AMD�̎�����APU/CPU�ɂ��Č�낤��122����
�Q�Q�Q_
�_.�Q�@ | �r�炵�E����E�~�[�͕��u����ԁB
�^|�Q|�@| �ނ�ꂸ�ɃX���[���܂��傤�B
|�Q�^�_! sage�i�s�Ń}�^�[�������܂���
�����AMD�n�X���b�h�ߋ����O�ۑ��T�C�g�l
http://amd.jisakuita.net/
Intel�̎�����CPU�ɂ��Č�낤 48
http://hibari.2ch.net/test/read.cgi/jisaku/1320688547/
CPU�A�[�L�e�N�`���ɂ��Č�� 20
http://hibari.2ch.net/test/read.cgi/jisaku/1318113870/
��ARM�̎�����core, SoC�ɂ��Č��X�� #001��
http://hibari.2ch.net/test/read.cgi/jisaku/1319938708/
�O�X��
AMD�̎�����APU/CPU�ɂ��Č�낤��121����
http://hibari.2ch.net/test/read.cgi/jisaku/1321802612/
�_.�Q�@ | �r�炵�E����E�~�[�͕��u����ԁB
�^|�Q|�@| �ނ�ꂸ�ɃX���[���܂��傤�B
|�Q�^�_! sage�i�s�Ń}�^�[�������܂���
�����AMD�n�X���b�h�ߋ����O�ۑ��T�C�g�l
http://amd.jisakuita.net/
Intel�̎�����CPU�ɂ��Č�낤 48
http://hibari.2ch.net/test/read.cgi/jisaku/1320688547/
CPU�A�[�L�e�N�`���ɂ��Č�� 20
http://hibari.2ch.net/test/read.cgi/jisaku/1318113870/
��ARM�̎�����core, SoC�ɂ��Č��X�� #001��
http://hibari.2ch.net/test/read.cgi/jisaku/1319938708/
�O�X��
AMD�̎�����APU/CPU�ɂ��Č�낤��121����
http://hibari.2ch.net/test/read.cgi/jisaku/1321802612/
|
|
|
��AMD�̎�����APU/CPU
��Trinity
�@Piledriver Core (��2���� Bulldozer Core)
�@32nm�v���Z�X
�@�ő�20%�㏸ vs. Llano (��AMD���\������f�W�^�����f�B�A�̍��)
�@Turbo Core 3.0
�@�V�������߂̃T�|�[�g (FMA3, Converged BMI instructions)
�@DDR3-2133
�@�ō�4�R�A L2�F4MB
�@FM2 Socket 904pin
�@�`�b�v�Z�b�g�FA55/A75/A85FX FCH (Hudson-D2/D3/D4)
�@30%�̃O���t�B�b�N�X���\���� vs. Llano
�@HD7350/HD7450/HD7550 (VLIW4)
�@UVD3 with Secure Asset ManagementUnit (SAMU)
�@Video Compression Engine (VCE)
�@������DirectX 11
�@AMD Eyefinity Technology (3��ʈȏ�̃}���`�f�B�X�v���C)
�@DisplayPort 1.2
�@TDP 65W/100W/125W
�@2012 Q1-Q2
��Vishera
�@Piledriver Core (��2���� Bulldozer Core)
�@32nm�v���Z�X
�@10% x86���\���㏸ vs. Bulldozer Core (��AMD���\������f�W�^�����f�B�A�̍��)
�@Turbo Core 3.0
�@�V�������߂̃T�|�[�g (FMA3, Converged BMI instructions)
�@IOMMU v2
�@DDR3-1866
�@�ō�8�R�A L2�F8MB
�@AM3+ Socket (AMD 9-series 10-series �`�b�v�Z�b�g)
�@2012 Q3
��Wichita / Krishna �L�����Z�� �� Brazos 2.0 (TSMC 28nm or 40nm/2012 Q2)
��High-Performance core roadmap
�@���b�g������̐��\�����N10�`15%����
�@2011 Bulldozer �� 2012 Piledriver �� 2013 Steamroller �� 2014 Excavator
��Trinity
�@Piledriver Core (��2���� Bulldozer Core)
�@32nm�v���Z�X
�@�ő�20%�㏸ vs. Llano (��AMD���\������f�W�^�����f�B�A�̍��)
�@Turbo Core 3.0
�@�V�������߂̃T�|�[�g (FMA3, Converged BMI instructions)
�@DDR3-2133
�@�ō�4�R�A L2�F4MB
�@FM2 Socket 904pin
�@�`�b�v�Z�b�g�FA55/A75/A85FX FCH (Hudson-D2/D3/D4)
�@30%�̃O���t�B�b�N�X���\���� vs. Llano
�@HD7350/HD7450/HD7550 (VLIW4)
�@UVD3 with Secure Asset ManagementUnit (SAMU)
�@Video Compression Engine (VCE)
�@������DirectX 11
�@AMD Eyefinity Technology (3��ʈȏ�̃}���`�f�B�X�v���C)
�@DisplayPort 1.2
�@TDP 65W/100W/125W
�@2012 Q1-Q2
��Vishera
�@Piledriver Core (��2���� Bulldozer Core)
�@32nm�v���Z�X
�@10% x86���\���㏸ vs. Bulldozer Core (��AMD���\������f�W�^�����f�B�A�̍��)
�@Turbo Core 3.0
�@�V�������߂̃T�|�[�g (FMA3, Converged BMI instructions)
�@IOMMU v2
�@DDR3-1866
�@�ō�8�R�A L2�F8MB
�@AM3+ Socket (AMD 9-series 10-series �`�b�v�Z�b�g)
�@2012 Q3
��Wichita / Krishna �L�����Z�� �� Brazos 2.0 (TSMC 28nm or 40nm/2012 Q2)
��High-Performance core roadmap
�@���b�g������̐��\�����N10�`15%����
�@2011 Bulldozer �� 2012 Piledriver �� 2013 Steamroller �� 2014 Excavator
3 �FSocket774�F2011/12/03(�y) 19:10:42.54 ID:hr/23bu3
�gBulldozer / Orochi�h�̃g�����W�X�^���̘b�\20���ł͂Ȃ�12���H
http://northwood.blog60.fc2.com/blog-entry-5495.html
6M12C�������˂���B
�ꎞ�͂����ʖڂ��Ǝv�������ǁB�S���]�T�Ȃ�ł���B
http://northwood.blog60.fc2.com/blog-entry-5495.html
6M12C�������˂���B
�ꎞ�͂����ʖڂ��Ǝv�������ǁB�S���]�T�Ȃ�ł���B
>>3
�Ȃ�[���B���X�������闝�R���킩���B
�ԈႦ�Ă���Ȃ�����ƑO�Ɏw�E������Ęb�B
�L���gdgd����Ȃ��̂��c����B
����Ȋ����̊뜜���������т܂���B�͂��B
�Ȃ�[���B���X�������闝�R���킩���B
�ԈႦ�Ă���Ȃ�����ƑO�Ɏw�E������Ęb�B
�L���gdgd����Ȃ��̂��c����B
����Ȋ����̊뜜���������т܂���B�͂��B
5 �FSocket774�F2011/12/03(�y) 21:15:48.52 ID:IZx9yxwF
FX-8150
http://www.4gamer.net/games/100/G010000/20111014094/
���Q�[�}�[���u�Q�[���ɂ����鐫�\����v�����߂��ꍇ�ɁCFX-8150�́C�I�����ƂȂ�悤��CPU�ł͂Ȃ��B
��AMD�̍ŐVCPU��Ȃ��ƋC���ς܂Ȃ��Ƃ��C�Ƃɂ����V�����A�[�L�e�N�`����CPU��G���Ă݂����Ƃ��C
���Ђ����獂�N���b�N��_���Ă݂����Ƃ��������R������}�j�A�̂��߂̃R���N�^�[�Y�A�C�e���ł���B
FX-6100��FX-4100
http://www.4gamer.net/games/100/G010000/20111021082/
��FX-6100��FX-4100�̃e�X�g���s�������C�ʂ��Ď��ۂ́u�킴�킴�I�ԗ��R���Ȃ��v�ł���B
�@�@�@�@�@�@
(�@߄t�)��
�L��ް �͊��o
7 �FSocket774�F2011/12/03(�y) 21:19:18.08 ID:37FWgFdr
�gZambezi�h�������킯����Ȃ��F�u�������]���ł���x���`�}�[�N�e�X�g�͂܂��Ȃ��v����AMD�ɕ����gFX���x���h���R
http://plusd.itmedia.co.jp/pcuser/articles/1112/02/news041.html
�gZambezi�h�������킯����Ȃ��F�u�������]���ł���x���`�}�[�N�e�X�g�͂܂��Ȃ��v����AMD�ɕ����gFX���x���h���R
http://plusd.itmedia.co.jp/pcuser/articles/1112/02/news041.html
�gZambezi�h�������킯����Ȃ��F�u�������]���ł���x���`�}�[�N�e�X�g�͂܂��Ȃ��v����AMD�ɕ����gFX���x���h���R
http://plusd.itmedia.co.jp/pcuser/articles/1112/02/news041.html
���`(�P���P)
http://plusd.itmedia.co.jp/pcuser/articles/1112/02/news041.html
�gZambezi�h�������킯����Ȃ��F�u�������]���ł���x���`�}�[�N�e�X�g�͂܂��Ȃ��v����AMD�ɕ����gFX���x���h���R
http://plusd.itmedia.co.jp/pcuser/articles/1112/02/news041.html
�gZambezi�h�������킯����Ȃ��F�u�������]���ł���x���`�}�[�N�e�X�g�͂܂��Ȃ��v����AMD�ɕ����gFX���x���h���R
http://plusd.itmedia.co.jp/pcuser/articles/1112/02/news041.html
���`(�P���P)
>>7
AMD�͎Г��Ő������]���ł���x���`�}�[�N�ł���\�t�g�����Ă�̂ɂǂ����Č��J���Ȃ��́H
�V���i���\���ɂ悭���ЂƔ�r�����x���`���ʏo����ˁH
���R�����ˁH
AMD�͎Г��Ő������]���ł���x���`�}�[�N�ł���\�t�g�����Ă�̂ɂǂ����Č��J���Ȃ��́H
�V���i���\���ɂ悭���ЂƔ�r�����x���`���ʏo����ˁH
���R�����ˁH
>>8
�P�Ƀ��~�b�^�[�t���ĕ��]�ł����������ĕK���Ȃ�ˁH
�P�Ƀ��~�b�^�[�t���ĕ��]�ł����������ĕK���Ȃ�ˁH
���ꂾ��>�������]���ł���x���`�}�[�N
http://img.donanimhaber.com/images/haber/amdfxpressdeck_15a_dh_fx57.jpg
�Ȃɂ���i7-2600K���56�{��@���o���X�[�p�[�x���`��
http://img.donanimhaber.com/images/haber/amdfxpressdeck_15a_dh_fx57.jpg
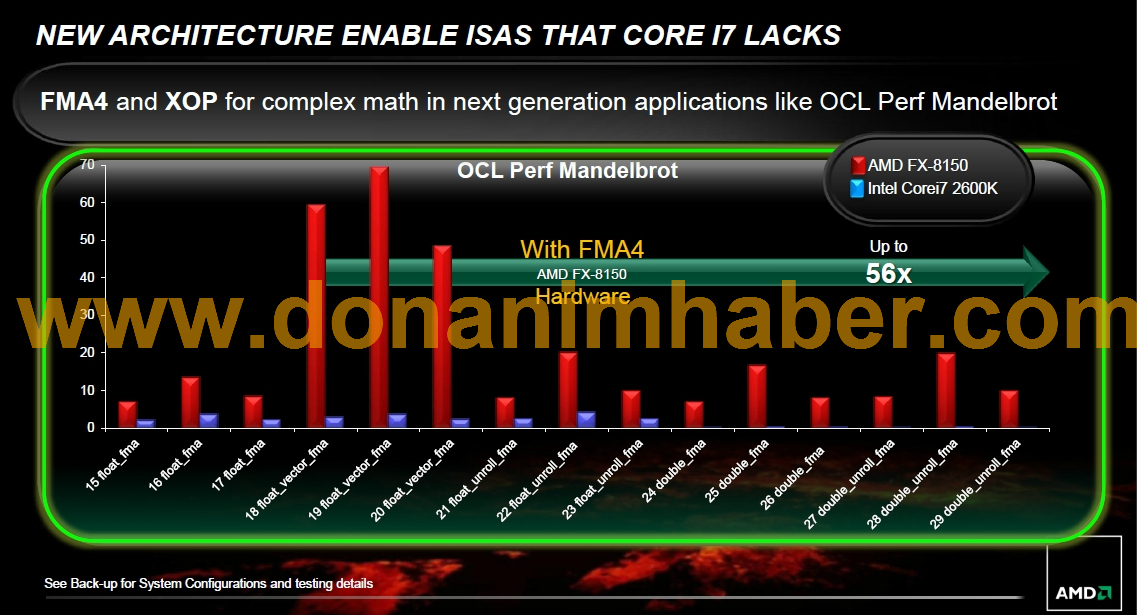{kind=link}
�Ȃɂ���i7-2600K���56�{��@���o���X�[�p�[�x���`��
���ꑽ��FMA�Ɠ����̐��x�o�����߂�x87���ȂŃG�~�����[�V�������Ă�낤��
�ǂ�����A����������ACPU��I�Ԃ̂ł͂Ȃ��B�B�B
�����̂͂��ꂪ�D��������\�\�\�\�\�\�\�\�\�b
�����̂͂��ꂪ�D��������\�\�\�\�\�\�\�\�\�b
AMD���i�S�ʁA����bulldozer ������Ȃ��͕̂��]��Q�̂����������
���{�͓��ɂ��̌X�����Ђǂ�
�z���g�}�X�S�~�ɗx�炳��邵�傤���Ȃ�����������
���{�͓��ɂ��̌X�����Ђǂ�
�z���g�}�X�S�~�ɗx�炳��邵�傤���Ȃ�����������
http://cybergarden.cocolog-nifty.com/blog/2011/10/amd32nmintel-f9.html
>AMD��32nm�͕����܂�ŋ�킵�Ă��邪�AIntel���g�����W�X�^���������B
>�Ȃ��20���g�����W�X�^��300����mm�Ȃ�?
>GLOBALFOUNDERIES�͐������Ƃ����Ă���B�ō�����!
��
http://www.anandtech.com/show/5176/amd-revises-bulldozer-transistor-count-12b-not-2b
����12���g�����W�X�^
��
http://cybergarden.cocolog-nifty.com/blog/2011/12/amd32nm12bintel.html
�g�����W�X�^�����Ȃ��ō������I�I�I
>AMD��32nm�͕����܂�ŋ�킵�Ă��邪�AIntel���g�����W�X�^���������B
>�Ȃ��20���g�����W�X�^��300����mm�Ȃ�?
>GLOBALFOUNDERIES�͐������Ƃ����Ă���B�ō�����!
��
http://www.anandtech.com/show/5176/amd-revises-bulldozer-transistor-count-12b-not-2b
����12���g�����W�X�^
��
http://cybergarden.cocolog-nifty.com/blog/2011/12/amd32nm12bintel.html
�g�����W�X�^�����Ȃ��ō������I�I�I
�����炾�낤�����\�͕ς��Ȃ�
12�����낤��sandy��GPU���������̔{�߂�����
12�����낤��sandy��GPU���������̔{�߂�����
���Ȃ��Ă��N���M���Ȃ�����_�߂Ă݂�B
�g�����W�X�^���Ȃ��Ă�����d�͍�����
�g�����W�X�^�����Ȃ�����ǂ��Ȃ���
�g�����W�X�^�����Ȃ�����ǂ��Ȃ���
http://news.mynavi.jp/special/2011/zambezi2/016.html
>����Ȗ�ŁABulldozer�R�A���̂��̂́A��ꐢ��Ƃ��Ă͔�r�I�ǂ��܂Ƃ܂����A
����Ȃ�̊����x�����������i���ƕM�҂͕]�������B
�ܘ_�r���ȕ����͂܂��c���Ă��邪�A����͍���̃u���b�V���A�b�v�Ɋ��҂ł���B
�����A���ꂪDesktop�����ɂ�������Ă��Ȃ��A�Ƃ����̂����̍ő�̉ۑ�ł��낤�B
>����Ȗ�ŁABulldozer�R�A���̂��̂́A��ꐢ��Ƃ��Ă͔�r�I�ǂ��܂Ƃ܂����A
����Ȃ�̊����x�����������i���ƕM�҂͕]�������B
�ܘ_�r���ȕ����͂܂��c���Ă��邪�A����͍���̃u���b�V���A�b�v�Ɋ��҂ł���B
�����A���ꂪDesktop�����ɂ�������Ă��Ȃ��A�Ƃ����̂����̍ő�̉ۑ�ł��낤�B
�k�X�����p
http://top500.org/blog/2011/10/26/about_joy_and_frustration
FX��LINPACK�������A
FX takes advantage of its two floating-point division units per module and is about twice as fast as the Core i7-2600 when processing SSE3 operations.
2600k��2�{�̑���
http://top500.org/blog/2011/10/26/about_joy_and_frustration
FX��LINPACK�������A
FX takes advantage of its two floating-point division units per module and is about twice as fast as the Core i7-2600 when processing SSE3 operations.
2600k��2�{�̑���
>>19
k�͖�������
k�͖�������
>>19
LINPACK����HT�����ق���2�{�����Ȃ�x���`����
http://news.mynavi.jp/photo/special/2011/sandybridge/images/Graph58l.jpg
LINPACK����HT�����ق���2�{�����Ȃ�x���`����
http://news.mynavi.jp/photo/special/2011/sandybridge/images/Graph58l.jpg
{kind=link}
>>21
ht�Ȃɏo�開�͖���
ht�Ȃɏo�開�͖���
Bull�̃��W���[������HTT�݂����ɐ��\��������Ă��Ƃ͂Ȃ��̂�
FX��LINPACK������ �Ȃ�ď����ĂȂ�
(LINPACK�͉��Z�Ə�Z�݂̂����g��Ȃ�����) ���Z��2600�̔{���� �Ƃ͏����Ă��邪
when processing SSE3 operations�������w���̂��͂悭�������
(LINPACK�͉��Z�Ə�Z�݂̂����g��Ȃ�����) ���Z��2600�̔{���� �Ƃ͏����Ă��邪
when processing SSE3 operations�������w���̂��͂悭�������
����������IvyBridge�ŏ��Z��̉��ǂ��������
�T�[�o�AHPC�����ł͎��ǂ���������
�m�������Bull�̃X�p�R���[���������
�m�������Bull�̃X�p�R���[���������
�[�����̋L����HPC�����ɂ͎��ǂ��Ƃ����������L�����Ⴀ�S���Ȃ���
�ŏ��̂ق���v���
Bulldozer�̃e�X�^�[�͂��̐��\�̒Ⴓ�Ə���d�͂̍����Ɏ��]���Ă���
���̏㊮���i���[�i���ꂽ�̂����������[�X���̋͂������O�Ńe�X�g���鎞�Ԃ���낭�ɖ�������
�Ō�̕���
�����b����ł͂Ȃ��āALINPACK�Ŏg���Ȃ����Z��Sandy�̔{����
�ƃt�H���[���Ă邾��
�ŏ��̂ق���v���
Bulldozer�̃e�X�^�[�͂��̐��\�̒Ⴓ�Ə���d�͂̍����Ɏ��]���Ă���
���̏㊮���i���[�i���ꂽ�̂����������[�X���̋͂������O�Ńe�X�g���鎞�Ԃ���낭�ɖ�������
�Ō�̕���
�����b����ł͂Ȃ��āALINPACK�Ŏg���Ȃ����Z��Sandy�̔{����
�ƃt�H���[���Ă邾��
>>27
�E�V���c�b�g�K���h��
�E�G�W���o����
�E�X�C�X�����i2�V�X�e�������j
�EORNL�i�I�[�N���b�W�����������j
�ENCSA�i�C���m�C�w�ABluewaters�j
�E����
�������炵����
�E�V���c�b�g�K���h��
�E�G�W���o����
�E�X�C�X�����i2�V�X�e�������j
�EORNL�i�I�[�N���b�W�����������j
�ENCSA�i�C���m�C�w�ABluewaters�j
�E����
�������炵����
green500�̏�ʁAMFLOPS/W�l���������̂́A�f�X�N�g�b�v�̍����i����
���������R�A�����߁A�N���b�N��߂̌X������
���������R�A�����߁A�N���b�N��߂̌X������
>>19�̋L���Â���
�����p�������Ă邾�낤��
�����p�������Ă邾�낤��
>>30
�A�[�L�̎v�z�A�p�r���Ⴄ�����@�D��̖��ł͂Ȃ�
�A�[�L�̎v�z�A�p�r���Ⴄ�����@�D��̖��ł͂Ȃ�
�������̃��A��8�R�A�i�j������ȁB
���ꂪ�N�A�b�h�R�A�Ƀt���{�b�R�B
�A�[�L�̎v�z�A�p�r���Ⴄ�A�Ȃ�Ęb�ōςޖ��ł͂Ȃ��B
���ꂪ�N�A�b�h�R�A�Ƀt���{�b�R�B
�A�[�L�̎v�z�A�p�r���Ⴄ�A�Ȃ�Ęb�ōςޖ��ł͂Ȃ��B
��̎������肵���������i�͂��̖{�̂��o���鍠�ɂ͎���x��ƂȂ��Ă��邩���
�ň��͂����������オ���Ȃ��ꍇ���炠��
���I�ȉ��P�͖]�߂Ȃ��Ă����s�̂������Ɍ��コ�����X�Ɏ���ɍ��킹���ύX���Ă����̂���Ԃ��Ǝv��
�ň��͂����������オ���Ȃ��ꍇ���炠��
���I�ȉ��P�͖]�߂Ȃ��Ă����s�̂������Ɍ��コ�����X�Ɏ���ɍ��킹���ύX���Ă����̂���Ԃ��Ǝv��
�Z�p�͉]�X�ł͂Ȃ��AAMD�Ђ̓����Ɋw�ۓI�Ȍ��n�Ń��m���l������l�͂�������H
SPARC T�V���[�Y�̌�ǂ��ł�����
����̐���ł͂Ȃ�
����̐���ł͂Ȃ�
���������AFX����32bit���[�h��64bit���[�h�Ŕ{�ȏ�L���b�V���ш���ˁH
Opteron����r�I�����\�o�����R���Ă��̕ӂɂ���̂����B
Opteron����r�I�����\�o�����R���Ă��̕ӂɂ���̂����B
�P�ɎI�x���`���Ɨǂ����Ă�������Ȃ��́H
�܂�130W�Ŕ{���x120GFOPS�o��̂͒��X������ˁH
>>39
�C�̂�����������B
VC��malloc��64bit���ƃf�t�H���g��16byte�A���C�������g�Ŋm�ۂ���Ă��邾�������B
�����Amovups�ŃA���C�������g�����ĂȂ����̃y�i���e�B��
PhenomII�ɂ͂Ȃ������C�����邯��FX�̓y�i���e�B�Ă���ۂ��B
�C�̂�����������B
VC��malloc��64bit���ƃf�t�H���g��16byte�A���C�������g�Ŋm�ۂ���Ă��邾�������B
�����Amovups�ŃA���C�������g�����ĂȂ����̃y�i���e�B��
PhenomII�ɂ͂Ȃ������C�����邯��FX�̓y�i���e�B�Ă���ۂ��B
>>35
������AMD�̓\�t�g�E�F�A�J���x���\�͂��Ⴂ�Ɨ��Ă���B
�\�t�g�Ő��\���B�x���`�Ő��\���c�Ƃ������Ƃ���ŁA
AMD�ɂ͂���ɑ���J���x���������ł���̐��������Ă��Ȃ��̂�����A
�u�����Ő��\���o��v�͒P�ɏ��b�ɂ����Ȃ�Ȃ����
������AMD�̓\�t�g�E�F�A�J���x���\�͂��Ⴂ�Ɨ��Ă���B
�\�t�g�Ő��\���B�x���`�Ő��\���c�Ƃ������Ƃ���ŁA
AMD�ɂ͂���ɑ���J���x���������ł���̐��������Ă��Ȃ��̂�����A
�u�����Ő��\���o��v�͒P�ɏ��b�ɂ����Ȃ�Ȃ����
MS��libc���āAmalloc(16)��16�o�C�g�A���C�����ꂽ�|�C���^�Ԃ��ė��Ȃ���?
32bit���ŕ��ʂ�malloc��16B�A���C�������g��ۏ��Ă鏈���n����OSX���炢�����m���
BSD�n��jemalloc��16�o�C�g�ȏ�Ȃ�16�o�C�g�A���C��������Ȃ�����?
glibc/dlmalloc�͏��8���B
4/8/16�o�C�g���E�܂ł͈Öقɏ��炳���ׂ��ߖڂ��Ǝv���Ă������A
���Ԃ̕W�����C�u�����͌��\��g�ȂȁB
glibc/dlmalloc�͏��8���B
4/8/16�o�C�g���E�܂ł͈Öقɏ��炳���ׂ��ߖڂ��Ǝv���Ă������A
���Ԃ̕W�����C�u�����͌��\��g�ȂȁB
46 �FSocket774�F2011/12/04(��) 21:29:08.37 ID:YUrgOpdo
{kind=link}
Interlagos���̗p����Ă���̂�Top500�ł�SGI��1����̂����Ă��ׂ�Cray
Cray�̔����Cray�Ǝ��̃C���^�R�l�N�g
����ł͐��S�m�[�h���x�̃X�p�R������IB�̂P���b�N�̃X�C�b�`���g����̂�
IB+Xeon 2P�őg�ނ̂����\���悭�R�X�g�p�t�H�[�}���X������
SNB-EP���o�����
Cray���A�h�o���e�[�W������̂͂������K�͂ȃX�p�R��
200TFlop�ȏキ�炢
�Ȃ��Interlagos���̗p����Ă���̂͂��̃N���X�������킯
��������Top500�̓������Ƃ������̂�GbE�N���X�^��
����͂������LINPACK�����ł���Ⴂ
�܂�m�[�h�ԒʐM���d�����Ȃ����[�U�����\�����Ƃ����̂͒��ӂ��ׂ�
Cray�̔����Cray�Ǝ��̃C���^�R�l�N�g
����ł͐��S�m�[�h���x�̃X�p�R������IB�̂P���b�N�̃X�C�b�`���g����̂�
IB+Xeon 2P�őg�ނ̂����\���悭�R�X�g�p�t�H�[�}���X������
SNB-EP���o�����
Cray���A�h�o���e�[�W������̂͂������K�͂ȃX�p�R��
200TFlop�ȏキ�炢
�Ȃ��Interlagos���̗p����Ă���̂͂��̃N���X�������킯
��������Top500�̓������Ƃ������̂�GbE�N���X�^��
����͂������LINPACK�����ł���Ⴂ
�܂�m�[�h�ԒʐM���d�����Ȃ����[�U�����\�����Ƃ����̂͒��ӂ��ׂ�
>>45
glibc��8�o�C�g����
glibc��8�o�C�g����
>>47
�ڂ����������畷��������
�����Ė{���̘b�Ȃ̂��H
39xx�ł���STREAM��37GB/s�ʏo�Ă�������������Ǝv���Ă��
>�C���e�� Xeon �v���Z�b�T�[ E5�n [�ҏW]
>2�\�P�b�g�����𒆐S��2012�N�ɏo�ח\��B1600MHz�ɑΉ����Ă��郁�������A1�`�����l��������2DIMM�ɂȂ��1333MHz�A3DIMM�ɂȂ��800MHz�Ƒ��x��������B
http://ja.wikipedia.org/wiki/Xeon
�ڂ����������畷��������
�����Ė{���̘b�Ȃ̂��H
39xx�ł���STREAM��37GB/s�ʏo�Ă�������������Ǝv���Ă��
>�C���e�� Xeon �v���Z�b�T�[ E5�n [�ҏW]
>2�\�P�b�g�����𒆐S��2012�N�ɏo�ח\��B1600MHz�ɑΉ����Ă��郁�������A1�`�����l��������2DIMM�ɂȂ��1333MHz�A3DIMM�ɂȂ��800MHz�Ƒ��x��������B
http://ja.wikipedia.org/wiki/Xeon
�m��Ȃ�
wikipedia��Nehalem-EP�̍��ɏ����Ă���悤�Ȃ��Ƃ́ASandyBridge�ł����ʂɂ����Ȃ�?
http://www.supermicro.com/xeon_5500/files/xeon5500/DDR3_Memory_Preview_960x720.jpg
http://www.supermicro.com/xeon_5500/files/xeon5500/DDR3_Memory_Preview_960x720.jpg
{kind=link}
umm
���̃������o���h������HPC������EX������Ď�����
������҂Ƃ��悤
���̃������o���h������HPC������EX������Ď�����
������҂Ƃ��悤
53 �FSocket774�F2011/12/05(��) 00:50:15.23 ID:uZ0Skw5h
(1) Bulldozer��AM3+�}�U�[�ŏI���B(���N�V�����̂��o��)
(2) AM3�}�U�[��Bulldozer����邩�ǂ����̓}�U�[�x���_����
(3) �V����FMA�ɑΉ�����������������i���ۂ݂����̂͂��Ȃ�
(4) ���A�v���ł͐��\����͌����߂Ȃ�
(5) GPU�͍ڂ��Ă��Ȃ�
(6) ���i�Ńx���`��i3�ȉ��Ai5/i7�Ɣ�r����͎̂��������
(7) �ŏ�ʂ�245�h���Ƒ������
�@�����Ǔ��{�ł͕������킹�ō�������������N�[���[����500����Ŗ�35,000�~
(8) �N�P�ʂŒx��ɒx��Đ��\���x��Ă���
(9) 8�R�A�̗D�ʐ���O�ʂɔ���o�����̂�4�E6�R�A����ɔ̔��ƂȂ�
�@�f�����ł͌��w�҂���u�[�C���O���@
(10) 4.5GHz�܂�OC���Ă�2500K�̃f�t�H���g�N���b�N�ɂ�����ׂȂ�
�@������8GHz��ڎw���Ɨǂ��R����@
(11) �X�R�A�͋��낵���Ⴂ����OC
�@���̂�������d�͉͂ߋ��ŋ�
(12) AMD�̎x�����ĊJ�����ꂽ TotalWar:Shogun2 �� BSOD ���������ē��삵�Ȃ�
�@���͂�̂����M���O
(13) 8�R�A�q���Ŕ�������FX-8120/FX-6100/FX-4100�� Phenom II/Athlon II/A�V���[�Y�����C�o��
(14) �L�����y�[���̌i�i�͂��َq�̋� (�����ς������̍���
(15) �f�t�H�Ń��~�b�^�[���ځA��i�ł����ׂ�������Ɣ���
�@�}�U�[�ɂ���Ă͉����\�����A���x��C'n'Q�̌����Ȃ��펞�S�͉^�]�ɂȂ�
(16) ���ٓI�Ȕ̔��s�U�ɂ�蔭������ꃖ�����o�����ɉ��i����A���l�Ȓl������]�V�Ȃ������
(17) ���\���Ⴂ�͎̂��ۂ̐��\���v���ł���x���`���܂�������(��p�i���K�v�����o����\�������
(18) �Ȃ�Ǝ��ۂ̃g�����W�X�^���͌��̒l��20���ł͂Ȃ�������12���ɉ߂��Ȃ����������B
�ʐϓ�����̃g�����W�X�^���x��32nm�ōň��B
GLOBALFOUNDERIES�͐������̂����Ă����A�ŒႾ���I
�Ӗ����킩��Ȃ�
(2) AM3�}�U�[��Bulldozer����邩�ǂ����̓}�U�[�x���_����
(3) �V����FMA�ɑΉ�����������������i���ۂ݂����̂͂��Ȃ�
(4) ���A�v���ł͐��\����͌����߂Ȃ�
(5) GPU�͍ڂ��Ă��Ȃ�
(6) ���i�Ńx���`��i3�ȉ��Ai5/i7�Ɣ�r����͎̂��������
(7) �ŏ�ʂ�245�h���Ƒ������
�@�����Ǔ��{�ł͕������킹�ō�������������N�[���[����500����Ŗ�35,000�~
(8) �N�P�ʂŒx��ɒx��Đ��\���x��Ă���
(9) 8�R�A�̗D�ʐ���O�ʂɔ���o�����̂�4�E6�R�A����ɔ̔��ƂȂ�
�@�f�����ł͌��w�҂���u�[�C���O���@
(10) 4.5GHz�܂�OC���Ă�2500K�̃f�t�H���g�N���b�N�ɂ�����ׂȂ�
�@������8GHz��ڎw���Ɨǂ��R����@
(11) �X�R�A�͋��낵���Ⴂ����OC
�@���̂�������d�͉͂ߋ��ŋ�
(12) AMD�̎x�����ĊJ�����ꂽ TotalWar:Shogun2 �� BSOD ���������ē��삵�Ȃ�
�@���͂�̂����M���O
(13) 8�R�A�q���Ŕ�������FX-8120/FX-6100/FX-4100�� Phenom II/Athlon II/A�V���[�Y�����C�o��
(14) �L�����y�[���̌i�i�͂��َq�̋� (�����ς������̍���
(15) �f�t�H�Ń��~�b�^�[���ځA��i�ł����ׂ�������Ɣ���
�@�}�U�[�ɂ���Ă͉����\�����A���x��C'n'Q�̌����Ȃ��펞�S�͉^�]�ɂȂ�
(16) ���ٓI�Ȕ̔��s�U�ɂ�蔭������ꃖ�����o�����ɉ��i����A���l�Ȓl������]�V�Ȃ������
(17) ���\���Ⴂ�͎̂��ۂ̐��\���v���ł���x���`���܂�������(��p�i���K�v�����o����\�������
(18) �Ȃ�Ǝ��ۂ̃g�����W�X�^���͌��̒l��20���ł͂Ȃ�������12���ɉ߂��Ȃ����������B
�ʐϓ�����̃g�����W�X�^���x��32nm�ōň��B
GLOBALFOUNDERIES�͐������̂����Ă����A�ŒႾ���I
�Ӗ����킩��Ȃ�
anand����GF�������̂��E�E�E���͗�̃A��
�ȂǂƈӖ��s���ȋ��q�����Ă���
�����Opteron��ks
58 �FSocket774�F2011/12/05(��) 19:44:54.22 ID:qAuMskKq
(1) Bulldozer��AM3+�}�U�[�ŏI���B(���N�V�����̂��o��)
(2) AM3�}�U�[��Bulldozer����邩�ǂ����̓}�U�[�x���_����
(3) �V����FMA�ɑΉ�����������������i���ۂ݂����̂͂��Ȃ�
(4) ���A�v���ł͐��\����͌����߂Ȃ�
(5) GPU�͍ڂ��Ă��Ȃ�
(6) ���i�Ńx���`��i3�ȉ��Ai5/i7�Ɣ�r����͎̂��������
(7) �ŏ�ʂ�245�h���Ƒ������
�@�����Ǔ��{�ł͕������킹�ō�������������N�[���[����500����Ŗ�35,000�~
(8) �N�P�ʂŒx��ɒx��Đ��\���x��Ă���
(9) 8�R�A�̗D�ʐ���O�ʂɔ���o�����̂�4�E6�R�A����ɔ̔��ƂȂ�
�@�f�����ł͌��w�҂���u�[�C���O���@
(10) 4.5GHz�܂�OC���Ă�2500K�̃f�t�H���g�N���b�N�ɂ�����ׂȂ�
�@������8GHz��ڎw���Ɨǂ��R����@
(11) �X�R�A�͋��낵���Ⴂ����OC
�@���̂�������d�͉͂ߋ��ŋ�
(12) AMD�̎x�����ĊJ�����ꂽ TotalWar:Shogun2 �� BSOD ���������ē��삵�Ȃ�
�@���͂�̂����M���O
(13) 8�R�A�q���Ŕ�������FX-8120/FX-6100/FX-4100�� Phenom II/Athlon II/A�V���[�Y�����C�o��
(14) �L�����y�[���̌i�i�͂��َq�̋� (�����ς������̍���
(15) �f�t�H�Ń��~�b�^�[���ځA��i�ł����ׂ�������Ɣ���
�@�}�U�[�ɂ���Ă͉����\�����A���x��C'n'Q�̌����Ȃ��펞�S�͉^�]�ɂȂ�
(16) ���ٓI�Ȕ̔��s�U�ɂ�蔭������ꃖ�����o�����ɉ��i����A���l�Ȓl������]�V�Ȃ������
(17) ���\���Ⴂ�͎̂��ۂ̐��\���v���ł���x���`���܂�������(��p�i���K�v�����o����\�������
(18) �Ȃ�Ǝ��ۂ̃g�����W�X�^���͌��̒l��20���ł͂Ȃ�������12���ɉ߂��Ȃ����������B
�ʐϓ�����̃g�����W�X�^���x��32nm�ōň��B
GLOBALFOUNDERIES�͐������̂����Ă����A�ŒႾ���I
�킯���킩��Ȃ���_(^o^)�^
59 �FSocket774�F2011/12/05(��) 20:39:30.62 ID:qy+cGGrT
bul���̂ɐ��\���Ĕ����z�Ȃ�Ă���̂��H���͂W�R�A������Ȉ����Ŕ�������ė��R������
��������
��������
AMD��FX�����ė~�����Ȃ����āB
FX�Ŕ�����MCM��Interlagos�ɂ����4�{�̉��i�Ŕ����킯�����B
�����炠����PC�Ő��\�łȂ��悤�������Ă����B
�����Ȃ���ɕ�[�̕K�v�Ȃ����炻�̕�Interlagos�ɂ܂킹�铹���B
����܂�AMD�ȊO�Ŏ��삵�����ƂȂ��݂����ȔM�S��AMDer�ȊO�͎��d���Ă���B
FX�Ŕ�����MCM��Interlagos�ɂ����4�{�̉��i�Ŕ����킯�����B
�����炠����PC�Ő��\�łȂ��悤�������Ă����B
�����Ȃ���ɕ�[�̕K�v�Ȃ����炻�̕�Interlagos�ɂ܂킹�铹���B
����܂�AMD�ȊO�Ŏ��삵�����ƂȂ��݂����ȔM�S��AMDer�ȊO�͎��d���Ă���B
55 �F���������ܖڂł��B(WiMAX)�F2011/12/05(��) 20:57:00.75 ID:L1G092ox0
AMD�̎��_�Ńn�C�G���h����Ȃ�
�~�h���G���h����AMD�̍����i�̂��Ƃ������̂�
�Ȃ���ȃV�X�e��������Ă݂��������炨�D����Bull���ǂ���
60�����炢�������SPARC Enterprise M8000���鉉�Z�\�͂���ɓ���܂���
60�����炢�������SPARC Enterprise M8000���鉉�Z�\�͂���ɓ���܂���
Q4���Ƀh���X�f���̑����������ғ�����炵������A32nm�̐��Y�ʂ���������
��������45nm���i�̏I���ɃT�[�o�[����Interlagos�̔��\�iFacebook���T�[�o�[�ō̗p�Ƃ̂��Ɓj�ƁA
���悢��{�i�I��32nm�Ɉڍs����
���Ȃ݂�960T�̏o�ׂ͂܂��������Ęb������A45nm�ň�ԍŌ�܂ł����͕̂�Magny-cours����
��������45nm���i�̏I���ɃT�[�o�[����Interlagos�̔��\�iFacebook���T�[�o�[�ō̗p�Ƃ̂��Ɓj�ƁA
���悢��{�i�I��32nm�Ɉڍs����
���Ȃ݂�960T�̏o�ׂ͂܂��������Ęb������A45nm�ň�ԍŌ�܂ł����͕̂�Magny-cours����
>>60
�܂�������
opteron�ɂ����cry�Ȃ����{���̒l�i�Ŕ����Ă�������킴�킴pc�����ɏo���Ӗ�������
�o���Ώo���قǑ�������
�܂�������
opteron�ɂ����cry�Ȃ����{���̒l�i�Ŕ����Ă�������킴�킴pc�����ɏo���Ӗ�������
�o���Ώo���قǑ�������
>opteron�ɂ����cry�Ȃ����{���̒l�i�Ŕ����Ă�������킴�킴pc�����ɏo���Ӗ�������
>�o���Ώo���قǑ�������
����A����̓I���R���ƌ����Ă�̂������Ȃ��ǎ��o����́H
>�o���Ώo���قǑ�������
����A����̓I���R���ƌ����Ă�̂������Ȃ��ǎ��o����́H
�ނ����ʌ����Ƌ��ʉ������A�[�L�e�N�`���Ő����o���Ȃ���
�J�������ł��Ȃ���Ȃ���
�T�[�o�EHPC�������Ă�����SPARC�Ƃ�Itanium�Ƃ��ɂȂ�킯��
�������ɂ��R�X�g�p�t�H�[�}���X�͗ǂ��Ȃ����A���鑤�̗��v���傫���Ȃ�
�J�������ł��Ȃ���Ȃ���
�T�[�o�EHPC�������Ă�����SPARC�Ƃ�Itanium�Ƃ��ɂȂ�킯��
�������ɂ��R�X�g�p�t�H�[�}���X�͗ǂ��Ȃ����A���鑤�̗��v���傫���Ȃ�
>>65
����AMD�̎���������I���R���ƌ������Ƃ���ʼn�����肪����́H
����AMD�̎���������I���R���ƌ������Ƃ���ʼn�����肪����́H
>>65
����Ȃ������ɃI���R���݂����Ȃ���
����Ȃ������ɃI���R���݂����Ȃ���
69 �FSocket774�F2011/12/06(��) 06:19:19.25 ID:HUVgHQ39
Phenom�U���������ƃf�B�X�R���ɂ����������
1mm����1�h���ȉ��̃v���Z�b�T�ȂC���e���ɂ���Ă���B
AMD�Ɣ��Ȃ��]�[���ł����Ȃ�ڂ�������̂�Sandy-E�ł�����������
AMD�����Ȃ��Ă��M�҂������x����I�b�P�[�ł���B
1mm����1�h���ȉ��̃v���Z�b�T�ȂC���e���ɂ���Ă���B
AMD�Ɣ��Ȃ��]�[���ł����Ȃ�ڂ�������̂�Sandy-E�ł�����������
AMD�����Ȃ��Ă��M�҂������x����I�b�P�[�ł���B
���o�Ȃ�ă~�h���G���h��>61�ɐ�ɕ�����
�X���̐������\�[�g�ŁA�����������Ԃ������ȁB
�X�}�z�����̉e���łȂ��H
���Ƃ�AMD�L���I�Ȍ����o���Ƃ��������ے����Ă���z���������C�����B
���Ƃ�AMD�L���I�Ȍ����o���Ƃ��������ے����Ă���z���������C�����B
�c�q�������������(�P���P)
���������悤�Ȏ����������
�܂����ɖ�ڂ��I������X������
�܂����ɖ�ڂ��I������X������
CPU�͍���������ǂ͑������낤���A���S�ȐV�A�[�L�e�N�`����10�N�߂���ɂȂ邩���
GPU���ɂ��Ă�GCN���ڂ�APU�܂ő傫�Șb��͖�����
�ŁA12/5�ɊW�Ҍ����ɐV���[�h�}�b�v�����Ęb�����������A�܂���ƃ��[�N��������Ă����s�͂��ҏo��������
GPU���ɂ��Ă�GCN���ڂ�APU�܂ő傫�Șb��͖�����
�ŁA12/5�ɊW�Ҍ����ɐV���[�h�}�b�v�����Ęb�����������A�܂���ƃ��[�N��������Ă����s�͂��ҏo��������
����Ȃ̂�������
ttp://ascii.jp/elem/000/000/653/653627/
ttp://ascii.jp/elem/000/000/653/653627/
����Piledriver���Ăǂ��Ȃ�́H
�I�b�p�C���������������Ⴄ��
>>64
�����Ă�̂łȂ���A��������g�B
�����Ă�̂łȂ���A��������g�B
����N���b�N���Ⴄ�Ƃ͂����A���܂ł�Opteron�̌`�ł͉��o�ׂ��ꂽ��
���ꂪ500�̏o�ׂ���܂܂Ȃ�Ȃ�����AFX�͂ǂ��l���Ă�����C���Ȃ�
������AMD�������Ƃ����Ă��A�̔��P���̈Ⴂ���킩��Ȃ��قǒꖳ���̃o�J�ł͂Ȃ��Ƃ������Ƃ�
���ꂪ500�̏o�ׂ���܂܂Ȃ�Ȃ�����AFX�͂ǂ��l���Ă�����C���Ȃ�
������AMD�������Ƃ����Ă��A�̔��P���̈Ⴂ���킩��Ȃ��قǒꖳ���̃o�J�ł͂Ȃ��Ƃ������Ƃ�
81 �FSocket774�F2011/12/06(��) 13:36:23.66 ID:/BRDoP/G
�N�\�R�e�U���̔����V���[����www
http://hissi.org/read.php/jisaku/20111205/MXhPQi83c2c.html
��
http://hissi.org/read.php/jisaku/20111206/VHJqemEvbHA.html
http://hissi.org/read.php/jisaku/20111206/WkJFWnZHZTY.html
�@�@�@�@�@�@�@ �@ |�_�@�@ �@ �@ �@ �@ �^|
�@ �@�@�@�@ �@ �@ |�_�_�@�@ �@ �@ �^�^|
�@�@�@�@�@�@�@ �@ : �@,>�@�M�L�P�M�L�@<�@ ���@�@�@���߂���`���܂Œ�������Ⴀ��
.�@�@�@�@�@�@�@ �@ �u�@�m�@�@�@�@ �M�R �u �@�@�@�@���L�ɂȂ��Ċ�^���ԂȂ̂��܂�킩�肾�悗
.�@�@�@�@�@�@�@ �@ i{�@���@ �@ �@ �� �@}i�@�@�@�@ ����ȂɌ��{����Ȃ�Ă킯���킩��Ȃ��悗����
.�@�@�@�@�@�@�@�@..�����@�_,�_,�@������
�@ �@ �@ �@ �@/�܁R�R�@�@�T._�j �@�@�@/��i
�@�@�@�@�@�@�@�_ �@ �R��. ,�@�@.�C�@/�@ /
.�@�@�@�@�@�Q/�@�R�@�@�@�@�@ �@�@�@�__/�@ ',�Q_
http://hissi.org/read.php/jisaku/20111205/MXhPQi83c2c.html
��
http://hissi.org/read.php/jisaku/20111206/VHJqemEvbHA.html
http://hissi.org/read.php/jisaku/20111206/WkJFWnZHZTY.html
�@�@�@�@�@�@�@ �@ |�_�@�@ �@ �@ �@ �@ �^|
�@ �@�@�@�@ �@ �@ |�_�_�@�@ �@ �@ �^�^|
�@�@�@�@�@�@�@ �@ : �@,>�@�M�L�P�M�L�@<�@ ���@�@�@���߂���`���܂Œ�������Ⴀ��
.�@�@�@�@�@�@�@ �@ �u�@�m�@�@�@�@ �M�R �u �@�@�@�@���L�ɂȂ��Ċ�^���ԂȂ̂��܂�킩�肾�悗
.�@�@�@�@�@�@�@ �@ i{�@���@ �@ �@ �� �@}i�@�@�@�@ ����ȂɌ��{����Ȃ�Ă킯���킩��Ȃ��悗����
.�@�@�@�@�@�@�@�@..�����@�_,�_,�@������
�@ �@ �@ �@ �@/�܁R�R�@�@�T._�j �@�@�@/��i
�@�@�@�@�@�@�@�_ �@ �R��. ,�@�@.�C�@/�@ /
.�@�@�@�@�@�Q/�@�R�@�@�@�@�@ �@�@�@�__/�@ ',�Q_
Opteron�̂ق������������͍̂��܂ł����ē��������
�P���ɍ��N���b�N�i�����Ȃ���������
�P���ɍ��N���b�N�i�����Ȃ���������
�L���b�V�����C�e���V��A���R�A�̖ʐς��ǂ��܂ʼn��P����邩
32nm�̍����22nm�łǂ��Ȃ邩�������̂���
�����_�ł��I�ł��������s����悤�ȕ��͋C������
DT�ł����������s�����炢�ɂȂ邩�ǂ���
32nm�̍����22nm�łǂ��Ȃ邩�������̂���
�����_�ł��I�ł��������s����悤�ȕ��͋C������
DT�ł����������s�����炢�ɂȂ邩�ǂ���
AMD���I��������玩��̓I���R����
�����AMD�ɊW�Ȃ��I���R������B
>>82
����܂ł�Opteron����Ȃ���������Ȃ��B
����܂ł�Opteron����Ȃ���������Ȃ��B
89 �FSocket774�F2011/12/06(��) 19:54:25.75 ID:lov0IqH4
�C���e����22nm��CPU��ʎY�n�߂�̂ƁAIntel�ȊO��28�`32nm��CPU�ʎY���n�߂�̂�
���������ɂȂ肻��
���������ɂȂ肻��
>>87
�܂��A����������Ȃ��x��������邯�ǁi�[�̐^�j
�܂��A����������Ȃ��x��������邯�ǁi�[�̐^�j
>>83
L2DTLB��HW�v���t�F�b�`���L���ɂ���������2-3����PC�p�r�̐��\�オ���ˁH
�����Ax87�ւ̍œK�������Ă���ۂ��̂�
movups��16byte�A���C�������g�Ƃ��͎d�l�Ǝv������32bit���̓C�}�C�`�Ǝv���B
x87�͖�����SSE2�L���ɂ��ăr���h���Ă�x87�D��Ŏg��MS C�Ƃ��̖�肪�傫���Ǝv����...
AMD��Microsoft�ׂ�����Ȃ玟��MS C�����SSE�D�悷��悤�ɂȂ邩�ȁH
Windows8�]�X�̘b�͂��̕ӂ��痈��̂����m���ȁB
L2DTLB��HW�v���t�F�b�`���L���ɂ���������2-3����PC�p�r�̐��\�オ���ˁH
�����Ax87�ւ̍œK�������Ă���ۂ��̂�
movups��16byte�A���C�������g�Ƃ��͎d�l�Ǝv������32bit���̓C�}�C�`�Ǝv���B
x87�͖�����SSE2�L���ɂ��ăr���h���Ă�x87�D��Ŏg��MS C�Ƃ��̖�肪�傫���Ǝv����...
