AMDの次世代APU/CPUについて語ろう第121世代
____
\._ | 荒らし・煽り・厨房は放置が一番。
/|_| | 釣られずにスルーしましょう。
|_/\! sage進行でマターリいきますお
自作板AMD系スレッド過去ログ保存サイト様
http://amd.jisakuita.net/
Intelの次世代CPUについて語ろう 47
http://hibari.2ch.net/test/read.cgi/jisaku/1315933260/
CPUアーキテクチャについて語れ 20
http://hibari.2ch.net/test/read.cgi/jisaku/1318113870/
☆ARMの次世代core, SoCについて語るスレ #001☆
http://hibari.2ch.net/test/read.cgi/jisaku/1319938708/
前スレ
AMDの次世代APU/CPUについて語ろう第120世代
http://hibari.2ch.net/test/read.cgi/jisaku/1321225218/
\._ | 荒らし・煽り・厨房は放置が一番。
/|_| | 釣られずにスルーしましょう。
|_/\! sage進行でマターリいきますお
自作板AMD系スレッド過去ログ保存サイト様
http://amd.jisakuita.net/
Intelの次世代CPUについて語ろう 47
http://hibari.2ch.net/test/read.cgi/jisaku/1315933260/
CPUアーキテクチャについて語れ 20
http://hibari.2ch.net/test/read.cgi/jisaku/1318113870/
☆ARMの次世代core, SoCについて語るスレ #001☆
http://hibari.2ch.net/test/read.cgi/jisaku/1319938708/
前スレ
AMDの次世代APU/CPUについて語ろう第120世代
http://hibari.2ch.net/test/read.cgi/jisaku/1321225218/
|
|
|
■AMDの次世代APU/CPU
◆Trinity
Piledriver Core (第2世代 Bulldozer Core)
32nmプロセス
最大20%上昇 vs. Llano (※AMDが予測するデジタルメディアの作業)
Turbo Core 3.0
新しい命令のサポート (FMA3, Converged BMI instructions)
DDR3-2133
最高4コア L2:4MB
FM2 Socket 904pin
チップセット:A55/A75/A85FX FCH (Hudson-D2/D3/D4)
30%のグラフィックス性能向上 vs. Llano
HD7350/HD7450/HD7550 (VLIW4)
UVD3 with Secure Asset ManagementUnit (SAMU)
Video Compression Engine (VCE)
次世代DirectX 11
AMD Eyefinity Technology (3画面以上のマルチディスプレイ)
DisplayPort 1.2
TDP 65W/100W/125W
2012 Q1
◆Vishera
Piledriver Core (第2世代 Bulldozer Core)
32nmプロセス
10% x86性能が上昇 vs. Bulldozer Core (※AMDが予測するデジタルメディアの作業)
Turbo Core 3.0
新しい命令のサポート (FMA3, Converged BMI instructions)
IOMMU v2
DDR3-1866
最高8コア L2:8MB
AM3+ Socket (AMD 9-series 10-series チップセット)
2012 Q3
◆Wichita / Krishna
1チップに集積 (SoC)
Enhanced Bobcat CPU Core
28nmプロセス
最高4コア L2:2MB
最大20%の性能向上 vs. Ontario
Turbo Core 3.0
DDR3-1600
FT2 Socket BGA
25%のグラフィックス性能向上 vs. Ontario
HD7100 (VLIW4)
UVD3 with Secure Asset ManagementUnit (SAMU)
マルチメディアサポート強化
チップセットを統合 (Leverages Hudson2, USB3.0)
Wichita 4コア TDP20W
Krishna 2コア TDP8W
2012 Q2-Q3
キャンセル? http://semiaccurate.com/2011/11/15/exclusive-amd-kills-wichita-and-krishna/
◆High-Performance core roadmap
ワット当たりの性能が毎年10~15%増加
2011 Bulldozer → 2012 Piledriver → 2013 Steamroller → 2014 Excavator
◆Trinity
Piledriver Core (第2世代 Bulldozer Core)
32nmプロセス
最大20%上昇 vs. Llano (※AMDが予測するデジタルメディアの作業)
Turbo Core 3.0
新しい命令のサポート (FMA3, Converged BMI instructions)
DDR3-2133
最高4コア L2:4MB
FM2 Socket 904pin
チップセット:A55/A75/A85FX FCH (Hudson-D2/D3/D4)
30%のグラフィックス性能向上 vs. Llano
HD7350/HD7450/HD7550 (VLIW4)
UVD3 with Secure Asset ManagementUnit (SAMU)
Video Compression Engine (VCE)
次世代DirectX 11
AMD Eyefinity Technology (3画面以上のマルチディスプレイ)
DisplayPort 1.2
TDP 65W/100W/125W
2012 Q1
◆Vishera
Piledriver Core (第2世代 Bulldozer Core)
32nmプロセス
10% x86性能が上昇 vs. Bulldozer Core (※AMDが予測するデジタルメディアの作業)
Turbo Core 3.0
新しい命令のサポート (FMA3, Converged BMI instructions)
IOMMU v2
DDR3-1866
最高8コア L2:8MB
AM3+ Socket (AMD 9-series 10-series チップセット)
2012 Q3
◆Wichita / Krishna
1チップに集積 (SoC)
Enhanced Bobcat CPU Core
28nmプロセス
最高4コア L2:2MB
最大20%の性能向上 vs. Ontario
Turbo Core 3.0
DDR3-1600
FT2 Socket BGA
25%のグラフィックス性能向上 vs. Ontario
HD7100 (VLIW4)
UVD3 with Secure Asset ManagementUnit (SAMU)
マルチメディアサポート強化
チップセットを統合 (Leverages Hudson2, USB3.0)
Wichita 4コア TDP20W
Krishna 2コア TDP8W
2012 Q2-Q3
キャンセル? http://semiaccurate.com/2011/11/15/exclusive-amd-kills-wichita-and-krishna/
◆High-Performance core roadmap
ワット当たりの性能が毎年10~15%増加
2011 Bulldozer → 2012 Piledriver → 2013 Steamroller → 2014 Excavator
待て、それ全部キャンセルしたやつじゃないか?
そろそろテンプレ修正した方がよさそうだな
5 :Socket774:2011/11/21(月) 00:37:34.55 ID:jLqa/2VI
FX-8150
http://www.4gamer.net/games/100/G010000/20111014094/
>ゲーマーが「ゲームにおける性能向上」を求めた場合に,FX-8150は,選択肢となるようなCPUではない。
>AMDの最新CPUを買わないと気が済まないとか,とにかく新しいアーキテクチャのCPUを触ってみたいとか,
>ひたすら高クロックを狙ってみたいといった理由があるマニアのためのコレクターズアイテムである。
FX-6100とFX-4100
http://www.4gamer.net/games/100/G010000/20111021082/
>FX-6100とFX-4100のテストを行ったが,通して受ける印象は「わざわざ選ぶ理由がない」である。
( ゚д゚)つ┃
6 :Socket774:2011/11/21(月) 00:38:43.28 ID:hDUCvhsD
①BulldozerはAM3+マザーで終了。(来年新しいのが出る)
②AM3マザーにBulldozerが乗るかどうかはマザーベンダ次第
③新命令FMAに対応すればそこそこ速い(実際みたものはいない
④旧アプリでは性能向上は見込めない
⑤GPUは載っていない
⑥製品版ベンチはi3以下、i5/i7と比較するのは失礼なレベル
⑦最上位が245ドルと大安売り
だけど日本では抱き合わせで高負荷時爆音水冷クーラー同梱500個限定で約35,000円
⑧年単位で遅れに遅れて性能も遅れていた
⑨8コアの優位性を前面に売り出したのに4・6コアが先に販売となる
デモ会場では見学者からブーイングも
⑩4.5GHzまでOCしても2500Kのデフォルトクロックに並べない
そして8GHzを目指すと良く燃える
⑪スコアは恐ろしく低いがOCの伸び率は最強。
もちろん消費電力も過去最凶
⑫AMDの支援を受けて開発された TotalWar:Shogun2 が BSOD が発生して動作しない
もはや体を張ったギャグ
⑬8コア繋ぎで発売したFX-8120/FX-6100/FX-4100は Phenom II/Athlon II/Aシリーズがライバル
⑭キャンペーンの景品はお菓子の空き袋 (すっぱい葡萄の香り
⑮デフォでリミッター搭載、定格でも負荷がかかると発動
マザーによっては解除可能だが、今度はC'n'Qの効かない常時全力運転になる
1おつー
相変わらずAMDの話題は最初だけでスレが伸びずに
中盤以降にスレ違いのIntel VS ARMでブーストするスレだな
中盤以降にスレ違いのIntel VS ARMでブーストするスレだな
錯乱してARM心理教に入信してしまった彼が起きてきたらスタート
前スレも前々スレも土日でアンチx86 vs 団子の戦争が勃発してスレが埋まるという展開だからなw
新atomがスマフォ等に載ると期待してる淫虫
コスト無視
出してもほとんどどこも採用してもらえない状態w
今更だれが好き好んでintel縛りに付き合うんだw
x86縛りすら数年後には終わるわw
コスト無視
出してもほとんどどこも採用してもらえない状態w
今更だれが好き好んでintel縛りに付き合うんだw
x86縛りすら数年後には終わるわw
>>10
ARM君は正直面白くないんだよね。何も議論を提供できないから
団子はアセンブリ言語屋で、それ以上でもそれ以下でもない
命令セットには詳しいが、アーキテクトでも預言者でもない
しかしISAの話は普通に読めるレベル。個人的に賛否はあるけども
ARM君は正直面白くないんだよね。何も議論を提供できないから
団子はアセンブリ言語屋で、それ以上でもそれ以下でもない
命令セットには詳しいが、アーキテクトでも預言者でもない
しかしISAの話は普通に読めるレベル。個人的に賛否はあるけども
なんでそんなにx86が嫌いなのにAMDのスレに来るんかねえ
まだCUDA押しでRADEONオワタ!!って言ってくれたほうがわかりやすい
まだCUDA押しでRADEONオワタ!!って言ってくれたほうがわかりやすい
>>6
HPC ONでCnQが効かなくなるマザーってどれだ?
Bulldozerスレでも聞いたことないし、
少なくともうちのSabertooth 990FXでは効いてるぞ。
まとめるのはいいけど、間違いはちゃんと直そーぜ。
まぁ、Bullの現実が悲惨すぎて、今更どうでもいいけどな
HPC ONでCnQが効かなくなるマザーってどれだ?
Bulldozerスレでも聞いたことないし、
少なくともうちのSabertooth 990FXでは効いてるぞ。
まとめるのはいいけど、間違いはちゃんと直そーぜ。
まぁ、Bullの現実が悲惨すぎて、今更どうでもいいけどな
AMDスレだからAMDプロセッサへの友好的、批判的なレスなら良いんだけど
現状全く関係ないARM押しだから何がしたいんだか
現状全く関係ないARM押しだから何がしたいんだか
今週もkonozamaから届く気配なし
8コアのAPUはいつ頃発売されますか?
Intelの6コアが普及して、
デスクトップで使用するゲーム等アプリケーションが
4コア超に対応するようになってからじゃないでしょうか。
デスクトップで使用するゲーム等アプリケーションが
4コア超に対応するようになってからじゃないでしょうか。
そうは言うけどAMDもほとんどが4コア以下じゃん
原則的にユーザが一人しかいないデスクトップ用途では、
アムダールの法則によりマルチコアの効果は逓減していくので、
4コアを超えてコアを集積してもコストに見合う成果を得られるのは望めず、
よってコアを増やすよりは、周辺チップを統合するのが妥当になります。
アムダールの法則によりマルチコアの効果は逓減していくので、
4コアを超えてコアを集積してもコストに見合う成果を得られるのは望めず、
よってコアを増やすよりは、周辺チップを統合するのが妥当になります。
AMD 2012 MAINSTREAM DESKTOP PLATFORM - VIRGO
3DMark Vantage Performance Trinity A8:4500/A6:3600/A4:2500
Llano A8:3335/A6:2600/A4:2025
PCMark Vantage Trinity A8:7600/A6:6425/A4:6200
Llano A8:6500/A6:6000/A4:5300
CTP SP GFLOPS Trinity A8:715/A6:480/A4:335
Llano A8:415/A6:305/A4:240
Scalable performance at each brand tier
Note : Data is based on performance modeling using DDR3-1866 DIMMs with boost enabled
http://www.chw.net/2011/11/amd-trinity-rendimiento-de-los-a4-a6-y-a8-de-proxima-generacion/
http://www.youtube.com/watch?v=8sVuMFb54vs
3DMark Vantage Performance Trinity A8:4500/A6:3600/A4:2500
Llano A8:3335/A6:2600/A4:2025
PCMark Vantage Trinity A8:7600/A6:6425/A4:6200
Llano A8:6500/A6:6000/A4:5300
CTP SP GFLOPS Trinity A8:715/A6:480/A4:335
Llano A8:415/A6:305/A4:240
Scalable performance at each brand tier
Note : Data is based on performance modeling using DDR3-1866 DIMMs with boost enabled
http://www.chw.net/2011/11/amd-trinity-rendimiento-de-los-a4-a6-y-a8-de-proxima-generacion/
http://www.youtube.com/watch?v=8sVuMFb54vs
ゲハコテに煽られてそのまま次スレ案内すらなく埋まるとか、どんだけこのスレの民度は低いんだよ
>>21
GPUスゴーイは分かってるよCPUはどうなんだよと
GPUスゴーイは分かってるよCPUはどうなんだよと
GPUは帯域の縛りがありながらもきちんと効率上げることができてるっぽい
CPUも強化されたGPUの足を引っ張らないくらいには性能も上がってると見た
CPUも強化されたGPUの足を引っ張らないくらいには性能も上がってると見た
見せない物≒見せられない物
GPU能力はディスクリートの技術持ってくるだけであげられる
CPUについてはお察し下さい
GPU能力はディスクリートの技術持ってくるだけであげられる
CPUについてはお察し下さい
>>21
※ただしソケット互換性なし
※ただしソケット互換性なし
すげーな
こいつら本当に仕事でやってるんだろうな
こいつら本当に仕事でやってるんだろうな
いや知識の事じゃなくて煽り専門の仕事なんだろうなーってさ
2011年7月3日にFM1が発売、2012年Q1にはFM2が登場予定
予定通りに出れば超短命だし、延期したらしたでまた叩かれるだろw
予定通りに出れば超短命だし、延期したらしたでまた叩かれるだろw
ちなみにアム信者が散々叩いてた1156の寿命は1年4ヶ月
信者的にはどっちがダメージ少ないんだろうね、即死ソケットと延期
信者的にはどっちがダメージ少ないんだろうね、即死ソケットと延期
Llanoは自作向けじゃないとか言ってたやん(^_^;)
>>12
俺もISAについての話の部分とか読むに堪える場合があるのでNG認定しないでいる。
それ以外の部分は妄想や恣意的な拡大解釈、そして罵詈雑言(ほとんどこれ)が多くて辟易しているのだが。
知らないことまで語ろうとして結果自分の尻に火がついて火消しに躍起になるし。
団子もそういった雑音部分を排除しいちいち噛み付く癖を直せれば良いコテになれると思うのだが。
その場合レス数は今の10分の1以下になるだろうな。
俺もISAについての話の部分とか読むに堪える場合があるのでNG認定しないでいる。
それ以外の部分は妄想や恣意的な拡大解釈、そして罵詈雑言(ほとんどこれ)が多くて辟易しているのだが。
知らないことまで語ろうとして結果自分の尻に火がついて火消しに躍起になるし。
団子もそういった雑音部分を排除しいちいち噛み付く癖を直せれば良いコテになれると思うのだが。
その場合レス数は今の10分の1以下になるだろうな。
団子を煽るだけの簡単なお仕事です
>>23
pcmarkで性能上がってるならCPUもそれなりに上がってんじゃね?
pcmarkで性能上がってるならCPUもそれなりに上がってんじゃね?
>>35
PCMARKってVideoとかGameって項目なかったっけ。
PCMARKってVideoとかGameって項目なかったっけ。
38 :Socket774:2011/11/21(月) 18:22:35.41 ID:+j3P9UWx
PCmarkの数値がFX-4100と大差ない・・・
がっかりCPUか・・・
しかも125Wかもしれないと・・・
がっかりCPUか・・・
しかも125Wかもしれないと・・・
Zambeziのフルボッコっぷり考えたら今回も吹いてるだけだと思うが
TrinityはVLIW5
HD7000のローエンドはリネーム
これでつじつまが合う
HD7000のローエンドはリネーム
これでつじつまが合う
FX-4100でスコア8000だから、Piledriverコアの効果は見えず
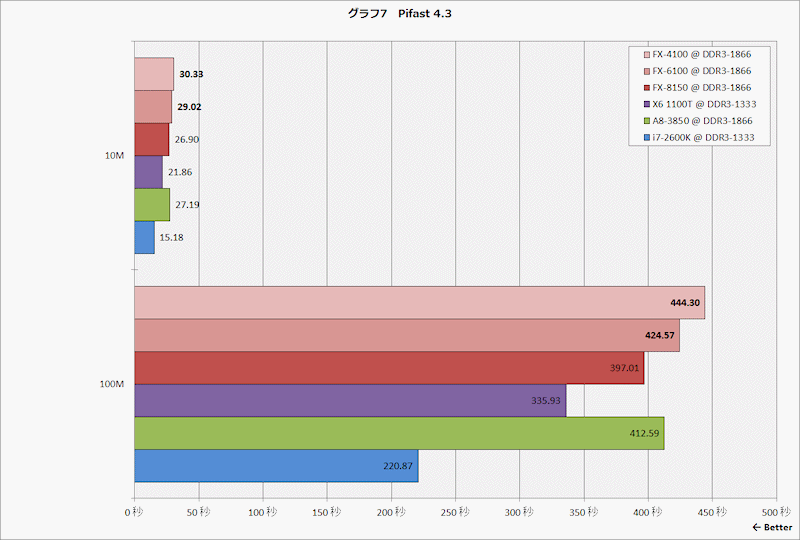
http://pc.watch.impress.co.jp/img/pcw/docs/486/640/graph09.gif
http://pc.watch.impress.co.jp/img/pcw/docs/486/640/graph09.gif
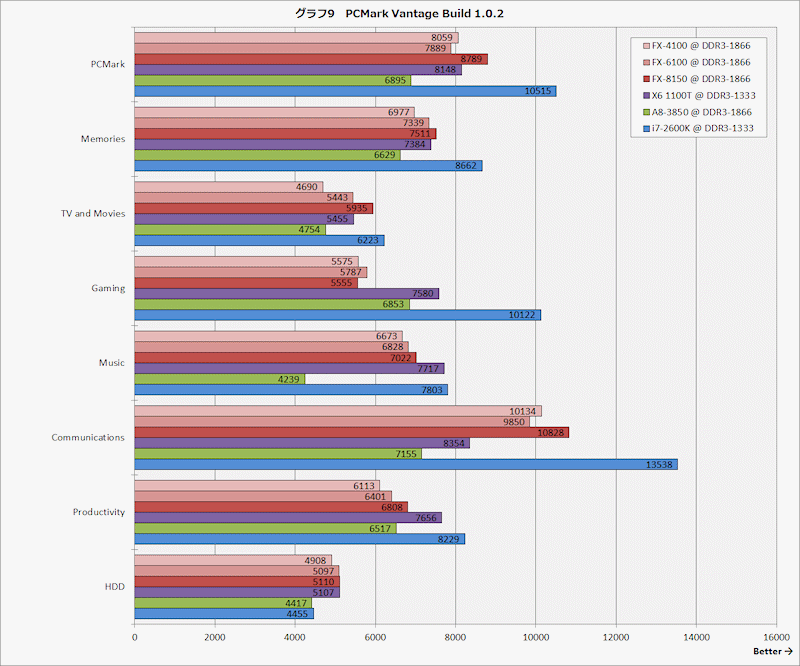{kind=link}
まんぐり返しも所詮Bulldozerなんですよ
根本的に変えなきゃダメなんですよ
ファブから何から何まで
根本的に変えなきゃダメなんですよ
ファブから何から何まで
Trinityのクロックは4GHzだから事実上性能ダウンか?w
TDP増加に見合うほどの性能が上がってるかどうかが重要だな。エンコだったらブルでやるしさ。
それより見どころなのがIvyを完膚なきまでにフルボッコに出来るということだ(・∀・)
Ivy vs Trinity = Ivy産廃
それより見どころなのがIvyを完膚なきまでにフルボッコに出来るということだ(・∀・)
Ivy vs Trinity = Ivy産廃
Trinity 4コアがFX-4100と同等以下ということは、大半のアプリでLlano以下だろ
うまくPCMark Vantageという都合のいいベンチマークだけ切り出したなw
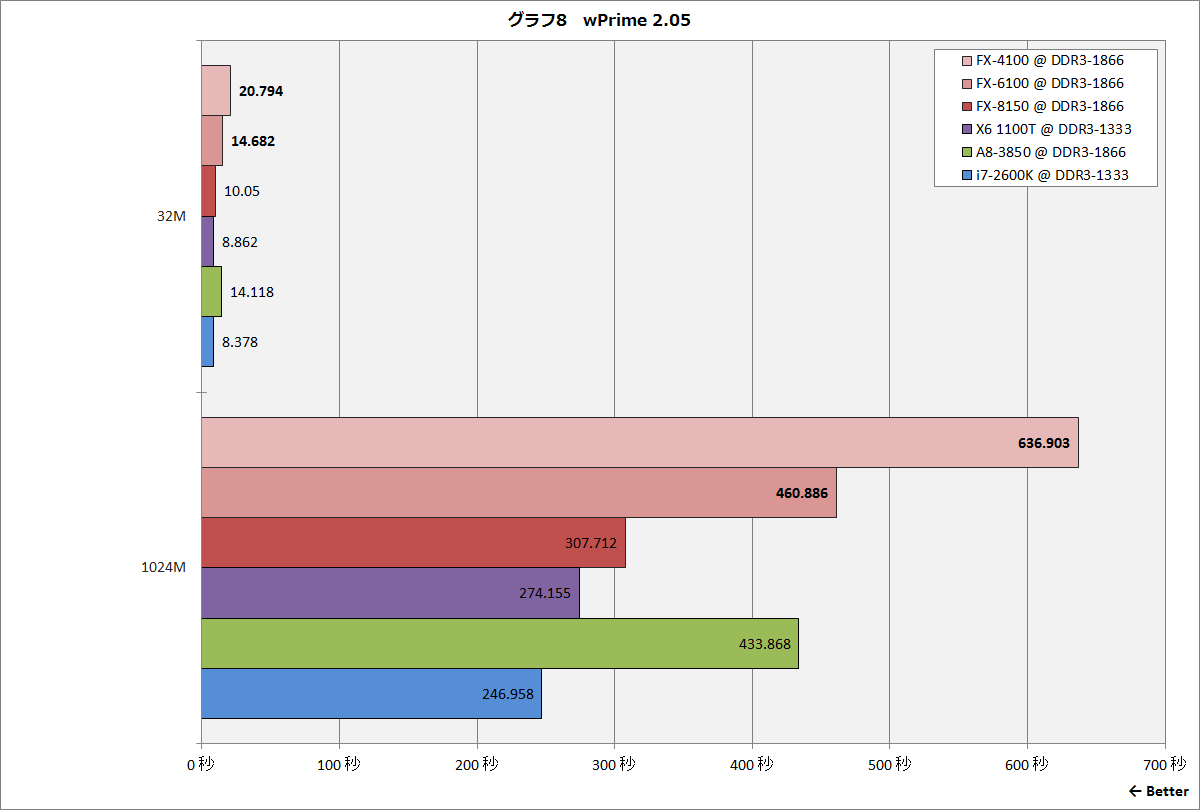
http://pc.watch.impress.co.jp/img/pcw/docs/486/640/graph04.gif
http://pc.watch.impress.co.jp/img/pcw/docs/486/640/graph05.gif
http://pc.watch.impress.co.jp/img/pcw/docs/486/640/graph06.gif
http://pc.watch.impress.co.jp/img/pcw/docs/486/640/graph07.gif
http://pc.watch.impress.co.jp/img/pcw/docs/486/640/graph08.gif
http://pc.nikkeibp.co.jp/article/news/20111020/1037863/ph14_px400.jpg
http://pc.nikkeibp.co.jp/article/news/20111020/1037863/ph15_px400.jpg
http://pc.nikkeibp.co.jp/article/news/20111020/1037863/ph16_px400.jpg
http://pc.nikkeibp.co.jp/article/news/20111020/1037863/ph17_px400.jpg
http://pc.nikkeibp.co.jp/article/news/20111020/1037863/ph18_px400.jpg
うまくPCMark Vantageという都合のいいベンチマークだけ切り出したなw
http://pc.watch.impress.co.jp/img/pcw/docs/486/640/graph04.gif
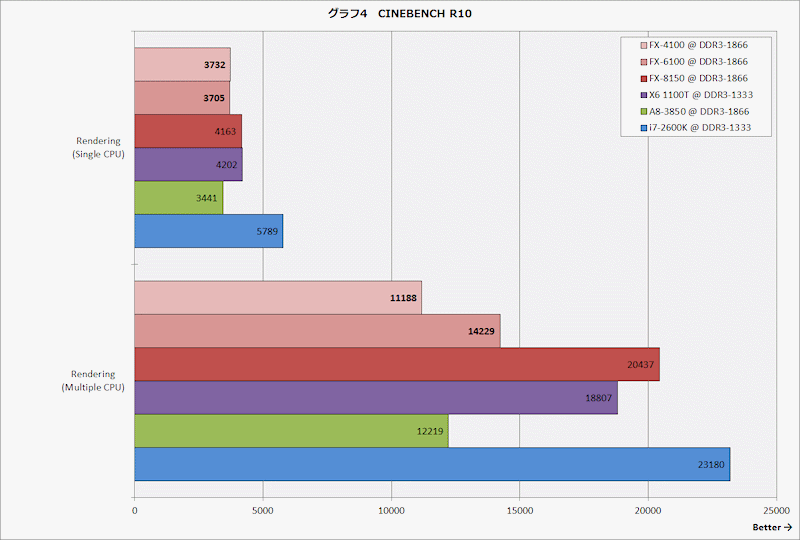{kind=link}
http://pc.watch.impress.co.jp/img/pcw/docs/486/640/graph05.gif
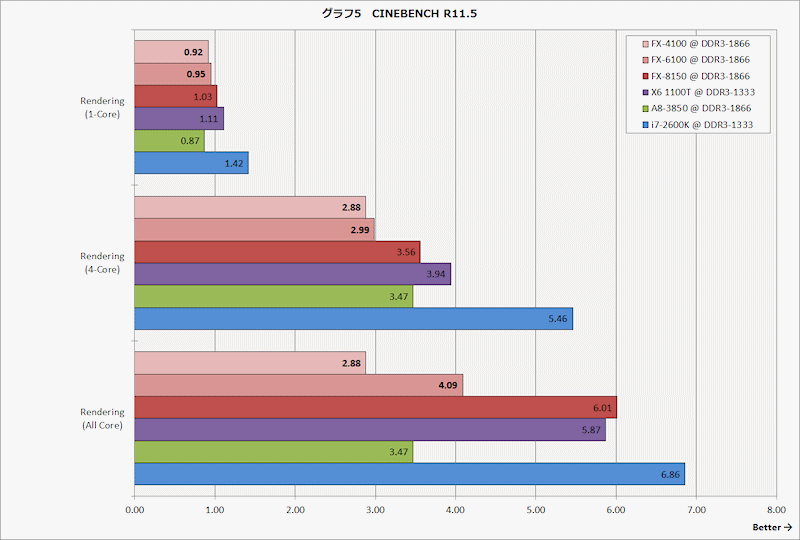{kind=link}
http://pc.watch.impress.co.jp/img/pcw/docs/486/640/graph06.gif
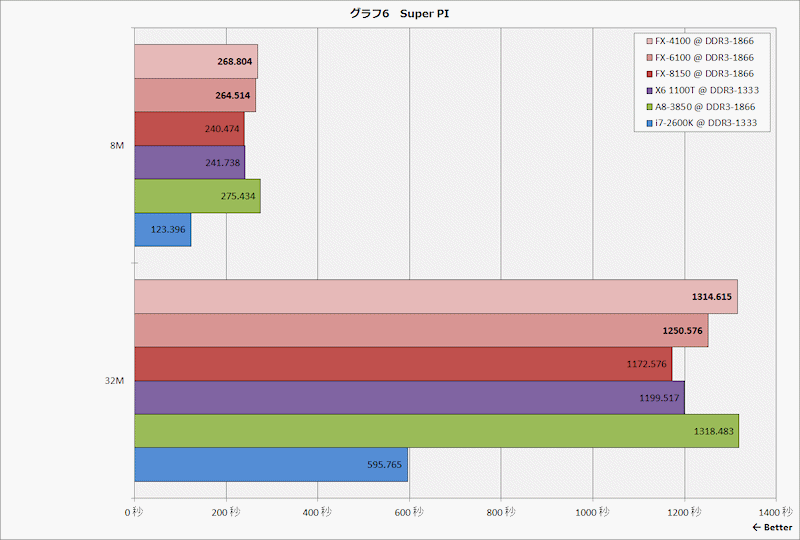{kind=link}
http://pc.watch.impress.co.jp/img/pcw/docs/486/640/graph07.gif
{kind=link}
http://pc.watch.impress.co.jp/img/pcw/docs/486/640/graph08.gif
{kind=link}
http://pc.nikkeibp.co.jp/article/news/20111020/1037863/ph14_px400.jpg
{kind=link}
http://pc.nikkeibp.co.jp/article/news/20111020/1037863/ph15_px400.jpg
{kind=link}
http://pc.nikkeibp.co.jp/article/news/20111020/1037863/ph16_px400.jpg
{kind=link}
http://pc.nikkeibp.co.jp/article/news/20111020/1037863/ph17_px400.jpg
{kind=link}
http://pc.nikkeibp.co.jp/article/news/20111020/1037863/ph18_px400.jpg
{kind=link}
A8-3850のスコアを基準に考えると普通にスコア上がってね?
ttp://www.xtremehardware.it/images/stories/AMD/A8-3850/grafici/12_a8_test_pcmark.jpg
ttp://www.xtremehardware.it/images/stories/AMD/A8-3850/grafici/12_a8_test_pcmark.jpg
{kind=link}
>>44
Ivyって最上位がTDP77wで、2500K後継の3500Kみたいな中堅モデルはTDP65wみたいだけど
TDP125wもあるTrinityってIvy最上位よりもCPU性能は2倍早いんでしょ?
GPUは別にRadeon付けるから必要ないけど
Ivyって最上位がTDP77wで、2500K後継の3500Kみたいな中堅モデルはTDP65wみたいだけど
TDP125wもあるTrinityってIvy最上位よりもCPU性能は2倍早いんでしょ?
GPUは別にRadeon付けるから必要ないけど
ivyで今のLlanoよりGPU性能があがるなら
GPU性能はそれくらいで満足。
GPU性能はそれくらいで満足。
チップセット
IvyBridge”は現行のLGA1155で対応できる。
“IvyBridge”用のチップセットとしてIntel 7 seriesが予定されており、PCI-Express 3.0への対応やUSB 3.0のサポートなどの特徴がある
CPU
“IvyBridge”のCPUコアは今までの“Tick”世代と同様、前世代のマイナーチェンジとなる。
そのため同一周波数では前世代(“SandyBridge”)から4~6%程の性能向上となるだろう
GPU
“SandyBridge”のExecution unit(EU)はMADs(≒積和演算)と超越関数を処理できる。
“IvyBridge”のEUはこのうちのMADsの多くが(“SandyBridge”のEU比で)1クロックあたり2倍の処理を行えるようになっている。
つまり、“IvyBridge”のEUは“SandyBridge”のEUの約2倍のIPCとなる。結果、GPU性能は“SandyBridge”の約60%増しになるだろう。
IvyBridge”は現行のLGA1155で対応できる。
“IvyBridge”用のチップセットとしてIntel 7 seriesが予定されており、PCI-Express 3.0への対応やUSB 3.0のサポートなどの特徴がある
CPU
“IvyBridge”のCPUコアは今までの“Tick”世代と同様、前世代のマイナーチェンジとなる。
そのため同一周波数では前世代(“SandyBridge”)から4~6%程の性能向上となるだろう
GPU
“SandyBridge”のExecution unit(EU)はMADs(≒積和演算)と超越関数を処理できる。
“IvyBridge”のEUはこのうちのMADsの多くが(“SandyBridge”のEU比で)1クロックあたり2倍の処理を行えるようになっている。
つまり、“IvyBridge”のEUは“SandyBridge”のEUの約2倍のIPCとなる。結果、GPU性能は“SandyBridge”の約60%増しになるだろう。
>>50
Ivyの完全勝利だな
Ivyの完全勝利だな
Llanoより上程度のGPUで満足する用途がわからんよな
ゲームしないならSandyIGPよりはるかに遅い785Gとかでもいいし
ゲームするならAPU()なんか使いものにならないし
ゲームしないならSandyIGPよりはるかに遅い785Gとかでもいいし
ゲームするならAPU()なんか使いものにならないし
あれ?
去年は785Gで充分だ、とか強弁してたよアムドちゃん( ̄▽ ̄)
去年は785Gで充分だ、とか強弁してたよアムドちゃん( ̄▽ ̄)
IvyのGPU性能はHD5770に匹敵する
TrinityはHD5550くらいだな・・・
メモリが遅いし・・・
IvyはDDR3-2800まで対応する
ソースは自分でググレカス
TrinityはHD5550くらいだな・・・
メモリが遅いし・・・
IvyはDDR3-2800まで対応する
ソースは自分でググレカス
サンデーvsLlanoのようつべ動画はLlano圧勝だったわけだが
APUも性能UP インテルGPUも性能UP
何時までたってもインテルはAMDに追い付けないなw 追いつけるとすれば今のLlanoと5年後のintelを比べる言いまわしくらいかな
>>52
何時の世代と比較してるの?PenDwinXPとサンデーwin7くらいの比較じゃね?
APUも性能UP インテルGPUも性能UP
何時までたってもインテルはAMDに追い付けないなw 追いつけるとすれば今のLlanoと5年後のintelを比べる言いまわしくらいかな
>>52
何時の世代と比較してるの?PenDwinXPとサンデーwin7くらいの比較じゃね?
ivyのGPUはLlanoのA6以下だろうな
いくらIvyのGPUが強力でも、ドライバがアレだからな。
GPUで話そらそうとしてるけどCPUはどうなの?
ねぇ、どうなの?w
Bull採用のTrinityのCPUはどうなの?w
ねぇ、どうなの?w
Bull採用のTrinityのCPUはどうなの?w
折角Piledriverの片鱗が見られたのにスルーかよ
信者に言わせるとPC向けにチューン(笑)したんだっけw
信者に言わせるとPC向けにチューン(笑)したんだっけw
CPUで負ければモッサリガー
GPUで負ければドライバガー
GPUで負ければドライバガー
次世代内蔵グラフィックス(笑)
http://www.4gamer.net/games/098/G009883/20110112028/SS/003.jpg
グラフィックス=ベンチスコアと勘違いする陰毛だが 綺麗に映らないと意味がない件 intelの破断が物語っている
A8-3850
http://www.4gamer.net/games/100/G010001/20110628065/SS/040.jpg
i7-2600K
http://www.4gamer.net/games/100/G010001/20110628065/SS/042.jpg
http://www.4gamer.net/games/098/G009883/20110112028/SS/003.jpg
{kind=link}
グラフィックス=ベンチスコアと勘違いする陰毛だが 綺麗に映らないと意味がない件 intelの破断が物語っている
A8-3850
http://www.4gamer.net/games/100/G010001/20110628065/SS/040.jpg
{kind=link}
i7-2600K
http://www.4gamer.net/games/100/G010001/20110628065/SS/042.jpg
{kind=link}
core iシリーズ2世代目のi7に内蔵されているintel超最高グレードのHD3000を殺すなんてモッタイナイネ(´・_・`)
>>67
おまいさんの書き込みから統一性が見えない。最後に切れただろうなって事だけは理解した。
おまいさんの書き込みから統一性が見えない。最後に切れただろうなって事だけは理解した。
俺様が興味ないものは全部ゴミ!
