l�i����������ł��B�ƌ����Ă��A��L���[�N�X�e�[�V�����̉��i���͂�������2����������ł����BAMD�͐^�̃}���`�R�A�Ƃ����Ƃ������Ă���悤�ł����A�����܂ň��|�I�Ȑ��\�����o��Ƙb�ɂȂ�܂���B
���̐E��ł͍���AAMD��APU�͓������Ȃ����ƂɂȂ��Ă��܂��B�\�����������ۂ̐��\���������Ȃ̂ŁB
����A�x���`�}�[�N�̂悤�ȃ`�[�g�����ő����R�[�h���͂��o���D�G�ȃR���p�C�����o��APU��Intel��CPU�𗽉킷�鎞�オ����ēx�������������邱�ƂɂȂ�ł��傤���A10�N�͂Ȃ��ł��傤�ˁB
�����Intel��CPU+�f�B�X�N���[�gGPU�͂�����Ƃ�������Ƃ��Đ������郌�x���ł��B
�������CPU��GPU�̃����N����ł����B
���̐E��ł͊w�p�v�Z�������̂ł����AAMD��APU�̓R�[�h���H�v������R���p�C����ς��Ă݂���w�p�v�Z�p�̃��C�u�������g���Ă݂��肵�Ă�����ς�x���ł��BGPU���Z�����Ă��x���B
AMD��Opteron��ς�32�R�A�̃��[�N�X�e�[�V�������A�����̃R�A���ŃN���b�N�����Xeon���ڂ̃��[�N�X�e�[�V�������_�u���X�R�A�ň��|���Ă���ł��B
AMD���������ꂽ���R�͂�����A�l�i����������ł��B�ƌ����Ă��A��L���[�N�X�e�[�V�����̉��i���͂�������2����������ł����BAMD�͐^�̃}���`�R�A�Ƃ����Ƃ������Ă���悤�ł����A�����܂ň��|�I�Ȑ��\�����o��Ƙb�ɂȂ�܂���B
���̐E��ł͍���AAMD��APU�͓������Ȃ����ƂɂȂ��Ă��܂��B�\�����������ۂ̐��\���������Ȃ̂ŁB
����A�x���`�}�[�N�̂悤�ȃ`�[�g�����ő����R�[�h���͂��o���D�G�ȃR���p�C�����o��APU��Intel��CPU�𗽉킷�鎞�オ����ēx�������������邱�ƂɂȂ�ł��傤���A10�N�͂Ȃ��ł��傤�ˁB
����������i7���̃G���R���p�ɂɂ��Ȃ���I�[�o�[�X�y�b�N�������A10-7850K�ʼn�����Ȃ�������GPU�̐��\�ł��Q�[���ݒ�ł͓��������Ȃ���ˁB
����͌l���ɓK�����Ջ��ɂ�邯��ǂ܂��ˁB���X�d������Đ����Ă�GPU���x10�x�O��ŗ₦�₦�����Ȃ��B
�܂��^6�R�A�ł�APU��]�ނ�BIntel��������܂��B�k�X�ɂ͂����b�ɂȂ�������ǁB
����͌l���ɓK�����Ջ��ɂ�邯��ǂ܂��ˁB���X�d������Đ����Ă�GPU���x10�x�O��ŗ₦�₦�����Ȃ��B
�܂��^6�R�A�ł�APU��]�ނ�BIntel��������܂��B�k�X�ɂ͂����b�ɂȂ�������ǁB
��̂��Ƃ������ȉ��Ȃ̂��A�������₦�₦�Ȃ̂�
����15�x�ȉ����đς����Ȃ����x�������
>>261
��ݻ��� ���Ă邩�������
��ݻ��� ���Ă邩�������
���݂̒���PC���ꂽ�炢����ˁH
�܂�APU��PC���ǂ��Ȃ�Ȃ炻��ł�����B
�����X�y�b�N���������Ō������������ė~�����B
ATOM�̒l�i��Core i5�̐��\�Ƃ�����Ă��Ȃ����Ƃ�����ȁB
�����X�y�b�N���������Ō������������ė~�����B
ATOM�̒l�i��Core i5�̐��\�Ƃ�����Ă��Ȃ����Ƃ�����ȁB
>>264
�ƒ�����������m��Ȃ�
�ƒ�����������m��Ȃ�
http://www.geocities.jp/andosprocinfo/wadai15/20150117.htm
TSMC��16nm finfet��6�`7�ւƃY����炵��
���̂����T���X��/GF��14nm finfet�͕����܂肪�啝�ɉ��P�������悤�B
TSMC��16nm finfet��6�`7�ւƃY����炵��
���̂����T���X��/GF��14nm finfet�͕����܂肪�啝�ɉ��P�������悤�B
�T���X���Ɗ؍��������Ă���˂�����
��������������ꂾ�����̃t�@�E���h���ɗ������邵
��������������ꂾ�����̃t�@�E���h���ɗ������邵
���ʏ����Ȃ��Ǝv�����A3�N���炢��ɒE������Ƃ��Ă��A
������̃t�@�E���h���Ƃ��Čp������ڂ�����B
�����Ȃ���{��Ƃ��o�J�݂����ɃJ�l������
�Ő�[�ݔ�������悩�����B
������̃t�@�E���h���Ƃ��Čp������ڂ�����B
�����Ȃ���{��Ƃ��o�J�݂����ɃJ�l������
�Ő�[�ݔ�������悩�����B
�G���s�ւ̗Z������ł�����{����������s���������Ȃ��w�^�����Ƃɉ����ł���Ƃ����̂ł�
DRAM��Ƃ��Ď��_�ŋl��ł��͖̂�������������ݗ��o�܂����ē��łƖ��������������悩����
���łɓ��ł��̂��̂����S���L�����Ď����̂�{�@�ւ�PC�𓌎Ő���
�����`�̖@�����Ƃł͋�����Ȃ��\�������ǂ�
���łɓ��ł��̂��̂����S���L�����Ď����̂�{�@�ւ�PC�𓌎Ő���
�����`�̖@�����Ƃł͋�����Ȃ��\�������ǂ�
AMD��������C�������Ȃ炱�̃X���o�Ă���w
���{�l�Ȃ�C���e���Q�t�H�Ō��܂�
>>272
�����͌��X���������
�ǂ����Ƃɂ��������Ƃɂ��ڂ���������
�������Ƃ���ڂ�w���A�ǂ����Ƃ���������
AMD�̈����ʂɂ͍������Ȃ��ے肵�A�I�J���g���_�Ԃ����܂���
AMD��J�ߏ̂���Ȃ牺�L�̃X���ɍs���Ɨǂ���
AMD�̎�����APU/SoC���������悤201����
http://anago.2ch.net/test/read.cgi/jisaku/1418046233/
�����͌��X���������
�ǂ����Ƃɂ��������Ƃɂ��ڂ���������
�������Ƃ���ڂ�w���A�ǂ����Ƃ���������
AMD�̈����ʂɂ͍������Ȃ��ے肵�A�I�J���g���_�Ԃ����܂���
AMD��J�ߏ̂���Ȃ牺�L�̃X���ɍs���Ɨǂ���
AMD�̎�����APU/SoC���������悤201����
http://anago.2ch.net/test/read.cgi/jisaku/1418046233/
�R���s���[�e�B���O�ɋ����̂���v���O���}�Ȃǂ�����Ȃ��HSA��Mantle�����
�ߎS�Ȃ��̐l���䂦�ɏ����ɋQ���Ă�m�Ⴊ�������������킯��
�ߎS�Ȃ��̐l���䂦�ɏ����ɋQ���Ă�m�Ⴊ�������������킯��
HSA�����̂͂���������
HSA�����X���ypart 3�z
http://peace.2ch.net/test/read.cgi/tech/1400582192/
�������ՎU�Ƃ��Ă邯��
HSA�����X���ypart 3�z
http://peace.2ch.net/test/read.cgi/tech/1400582192/
�������ՎU�Ƃ��Ă邯��
�܂��AAPU�Ƀn�C�G���h�n�D�A5���I�[�o�[�N���X��CPU���\��r��v�����邠����A������Ⴈ�@����
���Ђ��A���Ӗ����Ȃ��Ȃ�������PC�Ō�́u���V�сv������ꏊ�Ȃ̂ɁA�@���Ȑl���\�[�J�݂����Ȍ����点���Ă܂��ˁB
���Ђ��A���Ӗ����Ȃ��Ȃ�������PC�Ō�́u���V�сv������ꏊ�Ȃ̂ɁA�@���Ȑl���\�[�J�݂����Ȍ����点���Ă܂��ˁB
APU��pentium���A���Xi3���x�Ƃ�����r�o���Ȃ�
APU��pentium���A���Xi3���x�Ƃ�����r�o���Ȃ�
>>273
���{�l����Ȃ���Ɍ����Ă���
���{�l����Ȃ���Ɍ����Ă���
>>273
�C���e���Q���Ɍ������B�Q���݂����Ȃ��̂���ȁB�C���e���Ȃ�Ă�
�C���e���Q���Ɍ������B�Q���݂����Ȃ��̂���ȁB�C���e���Ȃ�Ă�
�A���`�����̎��i�Ŕт����܂�
��̃��[�G���h�̈��Q�t�H�őg��ł���̂��ăx���`()������
���i�g���̎��p���Ƃ͖����̂������肩����CPU�Ǝ����F��
�ň��ȑe��S�~���ł������邾�������
���i�g���̎��p���Ƃ͖����̂������肩����CPU�Ǝ����F��
�ň��ȑe��S�~���ł������邾�������
�܂��ϑz��
�x���`���`�����Q��
���Ɖ^�c�X�^�b�t��MMORPG���S�҂���������FF14
���Ɖ^�c�X�^�b�t��MMORPG���S�҂���������FF14
>>283
���₵���̂�ww���₵���̂�www
���₵���̂�ww���₵���̂�www
>>279-280
�m�[�g��Llano��i7��4�R�ATDP45W�Ɣ�r���Ă邵w
�m�[�g��Trinity��i7�̃f�X�N�g�b�v�ŏ��i7-3770K�Ɣ�r���Ă邵w
����ł�AMD�������Ă�̂���w
�m�[�g��Llano��i7��4�R�ATDP45W�Ɣ�r���Ă邵w
�m�[�g��Trinity��i7�̃f�X�N�g�b�v�ŏ��i7-3770K�Ɣ�r���Ă邵w
����ł�AMD�������Ă�̂���w
�����GPU�����Ȃ���intel����GPU�ɏ����ē�����O�����
�ł�i7�����悤�Ȑl��dGPU�}�������
����GPU�����Ȃ�ĈӖ����Ȃ���
�ł�i7�����悤�Ȑl��dGPU�}�������
����GPU�����Ȃ�ĈӖ����Ȃ���
���M�ʂŏ������ƌ����Ă���
>>288�̓m�[�g�ł̘b���Ă�̂ɂ�����dGPU�Ƃ������܂��Ă��E�E�E
�O���{���ݕs��i7�m�[�g��NUC�̓J�^���ł������
Carrizo��GPU�X�R�A��kaveri�̔{���ċL�������Ă邯��
�O�ɂ��̃X���Řb��ɂȂ������͂ǂ��������_�ɂȂ��������H
�O�ɂ��̃X���Řb��ɂȂ������͂ǂ��������_�ɂȂ��������H
�F���k�������Ƃ�HBM�ɑΉ�����̂��s���Ƃ�����Ȋ���
GPU�X�R�A���{����Ȃ��ă��b�g�p�t�H�[�}���X���{����H
�ǂ�ǂ����グ��Ȃ�H
�ǂ�ǂ����グ��Ȃ�H
�M�ŃN���b�N�_�E�������Ȃ��Ȃ���
���\�͑z���t���B
Kaveri��GPU��R7-260X�����GCN
Carrizo��GPU��R9-285�����GCN
512SP�ō��킹����A���҂͂����܂ŗD�ʍ��Ȃ��B
�ǂ����Ă�R9-280��R9-285�̍��������番���邪����SP�����B
�Ⴄ�̂�R9-280��933MHz��R9-285��918MHz�ƃN���b�N���������Ă�BR9-280��TDP250W�Ȃ̂ɑ���R9-285��TDP190W�ł���_�B
�m�[�gPC�Ō����Ȃ�TDP���Ⴂ�̂��D�܂�邩��Kaveri��GPU��25W�����Ă�Ƃ�����ACarrizo��GPU��19W�ł��ށB
Kaveri��GPU��R7-260X�����GCN
Carrizo��GPU��R9-285�����GCN
512SP�ō��킹����A���҂͂����܂ŗD�ʍ��Ȃ��B
�ǂ����Ă�R9-280��R9-285�̍��������番���邪����SP�����B
�Ⴄ�̂�R9-280��933MHz��R9-285��918MHz�ƃN���b�N���������Ă�BR9-280��TDP250W�Ȃ̂ɑ���R9-285��TDP190W�ł���_�B
�m�[�gPC�Ō����Ȃ�TDP���Ⴂ�̂��D�܂�邩��Kaveri��GPU��25W�����Ă�Ƃ�����ACarrizo��GPU��19W�ł��ށB
�m�[�g��i7�����悤�Ȏ���er�Ȃ�m�[�g��dGPU�t���������
�͂��H
Carrizo�̓m�[�g�����H
TDP�͍ő�ł�35W���B
�Ȃ̂ɉ��Ńf�X�N�g�b�v��TDP95W�̃n�C�G���hKaveri�Ɣ�r���Ă�H
�������������[��DDR3-1600�̃f���A���`�����l���B
����ȂჁ�����[�ш悪����Ȃ��B
512SP�Ȃ�DDR3-3200x2�͕K�v�B
����Ȓᑬ�������[��A10-7850K��2�{�̐��\�͂��肦�Ȃ�w
Carrizo�̓m�[�g�����H
TDP�͍ő�ł�35W���B
�Ȃ̂ɉ��Ńf�X�N�g�b�v��TDP95W�̃n�C�G���hKaveri�Ɣ�r���Ă�H
�������������[��DDR3-1600�̃f���A���`�����l���B
����ȂჁ�����[�ш悪����Ȃ��B
512SP�Ȃ�DDR3-3200x2�͕K�v�B
����Ȓᑬ�������[��A10-7850K��2�{�̐��\�͂��肦�Ȃ�w
Kaveri��FCH��TDP15W���邩��
Carrizo��TDP35W�ƌ����Ă��ACPU��GPU��FCH�܂ō��݂�SoC������TDP19W��Kaveri��TDP35W��Carrizo�Ɠ����̏���d�́B
TDP19W��Carrizo�Ȃ�TDP19W��Kaveri���15W�Ⴂ�V�X�e���S�̂̏���d�́B
�o�b�e���[�쓮���Ԃ͑啝�ɐL�т�B
���b�g�p�t�H�[�}���X��2�{�̎����B
���ꂱ����Carrizo�̊v���Ȃ̂����B
Carrizo��TDP35W�ƌ����Ă��ACPU��GPU��FCH�܂ō��݂�SoC������TDP19W��Kaveri��TDP35W��Carrizo�Ɠ����̏���d�́B
TDP19W��Carrizo�Ȃ�TDP19W��Kaveri���15W�Ⴂ�V�X�e���S�̂̏���d�́B
�o�b�e���[�쓮���Ԃ͑啝�ɐL�т�B
���b�g�p�t�H�[�}���X��2�{�̎����B
���ꂱ����Carrizo�̊v���Ȃ̂����B
>>300
�O�ɓ����i�悤�ȁj�\�[�X�b�肪�b��ɂȂ�������
�F���k�Ń������̗��p�������悭�Ȃ����Ƃ����ۂ̕`�ʐ��\����Ȃ����Ă��Ƃɗ����������B
�����悤�Șb���kaveri��1.9-3.2GHz��Carrizo 1.6-2.6GHz��CPU�X�R�A���������Ă̂��������B
�O�ɓ����i�悤�ȁj�\�[�X�b�肪�b��ɂȂ�������
�F���k�Ń������̗��p�������悭�Ȃ����Ƃ����ۂ̕`�ʐ��\����Ȃ����Ă��Ƃɗ����������B
�����悤�Șb���kaveri��1.9-3.2GHz��Carrizo 1.6-2.6GHz��CPU�X�R�A���������Ă̂��������B
Radeon290�~���ڂ����ꍇ��CPU�ʃQ�[�����\�ifps�j
i5-4670k 61.3fps�@�@�@�@�@�@�@�@�@�@�@passmark����7785
FX-8350 44.9fps �@�@�@�@�@�@�@�@�@�@�@�@ passmark����9051
i3-4340(i3-4160) 44.6fps �@ �@�@�@passmark����5200
G3420�iG3258��i�j�@�@�@35.2fps �@�@�@�@passmark����3467
G3220�@�@�@33.1fps �@�@�@passmark����3186
A10-7850k 31.9fps�@�@�@ passmark����5680
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_radeon_dx.png
mantle�ł�i3���R�X�p�ŋ��IA10�͕����Ă邯��
mantle
i3-4340(i3-4160�j78.8fps
FX-8350 77.4fps
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_radeon_mantle.png
i3��i7�ɍ����F���ɁIA10�͕����Ă邯��
http://www.extremetech.com/wp-content/uploads/2014/02/BF4-Mantle-Overall.png
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�Q,_,,, �Q
�@ �@ �@ �������� �@ �@���� �@�@�@�@�@�@�@�@�@�@�@�@�@_ _(_)�^ �@ �@ �@�@�_�@�v�M���[�I�I
�������������������������� �@�@�@�@�@�@�@�@�@l_j_j_j^���ցA �@ , �ց@�R
�������������@ ������������ �@ �@���� �@�@�@�@�R�@| �@ �@ |�P|�@�@�@�K�@| (_) _ _
�@ �@ �@ �����@ �@ ������������������������ �@�@�R�R�@�@�m�Q���@�@�@ ��_�@l_j_j_j
���������� �@ �@�������������������������@�@ /�@�@�@�[�\�\ �@�^�@ �m�P
�����������@ �@ �������������������@ �����@ /�@�@�@�@�@�@�@�@�^�[
���� �@ �@ �@ �@ �@�������������� ���@�@�� ����������������������������������
�����������@ �@ �������� �@ �@��������������������������������������������
���������� �@ �@���������@ �@ �@ �@ ����������������������������������������
i5-4670k 61.3fps�@�@�@�@�@�@�@�@�@�@�@passmark����7785
FX-8350 44.9fps �@�@�@�@�@�@�@�@�@�@�@�@ passmark����9051
i3-4340(i3-4160) 44.6fps �@ �@�@�@passmark����5200
G3420�iG3258��i�j�@�@�@35.2fps �@�@�@�@passmark����3467
G3220�@�@�@33.1fps �@�@�@passmark����3186
A10-7850k 31.9fps�@�@�@ passmark����5680
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_radeon_dx.png
mantle�ł�i3���R�X�p�ŋ��IA10�͕����Ă邯��
mantle
i3-4340(i3-4160�j78.8fps
FX-8350 77.4fps
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_radeon_mantle.png
i3��i7�ɍ����F���ɁIA10�͕����Ă邯��
http://www.extremetech.com/wp-content/uploads/2014/02/BF4-Mantle-Overall.png
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�Q,_,,, �Q
�@ �@ �@ �������� �@ �@���� �@�@�@�@�@�@�@�@�@�@�@�@�@_ _(_)�^ �@ �@ �@�@�_�@�v�M���[�I�I
�������������������������� �@�@�@�@�@�@�@�@�@l_j_j_j^���ցA �@ , �ց@�R
�������������@ ������������ �@ �@���� �@�@�@�@�R�@| �@ �@ |�P|�@�@�@�K�@| (_) _ _
�@ �@ �@ �����@ �@ ������������������������ �@�@�R�R�@�@�m�Q���@�@�@ ��_�@l_j_j_j
���������� �@ �@�������������������������@�@ /�@�@�@�[�\�\ �@�^�@ �m�P
�����������@ �@ �������������������@ �����@ /�@�@�@�@�@�@�@�@�^�[
���� �@ �@ �@ �@ �@�������������� ���@�@�� ����������������������������������
�����������@ �@ �������� �@ �@��������������������������������������������
���������� �@ �@���������@ �@ �@ �@ ����������������������������������������
304 �FSocket774�F2015/01/21(��) 00:27:41.76 ID:ei+zOkC/
carizzo�̐��\2�{��openCL�̔{���x���낤
GPU�̉��ǂŋ�肾�����{���x�̌��������P��������
�N���b�N��ALU���������ш�������ĂȂ���
GPU�̉��ǂŋ�肾�����{���x�̌��������P��������
�N���b�N��ALU���������ш�������ĂȂ���
>>301
�������ŁA�f�X�N�g�b�v�pCarr�C���l�Ȃ������
TDP35W�̃m�[�gCarr��7850K����CPU/GPU���\�ɂȂ������܂��������
�������ŁA�f�X�N�g�b�v�pCarr�C���l�Ȃ������
TDP35W�̃m�[�gCarr��7850K����CPU/GPU���\�ɂȂ������܂��������
AMD�̊������\�����Ƃ�E�E�E
CPU���x7��
CPU�p�b�P�[�W���x53��
M/B���x29 �C
A10-7850K�����O���t�B�b�N�X���x1 �C
(((((((( �G߄D�))))))))�������ٶ�����������
CPU�p�b�P�[�W���x53��
M/B���x29 �C
A10-7850K�����O���t�B�b�N�X���x1 �C
(((((((( �G߄D�))))))))�������ٶ�����������
��AMD���i�̌��ד������x�v���܂Ƃ�
�E�v�����s���m�ŋ����Ă�����Ԃ��炩�����ꂽ30�x�ȏ�Ⴂ�l�ƂȂ�הM�\���ɂȂ�₷���B
�E���x�v���������̂ЂƂ��������׃R�A���̉��x���܂��������炸�M�������F���B
�EAMD��CPU(x2/x3/x4/x6/4m8t)�̑S�Ăɖ�肪�L��B
�E��������u���y�����A����28�x�ŃR�A���x13.4�x�� �����ȉ��̒ቷ�������I
�E���x���\�t�g���N���������0����
�E����1�R�A�ɃX���b�h�w�肵�ĕ��ׂ����Ă�1�ӏ������v���ł��Ȃ��̂őS�R�A���������x������(���ԍ��Ŋ��U�肵�ĕ����Ɍ��������Ă邾����) ��new
(�@߄t�)
�E�v�����s���m�ŋ����Ă�����Ԃ��炩�����ꂽ30�x�ȏ�Ⴂ�l�ƂȂ�הM�\���ɂȂ�₷���B
�E���x�v���������̂ЂƂ��������׃R�A���̉��x���܂��������炸�M�������F���B
�EAMD��CPU(x2/x3/x4/x6/4m8t)�̑S�Ăɖ�肪�L��B
�E��������u���y�����A����28�x�ŃR�A���x13.4�x�� �����ȉ��̒ቷ�������I
�E���x���\�t�g���N���������0����
�E����1�R�A�ɃX���b�h�w�肵�ĕ��ׂ����Ă�1�ӏ������v���ł��Ȃ��̂őS�R�A���������x������(���ԍ��Ŋ��U�肵�ĕ����Ɍ��������Ă邾����) ��new
(�@߄t�)
2014 Q4
���㍂�@$12��4000��
�c�����@$3��3000��
�������@$3��6400��
2014
���㍂�@$55��1000��
�c�����@$1��5500��
�������@$4��300��
2015 Q1�\��
For Q1 2015, AMD expects revenue to decrease 15 percent, plus or minus 3 percent, sequentially.
���犲����ɂȂ�킗����������������������������������
�������炳���-15%�Ă���������������������������������������
�����J����2���h���肻��������������������������������������
���㍂�@$12��4000��
�c�����@$3��3000��
�������@$3��6400��
2014
���㍂�@$55��1000��
�c�����@$1��5500��
�������@$4��300��
2015 Q1�\��
For Q1 2015, AMD expects revenue to decrease 15 percent, plus or minus 3 percent, sequentially.
���犲����ɂȂ�킗����������������������������������
�������炳���-15%�Ă���������������������������������������
�����J����2���h���肻��������������������������������������
310 �FSocket774�F2015/01/21(��) 07:55:13.61 ID:cN1YoKqS
>>297
R9-285��R9-280�̌���I�ȈႢ�������Ƃ��Ă����B
R9-285��256bit�ł���AR9-280��384bit�Ȃ̂��B
���ɂ��ă������[�ш�1.5�{�Ő�Εs���ȏɂ��ւ�炸�A���\��285�����߂ɂ�����v�V�I�ȋZ�p�����荞�܂�Ă���B
�O�X����w�E����Ă����A�������[�ш�s���̖���APU�����������ƁB
����1.5�{�̃������[�ш捷��\����DDR3-1600x2��DDR3-2400x2�Ɣ�r���������B
����Ȃ̂ɑO�҂����\�������Ă�Ɠ��������B
R9-285��R9-280�̌���I�ȈႢ�������Ƃ��Ă����B
R9-285��256bit�ł���AR9-280��384bit�Ȃ̂��B
���ɂ��ă������[�ш�1.5�{�Ő�Εs���ȏɂ��ւ�炸�A���\��285�����߂ɂ�����v�V�I�ȋZ�p�����荞�܂�Ă���B
�O�X����w�E����Ă����A�������[�ш�s���̖���APU�����������ƁB
����1.5�{�̃������[�ш捷��\����DDR3-1600x2��DDR3-2400x2�Ɣ�r���������B
����Ȃ̂ɑO�҂����\�������Ă�Ɠ��������B
���甄��Ȃ���
The Elder Scrolls: Skyrim�@1,920 x 1,080, Ultra Settings,
Intel Core i7-4770K (3.5GHz)
Minimum 91fps
Average 139fps
Intel Core i5-4670K (3.4GHz)
Minimum 89fps
Average 138fps
Intel Pentium G3258-oc (4.8GHz)
Minimum 73 fps
Average 127fps
Intel Pentium G3258 (3.2GHz)
Minimum 51 fps
Average 103fps
AMD FX-8350-oc (4.8GHz)
Minimum 45fps
Average 107fps
AMD FX-8350 (4GHz)
Minimum 39 fps
Average 90fps
http://www.bit-tech.net/hardware/2014/06/24/intel-pentium-g3258-review/5
http://news.mynavi.jp/photo/special/2012/vishera01/images/graph42l.gif
http://news.mynavi.jp/photo/special/2012/vishera01/images/graph44l.gif
The Elder Scrolls: Skyrim�@1,920 x 1,080, Ultra Settings,
Intel Core i7-4770K (3.5GHz)
Minimum 91fps
Average 139fps
Intel Core i5-4670K (3.4GHz)
Minimum 89fps
Average 138fps
Intel Pentium G3258-oc (4.8GHz)
Minimum 73 fps
Average 127fps
Intel Pentium G3258 (3.2GHz)
Minimum 51 fps
Average 103fps
AMD FX-8350-oc (4.8GHz)
Minimum 45fps
Average 107fps
AMD FX-8350 (4GHz)
Minimum 39 fps
Average 90fps
http://www.bit-tech.net/hardware/2014/06/24/intel-pentium-g3258-review/5
http://news.mynavi.jp/photo/special/2012/vishera01/images/graph42l.gif
{kind=link}
http://news.mynavi.jp/photo/special/2012/vishera01/images/graph44l.gif
{kind=link}
313 �FSocket774�F2015/01/21(��) 10:26:51.16 ID:cN1YoKqS
FX8350��2012�N��CPU����H
����3�N�O��CPU�����o���Ĕ�r���Ă�́H
Trinity A10-4600M����TDP35W�̃m�[�gPC�Ȃ̂�TDP77W��intel�ŐV�̃f�X�N�g�b�v�ŏ�ʂƔ�r�Ƃ����B
�܂��A����ł�A10-4600M�̐��\�������d�͈����Ȗ�
http://www.4gamer.net/games/133/G013372/20120514010/
����3�N�O��CPU�����o���Ĕ�r���Ă�́H
Trinity A10-4600M����TDP35W�̃m�[�gPC�Ȃ̂�TDP77W��intel�ŐV�̃f�X�N�g�b�v�ŏ�ʂƔ�r�Ƃ����B
�܂��A����ł�A10-4600M�̐��\�������d�͈����Ȗ�
http://www.4gamer.net/games/133/G013372/20120514010/
AMD�A2014�N�x�͑�����4���h���̐Ԏ�
http://pc.watch.impress.co.jp/docs/news/20150121_684660.html
http://pc.watch.impress.co.jp/docs/news/20150121_684660.html
�����܂�1�h����ɂȂ肻��
�V�^��A10-6700T�ł�����Ȃ�����CPU�Ɋւ��Ă͊��s�ł�����
A10-7850�Ȃނ���A10-6800���CPU���\�����Ă�ʂ����邵��
http://viploader.net/desktop/src/vldesk008426.gif
�ł�����APU��PS4���݂ɂȂ�炵�����烍�[�G���hPC�s��ŏ����g�݂ɂȂ��͂�
�l�i�����������ǂ�
A10-7850�Ȃނ���A10-6800���CPU���\�����Ă�ʂ����邵��
http://viploader.net/desktop/src/vldesk008426.gif
{kind=link}
�ł�����APU��PS4���݂ɂȂ�炵�����烍�[�G���hPC�s��ŏ����g�݂ɂȂ��͂�
�l�i�����������ǂ�
>>312
�X�J�C�������Ă������l�g�Q���̂��Ȃ����牽�����Ȃ��ȁB
�p�\�R���ŃQ�[���Ƃ��Y��������ʼn����������낢�̂��T�b�p���킩���B
�X�J�C�������Ă������l�g�Q���̂��Ȃ����牽�����Ȃ��ȁB
�p�\�R���ŃQ�[���Ƃ��Y��������ʼn����������낢�̂��T�b�p���킩���B
���ł�����APU��PS4���݂ɂȂ�炵������
�������ш悪�����������Ă������APU���A
�A�z�݂����Ƀ��C���������ш摝������PS4���ɂȂ�킯���Ȃ��B
�����ɂ��Ă�XboxOne����B
�������ш悪�����������Ă������APU���A
�A�z�݂����Ƀ��C���������ш摝������PS4���ɂȂ�킯���Ȃ��B
�����ɂ��Ă�XboxOne����B
��1��PS4�������v���Z�b�T���g���Ă��邾��B���ӂ��Ⴄ����S�������ł͂Ȃ���
����
�Q�[���@�͉ߋ��ő勉�Ȃ̂ɗ��v���Ȃ��̂���
�����O�̖����݂�̂�AMD�̐M�҂̌�����
�����O�̖����݂�̂�AMD�̐M�҂̌�����
�Q�[����ЂɃ`�b�v�������ƍ����������悩������
�������肩�˂Ȃ�����DEC�o�g��CEO���ז��������낤����
�������肩�˂Ȃ�����DEC�o�g��CEO���ז��������낤����
�u���n�̂Ă�܂�CPU����͔���グ�������Ă�����������
K10�n���u���n�͑S�R�������Ȃ��Ȃ���������Ȃ�
325 �FSocket774�F2015/01/21(��) 16:25:55.36 ID:wqdUCm7J
����G���^�[�v���C�Y/�g�ݍ���/�Z�~�J�X�^�������PlayStation 4��Xbox One�Ɏx�����A�O�N������51%���̑����ƂȂ������̂́A���O����11%���ŁA�c�Ɨ��v�������Ă���B
�����؍��ł����ƈ������悤�ɂȂ�������{�̒�LSI�݂����ɓP�ނ����
�P�O�N�ȓ��Ƃ�������
�P�O�N�ȓ��Ƃ�������
>>326
�`�b�v���������Ȃ��Ƌt�ɒl�グ�̈��͂��|����悢
�`�b�v���������Ȃ��Ƌt�ɒl�グ�̈��͂��|����悢
>>327
�O���t�b�N�n��IP�����Ă��Ђ��x�߃`�����ɂȂ�����ł��Ȃ�
�O���t�b�N�n��IP�����Ă��Ђ��x�߃`�����ɂȂ�����ł��Ȃ�
�������Ȃ�������s���s�ɂȂ��Ă��ڂ邾�����
���i�����̈��͂��s���s�Ɠ������낤���J�X
>>328
������ƍٔ��ŕ����ē|�Y���邼
������ƍٔ��ŕ����ē|�Y���邼
>>332
�l�������͂��ٔ��ŔF�߂�Ƃ����̂���
�l�������͂��ٔ��ŔF�߂�Ƃ����̂���
�Ȃ��AMDer���Ă���ȍU���I�Ȃ�H
�k�r�̓Q�[���@�̐��\�v���ɂ���������PU�R�A�����ĂȂ�
���͓��l�ɃQ�[���@�p��GPU�R�A�����ĂȂ�
���ǐ��u�Q�[���@�͂���2�ЂƂ��P�ƂŎ�o���ł��삾�낤��
���͓��l�ɃQ�[���@�p��GPU�R�A�����ĂȂ�
���ǐ��u�Q�[���@�͂���2�ЂƂ��P�ƂŎ�o���ł��삾�낤��
336 �FSocket774�F2015/01/21(��) 16:39:21.69 ID:wqdUCm7J
powervr��ip�����������
337 �FSocket774�F2015/01/21(��) 16:40:18.09 ID:wqdUCm7J
>>335
denver��ps4��cpu��肾���ԃV���O�����\��ł���
denver��ps4��cpu��肾���ԃV���O�����\��ł���
338 �FSocket774�F2015/01/21(��) 16:41:50.66 ID:okekBTvc
AMD�̊���͗D��������Ԏ��ł������
>>337
�����p�b�P�[�W��8�R�A�����PS4�ȏ�̐��\���ďo��́H
�݊����̖���������Tegra X1�ł�Cortex�ɖ߂��݂��������Ǝ�����arm���ċ��������
�����p�b�P�[�W��8�R�A�����PS4�ȏ�̐��\���ďo��́H
�݊����̖���������Tegra X1�ł�Cortex�ɖ߂��݂��������Ǝ�����arm���ċ��������
CPU��GPU���Ƃ肦�̂Ȃ����̍���Ă��ƃ��[�J�[��
�ǂ��̃Q�[���@�ɂ��̗p����Ȃ��Ȃ��ďI���ł���
���̐��̒��ōŐ�[��IT�f�o�C�X�̓Q�[���@�A�[�L�e�N�`���Ȃ����
�ǂ��̃Q�[���@�ɂ��̗p����Ȃ��Ȃ��ďI���ł���
���̐��̒��ōŐ�[��IT�f�o�C�X�̓Q�[���@�A�[�L�e�N�`���Ȃ����
>>326
�_������
�_������
�� 2014�N �����̔��ド���L���O
http://eetimes.jp/ee/articles/1412/25/news147.html
AMD�̏��ʂ��}�~���ЂƂ蕉���_(^o^)�^
http://eetimes.jp/ee/articles/1412/25/news147.html
AMD�̏��ʂ��}�~���ЂƂ蕉���_(^o^)�^
344 �FSocket774�F2015/01/21(��) 17:01:46.91 ID:wqdUCm7J
>>342
4���h���̐Ԏ��͎_���ς��ł����`�H
4���h���̐Ԏ��͎_���ς��ł����`�H
>>344
�����p�b�P�[�W��8�R�A�����PS4�ȏ�̐��\���ďo��́H
Denver�R�A�̋����������Ō݊������ۂĂȂ��A�v�������o���Ă�
ttp://app-review.jp/news/243753
>�����Denver�R�A���ڐ��i�Ƃ��Ĉ�ʂɓ���\�ȗB��̐��i�ł���Google�́uNexus 9�v�ł�
(��)
>CPU�R�A�ȊO�͂قړ����\���̃}�V���Ő��퓮�삷��A�v�����i���Ȃ��Ƃ������J�n����̎��_�Łj���삵�Ȃ��A
>�Ȃǂ�CPU�̓����\���ɋN������ƍl������݊�����肪���Ȃ��炸����Ă��܂��B
>���̂��߁A�����͂Ƃ����������_�ł͂���Denver�R�A�͂����獂���ł����p���l����ƌ݊����Ɏ����
�����p�b�P�[�W��8�R�A�����PS4�ȏ�̐��\���ďo��́H
Denver�R�A�̋����������Ō݊������ۂĂȂ��A�v�������o���Ă�
ttp://app-review.jp/news/243753
>�����Denver�R�A���ڐ��i�Ƃ��Ĉ�ʂɓ���\�ȗB��̐��i�ł���Google�́uNexus 9�v�ł�
(��)
>CPU�R�A�ȊO�͂قړ����\���̃}�V���Ő��퓮�삷��A�v�����i���Ȃ��Ƃ������J�n����̎��_�Łj���삵�Ȃ��A
>�Ȃǂ�CPU�̓����\���ɋN������ƍl������݊�����肪���Ȃ��炸����Ă��܂��B
>���̂��߁A�����͂Ƃ����������_�ł͂���Denver�R�A�͂����獂���ł����p���l����ƌ݊����Ɏ����
347 �FSocket774�F2015/01/21(��) 17:13:24.58 ID:wqdUCm7J
>>346
�A�z�����L�����Ȃ�
64bit,android 5�̒[����nexus9�ȊO�ɍ����݂��Ă�̂����H
�A�v���������Ȃ�������android 5�ł�����
�A�z�����L�����Ȃ�
64bit,android 5�̒[����nexus9�ȊO�ɍ����݂��Ă�̂����H
�A�v���������Ȃ�������android 5�ł�����
�͂��`���ǑS���R�s�y���邱�ƂɂȂ�̂�
>�����Denver�R�A���ڐ��i�Ƃ��Ĉ�ʂɓ���\�ȗB��̐��i�ł���Google�́uNexus 9�v�ł�
>���̉s���������ɕ]�����W�܂����ŁAOS��Android 5.0�ɃA�b�v�O���[�h�����uSHIELD Tablet�v�A
>�܂�CPU�R�A�ȊO�͂قړ����\���̃}�V���Ő��퓮�삷��A�v����
>�i���Ȃ��Ƃ������J�n����̎��_�Łj���삵�Ȃ��A�Ȃǂ�CPU�̓����\���ɋN������ƍl������
>�݊�����肪���Ȃ��炸����Ă��܂��B
>�����Denver�R�A���ڐ��i�Ƃ��Ĉ�ʂɓ���\�ȗB��̐��i�ł���Google�́uNexus 9�v�ł�
>���̉s���������ɕ]�����W�܂����ŁAOS��Android 5.0�ɃA�b�v�O���[�h�����uSHIELD Tablet�v�A
>�܂�CPU�R�A�ȊO�͂قړ����\���̃}�V���Ő��퓮�삷��A�v����
>�i���Ȃ��Ƃ������J�n����̎��_�Łj���삵�Ȃ��A�Ȃǂ�CPU�̓����\���ɋN������ƍl������
>�݊�����肪���Ȃ��炸����Ă��܂��B
349 �FSocket774�F2015/01/21(��) 17:25:10.61 ID:wqdUCm7J
>>348
�[������SHIELD Tablet��android5.0�ł�32bit�ł���
����Ŕ�r���Ăǂ�����̂��H
���Ȃ݂�nexus9��android5.0��SQL�Ƀo�O������
Sony Reader�������Ȃ�������
�[������SHIELD Tablet��android5.0�ł�32bit�ł���
����Ŕ�r���Ăǂ�����̂��H
���Ȃ݂�nexus9��android5.0��SQL�Ƀo�O������
Sony Reader�������Ȃ�������
�܂�x86�ƈقȂ�64bit��ARM�̓D��32bit�A�v���Ƃ̌݊�����肪������
���ɗ����Ȃ��s�����OS�ł���denver�͖����ł���Ƃ�
OS�ɕs���Ԃ����Ƃ���Ŏ��ۖ��\�t�g�������Ȃ����Ƃɂ͘b�ɂȂ�Ȃ��킯����
���ɗ����Ȃ��s�����OS�ł���denver�͖����ł���Ƃ�
OS�ɕs���Ԃ����Ƃ���Ŏ��ۖ��\�t�g�������Ȃ����Ƃɂ͘b�ɂȂ�Ȃ��킯����
351 �FSocket774�F2015/01/21(��) 17:36:24.49 ID:wqdUCm7J
���������̋L��������apple�ɃR���v���b�N�X�����Ă�悤�ɏ����Ă邪��
A8x�ŒP���x512gflops�Ƃ�����������
���Z���256�킠�邪�����512gflops�o���ɂ�1ghz�œ������Ȃ��ᖳ��
������bench��K1�Ɠ�����������č��������P�ɌŒ�@�\�̕��ʂɂ�鐫�\��
�Ȃ̂�3dmark�ł�k1�ɑS�R�y�Ȃ�
���P�ł�gfxbench�Ŕ{�̍������Ă邵��
�����P���x512gflops�i�Ƃ����咣�j�Ȃ̂ɂ��i�Œ�@�\���͓����ɂȂ���(tmu16,rop16�j
���ʓ����Ő��\�����{�Ȃ�N���b�N���{�Ȃ�
�܂�500mhz���x�ł���A8X�͓����ĂȂ�
A8x�ŒP���x512gflops�Ƃ�����������
���Z���256�킠�邪�����512gflops�o���ɂ�1ghz�œ������Ȃ��ᖳ��
������bench��K1�Ɠ�����������č��������P�ɌŒ�@�\�̕��ʂɂ�鐫�\��
�Ȃ̂�3dmark�ł�k1�ɑS�R�y�Ȃ�
���P�ł�gfxbench�Ŕ{�̍������Ă邵��
�����P���x512gflops�i�Ƃ����咣�j�Ȃ̂ɂ��i�Œ�@�\���͓����ɂȂ���(tmu16,rop16�j
���ʓ����Ő��\�����{�Ȃ�N���b�N���{�Ȃ�
�܂�500mhz���x�ł���A8X�͓����ĂȂ�
352 �FSocket774�F2015/01/21(��) 17:39:22.32 ID:wqdUCm7J
>>350
�����Ȃ��\�t�g���ĂȂ��Hw
�����Ȃ��\�t�g���ĂȂ��Hw
353 �FSocket774�F2015/01/21(��) 17:43:24.83 ID:wqdUCm7J
���ۂ��������̂�os�N���œ����Ȃ�
https://play.google.com/store/apps/details?id=edu.berkeley.boinc&hl=ja
* Prevents the PlayStore from advertising BOINC on Android 5.0.
7.4.40+ should be Android 5.0 compatible.
https://play.google.com/store/apps/details?id=edu.berkeley.boinc&hl=ja
* Prevents the PlayStore from advertising BOINC on Android 5.0.
7.4.40+ should be Android 5.0 compatible.