AMD��Microsoft�ׂ�����Ȃ玟��MS C�����SSE�D�悷��悤�ɂȂ邩�ȁH
Windows8�]�X�̘b�͂��̕ӂ��痈��̂����m���ȁB
���x��MIPS�~�������H�I
���E����Android 4.0�^�u���b�g��99�h���œo��
http://pc.watch.impress.co.jp/docs/news/20111206_496097.html
���E����Android 4.0�^�u���b�g��99�h���œo��
http://pc.watch.impress.co.jp/docs/news/20111206_496097.html
����͍ŏ�����j�b�`����
94 �FSocket774�F2011/12/06(��) 22:53:22.64 ID:CdV4UMGO
(1) Bulldozer��AM3+�}�U�[�ŏI���B(���N�V�����̂��o��)
(2) AM3�}�U�[��Bulldozer����邩�ǂ����̓}�U�[�x���_����
(3) �V����FMA�ɑΉ�����������������i���ۂ݂����̂͂��Ȃ�
(4) ���A�v���ł͐��\����͌����߂Ȃ�
(5) GPU�͍ڂ��Ă��Ȃ�
(6) ���i�Ńx���`��i3�ȉ��Ai5/i7�Ɣ�r����͎̂��������
(7) �ŏ�ʂ�245�h���Ƒ������
�@�����Ǔ��{�ł͕������킹�ō�������������N�[���[����500����Ŗ�35,000�~
(8) �N�P�ʂŒx��ɒx��Đ��\���x��Ă���
(9) 8�R�A�̗D�ʐ���O�ʂɔ���o�����̂�4�E6�R�A����ɔ̔��ƂȂ�
�@�f�����ł͌��w�҂���u�[�C���O���@
(10) 4.5GHz�܂�OC���Ă�2500K�̃f�t�H���g�N���b�N�ɂ�����ׂȂ�
�@������8GHz��ڎw���Ɨǂ��R����@
(11) �X�R�A�͋��낵���Ⴂ����OC
�@���̂�������d�͉͂ߋ��ŋ�
(12) AMD�̎x�����ĊJ�����ꂽ TotalWar:Shogun2 �� BSOD ���������ē��삵�Ȃ�
�@���͂�̂����M���O
(13) 8�R�A�q���Ŕ�������FX-8120/FX-6100/FX-4100�� Phenom II/Athlon II/A�V���[�Y�����C�o��
(14) �L�����y�[���̌i�i�͂��َq�̋� (�����ς������̍���
(15) �f�t�H�Ń��~�b�^�[���ځA��i�ł����ׂ�������Ɣ���
�@�}�U�[�ɂ���Ă͉����\�����A���x��C'n'Q�̌����Ȃ��펞�S�͉^�]�ɂȂ�
(16) ���ٓI�Ȕ̔��s�U�ɂ�蔭������ꃖ�����o�����ɉ��i����A���l�Ȓl������]�V�Ȃ������
(17) ���\���Ⴂ�͎̂��ۂ̐��\���v���ł���x���`���܂�������(��p�i���K�v�����o����\�������
(18) �Ȃ�Ǝ��ۂ̃g�����W�X�^���͌��̒l��20���ł͂Ȃ�������12���ɉ߂��Ȃ����������B
�ʐϓ�����̃g�����W�X�^���x��32nm�ōň��B
GLOBALFOUNDERIES�͐������̂����Ă����A�ŒႾ���I
�킯���킩��Ȃ���_(^o^)�^
�R�s�y�~������
>>92
���E����Android 4.0�^�u���b�g��99�h���œo��
�`MIPS�x�[�X�v���Z�b�T�̗p��7�^
pc.watch.impress.co.jp/docs/news/20111206_496097.html
mips���邩�H�@�Ƃɂ�������
���E����Android 4.0�^�u���b�g��99�h���œo��
�`MIPS�x�[�X�v���Z�b�T�̗p��7�^
pc.watch.impress.co.jp/docs/news/20111206_496097.html
mips���邩�H�@�Ƃɂ�������
�������t�@�����X�@�ł��Ȃ��̂ɍ��̑�����
�����ǂ��Ȃ��Ă�
�����ǂ��Ȃ��Ă�
mips�̓o�C�G���f�B�A���ł������Ȃ��o�C�i�������邩�猙��
Amazon����Ȃ��Ȃ��o�ׂł��Ȃ��Ă��߂�˃��[�����Ă����ǁA
��Amazon�̃y�[�W������A�}�[�P�b�g�v���C�X��\41850�Ŕ����Ă���
�����ł����ڂ�������Ȃ̂ɔ����̂��˂�
��Amazon�̃y�[�W������A�}�[�P�b�g�v���C�X��\41850�Ŕ����Ă���
�����ł����ڂ�������Ȃ̂ɔ����̂��˂�
100 �F,,�E�L�́M�E,,�j��-�������F2011/12/07(��) 00:27:58.29 ID:k7YL3fDr
�����ŐVOS���ڂ��Ă邾���Ŏc�O�ȏo�����Ă̂͑�������˂�
GALAXY�Ȃ��Ƃ��E�E�E
GALAXY�Ȃ��Ƃ��E�E�E
>>91
RMMA�̌��ʂ���L2DTLB��HW�v���t�F�b�`�͑��݂���݂�������
�ǂ�����ُ�ɂ���ڂ�����
�������炪�s��̌��ʂł�����P�����\���͔ے肵�Ȃ�
x87�ւ̍œK�����Ȃɂ������Ă���̂��킩��Ȃ���
�e���߂�Throughput/Latency��SIMD�ɔ�ׂē��ɂ���ڂ��Ȃ��Ă͂��Ȃ�
movups�ƃA���C�������g��32bit���̖��͗����ł��Ȃ��̂ŋ����Ă��炦��H
���Ǝ茳��cl (VS2010)��SSE2�L����x87�̃R�[�h�͓f���Ȃ�����
�ǂ�������������x87��D�悷��́H
RMMA�̌��ʂ���L2DTLB��HW�v���t�F�b�`�͑��݂���݂�������
�ǂ�����ُ�ɂ���ڂ�����
�������炪�s��̌��ʂł�����P�����\���͔ے肵�Ȃ�
x87�ւ̍œK�����Ȃɂ������Ă���̂��킩��Ȃ���
�e���߂�Throughput/Latency��SIMD�ɔ�ׂē��ɂ���ڂ��Ȃ��Ă͂��Ȃ�
movups�ƃA���C�������g��32bit���̖��͗����ł��Ȃ��̂ŋ����Ă��炦��H
���Ǝ茳��cl (VS2010)��SSE2�L����x87�̃R�[�h�͓f���Ȃ�����
�ǂ�������������x87��D�悷��́H
wichita + win8 �̃^�u���b�g�Ȃ�L�[�{�[�h���邾���ŕ��ʂ�PC�ɂȂ邵�A���܂������ЂƂ̒�ԏ��i�ɂȂ邩������Ȃ��Ǝv���Ă��̂ɂ܂������ŊԂɍ���Ȃ��̂��B
���@���Ă����肾�ˁA�z���g�ɁB
���@���Ă����肾�ˁA�z���g�ɁB
Bulldozer�Ő��\�ɉe���̂���o�O�Ƃ�����
sqrtss���ُ�ɒx���̂̓o�O������������ʂȂ�Ȃ����Ǝv��
sqrtps 11 cycle
sqrtss 166 cycle�i�I�j
sqrtss���ُ�ɒx���̂̓o�O������������ʂȂ�Ȃ����Ǝv��
sqrtps 11 cycle
sqrtss 166 cycle�i�I�j
>>97
����Android2.3�Ƃ��Ŕ����Ă�@�B��Android4����ꂽ�������瑁���͉̂���̂�����
MIPS�����ł��v���X�����[�X�o���Ă邩��AMIPS���̂����炩�̌`�ňڐA��ƂɊ֗^���Ă�̂����B
����Android2.3�Ƃ��Ŕ����Ă�@�B��Android4����ꂽ�������瑁���͉̂���̂�����
MIPS�����ł��v���X�����[�X�o���Ă邩��AMIPS���̂����炩�̌`�ňڐA��ƂɊ֗^���Ă�̂����B
����W500�g���Ă邪�A
����܂�^�u���b�g�����������Ƃ͎v��Ȃ�(�X�}�z�������Ă邵)�̂ŁA
���������Ă��C�ɂȂ�Ȃ��ȁB�Ƃ̒��Ń_���_���g����Ώ\���B
W500�̓o�b�e���[�͈ӊO�Ǝ����ǂ�
����܂�^�u���b�g�����������Ƃ͎v��Ȃ�(�X�}�z�������Ă邵)�̂ŁA
���������Ă��C�ɂȂ�Ȃ��ȁB�Ƃ̒��Ń_���_���g����Ώ\���B
W500�̓o�b�e���[�͈ӊO�Ǝ����ǂ�
�����܂��A���̗p�r�ɂ����g��Ȃ��l�͐ϋɓI��Windows�^�u���b�g����Ȃ���ȁE�E�E
Android�^�u���b�g�ł����킵�Ă�̂ɁB
Android�^�u���b�g�ł����킵�Ă�̂ɁB
�n�[�h���\�t�g���A�^�u���b�g�ɗv��Ȃ����̂͑S���̂Ă�
�y���������Ȃ��ᔄ��Ȃ���A�^�u���b�g�́B
�y���������Ȃ��ᔄ��Ȃ���A�^�u���b�g�́B
windows�^�u���b�g�A�傫���͂���ȂɋC�ɂȂ�Ȃ���B�ǂ��������^�ԂȂ�X�}�z�����ˁB
�傫�������Ȃ̂́AWindows�Ƃ���OS�ƃ^�b�`����̑����̈������B
8�ł�����x���P�����Ƃ͂����A�����̃\�t�g�͂��̂܂܂��B
�Â��\�t�g�Ȃ̂Ă���Ă����Ȃ�AWindows�ł���K�v���Ȃ��B
�傫�������Ȃ̂́AWindows�Ƃ���OS�ƃ^�b�`����̑����̈������B
8�ł�����x���P�����Ƃ͂����A�����̃\�t�g�͂��̂܂܂��B
�Â��\�t�g�Ȃ̂Ă���Ă����Ȃ�AWindows�ł���K�v���Ȃ��B
���肢�A�������r�W�����グ��bulldozer�o���āc
�����������ʂ̃R���Ȃ���A�����ȒP�ɂ͍s���Ȃ���Ȃ��H
���łɔ����������ă��r�W�����グ�������
�P�Ƀ��r�W�����グ�������Œ�����o�O�͒����Ă���Ă���
�P�Ƀ��r�W�����グ�������Œ�����o�O�͒����Ă���Ă���
�[�����{�I�ɐv�v�z�������������v���S�������Ďϋl�܂��ĂȂ����炱�̌��ʂ������낤��
���r�W�����łǂ��ɂ��ł���قǂ̂��̂���Ȃ�����E�E�E�E
1����v���Ȃ������V�����A�[�L�e�N�`���̗p���邩���Ȃ��ƒN���̂܂�
���������Ntri��������Ă̂��|������
���r�W�����łǂ��ɂ��ł���قǂ̂��̂���Ȃ�����E�E�E�E
1����v���Ȃ������V�����A�[�L�e�N�`���̗p���邩���Ȃ��ƒN���̂܂�
���������Ntri��������Ă̂��|������
�܂���_�̃u�����Ȃ��I�u����CPU�Ȃ���
����̂̓n�C�G���h�u���̃Q�[�}�[��������
����̂̓n�C�G���h�u���̃Q�[�}�[��������
>>115
��Ђ̕��j���u���Ă�
��Ђ̕��j���u���Ă�
119 �F,,�E�L�́M�E,,�j��-�������F2011/12/07(��) 21:32:19.44 ID:xKk7Jj7U
120 �F,,�E�L�́M�E,,�j��-�������F2011/12/07(��) 22:24:47.25 ID:xKk7Jj7U
>>117
�����g�b�v�������ւ���ău���Ȃ���Ђ���������t�ɂ����[��
�����g�b�v�������ւ���ău���Ȃ���Ђ���������t�ɂ����[��
�喇�͂�����ATI��������ŁA
FSA�Ƃ�����������Ă�T�ŁA
��_�̃u���Ȃ��T�[�o�w�����Č����Ă�����
FSA�Ƃ�����������Ă�T�ŁA
��_�̃u���Ȃ��T�[�o�w�����Č����Ă�����
>>122
�T�[�o�ƃf�X�N�g�b�v�ƃ��o�C���ŎO���ʓ������W�J���āA
�����Ă�Ȃ疳�W�ƌ����Ă��ǂ����A�S���ʂŕ����Ă邶��Ȃ����B
Bulldozer���u��_�̃u���Ȃ��v�T�[�o�w���ō�����Ƃ���ŁA
����������ЂƂ��Ă̎����u���Ă邩��A�T�[�o�s��ł����ĂȂ��A�Ӗ��Ȃ����Ă��Ƃ���B
�T�[�o�ƃf�X�N�g�b�v�ƃ��o�C���ŎO���ʓ������W�J���āA
�����Ă�Ȃ疳�W�ƌ����Ă��ǂ����A�S���ʂŕ����Ă邶��Ȃ����B
Bulldozer���u��_�̃u���Ȃ��v�T�[�o�w���ō�����Ƃ���ŁA
����������ЂƂ��Ă̎����u���Ă邩��A�T�[�o�s��ł����ĂȂ��A�Ӗ��Ȃ����Ă��Ƃ���B
Bulledozer
>>124
rate����Ȃ�����SPECint�̃X�R�A�A���ׂĂ݂Ă�B
rate����Ȃ�����SPECint�̃X�R�A�A���ׂĂ݂Ă�B
>>124
Interlagos��ʂɑ�������Intel���i�́A���́i�܂��j�����Ǝv��
2P�܂őΉ���Westmere-EP��6�R�A�܂ŁB�n�C�G���h�p��Westmere-EX�͂��邪
RAS�@�\���������Ă�������Ŕ��ɍ��������牿�i�т�����Ȃ�
����Ȃ킯�ŁA����Westmere-EP���X�R�A���ǂ��Ă�����܂�������Ȃ��āA
SandyBridge-EP�Ƃǂ̒��x���荇���邩�����B����HPC�ł͋������n�܂��Ă�
Interlagos��ʂɑ�������Intel���i�́A���́i�܂��j�����Ǝv��
2P�܂őΉ���Westmere-EP��6�R�A�܂ŁB�n�C�G���h�p��Westmere-EX�͂��邪
RAS�@�\���������Ă�������Ŕ��ɍ��������牿�i�т�����Ȃ�
����Ȃ킯�ŁA����Westmere-EP���X�R�A���ǂ��Ă�����܂�������Ȃ��āA
SandyBridge-EP�Ƃǂ̒��x���荇���邩�����B����HPC�ł͋������n�܂��Ă�
�����ĂȂ����玎���悤���������A
��������Bull���āA���̃^�X�N�Ɏז����ꂸ���肵�����x��ۂĂ�
�Ƃ��Ȃ�Ƃ�����������CPU���Ď�����Ȃ����������H�o���Ⴂ����
�P�`�Q�^�X�N���x�̂̃N�\�d�����x���`�ł����点�Ȃ���
���̓K���ȃx���`���Ƃ��A����قǃX�R�A�ɍ����o�Ȃ��l�Ȃ�
����Ȃ�̉��b������E�E�E�ƁA�v�������������B
���ۂǂ��Ȃ낤���B
�����߂��Ȃ̂��ȉ��G�G
��������Bull���āA���̃^�X�N�Ɏז����ꂸ���肵�����x��ۂĂ�
�Ƃ��Ȃ�Ƃ�����������CPU���Ď�����Ȃ����������H�o���Ⴂ����
�P�`�Q�^�X�N���x�̂̃N�\�d�����x���`�ł����点�Ȃ���
���̓K���ȃx���`���Ƃ��A����قǃX�R�A�ɍ����o�Ȃ��l�Ȃ�
����Ȃ�̉��b������E�E�E�ƁA�v�������������B
���ۂǂ��Ȃ낤���B
�����߂��Ȃ̂��ȉ��G�G
�S�͂œ������s����̂�4�X���b�h�܂łȂ�SandyBridge�̕��������B
Bulldozer��5-8�X���b�h�܂ő��₵�Ă������ɂ����̂ŁA���͈̔͂ł�SandyBridge���t�]���邩������Ȃ��B
Bulldozer��5-8�X���b�h�܂ő��₵�Ă������ɂ����̂ŁA���͈̔͂ł�SandyBridge���t�]���邩������Ȃ��B
�܂��A���ۂ͋t�]����ǂ��납�������炢���ւ̎R�Ȃ̂�����
131 �F,,�E�L�́M�E,,�j��-�������F2011/12/08(��) 00:45:24.95 ID:s0p69/Mg
SPECint_rate�݂����ȃ^�X�N�Ԃ̈ˑ����̖����v���O���������ɓ����������̃x���`����
�ׂ�16�R�A�łȂ��Ă�4�R�A�̃}�V��4��ł��u�������ł��邩���
�ׂ�16�R�A�łȂ��Ă�4�R�A�̃}�V��4��ł��u�������ł��邩���
�����̓x���`�Ȃ���{�ԂƈႤ�̂͊���Ԃ낤��
>>127
���R�A16�͋��͂���ȁB
���R�A16�͋��͂���ȁB
����8�`12�R�A��������Ȃ�����
315mm2�j�R�C�`��Interlagos��240mm2��Westmere-EP�Ɠ����i�܂ŗ��Ƃ��Ă��r���Ă鎞�_�ŏ����Ă�Ƃ͓��X�ƌ����Ȃ�����
Intel�̃v���Z�X�ւ̓����z�ł�240mm2�ł����̒��x�̉��i�ɂ���K�v��������Ă�������ˁH
137 �F,,�E�L�́M�E,,�j��-�������F2011/12/08(��) 02:33:20.12 ID:s0p69/Mg
>>132
���������p�r�Ȃ�XeonE3-12xx�V���[�Y����g����Interlagos�ɂ��]�T�őR�ł�����Ă��Ƃ���B
E3-1260�}�V����4��g����SPECint_rate��600���邵Interlagos��DP�@�������ςށB
�v�����SPEC��rate�Ő��\�������ʂ��悤�ȗp�r����Interlagos�̋��ꏊ�͖����B
Xeon E3��Core i3���ڂ̃u���[�h�T�[�o�̓ƒd�ꂾ��B
���������p�r�Ȃ�XeonE3-12xx�V���[�Y����g����Interlagos�ɂ��]�T�őR�ł�����Ă��Ƃ���B
E3-1260�}�V����4��g����SPECint_rate��600���邵Interlagos��DP�@�������ςށB
�v�����SPEC��rate�Ő��\�������ʂ��悤�ȗp�r����Interlagos�̋��ꏊ�͖����B
Xeon E3��Core i3���ڂ̃u���[�h�T�[�o�̓ƒd�ꂾ��B
>>137
����d�͓I�ɂǂ��Ȃ̂���
����d�͓I�ɂǂ��Ȃ̂���
139 �F,,�E�L�́M�E,,�j��-�������F2011/12/08(��) 02:54:43.82 ID:s0p69/Mg
�d�͂����萫�\�𑪂�x���`�}�[�N�Ƃ��Ă�SPECpower_ssj���Ă����̂����邯��
Sandy Bridge�x�[�X��1�\�P�b�gXeon����ʂ��r�߂��Ă�
Sandy Bridge�x�[�X��1�\�P�b�gXeon����ʂ��r�߂��Ă�
>>137
�P���Ƀ��b�g�p�t�H�[�}���X��R�X�g�p�t�H�[�}���X�l�����
1P���m�[�h�ŋ����ĂȂ����Ⴄ����
SMP�T�[�o��VM���������グ�����
�Ǘ����y�������
�P���Ƀ��b�g�p�t�H�[�}���X��R�X�g�p�t�H�[�}���X�l�����
1P���m�[�h�ŋ����ĂȂ����Ⴄ����
SMP�T�[�o��VM���������グ�����
�Ǘ����y�������
141 �F,,�E�L�́M�E,,�j��-�������F2011/12/08(��) 03:02:11.06 ID:s0p69/Mg
DP�@�ɕ����l�ߍ��ނ���1P�T�[�o�œK�ʉғ������ق���QoS�����₷�����ǂȁB
143 �F,,�E�L�́M�E,,�j��-�������F2011/12/08(��) 03:05:08.18 ID:s0p69/Mg
Opteron�̃��j���O�R�X�g��1P Xeon 4����͂邩�ɍ����̒m���ĂČ����Ă�̂��H
>>141
����������P��ɓ��肫�邱�Ƃ��O����
�����̃e�X�g�T�[�o��4P�}�V���Ŋ��ʂɕ���VM���グ�Ă�
�R�X�g�p�t�H�[�}���X�͈�������
���������Ɩʓ|�����������b�N���x���Ⴂ��
�Ȃ��ł��ꂪ�y�Ƃ������_�ɂȂ��Ă�
����������P��ɓ��肫�邱�Ƃ��O����
�����̃e�X�g�T�[�o��4P�}�V���Ŋ��ʂɕ���VM���グ�Ă�
�R�X�g�p�t�H�[�}���X�͈�������
���������Ɩʓ|�����������b�N���x���Ⴂ��
�Ȃ��ł��ꂪ�y�Ƃ������_�ɂȂ��Ă�
145 �F,,�E�L�́M�E,,�j��-�������F2011/12/08(��) 03:20:01.77 ID:s0p69/Mg
�y��������Ȃ��������}�V��1�䎀�牼�z�}�V���S�����A�ꂾ��
���̂ւ�͐M�����Ƃ̃o�����X����
���̂ւ�͐M�����Ƃ̃o�����X����
��낵��
�Ȃ��Opteron��
�Ȃ��Opteron��
�V���^�z����������Ƃ�������Atom�����グ�ĂĂ�����
���̐M�S��ʂ̃u�����h�o���ĉB���Ă�̂�������
���̐M�S��ʂ̃u�����h�o���ĉB���Ă�̂�������
149 �FSocket774�F2011/12/08(��) 08:15:23.74 ID:oy3n7Fcp
���ĂȂ��A�̂ł͂Ȃ������ɂȂ�Ȃ��B
�ł��Ȃ��A�̃f�X(�P���P)
�ł��Ȃ��A�̃f�X(�P���P)
�T�[�o�[�ł̓����j���O�R�X�g���厖�Ȃ�
Facebook�Ƃ��f�[�^�Z���^�[�̃T�[�o�[��Magy-cours/Westmere���瑍����ւ����邪�A���̕����o�ϓI�炵��
CPU�g�p�����X�p�R���̏�ʐw���ł������펞�ғ��i�X�p�R���͉ғ����Ԃ͒Z���j���Ƃ����Ȃ��
Facebook�Ƃ��f�[�^�Z���^�[�̃T�[�o�[��Magy-cours/Westmere���瑍����ւ����邪�A���̕����o�ϓI�炵��
CPU�g�p�����X�p�R���̏�ʐw���ł������펞�ғ��i�X�p�R���͉ғ����Ԃ͒Z���j���Ƃ����Ȃ��
�X�p�R���̓^�X�N�ς�ŏ펞�ғ��ɋ߂��^�p�Ȃ�?
����Facebook�̃T�[�o�[�����A�ȃX�y�[�X�@���ۂ��ȁi7/25�y�[�W�ɐ}���L��j
http://opencompute.org/wp/wp-content/uploads/2011/07/Open_Compute_Project_AMD_Motherboard_v2.0_YGM.pdf
�ŋ߂��̌`���Ă��Ă��
http://opencompute.org/wp/wp-content/uploads/2011/07/Open_Compute_Project_AMD_Motherboard_v2.0_YGM.pdf
�ŋ߂��̌`���Ă��Ă��
�f�[�^�Z���^�[��PC�͊��S�Ƀ��W���[��������Ă邾�����Ǝv�����c
�T�[�o�͊�{�펞�ғ�����H�X�p�R�����ғ����ԒZ���Ƃ��͂��߂ĕ�����
�T�[�o�͊�{�펞�ғ�����H�X�p�R�����ғ����ԒZ���Ƃ��͂��߂ĕ�����
Facebook���A�N��������������V����T�[�o�����^�p�J�n���Ȃ�����Ă�����
�킴�킴�������Ă�T�[�o��SandyBridge/Interagos�ɓ���ւ�����͂��Ȃ��ł���B
�킴�킴�������Ă�T�[�o��SandyBridge/Interagos�ɓ���ւ�����͂��Ȃ��ł���B
�܂�IB��LAN�����\�����ł��Ȃ�d�C�H�����
>>154
Bull�ɓ���ւ����ĕ�������
Bull�ɓ���ւ����ĕ�������
>>156
���p���Ĕ��\���������肾��
���p���Ĕ��\���������肾��
��Ђɗ���ƁA�����������Ƃ��|������ȁB
�l�i��グ��ꂽ��B
�l�i��グ��ꂽ��B
�u���h�[�U�[�Ȃ�Ė��O�������_�T��������
161 �FSocket774�F2011/12/08(��) 17:30:09.95 ID:fa8F1fZM
�C���v���X�̌㓡����L���A
���L���\�[�X�� 6�� ������̂� 8�R�A �Ƃ��t�J�V��������u���y����
�����x����K���N�^��
�c�� 4�� �̂ݐ�L�A���l�O�ɖ����Ȃ��J�X
���p���Ă�̂�6���Ȃ̂�
8*0.4+8/2*0.6 = 5.6
���� 6�R�A �����Ȃ����ɁI�H
����� 8 �R�A �Ƃ͎o���������т�����
http://pc.watch.impress.co.jp/docs/column/kaigai/20111019_484609.html
>>160
���XFacebook��AMD��intel�����g����
���XFacebook��AMD��intel�����g����
���X���b�h����ƃf�[�^����ւƏd�_���ڂ�AMD�̐헪
��
���f�X�N�g�b�v��Bulldoze�ł́A���������헪�I�ȃr�W�����͂قƂ�Nj������Ă��Ȃ�
���f�X�N�g�b�v��Bulldozer�́A�R�A��������������g���̍���CPU�Ƃ��ăv�b�V������Ă���B
�i�R�A���������X���b�h����ɏd�_�j
��Intel�ƃV���O���X���b�h�̐��\����ŋ����̂ł͂Ȃ�
��
���f�X�N�g�b�v��Bulldozer�́A�R�A��������������g���̍���CPU�Ƃ��ăv�b�V������Ă���B
�i�N���b�N�オ��ΐ��\�オ��i���Ɉˑ����̋��������X�J���Łj�j
�㓡���ď��̐M�����͂Ƃ������l�I�����͉������Ă邩����Ȃ����x���������肷���
��
���f�X�N�g�b�v��Bulldoze�ł́A���������헪�I�ȃr�W�����͂قƂ�Nj������Ă��Ȃ�
���f�X�N�g�b�v��Bulldozer�́A�R�A��������������g���̍���CPU�Ƃ��ăv�b�V������Ă���B
�i�R�A���������X���b�h����ɏd�_�j
��Intel�ƃV���O���X���b�h�̐��\����ŋ����̂ł͂Ȃ�
��
���f�X�N�g�b�v��Bulldozer�́A�R�A��������������g���̍���CPU�Ƃ��ăv�b�V������Ă���B
�i�N���b�N�オ��ΐ��\�オ��i���Ɉˑ����̋��������X�J���Łj�j
�㓡���ď��̐M�����͂Ƃ������l�I�����͉������Ă邩����Ȃ����x���������肷���
������g���������Ƃ����̂́h�X���b�h����ƃf�[�^����ւƏd�_���ڂ�AMD�̐헪�h�Ƃ͖������Ă��邵
������g���������ɂ�������炸�h�V���O���X���b�h�̐��\�h�͒Ⴂ����
����Ȃɂ��������Ȃ��C������
������g���������ɂ�������炸�h�V���O���X���b�h�̐��\�h�͒Ⴂ����
����Ȃɂ��������Ȃ��C������
>>143
�ǂ����Ă��������E�\���V���b�ƌ����邩�ȁB1P 4���TCO��4P���Ⴂ�Ȃ�ĕ��������ƂȂ���B
�ǂ����Ă��������E�\���V���b�ƌ����邩�ȁB1P 4���TCO��4P���Ⴂ�Ȃ�ĕ��������ƂȂ���B
>>164
�������Ă�̂��f�t�H���ė�����
�������Ă�̂��f�t�H���ė�����
TCO�́A�����j���O�R�X�g+�����擾�R�X�g
�T�[�o�[����Atom�̍\����������Əo�Ă�����
http://blog.livedoor.jp/amd646464/archives/52236952.html
�ł�ARM�w�c���J�����Ă�T�[�o�[����CPU�Ɣ�ׂ�Ɣ��ɂ���ڂ��E�E�E
Xeon��Atom�ɋ����̂�����邽�߂���
�T�[�o�[����Bob���������R�ł��̒��x�ɂ�����Ȃ��Ȃ猵������
http://blog.livedoor.jp/amd646464/archives/52236952.html
�ł�ARM�w�c���J�����Ă�T�[�o�[����CPU�Ɣ�ׂ�Ɣ��ɂ���ڂ��E�E�E
Xeon��Atom�ɋ����̂�����邽�߂���
�T�[�o�[����Bob���������R�ł��̒��x�ɂ�����Ȃ��Ȃ猵������
���^�ŋl�ߍ��ޗp������A���������d�l�ɂȂ�����Ȃ��́H
�����̃R�A�K�v�Ȃ�APCIe�Ȃ�AGb�C�[�T�Ȃ�Ȃ�Ȃ�ŁA�N���X�^����āA
1�`�b�v�̃{�[�h���ʂɋl�ߍ��ނ��Č`�ɂ���낤�B
���ɂ��A�l�b�g���[�N�@��Ȃ̃x�[�X�p�Ƃ��F�X���p����邱�Ƃ��l���Ă��ˁH
�����̃R�A�K�v�Ȃ�APCIe�Ȃ�AGb�C�[�T�Ȃ�Ȃ�Ȃ�ŁA�N���X�^����āA
1�`�b�v�̃{�[�h���ʂɋl�ߍ��ނ��Č`�ɂ���낤�B
���ɂ��A�l�b�g���[�N�@��Ȃ̃x�[�X�p�Ƃ��F�X���p����邱�Ƃ��l���Ă��ˁH
Atom�̃N���b�N���オ��Ȃ��̂��m�[�X�������������Ă邹���ɂ��Ă��i����o���j�C���������z���R�e����������
���̃`�b�v�Z�b�g��FSB�N���b�N����Εʂɂ���Ȃ��Ƃ͖���
����ς��d���^�C�v�̃g�����W�X�^�g���Ă邽�߂̌��E���Ƃ������_�ŗǂ������͂�
�ǂ��������Ă�Atom�Ȃ����ɓd�͌����Ƃ��l�����炻��ȂƂ��낪���E�Ȃ�Ȃ��́A�I����
���̃`�b�v�Z�b�g��FSB�N���b�N����Εʂɂ���Ȃ��Ƃ͖���
����ς��d���^�C�v�̃g�����W�X�^�g���Ă邽�߂̌��E���Ƃ������_�ŗǂ������͂�
�ǂ��������Ă�Atom�Ȃ����ɓd�͌����Ƃ��l�����炻��ȂƂ��낪���E�Ȃ�Ȃ��́A�I����
�T�[�o�[����bob���āABull���̂��R�A���ȗ������Ă̑��R�A�H���Ȃ���A
������bob�I�Ȃ���������䖳������Ȃ����B
������bob�I�Ȃ���������䖳������Ȃ����B
>>171
http://pc.watch.impress.co.jp/docs/column/kaigai/20111109_489233.html
Xeon�AOpteron�g�����T�[�o�[��ARM�AAtom�ABobcat�R�A�Ȃǂ��g�����T�[�o�[�͋������Ȃ��ł���
http://pc.watch.impress.co.jp/docs/column/kaigai/20111109_489233.html
Xeon�AOpteron�g�����T�[�o�[��ARM�AAtom�ABobcat�R�A�Ȃǂ��g�����T�[�o�[�͋������Ȃ��ł���
>>163
�㓡�O�̘b�̎����Ă������ň�Ԃ��������̂�
�}���`�X���b�h���\���グ�邽�߂ɃV���O���X���b�h���\�͋]���ɂ���
�Ƃ������B
�V���O���ƃ}���`�̐��\����͑S���r���I����Ȃ��̂ɁB
�㓡�O�̘b�̎����Ă������ň�Ԃ��������̂�
�}���`�X���b�h���\���グ�邽�߂ɃV���O���X���b�h���\�͋]���ɂ���
�Ƃ������B
�V���O���ƃ}���`�̐��\����͑S���r���I����Ȃ��̂ɁB
���R�e�͖��킸NG���[�h�ւǂ���
�����x�T�[�o�̘b�́A����I�N���Ă��Ă̓|�V�����ȁ[
�Ƃ��Ɍi�C�̐��ފ��ɗN���Ă���B
�Ƃ��Ɍi�C�̐��ފ��ɗN���Ă���B
�V���O���X���b�h���\�̓R�A�̃g�����W�X�^���ɔ�Ⴗ���
�_�C�ɑ������܂�R�A���������͓̂����Ȗ��
�㓡�搶�͔����������O����Bull��K10��菬�����ƌ����Ă����
������ւ�͗ǂ��������Ă������锤
�_�C�ɑ������܂�R�A���������͓̂����Ȗ��
�㓡�搶�͔����������O����Bull��K10��菬�����ƌ����Ă����
������ւ�͗ǂ��������Ă������锤
�V���O���X���b�h���\ �� �g�����W�X�^���̕������ɔ��
�}���`�X���b�h���\�@���@�R�A��(�g�����W�X�^��)�ɔ��
�}���`�X���b�h���\�@���@�R�A��(�g�����W�X�^��)�ɔ��
>>173
����ꂽ�_�C�T�C�Y�̒��ŁA�ƍl������������͂Ȃ��Ǝv�����B
�V���O���X���b�h���\��Nj�����R�A�̑傫������傷�邪�A�|���b�N�̖@����
�ʐ�2�{�ł����\�͖�1.4�{�ɂ����Ȃ�Ȃ�����A�������悭�Ȃ����Ď��ɂȂ�B
�Ƃ͂����V���O�������S�����͂ł��Ȃ�����A�o�����X���ǂ��Ŏ�邩�̖��B
����ꂽ�_�C�T�C�Y�̒��ŁA�ƍl������������͂Ȃ��Ǝv�����B
�V���O���X���b�h���\��Nj�����R�A�̑傫������傷�邪�A�|���b�N�̖@����
�ʐ�2�{�ł����\�͖�1.4�{�ɂ����Ȃ�Ȃ�����A�������悭�Ȃ����Ď��ɂȂ�B
�Ƃ͂����V���O�������S�����͂ł��Ȃ�����A�o�����X���ǂ��Ŏ�邩�̖��B
���V���O�����\�ƃ}���`���\�͓�������Ȃ������
�V���O���������Ȃ�}���`�������Ȃ邯�ǁA���̋t�͕K�������������Ȃ�
������ł��邾���V���O���d���ō���������ق�������
�V���O���������Ȃ�}���`�������Ȃ邯�ǁA���̋t�͕K�������������Ȃ�
������ł��邾���V���O���d���ō���������ق�������
>>173
���̋L�����̂ق����������ǂ�łȂ�����
�u�ǂ�����Ԃ��v�Ƃ��b����Ă����邗
���ƁA�f�[�^����SIMD�i��SIMM�j��
Bull��Sandy�̔����̃r�b�g��
K10��ʐϔ�ő啪���\�[�X���炵�čœK���ʼn��Ƃ����Ă�������
���ĕ����ɂ��������Ȃ����ǂ��l���Ă��d�_�u���ĂȂ����
GPU�ɉ\�肾�낤��
���̋L�����̂ق����������ǂ�łȂ�����
�u�ǂ�����Ԃ��v�Ƃ��b����Ă����邗
���ƁA�f�[�^����SIMD�i��SIMM�j��
Bull��Sandy�̔����̃r�b�g��
K10��ʐϔ�ő啪���\�[�X���炵�čœK���ʼn��Ƃ����Ă�������
���ĕ����ɂ��������Ȃ����ǂ��l���Ă��d�_�u���ĂȂ����
GPU�ɉ\�肾�낤��
181 �F,,�E�L�́M�E,,�j��-�������F2011/12/08(��) 20:50:10.67 ID:I95SPawS
>>176
�g�����W�X�^�������Ō���Ȃ�Bulldozer��1���W���[��������3500��Tr����
Core 2(Merom)��1�R�A�̂����悻2�{�Ȃ�
�g�����W�X�^�������Ō���Ȃ�Bulldozer��1���W���[��������3500��Tr����
Core 2(Merom)��1�R�A�̂����悻2�{�Ȃ�
�܂�Bull�̓R�A�ӂ��FPU���\���Ⴍ�Ȃ��Ă���
�����Directx11��GPGPU�T�|�[�g���l�����Ή���������Ȃ���
FPU���\��v������Q�[���̓W�I���g��������CPU�ł���Ă�낤
���ꂪGPGPU�Ōv�Z�����悤�ɂȂ��CPU��FPU�̔�剻�͗}������ƍl�������
�W�I���g�������͕��̍�����肾��
CPU��FPU�͕��������v�Z��������ɂ̓p���[�s����
�����Directx11��GPGPU�T�|�[�g���l�����Ή���������Ȃ���
FPU���\��v������Q�[���̓W�I���g��������CPU�ł���Ă�낤
���ꂪGPGPU�Ōv�Z�����悤�ɂȂ��CPU��FPU�̔�剻�͗}������ƍl�������
�W�I���g�������͕��̍�����肾��
CPU��FPU�͕��������v�Z��������ɂ̓p���[�s����
�g�����W�X�^���̓L���b�V���̔䗦��������Β��ˏオ��
�L���b�V�������O�������Ŕ�ׂȂĂ���Ȃ��Ƃ悭�킩���
�L���b�V�������O�������Ŕ�ׂȂĂ���Ȃ��Ƃ悭�킩���
��Trinity�ɂ��Ă�
dGPU�������ꍇ��iGPU��GPU�Ƃ��Ďg��
dGPU������ꍇ��iGPU��FPU�Ƃ��Ďg���̂����z�I�ƍl������
dGPU�������ꍇ��iGPU��GPU�Ƃ��Ďg��
dGPU������ꍇ��iGPU��FPU�Ƃ��Ďg���̂����z�I�ƍl������
���Ȃ��Ƃ��ATrinity�̓���GPU��FPU�̑���ɂȂȂ�Ȃ����낤�B
AMD�͂��̂��薞�X�Ȃ͂������A���z�͂����Ȃ낤�ȁB
RADEON�����̐���ł͂��̕����Ői������i�͂��j
RADEON�����̐���ł͂��̕����Ői������i�͂��j
����������ł�sandy�ɒǂ�������̂�����t�̗\��
188 �F,,�E�L�́M�E,,�j��-�������F2011/12/08(��) 21:02:07.20 ID:I95SPawS
> �܂�Bull�̓R�A�ӂ��FPU���\���Ⴍ�Ȃ��Ă���
> �����Directx11��GPGPU�T�|�[�g���l�����Ή���������Ȃ���
����͂��ƕt�����k�ق���
�I���W�i���v�����ł͑�Nehalem�����A4C8T��4M8C�Ń}���`�X���b�h���\���A�s�[����
�X�ɁuFMA���g���s�[�NFP���\2�{�v�𐺍����ɂ������Ă����Ƃ��낤�B
���Ƃ���FP�d���̐v�Ȃ̂Ɍ��ɉ�������ƂŁA���̐��\�������o���̂ɕK�v��
�Ǝ����߂��A�s�[������@����킵���B
> �����Directx11��GPGPU�T�|�[�g���l�����Ή���������Ȃ���
����͂��ƕt�����k�ق���
�I���W�i���v�����ł͑�Nehalem�����A4C8T��4M8C�Ń}���`�X���b�h���\���A�s�[����
�X�ɁuFMA���g���s�[�NFP���\2�{�v�𐺍����ɂ������Ă����Ƃ��낤�B
���Ƃ���FP�d���̐v�Ȃ̂Ɍ��ɉ�������ƂŁA���̐��\�������o���̂ɕK�v��
�Ǝ����߂��A�s�[������@����킵���B
190 �FSocket774�F2011/12/08(��) 21:29:30.52 ID:T/LTcpcX
�W�I���g��������DX7����GPU����
�uFP�d��������FP���\�[�X���Ȃ����܂����v�ȋC���������b�̓z���Ƃ�������Ă���
192 �F,,�E�L�́M�E,,�j��-�������F2011/12/08(��) 21:32:24.29 ID:I95SPawS
FP���\�[�X�����Ȃ�������
�����n�������邗��
�����n�������邗��
>>184
GPU�̉��Z��ƃ��W�X�^�t�@�C���͊T��CPU��10�{���炢�̃��C�e���V
�����炱�����̖��x�ƃ��b�g�p�t�H�[�}���X�������ł��Ă���
����GPU��CU��CPU�ɒ������ăf�[�^�ړ��R�X�g���ł����ԂɂȂ����Ƃ��Ă�
����FPU�̑S�Ẵ^�X�N���ւ͂ł��Ȃ�
GPU�̉��Z��ƃ��W�X�^�t�@�C���͊T��CPU��10�{���炢�̃��C�e���V
�����炱�����̖��x�ƃ��b�g�p�t�H�[�}���X�������ł��Ă���
����GPU��CU��CPU�ɒ������ăf�[�^�ړ��R�X�g���ł����ԂɂȂ����Ƃ��Ă�
����FPU�̑S�Ẵ^�X�N���ւ͂ł��Ȃ�
�c�q�̓z��
�ǂ���ł������o���邪��������
DX9�ӂ肾�ƃW�I���g�������܂ł�CPU���ł��������\�{������������
���_�����Ƃ�������ɂ��Ȃ��悤�ɂ�
DX9�ӂ肾�ƃW�I���g�������܂ł�CPU���ł��������\�{������������
���_�����Ƃ�������ɂ��Ȃ��悤�ɂ�
��������ɂ��Ă܂���
197 �F,,�E�L�́M�E,,�j��-�������F2011/12/08(��) 21:39:30.06 ID:I95SPawS
�u�œK�����ꂽ2�R�A�v���Ă̂��k�قȂ킯�ŁA�����܂Őv�ɂ��������Andy�̌����Ƃ���
�u2�̐����N���X�^������1�R�A�v����B
Nehalem�Ɣ�ׂ��4���W���[����Bulldozer�͐���ALU�̐���4/3�{�ł����Ȃ���
�s�[�NFP���\�͔{�߂������B
�㔭�ɂȂ�͂�������Sandy Bridge��FP���\��2�{�ɋ������Ă��ĂȂ�����ɏo���ꂽ����
FP���\��ɂł��Ȃ��Ȃ��������B��Z�ȊO�̂Ȃ�ł��Ȃ��B
�u2�̐����N���X�^������1�R�A�v����B
Nehalem�Ɣ�ׂ��4���W���[����Bulldozer�͐���ALU�̐���4/3�{�ł����Ȃ���
�s�[�NFP���\�͔{�߂������B
�㔭�ɂȂ�͂�������Sandy Bridge��FP���\��2�{�ɋ������Ă��ĂȂ�����ɏo���ꂽ����
FP���\��ɂł��Ȃ��Ȃ��������B��Z�ȊO�̂Ȃ�ł��Ȃ��B
198 �F,,�E�L�́M�E,,�j��-�������F2011/12/08(��) 21:45:44.46 ID:I95SPawS
>>195
Geometry Shader�Ή���DX10���炾���炻�ꂪ�����B
Geometry Shader�Ή���DX10���炾���炻�ꂪ�����B
200 �F,,�E�L�́M�E,,�j��-�������F2011/12/08(��) 21:53:44.42 ID:I95SPawS
>>199
HPC�ȊO�̃T�[�o�R���s���[�e�B���O�ł͖w�ǓK�p�ł�����̖�����
HPC�ȊO�̃T�[�o�R���s���[�e�B���O�ł͖w�ǓK�p�ł�����̖�����
���c�q
�u�I�ƌ����ΐ����X�J����SIMD�i��SIMD�j��99%���ʁv�Ƃ���
���ɏ펯�����Ă��邾�낤AMD�������X�b�|�����������Ă�̂�
�uFP�ƌ����Η����i��������j����v�Ƃ����ϑz����S�Ă��n�܂��Ă邩��Ȃ낤��
�R�Ȃ̂��^���̂���̖ϑz�Ȃ̂��킯����Ȃ���������Ńz���ȊO�ł��C����������
���ɏ펯�����Ă��邾�낤AMD�������X�b�|�����������Ă�̂�
�uFP�ƌ����Η����i��������j����v�Ƃ����ϑz����S�Ă��n�܂��Ă邩��Ȃ낤��
�R�Ȃ̂��^���̂���̖ϑz�Ȃ̂��킯����Ȃ���������Ńz���ȊO�ł��C����������
203 �F,,�E�L�́M�E,,�j��-�������F2011/12/08(��) 22:07:22.94 ID:I95SPawS
�n�����Ⴆ�Ă��
204 �F,,�E�L�́M�E,,�j��-�������F2011/12/08(��) 22:15:23.95 ID:I95SPawS
CPU����FP���\���ǂ��ł������Ȃ�A�킴�킴�J�����]���ɂ�����SSE5�i�j���L�����Z������
�㔭��AVX�ƌ݊��Ƃ�����Ȃ�Ă��Ȃ�����B
SSE5���낤��XOP/FMA4���낤���^�_�т��H���Ȃ����Ƃɂ͕ς��Ȃ��B
�㔭��AVX�ƌ݊��Ƃ�����Ȃ�Ă��Ȃ�����B
SSE5���낤��XOP/FMA4���낤���^�_�т��H���Ȃ����Ƃɂ͕ς��Ȃ��B
205 �F,,�E�L�́M�E,,�j��-�������F2011/12/08(��) 22:20:24.06 ID:I95SPawS
�܂����̃C�J�ꂽ�N�\�R�e�����Ă�́H
207 �F,,�E�L�́M�E,,�j��-�������F2011/12/08(��) 22:30:16.23 ID:I95SPawS
ProLiant DL165 G7 (2.30 GHz, AMD Opteron 6276 processor
http://www.spec.org/power_ssj2008/results/res2011q4/power_ssj2008-20111018-00401.html
1,180,059ssj_ops@308W
Fujitsu PRIMERGY TX120 S3 (Intel Xeon E3-1260L)
http://www.spec.org/power_ssj2008/results/res2011q2/power_ssj2008-20110531-00379.html
322,691ssj_ops@54W
1260L��4�m�[�h�������������}�V���ȁB
http://www.spec.org/power_ssj2008/results/res2011q4/power_ssj2008-20111018-00401.html
1,180,059ssj_ops@308W
Fujitsu PRIMERGY TX120 S3 (Intel Xeon E3-1260L)
http://www.spec.org/power_ssj2008/results/res2011q2/power_ssj2008-20110531-00379.html
322,691ssj_ops@54W
1260L��4�m�[�h�������������}�V���ȁB
�W�I���g�������́A�|���S���̍��W�ϊ��iTransform�j�ƁA�|���S���̖ʂ̖��邳�̌v�Z�iLightning�F���������j�ł��B
DirectX 7.0���O�́ACPU���W�I���g���������s���A�O���t�B�b�N�`�b�v�������_�����O�������s���Ă��܂����B
���邢�́A�\�����~�ȏ�̍����ȃO���t�B�b�N�J�[�h�ɂ����ẮA�W�I���g����������ɍs���n�[�h�E�F�A�𓋍ڂ��Ă��܂����B
DirectX 7.0�ɂ����āA�O���t�B�b�N�`�b�v���W�I���g�������̂��߂̃n�[�h�E�F�A��H���������悤�ɂȂ�A
�W�I���g���������s���悤�ɂȂ�܂����B���̃n�[�h�E�F�A��H�́u�n�[�h�E�F�AT&L�iTransform and Lighting�j�v�ƌĂ�Ă��܂��B
DirectX 7.0���O�́ACPU���W�I���g���������s���A�O���t�B�b�N�`�b�v�������_�����O�������s���Ă��܂����B
���邢�́A�\�����~�ȏ�̍����ȃO���t�B�b�N�J�[�h�ɂ����ẮA�W�I���g����������ɍs���n�[�h�E�F�A�𓋍ڂ��Ă��܂����B
DirectX 7.0�ɂ����āA�O���t�B�b�N�`�b�v���W�I���g�������̂��߂̃n�[�h�E�F�A��H���������悤�ɂȂ�A
�W�I���g���������s���悤�ɂȂ�܂����B���̃n�[�h�E�F�A��H�́u�n�[�h�E�F�AT&L�iTransform and Lighting�j�v�ƌĂ�Ă��܂��B
209 �FSocket774�F2011/12/08(��) 22:59:32.54 ID:T/LTcpcX
GS�܂Ƃ��ɏ����o����̂�
S3��chrome����
S3��chrome����
210 �FSocket774�F2011/12/08(��) 23:00:42.46 ID:SMJqhrjJ
�n�[�h�E�F�AT&L����DX9�Ŕp�~�ɂȂ�Ȃ������H
���̃O���{�ł��c���Ă�̂��H
���̃O���{�ł��c���Ă�̂��H
211 �F,,�E�L�́M�E,,�j��-�������F2011/12/08(��) 23:02:56.05 ID:I95SPawS
Wii��GPU���炢�����m��Ȃ���
VS�Œu��������ꂽ
213 �F,,�E�L�́M�E,,�j��-�������F2011/12/09(��) 00:18:08.76 ID:HaOcUE8E
��������4���߂̃f�R�[�h�ш�ɑ���FMAC��2���āA�\�����b�`�ȍ\���Ȃ�
�����̐��������Ȃ̂悤�ɂ����uBulldozer��FPU���n��v�i�j���ĉ��������Č����Ă�̂��ˁH
����ȏ�o�b�N�G���h���₵�Ă��O�i���Ԃɍ����܂��炗����
�]��SSE�܂łȂ�s�[�N�̔����܂ł����g���Ȃ��̂�Intel�̎����i256�r�b�gSIMD�j�ł������B
Bulldozer��FP�̎������\���Ⴂ�̂̓��j�b�g�������Ȃ�����ł͂Ȃ��A
���C�e���V���傫�����ă��j�b�g�̉ғ������Ⴂ���炾�B�܂�ނ���L���p���]���Ă��B
������X�Ƀ��C�e���V�̑傫��GPU�ɒu��������ΐ��\��������Ƃ��ǂ��Ԕ����悗����
�����̐��������Ȃ̂悤�ɂ����uBulldozer��FPU���n��v�i�j���ĉ��������Č����Ă�̂��ˁH
����ȏ�o�b�N�G���h���₵�Ă��O�i���Ԃɍ����܂��炗����
�]��SSE�܂łȂ�s�[�N�̔����܂ł����g���Ȃ��̂�Intel�̎����i256�r�b�gSIMD�j�ł������B
Bulldozer��FP�̎������\���Ⴂ�̂̓��j�b�g�������Ȃ�����ł͂Ȃ��A
���C�e���V���傫�����ă��j�b�g�̉ғ������Ⴂ���炾�B�܂�ނ���L���p���]���Ă��B
������X�Ƀ��C�e���V�̑傫��GPU�ɒu��������ΐ��\��������Ƃ��ǂ��Ԕ����悗����
L3-�������̃��C�e���V����ɂ���Ȃ獡�̃X�P�W���[���K�͂ł��\�����낤��
L1-L2�̃��C�e���V����ɂ���Ȃ�FP���C�e���V�����Ă镪���������K�͑傫�����Ă����������ȁB
L1-L2�̃��C�e���V����ɂ���Ȃ�FP���C�e���V�����Ă镪���������K�͑傫�����Ă����������ȁB
��������H
Intel��Sandy�Ń��[�h�X�g�A���������ꂽ�̂ɍ��킹��SSE���قڑS���߂Ń��C�e���V1�Ŏ��s�ł���悤�ɂȂ��������H
�������j�b�g�������Ă��������W�ア�܂܂̃u�����Ƃ��̂ւ�Őh���̂�
�������j�b�g�������Ă��������W�ア�܂܂̃u�����Ƃ��̂ւ�Őh���̂�
Bulldozer�����[�h�X�g�A�͋�������Ă�͂��Ȃ���
���ۂ̐��\����ƃ��[�h�X�g�A�������������Ă銴���B
���ۂ̐��\����ƃ��[�h�X�g�A�������������Ă銴���B
>>173
�̎Z�Ƃ��_�C�T�C�Y�͌��܂��Ă邩��
�P�Ƀ��j�b�g�����₵�Ă����}���`�X���b�h�d���H���Ƃ���
�K���s���l�܂邩��ȁB
����AMD�̃��W���[���\���Ƃ��͑��e������ɔj�]�������B
�̎Z�Ƃ��_�C�T�C�Y�͌��܂��Ă邩��
�P�Ƀ��j�b�g�����₵�Ă����}���`�X���b�h�d���H���Ƃ���
�K���s���l�܂邩��ȁB
����AMD�̃��W���[���\���Ƃ��͑��e������ɔj�]�������B
220 �FSocket774�F2011/12/09(��) 08:00:36.16 ID:Gj3es6KO
�ڂ��̂������������傤CPU�B���K���N�^�������������u���y����
������ǂłȂ�Ƃ��Ȃ�̂��˃u��������
>>221
�A�[�L�e�N�`���̉��ǖ���10�`20%�̃��b�g�p�t�H�[�}���XUP����������
���ɂ����B���ł��Ă��A�T�[�o�͂Ƃ������f�X�N�g�b�v��intel�ɒǂ����̂͌������\��
������AMD�͒Z���ԂɃA�[�L�e�N�`���̉��ǂƂ����̂����܂ł�������Ƃ��Ȃ�
��̂��v���Z�X�̉��ǁA�R�A��L���b�V���̑��ʒ��x
��肭���������S�z��
������32nm�̑f���̈���
�����ł����v���Z�X���[���̐i�����݉����Ă���Ă̂ɂ���͑���������������
�v���Z�X�̉��ǂ����ӂ�GF���f���̈���65nm�ł͒��X�N���b�N���グ��Ȃ�����
��������̊�Ղ��~�����Ȃ����
�A�[�L�e�N�`���̉��ǖ���10�`20%�̃��b�g�p�t�H�[�}���XUP����������
���ɂ����B���ł��Ă��A�T�[�o�͂Ƃ������f�X�N�g�b�v��intel�ɒǂ����̂͌������\��
������AMD�͒Z���ԂɃA�[�L�e�N�`���̉��ǂƂ����̂����܂ł�������Ƃ��Ȃ�
��̂��v���Z�X�̉��ǁA�R�A��L���b�V���̑��ʒ��x
��肭���������S�z��
������32nm�̑f���̈���
�����ł����v���Z�X���[���̐i�����݉����Ă���Ă̂ɂ���͑���������������
�v���Z�X�̉��ǂ����ӂ�GF���f���̈���65nm�ł͒��X�N���b�N���グ��Ȃ�����
��������̊�Ղ��~�����Ȃ����
����Intel�Ő��Y���ĖႦ��
���̐��i��Intel�ō���Ė���Ă����ǂ͓������ʂɂȂ�Ǝv����
���{�I�Ȗ�������Ă���͖̂��炩�ɐv���������
���{�I�Ȗ�������Ă���͖̂��炩�ɐv���������
32nm�ł̉��ǂƂȂ�Piledriver�����łȂ��A���̐�̃v���Z�X�ɂ����Ă����Ǖ���10�`20���ƌ����Ă�
�����Core�n�ɒǂ��������ċC���������Ă���
�匴�������؋L���̑����ŏq�ׂĂ邪�A�v�����AMD�͍���Bulldozer�̐��\�ɖ������Ă��
�܂��匴����Bulldozer�̕������̓f�X�N�g�b�v�Ƀ}�b�`���Ȃ��Ƃ��q�ׂĂ���
�܂�́AAMD�͂�����܂߂���Ŗ������Ă�A�������͂����f�X�N�g�b�v�͎����Ă������ƍl���Ă���Ď�����
�����Core�n�ɒǂ��������ċC���������Ă���
�匴�������؋L���̑����ŏq�ׂĂ邪�A�v�����AMD�͍���Bulldozer�̐��\�ɖ������Ă��
�܂��匴����Bulldozer�̕������̓f�X�N�g�b�v�Ƀ}�b�`���Ȃ��Ƃ��q�ׂĂ���
�܂�́AAMD�͂�����܂߂���Ŗ������Ă�A�������͂����f�X�N�g�b�v�͎����Ă������ƍl���Ă���Ď�����
Intel���t�@�E���_�����n�߁AAMD��Intel�̍ŐV�v���Z�X���g����E�E�E���Ď��Ȃ�
�_�C�����͂���قǏd�����Ȃ��ėǂ��ASandy�̂悤�ȑ�^�R�A�H���ɐ�ւ��Ă���
Bull���_�C�����d���̃A�[�L�e�N�`���ɂ����̂́A�����v���Z�X�̔�����1�T�x�������邩�炾��
Intel�ɑ����ŁA�g���鐻���v���Z�X�̍����l����ƃ_�C�����d���H���ȊO�ɑI�������������Ă̂͌��낤
�_�C�����͂���قǏd�����Ȃ��ėǂ��ASandy�̂悤�ȑ�^�R�A�H���ɐ�ւ��Ă���
Bull���_�C�����d���̃A�[�L�e�N�`���ɂ����̂́A�����v���Z�X�̔�����1�T�x�������邩�炾��
Intel�ɑ����ŁA�g���鐻���v���Z�X�̍����l����ƃ_�C�����d���H���ȊO�ɑI�������������Ă̂͌��낤
>>173
�ō��̐��Ƃł��郁�[�J�[�́A��������������ɑ��đË��������߂Ă͂��Ȃ���ȁB
�ō��̐��Ƃł��郁�[�J�[�́A��������������ɑ��đË��������߂Ă͂��Ȃ���ȁB
�܂��o���C������̂��s�v�c
Bulldozer���Ȃ�Ƃ����Ă��玟�ɍs����
Bulldozer���Ȃ�Ƃ����Ă��玟�ɍs����
230 �FSocket774�F2011/12/09(��) 10:17:42.98 ID:wAocY3pX
>>167
1P 4��̕���4P 1���菉�������͏������B�ł�TCO��4P�̕����Ⴂ�B����?