全部ゴミ!
全部ゴミ!
俺が見る所、AMDの次期APUは相当有望。Trinityの次ぐらいの話ね。
ブルドーザーコアは意外と省電力な一面が有る。
アイドル時は既にintelに優ってるし、
オクタコアの最適化により省電力化はまだまだ余地が有る。
GPU性能ではintelはAMDには勝てない。
>63
の通り、intelのドライバー開発能力はクズだ。
Piledriverコア + radeon でintelに勝つ時が来る。
だが今一つ足りない。
そこでだ、メインメモリーにGDDR5を採用するのだ。
モジュール化は無理なようなので、マザーボードPCBに搭載させる。
4GBぐらい有れば十分だろう。
これでintelに勝つる!
ブルドーザーコアは意外と省電力な一面が有る。
アイドル時は既にintelに優ってるし、
オクタコアの最適化により省電力化はまだまだ余地が有る。
GPU性能ではintelはAMDには勝てない。
>63
の通り、intelのドライバー開発能力はクズだ。
Piledriverコア + radeon でintelに勝つ時が来る。
だが今一つ足りない。
そこでだ、メインメモリーにGDDR5を採用するのだ。
モジュール化は無理なようなので、マザーボードPCBに搭載させる。
4GBぐらい有れば十分だろう。
これでintelに勝つる!
無茶言うなし
Llanoが本命 -> Trinityが本命 -> Trinityの次が本命
PC MarkはAESを付けただけでスコアが跳ね上がるでしょ
オマケにQSVもつければ更に跳ね上がるんだが
てか、あのベンチでは2コアを超えるコア数やGPUやクロック、キャッシュ、メモリ、その他諸々はオマケ
特にGPUはIntelの統合GPU以外の製品で出るスコアはカットしてくれる素敵仕様
Intel-CPUでの機能制限によるi3/i5/i7/Pentium/Celeronのカテゴリー&価格の階層を正当化するためにあるベンチ
オマケにQSVもつければ更に跳ね上がるんだが
てか、あのベンチでは2コアを超えるコア数やGPUやクロック、キャッシュ、メモリ、その他諸々はオマケ
特にGPUはIntelの統合GPU以外の製品で出るスコアはカットしてくれる素敵仕様
Intel-CPUでの機能制限によるi3/i5/i7/Pentium/Celeronのカテゴリー&価格の階層を正当化するためにあるベンチ
陰謀論はその辺にしとけ
TrinityはシングルコアCeleron並のCPU性能でHD5550並のGPU性能で125W
IvyはOCすればSandy-Eの6コアに匹敵するCPU性能でHD5770並のGPU性能で77W
3DMark11やったら5倍くらいの差が出るだろうな
Ivy BridgeはTick+!!!
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20110916_478013.html
IvyはOCすればSandy-Eの6コアに匹敵するCPU性能でHD5770並のGPU性能で77W
3DMark11やったら5倍くらいの差が出るだろうな
Ivy BridgeはTick+!!!
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20110916_478013.html
HD3000は120GFLOPS
Llanoは350GFLOPSだぜ
Llanoは350GFLOPSだぜ
インテル副社長さんが言うんだから間違いは無いだろう( -_-)フッww
Ivyの話はIntelスレでやったら?
IntelのGPUすげー!って言っても鼻で笑われるだろうがw
IntelのGPUすげー!って言っても鼻で笑われるだろうがw
80 :Socket774:2011/11/21(月) 23:31:39.21 ID:Vrsx677x
Trinity内部ベンチ
3DMarkVantageでは3割前後、PCMark Vantageでは2割前後、
コンピューティング能力は5割前後の向上。
第2世代BulldozerのPiledriverコアと、HD 6900と同じくVLIW4アーキテクチャのGPUを採用。
http://www.techpowerup.com/155483/AMD-Trinity-Internal-Benchmarks-Surface.html
後は性能のネック、メモリの問題を取り除くのみ。
GDDR5をマザーボードにオンボードすれば良い。
3DMarkVantageでは3割前後、PCMark Vantageでは2割前後、
コンピューティング能力は5割前後の向上。
第2世代BulldozerのPiledriverコアと、HD 6900と同じくVLIW4アーキテクチャのGPUを採用。
http://www.techpowerup.com/155483/AMD-Trinity-Internal-Benchmarks-Surface.html
後は性能のネック、メモリの問題を取り除くのみ。
GDDR5をマザーボードにオンボードすれば良い。
81 :Socket774:2011/11/21(月) 23:40:24.79 ID:mX/sotbD
効率悪いな
82 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/21(月) 23:51:56.81 ID:ZKeKY3pA
こっちに転載しておく
http://cybergarden.cocolog-nifty.com/blog/2011/10/amd32nmintel-f9.html
AMDの32nmは歩留まりで苦戦しているが、Intelよりトランジスタが小さい。なんで20億トランジスタが300平方mmなんだ?
GLOBALFOUNDERIESは凄いことをしている。最高だぜ!
http://cybergarden.cocolog-nifty.com/blog/2011/11/sandybridge-ecp.html
SandyBridge-Eは旧時代の恐竜~CPUの進化の袋小路
AMDのアーキテクチャはエレガントだ。
単純にシンプルコアを増やすのではなく、二つのスレッドがスケジューラなどを共有できることがポイントだ。
AMDがダイレクトコネクトを採用したときのような、革新を感じる。
http://cybergarden.cocolog-nifty.com/blog/2011/10/amd32nmintel-f9.html
AMDの32nmは歩留まりで苦戦しているが、Intelよりトランジスタが小さい。なんで20億トランジスタが300平方mmなんだ?
GLOBALFOUNDERIESは凄いことをしている。最高だぜ!
http://cybergarden.cocolog-nifty.com/blog/2011/11/sandybridge-ecp.html
SandyBridge-Eは旧時代の恐竜~CPUの進化の袋小路
AMDのアーキテクチャはエレガントだ。
単純にシンプルコアを増やすのではなく、二つのスレッドがスケジューラなどを共有できることがポイントだ。
AMDがダイレクトコネクトを採用したときのような、革新を感じる。
83 :Socket774:2011/11/21(月) 23:58:13.43 ID:mX/sotbD
>73
TrinityはAES NI使えないの?
あとエンコ専用回路あったはず
TrinityはAES NI使えないの?
あとエンコ専用回路あったはず
84 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/22(火) 00:00:39.10 ID:reyen26Y
TrinityはBulldozerベースならAESはサポートしてるはずだぞ。
あるいはAMDがIntelよろしく価格の差別化のために削ってるなら別だが。
あるいはAMDがIntelよろしく価格の差別化のために削ってるなら別だが。
>二つのスレッドがスケジューラなどを共有できることがポイントだ。
ワーストケース時に
フロントエンドで何が起きるか考えれば
一番のガンだよな コレ。
ワーストケース時に
フロントエンドで何が起きるか考えれば
一番のガンだよな コレ。
86 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/22(火) 00:02:53.90 ID:ZKeKY3pA
FMA君の日記帳じゃないのこれ?
AES-NI無しでPCMARK上がったならそこそこ改善されてると思うが
多分AES-NI有りだろう
他が下がってAES-NIで水増し
PCMARKは嘘つかないから実質CPU性能アップ(キリ
多分AES-NI有りだろう
他が下がってAES-NIで水増し
PCMARKは嘘つかないから実質CPU性能アップ(キリ
そもそもFX-4100と比べて良くなってないのだから改善もクソもない
Piledriverは救世主でも何でもなかったということだ
Piledriverは救世主でも何でもなかったということだ
91 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/22(火) 00:33:26.90 ID:reyen26Y
ステッピングの変更にあわせて命令セット追加したくらいかな
92 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/22(火) 00:37:17.33 ID:reyen26Y
256ビットAVXを2μOPで処理してるのって技術者向けのマニュアルには書いてあるのに
未だに素人向けのスライドには2個のユニット合体して256ビットとか
大嘘ついてるんだな。とことんゲスな企業だ。
未だに素人向けのスライドには2個のユニット合体して256ビットとか
大嘘ついてるんだな。とことんゲスな企業だ。
目糞鼻糞を笑うってやつねえ・・・
94 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/22(火) 00:45:25.84 ID:reyen26Y
高さ制限のあるトンネルが2本あってさ、当然ながらトラックの積荷を半分にして通るじゃん。
AMDの言ってるのは「2つのトンネルを組み合わせて高さを2倍にします」
嘘でしょそれは。
AMDの言ってるのは「2つのトンネルを組み合わせて高さを2倍にします」
嘘でしょそれは。
まあ言いたいことが分からんでもない・・・
http://cybergarden.cocolog-nifty.com/blog/
ダイサイズが倍になって、性能が10%アップなんて、無駄のカタマリだね。
仕分けされちゃうよ。
投稿: ヨリテル | 2011年11月22日 (火) 00時31分
ダイサイズが倍になって、性能が10%アップなんて、無駄のカタマリだね。
仕分けされちゃうよ。
投稿: ヨリテル | 2011年11月22日 (火) 00時31分
POWER6の高クロック路線はPOWER7ですぐに修正したけど、
AMDは遅れに遅れてBulldozer出した挙句に修正する余力あるのかね?
AMDは遅れに遅れてBulldozer出した挙句に修正する余力あるのかね?
余力もやる気もないんじゃないの、$150以上のセグメントは潔くあきらめる
TrinityのTDP枠引き上げは上も狙いたいのかもしれんが土台無理な話
TrinityのTDP枠引き上げは上も狙いたいのかもしれんが土台無理な話
FX4100以下 = 大半のアプリでLlano以下
まあ、K10は定評があるよな
遅いという
遅いという
しかもTDP125W枠増設ということは
A8-3850後継の最上位モデルではむしろ消費電力は上がるんじゃないかw
A8-3850後継の最上位モデルではむしろ消費電力は上がるんじゃないかw
PCMarkに関して言えば総合ベンチって性質はあるけど
AthlonIIとPhenomIIで20%程度差があるしこれがL3あるなしの差だろうに。
L3あるなしで20%近く差が出るのにFX-4100とほぼ互角なら
素直にLlanoからの性能は上がってると思うけどなあ。
AthlonIIとPhenomIIで20%程度差があるしこれがL3あるなしの差だろうに。
L3あるなしで20%近く差が出るのにFX-4100とほぼ互角なら
素直にLlanoからの性能は上がってると思うけどなあ。
どこかで4100とひかくしてるのか?
piledriverにL3ついた時が面白そうだな。
またL2DTLBとか無効になってんだろうか。
またL2DTLBとか無効になってんだろうか。
今でもL2DTLBは無効になってないけどな
>>109
インテルは捨てて無い
インテルは捨てて無い
>>109
Niagaraもコア数減らしたろ
Niagaraもコア数減らしたろ
>>104
20%はねーよ
せいぜい5%
http://www.dosv.jp/feature/1102/images/05/img01_l.jpg
http://www.dosv.jp/feature/0909/img/pop/042.gif
http://www.extremeoverclocking.com/reviews/processors/images/AMD_Athlon_II_X4_640/PCMark_Vantage.gif
http://www.hardwaresecrets.com/imageview.php?image=32279
http://media.bestofmicro.com/N/1/227629/original/PCMark.png
まあPCMarkはCPUだけを測ってるわけじゃないので環境によりけりだろうけど
20%はねーよ
せいぜい5%
http://www.dosv.jp/feature/1102/images/05/img01_l.jpg
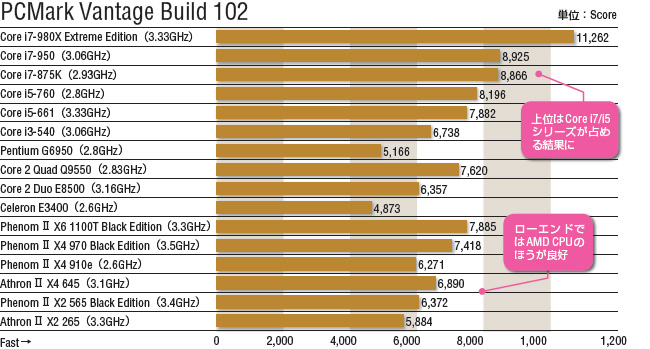{kind=link}
http://www.dosv.jp/feature/0909/img/pop/042.gif
{kind=link}
http://www.extremeoverclocking.com/reviews/processors/images/AMD_Athlon_II_X4_640/PCMark_Vantage.gif
{kind=link}
http://www.hardwaresecrets.com/imageview.php?image=32279
http://media.bestofmicro.com/N/1/227629/original/PCMark.png
{kind=link}
まあPCMarkはCPUだけを測ってるわけじゃないので環境によりけりだろうけど
20%とまではいかないが5%よか差はある気がする
L3はCPU-NBと同期だけど、データの流れ的にL3が介される時点でNBのデータ処理に余裕がなくなる部分で処理が滞るとかあるかな?
L3付きで設計されてるから十分高速って訳でもないしな、あのNBは
L3はCPU-NBと同期だけど、データの流れ的にL3が介される時点でNBのデータ処理に余裕がなくなる部分で処理が滞るとかあるかな?
L3付きで設計されてるから十分高速って訳でもないしな、あのNBは
次世代に期待できないなら次々世代とかに期待すればいいんだよな。
次世代に期待できないなら旧世代を安く売ればいいだよな。
Phenom II X6 1100T → 9000円が妥当な値段
Phenom II X6 1100T → 9000円が妥当な値段
普通にPhenomの方が需要高い気がするわ…
いつの間にかORNLのXE6改が稼動してるな
ちなみにXE6のMagny-coursをInterlagosに換装し、更にInterlagosを最初から搭載したXE6改も
追加してソケット数を倍増させたやつだな
新旧の比較結果としては
ソケット数で2576→4864(188%)
スコア194.4→715.98(368%)
消費電力610.7→972(159%)
ワットパフォーマンスにすると2.31倍かな?
新ユニット追加分はともかく、CPU換装部分はかなり安いだろうしコスパは良さそうだな
追加してソケット数を倍増させたやつだな
新旧の比較結果としては
ソケット数で2576→4864(188%)
スコア194.4→715.98(368%)
消費電力610.7→972(159%)
ワットパフォーマンスにすると2.31倍かな?
新ユニット追加分はともかく、CPU換装部分はかなり安いだろうしコスパは良さそうだな
今日日最新の重ゲーやるでもなし
何が出ようが買い換えはしない訳だが
俺の中では今もCPU買い換えてる奴ってのは都市伝説
何が出ようが買い換えはしない訳だが
俺の中では今もCPU買い換えてる奴ってのは都市伝説
120 :Socket774:2011/11/22(火) 20:15:59.31 ID:6mSFv204
FX-8150
http://www.4gamer.net/games/100/G010000/20111014094/
>ゲーマーが「ゲームにおける性能向上」を求めた場合に,FX-8150は,選択肢となるようなCPUではない。
>AMDの最新CPUを買わないと気が済まないとか,とにかく新しいアーキテクチャのCPUを触ってみたいとか,
>ひたすら高クロックを狙ってみたいといった理由があるマニアのためのコレクターズアイテムである。
FX-6100とFX-4100
http://www.4gamer.net/games/100/G010000/20111021082/
>FX-6100とFX-4100のテストを行ったが,通して受ける印象は「わざわざ選ぶ理由がない」である。
( ゚д゚)つ┃
PCでなにがしたいか?じゃなくて、
組むこと自体が趣味だったりするからなぁ、この板の人たちは。(自分含む)
組むこと自体が趣味だったりするからなぁ、この板の人たちは。(自分含む)
>>119
重いゲームさんはGPUをよく使うのでCPUはむしろ・・・
ただ無料ゲーで4T実行とかもあるから
しかも裏でVCやモニタリングも走る、
こーなるとヘボくてもペナルティがほぼ無い8cってのは良いわ
重いゲームさんはGPUをよく使うのでCPUはむしろ・・・
ただ無料ゲーで4T実行とかもあるから
しかも裏でVCやモニタリングも走る、
こーなるとヘボくてもペナルティがほぼ無い8cってのは良いわ
宗教戦争って大変だな
あああ~
118だがデータ拾い間違ってるや
ちょっとやり直し
ソケット数:2576→4864(+188%)
スコア:194.4→565.7(+291%)
消費電力:610.7→972(+159%)
ワッパ:+183%
酔ってるのでまた間違ってるなんてこともあるかも・・・
あと、エジンバラ大のスパコンでもMagny-coursからInterlagosに換装してるっぽい
118だがデータ拾い間違ってるや
ちょっとやり直し
ソケット数:2576→4864(+188%)
スコア:194.4→565.7(+291%)
消費電力:610.7→972(+159%)
ワッパ:+183%
酔ってるのでまた間違ってるなんてこともあるかも・・・
あと、エジンバラ大のスパコンでもMagny-coursからInterlagosに換装してるっぽい
126 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/22(火) 21:09:31.23 ID:reyen26Y
北森のバブルソートの件は吹いた。
おかしいよねパラメータ変わってもO(N^2)で計算時間変わるわけが無いのに。
おかしいよねパラメータ変わってもO(N^2)で計算時間変わるわけが無いのに。
でもってエジンバラ大のスパコンのXE6のCPU換装?前後の比較は・・・
ソケット数:3698→5632(+152%)
スコア:279.64→660.24(+236%)
消費電力関係は不明
エジンバラ大とORNLのCPU換装による性能向上は155%って所かな
※メモリその他の換装の有無などは不明なので悪しからず
ソケット数:3698→5632(+152%)
スコア:279.64→660.24(+236%)
消費電力関係は不明
エジンバラ大とORNLのCPU換装による性能向上は155%って所かな
※メモリその他の換装の有無などは不明なので悪しからず
tp://news.mynavi.jp/special/2005/dualcore/009.html
>そんな訳で、デュアルコア対決はAMDのほぼ圧勝
この頃のAMDは良かったな
筆者の悪寒がモロに当ったわけだが↓
>Yonah/Conroeが出てくると、かなり厳しい戦いになるであろう事は想像がつく。本命は来年後半のConroeだろう
>そんな訳で、デュアルコア対決はAMDのほぼ圧勝
この頃のAMDは良かったな
筆者の悪寒がモロに当ったわけだが↓
>Yonah/Conroeが出てくると、かなり厳しい戦いになるであろう事は想像がつく。本命は来年後半のConroeだろう
>>127
ソケットあたりのピーク性能は
12->16コア 2.1GHz -> 2.3GHzで
146%だから妥当な気がする
LINPACK効率で5%程度改善されている
メモリ帯域はほぼ据え置きだろうけど
GEMMはある程度の大きさのL3があればメモリ帯域は必要ない
もともと効率が75%弱と低いものだったし
効率が改善された原因がどこにあるかはよくわからないね
ソケットあたりのピーク性能は
12->16コア 2.1GHz -> 2.3GHzで
146%だから妥当な気がする
LINPACK効率で5%程度改善されている
メモリ帯域はほぼ据え置きだろうけど
GEMMはある程度の大きさのL3があればメモリ帯域は必要ない
もともと効率が75%弱と低いものだったし
効率が改善された原因がどこにあるかはよくわからないね
一方でシュツットガルド大やスイス版理研のスパコンは最初からInterlagosを載せた新造のXE6かな?
クレイのスパコンとしてはTeslaと組み合わせたXK6の方が上な気もするが、
こっちはTOP500のエントリーには間に合ってないのか、それともKepler待ちなのか
クレイのスパコンとしてはTeslaと組み合わせたXK6の方が上な気もするが、
こっちはTOP500のエントリーには間に合ってないのか、それともKepler待ちなのか
131 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/22(火) 21:32:18.17 ID:reyen26Y
>>129
マルチスレッドによるレイテンシ隠蔽とか
あと、SIMDのFPパイプとINTパイプが分離されて独立したLoad/Store命令とFP積和命令を
同時実行できるとか。
>>130
XE6はGPU混載向けのシャーシじゃないでしょ
マルチスレッドによるレイテンシ隠蔽とか
あと、SIMDのFPパイプとINTパイプが分離されて独立したLoad/Store命令とFP積和命令を
同時実行できるとか。
>>130
XE6はGPU混載向けのシャーシじゃないでしょ
132 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/22(火) 23:55:08.36 ID:reyen26Y
http://northwood.blog60.fc2.com/blog-entry-5450.html
> 04156
> 使ってみたらわかるが、Opteron鯖向けCPUとしては使いやすくていいぞ。
> XeonというよりIntelのCPUは直線番長過ぎて処理によって速度が変わりすぎて扱いづらくてしゃれにならん。
> その分Opteronはコンテキストスイッチでもっさりしないし、何やらせても大体同じ速度でこなしてくれる。
>
> 例として適当にバブルソートのコード走らせてみるといい。
> もちろん殆ど混ざってないのは除外して、Intelさんのは入力が変わるだけで速度が開きが7倍以上来るのにAMDさんは開いて2倍くらいだから。
> これで平均取ると意外や意外でAMDさんの方が早かったりするから驚き。
>
> まあ、Mpegデコードみたいな似たような繰り返しとかは圧倒的にIntelで、それはマルチメディア系処理全般に言えることなんだけど。
> 2011/11/20(日) 12:42 | URL | LGA774 #-[ 編集]
> 104186
> >104156
> 整数一億個のバブルソートをやらせてみたけど、ブルとSandyで比較したがSandyの方が早かったよ。
> 私が使ったのはR.セジウィック著のアルゴリズムC++初版のものをそのままGNUでコンパイルしたのだけれどね。
> 2011/11/20(日) 17:28 | URL | LGA774 #-[ 編集]
> 104191
> >104186
> >104156はAMDキビキビテクノロジー搭載なんでしょうw
> crayもxeonにスイッチするみたいだしエンタープライズ市場から完全に締め出しですね
> 2011/11/20(日) 18:20 | URL | LGA774 #-[ 編集]
> 04156
> 使ってみたらわかるが、Opteron鯖向けCPUとしては使いやすくていいぞ。
> XeonというよりIntelのCPUは直線番長過ぎて処理によって速度が変わりすぎて扱いづらくてしゃれにならん。
> その分Opteronはコンテキストスイッチでもっさりしないし、何やらせても大体同じ速度でこなしてくれる。
>
> 例として適当にバブルソートのコード走らせてみるといい。
> もちろん殆ど混ざってないのは除外して、Intelさんのは入力が変わるだけで速度が開きが7倍以上来るのにAMDさんは開いて2倍くらいだから。
> これで平均取ると意外や意外でAMDさんの方が早かったりするから驚き。
>
> まあ、Mpegデコードみたいな似たような繰り返しとかは圧倒的にIntelで、それはマルチメディア系処理全般に言えることなんだけど。
> 2011/11/20(日) 12:42 | URL | LGA774 #-[ 編集]
> 104186
> >104156
> 整数一億個のバブルソートをやらせてみたけど、ブルとSandyで比較したがSandyの方が早かったよ。
> 私が使ったのはR.セジウィック著のアルゴリズムC++初版のものをそのままGNUでコンパイルしたのだけれどね。
> 2011/11/20(日) 17:28 | URL | LGA774 #-[ 編集]
> 104191
> >104186
> >104156はAMDキビキビテクノロジー搭載なんでしょうw
> crayもxeonにスイッチするみたいだしエンタープライズ市場から完全に締め出しですね
> 2011/11/20(日) 18:20 | URL | LGA774 #-[ 編集]
整数一億個じゃただのメモリベンチだろ
134 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/23(水) 00:03:28.85 ID:reyen26Y
というか、何の反証も用意できなかった時点でハッタリがミエミエ。
そもそもバブルソート(笑)とかキャッシュ効率も悪ければマルチスレッド化もしにくいものを
例に出すあたり、はっきり言って学校で覚えたてのFランク大学生の匂いがする。
そもそもバブルソート(笑)とかキャッシュ効率も悪ければマルチスレッド化もしにくいものを
例に出すあたり、はっきり言って学校で覚えたてのFランク大学生の匂いがする。
XeonとOpteronと言ってるだけでそれぞれどの世代かは明言してないのがミソだな
L1範囲内でCore2/Nehalem vs K10だと
K10の方が速いというのは結構あり得ると思う
K10の方が速いというのは結構あり得ると思う
137 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/23(水) 00:16:18.07 ID:Kw52LbpC
K10とかStore帯域が狭いしw
というか数年前にム板で話題振られてPentium 4でまさにバブルソートやった気がする。
CMOVと条件分岐どっちが有利か、みたいな感じで。
んでMersenne Twisterで初期化して複数回計測したけど、条件分岐版でもかかった時間は誤差の範囲になった。
(というかCMOV遅い)
そもそもバブルソートなんて理屈上並べ替えが進むにつれ分岐予測ヒット率が上がっていくので
そっち系の性能測るにも不適なんだわ。
というか数年前にム板で話題振られてPentium 4でまさにバブルソートやった気がする。
CMOVと条件分岐どっちが有利か、みたいな感じで。
んでMersenne Twisterで初期化して複数回計測したけど、条件分岐版でもかかった時間は誤差の範囲になった。
(というかCMOV遅い)
そもそもバブルソートなんて理屈上並べ替えが進むにつれ分岐予測ヒット率が上がっていくので
そっち系の性能測るにも不適なんだわ。
MagnyCours -> InterlagosはTurban -> Zambeziに比べるとよく性能上がってるようだな。
139 :Socket774:2011/11/23(水) 00:23:17.48 ID:6Sir8FS3
いまんとこ28nmをまともに量産できるのってインテルしかないな
インテルは他社GPUの受託生産もやれよ
TSMCやサムスン、GFなんて待ってたらいつまでも28nmの量産ができない
インテルは他社GPUの受託生産もやれよ
TSMCやサムスン、GFなんて待ってたらいつまでも28nmの量産ができない
140 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/23(水) 00:23:32.31 ID:Kw52LbpC
Magny-CoursはTC無しだし
141 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/23(水) 00:24:00.61 ID:Kw52LbpC
> いまんとこ28nmをまともに量産できるのってインテルしかないな
え?Intelが28nm?ご冗談を
え?Intelが28nm?ご冗談を
**nmプロセスって書いてあるのは当社比なんだろ
会社間で何の共通性も無いらしい
そして某社のダイは何故か異様に大きい
会社間で何の共通性も無いらしい
そして某社のダイは何故か異様に大きい
Interlagosの性能向上をTurboCOREに持ってくのは無茶だろw
コア当たりの性能向上率というか下落率が30%位違うから全コア3GHZで回りっぱなしかよw
コア当たりの性能向上率というか下落率が30%位違うから全コア3GHZで回りっぱなしかよw
144 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/23(水) 00:31:00.59 ID:Kw52LbpC
20億使ってこれかよ!!が12億使ってこれかよ…程度には変化するんじゃね
146 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/23(水) 00:35:59.04 ID:Kw52LbpC
やはり平均ゲートピッチはSandy Bridgeのほうが小さかった。
SRAMはわざと(他社比で)ピッチ大きめにとってリーク電流抑えてるらしいけどね。
SRAMはわざと(他社比で)ピッチ大きめにとってリーク電流抑えてるらしいけどね。
L2+L3で16Mbyte
ECCに64bitあたり8bit使うとすると
6TSRAMなら
それだけで9億トランジスタ強
コアだけで3億とかなんか信じがたいんだけど
ECCに64bitあたり8bit使うとすると
6TSRAMなら
それだけで9億トランジスタ強
コアだけで3億とかなんか信じがたいんだけど
いや、K10が3500万トランジスタらしいから妥当かな
ついに微細化詐欺説までキターーーー !!!
1moduleで2.13億でしょ
L3 8MBで4.5億
合わせると13億になるけどな
L3 8MBで4.5億
合わせると13億になるけどな
さらにクロスバとHTとメモコンがあるから
12億には収まる気がしないな
12億には収まる気がしないな
発想をかえよう
6T-SRAMじゃなく1T-RAMだからトランジスタが大幅に削減されてる、その代償としてL2が激遅になってるのだと
6T-SRAMじゃなく1T-RAMだからトランジスタが大幅に削減されてる、その代償としてL2が激遅になってるのだと
12億ってのがガセなんだろう
20億は公式発表って記事はみた
20億は公式発表って記事はみた
154 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/23(水) 01:07:10.10 ID:Kw52LbpC
別にトランジスタ数が多かろうが少なかろうがあの性能だろ・・・
>>154
ところで12億ってどっから出てきたんだ?
ところで12億ってどっから出てきたんだ?
156 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/23(水) 01:14:02.81 ID:Kw52LbpC
The Interlagos chip has a total of 2.4 billion transitions, which means the Valencia chip has 1.2 billion.
http://www.theregister.co.uk/2011/11/14/amd_opteron_4200_6200_launch/
http://www.theregister.co.uk/2011/11/14/amd_opteron_4200_6200_launch/
>>156
この記事が載ってる掲示板はここと同じような議論になってるな
> So either the 1.2b and 2.4b numbers are wrong or the 2b number is wrong. Or maybe (and this is my current guess) they're all wrong.
この記事が載ってる掲示板はここと同じような議論になってるな
> So either the 1.2b and 2.4b numbers are wrong or the 2b number is wrong. Or maybe (and this is my current guess) they're all wrong.
自分の頭で考えないから数字に疑問を持たないんだよな
Intel自慢のプロセスで10億トランジスタが220mm^2程度なんだし
GF32nmが320mm^2程度へ20億詰め込めるとは思えんがな。
Intelと同等の密度でも15億、GFの方が劣っているなら12億ってのもそこまでおかしい数字じゃない。
GF32nmが320mm^2程度へ20億詰め込めるとは思えんがな。
Intelと同等の密度でも15億、GFの方が劣っているなら12億ってのもそこまでおかしい数字じゃない。
GateFirst 密度で有利 低性能 低コスト
GateLast 高性能 高コスト 低リーク
GateLast 高性能 高コスト 低リーク
大原がBulldozer記事入稿したらしい
今週中に来るかな
今週中に来るかな
162 :Socket774:2011/11/23(水) 05:03:59.62 ID:6Sir8FS3
いまんとこ28nmをまともに量産できるのってインテルしかないな
インテルは他社GPUの受託生産もやれよ
TSMCやサムスン、GFなんて待ってたらいつまでも28nmの量産ができない
インテルは他社GPUの受託生産もやれよ
TSMCやサムスン、GFなんて待ってたらいつまでも28nmの量産ができない
22nmを量産体制に入れつつあるIntelが
何が悲しくてハーフノードに手を出すんだよ
何が悲しくてハーフノードに手を出すんだよ
164 :Socket774:2011/11/23(水) 06:22:17.74 ID:BzX0is57
AMD Cancels 28nm APUs, Starts From Scratch At TSMC
http://hardware.slashdot.org/story/11/11/22/195236/amd-cancels-28nm-apus-starts-from-scratch-at-tsmc?utm_source=slashdot&utm_medium=twitter
Ω\ζ°)チーン
http://hardware.slashdot.org/story/11/11/22/195236/amd-cancels-28nm-apus-starts-from-scratch-at-tsmc?utm_source=slashdot&utm_medium=twitter
Ω\ζ°)チーン
鳥は全然CPU部分の性能と消費電力が漏れてこないね
出てくるのはGPUのみ
出てくるのはGPUのみ
>>164
TSMCで製造するAPUをフロムスクラッチからとかまた大胆だな。
TSMCで製造するAPUをフロムスクラッチからとかまた大胆だな。
ARM互換のコアかBobcatをさらにコンパクトにしたARM対抗のコアのどちらかだな
ファウンダリ各社、28nm(&32nm)プロセスの歩留まり向上に苦戦
http://eetimes.jp/ee/articles/1111/07/news030.html
同社(GF)はAMDに32nm SOIチップを提供する契約を結んでいたが、歩留まりが低かったため、提供するウエハーの数を増やすことで対応
また
・GFのFab1は28nmと32nmを転換出来る
・GFが32nm用のウェハの製造能力を予定より引き上げたと言う情報は出て無い
ってことで、28nmに割り当てられる予定だったウェハの一部、或いは全てが32nmに回されたんだろう
http://eetimes.jp/ee/articles/1111/07/news030.html
同社(GF)はAMDに32nm SOIチップを提供する契約を結んでいたが、歩留まりが低かったため、提供するウエハーの数を増やすことで対応
また
・GFのFab1は28nmと32nmを転換出来る
・GFが32nm用のウェハの製造能力を予定より引き上げたと言う情報は出て無い
ってことで、28nmに割り当てられる予定だったウェハの一部、或いは全てが32nmに回されたんだろう
ちなみにTSMCも28nmの価格を急遽25%引き上げた
これは
①TSMCも歩留まりが悪い
②他社の計画が遅れてるから独占状態→ここは儲けるチャンス!
のどっちかなん
APUをTSMCに委託するって事は、一定の供給量は確保出来るってことだろうから②かね
これは
①TSMCも歩留まりが悪い
②他社の計画が遅れてるから独占状態→ここは儲けるチャンス!
のどっちかなん
APUをTSMCに委託するって事は、一定の供給量は確保出来るってことだろうから②かね
http://pc.watch.impress.co.jp/docs/column/kaigai/20100901_390769.html
> AMDはBobcatを、ほぼ論理合成可能な設計にして、半導体ベンダー間で容易に
> 移植ができるようにした
GFからTSMCへの移行を余儀なくされても、ダメージは最小のはずなんだけどね。
from scratch が何を指しているのかわからないな。
> AMDはBobcatを、ほぼ論理合成可能な設計にして、半導体ベンダー間で容易に
> 移植ができるようにした
GFからTSMCへの移行を余儀なくされても、ダメージは最小のはずなんだけどね。
from scratch が何を指しているのかわからないな。
いずれにせよ、GFで生産できない=GF経由でオイルマネー無心出来ないということだから、
AMDはおしまいです。
AMDはおしまいです。
今のAMDはオイルマネーと関係ないだろ
>>170
需要と供給の問題だろうな
http://focustaiwan.tw/ShowNews/WebNews_Detail.aspx?Type=aALL&ID=201109180005
TSMCの28nmには注文が殺到
TSMCは需要予測の見誤りにより既にオーバーキャパシティ
GFの28nmが体制強化され予想より前倒しされているように見える
だと
需要と供給の問題だろうな
http://focustaiwan.tw/ShowNews/WebNews_Detail.aspx?Type=aALL&ID=201109180005
TSMCの28nmには注文が殺到
TSMCは需要予測の見誤りにより既にオーバーキャパシティ
GFの28nmが体制強化され予想より前倒しされているように見える
だと
>>173
先端プロセスのための莫大な設備投資をオイルマネーに肩代わりしてもらってる状態ですよ。
通常のファブであれば設備投資はチップの価格に転嫁されます。TSMC 28nmと異なり、
GF 32nm SOIはユーザがAMDしかおらず生産量が少ない。本来ならチップ1枚あたりの
固定費は極めて高額になるところを、ユーザーの代わりにGFがオイルマネーで
補填しているから、AMDのチップは市場で競争力のある値段で売れるのです。
先端プロセスのための莫大な設備投資をオイルマネーに肩代わりしてもらってる状態ですよ。
通常のファブであれば設備投資はチップの価格に転嫁されます。TSMC 28nmと異なり、
GF 32nm SOIはユーザがAMDしかおらず生産量が少ない。本来ならチップ1枚あたりの
固定費は極めて高額になるところを、ユーザーの代わりにGFがオイルマネーで
補填しているから、AMDのチップは市場で競争力のある値段で売れるのです。
176 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/23(水) 10:33:02.23 ID:+CJ2d1PN
別に肩代わりしてるわけじゃない。
投資額の減価償却費がウェハ単価に上乗せされるし、AMDはGFに相応分の金を払ってる。
投資額の減価償却費がウェハ単価に上乗せされるし、AMDはGFに相応分の金を払ってる。
177 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/23(水) 10:36:32.18 ID:+CJ2d1PN
そういう収益構造はどこも同じなわけで、GFは現金があるから資金難でひいひい言ってる
ほかのFab屋よりは先行して先端Fabに投資がしやすいだけ。
回収できずに資産が目減りするのは資産運用ではない。
ほかのFab屋よりは先行して先端Fabに投資がしやすいだけ。
回収できずに資産が目減りするのは資産運用ではない。
AMDが設備投資をウェハ単価の形で負担しているなら、
AMDはファブを持っていたときと同様に今も赤字になるよ。
先端プロセス開発をAMD一社の需要で支える構造は未だに変わっていないのだから。
AMDはファブを持っていたときと同様に今も赤字になるよ。
先端プロセス開発をAMD一社の需要で支える構造は未だに変わっていないのだから。
179 :Socket774:2011/11/23(水) 10:44:43.75 ID:aLS+iacZ
AMD Cancels 28nm APUs, Starts From Scratch At TSMC
http://hardware.slashdot.org/story/11/11/22/195236/amd-cancels-28nm-apus-starts-from-scratch-at-tsmc?utm_source=slashdot&utm_medium=twitter
Ω\ζ°)チーン
GFはファブ化したから他の企業も代金に含まれた開発費用を払うけどな
アラブのお金持ちが投資しているだけに過ぎない
アラブのお金持ちが投資しているだけに過ぎない
> 回収できずに資産が目減りするのは資産運用ではない。
アラブの王子に言わせれば、産業育成という名目の30年とか100年単位での投資なんでしょう。
石油が湧き出るという事情を鑑みれば半分はわかるが、半分は詐欺だと思う。
しかし誰が誰を騙しているのかはよくわからない。
AMDがアブダビを? アブダビがAMDを? 産油国の国王が国民を?
