Intelの次世代CPU/SoCについて語ろう 75
1 :Socket774:
Intelの次世代CPUや、それに関連する内容についてのスレッドです
■前スレ
Intelの次世代CPUについて語ろう 74
http://anago.2ch.net/test/read.cgi/jisaku/1396189438/
■前スレ
Intelの次世代CPUについて語ろう 74
http://anago.2ch.net/test/read.cgi/jisaku/1396189438/
|
|
|
2 :Socket774:2014/04/18(金) 00:26:44.44 ID:cW3Icrqu
Intel様だけが人類の未来を切り開ける唯一神
全人類はIntel様の下に平伏しIntel様だけを崇拝し
Intel様に全てを捧げるべきである
Intel様万歳!!!!!
全人類はIntel様の下に平伏しIntel様だけを崇拝し
Intel様に全てを捧げるべきである
Intel様万歳!!!!!
Windows 8.1めっちゃ起動・終了速いし
やはりプログラマを殴れということか
やはりプログラマを殴れということか
内閣府が17日発表した消費動向調査で、3月末のスマートフォンの世帯普及率が54・7%、タブレット端末が20・9%となった。
http://www.asahi.com/articles/ASG4K51RSG4KULFA01V.html
http://www.asahi.com/articles/ASG4K51RSG4KULFA01V.html
Intel pledges Skylake ramp in 2015
http://www.bit-tech.net/news/hardware/2014/04/17/intel-skylake-2015/1
微妙に英語読めてないかもしれんが、
・既にBroadwellは大量生産段階に
・Skylakeは今年生産開始。来年後半(?)に登場
・来年にはSoFIAをIntel 14nmへ移行
SkylakeのスケジュールはHaswellに類似しているように見える
あとは、いくつかのサイトを見ると、Skylakeは"a bunch of special-purpose accelerators"を備えるとか、
後継がAirlakeだとかCannonlakeだとか、Broxton-LTEが云々とか、
まだ色々な噂があるらしいが、全体的にイマイチまとまっていない感が
http://www.bit-tech.net/news/hardware/2014/04/17/intel-skylake-2015/1
微妙に英語読めてないかもしれんが、
・既にBroadwellは大量生産段階に
・Skylakeは今年生産開始。来年後半(?)に登場
・来年にはSoFIAをIntel 14nmへ移行
SkylakeのスケジュールはHaswellに類似しているように見える
あとは、いくつかのサイトを見ると、Skylakeは"a bunch of special-purpose accelerators"を備えるとか、
後継がAirlakeだとかCannonlakeだとか、Broxton-LTEが云々とか、
まだ色々な噂があるらしいが、全体的にイマイチまとまっていない感が
special-purposeってまた随分あいまいなw
>>3
マルチコア対応とかGPGPU対応とか、とりあえず実験目的でやらせりゃいいのにな
OSの最適化だけで8コア以上不要論も覆せる可能性が高い(特定のアプリでシングルコアだけ酷使させる現象も解決させる)
マルチコア対応とかGPGPU対応とか、とりあえず実験目的でやらせりゃいいのにな
OSの最適化だけで8コア以上不要論も覆せる可能性が高い(特定のアプリでシングルコアだけ酷使させる現象も解決させる)
8 :,,・´∀`・,,)っ-○○○:2014/04/18(金) 07:53:54.28 ID:vWpXGvHq
> (特定のアプリでシングルコアだけ酷使させる現象も解決させる)
そんな魔法はない
CreateProcess/CreateThreadやったぶんだけしか動きません
そんな魔法はない
CreateProcess/CreateThreadやったぶんだけしか動きません
500円の鱈乗ってるやつ買うか
前スレ >>994
> ハードウェア・ソフトウェア工学の知識がある人間がこぞって
> GPGPUは無駄だと口を酸っぱくして言ってるのに
> ド素人ができるはずだと願望を叫んだところで不毛だと思うわけで
> まず、ド素人を卒業してくださいな。
GPGPUに真剣に取り組んでるセンセイ方もいるのにシツレイなヤツだな。
計算工学の分野じゃ当たり前に使われてるよ。NVIDIAのセミナーとか聴いて見聞を広めた方が良いよ。
> ハードウェア・ソフトウェア工学の知識がある人間がこぞって
> GPGPUは無駄だと口を酸っぱくして言ってるのに
> ド素人ができるはずだと願望を叫んだところで不毛だと思うわけで
> まず、ド素人を卒業してくださいな。
GPGPUに真剣に取り組んでるセンセイ方もいるのにシツレイなヤツだな。
計算工学の分野じゃ当たり前に使われてるよ。NVIDIAのセミナーとか聴いて見聞を広めた方が良いよ。
というか一般向けで浮動小数点が必要な重いソフトって大抵すでにGPGPU対応してる
エンコみたいな整数ゴリ押しの分野で期待できないってなら分かるんだけど
Phiの廉価盤の整数アクセラレータボードとか出ないかな
エンコみたいな整数ゴリ押しの分野で期待できないってなら分かるんだけど
Phiの廉価盤の整数アクセラレータボードとか出ないかな
GPGPUでも、アメリカ勢がソフトウェア・ミドルウェアを作って、
日本勢はそれをつかったSIをする側になるよ
GPGPUは、ちょっと前まではサイエンス・アカデミック方面が中心だったのが、
いま米国では直接目の前にお金がぶら下がってる分野でGPGPU利用が増えてきた
日本勢はそれをつかったSIをする側になるよ
GPGPUは、ちょっと前まではサイエンス・アカデミック方面が中心だったのが、
いま米国では直接目の前にお金がぶら下がってる分野でGPGPU利用が増えてきた
団子のいう部分はある程度合ってるよ
日本のいわゆる受託開発が基本の企業では、GPGPU使って採算が合う案件が見つけられない
ところが、アメリカ企業は、GPGPUでお金になる分野をいっぱい掘り当ててる
で、アメリカ企業がGPGPU使いこなしたソフトウェア・ミドルウェアを作って、
日本企業がそれを導入したソリューションを提供するようになる
いまのOSやミドルウェアをほとんどアメリカ企業が提供して、それを日本企業が利用してるのと
おなじパターンにGPGPUがなるだけ
日本のいわゆる受託開発が基本の企業では、GPGPU使って採算が合う案件が見つけられない
ところが、アメリカ企業は、GPGPUでお金になる分野をいっぱい掘り当ててる
で、アメリカ企業がGPGPU使いこなしたソフトウェア・ミドルウェアを作って、
日本企業がそれを導入したソリューションを提供するようになる
いまのOSやミドルウェアをほとんどアメリカ企業が提供して、それを日本企業が利用してるのと
おなじパターンにGPGPUがなるだけ
14 :Socket774:2014/04/18(金) 13:07:42.99 ID:Jm49g7+t
>>11
前スレの994はエンコでGPUに期待→皆が否定の流れからの話で、H264とH265のアルゴリズムの話をした後の発言だよ。
前スレの994はエンコでGPUに期待→皆が否定の流れからの話で、H264とH265のアルゴリズムの話をした後の発言だよ。
15 :Socket774:2014/04/18(金) 13:19:58.64 ID:Twe+sAGX
>GPGPUでお金になる分野をいっぱい掘り当ててる
詳しく
詳しく
流れ無視で悪いが
>Sandy BridgeではPCIeスイッチのバンド幅が低く、DMAの性能が
>低かったが、Ivy Bridgeでは、これが改善された
ttp://news.mynavi.jp/articles/2014/04/18/gtc2014_tca_02/
Sandy Bridge-EPもPCIe3.0を名乗っていたけど
性能は出ていなかったんだな。自作板で一般的な組み上げでは
GPUくらいしか使わないからPCIeを使い切らなくて気づかないと
>Sandy BridgeではPCIeスイッチのバンド幅が低く、DMAの性能が
>低かったが、Ivy Bridgeでは、これが改善された
ttp://news.mynavi.jp/articles/2014/04/18/gtc2014_tca_02/
Sandy Bridge-EPもPCIe3.0を名乗っていたけど
性能は出ていなかったんだな。自作板で一般的な組み上げでは
GPUくらいしか使わないからPCIeを使い切らなくて気づかないと
Device to Deviceの転送なんかグラフィックス用途では大して使わんだろうしなあ
>>16
今でもGPU用途では使いきれてないよな
今でもGPU用途では使いきれてないよな
これ人類に反乱を起こすタイプのソフトだ
今は人間がGPUの使い道を考えてるが100年後はGPUが人間の使い道を考えてる
今は人間がGPUの使い道を考えてるが100年後はGPUが人間の使い道を考えてる
gtc直後にnvidiaがskynetになるってジョークがあったわ
こういうのできるのはnvだからだろうなと思う
amdの環境では生まれない
こういうのできるのはnvだからだろうなと思う
amdの環境では生まれない
偉人や天才のニューラルネットワークをスキャンしてコンピュータに移植し
それを10万台つなげて100倍のクロックで動かしたらもう人類は負ける
そういえばアインシュタインの脳がどこかに保存されてたっけな
それを10万台つなげて100倍のクロックで動かしたらもう人類は負ける
そういえばアインシュタインの脳がどこかに保存されてたっけな
23 :,,・´∀`・,,)っ-○○○:2014/04/18(金) 19:45:46.55 ID:vWpXGvHq
>>11
逆だよ。民間が手をつけたがらない超ニッチな技術だからこそ
大学しかやるところがない。
半導体工学におけるISSCCしかり、ソフトウェア科学におけるICSEしかり、
大学よりも民間のほうが採択論文が多いくらいじゃん。
特に前者は機関別だと採択数はIntelがダントツトップ。
本当に金になる技術の研究ってのは、大学がやらなくても民間がやってるんだわ。
即実用にならなくともそれで特許とったりしてる。
大学が研究でGPGPUをやる理由は3つある。
1.ほかが研究やらないからネタがかぶらずにすむ
2.貧乏研究室でも低予算で理論演算性能を稼げる
3.研究室の学生には「人件費」が発生しない
逆だよ。民間が手をつけたがらない超ニッチな技術だからこそ
大学しかやるところがない。
半導体工学におけるISSCCしかり、ソフトウェア科学におけるICSEしかり、
大学よりも民間のほうが採択論文が多いくらいじゃん。
特に前者は機関別だと採択数はIntelがダントツトップ。
本当に金になる技術の研究ってのは、大学がやらなくても民間がやってるんだわ。
即実用にならなくともそれで特許とったりしてる。
大学が研究でGPGPUをやる理由は3つある。
1.ほかが研究やらないからネタがかぶらずにすむ
2.貧乏研究室でも低予算で理論演算性能を稼げる
3.研究室の学生には「人件費」が発生しない
24 :,,・´∀`・,,)っ-○○○:2014/04/18(金) 19:52:38.74 ID:vWpXGvHq
>>13
お前の厨二ラノベの中に出てくる架空の企業の話なんて誰も聞いてないよ。
そんな痛い小説を披露するのはお前の家族だけにしておけ。
そもそも民間にはそういう技術の需要自体がない。
フリーランス向けの仕事募集サイトだけどGPGPUプログラマなんて募集が
出たの過去3年でたった1件だけ。
http://www.e-engineer.jp/list/?id=6146
お前の厨二ラノベの中に出てくる架空の企業の話なんて誰も聞いてないよ。
そんな痛い小説を披露するのはお前の家族だけにしておけ。
そもそも民間にはそういう技術の需要自体がない。
フリーランス向けの仕事募集サイトだけどGPGPUプログラマなんて募集が
出たの過去3年でたった1件だけ。
http://www.e-engineer.jp/list/?id=6146
26 :,,・´∀`・,,)っ-○○○:2014/04/18(金) 20:12:53.60 ID:vWpXGvHq
松岡先生とか牧野先生のところはそうだろうよ。金引っ張ってこれるし。
大規模スパコンでのFFTとかNBODYみたいな花形の研究ができる。
彼らはGPUが費用対効果がでかいから結果的に使ってるわけで
決してGPUを使うことを自己目的化してるわけではない。
弱小研究室はハードウェアの実装方法が変わったら実用にならなくなる類の
2〜3年で陳腐化する「実装方法」ありきのつまらない論文ばかり書いてる。
より良いスパコンを求めて結果的にGPUを使ってるところと、
GPGPUを使うことを自己目的化してるところの違い。
大規模スパコンでのFFTとかNBODYみたいな花形の研究ができる。
彼らはGPUが費用対効果がでかいから結果的に使ってるわけで
決してGPUを使うことを自己目的化してるわけではない。
弱小研究室はハードウェアの実装方法が変わったら実用にならなくなる類の
2〜3年で陳腐化する「実装方法」ありきのつまらない論文ばかり書いてる。
より良いスパコンを求めて結果的にGPUを使ってるところと、
GPGPUを使うことを自己目的化してるところの違い。
ごもっとも
28 :,,・´∀`・,,)っ-○○○:2014/04/18(金) 21:21:05.67 ID:vWpXGvHq
「GPGPUがつかわれないのはどう考えてもお前らが悪い」
という立場をとるよりは、多少批判的であったほうがいいのだよね。
CPUはシングルスレッドで最適化なし、GPUはガッツリ最適化やって
「○○倍はやくなりました」みたいなGPUの提灯持ち論文ほどクソなものはないよ
効果を誇張したいのだろうけど産業界にはまったく意味がない
という立場をとるよりは、多少批判的であったほうがいいのだよね。
CPUはシングルスレッドで最適化なし、GPUはガッツリ最適化やって
「○○倍はやくなりました」みたいなGPUの提灯持ち論文ほどクソなものはないよ
効果を誇張したいのだろうけど産業界にはまったく意味がない
必死に最適化しても2倍しか早くならない、されど2倍は早くなるというリアルな出てたな。
必死に最適化しても2倍しか早くならない、されど2倍は早くなるというリアルな数字が出てたな。
Intelってこれまでは過去のスパコンとかの技術を参考にCPUを開発してきたらしいけど
これからは参考にする技術が尽きたから新しく自分で考えなきゃいけないらしいけど
どんなの考えるんだろう
これからは参考にする技術が尽きたから新しく自分で考えなきゃいけないらしいけど
どんなの考えるんだろう
サウジ政府が気付いていないわけではない。
「あなたのエアコンに認証ラベルが張ってなければこの番号に電話を」。
サウジ紙に2月、山積みのエアコンを建機で押しつぶす写真とともにこう呼びかける記事が載った。
サウジ政府は今年から、エアコンについて基準以下の電力消費量でなければ流通を認めない規制を導入した。
これいいな。
PC版だとPen4やAMDを潰す展開かw
「あなたのエアコンに認証ラベルが張ってなければこの番号に電話を」。
サウジ紙に2月、山積みのエアコンを建機で押しつぶす写真とともにこう呼びかける記事が載った。
サウジ政府は今年から、エアコンについて基準以下の電力消費量でなければ流通を認めない規制を導入した。
これいいな。
PC版だとPen4やAMDを潰す展開かw
34 :,,・´∀`・,,)っ-○○○:2014/04/18(金) 21:57:13.54 ID:vWpXGvHq
十分効果があったテイで論文書かないと翌年度の研究予算削られちゃうから
みたいな風潮もあるのかねぇ
ダメだね大学って。小保方先生を笑えない。
みたいな風潮もあるのかねぇ
ダメだね大学って。小保方先生を笑えない。
35 :,,・´∀`・,,)っ-○○○:2014/04/18(金) 22:50:51.29 ID:vWpXGvHq
>>32
ぶっちゃけGPUも150W以上は禁止にしちゃっていいんじゃないの
そっちのほうがVRAM帯域依存をやめてキャッシュを有効活用する
流れにさせやすい
(CPUとGPUのアーキテクチャの差異を埋めるためにもなる)
ぶっちゃけGPUも150W以上は禁止にしちゃっていいんじゃないの
そっちのほうがVRAM帯域依存をやめてキャッシュを有効活用する
流れにさせやすい
(CPUとGPUのアーキテクチャの差異を埋めるためにもなる)
>>35
仮にそんなあほなことになったとしても複数枚刺しが当たり前になるだけだろそれ
仮にそんなあほなことになったとしても複数枚刺しが当たり前になるだけだろそれ
37 :Socket774:2014/04/19(土) 00:56:45.37 ID:H6WSkZwu
>>35
すでに規格を超えた消費電力のグラボが出てるんだから、150W以上禁止したところで普通に150W超えた物が出てくるよ。
すでに規格を超えた消費電力のグラボが出てるんだから、150W以上禁止したところで普通に150W超えた物が出てくるよ。
150W以上禁止したらIntelとNVIDIAが終わるけどね
仮にIntelが禁止したら、禁止しないAMDプラットフォームで出すだけ
そしてAMDプラットフォームではゲフォは売れない
仮にIntelが禁止したら、禁止しないAMDプラットフォームで出すだけ
そしてAMDプラットフォームではゲフォは売れない
39 :Socket774:2014/04/19(土) 02:34:05.59 ID:H6WSkZwu
>>38
何故そこでIntelとかNVIDIAの名前が出てくるんだ?
グラボへの電力供給量の規格を決めているのはPCI-SIGだぞ。
PCI-EXPRESSx16(75W) + 6Pin(75W)x1 + 8Pin(150W)x1 = 300W
が正式に認定されている電力供給量。
IntelもAMDも同じPCI-EXPRESSを使っているんだから、IntelかAMDのどちらかがPCI-EXPRESSの規格を逸脱した仕様に変更しない限りAMDでしか動かないグラボは出来ない。
逸脱すれば互換が無くなるのでIntelで動くグラボがAMDで動かないことになる。
何故そこでIntelとかNVIDIAの名前が出てくるんだ?
グラボへの電力供給量の規格を決めているのはPCI-SIGだぞ。
PCI-EXPRESSx16(75W) + 6Pin(75W)x1 + 8Pin(150W)x1 = 300W
が正式に認定されている電力供給量。
IntelもAMDも同じPCI-EXPRESSを使っているんだから、IntelかAMDのどちらかがPCI-EXPRESSの規格を逸脱した仕様に変更しない限りAMDでしか動かないグラボは出来ない。
逸脱すれば互換が無くなるのでIntelで動くグラボがAMDで動かないことになる。
40 :Socket774:2014/04/19(土) 02:39:17.80 ID:H6WSkZwu
>>39
補足:規格を逸脱というのは信号の事ね。
補足:規格を逸脱というのは信号の事ね。
41 :,,・´∀`・,,)っ-○○○:2014/04/19(土) 06:15:45.74 ID:7LXZnrmb
Pentium4で爆熱化したのがIntelの転換点
GPUはまだ省みてない
結論: GPU技術者を殴れ
GPUはまだ省みてない
結論: GPU技術者を殴れ
いやkepler以降は違うでしょ
maxwellは特に
750tiはbiosでボードは38wリミッターだし
500wとか規格無視したもの出すところはしらん
maxwellは特に
750tiはbiosでボードは38wリミッターだし
500wとか規格無視したもの出すところはしらん
43 :,,・´∀`・,,)っ-○○○:2014/04/19(土) 06:36:41.38 ID:7LXZnrmb
まあ着眼点はいいよな
AMDの熱いAPUとIntelの廉価版CPUの差額でお釣りがくるレベルの
価格・消費電力に抑えた製品を作れば売れると
大手サイトでは見込んだ通りにレビューがなされてる。
AMDの熱いAPUとIntelの廉価版CPUの差額でお釣りがくるレベルの
価格・消費電力に抑えた製品を作れば売れると
大手サイトでは見込んだ通りにレビューがなされてる。
44 :Socket774:2014/04/19(土) 07:51:33.72 ID:ys1aB8O/
ip売りするmaxwellとしては28nmで出た750tiの役割は大きい
keplerと同じプロセスで作ることで省電力であるアピールが出来る
デフォルト設定でマイニング時ボード単体28w
http://cryptomining-blog.com/1141-a-bit-more-on-the-actual-power-usage-of-geforce-gtx-750-ti/
nvがtegraでmaxwell世代になるのは第二世代のdenver込のものになる
ip販売は第一世代のものだろう
keplerと同じプロセスで作ることで省電力であるアピールが出来る
デフォルト設定でマイニング時ボード単体28w
http://cryptomining-blog.com/1141-a-bit-more-on-the-actual-power-usage-of-geforce-gtx-750-ti/
nvがtegraでmaxwell世代になるのは第二世代のdenver込のものになる
ip販売は第一世代のものだろう
そもそも、PCI-SIGの300W制限ってはっきりいってGPUにとっては関係ないだろ
ハイエンドGPUは独自にファン持ってかつ独自に排気するから、
300W以上電気食ったとしてべつにマザーボードに熱的・電気的な影響与えるわけでもないし、
なんでPCI-SIGがこんなわけのわからん制限してるのか不明
ハイエンドGPUは独自にファン持ってかつ独自に排気するから、
300W以上電気食ったとしてべつにマザーボードに熱的・電気的な影響与えるわけでもないし、
なんでPCI-SIGがこんなわけのわからん制限してるのか不明
8pin(150w)*2+PCI-e(75w)=375Wを超えるものを出すのが異常だと思うけど
次世代とか言うなら2ナノプロセスで1千億トランジスタとかだろJK
48 :Socket774:2014/04/19(土) 08:34:28.37 ID:H6WSkZwu
>>45
『制限』というより『認定していない』だけだが、6Pin×1 + 8Pin×1までというのは本当に意味不明。
実際に無視したカードがいくつも出ているから。
一方、6Pin:75W、8Pin:150Wという規格の法には意味がある。
電源メーカーはそれを基準にマージンを取った設計をすれば、規格に沿った電源+グラボなら安全に使えると言うことになる。
Radeon R9 295X2みたいに、最大消費電力500Wで8Pin×2って下手な電源使ったら燃えるだろw
『制限』というより『認定していない』だけだが、6Pin×1 + 8Pin×1までというのは本当に意味不明。
実際に無視したカードがいくつも出ているから。
一方、6Pin:75W、8Pin:150Wという規格の法には意味がある。
電源メーカーはそれを基準にマージンを取った設計をすれば、規格に沿った電源+グラボなら安全に使えると言うことになる。
Radeon R9 295X2みたいに、最大消費電力500Wで8Pin×2って下手な電源使ったら燃えるだろw
PCI-SIGが決めてるのは75Wだけだろ
それ以上は、PCIバス関係ないし冷却や電源供給の都合によるだけ
それ以上は、PCIバス関係ないし冷却や電源供給の都合によるだけ
50 :Socket774:2014/04/19(土) 11:04:31.96 ID:H6WSkZwu
>>49
http://www.pcisig.com/developers/main/training_materials/get_document?doc_id=fa4ec3357012d69821baa0856011c665ac770768
http://www.pcisig.com/developers/main/training_materials/get_document?doc_id=fa4ec3357012d69821baa0856011c665ac770768
>>前スレ912
>現状、C++のstd::find()使ってりゃ勝手にAVXコード吐いてくれるけど
これマジ?
Intelコンパイラ限定?
VC++でも吐いてくれる?
>現状、C++のstd::find()使ってりゃ勝手にAVXコード吐いてくれるけど
これマジ?
Intelコンパイラ限定?
VC++でも吐いてくれる?
glibcの最新版とかすでにavx対応コードが一部入ってたりする
独自にやらずにglibcの関数呼べば、一部関数は勝手にavx使ってくれる気がした
独自にやらずにglibcの関数呼べば、一部関数は勝手にavx使ってくれる気がした
VC++でも、/arch:AVX 指定すれば、一部関数が対応の物に置き換わると聞いた
持ってないので試せないけれど
持ってないので試せないけれど
56 :,,・´∀`・,,)っ-○○○:2014/04/19(土) 13:09:16.15 ID:7LXZnrmb
独自にループ回しても依存関係さえなければ最適化かけてくれるけどね
なんかGPGPUが話題になってるけど
ちょっと昔の
CPUは10GHzに向かって高速化を続けるからプログラマは無能でもプログラムは高速化される派 VS
ムーアの法則は終わったCPUの高速化は頭打ちでマルチコアに向かうからプログラマはハードの都合に合わせてコードを書かなければならない派
が争ってた頃のループを繰り返してるんですか
ちょっと昔の
CPUは10GHzに向かって高速化を続けるからプログラマは無能でもプログラムは高速化される派 VS
ムーアの法則は終わったCPUの高速化は頭打ちでマルチコアに向かうからプログラマはハードの都合に合わせてコードを書かなければならない派
が争ってた頃のループを繰り返してるんですか
いずれにせよ決着がつく。
>>57
それはたぶん的外れ
それはたぶん的外れ
60 :,,・´∀`・,,)っ-○○○:2014/04/19(土) 14:24:23.24 ID:7LXZnrmb
NetBurstって別に保守的なコード速くなかったでしょ
10GHzとか液体窒素使っても無理
コア数も4スレッド以上はエンコ以外殆ど使われない
Ipcも増えない
省電力にはなるけど熱密度が高くて冷却が厳しい
今以上の性能向上を目指すなら、iGPU強化やGPGPUに向かわざるを得ない状況なのは確か
コア数も4スレッド以上はエンコ以外殆ど使われない
Ipcも増えない
省電力にはなるけど熱密度が高くて冷却が厳しい
今以上の性能向上を目指すなら、iGPU強化やGPGPUに向かわざるを得ない状況なのは確か
CPUのsimd拡張でいいよ
63 :,,・´∀`・,,)っ-○○○:2014/04/19(土) 14:45:28.02 ID:7LXZnrmb
並列化やるのにGPGPUである必要はないけどね
小さいコアを大量に並べるだけでいい。
小さいコアを大量に並べるだけでいい。
64 :Socket774:2014/04/19(土) 14:58:53.33 ID:H6WSkZwu
>>61
言っていることが見当違いだよ。
NetBurstの中期頃までは10GHzに到達すると『言われていた』だけで、57が言っているのは『プロセスの微細化による高速化に陰りが見えてきた時』の論争のこと。
で、GPUというのはCPUより圧倒的にコア数の多い超並列プロセッサで、性能向上のほとんどはコア数の増加で行われているんだが。
CPUで並列化の効果出せないプログラムは、GPUだともっと性能が出ない。
そして、今の上位GPUはCPUより遙かに消費電力が多く、遙かに発熱量が大きく冷却が厳しい。
おまえの言うとおりの状況なら、今以上の性能向上を目指すならGPUは出来るだけ小さくして、シングルスレッド性能の高いプロセッサに向かわざるを得ない状況になるんだが?
言っていることが見当違いだよ。
NetBurstの中期頃までは10GHzに到達すると『言われていた』だけで、57が言っているのは『プロセスの微細化による高速化に陰りが見えてきた時』の論争のこと。
で、GPUというのはCPUより圧倒的にコア数の多い超並列プロセッサで、性能向上のほとんどはコア数の増加で行われているんだが。
CPUで並列化の効果出せないプログラムは、GPUだともっと性能が出ない。
そして、今の上位GPUはCPUより遙かに消費電力が多く、遙かに発熱量が大きく冷却が厳しい。
おまえの言うとおりの状況なら、今以上の性能向上を目指すならGPUは出来るだけ小さくして、シングルスレッド性能の高いプロセッサに向かわざるを得ない状況になるんだが?
そうだね
だけど、intel自身がマルチスレッドやiGPU強化に必死なんだよ
GT3はGPUコア大盛りだし、eDRAM付けたし、Phiは60コア 512bitSIMDだからね
Atomも8コアとか用意してるし、シングルスレッド偏重はもう終わりなんだよ
だけど、intel自身がマルチスレッドやiGPU強化に必死なんだよ
GT3はGPUコア大盛りだし、eDRAM付けたし、Phiは60コア 512bitSIMDだからね
Atomも8コアとか用意してるし、シングルスレッド偏重はもう終わりなんだよ
SIMDははっきり言って超強力だ。
GPUは汎用的に利用するにはオーバーヘッドが大きすぎる。
ただ、SIMDはユーザがアセンブリやイントリンシックで記述してやらないといけない。
データのアライメントも面倒だ。
これさえ、何とかなれば・・・。
つーか、アライメントくらいpragmaとかコンパイラオプションでできるようにしろよ!
GPUは汎用的に利用するにはオーバーヘッドが大きすぎる。
ただ、SIMDはユーザがアセンブリやイントリンシックで記述してやらないといけない。
データのアライメントも面倒だ。
これさえ、何とかなれば・・・。
つーか、アライメントくらいpragmaとかコンパイラオプションでできるようにしろよ!
67 :,,・´∀`・,,)っ-○○○:2014/04/19(土) 15:13:32.70 ID:7LXZnrmb
Opteronをシュリンクする努力を放棄した会社が
ソフト屋には血を流せと無責任なことをいってるわけだから
茶番もいいところだよ
ソフト屋には血を流せと無責任なことをいってるわけだから
茶番もいいところだよ
phiはGPUではなくsimd拡張したCPUのメニーコア
69 :Socket774:2014/04/19(土) 15:44:06.26 ID:H6WSkZwu
>>65
シングルスレッド偏重はもう終わりという事に関しては同意見だ。
あくまでも61の『コア数も4スレッド以上はエンコ以外殆ど使われない』という状況なら、シングルスレッド性能が重要になるというだけだから。
そして、GT3eでeDRAMを搭載したのは『CPUと同じダイに乗せて、メモリーを共有する形だと』メモリーの帯域が不足してGPUの性能が発揮出来ないからなんだ。
つまり、『iGPUをこれ以上大きくしてもダイサイズ増大の割に性能が出ない』とIntelは判断しているということなんだよ。
シングルスレッド偏重はもう終わりという事に関しては同意見だ。
あくまでも61の『コア数も4スレッド以上はエンコ以外殆ど使われない』という状況なら、シングルスレッド性能が重要になるというだけだから。
そして、GT3eでeDRAMを搭載したのは『CPUと同じダイに乗せて、メモリーを共有する形だと』メモリーの帯域が不足してGPUの性能が発揮出来ないからなんだ。
つまり、『iGPUをこれ以上大きくしてもダイサイズ増大の割に性能が出ない』とIntelは判断しているということなんだよ。
終わりのくせにnVIDIAはDenverなんて作ってますけどね
エンコにしても、E5-2650*2よりE5-2687Wの方が速いから
シングルスレッド性能が重要なのは変わりない
シングルスレッド性能が重要なのは変わりない
72 :Socket774:2014/04/19(土) 16:26:04.50 ID:H6WSkZwu
偏重:物事の一面だけを重んじること
65が考える『シングルスレッド偏重』が俺の考えている意味と同じかどうかは知らないが、『多コア化はプログラムで指定しないと速くならないが、シングルスレッド性能が上がればどんなプログラムでも速くなる』と言ってポラックの法則を無視する事だと俺は考えている。
シングルスレッド性能を上げる事自体は否定するどころかむしろ賛成だよ。
65が考える『シングルスレッド偏重』が俺の考えている意味と同じかどうかは知らないが、『多コア化はプログラムで指定しないと速くならないが、シングルスレッド性能が上がればどんなプログラムでも速くなる』と言ってポラックの法則を無視する事だと俺は考えている。
シングルスレッド性能を上げる事自体は否定するどころかむしろ賛成だよ。
DalvikにしろHTML5にしろ、まず第一に必要なのはシングルスレッド性能だわな
そういう意味で4コア6コア8コアとコア数インフレ競争してる泥スマホ勢は滑稽
そういう意味で4コア6コア8コアとコア数インフレ競争してる泥スマホ勢は滑稽
74 :,,・´∀`・,,)っ-○○○:2014/04/19(土) 16:42:32.68 ID:7LXZnrmb
GPGPUを使わないことこそが成功の秘訣
CookpadもFacebookもGPGPUを使ってない
CookpadもFacebookもGPGPUを使ってない
75 :Socket774:2014/04/19(土) 16:47:11.45 ID:H6WSkZwu
もし、一般向けソフトでGPGPUが効率良かったら、AMDはHSAなんてせずにCPUコアをGPUの構造に近づけるよなw
76 :,,・´∀`・,,)っ-○○○:2014/04/19(土) 17:12:55.51 ID:7LXZnrmb
よりマルチスレッド性能が求められるサーバ市場でろくに使われてないものが
クライアントで普及するわけがないだろう
クライアントで普及するわけがないだろう
77 :Socket774:2014/04/19(土) 17:27:37.12 ID:H6WSkZwu
GPGPU厨はGPUのピーク性能ばかり偏重して現実を見ていないからな
79 :,,・´∀`・,,)っ-○○○:2014/04/19(土) 19:39:38.42 ID:7LXZnrmb
大体に、いまGPGPU対応を進めてるごく一握りの企業って
CPUのマルチスレッド対応も早かったろ?
CPUのマルチスレッドすらうまく使えないソフトがGPGPUに対応する可能性も
ましてCPUより速くなる可能性も0に等しいよ
CPUのマルチスレッド対応も早かったろ?
CPUのマルチスレッドすらうまく使えないソフトがGPGPUに対応する可能性も
ましてCPUより速くなる可能性も0に等しいよ
事務作業なんか・・・・・・だし
末端プログラマはコピペばっかりだから
末端プログラマはコピペばっかりだから
>>78
微細化の分CPUコア増やせよボケというのがこのスレの総意みたいなもんだろ
微細化の分CPUコア増やせよボケというのがこのスレの総意みたいなもんだろ
総意とは
83 :,,・´∀`・,,)っ-○○○:2014/04/19(土) 20:17:02.73 ID:7LXZnrmb
コアが欲しいならLGA2011版i7買えばいいじゃない
84 :,,・´∀`・,,)っ-○○○:2014/04/19(土) 20:20:53.83 ID:7LXZnrmb
「全俺が求めた」的な意味での総意、あるいは異端という意味での「相違」では?