>>207
HW�Ɋւ��Ă̓V���[�g����ȂˁB
��d�͔�(45W)�Ɣ�ׂĂǂ�����B���ƃm�[�h�ԃI�[�o�[�w�b�h���ǂ�قǂ̂��̂������ĂȂ��ł���? ��K�̓T�[�o��������4P�ȏ�̃m�[�h���̗p���Ă��闝�R���l���Ă݂�Ƃ�����B
1P 4��̕���4P 1���菉�������͏������B�ł�TCO��4P�̕����Ⴂ�B����?
>>207
HW�Ɋւ��Ă̓V���[�g����ȂˁB
��d�͔�(45W)�Ɣ�ׂĂǂ�����B���ƃm�[�h�ԃI�[�o�[�w�b�h���ǂ�قǂ̂��̂������ĂȂ��ł���? ��K�̓T�[�o��������4P�ȏ�̃m�[�h���̗p���Ă��闝�R���l���Ă݂�Ƃ�����B
>>230
Interlagos���̂���d���쓮�̑I�ʕi��MCM���������̂̂͂������H
�������I�ʗ�����Zambezi�Ƃ��ăf�X�N�g�b�v�s��ɁB
Interlagos���̂���d���쓮�̑I�ʕi��MCM���������̂̂͂������H
�������I�ʗ�����Zambezi�Ƃ��ăf�X�N�g�b�v�s��ɁB
Web�z�X�e�B���O�Ȃ�1P�̍����x�u���[�h�T�[�o���悭�g���Ă邵
�p�r�����肵�Ȃ��Ń\�P�b�g����������ق�TCO���팸�ł���Ȃ�Ă̂͂��܂�ɖ��m�B
���Ȃ݂�Facility Cost�ɐ�߂�d�C��i�T�[�o�{�́{�j�̊�����8���ȏ�B�X�y�[�X��Ȃ�đ��ǂ�����Ă���B
�p�r�����肵�Ȃ��Ń\�P�b�g����������ق�TCO���팸�ł���Ȃ�Ă̂͂��܂�ɖ��m�B
���Ȃ݂�Facility Cost�ɐ�߂�d�C��i�T�[�o�{�́{�j�̊�����8���ȏ�B�X�y�[�X��Ȃ�đ��ǂ�����Ă���B
1P4�Ȃ�����z��4�{�ɂȂ邵�d�C�ォ���邶����
4P�Ȃ�S���K�v�����R�X�g�Ȃ��
4P�Ȃ�S���K�v�����R�X�g�Ȃ��
���������p�r���w�肵�Ȃ��Łu��K�̓T�[�o�v�����Ă��Ȃ�
Web�Ȃ̂��f�[�^�x�[�X�Ȃ̂����C���t���[���Ȃ̂��p�r�ō\���ς�邵
���̃��X�i>>207�j�̏����O����̗���݂�Βc�q�̌����p�r����Web�Ƃ������̍����x�T�[�o����A�m�[�h�ԃI�[�o�w�b�h�Ȃ�čl������悤�Ȃ��̂��H
Web�Ȃ̂��f�[�^�x�[�X�Ȃ̂����C���t���[���Ȃ̂��p�r�ō\���ς�邵
���̃��X�i>>207�j�̏����O����̗���݂�Βc�q�̌����p�r����Web�Ƃ������̍����x�T�[�o����A�m�[�h�ԃI�[�o�w�b�h�Ȃ�čl������悤�Ȃ��̂��H
Web�z�X�e�B���O�Ńu���[�h�T�[�o�[�H
��������Ă������̈Ⴂ���킩��Ȃ��Ȃ�A���ꂱ�ꓪ�ōl����O��
�܂���1P��4P���g���Ă݂�����
�������������ȁB
�܂�����ȉɂȉ�Ђ��Ȃ��Ƃ͎v�����B
�܂���1P��4P���g���Ă݂�����
�������������ȁB
�܂�����ȉɂȉ�Ђ��Ȃ��Ƃ͎v�����B
����VM����
�����I�ɕ�����Ă�ׂ��Ƃ��A�z�߂���
�����I�ɕ�����Ă�ׂ��Ƃ��A�z�߂���
>>235
i7-610E�ŃO�O��Ƃ�����B�ǂ��������i�����v����̂��킩��͂��B
��������SPECint_rate�Ő��\�]���ł���悤�ȗp�r�Ȃ��Web�̃t�����g�G���h���炢�̂��B
���U�T�[�o�ŏ\������Infiniband���s�v�B
i7-610E�ŃO�O��Ƃ�����B�ǂ��������i�����v����̂��킩��͂��B
��������SPECint_rate�Ő��\�]���ł���悤�ȗp�r�Ȃ��Web�̃t�����g�G���h���炢�̂��B
���U�T�[�o�ŏ\������Infiniband���s�v�B
>>237
�n���ł����H
�t�����g�G���h�T�[�o��1P��4��Ȃ�A1�䎀��ł�3�䐶���Ă��75%�̉��Z���\�[�X�ŃT�[�r�X���p���ł���B
���������p�r�ł͕����䐔���̂��̂�QoS�ɒ�������B
��K��Web�T�[�r�X��RAS�@�\���n���4P�T�[�o���g���Ȃ�Ĕ�펯�������Ƃ���B
���F��M���x�̃T�[�r�X��������B
�ɂȂ�2ch�̃T�[�o�\���ׂĂ݂Ă���B
�n���ł����H
�t�����g�G���h�T�[�o��1P��4��Ȃ�A1�䎀��ł�3�䐶���Ă��75%�̉��Z���\�[�X�ŃT�[�r�X���p���ł���B
���������p�r�ł͕����䐔���̂��̂�QoS�ɒ�������B
��K��Web�T�[�r�X��RAS�@�\���n���4P�T�[�o���g���Ȃ�Ĕ�펯�������Ƃ���B
���F��M���x�̃T�[�r�X��������B
�ɂȂ�2ch�̃T�[�o�\���ׂĂ݂Ă���B
>>238
Web�Ŏg���Ă�y�[�W�ɒH�蒅���Ȃ��߂��Đ���������
Web�Ŏg���Ă�y�[�W�ɒH�蒅���Ȃ��߂��Đ���������
�f�[�^�Z���^�[��Atom����ARM���̎g�����Ƃ�������̓m�[�h������̐��\�ł͂Ȃ��A�����m�[�h���Ńg�[�^�����\���҂����߂̂��́B
�C���^�[�R�l�N�g���ǂ��Ƃ��͓I�O�ꂷ����B
GbE�̃��^�����̏���d�͂�����Ȃɂ��̂������Ƃł��v���Ă�̂��H��
�C���^�[�R�l�N�g���ǂ��Ƃ��͓I�O�ꂷ����B
GbE�̃��^�����̏���d�͂�����Ȃɂ��̂������Ƃł��v���Ă�̂��H��
�M�K�r�b�g�C�[�T����CPU�Ȃ�ĉ��N���O���炠�邵��
GbE�̃��^�����𗬂��d�͔͂��������ǁA
GbE�z���ɓ��������̂͂���Ȃ�ɂ��������Ă�B
�������K�v���Ȃ������ł������ǂˁB
�l�I�ɂ́A���������ꂽ����ȒP�̃R���s���[�^���w�����闬��͌�������Ȃ����B
�܂����ǂ͏��������ǂȁB
GbE�z���ɓ��������̂͂���Ȃ�ɂ��������Ă�B
�������K�v���Ȃ������ł������ǂˁB
�l�I�ɂ́A���������ꂽ����ȒP�̃R���s���[�^���w�����闬��͌�������Ȃ����B
�܂����ǂ͏��������ǂȁB
���\�ŕ�����Ɓu�䐔�𑝂₹�����v���Ċ��^���Ԃɂ��đ��������~���ĂȂ�Ȃ́H
���\�ŕ�����Ɓu�R�A�𑝂₹�����v���Ċ��^���Ԃ�(ry
>>244
Bulldozer�̓d�͐��\�����������A16�R�A�܂ŃX�P�[���������ǒn���p�ɂȂ��Ă���B
Bulldozer�̓d�͐��\�����������A16�R�A�܂ŃX�P�[���������ǒn���p�ɂȂ��Ă���B
>>244
����̓M���O�ł����H
�`�b�v������̐�ΐ��\�ł͂��Ȃ�Ȃ�����j�R�C�`����12�R�A���Ƃ�16�R�A���Ƃ��o���[�́A
�d�͌����������iXeon X56xx��DP��200W���x�ɑ�62xx��DP��300W�j���牿�i���Ƃ��[�́A
����ł��Ȃ��T�[�o�s��̃V�F�A�𗎂Ƃ������Ă�̂�AMD����B
����������ΐ��\�ł�8�\�P�b�g�Ή���Westmere-EX�ɑR�ł��鐻�i��AMD�ɂ͂Ȃ��B
����̓M���O�ł����H
�`�b�v������̐�ΐ��\�ł͂��Ȃ�Ȃ�����j�R�C�`����12�R�A���Ƃ�16�R�A���Ƃ��o���[�́A
�d�͌����������iXeon X56xx��DP��200W���x�ɑ�62xx��DP��300W�j���牿�i���Ƃ��[�́A
����ł��Ȃ��T�[�o�s��̃V�F�A�𗎂Ƃ������Ă�̂�AMD����B
����������ΐ��\�ł�8�\�P�b�g�Ή���Westmere-EX�ɑR�ł��鐻�i��AMD�ɂ͂Ȃ��B
�A�ъ�^���Ԃ��Ȃ�������������
�I�s��ŃV�F�A���Ƃ����̂�CPU�̏��ׂ���Ȃ���nVidia��BroadCOM��
�`�b�v�Z�b�g����P�ނ�������
�`�b�v�Z�b�g����P�ނ�������
nVidia�ް NEW!
Broadcom�ް NEW!
Broadcom�ް NEW!
�������Ė{���ɓ��C�J��Ă�̂�
�T�[�h�p�[�e�B�[���`�b�v�Z�b�g����P�ނ������R��ATI�̔���
�V�F�A�𗎂Ƃ������R�͂��������邪Intel���18�������x���4�R�A�������[�X�����̂��I���̎n�܂�
�V�F�A�𗎂Ƃ������R�͂��������邪Intel���18�������x���4�R�A�������[�X�����̂��I���̎n�܂�
AMD�M�҂ɂ͕����Ă邯�ǂȁA���X�̓��e������Ε�����
���̓�l�Ƃ��T�^�I
ID:/XkIXIFT
ID:cI79NIxt
���̓�l�Ƃ��T�^�I
ID:/XkIXIFT
ID:cI79NIxt
>>250
n��Opteron�����`�b�v�Z�b�g����P�ނ����̂�PC�s�ꂩ��nForce��ǂ��o���ĊW����������AMD�̎��Ǝ�������n��
n��Opteron�����`�b�v�Z�b�g����P�ނ����̂�PC�s�ꂩ��nForce��ǂ��o���ĊW����������AMD�̎��Ǝ�������n��
>>253
18�������Ă܂��v���X�R����o�ĂȂ�������4�R�AXeon�������́H
>>255
�ǂ��o���ĂȂ��A690G�ȍ~��AMD�`�b�v�Z�b�g����������NV�������ł�
�o���Ȃ��Ȃ��ēP�ނ�������
18�������Ă܂��v���X�R����o�ĂȂ�������4�R�AXeon�������́H
>>255
�ǂ��o���ĂȂ��A690G�ȍ~��AMD�`�b�v�Z�b�g����������NV�������ł�
�o���Ȃ��Ȃ��ēP�ނ�������
4�R�AOpteron�͍P��̊J���x����2008�N��4���܂ł��ꍞ��
����ł�Phenom�̂��Ƃ��茾���邪TLB�o�O�Ő[���ȃ_���[�W�����̂�Opteron
����ł�Phenom�̂��Ƃ��茾���邪TLB�o�O�Ő[���ȃ_���[�W�����̂�Opteron
258 �FSocket774�F2011/12/09(��) 16:57:16.12 ID:IsKsNozC
�ް�ް�ް �� new!
�܂�ł��Ђ邾��
�܂�ł��Ђ邾��
nVidia���`�b�v�Z�b�g����P�ނ����̂́AAMD�������o���Ȃ��ƌ������R�������悤�ȁc�c
������Z�p�I�ɂ͉\����������ǁA�}�[�P�e�B���O��̗��R�ŋ��ł��Ȃ����Ęb�������͂��B
���Ă��A�I�s��ŃV�F�A�𗎂Ƃ����̂͐F�X�ȗ��R�����ݍ����Ă���
������(AMD�ɂ���T�[�h�p�[�e�B���`�b�v�Z�b�g�ɂ���)�������ɋ����o���Ȃ����������
���i�̐��\�ɖ�肪�������킯����Ȃ��B�J�됫�\�ʂŌ����������ċ����͂͏\���ɂ���i�B
������Z�p�I�ɂ͉\����������ǁA�}�[�P�e�B���O��̗��R�ŋ��ł��Ȃ����Ęb�������͂��B
���Ă��A�I�s��ŃV�F�A�𗎂Ƃ����̂͐F�X�ȗ��R�����ݍ����Ă���
������(AMD�ɂ���T�[�h�p�[�e�B���`�b�v�Z�b�g�ɂ���)�������ɋ����o���Ȃ����������
���i�̐��\�ɖ�肪�������킯����Ȃ��B�J�됫�\�ʂŌ����������ċ����͂͏\���ɂ���i�B
>>259
���痘���������Xeon�ɒ�R���Ă錵������Ԃ������͂�����Ȃ�ĉ��߂��ł���Ȃ�Ƃł��������ȁB
���̃T�[�o���v�g����ɏ]�ƈ�1������Ӗ����l����A�ǂ�������Ԃ��͂킩�肻���Ȃ����B
���痘���������Xeon�ɒ�R���Ă錵������Ԃ������͂�����Ȃ�ĉ��߂��ł���Ȃ�Ƃł��������ȁB
���̃T�[�o���v�g����ɏ]�ƈ�1������Ӗ����l����A�ǂ�������Ԃ��͂킩�肻���Ȃ����B
262 �FSocket774�F2011/12/09(��) 17:27:03.86 ID:E30u54ub
��������ȁA������FX�̂����������X��
332 ���O:Socket774 [sage] :2011/11/08(��) 01:13:27.77 ID:/CeWOR1O
8150�A���ʂɎg���Ă邯��W
4���Ԃ�Ɏd���p��1090T�̃}�V������������
�������芴����
876 ���O:Socket774 [age] :2011/12/07(��) 20:57:23.87 ID:YZT0CEMR
����1090T����FX8150�ɏ�芷������������
���X�߂�Ȃ����炢8150�̕������K�����H
332 ���O:Socket774 [sage] :2011/11/08(��) 01:13:27.77 ID:/CeWOR1O
8150�A���ʂɎg���Ă邯��W
4���Ԃ�Ɏd���p��1090T�̃}�V������������
�������芴����
876 ���O:Socket774 [age] :2011/12/07(��) 20:57:23.87 ID:YZT0CEMR
����1090T����FX8150�ɏ�芷������������
���X�߂�Ȃ����炢8150�̕������K�����H
Bulldozer�͎I�������Č����Ă銄�ɂ́A
�ŏ�ʂ�Opteron��1019�h��������ȁB
2�`�b�v�g���Ă�̂ŁA1�`�b�v�ӂ�500�h��������ƁiMCM�̃R�X�g�������邪�j������
FX�Ƃ��Ĕ����藘�v����낤���ǁB
�ŏ�ʂ�Opteron��1019�h��������ȁB
2�`�b�v�g���Ă�̂ŁA1�`�b�v�ӂ�500�h��������ƁiMCM�̃R�X�g�������邪�j������
FX�Ƃ��Ĕ����藘�v����낤���ǁB
�Ȃ�Œc�q�N��
�R�e�͂�����
���Ԃ���^���ԂɂȂ��ď�������ł���́H
�R�e�͂�����
���Ԃ���^���ԂɂȂ��ď�������ł���́H
>>259
AMD�̂����Ƃ������̂ł��Ȃ����ǂȁB
intel��AMD���AGPU��m�[�X�Ȃǂ�CPU�ɓ������Ă��܂����̂ŁA
�`�b�v�Z�b�g���[�J�[�Ƃ��Ă�NV�ɂ͏o�開���Ȃ��Ȃ����B
AMD�̂����Ƃ������̂ł��Ȃ����ǂȁB
intel��AMD���AGPU��m�[�X�Ȃǂ�CPU�ɓ������Ă��܂����̂ŁA
�`�b�v�Z�b�g���[�J�[�Ƃ��Ă�NV�ɂ͏o�開���Ȃ��Ȃ����B
���R�e�̒m���͌��l��
>>219
�Ă������R�A���ɕ����킹�����ʍ���
�����Ɏ��M���L��Intel�������ׂ���@�Ȃ���
32nm�v���Z�X�ł���g�����Ȃ��ĂȂ�AMD��
���W���[�����₵�Đ��\�̃X�P�[�����Ȃ�ăA�z����
�Ă������R�A���ɕ����킹�����ʍ���
�����Ɏ��M���L��Intel�������ׂ���@�Ȃ���
32nm�v���Z�X�ł���g�����Ȃ��ĂȂ�AMD��
���W���[�����₵�Đ��\�̃X�P�[�����Ȃ�ăA�z����
bulldozer 2M4C
bobcat 2C
radeon
�`�b�v�Z�b�g
����
�̃m�[�g�p�v���Z�b�T�܂��H
bobcat 2C
radeon
�`�b�v�Z�b�g
����
�̃m�[�g�p�v���Z�b�T�܂��H
>>234
���������O�B
���[�h�o�����T�[�̔w�ゾ������Antt-x�X�g�A������Ŕ����Ă錃���Z�������T�[�o�[���ׂ�Ώ\�����ˁB
���������O�B
���[�h�o�����T�[�̔w�ゾ������Antt-x�X�g�A������Ŕ����Ă錃���Z�������T�[�o�[���ׂ�Ώ\�����ˁB
�R�A�����ʍ��Ŏv���o��������
�X���b�h���f�[�^����̃����r���č��ǂ����Ă�́H
����ł��̃����r�ƃu�����������Ă�L���R�e�������ł݂����Ȃ̂����ł₽�瑽���́H
http://img121.imageshack.us/img121/9738/61910420.jpg
�P�Ȃ閼�����͂���悭�����
Bull�̓t�����g�G���h�Ɛ����R�A���f�J�C
�X���b�h���f�[�^����̃����r���č��ǂ����Ă�́H
����ł��̃����r�ƃu�����������Ă�L���R�e�������ł݂����Ȃ̂����ł₽�瑽���́H
http://img121.imageshack.us/img121/9738/61910420.jpg
{kind=link}
�P�Ȃ閼�����͂���悭�����
Bull�̓t�����g�G���h�Ɛ����R�A���f�J�C
>>259
���������A�d�l���I�[�v���Ȃ̂����珟��ɍ���Ĕ��邱�Ƃ��ł����͂��B����܂łɂ�����Ă�����A�Z�p�I�ȏ�ǂ͖����BAMD���`�b�v�Z�b�g����ׂ���Ȃ�����A�P�ނ��ė~�����͂Ȃ������n�Y�B
NV��AMD����ׂ���Ȃ��Ɣ��f���������Ȃ̂ł́B
�C���e������͕ߏo���ꂽ�悤�����ǂˁB
���������A�d�l���I�[�v���Ȃ̂����珟��ɍ���Ĕ��邱�Ƃ��ł����͂��B����܂łɂ�����Ă�����A�Z�p�I�ȏ�ǂ͖����BAMD���`�b�v�Z�b�g����ׂ���Ȃ�����A�P�ނ��ė~�����͂Ȃ������n�Y�B
NV��AMD����ׂ���Ȃ��Ɣ��f���������Ȃ̂ł́B
�C���e������͕ߏo���ꂽ�悤�����ǂˁB
����������sqrtps��11cycle�Ȃ̂�sqrtss��166cycle���Ęb�����������ǁA
Cinebench�̐��\�Ⴂ�̂͂��ꂪ��������ˁH
http://www.freeweb.hu/instlatx64/AuthenticAMD0600F12_K15_Bulldozer_InstLatX86.txt
>>222
sqrtss��166cycle�Ƃ��͎����C����ΊȒP�Ɏ���Ǝv���B
�}�C�N���R�[�h��sqrtps�Ƌ��ʂł����킯�����B
�����Ȃ��Ȃ炻��ł��r�W�l�X������������Ď������炻��͂����AMD���ǂ��������Ė��ɂ͂Ȃ�Ȃ��B
�܂��AAMDer�I�ɂ͑��肾��w
AMD�I�ɂ͍œK����������Ɛ��\�o����ė��ꂾ����A10~20%���Č����̂͂������낤�B
�t�Ɍ����Ȃ�f�X�N�g�b�v�����͊��S�Ȗ��m���B
��C��50%�Ƃ����\�オ�邩������A�t�ɂ����ƂЂǂ��Ȃ邩���m���B
Cinebench�̐��\�Ⴂ�̂͂��ꂪ��������ˁH
http://www.freeweb.hu/instlatx64/AuthenticAMD0600F12_K15_Bulldozer_InstLatX86.txt
>>222
sqrtss��166cycle�Ƃ��͎����C����ΊȒP�Ɏ���Ǝv���B
�}�C�N���R�[�h��sqrtps�Ƌ��ʂł����킯�����B
�����Ȃ��Ȃ炻��ł��r�W�l�X������������Ď������炻��͂����AMD���ǂ��������Ė��ɂ͂Ȃ�Ȃ��B
�܂��AAMDer�I�ɂ͑��肾��w
AMD�I�ɂ͍œK����������Ɛ��\�o����ė��ꂾ����A10~20%���Č����̂͂������낤�B
�t�Ɍ����Ȃ�f�X�N�g�b�v�����͊��S�Ȗ��m���B
��C��50%�Ƃ����\�オ�邩������A�t�ɂ����ƂЂǂ��Ȃ邩���m���B
>�����Ȃ��Ȃ炻��ł��r�W�l�X������������Ď������炻��͂����AMD���ǂ��������Ė��ɂ͂Ȃ�Ȃ��B
�A�z����
NV�����l�[��������Intel���{�b�^���b���肵����S�͂Œ@��������
�A�z����
NV�����l�[��������Intel���{�b�^���b���肵����S�͂Œ@��������
>>274
�N���ʂ̐l�Ɗ��Ⴂ���ĂȂ����H
�N���ʂ̐l�Ɗ��Ⴂ���ĂȂ����H
���������N���e�B�J���ȕ�����sqrtss�Ȃ�Ďg���Ƃ��
����Ƃ��Ă�sqrtps��rsqrt+�ق��ق�
>�}�C�N���R�[�h��sqrtps�Ƌ��ʂł���
partial register access��sqrtss�̕����ˑ��W���������镪�ʓ|
����Ƃ��Ă�sqrtps��rsqrt+�ق��ق�
>�}�C�N���R�[�h��sqrtps�Ƌ��ʂł���
partial register access��sqrtss�̕����ˑ��W���������镪�ʓ|
>>277
�܂�160cycle���Č������炿����Ƃ������[�v��1�lj������ʂ̃C���p�N�g���邯�ǂȁB
�܂�160cycle���Č������炿����Ƃ������[�v��1�lj������ʂ̃C���p�N�g���邯�ǂȁB
���C�g���[�V���O���ĂЂ�����ρE�a���Ċ�������Ȃ���
Bull�̃����_�����O�\�t�g�̃X�R�A���R���p�C������ő傫���ς���Ă���Ă̂����邵
���Ă݂�����sqrtps/sqrtss����500���x���Ȃ��B
����������Ă�Ƃ���ĊO�����ˁB
166cycle�݂����ȏ������ˑR�o�����Ă�
���ɂȂ�Ȃ��悤�ȏꏊ�ł���sqrtss�g���ĂȂ��Ƃ����ˁB
�N�������̂��͒m��ǁB
����������Ă�Ƃ���ĊO�����ˁB
166cycle�݂����ȏ������ˑR�o�����Ă�
���ɂȂ�Ȃ��悤�ȏꏊ�ł���sqrtss�g���ĂȂ��Ƃ����ˁB
�N�������̂��͒m��ǁB
>>279
�I�u�W�F�N�g�����ŕ\�����邩�ɂ�����Ȃ����B
���͑S���|���S���ł���Ă��܂��̂�������Ȃ����A�܂��|���S������
�������Ȃ��������͋Ȗʕ\���ɐF�X�Ȋ����g���Ă���
�I�u�W�F�N�g�����ŕ\�����邩�ɂ�����Ȃ����B
���͑S���|���S���ł���Ă��܂��̂�������Ȃ����A�܂��|���S������
�������Ȃ��������͋Ȗʕ\���ɐF�X�Ȋ����g���Ă���
>>281
166cycle���ă��[�v�̒��ɓ����Ă��炩�Ȃ��肠�肾��
166cycle���ă��[�v�̒��ɓ����Ă��炩�Ȃ��肠�肾��
�œK���K�C�h�����sqrtps��sqrtss�Ń��C�e���V�͓����H
285 �F,,�E�L�́M�E,,�j��-�������F2011/12/09(��) 22:46:05.70 ID:HaOcUE8E
>>277
> partial register access��sqrtss�̕����ˑ��W���������镪�ʓ|
����͂Ȃ��B
�d�l��ADEST[127:32]�̒l�́u����`�v������[���N���A�ł��A���邢��sqrtps�Ɠ��������ł�
����ȊO�̓����ł��\��Ȃ��B
> partial register access��sqrtss�̕����ˑ��W���������镪�ʓ|
����͂Ȃ��B
�d�l��ADEST[127:32]�̒l�́u����`�v������[���N���A�ł��A���邢��sqrtps�Ɠ��������ł�
����ȊO�̓����ł��\��Ȃ��B
http://www.obr-hardware.com/2011/12/amd-is-trying-to-deceive-you-you-all.html
20���ł��ˁ[����12���ł��ˁ[
20���ł��ˁ[����12���ł��ˁ[
�_�C�T�C�Y����v�Z�������Ƃ��邪
���̎���16��8000�����炢�������悤��
���̎���16��8000�����炢�������悤��
288 �FSocket774�F2011/12/09(��) 23:51:17.53 ID:P906iD80
>>285
����ADEST[127:32]�̒l�͕s�ςƋK�肳��Ă邪�B
����ADEST[127:32]�̒l�͕s�ςƋK�肳��Ă邪�B
289 �FSocket774�F2011/12/09(��) 23:55:13.63 ID:8iPRKMth
(1) Bulldozer��AM3+�}�U�[�ŏI���B(���N�V�����̂��o��)
(2) AM3�}�U�[��Bulldozer����邩�ǂ����̓}�U�[�x���_����
(3) �V����FMA�ɑΉ�����������������i���ۂ݂����̂͂��Ȃ�
(4) ���A�v���ł͐��\����͌����߂Ȃ�
(5) GPU�͍ڂ��Ă��Ȃ�
(6) ���i�Ńx���`��i3�ȉ��Ai5/i7�Ɣ�r����͎̂��������
(7) �ŏ�ʂ�245�h���Ƒ������
�@�����Ǔ��{�ł͕������킹�ō�������������N�[���[����500����Ŗ�35,000�~
(8) �N�P�ʂŒx��ɒx��Đ��\���x��Ă���
(9) 8�R�A�̗D�ʐ���O�ʂɔ���o�����̂�4�E6�R�A����ɔ̔��ƂȂ�
�@�f�����ł͌��w�҂���u�[�C���O���@
(10) 4.5GHz�܂�OC���Ă�2500K�̃f�t�H���g�N���b�N�ɂ�����ׂȂ�
�@������8GHz��ڎw���Ɨǂ��R����@
(11) �X�R�A�͋��낵���Ⴂ����OC
�@���̂�������d�͉͂ߋ��ŋ�
(12) AMD�̎x�����ĊJ�����ꂽ TotalWar:Shogun2 �� BSOD ���������ē��삵�Ȃ�
�@���͂�̂����M���O
(13) 8�R�A�q���Ŕ�������FX-8120/FX-6100/FX-4100�� Phenom II/Athlon II/A�V���[�Y�����C�o��
(14) �L�����y�[���̌i�i�͂��َq�̋� (�����ς������̍���
(15) �f�t�H�Ń��~�b�^�[���ځA��i�ł����ׂ�������Ɣ���
�@�}�U�[�ɂ���Ă͉����\�����A���x��C'n'Q�̌����Ȃ��펞�S�͉^�]�ɂȂ�
(16) ���ٓI�Ȕ̔��s�U�ɂ�蔭������ꃖ�����o�����ɉ��i����A���l�Ȓl������]�V�Ȃ������
(17) ���\���Ⴂ�͎̂��ۂ̐��\���v���ł���x���`���܂�������(��p�i���K�v�����o����\�������
(18) �Ȃ�Ǝ��ۂ̃g�����W�X�^���͌��̒l��20���ł͂Ȃ�������12���ɉ߂��Ȃ����������B
�ʐϓ�����̃g�����W�X�^���x��32nm�ōň��B
GLOBALFOUNDERIES�͐������̂����Ă����A�ŒႾ���I
�킯���킩��Ȃ���_(^o^)�^
290 �F,,�E�L�́M�E,,�j��-�������F2011/12/09(��) 23:55:35.48 ID:/A8MRJZB
�܁AIntel�̃T�[�o���낤��AMD�̃T�[�o���낤���A
�o���X�ɑς����Ȃ��̂�������c
�o���X�ɑς����Ȃ��̂�������c
�܂��ǂ����ɂ���166cycle�ɂ��Ȃ��Ă������ƃ}�V�ȑ����@���������낤��...
>>286
OBR�����܂�M�����Ȃ���Anand���K�������Ă����Ď��H
OBR�����܂�M�����Ȃ���Anand���K�������Ă����Ď��H
�P���ɓ����x�̐��\��Intel�v���Z�b�T��2�{�����Ă邾���Ȃ�Ȃ��́H
12���錾�͌�����FX-8150�̐��\��2600K�ȉ��ƔF�߂��Ǝv�����B
12���錾�͌�����FX-8150�̐��\��2600K�ȉ��ƔF�߂��Ǝv�����B
�g�����W�X�^�̐������̈Ⴂ�͂��邩����
�璷���͊܂ނ��܂܂Ȃ���
����ɂȂ��Ă���g�����W�X�^�͓�d�ɐ����邩��Ɛ����邩
�璷���͊܂ނ��܂܂Ȃ���
����ɂȂ��Ă���g�����W�X�^�͓�d�ɐ����邩��Ɛ����邩
>>225
�f�X�N�g�b�v�͍��⑊���Ƀj�b�`�������
�f�X�N�g�b�v�͍��⑊���Ƀj�b�`�������
����CPU�̃N���b�N����MHz���������Ƃ͈Ⴄ����Ȃ�
�����ɃV���O���R�A��sempron�m�[�g�����邪
Chrome����ꂽ�猋�\�n�b�s�[�Ɏg���Ă邺
�����ɃV���O���R�A��sempron�m�[�g�����邪
Chrome����ꂽ�猋�\�n�b�s�[�Ɏg���Ă邺
>>225
�f�X�N�g�b�v�̃x���`��SIMD���܂킷
AMD�́A�f�X�N�g�b�v��GCN�R�A��Fusion���Ă��炪�{���̐킢���Ǝv���Ă�
����܂ł͏��Ă܂�����Č����Ă�
�f�X�N�g�b�v�̃x���`��SIMD���܂킷
AMD�́A�f�X�N�g�b�v��GCN�R�A��Fusion���Ă��炪�{���̐킢���Ǝv���Ă�
����܂ł͏��Ă܂�����Č����Ă�
������AGCN�̊T�v�ɁuCPU��GPU�ԂŃL���b�V���ƃ������̃R�q�[�����V���Ƃ�v�Ƃ���
L1D�����C�g�X���[�Ȃ̂�L2�Œ��₷���
L1D�����C�g�X���[�Ȃ̂�L2�Œ��₷���
Llano��Onion�o�X�Ƃ��̃R���s���[�e�B���O�����̋@�\��p�ӂ��Ă��邯��
SDK���o��C�z�͂Ȃ����
�����ł̕]���p�Ȃ̂���
FSA�͂���Ȃ�Ɋ��҂��Ă����
SDK���o��C�z�͂Ȃ����
�����ł̕]���p�Ȃ̂���
FSA�͂���Ȃ�Ɋ��҂��Ă����
FSA�݂����ȍL�͈͂ȃ\�t�g�E�F�A�T�|�[�g���܂ރA�[�L�e�N�`����AMD���\�z�ł��邩�^�킵�����̂��B
>>268
���ނł����낤�Ƃ��ăR�P��
���ނł����낤�Ƃ��ăR�P��
DirectX��OpenCL�̂悤�ȋ���API�𗘗p����̂������I�ȋC������
Mac�ł�Apple���ւ���Ă�OpenCL�T�|�[�g���낤��
Mac�ł�Apple���ւ���Ă�OpenCL�T�|�[�g���낤��
�����������̑OSteam�̃Q�[��������
OpenCL�̃C���X�g�[�������߂�ꂽ��
OpenCL�̃C���X�g�[�������߂�ꂽ��
����Phenom�ł̓N���b�N�����Ă����\���オ��Ȃ����Ƃ���肾�����悤�ȋC��������A
������v����32nmPhenomIII6�R�A4,5GHzTDP80W���o���������}�V�������悤�ȋC�͂���B
������v����32nmPhenomIII6�R�A4,5GHzTDP80W���o���������}�V�������悤�ȋC�͂���B
>>308
����B
���͂����v���B
���̃��x����CPU��BE���f����2���~�ȓ��ŏo�����
������ł�2600K�ɕC�G������������Ȃ�����
����B
���͂����v���B
���̃��x����CPU��BE���f����2���~�ȓ��ŏo�����
������ł�2600K�ɕC�G������������Ȃ�����
��l����Phenom��HTT���Ă���ǂ��Ȃ����낤��
����������PowerVR�����N����AARM��Mali��6xx���ォ��OpenCL�ɑΉ������
32nmPhenomIII8�R�A4,5GHz(TB4.8GHz�i4�R�A�j)TDP100W
�����Ă邾���ş��o���[
>>310
�Q�[������Ƃ��G���[�o�܂���ŁABull�ȏ�ɒ@����Ă����Ǝv���B
�����Ă邾���ş��o���[
>>310
�Q�[������Ƃ��G���[�o�܂���ŁABull�ȏ�ɒ@����Ă����Ǝv���B
SMT�����ɕK�v�ȃg�����X�^�����{15���A45nm��32nm�Ńg�����W�X�^�̓d�͐��\�̌��オ+20���Ƃ����
����d�͂̍팸��4���ق�
�Ƃ���ƃN���b�N�Ɋ��Z����ƁA�����d�͘g�Ȃ�+1�`2�����ĂƂ��낾��
SMT���L���ȃ\�t�g�ł͌��ʗL�邩�ȁH���Ċ�������
�܂��_�C�ʐς̓g�����W�X�^��������+15���A�V�������N����30�`40���Ƃ���ƁAThuban��70�`80�����x�Ɏ��܂�
230�`260mm2�O��ő啪�������Ȃ��
����d�͂̍팸��4���ق�
�Ƃ���ƃN���b�N�Ɋ��Z����ƁA�����d�͘g�Ȃ�+1�`2�����ĂƂ��낾��
SMT���L���ȃ\�t�g�ł͌��ʗL�邩�ȁH���Ċ�������
�܂��_�C�ʐς̓g�����W�X�^��������+15���A�V�������N����30�`40���Ƃ���ƁAThuban��70�`80�����x�Ɏ��܂�
230�`260mm2�O��ő啪�������Ȃ��
�~�h�������W�ȏ��4�R�A��
2500K�ʂ̑ϐ������邾����
�S����������ς�邩��ˁB�B�B
2500K�ʂ̑ϐ������邾����
�S����������ς�邩��ˁB�B�B
�������AAVX���ڂ��悤�Ƃ���Ƒ啪�ς�邩��
K10��SIMD���j�b�g�̖ʐς̓R�A��30��������A�{������ƁE�E�E�R�A�̃g�����W�X�^����30���قǂł����Ȃ�
�Ƃ����300�`340mm2�i���j�ŁABulldozer�Ɠ��N���X����
���A���R�A���܂Ŋ܂߂�+30�������̂ł��������������͏o���邩
����d�͂�SIMD�{�����ƁA�쓮������g�����W�X�^��������������������i���j
��������̂�AVX�g�p�������ŁASSE�g�p���͕ς��Ȃ���
K10��SIMD���j�b�g�̖ʐς̓R�A��30��������A�{������ƁE�E�E�R�A�̃g�����W�X�^����30���قǂł����Ȃ�
�Ƃ����300�`340mm2�i���j�ŁABulldozer�Ɠ��N���X����
���A���R�A���܂Ŋ܂߂�+30�������̂ł��������������͏o���邩
����d�͂�SIMD�{�����ƁA�쓮������g�����W�X�^��������������������i���j
��������̂�AVX�g�p�������ŁASSE�g�p���͕ς��Ȃ���
�I�������_����MCM�O��̃`�b�v������_�C������������̂͌�������
����������CPU�R�A�Ƀg�����W�X�^�������Ă��悩�������낤���ǁA�ꉞ���o�C�������ɂ����p���邩�炠����x�ߖ�K�v���������̂���
����������CPU�R�A�Ƀg�����W�X�^�������Ă��悩�������낤���ǁA�ꉞ���o�C�������ɂ����p���邩�炠����x�ߖ�K�v���������̂���
�g�����W�X�^���Ō�����
30���������������́B�B
���[��
�������T�[�o�����Ȃ̂ɂȂ���
�A�O���b�V�u�ȃf�X�N�g�b�v�}�U�[����
�o�ĂȂ��̂�������ƂȂ��B�B�B
���߂�P8BWS�̗l�ȑ�ǓI�ȃ}�U�[���Ȃ����E�E�E�B
30���������������́B�B
���[��
�������T�[�o�����Ȃ̂ɂȂ���
�A�O���b�V�u�ȃf�X�N�g�b�v�}�U�[����
�o�ĂȂ��̂�������ƂȂ��B�B�B
���߂�P8BWS�̗l�ȑ�ǓI�ȃ}�U�[���Ȃ����E�E�E�B
�����Ȃ��́ABull�����R�C�`32�R�A���o�������Ȃ��B
����ŐV���Ȏ��オ��͂��B
����ŐV���Ȏ��オ��͂��B
>>308
K10�M�ɂ͓˂����܂Ȃ��ł������A����ȃN���b�N�ŏo����Ɩ{�C�Ŏv���Ă�̂��H
intel��32nm������4.5GHz�o�����Ƃ�����TDP�͌y��130W�ȏア�����H
K10�M�ɂ͓˂����܂Ȃ��ł������A����ȃN���b�N�ŏo����Ɩ{�C�Ŏv���Ă�̂��H
intel��32nm������4.5GHz�o�����Ƃ�����TDP�͌y��130W�ȏア�����H
>>320
�܂��B�B���̂��炢�̑ϐ����~�������Ă����̂͐����ȏ��ł��傤
�܂��B�B���̂��炢�̑ϐ����~�������Ă����̂͐����ȏ��ł��傤
>>320
K10���̂܂܂ŏo����Ƃ͎v���ĂȂ���B
�{����32nm��4GHz�z�����o����Ȃ�ALlano�̃N���b�N��2.9GHz�ǂ܂���Ă��Ƃ͂Ȃ��͂��B
K10���̂܂܂ŏo����Ƃ͎v���ĂȂ���B
�{����32nm��4GHz�z�����o����Ȃ�ALlano�̃N���b�N��2.9GHz�ǂ܂���Ă��Ƃ͂Ȃ��͂��B
AMD���f�X�N�g�b�v�����n�C�G���h�ɂ�����]�T���ł�����
Bulldozer�̃o�O�H���čU�߂ɏo���ˁH
Bulldozer�͊�{�I�ɂ�K10���͑S�R�������̂Ǝv���B
Bulldozer�̃o�O�H���čU�߂ɏo���ˁH
Bulldozer�͊�{�I�ɂ�K10���͑S�R�������̂Ǝv���B
324 �F,,�E�L�́M�E,,�j��-�������F2011/12/10(�y) 13:34:47.35 ID:DK7iOzHK
�N�\�^�ʖڂ�4�R�C�`�ɂ����ꍇ��HT�̔z�����l���Ă݂��B
�o�����ڑ��͂�����߂邵�������ȁB
(�O��) (�O��)
�@���@�@�@ ��
[Bull]��[Bull]
�@���@�~�@��
[Bull]��[Bull]
�@���@�@�@ ��
(�O��) (�O��)
�o�����ڑ��͂�����߂邵�������ȁB
(�O��) (�O��)
�@���@�@�@ ��
[Bull]��[Bull]
�@���@�~�@��
[Bull]��[Bull]
�@���@�@�@ ��
(�O��) (�O��)
AVX��FMA�ƃp���[�Q�[�e�B���O�ւ̑Ή��͐i�����낤�Ȃ�
�R�A�̃T�C�Y��K10����⏬����
�W�F�K�����w�r�[�K���ɂȂ������炢���˂�
�R�A�̃T�C�Y��K10����⏬����
�W�F�K�����w�r�[�K���ɂȂ������炢���˂�
326 �F,,�E�L�́M�E,,�j��-�������F2011/12/10(�y) 13:51:14.02 ID:DK7iOzHK
�����128bit SSE5���j�b�g�ɂ�����ƕύX�������ăf�R�[�_��}���ւ��������̕t���Đn�����ǂ�
�t�Ɍ����Ƃ��ꂾ�����ǂ̗]�n������
�t�Ɍ����Ƃ��ꂾ�����ǂ̗]�n������
�ނ���Ez8����
�o�O����܂���Ŋ����\�t�g�E�F�A�̐��\��ł��ĂĂ��S����@���͂����Ƃ��E�E�E
SSE5���Ă܂�Bull�͒x�点����̂������̂������Ɏv����
SSE5�̂܂�2009�N�ɏo����2011�N��AVX�Ή����銴���ł悩�����Ǝv��
SSE5�̂܂�2009�N�ɏo����2011�N��AVX�Ή����銴���ł悩�����Ǝv��
4�R�A45W AM3+�͏o���ė~���������
���̂�Opteron 3260�Ƃ��Ĕ����Ă��邵
���ꔃ���Ηǂ������׃V���b�v����
���̂�Opteron 3260�Ƃ��Ĕ����Ă��邵
���ꔃ���Ηǂ������׃V���b�v����
SSE5�̂܂܍s���Ă�����A�g�����ߓo�^�g�����ł��Ă���Ȃ���
332 �F,,�E�L�́M�E,,�j��-�������F2011/12/10(�y) 15:08:49.57 ID:DK7iOzHK
�����R�X�g��������f�R�[�h�A���S���Y����2�n���T�|�[�g����]�T���Ȃ�������ł���B
>>328
�����o�O�����������H
>>329
AVX�Ή������邽�߂ɂ͍��{�I�ɉ��ǂ��K�v�������낤�B
2009�N�̓�N��ɂ���Ƀt���X�N���b�`�ł�AMD�ɂ͌���������B
>>331
SSE5��AVX�ɓ�������Ă��邵�A�u�o�^�g�̏��Łv���ĂȂɁH
�����o�O�����������H
>>329
AVX�Ή������邽�߂ɂ͍��{�I�ɉ��ǂ��K�v�������낤�B
2009�N�̓�N��ɂ���Ƀt���X�N���b�`�ł�AMD�ɂ͌���������B
>>331
SSE5��AVX�ɓ�������Ă��邵�A�u�o�^�g�̏��Łv���ĂȂɁH
�M�E,,�j��-������
336 �F,,�E�L�́M�E,,�j��-�������F2011/12/10(�y) 20:46:59.13 ID:DK7iOzHK
���Ⴀ������
[Bull]��[Bull]
�@||�@�@�@�@||
[Bull]�@[Bull]
�@||�@�@�@�@||
(�O��) �i�O��)
[Bull]��[Bull]
�@||�@�@�@�@||
[Bull]�@[Bull]
�@||�@�@�@�@||
(�O��) �i�O��)
337 �FSocket774�F2011/12/10(�y) 21:01:39.52 ID:m/eg0RaP
�����O���ۂ�
338 �F,,�E�L�́M�E,,�j��-�������F2011/12/10(�y) 21:17:00.08 ID:DK7iOzHK
���邢��
(�O��) �i�O��)
�@���@�@�@��
[Bull]��[Bull]
�@���@�@�@��
[Bull]��[Bull]
�@���@�@�@��
(�O��) �i�O��)
(�O��) �i�O��)
�@���@�@�@��
[Bull]��[Bull]
�@���@�@�@��
[Bull]��[Bull]
�@���@�@�@��
(�O��) �i�O��)
>>338
HT�����N��8bit���ɕ����Ĉꕔ�N���X���Ă�B��Ώ̂��Č����������B
HT�����N��8bit���ɕ����Ĉꕔ�N���X���Ă�B��Ώ̂��Č����������B
HT DP�AMP
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20090826_310619.html
QPI DP�AMP
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20100426_363357.html
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20090826_310619.html
QPI DP�AMP
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20100426_363357.html
QPI�͂��������ȁB8�\�P�b�g�̃g�|���W�[���ڂ��Ă�
ttp://pc.watch.impress.co.jp/docs/2009/0212/kaigai490.htm
ttp://pc.watch.impress.co.jp/docs/2009/0212/kaigai490.htm
http://ascii.jp/elem/000/000/651/651690/
�^�C�g���̊ԈႢ���̂܂ɂ��C�����Ă�Ȃ�
�^�C�g���̊ԈႢ���̂܂ɂ��C�����Ă�Ȃ�
AMD��CPU��4P�ł����g8�R�A������
Intel��8�\�P�b�g���ɃC���^�[�R�l�N�g�̃I�[�o�[�w�b�h�ŐH���镪���傫���Ȃ�悤�ȁB
Intel��8�\�P�b�g���ɃC���^�[�R�l�N�g�̃I�[�o�[�w�b�h�ŐH���镪���傫���Ȃ�悤�ȁB
8�R�A����Ȃ��A8�_�C���B
��������MCM�Ńj�R�C�`�Ƃ����A�v���[�`���K�Ȃ̂��ǂ���
���낻��Č����K�v�Ȃ̂ł͂Ȃ���
��������MCM�Ńj�R�C�`�Ƃ����A�v���[�`���K�Ȃ̂��ǂ���
���낻��Č����K�v�Ȃ̂ł͂Ȃ���
���C�Z���X�����\�P�b�g���ˑ��̃\�t�g�����������Ƃ�
�e���������̂���Ȃ����B
�e���������̂���Ȃ����B
�����������z������Ȃ�
�R�A���₳�Ȃ��ł���
�R�A���₳�Ȃ��ł���
�Y�p���o���Ď������M�p�͑傫����
�@����Ȃ���������Ȃ����ǁA���\�������甄��Ȃ��ł���
>>348
���\���o�Ȃ����班���ł����N���b�N�ɂ���
�����甚�M�ɂȂ�
X1800�Ƃ�HD 2900�Ƃ�FX 5800(5�R�ACPU�ł͂Ȃ�)�Ƃ��O�������
���\���o�Ȃ����班���ł����N���b�N�ɂ���
�����甚�M�ɂȂ�
X1800�Ƃ�HD 2900�Ƃ�FX 5800(5�R�ACPU�ł͂Ȃ�)�Ƃ��O�������
8�R�ACPU�Ƃ��Ă͍����킯����Ȃ��C�����邯�ǂ�
���ƃN���b�N��3.7G�܂ŗ}����Έ����͂Ȃ��͂�
������\�͂ǂ����悤���Ȃ����ǂ�
���ƃN���b�N��3.7G�܂ŗ}����Έ����͂Ȃ��͂�
������\�͂ǂ����悤���Ȃ����ǂ�
�Ƃ������A8�R�A�Ǝ��̂��邮�炢�����A�s�[���|�C���g���Ȃ�
8�R�A���Ă̂��c�Ə�̕\�������ȁc
8�R�A�Ǝ��̂�����x�����A�s�[���|�C���g�Ȃ��悤��
���\�������Ă�̊ԈႢ����ˁH
���\�������Ă�̊ԈႢ����ˁH
355 �FSocket774�F2011/12/12(��) 00:35:13.19 ID:mRdc7DZN
�C���v���X�̌㓡����L���A
���L���\�[�X�� 6�� ������̂� 8�R�A �Ƃ��t�J�V��������u���y����
�����x����K���N�^��
�c�� 4�� �̂ݐ�L�A���l�O�ɖ����Ȃ��J�X
���p���Ă�̂�6���Ȃ̂�
8*0.4+8/2*0.6 = 5.6
���� 6�R�A �����Ȃ����ɁI�H
����� 8 �R�A �Ƃ͎o���������т�����
http://pc.watch.impress.co.jp/docs/column/kaigai/20111019_484609.html
FX�����^�̂Ȃ����8�R�A
���̐��\��8�R�A���ƌ����͔̂߂����Ȃ邩�����
32nm�V�������NPhenomII X8 ���o���������܂��ǂ������C������
AMD FX�v���Z�b�T�[������r
ttp://www.amd.com/jp/products/desktop/processors/amdfx/Pages/amdfx-competitive-comparison.aspx
�R�����Ă�ƈ������Ȃ�
ttp://www.amd.com/jp/products/desktop/processors/amdfx/Pages/amdfx-competitive-comparison.aspx
�R�����Ă�ƈ������Ȃ�
�J�^���O�X�y�b�N��낽
���ۂ̐��\���E��荂���Ƃ͌����ĂȂ��̂��~�\����
���ۂ̐��\���E��荂���Ƃ͌����ĂȂ��̂��~�\����
361 �FSocket774�F2011/12/12(��) 01:08:37.87 ID:oIUIxXyb
AMD FX-8150 Intel Core i5/i7 [Sandy Bridge]
�l�C�e�B�uDDR3-1866�T�|�[�g �l�C�e�B�uDDR3-1333�T�|�[�g �@�Ȃ̂ɒx���I
8 X86 �R�A 4 X86 �R�A �R�A���{�����ǒx���I�I�I�I
8MB L2 �L���b�V�� 1MB L2 �L���b�V�� L2 8�{�Ȃ̂ɒx��!!