> GFはファブ化したから他の企業も代金に含まれた開発費用を払うけどな
GF 32nm SOI/28nmのユーザーであるAMD以外の企業とは、具体的に誰か?
アラブの王子に言わせれば、産業育成という名目の30年とか100年単位での投資なんでしょう。
石油が湧き出るという事情を鑑みれば半分はわかるが、半分は詐欺だと思う。
しかし誰が誰を騙しているのかはよくわからない。
AMDがアブダビを? アブダビがAMDを? 産油国の国王が国民を?
> GFはファブ化したから他の企業も代金に含まれた開発費用を払うけどな
GF 32nm SOI/28nmのユーザーであるAMD以外の企業とは、具体的に誰か?
183 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/23(水) 10:53:43.36 ID:+CJ2d1PN
アブダビをAMDの窮地を救った救世主のように思うのは勝手だけど
ATICからすればAMDの窮地を見計らって作りかけの最先端Fabを含む資産を格安で買収しただけだしな
>>180
SOIの利用客が増えればAMDの負担は減らせるかもねえ。
現状そうなってないが。
ATICからすればAMDの窮地を見計らって作りかけの最先端Fabを含む資産を格安で買収しただけだしな
>>180
SOIの利用客が増えればAMDの負担は減らせるかもねえ。
現状そうなってないが。
その通り、誰が誰を救ったわけでもない。
AMDは市場を歪める不透明な資本投下で延命するのではなく、潰すべきでした。
延命したところで、うんこ製造機には価値がないままなのだから。
AMDは市場を歪める不透明な資本投下で延命するのではなく、潰すべきでした。
延命したところで、うんこ製造機には価値がないままなのだから。
GFのウェハ製造量は30mm換算で月産14万枚前後
そのうちAMDが使うのは4万枚前後かな
あとはどこが使ってるんだろうね
取引先メーカーは多数有るが、どの企業向けにラインを使ってるのかまでは判らんよね
そのうちAMDが使うのは4万枚前後かな
あとはどこが使ってるんだろうね
取引先メーカーは多数有るが、どの企業向けにラインを使ってるのかまでは判らんよね
最終的にはアブダビに研究開発拠点を含む半導体産業を育成する計画なんだし
0からはじめているのだから相当の覚悟でやっているのだろう。
ここ最近勢いはなくても、産油国が数年でどうのということもないでしょ。
いらん心配
0からはじめているのだから相当の覚悟でやっているのだろう。
ここ最近勢いはなくても、産油国が数年でどうのということもないでしょ。
いらん心配
187 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/23(水) 11:06:55.45 ID:+CJ2d1PN
>>178
> AMDが設備投資をウェハ単価の形で負担しているなら、
> AMDはファブを持っていたときと同様に今も赤字になるよ。
だから、赤字だから従業員リストラなんだか。
世代落ちするとFabの減価ペースは緩やかになるから、Q3まで生産していた45nmの製造単価は大してかかってない。
今後32nmに本格移行するから赤字になる。
> AMDが設備投資をウェハ単価の形で負担しているなら、
> AMDはファブを持っていたときと同様に今も赤字になるよ。
だから、赤字だから従業員リストラなんだか。
世代落ちするとFabの減価ペースは緩やかになるから、Q3まで生産していた45nmの製造単価は大してかかってない。
今後32nmに本格移行するから赤字になる。
次期xboxはインテルのGMAじゃないのかよ
>>182
32nm SOIはAMDしか使わないだろうな
GFが出来たタイミングからしてもAMDがほとんど出資したものと思われる
GFの顧客で28nmの先端プロセスを必要とするのは
スマフォ/タブレット向けチップを作るサムソンとクアルコム辺り
32nm SOIはAMDしか使わないだろうな
GFが出来たタイミングからしてもAMDがほとんど出資したものと思われる
GFの顧客で28nmの先端プロセスを必要とするのは
スマフォ/タブレット向けチップを作るサムソンとクアルコム辺り
IntelはGMAをやめてララビー系のに移行じゃなかった?
あとローエンドのGPUについてはPoweVR、場合によってはARM社のMaliになるんじゃないか
あとローエンドのGPUについてはPoweVR、場合によってはARM社のMaliになるんじゃないか
赤字を子会社に移して本体を黒字にするのは、リストラでなく飛ばしじゃないかな。
まあ、GFは子会社でもないのに赤字を引き受けてくれる奇特な会社なのだが。
まあ、GFは子会社でもないのに赤字を引き受けてくれる奇特な会社なのだが。
産業くれたら金出しますってところか
友好的に買収するには良い手だな
友好的に買収するには良い手だな
でも、こういうやり方では、30年たっても100年たっても
自立できず産業として成立しないと思うのだよ。
自立できず産業として成立しないと思うのだよ。
194 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/23(水) 11:31:59.74 ID:+CJ2d1PN
たとえ過渡期の32nm世代だろうと、預金のつもりで投資した金が返ってこないってことになると
撤退するしか無いと思う。
撤退するしか無いと思う。
_─-、 -‐;z.__
> ` " ゙ <
/ " " " " ゙ ゙ ゙ ゙\
l " " ", ,ィ バ i ゙、 ゙、ヾ
| " "ノlノメ、 |ノjムヘ. N 断わる
! r,コ| =。= ,。==ハリ
| |ヒ.j|  ̄ r_ \7 ……
j `ァヘ ⊂ニニァ7′ 倍プッシュだ…!
. _/∨ :::\ = ∧
-‐'''"´ |. ヽ. ::::\,.イ |`'''‐- 、.._
| \ :::::/ │ ハ
. | ,ヘ 〉 |へ、| l. l
l_/ ゚〈`ー'| ヽ! │ |
|:::::::| 「 ̄ ̄| │ |
> ` " ゙ <
/ " " " " ゙ ゙ ゙ ゙\
l " " ", ,ィ バ i ゙、 ゙、ヾ
| " "ノlノメ、 |ノjムヘ. N 断わる
! r,コ| =。= ,。==ハリ
| |ヒ.j|  ̄ r_ \7 ……
j `ァヘ ⊂ニニァ7′ 倍プッシュだ…!
. _/∨ :::\ = ∧
-‐'''"´ |. ヽ. ::::\,.イ |`'''‐- 、.._
| \ :::::/ │ ハ
. | ,ヘ 〉 |へ、| l. l
l_/ ゚〈`ー'| ヽ! │ |
|:::::::| 「 ̄ ̄| │ |
GFが非公開活かしてアブダビから資金じゃぶじゃぶしないと赤字って話自体が妄想の域ってことわすれんなよw
なんだかんだ言って優良パートナーも多いだろ。
なんだかんだ言って優良パートナーも多いだろ。
199 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/23(水) 11:42:57.69 ID:+CJ2d1PN
GFの株購入と同時にATICはAMDに一定額融資してるけど、その気になればいつでも貸し剥がせる。
当然AMDは切り売りするものがないので持ってるGF株を差し出す他は無い。
「GFはAMDのために赤字を出すのが当然だ」なんてことは絶対ありえない。
当然AMDは切り売りするものがないので持ってるGF株を差し出す他は無い。
「GFはAMDのために赤字を出すのが当然だ」なんてことは絶対ありえない。
てかATICはGFを手放したとして、替わりにどこに投資するんだろうな
ATICは投資可能な分野が決められてるしね
ATICは投資可能な分野が決められてるしね
201 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/23(水) 11:45:38.47 ID:+CJ2d1PN
>>197
AMDの製造部門(赤字)とChartared(赤字)をがっちゃんこして
どうして黒字になるのさ。規模の経済は万能じゃない。
>>199
(今のところは)GFとAMDは相互依存の関係にあり、
AMDが赤字企業なのはGFにとって困るんじゃないかな。
AMDの製造部門(赤字)とChartared(赤字)をがっちゃんこして
どうして黒字になるのさ。規模の経済は万能じゃない。
>>199
(今のところは)GFとAMDは相互依存の関係にあり、
AMDが赤字企業なのはGFにとって困るんじゃないかな。
203 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/23(水) 11:48:22.46 ID:+CJ2d1PN
それすら顧客を増やすまでの「繋ぎ」だろ。
ちなみにATICは20年計画で臨んでいる
※2020年じゃなくて20年間、2030年に産業として成立させる計画
※2020年じゃなくて20年間、2030年に産業として成立させる計画
そしてまだ「繋ぎ」のフェーズだよね。
GFがAMDに望むのは優秀な製品開発による需要の喚起で、
そのためには金には糸目をつけず注ぎ込んできた。
にもかかわらずAMDの出してきたものはBulldozerで……(ノ∀`) アチャー
GF自身の先端プロセス開発失敗と相まって、
さてどうするんだろうね……
GFがAMDに望むのは優秀な製品開発による需要の喚起で、
そのためには金には糸目をつけず注ぎ込んできた。
にもかかわらずAMDの出してきたものはBulldozerで……(ノ∀`) アチャー
GF自身の先端プロセス開発失敗と相まって、
さてどうするんだろうね……
206 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/23(水) 11:53:10.45 ID:+CJ2d1PN
>>204
たとえ20年計画だろうと現時点の最先端Fabなんて2年で陳腐化するだろ。
Fabの固定資産としての価値が落ちた分は損失として計上しないといけない。
きちんと成立する「商売」をしながらでないと事業を継続することは不可能だよ。
たとえ20年計画だろうと現時点の最先端Fabなんて2年で陳腐化するだろ。
Fabの固定資産としての価値が落ちた分は損失として計上しないといけない。
きちんと成立する「商売」をしながらでないと事業を継続することは不可能だよ。
2011は1,2,3期全部黒字決算だったし、通年でも黒字予測だろ
208 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/23(水) 11:58:10.49 ID:+CJ2d1PN
リストラしなきゃ余裕で赤でしょ
ウェハ単価の高い32nmに全面移行するのに、更にプロセスルールの進んだIntelの22nmと戦わなければいけない
しかもBulldozerアーキテクチャの出来は・・・これはやめとくか
ウェハ単価の高い32nmに全面移行するのに、更にプロセスルールの進んだIntelの22nmと戦わなければいけない
しかもBulldozerアーキテクチャの出来は・・・これはやめとくか
それにしても半導体産業って熾烈だな
半導体のFabはただ稼動し続ければ初期投資を回収ができる
とは言っても、ライバル社が微細化すれば価値は下がるから、自社も微細化しなければならない
で、微細化で問題になるのは
①既存Fabで設備だけ更新して対応
②既存Fabはそのまま運転し、新Fabを建設で対応
のどちらにするか
Fabの初期費用は製造装置と建物が半々
ってことで金が無ければ①、金があるなら②が良い
でも、長期的に見れば旧Fabからの売上も有る②が絶対的に有利
ってことで、既存Fabの初期コストを回収する前に新Fabに投資できる、国家などがバックに着いたFabが絶対有利
半導体のFabはただ稼動し続ければ初期投資を回収ができる
とは言っても、ライバル社が微細化すれば価値は下がるから、自社も微細化しなければならない
で、微細化で問題になるのは
①既存Fabで設備だけ更新して対応
②既存Fabはそのまま運転し、新Fabを建設で対応
のどちらにするか
Fabの初期費用は製造装置と建物が半々
ってことで金が無ければ①、金があるなら②が良い
でも、長期的に見れば旧Fabからの売上も有る②が絶対的に有利
ってことで、既存Fabの初期コストを回収する前に新Fabに投資できる、国家などがバックに着いたFabが絶対有利
もちろんIntelのように技術と自前の資金のみでも圧倒してる例外も有るけどね
211 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/23(水) 12:08:18.77 ID:+CJ2d1PN
東南アジア経済の優等生と言われたシンガポールをバックに持つCharterdですら持たなかったわけだし
いくら投資しても回収できなきゃ事業として成り立たない。
安くしろとせびる不良顧客を切り捨てないと身が持たないよ。
いくら投資しても回収できなきゃ事業として成り立たない。
安くしろとせびる不良顧客を切り捨てないと身が持たないよ。
>>202
だが半導体fabの赤字の原因は新プロセス開発に必要なコストが主な原因だろう。
だとすれば重複した研究開発の統合で劇的に改善するんじゃね?
まあ、効果が分かるのはもう少し先と思うが。
piledriverの次からはAMDもハイエンド品のハーフノードも計画してるようだし、
将来的にはもっと統合が進むと思う。
だが半導体fabの赤字の原因は新プロセス開発に必要なコストが主な原因だろう。
だとすれば重複した研究開発の統合で劇的に改善するんじゃね?
まあ、効果が分かるのはもう少し先と思うが。
piledriverの次からはAMDもハイエンド品のハーフノードも計画してるようだし、
将来的にはもっと統合が進むと思う。
>>210
x86CPUって単価高いチップの大半を作っているから、次世代のFab作る前に、
ほぼ回収できたからじゃないの?
それに、最近のintelはすでにたくさん建物はあるから、既存のFab改修の方が多いし。
x86CPUって単価高いチップの大半を作っているから、次世代のFab作る前に、
ほぼ回収できたからじゃないの?
それに、最近のintelはすでにたくさん建物はあるから、既存のFab改修の方が多いし。
自前の資金で回収出来なさそうだから下請け始めたんじゃ?
215 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/23(水) 12:38:09.72 ID:+CJ2d1PN
450mmウェハとはなんだったのか
>>214
黒字でも同業他社との協業化は、普通の掲載行動だよ。
黒字でも同業他社との協業化は、普通の掲載行動だよ。
とはいえ現状先端プロセス開発ではIntel独走、TSMCがどうにか後に続き、
他はぼろぼろなので、Intelが他所と組むことはあり得ないような。
他はぼろぼろなので、Intelが他所と組むことはあり得ないような。
220 :Socket774:2011/11/23(水) 13:07:57.34 ID:352B2b3B
昔は携帯電話用チップなんてPC用CPUより1世代以上旧型のプロセスで作られてたのに、
いまじゃ携帯電話用がPCのCPU並みに最新プロセスを必要とする時代
スマホ関連は28~32nmの以降が必須なので、需要はたくさんある
いまじゃ携帯電話用がPCのCPU並みに最新プロセスを必要とする時代
スマホ関連は28~32nmの以降が必須なので、需要はたくさんある
221 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/23(水) 13:16:41.47 ID:+CJ2d1PN
普通の自社製品作ってる分にはIntelはARMのライセンス更新したりMaliのライセンスとったりはしない
どっかの会社の製品を製造する予定でもあるんじゃねーの?
どっかの会社の製品を製造する予定でもあるんじゃねーの?
AMDが恐れているのはこれ
AtomとCoreデザインチームを共通化
http://pc.watch.impress.co.jp/docs/news/event/20110915_477606.html
Bobcatじゃ対抗できないからキャンセル
AtomとCoreデザインチームを共通化
http://pc.watch.impress.co.jp/docs/news/event/20110915_477606.html
Bobcatじゃ対抗できないからキャンセル
自作用atomはBobcatに駆逐されちゃったけどな
次はintelも本気出す予定なのかしらんが
次はintelも本気出す予定なのかしらんが
Wichita/Krishnaがキャンセルされたのは32nmAtomがクソすぎてやる気なくしたのと2013年のAtomに対して万全の体制で挑むため
カカク.comのノート売り上げ1, 2位がAMD CPUな件
一般の人は今時のCPUなら何でも良い様子
一般の人は今時のCPUなら何でも良い様子
一般人はまず値段だから。
ジョーシンの広告が入ってたんだけどK53TAのところにでかでかと「クアットコア!」って書いててなんか悲しくなった。
ジョーシンの広告が入ってたんだけどK53TAのところにでかでかと「クアットコア!」って書いててなんか悲しくなった。
ある程度高めのK53TAが一位なところ
グラフィックス機能はそれなりに度重視されている印象かな
グラフィックス機能はそれなりに度重視されている印象かな
価格の売れ筋は実売じゃないと何度言えばw
POSランキングだと週間で7位、月間で13位だよK53TA
POSランキングだと週間で7位、月間で13位だよK53TA
APU が載った i7 が欲しい
>>222
>AtomとCoreの設計チームを1つにして両方の質を高めていく
ってのはかなりミスリードっぽい見出しで
>大きな意味で1つのチームになった
>相互にやりとりができるようになった
のレベルだがな。
>AtomとCoreの設計チームを1つにして両方の質を高めていく
ってのはかなりミスリードっぽい見出しで
>大きな意味で1つのチームになった
>相互にやりとりができるようになった
のレベルだがな。
KomodoとWichita/Krishnaがキャンセルされて
来年のラインナップが整理されてきましたね
2012 AMD デスクトップラインナップ予想
Vishera 32nm AM3+ TDP150W
Vishera 32nm AM3+ TDP125W
Vishera 32nm AM3+ TDP95W
Trinity 32nm FM2 TDP125W
Trinity 32nm FM2 TDP100W
Trinity 32nm FM2 TDP65W
Zacate 40nm FT1 TDP18W
デスクトップはTDPの上限を上げた分どこまで性能を上げられるのか
熱いけど性能は良いというところまで行けるでしょうか
TDP150Wの存在はかなり怪しいけど
TrinityでTDP125Wを出すという事でありかなと思いました
2012 AMD モバイルラインナップ予想
Trinity 32nm FS1r2 TDP35W
Trinity 32nm FS1r2 TDP17W
Zacate 40nm FT1 TDP18W
Ontario 40nm FT1 TDP9W
Hondo 40nm FT1 TDP4.5W
モバイルは逆にTDPの上限を下げて勝負に出るでしょう
あとは生産が上手くいくかどうかにかかってます
Zacate以下はどうなるでしょう40nmのままいくのか
28nmにシュリンクもしくは2013年予定のKeralaを前倒しするかも知れません
来年のラインナップが整理されてきましたね
2012 AMD デスクトップラインナップ予想
Vishera 32nm AM3+ TDP150W
Vishera 32nm AM3+ TDP125W
Vishera 32nm AM3+ TDP95W
Trinity 32nm FM2 TDP125W
Trinity 32nm FM2 TDP100W
Trinity 32nm FM2 TDP65W
Zacate 40nm FT1 TDP18W
デスクトップはTDPの上限を上げた分どこまで性能を上げられるのか
熱いけど性能は良いというところまで行けるでしょうか
TDP150Wの存在はかなり怪しいけど
TrinityでTDP125Wを出すという事でありかなと思いました
2012 AMD モバイルラインナップ予想
Trinity 32nm FS1r2 TDP35W
Trinity 32nm FS1r2 TDP17W
Zacate 40nm FT1 TDP18W
Ontario 40nm FT1 TDP9W
Hondo 40nm FT1 TDP4.5W
モバイルは逆にTDPの上限を下げて勝負に出るでしょう
あとは生産が上手くいくかどうかにかかってます
Zacate以下はどうなるでしょう40nmのままいくのか
28nmにシュリンクもしくは2013年予定のKeralaを前倒しするかも知れません
以前と違うのは、「Bulldozerが出た暁には……」という希望と妄想に満ちた言い訳が
通用しなくなったところだな。
通用しなくなったところだな。
>>221
自社のAtomと競合する領域の製品委託を受けるかなあ
かといってローエンドARMじゃIntelが受ける意味がないと思うが
これまでの実績だとFPGAベンジャーだから、確かにIntelの本業とは被らなかった
ハイエンドで、あんまりIntelと被らないが、ARMを使うとなると……
NVIDIAのDenverとか?w
自社のAtomと競合する領域の製品委託を受けるかなあ
かといってローエンドARMじゃIntelが受ける意味がないと思うが
これまでの実績だとFPGAベンジャーだから、確かにIntelの本業とは被らなかった
ハイエンドで、あんまりIntelと被らないが、ARMを使うとなると……
NVIDIAのDenverとか?w
Intelからx86エミュレーションハードを持つARMプロセッサとか出てきたら驚くね。
本来はAMDがやるべき領域だと思うけど。
本来はAMDがやるべき領域だと思うけど。
235 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/23(水) 18:01:30.77 ID:+CJ2d1PN
GFって本気で根本的な問題あんじゃないのか・・・。
http://www.tomshardware.com/news/amd-globalfoundries-28nm-apu-tsmc,14073.html
http://www.tomshardware.com/news/amd-globalfoundries-28nm-apu-tsmc,14073.html
28nmはIBMとかSamsungとfab syncしてるんじゃなかったの
239 :Socket774:2011/11/23(水) 18:28:40.17 ID:e0N6kyzs
無理
nvがもともとx86ようにVLIWとCMS準備してたのを
ARM用にしたとの噂はあったが
nvがもともとx86ようにVLIWとCMS準備してたのを
ARM用にしたとの噂はあったが
240 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/23(水) 18:32:57.75 ID:+CJ2d1PN
x86命令セットをデコードするハードウェア全般に、ほぼ回避不可能なIntelの特許がある。
2015年までは無理じゃね?
2015年までは無理じゃね?
242 :Socket774:2011/11/23(水) 18:45:59.13 ID:Xo5F98gT
IntelかAMDがARMアーキテクチャライセンスを受ければ
両対応CPUを作れるということか
両対応CPUを作れるということか
243 :Socket774:2011/11/23(水) 18:50:51.10 ID:H2zitABi
①BulldozerはAM3+マザーで終了。(来年新しいのが出る)
のはずだったがkomodo 10コアがキャンセルになりAM3+延命(2012年Q3にはPiledriver 8コアが発売予定)
②AM3マザーにBulldozerが乗るかどうかはマザーベンダ次第
③新命令FMAに対応すればそこそこ速い(実際みたものはいない
④旧アプリでは性能向上は見込めない
⑤GPUは載っていない
⑥製品版ベンチはi3以下、i5/i7と比較するのは失礼なレベル
⑦最上位が245ドルと大安売り
だけど日本では抱き合わせで高負荷時爆音水冷クーラー同梱500個限定で約35,000円
⑧年単位で遅れに遅れて性能も遅れていた
⑨8コアの優位性を前面に売り出したのに4・6コアが先に販売となる
デモ会場では見学者からブーイングも
⑩4.5GHzまでOCしても2500Kのデフォルトクロックに並べない
そして8GHzを目指すと良く燃える
⑪スコアは恐ろしく低いがOCの伸び率は最強。
もちろん消費電力も過去最凶
⑫AMDの支援を受けて開発された TotalWar:Shogun2 が BSOD が発生して動作しない
もはや体を張ったギャグ
⑬8コア繋ぎで発売したFX-8120/FX-6100/FX-4100は Phenom II/Athlon II/Aシリーズがライバル
⑭キャンペーンの景品はお菓子の空き袋 (すっぱい葡萄の香り
⑮デフォでリミッター搭載、定格でも負荷がかかると発動
マザーによっては解除可能だが、今度はC'n'Qの効かない常時全力運転になる
⑯驚異的な販売不振により発売から一ヶ月も経たずに価格改定、無様な値下げを余儀なくされる
のはずだったがkomodo 10コアがキャンセルになりAM3+延命(2012年Q3にはPiledriver 8コアが発売予定)
②AM3マザーにBulldozerが乗るかどうかはマザーベンダ次第
③新命令FMAに対応すればそこそこ速い(実際みたものはいない
④旧アプリでは性能向上は見込めない
⑤GPUは載っていない
⑥製品版ベンチはi3以下、i5/i7と比較するのは失礼なレベル
⑦最上位が245ドルと大安売り
だけど日本では抱き合わせで高負荷時爆音水冷クーラー同梱500個限定で約35,000円
⑧年単位で遅れに遅れて性能も遅れていた
⑨8コアの優位性を前面に売り出したのに4・6コアが先に販売となる
デモ会場では見学者からブーイングも
⑩4.5GHzまでOCしても2500Kのデフォルトクロックに並べない
そして8GHzを目指すと良く燃える
⑪スコアは恐ろしく低いがOCの伸び率は最強。
もちろん消費電力も過去最凶
⑫AMDの支援を受けて開発された TotalWar:Shogun2 が BSOD が発生して動作しない
もはや体を張ったギャグ
⑬8コア繋ぎで発売したFX-8120/FX-6100/FX-4100は Phenom II/Athlon II/Aシリーズがライバル
⑭キャンペーンの景品はお菓子の空き袋 (すっぱい葡萄の香り
⑮デフォでリミッター搭載、定格でも負荷がかかると発動
マザーによっては解除可能だが、今度はC'n'Qの効かない常時全力運転になる
⑯驚異的な販売不振により発売から一ヶ月も経たずに価格改定、無様な値下げを余儀なくされる
244 :Socket774:2011/11/23(水) 18:54:11.49 ID:e0N6kyzs
x86 ARM両方持っているVIAが
両対応CPUなんて作ってない
Intelもそんなことしなかったろ
両対応CPUなんて作ってない
Intelもそんなことしなかったろ
Bulldozerは要所要所はせっかく強化してるのにL2DTLBが全く仕事してないみたいなアホな仕様で台無しにてるのがなあ。
これまで数年おきでしか出来なかったマイナーチェンジを毎年複数こなすほど開発力上がってるはずなのに不思議なもんだな。
これまで数年おきでしか出来なかったマイナーチェンジを毎年複数こなすほど開発力上がってるはずなのに不思議なもんだな。
VIAグループって言っても、X86はVIA、ARMはHTCって分けてるけどね
247 :Socket774:2011/11/23(水) 19:05:34.91 ID:e0N6kyzs
いやHTCじゃなくて
VIAもあるよWM
VIAもあるよWM
>>242
1%のロイヤリティ契約なら、単価200ドルのCPU作ったら2ドルほどARMに支払われる。
それではあまりにARMが力を持ちすぎるだろ。
というかそもそもメリットがない。
わざわざ非x86への移行を支援するようなものだ。
1%のロイヤリティ契約なら、単価200ドルのCPU作ったら2ドルほどARMに支払われる。
それではあまりにARMが力を持ちすぎるだろ。
というかそもそもメリットがない。
わざわざ非x86への移行を支援するようなものだ。
てかVIAは部門をグループ企業のHTCに売却しながら赤字を補填してる状態
Windows8の状況によってはVIAの方はたたむかもね
Windows8の状況によってはVIAの方はたたむかもね
250 :Socket774:2011/11/23(水) 19:06:35.13 ID:uuKQDqSL
■全国販売店のPOSデータに連動した「販売実績」ランキング
http://bcnranking.jp/category/subcategory_0026.html
→ 1位 Core i7-2600K(3.4GHz)
↑ 2位 Core i7-2700K(3.5GHz)
↓ 3位 Core i5-2500K(3.3GHz)
☆ 4位 Core i7-3930K(3.8GHz)
↓ 5位 Core i3-2100(3.1GHz)
→ 6位 CelernDC G530(2.4GHz)
↓ 7位 Core i7-2600(3.4GHz)
☆ 8位 Core i7-3960X(3.9GHz)
↓ 9位 Core i5-2500(3.3GHz)
↓10位 Core i5-2400(3.1GHz)
------------------------------------------
※AMD石は売上不振でランク外ですw
251 :Socket774:2011/11/23(水) 19:09:33.38 ID:e0N6kyzs
S3の移動はApple対策だが
>>242
AndroidのソフトをWindows上で動かすためのソフトを開発してるソフトメーカーと提携はしてるよ
ただまあ、『今後モバイルでスマホの他に持ち歩くとしたら何か』という市場調査で
ノート/ネットブック/タブレットはほぼ1:1:1で、並んだ
また現行のタブレットユーザーに対する『次のモバイルは何を買うか』では『次もタブレット』が80%を越える
2~3年もすると両対応とか無意味になるかもね
AndroidのソフトをWindows上で動かすためのソフトを開発してるソフトメーカーと提携はしてるよ
ただまあ、『今後モバイルでスマホの他に持ち歩くとしたら何か』という市場調査で
ノート/ネットブック/タブレットはほぼ1:1:1で、並んだ
また現行のタブレットユーザーに対する『次のモバイルは何を買うか』では『次もタブレット』が80%を越える
2~3年もすると両対応とか無意味になるかもね
あれだけ数がないFX-8150でもBCN売り上げランキングでは先週10位で今週13位って
自作用CPUって本当にたいして数の出ない市場になっているんだな
自作用CPUって本当にたいして数の出ない市場になっているんだな
>>253
数は大量に出ているのが上位の数種類だけという場合もあるから実数がわからないと何とも言えない
数は大量に出ているのが上位の数種類だけという場合もあるから実数がわからないと何とも言えない
2500Kから上の桟橋を除いたらコロコロ順位変わるから、少なくともその辺のCPUは大した数売れてないだろうね
256 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/23(水) 19:35:58.88 ID:+CJ2d1PN
>>252
あれってWindows上でARM仮想マシンを動かしてその上でAndroidを実行するだけだろ?
エミュレータやJITコンパイラを作るだけなら別に特許に触れないからね。
ソフトウェアに特許を適用するのって実は結構難しいんだわ。
中国のGodsonもTransmetaのあれもIntelにライセンス料払ってるかどうか・・・
物理的に特許の対象になるハードウェアを積んで無いからね。
あれってWindows上でARM仮想マシンを動かしてその上でAndroidを実行するだけだろ?
エミュレータやJITコンパイラを作るだけなら別に特許に触れないからね。
ソフトウェアに特許を適用するのって実は結構難しいんだわ。
中国のGodsonもTransmetaのあれもIntelにライセンス料払ってるかどうか・・・
物理的に特許の対象になるハードウェアを積んで無いからね。
結局、GloFoの32nmプロセスは320mm^2に20億トランジスタ詰め込めるん?
どんなに詰め込んでも15億程度と思うが。
どんなに詰め込んでも15億程度と思うが。
毎クロック2命令でデコード能力足りなくなるほど処理性能高いなら俺もう満足だわw
260 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/23(水) 19:47:05.10 ID:+CJ2d1PN
BulldozerはL1の時点でプリデコード済みだから
デコーダのway数を増やすのは比較的楽だろう
デコーダのway数を増やすのは比較的楽だろう
262 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/23(水) 19:57:55.50 ID:+CJ2d1PN
デコーダ分けるほうが安くつきそうだな。
プリデコード済みなら
デコーダの実装コストはway数に比例するから分けても特別有利なことはない
フェッチは分けた方が良い
デコーダの実装コストはway数に比例するから分けても特別有利なことはない
フェッチは分けた方が良い
2004年を境に、アクティブ自作er(三年以内にPCを新規で組むユーザー)が減っているらしい
2004年の18万人が今では7万人だと
2004年の18万人が今では7万人だと
265 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/23(水) 20:04:19.90 ID:+CJ2d1PN
4デコードに2ALU×2って別に少なくないっしょ。
いずれにしてもバックエンドを強化する算段がついてからの話では?
いずれにしてもバックエンドを強化する算段がついてからの話では?
そういえばさFXってプリフェッチャも効いてなくない?
Liner Read LatencyのL2キャッシュ範囲の話だけど、
8,16,32の時は同じキャッシュライン内で複数回アクセスされるから
レイテンシがその回数に応じて平均化されるのは分かる。
でも64の時は1キャッシュライン毎に1回のアクセスになるから
プリフェッチが掛からない限りL2レイテンシそのままになるはず。
ここでK10やBobcatの数字だけどL2キャッシュ範囲の64単位でのアクセスの時に
L2レイテンシよりかなり小さい値になってる。
K10はL2レイテンシ12cycleで実効は16-17cycle程度だけど9cycle、
BobcatはL2レイテンシ20cycleだけど13-14cycle。
これはリニアリードに対してプリフェッチャが効いてるからと思う。
だけどBulldozerの場合は20cycleというL2レイテンシそのものの値になる。
これはBulldozerの強化されたというふれこみのプリフェッチャが
K10やBobcatですら効果がある状況で効いていないはないかと。
http://www.freeweb.hu/instlatx64/AuthenticAMD0100FA0_K10_Thuban_MemLatX64.txt
http://www.freeweb.hu/instlatx64/AuthenticAMD0500F10_K14_Bobcat_MemLatX64.txt
http://www.freeweb.hu/instlatx64/AuthenticAMD0600F12_K15_Bulldozer_MemLatX64.txt
Liner Read LatencyのL2キャッシュ範囲の話だけど、
8,16,32の時は同じキャッシュライン内で複数回アクセスされるから
レイテンシがその回数に応じて平均化されるのは分かる。
でも64の時は1キャッシュライン毎に1回のアクセスになるから
プリフェッチが掛からない限りL2レイテンシそのままになるはず。
ここでK10やBobcatの数字だけどL2キャッシュ範囲の64単位でのアクセスの時に
L2レイテンシよりかなり小さい値になってる。
K10はL2レイテンシ12cycleで実効は16-17cycle程度だけど9cycle、
BobcatはL2レイテンシ20cycleだけど13-14cycle。
これはリニアリードに対してプリフェッチャが効いてるからと思う。
だけどBulldozerの場合は20cycleというL2レイテンシそのものの値になる。
これはBulldozerの強化されたというふれこみのプリフェッチャが
K10やBobcatですら効果がある状況で効いていないはないかと。
http://www.freeweb.hu/instlatx64/AuthenticAMD0100FA0_K10_Thuban_MemLatX64.txt
http://www.freeweb.hu/instlatx64/AuthenticAMD0500F10_K14_Bobcat_MemLatX64.txt
http://www.freeweb.hu/instlatx64/AuthenticAMD0600F12_K15_Bulldozer_MemLatX64.txt
SSE系の分岐の少ないコードだと足りないかもと思うけど
SandyBridgeもSSEやAVXの密度の高いコードだとuOPキャッシュ使わないと全然速度でないでしょ
SandyBridgeもSSEやAVXの密度の高いコードだとuOPキャッシュ使わないと全然速度でないでしょ
K10やBobcatの64byteストライドでL2のレイテンシ以下になるのはOoOのおかげかな
BDでなんで効かないのかは謎だが
BDでなんで効かないのかは謎だが
いやさすがにそんなコードにはなってないはずか
ごめん取り消します
連投すまん
ごめん取り消します
連投すまん
てかBulldozerってアウトオブオーダにすべてをかけたお化けでしょ。
恐らくメモリ空間が連続してるだけで検証プログラムは
他と同じ「p = *p」を繰り返すような作りと思うけどこれだとアウトオブオーダは掛からない...