44 �F�����������������ς��B�F2014/11/06(��) 16:31:04.71 ID:Qb4sAdFc.net[6/13] ���̂Ƃ���茳�̃A�v����Nexus 9�ALollipop�œ����Ȃ��A��肪�������A�v����
Sony Reader: �N���ɃG���[���o��
Kinoppy: �N�����̖{�I�ւ̒lj��Ń��[�v�ɂȂ�
MLPlayerDTV: �N���シ���ɃG���[���o��
AquaMail: ���삷����̂̐ݒ肪�C���|�[�g�ł��Ȃ�
Helium: ���X�g�A�����s����
���ȁB
Kinoppy�͕ʂ̒[����adb backup�Ŏ�����o�b�N�A�b�v��Nexus 9��
adb restore�Ŗ߂��ƃN���E�h�{�I�Ƃ̓����͎��Ȃ����̖̂{��ǂނ��Ƃ�
�o����B�܂��AMLPlayerDTV�̃G���[�������
android.database.sqlite.SQLiteReadonlyDatabaseException ���o�Ă��邩��
Lollipop��SQLite����Ƀo�O���d�l�ύX�������ď�L (Helium������)�̃A�v����
�����Ȃ��̂��Ǝv���B
Sony Reader: �N���ɃG���[���o��
Kinoppy: �N�����̖{�I�ւ̒lj��Ń��[�v�ɂȂ�
MLPlayerDTV: �N���シ���ɃG���[���o��
AquaMail: ���삷����̂̐ݒ肪�C���|�[�g�ł��Ȃ�
Helium: ���X�g�A�����s����
���ȁB
Kinoppy�͕ʂ̒[����adb backup�Ŏ�����o�b�N�A�b�v��Nexus 9��
adb restore�Ŗ߂��ƃN���E�h�{�I�Ƃ̓����͎��Ȃ����̖̂{��ǂނ��Ƃ�
�o����B�܂��AMLPlayerDTV�̃G���[�������
android.database.sqlite.SQLiteReadonlyDatabaseException ���o�Ă��邩��
Lollipop��SQLite����Ƀo�O���d�l�ύX�������ď�L (Helium������)�̃A�v����
�����Ȃ��̂��Ǝv���B
355 �FSocket774�F2015/01/21(��) 17:49:35.67 ID:wqdUCm7J
�[�����ȏ�̓ǂ߂Ȃ�������w�H
>>354
>>349
�����Ȃ݂�nexus9��android5.0��SQL�Ƀo�O������
��Sony Reader�������Ȃ�������
>>354
>>349
�����Ȃ݂�nexus9��android5.0��SQL�Ƀo�O������
��Sony Reader�������Ȃ�������
356 �FSocket774�F2015/01/21(��) 17:50:18.05 ID:wqdUCm7J
���HCPU���������H
>>354
��Lollipop��SQLite����Ƀo�O���d�l�ύX�������ď�L (Helium������)�̃A�v����
�������Ȃ��̂��Ǝv���B
>>354
��Lollipop��SQLite����Ƀo�O���d�l�ύX�������ď�L (Helium������)�̃A�v����
�������Ȃ��̂��Ǝv���B
blog��ɐq�˂邵���Ȃ���Ȃ�
���Ȃ��Ƃ��݊�����肪����Ǝ咣���Ă�̂�����
�I���͖₢���킹��C�͂Ȃ���
���Ȃ��Ƃ��݊�����肪����Ǝ咣���Ă�̂�����
�I���͖₢���킹��C�͂Ȃ���
358 �FSocket774�F2015/01/21(��) 17:55:44.26 ID:wqdUCm7J
>>357
����������p����ȃJ�X
����������p����ȃJ�X
>>358
����������Ύ����ŕ�����R�~���႗
����������Ύ����ŕ�����R�~���႗
360 �FSocket774�F2015/01/21(��) 18:03:11.27 ID:wqdUCm7J
NVIDIA�̃|���R�cCPU Denver��TegraX1�Ő�ꂽ�����
��������̂������͂Ȃ���
��������̂������͂Ȃ���
�N�A�h���͗ǂ��ƕ]�����������������ꂽ
364 �FSocket774�F2015/01/21(��) 18:10:48.64 ID:wqdUCm7J
�{�b�^�N�A�h���̓��m�{�ł��{��悤�ɂȂ�����������I���R���ł���
����64bit ARM�̃f���p�̌����ʂɂ͂Ȃ�����˂��́H�s����ڂł�����>denver
�Ƃ��nexus9�ɂ͍̗p���ꂽ���P����
������̂�������m��ǂ�
����64bit ARM�̃f���p�̌����ʂɂ͂Ȃ�����˂��́H�s����ڂł�����>denver
�Ƃ��nexus9�ɂ͍̗p���ꂽ���P����
������̂�������m��ǂ�
366 �FSocket774�F2015/01/21(��) 18:13:09.11 ID:wqdUCm7J
amd�͂ǂ��Ɏg����낤�Ȃ�
�ˁ[��ǂ���
�ˁ[��ǂ���
>>364
AMD��ATi�����č���ATi�g���u�C�u�C���킹�Ă��
�k�r��������3dfx�Ƃ�ATi�ւ̌����点�ɔ�������ULi�Ƃ������Ă�̂��H��
AMD��ATi�����č���ATi�g���u�C�u�C���킹�Ă��
�k�r��������3dfx�Ƃ�ATi�ւ̌����点�ɔ�������ULi�Ƃ������Ă�̂��H��
�X�}�z�W���}�b�N�Ɏ����čs���ꂽ
>>366
PS4�Ƃ�����Ƃ��m���́H�V�[���h(��)��p�z�M�^�C�g�����ĂȂ���́H
PS4�Ƃ�����Ƃ��m���́H�V�[���h(��)��p�z�M�^�C�g�����ĂȂ���́H
370 �FSocket774�F2015/01/21(��) 18:18:51.43 ID:wqdUCm7J
���܂���a57�̃T�[�o�Ƃ��N���g������
�k�r�ɂ̓{�b�^�N�A�h���Ƌ���3D CAD�E�̋��l�Ƃ���OpenGL�ƂƂ���
���i���K���ɕ�炵�Ă��炢������
���i���K���ɕ�炵�Ă��炢������
372 �FSocket774�F2015/01/21(��) 18:21:31.55 ID:wqdUCm7J
�����܂��Ԏ�����������
��AMD�͂�
��AMD�͂�
�}���`�R�A�ɏ�肭����U������s����C�����邪�߂�ǂ�������
CELL�܂��̓g�����X���^��CPU�Ŋw�Ȃ�����NVIDIA�͂�������
Apple���Ⴀ��܂������œ����߂����J��Ԃ����Ƃ����̂��낤
Apple���Ⴀ��܂������œ����߂����J��Ԃ����Ƃ����̂��낤
�ꉞ�n�[�h�E�F�A�ɂ��ARM v8�݊����߃f�R�[�_�𓋍ڂ��Ė��̉����Ƃ����悤����
x86�̌݊�����������肭���Ȃ��Ă���AMD���̎����͂͂Ȃ������Ƃ݂�ׂ����낤��
�D�̌݊����̃}�Y���ɂԂ������Ƃ���nvidia troll�̌������������邪
OS�Ƃ��Ă��n�[�h�E�F�A�Ƃ��Ă��D�^�u�͏��F�g���̂ẴS�~�ł����Ȃ������
����FX�͋@�B�v()�ƒ@����Ă����g���Ă݂�ƃL���͉������Ă����Ė�L�X���[�Y�ɓ��������
x86�̌݊�����������肭���Ȃ��Ă���AMD���̎����͂͂Ȃ������Ƃ݂�ׂ����낤��
�D�̌݊����̃}�Y���ɂԂ������Ƃ���nvidia troll�̌������������邪
OS�Ƃ��Ă��n�[�h�E�F�A�Ƃ��Ă��D�^�u�͏��F�g���̂ẴS�~�ł����Ȃ������
����FX�͋@�B�v()�ƒ@����Ă����g���Ă݂�ƃL���͉������Ă����Ė�L�X���[�Y�ɓ��������
��������̏�����W�U�R�[�h������U���Ă�̂�������ǂ���������
FreeBSD�̃f�B�X�g���r���[�V�����Œ��g�̈Ⴄ���������ˁH
�[�Ƃ܂��܂��}�b�N�D�ʂ�����
FreeBSD�̃f�B�X�g���r���[�V�����Œ��g�̈Ⴄ���������ˁH
�[�Ƃ܂��܂��}�b�N�D�ʂ�����
377 �FSocket774�F2015/01/21(��) 19:14:34.62 ID:ysw4VZKs
GTX960 vs R9 280����
http://wccftech.com/wp-content/uploads/2015/01/GTX-960-Vs-R9-280-4K-Benchmarks-.png
http://wccftech.com/wp-content/uploads/2015/01/GTX-960-Vs-R9-280-4K-Benchmarks-.png
{kind=link}
378 �FSocket774�F2015/01/21(��) 19:27:58.07 ID:wqiejD5g
http://browser.primatelabs.com/geekbench3/compare/1713791?baseline=1720602
a57 53��8core���������肷����
a57 53��8core���������肷����
�T���`�����ɔ������ꂽ���ǂ��O��`�����̂��߂�AMD�����́H
���������Ă��O��͍ݓ��H�ݓ��Ȃ疾������؍��s���ďZ���o�^�ƕ��������Ă��Ȃ�
�A��Ɉ���������ăT���`��������������AMD���i����������Ȃ�
���������Ă��O��͍ݓ��H�ݓ��Ȃ疾������؍��s���ďZ���o�^�ƕ��������Ă��Ȃ�
�A��Ɉ���������ăT���`��������������AMD���i����������Ȃ�
���N�l�̍��Z�̖ό��ł���
>>381
�o�[�J
�o�[�J
384 �FSocket774�F2015/01/21(��) 20:19:39.12 ID:MscXsymI
AMD��samsung�Ƃ�hynix�ƒ�����������A���̂����������ゾ�����g����Ȃ���
>>345
�o�J�ۏo��
�o�J�ۏo��
388 �FSocket774�F2015/01/21(��) 21:25:45.99 ID:eWfbwkRS
Catalyst Omega�Ń��f�͐L�т邾�낤���R���V���[�}�Q�[���@�ւ̑g�ݍ��݂Ŏ����Ă銴������
�X�}�z�����J���ɗ͂�����̂�
FX�̌�p��Phenom III���o���܂������Ԃ���
�X�}�z�����J���ɗ͂�����̂�
FX�̌�p��Phenom III���o���܂������Ԃ���
AMD�Ј��ł��Ȃ��̂ɐM�҂����K������
Zen��O�|���Ń����[�X�Ƃ��͂Ȃ����낤�Ȃ��E�E�E
>>390
GF�łȂ��T���t�@�u�g���ΑO�|���ł���Zen�ő叟������
AMD�s�U�̌�����AMD�ł͂Ȃ�GF�BAMD�̓T���t�@�u�ő叟������
GF�łȂ��T���t�@�u�g���ΑO�|���ł���Zen�ő叟������
AMD�s�U�̌�����AMD�ł͂Ȃ�GF�BAMD�̓T���t�@�u�ő叟������
>>389
������AMD�Ј�����Ȃ��ƍ��o���Ă����H
������AMD�Ј�����Ȃ��ƍ��o���Ă����H
393 �FSocket774�F2015/01/21(��) 22:29:12.45 ID:1hooODzG
�X�}�z�����Ƃ��킹��
4���h���Ԏ��Ƃ����v��
�������Ȃ��Ȃ�Ɛi�����~�܂邵
���i�����~�܂�ɂȂ��ėǂ����ƂȂ���
�������Ȃ��Ȃ�Ɛi�����~�܂邵
���i�����~�܂�ɂȂ��ėǂ����ƂȂ���
GF�ɕ�����2���h�����܂�ł��
Phenom�U�܂��P�����@���p��A10�Ɠ������炢
AMD���������ăj���[�X�͂��܂茩�����Ƃ�����
�L���q���̕�����2019�N����ɂȂ����Ǝv��������
�܂�����܂ł�5�N�Ԃ����O�ꂾ��
�܂�����܂ł�5�N�Ԃ����O�ꂾ��
AMD�����Œׂ�悤���ǂ��ł���������
�������i���o���甃����
�������i���o���甃����
>>326
���̂Ă�ꂽ�̃k�r�̕��ł���
SHIELD�o���ĉƒ�p�Q�[���̎���͏I��肾�Ƃ�
PC�̕������\��������ƒ�p�Q�[���̎���͏I��肾�Ƃ��ӎ����܂���ȃA�s�[�����Ă邵
���̂Ă�ꂽ�̃k�r�̕��ł���
SHIELD�o���ĉƒ�p�Q�[���̎���͏I��肾�Ƃ�
PC�̕������\��������ƒ�p�Q�[���̎���͏I��肾�Ƃ��ӎ����܂���ȃA�s�[�����Ă邵
�����u���Q�[���@�����Ȃ��ƍX�ɔߎS�Ȏ��ɁB
403 �FSocket774�F2015/01/21(��) 23:26:45.63 ID:AZ8Pz4FF
AMD�ʊ�����グ
2006 56��4900���h��
2007 58��5800���h��
2008 58��800���h��
2009 54��300���h��
2010 64��9000���h��
2011 65��7000���h��
2012 54��2000���h��
2013 53���h��
2014 55��1,000���h��
>��4�l�����̓R���s���[�e�B���O�ƃO���t�B�b�N�X���傪���ɕs���ŁA
>�O�N�����Ɣ�r����16%���ƂȂ����B���Ƀf�X�N�g�b�vGPU���s���������Ƃ��Ă���B
>2015�N��1�l������15%�̔��㌸��\�����Ă���B
�叟���I
2006 56��4900���h��
2007 58��5800���h��
2008 58��800���h��
2009 54��300���h��
2010 64��9000���h��
2011 65��7000���h��
2012 54��2000���h��
2013 53���h��
2014 55��1,000���h��
>��4�l�����̓R���s���[�e�B���O�ƃO���t�B�b�N�X���傪���ɕs���ŁA
>�O�N�����Ɣ�r����16%���ƂȂ����B���Ƀf�X�N�g�b�vGPU���s���������Ƃ��Ă���B
>2015�N��1�l������15%�̔��㌸��\�����Ă���B
�叟���I
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@, r::':::::::::::::..�R �A
�@�@�@�@�@�@�@�@�@�@�@�@�@�^::::::::::::::::.:::::..::::::::�R�A
�@�@�@ �@ �@ �@ �@ �@ �@ /:::�::N�..iv�..:..:..:.:.::::::::vr�|�
/�܁Rr�|�A�@ _�@�@�@ /i::;;;:/�\�SN-�Ni:::i!:::::/�@�@�@ i
���� i!�@::.'�L / ��R�@ '�@Y:::i �� ,�@��`}::N)::i�@�Ӕ� .!
�� �� i!�@�@�@�@ ,,�@`��,/N:::!.'' r-v, '' ,}rr�::|�@���� |
��.�� i!�@ r�|��@�r�:/ .i!N;;��`� �C/�;;;���@��.�� |
.��� �� �R�@:::�==�L=}�@�@�@_,.r'r'|�@,./�@` >! .��@�@.|
��@�@i!�Rr=>�@ �@`�>V��)||�@,iĤ_,/�@�@Ɂ^� !!�@ /
�I�@./�@�@|'/,�7�@�@ /��i:/Ĥ�`�@�S�Oò'�@�@.i�['
`�['�@�@�@�' ' �i�@�@ �@ �m'::i�M�[i�@�@�R�L ./.:�@�@ |
�@�@�@�@�@�@�@�@�@�@�@�@�@�^::::::::::::::::.:::::..::::::::�R�A
�@�@�@ �@ �@ �@ �@ �@ �@ /:::�::N�..iv�..:..:..:.:.::::::::vr�|�
/�܁Rr�|�A�@ _�@�@�@ /i::;;;:/�\�SN-�Ni:::i!:::::/�@�@�@ i
���� i!�@::.'�L / ��R�@ '�@Y:::i �� ,�@��`}::N)::i�@�Ӕ� .!
�� �� i!�@�@�@�@ ,,�@`��,/N:::!.'' r-v, '' ,}rr�::|�@���� |
��.�� i!�@ r�|��@�r�:/ .i!N;;��`� �C/�;;;���@��.�� |
.��� �� �R�@:::�==�L=}�@�@�@_,.r'r'|�@,./�@` >! .��@�@.|
��@�@i!�Rr=>�@ �@`�>V��)||�@,iĤ_,/�@�@Ɂ^� !!�@ /
�I�@./�@�@|'/,�7�@�@ /��i:/Ĥ�`�@�S�Oò'�@�@.i�['
`�['�@�@�@�' ' �i�@�@ �@ �m'::i�M�[i�@�@�R�L ./.:�@�@ |
405 �FSocket774�F2015/01/22(��) 01:35:43.93 ID:6fQ+aIqq
�ׂ�Ă͍���Ǝv���Ă���Intel nvidia
AMD���Z
2014Q4�@�@�i2013Q4�j
���㍂�@12��4000���h���@�i15��9000���h���j
�c�Ƒ��v�@�Ԏ�3��3000���h���@�i����1��3500���h���j
�����v�@�Ԏ�3��6400���h���@�i����8900���h���j
2014�N�ʔN�@�@�i2013�N�j
���㍂�@55��1000���h���@�i53���h���j
�c�Ƒ��v�@�Ԏ�1��5500���h���@�i����1��300���h���j
�����v�@�Ԏ�4��300���h���@�i�Ԏ�8300���h���j
�����AMD�̗\���ł�2015�N��1�l������15%�̔��㌸
2014Q4�@�@�i2013Q4�j
���㍂�@12��4000���h���@�i15��9000���h���j
�c�Ƒ��v�@�Ԏ�3��3000���h���@�i����1��3500���h���j
�����v�@�Ԏ�3��6400���h���@�i����8900���h���j
2014�N�ʔN�@�@�i2013�N�j
���㍂�@55��1000���h���@�i53���h���j
�c�Ƒ��v�@�Ԏ�1��5500���h���@�i����1��300���h���j
�����v�@�Ԏ�4��300���h���@�i�Ԏ�8300���h���j
�����AMD�̗\���ł�2015�N��1�l������15%�̔��㌸
���H���N�̍�����Ɣ�r�H
���N��Kaveri�̃n�C�G���h�����̎����ɏo�Ă�B
�݂�Ȃ������Ĕ������B
���N�͖����B
���N�x�[�X�Ŕ�r���Ă����傤���Ȃ�����w
���N��Kaveri�̃n�C�G���h�����̎����ɏo�Ă�B
�݂�Ȃ������Ĕ������B
���N�͖����B
���N�x�[�X�Ŕ�r���Ă����傤���Ȃ�����w
��Ԏ������ĂĂ����傤���Ȃ��ōς܂���̂������è
���ЃX���ɏ�荞��ł͉����R�s�y�A��
�K�����߂��A�Ă���
���܂̓Ɛ�́A��������Ȃɕ|��������s���������肷��̂�
�]������Ă�̂Ȃ�[������
�K�����߂��A�Ă���
���܂̓Ɛ�́A��������Ȃɕ|��������s���������肷��̂�
�]������Ă�̂Ȃ�[������
411 �FSocket774�F2015/01/22(��) 07:01:39.53 ID:x33Ti7y7
>>337
silvermont��jaguar�������x�ł����Ȃ�����Ȃ�
denver�͂������{������
�Ă�a57��silvermont���x�ł����Ȃ���Ȃ�
silvermont��jaguar�������x�ł����Ȃ�����Ȃ�
denver�͂������{������
�Ă�a57��silvermont���x�ł����Ȃ���Ȃ�
Cyclone 1.5GHz *3core
SingleT SP max: 23.568 GFLOPS
SingleT DP max: 11.751 GFLOPS
MultiT SP max: 68.591 GFLOPS
MultiT DP max: 33.968 GFLOPS
Denver 2.5GHz *2core
SingleT SP max: 17.906 GFLOPS
SingleT DP max: 8.762 GFLOPS
MultiT SP max: 34.888 GFLOPS
MultiT DP max: 17.601 GFLOPS
Silvermont 2.0-2.4GHz *4core
SingleT SP max: 14.477 GFLOPS
SingleT DP max: 3.619 GFLOPS
MultiT SP max: 57.902 GFLOPS
MultiT DP max: 14.471 GFLOPS
Jaguar 2.0GHz *4core
SingleT SP max: 15.943 GFLOPS
SingleT DP max: 6.127 GFLOPS
MultiT SP max: 63.737 GFLOPS
MultiT DP max: 24.504 GFLOPS
������Denver
�Ԃ�������̃S�~����
SingleT SP max: 23.568 GFLOPS
SingleT DP max: 11.751 GFLOPS
MultiT SP max: 68.591 GFLOPS
MultiT DP max: 33.968 GFLOPS
Denver 2.5GHz *2core
SingleT SP max: 17.906 GFLOPS
SingleT DP max: 8.762 GFLOPS
MultiT SP max: 34.888 GFLOPS
MultiT DP max: 17.601 GFLOPS
Silvermont 2.0-2.4GHz *4core
SingleT SP max: 14.477 GFLOPS
SingleT DP max: 3.619 GFLOPS
MultiT SP max: 57.902 GFLOPS
MultiT DP max: 14.471 GFLOPS
Jaguar 2.0GHz *4core
SingleT SP max: 15.943 GFLOPS
SingleT DP max: 6.127 GFLOPS
MultiT SP max: 63.737 GFLOPS
MultiT DP max: 24.504 GFLOPS
������Denver
�Ԃ�������̃S�~����
Win10�ɂȂ�}���g���S�~�ɂȂ邶���
Radeon�Ƃ����S�~���s�v�ɂȂ邵CPU�͌��X
�M�҂��x���Ĕ����Ĕ�����Ȃ�Ƃ��m�ۂ���
�������ƃT���`�����ɔ�������Ȃ��Ɗ؍������ȉ���
�S�߂Ȗ��H�����Ȃ���
���O�����������Intel��Geforce�ɏ�芷����
Radeon�Ƃ����S�~���s�v�ɂȂ邵CPU�͌��X
�M�҂��x���Ĕ����Ĕ�����Ȃ�Ƃ��m�ۂ���
�������ƃT���`�����ɔ�������Ȃ��Ɗ؍������ȉ���
�S�߂Ȗ��H�����Ȃ���
���O�����������Intel��Geforce�ɏ�芷����
2015Q1�̔��㌸�̓N���X�}�X����̌�ŃQ�[���@�̔��オ�������邩�炾��
�Q�[���@���e�ő叟���I���������ʂɂ͂��������I���̂Ă�ꂽ�k�r��
��
AMD�A2014�N�x�͑�����4���h���̐Ԏ�
��
AMD�A2014�N�x�͑�����4���h���̐Ԏ�
417 �FSocket774�F2015/01/22(��) 09:29:20.61 ID:K3Uz7CF/
denver�ŋ����̂�OS�A�A�v���ł����Ƃ��d�v�Ȑ����v�Z
fp��dynamic code optimization�œ��ɉ������Ȃ���
http://proc-cpuinfo.fixstars.com/2015/01/denver.html
Denver �̍œK���@�\�ׂ�
fp��dynamic code optimization�œ��ɉ������Ȃ���
http://proc-cpuinfo.fixstars.com/2015/01/denver.html
Denver �̍œK���@�\�ׂ�
418 �FSocket774�F2015/01/22(��) 09:32:09.74 ID:K3Uz7CF/
>>412
��Jaguar�����[��
��Jaguar�����[��
Denver���ʂɖʔ������Ɍ����邯�ǂȁB
>>418
���A�[�L�e�N�`���ŃN���b�N�����Silvermont���͑�������
Cyclone���ĂȂ�Ȃ��̒����ƂԂ��������Ă邯��
>>418
���A�[�L�e�N�`���ŃN���b�N�����Silvermont���͑�������
Cyclone���ĂȂ�Ȃ��̒����ƂԂ��������Ă邯��
420 �FSocket774�F2015/01/22(��) 11:03:07.53 ID:K3Uz7CF/
Cyclone��FP����������
3dmark��physics�͒x����˂�denver���
���ł�nexus9��denver��2.3GHz���
3dmark��physics�͒x����˂�denver���
���ł�nexus9��denver��2.3GHz���
> ���A�[�L�e�N�`���ŃN���b�N�����Silvermont���͑�������
FMUL���j�b�g��64bit�������Ȃ�Silvermont�Ɣ�ׂĂ��Ȃ�
�ʂ�FP�ɓ������Ă�킯����Ȃ���
������������d�̓����W���ႤJaguar��Silvermont��ׂ�͍̂�����Ȃ��̂�
�T�[�o�p��Kyoto����GPU������X1150��TDP Max 17W
2.4GHz 20W��8�R�A�ς�ł�̂�Atom
FMUL���j�b�g��64bit�������Ȃ�Silvermont�Ɣ�ׂĂ��Ȃ�
�ʂ�FP�ɓ������Ă�킯����Ȃ���
������������d�̓����W���ႤJaguar��Silvermont��ׂ�͍̂�����Ȃ��̂�
�T�[�o�p��Kyoto����GPU������X1150��TDP Max 17W
2.4GHz 20W��8�R�A�ς�ł�̂�Atom
Denver 2.5GHz *2core�@10W
Silvermont 2.4GHz *4core�@3W
Jaguar 2.0GHz *4core�@25W
Silvermont 2.4GHz *4core�@3W
Jaguar 2.0GHz *4core�@25W
AMD��{�c���\���
http://ir.amd.com/phoenix.zhtml?c=74093&p=irol-newsArticle_print&ID=1824731
���ꂼ��X1150�ɂ�����SPECint2006��single��rate�̐���X�R�A�炵����
> 5.2 @ 2 GHz (single)
> 13.0 @ 2 GHz (rates)
�T�[�o�x���_�[�Ɏ��ۂɍ̗p���Ȃ�����u����l�v�~�܂�Ȃ̂�AMD�N�I���e�B
���_Atom C2750�͎����l����
CINT2006 17.5
�@https://www.spec.org/cpu2006/results/res2014q3/cpu2006-20140617-29942.html
CINT2006 Rates 103
�@https://www.spec.org/cpu2006/results/res2014q3/cpu2006-20140617-29941.html
�N���b�N���Ƃ��������ш捷�ȑO�̖�肾��
http://ir.amd.com/phoenix.zhtml?c=74093&p=irol-newsArticle_print&ID=1824731
���ꂼ��X1150�ɂ�����SPECint2006��single��rate�̐���X�R�A�炵����
> 5.2 @ 2 GHz (single)
> 13.0 @ 2 GHz (rates)
�T�[�o�x���_�[�Ɏ��ۂɍ̗p���Ȃ�����u����l�v�~�܂�Ȃ̂�AMD�N�I���e�B
���_Atom C2750�͎����l����
CINT2006 17.5
�@https://www.spec.org/cpu2006/results/res2014q3/cpu2006-20140617-29942.html
CINT2006 Rates 103
�@https://www.spec.org/cpu2006/results/res2014q3/cpu2006-20140617-29941.html
�N���b�N���Ƃ��������ш捷�ȑO�̖�肾��
���܂�S1260�̂ق��������B
Jaguar�͂��������B�ߎS�Ȃ��Ƃɂ͕ς��Ȃ����B
28.9 @ 2 GHz (CPU)(est.)
10.0 @ 2 GHz (CPU)(est.)
Jaguar�͂��������B�ߎS�Ȃ��Ƃɂ͕ς��Ȃ����B
28.9 @ 2 GHz (CPU)(est.)
10.0 @ 2 GHz (CPU)(est.)
425 �FSocket774�F2015/01/22(��) 12:53:58.68 ID:K3Uz7CF/
denver��k1��5W
APU�Ƃ͖��W�ȁAAMD�l�K�R�s�y�����\��p���Ȃ���ł��˂�����
�����n�̐K�ɏ���āA�����h�C���̏����錾�����Ƃ�������
�l���[�A�����̃����^���e�B�[���āA���ɂȂ��Ă��o�H�̂��Ƃ����ȁB
�����n�̐K�ɏ���āA�����h�C���̏����錾�����Ƃ�������
�l���[�A�����̃����^���e�B�[���āA���ɂȂ��Ă��o�H�̂��Ƃ����ȁB
�R�s�y����
Silvermont�Ɍ�o���ŕ����Ă�̂�A1100
CPU Core Configuration
AMD Opteron A1100�@8 x ARM Cortex A57
AMD Opteron X2150�@4 x AMD Jaguar
CPU Frequency
AMD Opteron A1100�@2GHz
AMD Opteron X2150�@1.9GHz
SPECint_rate Estimate
AMD Opteron A1100�@80
AMD Opteron X2150�@28.1
Estimated TDP
AMD Opteron A1100�@25W
AMD Opteron X2150�@22W
http://www.anandtech.com/show/7724/it-begins-amd-announces-its-first-arm-based-server-soc-64bit8core-opteron-a1100
Silvermont�Ɍ�o���ŕ����Ă�̂�A1100
CPU Core Configuration
AMD Opteron A1100�@8 x ARM Cortex A57
AMD Opteron X2150�@4 x AMD Jaguar
CPU Frequency
AMD Opteron A1100�@2GHz
AMD Opteron X2150�@1.9GHz
SPECint_rate Estimate
AMD Opteron A1100�@80
AMD Opteron X2150�@28.1
Estimated TDP
AMD Opteron A1100�@25W
AMD Opteron X2150�@22W
http://www.anandtech.com/show/7724/it-begins-amd-announces-its-first-arm-based-server-soc-64bit8core-opteron-a1100
>>421
3W�ł��ꂾ���X�Q�[�Ƃ͎v������
>FMUL���j�b�g��64bit�������Ȃ�
>�ʂ�FP�ɓ������Ă�킯����Ȃ�
���ꌾ���o�����炠���镨���u�\���̈Ⴂ�����镨���r�ł���킯�Ȃ��v�ŕЕt�����邩��Ȃ�
>>412�ŃN���b�N�E�A�[�L�e�N�`���E�R�A���E�v�̍����܂���Ɩ������Ĕ�r���Ă���炻�������咣�͒ʂ�ɂ����Ǝv��
3W�ł��ꂾ���X�Q�[�Ƃ͎v������
>FMUL���j�b�g��64bit�������Ȃ�
>�ʂ�FP�ɓ������Ă�킯����Ȃ�
���ꌾ���o�����炠���镨���u�\���̈Ⴂ�����镨���r�ł���킯�Ȃ��v�ŕЕt�����邩��Ȃ�
>>412�ŃN���b�N�E�A�[�L�e�N�`���E�R�A���E�v�̍����܂���Ɩ������Ĕ�r���Ă���炻�������咣�͒ʂ�ɂ����Ǝv��
�~�j�}���T�[�o�[��ARM�R�A���Ax86�ɔėp���ŏ��Ă�킯���Ȃ�㩂�
���̃R�s�y�����ŁA���f�ł���v�f0�����A�����̃X���`�B
���̃R�s�y�����ŁA���f�ł���v�f0�����A�����̃X���`�B
Jaguar��2GHz 4�R�A�̎��_�ŃA�N�e�B�u�N�[�����O�K�{����
2�R�A�ɍ����1GHz�܂ŗ��Ƃ��Ă��낤����11�C���`�^�u�ɍڂ���x
������^�u���b�g��X�}�z�ɕ����I�ɍڂ�Ȃ��`�b�v�����������ɏo�����_��
�n���ɂ���Ӑ}�ȏ�̂��̂͂Ȃ��Ǝv����
2�R�A�ɍ����1GHz�܂ŗ��Ƃ��Ă��낤����11�C���`�^�u�ɍڂ���x
������^�u���b�g��X�}�z�ɕ����I�ɍڂ�Ȃ��`�b�v�����������ɏo�����_��
�n���ɂ���Ӑ}�ȏ�̂��̂͂Ȃ��Ǝv����
AMD��TDP4.5W/SDP2.8W�ŁA4�R�A�E1.2GHz(2.2GHz)�܂ł�Mullins��������ǂ�
Silvermont���ASDP2-2.2W��1.33-1.59GH���i1.83-2.41GHz�j��Bay Trai����������Ȃ���
Silvermont���ASDP2-2.2W��1.33-1.59GH���i1.83-2.41GHz�j��Bay Trai����������Ȃ���
432 �FSocket774�F2015/01/22(��) 15:19:35.89 ID:K3Uz7CF/
http://browser.primatelabs.com/geekbench3/compare/541587?baseline=569477
Intel Atom Z3770 @ 1.46 GHz 1 processor, 4 cores
AMD A10 Micro-6700T APU+AMD Radeon R6 Graphics @ 1.20 GHz
Intel Atom Z3770 @ 1.46 GHz 1 processor, 4 cores
AMD A10 Micro-6700T APU+AMD Radeon R6 Graphics @ 1.20 GHz
���\��������d�͓�{
���ꂪ���ނ�
���ꂪ���ނ�
���{�l�Ȃ�C���e���Q�t�H�Ō��܂肾�˂�
20BN000UGE����ThinkPad 8�̋����f�����B
Z3795���ڂ�LPDDR3��64�r�b�gOS��4GB�ς�ł錻�s���f���Ɣ�ׂĂ��Ȃ��E�E�E
Airmont�����낻��o�ׂ��ꂻ���Ȃ��̎�����Mullins���ڋ@�������ɏo�ĂȂ�
Windows, Android�ɂ����炸�ASilvermont�̃��C���^�[�Q�b�g����7-8�C���`�̃^�u���b�g�Ȃ�ˁB
Mullins�͍��̂Ƃ���10�C���`�N���X�����I�t�@�[���Ȃ��������������B
Z3795���ڂ�LPDDR3��64�r�b�gOS��4GB�ς�ł錻�s���f���Ɣ�ׂĂ��Ȃ��E�E�E
Airmont�����낻��o�ׂ��ꂻ���Ȃ��̎�����Mullins���ڋ@�������ɏo�ĂȂ�
Windows, Android�ɂ����炸�ASilvermont�̃��C���^�[�Q�b�g����7-8�C���`�̃^�u���b�g�Ȃ�ˁB
Mullins�͍��̂Ƃ���10�C���`�N���X�����I�t�@�[���Ȃ��������������B
437 �FSocket774�F2015/01/22(��) 16:38:46.54 ID:K3Uz7CF/
LENOVO 20BN000UGE
Microsoft Windows 8.1 (32-bit)
Intel Atom Z3770 @ 1.46 GHz 1 processor, 4 cores
1936 MB -1MHz
��
Microsoft Windows 8.1 Enterprise (64-bit)
AMD A10 Micro-6700T APU+AMD Radeon R6 Graphics @ 1.20 GHz 1 processor, 4 cores
3510 MB -1MHz
Microsoft Windows 8.1 (32-bit)
Intel Atom Z3770 @ 1.46 GHz 1 processor, 4 cores
1936 MB -1MHz
��
Microsoft Windows 8.1 Enterprise (64-bit)
AMD A10 Micro-6700T APU+AMD Radeon R6 Graphics @ 1.20 GHz 1 processor, 4 cores
3510 MB -1MHz
>>432�ɂ��Ă��A������Ɗ���^�u���b�g➑̂Ɏ��܂�����Ԃł̃X�R�A�Ȃ̂��ǂ���
���������^�u���b�g�͊�{�o�b�N�O���E���h�ŏd�����^�X�N�����悤�Ȃ��Ƃ͂��Ȃ��̂���
�Z���������i�[������A�M�ƃo�b�e���[�̖�肪�����͂𐧌�����B
�ǂ���Android��������Ȃ���Windows��p�Ȃ낤���ǁAWindows�^�u���b�g���Ă�̂�
�l���[�U�[�͓��{���S�ł��Ƃ͖@�l�������
���낻�����v�����ɂȂ��Ă邵Flash�̐��\�łԂ������邭�炢�łȂ��Ƃ܂�����Ȃ����낤��
�@����̗��R��Intel�������Ȃ��l�Ɏ��v��������x���B
���������^�u���b�g�͊�{�o�b�N�O���E���h�ŏd�����^�X�N�����悤�Ȃ��Ƃ͂��Ȃ��̂���
�Z���������i�[������A�M�ƃo�b�e���[�̖�肪�����͂𐧌�����B
�ǂ���Android��������Ȃ���Windows��p�Ȃ낤���ǁAWindows�^�u���b�g���Ă�̂�
�l���[�U�[�͓��{���S�ł��Ƃ͖@�l�������
���낻�����v�����ɂȂ��Ă邵Flash�̐��\�łԂ������邭�炢�łȂ��Ƃ܂�����Ȃ����낤��
�@����̗��R��Intel�������Ȃ��l�Ɏ��v��������x���B
ARM opteron�o��ŃT�[�o�[atom����Ō��Ȃ�
AMD�͑啪���ƂɑR���o������A���R�����Ȃ�Ȃ��Ƃ����Ȃ�
>>438
���̉�Ђł�win �^�u���ɓ������Ă���B
��Ɏ�����/�����đ���ł�����ĕێ�E�_������A���ɂ͂������֗��炵��
AMD�͑啪���ƂɑR���o������A���R�����Ȃ�Ȃ��Ƃ����Ȃ�
>>438
���̉�Ђł�win �^�u���ɓ������Ă���B
��Ɏ�����/�����đ���ł�����ĕێ�E�_������A���ɂ͂������֗��炵��
�d�����ጋ��Win1��
�D���ь���Q�[����web�{�����傾���𗧂���
�D���ь���Q�[����web�{�����傾���𗧂���
�܂�android�ł�office�g�����ł����ǂ�
win tab�̎g�������ق�Ƃ��ɂȂ��悟
win tab�̎g�������ق�Ƃ��ɂȂ��悟
�������ɎY�pdenver�����グ�Ă���z������Ƃ͎v�������
443 �FSocket774�F2015/01/23(��) 19:17:51.19 ID:mEO+TN25
http://tctechcrunch2011.files.wordpress.com/2015/01/img_8312.jpg
http://tctechcrunch2011.files.wordpress.com/2015/01/img_8310.jpg
http://i.imgur.com/CG3HSUoh.jpg
http://i.imgur.com/B4T7bODh.jpg
a57�͂�����
����
http://tctechcrunch2011.files.wordpress.com/2015/01/img_8310.jpg
http://i.imgur.com/CG3HSUoh.jpg
http://i.imgur.com/B4T7bODh.jpg
a57�͂�����
����
�p���[�}�b�N300Mhz����͂P�T�Ԃ������Ă��͗l
445 �FSocket774�F2015/01/23(��) 19:33:54.82 ID:XeRD6pyM
denver���S�s�Ȃ�arm�͑S���S�s���Ȃ�
denver��NVIDIA������ᐫ�\�Ȃ�����
ARM�͂���Ȃ��Ɩ�������S�z����ȁB
ARM�͂���Ȃ��Ɩ�������S�z����ȁB
447 �FSocket774�F2015/01/24(�y) 06:28:07.57 ID:He41RGx3
denver�͗D�G����
android�ŃR�C��mining(mona)�����Ƃ�a15��tegra note����
�[�d�������ɊԂɍ���Ȃ���nexus9�ł͏[�d���Ԃɍ���
soc�͂Ƃ���28nm
�\�t�g�̊W���ʂ͏펞ON�̏�Ԃ�
�[�d���tegra note��5v 2a(10w)�ł���̂ɑ���nexus9��5v 1.5a(7.5w)
��ʂ�tegra note��7inch 1280x800,nexus9��8.9inch 2048x1536
���Ȃ��Ƃ�cpu���ׂ��������ꍇ�̓V�X�e���S�̂�7.5w�Ŗ����̏���d�͂ł���ł���킯��
���Ȃ݂�tn��4core��6khash/s,n9��2core��12khash/s���x�ł�������
android�ŃR�C��mining(mona)�����Ƃ�a15��tegra note����
�[�d�������ɊԂɍ���Ȃ���nexus9�ł͏[�d���Ԃɍ���
soc�͂Ƃ���28nm
�\�t�g�̊W���ʂ͏펞ON�̏�Ԃ�
�[�d���tegra note��5v 2a(10w)�ł���̂ɑ���nexus9��5v 1.5a(7.5w)
��ʂ�tegra note��7inch 1280x800,nexus9��8.9inch 2048x1536
���Ȃ��Ƃ�cpu���ׂ��������ꍇ�̓V�X�e���S�̂�7.5w�Ŗ����̏���d�͂ł���ł���킯��
���Ȃ݂�tn��4core��6khash/s,n9��2core��12khash/s���x�ł�������
448 �FSocket774�F2015/01/24(�y) 06:32:08.50 ID:He41RGx3
tegra x1
http://tctechcrunch2011.files.wordpress.com/2015/01/img_8312.jpg
http://tctechcrunch2011.files.wordpress.com/2015/01/img_8310.jpg
nexus9
http://i.imgur.com/CG3HSUoh.jpg
http://i.imgur.com/B4T7bODh.jpg
a57,53��8core�쓮���\�ł��邪�A�܂�a57 4core�Ƃ��Ă�
�����Ȍ��ʂł���
x1��gpu���\�������Ă�̂�antutu�ŕ����Ă邵��
http://tctechcrunch2011.files.wordpress.com/2015/01/img_8312.jpg
http://tctechcrunch2011.files.wordpress.com/2015/01/img_8310.jpg
nexus9
http://i.imgur.com/CG3HSUoh.jpg
http://i.imgur.com/B4T7bODh.jpg
a57,53��8core�쓮���\�ł��邪�A�܂�a57 4core�Ƃ��Ă�
�����Ȍ��ʂł���
x1��gpu���\�������Ă�̂�antutu�ŕ����Ă邵��
28nm�������ƌ���ŕς���Ă邩��B
800��801�Ɣ�r���Ă��N���b�N���オ���Ă�̂ɏ���d�͉������Ă�B
800��801�Ɣ�r���Ă��N���b�N���オ���Ă�̂ɏ���d�͉������Ă�B
Denver����Java��Hotspot�Ɠ����l������Ȃ��́H
1��ڂ͉�́A2��ڈȍ~�ōœK���Ȃ炻��Ȃ�̊��Ԏg��Ȃ����萳�������\�]���ł��A
�Z���Ԃ������s����Ȃ��x���`�̌��ʂ��ǂ��Ȃ�����ᐫ�\�Ȃ�Č��߂��͔n�����ۂ�
1��ڂ͉�́A2��ڈȍ~�ōœK���Ȃ炻��Ȃ�̊��Ԏg��Ȃ����萳�������\�]���ł��A
�Z���Ԃ������s����Ȃ��x���`�̌��ʂ��ǂ��Ȃ�����ᐫ�\�Ȃ�Č��߂��͔n�����ۂ�
2��ڂƂ�����Ȃ��悤��
��������̃J�E���^�[�����Ă��ė��p�p�x�ɍ������ɂ���
�R�[�h�̍œK�����s���悤�ł�
�K���Ȃ̂�in order�Ȃ���n�[�h�ł�2���߂̃f�R�[�_�����Ă��邱��
�g�����X���^�̂悤�ɍŏ�����\�t�g�����̂������C���^�[�v���^�[�ł͂�������x�������Ă��܂�
���s�|�[�g��7�ł��邽�߈ꉞ7���߂܂ł̕��s�\���Ă��Ƃɂ��Ă邯��
�œK���Ŗ��ʂȖ��߂��Ȃ��Ă��܂��̂�arm���߃J�E���g����ȏ�̂��Ƃ�����
��������̃J�E���^�[�����Ă��ė��p�p�x�ɍ������ɂ���
�R�[�h�̍œK�����s���悤�ł�
�K���Ȃ̂�in order�Ȃ���n�[�h�ł�2���߂̃f�R�[�_�����Ă��邱��
�g�����X���^�̂悤�ɍŏ�����\�t�g�����̂������C���^�[�v���^�[�ł͂�������x�������Ă��܂�
���s�|�[�g��7�ł��邽�߈ꉞ7���߂܂ł̕��s�\���Ă��Ƃɂ��Ă邯��
�œK���Ŗ��ʂȖ��߂��Ȃ��Ă��܂��̂�arm���߃J�E���g����ȏ�̂��Ƃ�����
�̐S�Ȃ͍̂œK���̃v���Z�X���n�[�h�E�F�A�Ŏ������Ă���Ď������
1����ŏI��点�Ȃ��ō���������ƊJ�������Ă����ė~�����Ȃ���
1����ŏI��点�Ȃ��ō���������ƊJ�������Ă����ė~�����Ȃ���
453 �FSocket774�F2015/01/24(�y) 07:56:59.19 ID:V8cbwdqy
�œK���̓\�t�g�ł���
�n�[�h�ł̍œK�����Ă̂�intel�̃f�R�[�_�̂悤�ɕ��G�ɂȂ�K�͂��傫���Ȃ��Ă��܂�
�Ȃ̂�denver�ł͈�x�ڃn�[�h�f�R�[�_�[�g������̓R�[�h�[�L���b�V���ɓ�����
�ȍ~�����R�[�h�������炻������ǂݏo������
������x���p�p�x�̍������̂͂�������\�t�g�E�G�A�ōœK�����s����
�R�[�h�[�L���b�V���͊e�R�A�ŋ��L�����̂ő��R�A����������ɗL���ł�����
2���߂�in order�ł����Ȃ��̂�core�̋K�͂͑傫���͂Ȃ�
�V���O���X���b�h�͍��߂�������core�K�͂͑傫���������Ȃ����ĂƂ��낪��
�����͈̔͂�cpu�����łȂ�gpu���ӂ��܂�Ă��̂�
cpu���߂��Ƃ��ĉ\�Ȃ��̂�sm(gpu)�ɂӂ�Ȃ�Ă��Ƃ�
�߂�������邩������Ȃ�
parker����
�n�[�h�ł̍œK�����Ă̂�intel�̃f�R�[�_�̂悤�ɕ��G�ɂȂ�K�͂��傫���Ȃ��Ă��܂�
�Ȃ̂�denver�ł͈�x�ڃn�[�h�f�R�[�_�[�g������̓R�[�h�[�L���b�V���ɓ�����
�ȍ~�����R�[�h�������炻������ǂݏo������
������x���p�p�x�̍������̂͂�������\�t�g�E�G�A�ōœK�����s����
�R�[�h�[�L���b�V���͊e�R�A�ŋ��L�����̂ő��R�A����������ɗL���ł�����
2���߂�in order�ł����Ȃ��̂�core�̋K�͂͑傫���͂Ȃ�
�V���O���X���b�h�͍��߂�������core�K�͂͑傫���������Ȃ����ĂƂ��낪��
�����͈̔͂�cpu�����łȂ�gpu���ӂ��܂�Ă��̂�
cpu���߂��Ƃ��ĉ\�Ȃ��̂�sm(gpu)�ɂӂ�Ȃ�Ă��Ƃ�
�߂�������邩������Ȃ�
parker����
�����}�ȊO�̎x���҂́A�e�����X�g��X�p�C�ɖ������Ă鎖�ɋC�t���āI
�y�N��z�����}�u���@�̂����œ���̏@�������U�������Ȃ��v
http://www.log-channel.net/bbs/poverty/1386937136/
�����̃I�E�������U�������Ȃ����̎i�@�ƌ��@�͖��Ǝv���܂��H
���I�E���̃T���������̂Ƃ��ɁA�����}�������I�E���ɔj�h�@��K�p���悤�Ƃ��A
���d�߁i�e���𖢑R�ɖh���@���A�܂����̖@��������A���������d�҂Ƃ��ĎE�l�߂ɖ₦���B�j
�����肵�悤�Ƃ������A�����}�ȊO�����ŁA�{�c
���ꂪ�A�\�����̋U���Ƃ͗����ɁA�����}�ȊO�̐��}�E�c�����A�݂�Ȓ��Ԃǂ����i�ݓ��A���H�j
�ł��邱�Ƃ̏ł͂Ȃ��ł��傤���B�B
�������̘A���O�܂ŁA�n���̐�����v��ᔻ���Ă��͎̂����̂݁B
���݂̖���}�⋤�Y�}�ɂ��ᔻ�́A��������(�n���E�ݓ��^�u�[�̉���)��j�~���邽�߂�
�u�ނ�v�u�U���v�Ǝv����B
�@���{�A����閧�ی�@�ɂ���
�u�H�����e�����X�g�A�X�p�C������ŁA�����͑S���W�Ȃ��B�v
http://headlines.yahoo.co.jp/hl?a=20141119-00000002-mai-pol
�y�N��z�����}�u���@�̂����œ���̏@�������U�������Ȃ��v
http://www.log-channel.net/bbs/poverty/1386937136/
�����̃I�E�������U�������Ȃ����̎i�@�ƌ��@�͖��Ǝv���܂��H
���I�E���̃T���������̂Ƃ��ɁA�����}�������I�E���ɔj�h�@��K�p���悤�Ƃ��A
���d�߁i�e���𖢑R�ɖh���@���A�܂����̖@��������A���������d�҂Ƃ��ĎE�l�߂ɖ₦���B�j
�����肵�悤�Ƃ������A�����}�ȊO�����ŁA�{�c
���ꂪ�A�\�����̋U���Ƃ͗����ɁA�����}�ȊO�̐��}�E�c�����A�݂�Ȓ��Ԃǂ����i�ݓ��A���H�j
�ł��邱�Ƃ̏ł͂Ȃ��ł��傤���B�B
�������̘A���O�܂ŁA�n���̐�����v��ᔻ���Ă��͎̂����̂݁B
���݂̖���}�⋤�Y�}�ɂ��ᔻ�́A��������(�n���E�ݓ��^�u�[�̉���)��j�~���邽�߂�
�u�ނ�v�u�U���v�Ǝv����B
�@���{�A����閧�ی�@�ɂ���
�u�H�����e�����X�g�A�X�p�C������ŁA�����͑S���W�Ȃ��B�v
http://headlines.yahoo.co.jp/hl?a=20141119-00000002-mai-pol
>>454
�l�g�E���͑��ɋA��B
�l�g�E���͑��ɋA��B
���{�l�Ȃ�C���e���Q�t�H�Ō��܂�
�`�����Q���Ȃ���Q�t�H�Ō��܂�
459 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 00:06:06.62 ID:9zfd46sr
���������ǁAIntel�X���ɍ�����AMD�t�@���{�[�C���N���Ėϑz�J��Ԃ��Ă�̂�
�N�����̃t�@���{�[�C�X�����ĂĂ����Ă�������
�N�����̃t�@���{�[�C�X�����ĂĂ����Ă�������
�b��s���������̂�����オ���Ă܂��ˁB
����ς���{�l�Ȃ�C���e���Q�t�H�������
�悭���̏ł���Ȕ\�V�C�Ȃ��ƌ����Ă���Ȃ�
�o�J����˂��́H��
�o�J����˂��́H��
463 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 02:58:25.88 ID:9zfd46sr
�y�v�_�܂Ƃ߁z
HSA Libraries
https://github.com/HSA-Libraries/
HSA-Runtime-AMD
https://github.com/HSAFoundation/HSA-Runtime-AMD
HSA-Drivers-Linux-AMD
https://github.com/HSAFoundation/HSA-Drivers-Linux-AMD
HSA�͐��E���̃v���O���}�ɑҖ]����Ă�I�Ƃ����t�@���{�[�C�̖ϑz�Ƃ͗�����
���̂��������������̂ł�150������ƁA������2���~�܂�Ƃ�������
���ɂ��c����Ƃ���X�I�ɐ�`���Ă�c�[���ł����܂ŕs�l�C�ȃc�[���͑��ɂȂ��Ǝv���
AMD���s�l�C�Ƃ������A��������GPGPU�E�G�̎��v�����̒��x�Ƃ�����
HSA Libraries
https://github.com/HSA-Libraries/
HSA-Runtime-AMD
https://github.com/HSAFoundation/HSA-Runtime-AMD
HSA-Drivers-Linux-AMD
https://github.com/HSAFoundation/HSA-Drivers-Linux-AMD
HSA�͐��E���̃v���O���}�ɑҖ]����Ă�I�Ƃ����t�@���{�[�C�̖ϑz�Ƃ͗�����
���̂��������������̂ł�150������ƁA������2���~�܂�Ƃ�������
���ɂ��c����Ƃ���X�I�ɐ�`���Ă�c�[���ł����܂ŕs�l�C�ȃc�[���͑��ɂȂ��Ǝv���
AMD���s�l�C�Ƃ������A��������GPGPU�E�G�̎��v�����̒��x�Ƃ�����
464 �F,,�E�L�́M�E,,�j��-�������F2015/01/25(��) 03:02:35.27 ID:9zfd46sr
���Ƃ�����i�����_�Ł�34,396�j
258 �FSocket774 [��] �F2015/01/24(�y) 23:09:54.29 ID:qaUkC3Ba
�ő�h����Web�n�Ɣ�ׂ�̂��������AGitHub�̊����ȃv���W�F�N�g���Ă̂̓t�@�{����
����2�Ⴄ����ȁB
https://github.com/angular/angular.js
258 �FSocket774 [��] �F2015/01/24(�y) 23:09:54.29 ID:qaUkC3Ba
�ő�h����Web�n�Ɣ�ׂ�̂��������AGitHub�̊����ȃv���W�F�N�g���Ă̂̓t�@�{����
����2�Ⴄ����ȁB
https://github.com/angular/angular.js
�T���`�����P���A���`������
20nm APU��GPU���o�Ȃ����x��邩��A���N�̓l�^�����������R������
���̕��N���◈�N��14/16nm����ɂȂ��āAAPU��GPU���V���オ���X�o���ɁAMantle�Q�[����������DX12���o�ꂵ�ăl�^�̑�^�����N���邯�ǂ�
���̕��N���◈�N��14/16nm����ɂȂ��āAAPU��GPU���V���オ���X�o���ɁAMantle�Q�[����������DX12���o�ꂵ�ăl�^�̑�^�����N���邯�ǂ�
467 �FSocket774�F2015/01/25(��) 06:38:07.67 ID:gl/8vhKA
mantle���ĂȂłĂ�́H
���̃X������֎~��
R9 M385
http://gfxbench.com/device.jsp?benchmark=gfx30&os=Windows&api=gl&D=AMD+Radeon+%28TM%29+R9+M385&testgroup=overall
�����Carrizo��iGPU���ۂ���
http://gfxbench.com/device.jsp?benchmark=gfx30&os=Windows&api=gl&D=AMD+Radeon+%28TM%29+R9+M385&testgroup=overall
�����Carrizo��iGPU���ۂ���
�[�j�}�b�N�X�ƃx�[�X�^�ɋ�������
�R�����Ƃ�AMD��������AMD�ŒႾ
�R�����Ƃ�AMD��������AMD�ŒႾ
>>469
http://gfxbench.com/device.jsp?benchmark=gfx30&os=Windows&api=gl&D=AMD%20Radeon%20R7%20Graphics
�ӊO�Ƒ債�������Ȃ��H
http://gfxbench.com/device.jsp?benchmark=gfx30&os=Windows&api=gl&D=AMD%20Radeon%20R7%20Graphics
�ӊO�Ƒ債�������Ȃ��H
x1�̐��\�őS���̗p����ĂȂ��̂������Amur�Ƃ��ǂ��Ȃ�̂���
3DS������ɓ��ڂ��ꂽ�炻�ꂾ���ŏI����āA���ڂ���Ȃ���ŏ�����I����Ȃ��낤��
3DS������ɓ��ڂ��ꂽ�炻�ꂾ���ŏI����āA���ڂ���Ȃ���ŏ�����I����Ȃ��낤��
>>470-471
���߂�A�Ȃ�낽
���߂�A�Ȃ�낽
>>474
�`�b�v�̔��\����̗p���i���o�Ă���܂łɂ͌��\���Ԃ�����
Mullins���^�u���b�g�����Ƃ��Đ������\���ꂽ�̂͋��N��4������
���ڃ^�u���b�g�͂悤�₭�����ɓo�ꂷ��
http://pc.watch.impress.co.jp/docs/news/20140429_646504.html
http://pc.watch.impress.co.jp/docs/news/20150109_683098.html
Amur�͐������\���܂������̗p���i�����������̂͗��N���낤
�`�b�v�̔��\����̗p���i���o�Ă���܂łɂ͌��\���Ԃ�����
Mullins���^�u���b�g�����Ƃ��Đ������\���ꂽ�̂͋��N��4������
���ڃ^�u���b�g�͂悤�₭�����ɓo�ꂷ��
http://pc.watch.impress.co.jp/docs/news/20140429_646504.html
http://pc.watch.impress.co.jp/docs/news/20150109_683098.html
Amur�͐������\���܂������̗p���i�����������̂͗��N���낤
AMD�̃Q�[���@�����͐��u������Ȃ�����
�ė��N�Ȃ�Ƃ��������N�Ɍg�уQ�[���@���������͖���������
�ė��N�Ȃ�Ƃ��������N�Ɍg�уQ�[���@���������͖���������
http://gfxbench.com/compare.jsp?benchmark=gfx30&D1=Qualcomm+MSM8994+for+arm64+%28Adreno+430%2C+development+board%29&os1=Android&api1=gl&D2=Google+Nexus+9&cols=2
810��k1��shader�����ŌŒ�@�\�ő啝�ɏ����Ă�̂�
�Ȃ�ŕ����Ă�
�h���C�o�[�̃I�[�o�[�w�b�h���ł����݂���������
cpu���Ă������̂��Ȃ̂�
810��k1��shader�����ŌŒ�@�\�ő啝�ɏ����Ă�̂�
�Ȃ�ŕ����Ă�
�h���C�o�[�̃I�[�o�[�w�b�h���ł����݂���������
cpu���Ă������̂��Ȃ̂�
>>474
K1�����N�̈ꌎ���\�Ŏ��Ђ�SHIELD�^�u�܂Ŕ��N�A�l�N9�܂�3�l�����������Ă邩��
�����ɍs���Ă����ꂮ�炢�������Ȃ�����
�Ƃ�����K1�ł��t�����p�����Q�[���o�Ȃ���GPU���ė]���Ă邩��
�ϋɓI�ɑI�ԓz���Ȃ���Ȃ���
nvidia�����ꕪ�����Ă邩��₽��ԍڃA�s�[�����Ă���
K1�����N�̈ꌎ���\�Ŏ��Ђ�SHIELD�^�u�܂Ŕ��N�A�l�N9�܂�3�l�����������Ă邩��
�����ɍs���Ă����ꂮ�炢�������Ȃ�����
�Ƃ�����K1�ł��t�����p�����Q�[���o�Ȃ���GPU���ė]���Ă邩��
�ϋɓI�ɑI�ԓz���Ȃ���Ȃ���
nvidia�����ꕪ�����Ă邩��₽��ԍڃA�s�[�����Ă���
gpu�������Ă������I�Ƀ��o�C���ł͐��������ʂ��Ȃ��̂ł�
16bit���Z�Ȃ̓Z���T�[�����ނ�����
�������P�Œ�@�\���啝�ɐ��\�オ���Ă�̂Ŗڂ�t����Ƃ��͂��邾�낤��
fillrate�ł��������ш�ł�ps3,xbox360��������
16bit���Z�Ȃ̓Z���T�[�����ނ�����
�������P�Œ�@�\���啝�ɐ��\�オ���Ă�̂Ŗڂ�t����Ƃ��͂��邾�낤��
fillrate�ł��������ш�ł�ps3,xbox360��������
�܂�������Ă��ɂ�a57��denver���Ă������̂��ł�������Ȃ̂�
parker�܂Ŕ������m���Ȃ�
parker�܂Ŕ������m���Ȃ�
k1��es��������Ȃ���opengl���g���邵
Llano�o��̋łɂ�
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
Steamroller�EExcavator��FX��Desktop��Carrizo���o���Ȃ�����or�o���Ȃ��̂͊��S�ɐ헪�~�X
Youtube��UL����Ă���}���`�^�X�L���O�����F�X�ς����ǁA��͂�FX�̂����������炵��
AMD���[�U�[��Bulldozer�ɋ��߂Ă���̂͂�����̐��\���Ǝv����B
�Ȃ̂ɂ��낤����FX�̐V�K�J���𒆎~����APU��{�ɂ��Ă��܂����B
HW�A�N�Z�����[�^�Ƀ^�X�N�I�t���[�h�ł���Ƃ����Ă�CPU�ōs���鏈���S�Ă����Ȃ�����FX�̑���ɂ͂Ȃ�Ȃ��B
Carrizo��HSA�����^�C���̃t���@�\���T�|�[�g��������APU�B
����Ȃ瓯�v���b�g�z�[���𐄐i����ׂ�HSA�����A�v���J���pPC�Ƃ��Ă̖������������͂��B
����Ȃ̂Ƀf�X�N�g�b�v�������l���Ȃ��łǂ�����Ƃ����̂��B
�m�[�g��^�u���b�g�ł������Ȃ��̂͂��Ȃ�ɂ��B
Youtube��UL����Ă���}���`�^�X�L���O�����F�X�ς����ǁA��͂�FX�̂����������炵��
AMD���[�U�[��Bulldozer�ɋ��߂Ă���̂͂�����̐��\���Ǝv����B
�Ȃ̂ɂ��낤����FX�̐V�K�J���𒆎~����APU��{�ɂ��Ă��܂����B
HW�A�N�Z�����[�^�Ƀ^�X�N�I�t���[�h�ł���Ƃ����Ă�CPU�ōs���鏈���S�Ă����Ȃ�����FX�̑���ɂ͂Ȃ�Ȃ��B
Carrizo��HSA�����^�C���̃t���@�\���T�|�[�g��������APU�B
����Ȃ瓯�v���b�g�z�[���𐄐i����ׂ�HSA�����A�v���J���pPC�Ƃ��Ă̖������������͂��B
����Ȃ̂Ƀf�X�N�g�b�v�������l���Ȃ��łǂ�����Ƃ����̂��B
�m�[�g��^�u���b�g�ł������Ȃ��̂͂��Ȃ�ɂ��B
��������Bulldozer���J�������Ƃ��납�犮�S�Ȑ헪�~�X������E�E�E
�ǂ����ɂ���}�U�[���Ȃ����玟�ō����ł��Ċ����Ȃ낤
�����̏������f�X�N�g�b�v�����Ƃ�
�_�C�T�C�Y�̊��Ɉ����肵�Ȃ��Ⴂ���Ȃ�FX�Ƃ�
�Ԏ��ŋꂵ��ł�ȏ����͎̂d���Ȃ��Ƃ�����
�_�C�T�C�Y�̊��Ɉ����肵�Ȃ��Ⴂ���Ȃ�FX�Ƃ�
�Ԏ��ŋꂵ��ł�ȏ����͎̂d���Ȃ��Ƃ�����
�Z�~�J�X�^�����Ƃ�����Ă邹���ŊJ�����\�[�X����Ȃ��낤��
Bulldozer���̎��s�ƌ����������낤���A����ł������������헪�����Ă����ׂ�����Ȃ����ȁB
��������HSA�����A�v�����������������^�C������܂��o���オ���Ă��Ȃ��̂�FX���Ƃ����蓾�Ȃ��B
��������HSA�����A�v�����������������^�C������܂��o���オ���Ă��Ȃ��̂�FX���Ƃ����蓾�Ȃ��B
>FX�̐V�K�J��
����Ȃ���FX��Opteron�̂�������Ȃ���Opteron���x���Ă����ƊJ������悤�Ɍ���Ȃ��Ƃ��傤���Ȃ�����
����Ȃ���FX��Opteron�̂�������Ȃ���Opteron���x���Ă����ƊJ������悤�Ɍ���Ȃ��Ƃ��傤���Ȃ�����
�C���e���̐��\���Ă������N�w�Ǐオ���ĂȂ��̂ɂȂ�Ŗ�����AMD�͒ǂ����Ȃ��̂�
����APU�̕`��i���ɂ��܂��ɒǂ����Ȃ����si7�̃C���e�������ꌾ���Ă��c
���W���[���ƃR�A�̈Ӗ������ւ����̂��ɂ��B
Bulldozer�����ӂƂ����DB�W�̓R�A�ۋ�����������
�R�X�g�̖ʂō̗p���������Ă��܂����P�[�X���������̂ł͂Ȃ����낤���B
Piledriver FX�̓G���R����Ivy�Ƃقړ����̃p�t�H�[�}���X�������邩��
������CPU�R�A�����ǂ��Ă�����Haswell�ɂ��R�ł�����������Ȃ��B
����APU��{�ɍi�����������ł��̉���E�܂�Ă��܂����B
Bulldozer�����ӂƂ����DB�W�̓R�A�ۋ�����������
�R�X�g�̖ʂō̗p���������Ă��܂����P�[�X���������̂ł͂Ȃ����낤���B
Piledriver FX�̓G���R����Ivy�Ƃقړ����̃p�t�H�[�}���X�������邩��
������CPU�R�A�����ǂ��Ă�����Haswell�ɂ��R�ł�����������Ȃ��B
����APU��{�ɍi�����������ł��̉���E�܂�Ă��܂����B
�܂��A�ǂ��ł������ꕔ�̐l�ɂ����p���Ȃ��b������Ă��Ȃ�
�ꕔ�̘b������X���Ȃ���
�����₷�ɂ�������X���^�C�ǂ߂�
�����₷�ɂ�������X���^�C�ǂ߂�
�t�@�C���T�[�o�[�Ƃ��A�G���R��p�}�V���Ƃ�
APU�EAM1SoC���嗬��AMD����s��ɂ́A�ق�Ƃǂ��ł������b�B
�����������l���A�����\�A�����Ȋ���p�ӂ��Ă���Ă����
�n�C�G���h���K�v�ȕ��́A�����`�l�c�͒��߂Ă�������������
APU�EAM1SoC���嗬��AMD����s��ɂ́A�ق�Ƃǂ��ł������b�B
�����������l���A�����\�A�����Ȋ���p�ӂ��Ă���Ă����
�n�C�G���h���K�v�ȕ��́A�����`�l�c�͒��߂Ă�������������
APU���t�@�C���I�ɂ��Ă�������˂���
Opteron�̒��f�`���[���łƍl���Ă���������
Opteron�̒��f�`���[���łƍl���Ă���������
�ނ���ŏ�����FX����Ă������ق����ǂ�������������Ȃ��B
����I�Ђ̃��C�o�����i�ɑR����ׂɃN���b�N�グ�����̂�
���̈��]�����グ���悤�Ȃ����B
����I�Ђ̃��C�o�����i�ɑR����ׂɃN���b�N�グ�����̂�
���̈��]�����グ���悤�Ȃ����B
FX�ō��N���b�N�̉��b�ɗ^���̂̓A�[�L�e�N�`���̗ǂ������ł����ăl�g�o�Ƃ͕ʂ���H
�g�������Ƃ̂Ȃ��l�̓C���[�W�Ō�����Ⴄ����
�g�������Ƃ̂Ȃ��l�̓C���[�W�Ō�����Ⴄ����
�}���`�^�X�L���O���\�����߂Ă���l��APU��FX�ǂ����E�߂邩�ƌ������畁�ʂ�FX���낤�B
���������s��AM3+�v���b�g�z�[���ŌÉ߂��邩��E�ߐh���Ƃ����W�����}�B
FMx��SteamrollerFX���o���Ă����Ηǂ������̂ɂƂ��Â��v���B
���^➑̂�r�W�l�X���������p�N���C�A���gPC��APU���œK�Ȃ̂͂��̒ʂ�Ȃ̂���
����͂��ꂾ������Ȃ����낤�B
���{�ł�i7������Ă���悤�ɂˁB
���������s��AM3+�v���b�g�z�[���ŌÉ߂��邩��E�ߐh���Ƃ����W�����}�B
FMx��SteamrollerFX���o���Ă����Ηǂ������̂ɂƂ��Â��v���B
���^➑̂�r�W�l�X���������p�N���C�A���gPC��APU���œK�Ȃ̂͂��̒ʂ�Ȃ̂���
����͂��ꂾ������Ȃ����낤�B
���{�ł�i7������Ă���悤�ɂˁB
APU��6�R�A�A8�R�A�ɂȂ�Ή������Ȃ���
>>499
���N���b�N���̂�ے肵�Ă�킯����Ȃ��A]����Bull�́i�Ⴄ�Ӗ��ł́j�C���p�N�g�̑傫�������������Ǝv���B
�ŏ���Trinity�݂̂�fx��steamroller�܂ł��������̂ق������͐����Ɨ\�z�B
�E�E�ゾ���W�����P�������ǁB
>>501
16/14nm�ɂȂ�A���ꂪ�\�ɂȂ�B
���N���b�N���̂�ے肵�Ă�킯����Ȃ��A]����Bull�́i�Ⴄ�Ӗ��ł́j�C���p�N�g�̑傫�������������Ǝv���B
�ŏ���Trinity�݂̂�fx��steamroller�܂ł��������̂ق������͐����Ɨ\�z�B
�E�E�ゾ���W�����P�������ǁB
>>501
16/14nm�ɂȂ�A���ꂪ�\�ɂȂ�B
����Ⴄ�B
�X�`�[�����[���[����́ASOI��߂Ă邩��N���b�N���オ��Ȃ��B
�m���Ɍ������グ�Ă邪�A�N���b�N����������Cinebench�͋t�ɃX�R�A�[���Ƃ��Ă�Ƃ��B
�o���Ӌ`�������Ȃ�������o���ĂȂ������B
�����AGPU����͂�VLIW4����GCN�ɕς���Ă邩�獡�܂�CPU��鏈����GPU�ł�������������ɂȂ�B
�X�`�[�����[���[����́ASOI��߂Ă邩��N���b�N���オ��Ȃ��B
�m���Ɍ������グ�Ă邪�A�N���b�N����������Cinebench�͋t�ɃX�R�A�[���Ƃ��Ă�Ƃ��B
�o���Ӌ`�������Ȃ�������o���ĂȂ������B
�����AGPU����͂�VLIW4����GCN�ɕς���Ă邩�獡�܂�CPU��鏈����GPU�ł�������������ɂȂ�B
����ōŏI�I�ɂ̓p�C���h���C�o�[�R�A��8�R�A5GHz�܂ł̐��i���ŏI�������B
�X�`�[�����[���[�̓o���N�����炻���܂ŃN���b�N���L�тȂ��B
�G�N�X�J�x�[�^�[�ɂ��Ă��͓����ACarrizo��Kaveri������N���b�N�Ƃ��A�f�X�N�g�b�v�ŏo���Ӌ`�������́B
�����͂��Ȃ�ǂ��Ȃ��Ă邪�A�N���b�N�����������ꕔ�x���`�ł͉�����Ɨ\�z���Ă�B
����ɂ��ẮA14nm�̃u���[�h�E�F����22nm�̃A�g����GPU�ł͈�������Cinebrnch�ł̓{���������Ă邩�炵�Č����邱�ƁB
�X�`�[�����[���[�̓o���N�����炻���܂ŃN���b�N���L�тȂ��B
�G�N�X�J�x�[�^�[�ɂ��Ă��͓����ACarrizo��Kaveri������N���b�N�Ƃ��A�f�X�N�g�b�v�ŏo���Ӌ`�������́B
�����͂��Ȃ�ǂ��Ȃ��Ă邪�A�N���b�N�����������ꕔ�x���`�ł͉�����Ɨ\�z���Ă�B
����ɂ��ẮA14nm�̃u���[�h�E�F����22nm�̃A�g����GPU�ł͈�������Cinebrnch�ł̓{���������Ă邩�炵�Č����邱�ƁB
>>477
������2016�N�����Ă����Ŏ��ۂ�2017�N�ɓ����Ȃ�����
�����u���Ȃ�ARM����Ȃ�x86�̕������
ARM���g�ы@�������Ǝv��
������2016�N�����Ă����Ŏ��ۂ�2017�N�ɓ����Ȃ�����
�����u���Ȃ�ARM����Ȃ�x86�̕������
ARM���g�ы@�������Ǝv��
MS���炱������Windows��肽�����炱����������Ă������Ă���
���ʂ̊W�ɂȂ������ˁH
���ʂ̊W�ɂȂ������ˁH
>>504
���̌����������̂����Ȃ�Ȃ����H
���\���グ�邽�߂̍��N���b�N�����Ă����M�͊m���ɑ���
���\��i7�iNehalem�����͂�������H�j�ɋy�Ȃ�����l�^�ɂ����B
���̌����������̂����Ȃ�Ȃ����H
���\���グ�邽�߂̍��N���b�N�����Ă����M�͊m���ɑ���
���\��i7�iNehalem�����͂�������H�j�ɋy�Ȃ�����l�^�ɂ����B
�����\��i7�iNehalem�����͂�������H�j�ɋy�Ȃ�
���ꂪ�܂��A���Ȗ�łȂ�
�{���ɐ��\���̂��y�Ȃ��̂��A�x���`���l�������y�Ȃ��̂�
���̕ӁA���f�B�A�����ɂ���������A���̃��f�B�A�ׂ͒���邵
�f�l�������悤���̂Ȃ�A��ƍH��J�L�R�����o�ŗ���������
�����������A���̂���悤��������
��������Fx�͍����\�ቿ�i�ł��������̓d�͐��\�Ȃ�ŁA�Ƒ���
�F����ŃQ�[��������Ă邵�����Ȃ��ǂȂ�
�|�����̒�����Ȃ�
���ꂪ�܂��A���Ȗ�łȂ�
�{���ɐ��\���̂��y�Ȃ��̂��A�x���`���l�������y�Ȃ��̂�
���̕ӁA���f�B�A�����ɂ���������A���̃��f�B�A�ׂ͒���邵
�f�l�������悤���̂Ȃ�A��ƍH��J�L�R�����o�ŗ���������
�����������A���̂���悤��������
��������Fx�͍����\�ቿ�i�ł��������̓d�͐��\�Ȃ�ŁA�Ƒ���
�F����ŃQ�[��������Ă邵�����Ȃ��ǂȂ�
�|�����̒�����Ȃ�
>>499
�ł��������Ƃ����l�ɂ͏��Ȃ��炸�A�g�������Ƃ̖����l�����ꂩ��g�������ɂ��邩�Ŗ����Ă�
�ł��������Ƃ����l�ɂ͏��Ȃ��炸�A�g�������Ƃ̖����l�����ꂩ��g�������ɂ��邩�Ŗ����Ă�
>>504
������Kaveri Reflesh���o���Ƃ�������28nm�ł�����Ȃ�ɍ��N���b�N�ŋ쓮�ł���l�ɂȂ�����Ȃ��́H
nVIDIA��Intel��iGPU�����p���Ă������ꂾ����APU�̕��������̂͋��炭�Ԉ���Ă��Ȃ��B
���������������]���Ƃ͈Ⴄ�H���̃n�[�h�͎s��ɐZ������̂��x��
�܂��\�t�g�E�F�A�̐������\���ł͂Ȃ���ԁB
�̂Ɉڍs���Ԃ�FX�Ƃ̓�{���Ăōs���ׂ��������Ǝv���B
Piledriver���}���`�X���b�h�Ȃ�Nehalem���͑�����B
�ǂ��炩�Ƃ����Ƌ���Cinebench�ł��珟�ĂĂ�B
������Kaveri Reflesh���o���Ƃ�������28nm�ł�����Ȃ�ɍ��N���b�N�ŋ쓮�ł���l�ɂȂ�����Ȃ��́H
nVIDIA��Intel��iGPU�����p���Ă������ꂾ����APU�̕��������̂͋��炭�Ԉ���Ă��Ȃ��B
���������������]���Ƃ͈Ⴄ�H���̃n�[�h�͎s��ɐZ������̂��x��
�܂��\�t�g�E�F�A�̐������\���ł͂Ȃ���ԁB
�̂Ɉڍs���Ԃ�FX�Ƃ̓�{���Ăōs���ׂ��������Ǝv���B
Piledriver���}���`�X���b�h�Ȃ�Nehalem���͑�����B
�ǂ��炩�Ƃ����Ƌ���Cinebench�ł��珟�ĂĂ�B
>>508
�x���`�͒m��Ȃ�����kaveri�̐��l�i���p�v���j��{�i���z4M�j�Ɂv������ق�i7���ɂȂ�
�l�I�ɔ��ɂ��������Ȃ��ȂƎv�����ǁA�J���R�X�g�Ƃ������I�ȃv�������l�����
�X�L�b�v����������Ȃ��낤�ȁE�E�B
�x���`�͒m��Ȃ�����kaveri�̐��l�i���p�v���j��{�i���z4M�j�Ɂv������ق�i7���ɂȂ�
�l�I�ɔ��ɂ��������Ȃ��ȂƎv�����ǁA�J���R�X�g�Ƃ������I�ȃv�������l�����
�X�L�b�v����������Ȃ��낤�ȁE�E�B
���܂�AMD��MS�Ƃ��\�j�[�ɃJ�X�^��CPU�����ČЌ������̂��m���̊�Ƃ���
�C���e���̊����͏㏸�𑱂��Ă�̂�AMD�͊����������L�l
�C���e���̊����͏㏸�𑱂��Ă�̂�AMD�͊����������L�l
����()�Ɛ��i�̎��ɂ͉��̊W������܂��H
����ȏ㉺����킯�Ȃ��Ƃ���܂ŗ����Ă��ꂩ��㏸�������肦�Ȃ���ʂ�
�܂��������Ă�̂��ȁE�E�E
�u���n�̂ĂĐV���ɊJ������CPU�ڂ��Ȃ��Ɗ����Ԃ��Ȃ��Ǝv��
��ǂ���D����AMD������CPU��Sandy Bridge�ς����Ă��邾���ł������̂ɂ�
�܂��������Ă�̂��ȁE�E�E
�u���n�̂ĂĐV���ɊJ������CPU�ڂ��Ȃ��Ɗ����Ԃ��Ȃ��Ǝv��
��ǂ���D����AMD������CPU��Sandy Bridge�ς����Ă��邾���ł������̂ɂ�
����CPU�L���b�V�����\�Ɋւ��Ă͔�`�̃^���Ȃ�˂�����
HD�O�����h�������撣���Ă����Ȃ̂Ɠ����ł���
�����J��Ԃ��������͍���Ă鐻�i�̎��Ƃ͖��W����
HD�O�����h�������撣���Ă����Ȃ̂Ɠ����ł���
�����J��Ԃ��������͍���Ă鐻�i�̎��Ƃ͖��W����
�`�l�c�͗����Nj�����Ӑ}���Ȃ��A�r�㍑�ł̂o�b���y�ƐV�K�s�u�Y�Ǝx���Ŋ������Ă邩��ȁB
�A���`�����́A���������Ȃ���`�l�c�Ȃ�ĐG��K�v���Ȃ����A����Ȃ��Ă�����ł���H
�A���`�����́A���������Ȃ���`�l�c�Ȃ�ĐG��K�v���Ȃ����A����Ȃ��Ă�����ł���H
��`�̃^���Ƃ�����Ȃ��ĒP���ɕ��ʂ��Ⴄ��������B
�G�N�X�N���[�V�u�L���b�V�����ł�����̂����A
���낢��P�`���Ēx�����Ă�̂�AMD�A�P�`�炸�ɑ����̂�Intel�B
���邢�͒x�������ɃP�`����@������̂����m��Ȃ����P����
L2���P�`�炸�ɂ�����ƍڂ�������L1�̗e�ʂ�}���Ēx�����Ȃ�
�Ƃ������Ƃ�����Ă��邩���Ȃ������Ǝv����B
L3�ɂ��Ă�GPU��������������\���ɂȂ��Ă��邩���Ȃ��������肻�������B
�G�N�X�N���[�V�u�L���b�V�����ł�����̂����A
���낢��P�`���Ēx�����Ă�̂�AMD�A�P�`�炸�ɑ����̂�Intel�B
���邢�͒x�������ɃP�`����@������̂����m��Ȃ����P����
L2���P�`�炸�ɂ�����ƍڂ�������L1�̗e�ʂ�}���Ēx�����Ȃ�
�Ƃ������Ƃ�����Ă��邩���Ȃ������Ǝv����B
L3�ɂ��Ă�GPU��������������\���ɂȂ��Ă��邩���Ȃ��������肻�������B
���ʂ����C���e��HD�O�����}�g���ɂȂ�c
����Ȃӂ��ɍl���Ă������������ɂ�����܂���
����Ȃӂ��ɍl���Ă������������ɂ�����܂���
GPU�Ɋւ��Ă̓`�[�g�h���C�o�[�̃m�E�n�E�̍����傫�߂���̂͂���B
�x���`�̃f�[�^�ł�AMD�͋����B
�x���`�̃f�[�^�ł�AMD�͋����B
�����ƁA�o�u�q�̂h�o����Ȃ���A�u�f�`�h���C�o�[�̃����[�X���o���Ȃ����������������̈����͎~�߂Ă����B
�g�c�O���t�B�b�N�X���_���Ȃ̂́A�\�t�g�E�F�A�ŕ`�悷��t�@���N�V��������������Ƃ��납�炾��B
�g�c�O���t�B�b�N�X���_���Ȃ̂́A�\�t�g�E�F�A�ŕ`�悷��t�@���N�V��������������Ƃ��납�炾��B
�Ă�k8��16�R�A�̕ϑ�FX�������]
>>520
�C���e��HD�������Ƃ����̂̓x���`�]�X�ł͂Ȃ��̂����c
�C���e��HD�������Ƃ����̂̓x���`�]�X�ł͂Ȃ��̂����c
524 �FSocket774�F2015/01/26(��) 03:15:46.73 ID:hZmeIi4C
>>520
�ނ���x���`�����ŋ����̂�intelHD���B����iris
�ނ���x���`�����ŋ����̂�intelHD���B����iris
�܂�IntelGPU���x���`�Ԓ��Ƃ�������̂͒�i�N���b�N�ƃu�[�X�g�N���b�N�ŊJ�������肷���镔�����傫������
CPU�ɂقƂ�Ǖ��|����Ȃ�3DMark�ł�GPU���ő�N���b�N�łԂ��̂ō������\�����ł�����̂́E�E�E
CPU�ɂقƂ�Ǖ��|����Ȃ�3DMark�ł�GPU���ő�N���b�N�łԂ��̂ō������\�����ł�����̂́E�E�E
526 �FSocket774�F2015/01/26(��) 04:35:13.59 ID:J0h/pY2p
>>504
������ɂ��ẮA14nm�̃u���[�h�E�F����22nm�̃A�g����GPU�ł͈�������Cinebrnch�ł̓{���������Ă邩�炵�Č����邱�ƁB
�Q�R�A/��i800MHz/�w�V���O���`���l���x�������[��Let's note RZ4���S�R�A/��i1.59GHz/�w�f���A���`���l���x�������[��Atom�^�u���b�g���Cinebench�X�R�A���Ⴉ�����Ƃ����L���̘b���ˁB
http://www.itmedia.co.jp/pcuser/articles/1410/02/news069_3.html
�܂��A���ۂ̓������[����Ȃǂ��l�b�N�ɂȂ�Ȃ������Ȋ����Ȃ̂����B
http://tweakers.net/reviews/3751/4/intel-broadwell-preview-eerste-tablet-met-core-m-processor-getest-synthetische-benchmarks.html
>>510
��nVIDIA��Intel��iGPU�����p���Ă������ꂾ����APU�̕��������̂͋��炭�Ԉ���Ă��Ȃ��B
����ANVIDIA�͐i���̌����Ƃ��Ă�APU�Ƃ͋t�����Ȃ��E�E�E
��Piledriver���}���`�X���b�h�Ȃ�Nehalem���͑�����B
���F�}���`�X���b�h�Ȃ�Bloomfield�ALynnfield�ASandy Bridge(��i�AAVX�s�g�p�ȃ\�t�g)���͑�����B
Nehalem�n����Gulftown������̂ŁB
>>518
Core i7���FX�̕���L2�L���b�V��������ł����B
������ɂ��ẮA14nm�̃u���[�h�E�F����22nm�̃A�g����GPU�ł͈�������Cinebrnch�ł̓{���������Ă邩�炵�Č����邱�ƁB
�Q�R�A/��i800MHz/�w�V���O���`���l���x�������[��Let's note RZ4���S�R�A/��i1.59GHz/�w�f���A���`���l���x�������[��Atom�^�u���b�g���Cinebench�X�R�A���Ⴉ�����Ƃ����L���̘b���ˁB
http://www.itmedia.co.jp/pcuser/articles/1410/02/news069_3.html
�܂��A���ۂ̓������[����Ȃǂ��l�b�N�ɂȂ�Ȃ������Ȋ����Ȃ̂����B
http://tweakers.net/reviews/3751/4/intel-broadwell-preview-eerste-tablet-met-core-m-processor-getest-synthetische-benchmarks.html
>>510
��nVIDIA��Intel��iGPU�����p���Ă������ꂾ����APU�̕��������̂͋��炭�Ԉ���Ă��Ȃ��B
����ANVIDIA�͐i���̌����Ƃ��Ă�APU�Ƃ͋t�����Ȃ��E�E�E
��Piledriver���}���`�X���b�h�Ȃ�Nehalem���͑�����B
���F�}���`�X���b�h�Ȃ�Bloomfield�ALynnfield�ASandy Bridge(��i�AAVX�s�g�p�ȃ\�t�g)���͑�����B
Nehalem�n����Gulftown������̂ŁB
>>518
Core i7���FX�̕���L2�L���b�V��������ł����B
527 �FSocket774�F2015/01/26(��) 06:55:37.48 ID:X0JcFd5m
nv��intel�͓�����������
amd�͉G���̏O�����A��ĕʂ̕�����簐i���Ă���
�C�����ƌ��ɂ͒N�����Ȃ��Ȃ���
������[�E�E�E���ꗧ���������Ă�̂���
amd�͉G���̏O�����A��ĕʂ̕�����簐i���Ă���
�C�����ƌ��ɂ͒N�����Ȃ��Ȃ���
������[�E�E�E���ꗧ���������Ă�̂���
2�`3�N�H
���Ɣ��N�҂�
���{�l�Ȃ�C���e���Q�t�H������˂�
>>518
�G�N�X�N���[�V�u�L���b�V�����ł�����̂����A
K8�̍��͗e�ʕӂ�̖ʐύL������Ă��Đ��\�I�ɂ�Intel�Ɉ��������Ȃ�����
K10�ŖʐσP�`���Ēx���Ȃ�
����ɂ��Ă�����ς�ʐϔ��Intel�����炢�ɂ��Ă邩�琫�\�ő����ł��o���Ȃ�
http://www.chip-architect.com/news/2007_02_19_Various_Images.html
���]�I�ɂ̓G�N�X�N���[�V�u�L���b�V�����ł�����̂����A
�G�N�X�N���[�V�u�L���b�V�����ł�����̂����A
K8�̍��͗e�ʕӂ�̖ʐύL������Ă��Đ��\�I�ɂ�Intel�Ɉ��������Ȃ�����
K10�ŖʐσP�`���Ēx���Ȃ�
����ɂ��Ă�����ς�ʐϔ��Intel�����炢�ɂ��Ă邩�琫�\�ő����ł��o���Ȃ�
http://www.chip-architect.com/news/2007_02_19_Various_Images.html
���]�I�ɂ̓G�N�X�N���[�V�u�L���b�V�����ł�����̂����A
K8�͑���������ȁB������������킷�邱�ƂȂ��ʎY���Ĉ�����ʂɋ����ł��Ă�v���X�R�C���e������łɒǂ���ꂽ�̂ɁB
�C���e���Q�t�H����̃��[�U�[�����@�������˂�
K8�̂Ƃ���Intel�ɗ��Ȃ��ڂ������艿�i�ݒ�ɂ��Ă���
AMD���{���I�ɂ�Intel�ƕς��Ȃ�
���͂܂Ƃ��ɑ����ł��ł��Ȃ���������Ȃ��Ă邾��
AMD���{���I�ɂ�Intel�ƕς��Ȃ�
���͂܂Ƃ��ɑ����ł��ł��Ȃ���������Ȃ��Ă邾��
K8�̂Ƃ���Fab���t����]�łǂ��l���Ă������s���������ł���
�����������Ȃ��ȏ�A�����肵�Ă��V�F�A�͊l�ꂸ���ʂɑ̗͍�邾��
Fab36�������ɗ����オ���Ă�Ηǂ������낤���ǁAK7�̍���Intel��
���͂Ŕ��グ���L�т���Fab�̌��݂��ꎞ�~�܂������Ă̂������Ƃ��Ă���
�����������Ȃ��ȏ�A�����肵�Ă��V�F�A�͊l�ꂸ���ʂɑ̗͍�邾��
Fab36�������ɗ����オ���Ă�Ηǂ������낤���ǁAK7�̍���Intel��
���͂Ŕ��グ���L�т���Fab�̌��݂��ꎞ�~�܂������Ă̂������Ƃ��Ă���
K8�Ŗׂ�������ATi�����ɑ����ĂȂ�₩��₠���č��̑̂��炭�Ƃ�
���Â��������ڂȂ���Ђ���
���Â��������ڂȂ���Ђ���
538 �FSocket774�F2015/01/26(��) 11:08:24.50 ID:J0h/pY2p
>>532
K10��L1�̑ш悪K8�̂S�{�����
K10��L1�̑ш悪K8�̂S�{�����
�܂��ɔ�`�̃^�������
Intel���̑��x���o���Ȃ�����A�ʂʼn҂������Ȃ��B
���ɁAL1�Ɋւ��Ắ@���[���Ƃ��̌X���������ȁB
�L���b�V���́A���W�b�N�Ȃ��@�y���Ƀv���Z�X�Ɩ��ڂȊW���L�邩���
AMD�ɂ́A�v���Z�X�Ɍ��o���o����悤�� ��C�̃L���b�V���E�l�����Ȃ��낤�B
Intel���̑��x���o���Ȃ�����A�ʂʼn҂������Ȃ��B
���ɁAL1�Ɋւ��Ắ@���[���Ƃ��̌X���������ȁB
�L���b�V���́A���W�b�N�Ȃ��@�y���Ƀv���Z�X�Ɩ��ڂȊW���L�邩���
AMD�ɂ́A�v���Z�X�Ɍ��o���o����悤�� ��C�̃L���b�V���E�l�����Ȃ��낤�B
�L���b�V���������ƃL���b�V���t���[�̓�d��
�L���b�V���������̓I�[�o�[�t���[
�L���b�V���t���[�̓A���_�[�t���[
�L���b�V���t���[�̓A���_�[�t���[
�����E�����Ȋw�Z�p���Z�Ȃǂ̃A�v���P�[�V�����̃j�[�Y�ɉ����Đi�����Ă���
SSE��AVX�Ƃ͈����GPGPU�͎������Ă݂Ă���g������͍����Ă��Ԃ�����
�ǂ����Ă�AMD�ƃ\�t�g�J���҂ɉ��x����������
�g�������͂����肵�ĂȂ��̂Ƀ����^�C����C�u���������Ďg���₷���Ƃ����Ă�
���܂ǂ��̍������ꃌ�x���̃G���W�j�A�ɂ͖��p�̒���
�uGPGPU���g���������ǎg���ɂ����v�ƌ����Ă�l�Ȃ�Ă����ꈬ���
�命���́u��������������̕���ʼn��̖��ɗ��́H�v�Ǝv���Ă�
CPU�̐��\���P�͌�҂̐l�ɂ��_�C���N�g�Ƀ����b�g�������炷��
���������đO�҂�簐i���Ă����ʓI��AMD�ɗ��v�͂����炳��Ȃ��̂�
SSE��AVX�Ƃ͈����GPGPU�͎������Ă݂Ă���g������͍����Ă��Ԃ�����
�ǂ����Ă�AMD�ƃ\�t�g�J���҂ɉ��x����������
�g�������͂����肵�ĂȂ��̂Ƀ����^�C����C�u���������Ďg���₷���Ƃ����Ă�
���܂ǂ��̍������ꃌ�x���̃G���W�j�A�ɂ͖��p�̒���
�uGPGPU���g���������ǎg���ɂ����v�ƌ����Ă�l�Ȃ�Ă����ꈬ���
�命���́u��������������̕���ʼn��̖��ɗ��́H�v�Ǝv���Ă�
CPU�̐��\���P�͌�҂̐l�ɂ��_�C���N�g�Ƀ����b�g�������炷��
���������đO�҂�簐i���Ă����ʓI��AMD�ɗ��v�͂����炳��Ȃ��̂�
Llano�o��̋łɂ�
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
�� 2014�N �����̔��ド���L���O
http://eetimes.jp/ee/articles/1412/25/news147.html
��AMD�A2014�N�x��4���h���̐Ԏ�
http://pc.watch.impress.co.jp/docs/news/20150121_684660.html
AMD�̏��ʂ������}�~���ЂƂ蕉���_(^o^)�^
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
�� 2014�N �����̔��ド���L���O
http://eetimes.jp/ee/articles/1412/25/news147.html
��AMD�A2014�N�x��4���h���̐Ԏ�
http://pc.watch.impress.co.jp/docs/news/20150121_684660.html
AMD�̏��ʂ������}�~���ЂƂ蕉���_(^o^)�^
office�A�v���ɂ������b�g�̂���2D�̐��\���P�ƃI�t���[�h���������̂ɂ�������Ȃ��������҂��猩����������Ȃ���B
�Ƃ肠����Adobe�ɓ���������PDF��flash��CPU���ׂȂ��ɍ����\�������悤�ɂ��邾���ł������ǂȁB
�Ƃ肠����Adobe�ɓ���������PDF��flash��CPU���ׂȂ��ɍ����\�������悤�ɂ��邾���ł������ǂȁB
�������Ă邯��
���{�l�Ȃ�C���e���Q�t�H�Ō��܂肾��
SSE��AVX�͎������Ă݂Ă���g������͍����Ă��Ԃ�����
�命���́u��������������̕���ʼn��̖��ɗ��́H�v�Ǝv���Ă�
������xmmintrin.h�Ƃ����邾���Ŏg����̂Ŋ���o����
HSA�ł͌���܂�R���p�C�����Ή�����Βm��Ȃ��ԂɎg���Ă�
�命���́u��������������̕���ʼn��̖��ɗ��́H�v�Ǝv���Ă�
������xmmintrin.h�Ƃ����邾���Ŏg����̂Ŋ���o����
HSA�ł͌���܂�R���p�C�����Ή�����Βm��Ȃ��ԂɎg���Ă�
8%���x��apu�����
Windows 7�ȍ~��C++�ɂ�Direct3D��2�����`��ɒu��������Direct2D/DirectWrite���p�ӂ���
������.NET�ł͂�������x�Ƀ��b�v����WPF���`��̊�{API�ƈʒu�Â����Ă���B
�i���ꎩ�͕̂ʂɁAGPU���揈���p�r�Ɏg���Ă邾����GPGPU�Ƃ͊W�Ȃ��j
�������Windows�X�g�A�A�v���͑S��DirectX�x�[�X���B
�ł������ɂ̓X�}�zSoC�̐��\�ŊԂɍ����Ă��܂����x��GPU���\�v�������Ȃ�����
AMD�̃A�h�o���e�[�W�͂Ȃ��B�Ƃ�����APU�^�u���b�g���قƂ�ǖ����ɓ������̂����B
�^�u���b�g��Intel����^��K�͓����������A���l�ɐV�����s��ւ̃A�s�[���Ɗ������
��Ԏ����ꗬ���o�����AMD�ɂ͂��邩�ˁB
������.NET�ł͂�������x�Ƀ��b�v����WPF���`��̊�{API�ƈʒu�Â����Ă���B
�i���ꎩ�͕̂ʂɁAGPU���揈���p�r�Ɏg���Ă邾����GPGPU�Ƃ͊W�Ȃ��j
�������Windows�X�g�A�A�v���͑S��DirectX�x�[�X���B
�ł������ɂ̓X�}�zSoC�̐��\�ŊԂɍ����Ă��܂����x��GPU���\�v�������Ȃ�����
AMD�̃A�h�o���e�[�W�͂Ȃ��B�Ƃ�����APU�^�u���b�g���قƂ�ǖ����ɓ������̂����B
�^�u���b�g��Intel����^��K�͓����������A���l�ɐV�����s��ւ̃A�s�[���Ɗ������
��Ԏ����ꗬ���o�����AMD�ɂ͂��邩�ˁB
>>547
SSE��AVX��SIMD���j�b�g��CPU�R�A�ɓ�������ăX�J���������j�b�g�Ɠ���
�N���b�N�X�s�[�h�œ�������A���p�ɂ��p�t�H�[�}���X��̃f�����b�g���قڊF���Ȃ�
�����當�����݂����Ȑ�����`���\����̌y���������C���˂Ȃ��I�t���[�h�ł���B
AMD��GPU�͂�������800MHz���x�̃X�g���[���v���Z�b�T�œ������߂�4��ʂ��d�l������
�����I�Ɂu200MHz�̐���`��������̊O�t��FPU�v�̃C���[�W�Ŏg��Ȃ��Ƃ����Ȃ��B
�����烁���������ă\�t�g�����Ă��A�����I�Ɏg���Ȃ��P�[�X�̂ق������|�I�ɑ����̂��B
SSE��AVX��SIMD���j�b�g��CPU�R�A�ɓ�������ăX�J���������j�b�g�Ɠ���
�N���b�N�X�s�[�h�œ�������A���p�ɂ��p�t�H�[�}���X��̃f�����b�g���قڊF���Ȃ�
�����當�����݂����Ȑ�����`���\����̌y���������C���˂Ȃ��I�t���[�h�ł���B
AMD��GPU�͂�������800MHz���x�̃X�g���[���v���Z�b�T�œ������߂�4��ʂ��d�l������
�����I�Ɂu200MHz�̐���`��������̊O�t��FPU�v�̃C���[�W�Ŏg��Ȃ��Ƃ����Ȃ��B
�����烁���������ă\�t�g�����Ă��A�����I�Ɏg���Ȃ��P�[�X�̂ق������|�I�ɑ����̂��B
���̎d�l���Ɛ̖̂��߂̓G�~�����[�V�������낤�Ǝv��
����MSVC���ߔN�悤�₭�����x�N�^���C�Y�@�\��������A/Qpar /arch:AVX2
�Ƃ��̃I�v�V��������Ƃ��킴�킴SIMD�g�ݍ��݊��Ȃ�Ďg��Ȃ��Ă�
�R���p�C���̉�͔͈͂ŏ���Ƀx�N�g�������Ă�����
�ŐV��Linux(x86��Android�܂ށj��MacOS��C�����^�C�����x����AVX2�ւ̍œK����
�Ȃ���Ă邩��A�v�������Ή����ĂȂ��Ă��Ăяo�������^�C�����ɂ���ĊԐړI��
�x�N�g�����̉��b�������邱�Ƃ��ł���B
HSA�͍��̂Ƃ���OS�E�����x���Ńt�H���[���Ă�Ȃ�Ęb���Ȃ��ȁB
�Ƃ��̃I�v�V��������Ƃ��킴�킴SIMD�g�ݍ��݊��Ȃ�Ďg��Ȃ��Ă�
�R���p�C���̉�͔͈͂ŏ���Ƀx�N�g�������Ă�����
�ŐV��Linux(x86��Android�܂ށj��MacOS��C�����^�C�����x����AVX2�ւ̍œK����
�Ȃ���Ă邩��A�v�������Ή����ĂȂ��Ă��Ăяo�������^�C�����ɂ���ĊԐړI��
�x�N�g�����̉��b�������邱�Ƃ��ł���B
HSA�͍��̂Ƃ���OS�E�����x���Ńt�H���[���Ă�Ȃ�Ęb���Ȃ��ȁB
GNU LibC��strlen�݂����ȒP���ȕ��������̃��x������AVX*�ɂ������s���Ă�
math.h�̒��z���ł���A�����鎞�Ԃ͂����������S�T�C�N���I�[�_�[�ɂ����Ȃ��B
CPU-GPU�̃������R�s�[���Ȃ��ꂽ�Ƃ��Ă��AGPU�J�[�l�����N�����Ďw���o���܂ł̃T�C�N������
����T�C�N���������Ă��܂��B
�����Ȃ��Ƃ��A�ʏ��C�����^�C������GPU�R�A�ɃI�t���[�h�ł�����̂͂ȂɈ�Ȃ��B
�����ˑ��W���قƂ�ǔ������Ȃ����������̏�����CPU�Ő����T�C�N����������̂�
�܂邲�Ɠ����Ȃ��ƌ��͂Ƃ�Ȃ��B����A���̂���������I�B
CPU���x���̂�GPGPU�ŃJ�o�[���悤�Ƃ������z�����łɕ����̃��[�`����
math.h�̒��z���ł���A�����鎞�Ԃ͂����������S�T�C�N���I�[�_�[�ɂ����Ȃ��B
CPU-GPU�̃������R�s�[���Ȃ��ꂽ�Ƃ��Ă��AGPU�J�[�l�����N�����Ďw���o���܂ł̃T�C�N������
����T�C�N���������Ă��܂��B
�����Ȃ��Ƃ��A�ʏ��C�����^�C������GPU�R�A�ɃI�t���[�h�ł�����̂͂ȂɈ�Ȃ��B
�����ˑ��W���قƂ�ǔ������Ȃ����������̏�����CPU�Ő����T�C�N����������̂�
�܂邲�Ɠ����Ȃ��ƌ��͂Ƃ�Ȃ��B����A���̂���������I�B
CPU���x���̂�GPGPU�ŃJ�o�[���悤�Ƃ������z�����łɕ����̃��[�`����
300�l��������Ɣ�ׂ�ƃN���b�N�P�O�{�Ń��W�X�^�̐��\���オ���Ă邩��
555
HSA�łǂ̂��炢���C�e���V�̍팸��������H
Bull��L1���߃L���b�V����way�������Ȃ�����AL2��傫������K�v���������Ɨ\�z�B
Bull��2way�Asteam�ł�3way�����iIntel��8way�j�A���Ԃ�k10�̎d�l�����������Ă邾�낤���ǁB
Bull��L1���߃L���b�V����way�������Ȃ�����AL2��傫������K�v���������Ɨ\�z�B
Bull��2way�Asteam�ł�3way�����iIntel��8way�j�A���Ԃ�k10�̎d�l�����������Ă邾�낤���ǁB
C++�ŏ����ꂽ�v���O�����̃p�t�H�[�}���X���o�Ȃ��������v���t�@�C���������Ƃ�������
���s���Ԃ��߂Ă�R�s�[�R���X�g���N�^�����s���Ԃ̑啔�����߂ĂāA
�J�X�^���A���P�[�^�����ă������v�[�������P������A�|�C���^�R�s�[���Ȃ����肵��
�悤�₭�܂Ƃ��ȑ��x�ɂȂ����B
�ł����̏�Ԃł���ASSE���AVX�ŕ��ł��郋�[�v���x�N�g�������ĉ��P�ł���
�Ȃ�ĂƂ���͑S���s���Ԃ�1%����Ȃ������B
�������ȂƂ�����œK���撣�������Ė��ʂȓw�́B
���ꂪ��ʓI�ȃr�W�l�X�A�v���P�[�V�����̌���Ȃ�ˁB
GPGPU�Ȃ�Ă낭�Ɏ��v����킯�Ȃ��B
���s���Ԃ��߂Ă�R�s�[�R���X�g���N�^�����s���Ԃ̑啔�����߂ĂāA
�J�X�^���A���P�[�^�����ă������v�[�������P������A�|�C���^�R�s�[���Ȃ����肵��
�悤�₭�܂Ƃ��ȑ��x�ɂȂ����B
�ł����̏�Ԃł���ASSE���AVX�ŕ��ł��郋�[�v���x�N�g�������ĉ��P�ł���
�Ȃ�ĂƂ���͑S���s���Ԃ�1%����Ȃ������B
�������ȂƂ�����œK���撣�������Ė��ʂȓw�́B
���ꂪ��ʓI�ȃr�W�l�X�A�v���P�[�V�����̌���Ȃ�ˁB
GPGPU�Ȃ�Ă낭�Ɏ��v����킯�Ȃ��B
�����Z�������ŏ\�������E�E
�h�b�`�b�v�Ȃ�10101�̃}�V����ł������邯��
���̃��x���ɂȂ�Ƃ����ς�킩��˂�
���̃��x���ɂȂ�Ƃ����ς�킩��˂�
>>556
����Ȃ���m��Ă��B
���Lj�ʓI�ȃv���O�����ł́A�������ɂ�malloc���x����B
malloc������X��OS�Ƀ�������v������V�X�e���R�[�����x���B
�������R�s�[���K�v�Ȃ��Ȃ���������āAGPU���g�����V���ĂɃV�X�e���R�[�����K�v�̎��_��
���x���C�y�ɌĂяo����㕨�ł͂Ȃ��B
����̈Í��A�N�Z�����[�V�����݂����Ȉ�x�Ă炸���ƒ���t���Ă�n�̃^�X�N�����g����B
�ł����������̂͑��X�n�[�h�����Ɉڍs���Ă邩��GPU�͂�����ƂƂ���㩁B
����Ȃ���m��Ă��B
���Lj�ʓI�ȃv���O�����ł́A�������ɂ�malloc���x����B
malloc������X��OS�Ƀ�������v������V�X�e���R�[�����x���B
�������R�s�[���K�v�Ȃ��Ȃ���������āAGPU���g�����V���ĂɃV�X�e���R�[�����K�v�̎��_��
���x���C�y�ɌĂяo����㕨�ł͂Ȃ��B
����̈Í��A�N�Z�����[�V�����݂����Ȉ�x�Ă炸���ƒ���t���Ă�n�̃^�X�N�����g����B
�ł����������̂͑��X�n�[�h�����Ɉڍs���Ă邩��GPU�͂�����ƂƂ���㩁B
gpu��gpu�Ƃ��Ă��������ĉ���肾��
562 �FSocket774�F2015/01/26(��) 15:33:43.55 ID:J0h/pY2p
NVIDIA�F�Q�[���p�r�������Ǝ��v�Ɍ��肪����̂�GPGPU�������J��
��GPGPU�̌��ʂ��֑�L�������e���ւ̐ϋɓI�ȓ�������
�@Fermi�����GeForce�ł͎��s���������ATesla�ő听��
���R���V���[�}�o�b�ł͍���GPGPU���\�̎��v�������킸���Ɍ����Ă��锻�f���A�Q�[�����\�d���̃A�[�L�e�N�`����
�@�o�b�ȊO��GPGPU����������s����J�邽�߂ɐϋɓI�Ȑ��i�J��
AMD�FCPU���\�ő��Ђɒǂ����Ȃ��̂�iGPU���\������
��HSA�ƌ����K�i�������A�ǂ̂悤�ȗp�r�łǂ̒��x�̌��ʂ������߂邩�̋�̐�������
��Kaveri�o�ꂩ��P�N�o���Ă��ς�炸
�@���������A���s��APU�Ƃ�������ꂽ���i�̒����������Ă�Kabini/Beema/Mullins/Richland(�܂�EOL���Ă��Ȃ�)�Ȃ�HSA�Ή����ĂȂ����f���̕�������
Intel�FGPU�Ɋۓ����o���Ȃ�������GPGPU�g�����SIMD�ŏ�����������������y������AVX���������B
��GPGPU�̌��ʂ��֑�L�������e���ւ̐ϋɓI�ȓ�������
�@Fermi�����GeForce�ł͎��s���������ATesla�ő听��
���R���V���[�}�o�b�ł͍���GPGPU���\�̎��v�������킸���Ɍ����Ă��锻�f���A�Q�[�����\�d���̃A�[�L�e�N�`����
�@�o�b�ȊO��GPGPU����������s����J�邽�߂ɐϋɓI�Ȑ��i�J��
AMD�FCPU���\�ő��Ђɒǂ����Ȃ��̂�iGPU���\������
��HSA�ƌ����K�i�������A�ǂ̂悤�ȗp�r�łǂ̒��x�̌��ʂ������߂邩�̋�̐�������
��Kaveri�o�ꂩ��P�N�o���Ă��ς�炸
�@���������A���s��APU�Ƃ�������ꂽ���i�̒����������Ă�Kabini/Beema/Mullins/Richland(�܂�EOL���Ă��Ȃ�)�Ȃ�HSA�Ή����ĂȂ����f���̕�������
Intel�FGPU�Ɋۓ����o���Ȃ�������GPGPU�g�����SIMD�ŏ�����������������y������AVX���������B
��ʂ̃f�[�^�ɓ����������{���Ƃ����v���Z�b�T�\���������Ƃ����ɗ��p�r����
���ǃO���t�B�b�N���������C���ł����B
CPU�̃^�X�N�͒������������C��������CPU�͂����������ɐi�����Ă����킯��
�����ɒ���������߂�������Ȃ�ĕ��i���̓s�����ʂ�킯���Ȃ��ł���B
NVIDIA�̓p�\�R�������A�v����GPU�Ɍ����ĂȂ������������Ɋ撣�点�����
�ԍڏ��[���̋�ԔF���݂����ȁAGPU�̓������\���Ɋ������镪���
�V���ȏd�_������ɂ��Ă�B
NVIDIA�̐H���c����AMD��GPU�\�����������镪����Ăǂꂾ���c���Ă��ł��傤�ˁH
���ǃO���t�B�b�N���������C���ł����B
CPU�̃^�X�N�͒������������C��������CPU�͂����������ɐi�����Ă����킯��
�����ɒ���������߂�������Ȃ�ĕ��i���̓s�����ʂ�킯���Ȃ��ł���B
NVIDIA�̓p�\�R�������A�v����GPU�Ɍ����ĂȂ������������Ɋ撣�点�����
�ԍڏ��[���̋�ԔF���݂����ȁAGPU�̓������\���Ɋ������镪���
�V���ȏd�_������ɂ��Ă�B
NVIDIA�̐H���c����AMD��GPU�\�����������镪����Ăǂꂾ���c���Ă��ł��傤�ˁH
���Ȃ��Ƃ����ƌ������Ȃ��܂�
�u�ʊw���Ԃ��Z���Ȃ�悤�Ƀo�X��^�N�V�[�Ŋw�Z�E�m�ɒʂ킹������̎q�͐L�т��v
�݂����ȃY�������Ƃ���Ă邩�炢�܂ł����ʂ��o�Ȃ��̂����܂�AMD
�O�Y�O�Y���Ďԍڒ[������ɔ��荞�݂������邱�Ƃ��点���ɂ��邪
�������r�W�l�X�`�����X�����Ă�Ǝv���̂����ǂȁB
�u�ʊw���Ԃ��Z���Ȃ�悤�Ƀo�X��^�N�V�[�Ŋw�Z�E�m�ɒʂ킹������̎q�͐L�т��v
�݂����ȃY�������Ƃ���Ă邩�炢�܂ł����ʂ��o�Ȃ��̂����܂�AMD
�O�Y�O�Y���Ďԍڒ[������ɔ��荞�݂������邱�Ƃ��点���ɂ��邪
�������r�W�l�X�`�����X�����Ă�Ǝv���̂����ǂȁB
>>564
���̗Ⴆ�A�T�b�p���������B
���̗Ⴆ�A�T�b�p���������B
AMD��CPU�ƃ�������Ԃ̓������ċ�����Z������Ί��p�͈͂��L����Ǝv���Ă�̂�����
���������唼�̃v���O�����ɂ�GPU�ɃI�t���[�h�ł��邾���̕��\�ȃ^�X�N���F���Ƃ�������
�L�т��낪�Ȃ��̂ɖ��ʂȓw�͂����Ă��Ӗ��͂Ȃ����낤�H
���������唼�̃v���O�����ɂ�GPU�ɃI�t���[�h�ł��邾���̕��\�ȃ^�X�N���F���Ƃ�������
�L�т��낪�Ȃ��̂ɖ��ʂȓw�͂����Ă��Ӗ��͂Ȃ����낤�H
�Ȃ�ق�FPU�������������Ă���Intel�̓A�z�A�ƁB
AVX512�Ƃ��g�������Ȃ��̂ɖ��Ӗ��Ȋg�����������Ă���Intel�̓}�W��AMD���ɖ��\�B
AVX512�Ƃ��g�������Ȃ��̂ɖ��Ӗ��Ȋg�����������Ă���Intel�̓}�W��AMD���ɖ��\�B
REP MOVS�Ƃ��̃}�C�N���R�[�h���߂���CPU�����ŏ����SSE/AVX���g���đ����Ȃ�Ƃ����͕̂��������Ƃ�����B
�揜�Z��Pentium�̍����łɐ������FPU�̕����������琮�������K�v�Ȃ��Ă�double�ŕϐ����Ƃ��Ɨǂ��Ƃ��������ȁB���͏����SSE/AVX���Z��g���Đ������Z�������Ȃ��Ă�B
GPGPU�ł���������O�v�炸�̃����b�g���ĊF������ˁB
�ŏ�����GPU�x���̌����摜�����ő����V�F�[�_�̎��R�x���オ���Č���d�l��C++�ۂ��Ȃ�������Ƃ����Ă��V�F�[�_�ōςނ��Ƃ̓V�F�[�_�̂܂܂̕�����ԗv�炸�ő������B
�揜�Z��Pentium�̍����łɐ������FPU�̕����������琮�������K�v�Ȃ��Ă�double�ŕϐ����Ƃ��Ɨǂ��Ƃ��������ȁB���͏����SSE/AVX���Z��g���Đ������Z�������Ȃ��Ă�B
GPGPU�ł���������O�v�炸�̃����b�g���ĊF������ˁB
�ŏ�����GPU�x���̌����摜�����ő����V�F�[�_�̎��R�x���オ���Č���d�l��C++�ۂ��Ȃ�������Ƃ����Ă��V�F�[�_�ōςނ��Ƃ̓V�F�[�_�̂܂܂̕�����ԗv�炸�ő������B
PyCUDA��Barracuda�݂����ȃX�N���v�g���ꂩ��CUDA���Ăяo�����߂̃��C�u����
���邯�ǂ���Ȃ�����p�A�v���Ŏg���Ă��͂��Ȃ���
�Z�p�f���Ƃ������A�ꉞ����˂Ƃ������x�̂���
GPGPU�ƍ�������̃o�C���f�B���O�Ȃ�āA�Ђ܂ȃv���O���}�̂̂��V�у��x����
�����Ȃ��̂ɂ���Ȃ��̂Ɏ��А��i�̗��p�Ҋg��̃`�����X������Ǝv�������
��Ђ̑��S������������������ႤAMD�͎O��
���邯�ǂ���Ȃ�����p�A�v���Ŏg���Ă��͂��Ȃ���
�Z�p�f���Ƃ������A�ꉞ����˂Ƃ������x�̂���
GPGPU�ƍ�������̃o�C���f�B���O�Ȃ�āA�Ђ܂ȃv���O���}�̂̂��V�у��x����
�����Ȃ��̂ɂ���Ȃ��̂Ɏ��А��i�̗��p�Ҋg��̃`�����X������Ǝv�������
��Ђ̑��S������������������ႤAMD�͎O��
knl��skl��avx��cpu���l�C�e�B�u�ł��̂܂g����
�ׂɂ悯���ȃ����^�C�����T�C�N�������ČĂяo���K�v���Ȃ�
�ׂɂ悯���ȃ����^�C�����T�C�N�������ČĂяo���K�v���Ȃ�
>>567
�A�z���ȁA�Ȋw�Z�p���Z��r�b�O�f�[�^��͂ȂǎY�ƊE����̎��v�����邩��Ɍ��܂��Ă邾��
AVX512��Xeon��Xeon Phi�����Ή���\�����ĂȂ�
�R���V���[�}�������i�ł̑Ή������͖���ɂȂ��Ă�B��ʗp�r�ł͎��v�������Ȃ����炾�B
�A�z���ȁA�Ȋw�Z�p���Z��r�b�O�f�[�^��͂ȂǎY�ƊE����̎��v�����邩��Ɍ��܂��Ă邾��
AVX512��Xeon��Xeon Phi�����Ή���\�����ĂȂ�
�R���V���[�}�������i�ł̑Ή������͖���ɂȂ��Ă�B��ʗp�r�ł͎��v�������Ȃ����炾�B
>>550
SSE��AVX��SIMD���j�b�g��CPU�R�A�ɓ�������ăX�J���������j�b�g�Ɠ���
�N���b�N�X�s�[�h�œ�������A���p�ɂ��ʐϏ�̃f�����b�g�����Ȃ�
�����當�����݂����Ȑ�����`���\����̌y�������ɉ����邱�ƂȂ��I�t���[�h���˂Ȃ�܂��B
AMD��GPU�͂Ƃ�����
�����炘86�����g�債��AVX��LNI�Ɠ������Ă��A�����I�Ɏg���Ȃ�GPU�̂ق������|�I�ɋ����̂��B
SSE��AVX��SIMD���j�b�g��CPU�R�A�ɓ�������ăX�J���������j�b�g�Ɠ���
�N���b�N�X�s�[�h�œ�������A���p�ɂ��ʐϏ�̃f�����b�g�����Ȃ�
�����當�����݂����Ȑ�����`���\����̌y�������ɉ����邱�ƂȂ��I�t���[�h���˂Ȃ�܂��B
AMD��GPU�͂Ƃ�����
�����炘86�����g�債��AVX��LNI�Ɠ������Ă��A�����I�Ɏg���Ȃ�GPU�̂ق������|�I�ɋ����̂��B
��
�R�s�y���ςŔ�����Ă���肩������Ȃ����ǒv���I�ɓ�������ĂȂ���
Windows8.1��OS���x����SSE2�ȏ�K�{�ɂ��Ă�
�����Ă��̋ސ��\�t�g�E���C�u������AVX2�܂ŕW���Ή����Ă܂��������H
SIMD���\�ō������Ă邩��x���`�ł������Č��ʔ���Ȃ��̂ł���
�R�s�y���ςŔ�����Ă���肩������Ȃ����ǒv���I�ɓ�������ĂȂ���
Windows8.1��OS���x����SSE2�ȏ�K�{�ɂ��Ă�
�����Ă��̋ސ��\�t�g�E���C�u������AVX2�܂ŕW���Ή����Ă܂��������H
SIMD���\�ō������Ă邩��x���`�ł������Č��ʔ���Ȃ��̂ł���
��̓I�Ȑ����o���Ȃ��ƐM���Ȃ����낤���ǂ���Ȋ����ł���
http://us.hardware.info/reviews/5156/26/amd-a10-7850k-kaveri-review-amds-new-apu-benchmarks-igpu-microsoft-word-2013
http://us.hardware.info/reviews/5156/26/amd-a10-7850k-kaveri-review-amds-new-apu-benchmarks-igpu-microsoft-word-2013
�W�����C�u�����Ŏ����Ŏg��ꂽ�炢�����Ă���Ȃ��B
�Ԃ����ႯSSE���g����2GHz�ȏ�œ����Ώ\�����p�I�ł�����Ă��ƁB
���ʂ̃v���O�����̓V���O�����d�v�Ȃ̂�FPU������g������
���������̃v���Z�X�̃��[�h�𗘗p����iGPU���葝�₵�܂����Ă�Intel�}�W���\�B
http://images.anandtech.com/doci/8814/Slide%2010%20-%20Iris%206100%20Die%20Labelled_678x452.png
�Ԃ����ႯSSE���g����2GHz�ȏ�œ����Ώ\�����p�I�ł�����Ă��ƁB
���ʂ̃v���O�����̓V���O�����d�v�Ȃ̂�FPU������g������
���������̃v���Z�X�̃��[�h�𗘗p����iGPU���葝�₵�܂����Ă�Intel�}�W���\�B
http://images.anandtech.com/doci/8814/Slide%2010%20-%20Iris%206100%20Die%20Labelled_678x452.png
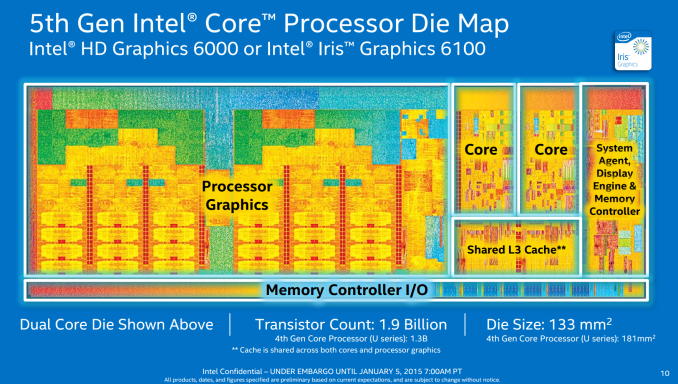{kind=link}
Word������PDF�ϊ��݂����ȏd���������Ńt���O�V�b�v��7850K���Celeron�̂ق�����������
�����@�l�pPC��AMD�������킯���Ȃ��ł���
�����@�l�pPC��AMD�������킯���Ȃ��ł���
ttp://pc.watch.impress.co.jp/docs/2006/1013/kaigai03l.gif
�h���s�V���Ȃ̂�������Ȃ��̂łƂ肠������K10�R�A�u���b�N�}������
FPU��SSE�i�܂ށj���낤
�u�����S�̂�1%���x�ȏ������Z�v�i�N�̔������������j������SIMD���Z
����Ȃ���̂��߂ɂ��Ȃ�̖ʐϐH���Ă�
AVX��LNI�����Œ�����ăo���o���g���ꕔ�̃A�v���̂��߂�
������MMX�ł�SSE�ł��\��炢�̂�����Ƃ������Z�̂��߂�
���ƒ��d�v��L1��L2�L���b�V�������郊�\�[�X���IIntel�́I
�����E�E�E���������ł��E�E�E
{kind=link}
�h���s�V���Ȃ̂�������Ȃ��̂łƂ肠������K10�R�A�u���b�N�}������
FPU��SSE�i�܂ށj���낤
�u�����S�̂�1%���x�ȏ������Z�v�i�N�̔������������j������SIMD���Z
����Ȃ���̂��߂ɂ��Ȃ�̖ʐϐH���Ă�
AVX��LNI�����Œ�����ăo���o���g���ꕔ�̃A�v���̂��߂�
������MMX�ł�SSE�ł��\��炢�̂�����Ƃ������Z�̂��߂�
���ƒ��d�v��L1��L2�L���b�V�������郊�\�[�X���IIntel�́I
�����E�E�E���������ł��E�E�E
>>576
��Ƃ́g�X�J���N���[�N�X�h���ŖS���闝�R
http://itpro.nikkeibp.co.jp/atcl/column/14/476124/120900011/
��Ƃ́g�X�J���N���[�N�X�h���ŖS���闝�R
http://itpro.nikkeibp.co.jp/atcl/column/14/476124/120900011/
�\�t�g�ŐV�K���Ƃ��Ȃ�iOS��Android�����o���̂͑�O��
�p�\�R���̔��䐔��1���ɂ������Ȃ�AMD�̈ꕔ���i�ɓ��������\�t�g���J������̂�
�܂��オ���o���Ȃ���B
�p�\�R���̔��䐔��1���ɂ������Ȃ�AMD�̈ꕔ���i�ɓ��������\�t�g���J������̂�
�܂��オ���o���Ȃ���B
>>579
����͂����ǂ�
���ς�炸�̓��j�̃~�X���[�h�L��
�Ȃ��{�Ƃ̃X�J���N���[�N�X�͂܂����ĂȂ��H������l����킩��
���{�̗X�����Ђ͖��c�������̂ɃA�����J�͌��c�̃}�}
���j�̌����Ȃ�ɓ��{�̑���Ƃ͎x�߂ɍH����ړ]���Ă��A�����J�͖{���ɐ��Y�͂��c���Ă�
���������_�u�X�^�����V�������j�V��
���Ȃ݂ɂ��̕���V���ɐ����ăA�i���O�f�o�C�X�J������߂����{�̏���Ƒ���
����͂����ǂ�
���ς�炸�̓��j�̃~�X���[�h�L��
�Ȃ��{�Ƃ̃X�J���N���[�N�X�͂܂����ĂȂ��H������l����킩��
���{�̗X�����Ђ͖��c�������̂ɃA�����J�͌��c�̃}�}
���j�̌����Ȃ�ɓ��{�̑���Ƃ͎x�߂ɍH����ړ]���Ă��A�����J�͖{���ɐ��Y�͂��c���Ă�
���������_�u�X�^�����V�������j�V��
���Ȃ݂ɂ��̕���V���ɐ����ăA�i���O�f�o�C�X�J������߂����{�̏���Ƒ���
>>581
��������PC�̔̔��䐔��7�`8%������߂ĂȂ�APU�ɓ��������\�t�g�ŋN������
�C�m�x�[�V�������ĂȂˁH
�n�R�l����̃r�W�l�X�͕ꐔ�������Ȃ��Ɛ������Ȃ��B
7�`8%�̕�̂��^�[�Q�b�g�ɂ���Ȃ�A���������[�U�[�̑���Mac�ɂ���ł��傤�B
Yosemite�ŋ������ꂽiOS�Ƃ̘A�g�@�\�ȂǁA����Ȃ�Ƀl�^�͂��邩��ȁB
��������PC�̔̔��䐔��7�`8%������߂ĂȂ�APU�ɓ��������\�t�g�ŋN������
�C�m�x�[�V�������ĂȂˁH
�n�R�l����̃r�W�l�X�͕ꐔ�������Ȃ��Ɛ������Ȃ��B
7�`8%�̕�̂��^�[�Q�b�g�ɂ���Ȃ�A���������[�U�[�̑���Mac�ɂ���ł��傤�B
Yosemite�ŋ������ꂽiOS�Ƃ̘A�g�@�\�ȂǁA����Ȃ�Ƀl�^�͂��邩��ȁB
�Ȃ�ł������ł����A�u�����h��V�F�A�ł����A�]���ł��Ȃ��̂���ԂނȂ����ł��ˁB
�u�����h��V�F�A���Ȃ��n�[�h�����Ƀ\�t�g�������
�������o�������\�t�g�n�E�X�͑��݂��Ȃ��Ǝv���܂���
������\�t�g�J���҂͊�{Intel���i�����g��Ȃ�
�������o�������\�t�g�n�E�X�͑��݂��Ȃ��Ǝv���܂���
������\�t�g�J���҂͊�{Intel���i�����g��Ȃ�
����̓C�m�x�[�V�����Ƃ͖��W�Șb����
���ꂪ�D�G�ł���ɉz�������Ƃ͂Ȃ������������p�~����Ƃ͕��т��낤��
�A�����J�͓��{��Ƃ̃C�m�x�[�V��������������Ă��邩��
���]�̐敺�̓��j���g���Ė��͉��U�����d�|���Ă��Ă�
�A�����J�͓��{��Ƃ̃C�m�x�[�V��������������Ă��邩��
���]�̐敺�̓��j���g���Ė��͉��U�����d�|���Ă��Ă�
����́��̐���AMD�̕s�l�C�̉����̏؋��ł���
HSA Libraries
https://github.com/HSA-Libraries/
HSA-Runtime-AMD
https://github.com/HSAFoundation/HSA-Runtime-AMD
HSA-Drivers-Linux-AMD
https://github.com/HSAFoundation/HSA-Drivers-Linux-AMD
���E�̂ǂ����̃X�J���N���[�N�X�i�j��AMD���~�ς��Ă����͂��I�݂����Ȋ�]�͎̂Ă�ׂ�����
�Ȃ�Ȃ�N��HSA�̊J���ɎQ�����Ă�����ǂ������H
�I�[�v���\�[�X������A�����Ɏn�߂邱�Ƃ��ł����
HSA Libraries
https://github.com/HSA-Libraries/
HSA-Runtime-AMD
https://github.com/HSAFoundation/HSA-Runtime-AMD
HSA-Drivers-Linux-AMD
https://github.com/HSAFoundation/HSA-Drivers-Linux-AMD
���E�̂ǂ����̃X�J���N���[�N�X�i�j��AMD���~�ς��Ă����͂��I�݂����Ȋ�]�͎̂Ă�ׂ�����
�Ȃ�Ȃ�N��HSA�̊J���ɎQ�����Ă�����ǂ������H
�I�[�v���\�[�X������A�����Ɏn�߂邱�Ƃ��ł����
AMD�̒���HSA�𗘗p���Đ���オ����Ƃ���������������̘b
����͎��R���낤��
��Ɣ����̕K�v����Ȃ��̂Ń��[���X�N�n�C���^�[��
����͎��R���낤��
��Ɣ����̕K�v����Ȃ��̂Ń��[���X�N�n�C���^�[��
���^�[������́H
�ux86�̂܂܂œ����IGHz�œ����I�R�A��債�Č��������Ȃ邩������ǂ�ǂ₷�I
���̂܂܂��ƒx���������Ȃ��H����Ȃ̒m�邩�I�v���Ă̂�AVX��LNI
�u�ʂɃN���b�N�v���������K�v������ȁB���Z�X���b�h�p�̃R�A���݂�Ƃ��������ŁB
���߃Z�b�g�͒��Ԍ��ꋲ��ł����W���[������Ή����₷���Ȃ��ăn�[�h���D���ɃA�[�L�e�N�`���ς��Ă������v���Ă̂�HSA
����ȏ�ɐ��I�{�i�I�ɃA�v���S�̂ŕ��Z�������Ȃ��p�����GPU�J�[�h��
���̂܂܂��ƒx���������Ȃ��H����Ȃ̒m�邩�I�v���Ă̂�AVX��LNI
�u�ʂɃN���b�N�v���������K�v������ȁB���Z�X���b�h�p�̃R�A���݂�Ƃ��������ŁB
���߃Z�b�g�͒��Ԍ��ꋲ��ł����W���[������Ή����₷���Ȃ��ăn�[�h���D���ɃA�[�L�e�N�`���ς��Ă������v���Ă̂�HSA
����ȏ�ɐ��I�{�i�I�ɃA�v���S�̂ŕ��Z�������Ȃ��p�����GPU�J�[�h��
ID�^���Ԃɂ��Ă�A�����M���Ȃ�߂��ĂĂ��͂≽�����������̂����������E�E�E
������Ό��X�������Ă�����B�܂���205�X���������Ăčŏ����炶��Ȃ���ȁB
������Ό��X�������Ă�����B�܂���205�X���������Ăčŏ����炶��Ȃ���ȁB
>>589
> AMD�̒���HSA�𗘗p���Đ���オ�����
��HSA Foundation�ł͋��߂ĂāA�����o�[��Ƃ��W���Ă�̂���
���ꂪ���̃T�C�g�Ɍf�����ꂽ�����������Ȃ��̂ł�
�ŏ�ʃN���X�͂Ƃ������N��1000�h���Ȃ�MSDN�̔N��������
AMD�̃v���v���C�G�^���ȊJ���c�[���������Ȃǂ̓��T������̂�
�����o�[�����ꂾ���Ȃ�ł�
�p�\�R���̈ꕔ�@�����̃A�v���Ȃ�č���Ă���
��葽���̃��[�U�[���g��iOS��Android�ŃA�v��������ق���
�͂邩�Ɏs�ꐫ�傫���̂͌N�����Ă킩��Ȃ��킯�Ȃ��ł���H
> AMD�̒���HSA�𗘗p���Đ���オ�����
��HSA Foundation�ł͋��߂ĂāA�����o�[��Ƃ��W���Ă�̂���
���ꂪ���̃T�C�g�Ɍf�����ꂽ�����������Ȃ��̂ł�
�ŏ�ʃN���X�͂Ƃ������N��1000�h���Ȃ�MSDN�̔N��������
AMD�̃v���v���C�G�^���ȊJ���c�[���������Ȃǂ̓��T������̂�
�����o�[�����ꂾ���Ȃ�ł�
�p�\�R���̈ꕔ�@�����̃A�v���Ȃ�č���Ă���
��葽���̃��[�U�[���g��iOS��Android�ŃA�v��������ق���
�͂邩�Ɏs�ꐫ�傫���̂͌N�����Ă킩��Ȃ��킯�Ȃ��ł���H
���Ƃ���10�{gpu�������Ă����ۂɌv�Z�n�߂�܂ł�
10�{���Ԃ�����Ȃ�Ӗ����Ȃ��Ƃ����ȒP�Șb�Ȃ̂�
10�{���Ԃ�����Ȃ�Ӗ����Ȃ��Ƃ����ȒP�Șb�Ȃ̂�
>>590
����Ȗ{�Ƃ�GitHub�̊ՌÒ����Ղ��������N����낤�Ǝv��Ȃ��ł���
�T�N���ł��������ĉ������̃v���O���}���S�������Ă�A�s�[�����Ȃ���
�܂��܂��N�����t���Ȃ�
����Ȗ{�Ƃ�GitHub�̊ՌÒ����Ղ��������N����낤�Ǝv��Ȃ��ł���
�T�N���ł��������ĉ������̃v���O���}���S�������Ă�A�s�[�����Ȃ���
�܂��܂��N�����t���Ȃ�
>>594
���[��A������ƈႤ�B
�Ⴆ��Ȃ�k��3���̃R���r�j�ɔ��o���ɍs���̂�10km���ԏ�ɎԂ����ɍs���悤�Ȃ��́B
HSA��5km��̒��ԏ�ɂ���Z�p�B
���[��A������ƈႤ�B
�Ⴆ��Ȃ�k��3���̃R���r�j�ɔ��o���ɍs���̂�10km���ԏ�ɎԂ����ɍs���悤�Ȃ��́B
HSA��5km��̒��ԏ�ɂ���Z�p�B
CPU��GPU����ʂ��Ȃ��܂łɓ��������邱�Ƃ��ďo���Ȃ��́H
����ς���{�l�Ȃ�C���e���Q�t�H������˂�
���������̂�phi
>>597
�{���I��GPU�p�~���đS��CPU�ŏ�������Ⴂ���ł�����Ă����̂Ɠ�������
�{���I��GPU�p�~���đS��CPU�ŏ�������Ⴂ���ł�����Ă����̂Ɠ�������
�\�t�g�E�F�A�H�w�ɋ�̒e�ۂȂ�����[
No Silver Bullet (�P���P)
http://www.itmedia.co.jp/im/spv/0706/25/news104.html
No Silver Bullet (�P���P)
http://www.itmedia.co.jp/im/spv/0706/25/news104.html
http://www.google.com/patents/US20140176569
http://patentimages.storage.googleapis.com/US20140176569A1/US20140176569A1-20140626-D00000.png
nv�͂������悤�Ƃ��Ă�
http://patentimages.storage.googleapis.com/US20140176569A1/US20140176569A1-20140626-D00000.png
{kind=link}
nv�͂������悤�Ƃ��Ă�
���Ƃ���AMD�̃p�\�R���ɁA�T�C�g�̉{��������w�����Ȃǂ̏��������I�ɃT�[�o�ɑ��M��
����ɉ����ď��ƍL�����|�b�v�A�b�v����\�t�g�E�F�A��W���o���h������
���A���C���X�g�[���s�\�ɂ���A�����Ȋ�Ƃ���̃T�|�[�g�͎��邩������Ȃ���B
����ɉ����ď��ƍL�����|�b�v�A�b�v����\�t�g�E�F�A��W���o���h������
���A���C���X�g�[���s�\�ɂ���A�����Ȋ�Ƃ���̃T�|�[�g�͎��邩������Ȃ���B
����Ǝ����悤�Ȃ��Ƃ��Ă�̂��O�[�O������
�t�ɁA���j�[�R�A��HPC����GPGPU��ǂ��o����
GPGPU�̖����ӂ���AMD��Zen�̊J���E������簐i���Ă���邩�ȁB
GPGPU�̖����ӂ���AMD��Zen�̊J���E������簐i���Ă���邩�ȁB
Fire Pro���㔭��Xeon Phi���X�p�R���ł̗̍p���L�тĂ鎞�_�ŕ��j�ύX���l����ׂ��i�K�Ȃ�
AMD�͖��ʂɒ��߂��������
AMD�͖��ʂɒ��߂��������
�C���e���Q�t�H���
�T���`�����P���s�v��
�T���`�����P���s�v��
������߂�������Ȃ���
���ɉ������炢���̂�������Ȃ��낤
���ɉ������炢���̂�������Ȃ��낤
609 �FSocket774�F2015/01/26(��) 18:46:07.56 ID:J0h/pY2p
>>578
�wSSE���AVX�ŕ��ł��郋�[�v���x�N�g�������ĉ��P�ł���Ȃ�ĂƂ���͑S���s���Ԃ�1%����Ȃ������x�Ƃ����̂́uGPU�ō������o���镔�����P�������v�Ƃ����Ӗ��ł����āw�����S�̂�1%���x�ȏ������Z�x�Ƃ͈Ӗ����S�R�Ⴄ��B
>>594
�Ⴆ��Ȃ�
�W�b�̏������Ԍ�ɂQ�b�łP�O�O�̕��i�����@�B��GPU�A�P�b�łS�̕��i�����@�B��SIMD�B
HSA�͏������Ԃ������ɂȂ銴���B
���������A���i��ۊǂ���ꏊ�͖����̂ŁA���̎��g��Ȃ��������i����Ŏg�����Ƃ͏o���Ȃ�
�wSSE���AVX�ŕ��ł��郋�[�v���x�N�g�������ĉ��P�ł���Ȃ�ĂƂ���͑S���s���Ԃ�1%����Ȃ������x�Ƃ����̂́uGPU�ō������o���镔�����P�������v�Ƃ����Ӗ��ł����āw�����S�̂�1%���x�ȏ������Z�x�Ƃ͈Ӗ����S�R�Ⴄ��B
>>594
�Ⴆ��Ȃ�
�W�b�̏������Ԍ�ɂQ�b�łP�O�O�̕��i�����@�B��GPU�A�P�b�łS�̕��i�����@�B��SIMD�B
HSA�͏������Ԃ������ɂȂ銴���B
���������A���i��ۊǂ���ꏊ�͖����̂ŁA���̎��g��Ȃ��������i����Ŏg�����Ƃ͏o���Ȃ�
>>609
��ʂ̃v���O�����͕��i�͊e�푽���Ƃ�4��5�ŏ\���Ȃ�ł��������
�V"��. _,,_
����<�M�D�L> 100�̕��i���g���đg�ݗ��Ă�悤��
�@�__�Q�@����������!
GPGPU�̓���͌����n�[�h�d�l�̎擾��Փx����
����ɍ��킹���v���O�����̍��ς�����̑I�ʂȂ��
��ʂ̃v���O�����͕��i�͊e�푽���Ƃ�4��5�ŏ\���Ȃ�ł��������
�V"��. _,,_
����<�M�D�L> 100�̕��i���g���đg�ݗ��Ă�悤��
�@�__�Q�@����������!