しょうゆう(総意ソース)ことか・・・
日本は劇的な変化や改革はなかなか受け入れられない体質だしな・・・
ブレークスルーが起きたら一気に変わる極端な体質でもある。
当然ブレークスルーが起きたとしても日本発ではなく、欧米発だろうけどな。
ブレークスルーが起きたら一気に変わる極端な体質でもある。
当然ブレークスルーが起きたとしても日本発ではなく、欧米発だろうけどな。
90 :,,・´∀`・,,)っ-○○○:2014/04/20(日) 01:06:03.59 ID:Zy1MiAZ6
優れた技術が浸透し、そうでない技術が受け入れられないのは万国共通だよ
バブル経済と後処理とかポケッタブル端末のネット接続(i-mode)とか
電子手帳とか電卓とか日本が先頭
パッド型ハードの原型もSONYでつばつけてる。
サービスとのセットではなく鳴かず飛ばずだったが
電子手帳とか電卓とか日本が先頭
パッド型ハードの原型もSONYでつばつけてる。
サービスとのセットではなく鳴かず飛ばずだったが
先頭?
ベースとなるものは全て外国じゃんよ
ベースとなるものは全て外国じゃんよ
バブル経済の先頭ってチューリップでも売ったのか
日本で実用化されても海外の発明と日本をバカにし
日本で発明され日本で実用化が遅れても日本をバカにする
ゴクロウサン
日本で発明され日本で実用化が遅れても日本をバカにする
ゴクロウサン
起源主張シタイの?
96 :,,・´∀`・,,)っ-○○○:2014/04/20(日) 02:12:37.70 ID:Zy1MiAZ6
GPGPUがIT業界で総スカンなのはワールドワイドの話です
97 :,,・´∀`・,,)っ-○○○:2014/04/20(日) 02:16:21.78 ID:Zy1MiAZ6
たらこは言ってたよな。
日本人って日本をダメだって言うのが好きだ。
日本がダメだから自分がダメでも仕方ない。
そういう思考。
日本人って日本をダメだって言うのが好きだ。
日本がダメだから自分がダメでも仕方ない。
そういう思考。
98 :,,・´∀`・,,)っ-○○○:2014/04/20(日) 02:20:48.78 ID:Zy1MiAZ6
GPGPUをうまく扱えないからダメだといいたいのであれば
それは日本人がダメなのではなくGPUメーカーがダメなだけです
Cellの失敗に学べ
それは日本人がダメなのではなくGPUメーカーがダメなだけです
Cellの失敗に学べ
GPUがそんなにいいもんなら最初からGPU作ってたわ
みたいな所はあるな
みたいな所はあるな
>>57
> CPUは10GHzに向かって高速化を続けるからプログラマは無能でもプログラムは高速化される派 VS
> ムーアの法則は終わったCPUの高速化は頭打ちでマルチコアに向かうからプログラマはハードの都合に合わせてコードを書かなければならない派
どちらも間違い。シングルコアにもマルチコアにも出口はない。
故にプログラマを殴るしかない、派も追加してくれw
グラフェンプロセッサでも待つかね
> CPUは10GHzに向かって高速化を続けるからプログラマは無能でもプログラムは高速化される派 VS
> ムーアの法則は終わったCPUの高速化は頭打ちでマルチコアに向かうからプログラマはハードの都合に合わせてコードを書かなければならない派
どちらも間違い。シングルコアにもマルチコアにも出口はない。
故にプログラマを殴るしかない、派も追加してくれw
グラフェンプロセッサでも待つかね
つーか毎年毎年倍々ゲームでプロセッサ性能が上がってたのに慣れきってしまって
今の停滞を、そんなはずはないと否認してるやつが多いんだよな。心理的に受け止められないの。
スマホどころかウェアラブルになったらさらに悲惨だぞ。
例えばGoogle Glassなんぞ、耳元にちょこんとバッテリーが入ってるにすぎないからな。
しかもこめかみが熱で熱くなるwwwどうすんべって状態ですよ。
もうプロセッサ屋はこの苦悩を解決してくれないのだ。
結論:プログラマを殴れw
今の停滞を、そんなはずはないと否認してるやつが多いんだよな。心理的に受け止められないの。
スマホどころかウェアラブルになったらさらに悲惨だぞ。
例えばGoogle Glassなんぞ、耳元にちょこんとバッテリーが入ってるにすぎないからな。
しかもこめかみが熱で熱くなるwwwどうすんべって状態ですよ。
もうプロセッサ屋はこの苦悩を解決してくれないのだ。
結論:プログラマを殴れw
>>101
一方、日本では、体温で発電する腕時計を作った
一方、日本では、体温で発電する腕時計を作った
なんかもう新しいパラダイムシフトが無いと行き詰まってる感はあるな
シュリンクも7nmまでとか言われてるしシリコン使った半導体じゃそろそろ限界
そろそろ量子コンピュータとか光コンピュータとか超伝導半導体とか、とにかく全く新しいものが必要とされてくる
シュリンクも7nmまでとか言われてるしシリコン使った半導体じゃそろそろ限界
そろそろ量子コンピュータとか光コンピュータとか超伝導半導体とか、とにかく全く新しいものが必要とされてくる
104 :,,・´∀`・,,)っ-○○○:2014/04/20(日) 08:20:51.27 ID:Zy1MiAZ6
gpuが得意(効率いい)なのは結局画像処理なんだと思うよ
車載のやつもそうだけどニューラルネットワークの奴も画像処理だし
車載のやつもそうだけどニューラルネットワークの奴も画像処理だし
>>85
COREとATOMのbig.LITTLEはやらんのかな?
COREとATOMのbig.LITTLEはやらんのかな?
あるとしてもバッテリー使用時の待機電力には効果がありそうなAtomとQuarkのbig.LITTLEぐらいかな。
バッテリー用途でモニタが大きいとCPUの消費電力を減らしても効果が薄いし、AC電源ならAC-DC変換効率のほうが効いてくる。
バッテリー用途でモニタが大きいとCPUの消費電力を減らしても効果が薄いし、AC電源ならAC-DC変換効率のほうが効いてくる。
VRのオンダイ化に成功した時点で、Intelにはbig.LITTLE的アプローチは一切不要になった
処理が終われば即座にhaltで寝て電力0にできて次のタイムスライスor割り込みですぐ起きれるんだから
処理が終われば即座にhaltで寝て電力0にできて次のタイムスライスor割り込みですぐ起きれるんだから
いやいや既にNTVの段階でbLなんか足元にも及ばない優位性を発揮してるから。
その上、近閾電圧が投入されれば、ARMの息の根は止まる。
AMDも殺せないのにARMを殺せるわけないだろ
まずはモデム内蔵してからだろ
まずはモデム内蔵してからだろ
殺したら独占なんとかで禁止されてるからな。
intelのはコストかかりすぎるからARM駆逐は無理だろ。
i7がバンバン売れる自作市場とは異なり、あっちは価格性能比が重要だから。
14nmなんて4重+カッティングエッジ露光になって工程がとんでもなく増えてて
最終製品まで手がけているインテルですらコストを吸収できるか怪しい。
i7がバンバン売れる自作市場とは異なり、あっちは価格性能比が重要だから。
14nmなんて4重+カッティングエッジ露光になって工程がとんでもなく増えてて
最終製品まで手がけているインテルですらコストを吸収できるか怪しい。
114 :Socket774:2014/04/20(日) 13:23:41.62 ID:DXCg77Gs
Intel様だけが人類の未来を切り開けるのだから
Intel様にたてつくカス共は糞チョン同類の人類の敵
今すぐ地上から一掃すべき
Intel様にたてつくカス共は糞チョン同類の人類の敵
今すぐ地上から一掃すべき
>>113
ハイエンドARMは20nmから最終的には16nm FinFETになるコストは安くない。
ローエンドARMにぶつけるのはSoFIAなんで、プロセスコストは同等になるはず。
やりようによっては勝負できるだろ。
ハイエンドARMは20nmから最終的には16nm FinFETになるコストは安くない。
ローエンドARMにぶつけるのはSoFIAなんで、プロセスコストは同等になるはず。
やりようによっては勝負できるだろ。
116 :,,・´∀`・,,)っ-○○○:2014/04/20(日) 16:47:48.27 ID:Zy1MiAZ6
Cortex-A53相手にClovertrail世代のAtomなら十分やりあえるわな。
Qualcommのシェアを切り取るためにはLTEモデム内蔵は必須
SoFIAは将来的にはLTE/BT/Wifi/GPS内蔵予定だっけ?
SoFIAは将来的にはLTE/BT/Wifi/GPS内蔵予定だっけ?
>>115
外部委託じゃプロセスで差がつかないし、わざわざインテル選ぶ必要も無い。
やりようによっては勝負できてもARM駆逐は無理だと思う。
不気味なのは、ムーアの法則維持できるくらい安く作れるらすいFD-SOIだと思う。
3GHzくらいまでしか効果ないらしいが、意識している方のA社には関係ないし。
外部委託じゃプロセスで差がつかないし、わざわざインテル選ぶ必要も無い。
やりようによっては勝負できてもARM駆逐は無理だと思う。
不気味なのは、ムーアの法則維持できるくらい安く作れるらすいFD-SOIだと思う。
3GHzくらいまでしか効果ないらしいが、意識している方のA社には関係ないし。
元Infineon通信部門を活用したスマートフォン向け事業に関しては完全に失敗した
早く手仕舞いを考えた方がいい
Q1決算を反映しての投資家向けアピールなのかもしれんが
スマホ向けより儲かるIoT・自動車分野へとシフトチェンジを図っとるね
IoTのカギはデータを統合するゲートウェイ--米インテル、自動車分野に注力
http://japan.cnet.com/news/business/35046761/
IoTで自動車の進化を支援するインテル
http://www.itmedia.co.jp/pcuser/spv/1404/17/news138.html
インテル、IoT分野に関する説明会を開催 - 積極的な取り組みをアピール
http://news.mynavi.jp/news/2014/04/17/520/
インテル、自動車向けなど産業分野のIoT促進に注力
〜IoT部門のトップが来日
http://pc.watch.impress.co.jp/docs/news/20140417_644855.html
早く手仕舞いを考えた方がいい
Q1決算を反映しての投資家向けアピールなのかもしれんが
スマホ向けより儲かるIoT・自動車分野へとシフトチェンジを図っとるね
IoTのカギはデータを統合するゲートウェイ--米インテル、自動車分野に注力
http://japan.cnet.com/news/business/35046761/
IoTで自動車の進化を支援するインテル
http://www.itmedia.co.jp/pcuser/spv/1404/17/news138.html
インテル、IoT分野に関する説明会を開催 - 積極的な取り組みをアピール
http://news.mynavi.jp/news/2014/04/17/520/
インテル、自動車向けなど産業分野のIoT促進に注力
〜IoT部門のトップが来日
http://pc.watch.impress.co.jp/docs/news/20140417_644855.html
x86のソフト資産捨てて
armを選ぶ理由もない
msが以前isa変えてまでarmにするんなら
コストで2倍以上の差がないと難しいとしていた
armを選ぶ理由もない
msが以前isa変えてまでarmにするんなら
コストで2倍以上の差がないと難しいとしていた
>>119
あんまり関係ないでしょ
IoTはもともとレネイ・ジェームズ氏が主導しているようで
だいぶ前からWind RiverやらMcAfeeの買収などでカードを増やしていた
それが最近盛り上がってきたよね、というだけの話にすぎないし
自動車向けもだいぶ前からやってたのがようやく製品レベルで形になるかどうかという段階
どのみちIoTを推進するなら通信関係のモジュールに投資しないわけにはいかないので
当面赤字でも続けるだろうね
あんまり関係ないでしょ
IoTはもともとレネイ・ジェームズ氏が主導しているようで
だいぶ前からWind RiverやらMcAfeeの買収などでカードを増やしていた
それが最近盛り上がってきたよね、というだけの話にすぎないし
自動車向けもだいぶ前からやってたのがようやく製品レベルで形になるかどうかという段階
どのみちIoTを推進するなら通信関係のモジュールに投資しないわけにはいかないので
当面赤字でも続けるだろうね
122 :,,・´∀`・,,)っ-○○○:2014/04/20(日) 18:48:13.58 ID:Zy1MiAZ6
>>119
IoT強化は既定路線で何ら驚くべきこともない。
むしろ去年のQ4で新設されたに過ぎないIoT部門がなぜ利益を
計上できてるのか疑問に思わないのかね?
(しかも部門設立以前から利益を計上していることになってる。
簡単に言うとネットブック・MID用としていったん損失として計上された
Atomの棚卸資産が、産業向け組み込み等の用途での採用で
価値が再評価されたからだよ。
Quarkより前にチップを製造してないIoT部門が黒字なのはある意味当然。
帳簿を付け替えただけなのだから。
件のモバイル部門だが、アジアやアフリカの新興市場向けに
でかいIntelロゴ入れることを条件に激安で売ってるのは
広告宣伝を兼ねてるからだ。
企業全体としての黒字は既存部門で十分確保できてる。
市場開拓は赤字出してナンボの世界。
IoT強化は既定路線で何ら驚くべきこともない。
むしろ去年のQ4で新設されたに過ぎないIoT部門がなぜ利益を
計上できてるのか疑問に思わないのかね?
(しかも部門設立以前から利益を計上していることになってる。
簡単に言うとネットブック・MID用としていったん損失として計上された
Atomの棚卸資産が、産業向け組み込み等の用途での採用で
価値が再評価されたからだよ。
Quarkより前にチップを製造してないIoT部門が黒字なのはある意味当然。
帳簿を付け替えただけなのだから。
件のモバイル部門だが、アジアやアフリカの新興市場向けに
でかいIntelロゴ入れることを条件に激安で売ってるのは
広告宣伝を兼ねてるからだ。
企業全体としての黒字は既存部門で十分確保できてる。
市場開拓は赤字出してナンボの世界。
次に出るxxxxこそは! と言い続けて数年
IntelにせよNvにせよ、LTEモデム事業は敗戦処理の段階だよ
IntelにせよNvにせよ、LTEモデム事業は敗戦処理の段階だよ
124 :,,・´∀`・,,)っ-○○○:2014/04/20(日) 22:55:45.14 ID:Zy1MiAZ6
何言ってんだこいつ
XMM7260はようやく2世代目ですが
XMM7260はようやく2世代目ですが
>次に出るxxxxこそは! と言い続けて数年
それ何を加速してるんだか謎の某社のAcceleratedナントカでは...
それ何を加速してるんだか謎の某社のAcceleratedナントカでは...
126 :,,・´∀`・,,)っ-○○○:2014/04/20(日) 23:16:54.22 ID:Zy1MiAZ6
Intelのワイヤレスは「LTE事業」(←嘲笑)というほどLTEに特化してるわけでもないし
むしろ近年ようやくWiMAXから切り替えたくらいだし。
今年出るSoCのSoFIAも新興市場向けだから3Gモデムだし
LTE内蔵のSoCはまだ立ち上がってないですよ
むしろ近年ようやくWiMAXから切り替えたくらいだし。
今年出るSoCのSoFIAも新興市場向けだから3Gモデムだし
LTE内蔵のSoCはまだ立ち上がってないですよ
赤字続きだったインテルの「モバイル&通信」事業
財務報告の事業区分変更で明らかに
http://jbpress.ismedia.jp/articles/-/40469
「モバイル&通信」の赤字額、四半期ごとに拡大
同事業の営業損益は、9億2900万ドルの赤字だった。今回の事業区分の変更で
もう1つ明らかになったことは、この事業の赤字が少なくとも5四半期続いていること。
1年前の赤字額は7億300万ドルだったが、その後、7億6100万ドル、
8億1000万ドル、8億7400万ドル、9億2900万ドルと一貫して増えている。
財務報告の事業区分変更で明らかに
http://jbpress.ismedia.jp/articles/-/40469
「モバイル&通信」の赤字額、四半期ごとに拡大
同事業の営業損益は、9億2900万ドルの赤字だった。今回の事業区分の変更で
もう1つ明らかになったことは、この事業の赤字が少なくとも5四半期続いていること。
1年前の赤字額は7億300万ドルだったが、その後、7億6100万ドル、
8億1000万ドル、8億7400万ドル、9億2900万ドルと一貫して増えている。
インテルのCFOが明かす赤字の理由
米ウォールストリート・ジャーナルによると、これには2つの理由があると、
インテルのステイシー・スミス最高財務責任者(CFO)は話している。
1つは「コントラレベニュー」とインテルが呼んでいるタブレット端末に対する補助金だ。
インテルは同社製半導体を採用するタブレット端末のメーカーに対し、
製造・開発費用の一部を支払っており、その費用がかさんでいるという。
もう1つの理由は、無線通信の信号を処理するベースバンドプロセッサーだ。
昨今の主流であるLTE(4G)用では、米クアルコムが最大のメーカーとなっている。
これにより、インテルのベースバンドプロセッサーは売り上げが減少している。
これに加えインテルでは、LTEベースバンドプロセッサーの開発や改良にかかる費用が膨らんでいる。
米ウォールストリート・ジャーナルによると、これには2つの理由があると、
インテルのステイシー・スミス最高財務責任者(CFO)は話している。
1つは「コントラレベニュー」とインテルが呼んでいるタブレット端末に対する補助金だ。
インテルは同社製半導体を採用するタブレット端末のメーカーに対し、
製造・開発費用の一部を支払っており、その費用がかさんでいるという。
もう1つの理由は、無線通信の信号を処理するベースバンドプロセッサーだ。
昨今の主流であるLTE(4G)用では、米クアルコムが最大のメーカーとなっている。
これにより、インテルのベースバンドプロセッサーは売り上げが減少している。
これに加えインテルでは、LTEベースバンドプロセッサーの開発や改良にかかる費用が膨らんでいる。
スマフォ分野じゃIntelブランドは通用しないし、唯一のメリットのシングル性能はどうでもいいし、
重要なグラフィックはどうにもならないという手詰まり状態だからね
いくら開発支援という名のリベートをばら撒いてもさっぱり成果が出ないのは厳しいね
AMDを追い落とすために散々やってきた悪行も、ARM相手に全く通用してないからもう勝ち目ないな
重要なグラフィックはどうにもならないという手詰まり状態だからね
いくら開発支援という名のリベートをばら撒いてもさっぱり成果が出ないのは厳しいね
AMDを追い落とすために散々やってきた悪行も、ARM相手に全く通用してないからもう勝ち目ないな
ポエムはよそでやってくれ
私の歌(ポエム) ウナ銀河に届け〜♪
自社iGPUが使いものにならないからPowerVR使ってるということだろ
ハードウェアもドライバもソフトウェアも他社任せになるし、PowerVR自体将来HSA対応されるからな
仮に何かの間違いでHSA対応しなかった場合、CPUとの高効率な連携ができないということで市場から淘汰される
もちろん、x86と連携するような機構は搭載されないから、Atomに内蔵されてもオマケ扱いしかされない
ハードウェアもドライバもソフトウェアも他社任せになるし、PowerVR自体将来HSA対応されるからな
仮に何かの間違いでHSA対応しなかった場合、CPUとの高効率な連携ができないということで市場から淘汰される
もちろん、x86と連携するような機構は搭載されないから、Atomに内蔵されてもオマケ扱いしかされない
妄想は向こうでやれ
来年のBroxtonはどうなるんだろうね
スマホとタブレットの両方をカバーするという噂もあったような気がするけど、
もしそうなら、PowerVRをやめてGen9(Skylakeと共通?)にするのかどうか
そういえば、前のCherryTrailはGen8 16EUだという噂だが、やり過ぎな気がする
IvyBridgeもびっくり
スマホとタブレットの両方をカバーするという噂もあったような気がするけど、
もしそうなら、PowerVRをやめてGen9(Skylakeと共通?)にするのかどうか
そういえば、前のCherryTrailはGen8 16EUだという噂だが、やり過ぎな気がする
IvyBridgeもびっくり
ちなみにHSAの抽象化の分厚さを大問題のようにしているようだけど、大したことじゃないな
HSAの世代が進めば抽象度は効率良くなるし、プロセッサ側にもHSA支援の命令なりが追加されていく
VirtualBOXとかとIntel VTやAMD Vみたいな関係になって直ぐに気にならなくなるだろうよ
というかスマフォ向けはARMに特化して極力薄くするくらいのことはするだろう
XBOX1のOSやDirectXもPC版より遥かに高効率だし、同じことをスマフォでやるくらいだれでも考えるだろ
HSAの世代が進めば抽象度は効率良くなるし、プロセッサ側にもHSA支援の命令なりが追加されていく
VirtualBOXとかとIntel VTやAMD Vみたいな関係になって直ぐに気にならなくなるだろうよ
というかスマフォ向けはARMに特化して極力薄くするくらいのことはするだろう
XBOX1のOSやDirectXもPC版より遥かに高効率だし、同じことをスマフォでやるくらいだれでも考えるだろ
powerVR一旦止めたのにまた採用したのか?
それだけintelHDがダメってことか
CPUそっちのけで金つぎこんてるのに実を結ばないな
それだけintelHDがダメってことか
CPUそっちのけで金つぎこんてるのに実を結ばないな
スマホ向けAtom SoCはずっとPowerVR
IntelHD向けのドライバー作成する余力がまだなさそう
性能的には十分だと思うんだが、ドライバーの年季はPowerVRには勝てっこない
性能的には十分だと思うんだが、ドライバーの年季はPowerVRには勝てっこない
>>136
すべてが妄想だな
すべてが妄想だな
PowerVRのドライバも相当ひどいらしいけどね
それで一旦やめたらしいけど、自分とこのが更にひどいから結局また採用したんだっけ
それで一旦やめたらしいけど、自分とこのが更にひどいから結局また採用したんだっけ
Intel潰れちゃうの?(´・ω・`)
既に兆しはあるが、先ずはPC向けCPUが蔑ろにされる事だろうね。
今までのような性能アップ率やハンダ仕様云々などが期待出来ず、
性能・OC重視のジサカーの阿鼻叫喚がより高まりそうだ。
今までのような性能アップ率やハンダ仕様云々などが期待出来ず、
性能・OC重視のジサカーの阿鼻叫喚がより高まりそうだ。
146 :Socket774:2014/04/21(月) 12:55:52.95 ID:iBELj7Db
Intelの業績は楽観できるものでは無いね。
Intelの第1四半期の業績で過去最高益だった2011年の決算では、Intel32億ドルとIBM(29億ドル)を上回る純利益を出していたのに、今期の純利益はIntel19億ドルと3年前の40%から落ちている。(IBMの今期純利益は24億ドル)
えっ、えーえむでーですか?もちろんじゅんちょーのはずですよ。
3年前(2011年第1四半期)は純利益でIntelと38億ドル近い差があったのに、今期は19億ドル強まで差を縮めましたから。
http://japan.cnet.com/news/business/35046697/
http://pc.watch.impress.co.jp/docs/news/20140418_645046.html?ref=rss
http://pc.watch.impress.co.jp/docs/news/20140416_644605.html?ref=rss
Intelの第1四半期の業績で過去最高益だった2011年の決算では、Intel32億ドルとIBM(29億ドル)を上回る純利益を出していたのに、今期の純利益はIntel19億ドルと3年前の40%から落ちている。(IBMの今期純利益は24億ドル)
えっ、えーえむでーですか?もちろんじゅんちょーのはずですよ。
3年前(2011年第1四半期)は純利益でIntelと38億ドル近い差があったのに、今期は19億ドル強まで差を縮めましたから。
http://japan.cnet.com/news/business/35046697/
http://pc.watch.impress.co.jp/docs/news/20140418_645046.html?ref=rss
http://pc.watch.impress.co.jp/docs/news/20140416_644605.html?ref=rss
147 :Socket774:2014/04/21(月) 13:13:54.42 ID:iBELj7Db
しょーもね
んなこというなら5年前から300%くらい増えてる
んなこというなら5年前から300%くらい増えてる
×5年前から300%くらい増えてる
○5年前から300%くらいに増えてる
○5年前から300%くらいに増えてる
>>145
core i7のK型番をはんだにするっていう情報が先月頃に流れたジャン
core i7のK型番をはんだにするっていう情報が先月頃に流れたジャン
独占状態だしPC需要が無くなる事は無いから値上げすればいいだけなんだよな
152 :Socket774:2014/04/21(月) 14:50:17.80 ID:iBELj7Db
期待にそえずスマンカッタorz
>>150
ハンダじゃなくてもっといいグリスじゃなかった?
ハンダじゃなくてもっといいグリスじゃなかった?
156 :,,・´∀`・,,)っ-○○○:2014/04/21(月) 20:56:50.44 ID:RQUqYQpO
記者仲間で焚き付けてるだけじゃん。
MSにしてもIntelにしてもだが「勝つまでやめない」からこそ強いのだよ。
そして持久戦をできるだけの体力もある。
IntelがPentium Proでいくら赤字出したよ?
MSにしてもIntelにしてもだが「勝つまでやめない」からこそ強いのだよ。
そして持久戦をできるだけの体力もある。
IntelがPentium Proでいくら赤字出したよ?
ありゃアンドリュー・グローブの手腕によるものだ
オッテリーニは中途で匙を投げたしクルザニッチには荷が重かろうよ
オッテリーニは中途で匙を投げたしクルザニッチには荷が重かろうよ
BroadwellでSDP 2.8WとなればタブレットでAtomを使う必要はなくなってくるんじゃない?
そんな高コストチップでますます自分の首絞めるの?
160 :,,・´∀`・,,)っ-○○○:2014/04/21(月) 22:09:34.87 ID:RQUqYQpO
山吹色のお菓子でももらったのかねこの記者は
Androidの64ビット化の流れに出遅れたQualcommは
急造のCortex-A57/A53で茶を濁そうとしてるが
明らかな焦りが伺えるのだが。
たいていのソフトベンダーはNDKでARMv8A(A64)をターゲットに
追加する手間のついでにx86/x64対応もやっちゃうよね?
そういうことだ。
Androidの64ビット化の流れに出遅れたQualcommは
急造のCortex-A57/A53で茶を濁そうとしてるが
明らかな焦りが伺えるのだが。
たいていのソフトベンダーはNDKでARMv8A(A64)をターゲットに
追加する手間のついでにx86/x64対応もやっちゃうよね?
そういうことだ。
>>160
最初はARMのデザインそのままで出して、次からは改良版投入しておけばいいよ
最初はARMのデザインそのままで出して、次からは改良版投入しておけばいいよ
>>156
PentiumProは、当時主流だったWin95が遅かっただけで、
WindowsNT4.0使ってる人にとってはかなり魅力のあるチップだったよな
おれはあまりにも95が不安定なので、自分のマシン(通常のデスクトップ用途)を
NT4.0いれてで使ってたわ
PentiumProは、当時主流だったWin95が遅かっただけで、
WindowsNT4.0使ってる人にとってはかなり魅力のあるチップだったよな
おれはあまりにも95が不安定なので、自分のマシン(通常のデスクトップ用途)を
NT4.0いれてで使ってたわ
> Androidの64ビット化の流れに出遅れたQualcommは
> 急造のCortex-A57/A53で茶を濁そうとしてるが
そんな流れまだ何処にもないから出遅れてないな
> たいていのソフトベンダーはNDKでARMv8A(A64)をターゲットに
> 追加する手間のついでにx86/x64対応もやっちゃうよね?
v8A対応は必須だから手間でもやるけど、x64対応は無くても困らないからやらないとこ多いだろ
Windowsですらx64対応してないソフト多いのに、ARM前提のスマフォでそんな手間かけるとこなんか殆ど無いよw
> 急造のCortex-A57/A53で茶を濁そうとしてるが
そんな流れまだ何処にもないから出遅れてないな
> たいていのソフトベンダーはNDKでARMv8A(A64)をターゲットに
> 追加する手間のついでにx86/x64対応もやっちゃうよね?