恐らくメモリ空間が連続してるだけで検証プログラムは
他と同じ「p = *p」を繰り返すような作りと思うけどこれだとアウトオブオーダは掛からない...
272 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/23(水) 20:45:38.26 ID:+CJ2d1PN
まあ、16バイト帯域の命令フェッチャ+μOPs cacheってのは割り切り方としては上手いね
平均命令長が4バイトを超えるのはSSEを使うときが多いし、1536エントリもキャッシュすれば
大概の反復処理は再フェッチ・デコードを回避できる。
32バイトにすれば4命令なら平均8バイトで、SSEを含む大概の拡張命令を
供給できるが分岐の多いコードでは無駄が多くなる。
こう言ってしまうとμOPsは絶対的に優れた美味しい技術に思えてしまうが
μOPsは語長が長くなるので格納効率はx86にはるかに劣るし、6μOPsもフェッチするのって
かなり負担は大きい。
それでも再デコードするよりは電力効率的にましなんだろうね。
>>271
確かにRMMAとかのソースで mov edx, [edx] の羅列を見た気がする。
平均命令長が4バイトを超えるのはSSEを使うときが多いし、1536エントリもキャッシュすれば
大概の反復処理は再フェッチ・デコードを回避できる。
32バイトにすれば4命令なら平均8バイトで、SSEを含む大概の拡張命令を
供給できるが分岐の多いコードでは無駄が多くなる。
こう言ってしまうとμOPsは絶対的に優れた美味しい技術に思えてしまうが
μOPsは語長が長くなるので格納効率はx86にはるかに劣るし、6μOPsもフェッチするのって
かなり負担は大きい。
それでも再デコードするよりは電力効率的にましなんだろうね。
>>271
確かにRMMAとかのソースで mov edx, [edx] の羅列を見た気がする。
>>271
ハードウェアプリフェッチがかかってると
64MBあたりみたいに数百byteあたりまでのstrideで効果がでていいように思う
K10は次のラインはL1に読み込みみたいな単純な機構もついてるとかかな?
ちなみに>>268のソースはAgner Fogの資料なんで公式ではないです
>>272
intelの三角関数ライブラリはuOP$にヒットさせないと本気が出ないからな
SandyBridge以前のコードはなるべくアンロールしたものが最適だったけど
SandyBridge向けはこまめにループを切ってuOP$に入るように調整する必要が出てきた
32byteフェッチ幅+uOP$という選択肢もあったのに
intelがそこまで16byteのフェッチ幅にこだわるのは
プリデコードがそれだけ重いということなのかな
ハードウェアプリフェッチがかかってると
64MBあたりみたいに数百byteあたりまでのstrideで効果がでていいように思う
K10は次のラインはL1に読み込みみたいな単純な機構もついてるとかかな?
ちなみに>>268のソースはAgner Fogの資料なんで公式ではないです
>>272
intelの三角関数ライブラリはuOP$にヒットさせないと本気が出ないからな
SandyBridge以前のコードはなるべくアンロールしたものが最適だったけど
SandyBridge向けはこまめにループを切ってuOP$に入るように調整する必要が出てきた
32byteフェッチ幅+uOP$という選択肢もあったのに
intelがそこまで16byteのフェッチ幅にこだわるのは
プリデコードがそれだけ重いということなのかな
K10もBulldozerもL1へのHW Prefetcherが存在するって最適化ガイドに書いてあるな
K8には無いみたいだが
K8には無いみたいだが
275 :Socket774:2011/11/23(水) 21:59:36.16 ID:GKWHhQ3m
IntelはARMのライセンス受けるより、ARMと命令レベルで互換性のある独自チップを作ったほうがいいんじゃね?
せっかく大容量キャッシュ搭載してるのに...
L2DTLBが仕事せずにランダムアクセス死亡。
プリフェッチャがまともに仕事せずにリニアアクセス死亡。
ひどい話だ...
L2DTLBが仕事せずにランダムアクセス死亡。
プリフェッチャがまともに仕事せずにリニアアクセス死亡。
ひどい話だ...
277 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/23(水) 22:28:22.15 ID:+CJ2d1PN
>>275
それをやってるのがQualcommのSnapdragonでありかつてのIntel XScale
それをやってるのがQualcommのSnapdragonでありかつてのIntel XScale
>>276
確かに256KBからランダムアクセスで急激に悪化するけどDTLBだけの問題じゃないような気がする
CoreDuoも512KBまでしかTLBが効かないからそれ以降悪化するもののBullほどじゃないしな
精々3-5サイクル程度悪化するだけだし
128KB→256KBで20サイクルから42サイクルに悪化なんでキャッシュ階層の変化レベルだろ
確かに256KBからランダムアクセスで急激に悪化するけどDTLBだけの問題じゃないような気がする
CoreDuoも512KBまでしかTLBが効かないからそれ以降悪化するもののBullほどじゃないしな
精々3-5サイクル程度悪化するだけだし
128KB→256KBで20サイクルから42サイクルに悪化なんでキャッシュ階層の変化レベルだろ
>>277
qualcommにせよintelにせよARMのアーキテクチャライセンスを受けているはずだけど。
275の書いたようにARMのライセンスを受けずにsnapdragonやxscaleを開発しているの
なら大変なことになると思うぞ。
qualcommにせよintelにせよARMのアーキテクチャライセンスを受けているはずだけど。
275の書いたようにARMのライセンスを受けずにsnapdragonやxscaleを開発しているの
なら大変なことになると思うぞ。
280 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/24(木) 00:23:35.78 ID:Ox+2A5cQ
まあ、互換実装作るにもライセンスは必要だな
竜芯はそれをやって問題になったんだよなwww
竜芯はそれをやって問題になったんだよなwww
>>188
xbox潰す気かw
xbox潰す気かw
ARM真理教はいい加減コテつけりゃいいのに
>>225
それが現実だな
ここの淫虫たちは日常の憂さ晴らし第一でそれが見えない
amdなんてちょっと前まで市場のメインストリームのノートでほとんどシェアを取れていなかった ほぼ0
それが2割弱でもシェアを取れるようになったらもう大躍進
しかもfabのコストや製造に関する研究開発費もほぼ0になったんだからそら財務も大幅に改善するわけだ(amdにしては珍しく四半期決算黒字続き)
リストラに関しては世界経済が縮小するのとデスクトップ、自作(oem)関連だな
ここの人間は受け入れないだろうがデスクトップ縮小は企業として極めて正常な判断
amd規模で自作市場なんかに力を入れてたらそれこそ会社が傾く 余技のまた余技でやる程度だろ
それが現実だな
ここの淫虫たちは日常の憂さ晴らし第一でそれが見えない
amdなんてちょっと前まで市場のメインストリームのノートでほとんどシェアを取れていなかった ほぼ0
それが2割弱でもシェアを取れるようになったらもう大躍進
しかもfabのコストや製造に関する研究開発費もほぼ0になったんだからそら財務も大幅に改善するわけだ(amdにしては珍しく四半期決算黒字続き)
リストラに関しては世界経済が縮小するのとデスクトップ、自作(oem)関連だな
ここの人間は受け入れないだろうがデスクトップ縮小は企業として極めて正常な判断
amd規模で自作市場なんかに力を入れてたらそれこそ会社が傾く 余技のまた余技でやる程度だろ
>>248
200ドルのcpuなんて一般的にはどんどんマイナーな存在になっていくだろうね
それだけの価格のcpu買うんだったらx86とarm別個で買った方がいいし
用途が結構被るからx86もarmと間接的に価格競争を強いられてメインストリーム価格は下振れせざるを得ない
200ドルのcpuなんて一般的にはどんどんマイナーな存在になっていくだろうね
それだけの価格のcpu買うんだったらx86とarm別個で買った方がいいし
用途が結構被るからx86もarmと間接的に価格競争を強いられてメインストリーム価格は下振れせざるを得ない
>>246
”ARMはHTC”でかいよな
amdみたいに中途半端にx86のシェア持ってなかったからこそできた戦略だな はっきり勝ち組みと断言できる
htc見てamdの株主や幹部は1年前くらいから感じるものがあってこの春先の騒ぎになったんではないかな
viaとhtcは古河電気と富士通以上の子が親を上回る例になりそうだ
”ARMはHTC”でかいよな
amdみたいに中途半端にx86のシェア持ってなかったからこそできた戦略だな はっきり勝ち組みと断言できる
htc見てamdの株主や幹部は1年前くらいから感じるものがあってこの春先の騒ぎになったんではないかな
viaとhtcは古河電気と富士通以上の子が親を上回る例になりそうだ
>>278
SandyBridgeのLLCがレイテンシ26-31クロックサイクル、
NehalemでもL3が35-40サイクル、という事を考えるなら
42がいかに異常事態かという事ではある。どう考えても変
SandyBridgeのLLCがレイテンシ26-31クロックサイクル、
NehalemでもL3が35-40サイクル、という事を考えるなら
42がいかに異常事態かという事ではある。どう考えても変
>>248
てか既に巨大だが数年後に質の面でトップの半導体系企業になるだろうARM Limitedは
今ならアーキテクトにintel以上の給与を出せるんでは?ストックオプション絡めれば大差つけられると思うし
てか少々給与で下回っても仕事として面白いのは明らかにarmだと思う
armが力を持ち過ぎるようになったらまたそれを覆すような凄いアイデアを持ったcpuアーキが出てきて欲しいな でないと面白く無い
てか既に巨大だが数年後に質の面でトップの半導体系企業になるだろうARM Limitedは
今ならアーキテクトにintel以上の給与を出せるんでは?ストックオプション絡めれば大差つけられると思うし
てか少々給与で下回っても仕事として面白いのは明らかにarmだと思う
armが力を持ち過ぎるようになったらまたそれを覆すような凄いアイデアを持ったcpuアーキが出てきて欲しいな でないと面白く無い
293 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/24(木) 03:27:32.64 ID:Ox+2A5cQ
> てか少々給与で下回っても仕事として面白いのは明らかにarmだと思う
そーいやK7のアーキテクトはAMDが詰まらないのでARMに移籍したんだよなwwww
そーいやK7のアーキテクトはAMDが詰まらないのでARMに移籍したんだよなwwww
294 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/24(木) 03:50:53.88 ID:Ox+2A5cQ
ARMv8の64ビットモードって8ビット・16ビット単位のロード・ストアもプレディケートもなくなった時点で
命令セットとしては既にPowerPC以下の駄作確定だけどな。
PowerPCといえば同じパワーレンジで強力なコア作ってもx86には及ばなくて撤退したんだけどな。
命令セットとしては既にPowerPC以下の駄作確定だけどな。
PowerPCといえば同じパワーレンジで強力なコア作ってもx86には及ばなくて撤退したんだけどな。
団子だけ釣られてるのか
>>293
そら未来の無い化石x86延命策搾り出す仕事が面白いわけがないw
そら未来の無い化石x86延命策搾り出す仕事が面白いわけがないw
297 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/24(木) 04:24:30.72 ID:Ox+2A5cQ
AMDがつまらないだけだろ?
299 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/24(木) 04:32:25.86 ID:Ox+2A5cQ
馬鹿すぎる
それをいうならARMみたいな継ぎ接ぎだらけのクソ命令セットなんかよりCellでもマンセーしてろよ
それをいうならARMみたいな継ぎ接ぎだらけのクソ命令セットなんかよりCellでもマンセーしてろよ
AndyGlewはIntelを二度辞めた
アーキテクトはより良い待遇を求めて
グルグル転職するのが普通なんだろう
本人のブログを見ても、いろんな所に行ってる。Intelの他にもいろいろ
> currently of MIPS Technologies, in the past of other companies such as
> Intellectual Ventures, Intel, AMD, Motorola, and Gould
グルグル転職するのが普通なんだろう
本人のブログを見ても、いろんな所に行ってる。Intelの他にもいろいろ
> currently of MIPS Technologies, in the past of other companies such as
> Intellectual Ventures, Intel, AMD, Motorola, and Gould
欧米企業の奴らの肩書きに"元'"がつかないやつなんてそういないだろ
団子は恣意的過ぎんだよ
団子は恣意的過ぎんだよ
糞コテはNGワードへ登録推奨
>>294
ARMv7の延長で64ビットモードを定義する方が簡単なわけで、
ARMの特徴を捨ててでもレジスタ指定に5bit割きたかった(割く方が効率が良いと判断した)
ということだと思うけど。
ていうか「8ビット・16ビット単位のロード・ストア」が無くなったって話はどこに?
ARMv7の延長で64ビットモードを定義する方が簡単なわけで、
ARMの特徴を捨ててでもレジスタ指定に5bit割きたかった(割く方が効率が良いと判断した)
ということだと思うけど。
ていうか「8ビット・16ビット単位のロード・ストア」が無くなったって話はどこに?
Bulldozerがmemory disambiguationを導入しているなら
L2レイテンシをOoOで隠蔽できないがハードウェアプリフェッチは有効という状況はそんなにないだろうから
L2->L1のプリフェッチをなくしていたとしても不思議はないけどな
プリフェッチが外れたらただでさえ小さいL1を無駄に使ってしまうわけだし
と思ったけど
連続領域から取りたてのリンクリストとかはハードウェアプリフェッチは有効かな
L2レイテンシをOoOで隠蔽できないがハードウェアプリフェッチは有効という状況はそんなにないだろうから
L2->L1のプリフェッチをなくしていたとしても不思議はないけどな
プリフェッチが外れたらただでさえ小さいL1を無駄に使ってしまうわけだし
と思ったけど
連続領域から取りたてのリンクリストとかはハードウェアプリフェッチは有効かな
ロードストアに先行するロード並べ替えはK10で実装済みじゃね?
307 :Socket774:2011/11/24(木) 20:50:39.26 ID:2lATmYe9
過疎ってるな
AMD信者もさすがに見切ったか
AMD信者もさすがに見切ったか
むしろ駄作を作ってからがAMDの勝負所だったりして
いや、スルー力がようやく付いたんでしょ
AMDと関係ない話で数日でスレが埋まるよりは過疎の方がマシ
AMDと関係ない話で数日でスレが埋まるよりは過疎の方がマシ
もともと騒いでるのは荒らしだけやん
むしろAMDがフルスクラッチで作ってよくこれですんだなと
競技人口7万人じゃ過疎るわな
自○自体がオワコン
自○自体がオワコン
313 :Socket774:2011/11/25(金) 00:25:50.73 ID:u+fgb8qQ
{kind=link}
宗教戦争って大変だな
大変だね(´・ω・`)
大変だね(´・ω・`)
315 :Socket774:2011/11/25(金) 01:37:58.46 ID:mz4V3w0l
FX-8150
http://www.4gamer.net/games/100/G010000/20111014094/
>ゲーマーが「ゲームにおける性能向上」を求めた場合に,FX-8150は,選択肢となるようなCPUではない。
>AMDの最新CPUを買わないと気が済まないとか,とにかく新しいアーキテクチャのCPUを触ってみたいとか,
>ひたすら高クロックを狙ってみたいといった理由があるマニアのためのコレクターズアイテムである。
FX-6100とFX-4100
http://www.4gamer.net/games/100/G010000/20111021082/
>FX-6100とFX-4100のテストを行ったが,通して受ける印象は「わざわざ選ぶ理由がない」である。
( ゚д゚)つ┃
ってかさぁ、なんでお前らって、そんなに人気・不人気に対して
そこまで拘るわけ?
仮にも、人気が高かったら何かまずいわけか?
別に興味ねーなら、構う必要ねーじゃんw
なんで、そんなに必死なの?
それが不思議w
そこまで拘るわけ?
仮にも、人気が高かったら何かまずいわけか?
別に興味ねーなら、構う必要ねーじゃんw
なんで、そんなに必死なの?
それが不思議w
AMDが開発にも製造にも失敗している目の前の現実にはいつ向き合うのだ?
何度もコピペするのが信者の義務なのか
たしかに宗教戦争って大変だな
たしかに宗教戦争って大変だな
今のところCPUがダメでもさ、APUで巻き返せたりしないのかね。
今のAPUって CPUとGPUが別々に入ってるだけだけど、そのうちホントに1つになってくんでしょ?
x86とかARMがどうとかより、Fusionのが面白そうな革命なのになんで無視するんだよ。
今のAPUって CPUとGPUが別々に入ってるだけだけど、そのうちホントに1つになってくんでしょ?
x86とかARMがどうとかより、Fusionのが面白そうな革命なのになんで無視するんだよ。
APUは歩留まりがよければ採用メーカーも増えて何とかなったと思うけど
現状がアレだし
しかも、Macbookで生産直前までいってたのに数を用意できなかったなんて噂まで出る始末
現状がアレだし
しかも、Macbookで生産直前までいってたのに数を用意できなかったなんて噂まで出る始末
Appleの広告戦略的に前世代より圧倒的に低速な新型機はありえないから、
どこまで本当だったんだか
どこまで本当だったんだか
>>320
Bulldozerの最終世代辺りにやっと鯖向けにAPUが出るかなって物だぞ
そういう意味では、コプロセッサとして機能するAPUは当分出ない
つまり今まで通りCPU性能とGPU性能を別々に喧伝していくしかない
Bulldozerの最終世代辺りにやっと鯖向けにAPUが出るかなって物だぞ
そういう意味では、コプロセッサとして機能するAPUは当分出ない
つまり今まで通りCPU性能とGPU性能を別々に喧伝していくしかない
324 :Socket774:2011/11/25(金) 05:33:19.19 ID:oALUh/Fe
喧伝の意味解って使ってるのか?
おっと、誤字失礼
×喧伝
◯宣伝
iOS5にしてからフリップの精度が落ちてたまらん(´・ω・`)
×喧伝
◯宣伝
iOS5にしてからフリップの精度が落ちてたまらん(´・ω・`)
もうAPUメーカーになったほうがいいな
ブルにはもう勝利の目は無い
ATI拾っておいてよかったな、これだけがintelに勝ってる所だ
ブルにはもう勝利の目は無い
ATI拾っておいてよかったな、これだけがintelに勝ってる所だ
>>313
Low設定とHight設定でスコアが殆ど変わらないってどういうことよ?
Low設定とHight設定でスコアが殆ど変わらないってどういうことよ?
最後の望みの綱であるAPUにも劣化版ブルがくっ付くという未来が確定している時点でもう詰んでる
329 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/25(金) 07:44:25.20 ID:MPA1bygq
L2DTLBやHW prefetcherとかいろいろは無効になってるみたいだし
こいつらの性能改善するだけでだいぶ性能あがるんでわは?
こいつらの性能改善するだけでだいぶ性能あがるんでわは?
性能改善じゃなくて有効化するだけだた
>>328
悟空がベジータとのフュージョンじゃなくて、ミスターサタンとフュージョンするようなもんだからな
悟空がベジータとのフュージョンじゃなくて、ミスターサタンとフュージョンするようなもんだからな
BullもやばいがGCNもやばい。
今までのRadeonのゲーム特化という優位を捨てて
既にnVが技術と市場を確立済みのGPGPU側にすり寄るんだからな。
ゲームのシェアを失ってGPGPUにも食い込めない最悪の事態が待っている。
今までのRadeonのゲーム特化という優位を捨てて
既にnVが技術と市場を確立済みのGPGPU側にすり寄るんだからな。
ゲームのシェアを失ってGPGPUにも食い込めない最悪の事態が待っている。
GPUに関しては、MSの言いなりになってれば開発環境を揃えてもらえそう。
Gates-fisrtって事だ。
Gates-fisrtって事だ。
AMDのプログラマがテヘと全く同じ事をいって
同じ事をやろうとしているな
http://pc.watch.impress.co.jp/docs/column/kaigai/20110616_453498.html
同じ事をやろうとしているな
http://pc.watch.impress.co.jp/docs/column/kaigai/20110616_453498.html
http://livedoor.blogimg.jp/amd646464/imgs/4/9/49876798.png
総合でx4の2倍くらいの速さ
クロックで性能を稼ぐアーキテクチャは普段使いで消費電力を大幅に下げられる
{kind=link}
総合でx4の2倍くらいの速さ
クロックで性能を稼ぐアーキテクチャは普段使いで消費電力を大幅に下げられる
337 :Socket774:2011/11/25(金) 13:07:04.94 ID:GBNHXmu1
ARM馬鹿はamd's cafeの管理人か
(笑)
(笑)
あほ
339 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/25(金) 20:10:49.25 ID:MPA1bygq
なんとかガーデンの管理人かもw
>>336
Pentium4のことか?
Pentium4のことか?
AMD E-450のCPUファンって交換できると思う?
まだ現物が届いていないから自分じゃ判断できないんだが、小口径だから
たぶん結構音はしそうなんだよね。
もうちっと口径を大きくしてゆるゆる回したい
まだ現物が届いていないから自分じゃ判断できないんだが、小口径だから
たぶん結構音はしそうなんだよね。
もうちっと口径を大きくしてゆるゆる回したい
鯖がおかしい(´・ω・`)
アイドルで常用するなら、もっと消費電力の低い安いCPUで事足りるんじゃない?
アイドル低いって話から、なんでアイドルで常用するって話になるのさ。
結局8コアなんか必要ないんだよ
見栄張りたいだけ
見栄張りたいだけ
347 :Socket774:2011/11/25(金) 22:57:36.21 ID:YoVhzUd4
インプレスの後藤さん記事、
共有リソースが 6割 もあるのに 8コア とかフカシすぎじゃんかブル土下座
そりゃ遅いわガラクタだ
残り 4割 のみ専有、半人前に満たないカス
共用してるのが6割なので
8*0.4+8/2*0.6 = 5.6
実は 6コア 分もない事に!?
これで 8 コア とは姉歯物件もびっくり
http://pc.watch.impress.co.jp/docs/column/kaigai/20111019_484609.html
AMD使ってる奴って見栄はるのが好きなんだね(´・ω・`)
ぶっちゃけデュアルコアで十分じゃないかね
4つは要らないとするとトリプルも案外良いんじゃないか
4つは要らないとするとトリプルも案外良いんじゃないか
4コアを無理矢理1つ削った代物なんて嫌だよ
2コアで十分
ソフトウェアを作る側から見ると、
2コアはマルチコア対応のコストの割にメリットが薄い。
しかし4コアを超えるとスケールしにくい。
コア数は4に留めて、あとは他の事にトランジスタを費やした方が無駄が無い。
2コアはマルチコア対応のコストの割にメリットが薄い。
しかし4コアを超えるとスケールしにくい。
コア数は4に留めて、あとは他の事にトランジスタを費やした方が無駄が無い。
>>349
AMDの「だいたいの場面は2コアで十分、3つめはOSのためのものだ」って主張は正しいと思う
ただ>>350も言ってるとおり、3コアは4コアの選別落ちでしかなく、TDPも4コアと一緒だったしそもそも4コアが安いし、と売り方が…
AMDの「だいたいの場面は2コアで十分、3つめはOSのためのものだ」って主張は正しいと思う
ただ>>350も言ってるとおり、3コアは4コアの選別落ちでしかなく、TDPも4コアと一緒だったしそもそも4コアが安いし、と売り方が…
俺もオイルマネーがほしいとです
いや4コア必要だよ
特にブラウザゲームとか2コアだと100%近く負荷が跳ね上がって苦労したわ
特にブラウザゲームとか2コアだと100%近く負荷が跳ね上がって苦労したわ
2C4Tのi3かAMDの4コアは欲しいね
APUやGPUってブラウザゲームではあまり効果ない?
ゲームやら無いから判らん
ところで、とある登録数3億人のブラウザゲームで
10万円の課金アイテムだしたら2000個売れたってニュースになってるな
ゲームやら無いから判らん
ところで、とある登録数3億人のブラウザゲームで
10万円の課金アイテムだしたら2000個売れたってニュースになってるな
>>358
使うブラウザなら効果有る。
使うブラウザなら効果有る。
Sandy-Eも8コアの選別落ちなんだよな
10万近く出して産廃のリサイクルとか泣けてくるな
10万近く出して産廃のリサイクルとか泣けてくるな
ChromeはGPUあんまり使わないし
無理やり使う設定にすると崩壊するんだよな
Firefoxとかいいの?
無理やり使う設定にすると崩壊するんだよな
Firefoxとかいいの?
>>360
他所でたとえ20万円出しても同等のものは買えないから、しょうがない。
他所でたとえ20万円出しても同等のものは買えないから、しょうがない。
Sandy-Eで8コア有効にする裏ワザとかでるのかなw
Cell同様、8のうち7コアまでは生きているのが多数ありそうだけど、
6なのは理由があるのかな。
6なのは理由があるのかな。
SandyBridge-EPはスパコン向けにTop500に載ってるだけで少なくとも30万個以上はすでに出荷されてる
時期的にバグありステッピング
時期的にバグありステッピング
スパコンだと判ってる人が使うだけだからバグ回避すればいいけど、
汎用のXEONだとマズーなのか。
汎用のXEONだとマズーなのか。
スパコン向けに作ったものが、
今Core i7 3000シリーズとして6coreで売られている、ということなら、
やはり選別落ちなのでないかい?
今Core i7 3000シリーズとして6coreで売られている、ということなら、
やはり選別落ちなのでないかい?
スパコン向けは基本8コアしか使わないから
6コアで高クロックで動くものをSandyBridge-Eに回している可能性は高いと思う
6コアで高クロックで動くものをSandyBridge-Eに回している可能性は高いと思う
Bullなんとかさんも6コア品が売り物になればよかったのにね
あんまり売る気ないからL2DTLBとかHW Prefetcherが無効になってんじゃね?
無理に演算能力で比べなくてもいいのにな
ニッチな自作はともかく一般向けは性能上げたって売れてない
AMD好きなのは分かるがその方向性も少しは理解しとけと
ニッチな自作はともかく一般向けは性能上げたって売れてない
AMD好きなのは分かるがその方向性も少しは理解しとけと
375 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/26(土) 16:10:10.97 ID:9z15iF4g
Nehalem-EXのHPC向けは2コア殺しの6コアだったぞ
コア殺しでの製品分けはどうしようも無いだろ
それともなんかいい代案でも出せんの?
それともなんかいい代案でも出せんの?
377 :Socket774:2011/11/26(土) 17:49:08.12 ID:eEqSpD1+
過疎
ここであえての5コアで
死んでる分安いんだから構わんだろ。
運がよけりゃ復活だってする。
その辺、叩きたいだけの連中は認識が歪んでるぜ。
運がよけりゃ復活だってする。
その辺、叩きたいだけの連中は認識が歪んでるぜ。
>>378
5コア7コアが登場すれば見直すよなw
5コア7コアが登場すれば見直すよなw
381 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/26(土) 19:13:46.50 ID:9z15iF4g
>>375のは6コアでなおかつHT殺しだったかな。
まあ、HTなしでも性能出るように組んだプログラムでは逆にHT使うと性能落ちるからどうでもいいんだが。
Bulldozerも4モジュール4コアみたいなバリエーションはありなんじゃないの?
まあ、HTなしでも性能出るように組んだプログラムでは逆にHT使うと性能落ちるからどうでもいいんだが。
Bulldozerも4モジュール4コアみたいなバリエーションはありなんじゃないの?
3850だけなんでディスコンなの?
Bulldozerモジュールの場合は片コアだけ死んでるケースって少ないような
>>383
モジュールを1単位としてるっぽいからAMDが言うところの1コアだけディセーブルにするってことができるのか微妙だな。
モジュールを1単位としてるっぽいからAMDが言うところの1コアだけディセーブルにするってことができるのか微妙だな。
385 :Socket774:2011/11/26(土) 20:16:47.55 ID:sY85uaSC
隣の家の震撼性能な息子さんより自分ちのデキの悪いニートの心配したら?
http://pc.nikkeibp.co.jp/article/news/20111125/1039224/
http://pc.nikkeibp.co.jp/article/news/20111125/1039224/
このスレではみんなちゃんとBulldozerの心配をしていると思うが。
387 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/26(土) 23:01:32.08 ID:9z15iF4g
Radeonくっつけとけば売れるって楽観的な予想しか聞こえてこないが
まともなCPUにゴミGPUをおまけでつけてもCPUの値段で売れるけど、
まともなGPUにゴミCPUをおまけでつけたらゴミの値段でしか売れない、という悲劇が。
まともなGPUにゴミCPUをおまけでつけたらゴミの値段でしか売れない、という悲劇が。
|
\ __ /
_ (m) _ピコーン
|ミ|
/ .`´ \
∧_∧ / ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄
(・∀・∩< PCIeに挿すCPU(カード)!
(つ 丿 \_________
⊂_ ノ
(_)
\ __ /
_ (m) _ピコーン
|ミ|
/ .`´ \
∧_∧ / ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄
(・∀・∩< PCIeに挿すCPU(カード)!
(つ 丿 \_________
⊂_ ノ
(_)
メインメモリが1GB固定とかでいいならそれもありだけど。
まあIntelのKnights Cornerみたいな例は成立するかもだけど、
やっぱりアクセラレータとして相応の性能が必要なのは変わりない
やっぱりアクセラレータとして相応の性能が必要なのは変わりない
電力固定だから何をどうしても限界がある。
限りアルトランジスタやTDPをコア数増加に使うより
大容量メインメモリを混載する方が可能性があると思う
(帯域が飛躍的に増やせる上に、データの移動が減るから)。
Bulldozerは間違った方向を向いている。
限りアルトランジスタやTDPをコア数増加に使うより
大容量メインメモリを混載する方が可能性があると思う
(帯域が飛躍的に増やせる上に、データの移動が減るから)。
Bulldozerは間違った方向を向いている。
鯖向けだと1Gぐらいの高速メモリが増えてもあまり意味無さそう
メモリ帯域が2倍になれば普通は熱も2倍以上出るよな
メモリ帯域が2倍になれば普通は熱も2倍以上出るよな
つまりデュアルチャンネルにすると
2倍以上の消費電力になると・・・。
2倍以上の消費電力になると・・・。
Bulldozerはとりあえず最適化ガイドに書いてある機能位は有効にしてくれw
1モジュールの1コア殺して4.5コアが登場
次世代で4コアクラスタに進化できるわけでもなく
むしろデコーダもFPUも分離して普通のコアに戻した方が効率が良い。
一世代目にして早くもどん詰まりのクラスタ化というアプローチ。
むしろデコーダもFPUも分離して普通のコアに戻した方が効率が良い。
一世代目にして早くもどん詰まりのクラスタ化というアプローチ。
それは効率じゃなくて絶対性能だろ
でかいのに遅いのは低効率
結局効率なんてのは性能/面積だからなあ。
Bulldozerは現状ではK10より低効率。
まあ、PC用途としての話だが。
Bulldozerは現状ではK10より低効率。
まあ、PC用途としての話だが。
402 : 忍法帖【Lv=7,xxxP】 :2011/11/27(日) 09:27:50.00 ID:oGXuJ+Ld
1モジュールTDP45Wのpileマダー?
Athlonから早く乗り換えたいよ
Athlonから早く乗り換えたいよ
A8-3850を4GHzで使ってる
TrinityはDDR3-2133サポートか
3800は手に入らないしさっさと出てほしいものだが
3800は手に入らないしさっさと出てほしいものだが
爆音っぽいな
>>359
効果なかったよ ハンゲのフラッシュゲームはまったく
効果なかったよ ハンゲのフラッシュゲームはまったく
400mm^2オーバーのビッグダイとか歩留まりもかなり悪そうだからなあ...
409 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/27(日) 13:39:14.99 ID:oP/KXLH+
2DのFlashにGPUアクセラレーションなんて利かないよ。
11で3Dサポートされたけど対応コンテンツ少ない(シェーダ言語で書き直しの必要アリ)ので
Flashゲーやる人はCPU性能(シングルスレッド)だけ重視で組んだ方が良い。
CPUコアのIPCもクロックも低いLlanoなんかが一番悲惨な選択
11で3Dサポートされたけど対応コンテンツ少ない(シェーダ言語で書き直しの必要アリ)ので
Flashゲーやる人はCPU性能(シングルスレッド)だけ重視で組んだ方が良い。
CPUコアのIPCもクロックも低いLlanoなんかが一番悲惨な選択
410 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/27(日) 13:56:29.38 ID:oP/KXLH+
あ、Flash 11以前からあるレイヤーと拡大縮小を組み合わせた疑似3D(Flash 2.5D)も
CPU処理ね。
CPU処理ね。
フラッシュがシングルスレッド性能を要求するのは確かだが
Llanoでまともに動かないフラッシュゲームは
何かいろいろ間違えているとも思う。
Llanoでまともに動かないフラッシュゲームは
何かいろいろ間違えているとも思う。
ハンゲのハッピーシリーズはガチで重い。しかもアップデートのたびに重くなる一方
何個も立ち上げたり考えると2500KでZ68の構成にすればよかったと激しく後悔してるわ。
何個も立ち上げたり考えると2500KでZ68の構成にすればよかったと激しく後悔してるわ。
ハンゲだかチンゲだかの話題は、他でやってくれ。
シングルスレッドなFlashはAMDのCPUにはきついケースも有りそうだが・・・
Flash自体が終わっちゃったからいいか
Adobeに買われたのが運の尽きだったな
Flash自体が終わっちゃったからいいか
Adobeに買われたのが運の尽きだったな
416 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/27(日) 19:22:29.54 ID:6XLJ9BeM
HTML5ってまだ規格すら決まってないんだぜ。
マクロメディアとか懐かし
スパコンなら1スレッドに1FPUでいいんじゃない
鯖やPCなら複数スレッドに1FPUで良さそう
鯖やPCなら複数スレッドに1FPUで良さそう
フロントエンド共有も、そこがボトルネックになっていたら止めざるを得ない。
x86では今以上にリッチなデコーダには出来ないから。
x86では今以上にリッチなデコーダには出来ないから。
鯖用鯖用と書きまくってるけど、どういう利点でブルが鯖向きなのか気になるなぁ。
鯖で3Dベンチなんて回さないし。
鯖向けベンチの何かが優秀かというと
そうでもないようだし、大容量キャッシュは鯖っぽいと思いきや
どの程度効いてるのかよく分からんし
そうでもないようだし、大容量キャッシュは鯖っぽいと思いきや
どの程度効いてるのかよく分からんし
http://finance.yahoo.com/news/New-AMD-Opteron-TM-Processors-iw-4190901655.html?x=0&l=1
New AMD Opteron(TM) Processors Deliver the Ultimate in Performance, Scalability and Efficiency
New AMD Opteron(TM) Processors Deliver the Ultimate in Performance, Scalability and Efficiency
メモリ系のスループットが公称通り全世代比+70%ならサーバ向けと言っていいんじゃね?