8MB L3 �L���b�V�� 8 MB L3 �L���b�V��
3.6GHz �x�[�X���g�� 3.4GHz �x�[�X���g�� �Ȃ̂ɒx���I�I
4.2Ghz �x�[�X���g�� 3.8Ghz �x�[�X���g�� �Ȃ̂ɒx���I�I�I
+600MHz Turbo +400MHz Turbo 600Mhz��������̂ɒx���I�I�I�I
�Ȃ��s�I����
�l�C�e�B�uDDR3-1866�T�|�[�g �l�C�e�B�uDDR3-1333�T�|�[�g �@�Ȃ̂ɒx���I
8 X86 �R�A 4 X86 �R�A �R�A���{�����ǒx���I�I�I�I
8MB L2 �L���b�V�� 1MB L2 �L���b�V�� L2 8�{�Ȃ̂ɒx��!!
8MB L3 �L���b�V�� 8 MB L3 �L���b�V��
3.6GHz �x�[�X���g�� 3.4GHz �x�[�X���g�� �Ȃ̂ɒx���I�I
4.2Ghz �x�[�X���g�� 3.8Ghz �x�[�X���g�� �Ȃ̂ɒx���I�I�I
+600MHz Turbo +400MHz Turbo 600Mhz��������̂ɒx���I�I�I�I
�Ȃ��s�I����
AMD�̓R���V���[�}����CPU����P�ނ��āA�T�[�o�[������ƂɂȂ肻���ȋC������
���Y�\�͏オ������܂��R���V���[�}�����n�C�G���h�ɂ��߂��Ă��邾�낤��B
364 �FSocket774�F2011/12/12(��) 01:55:15.00 ID:smtfE2+G
���̃X�p�C�����ɓ˓����Ă����Ȃ̂͋C�̂����ł����Ăق����E�E�E
bull�ł�����
��
���R�A����Ȃ�
��
�J���Ɏx��A�R�X�g�팸��Ől������
��
�Z�p�͒ቺ�A���\�ŏ��ĂȂ����J��Ԃ�
�͂₭�q�b�g�����Ă���w
bull�ł�����
��
���R�A����Ȃ�
��
�J���Ɏx��A�R�X�g�팸��Ől������
��
�Z�p�͒ቺ�A���\�ŏ��ĂȂ����J��Ԃ�
�͂₭�q�b�g�����Ă���w
365 �FSocket774�F2011/12/12(��) 01:59:55.84 ID:jgRCmDJc
>>364
����Phenom�ő厸�s��炩���Ă�II�ł̋C��������������Ă��ꂽ����Ȃ����B
AMD�͂����������[�J�[����B���{�̐����Ƃ����K���B
����Phenom�ő厸�s��炩���Ă�II�ł̋C��������������Ă��ꂽ����Ȃ����B
AMD�͂����������[�J�[����B���{�̐����Ƃ����K���B
>>364
�� Interlagos,Llano
�� Interlagos,Llano
Zacate���q�b�g���ȁB
����1�N�o���A�[�L��Zambezi�ȊO�͑�q�b�g
Zambezi��L2DTLB�Ƃ�sqrtss�Ƃ�������₷��������������ł����\���ˏオ�邾�낤�ɁB
����1�N�o���A�[�L��Zambezi�ȊO�͑�q�b�g
Zambezi��L2DTLB�Ƃ�sqrtss�Ƃ�������₷��������������ł����\���ˏオ�邾�낤�ɁB
age�ƘA���X�}�\�B
FX�̓_�����ۂ�����A�V���[�Y�͂悳������Ȃ����B
��d���ł��҂������������B
�W�T�b�J�[��������ĉ������ł��n�C�G���h���Ă�����肶��Ȃ�����B
���������̐��\�ŁA�}�U�[�̋@�\���_��Ȃ̂��~�������Đl�Ԃ�������Ȃ��́H
�������������ǁc�c
FX�̓_�����ۂ�����A�V���[�Y�͂悳������Ȃ����B
��d���ł��҂������������B
�W�T�b�J�[��������ĉ������ł��n�C�G���h���Ă�����肶��Ȃ�����B
���������̐��\�ŁA�}�U�[�̋@�\���_��Ȃ̂��~�������Đl�Ԃ�������Ȃ��́H
�������������ǁc�c
�����x�点�Ă܂Œ����܂��������ʂ��A���Ȃ̂�
����̐��\�̉��P�ɂ��Ă͂��@��������
����̐��\�̉��P�ɂ��Ă͂��@��������
�ǂ�������Ă�����Ȃ�����{�C�o���Ȃ���
�uAMD FX�v�̓��T���b�����|�[�g�BFX�͂Ȃ��u�Q�[�}�[�����łȂ��v�̂�
ttp://www.4gamer.net/games/100/G010000/20111209066/
ttp://www.4gamer.net/games/100/G010000/20111209066/
�O���t20���������AFX�̐����́g�����R�A���Ƃ����������h�ł�1090T���21�`58�����オ���Ă��
�g�p���߃Z�b�g��������Ė����ď���������Ȃ��̂��c�O����
�g�p���߃Z�b�g��������Ė����ď���������Ȃ��̂��c�O����
����FP�̕��ł͂�͂�SSE/AVX�̃X�R�A�͐U���Ȃ���
����v���O�����Ȃ�FMA�ł̃X�R�A����ꂻ���Ȃ��̂����E�E�E
���̃T�C�g�ł�FMA�ɂ��Ă͔����Ă邪�A�K���ł��������Ă�̂���
����v���O�����Ȃ�FMA�ł̃X�R�A����ꂻ���Ȃ��̂����E�E�E
���̃T�C�g�ł�FMA�ɂ��Ă͔����Ă邪�A�K���ł��������Ă�̂���
>>374
Windows��FMA4��f���R���p�C���̑I�������قƂ�ǂȂ����炾�낤
VS2010��AVX�܂�
ICC12.1��FMA3�̂�(������CPUID������j
Open64��Windows�ł��Ȃ�
gcc�̍ŐV�ł�cygwin�œ��������炢���H
�Ȃ�������VS�g���l����������
VS���Ή����Ȃ��Ƃǂ��ɂ��Ȃ�낤
Windows��FMA4��f���R���p�C���̑I�������قƂ�ǂȂ����炾�낤
VS2010��AVX�܂�
ICC12.1��FMA3�̂�(������CPUID������j
Open64��Windows�ł��Ȃ�
gcc�̍ŐV�ł�cygwin�œ��������炢���H
�Ȃ�������VS�g���l����������
VS���Ή����Ȃ��Ƃǂ��ɂ��Ȃ�낤
�܂��OS�̎d�l�Ȃ̂��ˁH
����Ƃ�HW�̎d�l�H
����Ƃ�HW�̎d�l�H
OS�͑Ή����Ă���
AMD��FMA�����̃R�[�h���ł��� VS�ŊȒP�Ɏg����R���p�C�����Ȃ�
���Intel��Haswell�Ή��R���p�C�������Ƀ����[�X���Ă���
AMD��FMA�����̃R�[�h���ł��� VS�ŊȒP�Ɏg����R���p�C�����Ȃ�
���Intel��Haswell�Ή��R���p�C�������Ƀ����[�X���Ă���
��o�����߂�
�R���p�C���������[�X����Ȃ����Ă��Ƃ�
�J���ɉe��������H
����Ƃ��R���V���[�}���x���̎g�p���̐��\��
�e��������́H
�R���p�C���������[�X����Ȃ����Ă��Ƃ�
�J���ɉe��������H
����Ƃ��R���V���[�}���x���̎g�p���̐��\��
�e��������́H
379 �FSocket774�F2011/12/12(��) 09:44:11.11 ID:mRdc7DZN
���ꂪ�A�V�F�A�ꊄ�ȉ��̕��ׂ̈Ɋ���������H
http://msdn.microsoft.com/ja-jp/library/gg445134.aspx
Visual Studio 2010 SP1 �p�ɒlj����ꂽ FMA4 �g�ݍ���
Visual Studio 2010
�X�V : 2011 �N 3 ��
Visual Studio 2010 SP1 ���K�v�ł��B
Visual C++ �R���p�C���ɂ́AFMA4 �A�[�L�e�N�`���Ŏg�p�ł��鎟�̑g�ݍ��݂��p�ӂ���Ă��܂��B
http://msdn.microsoft.com/ja-jp/library/gg466493.aspx
Visual Studio 2010 SP1 �p�ɒlj����ꂽ XOP �g�ݍ���
Visual Studio 2010
�X�V : 2011 �N 3 ��
Visual Studio 2010 SP1 ���K�v�ł��B
Visual C++ �R���p�C���ɂ́AXOP �A�[�L�e�N�`���Ŏg�p�ł��鎟�̑g�ݍ��݂��p�ӂ���Ă��܂��B
Visual Studio 2010 SP1 �p�ɒlj����ꂽ FMA4 �g�ݍ���
Visual Studio 2010
�X�V : 2011 �N 3 ��
Visual Studio 2010 SP1 ���K�v�ł��B
Visual C++ �R���p�C���ɂ́AFMA4 �A�[�L�e�N�`���Ŏg�p�ł��鎟�̑g�ݍ��݂��p�ӂ���Ă��܂��B
http://msdn.microsoft.com/ja-jp/library/gg466493.aspx
Visual Studio 2010 SP1 �p�ɒlj����ꂽ XOP �g�ݍ���
Visual Studio 2010
�X�V : 2011 �N 3 ��
Visual Studio 2010 SP1 ���K�v�ł��B
Visual C++ �R���p�C���ɂ́AXOP �A�[�L�e�N�`���Ŏg�p�ł��鎟�̑g�ݍ��݂��p�ӂ���Ă��܂��B
FMA4��FMA Now!�������
������Intel�݊���FMA3���lj�����邩��
�V�F�A0%��AMD�Ǝ����߂ɑΉ�������Ӗ��͊F��
������Intel�݊���FMA3���lj�����邩��
�V�F�A0%��AMD�Ǝ����߂ɑΉ�������Ӗ��͊F��
>>380
�x���`��VS�g����悤�ɂȂ�ΐF�X�ς�肻������
�x���`��VS�g����悤�ɂȂ�ΐF�X�ς�肻������
����Ҷް
VisualStudio�ް
�����Ȃ����_�����͗��h����
���҂ɕs���̌��������߂Ă�������
�i���ɔs�҂̂܂܂���
VisualStudio�ް
�����Ȃ����_�����͗��h����
���҂ɕs���̌��������߂Ă�������
�i���ɔs�҂̂܂܂���
>>380
�����intrinsics�̑Ή�����
�����intrinsics�̑Ή�����
385 �FSocket774�F2011/12/12(��) 12:15:20.94 ID:awkhIkzc
�R���p�C����FMA�����sqrtss������Ȃ���
X86�i�����j���g��AIDA64-Photo Worxx��8150��1090T��1.71�{
MMX/SSE2/SSE3�i����������j���g��AIDA64-CPU Queen��8150��1090T��1�{
ALU�i�X�J���j��Thuban���啪�L���Ă邪�ASIMD�i�x�N�^�j��Bull�p��SIMD���ߑΉ��҂����Ċ�����
MMX/SSE2/SSE3�i����������j���g��AIDA64-CPU Queen��8150��1090T��1�{
ALU�i�X�J���j��Thuban���啪�L���Ă邪�ASIMD�i�x�N�^�j��Bull�p��SIMD���ߑΉ��҂����Ċ�����
FMA4��3���Ɩ��ɂȂ��Ă邯�ǁA
����܂�a�\�[�X��ۑ����Ȃ��Ⴂ���Ȃ��P�[�X���v�����Ȃ����
���Ȃ��Ƃ��A�s��ςɂ͕K�v�����Ǝv����
����܂�a�\�[�X��ۑ����Ȃ��Ⴂ���Ȃ��P�[�X���v�����Ȃ����
���Ȃ��Ƃ��A�s��ςɂ͕K�v�����Ǝv����
�s��XOP�̎啑�䂶��Ȃ��H
FMA3�ŏ\���Ƃ����Ӗ��Ȃ̂���
Pov-Ray�ł�i7��葁���Ƃ��A���̂��߂ɏo���悤��CPU���ȁB
AMD�T�[�o�[���i�̊���ɕ���Bulldozer�̐^�� �O��
ttp://ascii.jp/elem/000/000/655/655539/
ttp://ascii.jp/elem/000/000/655/655539/
http://ascii.jp/elem/000/000/655/655539/index-4.html
���u�C���e����Haswell�������[�X����^�C�~���O�ŁAAMD��FMA3���T�|�[�g���邱�ƂɂȂ�v
piledriver�ł�FMA3�͖������B
���u�C���e����Haswell�������[�X����^�C�~���O�ŁAAMD��FMA3���T�|�[�g���邱�ƂɂȂ�v
piledriver�ł�FMA3�͖������B
���Ɏ����Ă���ƌ������A�C���e����l��������
�}�C�N���\�t�g�Ɏ���ēs������������AAMD�ւ�
����ˌ���ϋɓI�ɂ���B
�}�C�N���\�t�g�Ɏ���ēs������������AAMD�ւ�
����ˌ���ϋɓI�ɂ���B
���͂�x86��������Ȃ�MS�ɂƂ���AMD�����삷�鉿�l����̂���
>>372
P�X�e�[�g/C�X�e�[�g�̒�`���ԈႦ�Ă邵�A��{�I�ȗ������ł��Ă��Ȃ��B�M�p�ɒl���Ȃ��L�����ȁB
P�X�e�[�g/C�X�e�[�g�̒�`���ԈႦ�Ă邵�A��{�I�ȗ������ł��Ă��Ȃ��B�M�p�ɒl���Ȃ��L�����ȁB
>>394
Piledriver�̓n�[�h��ł͑Ή����Ă邪�A�T�|�[�g����^�C�~���O��Haswell�o�Ă���ɂȂ�낤
FMA4�ł��܂��\�t�g�ʂ��͂����݂����Intel�ɑ��ċ��݂ɂȂ�̂ł킴�킴FMA3���T�|�[�g���闝�R�͖���
�͂����ݎ��s���Ă�Intel��FMA�ƌ݊��������X�N�͖���
Piledriver�̓n�[�h��ł͑Ή����Ă邪�A�T�|�[�g����^�C�~���O��Haswell�o�Ă���ɂȂ�낤
FMA4�ł��܂��\�t�g�ʂ��͂����݂����Intel�ɑ��ċ��݂ɂȂ�̂ł킴�킴FMA3���T�|�[�g���闝�R�͖���
�͂����ݎ��s���Ă�Intel��FMA�ƌ݊��������X�N�͖���
�Q�[�}�[�����ǂ��납�A�ȂɌ����ł��Ȃ�����Ȃ�
�K���ȋL�����B
�����Č����Ȃ�A���^�������Ċ���
�K���ȋL�����B
�����Č����Ȃ�A���^�������Ċ���
4game�̋L���Ȃ���Q�[�}�[��ŏ����͓̂��R
�����L���̓��e���u���낤���ăT�[�o�[�p�r�ɂ͎g���Ȃ����Ƃ��Ȃ��v������Q�[�}�[�ȑO�̃I�`�ɂȂ��Ă邯��
�����L���̓��e���u���낤���ăT�[�o�[�p�r�ɂ͎g���Ȃ����Ƃ��Ȃ��v������Q�[�}�[�ȑO�̃I�`�ɂȂ��Ă邯��
>>398
��������Haswell���o��O��FMA3���g������𐮂���̂�Intel�������ѐH���悤�Ȃ��̂������
��������Haswell���o��O��FMA3���g������𐮂���̂�Intel�������ѐH���悤�Ȃ��̂������
MS��BingMaps�̃V�X�e����Interlagos�g����
Interlagos���K���Ă����̂��A�����P��Dell�̃f�[�^�[�Z���^�[��Interlagos�����炻���Ȃ������Ęb�Ȃ̂��͕s��
Interlagos���K���Ă����̂��A�����P��Dell�̃f�[�^�[�Z���^�[��Interlagos�����炻���Ȃ������Ęb�Ȃ̂��͕s��
�n��������ΗǍD�Ȑ��\�����͓̂��R�Ƃ��Ēn�����߂Ă���̂͂킴�Ƃ���w
28nm HKMG�������Ƃ��邯�ǎʐ^��200mm�E�F�n���H
�d���Q�[�����Ȃ��Ƌt�ɗ��̃G���R�Ƃ����ł��镪�������ăR�A�����E�E�E
�Ƃ���ŋ�����8c�͂܂���
�Ƃ���ŋ�����8c�͂܂���
Fab1�ł�28nm���̂��BCPU�ɂ��n�[�t�m�[�h�g���Ƃ����͖̂{���Ȃ̂��ȁB
���낻��^��ǂł��ł��邱�Ƃ��瑲�Ƃ��܂��傤��
����ɂ��炳��Ė������狣�����N�\���Ȃ���B�B�B�B
http://eetimes.jp/ee/articles/1112/12/news100.html
��Fab 8�i�j���[���[�N�j�͌��݁A32nm�����28nm����̐������u��������Ă���Ƃ���
32nm�����28nm����̐������u�E�E�E���Ă̂�
�@�`�A32nm����̐������u��28nm����̐������u
�@�a�A32nm/28nm���㋤�p�̐������u
�̂ǂ��炩����Ȃ����A�`�Ȃ�j���[���[�N�ł�SOI��CPU������Ȃ���
�a�Ȃ�n�[�t�m�[�h��CPU�̉\���������͖���������
��Fab 8�i�j���[���[�N�j�͌��݁A32nm�����28nm����̐������u��������Ă���Ƃ���
32nm�����28nm����̐������u�E�E�E���Ă̂�
�@�`�A32nm����̐������u��28nm����̐������u
�@�a�A32nm/28nm���㋤�p�̐������u
�̂ǂ��炩����Ȃ����A�`�Ȃ�j���[���[�N�ł�SOI��CPU������Ȃ���
�a�Ȃ�n�[�t�m�[�h��CPU�̉\���������͖���������
���ɂȂ������������ȁH
���ʑҋ���AMD���瓦���o��GF�̃o���NCMOS�v���Z�X�ŒN���������̂�?
416 �FSocket774�F2011/12/12(��) 20:29:57.59 ID:ffNbz/7Y
�I�p�̃X���b�h�X���[�v�b�g�d���ł܂������f�X�N�g�b�v���ӎ����ĂȂ����̐�
�ǂ�����FX�Ȃ�Ċ��������̂��E�E�E
AMD�W�����E�t���[���̃C���^�r���[�ǂތ���
�����I�p�ƃf�X�N�g�b�v�p�Ő��ĊJ�����邵���Ȃ��Ǝv���̂���
�ǂ����Ă���ȎI�ΏdCPU���f�X�N�g�b�v�ŏo���C�ɂȂ����̂�
�}�W�ł����CPU���Ꮻ�����ǂ��Ă����Ă��A�f�X�N�g�b�v���삶��ꐶ�C���e���ɒǂ����Ȃ���
�ǂ�����FX�Ȃ�Ċ��������̂��E�E�E
AMD�W�����E�t���[���̃C���^�r���[�ǂތ���
�����I�p�ƃf�X�N�g�b�v�p�Ő��ĊJ�����邵���Ȃ��Ǝv���̂���
�ǂ����Ă���ȎI�ΏdCPU���f�X�N�g�b�v�ŏo���C�ɂȂ����̂�
�}�W�ł����CPU���Ꮻ�����ǂ��Ă����Ă��A�f�X�N�g�b�v���삶��ꐶ�C���e���ɒǂ����Ȃ���
TSMC��GF�ȊO��32/28nm�̃t�@�u���������甭�����邵���������낤
TSMC�ɂ��Ă����ʂ̐����\�͂͌��Y2���E�F�n�����Ȃ��AGF�ȉ�����Ȃ����ȁH
�܂��ATSMC�͗��N���ɂ�10���E�F�n�iTSMC�ˁj�ɂ܂ň����グ����Ęb����
��GF��32/28nm��10�`14���E�F�n�����肩
TSMC�ɂ��Ă����ʂ̐����\�͂͌��Y2���E�F�n�����Ȃ��AGF�ȉ�����Ȃ����ȁH
�܂��ATSMC�͗��N���ɂ�10���E�F�n�iTSMC�ˁj�ɂ܂ň����グ����Ęb����
��GF��32/28nm��10�`14���E�F�n�����肩
>>410
����Bobcat���n�[�t�m�[�h�Ő������Ĕ̔������Ă邩��n�[�t�m�[�h�͖�肶��Ȃ���H
����Bobcat���n�[�t�m�[�h�Ő������Ĕ̔������Ă邩��n�[�t�m�[�h�͖�肶��Ȃ���H
419 �F,,�E�L�́M�E,,�j��-�������F2011/12/12(��) 20:54:20.80 ID:4uhnXjeQ
>>407
Intel�̗���������ł�C��������ǂˁB
�ǂ���SIMD�œK������̃G���W����Intel�̋��R���p�C���̂��������MS��������Ă邾���̂悤�����B
Intel�̗���������ł�C��������ǂˁB
�ǂ���SIMD�œK������̃G���W����Intel�̋��R���p�C���̂��������MS��������Ă邾���̂悤�����B
>>412
���܂ŎU�X���@�A�@�̔̔��W�Q���Ă��̂ɂ�
���܂ŎU�X���@�A�@�̔̔��W�Q���Ă��̂ɂ�
421 �F,,�E�L�́M�E,,�j��-�������F2011/12/12(��) 20:55:33.70 ID:4uhnXjeQ
>>416
�f�X�N�g�b�v���̂قƂ�Ǐ����������Ǝv���Ă�؋�����
�Ԉ���Ă͂��Ȃ��Ƃ��������������f��
������������o���ƑS�ĂŎ��s�����˂Ȃ�
�f�X�N�g�b�v���̂قƂ�Ǐ����������Ǝv���Ă�؋�����
�Ԉ���Ă͂��Ȃ��Ƃ��������������f��
������������o���ƑS�ĂŎ��s�����˂Ȃ�
423 �F,,�E�L�́M�E,,�j��-�������F2011/12/12(��) 21:02:08.85 ID:4uhnXjeQ
Intel���炵�āA���[�h�}�b�v�}���ォ�珇�Ɂ@�T�[�o���m�[�g���f�X�N�g�b�v�@�ł���
�f�X�N�g�b�v�����̓n�C�p�t�H�[�}���X�m�[�g�����̑I�ʗ����i�ɉ߂��Ȃ��B
�f�X�N�g�b�v�����̓n�C�p�t�H�[�}���X�m�[�g�����̑I�ʗ����i�ɉ߂��Ȃ��B
>8�R�A�Ǝ��̂�����x�����A�s�[���|�C���g�Ȃ��悤�ɐ��\�������Ă�
>�����ăf�X�N�g�b�v�Ő��\�łȂ��悤�ɂ��Ă�
�ց[
>�����ăf�X�N�g�b�v�Ő��\�łȂ��悤�ɂ��Ă�
�ց[
i7���m��r����ƃf�X�N�g�b�v�ƃm�[�g��3���������o�Ȃ��x���`���قƂ�ǂ�����Ȃ�
TB�̂������ŃN���b�N���̑̊����x�Ȃ�Ă܂���������������
Intel�ł�����Ivy�AHaswell�Ɛ��\���ȓd�͏d��������A���̂����f�X�N�g�b�vCPU�����Ȃ��˂Ǝv��
�����������N��ɂ悤�₭�ш�2�{�Ƃ����C�Ȃ��̂ɁA���o�C�������������͂ǂ�ǂ�g������邵
TB�̂������ŃN���b�N���̑̊����x�Ȃ�Ă܂���������������
Intel�ł�����Ivy�AHaswell�Ɛ��\���ȓd�͏d��������A���̂����f�X�N�g�b�vCPU�����Ȃ��˂Ǝv��
�����������N��ɂ悤�₭�ш�2�{�Ƃ����C�Ȃ��̂ɁA���o�C�������������͂ǂ�ǂ�g������邵
428 �FSocket774�F2011/12/12(��) 21:29:50.12 ID:LWYvoaaj
�S�T�Ńu���y�����̐V�L���������B
http://www.4gamer.net/games/100/G010000/20111209066/
>���f�B�A�̕]���͑S���E�K�͂ŒႭ�E�E�E �ȏ���܂Ƃ߂�ƁC�ȉ��̂悤�Ȋ����ɂȂ�B
�EFX�v���Z�b�T������CPU�R�A������̐��\��Phenom II X6�ɋy�Ȃ�
�EFX�v���Z�b�T�̐������Z���\�͂��قǒႭ�Ȃ��C����������̊g�����g�����h���Ƃ�����
�EFX�v���Z�b�T�͕��������_���Z�����ӂł͂Ȃ�
�EBulldozer���W���[����HTT���m���ɍ��������œ��삷�邪�C���\�[�X�̋��������������ꍇ�C�ő�50����̐��\�ቺ����������
�S�~
http://www.4gamer.net/games/100/G010000/20111209066/
>���f�B�A�̕]���͑S���E�K�͂ŒႭ�E�E�E �ȏ���܂Ƃ߂�ƁC�ȉ��̂悤�Ȋ����ɂȂ�B
�EFX�v���Z�b�T������CPU�R�A������̐��\��Phenom II X6�ɋy�Ȃ�
�EFX�v���Z�b�T�̐������Z���\�͂��قǒႭ�Ȃ��C����������̊g�����g�����h���Ƃ�����
�EFX�v���Z�b�T�͕��������_���Z�����ӂł͂Ȃ�
�EBulldozer���W���[����HTT���m���ɍ��������œ��삷�邪�C���\�[�X�̋��������������ꍇ�C�ő�50����̐��\�ቺ����������
�S�~
>>428
�ȂA�C�}�X2�̒L�������ăM�����Q�łԂ���������܂�����4�T���B
�ȂA�C�}�X2�̒L�������ăM�����Q�łԂ���������܂�����4�T���B
�����̓f�X�N�g�b�v�����̃R�A��ʓr�J������]�͂����������ɂ������邪
�f�X�N�g�b�v�����łȂ�CPU���f�X�N�g�b�v�ɓ����������ɈႢ�͂Ȃ��B
�����ĈӐ}�I�ɂ���Ă�̂Ȃ�ނ��눫������ȁB
�����Ă��Ȃ��ƕ������Ă�CPU���ŐV�E�����\�Ə̂��Ĕ�����Ă���B
�f�X�N�g�b�v�����łȂ�CPU���f�X�N�g�b�v�ɓ����������ɈႢ�͂Ȃ��B
�����ĈӐ}�I�ɂ���Ă�̂Ȃ�ނ��눫������ȁB
�����Ă��Ȃ��ƕ������Ă�CPU���ŐV�E�����\�Ə̂��Ĕ�����Ă���B
Craving Explorer AVCHD(1920�~1080)��MPEG-4AVC(1024�~576)�ɕϊ�
�@Core i7-3960X EE 2���@Core i7-2600K 2��3�b�@�@Core i5-2500K 2��8�b
�@Core i3-2100 2��30�b�@FX-8150�@2��35�b�@Celeron G540 3��4�b
SILKYPIX Developer Studio Pro5��RAW�`���摜�ް���JPEG�`���Ɍ�������
�@Core i7-3960X EE 1��9�b�@Core i7-2600K 1��35�b�@�@Core i5-2500K 2��4�b
�@FX-8150�@2��35�b�@Core i3-2100 3��21�b�@Celeron G540 5��34�b
iTunes ��1���Ԃ̋Ȃ�AAC�ϊ�
�@Core i7-3960X EE 1��18�b�@Core i7-2600K 1��21�b�@�@Core i5-2500K 1��24�b
�@Core i3-2100 1��38�b�@Celeron G540 2��1�b�@FX-8150�@2��9�b
�@Core i7-3960X EE 2���@Core i7-2600K 2��3�b�@�@Core i5-2500K 2��8�b
�@Core i3-2100 2��30�b�@FX-8150�@2��35�b�@Celeron G540 3��4�b
SILKYPIX Developer Studio Pro5��RAW�`���摜�ް���JPEG�`���Ɍ�������
�@Core i7-3960X EE 1��9�b�@Core i7-2600K 1��35�b�@�@Core i5-2500K 2��4�b
�@FX-8150�@2��35�b�@Core i3-2100 3��21�b�@Celeron G540 5��34�b
iTunes ��1���Ԃ̋Ȃ�AAC�ϊ�
�@Core i7-3960X EE 1��18�b�@Core i7-2600K 1��21�b�@�@Core i5-2500K 1��24�b
�@Core i3-2100 1��38�b�@Celeron G540 2��1�b�@FX-8150�@2��9�b
>>431
http://wiki.crav-ing.com/index.php?%E8%A6%81%E6%9C%9B
>�� �}���`�R�A�A�Ή����Ă܂���B
>�����A�W����Ԃł͎g��Ȃ��悤�ɂȂ��Ă��邾���ł��B
>�����I�ɂ͐�ւ��܂���B
http://wiki.crav-ing.com/index.php?%E8%A6%81%E6%9C%9B
>�� �}���`�R�A�A�Ή����Ă܂���B
>�����A�W����Ԃł͎g��Ȃ��悤�ɂȂ��Ă��邾���ł��B
>�����I�ɂ͐�ւ��܂���B
>>430
>�����ĈӐ}�I�ɂ���Ă�̂Ȃ�ނ��눫������ȁB
���������v����B
�ړI���T�v���C�`�F�[���̕ی삾�낤������ɂƂ��Ă�
�y���ނ��߂̃l�^���ʂɒD��ꂽ���͕ς��Ȃ��B
>�����ĈӐ}�I�ɂ���Ă�̂Ȃ�ނ��눫������ȁB
���������v����B
�ړI���T�v���C�`�F�[���̕ی삾�낤������ɂƂ��Ă�
�y���ނ��߂̃l�^���ʂɒD��ꂽ���͕ς��Ȃ��B
�f�X�N�g�b�v�n�C�G���h�ɃT�[�oCPU�𗬗p����̂�Intel���������낤
Bulldozer���f�X�N�g�b�v�̃��[�N���[�h�Ɍ����ĂȂ��Ƃ����̂��{���ɂ܂����̂�
�قړ����R�A�����o�C���ɂ��W�J����\�肾����
Bulldozer���f�X�N�g�b�v�̃��[�N���[�h�Ɍ����ĂȂ��Ƃ����̂��{���ɂ܂����̂�
�قړ����R�A�����o�C���ɂ��W�J����\�肾����
�R�X�g�팸�̔ے�Ƃ�
llano 4�R�A <- -> trinity 2M4C
�̂ǂ������������͑҂��ԍl����Ɣ���
LLano �̂ق������\�����Ȃ�
���N�̃��f���Ńm�[�g�������Ⴂ������USB3.0���ɗ~�����̂��Ȃ����
�̂ǂ������������͑҂��ԍl����Ɣ���
LLano �̂ق������\�����Ȃ�
���N�̃��f���Ńm�[�g�������Ⴂ������USB3.0���ɗ~�����̂��Ȃ����
>>435
�Ӑ}�I��PC�p�r�Ő��\�ቺ���鉽�����d���ނƃR�X�g�팸�ɂȂ�H
�Ӑ}�I��PC�p�r�Ő��\�ቺ���鉽�����d���ނƃR�X�g�팸�ɂȂ�H
438 �F,,�E�L�́M�E,,�j��-�������F2011/12/12(��) 22:34:20.42 ID:4uhnXjeQ
Intel���f�������p�ӂ���K�v�Ȃ��Ȃ邩��R�X�g�팸�ɂȂ��
�N���������Ȃ�����A�f�X�N�g�b�v��p��CPU�Y���Ȃ��čςށB
���D�����������Ă�����I�����̔���c�肩�I�ʗ�������������ςށB
���D�����������Ă�����I�����̔���c�肩�I�ʗ�������������ςށB
L2DTLB��sqrtss�͕ʂɌ��I�ɐ��\��������v���ł͂Ȃ�����
���������f�X�N�g�b�v�p�r��TLB���\���N���e�B�J���ɂȂ��ʂ͏��Ȃ�
���ɂȂ�Ȃ烉�[�W�y�[�W���g��
�����ā@���炩�ɂ�sqrtss���g��Ȃ��ł��낤�x���`�}�[�N���x��
Bulldozer�͓���̃{�g���l�b�N������Ƃ������
�܂�ׂ�Ȃ��x��
���������f�X�N�g�b�v�p�r��TLB���\���N���e�B�J���ɂȂ��ʂ͏��Ȃ�
���ɂȂ�Ȃ烉�[�W�y�[�W���g��
�����ā@���炩�ɂ�sqrtss���g��Ȃ��ł��낤�x���`�}�[�N���x��
Bulldozer�͓���̃{�g���l�b�N������Ƃ������
�܂�ׂ�Ȃ��x��
>>431
i5�Ai3�A�Z���܂Ŏ����o����FX���Ȃ߂Ă����Ȃ���A
A-�V���[�Y�̓V�J�g�Ȏ��_�ł��O��Intel�̒����Ȃ̂͂悭�������B
i5�Ai3�A�Z���܂Ŏ����o����FX���Ȃ߂Ă����Ȃ���A
A-�V���[�Y�̓V�J�g�Ȏ��_�ł��O��Intel�̒����Ȃ̂͂悭�������B
�ɂ��q�͎G�k�X������o�Ă��Ȃ��悤��
�˂����ݎĂ�������Web��Ńf�[�^�o�������グ�Ă邾���ŁB
HW�v���t�F�b�`���������Ă�̂��ǂ����C�}�C�`�������Ƃ�
x87�̍œK���͂��Ԃ�����Ă�Ƃ�
16byte�A���C�������g�����ĂȂ���memcpy�ш挃���Ƃ����낢�날���B
sqrtss�͊m����10->20���x�łȂ�ǂ��ɂ��Ȃ��10->166�����˂��B
�ꍇ�ɂ���Ă͑S�̂̐�%�̃��[�v��10%���x�܂ň����グ��C���p�N�g�͂���Ǝv����B
L2DTLB���S�̂Ƃ��Ă݂�Βv���I����Ȃ��Ǝv�����Njɒ[�ɉe������P�[�X�����邾�낤�B
HW�v���t�F�b�`���������Ă�̂��ǂ����C�}�C�`�������Ƃ�
x87�̍œK���͂��Ԃ�����Ă�Ƃ�
16byte�A���C�������g�����ĂȂ���memcpy�ш挃���Ƃ����낢�날���B
sqrtss�͊m����10->20���x�łȂ�ǂ��ɂ��Ȃ��10->166�����˂��B
�ꍇ�ɂ���Ă͑S�̂̐�%�̃��[�v��10%���x�܂ň����グ��C���p�N�g�͂���Ǝv����B
L2DTLB���S�̂Ƃ��Ă݂�Βv���I����Ȃ��Ǝv�����Njɒ[�ɉe������P�[�X�����邾�낤�B
�܂��A�}�W�Ŏd�l�Ȃ̂����m��Ȃ����̂����邪�B
x87�̍œK���͂��Ԃ�����Ă���ĉ����悗
x87�̓X�^�b�N�}�V��������P���ɂ̓A�E�g�I�u�I�[�_�ł��Ȃ����ߓ��ʂȍœK�����K�v�B
Intel�͂������������Pen4��SSE2�ɒu�������}�������ǁAAMD�͗��ŃR�c�R�c����Ă��B
���ǂ�Nehalem��x87�̍œK���������Ǎ��x��AMD����Ȃ��Ȃ������ۂ��B
SSE2�X�J����x87�̃X�R�A�̈Ⴂ��K10����20%���x�Ȃ̂�Bulldozer���Ɣ{�߂�������̗\�z�B
�������Ⴄ���R�Ő��\���������Ă�\��������B
Intel�͂������������Pen4��SSE2�ɒu�������}�������ǁAAMD�͗��ŃR�c�R�c����Ă��B
���ǂ�Nehalem��x87�̍œK���������Ǎ��x��AMD����Ȃ��Ȃ������ۂ��B
SSE2�X�J����x87�̃X�R�A�̈Ⴂ��K10����20%���x�Ȃ̂�Bulldozer���Ɣ{�߂�������̗\�z�B
�������Ⴄ���R�Ő��\���������Ă�\��������B
Opteron 3260 EE 4c 2.7 GHz 45W \11154
Phenom II X4 910e 4c 2.6GHz 65W \10000(���炢?)
�������Ă݂�ƒ��X�ȓd��
Phenom II X4 910e 4c 2.6GHz 65W \10000(���炢?)
�������Ă݂�ƒ��X�ȓd��
���₢��Auop�ɂȂ��ĕ������W�X�^���A���P�[�g����i�K�ŃX�^�b�N�}�V���Ȃ�Ăǂ��ł��ǂ��Ȃ�ł���
WAW/WAR�n�U�[�h����������̂Ɠ���
WAW/WAR�n�U�[�h����������̂Ɠ���
451 �F,,�E�L�́M�E,,�j��-�������F2011/12/12(��) 23:51:39.39 ID:4uhnXjeQ
>>444
�g�������Ȗ��߂�vpermil2ps/pd���炢�����v�������Ȃ������B
�g�������Ȗ��߂�vpermil2ps/pd���炢�����v�������Ȃ������B
>>450
uop�ɂȂ邾���ʼn�������Ȃ�Pen4/Core2�ȑO�͂Ȃ�ň��������B
uop�ɂȂ邾���ʼn�������Ȃ�Pen4/Core2�ȑO�͂Ȃ�ň��������B
���Z�킪����̃|�[�g�ɔz�u����Ă�����A��Z�̃X���[�v�b�g���������������炾��
Pen4��Core2��fmul�̃X���[�v�b�g��mulsd�̔���
�P����80bit���Z��̎������T�{������ł���
Bull�͓����B
�P����80bit���Z��̎������T�{������ł���
Bull�͓����B
P5->P6
�̂�����̕ω���m���̂���
�e���߂̃��C�e���V�ɂ���̂���FPU��OoO�̐^�������낤��
P6��fxch���قڃ^�_�ɂȂ����̂͏Ռ��I������
>>452
�̂�fadd��fmul��port0��������
�̂�����̕ω���m���̂���
�e���߂̃��C�e���V�ɂ���̂���FPU��OoO�̐^�������낤��
P6��fxch���قڃ^�_�ɂȂ����̂͏Ռ��I������
>>452
�̂�fadd��fmul��port0��������
>452
��AMD��FPU�������Ȃ����̂�Penryn�ŏ��Z�����������Ă��炾��
�����Nehalem�ŏ�Z�X���[�v�b�g��1�ɂȂ��Ă���ɍ���������
����ȊO�͓���X87�ł͘M���ĂȂ���Ȃ����H
��AMD��FPU�������Ȃ����̂�Penryn�ŏ��Z�����������Ă��炾��
�����Nehalem�ŏ�Z�X���[�v�b�g��1�ɂȂ��Ă���ɍ���������
����ȊO�͓���X87�ł͘M���ĂȂ���Ȃ����H
457 �F,,�E�L�́M�E,,�j��-�������F2011/12/13(��) 00:03:55.91 ID:Sxkj2nno
> ���Z�킪����̃|�[�g�ɔz�u����Ă�����A
FLOAD/FSTORE��MMX-ALU�������|�[�g�AFMAC1��XBAR�������|�[�g
> ��Z�̃X���[�v�b�g���������������炾��
�����N���X�^�̏�Z���j�b�g
�v�����Bulldozer�ɓ��Ă͂܂��������������
FLOAD/FSTORE��MMX-ALU�������|�[�g�AFMAC1��XBAR�������|�[�g
> ��Z�̃X���[�v�b�g���������������炾��
�����N���X�^�̏�Z���j�b�g
�v�����Bulldozer�ɓ��Ă͂܂��������������
���Ⴀ�ABulldozer��x87�͓��ɉ������R�Ȃ��̂ɃX���[�v�b�g�����ɂȂ���Ď����B
>>458
Bull��Fmul��Fadd��2�|�[�g�Ŕ��s���Ă��X���[�v�b�g0.71������Fmul��Fadd�������s����ꍇ�A�]�����x���Ȃ��Ȃ����H
Inst 576 X87 : FADD st(i), st (st = 0.0) L: 1.38ns= 5.0c T: 0.20ns= 0.71c
Inst 577 X87 : FADD st(i), st L: 1.38ns= 5.0c T: 0.20ns= 0.71c
Inst 578 X87 : FADD st, st(i), FXCH st(i) L: 1.38ns= 5.0c T: 0.55ns= 2.00c
Inst 579 X87 : FMUL st(i), st (st = 0.0) L: 1.38ns= 5.0c T: 0.20ns= 0.71c
Inst 580 X87 : FMUL st(i), st L: 1.38ns= 5.0c T: 0.20ns= 0.71c
Inst 581 X87 : FMUL st, st(i), FXCH st(i) L: 1.38ns= 5.0c T: 0.28ns= 1.00c
Bull��Fmul��Fadd��2�|�[�g�Ŕ��s���Ă��X���[�v�b�g0.71������Fmul��Fadd�������s����ꍇ�A�]�����x���Ȃ��Ȃ����H
Inst 576 X87 : FADD st(i), st (st = 0.0) L: 1.38ns= 5.0c T: 0.20ns= 0.71c
Inst 577 X87 : FADD st(i), st L: 1.38ns= 5.0c T: 0.20ns= 0.71c
Inst 578 X87 : FADD st, st(i), FXCH st(i) L: 1.38ns= 5.0c T: 0.55ns= 2.00c
Inst 579 X87 : FMUL st(i), st (st = 0.0) L: 1.38ns= 5.0c T: 0.20ns= 0.71c
Inst 580 X87 : FMUL st(i), st L: 1.38ns= 5.0c T: 0.20ns= 0.71c
Inst 581 X87 : FMUL st, st(i), FXCH st(i) L: 1.38ns= 5.0c T: 0.28ns= 1.00c
462 �F,,�E�L�́M�E,,�j��-�������F2011/12/13(��) 00:13:09.00 ID:Sxkj2nno
FP�X�^�b�N���W�X�^��8�{�ɑ��A���C�e���V6��FMA��2�B
�v����ɘ_�����W�X�^�̖{���l�b�N���ȁB
FPU�̃��C�e���V���̂��̂��l�b�N�Ƃł������ׂ����B
2�X���b�h���ƃX���[�v�b�g���P����邩����
�v����ɘ_�����W�X�^�̖{���l�b�N���ȁB
FPU�̃��C�e���V���̂��̂��l�b�N�Ƃł������ׂ����B
2�X���b�h���ƃX���[�v�b�g���P����邩����
x86���ł�addps/mulps��0.63�����o�Ȃ��̂��������R����
FPU�̃X���[�v�b�g�͏オ��������
���C�e���V������������
�_�����W�X�^���̏��Ȃ�x87�����ΓI�ɒx���Ȃ����̂���
FPU�̃X���[�v�b�g�͏オ��������
���C�e���V������������
�_�����W�X�^���̏��Ȃ�x87�����ΓI�ɒx���Ȃ����̂���
>>462
�\�����_����������Ȃ��̂�
�܂��������ǂ����ăR�C�c���o�Ă����낤
�n�i����bull�ōs���C�Ȃ�llano�ɍڂ��Ă��ǂ������Ȃ��́i���\�͕ʂɂ��āj
�ŁA�т�pile�Ƃ����Ƃ��납�猩��ɖ{��bull���o�Ă���\��͂Ȃ������̂ł͂Ȃ����ȂƂ��v����
�����Ƃ��A����pile���ǁ[�Ȃ邩�킩���
�\�����_����������Ȃ��̂�
�܂��������ǂ����ăR�C�c���o�Ă����낤
�n�i����bull�ōs���C�Ȃ�llano�ɍڂ��Ă��ǂ������Ȃ��́i���\�͕ʂɂ��āj
�ŁA�т�pile�Ƃ����Ƃ��납�猩��ɖ{��bull���o�Ă���\��͂Ȃ������̂ł͂Ȃ����ȂƂ��v����
�����Ƃ��A����pile���ǁ[�Ȃ邩�킩���
>>459
����ł����H
http://codepad.org/9OB2uEge
�������̂�VC�ȁBExpress�����ǁB
SSE���Č����Ă�̂�x64�����r���h�������B
PhenomII���ƈ�����20%���x������FX�ł͔{���x�Ɉ�������B
���Ȃ݂ɒP���ȃP�[�X�ł�mul��fmul���X���[�v�b�g������������B
����ł����H
http://codepad.org/9OB2uEge
�������̂�VC�ȁBExpress�����ǁB
SSE���Č����Ă�̂�x64�����r���h�������B
PhenomII���ƈ�����20%���x������FX�ł͔{���x�Ɉ�������B
���Ȃ݂ɒP���ȃP�[�X�ł�mul��fmul���X���[�v�b�g������������B
gcc�Ŏ����Ă݂����ǂ�͂�{���炢�ɂȂ��
���C�����[�v�����A�Z���u�����o���Ă݂���
http://codepad.org/hT8dHtus
�C�ɂȂ�̂�fxch�̃p�t�H�[�}���X��
�œK���}�j���A���ł�p0/1 latency=2�ɂȂ��Ă���
���s���j�b�g��ʂ��Ă���\��������
P6�ȍ~��Intel��K7~K10��fxch�̓X�P�W���[���łȂ��Ȃ邩�����latency=0������
���C�����[�v�����A�Z���u�����o���Ă݂���
http://codepad.org/hT8dHtus
�C�ɂȂ�̂�fxch�̃p�t�H�[�}���X��
�œK���}�j���A���ł�p0/1 latency=2�ɂȂ��Ă���
���s���j�b�g��ʂ��Ă���\��������
P6�ȍ~��Intel��K7~K10��fxch�̓X�P�W���[���łȂ��Ȃ邩�����latency=0������
����H
570 X87 :FXCH st(i) L: 0.15ns= 0.5c T: 0.15ns= 0.48c
��������Latency=0.5�ɂȂ��Ă��
��
570 X87 :FXCH st(i) L: 0.15ns= 0.5c T: 0.15ns= 0.48c
��������Latency=0.5�ɂȂ��Ă��
��
���Ă�A-�V���[�Y�̕����R�X�g�䂩��l���Ă����������������o���Ă��B
Phenom II�̌�p�[���Ƃ܂邾��BFX�ɂ������K�v�Ȃǂ��ɂ��Ȃ��B
Phenom II�̌�p�[���Ƃ܂邾��BFX�ɂ������K�v�Ȃǂ��ɂ��Ȃ��B
A6��A8����A��������Athlon�U�̌�p����
A�V���[�Y�̂܂Ƃ��ȓz�͎s��ɖ����ɏo�ׂł��Ă��Ȃ��킯������낵����
471 �F,,�E�L�́M�E,,�j��-�������F2011/12/13(��) 01:54:15.26 ID:Sxkj2nno
>>467
�������0�����ǃf�R�[�h���ɔ�����Ƃ�
�������0�����ǃf�R�[�h���ɔ�����Ƃ�
>>468
����A�V���[�Y�̒��g��Bulldozer�ɂȂ�킯�Łc
����A�V���[�Y�̒��g��Bulldozer�ɂȂ�킯�Łc
>>471
K10�Ƃ��ł�uOP�͐�������邩��f�R�[�h���ɔ�����͕̂����邯��
>570 X87 :FXCH st(i) L: 0.15ns= 0.5c T: 0.15ns= 0.48c
��Bulldozer�̑���l��
�œK���}�j���A����latency=2�Ɩ�������Ȃ�
K10�Ƃ��ł�uOP�͐�������邩��f�R�[�h���ɔ�����͕̂����邯��
>570 X87 :FXCH st(i) L: 0.15ns= 0.5c T: 0.15ns= 0.48c
��Bulldozer�̑���l��
�œK���}�j���A����latency=2�Ɩ�������Ȃ�
AthlonII�Ƀr�f�I�J�[�h�}���ςނ��Ƃ����AFM2�ƌ݊�������
Llano��I�ԗ��R���Ȃ���
Llano��I�ԗ��R���Ȃ���
�Ƃ��낪AMD�ɂ�PhenomII/AthlonII�̐��Y����߂�Llano��Bobcat(�ƃE���R)�ɍi�闝�R������̂�
>>434
L3�Ȃ����璷������邵�ōł��d�v�ȏ���d�͂ŕW���i��35w��45w�I�ʕi��17w��gpu����
�܂�cpu����8w�O�ォ��20w�O�キ�炢
�����ɐv�Ӑ}�ǂ���̌��ʂ��o�Ă��
���\�͕K�v�Ȏ��ɃN���b�N�A�b�v��tb����2.5Ghz�ȏ�o���llano��肢���@
gpu�͊m���ɏ��邾�낤��
L3�Ȃ����璷������邵�ōł��d�v�ȏ���d�͂ŕW���i��35w��45w�I�ʕi��17w��gpu����
�܂�cpu����8w�O�ォ��20w�O�キ�炢
�����ɐv�Ӑ}�ǂ���̌��ʂ��o�Ă��
���\�͕K�v�Ȏ��ɃN���b�N�A�b�v��tb����2.5Ghz�ȏ�o���llano��肢���@
gpu�͊m���ɏ��邾�낤��
A-3850���ċT�̃Q�[���x���`��i3�ɑS�������Ă������
FMA�N�̖ϑz�͉ʂĂ��Ȃ��L����B������i3���Ƃ��ɎS�s
>>437
opteron�p�����Ă�����Ȃ��čςނ���
�����g��̋@�������Ȃ��čς�
�A������Ɏ���悤�ɂȂ�Ɓh���\�i��h���J�������˂���Ӗ����Ȃ��Ȃ邩��@bull�ȍ~���Ǝv������
opteron�p�����Ă�����Ȃ��čςނ���
�����g��̋@�������Ȃ��čς�
�A������Ɏ���悤�ɂȂ�Ɓh���\�i��h���J�������˂���Ӗ����Ȃ��Ȃ邩��@bull�ȍ~���Ǝv������
�ϑz�𐂂ꗬ��������ARM�^�����͋A��
>>479
�k�X�ɋA��
�k�X�ɋA��
>>478
�O���{�t���Ă��Ӗ��ˁ[����
�����O���t�B�b�N�ŏ�������悗
http://www.4gamer.net/games/100/G010001/20110628065/
�O���{�t���Ă��Ӗ��ˁ[����
�����O���t�B�b�N�ŏ�������悗
http://www.4gamer.net/games/100/G010001/20110628065/
>>474
llano�͖{���m�[�g�����@�܂�f�X�N�g�b�v�͂��܂�
amd�͈�ʌ����͊��S�Ƀm�[�g���S�ɃV�t�g
�������łق�0�������m�[�g�����V�F�A�͍D�]�ƌ�������x�܂ő������i�����܂�̊W��20���O�ゾ�낤���j
"desktop�͂��܂��H��"�~���Ė���������߂�������Ђ������Ȃ���Ă��Ƃ���������ттĂ������낤
tri��llano���X�ɏ���d�͌��邵�����gpu���\�オ�邩��E�}�[
llano�͖{���m�[�g�����@�܂�f�X�N�g�b�v�͂��܂�
amd�͈�ʌ����͊��S�Ƀm�[�g���S�ɃV�t�g
�������łق�0�������m�[�g�����V�F�A�͍D�]�ƌ�������x�܂ő������i�����܂�̊W��20���O�ゾ�낤���j
"desktop�͂��܂��H��"�~���Ė���������߂�������Ђ������Ȃ���Ă��Ƃ���������ттĂ������낤
tri��llano���X�ɏ���d�͌��邵�����gpu���\�オ�邩��E�}�[
������A-�V���[�Y���x�̃O���t�B�b�N���\���u�����ł��Ȃ���ŃR�v���ɂ��܂��vwww
���������A���o�C���͂ǂ�����A�V���[�v�叟����!?
���������A���o�C���͂ǂ�����A�V���[�v�叟����!?