v8A対応は必須だから手間でもやるけど、x64対応は無くても困らないからやらないとこ多いだろ
Windowsですらx64対応してないソフト多いのに、ARM前提のスマフォでそんな手間かけるとこなんか殆ど無いよw
164 :,,・´∀`・,,)っ-○○○:2014/04/21(月) 22:59:22.87 ID:RQUqYQpO
ID:TYRIJuZp こいつ必死すぎるわ
165 :,,・´∀`・,,)っ-○○○:2014/04/21(月) 23:00:47.48 ID:RQUqYQpO
> Windowsですらx64対応してないソフト多いのに、
AMDスレでHSAは対応するベンダーあまたという幸せ回路全快で
よくこんな矛盾した書き込みができるものだ
AMDスレでHSAは対応するベンダーあまたという幸せ回路全快で
よくこんな矛盾した書き込みができるものだ
団子さん、最前線で仕事することなくなったらライターになってよ。
ポスト後藤。
ポスト後藤。
167 :,,・´∀`・,,)っ-○○○:2014/04/21(月) 23:22:53.36 ID:RQUqYQpO
ちなみにAndroidのx86/x64向けNDKのビルドなら、ほぼMakefileに
コンパイルターゲットを追加するだけですむよ。現に俺がやったしwww
64ビットARMに移植で問題が起きないようにきちんと考慮されたコードなら
x86/x64でも問題は発生することはまずないと思う。
そもそも64ビットARM対応のAndroidスマホ/タブレットって
現時点で【動作確認用の環境がない】からなー。
Androidのタブレット・スマホはASUSが複数機種出してるし
次期NexusがAtomならARMv8Aより64ビット対応で先行することは確定。
なにせLinux向けのコード資産そのまま流用できるものすらあるからな。
HSA対応(笑)はコードの全面的な書き直しが必要だから
次期Nexusにも載るといわれてるx86/x64対応すらめんどくさがるベンダーが
使う可能性なんて0ですよ
コンパイルターゲットを追加するだけですむよ。現に俺がやったしwww
64ビットARMに移植で問題が起きないようにきちんと考慮されたコードなら
x86/x64でも問題は発生することはまずないと思う。
そもそも64ビットARM対応のAndroidスマホ/タブレットって
現時点で【動作確認用の環境がない】からなー。
Androidのタブレット・スマホはASUSが複数機種出してるし
次期NexusがAtomならARMv8Aより64ビット対応で先行することは確定。
なにせLinux向けのコード資産そのまま流用できるものすらあるからな。
HSA対応(笑)はコードの全面的な書き直しが必要だから
次期Nexusにも載るといわれてるx86/x64対応すらめんどくさがるベンダーが
使う可能性なんて0ですよ
HSAは、AMDがLinux OSへのパッチやデバイスドライバ等作って
Androidにマージしてもらう用に活動しないと、
とりあえず考えたのでだれか実装してください状態じゃ
いつまでたっても進まないと思う
最低でもGoogleは巻き込まないとどうにもならん
Androidにマージしてもらう用に活動しないと、
とりあえず考えたのでだれか実装してください状態じゃ
いつまでたっても進まないと思う
最低でもGoogleは巻き込まないとどうにもならん
169 :,,・´∀`・,,)っ-○○○:2014/04/21(月) 23:38:23.14 ID:RQUqYQpO
AparapiだSumatraだと騒いでるけど
AndroidもChromeOSもOracleのJavaに対応してないしねー
Pure Darvikで動かす分にはx86/x64/ARMv5TE/v7A/ARMv8A/AA64は
関係ないからほとんど問題にならないでしょ。
推奨端末ではないにせよガンホーはIntelスマホ・タブでのパズドラの
動作対応を進めてる。
AndroidもChromeOSもOracleのJavaに対応してないしねー
Pure Darvikで動かす分にはx86/x64/ARMv5TE/v7A/ARMv8A/AA64は
関係ないからほとんど問題にならないでしょ。
推奨端末ではないにせよガンホーはIntelスマホ・タブでのパズドラの
動作対応を進めてる。
Androidが正式にJavaを名乗ってないのは、
MSが使ってた本家Sunより軽くて高速で使いやすいJava/JVMが裁判で潰されたからでしょう
だから、JavaではないがJavaによく似たJava風のなにかを使ってる
MSが使ってた本家Sunより軽くて高速で使いやすいJava/JVMが裁判で潰されたからでしょう
だから、JavaではないがJavaによく似たJava風のなにかを使ってる
171 :,,・´∀`・,,)っ-○○○:2014/04/21(月) 23:49:06.02 ID:RQUqYQpO
ソースコードがJava言語なだけでしょ
バイトコードに互換性が無い
バイトコードに互換性が無い
>>168
> HSAは、AMDがLinux OSへのパッチやデバイスドライバ等作って
> Androidにマージしてもらう用に活動しないと、
そうだね
だから、とっくにその方向で動いているよ
AMD Demoes its Next-Gen x86 APU Running Fedora Linux
http://www.techpowerup.com/199925/amd-demoes-its-next-gen-x86-apu-running-fedora-linux.html
確かUbuntsもHSA加盟してたような、スポンサードしてるOpenSUSEも密かに対応進めてそうだ
> とりあえず考えたのでだれか実装してください状態じゃ
> いつまでたっても進まないと思う
そんな状態は最初からないし、今は水面下で色々働きかけてるところだろ
その一部がOpenCL2.0のhUMA対応や、LibreofficeとSumatraだし、他にも色々進んでいる
OpenCLに積極的だったとこ、例えばAdobe辺りとはKaveri使って既に開発進めてるだろうね
発表できる段階になったら、その都度表に出てくるだけ、今はまだその段階じゃないだけ
> HSAは、AMDがLinux OSへのパッチやデバイスドライバ等作って
> Androidにマージしてもらう用に活動しないと、
そうだね
だから、とっくにその方向で動いているよ
AMD Demoes its Next-Gen x86 APU Running Fedora Linux
http://www.techpowerup.com/199925/amd-demoes-its-next-gen-x86-apu-running-fedora-linux.html
確かUbuntsもHSA加盟してたような、スポンサードしてるOpenSUSEも密かに対応進めてそうだ
> とりあえず考えたのでだれか実装してください状態じゃ
> いつまでたっても進まないと思う
そんな状態は最初からないし、今は水面下で色々働きかけてるところだろ
その一部がOpenCL2.0のhUMA対応や、LibreofficeとSumatraだし、他にも色々進んでいる
OpenCLに積極的だったとこ、例えばAdobe辺りとはKaveri使って既に開発進めてるだろうね
発表できる段階になったら、その都度表に出てくるだけ、今はまだその段階じゃないだけ
173 :,,・´∀`・,,)っ-○○○:2014/04/22(火) 00:28:30.41 ID:lKj/IS+j
> 確かUbuntsもHSA加盟してたような、スポンサードしてるOpenSUSEも密かに対応進めてそうだ
Androidと全く関係ないじゃん
バカじゃねーの
Androidと全く関係ないじゃん
バカじゃねーの
Intel is losing billions every year on tablets and smartphones
http://silverlining.postach.io/intel-is-losing-billions-every-year-on-tablets-and-smartphones-thevergeyori
http://silverlining.postach.io/intel-is-losing-billions-every-year-on-tablets-and-smartphones-thevergeyori
7インチと8インチのMeMO Pad後続がBayTrail採用で、アメリカの通販サイトで価格が乗り始めたらしいけど
AndroidのBayTrail機出てくるまで長かったなー
AndroidのBayTrail機出てくるまで長かったなー
実際使えるアプリが制限されるようなことにはならんのかね?>android intelスマホ
Bay Trailが実現する、WindowsとAndroidが共存するタブレット
〜x86版Androidで互換性の問題が非常に少ない理由
http://pc.watch.impress.co.jp/docs/column/ubiq/20130926_616841.html
インテル入ってるAndroidで,ゲームはどれだけ動くのか
ASUS Fonepad ME371MG
http://www.4gamer.net/games/990/G999019/20130725009/
〜x86版Androidで互換性の問題が非常に少ない理由
http://pc.watch.impress.co.jp/docs/column/ubiq/20130926_616841.html
インテル入ってるAndroidで,ゲームはどれだけ動くのか
ASUS Fonepad ME371MG
http://www.4gamer.net/games/990/G999019/20130725009/
Windowsでストア紐付もすることなくアイコンワンクリックでandroidアプリが起動すれば最高やね
中華山塞がx86タブを大量にばらまいているので、大きなアプリじゃネイティブコードを
出来るだけ使わない方向にはなってるね。
あとはqualcommやAppleのモデム以外バリデーションを渋る各国キャリアの問題かね。
LTEだけなら金をばらまけば解決しそうな問題だ。3Gの実装に方言があるのが
キャリアが萎縮する最大の問題なんで。
VoLTEの通話ごときにエネルギー使いまくる問題さえ解決するんなら。
出来るだけ使わない方向にはなってるね。
あとはqualcommやAppleのモデム以外バリデーションを渋る各国キャリアの問題かね。
LTEだけなら金をばらまけば解決しそうな問題だ。3Gの実装に方言があるのが
キャリアが萎縮する最大の問題なんで。
VoLTEの通話ごときにエネルギー使いまくる問題さえ解決するんなら。
180 :,,・´∀`・,,)っ-○○○:2014/04/22(火) 02:38:40.82 ID:lKj/IS+j
独自OSの詳細はわからんが、こういう製品にすらIAが採用される時代なんだよな。
iCAT、独自OS搭載でハイレゾ対応のメディアサーバー/プレーヤー「AVCloud」
http://av.watch.impress.co.jp/docs/news/20140317_639991.html
Intel HD4600程度でも4K再生には十分な性能なんだよね
新しいコーデックもAVX2のパワーで柔軟に対応できるし。
AMDファンボーイが火病を起こしそうだけど、
iCAT、独自OS搭載でハイレゾ対応のメディアサーバー/プレーヤー「AVCloud」
http://av.watch.impress.co.jp/docs/news/20140317_639991.html
Intel HD4600程度でも4K再生には十分な性能なんだよね
新しいコーデックもAVX2のパワーで柔軟に対応できるし。
AMDファンボーイが火病を起こしそうだけど、
コンパイラが両対応だから、とりあえず作る分には大した手間はかからないだろうね
ただし、コードは別だからデバッグや最適化の手間は倍かかることになる
シンプルなものならいいけど、複雑で大規模なものだとコストが無視できなくなるだろう
ゲームだと、CPUはおろかGPU毎に調整が必要だから、動くけど表示がおかしいとかが多いかもね
ホームのPCゲームですら大して対応されないのに、アウェイのAndroidゲームでの対応は期待しないほうがいいな
今はまだ軽量でシンプルなゲームばかりだから大丈夫だろうけど、
性能向上に応じて重くて複雑になっていくから、その時はヤバイだろうね
ただし、コードは別だからデバッグや最適化の手間は倍かかることになる
シンプルなものならいいけど、複雑で大規模なものだとコストが無視できなくなるだろう
ゲームだと、CPUはおろかGPU毎に調整が必要だから、動くけど表示がおかしいとかが多いかもね
ホームのPCゲームですら大して対応されないのに、アウェイのAndroidゲームでの対応は期待しないほうがいいな
今はまだ軽量でシンプルなゲームばかりだから大丈夫だろうけど、
性能向上に応じて重くて複雑になっていくから、その時はヤバイだろうね
>>180
もちろん買うよな?
もちろん買うよな?
> Intel HD4600程度でも4K再生には十分な性能なんだよね
> 新しいコーデックもAVX2のパワーで柔軟に対応できるし。
AM1で対応できそうな内容だな
i5使わないと無理なIntelが逆に哀れだ
HD4600とか使わなくてもAM1のAPUでいいだろ
もちろんAVX対応してるから問題ない
対応は余裕だけど、出すリソースが無いのが悔やまれる
> AMDファンボーイが火病を起こしそうだけど、
AVX非対応でクソグラフィックのBaytrail使いが火病起こすんじゃねw
> 新しいコーデックもAVX2のパワーで柔軟に対応できるし。
AM1で対応できそうな内容だな
i5使わないと無理なIntelが逆に哀れだ
HD4600とか使わなくてもAM1のAPUでいいだろ
もちろんAVX対応してるから問題ない
対応は余裕だけど、出すリソースが無いのが悔やまれる
> AMDファンボーイが火病を起こしそうだけど、
AVX非対応でクソグラフィックのBaytrail使いが火病起こすんじゃねw
本来、Googleとしては長期的な目標は「Webブラウザによる世界支配」だったわけだから、
現状のAndroidのARMネイティブ環境依存な状況はよろしく思っていないだろう
ARMもQualcommも「ソフトメーカーも」、勘違いしちゃいけないんだよな
現状のAndroidのARMネイティブ環境依存な状況はよろしく思っていないだろう
ARMもQualcommも「ソフトメーカーも」、勘違いしちゃいけないんだよな
ネイティブじゃなく抽象化前提で、ソフトを動かすのにプロセッサやOSに縛られない世界にならないかな
あらゆるプロセッサに対応できる言語、高性能なVM、統一されたアドレス空間があれば実現できそうだけど
あらゆるプロセッサに対応できる言語、高性能なVM、統一されたアドレス空間があれば実現できそうだけど
TRONが潰されなければ
187 : ◆miyuri//Z7LS :2014/04/22(火) 05:00:49.20 ID:T6yO6xsw
ndk使ったネイティブソフトなんてほとんどない
今後はdalvikからartに移行していくんだろうけど
今後はdalvikからartに移行していくんだろうけど
ARTはLLVMだっけ、DalvikがJITでやってたのを事前コンパイルでどこまで速くできんのかね
むしろランタイムでのSIMD活用を狙ってのことなのか
まぁそんな事よりもIntelにとって大事なのはアプリの互換性なんだけども
むしろランタイムでのSIMD活用を狙ってのことなのか
まぁそんな事よりもIntelにとって大事なのはアプリの互換性なんだけども
dalvik,art使ってる分には関係ない
ネイティブの時だけ問題がある可能性がでる
ネイティブの時だけ問題がある可能性がでる
なるほどね、でもだったらARTにC++で吐いたLLVMのビットコード突っ込んじまえば
良いんじゃねって、なっていくのかな
良いんじゃねって、なっていくのかな
192 :,,・´∀`・,,)っ-○○○:2014/04/22(火) 07:33:59.29 ID:lKj/IS+j
>>183ほら火病おこしたwww
>>181
RealRacing3が動くんだから大丈夫だろう
RealRacing3が動くんだから大丈夫だろう
195 :,,・´∀`・,,)っ-○○○:2014/04/22(火) 07:55:12.33 ID:lKj/IS+j
>>183
あーちなみにスペック表みればわかるけど、Celeron 847も
AVX非対応だけど下位モデルには載ってるよ
Sandy Bridgeベースだけど
でもAPU(爆笑)には 絶 対 に 無 利
なぜならこの手の業界に絶望的に信頼が無いから。
今のAMDに一番足りない性能だな。
というかカビ煮(笑)のDDR3シングルチャネルじゃ技術的にもまともに
使いものにならんのでは?
リアルタイムシステム不向きだろ
あーちなみにスペック表みればわかるけど、Celeron 847も
AVX非対応だけど下位モデルには載ってるよ
Sandy Bridgeベースだけど
でもAPU(爆笑)には 絶 対 に 無 利
なぜならこの手の業界に絶望的に信頼が無いから。
今のAMDに一番足りない性能だな。
というかカビ煮(笑)のDDR3シングルチャネルじゃ技術的にもまともに
使いものにならんのでは?
リアルタイムシステム不向きだろ
196 :,,・´∀`・,,)っ-○○○:2014/04/22(火) 07:58:47.99 ID:lKj/IS+j
>>194
そもそもGoogleがデスクトップ・ノートPC向けに展開しようとしてるChromeOSは
Androidとは別系統のOSですし。
個人的にはあの独自描画システムをオープンにしてくれないかなと思う。
案外WaylandやMirよりパフォーマンスいいんじゃね?
そもそもGoogleがデスクトップ・ノートPC向けに展開しようとしてるChromeOSは
Androidとは別系統のOSですし。
個人的にはあの独自描画システムをオープンにしてくれないかなと思う。
案外WaylandやMirよりパフォーマンスいいんじゃね?
197 :Socket774:2014/04/22(火) 08:01:23.78 ID:pewMNfWy
Bay Trailの話なら、HD4600とかKabiniクラスのグラフィックなんて熱源搭載される方が迷惑なんだがな。
>>184
Webブラウザだと決済システムを作り上げて手数料を独占的に得るのが難しいから、
AndroidもFlash対応を辞めて、Appleみたいに自社ストア経由で課金して
手数料を上げることにしたんでしょう
もしwebベースのアプリで課金なら、appleやgoogleに3割も取られるくらいなら
大手は自前で決済システム作って3割分を自分のふところに入れるぜってやるから、
それをやらせないためにアプリのストア配信と課金は重要
Webブラウザだと決済システムを作り上げて手数料を独占的に得るのが難しいから、
AndroidもFlash対応を辞めて、Appleみたいに自社ストア経由で課金して
手数料を上げることにしたんでしょう
もしwebベースのアプリで課金なら、appleやgoogleに3割も取られるくらいなら
大手は自前で決済システム作って3割分を自分のふところに入れるぜってやるから、
それをやらせないためにアプリのストア配信と課金は重要
199 :,,・´∀`・,,)っ-○○○:2014/04/22(火) 08:28:07.45 ID:lKj/IS+j
次でHaswellと同じのが8EU載ることになってますけどね
200 :,,・´∀`・,,)っ-○○○:2014/04/22(火) 08:30:47.71 ID:lKj/IS+j
すまん16EUだた
201 :Socket774:2014/04/22(火) 08:40:11.31 ID:pewMNfWy
Cherry Trailは14nm世代じゃん
202 :,,・´∀`・,,)っ-○○○:2014/04/22(火) 08:40:58.31 ID:lKj/IS+j
ブラウザとネイティブ両対応のサービスもあるけど
たいていアプリ版選んでるねみんな。
たとえばギルドの仲間に「ボスが出たよ」みたいなプッシュ通知投げられるのは
ネイティブアプリならではの機能
たいていアプリ版選んでるねみんな。
たとえばギルドの仲間に「ボスが出たよ」みたいなプッシュ通知投げられるのは
ネイティブアプリならではの機能
>>198
その決済の独占による課金ピンハネの味を覚えてしまった…っていうのは、
結構Googleのアイデンティティにとって致命傷になりかねないんじゃないかと思うんだよなw
自分たちの飯の種は人間の活動の収集だったはずなのに…って
その決済の独占による課金ピンハネの味を覚えてしまった…っていうのは、
結構Googleのアイデンティティにとって致命傷になりかねないんじゃないかと思うんだよなw
自分たちの飯の種は人間の活動の収集だったはずなのに…って
Adobe Air comes to x86 Android
http://betanews.com/2014/04/21/adobe-air-comes-to-x86-android/
http://betanews.com/2014/04/21/adobe-air-comes-to-x86-android/
後藤弘茂のWeekly海外ニュース
Intelが「COOL Chips」カンファレンスでIoTソフトウェア戦略を説明
http://pc.watch.impress.co.jp/docs/column/kaigai/20140422_645444.html
Intelが「COOL Chips」カンファレンスでIoTソフトウェア戦略を説明
http://pc.watch.impress.co.jp/docs/column/kaigai/20140422_645444.html
えっ
遅いGPUとのデータのやり取りにソフト階層厚くして墓穴を掘るのがHSA
速いCPUに豊富なソフトウェアライブラリーを選んで使えるのがQuark
速いCPUに豊富なソフトウェアライブラリーを選んで使えるのがQuark
hsaはさらにデブ
>IoTと言っても、ARMの最小のCPUコアである
>Cortex-M系のコアを使うようなデバイスとは根本からソフトウェアの発想が異なることが分かる。
>ちなみに、Cortex-Mは、ARMがMMU(Memory Management Unit)を実装しないため、
>高度な汎用OSを使うことができないという制約がある。
>そのため、Cortex-MベースのIoTデバイスでは、ソフトウェアスタックは
>メタル(チップハードウェア)に近い極めて薄い層が一般的だ。
つまりHSAとかIoTじゃ使われる可能性が0ってことだ
>Cortex-M系のコアを使うようなデバイスとは根本からソフトウェアの発想が異なることが分かる。
>ちなみに、Cortex-Mは、ARMがMMU(Memory Management Unit)を実装しないため、
>高度な汎用OSを使うことができないという制約がある。
>そのため、Cortex-MベースのIoTデバイスでは、ソフトウェアスタックは
>メタル(チップハードウェア)に近い極めて薄い層が一般的だ。
つまりHSAとかIoTじゃ使われる可能性が0ってことだ
いかに80386が優れたオーパーツCPUだったか痛感するね
あの鈍足CPUがか?
386は本格的な32bitマルチタスクOSを動かせるからなぁ
まあ最新Linuxはいまでこそ386サポート打ち切られて486DX等FPUありの486移行しかサポートされてないが、
少し前のLunuxカーネルは386でも動く
まあ最新Linuxはいまでこそ386サポート打ち切られて486DX等FPUありの486移行しかサポートされてないが、
少し前のLunuxカーネルは386でも動く
215 :Socket774:2014/04/22(火) 20:05:51.60 ID:pewMNfWy
当時のMS-DOS一色の時代では同周波数の80286より遅い亀CPUと評価されても仕方ないが、Windowsが64bit版が主流になった今でも使われているx86-32bit命令セットを初めて搭載したCPUと考えれば、非常に重要なCPUであると言えるかも。
まあ、自作PC的には初めてクロックダブラーを採用した80486とか、現在のCoreシリーズやAtomの基本になっているP6マイクロアーキテクチャのPentium Proの方が重要なイメージが強いかもしれないがな。
まあ、自作PC的には初めてクロックダブラーを採用した80486とか、現在のCoreシリーズやAtomの基本になっているP6マイクロアーキテクチャのPentium Proの方が重要なイメージが強いかもしれないがな。
日本で386の時代から自作やってた人はどのくらいいるんだろ
ベーシック的な意味のYES/NOルーチンは全ての言語に共通
218 :,,・´∀`・,,)っ-○○○:2014/04/22(火) 20:38:42.74 ID:lKj/IS+j
コンピュータシステムってのはまず「機能」の要求があって、それの実現のために
プログラムを組むわけだ。
「性能」の要求は機能実現に当たってパフォーマンスの不足が起こってこそ
はじめて起こりうる。
HSAがダメなのは、実現できる機能がよくわからないのに
性能(それすら上位i7に負けうる中途半端さ)だけをアピールしてる点だな。
まあ、一番ダメなのは「ハードが売れてないこと」だけど。
市場シェアの少ないAMDの遅くて電気食いのCPUについてくるおまけで
何かしらができても大してうれしいことって無いんだよ。
そんなニッチなマーケットを相手にするよりCore*やXeonの市場を
狙ったほうが効果は大きいもん。
CPUで十分性能足りてることにGPGPUの需要なんてあるわけがないんだよ
仮に(金にならない)ユーザーが求めてもソフト屋が金にならないと看做したら
それまでよ。
そもそもやつらファンボーイはCore i3未満の低いCPU性能で妥協した時点で
HSAの実現する性能なんてものすら必要としてないという
大いなる矛盾があるのね。
プログラムを組むわけだ。
「性能」の要求は機能実現に当たってパフォーマンスの不足が起こってこそ
はじめて起こりうる。
HSAがダメなのは、実現できる機能がよくわからないのに
性能(それすら上位i7に負けうる中途半端さ)だけをアピールしてる点だな。
まあ、一番ダメなのは「ハードが売れてないこと」だけど。
市場シェアの少ないAMDの遅くて電気食いのCPUについてくるおまけで
何かしらができても大してうれしいことって無いんだよ。
そんなニッチなマーケットを相手にするよりCore*やXeonの市場を
狙ったほうが効果は大きいもん。
CPUで十分性能足りてることにGPGPUの需要なんてあるわけがないんだよ
仮に(金にならない)ユーザーが求めてもソフト屋が金にならないと看做したら
それまでよ。
そもそもやつらファンボーイはCore i3未満の低いCPU性能で妥協した時点で
HSAの実現する性能なんてものすら必要としてないという
大いなる矛盾があるのね。
hsaまだぁ?
http://car.watch.impress.co.jp/docs/news/20140421_645251.html
【GTC2014】リアルタイムレンダリングが可能になったホンダの試作レス確認ツール「TOPS」
Tesla K40×200ユニットのGPUクラスターで実現。新型「フィット」の輪切り映像掲載
http://www.sgi.co.jp/company_info/press_releases/us/1217775_1901.html
SGI、兵士の生命を救う正確でリアルタイムな地理空間レンダリングの提供でGIS FederalおよびNVIDIAと協業
他の計算データベースを凌駕する地理空間データベースを高性能インメモリー・ソリューションで提供
http://car.watch.impress.co.jp/docs/news/20140421_645251.html
【GTC2014】リアルタイムレンダリングが可能になったホンダの試作レス確認ツール「TOPS」
Tesla K40×200ユニットのGPUクラスターで実現。新型「フィット」の輪切り映像掲載
http://www.sgi.co.jp/company_info/press_releases/us/1217775_1901.html
SGI、兵士の生命を救う正確でリアルタイムな地理空間レンダリングの提供でGIS FederalおよびNVIDIAと協業
他の計算データベースを凌駕する地理空間データベースを高性能インメモリー・ソリューションで提供
画像などと言う大きいデータを扱ったら重くなるに決まってる
221 :Socket774:2014/04/22(火) 21:14:30.92 ID:FMexFOrn
222 :,,・´∀`・,,)っ-○○○:2014/04/22(火) 21:14:55.26 ID:lKj/IS+j
「性能を欲する為、ハード・ソフトに金を出すことを厭わない」
そんな積極的に性能を求める層は今Xeonやi7を使ってるでしょ
AMDのプロセッサ愛用者なんて潜在的に金にならない。
安いものしか買えないからな。
ソフトを提供する側も予算をかけられないから、金のかかるAMD独自の
GPGPU技術は極力避けることになる。
宗教上の理由でIntelの高性能CPUが買えない人
「Intelに負けて悔しいからソフト屋さんお願いします」
のほうがまだわかるが、どっかの基地外スレみたいに
「CPU性能は十分」(キリッ
なんていわれたら
「じゃあ性能足りてるならHSA対応も要らないね」
って話になるじゃん
そんな積極的に性能を求める層は今Xeonやi7を使ってるでしょ
AMDのプロセッサ愛用者なんて潜在的に金にならない。
安いものしか買えないからな。
ソフトを提供する側も予算をかけられないから、金のかかるAMD独自の
GPGPU技術は極力避けることになる。
宗教上の理由でIntelの高性能CPUが買えない人
「Intelに負けて悔しいからソフト屋さんお願いします」
のほうがまだわかるが、どっかの基地外スレみたいに
「CPU性能は十分」(キリッ
なんていわれたら
「じゃあ性能足りてるならHSA対応も要らないね」
って話になるじゃん
>>216
386時代は、CPUの上にかぶせてサイリックスとかの486相当?のCPUにするアクセラレータみたいなのが
出回ってたな
486時代は、数値演算コプロセッサのところにつっこむIntel公式のオーバードライブプロセッサとか、
IBMやサイリックスの互換品があった気がする
386時代は、CPUの上にかぶせてサイリックスとかの486相当?のCPUにするアクセラレータみたいなのが
出回ってたな
486時代は、数値演算コプロセッサのところにつっこむIntel公式のオーバードライブプロセッサとか、
IBMやサイリックスの互換品があった気がする
やめてやれよ、ブーメランしか得意技がないんだから>AMD信者
内蔵メモコンのレイテンシがバス越しのintel以下だった時は笑った
内蔵メモコンのレイテンシがバス越しのintel以下だった時は笑った
226 :,,・´∀`・,,)っ-○○○:2014/04/22(火) 21:32:34.41 ID:lKj/IS+j
そんな2〜3年したら廃れるかもしれないハードの実装ありきの
ソフトウェア技術なんてはやったためしがないけどな
しょせん大学の研究室止まり
ソフトウェア技術なんてはやったためしがないけどな
しょせん大学の研究室止まり
227 :Socket774:2014/04/22(火) 21:43:30.37 ID:pewMNfWy
HSAの致命的な問題点は『既存のハードウェアでは一切対応できない』くて『既存のソフトウェアが一切高速化されない』のに、大きなシェアを持つIntelとNVIDIAが対応しないこと。
効果云々以前の問題として、どうやって普及させるんだろう?
効果云々以前の問題として、どうやって普及させるんだろう?
228 :,,・´∀`・,,)っ-○○○:2014/04/22(火) 21:48:46.05 ID:lKj/IS+j
「性能は十分」なんて連呼すること自体、HSA対応ソフトウェアが
AMDの息のかかってないサードパーティから出てくる可能性を
完全否定することになるから、たいがいにしたほうがいい。
AMDerは「低性能で悔しい!」って言い続けたほうがいいよ
AMDの息のかかってないサードパーティから出てくる可能性を
完全否定することになるから、たいがいにしたほうがいい。
AMDerは「低性能で悔しい!」って言い続けたほうがいいよ
プログラマから見た表現・APIとしてはKhronosのOpenCLやSPIRに集約されるのだと思う
HSAとしての独自性はどうでもよくて、ただLLVMのバックエンドがHSAIRに接続されて
さらにAMDネイティブ環境へと変換されていく部分がARM系と共通化されるというだけの話に
要するに、HSAは壮大な野望を秘めた何かではなくて、
AMDとARMでソフトウェアスタックの一部実装を共有しましょうというコミュニティになるんじゃないかなあ
いや、本当にこうなるかは知らんが、軽く調べた感じでは他の未来が見えない
HSAとしての独自性はどうでもよくて、ただLLVMのバックエンドがHSAIRに接続されて
さらにAMDネイティブ環境へと変換されていく部分がARM系と共通化されるというだけの話に
要するに、HSAは壮大な野望を秘めた何かではなくて、
AMDとARMでソフトウェアスタックの一部実装を共有しましょうというコミュニティになるんじゃないかなあ
いや、本当にこうなるかは知らんが、軽く調べた感じでは他の未来が見えない
230 :,,・´∀`・,,)っ-○○○:2014/04/22(火) 21:59:47.72 ID:lKj/IS+j
去年11月12日から一切更新が無いサイトとか見て
さあ「ソフト作ろう」という気になれる独立系ベンダーは皆無
これは間違いない
さあ「ソフト作ろう」という気になれる独立系ベンダーは皆無
これは間違いない
231 :,,・´∀`・,,)っ-○○○:2014/04/22(火) 22:12:45.99 ID:lKj/IS+j
有体に言えば「AMD&ARM連合版のCUDA」だね。
ソフトの対応ではCUDAにおおきく水をあけられてるし、CUDAがやれてること
以上のことは未だ何一つできてない。
Aparapi→JCUDAが既にある
Bolt→Thrustの劣化猿真似
CUDAが流行ってないと感じるのならそれがHSAの潜在的限界でもあるということ。
ソフトの対応ではCUDAにおおきく水をあけられてるし、CUDAがやれてること
以上のことは未だ何一つできてない。
Aparapi→JCUDAが既にある
Bolt→Thrustの劣化猿真似
CUDAが流行ってないと感じるのならそれがHSAの潜在的限界でもあるということ。
そういやgccがopenaccに対応するみたいやね
さきはながいが
さきはながいが
お前らなにトンチンカンなこと言ってるんだ?
HSAの目的はCPUとGPUやDSP間でハードウェア前提で共通のメモリアドレスを扱うことなんだが
LLVMやSPIRとかは、本質じゃないし、AMDやコンパイラ開発者が考えればいいだけ
メモリコピーや別々のポインタとかいう非効率でクソッタレな仕組みを変えるための第一歩だな
HSAと同様のことを考えてるとこなんかいくらもありそうだし、
Intel以外はCPUと同列にGPUを扱いたがってるから、
HSAに類似したシステムも出てくるだろうし、hUMAと同等の機能を搭載したプロセッサの開発も増えていくよ
HSAの目的はCPUとGPUやDSP間でハードウェア前提で共通のメモリアドレスを扱うことなんだが
LLVMやSPIRとかは、本質じゃないし、AMDやコンパイラ開発者が考えればいいだけ
メモリコピーや別々のポインタとかいう非効率でクソッタレな仕組みを変えるための第一歩だな
HSAと同様のことを考えてるとこなんかいくらもありそうだし、
Intel以外はCPUと同列にGPUを扱いたがってるから、
HSAに類似したシステムも出てくるだろうし、hUMAと同等の機能を搭載したプロセッサの開発も増えていくよ
234 :,,・´∀`・,,)っ-○○○:2014/04/23(水) 00:20:05.09 ID:npzZM+Vv
↑お前何とんちんかんなこと言ってるんだ
> メモリコピーや別々のポインタとかいう非効率でクソッタレな仕組み
> を変えるための第一歩だな
で?
それで具体的にどんなソフトが作れるんですか?
IntelではCPUだけで演算すれば足りる演算が、CPU性能が足りないから
GPUを使わなきゃいけない、それをやると不便なことが起こるから
その解決策を用意しただけでしょ。
そんなマッチポンプはソフト開発者に何らメリットをもたらしません。
実際的外れなことをやってるAMDのシェアは低下の一途です。
スマホ・タブレットすら飽和気味になってより小さいIoTにシフトしようとしてる時期に
いまだにパソコンという枠に縛られてつまらない提案しかだせないAMDに
何らイノベーションは起こせんよ。
> メモリコピーや別々のポインタとかいう非効率でクソッタレな仕組み
> を変えるための第一歩だな
で?
それで具体的にどんなソフトが作れるんですか?
IntelではCPUだけで演算すれば足りる演算が、CPU性能が足りないから
GPUを使わなきゃいけない、それをやると不便なことが起こるから
その解決策を用意しただけでしょ。
そんなマッチポンプはソフト開発者に何らメリットをもたらしません。
実際的外れなことをやってるAMDのシェアは低下の一途です。
スマホ・タブレットすら飽和気味になってより小さいIoTにシフトしようとしてる時期に
いまだにパソコンという枠に縛られてつまらない提案しかだせないAMDに
何らイノベーションは起こせんよ。
なんかメモリコピーレスが神格化してないか?
CPU-GPU間のメモリコピーなんてGPGPUプログラマの誰も気にしてないけどAMDerだけが騒いでるという
237 :,,・´∀`・,,)っ-○○○:2014/04/23(水) 00:28:23.21 ID:npzZM+Vv
16コアOpteronがいつまで32nmなんですか?
自分らはXeonと性能競争して苦しい戦いをすることからは逃げたくせに
ソフト屋には性能を引き出すのが難しいプロセッサを出して
最適化しろと苦労を強いようとする。
まあ案の定総スカン状態ですけどね。
リスクから逃げるというAMDの経営理念に従うならば
ソフト屋は「HSAというリスク」を回避するのが当然ですわ。
自分らはXeonと性能競争して苦しい戦いをすることからは逃げたくせに
ソフト屋には性能を引き出すのが難しいプロセッサを出して
最適化しろと苦労を強いようとする。
まあ案の定総スカン状態ですけどね。
リスクから逃げるというAMDの経営理念に従うならば
ソフト屋は「HSAというリスク」を回避するのが当然ですわ。
shared virtual memoryあるいはunified virtual addressingの実現が
HSAによらなければならない必然性がよく分からないし
そもそもメモリコピーしたほうが効率がいい事もあるし
HSAによらなければならない必然性がよく分からないし
そもそもメモリコピーしたほうが効率がいい事もあるし
239 :,,・´∀`・,,)っ-○○○:2014/04/23(水) 00:34:39.00 ID:npzZM+Vv
XeonはSMPに対応してて1ノードに数十のCPUと数百GBのメモリを集積できるけど
Berlinは1ノード・1APUしか使えないから、大規模な演算をしようとしたら
ノード間コピーが発生してものすごく効率が悪くなります。
Berlinは1ノード・1APUしか使えないから、大規模な演算をしようとしたら
ノード間コピーが発生してものすごく効率が悪くなります。
アドレス統合はするけど、キャッシュ、メイン、ローカルの区別はあるみたいだから、
メインからローカルへのコピーも当然出来るよ
そのくらいの仕組みは当然最初から考慮されてる
APUとかのSOC + メインメモリみたいなシンプルなシステムでも一々メモリコピーするのはクソすぎるな
スマフォなんかシングルチャンネルで低速メモリだからな、メモリコピーの弊害が一番強いだろ
メインからローカルへのコピーも当然出来るよ
そのくらいの仕組みは当然最初から考慮されてる
APUとかのSOC + メインメモリみたいなシンプルなシステムでも一々メモリコピーするのはクソすぎるな
スマフォなんかシングルチャンネルで低速メモリだからな、メモリコピーの弊害が一番強いだろ
まあどっちにしろメモリコピーの問題は解決しないといけないね・・・
HSA使わないにしろ
HSA使わないにしろ
242 :,,・´∀`・,,)っ-○○○:2014/04/23(水) 00:55:39.79 ID:npzZM+Vv
一般の多くのGPGPUなんてめんどくさいことやらないから
そんな無駄なことやらずにCPUを強化しろボケ
これだけですよ
サーバでは複数CPUを束ねて大規模な演算をすることも求められるのですが
APU Oopteronは「Ethernetをまたいだコピー」が必要になるんですが?
そんな無駄なことやらずにCPUを強化しろボケ
これだけですよ
サーバでは複数CPUを束ねて大規模な演算をすることも求められるのですが
APU Oopteronは「Ethernetをまたいだコピー」が必要になるんですが?
