AMD�̐��\��������X��
1 �FSocket774�F
���I�ɐ��\�������Ă���x64�̐���
AMD�̃M�W�c���L����낤
AMD�̃M�W�c���L����낤
|
|
|
������Ȃ�
10�N�x��̃X��
4 �FSocket774�F2014/06/15(��) 18:53:01.19 ID:4G8Rb7Gq
Excavator��ǂ������邽�߂ɁA���܂ł�APU�͐��\�𗎂Ƃ��Ă�����
TDP65W������W�œ���N���b�N����������
CPU���\���̂�Richland/Kaveri/Carizzo�ŕς��Ȃ��\��
CPU���\���̂�Richland/Kaveri/Carizzo�ŕς��Ȃ��\��
kaveri���ǔłɊ��ҁB
k����Ȃ��Ȃ�&�N���b�N������������x��TDP�傫��������Ȃ�悵�B
���Ƃ͉��i���傫��������c�c
��1��3000�~�ł̒Ȃ�R�X�p��i5�z���邩�H
k����Ȃ��Ȃ�&�N���b�N������������x��TDP�傫��������Ȃ�悵�B
���Ƃ͉��i���傫��������c�c
��1��3000�~�ł̒Ȃ�R�X�p��i5�z���邩�H
Phenom�U�̉h���͂������Ȃ�
8 �FSocket774�F2014/06/17(��) 20:57:43.62 ID:92L+odcX
2000�N �f���A���R�APOWER4
��
2005�N�̓f���A���R�A���N�I���E���f���A���R�AAthlon64 X2�I
2003�N �N�A�b�h�R�APOWER5�A1�R�A2�X���b�hSMT
��
2007�N�A���ɃN�A�b�h�R�ACPU���o��IPhenom X4�I
2010�N2�� TurboCore���[�h�������POWER7
��
���N Turbo CORE��������Phenom II X6
2007�N �I�[�o�[5GHz POWER6�A1�R�A4�X���b�h
��
2013�N ���E����5GHz�AFX-9590�I
2014�N 12�R�A96�X���b�hPOWER8
��
2016�N(AMD����) ���E���ISMT����CPU�I�Ȃ�ƁI1�R�A������2�X���b�h�������Ă��܂��I
��
2005�N�̓f���A���R�A���N�I���E���f���A���R�AAthlon64 X2�I
2003�N �N�A�b�h�R�APOWER5�A1�R�A2�X���b�hSMT
��
2007�N�A���ɃN�A�b�h�R�ACPU���o��IPhenom X4�I
2010�N2�� TurboCore���[�h�������POWER7
��
���N Turbo CORE��������Phenom II X6
2007�N �I�[�o�[5GHz POWER6�A1�R�A4�X���b�h
��
2013�N ���E����5GHz�AFX-9590�I
2014�N 12�R�A96�X���b�hPOWER8
��
2016�N(AMD����) ���E���ISMT����CPU�I�Ȃ�ƁI1�R�A������2�X���b�h�������Ă��܂��I
9 �F,,�E�L�́M�E,,�j��-�������F2014/06/17(��) 21:02:33.63 ID:KDLX4szS
������lj����Ƃ���
http://www.amd.com/ja-jp/who-we-are/careers/culture
> ���E���� APU�i�A�N�Z�����[�e�b�h�v���Z�b�V���O ���j�b�g�j�\�i2010�N�j
AMD�Ǝ��p��Ȃ���A2�Ԗڂ̉�Ђ�3�Ԗڂ̉�Ђ����݂��Ȃ���
http://www.amd.com/ja-jp/who-we-are/careers/culture
> ���E���� APU�i�A�N�Z�����[�e�b�h�v���Z�b�V���O ���j�b�g�j�\�i2010�N�j
AMD�Ǝ��p��Ȃ���A2�Ԗڂ̉�Ђ�3�Ԗڂ̉�Ђ����݂��Ȃ���
2016�N��SMT�����ɂ���āAAMD��2003�N��IBM�ɒǂ����̂��A�������
11 �F,,�E�L�́M�E,,�j��-�������F2014/06/19(��) 22:49:32.27 ID:ZTyIw3UP
x86�Ɍ��肵�Ă�2002�N��Pentium 4(Northwood)�����H
����Willamette�Ŏ�������Ă����L���ɂ��ĂȂ����������Ƃ�����������Ŕ������Ă邯��
����Willamette�Ŏ�������Ă����L���ɂ��ĂȂ����������Ƃ�����������Ŕ������Ă邯��
12 �FSocket774�F2014/06/20(��) 17:40:39.17 ID:aJ01syMh
��cinebenchR11.5 �V���O��CPU
�C���e��(7�N��60%����)
2013 Haswell 1.76/3.9=0.451
2012 Ivy 1.66/3.9=0.425
2011 Sandy 1.55/3.8=0.407
2010 Arrandale 0.8/2.39=0.334
2009 Lynn 1/2.94=0.340
2008 Penryn 0.93/3=0.310
2006 Conroe 0.86/3=0.286
�A���h(7�N�Ԃ�20%�������ス����)
2013 FX 1.1/4=0.275
2006 939 Opteron 0.68/3=0.226
�C���e��(7�N��60%����)
2013 Haswell 1.76/3.9=0.451
2012 Ivy 1.66/3.9=0.425
2011 Sandy 1.55/3.8=0.407
2010 Arrandale 0.8/2.39=0.334
2009 Lynn 1/2.94=0.340
2008 Penryn 0.93/3=0.310
2006 Conroe 0.86/3=0.286
�A���h(7�N�Ԃ�20%�������ス����)
2013 FX 1.1/4=0.275
2006 939 Opteron 0.68/3=0.226
14 �FSocket774�F2014/06/20(��) 23:31:01.10 ID:Tvs5ohAw
15 �F,,�E�L�́M�E,,�j��-�������F2014/06/21(�y) 00:15:45.91 ID:LNZwKvi6
>>13
3�N���Ƃ�5�{�̃y�[�X�œd�͌������グ��Η��_��͉\���ˁB
�\���s�\���̔��f�ޗ��Ƃ��āAAMD�̉ߋ�3�N�Ԃ̐��\����̎��т����邱�Ƃ��B
3�N���Ƃ�5�{�̃y�[�X�œd�͌������グ��Η��_��͉\���ˁB
�\���s�\���̔��f�ޗ��Ƃ��āAAMD�̉ߋ�3�N�Ԃ̐��\����̎��т����邱�Ƃ��B
AMD���������肵�Ȃ�����intel���I�����s�b�N�����Ő��\10���A�b�v�ł��V�F�A����葱����
18 �FSocket774�F2014/06/21(�y) 10:11:33.77 ID:15yzK1hp
8350�̓o��ɂ���āA8150���������肵��
19 �F,,�E�L�́M�E,,�j��-�������F2014/06/21(�y) 10:17:47.56 ID:LNZwKvi6
�@�@�@�@ �Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q
�@�@�@�@�S�~ || || || || || || || ,l,,l,,l ��V�c|
�@�@�@�@�@V~~''-�R��''''""~ �@�@�S�jƜc|�@�@�@�@�@�@�@25�{�̓d�͌�������������E�E�E�E�E�E�I
�@�@�@�@ /�@��[�\''��@�@�@�@�@ �Sƃj���@�@�@�@�@�@ �������邪�E�E�E
�@�@�@ <'-.,�@�@�P�P �@ �@ _,,,..-�]��@�r�j�|�@�@�@�@�@�@�@����@�܂��@�x�[�X�ƂȂ�v���Z�b�T��
�@�@�@/"''-�,�]l �@�@l`__�j-�]'''""` /�j��|�@�@�@�@�@�@�@�w��܂ł͂��Ă��Ȃ�
�@�@�@|�@==���!�@�@`��====��@�@l =����=|
.�@�@�@| `�[߁]'/�@�@ `�[�]߁\' �@�@l.=l��|~|�@�@�@�@�@�@�@���̂��Ƃ�
�@�@�@ |`�[�]/�@�@�@�@`�[�\�\�@�@H<,�r|=|�@�@�@�@�@�@�@�ǂ������N���
�@�@�@ |�@�@/�@�@�@ ��@�@ �@�@ �@ �@ l|__�m�|�@�@�@�@�@�@�@�v���o��������������
.�@�@�@| �^`�[�@~�@���@�@ �_�@�@�@.|�S.�j|�R
�@�@�@ |���@����l��l��l��l���b�@ �@|�@�S_,|�@�_�@�@�@�@�@�܂�E�E�E�E
. �@ �@ |�@�@�@�@�߁@�@�@�@�@�@�@�@�@|�@�@ `l�@�@ �___�@�@�@��X�����̋C�ɂȂ��
�@�@�@�@!�A�@�@�@�@�@�@�@�@�@�@ _,,..-'�� �^l�@�@ �@ |�@~'''�@ FX-9590(TDP220W)�̒P���x300GFLOPS��
�]''"�P|�@`i�-..,,,�Q,,,,,....-�]'''"�@ �@ �^�@ |�@ �@ �@ |�@�@�@ 9W��APU�Ŏ�������Ƃ������Ƃ�
�@-�\|�@�@|�_�@�@�@�@�@�@�@�@�@ �^�@ �@ |�@�@�@ �@ |�@�@�@�\���낤�E�E�E�E�E�E�E�E�E�E�Ƃ������ƁE�E�E�E�I
�@ �@ |�@�@ |�@ �_�@�@�@�@�@�@�^�@ �@ �@ |�@�@�@�@�@ |
�@�@�@�@�S�~ || || || || || || || ,l,,l,,l ��V�c|
�@�@�@�@�@V~~''-�R��''''""~ �@�@�S�jƜc|�@�@�@�@�@�@�@25�{�̓d�͌�������������E�E�E�E�E�E�I
�@�@�@�@ /�@��[�\''��@�@�@�@�@ �Sƃj���@�@�@�@�@�@ �������邪�E�E�E
�@�@�@ <'-.,�@�@�P�P �@ �@ _,,,..-�]��@�r�j�|�@�@�@�@�@�@�@����@�܂��@�x�[�X�ƂȂ�v���Z�b�T��
�@�@�@/"''-�,�]l �@�@l`__�j-�]'''""` /�j��|�@�@�@�@�@�@�@�w��܂ł͂��Ă��Ȃ�
�@�@�@|�@==���!�@�@`��====��@�@l =����=|
.�@�@�@| `�[߁]'/�@�@ `�[�]߁\' �@�@l.=l��|~|�@�@�@�@�@�@�@���̂��Ƃ�
�@�@�@ |`�[�]/�@�@�@�@`�[�\�\�@�@H<,�r|=|�@�@�@�@�@�@�@�ǂ������N���
�@�@�@ |�@�@/�@�@�@ ��@�@ �@�@ �@ �@ l|__�m�|�@�@�@�@�@�@�@�v���o��������������
.�@�@�@| �^`�[�@~�@���@�@ �_�@�@�@.|�S.�j|�R
�@�@�@ |���@����l��l��l��l���b�@ �@|�@�S_,|�@�_�@�@�@�@�@�܂�E�E�E�E
. �@ �@ |�@�@�@�@�߁@�@�@�@�@�@�@�@�@|�@�@ `l�@�@ �___�@�@�@��X�����̋C�ɂȂ��
�@�@�@�@!�A�@�@�@�@�@�@�@�@�@�@ _,,..-'�� �^l�@�@ �@ |�@~'''�@ FX-9590(TDP220W)�̒P���x300GFLOPS��
�]''"�P|�@`i�-..,,,�Q,,,,,....-�]'''"�@ �@ �^�@ |�@ �@ �@ |�@�@�@ 9W��APU�Ŏ�������Ƃ������Ƃ�
�@-�\|�@�@|�_�@�@�@�@�@�@�@�@�@ �^�@ �@ |�@�@�@ �@ |�@�@�@�\���낤�E�E�E�E�E�E�E�E�E�E�Ƃ������ƁE�E�E�E�I
�@ �@ |�@�@ |�@ �_�@�@�@�@�@�@�^�@ �@ �@ |�@�@�@�@�@ |
APU�Ȃ�\�I
�Ȃ��Ȃ�GPU���v�Z�ɓ����邩��ˁB�B
>>15
���\�ł͂Ȃ��d�͌����ł݂Ȃ���
http://pc.watch.impress.co.jp/img/pcw/docs/654/324/html/2.jpg.html
�Ȃ��Ȃ�GPU���v�Z�ɓ����邩��ˁB�B
>>15
���\�ł͂Ȃ��d�͌����ł݂Ȃ���
http://pc.watch.impress.co.jp/img/pcw/docs/654/324/html/2.jpg.html
{kind=link}
21 �FSocket774�F2014/06/25(��) 00:47:40.43 ID:Sy84P8Xh
>>8
FX�͒�i5GHz����Ȃ�����A�܂��ǂ����Ă��Ȃ�
FX�͒�i5GHz����Ȃ�����A�܂��ǂ����Ă��Ȃ�
Llano�o��̋łɂ�
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014Q1�łȂ�Ɖߋ��Œ���L�^�I�i�j
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014Q1�łȂ�Ɖߋ��Œ���L�^�I�i�j
{kind=link}
{kind=link}
�܂����ĂȂ���
HSA Roadmap
http://benchmarkhardware.com/images/stories/2014/Mayo/semana4/AMD-EvolucionHSA-bh.jpg
�����̗\��
http://media.bestofmicro.com/amd-fusion-bio,5-4-347512-22.jpg
���̂�GF�߁E�E
HSA Roadmap
http://benchmarkhardware.com/images/stories/2014/Mayo/semana4/AMD-EvolucionHSA-bh.jpg
{kind=link}
�����̗\��
http://media.bestofmicro.com/amd-fusion-bio,5-4-347512-22.jpg
{kind=link}
���̂�GF�߁E�E
Bulldozer����
http://int.main.jp/txt/bulldozer/#sec3.3
K10 vs CoreMA
http://int.main.jp/txt/k10/#sec6
�f�l�ɂ��킩���_�͊m���ɒׂ��Ă��邾�낤����
�V����x86�v���Z�b�T�[�������������đ҂��Ă�
http://int.main.jp/txt/bulldozer/#sec3.3
K10 vs CoreMA
http://int.main.jp/txt/k10/#sec6
�f�l�ɂ��킩���_�͊m���ɒׂ��Ă��邾�낤����
�V����x86�v���Z�b�T�[�������������đ҂��Ă�
���i�����������v�c�[����32nm Bulldozer��FPU���Đv���Ȃ������̐}
�ō��N���b�N�̒ቺ�ƈ��������ɖʐςƏ���d�ʂ�30%�팸
http://images.anandtech.com/doci/6201/Screen%20Shot%202012-08-28%20at%204.38.31%20PM.png
���L��
http://www.anandtech.com/show/6201/amd-details-its-3rd-gen-steamroller-architecture/2
http://anago.2ch.net/test/read.cgi/software/1381149351/556
�ō��N���b�N�̒ቺ�ƈ��������ɖʐςƏ���d�ʂ�30%�팸
http://images.anandtech.com/doci/6201/Screen%20Shot%202012-08-28%20at%204.38.31%20PM.png
{kind=link}
���L��
http://www.anandtech.com/show/6201/amd-details-its-3rd-gen-steamroller-architecture/2
http://anago.2ch.net/test/read.cgi/software/1381149351/556
�ӂ��E�E�܂����ĂȂ��āE�E�E
http://cdn.arstechnica.net/wp-content/uploads/2013/03/amd-on-ropes.jpg
http://cdn.arstechnica.net/wp-content/uploads/2013/03/amd-on-ropes.jpg
{kind=link}
CPU��GPU�̃�������Ԃꂷ��AMD�́uhUMA�v�A�[�L�e�N�`���i2013/5/2 00:00�j
http://pc.watch.impress.co.jp/docs/column/kaigai/20130502_598132.html
AMD�̎�����APU�uKaveri�v�̓A�[�L�e�N�`���̓]���_�i2013/7/4 00:00�j
http://pc.watch.impress.co.jp/docs/column/kaigai/20130704_606220.html
AMD�����i����HSA�\�z�̃J�M�ƂȂ�uhQ�v�i2013/10/25 06:00�j
http://pc.watch.impress.co.jp/docs/column/kaigai/20131025_620789.html
AMD�̊����`APU�uKaveri�v�̃A�[�L�e�N�`���i2014/1/14 22:01�j
http://pc.watch.impress.co.jp/docs/column/kaigai/20140114_630741.html
AMD Kaveri�̃������A�[�L�e�N�`���ƍ����APU�i���i2014/1/29 06:00�j
http://pc.watch.impress.co.jp/docs/column/kaigai/20140129_632794.html
AMD�A2020�N�܂ł�APU�̓d�͌�����25�{���コ����v��i2014/6/20 12:06�j
http://pc.watch.impress.co.jp/docs/news/20140620_654324.html
http://pc.watch.impress.co.jp/docs/column/kaigai/20130502_598132.html
AMD�̎�����APU�uKaveri�v�̓A�[�L�e�N�`���̓]���_�i2013/7/4 00:00�j
http://pc.watch.impress.co.jp/docs/column/kaigai/20130704_606220.html
AMD�����i����HSA�\�z�̃J�M�ƂȂ�uhQ�v�i2013/10/25 06:00�j
http://pc.watch.impress.co.jp/docs/column/kaigai/20131025_620789.html
AMD�̊����`APU�uKaveri�v�̃A�[�L�e�N�`���i2014/1/14 22:01�j
http://pc.watch.impress.co.jp/docs/column/kaigai/20140114_630741.html
AMD Kaveri�̃������A�[�L�e�N�`���ƍ����APU�i���i2014/1/29 06:00�j
http://pc.watch.impress.co.jp/docs/column/kaigai/20140129_632794.html
AMD�A2020�N�܂ł�APU�̓d�͌�����25�{���コ����v��i2014/6/20 12:06�j
http://pc.watch.impress.co.jp/docs/news/20140620_654324.html
AMD��ARM�����͊댯��
http://cpplover.blogspot.jp/2012/06/amdarm.html
GPGPU����̃n�b�V���A���S���Y��
http://cpplover.blogspot.jp/2012/04/gpgpu.html
OpenGL�h���C�o�[�i���̎���i�����ꂪ�ꎞ�����s�����x���_�[B�̌��l�^�j
http://cpplover.blogspot.jp/2014/05/opengl_19.html
���쌠�@�ɔ������璘�쌠�N�Q
http://cpplover.blogspot.jp/2012/02/blog-post_28.html
�y�ʐ^����z�����̈̐l�����̎q�����ӊO�߂���l���𑗂��Ă���
http://bakumatsu.org/blog/2012/04/bakumatsu-shison.html
http://cpplover.blogspot.jp/2012/06/amdarm.html
GPGPU����̃n�b�V���A���S���Y��
http://cpplover.blogspot.jp/2012/04/gpgpu.html
OpenGL�h���C�o�[�i���̎���i�����ꂪ�ꎞ�����s�����x���_�[B�̌��l�^�j
http://cpplover.blogspot.jp/2014/05/opengl_19.html
���쌠�@�ɔ������璘�쌠�N�Q
http://cpplover.blogspot.jp/2012/02/blog-post_28.html
�y�ʐ^����z�����̈̐l�����̎q�����ӊO�߂���l���𑗂��Ă���
http://bakumatsu.org/blog/2012/04/bakumatsu-shison.html
http://pc.watch.impress.co.jp/docs/topic/review/20140703_656109.html
TDP95W��7850�Ɣ�r����TDP45W�ɐ�������7800��7850�Ə���d�͂قڕς����
TDP50W�̍����o��قǏ���d�͂������ĂȂ���ł����ǂ�
(�@߄t�)
TDP95W��7850�Ɣ�r����TDP45W�ɐ�������7800��7850�Ə���d�͂قڕς����
TDP50W�̍����o��قǏ���d�͂������ĂȂ���ł����ǂ�
(�@߄t�)
����d�͂��̂܂܂ɔ��M��}���钴�Z�p�I
AMDʼ�ϯ�!
AMDʼ�ϯ�!
�Ȃɂ��̏���d�͍��\��
35 �FSocket774�F2014/07/31(��) 09:32:48.02 ID:PIUkKNu9
A10-7850K vs �Z������ �܂Ƃ�
�yPSO2 1080p �ݒ�5�z
A10-7850K �� 1,218
G1840 + GTX750 �� 17,111
�yMHF 720p�z
A10-7850K �� 4,907
G1840 + GTX750 �� 17,175
�yBF4 �ˌ��� 1080p �ō��ݒ�z
A10-7850K �� 16fps
G1820 + GTX750 �� 56fps
�yFF14 1080p �ō��z
A10-7850K �� 1,996
G1840 + GTX750 �� 7,223
�y����d�́z
A10-7850K �� 143W
G1840 + GTX750 �� 97W
�y���i�z
A10-7850K �� 19,086�~
G1840 + GTX750 �� 16,526�~
�@�@�^�P�P�P�_
�@�b�@�@�@�@�@�@�b�@�@�@�@�@���[�A�Z�������Ƀ{����������[
�@�b�@�@�@�@�@�@�b�@�Q�@�@�@�����낵��[�A�����낵��[
�@�b�@ �@^�@�@ ^ ) ///Ĥ
�@(�@�@�@>�(�Q)Y ////)|�@�@�@�얳�A���h���ʕ�
�@ �Ș� i-=�j=|�b�@�b|
�^�_�_�_ �P�m.�b�@Ƀm
�^�@ �_�_�P �@./�@/ |
�yPSO2 1080p �ݒ�5�z
A10-7850K �� 1,218
G1840 + GTX750 �� 17,111
�yMHF 720p�z
A10-7850K �� 4,907
G1840 + GTX750 �� 17,175
�yBF4 �ˌ��� 1080p �ō��ݒ�z
A10-7850K �� 16fps
G1820 + GTX750 �� 56fps
�yFF14 1080p �ō��z
A10-7850K �� 1,996
G1840 + GTX750 �� 7,223
�y����d�́z
A10-7850K �� 143W
G1840 + GTX750 �� 97W
�y���i�z
A10-7850K �� 19,086�~
G1840 + GTX750 �� 16,526�~
�@�@�^�P�P�P�_
�@�b�@�@�@�@�@�@�b�@�@�@�@�@���[�A�Z�������Ƀ{����������[
�@�b�@�@�@�@�@�@�b�@�Q�@�@�@�����낵��[�A�����낵��[
�@�b�@ �@^�@�@ ^ ) ///Ĥ
�@(�@�@�@>�(�Q)Y ////)|�@�@�@�얳�A���h���ʕ�
�@ �Ș� i-=�j=|�b�@�b|
�^�_�_�_ �P�m.�b�@Ƀm
�^�@ �_�_�P �@./�@/ |
G1820 VS Athlon5150�i���܂�7850K�j
�yHyper�p�C�z
G1820 �� 14.150�b
Athlon5150 �� 39.627�b
A10-7850K �� 18.829�b
�yCINEBENCH R11.5�z
G1820 �� 2.30
Athlon5150 �� 1.48
A10-7850K �� 3.53
�y�哢���z
G1820 �� 2,523
Athlon5150 �� 1,605
A10-7850K �� 4,438
�y�V��FFXIV�z
G1820 �� 4,044
Athlon5150 �� 2,264
A10-7850K �� 5,687
�y����d�̓A�C�h���z
G1820 �� 18.3W
Athlon5150 �� 24W
A10-7850K �� 49W
�y����d�͍����ׁz
G1820 �� 65.2W
Athlon5150 �� 50W
A10-7850K �� 143W
�y���i�z
G1820 �� 4,480�~
Athlon5150 �� 5,250�~
A10-7850K �� 21,280�~
�@ �@�@�@�@ �Q�Q�Q__
�@�@�@�^�P.....//.... �ƁP��
�@ ��|::::::::::::::U:: �� ::::::<
����|::::::::::::::::::::::::::�ƁQ��
�@�@�@�P�ځ^�P�P�@�@�@ �Vathlon�����
�yHyper�p�C�z
G1820 �� 14.150�b
Athlon5150 �� 39.627�b
A10-7850K �� 18.829�b
�yCINEBENCH R11.5�z
G1820 �� 2.30
Athlon5150 �� 1.48
A10-7850K �� 3.53
�y�哢���z
G1820 �� 2,523
Athlon5150 �� 1,605
A10-7850K �� 4,438
�y�V��FFXIV�z
G1820 �� 4,044
Athlon5150 �� 2,264
A10-7850K �� 5,687
�y����d�̓A�C�h���z
G1820 �� 18.3W
Athlon5150 �� 24W
A10-7850K �� 49W
�y����d�͍����ׁz
G1820 �� 65.2W
Athlon5150 �� 50W
A10-7850K �� 143W
�y���i�z
G1820 �� 4,480�~
Athlon5150 �� 5,250�~
A10-7850K �� 21,280�~
�@ �@�@�@�@ �Q�Q�Q__
�@�@�@�^�P.....//.... �ƁP��
�@ ��|::::::::::::::U:: �� ::::::<
����|::::::::::::::::::::::::::�ƁQ��
�@�@�@�P�ځ^�P�P�@�@�@ �Vathlon�����
A10-7850K vs �Z������ �܂Ƃ�
�yPSO2 1080p �ݒ�5�z
A10-7850K �� 1,218
G1820 + GTX750 �� 16,610
�yMHF 720p�z
A10-7850K �� 4,907
G1840 + GTX750 �� 17,175
�yBF4 �ˌ��� 1080p �ō��ݒ�z
A10-7850K �� 16fps
G1820 + GTX750 �� 56fps
�yFF14 1080p �ō��z
A10-7850K �� 1,996
G1820 + GTX750 �� 7,032
�y����d�́z
A10-7850K �� 143W
G1840 + GTX750 �� 97W
�y���i�z
A10-7850K �� 19,086�~
G1840 + GTX750 �� 16,526�~
�@�@�@�@�@�@�@�@ �@�Q�Q�Q_
�@�@�@�@�@�@�@�@�^�@�@ �@ �@�_
�@�@�@�@�@ �@�^�@�@�^�@ �@ �_�_�@�@�@����͂Ђǂ���
�@�@�@�@�@�^�@�@�@�@�܁@�@ �܁@ �_
�@�@�@�@�@|�@ �@�@ �@ ,�(�_, )�R�@ �@ |
�@�@ �@�@ �_�@�@ �@�@ Ī����@ �@�^
�@�@ �@ �@ �^�@�@�@_�@�R�j�,�@ ��
�yPSO2 1080p �ݒ�5�z
A10-7850K �� 1,218
G1820 + GTX750 �� 16,610
�yMHF 720p�z
A10-7850K �� 4,907
G1840 + GTX750 �� 17,175
�yBF4 �ˌ��� 1080p �ō��ݒ�z
A10-7850K �� 16fps
G1820 + GTX750 �� 56fps
�yFF14 1080p �ō��z
A10-7850K �� 1,996
G1820 + GTX750 �� 7,032
�y����d�́z
A10-7850K �� 143W
G1840 + GTX750 �� 97W
�y���i�z
A10-7850K �� 19,086�~
G1840 + GTX750 �� 16,526�~
�@�@�@�@�@�@�@�@ �@�Q�Q�Q_
�@�@�@�@�@�@�@�@�^�@�@ �@ �@�_
�@�@�@�@�@ �@�^�@�@�^�@ �@ �_�_�@�@�@����͂Ђǂ���
�@�@�@�@�@�^�@�@�@�@�܁@�@ �܁@ �_
�@�@�@�@�@|�@ �@�@ �@ ,�(�_, )�R�@ �@ |
�@�@ �@�@ �_�@�@ �@�@ Ī����@ �@�^
�@�@ �@ �@ �^�@�@�@_�@�R�j�,�@ ��
�w�e���W�j�A�X�m��_
��O�̑I��(DLP�̉\��)
http://www.ne.jp/asahi/comp/tarusan/main90.htm
�ő�s�l�C�L�������ɓ��̖�(AMD��ATI��)
http://www.ne.jp/asahi/comp/tarusan/main145.htm
���ꂼ��̍�����(�w�e���R�A�̃_�C�T�C�Y����l����B)
http://www.ne.jp/asahi/comp/tarusan/main134.htm
CPU�̏ȃG�l�A�O��(�x�N�g���@���Q�l�ɍl����B)
http://www.ne.jp/asahi/comp/tarusan/main189.htm
CPU�̏ȃG�l�A���(CELL�ABG/L���Q�l�ɍl����B)
http://www.ne.jp/asahi/comp/tarusan/main190.htm
��O�̑I��(DLP�̉\��)
http://www.ne.jp/asahi/comp/tarusan/main90.htm
�ő�s�l�C�L�������ɓ��̖�(AMD��ATI��)
http://www.ne.jp/asahi/comp/tarusan/main145.htm
���ꂼ��̍�����(�w�e���R�A�̃_�C�T�C�Y����l����B)
http://www.ne.jp/asahi/comp/tarusan/main134.htm
CPU�̏ȃG�l�A�O��(�x�N�g���@���Q�l�ɍl����B)
http://www.ne.jp/asahi/comp/tarusan/main189.htm
CPU�̏ȃG�l�A���(CELL�ABG/L���Q�l�ɍl����B)
http://www.ne.jp/asahi/comp/tarusan/main190.htm
�x�N�g���E�v���Z�b�T�[�̃������ɂ���
CELL�̑��Ε]���Ɛ�Ε]��
http://www.ne.jp/asahi/comp/tarusan/main111.htm
�b�o�t�̃��X�g������(x86��CELL�̔�r�ōl����B)
http://www.ne.jp/asahi/comp/tarusan/main113.htm
�b�o�t�̃��X�g��(�X�p�R���Ɏ��Ă����H)
http://www.ne.jp/asahi/comp/tarusan/main117.htm
�v���̐��E���_�Ԍ����j(�n���V�~�����[�^���w�L�E�x�N�g���v���Z�b�T��)
http://www.ne.jp/asahi/comp/tarusan/main64.htm
CELL�̑��Ε]���Ɛ�Ε]��
http://www.ne.jp/asahi/comp/tarusan/main111.htm
�b�o�t�̃��X�g������(x86��CELL�̔�r�ōl����B)
http://www.ne.jp/asahi/comp/tarusan/main113.htm
�b�o�t�̃��X�g��(�X�p�R���Ɏ��Ă����H)
http://www.ne.jp/asahi/comp/tarusan/main117.htm
�v���̐��E���_�Ԍ����j(�n���V�~�����[�^���w�L�E�x�N�g���v���Z�b�T��)
http://www.ne.jp/asahi/comp/tarusan/main64.htm
�V���O��/�}���`�R�A�_��
Hyper-Threading Technology�Z�](���邳��I�O�ʈ�̐�)
http://www.ne.jp/asahi/comp/tarusan/main49.htm
���j�͌J��Ԃ�(Hyper-Threading ���x�����Z�]��)
http://www.ne.jp/asahi/comp/tarusan/main50.htm
�N���C�A���g�p�}���`�R�A�̗J�T
http://www.ne.jp/asahi/comp/tarusan/main72.htm
���q�̍𐔂��Ă݂�B(�V���O���E�f���A�����z�Ό�)
http://www.ne.jp/asahi/comp/tarusan/main119.htm
Hyper-Threading Technology�Z�](���邳��I�O�ʈ�̐�)
http://www.ne.jp/asahi/comp/tarusan/main49.htm
���j�͌J��Ԃ�(Hyper-Threading ���x�����Z�]��)
http://www.ne.jp/asahi/comp/tarusan/main50.htm
�N���C�A���g�p�}���`�R�A�̗J�T
http://www.ne.jp/asahi/comp/tarusan/main72.htm
���q�̍𐔂��Ă݂�B(�V���O���E�f���A�����z�Ό�)
http://www.ne.jp/asahi/comp/tarusan/main119.htm
�L���b�V���ɂ���
�s���̂S�ԑŎ�(�L���b�V���E����\���̏d�v��)
http://www.ne.jp/asahi/comp/tarusan/main78.htm
�����K�i�����\���グ��B(�L���b�V�������ɗ���Ȃ����R�B)
http://www.ne.jp/asahi/comp/tarusan/main165.htm
�L���b�V���̗��z�ƌ��E(�V���E�g�̍l�����ł�)
http://www.ne.jp/asahi/comp/tarusan/main168.htm
�s���̂S�ԑŎ�(�L���b�V���E����\���̏d�v��)
http://www.ne.jp/asahi/comp/tarusan/main78.htm
�����K�i�����\���グ��B(�L���b�V�������ɗ���Ȃ����R�B)
http://www.ne.jp/asahi/comp/tarusan/main165.htm
�L���b�V���̗��z�ƌ��E(�V���E�g�̍l�����ł�)
http://www.ne.jp/asahi/comp/tarusan/main168.htm
���܂�
�������A�������v�v�z�Ȃ̂ł��B(Isaiah�̐v�v�z)
http://www.ne.jp/asahi/comp/tarusan/main182.htm
CPU���ח����Ⴂ�̂������\�̏؋����āH�H�H
http://www.ne.jp/asahi/comp/tarusan/main211.htm
���ʉt���e���r���w�����Ďv�������ƁB
http://www.ne.jp/asahi/comp/tarusan/main170.htm
�o�ώj�Ɋw�Ԃׂ��ł͂Ȃ����낤���H
http://www.ne.jp/asahi/comp/tarusan/main228.htm
> ����A�؍���Ƃ����{��Ƃ����Ɉ��������Ȃ��l�ޕ��삪���邱�Ƃ����������낤���H�@
> ����́A�o�c�ҁA��敔��A�c�Ƃ̂R����ł���B
�������A�������v�v�z�Ȃ̂ł��B(Isaiah�̐v�v�z)
http://www.ne.jp/asahi/comp/tarusan/main182.htm
CPU���ח����Ⴂ�̂������\�̏؋����āH�H�H
http://www.ne.jp/asahi/comp/tarusan/main211.htm
���ʉt���e���r���w�����Ďv�������ƁB
http://www.ne.jp/asahi/comp/tarusan/main170.htm
�o�ώj�Ɋw�Ԃׂ��ł͂Ȃ����낤���H
http://www.ne.jp/asahi/comp/tarusan/main228.htm
> ����A�؍���Ƃ����{��Ƃ����Ɉ��������Ȃ��l�ޕ��삪���邱�Ƃ����������낤���H�@
> ����́A�o�c�ҁA��敔��A�c�Ƃ̂R����ł���B
>>43
����Ӗ��ÏL���f�U�C�������A���\�킩��₷���A
���̐l�̎����ł͂��邪���ݍ����e������B
�X�V�I������܂ŗǃT�C�g�Ƃ���Ă����B
�܂��E�F�u�f�U�C�����i�����邩��B
����Ӗ��ÏL���f�U�C�������A���\�킩��₷���A
���̐l�̎����ł͂��邪���ݍ����e������B
�X�V�I������܂ŗǃT�C�g�Ƃ���Ă����B
�܂��E�F�u�f�U�C�����i�����邩��B
������̂̃R���e���c�Ȃ̂�
���߂ŃU���U���w�i�Ƃ�
�ÏL���̃��x���łȂ�����
���߂ŃU���U���w�i�Ƃ�
�ÏL���̃��x���łȂ�����
AMD 16nm Opteron and FX Processors with Upto 20 Cores are a Possibility in 2016-2017
http://wccftech.com/amd-16nm-opteron-fx-processors-possibly-upto-20-cores-2016-2017/
http://wccftech.com/amd-16nm-opteron-fx-processors-possibly-upto-20-cores-2016-2017/
47 �FSocket774�F2014/08/15(��) 17:46:15.26 ID:/F/ERFNn
�X�^�b�N�hDRAM�t��APU�����o���L3�L���b�V�����Ȃ�L2�L���b�V����4MB�N���X��APU�ł�����I
A10-7850K vs �Z������ �܂Ƃ�
�yPSO2 1080p �ݒ�5�z
A10-7850K �� 1,218
G1840 + GTX750 �� 17,111
�yMHF 720p�z
A10-7850K �� 4,907
G1840 + GTX750 �� 17,175
�yBF4 �ˌ��� 1080p �ō��ݒ�z
A10-7850K �� 16fps
G1820 + GTX750 �� 56fps
�yFF14 1080p �ō��z
A10-7850K �� 1,996
G1840 + GTX750 �� 7,223
�y����d�́z
A10-7850K �� 143W
G1840 + GTX750 �� 97W
�y���i�z
A10-7850K �� 19,086�~
G1840 + GTX750 �� 16,526�~
�@�@�^�P�P�P�_
�@�b�@�@�@�@�@�@�b�@�@�@�@�@���[�A�Z�������Ƀ{����������[
�@�b�@�@�@�@�@�@�b�@�Q�@�@�@�����낵��[�A�����낵��[
�@�b�@ �@^�@�@ ^ ) ///Ĥ
�@(�@�@�@>�(�Q)Y ////)|�@�@�@�얳�A���h���ʕ�
�@ �Ș� i-=�j=|�b�@�b|
�^�_�_�_ �P�m.�b�@Ƀm
�^�@ �_�_�P �@./�@/ |
�yPSO2 1080p �ݒ�5�z
A10-7850K �� 1,218
G1840 + GTX750 �� 17,111
�yMHF 720p�z
A10-7850K �� 4,907
G1840 + GTX750 �� 17,175
�yBF4 �ˌ��� 1080p �ō��ݒ�z
A10-7850K �� 16fps
G1820 + GTX750 �� 56fps
�yFF14 1080p �ō��z
A10-7850K �� 1,996
G1840 + GTX750 �� 7,223
�y����d�́z
A10-7850K �� 143W
G1840 + GTX750 �� 97W
�y���i�z
A10-7850K �� 19,086�~
G1840 + GTX750 �� 16,526�~
�@�@�^�P�P�P�_
�@�b�@�@�@�@�@�@�b�@�@�@�@�@���[�A�Z�������Ƀ{����������[
�@�b�@�@�@�@�@�@�b�@�Q�@�@�@�����낵��[�A�����낵��[
�@�b�@ �@^�@�@ ^ ) ///Ĥ
�@(�@�@�@>�(�Q)Y ////)|�@�@�@�얳�A���h���ʕ�
�@ �Ș� i-=�j=|�b�@�b|
�^�_�_�_ �P�m.�b�@Ƀm
�^�@ �_�_�P �@./�@/ |
28nm -> 14nm�Ŕ{�̃g�����W�X�^���g����悤�ɂȂ�Ɖ��肷�邷��Ȃ�
(Jaguar��)3way���ƍ��N���b�N���i3GHz�ȏ�j�ɂ��Ă�����Jaguar�Ɠ����傫���ɂȂ邾�낤��
Jaguar�Ɠ����Ƃ������Ƃ�Kaveri�Ɠ����傫����8�R�A�{1024sp�𓋍ڂ��邱�Ƃ��\�B
���\��IPC���オ�邵�A��(Kaveri)�̉��z4�R�A���烊�A��8�R�A�ւƑ����邱�Ƃɂ��
�i�x���`�ƃG���R�́j����4�R�Ai7�ɕ��Ԃ��Ƃ��\���ƍl����B
��6/8�R�AXenon�ɂ�>46��FX�őR
(Jaguar��)3way���ƍ��N���b�N���i3GHz�ȏ�j�ɂ��Ă�����Jaguar�Ɠ����傫���ɂȂ邾�낤��
Jaguar�Ɠ����Ƃ������Ƃ�Kaveri�Ɠ����傫����8�R�A�{1024sp�𓋍ڂ��邱�Ƃ��\�B
���\��IPC���オ�邵�A��(Kaveri)�̉��z4�R�A���烊�A��8�R�A�ւƑ����邱�Ƃɂ��
�i�x���`�ƃG���R�́j����4�R�Ai7�ɕ��Ԃ��Ƃ��\���ƍl����B
��6/8�R�AXenon�ɂ�>46��FX�őR
�܂�o���F�ł���B
>>49
�ӂƎv�������A14nm���ł���2016�N�ɂ�Intel��10nm�s���Ă��ˁH
8�R�ABroadwell�ǂ��낶��Ȃ��ł���B�����ƃ��b�`�ō�IPC�ȃR�A��
8�R�A�ς߂�B
�܂��V�R�A�Ɋ��҂��邵���Ȃ��ˁB
��IPC�R�A�����R�A�����Ă鍡�A����Ȃ鑽�R�A�����������^�₪�c��B
�ӂƎv�������A14nm���ł���2016�N�ɂ�Intel��10nm�s���Ă��ˁH
8�R�ABroadwell�ǂ��낶��Ȃ��ł���B�����ƃ��b�`�ō�IPC�ȃR�A��
8�R�A�ς߂�B
�܂��V�R�A�Ɋ��҂��邵���Ȃ��ˁB
��IPC�R�A�����R�A�����Ă鍡�A����Ȃ鑽�R�A�����������^�₪�c��B
>>51
14nm�ł������ɃV�������N�ł��Ă�݂���������ˁB
�������AInel�������Ă��Ă�"�����ƃ��b�`�ō�IPC�ȃR�A"�͂�����������Ƃ͍��Ȃ���
1 for 1�̖@���͍��������Ă邾�낤��
http://pc.watch.impress.co.jp/docs/2008/0424/kaigai437.htm
�܁A�g�����W�X�^�ɂ���M�ɂ���Intel����ΓI�ɗL���Ȃ͕̂ς���
14nm�ł������ɃV�������N�ł��Ă�݂���������ˁB
�������AInel�������Ă��Ă�"�����ƃ��b�`�ō�IPC�ȃR�A"�͂�����������Ƃ͍��Ȃ���
1 for 1�̖@���͍��������Ă邾�낤��
http://pc.watch.impress.co.jp/docs/2008/0424/kaigai437.htm
�܁A�g�����W�X�^�ɂ���M�ɂ���Intel����ΓI�ɗL���Ȃ͕̂ς���
�����炱�����b�`�R�Avs�~�h���R�A�͊y���݂ł͂���
�F�B�ǂ��납�e�ɂ����̂Ă��Ă���{��ʂ��Ȃ��z�������������؍����ƑS������l���̃l���G���ؑ��E�Ғc�q�̏Z���̈ꕔWWWWWWWWWWWWWWWW
�yLGA1150�zDevil's Canyon #12�y22nm�z
http://anago.2ch.net/test/read.cgi/jisaku/1406494818/
�v���X�e2�G�~���ɂ��Č�낤�yPCSX2�zvol105�@�@�G���Q��D���ؑ������ߖ{���
http://anago.2ch.net/test/read.cgi/software/1401620932/
�z���R�s�y���Ă��C���������S�~���G���Q�Ŋm��W
�yFEZ�z�t�@���^�W�[�A�[�X�[���G�ؑ��X��1152
http://peace.2ch.net/test/read.cgi/mmo/1407600338/
�yP2P�z PC�Q�[�������X�� Vol.423 �yWarez�z
http://awabi.2ch.net/test/read.cgi/download/1407865857/
BT�ŏE����A�j�� 78
http://awabi.2ch.net/test/read.cgi/download/1407852761/
Intel�̎�����Z�p�ɂ��Č�낤 77
http://anago.2ch.net/test/read.cgi/jisaku/1403855657/
�ytamchin777�z�c���m���N�̃X�� ����4�@�@�����o���ɖ{���Z���o����
http://anago.2ch.net/test/read.cgi/jisaku/1368457357/
mabinogi -�}�r�m�M- kukululive�����X��41
http://awabi.2ch.net/test/read.cgi/net/1400146591/
�yFEZ�z�t�@���^�W�[�A�[�X�[���ާٖo�Ž� 1128�@
http://toro.2ch.net/test/read.cgi/mmo/1392717222/
�yFEZ�z̧���ް������ I�I�l�c�@�����N���X��45
http://awabi.2ch.net/test/read.cgi/net/1406924362/
�}�k�P�̔S�������U�����ꂽ�Ǝv�������悭�g���l�|�P��
�R�C�c�n���^�������ؖ��_���L�`�K�C�n�Q�A�z�N�Y�S�~�J�X�{�P�G����ӕn�R�l�`�����L���`�V���h�[�{�N�V���O��X�y�������|���ڒ���
�~���W���N���ȏЉ�Ă��Ȃ������Ȃ��G�Εa�����K�L�t�@�r�����i���ݏ��_�T�����ك����^����ɂ��Ȃ�NG�錾������m�������E�U��
���ɕ�����₷�������́A�B���ُ�ɑ����A����ID����ς��܂���Ŏ����A�t�@�r����Ǝv�l��~���ăI�E���Ԃ��ɃV�t�g
���_��AA�P��3�Ŋ當������u�v�i�j�H�E�E�E�B�B�B�I�I�IID:�`^^��l�g�E�������Ȃǂ𑽗p����A�X�y�����a���҂����܂������߂Ă݂܂��傤��
�yLGA1150�zDevil's Canyon #12�y22nm�z
http://anago.2ch.net/test/read.cgi/jisaku/1406494818/
�v���X�e2�G�~���ɂ��Č�낤�yPCSX2�zvol105�@�@�G���Q��D���ؑ������ߖ{���
http://anago.2ch.net/test/read.cgi/software/1401620932/
�z���R�s�y���Ă��C���������S�~���G���Q�Ŋm��W
�yFEZ�z�t�@���^�W�[�A�[�X�[���G�ؑ��X��1152
http://peace.2ch.net/test/read.cgi/mmo/1407600338/
�yP2P�z PC�Q�[�������X�� Vol.423 �yWarez�z
http://awabi.2ch.net/test/read.cgi/download/1407865857/
BT�ŏE����A�j�� 78
http://awabi.2ch.net/test/read.cgi/download/1407852761/
Intel�̎�����Z�p�ɂ��Č�낤 77
http://anago.2ch.net/test/read.cgi/jisaku/1403855657/
�ytamchin777�z�c���m���N�̃X�� ����4�@�@�����o���ɖ{���Z���o����
http://anago.2ch.net/test/read.cgi/jisaku/1368457357/
mabinogi -�}�r�m�M- kukululive�����X��41
http://awabi.2ch.net/test/read.cgi/net/1400146591/
�yFEZ�z�t�@���^�W�[�A�[�X�[���ާٖo�Ž� 1128�@
http://toro.2ch.net/test/read.cgi/mmo/1392717222/
�yFEZ�z̧���ް������ I�I�l�c�@�����N���X��45
http://awabi.2ch.net/test/read.cgi/net/1406924362/
�}�k�P�̔S�������U�����ꂽ�Ǝv�������悭�g���l�|�P��
�R�C�c�n���^�������ؖ��_���L�`�K�C�n�Q�A�z�N�Y�S�~�J�X�{�P�G����ӕn�R�l�`�����L���`�V���h�[�{�N�V���O��X�y�������|���ڒ���
�~���W���N���ȏЉ�Ă��Ȃ������Ȃ��G�Εa�����K�L�t�@�r�����i���ݏ��_�T�����ك����^����ɂ��Ȃ�NG�錾������m�������E�U��
���ɕ�����₷�������́A�B���ُ�ɑ����A����ID����ς��܂���Ŏ����A�t�@�r����Ǝv�l��~���ăI�E���Ԃ��ɃV�t�g
���_��AA�P��3�Ŋ當������u�v�i�j�H�E�E�E�B�B�B�I�I�IID:�`^^��l�g�E�������Ȃǂ𑽗p����A�X�y�����a���҂����܂������߂Ă݂܂��傤��
�A�[�L�e�N�`�������̃��f���i���o�[�̃t�J�V�������S�z
����������Ȃ��Ȃ肻��
����������Ȃ��Ȃ肻��
Phenom���i�f�X�N�����jFX��9000�ԑ�܂ł�������������ˁB
�� ���f���i���o�[���E�˔j�X�t�B�A
�� �Г��̃��\�[�X��S��FX�փX�t�B�A
Radeon��HD8000�܂ł�������
FX��8550�Ƃ��ɂȂ�̂���...?����Ƃ�FXII�݂����Ȋ�������
���̂��݂���
FX��8550�Ƃ��ɂȂ�̂���...?����Ƃ�FXII�݂����Ȋ�������
���̂��݂���
FX-Black 8390FX Black Edition XE
Mobile������Carrizo�̓I���_�C�̐ϑw�������͓��ڂ����A�Ή����郁�C����������DDR3�܂łɂƂǂ܂�
2015�N�̃f�X�N�g�b�v����APU��Kaveri Refresh
AMD Kaveri Refresh Coming 2015 and Carrizo APU to be Mobile Only For Now
http://wccftech.com/amd-kaveri-refresh-coming-2015-carrizo-apu-mobile/
�EAMD's FM3+ Socket in 2016.
�ENew Post Bulldozer/SMT Architecture in 2016.
�ENo DDR4 Support in Desktop Processors till 2016.
�EKaveri Refresh in 2015 (Better Revision and Higher Clocks)
�ECarrizo Notebook in 2015
�_�����R���A
2015�N�̃f�X�N�g�b�v����APU��Kaveri Refresh
AMD Kaveri Refresh Coming 2015 and Carrizo APU to be Mobile Only For Now
http://wccftech.com/amd-kaveri-refresh-coming-2015-carrizo-apu-mobile/
�EAMD's FM3+ Socket in 2016.
�ENew Post Bulldozer/SMT Architecture in 2016.
�ENo DDR4 Support in Desktop Processors till 2016.
�EKaveri Refresh in 2015 (Better Revision and Higher Clocks)
�ECarrizo Notebook in 2015
�_�����R���A
2015�N�̓m�[�g������DDR3�̗p�I
�f�X�N�g�b�v��Kaveri������DDR3
Intel��2015�N�ɓ����Ă��A�܂�DDR4�̂܂�
���ꂩ���DDR3�̎���I
2015�N��DDR3���N�I
�f�X�N�g�b�v��Kaveri������DDR3
Intel��2015�N�ɓ����Ă��A�܂�DDR4�̂܂�
���ꂩ���DDR3�̎���I
2015�N��DDR3���N�I
63 �FSocket774�F2014/08/27(��) 23:12:40.43 ID:RRtz8d1N
>>62
DDR3�������̂͂܂��������ꂽ���肾����ȂȁI
DDR3�������̂͂܂��������ꂽ���肾����ȂȁI
���Ƃ����Ȃ���
http://hardware.slashdot.jp/story/14/09/01/0549220/RISC�^CPU�̓G�l���M�[�������ǂ��A�Ƃ����킯�ł͂Ȃ�
http://hardware.slashdot.jp/story/14/09/01/0549220/RISC�^CPU�̓G�l���M�[�������ǂ��A�Ƃ����킯�ł͂Ȃ�
���������A�W���E�P���[��ARM�A�[�L�e�N�`���͌������悢�Ƃ��C�ɓ���B
AVX�̊g���Ƃ��ŁA���Ђ̎d�l�ɂ��荇�킹�Ȃ��ă��N�Ƃ��B
�����い�@4way�f�R�[�_�[��4���s�p�C�v��SMT�r�b�N�R�A
���ȂȂߏい�@steamroller�̐���������4���s������SMT�ŋ��L
���い�@Jaguar�����3way�Ɋg��
�������@�v������B2way�̂܂ܓ���RS���Ƃ��H
���ȂȂߏい�@steamroller�̐���������4���s������SMT�ŋ��L
���い�@Jaguar�����3way�Ɋg��
�������@�v������B2way�̂܂ܓ���RS���Ƃ��H
>>67
http://pc.watch.impress.co.jp/docs/column/kaigai/20140801_660442.html
�ǂ���̃R�A���č\�����Ă���A�Ƃ������Ƃ����炩�Ȃ�ύX������낤�B
http://pc.watch.impress.co.jp/docs/column/kaigai/20140801_660442.html
�ǂ���̃R�A���č\�����Ă���A�Ƃ������Ƃ����炩�Ȃ�ύX������낤�B
ARM��A57���ĂȂɂ���3way�f�R�[�_�[�ȂB
HSA�����ƍ��i����10�{���݂����ȃO���t�B�b�N�X���C�u�����Ƃ��������ȁH
JPEG��PNG�̈��k�E�W�J�A�⊮�t�����T�C�Y�����肪�����Ȃ�Ƃ��ꂵ����
�������}���`�X���b�h�Ή�
JPEG��PNG�̈��k�E�W�J�A�⊮�t�����T�C�Y�����肪�����Ȃ�Ƃ��ꂵ����
�������}���`�X���b�h�Ή�
Carrizo��Kaveri�Ɣ�ׂ�50�����x�̐��\/����d�͔���P�ɂȂ�H
http://ascii.jp/elem/000/000/877/877671/index-3.html
�T���X���ƒ�g����GLOBALFOUNDRIES��14nm FinFET�헪
http://ascii.jp/elem/000/000/888/888610/
2020�N�܂łɃJ�[�{���i�m�`���[�u���g�����W�X�^���s��ɏo���������Ƃ����j���[�X��gizmodo
http://www.gizmodo.jp/2014/07/2020315ibm.html
http://ascii.jp/elem/000/000/877/877671/index-3.html
�T���X���ƒ�g����GLOBALFOUNDRIES��14nm FinFET�헪
http://ascii.jp/elem/000/000/888/888610/
2020�N�܂łɃJ�[�{���i�m�`���[�u���g�����W�X�^���s��ɏo���������Ƃ����j���[�X��gizmodo
http://www.gizmodo.jp/2014/07/2020315ibm.html
�t�@�C�������\�t�g�͂��ꂪ��������
http://www.forest.impress.co.jp/library/software/recuva/
http://www.forest.impress.co.jp/library/software/recuva/
>>73
�O������
�O������
�Ȃ�ł�˂�
76 �FSocket774�F2014/09/07(��) 17:13:49.97 ID:rAZHaApK
ID:dC/+eXPO
�딚���������Ȃ̂ɂȂ��E�E
�ۂ������ID:dC/+eXPO�̐^�������āA�딚�����ӂ肵�ăA�t�B�T�C�g�\��ˁI
�o�������E�E�B
�O�t��HDD�Ńg���u�����Ƃ��A�B��}�g���ɓ������A�v�������烁���ւ��ɏ������B
���̎Ђ��A�t�B�T�C�g�Ȃ̂͒m��Ȃ���������A������͌��������L���Ƃ��B
�O�t��HDD�Ńg���u�����Ƃ��A�B��}�g���ɓ������A�v�������烁���ւ��ɏ������B
���̎Ђ��A�t�B�T�C�g�Ȃ̂͒m��Ȃ���������A������͌��������L���Ƃ��B
Intel��18 CPU�R�A�̒�����uHaswell-E�v�t�@�~���\
http://pc.watch.impress.co.jp/docs/column/kaigai/20140909_665735.html
�R�ł���C���܂��������Ȃ�
http://pc.watch.impress.co.jp/docs/column/kaigai/20140909_665735.html
�R�ł���C���܂��������Ȃ�
16�R�A5GHz Opteron�ł����Ă��
�y���r���[�z�v�X�ɓo�ꂵ��AMD FX�V���f���uFX-8370E�v �`TDP 95W��8�R�A����
http://pc.watch.impress.co.jp/docs/topic/review/20140902_664815.html
>������{�����x���`�}�[�N�e�X�g�̌��ʂ���AFX-8370��FX-8350�ɑ��Ė��m�ȃA�h�o���e�[�W�������Ă��Ȃ����Ƃ�������B
�͂�����ƒf�����ꂿ����Ă�˂�
http://pc.watch.impress.co.jp/docs/topic/review/20140902_664815.html
>������{�����x���`�}�[�N�e�X�g�̌��ʂ���AFX-8370��FX-8350�ɑ��Ė��m�ȃA�h�o���e�[�W�������Ă��Ȃ����Ƃ�������B
�͂�����ƒf�����ꂿ����Ă�˂�
���M�͌|��������ǂ���
IPC���オ���̂�������
IPC���オ���̂�������
20�`50w�قƏ���d�͂̏��Ȃ�8370E�͂Ȃ��Ȃ��E�E
http://pc.watch.impress.co.jp/img/pcw/docs/664/815/html/19.jpg.html
http://pc.watch.impress.co.jp/img/pcw/docs/664/815/html/19.jpg.html
{kind=link}
���@1,920�~1,080�h�b�g���ɂ�Core i7-4790K�̃X�R�A�������Ă���B���̂悤�Ƀ}���`�X���b�h�ւ̍œK�����i��ł���Q�[���ł���A
���@Intel�ő���4�R�A8�X���b�hCPU���t�]�ł���\���͂���悤���B
���@Intel�ő���4�R�A8�X���b�hCPU���t�]�ł���\���͂���悤���B
AMD FX��
5GHz�ɂ܂ŃI�[�o�[�N���b�N���Ă�i5-3570K�ɂ���͂��Ȃ�
http://www.4gamer.net/games/189/G018967/20121021001/
�y���̎��̏���d�́z
i5-3570K �� 167W
[email protected] �� 588W �i�j
(�@߄t�)��
5GHz�ɂ܂ŃI�[�o�[�N���b�N���Ă�i5-3570K�ɂ���͂��Ȃ�
http://www.4gamer.net/games/189/G018967/20121021001/
�y���̎��̏���d�́z
i5-3570K �� 167W
[email protected] �� 588W �i�j
(�@߄t�)��
1920x1080�̎��ɂ�
FX-8370E��25.518��4790K��25.220������
1.1%�����Ă�悤�Ɍ�����
2560x1440�̎��ɂ�
FX-8370E��16.757��4790K��16.985������
1.4%�����Ă邱�ƂɂȂ�
���������̂�>>85�݂����ɂ����̂͂ǂ��Ȃ낤��
AMD������ł��ς܂�Ă�낤��
FX-8370E��25.518��4790K��25.220������
1.1%�����Ă�悤�Ɍ�����
2560x1440�̎��ɂ�
FX-8370E��16.757��4790K��16.985������
1.4%�����Ă邱�ƂɂȂ�
���������̂�>>85�݂����ɂ����̂͂ǂ��Ȃ낤��
AMD������ł��ς܂�Ă�낤��
K12 ARM�̑ƂȂ�AMD�̎��̍����\x86�R�A�̃R�[�h�l�[���́gZen�h
http://northwood.blog60.fc2.com/blog-entry-7752.html
���p���F�@http://wccftech.com/breaking-amds-gen-x86-high-performance-core-code-named-zen-debut-k12/
http://northwood.blog60.fc2.com/blog-entry-7752.html
���p���F�@http://wccftech.com/breaking-amds-gen-x86-high-performance-core-code-named-zen-debut-k12/
���\���ł�̂��A����邩�͒m��A
���{�̃W�T�J�[�E�G�ł�Zen��Xen���g���Ƃ����l�^���o�Ă���Ɨ\�����Ă����B
���{�̃W�T�J�[�E�G�ł�Zen��Xen���g���Ƃ����l�^���o�Ă���Ɨ\�����Ă����B
91 �FSocket774�F2014/09/16(��) 15:25:12.62 ID:FC2FqTA6
�ێ�
FPU��256bit�����Ĕ�₷�R�X�g�Ɍ������������\���オ���Ă�ƌ�����̂���
http://rigaya34589.blog135.fc2.com/blog-entry-492.html
�������FPU�őË����Ă���������R�A���őË����Ăق����Ȃ��ȁB
http://rigaya34589.blog135.fc2.com/blog-entry-492.html
�������FPU�őË����Ă���������R�A���őË����Ăق����Ȃ��ȁB
93 �FSocket774�F2014/09/16(��) 19:39:30.16 ID:0Doymbqc
�u����AVX��Pen4�����SSE2�Ɠ���
Bull��2�X���b�h���s�ł���1�R�A���Ǝv�����ނ��Ƃɂ��Ă邩�疳���B
����Intel�̕���SSE���牉�Z���{�����Ă�ɂ��ւ�炸1.2ms�����Z�k�ł��Ă��Ȃ��B
������ă��^�[���Ƃ��Ăǂ��H���Ęb�B
����Intel�̕���SSE���牉�Z���{�����Ă�ɂ��ւ�炸1.2ms�����Z�k�ł��Ă��Ȃ��B
������ă��^�[���Ƃ��Ăǂ��H���Ęb�B
95 �FSocket774�F2014/09/16(��) 22:08:38.70 ID:0Doymbqc
�܂��g�����Ă���̍œK������
Core2��1�T�C�N��SSE2�Ɠ���
AVX-512�ɂ��Ă���邩��
Core2��1�T�C�N��SSE2�Ɠ���
AVX-512�ɂ��Ă���邩��
>>94
256bit SIMD�ɂ���č���������镔�����S�̂̏����̂ǂꂮ�炢�̊������߂Ă��邩
�Ƃ����P���Ȃ��b
�}���`�R�A���̍ۂ̃A���_�[���̖@���Ɠ�����
�ނ���S�z���ׂ���SIMD�Ȃ�->����(SSE2)�Ƃ����S�����������ɂ�����
>4770K��SIMD���ɂ���č������ʂ���������̂�(x2.7�{��)�A7850K�̂ق��͂��܂���(x1.5�{��)�B
����Ȃ��́H128bit���߂̃X���[�v�b�g�͗��҂Ƃ������ŁA�����ō����t���Ă���Ƃ������Ƃ�
AMD�̃R�A�͂��Ȃ�����������Ƃ������ƁB
256bit SIMD�ɂ���č���������镔�����S�̂̏����̂ǂꂮ�炢�̊������߂Ă��邩
�Ƃ����P���Ȃ��b
�}���`�R�A���̍ۂ̃A���_�[���̖@���Ɠ�����
�ނ���S�z���ׂ���SIMD�Ȃ�->����(SSE2)�Ƃ����S�����������ɂ�����
>4770K��SIMD���ɂ���č������ʂ���������̂�(x2.7�{��)�A7850K�̂ق��͂��܂���(x1.5�{��)�B
����Ȃ��́H128bit���߂̃X���[�v�b�g�͗��҂Ƃ������ŁA�����ō����t���Ă���Ƃ������Ƃ�
AMD�̃R�A�͂��Ȃ�����������Ƃ������ƁB
AVX�f�b�J�`��INTEL�ƁAGPU�f�b�J�`��AMD
���͕������͈ꏏ
���͕������͈ꏏ
>>96
Haswell���R�A������2�~256bit��4�R�A�A
7850k�����W���[��������2�~128�r�b�g��2���W���[���A
128bitSIMD�̃N���b�N������X���[�v�b�g���������Ƃ����
���ꂼ��N���b�N�ǂ̂��炢�ȂH
Haswell���R�A������2�~256bit��4�R�A�A
7850k�����W���[��������2�~128�r�b�g��2���W���[���A
128bitSIMD�̃N���b�N������X���[�v�b�g���������Ƃ����
���ꂼ��N���b�N�ǂ̂��炢�ȂH
�ԈႦ���B�N���b�N�����肶��Ȃ��ȁB
128bitSIMD�̃X���[�v�b�g���������Ƃ����
���ꂼ��N���b�N�ǂ̂��炢�ȂH
128bitSIMD�̃X���[�v�b�g���������Ƃ����
���ꂼ��N���b�N�ǂ̂��炢�ȂH
����4.4GHz���������ǁA���������b����Ȃ��H
>>101
�����N���b�N��������N���b�N������128bitSIMD��
Haswell��8�AKaveri��4�ŃX���[�v�b�g�������ɂȂ�킯���Ȃ��Ǝv���̂����B
�ǂ���>>96�Ƃ͍l�������Ⴄ�̂��ˁH
�����N���b�N��������N���b�N������128bitSIMD��
Haswell��8�AKaveri��4�ŃX���[�v�b�g�������ɂȂ�킯���Ȃ��Ǝv���̂����B
�ǂ���>>96�Ƃ͍l�������Ⴄ�̂��ˁH
>Haswell��8�AKaveri��4
�ǂ������v�Z���H
SIMD fp add/mul�s�ł���p�C�v�͂ǂ�����2�{
256bit�̉��Z��ɂȂ�������Ƃ�����
1�̉��Z���128bit���߂�2�����ɏ����ł���킯����Ȃ�����ˁH
�ǂ������v�Z���H
SIMD fp add/mul�s�ł���p�C�v�͂ǂ�����2�{
256bit�̉��Z��ɂȂ�������Ƃ�����
1�̉��Z���128bit���߂�2�����ɏ����ł���킯����Ȃ�����ˁH
>>103
���ႠSIMD���Z��̖{�����R�A���ƂɌv�Z���Ă݂悤���B
Kaveri�̓��W���[��������128bit��2�{�Ȃ̂�1�R�A������1�{����ȁH
Haswell��1�R�A�����艽�{��256bitSIMD������H
���ႠSIMD���Z��̖{�����R�A���ƂɌv�Z���Ă݂悤���B
Kaveri�̓��W���[��������128bit��2�{�Ȃ̂�1�R�A������1�{����ȁH
Haswell��1�R�A�����艽�{��256bitSIMD������H
>>104
���₾�����ΐ��\�̘b�����Ă��Ȃ���
SIMD(SSE2)���g��Ȃ���->�g�����̌��㗦�̘b�����Ă���ǁB
Haswell��2�I�y���[�V����/�N���b�N/�R�A->8�I�y���[�V����/�N���b�N/�R�A
Kaveri��2�I�y���[�V����/�N���b�N/���W���[��->8�I�y���[�V����/�N���b�N/���W���[��
�ǂ����SSE2�g�p�ɂ��X���[�v�b�g�̌��㗦��4�{�������\���㗦��Haswell�̕����y���ɍ���
���₾�����ΐ��\�̘b�����Ă��Ȃ���
SIMD(SSE2)���g��Ȃ���->�g�����̌��㗦�̘b�����Ă���ǁB
Haswell��2�I�y���[�V����/�N���b�N/�R�A->8�I�y���[�V����/�N���b�N/�R�A
Kaveri��2�I�y���[�V����/�N���b�N/���W���[��->8�I�y���[�V����/�N���b�N/���W���[��
�ǂ����SSE2�g�p�ɂ��X���[�v�b�g�̌��㗦��4�{�������\���㗦��Haswell�̕����y���ɍ���
�I�y���[�V�����Ă̂͒P���x��FLOP�Ɠǂݑւ��Ă���č\��Ȃ�
>>105
SIMD�g������SIMD���Z�킪2�{�i256bit���g����4�{�j����Intel�̕���
���㗦�����ē��R���Ǝv���̂����B
����������AMD�̕����s���ȏ����Ŕ�������ƌ����Ă�̂������ė~�����ˁB
SIMD�g������SIMD���Z�킪2�{�i256bit���g����4�{�j����Intel�̕���
���㗦�����ē��R���Ǝv���̂����B
����������AMD�̕����s���ȏ����Ŕ�������ƌ����Ă�̂������ė~�����ˁB
�Z���̎��Ƃ��K�v���H
���Ƃ��� 4�� (2�� x 2���W���[��) �̉��Z�킪�g����7850K�����
SSE2�ɂ���� 16�� (2�� x 4���� x 2���W���[��) �̉��Z�킪������悤�ɂȂ�܂���
���Ƃ��� 8�� (2�� x 4�R�A) �̉��Z�킪�g����4770K�����
SSE2�ɂ���� 32�� (2�� x 4���� x 4�R�A) �̉��Z�킪������悤�ɂȂ�܂���
�ǂ���̂ق������Ƃ��Ƃ̐��\����̌��㗦���������ł����H
���Ƃ��� 4�� (2�� x 2���W���[��) �̉��Z�킪�g����7850K�����
SSE2�ɂ���� 16�� (2�� x 4���� x 2���W���[��) �̉��Z�킪������悤�ɂȂ�܂���
���Ƃ��� 8�� (2�� x 4�R�A) �̉��Z�킪�g����4770K�����
SSE2�ɂ���� 32�� (2�� x 4���� x 4�R�A) �̉��Z�킪������悤�ɂȂ�܂���
�ǂ���̂ق������Ƃ��Ƃ̐��\����̌��㗦���������ł����H
>>108
256bit�̉��Z�킪�����Ȃ����Haswell��128bitSIMD����������킯�Ȃ��낤�B
256bit�̉��Z�킪������128bit�Ƃ��ē��삷���B
�����߂�ǂ������̂�>>92�̃����N����݂Ă���B
Haswell��1�R�A������2��256bit���Z�킪������ď����Ă��邾��B
�ŁA4�R�A�~2��8��256bit���Z�킾����Kaveri���X���[�v�b�g�͏�B
256bit�̉��Z�킪�����Ȃ����Haswell��128bitSIMD����������킯�Ȃ��낤�B
256bit�̉��Z�킪������128bit�Ƃ��ē��삷���B
�����߂�ǂ������̂�>>92�̃����N����݂Ă���B
Haswell��1�R�A������2��256bit���Z�킪������ď����Ă��邾��B
�ŁA4�R�A�~2��8��256bit���Z�킾����Kaveri���X���[�v�b�g�͏�B
>>110
������SSE2���߂����g��Ȃ����256bit�̂���128bit�������g���Ȃ��Ŕ����͗V�Ԃ�
�X���[�v�b�g�̐�Βl����Ȃ��ăX���[�v�b�g�̌��㗦�̘b�����Ă�ƌ����Ă�̂ɉ��x�����Ε�����́H
������SSE2���߂����g��Ȃ����256bit�̂���128bit�������g���Ȃ��Ŕ����͗V�Ԃ�
�X���[�v�b�g�̐�Βl����Ȃ��ăX���[�v�b�g�̌��㗦�̘b�����Ă�ƌ����Ă�̂ɉ��x�����Ε�����́H
���Ă�����>>109�̌v�Z�݂Ă킩�������A�n�C�p�[�X���b�f�B���O���v�Z�ɓ���Ă�̂��B
���揈���̃x���`�ł���Ȍv�Z����z���߂Č����B
���ꂶ�Ⴀ��������Haswell��Original�̐������������邾��B8�R�A�Ȃ̂ɁB
���z�R�A�ŕ��ꂪ�Ⴍ�łĂ��B
���揈���̃x���`�ł���Ȍv�Z����z���߂Č����B
���ꂶ�Ⴀ��������Haswell��Original�̐������������邾��B8�R�A�Ȃ̂ɁB
���z�R�A�ŕ��ꂪ�Ⴍ�łĂ��B
���������Ă�̂������ς蕪�����
2�� x 4�R�A �Ă̂̓R�A�����蕂�������_���Z���߂��t����p�C�v��2�Ƃ����Ӗ��ł�����
SMT�Ƃ��S���W�Ȃ�
2�� x 4�R�A �Ă̂̓R�A�����蕂�������_���Z���߂��t����p�C�v��2�Ƃ����Ӗ��ł�����
SMT�Ƃ��S���W�Ȃ�
>>113
���\���㗦���Č�������SMT�ł��ׂď�������ꍇ�̐��\������A
CPU���畨��SIMD���Z��ɏ����𓊂���ꍇ�̐��\�����q�ɂȂ�̂ŁA
SMT���W�Ȃ��킯���Ȃ��B���q���������ቺ�����Ă���B
�W�Ȃ��Ƃ�����Haswell��SIMD���Z��̓L�b�N����CPU�̐��\�����肸�ɗV��ł���B
���\���㗦���Č�������SMT�ł��ׂď�������ꍇ�̐��\������A
CPU���畨��SIMD���Z��ɏ����𓊂���ꍇ�̐��\�����q�ɂȂ�̂ŁA
SMT���W�Ȃ��킯���Ȃ��B���q���������ቺ�����Ă���B
�W�Ȃ��Ƃ�����Haswell��SIMD���Z��̓L�b�N����CPU�̐��\�����肸�ɗV��ł���B
SMT�̐��\���㗦�̘b�Ȃ�Ă��ĂȂ�
(SMT���g����)SSE2���g�킸�ɑS�R�A���������ꍇ
(SMT���g����)SSE2���g���đS�R�A���������ꍇ
�̔�r��
��������SMT�ŗ��_���\�̃s�[�N�͕ς���
(SMT���g����)SSE2���g�킸�ɑS�R�A���������ꍇ
(SMT���g����)SSE2���g���đS�R�A���������ꍇ
�̔�r��
��������SMT�ŗ��_���\�̃s�[�N�͕ς���
������������ȑO����ǂ�ǂ�t�������Ėϑz��c��܂��Ă銴���Ȃ���
���{�ꂪ�ʂ��Ȃ��l�Ȃ̂��Ȃ�...
���{�ꂪ�ʂ��Ȃ��l�Ȃ̂��Ȃ�...
>>115,116
���Ⴀ������BAMD�̌����Ⴂ���Ă��Ƃɂ��Ă������������B
SMT�ɂ�鐫�\����Ȃ�Ĉꌾ�������ĂȂ����A�ꉞ������̎咣�͐������Ă����B
SMT�͉��z2�R�A�Ȃ̂ŕ���2�R�A�ɔ�ׂĐ��\�ቺ���N����B
SIMD���Z��͕����I�Ɏ�������Ă�̂ŁASMT�ɂ�鐫�\�ቺ�̉e���́A
CPU�ɂ�鏈������SIMD�g�p��
�ɂȂ�B����͐��\���㗦�̕���ƕ��q�̊W�Ȃ̂ŁASIMD�ɂ�鐫�\���㗦��
Haswell�̕��������Ȃ�B
���܂łɍēx�������ނ�������Ȃ����ǁA���Ȃ��Ⴂ���Ȃ����Ƃ����ňꎞ�I�ɗ�����B
���Ⴀ������BAMD�̌����Ⴂ���Ă��Ƃɂ��Ă������������B
SMT�ɂ�鐫�\����Ȃ�Ĉꌾ�������ĂȂ����A�ꉞ������̎咣�͐������Ă����B
SMT�͉��z2�R�A�Ȃ̂ŕ���2�R�A�ɔ�ׂĐ��\�ቺ���N����B
SIMD���Z��͕����I�Ɏ�������Ă�̂ŁASMT�ɂ�鐫�\�ቺ�̉e���́A
CPU�ɂ�鏈������SIMD�g�p��
�ɂȂ�B����͐��\���㗦�̕���ƕ��q�̊W�Ȃ̂ŁASIMD�ɂ�鐫�\���㗦��
Haswell�̕��������Ȃ�B
���܂łɍēx�������ނ�������Ȃ����ǁA���Ȃ��Ⴂ���Ȃ����Ƃ����ňꎞ�I�ɗ�����B
���Ƃ��������̂������g���f�������ł���
Haswell��Kaveri���X�J��FPU��SIMD��2�X���b�h�ŋ��L����Ă���̂�
SMT�̉e���͓����悤�Ɏ�
117�̔]���ł̓X�J�����Z���4�R�A������������SIMD���Z���8�X���b�h���p�ӂ���Ă���
�Ƃ����ݒ�Ȃ̂��낤���H
Haswell��Kaveri���X�J��FPU��SIMD��2�X���b�h�ŋ��L����Ă���̂�
SMT�̉e���͓����悤�Ɏ�
117�̔]���ł̓X�J�����Z���4�R�A������������SIMD���Z���8�X���b�h���p�ӂ���Ă���
�Ƃ����ݒ�Ȃ̂��낤���H
>>118
������Ƃ�������
����όN>>92�ǂ݂Ȃ����Ă��Ȃ�BHaswell��SIMD���Z���
256bit���R�A������2�i�s��8�j�����Ă����Ə����Ă����B
�iIntel�����̏���Ƃ݂���Ȃ��������A�x���`�Ȃǂ��琳�����Ǝv���B�j
��������SMT�ƃ��W���[���\���Ƃ��ᐫ�\�ɗ^����e�����Ⴄ���B
������Ƃ�������
����όN>>92�ǂ݂Ȃ����Ă��Ȃ�BHaswell��SIMD���Z���
256bit���R�A������2�i�s��8�j�����Ă����Ə����Ă����B
�iIntel�����̏���Ƃ݂���Ȃ��������A�x���`�Ȃǂ��琳�����Ǝv���B�j
��������SMT�ƃ��W���[���\���Ƃ��ᐫ�\�ɗ^����e�����Ⴄ���B
>>119
������117�Ō����uCPU�ɂ�鏈���v�����邽�߂̉��Z��������悤��
�R�A������2�i�s��8�j������ǁH
SIMD�Ȃ��ł�����ł�8��4�R�A������
������117�Ō����uCPU�ɂ�鏈���v�����邽�߂̉��Z��������悤��
�R�A������2�i�s��8�j������ǁH
SIMD�Ȃ��ł�����ł�8��4�R�A������
>>120
��������117�Ō����uCPU�ɂ�鏈���v�����邽�߂̉��Z��������悤��
���R�A������2�i�s��8�j������ǁH
����͘_���R�A�ŕ����I�Ɏ�������ĂȂ��B
http://e-words.jp/w/E3838FE382A4E38391E383BCE382B9E383ACE38383E38387E382A3E383B3E382B0.html
��������117�Ō����uCPU�ɂ�鏈���v�����邽�߂̉��Z��������悤��
���R�A������2�i�s��8�j������ǁH
����͘_���R�A�ŕ����I�Ɏ�������ĂȂ��B
http://e-words.jp/w/E3838FE382A4E38391E383BCE382B9E383ACE38383E38387E382A3E383B3E382B0.html
>>121
�����������...
SMT�ɂ��2����Ȃ��ĕ��ʂɕ����I��2������ǁH
http://cdn.arstechnica.net/wp-content/uploads/2013/04/HSW_IMG_3-640x390.png
FP Multiply��FP Add���Ă̂������
�����������...
SMT�ɂ��2����Ȃ��ĕ��ʂɕ����I��2������ǁH
http://cdn.arstechnica.net/wp-content/uploads/2013/04/HSW_IMG_3-640x390.png
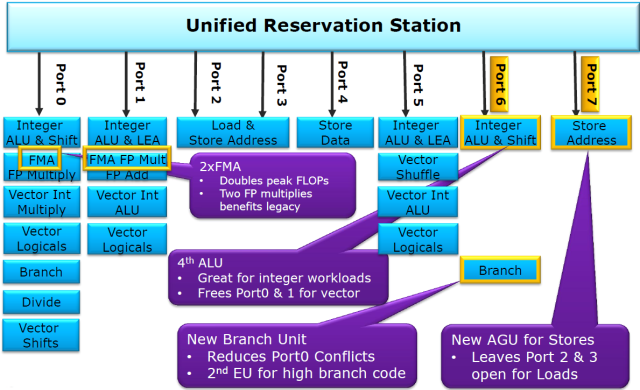{kind=link}
FP Multiply��FP Add���Ă̂������
>>122
�����FPU�̎������l���ĂȂ�����BFPU���������Ă��ALU�͂�����ł�̂���B
�Ƃ�����Haswell��9.4�b�����鏈����Kaveri��15�b�łł��Ă�̂Ȃ�
�_���R�A���ɑ��Đ��\���X�P�[�����ĂȂ����Ċm�݂����Ȃ��B
�����FPU�̎������l���ĂȂ�����BFPU���������Ă��ALU�͂�����ł�̂���B
�Ƃ�����Haswell��9.4�b�����鏈����Kaveri��15�b�łł��Ă�̂Ȃ�
�_���R�A���ɑ��Đ��\���X�P�[�����ĂȂ����Ċm�݂����Ȃ��B
�������������̂��������
SIMD���g�������g���܂������������_���Z���s�����j�b�g�̓R�A������2�i�s��8�j
�R�A���ɑ��鐫�\�̃X�P�[���̘b����Ȃ���
SIMD�I�t/�I���ł̐��\�̃X�P�[���̘b�����Ă���ǁH
SIMD���g�������g���܂������������_���Z���s�����j�b�g�̓R�A������2�i�s��8�j
�R�A���ɑ��鐫�\�̃X�P�[���̘b����Ȃ���
SIMD�I�t/�I���ł̐��\�̃X�P�[���̘b�����Ă���ǁH
SIMD�I�t�A�I���ł̃X�P�[���Ȃ�Haswell��Original�̏������ُ�ɒx���̂��Ȃ�������Ȃ�ˁH
8�R�A�Ȃ̂ɁB
�s���̈������ɂ͖ڂ��Ԃ�܂����ˁB
8�R�A�Ȃ̂ɁB
�s���̈������ɂ͖ڂ��Ԃ�܂����ˁB
8�R�A����Ȃ���4�R�A8�X���b�h
���������Ĉٗl�ɒx���Ƃ��Ă���̂����������
������O�����A���_�[���̖@���ŃR�A����������قǐ��\����͊ɂ₩�ɂȂ邩���
���������Ĉٗl�ɒx���Ƃ��Ă���̂����������
������O�����A���_�[���̖@���ŃR�A����������قǐ��\����͊ɂ₩�ɂȂ邩���
�܂Ƃ��ȃo�C�i���œ��揈������ꍇ��4�R�A�ȏ�ł����Ȃ�X�P�[������B
�Â��o�C�i����3�`4�œ��ł����������B
>>92�����߂Č��Ȃ����Ă݂�ƁA�O���t�̃O���[�̕�����
Haswell��Original�̂��̂����䗦�I�ɑ傫���B
�u���O��̐������Ɛ������ƕ��������_���������K�v�Ȃ悤�Ȃ̂ŁA
�������j�b�g���L�ɂ���ăX�P�[�����Ă��Ȃ��Ƃ����̂�
��̐����Ƃ��Ă��肦�������B
�悭�ǂނƏ����Ă�����ˁB
�Â��o�C�i����3�`4�œ��ł����������B
>>92�����߂Č��Ȃ����Ă݂�ƁA�O���t�̃O���[�̕�����
Haswell��Original�̂��̂����䗦�I�ɑ傫���B
�u���O��̐������Ɛ������ƕ��������_���������K�v�Ȃ悤�Ȃ̂ŁA
�������j�b�g���L�ɂ���ăX�P�[�����Ă��Ȃ��Ƃ����̂�
��̐����Ƃ��Ă��肦�������B
�悭�ǂނƏ����Ă�����ˁB
�t�ł���
Kaveri�͐������Z�̓X�J�����ƃR�A���Ƃɉ��Z�킪���邯��
SIMD������ƕ��������_/SIMD�N���X�^�Ɉڂ���2�R�A�ʼn��Z������L����悤�ɂȂ邩��
Haswell�ق�SIMD���̉��b���Ȃ�
Kaveri�͐������Z�̓X�J�����ƃR�A���Ƃɉ��Z�킪���邯��
SIMD������ƕ��������_/SIMD�N���X�^�Ɉڂ���2�R�A�ʼn��Z������L����悤�ɂȂ邩��
Haswell�ق�SIMD���̉��b���Ȃ�
>>128
�����Haswell��8�R�A�i>>109��������Q�Ƃɘ_���R�A���ōs���j�ł���ɂ�������炸�A
Kaveri�ɑ��ăR�A���Ȃ�̃A�h�o���e�[�W�����ĂĂȂ����̐����ɂ͂Ȃ�Ȃ���ˁB
�P�ɁA�ȑO�����AMD�̃R�A�͕s�����Ƃ����������J��Ԃ�����������ˁB
�����Haswell��8�R�A�i>>109��������Q�Ƃɘ_���R�A���ōs���j�ł���ɂ�������炸�A
Kaveri�ɑ��ăR�A���Ȃ�̃A�h�o���e�[�W�����ĂĂȂ����̐����ɂ͂Ȃ�Ȃ���ˁB
�P�ɁA�ȑO�����AMD�̃R�A�͕s�����Ƃ����������J��Ԃ�����������ˁB
������N���R�A���Ȃ�̃A�h�o���e�[�W�Ȃ�Ď咣���ĂȂ�����
SIMD�I���I�t�łǂꂾ�����\�����シ�邩�Ƃ����b�������ĂȂ�
�ł����Ė���109��SMT��x2����Ă�Ɗ��Ⴂ���Ă�킯�H
SIMD�I���I�t�łǂꂾ�����\�����シ�邩�Ƃ����b�������ĂȂ�
�ł����Ė���109��SMT��x2����Ă�Ɗ��Ⴂ���Ă�킯�H
>>130
���Ⴀ�A�h�o���e�[�W�������Ȃ����ɂ͖ڂ��Ԃ낤�B
�����Kaveri��SIMD�g�����ꍇ�ɂ�1.5�{�ɂ����Ȃ�Ȃ�����
Haswell�Ȃ�2.7�{�ɂȂ���Ă����͈̂Ӗ����Ȃ������ɂȂ邯�ǁB
�Ӗ��������咣�̂��߂ɈӖ����Ȃ��c�_�����܂����ˁA�ƁB
���Ⴀ�A�h�o���e�[�W�������Ȃ����ɂ͖ڂ��Ԃ낤�B
�����Kaveri��SIMD�g�����ꍇ�ɂ�1.5�{�ɂ����Ȃ�Ȃ�����
Haswell�Ȃ�2.7�{�ɂȂ���Ă����͈̂Ӗ����Ȃ������ɂȂ邯�ǁB
�Ӗ��������咣�̂��߂ɈӖ����Ȃ��c�_�����܂����ˁA�ƁB
132 �FSocket774�F2014/09/17(��) 08:13:11.56 ID:Ow3mPcoS
�Ȃ��AAMD���[�U�[�ɂ��AHTT��SMT�͕ʕ��ł���
AMD�̎�����A�[�L�e�N�`��CPU�͐��E����SMT����CPU�ɂȂ�\��ł���
AMD�̎�����A�[�L�e�N�`��CPU�͐��E����SMT����CPU�ɂȂ�\��ł���
��cinebenchR11.5 �V���O��CPU
�C���e��(7�N��60%����)
2013 Haswell 1.76/3.9=0.451
2012 Ivy 1.66/3.9=0.425
2011 Sandy 1.55/3.8=0.407
2010 Arrandale 0.8/2.39=0.334
2009 Lynn 1/2.94=0.340
2008 Penryn 0.93/3=0.310
2006 Conroe 0.86/3=0.286
�A���h(7�N�Ԃ�20%�������ス����)
2013 FX 1.1/4=0.275
2006 939 Opteron 0.68/3=0.226
(�@߄t�)
�C���e��(7�N��60%����)
2013 Haswell 1.76/3.9=0.451
2012 Ivy 1.66/3.9=0.425
2011 Sandy 1.55/3.8=0.407
2010 Arrandale 0.8/2.39=0.334
2009 Lynn 1/2.94=0.340
2008 Penryn 0.93/3=0.310
2006 Conroe 0.86/3=0.286
�A���h(7�N�Ԃ�20%�������ス����)
2013 FX 1.1/4=0.275
2006 939 Opteron 0.68/3=0.226
(�@߄t�)
���`��A�悭�������B
���_�Ƃ��Ắui7�̔�SIMD�����͒x�����v�ł����H
���_�Ƃ��Ắui7�̔�SIMD�����͒x�����v�ł����H
�I���W�i���ł�SIMD�͈�؍s���Ă��Ȃ����ƂȂW���肻���H
>>134
AMD�Ɣ�ׂ��ނ��둬�����ǁASIMD�g������2.7�{���Đ����ɂ͋^�₪�c��B
��������ɃR�A�̌����]�X�͌����Ȃ��B
�Ƃ������AOriginal�ł���SIMD�g���ĂȂ��̂��ˁH
�قƂ�Ǖ��������_���Z���Ƃ����������A�ꕔMMX�Ƃ��������Ƃ͂Ȃ��̂��ˁB
�܂�MMX��p���j�b�g�Ȃ��Ȃ����͂��Ȃ̂ł����Kaveri��Haswell�����������B
AMD�Ɣ�ׂ��ނ��둬�����ǁASIMD�g������2.7�{���Đ����ɂ͋^�₪�c��B
��������ɃR�A�̌����]�X�͌����Ȃ��B
�Ƃ������AOriginal�ł���SIMD�g���ĂȂ��̂��ˁH
�قƂ�Ǖ��������_���Z���Ƃ����������A�ꕔMMX�Ƃ��������Ƃ͂Ȃ��̂��ˁB
�܂�MMX��p���j�b�g�Ȃ��Ȃ����͂��Ȃ̂ł����Kaveri��Haswell�����������B
�U�X���m���N��������ɋ^�₪�c�����...
>>137
�����̎����݂����Ȑ����T�C�N���Ő������Ă�z���ɂ��Ȃ��Ǝv���Ă���B
�Ƃ������A�Ⴄ�Ǝv���Ȃ番��]�X�Ɋւ��Ă����_���Ă���B
���_����CPU�R�A�ɂ͑��ɂ����\�ɉe������v�f������Ǝv�����A
���\���㗦�̍���AMD�̃R�A�̒�����ɗR�����鎖���ؖ����Ă���B
�����̎����݂����Ȑ����T�C�N���Ő������Ă�z���ɂ��Ȃ��Ǝv���Ă���B
�Ƃ������A�Ⴄ�Ǝv���Ȃ番��]�X�Ɋւ��Ă����_���Ă���B
���_����CPU�R�A�ɂ͑��ɂ����\�ɉe������v�f������Ǝv�����A
���\���㗦�̍���AMD�̃R�A�̒�����ɗR�����鎖���ؖ����Ă���B
����������Ă�̂ɕςȖϑz����������ŗ������悤�Ƃ��Ȃ������ł���
Kaveri,Haswell���ꂼ��ɂ���
SIMD���g��Ȃ��ꍇ�̗��_FLOPS�l��ASIMD��(SSE2�܂�)�g�����ꍇ�̗��_FLOPS�l�q�Ƃ���
�����ŗ��_��̐��\������E�l���v�Z���Ă݂�
SMT�͎����l�𗝘_�l�ɋ߂Â�����ʂ͂����Ă��A���_�l���グ����ʂ͂Ȃ������
Kaveri,Haswell���ꂼ��ɂ���
SIMD���g��Ȃ��ꍇ�̗��_FLOPS�l��ASIMD��(SSE2�܂�)�g�����ꍇ�̗��_FLOPS�l�q�Ƃ���
�����ŗ��_��̐��\������E�l���v�Z���Ă݂�
SMT�͎����l�𗝘_�l�ɋ߂Â�����ʂ͂����Ă��A���_�l���グ����ʂ͂Ȃ������
�I���W�i���Ǝv����v0.14��readme�ɂ́��ƂȂ��Ă�C����ŏ�����Ă�i�炵���j�B
���@�ESSE�Ȃǂ͈�؎g�p���Ă��܂���B�}���`�X���b�h�ɂ͑Ή����Ă��܂��B
��������256bit FMACx2�Ƃ����������B
http://pc.watch.impress.co.jp/img/pcw/docs/601/851/html/18.jpg.html
���@�ESSE�Ȃǂ͈�؎g�p���Ă��܂���B�}���`�X���b�h�ɂ͑Ή����Ă��܂��B
��������256bit FMACx2�Ƃ����������B
http://pc.watch.impress.co.jp/img/pcw/docs/601/851/html/18.jpg.html
{kind=link}
steamroller�����Ƃ�
http://pc.watch.impress.co.jp/img/pcw/docs/556/374/html/13.jpg.html
http://pc.watch.impress.co.jp/img/pcw/docs/556/374/html/13.jpg.html
{kind=link}
>>141
��{�̘b�Ƃ͊W�Ȃ����AAMD��256bit���ւ̃��`�x�[�V�����������ȋC������ˁB
K12��ZEN���o���R�A���Ƃ���ƁANEON�̕���256bit�����Ȃ��ƁB
����Ƃ�128bit�~4�Ƃ��c�c
��{�̘b�Ƃ͊W�Ȃ����AAMD��256bit���ւ̃��`�x�[�V�����������ȋC������ˁB
K12��ZEN���o���R�A���Ƃ���ƁANEON�̕���256bit�����Ȃ��ƁB
����Ƃ�128bit�~4�Ƃ��c�c
http://info.nuje.de/BulldozerModuleHansVsAMD.jpg
���L���Fhttp://www.semiaccurate.com/forums/showthread.php?p=100029
�_�C�S�̂ɐ�߂銄���Ō�����256bit�����Ă����������͂Ȃ����ǁB
����ȑO��14nm��fab�����肵�ĉғ����Ȃ�������̂��悤���Ȃ��E�E�B
{kind=link}
���L���Fhttp://www.semiaccurate.com/forums/showthread.php?p=100029
�_�C�S�̂ɐ�߂銄���Ō�����256bit�����Ă����������͂Ȃ����ǁB
����ȑO��14nm��fab�����肵�ĉғ����Ȃ�������̂��悤���Ȃ��E�E�B
�Ƃ肠����4770K��8�R�A�Ƃ������Ă�ID:Kc8yNRh7��
�]�݂����M�ŗn���ĕ����Ă���Ă��Ƃł����H
�]�݂����M�ŗn���ĕ����Ă���Ă��Ƃł����H
���̃��x����AMD�L�`���Ƒ���ɂ����Ⴂ���Ȃ����x��
�M�ҁuSIMD��Haswell Core i7�Ɠ������������Ă�Kaveri�̏������x�͗��_��C�R�[���I�v
��ʃA���_�[�u�M�җ��_�}�W�p�l�F�����v
�����������ƁH
��ʃA���_�[�u�M�җ��_�}�W�p�l�F�����v
�����������ƁH
��cinebenchR11.5 �V���O��CPU
�C���e��(7�N��60%����)
2013 Haswell 1.76/3.9=0.451
2012 Ivy 1.66/3.9=0.425
2011 Sandy 1.55/3.8=0.407
2010 Arrandale 0.8/2.39=0.334
2009 Lynn 1/2.94=0.340
2008 Penryn 0.93/3=0.310
2006 Conroe 0.86/3=0.286
�A���h(7�N�Ԃ�20%�������ス����)
2013 FX 1.1/4=0.275
2006 939 Opteron 0.68/3=0.226
((((�G߄D�)))))))
�C���e��(7�N��60%����)
2013 Haswell 1.76/3.9=0.451
2012 Ivy 1.66/3.9=0.425
2011 Sandy 1.55/3.8=0.407
2010 Arrandale 0.8/2.39=0.334
2009 Lynn 1/2.94=0.340
2008 Penryn 0.93/3=0.310
2006 Conroe 0.86/3=0.286
�A���h(7�N�Ԃ�20%�������ス����)
2013 FX 1.1/4=0.275
2006 939 Opteron 0.68/3=0.226
((((�G߄D�)))))))
149 �FSocket774�F2014/09/18(��) 08:33:50.51 ID:k77d135V
>>147
SIMD�͐��\������Haswell i7�̕����ゾ���炻��Ȏ������̂͐M�҂ł��Ȃ������̔n���B
���������A�m�[�g�p�̂Q�R�A��i7������
�`�l�c�wSIMD��GPU�̉��Z���\�̍��v��Kaveri��Haswell i7�œ������炢�B������Kaveri��i7���I�x
SIMD�͐��\������Haswell i7�̕����ゾ���炻��Ȏ������̂͐M�҂ł��Ȃ������̔n���B
���������A�m�[�g�p�̂Q�R�A��i7������
�`�l�c�wSIMD��GPU�̉��Z���\�̍��v��Kaveri��Haswell i7�œ������炢�B������Kaveri��i7���I�x
�������A����̓X�}���������B
�G���R�̘b�Ȃ̂�SIMD�������đz���ł��Ȃ���������
�G���R�̘b�Ȃ̂�SIMD�������đz���ł��Ȃ���������
�����Ƃ��ԈႦ��
29 �F,,�E�L�́M�E,,�j��-�������F2011/04/14(��) 12:15:12.08
Pentium4��HT���g���ƃg�[�^���X���[�v�b�g�������錴������L1�L���b�V���~�X�ł��B
8KB�Ƃ�16KB�̏������L���b�V�����X�ɋ��L����Ƃ��A�����������ƎR�̔@���B
Bulldozer��L1�Ɨ��Ȃ̂�L1�e�ʂ��l�b�N�ɂȂ�R�[�h�͐��\��������Ƃ������
�ŏ�����x���Ǝv���B1�X���b�h�������点���������L1D��32KB�Ƃ��Ă��Ďg����킯���ᖳ����
�ŏ�����16KB�Œ芄�蓖�Ă����ˁB
�������A2�R�A�����ɃL���b�V���~�X or prefetch������L2�̑ш���v������H���Ă̂͂���B
HPC�łƖ��ł���Nehalem-EX��6�R�A�E2.66GHz�ł͍ŏ�����HT�͖����ɂ��Ă���B
���Bulldozer��SIMD���߂̓��C�e���V���傫������̂�2�X���b�h�g��Ȃ��Ɩ��܂�Ȃ��C������B
Pentium4��HT���g���ƃg�[�^���X���[�v�b�g�������錴������L1�L���b�V���~�X�ł��B
8KB�Ƃ�16KB�̏������L���b�V�����X�ɋ��L����Ƃ��A�����������ƎR�̔@���B
Bulldozer��L1�Ɨ��Ȃ̂�L1�e�ʂ��l�b�N�ɂȂ�R�[�h�͐��\��������Ƃ������
�ŏ�����x���Ǝv���B1�X���b�h�������点���������L1D��32KB�Ƃ��Ă��Ďg����킯���ᖳ����
�ŏ�����16KB�Œ芄�蓖�Ă����ˁB
�������A2�R�A�����ɃL���b�V���~�X or prefetch������L2�̑ш���v������H���Ă̂͂���B
HPC�łƖ��ł���Nehalem-EX��6�R�A�E2.66GHz�ł͍ŏ�����HT�͖����ɂ��Ă���B
���Bulldozer��SIMD���߂̓��C�e���V���傫������̂�2�X���b�h�g��Ȃ��Ɩ��܂�Ȃ��C������B
10Socket774 [sage] 2013/01/18(��) 01:19:18.38 ID:C3wIcvo9
�����₩�ȔR�������B?
AMD�Ј��́uBulldozer�͈����Ȃ�����\�t�g����������v?
�Ƃ���������ɐ����͂�^���Ă݂悤�Ƃ���e�X�g�B?
ttp://www1.axfc.net/uploader/so/2758887.png?
�}���́u4C8T�v��Intel 4�R�A(HT)�A�u8C8T�v��8�R�ABulldozer�B?
1�`8�̃X���b�h��ڈ�t�Ԃ�����ɁA?
CPU�S�̂̃s�[�N���\�̂��������g������邩���O���t�ɂ��Ă݂��B?
4�X���b�h�܂ł͐��������ŗ�����āA8�X���b�h�Œǂ����B?
���Ƀs�[�N���\�������������Ƃ��āABulldozer��FP���ォ������Ƃ�?
�����̈Ⴂ�����邵�A���̒ʂ�̌��ʂɂ͂Ȃ�Ȃ������m��Ȃ����ǁA?
�uIvy Bridge�̔����������\�o�Ȃ���v�݂����Șb�́A?
��������8�X���b�h�ɂ����ƍœK������Ă�̂��^��B?
�����ƃ}���`�X���b�h�ɍœK�������\�t�g�Ȃ�Intel�ɕ�������炸����Bulldozer�A?
�����l���Ȃ��œK���ɍ�����\�t�g�ł����\���o��Intel�Ƃ�����ہB
22Socket774 [sage] 2013/01/18(��) 19:40:50.78 ID:C3wIcvo9
>>17?
�ނ���>>10�̘b�ɂȂ邯�ǁA�����������Ă�z����?
http://scalibq.wordpress.com/2012/02/14/the-myth-of-cmt-cluster-based-multithreading/?
�x���`�}�[�N��(���̏ꍇ�ΏƂ�Intel��6�R�A������)�܂��ɂ��̒ʂ�̌X���������Ă���ۂ�?
http://openbenchmarking.org/result/1110201-AR-BULLSCALI82?
CMT��SMT�ǂ����������Ƃ��ACMT����߂�SMT�ɂ��ׂ��Ƃ����b����Ȃ��Ă��A?
�ESMT��CMT�i�őΔ䂷��Ȃ�SMT�̐��\��̑ΏƂ�CMT2�R�A(=1���W���[��)�����?
�E�ł�CMT���ėv��FPU�����L���鐫�\������Q�R�A����ׂ鎖�Ɠ��������?
�E���Ⴀ8�R�ACMT���ăV���O���X���b�h���\���Ⴂ4�R�ASMT�Ƃقړ��`�����?
�E�ǂ����Ȃ�CMT��1�R�A��SMT������s�[�N���\�҂���̂�?
�E�v�́uK10��SMT������FPU�������v�݂����ȍ\���̂��̍�����ق����悩������ˁH?
���Ă����b�B�����������炷�܂�B�ǂ��ł������^���b���Ă��ƂŁB
�����₩�ȔR�������B?
AMD�Ј��́uBulldozer�͈����Ȃ�����\�t�g����������v?
�Ƃ���������ɐ����͂�^���Ă݂悤�Ƃ���e�X�g�B?
ttp://www1.axfc.net/uploader/so/2758887.png?
{kind=link}
�}���́u4C8T�v��Intel 4�R�A(HT)�A�u8C8T�v��8�R�ABulldozer�B?
1�`8�̃X���b�h��ڈ�t�Ԃ�����ɁA?
CPU�S�̂̃s�[�N���\�̂��������g������邩���O���t�ɂ��Ă݂��B?
4�X���b�h�܂ł͐��������ŗ�����āA8�X���b�h�Œǂ����B?
���Ƀs�[�N���\�������������Ƃ��āABulldozer��FP���ォ������Ƃ�?
�����̈Ⴂ�����邵�A���̒ʂ�̌��ʂɂ͂Ȃ�Ȃ������m��Ȃ����ǁA?
�uIvy Bridge�̔����������\�o�Ȃ���v�݂����Șb�́A?
��������8�X���b�h�ɂ����ƍœK������Ă�̂��^��B?
�����ƃ}���`�X���b�h�ɍœK�������\�t�g�Ȃ�Intel�ɕ�������炸����Bulldozer�A?
�����l���Ȃ��œK���ɍ�����\�t�g�ł����\���o��Intel�Ƃ�����ہB
22Socket774 [sage] 2013/01/18(��) 19:40:50.78 ID:C3wIcvo9
>>17?
�ނ���>>10�̘b�ɂȂ邯�ǁA�����������Ă�z����?
http://scalibq.wordpress.com/2012/02/14/the-myth-of-cmt-cluster-based-multithreading/?
�x���`�}�[�N��(���̏ꍇ�ΏƂ�Intel��6�R�A������)�܂��ɂ��̒ʂ�̌X���������Ă���ۂ�?
http://openbenchmarking.org/result/1110201-AR-BULLSCALI82?
CMT��SMT�ǂ����������Ƃ��ACMT����߂�SMT�ɂ��ׂ��Ƃ����b����Ȃ��Ă��A?
�ESMT��CMT�i�őΔ䂷��Ȃ�SMT�̐��\��̑ΏƂ�CMT2�R�A(=1���W���[��)�����?
�E�ł�CMT���ėv��FPU�����L���鐫�\������Q�R�A����ׂ鎖�Ɠ��������?
�E���Ⴀ8�R�ACMT���ăV���O���X���b�h���\���Ⴂ4�R�ASMT�Ƃقړ��`�����?
�E�ǂ����Ȃ�CMT��1�R�A��SMT������s�[�N���\�҂���̂�?
�E�v�́uK10��SMT������FPU�������v�݂����ȍ\���̂��̍�����ق����悩������ˁH?
���Ă����b�B�����������炷�܂�B�ǂ��ł������^���b���Ă��ƂŁB
29 ���O�F,,�E�L�́M�E,,�j��-������[] ���e���F2014/05/14(��) 23:28:04.67 ID:/Flgj8qu
���\�͒P���ȉ��Z���j�b�g�̐��Ō��܂�킯����Ȃ�����
��T�ɂ͂����Ȃ��B
���������邱�Ƃ�
�v���O�����͓������q�ŋx�݂Ȃ����Z���j�b�g������킯�ł͂Ȃ�
�L���b�V���~�X��ˑ��W�ł�������イ�~�܂�����l�܂������
�J��Ԃ��Ă�̂ŁA�s�[�N�݂̂Ƀt�H�[�J�X�����A�[�L�͕K������
�������悭�Ȃ��Ƃ������ƁB
Phenom�͍ő�3��ALU���Ɏg���邯�ǁA�K������
�g����킯����Ȃ��B
Bulldozer��1�X���b�h�����肪�g���鐮�����Z���j�b�g��2�ɐ��������B
�������2�ɍ�������́A�s�[�N���̐��\�����������B
���ꂪ�������̂��́A���ǂ̓x�X�g�P�[�X�ƃ��[�X�g�P�[�X��
�o�����X�����Ȃ�ˁB
���[�X�g�P�[�X�ł͂��ꂱ���L���b�V���~�X�ȂǂŊ��S�Ɏ~�܂�B
���Ⴀ�~�܂����Ƃ����ĉ��Z���j�b�g�Ă邯�ǁA
���̊Ԃɂق��̃X���b�h���s�ł��������������ˁH
Intel�͂��������ĂāABulldozer�͂���ĂȂ��B
��Ɋe�X���b�h��p��2��ALU�����蓖�ĂĂ���B
Bulldozer�̓x�X�g�P�[�X�i��1�X���b�h����3���ߓ����ɓ�������j��
�̂ĂĂ�悤�Ɍ����Ď��͕ʂ̃x�X�g�P�[�X�Ɉˑ����Ă���B
����́A�S�X���b�h����~�����ɓ����Ƃ����A���Ȃ茵�����O�B
���\�͒P���ȉ��Z���j�b�g�̐��Ō��܂�킯����Ȃ�����
��T�ɂ͂����Ȃ��B
���������邱�Ƃ�
�v���O�����͓������q�ŋx�݂Ȃ����Z���j�b�g������킯�ł͂Ȃ�
�L���b�V���~�X��ˑ��W�ł�������イ�~�܂�����l�܂������
�J��Ԃ��Ă�̂ŁA�s�[�N�݂̂Ƀt�H�[�J�X�����A�[�L�͕K������
�������悭�Ȃ��Ƃ������ƁB
Phenom�͍ő�3��ALU���Ɏg���邯�ǁA�K������
�g����킯����Ȃ��B
Bulldozer��1�X���b�h�����肪�g���鐮�����Z���j�b�g��2�ɐ��������B
�������2�ɍ�������́A�s�[�N���̐��\�����������B
���ꂪ�������̂��́A���ǂ̓x�X�g�P�[�X�ƃ��[�X�g�P�[�X��
�o�����X�����Ȃ�ˁB
���[�X�g�P�[�X�ł͂��ꂱ���L���b�V���~�X�ȂǂŊ��S�Ɏ~�܂�B
���Ⴀ�~�܂����Ƃ����ĉ��Z���j�b�g�Ă邯�ǁA
���̊Ԃɂق��̃X���b�h���s�ł��������������ˁH
Intel�͂��������ĂāABulldozer�͂���ĂȂ��B
��Ɋe�X���b�h��p��2��ALU�����蓖�ĂĂ���B
Bulldozer�̓x�X�g�P�[�X�i��1�X���b�h����3���ߓ����ɓ�������j��
�̂ĂĂ�悤�Ɍ����Ď��͕ʂ̃x�X�g�P�[�X�Ɉˑ����Ă���B
����́A�S�X���b�h����~�����ɓ����Ƃ����A���Ȃ茵�����O�B
�Ȃ������������X��\�������Ƃ�����
CMT����߂鎟���R�A�ł͑啝�Ȑ��\���オ�͂����������Ă��ƁB
CMT����߂鎟���R�A�ł͑啝�Ȑ��\���オ�͂����������Ă��ƁB
AMD�̎�����A�[�L�e�N�`���͐��E����SMT����CPU�炵����
�f�����܂����Ⴂ�܂��B
���E����SMT����APU�ł��B
���E����SMT����APU�ł��B
�� CPU Hierarchy Chart 2014
AMD�ߎS�������
�܂�ŏ����ɂȂ��ĂȂ���
5�N�O�̐ɂ��畉���Ă��
������x��Ȃ���
http://www.tomshardware.com/reviews/gaming-cpu-review-overclock,3106-5.html
AMD�ߎS�������
�܂�ŏ����ɂȂ��ĂȂ���
5�N�O�̐ɂ��畉���Ă��
������x��Ȃ���
http://www.tomshardware.com/reviews/gaming-cpu-review-overclock,3106-5.html
����14nm �������炢���ȁB
�G���g���[�m�[�gPC�����́gCarrizo-L�h��2014�N��4�l�����ɓo�ꂷ��͗l
http://northwood.blog60.fc2.com/blog-entry-7790.html
Intel,GF,TSMC�e�Ђ�1x nm����̃Q�[�g�s�b�`��r
http://pc.watch.impress.co.jp/img/pcw/docs/663/363/html/13.jpg.html
�G���g���[�m�[�gPC�����́gCarrizo-L�h��2014�N��4�l�����ɓo�ꂷ��͗l
http://northwood.blog60.fc2.com/blog-entry-7790.html
Intel,GF,TSMC�e�Ђ�1x nm����̃Q�[�g�s�b�`��r
http://pc.watch.impress.co.jp/img/pcw/docs/663/363/html/13.jpg.html
{kind=link}
{kind=link}
�g�V���v���R�A�h�Ɍ�����������CPU�A�[�L�e�N�`��
http://pc.watch.impress.co.jp/docs/2006/0821/kaigai296.htm
���@Tejas�̃_�C��Prescott(112����mm)��2�{�߂��T�C�Y��213����mm�ɂȂ�\�肾�����B�i���j
���@�����Core Microarchitecture�ł́A�A�[�L�e�N�`�����V�ł��Ȃ�̊g�����s�Ȃ��Ă���B
���@�������AAMD�Ɠ��l�ɁACPU�R�A��{�X�Ƀ��b�`�ɂ���Ƃ����y�[�X�ł͂Ȃ��B
���@CPU�̃_�C��143����mm�ƁAIntel�̐V�}�C�N���A�[�L�e�N�`��CPU�Ƃ��Ă͍ŏ��ŁA�g�����W�X�^����2��9,100��(291M)�B
Exploring AMD�fs And Intel�fs Architectural Philosophies ? What Does The Future Hold ? (Part II)
http://wccftech.com/article/exploring-amds-intels-architectural-philosophies-future-hold-part-ii/
���@Once you examine all the major players carefully, a crystal-clear image of the entire industry moving towards heterogeneous computing appears.
���@AMD, Nvidia and Intel are all addressing the same challenges.
(�́L��`��)�@�݂�� ����Ȃ����`
http://pc.watch.impress.co.jp/docs/2006/0821/kaigai296.htm
���@Tejas�̃_�C��Prescott(112����mm)��2�{�߂��T�C�Y��213����mm�ɂȂ�\�肾�����B�i���j
���@�����Core Microarchitecture�ł́A�A�[�L�e�N�`�����V�ł��Ȃ�̊g�����s�Ȃ��Ă���B
���@�������AAMD�Ɠ��l�ɁACPU�R�A��{�X�Ƀ��b�`�ɂ���Ƃ����y�[�X�ł͂Ȃ��B
���@CPU�̃_�C��143����mm�ƁAIntel�̐V�}�C�N���A�[�L�e�N�`��CPU�Ƃ��Ă͍ŏ��ŁA�g�����W�X�^����2��9,100��(291M)�B
Exploring AMD�fs And Intel�fs Architectural Philosophies ? What Does The Future Hold ? (Part II)
http://wccftech.com/article/exploring-amds-intels-architectural-philosophies-future-hold-part-ii/
���@Once you examine all the major players carefully, a crystal-clear image of the entire industry moving towards heterogeneous computing appears.
���@AMD, Nvidia and Intel are all addressing the same challenges.
(�́L��`��)�@�݂�� ����Ȃ����`
http://www.tomshardware.com/news/intel-core-m-broadwell-benchmarks,27656.html
http://media.bestofmicro.com/Z/N/453587/gallery/3DMark_w_600.png
http://media.bestofmicro.com/Z/O/453588/gallery/SunSpider_w_600.png
http://media.bestofmicro.com/Z/P/453589/gallery/Cinebench_w_600.png
((((�G߄D�)))))))
http://media.bestofmicro.com/Z/N/453587/gallery/3DMark_w_600.png
{kind=link}
http://media.bestofmicro.com/Z/O/453588/gallery/SunSpider_w_600.png
{kind=link}
http://media.bestofmicro.com/Z/P/453589/gallery/Cinebench_w_600.png
{kind=link}
((((�G߄D�)))))))
�A���z�ꁄ���܁AAPU�A�}���g��GPU�A�Q�[����AMD�͂������D���B
�A���z�ꁄ���̍D���͍��㐔�N�͌p�����邾�낤�B
���ϑz
������
AMD�A�S�]�ƈ���7�����ꎞ���قցB
2014�N��4�l�����i10�`12�����j�̔��㍂�͂����13���������錩���݁B
http://eetimes.jp/ee/articles/1410/22/news055.html
>> �����13���������錩���݂��Ƃ���
>> 13���������錩����
>> 13������
�A���z�ꁄ���̍D���͍��㐔�N�͌p�����邾�낤�B
���ϑz
������
AMD�A�S�]�ƈ���7�����ꎞ���قցB
2014�N��4�l�����i10�`12�����j�̔��㍂�͂����13���������錩���݁B
http://eetimes.jp/ee/articles/1410/22/news055.html
>> �����13���������錩���݂��Ƃ���
>> 13���������錩����
>> 13������
������Ȃ��Ƃ����ł��������[�J�[�́A���R�����Ԃ��������s�ׂ��L������邱�ƂɂȂ�B�����^�Ђ�
�u���AMD���i��g�ݍ��݂Ɏg��Ȃ��v�ƒf�����Ă���B
ttp://ascii.jp/elem/000/000/642/642559/index-3.html
���ڋq���炷��u�܂�AMD�����₪�������v�Ƃ����b�ɂȂ�B
����ɂ��x���_�[�̑唼�Ɍ����邱�ƂɂȂ��Ă��܂����B
ttp://ascii.jp/elem/000/000/648/648702/index-4.html
�u���AMD���i��g�ݍ��݂Ɏg��Ȃ��v�ƒf�����Ă���B
ttp://ascii.jp/elem/000/000/642/642559/index-3.html
���ڋq���炷��u�܂�AMD�����₪�������v�Ƃ����b�ɂȂ�B
����ɂ��x���_�[�̑唼�Ɍ����邱�ƂɂȂ��Ă��܂����B
ttp://ascii.jp/elem/000/000/648/648702/index-4.html
Llano�o��̋łɂ�
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�ɂĉߋ��u�Œ�v���L�^�I�i�j
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�ɂĉߋ��u�Œ�v���L�^�I�i�j
��AMD���i�̌��ד������x�v���܂Ƃ�
�E�v�����s���m�ŋ����Ă�����Ԃ��炩�����ꂽ30�x�ȏ�Ⴂ�l�ƂȂ�הM�\���ɂȂ�₷���B
�E���x�v���������̂ЂƂ��������׃R�A���̉��x���܂��������炸�M�������F���B
�EAMD��CPU(x2/x3/x4/x6/4m8t)�̑S�Ăɖ�肪�L��B
�E��������u���y�����A����28�x�ŃR�A���x13.4�x�� �����ȉ��̒ቷ�������I
�E���x���\�t�g���N���������0����
�E����1�R�A�ɃX���b�h�w�肵�ĕ��ׂ����Ă�1�ӏ������v���ł��Ȃ��̂őS�R�A���������x������(���ԍ��Ŋ��U�肵�ĕ����Ɍ��������Ă邾����) ��new
(�@߄t�)
�E�v�����s���m�ŋ����Ă�����Ԃ��炩�����ꂽ30�x�ȏ�Ⴂ�l�ƂȂ�הM�\���ɂȂ�₷���B
�E���x�v���������̂ЂƂ��������׃R�A���̉��x���܂��������炸�M�������F���B
�EAMD��CPU(x2/x3/x4/x6/4m8t)�̑S�Ăɖ�肪�L��B
�E��������u���y�����A����28�x�ŃR�A���x13.4�x�� �����ȉ��̒ቷ�������I
�E���x���\�t�g���N���������0����
�E����1�R�A�ɃX���b�h�w�肵�ĕ��ׂ����Ă�1�ӏ������v���ł��Ȃ��̂őS�R�A���������x������(���ԍ��Ŋ��U�肵�ĕ����Ɍ��������Ă邾����) ��new
(�@߄t�)
Core is Back 2014!�Ɋ���
ttp://pc.watch.impress.co.jp/docs/topic/feature/20140808_660002.html
> 3�`4�N�O�̓��Ђ̍���GPU�V�F�A��5���߂������B�������ABCN�̃f�[�^�ɂ��ƁA
> ���݂ł�2������x�ɂ܂ʼn������Ă���Ƃ����B
(�@߄t�)
> 3�`4�N�O�̓��Ђ̍���GPU�V�F�A��5���߂������B�������ABCN�̃f�[�^�ɂ��ƁA
> ���݂ł�2������x�ɂ܂ʼn������Ă���Ƃ����B
(�@߄t�)
�uCatalyst 14.11.2 Beta�v�o��B���x�́uDragon Age�FInquisition�v�ƁuFar Cry 4�v�ւ̍œK����
http://www.4gamer.net/games/022/G002212/20141118106/
http://www.4gamer.net/games/022/G002212/20141118106/
�Ȃ��Ő��\�͎��s�p�C�v�Ɉˑ�����݂���������i���s�p�C�v���X���b�h������2�{��Bull��Bob��IPC���قړ����j
��������s�p�C�v��3�{��4�{���炢�ɑ��₷������Intel�ƌ݊p�ł�肠�����
��������s�p�C�v��3�{��4�{���炢�ɑ��₷������Intel�ƌ݊p�ł�肠�����
�����ȒP�ɑ��₹��Ȃ�Ƃ����ɂ���Ă�
�ȒP�ł���
zen�ł̓N���X�^�[�h�E�A�[�L�e�N�`�����~�߂邵
zen�ł̓N���X�^�[�h�E�A�[�L�e�N�`�����~�߂邵
���s�p�C�v���C���𑝂₵�������ł͐��\�͏オ��Ȃ����B
�C���e���Ɠ���4�{�ɑ��₵������2�{�̍���1.4�{�ɂȂ�̂������������ˁB
�C���e���Ɠ���4�{�ɑ��₵������2�{�̍���1.4�{�ɂȂ�̂������������ˁB
>>173
����͓��R�����ǁAbob�n��胊�b�`�ȋ@�\��ς�ł���̂�bob��IPC�Ɠ����x�B
�܂���s�p�C�v���������������Ă�ƍl�����ق������R����Ȃ��H
�ꉞi5/i7�R��FX�Ȃ���{�����͂Ȃ���
����͓��R�����ǁAbob�n��胊�b�`�ȋ@�\��ς�ł���̂�bob��IPC�Ɠ����x�B
�܂���s�p�C�v���������������Ă�ƍl�����ق������R����Ȃ��H
�ꉞi5/i7�R��FX�Ȃ���{�����͂Ȃ���
�Ƃ������A�X�P�W���[���Ƃ�����\���̖��Ȃ�3�p�C�v�܂ł͋�Stars�n�̎��ɂ���Ă�B
���j�A��3�p�C�v��1.5�{�Ƃ��͂Ȃ�Ȃ����낤���ǁA�ǂ݂̂�����Bobcat�n�͓��ł��B
���j�A��3�p�C�v��1.5�{�Ƃ��͂Ȃ�Ȃ����낤���ǁA�ǂ݂̂�����Bobcat�n�͓��ł��B
��O�ō����x64�̖��߃f�R�[�h���l�b�N�ɂȂ��Č�i�����b�`�ɂ��Ă����\���o�Ȃ��Ƃ����̂����낤�B
Intel�̓f�R�[�h�������߂��g���[�X�L���b�V���ɓ���đĂ��邯�ǃg�����W�X�^�����������Ȃ邩��AMD�Ƃ��Ă͂�肽���Ȃ��B
ILP���オ�ǂɂԂ��������Ă��邩�炱���}���`�R�A����Ƀw�e���W�j�A�X�}���`�R�A�Ƃ��Ă�APU������Ă���̂��������N�Ȃ̂����A������g�����Ȃ����߂̃\�t�g�E�F�A�J�����ł��Ȃ��ĕ�̎�������Ƃ��������ݔ\�͂��ł��Ȃ���Ԃ������Ă���B
Intel��Atom��Xeon phi�ł���Ă邱�Ƃ͓����������v�x�O���ŏ������邵���Ȃ����ɐ��ʂ��o���Ȃ�����Core MA����͂̏�Ԃ��甲���o���Ȃ��B
Intel�̓f�R�[�h�������߂��g���[�X�L���b�V���ɓ���đĂ��邯�ǃg�����W�X�^�����������Ȃ邩��AMD�Ƃ��Ă͂�肽���Ȃ��B
ILP���オ�ǂɂԂ��������Ă��邩�炱���}���`�R�A����Ƀw�e���W�j�A�X�}���`�R�A�Ƃ��Ă�APU������Ă���̂��������N�Ȃ̂����A������g�����Ȃ����߂̃\�t�g�E�F�A�J�����ł��Ȃ��ĕ�̎�������Ƃ��������ݔ\�͂��ł��Ȃ���Ԃ������Ă���B
Intel��Atom��Xeon phi�ł���Ă邱�Ƃ͓����������v�x�O���ŏ������邵���Ȃ����ɐ��ʂ��o���Ȃ�����Core MA����͂̏�Ԃ��甲���o���Ȃ��B
>>175
��10�̂Ƃ��͕��URS��Bull�͓���RS�炵���B
������Bull��AGU�������Ă��p�t�H�[�}���X�͉������ĂȂ������E�E���Đ���オ�����������������ǂȁB
��10�̂Ƃ��͕��URS��Bull�͓���RS�炵���B
������Bull��AGU�������Ă��p�t�H�[�}���X�͉������ĂȂ������E�E���Đ���オ�����������������ǂȁB
Fluid Motion Video�ɕK�v�ȃX�y�b�N�������������悤�B
���@GPU�R�A��6GPU�ȏ������APU
���@260�285�290�Ԃ�RADEON
�^��l�Ԃ̖��H�uFluid Motion Video�̗ǂ���PowerDVD�̓�����m�낤�v
http://blog.goo.ne.jp/krmmk3/e/991996a3bb4b8d87013888bbd1119051
���@GPU�R�A��6GPU�ȏ������APU
���@260�285�290�Ԃ�RADEON
�^��l�Ԃ̖��H�uFluid Motion Video�̗ǂ���PowerDVD�̓�����m�낤�v
http://blog.goo.ne.jp/krmmk3/e/991996a3bb4b8d87013888bbd1119051
amazon�ňꕔ�Q�[���̃T���g���������̔�����Ă��B
ICO�Ƃ������_�̋����Ƃ���390�~����B
�É�Athlon�Ŋ��\���ׂ�
ICO�Ƃ������_�̋����Ƃ���390�~����B
�É�Athlon�Ŋ��\���ׂ�
AMD�́ASeattle��SeaMicro�̃g�[���X�l�b�g�C���^�[�t�F�C�X�uFreedom Fabric�v������\�肾�������A����ɂ��Ă͌��y����Ȃ������B
Freedom Fabric�͊J���̒x�ꂪ�\����Ă������A���ꂪ�����ꂽ�`���B
http://pc.watch.impress.co.jp/docs/column/kaigai/20140819_662558.html
AMD�������ƂȂɂ������S�Ă��_���ɂȂ�_(^o^)�^
Freedom Fabric�͊J���̒x�ꂪ�\����Ă������A���ꂪ�����ꂽ�`���B
http://pc.watch.impress.co.jp/docs/column/kaigai/20140819_662558.html
AMD�������ƂȂɂ������S�Ă��_���ɂȂ�_(^o^)�^
���̖��́uCatalyst Omega�v�BAMD�CCatalyst�̑�K�̓A�b�v�f�[�g�\ http://www.4gamer.net/games/022/G002212/20141208082/
417 ���O�FSocket774[sage] ���e���F2014/12/09(��) 13:24:04.66 ID:kdSRXge1
�}�C�N���\�t�g�͂ǂ������Bing��FPGA�Ŏ���������
ttp://qiita.com/kazunori279/items/6f517648e8a408254a50
�}�C�N���\�t�g�͂ǂ������Bing��FPGA�Ŏ���������
ttp://qiita.com/kazunori279/items/6f517648e8a408254a50
��
���̃X���ɃR�s�y���Ă��ꂽ��
���肪�Ƃ��I
���̃X���ɃR�s�y���Ă��ꂽ��
���肪�Ƃ��I
Kaveri�ɂ����铮��Đ��̉掿���P���ʂ�������@�`GPU�ɂ���ĉ掿���قȂ�̂�
http://pc.watch.impress.co.jp/docs/topic/review/20140318_640038.html
A10-5800K�ł̓���Đ��iVECC�ݒ蓙�j
ttp://blog.livedoor.jp/korishu210/archives/19461735.html
http://pc.watch.impress.co.jp/docs/topic/review/20140318_640038.html
A10-5800K�ł̓���Đ��iVECC�ݒ蓙�j
ttp://blog.livedoor.jp/korishu210/archives/19461735.html
Intel��TSMC/Samsung��3D�g�����W�X�^�Ō���
http://pc.watch.impress.co.jp/docs/column/kaigai/20140903_664921.html
2015�N�̃��o�C��SoC��GPU��i��������t�@�E���_����FinFET�v���Z�X
http://pc.watch.impress.co.jp/docs/column/kaigai/20141014_671062.html
GPU�A�[�L�e�N�`���ɂ��e�����y�ڂ��v���Z�X�Z�p�̖��
http://pc.watch.impress.co.jp/docs/column/kaigai/20140924_667985.html
3D�g�����W�X�^��16/14nm�v���Z�X�ւƐ����ł�2015�N�̃`�b�v
http://pc.watch.impress.co.jp/docs/column/kaigai/20141010_670675.html
2014�N�Ō�̕ێ�B
���̃X�s�[�h�ōs����2016�N��zen�܂ł����������B
http://pc.watch.impress.co.jp/docs/column/kaigai/20140903_664921.html
2015�N�̃��o�C��SoC��GPU��i��������t�@�E���_����FinFET�v���Z�X
http://pc.watch.impress.co.jp/docs/column/kaigai/20141014_671062.html
GPU�A�[�L�e�N�`���ɂ��e�����y�ڂ��v���Z�X�Z�p�̖��
http://pc.watch.impress.co.jp/docs/column/kaigai/20140924_667985.html
3D�g�����W�X�^��16/14nm�v���Z�X�ւƐ����ł�2015�N�̃`�b�v
http://pc.watch.impress.co.jp/docs/column/kaigai/20141010_670675.html
2014�N�Ō�̕ێ�B
���̃X�s�[�h�ōs����2016�N��zen�܂ł����������B
20nm�v���Z�X���������2015�N��APU�\�gNolan�h
2014/05/20(Tue)
http://northwood.blog60.fc2.com/blog-entry-7541.html
AMD��2015�N�Ɍ����č����\x86 CPU�̐V�A�[�L�e�N�`�����J�����炵��
2014/05/13(Tue)
http://northwood.blog60.fc2.com/blog-entry-7531.html
K12��2016�N��1�l�����Ƀ����[�X�\��
2014/09/08(Mon)
http://northwood.blog60.fc2.com/blog-entry-7747.html
K12 ARM�̑ƂȂ�AMD�̎��̍����\x86�R�A�̃R�[�h�l�[���́gZen�h
2014/09/10(Wed)
http://northwood.blog60.fc2.com/blog-entry-7752.html
20nm�v���Z�X�̍����\x86 APU�͗\�肳��Ă��Ȃ�
2014/09/28(Sun)
http://northwood.blog60.fc2.com/blog-entry-7776.html
�f�X�N�g�b�v�����́gCarrizo�h�̌v��͌����_�ł͑��݂��Ȃ�
2015/01/11(Sun)
http://northwood.blog60.fc2.com/blog-entry-7906.html
�f�X�N�g�b�v�����ɂ́gKaveri Refresh�h���\�肳��Ă���
2015/01/15(Thu)
http://northwood.blog60.fc2.com/blog-entry-7912.html
2016�N�̏�����Zen APU���o�ꂷ��t���O���r���r�������Ă�
2014/05/20(Tue)
http://northwood.blog60.fc2.com/blog-entry-7541.html
AMD��2015�N�Ɍ����č����\x86 CPU�̐V�A�[�L�e�N�`�����J�����炵��
2014/05/13(Tue)
http://northwood.blog60.fc2.com/blog-entry-7531.html
K12��2016�N��1�l�����Ƀ����[�X�\��
2014/09/08(Mon)
http://northwood.blog60.fc2.com/blog-entry-7747.html
K12 ARM�̑ƂȂ�AMD�̎��̍����\x86�R�A�̃R�[�h�l�[���́gZen�h
2014/09/10(Wed)
http://northwood.blog60.fc2.com/blog-entry-7752.html
20nm�v���Z�X�̍����\x86 APU�͗\�肳��Ă��Ȃ�
2014/09/28(Sun)
http://northwood.blog60.fc2.com/blog-entry-7776.html
�f�X�N�g�b�v�����́gCarrizo�h�̌v��͌����_�ł͑��݂��Ȃ�
2015/01/11(Sun)
http://northwood.blog60.fc2.com/blog-entry-7906.html
�f�X�N�g�b�v�����ɂ́gKaveri Refresh�h���\�肳��Ă���
2015/01/15(Thu)
http://northwood.blog60.fc2.com/blog-entry-7912.html
2016�N�̏�����Zen APU���o�ꂷ��t���O���r���r�������Ă�
�� 2014�N �����̔��ド���L���O
http://eetimes.jp/ee/articles/1412/25/news147.html
AMD�̏��ʂ��}�~���ЂƂ蕉���_(^o^)�^
http://eetimes.jp/ee/articles/1412/25/news147.html
AMD�̏��ʂ��}�~���ЂƂ蕉���_(^o^)�^
188 �FSocket774�F2015/01/21(��) 15:24:06.33 ID:M8iJJHNs
2000�N �f���A���R�APOWER4
��
2005�N�̓f���A���R�A���N�I���E���f���A���R�AAthlon64 X2�I
2003�N �N�A�b�h�R�APOWER5�A1�R�A2�X���b�hSMT
��
2007�N�A���ɃN�A�b�h�R�ACPU���o��IPhenom X4�I
2010�N2�� TurboCore���[�h�������POWER7�A1�R�A������4�X���b�hSMT
��
���N Turbo CORE��������Phenom II X6
2007�N �I�[�o�[5GHz POWER6
��
2013�N ���E����5GHz�AFX-9590�I(�{����4.7GHz)
2014�N 12�R�A96�X���b�hSMT�APOWER8
��
2016�N(AMD����) ���E���ISMT����CPU�I�Ȃ�ƁI1�R�A������2�X���b�h�������Ă��܂��I���ꂩ���SMT�̎���IIntel�����ǂ��Ă��邩�ȁH
��
2005�N�̓f���A���R�A���N�I���E���f���A���R�AAthlon64 X2�I
2003�N �N�A�b�h�R�APOWER5�A1�R�A2�X���b�hSMT
��
2007�N�A���ɃN�A�b�h�R�ACPU���o��IPhenom X4�I
2010�N2�� TurboCore���[�h�������POWER7�A1�R�A������4�X���b�hSMT
��
���N Turbo CORE��������Phenom II X6
2007�N �I�[�o�[5GHz POWER6
��
2013�N ���E����5GHz�AFX-9590�I(�{����4.7GHz)
2014�N 12�R�A96�X���b�hSMT�APOWER8
��
2016�N(AMD����) ���E���ISMT����CPU�I�Ȃ�ƁI1�R�A������2�X���b�h�������Ă��܂��I���ꂩ���SMT�̎���IIntel�����ǂ��Ă��邩�ȁH
�ŐV�̃n�C�p�t�H�[�}���X�`�b�v�̘b�肪�W���uHot Chips 25�v�@Hisa Ando�@ [2013/10/07]
AMD���ǂ����߂鐹�t�uHeterogeneous System Architecture(HSA)�v(1�`5�܂�)
http://news.mynavi.jp/column/hotchips25/018/
AMD���ǂ����߂鐹�t�uHeterogeneous System Architecture(HSA)�v(1�`5�܂�)
http://news.mynavi.jp/column/hotchips25/018/
�l���̓�{�̐Ԏ�����I����Ă��
�Ȃɂ���|��
696 ���O�FSocket774[sage] ���e���F2015/01/27(��) 13:44:26.93 ID:75FTvt3a
�V�����A�[�L��Zen��Q3 2016�ɂł���Ă��B
ttp://wccftech.com/amd-zen-featured-summit-ridge-family-14nm-processors-rumored-feature-fm3-socket-support-ddr4-memory-compatiblity/
�V�����A�[�L��Zen��Q3 2016�ɂł���Ă��B
ttp://wccftech.com/amd-zen-featured-summit-ridge-family-14nm-processors-rumored-feature-fm3-socket-support-ddr4-memory-compatiblity/
>>193
�Ȃ�Ō������̃X���łقڃX���[�Ȃ̂��^�₾�ȁB
8�R�A�ȏ�Ƃ̎������ABroadwell���f�X�N�g�b�v����8�R�A���o�Ă���̂�
���̋L�������ł͂܂��ǂ̒��x�̃��b�`�R�A�Ȃ̂��悭�킩���ȁB
�Ȃ�Ō������̃X���łقڃX���[�Ȃ̂��^�₾�ȁB
8�R�A�ȏ�Ƃ̎������ABroadwell���f�X�N�g�b�v����8�R�A���o�Ă���̂�
���̋L�������ł͂܂��ǂ̒��x�̃��b�`�R�A�Ȃ̂��悭�킩���ȁB
AMD�p��i�j���ƍ���APU�i�j�ł�12�R�A�ł����Ă�i�j
>>AMD�́AKaveri���g12�R���s���[�g�R�A�hAPU�Ə̂���B�i�j
>>����́ACPU�R�A4�ƁA�ėp���Z�ɗp����GPU�N���X�^8��̍��v12�̉��Z�R�A��L���Ă��邱�Ƃ������i�j
http://www.itmedia.co.jp/pcuser/spv/1401/14/news164.html
>>AMD�́AKaveri���g12�R���s���[�g�R�A�hAPU�Ə̂���B�i�j
>>����́ACPU�R�A4�ƁA�ėp���Z�ɗp����GPU�N���X�^8��̍��v12�̉��Z�R�A��L���Ă��邱�Ƃ������i�j
http://www.itmedia.co.jp/pcuser/spv/1401/14/news164.html
>>194
�����B
�܂��ڕ���Ă킯����Ȃ����琷��オ��Ȃ��͎̂d���Ȃ����ǃX���[�Ȃ�ˁB
CPU�Ɋւ��đË����ĂȂ�Intel�ł������ȏ�Ԃ�����ǂ��t���͓̂���Ȃ��͂��B
http://anago.2ch.net/test/read.cgi/jisaku/1421580486/22
����ɍ���APU�ł����l��{�i���z4M�j�ɂ����猋�\�����������Ă邩��A
�܂��Ƃ��ȁi���ʂ́jCPU�̕����Ŋ撣��ΑΓ��ɐ킦��Ǝv���B
Intel��16�R�ACPU��i7�Ŕ���悤�Ȃ��Ƃ����Ȃ���E�E
�����B
�܂��ڕ���Ă킯����Ȃ����琷��オ��Ȃ��͎̂d���Ȃ����ǃX���[�Ȃ�ˁB
CPU�Ɋւ��đË����ĂȂ�Intel�ł������ȏ�Ԃ�����ǂ��t���͓̂���Ȃ��͂��B
http://anago.2ch.net/test/read.cgi/jisaku/1421580486/22
����ɍ���APU�ł����l��{�i���z4M�j�ɂ����猋�\�����������Ă邩��A
�܂��Ƃ��ȁi���ʂ́jCPU�̕����Ŋ撣��ΑΓ��ɐ킦��Ǝv���B
Intel��16�R�ACPU��i7�Ŕ���悤�Ȃ��Ƃ����Ȃ���E�E
>>196
���̃_�C��2�R�A������ł���B8�R�A�ł�GPU�Ȃ��_�C���g������Ă���B
�ނ���Zen�ƃ��f�ł���Intel�Ɠ����悤�ȍ\�������̂�AMD�̍őO���
Haswell���̍�IPC�u���ɂ���ׂ������A�L�n���ǂƂ�������܂��������B
���̃_�C��2�R�A������ł���B8�R�A�ł�GPU�Ȃ��_�C���g������Ă���B
�ނ���Zen�ƃ��f�ł���Intel�Ɠ����悤�ȍ\�������̂�AMD�̍őO���
Haswell���̍�IPC�u���ɂ���ׂ������A�L�n���ǂƂ�������܂��������B
�����㐘�u�Q�[���@�̋Z�p�f�������˂����Ȃ�L�n���ǂ͐��������
�������Ă�4�R�A�ȏ�̃_�C�ʐ^���o�Ă��Ȃ��������B
�ł�6���ȏ�GPU�Ɋ���U��Ȃ��Ⴂ���Ȃ��̂́A�m����APU�̃A�L���X�F���ˁi8�R�A�ڂ���Ƃ�����j�B
�����Ƃ�x265�Ɋւ��Ă͍��̃t��4M�ł��ӊO�ƑR�ł��Ă邩��A�M�ȊO�͐S�z���ĂȂ������肷��B
��������14nm�ł�2�R�ASMT�{GPU��������ς����Ȃ����ǁB
�ł�6���ȏ�GPU�Ɋ���U��Ȃ��Ⴂ���Ȃ��̂́A�m����APU�̃A�L���X�F���ˁi8�R�A�ڂ���Ƃ�����j�B
�����Ƃ�x265�Ɋւ��Ă͍��̃t��4M�ł��ӊO�ƑR�ł��Ă邩��A�M�ȊO�͐S�z���ĂȂ������肷��B
��������14nm�ł�2�R�ASMT�{GPU��������ς����Ȃ����ǁB
>>198
�ނ���^��Ȃ��A�Ȃ�ŃQ�[����8�R�A8�X�����g�����Ă�̂��B
���\���o�����߂�8�X���g���悤�Ƀv���O���~���O���Ă���Ƃ������Ȃ�A
�t��SMT�Ή��ɍœK�����Ă������b�`�R�A�H���ł����\���o��������B
�t�ɃX���b�h��������Α����قǂ����Ȃ�L�n�p�����������Ƃ��Ȃ肻�������B
�ނ���^��Ȃ��A�Ȃ�ŃQ�[����8�R�A8�X�����g�����Ă�̂��B
���\���o�����߂�8�X���g���悤�Ƀv���O���~���O���Ă���Ƃ������Ȃ�A
�t��SMT�Ή��ɍœK�����Ă������b�`�R�A�H���ł����\���o��������B
�t�ɃX���b�h��������Α����قǂ����Ȃ�L�n�p�����������Ƃ��Ȃ肻�������B
202 �F,,�E�L�́M�E,,�j��-�������F2015/01/27(��) 21:52:38.21 ID:bt23XFwe
Broadwell�͍ŏ��̐��i��Core M������ł���
4�R�A�͌ォ��o���
4�R�A�͌ォ��o���
>>200
���u�̓C���X�g�[���x�[�X�̑����ƃt���b�g�ȃn�[�h�E�F�A�\���ł���Ƃ�������
�\�t�g��CPU���ǂꂾ���g���Ă��R�A���ۋ��͂Ȃ����ăg�R���ł��傤��
PC�Q�[���͂Ă�Ńo���o���̃n�[�h�E�F�A�\���ƃh���C�o��OS�Ƀ������T�C�Y��
�قƂ�NJC���łƂ������`���N�`���ł���
���u�̓C���X�g�[���x�[�X�̑����ƃt���b�g�ȃn�[�h�E�F�A�\���ł���Ƃ�������
�\�t�g��CPU���ǂꂾ���g���Ă��R�A���ۋ��͂Ȃ����ăg�R���ł��傤��
PC�Q�[���͂Ă�Ńo���o���̃n�[�h�E�F�A�\���ƃh���C�o��OS�Ƀ������T�C�Y��
�قƂ�NJC���łƂ������`���N�`���ł���
204 �F,,�E�L�́M�E,,�j��-�������F2015/01/27(��) 21:59:51.01 ID:bt23XFwe