�L�`�K�C�����͌����̃r�W�l�X����Ȃ��r�����������
amd�����܂ō����o���Ȃ������̂�fab�������̂Ǝs��̂قƂ�ǂ��߂�m�[�g�s��ŃV�F�A�����Ȃ���������
�����������ł�������v���Ԃ�̍����ɂȂ���
AMD��2011�NQ3���Z�\���A���㍂��16��9000���h���őO����7%���A�O�N������4%���ƂȂ�܂���
�����v�͍�����9700���h���ƂȂ��Ă���A�O����59%���A�O�N�����̐Ԏ����獕�����ɐ������Ă��܂�
APU�̗̍p���i��ł���A���o�C�������ł͔��㍂35%�ƂȂ����Ƃ̂���
�܂��A������C���h�Ȃǂ̐V���s���2�P�^�������邱�Ƃ��ł����Ƃ̂��Ƃł�
����ʂŌ���ƁA���o�C�������ƃT�[�o�[������ASP����ɂ��R���s���[�e�B���O�����6%���A�O���t�B�b�N�X����ō������v�ɂ��10%���ƂȂ����Ƃ̂���
2011�NQ4�Ɋւ��ẮA3%�̔��㍂���������܂�Ă��܂�
http://blog.livedoor.jp/amd646464/archives/52227578.html
�f�X�N�g�b�v�Ȃ�ăj�b�`�Ȃ��̂ɗ͓���Ă����Ђ������Ȃ��Ă��킗
amd�����܂ō����o���Ȃ������̂�fab�������̂Ǝs��̂قƂ�ǂ��߂�m�[�g�s��ŃV�F�A�����Ȃ���������
�����������ł�������v���Ԃ�̍����ɂȂ���
AMD��2011�NQ3���Z�\���A���㍂��16��9000���h���őO����7%���A�O�N������4%���ƂȂ�܂���
�����v�͍�����9700���h���ƂȂ��Ă���A�O����59%���A�O�N�����̐Ԏ����獕�����ɐ������Ă��܂�
APU�̗̍p���i��ł���A���o�C�������ł͔��㍂35%�ƂȂ����Ƃ̂���
�܂��A������C���h�Ȃǂ̐V���s���2�P�^�������邱�Ƃ��ł����Ƃ̂��Ƃł�
����ʂŌ���ƁA���o�C�������ƃT�[�o�[������ASP����ɂ��R���s���[�e�B���O�����6%���A�O���t�B�b�N�X����ō������v�ɂ��10%���ƂȂ����Ƃ̂���
2011�NQ4�Ɋւ��ẮA3%�̔��㍂���������܂�Ă��܂�
http://blog.livedoor.jp/amd646464/archives/52227578.html
�f�X�N�g�b�v�Ȃ�ăj�b�`�Ȃ��̂ɗ͓���Ă����Ђ������Ȃ��Ă��킗
>>474
�ʂɂ��O����Athlon II�Ŗ������Ă���Ȃ炻��͂���ŕʂɍ\���͂��Ȃ��B
�����̍D�݂Ɨp�r�ɂ��킹��Ⴂ�������Ȃ���ȁB
4�T�̒x���`�ɂ��ǂ炳��Ă�u�������ł��n�C�G���h�v�̃o�J���C�ɓ���Ȃ������B
��́A�m�[�g�p�̃A�[�L�e�N�`�����f�X�N�g�b�v�����Ƀ}�b�`���O�������̂́A
�v���X�R�̔��M�ɋ�������Ă�����Intel�~�̕����悾��B
���o�C����������Ńf�X�N�g�b�v�������]�B���\����Ȃ����B
�ȃG�l���̂������A�u���[�J�[�̌_��A�グ�Ȃ���Ȃ�Ȃ��悤��PC�Ȃ�����肽���Ȃ���B
���Ă�����ĂȂ����ǂȁBAthlon64�APhenom II X4��d���ŁA�O���{���~�h���܂łɗ}���āB
�ʂɂ��O����Athlon II�Ŗ������Ă���Ȃ炻��͂���ŕʂɍ\���͂��Ȃ��B
�����̍D�݂Ɨp�r�ɂ��킹��Ⴂ�������Ȃ���ȁB
4�T�̒x���`�ɂ��ǂ炳��Ă�u�������ł��n�C�G���h�v�̃o�J���C�ɓ���Ȃ������B
��́A�m�[�g�p�̃A�[�L�e�N�`�����f�X�N�g�b�v�����Ƀ}�b�`���O�������̂́A
�v���X�R�̔��M�ɋ�������Ă�����Intel�~�̕����悾��B
���o�C����������Ńf�X�N�g�b�v�������]�B���\����Ȃ����B
�ȃG�l���̂������A�u���[�J�[�̌_��A�グ�Ȃ���Ȃ�Ȃ��悤��PC�Ȃ�����肽���Ȃ���B
���Ă�����ĂȂ����ǂȁBAthlon64�APhenom II X4��d���ŁA�O���{���~�h���܂łɗ}���āB
>>486
�����A�s�c�n���S���Ԏ��Ԏ��Ƃ������Ȃ���A
��]�ː��̌��݂ƎO�c����ATO���̏��p�ŐԂ������ŁA
���ۂ̉^�s�W���͗��h�ɍ����̂Ɠ������Ă��Ƃ��ȁB
�����A�s�c�n���S���Ԏ��Ԏ��Ƃ������Ȃ���A
��]�ː��̌��݂ƎO�c����ATO���̏��p�ŐԂ������ŁA
���ۂ̉^�s�W���͗��h�ɍ����̂Ɠ������Ă��Ƃ��ȁB
iTunes ��1���Ԃ̋Ȃ�AAC�ϊ�
81�b�@Intel Core i7 2600K�i4�R�A�j�@\23,309
84�b�@Intel Core i5 2500K�i4�R�A�j�@\16,716
98�b�@Intel Core i3 2100�i2�R�A�j�@�@ \9,170
121�b�@Intel Celeron G540�i2�R�A�j�@ \4,330
129�b�@AMD FX-8150�i8�R�A�j�@�@�@�@\24,280
81�b�@Intel Core i7 2600K�i4�R�A�j�@\23,309
84�b�@Intel Core i5 2500K�i4�R�A�j�@\16,716
98�b�@Intel Core i3 2100�i2�R�A�j�@�@ \9,170
121�b�@Intel Celeron G540�i2�R�A�j�@ \4,330
129�b�@AMD FX-8150�i8�R�A�j�@�@�@�@\24,280
AMD�͍��͓���GPU�ŃA�h�o���e�[�W�����邯��
�P�D�������ш惊�~�b�g�ɍ����|�����Ă��Đ��\���オ���
�Q�DIntel���ĊO�{�C��GPU�Ƀ��\�[�X�������Ă���
�R�D���Ƀ��o�C���ł̓v���Z�X�̊i���̉e�����傫��
���炠��܂�y�ς͂ł��Ȃ���Ȃ����Ǝv����
�P�D�������ш惊�~�b�g�ɍ����|�����Ă��Đ��\���オ���
�Q�DIntel���ĊO�{�C��GPU�Ƀ��\�[�X�������Ă���
�R�D���Ƀ��o�C���ł̓v���Z�X�̊i���̉e�����傫��
���炠��܂�y�ς͂ł��Ȃ���Ȃ����Ǝv����
>>489
CPU���������Ă�����Ă����̈Ӗ����Ȃ���ɁA
�܂���ɂ����FX�������낷�̂ɃZ���܂œ������Ƃ��ăZ���Ɠ����i�т�A-�V���[�Y�̓V�J�g�B
��峂͂�ق�A-�V���[�Y���|���炵��ww
i3���Ƃ����āAA-�V���[�Y��i3��荂���̂�A8�����Ȃ���ł����ǁI
CPU���������Ă�����Ă����̈Ӗ����Ȃ���ɁA
�܂���ɂ����FX�������낷�̂ɃZ���܂œ������Ƃ��ăZ���Ɠ����i�т�A-�V���[�Y�̓V�J�g�B
��峂͂�ق�A-�V���[�Y���|���炵��ww
i3���Ƃ����āAA-�V���[�Y��i3��荂���̂�A8�����Ȃ���ł����ǁI
IvyBridge�͎�͂̃��o�C��2�R�A�ł���GPU�̕���CPU+LL���傫��
dGPU�O��Ȃ�4�R�A����D�悷��Ƃ����I�������������͂�
�{�C�x�͍����Ǝv��
���������ۂ̐��\��@�\�Œǂ����̂͂���Ɍ�̐���ɂȂ�Ƃ͎v������
dGPU�O��Ȃ�4�R�A����D�悷��Ƃ����I�������������͂�
�{�C�x�͍����Ǝv��
���������ۂ̐��\��@�\�Œǂ����̂͂���Ɍ�̐���ɂȂ�Ƃ͎v������
>>490
�܂��y�ςȂ�ē���ł��Ȃ�
arm�Ƃ�������Ӗ��X�ɋ���ȓG���T���Ă���킯������
����intel���œG��amd����arm�ɕς�����̂͊ԈႢ���낤��
����d��77w�Ƃ��Q�������Ă��炽���܂�arm�ɂ���Ă��܂����낤��3�N���炢�͂܂����v���낤����
intel��amd�����܂���قǔn������˂����炨�O����]����@�������Ă邾�낤��
amd�I�ɂ�arm�i�o�����肪�Ȃ��Ƃ���������intel��1w100�h���ȉ��ŏ����ł��邩�ǂ�������
100�h���ȉ����Ă��Ƃ�����I�Ɍ��������Ő�������Ƃ���
�����ɂ�70�h���ȉ������ꂾ���ǃn�C�G���h�Ȃ�100�h���ł�������̂ł͂Ȃ���
�n�C�G���h��100�h�������獡��1/4�ȉ���
�E���g���n�C�G���h�͓���x86�g�����낤�����͂�1000�h���N���X�@�����������o�Ȃ�������v�͑���������������
�܂��y�ςȂ�ē���ł��Ȃ�
arm�Ƃ�������Ӗ��X�ɋ���ȓG���T���Ă���킯������
����intel���œG��amd����arm�ɕς�����̂͊ԈႢ���낤��
����d��77w�Ƃ��Q�������Ă��炽���܂�arm�ɂ���Ă��܂����낤��3�N���炢�͂܂����v���낤����
intel��amd�����܂���قǔn������˂����炨�O����]����@�������Ă邾�낤��
amd�I�ɂ�arm�i�o�����肪�Ȃ��Ƃ���������intel��1w100�h���ȉ��ŏ����ł��邩�ǂ�������
100�h���ȉ����Ă��Ƃ�����I�Ɍ��������Ő�������Ƃ���
�����ɂ�70�h���ȉ������ꂾ���ǃn�C�G���h�Ȃ�100�h���ł�������̂ł͂Ȃ���
�n�C�G���h��100�h�������獡��1/4�ȉ���
�E���g���n�C�G���h�͓���x86�g�����낤�����͂�1000�h���N���X�@�����������o�Ȃ�������v�͑���������������
>>494
10�N���intel�͍��̐����̈�̋K�͂���
fab�Ɨ��Ńt�@�E���_���Ő������邾�낤��x86�̔����ȉ��̐����R�X�g�����߂��邾�낤������v�I�ɂ͌��������낤��
10�N���intel�͍��̐����̈�̋K�͂���
fab�Ɨ��Ńt�@�E���_���Ő������邾�낤��x86�̔����ȉ��̐����R�X�g�����߂��邾�낤������v�I�ɂ͌��������낤��
�Ȃ�Ŏ������Ă�́H
>>493
�Ȃ�Ă������A�V�������N�ŗ]�����_�C��TDP��S��GPU�ɓ˂�����
���[�N���ꂽ3DMark�̃X�R�A����
Intel HD2000��ł�������2.5�`3�{�炵������ALlano�ł���A6�`A8���炢
CPU�����̓^�[�{�̋����ƃR�A�̏����ǂ����邵�܂��c�c���Ă����ӂ肩
�Ƃ������Ƃ�Trinity����ł��i��ʂɌ����Č����jAMD��GPU���\�D�ʂ͕ς��Ȃ�
�������̌�́A�������ш悪�債�ĉ��P����Ȃ��̂œ��ł�
�����Ȃ��̂͂ނ���AMD�I�Ɉ�������Ȃ̂ŁA�����H�v���K�{�ȏ�
�Ȃ�Ă������A�V�������N�ŗ]�����_�C��TDP��S��GPU�ɓ˂�����
���[�N���ꂽ3DMark�̃X�R�A����
Intel HD2000��ł�������2.5�`3�{�炵������ALlano�ł���A6�`A8���炢
CPU�����̓^�[�{�̋����ƃR�A�̏����ǂ����邵�܂��c�c���Ă����ӂ肩
�Ƃ������Ƃ�Trinity����ł��i��ʂɌ����Č����jAMD��GPU���\�D�ʂ͕ς��Ȃ�
�������̌�́A�������ш悪�債�ĉ��P����Ȃ��̂œ��ł�
�����Ȃ��̂͂ނ���AMD�I�Ɉ�������Ȃ̂ŁA�����H�v���K�{�ȏ�
>>490
�v���Z�X�Ŏ���x��ɂȂ�ƃ��o�������ȁB
�v���Z�X�Ŏ���x��ɂȂ�ƃ��o�������ȁB
GeForce��28nm�͐�s���s�������AAMD�ƒ��ǂ����l�[���ōς܂��Ă��܂��悤������Trinity�͂��Ȃ肢�������������Ă��
���萫���i���������ǂ�����GPU�͘_�O����
���萫���i���������ǂ�����GPU�͘_�O����
502 �FSocket774�F2011/12/13(��) 05:48:08.28 ID:xO8Qck/k
�����t��A-�V���[�Y�i�j
CPU��i3�ȉ��AGPU�̓��[�G���h������6000�~�̍ŐV�Q�[�����܂����Ă܂��O���O
CPU��i3�ȉ��AGPU�̓��[�G���h������6000�~�̍ŐV�Q�[�����܂����Ă܂��O���O
>>499
�������ш��TSV�ʼn��Ƃ������Ȃ��H�@TSV������ɓ���Ă�݂�������
ttp://www.4gamer.net/games/017/G001762/20110425023/
�������ш��TSV�ʼn��Ƃ������Ȃ��H�@TSV������ɓ���Ă�݂�������
ttp://www.4gamer.net/games/017/G001762/20110425023/
504 �FSocket774�F2011/12/13(��) 06:06:46.17 ID:xO8Qck/k
�������ᐫ�\�����i�Ƃ����}�j�A������A-�V���[�Y�i�j��I
A4-3300 \5,280 �������� Amazon.co.jp
Celeron G530 \3,480 �������� Amazon.co.jp
A4-3300 \5,280 �������� Amazon.co.jp
Celeron G530 \3,480 �������� Amazon.co.jp
>>499
����GPU����HT�o�R���Đ�pVRAM���Ă̂́c�c������Ȃ�ł��������B
����GPU����HT�o�R���Đ�pVRAM���Ă̂́c�c������Ȃ�ł��������B
�ƁA������A-�V���[�Y�̃x���`�͂܂������o���Ȃ��A
A-�V���[�Y�ɃK�N�u���̈�峂������B
A-�V���[�Y�ɃK�N�u���̈�峂������B
��߂Ȃ�
>>486
���܂ł�AMD�̒��ł͗ǂ��Ȃ��������ŁA���ЂƔ�r�����ASP��40%�ƒᐅ�����Ȃ͕̂ς��Ȃ��B
INTEL�͂�����60%��L�[�v�BNvidia��50%��ɉ��Ă�B
�@
���̏؋��ɂǂ�����AMD����́A�ׂ������̓�����̂������A
���v���������ǁANvidia��AMD�Ƃ͌��Ⴂ�ɗ��v�グ�Ă�ˁB
�y���㍂��10��6,620���h���A�����v��1��7,830���h���z
http://pc.watch.impress.co.jp/docs/news/20111111_490233.html
�@
AMD 2011 Q2
���㍂�@15��7000���h���@�����v�@6100���h��
2011 Q3
���㍂ 16��9000���h�� �����v�@9700���h��
Nvidia 2011 Q2
���㍂�@10��2000���h���@�����v 1��5160���h��
�@
Nvidia 2011 Q3
���㍂�@10��6620���h���@�����v 1��7830���h��
Intel 2011�NQ3
���㍂ 142���h�� �����v 35���h��
���܂ł�AMD�̒��ł͗ǂ��Ȃ��������ŁA���ЂƔ�r�����ASP��40%�ƒᐅ�����Ȃ͕̂ς��Ȃ��B
INTEL�͂�����60%��L�[�v�BNvidia��50%��ɉ��Ă�B
�@
���̏؋��ɂǂ�����AMD����́A�ׂ������̓�����̂������A
���v���������ǁANvidia��AMD�Ƃ͌��Ⴂ�ɗ��v�グ�Ă�ˁB
�y���㍂��10��6,620���h���A�����v��1��7,830���h���z
http://pc.watch.impress.co.jp/docs/news/20111111_490233.html
�@
AMD 2011 Q2
���㍂�@15��7000���h���@�����v�@6100���h��
2011 Q3
���㍂ 16��9000���h�� �����v�@9700���h��
Nvidia 2011 Q2
���㍂�@10��2000���h���@�����v 1��5160���h��
�@
Nvidia 2011 Q3
���㍂�@10��6620���h���@�����v 1��7830���h��
Intel 2011�NQ3
���㍂ 142���h�� �����v 35���h��
����ARM��x86���Ē��ڂԂ������Ȃ��悤�ȋC�����邯�ǂȂ��c�c
ARM��Motolora�̌n�������瓯���A�v���P�[�V�������������Ƃ�����A
OS���x����������Ƌz��������Ȃ����烁��������S�����������ă��R���p�C���K�v�����c�c
(���Ȃ݂ɔC�V�����̗p���Ă�̂�FC��6502���̗p���Ĉȗ�Motorola�̌n��������)
MS���ǂ��܂ŗ͓���邩�ɂ���邾�낤���ǁc�c
ARM��Motolora�̌n�������瓯���A�v���P�[�V�������������Ƃ�����A
OS���x����������Ƌz��������Ȃ����烁��������S�����������ă��R���p�C���K�v�����c�c
(���Ȃ݂ɔC�V�����̗p���Ă�̂�FC��6502���̗p���Ĉȗ�Motorola�̌n��������)
MS���ǂ��܂ŗ͓���邩�ɂ���邾�낤���ǁc�c
��������g�����X���^���ŏ��A�䂪�Ђ�CPU�̓C���e���Ƌ������Ȃ����Č����Ă�����
RISC��m��Ȃ���B
���������̏����z��
���������̏����z��
Android-x86�g���Ă݂�����apk���̂܂܂Ԃ����瓮�����B
1���ԂŖO�������ǂˁB
1���ԂŖO�������ǂˁB
>>509
���������Ă�̂�������Ƃ悭�킩��܂���
���������Ă�̂�������Ƃ悭�킩��܂���
Bulldozer�Ŗ��ɒx���R�[�h������Ǝv������
����1���[�v��3cycle��������ۂ�����
..B12.11:
incl %esi
movaps %xmm0, (%ecx)
addl $16, %ecx
cmpl %eax, %esi
jl ..B12.11
Core2�`SandyBridge��1cycle
K10��1.5cycle���炢
����1���[�v��3cycle��������ۂ�����
..B12.11:
incl %esi
movaps %xmm0, (%ecx)
addl $16, %ecx
cmpl %eax, %esi
jl ..B12.11
Core2�`SandyBridge��1cycle
K10��1.5cycle���炢
L1D�A�N�Z�X����̂�1�T�C�N���ʼn���? �ŋ߂�CPU�͂������ˁB
>>512
Android��NDK�g�����A�v���łȂ�����java�Ń\�t�g�E�F�A��CPU�Ɨ����������Ă���B
�����炱��MIPS�@�Ȃ�Ă��̂��o���Ď��ۂɏo�ׂ���Ă�����c
Android��NDK�g�����A�v���łȂ�����java�Ń\�t�g�E�F�A��CPU�Ɨ����������Ă���B
�����炱��MIPS�@�Ȃ�Ă��̂��o���Ď��ۂɏo�ׂ���Ă�����c
http://www.4gamer.net/games/100/G010000/20111211001/
�Ȃ��Ȃ������[�����Ƃ�������Ă���
�Ȃ��Ȃ������[�����Ƃ�������Ă���
518 �FSocket774�F2011/12/13(��) 12:31:52.89 ID:7KE1+ZLs
�A���h�A�T�Ԃ����Ԃ���ł��Ƃ�w
http://bcnranking.jp/category/subcategory_0026_month.html
http://bcnranking.jp/category/subcategory_0026.html
>>517
�{�ԂɃC���^�r���[������Ȃ悗����
�{�ԂɃC���^�r���[������Ȃ悗����
>>517
2012�N��FSA���N
�ƌ������炢������2012���ɂ�SDK���o��̂���
C++AMP���̂�Visual Studio 11����Ή�������
VS11�̃����[�X�͂����炭2013�����
2012�N��FSA���N
�ƌ������炢������2012���ɂ�SDK���o��̂���
C++AMP���̂�Visual Studio 11����Ή�������
VS11�̃����[�X�͂����炭2013�����
�Ƃ���AMD�̍s���͒x���Ɏ����鎖����������Ȃ�
FSA���ĕʂɃn�[�h�Ɉˑ�����Z�p����Ȃ��B
���Ԉ�ʂ�CPU/GPU�ł�����Ȃ�ɓ����āA����FSA�O���AMD APU�Ȃ�����悭�����A�Ƃ������̂̂͂��B
�����甭�\�Ɠ����ɂ��łɃ��ł�܂��Ă邮�炢�̐�������Ȃ��ᗧ���グ�͊o�������B
�\�t�g�̎����Ȃ��̂Ɂu2012�N��FSA���N(�د�v�Ƃ������Ă鎞�_�ł��@�����������B
���Ԉ�ʂ�CPU/GPU�ł�����Ȃ�ɓ����āA����FSA�O���AMD APU�Ȃ�����悭�����A�Ƃ������̂̂͂��B
�����甭�\�Ɠ����ɂ��łɃ��ł�܂��Ă邮�炢�̐�������Ȃ��ᗧ���グ�͊o�������B
�\�t�g�̎����Ȃ��̂Ɂu2012�N��FSA���N(�د�v�Ƃ������Ă鎞�_�ł��@�����������B
Intel���Ɨ��x�ɂ����MIC��GPU�g�������Ƃ��ɂȂ�̂��ˁH
FSA�̓O���t�B�N�X�ƓƗ������R���s���[�e�B���O�����̃h���C�o�X�^�b�N�����
�Ƃ����b������OpenCL�x�[�X�����ǒ�C�e���V�ŒʐM�ł��Ă܂��Ƃ��������̃f���ł������̂�
�������������x���̃f������Ȃ������
Open64��C++AMP�T�|�[�g�͍D�ӓI�Ɍ��Ă�������
�Ƃ����b������OpenCL�x�[�X�����ǒ�C�e���V�ŒʐM�ł��Ă܂��Ƃ��������̃f���ł������̂�
�������������x���̃f������Ȃ������
Open64��C++AMP�T�|�[�g�͍D�ӓI�Ɍ��Ă�������
���̑O���炠�����������Ō����Ă邯�ǁA����Ȃɂ���̂���
�C�O�ł�����Ă�̂����{�����Ȃ̂�
�C�O�ł�����Ă�̂����{�����Ȃ̂�
NVIDIA��CUDA��5�N�撣���āA�X���[�v�b�g�d���̕����
����Ɨ����オ���Ă������x�̐i��������
�}���ȕ��y�Ȃǖ]�ނׂ����Ȃ�
IvdyBridge�ȍ~��OpenCL�Ή���CPU����ʂɏo�ׂ���n�߁A
���N��悤�₭�f�n���ł��邩���A���炢�Ɍ��Ă����Ȃ���
>>524
MIC��GPGPU�Ƌ������鎖�ɂȂ�͂�
�Ƃ͂������\�̏o�������Ⴄ�͂��Ȃ̂ŁA���ꂼ��Ɍ��������삪���邩������Ȃ�
����Ɨ����オ���Ă������x�̐i��������
�}���ȕ��y�Ȃǖ]�ނׂ����Ȃ�
IvdyBridge�ȍ~��OpenCL�Ή���CPU����ʂɏo�ׂ���n�߁A
���N��悤�₭�f�n���ł��邩���A���炢�Ɍ��Ă����Ȃ���
>>524
MIC��GPGPU�Ƌ������鎖�ɂȂ�͂�
�Ƃ͂������\�̏o�������Ⴄ�͂��Ȃ̂ŁA���ꂼ��Ɍ��������삪���邩������Ȃ�
�œK������Ȃ��Ƃ����̐��\�����ł���̂�AMDCPU���Ǝv���Ă��̂�
���B��@�ް
531 �FSocket774�F2011/12/13(��) 15:58:12.43 ID:S1vfBkXa
ARM�Ȃ�AMD�̑����ɂ��y�Ȃ���
���ꂾ����ARM�M�҂͍���
���ꂾ����ARM�M�҂͍���
ARM��AMD�̑����ɂ��y�Ȃ���������Ȃ����AAMD�̑����͗h�炢�ł邩������Ȃ��B
>>532
�h������AMD-E�N���X���A�V�����Ŕ��ꂽ���lj��B���Ɨ\�z�������тȂ��ƌ���ꂽ�ˁB
�P���ɁAx86��ARM�͎b����Windows�ŋ������Ȃ����ǁA
�R���~�O���Windows�m�[�g���̂��AAndroid�̃X�}�z���ɕς�鎖�ŁA
����������������Ă����s��Ƃ�����Ă�B
�@
AMD���X�}�z����ɁAVAIO P�݂����ȃ��o�C��Windows�y������ΕʂȂ̂����E�E�E
�h������AMD-E�N���X���A�V�����Ŕ��ꂽ���lj��B���Ɨ\�z�������тȂ��ƌ���ꂽ�ˁB
�P���ɁAx86��ARM�͎b����Windows�ŋ������Ȃ����ǁA
�R���~�O���Windows�m�[�g���̂��AAndroid�̃X�}�z���ɕς�鎖�ŁA
����������������Ă����s��Ƃ�����Ă�B
�@
AMD���X�}�z����ɁAVAIO P�݂����ȃ��o�C��Windows�y������ΕʂȂ̂����E�E�E
>>505
��������APU��HT-Link�O�ɏo�ĂȂ������
��������APU��HT-Link�O�ɏo�ĂȂ������
win95�`98�����3D�Q�[����邽�߂�E450�őg�ނ̂���ł����H
OS��XP�ŁB
OS��XP�ŁB
>>535�@�S��DX10�ȍ~���炢�̋@�\���g���ꍇ�ɑ��������B
XP�ȑO���Ⴂ�܂ǂ���GPU�����͊W�Ȃ�����CPU�̑����őI�ׂ�k
E350�Ƃ�����A�ギ�炢�O�̃m�[�g�����Z�������Ɠ����x�����ǂ���ł����Ȃ�\���B
XP�ȑO���Ⴂ�܂ǂ���GPU�����͊W�Ȃ�����CPU�̑����őI�ׂ�k
E350�Ƃ�����A�ギ�炢�O�̃m�[�g�����Z�������Ɠ����x�����ǂ���ł����Ȃ�\���B
http://www.4gamer.net/games/100/G010000/20111211001/
���ς�炸������������ȁ@
���ς�炸������������ȁ@
>>492
ivy�̃m�[�g�p�̓f�X�N�p���N���b�N�������AMD��GPU�̔���グ��������̂͊m��
haswell����ɂȂ�����w�ǒlj��O���{�쒀����邩�ƁB�m�[�g�ŃQ�[������悤�Ȑl�ȊO
ivy�̃m�[�g�p�̓f�X�N�p���N���b�N�������AMD��GPU�̔���グ��������̂͊m��
haswell����ɂȂ�����w�ǒlj��O���{�쒀����邩�ƁB�m�[�g�ŃQ�[������悤�Ȑl�ȊO
�m�[�g�̂��ƂȁB
>>537�@������i�����Ȃ�AMD�Ƃ͂����A�����܂Œx���Ȃ���Ȃ����ȁB
������啪�����͂��B
ATOMD525�@<�@E-350�@<�@SU2300�@<�z�����Ȃ���<�@3000�~���炢��Sandy�Z��
�Ƃ肠����GPU�g��Ȃ��Ȃ�AATOM�ɖт����������x�B
XP�ȑO��OS�ŁAGPU�g��Ȃ��Ȃ炠���Ĕ����K�v�͑S���Ȃ��B
������啪�����͂��B
ATOMD525�@<�@E-350�@<�@SU2300�@<�z�����Ȃ���<�@3000�~���炢��Sandy�Z��
�Ƃ肠����GPU�g��Ȃ��Ȃ�AATOM�ɖт����������x�B
XP�ȑO��OS�ŁAGPU�g��Ȃ��Ȃ炠���Ĕ����K�v�͑S���Ȃ��B
Intel Celeron G440 vs. AMD E-350
http://www.xbitlabs.com/articles/cpu/display/celeron-g540-g440_8.html
http://www.xbitlabs.com/articles/cpu/display/celeron-g540-g440_8.html
>>502
�m�[�g�ł͂��̒��x���œK�ȃ`���C�X����
�m�[�g�ł͂��̒��x���œK�ȃ`���C�X����
>>504
Celeron�Ȃ��y���ɃA�s�[��������̂�����Ǝv���悿�����pc�m���Ă�w�ɂ�
Celeron�Ȃ��y���ɃA�s�[��������̂�����Ǝv���悿�����pc�m���Ă�w�ɂ�
>>508
���Ⴂ���Ă�����2�{�s���ĂȂ����ǂȂ�
���Ⴂ���Ă�����2�{�s���ĂȂ����ǂȂ�
>>509
arm window���{���ɉH�����̂�5�N�ȏ�悾��
���̑O��armadroid vs wintel �̐킢�������ĔN�Xarmaroid�̃V�F�A���オ���Ă���
x86�Ɋւ��Ă͍Ő����͊��S�ɉ߂�������@�@
�R�X�g�I�ɂ�����d�͓I�ɂ��Ȃ�疣�͂��Ȃ���
arm window���{���ɉH�����̂�5�N�ȏ�悾��
���̑O��armadroid vs wintel �̐킢�������ĔN�Xarmaroid�̃V�F�A���オ���Ă���
x86�Ɋւ��Ă͍Ő����͊��S�ɉ߂�������@�@
�R�X�g�I�ɂ�����d�͓I�ɂ��Ȃ�疣�͂��Ȃ���
������AMD����������肢��ȁB
���AM3+�킹�Ă����āA�d���Ȃ�FX��������Ƃ�
���AM3+�킹�Ă����āA�d���Ȃ�FX��������Ƃ�
����͏�肢�Ƃ����Ă����̂��낤��
>>518
�����f�X�N�g�b�v�Ȃǂ��ł��������낗
�����f�X�N�g�b�v�Ȃǂ��ł��������낗
>>529
����Ȃ��ƂƂ����ɗ\���ł����̂ɂȂ�
�w�W�Ƃ��Ă��ꂾ���������]��܂����Ă邵arm�ɉ�����܂����Ă邵intel�m�[�g������n���Ȃ̂�intel�̋Ɛт������킯���Ȃ�
����Ȃ̂ɓ����Ԕ��̈�����intel�Ɛѐ�D���ƌ����ď���Ȃ�������w
�����ɋߔN�ɖ����Ɛт����̂�amd�����Ắ@�@
�قڃV�F�A�O�������m�[�g��2���O��̃V�F�A����ꂽ�킯����fab����P�ނ�����
���E�o�ς̑匸���ō����i�̃m�[�g�͉v�X����Ȃ��Ȃ��čX��intel�̋Ɛт͋ꂵ���Ȃ邾�낤��
����Ȃ��ƂƂ����ɗ\���ł����̂ɂȂ�
�w�W�Ƃ��Ă��ꂾ���������]��܂����Ă邵arm�ɉ�����܂����Ă邵intel�m�[�g������n���Ȃ̂�intel�̋Ɛт������킯���Ȃ�
����Ȃ̂ɓ����Ԕ��̈�����intel�Ɛѐ�D���ƌ����ď���Ȃ�������w
�����ɋߔN�ɖ����Ɛт����̂�amd�����Ắ@�@
�قڃV�F�A�O�������m�[�g��2���O��̃V�F�A����ꂽ�킯����fab����P�ނ�����
���E�o�ς̑匸���ō����i�̃m�[�g�͉v�X����Ȃ��Ȃ��čX��intel�̋Ɛт͋ꂵ���Ȃ邾�낤��
>>543 �V���O���R�A�̂��������[�G���h�̂�����̂Ƃ��������Ƃ̓A�����v���o���ȁB
8�R�A��4�R�A�Ɋ��t���邠��CPU���BATOM�Ƒ卷�Ȃ��̂��₵����w
8�R�A��4�R�A�Ɋ��t���邠��CPU���BATOM�Ƒ卷�Ȃ��̂��₵����w
�܂�AHTT����ɓ��ꂽ��G460���ŋ����Ă��ƁH
����!
����X���I��E450�ŋ����Ă������Ƃł����Ǝv���B
>>552
����d�͂�^�[�Q�b�g�i�Ђ�����d�̓m�[�g�Ђ�f�X�N�g�b�v�����Łj�Ⴄ���̔�ׂĉ�������������
����d�͂�2�{���Ⴄ�̂�
����d�͂�^�[�Q�b�g�i�Ђ�����d�̓m�[�g�Ђ�f�X�N�g�b�v�����Łj�Ⴄ���̔�ׂĉ�������������
����d�͂�2�{���Ⴄ�̂�
>>551
����AINTEL�������Ă�̂́A�^����HDD�̐���ȋ������o���Ė�����������\�z��艺�����B
AMD��HDD���g���Ė����̂��Hw
����AINTEL�������Ă�̂́A�^����HDD�̐���ȋ������o���Ė�����������\�z��艺�����B
AMD��HDD���g���Ė����̂��Hw
Hof3uyuL�͕a�C�×{��������G��Ȃ��ł�����
>>556 ���̃f�X�N�g�b�v�����łƏ���d�͂ɍ����Ȃ��̂��₵���ȁE�E�E�B
�܂�@���Ă�����E�E�E�E�B
http://www.xbitlabs.com/images/cpu/celeron-g540-g440/second/power-1.png
http://www.xbitlabs.com/images/cpu/celeron-g540-g440/second/power-2.png
�܂�@���Ă�����E�E�E�E�B
http://www.xbitlabs.com/images/cpu/celeron-g540-g440/second/power-1.png
{kind=link}
http://www.xbitlabs.com/images/cpu/celeron-g540-g440/second/power-2.png
{kind=link}
>>551
���܂ł�AMD�̒��ł͗ǂ��Ȃ��������ŁA���ЂƔ�r�����ASP��40%�ƒᐅ�����Ȃ͕̂ς��Ȃ��B
INTEL�͂�����60%��L�[�v�BNvidia��50%��ɉ��Ă�B
ASP
70%�I�[�o�[�@�{�b�^�N��
50�`60%��@����ȑe���v�@
40%��@�قړ�����
30%��@������@�`�l�c��
20%��ȉ��@�|�Y�ԋ߁@
���̏؋��ɂǂ�����AMD����́A�ׂ������̓�����̂������A
����グ�̊���ɗ��v���������ǁANvidia��AMD�Ƃ͌��Ⴂ�ɗ��v�グ�Ă�ˁB
�y���㍂��10��6,620���h���A�����v��1��7,830���h���z
http://pc.watch.impress.co.jp/docs/news/20111111_490233.html
�@
AMD 2011 Q2
���㍂�@15��7000���h���@�����v�@6100���h��
2011 Q3
���㍂ 16��9000���h�� �����v�@9700���h��
Nvidia 2011 Q2
���㍂�@10��2000���h���@�����v 1��5160���h��
�@
Nvidia 2011 Q3
���㍂�@10��6620���h���@�����v 1��7830���h��
Intel 2011�NQ3
���㍂ 142���h�� �����v 35���h��
���܂ł�AMD�̒��ł͗ǂ��Ȃ��������ŁA���ЂƔ�r�����ASP��40%�ƒᐅ�����Ȃ͕̂ς��Ȃ��B
INTEL�͂�����60%��L�[�v�BNvidia��50%��ɉ��Ă�B
ASP
70%�I�[�o�[�@�{�b�^�N��
50�`60%��@����ȑe���v�@
40%��@�قړ�����
30%��@������@�`�l�c��
20%��ȉ��@�|�Y�ԋ߁@
���̏؋��ɂǂ�����AMD����́A�ׂ������̓�����̂������A
����グ�̊���ɗ��v���������ǁANvidia��AMD�Ƃ͌��Ⴂ�ɗ��v�グ�Ă�ˁB
�y���㍂��10��6,620���h���A�����v��1��7,830���h���z
http://pc.watch.impress.co.jp/docs/news/20111111_490233.html
�@
AMD 2011 Q2
���㍂�@15��7000���h���@�����v�@6100���h��
2011 Q3
���㍂ 16��9000���h�� �����v�@9700���h��
Nvidia 2011 Q2
���㍂�@10��2000���h���@�����v 1��5160���h��
�@
Nvidia 2011 Q3
���㍂�@10��6620���h���@�����v 1��7830���h��
Intel 2011�NQ3
���㍂ 142���h�� �����v 35���h��
>>559
http://www.xbitlabs.com/images/cpu/celeron-g540-g440/second/farcry.png
http://www.xbitlabs.com/images/cpu/celeron-g540-g440/second/dirt.png
�����^��
http://www.xbitlabs.com/images/cpu/celeron-g540-g440/second/farcry.png
{kind=link}
http://www.xbitlabs.com/images/cpu/celeron-g540-g440/second/dirt.png
{kind=link}
�����^��
>>560
���ނ���x86�ȂɌ������������ɗ������}����arm�ɐi�o�������Ƃ͖J�߂Ă�邗
���ނ���x86�ȂɌ������������ɗ������}����arm�ɐi�o�������Ƃ͖J�߂Ă�邗
563 �F,,�E�L�́M�E,,�j��-�������F2011/12/13(��) 20:23:55.63 ID:lKpxTvb2
Intel��2�ʂ̃T���X����傫���������������̋ƊE�_���g�c�̃g�b�v
���ނ��Ă�̂�ARM�z�[���f�B���O�X�̎������z��1/3�܂ŗ������ڂꂽAMD����������
���ނ��Ă�̂�ARM�z�[���f�B���O�X�̎������z��1/3�܂ŗ������ڂꂽAMD����������
>>563
�悪�ǂ߂Ȃ����\�͏�ɗ{���ƂȂ��߂���skysell�N��
�悪�ǂ߂Ȃ����\�͏�ɗ{���ƂȂ��߂���skysell�N��
���ꂩ�A�m���ɖ��Ђ��@�\�s�S�Ɋׂ��Ă���悤��
IHS iSuppli
2011�N���E�����̔��㍂�����L���O�g�b�v20�Ёi���O�\���j
���㍂3128���ăh��
�C���e���@49.685%�@�O�N��+23%
�T���\���@29.242%�@+3%
TI�@�@�@�@�@14.081%
���Ł@�@�@13.382%�@+2.7%
���l�T�X�@11.153%
�N�A���R���@10.080%
ST�}�C�N���@9.792%
�n�C�j�N�X�@8.911%
�}�C�N�����@7.344%
�u���[�h�R���@7.153%
AMD�@�@�@�@�@�@6.483%�@+2.2%
�C���t�B�j�I���@5.403%
�\�j�[�@�@�@�@�@5.153%
�t���[�X�P�[���@4.465%
�G���s�[�_�@�@3.854%�@-40.2%
NXP�@�@�@�@�@�@3.838%
nVidia�@�@�@�@�@3.672%�@+14.9%
marvel�@�@�@�@3.448%
ON�Z�~�R���@3.423%
�p�i�\�j�b�N�@3.365%
IHS iSuppli
2011�N���E�����̔��㍂�����L���O�g�b�v20�Ёi���O�\���j
���㍂3128���ăh��
�C���e���@49.685%�@�O�N��+23%
�T���\���@29.242%�@+3%
TI�@�@�@�@�@14.081%
���Ł@�@�@13.382%�@+2.7%
���l�T�X�@11.153%
�N�A���R���@10.080%
ST�}�C�N���@9.792%
�n�C�j�N�X�@8.911%
�}�C�N�����@7.344%
�u���[�h�R���@7.153%
AMD�@�@�@�@�@�@6.483%�@+2.2%
�C���t�B�j�I���@5.403%
�\�j�[�@�@�@�@�@5.153%
�t���[�X�P�[���@4.465%
�G���s�[�_�@�@3.854%�@-40.2%
NXP�@�@�@�@�@�@3.838%
nVidia�@�@�@�@�@3.672%�@+14.9%
marvel�@�@�@�@3.448%
ON�Z�~�R���@3.423%
�p�i�\�j�b�N�@3.365%
566 �F,,�E�L�́M�E,,�j��-�������F2011/12/13(��) 20:34:15.32 ID:lKpxTvb2
���ȕ��͂�
NV���Ăǂ��������Ƃ����Ă������H
����������+14.9�����Ƃ����琦����
����������+14.9�����Ƃ����琦����
Icera�����܂���
IHS�̎����ɂ��ƁATegra2�ƃ��[�N�X�e�[�V���������̃O���t�B�b�N�v���Z�b�T�̍D�����㉟�������Ƃ�
ON�Z�~�R���_�N�^���Ă̂͏����̐l�������������ǁA�p�i����T�����[��������Ŗ��i
ON�Z�~�R���_�N�^���Ă̂͏����̐l�������������ǁA�p�i����T�����[��������Ŗ��i
>>567
���N��5�`6���ɁAIcera��3��6700���h�������Ŕ��������B
���N��5�`6���ɁAIcera��3��6700���h�������Ŕ��������B
>>568-870
���肪�ƁO�O
���肪�ƁO�O
Tesla�����\����Ă�݂�����
�Ȃ����4�R�A��TDP95W�̃S�~���
�}�V����Ȃ��ł���?
�}�V����Ȃ��ł���?
���̃S�~���x���ēd�C�H����E350�̈����͂����܂ł�
TDP2�{�Ⴄ�̂ɋt�]����Ƃ��M�����Ȃ���Ȃ�
TDP2�{�Ⴄ�̂ɋt�]����Ƃ��M�����Ȃ���Ȃ�
TDP2�{�ŃQ�[���̃x���`�͓����Ȃ��Ƃ������X
����d�͂�G440�̕���������Ȃ�����
http://www.xbitlabs.com/images/cpu/celeron-g540-g440/second/starcraft.png
TDP�{�Ȃ̂Ƀ_�u���X�R�A�ŕ�����Ƃ́E�E�E
{kind=link}
TDP�{�Ȃ̂Ƀ_�u���X�R�A�ŕ�����Ƃ́E�E�E
>>578
�S�R�ڍׂ������ĂȂ���3�y�[�W�ڂ�880W�d����HD6970�}���Ă���
����d�͂��Ă����Ȃ�J�߂Ă�����
�܂�SATA3����t���ĂȂ�H61�}�}���Ȃ�Ă���ˁ[���ǂ�
�S�R�ڍׂ������ĂȂ���3�y�[�W�ڂ�880W�d����HD6970�}���Ă���
����d�͂��Ă����Ȃ�J�߂Ă�����
�܂�SATA3����t���ĂȂ�H61�}�}���Ȃ�Ă���ˁ[���ǂ�
>>569
�i�V���i���Z�~�R���_�N�^��m���̂�w
�i�V���i���Z�~�R���_�N�^��m���̂�w
�i�V���i���Z�~�R���_�N�^�ƃI���Z�~�R���_�N�^���ē�����Ђ�������
�ց[
�ց[
>>581
�I���Z�~���Ă̂͌����g���[������c
�I���Z�~���Ă̂͌����g���[������c
���łɏ����Ƃ��ƃi�V���Z�~��TI�ɔ������ꂽ����B
>>517
��������Bulldozer���ă��W�X�^�Ԃ�movups/movaps�����l�[���ŏ����Ă���Ȃ��P�[�X�����\����ȁB
�P���ȃp�^�[�����Ƃ����Ə����邯�ǂ��傢�Ǝ��p�I�ȃp�^�[�����Ə����Ȃ��B
AVX��3op���߂܂Ŏg���Ή����i���邯��Bulldozer�������A�v���P�[�V�����Ő��\�łȂ��̂�
���W���[���\���Ƃ��X�s�[�h�ƃX���[�v�b�g(��)�Ƃ��W�Ȃ���
���������s�𗝂Ȑ��\����������p�^�[���̐ςݏd�˂���Ȃ����낤���B
x87���P���ȃp�^�[�����ƃL�`���Ɛ��\�o�邯�ǂ�����ƕ��G�ɂȂ�Ɛ��\�K�^��������P�[�X�������݂��������B
L2DTLB��sqrtss���R��B
��������Bulldozer���ă��W�X�^�Ԃ�movups/movaps�����l�[���ŏ����Ă���Ȃ��P�[�X�����\����ȁB
�P���ȃp�^�[�����Ƃ����Ə����邯�ǂ��傢�Ǝ��p�I�ȃp�^�[�����Ə����Ȃ��B
AVX��3op���߂܂Ŏg���Ή����i���邯��Bulldozer�������A�v���P�[�V�����Ő��\�łȂ��̂�
���W���[���\���Ƃ��X�s�[�h�ƃX���[�v�b�g(��)�Ƃ��W�Ȃ���
���������s�𗝂Ȑ��\����������p�^�[���̐ςݏd�˂���Ȃ����낤���B
x87���P���ȃp�^�[�����ƃL�`���Ɛ��\�o�邯�ǂ�����ƕ��G�ɂȂ�Ɛ��\�K�^��������P�[�X�������݂��������B
L2DTLB��sqrtss���R��B
�X���[�v�b�g(��)���ĉ�����
�u�X�s�[�h�ƃX���[�v�b�g�v(��)�Ǝ���Ă��炦��B
�l�I�ɂ͍ŋ߃q�b�g������������w
�{���̖�肩��ڂ�w���ĕK���Ƀ~�X���[�h���悤�Ƃ���AMD�̉c�Ƃ��Č��Ăă����G�ˁH
�l�I�ɂ͍ŋ߃q�b�g������������w
�{���̖�肩��ڂ�w���ĕK���Ƀ~�X���[�h���悤�Ƃ���AMD�̉c�Ƃ��Č��Ăă����G�ˁH
>>565
�G���s�̈�l�������@orz
�����������ɂ�������Ă��Ȃ�̃����b�g���Ȃ��Ȃ��낻�뒪���@�ŋ������Ȃ�ĂƂ�ł��Ȃ�
�Ă����{�������̂Ŗׂ�����͖̂Œ��ꒃ�j�b�`�ł��̕���Ő��E�V�F�A�̂قƂ�ǎ���Ă邩�p���[�����̂��炢��
�p���[�n�̓T�������厑�{�������Ă����烄�o�C�ȁ@�X�}�[�g�O���b�h����݂Ő��E�����������Ă�������
���[����tdk���ŋ߃C�}�C�`�炵�����Ǒ��v��
�G���s�̈�l�������@orz
�����������ɂ�������Ă��Ȃ�̃����b�g���Ȃ��Ȃ��낻�뒪���@�ŋ������Ȃ�ĂƂ�ł��Ȃ�
�Ă����{�������̂Ŗׂ�����͖̂Œ��ꒃ�j�b�`�ł��̕���Ő��E�V�F�A�̂قƂ�ǎ���Ă邩�p���[�����̂��炢��
�p���[�n�̓T�������厑�{�������Ă����烄�o�C�ȁ@�X�}�[�g�O���b�h����݂Ő��E�����������Ă�������
���[����tdk���ŋ߃C�}�C�`�炵�����Ǒ��v��
���̇X�Ƃ���������
�ăC���e���|�啝�����@4Q���㍂�Ƒe���v�������������AHDD�s���ɂ��T�v���C�`�F�[�����Ɉ��k
http://www.traders.co.jp/news/news_top.asp?type=1&newscode=585372
>�n�[�h�E�f�B�X�N�E�h���C�u�iHDD�j�̋����s���ɂ��APC�̃T�v���C�`�F�[�������E�I��
>�ɂ����k���Ă��邱�ƂɂƂ��ɁA�����̂̍w�����������Ă���Ǝw�E�����B
>���̌��ۂ�2012�N1-3�������Â��\��������Ƃ݂Ă���B
����Ȃ̂܂Ƃ��ɐM�����͈ꐶ�{���l��
�����ƑO����m�[�g�͓�����Apc�����K���K���A��������\��
http://www.traders.co.jp/news/news_top.asp?type=1&newscode=585372
>�n�[�h�E�f�B�X�N�E�h���C�u�iHDD�j�̋����s���ɂ��APC�̃T�v���C�`�F�[�������E�I��
>�ɂ����k���Ă��邱�ƂɂƂ��ɁA�����̂̍w�����������Ă���Ǝw�E�����B
>���̌��ۂ�2012�N1-3�������Â��\��������Ƃ݂Ă���B
����Ȃ̂܂Ƃ��ɐM�����͈ꐶ�{���l��
�����ƑO����m�[�g�͓�����Apc�����K���K���A��������\��
>>551
HDD�̕i�s����������Ĕ��\���Ă邾��A�z��
HDD�̕i�s����������Ĕ��\���Ă邾��A�z��
>>590
�����O�̔��\�͉ߋ��ō��̔���グ��������@���Q�ڂ������Ƃ����Ă��
�����O�̔��\�͉ߋ��ō��̔���グ��������@���Q�ڂ������Ƃ����Ă��
593 �FSocket774�F2011/12/14(��) 05:51:17.75 ID:cGMQXH3u
Intel�ɂ�HDD���v�~������SSD�̉��i�j������҂�����
594 �FSocket774�F2011/12/14(��) 07:33:55.72 ID:P2nZJYIR
AMD�ɂ͂������肾�ˁB
�|���R�cAPU�����Ď����ゾ���āI�I
����ŃV���O���X���b�h�Œx���������n���ҁI�I
AMD��A����Ȃ�I�I
595 �F,,�E�L�́M�E,,�j��-�������F2011/12/14(��) 07:35:22.51 ID:PYjQOL5E
>>585
> ��������Bulldozer���ă��W�X�^�Ԃ�movups/movaps�����l�[���ŏ�����
�������Ȃ���Ȃ̂���������
���N���������Ă��@�\���Ă���ς蒆�r���[�����ǎ�������Ă��̂�������
����A�܂Ƃ��Ɏ�������Ă�������������Ȃ��������ˁB
> ��������Bulldozer���ă��W�X�^�Ԃ�movups/movaps�����l�[���ŏ�����
�������Ȃ���Ȃ̂���������
���N���������Ă��@�\���Ă���ς蒆�r���[�����ǎ�������Ă��̂�������
����A�܂Ƃ��Ɏ�������Ă�������������Ȃ��������ˁB
http://www.fudzilla.com/home/item/25191-nigel-dessau-is-out-of-amd
Nigel Dessau is out of AMD
Nigel Dessau is out of AMD
hdd���Y�����Ă�pc�Ȃ����킯������
���\���O�a���Ă��܂��Ĉ�ʐl�̓m�[�g�̃��������SG�܂ő��₷�����ꂷ�炵�Ȃ�
�X�}�z�ƈ���ăt�@�b�V�������Ȃ�����f���A���R�Apc�����Ă��܂��S,�T�N�ȏ�͔����ւ����Ȃ����낤��
�Ƃɂ��������ւ��܂ł̊��Ԃ͂ǂ�ǂтĐV�������v��100�h��pad�␔�\�h���̒���pc�ɐH���邾�낤���E�o�ς̈����ŔN�X���̌X���͋��܂�
�V�����ł̐��\�h���͓��{�~���Ɛ����~�̊��o������
���\���O�a���Ă��܂��Ĉ�ʐl�̓m�[�g�̃��������SG�܂ő��₷�����ꂷ�炵�Ȃ�
�X�}�z�ƈ���ăt�@�b�V�������Ȃ�����f���A���R�Apc�����Ă��܂��S,�T�N�ȏ�͔����ւ����Ȃ����낤��
�Ƃɂ��������ւ��܂ł̊��Ԃ͂ǂ�ǂтĐV�������v��100�h��pad�␔�\�h���̒���pc�ɐH���邾�낤���E�o�ς̈����ŔN�X���̌X���͋��܂�
�V�����ł̐��\�h���͓��{�~���Ɛ����~�̊��o������
600 �FSocket774�F2011/12/14(��) 08:11:40.12 ID:BnoAlDOG
����ȃK���N�^�A�ǂ����傤���Ȃ��B�Ƃ������Ƃ�
�}�[�P�e�B���O�ӔC�҂��g���Y��(�P���P)
�}�[�P�e�B���O�ӔC�҂��g���Y��(�P���P)
�v���Z�b�T CPU�����_���\
(GFLOPS) �����������_���\
(GB/s)
2S �� Xeon X5690 3.46GHz DDR3-1333MHz 2p 12c (32nm Westmere 2S) 166 64
�� Opteron 6176 2.3GHz DDR3-1333MHz 2p 24c (45nm Magny-Cours 2S) 221 85
�V Opteron 6276 2.3GHz DDR3-1600MHz 2p 32c (32nm Interlagos 2S) �@�@�@�@�@�@�@294
(AVX : 294) 102
(��) (E5 2.8GHz DDR3-1600MHz 2p 16c (Sandy Bridge)) * �@�@�@�@�@�@�@�@�@�@�@�@�@179
(AVX : 358)* (102) *
4S �� Xeon E7-4870 2.4GHz DDR3-1066MHz 4p 40c (32nm Westmere 4S) 384 157
�� Opteron 6176 2.3GHz DDR3-1333MHz 4p 48c (45nm Magny-Cours 4S) 442 170
�V Opteron 6276 2.3GHz DDR3-1600MHz 4p 64c (32nm Interlagos 4S) �@�@�@�@�@�@�@589 205
http://hpc-technologies.co.jp/solution/cpu-comp3-spec-Interlagos-Westmere.html
��]��2ch�̈����̏������݂��̂܂ܐM���Ƃ���
(GFLOPS) �����������_���\
(GB/s)
2S �� Xeon X5690 3.46GHz DDR3-1333MHz 2p 12c (32nm Westmere 2S) 166 64
�� Opteron 6176 2.3GHz DDR3-1333MHz 2p 24c (45nm Magny-Cours 2S) 221 85
�V Opteron 6276 2.3GHz DDR3-1600MHz 2p 32c (32nm Interlagos 2S) �@�@�@�@�@�@�@294
(AVX : 294) 102
(��) (E5 2.8GHz DDR3-1600MHz 2p 16c (Sandy Bridge)) * �@�@�@�@�@�@�@�@�@�@�@�@�@179
(AVX : 358)* (102) *
4S �� Xeon E7-4870 2.4GHz DDR3-1066MHz 4p 40c (32nm Westmere 4S) 384 157
�� Opteron 6176 2.3GHz DDR3-1333MHz 4p 48c (45nm Magny-Cours 4S) 442 170
�V Opteron 6276 2.3GHz DDR3-1600MHz 4p 64c (32nm Interlagos 4S) �@�@�@�@�@�@�@589 205
http://hpc-technologies.co.jp/solution/cpu-comp3-spec-Interlagos-Westmere.html
��]��2ch�̈����̏������݂��̂܂ܐM���Ƃ���
603 �FSocket774�F2011/12/14(��) 09:24:37.01 ID:4bJ/Cj1G
�u���́A
�T�[�o�E�E�E�~
�f�X�N�g�b�v�E�E�E�~
�Q�[���E�E�E�~
HPC�E�E�E��
����
HPC�ł����g�����ɂȂ�Ȃ��`�b�v�����AMD�͂Ȃɂ��������킩���
�T�[�o�E�E�E�~
�f�X�N�g�b�v�E�E�E�~
�Q�[���E�E�E�~
HPC�E�E�E��
����
HPC�ł����g�����ɂȂ�Ȃ��`�b�v�����AMD�͂Ȃɂ��������킩���
>>601
�����o��������Ȃ��̂ɂ���Ȃɍ����ĕs���R�Ȃ���Ȃ�������Ă����۔���Ė�����Ȃ�
ultrabook�Ȃ����ĂĂ���������ڂ��Ă���Ȃ�����X�}�z�ɋ������@
�������͐i���������疈�N�����ւ����K�v����2�N���Ƃɉ��̐i�����Ȃ����g�є�����������}�V�Ȃ낤��
�����o��������Ȃ��̂ɂ���Ȃɍ����ĕs���R�Ȃ���Ȃ�������Ă����۔���Ė�����Ȃ�
ultrabook�Ȃ����ĂĂ���������ڂ��Ă���Ȃ�����X�}�z�ɋ������@
�������͐i���������疈�N�����ւ����K�v����2�N���Ƃɉ��̐i�����Ȃ����g�є�����������}�V�Ȃ낤��
http://www.idc.com/getdoc.jsp?containerId=prUS23119811
3Q11 Vendor Highlights
CPU�S��
Intel 80.2% +0.9%
AMD 19.7% -0.7%
VIA 0.1% -0.1%
mobile PC processor
Intel 82.3% -2.1%
AMD 17.6% +2.4%
VIA 0.1%
PC server/workstation processor
Intel 95.1% +0.6%
AMD 4.9% -0.6%
desktop PC processor
Intel 75.8% +4.8%
AMD 24.1% -4.8%
3Q11 Vendor Highlights
CPU�S��
Intel 80.2% +0.9%
AMD 19.7% -0.7%
VIA 0.1% -0.1%
mobile PC processor
Intel 82.3% -2.1%
AMD 17.6% +2.4%
VIA 0.1%
PC server/workstation processor
Intel 95.1% +0.6%
AMD 4.9% -0.6%
desktop PC processor
Intel 75.8% +4.8%
AMD 24.1% -4.8%
�Ƃ��Ƃ�Opteron5%���������A�f�X�N�g�b�v���オ��ڂȂ���
�������S�Ƀ��o�C����{�ōs����
�������S�Ƀ��o�C����{�ōs����
>>599
>�V�����ł̐��\�h���͓��{�~���Ɛ����~�̊��o������
AMD�̌��O�́ABobcat�ȍ~�̔����ւ����V�����Ŗ����Ȃ�ƁA
���N�x�Ɛї\�z���������Ȃ�炵�����B
�@
>�V�����ł̐��\�h���͓��{�~���Ɛ����~�̊��o������
AMD�̌��O�́ABobcat�ȍ~�̔����ւ����V�����Ŗ����Ȃ�ƁA
���N�x�Ɛї\�z���������Ȃ�炵�����B
�@
�J�^���O�X�y�b�N��D��
���~�b�^�[��D��
���~�b�^�[��D��
HDD�̋����s�����ă��[�G���h�@����ԉe�����傫����ˁB
��ʋ@��͗������傫����SSD�̊����I�v�V������p�ӂ��Ă邱�Ƃ����邪
���i���̃��[�G���h��HDD�̉��i�����̉e��������Ɏ�B
Intel��Celeron�N���X�͌�������AMD�͉�œI����B
��ʋ@��͗������傫����SSD�̊����I�v�V������p�ӂ��Ă邱�Ƃ����邪
���i���̃��[�G���h��HDD�̉��i�����̉e��������Ɏ�B
Intel��Celeron�N���X�͌�������AMD�͉�œI����B
AMD�̃V�F�A�͉i����2���̂܂ܑ���������������A
�����������̑傫�����������s��ł�Intel�ɃL���b�`�A�b�v�ł������ߏo�����A�Ƃ����̂�
Intel�ɂƂ��Ďs��Ɛ�̌x�������ɗ��v���ő剻�ł��闝�z�̃V�i���I�B
�����������̑傫�����������s��ł�Intel�ɃL���b�`�A�b�v�ł������ߏo�����A�Ƃ����̂�
Intel�ɂƂ��Ďs��Ɛ�̌x�������ɗ��v���ő剻�ł��闝�z�̃V�i���I�B
Opteron�̕��ϔ̔����i��3�N��390�j��420�j�ɏオ���Ă�
�V�F�A�������E�ł��Ă邩�ǂ������L������
�V�F�A�������E�ł��Ă邩�ǂ������L������
�Ԉ����
290�j��420�j��
290�j��420�j��
amd�̓��o�C��0����������20���炢�ɑ��₷
opteron��œI����������V�A�[�L�J���Ş��q����
���H������fab���p
�m���ɉۑ�����Ȃ��ē��ʂ̐����c����v����
������3�N��ʂɗ���arm�Ƃ̑S�ʐ푈�ɂ���ŏ��Ă邩�͋^��
���ǂǂ�������������`�ɂȂ�Ƃ͎v��
opteron��œI����������V�A�[�L�J���Ş��q����
���H������fab���p
�m���ɉۑ�����Ȃ��ē��ʂ̐����c����v����
������3�N��ʂɗ���arm�Ƃ̑S�ʐ푈�ɂ���ŏ��Ă邩�͋^��
���ǂǂ�������������`�ɂȂ�Ƃ͎v��
>>598
�悤�₭�����̍�������������
�悤�₭�����̍�������������
616 �FSocket774�F2011/12/14(��) 12:32:19.06 ID:We4czzlx
����ȃK���N�^�A�ǂ����傤���Ȃ��B�Ƃ������Ƃ�
�}�[�P�e�B���O�ӔC�҂��g���Y��(�P���P)
�}�[�P�e�B���O�ӔC�҂��g���Y��(�P���P)
617 �FSocket774�F2011/12/14(��) 12:46:36.18 ID:wASp5bYP
�܂�Q4���Ă̂��y���݂ƌ������Ƃ����낤�B
Llano�̔���C�}�C�`�ŗ\��ʂ�̐��Y���ł��ĂȂ��͎̂����Ǝv�����B
Llano�̔���C�}�C�`�ŗ\��ʂ�̐��Y���ł��ĂȂ��͎̂����Ǝv�����B
>���N�����������@�\����
>���N�����������@�\����
>���N�����������@�\����
�c�q����!