そうだよな。普通はGPUとCPUがLLCを共有してわざわざ遅いメインメモリなんか使わずにデータをやり取りできるようにするよな。
>>238
> shared virtual memoryあるいはunified virtual addressingの実現が
> HSAによらなければならない必然性がよく分からないし
hUMAみたいなハードウェア実装じゃないと意味ないし、HSAは一番実現に近いというだけで必然じゃないよ
OpenCL2.0でも対応できそうだからね
> そもそもメモリコピーしたほうが効率がいい事もあるし
dGPU積んでるとコピーした方がいい場面も出てくるだろうけど、
メインメモリを共有しているdGPU積んでないシステムだと非効率極まりないな
> shared virtual memoryあるいはunified virtual addressingの実現が
> HSAによらなければならない必然性がよく分からないし
hUMAみたいなハードウェア実装じゃないと意味ないし、HSAは一番実現に近いというだけで必然じゃないよ
OpenCL2.0でも対応できそうだからね
> そもそもメモリコピーしたほうが効率がいい事もあるし
dGPU積んでるとコピーした方がいい場面も出てくるだろうけど、
メインメモリを共有しているdGPU積んでないシステムだと非効率極まりないな
245 :,,・´∀`・,,)っ-○○○:2014/04/23(水) 01:00:36.52 ID:npzZM+Vv
OpteronはCPU32コアでシステムを構築するには従来2ソケットで1台で済んでたのが
新しいAPU版Opteronは8台のサーバを用意しなければならなくなり、
1台に積めるメモリの用量も32GBに制限。
ほかのコアのデータを取ってくるのにEthernet経由でのコピーが必要になりました。
メモリコピーからの開放?とんでもない。
メモリーコピー地獄です。
新しいAPU版Opteronは8台のサーバを用意しなければならなくなり、
1台に積めるメモリの用量も32GBに制限。
ほかのコアのデータを取ってくるのにEthernet経由でのコピーが必要になりました。
メモリコピーからの開放?とんでもない。
メモリーコピー地獄です。
スパコン用だとネットワークが超強力なら1ノード1ソケでも問題ない
むしろ1ノードのCPUを増やしすぎるとネットワークがボトルネックになって効率が落ちる
京も1ノード1ソケだったし
むしろ1ノードのCPUを増やしすぎるとネットワークがボトルネックになって効率が落ちる
京も1ノード1ソケだったし
247 :,,・´∀`・,,)っ-○○○:2014/04/23(水) 01:12:15.35 ID:npzZM+Vv
>>246
京は各コアごとに倍精度4積和のSIMDユニット積んで8〜16コア
ソケットごとにDDR3 6chの広帯域メモリ搭載。
更にTofu Interconnectでつながれたノードを同一メモリ空間として
扱えるようになってるでしょ。
APUはノードをまたいだメモリ空間の統合をハードでサポートしてないはずだけど?
京は各コアごとに倍精度4積和のSIMDユニット積んで8〜16コア
ソケットごとにDDR3 6chの広帯域メモリ搭載。
更にTofu Interconnectでつながれたノードを同一メモリ空間として
扱えるようになってるでしょ。
APUはノードをまたいだメモリ空間の統合をハードでサポートしてないはずだけど?
>>243
たかが数MBのLLCで共有とかかなり限定されるだろ
ちなみにIntelは共有したくないから、eDRAMくっつけている
LLCで共有しているGT2やGT3の性能は、メインメモリで共有しているAPUよりかなり劣っているよ
たかが数MBのLLCで共有とかかなり限定されるだろ
ちなみにIntelは共有したくないから、eDRAMくっつけている
LLCで共有しているGT2やGT3の性能は、メインメモリで共有しているAPUよりかなり劣っているよ
249 :,,・´∀`・,,)っ-○○○:2014/04/23(水) 01:15:56.92 ID:npzZM+Vv
ARMのCTOも言ってたじゃん
HSAはマルチCPUへのスケーラビリティは低くHPC用途には向かないって
HSAはマルチCPUへのスケーラビリティは低くHPC用途には向かないって
>>248
いやGT2やGT3がAPUに負けてるのはシェーダのFLOPSであってCPUとの間のデータ転送速度じゃないでしょ。
そもそもeDRAMはCPUから見たらL4CであってGPUとの共有キャッシュそのものだし。
いやGT2やGT3がAPUに負けてるのはシェーダのFLOPSであってCPUとの間のデータ転送速度じゃないでしょ。
そもそもeDRAMはCPUから見たらL4CであってGPUとの共有キャッシュそのものだし。
251 :,,・´∀`・,,)っ-○○○:2014/04/23(水) 01:30:08.33 ID:npzZM+Vv
http://www.extremetech.com/computing/174632-amd-kaveri-a10-7850k-and-a8-7600-review-was-it-worth-the-wait-for-the-first-true-heterogeneous-chip/5
CPU+GPUの理論FLOPS数合計では7850K(832GFLOPS)>i5-4670S(800GFLOPS弱)
だが実効性能はそうでもなかったようだね
CPU+GPUの理論FLOPS数合計では7850K(832GFLOPS)>i5-4670S(800GFLOPS弱)
だが実効性能はそうでもなかったようだね
仕様を読んでみてるけど、
HSAIRはIRなだけあって、ほとんど具体的なハードウェアを仮定していない
だからまあ、すごいハードウェアがGlobalメモリのコヒーレントをとってくれれば
分散メモリ環境でも効率よく動くのかも……w
とはいえ現実的な想定としてはOpenCLと似たような事しか言ってない雰囲気
HSAIRはIRなだけあって、ほとんど具体的なハードウェアを仮定していない
だからまあ、すごいハードウェアがGlobalメモリのコヒーレントをとってくれれば
分散メモリ環境でも効率よく動くのかも……w
とはいえ現実的な想定としてはOpenCLと似たような事しか言ってない雰囲気
結局HSAって絵に描いた餅を少し焦がして、いい香りを出せただけにとどまっている
美味しいわこれ!とはまだ誰も言うに至ってない
cudaは特定分野でそれを言わせて大規模導入に成功しているがamdにはそれがない
HSAの性能を知らしめるビッグチップはまだかね
そこそこなチップで「我々はマイルストーンを云々」とか言ってないで、はよtitan潰しに全力出せよと
美味しいわこれ!とはまだ誰も言うに至ってない
cudaは特定分野でそれを言わせて大規模導入に成功しているがamdにはそれがない
HSAの性能を知らしめるビッグチップはまだかね
そこそこなチップで「我々はマイルストーンを云々」とか言ってないで、はよtitan潰しに全力出せよと
254 :,,・´∀`・,,)っ-○○○:2014/04/23(水) 01:44:57.96 ID:npzZM+Vv
分散メモリ環境で動くものなんてせいぜいHadoopがいいところでしょ
SeaMicroも一応Hadoopにも向くようなネットワーク構造だから
技術的にミスマッチはないようには見えるが
SeaMicroも一応Hadoopにも向くようなネットワーク構造だから
技術的にミスマッチはないようには見えるが
日本でGPGPUが使われそうな分野って、
画像認識・顔認証とかそっち方面だと思う
それなりに市場規模が見込めるので、GPGPU化しても十分ペイできそうだし
画像認識・顔認証とかそっち方面だと思う
それなりに市場規模が見込めるので、GPGPU化しても十分ペイできそうだし
問題はそれが広く使われる時には固定機能として専用ユニット化されてカメラコントローラーに内蔵されるってことかな。
GPGPUが有効そうなのは画像と動画と3D全般だろ
SSEやAVXの得意分野と大体重なる
SSEやAVXの得意分野と大体重なる
386という数字を見るとどうしてもBSD/386を思い出すw
固定機能の専用ユニットは正直高くつく事多いからあんまり好きじゃない
GPGPUに対抗する秘策
SkylakeでKnights Landingのコアと同等の機能をもったAtomにEUの代わりをさせる
そのほかの部分はIrisを受け継げばGPUとしての効率はLarrabeeよりよくなるはず
おまけにローエンドからハイエンドまでXeon Phiとして売れる
SkylakeでKnights Landingのコアと同等の機能をもったAtomにEUの代わりをさせる
そのほかの部分はIrisを受け継げばGPUとしての効率はLarrabeeよりよくなるはず
おまけにローエンドからハイエンドまでXeon Phiとして売れる
261 :Socket774:2014/04/23(水) 02:30:54.72 ID:RD6yzqVA
NVIDIAがFXドライヤーの頃からしていたGPGPUへの努力が実って、TeslaやQuadroが好調。
その市場に割り込みたいけど、CUDAで標準化されていて無理。
OpenCLを推進したところで、CUDAもOpenCLも使えるNVIDIAのシェアは奪えない。
『CUDAを使えない』ようにした、GPGPUのための新たな標準規格が欲しい。
というのがHSAの本質だろ。
IntelにしてもNVIDIAにしてもHSAに参加する商業的なメリットが無く、最低でもその2社の内どちらかの参加が無ければPC/WSでは普及しようが無いのだから、HSAというのはその構造以前の問題として戦略的に敗北している。
その市場に割り込みたいけど、CUDAで標準化されていて無理。
OpenCLを推進したところで、CUDAもOpenCLも使えるNVIDIAのシェアは奪えない。
『CUDAを使えない』ようにした、GPGPUのための新たな標準規格が欲しい。
というのがHSAの本質だろ。
IntelにしてもNVIDIAにしてもHSAに参加する商業的なメリットが無く、最低でもその2社の内どちらかの参加が無ければPC/WSでは普及しようが無いのだから、HSAというのはその構造以前の問題として戦略的に敗北している。
Teslaが28nmで停滞しているうちにKnights Landingがでますよ
CUDAは短い天下だったね
CUDAは短い天下だったね
263 :Socket774:2014/04/23(水) 03:05:15.31 ID:iLtITvgs
>>237
AMDは一気に14nmにいくよ
【PC】AMDの14nmプロセッサ、Samsungで製造か[2014/04/22]
http://anago.2ch.net/test/read.cgi/bizplus/1398161914/
AMDは一気に14nmにいくよ
【PC】AMDの14nmプロセッサ、Samsungで製造か[2014/04/22]
http://anago.2ch.net/test/read.cgi/bizplus/1398161914/
FireProは倍精度2.6Tだからなあ
TeslaとPhiは2T超えてないだろ
所詮HPCは性能最優先だからシェア伸ばすのは時間の問題だな
TeslaとPhiは2T超えてないだろ
所詮HPCは性能最優先だからシェア伸ばすのは時間の問題だな
>>261
結局グラボとAPUに専念って流れになりそうねAMDは
APUがグラボ付きでWindows8でCorei3+GPUと同じぐらいになる実用的な速度になればいいが、難しいだろうし
APUと小型PCでの使用は悪くないとは思うよ、Intelの苦手なグラフィック面での信用に強いし
(androidのATOMには信頼性の高いPowerVR使うぐらいだからドライバ面は物好きが使う未成熟扱いでいいと思う)
結局グラボとAPUに専念って流れになりそうねAMDは
APUがグラボ付きでWindows8でCorei3+GPUと同じぐらいになる実用的な速度になればいいが、難しいだろうし
APUと小型PCでの使用は悪くないとは思うよ、Intelの苦手なグラフィック面での信用に強いし
(androidのATOMには信頼性の高いPowerVR使うぐらいだからドライバ面は物好きが使う未成熟扱いでいいと思う)
fermi末期でもamdの方が数字は大きかったよ
で、どうなりましたかw
で、どうなりましたかw
TDP25W でTDP10Wのセロリン並の性能だっけ?
>>265
i3どころかi7-3960Xとの比較でこの程度の差しかないよ
http://www.pcper.com/reviews/General-Tech/AMD-AM1-Platform-and-Athlon-5350-GTX-750-Ti-1080p-under-450
i3どころかi7-3960Xとの比較でこの程度の差しかないよ
http://www.pcper.com/reviews/General-Tech/AMD-AM1-Platform-and-Athlon-5350-GTX-750-Ti-1080p-under-450
>>269
そりゃゲーム性能に限ればだろ
ブラウザとか実務上の性能はグラボに頼れないから劣る
逆に言えばブラウザも動画も全部GPU偏重になるかHSAで管理すれば、
ある程度は普段使いの性能も補えてリビングはAMDが強いってことになりそう
その前にIntelがGPU強化が間に合うかの勝負だな
そりゃゲーム性能に限ればだろ
ブラウザとか実務上の性能はグラボに頼れないから劣る
逆に言えばブラウザも動画も全部GPU偏重になるかHSAで管理すれば、
ある程度は普段使いの性能も補えてリビングはAMDが強いってことになりそう
その前にIntelがGPU強化が間に合うかの勝負だな
全てが妄想なのがすごい
272 :,,・´∀`・,,)っ-○○○:2014/04/23(水) 07:43:53.79 ID:npzZM+Vv
>>260
だからさ、所詮デュアルチャネルの狭い帯域でXeon Phi載せても意味ねーだろ?
DDR4デュアルチャネルの帯域なんて最大でも現行DDR3の2倍ほどなんだし
AVX2の更に2倍+αの理論性能を弾き出せるAVX-512だけでお腹いっぱいでしょ。
帯域が足りないまま演算ユニットを増やしても
少ない入出力データの数に対して演算回数がバカみたいに多い処理
たとえば暗号のクラック(→コイン掘りにも流用されてる)くらいしか
使い道が無くて頭打ちになるよ。
帯域ネックの処理ではそれこそCeleron+廉価なMaxwellの組み合わせ
にすら負けかねない。
無駄にコストかけるくらいなら安く抑えたほうが理にかなってる。
だからさ、所詮デュアルチャネルの狭い帯域でXeon Phi載せても意味ねーだろ?
DDR4デュアルチャネルの帯域なんて最大でも現行DDR3の2倍ほどなんだし
AVX2の更に2倍+αの理論性能を弾き出せるAVX-512だけでお腹いっぱいでしょ。
帯域が足りないまま演算ユニットを増やしても
少ない入出力データの数に対して演算回数がバカみたいに多い処理
たとえば暗号のクラック(→コイン掘りにも流用されてる)くらいしか
使い道が無くて頭打ちになるよ。
帯域ネックの処理ではそれこそCeleron+廉価なMaxwellの組み合わせ
にすら負けかねない。
無駄にコストかけるくらいなら安く抑えたほうが理にかなってる。
273 :,,・´∀`・,,)っ-○○○:2014/04/23(水) 07:47:45.43 ID:npzZM+Vv
>>262
http://www.hpc.co.jp/benchmark20140422.html
問題サイズが小さいときは Xeon Phi の性能が Tesla に迫ります。サイズが大きくなるとXeon Phi は性能が急速に劣化しますが、
Teslaは理論通りの O(N2) に近いスケーラビリティを保ちます。
処理内容が比較的単純な密度計算は Xeon Phi でも理論通りにスケーラブルですが、
複雑度が増す圧力計算の性能劣化が Tesla に比べて Xeon Phi で大きくなっており、
「単純なタスクに強いがタスクが複雑になると性能が落ちる」という GPGPUのイメージに近いのは
むしろ Xeon Phi であると言える結果になっています。
http://www.hpc.co.jp/benchmark20140422.html
問題サイズが小さいときは Xeon Phi の性能が Tesla に迫ります。サイズが大きくなるとXeon Phi は性能が急速に劣化しますが、
Teslaは理論通りの O(N2) に近いスケーラビリティを保ちます。
処理内容が比較的単純な密度計算は Xeon Phi でも理論通りにスケーラブルですが、
複雑度が増す圧力計算の性能劣化が Tesla に比べて Xeon Phi で大きくなっており、
「単純なタスクに強いがタスクが複雑になると性能が落ちる」という GPGPUのイメージに近いのは
むしろ Xeon Phi であると言える結果になっています。
275 :,,・´∀`・,,)っ-○○○:2014/04/23(水) 08:06:17.73 ID:npzZM+Vv
複雑と言ってもTeslaで実装できてる処理について論じてるにすぎないからな。
できてるものなら先行するTeslaのほうがチューンされてても仕方ない。
複雑のうちに入らないよ。
それよりもっと複雑な処理、たとえばApacheやnginxをTeslaに移植できるか?
Phiならやろうと思えばできる。
できてるものなら先行するTeslaのほうがチューンされてても仕方ない。
複雑のうちに入らないよ。
それよりもっと複雑な処理、たとえばApacheやnginxをTeslaに移植できるか?
Phiならやろうと思えばできる。
277 :,,・´∀`・,,)っ-○○○:2014/04/23(水) 08:33:53.66 ID:npzZM+Vv
Phiはそういうことすら使える汎用性の高さで利用が急速に広がってるんだけどな
データの圧縮・展開すらホストに頼らずにできるのは強みだよ
データの圧縮・展開すらホストに頼らずにできるのは強みだよ
CPUだしね
仮想化でリモートデスクトップのサーバーとかも使えそうなきもする
仮想化でリモートデスクトップのサーバーとかも使えそうなきもする
279 :,,・´∀`・,,)っ-○○○:2014/04/23(水) 09:03:02.24 ID:npzZM+Vv
vSMP Foundationがかなりのキラーソフトですな。
指摘の通りx86ベースのCPUだからホストのメモリ空間に統合できる。
Phiを4枚刺したXeonサーバを更に4台Infinibandで繋げて
1000コア以上からなる仮想ノードも作れる。
その点、APUサーバのサーバ・HPC利用はかなり限定的なものになる。
FireProをOpteronのHyperTransport接続してメモリコヒーレンシとれるように
やりゃマルチソケット環境でHSAが構築できるだろうにそれをやらない。
技術もビジョンも無い。
指摘の通りx86ベースのCPUだからホストのメモリ空間に統合できる。
Phiを4枚刺したXeonサーバを更に4台Infinibandで繋げて
1000コア以上からなる仮想ノードも作れる。
その点、APUサーバのサーバ・HPC利用はかなり限定的なものになる。
FireProをOpteronのHyperTransport接続してメモリコヒーレンシとれるように
やりゃマルチソケット環境でHSAが構築できるだろうにそれをやらない。
技術もビジョンも無い。
Knights LandingはLRBniとAVX-512の両方の命令群をサポートするって事になるのかな?
モデルチェンジいつ?
6月くらい?
6月くらい?
SIMD強化とCPUコア増加とGPUコア増加
どれが正解なの
素人から見るとGPUの有効活用しようぜっていう雰囲気に感じるけど
実は袋小路なの?
どれが正解なの
素人から見るとGPUの有効活用しようぜっていう雰囲気に感じるけど
実は袋小路なの?
例えば10年後のPCとかタブレットでは
CPU100コアとか200コアが当たり前になってGPUはそこまで重要じゃないというふうになったりするのかな
CPU100コアとか200コアが当たり前になってGPUはそこまで重要じゃないというふうになったりするのかな
>>282
全部だろ
>>283
逆だよ
動画や画像とかのコンテンツがリッチになって解像度も増えるからGPUの重要度は上がる
CPUが100コアならGPUは1000コアとかになるから、並列度でCPUはGPUには絶対勝てない
全部だろ
>>283
逆だよ
動画や画像とかのコンテンツがリッチになって解像度も増えるからGPUの重要度は上がる
CPUが100コアならGPUは1000コアとかになるから、並列度でCPUはGPUには絶対勝てない
数年前は2020年までにCPU32コアとか言われてたなあ。。。
リッチなコンテンツの極みである8K動画再生にはどのくらいのGPUパワーが必要なんだろう?
リッチなコンテンツの極みである8K動画再生にはどのくらいのGPUパワーが必要なんだろう?
再生なら余裕だろ
8k/HEVC対応の動画再生支援回路を積むなら、再生できるようになるまで速いと思う
そういった動画再生支援回路使わずに汎用的な利用法で8k描画は当面難しそう
そういった動画再生支援回路使わずに汎用的な利用法で8k描画は当面難しそう
ついにインテルスレでもGPGPUの話か・・・
ぶっちゃけcoreシリーズもAVXの拡張くらいじゃ買い替え需要はつくれなそーだし
ヘテロにいくんじゃね、結局w
ぶっちゃけcoreシリーズもAVXの拡張くらいじゃ買い替え需要はつくれなそーだし
ヘテロにいくんじゃね、結局w
使い道もないのにgpgpuで買い換えなんて起こらない
290 :,,・´∀`・,,)っ-○○○:2014/04/23(水) 19:42:08.29 ID:npzZM+Vv
GPGPUが買い替え需要を作れた例なんてないけどな
FPGAにハードウェア浮動小数点DSP内蔵、電力効率でGPGPUの上を行く
ttp://eetimes.jp/ee/articles/1404/23/news063.html
...snip... Stratix 10で最大10T FLOPSを実現できるという
ttp://eetimes.jp/ee/articles/1404/23/news063.html
...snip... Stratix 10で最大10T FLOPSを実現できるという
292 :,,・´∀`・,,)っ-○○○:2014/04/23(水) 19:53:35.18 ID:npzZM+Vv
グラフィック以外でのGPGPUって
ニーズが少なすぎて採算があわないか
ニーズが普遍化する頃にはより効率のいい固定ハードが出てきて
結局使い物にならなくなるかのパターンが多いんだよね
AES-NI、QSV、RDRAND、その他諸々。
アプリケーションに特化した機能を追加する方向でいいんじゃないから
ソフト屋が使いにくいハードなんて出したところで最終的には消費者が損をする
ニーズが少なすぎて採算があわないか
ニーズが普遍化する頃にはより効率のいい固定ハードが出てきて
結局使い物にならなくなるかのパターンが多いんだよね
AES-NI、QSV、RDRAND、その他諸々。
アプリケーションに特化した機能を追加する方向でいいんじゃないから
ソフト屋が使いにくいハードなんて出したところで最終的には消費者が損をする
293 : ◆miyuri//Z7LS :2014/04/23(水) 19:54:40.85 ID:Bhu4Vkya
294 :,,・´∀`・,,)っ-○○○:2014/04/23(水) 20:01:41.39 ID:npzZM+Vv
> 新規のアクセラレータ的な意味ならMMX。
CPUじゃん
いつGPUの機能になったんですか?
MMX以降、ソフトウェア音源が台頭し、サウンドカードが駆逐された。
結局、コストダウンにつながる技術は浸透する。
GPGPUは何のコストを下げてくれるんですかね?
ソフトウェアの開発コストが上がったわりに需要がなさすぎて
コストダウンになりえないから
スパコン業界を見ろ、2010年をピークにトップ500に占めるGPGPU
搭載スパコンの数は減少を続けている。
AVXがGPGPUの需要を奪った。
まるでサウンドカードのときみたいだね。
CPUじゃん
いつGPUの機能になったんですか?
MMX以降、ソフトウェア音源が台頭し、サウンドカードが駆逐された。
結局、コストダウンにつながる技術は浸透する。
GPGPUは何のコストを下げてくれるんですかね?
ソフトウェアの開発コストが上がったわりに需要がなさすぎて
コストダウンになりえないから
スパコン業界を見ろ、2010年をピークにトップ500に占めるGPGPU
搭載スパコンの数は減少を続けている。
AVXがGPGPUの需要を奪った。
まるでサウンドカードのときみたいだね。
>>291
うまくハマれば1〜2桁ぐらい電力効率は良くなるはずだが、
現状のFPGAはソフトウェア屋が卒倒するほど開発効率が悪い上に高価
だからまあ、少なくとも当分はメインストリームではなくて補完的に使われるだろうと思う
うまくハマれば1〜2桁ぐらい電力効率は良くなるはずだが、
現状のFPGAはソフトウェア屋が卒倒するほど開発効率が悪い上に高価
だからまあ、少なくとも当分はメインストリームではなくて補完的に使われるだろうと思う
296 :,,・´∀`・,,)っ-○○○:2014/04/23(水) 21:17:20.54 ID:npzZM+Vv
> ソフトウェア屋が卒倒するほど開発効率が悪い
VHDLって悪名高いAdaベースだしねwww
いまOpenCLで開発できるからGPGPUとそれほど開発効率は変わらないが
OpenCLもまた卒倒するほど開発効率が悪い言語のひとつだから
結局同じか
VHDLって悪名高いAdaベースだしねwww
いまOpenCLで開発できるからGPGPUとそれほど開発効率は変わらないが
OpenCLもまた卒倒するほど開発効率が悪い言語のひとつだから
結局同じか
>>295
試作品を作って、成功してたくさん売れるようになったら同じHDLでASICを起こすことが出来るようになるんだよ。
なら、浮動小数点まで実装していれば楽が出来る。
でかいルータだと、使う機能によってリコンフィグしてハードを有効利用するという使い道もある。
同じ箱がUTMにもルータにもなる。
試作品を作って、成功してたくさん売れるようになったら同じHDLでASICを起こすことが出来るようになるんだよ。
なら、浮動小数点まで実装していれば楽が出来る。
でかいルータだと、使う機能によってリコンフィグしてハードを有効利用するという使い道もある。
同じ箱がUTMにもルータにもなる。
>>292
AES-NI的なSSLアクセラレーション命令やら、乱数生成系命令って、スマホ・タブレット用チップやら、
組み込みネットワーク機器用チップで必要だと思う
スマホ・タブは高速化・消費電力削減、ネットワーク機器じゃSSLやVPNのスループット向上のために
デスクトップ用チップじゃ、べつにそんなの使わなくてもじゅうぶんな処理能力がある
いちばん必要なサーバ用チップはすでにそういったのに対応済み
AES-NI的なSSLアクセラレーション命令やら、乱数生成系命令って、スマホ・タブレット用チップやら、
組み込みネットワーク機器用チップで必要だと思う
スマホ・タブは高速化・消費電力削減、ネットワーク機器じゃSSLやVPNのスループット向上のために
デスクトップ用チップじゃ、べつにそんなの使わなくてもじゅうぶんな処理能力がある
いちばん必要なサーバ用チップはすでにそういったのに対応済み
シリコンからの脱却早くしろ
非シリコン半導体は、現状シリコンみたいな微細化・低コスト化が不可能
トランジスタ数が現状の1000分の1のCPUとかなら、非シリコンでもいけるだろうけど、
トランジスタ数1000分の1なら、たとえクロック周波数10GHzにできたとしてもかなり低速化するんじゃね?
トランジスタ数が現状の1000分の1のCPUとかなら、非シリコンでもいけるだろうけど、
トランジスタ数1000分の1なら、たとえクロック周波数10GHzにできたとしてもかなり低速化するんじゃね?
VHDLで組んでるが、たしかに卒倒するほど効率が悪い。
GPGPUのほうが遥かにマシだ。
GPGPUのほうが遥かにマシだ。
団子がAVX凄いマンセーしてるけど、
SSEからAVX、AVXからAVX2で何が変わったのか正直分からないんだよな
SSEからAVXでSIMDの実性能って倍は変わってないよね、良くて5割位じゃないか?
そしてAVX2採用で実質変わったのって、256bit整数使うエンコ位だろ
こんな状態でAVX512が出てきたとして、一体何に恩恵があるんだろうか
そしてFMA3は一体何処に行ってしまったのか
SSEからAVX、AVXからAVX2で何が変わったのか正直分からないんだよな
SSEからAVXでSIMDの実性能って倍は変わってないよね、良くて5割位じゃないか?
そしてAVX2採用で実質変わったのって、256bit整数使うエンコ位だろ
こんな状態でAVX512が出てきたとして、一体何に恩恵があるんだろうか
そしてFMA3は一体何処に行ってしまったのか
てかなんで勝手にスレタイ改ざんしてんだろ
別にどこにも行ってないが>FMA3
とりあえず最低限の回路規模でQSVにHEVCエンコ・デコ機能さっさとのっけちゃえば良いんだよ
APIは同じままでCPU世代上がる毎に規模拡大・改良してけば買い替えも進む上に互換性もあって良し
APIは同じままでCPU世代上がる毎に規模拡大・改良してけば買い替えも進む上に互換性もあって良し
>>302
hpcで恩恵がある
hpcで恩恵がある
>>303
もうCPUだけでホルホルしてればいい時代じゃないのよ
もうCPUだけでホルホルしてればいい時代じゃないのよ
SoCと呼ばれてるものがそのうちCPUという名前になっていくんだろうね
x87-FPUが統合されるかどうかの過渡期のように
x87-FPUが統合されるかどうかの過渡期のように
ならないよw
CPUという名前が廃れるだけ
CPUという名前が廃れるだけ
eDRAMとPCHのダイ統合はよ!!
既存ソフトでパフォーマンスあげたいんななら
クロックなりキャッシュを上げてシングルスレッドパフォーマンスあげるしかない
あとはリスク覚悟でcpuにバイナリートランスレータを入れて
cpuなりgpuなりavxなりfpgaなりに最適化すればいい
クロックなりキャッシュを上げてシングルスレッドパフォーマンスあげるしかない
あとはリスク覚悟でcpuにバイナリートランスレータを入れて
cpuなりgpuなりavxなりfpgaなりに最適化すればいい
>>310
だって、セントラルプロセッシングユニットだよ? 中央処理装置、CPUメーカーが色々頑張る限り全然言葉が古くならない
システムオンチップじゃ「そんなの当たり前じゃん」って言われて、それを達成したら途端に言葉が古くなるし石自体を表わす言葉じゃないし
だって、セントラルプロセッシングユニットだよ? 中央処理装置、CPUメーカーが色々頑張る限り全然言葉が古くならない
システムオンチップじゃ「そんなの当たり前じゃん」って言われて、それを達成したら途端に言葉が古くなるし石自体を表わす言葉じゃないし
314 :,,・´∀`・,,)っ-○○○:2014/04/24(木) 07:06:26.53 ID:GloLfo6U
>>302
命令セットの拡張が無駄だと思ってるだろ?
複数のソフトベンダーにヒヤリングを行いつつ必要な機能を選んで
実装してるわけで無駄なものなんてありはしないよ。
しがないPCオタクが容易に価値を理解できるようなものじゃない。
AMDのSSE4Aってたしか4命令くらいあったけど、VEX/XOPで
再エンコーディングされた命令ってあるの?
AVX(YMMステート)と混ぜて使うときに部分レジスタ書き込みの
ペナルティが生じるのでYMM上位を明示的にクリアしてやる
必要があるのだが。
実際それがされてない。
あれは本当に使う価値のない無駄な命令なんだろうな。
Jaguarでもサポートされてない。
逆にCarrizoではAVX2をサポートする。これは、必要だと認めたってことだ。
結局AMDには権限なんてものはない。
ソフト業界が「GPGPUなんて使ってられっかー」って言ったら
AMDはこれ以上HSAを推すことはできない。
それは宿命だよ。
命令セットの拡張が無駄だと思ってるだろ?
複数のソフトベンダーにヒヤリングを行いつつ必要な機能を選んで
実装してるわけで無駄なものなんてありはしないよ。
しがないPCオタクが容易に価値を理解できるようなものじゃない。
AMDのSSE4Aってたしか4命令くらいあったけど、VEX/XOPで
再エンコーディングされた命令ってあるの?
AVX(YMMステート)と混ぜて使うときに部分レジスタ書き込みの
ペナルティが生じるのでYMM上位を明示的にクリアしてやる
必要があるのだが。
実際それがされてない。
あれは本当に使う価値のない無駄な命令なんだろうな。
Jaguarでもサポートされてない。
逆にCarrizoではAVX2をサポートする。これは、必要だと認めたってことだ。
結局AMDには権限なんてものはない。
ソフト業界が「GPGPUなんて使ってられっかー」って言ったら
AMDはこれ以上HSAを推すことはできない。
それは宿命だよ。
>>313
GPUや専用回路の面積が増えてきてCPUという単語を推す意味なんて無い
GPUや専用回路の面積が増えてきてCPUという単語を推す意味なんて無い
316 :,,・´∀`・,,)っ-○○○:2014/04/24(木) 07:22:28.53 ID:GloLfo6U
これは重要なことだけど
IntelはCPUのAVX命令を使うOpenCLランタイムを提供しているので、
ソフト屋がGPGPU対応のコードを書けば、Intelの提供するランタイムによって
自動的に新しいAVX命令にも対応できる。
逆に明示的にAVX*のコードをダイレクトに記述したた場合には
GPGPUには対応できない。
つまりAVX*はGPGPU(OpenCL)に対して上位互換の関係を持つので
PCでの普及度では絶対にGPGPUに負けない。
これ重要よ。
IntelはCPUのAVX命令を使うOpenCLランタイムを提供しているので、
ソフト屋がGPGPU対応のコードを書けば、Intelの提供するランタイムによって
自動的に新しいAVX命令にも対応できる。
逆に明示的にAVX*のコードをダイレクトに記述したた場合には
GPGPUには対応できない。
つまりAVX*はGPGPU(OpenCL)に対して上位互換の関係を持つので
PCでの普及度では絶対にGPGPUに負けない。
これ重要よ。
>>315
言ったら「足し算演算器」だって専用回路だけどね、足し算の
「足し算演算器」と「浮動小数点足し算演算器」と「AES演算器」と「H264演算器」と「テクスチャ補間演算器」という専用回路が
並列に置いてあるのがCPUって事になっていくんだろうね
言ったら「足し算演算器」だって専用回路だけどね、足し算の
「足し算演算器」と「浮動小数点足し算演算器」と「AES演算器」と「H264演算器」と「テクスチャ補間演算器」という専用回路が
並列に置いてあるのがCPUって事になっていくんだろうね
319 :,,・´∀`・,,)っ-○○○:2014/04/24(木) 07:46:21.22 ID:GloLfo6U
>>306
新しいMediaSDKにHEVCのサポートが追加されてるよ。
Haswellでも使えるからソフト実装みたいだけど、同じAPIを呼ぶだけで
将来のハード実装にもアクセスできるようになってるみたい。
新しいMediaSDKにHEVCのサポートが追加されてるよ。
Haswellでも使えるからソフト実装みたいだけど、同じAPIを呼ぶだけで
将来のハード実装にもアクセスできるようになってるみたい。
>>319
いやー素晴らしいねIntel、良くわかっていらっしゃる
いやー素晴らしいねIntel、良くわかっていらっしゃる
321 :,,・´∀`・,,)っ-○○○:2014/04/24(木) 07:57:33.50 ID:GloLfo6U
322 :,,・´∀`・,,)っ-○○○:2014/04/24(木) 08:58:34.08 ID:GloLfo6U
Skylakeの魅力はAVX-512だけじゃないですよ
BOUND命令がかなり強力ですわ。
高級言語においては、配列アクセス時に添字が範囲内に収まってるかをチェックして
収まってなければ例外を吐いたり、配列のサイズを変えなければいけない。
これはボトルネックの代表例。
(JavaScriptでもJavaでもRubyでもPHPでも、ね)
バウンダリチェック用に専用レジスタを4本(上限・下限としてカウントすれば8本分)
用意したことで汎用レジスタに余裕ができるのでかなり効率的なコードが書ける。
IntelはJavaScriptの最適化なんかにも着手してるから
こういう問題に対処するようになったわけだ。
「ハードの性能を引き出すためにみんなCやOpenCLで書けばいいじゃん」は
ハード屋としては理想ではあるが現実には程遠いから
こういうアプローチはすごく大事。
BOUND命令がかなり強力ですわ。
高級言語においては、配列アクセス時に添字が範囲内に収まってるかをチェックして
収まってなければ例外を吐いたり、配列のサイズを変えなければいけない。
これはボトルネックの代表例。
(JavaScriptでもJavaでもRubyでもPHPでも、ね)
バウンダリチェック用に専用レジスタを4本(上限・下限としてカウントすれば8本分)
用意したことで汎用レジスタに余裕ができるのでかなり効率的なコードが書ける。
IntelはJavaScriptの最適化なんかにも着手してるから
こういう問題に対処するようになったわけだ。
「ハードの性能を引き出すためにみんなCやOpenCLで書けばいいじゃん」は
ハード屋としては理想ではあるが現実には程遠いから
こういうアプローチはすごく大事。
それ、へぼ・プログラマー向けの機能やん。
ほとんどがへぼだという現実があるからな……
世界にスーパープログラマだけしかいなければいいんだが決してそんなことにはならないだろうし
世界にスーパープログラマだけしかいなければいいんだが決してそんなことにはならないだろうし
ハード屋がAPI屋に売り込めば良い
326 :Socket774:2014/04/24(木) 12:23:42.93 ID:rIk7zwM/
プログラマーがミスらない前提の実行エンジンはヘボじゃないのか
http://www.forbes.com/sites/alexkonrad/2014/04/23/ibm-debuts-new-power-servers-and-new-open-platform-partnership-with-google/
IBM Spends $2.4 Billion On New Power Servers And Partners With Google And Nvidia To Go After Intel
http://www-06.ibm.com/jp/press/2014/04/2401.html
オープン・イノベーションでビッグデータの課題に挑むPOWER
IBM Spends $2.4 Billion On New Power Servers And Partners With Google And Nvidia To Go After Intel
http://www-06.ibm.com/jp/press/2014/04/2401.html
オープン・イノベーションでビッグデータの課題に挑むPOWER
スーパープログラマはへぼでも使いやすいコンパイラやエンジンを作っているだろ
http://jun-makino.sakura.ne.jp/Journal/journal-2014-04.html#23
引用:単精度浮動小数点演算の理論上の性能として、Arria 10では最大1.5TFLOPS、Stratix 10では最大10TFLOPSを得られる。
電力性能ははGPUよりいいと思うんだけど、価格性能比がねえ、、、 Stratix 10 の最大サイズのチップって多分1個100万円とかだし。
しかし、そういうわけでエクサスケールスパコンは大変なわけである。
これは、プロセッサアーキテクチャを演算あたりの消費電力が下がる側に ふる、
つまり、演算器以外のコアロジックを単純化するとか SIMD 幅を増やす とかしないと
消費電力が現実的な範囲に収まらなくなってくることを意味する。
10nm といってるものが実質11だとしても、0.7V まで下げたとして 電力性能は 45nm の6.8 倍である。
なので、アーキテクチャで7倍あげて、エクサになって電力が「京」の2倍 にはいる。
じゃあ7倍かせげるか?というと、「京」と同じ 40nm 世代の GPU だっ て3倍もいかないわけで
まともにやったのでは到底無理である。
実際問題とし ては SIMD 幅をいくら増やしても2倍ちょっと改善すれば万歳であろう。
つまり、汎用プロセッサでものすごく SIMD 幅を増やしたもの (まあ要するに Intel MIC みたいなもの)では
エクサスケールでは消費電力が 60-100MW になる。
空調とか入れるともっと増える。
原発0.1基分くらい。
関西電力の販売電力量は年間平均では 1700万KW、つまり、17,000MW な ので、その 0.3-0.6%にもなる。
電気代だけで100億円くらい。
というわけでGRAPE-X/PACS-Gの宣伝でした
引用:単精度浮動小数点演算の理論上の性能として、Arria 10では最大1.5TFLOPS、Stratix 10では最大10TFLOPSを得られる。
電力性能ははGPUよりいいと思うんだけど、価格性能比がねえ、、、 Stratix 10 の最大サイズのチップって多分1個100万円とかだし。
しかし、そういうわけでエクサスケールスパコンは大変なわけである。
これは、プロセッサアーキテクチャを演算あたりの消費電力が下がる側に ふる、
つまり、演算器以外のコアロジックを単純化するとか SIMD 幅を増やす とかしないと
消費電力が現実的な範囲に収まらなくなってくることを意味する。
10nm といってるものが実質11だとしても、0.7V まで下げたとして 電力性能は 45nm の6.8 倍である。
なので、アーキテクチャで7倍あげて、エクサになって電力が「京」の2倍 にはいる。
じゃあ7倍かせげるか?というと、「京」と同じ 40nm 世代の GPU だっ て3倍もいかないわけで
まともにやったのでは到底無理である。
実際問題とし ては SIMD 幅をいくら増やしても2倍ちょっと改善すれば万歳であろう。
つまり、汎用プロセッサでものすごく SIMD 幅を増やしたもの (まあ要するに Intel MIC みたいなもの)では
エクサスケールでは消費電力が 60-100MW になる。
空調とか入れるともっと増える。
原発0.1基分くらい。
関西電力の販売電力量は年間平均では 1700万KW、つまり、17,000MW な ので、その 0.3-0.6%にもなる。
電気代だけで100億円くらい。
というわけでGRAPE-X/PACS-Gの宣伝でした
Intel、GPUクロックを約16%高めたAtom 3775/3745
〜ベース1.66GHz駆動の最上位SKU Atom Z3795も
http://pc.watch.impress.co.jp/docs/news/20140424_645825.html
〜ベース1.66GHz駆動の最上位SKU Atom Z3795も
http://pc.watch.impress.co.jp/docs/news/20140424_645825.html
ttp://viper.2ch.net/test/read.cgi/news4vip/1398260134/
113 名前:以下、転載禁止でVIPがお送りします[sage] 投稿日:2014/04/24(木) 15:17:45.37 ID:Zi0M/CZG0
いや、別にどうでもいいけど
いつもは発表=発売を続けてたので
今回発表=発売じゃなかったからまだ発表してなくねっていったんだけど
何か発表の意味がそれぞれで違うし説明するのもメンドクサイし
脳内の思考ルーチンがIQが高いので人と合わないことはわかってるからどうでもいい
113 名前:以下、転載禁止でVIPがお送りします[sage] 投稿日:2014/04/24(木) 15:17:45.37 ID:Zi0M/CZG0
いや、別にどうでもいいけど
いつもは発表=発売を続けてたので
今回発表=発売じゃなかったからまだ発表してなくねっていったんだけど
何か発表の意味がそれぞれで違うし説明するのもメンドクサイし
脳内の思考ルーチンがIQが高いので人と合わないことはわかってるからどうでもいい
>>308
次スレはSOCだけでよさそう
次スレはSOCだけでよさそう
マルチコアやめてシングルで10ギガくらいの
出してほしい。
ゲームは基本的にシングルだからな。
出してほしい。
ゲームは基本的にシングルだからな。
>>334
Pentium4 系列の ALU が 10GHz だったことを思い出して下さい
Pentium4 系列の ALU が 10GHz だったことを思い出して下さい
AVX3ことLNIが実装されてからがGPGPU潰しの本番だろ
337 :,,・´∀`・,,)っ-○○○:2014/04/24(木) 20:43:07.72 ID:p4A7hDrZ
>>328
存在しもしないスーパープログラマ(笑)なんて偶像にすがるのをやめるべきだな。
高機動性(速度)と重装甲(セキュリティ)の両立が困難なのは兵器も
ソフトウェアでも同じだよ。
ナーシャ・ジベリは速いコードを書くのは天才的といわれたが
バグも大量に入れ込んでる。
ちなみにOpenSSLの脆弱性問題もまさにバウンダリチェックの抜けなんだよね。
Cは動的言語が持つような暗黙的なバウンダリチェック機構を持たない。
なぜなら、いちいちチェックしてたらコードが肥大化して遅くなるから。
MPXの提供するバウンダリチェック命令を使うことで
Cなどの低レベル言語処理系はパフォーマンスを犠牲にせずに
セキュアなコードを書けるようになり、また、高級言語ではパフォーマンスを
向上させることができる。
俺は企業のエンドユーザーにSkylakeは薦めやすいと思ってるよ。
まあ、現時点では存在しないからありもののシステムで組むのだけどね。
存在しもしないスーパープログラマ(笑)なんて偶像にすがるのをやめるべきだな。
高機動性(速度)と重装甲(セキュリティ)の両立が困難なのは兵器も
ソフトウェアでも同じだよ。
ナーシャ・ジベリは速いコードを書くのは天才的といわれたが
バグも大量に入れ込んでる。
ちなみにOpenSSLの脆弱性問題もまさにバウンダリチェックの抜けなんだよね。
Cは動的言語が持つような暗黙的なバウンダリチェック機構を持たない。
なぜなら、いちいちチェックしてたらコードが肥大化して遅くなるから。
MPXの提供するバウンダリチェック命令を使うことで
Cなどの低レベル言語処理系はパフォーマンスを犠牲にせずに
セキュアなコードを書けるようになり、また、高級言語ではパフォーマンスを
向上させることができる。
俺は企業のエンドユーザーにSkylakeは薦めやすいと思ってるよ。
まあ、現時点では存在しないからありもののシステムで組むのだけどね。
単語がわかんね
ヲタはこうでないと
ヲタはこうでないと
339 :,,・´∀`・,,)っ-○○○:2014/04/24(木) 20:55:05.47 ID:p4A7hDrZ
いちAMD信者的には、コピペより団子の正論の方がよっぽど重いわ。
それでも信者やめないけどなw
それでも信者やめないけどなw
341 :Socket774:2014/04/24(木) 21:35:29.94 ID:NE+n64Kv
>>340
このスレによく湧くAMDの太鼓持ちは信者じゃないですよ。
本当のAMD信者は、AMDの方が劣ることを承知で「宗教上の理由でIntelは採用できませぬ」とか言って、AMDのCPUを買うから。
AMDに対する信仰心など無いから、IntelよりAMDの方が性能が上だと思い込まないとAMD製品を買えないキチガイなんですよ。
このスレによく湧くAMDの太鼓持ちは信者じゃないですよ。
本当のAMD信者は、AMDの方が劣ることを承知で「宗教上の理由でIntelは採用できませぬ」とか言って、AMDのCPUを買うから。
AMDに対する信仰心など無いから、IntelよりAMDの方が性能が上だと思い込まないとAMD製品を買えないキチガイなんですよ。
こんなこと言ってるバカがいましたよコピペを作るための、マッチポンプ
343 :,,・´∀`・,,)っ-○○○:2014/04/24(木) 21:48:25.35 ID:p4A7hDrZ
まあ、AMDのCPUコアの改良もペースが遅いとは言え辞めてないわけだし
ソフト屋の求めるものさえ的確に捉えてハード出してりゃ見捨てられはしないさ。
次のAPUのCarrizoの何がセールスポイントになるかって、GPU機能よりむしろ
VIA Padlockをサポートした点だと思ってる(VIAがライセンスしたのかな?)
セキュリティに敏感な企業にクラウド技術を売り込むには裏づけになる技術って
大事だからね。
SHA-3の仕様もほぼ決まったみたいだし、そろそろアクセラレータを実装しようず。
IntelでもAMDでもARMでもいいから。
ソフト屋の求めるものさえ的確に捉えてハード出してりゃ見捨てられはしないさ。
次のAPUのCarrizoの何がセールスポイントになるかって、GPU機能よりむしろ
VIA Padlockをサポートした点だと思ってる(VIAがライセンスしたのかな?)
セキュリティに敏感な企業にクラウド技術を売り込むには裏づけになる技術って
大事だからね。
SHA-3の仕様もほぼ決まったみたいだし、そろそろアクセラレータを実装しようず。
IntelでもAMDでもARMでもいいから。
padlockだと?
それは本当ですかい
それは本当ですかい
345 :,,・´∀`・,,)っ-○○○:2014/04/24(木) 22:15:11.51 ID:p4A7hDrZ
>>344
https://sourceware.org/ml/binutils/2013-09/msg00155/bdver4.patch
> +#as: -march=bdver4+vmx+smx+ept+padlock
AMDがVIAの遺伝子を引き継いだというのは感慨深いね
それを以てVIAが一大勢力を誇ったx86組み込み市場に
浸透させることができるかというと、かなり微妙だが
https://sourceware.org/ml/binutils/2013-09/msg00155/bdver4.patch
> +#as: -march=bdver4+vmx+smx+ept+padlock
AMDがVIAの遺伝子を引き継いだというのは感慨深いね
それを以てVIAが一大勢力を誇ったx86組み込み市場に
浸透させることができるかというと、かなり微妙だが
sha関連のためかな
347 :,,・´∀`・,,)っ-○○○:2014/04/24(木) 22:49:56.66 ID:p4A7hDrZ
Padlockはともかくとして、このパッチ見るに
VMFOFFとかINVEPTまで対応してやがるのよ。
つまりVMXとかSMXとかのフラグはIntelのそれと同じ意味だ。
仮想化支援命令ってAMDとIntelとで別々の命令実装してて
AMDは独自性が売りだったよな。
ここにきてAMDがプライドを捨ててきました。
仮想化でAMDの神通力の及ばない市場に殴り込みをかけたいのだと思われるが
具体的にはMacとかMacとかMacとか
VMFOFFとかINVEPTまで対応してやがるのよ。
つまりVMXとかSMXとかのフラグはIntelのそれと同じ意味だ。
仮想化支援命令ってAMDとIntelとで別々の命令実装してて
AMDは独自性が売りだったよな。
ここにきてAMDがプライドを捨ててきました。
仮想化でAMDの神通力の及ばない市場に殴り込みをかけたいのだと思われるが
具体的にはMacとかMacとかMacとか
348 : ◆miyuri//Z7LS :2014/04/24(木) 22:52:57.28 ID:6blGb83X
>>337
MPXは、範囲検査している言語だと嬉しいけど、Cとかだと書き換える手間に見合わない予感。
MPXは、範囲検査している言語だと嬉しいけど、Cとかだと書き換える手間に見合わない予感。
349 :,,・´∀`・,,)っ-○○○:2014/04/24(木) 22:56:39.31 ID:p4A7hDrZ
コンパイルオプションで対応してるらしい。
MSのコンパイラはANSI/ISOかなぐり捨ててまで独自にセキュアC関数とか
用意してるくらいだし、次のコンパイラではデフォルトMPX有効に
してくれてもいいくらいだと思ってる。
明示的な最適化でチェックを消せるようにすればいい。
非対応CPUだとNOPとして解釈されるから分岐を書く手間も省ける。
MSのコンパイラはANSI/ISOかなぐり捨ててまで独自にセキュアC関数とか
用意してるくらいだし、次のコンパイラではデフォルトMPX有効に
してくれてもいいくらいだと思ってる。
明示的な最適化でチェックを消せるようにすればいい。
非対応CPUだとNOPとして解釈されるから分岐を書く手間も省ける。
>>321
QSVでエンコして、それをWifiでスマホとかタブレットに飛ばすってプログラムしてみたいんだけど、
QSVはこれ買わんといけないのか。
お金さえ払えば、このソフトのライブラリをリンクしてAPI呼ぶだけでできる?
エンコさえできれば後はWinSockで送信でいいか。
QSVでエンコして、それをWifiでスマホとかタブレットに飛ばすってプログラムしてみたいんだけど、
QSVはこれ買わんといけないのか。
お金さえ払えば、このソフトのライブラリをリンクしてAPI呼ぶだけでできる?
エンコさえできれば後はWinSockで送信でいいか。
配列のアライメントもコンパイラオプションで自動的に対応してほしいなぁ。
SIMD化の際、楽だ。
メモリアクセス効率も若干上がりそうだし。
SIMD化の際、楽だ。
メモリアクセス効率も若干上がりそうだし。
つまりバウンダリチェックが出来ない今のシステムは全部セキュリティがスカスカなゴミクズってことか
そんな重大な欠陥今まで何処も対応してなかったのは何でだ?
そんな重大な欠陥今まで何処も対応してなかったのは何でだ?
>>334
Unrealエンジンなめてない?
Unrealエンジンなめてない?
355 : ◆miyuri//Z7LS :2014/04/25(金) 04:47:35.26 ID:pYHvJaiu
358 :,,・´∀`・,,)っ-○○○:2014/04/25(金) 08:01:37.26 ID:+A7B6g4Z
>>353
お偉いさんが能天気だからに決まってるでしょ
このスレにプログラマを殴れとかズレたこと言ってるバカが居座ってるじゃん
土建屋に置き換えるなら欠陥建築が生まれるのは建築士じゃなくて
末端の土木作業者だと勘違いしてるようなもの。
もちろん手抜き工事が行われることもあるのだが、それをさせない
ために現場監督がいるわけだし、上が突貫工事を指示してる場合すらある。
お偉いさんが能天気だからに決まってるでしょ
このスレにプログラマを殴れとかズレたこと言ってるバカが居座ってるじゃん
土建屋に置き換えるなら欠陥建築が生まれるのは建築士じゃなくて
末端の土木作業者だと勘違いしてるようなもの。
もちろん手抜き工事が行われることもあるのだが、それをさせない
ために現場監督がいるわけだし、上が突貫工事を指示してる場合すらある。
つまり配列のポインタとかunionとかsizeofの互換性を全部投げ捨てろと?
361 :Socket774:2014/04/25(金) 13:26:54.66 ID:pMnB1q3h
コマンド→すてる→はいれつのポインタ
それをすてるなんてとんでもない!
それをすてるなんてとんでもない!
362 :,,・´∀`・,,)っ-○○○:2014/04/25(金) 19:24:18.60 ID:+A7B6g4Z
あらかじめデータサイズがわかってる構造体とかならいいが、
配列や文字列をポインタ渡しする関数ではバウンダリチェックが
できないんだよな。
自動的にバウンダリチェックのコードを挿入できるのは
コンパイル時にサイズを解決できる範囲内でしか使えない。
たいがい配列や文字列をポインタ渡しした時点でアウト。
「第1引数がポインタで、第2引数が長さ情報だよー」みたいなのを
指示してやる必要が出てくるので結局手作業。
C++のvectorとかbasic_string使えばいいんだよ!
範囲外の添字指定したときにリサイズしないバージョンが欲しいところだが。
配列や文字列をポインタ渡しする関数ではバウンダリチェックが
できないんだよな。
自動的にバウンダリチェックのコードを挿入できるのは
コンパイル時にサイズを解決できる範囲内でしか使えない。
たいがい配列や文字列をポインタ渡しした時点でアウト。
「第1引数がポインタで、第2引数が長さ情報だよー」みたいなのを
指示してやる必要が出てくるので結局手作業。
C++のvectorとかbasic_string使えばいいんだよ!
範囲外の添字指定したときにリサイズしないバージョンが欲しいところだが。
363 :,,・´∀`・,,)っ-○○○:2014/04/25(金) 19:41:34.97 ID:+A7B6g4Z
OpenSSL脆弱性の再発防止へ、業界大手が重要オープンソースプロジェクトを支援
http://www.itmedia.co.jp/enterprise/articles/1404/25/news047.html
> OpenSSLは多くのWebサーバやOS、ソフトウェア、ネットワーク機器などに利用され、
> インターネットインフラの根幹を支える存在だ。ところがOpenSSL Software
> Foundation幹部によれば、寄付などを通じて得る収入は年間2000ドル程度にすぎず、
> フルタイムでOpenSSLの開発にかかわる担当者は1人だけだという。
まあ、これ見ても「プログラマが悪い」といえるバカは豆腐の角に頭ぶつけてこいと。
年間20万円程度の予算で品質の高いコード書けっていうほうが所詮無理なんだよ
プログラムを組んだこともないやつが勝手な願望を述べるのは簡単だが
現実を直視できていない。
お前ら、ソフトには金払えよ。オープンソースには寄付してやんなよ。
http://www.itmedia.co.jp/enterprise/articles/1404/25/news047.html
> OpenSSLは多くのWebサーバやOS、ソフトウェア、ネットワーク機器などに利用され、
> インターネットインフラの根幹を支える存在だ。ところがOpenSSL Software
> Foundation幹部によれば、寄付などを通じて得る収入は年間2000ドル程度にすぎず、
> フルタイムでOpenSSLの開発にかかわる担当者は1人だけだという。
まあ、これ見ても「プログラマが悪い」といえるバカは豆腐の角に頭ぶつけてこいと。
年間20万円程度の予算で品質の高いコード書けっていうほうが所詮無理なんだよ
プログラムを組んだこともないやつが勝手な願望を述べるのは簡単だが
現実を直視できていない。
お前ら、ソフトには金払えよ。オープンソースには寄付してやんなよ。
GPLv3が致命的な一撃を与えてしまったような気がするな…各方面に
勝手にオープンソースで作ってるんだから金を払う必要はないんじゃない。
オープンソースって俺が無料にするからおまえも無料にしろだからすでにオープンソースを使う利益を得ているのでは。
オープンソースって俺が無料にするからおまえも無料にしろだからすでにオープンソースを使う利益を得ているのでは。
366 :,,・´∀`・,,)っ-○○○:2014/04/25(金) 22:43:56.60 ID:+A7B6g4Z
新しいハードウェアの機能に対応する為にそれをテストするための機材が
必要だったりするわけで。
なんだかんだで質のいいオープンソースソフトウェアは寄付なしには成り立たない。
必要だったりするわけで。
なんだかんだで質のいいオープンソースソフトウェアは寄付なしには成り立たない。
367 :Socket774:2014/04/25(金) 23:05:15.33 ID:C22l4cff
散々利用してきて今まで放置していたサーバー最大手のインテルの罪はデカいな
Xeon全部無償交換位当然するよな
Xeon全部無償交換位当然するよな
368 :,,・´∀`・,,)っ-○○○:2014/04/25(金) 23:06:29.24 ID:+A7B6g4Z
> Xeon全部無償交換
なんで無償交換?CPUの不具合じゃないじゃんww
なんで無償交換?CPUの不具合じゃないじゃんww
GPLv3が致命的な一撃ってどゆこと?
371 :Socket774:2014/04/25(金) 23:35:23.55 ID:pMnB1q3h
>>371
えっ
あ、でもそういう意味だと話が繋がるな
なんか初見の先入観のせいか、スレ読み返しても素で>>367が脈絡なさすぎてOpenSSLの話となかなか繋がらない
いや、解釈ども。すっきりしないものの、なんかそういう流れに感じなくもないので静観ます
えっ
あ、でもそういう意味だと話が繋がるな
なんか初見の先入観のせいか、スレ読み返しても素で>>367が脈絡なさすぎてOpenSSLの話となかなか繋がらない
いや、解釈ども。すっきりしないものの、なんかそういう流れに感じなくもないので静観ます
374 :,,・´∀`・,,)っ-○○○:2014/04/26(土) 02:16:08.50 ID:n6EnYYXi
>>372
義務は無いよ
ただ、資金難になって開発が困難になったり、セキュリティホールがあって
直せなかったとしても利用者の責任だ。
プロプライエタリなソフトは対価を要求する代わりに、ユーザーのために
全力で問題に対処するが、オープンソースはそれがない。
そもそもオープンソースにおけるフリーは自由の意味であって
「金をとらない」という意味ではない。
ユーザーには多くの場合において、ソフトの発展のために金銭的な、あるいは
技術的な協力を行う選択肢が与えられている。開発者になることもできる。
しない選択もあるけどね。
「やってくれるのが当然」という価値観は捨てなきゃいけない。
義務は無いよ
ただ、資金難になって開発が困難になったり、セキュリティホールがあって
直せなかったとしても利用者の責任だ。
プロプライエタリなソフトは対価を要求する代わりに、ユーザーのために
全力で問題に対処するが、オープンソースはそれがない。
そもそもオープンソースにおけるフリーは自由の意味であって
「金をとらない」という意味ではない。
ユーザーには多くの場合において、ソフトの発展のために金銭的な、あるいは
技術的な協力を行う選択肢が与えられている。開発者になることもできる。
しない選択もあるけどね。
「やってくれるのが当然」という価値観は捨てなきゃいけない。
フリーソフト、例えば圧縮/解凍ソフトのように目的の機能実装ができた後は
セキュリティ/バグ以外ではバージョンアップが停止するのにオープンソースは
なんでいつまでも機能追加のバージョンアップし続けるんだ。
開発にある終着点が存在しているなら時間がかかっても有償製品以上の
完成度になるんだろうけど、そうでないなら個人の趣味の領域を超えないから
開発費の割に安いWindowsを買い続けるのが一番いいんだよな。
セキュリティ/バグ以外ではバージョンアップが停止するのにオープンソースは
なんでいつまでも機能追加のバージョンアップし続けるんだ。
開発にある終着点が存在しているなら時間がかかっても有償製品以上の
完成度になるんだろうけど、そうでないなら個人の趣味の領域を超えないから
開発費の割に安いWindowsを買い続けるのが一番いいんだよな。
i5とi7でPCの性能変わってくるのでしょうか?
安くしたいのですが友人はi7一択と言ってて、調べてもいまいち違いを見つけられませんでした。
用途はBFなどのFPSやネトゲです
安くしたいのですが友人はi7一択と言ってて、調べてもいまいち違いを見つけられませんでした。
用途はBFなどのFPSやネトゲです
安くしたいという目の当りのハードルがあるのならi5にすればいいじゃない
HTTならゲームにあまり関係ないしクロックだけ見ておけば
CPUよりはGPUに予算割いた方が良いと思われ
本当にゲーマーは大変だな…
HTTならゲームにあまり関係ないしクロックだけ見ておけば
CPUよりはGPUに予算割いた方が良いと思われ
本当にゲーマーは大変だな…
FPSならi7最上位当然でGTX760ti以上でしょう。
BF4はそれでも足りない。
BF4はそれでも足りない。
GPUは770で考えてます
FPSはi7の方がいいものなんですか・・
レスありがとうございます
FPSはi7の方がいいものなんですか・・
レスありがとうございます
上手い奴がハイエンドマシン使ってるかというと、そうでもない。
でもその友人の性格だと、i5にした場合なにかあるたびに、これだからi5は〜ってバカにしてきそう
でもその友人の性格だと、i5にした場合なにかあるたびに、これだからi5は〜ってバカにしてきそう
メンタルまではケアできんよ流石に
382 :Socket774:2014/04/26(土) 12:49:55.74 ID:6weglfEx
skylakeはDDR4?
つーか、HTなんて不要っしょ。
確かにHyperTransportは要らない
385 :,,・´∀`・,,)っ-○○○:2014/04/26(土) 13:27:55.18 ID:n6EnYYXi
放課後ティータイムは人による
今となってはゴミだな>HTT(放課後ティータイム)
しかもOSからは物理コアと同様にカウントされてしまうため、
ソフトからコア数に応じてスレッドを起動するようにすると、効率が落ちてしまう。
99害あって1利しかない。
ソフトからコア数に応じてスレッドを起動するようにすると、効率が落ちてしまう。
99害あって1利しかない。
古いOSだとそうらしいね
リアルコアだが仮想コアだと認識させないといけないCPUがあってな
390 :,,・´∀`・,,)っ-○○○:2014/04/26(土) 13:55:33.92 ID:n6EnYYXi
スレッドアフィニティの設定がめんどくさくなって結局ユーザーに
どの論理コア使うか選ばせるダイアログ組んでみたりとか
どの論理コア使うか選ばせるダイアログ組んでみたりとか
391 :Socket774:2014/04/26(土) 14:00:21.01 ID:GMA0r6qA
>>387
Windows2000の頃はそうだったな。
CPUに余裕があっても動画再生でコマ落ちして困ったものでしたよ。
今だと特にそんなことも無いし、x264エンコードで20%くらい高速化されるので非常に利益が大きいけどね。
Windows2000の頃はそうだったな。
CPUに余裕があっても動画再生でコマ落ちして困ったものでしたよ。
今だと特にそんなことも無いし、x264エンコードで20%くらい高速化されるので非常に利益が大きいけどね。
393 :,,・´∀`・,,)っ-○○○:2014/04/26(土) 14:05:21.79 ID:n6EnYYXi
>>389
あれはマーケティング上リアルコアだが言い分次第では1物理コア・2論理コアの
扱いにもなりうる代物では?
数年前までx86サーバ向けの商用ソフトはソケット単位課金が主流だったから
ソケットあたりのコア数が多いほうがマーケティング上有利だったこともあるが
今は商用ソフトで性能の低い多コアが不利になる料金体系が主流だから
不利だわなー
そのソケット単位課金がなくなったのも、6コア×最大8ソケットをニコイチで
12コア×最大4ソケットとかやった会社があったからだとかそうでないとか。
あれはマーケティング上リアルコアだが言い分次第では1物理コア・2論理コアの
扱いにもなりうる代物では?
数年前までx86サーバ向けの商用ソフトはソケット単位課金が主流だったから
ソケットあたりのコア数が多いほうがマーケティング上有利だったこともあるが
今は商用ソフトで性能の低い多コアが不利になる料金体系が主流だから
不利だわなー
そのソケット単位課金がなくなったのも、6コア×最大8ソケットをニコイチで
12コア×最大4ソケットとかやった会社があったからだとかそうでないとか。
今paypalに偽装したフィッシングのメールがきた
395 :,,・´∀`・,,)っ-○○○:2014/04/26(土) 14:44:56.22 ID:n6EnYYXi
そんなもの踏んだこと無いなー
しかし徐々にレジスタが増えたり幅が増えたりしてそろそろHTに必要な2本分の
ハードウェアリソースが結構ネックになったりしてないんだろうか
ハードウェアリソースが結構ネックになったりしてないんだろうか
今やCPUダイに占めるコアの割合って3割ほどでしょ?
HT用のリソースなんて、体重測る際のパンツ程度じゃない?
HT用のリソースなんて、体重測る際のパンツ程度じゃない?
サイズなんかより、発熱の方がネックだろ
399 :,,・´∀`・,,)っ-○○○:2014/04/26(土) 14:58:19.96 ID:n6EnYYXi
たかだか各16本の論理レジスタよりもリネーミングで割り当てる物理ファイルのほうが
はるかに大きいからな。
実際AMDなんか128ビットレジスタのままで256bit AVXを実装できてるし。
はるかに大きいからな。
実際AMDなんか128ビットレジスタのままで256bit AVXを実装できてるし。
結局x86最強ってことか
異論はない。
プログラマに楽をさせるとかの方向の話で言うと、
CPUがGC処理に対して何か支援をするとかの方向に進んで行ったりしないの?
メモリ管理とか誰もやりたくない
CPUがGC処理に対して何か支援をするとかの方向に進んで行ったりしないの?
メモリ管理とか誰もやりたくない
何もしなくても作ったソフトが早く実行できるようになる時代が終わったのなら何か工夫すればいいじゃない
28nmのjaguarと22nm Baytrailで互角の勝負されてる時点でIntelの完敗だろ
次のPumaで電力性能倍になるから、ARMにもAMDにも勝てなくてAtom終わりだな
次のPumaで電力性能倍になるから、ARMにもAMDにも勝てなくてAtom終わりだな
>>404
32nmのsandyと28nmのSteamroller(以下略
32nmのsandyと28nmのSteamroller(以下略
TDP25WのKabiniがファンレスタブレットに載ったら呼んでくれ
電力性能比が倍になるって信じてるって頭おかしいんじゃないの?