小規模ウェブサーバレベルだとPCと同じでやっぱキャッシュ性能が重要と思うけど。
HPCも演算能力系ベンチは基本的にキャッシュベンチだけど実践用途では
メモリ周りやデータ転送が物を言うだろうし、大規模サーバー/HPCはこれらの分野はそれでイイと思う。
キャッシュをアホほどテンコ盛りしてるから
キャッシュヒット時の性能放棄してるわけではないんだろうけど、
なんかいろいろ計ってみてもキャッシュ周りの性能がよく分からん事になってる。
小規模ウェブサーバレベルだとPCと同じでやっぱキャッシュ性能が重要と思うけど。
HPCも演算能力系ベンチは基本的にキャッシュベンチだけど実践用途では
メモリ周りやデータ転送が物を言うだろうし、大規模サーバー/HPCはこれらの分野はそれでイイと思う。
キャッシュをアホほどテンコ盛りしてるから
キャッシュヒット時の性能放棄してるわけではないんだろうけど、
なんかいろいろ計ってみてもキャッシュ周りの性能がよく分からん事になってる。
426 :Socket774:2011/11/27(日) 21:26:49.10 ID:mlL9TWuz
tomsもこんな屍体に鞭打つようなテストをしなくてもいいのに( ̄▽ ̄)
http://media.bestofmicro.com/K/2/311762/original/efficiency_single_wh.png
http://media.bestofmicro.com/J/X/311757/original/efficiency_multi_wh.png
http://media.bestofmicro.com/K/4/311764/original/efficiency_total_wh.png
http://media.bestofmicro.com/K/0/311760/original/efficiency_score.png
http://media.bestofmicro.com/K/2/311762/original/efficiency_single_wh.png
{kind=link}
http://media.bestofmicro.com/J/X/311757/original/efficiency_multi_wh.png
{kind=link}
http://media.bestofmicro.com/K/4/311764/original/efficiency_total_wh.png
{kind=link}
http://media.bestofmicro.com/K/0/311760/original/efficiency_score.png
{kind=link}
まともな環境のまともなベンチがない
Intel独裁洗脳グラフのみ
ホント判り易いね。
>>427
脳味噌花畑乙
脳味噌花畑乙
>>425
前世代比じゃなくてXeon X5670(Westmere-EP)との比較っぽいけど
チャンネル数とメモリクロックの差が素直に出てるだけだと思う
つーかTDPを「コア数」で割って"1/2 the power-per-core"とか斬新すぎる……
なんか引用データによって比較対象をコロコロ変えててわけわからん
とりあえずICCは12.1を使ってやってくれ
前世代比じゃなくてXeon X5670(Westmere-EP)との比較っぽいけど
チャンネル数とメモリクロックの差が素直に出てるだけだと思う
つーかTDPを「コア数」で割って"1/2 the power-per-core"とか斬新すぎる……
なんか引用データによって比較対象をコロコロ変えててわけわからん
とりあえずICCは12.1を使ってやってくれ
430 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/27(日) 21:51:09.22 ID:6XLJ9BeM
>>427
これがCyberGardenの管理人か
これがCyberGardenの管理人か
VMmarkで10コアXeonを28%上回るってことなら、サーバーでは良いんじゃないの
価格もチェックしような
GFはアブダビにもFab作るのか
元ネタはX-bitだから当てにはならないが・・・
※そのATIC(GFだったかも)は4月の会見で
『今後アブダビに何らかの拠点を作れるように用地の取得は始めている。
ただし直ちにCPUを生産するって言う話ではないよ』
と言ってる
元ネタはX-bitだから当てにはならないが・・・
※そのATIC(GFだったかも)は4月の会見で
『今後アブダビに何らかの拠点を作れるように用地の取得は始めている。
ただし直ちにCPUを生産するって言う話ではないよ』
と言ってる
3960を5万で売ってくれないかなー
http://sharikou.blogspot.com/2011/11/bulldozer-opterons-totally-frags-intel.html
>In SpecFp2006_rate, a 2P Bulldozer Opteron server achieves a score of 403. Simply put, there is no 2P Xeon can match this score.
何故BulldozerのSpecFPが良いんだろうな
混乱して来たぜ
>In SpecFp2006_rate, a 2P Bulldozer Opteron server achieves a score of 403. Simply put, there is no 2P Xeon can match this score.
何故BulldozerのSpecFPが良いんだろうな
混乱して来たぜ
436 :Socket774:2011/11/28(月) 00:21:32.19 ID:M1MtQPrz
>>435
それWestmereと比較してるだけだぜ
それWestmereと比較してるだけだぜ
437 :Socket774:2011/11/28(月) 00:24:56.30 ID:4eLXR9qv
さぁ、みなさんおまちかね!虐殺ショーの始まりです↓
FX8150 vs i7-2600k
http://www.anandtech.com/bench/Product/434?vs=287
圧倒的大差で完敗なブル土下座\(^o^)/
Lower is better のいみがわからないおともだちはパパかママにきいてみてね
438 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/28(月) 00:26:30.04 ID:Xjhm1Dtk
>>435
コンパイラのOpen64がFMAに対応してるからじゃないの
コンパイラのOpen64がFMAに対応してるからじゃないの
440 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/28(月) 01:02:45.57 ID:Xjhm1Dtk
FP性能なんて大して問題じゃないだろ
当面の問題はキャッシュ周り等、かな
今sandraかけてみたらソケットがFS1になっとる・・・何故
今sandraかけてみたらソケットがFS1になっとる・・・何故
SPECfpはコア数にほぼ比例、コア数やクロックにほぼ比例するからメモリ帯域はたぶん関係ない、
MagnyCoursと比較するとコア当たりは落ちてる。
ただ、PC向けベンチの多くで見られるCinebenchのコア当たり性能-30%みたいな状態ではない。
AnandによるとInterlagosのCinbenchR11.5のスコアはFXから予想できる数字そのままなんで、
サーバー/HT向け機能を除けばInterlagosだけ制限が解放されてるみたいな事はないと思う。
PC向けベンチと比較して性能向上率がいいと言うかコア当たり悪化率が低いのは
HPC向けベンチの多くはSIMD化が自動SIMD化の枠内に限られるから
演算能力にしめる演算の割合が大きいんじゃないかと。
結果的にSIMD化が進んでいるPC向けベンチよりキャッシュがダメな影響を受けにくくなってると予想。
MagnyCoursと比較するとコア当たりは落ちてる。
ただ、PC向けベンチの多くで見られるCinebenchのコア当たり性能-30%みたいな状態ではない。
AnandによるとInterlagosのCinbenchR11.5のスコアはFXから予想できる数字そのままなんで、
サーバー/HT向け機能を除けばInterlagosだけ制限が解放されてるみたいな事はないと思う。
PC向けベンチと比較して性能向上率がいいと言うかコア当たり悪化率が低いのは
HPC向けベンチの多くはSIMD化が自動SIMD化の枠内に限られるから
演算能力にしめる演算の割合が大きいんじゃないかと。
結果的にSIMD化が進んでいるPC向けベンチよりキャッシュがダメな影響を受けにくくなってると予想。
訂正:サーバー/HPC向け・・・まあいいけど・・・
自前でコンパイルして動かすfp系のベンチの場合
コンパイラを選びさえすればスカラのfmaddを使ってくれるので
その分性能が上がってるだけだと思うが
コンパイラを選びさえすればスカラのfmaddを使ってくれるので
その分性能が上がってるだけだと思うが
単純に自動ベクトル化でAVXを使ってるからじゃないの
FMA単独でこんなに効くとは思えない
FMA単独でこんなに効くとは思えない
446 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/28(月) 07:40:53.77 ID:Xjhm1Dtk
spec.orgに登録されるのを待ちましょう
今でも結構ぶっちぎりだがBullの本来の能力出るのはpgccが来てからだな
Ivy BridgeがSandyBridgeのクロックそのままでまったく上がらない
GPUも大半は5450~5550程度の糞だし
来年改良されたブル&鳥でAMD大勝利できそうだ
GPUも大半は5450~5550程度の糞だし
来年改良されたブル&鳥でAMD大勝利できそうだ
って思ってるのはアムドの中でも少数派だ
Trinityが本当に高性能でやばくなったら、急遽TDP95W枠復活させるんじゃないの?
パラノイアなintelだったら、多少製品ラインナップ崩れようが、それくらいやりかねない。
パラノイアなintelだったら、多少製品ラインナップ崩れようが、それくらいやりかねない。
Trinityだけだと狭いな。
Piledriverコアの間違い。
Piledriverコアの間違い。
2012年 32nm Piledriverコア(Bulldozer+)
2013年 28nm? Steamrollerコア(Bulldozer++)
2014年 22nm Excavatorコア(Bulldozer2) →DDR4移行
こんな理解で合ってるのかな
2013年 28nm? Steamrollerコア(Bulldozer++)
2014年 22nm Excavatorコア(Bulldozer2) →DDR4移行
こんな理解で合ってるのかな
自動ベクトル化ってそんなに進んでるん?
むしろC言語にベクトル型導入みたいな勢いあるのに
あてになるほど有効なのかな?
むしろC言語にベクトル型導入みたいな勢いあるのに
あてになるほど有効なのかな?
並列に処理できるかどうかソースを解析する
(主に依存関係の有無の判定)なら
20年以上前からやってるが、それで進んでいなかったら
何をやってたんだということになるな。
(主に依存関係の有無の判定)なら
20年以上前からやってるが、それで進んでいなかったら
何をやってたんだということになるな。
456 :Socket774:2011/11/28(月) 19:11:58.60 ID:C//t6GoO
先週末も「Sandy Bridge-E」関連パーツの新製品がたくさん登場した。インテル陣営が勢いに乗る一方で
AMDは、ハイエンドの8コアCPU「FX-8150(空冷版)」が2万5000円前後と比較的安価で人気を集めているが、こちらも売り切れが多発している。ただし、
「潜在需要がインテルとまったく違うので、FX-8150が潤沢化したら、すぐに需要が満たされて動きが止まると思います。
正直、現在のAMDはインテルのライバルとは呼べないくらい、シェアが落ち込んでいます。」
http://plusd.itmedia.co.jp/pcuser/articles/1111/28/news030.html
( ̄▽ ̄)
だね。
悪魔を火あぶりにする様な悪事で、
インテルが滅ぼしてしまったから。
悪魔を火あぶりにする様な悪事で、
インテルが滅ぼしてしまったから。
チートベンチでインチキマーケティングしてるだけで
実性能ははるかにAMDの方が上。
価格サイト見れば分かるとおり売上もそれなりにあるしな
実性能ははるかにAMDの方が上。
価格サイト見れば分かるとおり売上もそれなりにあるしな
460 :Socket774:2011/11/28(月) 19:46:28.45 ID:4UEJVv5m
■全国販売店のPOSデータに連動した「販売実績」ランキング
http://bcnranking.jp/category/subcategory_0026.html
→ 1位 Core i7-2600K(3.4GHz)
↑ 2位 Core i7-2700K(3.5GHz)
↓ 3位 Core i5-2500K(3.3GHz)
☆ 4位 Core i7-3930K(3.8GHz)
↓ 5位 Core i3-2100(3.1GHz)
→ 6位 CelernDC G530(2.4GHz)
↓ 7位 Core i7-2600(3.4GHz)
☆ 8位 Core i7-3960X(3.9GHz)
↓ 9位 Core i5-2500(3.3GHz)
↓10位 Core i5-2400(3.1GHz)
------------------------------------------
※AMD石は売上不振でランク外ですw
ついに体感ガーに加えて、幻でしかない実性能ガーが来たか
実性能ガーはK6時代からの伝統だろ。
お客さん、うちのCPUは競合他社さんのCPUより(3DNowに対応したソフトなら)速いんですよ!
具体的にはAVXだと
Bull-4M8C:256bit幅の積と和を合わせて4処理(積と和の配分は自由)
Sandy-2C:256bit幅の積2+和2で合わせて4処理
のような
違ってたらすまない
Bull-4M8C:256bit幅の積と和を合わせて4処理(積と和の配分は自由)
Sandy-2C:256bit幅の積2+和2で合わせて4処理
のような
違ってたらすまない
>>463
AVX単体だと3オペランド化ぐらいしか効かないでしょ
FMA4は自動ベクトル化がほとんど効かないという前提でもスカラの理論FLOPSが倍になるから
こっちの方がSPECfpには効くと思うけどね
AVX単体だと3オペランド化ぐらいしか効かないでしょ
FMA4は自動ベクトル化がほとんど効かないという前提でもスカラの理論FLOPSが倍になるから
こっちの方がSPECfpには効くと思うけどね
この前最近のPOSはIntel製CPUが入ってる事が多いからPOS由来のランキングはチート集計ってどこかで見た
>>467
PosがVIA製でメインマシンがintelでMeとかよくある
PosがVIA製でメインマシンがintelでMeとかよくある
AMDer にとって重要なのは
SSD, RAMdisk, iGPU などを駆使してCPU性能から
一般ユーザーの目をそらす事
SSD, RAMdisk, iGPU などを駆使してCPU性能から
一般ユーザーの目をそらす事
“Brazos”の後継製品はTSMC 28nmプロセスで製造される
http://northwood.blog60.fc2.com/blog-entry-5461.html
なにがなんだか分からん……
まさかZacateも終わコンにしてLlano一本化とか言い出すんじゃないんだろうな。
http://northwood.blog60.fc2.com/blog-entry-5461.html
なにがなんだか分からん……
まさかZacateも終わコンにしてLlano一本化とか言い出すんじゃないんだろうな。
473 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/28(月) 20:50:42.09 ID:Xjhm1Dtk
>>465
全然違うやん。
全然違うやん。
>>471
EE-Timesにも記事が来てるね
http://eetimes.jp/ee/articles/1111/28/news029.html
http://eetimes.jp/ee/articles/1111/07/news030.html
2個の記事を併せて考えると、32nm世代(32/28nm)の歩留まりが悪く、Bull/Llanoだけで手一杯なんだろう
※28nmではQualcommなどとの契約もある
EE-Timesにも記事が来てるね
http://eetimes.jp/ee/articles/1111/28/news029.html
http://eetimes.jp/ee/articles/1111/07/news030.html
2個の記事を併せて考えると、32nm世代(32/28nm)の歩留まりが悪く、Bull/Llanoだけで手一杯なんだろう
※28nmではQualcommなどとの契約もある
476 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/28(月) 21:06:18.70 ID:Xjhm1Dtk
Bullはモジュールあたり 256bit (add or mul) x1
128ビット×2だろ。
256ビットSIMDユニットを128ビット×2としては使えないし、
逆にFMACを独立したFADD+FMULとしては使えない。
128ビット×2だろ。
256ビットSIMDユニットを128ビット×2としては使えないし、
逆にFMACを独立したFADD+FMULとしては使えない。
>>455
静的解析では並列化できるかどうかの判断に限界があるって言うのが今の結論じゃね?
自動ベクトル化もシャッフル駆使して並列化してくれると考えると
かなり美味しいけど一方で明示的にベクトルデータ型使う流れが強くて分け分からん。
使い物になるんだったら個人的には使いたいんだが。
静的解析では並列化できるかどうかの判断に限界があるって言うのが今の結論じゃね?
自動ベクトル化もシャッフル駆使して並列化してくれると考えると
かなり美味しいけど一方で明示的にベクトルデータ型使う流れが強くて分け分からん。
使い物になるんだったら個人的には使いたいんだが。
478 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/28(月) 21:11:11.82 ID:Xjhm1Dtk
シャッフルとFMAC1が同じポートだから残念
sandy XEON糞そうだから暫くbullが光りそうだな
Xeon プロセッサー E5系
2ソケット向けを中心に2012年に出荷予定。1600MHzに対応しているメモリも、1チャンネルあたり2DIMMになると1333MHz、3DIMMになると800MHzと速度が落ちる。
Xeon プロセッサー E5系
2ソケット向けを中心に2012年に出荷予定。1600MHzに対応しているメモリも、1チャンネルあたり2DIMMになると1333MHz、3DIMMになると800MHzと速度が落ちる。
>>476
いや...そうなんだけど465のどこがおかしいの
いや...そうなんだけど465のどこがおかしいの
まあ、お前さんはOpteron買ってればいいよ
世間はみんなXeon買うからさ
世間はみんなXeon買うからさ
483 :Socket774:2011/11/28(月) 21:34:24.52 ID:9OJTWHL+
今日の一句
Armが強すぎて
Mもうダメです
Dどうしましょ
Armが強すぎて
Mもうダメです
Dどうしましょ
>・Core i7 3770K (4C/8T/3.5GHz・650MHz/TB時3.9GHz・1150MHz/L3 8MB/77W/HD 4000)
おいおい、もうHD4000まで来たぞ。
あと2000で追いつかれるな。
おいおい、もうHD4000まで来たぞ。
あと2000で追いつかれるな。
パソコン捨てる
ケータイも解約
電話も解約
テレビも見ないしラジオも聞かない
限界集落で自給自足の生活
ケータイも解約
電話も解約
テレビも見ないしラジオも聞かない
限界集落で自給自足の生活
AMD最高だお
GFの28nmバルクAPUをキャンセルとなるとよほど28nmの歩留まり悪いのか
それとも32nmSOIの歩留まりがかなり改善した可能性もあるな
それとも32nmSOIの歩留まりがかなり改善した可能性もあるな
>>477
Cでの自動ベクトル化は、特に
ポインタが何を指しているのか静的解析しきるのが無理な関係で
原理的に困難な所が残ってしまう。たぶん将来的にも困難
ICCでも必要な依存関係の仮定をプラグマにして
プログラマが明示的に書いてやらないと、自動ベクトル化がうまくいかない事もある
(逆にプラグマだけでうまくい事もあると考えれば、まあ低コストで美味しいとも言えるけど)
Cでの自動ベクトル化は、特に
ポインタが何を指しているのか静的解析しきるのが無理な関係で
原理的に困難な所が残ってしまう。たぶん将来的にも困難
ICCでも必要な依存関係の仮定をプラグマにして
プログラマが明示的に書いてやらないと、自動ベクトル化がうまくいかない事もある
(逆にプラグマだけでうまくい事もあると考えれば、まあ低コストで美味しいとも言えるけど)
>>488
opteronが早いのはFMA対応コンパイラ通した(Open64)からじゃないの
↓使うコンパイラの違いによる速度の差異
http://www.phoronix.com/scan.php?page=article&item=amd_bulldozer_compilers&num=2
ちなみにGCCもFMA4とXOPへの対応するらしい
http://www.theinquirer.net/inquirer/news/2124866/amd-bulldozer-fma4-xop-instructions-supported-gcc
opteronが早いのはFMA対応コンパイラ通した(Open64)からじゃないの
↓使うコンパイラの違いによる速度の差異
http://www.phoronix.com/scan.php?page=article&item=amd_bulldozer_compilers&num=2
ちなみにGCCもFMA4とXOPへの対応するらしい
http://www.theinquirer.net/inquirer/news/2124866/amd-bulldozer-fma4-xop-instructions-supported-gcc
リミッターとか言ってる馬鹿に何を言っても無駄
493 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/28(月) 22:48:45.24 ID:Xjhm1Dtk
リミッターっていうかボトルネックなんだけどな
494 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/28(月) 22:56:40.67 ID:Xjhm1Dtk
最適化コンパイラで速くなるってのは、FMAだのXOPだの新命令を使うことよりも寧ろ、
最適化マニュアルに書いてあるような、劇的に遅くなるようなボトルネックを
回避するための代替コード生成のほうがウェイトとしては大きい気がする。
最適化マニュアルに書いてあるような、劇的に遅くなるようなボトルネックを
回避するための代替コード生成のほうがウェイトとしては大きい気がする。
リミッター言ってるのはarm馬鹿だろ
おかしな空白
安携帯は大変だ
おかしな空白
安携帯は大変だ
奴が低燃費かは知らんがARMのように低性能なのは間違いないな
497 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/28(月) 23:23:23.68 ID:Xjhm1Dtk
1回の改行キーでCRLFが2つ入っちゃう欠陥仕様か。なるほど。
498 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/28(月) 23:24:17.05 ID:Xjhm1Dtk
ひょっとして彼はEnterキーがチャタってるんじゃないの?
なんでキチガイ団子はこんなに必死なんだ?
>>465
256Bitだとデコード帯域で差がつくだろ
Bullは256Bitだと2分割だから4デコーダ合計で2命令/サイクルに落ちて、パイプラインも埋まるからそれ以上ほかの命令は通れない
Sandyは分割なしだから256Bit加算と乗算とそれ以外がデコード出来るしパイプラインも通れる
256Bitだとデコード帯域で差がつくだろ
Bullは256Bitだと2分割だから4デコーダ合計で2命令/サイクルに落ちて、パイプラインも埋まるからそれ以上ほかの命令は通れない
Sandyは分割なしだから256Bit加算と乗算とそれ以外がデコード出来るしパイプラインも通れる
502 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/29(火) 01:22:17.57 ID:fap3N+W7
>>501
SIMDは一応4ユニットあるんだけど何を根拠にいってるんだ?
SIMDは一応4ユニットあるんだけど何を根拠にいってるんだ?
FMAユニットの話ね
504 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/29(火) 01:43:56.37 ID:fap3N+W7
フロントエンドの帯域が1命令分ってのはおかしいだろwww
バカジャネーノ?
vmov*やビット論理演算は整数側で発行するので256ビット換算でも2命令分発行できるはず。
バカジャネーノ?
vmov*やビット論理演算は整数側で発行するので256ビット換算でも2命令分発行できるはず。
だからFMAユニットを使うAVX256bit1命令+2 MacroOp分と言ってるじゃん
2 MacroOpが残りのP2/P3で動く256bit命令ならもう一つディスパッチできるさ
2 MacroOpが残りのP2/P3で動く256bit命令ならもう一つディスパッチできるさ
506 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/29(火) 01:58:15.28 ID:fap3N+W7
>>500の言ってることと何が違うんだ?
それにFMAなら乗算+加算で2オペレーション分としてカウントしてもいいはずだぞ
それにFMAなら乗算+加算で2オペレーション分としてカウントしてもいいはずだぞ
だから
>256Bit加算と乗算
を同時に実行する能力がそもそもBulldozerには無いから
フロントエンドでそんなことを考えても仕方がないということだ
>256Bit加算と乗算
を同時に実行する能力がそもそもBulldozerには無いから
フロントエンドでそんなことを考えても仕方がないということだ
いつもどおり人格攻撃から入る
(議論するうえでは自制・忌避すべきとされる行為)団子に対し
冷静に相手の主張を受け止めた上で自分の主張を返すID:0hJnGVgS のやりとりは
一服の清涼剤のように感じる
願わくば団子には人格攻撃のような無意義なノイズを自重して
冷静に主義主張を対決させるための技を見につけて欲しい
せっかく議論に値する主張を有している場合もあるのだから
もったいない
(議論するうえでは自制・忌避すべきとされる行為)団子に対し
冷静に相手の主張を受け止めた上で自分の主張を返すID:0hJnGVgS のやりとりは
一服の清涼剤のように感じる
願わくば団子には人格攻撃のような無意義なノイズを自重して
冷静に主義主張を対決させるための技を見につけて欲しい
せっかく議論に値する主張を有している場合もあるのだから
もったいない
何で>>508が一番偉そうなのか
さっぱり分からん
さっぱり分からん
最適化をうまく調整して命令キャッシュサイズに収めたとか……ないか
APUをTSMC28nに移したらGPU/APU共に年単位品不足が確定する
歩留まり/価格/性能にいくら差があろうが40nよりマシだろうし売るものないより遥かにマシ
すでにテープアウトしてるKrishna/Wichitaをキャンセルしたというのは愚行にしか思えん
歩留まり/価格/性能にいくら差があろうが40nよりマシだろうし売るものないより遥かにマシ
すでにテープアウトしてるKrishna/Wichitaをキャンセルしたというのは愚行にしか思えん
TSMCの40nmの方がマシってくらいGFの28nmの出来が酷かったんじゃないの?
EE-TimesによるとAMDとGFはKrishna/Wichitaの契約に至ってないって話だよ
またGFの32nmSOIは歩留まりが悪く、つまり1枚のウェハ採れるチップの数が少なく、
GFはこの問題に対しウェハ供給量を増やす事で対応しているとの事
32nm世代用ウェハってはの32/28nm共用らしいから(GFは過去の会見で融通しあえると述べている)、
Krishna/WichitaをGFで作るならその分32nmSOIを減らさなきゃならないのだろう
またGFの32nmSOIは歩留まりが悪く、つまり1枚のウェハ採れるチップの数が少なく、
GFはこの問題に対しウェハ供給量を増やす事で対応しているとの事
32nm世代用ウェハってはの32/28nm共用らしいから(GFは過去の会見で融通しあえると述べている)、
Krishna/WichitaをGFで作るならその分32nmSOIを減らさなきゃならないのだろう
となると、他製品との兼ね合いで、TSMC、GFどっちの28nmにも移行できなくなったのか
ノウハウが無いのにいきなりニコイチなんて高度なことやろうとするから悪い
Intelみたいに段階踏んでる余裕が無かった
http://www.ne.jp/asahi/comp/tarusan/main241.htm
BlueWater、コケていたのか……あれだけ鳴り物入りだったのに。
そして一位じゃないとダメだよね。とくにスパコンは。
BlueWater、コケていたのか……あれだけ鳴り物入りだったのに。
そして一位じゃないとダメだよね。とくにスパコンは。
情弱さんは何ヶ月前の話題を…
3930K性能いいかんじだね。
ところで
AMDの擬似8コアってなぜ遅いの?
ところで
AMDの擬似8コアってなぜ遅いの?
GFの28nmの熟成を待つよりTSMCに乗り換えた方が早い、という判断になったのが
今ひとつ解せんのよね。
歩留まり以外の、直しようのない致命的な欠陥があったと解釈するしかないもの。
今ひとつ解せんのよね。
歩留まり以外の、直しようのない致命的な欠陥があったと解釈するしかないもの。
>>522
金の問題だけじゃないのー?
金の問題だけじゃないのー?
そうそう、7950遅れるんだね。残念だよね。
>>523
金の問題とは? GFがAMDに対してTSMCよりも高い支払いを要求したら、
AMDはTSMCに流れ、GFの28nmは稼働率が0になってしまう。
AMDは(実績の薄い=信頼のない)GFを使ってくれる唯一の大事な顧客であり、
AMDの「成功例」を見て他の顧客がTSMCから移ってきてくれるまでは、
GFはAMDを厚遇せざるを得ない。
……にも関わらずAMDがGFを切ってしまったところに、金以外の、
どうにもならない技術的な問題があったと思っているのだが。
金の問題とは? GFがAMDに対してTSMCよりも高い支払いを要求したら、
AMDはTSMCに流れ、GFの28nmは稼働率が0になってしまう。
AMDは(実績の薄い=信頼のない)GFを使ってくれる唯一の大事な顧客であり、
AMDの「成功例」を見て他の顧客がTSMCから移ってきてくれるまでは、
GFはAMDを厚遇せざるを得ない。
……にも関わらずAMDがGFを切ってしまったところに、金以外の、
どうにもならない技術的な問題があったと思っているのだが。
一応技術的には少々厳しそうなのがあったのが問題だったんでしょうか?
FCHまで内蔵するとなると最先端プロセスでSATA、USB3.0などのアナログロジックまで統合するわけですから、これまでその手に乏しかったGFの手に余ったことも考えられます。
MCMにすれば一応の解決はできますが、少なくともその気は無かったとは見えますね。
これまで出ている情報がほとんど出所不明のオンラインソースとその焼き直しですし、プレスリリースもロードマップも無い以上なんともいえません。来年にならないとわからないでしょう。
まあ競合が自爆した今となっては、あえて急ぐような理由もそのリソースもあるともいえないのが現在のAMDですしね。
FCHまで内蔵するとなると最先端プロセスでSATA、USB3.0などのアナログロジックまで統合するわけですから、これまでその手に乏しかったGFの手に余ったことも考えられます。
MCMにすれば一応の解決はできますが、少なくともその気は無かったとは見えますね。
これまで出ている情報がほとんど出所不明のオンラインソースとその焼き直しですし、プレスリリースもロードマップも無い以上なんともいえません。来年にならないとわからないでしょう。
まあ競合が自爆した今となっては、あえて急ぐような理由もそのリソースもあるともいえないのが現在のAMDですしね。
対Intelで供給量的にGFの稼動は絶対条件だから今後も共同開発は続けていかなきゃいけないからな、
今回のキャンセルはKrishna/Wichitaだけの一時的なもので、今後も積極的に共同開発はしていくだろうね
ちなみにIBM連合のサムソンならAPU製造の移行もTSMCよりは楽なんじゃないかと思わなくはない
今回のキャンセルはKrishna/Wichitaだけの一時的なもので、今後も積極的に共同開発はしていくだろうね
ちなみにIBM連合のサムソンならAPU製造の移行もTSMCよりは楽なんじゃないかと思わなくはない
64bit-ARMの開発が発表されて修正が必要になったって可能性も有るかもね
すでにメーカーの開発が始まってるが、
2(~8)コア/1コアの消費電力は2w/キャッシュ8MB/DDR3-4Ch/マルチソケット対応とかのもあるから
Krishna/Wichitaだと厳しいものがあるのかもしれない
すでにメーカーの開発が始まってるが、
2(~8)コア/1コアの消費電力は2w/キャッシュ8MB/DDR3-4Ch/マルチソケット対応とかのもあるから
Krishna/Wichitaだと厳しいものがあるのかもしれない
一応言っとくと、各社から64bit-ARMが出てくるのはまだずっと先だから
Krishna/Wichitaと直接対決になるって訳ではない
Krishna/Wichitaと直接対決になるって訳ではない
>>526
IntelとAMDのアーキテクチャ切り分けは微妙に違うからな
Intelは10WまでがAtomで18W以上がSandyBridge
AMDは18WまでがBobcatで35W以上がLlano
Wichitaの競合はAtomだからAtomも遅れてるしまぁ良いかもしれないけど
KrishnaはSandyBridge/IvyBridgeと同TDP帯だから計画が後退すると特に価格面で不利になる
特にTDP18WはUltorabookが当たった場合市場を無視できない
IntelとAMDのアーキテクチャ切り分けは微妙に違うからな
Intelは10WまでがAtomで18W以上がSandyBridge
AMDは18WまでがBobcatで35W以上がLlano
Wichitaの競合はAtomだからAtomも遅れてるしまぁ良いかもしれないけど
KrishnaはSandyBridge/IvyBridgeと同TDP帯だから計画が後退すると特に価格面で不利になる
特にTDP18WはUltorabookが当たった場合市場を無視できない
>>530
んなもん選別品だし価格面で値を吊り上げるのは目に見えている>18W以上がSandyBridge
初っ端から勢いが削がれつつあるUltrabookに注力しなくても十分でしょ。Zacateを少々スペック調整すればTDP枠内に収まるでしょうし1から作るほどでもない。
性能面でもこの価格帯でSandyクラスのCPU性能なんて必要あるんでしょうかね。SandyのCULV版が降りたところでGPU面ではZacateでも上回りそうだし。
んなもん選別品だし価格面で値を吊り上げるのは目に見えている>18W以上がSandyBridge
初っ端から勢いが削がれつつあるUltrabookに注力しなくても十分でしょ。Zacateを少々スペック調整すればTDP枠内に収まるでしょうし1から作るほどでもない。
性能面でもこの価格帯でSandyクラスのCPU性能なんて必要あるんでしょうかね。SandyのCULV版が降りたところでGPU面ではZacateでも上回りそうだし。
>>531
18Wに大したGPUは要らんだろ。
存在したとして、18Wの内のかなりの部分をGPUに割り当てて、その代償とするCPUが貧弱な製品が好まれているのか?
CPUとGPUのベンチのスコアの合算が同じなら、構成は何でも構わないなんてことが有るわけ無い。
18Wに大したGPUは要らんだろ。
存在したとして、18Wの内のかなりの部分をGPUに割り当てて、その代償とするCPUが貧弱な製品が好まれているのか?
CPUとGPUのベンチのスコアの合算が同じなら、構成は何でも構わないなんてことが有るわけ無い。
Ultrabookは先進国をターゲットにした商品だから
今年来年は微妙に終わりそうではあるよな
今年来年は微妙に終わりそうではあるよな
チップの開発だけして、その後のことには何も頭が回らないのがAMD。
製造できない、どう儲けるかのビジネスモデルもない。
「Atom以上、SandyBridge未満」の狭いターゲットに、違うCPUを何個も作ってどうするの?
ディスクリートGPUの市場を食ったって利益は増えないよ?
製造できない、どう儲けるかのビジネスモデルもない。
「Atom以上、SandyBridge未満」の狭いターゲットに、違うCPUを何個も作ってどうするの?
ディスクリートGPUの市場を食ったって利益は増えないよ?
LlanoがSandyBridge未満になってしまったのは
そういう計画というよりも匹敵する製品が作れなかったというだけで
そういう計画というよりも匹敵する製品が作れなかったというだけで
CPU/APUで+6%、GPUで+10%で、今のところGPUを喰ってるって感じは無いな
http://www.newslogplus.com/2011/10/amd3fusion-apu.html
http://www.newslogplus.com/2011/10/amd3fusion-apu.html
でも下位のラインナップを廃止して行ってるから、台数ベースだとシェアは下がってるかもね
Ultrabookは来年始めのCESで30~50機種展示されるらしいね
SandyのUrtrabookは序章にすぎない
SandyのUrtrabookは序章にすぎない
>>539
すでにSandy機でも発売時点6万円台からあるけどね
すでにSandy機でも発売時点6万円台からあるけどね
intelはノートPCの低価格化が進んで収益が落ちるのを嫌っているから、
新たにUltrabookを大々的に宣伝して高価格帯を売りたいわけで
BobcatやLlanoのようなAPUの需要がなくなるわけではないでしょう。
AMDとしてはBobcatやLlanoでノート市場に食い込めたことに意味あるわけで、
AMDの業績に貢献しているのも事実でしょ。
TSMCの利用拡大もするようだが、依然としてGFの製造能力に問題はあるし、
次期APUのTrinityに向けてもGFの歩留まり改善は一層の必要になるだろうけどね。
新たにUltrabookを大々的に宣伝して高価格帯を売りたいわけで
BobcatやLlanoのようなAPUの需要がなくなるわけではないでしょう。
AMDとしてはBobcatやLlanoでノート市場に食い込めたことに意味あるわけで、
AMDの業績に貢献しているのも事実でしょ。
TSMCの利用拡大もするようだが、依然としてGFの製造能力に問題はあるし、
次期APUのTrinityに向けてもGFの歩留まり改善は一層の必要になるだろうけどね。
>>531
ふっつーにEclipseもVS2010もWPF/Silverlight/Blendあたりだと
クソ重いしCPU性能はいくらあってもたんねー。
Android SDKも2.3以降クッソ重くてMerom機でも重たくてたまんねーのに
Zacateとか使ってらんねー。
ふっつーにEclipseもVS2010もWPF/Silverlight/Blendあたりだと
クソ重いしCPU性能はいくらあってもたんねー。
Android SDKも2.3以降クッソ重くてMerom機でも重たくてたまんねーのに
Zacateとか使ってらんねー。
あと主な用途も価格帯も無視して
いるか、いらないかとかいう話をしても意味ないような
intelはCPUに強みがあるから、CPU重視の製品になっていて
AMDはGPUに強みがあるから、GPU重視の製品になっているだけだし
いるか、いらないかとかいう話をしても意味ないような
intelはCPUに強みがあるから、CPU重視の製品になっていて
AMDはGPUに強みがあるから、GPU重視の製品になっているだけだし
>>542
おとなしくデスクトップなり高性能ノートなりでやればいいんじゃね?そんなプログラミングをZacate機にやらせる時点で何か履き違えてると思うが。
普通のウェブブラウジングや動画視聴、オフィスソフトでSandyのCPU能力が必要か?
おとなしくデスクトップなり高性能ノートなりでやればいいんじゃね?そんなプログラミングをZacate機にやらせる時点で何か履き違えてると思うが。
普通のウェブブラウジングや動画視聴、オフィスソフトでSandyのCPU能力が必要か?
>普通のウェブブラウジングや動画視聴、オフィスソフト
GPU能力は尚更いらねーから
GPU能力は尚更いらねーから
GPU性能関係ないじゃん
548 :Socket774:2011/11/30(水) 07:33:04.82 ID:LpEf0/DT
LlanoのCPU能力が必要か?
手持ちのモバイルプレスコPen4 3.46GHzのノートは再生支援は無いが
1080pで10Mbps以下の低ビットレートのH.264ファイルなら
問題なく再生可能だな
1080pで10Mbps以下の低ビットレートのH.264ファイルなら
問題なく再生可能だな
HD3000は再生支援あってもフルHDフレームドロップするんだっけ
ZacateのGPUはフルHDなら2画面までサポートじゃないの
CPUも使うと3画面目もかろうじてOKだったような
CPUも使うと3画面目もかろうじてOKだったような
>>548
GDDR5がどういうものか分かってる?
GDDR5がどういうものか分かってる?