�@�@�j�j�j��[[[[[)�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�j�j�j��[[[[[)
�@�@�@�@�@�@�@�@�@�@�@�j�j�j��[[[[[)
�j�j�j��[[[[[)�@�@�@�@�@�@�@�@�@�@�@�@�@�j�j�j��[[[[[)
>���N�����������@�\����
>���N�����������@�\����
�c�q����!
�@�@�j�j�j��[[[[[)�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�j�j�j��[[[[[)
�@�@�@�@�@�@�@�@�@�@�@�j�j�j��[[[[[)
�j�j�j��[[[[[)�@�@�@�@�@�@�@�@�@�@�@�@�@�j�j�j��[[[[[)
619 �FSocket774�F2011/12/14(��) 12:55:26.50 ID:wASp5bYP
����łȂ��ĕ����܂肾�낤�B
���Ȃɏ����Ăc
���Ȃɏ����Ăc
>>598
AMD�ő�̐�����K7�̌��J�҂���n�܂�����l���͈�̂ǂ��Ŏ~�܂�̂��
�I��������ɂ܂Ƃ��ȃA�[�L�e�N�g���c���Ă�Ƃ����ł���
���̈������������c���ĉ�А��Z�Ƃ����ق��Ă���������
AMD�ő�̐�����K7�̌��J�҂���n�܂�����l���͈�̂ǂ��Ŏ~�܂�̂��
�I��������ɂ܂Ƃ��ȃA�[�L�e�N�g���c���Ă�Ƃ����ł���
���̈������������c���ĉ�А��Z�Ƃ����ق��Ă���������
621 �FSocket774�F2011/12/14(��) 14:44:38.56 ID:TdOPNfi8
>>612
�P������������葁�����@�A
�f�X�N�g�b�v��200-300CPU���~�߂邱�Ƃ��ȁB
APU�Ȃ�_�C�T�C�Y1�ؕ��ā�1�ACPU�Ȃ�1�ؕ��ā�1.2��鉿�i����߂Ă��܂������B
����̓C���e��������Ă���邩��w
���̑���C���e���̂ڂ�������1���ā�5�ȏ�̃��C���z�łԂ���I�b�P�[�B
�P������������葁�����@�A
�f�X�N�g�b�v��200-300CPU���~�߂邱�Ƃ��ȁB
APU�Ȃ�_�C�T�C�Y1�ؕ��ā�1�ACPU�Ȃ�1�ؕ��ā�1.2��鉿�i����߂Ă��܂������B
����̓C���e��������Ă���邩��w
���̑���C���e���̂ڂ�������1���ā�5�ȏ�̃��C���z�łԂ���I�b�P�[�B
3�N��390�j��420�j���ĕ��ʂɕ����㏸�����x���
>>622
�悭�ǂߔn��
�悭�ǂߔn��
�I��ŏ�Ԃ����ǁA�j�R�C�`16�R�A�u���h�U�ő����͐���Ԃ��Ǝv���H�������B
626 �FSocket774�F2011/12/14(��) 16:49:22.37 ID:l+F7yf9Z
>>621
�����o��f�X�N�g�b�v�p���A�T�[�o�p�����ŊJ���������Ȃ��Ƃ����Ȃ��̂�
�P��������ɒ��ˏオ�邾��
���̃T�[�o��p�̍�����CPU������Ă郁�[�J�[���ꂵ���̂́A
���Y�ʂ����Ȃ����Ƃɂ�鉿�i�����Ȃ̂�
�����o��f�X�N�g�b�v�p���A�T�[�o�p�����ŊJ���������Ȃ��Ƃ����Ȃ��̂�
�P��������ɒ��ˏオ�邾��
���̃T�[�o��p�̍�����CPU������Ă郁�[�J�[���ꂵ���̂́A
���Y�ʂ����Ȃ����Ƃɂ�鉿�i�����Ȃ̂�
��������̓m�[�g����
�f�X�N�͍���k������
�f�X�N�͍���k������
>>560
�{�b�^�N���Ă�̂ɂ��Ԕ����Ȃ�
�{�b�^�N���Ă�̂ɂ��Ԕ����Ȃ�
�������̃m�[�g�������悤���Ȃ��ȁB
A6����A6������Ō��E�����AIntel�ł�������ȁ[�B
A6����A6������Ō��E�����AIntel�ł�������ȁ[�B
>>629
�ڂ����������fx8150�̂��ƁH��
�ڂ����������fx8150�̂��ƁH��
>>559
���N���b�N�̃V���O���R�A����ɒ���I�ȑP�킾�ȁB
���N���b�N�̃V���O���R�A����ɒ���I�ȑP�킾�ȁB
634 �FSocket774�F2011/12/14(��) 17:48:00.59 ID:MTEWOuNr
�傫���o�O�t�B�b�N�X�̐i�uCatalyst 11.12�v�ƁCRadeon HD 7000�T�|�[�g�̉�������uCatalyst 12.1 Preview�v���قړ��������[�X
http://www.4gamer.net/games/022/G002212/20111214010/
���̃X���I�ɂ͂�����
���EVISION Engine Control Center�̊g��
�� �uDual Graphics�v�̗L���������s���₷���Ȃ���
http://www.4gamer.net/games/022/G002212/20111214010/
���̃X���I�ɂ͂�����
���EVISION Engine Control Center�̊g��
�� �uDual Graphics�v�̗L���������s���₷���Ȃ���
RADEON�X����AMD�G�k�X�������̘b�肩��
>>632
���̒l�i�ł��ꂾ�����\�o�Ă�A�ڂ�������ꂽ�C�����Ȃ��ȁB
�ނ���I�g�N�Ȋ����B
�g�������Ɩ������c��dis���Ă邾���B
���̒l�i�ł��ꂾ�����\�o�Ă�A�ڂ�������ꂽ�C�����Ȃ��ȁB
�ނ���I�g�N�Ȋ����B
�g�������Ɩ������c��dis���Ă邾���B
>>636
2500k�̂ق��������Ƃ�������
2500k�̂ق��������Ƃ�������
�n����������K10�ȏ�̐��\�͂����Ƃł邩��Ȃ��B
64Bit�̕����n�����݂ɂ����������A���������C���Ŏg���Ă�l�ɂ͔j�i�̍����\CPU�����B
64Bit�̕����n�����݂ɂ����������A���������C���Ŏg���Ă�l�ɂ͔j�i�̍����\CPU�����B
Intel�M�҉�
���Ђ̃n�C�G���h�ł���i7 3960X��FX8150���ׂ�Έ�h��������̏����\�͂ƈ�R�A������̒l�i�͂͂邩�ɂ������Ƃ����̂�
���Ђ̃n�C�G���h�ł���i7 3960X��FX8150���ׂ�Έ�h��������̏����\�͂ƈ�R�A������̒l�i�͂͂邩�ɂ������Ƃ����̂�
>>639
�ӂ���
�ӂ���
����AMD�͍D�����@�D�������V�F�A�̂��߂Ɋ撣���Ăق����Ƃ��v�����E�E�E
������g�ނȂ�i5-2500K�Ƃ�T�̕���������
��������d�͂�����̐��\�A���M���Ђǂ�����
������g�ނȂ�i5-2500K�Ƃ�T�̕���������
��������d�͂�����̐��\�A���M���Ђǂ�����
AID64��CPU Photoworxx��VMmark�Ȃǂ�ALU�g�p���̏���d�͌��Ă݂�����
�d�͂�����Ă�̂̓X�J���Ȃ̂��x�N�^�Ȃ̂��A�����͂��̑��Ȃ̂�
�d�͂�����Ă�̂̓X�J���Ȃ̂��x�N�^�Ȃ̂��A�����͂��̑��Ȃ̂�
643 �FSocket774�F2011/12/14(��) 18:58:09.46 ID:TdOPNfi8
>>626 >>628
��1000�ȏ��CPU�s��r�炳�Ȃ��ŁA���c�l���ޯ��ڂȂ��Ȃ����Ⴄ�B
�܂œǂB
�����Ȃ��̂ɂȂ�Ńr�b�O�_�C��bull���o����B
��1000�ȏ��CPU�s��r�炳�Ȃ��ŁA���c�l���ޯ��ڂȂ��Ȃ����Ⴄ�B
�܂œǂB
�����Ȃ��̂ɂȂ�Ńr�b�O�_�C��bull���o����B
>>643
�����Ȃ瑽�����邵�����v��������@���Ȃ��̂�
�������Y�Ŕ����ɂ���Ƃ��n�����남�O��������
�����������ł��������܂舫���̂ɒቿ�i�т����č����i�тɒ��͂�����܂��܂�����镨�Ȃ��Ȃ邶���
�����Ȃ瑽�����邵�����v��������@���Ȃ��̂�
�������Y�Ŕ����ɂ���Ƃ��n�����남�O��������
�����������ł��������܂舫���̂ɒቿ�i�т����č����i�тɒ��͂�����܂��܂�����镨�Ȃ��Ȃ邶���
�u�����h�͂���(�����������ƂȂ���)�������Ȃ�ቿ�i�т�CPU�ő���������i�͑��������Ƃ�Intel�����|���ĕ�����v�f���������炢�̍����\CPU���o���������ȁB
�}���`�\�P�b�g�T�[�o�[�����̃`�b�v�Ƃ��Ă�Bull�͕��ʂ��Ǝv�����ǂ�
MCM��Opteron6200�ł͔{�ɂ����600mm2�z���ɂȂ邪�A
����Fab�ō��Ȃ�600mm2��1�`�b�v���300mm2��2�`�b�v�̕��������܂�̊W�Ōo�ϓI�ɍ��邾�낤
MCM��Opteron6200�ł͔{�ɂ����600mm2�z���ɂȂ邪�A
����Fab�ō��Ȃ�600mm2��1�`�b�v���300mm2��2�`�b�v�̕��������܂�̊W�Ōo�ϓI�ɍ��邾�낤
http://www.nordichardware.com/news/69-cpu-chipset/44876-ivy-bridge-3770k-benchmarks.html
�`�o�t�������������@�A�z���{�߂�IPC�Ⴄ����ˁ[��
�`�o�t�������������@�A�z���{�߂�IPC�Ⴄ����ˁ[��
��������Llano����̃V���O���R�A���ᐫ�\�߂��ď���
�R�A����{�v�b�V����
650 �F,,�E�L�́M�E,,�j��-�������F2011/12/14(��) 19:58:52.93 ID:PYjQOL5E
>>647
�����������ɒ������Ă���瓖�R����H
�����������ɒ������Ă���瓖�R����H
652 �F,,�E�L�́M�E,,�j��-�������F2011/12/14(��) 20:11:41.77 ID:PYjQOL5E
�Ȃ�ق�AMD�͂킴�ƒx���Ȃ�悤�ɒ������Ă�̂�������
�I���Ȑ헪���Ȃ�������
�I���Ȑ헪���Ȃ�������
653 �FSocket774�F2011/12/14(��) 20:18:58.34 ID:e68pg+R4
�܂��A���ʂ��S�Ă����
�A���h��ł��Ƃ�w
http://bcnranking.jp/category/subcategory_0026_month.html
http://bcnranking.jp/category/subcategory_0026.html
�A���h��ł��Ƃ�w
http://bcnranking.jp/category/subcategory_0026_month.html
http://bcnranking.jp/category/subcategory_0026.html
GPU�Ȃォ��t�����邩�炢����CPU���������Ȃ�APU�̂ǂ���������
655 �F,,�E�L�́M�E,,�j��-�������F2011/12/14(��) 20:27:58.12 ID:PYjQOL5E
AMD��QPI�̃��C�Z���X�����i7�p��Fusion�����������������Ȃ��̂��H
AMD��FX����C�Ȃ����đO��ōl����ƂƂĂ����덇������B
AMD�I�ɂ�Opteron�����ł����Y�ǂ����Ȃ�������Ȃ�
AMD�ɂƂ���FX��PC����CPU����Ă���Ď��э��̈Ӗ������Ȃ����B
�C�^�C�c�Ƃ̂����킯���D�]��Opteron�̐��\��
Bulldozer�̃l�K�L�����U���������Êς���AMD�̎p�������덇�����B
�ꉞ�ABTO�D��ȂŔ̔��X�D�����Ă݂���p�C�v�͂Ȃ��Œu�������݂���������
���Ԃ�Opteron�O�a������PC�����ł��{�C�o����Ȃ��H
AMD�I�ɂ�Opteron�����ł����Y�ǂ����Ȃ�������Ȃ�
AMD�ɂƂ���FX��PC����CPU����Ă���Ď��э��̈Ӗ������Ȃ����B
�C�^�C�c�Ƃ̂����킯���D�]��Opteron�̐��\��
Bulldozer�̃l�K�L�����U���������Êς���AMD�̎p�������덇�����B
�ꉞ�ABTO�D��ȂŔ̔��X�D�����Ă݂���p�C�v�͂Ȃ��Œu�������݂���������
���Ԃ�Opteron�O�a������PC�����ł��{�C�o����Ȃ��H
>>656
FX����APU�������̂��A�m��Ȃ�����
FX����APU�������̂��A�m��Ȃ�����
658 �F,,�E�L�́M�E,,�j��-�������F2011/12/14(��) 20:39:08.96 ID:PYjQOL5E
�T�[�o�`�b�v��ASP�����͒P����09�N�O��̕s���̔����ɂ��
�T�[�o���v���[�X���v�̉ߑ��̂����ł����āA�s�[�N�߂�����ǂ��Ȃ邩�킩���B
�T�[�o���v���[�X���v�̉ߑ��̂����ł����āA�s�[�N�߂�����ǂ��Ȃ邩�킩���B
659 �F,,�E�L�́M�E,,�j��-�������F2011/12/14(��) 20:40:15.83 ID:PYjQOL5E
>>657
APU�Ȃ�āuAMD Processor Unit�v���x�̈Ӗ������Ȃ��������͂ǂ��ł������ł���B
APU�Ȃ�āuAMD Processor Unit�v���x�̈Ӗ������Ȃ��������͂ǂ��ł������ł���B
>>659
Accelerated Processing Unit����Ȃ��̂�H
Accelerated Processing Unit����Ȃ��̂�H
�L���z�����ϐ��ӂ�����ID������
APU�̓O�����\�Ɍ�������CPU���Ă������낗
CPU�����ł��I���{����ڂ��Ȃ�A�O���{�ڂ��邵���I�����Ȃ���
�����o�����X�ǂ��Ȃ��ƁA�RD�Ƃ��͈Ӗ��Ȃ������
CPU�����ł��I���{����ڂ��Ȃ�A�O���{�ڂ��邵���I�����Ȃ���
�����o�����X�ǂ��Ȃ��ƁA�RD�Ƃ��͈Ӗ��Ȃ������
>>656
�P�ɃN���b�N������Ȃ��Ƃ��Ȃ炻������������ł��邯��
�x����ɓ��������甚�M�d�l�ɂȂ�Ƃ�bull�̃A�[�L�e�N�`�����̂��I����Ă���Ă��Ƃ����������
�P�ɃN���b�N������Ȃ��Ƃ��Ȃ炻������������ł��邯��
�x����ɓ��������甚�M�d�l�ɂȂ�Ƃ�bull�̃A�[�L�e�N�`�����̂��I����Ă���Ă��Ƃ����������
i3��Llano���ăR�A�ʐς����傤�Ǔ��N���X�����ACinebench��Llano�̂ق�����Ȃ�
�����Ƃ��ACinebench��AVX�Ή������ꍇ��i3�����邾�낤����
�����Ƃ��ACinebench��AVX�Ή������ꍇ��i3�����邾�낤����
4�R�A��2�R�A�ɕ�����̂͑�p����
�����ē�����O
�����ē�����O
�l�i����������������̂͑�p����
�����ē�����O
�����ē�����O
����Llano��FX��SSE�̉��Z���j�b�g���͓��������A�ӊO�ƍ����t�����Ȃ�
���߂�A���������̃R�A�ʐς���Ȃ��ă_�C�ʐς�������
671 �F,,�E�L�́M�E,,�j��-�������F2011/12/14(��) 21:21:22.10 ID:PYjQOL5E
4�R�A��2�R�A�����Ȃ��B
Trinity�ɂȂ��CPU����Bulldozer�x�[�X�̎���4�R�A�ɂȂ邩��Cinebench�X�R�A��i3�ɂ����ĂȂ��Ȃ�ł���B
Trinity�ɂȂ��CPU����Bulldozer�x�[�X�̎���4�R�A�ɂȂ邩��Cinebench�X�R�A��i3�ɂ����ĂȂ��Ȃ�ł���B
>>637
3DMark06 6841����A8-3850�ɒǂ��������Ȃ��ǂ�
3DMark06 6841����A8-3850�ɒǂ��������Ȃ��ǂ�
>>664
�x���������͂��Ă����ƃA�[�L���̂��I����Ă�ƌ������l�߂��Â������B
�Ƃ������͂��͂�U�Ƃ���Ă�Ƃ����v���x��w
sqrtss 166cycle(�{����sqrtps�Ɠ���11cycle?)
�@�g��Ȃ���ǂ��ƌ������ƂȂ����Ǎ��g���Ă�v���O�����͂ǂ����悤���Ȃ��B
�@���Ԃ�R���p�C�����f���܂���B
�@�b��Ώ��ł������ƃ}�V�ȕ��@�����邾�낤�B
movups/movaps xmm,xmm�����l�[�~���O�ŏ����Ȃ�
�@AVX�̔�j��I���߂�FMA4�g���Ή���͉\
�@���\���X�P�W���[���K�͂ɃX�P�[������ꍇ�͖��ߔ䗦���̃y�i���e�B������Ǝv���Ă����B1-2�����x�H
�@�P���ȃP�[�X�ł͏����邩�爫���B���Ă������d�l�ł͂����Ə�����͂��B
x87�����x
�@�P���ȃP�[�X�ł�SSE�X�J���Ɠ����̃X���[�v�b�g�ł��邱�Ƃ���
�@movups/movaps�Ɠ����悤�ɏ�����ׂ����߂��������ɃX���[�v�b�g���Ƃ��Ă���̂ł͂Ȃ����Ǝv���B
L2DTLB���I�����
�@�����i�͂Ȃ����ɒ[�ɉe���o�镪��͂킸���B
�@��蕪��Ƃ��ċ��e�ł���͈́B
�x���������͂��Ă����ƃA�[�L���̂��I����Ă�ƌ������l�߂��Â������B
�Ƃ������͂��͂�U�Ƃ���Ă�Ƃ����v���x��w
sqrtss 166cycle(�{����sqrtps�Ɠ���11cycle?)
�@�g��Ȃ���ǂ��ƌ������ƂȂ����Ǎ��g���Ă�v���O�����͂ǂ����悤���Ȃ��B
�@���Ԃ�R���p�C�����f���܂���B
�@�b��Ώ��ł������ƃ}�V�ȕ��@�����邾�낤�B
movups/movaps xmm,xmm�����l�[�~���O�ŏ����Ȃ�
�@AVX�̔�j��I���߂�FMA4�g���Ή���͉\
�@���\���X�P�W���[���K�͂ɃX�P�[������ꍇ�͖��ߔ䗦���̃y�i���e�B������Ǝv���Ă����B1-2�����x�H
�@�P���ȃP�[�X�ł͏����邩�爫���B���Ă������d�l�ł͂����Ə�����͂��B
x87�����x
�@�P���ȃP�[�X�ł�SSE�X�J���Ɠ����̃X���[�v�b�g�ł��邱�Ƃ���
�@movups/movaps�Ɠ����悤�ɏ�����ׂ����߂��������ɃX���[�v�b�g���Ƃ��Ă���̂ł͂Ȃ����Ǝv���B
L2DTLB���I�����
�@�����i�͂Ȃ����ɒ[�ɉe���o�镪��͂킸���B
�@��蕪��Ƃ��ċ��e�ł���͈́B
FX��1100T������̂��āA�z�����Ă݂�Ƒs�₾��
SSE�̃��j�b�g����1100T��2/3�Ȃ���AFX�ł͂��̕����j�b�g��3/2�{�Ԃ�Ă�킯��
���̏�ASSE��FMA���j�b�g�ŏ���������Ă��Ƃ́A�����S�̔���ނ��̂Ƀi�^�������o���Ă�悤�Ȃ���
�d�͋܂��邾�낤��
SSE�̃��j�b�g����1100T��2/3�Ȃ���AFX�ł͂��̕����j�b�g��3/2�{�Ԃ�Ă�킯��
���̏�ASSE��FMA���j�b�g�ŏ���������Ă��Ƃ́A�����S�̔���ނ��̂Ƀi�^�������o���Ă�悤�Ȃ���
�d�͋܂��邾�낤��
�Ă����j�b�g��1.5�{�̃N���b�N�ʼn�]��������A����d�͂�2.3�`3.4�{�H
�d�͌����������
�d�͌����������
FPU���j�b�g���̂�Phenom���傫������V���O���ł͗ǂ��̂ł́H
4�X���b�h���͂����
4�X���b�h���͂����
�ނ���fpu�ǂ��ɂ�������L���b�V������Đ����p�C�|3�{�ɖ߂��Ă���
Bull��Phenom���Cinebench�͂��ゾ���
Bull��FPU��4�ɑ���Phenom��6�Ƃ����
FPU�ӂ��Bull��FPU��1.5�{���炢���\������������
Bull��FPU��4�ɑ���Phenom��6�Ƃ����
FPU�ӂ��Bull��FPU��1.5�{���炢���\������������
681 �F,,�E�L�́M�E,,�j��-�������F2011/12/14(��) 22:36:07.28 ID:PYjQOL5E
K10��4C��2M4C�̔�r���ƁE�E�E
�����đ�����Ή����ł�������
�n���ǂ�
amd�͈�ʌ����͐��m�[�g�ɒ��͂�
�������apu�����̐헪�̈��
����Ȃ��Ƃ������炸�������݂���Ȃ�
amd�͈�ʌ����͐��m�[�g�ɒ��͂�
�������apu�����̐헪�̈��
����Ȃ��Ƃ������炸�������݂���Ȃ�
684 �F,,�E�L�́M�E,,�j��-�������F2011/12/14(��) 22:40:44.90 ID:PYjQOL5E
Bulldozer���̂��̂̓m�[�g�ɑS�������ĂȂ����ǂ�
>>664
�����������ĂȂ���\�͖ق��Ă낗
�����������ĂȂ���\�͖ق��Ă낗
686 �F,,�E�L�́M�E,,�j��-�������F2011/12/14(��) 22:42:05.80 ID:PYjQOL5E
>>683�������������ĂȂ���\
>>666
�n��
�n��
>>667
����͐^��
����͐^��
����ID�ς���̖Y��Ă邼
OpenCL�����ɂ�����
ttp://www.4gamer.net/games/076/G007660/20111214033/
ttp://www.4gamer.net/games/076/G007660/20111214033/
>>449������ɏ���d�͂̓R�A�ӂ�Phenom��2/3���炢
�m�[�g�ɂ͌����Ă���ƌ�����̂ł́H
�m�[�g�ɂ͌����Ă���ƌ�����̂ł́H
����ɏ����Ă鎖�Ɏ��g���邵�����Ȃ�ĖŒ��ꒃ�ڗ�Ȃ��Ƃ��Ǝv���Ă邩�牴�̐��ɍ����
�R�����ĉR�Ȃ��
AMD��HDD�����s���̉e���Ȃ���
���オ������킯�ł͂Ȃ����A�\��ʂ�ɍs�������Ȃ�܂����̎����ȁH
���オ������킯�ł͂Ȃ����A�\��ʂ�ɍs�������Ȃ�܂����̎����ȁH
35w �݂̂ɂȂ�̂�intel �m�[�g��➑̂̎g���_����
ivy ��������������
ivy ��������������
Iby��GPU���\�����[�N������
3DMark Vantage��HD2000��3�{���x��3000���炢�o��Ǝv���
���Ȃ݂�Llano��3300 Trinity��4500���x
3DMark Vantage��HD2000��3�{���x��3000���炢�o��Ǝv���
���Ȃ݂�Llano��3300 Trinity��4500���x
701 �FSocket774�F2011/12/14(��) 23:15:02.17 ID:pWi7t9AG
>>646
�ӂ��̃T�[�o�p�r�ɂ̓L���b�V���������ق���������
�u���������Ă�̂͂�����HPC����
�T�[�o���Č����Ă��A��ʂ̋Ɩ��p�T�[�o��HPC�p����A�K�v�Ȑ��\���قȂ�
�ӂ��̃T�[�o�p�r�ɂ̓L���b�V���������ق���������
�u���������Ă�̂͂�����HPC����
�T�[�o���Č����Ă��A��ʂ̋Ɩ��p�T�[�o��HPC�p����A�K�v�Ȑ��\���قȂ�
amd�͌��\�������Ă��h���C����
3�N�キ�炢�ɂ͉v�X�f�X�N�g�b�v�s�ꂪ�k�����ăm�[�g��300�h������400�h���ȉ����ł�����ɂȂ���ɂ�ł�Ǝv��
�ǂ���ɂ��Ă������c����|����opteron�ƃm�[�g�ɗ͂����Ȃ��Ƒ����s�\�Ǝv���Ă�͂�
bull�n�̕����܂�オ���ė]�T���ł���Ώ����̓f�X�N�g�b�v�ɗ͂����邩�ȁ@������������ɂ��Ă��D�揇�ʂ͍ł��Ⴂ��
3�N�キ�炢�ɂ͉v�X�f�X�N�g�b�v�s�ꂪ�k�����ăm�[�g��300�h������400�h���ȉ����ł�����ɂȂ���ɂ�ł�Ǝv��
�ǂ���ɂ��Ă������c����|����opteron�ƃm�[�g�ɗ͂����Ȃ��Ƒ����s�\�Ǝv���Ă�͂�
bull�n�̕����܂�オ���ė]�T���ł���Ώ����̓f�X�N�g�b�v�ɗ͂����邩�ȁ@������������ɂ��Ă��D�揇�ʂ͍ł��Ⴂ��
703 �F,,�E�L�́M�E,,�j��-�������F2011/12/14(��) 23:22:07.04 ID:PYjQOL5E
>>692
�����OpenCL�Ɍ��炸�S�����Ȃ�����
OpenGL�����X��SGI�̃v���v���C�G�^���ȃ��C�u�������x�[�X����
�����Ƃ��s��̕]���������n���W�����������͓̂��R�̗���B
�����OpenCL�Ɍ��炸�S�����Ȃ�����
OpenGL�����X��SGI�̃v���v���C�G�^���ȃ��C�u�������x�[�X����
�����Ƃ��s��̕]���������n���W�����������͓̂��R�̗���B
Khronos�̃g�b�v��nv�̐l����
OpenCL���̂���CUDA��������
OpenCL���̂���CUDA��������
�����݂��CUDA�ɏ���������
����ł������
����ł������
���O��ǂ��������Ȃ����낗�@amazon�Ɋ��ӂ��낗
MS��C++AMP�����邩��A�I�[�v���ɂȂ����Ƃ��Ă�CUDA�͕������Ȃ���ˁH
�����͎v���ȁ@apple�n��android�̃V�F�A���オ��ɂ�open GL�̃V�F�A���d�v�����オ�邳
OpenCL��OpenGL�ɑg�ݍ��܂ꂿ����Ă邩���
CUDA�̕�����������
CUDA�̕�����������
�~�d�v�Ȃ̂�
��AMD�����Ă����Ȃ̂�
��AMD�����Ă����Ȃ̂�
��������GPU��DX11�Ή��ɂ��Ă�����܂�Ӗ��Ȃ���
�Ⴆ�e�b�Z���[�V�������g�����Q�[�������p�I�ȑ��x�œ����Ƃ͎v���Ȃ���
�Ⴆ�e�b�Z���[�V�������g�����Q�[�������p�I�ȑ��x�œ����Ƃ͎v���Ȃ���
713 �F,,�E�L�́M�E,,�j��-�������F2011/12/14(��) 23:49:46.04 ID:PYjQOL5E
>>707
C++AMP�Ȃ�C#��ECMA�W��������Ă�̂Ɠ������炢��C�B
5�N�ɂ킽����т�ς�GPGPU�̃f�t�@�N�g�X�^���_�[�h�̏����n��
���̂܂܃I�[�v����������CUDA�̏��������͊m��B
>>709
OpenCL�Ȃ�č����̂�CUDA�̗ł���OpenGL�ɑg�ݍ��܂ꂽ�Ƃ���ŏ͕ς���B
C++AMP�Ȃ�C#��ECMA�W��������Ă�̂Ɠ������炢��C�B
5�N�ɂ킽����т�ς�GPGPU�̃f�t�@�N�g�X�^���_�[�h�̏����n��
���̂܂܃I�[�v����������CUDA�̏��������͊m��B
>>709
OpenCL�Ȃ�č����̂�CUDA�̗ł���OpenGL�ɑg�ݍ��܂ꂽ�Ƃ���ŏ͕ς���B
������AMD��ultrabook �̏����Ƀm���O���A�p�l���Ƃ���������
������Ƃ��ǂ���
������Ƃ��ǂ���
Cg�̎��������悤�Ȏ������Ă�����
���NV�ȊO�����Ȃ��̂ɒN���T�|�[�g����̂�
���NV�ȊO�����Ȃ��̂ɒN���T�|�[�g����̂�
Llano��Bulldozer���o�בO���玟����R�A�̃v���[������Ă��̂͂���ϒᐫ�\�Ȃ̂�AMD����Ԃ悭�m���Ă�����Ȃ낤��
�m�[�g�ŃQ�[�������ʐl�i�j��DX11�Ȃ������ˁ[���낗
tegra�̏����ł�cuda�g���悤�ɂȂ�炵�����炻��̕z�ł�����̂���
����3dlabs��powerVR�Ȃ��ėp���Z������GPU���ڂ��̂��v�悵�Ă邵
nv��tegra�̓^�u���b�g�A�X�}�z�Ō��\�ȃV�F�A�l���ɐ�������
gpu���Z��������ƂȂ�Ƃ���͂����E�E
�W�F���X���̋��̂ɂ�����k��������͔͂��[�Ȃ�
����3dlabs��powerVR�Ȃ��ėp���Z������GPU���ڂ��̂��v�悵�Ă邵
nv��tegra�̓^�u���b�g�A�X�}�z�Ō��\�ȃV�F�A�l���ɐ�������
gpu���Z��������ƂȂ�Ƃ���͂����E�E
�W�F���X���̋��̂ɂ�����k��������͔͂��[�Ȃ�
GPGPU�̊������낢��������
http://pc.watch.impress.co.jp/docs/column/kaigai/20111215_498528.html
���ƁA�r���Ƀt���A�v�����̐}���o�Ă邪�A�����v���Ƃ����Ȃ���
http://pc.watch.impress.co.jp/docs/column/kaigai/20111215_498528.html
���ƁA�r���Ƀt���A�v�����̐}���o�Ă邪�A�����v���Ƃ����Ȃ���
GPGPU�͍����̐��\���~�����l�������g���Ă�킯�ŁA�ŐV�̃n�[�h�E�F�A�ɑΉ�����SDK���o����Ƃ���͋����ł���ˁB
��������ς���ƃV�F�A�ێ��̂��߂ɂ͂��ꂩ���Kepler�AMaxwell�`�ւ̑Ή���nVidia�͐l�I���\�[�X�𒍂������Ȃ����
�����Ȃ��킯�ŁA����̂͂��̂��������̌��ӂ̕\��Ǝ���Ǝv���܂��B
�I�[�v���������Ƃ͂����A�n�[�h�E�F�A��nVidia��������CUDA�̎d�l�͊��S�Ƀn�[�h�E�F�A�ɏ]������`�ɂȂ�͂��B
�Ȃ̂ŃI�[�v���R�~��(�H)��CUDA�Ƃ��������̋Z�p�I�t�B�[�h�o�b�N�Ăɂ��Ă���킯�ł͂Ȃ��A
���[�U�[���i�J���Ґ��j�̒�グ�E�͂����݂��_���̂قƂ�ǂł��傤�ˁB
��������ς���ƃV�F�A�ێ��̂��߂ɂ͂��ꂩ���Kepler�AMaxwell�`�ւ̑Ή���nVidia�͐l�I���\�[�X�𒍂������Ȃ����
�����Ȃ��킯�ŁA����̂͂��̂��������̌��ӂ̕\��Ǝ���Ǝv���܂��B
�I�[�v���������Ƃ͂����A�n�[�h�E�F�A��nVidia��������CUDA�̎d�l�͊��S�Ƀn�[�h�E�F�A�ɏ]������`�ɂȂ�͂��B
�Ȃ̂ŃI�[�v���R�~��(�H)��CUDA�Ƃ��������̋Z�p�I�t�B�[�h�o�b�N�Ăɂ��Ă���킯�ł͂Ȃ��A
���[�U�[���i�J���Ґ��j�̒�グ�E�͂����݂��_���̂قƂ�ǂł��傤�ˁB
721 �FSocket774�F2011/12/15(��) 00:11:54.62 ID:MpBI/ANH
�@�@�@�@�@��������������������
�@�@�@�@�@���@ �^�@�@/�܁R�@�_�@��Bulldozer�����͐��܂��cache��IPC���キ
�@�@�@�@�@���^�@�@�@�T___�m.�@�@�_������x��̐����v���Z�X�A�����̒x��ŏ��@������
�@�@�@�@�@���@.)�_ �@�@|�@�@ �^(.�@���Y�܂ꂽ�Ɠ�����TDP�̍�������R���s���܂����B
�@�@�@�@�@���@(OV.�P�P�PVO).�@��
�@�@�@�@�@���@ >�@ ::�_:::�^:: <�@�@��Bulldozer�����̖����鍰���~�����߂�
�@�@�@�@�@��.�^::<��>:::<��>::�_. ���ǂ��������͂����肢���܂��B
�@�@�@�@�@��|�@�@�@ �i__�l_�j �@�@.| ��
�@�@�@�@�@���_�@�@�@�M�[�f�L �@ �^ ��
�@�@�@�@�@���^�P�P�P�P�P�_�@ ��
�@�@�@�@�@��������������������
�@�@�@�@�@�@Bulldozer�����i���N0)
�@�@�@�@�@���@ �^�@�@/�܁R�@�_�@��Bulldozer�����͐��܂��cache��IPC���キ
�@�@�@�@�@���^�@�@�@�T___�m.�@�@�_������x��̐����v���Z�X�A�����̒x��ŏ��@������
�@�@�@�@�@���@.)�_ �@�@|�@�@ �^(.�@���Y�܂ꂽ�Ɠ�����TDP�̍�������R���s���܂����B
�@�@�@�@�@���@(OV.�P�P�PVO).�@��
�@�@�@�@�@���@ >�@ ::�_:::�^:: <�@�@��Bulldozer�����̖����鍰���~�����߂�
�@�@�@�@�@��.�^::<��>:::<��>::�_. ���ǂ��������͂����肢���܂��B
�@�@�@�@�@��|�@�@�@ �i__�l_�j �@�@.| ��
�@�@�@�@�@���_�@�@�@�M�[�f�L �@ �^ ��
�@�@�@�@�@���^�P�P�P�P�P�_�@ ��
�@�@�@�@�@��������������������
�@�@�@�@�@�@Bulldozer�����i���N0)
�͂����݂ł��܂���ł����A�Ƃ��������Ȃ��̂��Ȃ�Ƃ��c
>>719
Bobcat�������悤�Ȃ��̂����A�l��ōœK�����Ȃ����肫�ꂢ�ȃu���b�N��ɂ͕�����܂���B
>>719
Bobcat�������悤�Ȃ��̂����A�l��ōœK�����Ȃ����肫�ꂢ�ȃu���b�N��ɂ͕�����܂���B
����ʂɃu���b�N��ɔz�u���邮�炢�Ȃ�c�[���ł��o���邼
>>720
���ɓ��ӂ����
HPC����Ȃ���̉��Z�@�Ő��\���グ��ׂɃv���b�g�t�H�[�������芷���邾�낤����
���������悤��NV�ȊO��GPU�Ƃ͂قږ��W�ɂȂ邾�낤
���ɓ��ӂ����
HPC����Ȃ���̉��Z�@�Ő��\���グ��ׂɃv���b�g�t�H�[�������芷���邾�낤����
���������悤��NV�ȊO��GPU�Ƃ͂قږ��W�ɂȂ邾�낤
Mali��SIMD�͒P���x�Ɣ{���x�̏�������2�F1�ŁA�{���x���g��GPGPU�̌�����Radeon���ǂ������H
>>692
AMD�Ȃ�CUDAToolKit�̃R���p�C����Radeon��CUDA�p�t�H�[�}���X��s���ɐ������Ă�I�I
���Č����i�����N�������˂Ȃ���˂�
AMD�Ȃ�CUDAToolKit�̃R���p�C����Radeon��CUDA�p�t�H�[�}���X��s���ɐ������Ă�I�I
���Č����i�����N�������˂Ȃ���˂�
PowerVR��GPGPU���������Ă��邵�A���悢�敁�y���ɓ�����Ċ�������
AMD��CPU��FP�p�R�v���Ƃ��Ďg���C�͂Ȃ��Ȃ����悤�����A
�����CPU��GPU�͕������܂܍��ڂ��āAGPGPU�ł��ł������ȏ�����GPU�ɃI�t���[�h����
CPU���t���[�ɂ�����w�e���W�j�A�X�^�ɂȂ�낤��
���̕����J�����y�����A�g�ݍ��킹�̎��R�x���������낤����
AMD��CPU��FP�p�R�v���Ƃ��Ďg���C�͂Ȃ��Ȃ����悤�����A
�����CPU��GPU�͕������܂܍��ڂ��āAGPGPU�ł��ł������ȏ�����GPU�ɃI�t���[�h����
CPU���t���[�ɂ�����w�e���W�j�A�X�^�ɂȂ�낤��
���̕����J�����y�����A�g�ݍ��킹�̎��R�x���������낤����
728 �F,,�E�L�́M�E,,�j��-�������F2011/12/15(��) 00:47:02.95 ID:s5pZBSql
>>715
Cg��NVIDIA��p�̃v���v���C�G�^�������n�ACUDA�͍���I�[�v������
SSE/AVX��MIC�ɂ��ڐA�ł���悤�ɂȂ�B
AMD�ɂƂ��Ėʔ����Ȃ������ŁA����CUDA�̃R�[�h���Y��~�ς��Ă�ƊE�Ƃ��Ă�
CUDA����葽���̃f�o�C�X�ŃT�|�[�g���ꂽ���������b�g���傫���B
Cg��NVIDIA��p�̃v���v���C�G�^�������n�ACUDA�͍���I�[�v������
SSE/AVX��MIC�ɂ��ڐA�ł���悤�ɂȂ�B
AMD�ɂƂ��Ėʔ����Ȃ������ŁA����CUDA�̃R�[�h���Y��~�ς��Ă�ƊE�Ƃ��Ă�
CUDA����葽���̃f�o�C�X�ŃT�|�[�g���ꂽ���������b�g���傫���B
>>724
HPC�����GPGPU�ɂƂ��đ�Ȃ��q����ł��ˁB
�ǂ��E�N���n�߂��̂��m��܂���HPC�����ƈ�ʌ����ɓ���(�悤��)���m���悤�ɂ����̂�
GPU���[�J�[�̐����c����Ƃ��đf���炵���Ǝv���܂��B
AMD��Fusion���w���Ă���CPU+GPU�̓������A���̊��o���ƃ������A�N�Z�X���ǂ��ɂ����Ȃ�����
�������Ȃ���Ȃ����Ǝv���܂����A�����܂������ʂ̎g�������o�Ă������Ŋy���݂ł��B
HPC�����GPGPU�ɂƂ��đ�Ȃ��q����ł��ˁB
�ǂ��E�N���n�߂��̂��m��܂���HPC�����ƈ�ʌ����ɓ���(�悤��)���m���悤�ɂ����̂�
GPU���[�J�[�̐����c����Ƃ��đf���炵���Ǝv���܂��B
AMD��Fusion���w���Ă���CPU+GPU�̓������A���̊��o���ƃ������A�N�Z�X���ǂ��ɂ����Ȃ�����
�������Ȃ���Ȃ����Ǝv���܂����A�����܂������ʂ̎g�������o�Ă������Ŋy���݂ł��B
PC�����̂قƂ�ǑS�Ă�AMD��Intel�̓���GPU�Ő�߂�悤�ɂȂ邩��ACUDA�̏�������HPC����ł����Ȃ��Ȃ��
AMD��GPU���\�����啝��������邵�A���N����ł�HPC��NGC��W�J���邩��HPC����ł��猻����ێ��ł��邩�͕s��
���Ȃ݂Ƀ��������L�\������A�v���O���~���O��œK���������肩�Ȃ���₷���Ȃ肻��
AMD��GPU���\�����啝��������邵�A���N����ł�HPC��NGC��W�J���邩��HPC����ł��猻����ێ��ł��邩�͕s��
���Ȃ݂Ƀ��������L�\������A�v���O���~���O��œK���������肩�Ȃ���₷���Ȃ肻��
>>729
Fusion�̗��_��CPU-GPU�ԒʐM�̍���������
���ꂪ���݂̂f�o�f�o�t�̑傫�ȃl�b�N�ł�����A���ꂪ���������̂��傫��
�������A�N�Z�X�̐����͏����̍�����������TSV�̗p�ʼn�������邩�炻��قNjC�ɂ���K�v���Ȃ�
Fusion�̗��_��CPU-GPU�ԒʐM�̍���������
���ꂪ���݂̂f�o�f�o�t�̑傫�ȃl�b�N�ł�����A���ꂪ���������̂��傫��
�������A�N�Z�X�̐����͏����̍�����������TSV�̗p�ʼn�������邩�炻��قNjC�ɂ���K�v���Ȃ�
��������Ă��Ԕ��ȃn�[�h�E�F�A�A�s�[�����肾��
ATI Stream���Y�b�R�P�Ă�ԂɁANvidia�͍��Z��������CUDA�Z�~�i�[�N����Ă�
AMDATI�Ɉ�ԑ���Ȃ����̂𗝉����Ȃ������菟���ڂ͂Ȃ���
ATI Stream���Y�b�R�P�Ă�ԂɁANvidia�͍��Z��������CUDA�Z�~�i�[�N����Ă�
AMDATI�Ɉ�ԑ���Ȃ����̂𗝉����Ȃ������菟���ڂ͂Ȃ���
����GPU�̍����\����CUDA�̎��s��������̂͒ɂ��ł��ˁB
����܂ł͎Љ�S�̂�GPGPU�ւ̊J����S���Ă��I�ȑ��ʂ��������̂ɂ�
�����׃Q�[���ł̃j�[�Y�͎c��ɂ��Ă��A���܂łقǂɂ͈�ʌ����ŊJ���������ł��Ȃ��Ȃ��Ēl�グetc
������ʌ����̃L���[�A�v�������������ł����cGPGPU�ɓ��������r�f�Icodec���o�ꂷ��Ƃ��B
>>731
������������ł��ˁB�Ă�����(�����ɂ����̂ł��傤����)GPU-VRAM�Ԃ̒ʐM��1�Ԃ̃l�b�N���Ǝv���Ă����̂�
DDR3(���̎����CPU����������)���g�����胍�[�G���h�O���{�ɂ��GPGPU�ƍ��͂��Ȃ����낤�Ǝv���Ă܂����B
����܂ł͎Љ�S�̂�GPGPU�ւ̊J����S���Ă��I�ȑ��ʂ��������̂ɂ�
�����׃Q�[���ł̃j�[�Y�͎c��ɂ��Ă��A���܂łقǂɂ͈�ʌ����ŊJ���������ł��Ȃ��Ȃ��Ēl�グetc
������ʌ����̃L���[�A�v�������������ł����cGPGPU�ɓ��������r�f�Icodec���o�ꂷ��Ƃ��B
>>731
������������ł��ˁB�Ă�����(�����ɂ����̂ł��傤����)GPU-VRAM�Ԃ̒ʐM��1�Ԃ̃l�b�N���Ǝv���Ă����̂�
DDR3(���̎����CPU����������)���g�����胍�[�G���h�O���{�ɂ��GPGPU�ƍ��͂��Ȃ����낤�Ǝv���Ă܂����B
������������TSV�̗p����邱��ɂ́A���R�P��CPU/GPU�̃������������Ȃ�킯������
�����ɔ�ׂ�APU�̃��������x���\�}�͕ς��Ȃ����
�����ɔ�ׂ�APU�̃��������x���\�}�͕ς��Ȃ����
�����DDR4�ł��˂Ă�^���[�J�[���������������Ă邩�炾��@USB3.0������Ȋ�����������
>>732
CPU�Ɍ��炸AMD�͒lj����ߕ��u����������ȁB
CPU�Ɍ��炸AMD�͒lj����ߕ��u����������ȁB
739 �F,,�E�L�́M�E,,�j��-�������F2011/12/15(��) 03:08:51.66 ID:s5pZBSql
>>734
�������Ă�́H�n�[�h�����ł��������ĉ�����̓I�Ȃ��̂���炸���u���Ă�̂�AMD��������B
�t�Ɍ�����Intel��CUDA���T�|�[�g����ΌǗ�����̂�AMD���ȁB
�܂��ʂɌ��ꏈ���n�Ȃ�Ăǂ��ł��������B
C�̕����̗��������邱�ƂȂ�ĒN�����߂ĂȂ���B
�������Ă�́H�n�[�h�����ł��������ĉ�����̓I�Ȃ��̂���炸���u���Ă�̂�AMD��������B
�t�Ɍ�����Intel��CUDA���T�|�[�g����ΌǗ�����̂�AMD���ȁB
�܂��ʂɌ��ꏈ���n�Ȃ�Ăǂ��ł��������B
C�̕����̗��������邱�ƂȂ�ĒN�����߂ĂȂ���B
�Ȃ�ł���������bull�Ȃ��������ɂ��Ď��̏o������Ďv��
���������v�Ȃ̂��Ȃ���͍��邴��
���������v�Ȃ̂��Ȃ���͍��邴��
�킩��Ǝv����AMD�Ɂu���v�Ȃǖ���
>741
AMD�ɕK�v�Ȃ͎̂��̃`�b�v�ł͂Ȃ�
bull�����Ɏg�����Abull���g���Ɖ����o���邩���Ă����u��āv
�n�[�h�̗D�z���Ȃ��Ƃ����i�ɖ��͂�t�����邱�Ƃ͏o�����
Apple�݂�Δ��邾��H
AMD�ɕK�v�Ȃ͎̂��̃`�b�v�ł͂Ȃ�
bull�����Ɏg�����Abull���g���Ɖ����o���邩���Ă����u��āv
�n�[�h�̗D�z���Ȃ��Ƃ����i�ɖ��͂�t�����邱�Ƃ͏o�����
Apple�݂�Δ��邾��H
C++AMP��Windows���ł͂��������s���Ă�Ǝv�����ǂ�
�ʂ�CUDA�R�Z�p�Ƃ����킯�ł͂Ȃ���
VS11�̂�DirectCompute��ɔ炩�Ԃ�����̂ł���H
NVIDIA��C++AMP�����Z�p��C++ACC��
����͏o�x��Ă銴������̂�
2012�����Intel GPU�̃T�|�[�g���{�i�I�ɖ��ɂȂ�̂�
C++AMP�̂ق������̂Ƃ���A�h�o���e�[�W�͂���Ǝv��
HPC�͑��ς�炸CUDA���낤����
C++AMP on FSA���ǂ��Ȃ邩�͋ɂ߂ĕs����
�ʂ�CUDA�R�Z�p�Ƃ����킯�ł͂Ȃ���
VS11�̂�DirectCompute��ɔ炩�Ԃ�����̂ł���H
NVIDIA��C++AMP�����Z�p��C++ACC��
����͏o�x��Ă銴������̂�
2012�����Intel GPU�̃T�|�[�g���{�i�I�ɖ��ɂȂ�̂�
C++AMP�̂ق������̂Ƃ���A�h�o���e�[�W�͂���Ǝv��
HPC�͑��ς�炸CUDA���낤����
C++AMP on FSA���ǂ��Ȃ邩�͋ɂ߂ĕs����
apple�̏ꍇ�͕ʂ�win�@���S�݊�����Ȃ������
CPU�s��͊��S�݊�����Ȃ���ΈӖ����Ȃ�����via�݂����ɑ_���w�m�ɕς��Ă��Ȃ����薳������
2500k�Ƃ���ׂĔM���A�x���A������trinity���ᖣ�͂Ȃ�Ă݂��邱�Ƃ���ł��Ȃ�
���͂����邽�߂ɂ͒n����bull�ɍœK�������\�t�g�J�����x�����邵���Ȃ���
�������������I�W�]��amd���������o������
CPU�s��͊��S�݊�����Ȃ���ΈӖ����Ȃ�����via�݂����ɑ_���w�m�ɕς��Ă��Ȃ����薳������
2500k�Ƃ���ׂĔM���A�x���A������trinity���ᖣ�͂Ȃ�Ă݂��邱�Ƃ���ł��Ȃ�
���͂����邽�߂ɂ͒n����bull�ɍœK�������\�t�g�J�����x�����邵���Ȃ���
�������������I�W�]��amd���������o������
C++AMP�Ƃ�����AMD�̐��i���Ă�FSA�͎������DirectX�ɑ傫���e������Ă������낤��
CUDA�͈�ʌ����ɂ͗��s��Ȃ����낤
CUDA�͈�ʌ����ɂ͗��s��Ȃ����낤
>>731
���݂�CPU-GPU�Ԃ̒ʐM���C�e���V�͐��\us���x
PCIe�̒ʐM���C�e���V�͐�us�ȉ�
���ۂ�IB��HCA���ł�2us���x�̃��C�e���V�������ł��Ă���
�܂�قƂ�ǂ̓\�t�g�E�F�A�X�^�b�N�̃��C�e���V
FSA�͂��̉�����_��������
������A�{���͏��ԂƂ��Ă�
FSA -> CPU/GPU�R�q�[�����g�L���b�V��
�Ƃ����̂����R��������FSA�͂܂��e���`���Ȃ�
����肽���̂��킩��Ȃ����x��
������>>739�݂�����
�n�[�h�����ł����グ�ā@�ƌ�����̂������Ƃ��Șb
�Ƃ������������̃n�[�h���L���ɓ��삷����̂Ȃ̂��͋^�킵��
�h�@�\�h�����̂���̂͊ȒP������
���݂�CPU-GPU�Ԃ̒ʐM���C�e���V�͐��\us���x
PCIe�̒ʐM���C�e���V�͐�us�ȉ�
���ۂ�IB��HCA���ł�2us���x�̃��C�e���V�������ł��Ă���
�܂�قƂ�ǂ̓\�t�g�E�F�A�X�^�b�N�̃��C�e���V
FSA�͂��̉�����_��������
������A�{���͏��ԂƂ��Ă�
FSA -> CPU/GPU�R�q�[�����g�L���b�V��
�Ƃ����̂����R��������FSA�͂܂��e���`���Ȃ�
����肽���̂��킩��Ȃ����x��
������>>739�݂�����
�n�[�h�����ł����グ�ā@�ƌ�����̂������Ƃ��Șb
�Ƃ������������̃n�[�h���L���ɓ��삷����̂Ȃ̂��͋^�킵��
�h�@�\�h�����̂���̂͊ȒP������
>>746
FSA��C++AMP�͍�������₷�����ǑS���Ⴄ���̂������
C++AMP��SMP�̃}���`�R�A����GPU�A���U�������V�X�e���܂ł�
����̃V���^�b�N�X�Ńv���O���~���O���邱�Ƃ�_��������
�ŏ���C++AMP������DirectCompute��Ɏ��������
�n�[�h�E�F�A�x���_�̈͂����݂�������
�\�t�g�E�F�A�w�̉��l�𑊑ΓI�ɍ��߂�
���̉ߒ���CUDA�Ɏ���Ă����哱����D���̂������炭MS�̑_��
C++AMP��FSA�ɂ͑S���ˑ����Ă��Ȃ�
FSA��C++AMP�͍�������₷�����ǑS���Ⴄ���̂������
C++AMP��SMP�̃}���`�R�A����GPU�A���U�������V�X�e���܂ł�
����̃V���^�b�N�X�Ńv���O���~���O���邱�Ƃ�_��������
�ŏ���C++AMP������DirectCompute��Ɏ��������
�n�[�h�E�F�A�x���_�̈͂����݂�������
�\�t�g�E�F�A�w�̉��l�𑊑ΓI�ɍ��߂�
���̉ߒ���CUDA�Ɏ���Ă����哱����D���̂������炭MS�̑_��
C++AMP��FSA�ɂ͑S���ˑ����Ă��Ȃ�
trinity����fx���O�ʈ�̂̎O�d����ĈӖ�����
���i��tri�Ɣ�ׂ���ivy�Ɣ�ׂ�Ɍ��܂��Ă邶�����
���i��tri�Ɣ�ׂ���ivy�Ɣ�ׂ�Ɍ��܂��Ă邶�����
�h�f�l��VB/C#�œK���ɏ������v���O������
�����I��GPU�𗘗p����悤�ɂȂ�̂͂�����ɂȂ�܂���
�����I��GPU�𗘗p����悤�ɂȂ�̂͂�����ɂȂ�܂���
cuda�����
AMD�������ɓ������ςȂ��W���[�}���Ȃ̂���Ɋ��ł���
AMD�������ɓ������ςȂ��W���[�}���Ȃ̂���Ɋ��ł���
6���W���[���u�������͂�
�{���̌v��ł�Llano�̂悤�ȃn�[�h�E�F�A���Fusion�ɐ�s����
HT��Trrenza��PCIe��œ��삷��FSA���������ă\�t�g�E�F�A���J�����Ă��炤
�ʼn��n�������������Llano���o����ăV�i���I��������Ȃ����낤��
�Ƃ��낪���ۂ͐�s����ǂ��납
Llano�ɒǂ��z�����
Trinity�ɒǂ��z�����
Southern Islands�ɒǂ��z�����Ƃ���
FSA�������[�X����邱��ɂ�Trinity�̎��̂��o�Ă��Ȃ�����
HT��Trrenza��PCIe��œ��삷��FSA���������ă\�t�g�E�F�A���J�����Ă��炤
�ʼn��n�������������Llano���o����ăV�i���I��������Ȃ����낤��
�Ƃ��낪���ۂ͐�s����ǂ��납
Llano�ɒǂ��z�����
Trinity�ɒǂ��z�����
Southern Islands�ɒǂ��z�����Ƃ���
FSA�������[�X����邱��ɂ�Trinity�̎��̂��o�Ă��Ȃ�����
��N�O��CUDA��x86�T�|�[�g�����\�����
�����LLVM��
�����LLVM��
TexasA&M��w��Interlagos�̃X�p�R�����������܂�����
Intel��AMD��Apple��OpenCL��LLVM�ˑ�
>>756�̒���
Opteron��HPC����Ȃ��āAOpteron��HPC�p�̊Ǘ��p�\�t�g�����Ă��Ƃ�����
Opteron��HPC����Ȃ��āAOpteron��HPC�p�̊Ǘ��p�\�t�g�����Ă��Ƃ�����
CPU��SSE����4way simd���j�b�g��4�Ȃ���8����ł銴���ł���
S3�`�b�N��
S3�`�b�N��
4 way SIMD x N way��SIMD�Ƃ���������
���x�͂P�Ƃ��邩���
���x�͂P�Ƃ��邩���
763 �FSocket774�F2011/12/15(��) 10:30:52.95 ID:tlJe9nhF
HPC�����Linux���傫�ȃV�F�A�����邩��
GPGPU�ŕ��y����ɂ�Windows�����łȂ�Linux�ł����삵�Ȃ��Ƃ����Ȃ�
GPGPU�ŕ��y����ɂ�Windows�����łȂ�Linux�ł����삵�Ȃ��Ƃ����Ȃ�
>>416
���XFX��3DCG�����_�����O�T�[�o�[�����Ƃ��������B
���XFX��3DCG�����_�����O�T�[�o�[�����Ƃ��������B
Brazos 2.0 �̌�p�͍����ɂȂ��Ă�́H
>>751
XNA
XNA
>>750
�n���H
���ʐl�͗\�Z�Ō��߂�
�܂��f�X�N�g�b�v�Ȃ�ăj�b�`�Ŗׂ����o�Ȃ��s���amd�����͂����炽���܂����S�t���O����
����mobile��opteron�ɗ͂����ė]�T���ł�����f�X�N�g�b�v�ɗ͂�?����Ă݂邩�����ĂƂ�����
�Ƃɂ�����Ƃׂ͖��Ȃ���Α����ł��Ȃ�����˔n���ȃI�^�N�ɕt�������Ď���ł��܂����猳���q���Ȃ�
�n���H
���ʐl�͗\�Z�Ō��߂�
�܂��f�X�N�g�b�v�Ȃ�ăj�b�`�Ŗׂ����o�Ȃ��s���amd�����͂����炽���܂����S�t���O����
����mobile��opteron�ɗ͂����ė]�T���ł�����f�X�N�g�b�v�ɗ͂�?����Ă݂邩�����ĂƂ�����
�Ƃɂ�����Ƃׂ͖��Ȃ���Α����ł��Ȃ�����˔n���ȃI�^�N�ɕt�������Ď���ł��܂����猳���q���Ȃ�
770 �FSocket774�F2011/12/15(��) 18:38:02.94 ID:V4iQDdZg
https://twitter.com/99_honten_parts/status/147230070556209153
���̓��ׁ_(^o^)�^
�ǂ�����ĂȂ��̂��A
����ȎS��Ŋ����Ƃ������Ă�́H(�P���P)
���̓��ׁ_(^o^)�^
�ǂ�����ĂȂ��̂��A
����ȎS��Ŋ����Ƃ������Ă�́H(�P���P)
>>753
4���W���[���̎��_�Ń_�C�T�C�Y�I�Ɉ�t��t
�s����������_�Ŋ��Ɍ��E��I��
���W���Ƃ��g�������S�������̂�Bulldozer�A�[�L�e�N�`��
4���W���[���̎��_�Ń_�C�T�C�Y�I�Ɉ�t��t
�s����������_�Ŋ��Ɍ��E��I��
���W���Ƃ��g�������S�������̂�Bulldozer�A�[�L�e�N�`��
>>768
CPU������TDP15W+��1M2C�H2M4C�H�N���b�N�ǂꂭ�炢�ɂȂ�́H
CPU������TDP15W+��1M2C�H2M4C�H�N���b�N�ǂꂭ�炢�ɂȂ�́H
6���W���[���A3���ATDP80W�Ȃ甃���I
�Ǝv�������ǁA6���W���[��12�R�A�ɂȂ��Ă�2600k�Ɠ������炢��
�V���O���X���b�h��10�N�O�̑������Ⴂ���ȁE�E
�Ǝv�������ǁA6���W���[��12�R�A�ɂȂ��Ă�2600k�Ɠ������炢��
�V���O���X���b�h��10�N�O�̑������Ⴂ���ȁE�E
775 �FSocket774�F2011/12/15(��) 19:25:04.56 ID:DpOABLID
�����W���[���ɂȂ낤�ƈ�l����FF14�x���`CPU���ł����Ǝv������
>>771
�����ō��ɔn����
�����ō��ɔn����
>>768
�܂���������Ă�������zambezi�ł���bull�����M�Ŏ��s���Ă���[�̂�
�����S�n�ȂȂ�
fx�̂Ƃ��݂����ɔ�����ǂ��ɓ˂����Ƃ���Ȃ��Ⴂ�����ǂ���
�܂���������Ă�������zambezi�ł���bull�����M�Ŏ��s���Ă���[�̂�
�����S�n�ȂȂ�
fx�̂Ƃ��݂����ɔ�����ǂ��ɓ˂����Ƃ���Ȃ��Ⴂ�����ǂ���
���������AK10�V���[�Y�̏o�~�߂��̂��Ċ��S�Ɏ֑�����Ȃ���
mobile tri��cpu����15w+�ʁi�د�j���Ƃ������Ă�z�����l��n���Ă�肩�悗
���b�p�ň���Bull�A�[�L�A15W�ʼn����o�����
���b�p�ň���Bull�A�[�L�A15W�ʼn����o�����
�֑��H
���ʂɕt����������ĈӖ������A�~�߂遁�֑��ƂȂ�\�}�������Ă��Ȃ���
���ʂɕt����������ĈӖ������A�~�߂遁�֑��ƂȂ�\�}�������Ă��Ȃ���
>>769
��ʐl��mobile�Ȃ�Z���������y���e�B�A���ŏ\���Ƃ�������������
�T�[�o�[�p�����M�d�l��bull�łǂꂾ�����v�ł����
��ʐl��mobile�Ȃ�Z���������y���e�B�A���ŏ\���Ƃ�������������
�T�[�o�[�p�����M�d�l��bull�łǂꂾ�����v�ł����
���͂���X���ł͂Ȃ��@���X������
���Ɠт�CPU����Bulldozer����Ȃ���
���Ɠт�CPU����Bulldozer����Ȃ���
bull�̃A�[�L�e�N�`���𗬗p�������̂�����amd��1�N�łǂꂾ���܂Ƃ��Ɏd�グ�����E�E�E�E
�Ƃɂ�������amd��bull�����߂��Ăǂ����悤���Ȃ�
�Ƃɂ�������amd��bull�����߂��Ăǂ����悤���Ȃ�
784 �FSocket774�F2011/12/15(��) 20:01:37.95 ID:sq1zCwsl
���`
OS��\�t�g�E�F�A���u���ɍœK��������Α����Ȃ���Č����Ă�킯������
�n�[�h�̉��ǂȂ������ĂЂ����獡�̃\�t�g�͌Â��AOS�͎���x����ĘA�Ă��Ă��邾���ł����̂�
�n�[�h�̉��ǂȂ������ĂЂ����獡�̃\�t�g�͌Â��AOS�͎���x����ĘA�Ă��Ă��邾���ł����̂�
�\�t�g��OS���ǂ��������ɂ͍���Bull�͎���x��ɂȂ��Ă��������ǂ�
�n�[�h�̉��ǂ��Č����Ă��APiledriver�ł�FMA��256bit-wide���߂ɗ��ފg���͂��邪
SSE�Ȃǂ̏]�����߂ɂ��Ă͕��u����Ȃ���
SSE�Ȃǂ̏]�����߂ɂ��Ă͕��u����Ȃ���
>>782
�R�e���V���^�T���Ė\���X������
�R�e���V���^�T���Ė\���X������
>>779
�����Trinity���A���ɑI���̂Ȃ������t�������肾�����
�����Trinity���A���ɑI���̂Ȃ������t�������肾�����
�[���@���X�����Ă����Ă�amd�Ɍ���v���X�ޗ�������悤�Ɏv���Ȃ����A����܂�����Ō��Ƃ�����}�C�i�X�����������Ȃ�ɂ��܂��Ă邾��
intel�����ԂȂ��z�w�����Ă錻���fx�͎����AA��E��C��������������ɂȂ�
�������܂Ƃ��ɗ��v�ł����Ƃ�������llano�̕����܂�͈����A���̂���fx�̂��߂̊J�����x�����܂Ƃ��ɂł��ĂȂ�
����ȏʼn��Ɋ��҂���Ηǂ���
�D�]�ޗ�������Ȃ����
������ivy��GPU���\�����Ă��Ă����APU�͋ꂵ���Ȃ邾�낤��
intel�����ԂȂ��z�w�����Ă錻���fx�͎����AA��E��C��������������ɂȂ�
�������܂Ƃ��ɗ��v�ł����Ƃ�������llano�̕����܂�͈����A���̂���fx�̂��߂̊J�����x�����܂Ƃ��ɂł��ĂȂ�
����ȏʼn��Ɋ��҂���Ηǂ���
�D�]�ޗ�������Ȃ����
������ivy��GPU���\�����Ă��Ă����APU�͋ꂵ���Ȃ邾�낤��
793 �FSocket774�F2011/12/15(��) 20:50:09.65 ID:EjDiM5MS
�v���Ȃ��ł͂Ȃ��v�������Ȃ��̊ԈႢ����ˁH
>>771
���W���[�������₵�Đ��\�グ�Ă����A�ƌ����Ă�
���₹�鐔�ɂ͏�����邵�ȁB
���ǃR�A������̐��\�グ�Ă��������Ȃ���
AMD�������������̐^�t�Ȍ��_�ɂȂ�킯�����B
���W���[�������₵�Đ��\�グ�Ă����A�ƌ����Ă�
���₹�鐔�ɂ͏�����邵�ȁB
���ǃR�A������̐��\�グ�Ă��������Ȃ���
AMD�������������̐^�t�Ȍ��_�ɂȂ�킯�����B
�����4�R�A��葽���ƌ��ʓI�ȏd���v���O�����Ȃ�Ă��������Ȃ���[
>>794
���ꌾ������R�A������̐��\�ɂ����������Ǝv����
���ꌾ������R�A������̐��\�ɂ����������Ǝv����
tri�̏ȓd�̓��f���Ȃ��CPU���S�~�Ɍ��܂��Ă邾��
�����X�J�����\���グ�邽�߂�
�p�C�v���C���ȗ������ăN���b�N���コ����
����������L���b�V������
�I�ł̓������ш�Ō떂��������������DT�ł͂��������킯�ɂ������Ȃ�
����piledriver��DT�ł��ʗp����悤�ɂȂ�ƌ����̂Ȃ�
��͂�L���b�V�����܂Ƃ��ɂ��ė����ł͂Ȃ���
����ɂ͖������R�e������ɒm�\�������đR����\��
�p�C�v���C���ȗ������ăN���b�N���コ����
����������L���b�V������
�I�ł̓������ш�Ō떂��������������DT�ł͂��������킯�ɂ������Ȃ�
����piledriver��DT�ł��ʗp����悤�ɂȂ�ƌ����̂Ȃ�
��͂�L���b�V�����܂Ƃ��ɂ��ė����ł͂Ȃ���
����ɂ͖������R�e������ɒm�\�������đR����\��
http://www.overclock.net/t/1184841/amds-upcoming-trinity-apu-playing-deus-exhttp://www.overclock.net/t/1184841/amds-upcoming-trinity-apu-playing-deus-ex
�R�A��IPC�N���b�N���ꂼ��ɏ��������ꍇ�A�s���������͓�������
�A�v���[�`�����قȂ邪
�A�v���[�`�����قȂ邪
�������Ȃ��̂�Atom��30%�ȏ�V�F�A�����ĒS�����Ă����В��N�r�ɂȂ����̂�
>>800
����R�A�����₵�Ă��R�A���\�����Ȃ����肽�����Đ��\��������Ȃ����Ă̂͂킩�肫�������Ƃ����
���Ă��ƂŃR�A���łɑ��₵�Ă����܂�Ӗ��Ȃ�
����bull�̃A�[�L�e�N�`���͖��炩�ɂP�R�A������̐��\�グ�����������Ȃ����畳�����Ă����Ă邾��
����R�A�����₵�Ă��R�A���\�����Ȃ����肽�����Đ��\��������Ȃ����Ă̂͂킩�肫�������Ƃ����
���Ă��ƂŃR�A���łɑ��₵�Ă����܂�Ӗ��Ȃ�
����bull�̃A�[�L�e�N�`���͖��炩�ɂP�R�A������̐��\�グ�����������Ȃ����畳�����Ă����Ă邾��
803 �F,,�E�L�́M�E,,�j��-�������F2011/12/15(��) 21:48:47.14 ID:s5pZBSql
�����������Ԃ�4�R�A�ESMT�{���Ȃ̂ɃR�A���𑝂₵�܂����Ƃ������܂��Ă�
��������amd��C�QQ��^��4�R�A����Ȃ��Ƃ������Ă����Ƃ��������ȁE�E�E
��������8�R�A�Ƃ��������炢����̂�
4�R�A���Č����Ă����悩�������
4�R�A���Č����Ă����悩�������
ARM����CUDA�J���L�b�g�̒��n�܂邩
NV�͍��N��Tegla�̏o�א����ڕW�ɒB���Ȃ����������N�͒B��������ƌ����Ă�
�����オ���������ARM�ł�GPGPU�Ŕe���������Α傫�Ȑ��������ł͂Ȃ���
�Ⴆ�R���V���[�}�����ł͂��܂������Ȃ��Ă�ARM�X�p�R���ł͎g���邩�疳�ʂɂ͂Ȃ�Ȃ����낤��
AMD��APU�őR����ȁH
NV�͍��N��Tegla�̏o�א����ڕW�ɒB���Ȃ����������N�͒B��������ƌ����Ă�
�����オ���������ARM�ł�GPGPU�Ŕe���������Α傫�Ȑ��������ł͂Ȃ���
�Ⴆ�R���V���[�}�����ł͂��܂������Ȃ��Ă�ARM�X�p�R���ł͎g���邩�疳�ʂɂ͂Ȃ�Ȃ����낤��
AMD��APU�őR����ȁH
>>805
���Ⴀ���W���[�����ɍ����݂̃��W���[���̒��g2���Ԃ������FPU������A��ł��������̃��W���[���\���Ƃ���1�R�A�Ƃ��܂�
�ƂȂ�Ƃǂ��Ȃ��
���Ⴀ���W���[�����ɍ����݂̃��W���[���̒��g2���Ԃ������FPU������A��ł��������̃��W���[���\���Ƃ���1�R�A�Ƃ��܂�
�ƂȂ�Ƃǂ��Ȃ��
>>807
4C8T��4C16T�ɂȂ邾������Ȃ��̂��B
4gamer�̃C���^�r���[�ɂ���Windows8�̃X�P�W���[���ł�Bulldozer�ł�
���ʂ�SMT�Ɠ����悤�ɘ_���R�A���珇�Ɏg���Ă��悤�ɉ��P�����ƌ������Ƃ����A
�ŏ�����4C8T�Ɍ�����悤�ɂ��Ă����Ό��s��Windows7�Ŗ��Ȃ��X�P�W���[�����O�ł����͂��ŁA
4M8C�Ƃ����͖̂��炩�Ɏ��s�ł��낤�B4C8T�Ƃ����Ƃ���Ŏ������͉̂����Ȃ��̂����B
4C8T��4C16T�ɂȂ邾������Ȃ��̂��B
4gamer�̃C���^�r���[�ɂ���Windows8�̃X�P�W���[���ł�Bulldozer�ł�
���ʂ�SMT�Ɠ����悤�ɘ_���R�A���珇�Ɏg���Ă��悤�ɉ��P�����ƌ������Ƃ����A
�ŏ�����4C8T�Ɍ�����悤�ɂ��Ă����Ό��s��Windows7�Ŗ��Ȃ��X�P�W���[�����O�ł����͂��ŁA
4M8C�Ƃ����͖̂��炩�Ɏ��s�ł��낤�B4C8T�Ƃ����Ƃ���Ŏ������͉̂����Ȃ��̂����B
>806
���ꂩ
ttp://www.4gamer.net/games/076/G007660/20111215074/
SoC�̕���������낤���ǁA�����炭project denver���ɂ��ł̊J���L�b�g�ł���
96sp�Ƃ͍T���߂�����
���ꂩ
ttp://www.4gamer.net/games/076/G007660/20111215074/
SoC�̕���������낤���ǁA�����炭project denver���ɂ��ł̊J���L�b�g�ł���
96sp�Ƃ͍T���߂�����
�ȃG�l�ȃX�y�[�X�͉����s�����E�E�E�E�E
bull������opteron������\���ɋ����͂�����
�������Ă���@�\���J�����Ă��邩�炾��tri�͂���ɉ�����pc�ɖ��Ӗ��ŏ���d�͔n���H����L3�i8MB�j���o�b�T���邾���łȂ�������pc�ɂ͖��Ӗ���4�R�A�ȏ�̕������̂Ă�
���Rpc�ɂ͕K�v�Ȃ��璷��������̂Ă�
�����Č������\�Ń��o�C��llano45w����35w�Ɂ@������gpu��llano��萫�\up
�ǂ��l���Ă�cpu��tdp����35���̔����ȉ�������15w�{�ƕ\�������������͓����߂��Ă��̘_���I�A���������ł��Ȃ�����
cpu���͓����i�̋����ɗ�邩������Ȃ���gpu�Ŗ��炩�ɏ���@�����`�b�v�Z�b�g�͋����������@�@
�����ł����ׂ���Ȃ�pc�Ȃ��狣�����`�b�v�Z�b�g��8�`10�h���������hp���ppc���[�J�[�������l����Ă���邾��
ivy�������Ȃ�Ԃ��邩�ǂ����킩��Ȃ��@�������Ƀ��o�C���ŏo�Ă����i�I�ɋ������Ȃ��Ǝv�����
cpu�{�`�b�v�Z�b�g��60�h�����炢�̍�
�Z�b�g���i�ł�100����200�h���ȏ�̍������Ǝv���@���̉��i����cpu���\�ŕ���gpu���\�ŏ���
�܂������ɂ���Șb���Ă������߂��ė����ł��Ȃ��Ǝv�����ǂ�
�������Ă���@�\���J�����Ă��邩�炾��tri�͂���ɉ�����pc�ɖ��Ӗ��ŏ���d�͔n���H����L3�i8MB�j���o�b�T���邾���łȂ�������pc�ɂ͖��Ӗ���4�R�A�ȏ�̕������̂Ă�
���Rpc�ɂ͕K�v�Ȃ��璷��������̂Ă�
�����Č������\�Ń��o�C��llano45w����35w�Ɂ@������gpu��llano��萫�\up
�ǂ��l���Ă�cpu��tdp����35���̔����ȉ�������15w�{�ƕ\�������������͓����߂��Ă��̘_���I�A���������ł��Ȃ�����
cpu���͓����i�̋����ɗ�邩������Ȃ���gpu�Ŗ��炩�ɏ���@�����`�b�v�Z�b�g�͋����������@�@
�����ł����ׂ���Ȃ�pc�Ȃ��狣�����`�b�v�Z�b�g��8�`10�h���������hp���ppc���[�J�[�������l����Ă���邾��
ivy�������Ȃ�Ԃ��邩�ǂ����킩��Ȃ��@�������Ƀ��o�C���ŏo�Ă����i�I�ɋ������Ȃ��Ǝv�����
cpu�{�`�b�v�Z�b�g��60�h�����炢�̍�
�Z�b�g���i�ł�100����200�h���ȏ�̍������Ǝv���@���̉��i����cpu���\�ŕ���gpu���\�ŏ���
�܂������ɂ���Șb���Ă������߂��ė����ł��Ȃ��Ǝv�����ǂ�
�p�[�c���͑�ς�������
ttp://www.gdm.or.jp/voices_html/201112/15a.html
ttp://www.gdm.or.jp/voices_html/201112/15a.html
�L���b�V������̖���L2DTLB�𑶍݂���ƌ����Ă����̂��^�₪�c��̂�
HW�v���t�F�`���������Ă���̂����������Ď����Ȃ��B
�ǂ������œK���K�C�h��͑��݂��邵HW�v���t�F�`����K10���狭�����ꂽ���ĐG�ꍞ�݂�����
�o�O�C�������~�b�^�����ł����Ԑ��\���P���邩�ȁB
���ƃ��W�X�^�ԃR�s�[�͂����ƃ��l�[�~���O�ŏ����Ă����B
HW�v���t�F�`���������Ă���̂����������Ď����Ȃ��B
�ǂ������œK���K�C�h��͑��݂��邵HW�v���t�F�`����K10���狭�����ꂽ���ĐG�ꍞ�݂�����
�o�O�C�������~�b�^�����ł����Ԑ��\���P���邩�ȁB
���ƃ��W�X�^�ԃR�s�[�͂����ƃ��l�[�~���O�ŏ����Ă����B
>>811
FX��Opteron�̓T�[�o�[/HPC�����@�\���������Ă���ȊO�͓����d�l�Ǝv���B
FX���n�����������������Ɛ��\�オ���B
���͒n���������̂�AVX�K�{�Ȃ��Ƃ���w
FX��Opteron�̓T�[�o�[/HPC�����@�\���������Ă���ȊO�͓����d�l�Ǝv���B
FX���n�����������������Ɛ��\�オ���B
���͒n���������̂�AVX�K�{�Ȃ��Ƃ���w
K10���M�X��bull�̃A�[�L�e�N�`�������p���ł�̂�llano�ɂ���ׂĂ܂Ƃ���TDP����������́H
������bull�Ɠ�����1���W���[��2�R�A��4�R�A��邩����ۂɂ�4�R�A�ł���Ȃ���
bull�����O�ɂ�������đ厸�s���܂������̂����肩�������
������bull�Ɠ�����1���W���[��2�R�A��4�R�A��邩����ۂɂ�4�R�A�ł���Ȃ���
bull�����O�ɂ�������đ厸�s���܂������̂����肩�������
CPU���̂��̂��Ꮯ���ɂȂ�Ȃ��������
CPU�̂��܂���GPU�Ƃ�����ׂđ叟���I�Ƃ�
����Ă邩�炱���܂ō���������ȁE�E�E
����A�������߂������炻��������Ȃ��Ȃ����̂��E�E�E
�܂��ǂ����ł������ₗ
����Ȉ����낤�����낤�̃S�~����܂���
���ɂ�����ɗ���悤�ȓz��
�u4�R�A�ȏ�͖��Ӗ��I�v�Ƃ����[�G���h�ȊO��PC��
�ے肷��悤�Ȃ��Ƃ������Ă�����Ă��邗
�����܂ł��Ȃ���AMD�����グ���Ȃ��̂��悗��
CPU�̂��܂���GPU�Ƃ�����ׂđ叟���I�Ƃ�
����Ă邩�炱���܂ō���������ȁE�E�E
����A�������߂������炻��������Ȃ��Ȃ����̂��E�E�E
�܂��ǂ����ł������ₗ
����Ȉ����낤�����낤�̃S�~����܂���
���ɂ�����ɗ���悤�ȓz��
�u4�R�A�ȏ�͖��Ӗ��I�v�Ƃ����[�G���h�ȊO��PC��
�ے肷��悤�Ȃ��Ƃ������Ă�����Ă��邗
�����܂ł��Ȃ���AMD�����グ���Ȃ��̂��悗��
>>816
Bulldozer�̏ꍇ����Ă鎖�ɂȂ��Ă邯��
���ۂɂ���Ă�̂��ǂ����^�킵�����̂��������邾��B
��������̈�B
Intel�����̒��x�̎��͂���Ă邾�낤
����ĂȂ��Ȃ�4OP FMA��3OP FMA�̗���͂Ȃ������낤���B
Bulldozer�̏ꍇ����Ă鎖�ɂȂ��Ă邯��
���ۂɂ���Ă�̂��ǂ����^�킵�����̂��������邾��B
��������̈�B
Intel�����̒��x�̎��͂���Ă邾�낤
����ĂȂ��Ȃ�4OP FMA��3OP FMA�̗���͂Ȃ������낤���B
>>820
����ĂȂ�����B
����ĂȂ�����B
>>819
�����Ȃ����ʗp�r�ɖ��Ӗ��ł���`����ɂȂ�뎩���ԋƊE�Ȃł��悭����b
>>817
������������������������
�x���`�}�[�N�ȊO�łW�R�A���t�����[�h�ɂȂ�A�v���Ȃ�Ă���Ǝv�����@�G���R�͒m���
�t�����[�h�ȊO�͂ނ���k�P�O�������d�͂��Ă̂͂����Ă���̂�m��Ȃ��̂�
�R�A�̓d�͊Ǘ��͑啝�ɐi�����Ă��邵�����͂���ꂽ�|�C���g
>>818
������b�����܂ł��r��
����P�N�ʂ̓f�X�N�g�b�v�ŗ͂̓��������͏o�Ȃ��o���Ȃ��@
����ȃj�b�`�Ȏs��ɗ͂����Ă���Ђ̑����ɂ͊�^���Ȃ��̂�����
�L���I�^����Ԃ������Ă���Ђ��Ȃ��Ȃ�����Ӗ��Ȃ����낗
�����Ȃ����ʗp�r�ɖ��Ӗ��ł���`����ɂȂ�뎩���ԋƊE�Ȃł��悭����b
>>817
������������������������
�x���`�}�[�N�ȊO�łW�R�A���t�����[�h�ɂȂ�A�v���Ȃ�Ă���Ǝv�����@�G���R�͒m���
�t�����[�h�ȊO�͂ނ���k�P�O�������d�͂��Ă̂͂����Ă���̂�m��Ȃ��̂�
�R�A�̓d�͊Ǘ��͑啝�ɐi�����Ă��邵�����͂���ꂽ�|�C���g
>>818
������b�����܂ł��r��
����P�N�ʂ̓f�X�N�g�b�v�ŗ͂̓��������͏o�Ȃ��o���Ȃ��@
����ȃj�b�`�Ȏs��ɗ͂����Ă���Ђ̑����ɂ͊�^���Ȃ��̂�����
�L���I�^����Ԃ������Ă���Ђ��Ȃ��Ȃ�����Ӗ��Ȃ����낗
>>803
���̊̐S�̃��̕������S�R��������Ȃ��̂���
���̊̐S�̃��̕������S�R��������Ȃ��̂���
>>822
�����܂�ň��łȂ���ʃ��f�����o����H
���ۂ̕����܂�͂ǂ������m��R�X�g�팸�̂��ߔώG�߂��郂�f�����팸�ŗ��v�̌����}�����Ƃ��l������
�Ƃɂ�������amd�͂����閳�ʂ��폜���悤�Ƃ��Ă���Ǝv��
���E�o�ς̋}���ȏk�����\�z����邱�ƂƂQ�`3�N��ɑ匃�˂��\�z�����arm����̔P�o�̂��߂��Ǝv����
�����܂�ň��łȂ���ʃ��f�����o����H
���ۂ̕����܂�͂ǂ������m��R�X�g�팸�̂��ߔώG�߂��郂�f�����팸�ŗ��v�̌����}�����Ƃ��l������
�Ƃɂ�������amd�͂����閳�ʂ��폜���悤�Ƃ��Ă���Ǝv��
���E�o�ς̋}���ȏk�����\�z����邱�ƂƂQ�`3�N��ɑ匃�˂��\�z�����arm����̔P�o�̂��߂��Ǝv����
�����疞���ɏo���Ăˁ[����A�z��
http://akiba-pc.watch.impress.co.jp/hotline/20111217/p_cpu.html
A8-3850�ł���ɓX��1���A3870K�͔���ꂽ�玟��͗��N2��
http://akiba-pc.watch.impress.co.jp/hotline/20111217/p_cpu.html
A8-3850�ł���ɓX��1���A3870K�͔���ꂽ�玟��͗��N2��
>>819
�⑫
�{���́A���̕ӂ�intel����ԓ��ӂȎ�@
���ۂ̓���p�r�ł͖��Ӗ��ȃM�~�b�N����p�}�X�R�~�g���Đ��点�Ă����������ʂ�����悤�ɒ�]�Ɏv�킹���@
�}�[�L�e�N�`�����Č��t�m��Ȃ��̂��H��
�⑫
�{���́A���̕ӂ�intel����ԓ��ӂȎ�@
���ۂ̓���p�r�ł͖��Ӗ��ȃM�~�b�N����p�}�X�R�~�g���Đ��点�Ă����������ʂ�����悤�ɒ�]�Ɏv�킹���@
�}�[�L�e�N�`�����Č��t�m��Ȃ��̂��H��
MIPS32? 1074K�������s�ꒆ�S�ɔn�����ꂵ�����Ȃ�Ȃ�
���i��arm�������Đ��\��Corex A9�ȏ�EA15�����炵��
arm�^�������Č����Ă��邯�Nj������������Ȃ�Ȃ�ł������̂ő傢�ɉ���������
5�N��arm������ɂȂ��Ă�肽�����肳��Ă����Ȃ�������Ȃ��Ɛ��\���i�����Ȃ���
���i��arm�������Đ��\��Corex A9�ȏ�EA15�����炵��
arm�^�������Č����Ă��邯�Nj������������Ȃ�Ȃ�ł������̂ő傢�ɉ���������
5�N��arm������ɂȂ��Ă�肽�����肳��Ă����Ȃ�������Ȃ��Ɛ��\���i�����Ȃ���
>>829
������ւ�͍��Ɏn�܂������Ƃ���Ȃ�
x86���i���ɓˌ��ł��Ȃ��s���ARM�����̑�������Ă���
���܂���ARM���ڗ����Ă���x86�M��҂��Q�ĂĂ邾������
������ւ�͍��Ɏn�܂������Ƃ���Ȃ�
x86���i���ɓˌ��ł��Ȃ��s���ARM�����̑�������Ă���
���܂���ARM���ڗ����Ă���x86�M��҂��Q�ĂĂ邾������
ID:t0w81xHj
�����͈ȑO���炱�̃X���ɐ�������PC�����`���[��()�N����
�ӐM�I��Trinty�̐�����M���ċ^��Ȃ���n�O������ق��Ƃ�
�����͈ȑO���炱�̃X���ɐ�������PC�����`���[��()�N����
�ӐM�I��Trinty�̐�����M���ċ^��Ȃ���n�O������ق��Ƃ�
http://northwood.blog60.fc2.com/blog-entry-5525.html
��������Ђ̂��������������arm�ɗ������đ����ꂻ�����Ȃ�
>>831
�ʂ�tri�̐����Ƃ��ǂ��ł�����
mobile tri�͋����������o�����Ƃ�2���O��̃V�F�A�����Ǝv���Ă��邾��
�܂荡�Ƃ��قǕς�����S����r����
��������Ђ̂��������������arm�ɗ������đ����ꂻ�����Ȃ�
>>831
�ʂ�tri�̐����Ƃ��ǂ��ł�����
mobile tri�͋����������o�����Ƃ�2���O��̃V�F�A�����Ǝv���Ă��邾��
�܂荡�Ƃ��قǕς�����S����r����
ARM�^������������ARM�̐��\�͈͓̔��Ő�D������
Intel�w�c�Ȃ猩��������@����ē�x�Ə������߂Ȃ����x������
Intel�w�c�Ȃ猩��������@����ē�x�Ə������߂Ȃ����x������
>>820
mov����������̂�IvyBridge����ƌ����Ă���
��������PRF�������̂�SandyBridge���炾��������
����Ƃ��Ă�SandyBridge�ȍ~
mov����������̂�IvyBridge����ƌ����Ă���
��������PRF�������̂�SandyBridge���炾��������
����Ƃ��Ă�SandyBridge�ȍ~
>>823
�����8�R�A���t�����[�h�ɂȂ�͂��������Ȃ����낤���A�܂�amd�̃^�[�{�R�A�̓R�A������Ȃ��ă��W���[�����Ƀ^�[�{���邩��d�͌���������
������tri����2���W���[��4�R�A�ɂȂ邩��8�R�A���ƈ���ăt�����[�h�ɂȂ�R�A�̊����������Ȃ邶���
�x���`��1�X���b�h�����Ƃ����܂ŏ���d�͂������ĂȂ�����4�X���b�h�����Ɣ����I�ɏオ���Ă邵�Ȃ�
http://pc.watch.impress.co.jp/img/pcw/docs/483/000/html/graph26.gif.html
�����8�R�A���t�����[�h�ɂȂ�͂��������Ȃ����낤���A�܂�amd�̃^�[�{�R�A�̓R�A������Ȃ��ă��W���[�����Ƀ^�[�{���邩��d�͌���������
������tri����2���W���[��4�R�A�ɂȂ邩��8�R�A���ƈ���ăt�����[�h�ɂȂ�R�A�̊����������Ȃ邶���
�x���`��1�X���b�h�����Ƃ����܂ŏ���d�͂������ĂȂ�����4�X���b�h�����Ɣ����I�ɏオ���Ă邵�Ȃ�
http://pc.watch.impress.co.jp/img/pcw/docs/483/000/html/graph26.gif.html
{kind=link}
intel��ivy�̓��o�C���d����35w�H���@�@���o�C���d���͎s����l����Γ��R����
�L���I�^�r���Ɍ}�����ăf�X�N�g�b�v�Ȃd���������ɂᗘ�v�������Ă��܂���
����������I�ŏd���Ėʔ���pc�Q�[�����łȂ�����f�X�N�g�b�v�͓~�̎��ゾ��
�܂��]�ݔ������
i��A�����S���ă��o�C���ɗ͂������鎞�ゾ��
�L���I�^�r���Ɍ}�����ăf�X�N�g�b�v�Ȃd���������ɂᗘ�v�������Ă��܂���
����������I�ŏd���Ėʔ���pc�Q�[�����łȂ�����f�X�N�g�b�v�͓~�̎��ゾ��
�܂��]�ݔ������
i��A�����S���ă��o�C���ɗ͂������鎞�ゾ��
>>835
�m�[�gpc�łS�R�A���t�����[�h���ĂقƂ�Ǒz���ł��Ȃ���
���Ƀt�����[�h�ł�35w�Ȃ炳�قǖ��Ȃ��킯����
intel�̓m�[�g��6�R�A�Ƃ��o���̂��H�悭�m��唼�̐l�ɂ͖��Ӗ����Ȃ�
�m�[�gpc�łS�R�A���t�����[�h���ĂقƂ�Ǒz���ł��Ȃ���
���Ƀt�����[�h�ł�35w�Ȃ炳�قǖ��Ȃ��킯����
intel�̓m�[�g��6�R�A�Ƃ��o���̂��H�悭�m��唼�̐l�ɂ͖��Ӗ����Ȃ�
ARM�N�͂����������̎���̘b�����Ƃ�̂�
Intel�����o�C���d���ɂȂ����̂͒x���Ƃ�2000�N��O���ŁA
AMD�ɂ������Ă����ɒ[�Ɏs��̔F�����Y����͂����Ȃ��̂�
��Intel��Core i=Nehalem(�l�n�[����)�}�C�N���A�[�L�e�N�`���̊J����5�N���������B
���X�^�[�g�́A2003�N�ŁA�܂��T�[�o�[�ƃ��o�C��(�m�[�gPC)��D��Ƃ��邱�Ƃ����߂�ꂽ�B
http://pc.watch.impress.co.jp/docs/column/kaigai/20100528_369840.html
Intel�����o�C���d���ɂȂ����̂͒x���Ƃ�2000�N��O���ŁA
AMD�ɂ������Ă����ɒ[�Ɏs��̔F�����Y����͂����Ȃ��̂�
��Intel��Core i=Nehalem(�l�n�[����)�}�C�N���A�[�L�e�N�`���̊J����5�N���������B
���X�^�[�g�́A2003�N�ŁA�܂��T�[�o�[�ƃ��o�C��(�m�[�gPC)��D��Ƃ��邱�Ƃ����߂�ꂽ�B
http://pc.watch.impress.co.jp/docs/column/kaigai/20100528_369840.html
>>832
���܂�ɂ��h����ŷد�Șb�����Ă邩��GPU()��PC�����`���[��()��Trinty�叟���I�ƌ��������̂���
�v�͍��ƕς��Ȃ��V�F�A�W���n��������ł���
���܂�ɂ��h����ŷد�Șb�����Ă邩��GPU()��PC�����`���[��()��Trinty�叟���I�ƌ��������̂���
�v�͍��ƕς��Ȃ��V�F�A�W���n��������ł���
�����܂�ǂ��ɂ����Ȃ��Ƃ���
intel��Fab���������邾�����������
intel��Fab���������邾�����������
�܂�GPUGPU�ATDPTDP�����Ă邯��intel��ivy����GPU���\��TDP���\�����Ă�����ǂ�
CPU�����|�I�ɕ����Ă��Ԃłǂ�tri�ɋ��ꏊ�����
CPU�����|�I�ɕ����Ă��Ԃłǂ�tri�ɋ��ꏊ�����
�u��4100��Llano��2.9G�ɎS�s���Ă�Ƃ�����݂����
���ɂ͊��҂��ĂȂ�
���ɂ͊��҂��ĂȂ�
�ŐV�̗m���Q�[�A�}���`�X���b�h��DX11�g�p�̃Q�[���x���`�Ƃ�
�ŐV��3D�@�\�x���`�}�[�N���āA
�S�~�݂�����CPU���W�߂ăR�A���ŃA�s�[��
�R���Ɍ��܂��Ă댾�킹��Ȃ�͂�������
�ŐV��3D�@�\�x���`�}�[�N���āA
�S�~�݂�����CPU���W�߂ăR�A���ŃA�s�[��
�R���Ɍ��܂��Ă댾�킹��Ȃ�͂�������
���~�b�^�[�i�j
���ӎ��ߏ�u�X
���ӎ��ߏ�u�X
>>826
���̒��x�̊ϑ������o���Ȃ��̂Ȃ�A���l�l�����Ƃ��v���オ��͎~�߂Ƃ��Ȃ您�O�͓��������̂�����B
���̒��x�̊ϑ������o���Ȃ��̂Ȃ�A���l�l�����Ƃ��v���オ��͎~�߂Ƃ��Ȃ您�O�͓��������̂�����B
���ӎ��ߏ�u�X������d��������
>>828
�C���e������ԓ��ӂ��Ƃ���ƁA�C���e���̋�̗���o��������������B
�}�[�L�e�N�`���Ȃ�Č��t�͒m��Ȃ����A�c��ȃR�X�g��v����@�\�́A�lj����̂������킹�郂�m�ŁA�����킹���瑶�݂��Ȃ��̂����炻���ɂ͂��Ȃ���B
�C���e������ԓ��ӂ��Ƃ���ƁA�C���e���̋�̗���o��������������B
�}�[�L�e�N�`���Ȃ�Č��t�͒m��Ȃ����A�c��ȃR�X�g��v����@�\�́A�lj����̂������킹�郂�m�ŁA�����킹���瑶�݂��Ȃ��̂����炻���ɂ͂��Ȃ���B
ivy�̃T���v����2G�Ŏ��Ђ̋����i�Ɣ�ׂĂǂ������Ƃ�
���̃X�����Ĕn�����̂����ɂ̂���ꏊ����Ȃ��͂������Ȃ��E�E�E
���̃X�����Ĕn�����̂����ɂ̂���ꏊ����Ȃ��͂������Ȃ��E�E�E
>>836
���b�p�������ۂ��ăX�P�[���u���Ƀp�t�H�[�}���X���g���o����d�l�ɂ���ׂ��ŁA��}�b�N�X����d�͂ɍ��킹���v�͗p�r�����肳��Ă��Ė��ʂ��傫���B
���b�p�������ۂ��ăX�P�[���u���Ƀp�t�H�[�}���X���g���o����d�l�ɂ���ׂ��ŁA��}�b�N�X����d�͂ɍ��킹���v�͗p�r�����肳��Ă��Ė��ʂ��傫���B
�����n�����L�`�K�C���G���R�~�������̃X�����ĂȂ�����
�C���e����CPU�����`�F�b�N���Ă�������ゾ���A�G���R�~�ƋL�҈ȊO��
�C���e����CPU�����`�F�b�N���Ă�������ゾ���A�G���R�~�ƋL�҈ȊO��
�܂������I�ɑS�̂�����Ώ����ɂȂ�������������ł���
���ƃ}�[�L�e�N�`���͏��߂ĕ��������A���ɓI���˂Ă���P�ꂾ��
���ƃ}�[�L�e�N�`���͏��߂ĕ��������A���ɓI���˂Ă���P�ꂾ��
>>852
GPU�G���R�̉f���i�����啝�Ɍ��サ�āA�G���R���x�������x�ȏ�Ȃ�CPU�ł̃G���R��
����Ȃ��Ȃ邾�낤����ǁA���ɂȂ���E�E�E
GPU�G���R�̉f���i�����啝�Ɍ��サ�āA�G���R���x�������x�ȏ�Ȃ�CPU�ł̃G���R��
����Ȃ��Ȃ邾�낤����ǁA���ɂȂ���E�E�E
�n���ŗL���ȃz���R�e���U�X�\��Ă�Ƃ��Ȃ̂�
���X�������Ƃł��ˁ[���
���X�������Ƃł��ˁ[���
�܂����ۂ̓Q�[���Ƃ���Ȋ�����Sandy�̑��x�K�^�������ċt�]�����Ⴄ��ł����ǂ�
http://ascii.jp/elem/000/000/653/653892/img.html
http://ascii.jp/elem/000/000/653/653892/img.html
�u��������p�C�v���₵�Ă���Ȃ�����
>>850
Phenom�̓`�[�g���i
Phenom�̓`�[�g���i
�z�����̃V���^���̘A�Ă���L�`�K�C���܂��N���o�����̂�
�����c�q�ȏ�ɂ��������Ă���Ď��o�Ȃ��̂���
�����c�q�ȏ�ɂ��������Ă���Ď��o�Ȃ��̂���
>>856
2500k�Ɣ�r���ď����錾���Ăǂ�����悗
�u�����đ����� �~�{�[�i�X�Ŕ���AMD�I�����[������W�v�̃^�C�g���I�ɒl�i�߂�2700k�Ɣ�ׂ�ׂ��Ȃ̂ɂ�������
2500k�Ɣ�r���ď����錾���Ăǂ�����悗
�u�����đ����� �~�{�[�i�X�Ŕ���AMD�I�����[������W�v�̃^�C�g���I�ɒl�i�߂�2700k�Ɣ�ׂ�ׂ��Ȃ̂ɂ�������
861 �FSocket774�F2011/12/16(��) 12:48:48.78 ID:KJuTymo5
8150��245�h��
2500k��肿�傢��
���i�I�ɂ����������Ȃ���
2500k��肿�傢��
���i�I�ɂ����������Ȃ���
����d�͉͂B���ł��������ł���
35 �FSocket774 [��] �F2011/12/16(��) 12:54:51.17 ID:oz5oIRP3
Bulldozer�̃p�t�H�[�}���X�����コ����Windows Hotfix�����J
http://support.microsoft.com/kb/2592546/
Bulldozer�̃p�t�H�[�}���X�����コ����Windows Hotfix�����J
http://support.microsoft.com/kb/2592546/
���i�I�ɂ�8120��2500k������
���ƃQ�[���ł́A����Ȃ���LostPlanet2�̍��𑜓x�ł͂ƌ����ׂ�����
���ƃQ�[���ł́A����Ȃ���LostPlanet2�̍��𑜓x�ł͂ƌ����ׂ�����
���̓x���`���ڂ��ו����������ē���s���肪�������邩���
�S�Ăɂ����Ċ����ɏ�ʂ̂��̂��Ȃ��A����Ⴛ�ꔃ���̂ɂ߂�ǂ�����
�S�Ăɂ����Ċ����ɏ�ʂ̂��̂��Ȃ��A����Ⴛ�ꔃ���̂ɂ߂�ǂ�����
Intel��HT�L�����Ɠ����X���b�h�̊���U�������Ă邾���ŁA�ŏ�����4C8T�Ƃ��������ɂ��Ă�ΕK�v�Ȃ������C�����ȁB
�����R�A8���Ƃ��l�܂�Ȃ����h�ɕt�����킳���MS����J���ς��Ȃ��ȁB
�����R�A8���Ƃ��l�܂�Ȃ����h�ɕt�����킳���MS����J���ς��Ȃ��ȁB
�A�X�L�[����AMD�L���̃f�[�^�����Ă����
���Ƃ͑S�ăC���e���̖ϑz�x���`�����̂��Ȃ�
���Ƃ͑S�ăC���e���̖ϑz�x���`�����̂��Ȃ�
�܂�AMD�Ղ�J�Ì���@2011�N12��17���`2012�N1��9��
http://pc.watch.impress.co.jp/docs/news/20111216_499410.html
�N���N�n���������
�}�W�ŗ~�������i�Ɍ����ĕ����Ȃ��\�z�ȏ�ɔ���ĂȂ��Ƃ��͌���
3800��3600�͍ŏ�����Ȃ�����
http://pc.watch.impress.co.jp/docs/news/20111216_499410.html
�N���N�n���������
�}�W�ŗ~�������i�Ɍ����ĕ����Ȃ��\�z�ȏ�ɔ���ĂȂ��Ƃ��͌���
3800��3600�͍ŏ�����Ȃ�����
�A���~�ɂ͓��v�Ƃ������̂𗝉��ł��邾���̋���A�m�\���Ȃ��̂�
�@ �@ �@�@�@�@�@�@�@ �@ �@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ,.��
�@�@___ �@�@�@�@�@�@�@ �@ �@ �@ �@ �@�@�@�@�@�@�@�@�@�@�@�@с@�@i
�@�u �_i�r�@�@�@ �@ �@�@�@�@�@�@ �@ �@�@�@�@�@�@�@�@�@�@�@�@ �T�@�q
�@ā@�m �@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@i�j(()
�@i �@{ �@ �@�@�@�@�@�@�@ �@�@�@�Q�Q�Q_ �@ �@�@�@�@�@�@�@�@| �@�R
�@i�@�@i�@�@�@ �@�@�@�@�@�@�@�^__,�@ , �]-�_ �@ �@ �@ �@ �@�@i �@�@}
�@|�@�@ i�@�@�@�@�@�@ �@�@�^�i��) �@ ( �� )�_�@�@�@�@�@�@ {��@ ��
�@�g�|��.�@�@�@�@�@�@�^ �@ �@�i__�l__�j �@�@�@�_�@�@�@ ,�m�@�P ,!