GPGPU�̓���͌����n�[�h�d�l�̎擾��Փx����
����ɍ��킹���v���O�����̍��ς�����̑I�ʂȂ��
>>609
�������Ԃ�8�b�͒Z�����B�����Ƃ�10���A���ꂪHSA��5���ɂȂ�܂����ĂƂ��B2�b��100��20�b��1000�̕������Ԃɋ߂��B
�������Ԃ�8�b�͒Z�����B�����Ƃ�10���A���ꂪHSA��5���ɂȂ�܂����ĂƂ��B2�b��100��20�b��1000�̕������Ԃɋ߂��B
>>609
���Ƃ����̂�
�d�g�͗v��Ȃ���
�v���O�����ł�int����g����float�Ȃǂ͍��W���炢�ɂ����g��Ȃ�
�g��Ȃ��A�v���͑S���������Z������I�ȉ��Z���g��Ȃ���
�g�������̓K�b�c���g�����̂̋ɏ���
�Ƃ����Ӗ��ł�����
SSE���AVX�̓x�N�g�����Z�ł͂Ȃ�������߂ăx�N�g�����o����
�ȂǂƂ����Ӗ��ł͒f���Ė���
���Ƃ����̂�
�d�g�͗v��Ȃ���
�v���O�����ł�int����g����float�Ȃǂ͍��W���炢�ɂ����g��Ȃ�
�g��Ȃ��A�v���͑S���������Z������I�ȉ��Z���g��Ȃ���
�g�������̓K�b�c���g�����̂̋ɏ���
�Ƃ����Ӗ��ł�����
SSE���AVX�̓x�N�g�����Z�ł͂Ȃ�������߂ăx�N�g�����o����
�ȂǂƂ����Ӗ��ł͒f���Ė���
613 �FSocket774�F2015/01/26(��) 19:13:02.91 ID:J0h/pY2p
>>612
SIMD�͐������Z�ɂ��g����̂����A�Ȃ�ŏ������Z�����Ɍ����Ă���H
���������A���Z�o���镔�����������GPU�ō������o���镔�����������A�����͂ǂ��Ȃ��Ă���H
SIMD�͐������Z�ɂ��g����̂����A�Ȃ�ŏ������Z�����Ɍ����Ă���H
���������A���Z�o���镔�����������GPU�ō������o���镔�����������A�����͂ǂ��Ȃ��Ă���H
�̎d���ŐG����ARM9��SoC�ŁA�摜��90�x��]���p�n�[�h�ł����
�\�t�g�iCPU�����j�ł�����ق���5�{���炢�����������Ƃ�����
���R�p�x�Ƃ��A���邢�͕������̉摜���d�˂���o�b�`�����݂����Ȃ��Ƃ���Ȃ�
�n�[�h�̂ق������ӂ����ǁA�P���̊G��f������������̂��ƒx�����Ђǂ���
���A���^�C���\���ɂ͎g���Ȃ����x���݂�����
���i���̓\�t�g���̕K�v�Ƃ�����̂�����Ă���������
���i���̂��߂Ƀ\�t�g���킯����Ȃ�����
CPU�̐��\���オ�����ɒǂ��t���Ȃ�����GPU�g���Ċ撣���Ă���Ȃ�Ă̂̓G�S�ł����Ȃ�
�u��������AMD�g��ˁ[��v�ŏI���ł���
�\�t�g�iCPU�����j�ł�����ق���5�{���炢�����������Ƃ�����
���R�p�x�Ƃ��A���邢�͕������̉摜���d�˂���o�b�`�����݂����Ȃ��Ƃ���Ȃ�
�n�[�h�̂ق������ӂ����ǁA�P���̊G��f������������̂��ƒx�����Ђǂ���
���A���^�C���\���ɂ͎g���Ȃ����x���݂�����
���i���̓\�t�g���̕K�v�Ƃ�����̂�����Ă���������
���i���̂��߂Ƀ\�t�g���킯����Ȃ�����
CPU�̐��\���オ�����ɒǂ��t���Ȃ�����GPU�g���Ċ撣���Ă���Ȃ�Ă̂̓G�S�ł����Ȃ�
�u��������AMD�g��ˁ[��v�ŏI���ł���
>>613
�ǂ��ł��������lj��ł���Ȓm��ȂH
�����̘b�́u���������Ӗ��̘b�����p�����v����
GPGPU�̗p�r�������錏�ɂ��Ă�
�u����Ȍ���ꂽ�p�r�Ɍ������đS�͂�AVX&LNI�R�A���v�M���[�I�v
���ĎU�X�����Ă�̂ɉ��Ō����Ȃ���
�ǂ��ł��������lj��ł���Ȓm��ȂH
�����̘b�́u���������Ӗ��̘b�����p�����v����
GPGPU�̗p�r�������錏�ɂ��Ă�
�u����Ȍ���ꂽ�p�r�Ɍ������đS�͂�AVX&LNI�R�A���v�M���[�I�v
���ĎU�X�����Ă�̂ɉ��Ō����Ȃ���
lni��avx512��hpc����������
���ꂪ�Ȃɂ�
���ꂪ�Ȃɂ�
Kaveri��512SP�̃V�F�[�_��]�����ƂȂ��g���ɂ́A�P���x�ł����Ȃ�A�Œ�2048�A
�S����������������f�[�^���K�v�ł��ˁB
���Z���̂̃��C�e���V�Ȃǂ�����̂Ŏ��ۂɂ͂���̐��{�͕K�v�ł��B
AVX�͂�������8�AAVX512��16����f�[�^���ǂ��A�ق��̃R�A�͕ʁX�̃R�[�h��
�������ĂĂĂ������ł��B
�f�[�^�̕����l�����Փx�͂͂邩�ɈႢ�܂��ˁB
�S����������������f�[�^���K�v�ł��ˁB
���Z���̂̃��C�e���V�Ȃǂ�����̂Ŏ��ۂɂ͂���̐��{�͕K�v�ł��B
AVX�͂�������8�AAVX512��16����f�[�^���ǂ��A�ق��̃R�A�͕ʁX�̃R�[�h��
�������ĂĂĂ������ł��B
�f�[�^�̕����l�����Փx�͂͂邩�ɈႢ�܂��ˁB
�܂�����ł��摜�����͉��p�͈͂��L������ȁB
�O���t�B�b�N�X�����łȂ���������ł͌������u�Ɏg�����Ƃ������������邵
������������APU���������Ȃ����낤���B
�O���t�B�b�N�X�����łȂ���������ł͌������u�Ɏg�����Ƃ������������邵
������������APU���������Ȃ����낤���B
>>618
AMD�`�b�v�̗p�����Y�Ɨp�}�U�[���Ă܂������݂܂���ˁB
Atom��Core i*�͂悭����̂����ǁB
Geode�ł�炩�������猙���Ă�̂ł́H
AMD�`�b�v�̗p�����Y�Ɨp�}�U�[���Ă܂������݂܂���ˁB
Atom��Core i*�͂悭����̂����ǁB
Geode�ł�炩�������猙���Ă�̂ł́H
�Y�ƌ����͈�ʂ�PC��T�[�o�Ɣ�ׂĂ��y���Ƀp�C�͏��Ȃ���
�Ȃ����ő�10�N�Ԃ̒����̕��i���������߂���
Intel��NUC���J�X�^��PC�s��A��ʖ@�l�����A�Y��PC�����ƕ��L���W�J���邱�Ƃ�
�ʎY�R�X�g���������苟���̐�����낤�Ƃ��Ă邯��
AMD��1�̃��f���Ŕ����I�ɔ����悤�Ȑ��i���Ȃ��ł���H
�Ȃ����ő�10�N�Ԃ̒����̕��i���������߂���
Intel��NUC���J�X�^��PC�s��A��ʖ@�l�����A�Y��PC�����ƕ��L���W�J���邱�Ƃ�
�ʎY�R�X�g���������苟���̐�����낤�Ƃ��Ă邯��
AMD��1�̃��f���Ŕ����I�ɔ����悤�Ȑ��i���Ȃ��ł���H
>>621
�ꉞ�O���t�B�b�N�p�r�炵���̂������B
http://ascii.jp/elem/000/000/818/818030/index-3.html
Phi��GPGPU��1/5�̍H���Ń\�t�g����Ƃ��B
��r�ΏۂɂȂ��Ă�̂�Tesla�ł�����FirePro����Ȃ����ǂ���
������̔����ŁA�Ď��J�����̉f���Ŕƍߎ҂���肷��Ƃ����������p�r�Ŏg����݂���
�ꉞ�O���t�B�b�N�p�r�炵���̂������B
http://ascii.jp/elem/000/000/818/818030/index-3.html
Phi��GPGPU��1/5�̍H���Ń\�t�g����Ƃ��B
��r�ΏۂɂȂ��Ă�̂�Tesla�ł�����FirePro����Ȃ����ǂ���
������̔����ŁA�Ď��J�����̉f���Ŕƍߎ҂���肷��Ƃ����������p�r�Ŏg����݂���
�m��u�ėpPC�ɂ܂ōڂ���v�悾�����i�ߋ��`�H�jLNI�̓O���t�B�b�N�p�r�I�v
�����Ȃ�߂������d�g�߂�
��������x86SIMD�ւ�Intel�̎p���݂̂����Ă��̂�
�����Ȃ�߂������d�g�߂�
��������x86SIMD�ւ�Intel�̎p���݂̂����Ă��̂�
>>624
�d�g�͂Ă߁[����w
�d�g�͂Ă߁[����w
sse5�͂ǂ����Ă낤��
����������
3dnow!�́H
brook+�́H
stream�́H
sse4a w
����������
3dnow!�́H
brook+�́H
stream�́H
sse4a w
havoc��opencl�Ή����Ăǂ��Ȃ�����H��
�����ƃx�N�^�f�[�^�����������Ⴂ�����B
�x�N�^�f�[�^�͉����̃f�[�^���g�ݍ��킳���ĂЂƂ̕���\�������́B��\�I�ȃx�N�^�f�[�^��RGBA�̉摜�s�N�Z���f�[�^��XYZ��3�������W�f�[�^�B
�x�N�^�f�[�^�̊e�v�f�ɂ͓���̉��Z���s�����Ƃ�������ꂼ��قȂ�v�Z���̉��Z���s�����Ƃ�����B
�����͓����f�[�^�����ԓI��ԓI�_���I�ɕ��z���Ă��鑍�̂��������ɗ��p�ł�����̂ŁA���ɑ�K�͂ȕ��������̂��Ƃ�O��Ƃ��Ă���B�Ⴆ�f�W�J���̉摜�͈ꖇ�Ő��疜�̕������B
�����ł͊�{�I�ɂ��ׂĂ̗v�f�ɑ��ē���v�Z���̉��Z���s���B
SSE/AVX�͒P��̃x�N�^�f�[�^�������Ă����ʂ̏��Ȃ����x�̗��x�Ȃ̂ɑ���GPU�͉摜�Ƃ�����K�͂ȃx�N�^�f�[�^�Q����x�Ɉ����̂ɓK�������x��L����BGPU�ł͕����̂悤�ȃf�[�^���������Ƃ͂ł��Ȃ��B
�x�N�^�f�[�^�͉����̃f�[�^���g�ݍ��킳���ĂЂƂ̕���\�������́B��\�I�ȃx�N�^�f�[�^��RGBA�̉摜�s�N�Z���f�[�^��XYZ��3�������W�f�[�^�B
�x�N�^�f�[�^�̊e�v�f�ɂ͓���̉��Z���s�����Ƃ�������ꂼ��قȂ�v�Z���̉��Z���s�����Ƃ�����B
�����͓����f�[�^�����ԓI��ԓI�_���I�ɕ��z���Ă��鑍�̂��������ɗ��p�ł�����̂ŁA���ɑ�K�͂ȕ��������̂��Ƃ�O��Ƃ��Ă���B�Ⴆ�f�W�J���̉摜�͈ꖇ�Ő��疜�̕������B
�����ł͊�{�I�ɂ��ׂĂ̗v�f�ɑ��ē���v�Z���̉��Z���s���B
SSE/AVX�͒P��̃x�N�^�f�[�^�������Ă����ʂ̏��Ȃ����x�̗��x�Ȃ̂ɑ���GPU�͉摜�Ƃ�����K�͂ȃx�N�^�f�[�^�Q����x�Ɉ����̂ɓK�������x��L����BGPU�ł͕����̂悤�ȃf�[�^���������Ƃ͂ł��Ȃ��B
����gpu�ɐ�ւ����Ƃ���K�N�K�N�ɂȂ��Ă����
Phi�̂ق����㔭�Ȃ̂�Phi��蔄��ĂȂ��̂�FirePro
���������Ή��I�v�V�������p�ӂ���ĂȂ�
http://jp.fujitsu.com/platform/server/primergy/peripheral/card/
http://jpn.nec.com/workstation/needs/calculation/
����������Z�p�R�v���Z�b�T�Ƃ��đI�ׂ�̂�Telsa, Xeon Phi�̂�
���������Ή��I�v�V�������p�ӂ���ĂȂ�
http://jp.fujitsu.com/platform/server/primergy/peripheral/card/
http://jpn.nec.com/workstation/needs/calculation/
����������Z�p�R�v���Z�b�T�Ƃ��đI�ׂ�̂�Telsa, Xeon Phi�̂�
�x�N�^�Ƃ̓f�[�^����̂��Ƃł���SIMD�ł���
�X���b�h����̓f�[�^�����߂��ʂ����f�[�^�ˑ������������̂�����
GPU��SIMD�Ƃ�����SIMT����LNI�ӂ��������SIMT�ł���
�f�[�^����Ȃ͈̂ꏏ���������ƊȒP�Ɍ����Ă��܂��č����x������
�ނ���x86SIMD�Ɍ���ɂȂ��Ă�Intel���̂ɍ����x���Ƃ������x�Ⴊ����
����͕������┻�f�͂�m�\�̖��ł��邩��܂�m��ł���
�X���b�h����̓f�[�^�����߂��ʂ����f�[�^�ˑ������������̂�����
GPU��SIMD�Ƃ�����SIMT����LNI�ӂ��������SIMT�ł���
�f�[�^����Ȃ͈̂ꏏ���������ƊȒP�Ɍ����Ă��܂��č����x������
�ނ���x86SIMD�Ɍ���ɂȂ��Ă�Intel���̂ɍ����x���Ƃ������x�Ⴊ����
����͕������┻�f�͂�m�\�̖��ł��邩��܂�m��ł���
633 �F,,�E�L�́M�E,,�j��-�������F2015/01/26(��) 20:46:26.83 ID:LeFQQ2yV
> LNI�ӂ��������SIMT�ł���
�[��
�[��
�A���_�[�����o�J�����Ƃ����ė~�����B
�����ł���AVX��2�{�̋K�͂Ȃ̂�
LNI��SIMT���܂ł�����Ƃ������Ƃ͂���Ƀ��\�[�X��傷�邱�ƂɂȂ�
�����܂ŃR�A��傳���������b�g���uGPU���������Ȃ��I�v
���i��x86�̂��ו��Œ��d�v�ȏ�ʂł�GPU�Ƀ{������
�u���̂��炢�̗��x�Ȃ�I�v�Ƃ����j�b�`�Ȏ��v�̂��߂ɂ����R�A���
�ǂ������@���Ȃ�
LNI��SIMT���܂ł�����Ƃ������Ƃ͂���Ƀ��\�[�X��傷�邱�ƂɂȂ�
�����܂ŃR�A��傳���������b�g���uGPU���������Ȃ��I�v
���i��x86�̂��ו��Œ��d�v�ȏ�ʂł�GPU�Ƀ{������
�u���̂��炢�̗��x�Ȃ�I�v�Ƃ����j�b�`�Ȏ��v�̂��߂ɂ����R�A���
�ǂ������@���Ȃ�
64bit�͈�x�ɑ�ʂ̏������o����@�͂�������
637 �F,,�E�L�́M�E,,�j��-�������F2015/01/26(��) 21:17:55.93 ID:LeFQQ2yV
SIMT����Single Instruction Multi-Thread�̈Ӗ��Ŏg���Ă���Ďv���Ă����́H
Xeon Phi��Skykake-Xeon��SIMT�ł͂Ȃ�
Xeon Phi��Skykake-Xeon��SIMT�ł͂Ȃ�
AMD�̐��i�Q��GPGPU����FirePro�͎��ɑ̂ł���
APU��HSA�ɕK���ɂȂ��Ă�̌��Ă���dGPU�n��ɓ������镨�D���͂����������Ȃ����
�悭�G�R�n�̃����L���O�Ńg�b�v�����ăR�s�y�\�邯�njւ�l�^�����ꂵ���Ȃ��Ƃ���
���ႠHSA�̓E�P�Ă�̂��ƌ������炻��Ȃ��Ƃ��Ȃ�
�㓡�ɂ���HPC������CUDA��phi�ŐȖ��܂��Ă�݂����ȋL�����������n��
APU��HSA�ɕK���ɂȂ��Ă�̌��Ă���dGPU�n��ɓ������镨�D���͂����������Ȃ����
�悭�G�R�n�̃����L���O�Ńg�b�v�����ăR�s�y�\�邯�njւ�l�^�����ꂵ���Ȃ��Ƃ���
���ႠHSA�̓E�P�Ă�̂��ƌ������炻��Ȃ��Ƃ��Ȃ�
�㓡�ɂ���HPC������CUDA��phi�ŐȖ��܂��Ă�݂����ȋL�����������n��
639 �F,,�E�L�́M�E,,�j��-�������F2015/01/26(��) 21:31:16.46 ID:LeFQQ2yV
>>638
GREEN500���������������Ȃ��
FirePro�͕��x�e�����Đ���Ƃ��M�͊w�Ƃ��̎��p�I�ȃR�[�h�ł̓{���{���Ȃ�
�X�p�R���̑��x�̃����L���O���߂�̂�LINPACK������
�X�p�R���̗��p�ړI�͎��p�v���O�����������Ƃł�����
�uLINPACK�������Ɓv����Ȃ���ł��B�c�O�Ȃ���B
Hisa Ando�����w�E���Ă邪�A�߂�LINPACK�̓X�p�R���̐��\�]���Ɏg���Ȃ��Ȃ�B
GREEN500���������������Ȃ��
FirePro�͕��x�e�����Đ���Ƃ��M�͊w�Ƃ��̎��p�I�ȃR�[�h�ł̓{���{���Ȃ�
�X�p�R���̑��x�̃����L���O���߂�̂�LINPACK������
�X�p�R���̗��p�ړI�͎��p�v���O�����������Ƃł�����
�uLINPACK�������Ɓv����Ȃ���ł��B�c�O�Ȃ���B
Hisa Ando�����w�E���Ă邪�A�߂�LINPACK�̓X�p�R���̐��\�]���Ɏg���Ȃ��Ȃ�B
>>637
���O�O�O��Ȃ��Ȃ������蓾�����Ȃ����Ⴄ��
���O�O�O��Ȃ��Ȃ������蓾�����Ȃ����Ⴄ��
641 �F,,�E�L�́M�E,,�j��-�������F2015/01/26(��) 21:35:14.64 ID:LeFQQ2yV
SIMT�̈Ӗ���������Ă�������
642 �F,,�E�L�́M�E,,�j��-�������F2015/01/26(��) 21:36:01.69 ID:LeFQQ2yV
TOP500�̃����L���O���[�����ς��? - LINPACK�ɕς��x���`�}�[�N�����
http://news.mynavi.jp/articles/2013/06/25/linpack_next/
http://news.mynavi.jp/articles/2013/06/25/linpack_next/
>>619
��Geode�ł�炩�������猙���Ă�̂ł́H
������Ȃ��Ƃ����ł��������[�J�[�́A���R�����Ԃ��������s�ׂ��L������邱�ƂɂȂ�B�����^�Ђ�
�u���AMD���i��g�ݍ��݂Ɏg��Ȃ��v�ƒf�����Ă���B
ttp://ascii.jp/elem/000/000/642/642559/index-3.html
���ڋq���炷��u�܂�AMD�����₪�������v�Ƃ����b�ɂȂ�B
����ɂ��x���_�[�̑唼�Ɍ����邱�ƂɂȂ��Ă��܂����B
ttp://ascii.jp/elem/000/000/648/648702/index-4.html
��Geode�ł�炩�������猙���Ă�̂ł́H
������Ȃ��Ƃ����ł��������[�J�[�́A���R�����Ԃ��������s�ׂ��L������邱�ƂɂȂ�B�����^�Ђ�
�u���AMD���i��g�ݍ��݂Ɏg��Ȃ��v�ƒf�����Ă���B
ttp://ascii.jp/elem/000/000/642/642559/index-3.html
���ڋq���炷��u�܂�AMD�����₪�������v�Ƃ����b�ɂȂ�B
����ɂ��x���_�[�̑唼�Ɍ����邱�ƂɂȂ��Ă��܂����B
ttp://ascii.jp/elem/000/000/648/648702/index-4.html
�R���V���[�}�[�E�Ō���Super �݂����ȃ��������Ăˁ�LINPACK
�ߋ�����̒~�ς����邩���r�Ƃ��Ďg���邯�Ǥ���p��͂����g���Ȃ����߂��g�������v���O�����
�ߋ�����̒~�ς����邩���r�Ƃ��Ďg���邯�Ǥ���p��͂����g���Ȃ����߂��g�������v���O�����
645 �FSocket774�F2015/01/26(��) 21:39:01.10 ID:X0JcFd5m
>>631
�����
�����
>>641
�f�[�^����ŕ�����ꍇ�ɃX���b�h�����Ċe�X���s
�f�[�^����ŕ�����ꍇ�ɃX���b�h�����Ċe�X���s
647 �FSocket774�F2015/01/26(��) 21:44:49.65 ID:X0JcFd5m
>>646
�p��ŏ�����
�p��ŏ�����
648 �F,,�E�L�́M�E,,�j��-�������F2015/01/26(��) 21:47:06.59 ID:LeFQQ2yV
x86��1�̖��߂��e������̂͊�{1�X���b�h�݂̂ł��B
SIMT��SIMD���j�b�g�̊e�G�������g���u�R�A�v�Ɠǂݑւ���NVIDIA�Ǝ��̕\����
1��SIMD���j�b�g��S�ăR�A�ɓ����Intel�ɂ͓��Ă͂܂�Ȃ�
NVIDIA���̕\��������Ȃ�1��Xeon Phi��16 CUDA Core��
1���[�v������16�X���b�h�����s�ł�����ĂƂ�����
�ł��A��ʓI�ȗp���SPMD���Ă�����ł���
SIMT��SIMD���j�b�g�̊e�G�������g���u�R�A�v�Ɠǂݑւ���NVIDIA�Ǝ��̕\����
1��SIMD���j�b�g��S�ăR�A�ɓ����Intel�ɂ͓��Ă͂܂�Ȃ�
NVIDIA���̕\��������Ȃ�1��Xeon Phi��16 CUDA Core��
1���[�v������16�X���b�h�����s�ł�����ĂƂ�����
�ł��A��ʓI�ȗp���SPMD���Ă�����ł���
��
650 �F,,�E�L�́M�E,,�j��-�������F2015/01/26(��) 21:56:50.51 ID:LeFQQ2yV
651 �F,,�E�L�́M�E,,�j��-�������F2015/01/26(��) 22:01:27.49 ID:LeFQQ2yV
652 �FSocket774�F2015/01/26(��) 22:03:28.87 ID:X0JcFd5m
���Ƃ���nv�֘A��Dynamic Warp Formation�Ƃ�subdivision���Ę_���ł�warp���̃f�[�^��ׂɕ�����warp���č\�z���Ė��ʂ����炷���Ă��̂͂��邪
�ŋ߂��ƊK�w�^�̃X�P�W���[�����O��warp�̗��x��������������ɐi��ł�
����ς���ŏ���������Ă��ƂȂ̂Ń\�t�g���䂾��
phi�͌��X�\�t�g���䂪�\�Ȃ낤����
�ŋ߂��ƊK�w�^�̃X�P�W���[�����O��warp�̗��x��������������ɐi��ł�
����ς���ŏ���������Ă��ƂȂ̂Ń\�t�g���䂾��
phi�͌��X�\�t�g���䂪�\�Ȃ낤����
>>648
�[��
����n�܂��Čh�ꂪ�����Ă�̂���������
�ق�Ƃ܂����O�O�O��Ȃ��Ȃ����獡�x�������������Ȃ邼
http://pc.watch.impress.co.jp/docs/column/kaigai/20091201_332428.html
http://pc.watch.impress.co.jp/docs/column/kaigai/20120719_547768.html
�[��
����n�܂��Čh�ꂪ�����Ă�̂���������
�ق�Ƃ܂����O�O�O��Ȃ��Ȃ����獡�x�������������Ȃ邼
http://pc.watch.impress.co.jp/docs/column/kaigai/20091201_332428.html
http://pc.watch.impress.co.jp/docs/column/kaigai/20120719_547768.html
654 �F,,�E�L�́M�E,,�j��-�������F2015/01/26(��) 22:05:26.03 ID:LeFQQ2yV
> �ق�Ƃ܂����O�O�O��Ȃ��Ȃ����獡�x�������������Ȃ邼
���ȏЉ
�N�A�O�O�������e�������̓��ōl���ď������邱�Ƃ��ł��Ȃ���
���ȏЉ
�N�A�O�O�������e�������̓��ōl���ď������邱�Ƃ��ł��Ȃ���
655 �F,,�E�L�́M�E,,�j��-�������F2015/01/26(��) 22:10:10.42 ID:LeFQQ2yV
�uLNI��SIMT�ł���v�Ƃ����N�̐��𗧏��镶�͂������邱�Ƃ͂ł��ĂȂ��悤������
656 �FSocket774�F2015/01/26(��) 22:13:52.74 ID:X0JcFd5m
�}�X�N���Ă����Ǖ����p�X�Ȃ��Ⴂ���Ȃ�����
�d�͌��������Ă���[�Ȃ�������s���x���ł̗��x32����4���悤���ĂƂ��낪�����Ă�
�d�͌��������Ă���[�Ȃ�������s���x���ł̗��x32����4���悤���ĂƂ��낪�����Ă�
657 �F,,�E�L�́M�E,,�j��-�������F2015/01/26(��) 22:16:22.71 ID:LeFQQ2yV
double��longlong����8���B
>>655
���ŋ}�Ɏ������n�߂�����������
�u����v�u�X���b�h�v�Ƃ��P��o���ă����N�\���Ă�̂�
�y�[�W��������o���Ȃ��Ȃ�Ă����I����Ă邼
��SIMT��SIMD(Single Instruction Stream, Multiple Data Stream)�̑傫�ȈႢ�́A���T�|�[�g�����_
���x�N�g�����̊e�X���b�h(Larrabee�p��ł̓X�g�����h)
���ŋ}�Ɏ������n�߂�����������
�u����v�u�X���b�h�v�Ƃ��P��o���ă����N�\���Ă�̂�
�y�[�W��������o���Ȃ��Ȃ�Ă����I����Ă邼
��SIMT��SIMD(Single Instruction Stream, Multiple Data Stream)�̑傫�ȈႢ�́A���T�|�[�g�����_
���x�N�g�����̊e�X���b�h(Larrabee�p��ł̓X�g�����h)
659 �F,,�E�L�́M�E,,�j��-�������F2015/01/26(��) 22:25:17.22 ID:LeFQQ2yV
��SIMT��SIMD(Single Instruction Stream, Multiple Data Stream)�̑傫�ȈႢ�́A���T�|�[�g�����_
Xeon Phi�̓x�N�g���v�f�P�ʂ�predication(�����t�����s)�͂��邯��branch(����)���T�|�[�g���ĂȂ��̂ł����H
AVX2�ł���vfmadd231ps + vblendvps�����̑����1���߂ł��Ȃ��邾���ł���
�������T�|�[�g���Ă�Ƃ͌����܂���B
Xeon Phi�̓x�N�g���v�f�P�ʂ�predication(�����t�����s)�͂��邯��branch(����)���T�|�[�g���ĂȂ��̂ł����H
AVX2�ł���vfmadd231ps + vblendvps�����̑����1���߂ł��Ȃ��邾���ł���
�������T�|�[�g���Ă�Ƃ͌����܂���B
660 �F,,�E�L�́M�E,,�j��-�������F2015/01/26(��) 22:28:05.40 ID:LeFQQ2yV
�܂������Ƃ�NVIDIA�́u����v�ƌ����Ă�T�O�����ۂ͂�����predication�Ȃ�ł����ǂ�
662 �F,,�E�L�́M�E,,�j��-�������F2015/01/26(��) 22:43:17.87 ID:LeFQQ2yV
ptx��cubin�̃R�[�h�_���v��ǂ�ł݂�킩�邯�ǁA�v�f���ƂɑJ�ڐ�̕ς��
if-else�̓R���p�C�����_�Ńv���f�B�P�[�g���s�ɓW�J����Ă܂���B
SIMT����CUDA Core���̂͂����܂Ń}�[�L�e�N�`���ɂ�����
����Load/Store���j�b�g��gather/scatter�����v�f�P�ʂ�predication��
�T�|�[�g����SIMD�^�v���Z�b�T�A���ꂪTesla/GeForce�̎��Ԃł���
if-else�̓R���p�C�����_�Ńv���f�B�P�[�g���s�ɓW�J����Ă܂���B
SIMT����CUDA Core���̂͂����܂Ń}�[�L�e�N�`���ɂ�����
����Load/Store���j�b�g��gather/scatter�����v�f�P�ʂ�predication��
�T�|�[�g����SIMD�^�v���Z�b�T�A���ꂪTesla/GeForce�̎��Ԃł���
���XNVIDIA�����p��ō����SIMT�̊T�O��
AMD�����������HSA�Ŏg���Ă�̂�����ƃ����b�Ƃ���Ȃ�
����x��Ő^����Ȃ������փn�[�h�ɓO����Ηǂ��̂�
AMD�����������HSA�Ŏg���Ă�̂�����ƃ����b�Ƃ���Ȃ�
����x��Ő^����Ȃ������փn�[�h�ɓO����Ηǂ��̂�
664 �F,,�E�L�́M�E,,�j��-�������F2015/01/26(��) 22:45:21.01 ID:LeFQQ2yV
665 �F,,�E�L�́M�E,,�j��-�������F2015/01/26(��) 22:54:17.61 ID:LeFQQ2yV
>>663
���HSIMT���Č����Ă�̌㓡�Ƃ��̃��C�^�[�������Ǝv���Ă�����
CUDA�̎��s�̎d�g�݂̊ۃp�N������X�^�[�g���Ă邩������s�ǂ̂܂ܓƎ��p���
�A�������Ⴄ�낤��
���HSIMT���Č����Ă�̌㓡�Ƃ��̃��C�^�[�������Ǝv���Ă�����
CUDA�̎��s�̎d�g�݂̊ۃp�N������X�^�[�g���Ă邩������s�ǂ̂܂ܓƎ��p���
�A�������Ⴄ�낤��
667 �F,,�E�L�́M�E,,�j��-�������F2015/01/26(��) 23:03:10.01 ID:LeFQQ2yV
CUDA��SIMT��1�X���b�h�ɂ�1�v�f��FPU�ɂ����A�N�Z�X�ł��Ȃ������邪
Phi�̃R�A��1�X���b�h�̒���512�r�b�gSIMD���j�b�g��1�Ԗڂ���16�Ԗڂ܂ł̑S�v�f�ɃA�N�Z�X�ł���
�����SIMT�Ƃ͌����܂����B
Phi�̃R�A��1�X���b�h�̒���512�r�b�gSIMD���j�b�g��1�Ԗڂ���16�Ԗڂ܂ł̑S�v�f�ɃA�N�Z�X�ł���
�����SIMT�Ƃ͌����܂����B
668 �F,,�E�L�́M�E,,�j��-�������F2015/01/26(��) 23:06:11.43 ID:LeFQQ2yV
>>666
�s���R�Ŏd���Ȃ����ǂ˂���B
�x�N�g���v�f�Ԃ�shuffle�Ƃ�Kepler�ł悤�₭�T�|�[�g���ꂽ�ł���
CPU�ł�SSE�̎��ォ�炠��̂ɁB
�s���R�Ŏd���Ȃ����ǂ˂���B
�x�N�g���v�f�Ԃ�shuffle�Ƃ�Kepler�ł悤�₭�T�|�[�g���ꂽ�ł���
CPU�ł�SSE�̎��ォ�炠��̂ɁB
Intel��Phi�́APhi�Ƃ�����̃v���Z�b�T�Ƃ������CPU�̉�ł���H
������nvidia�̓Ǝ��p�ꂪGPU�̎��s�������A�I�m�ɕ\���Ă�Ȃ�SIMT�Œʗp�����Ȃ����H
������nvidia�̓Ǝ��p�ꂪGPU�̎��s�������A�I�m�ɕ\���Ă�Ȃ�SIMT�Œʗp�����Ȃ����H
670 �F,,�E�L�́M�E,,�j��-�������F2015/01/26(��) 23:32:29.47 ID:LeFQQ2yV
SPMD�X�^�C���̃v���O���~���O���f�������������̂�CUDA
SPMD�^�̌�����g����iOpenCL�j����SIMD��SIMD�Ƃ��Ă��̂܂g�����Ƃ��ł���̂�Phi
SPMD�^�̌�����g����iOpenCL�j����SIMD��SIMD�Ƃ��Ă��̂܂g�����Ƃ��ł���̂�Phi
671 �F,,�E�L�́M�E,,�j��-�������F2015/01/26(��) 23:49:52.33 ID:LeFQQ2yV
>>669
CPU�̉�Ƃ������A60�R�A��CPU�ł����ȁB
SPMD�^�̃v���O���~���O���f���́u����v���Ǝv���Ă�
���Ƃ���Ȃ�ԂƐ̃t�B�����\�����ÓT�I�ȁu3D���K�l�v�Ō��鐢�E�B
�Ȃ������̃��K�l���O���Ȃ��B
CPU�̉�Ƃ������A60�R�A��CPU�ł����ȁB
SPMD�^�̃v���O���~���O���f���́u����v���Ǝv���Ă�
���Ƃ���Ȃ�ԂƐ̃t�B�����\�����ÓT�I�ȁu3D���K�l�v�Ō��鐢�E�B
�Ȃ������̃��K�l���O���Ȃ��B
672 �F,,�E�L�́M�E,,�j��-�������F2015/01/27(��) 00:08:37.24 ID:kAM0byxN
CUDA��OpenCL�̍l�����͊�{����B
�x�N�g����}���`�v���Z�b�T���B�����A��������̂𐧌����邱�Ƃ�
����̉��Z��P���ȃR�[�h�L�q�ŕ\�����邱�Ƃ��ł���B
�ł��A���Z�́A���́u����̉��Z�v�ɓ��Ă͂܂�Ȃ����̂�����
SPMD���ƋL�q���������Ėʓ|�������肻�������\���ł��Ȃ�������B
�����琧�����邱�Ƃ��D���A��������Phi����OpenCL�𐄏����ĂȂ��ł���B
�g���邯�ǁA�]���^�v���O���~���O���f���łȂ�����֗̕��Ȗ��߂̂����ꕔ����
�A�N�Z�X���邱�Ƃ��ł��Ȃ��B
������C++�iCUDA�̂悤�Ȑ������̂ł͂Ȃ��W���́j�ł̊J���𐄏����Ă����B
�x�N�g����}���`�v���Z�b�T���B�����A��������̂𐧌����邱�Ƃ�
����̉��Z��P���ȃR�[�h�L�q�ŕ\�����邱�Ƃ��ł���B
�ł��A���Z�́A���́u����̉��Z�v�ɓ��Ă͂܂�Ȃ����̂�����
SPMD���ƋL�q���������Ėʓ|�������肻�������\���ł��Ȃ�������B
�����琧�����邱�Ƃ��D���A��������Phi����OpenCL�𐄏����ĂȂ��ł���B
�g���邯�ǁA�]���^�v���O���~���O���f���łȂ�����֗̕��Ȗ��߂̂����ꕔ����
�A�N�Z�X���邱�Ƃ��ł��Ȃ��B
������C++�iCUDA�̂悤�Ȑ������̂ł͂Ȃ��W���́j�ł̊J���𐄏����Ă����B
�����Č����Ȃ�A4k��8k�̓����3D�̍Đ���ҏW��APU�ł�낤�Ƃ��Ă�̂�AMD
CPU+dGPU�̑g�����ł�邵���Ȃ��̂��C���e���Q�t�H
TFlops����iGPU��16��32G�̃��C��������������Ȃ�o���邾�낤
CPU+dGPU�̑g�����ł�邵���Ȃ��̂��C���e���Q�t�H
TFlops����iGPU��16��32G�̃��C��������������Ȃ�o���邾�낤
AMD������Ȃ��̂͒P��Intel���J����f�B�A�̘g�����������͂�����ł邩�炾��
�����炢���v���Z�b�T������Ă��A���[�J�[�̃��\�[�X���[�����Ꮴ�i�����Ȃ�
�����č�����Ƃ��Ă��Aweb��G���̖w�ǂ�Intel�Q�t�H�Ő�߂��邩��A���[�U�[���C�Â��Ȃ�
CPU��GPU��AVX��GPGPU���ǂ��̂����̂���Ȃ���
�h�������������������点�āA���������`���邩��AAMD�̓��錄���Ȃ�����
�����Ă��̏́A���Ęa���������ɂ͊��Ɋ������Ă�������ǂ����悤���Ȃ�
�����炢���v���Z�b�T������Ă��A���[�J�[�̃��\�[�X���[�����Ꮴ�i�����Ȃ�
�����č�����Ƃ��Ă��Aweb��G���̖w�ǂ�Intel�Q�t�H�Ő�߂��邩��A���[�U�[���C�Â��Ȃ�
CPU��GPU��AVX��GPGPU���ǂ��̂����̂���Ȃ���
�h�������������������点�āA���������`���邩��AAMD�̓��錄���Ȃ�����
�����Ă��̏́A���Ęa���������ɂ͊��Ɋ������Ă�������ǂ����悤���Ȃ�
�T���`�����P���A���`�����t�@���{�[�C���K����
���{�l�Ȃ�C���e���Q�t�H�����
���{�l�Ȃ�C���e���Q�t�H�����
676 �FSocket774�F2015/01/27(��) 04:12:24.48 ID:MKINHEKM
�܂�Ӎ߂Ɣ������N�����Ă����Ă��Ƃ���
>>674
�匴�̋L���ɂȂ��_�Ȃ��́H
�����炢���v���Z�b�T���܂����[�W���ɂ��������Ă܂��[�ł�
�������ςȂ��O�ȂŐM�p����ĂȂ���
�匴�̋L���ɂȂ��_�Ȃ��́H
�����炢���v���Z�b�T���܂����[�W���ɂ��������Ă܂��[�ł�
�������ςȂ��O�ȂŐM�p����ĂȂ���
���{�l�Ȃ�T���`�����P���A���`�����͂Ȃ����
�����v���Z�b�T�ƌ����Ă��������А��i�Ɠ����x�ł͒N������ɂ��Ă���Ȃ���B
�l�i�Ə���d�͂������Ő��\��1.5�{�ł�
�l�i�Ɛ��\�������ŏ���d�͂������ł�
����d�͂Ɛ��\�������Œl�i��1/3�ł�
����ʂ̃C���p�N�g���Ȃ��ƌ����ɂ�����Ȃ��B
APU���}�U�{�ƃZ�b�g�Ő���~�Ȃ甄����B���ꂭ�炢�̉��l�͂���B
�l�i�Ə���d�͂������Ő��\��1.5�{�ł�
�l�i�Ɛ��\�������ŏ���d�͂������ł�
����d�͂Ɛ��\�������Œl�i��1/3�ł�
����ʂ̃C���p�N�g���Ȃ��ƌ����ɂ�����Ȃ��B
APU���}�U�{�ƃZ�b�g�Ő���~�Ȃ甄����B���ꂭ�炢�̉��l�͂���B
1.5�{�ǂ��납7�{�̐��\����̂���
����x���`�ł���7�{�A���W���[�ȃ\�t�g�ł͔����̐��\�������B
7�{�ǂ��납56�{�̐��\����̂���
http://www.4gamer.net/games/100/G010000/20111009002/screenshot.html?num=009
http://www.4gamer.net/games/100/G010000/20111009002/screenshot.html?num=009
athlon64��P4��肷��������������������ł�4���̃V�F�A����ꂽ��
684 �FSocket774�F2015/01/27(��) 08:35:33.88 ID:1/MM/46u
OCR�Ƃ��Ɏg���Ȃ��̂���
Llano�o��̋łɂ�
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
686 �FSocket774�F2015/01/27(��) 08:56:13.04 ID:jH5e4XYN
>>680,>>681
�V�{���đ��А��i�Ƃ̔�r�ł͖����AKaveri��CPU(SIMD)�s�[�N���\�ɑ���GPU�s�[�N���\�B
���R�x���`���ʂȂǂł͖����_�����Z���\�B
�V�{���đ��А��i�Ƃ̔�r�ł͖����AKaveri��CPU(SIMD)�s�[�N���\�ɑ���GPU�s�[�N���\�B
���R�x���`���ʂȂǂł͖����_�����Z���\�B
>>674
�P��AMD���L����`��������Ȃ������ł���
���ɓ��{�ł͂܂������e���rCM��ł��ĂȂ�
����GPU���\��CPU�̐��\���ƍ��̂��Ă��c�O�Ȃ��猫������҂͂����͌��Ȃ����
GPU��GPU����CPU��CPU
�P��AMD���L����`��������Ȃ������ł���
���ɓ��{�ł͂܂������e���rCM��ł��ĂȂ�
����GPU���\��CPU�̐��\���ƍ��̂��Ă��c�O�Ȃ��猫������҂͂����͌��Ȃ����
GPU��GPU����CPU��CPU
Intel�̃��C���X�g���[�����烍�[�G���h�܂őS���AGPU���ڂɂȂ�������
���ʓI��iGPU�䗦���オ���Ă��邾���ŁA�f�B�X�N���[�g�𗘗p����l��
iGPU�������I�ɔ������ƂɂȂ邩�猋�ʓI��iGPU�̃V�F�A���オ�����悤�ɂ݂���
APU�Ɍ����Č����ACPU�{�}�U�[�{�[�hGPU�̎���Ƃ���ׂĂ������܂Ŕ���ĂȂ�
APU�Ɣ�ׂ�GeForce��Radeon�Ȃǂ����킹���f�B�X�N���[�gGPU��
���܂����[���h���C�h��2�`3�{�̎s��K�͂�����킯�������̏�
����GPU���\���d�v���Ȃ�Č����Ă��Ȃ�̐����͂��Ȃ����
���ʓI��iGPU�䗦���オ���Ă��邾���ŁA�f�B�X�N���[�g�𗘗p����l��
iGPU�������I�ɔ������ƂɂȂ邩�猋�ʓI��iGPU�̃V�F�A���オ�����悤�ɂ݂���
APU�Ɍ����Č����ACPU�{�}�U�[�{�[�hGPU�̎���Ƃ���ׂĂ������܂Ŕ���ĂȂ�
APU�Ɣ�ׂ�GeForce��Radeon�Ȃǂ����킹���f�B�X�N���[�gGPU��
���܂����[���h���C�h��2�`3�{�̎s��K�͂�����킯�������̏�
����GPU���\���d�v���Ȃ�Č����Ă��Ȃ�̐����͂��Ȃ����
Intel������GPU����������̂́A�܂��m�[�gPC�����C���^�[�Q�b�g��
�O�t��GPU���Ȃ��Đ����R�X�g�������������[�J�[�̗v�]�ɂ����̂�
�X�Ƀf�X�N�g�b�v�̓m�[�g�̑I�ʗ������g���Ă邾���B
CPU�̐��\�s����GPU�ŕ₢����AMD�Ƃ͂܂��������ꂪ�Ⴄ�B
����̈Ⴂ���킫�܂����A�t�@���{�[�C�͂�������
�u����GPU���d������鎞�ゾ����AMD�̕����͐������I�叟���I�v
AMD��APU�����[�J�[�ɐl�C�Ńm�[�gPC�̃V�F�A���オ���Ă�Ȃ�ꗝ����̂���
�����ɂ͂ǂ�ǂ����Ă邩���
�O�t��GPU���Ȃ��Đ����R�X�g�������������[�J�[�̗v�]�ɂ����̂�
�X�Ƀf�X�N�g�b�v�̓m�[�g�̑I�ʗ������g���Ă邾���B
CPU�̐��\�s����GPU�ŕ₢����AMD�Ƃ͂܂��������ꂪ�Ⴄ�B
����̈Ⴂ���킫�܂����A�t�@���{�[�C�͂�������
�u����GPU���d������鎞�ゾ����AMD�̕����͐������I�叟���I�v
AMD��APU�����[�J�[�ɐl�C�Ńm�[�gPC�̃V�F�A���オ���Ă�Ȃ�ꗝ����̂���
�����ɂ͂ǂ�ǂ����Ă邩���
����AAPU���Ӗ��͂�������
���܂܂ŗʔ̓X��AMD�m�[�g�Ƃ��F���������̂�
1��Ƃ�2���AMD�ɂȂ���
�܌����̔L�n�l�b�g�u�b�N������������w
���܂܂ŗʔ̓X��AMD�m�[�g�Ƃ��F���������̂�
1��Ƃ�2���AMD�ɂȂ���
�܌����̔L�n�l�b�g�u�b�N������������w
�ʔ̂�HP��APU�m�[�g��������ˁB
>>602
�����ς�킩���̂����ǂ������ӂ��ɂȂ�̂���
�����ς�킩���̂����ǂ������ӂ��ɂȂ�̂���
PC���[�J�[��\�t�g�n�E�X��GPGPU���w�e���W�j�A�X�R���s���[�e�B���O���̋������Ă���
�Ȃ�ėv�]���Ă�킯����Ȃ���AMD���ƑP�ł���Ă邾���������
���[�J�[�����~�������\�E�@�\���\���p�ӏo������ł��̗]�T�ł��Ȃ疳��肾��
�����ɂ͂�������Ȃ��ƁB
������œK������ΐ��\���オ��ƌ����Ă��A����Ȃ��ᖢ�����Ȃ������
����ĂȂ��n�[�h�̂��߂Ƀ\�t�g�����Ȃ��B
HSA���x�����Ă�v���O���}�͐��E�ł�2�`3���قǂ������Ȃ������܂���
�����ł���i��]�j���Ƃł͂Ȃ��A���ł��邱�ƂŔ���̂��܂��l���Ȃ��ƁB
�Ȃ�ėv�]���Ă�킯����Ȃ���AMD���ƑP�ł���Ă邾���������
���[�J�[�����~�������\�E�@�\���\���p�ӏo������ł��̗]�T�ł��Ȃ疳��肾��
�����ɂ͂�������Ȃ��ƁB
������œK������ΐ��\���オ��ƌ����Ă��A����Ȃ��ᖢ�����Ȃ������
����ĂȂ��n�[�h�̂��߂Ƀ\�t�g�����Ȃ��B
HSA���x�����Ă�v���O���}�͐��E�ł�2�`3���قǂ������Ȃ������܂���
�����ł���i��]�j���Ƃł͂Ȃ��A���ł��邱�ƂŔ���̂��܂��l���Ȃ��ƁB
���}���̂�������Ȃ������Ƃ������߂����
�������̂͂��̂قƂ�ǂ��m��Intel�ւ̃u�[������
�����҂����Y��������ɍs�����f�J���Ē���������Intel�ւ̃u�[������������
�����҂����Y��������ɍs�����f�J���Ē���������Intel�ւ̃u�[������������
�V�����A�[�L��Zen��Q3 2016�ɂł���Ă��B
ttp://wccftech.com/amd-zen-featured-summit-ridge-family-14nm-processors-rumored-feature-fm3-socket-support-ddr4-memory-compatiblity/
ttp://wccftech.com/amd-zen-featured-summit-ridge-family-14nm-processors-rumored-feature-fm3-socket-support-ddr4-memory-compatiblity/
697 �FSocket774�F2015/01/27(��) 14:23:30.78 ID:1/MM/46u
http://neareal.net/index.php?Programming%2FOpenCL%2FOpenCLSharp%2FTutorial%2F5_TimeOfSimpleOpenCLTask
���̂��Ƃ���A����̂悤�ȃT���v���ł��������A�����l���Ȃ��ɂ߂ăV���v���ȉ��Z�ł́A
OpenCL(GPU) �𗘗p����Ƃ������Ēx���Ȃ�A�Ƃ������Ƃ�������܂��B
OpenCL �͂��̋@�\��L���Ɋ��p������@��������Ɖ������Ă����K�v������܂��B
OpenCL �́A�Ƃ肠�����g���Α����Ȃ�A�Ƃ��������@�̃c�[���ł͂Ȃ��킯�ł��B
�ŏI�I�ɂ����������Ԃ́A���悻 640msec�A�p�ӂ�����ʓI�Ȏ�@�� 10msec �Ƃ���ƁA���s���Ԃ� 64 �{�̈Ⴂ�ł��B
�r�b�N������قǖ��Ӗ��� OpenCL(GPU) �̎g���������Ă��邱�Ƃ�������܂��B
���̂��Ƃ���A����̂悤�ȃT���v���ł��������A�����l���Ȃ��ɂ߂ăV���v���ȉ��Z�ł́A
OpenCL(GPU) �𗘗p����Ƃ������Ēx���Ȃ�A�Ƃ������Ƃ�������܂��B
OpenCL �͂��̋@�\��L���Ɋ��p������@��������Ɖ������Ă����K�v������܂��B
OpenCL �́A�Ƃ肠�����g���Α����Ȃ�A�Ƃ��������@�̃c�[���ł͂Ȃ��킯�ł��B
�ŏI�I�ɂ����������Ԃ́A���悻 640msec�A�p�ӂ�����ʓI�Ȏ�@�� 10msec �Ƃ���ƁA���s���Ԃ� 64 �{�̈Ⴂ�ł��B
�r�b�N������قǖ��Ӗ��� OpenCL(GPU) �̎g���������Ă��邱�Ƃ�������܂��B
����GCN����Ȃ���VLIW�̌��،��ʂ���
�A�~�͂���ȃJ�r�L���l�K�L�����\�[�X���������Ă���Ȃ��̂��N�\�b�^����
�A�~�͂���ȃJ�r�L���l�K�L�����\�[�X���������Ă���Ȃ��̂��N�\�b�^����
GPGPGU��(�N�\���Ӗ��ȏ�����)�g���Ȃ�
CUDA�ł������X���Ȃ��ǂ�
SSE��AVX�̂悤��4�A8�P�ʂł͂Ȃ��A����E�����P�ʂő�ʂɃf�[�^�ɓ�������������
��������ȗp�r�łȂ��ƃy�C�ł��Ȃ��B
�����āA����Ȃ��͈̂�ʓI�ȃ\�t�g�ɂ͂قƂ�ǖ����B
SSE��AVX�̂悤��4�A8�P�ʂł͂Ȃ��A����E�����P�ʂő�ʂɃf�[�^�ɓ�������������
��������ȗp�r�łȂ��ƃy�C�ł��Ȃ��B
�����āA����Ȃ��͈̂�ʓI�ȃ\�t�g�ɂ͂قƂ�ǖ����B
��Ƒ��̐H�������̂ɁA�t�[�h�v���Z�b�T�͑傢�ɖ𗧂�
�H�i�H��͂܂��������ɗ����Ȃ��A�݂����ȁB
�H�i�H��͂܂��������ɗ����Ȃ��A�݂����ȁB
H.265�G���R�[�_��GPGPU�EHSA�̎������o�Ă���O�ɐ�p�n�[�h�����y���Ă邾�낤��
���掿�����߂��H.264�Ɠ��l�A���x�ȉ�͂�v��CPU�̃X�J���������\���v������
����GPU����Ȃ��Ǝv���B
�ł�C++�Ƃ�����Ȃ���C#���x���̂͂��Ȃ�E�P���
���掿�����߂��H.264�Ɠ��l�A���x�ȉ�͂�v��CPU�̃X�J���������\���v������
����GPU����Ȃ��Ǝv���B
�ł�C++�Ƃ�����Ȃ���C#���x���̂͂��Ȃ�E�P���
>>698
�قƂ�ǃA�[�L�e�N�`���͊W����
�J�[�h�Ƀf�[�^�n���ꍇ�̌��،���
�ꉞ���Z���Ă邯�NJ|���Z2��ő����Z1��
�������l���Ȃ��ɂ߂ăV���v���ȉ��Z�ł́A
�ł͂Ȃ��u�������ĂȂ��ɂ߂ă`�[�v�ȉ��Z�v��
�قƂ�ǃA�[�L�e�N�`���͊W����
�J�[�h�Ƀf�[�^�n���ꍇ�̌��،���
�ꉞ���Z���Ă邯�NJ|���Z2��ő����Z1��
�������l���Ȃ��ɂ߂ăV���v���ȉ��Z�ł́A
�ł͂Ȃ��u�������ĂȂ��ɂ߂ă`�[�v�ȉ��Z�v��
�y�T���ł킩��ŐV�L�[���[�h����z�����v���Z�b�T�̐��ݔ\�͂������o���V�t���[�����[�N�uHSA�v
http://news.mynavi.jp/news/2015/01/27/151/
http://news.mynavi.jp/news/2015/01/27/151/
1920 * 1080������[�v���s���Ă�̂ɉ������ĂȂ��Ƃ������ˁE�E�E�E
�� �ꉞ���Z���Ă邯�NJ|���Z2��ő����Z1��
�����n��������
for���̐���\������ǂ߂Ȃ��f�l�ۏo��
���[�v�̓�����������s����邩�Ȃ�āA���w�Z��1�N���ł������������邼
����ς�AMD�t�@���{�[�C�͔n���������Ȃ��悤���B
�� �ꉞ���Z���Ă邯�NJ|���Z2��ő����Z1��
�����n��������
for���̐���\������ǂ߂Ȃ��f�l�ۏo��
���[�v�̓�����������s����邩�Ȃ�āA���w�Z��1�N���ł������������邼
����ς�AMD�t�@���{�[�C�͔n���������Ȃ��悤���B
�m��͓��̏�Ŏw���������Ń��[�v���Ă邩�烋�[�s�[�i�N���N���p�[�j�ƌ����邪
����͂Ƃ��������Z���ʂ��i�[����f�[�^�e�ʂ�8MB
���Z�O�̃f�[�^�͂����Ə��Ȃ�
��Ŋi�[����O�ɍs�����Z���|���Z2��ő����Z1��
�m��Ȃ�Δ]���ʼn��x������������邯��
�������͂܂���Ȃ�ɂ�Radeon�Ȃ��炻��Ȃ��Ƃɂ͂Ȃ�Ȃ�
����͂Ƃ������킴�킴�O���t�B�b�N�������Ƀf�[�^�n���čs�����Z���|���Z2��ő����Z1��
HSA�͂���ȕs�K���N����Ȃ��悤����GPU�݂̂Ƃ�
�K�b�c���s�����Z�̂ݐ�p����ł��悤�ɂ����낤����
�Ƃɂ��������牽�ł��|���Z2���Z1��͂Ȃ�����
����͂Ƃ��������Z���ʂ��i�[����f�[�^�e�ʂ�8MB
���Z�O�̃f�[�^�͂����Ə��Ȃ�
��Ŋi�[����O�ɍs�����Z���|���Z2��ő����Z1��
�m��Ȃ�Δ]���ʼn��x������������邯��
�������͂܂���Ȃ�ɂ�Radeon�Ȃ��炻��Ȃ��Ƃɂ͂Ȃ�Ȃ�
����͂Ƃ������킴�킴�O���t�B�b�N�������Ƀf�[�^�n���čs�����Z���|���Z2��ő����Z1��
HSA�͂���ȕs�K���N����Ȃ��悤����GPU�݂̂Ƃ�
�K�b�c���s�����Z�̂ݐ�p����ł��悤�ɂ����낤����
�Ƃɂ��������牽�ł��|���Z2���Z1��͂Ȃ�����
���āA���w���ł��킩��Z���̖��ł�
1920 * 1080 % 1440(SP) = ?
1920 * 1080 % 1440(SP) = ?
��%����Ȃ��ā�����
%�͑��̌���Ŋ���Z�����]������߂鉉�Z�q������
�m��̉��l�ςł̓f�[�^�R�s�[�ɔ�₷���Ԉȏ��
�]�肪0�������͑����ق����d��ȂȂ�
�m��̉��l�ςł̓f�[�^�R�s�[�ɔ�₷���Ԉȏ��
�]�肪0�������͑����ق����d��ȂȂ�
�ŁAID:FjieJZ87�̂�������͎Z���̖��͉����Ȃ���ł����H
������GPU��SP�ŕ����������邩��Ƃ����Ă�
�}�V���S�̂ŏ���������ς��킯����Ȃ��̂ł���
������GPU��SP�ŕ����������邩��Ƃ����Ă�
�}�V���S�̂ŏ���������ς��킯����Ȃ��̂ł���
����ȂƂ����%��u�����������w���Ɍ������珬�w�����u�`�ꂻ����
OpenCL Setup Time - 1 : 279.0702�@# OpenCL�����^�C���̋N������
OpenCL Setup Time - 2 : 8.7545�@�@ # CPU��GPU�̃f�[�^�]������
OpenCL Calc Time : 341.7137�@�@�@�@ # ���Z�{�̂̎��s����
OpenCL End Time : 9.1246�@�@�@�@�@�@# ���Z���ʂ�GPU��CPU�ɏ����߂�����
OpenCL Total Time : 638.6596�@�@�@�@# �g�[�^������
���̒��x�̒P���Ȗ�肾�ƁA�f�[�^�̃R�s�[�ɂ������Ă鎞�ԂȂ�Ă����������ƂȂ���ˁB
���Z�f�[�^�̓��͂���������6KB, �o�͂�8MB�قǂ����B
OpenCL Setup Time - 2 : 8.7545�@�@ # CPU��GPU�̃f�[�^�]������
OpenCL Calc Time : 341.7137�@�@�@�@ # ���Z�{�̂̎��s����
OpenCL End Time : 9.1246�@�@�@�@�@�@# ���Z���ʂ�GPU��CPU�ɏ����߂�����
OpenCL Total Time : 638.6596�@�@�@�@# �g�[�^������
���̒��x�̒P���Ȗ�肾�ƁA�f�[�^�̃R�s�[�ɂ������Ă鎞�ԂȂ�Ă����������ƂȂ���ˁB
���Z�f�[�^�̓��͂���������6KB, �o�͂�8MB�قǂ����B
����͂����ƁA���傪����Ȃ�GitHub�ł�pastebin�ł���������
�͔͓I�ȃR�[�h�������Ď��������Ǝv����
�R�[�h�����Ȃ��z���������z�̃R�[�h��ᔻ���鎑�i�͂Ȃ��B
�͔͓I�ȃR�[�h�������Ď��������Ǝv����
�R�[�h�����Ȃ��z���������z�̃R�[�h��ᔻ���鎑�i�͂Ȃ��B
714 �FSocket774�F2015/01/27(��) 16:26:12.95 ID:1/MM/46u
���Ԃ�3.1415*3.1415��1920*1080=2073600�����Ă�Ǝv������
�o�J�u�|���Z2��{�����Z1��v
�z��̓Y���v�Z�Ȃ�ĉ��Z���Ԃɓ���Ȃ��ł���
�z��̓Y���v�Z�Ȃ�ĉ��Z���Ԃɓ���Ȃ��ł���
716 �FSocket774�F2015/01/27(��) 16:38:34.48 ID:sUg6ju5z
VCE��UVD��GPU�̐��\�S���W�����B
��p��H������ȁB
�悤����ɃG���R�[�h���Ă�GPU�ŏ����͂��Ė������A�Y��ȓ�������Ă�GPU�ŏ����͂��Ė����B
������CPU�ɏ�������点�Ă�킯�ł͂������Ȃ��B
������AMD�̏ꍇ�͓����Ɏ��s���Ă��e�������ŏo����B
��p��H������ȁB
�悤����ɃG���R�[�h���Ă�GPU�ŏ����͂��Ė������A�Y��ȓ�������Ă�GPU�ŏ����͂��Ė����B
������CPU�ɏ�������点�Ă�킯�ł͂������Ȃ��B
������AMD�̏ꍇ�͓����Ɏ��s���Ă��e�������ŏo����B
�l�@�ɂ���ʂ�"Setup Time - 2"�͎�ɃJ�[�l���Ɉ�����ݒ肷�鏈��
���ƈ����܂薽�߂̗p��
��]�t�H�[�C�[�`�̐��E�̂��Ƃ͒m��Ȃ���
�f�[�^�]���̂��Ƃ�"Calk Time"�ɏ����Ă���
�����܂��Ԓd�։��]���̐��E�Ȃ疽�߁��f�[�^�ł�
���O���v���Ȃ炻���Ȃ낤�ƌ�����葼������
���ƈ����܂薽�߂̗p��
��]�t�H�[�C�[�`�̐��E�̂��Ƃ͒m��Ȃ���
�f�[�^�]���̂��Ƃ�"Calk Time"�ɏ����Ă���
�����܂��Ԓd�։��]���̐��E�Ȃ疽�߁��f�[�^�ł�
���O���v���Ȃ炻���Ȃ낤�ƌ�����葼������
718 �FSocket774�F2015/01/27(��) 16:53:35.51 ID:1/MM/46u
�����牽�ł��|���Z2���Z1��͂Ȃ�����
�|���Z2���Z1��
�|���Z2���Z1��
�|���Z2���Z1��
�|���Z2���Z1��
�|���Z2���Z1��
�|���Z2���Z1��
�|���Z2���Z1��
�|���Z2���Z1��
�|���Z2���Z1��
�|���Z2���Z1��
�|���Z2���Z1��
�|���Z2���Z1��
�|���Z2���Z1��
�|���Z2���Z1��
�|���Z2���Z1��
�|���Z2���Z1��
�|���Z2���Z1��
�|���Z2���Z1��
�|���Z2���Z1��
�|���Z2���Z1��
�|���Z2���Z1��
�|���Z2���Z1��
�|���Z2���Z1��
�|���Z2���Z1��
�|���Z2���Z1��
�|���Z2���Z1��
�|���Z2���Z1��
�|���Z2���Z1��
�|���Z2���Z1��
2016�N���������҂��Ă��̂ɁE�E
�ł�͂�Cheetah��zen�ł����̂��ȁH
�ł�͂�Cheetah��zen�ł����̂��ȁH
���{�l�Ȃ�C���e���Q�t�H���
�C���e���Q�t�H����ɒނ���970�������o�J�����@����
���Ô��悷�狑�ۂ�
���Ô��悷�狑�ۂ�
724 �FSocket774�F2015/01/27(��) 18:06:49.80 ID:1/MM/46u
GTX970�������Ȃ����甃��
���O�J�r�̐�����VLIW�ł̌��،��ʎ����Ă����H�����
���Âœ��������ԃW����
�܂��ɔ�����s�ꂾ��
�I����ɉ���������10�����炢�����ė����悗
���Âœ��������ԃW����
�܂��ɔ�����s�ꂾ��
�I����ɉ���������10�����炢�����ė����悗
726 �FSocket774�F2015/01/27(��) 18:17:41.55 ID:1/MM/46u
�������ɂ���͏���
"�����牽�ł��|���Z2���Z1��͂Ȃ�����"
��VLIW,GCN�W�Ȃ��O�����̒i�K�Řb�ɂȂ��ĂȂ����낤�Ǝv����ł����ǂ�
279.0702+8.7545>>>10
287.8/10��28.78
CPU�Ȃ瓯���v�Z��28��ȏ�ł��Ă�
"�����牽�ł��|���Z2���Z1��͂Ȃ�����"
��VLIW,GCN�W�Ȃ��O�����̒i�K�Řb�ɂȂ��ĂȂ����낤�Ǝv����ł����ǂ�
279.0702+8.7545>>>10
287.8/10��28.78
CPU�Ȃ瓯���v�Z��28��ȏ�ł��Ă�
727 �FSocket774�F2015/01/27(��) 18:21:37.79 ID:9qQ+1PEq
260 ���O�FSocket774 ���e���F2015/01/24(�y) 23:19:55.53 ID:+AIb2+88
AMD����X�I�ɐ�`���Ă�HSA���C�u��������
Intel�����ł�������J�����Ă邨�V�уc�[���ɂ����Ȃ�ispc�̂ق���
���̐����{�ȏ㑽�����Ăǂ��������Ƃ��낤��
https://github.com/ispc/ispc
https://github.com/HSA-Libraries/
AMD����X�I�ɐ�`���Ă�HSA���C�u��������
Intel�����ł�������J�����Ă邨�V�уc�[���ɂ����Ȃ�ispc�̂ق���
���̐����{�ȏ㑽�����Ăǂ��������Ƃ��낤��
https://github.com/ispc/ispc
https://github.com/HSA-Libraries/
�ǂ��ł�������
���Â�GTX970��10�������̂��H100�������̂��H
�������Ɣ�����ID�t���̎ʐ^�Ŋ��C�݂��Ă����
���Â�GTX970��10�������̂��H100�������̂��H
�������Ɣ�����ID�t���̎ʐ^�Ŋ��C�݂��Ă����
729 �FSocket774�F2015/01/27(��) 18:24:39.12 ID:1/MM/46u
>>728
�ǂ��ł������킗
�ǂ��ł������킗
�����������\���悱�̃`�L������
�N�����ăo�O�t���͈����낤�����������˂����
���������Ȃ��Ə����Ȃ�n�Q
�N�����ăo�O�t���͈����낤�����������˂����
���������Ȃ��Ə����Ȃ�n�Q
�����Ȃ�����GTX970�����I�Ƃ����_�b�Tw
732 �FSocket774�F2015/01/27(��) 18:26:56.76 ID:1/MM/46u
�₷�����1������
GTX960�������₷�����Ȃ�
GTX960�������₷�����Ȃ�
1�R�Ƃ��H����炵���˂��Ȃ��`
�����Ɣ��������
�����ł����l�C�̂Ȃ��A�L�o�̎���PC�V���b�v���܁`���|�Y�����Ⴄ��H��
�����Ɣ��������
�����ł����l�C�̂Ȃ��A�L�o�̎���PC�V���b�v���܁`���|�Y�����Ⴄ��H��
734 �FSocket774�F2015/01/27(��) 18:31:43.50 ID:1/MM/46u
AMD���i��舵��Ȃ������v����
�܂��L�����x���Ĕ����Ă�������Ƃ̖��H�Ȃ�Ă���Ȃ����
����ŕ��������F�̃Q�t�H������Ă�Ƃ��Ӗ��s����������
���̐����łǂ����̃V���b�v���|�Y�Ղ肾�낤��
����҂��k�r�̏o����҂���BTO�������������Ȃ����낤��
����ŕ��������F�̃Q�t�H������Ă�Ƃ��Ӗ��s����������
���̐����łǂ����̃V���b�v���|�Y�Ղ肾�낤��
����҂��k�r�̏o����҂���BTO�������������Ȃ����낤��
736 �FSocket774�F2015/01/27(��) 18:38:07.81 ID:1/MM/46u
�V���b�v���|�Y���悤��1�~�����W�Ȃ����炢�����ǂ�
�͂擊�����藈��
�͂擊�����藈��
�Q�t�H�~�͏������|�Y���悤���ǂ��ł��������Ă�
���O�݂����ȃC�k�̂������W�͏���������Ȃ������
���O�݂����ȃC�k�̂������W�͏���������Ȃ������
738 �FSocket774�F2015/01/27(��) 18:43:58.14 ID:1/MM/46u
�����|�Y�ӂ����ɂ�AMD���i��舵��Ȃ��̂���Ԃ���
739 �FSocket774�F2015/01/27(��) 18:44:08.45 ID:lC+Yh8JI
AMD�̊������}���I�I�@�������L��Ƃɔ�������錩�����L���� [�]�ڋ֎~](c)2ch.net [895142347]
http://fox.2ch.net/test/read.cgi/poverty/1422345267/
http://fox.2ch.net/test/read.cgi/poverty/1422345267/
���Q�t�H��8���ȏ�̃V�F�A�������ĂĂ�����PC�W�̏������|�Y���Ă錻�������
����PC�f�l�ł���q�ɂ�����Q�t�H�̃C�m�x�[�V�����s���������Ă�
����PC�f�l�ł���q�ɂ�����Q�t�H�̃C�m�x�[�V�����s���������Ă�
741 �FSocket774�F2015/01/27(��) 18:50:14.03 ID:1/MM/46u
�C�m�x�[�V������
�����Y��Ă��k�r�Ɋւ��Ă̓C�m�x�[�V�����͂�������
�q���x���X�y�b�N���\�̋Z�pw
�x���`�͐����Ă������肩�����C���e��CPU�Ƃ����R���r����
�ǂ����������ĂĂ������̂����f�t���˂��悗
�q���x���X�y�b�N���\�̋Z�pw
�x���`�͐����Ă������肩�����C���e��CPU�Ƃ����R���r����
�ǂ����������ĂĂ������̂����f�t���˂��悗
�ǂ��������ɂ������肩�����C���e��CPU�p�̃O���{�Ȃ�H��
���傱���Ǝd�l���떂���������Ă���ȋ̈����S�~CPU�ɊÂĂ�ǂ�����
�ǂ����o���˂���(��)���ĂƂ��낾�낤��
���傱���Ǝd�l���떂���������Ă���ȋ̈����S�~CPU�ɊÂĂ�ǂ�����
�ǂ����o���˂���(��)���ĂƂ��낾�낤��
744 �FSocket774�F2015/01/27(��) 19:00:23.69 ID:yH/Gny85
���\�Ƃ�����amd
�܂��ǎg�����ɂȂ�Ȃ�hsa���
���N�J�x���o���Ƃ������ɂ����ꂩ��Ή��\�t�g�o�܂���Ă��Ȃ���ł���
���lj����Ȃ�����
����Hcomputex�܂ł�h.264�f�R�[�h����Ƃ��ق����ĂȂ���������
�܂��ǎg�����ɂȂ�Ȃ�hsa���
���N�J�x���o���Ƃ������ɂ����ꂩ��Ή��\�t�g�o�܂���Ă��Ȃ���ł���
���lj����Ȃ�����
����Hcomputex�܂ł�h.264�f�R�[�h����Ƃ��ق����ĂȂ���������
�������肩�����C���e��CPU��3.5GB�ȏ��VRAM�g���Ƃ������肷��GTX970
������ĕs��Ȃ��Ɗy�����Ȃ��Ƃ͂���������ăh���C�o�X�V�ʼn��P����o�O���x���̘b������Ȃ�
�X�y�b�R���\�͕s��Ƃ͌����܂������H��
������ĕs��Ȃ��Ɗy�����Ȃ��Ƃ͂���������ăh���C�o�X�V�ʼn��P����o�O���x���̘b������Ȃ�
�X�y�b�R���\�͕s��Ƃ͌����܂������H��
746 �FSocket774�F2015/01/27(��) 19:02:27.18 ID:yH/Gny85
�|���Z2���Z1��
���F���̒��x�̗������o���Ȃ��n���������Ă���̂�����d�����Ȃ�
�C�m�x�[�V�����i�j
���F���̒��x�̗������o���Ȃ��n���������Ă���̂�����d�����Ȃ�
�C�m�x�[�V�����i�j
GTX970�ł������肩�����܂�
�����܊���(�_�A�v�����o�Ă��ĉΏ����̉R�Ŏd�l���\�ł���)
�C���e��CPU�ł������肩�����܂�
�����܊���
�v���O���������悤�Ƃ����ӗ~���킢�Ă����ł���H��
�����܊���(�_�A�v�����o�Ă��ĉΏ����̉R�Ŏd�l���\�ł���)
�C���e��CPU�ł������肩�����܂�
�����܊���
�v���O���������悤�Ƃ����ӗ~���킢�Ă����ł���H��
����̈�̃��������g���x���`���D��Ă�������Ηǂ����i�ł���Ƃ���4gamer�I�\�����͍��b�I�ł�
2015�N�͍L������ŃV�F�A()������Ă���������Ƃ̂��̎�̍��\���\�����N�ɂȂ肻������
����`�V�N���X�����X�^�[�g���܂�����
2015�N�͍L������ŃV�F�A()������Ă���������Ƃ̂��̎�̍��\���\�����N�ɂȂ肻������
����`�V�N���X�����X�^�[�g���܂�����
749 �FSocket774�F2015/01/27(��) 19:10:39.70 ID:4uFRmbnI
kaveri��i7��56�{�����Ȃ�܂���
brook�������܂���
stream�������܂���
havoc��opencl�����܂���
3dnow!�������܂���
brook�������܂���
stream�������܂���
havoc��opencl�����܂���
3dnow!�������܂���
750 �FSocket774�F2015/01/27(��) 19:11:08.54 ID:4uFRmbnI
sse5�������܂���
�n�n�n��
���~�������Ă炗����
���~�������Ă炗����
752 �FSocket774�F2015/01/27(��) 19:16:22.30 ID:Jk0JbhW9
>>749
amd�̍��\�͂��ꂢ�ȍ��\
amd�̍��\�͂��ꂢ�ȍ��\
ID�ς��ĘA������
�����ʂ�ɓs���������Ȃ�ƃ~�G�~�G�̎���ŃX���������˂�
�����ʂ�ɓs���������Ȃ�ƃ~�G�~�G�̎���ŃX���������˂�
754 �FSocket774�F2015/01/27(��) 19:22:00.50 ID:59wc4Anv
�܂������Ȃ��G�Ƃ��������Ă�́H
���ꂪ������Ȃ���A�z�ł���
����������a�l�ƌ��Ȃ��U���p�e���v���g���Ă܂ŕK��
����������a�l�ƌ��Ȃ��U���p�e���v���g���Ă܂ŕK��
756 �FSocket774�F2015/01/27(��) 19:27:27.81 ID:MKINHEKM
>>706
�Ȃ��܂����m�I��Q�҂������̂�
�Ȃ��܂����m�I��Q�҂������̂�
�ق�ق�e��������H����Ȃɂ���Ă�́H��
758 �F,,�E�L�́M�E,,�j��-�������F2015/01/27(��) 19:31:27.57 ID:bt23XFwe
�����܂��܂Ƃ��Ȑl�Ȃ疈����������������AMD�X���ɋ������ĂȂ��Ǝv���B
759 �F,,�E�L�́M�E,,�j��-�������F2015/01/27(��) 19:44:38.35 ID:bt23XFwe
SIMT���邩�[�H
>>737
AMD������ɔ���邩����v�i�_
AMD������ɔ���邩����v�i�_
762 �F,,�E�L�́M�E,,�j��-�������F2015/01/27(��) 19:58:16.54 ID:bt23XFwe
MCM��G34 Opteron�̓������̈�ɂ���Ĕ{�ȏ�̑ш捷���o�邪�A����͂����̂��H
765 �FSocket774�F2015/01/27(��) 20:02:04.16 ID:9qQ+1PEq
>>763
���炩���߃f�[�^�V�[�g�ɂ��������Ă���ꍇ�͖��ɂȂ�Ȃ��ł���H
nvidia�́A�ォ��3.5G�ȏオ�x���Ȃ���Ĕ��o��������A���Ă͂܂�Ȃ�����
���炩���߃f�[�^�V�[�g�ɂ��������Ă���ꍇ�͖��ɂȂ�Ȃ��ł���H
nvidia�́A�ォ��3.5G�ȏオ�x���Ȃ���Ĕ��o��������A���Ă͂܂�Ȃ�����
766 �F,,�E�L�́M�E,,�j��-�������F2015/01/27(��) 20:02:47.60 ID:bt23XFwe
�������������
HSA�����^�C���̍ŐV�ł�����������x�����Ă��H
����ȒP���Ȋ|���Z�Ȃ�܂������Ȃ��Ǝv����B
HSA�����^�C���̍ŐV�ł�����������x�����Ă��H
����ȒP���Ȋ|���Z�Ȃ�܂������Ȃ��Ǝv����B
>>766
AMD��HSA�AGPGPU�Œ��o������I���ĕK���Ɍ����Ă��Ă��A
Kaveri����er�Ŏ��ۂ�OpenCL(HSA)�J�����������Ă���z���ĂقƂ�ǂ��Ȃ��悤�ȃL�K�X
AMD��HSA�AGPGPU�Œ��o������I���ĕK���Ɍ����Ă��Ă��A
Kaveri����er�Ŏ��ۂ�OpenCL(HSA)�J�����������Ă���z���ĂقƂ�ǂ��Ȃ��悤�ȃL�K�X
�c�q��GitHub�̎����Ղ�����߂Ďw�E��������
�֏悵��AMD�̃C���h�l���ׁX�ƃ����e���Ă��邾���Ȃ̂��w�E������A
���O�͉����������Ă��Ȃ��o�J���ƌ������z
�����Ă邩�`�}��
�֏悵��AMD�̃C���h�l���ׁX�ƃ����e���Ă��邾���Ȃ̂��w�E������A
���O�͉����������Ă��Ȃ��o�J���ƌ������z
�����Ă邩�`�}��
769 �F,,�E�L�́M�E,,�j��-�������F2015/01/27(��) 20:25:14.14 ID:bt23XFwe
>>767
�u�v���O���~���O�����ȒP�ɂȂ�v�Ȃ��
���ۂɃv���O���������Ȃ��z���������Ƃ���Ȃ��Ǝv���̂���
�Ȃ�ł������r�b�O�}�E�X�����̂��͗����ɋꂵ��
�u�v���O���~���O�����ȒP�ɂȂ�v�Ȃ��
���ۂɃv���O���������Ȃ��z���������Ƃ���Ȃ��Ǝv���̂���
�Ȃ�ł������r�b�O�}�E�X�����̂��͗����ɋꂵ��
>>764
�o�C�i���[�������������̂�
�o�C�i���[�������������̂�
���͎��c�Ɓi���e�j���Ȃ���G�`���ăQ�[������Ď��p�A�v������ċƖ��p�A�v������Ă邯��
�����Ȃy�C���g�\�t�g�Ŋ��p�o���邩�ȁH���炢�Ŗ{���͗p���������
HSA�Ń��W���[���ꂪ�Ή�������}���`�X���b�h���炢�̊��o�Ŏ����Ɏg���Ă��邾�낤���Ă��炢��
�����Ȃy�C���g�\�t�g�Ŋ��p�o���邩�ȁH���炢�Ŗ{���͗p���������
HSA�Ń��W���[���ꂪ�Ή�������}���`�X���b�h���炢�̊��o�Ŏ����Ɏg���Ă��邾�낤���Ă��炢��
772 �F,,�E�L�́M�E,,�j��-�������F2015/01/27(��) 20:32:05.32 ID:bt23XFwe
>>768
Bolt�i�j�̎c�O��������2�N�O���炢����悭�l�^�ɂ��Ă�C�����邯��
���͎Г��ŃN���[�Y�h�ŊJ�����Ă�o�[�W������HSA�͏������Ƃ�
�A�z�Ȃ��ƌ����Ă��Ȃ炢����B
�Ȃ�̂��߂ɃI�[�v���\�[�X�̃z�X�e�B���O�T�C�g�Ƀ��|�W�g�������Ă����Ďv�����B
�Ǘ����ł��Ȃ��Ȃ邶���B
Bolt�i�j�̎c�O��������2�N�O���炢����悭�l�^�ɂ��Ă�C�����邯��
���͎Г��ŃN���[�Y�h�ŊJ�����Ă�o�[�W������HSA�͏������Ƃ�
�A�z�Ȃ��ƌ����Ă��Ȃ炢����B
�Ȃ�̂��߂ɃI�[�v���\�[�X�̃z�X�e�B���O�T�C�g�Ƀ��|�W�g�������Ă����Ďv�����B
�Ǘ����ł��Ȃ��Ȃ邶���B
���{�l�Ȃ�C���e���Q�t�H���
���~�̔����͂������m����
776 �F,,�E�L�́M�E,,�j��-�������F2015/01/27(��) 20:37:40.89 ID:bt23XFwe
�\�[�X�R�[�h������玩���ŃR���p�C������Ⴂ���̂�
�����G�A�v���O���}�ɂ͖����ł���
�����G�A�v���O���}�ɂ͖����ł���
AMD�͉�Ђ��t�@���{�[�C���r�b�O�}�E�X�������
�k�r�̃X�y�b�N���̂̌떂��������
779 �F,,�E�L�́M�E,,�j��-�������F2015/01/27(��) 20:50:03.74 ID:bt23XFwe
���O�ŃR���p�C�����Ď��s���Ă݂�
���s����Core i3-4000M / HD4600
OpenCL Setup Time - 1 : 278.2095
OpenCL Setup Time - 2 : 1.0511
OpenCL Calc Time : 5.822
OpenCL End Time : 4.1704
OpenCL Total Time : 289.2518
���s����Core i3-4000M / HD4600
OpenCL Setup Time - 1 : 278.2095
OpenCL Setup Time - 2 : 1.0511
OpenCL Calc Time : 5.822
OpenCL End Time : 4.1704
OpenCL Total Time : 289.2518
780 �FSocket774�F2015/01/27(��) 20:50:23.77 ID:jH5e4XYN
>>774
��APU�ł��Β������ʂɂȂ��
EOL���Ă��Ȃ����s���f����APU�����Ō��Ă�HSA�Ή����Ă��Ȃ����i�̕��������̂�����AHSA�W�Ȃ�APU�Ȃ瑬���Ȃ�Ǝv���Ă����Ȃ��̂��H
��APU�ł��Β������ʂɂȂ��
EOL���Ă��Ȃ����s���f����APU�����Ō��Ă�HSA�Ή����Ă��Ȃ����i�̕��������̂�����AHSA�W�Ȃ�APU�Ȃ瑬���Ȃ�Ǝv���Ă����Ȃ��̂��H
781 �F,,�E�L�́M�E,,�j��-�������F2015/01/27(��) 20:51:58.35 ID:bt23XFwe
�Ă����A���ꂪCL�̃J�[�l������H200���[�v�̃C���X�^���X1��������
//OpenCLC�ɂ���ċL�q�����\�[�X�R�[�h
string[] sourceCode = new string[]
{
"__kernel void\n"+
"mul(__global const float xDataArray[],\n"+
" __global const float yDataArray[],\n"+
" __global float rDataArray[])\n"+
"{\n"+
" for(int y = 0; y < 1080 ; y++)\n" +
" for(int x = 0; x < 1920; x++)\n"+
" {\n"+
" rDataArray[x + y * 1920] = xDataArray[x] * yDataArray[y];\n"+
" }\n"+
"}\n"
};
//OpenCLC�ɂ���ċL�q�����\�[�X�R�[�h
string[] sourceCode = new string[]
{
"__kernel void\n"+
"mul(__global const float xDataArray[],\n"+
" __global const float yDataArray[],\n"+
" __global float rDataArray[])\n"+
"{\n"+
" for(int y = 0; y < 1080 ; y++)\n" +
" for(int x = 0; x < 1920; x++)\n"+
" {\n"+
" rDataArray[x + y * 1920] = xDataArray[x] * yDataArray[y];\n"+
" }\n"+
"}\n"
};
782 �F,,�E�L�́M�E,,�j��-�������F2015/01/27(��) 20:54:53.32 ID:bt23XFwe
���̃R�[�h����ǂ����Z�ʑ����Ă�GPU�̂ق���CPU�̑��x�����邱�Ƃ͂���܂����
�������Q�t�H�~���A�z����
�Q�t�H��Power�ƃR�q�[�����g�o�X�Ōq�����A�C���e�����X�J�C���[�N����R�q�[�����g�o�X�������Ă���
CPU��GPU�̘A�g�����͂Ƃ����Ɋ���H���Ȃ�w
�C���e���ȂƂ�����CPU�̋����Ȃ�Ē��߂�GPU�����ɍ��X�K��
AVX512�Ƃ�����ł邯�ǁAAVX128��AVX256�̍����S���Ȃ����玀�Y�m�肾��
IPC�オ���A�N���b�N�オ���AAVX���������Ӗ��A�Ƃ�����4k8k�������܂߂�GPU�������������Ȃ��̂����Ă�
�Q�t�H��Power�ƃR�q�[�����g�o�X�Ōq�����A�C���e�����X�J�C���[�N����R�q�[�����g�o�X�������Ă���
CPU��GPU�̘A�g�����͂Ƃ����Ɋ���H���Ȃ�w
�C���e���ȂƂ�����CPU�̋����Ȃ�Ē��߂�GPU�����ɍ��X�K��
AVX512�Ƃ�����ł邯�ǁAAVX128��AVX256�̍����S���Ȃ����玀�Y�m�肾��
IPC�オ���A�N���b�N�オ���AAVX���������Ӗ��A�Ƃ�����4k8k�������܂߂�GPU�������������Ȃ��̂����Ă�
����APU���g���Α̊��ő����i�د
���̃R�[�h���̊����ƁACL_DEVICE_TYPE_DEFAULT��CPU�g���悤�ɂȂ��Ƃ�
>>774
����HSA�ɍS�邱���Ȃ����낤
Kaveri��OpenCL�ɑΉ����Ă邾�낤���������̂܂��s�������
�ł�����҂����łɁu�]���̃I�[�o�[�w�b�h�v���Č����Ă邵
���ꂪ���_�ł������
�������u���߁��f�[�^�v�Ȑ��E���Ƃǂ��Ȃ邩�͖��m����
�u�u�|���Z2��ő����Z1��v�Łu8MB�v�Ƃ͂܂�f�[�^�ɏ��Ŗ��ߋɑ�v�Ƃ͂ǂ��������Ƃ��H
�O��������Ղ��邾���Ō������t����
�u���ނ�GPU�͓���SIMT���������ނ�GPU������SIMT�Ȃ킯���Ȃ��v
�Ƃ��������Ƀq���g���B����Ă���悤�ȋC�����邪
���ꂷ�痝��s�\�Ȃ̂ł�͂�ܗ�����
�ꐡ��̓~�j�I�l�A
����HSA�ɍS�邱���Ȃ����낤
Kaveri��OpenCL�ɑΉ����Ă邾�낤���������̂܂��s�������
�ł�����҂����łɁu�]���̃I�[�o�[�w�b�h�v���Č����Ă邵
���ꂪ���_�ł������
�������u���߁��f�[�^�v�Ȑ��E���Ƃǂ��Ȃ邩�͖��m����
�u�u�|���Z2��ő����Z1��v�Łu8MB�v�Ƃ͂܂�f�[�^�ɏ��Ŗ��ߋɑ�v�Ƃ͂ǂ��������Ƃ��H
�O��������Ղ��邾���Ō������t����
�u���ނ�GPU�͓���SIMT���������ނ�GPU������SIMT�Ȃ킯���Ȃ��v
�Ƃ��������Ƀq���g���B����Ă���悤�ȋC�����邪
���ꂷ�痝��s�\�Ȃ̂ł�͂�ܗ�����
�ꐡ��̓~�j�I�l�A
>>782
OpenCL�g����for�̂Ƃ���������I�ɕ����Ă����Ȃ��̂��H
openMP�̂Ƃ��͂��������Ă˂���pragma�w�肵�Ȃ��Ƒʖڂ��������A
openCL�ł͂��ꂪ����Ȃ���Ȃ��̂��B�Ɩϑz
OpenCL�g����for�̂Ƃ���������I�ɕ����Ă����Ȃ��̂��H
openMP�̂Ƃ��͂��������Ă˂���pragma�w�肵�Ȃ��Ƒʖڂ��������A
openCL�ł͂��ꂪ����Ȃ���Ȃ��̂��B�Ɩϑz
����Ȍf���łǂ������ǂ����ł�[����i�j
>>790
�m���ɍ��̂Ƃ���HSA��dGPU���T�|�[�g���Ă��Ȃ����ĕ������ȁB
�w�e���Ȃ瓖�RdGPU���T�|�[�g�������ċC�����邪
�`�b�v���̂��̌���Ȃ̂���
�m���ɍ��̂Ƃ���HSA��dGPU���T�|�[�g���Ă��Ȃ����ĕ������ȁB
�w�e���Ȃ瓖�RdGPU���T�|�[�g�������ċC�����邪
�`�b�v���̂��̌���Ȃ̂���
>>783
AMD��R&D�Ƀ^�_��肷�邽�߂�APU�����҂��Ă����
����IBM�݂����ȕ���Ђ̐��i�g�������o�J�͂��˂����낗
>>790
>AMD��HSA��dGPU�̂ĂĂ鈵������Ă����
mantle��APU��R9 290�Ő��\����̋L���ǂ�łȂ��H
AMD��R&D�Ƀ^�_��肷�邽�߂�APU�����҂��Ă����
����IBM�݂����ȕ���Ђ̐��i�g�������o�J�͂��˂����낗
>>790
>AMD��HSA��dGPU�̂ĂĂ鈵������Ă����
mantle��APU��R9 290�Ő��\����̋L���ǂ�łȂ��H
http://japan.zdnet.com/article/35056660/
�ăG�l���M�[�ȁA���E�ő��̃X�p�R���J����--IBM��NVIDIA����w��
�ăG�l���M�[�Ȃ́AIBM�ANVIDIA�AMellanox�Ƌ����Ő��E�ő��̃X�[�p�[�R���s���[�^���J������Ɣ��\�����B
���̃v���W�F�N�g�ɂ�3��2500���h������������A2017�N�܂ł�2��̃X�[�p�[�R���s���[�^�A�uSummit�v����сuSierra�v�̊�����ڎw���B
���R���s���[�^��IBM�́uOpenPOWER�v�`�b�v��NVIDIA�́uVolta�v�O���t�B�b�N�X�`�b�v�𓋍ڂ��A
�S�R���|�[�l���g��Mellanox�̍����l�b�g���[�N�Z�p�ő��ݐڑ������B
�ăG�l���M�[�ȁA���E�ő��̃X�p�R���J����--IBM��NVIDIA����w��
�ăG�l���M�[�Ȃ́AIBM�ANVIDIA�AMellanox�Ƌ����Ő��E�ő��̃X�[�p�[�R���s���[�^���J������Ɣ��\�����B
���̃v���W�F�N�g�ɂ�3��2500���h������������A2017�N�܂ł�2��̃X�[�p�[�R���s���[�^�A�uSummit�v����сuSierra�v�̊�����ڎw���B
���R���s���[�^��IBM�́uOpenPOWER�v�`�b�v��NVIDIA�́uVolta�v�O���t�B�b�N�X�`�b�v�𓋍ڂ��A
�S�R���|�[�l���g��Mellanox�̍����l�b�g���[�N�Z�p�ő��ݐڑ������B
�O�ɂǂ����̃X���ŊO���O���{�ł�HSA�͑��x�����������f�[�^�]���̊W�㖳�����ƌ��������悤�ȁB
795 �F,,�E�L�́M�E,,�j��-�������F2015/01/27(��) 21:17:16.58 ID:bt23XFwe
>>787
����
�ǂ������Ƃ����Ƃ���Ȋ����ŁA1920*1080�ɖ�������B
__kernel void mul (__global const float xDataArray[], __global const float yDataArray[], __global float rDataArray[]) {
int id = get_global_id(0);
rDataArray[id] = xDataArray[id % 1920] * yDataArray[id / 1920];
}
�ł����ꂾ�Ə��Z�̃I�[�o�[�w�b�h�̂ق����傫�����Ȃ̂�1920����or1080�������Ó��ȂƂ��납
����
�ǂ������Ƃ����Ƃ���Ȋ����ŁA1920*1080�ɖ�������B
__kernel void mul (__global const float xDataArray[], __global const float yDataArray[], __global float rDataArray[]) {
int id = get_global_id(0);
rDataArray[id] = xDataArray[id % 1920] * yDataArray[id / 1920];
}
�ł����ꂾ�Ə��Z�̃I�[�o�[�w�b�h�̂ق����傫�����Ȃ̂�1920����or1080�������Ó��ȂƂ��납
796 �FSocket774�F2015/01/27(��) 21:21:00.00 ID:9G6A7a6/
>>783
���C�o����CPU������ڂ����邩��Intel��CPU�̋������Ȃ��Ă�����
Intel��CPU�������撣���Ă�̂��āAATOM�Ƃ�������������ł���H
�f�X�N�g�b�v��T�[�o��Intel�Ƒ��Ń��C�o���s�݂������
���C�o����CPU������ڂ����邩��Intel��CPU�̋������Ȃ��Ă�����
Intel��CPU�������撣���Ă�̂��āAATOM�Ƃ�������������ł���H
�f�X�N�g�b�v��T�[�o��Intel�Ƒ��Ń��C�o���s�݂������
�X���K��s IBM
�쑺�z�[���f�B���O�X IBM
�쑺�z�[���f�B���O�X IBM
>>792
�����A�ӂ��̃v���O���}�́A
OS�E�J���c�[���E�R���p�C���E���C�u�������̑��l�̐��ʂɃ^�_��肷��͓̂�����O����
TOKIO�݂����Ƀ��[�������̂ɏ�����������Ă��H
�����A�ӂ��̃v���O���}�́A
OS�E�J���c�[���E�R���p�C���E���C�u�������̑��l�̐��ʂɃ^�_��肷��͓̂�����O����
TOKIO�݂����Ƀ��[�������̂ɏ�����������Ă��H
799 �F,,�E�L�́M�E,,�j��-�������F2015/01/27(��) 21:23:10.06 ID:bt23XFwe
��肪�悭�Ȃ���
2�ׂ̂���̊���Z�Ȃ�V�t�g�ƃr�b�g�}�X�N�ł��ނƂ���
2�ׂ̂���̊���Z�Ȃ�V�t�g�ƃr�b�g�}�X�N�ł��ނƂ���
800 �FSocket774�F2015/01/27(��) 21:23:12.95 ID:egSB+kw0
2016�N(AMD����)
���E���ISMT����CPU�I
�Ȃ�ƁI1�R�A������2�X���b�h�������Ă��܂��I
���ꂩ���SMT�̎���IIntel�����ǂ��Ă��邩�ȁH
���E���ISMT����CPU�I
�Ȃ�ƁI1�R�A������2�X���b�h�������Ă��܂��I
���ꂩ���SMT�̎���IIntel�����ǂ��Ă��邩�ȁH
802 �F,,�E�L�́M�E,,�j��-�������F2015/01/27(��) 21:24:44.22 ID:bt23XFwe
>>798
HSA��GitHub�́��̐�����ƃ^�_��肵�����l���炢�Ă�3�����x�������Ȃ��悤�ł���
HSA��GitHub�́��̐�����ƃ^�_��肵�����l���炢�Ă�3�����x�������Ȃ��悤�ł���
HSA����25x20�̘b�ɂ��o�Ă��邯�Ǐ���d�͂����点��낤��
805 �F,,�E�L�́M�E,,�j��-�������F2015/01/27(��) 21:26:27.24 ID:bt23XFwe
�y��Ɓz�h�a�l�A��ʉ��ق\�@���Ј��S�̂̂Q�U���ɂ�����P�P���P�W�O�O�l�����ق���v��@??2ch.net
http://daily.2ch.net/test/read.cgi/newsplus/1422316447/
http://daily.2ch.net/test/read.cgi/newsplus/1422316447/
APU��HSA�ŁAGPU���ڂ̃}���`�v���Z�b�T��Mantle�ŋ����ł�����
�������X��HSA��Mantle�����Ă̂�AMD�̖ڕW���낤�A�Ƃ�����HSA+Mantle���{����HSA���낤
PS4��SDK��hUMA�ɑΉ��������AMantle�Q�[�������낻��N���X�t�@�C���̌�������Ɍ������n�߂Ă�
Mantle�̓^�_�̃Q�[��API�Ƃ������A���z�������g�����}���`GPU����API�����̂ȋC������
�����l����ƁAPS4��hUMA�Ή�APU���̗p���ꂽ����AAMD�̂�肽������HSA�̃\�t�g�ʂł̊J�����i��ł���悤�Ɍ�����
�������X��HSA��Mantle�����Ă̂�AMD�̖ڕW���낤�A�Ƃ�����HSA+Mantle���{����HSA���낤
PS4��SDK��hUMA�ɑΉ��������AMantle�Q�[�������낻��N���X�t�@�C���̌�������Ɍ������n�߂Ă�
Mantle�̓^�_�̃Q�[��API�Ƃ������A���z�������g�����}���`GPU����API�����̂ȋC������
�����l����ƁAPS4��hUMA�Ή�APU���̗p���ꂽ����AAMD�̂�肽������HSA�̃\�t�g�ʂł̊J�����i��ł���悤�Ɍ�����
50���l�ȏ㋏���̂��悗
�J�����i��ł��āA���̈ב̂Ȃ̂�
IBM��NVIDIA�Ƒg�̂̓G�N�T�X�P�[���X�p�R���̊J���v��ɑΉ����邽�߂��낤����
IBM�̓o���o���n�[�h�E�F�A�W�̎��Ƃ�蔄�肵�Ă邩��Ȃ�
POWER�����܂ł��̂��
IBM�̓o���o���n�[�h�E�F�A�W�̎��Ƃ�蔄�肵�Ă邩��Ȃ�
POWER�����܂ł��̂��
810 �F,,�E�L�́M�E,,�j��-�������F2015/01/27(��) 21:34:01.54 ID:bt23XFwe
����C#�R�[�h�ɂ��Ă���
for (int y = 0; y < yDataArray.Length; y++)
for (int x = 0; x < xDataArray.Length; x++)
{
rDataArray[] = xDataArray[x] * yDataArray[y];
}
SIMT����́A�C�e���[�V��������x + y * xDataArray.Length�̓Y���v�Z����Ǝv���Ă��ł���
���̒��x�Ȃ珉���I�ȍœK����y * xDataArray.Length�̕����͓����̃��[�v�̊O�ɏo�������ǂ�
����A�v���O�����g�o������Ȃ�펯����H�R���p�C�����ǂ�ȍœK�����邩�Ȃ��
�@�����牽�ł��|���Z2���Z1��͂Ȃ�����
���n���ۏo��
for (int y = 0; y < yDataArray.Length; y++)
for (int x = 0; x < xDataArray.Length; x++)
{
rDataArray[] = xDataArray[x] * yDataArray[y];
}
SIMT����́A�C�e���[�V��������x + y * xDataArray.Length�̓Y���v�Z����Ǝv���Ă��ł���
���̒��x�Ȃ珉���I�ȍœK����y * xDataArray.Length�̕����͓����̃��[�v�̊O�ɏo�������ǂ�
����A�v���O�����g�o������Ȃ�펯����H�R���p�C�����ǂ�ȍœK�����邩�Ȃ��
�@�����牽�ł��|���Z2���Z1��͂Ȃ�����
���n���ۏo��
Fanboy���L��HSA��Mantle�̓��ꎋ
���ʂ̎l�����Z���A�R���p�C���ʂ�����r�b�g�V�t�g���Z�Ƃ�����Ȃ̂Ōv�Z�ł���݂�����
�R�[�h�ɏ���ɏ�����������悤�ɂȂ��Ă���A
�R���p�C���̍œK���ɓ˂����ނ̂͂�߂�
�R�[�h�ɏ���ɏ�����������悤�ɂȂ��Ă���A
�R���p�C���̍œK���ɓ˂����ނ̂͂�߂�
>>798
�C���e����k�r��IBM�����ʂ̃v���O���}���݂��Ă���
�떂�����̋Z�p��AMD�������Ă�̂͊ԈႢ�Ȃ��g�R������
�Ȃ���FUD�̌��l�^�̉�Ђ����邵��
�\�t�g���n�[�h���S�~�������Ȃ��L���O�I�u����Ƃ̏W���̂ŃX�p�R��()�Ƃ�
�ǂ��������Q�o�̉��荇���ɂȂ�̂������̂���
�C���e����k�r��IBM�����ʂ̃v���O���}���݂��Ă���
�떂�����̋Z�p��AMD�������Ă�̂͊ԈႢ�Ȃ��g�R������
�Ȃ���FUD�̌��l�^�̉�Ђ����邵��
�\�t�g���n�[�h���S�~�������Ȃ��L���O�I�u����Ƃ̏W���̂ŃX�p�R��()�Ƃ�
�ǂ��������Q�o�̉��荇���ɂȂ�̂������̂���
openpower����power��ip�g����͂��Ȃ̂�
ibm��ip���ɂł��Ȃ�̂���
���X�g�����Ă�40���l�ȏ㋏�邯��
ibm��ip���ɂł��Ȃ�̂���
���X�g�����Ă�40���l�ȏ㋏�邯��
815 �F,,�E�L�́M�E,,�j��-�������F2015/01/27(��) 21:40:47.85 ID:bt23XFwe
����[�ł�Intel�̓t���X�N���b�`��SPMD�R���p�C�����悤�Ȃ����Ӗ��ł̕ϑԂ����邩��ȁE�E�E�E
>>809
IBM�͋��Z()�̋q����Ƀ{�b�^�ł��邩�瓖�����ł���
IBM�͋��Z()�̋q����Ƀ{�b�^�ł��邩�瓖�����ł���
�u�v���O�����ɏK�n����ƃR���p�C���̋���������v�Ƃ�������
���̎���Google�������Ă��ق����܂��m���t����
�u������E�ƃv���O���}����ӂ�������Ēm��ɂ����܂�̂��H�v���炢������
���Ȃ݂ɂ���C�R���p�C�����O�ō���Ă�l�����Ǖϑԉ߂���
������ۂ��R�[�h�̗�����ǂ��@�B��ɖ̂��͖{���ɃR���p�C���̍��莟��
tp://qiita.com/ruiu/items/4d471216b71ab48d8b74
���̎���Google�������Ă��ق����܂��m���t����
�u������E�ƃv���O���}����ӂ�������Ēm��ɂ����܂�̂��H�v���炢������
���Ȃ݂ɂ���C�R���p�C�����O�ō���Ă�l�����Ǖϑԉ߂���
������ۂ��R�[�h�̗�����ǂ��@�B��ɖ̂��͖{���ɃR���p�C���̍��莟��
tp://qiita.com/ruiu/items/4d471216b71ab48d8b74
818 �F,,�E�L�́M�E,,�j��-�������F2015/01/27(��) 21:44:32.52 ID:bt23XFwe
�O�O���Ď��U���Ă��N�̓��͌����Ȃ�܂����SIMT����
819 �F,,�E�L�́M�E,,�j��-�������F2015/01/27(��) 21:49:58.35 ID:bt23XFwe
�]�����c�Ƃ̖��ESIMT����
��̃k�r���p�G���h�O���{�����A�z��ʋq����ɃX�y�b�N���̂Ń{�b�^����
���̃J�l���p����GPU�R�A�J�����Ă邾���Ȃ̂�
GPGPU���\�~�����q�̓Q�t�H�̓��b�p()�D��Ō݊����ێ����邽�߂�
��������x��CUDA���\���������Ȃ�����
�{�b�^�N�A�h�����e�X���������ăn�b�L�������Ă���
maxwell�R�A�̃Q�[���J�[�h������CUDA�A�v���Ő��\�o�Ȃ����Ă���
�o�J�Ȕ�Q�҂��o�����ɍς̂ɂ�
���̃J�l���p����GPU�R�A�J�����Ă邾���Ȃ̂�
GPGPU���\�~�����q�̓Q�t�H�̓��b�p()�D��Ō݊����ێ����邽�߂�
��������x��CUDA���\���������Ȃ�����
�{�b�^�N�A�h�����e�X���������ăn�b�L�������Ă���
maxwell�R�A�̃Q�[���J�[�h������CUDA�A�v���Ő��\�o�Ȃ����Ă���
�o�J�Ȕ�Q�҂��o�����ɍς̂ɂ�
http://www.4gamer.net/games/234/G023477/20131114049/
Mantle�ł́CGCN����Ƃ�������͂�����̂́C�قȂ�X�y�b�N��GPU��g�ݍ��킹���}���`GPU���ł��C���ꂼ���GPU���t�����p�ł���
�uAPU�ƒP��GPU�Ƃ�g�ݍ��킹�āCAPU����GPU�R�A���|�X�g�G�t�F�N�g������p�Ŏg���v�ȂǂƂ������C�_��Ȏg�������\
Mantle�ł́C���������Ɖ��z�������̊��蓖�Ă��������}�b�s���O�e�[�u���𑀍�ł���悤�ɂȂ�B
���̕ӂ̓���́A�Q�[����O���t�B�b�N���肶��Ȃ��A���RGPGPU�ł��L��
>>803
�������R�s�[����Ȃ�����A���ׂ��������āA�ш�ߖ�ł��邩�瓖�R�ȓd�͂ɂȂ�
�܂��A�ŏ���HSA�͌����������œ��������炻�̕��d�͏��Ղ��āA���ʃv���}�C�[�����ĂƂ��납
�������A�����Ȃ����ɉ��P���邩��A�����b�g�����ɂȂ�̂����Ԃ̖��
Mantle�ł́CGCN����Ƃ�������͂�����̂́C�قȂ�X�y�b�N��GPU��g�ݍ��킹���}���`GPU���ł��C���ꂼ���GPU���t�����p�ł���
�uAPU�ƒP��GPU�Ƃ�g�ݍ��킹�āCAPU����GPU�R�A���|�X�g�G�t�F�N�g������p�Ŏg���v�ȂǂƂ������C�_��Ȏg�������\
Mantle�ł́C���������Ɖ��z�������̊��蓖�Ă��������}�b�s���O�e�[�u���𑀍�ł���悤�ɂȂ�B
���̕ӂ̓���́A�Q�[����O���t�B�b�N���肶��Ȃ��A���RGPGPU�ł��L��
>>803
�������R�s�[����Ȃ�����A���ׂ��������āA�ш�ߖ�ł��邩�瓖�R�ȓd�͂ɂȂ�
�܂��A�ŏ���HSA�͌����������œ��������炻�̕��d�͏��Ղ��āA���ʃv���}�C�[�����ĂƂ��납
�������A�����Ȃ����ɉ��P���邩��A�����b�g�����ɂȂ�̂����Ԃ̖��
�܂��A����t���Ă�̂����@�ɐl��̂���
�ʂɃv���O�����S�����f�o�t�ɓ�����킯�ł�������
�K�v�ȋ@�\�A�\�ȋ@�\���A���ꂼ��p�ӂ��āA���ꂼ�ꂪ���p������������B
���ꂪ�A��F��[�V�����g���b�N���x���Ƃ��A�t���������A�a�������r�����������x�ł��ǂ�㩁B
����Ȃ���A���ꂼ�ꂪ�D���Ȃ��̂��g�����������B
�ʂɃv���O�����S�����f�o�t�ɓ�����킯�ł�������
�K�v�ȋ@�\�A�\�ȋ@�\���A���ꂼ��p�ӂ��āA���ꂼ�ꂪ���p������������B
���ꂪ�A��F��[�V�����g���b�N���x���Ƃ��A�t���������A�a�������r�����������x�ł��ǂ�㩁B
����Ȃ���A���ꂼ�ꂪ�D���Ȃ��̂��g�����������B
823 �F,,�E�L�́M�E,,�j��-�������F2015/01/27(��) 22:12:30.74 ID:bt23XFwe
����Ⴂ���牽�ł��|���Z2���Z1��͂Ȃ������
HSA��Mantle�͕⊮�W�̋Z�p�������
HSA��APU���̃A�h���X���L�AMantle�͉��z�������Ń}���`�w�e���v���Z�b�T
�v���Z�b�T�̓��O�ŁA�������Ǘ�����Ɏ�Ԃ��|���ĊJ���i�߂Ă�̂�������
�܂��A�V���O���X���b�h�x���`���S�ẴC���e����A�x���`������Ⴡ�����Ǘ��Ƃ��N�\�ł������Q�t�H�g���ɂ͗����ł��Ȃ����낤����
HSA��APU���̃A�h���X���L�AMantle�͉��z�������Ń}���`�w�e���v���Z�b�T
�v���Z�b�T�̓��O�ŁA�������Ǘ�����Ɏ�Ԃ��|���ĊJ���i�߂Ă�̂�������
�܂��A�V���O���X���b�h�x���`���S�ẴC���e����A�x���`������Ⴡ�����Ǘ��Ƃ��N�\�ł������Q�t�H�g���ɂ͗����ł��Ȃ����낤����
Mantle�Ȃ�ď��FDX12�܂ł̌q���̋Z�p�Ȃ̂�
�Ȃ�ł���ȂɎ����グ��H
�Ȃ�ł���ȂɎ����グ��H
826 �F,,�E�L�́M�E,,�j��-�������F2015/01/27(��) 22:17:33.64 ID:bt23XFwe
�����グ�Ă��Ȃ��Ɛ��_�̈��肪�ۂĂȂ���ł���
���l���ǂ��v���Ă邩����Ȃ��Ď����������������Ƃɂ���Ď����̐��_�����肳������
���ɂ̎��Ȑ��]�V�X�e��
���l���ǂ��v���Ă邩����Ȃ��Ď����������������Ƃɂ���Ď����̐��_�����肳������
���ɂ̎��Ȑ��]�V�X�e��
828 �FSocket774�F2015/01/27(��) 22:20:20.71 ID:MKINHEKM
>>822
>��F��[�V�����g���b�N���x���Ƃ��A�t���������A�a�������r�����������x�ł��ǂ�㩁B
������Ă܂������Ă�́H�W�F�X�`���[���Ăǂ��Ȃ�����H
>��F��[�V�����g���b�N���x���Ƃ��A�t���������A�a�������r�����������x�ł��ǂ�㩁B
������Ă܂������Ă�́H�W�F�X�`���[���Ăǂ��Ȃ�����H
���̂��߂�AMDapp�Ȃ̂���
�ʂɁAAMD�����Ȑl�́A���������匙����AMD�̕������Ă���Ȃ��Ă��ǂ���ł���B
���̂��������ŁA���̏������{�l�̂��Ȃ�����Intel�Ƃ�V�����g���Ă��������ł��B
�ʂɁAAMD�����Ȑl�́A���������匙����AMD�̕������Ă���Ȃ��Ă��ǂ���ł���B
���̂��������ŁA���̏������{�l�̂��Ȃ�����Intel�Ƃ�V�����g���Ă��������ł��B
AMD��GPU�͗p�r�ɉ����Ďg�����肷���H
CPU��APU���g��Ȃ�������
CPU��APU���g��Ȃ�������
831 �FSocket774�F2015/01/27(��) 22:29:13.30 ID:MKINHEKM
�H�܂������Ă�́H
832 �F,,�E�L�́M�E,,�j��-�������F2015/01/27(��) 22:31:52.67 ID:bt23XFwe
Bluestacks�������AMD�̎��Y��������Ă邯�ǒP��OEM�������������ł�����
���l�̂��Ƃ�Intel������Ă܂���
���l�̂��Ƃ�Intel������Ă܂���
833 �FSocket774�F2015/01/27(��) 22:37:22.54 ID:MKINHEKM
atom�Ȓ��p�b�h��windows��android��dual os�����s�ł���
32gb�ł�
32gb�ł�
Maxwell��CUDA���\���҂��Ĕ������}�k�P�Ȃ�Ă���́H
GTX980�����O���GTX780Ti�Ƃ̔�r��CUDA��������Ȃ��̂̓n�b�L�����Ă������
PC�Q�[�������̃r�f�I�J�[�h�Ƃ��Ă͂���ŏ\������
GTX980�����O���GTX780Ti�Ƃ̔�r��CUDA��������Ȃ��̂̓n�b�L�����Ă������
PC�Q�[�������̃r�f�I�J�[�h�Ƃ��Ă͂���ŏ\������
�A���h�V���p�l�́��̊u���X���ŃI�i�j�[���Ƃ�
AMD�̎�����APU/SoC���������悤202����
http://anago.2ch.net/test/read.cgi/jisaku/1422145337/
AMD�̎�����APU/SoC���������悤202����
http://anago.2ch.net/test/read.cgi/jisaku/1422145337/
836 �F,,�E�L�́M�E,,�j��-�������F2015/01/27(��) 22:48:40.89 ID:bt23XFwe
��������CUDA6.0�̃e�X�g�x�b�h�ړI�ł����˂��B
750�ŏ\���ł���
750�ŏ\���ł���
�m�`�r�Ɩ����ƃm�[�g�p�\�R���ł���Ă݂�����
�^�u���b�g�̕����ǂ�����
�^�u���b�g�̕����ǂ�����
�����̊�ƂɂȂ����Ⴄ�́H
839 �FSocket774�F2015/01/27(��) 23:00:42.18 ID:MKINHEKM
>>834
maxwell�͂ނ���kepler�������Z�����ł�����
https://compubench.com/compare.jsp?benchmark=compu20&D1=NVIDIA+GeForce+GTX+980&os1=Windows&api1=cl&D2=NVIDIA+GeForce+GTX+780+Ti&cols=2
http://www.phoronix.com/scan.php?page=article&item=nvidia_gtx980_opencl&num=2
maxwell�͂ނ���kepler�������Z�����ł�����
https://compubench.com/compare.jsp?benchmark=compu20&D1=NVIDIA+GeForce+GTX+980&os1=Windows&api1=cl&D2=NVIDIA+GeForce+GTX+780+Ti&cols=2
http://www.phoronix.com/scan.php?page=article&item=nvidia_gtx980_opencl&num=2
{kind=link}
841 �FSocket774�F2015/01/27(��) 23:13:53.63 ID:MKINHEKM
842 �FSocket774�F2015/01/27(��) 23:20:05.60 ID:MKINHEKM
����ƃx���`��linpack�ӊO�͎��p��A�{���x�����܂�d�v�łȂ��Ƃ�
http://news.mynavi.jp/articles/2014/12/16/sc14_exascale/001.html
�E�̐}�̓A�v���P�[�V�����̐U�����ׂ��O���t�ŁA���ꂼ��8�F�̖_�O���t�����邪�A
�O�q��DoE��6�̃A�v���P�[�V������Top500������LINPACK��Green500������LINPACK�ɑΉ����A
�e�O���[�v�͍����珇�ɁAGPU��IPC�AGPU��Warp�̎����AGPU�̃������o���h���̗��p���AGPU��DP���Z�̗��p���A
�����āACPU�̗��p���A�l�b�g���[�N�̎g�p���AWeak Scaling�̌����������Ă���B
�����Č�����̂́ALINPACK�������ACPU�̗��p����GPU��DP���Z�̗��p�������ɒႢ�_���ڂ��䂭�B
http://news.mynavi.jp/articles/2014/12/16/sc14_exascale/images/013l.jpg
http://news.mynavi.jp/articles/2014/12/16/sc14_exascale/001.html
�E�̐}�̓A�v���P�[�V�����̐U�����ׂ��O���t�ŁA���ꂼ��8�F�̖_�O���t�����邪�A
�O�q��DoE��6�̃A�v���P�[�V������Top500������LINPACK��Green500������LINPACK�ɑΉ����A
�e�O���[�v�͍����珇�ɁAGPU��IPC�AGPU��Warp�̎����AGPU�̃������o���h���̗��p���AGPU��DP���Z�̗��p���A
�����āACPU�̗��p���A�l�b�g���[�N�̎g�p���AWeak Scaling�̌����������Ă���B
�����Č�����̂́ALINPACK�������ACPU�̗��p����GPU��DP���Z�̗��p�������ɒႢ�_���ڂ��䂭�B
http://news.mynavi.jp/articles/2014/12/16/sc14_exascale/images/013l.jpg
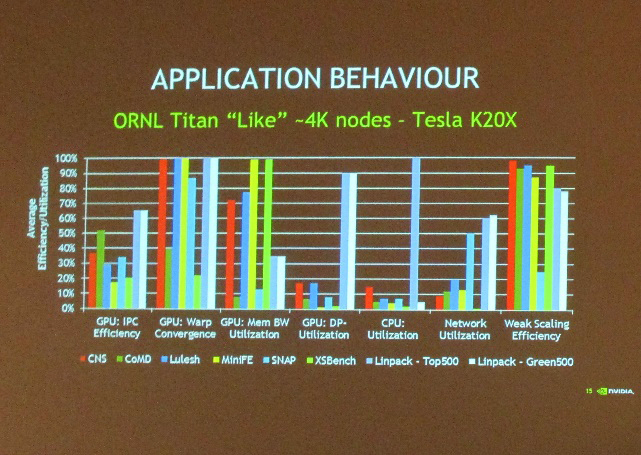{kind=link}
���{�l�Ȃ�C���e���Q�t�H���
�T���`�����P���A���`�����V���p���ꂗ
�T���`�����P���A���`�����V���p���ꂗ
844 �FSocket774�F2015/01/27(��) 23:27:08.15 ID:MKINHEKM
7nm�e�N�m���W�����ł�4�{�̉��P�����Ȃ��A�A�[�L�e�N�`�����H�̉��P���K�{�B
��Ă�����P�̓K�p�ŁALINPACK�ł�25�{�̉��P�͂ł������ł��邪�A�������̃A�v���ł͒B���ł��Ȃ��B
�����̓\�t�g��A���S���Y���̕ύX���K�v�ł���B
���ׂĂ̓G��|����Exascale�ւ̓��B���\�ɂ��閂�@�̒e�͑��݂��Ȃ�
��Ă�����P�̓K�p�ŁALINPACK�ł�25�{�̉��P�͂ł������ł��邪�A�������̃A�v���ł͒B���ł��Ȃ��B
�����̓\�t�g��A���S���Y���̕ύX���K�v�ł���B
���ׂĂ̓G��|����Exascale�ւ̓��B���\�ɂ��閂�@�̒e�͑��݂��Ȃ�
845 �F,,�E�L�́M�E,,�j��-�������F2015/01/27(��) 23:31:27.21 ID:bt23XFwe
>>842
ONRL�Ŕ{���x�����܂�g��Ȃ����Ă����b�Ȃ炻�����낤��
���ׂẴp�\�R�����������Ƃ�����Ǝ^�������˂��B
FFT�Ȃg���{���x�ł��ق������炢�����B
LINPACK�����p�ɑ����ĂȂ��x���`�Ȃ̂͂܂����ʂ̈ӌ����ˁB
ONRL�Ŕ{���x�����܂�g��Ȃ����Ă����b�Ȃ炻�����낤��
���ׂẴp�\�R�����������Ƃ�����Ǝ^�������˂��B
FFT�Ȃg���{���x�ł��ق������炢�����B
LINPACK�����p�ɑ����ĂȂ��x���`�Ȃ̂͂܂����ʂ̈ӌ����ˁB
846 �FSocket774�F2015/01/27(��) 23:34:58.42 ID:MKINHEKM
�܂��j�����̃V�~�����[�V�����Ƃ��͔{���x�g���͂��ł��傤�Ȃ�
847 �F,,�E�L�́M�E,,�j��-�������F2015/01/27(��) 23:46:59.66 ID:bt23XFwe
AMD�X���̑��̎��̃v���O���}�Ƃ͈���ĕЎR�䂤�����͎��ۂɉ��u����E�B���X���������
AMD�M�҂̂Ȃ��̐�����`�������
AMD�M�҂̂Ȃ��̐�����`�������
848 �FSocket774�F2015/01/27(��) 23:59:29.56 ID:zW0E6g7R
�y�T���ł킩��ŐV�L�[���[�h����z�����v���Z�b�T�̐��ݔ\�͂������o���V�t���[�����[�N�uHSA�v
http://news.mynavi.jp/news/2015/01/27/151/
�uHSA�v�͉���ڎw���̂��H
�uHSA�v�̑O��ɂȂ��Ă���̂�CPU��GPU�����ꂼ��}���`�R�A������1�̃`�b�v�ɏW�ς���A�ŋ߂̓����v���Z�b�T�̃n�[�h�E�F�A�\�����B
�uHSA�v�́uH�v�́u�w�e���W�j�A�X�v�i�َ퍬���Ƃ������Ӗ��j�̂��ƂŁACPU�AGPU�Ȃǂ̈قȂ�v���Z�b�T�̂��Ƃ��w���B
���̃V�X�e���A�[�L�e�N�`�����`���悤�Ƃ����̂��uHSA�v�ŁA�]���قȂ�v���O���~���O���K�v�������َ�v���Z�b�T���I�ɗ��p���A
�ŐV�����v���Z�b�T����߂�\����100�������o�����Ƃ�ڎw�����n�[�h�^�\�t�g���ʂ���̍œK���A�v���[�`���B
HSA�v�������́H
�ł́uHSA�v�͋�̓I�ɂǂ�ȉ��b�������炵�Ă���邾�낤���B
�܂��l������̂́A��͂�摜�f�[�^�Ȃǂ̕������B
�Ⴆ�A�f�W�^���J������CCD�f�q�̃f�[�^��PC�ŕ\���\�ɂ���uRAW�����v���f�U�C���Ɩ��Ȃǂŋ��߂��邪�A
�]���͍�����PC�ł������`���\���͂��̏����ɂ�����B���ꂪ�uHSA�v�ƍŐVAPU�Ȃ��u�Ŋ�������Ɗ��҂���Ă���B
����Ɂu4K�v��u8K�v�e���r�ŗ��p�����H.265�iHEVC�j�t�H�[�}�b�g�̉f���f�R�[�h�ւ̓K�p���L�͂ȕ��삾�B
�܂��A�f���f�R�[�h������������Ƃ������Ƃ́A���l�̋Z�p�𗘗p����Í���ǂ��܂�����������Ƃ������Ƃł�����B
����͈�ʂł͋��Ђł����邪�A�Í����f�[�^�𗘕��������p���邱�Ƃɍv�����������B
http://news.mynavi.jp/news/2015/01/27/151/
�uHSA�v�͉���ڎw���̂��H
�uHSA�v�̑O��ɂȂ��Ă���̂�CPU��GPU�����ꂼ��}���`�R�A������1�̃`�b�v�ɏW�ς���A�ŋ߂̓����v���Z�b�T�̃n�[�h�E�F�A�\�����B
�uHSA�v�́uH�v�́u�w�e���W�j�A�X�v�i�َ퍬���Ƃ������Ӗ��j�̂��ƂŁACPU�AGPU�Ȃǂ̈قȂ�v���Z�b�T�̂��Ƃ��w���B
���̃V�X�e���A�[�L�e�N�`�����`���悤�Ƃ����̂��uHSA�v�ŁA�]���قȂ�v���O���~���O���K�v�������َ�v���Z�b�T���I�ɗ��p���A
�ŐV�����v���Z�b�T����߂�\����100�������o�����Ƃ�ڎw�����n�[�h�^�\�t�g���ʂ���̍œK���A�v���[�`���B
HSA�v�������́H
�ł́uHSA�v�͋�̓I�ɂǂ�ȉ��b�������炵�Ă���邾�낤���B
�܂��l������̂́A��͂�摜�f�[�^�Ȃǂ̕������B
�Ⴆ�A�f�W�^���J������CCD�f�q�̃f�[�^��PC�ŕ\���\�ɂ���uRAW�����v���f�U�C���Ɩ��Ȃǂŋ��߂��邪�A
�]���͍�����PC�ł������`���\���͂��̏����ɂ�����B���ꂪ�uHSA�v�ƍŐVAPU�Ȃ��u�Ŋ�������Ɗ��҂���Ă���B
����Ɂu4K�v��u8K�v�e���r�ŗ��p�����H.265�iHEVC�j�t�H�[�}�b�g�̉f���f�R�[�h�ւ̓K�p���L�͂ȕ��삾�B
�܂��A�f���f�R�[�h������������Ƃ������Ƃ́A���l�̋Z�p�𗘗p����Í���ǂ��܂�����������Ƃ������Ƃł�����B
����͈�ʂł͋��Ђł����邪�A�Í����f�[�^�𗘕��������p���邱�Ƃɍv�����������B
849 �F,,�E�L�́M�E,,�j��-�������F2015/01/28(��) 00:10:48.38 ID:4T8jg6g0
�Í��Ɖf���̕������̋�ʂ̂��ĂȂ����܂ʂ����͂��R�s�y�����Ⴄ���Ƃ��̂ЂƂ���
850 �FSocket774�F2015/01/28(��) 00:15:34.77 ID:NjWcnTGk
���E����Ă����������Ȃ��c�q�̂ЂƂ���
H265�̉f���f�R�[�h�Ȃ�āAGPU���Ƀn�[�h�E�F�A�f�R�[�_���ς܂��悤�ɂȂ邾������
���܂�H264�Ɠ���
HSA/GPGPU�Ńf�R�[�h������AASIC�Ńf�R�[�h�����ق����͂邩�Ɍ����I
���܂�H264�Ɠ���
HSA/GPGPU�Ńf�R�[�h������AASIC�Ńf�R�[�h�����ق����͂邩�Ɍ����I
HSA�͂܂�Windows��œ��������^�C���ƊJ�����𗊂�
AMD��H.265�iHEVC�j�̃G���R�E�f�R�[�h��(HSA�ɏ�����)�n�[�h�E�F�A�ł��邷���Ȃ���������
���������̂��ȒP�ɐڑ����ė��p�ł�����Ă�����HSA����ȁBAMD ARM������g����ȁB
�Í���HSA�����̃n�[�h�ǂ����J��������B����AHSA�ɏ��������n�[�hIP�ǂ�ǂ�łĂ�����
���������̂��ȒP�ɐڑ����ė��p�ł�����Ă�����HSA����ȁBAMD ARM������g����ȁB
�Í���HSA�����̃n�[�h�ǂ����J��������B����AHSA�ɏ��������n�[�hIP�ǂ�ǂ�łĂ�����
854 �FSocket774�F2015/01/28(��) 00:30:57.88 ID:5ftdmKbu
HSA�ō��掿�����G���R�[�h
>>851
>GPU���Ƀn�[�h�E�F�A�f�R�[�_
(HSA��CPU)��HSA��GPU��HSA�̃n�[�h�E�F�A�f�R�[�_���ЂƂ̃_�C��ɂ̂���
>>852
�����A�����ƑO�ɏo�Ă����Ȃ��̂��@
>GPU���Ƀn�[�h�E�F�A�f�R�[�_
(HSA��CPU)��HSA��GPU��HSA�̃n�[�h�E�F�A�f�R�[�_���ЂƂ̃_�C��ɂ̂���
>>852
�����A�����ƑO�ɏo�Ă����Ȃ��̂��@
856 �F,,�E�L�́M�E,,�j��-�������F2015/01/28(��) 00:40:44.32 ID:4T8jg6g0
AMD�̂��߂ɑ��̃n�[�h�������Ă���Ă���i�ϑz�j�Ŕ^�`�W�����[�ł���
�킩��܂�
�킩��܂�
857 �F,,�E�L�́M�E,,�j��-�������F2015/01/28(��) 00:43:01.54 ID:4T8jg6g0
���̐��������҂��Ă�J���҂����܂���i����������߂�
https://github.com/HSAFoundation/
https://github.com/HSAFoundation/
>>856
AMD�̂��߂��Č������
ARM�w�c�ɉ����HSA�g���ė~������ΐF�XHSA�n�[�h�o������Č���ꂽ��������
AMD�͏��FHSA�w�c�̂ς��肾��
AMD�̂��߂��Č������
ARM�w�c�ɉ����HSA�g���ė~������ΐF�XHSA�n�[�h�o������Č���ꂽ��������
AMD�͏��FHSA�w�c�̂ς��肾��
859 �F,,�E�L�́M�E,,�j��-�������F2015/01/28(��) 00:54:53.23 ID:4T8jg6g0
�ėp�̃n�[�h�E�F�AIP�E���Ă��ăh���C�o��HSA��API�Ń��b�v���������ł���iAMD�Łj
���z���t�ق����Ď���
���z���t�ق����Ď���
860 �F,,�E�L�́M�E,,�j��-�������F2015/01/28(��) 00:58:35.38 ID:4T8jg6g0
AMD�̂͂��傹������f�o�C�X�����ł���H
�����f�o�C�X�݂̂Ȃ炸PCIe��QPI�ł̐ڑ�������API�ŃA�N�Z�X�ł���̂�����
https://01.org/packet-processing/intel%C2%AE-quickassist-technology-drivers-and-patches
��邱�Ƃ�5�N�x��Ă���PCIe��HyperTransport��Ή����ĔߎS����ˁH
�����f�o�C�X�݂̂Ȃ炸PCIe��QPI�ł̐ڑ�������API�ŃA�N�Z�X�ł���̂�����
https://01.org/packet-processing/intel%C2%AE-quickassist-technology-drivers-and-patches
��邱�Ƃ�5�N�x��Ă���PCIe��HyperTransport��Ή����ĔߎS����ˁH
AMD�͎��O��H.265�iHEVC�j�̃n�[�h�G���R�E�f�R�[�_�͊J���ł��Ȃ����낤����A�����Ȃ�̂͂��傤���Ȃ�
CPU����낭�Ȃ̂������Ȃ��Ȃ��āA���܂₿���Əo����̂�GPU�������Ċ����������
CPU����낭�Ȃ̂������Ȃ��Ȃ��āA���܂₿���Əo����̂�GPU�������Ċ����������
862 �F,,�E�L�́M�E,,�j��-�������F2015/01/28(��) 01:06:14.54 ID:4T8jg6g0
�y�t�@���{�[�C�̖ϑz�z
�@�i�L�D�M;�j�@�����̃f�R�[�_��IP��APU�ɓ������Ă�������
�@�@�@�Ɂj�@�@�Ȃ�ł��������܂�����
�@�@�@�i�i
�@�i�L�D�M;�j�@�����̃f�R�[�_��IP��APU�ɓ������Ă�������
�@�@�@�Ɂj�@�@�Ȃ�ł��������܂�����
�@�@�@�i�i
863 �FSocket774�F2015/01/28(��) 01:09:36.92 ID:hjGVhzQn
>>848
�ŋߌ����L���̒��ł͍ł��Ђǂ����e���B
�L���������Ă���{�l�����e�𗝉����Ă��炸�A�O�O�������e�𐳂������ǂ����̔��f������(�Ƃ������A�Ԉ���Ă�����e������)�A���̂܂܃R�s�y���Ă邱�Ƃ��ۂ킩��ȋL���B
�����������
���v���Z�b�T���[�J�[��AMD�����AARM��T���X���ȂǗL�͊�Ƃ��Q�����ĕW���d�l�����N4���ɍ��肳�ꂽ�B
�w���N4���ɍ��肳�ꂽ�x�Ƃ��邪�A�L���̓��t�����[2015/01/27]�Ȃ̂����B
��http://news.mynavi.jp/photo/news/2015/01/27/151/images/001l.jpg
����AHSA�ɔ�Ή���Trinity�R�A�Ȃ�ł����ǁE�E�EKaveri�o����O�̏����p���Ă��邾��B
�ŋߌ����L���̒��ł͍ł��Ђǂ����e���B
�L���������Ă���{�l�����e�𗝉����Ă��炸�A�O�O�������e�𐳂������ǂ����̔��f������(�Ƃ������A�Ԉ���Ă�����e������)�A���̂܂܃R�s�y���Ă邱�Ƃ��ۂ킩��ȋL���B
�����������
���v���Z�b�T���[�J�[��AMD�����AARM��T���X���ȂǗL�͊�Ƃ��Q�����ĕW���d�l�����N4���ɍ��肳�ꂽ�B
�w���N4���ɍ��肳�ꂽ�x�Ƃ��邪�A�L���̓��t�����[2015/01/27]�Ȃ̂����B
��http://news.mynavi.jp/photo/news/2015/01/27/151/images/001l.jpg
{kind=link}
����AHSA�ɔ�Ή���Trinity�R�A�Ȃ�ł����ǁE�E�EKaveri�o����O�̏����p���Ă��邾��B
Godavari������2015�N��AMD���K�N�F�̗��v���҂��Ă���
������2016�N�T���̋Z�p�Ő������ꂽ14nmSummit Ridge��AMD�叟�����m�肳��Ă���
������2016�N�T���̋Z�p�Ő������ꂽ14nmSummit Ridge��AMD�叟�����m�肳��Ă���
�T���`�����̎q�ɂȂ����Ⴂ�Ȃ���
866 �F,,�E�L�́M�E,,�j��-�������F2015/01/28(��) 01:26:36.03 ID:4T8jg6g0
�K�N�F�̌��Z�̐����i�Ԃ��Ƃ����Ӗ��j
�T���`�����������d��������̂̓X�}�z�E�^�u���b�g�ƃ������p�[�c�������Ǝv���Ă����E�E�E
�T���`�����R�͂����d���Ȃ�Ă��Ă˂�����A�z��
�ꂪ������AMD�͍��イ�Ȃ���肵�����肦�Ȃ�
�y���݂����Ȃ�
�y���݂����Ȃ�
��������������������
���������̍������̓A������apple�����ɔ[�i�o���郌�x���̊�Ƃ�
���������̍������̓A������apple�����ɔ[�i�o���郌�x���̊�Ƃ�
Galaxy�Ƃ������d�����Ă邺�B���Ȃ��Ƃ����j�[��Xperia��A�ŗь��ipad���͂ȁB
872 �F,,�E�L�́M�E,,�j��-�������F2015/01/28(��) 01:35:29.65 ID:4T8jg6g0
AMD�X���ł͋��N���瓊�����ꂽHaswell Refresh�ɂ́A�����N���b�N�グ���������Ƃ�
�茵�����ӌ���������ꂽ���̂����AGodavari���ǂ�ȃ_�u�X�^�Ԃ������Ă悢���傷��̂�
�y���݂ł���
Haswell��SATAe��M2�Ή��̐V�`�b�v�Z�b�g�̓���������������
�{���ɃN���b�N�グ�������Ȃ�I����������܂���
�茵�����ӌ���������ꂽ���̂����AGodavari���ǂ�ȃ_�u�X�^�Ԃ������Ă悢���傷��̂�
�y���݂ł���
Haswell��SATAe��M2�Ή��̐V�`�b�v�Z�b�g�̓���������������
�{���ɃN���b�N�グ�������Ȃ�I����������܂���
>>872
�I����Ă�̂ɏI�����Ƃ��Ӗ��s��
�I����Ă�̂ɏI�����Ƃ��Ӗ��s��
�ꕔ���f���̓O���X�����ǂ�����HD���O���͑��ς�炸����
����̊��҂𗠐�Ȃ��f����������_�u���O���X���i����˂������@�R��
����̊��҂𗠐�Ȃ��f����������_�u���O���X���i����˂������@�R��
���ۈꕔ��APU�����g�̓O���X�����ǂȁB
876 �F,,�E�L�́M�E,,�j��-�������F2015/01/28(��) 01:44:43.55 ID:4T8jg6g0
�ꕔ����Ȃ��đS��
���O���̃h���C�o�ɂ͐G��˂��̂Ȃ�
Llano�̓O���X����Ȃ��̂ňꕔ�Ə��������B
�O���X�̎��̖�肾��
���ۊk�������Ă��܂��O���X��h�邩��Ӗ��Ȃ����ǂȁB
�m�[�g�o�b�݂����Ƀq�[�g�X�v���b�_�����O���ăV���O���O���X�ɂ���̂Ȃ�ȒP������
882 �F,,�E�L�́M�E,,�j��-�������F2015/01/28(��) 02:21:31.20 ID:4T8jg6g0
Kaveri���ďo�n�߂����͂���Ȃ�ɔ��ꂽ���ǁAPentium 3258��Celeron G1840�Ƃ���
�ቿ�i��Haswell�ɘb�肩��������ăZ�[���X���ʂɗ������L�������Ȃ��̂�����
������100MHz�N���b�N�オ���������łǂ�������ł����˂�
�ቿ�i��Haswell�ɘb�肩��������ăZ�[���X���ʂɗ������L�������Ȃ��̂�����
������100MHz�N���b�N�オ���������łǂ�������ł����˂�
�ǂꂾ������邩�ǂ����͉��ɒu���Ă����Ƃ���
��ʓI�ȉƓd�ʔ̓X�Ŏ�舵����h�x�g����PC�̑唼��Intel���̗p���Ă���̂�
AMD�����{��PC�s��ɏo���Ȃ��ő�̗v�����낤��
��ʓI�ȉƓd�ʔ̓X�Ŏ�舵����h�x�g����PC�̑唼��Intel���̗p���Ă���̂�
AMD�����{��PC�s��ɏo���Ȃ��ő�̗v�����낤��
884 �FSocket774�F2015/01/28(��) 02:57:17.67 ID:hjGVhzQn
���{�̃��[�U�[�̑唼�ɂƂ��Ă�Kaveri��GPU���\�͕s�v�B
�����āAIntel HD Graphics�Ő��\�s���Ȑl�̑唼��Kaveri��iGPU�ł͖����ł��Ȃ��B
���ʂɍ��������Ȃ̂ŁA���{���[�J�[�ǂ��납Acer��Lenovo�̓��{�������f���ɂ��̗p����Ȃ��B
FX�͈�̌^�ƃX�����^�����Ȃ����{���[�J�[�ɍ̗p����邱�Ƃ͂Ȃ��B
Mullins��8�^�ȉ��̒ቿ�i�^�u���b�g�Ɏg���Ȃ��̂ŁA���{�s��Ɍ��炸���E�I�ɔ���Ă��Ȃ��B
Beema�͒ቿ�i�m�[�g�p�Ƃ��Ē��X�o�����X�ǂ��A�ቿ�i�Ȃ̂œ��{�s��ł��̗p���i������������B
AMD�����{�s��ɏo���Ȃ��̂́A�s��̗v�]�ɉ������i�����Ȃ����炾��B
�����āAIntel HD Graphics�Ő��\�s���Ȑl�̑唼��Kaveri��iGPU�ł͖����ł��Ȃ��B
���ʂɍ��������Ȃ̂ŁA���{���[�J�[�ǂ��납Acer��Lenovo�̓��{�������f���ɂ��̗p����Ȃ��B
FX�͈�̌^�ƃX�����^�����Ȃ����{���[�J�[�ɍ̗p����邱�Ƃ͂Ȃ��B
Mullins��8�^�ȉ��̒ቿ�i�^�u���b�g�Ɏg���Ȃ��̂ŁA���{�s��Ɍ��炸���E�I�ɔ���Ă��Ȃ��B
Beema�͒ቿ�i�m�[�g�p�Ƃ��Ē��X�o�����X�ǂ��A�ቿ�i�Ȃ̂œ��{�s��ł��̗p���i������������B
AMD�����{�s��ɏo���Ȃ��̂́A�s��̗v�]�ɉ������i�����Ȃ����炾��B
���܂����₽��s��̃{�X�C���Ȃ̂��C���b�Ƃ���ȁB
886 �FSocket774�F2015/01/28(��) 03:39:53.83 ID:QiaH0eyp
����HP��APU�m�[�g�ł�������B
http://pc.watch.impress.co.jp/docs/column/hothot/20141018_671978.html
http://www.itmedia.co.jp/pcuser/articles/1409/01/news020.html
�@�g�T�`�U�l���x�Ŕ����邵�m�[�g�ɂ��Ă͈��������낤�B
http://pc.watch.impress.co.jp/docs/column/hothot/20141018_671978.html
http://www.itmedia.co.jp/pcuser/articles/1409/01/news020.html
�@�g�T�`�U�l���x�Ŕ����邵�m�[�g�ɂ��Ă͈��������낤�B
����ς���{�l�̓C���e���Q�t�H����Ԃ��˂�
�����A�]��Q����
�����܂łЂǂ����Ƃ����Č����点�����Ēׂ��ɂ�������
����ł��܂��X���W�Q�܂ł���
�C���e���Ƃ�����Ђ́A
���������A�����͂�Ŏ����グ����
���������]��Q
�����܂łЂǂ����Ƃ����Č����点�����Ēׂ��ɂ�������
����ł��܂��X���W�Q�܂ł���
�C���e���Ƃ�����Ђ́A
���������A�����͂�Ŏ����グ����
���������]��Q
890 �FSocket774�F2015/01/28(��) 05:31:18.32 ID:BzEsgMlY
�]��Q
�����牽�ł��|���Z2���Z1��͂Ȃ�����
�����牽�ł��|���Z2���Z1��͂Ȃ�����
�A�v������҂�������Ă�u���̗p�Ӂv�Ƃ����������f�[�^�]�����ƒf����
�A�v������҂��u�f�[�^�]�����Ă�v����x���Ȃ��Ă�Ɛ������Ă镔���ł̓f�[�^�]���͖����ƒf������
���Ԕ��̂��Ƃ�lj����Ō�邵������������͖��߁��f�[�^
�u���߂��f�[�^�Ńf�[�^�����߂Łv���u�R���ł��n�܂�̂�
������u�|���Z2���Z1��v�ɐq��Ȃ炴�锽����������
SIMD����Ȃ���MISD�Ƃ������Ƃ��납
�~�X�h�̃h�[�i�c�̂悤�ɍ���]�ŃN���N�����A���S���Y������]�S�זE�ɔ�����Ă���Ƃ����̂�
�A�v������҂��u�f�[�^�]�����Ă�v����x���Ȃ��Ă�Ɛ������Ă镔���ł̓f�[�^�]���͖����ƒf������
���Ԕ��̂��Ƃ�lj����Ō�邵������������͖��߁��f�[�^
�u���߂��f�[�^�Ńf�[�^�����߂Łv���u�R���ł��n�܂�̂�
������u�|���Z2���Z1��v�ɐq��Ȃ炴�锽����������
SIMD����Ȃ���MISD�Ƃ������Ƃ��납
�~�X�h�̃h�[�i�c�̂悤�ɍ���]�ŃN���N�����A���S���Y������]�S�זE�ɔ�����Ă���Ƃ����̂�
>>883
�C�O���ᔄ��Ă�́H
�C�O���ᔄ��Ă�́H
�C�O�ł�FX��i3�̑R���i�Ƃ��Ă悭����Ă�
893�̂悤�ȃS�L�u�����x�����o�J���R�X�p()�Ƃ����b�p()�Ƃ������GTX970�݂����ȃJ�X��͂�
895 �FSocket774�F2015/01/28(��) 07:42:27.59 ID:s5zVc6D1
�Ƃɂ��������牽�ł��|���Z2���Z1��͂Ȃ�����
�Ȃ�Ŋ��݂���Ă邩������Ƃ킩��Ȃ��ł��ˁc
>>884
���{�̃��[�U�[�̑唼�ɂƂ��Ă�Intel��CPU���\�͕s�v�B
���ʂɍ��������Ȃ̂ŁA���E����Atom���ł�܂��Ă�B
ARM�ɕ������̂́AIntel�̖��͂��Ȃ����炾��B
���{�̃��[�U�[�̑唼�ɂƂ��Ă�Intel��CPU���\�͕s�v�B
���ʂɍ��������Ȃ̂ŁA���E����Atom���ł�܂��Ă�B
ARM�ɕ������̂́AIntel�̖��͂��Ȃ����炾��B
AMD 4���h����Ԏ��i��
Llano�o��̋łɂ�
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
>>863
�Ō�ɉߋ��L���̓]�ڂł����ď����Ă�������
�Ō�ɉߋ��L���̓]�ڂł����ď����Ă�������
���͂�L���������Ă���郉�C�^�[�ɕ������������̂�
>>897
���{�̃��[�U�[�̑唼�ɂƂ��Ă�AMD��HSA�n�b�^���͕s�v�B
FX�͖��ʂɏ���d�͂����������Ȃ̂ŁA���E���Ō��l�̔��z�ȉ��ł�܂��Ă���B
Intel�ɕ������̂́AAMD�̖��͂��Ȃ����炾��B
���{�̃��[�U�[�̑唼�ɂƂ��Ă�AMD��HSA�n�b�^���͕s�v�B
FX�͖��ʂɏ���d�͂����������Ȃ̂ŁA���E���Ō��l�̔��z�ȉ��ł�܂��Ă���B
Intel�ɕ������̂́AAMD�̖��͂��Ȃ����炾��B
Intel��ARM�ɏ��ĂȂ��Ǝv���Ē��q������ARM��Opteron�o������
8�R�AAtom�̃��b�p�ɑS�R���ĂȂ������Ƃ���
�̂��͂����M���O�����܂���ƁA���ꂪAMD
8�R�AAtom�̃��b�p�ɑS�R���ĂȂ������Ƃ���
�̂��͂����M���O�����܂���ƁA���ꂪAMD
���b�p�ŋ��͒�d����Xeon����
905 �FSocket774�F2015/01/28(��) 12:07:04.54 ID:QiaH0eyp
AMD���Ꮯ�ĂȂ�����ARM�����Ăă����^wwwwwwww
���܂ŕ������q���́u�����ɂ������Ă��v�Ȃ݂̎v�l�Ƃ�����
���l����Ƃ�����
���l����Ƃ�����
���gZen�h�A�[�L�e�N�`�����̗p�������i�Q�́gSummit Ridge�h�ƌĂ��Ƃ����B
���gSummit Ridge�h��14nm�v���Z�X�Ő�������A�R�A���͍ő��8-core�ƂȂ�B
��TDP�͍ő�95W�ł���B�������R���g���[����DDR4�ɑΉ��A�܂�PCI-Express 3.0���[�����������B
���Ή�Socket��SocketFM2+�̌�p�ƂȂ�SocketFM3�ł��邢�B
ttp://northwood.blog60.fc2.com/blog-entry-7932.html
���NPCI-Express 4.0�o��̂ɂ����3.0����
���gSummit Ridge�h��14nm�v���Z�X�Ő�������A�R�A���͍ő��8-core�ƂȂ�B
��TDP�͍ő�95W�ł���B�������R���g���[����DDR4�ɑΉ��A�܂�PCI-Express 3.0���[�����������B
���Ή�Socket��SocketFM2+�̌�p�ƂȂ�SocketFM3�ł��邢�B
ttp://northwood.blog60.fc2.com/blog-entry-7932.html
���NPCI-Express 4.0�o��̂ɂ����3.0����
�p�r�I�ɂ͖��Ȃ������
����i�Ђ��������̃f�X�N�g�b�v�������i��4.0�������o���Ă邩�͉������B
����4.0���K�v�ȗp�r�ɂ����ċ����͂̂��鐻�i��AMD�������p�ӏo���������Ȃ����Ƃ�
����i�Ђ��������̃f�X�N�g�b�v�������i��4.0�������o���Ă邩�͉������B
����4.0���K�v�ȗp�r�ɂ����ċ����͂̂��鐻�i��AMD�������p�ӏo���������Ȃ����Ƃ�
����ς���{�l�Ȃ�C���e���Q�t�H����Ԃ��˂�
PCie4.0�Ƃ�GPU�t���邭�炢�����Ӗ��Ȃ������
Intel����Ή����i�o���Ă����ʂ���
AMD�̃N���X�t�@�C����GPGPU�����ɂ����g�����
Intel����Ή����i�o���Ă����ʂ���
AMD�̃N���X�t�@�C����GPGPU�����ɂ����g�����
>TDP�͍ő�95W
PC���[�J�[���炷���Zen�̂����TDP95W�͔��M�߂����č̗p�������ĂȂ肻����
PC���[�J�[���炷���Zen�̂����TDP95W�͔��M�߂����č̗p�������ĂȂ肻����
�R�A�����������ł����\���S�R�Ⴄ����˂��E�E�E
>>913
������AMD�́u�ő�l�v���Ƃ����̂�Intel�́u���ϒl�v���Ƃ����ˁc�c
������AMD�́u�ő�l�v���Ƃ����̂�Intel�́u���ϒl�v���Ƃ����ˁc�c
���\��������d�͓�{��AMD�̊�{�������
918 �F,,�E�L�́M�E,,�j��-�������F2015/01/28(��) 20:33:22.65 ID:FzEfD0B2
>>915
���������v�l��~�����o�J�͉��N�����Ă��w�K���Ȃ�
http://pc.watch.impress.co.jp/img/pcw/docs/567/804/html/graph27.png.html
���������v�l��~�����o�J�͉��N�����Ă��w�K���Ȃ�
http://pc.watch.impress.co.jp/img/pcw/docs/567/804/html/graph27.png.html
{kind=link}
>>915
�����AMD��TDP125W��FX��TDP88W��i7��������d�͂��Ⴂ����
�����AMD��TDP125W��FX��TDP88W��i7��������d�͂��Ⴂ����
921 �F,,�E�L�́M�E,,�j��-�������F2015/01/28(��) 20:53:50.63 ID:FzEfD0B2
AMD��TDP���������������Ă��Ƃ͖��X���X����Ȃ���
Intel��TDP�Ɋւ��Ă͂��ꂪ�ǂ�����(sandy����)
http://www.hotchips.org/wp-content/uploads/hc_archives/hc23/HC23.19.9-Desktop-CPUs/HC23.19.921.SandyBridge_Power_10-Rotem-Intel.pdf
>>920
���C���X�g���[��PC��Zen�̂���TDP95W�͂Ȃ�������Ă���
zen��TDP95W��8�R�A+iGPU����B����łǂ�Ȑ��\��CPU�ɂȂ�̂��
http://www.hotchips.org/wp-content/uploads/hc_archives/hc23/HC23.19.9-Desktop-CPUs/HC23.19.921.SandyBridge_Power_10-Rotem-Intel.pdf
>>920
���C���X�g���[��PC��Zen�̂���TDP95W�͂Ȃ�������Ă���
zen��TDP95W��8�R�A+iGPU����B����łǂ�Ȑ��\��CPU�ɂȂ�̂��
220W�Ƃ��l�^CPU�o���Ă鎞�_�ŃA�������v�l���Ƃ܂��Ă�AMD�M�҂͑�����
924 �FSocket774�F2015/01/28(��) 20:56:37.93 ID:NjWcnTGk
>>918
���O�́u�d�́v�Ɓu�M�v�̈Ⴂ���킩��Ȃ��̂��H
���O�́u�d�́v�Ɓu�M�v�̈Ⴂ���킩��Ȃ��̂��H
925 �F,,�E�L�́M�E,,�j��-�������F2015/01/28(��) 20:57:29.98 ID:FzEfD0B2
�����̃��r���[�T�C�g�̕����AMD�̕����̏���d�͂͌���TDP���͂邩�ɒ����Ă��܂��Ă�̂���
926 �F,,�E�L�́M�E,,�j��-�������F2015/01/28(��) 20:58:42.17 ID:FzEfD0B2
927 �FSocket774�F2015/01/28(��) 20:58:44.45 ID:NjWcnTGk
�yAM3+�zAMD FX���� 54��ځyZambezi Vishera�z
http://anago.2ch.net/test/read.cgi/jisaku/1414167888/l50
972 ���O�F Socket774 [sage] ���e���F 2014/11/28(��) 12:45:21.06 ID:gA7INU9/
�������炱��ł�����BIntel��HP�ŁuTDP�͕��ϓd�͂����b�g�P�ʂɕ\�����v�Ə����Ă邼�B
http://i.imgur.com/FqDLf4x.png
http://ark.intel.com/ja/products/75121/Intel-Core-i7-4765T-Processor-8M-Cache-up-to-3_00-GHz
http://anago.2ch.net/test/read.cgi/jisaku/1414167888/l50
972 ���O�F Socket774 [sage] ���e���F 2014/11/28(��) 12:45:21.06 ID:gA7INU9/
�������炱��ł�����BIntel��HP�ŁuTDP�͕��ϓd�͂����b�g�P�ʂɕ\�����v�Ə����Ă邼�B
http://i.imgur.com/FqDLf4x.png
{kind=link}
http://ark.intel.com/ja/products/75121/Intel-Core-i7-4765T-Processor-8M-Cache-up-to-3_00-GHz
�t�@���{�[�C����������\������
>>924
�Ⴂ�������Ă���Ă���
�Ⴂ�������Ă���Ă���
930 �FSocket774�F2015/01/28(��) 21:01:43.25 ID:NjWcnTGk
Intel�́u���ρv�̔��M�������i�Ȃ̂Ƀx���`�ŘA��������Ԃɂ���Ƃ����Ȃ�B
(Intel Core i7 4790K TDP88W)
�܂�����i�ł���Ȕ��M�Ƃ́E�E�E
http://review.kakaku.com/review/K0000664335/ReviewCD=743112/#tab
�����ׂƏ����Ă��܂���Windows Update������������ŏ�L�̉��x�ɒ��ˏオ��܂��B
���ł�OCCT��85�x�˔j������~�܂�5�b�����܂���ł����B
���NJȈՐ���ɂ��Ăǂ��ɂ��ʏ�35�|50�x��Ɏ��܂�悤�ɂȂ�܂������A���X�}�ɉ��x��
65�x����Ђǂ�����73�x�܂Œ��ˏオ��i�x���u�U�[����Ȃ��̂Ŏ��ۂ�70�x��
�����Ă��Ȃ��悤�ł����j�t�@���������ł��B�O���X��1300�~���炢�̃V���o�[�O���X�ł��B
�T�C�h�t���[�N�[���[�̎��t���ʂ��G�b�W�����������悤�ȎC��������Ă����̂�
�Ђ���Ƃ���ƃq�[�g�X�v���b�_�������ł͂Ȃ��̂�������܂���B
�ĂƂ͂����܂�����i�^�p�ł���ȂɔM���Ȃ�Ƃ̓K�b�J���̈ꌾ��������܂���B
�i����PC�͓������ł�����ȂɔM���Ȃ�Ȃ��ł��j
���ۂ̎g�p�����ȓd�͒�N���b�N��Ԃ��畉�ׂ��������ăN���b�N���オ��܂ł̃��O�����ǂ���������܂葬���Ǝv���܂���B
���O�̖��͏ȓd�͐���4GHz�Œ�ɂ��ăt�@�����Œ葬�x�ɂ�������̂ł��傤���ǂȂ��Ȃ��ł��B
�i���������̃g�����ɂ͊���Ă��܂����BSSD������Α��E����Ă����ƋC�ɂȂ�Ȃ��Ȃ�Ǝv���܂��B�j
�����ǂl�̓O���X�̓h����������Ƃ��N�[���[���������Ƃ��ݒ肪�����Ƃ��F�X���ӌ�����ł��傤��
�o���N�i�Ȃ�Ƃ��������e�[���N�[���[�{��i�^�p�ŏ�L���x�Ȏ��_�ŏ��i�Ƃ��Ă��肦�Ȃ��Ǝv���܂��B
����CPU�̓I�[�o�[�N���b�J�[�̂��߂̂��̂Ŏd����Q�[���ɂ͕s�������Ǝv���܂��B
�����@�M���@�܂���Devil's Canyon�I
http://review.kakaku.com/review/K0000664335/ReviewCD=767666/#tab
�y���萫�z
��i�ʼn^�p���镪�ɂ͖�肪�����Ă͍���܂��ˁB
�����\�ʂ�̔��M�I�N�[���[�͐���H110���g�p���Ă���܂���
OCCT��15������80�����y�X�ƒ����Ă䂫�܂��B
�y�ȓd�͐��z
����88W�ł���܂����A���j�^�����O���Ă������135W���炢�͍s���Ă����ł��B
(Intel Core i7 4790K TDP88W)
�܂�����i�ł���Ȕ��M�Ƃ́E�E�E
http://review.kakaku.com/review/K0000664335/ReviewCD=743112/#tab
�����ׂƏ����Ă��܂���Windows Update������������ŏ�L�̉��x�ɒ��ˏオ��܂��B
���ł�OCCT��85�x�˔j������~�܂�5�b�����܂���ł����B
���NJȈՐ���ɂ��Ăǂ��ɂ��ʏ�35�|50�x��Ɏ��܂�悤�ɂȂ�܂������A���X�}�ɉ��x��
65�x����Ђǂ�����73�x�܂Œ��ˏオ��i�x���u�U�[����Ȃ��̂Ŏ��ۂ�70�x��
�����Ă��Ȃ��悤�ł����j�t�@���������ł��B�O���X��1300�~���炢�̃V���o�[�O���X�ł��B
�T�C�h�t���[�N�[���[�̎��t���ʂ��G�b�W�����������悤�ȎC��������Ă����̂�
�Ђ���Ƃ���ƃq�[�g�X�v���b�_�������ł͂Ȃ��̂�������܂���B
�ĂƂ͂����܂�����i�^�p�ł���ȂɔM���Ȃ�Ƃ̓K�b�J���̈ꌾ��������܂���B
�i����PC�͓������ł�����ȂɔM���Ȃ�Ȃ��ł��j
���ۂ̎g�p�����ȓd�͒�N���b�N��Ԃ��畉�ׂ��������ăN���b�N���オ��܂ł̃��O�����ǂ���������܂葬���Ǝv���܂���B
���O�̖��͏ȓd�͐���4GHz�Œ�ɂ��ăt�@�����Œ葬�x�ɂ�������̂ł��傤���ǂȂ��Ȃ��ł��B
�i���������̃g�����ɂ͊���Ă��܂����BSSD������Α��E����Ă����ƋC�ɂȂ�Ȃ��Ȃ�Ǝv���܂��B�j
�����ǂl�̓O���X�̓h����������Ƃ��N�[���[���������Ƃ��ݒ肪�����Ƃ��F�X���ӌ�����ł��傤��
�o���N�i�Ȃ�Ƃ��������e�[���N�[���[�{��i�^�p�ŏ�L���x�Ȏ��_�ŏ��i�Ƃ��Ă��肦�Ȃ��Ǝv���܂��B
����CPU�̓I�[�o�[�N���b�J�[�̂��߂̂��̂Ŏd����Q�[���ɂ͕s�������Ǝv���܂��B
�����@�M���@�܂���Devil's Canyon�I
http://review.kakaku.com/review/K0000664335/ReviewCD=767666/#tab
�y���萫�z
��i�ʼn^�p���镪�ɂ͖�肪�����Ă͍���܂��ˁB
�����\�ʂ�̔��M�I�N�[���[�͐���H110���g�p���Ă���܂���
OCCT��15������80�����y�X�ƒ����Ă䂫�܂��B
�y�ȓd�͐��z
����88W�ł���܂����A���j�^�����O���Ă������135W���炢�͍s���Ă����ł��B
931 �F,,�E�L�́M�E,,�j��-�������F2015/01/28(��) 21:01:45.64 ID:FzEfD0B2
�u����d�́v�Ƃ͈�̉��Ȃ̂�
���ꂷ�痝�����ĂȂ��悤��
���ꂷ�痝�����ĂȂ��悤��
932 �FSocket774�F2015/01/28(��) 21:01:49.33 ID:dN2rqN9Z
�蔲���O���X�ŔM������INTEL�͔���Ȃ�
AMD�͑f�ނ��V����i�����狰�낵���قǔM���Ȃ��ł�����d�͂͊��ق�
AMD�͑f�ނ��V����i�����狰�낵���قǔM���Ȃ��ł�����d�͂͊��ق�
PC�ŏ�����d�͂͑S���M�ɂȂ��
�R�C�����Ƃ��e��t�@���ނŏ���Ƃ����������̂͂Ƃ�ܒu���Ƃ���
�R�C�����Ƃ��e��t�@���ނŏ���Ƃ����������̂͂Ƃ�ܒu���Ƃ���
���M�Ɖ��x�̈Ⴂ���킩���ĂȂ��l������
AMD�̉��x��intel�̉��x���킩���ĂȂ��l������
�ǂ����AMD�t�@���{�[�C���Ċ�������
����ȃ��[�U�[����ő��v��
AMD�̉��x��intel�̉��x���킩���ĂȂ��l������
�ǂ����AMD�t�@���{�[�C���Ċ�������
����ȃ��[�U�[����ő��v��
CPU���PGhz���������肩��
�d���g�ł�������������Ɩ{�C�Ŏv���Ă�
�d���g�ł�������������Ɩ{�C�Ŏv���Ă�
AMD�M�҂͖��m���N���Ȓp��������
937 �F,,�E�L�́M�E,,�j��-�������F2015/01/28(��) 21:07:57.52 ID:FzEfD0B2
�������������̉�H���ăV���R���ɓd�C��R�^���ċ쓮������̂�����
��R������Γd�����Ղ��ĔM�ɂȂ�Ɍ��܂��Ă�
��R������Γd�����Ղ��ĔM�ɂȂ�Ɍ��܂��Ă�
AMD�͏퉷���d���Ȃ�@���킹��Ȓp��������
939 �F,,�E�L�́M�E,,�j��-�������F2015/01/28(��) 21:10:34.20 ID:FzEfD0B2
>>932
FX�̓\���_�����O�ł���B
�ł�Intel��105���Ƃ��Ă���TjMax������TcaseMax��70�������Ă����Ή��x�Ȃ̂�
�A�C�h�����Ɏ������Ⴂ���x�������Ƃ�ł����x�Z���T�[
FX�̓\���_�����O�ł���B
�ł�Intel��105���Ƃ��Ă���TjMax������TcaseMax��70�������Ă����Ή��x�Ȃ̂�
�A�C�h�����Ɏ������Ⴂ���x�������Ƃ�ł����x�Z���T�[
940 �FSocket774�F2015/01/28(��) 21:12:08.57 ID:NjWcnTGk
>>918
�y��ʏ���҂��x�����C�^�[�̘b�z
ttp://pcnomori.blog.fc2.com/blog-entry-124.html
�yBIOS���Ή��Ōv��&�x���`�̐ݒ���H������z
4gamer:FX-8350/4.0GHz
http://www.4gamer.net/games/189/G018967/20121021001/
Impress:AMD FX-8350�x���`�}�[�N���r���[�@��
http://pc.watch.impress.co.jp/docs/topic/feature/20121023_567804.html
Ascii:Vishera����AMD�uFX-8350�v�͒�\�Z����Ɋv�����N�������H
http://ascii.jp/elem/000/000/738/738028/
�}�C�i�r:Vishera���ƁuAMD FX-8350�v������
http://news.mynavi.jp/special/2012/vishera01/
FX-8350���������A�����ׂ�����PC�n�L����Ƃ��������킹�����̗l��8350��
���䂷��ׂ̃}�C�N���R�[�h�������Ă��Ȃ�BIOS�𗘗p���Čv�����Ă��܂��B
Croshair V Formula��BIOS�Ή��\��FX-8350(FD8350FRW8KHK,4.0GHz,8C,125W,rev.C0,AM3+)��
�����݂Č��܂��傤�B1703�Ƃ���BIOS�̃o�[�W�������m�F�ł���Ǝv���܂����A�����
���̃o�[�W��������Ή������Ƃ����Ӗ��ł��B�܂�A����ȑO��BIOS�ł͐���Ȑ��䂪
�o���Ȃ��̂ŁA���l��O���t�͑S���Ӗ����Ȃ��ǂނ������ʂƌ�������������܂��B
���݂ɁABIOS�̃o�[�W�����������Ă��Ȃ��Ă�1605�𗘗p���Ă���̂�
���̂킩�邩�Ƃ����ƁA�o�[�W����1703���o�����̂�2012/10/24������ł��B
����ɁA�����Ɠ����ɋL�����o���ׂɂ͂���ȑO�ɑg��Ō����Ȃ��ƑʖڂȂ̂ƁA
��s�z�z����Ă���Ȃ�A�킴�킴���Ή��o�[�W���������\����K�v��������
1703���z�z����Ă��Ȃ�����������܂��B
�ꕔ�ł́AAMD����n���ꂽ�ƌ���������Ă��鏊���L��܂����A�Ή����Ă��Ȃ�BIOS��
���r���[������ƌ�����킯���Ȃ����A��ʏ���҂ɂƂ��Đ���ł��Ă��Ȃ���Ԃł�
���l�Ȃ�đS���Ӗ����Ȃ��A�����������ɋL�����o���K�v�������̂ŗ��R�ɂȂ��Ă��܂���B
��Ai7-3770K���_�E���N���b�N����i5-3570K�����ɂ��Ă���ƈӖ��s���Ȃ��Ƃ������Ă��鏊��
����܂����ACPU�L���b�V���ʂ��Ⴄ�̂Ń_�E���N���b�N�����悤��i5-3570K�����ɂ͐���܂���B
���A���e���ݒ���H���Đ��\��Ⴍ���������Ă���̂��A���p��(�^��l�Ԃ̖��H)���\���Ă��܂��B
�y��ʏ���҂��x�����C�^�[�̘b�z
ttp://pcnomori.blog.fc2.com/blog-entry-124.html
�yBIOS���Ή��Ōv��&�x���`�̐ݒ���H������z
4gamer:FX-8350/4.0GHz
http://www.4gamer.net/games/189/G018967/20121021001/
Impress:AMD FX-8350�x���`�}�[�N���r���[�@��
http://pc.watch.impress.co.jp/docs/topic/feature/20121023_567804.html
Ascii:Vishera����AMD�uFX-8350�v�͒�\�Z����Ɋv�����N�������H
http://ascii.jp/elem/000/000/738/738028/
�}�C�i�r:Vishera���ƁuAMD FX-8350�v������
http://news.mynavi.jp/special/2012/vishera01/
FX-8350���������A�����ׂ�����PC�n�L����Ƃ��������킹�����̗l��8350��
���䂷��ׂ̃}�C�N���R�[�h�������Ă��Ȃ�BIOS�𗘗p���Čv�����Ă��܂��B
Croshair V Formula��BIOS�Ή��\��FX-8350(FD8350FRW8KHK,4.0GHz,8C,125W,rev.C0,AM3+)��
�����݂Č��܂��傤�B1703�Ƃ���BIOS�̃o�[�W�������m�F�ł���Ǝv���܂����A�����
���̃o�[�W��������Ή������Ƃ����Ӗ��ł��B�܂�A����ȑO��BIOS�ł͐���Ȑ��䂪
�o���Ȃ��̂ŁA���l��O���t�͑S���Ӗ����Ȃ��ǂނ������ʂƌ�������������܂��B
���݂ɁABIOS�̃o�[�W�����������Ă��Ȃ��Ă�1605�𗘗p���Ă���̂�
���̂킩�邩�Ƃ����ƁA�o�[�W����1703���o�����̂�2012/10/24������ł��B
����ɁA�����Ɠ����ɋL�����o���ׂɂ͂���ȑO�ɑg��Ō����Ȃ��ƑʖڂȂ̂ƁA
��s�z�z����Ă���Ȃ�A�킴�킴���Ή��o�[�W���������\����K�v��������
1703���z�z����Ă��Ȃ�����������܂��B
�ꕔ�ł́AAMD����n���ꂽ�ƌ���������Ă��鏊���L��܂����A�Ή����Ă��Ȃ�BIOS��
���r���[������ƌ�����킯���Ȃ����A��ʏ���҂ɂƂ��Đ���ł��Ă��Ȃ���Ԃł�
���l�Ȃ�đS���Ӗ����Ȃ��A�����������ɋL�����o���K�v�������̂ŗ��R�ɂȂ��Ă��܂���B
��Ai7-3770K���_�E���N���b�N����i5-3570K�����ɂ��Ă���ƈӖ��s���Ȃ��Ƃ������Ă��鏊��
����܂����ACPU�L���b�V���ʂ��Ⴄ�̂Ń_�E���N���b�N�����悤��i5-3570K�����ɂ͐���܂���B
���A���e���ݒ���H���Đ��\��Ⴍ���������Ă���̂��A���p��(�^��l�Ԃ̖��H)���\���Ă��܂��B
���M�҂����߂��Ă�[
942 �FSocket774�F2015/01/28(��) 21:16:37.75 ID:NjWcnTGk
���Ƃ��A�c�q��GTX970�̃X�y�b�N���\�ɂ���܂�̊�ƃT�C�g���悭�M�p�ł���ȁB
�l�T�����͍ŏ��i�삵�Ă����Č�Ŏ�̂Ђ��Ԃ��Ĉꉞ�ᔻ�������B
�l�T�����͍ŏ��i�삵�Ă����Č�Ŏ�̂Ђ��Ԃ��Ĉꉞ�ᔻ�������B
>>940
����Ȃ̂��A�u�d�́v�Ɓu�M�v�̈Ⴂ�������̂�\���Ă���
����Ȃ̂��A�u�d�́v�Ɓu�M�v�̈Ⴂ�������̂�\���Ă���
944 �F,,�E�L�́M�E,,�j��-�������F2015/01/28(��) 21:18:41.30 ID:FzEfD0B2
pcnomori����AMD�Ό��̃g���f���d�g�T�C�g���ǂ��������āH
�����O��킸�ǂ��ł�8350�͔��M�ł���
�����2013�N6��1���̋L�������ǂ��������ꂵ����������Ȃ���̂ł��傤
http://www.bit-tech.net/hardware/2013/06/01/intel-core-i7-4770k-cpu-review/7
�����O��킸�ǂ��ł�8350�͔��M�ł���
�����2013�N6��1���̋L�������ǂ��������ꂵ����������Ȃ���̂ł��傤
http://www.bit-tech.net/hardware/2013/06/01/intel-core-i7-4770k-cpu-review/7
NjWcnTGk�A�z�Ȃ����K�������邗
���������n����������邩��AMD�X�����Ė����ƂɗV�ꑱ�����
���������n����������邩��AMD�X�����Ė����ƂɗV�ꑱ�����
FX��ʋ@��Ȃ�Č���OC�݂����Ȃ���
�������������Ă�core i7�̑����ɂ��y�Ȃ����\
�������������Ă�core i7�̑����ɂ��y�Ȃ����\
{kind=link}
948 �FSocket774�F2015/01/28(��) 21:22:18.18 ID:TTgD5oEE
AMD�𐒔q��blog�ŏ^����ƕ���Ƃ������̂�T���Ŗ�����CPU�Q�b�g����
AMD�^����������
AMD�^����������
���{�l�Ȃ�C���e���Q�t�H���
950 �F,,�E�L�́M�E,,�j��-�������F2015/01/28(��) 21:23:43.36 ID:FzEfD0B2
>>947
������������������������������������������������������������������������������������������������������������������������������������������
������������������������������������������������������������������������������������������������������������������������������������������
951 �FSocket774�F2015/01/28(��) 21:24:41.02 ID:hjGVhzQn
TDP�́w�M�v�d�́x�ł����āA�w���M�ʁx�ł��w����d�́x�ł��Ȃ��B
��p���u��v����ۂɁA�ǂ̒��x�̋z�M�\�͂���������Ηǂ��������肷�邽�߂Ɏg����w�W�B
�����M�ʂ������ꍇ�ł�CPU�p�b�P�[�W���ł̔M�ړ�������_�C�̔M�ϐ��ɂ���Ă�TDP�͕ς��B(��F�������M�ʂȂ�O���X���n���_�̕���TDP�͒Ⴍ�Ȃ�A�������M�ʂȂ�_�C�T�C�Y������������TDP�������Ȃ�₷��)
��p���u��v����ۂɁA�ǂ̒��x�̋z�M�\�͂���������Ηǂ��������肷�邽�߂Ɏg����w�W�B
�����M�ʂ������ꍇ�ł�CPU�p�b�P�[�W���ł̔M�ړ�������_�C�̔M�ϐ��ɂ���Ă�TDP�͕ς��B(��F�������M�ʂȂ�O���X���n���_�̕���TDP�͒Ⴍ�Ȃ�A�������M�ʂȂ�_�C�T�C�Y������������TDP�������Ȃ�₷��)
952 �F���J�c���F2015/01/28(��) 21:24:47.18 ID:cNGCfBd4
���͓�ɂ킩�ꂽ�c���̗ǐS�Ȃ́B�K���_���E�����łł��Ă����
���̕Е��̎��쎩���ɏ悹���ĉ���ɉ��S���Ă��肵�܂����
���c��9��ID���g���čr�炵�܂����Ă܂�����C�����Ă�������
AMD���[�U�[�S�̂��i�i���^���邱�ƂɂȂ�܂�����
���̕Е��̎��쎩���ɏ悹���ĉ���ɉ��S���Ă��肵�܂����
���c��9��ID���g���čr�炵�܂����Ă܂�����C�����Ă�������
AMD���[�U�[�S�̂��i�i���^���邱�ƂɂȂ�܂�����
953 �FSocket774�F2015/01/28(��) 21:25:35.14 ID:NjWcnTGk
AMD���p����5GHz����CPU�uFX-9590�v�̃p�t�H�[�}���X���`�F�b�N����
ttp://reviewdays.com/archives/41833
OCCT Power Supply Test CPU���x
OCCT 4.4.0���g�p���AOCCT Power Supply Test�����s��CPU�̉��x���������B
�\�t�g�E�F�A�ǂ݂ƂȂ邽�߁A�啝�Ȍ덷�������Ă���\�������邱�Ƃ��������������������B
CPU0��CPU1�̉��x�f�[�^�����Ă���A�ȉ��̗l�Ȍ��ʂƂȂ����B
�@�@�@�@�A�C�h�����@�@����
CPU0�@�@��27�x�@�@ ��33�x
CPU1�@�@��24�x�@�@ ��54�x
CPU2�@�@ ��2�x�@�@�@��47�x
������22.1�x�Ō���
CPU0�̉��x�̓A�C�h�����A��27�x�A�����ł���33�x�Ƃ������ʂ͖��炩�ɂ��������Ǝv����̂Ŋ����B
CPU1�̉��x�̓A�C�h������18�x�A������49�x�ƂȂ��Ă���M�ߐ��͂��Ă����A����炵�������͎�邱�Ƃ��o�����B
CPU2�̉��x�̓A�C�h�����A��2�x�A�����ł���47�x�ƂȂ��Ă���A���炩�ɃA�C�h�����̉��x���Ⴗ����̂ł�����������B
CPU���x�Ɋւ��Ă̓}�U�[�{�[�h��CPU���̃Z���T�[�A�\�t�g�E�F�A�ɂ���đ傫�Ȍ덷�����܂�Ă��܂�����
����Ȓl����邱�Ƃ�������A 1�����邱�Ƃ́uTDP 220W�Ƃ������ɂ͗₽�������v�Ƃ������Ƃ��B
OCCT Linpack���Ă��鎞��CPU�N�[���[�̃t�B���̕�����x�[�X�����ɐG�ꂽ���A
�G��Ȃ��قǂ̔M���ł͂Ȃ��A�����ԐG���Ă��Ă��M���Ɗ����邱�Ƃ͂Ȃ������B
�������}�U�[�{�[�h��VRM���������Ȃ蔭�M���Ă���A�ԊO�����x�v��73�x����
���x�ɂȂ��Ă������߁A�}�U�[�{�[�h��VRM�����̗�p�ɂ͋C������ׂ����B
AMD��CPU��TDP�̐��l�������Ƃ�����ȉ��̔��M�ł��邱�Ƃ����ɑ����A
FX-9590��220W�ƌ����Ă������A�̊��I�ɂ�140W���x�Ȃ̂ł́H�Ɗ������B
ttp://reviewdays.com/archives/41833
OCCT Power Supply Test CPU���x
OCCT 4.4.0���g�p���AOCCT Power Supply Test�����s��CPU�̉��x���������B
�\�t�g�E�F�A�ǂ݂ƂȂ邽�߁A�啝�Ȍ덷�������Ă���\�������邱�Ƃ��������������������B
CPU0��CPU1�̉��x�f�[�^�����Ă���A�ȉ��̗l�Ȍ��ʂƂȂ����B
�@�@�@�@�A�C�h�����@�@����
CPU0�@�@��27�x�@�@ ��33�x
CPU1�@�@��24�x�@�@ ��54�x
CPU2�@�@ ��2�x�@�@�@��47�x
������22.1�x�Ō���
CPU0�̉��x�̓A�C�h�����A��27�x�A�����ł���33�x�Ƃ������ʂ͖��炩�ɂ��������Ǝv����̂Ŋ����B
CPU1�̉��x�̓A�C�h������18�x�A������49�x�ƂȂ��Ă���M�ߐ��͂��Ă����A����炵�������͎�邱�Ƃ��o�����B
CPU2�̉��x�̓A�C�h�����A��2�x�A�����ł���47�x�ƂȂ��Ă���A���炩�ɃA�C�h�����̉��x���Ⴗ����̂ł�����������B
CPU���x�Ɋւ��Ă̓}�U�[�{�[�h��CPU���̃Z���T�[�A�\�t�g�E�F�A�ɂ���đ傫�Ȍ덷�����܂�Ă��܂�����
����Ȓl����邱�Ƃ�������A 1�����邱�Ƃ́uTDP 220W�Ƃ������ɂ͗₽�������v�Ƃ������Ƃ��B
OCCT Linpack���Ă��鎞��CPU�N�[���[�̃t�B���̕�����x�[�X�����ɐG�ꂽ���A
�G��Ȃ��قǂ̔M���ł͂Ȃ��A�����ԐG���Ă��Ă��M���Ɗ����邱�Ƃ͂Ȃ������B
�������}�U�[�{�[�h��VRM���������Ȃ蔭�M���Ă���A�ԊO�����x�v��73�x����
���x�ɂȂ��Ă������߁A�}�U�[�{�[�h��VRM�����̗�p�ɂ͋C������ׂ����B
AMD��CPU��TDP�̐��l�������Ƃ�����ȉ��̔��M�ł��邱�Ƃ����ɑ����A
FX-9590��220W�ƌ����Ă������A�̊��I�ɂ�140W���x�Ȃ̂ł́H�Ɗ������B
954 �FSocket774�F2015/01/28(��) 21:27:46.55 ID:NjWcnTGk
�EFX�n��VRM�������Ȃ�d�C��H��
�EFX�n�͒�i�ł�CPU�͑債�ĔM���Ȃ�Ȃ���VRM�͔M���Ȃ�
�c�q�͂����m��Ȃ��́H
�EFX�n�͒�i�ł�CPU�͑債�ĔM���Ȃ�Ȃ���VRM�͔M���Ȃ�
�c�q�͂����m��Ȃ��́H
������ĂȂɂ�������
���Ƃ��A�\�t�g�E�F�A�J���ҁi�Ƃ���OS�E���C�u������R�[�h�œK���ɂ�������Ă�l�j���Ă�ŕ����Ȃ�Ƃ������A
������PC���^�E���샒�^�̃u���K�[�ǂ�ŕ�����āA������������ł��������L���������ĖႨ�����Ă����ł��傤
�ĂԂȂ���{�l��x264�R�[�h�R�~�b�g���Ă�悤�ȓz���Afreebsd/netbsd�̃R�[�h�����Ă�悤�ȓz���Ă�ŕ��������̂ɁA
���ꂩHPC�W�ҌĂ��HSA����Ƃ�
���Ƃ��A�\�t�g�E�F�A�J���ҁi�Ƃ���OS�E���C�u������R�[�h�œK���ɂ�������Ă�l�j���Ă�ŕ����Ȃ�Ƃ������A
������PC���^�E���샒�^�̃u���K�[�ǂ�ŕ�����āA������������ł��������L���������ĖႨ�����Ă����ł��傤
�ĂԂȂ���{�l��x264�R�[�h�R�~�b�g���Ă�悤�ȓz���Afreebsd/netbsd�̃R�[�h�����Ă�悤�ȓz���Ă�ŕ��������̂ɁA
���ꂩHPC�W�ҌĂ��HSA����Ƃ�
>>944
AMD��APU/CPU�{chipset�̓C���e���̂�肸���ƒ����d��
�ł��AAMD�V�X�e���ō����Ȃ�̂́A���M�C���e�����ĂȂ�Ȃ��悤��
�C���e���̈��͂ŁAAMD���̂ł͑��̕�������d�͂ɂ��Ȃ��Ƃ����Ȃ������B
Intel�����i�蔄���Ă���Ȃ��ƂȂ�ƁA�}�U�[�EPC���[�J�[
����Ă����Ȃ����炵�傤���Ȃ�����Ă���낤���ȁB�c�q�M���Ă�
>>954�����ꂾ��
AMD��APU/CPU�{chipset�̓C���e���̂�肸���ƒ����d��
�ł��AAMD�V�X�e���ō����Ȃ�̂́A���M�C���e�����ĂȂ�Ȃ��悤��
�C���e���̈��͂ŁAAMD���̂ł͑��̕�������d�͂ɂ��Ȃ��Ƃ����Ȃ������B
Intel�����i�蔄���Ă���Ȃ��ƂȂ�ƁA�}�U�[�EPC���[�J�[
����Ă����Ȃ����炵�傤���Ȃ�����Ă���낤���ȁB�c�q�M���Ă�
>>954�����ꂾ��
�����F�u����d�͂͑������ǔ��M�͏��Ȃ��v
�̂��猾��ꑱ���Ă��Ă���
�̂��猾��ꑱ���Ă��Ă���
APM���L���ɂȂ��Ă����Ԃŗ�p���ǂ����Ȃ��ꍇ�A�N���b�N�𗎂Ƃ��̂�
���x�͏オ��܂���B���ۂɎg���ĂȂ�����œd�g�u���O��ӐM���Ă��ł���
���z�Ȑl
���x�͏オ��܂���B���ۂɎg���ĂȂ�����œd�g�u���O��ӐM���Ă��ł���
���z�Ȑl
{kind=link}
960 �F,,�E�L�́M�E,,�j��-�������F2015/01/28(��) 21:36:59.54 ID:FzEfD0B2
���M�����[�^����Haswell�ł̓_�C�ɓ������Ă��Ȃ����������H
> �C���e���̈��͂ŁAAMD���̂ł͑��̕�������d�͂ɂ��Ȃ��Ƃ����Ȃ������B
����̋�̓I�ȏ؋��i�ϑz�ł͂Ȃ����ۂɒN�����Ă��������f�ł�����́j�������ꂽ��
> �C���e���̈��͂ŁAAMD���̂ł͑��̕�������d�͂ɂ��Ȃ��Ƃ����Ȃ������B
����̋�̓I�ȏ؋��i�ϑz�ł͂Ȃ����ۂɒN�����Ă��������f�ł�����́j�������ꂽ��
ID�FNjWcnTGk�您�O�͂悭�������AMD�̋���m�̌ւ肾
�ł�������F�߂悤�p�̏�h��ł݂Ă��Ȃ�
�ł�������F�߂悤�p�̏�h��ł݂Ă��Ȃ�
962 �FSocket774�F2015/01/28(��) 21:37:50.63 ID:hjGVhzQn
>>956
>>954��Zambezi/Piledriver�ł̓}�U�[���ɂ��Ă���d�����M�����[�^��Haswell��CPU�p�b�P�[�W���ɔ[�߂��邭�炢�]�T������ƌ����Ă����B
>>954��Zambezi/Piledriver�ł̓}�U�[���ɂ��Ă���d�����M�����[�^��Haswell��CPU�p�b�P�[�W���ɔ[�߂��邭�炢�]�T������ƌ����Ă����B
�㓡���K�������Đ������Ă���������d�����M�����[�^
964 �F,,�E�L�́M�E,,�j��-�������F2015/01/28(��) 21:41:51.85 ID:FzEfD0B2
�����������M�����[�^�̏���d�͂������Ȃ�̂�CPU�̓d�͂��z����邩�炶��Ȃ��́H����
�z�������PC�M���������
���R�A��K10�Ƃ̌݊�����������v�ɂ���������Ĉӌ�����������
���R�A��K10�Ƃ̌݊�����������v�ɂ���������Ĉӌ�����������
>>960
�@���̋��`�Ɠ����Ȃ���A�ׂ����킸�M�����
�@���̋��`�Ɠ����Ȃ���A�ׂ����킸�M�����
Haswell�ł́A�}�U�[�{�[�h���̃��M�����[�^���ȗ����ł�����Ă����ŁA
�}�U�[�{�[�h�Ƀ��M�����[�^�͕K�v����
�}�U�[�{�[�h�Ƀ��M�����[�^�͕K�v����
�M������̂͋d����
�����琅�≻���ă��W���O�ɏo���Ɖ��x��������B
CPU�̉��x�͎����ɏ����F��t�������x�̉��x�ň��肷�邵
�P�[�X���̉��x���M���������Ĉ��肷�邩��PC��������Ȃ�čl������B
CPU�̉��x�͎����ɏ����F��t�������x�̉��x�ň��肷�邵
�P�[�X���̉��x���M���������Ĉ��肷�邩��PC��������Ȃ�čl������B
Intel�̈��͂�AMD�֘A������n�[�h�ɂȂ��Ă���Č����Ȃ�
���ЂŃ��t�@�����X�n�[�h�o�����������
���ЂŃ��t�@�����X�n�[�h�o�����������
���������Ƃ����PC�̗��j�I�ɗ]�肢�����H�����ǂ��ĂȂ������߂��ق���������
>>971
Intel�͎��Ѓ}�U�{�o���Ă���NVIDIA�ł���tegra�Ń^�u���b�g�Ƃ������Ă�̂ɁH
��́AAMD���O���t�B�b�N�J�[�h�̓��t�@�����X��点�Ă邶���
Intel�͎��Ѓ}�U�{�o���Ă���NVIDIA�ł���tegra�Ń^�u���b�g�Ƃ������Ă�̂ɁH
��́AAMD���O���t�B�b�N�J�[�h�̓��t�@�����X��点�Ă邶���
�C���e���͔���s���s�U��NUC�ɓ����Ă�����
tegra�͊����̂������f�����ア����
���h���ɕ����č̗p�Ⴊ�L�тȂ�����ł���
tegra�͊����̂������f�����ア����
���h���ɕ����č̗p�Ⴊ�L�тȂ�����ł���
diamondmm�Ƃ�3dfx�Ƃ�3dlabs�Ƃ��c
�I�͌����ɂ��ŏI�I�ɑ���GPU�̗p�ɓ��ݐ�����
���Ƃ�Aureal�Ƃ�
�I�͌����ɂ��ŏI�I�ɑ���GPU�̗p�ɓ��ݐ�����
���Ƃ�Aureal�Ƃ�
>>972
Intel�͈Ӗ�����������~�߂����ANvidia�͑��肳��Ȃ����玩���ō���Ă邾��w
Intel�͈Ӗ�����������~�߂����ANvidia�͑��肳��Ȃ����玩���ō���Ă邾��w
�R���V���[�}�����͂Ƃ������A
HPC�����͎��А��������ǂ�
HPC�����͎��А��������ǂ�
�̂悤�ɗ~�[�Ȋ����[�������邾���̃p�t�H�[�}���X���グ���Ȃ������Ƃ������Ƃ��ȁ������}�U�[
���E�I�Ɍ���C���e�������}�U�[�łقړƐ��Ԃ�������������炵�����c
���E�I�Ɍ���C���e�������}�U�[�łقړƐ��Ԃ�������������炵�����c
�C���e���̈��̓K�[�Ȃ�Ă����Ă�ȂɃ��t�@�����X�͕K���Ŕے�Ƃ�
AMD�D���炵�������̑ł���������
AMD�D���炵�������̑ł���������
���t�@�d�l�̃O���{�͔����Ă邶��˂���
�ڈ�����
�ڈ�����
980 �FSocket774�F2015/01/29(��) 07:53:35.69 ID:Y/T5LYDk
>>944
�u��ƃT�C�g�̃C���`�L���w�E�v������u�Ό��̃g���f���d�g�v�ȂB�Ӂ[��B
�u��ƃT�C�g�̃C���`�L���w�E�v������u�Ό��̃g���f���d�g�v�ȂB�Ӂ[��B
981 �F,,�E�L�́M�E,,�j��-�������F2015/01/29(��) 08:11:19.78 ID:nSqH+Es3
FX�̏���d�͂�����������2�_�R�_���Ă邶��Ȃ���
���Ǎ��́uCPU�͈����Ȃ��{���e�[�W���M�����[�^���d�̓o�J�H���Ȃv��
���Ⴀpcnomori�̓f�^�����������Ă���Ă��ƂɂȂ�ł���
���Ǎ��́uCPU�͈����Ȃ��{���e�[�W���M�����[�^���d�̓o�J�H���Ȃv��
���Ⴀpcnomori�̓f�^�����������Ă���Ă��ƂɂȂ�ł���
982 �F,,�E�L�́M�E,,�j��-�������F2015/01/29(��) 08:11:50.05 ID:nSqH+Es3
��]�O�]
���[�U�[�T�|�[�g�������h�N�T�C����AMD�̋K�͂̉�Ђ�����ˁ[�����ˁ[����
������PS4��XB1�݂����ȃJ�X�^���`�b�v�̐v��������Ă邶���
����Ȃ�\�j�[��MS���̔���T�|�[�g����|���Ă����
������PS4��XB1�݂����ȃJ�X�^���`�b�v�̐v��������Ă邶���
����Ȃ�\�j�[��MS���̔���T�|�[�g����|���Ă����
985 �FSocket774�F2015/01/29(��) 08:19:47.08 ID:Y/T5LYDk
>>981
���O�ˑR���M�̘b�����Ȃ��Ȃ����ȁB
���O�ˑR���M�̘b�����Ȃ��Ȃ����ȁB
�v���X�R�̎����d�����ׂ̕ǂ������������
CPU���Ă���O�ɕ��ʂɃ}�U�[��VRM���Ă��Ă�
5GHz�O��ʼn���Ă�990FX�ŏĂ����b�͗]�蕷���Ȃ��̂�
�Z�p�I�ɂ͂��Ȃ�̐i���𐋂����Ǝv��
�l�g�o�ƈ���Ă�����������������Ȃ�����
CPU���Ă���O�ɕ��ʂɃ}�U�[��VRM���Ă��Ă�
5GHz�O��ʼn���Ă�990FX�ŏĂ����b�͗]�蕷���Ȃ��̂�
�Z�p�I�ɂ͂��Ȃ�̐i���𐋂����Ǝv��
�l�g�o�ƈ���Ă�����������������Ȃ�����
987 �F,,�E�L�́M�E,,�j��-�������F2015/01/29(��) 08:35:41.45 ID:nSqH+Es3
>>985
���x�ł�������
AMD�̓������x�Z���T�[��Intel��105���Ƃ��Ă���TjMax������TcaseMax��70����
�����Ă����Ή��x�Ȃ̂ŃA�C�h�����Ɏ������Ⴂ���x�������Ƃ�ł����x�Z���T�[
���x�ł�������
AMD�̓������x�Z���T�[��Intel��105���Ƃ��Ă���TjMax������TcaseMax��70����
�����Ă����Ή��x�Ȃ̂ŃA�C�h�����Ɏ������Ⴂ���x�������Ƃ�ł����x�Z���T�[
988 �F,,�E�L�́M�E,,�j��-�������F2015/01/29(��) 08:46:13.75 ID:nSqH+Es3
��������AMD�ɓs���̈��������͈�؏����������A�d�_�������A�˂�̂�pc�̐X�Ƃ��������A�t�B�u���O
�܂Ƃ߂��
AMD�͑��Ή��x�\���Ȃ̂Ŏ������Ⴂ�l���o�����肷��d�l�ɂȂ��Ă���
AMD�̓��M�����[�^�[���p�b�P�[�W�O���ɂ���A����d�͍͂�����CPU���̂͂���ȂɔM���Ȃ������M�����[�^�[�����M�ł���
����Ȋ����H
AMD�͑��Ή��x�\���Ȃ̂Ŏ������Ⴂ�l���o�����肷��d�l�ɂȂ��Ă���
AMD�̓��M�����[�^�[���p�b�P�[�W�O���ɂ���A����d�͍͂�����CPU���̂͂���ȂɔM���Ȃ������M�����[�^�[�����M�ł���
����Ȋ����H
��������TDP220W��FX��������}�U�[�Ȃ�Č����邶���
OC�}�U�[�������Ή����Ă邭�炢
��ʂɍ�����OC�}�U�[��VRM�̗e�ʂƂ��ɂ��]�T�������č���Ă��邵
OC�}�U�[�́AVRM�Ƀq�[�g�p�C�v�ƃt�B������Ȃ�ł����q�[�g�V���N���Ă�@�킪����
��ʂ̃}�U�[���q�[�g�V���N�����Ȃ̂Ƃ͈قȂ�
OC�}�U�[�������Ή����Ă邭�炢
��ʂɍ�����OC�}�U�[��VRM�̗e�ʂƂ��ɂ��]�T�������č���Ă��邵
OC�}�U�[�́AVRM�Ƀq�[�g�p�C�v�ƃt�B������Ȃ�ł����q�[�g�V���N���Ă�@�킪����
��ʂ̃}�U�[���q�[�g�V���N�����Ȃ̂Ƃ͈قȂ�
�g����̂Ƃ���ŐԊO���J�����ŎB�e���Ă������������
����PC�͐悪�����Ă��
���[�A�̖@���̓W�G���h
AVX�Ȃ�炢�������̃n�C�v�̓A�v���������ɖ𗧂��ĂȂ�
���ƃQ�[���ƊE�Ƃ������ԋƊE���n�C�G�i��낵���E�}�E�}��
�M��������ł���
���[�A�̖@���̓W�G���h
AVX�Ȃ�炢�������̃n�C�v�̓A�v���������ɖ𗧂��ĂȂ�
���ƃQ�[���ƊE�Ƃ������ԋƊE���n�C�G�i��낵���E�}�E�}��
�M��������ł���
�����ԋƊE�́A����͉^�]�⏕�A�����͎����^�]�ŁA
����ɑ���ȃv���Z�b�T�p���[��v������Ǝv��
����ɑ���ȃv���Z�b�T�p���[��v������Ǝv��
��������v���E�X�n�b�L���O���ău���[�L�����Ȃ�������o����炵����
���낵������ɂȂ�������
���낵������ɂȂ�������
�A���h���ăN�A���R����蔼���̐��Y�z���ɂȂ��Ă���
>>987
���̂��ACoreTemp�̉��x���m�@�\�̓}�U�{�̃Z���T�[�����ɍs���Ȃ����炠�Ăɂ���Ȃ�
���̂��ACoreTemp�̉��x���m�@�\�̓}�U�{�̃Z���T�[�����ɍs���Ȃ����炠�Ăɂ���Ȃ�
���{�l�Ȃ�C���e���Q�t�H������˂�
>>998
VRAM84%�̎�������������������������
VRAM84%�̎�������������������������
1000�������獡�NAMD��t�]�B
1001 �F�P�O�O�P�F
1��̃}�V�����g�ݏオ��܂����B�B�B
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://anago.2ch.net/jisaku/
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://anago.2ch.net/jisaku/