終戦
飛ばしかと思ってスルーしてたけどマジ話なのか
まて競合が居なくなると言う事は
価格競争も無ければ技術競争も無くなるんだぞ
これからは殆ど性能が向上してない製品に
馬鹿高い金を払ってアップグレードすることになる
価格競争も無ければ技術競争も無くなるんだぞ
これからは殆ど性能が向上してない製品に
馬鹿高い金を払ってアップグレードすることになる
559 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/30(水) 20:01:46.84 ID:BLsBPrps
早かれ遅かれこうなるって解ってたろ
このスレもそろそろ終了でいいだろ?
INTELの今後の脅威は現時点では光CPUだべ?
INTELの今後の脅威は現時点では光CPUだべ?
別にAMDがプロセッサから撤退するわけではないだろ
VIAの様に細々とやるんだろ
563 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/30(水) 20:21:03.31 ID:BLsBPrps
コストのかかるSOIラインを32nmまでにして、以降はBobcatとその派生の
省電力サーバ製品にフォーカスするっていうなら妥当な生存戦略だね。
Bobcatベースのサーバに言及した時点でInterlagosのラインは潰れるものだと思ってた。
省電力サーバ製品にフォーカスするっていうなら妥当な生存戦略だね。
Bobcatベースのサーバに言及した時点でInterlagosのラインは潰れるものだと思ってた。
インテル洗脳患者が望んだ世界。
欺瞞と収奪の限りを尽してきた企業が、すべての富を
さらに収奪する「高性能で豊かな世界」
恥を知れ。>あまたすべての不公正脳症「入ってる!」患者たち
欺瞞と収奪の限りを尽してきた企業が、すべての富を
さらに収奪する「高性能で豊かな世界」
恥を知れ。>あまたすべての不公正脳症「入ってる!」患者たち
intel もいいCPU作ってるしな。でも AMDは期待できると思うぜ。
数年後だけど。
I7 6コアの性能UP比率と ダイ面積を考えると AMDのブルは
革新的なまでに縮小に成功している。
数年後だけど。
I7 6コアの性能UP比率と ダイ面積を考えると AMDのブルは
革新的なまでに縮小に成功している。
566 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/30(水) 20:43:37.15 ID:BLsBPrps
まずBulldozerの8コアはi7の4コアの絶対性能に及んでないし
来年登場するIvy Bridgeは4コアでも第一世代i3/i5(Westmere)の2コアと同等の面積・消費電力に収まってるし
Intelは22nmへの移行は待ってくれないから、32nm同士でどうこう言っても周回遅れを挽回しないと
どうにもならない
来年登場するIvy Bridgeは4コアでも第一世代i3/i5(Westmere)の2コアと同等の面積・消費電力に収まってるし
Intelは22nmへの移行は待ってくれないから、32nm同士でどうこう言っても周回遅れを挽回しないと
どうにもならない
568 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/30(水) 20:54:28.50 ID:BLsBPrps
○Eシリーズ以外全滅のAMDの脅威がARM
569 :Socket774:2011/11/30(水) 20:59:40.80 ID:2y9Cq0x0
8コアなのに4コアより遅いとか
コア数なら50コアがでるなintel
コア数なら50コアがでるなintel
AMDは、収奪はしてないが欺瞞には満ちていたな。
一緒に恥を知っといたほうがいいぞ。
一緒に恥を知っといたほうがいいぞ。
571 :,, ・´ ∀ `・ ,,)っ-○○○:2011/11/30(水) 21:35:07.12 ID:BLsBPrps
低性能を公表せずに買い控えで市場を停滞させた罪は重いな
スマホやタブレットに注力って事はいよいよARMに転向かね
自作とは縁がなくなるな
X86は現状、パフォーマンスの向上は拡張命令の追加に頼っている
でもAMDはIntelと同じ命令は同時期には搭載する事は出来なく、2~3年は遅れる
※Snadyの様にIntel側が遅れればその差は縮まるが・・・
かといって独自の拡張命令を載せてもシェアが違いすぎるからソフトメーカーに使ってもらうのは難しい
AMDには打つ手は無く、X86やめる潮時だろうな
自作とは縁がなくなるな
X86は現状、パフォーマンスの向上は拡張命令の追加に頼っている
でもAMDはIntelと同じ命令は同時期には搭載する事は出来なく、2~3年は遅れる
※Snadyの様にIntel側が遅れればその差は縮まるが・・・
かといって独自の拡張命令を載せてもシェアが違いすぎるからソフトメーカーに使ってもらうのは難しい
AMDには打つ手は無く、X86やめる潮時だろうな
拡張命令抜きでも勝ててないだろ
ARMに逃げたって勝てないぞ
AMDやインテルのCPUをスマフォに積むとか無理
どこも採用しないわ
どこも採用しないわ
X86は衰退していくのかね~ いまさら新規参入なんてないだろうし、ARM勢が
どんどん食い込んでくる勢いだし、X86はIntelさんだけになっちゃったら困るだろうし・・・
ひょっとしたら最後に笑ってるのは、Nvidiaさんだったりして。
どんどん食い込んでくる勢いだし、X86はIntelさんだけになっちゃったら困るだろうし・・・
ひょっとしたら最後に笑ってるのは、Nvidiaさんだったりして。
AMDはIntelとの競争を諦める
ttp://blog.livedoor.jp/amd646464/archives/52235273.html
IvyBridgeは5月登場?
> AMDのBulldozerのパフォーマンスが奮わないため、急いでIvyBridgeを出す必要が無い
ttp://blog.livedoor.jp/amd646464/archives/52235245.html
ttp://blog.livedoor.jp/amd646464/archives/52235273.html
IvyBridgeは5月登場?
> AMDのBulldozerのパフォーマンスが奮わないため、急いでIvyBridgeを出す必要が無い
ttp://blog.livedoor.jp/amd646464/archives/52235245.html
AMDはモバイルでは必須な無線通信用チップを持ってないんだよね
そこはちょっと厳しいね
ライセンスを受ければ済む事は済むけど
で、当然今からARMを作るとなるとv8アーキテクチャだな
スマホ/タブレットオンリーならv7でも良いけども、
新カテゴリーでありどこも0からのスタートとなるv8の方が可能性があるかな
そこはちょっと厳しいね
ライセンスを受ければ済む事は済むけど
で、当然今からARMを作るとなるとv8アーキテクチャだな
スマホ/タブレットオンリーならv7でも良いけども、
新カテゴリーでありどこも0からのスタートとなるv8の方が可能性があるかな
で、自作板的にはRadeonが気になるね
PC向けディスクリートGPUは儲けが出てないから、X86-APUをやめならRadeonを作る理由も無くなる
当然ながら、儲からないRadeon部門を引き取って“製造を引き継いでくれる”企業もない
例え買っても知的財産権を抜き取るだけだろう
せめてWoA(Windows on ARM)あたりには留まってくれないとRadeonまで消えそうだ
PC向けディスクリートGPUは儲けが出てないから、X86-APUをやめならRadeonを作る理由も無くなる
当然ながら、儲からないRadeon部門を引き取って“製造を引き継いでくれる”企業もない
例え買っても知的財産権を抜き取るだけだろう
せめてWoA(Windows on ARM)あたりには留まってくれないとRadeonまで消えそうだ
それこそラデにARMくっ付けたら
ヌビの二番煎じだしな
ヌビの二番煎じだしな
旧ATIは消えていいよ
まぁAMDがx86を止める事は無いわ
世の中の大多数は既にCPUの性能は気にしてないからな
他にユーザー満足度を上げる方法がある事に気づいたんだろ
世の中の大多数は既にCPUの性能は気にしてないからな
他にユーザー満足度を上げる方法がある事に気づいたんだろ
むしろ旧ATiの方が必要だろ
AMDの方は全く見るべき所が無いのに対してRadeonはまだ見るべき所がある
AMDの方は全く見るべき所が無いのに対してRadeonはまだ見るべき所がある
Radeonにはゲームというコンテンツ(&ゲームソフトメーカー)を囲ってるって点では価値があるか
Geforceとの共有財産だけど
NVと組んでARM向けのゲームアプリストアを構築するってのはありかもね
Geforceとの共有財産だけど
NVと組んでARM向けのゲームアプリストアを構築するってのはありかもね
AMDはいつも他力本願だね
世の中そんなもんよ
あと鯖市場は何時でも性能に飢えてるからな
bulldozerが鯖向けに特化されているのは理にかなう
ただOpteronはFX付けても良い出来だが一般向けにFX付けたのは理解できん
bulldozerが鯖向けに特化されているのは理にかなう
ただOpteronはFX付けても良い出来だが一般向けにFX付けたのは理解できん
鯖向けはもう数パーしかないんだから、独占させてintelの分社化を狙った方がいいんじゃね?
もう一度ビットスライスプロセッサに挑戦
早くもIntelちゃんが調子に乗り始めてきてるのにAMDはギブアップ宣言か・・・
色んな意味で自作冬の時代到来かな
ARMがこちら側にまで食い込んできて、Intel大慌ての構図しか未来が無さそう
色んな意味で自作冬の時代到来かな
ARMがこちら側にまで食い込んできて、Intel大慌ての構図しか未来が無さそう
大多数は性能を気にしない
Atomの性能は足りない
どっちなの
Atomの性能は足りない
どっちなの
win8の段階じゃいつものβ商法とOS自体のできのせいでintelに分がありそうな予感
その間にどれだけintelが盤石な防御をしけるかだな
その間にどれだけintelが盤石な防御をしけるかだな
あれだけ盛り上がってたのにAMDだけ冬なんですかー。
ひじょーに残念すねー。
ひじょーに残念すねー。
「AMD FX-ショックの成り行きと、3DMark 2012-Androidの成り行き」
http://kishinkannet.blog.fc2.com/blog-entry-579.html
Bulldozer-CPUの不満足な結果は、傍で見ている以上に、AMDを深刻にしているようです。
techpowerup.comの記事によれば、AMDは、スポークスマンに、「x86市場でのIntelとの競争を終わらせる時期に来ているかもしれない。」とまで言わせました。
もっとも、とかく大げさに振舞いたがる白人の上に、泣き言を恥じないAMDの事ですから、どこまでが本心か分からないし、記事も、「だからと言って、スマートフォン、タブレット市場に加わるための明確なプランが示されているわけではない」と、慎重です。
が、たとえ、Bulldozerが破棄されることになっても、x86の新路線が、2014年にパフォーマンス50%アップを予告したBulldozerを超えられるとは考え難く、状況は変わらないだろうとも書いています。
AMDは、スポークスマンに、「x86市場でのIntelとの競争を終わらせる時期に来ているかもしれない。」とまで言わせました。
x86市場でのIntelとの競争を終わらせる時期に来ているかもしれない。
x86市場でのIntelとの競争を終わらせる時期に来ているかもしれない。
x86市場でのIntelとの競争を終わらせる時期に来ているかもしれない。
AMD\(^o^)/オワタ
プギャ━━━━━━m9(^Д^)━━━━━━!!!!!!
http://kishinkannet.blog.fc2.com/blog-entry-579.html
Bulldozer-CPUの不満足な結果は、傍で見ている以上に、AMDを深刻にしているようです。
techpowerup.comの記事によれば、AMDは、スポークスマンに、「x86市場でのIntelとの競争を終わらせる時期に来ているかもしれない。」とまで言わせました。
もっとも、とかく大げさに振舞いたがる白人の上に、泣き言を恥じないAMDの事ですから、どこまでが本心か分からないし、記事も、「だからと言って、スマートフォン、タブレット市場に加わるための明確なプランが示されているわけではない」と、慎重です。
が、たとえ、Bulldozerが破棄されることになっても、x86の新路線が、2014年にパフォーマンス50%アップを予告したBulldozerを超えられるとは考え難く、状況は変わらないだろうとも書いています。
AMDは、スポークスマンに、「x86市場でのIntelとの競争を終わらせる時期に来ているかもしれない。」とまで言わせました。
x86市場でのIntelとの競争を終わらせる時期に来ているかもしれない。
x86市場でのIntelとの競争を終わらせる時期に来ているかもしれない。
x86市場でのIntelとの競争を終わらせる時期に来ているかもしれない。
AMD\(^o^)/オワタ
プギャ━━━━━━m9(^Д^)━━━━━━!!!!!!
595 :Socket774:2011/11/30(水) 23:50:39.12 ID:u+Hbrju1
/\___/ヽ ヽ
/ ::::::::::::::::\ つ
. | ,,-‐‐ ‐‐-、 .:::| わ
| 、_(o)_,: _(o)_, :::|ぁぁ
. | ::< .::|あぁ
\ /( [三] )ヽ ::/ああ
/`ー‐--‐‐―´\ぁあ
/ ::::::::::::::::\ つ
. | ,,-‐‐ ‐‐-、 .:::| わ
| 、_(o)_,: _(o)_, :::|ぁぁ
. | ::< .::|あぁ
\ /( [三] )ヽ ::/ああ
/`ー‐--‐‐―´\ぁあ
一般人でGPUの性能を気にするようなやつて結局ゲーマーじゃね
それ以外はCPUの性能のほうが気にしてるとおもう
それ以外はCPUの性能のほうが気にしてるとおもう
…
We hosted meetings with AMD CEO Rory Read late last week with 4 key
takeaways: 1) Yields are steadily improving at fab partner GlobalFoundries (GF)
with Oct output in line, Nov ahead of plan; 2) Recent restructuring should improve
execution by reducing mgmt layers, with savings redeployed to platform and
software engineers, and new leadership focused on execution ? Mark Papermaster
(ex-Apple exec) is among the first of these; 3) HDD shortages from the Thailand
floods have not had any meaningful impact so far; 4) AMD is focused on x86 as
the platform of choice for both its mobile and PC strategies. …
…
News about cancellation of 28nm low-end at GF is misleading in our view
Post our checks, we view news last week about canceled 28nm low-end products at
GF misleading: 1) prior low-end 40nm products were fabbed at TSMC, 2) With the
yield issues at GF, we believe the status quo was extended, with TSMC to focus on
the low-end and GF on the high-end ? we do not view this as a major strategy shift.
ふむ…
>>591
Atomでは足りないのは事実だが、大多数は
「性能を気にしていない」のではなく「値段だけ見ている」
とはいえZacate/Ontarioノートなんて国産だと割高なのか
2流メーカのしかないし、結果としてこのレンジより1個上の
物が売れてんだろうと。
Atomでは足りないのは事実だが、大多数は
「性能を気にしていない」のではなく「値段だけ見ている」
とはいえZacate/Ontarioノートなんて国産だと割高なのか
2流メーカのしかないし、結果としてこのレンジより1個上の
物が売れてんだろうと。
早く新cpu30万円時代来ないかな 昔のpentium 120 の時みたいに
>>602
来てどうするの?
来てどうするの?
604 :Socket774:2011/12/01(木) 00:59:24.84 ID:NxGlVnsR
ああああ。ニュー速にこんなスレたてられちゃったよ・・・
おしまいかな。
AMDはIntelとの競争を諦める
http://ikura.2ch.net/test/read.cgi/news/1322662745/
おしまいかな。
AMDはIntelとの競争を諦める
http://ikura.2ch.net/test/read.cgi/news/1322662745/
どうせこのスレの誰かだろw
AMDがヤバイのは単にGFやTSMCの製造能力が足りてないだけ
ZacateやLlanoは需要はかなりでかいのに供給が全く追い付いてない
ZambeziやOpteronもそう
Llanoを優先しすぎてBulldozer系が全く製造できてない
A8 8150 が日本国内で500個とかw
とりあえずAMDプロセッサはIntelの脅威になるレベルではある
Llano 3800/3870kが出れば2500/2600kクラスのヒットになるし、
Zacate E350も出せば出すだけ売れてただろう
まあ、どんなに優れてても製造できなけりゃ意味ないけどな
とりあえず、Intelが何をだそうが製造した分のAPUは今後も売れることは変わらんよ
CPU性能が劣っている分はチップセットとGPUの品質で十分補えてるからね
ZacateやLlanoは需要はかなりでかいのに供給が全く追い付いてない
ZambeziやOpteronもそう
Llanoを優先しすぎてBulldozer系が全く製造できてない
A8 8150 が日本国内で500個とかw
とりあえずAMDプロセッサはIntelの脅威になるレベルではある
Llano 3800/3870kが出れば2500/2600kクラスのヒットになるし、
Zacate E350も出せば出すだけ売れてただろう
まあ、どんなに優れてても製造できなけりゃ意味ないけどな
とりあえず、Intelが何をだそうが製造した分のAPUは今後も売れることは変わらんよ
CPU性能が劣っている分はチップセットとGPUの品質で十分補えてるからね
北森はこの件(AMD白旗)についてはインパクトが大きい記事だしまた荒れるのを警戒してか
情報確度が上がるまでまだ様子見かな
情報確度が上がるまでまだ様子見かな
609 :Socket774:2011/12/01(木) 02:29:00.67 ID:0Ky0FUIW
A8 3800ってもうでてるの?
また、お花畑さんか
AMDの製品が売れるのは買ってもらうために価格を下げまくってるから
製品として純粋に優れてるのはBobcatだけで
他の製品はGTX 480を投売りして売れてるとかドヤ顔してるみたいなもん
AMDの製品が売れるのは買ってもらうために価格を下げまくってるから
製品として純粋に優れてるのはBobcatだけで
他の製品はGTX 480を投売りして売れてるとかドヤ顔してるみたいなもん
黒字だから問題ないな
新プロセス開発や工場建設をする必要がないから今の価格でも十分やっていける
開発の遅れですら最早大した問題じゃないし、AMDのネックが製造量だけなのは今後も変わらんよ
半年遅れたLlanoも結局ヒットしてるしな
未だに3800を待ち望む声が後を絶たないくらいには需要はある
新プロセス開発や工場建設をする必要がないから今の価格でも十分やっていける
開発の遅れですら最早大した問題じゃないし、AMDのネックが製造量だけなのは今後も変わらんよ
半年遅れたLlanoも結局ヒットしてるしな
未だに3800を待ち望む声が後を絶たないくらいには需要はある
CPUの原価って1個1000円強くらいだからVGAよりずっと利幅大きいぞ
電波は佐賀県かあ
AMDの足をひっぱてるのはLlanoの供給不足なのは常識だろ
モバイルのシェア奪われてるIntelの現実は見えないんだねインテル使いは
モバイルのシェア奪われてるIntelの現実は見えないんだねインテル使いは
>>612
原価厨ェ……
原価厨ェ……
AMDのASPはLlanoでかなり改善したらしいし悲観する必要はあまりないかな
しかしたのみのWhitica/krishnaがキャンセルした以上、来年のAMDはTrinity次第ということか
Ivyと時期が同じらしいけどどうなるかね
しかしたのみのWhitica/krishnaがキャンセルした以上、来年のAMDはTrinity次第ということか
Ivyと時期が同じらしいけどどうなるかね
ブルコアのTrinityとか誰が買うんだ罰ゲームか
もう何の未来もねえ
その上でのギブアップ宣言なんだろうけどさ
もう何の未来もねえ
その上でのギブアップ宣言なんだろうけどさ
GFの28nm が来年半場まで無理てのも痛手だね
悪いニュースでばかりだな
悪いニュースでばかりだな
来年半ばくらいまでなら余裕で耐えれるだろ
さすがにIntelも22nmを最初からフル稼働で大量出荷は無理だろうし、当分はSandyが大半を占めるはず
さすがにIntelも22nmを最初からフル稼働で大量出荷は無理だろうし、当分はSandyが大半を占めるはず
ivyは今も製造してるわけですが
AMDは組織的抵抗を諦めました
残された出来る事は散発的なゲリラ戦ぐらいか
624 :Socket774:2011/12/01(木) 08:39:35.80 ID:6ppj4Rxm
で、大原のBulldozer RMMAベンチ結果と考察はマイコミに載ったの?
・・・いつまで待たせる気?
大本営が敗北宣言したんだから、もう出せるよね?
出せないなら謝罪しろよ、エセ記者
・・・いつまで待たせる気?
大本営が敗北宣言したんだから、もう出せるよね?
出せないなら謝罪しろよ、エセ記者
せめてIONを追い出さなければAtomも少しはマシだったのにな
CPUもGPUも駄目駄目じゃそりゃシェア30%以上落とすわ
CPUもGPUも駄目駄目じゃそりゃシェア30%以上落とすわ
628 :Socket774:2011/12/01(木) 09:25:15.80 ID:2mXoLx6M
Krishnaキャンセルだと
たとえ後方互換性なくてもarm用windowsの需要高まりそうだな
たとえ後方互換性なくてもarm用windowsの需要高まりそうだな
省電力チップだけじゃなくて、普通のチップですらノース統合するんだから
第一世代AtomでのIONみたいな位置付けのチップは消えることが分かってただろ。
あれは2チップ構成に出来てIntel945+ICH7より省電力だからよかったけど
第一世代AtomでのIONみたいな位置付けのチップは消えることが分かってただろ。
あれは2チップ構成に出来てIntel945+ICH7より省電力だからよかったけど
アムド信者はアムド敗北でx86が潰れることを夢見てる。
あとは野となれ山となれってやつですな
AMDが逝くならINTELも道連れになってほしいとか発想が凄すぎるわw
AMDが逝くならINTELも道連れになってほしいとか発想が凄すぎるわw
>>629
判っていようが判ってなかろうが使う側にはそんな事関係ないわけで
判っていようが判ってなかろうが使う側にはそんな事関係ないわけで
>630
あーそれはあるかもw(自省)
今までの構図を無意味にするような革新が起きるといいな、っていう思考になってたわw
あーそれはあるかもw(自省)
今までの構図を無意味にするような革新が起きるといいな、っていう思考になってたわw
634 :Socket774:2011/12/01(木) 09:51:56.70 ID:2mXoLx6M
635 :Socket774:2011/12/01(木) 09:52:57.58 ID:uAYCgDo5
調子に乗ってぼったくったのはAMDだけ
>>635
それでもPenDより安かったけどね
それでもPenDより安かったけどね
637 :Socket774:2011/12/01(木) 10:00:03.00 ID:9jusQeur
オワタ・・・完全にオワタ・・・
高かった時代もIntelの同等性能に値段を合わせていただけなんだけど、
元が貧乏人向けのAMDだけ、いつまでも粘着されている。
貧乏人に。
元が貧乏人向けのAMDだけ、いつまでも粘着されている。
貧乏人に。
AMDのボッタクリは現在進行形だぜ
FX8150がなんで2600Kより高いんだよw
FX8150がなんで2600Kより高いんだよw
貧乏人の味方と思ってたから、裏着られた!と感じたんだろう
セレ対抗製品がラインナップから消えた時点で別に貧乏人の味方でも何でもないよな
>>639
希少価値
希少価値
>>639
陰信乙!貧乏人があんなゴミを買わないための神配慮だというのに!
・・・というのは嘘だけど、どうせ一部の物好きしか買わないからあんま被害なさそうw
来年のPCショップの福袋に入っているかもしれない。
陰信乙!貧乏人があんなゴミを買わないための神配慮だというのに!
・・・というのは嘘だけど、どうせ一部の物好きしか買わないからあんま被害なさそうw
来年のPCショップの福袋に入っているかもしれない。
出荷済みマザーボードの枚数ぐらいの需要はあるのに
供給を相当絞ってるから値段はしばらく下がらない
供給を相当絞ってるから値段はしばらく下がらない
>>634
結局、そうなんだよな。
だから、インテル使ってる俺も嫌な気分。
x86はいまだにリアルモードとかサポートしてるモンだし。
大昔の互換のために残ってるゴミ機能をすてて、
全く新しいアーキテクチャが出るなら、それは良いことだと思う。
結局、そうなんだよな。
だから、インテル使ってる俺も嫌な気分。
x86はいまだにリアルモードとかサポートしてるモンだし。
大昔の互換のために残ってるゴミ機能をすてて、
全く新しいアーキテクチャが出るなら、それは良いことだと思う。
64ビットモードはプレフィクス追加じゃなくて
もうちょっと刷新した方が良かったんじゃないですかねえ、アムドさん。
ARMv8みたいに。
もうちょっと刷新した方が良かったんじゃないですかねえ、アムドさん。
ARMv8みたいに。
647 :Socket774:2011/12/01(木) 10:51:08.48 ID:DZ8DR/k5
リストラで切られる広報部門が最後の嫌がらせしてるだけ
ほんっと切り捨てて正解
ほんっと切り捨てて正解
広報ガー New!
Athlon64でぼったくりしすぎだろあれ!
X4シリーズは11万とか13万とかどう考えても器の小さい企業としか思えんかったな。
X4シリーズは11万とか13万とかどう考えても器の小さい企業としか思えんかったな。
生活必需品でもないんだし、いいんでねーの
普段はIntelの同等品の価格にあわせてディスカウントしてるだけで(そうしないと商売にならないから)、
開発費と製造原価と生産量から計算したAMDの本来の適正価格はもっと高い。
開発費と製造原価と生産量から計算したAMDの本来の適正価格はもっと高い。
適正価格がいくらくらいかわからないけど、グロスマージンは50%くらいにしたいだろうな。
40%前半だとギリギリ黒字って状態だし。
40%前半だとギリギリ黒字って状態だし。
1ヶ月近くになるけど、今日もkonozamaから届く気配なし。
そろそろ、「用意できませんでした」ってメールが来るかな。
そろそろ、「用意できませんでした」ってメールが来るかな。
新潟さんの適当知ったか発言クソワロタ
こいつ知ってる言葉を並べてるだけだろw
>一方でBulldozerの場合、フェッチで発行された命令を
>デコーダが2つのコアのスケジューラにそれぞれ交互に命令を送るようになってる
>いくらスケジューラーで4MacroOPを8uOPに変換したところで、
>デコーダが非常に効率よくデコードしない限り、一方のコアは命令処理中。
>もう1つのコアはすでに命令処理が終わってて、命令発行を待ってるなんてことになる可能性が高い
こいつ知ってる言葉を並べてるだけだろw
>一方でBulldozerの場合、フェッチで発行された命令を
>デコーダが2つのコアのスケジューラにそれぞれ交互に命令を送るようになってる
>いくらスケジューラーで4MacroOPを8uOPに変換したところで、
>デコーダが非常に効率よくデコードしない限り、一方のコアは命令処理中。
>もう1つのコアはすでに命令処理が終わってて、命令発行を待ってるなんてことになる可能性が高い
659 :Socket774:2011/12/01(木) 12:45:47.20 ID:9jusQeur
ブルなんてゴミ作ってる場合じゃなかったんだ
4004をこっそり生産したほうが儲かるよ
セカンドソースに戻ってやりなおしか
新ロードマップどうなるかな
http://eetimes.jp/ee/articles/1112/01/news056.html
http://eetimes.jp/ee/articles/1112/01/news056.html
>>648
確か前にも、インテルで1台組むわwって捨て台詞はいて広報が辞めたよな
確か前にも、インテルで1台組むわwって捨て台詞はいて広報が辞めたよな
> 現在の契約では、AMDは有効な32nmダイにのみGLOBALFOUNDRIESに代金を支払
> うことになっている。歩留まり率の向上に苦慮するGLOBALFOUNDRIESにとって、
> この契約は収益の減少を意味するものだった。しかし、この契約の満了する
> 2012年1月1日以降、AMDは再び、ダイの品質にかかわらず、全てのウエハーに
> 対して代金を支払わなければならなくなる。これは、AMDにとって何としても
> 避けたい事態であるはずだ。
32nm SOIは歩留まり上がるまでしばらくOpteron(とその選別落ち品)限定、
ということになる。
> うことになっている。歩留まり率の向上に苦慮するGLOBALFOUNDRIESにとって、
> この契約は収益の減少を意味するものだった。しかし、この契約の満了する
> 2012年1月1日以降、AMDは再び、ダイの品質にかかわらず、全てのウエハーに
> 対して代金を支払わなければならなくなる。これは、AMDにとって何としても
> 避けたい事態であるはずだ。
32nm SOIは歩留まり上がるまでしばらくOpteron(とその選別落ち品)限定、
ということになる。
http://vr-zone.com/articles/report-production-of-amd-s-desktop-trinity-apus-from-march-2012/14099.html
Trinityは65w版の生産が3月からで100w版が5月から?らしいが
今回は小さいチップから先行するのは歩留まりの関係からかな?
それとも2コアのLlano2をキャンセルして、そのかわりとして65w版を充てるのか
Trinityは65w版の生産が3月からで100w版が5月から?らしいが
今回は小さいチップから先行するのは歩留まりの関係からかな?
それとも2コアのLlano2をキャンセルして、そのかわりとして65w版を充てるのか
TDP65WのA10、A8ブランドあるようだから、intelみたいな省電力も含めてのブランドじゃないなら、
4コア版も最初からあるんじゃないかな?
4コア版も最初からあるんじゃないかな?
誰に売るの?
2コア6GHzとか出せばマニアにうけるだろう
もうニッチ向けで生き残るしかない
もうニッチ向けで生き残るしかない
シングルコア性能がintelを上回れないからマルチコアやらAPUに逃げたと言うに
6ghzとかに目ざしたらもう水冷でもやばいだろw
6ghzとかに目ざしたらもう水冷でもやばいだろw
そんなん、今の性能維持したまま6GHz実現したら
例えシングルコアでもみんな買うわw
例えシングルコアでもみんな買うわw
ブルを6Ghzにしてもシングルスレッド性能はSandy3Ghzと同等くらいになるから売れないだろ
俺はあんまりメーカーにこだわらないからコストパフォーマンスの高い方買うわあ
AsusのK53TAは近日中に買うつもりやけんども
AsusのK53TAは近日中に買うつもりやけんども
VMmark来てるな
8ソケット同士の比較(上がHP ProLiantのDL585で下が同BL685)で
Magny-cours(2.5GHz)→9.91@13tiles
Interlagos(2.3GHz)→12.77@15tiles
8ソケット同士の比較(上がHP ProLiantのDL585で下が同BL685)で
Magny-cours(2.5GHz)→9.91@13tiles
Interlagos(2.3GHz)→12.77@15tiles
久しぶるにここ来た
Bullの鯖ベンチってもう出た?
すぐ上にVMmarkがあるけど他には?
Bullの鯖ベンチってもう出た?
すぐ上にVMmarkがあるけど他には?
>>664
GFが悪いんじゃねーか。
GFが悪いんじゃねーか。
歩留まりが良い→AMDが凄い
歩留まりが悪い→GFが悪い
歩留まりが悪い→GFが悪い
GFが悪い、広報が悪い、プログラムが悪い
買い支えなかった俺が悪い
681 :Socket774:2011/12/01(木) 18:41:08.25 ID:ox6N04j2
先週末も「Sandy Bridge-E」関連パーツの新製品がたくさん登場した。インテル陣営が勢いに乗る一方で
AMDは、ハイエンドの8コアCPU「FX-8150(空冷版)」が2万5000円前後と比較的安価で、こちらも売り切れが多発している。ただし、
「潜在需要がインテルとまったく違うので、FX-8150が潤沢化したら、すぐに需要が満たされて動きが止まると思います。
正直、現在のAMDはインテルのライバルとは呼べないくらい、シェアが落ち込んでいます。」
http://plusd.itmedia.co.jp/pcuser/articles/1111/28/news030.html
( ̄▽ ̄)
円高の今こそ、日本企業はこのインテルに完全敗北したAMDを買えばよくないか?
PCまわりでまったく活躍できていない日本企業の再生ができる気がするのだが
PCまわりでまったく活躍できていない日本企業の再生ができる気がするのだが
日本企業なんて、中国製品に、中国で作った「日本製」というシールを中国人に貼らせる仕事しかしてないだろ。
とりあえずNECは昔の裁判の和解条件があるからx86作れんぞ。
NECはもうPC部門無い
海外の統計でももうLenovoとして扱われてる
海外の統計でももうLenovoとして扱われてる
NECは元々国内だけだろ
てかもうARMの市場規模(売上)はIntelの総売上の半分まで来てる
X86部分のみと比較すると差はもっと小さくなるだろう
AMDを(合併などの形で)ただで手に入れるならまだ有りえるが、
金を出して買う場合はその費用を回収できないんじゃない
X86部分のみと比較すると差はもっと小さくなるだろう
AMDを(合併などの形で)ただで手に入れるならまだ有りえるが、
金を出して買う場合はその費用を回収できないんじゃない
最後が抜けた
AMDを買うくらいならARMのライセンスを受けた方が良い
AMDを買うくらいならARMのライセンスを受けた方が良い
GF的にはAMDがx86つくろうがARMつくろうがどっちでもいいだろうからな。
でもARMで成功するってビジョンが浮かんでこんが。
でもARMで成功するってビジョンが浮かんでこんが。
GFは28nm遅れて大口のAMDにキャンセルされたのが痛いわけやん
いちばんの大口がキャンセルすると予約いれていた別の企業も雪崩売ってキャンセルしてくると思うで
コレが一番おっかないわな
いちばんの大口がキャンセルすると予約いれていた別の企業も雪崩売ってキャンセルしてくると思うで
コレが一番おっかないわな
ARM載せたPCといわれてもMIPS版NT4が脳裡をよぎってしまふ俺。
潜在的なマルチタスク性能はBulldozerの方が明らかに上なのは確実なのに、
今のソフトはIntelのHTや1コアだけ特にOCされるセコい仕様に最適化されてしまっているから、
真の力を出しきれないのはもったいないな
Bulldozerは生まれる時代がちょっと早かったようだけど、
これからソフトも真のマルチコア対応が重要になってくるし、
多コア化の技術は先行してるから、すぐ時代が追いついて
AMDの天下になるのは間違いないな
今のソフトはIntelのHTや1コアだけ特にOCされるセコい仕様に最適化されてしまっているから、
真の力を出しきれないのはもったいないな
Bulldozerは生まれる時代がちょっと早かったようだけど、
これからソフトも真のマルチコア対応が重要になってくるし、
多コア化の技術は先行してるから、すぐ時代が追いついて
AMDの天下になるのは間違いないな
amdにそういうソフト面すぐ投げ出すから無理
Bullは3年前に出ていればな。
>>694
主語が抜けてたから悪かったが、"AMDが"ARMで成功するってビジョンが浮かんでこんが。だ。
主語が抜けてたから悪かったが、"AMDが"ARMで成功するってビジョンが浮かんでこんが。だ。
C2Dの時にBull出てラバまだ勝ち目はあった
CPUアーキテクチャについて語れ 20
http://hibari.2ch.net/test/read.cgi/jisaku/1318113870/
396 名前:Socket774[sage] 投稿日:2011/11/30(水) 20:15:28.61 ID:j5ymgfwb
米クレイ、京大からスパコン受注 富士通「京」に競り勝つ
スーパーコンピューター専業の米クレイ(ワシントン州)が、京都大学の次期スパコンを受注した。
学術情報メディアセンターに納入、2012年5月に稼働させる。旧帝大7校が海外製スパコンを主要機種として採用するのは初めて。
京大は1969年以来、富士通の牙城だった。受注額は外部記憶装置などを含め40億円未満。クレイは今回の受注を機に、国立大学や公共研究機関への販売を強化する。
403 名前:Socket774[sage] 投稿日:2011/11/30(水) 22:07:08.66 ID:+rXwWkIl
>>396
クレイってことは、これOpteronなのか?
413 名前:Socket774[sage] 投稿日:2011/12/01(木) 15:37:35.92 ID:Do65qa+4
>>403
12年のはOpteronだな。予定通りに14年に追加があるならそっちは
インターコネクトがPCI-EのCascade だから、その時点で性能のいい方になるだろう
京大がopteronマシン採用したっぽい
http://hibari.2ch.net/test/read.cgi/jisaku/1318113870/
396 名前:Socket774[sage] 投稿日:2011/11/30(水) 20:15:28.61 ID:j5ymgfwb
米クレイ、京大からスパコン受注 富士通「京」に競り勝つ
スーパーコンピューター専業の米クレイ(ワシントン州)が、京都大学の次期スパコンを受注した。
学術情報メディアセンターに納入、2012年5月に稼働させる。旧帝大7校が海外製スパコンを主要機種として採用するのは初めて。
京大は1969年以来、富士通の牙城だった。受注額は外部記憶装置などを含め40億円未満。クレイは今回の受注を機に、国立大学や公共研究機関への販売を強化する。
403 名前:Socket774[sage] 投稿日:2011/11/30(水) 22:07:08.66 ID:+rXwWkIl
>>396
クレイってことは、これOpteronなのか?