408 :Socket774:2014/04/27(日) 03:10:42.25 ID:5Bj8AhdH
電力性能比が2倍になることを信じるか否かよりもっと重要な問題があるだろ。
電力性能が非常に重要なタブレットを担う(はずだが、全く見向きもされていない)Temashの電力性能比が2倍になった程度ではCherry Trail-Tに対抗できそうも無いという問題がな・・・
電力性能が非常に重要なタブレットを担う(はずだが、全く見向きもされていない)Temashの電力性能比が2倍になった程度ではCherry Trail-Tに対抗できそうも無いという問題がな・・・
GFの32nmが酷すぎたせいでやっと28nmでintel32nmに追いついたって感じだしなぁ
まあAMDのタブ向けはTSMCのラインだから28nmのままでもワンチャンスあるかも
まあAMDのタブ向けはTSMCのラインだから28nmのままでもワンチャンスあるかも
410 :,,・´∀`・,,)っ-○○○:2014/04/27(日) 04:12:47.40 ID:JwIK0gC6
Llanoは2011年、Kaveriが2014年
32nm流用して3年もかかってる時点で中間ノードの意味ねえ
32nm流用して3年もかかってる時点で中間ノードの意味ねえ
今って根幹・根幹候補の技術基盤がことごとくLLVMになってる感じがある(Clang・ART・asm.js(emscripten))から、
CPUにGC高速化専用命令をぽんと追加してもLLVMがサクっと対応してくれて自動で使われるようにならないのかな
Clangで事前コンパイルしちゃうと再コンパイルが必要だけど…ってC++じゃGC使わんな、トランザクショナルメモリなんかも
CPUにGC高速化専用命令をぽんと追加してもLLVMがサクっと対応してくれて自動で使われるようにならないのかな
Clangで事前コンパイルしちゃうと再コンパイルが必要だけど…ってC++じゃGC使わんな、トランザクショナルメモリなんかも
ARMの数世代先を行く電力制御の技術をx64にも導入すれば余裕でしょ
電力性能比が2倍どころか200倍もイケる
電力性能比が2倍どころか200倍もイケる
中間コードで配布してインストール時にバイナリ生成でいいと思うわ
というかIBMのミニコンがそんな形式だったかな
というかIBMのミニコンがそんな形式だったかな
414 :,,・´∀`・,,)っ-○○○:2014/04/27(日) 09:07:58.95 ID:VuOYR7qb
GCというかアロケータから手を入れないとだめなんだろ
データ構造・アルゴリズムがハードウェアによって縛られるのはいかがなものか
一番必要としてるのはPCなんかよりよっぽど低スペックな石積んでる
組み込み機器だろ。あんなんでJavaとか動いてるんだぜ
特殊なハードでも載ってるならそれを参考にすればいいが何も載ってない
データ構造・アルゴリズムがハードウェアによって縛られるのはいかがなものか
一番必要としてるのはPCなんかよりよっぽど低スペックな石積んでる
組み込み機器だろ。あんなんでJavaとか動いてるんだぜ
特殊なハードでも載ってるならそれを参考にすればいいが何も載ってない
>>413
AOTのタイミングはexeの実行時が適切
実行環境(主にCPU)が前回実行時から変更された事をexe自身が起動時に検出して
AOTをやり直す仕組みが必要になる
インスコ作業に初回実行も含めれば初回起動時の違和感も持たれずに済む
AOTのタイミングはexeの実行時が適切
実行環境(主にCPU)が前回実行時から変更された事をexe自身が起動時に検出して
AOTをやり直す仕組みが必要になる
インスコ作業に初回実行も含めれば初回起動時の違和感も持たれずに済む
416 :,,・´∀`・,,)っ-○○○:2014/04/27(日) 09:33:08.83 ID:VuOYR7qb
インストーラでコンパイラ走らせるって午後のこーだが
特許回避のための手段として使ってたよな
特許回避のための手段として使ってたよな
wikipediaにあったわ
http://ja.wikipedia.org/wiki/System_i#.E7.89.B9.E9.95.B7
>実プロセッサが変わっても実行ファイルさえあれば変換(中間コードから機械語を再生成)することが可能で、
>ソースファイルが無くてもハードウェアを自由に交換できるという優れた可搬性を、実行速度を犠牲にすることなく実現している。
http://ja.wikipedia.org/wiki/System_i#.E7.89.B9.E9.95.B7
>実プロセッサが変わっても実行ファイルさえあれば変換(中間コードから機械語を再生成)することが可能で、
>ソースファイルが無くてもハードウェアを自由に交換できるという優れた可搬性を、実行速度を犠牲にすることなく実現している。
PCはOSシャットダウンしてストレージそのままでCPUを載せかえて再起動できてしまう
同じソケットでもCPUをダウングレードさせる事ができてしまうのでインスコ時1回だけってのはダメ
同じソケットでもCPUをダウングレードさせる事ができてしまうのでインスコ時1回だけってのはダメ
419 :,,・´∀`・,,)っ-○○○:2014/04/27(日) 09:50:44.32 ID:VuOYR7qb
起動時にCPUID見て前回起動時と違ったら再生成すりゃいいんじゃないの
それだとメインメモリも見て最適化したい時困る
もうOSに標準でLLVM実行ランタイム入れてしまえば良いのに、JVM・.NET・LLVMで速度競争起これ
もうOSに標準でLLVM実行ランタイム入れてしまえば良いのに、JVM・.NET・LLVMで速度競争起これ
421 :,,・´∀`・,,)っ-○○○:2014/04/27(日) 10:31:22.48 ID:VuOYR7qb
実行時にevalしたい局面もあるので何が何でもネイティブコードに
されるのも困るのだが。
むしろサーバだとボトルネックはDBだからCで書こうがRubyで書こうが
大して変わらんのよ。DBとの結合の弱いフロントエンドなら多少意味はあるかも。
されるのも困るのだが。
むしろサーバだとボトルネックはDBだからCで書こうがRubyで書こうが
大して変わらんのよ。DBとの結合の弱いフロントエンドなら多少意味はあるかも。
サーバ側の要求はそりゃ違うだろう、今のは大体クライアント側の動き
asm.js+WebGLによって、実はiOS・Androidのネイティブ売り場課金30%ピンハネパラダイムがぶっ壊れちゃう可能性があって、
UEとUnityがマジで乗っかってきちゃったからさあ大変っていう
asm.js+WebGLによって、実はiOS・Androidのネイティブ売り場課金30%ピンハネパラダイムがぶっ壊れちゃう可能性があって、
UEとUnityがマジで乗っかってきちゃったからさあ大変っていう
まだドラフト段階だがWebCLもあるな
http://jp.techcrunch.com/2014/03/20/20140319webcl-will-soon-let-web-developers-harness-the-power-of-multi-core-gpus-and-cpus-from-the-browser/
http://jp.techcrunch.com/2014/03/20/20140319webcl-will-soon-let-web-developers-harness-the-power-of-multi-core-gpus-and-cpus-from-the-browser/
>ChromeのNative Clientやプラグインのようなものを使わずに、ブラウザ内でWebアプリケーションをネイティブかつ高速に動かしたいと思うと、
>今のところFirefox上のJavaScriptスーパーセットasm.jsぐらいしか方法がない。
>しかし、ネイティブに近い速度を誇るasm.jsも並列処理はサポートしていないから、高速化にも限界がある。
>Trevettによると、asm.jsとWebCLの関係は排他的というよりむしろ相補的であり、
>WebCLのJavaScript結合(バインディング)も提供されるので、
>デベロッパはいつでも、asm.jsベースのアプリケーションからWebCLを呼び出すことができる。
asm.jsがマルチスレッドに対応してないんじゃシングルスレッドが遅いモバイルデバイスではダメダメだな
WebCLの大本のOpenCLもAndroid上ではシステムのアップデートで強制無効化される始末だし
OpenCLに積極的なはずのAppleに至ってはiOS上ではサポートすらしていない
>今のところFirefox上のJavaScriptスーパーセットasm.jsぐらいしか方法がない。
>しかし、ネイティブに近い速度を誇るasm.jsも並列処理はサポートしていないから、高速化にも限界がある。
>Trevettによると、asm.jsとWebCLの関係は排他的というよりむしろ相補的であり、
>WebCLのJavaScript結合(バインディング)も提供されるので、
>デベロッパはいつでも、asm.jsベースのアプリケーションからWebCLを呼び出すことができる。
asm.jsがマルチスレッドに対応してないんじゃシングルスレッドが遅いモバイルデバイスではダメダメだな
WebCLの大本のOpenCLもAndroid上ではシステムのアップデートで強制無効化される始末だし
OpenCLに積極的なはずのAppleに至ってはiOS上ではサポートすらしていない
425 :,,・´∀`・,,)っ-○○○:2014/04/27(日) 11:17:39.30 ID:VuOYR7qb
前にも書いたけどブラウザアプリに対するネイティブアプリの優位点は
プッシュ通知だよ。それだけでもアプリの起動頻度は変わってくる。
たとえばギルド全員が恩恵のある時間制限つきの消費アイテム使った、とか
レアなレイドボスが出て応援依頼が出たときにプッシュ通知があるとすぐに
駆けつけることができる。
ブラウザだと自分から確認しにいかないといけない。
人はそこまで能動的に動けない。
大体にソーシャルゲームとかで上位占めてるのアプリ組み込み型の
FlashたるAIRが多いわけでしょ。
サイバーエージェントがやってるブラウザゲームをそのまま埋め込んだだけの
アプリ出したらそっちのほうがユーザー増えたという事例もある。
モバグリショックが必ずしもHTMLの単純な「性能」不足によるものではないのは
業界では当たり前の見解なんだけどな
プッシュ通知だよ。それだけでもアプリの起動頻度は変わってくる。
たとえばギルド全員が恩恵のある時間制限つきの消費アイテム使った、とか
レアなレイドボスが出て応援依頼が出たときにプッシュ通知があるとすぐに
駆けつけることができる。
ブラウザだと自分から確認しにいかないといけない。
人はそこまで能動的に動けない。
大体にソーシャルゲームとかで上位占めてるのアプリ組み込み型の
FlashたるAIRが多いわけでしょ。
サイバーエージェントがやってるブラウザゲームをそのまま埋め込んだだけの
アプリ出したらそっちのほうがユーザー増えたという事例もある。
モバグリショックが必ずしもHTMLの単純な「性能」不足によるものではないのは
業界では当たり前の見解なんだけどな
という事はプッシュ通知機能を搭載したブラウザの開発競争が起こるわけだよ
AppleとGoogleが「起こさない判断をする」のであればMSとモジラと全エンジン&ゲームメーカーが組んでくるだろうね
AppleとGoogleが「起こさない判断をする」のであればMSとモジラと全エンジン&ゲームメーカーが組んでくるだろうね
HTML5はそこらへん早めに動きたいねえ
428 :,,・´∀`・,,)っ-○○○:2014/04/27(日) 17:37:02.06 ID:VuOYR7qb
そういう抜け穴になるアプリは規約改定の上rejectされて終了な気はする。
牢獄は外から破壊するしかない。
TizenでもFirefoxOSでもいいから各ベンダーもキャリアももう少し連携取れよ。
というか、ショバ代のレートさえ崩せば問題ないのだろう?
牢獄は外から破壊するしかない。
TizenでもFirefoxOSでもいいから各ベンダーもキャリアももう少し連携取れよ。
というか、ショバ代のレートさえ崩せば問題ないのだろう?
4960Xの次の4970Xとか出てくるのか
出てこなければ、4960Xが3970Xとほとんど変わらず、進化自体が止まって終わりだろ。
出てこなければ、4960Xが3970Xとほとんど変わらず、進化自体が止まって終わりだろ。
430 :Socket774:2014/04/28(月) 00:52:19.76 ID:dU4sxfoj
>>429
4970Xなんて出すわけ無いじゃん。
IntelはIvy Bridge-E6コアからシングルスレッド性能を落とさずにHaswell-E8コア出したいんだから。
Ivy Bridge-Eは性能を上げるために出したのでは無く、コストを下げるために出したんだよ。
4970Xなんて出すわけ無いじゃん。
IntelはIvy Bridge-E6コアからシングルスレッド性能を落とさずにHaswell-E8コア出したいんだから。
Ivy Bridge-Eは性能を上げるために出したのでは無く、コストを下げるために出したんだよ。
>>414
javaっていっても、フルスペックのjavaじゃなく、かつsun/oracleの糞JVMじゃなく独自JVMなんじゃ?
javaっていっても、フルスペックのjavaじゃなく、かつsun/oracleの糞JVMじゃなく独自JVMなんじゃ?
432 :,,・´∀`・,,)っ-○○○:2014/04/28(月) 08:12:39.76 ID:Jc5XLPMd
Androidのことを言ってるなら違うよ
家電とか自動販売機に使われてるEmbedded版だよ
家電とか自動販売機に使われてるEmbedded版だよ
この情勢下でブラウザに夢見れるやつがいるのが解らん。
今のスマホの流れ、下手したらブラウザ自体がなくなりかねないというのに。
アプリ86%、Web14%〜モバイル利用時間でアプリの優位が顕著に -INTERNET Watch
http://internet.watch.impress.co.jp/docs/news/20140402_642413.html
https://twitter.com/metaps_sato/status/454192485242527744
> アプリファーストの会社が、PC・Web中心の会社を凄いスピードで抜き去る事案が
> 世界中で増えているね。接触時間が違うからまあそうだよな。
> 消費者向けであれば、Webサイトすら作る必要なくなってきたしな。
実際、スマホ普通に使っててブラウザ全然使わないだろ?
軽くGoogle検索したり、LINEやFacebookやTwitterでWebページを表示したり、
そこからアプリをダウンロードする程度のことはするだろうが。
asm.js+WebGLのゲームにしても、
まずAndroid、iOS、それにFirefox OSできっちり動かして見せてくれないと話にならんよw
これまでに公開されている主だったデモ、全部スマホでは動かねーし、
PCですら1分も2分も待ってやっと動く状況なわけじゃん。あんなもので商売になるわけがない。
そもそも、何百MBというサイズの「Webページ」をブラウザで表示するのが非現実的。
まずユーザーが待てる時間で表示するための回線速度がまったく足りない。
光ファイバーですらBlu-ray程度のダウンロード速度しかないし
モバイル回線は1桁以上遅く、通信量制限がある。さらに多くの国で従量課金。
メモリの問題もある。最近は1GBや2GBのアプリも珍しくないのに、
最新のiPhoneやiPadですらメモリ1GBしか積んでいないんだぜ。
HTML5のしょぼいオフライン機能だので間に合うわけがない。
リソースだけでなく、でかいJavaScriptをパース・実行するにもすげーメモリ食う。
(FirefoxのAOTコンパイラは専用のパーサを書いているが)
Unity 5のWebGLデプロイも、当面はデスクトップで一部のブラウザから
しかもかなりの速度ペナルティがあると言っているよ。
(クソMozillaは大本営発表しかしないからほっとけ。Unityのフォーラム嫁w)
PCブラウザですら実用未満なんだ。
モバイルブラウザでAAA級の3Dゲームが動くには軽く5年か10年はかかるだろ。
今のスマホの流れ、下手したらブラウザ自体がなくなりかねないというのに。
アプリ86%、Web14%〜モバイル利用時間でアプリの優位が顕著に -INTERNET Watch
http://internet.watch.impress.co.jp/docs/news/20140402_642413.html
https://twitter.com/metaps_sato/status/454192485242527744
> アプリファーストの会社が、PC・Web中心の会社を凄いスピードで抜き去る事案が
> 世界中で増えているね。接触時間が違うからまあそうだよな。
> 消費者向けであれば、Webサイトすら作る必要なくなってきたしな。
実際、スマホ普通に使っててブラウザ全然使わないだろ?
軽くGoogle検索したり、LINEやFacebookやTwitterでWebページを表示したり、
そこからアプリをダウンロードする程度のことはするだろうが。
asm.js+WebGLのゲームにしても、
まずAndroid、iOS、それにFirefox OSできっちり動かして見せてくれないと話にならんよw
これまでに公開されている主だったデモ、全部スマホでは動かねーし、
PCですら1分も2分も待ってやっと動く状況なわけじゃん。あんなもので商売になるわけがない。
そもそも、何百MBというサイズの「Webページ」をブラウザで表示するのが非現実的。
まずユーザーが待てる時間で表示するための回線速度がまったく足りない。
光ファイバーですらBlu-ray程度のダウンロード速度しかないし
モバイル回線は1桁以上遅く、通信量制限がある。さらに多くの国で従量課金。
メモリの問題もある。最近は1GBや2GBのアプリも珍しくないのに、
最新のiPhoneやiPadですらメモリ1GBしか積んでいないんだぜ。
HTML5のしょぼいオフライン機能だので間に合うわけがない。
リソースだけでなく、でかいJavaScriptをパース・実行するにもすげーメモリ食う。
(FirefoxのAOTコンパイラは専用のパーサを書いているが)
Unity 5のWebGLデプロイも、当面はデスクトップで一部のブラウザから
しかもかなりの速度ペナルティがあると言っているよ。
(クソMozillaは大本営発表しかしないからほっとけ。Unityのフォーラム嫁w)
PCブラウザですら実用未満なんだ。
モバイルブラウザでAAA級の3Dゲームが動くには軽く5年か10年はかかるだろ。
で、それなら5年待てばブラウザは戦えるのかと言えば、その間にネイティブはさらに進化していて
ブラウザは、WebGL2はいつだYOだの、Oculus Rift対応はいつだYOだの言ってるんじゃねーの。
これは良いシナリオの方で、悪けりゃウェブは今のまま停滞しているか消滅してるかもしれん。
今のネットニュースのように、存在するが誰も知らない、使わないとかな。
それに、ハードのスペック向上速度も落ちているし、
途上国のデバイスは低スペックなことも忘れてはいけない。
ブラウザの性能が今のネイティブ並みになるだけでも一体何年かかることか。
>>422
> ネイティブ売り場課金30%ピンハネパラダイムが
あれを単にピンハネと呼ぶのはなぁ。
App StoreやGoogle Playの運用と配信・課金インフラには多大なコストがかかっているよ。
実際、AppleはApp Store単独ではまったく利益を出していない。ストアはただの呼び水だ。
それに、ブラウザでも自社でプラットフォーム持っているのでない限り
モバグリアメーバに「ピンハネ」されるのは同じことだぜ。
だから、プラットフォームであるモバグリアメーバは当然HTML5がHTML5がと言うんだが、
SAPがそれに付き合う義理は欠片もないね。
もしApp StoreやGoogle Playがけしからん、やつらの商売が気に食わんというなら
OSやハードウェアそのものから構築するしかないと思うぞ。
ブラウザは駄目だろ。HTML/CSS/JavaScriptスタックは単純に性能面でも品質面でも駄目すぎるし
金を出して開発・保守しているのは結局GoogleやAppleだ。
第二のブラウザ、第二のWebをゼロから作り上げるくらいの気概のある連中が
どこかにいれば面白そうだけどな。
ブラウザは、WebGL2はいつだYOだの、Oculus Rift対応はいつだYOだの言ってるんじゃねーの。
これは良いシナリオの方で、悪けりゃウェブは今のまま停滞しているか消滅してるかもしれん。
今のネットニュースのように、存在するが誰も知らない、使わないとかな。
それに、ハードのスペック向上速度も落ちているし、
途上国のデバイスは低スペックなことも忘れてはいけない。
ブラウザの性能が今のネイティブ並みになるだけでも一体何年かかることか。
>>422
> ネイティブ売り場課金30%ピンハネパラダイムが
あれを単にピンハネと呼ぶのはなぁ。
App StoreやGoogle Playの運用と配信・課金インフラには多大なコストがかかっているよ。
実際、AppleはApp Store単独ではまったく利益を出していない。ストアはただの呼び水だ。
それに、ブラウザでも自社でプラットフォーム持っているのでない限り
モバグリアメーバに「ピンハネ」されるのは同じことだぜ。
だから、プラットフォームであるモバグリアメーバは当然HTML5がHTML5がと言うんだが、
SAPがそれに付き合う義理は欠片もないね。
もしApp StoreやGoogle Playがけしからん、やつらの商売が気に食わんというなら
OSやハードウェアそのものから構築するしかないと思うぞ。
ブラウザは駄目だろ。HTML/CSS/JavaScriptスタックは単純に性能面でも品質面でも駄目すぎるし
金を出して開発・保守しているのは結局GoogleやAppleだ。
第二のブラウザ、第二のWebをゼロから作り上げるくらいの気概のある連中が
どこかにいれば面白そうだけどな。
パズドラとかの売上見る限り、あの決済代行でappleやgoogleが利益出してないと言うとか
そんなことありえねーわ
決済代行で利益出せないのなら、わざわざモバゲー・GREEが自前の決済に誘導しようとしたりしねーわ
ガラケーの場合は、ドコモ/au/sbのショバ代が10%台前半だったから、
わざわざどこも独自決済に力入れずに携帯キャリア任せだったんだよ
スマホになってショバ代が3割になって、しかもアプリ規約で独自決済への誘導に規制がかけられてるが、
それでもアプリ規約に反しない範囲でできるだけ独自決済に誘導しようと頑張ってるのは
高額なショバ代のせい
そんなことありえねーわ
決済代行で利益出せないのなら、わざわざモバゲー・GREEが自前の決済に誘導しようとしたりしねーわ
ガラケーの場合は、ドコモ/au/sbのショバ代が10%台前半だったから、
わざわざどこも独自決済に力入れずに携帯キャリア任せだったんだよ
スマホになってショバ代が3割になって、しかもアプリ規約で独自決済への誘導に規制がかけられてるが、
それでもアプリ規約に反しない範囲でできるだけ独自決済に誘導しようと頑張ってるのは
高額なショバ代のせい
>>436
正解
正解
今日さ、やたら最新のPC入れてる図書館に行ってきた
CPUがCore-i7の3770だった、メモリは4Gだ
けどさ、つっかかるんだよね…
最近のCPUは速いとか何の不満もないとか昔と違って絶賛のレヴューばかりだけど
まちがいなくデスクトップのOCしてる4GhzQ9550の方が速い
ノートもi7でメモリ8G持ってるけど、外で使ってると不満ないのに
家でデスクトップの合間に使うとやたら遅く感じる
あと10年は闘えそうな気がしてきたwww
CPUがCore-i7の3770だった、メモリは4Gだ
けどさ、つっかかるんだよね…
最近のCPUは速いとか何の不満もないとか昔と違って絶賛のレヴューばかりだけど
まちがいなくデスクトップのOCしてる4GhzQ9550の方が速い
ノートもi7でメモリ8G持ってるけど、外で使ってると不満ないのに
家でデスクトップの合間に使うとやたら遅く感じる
あと10年は闘えそうな気がしてきたwww
439 :,,・´∀`・,,)っ-○○○:2014/04/28(月) 20:15:16.94 ID:Jc5XLPMd
以下のいくつかはAppStoreに誘導する為にAppleがわざとやってる点は
踏まえたうえで、ブラウザアプリよりネイティブアプリが好まれる理由を挙げよう
1.Safariは一定時間毎にセッションが切れるので、ゲームにアクセスするには
都度ログイン操作が必要。ネイティブアプリならセッションを保持できる。
2.アプリなら複数アカウント持ちなどの不正がやりにくい
・iOSのSafariはガラケーのように端末IDをサーバに送信しない
・アプリからは端末ID代替の認証手段が用意されている
i) インストール毎にユニークなID(IUID)の発行およびサーバとの通信の許可
ii) iCloudにアクセスすることを認めている
3.アプリはゲームセンターで実績を公開・共有できる
4.AppStoreはiTunesとポイントを共有している
・音楽を買った残りのポイントでアプリのアイテム購入なども可能
5.アプリは、サーバから投げたプッシュ通知を受け取り、iPhoneの
トップ画面に表示させることができる。
これらの点については、どんだけJavaScriptが速くなって、どんだけサーバの
レスポンスがあがってもネイティブアプリには勝てんのよ。
アメーバもブラウザアプリに拘り続けてたがネイティブアプリの利便性には
勝てずに結局ネイティブへの切替を進めている。
踏まえたうえで、ブラウザアプリよりネイティブアプリが好まれる理由を挙げよう
1.Safariは一定時間毎にセッションが切れるので、ゲームにアクセスするには
都度ログイン操作が必要。ネイティブアプリならセッションを保持できる。
2.アプリなら複数アカウント持ちなどの不正がやりにくい
・iOSのSafariはガラケーのように端末IDをサーバに送信しない
・アプリからは端末ID代替の認証手段が用意されている
i) インストール毎にユニークなID(IUID)の発行およびサーバとの通信の許可
ii) iCloudにアクセスすることを認めている
3.アプリはゲームセンターで実績を公開・共有できる
4.AppStoreはiTunesとポイントを共有している
・音楽を買った残りのポイントでアプリのアイテム購入なども可能
5.アプリは、サーバから投げたプッシュ通知を受け取り、iPhoneの
トップ画面に表示させることができる。
これらの点については、どんだけJavaScriptが速くなって、どんだけサーバの
レスポンスがあがってもネイティブアプリには勝てんのよ。
アメーバもブラウザアプリに拘り続けてたがネイティブアプリの利便性には
勝てずに結局ネイティブへの切替を進めている。
440 :,,・´∀`・,,)っ-○○○:2014/04/28(月) 20:46:15.28 ID:Jc5XLPMd
Tizenなんか対抗馬としてもてはやすベンダーもいるかもしれないが
十分甘い汁すってるアプリ屋からすれば
「サムスンやdocomoがAppleやGoogleやりたいだけだろ」
てな具合になる。
厳しいだろうねえ。
IntelもiOSやAndroid向けのXMLベースのアプリ開発ツール公開してるし
既存の市場でどう戦うかを論じるべき時だよ。
PCならロイヤリティフリーだけど、ある意味Tizenより
新規参入の難しい業界だろう
十分甘い汁すってるアプリ屋からすれば
「サムスンやdocomoがAppleやGoogleやりたいだけだろ」
てな具合になる。
厳しいだろうねえ。
IntelもiOSやAndroid向けのXMLベースのアプリ開発ツール公開してるし
既存の市場でどう戦うかを論じるべき時だよ。
PCならロイヤリティフリーだけど、ある意味Tizenより
新規参入の難しい業界だろう
Intel Turbo Boost Technology Monitorってメモリリークのバグある気がする
ずっと起動してるとメモリ使用量がすげー増えてくる
最新版の2.6.20使ってるんだが....
まあずっと起動しておくもんじゃないのかな
ずっと起動してるとメモリ使用量がすげー増えてくる
最新版の2.6.20使ってるんだが....
まあずっと起動しておくもんじゃないのかな
442 :,,・´∀`・,,)っ-○○○:2014/04/28(月) 20:58:02.05 ID:Jc5XLPMd
バグ報告したほうがいいかもしれんねそれは
>>438
Diskkeeprだの監視ソフトだのいろいろ入れてるだろうからなー
Diskkeeprだの監視ソフトだのいろいろ入れてるだろうからなー
444 get !
セキュリティソフトが原因で
アホみたいに遅い事が多いわ
アホみたいに遅い事が多いわ
今時セキュリティソフトって…笑
漢ならノーガードでいいっしょw
漢ならノーガードでいいっしょw
>>436
正直そのショバ代もパッケージ販売と比べりゃ割安なんだがな・・・
正直そのショバ代もパッケージ販売と比べりゃ割安なんだがな・・・
>>439
PCと比べてスマホはブラウザが不便すぎるんだよな
PCと比べてスマホはブラウザが不便すぎるんだよな
30秒で電池を充電できる?「スーパーキャパシタ@25,000円」 | 「マイナビウーマン」
http://woman.mynavi.jp/article/130904-076/
https://www.google.co.jp/url?q=http://www.wakamatsu-net.com/cgibin/biz/page.cgi%3Fcate%3D2115&sa=U&ei=INxeU-zvHMX38QWUhoH4Bg&ved=0CEcQFjAF&sig2=MznIIxqt5yFf8qOz9htkgw&usg=AFQjCNH-ez9dzRpuJRs5OFeWWJ_EaecVdg
http://www.wakamatsu-net.com/cgibin/biz/page.cgi?cate=2115
http://woman.mynavi.jp/article/130904-076/
https://www.google.co.jp/url?q=http://www.wakamatsu-net.com/cgibin/biz/page.cgi%3Fcate%3D2115&sa=U&ei=INxeU-zvHMX38QWUhoH4Bg&ved=0CEcQFjAF&sig2=MznIIxqt5yFf8qOz9htkgw&usg=AFQjCNH-ez9dzRpuJRs5OFeWWJ_EaecVdg
http://www.wakamatsu-net.com/cgibin/biz/page.cgi?cate=2115
変なコテハンのやつはスレチだから消えろ
変なコテハンのやつはスレチだから消えろ
ソフト板でやってろ
ソフト板でやってろ
団子のことか?
良い団子と悪い団子がいるから仕方ない、多分本人も気づいてない
いる時に言えよw
団子は偏在しているからな
まさにユビキタス
まさにユビキタス
ソフトあってのハード
団子のダメなのはPCの話題にHPCで反論したつもりになってるとこ
460 :,,・´∀`・,,)っ-○○○:2014/04/30(水) 08:54:02.91 ID:laAJx0rq
>>459
何の話だね。
GPGPUが不毛な技術だといわれて悔しかったかね?
新しいアルゴリズムはHPCから生み出され、サーバ・ワークステーションを
経てPCに下方展開する。ホンダだって結局F1に復帰したじゃないか。
NVIDIAのCUDA普及計画だってこれに基づいている。
逆にコンシューマから上方展開できるソフト技術なんて稀なんだよ。
無償のプラットフォームを立ち上げてコンテンツクリエイター向け
有料ソフトで回収するビジネスモデル(eg: Adobe製品)もあるが、
基本的に支配者にならないと生き残れない。
何の話だね。
GPGPUが不毛な技術だといわれて悔しかったかね?
新しいアルゴリズムはHPCから生み出され、サーバ・ワークステーションを
経てPCに下方展開する。ホンダだって結局F1に復帰したじゃないか。
NVIDIAのCUDA普及計画だってこれに基づいている。
逆にコンシューマから上方展開できるソフト技術なんて稀なんだよ。
無償のプラットフォームを立ち上げてコンテンツクリエイター向け
有料ソフトで回収するビジネスモデル(eg: Adobe製品)もあるが、
基本的に支配者にならないと生き残れない。
まぁでもあれだよな、ネイティブだろうがWebだろうが、ネットに常時接続してソフトが常に最新版に更新される事が前提にできるんだから、
結局のところ需要(ブラウザ新機能等)・必要性(不具合等)があれば即座に更新対応されてユーザーも混乱しない
そういう環境ができたわけだから、もう後は純粋なプロセッサ性能競争になるわけで、後はIntelが障害を一つ一つ攻略するだけになった
Android-x86x64、Windowsの小型省電力化、そしてラスボスの3G・LTEモデム
結局のところ需要(ブラウザ新機能等)・必要性(不具合等)があれば即座に更新対応されてユーザーも混乱しない
そういう環境ができたわけだから、もう後は純粋なプロセッサ性能競争になるわけで、後はIntelが障害を一つ一つ攻略するだけになった
Android-x86x64、Windowsの小型省電力化、そしてラスボスの3G・LTEモデム
3Gモデムはすでに十分に実績のあるやつを持ってるんだよなあ・・・
3Gのみなら中華メーカーの安物があるからなぁ
>>456 それは遍在
偏在は逆の意味になるからスルーできない誤変換
偏在は逆の意味になるからスルーできない誤変換
GoogleがサーバをIntelからIBMの「OpenPOWER」陣営に乗換え、Intelにとっては大打撃
http://gigazine.net/news/20140430-google-shift-intel-to-ibm/
http://gigazine.net/news/20140430-google-shift-intel-to-ibm/
良い事じゃん、Intel依存のコードばかりになってると、逆に過去のIntelプロセッサに最適化された
コード・バイナリが現在のIntelプロセッサには合わない、という状況も発生したりするリスクがある
きちんと依存性を排除したプロジェクトにする事で未来のIntelプロセッサに恩恵が出る
コード・バイナリが現在のIntelプロセッサには合わない、という状況も発生したりするリスクがある
きちんと依存性を排除したプロジェクトにする事で未来のIntelプロセッサに恩恵が出る
同意
ARMかとおもいきやまさかのIBM
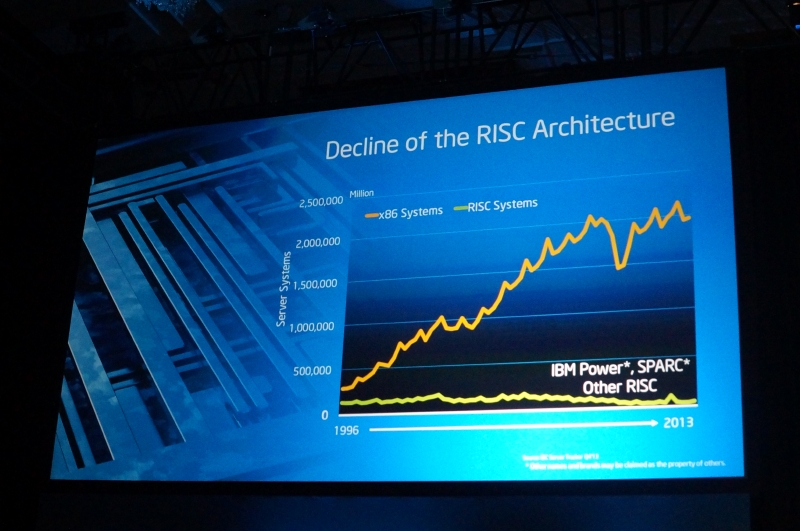{kind=link}
Google先生の掌で生かさず殺さずってところか
471 :,,・´∀`・,,)っ-○○○:2014/04/30(水) 19:36:27.72 ID:laAJx0rq
リスクヘッジ用の代替プラットフォームとして同じx86ベンダーとして
真っ先に名前が挙がるあそこが無視された事実のほうが大きい
真っ先に名前が挙がるあそこが無視された事実のほうが大きい
一体何に使うサーバなのだろうか
マザー上はかなり見慣れない配置のようだが
マザー上はかなり見慣れない配置のようだが
473 :,,・´∀`・,,)っ-○○○:2014/04/30(水) 20:02:13.00 ID:laAJx0rq
なにせGoogle様は独自にカスタマイズしたMySQLなんかのソースコードも
公開しないからね
公開しないからね
まさかもなにもopenpowerのトップはgoogleやで
googleの競争力の源泉となってるところはコミュニティーにフィードバックせずに自社オンリーなんでしょう
ただし、それ以外の部分や、公開したほうがgoogleのためになると判断した部分に関しては
googleの改変をかなりフィードバックしてるね
たとえばフリーソフトを魔改造してサーバが従来の半分で済んだとする
その改造部分をフィードバックすれば、ライバルもサーバ台数を半減できるが、
フィードバックしなければgoogleだけがライバルより同等のことを半分のサーバで行えるっていう
非常に大きな優位が発生する
ただし、それ以外の部分や、公開したほうがgoogleのためになると判断した部分に関しては
googleの改変をかなりフィードバックしてるね
たとえばフリーソフトを魔改造してサーバが従来の半分で済んだとする
その改造部分をフィードバックすれば、ライバルもサーバ台数を半減できるが、
フィードバックしなければgoogleだけがライバルより同等のことを半分のサーバで行えるっていう
非常に大きな優位が発生する
http://insidehpc.com/2014/04/29/podcast-nersc-build-70-million-cray-supercomputer-based-knights-landing/
Podcast: NERSC to Build $70 Million Cray Supercomputer based on Knights Landing
Podcast: NERSC to Build $70 Million Cray Supercomputer based on Knights Landing
>>475
サーバーを利用させる何かがないと不毛な話だな
サーバーを利用させる何かがないと不毛な話だな
478 :,,・´∀`・,,)っ-○○○:2014/04/30(水) 20:40:07.38 ID:laAJx0rq
Googleはx86レガシーコード依存からの脱却をするだけの勇気も資産もある
企業だが、なぜHSAに興味を示さないのか。
そこの見極めができてるかがAMDの今後を決めるだろうな。
AMDがたびたび言及するB-/B+Treeの高速化なんてGoogleのサービスにも
影響のある分野だ。
画像や動画も大量に扱うから、画処理を高速化するアクセラレータは
有効かもしれない。
しかしGoogleはHSA Foundationへの出資をしない。
この理由として考えられる可能性はひとつよ。
「こけおどし」に過ぎないと見透かされてるから。
まあ、HSAは旧経営陣の産み出した一番の膿だと思ってるので
ここを出し切らない限りは未来は無いだろう
企業だが、なぜHSAに興味を示さないのか。
そこの見極めができてるかがAMDの今後を決めるだろうな。
AMDがたびたび言及するB-/B+Treeの高速化なんてGoogleのサービスにも
影響のある分野だ。
画像や動画も大量に扱うから、画処理を高速化するアクセラレータは
有効かもしれない。
しかしGoogleはHSA Foundationへの出資をしない。
この理由として考えられる可能性はひとつよ。
「こけおどし」に過ぎないと見透かされてるから。
まあ、HSAは旧経営陣の産み出した一番の膿だと思ってるので
ここを出し切らない限りは未来は無いだろう
Intelがサーバー用プロセッサーを遺伝子解析に向ける、ソフトウエア企業と協業
http://techon.nikkeibp.co.jp/article/NEWS/20140430/349220/
http://techon.nikkeibp.co.jp/article/NEWS/20140430/349220/
480 :,,・´∀`・,,)っ-○○○:2014/04/30(水) 20:54:01.39 ID:laAJx0rq
Googleは1つのクエリを1000台のXeonサーバで分散処理するくらいに
マルチスレッドを使いこなす企業だが、そのGoogleですら
Xeonの代替として、POWER8のようなシングルスレッド性能の高いプロセッサを
必要としてるのも事実だな。
ぶっちゃけ、「ワットあたりのマルチスレッド性能」ならPOWER8よりベターな
ソリューションはいくらでもあるだろ?
SPECpower_ssj2008のスコアを見てもPOWERサーバってワットパフォーマンスは
Xeonよりむしろ悪い。
マルチスレッドを使いこなす企業だが、そのGoogleですら
Xeonの代替として、POWER8のようなシングルスレッド性能の高いプロセッサを
必要としてるのも事実だな。
ぶっちゃけ、「ワットあたりのマルチスレッド性能」ならPOWER8よりベターな
ソリューションはいくらでもあるだろ?
SPECpower_ssj2008のスコアを見てもPOWERサーバってワットパフォーマンスは
Xeonよりむしろ悪い。
>>475
魔改造ワロタw
魔改造ワロタw
POWERってウン千億の投資をペイできるほどの需要あるの?
openpowerはgoogleの為にあるといっても言い
484 :,,・´∀`・,,)っ-○○○:2014/04/30(水) 21:49:17.50 ID:laAJx0rq
Intelは、iris proみたいなedramをXeonに入れればいいのに
もちろん、GPUは積まずに全量をL4$として使用
L4$のタグ領域はメインダイのSRAM、L4$のデータをオンパッケージ別ダイeDRAMみたいな感じで
もちろん、GPUは積まずに全量をL4$として使用
L4$のタグ領域はメインダイのSRAM、L4$のデータをオンパッケージ別ダイeDRAMみたいな感じで
488 :,,・´∀`・,,)っ-○○○:2014/04/30(水) 23:48:05.45 ID:laAJx0rq
やるならHMCでしょ。
Xeon PhiのはHMCだと思うよ。
IrisProのeDRAMを16GB分重ねたら128枚必要になるし。
Xeon PhiのはHMCだと思うよ。
IrisProのeDRAMを16GB分重ねたら128枚必要になるし。
ARMの対抗馬はMIPSじゃなくてPPCだったのか
>>489
いいものはメインフレームに使って、ちょっと選別に落ちるものを
格安でGoogleが引き取ることにしたのか。
捨てるよりはマシだからな。
いいものはメインフレームに使って、ちょっと選別に落ちるものを
格安でGoogleが引き取ることにしたのか。
捨てるよりはマシだからな。
ARM一極化はGoogleも避けたかったけど
x86を支持したら間接的にWintelを後押ししてしまうから
第三の選択肢としてPPCになったということかな
x86を支持したら間接的にWintelを後押ししてしまうから
第三の選択肢としてPPCになったということかな
powerpcじゃなくてpowerだからw
自社で必要なIPを組み合わせるのにPowerが便利だったとかそういう話になるかもね
Googleぐらいの規模であれば、例えば動画像処理のために
専用回路を入れたIPを設計しても元が取れるかもしれない
まあなんかXeonも実はカスタム品を作ってるという話はあったが……
Googleぐらいの規模であれば、例えば動画像処理のために
専用回路を入れたIPを設計しても元が取れるかもしれない
まあなんかXeonも実はカスタム品を作ってるという話はあったが……
Intel Clang-based C++ Compilerが登場したらしい
バックエンドはicc由来のIntel謹製で、iccと性能は同等とのこと
Mac向けとか書いてある
http://llvm.org/devmtg/2014-04/PDFs/Posters/ClangIntel.pdf
バックエンドはicc由来のIntel謹製で、iccと性能は同等とのこと
Mac向けとか書いてある
http://llvm.org/devmtg/2014-04/PDFs/Posters/ClangIntel.pdf
>>491
Intelだと敵対してるMicrosoftにも間接的に利益いっちゃうからIBMなんだろうね
Intelだと敵対してるMicrosoftにも間接的に利益いっちゃうからIBMなんだろうね
企業間の政治的な駆け引きの話も面白いかもしれないが
技術が選択に与えた影響についても考えてみようじゃないか
POWER8の仕様はHaswellと比べてどうなんだ
8命令発行 10命令イシュー 16本の実行パイプライン
L1data 64KB / L2 512KB
L3 8MB(1coreあたり)/ L4 128MB(12coreあたり)
L2接続 R 64Byte*4GHz / W 16Byte*4GHz
L3接続 R 32Byte*4GHz / W 32Byte*4GHz
メモリー(12coreあたり) peak410GB/sec 実効230GB/sec
CAPI(Coherence Attach Processor Interface)
PCIe接続のプロセッサにキャッシュコヒーレンシーを提供
ただし相手側にも対応機構が必要
接続プロセッサはGPUの他NANDコントローラ等も想定
技術が選択に与えた影響についても考えてみようじゃないか
POWER8の仕様はHaswellと比べてどうなんだ
8命令発行 10命令イシュー 16本の実行パイプライン
L1data 64KB / L2 512KB
L3 8MB(1coreあたり)/ L4 128MB(12coreあたり)
L2接続 R 64Byte*4GHz / W 16Byte*4GHz
L3接続 R 32Byte*4GHz / W 32Byte*4GHz
メモリー(12coreあたり) peak410GB/sec 実効230GB/sec
CAPI(Coherence Attach Processor Interface)
PCIe接続のプロセッサにキャッシュコヒーレンシーを提供
ただし相手側にも対応機構が必要
接続プロセッサはGPUの他NANDコントローラ等も想定
Risk(Windows)
>>496
X86、ARM、MIPSあたりも並べてくれるとありがたい
X86、ARM、MIPSあたりも並べてくれるとありがたい
>465
CPUを決めうちしてアーキテクチャに依存する要素をソースの中に
ばら撒くことはできるだけ避けて、依存要素は分離・カプセル化しないと
気持ちが悪い、という癖は今もプログラマの文化として受け継がれていると思う。
サーバーサイドのプログラムなら、Gordon MacKeanの言ってる
ポーティングが容易だったという話をそれほど不思議だとは思わない。
CPUを決めうちしてアーキテクチャに依存する要素をソースの中に
ばら撒くことはできるだけ避けて、依存要素は分離・カプセル化しないと
気持ちが悪い、という癖は今もプログラマの文化として受け継がれていると思う。
サーバーサイドのプログラムなら、Gordon MacKeanの言ってる
ポーティングが容易だったという話をそれほど不思議だとは思わない。
TSVでHBMメモリーがスタックされたらeDRAMは要らない子に・・・・
インテルはひょっとして先走ってしまったのか?
まあeDRAMなんてすぐに取り除いてL4はHBMに変わるんだろうけど
インテルはひょっとして先走ってしまったのか?
まあeDRAMなんてすぐに取り除いてL4はHBMに変わるんだろうけど
>>500
Intel的には次までの繋ぎって位置付けだから想定の範囲内っしょ。
Intel的には次までの繋ぎって位置付けだから想定の範囲内っしょ。
HMCが完成した暁にはHBMなんていらない子に
どうだろう?
何だかんだでJEDEC準拠は大きいんでねーの?
何だかんだでJEDEC準拠は大きいんでねーの?
仕様を見ると帯域はHBM有利、容量はHMC有利になりそう
>>498
全部は勘弁
x86 Haswell-EP
8 pipe
L1data 32KB / L1inst 32KB / L2 256KB
L3 2.5MB(1coreあたり)
L1data R 64Byte/Cycle / W 32Byte/Cycle
L2 64Byte/Cycle
メモリー peak 85.333GB/s(E7v2 Ivy 〜15core)
peak 68.266GB/s(E5v3 〜14core)
LLCのByte/Cycle(リングバス通過なし)がわからん。
リングバスと同じスループット?
全部は勘弁
x86 Haswell-EP
8 pipe
L1data 32KB / L1inst 32KB / L2 256KB
L3 2.5MB(1coreあたり)
L1data R 64Byte/Cycle / W 32Byte/Cycle
L2 64Byte/Cycle
メモリー peak 85.333GB/s(E7v2 Ivy 〜15core)
peak 68.266GB/s(E5v3 〜14core)
LLCのByte/Cycle(リングバス通過なし)がわからん。
リングバスと同じスループット?
結局XEONとパワーはどっちが速いのさ?
Xeon
Intelからすると、自社fabの稼働率が低い場合は、eDRAMも自社で作ったほうがいい
自社fabの稼働率が高い場合は亜、eDRAMは外部から買ったほうがいい
自社製造か外部調達かは、自社fabの稼働率次第だろうね
自社fabの稼働率が高い場合は亜、eDRAMは外部から買ったほうがいい
自社製造か外部調達かは、自社fabの稼働率次第だろうね
Powerは大容量L4$があるから、サーバソフトの多くはL4$によってかなり処理速度が向上する
まあXeonが速いかPowerが速いかはアプリ次第だろうけど、
一般的なサーバ用途では高速化しやすい
まあXeonが速いかPowerが速いかはアプリ次第だろうけど、
一般的なサーバ用途では高速化しやすい
このスレにも変な嵐が住み着いたとかもう終わりだな
まあPOWER8はこのスレ向けの話題じゃないと思うけど
久々にRISC陣営が絶対性能でx86を脅かすチップを出してきたことに意義があると思う
ここでSPECint_rate2006, SPECfp_rate2006のスコアが公開されてるけど、
http://www-03.ibm.com/systems/power/hardware/benchmarks/hpc.html
6コアx4チップの24コア構成でint_rateが1750、fp_rateが[email protected]とかなり性能が高い
最新のIvy-EXなXeon E7の6コアx4構成と比べてもこのスコアは高い
http://www.spec.org/cpu2006/results/res2014q1/cpu2006-20140310-28957.html
http://www.spec.org/cpu2006/results/res2014q1/cpu2006-20140310-28948.html
int_rateが1200、fp_rateが[email protected]
A社が脱落してサーバ/HPC市場じゃ敵なしかと思われてたけど気合入れてやらなきゃいかん
久々にRISC陣営が絶対性能でx86を脅かすチップを出してきたことに意義があると思う
ここでSPECint_rate2006, SPECfp_rate2006のスコアが公開されてるけど、
http://www-03.ibm.com/systems/power/hardware/benchmarks/hpc.html
6コアx4チップの24コア構成でint_rateが1750、fp_rateが[email protected]とかなり性能が高い
最新のIvy-EXなXeon E7の6コアx4構成と比べてもこのスコアは高い
http://www.spec.org/cpu2006/results/res2014q1/cpu2006-20140310-28957.html
http://www.spec.org/cpu2006/results/res2014q1/cpu2006-20140310-28948.html
int_rateが1200、fp_rateが[email protected]
A社が脱落してサーバ/HPC市場じゃ敵なしかと思われてたけど気合入れてやらなきゃいかん
Xeonと比べてもコスパがいいとは言えないから
突くとしたらやっぱそこなんかね
突くとしたらやっぱそこなんかね
オプが死んでからXeonは価格をどんどん上げてきているのでコスパはPOWERとそれほど変わらないのかもしれない
なにしろNetBurst時代のXeonは4ソケット対応の最上位モデルが20万円台だったし(今は60万)
なにしろNetBurst時代のXeonは4ソケット対応の最上位モデルが20万円台だったし(今は60万)
>>513
それオプと関係なくね
それオプと関係なくね
516 :,,・´∀`・,,)っ-○○○:2014/05/01(木) 21:28:07.42 ID:TZCNwdXZ
>>491
ARM(AArch64)なんてのは、一極化以前の問題としてソフトがない。
ましてサーバだぜ。
ハードもソフトも実績もがないものをいきなり基幹システムに使うなんて
そんな怖いことできるわけがないじゃん
SPECintの推定スコアでA57を上回ってるAtom(Avoton)すらGoogleは
使ってるという話を聞かないから、省電力サーバって使える用途が
あるのかは疑問だな。データベースって基本的にキャッシュ命でしょ。
ARM(AArch64)なんてのは、一極化以前の問題としてソフトがない。
ましてサーバだぜ。
ハードもソフトも実績もがないものをいきなり基幹システムに使うなんて
そんな怖いことできるわけがないじゃん
SPECintの推定スコアでA57を上回ってるAtom(Avoton)すらGoogleは
使ってるという話を聞かないから、省電力サーバって使える用途が
あるのかは疑問だな。データベースって基本的にキャッシュ命でしょ。
517 :,,・´∀`・,,)っ-○○○:2014/05/01(木) 21:30:19.34 ID:TZCNwdXZ
>>511
別にPOWERの絶対性能はいつもどおりだよ。
むしろ脅威なのはPOWERプラットフォームのオープンシステム化で
エンプラ市場における「IBM互換機」がほかのベンダーでも
出せるようになったこと
別にPOWERの絶対性能はいつもどおりだよ。
むしろ脅威なのはPOWERプラットフォームのオープンシステム化で
エンプラ市場における「IBM互換機」がほかのベンダーでも
出せるようになったこと
>>504
HBMはインターポーザによる直結専用、HMCはBGAなんでソケット化に望みあり、と見てる。
HBMはインターポーザによる直結専用、HMCはBGAなんでソケット化に望みあり、と見てる。
519 :,,・´∀`・,,)っ-○○○:2014/05/01(木) 21:43:04.73 ID:TZCNwdXZ
http://www.hybridmemorycube.org/about.html
こんだけのメンバーがいたらJEDEC規格外でもデファクトスタンダードは
確定じゃないかね?
(そもそもロジックに何を載せるか定義しない以上はJEDECが規格化
しようがないわけだが、だからといって普及の障壁になるかというと
そんなことはないと思われ)
というか、HMCのほうが構造上キャッシュコントローラ(+α)を混載
しやすいのでメモリだけのHBMよりはPhiに向いたソリューションのはずだ
スパコン最大の学会「SC13」に見る先端技術 7 富士通の次期スパコンはどうなるのか(前編)
http://news.mynavi.jp/column/sc13/007/
この記事の中でHBM, HMC, DDR4, GDDR5の比較がなされている
http://news.mynavi.jp/photo/column/sc13/007/images/005l.jpg
こんだけのメンバーがいたらJEDEC規格外でもデファクトスタンダードは
確定じゃないかね?
(そもそもロジックに何を載せるか定義しない以上はJEDECが規格化
しようがないわけだが、だからといって普及の障壁になるかというと
そんなことはないと思われ)
というか、HMCのほうが構造上キャッシュコントローラ(+α)を混載
しやすいのでメモリだけのHBMよりはPhiに向いたソリューションのはずだ
スパコン最大の学会「SC13」に見る先端技術 7 富士通の次期スパコンはどうなるのか(前編)
http://news.mynavi.jp/column/sc13/007/
この記事の中でHBM, HMC, DDR4, GDDR5の比較がなされている
http://news.mynavi.jp/photo/column/sc13/007/images/005l.jpg
{kind=link}
HMCのいいところはHMC同士をデイジーチェーン接続していくらでも容量を増やせるところ
HBMで容量を増やそうとするとシリコンインターポーザとダイの再設計が必要になるがHMCなら基板の変更だけで済む
ピンもHBMより少ないからモジュール化も不可能ではないのでそもそも基盤の再設計すら不要の可能性もある
メモリを数百GB搭載するサーバではHBMオンリーは不可能でDDR4との組み合わせになるが、
HMCはHMCだけで必要な容量を確保できるだろう
HBMで容量を増やそうとするとシリコンインターポーザとダイの再設計が必要になるがHMCなら基板の変更だけで済む
ピンもHBMより少ないからモジュール化も不可能ではないのでそもそも基盤の再設計すら不要の可能性もある
メモリを数百GB搭載するサーバではHBMオンリーは不可能でDDR4との組み合わせになるが、
HMCはHMCだけで必要な容量を確保できるだろう
521 :,,・´∀`・,,)っ-○○○:2014/05/01(木) 21:56:07.75 ID:TZCNwdXZ
>>513
それE7じゃん。
ItaniumなみのRAS性能と品質保証が求められる最上位レンジだからこそ
設定可能な価格だよ。
そのレンジはNetBurst世代のXeon(共有バスのFSBベース)では弱すぎて
そもそも相手にされなかったし、また、8ソケット対応のOpteronが30万超えで
ブイブイ言わせてた。
ちなみにコア数が変わらないXeon E3とかE5下位は同コア数での価格設定は
そう大きく変わってない。
ハード屋としてはコア数が増えるほど同じ演算性能でのサーバ台数を減らすことが
できるので、一概に高いXeonがコストアップになるかと言うとそうもいえない。
それE7じゃん。
ItaniumなみのRAS性能と品質保証が求められる最上位レンジだからこそ
設定可能な価格だよ。
そのレンジはNetBurst世代のXeon(共有バスのFSBベース)では弱すぎて
そもそも相手にされなかったし、また、8ソケット対応のOpteronが30万超えで
ブイブイ言わせてた。
ちなみにコア数が変わらないXeon E3とかE5下位は同コア数での価格設定は
そう大きく変わってない。
ハード屋としてはコア数が増えるほど同じ演算性能でのサーバ台数を減らすことが
できるので、一概に高いXeonがコストアップになるかと言うとそうもいえない。
522 :,,・´∀`・,,)っ-○○○:2014/05/01(木) 22:16:58.04 ID:TZCNwdXZ
あ、HMCの仕様ドキュメントだけどユーザー登録フォームをスキップしても
PDFダウンロードはできるよ
PDFダウンロードはできるよ
流行りませぬ
グーグルとインテル、米国時間5月6日に「Chrome OS」関連プレス向け発表開催へ
http://japan.cnet.com/news/service/35047310/
http://japan.cnet.com/news/service/35047310/
>>517
エンプラ市場限定っていう縛りあるの?
エンプラ市場限定っていう縛りあるの?
527 :,,・´∀`・,,)っ-○○○:2014/05/01(木) 23:16:55.30 ID:TZCNwdXZ
ホームサーバ的に使うのならパソコンで十分だな。
既に使い慣れたWindowsがあるからユーザーは新たな操作を覚える必要はない。
つけっぱなしでも電気代も気にしなくてすむようにアイドル時消費電力を抑えられる
NUCはそういうコンセプトを実現しやすいプラットフォームだと思う。
既に使い慣れたWindowsがあるからユーザーは新たな操作を覚える必要はない。
つけっぱなしでも電気代も気にしなくてすむようにアイドル時消費電力を抑えられる
NUCはそういうコンセプトを実現しやすいプラットフォームだと思う。
Power系だと伝統的にDBに強いから、バックエンドサーバでXeonと競争してくれるといいね。
529 :,,・´∀`・,,)っ-○○○:2014/05/01(木) 23:21:57.93 ID:TZCNwdXZ
>>518
え?パソコンに使いたいの?
PowerMac買い支えてやらなかったことを悔やんでも遅いよ
今まで上位のUNIXサーバ市場でしか使えなかったPOWERサーバが
下位製品が中心ではあるものの、Xeonの主戦場であるDPサーバで
競合しうるレンジにも投入されるようになった。
これは大胆な方向転換だよ。
IBMはその戦略にとって邪魔になる自身のx86サーバ事業をLenovoに売却。
え?パソコンに使いたいの?
PowerMac買い支えてやらなかったことを悔やんでも遅いよ
今まで上位のUNIXサーバ市場でしか使えなかったPOWERサーバが
下位製品が中心ではあるものの、Xeonの主戦場であるDPサーバで
競合しうるレンジにも投入されるようになった。
これは大胆な方向転換だよ。
IBMはその戦略にとって邪魔になる自身のx86サーバ事業をLenovoに売却。
ARMとPOWERの板挟みか
531 :,,・´∀`・,,)っ-○○○:2014/05/01(木) 23:36:02.41 ID:TZCNwdXZ
命令セットの異なるプロセッサがしのぎを削り
移植性をきちんと考慮して組まれたソフトウェアが市場を獲得できる
これはソフトウェア産業の活性化のために歓迎すべき流れよ。
もちろんRubyはPOWERでも動くぜ。
ARMは・・・性能的にきついわ
「俺らのハードで動くプログラミング言語を選べ」みたいなハード屋の
エゴ丸出しのGPGPUばかりが自称x86のライバルじゃ
大半のプログラムは実質x86しか選べないからな。
移植性をきちんと考慮して組まれたソフトウェアが市場を獲得できる
これはソフトウェア産業の活性化のために歓迎すべき流れよ。
もちろんRubyはPOWERでも動くぜ。
ARMは・・・性能的にきついわ
「俺らのハードで動くプログラミング言語を選べ」みたいなハード屋の
エゴ丸出しのGPGPUばかりが自称x86のライバルじゃ
大半のプログラムは実質x86しか選べないからな。
OPENPOWERってエンプラ市場限定なの?
533 :,,・´∀`・,,)っ-○○○:2014/05/02(金) 00:11:44.64 ID:j0Zt3cQi
パソコンならないぞ。勿論スマホもだ。
まあHPCも広義のエンプラだからな。
まあHPCも広義のエンプラだからな。
Xeon+Xeon Phi
POWER+Tesla
Googleはこの二本立てで行くのね、A社×2はお呼びじゃないと
そういやDARPAのエクサスパコンもひょっとしてこの組み合わせ対決になるんか
POWER+Tesla
Googleはこの二本立てで行くのね、A社×2はお呼びじゃないと
そういやDARPAのエクサスパコンもひょっとしてこの組み合わせ対決になるんか
535 :,,・´∀`・,,)っ-○○○:2014/05/02(金) 01:04:37.77 ID:j0Zt3cQi
Googleはアクセラレータについて何も言及してない
TeslaやPhiをいったいどこで使うのだね
ちなみにYouTubeでVP9コーデックとかが本格運用されるようになったら
専用ASIC使うんじゃないかと思ってる
(スマホに搭載されてるものが既にあるし)
TeslaやPhiをいったいどこで使うのだね
ちなみにYouTubeでVP9コーデックとかが本格運用されるようになったら
専用ASIC使うんじゃないかと思ってる
(スマホに搭載されてるものが既にあるし)
537 :,,・´∀`・,,)っ-○○○:2014/05/02(金) 01:36:20.81 ID:j0Zt3cQi
死体蹴りもたいがいにしないと発狂するやつも多数出てきそうだが
敢えて言う。
結局IBMがオープン市場に参入してきたのはこれ。
・非x86に乗り換えるリスク以上に、このままIntelの対抗馬としてのポジションを
AMDに頼り続けるリスクのほうが大きい
・当然HSA(笑)も信用に値しない技術である
サーバだけじゃなくてクライアントもそうだけど、
AMDはIntelに局所的に勝利してれば安泰だという楽観的な戦略は
もはや通用しないということは理解するべきだな
PCベンダーもタブレットやChromebookなどで非x86のネット端末を採用して
その意味で(Intel以外の選択肢という意味で)AMDへの依存度を減らしている。
敢えて言う。
結局IBMがオープン市場に参入してきたのはこれ。
・非x86に乗り換えるリスク以上に、このままIntelの対抗馬としてのポジションを
AMDに頼り続けるリスクのほうが大きい
・当然HSA(笑)も信用に値しない技術である
サーバだけじゃなくてクライアントもそうだけど、
AMDはIntelに局所的に勝利してれば安泰だという楽観的な戦略は
もはや通用しないということは理解するべきだな
PCベンダーもタブレットやChromebookなどで非x86のネット端末を採用して
その意味で(Intel以外の選択肢という意味で)AMDへの依存度を減らしている。
x86、POWER、Sparcの三つ巴になるといいけど、SparcはOracleのせいで脱落しそうなところが。
三桁万円で買える売り切りサーバあたりまで降りてくるんでしょう。
少なくとも、Linux開発者が買えないんじゃお話にならないんで、エントリーマシンが数十万円くらいの
お値段で出てくる可能性はある。
TYANが協力メーカーなので、MBは多分出回るだろう。
三桁万円で買える売り切りサーバあたりまで降りてくるんでしょう。
少なくとも、Linux開発者が買えないんじゃお話にならないんで、エントリーマシンが数十万円くらいの
お値段で出てくる可能性はある。
TYANが協力メーカーなので、MBは多分出回るだろう。
539 :,,・´∀`・,,)っ-○○○:2014/05/02(金) 01:57:46.69 ID:j0Zt3cQi
そーいやPWRficientベースのAmigaって結局出なかったな
結構期待してたのだが
結構期待してたのだが
ん? AmigaOne X1000て発売されてないの?
ベンチマークの記事とかちらほら見たけど
http://www.amiga-news.de/en/news/AN-2012-02-00011-EN.html
別にG4/G5と比べて速くない
ベンチマークの記事とかちらほら見たけど
http://www.amiga-news.de/en/news/AN-2012-02-00011-EN.html
別にG4/G5と比べて速くない
中国はSPARCもどきFeiTeng、MIPSもどきLoongson、
AlphaもどきShenWeiを作ってるわけだが、全てをやめることは
ないだろう。売れる売れないとか関係ないからな
AlphaもどきShenWeiを作ってるわけだが、全てをやめることは
ないだろう。売れる売れないとか関係ないからな
542 :,,・´∀`・,,)っ-○○○:2014/05/02(金) 02:40:14.35 ID:j0Zt3cQi
PA6T-1682M自体はPAsemiをAppleが買収する前にいくつかの
サーバで採用されてるからX1000のみが唯一の搭載機というわけではない。
サーバで採用されてるからX1000のみが唯一の搭載機というわけではない。
543 :Socket774:2014/05/02(金) 03:30:23.61 ID:tqXFO87o
>>535
VP9コーデックの一番の問題は、クライアントがハードウェアデコードに対応してない点
クライアントがデスクトップPCなら、CPU処理でゴリゴリデコードすればいいが、
クライアントがスマホ・タブレットの場合、クライアントがハードウェアデコードに対応してないので、
バッテリー消耗しまくってCPUデコードしないといけないし、高解像度高fps画像ならCPU処理能力の関係で
一昔前の機種ならデコードさえ無理なんじゃないの?
どんなクライアントでもハードウェアデコードできるH264みたいに使うのは負荷
VP9コーデックの一番の問題は、クライアントがハードウェアデコードに対応してない点
クライアントがデスクトップPCなら、CPU処理でゴリゴリデコードすればいいが、
クライアントがスマホ・タブレットの場合、クライアントがハードウェアデコードに対応してないので、
バッテリー消耗しまくってCPUデコードしないといけないし、高解像度高fps画像ならCPU処理能力の関係で
一昔前の機種ならデコードさえ無理なんじゃないの?
どんなクライアントでもハードウェアデコードできるH264みたいに使うのは負荷
スマホ・タブレット用GPUが、H.265/HEVCのハードウェアデコード対応表明したり、すでに最新の一部では対応してるので、
モバイル用途考えるならもうH.264の次のコーデックはH.265/HEVCで決まりでしょう
PC用GPUももちろんH.265/HEVCのハードウェアデコーダを積んでくるでしょ?
モバイル用途考えるならもうH.264の次のコーデックはH.265/HEVCで決まりでしょう
PC用GPUももちろんH.265/HEVCのハードウェアデコーダを積んでくるでしょ?
>>535
一応openpowerの公式でこういうのが
NVIDIA GPUアクセラレーター
??- NVIDIAは、POWERプロセッサーとNVIDIA GPUの組み合わせに対するCUDAソフトウェア・サポートを追加します。
IBMとNVIDIAは、初のJava向け GPUアクセラレーター・フレームワークによって、CPUのみで実行する場合と比較して、
Hadoopアナリティクス・アプリケーションのパフォーマンスが飛躍的に向上することを紹介しました。
NVIDIAは、高速インターコネクトNVLinkをOpenPOWER Foundationの参加者向けに技術をライセンス提供します。
XilinxとAltera:CAPI接続のFPGAアクセラレーター??
- IBMは、CAPI接続可能な2つのアクセラレーター・ソリューションを説明しました。
遅延を大幅に削減しつつ、消費電力あたりの性能を35倍に向上させるメモリー内キャッシュKey-Value Storeと、
CAPI接続されたAlteraのFPGAを採用して200倍の高速化を実現するモンテカルロ法を用いた金融分野向けのモデルです。
一応openpowerの公式でこういうのが
NVIDIA GPUアクセラレーター
??- NVIDIAは、POWERプロセッサーとNVIDIA GPUの組み合わせに対するCUDAソフトウェア・サポートを追加します。
IBMとNVIDIAは、初のJava向け GPUアクセラレーター・フレームワークによって、CPUのみで実行する場合と比較して、
Hadoopアナリティクス・アプリケーションのパフォーマンスが飛躍的に向上することを紹介しました。
NVIDIAは、高速インターコネクトNVLinkをOpenPOWER Foundationの参加者向けに技術をライセンス提供します。
XilinxとAltera:CAPI接続のFPGAアクセラレーター??
- IBMは、CAPI接続可能な2つのアクセラレーター・ソリューションを説明しました。
遅延を大幅に削減しつつ、消費電力あたりの性能を35倍に向上させるメモリー内キャッシュKey-Value Storeと、
CAPI接続されたAlteraのFPGAを採用して200倍の高速化を実現するモンテカルロ法を用いた金融分野向けのモデルです。
547 :,,・´∀`・,,)っ-○○○:2014/05/02(金) 08:11:18.49 ID:zQZBVWhF
>>546
だからさ、OpenPOWERの参加企業がCUDAを使うことを強制されてる
わけじゃないよね?
すさまじい論理の飛躍だ。
そもそもGoogleの発表したオリジナルのMapReduceはC++で書かれているが
そしてそのアイディアに触発されて生まれたHadoopはJavaで掛かれている。
なぜGoogleがパクリのほうのHadoopとJavaを使わねばならんのだね?
まあただ、「HSAを使うことでB+/B-treeが高速化できる」(キリッ ってのが
相手にするに値しない与太話なのはGoogleすらHSA Foundationに参加
してない事から示されている(このネタはプレゼンでも使えるぜ)
だからさ、OpenPOWERの参加企業がCUDAを使うことを強制されてる
わけじゃないよね?
すさまじい論理の飛躍だ。
そもそもGoogleの発表したオリジナルのMapReduceはC++で書かれているが
そしてそのアイディアに触発されて生まれたHadoopはJavaで掛かれている。
なぜGoogleがパクリのほうのHadoopとJavaを使わねばならんのだね?
まあただ、「HSAを使うことでB+/B-treeが高速化できる」(キリッ ってのが
相手にするに値しない与太話なのはGoogleすらHSA Foundationに参加
してない事から示されている(このネタはプレゼンでも使えるぜ)
548 :,,・´∀`・,,)っ-○○○:2014/05/02(金) 08:29:22.58 ID:zQZBVWhF
>>544
だからVP9に対応するハードウェアデコーダのIPなら既にあるって
http://www.businesswire.com/news/home/20140407005133/ja/
> Hantro G2はシングルコアアーキテクチャーで4K@60 fpsを達成した
> 業界初のIPでHEVCとVP9のビデオフォーマットをサポートしています。
H.265は特許のライセンス料が発生するがVP9はGoogleが認める限り
ロイヤリティフリーだ
YouTubeってh.265使ってたっけ?VP9なら対応してた気がするんだがな
だからVP9に対応するハードウェアデコーダのIPなら既にあるって
http://www.businesswire.com/news/home/20140407005133/ja/
> Hantro G2はシングルコアアーキテクチャーで4K@60 fpsを達成した
> 業界初のIPでHEVCとVP9のビデオフォーマットをサポートしています。
H.265は特許のライセンス料が発生するがVP9はGoogleが認める限り
ロイヤリティフリーだ
YouTubeってh.265使ってたっけ?VP9なら対応してた気がするんだがな
Nexusみたいな形でPOWER使ったAndroid製品だしてほしい
551 :,,・´∀`・,,)っ-○○○:2014/05/02(金) 08:49:12.18 ID:zQZBVWhF
今のIBMはARMに対抗することを考えていない
大体にPSVitaのCPU(Cortex-A9)すらIBMも開発にかかわってる
大体にPSVitaのCPU(Cortex-A9)すらIBMも開発にかかわってる
インテルの落ちぶれっぷりが酷すぎ・・・誰がインテルを殺すの?
http://hayabusa3.2ch.net/test/read.cgi/morningcoffee/1398987985/
http://hayabusa3.2ch.net/test/read.cgi/morningcoffee/1398987985/
553 :,,・´∀`・,,)っ-○○○:2014/05/02(金) 08:52:20.50 ID:zQZBVWhF
> そしておそらくgoogleは使う
理解できんのかね?その論理の飛躍は「根拠に乏しい」と言ってるのだが?
反証として、GoogleはCUDAのデモや論文を発表したことは一度もない。
理解できんのかね?その論理の飛躍は「根拠に乏しい」と言ってるのだが?
反証として、GoogleはCUDAのデモや論文を発表したことは一度もない。
成果物を使えば良いからね
なんなら噂されてるgoogleのクラウドゲーミングサーバと兼用も出来るわね
なんなら噂されてるgoogleのクラウドゲーミングサーバと兼用も出来るわね
555 :,,・´∀`・,,)っ-○○○:2014/05/02(金) 09:06:09.75 ID:zQZBVWhF
> 成果物を使えば良いからね
GPGPUを使わないこともできる。
> 噂されてる
噂と真実を混同するバカでしたか
GPGPUを使わないこともできる。
> 噂されてる
噂と真実を混同するバカでしたか
いや、googleのクラウドゲーミングってのはGreen Throttle Gamesを買収した時から言われている
amazonが動き出したのでgoogleも動くでしょう
amazonが動き出したのでgoogleも動くでしょう
amazonのクラウドゲーミングは、たとえるなら、金鉱を掘りに来た人に高価なスコップを売ってる状態だからな
amazonが自分で掘ってるわけじゃない
で、金鉱を掘りに来た人の多くは、そろばんはじいて、こんな高価なスコップじゃ採算があわない
いまは試掘だけして将来スコップの値段が安くなれば本格的に掘るぞっていってる状態
amazonが自分で掘ってるわけじゃない
で、金鉱を掘りに来た人の多くは、そろばんはじいて、こんな高価なスコップじゃ採算があわない
いまは試掘だけして将来スコップの値段が安くなれば本格的に掘るぞっていってる状態
ARMの方では、ARM製LLVMバックエンドのAArch64とApple製ARM64が、ARM64ベースで統合されるとか
そのうちGoogleがPowerバックエンド作ったりして
そのうちGoogleがPowerバックエンド作ったりして
今後eDRAMは盲腸みたいになってしまわないようにSoCとして統合はないだろうな
いつでも切り離せるように現状のままにしておいて、HBMが実現したらさっさとおさらばと
L4キャッシュはHBM
Power8の方がむしろeDRAM切り離してHBMに移行するのに問題が発生しそう
いつでも切り離せるように現状のままにしておいて、HBMが実現したらさっさとおさらばと
L4キャッシュはHBM
Power8の方がむしろeDRAM切り離してHBMに移行するのに問題が発生しそう
シリコン半導体のメモリの基礎原理と
これまでの歴史でどのように変わって早くなってきたとか
SRAMとDRAMの違いを説明してください
これまでの歴史でどのように変わって早くなってきたとか
SRAMとDRAMの違いを説明してください
レイテンシや消費電力の点でHBMやHMCにHaswell eDRAMの
代わりがつとまるとは思えない
モジュール形式に対する需要はGPUメモリーでは強くないが
CPUでは残るだろう。そこがHBMやHMCで行けるのかも疑問
代わりがつとまるとは思えない
モジュール形式に対する需要はGPUメモリーでは強くないが
CPUでは残るだろう。そこがHBMやHMCで行けるのかも疑問
>>559
AArch64アセンブラの構文がApple記法に統一されるということ?
AArch64アセンブラの構文がApple記法に統一されるということ?
>>559
ソースわいな!
ソースわいな!
コンパイラ作ればいいから文法は同じなほうがいい
16進数は間違いやすいんだよね
ARM推奨記法
fadd v0.4s, v1.4s, v2.4s
Apple記法
fadd.4s v0, v1, v2
fadd v0.4s, v1.4s, v2.4s
Apple記法
fadd.4s v0, v1, v2
>>563-564
AppleとARM、64ビットARM向けコンパイラ開発リソースをLLVMに投入
http://developers.slashdot.jp/story/14/04/21/0516228/
Apple%E3%81%A8ARM%E3%80%8164%E3%83%93%E3%83%83%E3%83%88ARM%E5%90%91%E3%81%91%E3%82%B3%E3%83%B3%E3%83%91%E3%82%A4%E3%83%A9%E9%96%8B%E7%99%BA%E3%83%AA%E3%82%BD%E3%83%BC%E3%82%B9%E3%82%92LLVM%E3%81%AB%E6%8A%95%E5%85%A5
> Appleが64ビットARM向けのLLVMバックエンドをオープンソース化したそうだ。
> また、ARM社も64ビットARM向けには自社開発のコンパイラではなくLLVMを推奨する方向らしい(ARM 64bit でLLVMは見逃せない、Phoronix)。
> すでにLLVMには64ビットARM向けバックエンド(aarch64)があるが、今後はApplegはオープンソース化したLLVMバックエンド(arm64)をベースに統合作業を進めるという。
だそうで
x86・x64→LLVM本家とIntel、64bitARM→ARMとApple、Power→IBM
GoogleもPowerバックエンド作ったら面白いのに
AppleとARM、64ビットARM向けコンパイラ開発リソースをLLVMに投入
http://developers.slashdot.jp/story/14/04/21/0516228/
Apple%E3%81%A8ARM%E3%80%8164%E3%83%93%E3%83%83%E3%83%88ARM%E5%90%91%E3%81%91%E3%82%B3%E3%83%B3%E3%83%91%E3%82%A4%E3%83%A9%E9%96%8B%E7%99%BA%E3%83%AA%E3%82%BD%E3%83%BC%E3%82%B9%E3%82%92LLVM%E3%81%AB%E6%8A%95%E5%85%A5
> Appleが64ビットARM向けのLLVMバックエンドをオープンソース化したそうだ。
> また、ARM社も64ビットARM向けには自社開発のコンパイラではなくLLVMを推奨する方向らしい(ARM 64bit でLLVMは見逃せない、Phoronix)。
> すでにLLVMには64ビットARM向けバックエンド(aarch64)があるが、今後はApplegはオープンソース化したLLVMバックエンド(arm64)をベースに統合作業を進めるという。
だそうで
x86・x64→LLVM本家とIntel、64bitARM→ARMとApple、Power→IBM
GoogleもPowerバックエンド作ったら面白いのに
16進数はARMかAPPLEどっちなの
なんで記法とかわけわからんどうでもいい話になってんの
LLVMバックエンドの話なのに
LLVMバックエンドの話なのに
調べてみるとAppleバックエンドの特徴は
http://lists.cs.uiuc.edu/pipermail/llvmdev/2014-April/071935.html
ということらしい
>Both NEON syntax variants (general & iOS) are supported by ARM64 now.
最初から対応しとけよ...これのせいで移植性のあるコード書くのに苦労したんだ
http://lists.cs.uiuc.edu/pipermail/llvmdev/2014-April/071935.html
ということらしい
>Both NEON syntax variants (general & iOS) are supported by ARM64 now.
最初から対応しとけよ...これのせいで移植性のあるコード書くのに苦労したんだ
なるほど、しかしこれAndroidのARTにもRenderScriptにもそのまんま使われるんかな
Apple太っ腹〜
Apple太っ腹〜
gcc(x86)って、コンパイラがアセンブラ吐いてアセンブラがバイナリ吐くっていう2段階だよな?
まあふつうに使ってる限り途中のアセンブラは出てこないから直接バイナリ吐いてるように見えるけど
まあふつうに使ってる限り途中のアセンブラは出てこないから直接バイナリ吐いてるように見えるけど
575 :,,・´∀`・,,)っ-○○○:2014/05/02(金) 20:45:34.10 ID:zQZBVWhF
いいえ
CPU非依存でレジスタ数無限の中間コードを経て各プラットフォームの
バイナリコードです
-Sで出てくるのはあくまで諸々の最適化をかけたあとの
バイナリコードのダンプです。
CPU非依存でレジスタ数無限の中間コードを経て各プラットフォームの
バイナリコードです
-Sで出てくるのはあくまで諸々の最適化をかけたあとの
バイナリコードのダンプです。
POWER MacがGoogleから復刻されるとか胸が熱くなるな
だんごが上から来た
>>574
> gcc(x86)って、コンパイラがアセンブラ吐いてアセンブラがバイナリ吐くっていう2段階だよな?
> まあふつうに使ってる限り途中のアセンブラは出てこないから直接バイナリ吐いてるように見えるけど
あー、もしもし??
アセンブリ知らんの?
> gcc(x86)って、コンパイラがアセンブラ吐いてアセンブラがバイナリ吐くっていう2段階だよな?
> まあふつうに使ってる限り途中のアセンブラは出てこないから直接バイナリ吐いてるように見えるけど
あー、もしもし??
アセンブリ知らんの?
579 :,,・´∀`・,,)っ-○○○:2014/05/02(金) 21:32:12.31 ID:zQZBVWhF
Cがアセンブラのプリプロセッサだった時代の知識でとまってる系では?
580 :Socket774:2014/05/02(金) 21:53:50.82 ID:uH6caYrs
これ、どの程度のビデオカードいんの?
https://www.youtube.com/watch?v=4Jc51w_VCzE
記事
【ビデオ】超リアルなゲーム画面を実写と比較! 最新レースゲーム「Project CARS」の予告映像
http://jp.autoblog.com/2014/05/01/project-cars-video-game-laguna-seca/
https://www.youtube.com/watch?v=4Jc51w_VCzE
記事
【ビデオ】超リアルなゲーム画面を実写と比較! 最新レースゲーム「Project CARS」の予告映像
http://jp.autoblog.com/2014/05/01/project-cars-video-game-laguna-seca/
Android Studioが使えすぎてわろたw
Intel Broadwell graphics enhancements
ttp://www.cpu-world.com/news_2014/2014050101_Intel_Broadwell_graphics_enhancements.html
ttp://www.cpu-world.com/news_2014/2014050101_Intel_Broadwell_graphics_enhancements.html
>>582
順当進化といったところか。
順当進化といったところか。
584 :,,・´∀`・,,)っ-○○○:2014/05/03(土) 00:14:41.11 ID:07fOzIHW
地味だが必要なところは抑えてきたね
Sandy以降、正直EU数が増える以外強化されてるようには思えない
世代が8になったところで7との違いがよく分からん
今までも何かしら強化されてただろうけど、機能しているようには思えないな
どうせゲフォかラデ付けるし、eDRAM付きはクソ高いから、どうでもいいヤツばかりだろうな
世代が8になったところで7との違いがよく分からん
今までも何かしら強化されてただろうけど、機能しているようには思えないな
どうせゲフォかラデ付けるし、eDRAM付きはクソ高いから、どうでもいいヤツばかりだろうな
587 :Socket774:2014/05/03(土) 00:58:26.01 ID:LdB/GyC8
Sandy Bridge世代とHaswell世代のiGPUで比べるなら、4K解像度・3画面出力・DP対応とか機能面の強化も色々有るので、ローエンドグラボ購入層がiGPUで十分な層にどんどん変わってきているね。
Gen8はEUより固定機能を強化する方向なのかね
まあEUの中身を見ないとEU数だけじゃ判断できないけど
まあEUの中身を見ないとEU数だけじゃ判断できないけど
>>582
これがIntelのGen8、、、ちょっとした機能拡張とEU数が増えただけじゃないのか?!
これがIntelのGen8、、、ちょっとした機能拡張とEU数が増えただけじゃないのか?!
590 :,,・´∀`・,,)っ-○○○:2014/05/03(土) 01:27:45.91 ID:07fOzIHW
DDR3のままユニットだけ増やしてもスループット頭打ちになるの目に見えてるじゃん
ゲーマーしかdGPUを買わない日も来そうだ。
593 :Socket774:2014/05/03(土) 01:52:30.03 ID:LdB/GyC8
>>591
iGPUの性能で十分だけど、機能不足のせいでグラボ買っていた人たちというのは昔からいるんだよ。
Sandy Bridge世代だとWQXGAモニターをエクセルで使いたいだけの人もグラボが必要だった。
iGPUの性能で十分だけど、機能不足のせいでグラボ買っていた人たちというのは昔からいるんだよ。
Sandy Bridge世代だとWQXGAモニターをエクセルで使いたいだけの人もグラボが必要だった。
>>593
今も変わらんよ
あのドライバの出来だとIntelHDで我慢は厳しいなあ
後、本格的に4kを使いたいならIrisPro以上の性能は求めたい
が、現状IrisPro乗せてるCPUはまだまだコスパ的には高いんだよな
今も変わらんよ
あのドライバの出来だとIntelHDで我慢は厳しいなあ
後、本格的に4kを使いたいならIrisPro以上の性能は求めたい
が、現状IrisPro乗せてるCPUはまだまだコスパ的には高いんだよな
ドライバの出来って具体的に何?
法人なんかはオフィスPCにデュアルモニタにするためだけにGPU積んだりしてるな
うちもオフィス用途のPCにDDR3メモリのdGPUを積んでるけど、デュアルモニタ化するためだし
うちもオフィス用途のPCにDDR3メモリのdGPUを積んでるけど、デュアルモニタ化するためだし
597 :,,・´∀`・,,)っ-○○○:2014/05/03(土) 06:51:25.47 ID:07fOzIHW
おまいらがどんな業務やってるのか逆に疑問なんだが。
富士通やNECの法人向けスリムデスクトップなら内蔵グラフィックそのままだぞ
富士通やNECの法人向けスリムデスクトップなら内蔵グラフィックそのままだぞ
スリムデスクトップは、標準じゃDVI×1、アナログRGB×1ってのが多くね?
まあこれでも一応デュアルモニタ化はできたりするが、
デジタル出力×2が欲しいから、カスタムでdGPU積んでるよ
まあこれでも一応デュアルモニタ化はできたりするが、
デジタル出力×2が欲しいから、カスタムでdGPU積んでるよ
599 :,,・´∀`・,,)っ-○○○:2014/05/03(土) 07:19:20.65 ID:07fOzIHW
富士通のESPRIMOは確かにそうだがdGPUを選ぶとRAIDが組めなくなる
WUXGA程度ならUSB変換アダプタで対応できるんじゃね?
WUXGA程度ならUSB変換アダプタで対応できるんじゃね?
>>582
2xマルチサンプルアンチエイリアスのネイティブハードウェアサポートって書いてるけど
今までのIntelオンボのマルチサンプルアンチエイリアスって総じてクソ遅かった記憶があるが
やっぱ今まではソフトウェア処理でのエミュレートだったのか
2xマルチサンプルアンチエイリアスのネイティブハードウェアサポートって書いてるけど
今までのIntelオンボのマルチサンプルアンチエイリアスって総じてクソ遅かった記憶があるが
やっぱ今まではソフトウェア処理でのエミュレートだったのか
つか2xAA迄ってのがケチ臭いなぁ
NVIDIAはFermi以降は8xAAまでハードウェアで効率よく処理できるようにしてるってのに
更に次の世代当たりで普通に使うであろう4xAA位は高速化してほしい所だ
http://game.watch.impress.co.jp/img/gmw/docs/357/215/nvidia10.jpg
http://www.4gamer.net/games/099/G009929/20100117001/SS/018.jpg
NVIDIAはFermi以降は8xAAまでハードウェアで効率よく処理できるようにしてるってのに
更に次の世代当たりで普通に使うであろう4xAA位は高速化してほしい所だ
http://game.watch.impress.co.jp/img/gmw/docs/357/215/nvidia10.jpg
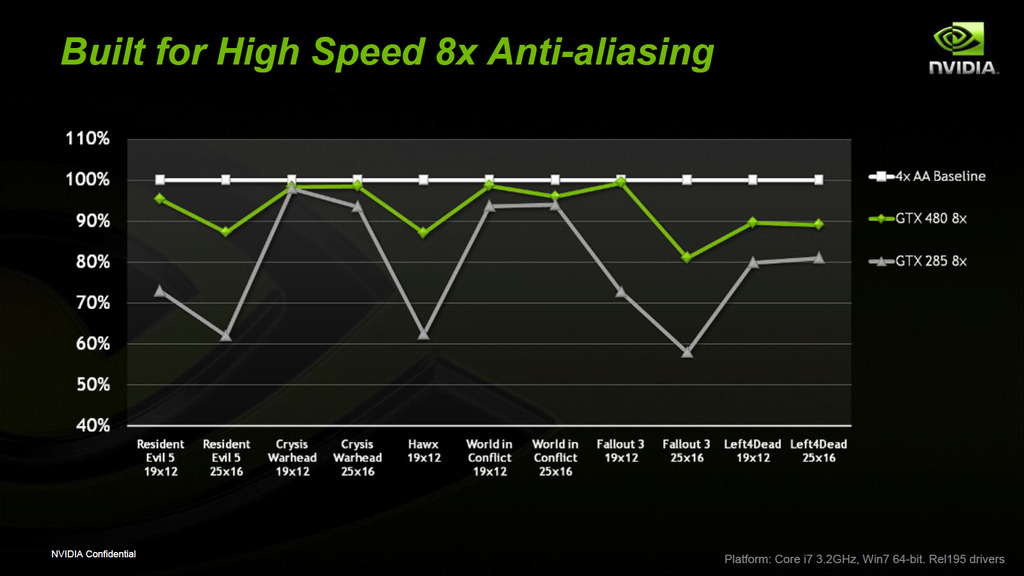{kind=link}
http://www.4gamer.net/games/099/G009929/20100117001/SS/018.jpg
{kind=link}
broadwellってsata3.2対応するの?
IBMはGPU内蔵のCPUは作ってないし
人人
人人
604 : ◆miyuri//Z7LS :2014/05/03(土) 09:07:49.09 ID:79pbNmlN
http://www.itmedia.co.jp/pcuser/articles/1204/27/news054.html
SNB, IVBは共に最大解像度 2560×1600ドット。
>>593
機能と言うよりも性能、メモリ帯域。
>>600
今時はシェーダで掛けるモノのハズ。
固定機能は無用の長物杉る。
SNB, IVBは共に最大解像度 2560×1600ドット。
>>593
機能と言うよりも性能、メモリ帯域。
>>600
今時はシェーダで掛けるモノのハズ。
固定機能は無用の長物杉る。
605 :Socket774:2014/05/03(土) 09:15:54.24 ID:LdB/GyC8
>>604
Sandy BridgeでWQXGA=2560x1440(1600ではなく)は標準では非対応、かつカスタム解像度で設定しても60Hz出力出来ない。
Sandy BridgeでWQXGA=2560x1440(1600ではなく)は標準では非対応、かつカスタム解像度で設定しても60Hz出力出来ない。
broadwellってsata3.2対応するの?
BroadwellでH265デコートのサポート間に合わないのか
完全にQualcommに後れを取ってるな
完全にQualcommに後れを取ってるな
608 : ◆miyuri//Z7LS :2014/05/03(土) 09:52:34.30 ID:79pbNmlN
>>605
向こうの記事よりも、こっちの投稿の方を信用できてしまうのが、何とも言えない。
向こうの記事よりも、こっちの投稿の方を信用できてしまうのが、何とも言えない。
>>604
いやいやMLAAやFXAA等のポストエフェクト系AAならともかく
MSAAをシェーダの演算だけで賄うとか馬鹿ですよ
普通のGPUならROPに任せる仕事ですし
>>593
もっとマシな嘘付けよ、自分は裏技でWQHD液晶に
HDMI経由でSandyBridgeノートは繋げてたけど
本体のモニタと同時でも普通に使えてたぞ(但し55Hz迄)
まあワンランク上のWQXGAだとDPかDL-DVI必須だろうから
そういう意味では大半の環境ではdGPUが必要だが
いやいやMLAAやFXAA等のポストエフェクト系AAならともかく
MSAAをシェーダの演算だけで賄うとか馬鹿ですよ
普通のGPUならROPに任せる仕事ですし
>>593
もっとマシな嘘付けよ、自分は裏技でWQHD液晶に
HDMI経由でSandyBridgeノートは繋げてたけど
本体のモニタと同時でも普通に使えてたぞ(但し55Hz迄)
まあワンランク上のWQXGAだとDPかDL-DVI必須だろうから
そういう意味では大半の環境ではdGPUが必要だが
611 :Socket774:2014/05/03(土) 12:50:16.73 ID:LdB/GyC8
>>610
すまん、2560x1440はWQXGAじゃなくWQHDだったな。
俺の発言は全てWQXGAの所をWQHDだと解釈してくれ。
2560x1440は設定すれば使えるのは知っているし、605でそのことは言っているだろ。
だがな、エクセルしか使わない程度のヤツにその設定をやれと言うのかよw
すまん、2560x1440はWQXGAじゃなくWQHDだったな。
俺の発言は全てWQXGAの所をWQHDだと解釈してくれ。
2560x1440は設定すれば使えるのは知っているし、605でそのことは言っているだろ。
だがな、エクセルしか使わない程度のヤツにその設定をやれと言うのかよw
たしかに、GDCの記事でMLAAのようなポストエフェクト系AAを推奨してたな。
まさかHWMSAAを搭載していなかったとは・・・。
最低でもx4は欲しいな。
ポストエフェクト系AAはそろそろDirectX標準としてサポートしてほしい。
まさかHWMSAAを搭載していなかったとは・・・。
最低でもx4は欲しいな。
ポストエフェクト系AAはそろそろDirectX標準としてサポートしてほしい。
MSAAサポート初期のSandyBridge世代なんて
MSAA2xと4xで描画負荷が変わらないなんて手ぬきっぷりだったからな
流石にIvy世代からは少しは改善したみたいだが
他所のdGPUや同クラスGPU性能ののAPUよりもMSAAの処理のコストが高めなのは相変わらず
MSAA2xと4xで描画負荷が変わらないなんて手ぬきっぷりだったからな
流石にIvy世代からは少しは改善したみたいだが
他所のdGPUや同クラスGPU性能ののAPUよりもMSAAの処理のコストが高めなのは相変わらず
MSAAはメモリ帯域を必要とする
高帯域なGDDR5メモリ積んでるハイエンドGPUが得意な分野だけど、
メモリがしょぼいiGPUには苦手な部分
最近はやりのポストエフェクトAAはメモリ帯域をあまり必要としないので、
メモリ帯域が足りないiGPUにはいちばん合ってる
高帯域なGDDR5メモリ積んでるハイエンドGPUが得意な分野だけど、
メモリがしょぼいiGPUには苦手な部分
最近はやりのポストエフェクトAAはメモリ帯域をあまり必要としないので、
メモリ帯域が足りないiGPUにはいちばん合ってる
なるほど・・・。
>>609
にしても新規でVP8はないわぁ
にしても新規でVP8はないわぁ
617 : ◆miyuri//Z7LS :2014/05/03(土) 14:09:05.12 ID:79pbNmlN
MSAAはパイプラインを止めるから、シェーダでやりましょうねっていう方向になったのだと思っているけど、どうだったかな...。
Intel製iGPUでMSAAは禁忌だな・・・。
619 : ◆miyuri//Z7LS :2014/05/03(土) 14:34:03.50 ID:79pbNmlN
何かの勘違いだったかも。
chromeでWebGLのMSAAがいつまで経ってもバグ扱いで実装されずに、最近になってバグ扱いさえも消えて無くなった理由がやっとわかった。
MSAAはIntelにかぎらず、GDDR5メモリ積んでるdGPU以外じゃパフォーマンス出ない
iGPUはポストプロセスAAが向いてる
iGPUはポストプロセスAAが向いてる
ついにポストプロセスAAを学ぶときが来たようだ・・・
8k、16k、32k、64kと解像度の上昇はとどまるところを知らず
さっさと4kで60fpsは余裕ぐらいクリアーして欲しい
さっさと4kで60fpsは余裕ぐらいクリアーして欲しい
4kって聞くとちょっと凄く聞こえるけど
800万画素って言い方だとデジカメ感あってぼちぼちに感じる
そうやってデジカメ的感覚で考えると8k≒3200万画素まではアリだけど
それ以上はもうイラネーんじゃねーかなー?
800万画素って言い方だとデジカメ感あってぼちぼちに感じる
そうやってデジカメ的感覚で考えると8k≒3200万画素まではアリだけど
それ以上はもうイラネーんじゃねーかなー?
16k(15360)あれば視力2.0の人の視野を128度カバーできる
成り下がったのかな。元々?
Intelだけが熱心な規格は早いがそうじゃない規格は遅いイメージがある
Intelだけが熱心な規格は早いがそうじゃない規格は遅いイメージがある
まぁ、主流の投影方法が変わればz軸なりαチャンネルなりでデータの処理は莫大に増えるだろ
SATAにそんな速度求めてどうすんだって思うけどなぁ
SSDなんてPCIeにぶっ刺すもんだろ、仕事やエンプラで使うもんは
SSDなんてPCIeにぶっ刺すもんだろ、仕事やエンプラで使うもんは
SATAは期待してるけどなあ。。。
開発ツールの起動はやはり速いし
開発ツールの起動はやはり速いし
ディスプレイにおける究極の目標は裸眼3Dと立体プロジェクターだからね
4k程度ではまだまだ目標には遠い
まあメモリーの進化を進めないと話にならないけど
スマホとタブレットが絶賛解像度向上中なんでいずれPCにも波及するかと
4k程度ではまだまだ目標には遠い
まあメモリーの進化を進めないと話にならないけど
スマホとタブレットが絶賛解像度向上中なんでいずれPCにも波及するかと
おっさんだからSCSIの転送10MB/sから使ってるからどれも十分早い
理論値だけならソケット7時代のメモリ帯域よりUSBのほうが速いんだよなあ。
そろそろ無線LANにも抜かれるか。
そろそろ無線LANにも抜かれるか。
PCも、25インチで300ppiクラスのパネル使うべき
>>634
レイテンシって知ってるか
レイテンシって知ってるか
637 :Socket774:2014/05/03(土) 23:51:30.80 ID:Yg7iRWGT
EU数96個のGT4もあると面白いんだが
ちなみにGT4eのeDRAMは256MBでw
ちなみにGT4eのeDRAMは256MBでw
そういえばVLで第二世代のeDRAMとか発表するようだね
保持時間を改善して消費電力を下げたという程度のようだけど
保持時間を改善して消費電力を下げたという程度のようだけど
MSAAをDRAM側に内蔵してくれりゃいいのに
Googleがその有り余る金と天才共をすべて次々世代の半導体装置の開発に注いできたときが本当の勝負どころだろ
脱シリコンを主導するのはgu-guruなのか
金さえあれば簡単に乗り越えられる問題だし
googleは金があるからいいものを使うはずだみたいなのは、
いかにも日本企業的な考え方だな
googleみたいな企業は、たとえば検索1件当たりの費用を一番低減できるハードは何か、
バナー広告1つあたりの費用を一番低減できるハードはなにか、
gmail1ユーザー当たりの費用を一番低減できるハードは何か、
みたいなのをシミュレーションして算出して、それによって使用ハードを変えてくる
金が余ってりゃ無駄にいいものを買って散財する日本企業とはいっしょにできない
いかにも日本企業的な考え方だな
googleみたいな企業は、たとえば検索1件当たりの費用を一番低減できるハードは何か、
バナー広告1つあたりの費用を一番低減できるハードはなにか、
gmail1ユーザー当たりの費用を一番低減できるハードは何か、
みたいなのをシミュレーションして算出して、それによって使用ハードを変えてくる
金が余ってりゃ無駄にいいものを買って散財する日本企業とはいっしょにできない
ドヤ顔でこんな当たり前のことを言う人って
日本の場合シミュレーションやっても役所や縁故で無視されたりひっくり返るだけ
646 :Socket774:2014/05/04(日) 11:31:10.58 ID:s+t3c9rc
ハズウェルリフレッシュってグリスじゃなくてハンダ式になってるのですか?
K型番の奴は、ハンダになるかどうかは知らんが放熱が改善されるってことをIntelがいってるな
K型番以外はいままで通りなんじゃね?
K型番以外はいままで通りなんじゃね?
648 :Socket774:2014/05/04(日) 17:47:42.23 ID:SbjXReD5
ちょうど3年前に自作デビューしたビギナーです
3770kの深夜販売に並んで、そこそこいいのを組みたいと思って18万ほど奮発しました
次に僕が買うべき、というかオススメはどの辺りになるんでしょうか
スカイレイク辺りでしょうか
熟練の先輩自作erさん達のアドバイスを頂きたく存じます
押忍!
3770kの深夜販売に並んで、そこそこいいのを組みたいと思って18万ほど奮発しました
次に僕が買うべき、というかオススメはどの辺りになるんでしょうか
スカイレイク辺りでしょうか
熟練の先輩自作erさん達のアドバイスを頂きたく存じます
押忍!
>>648
すかいらーく一択。
すかいらーく一択。
>>649
やはりスカイレークですか!ありがとうございます!
ハスウェルやブロードウェルは速度はあまり変わらず省エネ重視みたいな事を聞きました
スカイレークでは何か新規格になるのでしょうか
質問ばかりですみません
やはりスカイレークですか!ありがとうございます!
ハスウェルやブロードウェルは速度はあまり変わらず省エネ重視みたいな事を聞きました
スカイレークでは何か新規格になるのでしょうか
質問ばかりですみません
Skylakeは命令セットの追加があるが、Ivy->Haswellと同じようにパフォーマンスの変化は微妙だと思う。
GPUがどこまで強化されるかと、DDR4導入/電源系の改善による省電力化ぐらいしか変化がなさそう。
GPUがどこまで強化されるかと、DDR4導入/電源系の改善による省電力化ぐらいしか変化がなさそう。
SATA Expressに期待して買う。
>>651-652
成る程、ありがとうございます
成る程、ありがとうございます
SATA Expressのケーブルが試作研究レベルにしか見えない件について
655 :Socket774:2014/05/05(月) 02:09:12.24 ID:ekprZvzF
一瞬SkylakeがSexslaveに見えた
はたしてイスラエル産はつよいのか
657 :Socket774:2014/05/05(月) 02:28:17.37 ID:ffcIo3nD
>>647
そうですか、安物のグリスからちょっと上等のグリスになるとかだったら嫌ですね。
そうですか、安物のグリスからちょっと上等のグリスになるとかだったら嫌ですね。
IntelのCPUはイスラエル産とかコスタリカ産とかマレーシア産とかオレゴン産とか
色々あるみたいだけど
当たり石の確率や品質の平均点的にランク付けするとどうなるの?
できれば最良とワーストも知りたい
色々あるみたいだけど
当たり石の確率や品質の平均点的にランク付けするとどうなるの?
できれば最良とワーストも知りたい
そんなランキングはない
後工程に差はないよ。人件費の問題。
Intelってある時期からD1Xのラインを完全コピーするようになって
Fabの差はなくなったからね。昔の話だ。
Intelってある時期からD1Xのラインを完全コピーするようになって
Fabの差はなくなったからね。昔の話だ。
ダイ産地とパッケージ産地があって、Intelの場合、マレーシア産とかいうのはパッケージの産地ね
Intel Skylake 2015 Platform Details Revealed ? Compatible With 100 Series Chipset And Supports DDR4, GT4e Graphics Chip On Desktop
http://wccftech.com/intel-skylake-2015-platform-details-revealed-compatible-100-series-chipset-supports-ddr4-gt4e-graphics-chip-desktop/
http://wccftech.com/intel-skylake-2015-platform-details-revealed-compatible-100-series-chipset-supports-ddr4-gt4e-graphics-chip-desktop/
BroadwellもSkylakeも4コアが上限か
CPUの性能向上は完全に止まったな
CPUの性能向上は完全に止まったな
14nmプロセス期待ハズレもいいとこだなw
スカイレークはIPCとワッパ向上すればいいだろう
ただ、いい加減ここまでシュリンクが進んだのであれば
HTなんかせずともネイティブ8コアで出せよとは思う
チョップが簡単なのであれば、2,4,6コアで出してもいいはずだし
ただ、いい加減ここまでシュリンクが進んだのであれば
HTなんかせずともネイティブ8コアで出せよとは思う
チョップが簡単なのであれば、2,4,6コアで出してもいいはずだし
5,6年前は2015年頃にはとっくにネイティブオクタコアCPUが出ていると思ってました