�@i�@�@�@�T�_ �@�@�@�@|�@�@�@�@�@�L�P` �@ �@�@�@�@|�@,. '�Lʁ@�@�@,!
.�@�R�A �@�@�@�M`�@�,__�_ �@�@ �@ �@�@�@�@�@ �@ �^"�@�_ �@�R�^
�@�@�@�_�m�@Ɂ@�@�@ʁPr/:::r�\--�\/::�V�@�@ Ɂ@�@�@�@�^
�@ �@�@ �@ �R.�@�@�@�@�@�@�R::�q�G . '::. :' |::/�@�@ /�@�@�@,. "
�@�@�@�@�@�@�@ `� ��@�@�@�@�_�R::. ;::�F|/�@�@�@�@�@��'"
�@�@�@�@�@�^�P�����������������R
�@�@�@�@�@| �� |�@�@�@�@�@�@�@�@AMD��D���@�@�@�@�@�@�@��|
�@�@�@�@�@�_�Q�����������������m
�@Microsoft�CBulldozer�A�[�L�e�N�`���̃X�P�W���[���œK���p�b�`�����J
�@http://www.4gamer.net/games/086/G008641/20111216007/
�@�@___ �@�@�@�@�@�@�@ �@ �@ �@ �@ �@�@�@�@�@�@�@�@�@�@�@�@с@�@i
�@�u �_i�r�@�@�@ �@ �@�@�@�@�@�@ �@ �@�@�@�@�@�@�@�@�@�@�@�@ �T�@�q
�@ā@�m �@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@i�j(()
�@i �@{ �@ �@�@�@�@�@�@�@ �@�@�@�Q�Q�Q_ �@ �@�@�@�@�@�@�@�@| �@�R
�@i�@�@i�@�@�@ �@�@�@�@�@�@�@�^__,�@ , �]-�_ �@ �@ �@ �@ �@�@i �@�@}
�@|�@�@ i�@�@�@�@�@�@ �@�@�^�i��) �@ ( �� )�_�@�@�@�@�@�@ {��@ ��
�@�g�|��.�@�@�@�@�@�@�^ �@ �@�i__�l__�j �@�@�@�_�@�@�@ ,�m�@�P ,!
�@i�@�@�@�T�_ �@�@�@�@|�@�@�@�@�@�L�P` �@ �@�@�@�@|�@,. '�Lʁ@�@�@,!
.�@�R�A �@�@�@�M`�@�,__�_ �@�@ �@ �@�@�@�@�@ �@ �^"�@�_ �@�R�^
�@�@�@�_�m�@Ɂ@�@�@ʁPr/:::r�\--�\/::�V�@�@ Ɂ@�@�@�@�^
�@ �@�@ �@ �R.�@�@�@�@�@�@�R::�q�G . '::. :' |::/�@�@ /�@�@�@,. "
�@�@�@�@�@�@�@ `� ��@�@�@�@�_�R::. ;::�F|/�@�@�@�@�@��'"
�@�@�@�@�@�^�P�����������������R
�@�@�@�@�@| �� |�@�@�@�@�@�@�@�@AMD��D���@�@�@�@�@�@�@��|
�@�@�@�@�@�_�Q�����������������m
�@Microsoft�CBulldozer�A�[�L�e�N�`���̃X�P�W���[���œK���p�b�`�����J
�@http://www.4gamer.net/games/086/G008641/20111216007/
�P�Ȃ�SMT�����Ɍ��������邾���̃p�b�`�Ȃ�
�Е��̃��W���[�����~�����ē���N���b�N���グ��
MaxTurbo�̋����ƃ`�O�n�O�ɂȂ肻���Ȃ���
�Е��̃��W���[�����~�����ē���N���b�N���グ��
MaxTurbo�̋����ƃ`�O�n�O�ɂȂ肻���Ȃ���
{kind=link}
�Q�[���ƌ����L���b�V��������
�������펯�I�ȃ��x���̐��\�ɂ܂ŏオ���ė���E�E�E
�������펯�I�ȃ��x���̐��\�ɂ܂ŏオ���ė���E�E�E
����brazos2.0 ��40nm�H
�Ȃ��������ɂ��ꂽ���Ⴄ��
�����o����̂ƗL���Ȃ̂͑S���Ⴄ��
���ɗL�����Ĉ�ʓI�ɒN�ł��m���Ă�悤�ȏꍇ�Ɏg�����t���Ǝv����
����ȂɗL���Ȃ́H
���ɗL�����Ĉ�ʓI�ɒN�ł��m���Ă�悤�ȏꍇ�Ɏg�����t���Ǝv����
����ȂɗL���Ȃ́H
>>849
���܂�cpu����x86�̗��j�S���m��Ȃ�����
���܂�cpu����x86�̗��j�S���m��Ȃ�����
>>882
���ɂ�������cpu�ɂ��Č��X�������
�L���ȉp���T�C�g�Ƃ��ڂ�ʂ��Ă���Ǝv������
�@�����ŋ߃T�{���Ă邯��x86�̏����ɖ������ĂȂ��Ȃ��Ă������Ƃ��傫���Ȃ�
���\2.5�{����d�͐��\�{�l�i���{�Ƃ����ᖳ���Ȃ����낗
���ɂ�������cpu�ɂ��Č��X�������
�L���ȉp���T�C�g�Ƃ��ڂ�ʂ��Ă���Ǝv������
�@�����ŋ߃T�{���Ă邯��x86�̏����ɖ������ĂȂ��Ȃ��Ă������Ƃ��傫���Ȃ�
���\2.5�{����d�͐��\�{�l�i���{�Ƃ����ᖳ���Ȃ����낗
>>881
�A�[�L�e�N�`���̃A�̎����m��Ȃ�PC�����`���[��()�N���悭������
�h�����>>811�݂����ȋL�����������Ⴄ�z�����ɍs���Ă������͂Ȃ���
�A�[�L�e�N�`���̃A�̎����m��Ȃ�PC�����`���[��()�N���悭������
�h�����>>811�݂����ȋL�����������Ⴄ�z�����ɍs���Ă������͂Ȃ���
���������Ǝ��ۋ��o���Ă����ƂȂ��Intel�����Ȃ�����Ȃ��E�E�E�E
�{�[�i�X�o����2600k�����蔃�������Ȃ�
���Ɏg�����ĂȂ����ǂ�
���Ɏg�����ĂȂ����ǂ�
>>885
tri��pc�����`���[������Ȃ��Ǝv���Ă���Ȃ炨�܂�����������
tri��pc�����`���[������Ȃ��Ǝv���Ă���Ȃ炨�܂�����������
>>883
�������J��Ԃ��Ă��邨�O���A����B
�������J��Ԃ��Ă��邨�O���A����B
�`���[�����邾���Ő��\�����ˏオ��Ǝv���Ă�낗
�V�������N�Ƃ�����Ȃ��Ȃ�
�V�������N�Ƃ�����Ȃ��Ȃ�
������zambezi�̂Ƃ����I�O��Ȃ��ƌ����Ď����グ�Ă���˂�
���ʂ͒c�q�̗\�z�ȉ��̏o���������킯�����ǂ�
trinity�y���݂ł���
���ʂ͒c�q�̗\�z�ȉ��̏o���������킯�����ǂ�
trinity�y���݂ł���
>>890
phenom����phenom�U
conroe����Wolfdale
cpu�̐i���̓`���[���̗��j����@bull�͑S�ʓI�Ɏ����v�̉\�����邩��{�g���l�b�N�ɂȂ��Ă镔���Ɏ�������i��v�ł̌������j�̂�������Ȃ�
�ō���̗��penpro����pentium�U�m�[�gcpu���悤�Șb������{�I�ɃV�i���I�ʂ�Ȃ�
���܂łȂ�f�X�N�g�b�v�����Ƀ`���[�����Ă���̒����d�͔ł��m�[�g�ɂ����낤������͗\�Z��\�[�X�̊W�Ńf�X�N�g�b�v�͈�Ԍ�Ńm�[�g�����`���[���ɐ�O����
�f�X�N����tri�͑I�ʗ����݂����Ȃ���i���̕ӂ�core�ȍ~��intel���������낤�j
cpu���\�͓���llano��1���������炢���i�N���b�N�㏸���݁j����d�͂�22%�팸�i45����35���jgpu���\��2���������炢��
phenom����phenom�U
conroe����Wolfdale
cpu�̐i���̓`���[���̗��j����@bull�͑S�ʓI�Ɏ����v�̉\�����邩��{�g���l�b�N�ɂȂ��Ă镔���Ɏ�������i��v�ł̌������j�̂�������Ȃ�
�ō���̗��penpro����pentium�U�m�[�gcpu���悤�Șb������{�I�ɃV�i���I�ʂ�Ȃ�
���܂łȂ�f�X�N�g�b�v�����Ƀ`���[�����Ă���̒����d�͔ł��m�[�g�ɂ����낤������͗\�Z��\�[�X�̊W�Ńf�X�N�g�b�v�͈�Ԍ�Ńm�[�g�����`���[���ɐ�O����
�f�X�N����tri�͑I�ʗ����݂����Ȃ���i���̕ӂ�core�ȍ~��intel���������낤�j
cpu���\�͓���llano��1���������炢���i�N���b�N�㏸���݁j����d�͂�22%�팸�i45����35���jgpu���\��2���������炢��
�S���V�������N���Ă邶��ˁ[�����@�����
�T�[�o�[����Bloomfield����f�X�N�g�b�v����Lynnfield�͑債�Đ��\�オ��Ȃ��������ǂ�
�T�[�o�[����Bloomfield����f�X�N�g�b�v����Lynnfield�͑債�Đ��\�オ��Ȃ��������ǂ�
�t�_�L�`�K�C��s�������グ�Ă���Ď���Trinity�ɂ͈ꌇ�Ђ̖]�݂������Ȃ�
K53TA K53TA-SX0A6 [�_�[�N�u���E��]
�ň����i(�ō�)�F\41,875 (�O�T��F-125�~��) 7���O�̍ň����i�Ƃ̑Δ� ���i���ڃO���t������
* ���i�сF\41,875�`\53,700 (26�X��)
* �X�܈ꗗ
* ���[�J�[��]�������i�i�ŕʁj�F\47,429
* �������F2011�N 8��13�� ASUS�AAMD A6-3400M���ڂ�15.6�^�m�[�gPC
�m�[�g�p�\�R���̐l�C��������L���O
3�� (12426���i��)
K53TA K53TA-SX0A6 [�_�[�N�u���E��]�̃��[�U�[���r���[�@�����x�F4.56 (�̓_��:41�l)��������
K53TA K53TA-SX0A6 [�_�[�N�u���E��]�̃N�`�R�~�@�@833�� ��������
ASUS(�A�X�[�X)�̃m�[�g�p�\�R��
�܂��y��x86�͐��\�ǂ���2.5�{����d�͐��\�{�l�i���{�Ȏ��_�Ń_�������ǂ�
�ŋ߂̒��ڂ�MIPS32 1074K�ł��킗
�ŋ߂̒��ڂ�MIPS32 1074K�ł��킗
897 �F,,�E�L�́M�E,,�j��-�������F2011/12/16(��) 21:29:48.91 ID:HbBHTL7R
���O�����ڂ��悤���N�����O�ɒ��ڂ��Ȃ�����
>>897
���O�A�v�������蒍�ڂ��Ă��Ȃ�����
���O�A�v�������蒍�ڂ��Ă��Ȃ�����
899 �F,,�E�L�́M�E,,�j��-�������F2011/12/16(��) 22:08:42.21 ID:HbBHTL7R
NG�o�^����̂������h�C��B�G������������ȁB
����CPU��肽���Ȃ瑼�̔Ŏv���������B
����CPU��肽���Ȃ瑼�̔Ŏv���������B
�V���^�z���Ɣl�|���ꂽ��
�����Ƙ����������X�J�ɏ�ꂽ�肷���
�������Ă��炭���Ȃ��Ȃ��Ȃ�����
�����Ƙ����������X�J�ɏ�ꂽ�肷���
�������Ă��炭���Ȃ��Ȃ��Ȃ�����
901 �F,,�E�L�́M�E,,�j��-�������F2011/12/16(��) 22:51:11.81 ID:HbBHTL7R
�悤�V���^�z��
���ӎ��ߏ�u�X���܂����Ă�́H
903 �FSocket774�F2011/12/16(��) 23:43:15.07 ID:1KTwQXv2
�����̃A�b�v�f�[�g�ɂ��2�R�A����1���W���[����Windows����̓V���O���}���`�X���b�h�R�A�ƌ����邻����
��SandyBridge�Ƃ��݂�����4�R�A8�X���b�hCPU�Ƃ݂Ȃ���邻���ł�
�����̃A�b�v�f�[�g�ɂ��2�R�A����1���W���[����Windows����̓V���O���}���`�X���b�h�R�A�ƌ����邻����
��SandyBridge�Ƃ��݂�����4�R�A8�X���b�hCPU�Ƃ݂Ȃ���邻���ł�
�����̃A�b�v�f�[�g�ɂ��2�R�A����1���W���[����Windows����̓V���O���}���`�X���b�h�R�A�ƌ����邻����
��SandyBridge�Ƃ��݂�����4�R�A8�X���b�hCPU�Ƃ݂Ȃ���邻���ł�
(�P���P)
radeon7000�n��DX11.1�݂�������
Trinty��GPU��7000�n������11.1�Ȃ̂���
Trinty��GPU��7000�n������11.1�Ȃ̂���
���������`���[���Ɖ��ǂ͂ǂ��Ő���������H
>>893
Bloomfield�̓f�X�N�g�b�v����CPU����
�T�[�o����CPU�����̂܂܃f�X�N�g�b�v�Ɏ����Ă������ĈӖ��ł́A�T�[�o����CPU�Ƃ������邪
Bloomfield���̂̓f�X�N�g�b�v�����ɓ�������ׂ�CPU
Bloomfield�̓f�X�N�g�b�v����CPU����
�T�[�o����CPU�����̂܂܃f�X�N�g�b�v�Ɏ����Ă������ĈӖ��ł́A�T�[�o����CPU�Ƃ������邪
Bloomfield���̂̓f�X�N�g�b�v�����ɓ�������ׂ�CPU
>>905
Trinity��GPU��VLIW4�n
Trinity��GPU��VLIW4�n
910 �FSocket774�F2011/12/17(�y) 00:54:44.72 ID:Avrwdvqa
�x���Ȃ�P�[�X�̂ق��������݂�����
http://ht4u.net/news/24857_patch_soll_bulldozer_unter_windows_7_beschleunigen_-_ergebnisse_enttaeuschen/
�e���W���[���ɃX���b�h��z������ƁA���x�̓^�[�{��������ɂ����Ȃ�킯��
���ǂǂ���������ă_���A�v���炵�ĊԈ���Ă��
http://ht4u.net/news/24857_patch_soll_bulldozer_unter_windows_7_beschleunigen_-_ergebnisse_enttaeuschen/
�e���W���[���ɃX���b�h��z������ƁA���x�̓^�[�{��������ɂ����Ȃ�킯��
���ǂǂ���������ă_���A�v���炵�ĊԈ���Ă��
AMD�̌����Ƃ���唼�̕���ł͂ق�2�R�A���̐��\�o�Ă�낤�́B
������20%���x�̃N���b�N�ŋt�Ƀ}�C�i�X�ɂȂ邩�B
����x�����W���[�����̔����ȉ��̎��͈��肵�Đ��\���サ���������B
������20%���x�̃N���b�N�ŋt�Ƀ}�C�i�X�ɂȂ邩�B
����x�����W���[�����̔����ȉ��̎��͈��肵�Đ��\���サ���������B
���ׂ����W���[���P�ʂɕ��U���Ď��͐��\�ƈ��������ɏ���d�͂��L�т����ȃC���[�W�������
�ǂ������ƌ�����HTT�Ɠ��������ɂ����Ⴄ�悤�Ȃ�����ȁB
4M8C�̐v��������������悤�Ȃ��B����ł����̂�AMD�c
4M8C�̐v��������������悤�Ȃ��B����ł����̂�AMD�c
915 �FSocket774�F2011/12/17(�y) 01:22:10.30 ID:Avrwdvqa
(1) Bulldozer��AM3+�}�U�[�ŏI���B(���N�V�����̂��o��)
(2) AM3�}�U�[��Bulldozer����邩�ǂ����̓}�U�[�x���_����
(3) �V����FMA�ɑΉ�����������������i���ۂ݂����̂͂��Ȃ�
(4) ���A�v���ł͐��\����͌����߂Ȃ�
(5) GPU�͍ڂ��Ă��Ȃ�
(6) ���i�Ńx���`��i3�ȉ��Ai5/i7�Ɣ�r����͎̂��������
(7) �ŏ�ʂ�245�h���Ƒ������
�@�����Ǔ��{�ł͕������킹�ō�������������N�[���[����500����Ŗ�35,000�~
(8) �N�P�ʂŒx��ɒx��Đ��\���x��Ă���
(9) 8�R�A�̗D�ʐ���O�ʂɔ���o�����̂�4�E6�R�A����ɔ̔��ƂȂ�
�@�f�����ł͌��w�҂���u�[�C���O���@
(10) 4.5GHz�܂�OC���Ă�2500K�̃f�t�H���g�N���b�N�ɂ�����ׂȂ�
�@������8GHz��ڎw���Ɨǂ��R����@
(11) �X�R�A�͋��낵���Ⴂ����OC
�@���̂�������d�͉͂ߋ��ŋ�
(12) AMD�̎x�����ĊJ�����ꂽ TotalWar:Shogun2 �� BSOD ���������ē��삵�Ȃ�
�@���͂�̂����M���O
(13) 8�R�A�q���Ŕ�������FX-8120/FX-6100/FX-4100�� Phenom II/Athlon II/A�V���[�Y�����C�o��
(14) �L�����y�[���̌i�i�͂��َq�̋� (�����ς������̍���
(15) �f�t�H�Ń��~�b�^�[���ځA��i�ł����ׂ�������Ɣ���
�@�}�U�[�ɂ���Ă͉����\�����A���x��C'n'Q�̌����Ȃ��펞�S�͉^�]�ɂȂ�
(16) ���ٓI�Ȕ̔��s�U�ɂ�蔭������ꃖ�����o�����ɉ��i����A���l�Ȓl������]�V�Ȃ������
(17) ���\���Ⴂ�͎̂��ۂ̐��\���v���ł���x���`���܂�������(��p�i���K�v�����o����\�������
(18) �Ȃ�Ǝ��ۂ̃g�����W�X�^���͌��̒l��20���ł͂Ȃ�������12���ɉ߂��Ȃ����������B
�ʐϓ�����̃g�����W�X�^���x��32nm�ōň��B
GLOBALFOUNDERIES�͐������̂����Ă����A�ŒႾ���I
(19) Win7�̃p�b�`���o�����A����8�R�A������4�R�A�����Ɂi�j
�e���W���[���ɃX���b�h��z������ƁA���x�̓^�[�{��������ɂ����Ȃ�킯��
���ǂǂ���������ă_���A�x���Ȃ�P�[�X�̂ق�������
�I���R���_(^o^)�^
���ĂĂ����ĂȂ��Ă��卷�Ȃ����炢�����ǁA
�������N���炢�u�p�b�`���ł�E�E�E�E!�v���Ĉ������点�Ăق���������
�������甼�N�y���߂��̂ɁB
���́uWin7�Ƃ��S�~�����āA�u���ɂ��Ă���ĂȂ�Win8�Ȃ�E�E�E�I�v����
�������N���炢�u�p�b�`���ł�E�E�E�E!�v���Ĉ������点�Ăق���������
�������甼�N�y���߂��̂ɁB
���́uWin7�Ƃ��S�~�����āA�u���ɂ��Ă���ĂȂ�Win8�Ȃ�E�E�E�I�v����
�����͕��ʂɑ����������Ă邠��₱��₾����
�X�P�W���[�����O���x�ő啝���P����Ƃ͎v��������ǂˁB
�X�P�W���[�����O���x�ő啝���P����Ƃ͎v��������ǂˁB
���ɑΏ����邽�߂ɁA�}�C�N���\�t�g��Bulldozer�p�b�`����������
Microsoft Pulls Down the AMD Bulldozer Multi-Threaded Patch
http://vr-zone.com/articles/microsoft-pulls-down-the-amd-bulldozer-multi-threaded-patch/14267.html
Microsoft Pulls Down the AMD Bulldozer Multi-Threaded Patch
http://vr-zone.com/articles/microsoft-pulls-down-the-amd-bulldozer-multi-threaded-patch/14267.html
919 �F,,�E�L�́M�E,,�j��-�������F2011/12/17(�y) 02:40:02.17 ID:Yo2c/Fb2
>>813
Intel�`�̂ق��ɏ���������
�������W�X�^������ړ����ă��W�X�^���l�[�~���O�ŏ����̂�����������
Intel���{�i�I�ɂ��̂�Haswell�����肩�炾�Ǝv���Ă���ǂǂ�����H
Intel�`�̂ق��ɏ���������
�������W�X�^������ړ����ă��W�X�^���l�[�~���O�ŏ����̂�����������
Intel���{�i�I�ɂ��̂�Haswell�����肩�炾�Ǝv���Ă���ǂǂ�����H
>>919
Bull������Ă�̂�����movapd�݂����ȒP���ȓz�����ł���
Bull������Ă�̂�����movapd�݂����ȒP���ȓz�����ł���
921 �F,,�E�L�́M�E,,�j��-�������F2011/12/17(�y) 03:43:44.72 ID:Yo2c/Fb2
Bulldozer�̏ꍇ�͓���128�r�b�g�Ȃ̂�YMM�X�e�[�g�ɋ����ɑΉ������W�����邩��
���������܂������ĂȂ��̂�������Ȃ��ˁB
����2���킹��256�r�b�g�́uFlexFP�v�}�[�L�e�N�`���ł͂Ȃ��ɃX�P�W���[��������s���j�b�g�܂�
�^��256�r�b�g�����K�v�������ɂȂ���ˁB
���������܂������ĂȂ��̂�������Ȃ��ˁB
����2���킹��256�r�b�g�́uFlexFP�v�}�[�L�e�N�`���ł͂Ȃ��ɃX�P�W���[��������s���j�b�g�܂�
�^��256�r�b�g�����K�v�������ɂȂ���ˁB
>>921
����႟Intel��512�r�b�gCPU���o���������
�ܘ_���̍�AMD����86CPU����Ă�����ǂ�
�v���Z�X���[���Ŏ���x��ł�
�ȃg�����W�X�^����Intel��0.8�{��256�������ł��Ă���炵����
512�r�b�gvs�Ȃ����256�~2�̐킢�Ȃ�c�c�����Ɓc���݁c�c�����Ų
����႟Intel��512�r�b�gCPU���o���������
�ܘ_���̍�AMD����86CPU����Ă�����ǂ�
�v���Z�X���[���Ŏ���x��ł�
�ȃg�����W�X�^����Intel��0.8�{��256�������ł��Ă���炵����
512�r�b�gvs�Ȃ����256�~2�̐킢�Ȃ�c�c�����Ɓc���݁c�c�����Ų
�Ƃ肠���������v�c�[�����Ȃ�Ƃ�����
���̃A�b�v�f�[�g�ɂ��2�R�A����1���W���[����Windows����̓V���O���}���`�X���b�h�R�A�ƌ����邻����
���̋Z�p���W�����Ă����Ζ��̃��o�[�Xhtt�ł��Ȃ���
�܂�arm��biglittle����Ԍ����ȁ@�ᕉ����little�R�A�ō�������big�R�A
���̋Z�p���W�����Ă����Ζ��̃��o�[�Xhtt�ł��Ȃ���
�܂�arm��biglittle����Ԍ����ȁ@�ᕉ����little�R�A�ō�������big�R�A
>>923
1�N�ɂR�R�A���V��������@���������Ȃ�
1�N�ɂR�R�A���V��������@���������Ȃ�
��������MS�̃p�b�`�Ɋ��҂ł���킯���Ȃ�����
����ȏ�ɍ���amd�ɂ͊��҂ł��Ȃ�
���ꂾ�����������Ă���
���ꂾ�����������Ă���
MS�u���̕��͂Ȃɂ����Ă��������ȁE�E�E�i�m�j�v
��N��3�R�A������i�L���b
�������J��������1M3C�Ƃ�1M4C�Ƃ�����ɐ��������čs���ǂ����낤
16�f�R�[�_�P�Z�b�g�Ƃ��s���邩��
�����邢���Ȃ��͖��ł͂Ȃ�
�c�ƃE�P�̗ǂ��ł����������o�������
�c�ƃE�P�̗ǂ��ł����������o�������
��N3�R�A������������
Bobcat��Bulldozer�R�A�̎g������Ȃ����Ȃ�
Bobcat��Bulldozer�R�A�̎g������Ȃ����Ȃ�
>>935
�ŏ���4�R�A8���W���[���ƌ����Ă����A�[�L�e�N�g�͍��ł����������Ă邯�ǃ}�[�P�e�B���O��̕\���ł��̊Ԃɂ�����ւ������
�ŏ���4�R�A8���W���[���ƌ����Ă����A�[�L�e�N�g�͍��ł����������Ă邯�ǃ}�[�P�e�B���O��̕\���ł��̊Ԃɂ�����ւ������
3���W���[��OFF�ɂ��āA1���W���[�������J���J����OC�Ƃ��o���Ȃ��̂��ˁB
��������8GHz�B����������Ȃ��ł���
939 �FSocket774�F2011/12/17(�y) 11:52:23.23 ID:YBUMHqcE
�t�̒��f�ł�8�M�K�܂Ŋ撣���Ă�i5�̒�i�����̕����\�u���y�����_(^o^)�^
>>930
Alpha21464�iEV8�j�̓����[�X�O�ɖv�������A�R�A������4�X���b�h��SMT�Ɣ��\����Ă�
Alpha21464�iEV8�j�̓����[�X�O�ɖv�������A�R�A������4�X���b�h��SMT�Ɣ��\����Ă�
Power7��1�R�A4�X���b�h�ŁA1CPU8�R�A32�X���b�h���ȁB
>>939
�܂�������O�̘b��
8GHz�܂Ńu���Ă�1���W���[������ł�
�P�Ȃ�L���b�V�����x�̃V���O���R�A������ȁB
�c�тɃL���r�A�����Ă����������ɂ͂Ȃ��B
�܂�������O�̘b��
8GHz�܂Ńu���Ă�1���W���[������ł�
�P�Ȃ�L���b�V�����x�̃V���O���R�A������ȁB
�c�тɃL���r�A�����Ă����������ɂ͂Ȃ��B
�����Ƃ����œK�����Ȃ���ĂȂ��A���ė��R�Ńp�b�`�������݂���������
4M8T��������ȊO�ɂǂ������œK��������낤
4M8T��������ȊO�ɂǂ������œK��������낤
945 �FSocket774�F2011/12/17(�y) 13:44:42.93 ID:GNiP3eZo
Linux�̃A�v���ňꕔ2600K�ȏ�o�邩��MS���Q�ĂĂ���Ă�������B
OS���{�g���l�b�N�Ǝv����Ɠ��ɎI�����͕s��������ȁB
OS���{�g���l�b�N�Ǝv����Ɠ��ɎI�����͕s��������ȁB
�{���W���[�����Ȃ��āH
�������ɕ��U�����ăp�t�H�[�}���X���グ�邾������Ȃ��āA
�ꕉ���͋t�ɓ������W���[���ɏW�������ăA�C�h���d�͂������Ă����Ƃ��ꂵ���ȁB
�Ȃ�Windows Server�ɂ͂���ȋ@�\��������ĕ��������Ƃ�����B
�ꕉ���͋t�ɓ������W���[���ɏW�������ăA�C�h���d�͂������Ă����Ƃ��ꂵ���ȁB
�Ȃ�Windows Server�ɂ͂���ȋ@�\��������ĕ��������Ƃ�����B
>>944
�\�L��4C8T����A4M8C�ɂȂ��
�\�L��4C8T����A4M8C�ɂȂ��
>>947
Windows7�ł�core parking�͗L���ɂł����
Windows7�ł�core parking�͗L���ɂł����
OS�̃X�P�W���[���̓��\�[�X�̗��p���j�^�����O����
�X���b�h�z���ł���Ȃ����������ƃ}�V�ɂȂ肻�������˂��B
FP�X�P�W���[���K�͂��l�b�N�̎��̔��f��������ȁB
�X���b�h�z���ł���Ȃ����������ƃ}�V�ɂȂ肻�������˂��B
FP�X�P�W���[���K�͂��l�b�N�̎��̔��f��������ȁB
���߂���CPU
bulldozer
bulldozer
�T�[�o�����E�X���[�v�b�g�d����
SMT������(��)
SMT������(��)
>>934
�Ȃ킫��Ȃ����낗
�Ȃ킫��Ȃ����낗
FX�̃Z�b�g����9xx�`�b�v�Z�b�g���ڃ}�U�[�̂ݑΏۂ�
�C�Â����B����ς�FX����C�Ȃ���AMD�B8xx�V���[�Y������Ƃ���
���������l�����邩�������̂ɁB
�C�Â����B����ς�FX����C�Ȃ���AMD�B8xx�V���[�Y������Ƃ���
���������l�����邩�������̂ɁB
Opteron 6282 SE
���i:79000 �~ ���R�R����
SPECINTRate(4P) 1040
SCECFPRate(4P) 752
Opteron 6276
���i:61000�~ ���R�R����
SPECINTRate 973
SCECFPRate 746
power_ssj(4P) total 2,225,321 per watt 2,968 ���R�R����
power_ssj(32P) total 17,898,948 per watt 2,919
Xeon E7-4870
���i:342000�~
SPECINTRate(4P) 1100
SCECFPRate(4P) 753
power_ssj(4P) total2,242,893 per watt 1,816
�炵��
�\���D�ꂽcpu��
���i:79000 �~ ���R�R����
SPECINTRate(4P) 1040
SCECFPRate(4P) 752
Opteron 6276
���i:61000�~ ���R�R����
SPECINTRate 973
SCECFPRate 746
power_ssj(4P) total 2,225,321 per watt 2,968 ���R�R����
power_ssj(32P) total 17,898,948 per watt 2,919
Xeon E7-4870
���i:342000�~
SPECINTRate(4P) 1100
SCECFPRate(4P) 753
power_ssj(4P) total2,242,893 per watt 1,816
�炵��
�\���D�ꂽcpu��
�ǂ����̂͒l�i�������Ă������
����������Ȃ��Ⴂ���Ȃ��͈̂��ꂾ�ȁE�E�E
����������Ȃ��Ⴂ���Ȃ��͈̂��ꂾ�ȁE�E�E
958 �F,,�E�L�́M�E,,�j��-�������F2011/12/17(�y) 20:53:19.36 ID:Yo2c/Fb2
�A�z���ȁB
Westmere-EX�v���b�g�t�H�[�����Ȃ�œd�͐H���Ă�̂������ł��Ė��������B
Westmere-EX�v���b�g�t�H�[�����Ȃ�œd�͐H���Ă�̂������ł��Ė��������B
959 �FSocket774�F2011/12/17(�y) 21:05:14.24 ID:GNiP3eZo
����ώI�s��ŃC���e���̔��l�Ŕ����������ׂ�����āB
ASPw �Ȃ�Ă̂͂ڂ��������Ɛ蕪�삪���邩��D�G�ɂȂ���B
ASPw �Ȃ�Ă̂͂ڂ��������Ɛ蕪�삪���邩��D�G�ɂȂ���B
960 �F,,�E�L�́M�E,,�j��-�������F2011/12/17(�y) 21:48:25.52 ID:Yo2c/Fb2
Intel��1���ȉ��̃V�F�A�ōX�ɔ��l��
�������₳HP��5���~�ʂ̂�������̃T�[�o�[���ĕ��ʂɃZ�������ς�ł��肷�邯��
�T�[�o�[�V�F�A���Ă�������܂�ł�́H
�T�[�o�[�V�F�A���Ă�������܂�ł�́H
962 �F,,�E�L�́M�E,,�j��-�������F2011/12/17(�y) 22:14:52.40 ID:Yo2c/Fb2
���R�܂�ł邵�A���̏��ASP���Z�o���Ă���B
>>961
�@�т��I�Ɋ܂܂�܂��̂�
�@�т��I�Ɋ܂܂�܂��̂�
>>956
Xeon�Ɣ�r���ď���d��1.5�{�Ő��\8�{���A�����Ƃ��������悤��������
Xeon�Ɣ�r���ď���d��1.5�{�Ő��\8�{���A�����Ƃ��������悤��������
���Aparwatt�����琫�\�d�͔䂩
���Ⴂ����
���Ⴂ����
966 �F,,�E�L�́M�E,,�j��-�������F2011/12/18(��) 00:34:23.97 ID:Wnd/G1+M
>>964
�������Ƃ��������悤���������炗����
Westmere 2P��3000�����Ă邵����
http://www.spec.org/power_ssj2008/results/res2011q4/power_ssj2008-20111018-00402.html
http://www.spec.org/power_ssj2008/results/res2011q4/power_ssj2008-20111010-00398.html
XeonE7�͍��x��RAS�@�\�̂��߂ɓd�͌����̕s���ȃ��W���[�����������Ă�̂�
�����T�[�o�����ƒP����r�ł��Ȃ���B
�������Ƃ��������悤���������炗����
Westmere 2P��3000�����Ă邵����
http://www.spec.org/power_ssj2008/results/res2011q4/power_ssj2008-20111018-00402.html
http://www.spec.org/power_ssj2008/results/res2011q4/power_ssj2008-20111010-00398.html
XeonE7�͍��x��RAS�@�\�̂��߂ɓd�͌����̕s���ȃ��W���[�����������Ă�̂�
�����T�[�o�����ƒP����r�ł��Ȃ���B
�c�q���l����
�Ȃ��MS��Bull�p�b�`�͐��\���������H
���W���[���ϓ��ɃX���b�h������U���āA��{�V���O���R�A�i���W���[���j�Ƃ��Ďg����ł���
�f�R�[�_�ł̖��ߏ[�U����1�N���b�N���ݖ��ł͂Ȃ��A���N���b�N���ɐ�L�ł���̂ŗǂ���Ȃ��́H
1���W���[��2�X���b�h���̗l�Ȗ��ߏ[�U��������Ȃ��Ȃ鎖��������ł���
����ł��x���Ƃ����̂́AL3�L���b�V���̃��C�e���V���v���I���Ď��ł����Ȃ��悤��
1���W���[��2�X���b�h�Ȃ�L2�Ԃŋ��L�\������A1���W���[��1�X���b�h����
�Ȃ�ׂ��������������������̕\�ꂾ��
�}���`�X���b�h��CPU����Ȃ��āA�}���`�v���Z�X��CPU�ł���Bulldozer��
�@���Ƀv���Z�X�X���[�v�b�g���グ�邩�ɏd�_��������CPU���Ď�����
���W���[���ϓ��ɃX���b�h������U���āA��{�V���O���R�A�i���W���[���j�Ƃ��Ďg����ł���
�f�R�[�_�ł̖��ߏ[�U����1�N���b�N���ݖ��ł͂Ȃ��A���N���b�N���ɐ�L�ł���̂ŗǂ���Ȃ��́H
1���W���[��2�X���b�h���̗l�Ȗ��ߏ[�U��������Ȃ��Ȃ鎖��������ł���
����ł��x���Ƃ����̂́AL3�L���b�V���̃��C�e���V���v���I���Ď��ł����Ȃ��悤��
1���W���[��2�X���b�h�Ȃ�L2�Ԃŋ��L�\������A1���W���[��1�X���b�h����
�Ȃ�ׂ��������������������̕\�ꂾ��
�}���`�X���b�h��CPU����Ȃ��āA�}���`�v���Z�X��CPU�ł���Bulldozer��
�@���Ƀv���Z�X�X���[�v�b�g���グ�邩�ɏd�_��������CPU���Ď�����
�����̓z�Ȃ�MS���g����Intel�̖W�Q���I���炢������
>>969
����������Ȃ��Ȃ�b�ɍڂ�K�v�Ȃ���H
����������Ȃ��Ȃ�b�ɍڂ�K�v�Ȃ���H
�ˊэ�Ƃō�����i��炳�ꂽ�jBull�~�σp�b�`�Ȃ𗧂�������B
>>966
�l�i�͂W�{���炢�H��
�l�i�͂W�{���炢�H��
6120�̏�̌^��6150�Ƃ�����Ȃ���6200�ɃW�����v���Ă�̂́A�������r�W�������ς���Ă��肷��̂��ȁH
6200 3.80GHz / Max 4.10GHz ���Ȃ���Max��6120���Ⴂ
6120 3.60GHz / Max 4.20GHz
6100 3.30GHz / Max 3.90GHz
6200 3.80GHz / Max 4.10GHz ���Ȃ���Max��6120���Ⴂ
6120 3.60GHz / Max 4.20GHz
6100 3.30GHz / Max 3.90GHz
MS�̃p�b�`��SMT�̓�����œK�����邽�߂ɕ����R�A�ɗD�悵�ĕt�������蓖�Ă�Ǝv���Ă������A
�}�ɂ��Ƃނ���t�Ř_���R�A�߂Ă�����TurboCore�������ʓI�ɓ��삷�邱�Ƃ�_�������̂�������
http://assets.vr-zone.net/14256/suboptimal.jpg
�}�ɂ��Ƃނ���t�Ř_���R�A�߂Ă�����TurboCore�������ʓI�ɓ��삷�邱�Ƃ�_�������̂�������
http://assets.vr-zone.net/14256/suboptimal.jpg
{kind=link}
976 �F,,�E�L�́M�E,,�j��-�������F2011/12/18(��) 03:20:16.49 ID:Wnd/G1+M
>>972
�����l�����邩�炻�̒l�i�ɐݒ肵�Ă��B
������������Ă��x���`�}�[�N�̃X�R�A���A�s�[�����Ă��V�F�A���ቺ�������Ă�̂�
�j�[�Y�����߂ĂȂ����Ă��ƁB
�K�L����Ȃ��Ȃ炻�ꂭ�炢�킩���ȁH
�����l�����邩�炻�̒l�i�ɐݒ肵�Ă��B
������������Ă��x���`�}�[�N�̃X�R�A���A�s�[�����Ă��V�F�A���ቺ�������Ă�̂�
�j�[�Y�����߂ĂȂ����Ă��ƁB
�K�L����Ȃ��Ȃ炻�ꂭ�炢�킩���ȁH
>>975
�������Ⴂ���Ă����悤���B�m���ɂ��̏ꍇTurboCORE�ɓ���B
�ł����OC���Ă��IPC�����邵���̃p�b�`�͎ז��ɂȂ�ˁB�ʓ|�ȃW�����}���ˁB
�������Ⴂ���Ă����悤���B�m���ɂ��̏ꍇTurboCORE�ɓ���B
�ł����OC���Ă��IPC�����邵���̃p�b�`�͎ז��ɂȂ�ˁB�ʓ|�ȃW�����}���ˁB
�����N���b�N���������������A������ŏ�ʂł��Ȃ��̂ɁA
����ȃX���C�h�������200�ԑ�������肵�Ă�̂́A�Ȃv�f�������Ă̂��ƂȂ̂��˂��B
http://www.donanimhaber.com/islemci/haberleri/DH-Ozel-AMDnin-FX6200-islemcisi-hakkinda-resmi-detaylar.htm
���Ƀ��r�W�������オ���đ����o�O���ׂ���Ă��Ƃ��Ă��A���\�͐����Ēm��ׂ��B
����ȃX���C�h�������200�ԑ�������肵�Ă�̂́A�Ȃv�f�������Ă̂��ƂȂ̂��˂��B
http://www.donanimhaber.com/islemci/haberleri/DH-Ozel-AMDnin-FX6200-islemcisi-hakkinda-resmi-detaylar.htm
���Ƀ��r�W�������オ���đ����o�O���ׂ���Ă��Ƃ��Ă��A���\�͐����Ēm��ׂ��B
PhenomX6�̌�p�Ƃ��ăA�s�[���������̂�������Ȃ��B
980 �F,,�E�L�́M�E,,�j��-�������F2011/12/18(��) 03:36:20.41 ID:Wnd/G1+M
PowerEdge R710 �X�^���_�[�h�E�p�b�P�[�W - 3.5 HDD
X5690�o���ɂ��Ă�967,470�~�����ʂɍ����Ȃ���H
http://configure.apj.dell.com/dellstore/config.aspx?oc=as-per710*3.5-std&c=jp&l=ja&s=pad&cs=jppad1&model_id=poweredge-r710
Interlagos�f���A���@��12���~�Ŕ�����́H
X5690�o���ɂ��Ă�967,470�~�����ʂɍ����Ȃ���H
http://configure.apj.dell.com/dellstore/config.aspx?oc=as-per710*3.5-std&c=jp&l=ja&s=pad&cs=jppad1&model_id=poweredge-r710
Interlagos�f���A���@��12���~�Ŕ�����́H
Intel�ƃ}�C�N���\�t�g�͕s�p�ӂɂڂ������舵�����ꂷ�����B
�\�t�g�ł̓I���N��������̕����ڂ��������Ă邾�낤���B
AMD�́c�c�܂�Piledriver�ȍ~�Ɋ��ҁB
�\�t�g�ł̓I���N��������̕����ڂ��������Ă邾�낤���B
AMD�́c�c�܂�Piledriver�ȍ~�Ɋ��ҁB
4P�\���ň����̗~�����Ƃ���ɂƂ�����AAMD�̑I�����L��Ȃ�Ȃ��́H
����ɑR���邽�߂��낤���ǁAintel��E7�Ƃ͕ʂɁASandyBridge�ň���4P�ɂł���悤����\�肾���B
�����AAMD��6200�ł���Ɉ����肵�Ă�������Aintel�̕����܂����Ȃ荂�����ďɂȂ邾�낤���ǁB
����ɑR���邽�߂��낤���ǁAintel��E7�Ƃ͕ʂɁASandyBridge�ň���4P�ɂł���悤����\�肾���B
�����AAMD��6200�ł���Ɉ����肵�Ă�������Aintel�̕����܂����Ȃ荂�����ďɂȂ邾�낤���ǁB
���샒�^�݂����ɁA4P�ł��邱�Ƃ�ړI�ɑI������Ȃ�˂�
985 �FSocket774�F2011/12/18(��) 06:23:52.14 ID:981KjAO1
(1) Bulldozer��AM3+�}�U�[�ŏI���B(���N�V�����̂��o��)
(2) AM3�}�U�[��Bulldozer����邩�ǂ����̓}�U�[�x���_����
(3) �V����FMA�ɑΉ�����������������i���ۂ݂����̂͂��Ȃ�
(4) ���A�v���ł͐��\����͌����߂Ȃ�
(5) GPU�͍ڂ��Ă��Ȃ�
(6) ���i�Ńx���`��i3�ȉ��Ai5/i7�Ɣ�r����͎̂��������
(7) �ŏ�ʂ�245�h���Ƒ������
�@�����Ǔ��{�ł͕������킹�ō�������������N�[���[����500����Ŗ�35,000�~
(8) �N�P�ʂŒx��ɒx��Đ��\���x��Ă���
(9) 8�R�A�̗D�ʐ���O�ʂɔ���o�����̂�4�E6�R�A����ɔ̔��ƂȂ�
�@�f�����ł͌��w�҂���u�[�C���O���@
(10) 4.5GHz�܂�OC���Ă�2500K�̃f�t�H���g�N���b�N�ɂ�����ׂȂ�
�@������8GHz��ڎw���Ɨǂ��R����@
(11) �X�R�A�͋��낵���Ⴂ����OC
�@���̂�������d�͉͂ߋ��ŋ�
(12) AMD�̎x�����ĊJ�����ꂽ TotalWar:Shogun2 �� BSOD ���������ē��삵�Ȃ�
�@���͂�̂����M���O
(13) 8�R�A�q���Ŕ�������FX-8120/FX-6100/FX-4100�� Phenom II/Athlon II/A�V���[�Y�����C�o��
(14) �L�����y�[���̌i�i�͂��َq�̋� (�����ς������̍���
(15) �f�t�H�Ń��~�b�^�[���ځA��i�ł����ׂ�������Ɣ���
�@�}�U�[�ɂ���Ă͉����\�����A���x��C'n'Q�̌����Ȃ��펞�S�͉^�]�ɂȂ�
(16) ���ٓI�Ȕ̔��s�U�ɂ�蔭������ꃖ�����o�����ɉ��i����A���l�Ȓl������]�V�Ȃ������
(17) ���\���Ⴂ�͎̂��ۂ̐��\���v���ł���x���`���܂�������(��p�i���K�v�����o����\�������
(18) �Ȃ�Ǝ��ۂ̃g�����W�X�^���͌��̒l��20���ł͂Ȃ�������12���ɉ߂��Ȃ����������B
�ʐϓ�����̃g�����W�X�^���x��32nm�ōň��B
GLOBALFOUNDERIES�͐������̂����Ă����A�ŒႾ���I
(19) Win7�̃p�b�`���o�����A����8�R�A������4�R�A�����Ɂi�j
�e���W���[���ɃX���b�h��z������ƁA���x�̓^�[�{��������ɂ����Ȃ�킯��
���ǂǂ���������ă_���A�x���Ȃ�P�[�X�̂ق�������
�I���R���_(^o^)�^
AMD���ă\�P�b�gAM2�`3+���̃f�B�X�R����
���������Ă��Ȃ���
�����ŋ߂̓������炷��Ƃ���������B
�T�[�o�\�����[�V������ARM�iRISC�n�j�ƃ\�P�b�gFMx�ɂ��������B�B
�Ƃ��E�E
���������Ă��Ȃ���
�����ŋ߂̓������炷��Ƃ���������B
�T�[�o�\�����[�V������ARM�iRISC�n�j�ƃ\�P�b�gFMx�ɂ��������B�B
�Ƃ��E�E
988 �F,,�E�L�́M�E,,�j��-�������F2011/12/18(��) 09:23:39.30 ID:Wnd/G1+M
989 �F,,�E�L�́M�E,,�j��-�������F2011/12/18(��) 09:24:48.31 ID:Wnd/G1+M
>>981
���������Ȃ��E7�������o���Ă�
���������Ȃ��E7�������o���Ă�
990 �F,,�E�L�́M�E,,�j��-�������F2011/12/18(��) 09:35:34.23 ID:Wnd/G1+M
> �T�[�o�\�����[�V������ARM�iRISC�n�j�ƃ\�P�b�gFMx�ɂ��������B�B
AMD��ARM��IP�Ȃ�Ď����Ė������炗
Imageon�ƈꏏ�ɑg�ݍ������̎��Ǝ��́i�l�ނ��܂߂āj�p����������B
���XARM�Ȃ�Ė����Ȃ�
�A�z��ARM�^������GF��ARM�̐������C�Z���X���擾�����̂�AMD����芷���鍪�����ƌ����Ă邪
Fab�����������C�Z���X�������ĂȂ���ARM�̎���ł��Ȃ�����ɂ��܂��Ă邾��
�iAMD�Ƃ͑S���W�Ȃ��b�j
AMD��ARM��IP�Ȃ�Ď����Ė������炗
Imageon�ƈꏏ�ɑg�ݍ������̎��Ǝ��́i�l�ނ��܂߂āj�p����������B
���XARM�Ȃ�Ė����Ȃ�
�A�z��ARM�^������GF��ARM�̐������C�Z���X���擾�����̂�AMD����芷���鍪�����ƌ����Ă邪
Fab�����������C�Z���X�������ĂȂ���ARM�̎���ł��Ȃ�����ɂ��܂��Ă邾��
�iAMD�Ƃ͑S���W�Ȃ��b�j
991 �FSocket774�F2011/12/18(��) 09:36:18.40 ID:JSgR1TiT
Q4�ŎI�V�F�A���オ�邩�ۂ�
994 �F,,�E�L�́M�E,,�j��-�������F2011/12/18(��) 09:53:44.65 ID:Wnd/G1+M
�ׂ�SPEC�̃X���[�v�b�g��Βl�Ɖ��i�̈����������V�F�A���������v�f�Ȃ�
Magny-Cours���o���Ă��V�F�A��������Ӗ����킩��Ȃ���
���X�オ��v�f�����o������
Magny-Cours���o���Ă��V�F�A��������Ӗ����킩��Ȃ���
���X�オ��v�f�����o������
�V�^Opteron�ɉ��Z�ʂőR�ł���̂�
E7�V���[�Y�����������炶��Ȃ��́H
�ŏ�ʂ�4P�T�[�o�[�ł�120���~�������Ȃ���
E7�V���[�Y�����������炶��Ȃ��́H
�ŏ�ʂ�4P�T�[�o�[�ł�120���~�������Ȃ���
997 �F,,�E�L�́M�E,,�j��-�������F2011/12/18(��) 09:57:12.85 ID:Wnd/G1+M
���ɃV�F�A�T����\�z���o�Ă邪
998 �F,,�E�L�́M�E,,�j��-�������F2011/12/18(��) 09:59:27.95 ID:Wnd/G1+M
�܂荡�̃C���e���ɂ�
�V�^Opteron�ɑR�ł��鐻�i�������킯��
�V�^Opteron�ɑR�ł��鐻�i�������킯��
1000 �F,,�E�L�́M�E,,�j��-�������F2011/12/18(��) 10:06:35.88 ID:Wnd/G1+M
Magny-Cours��4P�܂őΉ����Ă����ǂ�
�R�ł��鐻�i���������G��ԂȂ̂ɂȂ����V�F�A���ቺ��������Opteron
���łɂ�����Opteron��8P�i���邢�͂���ȏ�j�s�ꂩ��P�ނ���
�R�ł��鐻�i���������G��ԂȂ̂ɂȂ����V�F�A���ቺ��������Opteron
���łɂ�����Opteron��8P�i���邢�͂���ȏ�j�s�ꂩ��P�ނ���
1001 �F�P�O�O�P�F
1��̃}�V�����g�ݏオ��܂����B�B�B
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://anago.2ch.net/jisaku/
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://anago.2ch.net/jisaku/