413 名前:Socket774[sage] 投稿日:2011/12/01(木) 15:37:35.92 ID:Do65qa+4
>>403
12年のはOpteronだな。予定通りに14年に追加があるならそっちは
インターコネクトがPCI-EのCascade だから、その時点で性能のいい方になるだろう
京大がopteronマシン採用したっぽい
>>695
Phenomの時同じ事言ってなかった?
Phenomの時同じ事言ってなかった?
>>695
そーゆーのを人任せにしてたから今の惨状なんだろ
そーゆーのを人任せにしてたから今の惨状なんだろ
http://www.xbitlabs.com/news/other/display/20111129224233_Globalfoundries_Expects_Fab_8_to_Begin_Operations_in_December_2012.html
GFは一年後にFab8の操業を始めるみたいね
顧客は付くのかな
さすがに歩留まり上がってるだろうか
GFは一年後にFab8の操業を始めるみたいね
顧客は付くのかな
さすがに歩留まり上がってるだろうか
で、調べたら京大に納入されるのは第一弾がXE6(Interlagos機)で、第二弾はXK6(Interlagos+Tesla)だな
ちなみにNCSAのBlueWaters計画(IBMが納入する予定だった)もXE6+XK6になった
ORNLも同じ構成
ちなみにNCSAのBlueWaters計画(IBMが納入する予定だった)もXE6+XK6になった
ORNLも同じ構成
国立は同じところから採用しないって暗黙のルールがあるからの
理由は簡単だわな
理由は簡単だわな
ARMer を叩いてた連中はいまでんな気持ちだろう
>>706の訂正
京大の第二弾はXK6じゃなくてXeonっぽいな
って、>>700氏がちゃんと書いてたね・・・
http://investors.cray.com/phoenix.zhtml?c=98390&p=irol-newsArticle&ID=1634415&highlight=
京大の第二弾はXK6じゃなくてXeonっぽいな
って、>>700氏がちゃんと書いてたね・・・
http://investors.cray.com/phoenix.zhtml?c=98390&p=irol-newsArticle&ID=1634415&highlight=
712 :,, ・´ ∀ `・ ,,)っ-○○○:2011/12/01(木) 21:37:07.62 ID:ohKngB0I
Xeon搭載の大規模スパコンの顧客第一号になるのかもな
Bulldozer Opteronは値段の割りに性能高すぎ
同等の性能のXeonと価格は同じだし、
先が無いことを考慮したら価格は高すぎるくらいじゃない?
先が無いことを考慮したら価格は高すぎるくらいじゃない?
インテル互換メーカーから出世して独自ソケットだしいいんじゃね?
最初から最後まで、本物を作るメーカーではなかった
CrayにはXeon系のCX1000シリーズも有るよ
ttp://www.iimc.kyoto-u.ac.jp/ja/services/comp/services/coming.html
第一弾がBullOpteronのXE6とXK6
2014以降のCascadeはcrayが売り込んでるだけでまだ未定って感じ
第一弾がBullOpteronのXE6とXK6
2014以降のCascadeはcrayが売り込んでるだけでまだ未定って感じ
そういやApproもOpteronのスパコン出すん?
う~ん
Opteron 6282 SE * 4
price:$1019 * 4
SPECINTRate 1040
SCECFPRate 752
Xeon E7-4860 * 4
price:$4394 * 4
SPECINTRate 1090
SCECFPRate 725
Opteron 6282 SE * 4
price:$1019 * 4
SPECINTRate 1040
SCECFPRate 752
Xeon E7-4860 * 4
price:$4394 * 4
SPECINTRate 1090
SCECFPRate 725
>>676
Opteron 6282 SE(\114,449)
SPECint®_rate2006 = 543
SPECint_rate_base2006 = 474
http://www.spec.org/cpu2006/results/res2011q4/cpu2006-20111024-18714.html
Xeon X5680(\139,649)
SPECint®_rate2006 = 395
SPECint_rate_base2006 = 367
http://www.spec.org/cpu2006/results/res2011q4/cpu2006-20111006-18658.html
Opteron 6282 SE(\114,449)
SPECint®_rate2006 = 543
SPECint_rate_base2006 = 474
http://www.spec.org/cpu2006/results/res2011q4/cpu2006-20111024-18714.html
Xeon X5680(\139,649)
SPECint®_rate2006 = 395
SPECint_rate_base2006 = 367
http://www.spec.org/cpu2006/results/res2011q4/cpu2006-20111006-18658.html
ダイサイズガー
Bulldozerはあとキャッシュ周りさえまともなら
ダイサイズ当たりの性能でもwestmere程度に遅れは取らなかったと思うけど惜しいなあ。
ダイサイズ当たりの性能でもwestmere程度に遅れは取らなかったと思うけど惜しいなあ。
Intelは圧倒的な製造技術と生産量でダイサイズの肥大化が怖くもなんともない
だからSany以降、シングル性能もマルチ性能も省電力も全部入りで欲張りな設計ができる
Fabを持った男らしいやり方だからできる方法
逆にAMDはファブレスに走ったが故にgdgd
もはやCPUのあーキテクチャがどうのこうのという次元に無い
だからSany以降、シングル性能もマルチ性能も省電力も全部入りで欲張りな設計ができる
Fabを持った男らしいやり方だからできる方法
逆にAMDはファブレスに走ったが故にgdgd
もはやCPUのあーキテクチャがどうのこうのという次元に無い
あの時ファブを売らないで潰れるべきだったよね
そっちのほうが潔い
そっちのほうが潔い
印虫が火病を発症させたか
これで鯖市場取られたらもうIntel後が無いな
もはや妄想にすがるしかなくなったか
俺の信じるAMDは勝つよ
今の状況はよく住み分けできてるように思うけどな
AMDは相変わらず歩止まりが悪いが
AMDは相変わらず歩止まりが悪いが
あれよね、ファブ持ちの頃は歩留まり悪くてもAMDのせいだったけど
いまはGFのせいにできるんだよな
いまはGFのせいにできるんだよな
鯖向きベンチのVMmarkではInterlagosより10コアXeonの方が20%以上上だよ
Xeonの方はHTTありのスコアだから単純には比較できないが、
実環境ではHTTオフとしても、やっぱりXeonの方がちょっと上って感じだな
そもそもItaniumの代替以外の用途で10コアXeonが使われる事なんてあるのかって話は有るが
Xeonの方はHTTありのスコアだから単純には比較できないが、
実環境ではHTTオフとしても、やっぱりXeonの方がちょっと上って感じだな
そもそもItaniumの代替以外の用途で10コアXeonが使われる事なんてあるのかって話は有るが
VMMark 6282 SEで検索したら下の記事ばかり引っかかる
Highest VMmark score for blade servers using 2 Host configuration with the BL685c G7 system - 28% higher score with 17% more VMs than the BL680c G7 running 10-core Xeon
Highest VMmark score for blade servers using 2 Host configuration with the BL685c G7 system - 28% higher score with 17% more VMs than the BL680c G7 running 10-core Xeon
北森さんとこ取り上げたね
結局勝手に先走った人が多かったって事か
結局勝手に先走った人が多かったって事か
>クラウドや低消費電力Mobile向けにより注力する
北森より。
まぁ妥当な路線だよなー
ハイエンドはどうなるんだよ、とか言いたくはなるけど。
北森より。
まぁ妥当な路線だよなー
ハイエンドはどうなるんだよ、とか言いたくはなるけど。
でも低消費電力技術もIntelに先手を取られてるしな…
>>735
2PシステムならWestmere-EPのほうが妥当でしょ
RAS機能とかを強化してあるWestmere-EXなんて使ったら
お値段が洒落にならないよ
いやInterlagosがそういうのをターゲットにしてるなら
まあ分からない話ではないんだが
2PシステムならWestmere-EPのほうが妥当でしょ
RAS機能とかを強化してあるWestmere-EXなんて使ったら
お値段が洒落にならないよ
いやInterlagosがそういうのをターゲットにしてるなら
まあ分からない話ではないんだが
>>737
クラウドって結構処理能力のいる分野だったと思うけど違ったかな?
クラウドって結構処理能力のいる分野だったと思うけど違ったかな?
>>740
処理能力いるからこそInterlagosなんだろうがと。
処理能力いるからこそInterlagosなんだろうがと。
742 :,, ・´ ∀ `・ ,,)っ-○○○:2011/12/02(金) 02:03:04.81 ID:hdpYeB/H
SPECintのrate(同じベンチを複数実効)で1ノードの性能を比較することに意味があるのかねえ。
実用レベルでその程度のスケーラビリティのある、たとえばWebサーバ用途なんて
2-4PのOpteronよりもXeon E3のLV版を複数台使ったほうがコスパいいんだが。
実用レベルでその程度のスケーラビリティのある、たとえばWebサーバ用途なんて
2-4PのOpteronよりもXeon E3のLV版を複数台使ったほうがコスパいいんだが。
744 :,, ・´ ∀ `・ ,,)っ-○○○:2011/12/02(金) 02:53:45.16 ID:hdpYeB/H
BobcatベースのサーバなんてWebサーバ程度のフロントエンド低負荷の用途に使える程度じゃねーの?
745 :,, ・´ ∀ `・ ,,)っ-○○○:2011/12/02(金) 03:02:37.88 ID:hdpYeB/H
SPECssj_2008でInterlagosは3000を下回りWestmere(56xxシリーズ)に遙かに及んでないし
サーバは導入コストよりラニングコストが重視されるから慎重にならざるを得ないよね。
安ければいいなら1Pブレードサーバ大量でもいいわけで。
サーバは導入コストよりラニングコストが重視されるから慎重にならざるを得ないよね。
安ければいいなら1Pブレードサーバ大量でもいいわけで。
FXはソフトの最適化で速くなる、AMD担当者インタビュー
ttp://pc.nikkeibp.co.jp/article/news/20111201/1039340/
ttp://pc.nikkeibp.co.jp/article/news/20111201/1039340/
最適化で速くならないプロセッサなんて存在しません><
>>727
キチガイはほっとけ
キチガイはほっとけ
>>746
もっとマルチスレッド全盛になると思ってました
これからそうなるように働きかけていかなければらないと思いました
来年にはたぶんFX生かせるソフト増えてると思うよ?
最適化すれば性能出るから、みんな早くFXに最適化してくださいお願いします
供給不足はGFのせい
8150水冷500セットも供給できてません
いつ改善されるか分かりません
Llanoも同じです
LlanoX4やFX8の95Wも出す、出すが、個人が買えるようになる時と場所はまだ
これからも改善を続けていきます、でもネット見てると現FX買った人満足してるよ?
なんやこれは
もっとマルチスレッド全盛になると思ってました
これからそうなるように働きかけていかなければらないと思いました
来年にはたぶんFX生かせるソフト増えてると思うよ?
最適化すれば性能出るから、みんな早くFXに最適化してくださいお願いします
供給不足はGFのせい
8150水冷500セットも供給できてません
いつ改善されるか分かりません
Llanoも同じです
LlanoX4やFX8の95Wも出す、出すが、個人が買えるようになる時と場所はまだ
これからも改善を続けていきます、でもネット見てると現FX買った人満足してるよ?
なんやこれは
ブルはPhenomIIよりも低性能で、現状の製品は欠陥品や不良品でもなく、
開発段階から想定していた通りの性能が発揮されているものであったと
AMDの人間が認めてしまった訳だがw
開発段階から想定していた通りの性能が発揮されているものであったと
AMDの人間が認めてしまった訳だがw
>>745
暗にAtomマンセーしてまたホモ暴れする前兆か何かか?
キモいのが居付いてるのはどうしようもないけど
Bullは現時点ではAgenaを65nm初期で出したような感じだろうから
そこからのリビジョンアップとかDeneb化とか色々先があるよな
暗にAtomマンセーしてまたホモ暴れする前兆か何かか?
キモいのが居付いてるのはどうしようもないけど
Bullは現時点ではAgenaを65nm初期で出したような感じだろうから
そこからのリビジョンアップとかDeneb化とか色々先があるよな
何をしようが無駄
nanoより遅いとか糞過ぎるbullは
nanoより遅いとか糞過ぎるbullは
完敗ではなく勝ち負け両方あるようにしか見えんが
しかも1.6GHz、1Moduleに制限してのスコア
しかも1.6GHz、1Moduleに制限してのスコア
クロック辺りの性能とかどうでもいいわ
そんなんでネガキャンできると思ったの?
そんなんでネガキャンできると思ったの?
AMD 28nm APUの発注中止
http://eetimes.jp/ee/articles/1112/01/news056.html
http://eetimes.jp/ee/articles/1112/01/news056.html
>Trinityについては消費電力当たりの性能を疑問視する声もある。タブレット端末や低消費電力のノートPCの普及が加速している今、Trinityは“超低消費電力の製品ラインアップ”のカテゴリには属さないのではないかというのである。
知ってた。
知ってた。
761 :Socket774:2011/12/02(金) 08:51:04.79 ID:Lij+N5X8
758 Socket774 [sage] 2011/12/02(金) 07:37:02.23 ID:ieQzVCTG Be:
クロック辺りの性能とかどうでもいいわ
そんなんでネガキャンできると思ったの?
クロック辺りの性能とかどうでもいいわ
そんなんでネガキャンできると思ったの?
762 :Socket774:2011/12/02(金) 08:59:53.79 ID:EYEh/Sjg
>インターネットにあるユーザーが購入した製品をレビューするサイトを見ていると、現在のFXを購入した人はみな満足している。
Newegg.com 5点満点中
Core i7-2600K
5点 92%(931)
4点 6%(60)
3点 1%(11)
2点 0%(2)
1点 1%(10)
Phenom II X6 1090T Black Edition
5点 91%(1419)
4点 6%(89)
3点 2%(25)
2点 0%(7)
1点 1%(16)
FX-8150
5点 68%(73)
4点 12%(13)
3点 11%(12)
2点 5%(5)
1点 4%(4)
あれれー?
Newegg.com 5点満点中
Core i7-2600K
5点 92%(931)
4点 6%(60)
3点 1%(11)
2点 0%(2)
1点 1%(10)
Phenom II X6 1090T Black Edition
5点 91%(1419)
4点 6%(89)
3点 2%(25)
2点 0%(7)
1点 1%(16)
FX-8150
5点 68%(73)
4点 12%(13)
3点 11%(12)
2点 5%(5)
1点 4%(4)
あれれー?
765 :Socket774:2011/12/02(金) 09:20:36.58 ID:Dmxe4gwi
bullの1m当たりのトランジスタ数は2.13億
nano x2のトランジスタ数は0.94x2=1.88億
メモコン搭載、L3 8MBとかいろいろ有利なおまけもあるんだが
それでもbullはnano x2に負けるのか
情けねー
nano x2のトランジスタ数は0.94x2=1.88億
メモコン搭載、L3 8MBとかいろいろ有利なおまけもあるんだが
それでもbullはnano x2に負けるのか
情けねー
FXはPhenomIIで再構築した信頼を一気にぶち壊したよね
ほとんどのひとは信頼なんてしてなかったから
そういう意味ではFXが壊したものはわずかだけどね
そういう意味ではFXが壊したものはわずかだけどね
____
/ \ /\ キリッ
. / (ー) (ー)\ <ほとんどのひとは信頼なんてしてなかったから
/ ⌒(__人__)⌒ \ そういう意味ではFXが壊したものはわずかだけどね
| |r┬-| |
\ `ー’´ /
苦肉のハードル下げ乙wwwwwwww
/ \ /\ キリッ
. / (ー) (ー)\ <ほとんどのひとは信頼なんてしてなかったから
/ ⌒(__人__)⌒ \ そういう意味ではFXが壊したものはわずかだけどね
| |r┬-| |
\ `ー’´ /
苦肉のハードル下げ乙wwwwwwww
まあ茶でも飲んで落ち着け。
決定的に信頼を壊したのはK10で、
この時点でサーバ・パフォーマンスデスクトップからの中長期スパンでの撤退は既定路線だよ。
だって信頼がないんだから。
出した後でK10を直したところで、信頼の回復にはならない。
Bulldozerは時間稼ぎ、万が一当たれば借金が返せる宝くじみたいな位置付けに過ぎなかった。
案の定外れた。
決定的に信頼を壊したのはK10で、
この時点でサーバ・パフォーマンスデスクトップからの中長期スパンでの撤退は既定路線だよ。
だって信頼がないんだから。
出した後でK10を直したところで、信頼の回復にはならない。
Bulldozerは時間稼ぎ、万が一当たれば借金が返せる宝くじみたいな位置付けに過ぎなかった。
案の定外れた。
うん。どう考えてもハードル下げじゃないでしょw
phenom2なんかで信頼してた奴なんて
それこそ某雑談スレの特濃信者くらいだw
ブル発売前の最後期型のphenom2ですらIPCはC2D以下だからなw
虎の子のブルなんざそのphenom2にすら劣るゴミw
安かろう悪かろうの典型例みたいなもんだが、
それでもsandy以前はそれなりに価格競争力だけはあった。それだけ
phenom2なんかで信頼してた奴なんて
それこそ某雑談スレの特濃信者くらいだw
ブル発売前の最後期型のphenom2ですらIPCはC2D以下だからなw
虎の子のブルなんざそのphenom2にすら劣るゴミw
安かろう悪かろうの典型例みたいなもんだが、
それでもsandy以前はそれなりに価格競争力だけはあった。それだけ
”sandy以前”だと今も入るか
”sandy発売前”だな
”sandy発売前”だな
ID:dJj0PnM9
ID:qBDbbtVH
糞ワロタ
ID:qBDbbtVH
糞ワロタ
フェノム出した直後に重度のエラッタでフェノム2に名前を変えて売り出した。
それならまだしも、同じ製品を名前を変えて消費者の知識を分断するのは時々するね。
それならまだしも、同じ製品を名前を変えて消費者の知識を分断するのは時々するね。
>>754
Agenaはプロセス的に無理があったからプロセスの更新で何とかマシなものになった
Bulldozerはプロセス的にもいいとは言えないし何よりアーキテクチャの問題がでかい
いくらAMDがプロセスの改良が得意と言っても素姓の悪い32nmでそれが出来るのか微妙だし、短いスパンでのアーキテクチャの更新は始めての試みになる
先があるかもしれないが、乗り越えるべきハードルは遥かに高いよ
Agenaはプロセス的に無理があったからプロセスの更新で何とかマシなものになった
Bulldozerはプロセス的にもいいとは言えないし何よりアーキテクチャの問題がでかい
いくらAMDがプロセスの改良が得意と言っても素姓の悪い32nmでそれが出来るのか微妙だし、短いスパンでのアーキテクチャの更新は始めての試みになる
先があるかもしれないが、乗り越えるべきハードルは遥かに高いよ
これ以上コア単体性能はリッチに出来ない(フロントエンドが限界)。
性能上げるにはモジュール増やすしかないアーキテクチャなのに
interconnectをクロスバで作るバカがいた。
性能上げるにはモジュール増やすしかないアーキテクチャなのに
interconnectをクロスバで作るバカがいた。
そうだね。Bulldozerの性能は最高で、AMDの未来は安泰だ。
君は何も心配せずに、ちゃんと薬を飲んで休むといい。
君は何も心配せずに、ちゃんと薬を飲んで休むといい。
AMDが大好きで考えることを放棄すれば誰でもアム厨になれる
真のマルチタスク性能でAMDに勝てないIntelに未来は無い
2コア共有のフロントエンドが限界ってことは
1フロントエンド1スケジューラ(コア)にしたら
コア辺りで逆に性能下がっちゃうわけか
流石はいつも通りの名無し版
1フロントエンド1スケジューラ(コア)にしたら
コア辺りで逆に性能下がっちゃうわけか
流石はいつも通りの名無し版
でもさ、合理的というか現実的に考えると
いまAMDで買ってもいいと思えるのって、モバイル用のLlanoくらいしかないんじゃね
E350も割りといいか
いまAMDで買ってもいいと思えるのって、モバイル用のLlanoくらいしかないんじゃね
E350も割りといいか
シングルスレッド性能の低いブルは、
サーバ→絶望的
個人→絶望的
HPC→こっちだけ有望
そもそも、PCやサーバと比べてはるかに小さいHPC市場くらいでしか売れなけりゃ儲かるわけないだろーに
サーバ→絶望的
個人→絶望的
HPC→こっちだけ有望
そもそも、PCやサーバと比べてはるかに小さいHPC市場くらいでしか売れなけりゃ儲かるわけないだろーに
TSMCがキャパ限界でGFがこけてるなら
UMCグループ企業やそのパートナーに発注するわけにはいかんのかな。
遠回しに「広島で作れないかな」という意味なわけだが。
UMCグループ企業やそのパートナーに発注するわけにはいかんのかな。
遠回しに「広島で作れないかな」という意味なわけだが。
今年のPCの成長率は13%・・・だが、タブレットの分を除くと1%だって
http://eetimes.jp/ee/articles/1112/02/news032.html
また別のニュースだが、PCメーカーの40%がWoAに興味だって
28nmのBobcat系で躓いてるのは痛いね
あとChromeの侵食が止まらなが・・・ChromeってGPUの支援って効くんだっけ?
機能としてはあるが余り効果が無かったような
http://www.itmedia.co.jp/news/articles/1112/02/news022.html
http://eetimes.jp/ee/articles/1112/02/news032.html
また別のニュースだが、PCメーカーの40%がWoAに興味だって
28nmのBobcat系で躓いてるのは痛いね
あとChromeの侵食が止まらなが・・・ChromeってGPUの支援って効くんだっけ?
機能としてはあるが余り効果が無かったような
http://www.itmedia.co.jp/news/articles/1112/02/news022.html
昔はUMCとプロセス開発で協力してたな
GFとして切り離した今は競合する立場になったわけだけど
BobcatあたりならUMCで作れない事もないだろうが、単にプロセス技術が高いからあっちやこっちにするわと簡単に移せるわけでもないだろう
長期的に見てもそんなコロコロ変えるのはデメリットの方が多そう
GFとして切り離した今は競合する立場になったわけだけど
BobcatあたりならUMCで作れない事もないだろうが、単にプロセス技術が高いからあっちやこっちにするわと簡単に移せるわけでもないだろう
長期的に見てもそんなコロコロ変えるのはデメリットの方が多そう
Chromeは使いにくいからイラネ
IEや狐でいいわ
IEや狐でいいわ
たぶんだけど、ChromeがIEと並ぶようになってfirefoxはシェアを奪われるばかりなんじゃないかな
流れ的に
流れ的に
>>792
Chromeの躍進は単純にAndroidスマホ分じゃね?
……と思ったらAndroidのブラウザ(のUser-Agent)はSafari(に見えるの)が多いのか
ttp://creamo.jp/webtech/android-useragent/
Chromeの躍進は単純にAndroidスマホ分じゃね?
……と思ったらAndroidのブラウザ(のUser-Agent)はSafari(に見えるの)が多いのか
ttp://creamo.jp/webtech/android-useragent/
>>752
おかげで読む手間が省けたわw
おかげで読む手間が省けたわw
Bulldozer世代の8コアCPU「AMD FX」"Zambezi"徹底攻略 - アーキテクチャ解析編
http://news.mynavi.jp/special/2011/zambezi2/index.html
やっと第二弾きたがな
http://news.mynavi.jp/special/2011/zambezi2/index.html
やっと第二弾きたがな
>>799
>ただ、それがDesktop向けにぜんぜん向いていない、というのが今の最大の課題であろう。
この締めが全てだな。と言うかAMDと同じこといってるじゃん「サーバ向け」だの
「まだ改良の余地はある」、Intelが全く何もしないで待ってるわけないだろ…
3.8GHz以上のクロックが性能伸びないのが分かってるんならOC向けだの
言ってるんじゃないよ…
>ただ、それがDesktop向けにぜんぜん向いていない、というのが今の最大の課題であろう。
この締めが全てだな。と言うかAMDと同じこといってるじゃん「サーバ向け」だの
「まだ改良の余地はある」、Intelが全く何もしないで待ってるわけないだろ…
3.8GHz以上のクロックが性能伸びないのが分かってるんならOC向けだの
言ってるんじゃないよ…
駄目なところは前から言われてたから予想通り。でも改良しても期待できないなこれ。
淡々といわてるけどデスクトップに何でつかったの?という疑問しか残らない。
淡々といわてるけどデスクトップに何でつかったの?という疑問しか残らない。
他に使えるものがないからに決まってるじゃん
>Memory AccessよりL3 Accessの方がLatencyが大きいという、ちょっと理解しがたい結果が出ているのが判る。
・・・
・・・
次の分析があるとしたら、スカラとベクタに切り分けての分析が欲しいな
マズイことだらけだが、設計半分、製造半分てところなんだろうな
807 :Socket774:2011/12/02(金) 17:07:11.61 ID:iouT/BR4
必要十分な性能だからだろ
シングルスレッドベンチで最強とかさわげないだけ
本当に評価出来るのは改良して統合したTrinity次第だろう
シングルスレッドベンチで最強とかさわげないだけ
本当に評価出来るのは改良して統合したTrinity次第だろう
必要十分な性能だからなんて作る側がそこで諦めたら試合終了
訴求できる商品を作れない企業は淘汰される運命
訴求できる商品を作れない企業は淘汰される運命
http://ascii.jp/elem/000/000/489/489200/index-2.html
現状のブルは大原のこの時の目論見よりも低いよな
>実質的なスループットはむしろK10よりも向上する可能性が高い。
ただし、単純なALU命令が続く場合は、当然ながらIPCは2命令/サイクルに留まるわけで、
このあたりを勘案すると(当然アプリケーションによるが)若干ながら同一周波数あたりの性能は、
K10世代より下がるのではないかと想像される。
現状のブルは大原のこの時の目論見よりも低いよな
>実質的なスループットはむしろK10よりも向上する可能性が高い。
ただし、単純なALU命令が続く場合は、当然ながらIPCは2命令/サイクルに留まるわけで、
このあたりを勘案すると(当然アプリケーションによるが)若干ながら同一周波数あたりの性能は、
K10世代より下がるのではないかと想像される。
810 :Socket774:2011/12/02(金) 17:13:17.04 ID:6WoFS6M1
改良の可能性が皆無とは言わんけど
これだけ遅らせても解決できなかったんだから、それなりに困難な道のりであるのは間違いない
これだけ遅らせても解決できなかったんだから、それなりに困難な道のりであるのは間違いない
triのときはもうivyだろ・・・どう考えても全方面で負ける
かろうじて内蔵GPUのスコアだけ勝てるかどうかってことだけじゃね
かろうじて内蔵GPUのスコアだけ勝てるかどうかってことだけじゃね
Trinityでキチンと歩留まり上げることができりゃ問題ない
逆にIvyぶっちぎりの性能で出しても歩留まり悪けりゃオワリ
逆にIvyぶっちぎりの性能で出しても歩留まり悪けりゃオワリ
そもだ、ivyで内蔵GPUは普通に使えるようになるのか?
>>802
AM的もBulldozerしか売らないならOpteron限定にしたいだろうね
でも、次に来るメインストリーム向けのTrnityを考えると、Trinity投入前にBullの存在によって少しでも拡張命令が普及してくれる方がいい
もしもBullをサーバー向け限定としたら、Trinityの時にまた拡張命令で苦労しそう
AM的もBulldozerしか売らないならOpteron限定にしたいだろうね
でも、次に来るメインストリーム向けのTrnityを考えると、Trinity投入前にBullの存在によって少しでも拡張命令が普及してくれる方がいい
もしもBullをサーバー向け限定としたら、Trinityの時にまた拡張命令で苦労しそう
>>813
directx11対応するしivyがTDP改善とGPU性能アップがメイン
directx11対応するしivyがTDP改善とGPU性能アップがメイン
まだ水冷が買えるらしい
http://pc.nikkeibp.co.jp/article/news/20111201/1039340/?set=rss
●水冷式CPUクーラーとFX-8150の限定500セットは出荷しきったのか。
まだ出荷し終えていない。
http://pc.nikkeibp.co.jp/article/news/20111201/1039340/?set=rss
●水冷式CPUクーラーとFX-8150の限定500セットは出荷しきったのか。
まだ出荷し終えていない。
ならないんじゃないか?まぁ自作しない辺りだと
HD Graphicsあたりでも満足してしまうからな。量産できて安く、消費電力も
Llanoより上がらないのが求められるなTrinityは。
HD Graphicsあたりでも満足してしまうからな。量産できて安く、消費電力も
Llanoより上がらないのが求められるなTrinityは。
大原のインプリメントレベルでの最適化が行われてない云々は、
自動設計の部分が致命的にわるいって事だろ
それとDATA-TLBの改善たって、これは要するに増やすしか無いわけだろ?
IPCもしかり。コア内演算基を増やすしかなく、増えた分に見合うだけの命令も供給しなきゃならない
フロントエンド部もまた増設
こうすると、デスクトップにおいてモジュール構造で得なのはあるのか?
ないだろ?
自動設計の部分が致命的にわるいって事だろ
それとDATA-TLBの改善たって、これは要するに増やすしか無いわけだろ?
IPCもしかり。コア内演算基を増やすしかなく、増えた分に見合うだけの命令も供給しなきゃならない
フロントエンド部もまた増設
こうすると、デスクトップにおいてモジュール構造で得なのはあるのか?
ないだろ?
IntelのGPUに期待するほうが間違いかと
AMDとしてはivyよりも投売りSandyの方が怖いんだよ
本来UltraBook(笑)向けなIvyとは競合しないと思う
Trinityの歩留まりが良かったとしてももさすがに数がとりにくい低電圧版じゃ戦うのが難しいとAMDも理解してるだろう
AMDとしてはivyよりも投売りSandyの方が怖いんだよ
本来UltraBook(笑)向けなIvyとは競合しないと思う
Trinityの歩留まりが良かったとしてももさすがに数がとりにくい低電圧版じゃ戦うのが難しいとAMDも理解してるだろう
>>810
バカなの?まさか遅れの理由が設計を弄くり回してたからだとでも?
バカなの?まさか遅れの理由が設計を弄くり回してたからだとでも?
おっと、820の補足
Magny-coursとInterlagosのスコアを見る限り、クロックとコア数を揃えてもALUのスループットは僅かだが向上してそうだよ
Magny-coursとInterlagosのスコアを見る限り、クロックとコア数を揃えてもALUのスループットは僅かだが向上してそうだよ
ivyはCPU性能は大して上げずにGPUとTDP性能に注力するんだよ
だからTriにしたら発売半年前にきちんと流通が確保されていてしかも製品仕様も似通ってるのがでてくるからな
ivyでできなくてtriでできるってゲームがどれだけ出てくるかじゃね
だからTriにしたら発売半年前にきちんと流通が確保されていてしかも製品仕様も似通ってるのがでてくるからな
ivyでできなくてtriでできるってゲームがどれだけ出てくるかじゃね
825 :Socket774:2011/12/02(金) 17:39:21.30 ID:Dmxe4gwi
ゲーム(笑)
Bulldozerはキャッシュが終わってるだけで
スケジューラ規模は従来よりかなり大きいし
メモリ勝負になればかなり性能上がるだろう。
だがメモリやバス性能の影響が大きい場合CPU性能としてはカウントされないらしい。
ソースは2ch
スケジューラ規模は従来よりかなり大きいし
メモリ勝負になればかなり性能上がるだろう。
だがメモリやバス性能の影響が大きい場合CPU性能としてはカウントされないらしい。
ソースは2ch
ゲーム以外で内蔵GPUの性能がCPU性能以上に重要な分野ってあったか?
動画なんてPentiumでも十分すぎるレベルだし一般人がGPU性能を気にするようなところって
結局ゲーム以外ない気がするんだが
他は大体CPU性能高い方がつぶし効くし
動画なんてPentiumでも十分すぎるレベルだし一般人がGPU性能を気にするようなところって
結局ゲーム以外ない気がするんだが
他は大体CPU性能高い方がつぶし効くし
http://news.mynavi.jp/special/2011/zambezi2/016.html
>たとえばFetchは32Bytes/cycleのままDecoderを5命令/Cycleに拡張、
各コアはALU×3、Load×2、Store×1程度の構成にすることも不可能ではないし、
この程度で大幅にIPCは改善するだろう。
この程度というレベルの拡張じゃないだろw
大幅に拡張しなきゃらなんぞ
スケジューラーやリタイア回りも拡張しなきゃならんし
他にもFMAの256Bit化とかやらなきゃならないことあるだろw
>たとえばFetchは32Bytes/cycleのままDecoderを5命令/Cycleに拡張、
各コアはALU×3、Load×2、Store×1程度の構成にすることも不可能ではないし、
この程度で大幅にIPCは改善するだろう。
この程度というレベルの拡張じゃないだろw
大幅に拡張しなきゃらなんぞ
スケジューラーやリタイア回りも拡張しなきゃならんし
他にもFMAの256Bit化とかやらなきゃならないことあるだろw
QSVだ。
ごめん。
ごめん。
>>829
重要か否かは大したことじゃない。AMDがIntelに勝てる部分かが問題なんだ。
仮にGMAの方がRadeonより高性能で、代わりにK10やZamzeziがSandyより
高速だったらそのときはCPUが重要なのさw
重要か否かは大したことじゃない。AMDがIntelに勝てる部分かが問題なんだ。
仮にGMAの方がRadeonより高性能で、代わりにK10やZamzeziがSandyより
高速だったらそのときはCPUが重要なのさw
× Zambezi
○ Zambezi
○ Zambezi
>>830
5命令/cycleは無理だと思うんだ
5命令/cycleは無理だと思うんだ
ユーザの9割はCPU重視としても
残りの1割に訴求できるならAMDの生きる道がある
残りの1割に訴求できるならAMDの生きる道がある
>>836
俺も同意見だけどこのスレの大半は過去の栄光が忘れられないんでしょ
俺も同意見だけどこのスレの大半は過去の栄光が忘れられないんでしょ
まぁtriでbull積むことは諦めた方が
スペック的にも開発費用的にも会社に優しいと思うんだけどな-
普通にllanoを順当進化させることを目指した方が・・・
スペック的にも開発費用的にも会社に優しいと思うんだけどな-
普通にllanoを順当進化させることを目指した方が・・・
>>828
デスクトップ向けのベンチはどれもALU/スカラじゃなくてSIMD/ベクタでしょ
大原氏も、個人レベルでInterlagosに鯖環境を想定した負荷を掛けるのは無理と言ってるが
つまりは鯖で使うのはALUなので大負荷となるほど命令を流し込むのは無理って事でしょ
デスクトップ向けのベンチはどれもALU/スカラじゃなくてSIMD/ベクタでしょ
大原氏も、個人レベルでInterlagosに鯖環境を想定した負荷を掛けるのは無理と言ってるが
つまりは鯖で使うのはALUなので大負荷となるほど命令を流し込むのは無理って事でしょ
>>839
K10信者はもういいから
K10信者はもういいから
めんどくさくなって>>840で酷い文書書いたので書き直し・・・
①PC向けベンチで計るのはほとんどがSIMD/ベクタ
②鯖向けベンチで計るのはALU/スカラ
だからMagny-cours⇔Interlagosの比較とThuban⇔Zambeziの比較では傾向が異なるんじゃないかってこと
①PC向けベンチで計るのはほとんどがSIMD/ベクタ
②鯖向けベンチで計るのはALU/スカラ
だからMagny-cours⇔Interlagosの比較とThuban⇔Zambeziの比較では傾向が異なるんじゃないかってこと
今更言わなくても、FPUが半分の時点で鯖用途しかないよ。
PC市場に売るようなモンじゃないし、ベンチの結果が悪いのも当然。
PC市場に売るようなモンじゃないし、ベンチの結果が悪いのも当然。
鯖向けベンチはLargePageの採用でTLBミスペナルティが減ってるんじゃないのかね
TrinityのCPU部分は2M4Cの4000シリーズの改良版
相手はpenGだろう…
相手はpenGだろう…
Trinity-2M4Cだと62?mm2だから、面積的にもライバルはSandyの2コア(60mm2)だろうね
>>847
く、クマー
く、クマー
9月頃まではllanoのおかげでbullにも期待が満ちあふれていたこのスレが・・・・
AMD Revises Bulldozer Transistor Count: 1.2B, not 2B
http://www.anandtech.com/show/5176/amd-revises-bulldozer-transistor-count-12b-not-2b
前にちょこっと噂に上ってたけど本当に訂正されたようだ
こうなってくると1moduleで2.13億トランジスタってのも、L3加えると12億overしそうだし本当なのか怪しいな
とはいえ学会に出す数値が間違ってるとも思えんが
http://www.anandtech.com/show/5176/amd-revises-bulldozer-transistor-count-12b-not-2b
前にちょこっと噂に上ってたけど本当に訂正されたようだ
こうなってくると1moduleで2.13億トランジスタってのも、L3加えると12億overしそうだし本当なのか怪しいな
とはいえ学会に出す数値が間違ってるとも思えんが
>>851
cyber-gardenのヨリテルがGFは315mm2に20億トランジスターも詰め込める高い技術力とか言ってたなw
http://cybergarden.cocolog-nifty.com/blog/2011/10/amd32nmintel-f9.html
GLOBALFOUNDERIESは凄いことをしている。最高だぜ!
cyber-gardenのヨリテルがGFは315mm2に20億トランジスターも詰め込める高い技術力とか言ってたなw
http://cybergarden.cocolog-nifty.com/blog/2011/10/amd32nmintel-f9.html
GLOBALFOUNDERIESは凄いことをしている。最高だぜ!