�Q�[���\�t�g�ŃR�A���ۋ�����Ă�^�C�g���Ȃ�ĂȂ�����
�܂���SQLServer��Oracle���Q�[���^�C�g�����Ǝv���Ă����H
�܂���SQLServer��Oracle���Q�[���^�C�g�����Ǝv���Ă����H
�R�C�c�͖{���ɓ�������
���R�A�g���Ă��ۋ��͂Ȃ�����\�t�g�Ń}�V���̍ő含�\�������o�����Ƃ���C���Z���e�B�u���������ď�������
�������������������Ȃ����炠����������
���R�A�g���Ă��ۋ��͂Ȃ�����\�t�g�Ń}�V���̍ő含�\�������o�����Ƃ���C���Z���e�B�u���������ď�������
�������������������Ȃ����炠����������
AMD Zen forst ut i Summit Ridge for 14 nanometer
http://www.sweclockers.com/nyhet/19954-amd-zen-forst-ut-i-summit-ridge-for-14-nanometer
http://www.sweclockers.com/nyhet/19954-amd-zen-forst-ut-i-summit-ridge-for-14-nanometer
207 �F,,�E�L�́M�E,,�j��-�������F2015/01/27(��) 22:09:32.53 ID:bt23XFwe
> ���R�A�g���Ă��ۋ��͂Ȃ�����
�������ˌN
�t��PC�Q�[���ɂ̓R�A�ۋ�������Ƃł��v���Ă�́H
�ȂɁH�g���R�A���ɂ����Microsoft���璥�����ꂿ�Ⴄ�́H�Ȃɂ���|��
�������ˌN
�t��PC�Q�[���ɂ̓R�A�ۋ�������Ƃł��v���Ă�́H
�ȂɁH�g���R�A���ɂ����Microsoft���璥�����ꂿ�Ⴄ�́H�Ȃɂ���|��
�R�e�n���C���̃U�R������������ł���˂�
�����H�Q�[���̊J����Ђ͓X�q�܂肠��Ӗ��Q�[����ЂɂƂ��Ă��q����Ȃ�
���̘A���ɂƂ��Ă̓Q�[���@�̐��\���ǂꂾ���g���|������
�Ȃ��̃��C�����e�B�̏�悹�͂Ȃ���
�����炠����͉̂����������ׂĎg���܂��傤�Ƃ������ƂɂȂ�
8�R�A�ɍœK������̂͂��������_��
PC�ƊE��GPGPU�ɑΉ������A�v���̎��ǂ��̂���������
CPU�R�A���ɂ��p�ۋ���������Ă悢���\�̃A�v���������ɓ���ł���`�����X������Ƃ������Ƃ�
�ǂ̕���̃\�t�g�ł����̋@����郏�P����˂����ǂ�
�������R�A���낤���C���ł����Ȃ�PC�Q�[��()�Ƀr�W�l�X�`�����X�Ȃ�Ă˂���
�\�t�g��Ђɂ���ŏo���Ă�����Ă邾��
�����H�Q�[���̊J����Ђ͓X�q�܂肠��Ӗ��Q�[����ЂɂƂ��Ă��q����Ȃ�
���̘A���ɂƂ��Ă̓Q�[���@�̐��\���ǂꂾ���g���|������
�Ȃ��̃��C�����e�B�̏�悹�͂Ȃ���
�����炠����͉̂����������ׂĎg���܂��傤�Ƃ������ƂɂȂ�
8�R�A�ɍœK������̂͂��������_��
PC�ƊE��GPGPU�ɑΉ������A�v���̎��ǂ��̂���������
CPU�R�A���ɂ��p�ۋ���������Ă悢���\�̃A�v���������ɓ���ł���`�����X������Ƃ������Ƃ�
�ǂ̕���̃\�t�g�ł����̋@����郏�P����˂����ǂ�
�������R�A���낤���C���ł����Ȃ�PC�Q�[��()�Ƀr�W�l�X�`�����X�Ȃ�Ă˂���
�\�t�g��Ђɂ���ŏo���Ă�����Ă邾��
209 �F,,�E�L�́M�E,,�j��-�������F2015/01/27(��) 22:26:00.69 ID:bt23XFwe
PC�Q�[���ɃR�A�ۋ��������ăR���V���[�}�@�ɂ͖������Ă����Ȃ�Ă߂��̌����ʂ肾��
��������Windows�̃Q�[���ɂ̓R�A�ۋ��ǂ��납MS�ւ̃��C�����e�B�̎x�������̂�
���݂��Ȃ��̂����H�iWindows�X�g�A�A�v���������j
�m�������Ԃ�͒p�������܂���
��������Windows�̃Q�[���ɂ̓R�A�ۋ��ǂ��납MS�ւ̃��C�����e�B�̎x�������̂�
���݂��Ȃ��̂����H�iWindows�X�g�A�A�v���������j
�m�������Ԃ�͒p�������܂���
����PC�Q�[��()�ɑS�͓��������\�t�g�n�E�X�͌X���Ă邾��
���������
�ėpPC��̃Q�[���̔ߎS�ȂƂ���͊��낤�������悤�����K�i����Ȃ��Q�[�����������܂�����
���������J�X���d�l�͐��u�ł͈�|����Ă���
���������
�ėpPC��̃Q�[���̔ߎS�ȂƂ���͊��낤�������悤�����K�i����Ȃ��Q�[�����������܂�����
���������J�X���d�l�͐��u�ł͈�|����Ă���
������PC���n�[�h�̃p���[���ւ����Ƃ���ŗV�т����Q�[�����Ȃ���ΈӖ����Ȃ�
���ꂷ�烀�[�A�̖@���̍s���l�܂�ňÉ_�Y������������
���ꂷ�烀�[�A�̖@���̍s���l�܂�ňÉ_�Y������������
��Ȃ̈���PC���[�U�[���������玩�Ǝ����ł͂���
��������PC�Q�[�}�[�̑����͊Q�l������
LoL�݂����ɃC�x���g��X�|���T�[�h�Ŗׂ��������ˁH
���{�݂����Ɉ����������ăV�R�V�R�ƃQ�[�������L�����^���肾�Ɩ]�ݔ�������
��������PC�Q�[�}�[�̑����͊Q�l������
LoL�݂����ɃC�x���g��X�|���T�[�h�Ŗׂ��������ˁH
���{�݂����Ɉ����������ăV�R�V�R�ƃQ�[�������L�����^���肾�Ɩ]�ݔ�������
214 �F,,�E�L�́M�E,,�j��-�������F2015/01/27(��) 22:41:42.96 ID:bt23XFwe
���������X�[�p�[�o�C�U��1�R�A�\�Ă�͂��Ȃ̂ɂǂ�����8�R�A�S���g�����ł����H
�m���悻��Ȃ���
����PC�ł͔Ⴂ����
����PC�ł͔Ⴂ����
216 �F,,�E�L�́M�E,,�j��-�������F2015/01/27(��) 22:44:51.68 ID:bt23XFwe
8�R�A�S�����Ă̂����O�̖ϑz������
�u���[�U�[�����h�Ŏg����R�A�S���v�Ȃ琳��
�u���[�U�[�����h�Ŏg����R�A�S���v�Ȃ琳��
14.�ׂ��������̃~�X���w�E������m�ƔF��������
���ꂩ
�܂��Q�X�R�e�̂��O�炵�����_����
���ꂩ
�܂��Q�X�R�e�̂��O�炵�����_����
218 �F,,�E�L�́M�E,,�j��-�������F2015/01/27(��) 22:57:56.72 ID:bt23XFwe
��{�����̃I�����C���Q�[���E�u���E�U�Q�[���͂ق�PC��p�ł���
Steam�ł�Workshop�Ń��[�U�[��MOD�����L���镶��������Ă��܂���
�C���f�B�[�Y�^�C�g�����������邵�A����̓R���V���[�}�@�ł͌����Ȃ����ہB
Steam�ł�Workshop�Ń��[�U�[��MOD�����L���镶��������Ă��܂���
�C���f�B�[�Y�^�C�g�����������邵�A����̓R���V���[�}�@�ł͌����Ȃ����ہB
>>200
SMT��SMT�ŃX���b�h�̊Ǘ���SMT�Ȃ�����ς炵������
���ꂽ�v�����ł�steamroller���l���Ă��炵��������ɂ������͂Ȃ��Ǝv���B
�Q�[���E�\�t�g�J�����́u�Q�[���@�v������K���ɍœK����i�߂邾������Ȃ��낤��
�ŁA�œK������Ȃ烊�b�`�ȃR�A�̂ق����悳���������ǁB
SMT��SMT�ŃX���b�h�̊Ǘ���SMT�Ȃ�����ς炵������
���ꂽ�v�����ł�steamroller���l���Ă��炵��������ɂ������͂Ȃ��Ǝv���B
�Q�[���E�\�t�g�J�����́u�Q�[���@�v������K���ɍœK����i�߂邾������Ȃ��낤��
�ŁA�œK������Ȃ烊�b�`�ȃR�A�̂ق����悳���������ǁB
�l�g�Q�Ŏ��S�͊؍����N���j�_
�܊p�p�`���R�������ł���PC�Q�[�Ȃ̂Ƀu���Q�Ȃ�APU�ł��\���Ȑ��\�����v������˂��̂ɂ�
�܊p�p�`���R�������ł���PC�Q�[�Ȃ̂Ƀu���Q�Ȃ�APU�ł��\���Ȑ��\�����v������˂��̂ɂ�
221 �F,,�E�L�́M�E,,�j��-�������F2015/01/27(��) 23:24:39.46 ID:bt23XFwe
�O���{������i3�m�[�g�ŗ]�T�ł�
>>210
steam�m��Ȃ��̂����O
��قǐ̂̃Q�[���Ȃ�Ƃ������Asteam�Q�[�͔F���Ȃ��Əo���Ȃ����A�o�����Ƃ��Ă��ꂽ��A�J�E���gBAN����邼
steam�m��Ȃ��̂����O
��قǐ̂̃Q�[���Ȃ�Ƃ������Asteam�Q�[�͔F���Ȃ��Əo���Ȃ����A�o�����Ƃ��Ă��ꂽ��A�J�E���gBAN����邼
�O���t�Ō���AMD CPU�A�[�L�e�N�`���[�ƃv���Z�X�̐i��
http://ascii.jp/elem/000/000/712/712692/
AMD�T�[�o�[���i�̊���ɕ���Bulldozer�̐^�� �O��
http://ascii.jp/elem/000/000/655/655539/
AMD�T�[�o�[���i�̊���ɕ���Bulldozer�̐^�� ���
http://ascii.jp/elem/000/000/656/656905/
http://ascii.jp/elem/000/000/712/712692/
AMD�T�[�o�[���i�̊���ɕ���Bulldozer�̐^�� �O��
http://ascii.jp/elem/000/000/655/655539/
AMD�T�[�o�[���i�̊���ɕ���Bulldozer�̐^�� ���
http://ascii.jp/elem/000/000/656/656905/
Llano�o��̋łɂ�
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
�� 2014�N �����̔��ド���L���O
http://eetimes.jp/ee/articles/1412/25/news147.html
��AMD�A2014�N�x��4���h���̐Ԏ�
http://pc.watch.impress.co.jp/docs/news/20150121_684660.html
AMD�̏��ʂ������}�~���ЂƂ蕉���_(^o^)�^
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
�� 2014�N �����̔��ド���L���O
http://eetimes.jp/ee/articles/1412/25/news147.html
��AMD�A2014�N�x��4���h���̐Ԏ�
http://pc.watch.impress.co.jp/docs/news/20150121_684660.html
AMD�̏��ʂ������}�~���ЂƂ蕉���_(^o^)�^
4 ���O�FSocket774[sage] ���e���F2015/01/25(��) 11:31:39.26 ID:icMDcGNq
http://anago.2ch.net/test/read.cgi/jisaku/1419807194/290
�F�F�F
�y2013�z H.265/HEVC �y7680x4320�z
http://toro.2ch.net/test/read.cgi/avi/1317066231/
185 ���O�F���������ҏW��[] ���e���F2012/06/27(��) 18:04:30.54 ID:oc8wehwn
���k���́uH.264�v��2�{�A�������ׂ�X�}�z������@���戳�k�Z�p�̎����㍑�ەW���uHEVC�v
��� �P�F ���\�j�[ �V�X�e�����\�t�g�E�F�A�e�N�m���W�[�v���b�g�t�H�[�� ���ʗv�f�Z�p���� �M�������Z�p1�� ��C�Z�t
http://techon.nikkeibp.co.jp/article/HONSHI/20120412/212513/
http://techon.nikkeibp.co.jp/article/NED/20120409/211909/
189 ���O�F���������ҏW��[sage] ���e���F2012/06/28(��) 00:20:19.54 ID:0L60umA2
�ǂ��Ljꕔ�v���
AVC�͍�����P�O�N�ȏ�O�Ɏd�l��N����W�������ꂽ���̂ŃG���R�[�h�Ɏg�����Z���u���V���O���R�A�Ői�����Ă����A
�N���b�N�����E���ɏオ���Ă������̂Ƒz�肵�ē���G���R�[�h���@���̗p���ĕW�������ꂽ�Ƃ�
HEVC�͊����Z�p�ɖ��@�̂悤�ȐV�Z�p�������Č��I�Ȉ��k��������͂���̂ł͂Ȃ�
�����Z�p�����嗬�̃}���`�R�ACPU�AGPU�A�����ւ̍œK���Ə����̊ȗ����A���̂P�O�N�ł̉��P���͂���݂���
�Ō�̃G���g���s�[��������CAVLC�͔p�~�A�i������CABAC�ֈ�{��
���̑��V�Z�p���������
�F�F�F
���ۂ�GPGPU�ł��̂ɂłł��邩�͕�����Ȃ����A������̕����i��ł�킯����Ȃ��B
�`�R�s�y�����܂Ł`
�̐S�̋L����ǂ�łȂ��������Ă������B
http://anago.2ch.net/test/read.cgi/jisaku/1419807194/290
�F�F�F
�y2013�z H.265/HEVC �y7680x4320�z
http://toro.2ch.net/test/read.cgi/avi/1317066231/
185 ���O�F���������ҏW��[] ���e���F2012/06/27(��) 18:04:30.54 ID:oc8wehwn
���k���́uH.264�v��2�{�A�������ׂ�X�}�z������@���戳�k�Z�p�̎����㍑�ەW���uHEVC�v
��� �P�F ���\�j�[ �V�X�e�����\�t�g�E�F�A�e�N�m���W�[�v���b�g�t�H�[�� ���ʗv�f�Z�p���� �M�������Z�p1�� ��C�Z�t
http://techon.nikkeibp.co.jp/article/HONSHI/20120412/212513/
http://techon.nikkeibp.co.jp/article/NED/20120409/211909/
189 ���O�F���������ҏW��[sage] ���e���F2012/06/28(��) 00:20:19.54 ID:0L60umA2
�ǂ��Ljꕔ�v���
AVC�͍�����P�O�N�ȏ�O�Ɏd�l��N����W�������ꂽ���̂ŃG���R�[�h�Ɏg�����Z���u���V���O���R�A�Ői�����Ă����A
�N���b�N�����E���ɏオ���Ă������̂Ƒz�肵�ē���G���R�[�h���@���̗p���ĕW�������ꂽ�Ƃ�
HEVC�͊����Z�p�ɖ��@�̂悤�ȐV�Z�p�������Č��I�Ȉ��k��������͂���̂ł͂Ȃ�
�����Z�p�����嗬�̃}���`�R�ACPU�AGPU�A�����ւ̍œK���Ə����̊ȗ����A���̂P�O�N�ł̉��P���͂���݂���
�Ō�̃G���g���s�[��������CAVLC�͔p�~�A�i������CABAC�ֈ�{��
���̑��V�Z�p���������
�F�F�F
���ۂ�GPGPU�ł��̂ɂłł��邩�͕�����Ȃ����A������̕����i��ł�킯����Ȃ��B
�`�R�s�y�����܂Ł`
�̐S�̋L����ǂ�łȂ��������Ă������B
�VOpteron�̏����
http://www.geocities.jp/andosprocinfo/wadai15/20150221.htm
2015�N2��20���ɑ��ŊJ�Â��ꂽPC Cluster Consortium�̃��[�N�V���b�v�ɂ�����
�Q�DAMD��HPC������APU�̊J���ɂ��Ĕ��\
�n�C�G���h��GPU���W�ς����C200�`300W�̏���d�͂�HPC������APU���J��
�R�DAMD��32�R�A�C64�X���b�h��ARM��x86�v���Z�T�i������v��
K12�Ɠ������x86�v���Z�T�Ƃ̓s���݊��ƂȂ�Ƃ̂��Ƃł��B�܂��C�����̃v���Z�T��32�R�A���W�ς��C
����܂�AMD�ł͍̗p���Ă��Ȃ������}���`�X���b�h���T�|�[�g����Ƃ̂��ƂŁC64�X���b�h�������s����v���Z�T�ƂȂ�Ƃ̂��Ƃł��B
2�́A����16�R�A32�X���b�h+4096sp�� + HBM 8GB + DDR4 64GB���炢�̐��\
3�́A32�R�A64�X���b�h�̃n�C�G���hCPU��x86��ARM��pin�݊�
�����炪����ɍ~��Ă���\���͔�����
http://www.geocities.jp/andosprocinfo/wadai15/20150221.htm
2015�N2��20���ɑ��ŊJ�Â��ꂽPC Cluster Consortium�̃��[�N�V���b�v�ɂ�����
�Q�DAMD��HPC������APU�̊J���ɂ��Ĕ��\
�n�C�G���h��GPU���W�ς����C200�`300W�̏���d�͂�HPC������APU���J��
�R�DAMD��32�R�A�C64�X���b�h��ARM��x86�v���Z�T�i������v��
K12�Ɠ������x86�v���Z�T�Ƃ̓s���݊��ƂȂ�Ƃ̂��Ƃł��B�܂��C�����̃v���Z�T��32�R�A���W�ς��C
����܂�AMD�ł͍̗p���Ă��Ȃ������}���`�X���b�h���T�|�[�g����Ƃ̂��ƂŁC64�X���b�h�������s����v���Z�T�ƂȂ�Ƃ̂��Ƃł��B
2�́A����16�R�A32�X���b�h+4096sp�� + HBM 8GB + DDR4 64GB���炢�̐��\
3�́A32�R�A64�X���b�h�̃n�C�G���hCPU��x86��ARM��pin�݊�
�����炪����ɍ~��Ă���\���͔�����
��ׂ�
32�R�AOpteron�ƃn�C�G���hAPU�Ȃ�C���e���k�r�����Ɏ��ʂ�
�Y�p�������Ȃ��_���h�i�j
Llano�o��̋łɂ�
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
�� 2014�N �����̔��ド���L���O
http://eetimes.jp/ee/articles/1412/25/news147.html
��AMD�A2014�N�x��4���h���̐Ԏ�
http://pc.watch.impress.co.jp/docs/news/20150121_684660.html
AMD�̏��ʂ������}�~���ЂƂ蕉���_(^o^)�^
Llano�o��̋łɂ�
Trinity�o��̋łɂ�
Richland�o��̋łɂ�
Kaveri�o��̋łɂ�
Carrizo�o��̋łɂ� �� new�I
�������߂Ȍ���
ttp://www.cpubenchmark.net/market_share.html
���҂�2014�N�łȂ�Ɖߋ��Œ���L�^�I�i�j
�� 2014�N �����̔��ド���L���O
http://eetimes.jp/ee/articles/1412/25/news147.html
��AMD�A2014�N�x��4���h���̐Ԏ�
http://pc.watch.impress.co.jp/docs/news/20150121_684660.html
AMD�̏��ʂ������}�~���ЂƂ蕉���_(^o^)�^
Carrizo�̌��I�ȃT�C�Y�̏k�����v�Z�p�ɂ���Ă����炳�ꂽ���̂łȂ��͎̂c�O�B
�f�X�N����Carrizo���Ək�����傫���Ȃ�̂��ȁB
�f�X�N����Carrizo���Ək�����傫���Ȃ�̂��ȁB
������ando����̋L���ɂ��ƁA�d�������������ɃG���[���o�Ȃ��悤�Ɂi�d���Ɂj�]�T�����������Ȃ�
�N���b�N�̂ق���������̂̓f�X�N�����v���Z�X�ł��g�������B
�N���b�N�̂ق���������̂̓f�X�N�����v���Z�X�ł��g�������B