GateFirstの方が、GateLastより詰め込めるって話だったから、
それで、Bulldozerのトランジスタ密度高いのかと思ってたんだけど…。
8コアBulldozerが本当に12億だったら、GateFirstのメリットってなんだったんだ?
それで、Bulldozerのトランジスタ密度高いのかと思ってたんだけど…。
8コアBulldozerが本当に12億だったら、GateFirstのメリットってなんだったんだ?
>>853
IEDMなんかに発表してる数値だとIBM系の方が確かにSRAMセルサイズは小さい
けどCPUはSRAMだけで出来てるわけじゃないので…
Uncore部自動配線→ダイサイズ肥大 説が現実味を帯びてる感じじゃないのか
>>854
TLB周りの考察に関してはこのスレの住人の方が一歩先を進んでるな
大原は最適化ガイドやBKDGを読んでないみたいだし、RMMAの測定方法による
見せかけのTLBレイテンシの増加に関しても気付いてないようだ
IEDMなんかに発表してる数値だとIBM系の方が確かにSRAMセルサイズは小さい
けどCPUはSRAMだけで出来てるわけじゃないので…
Uncore部自動配線→ダイサイズ肥大 説が現実味を帯びてる感じじゃないのか
>>854
TLB周りの考察に関してはこのスレの住人の方が一歩先を進んでるな
大原は最適化ガイドやBKDGを読んでないみたいだし、RMMAの測定方法による
見せかけのTLBレイテンシの増加に関しても気付いてないようだ
前にここに張られた結果ではブルのDTLBは1024エントリー以上で70サイクル位まで悪化してた
そんなインパクトのある結果を1000エントリーでぶった切るとかw
気を使ってるのかね
そんなインパクトのある結果を1000エントリーでぶった切るとかw
気を使ってるのかね
>>846-850
Trinityのレビューはこれだけで乗り切ろう
3DMark Vantage Performance GPU score
Trinity A10 : ?
Trinity A8 : 4500
Trinity A6 : 3600
Llano A8 : 3335
ivy HD4000 : 2700
Llano A6 : 2600
Trinity A4 : 2500
Llano A4 : 2025
SB HD3000 : 1400
SB HD2000 : 900
Trinityのレビューはこれだけで乗り切ろう
3DMark Vantage Performance GPU score
Trinity A10 : ?
Trinity A8 : 4500
Trinity A6 : 3600
Llano A8 : 3335
ivy HD4000 : 2700
Llano A6 : 2600
Trinity A4 : 2500
Llano A4 : 2025
SB HD3000 : 1400
SB HD2000 : 900
Windows8に向けてARM+Radeonの真のTrinityをつくりなおせ
ラデの上にブルドーザ載せたら、
爆発的に売れる新アーキテクチャになると思う
爆発的に売れる新アーキテクチャになると思う
>>854
キャッシュ悪化してデータロード待ちのために演算パイプ過疎化したら
演算器とか増やしても意味無いよな
ベンチとかには詳しそうだけど頭の出来がアレな感じ
それはそうとキャッシュ性能って
時間掛けて調整すれば大幅に改善出来るのか
せっかく簡素化したパイプラインまたいじらないと駄目なのか
「そもそも鯖向けには適度にあればいい」なのかどんなもんなんだろな
キャッシュ悪化してデータロード待ちのために演算パイプ過疎化したら
演算器とか増やしても意味無いよな
ベンチとかには詳しそうだけど頭の出来がアレな感じ
それはそうとキャッシュ性能って
時間掛けて調整すれば大幅に改善出来るのか
せっかく簡素化したパイプラインまたいじらないと駄目なのか
「そもそも鯖向けには適度にあればいい」なのかどんなもんなんだろな
大原氏は冷静な判断をしたという印象
TrinityについてはOpteronの低電力シリーズが参考になるかな
例えば4200 EEは(8C/1.6GHz/Turbo時2.8GHz/35W)
2コア10Wに満たないので中々良さそうではある
TrinityについてはOpteronの低電力シリーズが参考になるかな
例えば4200 EEは(8C/1.6GHz/Turbo時2.8GHz/35W)
2コア10Wに満たないので中々良さそうではある
bull開発やめたんだな。来年から3年掛けて新アーキテクチャ開発か
867 :,, ・´ ∀ `・ ,,)っ-○○○:2011/12/02(金) 22:13:03.62 ID:hdpYeB/H
>>865
選別品じゃんw
低消費電力の選別品を数出すにはそれ以上に選別落ち品が大量に出回る。
突然Core 2ベースのCULVがばったり市場から消えたのもCore 2そのものがフェードアウトしたからだ。
選別品じゃんw
低消費電力の選別品を数出すにはそれ以上に選別落ち品が大量に出回る。
突然Core 2ベースのCULVがばったり市場から消えたのもCore 2そのものがフェードアウトしたからだ。
1、2モジュール専用設計なTrinityなら一気に電力落とせるだろうな
普通にBulldozerの選別品より性能良くなりそう
普通にBulldozerの選別品より性能良くなりそう
870 :Socket774:2011/12/02(金) 22:49:45.93 ID:dCOGxHsh
ohanabatake
電力以上に性能がごっそり落ちて
「なんで作った?」と言われる無惨な結果になるけどな
「なんで作った?」と言われる無惨な結果になるけどな
L3取っ払ったTrinityは
普通にBulldozerより性能悪いだろ
普通にBulldozerより性能悪いだろ
874 :Socket774:2011/12/02(金) 22:56:18.71 ID:a/ROhFdA
Phenom II Athlon II出荷停止らしい
ようやくAMDの尻に火がつくな
ようやくAMDの尻に火がつくな
日曜大工みたいにちょちょいと作れるツール作ればええねん
お疲れ様!だね
感慨深いな
でも、AMDは設計専門の会社だってのに、設計図を他社にライセンスできないってのが何だかね
感慨深いな
でも、AMDは設計専門の会社だってのに、設計図を他社にライセンスできないってのが何だかね
L3取り払って更に消費電力が落ちたらZacateの代わりもできるじゃん
zacateのほうが速そうだ
>>873
L2が十分デカいのでその心配はいらない
コア自体改良され、アホみたいに肥大化してたアンコア部もすっきりするだろうからbullとは別物になってそう
それでもCPUでLlano超えられるか怪しい点もあるから期待しすぎるのも良くないけどね
L2が十分デカいのでその心配はいらない
コア自体改良され、アホみたいに肥大化してたアンコア部もすっきりするだろうからbullとは別物になってそう
それでもCPUでLlano超えられるか怪しい点もあるから期待しすぎるのも良くないけどね
それはあり得ないわ
BullコアはBobの260% K10の90%位のサイズだからな
BullコアはBobの260% K10の90%位のサイズだからな
>>873
大原氏のベンチ見るとL3$の効果が見えにくいしね~。
サバ用途だとスヌープとかに使えるけどデスクトップだと微妙。
デスクトップでは削除して、その電力をクロックUPに回した方が性能よさそう。
個人的にはVisheraはL3$省くのではと思ってたりする。
大原氏のベンチ見るとL3$の効果が見えにくいしね~。
サバ用途だとスヌープとかに使えるけどデスクトップだと微妙。
デスクトップでは削除して、その電力をクロックUPに回した方が性能よさそう。
個人的にはVisheraはL3$省くのではと思ってたりする。
FMAが使えないとFPは4コアLlanoの半分しかない
Trinityが出るまでに対応ソフト増えるといいな
Trinityが出るまでに対応ソフト増えるといいな
全てが手遅れ
もうアムドは終わり
もうアムドは終わり
>>882
コアあたりのFPU性能はPhenomの3/4ぐらいで半分とはならない
コアあたりのFPU性能はPhenomの3/4ぐらいで半分とはならない
885 :Socket774:2011/12/02(金) 23:40:07.99 ID:oSE/IU2d
インプレスの後藤さん記事、
共有リソースが 6割 もあるのに 8コア とかフカシすぎじゃんかブル土下座
そりゃ遅いわガラクタだ
残り 4割 のみ専有、半人前に満たないカス
共用してるのが6割なので
8*0.4+8/2*0.6 = 5.6
実は 6コア 分もない事に!?
これで 8 コア とは姉歯物件もびっくり
http://pc.watch.impress.co.jp/docs/column/kaigai/20111019_484609.html
もう、数年前からIPCを重視しない事を宣言していたブルは云わば計画通りの産物
それを世間が受け入れなかった、もしくは受け入れられなかっただけだが
そもそもの発端は、Core-MAを大した脅威と感じなかったAMDの自業自得かな・・・
誰もメリットを感じないCPUを世に出してしまったツケは大きかったw
それを世間が受け入れなかった、もしくは受け入れられなかっただけだが
そもそもの発端は、Core-MAを大した脅威と感じなかったAMDの自業自得かな・・・
誰もメリットを感じないCPUを世に出してしまったツケは大きかったw
俺は性能なんぞ気にしない
AMDがすることは全て肯定する
買わないけど
AMDがすることは全て肯定する
買わないけど
PiledriverをGoogle翻訳したら凄い言葉が出てきたんだけど
ttp://translate.google.co.jp/?q=Piledriver&rls=com.microsoft:ja:%7Breferrer:source%3F%7D&oe=UTF-8&rlz=1I7SNYL_ja&redir_esc=&um=1&ie=UTF-8&hl=ja&sa=N&tab=wT
ttp://translate.google.co.jp/?q=Piledriver&rls=com.microsoft:ja:%7Breferrer:source%3F%7D&oe=UTF-8&rlz=1I7SNYL_ja&redir_esc=&um=1&ie=UTF-8&hl=ja&sa=N&tab=wT
悪いな、既出だ
もうデスクトップあきらめて
AMD ノートの改造でもしよーぜ
AMD ノートの改造でもしよーぜ
そういや3800は遂に俺の視界には入ってこなかったな
Trinityも数出なそうな情報はないんだよな
Trinityも数出なそうな情報はないんだよな
なんかBulldozerのメモリ周りの性能計ってみたらキャッシュ性能が想像以上にやばかった...
http://ll.la/p8=Y
ザックリ説明するとシングルスレッドでいろんなサイズのバッファを
ひたすらmemcpyするプログラム。
http://ll.la/p8=Y
ザックリ説明するとシングルスレッドでいろんなサイズのバッファを
ひたすらmemcpyするプログラム。
俺の場合メリットはあったぜ
純粋に8C使える利点は大きかった
特にゲーム中にバックで何かさせる場合にペナルティが少なくなった
あとアンコア部が改善されてるお陰で、マザー次第ではあるがNB関連がイイ感じに上がる
まぁそれでももうちょっと高速ならばと思うときはあるが
純粋に8C使える利点は大きかった
特にゲーム中にバックで何かさせる場合にペナルティが少なくなった
あとアンコア部が改善されてるお陰で、マザー次第ではあるがNB関連がイイ感じに上がる
まぁそれでももうちょっと高速ならばと思うときはあるが
894 :Socket774:2011/12/03(土) 00:39:39.06 ID:Z4QEg3/d
インプレスの後藤さん記事、
共有リソースが 6割 もあるのに 8コア とかフカシすぎじゃんかブル土下座
そりゃ遅いわガラクタだ
残り 4割 のみ専有、半人前に満たないカス
共用してるのが6割なので
8*0.4+8/2*0.6 = 5.6
実は 6コア 分もない事に!?
これで 8 コア とは姉歯物件もびっくり
http://pc.watch.impress.co.jp/docs/column/kaigai/20111019_484609.html
AMDみたいに安売りはしないんじゃない?
分かっている限りBulldozerが優れるとされるのは
LINPACK、TPC-C、SPECint、SPECfp、VMmark辺り
LINPACK、TPC-C、SPECint、SPECfp、VMmark辺り
SPECの中でもrate限定ね。問題の並列性が十分にないと性能発揮できない。
AMDが優位だと言ってるのはWestmere比だからねえ
来年前半からSandyBridge-EP相手に戦えるのかが問題
来年前半からSandyBridge-EP相手に戦えるのかが問題
問題に並列性があるならBulldozerよりメニーコア、例えばSPARC T4の方がさらに優位だろう。
まあSPARCは高いけど、今後出てくるARMベースのメニーコアは
マルチスレッドアプリケーションにおいて価格性能比に優れることが予想される。
まあSPARCは高いけど、今後出てくるARMベースのメニーコアは
マルチスレッドアプリケーションにおいて価格性能比に優れることが予想される。
そういやARMも参入してたな
新Opteronの安さはXEON比だと4倍ぐらいお買い得でどうも変だ
ARMを意識したのかも分からんね
新Opteronの安さはXEON比だと4倍ぐらいお買い得でどうも変だ
ARMを意識したのかも分からんね
シングルスレッドアプリケーションが全廃出来るわけじゃないから
メニーコアは三文安い
メニーコアは三文安い
>>902
どう考えてもターゲットは被らんだろ……
高効率コアを大量投入するアプローチは
SeaMicroの超高密度Atomサーバが先駆者だが、
あくまで適合はWebフロントエンドなど、
独立したタスクが大量に押し寄せるケースでスループットを重視する場合
どう考えてもターゲットは被らんだろ……
高効率コアを大量投入するアプローチは
SeaMicroの超高密度Atomサーバが先駆者だが、
あくまで適合はWebフロントエンドなど、
独立したタスクが大量に押し寄せるケースでスループットを重視する場合
4並列超えたら16並列も64並列もたいしてかわらんよ(若干嘘)
HPC用 (大量導入時の)コストパフォーマンス、ワットパフォーマンス、帯域、帯域幅あたりの消費電力
サーバ用 大容量キャッシュ、シングルスレッド性能、1チップ当たりの性能
デスクトップ用 シングルスレッド性能、そこそこのキャッシュ、そこそこのコスト・消費電力
やっぱりHPC専用みたいなチップだな
サーバやデスクトップなら、たとえ消費電力上がっても、一般的なアプリの性能を上げないと
サーバ用 大容量キャッシュ、シングルスレッド性能、1チップ当たりの性能
デスクトップ用 シングルスレッド性能、そこそこのキャッシュ、そこそこのコスト・消費電力
やっぱりHPC専用みたいなチップだな
サーバやデスクトップなら、たとえ消費電力上がっても、一般的なアプリの性能を上げないと
http://plusd.itmedia.co.jp/pcuser/articles/1112/02/news041_2.html
> Bulldozerアーキテクチャの特性を十分に利用できていないため、スコアとして
> 反映されない。FXシリーズは先を見て開発しているのだ
対応ソフトが揃うまではSandy買っとけ
> Bulldozerアーキテクチャの特性を十分に利用できていないため、スコアとして
> 反映されない。FXシリーズは先を見て開発しているのだ
対応ソフトが揃うまではSandy買っとけ
>>829
それを言うならcpu性能はもっと気にしないぞ
例えば”i5-2520M ”性能なんて分かる人がどれだけいる
それに対して動画性能はだれでもすぐ実感できる
youtubeでHD動画や重い動画がカクカクしたらすぐにわかる
それを言うならcpu性能はもっと気にしないぞ
例えば”i5-2520M ”性能なんて分かる人がどれだけいる
それに対して動画性能はだれでもすぐ実感できる
youtubeでHD動画や重い動画がカクカクしたらすぐにわかる
>>830
オレの当初の評価通り
鯖特化アーキを無理やりpcに持ってきたってことだな
冗長部分をバッサリ切ってpcに特化 4コアまでのアーキにすべき それで消費電力は大幅に改善できる
てかモバ向けtriはtdp35wだからcpu部は15,6wになってるはず
オレの当初の評価通り
鯖特化アーキを無理やりpcに持ってきたってことだな
冗長部分をバッサリ切ってpcに特化 4コアまでのアーキにすべき それで消費電力は大幅に改善できる
てかモバ向けtriはtdp35wだからcpu部は15,6wになってるはず
こんな感じで、心の病を抱えた人がAMDを支えています。
皆様の厚い御支援をよろしくお願いします。
皆様の厚い御支援をよろしくお願いします。
ARM真理教は無駄な改行やめたの
2wayのスーパースケーラのコア2つではなく、
3wayのコアと1wayのコアをセットにしてモジュール化すればよかったんじゃないか。
3wayのコアと1wayのコアをセットにしてモジュール化すればよかったんじゃないか。
L3がメインメモリより遅いのならL3を無効にするかバッサリ切り捨てたらいいだけだなw
その方が性能が上がってダイサイズもコストも大幅に下がるしw
その方が性能が上がってダイサイズもコストも大幅に下がるしw
918 :Socket774:2011/12/03(土) 03:50:06.61 ID:Z4QEg3/d
http://www.anandtech.com/show/5176/amd-revises-bulldozer-transistor-count-12b-not-2b
なんとBullのトランジスタ数は20億ではなく12億だったとさ
面積当たりのトランジスタ密度は32nmで最悪
http://cybergarden.cocolog-nifty.com/blog/2011/10/amd32nmintel-f9.html
>AMDの32nmは歩留まりで苦戦しているが、Intelよりトランジスタが小さい。
>なんで20億トランジスタが300平方mmなんだ?
>GLOBALFOUNDERIESは凄いことをしている。最高だぜ!
http://www.anandtech.com/show/5176/amd-revises-bulldozer-transistor-count-12b-not-2b
だが実は12億トランジスタwww
>>863
馬鹿かおまえ
androidスマホなんて本格的に立ち上がって1年半程だしpadは更に歴史が浅い
padなんてtegra2ごときの性能でシェアのほとんどを取れた市場だぞユーザーの満足には程遠い
padはやっとよちよち歩きの段階
馬鹿かおまえ
androidスマホなんて本格的に立ち上がって1年半程だしpadは更に歴史が浅い
padなんてtegra2ごときの性能でシェアのほとんどを取れた市場だぞユーザーの満足には程遠い
padはやっとよちよち歩きの段階
>>916
非対称マルチコアは使いにくそうだ
非対称マルチコアは使いにくそうだ
>>873
馬鹿は書き込むなw
馬鹿は書き込むなw
なんか全部オレの予言通りになっていきそうだな
誰でも理論的に考えれば分かることではあるがw
誰でも理論的に考えれば分かることではあるがw
名無しのくせに俺の予言もへったくれもあるか
見分けてほしけりゃコテと鳥付けやがれ
鯖でXeon互換ソケットのKnightsCornerに負けてなけりゃいいな>ARM鯖
見分けてほしけりゃコテと鳥付けやがれ
鯖でXeon互換ソケットのKnightsCornerに負けてなけりゃいいな>ARM鯖
鯖はシングルスレッドって言うヤツはちょっと考え直した方がいいけど、
シングルスレッド性能が足りないというケースはあるらしく
Sunは多スレッド指向で突っ走りつつもクロック向上させてたりする。
まあARMもいずれ性能上げるだろう。この点が問題になったりはしないと思う。
シングルスレッド性能が足りないというケースはあるらしく
Sunは多スレッド指向で突っ走りつつもクロック向上させてたりする。
まあARMもいずれ性能上げるだろう。この点が問題になったりはしないと思う。
鯖とひとくくりにするのは乱暴がすぎるだろ
同様にHPCも典型的な問題が一つあるわけじゃないからな
同様にHPCも典型的な問題が一つあるわけじゃないからな
サーバ用途じゃ、キャッシュ強化がパフォーマンスに直結する
数多くの処理をキャッシュ内で主メモリにあまりアクセスせずに終えるほうがいい
IBMもSunもIntelもサーバ用CPUはキャッシュを強化してる
数多くの処理をキャッシュ内で主メモリにあまりアクセスせずに終えるほうがいい
IBMもSunもIntelもサーバ用CPUはキャッシュを強化してる
バックエンドのデータベースサーバみたいなものになると
確かに各トランザクションは並列に走っているが
一方で同期処理の塊でもあるので、理想的なマルチスレッドとも言い切れない
さすがにDB鯖にAtomってのは聞いたことがないのは、
第一に性能が出ないからなんだろうなあ
確かに各トランザクションは並列に走っているが
一方で同期処理の塊でもあるので、理想的なマルチスレッドとも言い切れない
さすがにDB鯖にAtomってのは聞いたことがないのは、
第一に性能が出ないからなんだろうなあ
>>911
一般人が見るレベルの動画ならそもそもpentiumGで十分見れるしなぁ・・・・
動画見る程度で要求される内蔵GPUの性能なんてたいしたことないし
あえてtriにする利点がゲームくらいしかないだろ
一般人が見るレベルの動画ならそもそもpentiumGで十分見れるしなぁ・・・・
動画見る程度で要求される内蔵GPUの性能なんてたいしたことないし
あえてtriにする利点がゲームくらいしかないだろ
x264 30fps 1080の動画ならx2でも見られるからなあ
今のCPUだとATOMだときついかもって世界
まあ速くなって損は無いんで値段次第か
今のCPUだとATOMだときついかもって世界
まあ速くなって損は無いんで値段次第か
向き不向きについて書かれてるかな
スモールコアサーバー
http://pc.watch.impress.co.jp/docs/column/kaigai/20111109_489233.html
性能/消費電力から(性能/消費電力)/コストへ(下段)
速度がいくらか下がっても良いからコストが10分の1のDRAMが欲しい
http://pc.watch.impress.co.jp/docs/news/event/20111111_489879.html
スモールコアサーバー
http://pc.watch.impress.co.jp/docs/column/kaigai/20111109_489233.html
性能/消費電力から(性能/消費電力)/コストへ(下段)
速度がいくらか下がっても良いからコストが10分の1のDRAMが欲しい
http://pc.watch.impress.co.jp/docs/news/event/20111111_489879.html
あ~やばい・・・
以前『サーバーメーカーは速度がいくら下がっても良いからコストが10分の1のDRAMが欲しいらしい』と書き込んだが、
正しくは『サーバーメーカーは速度がいくら「か」下がっても良いからコストが10分の1のDRAMが欲しいらしい』だった・・・
全然違った^^;;;;;;
以前『サーバーメーカーは速度がいくら下がっても良いからコストが10分の1のDRAMが欲しいらしい』と書き込んだが、
正しくは『サーバーメーカーは速度がいくら「か」下がっても良いからコストが10分の1のDRAMが欲しいらしい』だった・・・
全然違った^^;;;;;;
FM1もう死んでしまうん?
Trinityのデスク向けの生産開始が3月~4月って言われてるから
何だかんだ来年の夏ぐらいまで生きてそうな気がするよ
何だかんだ来年の夏ぐらいまで生きてそうな気がするよ
客をバカにしても売れるのだから仕方がない。
>>940
大変な事実がwwww
http://pc.nikkeibp.co.jp/article/news/20111201/1039340/?set=rss
●水冷式CPUクーラーとFX-8150の限定500セットは出荷しきったのか。
まだ出荷し終えていない。
大変な事実がwwww
http://pc.nikkeibp.co.jp/article/news/20111201/1039340/?set=rss
●水冷式CPUクーラーとFX-8150の限定500セットは出荷しきったのか。
まだ出荷し終えていない。
>>868
サーバーに必要なのはメインメモリ帯域と
一度にさばけるスレッド数だと思うんだが
ベンチ番長とかピーク番長はサーバーには向かない。
>>916
負荷に応じて、1コアずつクロック制御したらいいだけじゃね。
サーバーに必要なのはメインメモリ帯域と
一度にさばけるスレッド数だと思うんだが
ベンチ番長とかピーク番長はサーバーには向かない。
>>916
負荷に応じて、1コアずつクロック制御したらいいだけじゃね。
944 :Socket774:2011/12/03(土) 10:41:39.81 ID:FwllxdIi
しかしARMを持ち上げようとおもったら実はAMDが押しつぶされようとしてたなんてなぁ
>>943
サバサバ言っているが、サバの用途によるだろ。
サバサバ言っているが、サバの用途によるだろ。
http://plusd.itmedia.co.jp/pcuser/articles/1110/17/news091_2.html
最初から、500個出荷は厳しいって言ってたよ。
> 水冷キットをバンドルしたFX-8150に関しては、年内にはほぼ間違いなくいけます。
> クリスマスまでには……が、がんばります
なのに突然発売日11月4日に決まったから、何かと思ったら、
出来たぶんから順に出荷するということだったんだよね。
http://plusd.itmedia.co.jp/pcuser/articles/1110/28/news098.html
最初から、500個出荷は厳しいって言ってたよ。
> 水冷キットをバンドルしたFX-8150に関しては、年内にはほぼ間違いなくいけます。
> クリスマスまでには……が、がんばります
なのに突然発売日11月4日に決まったから、何かと思ったら、
出来たぶんから順に出荷するということだったんだよね。
http://plusd.itmedia.co.jp/pcuser/articles/1110/28/news098.html
通常版の8150がそれなりに出回ってる辺りを見るに、単に小売から発注が
来ないから500セット出荷できないってだけだろw
実際に売り切れてたのはアキバだけで、地方じゃしばらく売れずに残ってた様子だからなw
来ないから500セット出荷できないってだけだろw
実際に売り切れてたのはアキバだけで、地方じゃしばらく売れずに残ってた様子だからなw
949 :Socket774:2011/12/03(土) 10:57:38.73 ID:7sBfwAZ4
リソースの殆どをAPUに振り分けているからな、Zambeziは後回しになるのは仕方ない
そして量産されるキーホルダー
>>949
決まり文句になってるけど、ソースあるのそれ?
決まり文句になってるけど、ソースあるのそれ?
発注が来ないってだけなら、とっととkonozamaに出荷してくれや。
予約から1ヶ月以上やで。
予約から1ヶ月以上やで。
希少な良品、Opteronの名前で売れば何倍の値段にもなるんだから、
そりゃFXは「出しました」っていうアリバイ程度以上は出荷しないわな。
そりゃFXは「出しました」っていうアリバイ程度以上は出荷しないわな。
キ~ホルダ~♪ はじめました~♪
>>943
鯖でメモリのch数が要求されるのは帯域じゃなくて容量のためでしょ
※レンダリングサーバーとかは別だろうけど
MBによっては速度は犠牲にして、ブリッジチップを噛ませて1chに何枚もメモリを繋げたりする
鯖でメモリのch数が要求されるのは帯域じゃなくて容量のためでしょ
※レンダリングサーバーとかは別だろうけど
MBによっては速度は犠牲にして、ブリッジチップを噛ませて1chに何枚もメモリを繋げたりする
DB鯖はトランザクション処理が走るからあまりマルチスレッドに出来ない
理論的にはシングルスレッドが有利なCPUの方が強い
だけどDBはAMDCPUの方がぶっちぎりに速いんだよな
理論的にはシングルスレッドが有利なCPUの方が強い
だけどDBはAMDCPUの方がぶっちぎりに速いんだよな
ivyの内蔵にHD7670ぐらいしろ
DBがぶっちぎり? ご冗談を。
>>958
どういうことだってばよ
どういうことだってばよ
>>952
"Piledriver"がAPU先行の時点で…。
"Piledriver"がAPU先行の時点で…。
DBはマルチスレッドに向かない処理を無理矢理マルチスレッド化するから
メモリ帯域やメモリレイテンシの扱いが重要になるんだろうがjk
スレッド間の依存関係がないなら極論L3すらいらないし。
高価な多ソケットサーバ使わずに安物サーバ並べてもおk
Bulldozerの性能
キャッシュ性能 → キャッシュ性能は原因はワカランがとにかくヤバス
メモリ性能 → 安定している
メモリ帯域やメモリレイテンシの扱いが重要になるんだろうがjk
スレッド間の依存関係がないなら極論L3すらいらないし。
高価な多ソケットサーバ使わずに安物サーバ並べてもおk
Bulldozerの性能
キャッシュ性能 → キャッシュ性能は原因はワカランがとにかくヤバス
メモリ性能 → 安定している
Bulldozerのメモリバンド幅は73GB/sで相当早いと言えるだろうな
>>964
キャッシュ周りが完全に腐っているのが、
コアの腐りに拍車をかけているんだよな…。
いい加減本腰を入れて改良しろと思うわ。
前回の性能競争離脱の可能性の話で、
久しぶりにメインPCのCPUがIntelに変わって、
サブがAMD予定だよ。来年以降。
キャッシュ周りが完全に腐っているのが、
コアの腐りに拍車をかけているんだよな…。
いい加減本腰を入れて改良しろと思うわ。
前回の性能競争離脱の可能性の話で、
久しぶりにメインPCのCPUがIntelに変わって、
サブがAMD予定だよ。来年以降。
73GB/sとかDDR3-1600 4chより圧倒的に速い
>>966
せめてBulldozerのキャッシュ周りがK10相当になれば性能大幅に改善すると思う。
せめてBulldozerのキャッシュ周りがK10相当になれば性能大幅に改善すると思う。
>>967
すまん2Pでの数値だった
しかもLINPACKの測定値っぽい
73 GB/s, 2 x AMD Opteron? processors Model 6276 in Supermicro H8DGT, 64GB (8 x 8GB DDR3-1600) memory, SuSE LinuxR Enterprise Server 11 SP1 64-bit, x86 Open64 4.2.5-1 Compiler Suite
42 GB/s, 2 x Intel Xeon processors Model X5670 in Supermicro X8DTT server, 24GB (6 x 4GB DDR3-1333) memory, SuSE LinuxR Enterprise Server 11 SP1 64-bit, Intel Compiler v11.1.064
すまん2Pでの数値だった
しかもLINPACKの測定値っぽい
73 GB/s, 2 x AMD Opteron? processors Model 6276 in Supermicro H8DGT, 64GB (8 x 8GB DDR3-1600) memory, SuSE LinuxR Enterprise Server 11 SP1 64-bit, x86 Open64 4.2.5-1 Compiler Suite
42 GB/s, 2 x Intel Xeon processors Model X5670 in Supermicro X8DTT server, 24GB (6 x 4GB DDR3-1333) memory, SuSE LinuxR Enterprise Server 11 SP1 64-bit, Intel Compiler v11.1.064
ここでもインテルはベンチだけ速いと言ってたやつへのブーメランか!
>>972
知ってる。
知ってる。
GlobalFounrdriesからTSMCに変わったら生まれ変わる?
975 :Socket774:2011/12/03(土) 14:56:24.02 ID:+ZUt5v0l
ム
リ
AMDからは暫らく2600K以上のCPUはでないのかな?
出ないのであれば年末商戦はIntelに浮気してもよろしいでしょうか?
出ないのであれば年末商戦はIntelに浮気してもよろしいでしょうか?
>>976
好きなの買えよ。その判断ができないならばメーカー製でも買えよ。
好きなの買えよ。その判断ができないならばメーカー製でも買えよ。
年末だからCPUを買うって、年越しの儀式か何かなのか?
そろそろPCが必要、だから安くなる年末商戦でPCを買う、別におかしくないと思うが。
そこでFX-8150を買うとなにかおかしい感じがするが。
そこでFX-8150を買うとなにかおかしい感じがするが。
道楽に意味などいらない
AMD Cシリーズを究めてARMを撃退してくれよ
ぶっちゃけBulldozerでも
「動かないソフトはない」という意味で問題はないんだけどね
「動かないソフトはない」という意味で問題はないんだけどね
そう考えるとbullもあんまりゴミじゃない気がしてきた
つまり2500kは神CPU
>>984
低過ぎ、判断基準のレベルが。
低過ぎ、判断基準のレベルが。
http://www.anandtech.com/show/5176/amd-revises-bulldozer-transistor-count-12b-not-2b
なんとBullのトランジスタ数は20億ではなく12億だったとさ
面積当たりのトランジスタ密度は32nmで最悪
http://cybergarden.cocolog-nifty.com/blog/2011/10/amd32nmintel-f9.html
>AMDの32nmは歩留まりで苦戦しているが、Intelよりトランジスタが小さい。
>なんで20億トランジスタが300平方mmなんだ?
>GLOBALFOUNDERIESは凄いことをしている。最高だぜ!
http://www.anandtech.com/show/5176/amd-revises-bulldozer-transistor-count-12b-not-2b
だが実は12億トランジスタwww
http://cybergarden.cocolog-nifty.com/blog/2011/12/amd32nm12bintel.html
トランジスタが少ない最高だぜ!に変ってるw
なんとBullのトランジスタ数は20億ではなく12億だったとさ
面積当たりのトランジスタ密度は32nmで最悪
http://cybergarden.cocolog-nifty.com/blog/2011/10/amd32nmintel-f9.html
>AMDの32nmは歩留まりで苦戦しているが、Intelよりトランジスタが小さい。
>なんで20億トランジスタが300平方mmなんだ?
>GLOBALFOUNDERIESは凄いことをしている。最高だぜ!
http://www.anandtech.com/show/5176/amd-revises-bulldozer-transistor-count-12b-not-2b
だが実は12億トランジスタwww
http://cybergarden.cocolog-nifty.com/blog/2011/12/amd32nm12bintel.html
トランジスタが少ない最高だぜ!に変ってるw
988 : 忍法帖【Lv=11,xxxPT】 :2011/12/03(土) 17:23:20.52 ID:mY4fryan
>>987
CyberGardenは馬鹿の鏡だなw
CyberGardenは馬鹿の鏡だなw
>>986
やっぱり?w
やっぱり?w
>>988
乙。
乙。
キャッシュの詰めの甘さといいアンコアの詰めの甘さと(いうかツール任せ)といい
ほんっとに人手足りなかったんだな
AMDの規模でBullBobK10の3車線は今更ながら無謀
ほんっとに人手足りなかったんだな
AMDの規模でBullBobK10の3車線は今更ながら無謀
993 :Socket774:2011/12/03(土) 17:58:27.56 ID:8zfwlMXj
人手が足りないんじゃない
これが実力なんだ
これが実力なんだ
優秀な人材確保できるのも結局金の力だからな
元DECのAlphaチーム持ってたんだから
優秀な人材が確保できないのではなく、経営陣が使えなかっただけ
優秀な人材が確保できないのではなく、経営陣が使えなかっただけ
鯖用途からPCへという流れはそろそろ終わりと言うことだな。
>>988
おつうめ
おつうめ
999 :Socket774:2011/12/03(土) 19:59:52.80 ID:QlXcdQvK
うめ
1000 :Socket774:2011/12/03(土) 20:00:11.03 ID:QlXcdQvK
1000
1001 :1001: