AMD�̎�����CPU�ɂ��Č�낤 ��42����
�_.�Q�@ | �r�炵�E����E�~�[�͕��u����ԁB
�^|�Q|�@| �ނ�ꂸ�ɃX���[���܂��傤�B
|�Q�^�_! sage�i�s�Ń}�^�[�������܂��傤�B
���O�X��
AMD�̎�����CPU�ɂ��Č�낤 ��41����
http://hibari.2ch.net/test/read.cgi/jisaku/1279326700/
�����AMD�n�X���b�h�ߋ����O�ۑ��T�C�g�l
http://amd.jisakuita.net/
���֘A�X��
Intel�̎�����CPU�ɂ��Č�낤 43
http://hibari.2ch.net/test/read.cgi/jisaku/1270976684/
CPU�A�[�L�e�N�`���ɂ��Č�� 17
http://hibari.2ch.net/test/read.cgi/jisaku/1274809074/
�^|�Q|�@| �ނ�ꂸ�ɃX���[���܂��傤�B
|�Q�^�_! sage�i�s�Ń}�^�[�������܂��傤�B
���O�X��
AMD�̎�����CPU�ɂ��Č�낤 ��41����
http://hibari.2ch.net/test/read.cgi/jisaku/1279326700/
�����AMD�n�X���b�h�ߋ����O�ۑ��T�C�g�l
http://amd.jisakuita.net/
���֘A�X��
Intel�̎�����CPU�ɂ��Č�낤 43
http://hibari.2ch.net/test/read.cgi/jisaku/1270976684/
CPU�A�[�L�e�N�`���ɂ��Č�� 17
http://hibari.2ch.net/test/read.cgi/jisaku/1274809074/
|
|
|
2get
Llano���čŏ��͍��N�̏H�ɏo��͂��������̂�
���N�̏t���ɉ������ꂽ�킯�Ȃ́H
���N�̏t���ɉ������ꂽ�킯�Ȃ́H
�����Ȃ�ˁH
���̑���Ontario�����N���獡�N�ɑO�|�����ꂽ���ǂ�
Llano��Bulldozer��2011���炾��
http://pc.watch.impress.co.jp/docs/column/kaigai/20091112_328392.html
Sandy��2011�����A�������̓��[�J�[�ւ̏o�ׂɂ��Ă͔N���Ɏn�܂邩��
http://pc.watch.impress.co.jp/docs/column/kaigai/20091112_328392.html
Sandy��2011�����A�������̓��[�J�[�ւ̏o�ׂɂ��Ă͔N���Ɏn�܂邩��
����28nm�o���N�̐������s��NY�H���2012�N�ғ��\��ŁA���ɂ������X�n�ɍH������Ă�Ƃ��납��̃X�^�[�g������
������g��GPU�iHD7xxx�H�j��Ontario�̌�p���O�|���̉\���͏������Ǝv��
������g��GPU�iHD7xxx�H�j��Ontario�̌�p���O�|���̉\���͏������Ǝv��
NY��22nm�ȍ~(28nm���ꉞ�Ή��͂���炵������)
28nm�̓h���X�f�����g�����đΉ����Ă���
28nm�̓h���X�f�����g�����đΉ����Ă���
Bulldozer�������\�܂œ��{���Ԃ��Ƒ�̂���3����
>>9
�����̍H�ꂪ�����Đݔ��̍X�V�ōςނ̂Ȃ�A�[�����[�J�[���̏������������ΐ��Y���J�n�ł��邪
�H������Ă�̂ł���H��̌��݂��t���[�`���[�g�ɗ���ł���
�����炻���ȒP�ɂ͑O�|���ł��Ȃ���Ȃ��̂��Ęb��
>>8
GF��HP�ɂ�NY�ł�28�`���ď����Ă���̂ŁA���ꂪ��͂Ǝv���Ă������h���X�f���ł����Y����̂�
����Ȃ痈�N���ɐ��Y�J�n�����肻������
�����̍H�ꂪ�����Đݔ��̍X�V�ōςނ̂Ȃ�A�[�����[�J�[���̏������������ΐ��Y���J�n�ł��邪
�H������Ă�̂ł���H��̌��݂��t���[�`���[�g�ɗ���ł���
�����炻���ȒP�ɂ͑O�|���ł��Ȃ���Ȃ��̂��Ęb��
>>8
GF��HP�ɂ�NY�ł�28�`���ď����Ă���̂ŁA���ꂪ��͂Ǝv���Ă������h���X�f���ł����Y����̂�
����Ȃ痈�N���ɐ��Y�J�n�����肻������
�����܂ŘR��Ă��Ă�b�͂��܂�wktk�ł���悤�Ȃ��̂ł͂Ȃ��ȁB
IA������Rock��POWER�̂悤�ȍ����i�̃����X�^�[�`�b�v�ɂ͂Ȃ肦�Ȃ��A�Ƃ����͍̂��������Ƃ��Ă�
���W���[���݂����ȓƎ��̐V�Z�p���������ɂ��̃����b�g�����炩�łȂ��B
(�Ă����̂Ƃ���̓f�����b�g���������Ȃ�)
�{����NetBurst�̋t�P�������炻��͂���ŋ����M���Ȃ邪�B
IA������Rock��POWER�̂悤�ȍ����i�̃����X�^�[�`�b�v�ɂ͂Ȃ肦�Ȃ��A�Ƃ����͍̂��������Ƃ��Ă�
���W���[���݂����ȓƎ��̐V�Z�p���������ɂ��̃����b�g�����炩�łȂ��B
(�Ă����̂Ƃ���̓f�����b�g���������Ȃ�)
�{����NetBurst�̋t�P�������炻��͂���ŋ����M���Ȃ邪�B
TdU4OPxn
���É߂��ԈႢ����
���É߂��ԈႢ����
GLOBALFOUNDRIES�A2010�N���܂ł�28nm�v���Z�X�ł̗ʎY�J�n���v��
http://journal.mycom.co.jp/articles/2010/05/27/gf_2010/index.html
>GPU�iHD7xxx�H�j��Ontario�̌�p���O�|���̉\���͏������Ǝv��
>GPU�iHD7xxx�H�j��Ontario�̌�p���O�|���̉\���͏������Ǝv��
>GPU�iHD7xxx�H�j��Ontario�̌�p���O�|���̉\���͏������Ǝv��
�O�|���Ƃ��͂ǂ��ł�������
��p�Ɋւ��Ă�2015�N��Fusion�܂łɃ����X�e�b�v���ꂽ���p���I��
APU�����������\���̂ق����������
http://journal.mycom.co.jp/articles/2010/05/27/gf_2010/index.html
>GPU�iHD7xxx�H�j��Ontario�̌�p���O�|���̉\���͏������Ǝv��
>GPU�iHD7xxx�H�j��Ontario�̌�p���O�|���̉\���͏������Ǝv��
>GPU�iHD7xxx�H�j��Ontario�̌�p���O�|���̉\���͏������Ǝv��
�O�|���Ƃ��͂ǂ��ł�������
��p�Ɋւ��Ă�2015�N��Fusion�܂łɃ����X�e�b�v���ꂽ���p���I��
APU�����������\���̂ق����������
�^�د�u�y���͔\�����Ŋ��������ς����������d�����邩��]�T�͑S��������
�@�@�@�@�ݔ��X�V�Ȃ�X�P�W���[���⎑���J�薳�����Ă�������v
�@�@�@�@�ݔ��X�V�Ȃ�X�P�W���[���⎑���J�薳�����Ă�������v
6����COMPUTEX 2010���_�ł̃X�P�W���[��
Fab1�i�h���X�f���j�@�F����45nmSOI
�@�@�@�@�@�@�@�@�@�@�@�߂�������32nmSOI/HKMG�ֈڍs
�@�@�@�@�@�@�@�@�@�@�@2011�N��45/40nmHKMG�ғ�
�@�@�@�@�@�@�@�@�@�@�@����28nmHKMG�ֈڍs
Fab7�i�V���K�|�[���j�F����0.13um(60nm?)�`45nm�o���N
�@�@�@�@�@�@�@�@�@�@�@�����͔��׃v���Z�X�ֈڍs
Fab8�i�j���[���[�N�j�F2011�N���ɍH�ꊮ��
�@�@�@�@�@�@�@�@�@�@�@2012�N��28nmHKMG�ғ�
�@�@�@�@�@�@�@�@�@�@�@2013�N��22/20nmHKMG�ғ�
3�����߂��O�̔��\�ōŐV�ł͂Ȃ��̂ň������炸
Fab1�i�h���X�f���j�@�F����45nmSOI
�@�@�@�@�@�@�@�@�@�@�@�߂�������32nmSOI/HKMG�ֈڍs
�@�@�@�@�@�@�@�@�@�@�@2011�N��45/40nmHKMG�ғ�
�@�@�@�@�@�@�@�@�@�@�@����28nmHKMG�ֈڍs
Fab7�i�V���K�|�[���j�F����0.13um(60nm?)�`45nm�o���N
�@�@�@�@�@�@�@�@�@�@�@�����͔��׃v���Z�X�ֈڍs
Fab8�i�j���[���[�N�j�F2011�N���ɍH�ꊮ��
�@�@�@�@�@�@�@�@�@�@�@2012�N��28nmHKMG�ғ�
�@�@�@�@�@�@�@�@�@�@�@2013�N��22/20nmHKMG�ғ�
3�����߂��O�̔��\�ōŐV�ł͂Ȃ��̂ň������炸
�Ƃ������AAMD��TSMC��28nm���m�ۂ������ق�Nvidia�̊��蓖�Ă�����
��������TSMC��{�Ȃ���E�F�n�̊��蓖�Ă�����Α��V�F�A�k���Ɍq����
GPU��Bobcat���킴��TSMC�ɔ������āANVIDIA�̃V�F�A�i���Y�ʁj���R���g���[�����ɒu���������ǂ������ȋC������
GF�̕��͎��Y�Ŗ��߂Ă�
��������TSMC��{�Ȃ���E�F�n�̊��蓖�Ă�����Α��V�F�A�k���Ɍq����
GPU��Bobcat���킴��TSMC�ɔ������āANVIDIA�̃V�F�A�i���Y�ʁj���R���g���[�����ɒu���������ǂ������ȋC������
GF�̕��͎��Y�Ŗ��߂Ă�
globalfoundries��TSMC��28nm�̐��Y�\�͂��Ăǂꂭ�炢�ɂȂ��
����TSMC40nm�Ɠ����ʂȂ瑫��Ȃ�����ǂ����ɂ���2�ЕK�v����
����TSMC40nm�Ɠ����ʂȂ瑫��Ȃ�����ǂ����ɂ���2�ЕK�v����
>>18
�����z���̂��̂Ō���Ȃ�TSMC��葽������
���Y�\�͂͌݊p������ȏ�ɂ͂Ȃ���
�����A��p���{�̔����̊�Ƃւ̗D�����Ղ�������
�K���K���������ꂻ��������Ȃ��E�E�E
�����z���̂��̂Ō���Ȃ�TSMC��葽������
���Y�\�͂͌݊p������ȏ�ɂ͂Ȃ���
�����A��p���{�̔����̊�Ƃւ̗D�����Ղ�������
�K���K���������ꂻ��������Ȃ��E�E�E
Hot Chips 22
Session 7: New Processor Architectures
���{���� 8��25�� 09��00���`10��30��
�EIBM (The Next-generation System z Micro-Processor)
�EAMD ("Bulldozer" Core - a new approach to multithreaded compute performance for maximum efficiency and throughput)
�EAMD ("Bobcat" x86 Core - Small, Efficient and Strong)
Session 7: New Processor Architectures
���{���� 8��25�� 09��00���`10��30��
�EIBM (The Next-generation System z Micro-Processor)
�EAMD ("Bulldozer" Core - a new approach to multithreaded compute performance for maximum efficiency and throughput)
�EAMD ("Bobcat" x86 Core - Small, Efficient and Strong)
��͂���{�ł͖������B
AMD's Bobcat and Bulldozer, 2011 flagship CPU cores, detailed today
http://www.engadget.com/2010/08/24/amds-bobcat-and-bulldozer-2011-flagship-cpu-cores-detailed-to/
http://www.engadget.com/2010/08/24/amds-bobcat-and-bulldozer-2011-flagship-cpu-cores-detailed-to/
http://www.pcper.com/article.php?aid=985
http://www.lostcircuits.com/mambo//index.php?option=com_content&task=view&id=91&Itemid=1
http://www.hardocp.com/article/2010/08/23/amds_bulldozer_bobcat_processors_preview
http://www.anandtech.com/show/3863/amd-discloses-bobcat-bulldozer-architectures-at-hot-chips-2010
http://www.extremetech.com/article2/0,2845,2368185,00.asp
http://www.lostcircuits.com/mambo//index.php?option=com_content&task=view&id=91&Itemid=1
http://www.hardocp.com/article/2010/08/23/amds_bulldozer_bobcat_processors_preview
http://www.anandtech.com/show/3863/amd-discloses-bobcat-bulldozer-architectures-at-hot-chips-2010
http://www.extremetech.com/article2/0,2845,2368185,00.asp
>>23
�ǂނ̂�Anand�����ł�������
http://www.anandtech.com/show/3863/amd-discloses-bobcat-bulldozer-architectures-at-hot-chips-2010
���ƌ݊����ɂ���
http://www.extremetech.com/article2/0,2845,2368186,00.asp
AMD also told us that it will introduce a new AM3+ socket for consumer versions of Bulldozer CPUs. AM2 and AM3 processors will work in the AM3+ socket, but Bulldozer chips will not work in non-AM3+ motherboards.
�ǂނ̂�Anand�����ł�������
http://www.anandtech.com/show/3863/amd-discloses-bobcat-bulldozer-architectures-at-hot-chips-2010
���ƌ݊����ɂ���
http://www.extremetech.com/article2/0,2845,2368186,00.asp
AMD also told us that it will introduce a new AM3+ socket for consumer versions of Bulldozer CPUs. AM2 and AM3 processors will work in the AM3+ socket, but Bulldozer chips will not work in non-AM3+ motherboards.
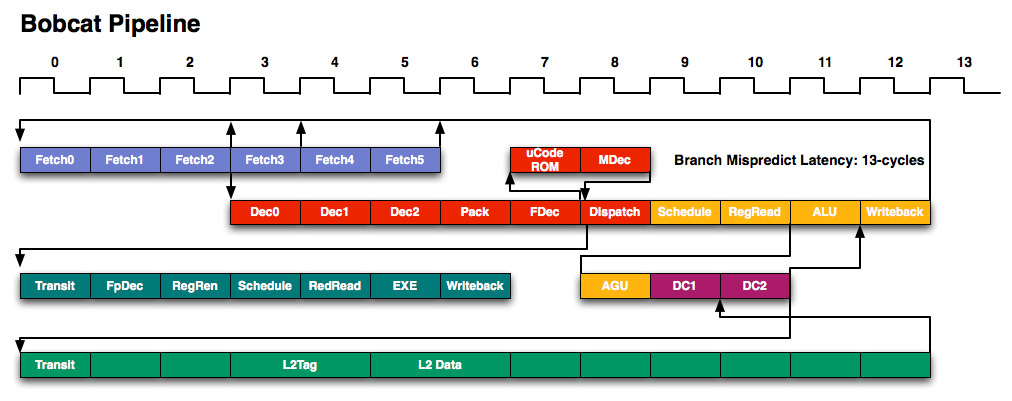
Bobcat 15 stage integer pipeline
Atom's 16 stage pipe
http://images.anandtech.com/reviews/cpu/amd/hotchips2010/bobcatpipe.jpg
http://images.anandtech.com/reviews/cpu/intel/atom/deepdive/pipeline.jpg
Bobcat
L1 3-cycle 64KB (32KB instruction + 32KB data cache) 8-way set associative
L2 17-cycle 512KB 16-way set associative
Atom
L1 3-cycles (32KB instruction and 24KB data)
L2 18 cycles respectively (I�fve heard numbers as low as 15 for Atom�fs L2) 8-way 512KB
Physical Register Files
Atom's 16 stage pipe
http://images.anandtech.com/reviews/cpu/amd/hotchips2010/bobcatpipe.jpg
{kind=link}
http://images.anandtech.com/reviews/cpu/intel/atom/deepdive/pipeline.jpg
{kind=link}
Bobcat
L1 3-cycle 64KB (32KB instruction + 32KB data cache) 8-way set associative
L2 17-cycle 512KB 16-way set associative
Atom
L1 3-cycles (32KB instruction and 24KB data)
L2 18 cycles respectively (I�fve heard numbers as low as 15 for Atom�fs L2) 8-way 512KB
Physical Register Files
26 �FSocket774�F2010/08/24(��) 22:23:47 ID:YwRlN2+C
Microsoft beats Intel, AMD to market with CPU/GPU combo chip
http://arstechnica.com/gaming/news/2010/08/microsoft-beats-intel-amd-to-market-with-cpugpu-combo-chip.ars
http://arstechnica.com/gaming/news/2010/08/microsoft-beats-intel-amd-to-market-with-cpugpu-combo-chip.ars
MS�̃`�b�v�Ƃ��g�������˂���
360�̊�Րv���߂��邵�Ȃ�
�}�E�X�ƃQ�[���R���g���[����������Ă�ƌ�������
�}�E�X�ƃQ�[���R���g���[����������Ă�ƌ�������
Bulldozer�A�[�L�e�N�`���T�v�}
http://images.anandtech.com/reviews/cpu/amd/hotchips2010/bulldozeruarch.jpg
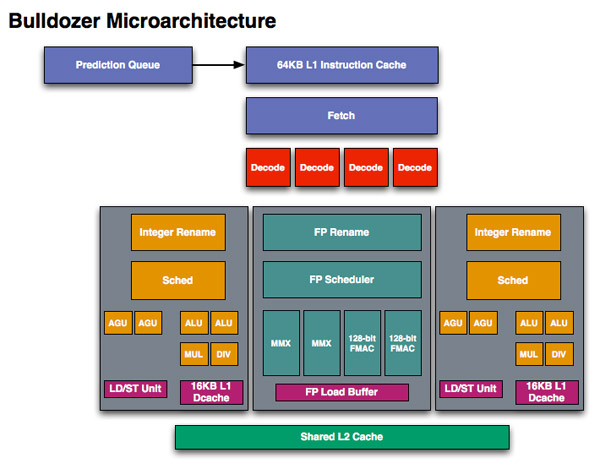{kind=link}
PhenomII �A�[�L�e�N�`���T�v�}
http://images.anandtech.com/reviews/cpu/amd/hotchips2010/p2uarch.jpg
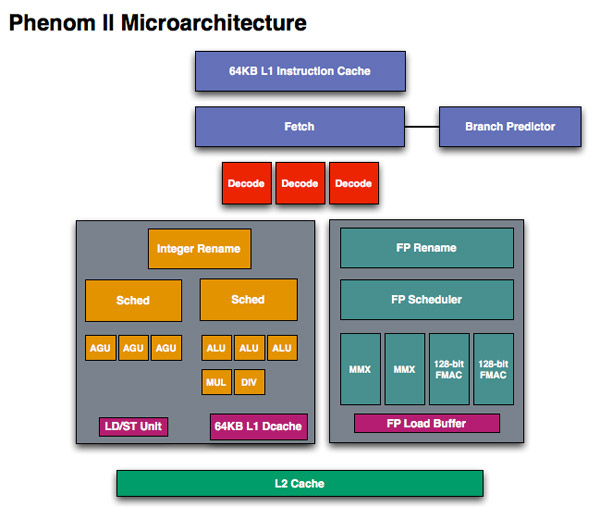{kind=link}
L1�����ǂ����8way�ɂȂ�́H���肪�����B
AMD�̔��\����Hot Chips�̃g���Ȃ�
�����Bulldozer�̃f�U�C�����炵�ċƊE�I�ɂ͂��ꂾ���̃C���p�N�g�͂���낤��
�����Bulldozer�̃f�U�C�����炵�ċƊE�I�ɂ͂��ꂾ���̃C���p�N�g�͂���낤��
���ǃu���h�[�U��AM3r2�łȂ��Ɠ����Ȃ��̂��B���s�}�U�[����_���Ȃ̂��B
��2���Ԃ�
�������ɋL�����o�Ă��邩��
�������ɋL�����o�Ă��邩��
AM3�̑��݈Ӌ`�Ƃ͉��������̂�
���\���Ȃ̂��ȁB�ǂ����ő�����Ȃ��B
����DDR3�͔���Ȃ��ƃ_�����ۂ���
���낻��4GB���W���[���������Ⴄ��
���낻��4GB���W���[���������Ⴄ��
�������R�����̂�DDR3�݂̂����炵�傤���Ȃ��B
�hBulldozer�h 20 Questions, Round One
http://blogs.amd.com/work/2010/08/23/%E2%80%9Dbulldozer%E2%80%9D-20-questions-round-one/
http://blogs.amd.com/work/2010/08/23/%E2%80%9Dbulldozer%E2%80%9D-20-questions-round-one/
�p��킩��ˁE�E�E�B�u�����o�Ă���̂͂����낤�ˁH
�]��x�ꂪ�o��Ivy Bridge�Ɣ�����猋�\�ȒɎ�ȗl��
�v���Z�X��1����x��Ă����|����قǂ̐��\������Ȃ�ǂ�����
���W�����[�f�U�C�����ǂ���̐��\�Ȃ̂����N���N�����
�]��x�ꂪ�o��Ivy Bridge�Ɣ�����猋�\�ȒɎ�ȗl��
�v���Z�X��1����x��Ă����|����قǂ̐��\������Ȃ�ǂ�����
���W�����[�f�U�C�����ǂ���̐��\�Ȃ̂����N���N�����
>>41
?�����ȃR�[�h�l�[���̃`�b�v�������č������Ă�����ǂǂ��Ȃ́H
?����ǂ�ǂ��B��{�̓R�A�����B
?�gInterlagos�h ? 16-core server processor
?�gValencia�h ? 8-core server processor
?�gZambezi�h ? 8-core client processor
?Intel�̐��i�Ɣ�ׁAAMD�̉��z���Z�p�̗��_�́H
?�R�A���ŊȒP�ɔ�r�ł����BOpteron6100���g���R�A����24�A�Ȃ�łQ�SVM������ł���B
?�܂����LL2�L���b�V�������������B
?�uBulldozer�v��Fusion APU�uOntario�v�͓����R�A�Ȃ́H
?�Ⴄ�B�uBobcat�v�R�A���x�[�X�ɂ����Ⴄ�v�`�b�v�B
?�uThuban�v�`�b�v�̂悤�ɁuTurboCore�v�ɑΉ�����́H
?���̒ʂ�B�T�[�o����ŏ��߂āuTurboCore�v�������B
?�uBulldozer�v�`�b�v�̓T�[�o����ł͂ǂ̂悤�ȃC���p�N�g������́H
?�����Ȏ��_�����邯�ǁA�܂��̓��W���[���\���̓�������������B
?���ɂ͐��\����ƒ����d�́B
?�܂����z���Z�p�̈�w�̐��\����B
http://leddown.wordpress.com/2010/08/24/amd%e3%81%ae%e6%ac%a1%e4%b8%96%e4%bb%a3cpu%e3%80%8cbulldozer%e3%80%8d%e3%81%ae%e8%a9%b3%e7%b4%b0%e6%83%85%e5%a0%b1%e3%81%8chot-chip22%e3%81%a7%e5%85%ac%e9%96%8b%e3%81%95%e3%82%8c%e3%82%8b%e3%80%82/
?�����ȃR�[�h�l�[���̃`�b�v�������č������Ă�����ǂǂ��Ȃ́H
?����ǂ�ǂ��B��{�̓R�A�����B
?�gInterlagos�h ? 16-core server processor
?�gValencia�h ? 8-core server processor
?�gZambezi�h ? 8-core client processor
?Intel�̐��i�Ɣ�ׁAAMD�̉��z���Z�p�̗��_�́H
?�R�A���ŊȒP�ɔ�r�ł����BOpteron6100���g���R�A����24�A�Ȃ�łQ�SVM������ł���B
?�܂����LL2�L���b�V�������������B
?�uBulldozer�v��Fusion APU�uOntario�v�͓����R�A�Ȃ́H
?�Ⴄ�B�uBobcat�v�R�A���x�[�X�ɂ����Ⴄ�v�`�b�v�B
?�uThuban�v�`�b�v�̂悤�ɁuTurboCore�v�ɑΉ�����́H
?���̒ʂ�B�T�[�o����ŏ��߂āuTurboCore�v�������B
?�uBulldozer�v�`�b�v�̓T�[�o����ł͂ǂ̂悤�ȃC���p�N�g������́H
?�����Ȏ��_�����邯�ǁA�܂��̓��W���[���\���̓�������������B
?���ɂ͐��\����ƒ����d�́B
?�܂����z���Z�p�̈�w�̐��\����B
http://leddown.wordpress.com/2010/08/24/amd%e3%81%ae%e6%ac%a1%e4%b8%96%e4%bb%a3cpu%e3%80%8cbulldozer%e3%80%8d%e3%81%ae%e8%a9%b3%e7%b4%b0%e6%83%85%e5%a0%b1%e3%81%8chot-chip22%e3%81%a7%e5%85%ac%e9%96%8b%e3%81%95%e3%82%8c%e3%82%8b%e3%80%82/
44 �FSocket774�F2010/08/25(��) 11:11:19 ID:AHyg9Tw+
Interlagos��16VM�����̂Ȃ�s�ς���
���l�i3�{�ɂȂ肻����Westmere10C��10VM�ǂ܂肾�낤��
���l�i3�{�ɂȂ肻����Westmere10C��10VM�ǂ܂肾�낤��
�ȑO�̏��Zambezi��DDR3-1866�̑Ή�
������ȑOPhenom2���o���Ƃ��Ɂw�������̂��߂�DDR3-1600�x�Ɩ������Ĕ����Ă�Ƒ�����
Phenom2�ł�DDR3-1600�ǂ��납DDR3�ł��郁���b�g�������̂�
Zambezi�͂�荂����DDR3-1866�ɑΉ����Ă邩��
������ȑOPhenom2���o���Ƃ��Ɂw�������̂��߂�DDR3-1600�x�Ɩ������Ĕ����Ă�Ƒ�����
Phenom2�ł�DDR3-1600�ǂ��납DDR3�ł��郁���b�g�������̂�
Zambezi�͂�荂����DDR3-1866�ɑΉ����Ă邩��
>>43
���͂�͂肱���̕\�L���B
>�\�P�b�g��AM3+�ƂȂ�A���s��AM2��AM3�\�P�b�g�ł́uBulldozer�v�͑Ή����Ȃ��B
�m����������"Bulldozer Ready"�Ŕ����Ă�����Ȃ����������H
���͂�͂肱���̕\�L���B
>�\�P�b�g��AM3+�ƂȂ�A���s��AM2��AM3�\�P�b�g�ł́uBulldozer�v�͑Ή����Ȃ��B
�m����������"Bulldozer Ready"�Ŕ����Ă�����Ȃ����������H
47 �FSocket774�F2010/08/25(��) 11:18:05 ID:AHyg9Tw+
>>46
G34��C32����Ȃ��āH
G34��C32����Ȃ��āH
>>42
���Ȃ݂Ɍ����_�̃T�[�o�s��̔̔��V�F�A9%������ȁB
��ԂĂ����ꂪ�K�v�Ȃ̂͊ԈႢ�Ȃ���ȁB
�܂��f�X�N�g�b�v���������������ǂȁB���l�ɓO���邱�Ƃł��낤���ăf�X�N�g�b�v�i����܂ށj�s���
3����̃V�F�A���l�����Ă邪�A4�R�A��Intel��2�R�A�N���X�Ɖ��i�Œ��荇���Ă������R�X�g�I�ɉ������ܖ��͂Ȃ��B
������_���č��R�X�g�̃v���Z�b�T�����́A�����̃��X�N�̏��Ȃ��v���Z�b�T�ɓO��������
AMD�̗͓̑I�ɂ͓s�����ǂ����낤�B
>>44
Westmere-10C��Nehalem-EX�Ɉ���������MCA���J�o���Ȃǂ������M�����d���̐v������
�����Ă��ڋq�͔����B�i���N���E�h�s���ڎw���Ȃ炻�������^�[�Q�b�g���Ⴄ�B
Interagos�����㋣������̂�Sandy Bridge/Ivy Bridge��8�R�A16�X���b�h�����肾�낤�B
3�_�CMCM��24�R�A�Ƃ��������Ȃ�����A���̃v���Z�X���[�����V��2013�N���炢�܂ł�����
32nm��8���W���[��16�R�A�Ő키�K�v�����邱�Ƃ��l����ƁA��������邭�炢�łȂ��ƌ������B
���Ȃ݂Ɍ����_�̃T�[�o�s��̔̔��V�F�A9%������ȁB
��ԂĂ����ꂪ�K�v�Ȃ̂͊ԈႢ�Ȃ���ȁB
�܂��f�X�N�g�b�v���������������ǂȁB���l�ɓO���邱�Ƃł��낤���ăf�X�N�g�b�v�i����܂ށj�s���
3����̃V�F�A���l�����Ă邪�A4�R�A��Intel��2�R�A�N���X�Ɖ��i�Œ��荇���Ă������R�X�g�I�ɉ������ܖ��͂Ȃ��B
������_���č��R�X�g�̃v���Z�b�T�����́A�����̃��X�N�̏��Ȃ��v���Z�b�T�ɓO��������
AMD�̗͓̑I�ɂ͓s�����ǂ����낤�B
>>44
Westmere-10C��Nehalem-EX�Ɉ���������MCA���J�o���Ȃǂ������M�����d���̐v������
�����Ă��ڋq�͔����B�i���N���E�h�s���ڎw���Ȃ炻�������^�[�Q�b�g���Ⴄ�B
Interagos�����㋣������̂�Sandy Bridge/Ivy Bridge��8�R�A16�X���b�h�����肾�낤�B
3�_�CMCM��24�R�A�Ƃ��������Ȃ�����A���̃v���Z�X���[�����V��2013�N���炢�܂ł�����
32nm��8���W���[��16�R�A�Ő키�K�v�����邱�Ƃ��l����ƁA��������邭�炢�łȂ��ƌ������B
�\�z�ł�
8�R�A��200mm2��
32n��12�R�A����Ă�Istanbul�ȉ��̃_�C�T�C�Y
��12�ɂ͎I�ɂ�Fusion�ƌ����Ă邩��Bul�R�AFusion��32n�㔼
>���̃v���Z�X���[�����V��2013�N���炢�܂ł�����
>32nm��8���W���[��16�R�A�Ő키�K�v�����邱�Ƃ��l�����
�����炱��Ȃ��Ƃ͖���
8�R�A��200mm2��
32n��12�R�A����Ă�Istanbul�ȉ��̃_�C�T�C�Y
��12�ɂ͎I�ɂ�Fusion�ƌ����Ă邩��Bul�R�AFusion��32n�㔼
>���̃v���Z�X���[�����V��2013�N���炢�܂ł�����
>32nm��8���W���[��16�R�A�Ő키�K�v�����邱�Ƃ��l�����
�����炱��Ȃ��Ƃ͖���
Shanghai��Istanbul�݂����ɁA�܂�1�`�b�v��4���W���[��8�R�A���o���āA
2012�N��6���W���[��12�R�A�Ɋg�����Ċ������ȁH
32nm��1�N�ڂ�����ŏ�����傫�߂̃_�C�T�C�Y�̃`�b�v�Ƀ`�������W����̂�����āB
2012�N��6���W���[��12�R�A�Ɋg�����Ċ������ȁH
32nm��1�N�ڂ�����ŏ�����傫�߂̃_�C�T�C�Y�̃`�b�v�Ƀ`�������W����̂�����āB
>>50
>>43�ɂ���4000�V���[�Y�́u2�`4���W���[���i4�`8�R�A�j�\���v����b�ƂȂ�Ȃ�A
"6000"�V���[�Y�́u6�`8���W���[���\���v��MCM�Ȃ̂��˂��H
�l�I�ɂ́u2���W���[���v���ďo�Ȃ��Ǝv���Ă������c�o���Ȃ��B
>>43�ɂ���4000�V���[�Y�́u2�`4���W���[���i4�`8�R�A�j�\���v����b�ƂȂ�Ȃ�A
"6000"�V���[�Y�́u6�`8���W���[���\���v��MCM�Ȃ̂��˂��H
�l�I�ɂ́u2���W���[���v���ďo�Ȃ��Ǝv���Ă������c�o���Ȃ��B
>>51
����MCM�Ȃ�Ȃ��́H
����Ȃ��ƁA1�`�b�v��8���W���[��16�R�A���ƁA�N���X�o�[��������剻���āA
�_�C�T�C�Y�{�ł��܂Ȃ��Ȃ�B
���W���[���\��������A�N���X�o�[�����̔�剻���}�����邵�A
�����l����ƌ����悢�v����ˁB
����MCM�Ȃ�Ȃ��́H
����Ȃ��ƁA1�`�b�v��8���W���[��16�R�A���ƁA�N���X�o�[��������剻���āA
�_�C�T�C�Y�{�ł��܂Ȃ��Ȃ�B
���W���[���\��������A�N���X�o�[�����̔�剻���}�����邵�A
�����l����ƌ����悢�v����ˁB
>>49
�T�[�o��Fusion�Ȃ�Ė��p�̒������B
�ނ��냂�o�C���E�f�X�N�g�b�v�Ń}�X�N���g��������������B
HPC�ł��Ȃ���ʂ̃T�[�o�ɔėp�v���Z�b�T�Ƃ��Ă̏_��̖R����GPU�𓋍ڂ��郁���b�g���Ȃ��B
�ނ���x86�R�A�̎����ʐς��킪��邾���B
�T�[�o��Fusion�Ȃ�Ė��p�̒������B
�ނ��냂�o�C���E�f�X�N�g�b�v�Ń}�X�N���g��������������B
HPC�ł��Ȃ���ʂ̃T�[�o�ɔėp�v���Z�b�T�Ƃ��Ă̏_��̖R����GPU�𓋍ڂ��郁���b�g���Ȃ��B
�ނ���x86�R�A�̎����ʐς��킪��邾���B
�A�z��
����Ȃ�����Tesla�Ȃ�Đi�o���ĂȂ���
Intel��MIC�Ȃ�ĊJ�����Ȃ�
����Ȃ�����Tesla�Ȃ�Đi�o���ĂȂ���
Intel��MIC�Ȃ�ĊJ�����Ȃ�
Opteron�������I�ɂǂ��炩����ɂȂ��Ȃ��āA�ėpCPU�R�A���ڂ����邾���ƁA
Fusion�̓��ނɂȂ邾�����Ⴀ�H
Fusion�̓��ނɂȂ邾�����Ⴀ�H
�{�i�I��HPC�ɐi�o���邱��ɂ͂��̏_��Ƃ�炪���P���ꂽAPU�𓊓����邾���̘b
2015�N���낤���ǂ�
2015�N���낤���ǂ�
�Â��ɂ���A�z��
>>56
���o�C���E�f�X�N�g�b�v�̃}�X�N�Ƌ��p�����邱�ƂŃR�X�g�_�E�����͂���A
���t�����l��CPU��CPU�R�A�I�����[�ł�����������B
Xeon���ቿ�i�т̂��̂ɂ�GPU�R�A���ڂ邵�B
HPC���ɂ�������Ȃ���B
��������HPC�s��Ȃ�ăT�[�o�s��̂����ꕔ�ŁAGPGPU�����ӂȖ��͂��̍X�Ɉꈬ��̕��삾��������ȁB
CPU�ƃ\�P�b�g�����邱�Ƃł�HPC�p�Ƃ��Ẵ����b�g���疾�m����Ȃ����ȁB
CPU�̃A�N�Z�����[�^�G���W���͓���SSE/AVX���嗬�ɂȂ�B
DDR4���o��܂ł́A�قƂ�ǂ���Ń������o���h���͖O�a����B
GPGPU��GDDR*�Ƃ�XDR���̍L�ш�ȃ������������Ă͂��߂Đ��\������̂ł�����
CPU�ƍ��ڂ��ă������ш���Ƃ肠���Ĕ��������㕨����Ȃ��B
�����炱��Intel�̓f�B�X�N���[�g�ȃA�N�Z�����[�^�`�b�v��V�K�J�����悤�Ƃ��Ă�B
�z�ʂ�FLOPS���������Ċ��ł�̂͋��{�̂Ȃ��n�������B
���o�C���E�f�X�N�g�b�v�̃}�X�N�Ƌ��p�����邱�ƂŃR�X�g�_�E�����͂���A
���t�����l��CPU��CPU�R�A�I�����[�ł�����������B
Xeon���ቿ�i�т̂��̂ɂ�GPU�R�A���ڂ邵�B
HPC���ɂ�������Ȃ���B
��������HPC�s��Ȃ�ăT�[�o�s��̂����ꕔ�ŁAGPGPU�����ӂȖ��͂��̍X�Ɉꈬ��̕��삾��������ȁB
CPU�ƃ\�P�b�g�����邱�Ƃł�HPC�p�Ƃ��Ẵ����b�g���疾�m����Ȃ����ȁB
CPU�̃A�N�Z�����[�^�G���W���͓���SSE/AVX���嗬�ɂȂ�B
DDR4���o��܂ł́A�قƂ�ǂ���Ń������o���h���͖O�a����B
GPGPU��GDDR*�Ƃ�XDR���̍L�ш�ȃ������������Ă͂��߂Đ��\������̂ł�����
CPU�ƍ��ڂ��ă������ш���Ƃ肠���Ĕ��������㕨����Ȃ��B
�����炱��Intel�̓f�B�X�N���[�g�ȃA�N�Z�����[�^�`�b�v��V�K�J�����悤�Ƃ��Ă�B
�z�ʂ�FLOPS���������Ċ��ł�̂͋��{�̂Ȃ��n�������B
>>56
��������̘b���Ă��R�v���Z�b�T�͂ǂ��Ȃ����낤�ȁH
�p�r�ɉ����čڂ��₷���v�ɂ���Ƃ����Ƃ�
�܂��n�߂�Fusion�ƌ����Ă���
��������̘b���Ă��R�v���Z�b�T�͂ǂ��Ȃ����낤�ȁH
�p�r�ɉ����čڂ��₷���v�ɂ���Ƃ����Ƃ�
�܂��n�߂�Fusion�ƌ����Ă���
>>60
Torrenza�\�z�Ȃ�_����c�@�Ŏ�����ڃU����
Torrenza�\�z�Ȃ�_����c�@�Ŏ�����ڃU����
�Ȃ�E�E�E�E���ƁE�E�E�E
>>60
����p�r�̃R�v���ڂ�����
�����ɂ���ăR�v�����f�b�h�X�y�[�X�����鋰�ꂪ����̂ł�߂��B
���ƃR�v���J���̃��\�[�X���n���ɂȂ��̂ł�������B
����p�r�̃R�v���ڂ�����
�����ɂ���ăR�v�����f�b�h�X�y�[�X�����鋰�ꂪ����̂ł�߂��B
���ƃR�v���J���̃��\�[�X���n���ɂȂ��̂ł�������B
�܂��BHT�Ōq�����Ă��邩��ėp�R�A�͏悹���邾�낯�ǁA
�l�b�N��>>63���������Ď��ŁB
�l�b�N��>>63���������Ď��ŁB
���\�̏ڂ����X���C�h���Ă�
http://www.anandtech.com/Gallery/Album/753#7
�ȓd�͎u���̂����ɖ��߃t�F�b�`��32B/cycle���Đ����ˁH
����ȂɕK�v�Ȃ́H
http://www.anandtech.com/Gallery/Album/753#7
�ȓd�͎u���̂����ɖ��߃t�F�b�`��32B/cycle���Đ����ˁH
����ȂɕK�v�Ȃ́H
�{����"�ȓd�͎u��"�Ȃ̂��킩��Ȃ�CPU���ȁc�B
68 �FSocket774�F2010/08/25(��) 17:58:57 ID:CyselUQn
�ȓd�͂ɗ��ŁA���������̂ɁA
�u���\�������Ȃ��Ƃ܂�����ˁv�ł悭���Ă݂���A
�u�����d�͂Ő��\�A�b�v�v�Ƃ����Ȃ�̓��F���Ȃ����̂��o�Ă������Ċ������B
�ȓd�͂Ƃ������ɂ͏ȓd�͂ł��Ȃ����A�\�̓A�b�v�͂��ꂵ�����\�͂ɂ������Ȃ瑼��CPU�ɂȂ邵�B
�u���\�������Ȃ��Ƃ܂�����ˁv�ł悭���Ă݂���A
�u�����d�͂Ő��\�A�b�v�v�Ƃ����Ȃ�̓��F���Ȃ����̂��o�Ă������Ċ������B
�ȓd�͂Ƃ������ɂ͏ȓd�͂ł��Ȃ����A�\�̓A�b�v�͂��ꂵ�����\�͂ɂ������Ȃ瑼��CPU�ɂȂ邵�B
AMD�Ƃ��ẮACULV����Netbook�܂ł��J�o�[�ł���CPU�Ƃ��č������Ȃ��́H
�g�ݍ��݂��_���Ă��邾�낤���ǁAIntel�݂����ɃX�}�[�g�t�H���ɓ����悤�Ȃ̂�
���Ȃ��Ƃ�Bobcat�ł͑_���ĂȂ���Ȃ����낤���B
�g�ݍ��݂��_���Ă��邾�낤���ǁAIntel�݂����ɃX�}�[�g�t�H���ɓ����悤�Ȃ̂�
���Ȃ��Ƃ�Bobcat�ł͑_���ĂȂ���Ȃ����낤���B
Atom��8B/cycle�ȁBAVX�Ƃ�AES/NI�Ή��Ȃǂ̂Ă�����͂���\���͂��邯��
��{���\�͂��̂܂܂ŏ���d�͂̒ጸ��ڎw���̂�����H�����낤�B
�m�[�X�u���b�W��IGP������100mm²���x�Ȃ�32nm�ȍ~��CULV�ł��\���R�X�g�v���͖��������B
��{���\�͂��̂܂܂ŏ���d�͂̒ጸ��ڎw���̂�����H�����낤�B
�m�[�X�u���b�W��IGP������100mm²���x�Ȃ�32nm�ȍ~��CULV�ł��\���R�X�g�v���͖��������B
>>68
AMD��"Bodcat"�Ɋւ��Ă���Ȏ��ꌾ�������Ă��Ȃ����ǁH
AMD��"Bodcat"�Ɋւ��Ă���Ȏ��ꌾ�������Ă��Ȃ����ǁH
�ő�9�I�y���[�V�����������s�̑�͋��C��`��K7�A�[�L�e�N�`�������o�C���v���Ɍ��������炠���Ȃ����������Ǝv���B
�ő�32B�t�F�b�`�������邢�킯����Ȃ���
���ߋ������Ԃɍ����Ă�ꍇ�ɂ����ƃA�O���b�V�u�Ƀp���[�_�E���ł��邩�ǂ���
���̓����肪�d�v���낤
�ő�32B�t�F�b�`�������邢�킯����Ȃ���
���ߋ������Ԃɍ����Ă�ꍇ�ɂ����ƃA�O���b�V�u�Ƀp���[�_�E���ł��邩�ǂ���
���̓����肪�d�v���낤
���O�S���ǂ�łȂ����낗
>>66
�ȓd�́u�u���v�Ǝ��ۂ̏ȓd�͕͂ʂȘb���낤���B
�����Atom�̌㔭��Atom���x�̐��\��������ǂ�������ɂ��Ȃ�����B
���Ƃ��Ɨ��N32nm��Atom���肾�Əȓd�͂ł͂܂����Ă�B
�ȓd�́u�u���v�Ǝ��ۂ̏ȓd�͕͂ʂȘb���낤���B
�����Atom�̌㔭��Atom���x�̐��\��������ǂ�������ɂ��Ȃ�����B
���Ƃ��Ɨ��N32nm��Atom���肾�Əȓd�͂ł͂܂����Ă�B
��Atom��8B/cycle
ttp://www.life-lab.com/amd-lab/amd686.html
��12�o�C�g���ȏ��x86����
Atom����1���߂���1�N���b�N�Ńt�F�b�`�o���Ȃ�����������Ă��ƁH
ttp://www.life-lab.com/amd-lab/amd686.html
��12�o�C�g���ȏ��x86����
Atom����1���߂���1�N���b�N�Ńt�F�b�`�o���Ȃ�����������Ă��ƁH
>>75
6�T�C�N����48�o�C�g���o�b�t�@�����O���Ă���Ă̂����m�ȂƂ���B
x86�̕��ϖ��ߒ���3�`4�o�C�g���x�ŁA��������SIMD������قNj��͂ȕ��͓��ڂ��ĂȂ�����
����ŏ\���B
���p�チ��������̃��[�h��SSSE3�ȍ~�̖��߂ł�10�`11�o�C�g����������B
12�o�C�g�ȏ�̖��߂Ȃ�Ď��p��w�ǎg�����Ƃ͂Ȃ��B
�����������ʂȃv���t�B�b�N�X����ʂɂ���NOP��
�p�f�B���O�Ɏg�����x����B
���������_�Ō����Bobcat�ɂ͍ő�32B/cycle�̖��ߑш�͖��ʂɌ�����
10�`11�o�C�g�̃������A�h���b�V���O�����߂�3���߃t�F�b�`�����Ƃ����
�o�b�N�G���h���܂��ǂ����Ȃ��B
6�T�C�N����48�o�C�g���o�b�t�@�����O���Ă���Ă̂����m�ȂƂ���B
x86�̕��ϖ��ߒ���3�`4�o�C�g���x�ŁA��������SIMD������قNj��͂ȕ��͓��ڂ��ĂȂ�����
����ŏ\���B
���p�チ��������̃��[�h��SSSE3�ȍ~�̖��߂ł�10�`11�o�C�g����������B
12�o�C�g�ȏ�̖��߂Ȃ�Ď��p��w�ǎg�����Ƃ͂Ȃ��B
�����������ʂȃv���t�B�b�N�X����ʂɂ���NOP��
�p�f�B���O�Ɏg�����x����B
���������_�Ō����Bobcat�ɂ͍ő�32B/cycle�̖��ߑш�͖��ʂɌ�����
10�`11�o�C�g�̃������A�h���b�V���O�����߂�3���߃t�F�b�`�����Ƃ����
�o�b�N�G���h���܂��ǂ����Ȃ��B
I�L���b�V����32KB������
�P�T�C�N����32�o�C�g
����������Ȃ�����
�P�T�C�N����32�o�C�g
����������Ȃ�����
���łɌ����ƁA���G�ȃ������A�h���b�V���O�����߂�1�T�C�N���ŏ����ł��Ȃ����Ƃ�
x86���m�̋����ł̓l�b�N�ɂȂ肤�邪�AARM�݂�����RISC�A�[�L�e�N�`���͂ނ���
�������A�h���b�V���O������ȏ�ɕn��B
�v����ɖ{���̃^�[�Q�b�g�i�n�C�G���hARM�R�j�ł͐��\�ʂŏ\���n�荇����B
Intel��MID�����Ɋ����̃R�[�h���g���ꍇ��Atom�����ɍăR���p�C�����邱�Ƃ𐄏����Ă邪
�A�[�L�e�N�`�����ƂɃR���p�C�����������Ƃ�ARM�ł�����Ă邱�Ƃ����ʂɖ��͂Ȃ��B
x86���m�̋����ł̓l�b�N�ɂȂ肤�邪�AARM�݂�����RISC�A�[�L�e�N�`���͂ނ���
�������A�h���b�V���O������ȏ�ɕn��B
�v����ɖ{���̃^�[�Q�b�g�i�n�C�G���hARM�R�j�ł͐��\�ʂŏ\���n�荇����B
Intel��MID�����Ɋ����̃R�[�h���g���ꍇ��Atom�����ɍăR���p�C�����邱�Ƃ𐄏����Ă邪
�A�[�L�e�N�`�����ƂɃR���p�C�����������Ƃ�ARM�ł�����Ă邱�Ƃ����ʂɖ��͂Ȃ��B
�ŁA���߂Ċm�F���邪Bobcat��Atom�R�Ȃ́HCULV Celeron�R�Ȃ́H
Intel��Atom��Bobcat�̑����������C���Ȃ��悤�Ȃ��B
Intel��Atom��Bobcat�̑����������C���Ȃ��悤�Ȃ��B
��������
Atom�͉��։��֍s�����痣��Ă�����
Atom�͉��։��֍s�����痣��Ă�����
bobcat������x���Atom�Ɠ����������낤
>>79
�u����ɂ�����C���Ȃ��v�̂ł͂Ȃ��āA�u���肪�ł��Ȃ��v�̊ԈႦ����B
���i�����N�I�ɂ͂ǂ��l���Ă��R�n�����H
�d�����Ȃ��̂�"CULV"�����낵�Ă͗��邾�낤���ǂ��B
�u����ɂ�����C���Ȃ��v�̂ł͂Ȃ��āA�u���肪�ł��Ȃ��v�̊ԈႦ����B
���i�����N�I�ɂ͂ǂ��l���Ă��R�n�����H
�d�����Ȃ��̂�"CULV"�����낵�Ă͗��邾�낤���ǂ��B
>>82
> �u���肪�ł��Ȃ��v
������������K�v���Ȃ�����ȁB
�l�b�g�u�b�N�p�̃|�W�V������CULV�������p���̂͊���H���B
> �u���肪�ł��Ȃ��v
������������K�v���Ȃ�����ȁB
�l�b�g�u�b�N�p�̃|�W�V������CULV�������p���̂͊���H���B
�S�R�K��H������˂���
�_�C�T�C�Y���ł����Ĉ�����ł���
�I�[�N�e�C����V�[�_�[�g���C��������ȏ�l�b�g�u�b�N��ATOM
�_�C�T�C�Y���ł����Ĉ�����ł���
�I�[�N�e�C����V�[�_�[�g���C��������ȏ�l�b�g�u�b�N��ATOM
atom�̑����ARM
>>84
Sandy Bridge�̃_�C��IGP�����ACPU1�R�A�AL3�L���b�V��1MB���炢�ɂ�����
�ǂ̒��x�̃_�C�T�C�Y�ɂȂ邩�v�Z�������Ƃ���H
���_�����ƍ���N4xx�V���[�Y�Ɠ����x�̃_�C�T�C�Y�͗]�T�ʼn\�B
Sandy Bridge�̃_�C��IGP�����ACPU1�R�A�AL3�L���b�V��1MB���炢�ɂ�����
�ǂ̒��x�̃_�C�T�C�Y�ɂȂ邩�v�Z�������Ƃ���H
���_�����ƍ���N4xx�V���[�Y�Ɠ����x�̃_�C�T�C�Y�͗]�T�ʼn\�B
>>83
�u����K�v�������v�Ƃ���A�ň����̃N���X����������Ƃ��邾�����B
>>85
ARM��ɂ���ɂ͏ȓd�͂ł��܂��G�킸�B
Ontario��ɂ���ɂ͐��\�œG��Ȃ��\��������B
�u����K�v�������v�Ƃ���A�ň����̃N���X����������Ƃ��邾�����B
>>85
ARM��ɂ���ɂ͏ȓd�͂ł��܂��G�킸�B
Ontario��ɂ���ɂ͐��\�œG��Ȃ��\��������B
>>87
�l�b�g�u�b�N��Intel���ł��������Ȃ���Ό��X���݂��Ȃ������ɓ������W������������
Intel�����̂Ă���Ɏs����ێ��ł��邩�ǂ��������������ǂȁB
32nm�A22nm�Ɛ�����d�˂邲�Ƃɂ����Ɠd�͗v���̌������V�l�b�g�u�b�N���ł��������邩����H
���Ƃ���500�O�����ȉ��Ƃ��B
�l�b�g�u�b�N��Intel���ł��������Ȃ���Ό��X���݂��Ȃ������ɓ������W������������
Intel�����̂Ă���Ɏs����ێ��ł��邩�ǂ��������������ǂȁB
32nm�A22nm�Ɛ�����d�˂邲�Ƃɂ����Ɠd�͗v���̌������V�l�b�g�u�b�N���ł��������邩����H
���Ƃ���500�O�����ȉ��Ƃ��B
�ϑz���Ђǂ���
�l�b�g�u�b�N�̎s�ꌩ�̂Ă��Ƃ��A�z������
�l�b�g�u�b�N�̎s�ꌩ�̂Ă��Ƃ��A�z������
���Ȃ݂Ƀ������ш�s������o�錋�_�́usp�����葝�₷�͖̂��Ӗ��v���Ó��ł�����
FLOPS�]�X�̓v���O�����̕����炢�ɂ����W���Ȃ�
FLOPS�]�X�̓v���O�����̕����炢�ɂ����W���Ȃ�
Netbook�s����@��N�������̂�Intel�����ǁA���\����ڂ��Ă��A����Ȃ�ɓ�����
�����̂Ȃ�ǂ����Ď��v�͎c���Ȃ��́H
500g�ȉ���Intel���ʂ̎s��@��N�������Ƃ��Ă��A
�����Netbook�̎s�ꂪ���̂܂܈ڍs����Ƃ͎v���Ȃ����B
�����̂Ȃ�ǂ����Ď��v�͎c���Ȃ��́H
500g�ȉ���Intel���ʂ̎s��@��N�������Ƃ��Ă��A
�����Netbook�̎s�ꂪ���̂܂܈ڍs����Ƃ͎v���Ȃ����B
������ wipeoutHD_EN_1080P.mp4(255MB)�@�ρ@�Œ�60fps�{over 1080p
http://sonycoment-6.vo.llnwd.net/e/wipeouthd/wipeoutHD_EN_1080P.zip
��CPU Athlon II X4 620�@ATI Radeon HD 4350 �@�x���L��
fps41 Drawn��5000 dropped�� 6300
�Đ�������d�́@��100w
http://up3.viploader.net/pc/src/vlpc004322.jpg
��atomZ�@+����GPU��Intel US15W�@
CPU���ו���30�`40�l
fps18�`24 Drawn��1500(AMDPC�ɔ�ׂ�3500��) dropped�� 1500(AMDPC�ɔ�ׂ�4800��)
�Đ�������d�́@��8w (AMDPC�ɔ�ׂ�92W��)
http://up3.viploader.net/pc/src/vlpc003849.jpg
��CPU Athlon II X4 620�@ATI Radeon HD 4350 �@�x������
4�R�ACPU���ώg�p��50�l
�Đ�������d�́@��110w
http://up3.viploader.net/pc/src/vlpc004323.jpg
http://sonycoment-6.vo.llnwd.net/e/wipeouthd/wipeoutHD_EN_1080P.zip
��CPU Athlon II X4 620�@ATI Radeon HD 4350 �@�x���L��
fps41 Drawn��5000 dropped�� 6300
�Đ�������d�́@��100w
http://up3.viploader.net/pc/src/vlpc004322.jpg
{kind=link}
��atomZ�@+����GPU��Intel US15W�@
CPU���ו���30�`40�l
fps18�`24 Drawn��1500(AMDPC�ɔ�ׂ�3500��) dropped�� 1500(AMDPC�ɔ�ׂ�4800��)
�Đ�������d�́@��8w (AMDPC�ɔ�ׂ�92W��)
http://up3.viploader.net/pc/src/vlpc003849.jpg
{kind=link}
��CPU Athlon II X4 620�@ATI Radeon HD 4350 �@�x������
4�R�ACPU���ώg�p��50�l
�Đ�������d�́@��110w
http://up3.viploader.net/pc/src/vlpc004323.jpg
{kind=link}
�ނ���Intel�݂̐����f�B�X�v���C�T�C�Y�Ƃ������������ʂȂǂ̐����������āA���[�J�[��
���������Ă�����̂Ȃ�CULV���ڂ�B5�m�[�g�N���X�����X�ڍs���Ă�̂������B
AMD��������悤�����܂����l�b�g�u�b�N�s��͏k������B
���������Ă�����̂Ȃ�CULV���ڂ�B5�m�[�g�N���X�����X�ڍs���Ă�̂������B
AMD��������悤�����܂����l�b�g�u�b�N�s��͏k������B
ID:pUhZh4IM��Intel�i��͉ʂĂ��Ȃ������̂ł������B
�o��������������������ǁA���ɖ{�����o��������Ȋ����ȁB
���AIntel�͍��N��"COMPUTEX TAIPEI"�Ŕ��\����"Oak Trail"�Ȃǂ�
�ϋɓI�Ƀl�b�g�u�b�N��^�u���b�g�n��_���Ă���킯�����B
����Ȏ�������Ȃ���Intel�M�҂���Ă�Ƃ��B����B
AMD��"Ontario"������"Oak Trail"�ȂǂɑR����̂ɁA
��ԃl�b�N�ɂȂ�̂�"�����\"�ł͂Ȃ��āA"�ȓd�͐��\"�B
�W�J��@���Ȃ���̕�������@���B�撣��B
�o��������������������ǁA���ɖ{�����o��������Ȋ����ȁB
���AIntel�͍��N��"COMPUTEX TAIPEI"�Ŕ��\����"Oak Trail"�Ȃǂ�
�ϋɓI�Ƀl�b�g�u�b�N��^�u���b�g�n��_���Ă���킯�����B
����Ȏ�������Ȃ���Intel�M�҂���Ă�Ƃ��B����B
AMD��"Ontario"������"Oak Trail"�ȂǂɑR����̂ɁA
��ԃl�b�N�ɂȂ�̂�"�����\"�ł͂Ȃ��āA"�ȓd�͐��\"�B
�W�J��@���Ȃ���̕�������@���B�撣��B
intel�͎�����atom��ARM�Ɠ����̏���d�͂ɂȂ�ƌ����Ă���ȁB
> AMD��"Ontario"������"Oak Trail"�ȂǂɑR����̂ɁA
> ��ԃl�b�N�ɂȂ�̂�"�����\"�ł͂Ȃ��āA"�ȓd�͐��\"�B
����Ȃ��Ƃ킴�킴���ɏo���Č����܂ł��Ȃ������Ǝv������
> ��ԃl�b�N�ɂȂ�̂�"�����\"�ł͂Ȃ��āA"�ȓd�͐��\"�B
����Ȃ��Ƃ킴�킴���ɏo���Č����܂ł��Ȃ������Ǝv������
�l�b�g�u�b�N�̍Đ���ڎw������@�uCanoe Lake�v
http://pc.watch.impress.co.jp/docs/column/hot/20100720_381849.html
http://pc.watch.impress.co.jp/docs/column/hot/20100720_381849.html
>>95
�ǂ��Ȃ낤�ˁH�@���ʂ�"x86 CPU"�������Ă����̂��������������͕ʂƂ��āA
���^��Windows�n�^�u���b�g���~�����̂Ŋ��҂��Ă���B
�s��̃p�C���炵�Ă��A���͂�����ɂ��L���邾�낤�Ȃ��B
����"Ontario"�́u1W�v�������w���Ă��邩�ŕς����c�B
�ǂ��Ȃ낤�ˁH�@���ʂ�"x86 CPU"�������Ă����̂��������������͕ʂƂ��āA
���^��Windows�n�^�u���b�g���~�����̂Ŋ��҂��Ă���B
�s��̃p�C���炵�Ă��A���͂�����ɂ��L���邾�낤�Ȃ��B
����"Ontario"�́u1W�v�������w���Ă��邩�ŕς����c�B
���X�̓g�����X���^�̎s�ꂾ�������ǂȃl�b�g�u�b�N
���C���t���Ă������œ���Intel�ɓ��܂�Ēׂ��ꂽ
���C���t���Ă������œ���Intel�ɓ��܂�Ēׂ��ꂽ
Bobcat���ăn�[�t�X�s�[�h��L2�L���b�V���Ȃ�
���߃t�F�b�`���ő�32bites/c�Ƃ������͂��Ȉ��
���߃t�F�b�`���ő�32bites/c�Ƃ������͂��Ȉ��
>>98
http://www.brightsideofnews.com/news/2010/8/24/bobcat-amds-answer-to-intel-atom2c-arm-movement.aspx
���̋L������1W�ȉ���C6�X�e�[�g�̂��ƂɂȂ��Ă���B
http://www.brightsideofnews.com/news/2010/8/24/bobcat-amds-answer-to-intel-atom2c-arm-movement.aspx
���̋L������1W�ȉ���C6�X�e�[�g�̂��ƂɂȂ��Ă���B
>>97
�m���Ă��B�����������˂��B
���4GB��64�r�b�g���ւ܂ł��������I
�����AEeePC�͏��オ���Ƃ���Celeron ULV�������킯����
�d�̓����W�I�ɏ�̕���CULV�ŏ\���d����킯�����ȁB�������Ontario�������B
�ł��l�b�g�u�b�N�ɑ���S�͗��₩����B
�����܂ߊe���[�J�[��������Windows�������Ȃ�ARM-Android�^�u���b�g�����X�Ɣ��\���Ă��B
�����̃m�[�gPC�s�������Ēቿ�iWindows PC��W�J����Ȃ�ĉ����̃��[�J�[���t���������B
�m���Ă��B�����������˂��B
���4GB��64�r�b�g���ւ܂ł��������I
�����AEeePC�͏��オ���Ƃ���Celeron ULV�������킯����
�d�̓����W�I�ɏ�̕���CULV�ŏ\���d����킯�����ȁB�������Ontario�������B
�ł��l�b�g�u�b�N�ɑ���S�͗��₩����B
�����܂ߊe���[�J�[��������Windows�������Ȃ�ARM-Android�^�u���b�g�����X�Ɣ��\���Ă��B
�����̃m�[�gPC�s�������Ēቿ�iWindows PC��W�J����Ȃ�ĉ����̃��[�J�[���t���������B
>>100
>Bobcat���ăn�[�t�X�s�[�h��L2�L���b�V���Ȃ�
��������d�͉��̍H�v���낤��
���\���ǂ����őË������v�ɂȂ��@
���̎�̃v���Z�b�T��
>Bobcat���ăn�[�t�X�s�[�h��L2�L���b�V���Ȃ�
��������d�͉��̍H�v���낤��
���\���ǂ����őË������v�ɂȂ��@
���̎�̃v���Z�b�T��
�l�b�g�u�b�N�̓J�j�o���[�[�V�����ɂȂ�Ȃ�������
�A���h���^�u���b�g�����l��
��Pad������
�A���h���^�u���b�g�����l��
��Pad������
�����҂�����
atom�ƃZ�������̒��Ԃ��炢�̐��\�Ɨ\�z���Ă݂�
atom�ƃZ�������̒��Ԃ��炢�̐��\�Ɨ\�z���Ă݂�
107 �F���邦���F2010/08/25(��) 21:34:02 ID:l9PNUBgh
NetBook���p�ꂽ���Ƃ̈���͂��܂��ATOM���A������������������ǂˁB
"Ontario"�͂��Ԃ�����Ȃ��̂ŁA���[�J�[�����Ȃ莩�R�ɐv�ł��������B
>>106
�ł��Ȃ��B���\�����ł͂����ς�ł���B����ς���@���������B
"Ontario"�͂��Ԃ�����Ȃ��̂ŁA���[�J�[�����Ȃ莩�R�ɐv�ł��������B
>>106
�ł��Ȃ��B���\�����ł͂����ς�ł���B����ς���@���������B
�ǂ��ł��������A
�c�q�搶�͂��������R�e������w
�������Ȃ�ė]�T�̖�����F�߂��悤�Ȃ��̂����B
�c�q�搶�͂��������R�e������w
�������Ȃ�ė]�T�̖�����F�߂��悤�Ȃ��̂����B
Atom�͂��Ƃ���ARM�ւ̑R�n�Ƃ���Intel��������B
�����ɂ͉R�������̉��߂�OK�B
�l�b�g�u�b�N��Intel�͂͂��߂͎��s����UMPC�̌�p�Ƃ��Ă��������̂ŁA
�͂��߂͂��C�����������ǁA�r������̓l�b�g�u�b�N�̒�`�����߂āA
�킴�킴CULV�Ƃ����J�e�S���̐��i�𓊓������肵�Ȃ���A��ʐ��i�Ƌ������Ȃ��悤�ɂ��Ă�B
�����ɂ͉R�������̉��߂�OK�B
�l�b�g�u�b�N��Intel�͂͂��߂͎��s����UMPC�̌�p�Ƃ��Ă��������̂ŁA
�͂��߂͂��C�����������ǁA�r������̓l�b�g�u�b�N�̒�`�����߂āA
�킴�킴CULV�Ƃ����J�e�S���̐��i�𓊓������肵�Ȃ���A��ʐ��i�Ƌ������Ȃ��悤�ɂ��Ă�B
Bobocat�͂��ꂪ�ǂ��݂Ă��ACULV��Atom�l�b�g�u�b�N�Ƌ������鐻�i���낤�B
�l�I�ɂ̓��o�C���s�ꂪ�g�債�Ă����ABulldozer�m�[�g���ӊO�ɖʔ����C�����Ă����B
Bulldozer��TDP�g���������Ă�����Ȃ�ɃN���b�N��������R���Z�v�g���낤����ȁB
�f�X�N�g�b�v��T�[�o�͋��G�������Č������Ǝv�����B
�l�I�ɂ̓��o�C���s�ꂪ�g�債�Ă����ABulldozer�m�[�g���ӊO�ɖʔ����C�����Ă����B
Bulldozer��TDP�g���������Ă�����Ȃ�ɃN���b�N��������R���Z�v�g���낤����ȁB
�f�X�N�g�b�v��T�[�o�͋��G�������Č������Ǝv�����B
HotChip��Bobcat�̔��\�����l�́A���XMotorola ��
PPC�̘_�������Ă�l���ۂ��ˁB
Atom��Bobcat���ʓ_�������ɂ��B
���ƁADresdenboy��Trace Cache�̃l�^�ɂȂ��Ă���̂�
AMD�̃e�L�T�X�B�I�[�X�e�B���`�[���̓����̂��悾���A
Llano�͂��̃`�[���炵���BBull�͈Ⴄ�͗l�B
Bobcat�̊J�����_���ǂ����͒m��Ȃ��B
PPC�̘_�������Ă�l���ۂ��ˁB
Atom��Bobcat���ʓ_�������ɂ��B
���ƁADresdenboy��Trace Cache�̃l�^�ɂȂ��Ă���̂�
AMD�̃e�L�T�X�B�I�[�X�e�B���`�[���̓����̂��悾���A
Llano�͂��̃`�[���炵���BBull�͈Ⴄ�͗l�B
Bobcat�̊J�����_���ǂ����͒m��Ȃ��B
�g���[�X�L���b�V���ڂ�Ȃ�AntiHT���C�P�邩���ȁA������������
>>108
���̐�����ۂ������Ƃ�9�`10�C���`�N���X�̉t���f�B�X�v���C�̒ቿ�i�������������Ƃ�������������킯��
���̓�����̌��߂͎�ς̈���o�Ȃ���
Atom���o��܂ł̃~�j�m�[�g�Ȃ��20�`30�����C�ł����B
CPU�����̒l�i�Œቿ�i�ɂȂ����킯�ł͂Ȃ��B
���̐�����ۂ������Ƃ�9�`10�C���`�N���X�̉t���f�B�X�v���C�̒ቿ�i�������������Ƃ�������������킯��
���̓�����̌��߂͎�ς̈���o�Ȃ���
Atom���o��܂ł̃~�j�m�[�g�Ȃ��20�`30�����C�ł����B
CPU�����̒l�i�Œቿ�i�ɂȂ����킯�ł͂Ȃ��B
>Atom���o��܂ł̃~�j�m�[�g�Ȃ��20�`30�����C�ł����B
EeePC�Y�ꂽ�̂�? Atom�ɂ���Ēቿ�i�~�j�m�[�g�s������ꂽ�Ȃ�Ă����Ȃ��B
�C�O���[�J�[�����Ƀ~�j�m�[�g�Ɏ��g�ݎn�߂����ʈ����m�[�g���ł��邫�������ɂȂ����B
Atom�������֓������B
EeePC�Y�ꂽ�̂�? Atom�ɂ���Ēቿ�i�~�j�m�[�g�s������ꂽ�Ȃ�Ă����Ȃ��B
�C�O���[�J�[�����Ƀ~�j�m�[�g�Ɏ��g�ݎn�߂����ʈ����m�[�g���ł��邫�������ɂȂ����B
Atom�������֓������B
116 �FSocket774�F2010/08/25(��) 22:13:39 ID:AXvvosf5
�X�}�[�g�t�H���̎���Ƀl�b�g�u�b�N���Ē��r���[�ȋC�����邪�Ȃ�
���ʂ̃m�[�g��5���Ŕ������
���ʂ̃m�[�g��5���Ŕ������
IS01��������l�b�g�u�b�N�v��Ȃ��Ȃ���
���^�ň����ȃm�[�g�ւ̒���Ȃ�Đ̂��炠�邾��B
Intel���@���Ԃ���"Crusoe"�Ȃ����̂͂��肾�ȁB
Intel���@���Ԃ���"Crusoe"�Ȃ����̂͂��肾�ȁB
>>115
���u���b�g��LOOX�������炵���Ǝv���Ă��E�E�E
����EeePC�͉t���f�B�X�v���C�̉�ʂ�7�C���`��800x480��������ƁA�m���Ɉ���������͂�����
�l�i�����Ɏc�O�ȃX�y�b�N�������̂��v���o���Ă�
��A100/A110���Ă������̊o���Ă�z����H
���u���b�g��LOOX�������炵���Ǝv���Ă��E�E�E
����EeePC�͉t���f�B�X�v���C�̉�ʂ�7�C���`��800x480��������ƁA�m���Ɉ���������͂�����
�l�i�����Ɏc�O�ȃX�y�b�N�������̂��v���o���Ă�
��A100/A110���Ă������̊o���Ă�z����H
�����i�m�[�g�������Ė����Ȃ��Ă�AMD�̒m������������Ȃ����
���������̂ɂ͍̗p����ĂȂ�����
���������̂ɂ͍̗p����ĂȂ�����
Crusoe/Efficeon���ڋ@�͔��^�ł͂��������nj����Ĉ����͂Ȃ������Ȃ�
������20���Ƃ�����
������20���Ƃ�����
�ꉞ�l�b�g�u�b�N�Ƃ����Â�ł������Ă��邯�ǁA
Intel�ƈ���ď_��ȑΉ��Ƃ�����ȃ^�C�v�̏ȃX�y�[�X&�ȓd��PC�֓W�J�ł��邾�낤�ȁB
Intel�̏ꍇ�͖ϑz����Atom�͏����̂��Ƃ��l����Ɠs������������A���܂萶�Y���Ȃ��ŁA
CULV��҃v�b�V���B�l�b�g�u�b�N�̔��e����O��鐻�i�ł͋ɗ͎g�킹�Ȃ��悤�ɂ��Ă��̂ł͂Ȃ����낤���B
���������Ȃ�AMD�͂��̂������Ƃ͋t�ɂƂ���Bobcat���x���_�[�D������ɐF�X��点�邱�Ƃ�
Intel�ւ̃v���b�V���[����������킯�ŁA��C�ɂ����Ȑ��i�ɉ��p����ăt�B�[�o�[����\��������B
Intel�ƈ���ď_��ȑΉ��Ƃ�����ȃ^�C�v�̏ȃX�y�[�X&�ȓd��PC�֓W�J�ł��邾�낤�ȁB
Intel�̏ꍇ�͖ϑz����Atom�͏����̂��Ƃ��l����Ɠs������������A���܂萶�Y���Ȃ��ŁA
CULV��҃v�b�V���B�l�b�g�u�b�N�̔��e����O��鐻�i�ł͋ɗ͎g�킹�Ȃ��悤�ɂ��Ă��̂ł͂Ȃ����낤���B
���������Ȃ�AMD�͂��̂������Ƃ͋t�ɂƂ���Bobcat���x���_�[�D������ɐF�X��点�邱�Ƃ�
Intel�ւ̃v���b�V���[����������킯�ŁA��C�ɂ����Ȑ��i�ɉ��p����ăt�B�[�o�[����\��������B
IBM��bobcat�g�ݍ��݂̃J�X�^���`�b�v�̔����̂���
>>123
�Ǝ��v���Ă̂͊J������������i���̃��[�`�����ȁB
�l�b�g�u�b�N�͌������X�y�b�N�������������A�����Y���݂����ɂǂ��������悤�ȃX�y�b�N�ɂȂ����B
���i�������i��ŁA�e���[�J�[���R�X�g�_�E���ɐs�͂������ʁA���i�̋��ʉ��Ȃǂ��v���A
�����̃X�P�[�������b�g�����ݏo���ꂽ�B
LOOX��Libletto�Ƃ�����]�����炠����UMPC�̒ቿ�i���Ƃ�����������
EeePC������Ɣ�ׂĂ���ʂƂ��L�[�{�[�h�̕i�����ʕ����ɉ��P���ꂽ��Ƃ�
���낢��ǂ��Ȃ�����B
�ʂɐ��ᔭ�M�ɂȂ��ĔM�v�����₷���Ȃ�����������Ȃ���B
���Ȃ��Ƃ�945GS�̂����̓`�b�v�Z�b�g������Ȃ�ɔM���������Ȃ�
�Ǝ��v���Ă̂͊J������������i���̃��[�`�����ȁB
�l�b�g�u�b�N�͌������X�y�b�N�������������A�����Y���݂����ɂǂ��������悤�ȃX�y�b�N�ɂȂ����B
���i�������i��ŁA�e���[�J�[���R�X�g�_�E���ɐs�͂������ʁA���i�̋��ʉ��Ȃǂ��v���A
�����̃X�P�[�������b�g�����ݏo���ꂽ�B
LOOX��Libletto�Ƃ�����]�����炠����UMPC�̒ቿ�i���Ƃ�����������
EeePC������Ɣ�ׂĂ���ʂƂ��L�[�{�[�h�̕i�����ʕ����ɉ��P���ꂽ��Ƃ�
���낢��ǂ��Ȃ�����B
�ʂɐ��ᔭ�M�ɂȂ��ĔM�v�����₷���Ȃ�����������Ȃ���B
���Ȃ��Ƃ�945GS�̂����̓`�b�v�Z�b�g������Ȃ�ɔM���������Ȃ�
VGA�݂������t�@�����X��Ք̔������肵�Ă�
CPU��GPU���t���Ă��Ȃ�GPU��CPU���t���Ă�݂����Ȋ�����
CPU��GPU���t���Ă��Ȃ�GPU��CPU���t���Ă�݂����Ȋ�����
Bulldozer�v���Z�b�T�̑�1�e�̓T�[�o�����́uInterlagos�v�i�J���R�[�h���j�ƂȂ錩���݂��B
nterlagos��12�`16�R�A�𓋍ڂ��A���N�Ƀ����[�X���\�肳��Ă���B
�@AMD�̃x���`�}�[�N�ł́ABulldozer�v���Z�b�T�́A���s��12�R�AOpteron�v���Z�b�T
�i�J���R�[�h���FMagny Cours�j�Ɠ����d�̓v���t�@�C���ɂ����āA50���������\���L�^�����ƁA
�}�b�L�j�[���͌�����B
http://www.computerworld.jp/topics/datac/189051.html
�܂��̓f�[�^�Z���^�[�����Ȃ̂��B
�܂�google�ɂƂ��Ă͗ǂ�CPU���낤�ȁB
nterlagos��12�`16�R�A�𓋍ڂ��A���N�Ƀ����[�X���\�肳��Ă���B
�@AMD�̃x���`�}�[�N�ł́ABulldozer�v���Z�b�T�́A���s��12�R�AOpteron�v���Z�b�T
�i�J���R�[�h���FMagny Cours�j�Ɠ����d�̓v���t�@�C���ɂ����āA50���������\���L�^�����ƁA
�}�b�L�j�[���͌�����B
http://www.computerworld.jp/topics/datac/189051.html
�܂��̓f�[�^�Z���^�[�����Ȃ̂��B
�܂�google�ɂƂ��Ă͗ǂ�CPU���낤�ȁB
Intel�̃��t�@�����X�f�U�C���͂���悤�����A������Ђ�ODM��OEM�ō���Ă邾�낤����A
��������V�X�e�����ł��������Ă��Ȃ����낤���B
�x���_�[���Ƃ̓��F�Ȃ�ĂȂ��Ȃ���ăf�����b�g�����邯�ǁB
��������V�X�e�����ł��������Ă��Ȃ����낤���B
�x���_�[���Ƃ̓��F�Ȃ�ĂȂ��Ȃ���ăf�����b�g�����邯�ǁB
�t���f�B�X�v���C�̃T�C�Y�ɐ����t���ĂȂ�������9�`10�C���`WSVGA�t��������ȂɈ����Ȃ�Ȃ��������낤��
���Ƃ��Ήt���p�l���͈�Ԃ悭����郌���W�̕��������Ȃ�B
���Ƃ����̓m�[�g�p�Ȃ�1366x768��15.4�C���`�p�l���������B
�i������ƑO�܂ł�1280x800�������j
�f�X�N�g�b�v�p�Ȃ�22�`24�C���`��1920x1080�p�l�����������������B
�����Ȃ��Ėь�������邾���̓Ǝ��Ȃ�ď���҂͋��߂Ȃ���B
���Ƃ����̓m�[�g�p�Ȃ�1366x768��15.4�C���`�p�l���������B
�i������ƑO�܂ł�1280x800�������j
�f�X�N�g�b�v�p�Ȃ�22�`24�C���`��1920x1080�p�l�����������������B
�����Ȃ��Ėь�������邾���̓Ǝ��Ȃ�ď���҂͋��߂Ȃ���B
��������EeePC�ȑO�́A�~�j�m�[�g���̂��C�O�ł̓}�j�A�b�N�ȑ��݂ŁA
�����̃~�j�m�[�g�v�̏펯�ƁAEeePC��l�b�g�u�b�N�ȍ~�̗���͕����čl����ׂ�����B
�m�[�g�p�̃}�U�[�����{�Őv���ꂽ���̂Ȃ̂��A
���{�ŃA�Z���u�����ꂽ���̂Ȃ̂��A
�ŋ߂̎���͂悭����Ȃ�����z�������A
��͂�C�O�ł��m�[�g�Ƃ����W����������͂ɂȂ��ĔF�m����Ă������Ƃ��ł����B
���ꂩ�炸���Ɛ̂���PC�̉��i�͏������ቺ���Ă���B���̃��[�G���h�����l�b�g�u�b�N�̗̈�܂ł��Ă���킯�ŁB
�����̃~�j�m�[�g�v�̏펯�ƁAEeePC��l�b�g�u�b�N�ȍ~�̗���͕����čl����ׂ�����B
�m�[�g�p�̃}�U�[�����{�Őv���ꂽ���̂Ȃ̂��A
���{�ŃA�Z���u�����ꂽ���̂Ȃ̂��A
�ŋ߂̎���͂悭����Ȃ�����z�������A
��͂�C�O�ł��m�[�g�Ƃ����W����������͂ɂȂ��ĔF�m����Ă������Ƃ��ł����B
���ꂩ�炸���Ɛ̂���PC�̉��i�͏������ቺ���Ă���B���̃��[�G���h�����l�b�g�u�b�N�̗̈�܂ł��Ă���킯�ŁB
>>131
> ���ꂩ�炸���Ɛ̂���PC�̉��i�͏������ቺ���Ă���B
���i�̋��ʉ��Ƃ���i�߂����ʂ���B
OEM����������������Ƃ������C�ł���B
> ���̃��[�G���h�����l�b�g�u�b�N�̗̈�܂ł��Ă���킯�ŁB
�����̃��[�J�[���X�y�b�N������f�����Ȃ��Ȃ�l�������邵���Ȃ�����ȁB
�V�����Ŕ����ɂ͒ቿ�i���͕K�{�v��������B
Atom�l�b�g�u�b�N�̃X�y�b�N������Intel���̈ӂɂ����ቿ�i���헪�B
> ���ꂩ�炸���Ɛ̂���PC�̉��i�͏������ቺ���Ă���B
���i�̋��ʉ��Ƃ���i�߂����ʂ���B
OEM����������������Ƃ������C�ł���B
> ���̃��[�G���h�����l�b�g�u�b�N�̗̈�܂ł��Ă���킯�ŁB
�����̃��[�J�[���X�y�b�N������f�����Ȃ��Ȃ�l�������邵���Ȃ�����ȁB
�V�����Ŕ����ɂ͒ቿ�i���͕K�{�v��������B
Atom�l�b�g�u�b�N�̃X�y�b�N������Intel���̈ӂɂ����ቿ�i���헪�B
�H�Ɛ��i�͓������������قǒP���͉�����B
�v����ɂ����������ƁB
���E�I�ɂ�PC�s��͂܂��g�債�Ă��邵�A�ك��[�J�[�ł����i�̋��ʉ���i�߂Ă���B
�����R�X�g�_�E���̂��߂̊�Ɠw�͂��Ȃ��ɏ������i��������킯���Ȃ��B
���邦��́A�{���ɔn���R�e����
�v����ɂ����������ƁB
���E�I�ɂ�PC�s��͂܂��g�債�Ă��邵�A�ك��[�J�[�ł����i�̋��ʉ���i�߂Ă���B
�����R�X�g�_�E���̂��߂̊�Ɠw�͂��Ȃ��ɏ������i��������킯���Ȃ��B
���邦��́A�{���ɔn���R�e����
���i�̋��ʉ���������邪���ꂾ������Ȃ��ȁB
PC�̕��ω��i�̒ቺ��80�N�ォ�炸���ƂȂ��ǁA90�N��̌㔼�ȍ~���p�����Ă���B
90�N��̌㔼�ȍ~�A����̕��i�̉��i�f�[�^���O���t�Ƀv���b�g���Ă����킩�邪
���i���ቺ���Ă���̂�CPU�ȊO�قڑS�Ẵp�[�c�B������CPU�����܂艺�����ĂȂ��̂��������B
90�N����㔼�ɂ͂���ƁA����ȍ~�ŋK�i������������ĕ��i�����ʉ����ꂽ�Ƃ����̂̓l�^�ꂵ���̂��قƂ�ǂȂ��Ȃ��Ă���B
PC�s�ꂪ�傫���Ȃ��Đ��Y�ʂ������A���i�̐�����A�Z���u�����l����̈������Ɉڂ����Ƃ����̂����邪�A
�{���̂Ƃ���́A80�N�ォ��PC�̐��\����̑��x���s��̗v�������킸���ɑ������炾�ƌ��_�Â�����B
���̎��ӂ̃Z�I���[���x�[�X��PC�̏��^���ƒቿ�i���A�@�\�̓�������2005�N���ɃX���ɏ�������A
���܂�ɂ��������肵�����đS��������Ȃ������ȁB
����l�ɂ́A���\���v���Ȃ��Ȃ�Ȃ�Č����ĂȂ��A���Ă̂������Ǝ嗬�̔F�����������ȁB
PC�̕��ω��i�̒ቺ��80�N�ォ�炸���ƂȂ��ǁA90�N��̌㔼�ȍ~���p�����Ă���B
90�N��̌㔼�ȍ~�A����̕��i�̉��i�f�[�^���O���t�Ƀv���b�g���Ă����킩�邪
���i���ቺ���Ă���̂�CPU�ȊO�قڑS�Ẵp�[�c�B������CPU�����܂艺�����ĂȂ��̂��������B
90�N����㔼�ɂ͂���ƁA����ȍ~�ŋK�i������������ĕ��i�����ʉ����ꂽ�Ƃ����̂̓l�^�ꂵ���̂��قƂ�ǂȂ��Ȃ��Ă���B
PC�s�ꂪ�傫���Ȃ��Đ��Y�ʂ������A���i�̐�����A�Z���u�����l����̈������Ɉڂ����Ƃ����̂����邪�A
�{���̂Ƃ���́A80�N�ォ��PC�̐��\����̑��x���s��̗v�������킸���ɑ������炾�ƌ��_�Â�����B
���̎��ӂ̃Z�I���[���x�[�X��PC�̏��^���ƒቿ�i���A�@�\�̓�������2005�N���ɃX���ɏ�������A
���܂�ɂ��������肵�����đS��������Ȃ������ȁB
����l�ɂ́A���\���v���Ȃ��Ȃ�Ȃ�Č����ĂȂ��A���Ă̂������Ǝ嗬�̔F�����������ȁB
�����̐l��������̂����܂ł��˂�
>�H�Ɛ��i�͓������������قǒP���͉�����
����ȓ�����O�̘b�A�����������y����܂ł��Ȃ�����B
����ȓ�����O�̘b�A�����������y����܂ł��Ȃ�����B
�Ԃ����Ⴏ�AAtom���o��܂�UMPC�̒l�i��������������͉t���p�l��������ȉ𑜓x������B
�N�X�t���p�l���̉��i�͗����Ă�Ƃ͂����A���h�b�g�s�b�`�̓����i�͑�T�������B
�������琔���o�Ȃ��������o�Ȃ����獂���B
EeePC����R���Ă����Ƃ�9�C���`��WSXGA�݂����ȍ����׃f�B�X�v���C��
����ł͂Ȃ���ʉ����邱�Ƃ��ł����B
�N�X�t���p�l���̉��i�͗����Ă�Ƃ͂����A���h�b�g�s�b�`�̓����i�͑�T�������B
�������琔���o�Ȃ��������o�Ȃ����獂���B
EeePC����R���Ă����Ƃ�9�C���`��WSXGA�݂����ȍ����׃f�B�X�v���C��
����ł͂Ȃ���ʉ����邱�Ƃ��ł����B
�t�����i����̗\�z�I�ɂ́A
Bobcat���o�ꂵ�Ă����i���ʉ��̓_����A�]���̃l�b�g�u�b�N�̂悤�ȃX�^�C���Ɏ��܂�
���Ęb�Ȃ낤�ˁB
Bobcat���o�ꂵ�Ă����i���ʉ��̓_����A�]���̃l�b�g�u�b�N�̂悤�ȃX�^�C���Ɏ��܂�
���Ęb�Ȃ낤�ˁB
�m�[�gPC�̏C�����i�ň�ԍ����͉̂t���p�l����
�����i�����ɍ����̂Ȃ�ď펯�̔��e����
�����i�����ɍ����̂Ȃ�ď펯�̔��e����
Bobcat���Ƃ�Ontario���Ď�������ɂ͏o�Ă���낤��
Atom�I��u�����������ł��邩��o�Ă���Ȃ��ƍ��邯��
Atom�I��u�����������ł��邩��o�Ă���Ȃ��ƍ��邯��
>>135
���͂⒆���̐l����͈����Ȃ���
�j���[�X���Ă�킩��Ǝv�����ǂȂ�
���X�N���傫���Ȃ��Ă邩��A�^�C�Ƃ����̍��ɃV�t�g���Ă�
���͂⒆���̐l����͈����Ȃ���
�j���[�X���Ă�킩��Ǝv�����ǂȂ�
���X�N���傫���Ȃ��Ă邩��A�^�C�Ƃ����̍��ɃV�t�g���Ă�
>>138
http://plusd.itmedia.co.jp/pcuser/articles/1004/05/news026.html
��s���ďo�Ă���1201N�iION)�Ƃقړ����V���[�V�̗p
�������Ă���Ȃ���
http://plusd.itmedia.co.jp/pcuser/articles/1004/05/news026.html
��s���ďo�Ă���1201N�iION)�Ƃقړ����V���[�V�̗p
�������Ă���Ȃ���
>>140
asus���J����������
asus���J����������
�����̐��������ؖ�����̂Ȃ�Bull, Bobcat�̓W�J��Intel��CULV��Atom�Ƃ̋������i�Ƃ̊W�ɂ���
��搶�̗\�z����ʂ蕷�����Ăق������̂��ˁB�������Ȃ���̘b�͓������̂ŁB
��搶�̗\�z����ʂ蕷�����Ăق������̂��ˁB�������Ȃ���̘b�͓������̂ŁB
�܂��A����Athlon Neo�����݂��邱�Ƃ��l�����
Ontario���o��������ē��ɕς���Ȃ��
Ontario���o��������ē��ɕς���Ȃ��
���H
Athlon Neo���Đ̂�AMD������X���ł̑O�]���͍�����������
�����A�܂����A�Ǝv���Ă��܂��킯��
�����A�܂����A�Ǝv���Ă��܂��킯��
�������������̂����番�����
�o��܂ł����͉����O�̂悤�ȍ��g��
�S�~�N�Y���R��K10�R�A�ƈꏏ�ɂ��Ă�����Ă͍���
���~���K���ɂȂ��ė����Ȃ�
154 �FSocket774�F2010/08/26(��) 03:19:24 ID:y2mceSBy
���~���K���ɂȂ炴������낤��
��s���`�����邩���m��Ȃ���ł�
������ɂ���intel�̏t�͏I�������
��s���`�����邩���m��Ȃ���ł�
������ɂ���intel�̏t�͏I�������
�T�~���̃A���~���̌����Ă�����Ԃ�����˂�
�L�����݂��Ή������Ă���
�L�����Ȃ��ȁ[�B
�J�~�\���㓡�͂Ȃɂ��Ă�B
�J�~�\���㓡�͂Ȃɂ��Ă�B
158 �FSocket774�F2010/08/26(��) 11:12:02 ID:OAOGfm1m
�u�������ɋL�����N�����ƂȂ�Ɖ������͊|�����Ȃ�����
��Ƃ���̎��M�˗�����Ȃ�����A�Ƃ��l�����ɋL�������Ċy���������肵��
��Ƃ���̎��M�˗�����Ȃ�����A�Ƃ��l�����ɋL�������Ċy���������肵��
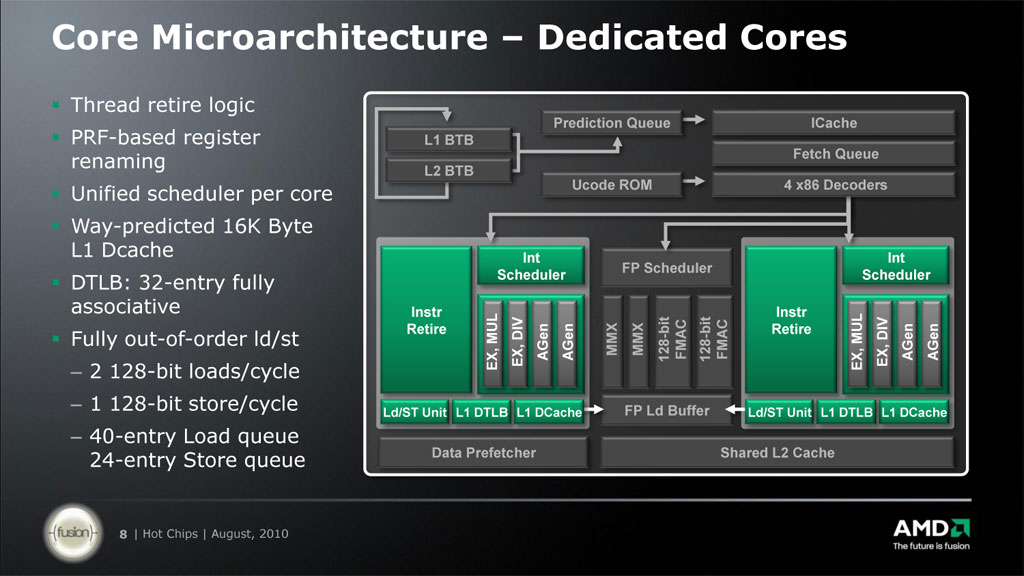
Way-predicted 16K Byte L1 Dcache
�ǂ������Ӗ��������āB�G���C�l�BL1D��2-way����Ȃ��Ȃ�̂��ȁH
http://www.techpowerup.com/img/10-08-25/bulldozer-8.jpg
�ǂ������Ӗ��������āB�G���C�l�BL1D��2-way����Ȃ��Ȃ�̂��ȁH
http://www.techpowerup.com/img/10-08-25/bulldozer-8.jpg
{kind=link}
L1D/Inst ���ꂼ��8way����Ȃ���������
�E�F�C�\���L���b�V���炵���B
�\�������E�F�C�ɂ����ƃf�[�^������A�ق��̃E�F�C�ɃA�N�Z�X���Ȃ��čςނ̂ŁA
����d�͏エ���炵���B
�\�������E�F�C�ɂ����ƃf�[�^������A�ق��̃E�F�C�ɃA�N�Z�X���Ȃ��čςނ̂ŁA
����d�͏エ���炵���B
�[�������x�[�X�̃��W�X�^���l�[�~���O�Ƃ����̂��C�ɂȂ�
>161
�@Bobcat�͂����݂����B
>162
���肪�Ƃ��B�O�O�b�Ă݂����ǂ�����ɂ͗����ł��Ȃ������B
�@Bobcat�͂����݂����B
>162
���肪�Ƃ��B�O�O�b�Ă݂����ǂ�����ɂ͗����ł��Ȃ������B
�`�l�c�b�o�t�A�`�s�h�r�f�I�J�[�h�ł̂g�c�Đ�����Đ��̎��̈����A
��������ɂ͒����ė~�����B
�Ǐ�B30fps�ȏ�ōĐ��ł��Ă�
�����~�܂�B����Ɖ��������B�J�N�c�N�B
�G�Ƀm�C�Y�@�o�O���o��B
�c�����o��B�����Ɏア�B
60fps����́A40fps���������ł���������B
CPU�Đ����ɁA�C���e���̏ꍇ��100�l����t������ł��A
�w�ǍŌ�ł́A��ʔj�]�Ɖ���͔����āAFPS�����ōς܂��̂ɁA
AMD��HD����@CPU�Đ��̏ꍇ�́A80�l�߂��ʼn�̃m�C�Y�A���g�r�@�Y���A
��ʔj�]���o��B
http://av.watch.impress.co.jp/video/avw/docs/356/414/00046.mts
60fps�o�Ȃ��ėǂ�����A��j�]�Ɖ��j�]�����ė~������ˁB
AMDCPU��ATI�͉�j�]�A���j�]�����N������ȁB
�����@������N�����炢�Ȃ�fps���Ƃ����Y��ɍĐ����ė~������ˁB
��������ɂ͒����ė~�����B
�Ǐ�B30fps�ȏ�ōĐ��ł��Ă�
�����~�܂�B����Ɖ��������B�J�N�c�N�B
�G�Ƀm�C�Y�@�o�O���o��B
�c�����o��B�����Ɏア�B
60fps����́A40fps���������ł���������B
CPU�Đ����ɁA�C���e���̏ꍇ��100�l����t������ł��A
�w�ǍŌ�ł́A��ʔj�]�Ɖ���͔����āAFPS�����ōς܂��̂ɁA
AMD��HD����@CPU�Đ��̏ꍇ�́A80�l�߂��ʼn�̃m�C�Y�A���g�r�@�Y���A
��ʔj�]���o��B
http://av.watch.impress.co.jp/video/avw/docs/356/414/00046.mts
60fps�o�Ȃ��ėǂ�����A��j�]�Ɖ��j�]�����ė~������ˁB
AMDCPU��ATI�͉�j�]�A���j�]�����N������ȁB
�����@������N�����炢�Ȃ�fps���Ƃ����Y��ɍĐ����ė~������ˁB
�`�l�c�b�o�t�AATI�I���{�@�`�s�h�r�f�I�J�[�h�ł�HD�Đ��B
�n�f�W�Đ��@1080P�Đ��@����ҏW�@youtube �j�R�j�R����X�g���[�~���O�Đ�
���y�Đ��A���̑��A���ƊG�̕���@�s������@�u���X�N�̍ŋ��g���I�B
������ł͎����グ�Ă��������B
100�l����t���ł��G�Ƃ���������Ȃ�CPU �`�b�v���J�����Ă��������B
�n�f�W�Đ��@1080P�Đ��@����ҏW�@youtube �j�R�j�R����X�g���[�~���O�Đ�
���y�Đ��A���̑��A���ƊG�̕���@�s������@�u���X�N�̍ŋ��g���I�B
������ł͎����グ�Ă��������B
100�l����t���ł��G�Ƃ���������Ȃ�CPU �`�b�v���J�����Ă��������B
AMD��ATI���āA
�C���e��CPU���ɃI�[�o�[�N���b�N���Ďg�p�����悤�Ȋ����Ȃ��ˁB
�����ׂ��獂���ׂ����ɐM�����������A
���ɉ��ƊG���ア���B
�����ăI�[�o�[�N���b�N�̐L�т���Ȃ������A
���x�������}�㏸����̂��A
���̌����Ȃ낤��??
������́A�����镔���ŁA��������}�[�W�������
�u���[�L�̕����Ȃ��Ԃ݂�������Ȃ�CPU�ƃ`�b�v������ė~�����ˁB
�y���ׂɋ���CPU�@�r�f�I�`�b�v����Ȃ��āA�����ׂɋ���CPU�ˁB
���\���A��j�]�@���m�C�Y�@100�l����t���ɋ����@�u���X�N�̖���CPU�@�`�b�v����ė~������ˁB
�C���e��CPU���ɃI�[�o�[�N���b�N���Ďg�p�����悤�Ȋ����Ȃ��ˁB
�����ׂ��獂���ׂ����ɐM�����������A
���ɉ��ƊG���ア���B
�����ăI�[�o�[�N���b�N�̐L�т���Ȃ������A
���x�������}�㏸����̂��A
���̌����Ȃ낤��??
������́A�����镔���ŁA��������}�[�W�������
�u���[�L�̕����Ȃ��Ԃ݂�������Ȃ�CPU�ƃ`�b�v������ė~�����ˁB
�y���ׂɋ���CPU�@�r�f�I�`�b�v����Ȃ��āA�����ׂɋ���CPU�ˁB
���\���A��j�]�@���m�C�Y�@100�l����t���ɋ����@�u���X�N�̖���CPU�@�`�b�v����ė~������ˁB
����AMDCPU��ATI�J�[�h���Ă�炵��
�J�N�c�L���u���X�N���������r��鎖����60fps�ōĐ����ꂽ�B�ǂ����悤
�J�N�c�L���u���X�N���������r��鎖����60fps�ōĐ����ꂽ�B�ǂ����悤
�ˑR���莎�����J�n���ꂽ�͗l
Steam Hardware & Software Survey: July 2010
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@7���@�@6������
ATI Radeon HD 4800Series�@�@7.21%�@�@0.00%
NVIDIA GeForce 8800�@�@�@�@�@ 5.99%�@-0.28%
NVIDIA GeForce 9800�@�@�@�@�@ 5.34%�@-0.14%
NVIDIA GeForce 9600�@�@�@�@�@ 4.10%�@-0.05%
NVIDIA GeForce 8600�@�@�@�@�@ 3.81%�@-0.13%
NVIDIA GeForce GTX 260�@�@�@3.33%�@-0.12%
ATI Radeon HD 5700 Series�@ 2.98%�@+0.31%
ATI Radeon HD 5800 Series�@ 2.82%�@+0.24%
NVIDIA GeForce GTS 150�@�@�@2.68%�@+0.15%
NVIDIA GeForce 9500�@�@�@�@�@ 2.61%�@+0.11%
gefo�F�E�E�E
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@7���@�@6������
ATI Radeon HD 4800Series�@�@7.21%�@�@0.00%
NVIDIA GeForce 8800�@�@�@�@�@ 5.99%�@-0.28%
NVIDIA GeForce 9800�@�@�@�@�@ 5.34%�@-0.14%
NVIDIA GeForce 9600�@�@�@�@�@ 4.10%�@-0.05%
NVIDIA GeForce 8600�@�@�@�@�@ 3.81%�@-0.13%
NVIDIA GeForce GTX 260�@�@�@3.33%�@-0.12%
ATI Radeon HD 5700 Series�@ 2.98%�@+0.31%
ATI Radeon HD 5800 Series�@ 2.82%�@+0.24%
NVIDIA GeForce GTS 150�@�@�@2.68%�@+0.15%
NVIDIA GeForce 9500�@�@�@�@�@ 2.61%�@+0.11%
gefo�F�E�E�E
>>165
���߂�A�܂���������ɍĐ����ꂿ����ċM�����������������̂�
�����ς蕪����Ȃ����ǁA���������Ē�d�����������ĂȂ������H
���߂�A�܂���������ɍĐ����ꂿ����ċM�����������������̂�
�����ς蕪����Ȃ����ǁA���������Ē�d�����������ĂȂ������H
>168
���S����
����245e�����Ă��邩��
���S����
����245e�����Ă��邩��
�@�O�̓z��Atom�̃l�K�L�����ɂ����Ȃ�Ȃ��Ƃ悤�₭��������B
CPU�ōĐ����Ă�����Ȃɍ����o��Ȃ�āc
�v�Z���ʂ��S���M�p�o���Ȃ�����Ȃ����I
�����CPU�Ȃ̂Ɉ��肵�ē����Ȃ��OS���Ă����[�ł��ˁI
�v�Z���ʂ��S���M�p�o���Ȃ�����Ȃ����I
�����CPU�Ȃ̂Ɉ��肵�ē����Ȃ��OS���Ă����[�ł��ˁI
�㓡�݂��ˁ[�[�[�[�[�I�I�I
�㓡�͑����܂�XCGPU
���̂ق��͂����l�^�M��
����ɒN�����߂ĂȂ�
��̋L���ŏȓd�͋Z�p�ɐG�����ď����Ă邵�B
�������Ƀu��������ł��邩������Ȃ�����
�������Ƀu��������ł��邩������Ȃ�����
��H�u����L1D��8way�ɂȂ����̂��B
�������4way�ďo�Ă����瑝�₵���̂��B
�������4way�ďo�Ă����瑝�₵���̂��B
Athlon II X2 M300�̂��Ƃ��v���o���Ă����Ă�������(�L�G�ցG�M)
���߂ƃf�[�^��way�����Ⴄ�L���������C�����邯�ǁA�\�[�X���ǂ����Ă����t����Ȃ����猩�ԈႢ�����B
�悭�l������R�A�ƃ��W���[����������܂��ɂȂ��Ă邾�������c
�R�A���Ƃ�L1D�����Ă��
�R�A���Ƃ�L1D�����Ă��
�㓡�������
>>185
Llano�������E���ł����
Llano�������E���ł����
9���܂ő҂�
Bulldozer�A�[�L�e�N�`������}
http://pc.watch.impress.co.jp/img/pcw/docs/389/491/8.jpg
{kind=link}
������CPU�Ƃ̔�r
http://pc.watch.impress.co.jp/img/pcw/docs/389/491/7.jpg
{kind=link}
Bulldozer��Bobcat��FP�X�P�W���[���[�����S�ɓƗ����Ă�̂�APU���z�肳��Ă邩��Ȃ낤��
>>182
http://www.techpowerup.com/img/10-08-25/bulldozer-7.jpg
L�P�̖��߂̕���2-way�Ƃ��邯�ǃf�[�^�̕���
http://www.techpowerup.com/img/10-08-25/bulldozer-8.jpg
Way-predicted 16K Byte L1 Dcache�Ƃ����Ă��邾����
way���킩��Ȃ��B
�㓡�����Ɋ��҂������Ǐ����ĂȂ��ˁB
16K Byte�ɏk������Ă�2-way�̂܂܂Ƃ��L�蓾�Ȃ��v�������B
http://www.techpowerup.com/img/10-08-25/bulldozer-7.jpg
{kind=link}
L�P�̖��߂̕���2-way�Ƃ��邯�ǃf�[�^�̕���
http://www.techpowerup.com/img/10-08-25/bulldozer-8.jpg
Way-predicted 16K Byte L1 Dcache�Ƃ����Ă��邾����
way���킩��Ȃ��B
�㓡�����Ɋ��҂������Ǐ����ĂȂ��ˁB
16K Byte�ɏk������Ă�2-way�̂܂܂Ƃ��L�蓾�Ȃ��v�������B
>>189
�����I�ɂ�FP���j�b�g��NV GPU��Streaming Multi-Processor�݂����Ȃ��̂ɒu������邩����
�����I�ɂ�FP���j�b�g��NV GPU��Streaming Multi-Processor�݂����Ȃ��̂ɒu������邩����
�Ƃ肠�����Q�[���ł�bull��i7�ǂ����������̂���
196 �FSocket774�F2010/08/27(��) 02:02:31 ID:CWQK7aRB
�O�]�������Ȃ�bull�����A�O�]���Ȃ�č��܂ŃA�e�ɂȂ������ƂȂ�����ȁB
���N�܂ő҂��Ȃ��Ƃ킩���B
���N�܂ő҂��Ȃ��Ƃ킩���B
���̓G���R���\�ōw�������߂��
>195
�Q�[���ɂ��Ƃ��肫����Ȏ��������Ă�����
�Q�[���ɂ��Ƃ��肫����Ȏ��������Ă�����
�}���`�X���b�h�����ł̓R�A���̓������s���̑��������L��������
�t�ɃV���O���X���b�h�����ł͏��Ȃ��R�A�����N���b�N�ʼn����L��
����TDP�g���ŃN���b�N/�R�A�̊���U����ǂ����邩�Ƃ�����Bulldozer�Ȃ̂���
�t�ɃV���O���X���b�h�����ł͏��Ȃ��R�A�����N���b�N�ʼn����L��
����TDP�g���ŃN���b�N/�R�A�̊���U����ǂ����邩�Ƃ�����Bulldozer�Ȃ̂���
�R�A���̉��Z�퐔��
���ɃV���O���X���b�h�ł͑����ق����L��
�������g������Ȃ����炢������������Ďז�
�������ǂ��̂�ALU*2���Ƃ����̂�Bull
���ɃV���O���X���b�h�ł͑����ق����L��
�������g������Ȃ����炢������������Ďז�
�������ǂ��̂�ALU*2���Ƃ����̂�Bull
>>195
�c�O�Ȃ���ǂ��l���Ă�i7
�����x*2��bulldozer����
�ɉ����č�����x������Nehalem�̕���
�s�[�N���\�͂ǂ����Ă������Ȃ�B
bulldozer�ɂ̓g���[�X�L���b�V�����Ȃ��̂��ɂ��B�܂��Q�[���ł͂���܂�Ӗ��Ȃ����������ǁB
�c�O�Ȃ���ǂ��l���Ă�i7
�����x*2��bulldozer����
�ɉ����č�����x������Nehalem�̕���
�s�[�N���\�͂ǂ����Ă������Ȃ�B
bulldozer�ɂ̓g���[�X�L���b�V�����Ȃ��̂��ɂ��B�܂��Q�[���ł͂���܂�Ӗ��Ȃ����������ǁB
���_
�o����킩��
�o����킩��
�����O�Ȃ�N���X�^�[�A�[�L�e�N�`���̃����b�g�E�f�����b�g�𗝉����悤�Ƃ�������
i7�ɏ��Ă�킯�Ȃ�����݂����Ȏ������Ă���A�~�R�e�n������������������
����͗�Âȕ]���ɂȂ��Ă�ȁB
�o����킩��B
i7�ɏ��Ă�킯�Ȃ�����݂����Ȏ������Ă���A�~�R�e�n������������������
����͗�Âȕ]���ɂȂ��Ă�ȁB
�o����킩��B
�G���R���ሳ�|���낤��
>>189
> Bulldozer��Bobcat��FP�X�P�W���[���[�����S�ɓƗ����Ă�̂�
���H��
K7�̎��ォ��APU���������Ă��́H��
>>203
�f�����b�g�B
���Ƃ��ΐ������Z�R�A�ŏd������MUL�ADIV��ABM�Ȃǂ̋K�͂̑傫�ȉ��Z��������Ȃ���Ȃ�Ȃ�
�g�����W�X�^�����̖��ʁB
�܂��A���Z���߂����s���Ă���ԁA�ˑ��W�Ńp�C�v���C���n�U�[�h���N���Ă�HT�Ή��̃R�A�Ȃ�
�����ЂƂ̃X���b�h���������邱�Ƃ��ł��邪�ABulldozer���Ɛ����R�A���ƃX�g�[�����閳�ʁB
Bulldozer�͗����̃X���b�h����ɃX�g�[�������ɓ����������ꍇ�Ɉ�Ԍ�����������
�T�[�o�̃��[�N���[�h�ł͂�������イ���C����������ǂ݂ɍs������Ȃ����Ԃ���������B
���̂�����ɂȂ�Ƃ����Е��̃X���b�h��ALU��S�������n����SMT�ɕ�������B
�f�X�N�g�b�v�s��̂�����݂������T�[�o�ɓ�������IBM POWER�ł���4issue + SMT���̗p��
�V���O���X���b�h���\�������ɍ��߂������Ƃ��Ă鎖�����������Ȃ��ˁB
�܂��AHT��������i5 7xx(4 issue)�ł��瑽���̃x���`�ɂ����ăN���b�N�����萫�\���K10(3 issue)��2���ȏ�
���������Ă邩�琢�b������B�X�P�W���[����L���b�V���R���g���[���̐��\��������낤���B
> Bulldozer��Bobcat��FP�X�P�W���[���[�����S�ɓƗ����Ă�̂�
���H��
K7�̎��ォ��APU���������Ă��́H��
>>203
�f�����b�g�B
���Ƃ��ΐ������Z�R�A�ŏd������MUL�ADIV��ABM�Ȃǂ̋K�͂̑傫�ȉ��Z��������Ȃ���Ȃ�Ȃ�
�g�����W�X�^�����̖��ʁB
�܂��A���Z���߂����s���Ă���ԁA�ˑ��W�Ńp�C�v���C���n�U�[�h���N���Ă�HT�Ή��̃R�A�Ȃ�
�����ЂƂ̃X���b�h���������邱�Ƃ��ł��邪�ABulldozer���Ɛ����R�A���ƃX�g�[�����閳�ʁB
Bulldozer�͗����̃X���b�h����ɃX�g�[�������ɓ����������ꍇ�Ɉ�Ԍ�����������
�T�[�o�̃��[�N���[�h�ł͂�������イ���C����������ǂ݂ɍs������Ȃ����Ԃ���������B
���̂�����ɂȂ�Ƃ����Е��̃X���b�h��ALU��S�������n����SMT�ɕ�������B
�f�X�N�g�b�v�s��̂�����݂������T�[�o�ɓ�������IBM POWER�ł���4issue + SMT���̗p��
�V���O���X���b�h���\�������ɍ��߂������Ƃ��Ă鎖�����������Ȃ��ˁB
�܂��AHT��������i5 7xx(4 issue)�ł��瑽���̃x���`�ɂ����ăN���b�N�����萫�\���K10(3 issue)��2���ȏ�
���������Ă邩�琢�b������B�X�P�W���[����L���b�V���R���g���[���̐��\��������낤���B
���_
K10�@K9�̓N���b�N�����萫�\�̗B
�u���X�N�B���y����Đ��Ō��p�N�ɂȂ�o�O�B
�n�f�W�L���v�`���[���ڊ��ł́A
���肵���Đ��@�^��@�ҏW���A�M�����̖����A
���[�J�[�f�X�N�g�b�vPC�B�m�[�g��AMD���̗p�������������R
�n�f�W���ڂƓ���A�f�����C���̑�^�t���Z�b�gPC���A
���Ƀ��[�J�[�l���猙����̗p�ɂȂ����B
���_�A�G���R�ƃQ�[������ꕔ��������Ȃ�����A
�������肵��CPU�ƃ��C���`�b�v�����B
K10�@K9�̓N���b�N�����萫�\�̗B
�u���X�N�B���y����Đ��Ō��p�N�ɂȂ�o�O�B
�n�f�W�L���v�`���[���ڊ��ł́A
���肵���Đ��@�^��@�ҏW���A�M�����̖����A
���[�J�[�f�X�N�g�b�vPC�B�m�[�g��AMD���̗p�������������R
�n�f�W���ڂƓ���A�f�����C���̑�^�t���Z�b�gPC���A
���Ƀ��[�J�[�l���猙����̗p�ɂȂ����B
���_�A�G���R�ƃQ�[������ꕔ��������Ȃ�����A
�������肵��CPU�ƃ��C���`�b�v�����B
��ׁ[�E�E�EPentium4����̒c�q�ė������E�E�E�r��܂���̊���orz
�Ȃ�ŃR�e�O�����Ȃ�
NG�ʓ|����������O���Ȃ�
NG�ʓ|����������O���Ȃ�
�����A���`���N���Ăă����^��
�C�J�L�����uALU1�̐�߂�ʐςȂǐ�%�ɉ߂��������������Ƃ���ŏȃX�y�[�X�ɉ��̑����ɂ��Ȃ�Ȃ��u���u���u�o�u�o�b�I�v
�@�@�@�@�@�@�@�@�uALU1���₷�����ł��̂������g�����W�X�^�����̖��ʃK�c�K�c���O���O�p�N�p�N�u���u���u�o�u�o�b�I�v
�@�@�@�@�@�@�@�@�u�����Е��̃X���b�h�ɃL���b�V����S�������n����SMT�ɕ�������y���y���`���[�`���[�u���u���u�o�u�o�b�I�u�{�b�I�v
�̂��̎O�A�E���R�ł���
�@�@�@�@�@�@�@�@�uALU1���₷�����ł��̂������g�����W�X�^�����̖��ʃK�c�K�c���O���O�p�N�p�N�u���u���u�o�u�o�b�I�v
�@�@�@�@�@�@�@�@�u�����Е��̃X���b�h�ɃL���b�V����S�������n����SMT�ɕ�������y���y���`���[�`���[�u���u���u�o�u�o�b�I�u�{�b�I�v
�̂��̎O�A�E���R�ł���
�����E�_�����Z���j�b�g�Ə�Z�E���Z���j�b�g�̎����R�X�g�������x���Ǝv���Ă�n��
�c�q�̂������Ƃ͐M�p���Ȃ�
���Ė��ł��B
64�r�b�g�~64�r�b�g�̏�Z�ɑΉ�����Integer Multipler��H�ɕK�v��Full Adder�͍ŒႢ���ł��傤�H
64�r�b�g�~64�r�b�g�̏�Z�ɑΉ�����Integer Multipler��H�ɕK�v��Full Adder�͍ŒႢ���ł��傤�H
FF14�ł͈�ʂ�H�삵�I������悤���E�E�E
���������Ƃ������Ă��E�E�E
���������Ƃ������Ă��E�E�E
�����O�ɂ���������
Bull�̏��Z�킪FPU�̂悤�ɋ��L�ɂȂ�̂��ʂɂȂ�̂�
����ɏ��Z��̃T�C�Y���m�炸�ɑ��ς�炸�o�O�R�s�y�����J��Ԃ��Ă����Ƃ�
�������Z�̕p�x�������Ǝv���Ȃ�ʂɎ����ĂĐ�������
�Ⴂ�Ȃ狤�L���Ă��̃f�����b�g���\�ꂽ�Ƃ��Ă��債�����ɂ͂Ȃ�Ȃ�
�v����ɃL���b�V����荇�����Ƃɔ�ׂ��牽�ł��Ȃ���
�Ƃɂ���������ŃE���R�H���Ă���Č��_�ɕς��͖���
Bull�̏��Z�킪FPU�̂悤�ɋ��L�ɂȂ�̂��ʂɂȂ�̂�
����ɏ��Z��̃T�C�Y���m�炸�ɑ��ς�炸�o�O�R�s�y�����J��Ԃ��Ă����Ƃ�
�������Z�̕p�x�������Ǝv���Ȃ�ʂɎ����ĂĐ�������
�Ⴂ�Ȃ狤�L���Ă��̃f�����b�g���\�ꂽ�Ƃ��Ă��債�����ɂ͂Ȃ�Ȃ�
�v����ɃL���b�V����荇�����Ƃɔ�ׂ��牽�ł��Ȃ���
�Ƃɂ���������ŃE���R�H���Ă���Č��_�ɕς��͖���
�R�A�̒��Ő������Z���j�b�g����߂�ʐςȂ��2�`3���ق�
���Z�̎��s�T�C�N����1.5�{���x�ɒx���Ȃ�悤��
http://svn.open64.net/filedetails.php?repname=Open64&path=%2Ftrunk%2Fosprey%2Fcommon%2Ftarg_info%2Fproc%2Fx8664%2Forochi_si.cxx&rev=2722
fp-load 2 -> 5
fadd/fmul 4 -> 6
fmadd 6
fdiv32 18 -> 27
fdiv64 20 -> 30
http://svn.open64.net/filedetails.php?repname=Open64&path=%2Ftrunk%2Fosprey%2Fcommon%2Ftarg_info%2Fproc%2Fx8664%2Forochi_si.cxx&rev=2722
fp-load 2 -> 5
fadd/fmul 4 -> 6
fmadd 6
fdiv32 18 -> 27
fdiv64 20 -> 30
�E���R�H���߂��Ȃ̂������i��������j����ŃV�R��߂��Ȃ̂�
�����s���Ȃ��炱�ꂿ����ƃo�O��߂�����
����f��FPU��f
div�͏��Z������fdiv�͏���o�O�v���Z�b�T�����тŗL���ȕ��������_���Z���j�b�g�ւ̂���
�����s���Ȃ��炱�ꂿ����ƃo�O��߂�����
����f��FPU��f
div�͏��Z������fdiv�͏���o�O�v���Z�b�T�����тŗL���ȕ��������_���Z���j�b�g�ւ̂���
�������Z���c�O�Ȃ��ƂɂȂ��Ă��
�m����Bulldozer�̏��Z���j�b�g�͑債���K�͂���Ȃ���������Ȃ�
�@�@�@�@�@Intel Core�@Bulldozer
div32�@�@�@ 18�@�@�@�@�@39
div64�@�@�@ 32�@�@�@�@�@71
idiv32�@�@�@22�@�@�@�@�@42
idiv64�@�@�@32�@�@�@�@�@74
http://svn.open64.net/filedetails.php?repname=Open64&path=/trunk/osprey/common/targ_info/proc/x8664/orochi_si.cxx
http://svn.open64.net/filedetails.php?repname=Open64&path=/trunk/osprey/common/targ_info/proc/x8664/core_si.cxx
�m����Bulldozer�̏��Z���j�b�g�͑債���K�͂���Ȃ���������Ȃ�
�@�@�@�@�@Intel Core�@Bulldozer
div32�@�@�@ 18�@�@�@�@�@39
div64�@�@�@ 32�@�@�@�@�@71
idiv32�@�@�@22�@�@�@�@�@42
idiv64�@�@�@32�@�@�@�@�@74
http://svn.open64.net/filedetails.php?repname=Open64&path=/trunk/osprey/common/targ_info/proc/x8664/orochi_si.cxx
http://svn.open64.net/filedetails.php?repname=Open64&path=/trunk/osprey/common/targ_info/proc/x8664/core_si.cxx
���z�_�ł͂Ȃ��������E�̎������ƁA2�X���b�h�ŋ��͂ȏ��Z���j�b�g�����p����Intel�����̂ق���ꡂ��Ɍ���������
���x��DIV���ߎ��s����������܂Ńp�C�v���C�����V�ԁ~�Q����
�V���O���X���b�h�ł��}���`�X���b�h�ł����Z�𑽗p����P�[�X�ł�Bulldozer�͕����\�B
���x��DIV���ߎ��s����������܂Ńp�C�v���C�����V�ԁ~�Q����
�V���O���X���b�h�ł��}���`�X���b�h�ł����Z�𑽗p����P�[�X�ł�Bulldozer�͕����\�B
�����@�{��������킵���B�B�B
���܂�ɃC�J�L����f������Z�̗��ɂȂ���������2ch�R�s�y�i�ߋ��X��32���瓙�j�����o���Ȃ��Ȃ�̂��͂ǂ��ł������Ƃ���
����32��K10�Ƃ̔�r�����݂Ŕ���₷���̂�������������\���Ƃ�
ttp://citavia.blog.de/2010/01/21/some-instruction-latency-numbers-of-bulldozer-7850137/
Bull�͏����_���W����悤�ȉ��Z�͏��Z�S�ʂ����݂ŃK�^�������邩�Ǝv������ł�����
�������Z��K10�Ƃ܂�����蓯������
�������Z��x/y�̏ꍇ�u0�ɂȂ�܂ł�x����y����������邩�v�Ƃ����v�Z�����邻��������
�����Ȃ�Ώ����_FPU�͑S�����W�ɂȂ�����
����32��K10�Ƃ̔�r�����݂Ŕ���₷���̂�������������\���Ƃ�
ttp://citavia.blog.de/2010/01/21/some-instruction-latency-numbers-of-bulldozer-7850137/
Bull�͏����_���W����悤�ȉ��Z�͏��Z�S�ʂ����݂ŃK�^�������邩�Ǝv������ł�����
�������Z��K10�Ƃ܂�����蓯������
�������Z��x/y�̏ꍇ�u0�ɂȂ�܂ł�x����y����������邩�v�Ƃ����v�Z�����邻��������
�����Ȃ�Ώ����_FPU�͑S�����W�ɂȂ�����
�c�q����
�܂������͊�{�I�ɖϑz����X�������
�ł�3�s������ƃL���C
�ł�3�s������ƃL���C
�ϑz�Ȃ����ė����
K10�����X2.0Ghz����2.5Ghz���x���œK�Ȃ̂�
�������N���b�N�グ����A��d�������������̖���������������������A
�u���h�[�U�[��4.5����5Ghz���x�̐ɂ��āA
�]�͂��\���Ɏ������i���̗ǂ�CPU�ɂ��Ă���B
3Ghz���f���ł��A�y�ɃI�[�o�[�N���b�N��4Ghz�s�����i����CPU�ɂ��Ă��������B
�������N���b�N�グ����A��d�������������̖���������������������A
�u���h�[�U�[��4.5����5Ghz���x�̐ɂ��āA
�]�͂��\���Ɏ������i���̗ǂ�CPU�ɂ��Ă���B
3Ghz���f���ł��A�y�ɃI�[�o�[�N���b�N��4Ghz�s�����i����CPU�ɂ��Ă��������B
������č��i���Ƃ����̂��H
K10�݂����Ɏ��̈����̏ꍇ�́A
�t�����[�h���̏���d�͌����Ƃ��M�}�㏸�Ƃ�
�����ȕs���������k���n�ɂȂ��ˁB
�u���h�[�U�[��3Ghz��4.5Ghz�I�[�o�[�N���b�N�o���āA
�n�C�G���h��5.5Ghz�`6Ghz�I�[�o�[�N���b�N�o����ɂ��Ă���B
�I�[�o�[�N���b�N���Ȃ��Ă��A���ꂪ�\�ŗL���
�t�����[�h���̓d�͏���̐L�я��Ȃ����낤��
Core�H Duo�݂����Ɉ��肵�āA�����g���邩��ˁB
�t�����[�h���̏���d�͌����Ƃ��M�}�㏸�Ƃ�
�����ȕs���������k���n�ɂȂ��ˁB
�u���h�[�U�[��3Ghz��4.5Ghz�I�[�o�[�N���b�N�o���āA
�n�C�G���h��5.5Ghz�`6Ghz�I�[�o�[�N���b�N�o����ɂ��Ă���B
�I�[�o�[�N���b�N���Ȃ��Ă��A���ꂪ�\�ŗL���
�t�����[�h���̓d�͏���̐L�я��Ȃ����낤��
Core�H Duo�݂����Ɉ��肵�āA�����g���邩��ˁB
�ւ�Ȃ̂ɍ\���Ă��܂����X�}��
230 �FSocket774�F2010/08/27(��) 12:31:52 ID:6iL12/DJ
�L�`�K�C���\���قǗD��CPU�Ƃ������Ƃł����B
�D�ǂ��ǂ����͂܂��킩����
�㓡���ł������f���͂��Ȃ���
�㓡���ł������f���͂��Ȃ���
�܂�K10��2.5GHz�܂ł���������Ȃ�����
> �u���h�[�U�[��3Ghz��4.5Ghz�I�[�o�[�N���b�N�o����
����4.5GHz��OC�o�����Ƃ��Ă����͂�����Ƃ͎v��Ȃ�����w
����4.5GHz��OC�o�����Ƃ��Ă����͂�����Ƃ͎v��Ȃ�����w
>>127
> �@AMD�̃x���`�}�[�N�ł́ABulldozer�v���Z�b�T�́A���s��12�R�AOpteron�v���Z�b�T
> �i�J���R�[�h���FMagny Cours�j�Ɠ����d�̓v���t�@�C���ɂ����āA50���������\���L�^�����ƁA
> �}�b�L�j�[���͌�����B
> http://www.computerworld.jp/topics/datac/189051.html
AVX�Ή��ł�256bitSSE���Z���l������Ɛ��\�I�ɍŒ�ł����ꂮ�炢�͓�����O�ł͂Ȃ����낤���H
Intel����100%�������\���o���ƌ����Ă�̂������
> �@AMD�̃x���`�}�[�N�ł́ABulldozer�v���Z�b�T�́A���s��12�R�AOpteron�v���Z�b�T
> �i�J���R�[�h���FMagny Cours�j�Ɠ����d�̓v���t�@�C���ɂ����āA50���������\���L�^�����ƁA
> �}�b�L�j�[���͌�����B
> http://www.computerworld.jp/topics/datac/189051.html
AVX�Ή��ł�256bitSSE���Z���l������Ɛ��\�I�ɍŒ�ł����ꂮ�炢�͓�����O�ł͂Ȃ����낤���H
Intel����100%�������\���o���ƌ����Ă�̂������
�EBulldozer�͏���d�͕ӂ�̐��\���d�����ĒNj������A�[�L�e�N�`��
�E�}���`�X���b�h������CPU�����̏������j�b�g���ő���Ɋ��p�ł���
�E�V���O���X���b�h����������d�͂�}���ăN���b�N��傫���グ����
�E���́u����TDP�i�M����d�́j�g���ł̍ő含�\�v
IPC=1�N���b�N������̖��ߓ������s���@�N���b�N��CPU�̓�����g��
CPU�̃V���O���X���b�h�������\�ɂ��Ă͂����悻�uIPC�~�N���b�N�v�ŕ\���ł���B
�܂萫�\���グ��ɂ́uIPC���グ��vor�u�N���b�N���グ��v��2�p�^�[�����l������B
�����������Ŗ��ɂȂ�̂͏���d�͂̕ǁBIPC���グ�����Ă��A�N���b�N���グ�����Ă�
����d�͂��啝�ɑ����Ă��܂��̂ŁA�A�[�L�e�N�`���̐v�͔��ɓ���B
�܂��}���`�X���b�h�����ƃV���O���X���b�h�����̗������ۑ�ɂȂ�B
�Ⴆ�Γ�������d�͂Ȃ�A4�R�A��N���b�N�̕����}���`�X���b�h�����ł͗L���ɂȂ邵
�t��2�R�A���N���b�N�̕����V���O���X���b�h�����ł͗L���ɂȂ��Ă��܂��B
���݂�CPU�ł�IPC�����ł��Ō��E�ɍ����|�����Ă���B�����Ȃ�ƃ}���`�X���b�h�����ł�
�R�A���i�������s�X���b�h���j�𑝂₵�A�V���O���X���b�h�����ł̓N���b�N���グ�邵�������B
�܂�u�R�A���𑝂₹�āv�u�N���b�N���グ����v�A�[�L�e�N�`�������߂��Ă���B
�����Ő��܂ꂽ�̂�����Bulldozer�ō̗p���ꂽ�u�N���X�^�^�v�A�[�L�e�N�`���B
�}���`�X���b�h������CPU���̏������j�b�g���X���b�h���m���H���������ƂȂ����p�ł���B
�܂�S�ẴR�A���t�����p����ۂɍő���̐��\���ł���悤�Ȑv�ɂȂ��Ă���B
�܂��V���O���X���b�h�������\�����߂����ʂł́A�����̃R�A�ɐ��\�����߂��邪
����d�͂��}�����Ă���̂ł��̕��N���b�N�����߂�Ƃ����_��Ȋ��p���ł���悤�ɂȂ����B
�E�}���`�X���b�h������CPU�����̏������j�b�g���ő���Ɋ��p�ł���
�E�V���O���X���b�h����������d�͂�}���ăN���b�N��傫���グ����
�E���́u����TDP�i�M����d�́j�g���ł̍ő含�\�v
IPC=1�N���b�N������̖��ߓ������s���@�N���b�N��CPU�̓�����g��
CPU�̃V���O���X���b�h�������\�ɂ��Ă͂����悻�uIPC�~�N���b�N�v�ŕ\���ł���B
�܂萫�\���グ��ɂ́uIPC���グ��vor�u�N���b�N���グ��v��2�p�^�[�����l������B
�����������Ŗ��ɂȂ�̂͏���d�͂̕ǁBIPC���グ�����Ă��A�N���b�N���グ�����Ă�
����d�͂��啝�ɑ����Ă��܂��̂ŁA�A�[�L�e�N�`���̐v�͔��ɓ���B
�܂��}���`�X���b�h�����ƃV���O���X���b�h�����̗������ۑ�ɂȂ�B
�Ⴆ�Γ�������d�͂Ȃ�A4�R�A��N���b�N�̕����}���`�X���b�h�����ł͗L���ɂȂ邵
�t��2�R�A���N���b�N�̕����V���O���X���b�h�����ł͗L���ɂȂ��Ă��܂��B
���݂�CPU�ł�IPC�����ł��Ō��E�ɍ����|�����Ă���B�����Ȃ�ƃ}���`�X���b�h�����ł�
�R�A���i�������s�X���b�h���j�𑝂₵�A�V���O���X���b�h�����ł̓N���b�N���グ�邵�������B
�܂�u�R�A���𑝂₹�āv�u�N���b�N���グ����v�A�[�L�e�N�`�������߂��Ă���B
�����Ő��܂ꂽ�̂�����Bulldozer�ō̗p���ꂽ�u�N���X�^�^�v�A�[�L�e�N�`���B
�}���`�X���b�h������CPU���̏������j�b�g���X���b�h���m���H���������ƂȂ����p�ł���B
�܂�S�ẴR�A���t�����p����ۂɍő���̐��\���ł���悤�Ȑv�ɂȂ��Ă���B
�܂��V���O���X���b�h�������\�����߂����ʂł́A�����̃R�A�ɐ��\�����߂��邪
����d�͂��}�����Ă���̂ł��̕��N���b�N�����߂�Ƃ����_��Ȋ��p���ł���悤�ɂȂ����B
Intel : Radix-16 SRT��Integer��FP/SIMD�ŋ��p
AMD : �x�����Z���2�X���b�h���Ƃ̐����N���X�^�ƁA���p��FP�N���X�^�Ōv3�ێ�
3�ڂ��Ă邩����ċ������ē����킯�ł��Ȃ���A1������̎����R�X�g���Ⴂ�킯�ł��Ȃ�
2 issue+���̐����p�C�v���C����70�T�C�N���~�܂�ƁA140���ߕ�������ȏ㖽�ߔ��s���邱�ƂɂȂ�A
�����Е��̃X���b�h�ł͋Ă郆�j�b�g�����̒�ؕ����t�H���[�ł��Ȃ��B
Intel Core�̕���(Radix-16 SRT�A���S���Y��)�ł�idiv64�ł�32�T�C�N�����x�ōςނ̂ŁA
�������߂����Ɍ����96���ߕ����x�̃��X�ł��ނ��AHT���L���Ȃ��������̃X���b�h��
���s���邱�ƂŌ��Ԃ̃T�C�N���߂邱�Ƃ��ł���B
�����������_�Ō����CMT��SMT���}���`�X���b�h�ɗL���ȃA�v���[�`�Ƃ͕K�����������Ȃ��
���Ƃ��̕ӂ������ǁA���̕ӂ̖��߂�DirectX��CPU�������ł͂悭�g������A�x���ƃQ�[���ɂ͌����Ȃ���
�@�@�@�@�@�@�@Core�@Bulldozer
sqrtps �@�@�@19�@�@32
sqrtpd �@�@�@19�@�@41
rsqrt*/rcp*�@3�@�@ 5
AMD : �x�����Z���2�X���b�h���Ƃ̐����N���X�^�ƁA���p��FP�N���X�^�Ōv3�ێ�
3�ڂ��Ă邩����ċ������ē����킯�ł��Ȃ���A1������̎����R�X�g���Ⴂ�킯�ł��Ȃ�
2 issue+���̐����p�C�v���C����70�T�C�N���~�܂�ƁA140���ߕ�������ȏ㖽�ߔ��s���邱�ƂɂȂ�A
�����Е��̃X���b�h�ł͋Ă郆�j�b�g�����̒�ؕ����t�H���[�ł��Ȃ��B
Intel Core�̕���(Radix-16 SRT�A���S���Y��)�ł�idiv64�ł�32�T�C�N�����x�ōςނ̂ŁA
�������߂����Ɍ����96���ߕ����x�̃��X�ł��ނ��AHT���L���Ȃ��������̃X���b�h��
���s���邱�ƂŌ��Ԃ̃T�C�N���߂邱�Ƃ��ł���B
�����������_�Ō����CMT��SMT���}���`�X���b�h�ɗL���ȃA�v���[�`�Ƃ͕K�����������Ȃ��
���Ƃ��̕ӂ������ǁA���̕ӂ̖��߂�DirectX��CPU�������ł͂悭�g������A�x���ƃQ�[���ɂ͌����Ȃ���
�@�@�@�@�@�@�@Core�@Bulldozer
sqrtps �@�@�@19�@�@32
sqrtpd �@�@�@19�@�@41
rsqrt*/rcp*�@3�@�@ 5
>>236
�N���b�N�I�ɕϓ������Đ��\�������グ��A�[�L�e�N�`�����Ă̂�
�ō��N���b�N���ɍ��킹�ăp�C�v���C����[���v���Ȃ��Ƃ����Ȃ�������A�����\�ȉ��Z���j�b�g��
������摗�肹����Ȃ�������ŁA���ꂾ�����\�ʂł̓y�i���e�B�v����s��ł���B
���[�N�d���������P���v�Z�ł��A����d�͂̓N���b�N��3��ɔ�Ⴗ��B
��IPC�̃R�A��1�`2����4GHz�ʼn���Ă�����Ȃɔ��������͂Ȃ����낤�B
K10��Nehalem�ɃN���b�N������V���O���X���b�h���\��3�������ĂāABulldozer��4��������̂ł���A
�������\����������̂�i7���4���ȏ㍂�N���b�N�ʼnȂ��Ƃ����Ȃ��ƌ������ƁB
�ʂ����ĉ\�Ȃ̂��H
�N���b�N�I�ɕϓ������Đ��\�������グ��A�[�L�e�N�`�����Ă̂�
�ō��N���b�N���ɍ��킹�ăp�C�v���C����[���v���Ȃ��Ƃ����Ȃ�������A�����\�ȉ��Z���j�b�g��
������摗�肹����Ȃ�������ŁA���ꂾ�����\�ʂł̓y�i���e�B�v����s��ł���B
���[�N�d���������P���v�Z�ł��A����d�͂̓N���b�N��3��ɔ�Ⴗ��B
��IPC�̃R�A��1�`2����4GHz�ʼn���Ă�����Ȃɔ��������͂Ȃ����낤�B
K10��Nehalem�ɃN���b�N������V���O���X���b�h���\��3�������ĂāABulldozer��4��������̂ł���A
�������\����������̂�i7���4���ȏ㍂�N���b�N�ʼnȂ��Ƃ����Ȃ��ƌ������ƁB
�ʂ����ĉ\�Ȃ̂��H
���ۂɃ��m���o�Ă��Ȃ��ƕ������̂ł́H
�c�q��Larrabee�����ꂾ���̎^���Ă����ǃR�P����
���������̂͌��ǐ�ɂ��ꂱ�ꌾ���Ă����ĂɂȂ��
�c�q��Larrabee�����ꂾ���̎^���Ă����ǃR�P����
���������̂͌��ǐ�ɂ��ꂱ�ꌾ���Ă����ĂɂȂ��
>>236
�[���A���̈������e�Ƃ����v���Ȃ��B
���R�A���𑝂₵���Ƃ����IO���\������I�ɏオ��킯�ł��Ȃ������I�Ȑ��\����͂��낻�듪�ł��ɂȂ��Ă�̂�����ł����
>127�ɕt���Ă��P��AVX�Ή�256bitSSE����̏ꍇ��128bitSSE�ɔ�ׂĔ{���ƂȂ�ABulldozer����8���W���[���Ŕ{���ƌv�Z�����
12�R�A128bitSSE���50%�������\���L�^����͓̂�����O�������������ĕ�������̌��ʂł���SSE���j�b�g�����̌��ʂł����Ȃ��B
�R�A������ɑ��₵�Ă������I�Ȑ��\����͓��ł��ɂȂ���邱�Ƃɔ�ׂ�SSE���j�b�g�����̓\�t�g�Ή��ɂ�菔�Ɍ����Ă��܂����ˁB
�[���A���̈������e�Ƃ����v���Ȃ��B
���R�A���𑝂₵���Ƃ����IO���\������I�ɏオ��킯�ł��Ȃ������I�Ȑ��\����͂��낻�듪�ł��ɂȂ��Ă�̂�����ł����
>127�ɕt���Ă��P��AVX�Ή�256bitSSE����̏ꍇ��128bitSSE�ɔ�ׂĔ{���ƂȂ�ABulldozer����8���W���[���Ŕ{���ƌv�Z�����
12�R�A128bitSSE���50%�������\���L�^����͓̂�����O�������������ĕ�������̌��ʂł���SSE���j�b�g�����̌��ʂł����Ȃ��B
�R�A������ɑ��₵�Ă������I�Ȑ��\����͓��ł��ɂȂ���邱�Ƃɔ�ׂ�SSE���j�b�g�����̓\�t�g�Ή��ɂ�菔�Ɍ����Ă��܂����ˁB
Larrabee�͂�����ׂ����Ă������C�����Ȃ����Ȃ���
���ꂪ�܂Ƃ��ɗ����オ��Ǝv���Ă��l�Ԃ̕������Ȃ�������Ȃ�
���ꂪ�܂Ƃ��ɗ����オ��Ǝv���Ă��l�Ԃ̕������Ȃ�������Ȃ�
>>232
19�X����MAD�I�^�������Ă�����Ȃ�
�ʐl�̃t�����Ȃ���ǂ���m�\0�������肢��������ID�呝�B��������
�R�[�g�ŗ��B����ʧʧ���Ă�I�o���݂�����
Bull�͕����v���t�F�b�`�Ȃǂ̗\���n���啝������CPU�炵���i�����Ǝv������
L1D�̏��Ȃ���������
�A�z�xway���Ƃ̌������l���Ă����Ȃ����̂�������Ȃ�����
��������Ƃ��̕ӂ�AMD�L���b�V���Z�p�̌��E�Ȃ̂��E�E�E
�S�~�v���X�R�݂����Ƀ��C�e���V4�ɂ������3�ɗ��߂��܂�
���̃��\�[�X�Ńq�b�g�����߂��ق����������낤��
19�X����MAD�I�^�������Ă�����Ȃ�
�ʐl�̃t�����Ȃ���ǂ���m�\0�������肢��������ID�呝�B��������
�R�[�g�ŗ��B����ʧʧ���Ă�I�o���݂�����
Bull�͕����v���t�F�b�`�Ȃǂ̗\���n���啝������CPU�炵���i�����Ǝv������
L1D�̏��Ȃ���������
�A�z�xway���Ƃ̌������l���Ă����Ȃ����̂�������Ȃ�����
��������Ƃ��̕ӂ�AMD�L���b�V���Z�p�̌��E�Ȃ̂��E�E�E
�S�~�v���X�R�݂����Ƀ��C�e���V4�ɂ������3�ɗ��߂��܂�
���̃��\�[�X�Ńq�b�g�����߂��ق����������낤��
>>238
�P���v�Z���Ə���d�͂̓N���b�N�ɔ��A�d����2��ɔ�Ⴖ��Ȃ����������H
�P���v�Z���Ə���d�͂̓N���b�N�ɔ��A�d����2��ɔ�Ⴖ��Ȃ����������H
���ƕ����I�Ȗ����傫���̂�������
�D�G�Ȑ����v���Z�X�Ȃ̂��ǂ������m������
�D�G�Ȑ����v���Z�X�Ȃ̂��ǂ������m������
HTT�̓Q�[���ɂ����Đ��\�ቺ�̋�������邩��Ȃ�ł�����ł��}���Z�[�͂悭�Ȃ�
>>245
HTT���I���g���R�c��CPU�ւ̊��蓖�Ď���B
HTT���I���g���R�c��CPU�ւ̊��蓖�Ď���B
>>238
> �P���v�Z���Ə���d�͂̓N���b�N�ɔ��
�����d�������W�Ȃ�ȁB
�N���b�N��������ɂ͓d�q�̈ړ��x���グ��K�v������A���̕��d����K�v������̂Ō��ʓI��3��ɂȂ�B
> �P���v�Z���Ə���d�͂̓N���b�N�ɔ��
�����d�������W�Ȃ�ȁB
�N���b�N��������ɂ͓d�q�̈ړ��x���グ��K�v������A���̕��d����K�v������̂Ō��ʓI��3��ɂȂ�B
>>239
�c�q�͏��F�Q�n�ɂ���n�[�h�M�҂Ɣ]�\���͕ς��Ȃ��B
Intel = �D�G
AMD= �_��
���̌��_����ɏo�Ă���̂ŁA�܂Ƃ��Ș_���̑g�ݗ��Ă����҂���������B
�c�q�͏��F�Q�n�ɂ���n�[�h�M�҂Ɣ]�\���͕ς��Ȃ��B
Intel = �D�G
AMD= �_��
���̌��_����ɏo�Ă���̂ŁA�܂Ƃ��Ș_���̑g�ݗ��Ă����҂���������B
> ���̌��_����ɏo�Ă���̂ŁA�܂Ƃ��Ș_���̑g�ݗ��Ă����҂���������B
��ɏo�Ă�̂ł͂Ȃ������������Ȃ��Ă��܂��Ă���BAMD�͂���������������悤�ȐV�v���I���Ă����Ɗ������̂���������������ۂ��B
��ɏo�Ă�̂ł͂Ȃ������������Ȃ��Ă��܂��Ă���BAMD�͂���������������悤�ȐV�v���I���Ă����Ɗ������̂���������������ۂ��B
>>248
�Q�n�̔n���ł�����Ȃ�ɓ��{��͎g���邾�낤
�ꏏ�ɂ��Ă���
��Ƃ��āuf�͏��Z�̈Ӗ��v���Ƃ�>247�Ƃ��{���ɍ���
Atom�̃g�����W�X�^�̌������R�o���ĂȂ����낤��
�Q�n�̔n���ł�����Ȃ�ɓ��{��͎g���邾�낤
�ꏏ�ɂ��Ă���
��Ƃ��āuf�͏��Z�̈Ӗ��v���Ƃ�>247�Ƃ��{���ɍ���
Atom�̃g�����W�X�^�̌������R�o���ĂȂ����낤��
>>250
���_��ɂ��肫�̘_���W�J�͍����̂��ς��Ȃ���B
���_��ɂ��肫�̘_���W�J�͍����̂��ς��Ȃ���B
>>238�̃y�i���e�B�v������Turbo Boost��������Nehalem�Ŏ��ۋN���Ă���������Ă���ǂ�
Nehalem�͑O�����Core MA���p�C�v���C���i����������L1�L���b�V���Ȃǂ̃��C�e���V�����債�Ă邵
Sandy Bridge�����̘H���P����B
Nehalem�͑O�����Core MA���p�C�v���C���i����������L1�L���b�V���Ȃǂ̃��C�e���V�����債�Ă邵
Sandy Bridge�����̘H���P����B
���������W���[���������ς��悹�Ă�����
�u�������
�u�������
ID:4DM0hQBM
���l�̓��{��̐S�z���A�܂��͎�������
���l�̓��{��̐S�z���A�܂��͎�������
�N���b�N�������Đ��\�������グ��A�v���[�`�̓m�[�g�ɂ͌����Ȃ���
�܂��Ď���8�R�A�Ƃ��K�v�Ȃ�
IPC�𗎂Ƃ��Ă��܂�����ቿ�i���ȊO�ɘH�͂Ȃ��B
�����ɍ����\�Œ��荇�����̓x�^�[Celeron�H���ōU�߂�������낤
����H�O�ƂȂɂ�����i����
�܂��Ď���8�R�A�Ƃ��K�v�Ȃ�
IPC�𗎂Ƃ��Ă��܂�����ቿ�i���ȊO�ɘH�͂Ȃ��B
�����ɍ����\�Œ��荇�����̓x�^�[Celeron�H���ōU�߂�������낤
����H�O�ƂȂɂ�����i����
�ŁA
����d�́��N���b�N��3��ŕ��傠��z����́H
http://journal.mycom.co.jp/column/architecture/004/index.html
> �O�ɏq�ׂ��悤�ɓd���d���ƃN���b�N�̊W�͔����̃v���Z�X���H�v�ɂ�邪�A
> �P���������P�[�X�ŃN���b�N�Ɠd���d������Ⴗ��Ƃ����ꍇ�ɂ́A
> �N���b�N�ቺ�䗦��3��ŏ���d�͂����邱�ƂɂȂ�B
> �܂�A2�R�A�ŃV���O���R�A�Ɠ���̏����œ�������2�{�̏���d�͂ł��邪�A
> 20%�N���b�N���������0.8��3��ŁA0.512 x2(�R�A)=1.024�Ō��̃V���O���R�A�Ɠ����x��
> ����d�͂ōςނ��ƂɂȂ�B
�����ے肷��͈̂�����͂��납���̕����w�̏펯���قǂ̐�҂�
�����̒s��҂��̂ǂ��������ȁB
����d�́��N���b�N��3��ŕ��傠��z����́H
http://journal.mycom.co.jp/column/architecture/004/index.html
> �O�ɏq�ׂ��悤�ɓd���d���ƃN���b�N�̊W�͔����̃v���Z�X���H�v�ɂ�邪�A
> �P���������P�[�X�ŃN���b�N�Ɠd���d������Ⴗ��Ƃ����ꍇ�ɂ́A
> �N���b�N�ቺ�䗦��3��ŏ���d�͂����邱�ƂɂȂ�B
> �܂�A2�R�A�ŃV���O���R�A�Ɠ���̏����œ�������2�{�̏���d�͂ł��邪�A
> 20%�N���b�N���������0.8��3��ŁA0.512 x2(�R�A)=1.024�Ō��̃V���O���R�A�Ɠ����x��
> ����d�͂ōςނ��ƂɂȂ�B
�����ے肷��͈̂�����͂��납���̕����w�̏펯���قǂ̐�҂�
�����̒s��҂��̂ǂ��������ȁB
�������Z���\�̓m�[�g�ł͋��߂��ĂȂ�
�قƂ�ǐ������Z���\�������߂��ĂȂ����ǂ�
���X���{�ꏑ���ĂȂ����ĉ\������������
>256�����悢����{��Ƃ��ēǂ߂Ȃ��Ȃ��Ă���
�܂�2�s�ڂ��������Ă������Ȃ�
1�A3�s�ڂ�Atom���Ȃ��Ă�ȊO�ɂȂ����낤���ˑR�߂��ė���s�\
����܂Ŏ����グ�ĂȂ��������H
4�s�ڂ��uAtom�͎̂Ă�Celeron�o����v�͂�����Atom�ō����\�H
�N���b�N�������E�M���M���Ȃ̂ɁH������IGP�̂����ɂ��Ă�̂��H
�����������q�T���U�炵�ɗ��Ă邾���ȊO�̉\�������Ȃ��ė����Ȃ����̓��@
>256�����悢����{��Ƃ��ēǂ߂Ȃ��Ȃ��Ă���
�܂�2�s�ڂ��������Ă������Ȃ�
1�A3�s�ڂ�Atom���Ȃ��Ă�ȊO�ɂȂ����낤���ˑR�߂��ė���s�\
����܂Ŏ����グ�ĂȂ��������H
4�s�ڂ��uAtom�͎̂Ă�Celeron�o����v�͂�����Atom�ō����\�H
�N���b�N�������E�M���M���Ȃ̂ɁH������IGP�̂����ɂ��Ă�̂��H
�����������q�T���U�炵�ɗ��Ă邾���ȊO�̉\�������Ȃ��ė����Ȃ����̓��@
�����Ă�ԂɃE���R�������Ă���
>257�̈����́u�P���������P�[�X�ŃN���b�N�Ɠd���d������Ⴗ��Ƃ����ꍇ�v�Ƃ�������������Ă���
������CPU�͂����������ɕ肪�����Ă������J�W���A��OC�̌��E�ɂȂ�
����ɉ�����>247�͂����̃A���J�~�X��
>243�̂�����1�����܂Ƃ��ɓǂ߂ĂȂ�
Atom�̃g�����W�X�^�����i�ȓd�͗p�j���o���ĂȂ�
����CPU���f���ł̔�r���Ƃ��Ă���L�̒ʂ�ł܂Ƃ��ȉӏ����S������
�{���ɐ����L�C��
>257�̈����́u�P���������P�[�X�ŃN���b�N�Ɠd���d������Ⴗ��Ƃ����ꍇ�v�Ƃ�������������Ă���
������CPU�͂����������ɕ肪�����Ă������J�W���A��OC�̌��E�ɂȂ�
����ɉ�����>247�͂����̃A���J�~�X��
>243�̂�����1�����܂Ƃ��ɓǂ߂ĂȂ�
Atom�̃g�����W�X�^�����i�ȓd�͗p�j���o���ĂȂ�
����CPU���f���ł̔�r���Ƃ��Ă���L�̒ʂ�ł܂Ƃ��ȉӏ����S������
�{���ɐ����L�C��
���ቿ�i�H���Ő키���߂Ƀ��W���[����������ł���H
> �O�ɏq�ׂ��悤�ɓd���d���ƃN���b�N�̊W�͔����̃v���Z�X���H�v�ɂ�邪�A
> �P���������P�[�X�ŃN���b�N�Ɠd���d������Ⴗ��Ƃ����ꍇ�ɂ́A
�ƒP���������P�[�X�Ə����Ă������A�K�������N���b�N����3��ő�����Ƃ�����Ȃ��Ⴀ�H
�Ƃ������A���������g�����N��HotChips�ɂ��Ă̋L����
http://journal.mycom.co.jp/articles/2010/08/27/hot_chips22_bulldozer/001.html
�ȓd�͂ƍ��N���b�N�̗�����_���Ă���̂���Ȃ����Ə����Ă��邯�ǁB
> �P���������P�[�X�ŃN���b�N�Ɠd���d������Ⴗ��Ƃ����ꍇ�ɂ́A
�ƒP���������P�[�X�Ə����Ă������A�K�������N���b�N����3��ő�����Ƃ�����Ȃ��Ⴀ�H
�Ƃ������A���������g�����N��HotChips�ɂ��Ă̋L����
http://journal.mycom.co.jp/articles/2010/08/27/hot_chips22_bulldozer/001.html
�ȓd�͂ƍ��N���b�N�̗�����_���Ă���̂���Ȃ����Ə����Ă��邯�ǁB
> �P���������P�[�X�ŃN���b�N�Ɠd���d������Ⴗ��Ƃ����ꍇ�ɂ́A
�Ƃ���̂́A���[�P�[�W�������邩��P�����ł͌v�Z�ł��Ȃ��Ȃ��Ă邩�炾��
�N���b�N��3��{�����x�Ɍ��Ȃ��Ƃ����Ȃ��B
�Ƃ���̂́A���[�P�[�W�������邩��P�����ł͌v�Z�ł��Ȃ��Ȃ��Ă邩�炾��
�N���b�N��3��{�����x�Ɍ��Ȃ��Ƃ����Ȃ��B
Bulldozer�Ƀm�[�g����������Ȃ�ď������ȁ[�i�_
>�P���������P�[�X�ŃN���b�N�Ɠd���d������Ⴗ��Ƃ����ꍇ�ɂ�
������p�C�v���C����[������(1�i������̒x��������������)�N���b�N���グ��ꍇ�ɂ�
���Ă͂܂�Ȃ��Ǝv�����ǁB
������p�C�v���C����[������(1�i������̒x��������������)�N���b�N���グ��ꍇ�ɂ�
���Ă͂܂�Ȃ��Ǝv�����ǁB
>>264
�t����
�v���Z�b�T�̏���d�͂�
�A�N�e�B�u�����{�X�^�e�B�b�N����
�ō\������Ă�B
�N���b�N��3��ɔ�Ⴗ��̂̓A�N�e�B�u�����̂݁B
�X�^�e�B�b�N�����̓g�����W�X�^���ɔ��B
������ǂ��l���Ă��N���b�N��3����ȉ�
�t����
�v���Z�b�T�̏���d�͂�
�A�N�e�B�u�����{�X�^�e�B�b�N����
�ō\������Ă�B
�N���b�N��3��ɔ�Ⴗ��̂̓A�N�e�B�u�����̂݁B
�X�^�e�B�b�N�����̓g�����W�X�^���ɔ��B
������ǂ��l���Ă��N���b�N��3����ȉ�
>>265
�i�_�@�Ə����Ă邩��{�C�ł͂Ȃ��̂����m��Ȃ����A������K10�Ő���Ă����Ƃ͎v���Ȃ���
�i�_�@�Ə����Ă邩��{�C�ł͂Ȃ��̂����m��Ȃ����A������K10�Ő���Ă����Ƃ͎v���Ȃ���
�㓡����ɑ�����������̋L����������A���Ȃ�ڂ���������Ă�
Hot Chips 22 - �v�v�z���ȓd�́A���N���b�N�ɐ�ւ���Bulldozer�R�A
http://journal.mycom.co.jp/articles/2010/08/27/hot_chips22_bulldozer/index.html
http://journal.mycom.co.jp/articles/2010/08/27/hot_chips22_bulldozer/001.html
Hot Chips 22 - �v�v�z���ȓd�́A���N���b�N�ɐ�ւ���Bulldozer�R�A
http://journal.mycom.co.jp/articles/2010/08/27/hot_chips22_bulldozer/index.html
http://journal.mycom.co.jp/articles/2010/08/27/hot_chips22_bulldozer/001.html
����ʂ̃}���`�X���b�h�v���Z�T�̏ꍇ�́A�������A�N�Z�X�҂��Ŏ��s���~�܂����X���b�h��
����ɂ��ĕʃX���b�h�ɐ�ւ��Ď��s����R�A�͗V�Ȃ����ABulldozer�ł�
�������R�A��V���Ȃ����߂ɂ̓L���b�V���~�X�����炷�v���t�F�b�`�̐��x��
���グ�邱�Ƃ��d�v�ɂȂ�̂ŁA�v���t�F�b�`�@�\���撣��̂͗����ł���A�v���[�`�ł���B
�Ȃ�قǁA�ʔ����ˁB
����ɂ��ĕʃX���b�h�ɐ�ւ��Ď��s����R�A�͗V�Ȃ����ABulldozer�ł�
�������R�A��V���Ȃ����߂ɂ̓L���b�V���~�X�����炷�v���t�F�b�`�̐��x��
���グ�邱�Ƃ��d�v�ɂȂ�̂ŁA�v���t�F�b�`�@�\���撣��̂͗����ł���A�v���[�`�ł���B
�Ȃ�قǁA�ʔ����ˁB
>>264
������������
> ���̓_�ł̓X���b�h���ƂɃR�A�����Ƃ����}���`�R�A���ǂ����A���[�e���V��������x�����Ă��ǂ��Ƃ����@�\�ɂ��Ă�
> �K�������X���b�h���ƂɎ��K�v�͂Ȃ��A�܂Ƃ߂Ď����������A�ʐρA�d�͌������ǂ��B���̂悤�ȃg���[�h�I�t���s�������ʁA
> �����X�P�W���[���A�������s���j�b�g�AL1�f�[�^�L���b�V���Ȃǂ̓X���b�h���ƂɎ����A���߂̃t�F�b�`����f�R�[�h�A
> ���������_���Z���j�b�g�AL2�L���b�V����2�̃X���b�h�ŋ��L����Ƃ���Bulldozer�̍\���ɂȂ����Ƃ����B���̍\���Ƃ��邱�Ƃɂ��A
> ���S��2�R�A�̐v�Ɣ�ׂ��80%���x�̐��\�����Ȃ菭�Ȃ��`�b�v�ʐςƓd�͂Ŏ����ł����Ƃ����B
�ŁA���ǃR�A�����肾��8���̐��\���B
�V���O���X���b�h���\�̊i���͂ǂ�ǂ�J���Ă����ȁB
>>265
���͎g��Ȃ��ėǂ�����ڂ��g���ď���B2�y�[�W�ڂ�
http://www.slideshare.net/AMDUnprocessed/amd-hot-chips-bulldozer-bobcat-presentation-5041615
>>267
�X���b�V�����h�i�ȉ���
������������
> ���̓_�ł̓X���b�h���ƂɃR�A�����Ƃ����}���`�R�A���ǂ����A���[�e���V��������x�����Ă��ǂ��Ƃ����@�\�ɂ��Ă�
> �K�������X���b�h���ƂɎ��K�v�͂Ȃ��A�܂Ƃ߂Ď����������A�ʐρA�d�͌������ǂ��B���̂悤�ȃg���[�h�I�t���s�������ʁA
> �����X�P�W���[���A�������s���j�b�g�AL1�f�[�^�L���b�V���Ȃǂ̓X���b�h���ƂɎ����A���߂̃t�F�b�`����f�R�[�h�A
> ���������_���Z���j�b�g�AL2�L���b�V����2�̃X���b�h�ŋ��L����Ƃ���Bulldozer�̍\���ɂȂ����Ƃ����B���̍\���Ƃ��邱�Ƃɂ��A
> ���S��2�R�A�̐v�Ɣ�ׂ��80%���x�̐��\�����Ȃ菭�Ȃ��`�b�v�ʐςƓd�͂Ŏ����ł����Ƃ����B
�ŁA���ǃR�A�����肾��8���̐��\���B
�V���O���X���b�h���\�̊i���͂ǂ�ǂ�J���Ă����ȁB
>>265
���͎g��Ȃ��ėǂ�����ڂ��g���ď���B2�y�[�W�ڂ�
http://www.slideshare.net/AMDUnprocessed/amd-hot-chips-bulldozer-bobcat-presentation-5041615
>>267
�X���b�V�����h�i�ȉ���
���A���ɃC���N���[�W�����L���b�V���ɕς�����̂��I
��������̋L���͂��Ȃ�ڍׂ܂œ˂�����ł��
��ŃL���b�V����Way��q�˂Ă��l���������ǂ�����ڂ��Ă��B
�����̃v���Z�T�ł�������x�A���삷�镔�������炷�悤�ȃ}�C�N���A�[�L�e�N�`���̗̍p���s���Ă��邪�A
�������܂œO�ꂵ�ďȓd�̓}�C�N���A�[�L�e�N�`����Njy�����v���Z�T�͕M�҂̒m��͈͂ł́A���߂Ăł���B
���܂��A��̓I�ɃN���b�N���ǂ̒��x�ɂȂ邩�͖��炩�ɂ���Ȃ��������A�N���b�N�������
���Q�[�g�i�������炷�v�ł���Əq�ׂ��Ă���AIBM�Ɠ���SOI�v���Z�X���g���ƍl�����邱�Ƃ���A
�����l�̒�Q�[�g�i���v�ł���POWER7���݂�4GHz����N���b�N����������̂ł͂Ȃ����Ɨ\�z�����B
������ŏ]���̃p���[�G���x���[�v����������A���ɋ��͂ȃv���Z�T�ɂȂ�ƍl������B
��������͊��ƃ|�W�e�B�u�Ɍ��Ă�̂��ȁE�E�E�H
��ŃL���b�V����Way��q�˂Ă��l���������ǂ�����ڂ��Ă��B
�����̃v���Z�T�ł�������x�A���삷�镔�������炷�悤�ȃ}�C�N���A�[�L�e�N�`���̗̍p���s���Ă��邪�A
�������܂œO�ꂵ�ďȓd�̓}�C�N���A�[�L�e�N�`����Njy�����v���Z�T�͕M�҂̒m��͈͂ł́A���߂Ăł���B
���܂��A��̓I�ɃN���b�N���ǂ̒��x�ɂȂ邩�͖��炩�ɂ���Ȃ��������A�N���b�N�������
���Q�[�g�i�������炷�v�ł���Əq�ׂ��Ă���AIBM�Ɠ���SOI�v���Z�X���g���ƍl�����邱�Ƃ���A
�����l�̒�Q�[�g�i���v�ł���POWER7���݂�4GHz����N���b�N����������̂ł͂Ȃ����Ɨ\�z�����B
������ŏ]���̃p���[�G���x���[�v����������A���ɋ��͂ȃv���Z�T�ɂȂ�ƍl������B
��������͊��ƃ|�W�e�B�u�Ɍ��Ă�̂��ȁE�E�E�H
>>271
�X���b�V�����h�i�ȉ������ĉ������������̂��������
>>267�ł̃X�^�e�B�b�N���������[�N�Ɉ�����̂���
���łɌ����Ό������E�̃v���Z�b�T���l����Ə���d�́i�A�N�e�B�u�����j��
�N���b�N��3����Ƃ����̂͂�͂�P�����������ȋC�������
�X���b�V�����h�i�ȉ������ĉ������������̂��������
>>267�ł̃X�^�e�B�b�N���������[�N�Ɉ�����̂���
���łɌ����Ό������E�̃v���Z�b�T���l����Ə���d�́i�A�N�e�B�u�����j��
�N���b�N��3����Ƃ����̂͂�͂�P�����������ȋC�������
>>275
��IPC���Ƃ������N���b�N���グ�Ď��߂��Ȃ�Ĕ��z
IPC�ƃN���b�N�͏���d�͂Ƃ����g���������g���[�h�I�t�Ȃ��瓖����O�ł���
���̒��łǂ��o�����X����邩�Ƃ������
��������炵���ƌ����̂͂�����Ɨ����o���Ȃ���
��IPC���Ƃ������N���b�N���グ�Ď��߂��Ȃ�Ĕ��z
IPC�ƃN���b�N�͏���d�͂Ƃ����g���������g���[�h�I�t�Ȃ��瓖����O�ł���
���̒��łǂ��o�����X����邩�Ƃ������
��������炵���ƌ����̂͂�����Ɨ����o���Ȃ���
IPC�������Ă��N���b�N�Ŏ��Ԃ���Ȃ�_�C�T�C�Y�������Ă��ޕ�����
�g�����W�X�^���̐ߖ�A�Ƃ����ϓ_�Ń����b�g�������
�c�q����̓v���Z�b�T�̕����I�Șb�ɂ͂��傢��߁H
�\�t�g����Ă�l������Ȃ̂���
�c�q����̓v���Z�b�T�̕����I�Șb�ɂ͂��傢��߁H
�\�t�g����Ă�l������Ȃ̂���
�����p�C�v�{�������Ō����
������3�{�ڂ��قƂ�ǎg���Ȃ�����Ƃ����Ă�
��������点��IPC�͓��R������
����������ŋ������L���b�V�����o�b�t�@���\���@�\����
���ʓI�Ɏg���h�o�b�͋t�ɏオ��
�ǂ��ł��������ǎ��ƒE�����H���̉i�v�@�ւ�IPC�Ȃ�ĊW����̂�
������3�{�ڂ��قƂ�ǎg���Ȃ�����Ƃ����Ă�
��������点��IPC�͓��R������
����������ŋ������L���b�V�����o�b�t�@���\���@�\����
���ʓI�Ɏg���h�o�b�͋t�ɏオ��
�ǂ��ł��������ǎ��ƒE�����H���̉i�v�@�ւ�IPC�Ȃ�ĊW����̂�
>IPC���Ƃ������N���b�N���グ�Ď��߂��Ȃ�Ĕ��z�̂��炵�������������킯�ŁA
�y��4�����ި���Ȃ�
�y��4�����ި���Ȃ�
�Ȃ�Œc�q�R�e�O������H
�f�X�N�g�b�v�͂Ƃ������m�[�g�͑��R�A�̗v���͏��Ȃ�����IPC���]���ɂ�����n�C�p�t�H�[�}���X�����W��_���Ȃ��B
�G���R�Ƃ��ɏd�����Q�[��������Ȃ��m�[�g�̓X���b�h���̗v�������Ȃ�����A�R�A���𑝂₷�����ł�
���\����͓��ɂ����B
�ŁA�����R�A���œ������x�̃N���b�N�ł͉Η͕s���A�N���b�N���グ�������d�͂���S�R���������Ȃ��B
>>280
Pentium 4-M����̋���t�@�����ڂ̂��邳���m�[�g�����߂邲��������Ȃ��Ǝv���B
�G���R�Ƃ��ɏd�����Q�[��������Ȃ��m�[�g�̓X���b�h���̗v�������Ȃ�����A�R�A���𑝂₷�����ł�
���\����͓��ɂ����B
�ŁA�����R�A���œ������x�̃N���b�N�ł͉Η͕s���A�N���b�N���グ�������d�͂���S�R���������Ȃ��B
>>280
Pentium 4-M����̋���t�@�����ڂ̂��邳���m�[�g�����߂邲��������Ȃ��Ǝv���B
>>262
�Ⴄ��B����Ɂu���W���[�����v�͒ቿ�i�����v�ł͂Ȃ��B
�Ⴄ��B����Ɂu���W���[�����v�͒ቿ�i�����v�ł͂Ȃ��B
�m�[�g��Ontario��Llano�ł��傤��
�u�����m�[�g�ɍ~��Ă���܂ł�
APU���g�����̐v�ɂȂ��Ă������
APU���g�����̐v�ɂȂ��Ă������
>>285
APU�́A�����I�ɂ͗l�X�ȍ\�z�͂��邯�ǁA
��{�I��CPU��GPU���ꏏ�ɏ���Ă�����x�̈Ӗ��ő��v�����H
Core�n��GPU�������̂Ƃ��قǕς��Ȃ��B
�l�b�N�͓�������GPU�����ʂɋ��͂����āA
�ȓd�͖ʂłǂ��Ȃ̂�����ȂƂ��낾�B
APU�́A�����I�ɂ͗l�X�ȍ\�z�͂��邯�ǁA
��{�I��CPU��GPU���ꏏ�ɏ���Ă�����x�̈Ӗ��ő��v�����H
Core�n��GPU�������̂Ƃ��قǕς��Ȃ��B
�l�b�N�͓�������GPU�����ʂɋ��͂����āA
�ȓd�͖ʂłǂ��Ȃ̂�����ȂƂ��낾�B
>>278
���g�����W�X�^���̐ߖ�
���ʂɂ���ĂĂ�CPU��������g�����W�X�^�o�W�F�b�g�]�邩����Ӄv���Z�b�T���������Ȃ���ƌ����Ă邲������
�R�A�̐��\�E���ł܂ŐϋɓI�ɍ��Ӗ������邩�ǂ������ȁB
�iAtom�̂悤�ɏ]��PC�ȊO�̕���Ɋg�傷��Ȃ�e���p�j
�R�A����������Α�����قǃV���O���X���b�h���\�͑��ΓI�Ƀ{�g���l�b�N�ɂȂ��Ă����B
���g�����W�X�^���̐ߖ�
���ʂɂ���ĂĂ�CPU��������g�����W�X�^�o�W�F�b�g�]�邩����Ӄv���Z�b�T���������Ȃ���ƌ����Ă邲������
�R�A�̐��\�E���ł܂ŐϋɓI�ɍ��Ӗ������邩�ǂ������ȁB
�iAtom�̂悤�ɏ]��PC�ȊO�̕���Ɋg�傷��Ȃ�e���p�j
�R�A����������Α�����قǃV���O���X���b�h���\�͑��ΓI�Ƀ{�g���l�b�N�ɂȂ��Ă����B
Sandy�����i3�ł̓��C���i�b�v�̑S�Ă�HTT���������������ĉ\��
�������IPC�̌���͂��Ȃ����Ă�������Ȃ��́H
22nm��AMD��CPU�̊�{�\���܂Œm���Ă�́H
22nm��AMD��CPU�̊�{�\���܂Œm���Ă�́H
���\�ł�Bull��IPC�オ�邼
IPC���オ����Ęb�͂łĂ��Ȃ���
�b����͓����d�͘g�ł̐��\�͏オ�邱�Ƃ͐����ł��邪�A���ꂪIPC�ɂ����̂��Ęb�͖�������
�b����͓����d�͘g�ł̐��\�͏オ�邱�Ƃ͐����ł��邪�A���ꂪIPC�ɂ����̂��Ęb�͖�������
ttp://northwood.blog60.fc2.com/blog-entry-4042.html
�����A�N���b�N�����肶��Ȃ��R�A�������
�������悭���������������
�����A�N���b�N�����肶��Ȃ��R�A�������
�������悭���������������
22nm�Ńg���[�X�L���b�V�����炢����
�V���O���X���b�h���オ��ƌ����Ă�
>�N���b�N�����肶��Ȃ��R�A�������
����IPC���Č���Ȃ�
����IPC���Č���Ȃ�
>>291
Nehalem��Westmere�ł���4�R�A����6�R�A�ɑ����ď���d�͂������Ă����
45nm��Magny-Cours���50%�̃X���[�v�b�g����Ȃ�ė�ÂɌ���C���p�N�g�Ɍ����邯�ǂ�
>>294
�����Magny-Cours�̒�N���b�N����݂�Α��ΓI�ɏオ�邾�낤
Nehalem��Westmere�ł���4�R�A����6�R�A�ɑ����ď���d�͂������Ă����
45nm��Magny-Cours���50%�̃X���[�v�b�g����Ȃ�ė�ÂɌ���C���p�N�g�Ɍ����邯�ǂ�
>>294
�����Magny-Cours�̒�N���b�N����݂�Α��ΓI�ɏオ�邾�낤
�㓡�̋L���Ȃ��B
GTX460�Ō������M���p�g�X�͂ǂ��֒u���Y�ꂽ�H
GTX460�Ō������M���p�g�X�͂ǂ��֒u���Y�ꂽ�H
Bob�̂ق��͔������̂�
Bull�̃p�C�v���C�����[����������Ȃ���������Ȃ����H
Bull�̃p�C�v���C�����[����������Ȃ���������Ȃ����H
IFA 2010�@9/3-8��Ontario�f��
http://www.nordichardware.com/news/69-cpu--chipset/40933-amd-to-show-fusion-apu-at-ifa-in-september.html
http://www.nordichardware.com/news/69-cpu--chipset/40933-amd-to-show-fusion-apu-at-ifa-in-september.html
���}��������Ċ�������ˁH
�����Ƃ��̃l�^�ň��������Ă����b���傫����
�����Ƃ��̃l�^�ň��������Ă����b���傫����
�w��BBS��m�R���V�A���Ɖ����Ăă����^
AMD�ȊO�̍u�������������AAMD�̍u���͍Ō�̍Ōゾ�����炵��
����Ȓ��ő��߂ɋL���ɂ��Ă�������Ƃ肠�����͂����l���Ċ�����
����Ȓ��ő��߂ɋL���ɂ��Ă�������Ƃ肠�����͂����l���Ċ�����
�܂��c�q�����ꂽ�̂��悗
�R�e�O���čr�炵�Ƃ͏�Ȃ���
�������ɋA���A�N�����O�̌������ƂȂM���Ȃ����炗
�R�e�O���čr�炵�Ƃ͏�Ȃ���
�������ɋA���A�N�����O�̌������ƂȂM���Ȃ����炗
�@�G�����������悤�Ȃ��Ƃ��������Ă��Ȃ��̂������ł������Ă���
����A�R�e���O������ł���H
����A�R�e���O������ł���H
�����Ă邱�Ƃɂ��Ă邩�畽���̒��Ԃ̓R�e�t���Ȃ��Ǝv���Ă�
�C�O�ݏZ�Ƃ������Ă����ǁA�ǂ����R���낗
�`�����l�Ƃ���
�ݓ����A���c�����炷��u�C�O�ݏZ�v������
�c�q���Ȃ��͔����
�t�Ɏ����グ��͓x�����ɂ���Ĕ���Ȃ�������o�ꂷ�炵�Ȃ�
Larrabee�݂�����
�t�Ɏ����グ��͓x�����ɂ���Ĕ���Ȃ�������o�ꂷ�炵�Ȃ�
Larrabee�݂�����
�C���e��6�R�A�ɑR����ɂ�6���W���[������Ȃ��ƃ_������
�Ȃɍl���Ă�
�Ȃɍl���Ă�
>>310
���O����������������c�B
���O����������������c�B
Sandy1�R�A��Bul1���W���[������̓����T�C�Y���ۂ�����
����͖{���Ȃ��肭�T�C�Y��}�����Ă��
65nmBarcelona�ł�2�R�AL3@2M��
45nmIstanbul��6�R�AL3@6M�i�_�C�T�C�Y�����j�Ȃ̂�
32nmBull��Valencia��Zambezi��8�R�A�~�܂肾��
�f�R�[�_�≉�Z�p�C�v������K10@2�R�A��茸���Ă�
����ȊO���啝���ʂ�����Ȃ���
45nmIstanbul��6�R�AL3@6M�i�_�C�T�C�Y�����j�Ȃ̂�
32nmBull��Valencia��Zambezi��8�R�A�~�܂肾��
�f�R�[�_�≉�Z�p�C�v������K10@2�R�A��茸���Ă�
����ȊO���啝���ʂ�����Ȃ���
�ԈႦ��
Barcelona4�R�A��
Barcelona4�R�A��
>32nmBull��Valencia��Zambezi��8�R�A�~�܂肾��
�~�܂肶��Ȃ���
32n���������烊�X�N����ŏ��������Ă��ł�����
�v���Z�X�����̏��`�b�v�ł��̂܂I���Ȃ�ăA�z�\�z�͂Ȃ�
�~�܂肶��Ȃ���
32n���������烊�X�N����ŏ��������Ă��ł�����
�v���Z�X�����̏��`�b�v�ł��̂܂I���Ȃ�ăA�z�\�z�͂Ȃ�
�`�b�v�T�C�Y�͂܂��s������
�V���O���`�b�v�̏�ʔł͍��܂�250mm2�O�ゾ��������Bull�������ʂƂ͎v����
�V���O���`�b�v�̏�ʔł͍��܂�250mm2�O�ゾ��������Bull�������ʂƂ͎v����
�c�q����͑ʖڃA�[�L�Ȃ����͐����������Ă�ȁI
CMT���������̂��ǂ����͕�����ǁA
bulldozer�̃��j�b�g�̎g������Nehalem�ɕ�����Ă���͎̂����ł���B
�v�v�z���ʖڂ�����B
CMT�͂���y�Ƀ��W�X�^���ʕ��̃����b�g�����邩��ʔ����g�����o���邩�ȁA
�Ǝv�������ǁA�����ɂ�����Ԃ��Ă��ꂽ�B���肪�Ƃ�bulldozer�B
���|�I�Ȑ������Z���\���������Ă�Ηǂ������̂Ɂc
CMT���������̂��ǂ����͕�����ǁA
bulldozer�̃��j�b�g�̎g������Nehalem�ɕ�����Ă���͎̂����ł���B
�v�v�z���ʖڂ�����B
CMT�͂���y�Ƀ��W�X�^���ʕ��̃����b�g�����邩��ʔ����g�����o���邩�ȁA
�Ǝv�������ǁA�����ɂ�����Ԃ��Ă��ꂽ�B���肪�Ƃ�bulldozer�B
���|�I�Ȑ������Z���\���������Ă�Ηǂ������̂Ɂc
>>318
�r���L���b�V������Ȃ��Ȃ������炨�O�̑�D���Ȓx���`���ƈ��|�I�Ȑ������Z���\�ɂȂ邺
�r���L���b�V������Ȃ��Ȃ������炨�O�̑�D���Ȓx���`���ƈ��|�I�Ȑ������Z���\�ɂȂ邺
�������������̂��悭�������
>>319
���r���L���b�V����K10�ŕς��Ȃ������͖̂{���ɒɍ��̑ʖڂ���������
���ꂪ�����ƕς���Ă�����core2�Ƃ������Ƃ����킢���o�����낤���A
4core������������Ƃ������i�Ŕ��ꂽ�낤�B
�����v���ƁA�ق�Ɣn���Ȏ������ȁA�Ǝv����B
���Ȃ݂ɒx���`���ƃg���[�X�L���b�V���̖���bulldozer�͂���ς�Nehalem�ɏ��ĂȂ�
>>320
���̌��t�͂ǂ��ł��|�G���ɂ�������Ă��炦�Ȃ��̂��c
���r���L���b�V����K10�ŕς��Ȃ������͖̂{���ɒɍ��̑ʖڂ���������
���ꂪ�����ƕς���Ă�����core2�Ƃ������Ƃ����킢���o�����낤���A
4core������������Ƃ������i�Ŕ��ꂽ�낤�B
�����v���ƁA�ق�Ɣn���Ȏ������ȁA�Ǝv����B
���Ȃ݂ɒx���`���ƃg���[�X�L���b�V���̖���bulldozer�͂���ς�Nehalem�ɏ��ĂȂ�
>>320
���̌��t�͂ǂ��ł��|�G���ɂ�������Ă��炦�Ȃ��̂��c
�łĂȂ�����M�S�Ɍ���Ă�Ⴛ���|�G������
�㓡����̃|�G���͖ʔ����˃��N���N�����Ă����
PC���̌ӎU�L�������肢�t�ƌ����Ă��ǂ�
�㓡����̃|�G���͖ʔ����˃��N���N�����Ă����
PC���̌ӎU�L�������肢�t�ƌ����Ă��ǂ�
���R�A�Ƌ��R�A�̐��\�����傫������G���R�ƃx���`�ȊO���������HTT
���W���[�����̃R�A�Ԃɐ��\������������p�r�ɊW�Ȃ����\�����₷��CMT
�ǂ��炪�D��Ă���̂��͖��炩����
�\�t�g��p�r�ɂ���Ă�HTT���������ɂȂ��Đ��\�ቺ�N�����ꍇ��������
��ɃQ�[���╨���R�A�����x�̃}���`�X���b�h�A�v����
����������DTM�n��HTT�����������ȁH
���W���[�����̃R�A�Ԃɐ��\������������p�r�ɊW�Ȃ����\�����₷��CMT
�ǂ��炪�D��Ă���̂��͖��炩����
�\�t�g��p�r�ɂ���Ă�HTT���������ɂȂ��Đ��\�ቺ�N�����ꍇ��������
��ɃQ�[���╨���R�A�����x�̃}���`�X���b�h�A�v����
����������DTM�n��HTT�����������ȁH
http://pc.watch.impress.co.jp/docs/column/kaigai/20100827_389491.html
> �S�̓I�Ɍ����ABulldozer�͗\�z�ʂ�X���b�h���\���d�������R�A�ŁA�����K�͂�Intel CPU���}���`�X���b�h���\�͍���
>�Ȃ�\���������B���̔��ʁA�������Z�n�p�C�v���A�]����K7/K8/K10�n���ׂ��������ƂŁA�V���O���X���b�h���\�ɂ͕s
>�����o��B�������AAMD��Bulldozer�̐v���AIPC(Instruction-per-Clock)�̃X�C�[�g�X�|�b�g��_�������̂ł���A�N���b�N��
>����̃Q�[�g�������Ȃ����邱�Ƃ��ړI�Ƃ��Ă���ƁA�v�Ӑ}����������BBulldozer�́A���ߕ���x�̍���CPU�R�A�Ɣ��
>���IPC�͉����邪�A�d�͓������IPC�̌����������A����ɓ�����g�����オ��Ɛ��������B
���X�����r�炷�Ƃ��͓s���̗ǂ����������R�s�y�����ɑS���͂��Ă���������
> �S�̓I�Ɍ����ABulldozer�͗\�z�ʂ�X���b�h���\���d�������R�A�ŁA�����K�͂�Intel CPU���}���`�X���b�h���\�͍���
>�Ȃ�\���������B���̔��ʁA�������Z�n�p�C�v���A�]����K7/K8/K10�n���ׂ��������ƂŁA�V���O���X���b�h���\�ɂ͕s
>�����o��B�������AAMD��Bulldozer�̐v���AIPC(Instruction-per-Clock)�̃X�C�[�g�X�|�b�g��_�������̂ł���A�N���b�N��
>����̃Q�[�g�������Ȃ����邱�Ƃ��ړI�Ƃ��Ă���ƁA�v�Ӑ}����������BBulldozer�́A���ߕ���x�̍���CPU�R�A�Ɣ��
>���IPC�͉����邪�A�d�͓������IPC�̌����������A����ɓ�����g�����オ��Ɛ��������B
���X�����r�炷�Ƃ��͓s���̗ǂ����������R�s�y�����ɑS���͂��Ă���������
Bulldozer��Netburst�̈�u�������́B
Bull��Netburst�ł͉ʂ����Ȃ�����10GH����������҂��Ă����
�������ȁH
Bull��Netburst�ł͉ʂ����Ȃ�����10GH����������҂��Ă����
�������ȁH
Istanbul��L3�͑�̃R�A2����
�܂�L3��2M���炷���_�C�T�C�Y��2�����炢���₹��
1����V�������N�ŃR�A2�{���\
���l�Ō�����32nmK10�̃R�A��10m�u�����Ƃ̂���
L2@512k��t����15m�u�Ƃ�
Bull1���W����K10@2�R�A��L3@6M��30m�u���Ƃ����
10���W����300m�u
8���W��+L3@6M�ł�300m�u
6���W��6M��240m�u
���̂��炢�Ȃ�32nm�ڍs�ł����o����������
���[�h�}�b�v��4���W���Ƃ����MCM���o�����肸���ƒlj��͖����i�̂͂��j
�u�V���O���X���b�h�őË����Ȃ��v�̔����ʂ�
��͂�u�����I�ȃT�C�Y��剻�v�����Ă�Ǝv��
�܂�L3��2M���炷���_�C�T�C�Y��2�����炢���₹��
1����V�������N�ŃR�A2�{���\
���l�Ō�����32nmK10�̃R�A��10m�u�����Ƃ̂���
L2@512k��t����15m�u�Ƃ�
Bull1���W����K10@2�R�A��L3@6M��30m�u���Ƃ����
10���W����300m�u
8���W��+L3@6M�ł�300m�u
6���W��6M��240m�u
���̂��炢�Ȃ�32nm�ڍs�ł����o����������
���[�h�}�b�v��4���W���Ƃ����MCM���o�����肸���ƒlj��͖����i�̂͂��j
�u�V���O���X���b�h�őË����Ȃ��v�̔����ʂ�
��͂�u�����I�ȃT�C�Y��剻�v�����Ă�Ǝv��
>>323
�����R�A�Ƌ��R�A�̐��\�����傫������G���R�ƃx���`�ȊO���������HTT
�����W���[�����̃R�A�Ԃɐ��\������������p�r�ɊW�Ȃ����\�����₷��CMT
���ǂ��炪�D��Ă���̂��͖��炩����
�ԈႢ�Ȃ�Nehalem���V���O���X���b�h���\�̒Ⴂbulldozer��O�ɂ��Ă��������܂����H
���̍��������炵�Ă���v���̈��SMT��CMT*2�̐v�v�z�̈Ⴂ���ĕ������Ă܂����H
�債���z���c
�����R�A�Ƌ��R�A�̐��\�����傫������G���R�ƃx���`�ȊO���������HTT
�����W���[�����̃R�A�Ԃɐ��\������������p�r�ɊW�Ȃ����\�����₷��CMT
���ǂ��炪�D��Ă���̂��͖��炩����
�ԈႢ�Ȃ�Nehalem���V���O���X���b�h���\�̒Ⴂbulldozer��O�ɂ��Ă��������܂����H
���̍��������炵�Ă���v���̈��SMT��CMT*2�̐v�v�z�̈Ⴂ���ĕ������Ă܂����H
�債���z���c
����܂��ԈႦ��
8���W��6M��270m�u
6���W��6M��210m�u����
�Ƃ肠����Bull�̋��LL2��1M��L3��6M�������C�����邩��
����Ōv�Z
8���W��6M��270m�u
6���W��6M��210m�u����
�Ƃ肠����Bull�̋��LL2��1M��L3��6M�������C�����邩��
����Ōv�Z
�ǂ����R�A�����߂���Ǝv������m�[�X�u���b�W�����̖ʐς�������E�E�E
��������͂�V�������N�ł̃R�A�����䗦��AMD�̎p���Ȃǂ��炷���
4���W��+MCM���\�Ŏ~�܂��Ă�͕̂ς�
��������͂�V�������N�ł̃R�A�����䗦��AMD�̎p���Ȃǂ��炷���
4���W��+MCM���\�Ŏ~�܂��Ă�͕̂ς�
>>327
�u��1���W���[���̃T�C�Y���T���f�B1�R�A�Ɠ����łȂ��Ɣ�r�ɂ���Ȃ��ĂȂ��̂ɂ�w
Radeon�Ɠ����Ń`�b�v�͉\�Ȍ��菬�����A�R�A������Ȃ�MCM�Ƃ����v�Ȃ낤���ǁA
���ɔ����͂Ȃ���B�{���ɃR�A�T�C�Y�������Ȃ炻��͂���Ŋ��}�����ǁB
�u��1���W���[���̃T�C�Y���T���f�B1�R�A�Ɠ����łȂ��Ɣ�r�ɂ���Ȃ��ĂȂ��̂ɂ�w
Radeon�Ɠ����Ń`�b�v�͉\�Ȍ��菬�����A�R�A������Ȃ�MCM�Ƃ����v�Ȃ낤���ǁA
���ɔ����͂Ȃ���B�{���ɃR�A�T�C�Y�������Ȃ炻��͂���Ŋ��}�����ǁB
>>323
�Ⴄ�ȁB���\�ቺ�̗v���̓L���b�V���~�X���B
�L���b�V���Ƀq�b�g�������Ă���g�[�^���X���[�v�b�g�͂�����B
32KB��L1D�L���b�V�����Ƃ肠��Nehalem��HTT
�e�X���b�h���Ƃ�16KB�����Ȃ�Bulldozer
�Ⴄ�ȁB���\�ቺ�̗v���̓L���b�V���~�X���B
�L���b�V���Ƀq�b�g�������Ă���g�[�^���X���[�v�b�g�͂�����B
32KB��L1D�L���b�V�����Ƃ肠��Nehalem��HTT
�e�X���b�h���Ƃ�16KB�����Ȃ�Bulldozer
>>333
AMD��SMT��������
ttp://images.anandtech.com/galleries/754/BulldozerHotChips_August24_8pmET_NDA-13_575px.jpg
AMD��SMT��������
ttp://images.anandtech.com/galleries/754/BulldozerHotChips_August24_8pmET_NDA-13_575px.jpg
{kind=link}
��?
SMT��Intel�ɂ�������HTT�ł���B
SMT��Intel�ɂ�������HTT�ł���B
�V���O�����\��Nehalem���Ⴂ���ǂ��ꂪ���ɂȂ�͖w�ǖ������ǂ�
����Ƀ^�[�{���݂������x���`��Bull��Fusion�������̋@�\�𓋍ڂ������ƂŗD�ʐ��͂قƂ�ǖ����Ȃ�
����ƍł������o��i3���܂�����HTT/TB��Ή�
HTT�t���ň����������炱������Ă�i3�̐��\���K�^����
i3 vs Llano�y���݂ɂ��Ă������Ǔo��O�ɏ�����������
i5�͔��������ĒN������낤
i7(H2�A4C/8T)��GPU�t���ƃn�C�G���h����Ȃ����Ƃł���ς�N������낤
H2�̎��S���Ղ肪�n���p�Ȃ�w
B2�͕���Ȃ������\�Ŕ���邾�낤���ǁA�����i�߂���X980����̏抷���ȊO�̎��v�͂Ȃ�
������Sandy�̎��S�͂قڊm�肵����
����Ƀ^�[�{���݂������x���`��Bull��Fusion�������̋@�\�𓋍ڂ������ƂŗD�ʐ��͂قƂ�ǖ����Ȃ�
����ƍł������o��i3���܂�����HTT/TB��Ή�
HTT�t���ň����������炱������Ă�i3�̐��\���K�^����
i3 vs Llano�y���݂ɂ��Ă������Ǔo��O�ɏ�����������
i5�͔��������ĒN������낤
i7(H2�A4C/8T)��GPU�t���ƃn�C�G���h����Ȃ����Ƃł���ς�N������낤
H2�̎��S���Ղ肪�n���p�Ȃ�w
B2�͕���Ȃ������\�Ŕ���邾�낤���ǁA�����i�߂���X980����̏抷���ȊO�̎��v�͂Ȃ�
������Sandy�̎��S�͂قڊm�肵����
Open64 x64�̃R�[�h����ɁABulldozer�̈�̐����N���X�^�͍ő�3����/clk���x��������邱�Ƃ�z�肵�Ă���悤���B
�ł��f�R�[�_��2�����R�A�ō��v4����/clk�Ȃ킯�ŁA�Е���3����/clk���x�Ȃ�����Е���1����/clk�ƂȂ�
���ǃX���b�h�̐��\�͋ψ�ɂ͂Ȃ�Ȃ����ǂȁB
�������W���[�����̕ʃX���b�h�̕��ׂɐ��\��������̂͌���Bulldozer�������B
�܂蓯�ꃂ�W���[�����̃R�A�Ԃ̐��\�̋ψꐫ�]�X���k��
�i���������ψ�Ȃ疽�߃f�R�[�_���L�ɂ���Ӗ����Ȃ��킯�Łj
�L���b�V���~�X�⏜�Z���߂ŃX���b�h���~�܂��Ă������Е��̃X���b�h�̓��\�[�X��L�����p�ł��Ȃ��Ȃ�
�}���`�X���b�h�ł���SMT�ɑ��閾�m�Ȍ��_�����݂���
�ł��f�R�[�_��2�����R�A�ō��v4����/clk�Ȃ킯�ŁA�Е���3����/clk���x�Ȃ�����Е���1����/clk�ƂȂ�
���ǃX���b�h�̐��\�͋ψ�ɂ͂Ȃ�Ȃ����ǂȁB
�������W���[�����̕ʃX���b�h�̕��ׂɐ��\��������̂͌���Bulldozer�������B
�܂蓯�ꃂ�W���[�����̃R�A�Ԃ̐��\�̋ψꐫ�]�X���k��
�i���������ψ�Ȃ疽�߃f�R�[�_���L�ɂ���Ӗ����Ȃ��킯�Łj
�L���b�V���~�X�⏜�Z���߂ŃX���b�h���~�܂��Ă������Е��̃X���b�h�̓��\�[�X��L�����p�ł��Ȃ��Ȃ�
�}���`�X���b�h�ł���SMT�ɑ��閾�m�Ȍ��_�����݂���
>>337
HTT��SMT�̈�̌`�ł�����SMT=HTT����Ȃ���
HTT��SMT�̈�̌`�ł�����SMT=HTT����Ȃ���
Turbo Boost�̓V���O���X���b�h���\�������グ��Z�p�����A
IPC��������Bulldozer�����܂˂������Ƃ���ŁA�N���b�N��2�{�Ƃ�3�{�ɂł��Ȃ�Ȃ�����D�ʐ��̋t�]�͂Ȃ��Ȃ�
IPC��������Bulldozer�����܂˂������Ƃ���ŁA�N���b�N��2�{�Ƃ�3�{�ɂł��Ȃ�Ȃ�����D�ʐ��̋t�]�͂Ȃ��Ȃ�
>>340
����Ⴛ������323�̌���HTT�̌��_��SMT�ɂ����̂܂ܓ��Ă͂܂邾�낤�B
����Ⴛ������323�̌���HTT�̌��_��SMT�ɂ����̂܂ܓ��Ă͂܂邾�낤�B
345 �FSocket774�F2010/08/28(�y) 00:20:22 ID:3xmt/V4a
���Ƃ��Ɠ��N���b�N��Core2��2/3���炢�������\�Ȃ��̂�
����ɂ���2/3���Ă��Ƃ́A���N���b�N�Ŕ����ȉ��̐��\�����o�Ȃ����Ď���
���i���C���i�b�v�̓R�A���Q�{������Ă�Ƃ��낪��
�[���珟������C�[���ȂȁBIntel��10�R�A��4�R�A�̌��ԏ��i�Ȃ�
����ɂ���2/3���Ă��Ƃ́A���N���b�N�Ŕ����ȉ��̐��\�����o�Ȃ����Ď���
���i���C���i�b�v�̓R�A���Q�{������Ă�Ƃ��낪��
�[���珟������C�[���ȂȁBIntel��10�R�A��4�R�A�̌��ԏ��i�Ȃ�
Nehalem�̃P�[�X��2�X���b�h��L1D��荇���Đ��\�ቺ����R�[�h��
�悤�����16KB�̗e�ʂł͕s������킯��
Bulldozer�ł͏�ɃX���b�V���O���N���Ă܂Ƃ��ɐ��\���o�Ȃ��\��������ȁB
> MacroFusion�ގ��̂���������炵������A
> �f�R�[�_4Way�ł�����ȏ�̖��ߐ��������ł����Ȃ��́H
�������������Nehalem���ő�5���߂�����r���߁{��������̓������炢�����K�p�ł��Ȃ���
�悤�����16KB�̗e�ʂł͕s������킯��
Bulldozer�ł͏�ɃX���b�V���O���N���Ă܂Ƃ��ɐ��\���o�Ȃ��\��������ȁB
> MacroFusion�ގ��̂���������炵������A
> �f�R�[�_4Way�ł�����ȏ�̖��ߐ��������ł����Ȃ��́H
�������������Nehalem���ő�5���߂�����r���߁{��������̓������炢�����K�p�ł��Ȃ���
L1D�͓Ɨ����Ă��
>>336
�����A�ʂ�SMT���̂�n���ɂ͂��ĂȂ�
���ł�HTT���n���ɂ������͂Ȃ�
���肳�ꂽ�Ȃ�f���炵�����\���ł��邩���
�����A���Ƌ��ł̐��\�����傫�����đ��ړI�ɂ͎g���h���Ƃ�������
Bull�̃��W���[���̓p�C�v���C����L1�L���b�V�����Ɨ����Ă��邩�琫�\�����w�Ǐo�Ȃ�(�͂�)
L2���L�̉e�����Ȃ�����(Core2�ɂ͖w�ǖ�������)
SMT�ɂ��X���b�h1��2�̍���\���Ƒ�������Ȃ���
Nehalem�n�F1 vs 0.3 (1/3��)
Bulldozer�F 0.8 vs 0.75 (1���ȉ�)
HTT�Ή��͓��ʂȍœK�����K�{�����A�����𐄏����ꂽ�������
BUll�̏ꍇ�A�قڑΓ�������K���ɃX���b�h������U���Ă����Ȃ������ȂقLj����₷����
����������HPC��T�[�o�[�ł�HTT�����������ȏꍇ�����邻����
�����A�ʂ�SMT���̂�n���ɂ͂��ĂȂ�
���ł�HTT���n���ɂ������͂Ȃ�
���肳�ꂽ�Ȃ�f���炵�����\���ł��邩���
�����A���Ƌ��ł̐��\�����傫�����đ��ړI�ɂ͎g���h���Ƃ�������
Bull�̃��W���[���̓p�C�v���C����L1�L���b�V�����Ɨ����Ă��邩�琫�\�����w�Ǐo�Ȃ�(�͂�)
L2���L�̉e�����Ȃ�����(Core2�ɂ͖w�ǖ�������)
SMT�ɂ��X���b�h1��2�̍���\���Ƒ�������Ȃ���
Nehalem�n�F1 vs 0.3 (1/3��)
Bulldozer�F 0.8 vs 0.75 (1���ȉ�)
HTT�Ή��͓��ʂȍœK�����K�{�����A�����𐄏����ꂽ�������
BUll�̏ꍇ�A�قڑΓ�������K���ɃX���b�h������U���Ă����Ȃ������ȂقLj����₷����
����������HPC��T�[�o�[�ł�HTT�����������ȏꍇ�����邻����
>>346
�����Ȃ̂��B
L1D�̘b�́AAndyGlew�Ɍ��킹��ƃL���b�V���e�ʂ����Ȃ����炶��Ȃ��A
2�X���b�h�Ŏ�荇���ɂȂ�̂���肾����ACbMT�ŕ������炵�����ǁB
�����Ȃ̂��B
L1D�̘b�́AAndyGlew�Ɍ��킹��ƃL���b�V���e�ʂ����Ȃ����炶��Ȃ��A
2�X���b�h�Ŏ�荇���ɂȂ�̂���肾����ACbMT�ŕ������炵�����ǁB
HTT���Ď�������Ă���啪�����ǁA�{���Ɏg���Ȃ����
�g�����ʂ���L���Ȃ͔̂F�߂邪�A�s��̂������Ɗ������
�g�����ʂ���L���Ȃ͔̂F�߂邪�A�s��̂������Ɗ������
>>348
���₾����AFPU/MMX/SSE/AVX�̖��߂�Bulldozer�ł�SMT�ȉ��Z��Ŏ��s��������...
�����̖��߂��x�z�I�ȃA�v���ł�HTT�Ɠ��l�ɐ��\�ቺ�������...
���₾����AFPU/MMX/SSE/AVX�̖��߂�Bulldozer�ł�SMT�ȉ��Z��Ŏ��s��������...
�����̖��߂��x�z�I�ȃA�v���ł�HTT�Ɠ��l�ɐ��\�ቺ�������...
>>351
������������ł̓N���e�B�J������Ȃ��Ƃ݂Ď������Ă�
������������ł̓N���e�B�J������Ȃ��Ƃ݂Ď������Ă�
353 �FSocket774�F2010/08/28(�y) 00:33:00 ID:g4jutbay
�ނ���fpu simd��smt�Ȃ�Ă���Ȃ�������Ȃ����낤��w
>>339
���\���ψ�Ȃ̂̓R�A���\����
�ψꐫ�\�����疽�߂�������K���ɊJ���Ă�R�A�Ɋ���U���Ƃ��������Ă���
HTT�݂����Ɏ��������f������Ȃ�Ėʓ|�Ȃ��Ƃ����Ȃ��čς�
�d�����������R�A�Ɋ��蓖�Ă�ꂽ�猙�����邾��
Bull�̏ꍇ�ǂ����Ɋ��蓖�ĂĂ��������Ԃ͂قƂ�Ljꏏ�����猙�Ƃ��v�����Ƃ��Ȃ�
���\���ψ�Ȃ̂̓R�A���\����
�ψꐫ�\�����疽�߂�������K���ɊJ���Ă�R�A�Ɋ���U���Ƃ��������Ă���
HTT�݂����Ɏ��������f������Ȃ�Ėʓ|�Ȃ��Ƃ����Ȃ��čς�
�d�����������R�A�Ɋ��蓖�Ă�ꂽ�猙�����邾��
Bull�̏ꍇ�ǂ����Ɋ��蓖�ĂĂ��������Ԃ͂قƂ�Ljꏏ�����猙�Ƃ��v�����Ƃ��Ȃ�
355 �FSocket774�F2010/08/28(�y) 00:37:47 ID:g4jutbay
L1I��64KB
�ꉞ�����Ƃ�w
�ꉞ�����Ƃ�w
>>353
��̃R�A�����ꂼ��FPU�����Ă���悤�Ɍ����邽�߂ɂ����Ȃ��Ă��Ȃ���
��̃R�A�����ꂼ��FPU�����Ă���悤�Ɍ����邽�߂ɂ����Ȃ��Ă��Ȃ���
ID:Xd/ldXaT�̓d�g���Ղ�ɒE�X
�����������ĂȂ悗
�����������ĂȂ悗
>>353
�܂��A�_��2�R�A�Ɍ����邽�߂Ɏ���������Ȃ������Ƃ͎v������
�܂��A�_��2�R�A�Ɍ����邽�߂Ɏ���������Ȃ������Ƃ͎v������
> HTT�݂����Ɏ��������f������Ȃ�Ėʓ|�Ȃ��Ƃ����Ȃ��čς�
Nehalem��HTT�����Ȃ�Bulldozer�͑S�ċ��݂����Ȃ���
���E���Ȃ�Ĕ��ʂ͂����������݂��Ȃ��B
�A�N�e�B�u�X���b�h�������Ȃ��ꍇ�ɓ������W���[����̃R�A�Ɋ���U��ꂽ�ꍇ�ɐ��\���ቺ������̂�
�����I�ɂ�HTT�Ɠ����B
Nehalem��HTT�����Ȃ�Bulldozer�͑S�ċ��݂����Ȃ���
���E���Ȃ�Ĕ��ʂ͂����������݂��Ȃ��B
�A�N�e�B�u�X���b�h�������Ȃ��ꍇ�ɓ������W���[����̃R�A�Ɋ���U��ꂽ�ꍇ�ɐ��\���ቺ������̂�
�����I�ɂ�HTT�Ɠ����B
�������ΈӖ��������邾��H
Module A�̃R�A0��Module B�̃R�A0�Ɋ���U�����ꍇ�F
���ꂼ��3����/clk���x�̓������ߔ��s���i2�X���b�h�̃g�[�^����6����/clk�j
Module A�̃R�A0�Ɠ�����Module A�̃R�A1�Ɋ���U�����ꍇ�F
3�F1�`1�F3�̊�����2�X���b�h�ō��킹��4����/clk���x�̓������ߔ��s��
�܂�Bulldozer�ł��X���b�h�̊��蓖�ĕ��Ńg�[�^�����\���ς��̂͑���CPU��SMT�Ɠ����B
�ʂ̃��W���[���ɂ�����Ɗ���U���Ă�Nehalem�قǂɂ͐L�т��낪���Ȃ������ł�
Module A�̃R�A0��Module B�̃R�A0�Ɋ���U�����ꍇ�F
���ꂼ��3����/clk���x�̓������ߔ��s���i2�X���b�h�̃g�[�^����6����/clk�j
Module A�̃R�A0�Ɠ�����Module A�̃R�A1�Ɋ���U�����ꍇ�F
3�F1�`1�F3�̊�����2�X���b�h�ō��킹��4����/clk���x�̓������ߔ��s��
�܂�Bulldozer�ł��X���b�h�̊��蓖�ĕ��Ńg�[�^�����\���ς��̂͑���CPU��SMT�Ɠ����B
�ʂ̃��W���[���ɂ�����Ɗ���U���Ă�Nehalem�قǂɂ͐L�т��낪���Ȃ������ł�
363 �FSocket774�F2010/08/28(�y) 00:59:56 ID:g4jutbay
�N���b�N���g�����ǂ��܂ŐL�т邩��
���\�͂��ꎟ��
���\�͂��ꎟ��
�X���C�h6����
�Eaverage of 80% of the CMP performance
������č��̃f���A���R�A�ɑ��Ă̑������N���b�N�ł̃p�t�H�[�}���X�����
2�X���b�h��0.8�{�Ȃ�A�V���O���X���b�h�ł�0.8�{
�ŁA
ttp://northwood.blog60.fc2.com/blog-entry-4042.html
�E33���̃R�A�������ŁA50���̐��\�������B
>1-core������̐��\��K10��100�Ƃ���ƁgBulldozer�h��112.5
K10��0.8�{�̐��\�̃R�A��K10���12.5%�L���ɂ�1.4�{�̎��g���œ������Ȃ��Ƃ���
��PhenomII��3.4GHz�o�Ă邩��A5GHz�ȏ�œo�ꂵ�Ă���Ȃ��Ɛ��\�̌���Ȃ����
Turbo CORE�łǂ��܂ŐL�т邩��
�Eaverage of 80% of the CMP performance
������č��̃f���A���R�A�ɑ��Ă̑������N���b�N�ł̃p�t�H�[�}���X�����
2�X���b�h��0.8�{�Ȃ�A�V���O���X���b�h�ł�0.8�{
�ŁA
ttp://northwood.blog60.fc2.com/blog-entry-4042.html
�E33���̃R�A�������ŁA50���̐��\�������B
>1-core������̐��\��K10��100�Ƃ���ƁgBulldozer�h��112.5
K10��0.8�{�̐��\�̃R�A��K10���12.5%�L���ɂ�1.4�{�̎��g���œ������Ȃ��Ƃ���
��PhenomII��3.4GHz�o�Ă邩��A5GHz�ȏ�œo�ꂵ�Ă���Ȃ��Ɛ��\�̌���Ȃ����
Turbo CORE�łǂ��܂ŐL�т邩��
5GHz�Ƃ��o��悤�ɂȂ����烂�f���i���o�[�p�~�����肵�Ă�
366 �FSocket774�F2010/08/28(�y) 01:22:29 ID:g4jutbay
�^�[�{1���W���[��5Ghz�ł�����
�C���p�N�g�����
�C���p�N�g�����
>>364
��r�Ώۂ�Bulldozer���W���[���̋��p�������S�ɕ����v�ɂ������z�f���A���R�A���Ǝv������
��r�Ώۂ�Bulldozer���W���[���̋��p�������S�ɕ����v�ɂ������z�f���A���R�A���Ǝv������
�Ȃ���G���R�ȊO������CPU�ɂȂ肻������
�G���R��AMD���Ď��オ����̂��H
�G���R��AMD���Ď��オ����̂��H
>������č��̃f���A���R�A�ɑ��Ă̑������N���b�N�ł̃p�t�H�[�}���X�����
�Ⴄ
�Ⴄ
>>362
AMD���z�肵�Ă閽�ߔ��s�́A�w�ǂ̏ꍇ2����/clk�ŋH��3���߈ȏ゠����x
�����炠�Ȃ��������Ă�1:3��3:1�͕p�x�Ƃ��Ă͏��Ȃ�����A
3���߈ȏ�̐��\�������Ă������I�ɂ͖��Ȃ��Ɣ��f���ăp�C�v��2�n���Ȃ�
2���߂�3���߈ȏ�̕p�x�̍����ǂꂭ�炢���͒m��Ȃ���5�{�Ƃ�10�{���炢���肻��
>>360
�����͈ꏏ�����ǐ��\�ቺ�̓x�������S���Ⴄ����
HTT�̘_���R�A�̓p�C�v��L���b�V���̊J���Ă��錄�Ԃŏ����ABull�͐�p�̃p�C�v�ƃL���b�V���������Ă���
�܂�������2�̒ቺ�x�����������Ƃł��������肩�H
AMD���z�肵�Ă閽�ߔ��s�́A�w�ǂ̏ꍇ2����/clk�ŋH��3���߈ȏ゠����x
�����炠�Ȃ��������Ă�1:3��3:1�͕p�x�Ƃ��Ă͏��Ȃ�����A
3���߈ȏ�̐��\�������Ă������I�ɂ͖��Ȃ��Ɣ��f���ăp�C�v��2�n���Ȃ�
2���߂�3���߈ȏ�̕p�x�̍����ǂꂭ�炢���͒m��Ȃ���5�{�Ƃ�10�{���炢���肻��
>>360
�����͈ꏏ�����ǐ��\�ቺ�̓x�������S���Ⴄ����
HTT�̘_���R�A�̓p�C�v��L���b�V���̊J���Ă��錄�Ԃŏ����ABull�͐�p�̃p�C�v�ƃL���b�V���������Ă���
�܂�������2�̒ቺ�x�����������Ƃł��������肩�H
�ǂ����ǂ����Ƃ����Ȃ���悭�������
>>367��������
>>368�ւ̃��X�ł�
�S�R�A�g���悤�ȃG���R���ƁASSE��D�������Ēx���Ȃ�H
>>374
����ȃG���R�}�j�A���������炷�悤�ȃ\�t�g������B
����ȃG���R�}�j�A���������炷�悤�ȃ\�t�g������B
�x���Ȃ�͌����߂���������Ȃ����ǁA�����ڏ�̃X���b�h���̊��ɑ����Ȃ�Ȃ������肷��̂��ȁB
>>335���\���Ă���}���炵�āA�eIntegerCore�֊���U��܂ł�VerticalMT������A
�f�R�[�_��1�x��1�X���b�h�����������ł��Ȃ��Ǝv�����ǁB
�f�R�[�_��1�x��1�X���b�h�����������ł��Ȃ��Ǝv�����ǁB
�@2����ڂɂȂ�TurboCore����肭�����Ɨǂ��̂����ǂˁB
Bull���IPC���ႢBobcat�R�A�ł�K10��9�����x�̐��\������A
Bull��IPC��K10��95%�ʂƌ��Ă������낤
�L���b�V���̍\�����G�N�X�N���[�V�u����C���N���[�V�u�ɖ߂��Đ��\�A�b�v���邩��A
���������ƌ��Ă����Ǝv��
���d�͉��ƃ^�[�{�@�\�ɂ���čő含�\�͐�������s�����낤
Bull 1���W���[��=Sandy 1�R�A�̐��\���Ƃ����
Sandy 4C/8T 3.4GHz 95W�ɑ��A��������Bull��8C 3.4G 95W��B������K�v������ȁB
�B���ł��邩��
Bull��IPC��K10��95%�ʂƌ��Ă������낤
�L���b�V���̍\�����G�N�X�N���[�V�u����C���N���[�V�u�ɖ߂��Đ��\�A�b�v���邩��A
���������ƌ��Ă����Ǝv��
���d�͉��ƃ^�[�{�@�\�ɂ���čő含�\�͐�������s�����낤
Bull 1���W���[��=Sandy 1�R�A�̐��\���Ƃ����
Sandy 4C/8T 3.4GHz 95W�ɑ��A��������Bull��8C 3.4G 95W��B������K�v������ȁB
�B���ł��邩��
>>364
�z�肷��f���A���R�A���AK10�Ȃ̂��A�f�R�[�_��FPU�����L����ĂȂ����Ƃ�z�肵�����zBulldozer�Ȃ̂�
���ꎟ��ł��ς���Ă���Ǝv�����B
�ŏ���K10���0.9����Ȃ��������H
��ł����āu50%�����v�Ƃ����̂������w���̂��悭�킩��ǂȁB
�Ƃ肠������r��Magny-Cours����H
���Ȃ݂�Magny-Cours 2.3GHz��1.4�{�̎��g����3.22GHz���Ă��ƂɂȂ邯�ǁAMCM�ł����܂ł�����̂��H
50%�������Ă̂��s�[�NFLOPS���̗��_�l�̂��Ƃ��Ƃ���ƁA�܂�1���W���[���������FLOPS����2�{�B
8���W���[����12�R�A��1.5�{�̐��\�́AMagny-Cours��1.125�{�̃N���b�N�ŒB���ł���B
���̉��肾�ƁAInteragos�̃n�C�G���h��2.6GHz���x�œ��삷��Ɛ���ł���B
������X�ɁuK10��0.9�v�̌v���ɓ��Ă͂߂�ƁA2.6*0.9��2.3GHz
���s��Magny-Cours���N���b�N�����u����16�R�A�ɂ����̂Ɠ����x�̐��\�Ƃ������ƂɂȂ�B
�������̂ق����O���t�Ƃ̐����������C�����邪
http://techreport.com/discussions.x/16797
�z�肷��f���A���R�A���AK10�Ȃ̂��A�f�R�[�_��FPU�����L����ĂȂ����Ƃ�z�肵�����zBulldozer�Ȃ̂�
���ꎟ��ł��ς���Ă���Ǝv�����B
�ŏ���K10���0.9����Ȃ��������H
��ł����āu50%�����v�Ƃ����̂������w���̂��悭�킩��ǂȁB
�Ƃ肠������r��Magny-Cours����H
���Ȃ݂�Magny-Cours 2.3GHz��1.4�{�̎��g����3.22GHz���Ă��ƂɂȂ邯�ǁAMCM�ł����܂ł�����̂��H
50%�������Ă̂��s�[�NFLOPS���̗��_�l�̂��Ƃ��Ƃ���ƁA�܂�1���W���[���������FLOPS����2�{�B
8���W���[����12�R�A��1.5�{�̐��\�́AMagny-Cours��1.125�{�̃N���b�N�ŒB���ł���B
���̉��肾�ƁAInteragos�̃n�C�G���h��2.6GHz���x�œ��삷��Ɛ���ł���B
������X�ɁuK10��0.9�v�̌v���ɓ��Ă͂߂�ƁA2.6*0.9��2.3GHz
���s��Magny-Cours���N���b�N�����u����16�R�A�ɂ����̂Ɠ����x�̐��\�Ƃ������ƂɂȂ�B
�������̂ق����O���t�Ƃ̐����������C�����邪
http://techreport.com/discussions.x/16797
http://www.anandtech.com/show/3863/amd-discloses-bobcat-bulldozer-architectures-at-hot-chips-2010/5
>but AMD mentioned that the 4-wide front end, fusion and other enhancements more than make up for this reduction.
>In other words, while there�fs fewer single thread integer execution resources in Bulldozer than Phenom II, single threaded
>integer performance should still be higher.
AMD��IPC���オ��ƌ����Ă�݂�������B>Bull
>but AMD mentioned that the 4-wide front end, fusion and other enhancements more than make up for this reduction.
>In other words, while there�fs fewer single thread integer execution resources in Bulldozer than Phenom II, single threaded
>integer performance should still be higher.
AMD��IPC���オ��ƌ����Ă�݂�������B>Bull
>>370
�����̖ϑz��ϑz�œh��ł߂�͎̂��߂Ȃ���
x86���߂�ALU��AGU�̗����ɍ��E���閽�߂�������Ȃ���B
�����R�A������3���ߏ�������L���p������B
�����I�ɂ�Load + Load&ALU + ALU �݂�����3���߂ł�1�̐����N���X�^�ŏ���������B
������y������x�܂ł́z�Е��̃X���b�h���X�g�[�����Ă������Е��̃R�A�̃��\�[�X���t�����p���邱�Ƃ�
�g�[�^���X���[�v�b�g�̒ቺ��}���邱�Ƃ��ł���B
�������SMT�̂ق����������苭�����ǂȁB
�����̖ϑz��ϑz�œh��ł߂�͎̂��߂Ȃ���
x86���߂�ALU��AGU�̗����ɍ��E���閽�߂�������Ȃ���B
�����R�A������3���ߏ�������L���p������B
�����I�ɂ�Load + Load&ALU + ALU �݂�����3���߂ł�1�̐����N���X�^�ŏ���������B
������y������x�܂ł́z�Е��̃X���b�h���X�g�[�����Ă������Е��̃R�A�̃��\�[�X���t�����p���邱�Ƃ�
�g�[�^���X���[�v�b�g�̒ቺ��}���邱�Ƃ��ł���B
�������SMT�̂ق����������苭�����ǂȁB
>>381
�c�c�c
�c�c�c
>>382
���Ⴀ�����̏������悤��
http://pc.watch.impress.co.jp/docs/column/kaigai/20091112_328392.html
> ���p�t�H�[�}���X��80%�A�b�v����Bulldozer
�܂�X���b�h������̐��\��0.9
���Ⴀ�����̏������悤��
http://pc.watch.impress.co.jp/docs/column/kaigai/20091112_328392.html
> ���p�t�H�[�}���X��80%�A�b�v����Bulldozer
�܂�X���b�h������̐��\��0.9
���x�v�����A�u���_��ɂ���v�Řb���n�߂�̂��B
�ϑz�ƉR�œh��ł߂鎩�̂ɂȂ�킯�ł����āc�B
�ϑz�ƉR�œh��ł߂鎩�̂ɂȂ�킯�ł����āc�B
80���A�b�v����̂́AK10��Ƃǂ��ɂ������ĂȂ��Ǝv�����ǁB
���Ȃ��Ƃ�Sandy���s��ɏo�Ă���܂ł�SandyBull���Ƀ��{�ƃT���v������������[�J�[�ƃ��[�U�̖ϑz���ɂ������݂��Ȃ�
���炭����Ȋ����Ő��Y���F���̔]���o�g����������Ȃ���
���i�o�Ă����Y���F���͑������ǂ�
���炭����Ȋ����Ő��Y���F���̔]���o�g����������Ȃ���
���i�o�Ă����Y���F���͑������ǂ�
>>388
���Ђ̌��s���i�̐��\�ȊO�Ɉ�̂Ȃɂ���ɂ����JK
���Ђ̌��s���i�̐��\�ȊO�Ɉ�̂Ȃɂ���ɂ����JK
>>391
���O�͖{���ɃA�z���ȁB
�N���X�^�[�h�A�[�L�e�N�`���̗��_������B
CPU�R�A�̃��\�[�X��50%���₷�����ŁA
80%���X���[�v�b�g���オ��Ɛ������Ă����B
���āA�{���ɂ��邪�H ���l�ŕ\���Ȃ�A
0.8�{�ł͂Ȃ��A1.8�{���B������K10�Ƃ��W�Ȃ��B
���O�͖{���ɃA�z���ȁB
�N���X�^�[�h�A�[�L�e�N�`���̗��_������B
CPU�R�A�̃��\�[�X��50%���₷�����ŁA
80%���X���[�v�b�g���オ��Ɛ������Ă����B
���āA�{���ɂ��邪�H ���l�ŕ\���Ȃ�A
0.8�{�ł͂Ȃ��A1.8�{���B������K10�Ƃ��W�Ȃ��B
>>392
Bulldozer�̂��Ƃ����Ė������Ă���B
> Moore���́A�����Analyst Day�ł��A�[�L�e�N�`���̐������s�Ȃ��ABulldozer��80%�̃X���[�v�b�g�A�b�v��B���ł���ƌ���Ă���B
> �܂��AAMD�́A�N���X�^�[�h�A�[�L�e�N�`���ɗ��������������\��(United States Patent Application 20090006814, 20090024836�Ȃ�)���Ă���B
���O����̒����ł�K10����Ȃ��ĉ������80%�Ȃ��H
�Ƃ���ŁA1.5�{�̃g�����W�X�^������1.8�{���āA�w�ǃg�����W�X�^�����Ȃ���1.2�`1.3�{�̐��\��������������SMT�ƃ��\�[�X�����͑債�ĕς����ˁB
Bulldozer�̂��Ƃ����Ė������Ă���B
> Moore���́A�����Analyst Day�ł��A�[�L�e�N�`���̐������s�Ȃ��ABulldozer��80%�̃X���[�v�b�g�A�b�v��B���ł���ƌ���Ă���B
> �܂��AAMD�́A�N���X�^�[�h�A�[�L�e�N�`���ɗ��������������\��(United States Patent Application 20090006814, 20090024836�Ȃ�)���Ă���B
���O����̒����ł�K10����Ȃ��ĉ������80%�Ȃ��H
�Ƃ���ŁA1.5�{�̃g�����W�X�^������1.8�{���āA�w�ǃg�����W�X�^�����Ȃ���1.2�`1.3�{�̐��\��������������SMT�ƃ��\�[�X�����͑債�ĕς����ˁB
>>393
������1�X���b�h������̌v����0.9�{���Č��������B0.8����Ȃ��ĂȁB
������1�X���b�h������̌v����0.9�{���Č��������B0.8����Ȃ��ĂȁB
K10�Ɣ�r����80%�A�b�v�Ƃ͂ǂ��ɂ������ĂȂ����
K10����50%�̃��\�[�X�A�b�v�Ƃ����킯�ł��Ȃ����낤��
K10����50%�̃��\�[�X�A�b�v�Ƃ����킯�ł��Ȃ����낤��
>>393
������ACbMT�g����80%�X���[�v�b�g�A�b�v����B
K10�䂶��Ȃ��B
�㓡�L���́A2005�N�̂Ƃ���CbMT�g����50%���\�[�X����80%�X���[�v�b�g�A�b�v�ƌ����Ă������A
2009�N��Bulldozer�̐����ł��������Ƃ����������Ă��Ƃ���B
������ACbMT�g����80%�X���[�v�b�g�A�b�v����B
K10�䂶��Ȃ��B
�㓡�L���́A2005�N�̂Ƃ���CbMT�g����50%���\�[�X����80%�X���[�v�b�g�A�b�v�ƌ����Ă������A
2009�N��Bulldozer�̐����ł��������Ƃ����������Ă��Ƃ���B
���s���i�Ƃ̔�r����Ȃ��Ƃ����+80%�Ȃ�Đ����ɑS���Ӗ����Ȃ����ƂɂȂ邯�ǂȁB
K10����Ȃ��Ȃ牽�����+80%�ȂH�܂���Nehalem���H
K10����Ȃ��Ȃ牽�����+80%�ȂH�܂���Nehalem���H
>>398
CbMT���������A����ȋZ�p���̗p����Bulldozer�͂�������A�݂�Ȃ����ɓ������Ă˂��Ă��ƁB
AMD��K10�Ɣ�r�����̂́Ablog�ł�Magny-Cours12�R�A��Bulldozer16�R�A����
�R�A����1.33�{�Ő��\1.5�{�ŁABulldozer�����������Ă��炢�B
CbMT���������A����ȋZ�p���̗p����Bulldozer�͂�������A�݂�Ȃ����ɓ������Ă˂��Ă��ƁB
AMD��K10�Ɣ�r�����̂́Ablog�ł�Magny-Cours12�R�A��Bulldozer16�R�A����
�R�A����1.33�{�Ő��\1.5�{�ŁABulldozer�����������Ă��炢�B
http://journal.mycom.co.jp/articles/2010/08/27/hot_chips22_bulldozer/index.html
�����̍\���Ƃ��邱�Ƃɂ��A���S��2�R�A�̐v�Ɣ�ׂ��80%���x�̐��\�����Ȃ菭�Ȃ��`�b�v�ʐςƓd�͂Ŏ����ł����Ƃ����B
�u���Ȃ菭�Ȃ��`�b�v�ʐςƓd�́v�̕���������d�͂ɗ]�T�������ăN���b�N�グ���邩��A�g�[�^���ł͏���Ƃ����b�ł��傤�B
�����̍\���Ƃ��邱�Ƃɂ��A���S��2�R�A�̐v�Ɣ�ׂ��80%���x�̐��\�����Ȃ菭�Ȃ��`�b�v�ʐςƓd�͂Ŏ����ł����Ƃ����B
�u���Ȃ菭�Ȃ��`�b�v�ʐςƓd�́v�̕���������d�͂ɗ]�T�������ăN���b�N�グ���邩��A�g�[�^���ł͏���Ƃ����b�ł��傤�B
>�@Moore���́A�����Analyst Day�ł��A�[�L�e�N�`���̐������s�Ȃ��A
>Bulldozer��80%�̃X���[�v�b�g�A�b�v��B���ł���ƌ���Ă���B
�����������ꂪk10�䂾�Ƃ��Ă��A
�u80%�̃X���[�v�b�g�A�b�v��B���ł���v�Ƃ�������A
�O��̕�������l���Ă�0.8�{�ł͂Ȃ��A1.8�{����ȁB
>Bulldozer��80%�̃X���[�v�b�g�A�b�v��B���ł���ƌ���Ă���B
�����������ꂪk10�䂾�Ƃ��Ă��A
�u80%�̃X���[�v�b�g�A�b�v��B���ł���v�Ƃ�������A
�O��̕�������l���Ă�0.8�{�ł͂Ȃ��A1.8�{����ȁB
>>401
���������u80%�v�͊��S�ȃf���A���R�A�Ɣ�r�����ꍇ�ƌ����Ă邩��
��r�Ώۂ̓R�A�����S�Ɨ��Ń��\�[�X���L���Ȃ����zBulldozer���낤
���������u80%�v�͊��S�ȃf���A���R�A�Ɣ�r�����ꍇ�ƌ����Ă邩��
��r�Ώۂ̓R�A�����S�Ɨ��Ń��\�[�X���L���Ȃ����zBulldozer���낤
>>383
3���߂̏����\�͂͂Ԃ����Ⴏ�ǂ��ł�������
3���߂̕p�x�������Ȃ�ALU2�Ȃ�Č��炷�킯�Ȃ������
�O�O�b�Ă݂��疽�ߏ�������3���2�̕������Ȃ葽���炵���ƐF��ȃ��C�^�[���R�����g���Ă���
�^�U�̒����̓I�ȃf�[�^����������Ȃ�����ڍׂ͒m���
�܂�AMD�̒��̐l��K10�ɑ�IPC��9�����瓯�����x�o����ƌ����Ă�炵�����C�ɂ��邱�Ƃ��Ȃ��Ǝv����
3���߂̏����\�͂͂Ԃ����Ⴏ�ǂ��ł�������
3���߂̕p�x�������Ȃ�ALU2�Ȃ�Č��炷�킯�Ȃ������
�O�O�b�Ă݂��疽�ߏ�������3���2�̕������Ȃ葽���炵���ƐF��ȃ��C�^�[���R�����g���Ă���
�^�U�̒����̓I�ȃf�[�^����������Ȃ�����ڍׂ͒m���
�܂�AMD�̒��̐l��K10�ɑ�IPC��9�����瓯�����x�o����ƌ����Ă�炵�����C�ɂ��邱�Ƃ��Ȃ��Ǝv����
�n�����ȁB
CPU��ALU�ɍ�p���閽�߂�������������킯�ł͂Ȃ��B
���Ƃ��ΒP�Ƃ̃��[�h�E�X�g�A���߂�ALU����؎g��Ȃ��B
���Ƃ���PPC970�͓������ߔ��s��4��������ALU��2���B
CPU��ALU�ɍ�p���閽�߂�������������킯�ł͂Ȃ��B
���Ƃ��ΒP�Ƃ̃��[�h�E�X�g�A���߂�ALU����؎g��Ȃ��B
���Ƃ���PPC970�͓������ߔ��s��4��������ALU��2���B
0.9�{����Ontario�̃��[�N�ł������悤�Ȑ��l�o�Ă����悤��
�F�X�H�v���Ă���͂���Bulldozer���ȈՃR�A��Bobcat�Ƒ卷�Ȃ��N���b�N���\�Ƃ������Ƃ͂�����ƍl���Â炢
�F�X�H�v���Ă���͂���Bulldozer���ȈՃR�A��Bobcat�Ƒ卷�Ȃ��N���b�N���\�Ƃ������Ƃ͂�����ƍl���Â炢
http://journal.mycom.co.jp/photo/articles/2005/04/28/coolchips1/images/009l.jpg
�A�E�g�I�u�I�[�_�[���Ƃ܂��Ⴄ�̂���
{kind=link}
�A�E�g�I�u�I�[�_�[���Ƃ܂��Ⴄ�̂���
>>404
�n���͂��O��w
����ȏd���̋����悤�ȗg������肵���o���Ȃ��قǁA
Bull��2ALU/2AGU�\���������t���悤���Ȃ����D�ꂽ�A�[�L�e�N�`���Ȃ͕̂�������w
�n���͂��O��w
����ȏd���̋����悤�ȗg������肵���o���Ȃ��قǁA
Bull��2ALU/2AGU�\���������t���悤���Ȃ����D�ꂽ�A�[�L�e�N�`���Ȃ͕̂�������w
����B�����������Ⴂ���Ă���I �o�J���I
>CPU�R�A�̃��\�[�X��50%���₷�����ŁA
>80%���X���[�v�b�g���オ��Ɛ������Ă����B
���\�ȉ��肾���A ���L�������������S��Bulldozer�R�A��
����ׂ�'���zBulldozer Dual�R�A'��z�肵�A
����́u�ʐς�200%�ŁA���\��100%�v�Ɖ��肵���ꍇ�B
CMT��'Bulldozer'�R�A�́u�ʐ�:150% ���\:80%�v���Ď����ȁB
>CPU�R�A�̃��\�[�X��50%���₷�����ŁA
>80%���X���[�v�b�g���オ��Ɛ������Ă����B
���\�ȉ��肾���A ���L�������������S��Bulldozer�R�A��
����ׂ�'���zBulldozer Dual�R�A'��z�肵�A
����́u�ʐς�200%�ŁA���\��100%�v�Ɖ��肵���ꍇ�B
CMT��'Bulldozer'�R�A�́u�ʐ�:150% ���\:80%�v���Ď����ȁB
���ς�炸worst case�iIntel�ɂ��Ă�best case�j��best����better case�ŋc�_���邩��S�����ݍ����ĂȂ���
�\���Ȃ�ĐG�ꕝ�������ē��R�Ȃ��A�ǂ����i�Ƃ������N�j�������̃X���ŏ�Ⴂ�Ȃ͎̂�����
�\���Ȃ�ĐG�ꕝ�������ē��R�Ȃ��A�ǂ����i�Ƃ������N�j�������̃X���ŏ�Ⴂ�Ȃ͎̂�����
>>409
�A�b�v�Ƃ����\�����g���Ă����Ⴄ���
�A�b�v�Ƃ����\�����g���Ă����Ⴄ���
�����ǂ���ς�AK10��Ȃ�ďo�Ă��Ȃ���ȁc�B
Bulldozer�̐��\��K10��Ō���Ă���ꏊ�́A
�u�����M�v�̏ꍇ�B33%�̃R�A�������ŁA50%�̐��\UP�v���ďꏊ�����B
Bulldozer�̐��\��K10��Ō���Ă���ꏊ�́A
�u�����M�v�̏ꍇ�B33%�̃R�A�������ŁA50%�̐��\UP�v���ďꏊ�����B
>>406
���āA�f���A���R�A��80%�Ƃ����Ă�̂ƃV���O���R�A��+80%�ƌ����Ă�̂͑S����r�Ώۂ��Ⴄ�Ǝv���̂����B�B
���āA�f���A���R�A��80%�Ƃ����Ă�̂ƃV���O���R�A��+80%�ƌ����Ă�̂͑S����r�Ώۂ��Ⴄ�Ǝv���̂����B�B
>>411
����B�܂��B�ςŒ��r���[�ȉ���ł��܂����B
�V���O���R�A�ɔ�ׂ�ƁA
Dual Core: �ʐ� 200% ���\200%
CMT. : �ʐ� 150% ���\180%
�Ƃł��Ȃ�̂��ȁH
����B�܂��B�ςŒ��r���[�ȉ���ł��܂����B
�V���O���R�A�ɔ�ׂ�ƁA
Dual Core: �ʐ� 200% ���\200%
CMT. : �ʐ� 150% ���\180%
�Ƃł��Ȃ�̂��ȁH
>>408
�����A���v�A��������K7�`K10�ōő哯�����ߔ��s��3��ALU3���Ăǂ��l���Ă�
ALU��100%�ғ������悤���Ȃ�����AALU��������������đ����\�ቺ�ɂ͌��т��Ȃ��B
�܂��ăV���O���X���b�h���\��2/3�ɒቺ����Ȃ�Ă̂͂��蓾�Ȃ���
�i������������̂R�̏�Ԃ����肦�Ȃ��̂Łj
Bulldozer��ALU+AGU�y�A�~2�ł͂Ȃ��AALU�����̃I�y���[�V������AGU�����̃I�y���[�V������
�������ď��������i���������Ӗ��ł͓������߂�MacroOps�ł͂Ȃ�MicroOps�Ƃ�����j�̂�
���[�h�ƎZ�p�_�����Z���������ĂȂ����߂Ȃ�A������͍ő�4���߂܂ł�1�̐����N���X�^��
���������ł��邱�ƂɂȂ�B
�܂��A�o���p�x����l���ĕ��ϓI�ɂ�3���߂��炢���낤�ˁB
Bulldozer�̃V���O���X���b�h���\�́A2�X���b�h�̃p�t�H�[�}���X�̑��a���Q�ł͂Ȃ��A
2�R�A�̂��������Е���1�R�A���x��ł��Ԃōő�������ł���p�t�H�[�}���X��_����ׂ����B
���������ꍇ�ł��AL1��16KB��������A���߂̎��s�T�C�N�������������Ă���A
K10�Ɣ�ׂĂ��p�t�H�[�}���X�̒ቺ������v�����U�������̂�Bulldozer�Ȃ��ǂȁB
�Ƃ������AK10��萫�\���オ�邩�����邩��_���Ă鎞�_�ŁA�����ɑ��鋣���͂͂Ȃ��B
�����A���v�A��������K7�`K10�ōő哯�����ߔ��s��3��ALU3���Ăǂ��l���Ă�
ALU��100%�ғ������悤���Ȃ�����AALU��������������đ����\�ቺ�ɂ͌��т��Ȃ��B
�܂��ăV���O���X���b�h���\��2/3�ɒቺ����Ȃ�Ă̂͂��蓾�Ȃ���
�i������������̂R�̏�Ԃ����肦�Ȃ��̂Łj
Bulldozer��ALU+AGU�y�A�~2�ł͂Ȃ��AALU�����̃I�y���[�V������AGU�����̃I�y���[�V������
�������ď��������i���������Ӗ��ł͓������߂�MacroOps�ł͂Ȃ�MicroOps�Ƃ�����j�̂�
���[�h�ƎZ�p�_�����Z���������ĂȂ����߂Ȃ�A������͍ő�4���߂܂ł�1�̐����N���X�^��
���������ł��邱�ƂɂȂ�B
�܂��A�o���p�x����l���ĕ��ϓI�ɂ�3���߂��炢���낤�ˁB
Bulldozer�̃V���O���X���b�h���\�́A2�X���b�h�̃p�t�H�[�}���X�̑��a���Q�ł͂Ȃ��A
2�R�A�̂��������Е���1�R�A���x��ł��Ԃōő�������ł���p�t�H�[�}���X��_����ׂ����B
���������ꍇ�ł��AL1��16KB��������A���߂̎��s�T�C�N�������������Ă���A
K10�Ɣ�ׂĂ��p�t�H�[�}���X�̒ቺ������v�����U�������̂�Bulldozer�Ȃ��ǂȁB
�Ƃ������AK10��萫�\���オ�邩�����邩��_���Ă鎞�_�ŁA�����ɑ��鋣���͂͂Ȃ��B
>>414
�����炳�A
K10��ŁA�V���O���R�A��180%�i�f���A���R�A��90%)
���\�[�X�L�̉��zBulldozer��ŁA�@�V���O���R�A��160%�i�f���A���R�A��80%�j
�ł�����Ȃ��́H
�����炳�A
K10��ŁA�V���O���R�A��180%�i�f���A���R�A��90%)
���\�[�X�L�̉��zBulldozer��ŁA�@�V���O���R�A��160%�i�f���A���R�A��80%�j
�ł�����Ȃ��́H
xmm-gpr�Ԃ�movd�Ƃ����ς�炸�x���ȁH
�܂������ɉ�������H������i��
CPU�̃v���t�F�b�`�@�\�͂܂��n��������
�u���L����L�̂ق����啪�}�V�v�ƌ����Ă�낤��
����ł����[�̐���ƒm�\���������Ă����������Ȗ^�����ꈤ�D�z���Ɣ�ׂ���y���ɓ��ǂ����낤����
�ʃX���b�h�̕��ׂ܂œǂݎ���Ď��ɂ̓��C�����߂�̂���������Ȃ�Č|���͗��ɖ������낤
CPU�̃v���t�F�b�`�@�\�͂܂��n��������
�u���L����L�̂ق����啪�}�V�v�ƌ����Ă�낤��
����ł����[�̐���ƒm�\���������Ă����������Ȗ^�����ꈤ�D�z���Ɣ�ׂ���y���ɓ��ǂ����낤����
�ʃX���b�h�̕��ׂ܂œǂݎ���Ď��ɂ̓��C�����߂�̂���������Ȃ�Č|���͗��ɖ������낤
���A�L���b�V���̘b�ˁA�ꉞ
�L���b�V�������Ȃ�肪�����Ă��
http://journal.mycom.co.jp/articles/2010/08/27/hot_chips22_bulldozer/001.html
�@
Bulldozer�R�A��64KB��1�����߃L���b�V���������A2�K�w��BTB(Branch Target Buffer)������Ă���B
BTB�͉ߋ��̕����A�h���X���L������L���b�V���ŁA����\�����Ԉ���Ă��Ȃ���A
��������̕������m�肷��O�Ɏ��̖��߃A�h���X��������B
Bulldozer�ł͂���BTB���g���Ăǂ�ǂ�Ɨ\�����������̖��߂�ǂݏo���Ă���B
���߃t�F�b�`�Ǝ��s�����邱�̂悤�ȕ����͒������͖������A
Bulldozer�ł�512�G���g����1��BTB��5K�G���g����2��BTB�����Ƃ����\�����Ƃ�A
�����q�b�g�������������e�ʂƁA�����A�N�Z�X�𗼗������Ă���B
�܂��A1��BTB�̃q�b�g���͂��Ȃ荂���Ǝv����̂ŁA�啔���̃P�[�X�ł�2��BTB�͓������A
����2�K�w�\���͏���d�͂̓_�ł��L���ł���Ǝv����B
�Ȃ��A������BTB��2�̃X���b�h�ŋ��L����Ă���A���߃L���b�V������f�R�[�_�܂ł�
�e���j�b�g�̓T�C�N�����Ƃɂǂ���̃X���b�h�̖��߂��������邩���ւ��Ă���B
http://journal.mycom.co.jp/articles/2010/08/27/hot_chips22_bulldozer/001.html
�@
Bulldozer�R�A��64KB��1�����߃L���b�V���������A2�K�w��BTB(Branch Target Buffer)������Ă���B
BTB�͉ߋ��̕����A�h���X���L������L���b�V���ŁA����\�����Ԉ���Ă��Ȃ���A
��������̕������m�肷��O�Ɏ��̖��߃A�h���X��������B
Bulldozer�ł͂���BTB���g���Ăǂ�ǂ�Ɨ\�����������̖��߂�ǂݏo���Ă���B
���߃t�F�b�`�Ǝ��s�����邱�̂悤�ȕ����͒������͖������A
Bulldozer�ł�512�G���g����1��BTB��5K�G���g����2��BTB�����Ƃ����\�����Ƃ�A
�����q�b�g�������������e�ʂƁA�����A�N�Z�X�𗼗������Ă���B
�܂��A1��BTB�̃q�b�g���͂��Ȃ荂���Ǝv����̂ŁA�啔���̃P�[�X�ł�2��BTB�͓������A
����2�K�w�\���͏���d�͂̓_�ł��L���ł���Ǝv����B
�Ȃ��A������BTB��2�̃X���b�h�ŋ��L����Ă���A���߃L���b�V������f�R�[�_�܂ł�
�e���j�b�g�̓T�C�N�����Ƃɂǂ���̃X���b�h�̖��߂��������邩���ւ��Ă���B
�A
2���L���b�V����16Way�ŋ��͂ȃf�[�^�v���t�F�b�`�@�\������Ă���B
�������A�N�Z�X�����̔Ԓn����(�X�g���C�h)�ɂȂ��Ă��邱�Ƃ����o���āA
���肵�Ď��̔Ԓn���v���t�F�b�`����@�\�����v���Z�T�͑������A
Bulldozer�̃v���t�F�b�`�@�\�́A���̂悤�ȃX�g���C�h�ɂ��Ă��n��X�g���C�h�T�C�Y��
�g�債�Ă��邾���ł͂Ȃ��A��Q�̃������A�N�Z�X���֘A�����肻���ȏꍇ��
�X�g���C�h�Ŗ����P�[�X���\�����s���ăv���t�F�b�`���s���Ƃ����B
��ʂ̃}���`�X���b�h�v���Z�T�̏ꍇ�́A�������A�N�Z�X�҂��Ŏ��s���~�܂����X���b�h��
��ɂ��ĕʃX���b�h�ɐ�ւ��Ď��s����R�A�͗V�Ȃ����ABulldozer�ł�
�����R�A��V���Ȃ����߂ɂ̓L���b�V���~�X�����炷�v���t�F�b�`�̐��x���グ�邱�Ƃ�
�d�v�ɂȂ�̂ŁA�v���t�F�b�`�@�\���撣��̂͗����ł���A�v���[�`�ł���B
�B
����܂ł�Opteron������������̃f�[�^��1���L���b�V���ɓ���A1���L���b�V����
�ǂ��o���ꂽ�f�[�^��2���L���b�V���ɓ����r�N�e�B���L���b�V���������g���Ă����̂ɑ��āA
Bulldozer�ł̓���������̃f�[�^��2���L���b�V���ɓ���A�����1���L���b�V���ɓ����Ƃ���
�C���N���[�W�����L���b�V���ɕύX���ꂽ�B
�m���C���C���N���[�W�����̌��݂̕����ł́A���R�A����̃X�k�[�v�v���ɑ��Ă�
1���A2���̗����̃L���b�V���̃^�O���X�k�[�v����K�v�����邪�A�C���N���[�W�����ɂ����
2���L���b�V���̃^�O�̃X�k�[�v�����ōςށB�܂��A�C���N���[�W���������̕���
�L���b�V���Ԃ̃L���b�V�����C���̈ړ������Ȃ��A�S�̂Ƃ��ď���d�͂����Ȃ��Ƃ����B
���ɂ������d�v��
����ʂ̃}���`�X���b�h�v���Z�T�̏ꍇ�́A�������A�N�Z�X�҂��Ŏ��s���~�܂����X���b�h��
����ɂ��ĕʃX���b�h�ɐ�ւ��Ď��s����R�A�͗V�Ȃ����ABulldozer�ł�
�������R�A��V���Ȃ����߂ɂ̓L���b�V���~�X�����炷�v���t�F�b�`�̐��x���グ�邱�Ƃ�
���d�v�ɂȂ�̂ŁA�v���t�F�b�`�@�\���撣��̂͗����ł���A�v���[�`�ł���B
�N�Ƃ͌���Ȃ�����SMT�Ƃ͎v�z���S�R�Ⴄ���猩���Ⴂ�̔ᔻ�����Ă��d���Ȃ���ȁE�E�E
����ʂ̃}���`�X���b�h�v���Z�T�̏ꍇ�́A�������A�N�Z�X�҂��Ŏ��s���~�܂����X���b�h��
����ɂ��ĕʃX���b�h�ɐ�ւ��Ď��s����R�A�͗V�Ȃ����ABulldozer�ł�
�������R�A��V���Ȃ����߂ɂ̓L���b�V���~�X�����炷�v���t�F�b�`�̐��x���グ�邱�Ƃ�
���d�v�ɂȂ�̂ŁA�v���t�F�b�`�@�\���撣��̂͗����ł���A�v���[�`�ł���B
�N�Ƃ͌���Ȃ�����SMT�Ƃ͎v�z���S�R�Ⴄ���猩���Ⴂ�̔ᔻ�����Ă��d���Ȃ���ȁE�E�E
>>423
����Core 2��Nehalem�̋����_�̈�B
SMT�͂����܂Ń��X�N�w�b�W�ł����āA���ꂾ���Ń������A�N�Z�X���\���J�o�[���Ă���킯�ł͂Ȃ��B
�ނ���A�L���b�V���~�X���A���I�ɋN���ăL���[�̏�������邾���ł����[�h�E�X�g�A���j�b�g���~�܂��Ă��܂��̂ŁA
�����ăL���b�V���~�X���������킯�ł͂Ȃ��B
���������Ӗ��ł̓��[�h�E�X�g�A���j�b�g��2�X���b�h�ŋ��L����SMT�ɂ����d�v�ȃA�v���[�`�B
�������������Bulldozer�����n�߂����݂ł��邩�̂悤�Ɍ����̂��@���ȕ����ƁB
����Core 2��Nehalem�̋����_�̈�B
SMT�͂����܂Ń��X�N�w�b�W�ł����āA���ꂾ���Ń������A�N�Z�X���\���J�o�[���Ă���킯�ł͂Ȃ��B
�ނ���A�L���b�V���~�X���A���I�ɋN���ăL���[�̏�������邾���ł����[�h�E�X�g�A���j�b�g���~�܂��Ă��܂��̂ŁA
�����ăL���b�V���~�X���������킯�ł͂Ȃ��B
���������Ӗ��ł̓��[�h�E�X�g�A���j�b�g��2�X���b�h�ŋ��L����SMT�ɂ����d�v�ȃA�v���[�`�B
�������������Bulldozer�����n�߂����݂ł��邩�̂悤�Ɍ����̂��@���ȕ����ƁB
���̐l�Ȃ�A�Q��܂Œ���t���ċN���Ă�������t����Ƃɓ�����
����ጻ��̂ǂ�CPU�ł��L���b�V���~�X���������̂͊�{�I�ȃ|�C���g����H
������ǂ�����Ď�������̂��A�v���[�`���Ⴄ���Ęb�Ȃ̂��ȉ����Ȃ��ł���
�iBulldozer�̏ꍇ�͂��̎�����N���e�B�J���ɂȂ邩�狭�����Ă�A�Ƃ����b�����j
������ǂ�����Ď�������̂��A�v���[�`���Ⴄ���Ęb�Ȃ̂��ȉ����Ȃ��ł���
�iBulldozer�̏ꍇ�͂��̎�����N���e�B�J���ɂȂ邩�狭�����Ă�A�Ƃ����b�����j
> �iBulldozer�̏ꍇ�͂��̎�����N���e�B�J���ɂȂ邩�狭�����Ă�A�Ƃ����b�����j
�����ƉŁBBulldozer�������N���e�B�J���Ȃ킯�ł͂Ȃ����ABulldozer���������P����Ƃ��Ă�킯�ł��Ȃ��B
�����ƉŁBBulldozer�������N���e�B�J���Ȃ킯�ł͂Ȃ����ABulldozer���������P����Ƃ��Ă�킯�ł��Ȃ��B
���⑼��CPU�����P������ĂȂ��Ȃ�Ĉꌾ�������ĂȂ����A�����A�v���[�`���Ⴄ���Č����Ă邾����
�����SMT�𗘗p���Ȃ�����X�g�[������Ɓ`�ƌ����Ă��̂͒c�q�����g�Ǝv���̂����E�E�E
�����SMT�𗘗p���Ȃ�����X�g�[������Ɓ`�ƌ����Ă��̂͒c�q�����g�Ǝv���̂����E�E�E
�l�N�X�g���C���t�F�b�`�Ƃ�
���f�[�^���K�v�ȃ��C���̂��̎��̃��C����
�߂������ɕK�v�ɂȂ�\���������Ƃ��Ă��炩���ߓǂ�ł�������
�����C���̃f�[�^�͌����C���قǂł͂Ȃ����߂������Ɏg����\���͍������낤
������1�X���b�h�ŃL���b�V�����L���Ă��Ȃ疳���ŗL�p�ȋ@�\���낤��
�����C�������邽�߂ɕʃX���b�h�̌����C����ǂ��o���Ă�悤�ł͒P�Ȃ�n��
���̕ӂ����܂��o����������o���Ȃ����炱����L�L���b�V�������Ě�����Ă���낤
>423�̕ӂ�Ɋւ��Ă�
�������҂��ŏ������~�܂�̂̓S�~Atom�̂悤�ȃC���I�[�_��
�ˑ����L�c���đ��ɕ���ő��点���鏈�����������̂�
�A�E�g�I�u�I�[�_��SMT�ƈႢ���X���b�h�ł����������Ƃ�����@�\
���f�[�^���K�v�ȃ��C���̂��̎��̃��C����
�߂������ɕK�v�ɂȂ�\���������Ƃ��Ă��炩���ߓǂ�ł�������
�����C���̃f�[�^�͌����C���قǂł͂Ȃ����߂������Ɏg����\���͍������낤
������1�X���b�h�ŃL���b�V�����L���Ă��Ȃ疳���ŗL�p�ȋ@�\���낤��
�����C�������邽�߂ɕʃX���b�h�̌����C����ǂ��o���Ă�悤�ł͒P�Ȃ�n��
���̕ӂ����܂��o����������o���Ȃ����炱����L�L���b�V�������Ě�����Ă���낤
>423�̕ӂ�Ɋւ��Ă�
�������҂��ŏ������~�܂�̂̓S�~Atom�̂悤�ȃC���I�[�_��
�ˑ����L�c���đ��ɕ���ő��点���鏈�����������̂�
�A�E�g�I�u�I�[�_��SMT�ƈႢ���X���b�h�ł����������Ƃ�����@�\
>>428
Nehalem�̓��[�h�E�X�g�A���j�b�g�����L1�����L�ł��邪�́AL1�L���b�V���~�X�ŋl�܂�����
�����̃X���b�h���X�g�[������ꍇ�����邪�ABulldozer��L1D�ELSU���Ɨ��ł��邪�́A
�Е��̃R�A���l�܂��Ă������Е��͐����Ă��邾��B
���_����肽���Ȃ炻�������A�v���[�`����U�߂��ق����������B
�i�����Ƃ��A���ׂɉ�����2�X���b�h�̊��蓖�Ă�ς�����A1�X���b�h�Ő�L�ł���Nehalem��L1D����
way���E�e�ʂ��̂��̂����Ȃ�Bulldoze�̂��ꂱ���X���b�V���O�̕p�x�͍����\���͂��邯�ǂˁj
>>422��Yonah��5�N����ɂ���Ă邱�Ƃ̃g���[�X�����ȁB
�܂�Yonah�ȍ~��Intel�A�[�L�̌�ǂ������獡�܂ł��������A�Ƃ�������̂��B
�V�K�J����4�`5�N������͓̂�����O�����B
�܂�ʂɐV�K���̂��邱�Ƃ�����Ă�킯�ł͂Ȃ��B
Nehalem�̓��[�h�E�X�g�A���j�b�g�����L1�����L�ł��邪�́AL1�L���b�V���~�X�ŋl�܂�����
�����̃X���b�h���X�g�[������ꍇ�����邪�ABulldozer��L1D�ELSU���Ɨ��ł��邪�́A
�Е��̃R�A���l�܂��Ă������Е��͐����Ă��邾��B
���_����肽���Ȃ炻�������A�v���[�`����U�߂��ق����������B
�i�����Ƃ��A���ׂɉ�����2�X���b�h�̊��蓖�Ă�ς�����A1�X���b�h�Ő�L�ł���Nehalem��L1D����
way���E�e�ʂ��̂��̂����Ȃ�Bulldoze�̂��ꂱ���X���b�V���O�̕p�x�͍����\���͂��邯�ǂˁj
>>422��Yonah��5�N����ɂ���Ă邱�Ƃ̃g���[�X�����ȁB
�܂�Yonah�ȍ~��Intel�A�[�L�̌�ǂ������獡�܂ł��������A�Ƃ�������̂��B
�V�K�J����4�`5�N������͓̂�����O�����B
�܂�ʂɐV�K���̂��邱�Ƃ�����Ă�킯�ł͂Ȃ��B
> �����SMT�𗘗p���Ȃ�����X�g�[������Ɓ`
Nehalem�̃A�v���[�`�Ȃ�L1�L���b�V���~�X�܂łȂ�A�܂��X���b�h��ւ��ŃJ�o�[�ł��邪
L2��艺�̃L���b�V���~�X�͑҂����Ԃ��������ė����̃X���b�h���~�܂郊�X�N������B
���[�h�E�X�g�A�̃L���[�̓X���b�h���Ƃɕ�����ĂȂ����炾�B
Nehalem�̃A�v���[�`�Ȃ�L1�L���b�V���~�X�܂łȂ�A�܂��X���b�h��ւ��ŃJ�o�[�ł��邪
L2��艺�̃L���b�V���~�X�͑҂����Ԃ��������ė����̃X���b�h���~�܂郊�X�N������B
���[�h�E�X�g�A�̃L���[�̓X���b�h���Ƃɕ�����ĂȂ����炾�B
>>430
�����ƁANehalem��L1D��32KB/8way�ŁABulldozer��L1D(/per IntCore)��16KB/4way�ł����
���Ƃ�������Victim��Inclusion�̂��Ƃ͐̂��猾���Ă�̂ł��ꂭ�炢�͔c�����Ă܂���H
�Ȃ���������s���g���Y���Ă�݂����ł����AIntel/AMD�̂ǂ������D��Ă�Ƃ����b�͂��Ă܂���
�c�q���͔��Ƀ~�N���ȃ|�C���g�ɂ���t�H�[�J�X���Ăǂ�������i��j���̉��i��ǂ��j���̌����Ă܂���
����Ȃ̂������Ă��s�тł����d���Ȃ��Ǝv���܂���B�v�͗g�������ȏ�̉����ł��Ȃ��̂�
����������Ƒ��l�ƌ��ݓI�ȋc�_�E�ӌ����������ׂ��ł͂Ȃ��ł��傤���B
�����ƁANehalem��L1D��32KB/8way�ŁABulldozer��L1D(/per IntCore)��16KB/4way�ł����
���Ƃ�������Victim��Inclusion�̂��Ƃ͐̂��猾���Ă�̂ł��ꂭ�炢�͔c�����Ă܂���H
�Ȃ���������s���g���Y���Ă�݂����ł����AIntel/AMD�̂ǂ������D��Ă�Ƃ����b�͂��Ă܂���
�c�q���͔��Ƀ~�N���ȃ|�C���g�ɂ���t�H�[�J�X���Ăǂ�������i��j���̉��i��ǂ��j���̌����Ă܂���
����Ȃ̂������Ă��s�тł����d���Ȃ��Ǝv���܂���B�v�͗g�������ȏ�̉����ł��Ȃ��̂�
����������Ƒ��l�ƌ��ݓI�ȋc�_�E�ӌ����������ׂ��ł͂Ȃ��ł��傤���B
�c�q�Ɍ��ݓI�Ȉӌ������߂Ă����ʂ�����
���_���肫�Ȃ���AAMD��@���������ė��R�̂Ȃ�
���_���肫�Ȃ���AAMD��@���������ė��R�̂Ȃ�
��ʂ��撣��Ȃ�
���̊C�O�ݏZ�̒c�q��
PC Watch�̋L����S���ǂ��
�����̓s���̗ǂ������������o�������_��ȉ���W�J
���Ă邾���ɂ����݂��Ȃ�
���̊C�O�ݏZ�̒c�q��
PC Watch�̋L����S���ǂ��
�����̓s���̗ǂ������������o�������_��ȉ���W�J
���Ă邾���ɂ����݂��Ȃ�
�s�т��z���Ɍ�������
����ƃY���Ă�̂̓s���g����Ȃ��ăY���Ɣ]�V�i�v�X
��L1�����L�ł��邪�́AL1�L���b�V���~�X�ŋl�܂�����
�������̃X���b�h���X�g�[������
���ς�L1��1way���H
�Е��̃X���b�h�̂��߂̃f�[�^�ŋ��L�L���b�V�������܂邾�Ȃ��
����������f�����b�g��荓����
���������A�v���[�`����U�߂Ă��S���_���[�W�����̂�
�����̂��Ƃ���������̂ł͂���
����ƃY���Ă�̂̓s���g����Ȃ��ăY���Ɣ]�V�i�v�X
��L1�����L�ł��邪�́AL1�L���b�V���~�X�ŋl�܂�����
�������̃X���b�h���X�g�[������
���ς�L1��1way���H
�Е��̃X���b�h�̂��߂̃f�[�^�ŋ��L�L���b�V�������܂邾�Ȃ��
����������f�����b�g��荓����
���������A�v���[�`����U�߂Ă��S���_���[�W�����̂�
�����̂��Ƃ���������̂ł͂���
�c�q��Intel������X���ł��R�e�O���Ă�̂���āA�r�炵��������Ă�����
�ǂ��ɂ����ꏊ���Ȃ����z�Ȃ��
�܂��A���Ǝ��������ǂ�
�ǂ��ɂ����ꏊ���Ȃ����z�Ȃ��
�܂��A���Ǝ��������ǂ�
�ז�������c�q��NG�ɂ��Ƃ���
>>206
>���_
>K10�@K9�̓N���b�N�����萫�\�̗B
>�u���X�N�B���y����Đ��Ō��p�N�ɂȂ�o�O�B
>�n�f�W�L���v�`���[���ڊ��ł́A
>���肵���Đ��@�^��@�ҏW���A�M�����̖����A
>���[�J�[�f�X�N�g�b�vPC�B�m�[�g��AMD���̗p�������������R
>�n�f�W���ڂƓ���A�f�����C���̑�^�t���Z�b�gPC���A
>���Ƀ��[�J�[�l���猙����̗p�ɂȂ����B
4�R�A��iC'n'Q�L���ŕ���1080p�����CPU�Đ�����A�Đ��ŏ��J�N�c�N����ȁB
�f�[�^�j����APC�������Ȃ����ǁA
�d��ő�ςȌ��ׂ���B
C'n'Q��800MHz�ȂC���e������500�`600MHz����������
�����Ȃ�ˁB
�����Ȃ��ǁA�A�C�h�����̏���d�͉�����������A
����Đ��A�n�f�W�ABD�Đ��ōŏ��J�N�c�L�A���p�N���A���Y����
���u���Ă���A���[�J�[�ɍ̗p����锤�Ȃ���ȁB
���́A���̂悤�ȏX�Ԃ��炳�Ȃ����h��CPU�ɂ��Ă�������!!
>���_
>K10�@K9�̓N���b�N�����萫�\�̗B
>�u���X�N�B���y����Đ��Ō��p�N�ɂȂ�o�O�B
>�n�f�W�L���v�`���[���ڊ��ł́A
>���肵���Đ��@�^��@�ҏW���A�M�����̖����A
>���[�J�[�f�X�N�g�b�vPC�B�m�[�g��AMD���̗p�������������R
>�n�f�W���ڂƓ���A�f�����C���̑�^�t���Z�b�gPC���A
>���Ƀ��[�J�[�l���猙����̗p�ɂȂ����B
4�R�A��iC'n'Q�L���ŕ���1080p�����CPU�Đ�����A�Đ��ŏ��J�N�c�N����ȁB
�f�[�^�j����APC�������Ȃ����ǁA
�d��ő�ςȌ��ׂ���B
C'n'Q��800MHz�ȂC���e������500�`600MHz����������
�����Ȃ�ˁB
�����Ȃ��ǁA�A�C�h�����̏���d�͉�����������A
����Đ��A�n�f�W�ABD�Đ��ōŏ��J�N�c�L�A���p�N���A���Y����
���u���Ă���A���[�J�[�ɍ̗p����锤�Ȃ���ȁB
���́A���̂悤�ȏX�Ԃ��炳�Ȃ����h��CPU�ɂ��Ă�������!!
�㓡���ԈႦ�Ă��Ȃ��̂Ȃ��
50%�A80%��Bull�V���O���R�A�ɑ��鑝���Ƃ����ǂ߂Ȃ���
100% > 150% ���\�[�X
100% > 180% �p�t�H�[�}���X
���ƁASSE���X�P�W���[����ɑ���128bit���Z���Ƃ����̂�
�ǂ��g�����Ȃ��̂��B2�X���b�h��128bit������~���������Ƃ���
���������ɓ��삷��قǃX�P�W���[���͌����̂��ǂ����B
AVX���߂̎���1�X���b�h�����������ł��Ȃ��̂͂͂����肵�Ă��邯��
50%�A80%��Bull�V���O���R�A�ɑ��鑝���Ƃ����ǂ߂Ȃ���
100% > 150% ���\�[�X
100% > 180% �p�t�H�[�}���X
���ƁASSE���X�P�W���[����ɑ���128bit���Z���Ƃ����̂�
�ǂ��g�����Ȃ��̂��B2�X���b�h��128bit������~���������Ƃ���
���������ɓ��삷��قǃX�P�W���[���͌����̂��ǂ����B
AVX���߂̎���1�X���b�h�����������ł��Ȃ��̂͂͂����肵�Ă��邯��
>>439
������Ȃ�ł�FP�X�P�W���[���[������Ȃ��o�J�Ȃ킯�Ȃ�����
������Ȃ�ł�FP�X�P�W���[���[������Ȃ��o�J�Ȃ킯�Ȃ�����
��������ASIMD���j�b�g���Ă��鎞��1�X���b�h��2��SIMD���j�b�g���g����̂��m�肽��
SIMD��SMT�œ����̂�AVX���p�����肶��Ȃ��́E
1�X���b�h��256bit �������߁A1�X���b�h��256bit ���������_�����߂ł�
�������s�\�Ȃ̂��Ȃ�
4�̉��Z������y�[�X�Ńf�[�^�����ł���H
�������s�\�Ȃ̂��Ȃ�
4�̉��Z������y�[�X�Ńf�[�^�����ł���H
����ᔭ�s��̉��Z�킪�ĂȂ���Е����X�g�[�����邾���ł���BSMT�Ȃ���B
int ��float �͓Ɨ����Ă��邩�瓯���ɗ���256bit ���Z��
int ��float �Ȃ牉�Z��͑����A�ł�512bit ���f�[�^������A���ł���
�����f�[�^�p�X�ɂ����������A�Ƃ����^��Ȃ̂���
int ��float �Ȃ牉�Z��͑����A�ł�512bit ���f�[�^������A���ł���
�����f�[�^�p�X�ɂ����������A�Ƃ����^��Ȃ̂���
256bit����Bull�̃x�N�^�̑S������
>>432
�����������Ȃ��悤���ȁB
x86�Ƃ����̂�destructive���B�����ȈӖ��łȁB
������destructive�Ɍ�낤���B
���ǂ̂Ƃ���ABulldozer�ō̗p����Ă��铊�@�I�ȃL���b�V����ǂ݂́A
Intel�ł�Core 2�����肩��{�i�I�Ɏg���͂���Nehalem�ł͍X�ɋ�������Ă���B
�P�DNehalem�̏ꍇ
�V���O���X���b�h�̐��\���グ��i�L���b�V���~�X�ɂ�鐫�\�ቺ��}�~����j�ׂɎg���Ă���B
HT���L���ł��낤�ƂȂ��낤�Ɛ��\����ɗL��������B
���̓_��SMT�͕ی��I�ɓ����Ă���ɉ߂��Ȃ����A��ǂ݂��O�ꂽ�ꍇ�ɂ́A�X�g�[�����ɕЕ��̃R�A�ɃR�A�̃��\�[�X��
�قڑS�Ė����n���邱�Ƃ͂�����x���X�N�w�b�W�Ƃ��Ă͍�p������B
�������A�L���b�V���~�X���̌����߂ɕʂ̃X���b�h�𑖂点�邱�ƂŃg�[�^���X���[�v�b�g���グ����̂́A
CGMT�ɂ��Hyper-Threading���̗p����Itanium 2�ł�������Ă���B
�Q�DBulldozer�̏ꍇ
�L���b�V���~�X������e�����N���X�^�����S�ɗV�Ԃ̂ŁA�L���b�V���~�X�̌y������ׂ̋Z�p��
�}���`�X���b�h�̐��\���グ��̂ɂ���K�v�ɂȂ��Ă���B
�K�v�ɂȂ闝�R����Ⴄ�����ŁA�{���I�ɂ͓����Z�p���g���Ă���B
�悤����Ɍ����������Ƃ́ANehalem��2�i�\���Ńg�[�^���X���[�v�b�g����Ɏ��g��ł���̂ɑ���
Bulldozer�͓��@�Ɏ��s����ƃp�t�H�[�}���X�̑�������N�����낤���������Ă���Ƃ������ƁB
���ƁA�������Nehalem�łǂ����̃X���b�h���~�܂�(>>431)���Ă̂̓L���b�V���~�X���A�������ꍇ�̃��[�X�g�P�[�X�̘b��
���ϓI�ȃ��[�N���[�h�ŕp�����郌�x���̘b�ł͂Ȃ��B
�����A���[�h�E�X�g�A�L���[�̃G���g�����𑝂₷�Ȃǂ̕����ŁA2�X���b�h�Ƃ��X�g�[�����鎖�Ԃ������������
Prescott�̒i�K�ł��s���Ă��邵�ANehalem�͌��킸�����ȁB
�����������Ȃ��悤���ȁB
x86�Ƃ����̂�destructive���B�����ȈӖ��łȁB
������destructive�Ɍ�낤���B
���ǂ̂Ƃ���ABulldozer�ō̗p����Ă��铊�@�I�ȃL���b�V����ǂ݂́A
Intel�ł�Core 2�����肩��{�i�I�Ɏg���͂���Nehalem�ł͍X�ɋ�������Ă���B
�P�DNehalem�̏ꍇ
�V���O���X���b�h�̐��\���グ��i�L���b�V���~�X�ɂ�鐫�\�ቺ��}�~����j�ׂɎg���Ă���B
HT���L���ł��낤�ƂȂ��낤�Ɛ��\����ɗL��������B
���̓_��SMT�͕ی��I�ɓ����Ă���ɉ߂��Ȃ����A��ǂ݂��O�ꂽ�ꍇ�ɂ́A�X�g�[�����ɕЕ��̃R�A�ɃR�A�̃��\�[�X��
�قڑS�Ė����n���邱�Ƃ͂�����x���X�N�w�b�W�Ƃ��Ă͍�p������B
�������A�L���b�V���~�X���̌����߂ɕʂ̃X���b�h�𑖂点�邱�ƂŃg�[�^���X���[�v�b�g���グ����̂́A
CGMT�ɂ��Hyper-Threading���̗p����Itanium 2�ł�������Ă���B
�Q�DBulldozer�̏ꍇ
�L���b�V���~�X������e�����N���X�^�����S�ɗV�Ԃ̂ŁA�L���b�V���~�X�̌y������ׂ̋Z�p��
�}���`�X���b�h�̐��\���グ��̂ɂ���K�v�ɂȂ��Ă���B
�K�v�ɂȂ闝�R����Ⴄ�����ŁA�{���I�ɂ͓����Z�p���g���Ă���B
�悤����Ɍ����������Ƃ́ANehalem��2�i�\���Ńg�[�^���X���[�v�b�g����Ɏ��g��ł���̂ɑ���
Bulldozer�͓��@�Ɏ��s����ƃp�t�H�[�}���X�̑�������N�����낤���������Ă���Ƃ������ƁB
���ƁA�������Nehalem�łǂ����̃X���b�h���~�܂�(>>431)���Ă̂̓L���b�V���~�X���A�������ꍇ�̃��[�X�g�P�[�X�̘b��
���ϓI�ȃ��[�N���[�h�ŕp�����郌�x���̘b�ł͂Ȃ��B
�����A���[�h�E�X�g�A�L���[�̃G���g�����𑝂₷�Ȃǂ̕����ŁA2�X���b�h�Ƃ��X�g�[�����鎖�Ԃ������������
Prescott�̒i�K�ł��s���Ă��邵�ANehalem�͌��킸�����ȁB
�����ɔn������˂��̂������E�E�E
Llano����AES-Ni�Ƃ��t���Ă�́H
Llano�͂��납Interlagos�ɂ��ڂ�܂���
���_�O��N�̒������܂��n�܂����B
2ALU�̃R�A��SMT�Ȃ�ėv���ł���
�����ƃ��\�[�X�������R�A�Ȃ瑊�ΓI�ɂ�SMT�̗p�̃����b�g�͑傫�����낤����
�����ƃ��\�[�X�������R�A�Ȃ瑊�ΓI�ɂ�SMT�̗p�̃����b�g�͑傫�����낤����
Bull4���W���[����SMT���g����16�X���b�h�������s�Ƃ������Ă���ʌ�������قڈӖ��Ȃ�����
>>455
1�X���b�h�����������ꍇ�A2ALU��2AGU�Ƃ������Z���\�[�X��4���߃f�R�[�h�ɑ��đÓ����ǂ����B
2�X���b�h�������Ă�1���W���[��������4����/clk�ɔ�����B
���Ȃ݂ɓ����ғ��ł��鉉�Z���j�b�g�̃|�[�g�������Ȃ�K10��Nehalem��1.5�{�ł��B
1�X���b�h�����������ꍇ�A2ALU��2AGU�Ƃ������Z���\�[�X��4���߃f�R�[�h�ɑ��đÓ����ǂ����B
2�X���b�h�������Ă�1���W���[��������4����/clk�ɔ�����B
���Ȃ݂ɓ����ғ��ł��鉉�Z���j�b�g�̃|�[�g�������Ȃ�K10��Nehalem��1.5�{�ł��B
Bull��Bob���A�E�g�I�u�I�[�_�����邩��SMT�v��Ȃ�
GPU���C���I�[�_�����ŏ[��SMT�v��Ȃ�
Atom�͂ǂ�����Ă��S�~������SMT�v��Ȃ�
GPU���C���I�[�_�����ŏ[��SMT�v��Ȃ�
Atom�͂ǂ�����Ă��S�~������SMT�v��Ȃ�
> Bull4���W���[����SMT���g����16�X���b�h�������s�Ƃ������Ă���ʌ�������قڈӖ��Ȃ�����
��������H
Bull4���W���[����SMT���g����8�X���b�h(8�R�A)�ғ����Ă���̂ł���B�������Ă��������ȁB
��������H
Bull4���W���[����SMT���g����8�X���b�h(8�R�A)�ғ����Ă���̂ł���B�������Ă��������ȁB
460 �FSocket774�F2010/08/28(�y) 15:36:43 ID:vXP1LtHu
Intel4�R�A8�X���b�h��AMD4���W���[��8�R�A
����Intel�ɂ�6�R�A12�X���b�h��8�R�A16�X���b�h���ڂ�LGA1356���܂����邩���
AMD�̓}�W�ł���ɂ��邾�낤
���\��Intel�ɑS���ǂ����Ȃ������N�ȍ~�������E�E�E
����Intel�ɂ�6�R�A12�X���b�h��8�R�A16�X���b�h���ڂ�LGA1356���܂����邩���
AMD�̓}�W�ł���ɂ��邾�낤
���\��Intel�ɑS���ǂ����Ȃ������N�ȍ~�������E�E�E
>>460
MCM�ł��������������b�����c�B
MCM�ł��������������b�����c�B
�܂������͎������Ȃ��Ƃ킩��Ȃ����ǁA�����_�Ō����邱��
2�X���b�h���v��ALU4�����CoreMA��3���葽���I����ŏ���I
���@x86�̈�ʓI�ȃR�[�h�ł͔ėpALU���g��Ȃ����߂̏o���p�x��2�`3���Ȃ̂�
�@���̓f�R�[�_�Ɠ����̔ėpALU��S�ĉғ��ł���P�[�X�̂ق����H
Load/Store�̍��v���ŏ���I
���@��ʓI�ɂ�Load�̕p�x��4�`5���߂�1��AStore��20���߂�1����x
�悤����Ƀ}���`�X���b�h�ł���Bulldozer���L�����Ƃ͎v���ĂȂ����Ă��Ƃł��B
���ƃL���b�V���̍\���Ƃ��͂��낢����Ȃ̂ł�߂Ƃ����B
>>461
Xeon�ł���12�R�A24�X���b�h�Ƃ�16�R�A32�X���b�h���\���Ă��Ƃ���ˁi�ɂ�����
���Ƃ���Intel����s���ĂāA�g����̂Ɋ����Ďg��Ȃ��J�[�h�ł��ȁB
�iAtom�Ƃ�32nm i3/i5�Ō����Ŏg���Ă邯�ǁj
2�X���b�h���v��ALU4�����CoreMA��3���葽���I����ŏ���I
���@x86�̈�ʓI�ȃR�[�h�ł͔ėpALU���g��Ȃ����߂̏o���p�x��2�`3���Ȃ̂�
�@���̓f�R�[�_�Ɠ����̔ėpALU��S�ĉғ��ł���P�[�X�̂ق����H
Load/Store�̍��v���ŏ���I
���@��ʓI�ɂ�Load�̕p�x��4�`5���߂�1��AStore��20���߂�1����x
�悤����Ƀ}���`�X���b�h�ł���Bulldozer���L�����Ƃ͎v���ĂȂ����Ă��Ƃł��B
���ƃL���b�V���̍\���Ƃ��͂��낢����Ȃ̂ł�߂Ƃ����B
>>461
Xeon�ł���12�R�A24�X���b�h�Ƃ�16�R�A32�X���b�h���\���Ă��Ƃ���ˁi�ɂ�����
���Ƃ���Intel����s���ĂāA�g����̂Ɋ����Ďg��Ȃ��J�[�h�ł��ȁB
�iAtom�Ƃ�32nm i3/i5�Ō����Ŏg���Ă邯�ǁj
�����͎����̃E���R20kg���H�����I����ŏ�����I���������C�ɒm�\0
�v���t�F�b�`�͖����ɏ[���ł͂Ȃ��L���b�V���̃q�b�g�����グ�邽�߂�
�`�����X�i�A�[�L���W���[�`�F���W�j������ǂ�ǂ���ׂ����Ƃł�����
Bull�ňӐ}�I�ɗ͂���ꂽ�̂͂ނ��땪���̂ق�����Ȃ�����
Bob���p�C�v���C��15�i��Bull���^���邩������Ȃ�
�i���オ��������d�v�ɂȂ�
�v���t�F�b�`�͖����ɏ[���ł͂Ȃ��L���b�V���̃q�b�g�����グ�邽�߂�
�`�����X�i�A�[�L���W���[�`�F���W�j������ǂ�ǂ���ׂ����Ƃł�����
Bull�ňӐ}�I�ɗ͂���ꂽ�̂͂ނ��땪���̂ق�����Ȃ�����
Bob���p�C�v���C��15�i��Bull���^���邩������Ȃ�
�i���オ��������d�v�ɂȂ�
�����̖ϑz�������Ř_�j
���\���͂��Ȃ��̂Ȃ����������������̘b
�m�[�g��T�[�o�����v���Z�b�T�̉��i�̌n�Ȃǂ�����悤���m������������Ȃ�����
�m�[�g��T�[�o�����v���Z�b�T�̉��i�̌n�Ȃǂ�����悤���m������������Ȃ�����
Intel�͎�����Xeon��Westmere-10C�𓊓����Ă���
���A��10�R�A��500�o2�ȏ�A�t�H�g�}�X�N�̏���t�߂̃`�b�v
����ɂ͗��ɏ��Ă�
���A��10�R�A��500�o2�ȏ�A�t�H�g�}�X�N�̏���t�߂̃`�b�v
����ɂ͗��ɏ��Ă�
>>465
�T�[�o�͎������x���d�v�Ȃ̂ŁA�Ƃ��Ƃ\��Nj����邩�A�Ƃ��Ƃ�ȓd�͂�Nj����邩�̂ǂ����������Ȃ��ł��B
�T�[�o�͎������x���d�v�Ȃ̂ŁA�Ƃ��Ƃ\��Nj����邩�A�Ƃ��Ƃ�ȓd�͂�Nj����邩�̂ǂ����������Ȃ��ł��B
���ƁAOpteron6xxx�V���[�Y�͋������S������ĂȂ�
Interlagos�ł����Nj����s���Ɋׂ邾�낤
Interlagos�ł����Nj����s���Ɋׂ邾�낤
�����s���Ƃ�����蔄��Ă��Ȃ������ł́H
���łɌ�����CPU�������������Ƃ���Ńu���[�h1��100����90���ɂȂ���x����Ă��ɐ�
�ڋq��CPU���i������̐��\�ł͂Ȃ��V�X�e�����i������̐��\������B
�����疳�������Ăł��\�P�b�g������̐��\�Œǂ������Ƃ��Ă�킯�B
Intel�ł��g����J�[�h���g���āB
�ڋq��CPU���i������̐��\�ł͂Ȃ��V�X�e�����i������̐��\������B
�����疳�������Ăł��\�P�b�g������̐��\�Œǂ������Ƃ��Ă�킯�B
Intel�ł��g����J�[�h���g���āB
���������j���[�X�͖�����
>>462�͒P�ɓd�g�ȉ��z�I�Ɛ���Ă邾������Ȃ�
���ς�@���Ă�������
�����ƃL���b�V���̍\���Ƃ��́i�G���ȁI��ΐG���ȁI�j
1�X���b�h3ALU�͑��߂����Ƃ���
2�Ɍ��炵�Ă܂��]�T������ƌ��Ă���AMD
�R�A�T�C�Y�ɗ]�T�o�Ă������牽�����₵�Ă݂邩��3ALU�ɂ������̂�
����ς�_�{���Ă����HTT�t���Ĕp�i������悤�Ƃ��Ă���Intel
2�X���b�h4ALU��2�X���b�h3ALU�Ȃ��҂̂ق������ʂ��������Ǝv������
�L���b�V����荇����������1�X���ȉ��ɂ܂Ő��\�ቺ����(?)���Ƃ��l�����
1+�i���܂ɂ���1�j�X���b�h3ALU�̂ق������ʂ��炯�ɂȂ�̂����R�Ȍ��_
�L���b�V�����p�[�c�P�̂̐��\�͗ǂ��̂ɐv���{���J�X��Intel��
�E�������ɍ����Ă�����1���A�I�m��Intel��ᔻ���Ă���
��������Ȃ�
���ς�@���Ă�������
�����ƃL���b�V���̍\���Ƃ��́i�G���ȁI��ΐG���ȁI�j
1�X���b�h3ALU�͑��߂����Ƃ���
2�Ɍ��炵�Ă܂��]�T������ƌ��Ă���AMD
�R�A�T�C�Y�ɗ]�T�o�Ă������牽�����₵�Ă݂邩��3ALU�ɂ������̂�
����ς�_�{���Ă����HTT�t���Ĕp�i������悤�Ƃ��Ă���Intel
2�X���b�h4ALU��2�X���b�h3ALU�Ȃ��҂̂ق������ʂ��������Ǝv������
�L���b�V����荇����������1�X���ȉ��ɂ܂Ő��\�ቺ����(?)���Ƃ��l�����
1+�i���܂ɂ���1�j�X���b�h3ALU�̂ق������ʂ��炯�ɂȂ�̂����R�Ȍ��_
�L���b�V�����p�[�c�P�̂̐��\�͗ǂ��̂ɐv���{���J�X��Intel��
�E�������ɍ����Ă�����1���A�I�m��Intel��ᔻ���Ă���
��������Ȃ�
>>465
>���\���͂��Ȃ��̂Ȃ����������������̘b
���ی����������ǂȁB
����������H���͌����ăl�K�e�B�u�Ȏ���������Ȃ�
����Ƃ̐��ݕ�����
�s�тȘJ�͂��g��Ȃ��Ă��ςނƂ��������b�g������킯�ŁB
�i�Ƃ����킯��Bobcat�ɂ͊��҂��Ă�킯�����j
>���\���͂��Ȃ��̂Ȃ����������������̘b
���ی����������ǂȁB
����������H���͌����ăl�K�e�B�u�Ȏ���������Ȃ�
����Ƃ̐��ݕ�����
�s�тȘJ�͂��g��Ȃ��Ă��ςނƂ��������b�g������킯�ŁB
�i�Ƃ����킯��Bobcat�ɂ͊��҂��Ă�킯�����j
6k�V���[�Y���Ă悤��Istanbul�̒�d���Łi�I�ʕi�j�~�Q�ł���
�����o��킯���Ȃ���B�B
Dell��BTO�ł�2.3GHz�͎̐����I�ɑI���ł��Ȃ������B
MCM�ɂ��R�A��2�{�\�����[�V�����́AIntel�ɃJ�[�h��点�Ȃ��A���肬�蕉���郉�C����
���������E�����A���Ƃ��A���������Ȃ��̂��肬��̊W��ۂ��Ȃ���ׁX��邵���Ȃ��ł���AMD��
TDP65W�̒�d����Xeon2��MCM���������i�o����邾���ŏu�E�B
�����o��킯���Ȃ���B�B
Dell��BTO�ł�2.3GHz�͎̐����I�ɑI���ł��Ȃ������B
MCM�ɂ��R�A��2�{�\�����[�V�����́AIntel�ɃJ�[�h��点�Ȃ��A���肬�蕉���郉�C����
���������E�����A���Ƃ��A���������Ȃ��̂��肬��̊W��ۂ��Ȃ���ׁX��邵���Ȃ��ł���AMD��
TDP65W�̒�d����Xeon2��MCM���������i�o����邾���ŏu�E�B
>>473
�^�����ʂ������Ă���ƋK�͓I�ɏ����ږ�������
�ӊO�ȂƂ���ɈӊO�Ȏs�ꂪ�]�����Ă����
Bobcat�T�[�o�Ȃ͌��\�ʔ����Ƃ���˂����Ȃ�����
�^�����ʂ������Ă���ƋK�͓I�ɏ����ږ�������
�ӊO�ȂƂ���ɈӊO�Ȏs�ꂪ�]�����Ă����
Bobcat�T�[�o�Ȃ͌��\�ʔ����Ƃ���˂����Ȃ�����
�������o����Ȃ�T�[�o�[�p�Ƃ��Ă͑f����Bulldozer�ŗǂ���
����VMmark�̃X�R�A�i4�\�P�b�g�@�j��Xeon�̂�76�i1��30���j�AOpteron��60�i1��10���H�j
���i�����l����Ώ\���ł���
�����Bobcat�T�[�o����낤�Ƃ���Ɠ��R�u���[�h�T�[�o�[�ɂȂ邪
�u���[�h�T�[�o�[�͌���ꂽ��胁�[�J�[�������Ȃ����ߍ��͎������Ă�
�x���`���[��Bobcat�T�[�o���o���̂��낤���ǁA�b��Â���ŏI��邾���ȋC������
����VMmark�̃X�R�A�i4�\�P�b�g�@�j��Xeon�̂�76�i1��30���j�AOpteron��60�i1��10���H�j
���i�����l����Ώ\���ł���
�����Bobcat�T�[�o����낤�Ƃ���Ɠ��R�u���[�h�T�[�o�[�ɂȂ邪
�u���[�h�T�[�o�[�͌���ꂽ��胁�[�J�[�������Ȃ����ߍ��͎������Ă�
�x���`���[��Bobcat�T�[�o���o���̂��낤���ǁA�b��Â���ŏI��邾���ȋC������
CPU�̉��i������ׂĂ��Ӗ����Ȃ��ƌ������T�����\����ktkr
���̗���́g���z�@���ԁh�ł͂Ȃ��g�����ȋ@�̂𐏎��X�V�h����
��������ӂƋC�ɂȂ������ǁA
Bulldozer��RAS���Ăǂ�Ȋ����Ȃ�H
Nehalem�x�[�X��Xeon��Itanium�Ƒ��F�Ȃ����炢�ɋ������ꂽ�炵������
Bulldozer��RAS���Ăǂ�Ȋ����Ȃ�H
Nehalem�x�[�X��Xeon��Itanium�Ƒ��F�Ȃ����炢�ɋ������ꂽ�炵������
CPU���������ւ���̂��H��
��������Intel��Xeon�ł��i�J�e�S���[�͈Ⴄ���ǂˁj�A
�����Ȑ��\��Nehalem-8C��Westmere-6C�����邪
Nehalem-8C�͏��ƃx�[�X�ɏ���Ă��Ȃ�
�����Ȑ��\��Nehalem-8C��Westmere-6C�����邪
Nehalem-8C�͏��ƃx�[�X�ɏ���Ă��Ȃ�
Bulldozer��PC�p�`�b�v�Ƌ��p�ł���
���C���t���[���̎d�l�ɑς�����悤�ȐM������^����͖̂������낤
�����������C���t���[������̓T�[�r�X�Ƃɂ܂œ��ݍ��܂Ȃ��Ⴂ���Ȃ�����
AMD�P�Ƃł͗Ⴆ�M�����̍����`�b�v��������Ƃ���œ��荞�ޗ]�n�͖���
���C���t���[���̎d�l�ɑς�����悤�ȐM������^����͖̂������낤
�����������C���t���[������̓T�[�r�X�Ƃɂ܂œ��ݍ��܂Ȃ��Ⴂ���Ȃ�����
AMD�P�Ƃł͗Ⴆ�M�����̍����`�b�v��������Ƃ���œ��荞�ޗ]�n�͖���
�������Ƃ��߂��Ⴍ���Ⴗ���ď������Ȃ�
�������Ƃ��߂��Ⴍ���Ⴗ���ď������Ȃ�
�c�q�������邱�Ƃ���Ȃ���Ȃ�
�����Ƀu�[�������ɂȂ��Ă�̂������ł��Ȃ��̂��A���̃A�z�͂�
�c�q�������邱�Ƃ���Ȃ���Ȃ�
�����Ƀu�[�������ɂȂ��Ă�̂������ł��Ȃ��̂��A���̃A�z�͂�
Nehalem�����ƃx�[�X�ɍڂ��ĂȂ��Ƃ�
4�\�POpteron�����M�����T�[�o�Ɍ����ĂȂ��Ƃ�
�킩���Ă�Ȃ�ŏ������ׂ�Ȃ��Ă���
4�\�POpteron�����M�����T�[�o�Ɍ����ĂȂ��Ƃ�
�킩���Ă�Ȃ�ŏ������ׂ�Ȃ��Ă���
������ł��������Ⴍ���ኚ�܂�Ă���l������
�����̏Z�l�̓L���|���̂��܂�������Ȃ����Ƃ������
�����̏Z�l�̓L���|���̂��܂�������Ȃ����Ƃ������
>>484
���F�́A�A�M�҂ł����Ȃ�����ȁB
�n�[�h�ł�����������悤�Ȏ���I�^�Ƃ͈���āA
���[�J�[���x�ŃG���N�g����A���͑��e��Ȃ��B
���F�́A�A�M�҂ł����Ȃ�����ȁB
�n�[�h�ł�����������悤�Ȏ���I�^�Ƃ͈���āA
���[�J�[���x�ŃG���N�g����A���͑��e��Ȃ��B
�y����PC�zIntel SandyBridge�v���r���[�@�~�h�������W��i7 980X/HD5450�ɑ���
http://kamome.2ch.net/test/read.cgi/news/1282980453/
http://kamome.2ch.net/test/read.cgi/news/1282980453/
>>488
���[�B�Ȃ��Ȃ��y�������Ɏd�グ�Ă����ȁB
"Llano"��GPU���\���R����肠����x�������A
�ȓd�͖ʂŗL���ł��Ȃ��Ɣ߂������ʂɂȂ肻������
���[�B�Ȃ��Ȃ��y�������Ɏd�グ�Ă����ȁB
"Llano"��GPU���\���R����肠����x�������A
�ȓd�͖ʂŗL���ł��Ȃ��Ɣ߂������ʂɂȂ肻������
�܂��ɖ@�������ł���
����Bull��AM3�ȑO�ɍڂ�Ȃ��̂�
�I�p��G34/C32�ɍڂ邭���ɈӖ��������
�I�p��G34/C32�ɍڂ邭���ɈӖ��������
G34/C32����AM3��萏���ザ��Ȃ����������H
�ȓd�͋@�\�iCPU�̃T�|�[�g�j�Ƃ��ɈႢ������낤�Ȃ�
�ȓd�͋@�\�iCPU�̃T�|�[�g�j�Ƃ��ɈႢ������낤�Ȃ�
PhenomX4 965BE�������Ă鉴�͂���AMD��CPU�������������������c
�킴�킴Bulldozer�̂��߂Ƀ}�}�����������Ȃ����c
�킴�킴Bulldozer�̂��߂Ƀ}�}�����������Ȃ����c
HD5450�ɑ��������牽���Ċ�������
>>494
�Ȃ�Δ���Ȃ���悭�ˁH�@���ꂾ���̘b�����B
�Ȃ�Δ���Ȃ���悭�ˁH�@���ꂾ���̘b�����B
�܂��ASandy Bridge��IGP�Ŗ����ł��Ȃ��w�̓f�B�X�N���[�g������
CPU���\��ꡂ��ɗ��Llano�i�j�Ȃ�Ċᒆ�ɂȂ����
CPU���\��ꡂ��ɗ��Llano�i�j�Ȃ�Ċᒆ�ɂȂ����
����Intel��GMA�͐��\�]�X�̖�肶��Ȃ��C���������
Sandy��IGP�͖��ʂɃV���R�����L���Ă��銴�������
�N�����Ђ�����咣����悤�ɃV���O���X���b�h���\���d�v�Ȃ�A���̂��߂Ɏg�������̂�
�N�����Ђ�����咣����悤�ɃV���O���X���b�h���\���d�v�Ȃ�A���̂��߂Ɏg�������̂�
501 �FSocket774�F2010/08/28(�y) 21:12:23 ID:vXP1LtHu
Llano�͊��S�Ɏ��s�삾�낗��������ڂ�CPU�ɐ���x���GPU
�S���ƌ����Ă����قlj��l���Ȃ�
����Ȃ������炢�Ȃ猻��̂��D����CPU�Ɋi�����[�G���h�O���{�iHD5550�j�ŏ\���������
AMD����鎞�͐^���ɂ��Ȃ��ƃ}�W�ŏI��邼�m���
�S���ƌ����Ă����قlj��l���Ȃ�
����Ȃ������炢�Ȃ猻��̂��D����CPU�Ɋi�����[�G���h�O���{�iHD5550�j�ŏ\���������
AMD����鎞�͐^���ɂ��Ȃ��ƃ}�W�ŏI��邼�m���
L2�̓C���N���[�V�u�ɂȂ����悤������L3�������Ȃ̂��H
ID:6WpQYegX���c�q�@ID:vXP1LtHu���e�w�H
�킴�킴AMD�X���́A������������X���ɗ��Ă܂œd�g����n���͂��̓�l�������낗
"Llano"�͊��S�ɉ��i�����ɏo��ȁB
�����TDP100W�N���X�͂���Ȃɏo���Ȃ��̋C������B
�����TDP100W�N���X�͂���Ȃɏo���Ȃ��̋C������B
>>503
����l��������
����l��������
Llano�͏K����Ċ���������
GF��32nm��Fusion�̂��߂�
Radeon��HD3XXX����݂�����
�����܂ł���ۂ�����
AMD�I�ɂ̓~�h�������W�ȉ���V�����̎s��ł�����x����������Ȃ����ȁH
GF��32nm��Fusion�̂��߂�
Radeon��HD3XXX����݂�����
�����܂ł���ۂ�����
AMD�I�ɂ̓~�h�������W�ȉ���V�����̎s��ł�����x����������Ȃ����ȁH
Hot Chips�ň�Ԋ��S����AMD��Bulldozer��Bobcat�R�A�̔��\
http://www.geocities.jp/andosprocinfo/wadai10/20100828.htm
�@�@�����C���S�����̂��Ƃ����ƁC�Ƃɂ����C����d�͂�O��I�ɍi�荞�ނƂ������ƂŃ}�C�N���A�[�L�e�N�`���̃g���[�h�I�t������Ă���_�ł��B
�@�@Bulldozer�́C���Ƃ���2�R�A��2�X���b�h���s�Ƃ����\������C2�X���b�h�ŋ��L�ł��镔���Ƌ��L����Ƒ傫�����\�������镔���ɋ�ʂ��C���ǁC
�������Z�p�C�v��1���f�[�^�L���b�V���̓X���b�h���ƂɎ����C���������_���Z�p�C�v��C���߂̃t�F�b�`�C�f�R�[�h�n��2�X���b�h�ŋ��L�Ƃ����\���ɂȂ��Ă��܂��B
����ŁC���p�Ȃ���2�R�A�Ɣ�r����80%�̐��\�����Ȃ菭�Ȃ��`�b�v�ʐςƏ���d�͂Ŏ����ł����Əq�ׂĂ��܂��B�܂��C
BTB��512�G���g����1��BTB��5K�G���g����2��BTB�Ƃ����\���ɂ��Ă���C�펞����1���͏���d�͂����炵�C1�����~�X�����ꍇ��������2��BTB�͑�e�ʂƂ����\���ł��B
�����āC1���f�[�^�L���b�V����Way prediction���g���C�ʏ�͂P��Way�����A�N�Z�X���Ȃ��Ƃ��������œd�͂����炵�������ł��B
�@�@�܂��CBobcat�ł́COut-of-Order���s�̂����Ƃ��āC�f�[�^�̈ړ���Future File�̂悤�Ȃ����͍̂炸�C�傫�ȕ������W�X�^�t�@�C�����g���āC
�f�[�^�̓ǂݏ����ɂƂ��Ȃ��d�͂����炵���Əq�ׂĂ��܂����B�܂��C�e��̃L���[���V�t�g���W�X�^�ł͂Ȃ��C�|�C���^�ňʒu���Ǘ�������@���̂�C�d�͂����炵�Ă��邻���ł��B
�@�@�ȓd�͂��d�v�ɂȂ�C�e�ЂƂ��N���b�N�Q�[�g�̒P�ʂ��ׂ��������肵�Ă��܂����C�����܂Ń}�C�N���A�[�L�ɓ��ݍ���œd�͂Ɛ��\�̃g���[�h�I�t�����̂́C���\��Ԃ�������Ǝv����̂ŁC����ɂ͊��S���܂����B
�������C���ꂪ�ǂ̒��x�����Ă���̂��́C�`�b�v�����\����āC�N���b�N�����d�͂��o�Ă��Ȃ��ƕ�����܂���B
�@�@�܂��CBulldozer�̔��\�ł́C�Q�[�g�i�������炵���v�Əq�ׂ��Ă���CIBM��POWER7�̂悤�ɍ��N���b�N��_���Ă���悤�ł��B�v���Z�X������SOI�ł����C
POWER7���݂̃N���b�N�ŏo�Ă���̂ł͂Ȃ����Ǝv���܂��B
http://www.geocities.jp/andosprocinfo/wadai10/20100828.htm
�@�@�����C���S�����̂��Ƃ����ƁC�Ƃɂ����C����d�͂�O��I�ɍi�荞�ނƂ������ƂŃ}�C�N���A�[�L�e�N�`���̃g���[�h�I�t������Ă���_�ł��B
�@�@Bulldozer�́C���Ƃ���2�R�A��2�X���b�h���s�Ƃ����\������C2�X���b�h�ŋ��L�ł��镔���Ƌ��L����Ƒ傫�����\�������镔���ɋ�ʂ��C���ǁC
�������Z�p�C�v��1���f�[�^�L���b�V���̓X���b�h���ƂɎ����C���������_���Z�p�C�v��C���߂̃t�F�b�`�C�f�R�[�h�n��2�X���b�h�ŋ��L�Ƃ����\���ɂȂ��Ă��܂��B
����ŁC���p�Ȃ���2�R�A�Ɣ�r����80%�̐��\�����Ȃ菭�Ȃ��`�b�v�ʐςƏ���d�͂Ŏ����ł����Əq�ׂĂ��܂��B�܂��C
BTB��512�G���g����1��BTB��5K�G���g����2��BTB�Ƃ����\���ɂ��Ă���C�펞����1���͏���d�͂����炵�C1�����~�X�����ꍇ��������2��BTB�͑�e�ʂƂ����\���ł��B
�����āC1���f�[�^�L���b�V����Way prediction���g���C�ʏ�͂P��Way�����A�N�Z�X���Ȃ��Ƃ��������œd�͂����炵�������ł��B
�@�@�܂��CBobcat�ł́COut-of-Order���s�̂����Ƃ��āC�f�[�^�̈ړ���Future File�̂悤�Ȃ����͍̂炸�C�傫�ȕ������W�X�^�t�@�C�����g���āC
�f�[�^�̓ǂݏ����ɂƂ��Ȃ��d�͂����炵���Əq�ׂĂ��܂����B�܂��C�e��̃L���[���V�t�g���W�X�^�ł͂Ȃ��C�|�C���^�ňʒu���Ǘ�������@���̂�C�d�͂����炵�Ă��邻���ł��B
�@�@�ȓd�͂��d�v�ɂȂ�C�e�ЂƂ��N���b�N�Q�[�g�̒P�ʂ��ׂ��������肵�Ă��܂����C�����܂Ń}�C�N���A�[�L�ɓ��ݍ���œd�͂Ɛ��\�̃g���[�h�I�t�����̂́C���\��Ԃ�������Ǝv����̂ŁC����ɂ͊��S���܂����B
�������C���ꂪ�ǂ̒��x�����Ă���̂��́C�`�b�v�����\����āC�N���b�N�����d�͂��o�Ă��Ȃ��ƕ�����܂���B
�@�@�܂��CBulldozer�̔��\�ł́C�Q�[�g�i�������炵���v�Əq�ׂ��Ă���CIBM��POWER7�̂悤�ɍ��N���b�N��_���Ă���悤�ł��B�v���Z�X������SOI�ł����C
POWER7���݂̃N���b�N�ŏo�Ă���̂ł͂Ȃ����Ǝv���܂��B
http://citavia.blog.de/2010/08/27/a-quick-round-of-links-9265110/
Bulldozer's 17 FO4 pipeline. This means a design which is aimed at a
20-30% higher clock frequency compared to K8 with 22 FO4 (same voltage and fab process).
Bulldozer�͓����v���Z�X�����d����Phenom�U�Ɣ�ׂ�20-30%�����N���b�N
Bulldozer's 17 FO4 pipeline. This means a design which is aimed at a
20-30% higher clock frequency compared to K8 with 22 FO4 (same voltage and fab process).
Bulldozer�͓����v���Z�X�����d����Phenom�U�Ɣ�ׂ�20-30%�����N���b�N
200�`300�������Ȃ��Ǝg�����ɂȂ��
���Ⴀ����PhenomII���啪������
����v���Z�X��20-30%�����\������
4G�͏\���^�[�Q�b�g�ɓ����Ă�������
4G�͏\���^�[�Q�b�g�ɓ����Ă�������
�\�������ȁA���\���҂ł�������
����A32nm�ŃX�^�[�g����Ȃ����������H
����v���Z�X�Ȃ�H
����v���Z�X�Ȃ�H
515 �FSocket774�F2010/08/28(�y) 21:59:33 ID:g4jutbay
HKMG�������҂��Ă�����ˁH
>>514
Llano�Ɣ�r�o���邾��
Llano�Ɣ�r�o���邾��
517 �FSocket774�F2010/08/28(�y) 22:02:43 ID:vXP1LtHu
�������v���Z�X��Phenom�U�Ɣ�ׂ�
�H�H�H���������ꒃ���Ȃ�
Sandy i5 2400���e�͖����S�{���\�߂��Ă��������Ȃ�������
�H�H�H���������ꒃ���Ȃ�
Sandy i5 2400���e�͖����S�{���\�߂��Ă��������Ȃ�������
>>514
����v���Z�X�ō������Ƃ������ƂȂ�Ȃ�
����1095T��3.2G��TC��3.6G������
Bull��v���Z�X�ō���3.8-3.9G��TC��4.3-4.6G
�܂�����ȒP���Ȃ���ł��Ȃ����낤����
����v���Z�X�ō������Ƃ������ƂȂ�Ȃ�
����1095T��3.2G��TC��3.6G������
Bull��v���Z�X�ō���3.8-3.9G��TC��4.3-4.6G
�܂�����ȒP���Ȃ���ł��Ȃ����낤����
Sandy(H2)���v�����قǑ債�����Ɩ����Ĉ��S����
i3�͑������\���E���R�����Ai5�̓��C�g�Q�[�}�[(MMO�Ƃ�)�����C�������Ȃ̂ɃQ�[�����o���Ȃ��E���R
i7�͍w���҂����Ȃ����Ӗ��ȑ���(���\���߂�z��B2��)
Llano��������v�f����AVX�ʂ����Ȃ���
i3�͑������\���E���R�����Ai5�̓��C�g�Q�[�}�[(MMO�Ƃ�)�����C�������Ȃ̂ɃQ�[�����o���Ȃ��E���R
i7�͍w���҂����Ȃ����Ӗ��ȑ���(���\���߂�z��B2��)
Llano��������v�f����AVX�ʂ����Ȃ���
X4 1090T�����s�Ȃ̂�
����ᕉ�����̉��i������
����ᕉ�����̉��i������
���߂�X6��
Sandy�o����AMD���Nvidia�̂����o�C��ˁH
������̂�GTX460���������Ȃ����Ⴄ�����B
������̂�GTX460���������Ȃ����Ⴄ�����B
524 �FSocket774�F2010/08/28(�y) 22:31:23 ID:vXP1LtHu
��Bulldozer�͓����v���Z�X�����d����Phenom�U�Ɣ�ׂ�20-30%�����N���b�N
�������1�R�A������H���Ƃ����8�R�A�Ŋ��Z����Ɠ���TDP����N���b�N����Ȃɏオ��ˁ[��ˁH
8�R�A125W��3.4�`3.8GH�����炢�����E�H���ɂ�����ς����\��
��i7 2600�ȏ�̐��\�o��̂�����H���������N�x��ďo����E�E�EAMD�������肵���}�W��
�������1�R�A������H���Ƃ����8�R�A�Ŋ��Z����Ɠ���TDP����N���b�N����Ȃɏオ��ˁ[��ˁH
8�R�A125W��3.4�`3.8GH�����炢�����E�H���ɂ�����ς����\��
��i7 2600�ȏ�̐��\�o��̂�����H���������N�x��ďo����E�E�EAMD�������肵���}�W��
���N���b�N�u�����ƃl�b�g�o�[�X�g���v���o���Ă��܂����ǁA
�O�ꂵ���ȓd�͉����ǂꂾ����肭���ݍ������y���݂��B
�O�ꂵ���ȓd�͉����ǂꂾ����肭���ݍ������y���݂��B
Bulldozer��1���W���[�����̐����R�A��SIMD���j�b�g�̐����āA�����I�ɑ��₹����̂Ȃ̂���
AMD�����\�����Z�p�͂����Ă��C���e���̕�����Ɏ������Ă��܂���
�l�b�g�o�[�X�g�̓p�C�v���C���[�����č��N���b�N�_���Ă�����Ȃ�
> �������1�R�A������H���Ƃ����8�R�A�Ŋ��Z����Ɠ���TDP����N���b�N����Ȃɏオ��ˁ[��ˁH
�t�ɉ�����ˁB
��{�I��Bulldozer�͌��s�R�A����50%����_����CPU������ˁB
TDP�ōs���ƌ��s���20%�`30%���N���b�N���͉������Ă��܂��v�Z�ɂȂ�̂��ȁH
�t�ɉ�����ˁB
��{�I��Bulldozer�͌��s�R�A����50%����_����CPU������ˁB
TDP�ōs���ƌ��s���20%�`30%���N���b�N���͉������Ă��܂��v�Z�ɂȂ�̂��ȁH
>>523
NVIDIA��TSMC�ŗ\�Ă�40nm�p�E�F�n�̈ꕔ���L�����Z����������A�����\���̏�������܂��Ă��܂���
40nm����ł͂����������t���Ă��
����͂܂�AMD��Intel�̊W�ƈꏏ����
�����\�͂̏��������ȏ�A���Y�ʂ𑝂₷�ɂ̓`�b�v�����������鑼�ɓ�������
NVIDIA��TSMC�ŗ\�Ă�40nm�p�E�F�n�̈ꕔ���L�����Z����������A�����\���̏�������܂��Ă��܂���
40nm����ł͂����������t���Ă��
����͂܂�AMD��Intel�̊W�ƈꏏ����
�����\�͂̏��������ȏ�A���Y�ʂ𑝂₷�ɂ̓`�b�v�����������鑼�ɓ�������
11�N�O���̓C���e��2�R�A�ɂ͏��Ă�������4�R�A�ɂ͕�����������
Bulldozer�������ɂ͂₭�s��ɏo���邩����
Llano�͒x��m��Ń_���|
Bulldozer�������ɂ͂₭�s��ɏo���邩����
Llano�͒x��m��Ń_���|
>>527
�����ł��Ȃ����A�����u��Ɏ����v���Ă���̂����s���B
�����ł��Ȃ����A�����u��Ɏ����v���Ă���̂����s���B
>>527
�ǂ����̑�@����Ђ�10Ghz�Ƃ������Ă������ɂȂ�������������
�ǂ����̑�@����Ђ�10Ghz�Ƃ������Ă������ɂȂ�������������
���̉�Ђ͉ߋ��ɁuCPU+GPU+�����R���v�������������ȁB
���̎���RDRAM�����ȂȂ���A���邢��DDR�ō���Ă�����A
�{����AMD�Ƀg�h�����������̂ɂˁB
���̎���RDRAM�����ȂȂ���A���邢��DDR�ō���Ă�����A
�{����AMD�Ƀg�h�����������̂ɂˁB
{kind=link}
���̎���̍��N���b�N�H����n���ɂ���z�͐�͂�������
AMD�͕t���Ă����Ȃ��������猋�ʓI�ɐ�������������
AMD�͕t���Ă����Ȃ��������猋�ʓI�ɐ�������������
�g�����h�Ȃ�ėh��߂������镨�����獂�N���b�N�H���ɂ܂���A����̂�������Ȃ�
���ǂ͂��̎���̋Z�p�Ƃ̃o�����X�����܂����Ƃ������Ƃ��낤
���ǂ͂��̎���̋Z�p�Ƃ̃o�����X�����܂����Ƃ������Ƃ��낤
>>536
K9�ӂ�̗\��\�����@����������
>>537
����BAMD��1GHz�̃N���b�N������ɁA
���N���b�N�u���̃A�[�L�e�B�N�`����
�����ς��̂ĂāA�}���`�X���b�h�d���Ői��ł����B
���Ԃ�1GHz�N���b�N�������P�Ƀ}�[�P�e�B���O�I�킢�ł����āA
���̎��O�ォ��N���b�N�����`�͎̂ĂĂ����悤�Ɏv����B
K9�ӂ�̗\��\�����@����������
>>537
����BAMD��1GHz�̃N���b�N������ɁA
���N���b�N�u���̃A�[�L�e�B�N�`����
�����ς��̂ĂāA�}���`�X���b�h�d���Ői��ł����B
���Ԃ�1GHz�N���b�N�������P�Ƀ}�[�P�e�B���O�I�킢�ł����āA
���̎��O�ォ��N���b�N�����`�͎̂ĂĂ����悤�Ɏv����B
>>524
���ۂ�Sandy�ƌ��˂���̂�2M(���W���[��)/4T�i���낤����A
TDP�ɂ��N���b�N������E�͂��܂�C�ɂ��Ȃ��Ă�����Ȃ��B
����ł�Sandy4C/4T��3.2�`3.4GHz�Ə�������Ȃ�A5�`5.5GHz�ʓ��肻�������ǁB
>>525
�����̐����Z�p���v�ɒǂ����Ȃ����������ŁA
���N���b�N�H�����̂̓V���O���^�X�N���\�̌��オ�����߂邩�爫���Ȃ��ƁB
���ۂ�Sandy�ƌ��˂���̂�2M(���W���[��)/4T�i���낤����A
TDP�ɂ��N���b�N������E�͂��܂�C�ɂ��Ȃ��Ă�����Ȃ��B
����ł�Sandy4C/4T��3.2�`3.4GHz�Ə�������Ȃ�A5�`5.5GHz�ʓ��肻�������ǁB
>>525
�����̐����Z�p���v�ɒǂ����Ȃ����������ŁA
���N���b�N�H�����̂̓V���O���^�X�N���\�̌��オ�����߂邩�爫���Ȃ��ƁB
542 �FSocket774�F2010/08/28(�y) 23:32:40 ID:23tGwAJ0
����d�́@VS PhenomII X6 1090T BE
http://images.anandtech.com/graphs/sandybridgepreview_082710002107/24416.png
��(` �E�t�L�E �G�j�Ư!?
CPU����GPU VS PhenomII X4 965BE 890GX �I���{
hhttp://images.anandtech.com/graphs/sandybridgegpu_082710013731/24417.png
(/�ށ��_)���-!����Ų
http://images.anandtech.com/graphs/sandybridgepreview_082710002107/24416.png
{kind=link}
��(` �E�t�L�E �G�j�Ư!?
CPU����GPU VS PhenomII X4 965BE 890GX �I���{
hhttp://images.anandtech.com/graphs/sandybridgegpu_082710013731/24417.png
{kind=link}
(/�ށ��_)���-!����Ų
�iBull�̉��z�́j�V���O���R�A�Ɣ�r������A�Ƃ�
��CPU�Ɠ���̃v���Z�X�ŐVCPU��������Ƃ�����A�Ƃ�
����������r�ɑ��ĕςɗ���ł�n���͂Ȃ�Ȃ�
��CPU�Ɠ���̃v���Z�X�ŐVCPU��������Ƃ�����A�Ƃ�
����������r�ɑ��ĕςɗ���ł�n���͂Ȃ�Ȃ�
�Ȃ��v������悤��Sandy�̏������ȁB
Bulldozer�̏������Ȃ��́H
Bulldozer�̏������Ȃ��́H
Sandy�I���{GPU�̑����Ontario�ŏ\����
GPU�e�X�g�@
http://images.anandtech.com/graphs/sandybridgegpu_082710013731/24418.png
http://images.anandtech.com/graphs/sandybridgegpu_082710013731/24419.png
cpu�e�X�g
http://images.anandtech.com/graphs/sandybridgepreview_082710002107/24397.png
�Q�[�����\�e�X�g*(Windows7)
http://images.anandtech.com/graphs/sandybridgepreview_082710002107/24412.png
�ބ�����(߄D�|||)�����!! ���x����������!!�i�L�D`�G�j�K�[��
http://images.anandtech.com/graphs/sandybridgegpu_082710013731/24418.png
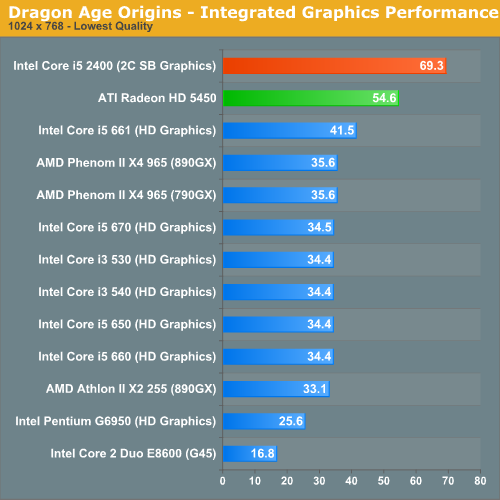{kind=link}
http://images.anandtech.com/graphs/sandybridgegpu_082710013731/24419.png
{kind=link}
cpu�e�X�g
http://images.anandtech.com/graphs/sandybridgepreview_082710002107/24397.png
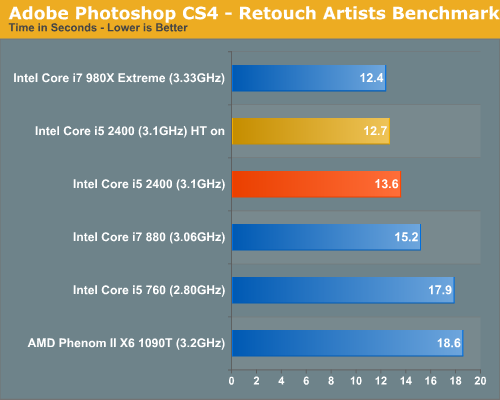{kind=link}
�Q�[�����\�e�X�g*(Windows7)
http://images.anandtech.com/graphs/sandybridgepreview_082710002107/24412.png
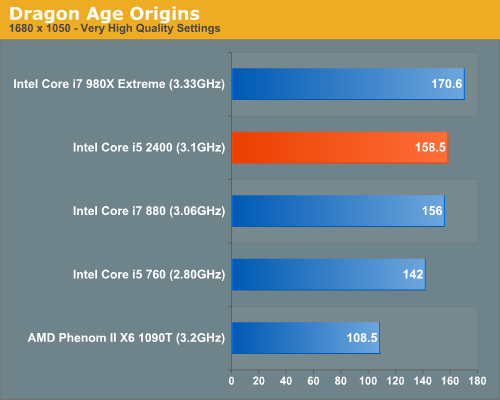{kind=link}
�ބ�����(߄D�|||)�����!! ���x����������!!�i�L�D`�G�j�K�[��
�x��ĂȂ������獡��Bulldozer�ALlano�̐��\�킩���Ă��E�E�E
�N���ɂ�Bulldozer�̂ق��͂킩����
�N���ɂ�Bulldozer�̂ق��͂킩����
Sandy���債�����ƂȂ���������o���ɂ��݂��Ă�낤
HotChips��Intel�̔��\�͂��܂舵���ĂȂ�����ȁ[�B
AMD�ƈ���ăl�^�I�Ɏア�Ǝv���āAES�̃x���`��������ˁH
AMD�ƈ���ăl�^�I�Ɏア�Ǝv���āAES�̃x���`��������ˁH
�c�q�ƃe�w�͂�������������ID���g���Ă����
2ch��ID:23tGwAJ0�N��������Ē���܂�邮�炢
>>552
����1�ł���
����1�ł���
Nvidia��Hot Chips��Fermi GF100�A�[�L�e�N�`���[�̍u���������͂��Ȃ��b��ɂ��Ȃ���
�܂����X����Ȃ��̐�������Ă��Ƃ��������ł͂��邯��
�܂����X����Ȃ��̐�������Ă��Ƃ��������ł͂��邯��
PC,�f�X�N�g�b�v�s��ł�8���W���[��16�X���b�h�o���Ăق����Ȃ�
����ς荡��k10�Ɠ����Ő��i�����n���Ă���܂�2,3�N�͂�����낤�Ȃ�
����Athlon2,Phenom2�Ȃ�45W,65W���f���������ď�����Phenom1�̂Ƃ��Ƃ͔�ו��ɂȂ�Ȃ��f�L
�������ꂽ�班���l�q�����K�v��������Ȃ�
����ς荡��k10�Ɠ����Ő��i�����n���Ă���܂�2,3�N�͂�����낤�Ȃ�
����Athlon2,Phenom2�Ȃ�45W,65W���f���������ď�����Phenom1�̂Ƃ��Ƃ͔�ו��ɂȂ�Ȃ��f�L
�������ꂽ�班���l�q�����K�v��������Ȃ�
���̂����o�邾�낤
AMD�͓���v���Z�X�Ői�������邩��ȁA�҂Ă�Ȃ�҂̂�����������
X6��125w����95w�ɂȂ�������
X6��125w����95w�ɂȂ�������
Sandy�ɏ��o����Ă��܂����ȏ�
���s�͋�����Ȃ����
�v�͗ǂ��Ă��n���Ɛ_���J��Ԃ��������ɐ�����������ƐS�z
�l�I�ɂ͌����I��4M-8T������
���s�͋�����Ȃ����
�v�͗ǂ��Ă��n���Ɛ_���J��Ԃ��������ɐ�����������ƐS�z
�l�I�ɂ͌����I��4M-8T������
2���W���[��4�R�A+APU��Bull���~������
�O���t�B�b�N�X�R�A��Llano�Ɠ����ł�������
�O���t�B�b�N�X�R�A��Llano�Ɠ����ł�������
��������͂ƂĂ��|�W�e�B�u�Ȍ�������
�R�DHot Chips�ň�Ԋ��S����AMD��Bulldozer��Bobcat�R�A�̔��\
http://www.geocities.jp/andosprocinfo/wadai10/20100828.htm
�����Hot Chips��AMD�͎������Bulldozer��Bobcat�R�A�\���܂����B
�R�A�̃A�[�L�e�N�`���I�Ȗʂɍi�������\�ŁC�N���b�N��\�Ȃǂ̋�̓I�Șb�͂Ȃ��C
�܂��C���i�Ƃ��Ăǂ̂悤�Ȍ`�ɂȂ�̂������\�̑ΏۊO�ł��B
�����C���S�����̂��Ƃ����ƁC�Ƃɂ����C����d�͂�O��I�ɍi�荞�ނƂ������Ƃ�
�}�C�N���A�[�L�e�N�`���̃g���[�h�I�t������Ă���_�ł��B
Bulldozer�́C���Ƃ���2�R�A��2�X���b�h���s�Ƃ����\������C2�X���b�h�ŋ��L�ł��镔����
���L����Ƒ傫�����\�������镔���ɋ�ʂ��C���ǁC�������Z�p�C�v��1���f�[�^�L���b�V���̓X���b�h���ƂɎ����C
���������_���Z�p�C�v��C���߂̃t�F�b�`�C�f�R�[�h�n��2�X���b�h�ŋ��L�Ƃ����\���ɂȂ��Ă��܂��B
����ŁC���p�Ȃ���2�R�A�Ɣ�r����80%�̐��\�����Ȃ菭�Ȃ��`�b�v�ʐςƏ���d�͂Ŏ����ł����Əq�ׂĂ��܂��B
�܂��CBTB��512�G���g����1��BTB��5K�G���g����2��BTB�Ƃ����\���ɂ��Ă���C�펞����1���͏���d�͂����炵�C
1�����~�X�����ꍇ��������2��BTB�͑�e�ʂƂ����\���ł��B�����āC1���f�[�^�L���b�V����Way prediction���g���C
�ʏ�͂P��Way�����A�N�Z�X���Ȃ��Ƃ��������œd�͂����炵�������ł��B�i�����j
�ȓd�͂��d�v�ɂȂ�C�e�ЂƂ��N���b�N�Q�[�g�̒P�ʂ��ׂ��������肵�Ă��܂����C�����܂Ń}�C�N���A�[�L�ɓ��ݍ����
�d�͂Ɛ��\�̃g���[�h�I�t�����̂́C���\��Ԃ�������Ǝv����̂ŁC����ɂ͊��S���܂����B
�������C���ꂪ�ǂ̒��x�����Ă���̂��́C�`�b�v�����\����āC�N���b�N�����d�͂��o�Ă��Ȃ��ƕ�����܂���B
�܂��CBulldozer�̔��\�ł́C�Q�[�g�i�������炵���v�Əq�ׂ��Ă���CIBM��POWER7�̂悤�ɍ��N���b�N��
�_���Ă���悤�ł��B�v���Z�X������SOI�ł����CPOWER7���݂̃N���b�N�ŏo�Ă���̂ł͂Ȃ����Ǝv���܂��B
�R�DHot Chips�ň�Ԋ��S����AMD��Bulldozer��Bobcat�R�A�̔��\
http://www.geocities.jp/andosprocinfo/wadai10/20100828.htm
�����Hot Chips��AMD�͎������Bulldozer��Bobcat�R�A�\���܂����B
�R�A�̃A�[�L�e�N�`���I�Ȗʂɍi�������\�ŁC�N���b�N��\�Ȃǂ̋�̓I�Șb�͂Ȃ��C
�܂��C���i�Ƃ��Ăǂ̂悤�Ȍ`�ɂȂ�̂������\�̑ΏۊO�ł��B
�����C���S�����̂��Ƃ����ƁC�Ƃɂ����C����d�͂�O��I�ɍi�荞�ނƂ������Ƃ�
�}�C�N���A�[�L�e�N�`���̃g���[�h�I�t������Ă���_�ł��B
Bulldozer�́C���Ƃ���2�R�A��2�X���b�h���s�Ƃ����\������C2�X���b�h�ŋ��L�ł��镔����
���L����Ƒ傫�����\�������镔���ɋ�ʂ��C���ǁC�������Z�p�C�v��1���f�[�^�L���b�V���̓X���b�h���ƂɎ����C
���������_���Z�p�C�v��C���߂̃t�F�b�`�C�f�R�[�h�n��2�X���b�h�ŋ��L�Ƃ����\���ɂȂ��Ă��܂��B
����ŁC���p�Ȃ���2�R�A�Ɣ�r����80%�̐��\�����Ȃ菭�Ȃ��`�b�v�ʐςƏ���d�͂Ŏ����ł����Əq�ׂĂ��܂��B
�܂��CBTB��512�G���g����1��BTB��5K�G���g����2��BTB�Ƃ����\���ɂ��Ă���C�펞����1���͏���d�͂����炵�C
1�����~�X�����ꍇ��������2��BTB�͑�e�ʂƂ����\���ł��B�����āC1���f�[�^�L���b�V����Way prediction���g���C
�ʏ�͂P��Way�����A�N�Z�X���Ȃ��Ƃ��������œd�͂����炵�������ł��B�i�����j
�ȓd�͂��d�v�ɂȂ�C�e�ЂƂ��N���b�N�Q�[�g�̒P�ʂ��ׂ��������肵�Ă��܂����C�����܂Ń}�C�N���A�[�L�ɓ��ݍ����
�d�͂Ɛ��\�̃g���[�h�I�t�����̂́C���\��Ԃ�������Ǝv����̂ŁC����ɂ͊��S���܂����B
�������C���ꂪ�ǂ̒��x�����Ă���̂��́C�`�b�v�����\����āC�N���b�N�����d�͂��o�Ă��Ȃ��ƕ�����܂���B
�܂��CBulldozer�̔��\�ł́C�Q�[�g�i�������炵���v�Əq�ׂ��Ă���CIBM��POWER7�̂悤�ɍ��N���b�N��
�_���Ă���悤�ł��B�v���Z�X������SOI�ł����CPOWER7���݂̃N���b�N�ŏo�Ă���̂ł͂Ȃ����Ǝv���܂��B
Desktop Bulldozer Processors Will Require New Platforms - AMD.
AMD Zambezi to Use AM3+ Platforms
http://www.xbitlabs.com/news/cpu/display/20100826225852_Desktop_Bulldozer_Processors_Will_Require_New_Platforms_AMD.html
AMD Zambezi to Use AM3+ Platforms
http://www.xbitlabs.com/news/cpu/display/20100826225852_Desktop_Bulldozer_Processors_Will_Require_New_Platforms_AMD.html
���x�����p���Ȃ��Ă�������
�u����Lla���͂₭ES�i����̐��\�m�肽���ˁ`
���~�͊��Ⴂ���Ă��邪Llano�R��i3�ȉ��ŁAi5�ȏ��Bulldozer���R�����
�����Llano 4�R�A�̓Q�[���pCPU������GPU�x���`�ł����^��������
����Đ���r�W�l�X�Ƃ��̈�ʌ�����Llano 2�R�A���S������
���i��\�̑R�͂���Ȃ���
Atom vs Ontario
celeG vs Llano X2
i3 vs Llano X4
i5 vs Bull 3���W���[��
i7 vs Bull 4���W���[��
i5 vs Llano X4��CPU���\�ŏ��������AIGP�ł̃Q�[�����\�ň��|���낤
�����Llano 4�R�A�̓Q�[���pCPU������GPU�x���`�ł����^��������
����Đ���r�W�l�X�Ƃ��̈�ʌ�����Llano 2�R�A���S������
���i��\�̑R�͂���Ȃ���
Atom vs Ontario
celeG vs Llano X2
i3 vs Llano X4
i5 vs Bull 3���W���[��
i7 vs Bull 4���W���[��
i5 vs Llano X4��CPU���\�ŏ��������AIGP�ł̃Q�[�����\�ň��|���낤
AM3+�Ƃ������Ƃ͉��������̂��˂�
���ʌ݊����̂Ȃ�HT4.0�Ȃǂ����肳��č̗p�����Ƃ����낤��
���ʌ݊����̂Ȃ�HT4.0�Ȃǂ����肳��č̗p�����Ƃ����낤��
>>568
> �����Llano 4�R�A�̓Q�[���pCPU������GPU�x���`�ł����^��������
�uCPU���\�͌��Ȃ��ł��肢�`�i���j�v
�ƌ����S�̐�����
> �����Llano 4�R�A�̓Q�[���pCPU������GPU�x���`�ł����^��������
�uCPU���\�͌��Ȃ��ł��肢�`�i���j�v
�ƌ����S�̐�����
Interlagos��G34�ɏ��Ƃ����Ă���牺�ʌ݊������Ȃ��Ƃ����̂͂Ȃ��ł���
���炵�܂���
�d�͊W�̉����Ȃ̂���
���炵�܂���
�d�͊W�̉����Ȃ̂���
>>568
�����������Ƃ͂킩�邵��肩�����ӂȂ��A���̑R�}���Ƃ܂��V���O���X���b�h�~���E�E�E
�l�i�I�ɂ�i5��i7�ɂ�Bull���ĂĂ��邾�낤���ǁA���i���Ⴂ�����邩����ۓI�ɂ͑R�Ƃ��Ẵ|�W�V������
���Ȃ���Ȃ����H
Ontario�ƎI��Bull�ʼn҂���Ƃ���ʼn҂��ŁA�R���V���[�}�̃n�C�G���h�͂��炭��ȂȋC���B
���̃|�W�V�����̓}���`�X���b�h�̃A�h�o���e�[�W�Ƃ�GPGPU���G�肷�邩������Ȃ�������ȍ~��
���҂��ȁB
�����������Ƃ͂킩�邵��肩�����ӂȂ��A���̑R�}���Ƃ܂��V���O���X���b�h�~���E�E�E
�l�i�I�ɂ�i5��i7�ɂ�Bull���ĂĂ��邾�낤���ǁA���i���Ⴂ�����邩����ۓI�ɂ͑R�Ƃ��Ẵ|�W�V������
���Ȃ���Ȃ����H
Ontario�ƎI��Bull�ʼn҂���Ƃ���ʼn҂��ŁA�R���V���[�}�̃n�C�G���h�͂��炭��ȂȋC���B
���̃|�W�V�����̓}���`�X���b�h�̃A�h�o���e�[�W�Ƃ�GPGPU���G�肷�邩������Ȃ�������ȍ~��
���҂��ȁB
>���p�Ȃ���2�R�A�Ɣ�r����80%�̐��\�����Ȃ菭�Ȃ��`�b�v�ʐςƏ���d�͂Ŏ����ł���
�܂�1���W���[����1�R�A�ɑ��Đ������Z��160%�̐��\���Ă��Ƃ�OK�Ȃ́H
�܂�1���W���[����1�R�A�ɑ��Đ������Z��160%�̐��\���Ă��Ƃ�OK�Ȃ́H
>>570
���ɋA���Ă��A���[��
���ɋA���Ă��A���[��
>>569
PowerPlane���ς��Ƃ������b�������Ԃ�O�ɂȂ�������
PowerPlane���ς��Ƃ������b�������Ԃ�O�ɂȂ�������
����DDR4�p��AM4�Ƃ����̂��J�����Ă��āA����Ƃ̌݊������悤�Ȑv�ɂȂ��Ă����肵��
�^�[�{�R�A�Ή����荂���ȃ������̂��߂ɂ�����AM3�Ƃ̌݊������߂Ă�Ƃ�
�^�[�{�R�A�Ή����荂���ȃ������̂��߂ɂ�����AM3�Ƃ̌݊������߂Ă�Ƃ�
�V���O���X���b�h�~�H
�V���O���X���b�h���\�͏�ɁA�F�����n�܂邩��I���܂ŁA�d�v�ł���Â��܂���B
�����~�Ƃ��A�������Ă�́H
����Bulldozer��web�I�����c����ĂȂ����āc
�V���O���X���b�h���\�͏�ɁA�F�����n�܂邩��I���܂ŁA�d�v�ł���Â��܂���B
�����~�Ƃ��A�������Ă�́H
����Bulldozer��web�I�����c����ĂȂ����āc
>>572
AMD���^�[�{�@�\�ɖ{�i�Ή����邩�獡�܂Œ��V���O���X���b�h�ō��͏o�Ȃ��Ǝv��
����Ɗ��Ⴂ���Ă��邯��Zambezi�͑�Intel�ɂ����ăn�C�G���h�ɂ͂Ȃ�Ȃ�
1���W���[����Sandy��HTT��菭���ゾ�낤����AZambezi�ł�Sandy��6�R�A�肷��̂�����t
�n�C�G���h��Sandy 8�R�A�ɂ͓���͂��Ȃ������
�撣���B2�̉��ʐ��i�Ɛ킦��ʂ��낤����AX6 vs i7�݂����ȏɂȂ邾�낤
AMD���^�[�{�@�\�ɖ{�i�Ή����邩�獡�܂Œ��V���O���X���b�h�ō��͏o�Ȃ��Ǝv��
����Ɗ��Ⴂ���Ă��邯��Zambezi�͑�Intel�ɂ����ăn�C�G���h�ɂ͂Ȃ�Ȃ�
1���W���[����Sandy��HTT��菭���ゾ�낤����AZambezi�ł�Sandy��6�R�A�肷��̂�����t
�n�C�G���h��Sandy 8�R�A�ɂ͓���͂��Ȃ������
�撣���B2�̉��ʐ��i�Ɛ킦��ʂ��낤����AX6 vs i7�݂����ȏɂȂ邾�낤
>>577
�@�R�A�P�̂̐��\�������ɍ����ɉz�������Ƃ͂Ȃ�����ǁA�_�C�ʐ�
�ӂ�̐��\�A����d�͕ӂ�̐��\�Ƃ̃o�����X����肾��ȁB
�@�R�A�P�̂̐��\�������ɍ����ɉz�������Ƃ͂Ȃ�����ǁA�_�C�ʐ�
�ӂ�̐��\�A����d�͕ӂ�̐��\�Ƃ̃o�����X����肾��ȁB
>>579
x86�͉�����ARM�ɔ����Ă�ȏ�A�X�[�p�[�X�J���I���z���ێ�����
�R�A�����荂IPC�ł��邵�������c����@�������Ǝv�����ǁB
Bulldozer�͂�����̂Ă��B
���͂���͖�肶��Ȃ����Ǝv���ȁ[�B
2�N�゠����AARM�̃u���[�h�I���������o�ė��邩������Ȃ����͋C�����ǁA
���̒���web�I�ł��������c��Ȃ�CPU����ARM�ɋ��ꂿ�Ⴄ�Ǝv����ˁB
���v�Ȃ̂��s������AAMD�́B
x86�͉�����ARM�ɔ����Ă�ȏ�A�X�[�p�[�X�J���I���z���ێ�����
�R�A�����荂IPC�ł��邵�������c����@�������Ǝv�����ǁB
Bulldozer�͂�����̂Ă��B
���͂���͖�肶��Ȃ����Ǝv���ȁ[�B
2�N�゠����AARM�̃u���[�h�I���������o�ė��邩������Ȃ����͋C�����ǁA
���̒���web�I�ł��������c��Ȃ�CPU����ARM�ɋ��ꂿ�Ⴄ�Ǝv����ˁB
���v�Ȃ̂��s������AAMD�́B
�@�l�����ł��ACPU�p���[���ŏd�v�ȗp�r�̓}���`�X���b�h�Ή���
�ǂ�ǂ�i��ł邩��Ȃ��BAMD�̕ʂ�Ȃ�A���p�セ��������
�Ȃ郌�x���̘b�Ƃ͎v���Ȃ��ȁB���_�̕��������Ƒ傫�����B
�@�܂��A�������Q�[���v���O�����̃x���`��Intel�Ɉ�������o��
��邱�Ƃ͂��邩������Ȃ����ǁA�ǂ��ł�������B
�ǂ�ǂ�i��ł邩��Ȃ��BAMD�̕ʂ�Ȃ�A���p�セ��������
�Ȃ郌�x���̘b�Ƃ͎v���Ȃ��ȁB���_�̕��������Ƒ傫�����B
�@�܂��A�������Q�[���v���O�����̃x���`��Intel�Ɉ�������o��
��邱�Ƃ͂��邩������Ȃ����ǁA�ǂ��ł�������B
ARM���ǂ�Ȃɍ����\�ɂȂ��Ă��I�t�B�X�⍂�𑜂ȃQ�[���͖������낤
ARM�͏��F�g�ы@�������CPU�ł�����x86�����������̂���Ȃ�
Bull�͌���H���͎̂Ă�����K10�Ɠ����ɍ����\�������薳��
�R�������Ȃ�Intel�����Ė��ɂȂ��
�ő�Intel�̗D�ʂ͌ÏL���V���O���X���b�h�x���`�ɂ����Ȃ��Ȃ��Ă��镪AMD��薢�����Ȃ�
�}���`�X���b�h�x�����Q�[�����x���AGPU�R�A�����ɗ��p�ł��Ȃ�(���ЂɃ��C�Z���X)�������
AMD�͍ň�GPU�R�A�ő����ł��邯��Intel��SSD���[�J�[�ɂȂ邵���Ȃ�
ARM�͏��F�g�ы@�������CPU�ł�����x86�����������̂���Ȃ�
Bull�͌���H���͎̂Ă�����K10�Ɠ����ɍ����\�������薳��
�R�������Ȃ�Intel�����Ė��ɂȂ��
�ő�Intel�̗D�ʂ͌ÏL���V���O���X���b�h�x���`�ɂ����Ȃ��Ȃ��Ă��镪AMD��薢�����Ȃ�
�}���`�X���b�h�x�����Q�[�����x���AGPU�R�A�����ɗ��p�ł��Ȃ�(���ЂɃ��C�Z���X)�������
AMD�͍ň�GPU�R�A�ő����ł��邯��Intel��SSD���[�J�[�ɂȂ邵���Ȃ�
�}���`�X���b�h�����s���Ă��A�r���E�A�g�~�b�N�ȏ������s���K�v������ȏ�A����x�������Ȃ�ق�
�V���O���X���b�h���\�͏d�v�ɂȂ��
�V���O���X���b�h���\�͏d�v�ɂȂ��
CPU�p���[���ŏd�v�ȗp�r�ɑ����g��ꂻ����FPU��SIMD�̃R�A�͑����Ȃ����ǂ�
�����ŋc�_����̂͂������ǁA����Ȃ�������]������Ȃ�����ȁc
���ށB�����f���ŋc�_�Ȃ�Ė��Ӗ��B
���낻��AMD�n���c�_����E�p���������h�̐^�ʖڂȃX�����K�v�Ȃ̂����ˁB
�c�_�͐~�[���g���Ȃ����X��A�����邾���ł悢�ӌ���������邾���B
���������Ă������N���̎�̃X�����݂Ă��邪�A�Ȃ�̐��Y�����Ȃ���B
�c�_�͐~�[���g���Ȃ����X��A�����邾���ł悢�ӌ���������邾���B
���������Ă������N���̎�̃X�����݂Ă��邪�A�Ȃ�̐��Y�����Ȃ���B
>>582
> �l�����ł��ACPU�p���[���ŏd�v�ȗp�r�̓}���`�X���b�h�Ή����ǂ�ǂ�i��ł邩��Ȃ��B
����Ⴛ�������A���ꂾ������������Ă��錻����ȏ�A���X�R�A���𑝂₵���Ƃ���ŏĂ��ɐ��Ȃ킯�łˁB
http://jisaku.155cm.com/src/1283015568_afc34da89e2a7e65ba98106f1b2b43e9f08080e4.jpg
> �l�����ł��ACPU�p���[���ŏd�v�ȗp�r�̓}���`�X���b�h�Ή����ǂ�ǂ�i��ł邩��Ȃ��B
����Ⴛ�������A���ꂾ������������Ă��錻����ȏ�A���X�R�A���𑝂₵���Ƃ���ŏĂ��ɐ��Ȃ킯�łˁB
http://jisaku.155cm.com/src/1283015568_afc34da89e2a7e65ba98106f1b2b43e9f08080e4.jpg
{kind=link}
>>488
�y����PC�zIntel SandyBridge�v���r���[�@�~�h�������W��i7 980X/HD5450�ɑ���
http://kamome.2ch.net/test/read.cgi/news/1282980453/
�����ٯ" (((( ;߄t�)))�����
�y����PC�zIntel SandyBridge�v���r���[�@�~�h�������W��i7 980X/HD5450�ɑ���
http://kamome.2ch.net/test/read.cgi/news/1282980453/
�����ٯ" (((( ;߄t�)))�����
llano��HD4670��5670�Ƃ��ŃQ�[������悤�ȃ��C�g�Q�[�}�[�ɂ͟����m�̈�i
�n�R�ȃQ�[�}�[�̊��҂̐�
HD4670�ς�PC���̂Ă邩�����ς����Llano�@�������邾���ŏȓd�͒�X�y�[�X�ɂȂ邩��ȁB
X2 250 + HD5450��Llano 3Ghz�������l�i���炢���ƍl����Ɣ������������Ȃ�z�����o���邾�낤
�n�R�ȃQ�[�}�[�̊��҂̐�
HD4670�ς�PC���̂Ă邩�����ς����Llano�@�������邾���ŏȓd�͒�X�y�[�X�ɂȂ邩��ȁB
X2 250 + HD5450��Llano 3Ghz�������l�i���炢���ƍl����Ɣ������������Ȃ�z�����o���邾�낤
AMD�̃r�f�I�J�[�h�������������
AnandTech��Core i5 2400(4C/4T/3.1GHz/TB��3.4GHz/L3 6MB/95W)�̃v���r���[
http://www.anandtech.com/show/3871/the-sandy-bridge-preview-three-wins-in-a-row/1
CPU�̃p�t�H�[�}���X�ɂ��ẮAHT�I����8�X���b�h�ɂ����ꍇ��Core i7 880(4C/8T/3.06GHz)�����ʂɏ����Ă��銴���ŁA
IPC�Ƃ��Ă�10%�O��̌��オ�����܂���
�܂�����̃`���[�j���O����ł̓p�t�H�[�}���X���オ���Ă���\��������܂��̂ŁA�����_�ł̌��ʂƂ��Ă͂Ȃ��Ȃ��ǂ������ł�
SandyBridge����̃��C���i�b�v�����������ł́A���s�����蓯���i�тŃN���b�N���L�тĂ��銴���Ȃ̂ŁA�R�X�g�p�t�H�[�}���X�����\�オ�肻���ł�
����d�͂̓A�C�h������Lynnfield�Ɠ����x�A���[�h����Core i5 760(4C/2.8GHz)��10W���x�����
�R�A������10�l�ȏ���サ�ď���d�͂�������SandyBridge
K10���R�A�������CPU�p�t�H�[�}���X��������u���B
��(߄t߄�) ˿˿( ߄t�)��ާ(߄t� )Ȫ����? ... (( �G߄D�)))))))��������
http://www.anandtech.com/show/3871/the-sandy-bridge-preview-three-wins-in-a-row/1
CPU�̃p�t�H�[�}���X�ɂ��ẮAHT�I����8�X���b�h�ɂ����ꍇ��Core i7 880(4C/8T/3.06GHz)�����ʂɏ����Ă��銴���ŁA
IPC�Ƃ��Ă�10%�O��̌��オ�����܂���
�܂�����̃`���[�j���O����ł̓p�t�H�[�}���X���オ���Ă���\��������܂��̂ŁA�����_�ł̌��ʂƂ��Ă͂Ȃ��Ȃ��ǂ������ł�
SandyBridge����̃��C���i�b�v�����������ł́A���s�����蓯���i�тŃN���b�N���L�тĂ��銴���Ȃ̂ŁA�R�X�g�p�t�H�[�}���X�����\�オ�肻���ł�
����d�͂̓A�C�h������Lynnfield�Ɠ����x�A���[�h����Core i5 760(4C/2.8GHz)��10W���x�����
�R�A������10�l�ȏ���サ�ď���d�͂�������SandyBridge
K10���R�A�������CPU�p�t�H�[�}���X��������u���B
��(߄t߄�) ˿˿( ߄t�)��ާ(߄t� )Ȫ����? ... (( �G߄D�)))))))��������
�i�����Ȃ��`�b�v�Z�b�g�iP67/H67/H61�j���S�~
http://www.anandtech.com/show/3871/the-sandy-bridge-preview-three-wins-in-a-row/3
http://www.anandtech.com/show/3871/the-sandy-bridge-preview-three-wins-in-a-row/3
PCI�����ɔp�~��
IPC�Ƃ��Ă͌��s������A10%��CPU�p�t�H�[�}���X����B
GPU�Ƃ��Ă͌��s����Core i5 540����2�{�̃p�t�H�[�}���X����B
����d�͂̓A�C�h���͌��s����Lynnfield�ƕς�炸�A
�t�����[�h��Core i5 760(4C/2.8GHz)10W���B���B
����̃`���[�j���O����ł̓p�t�H�[�}���X���X�ɏオ���Ă���\��������
(( �G߄D�))������ ˨�
GPU�Ƃ��Ă͌��s����Core i5 540����2�{�̃p�t�H�[�}���X����B
����d�͂̓A�C�h���͌��s����Lynnfield�ƕς�炸�A
�t�����[�h��Core i5 760(4C/2.8GHz)10W���B���B
����̃`���[�j���O����ł̓p�t�H�[�}���X���X�ɏオ���Ă���\��������
(( �G߄D�))������ ˨�
ID:picwUzHR
����̏���r�ŎQ�l�ɂ������̂ŋ����Ă�������
�J�W���A���ȃl�g�Q�⓮�悮�炢�������Ȃ��̂�GPU���\���ǂ��炵��Llano���l���Ă܂�
Liano��Intel�Ō���i3���炢�Ɣ�r���Ă��������̂ł��傤���H
�J�W���A���ȃl�g�Q�⓮�悮�炢�������Ȃ��̂�GPU���\���ǂ��炵��Llano���l���Ă܂�
Liano��Intel�Ō���i3���炢�Ɣ�r���Ă��������̂ł��傤���H
>>594 PCIe �� 5GT/s �ɑΉ����邾���ł������Ȃ�...
�J�W���A���ȃl�g�Q�Ƃ͌������ǁA�ǂ̒��x�̃Q�[����z�肵�Ă�H
Flash�Ƃ���CPU���\�̂ق����H�����Ƃ���������CPU���\���d����������������B
�����̃X���Z�l���킭Dirt2���x�Ȃ�790GX�ł��ʂ�ʂ铮���炵�����A
���̒��x�̐��\�Ȃ�Sandy Bridge, Llano�ǂ������]�T�ŃN���A���Ă���B
�����蕉�ׂ̌y���Q�[���Ȃ�GPU���\�Ȃ�Ă����Ă����ʂ�����B
Flash�Ƃ���CPU���\�̂ق����H�����Ƃ���������CPU���\���d����������������B
�����̃X���Z�l���킭Dirt2���x�Ȃ�790GX�ł��ʂ�ʂ铮���炵�����A
���̒��x�̐��\�Ȃ�Sandy Bridge, Llano�ǂ������]�T�ŃN���A���Ă���B
�����蕉�ׂ̌y���Q�[���Ȃ�GPU���\�Ȃ�Ă����Ă����ʂ�����B
5GT/s����PCIe Gen2.0�̐��l������
>>600
���������Q�[����GPU���\�Œ��ׂ���]�T�Œ����Ă��̂ő��v���Ǝv���܂�
���Ԃ�I�Ԕ�r��͒l�i�Ə���d�͂��炢�ɂȂ肻���ł�
������r����ɂ�������Llano�Ɖ����ׂ��炢���̂������Ă��܂���
���S�҂����ēI�O��Ȃ��Ƃ������Ă����炷�݂܂���
���������Q�[����GPU���\�Œ��ׂ���]�T�Œ����Ă��̂ő��v���Ǝv���܂�
���Ԃ�I�Ԕ�r��͒l�i�Ə���d�͂��炢�ɂȂ肻���ł�
������r����ɂ�������Llano�Ɖ����ׂ��炢���̂������Ă��܂���
���S�҂����ēI�O��Ȃ��Ƃ������Ă����炷�݂܂���
Llano2�R�A��CeleG��PenG�A4�R�A��i3�R�����肩��
�N���b�N�Ȃǂ�������Ȃ���łȂ�Ƃ������
AMD�X���Ȃ�ŃJ�W���A���Ȏg��������̂Ȃ�Llano��������Ȃ����ƑE�߂Ƃ�
DX11�ɑΉ����Ă邵�Q�[���ł̕s���Intel��GPU���͏��Ȃ��͂�
Sandy��GPU����DX10.1���炢�ɂ͑Ή����Ă���̂��˂�
�N���b�N�Ȃǂ�������Ȃ���łȂ�Ƃ������
AMD�X���Ȃ�ŃJ�W���A���Ȏg��������̂Ȃ�Llano��������Ȃ����ƑE�߂Ƃ�
DX11�ɑΉ����Ă邵�Q�[���ł̕s���Intel��GPU���͏��Ȃ��͂�
Sandy��GPU����DX10.1���炢�ɂ͑Ή����Ă���̂��˂�
>>605
�Ȃ�قǁA���̂�����Ȃ�ł���
�����Ȃ�ƒl�i���������ł�������
�����̋��߂Ă���̂�Llano�ɋ߂��C�����Ă�����ŕ������Ă��炢�܂���
�Ȃ�قǁA���̂�����Ȃ�ł���
�����Ȃ�ƒl�i���������ł�������
�����̋��߂Ă���̂�Llano�ɋ߂��C�����Ă�����ŕ������Ă��炢�܂���
>>601 H5x/P5x ��PCIe Gen 2 �ł� 2.5GT/s
����������ʼn��S���X�i��ł�悗
���؋��͂��̖��ʂȏ�M�𑼂Ɍ���������̂ɂ��Â��Ԕ����ȓz�炾
���؋��͂��̖��ʂȏ�M�𑼂Ɍ���������̂ɂ��Â��Ԕ����ȓz�炾
���������1�s���ʂɕt�������������ʼn��S���X���i�ނ킯�ł�
�R�s�y�A���ɏ�M�X����Ƃ͂���J�Ȃ�����
�����̗����Ō����͉��ɂ��ς���
�����̗����Ō����͉��ɂ��ς���
>>577
�}���`�X���b�h���\�Ȃ��
�v���O������Ń}���`���o���銄���̖�肾����ȁB
�V���O���X���b�h�����������R�[�h�͗L�蓾�Ȃ���
�����̔�d�͂��̐���ς���B
�}���`�X���b�h���\�Ȃ��
�v���O������Ń}���`���o���銄���̖�肾����ȁB
�V���O���X���b�h�����������R�[�h�͗L�蓾�Ȃ���
�����̔�d�͂��̐���ς���B
6EU�A�^�[�{�����ŁA���������ʃ��f���ł��̐��\���ƁA
12EU�A�^�[�{����̃f���A���R�A���f����IGP�͂��̔{�ȏ��
���\������ƌ��Ă������낤�B��������ƁA�ق�HD5500��
���\�����W���BLlano��GPU�̐��\�I�A�h�o���e�[�W���Ėw��
�Ȃ���E�E�E�B
12EU�A�^�[�{����̃f���A���R�A���f����IGP�͂��̔{�ȏ��
���\������ƌ��Ă������낤�B��������ƁA�ق�HD5500��
���\�����W���BLlano��GPU�̐��\�I�A�h�o���e�[�W���Ėw��
�Ȃ���E�E�E�B
���V���O���X���b�h�����������R�[�h
�ȁ@�Ɂ@���@��
�X���b�h�N���X�����ĂȂ��v���O�����̂��Ƃ��H
����Ƃ������I�ꎞ�I�ɃV���O���X���b�h�ɂ���Ƃ������Ӗ��s���ȍs���Ȃ̂��H
�ȁ@�Ɂ@���@��
�X���b�h�N���X�����ĂȂ��v���O�����̂��Ƃ��H
����Ƃ������I�ꎞ�I�ɃV���O���X���b�h�ɂ���Ƃ������Ӗ��s���ȍs���Ȃ̂��H
>>615
�������ш�ɐ��������GPU�̏������x���̂ɃA�h�o���e�[�W�͖����ł���
�厖�Ȃ̂́ARadeon���ڂ邱�ƂƁANB�̔p�~�ň���������悤�ɂȂ��Ȃ������Ă���
���ƍ���MB�p��2�`�b�v�g���Ă��邪����������Ȃ�
�`�b�v��1����������������邩�����ē_��������Ƃ��邩��
�������ш�ɐ��������GPU�̏������x���̂ɃA�h�o���e�[�W�͖����ł���
�厖�Ȃ̂́ARadeon���ڂ邱�ƂƁANB�̔p�~�ň���������悤�ɂȂ��Ȃ������Ă���
���ƍ���MB�p��2�`�b�v�g���Ă��邪����������Ȃ�
�`�b�v��1����������������邩�����ē_��������Ƃ��邩��
GPU�̓������ш悳���[���Ȃ�T�C�Y�{�Ő��\�{����
�������ASandy12EU�Ƃ��̃_�C�T�C�Y�������炩�m���
���ɃO�O���ďo�Ă���220m�u�Ƃ����
Llano��GPU�����̂�40m�u��5�{���͂�����
�����ق��Atom��f�i�Ƃ�����ȊO�Ɍ�邱�Ƃ��Ȃ�
�������ASandy12EU�Ƃ��̃_�C�T�C�Y�������炩�m���
���ɃO�O���ďo�Ă���220m�u�Ƃ����
Llano��GPU�����̂�40m�u��5�{���͂�����
�����ق��Atom��f�i�Ƃ�����ȊO�Ɍ�邱�Ƃ��Ȃ�
GMA��{�i�I�Ƀ`�����Q�ɍ��킷���߂ɃQ�[���h���C�o�̊J���ɂ����͂��Ă����Ȃ��Ƃ����Ȃ�
�قڃ[������̏o���Ɛ̂����RADEON�u�����h�Ƃ��ǂ������J���҂͂Ƃ邾�낤���E�E�E
�قڃ[������̏o���Ɛ̂����RADEON�u�����h�Ƃ��ǂ������J���҂͂Ƃ邾�낤���E�E�E
Llano�@���@32nm��K10�n�@CPU�R�APhenom II�x�[�X
�@�@�@�@�@GPU�R�A�����@(���o�C��HD5600or5500�V���[�Y�̏ȓd�͔Ł@SP��480)
Llano�@��CPU�R�APhenom II�x�[�X�@
ӁEӳ��ҁE�E�E. ~~(*/>_<)o��E�ǰ
Llano�@���@32nm��K10�n
(>< )o�_���[o( ><)o�_���[
�@�@�@�@�@GPU�R�A�����@(���o�C��HD5600or5500�V���[�Y�̏ȓd�͔Ł@SP��480)
Llano�@��CPU�R�APhenom II�x�[�X�@
ӁEӳ��ҁE�E�E. ~~(*/>_<)o��E�ǰ
Llano�@���@32nm��K10�n
(>< )o�_���[o( ><)o�_���[
�u���h�[�U�[�@�N���b�N������̐��\�@K10�ȉ��B
Llano�@���@32nm��K10�n�@L3�L���b�V�����X Phenom II�x�[�X
�V�K�ɍ��Ȃ��ȁB�'`,�'`,�(�L��`) '`,�'`,� ���ǁA�x������x���K10����A�������Ȃ��B
Llano�@���@32nm��K10�n�@L3�L���b�V�����X Phenom II�x�[�X
�V�K�ɍ��Ȃ��ȁB�'`,�'`,�(�L��`) '`,�'`,� ���ǁA�x������x���K10����A�������Ȃ��B
>>615
�A���l�i�͂T�`10�{��
�A���l�i�͂T�`10�{��
Llano�@���@32nm��K10�n�@CPU�R�APhenom II�x�[�X L3�L���b�V�����X
��U(���Á�o)�Ԃ��@���̒i�K�ŏI����Ă��B
http://images.anandtech.com/graphs/sandybridgepreview_082710002107/24397.png
6�R�A�@1090T����CPU���\�Ń��C�v�������Ă�̂�
4�R�AK10�n�@CPU�R�APhenom II�x�[�X���āE�E�E�E�B
�S(�V�E�ށE)�m ���͂�,
��U(���Á�o)�Ԃ��@���̒i�K�ŏI����Ă��B
http://images.anandtech.com/graphs/sandybridgepreview_082710002107/24397.png
6�R�A�@1090T����CPU���\�Ń��C�v�������Ă�̂�
4�R�AK10�n�@CPU�R�APhenom II�x�[�X���āE�E�E�E�B
�S(�V�E�ށE)�m ���͂�,
>>622
�N���b�N������̐��\�͂P�T������(����\�����\�ƃL���b�V�����̂̐��\����)
�N���b�N���̂�3���������ĂƂ��낾�낤��
�܁A�����������ɂ͕����Ȃ���˂�����
�N���b�N������̐��\�͂P�T������(����\�����\�ƃL���b�V�����̂̐��\����)
�N���b�N���̂�3���������ĂƂ��낾�낤��
�܁A�����������ɂ͕����Ȃ���˂�����
���M���Ȃ����̓R�e���O���čH�삷��_���S���S���_��
Sandy Bridge��L3�͍ŏ�ʂ�i7����8MB�ł���ȊO��6MBor3MB�Ȃ͉̂��̂��A�����ƍl���Ă�����
������B
�{���̗e�ʂ�1/4��IGP��p�Ƃ��Ďg���ĂāAi7�̓f�B�X�N���[�g�J�[�h��}�����Ƃ�z�肵��
IGP���E����8MB�t���Ɏg�����ǂ�����BIOS�ݒ肩�ȂőI���ł���A�Ƃ����\�����Ȃ�����
����GPU�p��L3��1�`2MB�����蓖�Ă��Ă�Ƃ���A�����܂������\����̗��R�������ł���Ǝv�����B
������B
�{���̗e�ʂ�1/4��IGP��p�Ƃ��Ďg���ĂāAi7�̓f�B�X�N���[�g�J�[�h��}�����Ƃ�z�肵��
IGP���E����8MB�t���Ɏg�����ǂ�����BIOS�ݒ肩�ȂőI���ł���A�Ƃ����\�����Ȃ�����
����GPU�p��L3��1�`2MB�����蓖�Ă��Ă�Ƃ���A�����܂������\����̗��R�������ł���Ǝv�����B
rade�Ƃ�gefo���ƃV�F�[�_�[��2�{�ŃQ�[���̃t���[�����[�g��1.3�`1.5�{�ɂȂ銴��
>>627
�P�ɍ��ʉ��ō���Ă��邾�����ƁB
����σ_�C�T�C�Y�ł�������A���������n���ȃR�X�g�팸�����Ȃ��ƁA
���i������ʂ��m�ۂ���̂ɑ�ς����炾�Ǝv�����B
�P�ɍ��ʉ��ō���Ă��邾�����ƁB
����σ_�C�T�C�Y�ł�������A���������n���ȃR�X�g�팸�����Ȃ��ƁA
���i������ʂ��m�ۂ���̂ɑ�ς����炾�Ǝv�����B
>>627
�\��������BIOS��VGA���E���邮�炢�͂ł��邾��B
�����A����Ȏg�����́A�����g�ݗ��Ăŋ��̂Ȃ���������n�I�^���A
���GPU��lj������ꍇ�ɂ��������g���������邩������Ȃ����A
����n�I�^�͕��ʂ�"Sandy Bridge"��"Socket H2"�����낤�ˁB
�I����"Nehalem"����̓X���[�����̂�"Socket H2"�͑_���Ă��邵�B
���������ŁAGPU�����̓��[�J�[��PC�ŏd�v�Ȗ������ʂ����B
"Llano"��GPU�����^�C�v��"Sandy Bridge"������
���ʂ̃f�X�N�g�b�v���A��^���u�m�[�g�n������̐��i����B
�����Ȃ�Ɖ��i�����ɂȂ�̂ŁA�_�C�����^��"Llano"���D�ʂɓW�J�ł���B
�\��������BIOS��VGA���E���邮�炢�͂ł��邾��B
�����A����Ȏg�����́A�����g�ݗ��Ăŋ��̂Ȃ���������n�I�^���A
���GPU��lj������ꍇ�ɂ��������g���������邩������Ȃ����A
����n�I�^�͕��ʂ�"Sandy Bridge"��"Socket H2"�����낤�ˁB
�I����"Nehalem"����̓X���[�����̂�"Socket H2"�͑_���Ă��邵�B
���������ŁAGPU�����̓��[�J�[��PC�ŏd�v�Ȗ������ʂ����B
"Llano"��GPU�����^�C�v��"Sandy Bridge"������
���ʂ̃f�X�N�g�b�v���A��^���u�m�[�g�n������̐��i����B
�����Ȃ�Ɖ��i�����ɂȂ�̂ŁA�_�C�����^��"Llano"���D�ʂɓW�J�ł���B
Llano��480SP�ƌ����̂��烋�[�}�[�̊�]�I�ϑ��̈���o�Ȃ�����
���́A�������x�̃_�C�T�C�Y�ł݂��ꍇ�A�ʐϓ�����̃g�����W�X�^������CPU��GPU�ł����傫���ς��Ȃ����Ƃ��킩��B
pc.watch.impress.co.jp/video/pcw/docs/380/148/10.pdf
����Radeon�ł��K�͂��������قǖʐϓ������SP���͏��Ȃ��Ȃ��Ă邵
�R���g���[���u���b�N�̔䗦�̏��Ȃ��n�C�G���h����ɔ�Z�p�������
�Ƃ�ł��Ȃ�����������\���͂����ȁB
Llano��GPU�����̖ʐς���40�`50mm²���x����H
40nm����32nm�ɃV�������N���Ă��A�悭�ăg�����W�X�^���x��1.3�`1.4�{�ɂȂ���x�B
�ƍl����ƁALlano��5450(40nm��59mm²)���̂܂�܂Ƃ����\������ے�ł��Ȃ��B
�悭�Ă����̔{���x���炢���B
����܂�n�[�h���グ�Ă��Ȃ�B
���́A�������x�̃_�C�T�C�Y�ł݂��ꍇ�A�ʐϓ�����̃g�����W�X�^������CPU��GPU�ł����傫���ς��Ȃ����Ƃ��킩��B
pc.watch.impress.co.jp/video/pcw/docs/380/148/10.pdf
����Radeon�ł��K�͂��������قǖʐϓ������SP���͏��Ȃ��Ȃ��Ă邵
�R���g���[���u���b�N�̔䗦�̏��Ȃ��n�C�G���h����ɔ�Z�p�������
�Ƃ�ł��Ȃ�����������\���͂����ȁB
Llano��GPU�����̖ʐς���40�`50mm²���x����H
40nm����32nm�ɃV�������N���Ă��A�悭�ăg�����W�X�^���x��1.3�`1.4�{�ɂȂ���x�B
�ƍl����ƁALlano��5450(40nm��59mm²)���̂܂�܂Ƃ����\������ے�ł��Ȃ��B
�悭�Ă����̔{���x���炢���B
����܂�n�[�h���グ�Ă��Ȃ�B
��������[�̊�n�O�����C���˂�
���\�ŏ����Ă�Ȃ�]�T���ł��čr�炵�Ȃ�Ă��Ȃ������ǂ�
�c�q���G������n�O�����炵�傤���Ȃ�����
���\�ŏ����Ă�Ȃ�]�T���ł��čr�炵�Ȃ�Ă��Ȃ������ǂ�
�c�q���G������n�O�����炵�傤���Ȃ�����
>>631
�ǂ����ɂ���SIMD�A���C������GPU�͓����Ȃ����낤
�K�v�ȏ�̊��҂����Ēp���������́A���Ȃ߂Ɍ��Ă����ďo�Ă������ɈӊO�Ɨǂ��Ǝv�����ق���
�ǂ��Ǝv�����B
����I�Ȃ̂́A40nm����32nm�͔��m�[�h���̏k�����ł����Ȃ��Ƃ������ƁB
Redwood�i�_�C�T�C�Y100mm²)�������ȉ��̖ʐςɂȂ蓾�邩�H
�ǂ����ɂ���SIMD�A���C������GPU�͓����Ȃ����낤
�K�v�ȏ�̊��҂����Ēp���������́A���Ȃ߂Ɍ��Ă����ďo�Ă������ɈӊO�Ɨǂ��Ǝv�����ق���
�ǂ��Ǝv�����B
����I�Ȃ̂́A40nm����32nm�͔��m�[�h���̏k�����ł����Ȃ��Ƃ������ƁB
Redwood�i�_�C�T�C�Y100mm²)�������ȉ��̖ʐςɂȂ蓾�邩�H
800sp��5770�̃T�C�Y��11.7�~15.2mm
http://www.4gamer.net/games/098/G009885/20091012005/
400sp��5670�̃T�C�Y��11�~11mm
http://www.4gamer.net/games/098/G009886/20100113063/
�������C���^�[�t�F�[�X�͓���128bit��
5770����5670�̖ʐό�������sp�������ɓ������Ƃ�����
400sp����57mm^2@40nm
�R�}���h�v���Z�b�T�Ƃ��e�b�Z���j�b�g�Ȃǂ������Ă�O���t�B�b�N�X�G���W��
���������Ă��\�����肻�������ǂ�
http://www.4gamer.net/games/098/G009885/20091012005/
400sp��5670�̃T�C�Y��11�~11mm
http://www.4gamer.net/games/098/G009886/20100113063/
�������C���^�[�t�F�[�X�͓���128bit��
5770����5670�̖ʐό�������sp�������ɓ������Ƃ�����
400sp����57mm^2@40nm
�R�}���h�v���Z�b�T�Ƃ��e�b�Z���j�b�g�Ȃǂ������Ă�O���t�B�b�N�X�G���W��
���������Ă��\�����肻�������ǂ�
������ʐϓ������SP�����������Ă�̂���Z�p�����Ă�
��������SP�̌����Ȃ�A40nm��59mm²��5450�ɂ�200SP���x�͓���Ȃ��Ƃ�����������
������������40nm�Ƃ����ď̂ł�����͐������[�J�[�̎��̂ł�����
���v���x�͈ꏏ����Ȃ��炵��
���v���x�͈ꏏ����Ȃ��炵��
�V���O���X���b�h�~���Ă̂�
�����̃E���R�����������H����
������x�������Ȃ�ق�
���V���O���X���b�h���\�͏d�v�ɂȂ��
�Ƃ�
���K�͂��������قǖʐϓ������SP���͏��Ȃ��Ȃ��Ă�
��Llano��5450(40nm��59mm�H)���̂܂��
�Ƃ������Ƃ������ēx�E���R�Y����悤��
Bull�ŃV���O���X���b�h���\2/3�Ƃ������Ė\���z�̂��Ƃ������Ă�ˁ[�́H
Bull�̓v���t�F�b�`�╪�������������Ɣ�����������
�����̃E���R�����������H����
������x�������Ȃ�ق�
���V���O���X���b�h���\�͏d�v�ɂȂ��
�Ƃ�
���K�͂��������قǖʐϓ������SP���͏��Ȃ��Ȃ��Ă�
��Llano��5450(40nm��59mm�H)���̂܂��
�Ƃ������Ƃ������ēx�E���R�Y����悤��
Bull�ŃV���O���X���b�h���\2/3�Ƃ������Ė\���z�̂��Ƃ������Ă�ˁ[�́H
Bull�̓v���t�F�b�`�╪�������������Ɣ�����������
>>628
���̗��_�ł�����40sp����200sp��5�{
�t���[�����[�g��3.25�{����3.75�{�ɂȂ�
880G��Clarkdale
880G*2��HD5450��Core i5 2400�炵���̂�
Core i5 2400�����S�ɏ����Ă��܂�
�����E����6EU�����S�ł�12EU�ɂ��Đ��\���{�ɂȂ�I
�Ƃ������@������Ȃ�b�͕ʂ���
���̗��_�ł�����40sp����200sp��5�{
�t���[�����[�g��3.25�{����3.75�{�ɂȂ�
880G��Clarkdale
880G*2��HD5450��Core i5 2400�炵���̂�
Core i5 2400�����S�ɏ����Ă��܂�
�����E����6EU�����S�ł�12EU�ɂ��Đ��\���{�ɂȂ�I
�Ƃ������@������Ȃ�b�͕ʂ���
> 800sp��5770�̃T�C�Y��11.7�~15.2mm
> http://www.4gamer.net/games/098/G009885/20091012005/
> 400sp��5670�̃T�C�Y��11�~11mm
> http://www.4gamer.net/games/098/G009886/20100113063/
>
> �������C���^�[�t�F�[�X�͓���128bit��
> 5770����5670�̖ʐό�������sp�������ɓ������Ƃ�����
> 400sp����57mm^2@40nm
�܂�ASP�������������ʐς�63mm²���x�łǂ������������x���Ă��Ƃ��ȁB
�����@�\�����5450��80SP���x�����ڂ�Ȃ��킯���B
480SP���������̂Ȃ��\���Ȃ̂���I�����܂����B
> http://www.4gamer.net/games/098/G009885/20091012005/
> 400sp��5670�̃T�C�Y��11�~11mm
> http://www.4gamer.net/games/098/G009886/20100113063/
>
> �������C���^�[�t�F�[�X�͓���128bit��
> 5770����5670�̖ʐό�������sp�������ɓ������Ƃ�����
> 400sp����57mm^2@40nm
�܂�ASP�������������ʐς�63mm²���x�łǂ������������x���Ă��Ƃ��ȁB
�����@�\�����5450��80SP���x�����ڂ�Ȃ��킯���B
480SP���������̂Ȃ��\���Ȃ̂���I�����܂����B
�G������̍����̐킢�́AGPU���������������Ȃ̂��A
�����ϑz�ʼn����邱�Ƃɂ���āA�グ�悤�Ƃ��Ă���̂��B
CPU�g�[�^���Ɠ������郌���W���Ⴄ�̂ɁA
�����܂ŕK���ɂȂ��̂͑A�܂����ȁB
�����ϑz�ʼn����邱�Ƃɂ���āA�グ�悤�Ƃ��Ă���̂��B
CPU�g�[�^���Ɠ������郌���W���Ⴄ�̂ɁA
�����܂ŕK���ɂȂ��̂͑A�܂����ȁB
llano�̎ʐ^
ttp://xtreview.com/images/AMD%20llano%20architecture%2005.jpg
�u���b�N�̐�����480sp��240sp����2�����ƕ��������Ƃ����邪
���ɂ͂ǂ���������̂��T�b�p���E�E�E
�����Ƃ肠�����E���R��
DisableGDDR�����R�����̃A���R�A����������sp������
40nmLlano��-20m�u�قǂ���ƌv�Z���Ă�̂���
ttp://xtreview.com/images/AMD%20llano%20architecture%2005.jpg
{kind=link}
�u���b�N�̐�����480sp��240sp����2�����ƕ��������Ƃ����邪
���ɂ͂ǂ���������̂��T�b�p���E�E�E
�����Ƃ肠�����E���R��
DisableGDDR�����R�����̃A���R�A����������sp������
40nmLlano��-20m�u�قǂ���ƌv�Z���Ă�̂���
65W��Llano(170mm2)��HD5570��
95W��i5 2400(220mm2)��HD5450��
HD5570 = HD5450x3�`5
���b�g�p�t�H�[�}���X��5�{���炢�����o��
�ǂ����Ă�Llano�̈����A�����͊��ɂ��Ă����
95W��i5 2400(220mm2)��HD5450��
HD5570 = HD5450x3�`5
���b�g�p�t�H�[�}���X��5�{���炢�����o��
�ǂ����Ă�Llano�̈����A�����͊��ɂ��Ă����
RV770�i800SP)�̏ꍇ
http://www.geeks3d.com/public/jegx/200806/rv770-die.jpg
Llano�ŕs�v�ɂȂ郁���R���EPCIe�����̐�߂�ʐςȂ�đ債��������Ȃ����Ƃ��킩��B
�܂�SP�ȊO�̖ʐςɔ������ȁB
400SP���ڂ�悤���Ȃ�
http://www.geeks3d.com/public/jegx/200806/rv770-die.jpg
{kind=link}
Llano�ŕs�v�ɂȂ郁���R���EPCIe�����̐�߂�ʐςȂ�đ債��������Ȃ����Ƃ��킩��B
�܂�SP�ȊO�̖ʐςɔ������ȁB
400SP���ڂ�悤���Ȃ�
���Ȃ݂�Ontario��80sp��HD5450��
�܂� i5 2400 = Ontario�Ƃ�������
�܂� i5 2400 = Ontario�Ƃ�������
Sandy��GPU���\����́ACPU��Vertex�AGeometry�������Ă��邩����Ă̂����邾�낤����A
2�R�A�ł�HD5450���̐��\�͖����ȋC������B
2�R�A�ł�HD5450���̐��\�͖����ȋC������B
���������K�v�ȋ@�\�����Ă��Ȃ�Intel iGPU�c�c�@�ŏ�������
http://www.xtremesystems.org/forums/showthread.php?p=4421074
40nm��Radeon HD5450��59mm²
Ontario�͓���40nm�ŁAx86�f���A���R�A�{GPU��87mm²
Ontario��GPU���\��HD5450�������Ƃ���Ȃ�2�R�A�{�m�[�X�u���b�W��28mm²�ȓ��ɔ[�߂Ȃ��Ƃ����Ȃ��B
Atom�ł��疳���Ȑ������ȁB
40nm��Radeon HD5450��59mm²
Ontario�͓���40nm�ŁAx86�f���A���R�A�{GPU��87mm²
Ontario��GPU���\��HD5450�������Ƃ���Ȃ�2�R�A�{�m�[�X�u���b�W��28mm²�ȓ��ɔ[�߂Ȃ��Ƃ����Ȃ��B
Atom�ł��疳���Ȑ������ȁB
Sandy���V�����}�C�N���`�b�v�E�V�A�[�L�e�N�`���B
�@�@�@�O����uNehalem�v�A�[�L�e�N�`���Ɏ���đ���V���m�B
�@�@�@�N���b�N�P�ʁ@���\���@GPU��{���@����d�́@�t�����[�h10W��
http://images.anandtech.com/graphs/sandybridgepreview_082710002107/24397.png
�@�@�@�@�@�@VS
Llano�@���@���Â�Phenom II��L3���X�ɂ��ď����ǂ���32nm��K10�n
�@�@�@�@�@CPU�R�A��Phenom II�x�[�X L3�L���b�V�����X�Ȃ̂ŁA
�N���b�N�P�ʁ@���\���BGPU�����@�����GPU���\�̂݁B
�V�����}�C�N���`�b�v�E�V�A�[�L�e�N�`���B
VS
���Â�K10�ˑ��̌Â��}�C�N���`�b�v�̏����ǁE����Phenom II�A�[�L�e�N�`��
(�P�[�P )�`�`K10���̐��܂ŃV���u���s�������`�`�۳� �۳ہ`�`���Ɛ�����K10���ǂōs����!�`�`�۳� �۳ہ`�`
�@�@�@�O����uNehalem�v�A�[�L�e�N�`���Ɏ���đ���V���m�B
�@�@�@�N���b�N�P�ʁ@���\���@GPU��{���@����d�́@�t�����[�h10W��
http://images.anandtech.com/graphs/sandybridgepreview_082710002107/24397.png
�@�@�@�@�@�@VS
Llano�@���@���Â�Phenom II��L3���X�ɂ��ď����ǂ���32nm��K10�n
�@�@�@�@�@CPU�R�A��Phenom II�x�[�X L3�L���b�V�����X�Ȃ̂ŁA
�N���b�N�P�ʁ@���\���BGPU�����@�����GPU���\�̂݁B
�V�����}�C�N���`�b�v�E�V�A�[�L�e�N�`���B
VS
���Â�K10�ˑ��̌Â��}�C�N���`�b�v�̏����ǁE����Phenom II�A�[�L�e�N�`��
(�P�[�P )�`�`K10���̐��܂ŃV���u���s�������`�`�۳� �۳ہ`�`���Ɛ�����K10���ǂōs����!�`�`�۳� �۳ہ`�`
sandy���l�n�[�����̉��ǂ���c
�Ղ肪�ł���ׂ������Ƃ͂Ƃ��ł������B
ttp://miner7.hp.infoseek.co.jp/
ttp://miner7.hp.infoseek.co.jp/
�܂����̈Ӗ��Ȃ������N��
http://j.mycom.jp/articles/2010/06/09/intel/images/008l.jpg
�j10���{����������Core Duo���ォ��p�t�H�[�}���X��2�{�`3�{�傫�����サ�Ă�̂ɁE�E�B
http://j.mycom.jp/articles/2010/06/09/intel/images/014l.jpg
CINEBENCH�𗘗p����Sandy Bridge�̃x���`�}�[�N�f���B�������s�̃C���e���N�A�b�h�R�ACPU�A�E�̍����ȕ���Sandy Bridge�Ƃ����
K10�x�[�X���āA�J���w�A�������Ă邩�A5�N�O�Ƀ^�C���X���b�v�����܂܂Ȃ�ˁ[��??
Core Duo����A���ĂȂ�K10�̍�����Ԃ�s�����ĉ����������̂�w
{kind=link}
�j10���{����������Core Duo���ォ��p�t�H�[�}���X��2�{�`3�{�傫�����サ�Ă�̂ɁE�E�B
http://j.mycom.jp/articles/2010/06/09/intel/images/014l.jpg
{kind=link}
CINEBENCH�𗘗p����Sandy Bridge�̃x���`�}�[�N�f���B�������s�̃C���e���N�A�b�h�R�ACPU�A�E�̍����ȕ���Sandy Bridge�Ƃ����
K10�x�[�X���āA�J���w�A�������Ă邩�A5�N�O�Ƀ^�C���X���b�v�����܂܂Ȃ�ˁ[��??
Core Duo����A���ĂȂ�K10�̍�����Ԃ�s�����ĉ����������̂�w
>>646
�����牟������̒��ŃE���R���M�d�ȐH���Ő��������������
�������E�ł͂����̔r��������
�E���R�F���Ă邩����Ė{���̃E���R�����킯�ł͒f���ĂȂ�
��ނ̃_�C���C�A�E�g�͌�����Ȃ���������
��̫�͂���
ttp://www.4gamer.net/games/050/G005004/20080614003/images/13.jpg
ttp://www.hothardware.com/articleimages/Item1167/die_overlay.jpg
rop�ƃo�b�t�@�ƃX�P�W���[���ӂ肩�s���Ȃ̂�
������x�������E���R�ł͒f���Ė�����
�����牟������̒��ŃE���R���M�d�ȐH���Ő��������������
�������E�ł͂����̔r��������
�E���R�F���Ă邩����Ė{���̃E���R�����킯�ł͒f���ĂȂ�
��ނ̃_�C���C�A�E�g�͌�����Ȃ���������
��̫�͂���
ttp://www.4gamer.net/games/050/G005004/20080614003/images/13.jpg
{kind=link}
ttp://www.hothardware.com/articleimages/Item1167/die_overlay.jpg
{kind=link}
rop�ƃo�b�t�@�ƃX�P�W���[���ӂ肩�s���Ȃ̂�
������x�������E���R�ł͒f���Ė�����
���̕����ƁAOntario��40SP�����ALlano��80�`160SP�����ŃI�`������������
ID:Eh0QYsBP
���̔n���܂����Ӗ��ȃ����N�\���čr�炵�Ă�̂���
�ǂ��撣���Ă�GPU���Ꮯ�ĂȂ����炗
���̔n���܂����Ӗ��ȃ����N�\���čr�炵�Ă�̂���
�ǂ��撣���Ă�GPU���Ꮯ�ĂȂ����炗
Sandy�̓`�b�v�Z�b�g���_���Ȃ̂��ɂ���
Llano+SB950?��HD5570+USB3+SATA3 6�|�[�g�ɑΉ��ł���
Sandy+H67����HD5450+USB2+SATA3 1�|�[�g�ɂ����Ή��ł��Ȃ�
CPU�͍����\�����ǁA����ȊO�����[�G���h��Sandy�͉���ڎw���Ă�낤
�S�Ă������x���Ȃ̂Ɉ�����Llano�Ƀp�C�Ă���CPU�V���O���X���b�h�x���`�������ĂȂ��̂̓}�Y�C��
Llano+SB950?��HD5570+USB3+SATA3 6�|�[�g�ɑΉ��ł���
Sandy+H67����HD5450+USB2+SATA3 1�|�[�g�ɂ����Ή��ł��Ȃ�
CPU�͍����\�����ǁA����ȊO�����[�G���h��Sandy�͉���ڎw���Ă�낤
�S�Ă������x���Ȃ̂Ɉ�����Llano�Ƀp�C�Ă���CPU�V���O���X���b�h�x���`�������ĂȂ��̂̓}�Y�C��
�m�[�g�s���Bulldozer�ŏ�������
���������ቿ�i�����W��PC��SATA3 6�|�[�g�Ȃ�ėv��Ȃ���
USB3.0��NEC�`�b�v�ł��\�����ȁB�`�b�v�����镪�T�[�h�p�[�e�B�̃T�u�`�b�v���ڂ��Ă�����قǃR�X�g�͏オ��Ȃ��B
�����Radeon Xpress��USB����̂���ڂ��͗L��
USB3.0��NEC�`�b�v�ł��\�����ȁB�`�b�v�����镪�T�[�h�p�[�e�B�̃T�u�`�b�v���ڂ��Ă�����قǃR�X�g�͏オ��Ȃ��B
�����Radeon Xpress��USB����̂���ڂ��͗L��
>>659
CPU�̃p�[�c�P�ʂł͐�����
CPU�A�[�L�e�N�`�����x���ɂȂ�ƃ_���_�����낤Intel
SOI�̓o���N���g�����W�X�^���l�߂���炵������
SOI��AMD�L���b�V�����o���N�̂h���������L���b�V���̂ق������炩�ɍ����\
�j10�łk2�k3�̃L���b�V�����x���h�����������ɂ������琫�\�{���{���ɂȂ����炵�����i�������͓��Ƀ\�[�X�����j
ttp://www.chip-architect.com/news/2007_02_19_Various_Images.html
�L���b�V�����\+SSE�ix86SIMMMM�j�K�i��+�v���Z�X�Z�p�@�ő����L���Ɏ���i�߂���̂�
�������G���b�^���������Ƃ�HTT�Ő��\�ቺ���Ƃ��\�z�����͂��Ȃ荓��
�Ƃ�����AMD�͂��Ȃ�I����
�R�A�����Ȃ�����ł͔r���L���b�V����
�R�A���o�[�X�g�������ɂȂ邩�Ǝv���Ε���L���W���[���v�ŃX�k�[�v���炷���X
�����͎��ɏ�肢�Ǝv����
CPU�̃p�[�c�P�ʂł͐�����
CPU�A�[�L�e�N�`�����x���ɂȂ�ƃ_���_�����낤Intel
SOI�̓o���N���g�����W�X�^���l�߂���炵������
SOI��AMD�L���b�V�����o���N�̂h���������L���b�V���̂ق������炩�ɍ����\
�j10�łk2�k3�̃L���b�V�����x���h�����������ɂ������琫�\�{���{���ɂȂ����炵�����i�������͓��Ƀ\�[�X�����j
ttp://www.chip-architect.com/news/2007_02_19_Various_Images.html
�L���b�V�����\+SSE�ix86SIMMMM�j�K�i��+�v���Z�X�Z�p�@�ő����L���Ɏ���i�߂���̂�
�������G���b�^���������Ƃ�HTT�Ő��\�ቺ���Ƃ��\�z�����͂��Ȃ荓��
�Ƃ�����AMD�͂��Ȃ�I����
�R�A�����Ȃ�����ł͔r���L���b�V����
�R�A���o�[�X�g�������ɂȂ邩�Ǝv���Ε���L���W���[���v�ŃX�k�[�v���炷���X
�����͎��ɏ�肢�Ǝv����
Sandy��USB/SATA/PCI-E�őш����荇������ǂꂩ���Ƃ�ǂꂩ�͎̂Ă�K�v���L������悤��
�����ׂĂȂ��̂ŊԈ���Ă邩��
NEC��USB3.0�`�b�v��ς��ŁA�K�i��3.0�ɑΉ����Ă����ő��x�͏o�Ȃ���Ȃ���
�������O���t�B�b�N�{�[�h��SATA�̑ш���i���USB3.0�ɉ邪
�����ׂĂȂ��̂ŊԈ���Ă邩��
NEC��USB3.0�`�b�v��ς��ŁA�K�i��3.0�ɑΉ����Ă����ő��x�͏o�Ȃ���Ȃ���
�������O���t�B�b�N�{�[�h��SATA�̑ш���i���USB3.0�ɉ邪
���̂������M/B���[�J�[���ǂ������Ăǂ���̂Ă邩����
�ق��Ƃ��Ă�SATA3��USB3���ςނ�
�ق��Ƃ��Ă�SATA3��USB3���ςނ�
Intel�Ƃ��Ă͂܂����Ђ̐V����SSD���o���Ă��Ȃ�����ASATA3.0�̑ш���i���Ă��炢�����낤��
http://www.gdm.or.jp/voices_html/201008/20100828a.html
Intel����SATA3.0��SSD�����\���ꂽ�瑽�����x��PCI-E�̑ш���i���Ȃ�����
http://www.gdm.or.jp/voices_html/201008/20100828a.html
Intel����SATA3.0��SSD�����\���ꂽ�瑽�����x��PCI-E�̑ш���i���Ȃ�����
���łɌ�����Llano��USB3.0�Ή���Hudson M3����
> NEC��USB3.0�`�b�v��ς��ŁA�K�i��3.0�ɑΉ����Ă����ő��x�͏o�Ȃ���Ȃ���
Hudson M3��USB�R���g���[���͑��x�ł�Ƃł��H
��ATI�̃`�b�v�Z�b�g��USB����ŋK�i�ő含�\�܂ŏo�������͂Ȃ��B
> NEC��USB3.0�`�b�v��ς��ŁA�K�i��3.0�ɑΉ����Ă����ő��x�͏o�Ȃ���Ȃ���
Hudson M3��USB�R���g���[���͑��x�ł�Ƃł��H
��ATI�̃`�b�v�Z�b�g��USB����ŋK�i�ő含�\�܂ŏo�������͂Ȃ��B
Sandy�p�̃`�b�v�Z�b�g�ł�DMI�̑��x�������グ���邩��5GT/s�ɂȂ�̂ő��v�炵��
����USB3.0���`�b�v�Z�b�g�ɐς�ł��Ȃ��Ƃ����̂͂��Ȃ�ӊO������
���y�̂��߂ɂ����ڂ��ė~�����������ǂ�
���؍�Ƃ��Ԃɍ���Ȃ������낤��
����USB3.0���`�b�v�Z�b�g�ɐς�ł��Ȃ��Ƃ����̂͂��Ȃ�ӊO������
���y�̂��߂ɂ����ڂ��ė~�����������ǂ�
���؍�Ƃ��Ԃɍ���Ȃ������낤��
Sandy��DMI2.0�ŕЕ���2GB/s�ɂȂ邯�ǁAAMD�͂�����T�E�X�̑ш�L���́H
���{��ɂȂ��ĂȂ��� ID:isDywkP1
�����Ƃ���͍ς܂Ȃ�
DMI2.0�ɂȂ��đ��x�A�b�v���Ēm��Ȃ�������
�����Ɗm�F���Ă����ׂ�������
DMI2.0�ɂȂ��đ��x�A�b�v���Ēm��Ȃ�������
�����Ɗm�F���Ă����ׂ�������
>>669
�T���N�X�B���Ⴀ�A�P��Intel�����炩�̗��R�Ŏ������Ȃ��A�ł��Ȃ����Ă������B
SandyBridge�ƈꏏ��LightPeak�����グ��悤�����A
�����ŋK�i�哱���������ɁAUSB3.0�̃l�C�e�B�u�T�|�[�g�͂��Ȃ�����Ȃ̂��ȁB
�T���N�X�B���Ⴀ�A�P��Intel�����炩�̗��R�Ŏ������Ȃ��A�ł��Ȃ����Ă������B
SandyBridge�ƈꏏ��LightPeak�����グ��悤�����A
�����ŋK�i�哱���������ɁAUSB3.0�̃l�C�e�B�u�T�|�[�g�͂��Ȃ�����Ȃ̂��ȁB
Intel�͖����Ƀv���b�g�t�H�[���̍��ʉ����s���Ă邩��Ȃ����
���C���X�g���[���ȉ��̃`�b�v�Z�b�g�͈Ӑ}�I�ɋ@�\�������Ă���̂������B
���C���X�g���[���ȉ��̃`�b�v�Z�b�g�͈Ӑ}�I�ɋ@�\�������Ă���̂������B
>>672
LightPeak��USB3.0�Ɍ��炸���ł����p�ł��邩��USB�ɍi���Ă��܂��K�v�Ȃ����낤
LightPeak��USB3.0�Ɍ��炸���ł����p�ł��邩��USB�ɍi���Ă��܂��K�v�Ȃ����낤
Hudson D1�͂ǂ�����Đڑ�����̂���
HT�Ȃ̂�PCIe�x�[�X�Ȃ̂�
HT�Ȃ̂�PCIe�x�[�X�Ȃ̂�
LightPeak���Ă��܂����悭�킩��Ȃ��B
���ł��g����Ƃ����Ă��A���������ϊ�����h���O���݂����Ȃ̕K�v���ƕs�ւ��Ǝv�����B
���ƁALightPeak�̃R�l�N�^��USB3.0�ƌ݊�����������炵�����ǁA
�R�l�N�^���LightPeak��USB3.0�̃R���g���[����2��ނ��Ȃ����Ă�Ƃ����\���ɂȂ�̂��H
���ł��g����Ƃ����Ă��A���������ϊ�����h���O���݂����Ȃ̕K�v���ƕs�ւ��Ǝv�����B
���ƁALightPeak�̃R�l�N�^��USB3.0�ƌ݊�����������炵�����ǁA
�R�l�N�^���LightPeak��USB3.0�̃R���g���[����2��ނ��Ȃ����Ă�Ƃ����\���ɂȂ�̂��H
���������USB3.0�̓��l�T���X����B�ǂ����B
QPI�ƈꏏ�Ō��Ǘ��s��Ȃ����낤��LightPeak����
���������g���ǂ���͂ǂ��Ȃ�
�Ƃ�����Intel�̘b�������Ȃ��z��Intel������X���ɍs����
���������g���ǂ���͂ǂ��Ȃ�
�Ƃ�����Intel�̘b�������Ȃ��z��Intel������X���ɍs����
llano��
���z
�C945�`965+5550�`5570�@95W
�A555�`+5550�`�@65W
����
�C640�`+5550�ȉ��@95W
�A250�`+5550�ȉ��@65W�ɂȂ肻��
���z
�C945�`965+5550�`5570�@95W
�A555�`+5550�`�@65W
����
�C640�`+5550�ȉ��@95W
�A250�`+5550�ȉ��@65W�ɂȂ肻��
>>679
�ǂ��Ȃ̂��ˁH Llano�R�A�͂����ԉ��ǂ�������Ęb�������ǁA
L3������Deneb�n��荂���Ȃ邩�͔�������Ȃ��H
GPU�͏o����킩�邾��B9�����Ƀf�����炵�����A
�����ł�����x�������͌������ˁH
�ǂ��Ȃ̂��ˁH Llano�R�A�͂����ԉ��ǂ�������Ęb�������ǁA
L3������Deneb�n��荂���Ȃ邩�͔�������Ȃ��H
GPU�͏o����킩�邾��B9�����Ƀf�����炵�����A
�����ł�����x�������͌������ˁH
���l�T���X���ĂȂH
���������̃X�����ǂ߂Ȃ��z�������Ȃ�
Intel�̘b������ȂƂ͌���Ȃ����A�����͉������Ƃ�������Ċ������Ȃ�
Intel�̘b������ȂƂ͌���Ȃ����A�����͉������Ƃ�������Ċ������Ȃ�
���܂�A��C�ǂ߂Ȃ����Ĉ��������B
Llano��L2�������Ă��镪�A�N���b�N������̐��\�̓Q�[���n�ł�
Deneb�N���X�͂����Ȃ��́H
PhenomII��AthlonII�ł��܂荷���o�Ȃ��x���`���������B
Llano��L2�������Ă��镪�A�N���b�N������̐��\�̓Q�[���n�ł�
Deneb�N���X�͂����Ȃ��́H
PhenomII��AthlonII�ł��܂荷���o�Ȃ��x���`���������B
Intel�̘b�Ȃ�܂�������
�ł��uAMD�̘b���Ǝv�킹�Ď��̓E���R�̘b�ł����v���Ă�����
������̒���AMD�̎������b���Ȃ��z�����݂��Ă�̂�����
���܂�ɂ��L���Ă������肳��Ă邯��
�ł��uAMD�̘b���Ǝv�킹�Ď��̓E���R�̘b�ł����v���Ă�����
������̒���AMD�̎������b���Ȃ��z�����݂��Ă�̂�����
���܂�ɂ��L���Ă������肳��Ă邯��
Regor�̐��\�l����Ə����\�ł�Deneb�܂ł͓͂��Ȃ���Ȃ�
Propus��Deneb�̒��Ԃ�����Ɏ��܂�Ǝv��
�ł��^�[�{�R�A����������ē��ڂ����悤��������̃P�[�X�ł͌݊p�ɐ키�Ɨ\�z
Propus��Deneb�̒��Ԃ�����Ɏ��܂�Ǝv��
�ł��^�[�{�R�A����������ē��ڂ����悤��������̃P�[�X�ł͌݊p�ɐ키�Ɨ\�z
Llano��59W��4�R�A 3GHz/HD5500�N���X�͂قڊm�肵�Ă���
����L2��������Ȃ���
��32nm�łł̃A�[�L�e�N�`����̊g��
�E���߃E�C���h�E���g�����A����/���������_(FP)�̎��s�X���[�v�b�g������
�E�n�[�h�E�F�A�������Z
�E���������_���Z(FP)���߂̃��C�e���V��Z�k
�E�f�[�^�v���t�F�b�`���g��
�E�������t�B���ƃL���b�V���X�e�C�g�̃g�����W�V������������
�E�t���̃v���Z�b�T�X�e�C�g�̃Z�[�u���܂߂�I/O�x�[�X��C�X�e�C�g
�E�o�[�`�����C�[�[�V�����̍������̂��߂�TLB�̊g��
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20100215_348705.html
���ł��܂����K�͊g���H�ȂǂƂ��v������
�f�̂܂܂���BullBob�R���r�ɑ傫������肷�邩��Q�ĂāE�E�E�Ȃ̂�������Ȃ���
��32nm�łł̃A�[�L�e�N�`����̊g��
�E���߃E�C���h�E���g�����A����/���������_(FP)�̎��s�X���[�v�b�g������
�E�n�[�h�E�F�A�������Z
�E���������_���Z(FP)���߂̃��C�e���V��Z�k
�E�f�[�^�v���t�F�b�`���g��
�E�������t�B���ƃL���b�V���X�e�C�g�̃g�����W�V������������
�E�t���̃v���Z�b�T�X�e�C�g�̃Z�[�u���܂߂�I/O�x�[�X��C�X�e�C�g
�E�o�[�`�����C�[�[�V�����̍������̂��߂�TLB�̊g��
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20100215_348705.html
���ł��܂����K�͊g���H�ȂǂƂ��v������
�f�̂܂܂���BullBob�R���r�ɑ傫������肷�邩��Q�ĂāE�E�E�Ȃ̂�������Ȃ���
>>681
���l�T�X�e�N�m���W�B
���l�T�X�e�N�m���W�B
>>687
���ꂾ������Ă����ۂɂ�5%���x�̌���ɂ����Ȃ�Ȃ����낤���ǂ�
>BullBob�R���r�ɑ傫������肷��
����͕ʂɍ\��됢�オ�Ⴄ����
�ǂ��炩�Ƃ����ƍ���̃��C���Ƃ��Đl�C���o��悤��K10�ɂ̓J�}�Z�ɂȂ��ė~�������낤��
�܂��A�Ō�̊g���Ƃ��Ďv��������̉��ǂ��s�����낤
���ꂾ������Ă����ۂɂ�5%���x�̌���ɂ����Ȃ�Ȃ����낤���ǂ�
>BullBob�R���r�ɑ傫������肷��
����͕ʂɍ\��됢�オ�Ⴄ����
�ǂ��炩�Ƃ����ƍ���̃��C���Ƃ��Đl�C���o��悤��K10�ɂ̓J�}�Z�ɂȂ��ė~�������낤��
�܂��A�Ō�̊g���Ƃ��Ďv��������̉��ǂ��s�����낤
5%���x�ł����サ���疜�X���낤��
5%�オ�邩���B���Ƃ͏ȓd�͌n�̉��ǂ������Ă��邩��A
�ǂꂾ���N���b�N���ێ��ł��邩�ɂ������Ă܂��ˁB
"Llano"���Ȃ��Ȃ��ʔ���CPU�ł͂���Ȃ��B
�ǂꂾ���N���b�N���ێ��ł��邩�ɂ������Ă܂��ˁB
"Llano"���Ȃ��Ȃ��ʔ���CPU�ł͂���Ȃ��B
5%���オ������呛�����Ǝv��
>>687
���{�I�ɖ��ߔ��s�̕������ς���ĂȂ���
�L���b�V����way���͂��̂܂�
�����̍����A�r���IL2�����̂܂�
K10����2011�N�ȍ~�키�͖̂���
Llano�̖{�Ԃ�CPU��Bull�R�A�ɕς���Ă��炾��
���{�I�ɖ��ߔ��s�̕������ς���ĂȂ���
�L���b�V����way���͂��̂܂�
�����̍����A�r���IL2�����̂܂�
K10����2011�N�ȍ~�키�͖̂���
Llano�̖{�Ԃ�CPU��Bull�R�A�ɕς���Ă��炾��
Llano�̓��X�N��������e�X�g�݂����Ȃ������
�����Ȃ�S���V�������̂ō�郊�X�N�͖�������
�����Ȃ�S���V�������̂ō�郊�X�N�͖�������
��������Ĕr���L���b�V�����̂܂܂��Ă̂͂ǂ��Ȃ̂�
���i�Ƃ��Ď��s���^���Â���ꂽ���̏o���̂͂ǂ��Ȃ̂�
���i�Ƃ��Ď��s���^���Â���ꂽ���̏o���̂͂ǂ��Ȃ̂�
��������^�����������Ȃ���
L2���L�ŏ����������܂���Intel���X�ɉ�������
�uL1�ŏ����������f�[�^��L2�ȉ��ɂ����f�����閳�ʂ������Ȃ�I�v�ȂǂƔr���܂ō̗p����������
�X�k�[�v�����̃f�����b�g�̓R�A��ɂ���HTT��10�X���b�h���炢���点�邱�Ƃőł�����
�uL1�ŏ����������f�[�^��L2�ȉ��ɂ����f�����閳�ʂ������Ȃ�I�v�ȂǂƔr���܂ō̗p����������
�X�k�[�v�����̃f�����b�g�̓R�A��ɂ���HTT��10�X���b�h���炢���点�邱�Ƃőł�����
�L���b�V���V�X�e����ύX����̂́A�傪���肷���Ă�߂���Ȃ��́H
�Ƃɂ���CPU��GPU��SOI�̃v���Z�X��1�`�b�v�ō���āA
��̂��߂̌o���ɂ���K�v�����邾�낤���B
�Ƃɂ���CPU��GPU��SOI�̃v���Z�X��1�`�b�v�ō���āA
��̂��߂̌o���ɂ���K�v�����邾�낤���B
������
�킟��
bobcat�����E�E�E
Bull�R�A��SI�R�A�����ɂ����悻�J���ς݂�����ABull+SI�̃V���~���[�V�������炢�͂��Ă��邩����
Llano��p�Ƃ�������ʔłƂ��āA�_�C�T�C�Y��\��啝���������o�[�W�����Ƃ����̂��ʔ�����
Llano (K10+HD5000) 170mm2 4C+480SP�ɑ��A
Llano2 (Bull+SI) 300mm2 6C+800SP�ŁA
���łɃ������ш�m�ۂ̂��߂�G34�̂悤�Ƀ�������4ch 256bit��DDR4�Ή��Ƃ�
Llano��p�Ƃ�������ʔłƂ��āA�_�C�T�C�Y��\��啝���������o�[�W�����Ƃ����̂��ʔ�����
Llano (K10+HD5000) 170mm2 4C+480SP�ɑ��A
Llano2 (Bull+SI) 300mm2 6C+800SP�ŁA
���łɃ������ш�m�ۂ̂��߂�G34�̂悤�Ƀ�������4ch 256bit��DDR4�Ή��Ƃ�
4ch�Ƃ���Ȃ�����
Llano���Ă̂�K10+5000�x�[�X�̃R�[�h�l�[������Ȃ��̂�
�܂������������Ƃ͕����邯��
�܂������������Ƃ͕����邯��
>>704
�����ł����������Ƃ͎v�����ǁAGPU���\�Ƀ������ш悪Llano�̒i�K�Ŋ��ɑ���Ȃ�����A
256bit���ł����Ȃ��Ɛ��\���オ�ł��Ȃ��̂͊m��
256bit�������GPU���\��HD5670��5750�߂��܂Ő��\���グ�邱�Ƃ��o����
����ɂ����CPU��}�U�[�̃R�X�g���{���x�ɂ͂Ȃ邩���m��Ȃ����ǂ�
Fusion�̍���̍����\���ɂ�256bit���͔����Ēʂ�Ȃ����ǂǂ�����낤��AMD�́B
�����ł����������Ƃ͎v�����ǁAGPU���\�Ƀ������ш悪Llano�̒i�K�Ŋ��ɑ���Ȃ�����A
256bit���ł����Ȃ��Ɛ��\���オ�ł��Ȃ��̂͊m��
256bit�������GPU���\��HD5670��5750�߂��܂Ő��\���グ�邱�Ƃ��o����
����ɂ����CPU��}�U�[�̃R�X�g���{���x�ɂ͂Ȃ邩���m��Ȃ����ǂ�
Fusion�̍���̍����\���ɂ�256bit���͔����Ēʂ�Ȃ����ǂǂ�����낤��AMD�́B
NorthBridge�@�\�S���������Ă����ɁA������4ch�Ȃ�āA
�\�P�b�g�̃s�����������ɂȂ�Ȃ��Ȃ邩��A
XDR�݂����ȃo�X�̃������ɂȂ�܂ŁAch�����₷�̂͑�����������Ȃ��́H
�\�P�b�g�̃s�����������ɂȂ�Ȃ��Ȃ邩��A
XDR�݂����ȃo�X�̃������ɂȂ�܂ŁAch�����₷�̂͑�����������Ȃ��́H
�ш�オ���Ă�AMD�̒�]�����R������
�����܂ŋ��߂�Ȃ�O�t����GPU�����ĂˁA�ƂȂ邾�낤�Ȃ��B
�ނ���GPU����CPU�R�A���ڂ��āE�E�E
�ނ���GPU����CPU�R�A���ڂ��āE�E�E
>>708
��]�͂��O����
��]�͂��O����
>>709
��������2GB����r�f�I�J�[�h�Ȃ�AXP���炢�͉��K�ɓ����̂��H��
��������2GB����r�f�I�J�[�h�Ȃ�AXP���炢�͉��K�ɓ����̂��H��
�ቿ�i�͖����Ȃ����Ńn�C�G���h�����Ȃ�\���낤G34��\�P�b�g2011�݂�����
130W 300mm2�g�ō��A3���W���[��6�R�A 4Ghz+800sp 800MHz�͂�����Ǝv��
256bit�������llano�̋����ł⎟����ŃR�����炢�C�P�����낤���Ă���
�������K�i�̕ύX�������ɂȂ邩������Ȃ�����A
����p���[�A�b�v����ɂ�256bit�������Ȃ��ȂƎv��������
�܂��A�����Ȃ�Llano�̃X�y�b�N�Ő��N���Ȃ���Ⴂ���Ȃ����ǂ�
130W 300mm2�g�ō��A3���W���[��6�R�A 4Ghz+800sp 800MHz�͂�����Ǝv��
256bit�������llano�̋����ł⎟����ŃR�����炢�C�P�����낤���Ă���
�������K�i�̕ύX�������ɂȂ邩������Ȃ�����A
����p���[�A�b�v����ɂ�256bit�������Ȃ��ȂƎv��������
�܂��A�����Ȃ�Llano�̃X�y�b�N�Ő��N���Ȃ���Ⴂ���Ȃ����ǂ�
GDDR5�����C���������ɂ���ʂȂ烁�������W���[���̋K�i�����݂���XDRDRAM�̕����ǂ��C������
http://www.rambus.com/jp/technology/solutions/xdr/xdimm.html
http://www.rambus.com/jp/technology/solutions/xdr/xdimm.html
�ӂ[�ɍl���ă������ϑw�B
������������Ǝ��ɍ̗p����̂̓��X�N���������邩��R���f�B�e�B�ȃ��������̗p�������邾��
�������̃`���l���𑝂₷�̂��}�U�[�Ȃǂ̃R�X�g�l����Ƃ���
�����̊ԃL���b�V���V�X�e���̉��ǂʼn��Ƃ������Ȃ�����
�ꉞ�ADDR3-12800��128bit�Ȃ�25.6GB/s�͊m�ۂł�����
CPU�ƐH�������Ƃ͂������[�G���h��64bit���͑傫���킯����
�������̃`���l���𑝂₷�̂��}�U�[�Ȃǂ̃R�X�g�l����Ƃ���
�����̊ԃL���b�V���V�X�e���̉��ǂʼn��Ƃ������Ȃ�����
�ꉞ�ADDR3-12800��128bit�Ȃ�25.6GB/s�͊m�ۂł�����
CPU�ƐH�������Ƃ͂������[�G���h��64bit���͑傫���킯����
XDR���嗬�ɂȂ�Ȃ�ĘI�قǂ��l���ĂȂ������Ǝv�����ǂˁB
�����ɍl����Ȃ�sp���̋�����DDR4�܂Ō����肾��B
�����ɍl����Ȃ�sp���̋�����DDR4�܂Ō����肾��B
Intel��3Q�̋Ɛї\�z�������C��������
AMD�����v�I�Ɍ��������ƂɂȂ邩��
�s������̂��߂��̍D�i�C�͏I��������ĂƂ��납��
�܂�AMD�iGF�j�I�ɂ́A�s���ɂȂ�t�@�E���_���̔����U���ĊJ�ł���̂Ŗ]�ނƂ���ł����邩��
�����s���������͉����ł��邩������Ȃ���
AMD�����v�I�Ɍ��������ƂɂȂ邩��
�s������̂��߂��̍D�i�C�͏I��������ĂƂ��납��
�܂�AMD�iGF�j�I�ɂ́A�s���ɂȂ�t�@�E���_���̔����U���ĊJ�ł���̂Ŗ]�ނƂ���ł����邩��
�����s���������͉����ł��邩������Ȃ���
�����z�t�j��WatchTower�FHot Chips 22�Ŏ����ꂽAMD�̎�����CPU�g�u�����{�u�h (2/3)
http://plusd.itmedia.co.jp/pcuser/articles/1008/30/news063_2.html
Hyper-Threading Technology�͌���������
http://plusd.itmedia.co.jp/pcuser/articles/1008/30/news063_2.html
Hyper-Threading Technology�͌���������
>Bulldozer�ł��AHyper-Threading Technology�̂悤��SMT���̗p���Ă��Ȃ�
���̈ꕶ�œǂމ��l����
���̈ꕶ�œǂމ��l����
���M�҂͋C�ɂ���Ȃ����͓͂ǂ݂܂���
�Ă����̃A�[�L��SMT�͂ǂ��݂Ă�����ˁ[����E�E�E
1�������Ō��ߕt����̂͗ǂ��Ȃ���
�u���\��萔�v���Ƃ��u1��������Ƃ������\���サ�Ȃ��v���Ƃ����Ȃ�n�����ۂ�
�u���\��萔�v���Ƃ��u1��������Ƃ������\���サ�Ȃ��v���Ƃ����Ȃ�n�����ۂ�
�[���ABull��SMT�����w
���Ƃ���HTT��L1����������̂��p�t�H�[�}���X�ቺ�Ɍq�����Ă�
��L1��Ɨ��ɂ���Ɛ������Z���Ɨ�������K�v������
�݂����ȗ����Bull�̃A�[�L����������b���ȑO�������悤�ȁB
��L1��Ɨ��ɂ���Ɛ������Z���Ɨ�������K�v������
�݂����ȗ����Bull�̃A�[�L����������b���ȑO�������悤�ȁB
HTT�̂悤��SMT�͍̗p���Ă��Ȃ��c�����B
�C�O�j���[�X�T�C�g�̋L���R�s�y������ɐ����Ă�юc�炸�ނ������悤�Ȋϑ��L�����������Ȃ��̂͂������
�E���R�̓V�~�����[�V�����̈Ӗ�����m��Ȃ����x��������ǂ��ł�������
FPU��SMT���Ă̂͂���AMD�����\���Ă��
ttp://pc.watch.impress.co.jp/img/pcw/docs/389/491/html/11.jpg.html
FPU��SMT���Ă̂͂���AMD�����\���Ă��
ttp://pc.watch.impress.co.jp/img/pcw/docs/389/491/html/11.jpg.html
{kind=link}
APU���������J�����Ƃ����l�^���������薳�����ď����Ă������
>>726
AndyGlew�ɂ��Ƃ�����������炵���B
HotChips�ł�AMD�̉������2�R�A����CbMT�ցA���������ǁB
>>729
�����A�e�R�A�֕������O��VerticalMT�Ȃ��ǁA�X���b�h�̐�ւ��͂ǂ������^�C�~���O�Ȃ낤�H
AndyGlew�ɂ��Ƃ�����������炵���B
HotChips�ł�AMD�̉������2�R�A����CbMT�ցA���������ǁB
>>729
�����A�e�R�A�֕������O��VerticalMT�Ȃ��ǁA�X���b�h�̐�ւ��͂ǂ������^�C�~���O�Ȃ낤�H
AMD�͂܂�RADEON HD2***�Ɠ������s���J��Ԃ��낤��
RADEON HD2***�́w���ꂩ��̓V�F�[�_�[�̎��ゾ�I�x��
�V�F�[�_�[���苭�����Ċ̐S�̑������y���������߂Ɏ����\�ŐL�єY��
����ɂ��Ă�AMD�ɂ��ATi�����̂ǂ�������
�v�ӔC�҂����ւ����̂�HD4***�ŏC�����ꂽ
�܂��w���ꂩ���Vista�̎��ゾ�I�x��2D���̂Ă���
��������XP���[�U�[�̕s�����ăh���C�o�̉��ǂ����邱�ƂɂȂ���
Bulldozer���w���ꂩ��̓}���`�X���b�h�̎��ゾ�I�x��
�V���O���X���b�h���y�����ĐL�єY�ނ낤��
RADEON HD2***�́w���ꂩ��̓V�F�[�_�[�̎��ゾ�I�x��
�V�F�[�_�[���苭�����Ċ̐S�̑������y���������߂Ɏ����\�ŐL�єY��
����ɂ��Ă�AMD�ɂ��ATi�����̂ǂ�������
�v�ӔC�҂����ւ����̂�HD4***�ŏC�����ꂽ
�܂��w���ꂩ���Vista�̎��ゾ�I�x��2D���̂Ă���
��������XP���[�U�[�̕s�����ăh���C�o�̉��ǂ����邱�ƂɂȂ���
Bulldozer���w���ꂩ��̓}���`�X���b�h�̎��ゾ�I�x��
�V���O���X���b�h���y�����ĐL�єY�ނ낤��
ttp://pc.watch.impress.co.jp/docs/news/20100830_390486.html
���悤�Ȃ�ATI�u�����h
���q����^�̐g���ւƌ������Ƃ���
���悤�Ȃ�ATI�u�����h
���q����^�̐g���ւƌ������Ƃ���
!?
>>732
�h���C�o��DirectX�̌���ATI�ӔC�ƌ������AMS�ӔC���傫���悤�ȁc�B
���Ɓu�}���`�X���b�h�̎��ゾ�v��Hammer�n�̎��ɑǂ���Ă��邩��B
>>735
����AAMD���S���������^�Ђɔz���������S��������H
�h���C�o��DirectX�̌���ATI�ӔC�ƌ������AMS�ӔC���傫���悤�ȁc�B
���Ɓu�}���`�X���b�h�̎��ゾ�v��Hammer�n�̎��ɑǂ���Ă��邩��B
>>735
����AAMD���S���������^�Ђɔz���������S��������H
�܂�Intel�Ƃ��Ă�AMD�������Ă�Ɩʔ����Ȃ����낤����Ȃ�
���S���Ă�Radeon�Ƃ����u�����h��傫���o���Ă����낤
���S���Ă�Radeon�Ƃ����u�����h��傫���o���Ă����낤
Llano�̓W���H���\�����9��1���H
>>739
"Llano"�̔��\��Ȃ�Ă���܂���B
�uFUSION�v���Z�b�T�̌��J�v�ł��B
9��3�`8���܂Ńh�C�c��IFA���ăC�x���g�����āB
"Llano"�̔��\��Ȃ�Ă���܂���B
�uFUSION�v���Z�b�T�̌��J�v�ł��B
9��3�`8���܂Ńh�C�c��IFA���ăC�x���g�����āB
����c�O
���M���X�ɔ��\���Ă���邩�Ǝv�����̂�
���M���X�ɔ��\���Ă���邩�Ǝv�����̂�
IFA�̂�Ontario����
���l�^��"Fuzilla"������Ȃ��B
���J�����Ƃ������Ƃ��������B
���J�����Ƃ������Ƃ��������B
����̃\�[�XFudzilla����Ȃ���
>>724
> �u���\��萔�v���Ƃ��u1��������Ƃ������\���サ�Ȃ��v���Ƃ����Ȃ�n�����ۂ�
�S�������Ă��̂Ƃ��肾��
�R�A�����������ăR�A�����҂����������A1��������Ƃ̌�����Ă��Ƃ�300MHz�ȏ�N���b�N�����シ����Ă��Ƃ�
X6 3.2GHz��X8 3.5GHz�ŁA�}���`�X���b�h���\�͖�5�����シ�邱�ƂɂȂ邩��˕��喳������
> �u���\��萔�v���Ƃ��u1��������Ƃ������\���サ�Ȃ��v���Ƃ����Ȃ�n�����ۂ�
�S�������Ă��̂Ƃ��肾��
�R�A�����������ăR�A�����҂����������A1��������Ƃ̌�����Ă��Ƃ�300MHz�ȏ�N���b�N�����シ����Ă��Ƃ�
X6 3.2GHz��X8 3.5GHz�ŁA�}���`�X���b�h���\�͖�5�����シ�邱�ƂɂȂ邩��˕��喳������
�\�[�X�AFudzilla�ȊO�ɂ���́H
�k�X�ɂ�Fudzilla��Fudzilla���������|�[�g���Ă���`���L����Expreview�����Ȃ��悤�����ǁB
�k�X�ɂ�Fudzilla��Fudzilla���������|�[�g���Ă���`���L����Expreview�����Ȃ��悤�����ǁB
�����������������ǁA�u�}���`�X���b�h�ɓ�������CPU�v�ƁA
AMD�������Ă���̂ɐ��\�㏸�����R�A���Ŋ���Ӗ����ĉ��H
������������A��R�A������̐��\�㏸�l�͂����ƒႭ�āA
���W���[���P�ʁB�}���`�R�A�P�ʂł͂Ȃ��Ƃ��b�ɂȂ�Ȃ���������Ȃ��̂ɁB
AMD�������Ă���̂ɐ��\�㏸�����R�A���Ŋ���Ӗ����ĉ��H
������������A��R�A������̐��\�㏸�l�͂����ƒႭ�āA
���W���[���P�ʁB�}���`�R�A�P�ʂł͂Ȃ��Ƃ��b�ɂȂ�Ȃ���������Ȃ��̂ɁB
>>745
������CPU�Łu1��������Ɓv�����\�オ��Ό�̎����낤�ɂ�
������CPU�Łu1��������Ɓv�����\�オ��Ό�̎����낤�ɂ�
>>747
> ���W���[���P�ʁB�}���`�R�A�P�ʂł͂Ȃ��Ƃ��b�ɂȂ�Ȃ���������Ȃ��̂ɁB
�������H
���ɃT�[�o�������ƁA���ꂪ�ł����߂��Ă�Ǝv�����ǂȁB
���C�Z���X���\�P�b�g�P�ʂ̂��������A���b�g�p�t�H�[�}���X�͍ŏd�������B
> ���W���[���P�ʁB�}���`�R�A�P�ʂł͂Ȃ��Ƃ��b�ɂȂ�Ȃ���������Ȃ��̂ɁB
�������H
���ɃT�[�o�������ƁA���ꂪ�ł����߂��Ă�Ǝv�����ǂȁB
���C�Z���X���\�P�b�g�P�ʂ̂��������A���b�g�p�t�H�[�}���X�͍ŏd�������B
�V���O���X���b�h���\�͒Ⴂ��Ȃ����Ƃ��������낤��
�ꕔ���\�[�X���L�ŃV���O���X���b�h���}���`�X���b�h�̕������\�オ���Ă��炻�����̕�����������
�ꕔ���\�[�X���L�ŃV���O���X���b�h���}���`�X���b�h�̕������\�オ���Ă��炻�����̕�����������
DB�̓R�A���ۋ������������������V���O���X���b�h���\���K�v������
��IPC�~�R�A��ʂ̃A�v���[�`�ƐH�����킹������
��IPC�~�R�A��ʂ̃A�v���[�`�ƐH�����킹������
�@����A���b�g�p�t�H�[�}���X���グ�邱�Ƃ��V���O���X���b�h���\��
�グ�邱�ƂƂقڃC�R�[��������ˁB
�グ�邱�ƂƂقڃC�R�[��������ˁB
��IPC�~�R�A��ʂ̃A�v���[�`�ƐH�����킹�������B
��IPC�@��N���b�N�@��ʃR�A�͐H�����킹���ǂ��B
��IPC�̓N���b�N�グ�Ă����\�㏸�J�[�u���݂��B
��IPC�͏��Ȃ��N���b�N�グ�ł����\�㏸�J�[�u�������߂�B
��IPC�@��N���b�N�@��ʃR�A�͐H�����킹���ǂ��B
��IPC�̓N���b�N�グ�Ă����\�㏸�J�[�u���݂��B
��IPC�͏��Ȃ��N���b�N�グ�ł����\�㏸�J�[�u�������߂�B
K10�̓��\�[�X��L3�ȊO�Ɨ����Ă���̂ɑ�Bulldozer�͂��Ȃ�̕��������L����Ă���
�V���O���X���b�h���ɂ̓��W���[������1�R�A�����\�[�X��L�ł������
K10���}���`�X���b�h���̐��\�������Ă�̂ɃV���O���X���b�h���\������Ă���Ƃ������Ƃ͂قږ���
����Ƃ����炻�����̕���������
�V���O���X���b�h���ɂ̓��W���[������1�R�A�����\�[�X��L�ł������
K10���}���`�X���b�h���̐��\�������Ă�̂ɃV���O���X���b�h���\������Ă���Ƃ������Ƃ͂قږ���
����Ƃ����炻�����̕���������
�V���O���X���b�h���\�͂��Ȃ荂����
Sandy�̕����X�ɍ������Ă���
Bulldozer�̃V���O�����\�ŕs������悤�ȏ����Ȃقږ����ƌ����Ă��������
�t��Bulldozer�ŕs������Ȃ�Sandy�ł��s������
Sandy�̕����X�ɍ������Ă���
Bulldozer�̃V���O�����\�ŕs������悤�ȏ����Ȃقږ����ƌ����Ă��������
�t��Bulldozer�ŕs������Ȃ�Sandy�ł��s������
Bulldozer�͖ʐϏ�������������IPC�ێ��A�������ăV�������N����������N���b�N�͐L�т�
bulldozer��2�R�A�Ń��\�[�X�̈ꕔ�����L���ĂāA1�R�A������̐��\�̓��\�[�X�Ɨ���2�R�A�Ɣ�r����
��8���̐��\�����ǁA����d�͂�ʐςŗL�����Ď�����ˁH
�ł�1�R�A�݂̂��r�W�[��Ԃ̎��A���\�[�X��1�R�A�݂̂Ŏg���邩�烊�\�[�X�̋��L�ɂ�鐫�\�_�E����
�قƂ�ǂȂ��ƍl���Ă����̂��낤���H
��8���̐��\�����ǁA����d�͂�ʐςŗL�����Ď�����ˁH
�ł�1�R�A�݂̂��r�W�[��Ԃ̎��A���\�[�X��1�R�A�݂̂Ŏg���邩�烊�\�[�X�̋��L�ɂ�鐫�\�_�E����
�قƂ�ǂȂ��ƍl���Ă����̂��낤���H
>>759
FPU�ESIMD�ɐ₦�ԂȂ�������������җ��L2�ɃA�N�Z�X���郌�x���܂ōœK������ĂȂ�����͑��v�B
FPU�ESIMD�ɐ₦�ԂȂ�������������җ��L2�ɃA�N�Z�X���郌�x���܂ōœK������ĂȂ�����͑��v�B
>>759
����ɂ��������Ƃ���TB����������}���`���쎞��萫�\�͏オ��͂�
����ɂ��������Ƃ���TB����������}���`���쎞��萫�\�͏オ��͂�
���X���肪�ƁB
�Ƃ������̓V���O�����\��������Ȃ��A�t�����[�h��������d�͂ɑ��Č����ǂ����\�����o������Ď�����ˁB
���\�͗ǂ������������͉��i���ˁB�ʐςł̗L���_�����i�ɔ��f�����Azambezi�������Ȃ��ǁB
�Ƃ������̓V���O�����\��������Ȃ��A�t�����[�h��������d�͂ɑ��Č����ǂ����\�����o������Ď�����ˁB
���\�͗ǂ������������͉��i���ˁB�ʐςł̗L���_�����i�ɔ��f�����Azambezi�������Ȃ��ǁB
���i�͐�s����C���e���ɍ��킹�Ă����Ȃ�
�ŋ߂�Thuban�Ȃnj��Ă������ȉ��i�Ƃ������Ƃɂ͂Ȃ�Ȃ��C������
�ŋ߂�Thuban�Ȃnj��Ă������ȉ��i�Ƃ������Ƃɂ͂Ȃ�Ȃ��C������
�v���t�F�b�`�E����\������
Macro-Fusion
�iL1�̌��ݎg���Ă郉�C���ȊO�̓d���I�t���j���߂��Ƃ��v���邭�炢�̏ȓd�͋@�\
IPC�E�N���b�N�㏸���Ɋ��ґ�
�����p�C�v���͂قډe���������낤����
�s���v�f��L1D�e�ʂƏȓd�͋@�\�ɂ��s����炢��
Macro-Fusion
�iL1�̌��ݎg���Ă郉�C���ȊO�̓d���I�t���j���߂��Ƃ��v���邭�炢�̏ȓd�͋@�\
IPC�E�N���b�N�㏸���Ɋ��ґ�
�����p�C�v���͂قډe���������낤����
�s���v�f��L1D�e�ʂƏȓd�͋@�\�ɂ��s����炢��
��7������t���������Ė�����core2�ɕ�����CPU���\������
�V�K�ɊJ�������u���͂��Ȃ���҂��Ă�
1�R�A������̐��\�ŕ����Ă�����d�͂ŏ��Ă���
�V�K�ɊJ�������u���͂��Ȃ���҂��Ă�
1�R�A������̐��\�ŕ����Ă�����d�͂ŏ��Ă���
>>765
Core2�Ɂc������H�@�ǂ�Core2�H
Core2�Ɂc������H�@�ǂ�Core2�H
int���\�Ƃ�int���\�Ƃ�sse���\�Ƃ�����ˁH
Super����Ȃ��́H
Core2�̍ŏ�ʋ@�����9650���H
1095T��9650�ɕ�����P�[�X�˂�
1095T��9650�ɕ�����P�[�X�˂�
�V���O������S�s����
1095T�Ƃ������Ƃ�3.6GHz����
�p�C�Ă݂����ȓ���Ȃ̈ȊO�V���O���X���b�h�ł��������������邩�H
�p�C�Ă݂����ȓ���Ȃ̈ȊO�V���O���X���b�h�ł��������������邩�H
�x���`�ȑO�Ɏg���C�������郂�b�T��Core2�Ƃ��ǂ��ł�����
llano����L3�Ȃ������畉������
3���̃C�x���g�ʼn������łȂ����ȁH
3���̃C�x���g�ʼn������łȂ����ȁH
> 1095T�Ƃ������Ƃ�3.6GHz����
> �p�C�Ă݂����ȓ���Ȃ̈ȊO�V���O���X���b�h�ł��������������邩�H
�]�T�ŕ����Ă邾��w
> �p�C�Ă݂����ȓ���Ȃ̈ȊO�V���O���X���b�h�ł��������������邩�H
�]�T�ŕ����Ă邾��w
>>773
�����O����L3�͂Ȃ����Ă����ĂȂ�������
�����O����L3�͂Ȃ����Ă����ĂȂ�������
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20100901_390769.html
Atom�ɒ���AMD�̏ȓd�̓R�A�uBobcat�v
Atom�ɒ���AMD�̏ȓd�̓R�A�uBobcat�v
�Ƃ肠����AM3�ł�����Ă��ꂽ�炢����
���Ȃ��Ă�AM3��6�R�A���l�����肷�������
���Ȃ��Ă�AM3��6�R�A���l�����肷�������
�V���O��Bull�ƃf���A��Bob���āA�ǂ������d�͌��������낤��
�f���A��Bob�ł���
���S�ɂ������ɐU�����A�[�L�e�N�`���[�Ȃ�
���S�ɂ������ɐU�����A�[�L�e�N�`���[�Ȃ�
���\��������ǂ��l���Ă�Bob����
Atom��CULV�̊Ԃɋ��܂����
Atom��CULV�̊Ԃɋ��܂����
zambezi��ontario����ǂ��Ȃ邩��
onta��TSMC��ٸ40nm�ŃR�X�g���܂߂������d������
onta��TSMC��ٸ40nm�ŃR�X�g���܂߂������d������
�ǂ��Ȃ邩�Ȃ̈Ӗ����悭������Ȃ�
��������������(߁��)������������ !!!!
Bobcat�n��28n��CbMT�ɂȂ邾�낤
3�`8���҂�����
>>776
�㓡�搶���Ȃ�}�C�N���A�[�L�e�N�`���ɂ��ĕ����Ă����ȁB
���܂܂Ō���ĂȂ��������Ƃ����������˂�����ł�ˁB
32B�t�F�b�`�͕���\���̂��߂���?
�㓡�搶���Ȃ�}�C�N���A�[�L�e�N�`���ɂ��ĕ����Ă����ȁB
���܂܂Ō���ĂȂ��������Ƃ����������˂�����ł�ˁB
32B�t�F�b�`�͕���\���̂��߂���?
�c�q���듚�Ă��@���̃A�b�v���͂��߂܂���
���̂������A�z�Ȃ��Ƃ��Ă��܂���������Ȃ���ł���
Bulldozer��Bobcat���Ă̂������āABulldozer���Ă̂��f�X�N�g�b�v������Bobcat���m�[�g����CPU���Ă��Ƃł����H
Bobcat��GPU�����Ă�̂�Ontario�ŁABulldozer��GPU�����Ă�̂�Llano�ł����H
�ق�Ƒf�l��i7�Ƃ��݂����ɐ������Ƃ킩��₷����ł����A�킩��₷�������Ȃǂ���T�C�g����������Ă�������
Bulldozer��Bobcat���Ă̂������āABulldozer���Ă̂��f�X�N�g�b�v������Bobcat���m�[�g����CPU���Ă��Ƃł����H
Bobcat��GPU�����Ă�̂�Ontario�ŁABulldozer��GPU�����Ă�̂�Llano�ł����H
�ق�Ƒf�l��i7�Ƃ��݂����ɐ������Ƃ킩��₷����ł����A�킩��₷�������Ȃǂ���T�C�g����������Ă�������
>>788�@�̂悤�Ȑl�͏��i�Ƃ��Č^�Ԃ��^������܂ő҂̂��g�B
i7�@�����āA�킩��₷���Ȃ��R�[�h�l�[�������t���ĂȂ��������������ł��傤
i7�@�����āA�킩��₷���Ȃ��R�[�h�l�[�������t���ĂȂ��������������ł��傤
�㓡�̋L�������B
Bobcat��L2�����H
���Ɣ�ׂ�90%�̐��\�Ȃ��c�c
Bobcat��L2�����H
���Ɣ�ׂ�90%�̐��\�Ȃ��c�c
>>788
Bulldozer�͎�����̓R�A�Ō��݂�Phenom�Ȃǂ̌�p�Ɏg����R�A
Bobcat�͏���d�͂̍팸���d�������R�A�ő��ɂ����l�b�g�u�b�N�Ȃǂ��^�[�Q�b�g
Llano��Bulldozer�x�[�X�ł͂Ȃ���K10�x�[�X
Bulldozer�͎�����̓R�A�Ō��݂�Phenom�Ȃǂ̌�p�Ɏg����R�A
Bobcat�͏���d�͂̍팸���d�������R�A�ő��ɂ����l�b�g�u�b�N�Ȃǂ��^�[�Q�b�g
Llano��Bulldozer�x�[�X�ł͂Ȃ���K10�x�[�X
�����ł����x���̂�
atom�ɔ�ׂ�ᑬ������\��
>>789
�Ȃ�قNJJ���������ł�����킩��₷���\�L�ɂȂ��ł���
>>791
���肪�Ƃ��������܂��A���ꂩ��L���Ƃ����鎞�̓C���[�W�����₷���ď�����܂�
�����܂���Bulldozer�@Llano�@Bobcat��3��ނ�������Ă��Ƃł���
�Ȃ�قNJJ���������ł�����킩��₷���\�L�ɂȂ��ł���
>>791
���肪�Ƃ��������܂��A���ꂩ��L���Ƃ����鎞�̓C���[�W�����₷���ď�����܂�
�����܂���Bulldozer�@Llano�@Bobcat��3��ނ�������Ă��Ƃł���
>>788
�S�R�Ⴄ�c�B�Ă�����>>776�̋L�����x���ǂ�ŗ����ł��Ȃ��̂��H
�R�A�A�[�L�e�B�N�`���̃R�[�h�l�[��
Bulldozer�F�V�R�A�iBobcat�Ƃ͕ʃR�A�j
Bobcat�@ �F�V�R�A�iBulldozer�Ƃ͕ʃR�A�j
Bulldozer�A�[�L�e�N�`���̐��i�R�[�h�l�[����
�T�[�o�[�@ �FInterlagos�AValencia
�f�X�N�g�b�v�FZambezi
Bobcat�A�[�L�e�N�`���̐��i�R�[�h�l�[��
�m�[�g�����FOntario�iBobcat + GPU�j
"Llano"�̓R�A���̂́uK10�v�Ȃ̂ŕʂɃR�A�A�[�L�e�B�N�`���̖��O�͖����ŁA
"Llano�iK10+GPU�j"���Ė��O�͐��i�R�[�h�l�[���ł������܂��ˁB
���̂ق���"Maranello"�A"San Marino"�A"Scorpius"�A"Lynx"�A"Sabine"�A"Brazos"�Ȃǂ́A
�u���i�v���b�g�t�H�[���̃R�[�h�l�[����炪���藐���̂ł��B
�Ƃ����킯�ŁA�����Œ��ׂȂ��悤��>>788�̐�����>>789�ł��ˁB
�S�R�Ⴄ�c�B�Ă�����>>776�̋L�����x���ǂ�ŗ����ł��Ȃ��̂��H
�R�A�A�[�L�e�B�N�`���̃R�[�h�l�[��
Bulldozer�F�V�R�A�iBobcat�Ƃ͕ʃR�A�j
Bobcat�@ �F�V�R�A�iBulldozer�Ƃ͕ʃR�A�j
Bulldozer�A�[�L�e�N�`���̐��i�R�[�h�l�[����
�T�[�o�[�@ �FInterlagos�AValencia
�f�X�N�g�b�v�FZambezi
Bobcat�A�[�L�e�N�`���̐��i�R�[�h�l�[��
�m�[�g�����FOntario�iBobcat + GPU�j
"Llano"�̓R�A���̂́uK10�v�Ȃ̂ŕʂɃR�A�A�[�L�e�B�N�`���̖��O�͖����ŁA
"Llano�iK10+GPU�j"���Ė��O�͐��i�R�[�h�l�[���ł������܂��ˁB
���̂ق���"Maranello"�A"San Marino"�A"Scorpius"�A"Lynx"�A"Sabine"�A"Brazos"�Ȃǂ́A
�u���i�v���b�g�t�H�[���̃R�[�h�l�[����炪���藐���̂ł��B
�Ƃ����킯�ŁA�����Œ��ׂȂ��悤��>>788�̐�����>>789�ł��ˁB
>>795
�R�A���R�[�h�l�[���Ɛ��i���R�[�h�l�[������������ɂȂ��Ă�
�R�A��Bulldozer�AK10�i���ݎg���Ă�R�A�j�ABobcat��������
GPU���������i��Llano�iK10)�AOntario�iBobcat�j������Ƃ�������
Bulldozer���g����GPU���������̃R�[�h�l�[���͂܂��o�ĂȂ��͂�
�R�A���R�[�h�l�[���Ɛ��i���R�[�h�l�[������������ɂȂ��Ă�
�R�A��Bulldozer�AK10�i���ݎg���Ă�R�A�j�ABobcat��������
GPU���������i��Llano�iK10)�AOntario�iBobcat�j������Ƃ�������
Bulldozer���g����GPU���������̃R�[�h�l�[���͂܂��o�ĂȂ��͂�
�������⏤�i���͂ǂ��Ȃ�낤
>>792
���肦��c�c�Ǝv�����o�Ă݂�܂ł͂Ȃ�Ƃ��ȁB
���肦��c�c�Ǝv�����o�Ă݂�܂ł͂Ȃ�Ƃ��ȁB
�ڂ����������肪�Ƃ��������܂����B���J�ł������킩��₷�������ł�
Bulldozer�@K10�@Bobcat�@����3��ނ̃R�A�ɂ��ꂼ�ꐻ�i����������Ă��ƂȂ�ł���
�������ŋL���₱���ł̘b���y�������ꂻ���ł�
Bulldozer�@K10�@Bobcat�@����3��ނ̃R�A�ɂ��ꂼ�ꐻ�i����������Ă��ƂȂ�ł���
�������ŋL���₱���ł̘b���y�������ꂻ���ł�
>>790
K10����
�r���L���b�V�����C���N���[�V�u�L���b�V���Ő��\���サ�������A�L���b�V���������œ����ɗ}�������ĂƂ��납��
�������ȓd�͉��o���邩��A���\�ێ��Əȓd�͉��̗������o�����낤
K10����
�r���L���b�V�����C���N���[�V�u�L���b�V���Ő��\���サ�������A�L���b�V���������œ����ɗ}�������ĂƂ��납��
�������ȓd�͉��o���邩��A���\�ێ��Əȓd�͉��̗������o�����낤
���ʂ����R�A��L2���S���Ɣ����Ă͉̂ߋ��ɗႪ�������
�ǂꂾ����������v���o��������Ȃ���
�ǂꂾ����������v���o��������Ȃ���
Katmai��Coppermine�̎��H
�������ɔ����̑��x�œ����Ă�Ƃ��������ŊO�t���ƃI���_�C�̕����ꏏ�ɂ���̂�
��́AK10��Bobcat���Ď��ʂ����R�A���H
�������ɔ����̑��x�œ����Ă�Ƃ��������ŊO�t���ƃI���_�C�̕����ꏏ�ɂ���̂�
��́AK10��Bobcat���Ď��ʂ����R�A���H
Bobcat��L2�����ŁAL2�S���̏ꍇ�Ɣ�ׂ�
�ǂꂾ�����\�Ɠd�͂��ς�邩�����ł�����Ęb�����
�ǂꂾ�����\�Ɠd�͂��ς�邩�����ł�����Ęb�����
>>790
Bobcat�̒u�������̑ΏۂƂȂ�Athron Neo(K8)����Ȃ�����
Bobcat�̒u�������̑ΏۂƂȂ�Athron Neo(K8)����Ȃ�����
>>805
bobcat�͒P��L2�������ɂȂ��Ă邾��������
Slot�����Pentium3��Athlon��L2�̃��C�e���V���s���Ȃ̂�
�P���ɓ��Ă͂߂��Ȃ�
bobcat�͒P��L2�������ɂȂ��Ă邾��������
Slot�����Pentium3��Athlon��L2�̃��C�e���V���s���Ȃ̂�
�P���ɓ��Ă͂߂��Ȃ�
�ʃ_�C�������I���_�C�����i�������e�ʔ����j
�I���_�C�������I���_�C�����i�e�ʔ{�j
�I���_�C�������I���_�C�����i�e�ʔ{�j
810 �FSocket774�F2010/09/02(��) 09:53:24 ID:z3+DSrgw
AMD�̌����u���O�ŁuBulldozer�v��20�̎���p�[�g2
http://leddown.wordpress.com/2010/09/01/amd%e3%81%ae%e5%85%ac%e5%bc%8f%e3%83%96%e3%83%ad%e3%82%b0%e3%81%a7%e3%80%8cbulldozer%e3%80%8d%e3%81%ae20%e3%81%ae%e8%b3%aa%e5%95%8f%e3%83%91%e3%83%bc%e3%83%882-%e3%83%90%e3%82%ab%e8%a8%b3/
http://leddown.wordpress.com/2010/09/01/amd%e3%81%ae%e5%85%ac%e5%bc%8f%e3%83%96%e3%83%ad%e3%82%b0%e3%81%a7%e3%80%8cbulldozer%e3%80%8d%e3%81%ae20%e3%81%ae%e8%b3%aa%e5%95%8f%e3%83%91%e3%83%bc%e3%83%882-%e3%83%90%e3%82%ab%e8%a8%b3/
��33%�̃R�A�������Ƃ��傫�ȃL���b�V���ŁA���݂̉�X��12�R�A�v���Z�b�T�Ɠ�������d�͂Ȃ�B
���Ă��Ƃ��炷��ƁAInterlagos��Magny-Cours��1.5�{���Ă̂́A
��������d�͂łƍl���ėǂ��������ȁB
���Ă��Ƃ��炷��ƁAInterlagos��Magny-Cours��1.5�{���Ă̂́A
��������d�͂łƍl���ėǂ��������ȁB
TDP����Ȃ�Ă�����Ƃ������ς���ĂȂ�
1.5�{���オ�����珟�����܂�����˂���
Bulldozer�̃_�C�ʐ^
http://www.pcper.com/comments.php?nid=9207
http://www.pcper.com/comments.php?nid=9207
>>814
����iAMD��Open64�R���p�C���ɃR�~�b�g�����R�[�h�j�ʂ肾��L2��2MB/module������
�ʐϔ䗦�I��L3��6MB���炢���ȁB
SRAM�̐�L�ʐς���t�Z����ƌy��Westmere-6C��2���ȏ�傫���B
L3��2.5MB/core���炢�ɑ��ʂ����炵��Sandy Bridge B2 6�R�A�ɕC�G���邩
������傫�����炢�ɂȂ肻���B
>>813
��������1.5�{���Ă̂����̃X�R�A�Ȃ̂��s���B
����FP�̃s�[�N���\�Ȃ�A������1.2�{����x�̃N���b�N���ゾ���ł��B���ł��鐔���B
����iAMD��Open64�R���p�C���ɃR�~�b�g�����R�[�h�j�ʂ肾��L2��2MB/module������
�ʐϔ䗦�I��L3��6MB���炢���ȁB
SRAM�̐�L�ʐς���t�Z����ƌy��Westmere-6C��2���ȏ�傫���B
L3��2.5MB/core���炢�ɑ��ʂ����炵��Sandy Bridge B2 6�R�A�ɕC�G���邩
������傫�����炢�ɂȂ肻���B
>>813
��������1.5�{���Ă̂����̃X�R�A�Ȃ̂��s���B
����FP�̃s�[�N���\�Ȃ�A������1.2�{����x�̃N���b�N���ゾ���ł��B���ł��鐔���B
Llano�̎ʐ^�Ɣ�r�����L2��2MB��L3�͍��v8MB����
>>816
���炩��L2���ʐς��L3�̂ق����������i7�����x�j
Westmere-6C�̏ꍇL3 12MB��240mm²
http://techreport.com/discussions.x/18415
300mm²�͍s���C��������B
���炩��L2���ʐς��L3�̂ق����������i7�����x�j
Westmere-6C�̏ꍇL3 12MB��240mm²
http://techreport.com/discussions.x/18415
300mm²�͍s���C��������B
��A�m���ɂ悭�����L3�̕₢��������������6M��
����ϖʐϓI�ɂ�Westmere-6C�Ɠ������炢���ȁB
��������L3�ƃA���R�A����������v6���W���[���{L2 12MB�l�ߍ��߂����Ɍ�����
�^�łԂ������2���W���[���̃_�C���ȒP�ɍ�ꂻ���ȋC������B
��������L3�ƃA���R�A����������v6���W���[���{L2 12MB�l�ߍ��߂����Ɍ�����
�^�łԂ������2���W���[���̃_�C���ȒP�ɍ�ꂻ���ȋC������B
�Ђǂ��^�C�v�~�X�����ȁE�E�E
Llano�̃R�A�ɔ�ׂĖڑ��Ŗ��{�Ƃ����Ƃ��낾�낤��
���������1���W���[��35�`40mm2
����������
Llano�̃R�A�ɔ�ׂĖڑ��Ŗ��{�Ƃ����Ƃ��낾�낤��
���������1���W���[��35�`40mm2
����������
L2��L3��SRAM�̃Z���T�C�Y���Ⴄ�Ƃ����\���͂���
822 �FSocket774�F2010/09/02(��) 14:06:50 ID:uvqClGzx
http://www.pcper.com/article.php?aid=991
�p�ꂪ���\�Ȑl������ނ���������
�p�ꂪ���\�Ȑl������ނ���������
Llano�@32nmSOI/HKMG�@170mm�`210mm2�H
�EL3�Ȃ��H���̂����L2��512������1024����
�@����ɂ���č���Athlon II��萫�\�A�b�v
�EGPU��480SP�@55*0�ȏ�56*0�ȉ�
�ELlano��CPU���\��SandyBridge�ɋy�Ȃ�
�@SandyBridge��GPU���ӊO�ɗǂ��̂�
�@AMD��5650���̐��\����������
�@�ł�DDR3�̑ш�㖳���@����ł��C���e����萫�\���i�����Ȃ�
�@AVIVO HD���g���ė������悢
�K���ɖ|��ɂႭ
�EL3�Ȃ��H���̂����L2��512������1024����
�@����ɂ���č���Athlon II��萫�\�A�b�v
�EGPU��480SP�@55*0�ȏ�56*0�ȉ�
�ELlano��CPU���\��SandyBridge�ɋy�Ȃ�
�@SandyBridge��GPU���ӊO�ɗǂ��̂�
�@AMD��5650���̐��\����������
�@�ł�DDR3�̑ш�㖳���@����ł��C���e����萫�\���i�����Ȃ�
�@AVIVO HD���g���ė������悢
�K���ɖ|��ɂႭ
>>823
��̃��W���[����Ɖ��̃��W���[����ő傫���Ⴄ�C������
��̃��W���[����Ɖ��̃��W���[����ő傫���Ⴄ�C������
�ŏ��̎ʐ^���Ǝ߂�����A�Ⴄ�悤�Ɍ����邾�����Ȃ��Ďv�������ǁA
�^���ʂ���̎ʐ^���Ɩ��炩�ɏ㉺�ňႤ�ˁA�Ȃ�ł��낤�B
�^���ʂ���̎ʐ^���Ɩ��炩�ɏ㉺�ňႤ�ˁA�Ȃ�ł��낤�B
photoshopped��������
http://www.amdzone.com/phpbb3/viewtopic.php?f=52&t=137904#p188312
http://www.amdzone.com/phpbb3/viewtopic.php?f=52&t=137904#p188312
�Ȃ�قǁA�t�H�[�����̑傫���摜�Ō����L2�c����ς��Ă邩��Z���̕����Ⴄ��
�R�A�����ڂ��������Ă邵���̂��߂̉��H���ēz��
�R�A�����ڂ��������Ă邵���̂��߂̉��H���ēz��
GF�Ƃ��Ă�32nmSOI�ō���Ă���`�b�v���Љ�����A
AMD�Ƃ��Ă͂܂��ڍׂ͌��������Ȃ����Ă��ƂȂ낤�ȁB
�Ƃ���ƁA���ۂ̃`�b�v�̏c���̔䗦���A�ʐ^�ʂ�Ƃ͌���Ȃ��̂��ȁB
AMD�Ƃ��Ă͂܂��ڍׂ͌��������Ȃ����Ă��ƂȂ낤�ȁB
�Ƃ���ƁA���ۂ̃`�b�v�̏c���̔䗦���A�ʐ^�ʂ�Ƃ͌���Ȃ��̂��ȁB
1���W���[�����ǂꂭ�炢�̑傫���ɂȂ邩�Ǝv����Llano���Q�l�ɂ��Ă��Ȃ��G�c�Ɍv�Z���Ă݂��B
Llano�̃R�A�͖�10mm2��1M��L2�L���b�V��+�p���[�Q�[�g�����O����8mm2(�㓡���̋L�����)
L2�L���b�V�������W���[������2M�Ȃ�P���ɍl���ăR�A�ƃL���b�V���̃T�C�Y��10+8*2=26mm2�ɂȂ�B
2�߂̐������Z���j�b�g��lj�����̂�12%���̑����ŏo�����Ƃ̂��ƂȂ̂�1���W���[���̃T�C�Y��26*1.12��30mm2���炢�B
���Ȃ��G�c�Ȍv�Z����Llano����ɍl���Ă��邩����ۂ̑傫���͈Ⴄ�͂������Njɒ[�ɊO��Ă���Ƃ������͂Ȃ��͂��B
>>820�̌����悤��35mm2���炢�ɂȂ肻���B
Llano�̃R�A�͖�10mm2��1M��L2�L���b�V��+�p���[�Q�[�g�����O����8mm2(�㓡���̋L�����)
L2�L���b�V�������W���[������2M�Ȃ�P���ɍl���ăR�A�ƃL���b�V���̃T�C�Y��10+8*2=26mm2�ɂȂ�B
2�߂̐������Z���j�b�g��lj�����̂�12%���̑����ŏo�����Ƃ̂��ƂȂ̂�1���W���[���̃T�C�Y��26*1.12��30mm2���炢�B
���Ȃ��G�c�Ȍv�Z����Llano����ɍl���Ă��邩����ۂ̑傫���͈Ⴄ�͂������Njɒ[�ɊO��Ă���Ƃ������͂Ȃ��͂��B
>>820�̌����悤��35mm2���炢�ɂȂ肻���B
>>800
Optedeon Phedeon Athlodeon
Optedeon Phedeon Athlodeon
���H���������L2�iLlano�Ɩ��x�����Ƃ���j�ƃR�A�̔䗦�Ō���̂���ԗǂ�����
���F�͉��H������Ȃ�
�R�A+L2��50m�u�Ȃ�_�C�S����300m�u������
45nm�ł͏�C�Ńn�C�G���h�̗\��
��
�֎q�݂��n�C�G���h
��
�������Ă�MCM�ŊԂɗ���o��
�Ƃ���������܂݂ɓ����Bull�ł�����MCM��\��ɓ���Ă���
�Ƃ����[���̂������e�ɂȂ����
ttp://pc.watch.impress.co.jp/img/pcw/docs/163/886/html/kaigai_7.jpg.html
���̂܂܉����x�I�ɕ��C�Ȋ炵��400�˓��Ȃ�Ă��Ƃ͗L��܂�
���F�͉��H������Ȃ�
�R�A+L2��50m�u�Ȃ�_�C�S����300m�u������
45nm�ł͏�C�Ńn�C�G���h�̗\��
��
�֎q�݂��n�C�G���h
��
�������Ă�MCM�ŊԂɗ���o��
�Ƃ���������܂݂ɓ����Bull�ł�����MCM��\��ɓ���Ă���
�Ƃ����[���̂������e�ɂȂ����
ttp://pc.watch.impress.co.jp/img/pcw/docs/163/886/html/kaigai_7.jpg.html
{kind=link}
���̂܂܉����x�I�ɕ��C�Ȋ炵��400�˓��Ȃ�Ă��Ƃ͗L��܂�
Duron������ް??
>>831
20Hr���o���Ă��炻�̑ʃ��X���Ăǂ���H
20Hr���o���Ă��炻�̑ʃ��X���Ăǂ���H
�������I
�u����Llano��480SP�Ȃ̂��v
�ł��肢���܂���邵�Ă�������
�u����Llano��480SP�Ȃ̂��v
�ł��肢���܂���邵�Ă�������
Llano���Ď��ۂ������ɂȂ��ˁH
>>823
> ���ʂ���̃_�C�ʐ^
> ttp://www.xbitlabs.com/news/cpu/display/20100901181239_AMD_Displays_Die_Shot_of_Upcoming_Eight_Core_Orochi_Processor_for_the_First_Time.html
�����Ƀ_�C�T�C�Y�̌v�Z�����Ă݂�
L2�����Ƀ_�C�S�̂𑪂�����L2��34��
Llano��Bulldozer��L2�������\��(�e�ʕӂ�̃T�C�Y���ꏏ)���Ɖ���
��Llano��L2��1MB��7mm2 (9.7mm2�̃R�A�̖�2/3)
Bulldozer��L2��2MB�̏ꍇ�A34*7*2��500mm2
��������500mm2�͂Ȃ����낤
L2��1M�̏ꍇ�A34*7��240mm2
�����I�Ȑ��l�ɂȂ���
L2 1MB 7mm2�ł͂Ȃ��ꍇ�ōl�@
�EL2��2MB�Ȃ�10mm2�ȏ�ɂȂ�_�C�T�C�Y��340mm2�ɂȂ�S�R�������Ȃ�
�@(2MB 10mm2��Intel���̖����T�C�Y)
�E��L�̏ꍇ1MB��5mm2�ɂȂ�_�C�T�C�Y��170mm2�ɂȂ�
�E1MB�̏ꍇ�ALlano�����J�����i���7mm2��菬�����Ȃ��Ă��邩���m��Ȃ�
�@6mm2����205mm2
�E7�`10mm2��1M�ȏ�̗e�ʂ��ƃL���������Ƃ����1.5MB
Bulldozer�̃_�C�T�C�Y��
L2 1.0MB 7mm2��240mm2
L2 2.0MB 10mm2��340mm2
L2 1.0MB 5mm2��170mm2
L2 1.0MB 7mm2��240mm2�A6mm2��210mm2
L2 1.5MB 8mm2��270mm2�A9mm2��310mm2
�̂ǂꂩ���Ǝv��
�L�蓾�����Ȃ̂�1MB 7mm2��240mm2���A6mm2��1.5MB 9mm2��310mm2�ӂ肩��
> ���ʂ���̃_�C�ʐ^
> ttp://www.xbitlabs.com/news/cpu/display/20100901181239_AMD_Displays_Die_Shot_of_Upcoming_Eight_Core_Orochi_Processor_for_the_First_Time.html
�����Ƀ_�C�T�C�Y�̌v�Z�����Ă݂�
L2�����Ƀ_�C�S�̂𑪂�����L2��34��
Llano��Bulldozer��L2�������\��(�e�ʕӂ�̃T�C�Y���ꏏ)���Ɖ���
��Llano��L2��1MB��7mm2 (9.7mm2�̃R�A�̖�2/3)
Bulldozer��L2��2MB�̏ꍇ�A34*7*2��500mm2
��������500mm2�͂Ȃ����낤
L2��1M�̏ꍇ�A34*7��240mm2
�����I�Ȑ��l�ɂȂ���
L2 1MB 7mm2�ł͂Ȃ��ꍇ�ōl�@
�EL2��2MB�Ȃ�10mm2�ȏ�ɂȂ�_�C�T�C�Y��340mm2�ɂȂ�S�R�������Ȃ�
�@(2MB 10mm2��Intel���̖����T�C�Y)
�E��L�̏ꍇ1MB��5mm2�ɂȂ�_�C�T�C�Y��170mm2�ɂȂ�
�E1MB�̏ꍇ�ALlano�����J�����i���7mm2��菬�����Ȃ��Ă��邩���m��Ȃ�
�@6mm2����205mm2
�E7�`10mm2��1M�ȏ�̗e�ʂ��ƃL���������Ƃ����1.5MB
Bulldozer�̃_�C�T�C�Y��
L2 1.0MB 7mm2��240mm2
L2 2.0MB 10mm2��340mm2
L2 1.0MB 5mm2��170mm2
L2 1.0MB 7mm2��240mm2�A6mm2��210mm2
L2 1.5MB 8mm2��270mm2�A9mm2��310mm2
�̂ǂꂩ���Ǝv��
�L�蓾�����Ȃ̂�1MB 7mm2��240mm2���A6mm2��1.5MB 9mm2��310mm2�ӂ肩��
�ҏW�r���ő��M���Ă��܂���
Bulldozer�̃_�C�T�C�Y��
L2 2.0MB 10mm2��340mm2
L2 1.5MB 8mm2��270mm2�A9mm2��310mm2
L2 1.0MB 7mm2��240mm2�A6mm2��210mm2�A5mm2��170mm2
�̂ǂꂩ���Ǝv��
�L�蓾�����Ȃ̂�1.5MB 8mm2��270�A1MB 7mm2��240mm2�A6mm2��210mm2�ӂ肾�Ǝv��
Bulldozer�̃_�C�T�C�Y��
L2 2.0MB 10mm2��340mm2
L2 1.5MB 8mm2��270mm2�A9mm2��310mm2
L2 1.0MB 7mm2��240mm2�A6mm2��210mm2�A5mm2��170mm2
�̂ǂꂩ���Ǝv��
�L�蓾�����Ȃ̂�1.5MB 8mm2��270�A1MB 7mm2��240mm2�A6mm2��210mm2�ӂ肾�Ǝv��
�R�A��L2�̔䗦������H���Ă������Ă����ALlano��Bulldozer��L2�̖��x����������
�킩��Ȃ�����ALlano��L2������Orochi�̃_�C�T�C�Y���肷��͓̂����Ȃ��́H
�킩��Ȃ�����ALlano��L2������Orochi�̃_�C�T�C�Y���肷��͓̂����Ȃ��́H
�ʐ^�̃R�A��L2���f�^����������w
�ǂꂩ����������Ȃ��S���f�^�������낤���猻�i�K�ŗ\�z�͕s�\����
�܂��ALlano��2�R�A���̃R�A+L2����33mm2������A1���W���[��������ȏ���Ă��Ƃ͂Ȃ��Ǝv��
L2�͂قڕς�炸�A2�R�A���̃T�C�Y���k������͂�������A1���W���[���͑傫���Ă�30mm2�ȉ����낤
���Ƀ��C���R�A��K10���̃R�A���Ƃ��Ă��A2�R�A����1.5�{��15mm2�ɂȂ�AL2���܂߂���29mm2�ɂȂ�
�ǂꂩ����������Ȃ��S���f�^�������낤���猻�i�K�ŗ\�z�͕s�\����
�܂��ALlano��2�R�A���̃R�A+L2����33mm2������A1���W���[��������ȏ���Ă��Ƃ͂Ȃ��Ǝv��
L2�͂قڕς�炸�A2�R�A���̃T�C�Y���k������͂�������A1���W���[���͑傫���Ă�30mm2�ȉ����낤
���Ƀ��C���R�A��K10���̃R�A���Ƃ��Ă��A2�R�A����1.5�{��15mm2�ɂȂ�AL2���܂߂���29mm2�ɂȂ�
AMD�̐l�����H���Ă�Ɩ������ʐ^���ɔ䗦�̖��炩�ɈႤL2�����Ď���ȏ�
L2�����ɎZ�o����͖̂��Ӗ����낤
�p�b�h�Ŕ�ׂ�����ǂ���Ȃ���
L2�����ɎZ�o����͖̂��Ӗ����낤
�p�b�h�Ŕ�ׂ�����ǂ���Ȃ���
>>841
�܂��AL2�̍\�����ꏏ�ȃ��P�Ȃ����ǁA�͂��Ȃ��͂��ŁA�����͗ǂ��Ȃ��Ă���Ǝv��
�Ƃ͂����AIntel����قlj��P����Ƃ��v���Ȃ�
Llano L2 2M��14mm2��1M 7mm2
Sandy L2 2M��11�`12mm2��1M 5.5�`6mm2
������AL2 1M�ӂ�1mm2�k���ł��邩�ǂ������Ǝv��(����Ɩw�Ǖς��Ȃ�)
�܂��AL2�̍\�����ꏏ�ȃ��P�Ȃ����ǁA�͂��Ȃ��͂��ŁA�����͗ǂ��Ȃ��Ă���Ǝv��
�Ƃ͂����AIntel����قlj��P����Ƃ��v���Ȃ�
Llano L2 2M��14mm2��1M 7mm2
Sandy L2 2M��11�`12mm2��1M 5.5�`6mm2
������AL2 1M�ӂ�1mm2�k���ł��邩�ǂ������Ǝv��(����Ɩw�Ǖς��Ȃ�)
>>844
SandyBridge��11�`12mm2���āAL2����Ȃ���L3����Ȃ��H
�R�A���ɂ���256KB��L2�̃T�C�Y����̓I�ɏ����Ă���̂͌������ƖS�����ǁB
SandyBridge��11�`12mm2���āAL2����Ȃ���L3����Ȃ��H
�R�A���ɂ���256KB��L2�̃T�C�Y����̓I�ɏ����Ă���̂͌������ƖS�����ǁB
>>846
���\���[�N�Ȃ�Ĕ������O�܂ł��ˁ[��B
���\���[�N�Ȃ�Ĕ������O�܂ł��ˁ[��B
>>835
DDR3-1866�ɑΉ����邩�Ǝv�������ǁA����DDR3-1600�~�܂�Ȃ̂�
DDR3-1866�ɑΉ����邩�Ǝv�������ǁA����DDR3-1600�~�܂�Ȃ̂�
HD5670���̐��\�o������
5670������GPU���݉��l����C�ɂȂ��Ȃ�B
������AHD6000�̓~�h���ƃG���g���[���痈��̂��ȁB
5670������GPU���݉��l����C�ɂȂ��Ȃ�B
������AHD6000�̓~�h���ƃG���g���[���痈��̂��ȁB
������x���C�g�ȃQ�[���⓮��Đ����x����Sandy Bridge��IGP�ł��\���Ȑ��\�o���邾�낤��
�X�y�b�N���K�v�ȃQ�[���ł̓f�B�X�N���[�gGPU���g�킴��Ȃ����A����ł�CPU���\�͐����Ă���B
�m�[�gPC�p�Ƃ��Ă͏\������Ȃ�
Llano�̓��C�g�ȃQ�[���Ȃɂ�GPU�̓I�[�o�[�X�y�b�N�߂��邵�A�d����Flash�Ƃ��̍Đ��ɂ�
CPU�̂ق����l�b�N�ɂȂ��Ă���B
�n�C�X�y�b�N��v������ŐV�̃Q�[������CPU�EGPU���\�Ƃ��ɐS���ƂȂ��B
1�`2����O�̃Q�[����V�Ԃɂ͂��傤�Ǘǂ��������Ǝv�����AAMD�Ƃ��Ă�����ق�
����₷���͂Ȃ����낤�Ȃ��B
�܂��������AATi�u�����h�̂Ă�AMD�ɓ��ꂷ����Ă̂͂ǂ��Ȃ낤
AMD�u�����h�������Ȑl��NVIDIA�g�����肷��낤���H
�X�y�b�N���K�v�ȃQ�[���ł̓f�B�X�N���[�gGPU���g�킴��Ȃ����A����ł�CPU���\�͐����Ă���B
�m�[�gPC�p�Ƃ��Ă͏\������Ȃ�
Llano�̓��C�g�ȃQ�[���Ȃɂ�GPU�̓I�[�o�[�X�y�b�N�߂��邵�A�d����Flash�Ƃ��̍Đ��ɂ�
CPU�̂ق����l�b�N�ɂȂ��Ă���B
�n�C�X�y�b�N��v������ŐV�̃Q�[������CPU�EGPU���\�Ƃ��ɐS���ƂȂ��B
1�`2����O�̃Q�[����V�Ԃɂ͂��傤�Ǘǂ��������Ǝv�����AAMD�Ƃ��Ă�����ق�
����₷���͂Ȃ����낤�Ȃ��B
�܂��������AATi�u�����h�̂Ă�AMD�ɓ��ꂷ����Ă̂͂ǂ��Ȃ낤
AMD�u�����h�������Ȑl��NVIDIA�g�����肷��낤���H
�Ȃ��GPU�͉ߏ肾���Č����̂ɁACPU�͑���Ȃ����Ƃ��O��̘b�Ȃ́H
�Ⴆ�����C�g�Q�[�}�[�H�Ō��Ȃ�CPU���\�����Ǝv������
�Ⴆ�����C�g�Q�[�}�[�H�Ō��Ȃ�CPU���\�����Ǝv������
�v���C���Ă��炤�l�Ԃ����C�g�Q�[�}�[���Ă��Ƃ́A
�V����PC��������Ȃ��āA�Â�������PC���l�����Ȃ��Ƃ����Ȃ���Ȃ��́H
�ŐV��PC��Â߂̃~�h���A�b�p�[�ȏザ��Ȃ��ƃv���C�ł��Ȃ�Flash�̃Q�[������
�l�C�o��̂��H
�V����PC��������Ȃ��āA�Â�������PC���l�����Ȃ��Ƃ����Ȃ���Ȃ��́H
�ŐV��PC��Â߂̃~�h���A�b�p�[�ȏザ��Ȃ��ƃv���C�ł��Ȃ�Flash�̃Q�[������
�l�C�o��̂��H
�\�[�V�����Q�[���o�u�����͂��������AFlash���g�����d�ʋ��̃R���e���c�Ȃ�Ă����o�Ȃ���
Intel��12EU�ł��p�ӂ��Ă邱�Ƃ��l�����GPU���\���\���Ȃ�Ă��Ƃ͖����ł���
�~�m�[�gPC�p�Ƃ��Ă͏\������Ȃ�
���m�[�gPC�p�Ƃ��Ă͏\������Ȃ��H
>>852
���[�U�[���I�Ԗ�Ȃ��ă��[�J�[�����߂���ǂȁB
mixi�̍L���Ɂu��������PC�v�݂����ȍL�����o�Ă錻���A�d�ʋ���Flash�Q�[����PC����������
�����͂ɂ͂Ȃ��Ă�݂�����B
PC���[�J�[��Flash�Q�[���Ɍ����ꂵ�Ă�̂́A�Q�[���ׂ̈�PC���������Ȃ��āA���̒��x��
����ڂ��Q�[�������K�ɂł��Ȃ��Ȃ瑼�̍�Ƃɂ��x�Ⴊ�ł邩�甃��������������Ȃ�����
�w���ӗ~�����헪����B
���Ȃ݂�Flash���d�����̂�CPU�����_�����O�̕��ׂ����C��������A�d�����Ƃ����Ă�Flash�Q�[����
�����_�����O�𑜓x���Ƃ��l�b�g�u�b�N�ł���Ȃ�Ƃ��ł�����x�ɂ͂Ȃ�B
���ꂪ���K���Č����̂��͂��Ă����B
>>853
> �\�[�V�����Q�[���o�u�����͂�������
�\�[�V�����Q�[�����o�u�����Ă͓̂��ӂ����܂��e����C�z�͂Ȃ��ȁB
����HTML5�Ƃ�Silverlight, JavaFX�݂�����RIA�v���b�g�t�H�[�����{�i���y��������CPU���\�͕s������B
���IE9�x���`���A����ۂǂ���ڂ�GPU�ł��ς܂Ȃ����茋�ǂ�CPU�����B
Bulldozer��CPU���\�������H
���m�[�gPC�p�Ƃ��Ă͏\������Ȃ��H
>>852
���[�U�[���I�Ԗ�Ȃ��ă��[�J�[�����߂���ǂȁB
mixi�̍L���Ɂu��������PC�v�݂����ȍL�����o�Ă錻���A�d�ʋ���Flash�Q�[����PC����������
�����͂ɂ͂Ȃ��Ă�݂�����B
PC���[�J�[��Flash�Q�[���Ɍ����ꂵ�Ă�̂́A�Q�[���ׂ̈�PC���������Ȃ��āA���̒��x��
����ڂ��Q�[�������K�ɂł��Ȃ��Ȃ瑼�̍�Ƃɂ��x�Ⴊ�ł邩�甃��������������Ȃ�����
�w���ӗ~�����헪����B
���Ȃ݂�Flash���d�����̂�CPU�����_�����O�̕��ׂ����C��������A�d�����Ƃ����Ă�Flash�Q�[����
�����_�����O�𑜓x���Ƃ��l�b�g�u�b�N�ł���Ȃ�Ƃ��ł�����x�ɂ͂Ȃ�B
���ꂪ���K���Č����̂��͂��Ă����B
>>853
> �\�[�V�����Q�[���o�u�����͂�������
�\�[�V�����Q�[�����o�u�����Ă͓̂��ӂ����܂��e����C�z�͂Ȃ��ȁB
����HTML5�Ƃ�Silverlight, JavaFX�݂�����RIA�v���b�g�t�H�[�����{�i���y��������CPU���\�͕s������B
���IE9�x���`���A����ۂǂ���ڂ�GPU�ł��ς܂Ȃ����茋�ǂ�CPU�����B
Bulldozer��CPU���\�������H
���܂�FlashFlash�����Ă�
���̐l�������Ă�Sandy��CPU���\�Ȃ�悭��Llano��CPU���\���Ɖ��K�ɏo���Ȃ�Flash�Q�[�����ĉ��H
���������C�g�Q�[�}�[�����߂�p�r��
�ǂ������������͂��̐l�̗p�r���悾����D���ɂ���������ǁA�b���ɒ[������
���������C�g�Q�[�}�[�����߂�p�r��
�ǂ������������͂��̐l�̗p�r���悾����D���ɂ���������ǁA�b���ɒ[������
�ނ��낱�ꂩ���Silverlight����
���Ƃ�MS������C�����邩�̖��BAdobe��������������Ȃ����낤���ǂˁB
http://journal.mycom.co.jp/articles/2010/06/16/slmd/index.html
���Ƃ�MS������C�����邩�̖��BAdobe��������������Ȃ����낤���ǂˁB
http://journal.mycom.co.jp/articles/2010/06/16/slmd/index.html
>>857
> ���̐l�������Ă�Sandy��CPU���\�Ȃ�悭��Llano��CPU���\���Ɖ��K�ɏo���Ȃ�Flash�Q�[�����ĉ��H
Sandy Bridge�ŏ\�����Ď��͂����炭�����Ǝv����B
Flash��1�X���b�h�ŕ`�悷��B
�f���A���R�A��50%�i4�R�A�Ȃ�25%�j�Ƃ��\��t�����Ⴄ�Q�[�����������A�v�����1�R�A�̐��\�Ńt���[�����[�g���ς���Ă��܂��B
�i25%������S�R�]�T������Ȃ�Ďv���Ă����Ⴂ�j
Silverlight��GPU�A�N�Z�����[�V�����������₷�����A��Ղ�C#.NET�Ȃ̂ŃX���b�h���N�����Η�����}���`�R�A�ɂ��Ή��ł���B
����ł�C#���̂��d��������A��͂�GPU���CPU�l�b�N�ɂȂ�₷�����낤��B
> ���̐l�������Ă�Sandy��CPU���\�Ȃ�悭��Llano��CPU���\���Ɖ��K�ɏo���Ȃ�Flash�Q�[�����ĉ��H
Sandy Bridge�ŏ\�����Ď��͂����炭�����Ǝv����B
Flash��1�X���b�h�ŕ`�悷��B
�f���A���R�A��50%�i4�R�A�Ȃ�25%�j�Ƃ��\��t�����Ⴄ�Q�[�����������A�v�����1�R�A�̐��\�Ńt���[�����[�g���ς���Ă��܂��B
�i25%������S�R�]�T������Ȃ�Ďv���Ă����Ⴂ�j
Silverlight��GPU�A�N�Z�����[�V�����������₷�����A��Ղ�C#.NET�Ȃ̂ŃX���b�h���N�����Η�����}���`�R�A�ɂ��Ή��ł���B
����ł�C#���̂��d��������A��͂�GPU���CPU�l�b�N�ɂȂ�₷�����낤��B
������PC�Ŏ��ۂɍ�Ƃ��Ă��Ė��Ȃ��̂ɁAFlash���̃Q�[���ł��Ȃ�������ė��R����Ȃ��āA
Flash�̃Q�[���ł��Ȃ�����A�����Ȃ���Ƃɂ��x��ł邩�����Ďv���Ĕ����ւ�����
�ǂꂭ�炢����낤�B
�Â�PC�Ŏ��ۂɍ�ƂɎx��łĂ���Ȃ�A���łɃQ�[���ł������
�����ւ���ΏۂƂ��ėǂ����Ȃ��Ďv���Ȃ�Ƃ������B
Flash�̃Q�[���ł��Ȃ�����A�����Ȃ���Ƃɂ��x��ł邩�����Ďv���Ĕ����ւ�����
�ǂꂭ�炢����낤�B
�Â�PC�Ŏ��ۂɍ�ƂɎx��łĂ���Ȃ�A���łɃQ�[���ł������
�����ւ���ΏۂƂ��ėǂ����Ȃ��Ďv���Ȃ�Ƃ������B
Flash��GPU�ŕ��y���ł����Ȃ���
>>859
�����O��ɂ��Ă����C�g�Q�[�}�[�����C�g���[�U�[���W�Ȃ��Ȃ��Ă邶���
�����Sandy��Llano�Ŕ�r���Ă��̂ɂ��ꂷ����W�Ȃ�������
�����O��ɂ��Ă����C�g�Q�[�}�[�����C�g���[�U�[���W�Ȃ��Ȃ��Ă邶���
�����Sandy��Llano�Ŕ�r���Ă��̂ɂ��ꂷ����W�Ȃ�������
�V���O���X���b�h���\�Ȃ�ăn�C�G���h�����Ă�2�`3�N�̂�2�`3�����ς��Ȃ�����
�C���p�N�g�͂Ȃ�������
�����ACPU���\�͕K�v�Ȃ��Ȃ�Ă������Ⴄ�̂͋������Ƃ��������̘b
Silverlight�̂ق���CPU���ׂ͍������ǃ}���`�R�A�̃X�P�[���r���e�B�͂���B
http://bygzam.seesaa.net/article/130755836.html
http://newslog2ch.blog8.fc2.com/blog-entry-352.html
�C���p�N�g�͂Ȃ�������
�����ACPU���\�͕K�v�Ȃ��Ȃ�Ă������Ⴄ�̂͋������Ƃ��������̘b
Silverlight�̂ق���CPU���ׂ͍������ǃ}���`�R�A�̃X�P�[���r���e�B�͂���B
http://bygzam.seesaa.net/article/130755836.html
http://newslog2ch.blog8.fc2.com/blog-entry-352.html
�Ȃ�قǁALlano4�R�A��SandyBridge2�R�A�̉��i�т����Ԃ�Ƃ��낾�ƁA
Llano4�R�A�̕����ǂ����Ă��Ƃ���
Llano4�R�A�̕����ǂ����Ă��Ƃ���
�s���͈Ă̒�AS�̌�����o���Ă܂���
>>855
�\�[�V�����o�u���͋��N�̏I���ɂ͂����͂����Ă�
���v�Ƃ��ďo�Ă����͍̂��N�ɂȂ��Ă��炾��
���{�ł͂܂��u�[�������A�C�O�ł̓A�N�e�B�u�l���i-15���j�A��l������̉ۋ��z�i-30���j
�S�̂̔���グ��3�v�f�S�ĂŌ������ău�[���͏I�������
�\�[�V�����o�u���͋��N�̏I���ɂ͂����͂����Ă�
���v�Ƃ��ďo�Ă����͍̂��N�ɂȂ��Ă��炾��
���{�ł͂܂��u�[�������A�C�O�ł̓A�N�e�B�u�l���i-15���j�A��l������̉ۋ��z�i-30���j
�S�̂̔���グ��3�v�f�S�ĂŌ������ău�[���͏I�������
�ƌ������t���b�V���x���`�Ƃ����ƕ������g���Ă��Ȃ������ł�CPU�g�p����P�^�䂾��
�������GPU�Ŏx�����Ă��Ȃ���
�������GPU�Ŏx�����Ă��Ȃ���
���Ȃ݂ɁA�\�[�V�����Q�[���Ō���200�~�ȏ�g���l�̔䗦��2���ȉ�
���̏�A�v����u���Ă��炤�ɂ̓v���o�C�_�[�ւ̏�[���K�v
�l�ŃQ�[��������ď������҂��ɂ͗ǂ����A��ƂƂ��āw�p���I�Ɂx���v���グ��͓̂��
�Ȃ̂ō��i���Œ������̃Q�[�����o�ꂵ�Ȃ�
�A�^���V���b�N�̂悤�ȏ���
���̏�A�v����u���Ă��炤�ɂ̓v���o�C�_�[�ւ̏�[���K�v
�l�ŃQ�[��������ď������҂��ɂ͗ǂ����A��ƂƂ��āw�p���I�Ɂx���v���グ��͓̂��
�Ȃ̂ō��i���Œ������̃Q�[�����o�ꂵ�Ȃ�
�A�^���V���b�N�̂悤�ȏ���
�e�w�c�q�͖{����flash���D���ȂȂ�
Llano�ɂ�480SP�����ڂ����Ƃ̂��Ƃ���
����ɂ��ĉ����ꌾ�B�B�B
����ɂ��ĉ����ꌾ�B�B�B
���Ȃ݂Ƀ\�[�V�����Q�[�����u���E�U�Q�[����
>>873
�ǂ݂̂��S���������邾���̑ш摫��Ȃ����Č������Ă邶���B
���܂��܃��W�X�^�ɂ͂܂�P�[�X�ł���������������Ȃ����ǂ���ȏ�ł�����ȉ��ł��Ȃ����
�ǂ݂̂��S���������邾���̑ш摫��Ȃ����Č������Ă邶���B
���܂��܃��W�X�^�ɂ͂܂�P�[�X�ł���������������Ȃ����ǂ���ȏ�ł�����ȉ��ł��Ȃ����
�@�N������̃o�C�A�X�|����܂���ȗ\�z�͑S���A�e�ɂȂ�Ȃ��ȁB
flash���̂���
Flash�Ƃ��\�[�V�����Q�[���Ƃ����Č����Ă邯�ǁALlano�͂��������Q�[�����������Đl��������Ȃ���
WoW�AStarCraft2�ADiablo3�ACoD4�AL4D2�Ȃǂʼn掿��𑜓x���Ƃ���60fps
�Œ�ł�30fps�o��������B�݂����Ȋ�����
WoW�AStarCraft2�ADiablo3�ACoD4�AL4D2�Ȃǂʼn掿��𑜓x���Ƃ���60fps
�Œ�ł�30fps�o��������B�݂����Ȋ�����
Llano�ɍ��킹�Đ�p�̃`�b�v�Z�b�g���o��
�I���{�O����Hybrid CFX �ŃE�}�[
�c�������炢���ȂƖϑz���鍡�����̍�
�I���{�O����Hybrid CFX �ŃE�}�[
�c�������炢���ȂƖϑz���鍡�����̍�
>>879
�Q�[�����^�����v���C���Ȃ��悤�ȃ^�C�g�����苓����Ȃ�
�Q�[�����^�����v���C���Ȃ��悤�ȃ^�C�g�����苓����Ȃ�
�e�w�c�q���ꈫ���̂�������
SandyBridge���[�U�[��AMD�ɂƂ��Ă��㓙�Ȍڋq�Ȃ��
�Ȃ�Intel CPU�������z��AMD GPU���Ă���邩���
�Ȃ�Intel CPU�������z��AMD GPU���Ă���邩���
�c�q�͋t�w�W�ł���A�u�[�������������邵�A��ʑ̐[�x�ɂ����������Ă���
����ȃi�C�X�Ȃ�������Ȃ�
����ȃi�C�X�Ȃ�������Ȃ�
�W�����N����2�K�ɂ���A�����̕������݂����Ȃ�����ˁB
�c�q�͒��O�܂ŁA
"Llano"��480SP�͐��4���肦�Ȃ��B
���[�}�T�C�g�̋Y�ꌾ���I
�Ȃǂƌ����Ă������A���܂ǂ�ȋC�����H
����Flas�Q�[���͍���Ă���l��AS�ɏڂ����Ă��A
�u�v���O���}�ɂ͏ڂ����Ƃ͌���Ȃ��v�̂ŁA
�������Ǘ��Ȃǂ��K���ŏd�ʋ��ɂ݂��邱�Ƃ������ł��B�͂��B
"Llano"��480SP�͐��4���肦�Ȃ��B
���[�}�T�C�g�̋Y�ꌾ���I
�Ȃǂƌ����Ă������A���܂ǂ�ȋC�����H
����Flas�Q�[���͍���Ă���l��AS�ɏڂ����Ă��A
�u�v���O���}�ɂ͏ڂ����Ƃ͌���Ȃ��v�̂ŁA
�������Ǘ��Ȃǂ��K���ŏd�ʋ��ɂ݂��邱�Ƃ������ł��B�͂��B
1.Larrabee
2.Flash
3.480SP ��New!
�̂̂��Ƃ͒m��܂���
2.Flash
3.480SP ��New!
�̂̂��Ƃ͒m��܂���
�c�q���Ăǂ�Ȑl���m��Ȃ��ł����A��������Ȋ����Ȃ́H
���̃X���ɋ���K�v�����Ȃ��悤��
���̃X���ɋ���K�v�����Ȃ��悤��
�G��������Ȃ�
>>888
���v���O���}�ɂ͏ڂ���
���Ăǂ�Ȃ悗
�u�������Č����ǂ��g�߂Ȃ��v��
�u�f�[�^�T�C�Y�Ɋւ���m���E�Z�p�ɑa���iAS�ɏڂ����Ȃ��j�v���̂ǂ���������
���v���O���}�ɂ͏ڂ���
���Ăǂ�Ȃ悗
�u�������Č����ǂ��g�߂Ȃ��v��
�u�f�[�^�T�C�Y�Ɋւ���m���E�Z�p�ɑa���iAS�ɏڂ����Ȃ��j�v���̂ǂ���������
����3�N�ł́AAMD��Bulldozer�������Ƃ��v�V�ICPU�A�[�L�e�N�`���ɂȂ肻���Ȃ̂�
��̊m��I����
�A�[�L�e�N�`���Ƃ��Ă�����Α傫������������
Intel���ANehalem���i32nm�j��Westmere���i���ǁE�������E�ȓd�͉��EAVX�j��SandyBridge���i22nm�j��Ivy Bridge
�ƁA�A�[�L�e�N�`��������3�N�͂����Ȃ������ȏ���m�肵���邩��E�E�E
��̊m��I����
�A�[�L�e�N�`���Ƃ��Ă�����Α傫������������
Intel���ANehalem���i32nm�j��Westmere���i���ǁE�������E�ȓd�͉��EAVX�j��SandyBridge���i22nm�j��Ivy Bridge
�ƁA�A�[�L�e�N�`��������3�N�͂����Ȃ������ȏ���m�肵���邩��E�E�E
�c�q���p���������ăR�e���t�����Ȃ��Ȃ�����ȁA400SP�ȏ�m�肵�Ă��炗
���F��AMD��@�����������́A�n���Ń}�k�P�Ŗ��m�ȓz�������Ȃ�
���F��AMD��@�����������́A�n���Ń}�k�P�Ŗ��m�ȓz�������Ȃ�
Fusion�̃f���̓}�_���H
>>892
Web�n����������l����������A
�u�f�[�^�T�C�Y�Ɋւ���m���E�Z�p�v
���ꎩ�̂�����ӂ�Ȑl���������H
������́B����Ȃ�������������̂ĂĂĐ����悤�ȁB
���������g�ݕ������܂��肭�Ȃ��B
�ϐ��̌^�Ƃ����m��Ȃ��ꍇ�������邺�B
Web�n����������l����������A
�u�f�[�^�T�C�Y�Ɋւ���m���E�Z�p�v
���ꎩ�̂�����ӂ�Ȑl���������H
������́B����Ȃ�������������̂ĂĂĐ����悤�ȁB
���������g�ݕ������܂��肭�Ȃ��B
�ϐ��̌^�Ƃ����m��Ȃ��ꍇ�������邺�B
>>621
> Llano�@���@32nm��K10�n�@CPU�R�APhenom II�x�[�X
> �@�@�@�@�@GPU�R�A�����@(���o�C��HD5600or5500�V���[�Y�̏ȓd�͔Ł@SP��480)
> Llano�@��CPU�R�APhenom II�x�[�X�@
> ӁEӳ��ҁE�E�E. ~~(*/>_<)o��E�ǰ
�lj��B
�R�A2�f���I��7�`8���̃V���O���X���b�h���\��k10Phenom II��90�����x��cpu���\
Sandy Bridge3Ghz������cpu���\����ɂ́ALlano����5Ghz���炢����Ȃ��ƒǂ����Ȃ�??
���݂�GPU��Sandy Bridge�@gpu������邩�����B
http://www.pcper.com/article.php?aid=991
> Llano�@���@32nm��K10�n�@CPU�R�APhenom II�x�[�X
> �@�@�@�@�@GPU�R�A�����@(���o�C��HD5600or5500�V���[�Y�̏ȓd�͔Ł@SP��480)
> Llano�@��CPU�R�APhenom II�x�[�X�@
> ӁEӳ��ҁE�E�E. ~~(*/>_<)o��E�ǰ
�lj��B
�R�A2�f���I��7�`8���̃V���O���X���b�h���\��k10Phenom II��90�����x��cpu���\
Sandy Bridge3Ghz������cpu���\����ɂ́ALlano����5Ghz���炢����Ȃ��ƒǂ����Ȃ�??
���݂�GPU��Sandy Bridge�@gpu������邩�����B
http://www.pcper.com/article.php?aid=991
AMD Ontario TDP is 9W, Die Shots Revealed
http://vr-zone.com/articles/amd-ontario-tdp-is-9w-die-shots-revealed/9754.html
http://www.computerbase.de/news/hardware/prozessoren/amd/2010/september/amds-fusion-apu-auf-der-ifa-im-einsatz/
http://pics.computerbase.de/3/0/6/6/8/2.jpg
http://pics.computerbase.de/3/0/6/6/8/5.jpg
Ontario�@9W
Desktop�@Zacate�@18W
100mm2�ȉ�
http://vr-zone.com/articles/amd-ontario-tdp-is-9w-die-shots-revealed/9754.html
http://www.computerbase.de/news/hardware/prozessoren/amd/2010/september/amds-fusion-apu-auf-der-ifa-im-einsatz/
http://pics.computerbase.de/3/0/6/6/8/2.jpg
{kind=link}
http://pics.computerbase.de/3/0/6/6/8/5.jpg
{kind=link}
Ontario�@9W
Desktop�@Zacate�@18W
100mm2�ȉ�
SandyBridge��GPU�̑����Zacate�ŏ\����
>>897
�d�����������{��\�L�������
�d�����������{��\�L�������
SandyBridge H2�����������Ĉ��~���ł���X���[����̂������݂����Ȃ�
OC�s��
���`�b�v�Z�b�g
��GPU
�Ƃ������Ƃł�
OC�s��
���`�b�v�Z�b�g
��GPU
�Ƃ������Ƃł�
�����J���̖ʓ|�Ȃ̂ŊԈ���Ă邩������Ȃ����A
���N�O���ɏo��Llano�́A�r�W�l�X�]�[���ɃT���v�����邯�ǁA�ʐ^�s���B
�����ɂ͓������邾�낤������A���̂Ƃ�������A���Ċ����B
���N�O���ɏo��Llano�́A�r�W�l�X�]�[���ɃT���v�����邯�ǁA�ʐ^�s���B
�����ɂ͓������邾�낤������A���̂Ƃ�������A���Ċ����B
>>897
����������ƃ}�V�Ȃ�����A�n�������邗
����������ƃ}�V�Ȃ�����A�n�������邗
�������ɃT�u�����������
Llano���������ǁAGigano���ˁB
ttp://www.higano.jp/
ttp://www.higano.jp/
>>908
�C���������B�A�{���]�T�ł����B
�C���������B�A�{���]�T�ł����B
>>621
> Llano�@���@32nm��K10�n�@CPU�R�APhenom II�x�[�X
> �@�@�@�@�@GPU�R�A�����@(���o�C��HD5600or5500�V���[�Y�̏ȓd�͔Ł@SP��480)
> Llano�@��CPU�R�APhenom II�x�[�X�@
> ӁEӳ��ҁE�E�E. ~~(*/>_<)o��E�ǰ
�lj��B
Core2Duo�Ɣ�r���A�V���O���X���b�h���\70���`80�������Ȃ�AMDk10Phenom II�B
����AMDk10Phenom II�̃V���O���X���b�h���\���璴�����Ȃ�Llano�B
Phenom II��90�����x����cpu���\����Llano�B
�C���e��Sandy Bridge3Ghz����cpu���\��Llano�œ���ɂ́A5Ghz���x�K�v�Ƃ����B
���݂�Llano����GPU��Sandy Bridge����gpu������邩�����B
�\�[�X
http://www.pcper.com/article.php?aid=991
GPU�e�X�g�@
http://images.anandtech.com/graphs/sandybridgegpu_082710013731/24418.png
http://images.anandtech.com/graphs/sandybridgegpu_082710013731/24419.png
cpu�e�X�g
http://images.anandtech.com/graphs/sandybridgepreview_082710002107/24397.png
�Q�[�����\�e�X�g*(Windows7)
http://images.anandtech.com/graphs/sandybridgepreview_082710002107/24412.png
> Llano�@���@32nm��K10�n�@CPU�R�APhenom II�x�[�X
> �@�@�@�@�@GPU�R�A�����@(���o�C��HD5600or5500�V���[�Y�̏ȓd�͔Ł@SP��480)
> Llano�@��CPU�R�APhenom II�x�[�X�@
> ӁEӳ��ҁE�E�E. ~~(*/>_<)o��E�ǰ
�lj��B
Core2Duo�Ɣ�r���A�V���O���X���b�h���\70���`80�������Ȃ�AMDk10Phenom II�B
����AMDk10Phenom II�̃V���O���X���b�h���\���璴�����Ȃ�Llano�B
Phenom II��90�����x����cpu���\����Llano�B
�C���e��Sandy Bridge3Ghz����cpu���\��Llano�œ���ɂ́A5Ghz���x�K�v�Ƃ����B
���݂�Llano����GPU��Sandy Bridge����gpu������邩�����B
�\�[�X
http://www.pcper.com/article.php?aid=991
GPU�e�X�g�@
http://images.anandtech.com/graphs/sandybridgegpu_082710013731/24418.png
http://images.anandtech.com/graphs/sandybridgegpu_082710013731/24419.png
cpu�e�X�g
http://images.anandtech.com/graphs/sandybridgepreview_082710002107/24397.png
�Q�[�����\�e�X�g*(Windows7)
http://images.anandtech.com/graphs/sandybridgepreview_082710002107/24412.png
cpu�e�X�g
http://images.anandtech.com/graphs/sandybridgepreview_082710002107/24397.png
6�R�A�ŃN���b�N�����~6�@1090T��Sandy Bridge��cpu�e�X�g�ő卷�������Ă�̌���ƁA
Llano���Ȃ茵�����ȁE�E�E�E�B
http://images.anandtech.com/graphs/sandybridgepreview_082710002107/24397.png
6�R�A�ŃN���b�N�����~6�@1090T��Sandy Bridge��cpu�e�X�g�ő卷�������Ă�̌���ƁA
Llano���Ȃ茵�����ȁE�E�E�E�B
GPU�e�X�g�@
http://images.anandtech.com/graphs/sandybridgegpu_082710013731/24418.png
http://images.anandtech.com/graphs/sandybridgegpu_082710013731/24419.png
���ꂪSandyGPU�̔s�k�錾�Ȃ̂��킩��Ȃ��̂��H��
����5450������
http://images.anandtech.com/graphs/sandybridgegpu_082710013731/24418.png
http://images.anandtech.com/graphs/sandybridgegpu_082710013731/24419.png
���ꂪSandyGPU�̔s�k�錾�Ȃ̂��킩��Ȃ��̂��H��
����5450������
980���݂�ƃR�A���͊W�Ȃ���
sandy�̓N���b�N�A�b�v���������\�L�тĂȂ���
���\���͂��܂ƕς�炸�ł��傤
���ȏ�ɂ͗�����Ȃ�������v�Ȃ��
sandy�̓N���b�N�A�b�v���������\�L�тĂȂ���
���\���͂��܂ƕς�炸�ł��傤
���ȏ�ɂ͗�����Ȃ�������v�Ȃ��
���o�C��HD5600or5500���ăf�X�N�g�b�vPC���ݗp�r�f�I�J�[�h�̓��^�Ԃ��B���Ȃ萫�\�Ⴂ�����m��������Ă���ǁE�E
�������X�ɏȓd�͂ɂ��Ă�(((;-_-(-_-;))) ˿˿�@�ʖڂ��ȁB
�������X�ɏȓd�͂ɂ��Ă�(((;-_-(-_-;))) ˿˿�@�ʖڂ��ȁB
�������Sandy Bridge����gpu�̊e�f�[�^���\����Ă邩��A
GPU���\�����͍Ō�̒����@�`���[�j���O�Ŗ������ɂ��������\����d�l�ɂ����Ȃ��̂��ȁB
���߂�gpu�����ł����炢�ƑS������Ȃ������(/^-^(^ ^*)o ˿˿
GPU���\�����͍Ō�̒����@�`���[�j���O�Ŗ������ɂ��������\����d�l�ɂ����Ȃ��̂��ȁB
���߂�gpu�����ł����炢�ƑS������Ȃ������(/^-^(^ ^*)o ˿˿
�Q�TW��Regar�ƌ݊p������Ontario�͂XW���Ă��ƁH
GPU�܂ŏ�����Ă�̂ɁH
�ɂ킩�ɂ͐M�����Ȃ���
GPU�܂ŏ�����Ă�̂ɁH
�ɂ킩�ɂ͐M�����Ȃ���
�ėpDDR�̃����R�������p���Ă���GPU������������d��UP�Ȃ�Ĕ��X�������ł���
���x�͒��ÏL���當���I�W�T�����o�ꂗ
���\�͂ǂ��ł���R�X�p�����K���Ȃ甄��邯�ǂ�
AMD�̃V�F�A�͑S�R�L�тĂ��Ȃ����A����ł��s��K�͎��̂��N10���̃y�[�X�ŐL�тĂ��邩��
AMD�̏o�א���10�N��2.5�{���炢�ɂ͂Ȃ��Ă邾�낤
AMD�̃V�F�A�͑S�R�L�тĂ��Ȃ����A����ł��s��K�͎��̂��N10���̃y�[�X�ŐL�тĂ��邩��
AMD�̏o�א���10�N��2.5�{���炢�ɂ͂Ȃ��Ă邾�낤
920 �FSocket774�F2010/09/04(�y) 08:44:27 ID:LXWh1Zyz
AMD Zacate APU���J
ttp://translate.google.de/translate?js=n&prev=_t&hl=de&ie=UTF-8&layout=2&eotf=1&sl=de&tl=en&u=http%3A%2F%2Fwww.hardware-infos.com%2Fnews.php%3Fnews%3D3681
ttp://www.hardware-infos.com/img/startseite/klein/img_3957.jpg
Bobcat 2�R�A�{GPU��TDP18���b�g
IE9��Flying Image Test��60fps�B
FullHD �f�擮�����������Đ�
MMO��City of Heroes���~�j�}���ɋ߂��I�v�V�����ŃX���[�Y�ɓ���
�X�^�N��2���~�f�B�A���Z�b�e�B���O�Ńv���C�\
�p�b�P�[�W�T�C�Y1.5x1.5cm�B�_�C�T�C�Y��RV810(63mm2)�����������B
Ontario�͍X�ɒ����d�͂ŁA9W�B
���҂�2�R�A�œ����ł���A�@�\�ʂ������B�Ⴄ�̂̓N���b�N�����B
GPU�R���s���[�e�B���O�ɍœK�������VCPU-GPU�ԃo�X
����APU��Intel��Pentium Dual Core��������
Atom�̃l�b�g�u�b�N���y���ɉ��K
Llano�����������B�e������Ȃ�����
�T�C�Y��169mm2�A�ڎ��ł͍ג����_�C������
ttp://translate.google.de/translate?js=n&prev=_t&hl=de&ie=UTF-8&layout=2&eotf=1&sl=de&tl=en&u=http%3A%2F%2Fwww.hardware-infos.com%2Fnews.php%3Fnews%3D3681
ttp://www.hardware-infos.com/img/startseite/klein/img_3957.jpg
{kind=link}
Bobcat 2�R�A�{GPU��TDP18���b�g
IE9��Flying Image Test��60fps�B
FullHD �f�擮�����������Đ�
MMO��City of Heroes���~�j�}���ɋ߂��I�v�V�����ŃX���[�Y�ɓ���
�X�^�N��2���~�f�B�A���Z�b�e�B���O�Ńv���C�\
�p�b�P�[�W�T�C�Y1.5x1.5cm�B�_�C�T�C�Y��RV810(63mm2)�����������B
Ontario�͍X�ɒ����d�͂ŁA9W�B
���҂�2�R�A�œ����ł���A�@�\�ʂ������B�Ⴄ�̂̓N���b�N�����B
GPU�R���s���[�e�B���O�ɍœK�������VCPU-GPU�ԃo�X
����APU��Intel��Pentium Dual Core��������
Atom�̃l�b�g�u�b�N���y���ɉ��K
Llano�����������B�e������Ȃ�����
�T�C�Y��169mm2�A�ڎ��ł͍ג����_�C������
�������ۂ���
����Łg�}�[�P�e�B���O�̓s���ł̃��j�^�T�C�Y�����h�Ƃ��������悤�Ȃ�
�V���N���C�A���g��N���E�h�u�b�N�ɍœK����
����Łg�}�[�P�e�B���O�̓s���ł̃��j�^�T�C�Y�����h�Ƃ��������悤�Ȃ�
�V���N���C�A���g��N���E�h�u�b�N�ɍœK����
>>916
25W Regar�ƌ݊p�Ȃ̂�18W�̕�����Ȃ��H
Atom��SandyBridge�I�������
http://translate.google.de/translate?js=n&prev=_t&hl=de&ie=UTF-8&layout=2&eotf=1&sl=de&tl=en&u=http%3A%2F%2Fwww.hardware-infos.com%2Fnews.php%3Fnews%3D3681
Ontario 63mm2
Llano 169mm2
Atom 80mm2�O��
SandyBridge 220mm2�O��
25W Regar�ƌ݊p�Ȃ̂�18W�̕�����Ȃ��H
Atom��SandyBridge�I�������
http://translate.google.de/translate?js=n&prev=_t&hl=de&ie=UTF-8&layout=2&eotf=1&sl=de&tl=en&u=http%3A%2F%2Fwww.hardware-infos.com%2Fnews.php%3Fnews%3D3681
Ontario 63mm2
Llano 169mm2
Atom 80mm2�O��
SandyBridge 220mm2�O��
Llano���ג����_�C�c
�㓡��AMD�����J���Ă�̂ƈႤ�_�C�ʐ^���o����Ă���ă`���b�Ə����Ă��ȁc
�㓡��AMD�����J���Ă�̂ƈႤ�_�C�ʐ^���o����Ă���ă`���b�Ə����Ă��ȁc
�mCEDEC 2010�n�����V�~�����[�V�����̓Q�[���Ƃǂ��ւ��ׂ����B
�u�Q�[���J���}�j�A�b�N�X�`�����V�~�����[�V�����ҁv���|�[�g
ttp://www.4gamer.net/games/105/G010549/20100903062/
�\�j�[�A�J�v�R���A�R�[�G�[�AAMD�A�o���_�C�A�R�i�~
Physx��Nvidia�͂ǂ������H
�u�Q�[���J���}�j�A�b�N�X�`�����V�~�����[�V�����ҁv���|�[�g
ttp://www.4gamer.net/games/105/G010549/20100903062/
�\�j�[�A�J�v�R���A�R�[�G�[�AAMD�A�o���_�C�A�R�i�~
Physx��Nvidia�͂ǂ������H
in�ׂ�>>910�ɂ���悤�ȉR����
�R�s�y���Ɏg��Ȃ��ƃ��o�C�قǂɁA
����͌x�����Ă���낤�ȁB
�ʂ�AMD��Intel�ɐؔ������Ƃ���ŁA
�o�����M���M���̉��i����������"����"������A
�ǂ��l���Ă�����̓��ɂȂ邾���Ȃ̂Ɂc�B
�M�҂��Ă̂͋C���������ȁc�z���g�ɁB
�R�s�y���Ɏg��Ȃ��ƃ��o�C�قǂɁA
����͌x�����Ă���낤�ȁB
�ʂ�AMD��Intel�ɐؔ������Ƃ���ŁA
�o�����M���M���̉��i����������"����"������A
�ǂ��l���Ă�����̓��ɂȂ邾���Ȃ̂Ɂc�B
�M�҂��Ă̂͋C���������ȁc�z���g�ɁB
SandyBridge �A���o�C�������Ō����� 35W �ȏ�Ƃ����蓾��B
�Q�[������CPU�AGPU���������ׂ���������A5����������{�̐G��Ȃ����낱��B
http://northwood.blog60.fc2.com/blog-entry-4130.html
�Q�[������CPU�AGPU���������ׂ���������A5����������{�̐G��Ȃ����낱��B
http://northwood.blog60.fc2.com/blog-entry-4130.html
Q1�ɏo���̂�35W���f�����Ă����B
����TDP�̂�Q2�ȍ~�B
����TDP�̂�Q2�ȍ~�B
>>926
���̋�̓I�����Ă���H
�ꉞ�V�v�ŏo���������CPU���A3�����Ő��\���Ƃ����d�͒ጸ�͂��낢�떳��������Ǝv���B
����Ȃ̏o����AQ1���f����������́u���܂��ꂽ�v���Ƃɂ��Ȃ邵�BQ1���f���ŃX�y�b�N�D��
����Ƃ��āA���ۏo���Q2���f���͒�N���b�N�łƂ�GPU 6EU�łƂ����Ă�����Ȃ�Ȃ�
�̂��ȁB
���̋�̓I�����Ă���H
�ꉞ�V�v�ŏo���������CPU���A3�����Ő��\���Ƃ����d�͒ጸ�͂��낢�떳��������Ǝv���B
����Ȃ̏o����AQ1���f����������́u���܂��ꂽ�v���Ƃɂ��Ȃ邵�BQ1���f���ŃX�y�b�N�D��
����Ƃ��āA���ۏo���Q2���f���͒�N���b�N�łƂ�GPU 6EU�łƂ����Ă�����Ȃ�Ȃ�
�̂��ȁB
���܂����A929 �� >>927 �ւ̃��X�ł����B
>>929
�Ȃ��TDP35W�ȏ�Ɠ������\�̂�TDP25W�ŏo�����ď����Ă�Ǝv���́H
���\���Ƃ��Ɍ��܂��Ă邶���AIntel�̂���܂ł̐��i�̏o�������炵�āB
���[�h�}�b�v�ɂ�TDP25W�ȉ��̌�p��Q2�ȍ~������A����TDP��Q2�ȍ~�ɏo����ď�������������B
�Ȃ��TDP35W�ȏ�Ɠ������\�̂�TDP25W�ŏo�����ď����Ă�Ǝv���́H
���\���Ƃ��Ɍ��܂��Ă邶���AIntel�̂���܂ł̐��i�̏o�������炵�āB
���[�h�}�b�v�ɂ�TDP25W�ȉ��̌�p��Q2�ȍ~������A����TDP��Q2�ȍ~�ɏo����ď�������������B
���f�X�N�g�b�v�p��Core-i���g�����m�[�g���������
���łȂ��C�O�p�ɂ͍���Ă�悤��
�m�[�g�p�ƃf�X�N�g�b�v�p��CPU�͒l�i���啪�Ⴄ���A
����d�͂ł�Core-i�̓m�[�g�p/�f�X�N�g�b�v�p�ł���قǍ��������A�f�X�N�g�b�v�p���g�������������b�g���傫���Ƃ̂���
���łȂ��C�O�p�ɂ͍���Ă�悤��
�m�[�g�p�ƃf�X�N�g�b�v�p��CPU�͒l�i���啪�Ⴄ���A
����d�͂ł�Core-i�̓m�[�g�p/�f�X�N�g�b�v�p�ł���قǍ��������A�f�X�N�g�b�v�p���g�������������b�g���傫���Ƃ̂���
�����̉�Ђ��V�KPC�͊�{�m�[�g�{�t�����j�^�[�ɂȂ���������B
���v�Ńg���v�����j�^�[�ɂȂ邩��܂��������ǁB
���v�Ńg���v�����j�^�[�ɂȂ邩��܂��������ǁB
>>926
����Core i�iClarksfield�AArrandale�j��TDP��55W�A45W�A35W����B
��d���ŁE����d���ł�25W�A18W
SandyBridge��Clarksfield�AArrandale�Ɠ�������ˁH
����Core i�iClarksfield�AArrandale�j��TDP��55W�A45W�A35W����B
��d���ŁE����d���ł�25W�A18W
SandyBridge��Clarksfield�AArrandale�Ɠ�������ˁH
>>934
�Ȃ����^�B������ƃA�z���ۂ�w
�Ȃ����^�B������ƃA�z���ۂ�w
�x��x�ꂗ����
���ؗܖڒE��������
���ؗܖڒE��������
>>922
169mm2����Propus�̃T�C�Y������B
169mm2����Propus�̃T�C�Y������B
>>934
��{�I�� �ȁB
��{�I�� �ȁB
>>931
Core i5 520E 2.4/3.0GHz 35W �� 540UM 1.2GHz 18W �����\�I�ɓ���Ƃ͌�������������B
������uArrandale�ɂ�35W�ł̂ق���18W�ł�����v�Ƃ��������̂́A�������ĂĂ�������Ȃ�
�ڂ���������������ˁB����ጾ�t�I�ɂ͐��������낤���B�ŁA�킴�Ƃ��H�Ƃ����A������
�܂܂�Ă܂����B
���ӂ��Ȃ������̂Ȃ�A���߂�B
Core i5 520E 2.4/3.0GHz 35W �� 540UM 1.2GHz 18W �����\�I�ɓ���Ƃ͌�������������B
������uArrandale�ɂ�35W�ł̂ق���18W�ł�����v�Ƃ��������̂́A�������ĂĂ�������Ȃ�
�ڂ���������������ˁB����ጾ�t�I�ɂ͐��������낤���B�ŁA�킴�Ƃ��H�Ƃ����A������
�܂܂�Ă܂����B
���ӂ��Ȃ������̂Ȃ�A���߂�B
>>941
����Ȃ��������ǂݕ����Ȃ��Ă����Ďv�����ǁc�B
�܂��A�ςȂ̂�������₷������A���\�������邯�ǒ�TDP����������
�����Ηǂ������Ƃ����̂ɂ͎ӂ��B
����Ȃ��������ǂݕ����Ȃ��Ă����Ďv�����ǁc�B
�܂��A�ςȂ̂�������₷������A���\�������邯�ǒ�TDP����������
�����Ηǂ������Ƃ����̂ɂ͎ӂ��B
Llano��Athlon�U�ƃ��o�C��RADEON5500�`5600���x�Ƃ݂��ق���������
CPU�͑�s�AGPU�͈�������
CPU�͑�s�AGPU�͈�������
ID:O9Jw8Jgz�͂ǂ����Đ��������������ł��Ȃ��B
TDP35W�N���X���f�X�N�g�b�v��փm�[�g�pCPU�̎嗬�Ȃ̂́A���Ɏn�܂���������Ȃ��Ƃ����̂ɁB
���o�C�����������\�}���Ē�TDP�ɂ��Ă�̂��A���Ɏn�܂���������Ȃ��Ƃ����̂ɁB
TDP35W�N���X���f�X�N�g�b�v��փm�[�g�pCPU�̎嗬�Ȃ̂́A���Ɏn�܂���������Ȃ��Ƃ����̂ɁB
���o�C�����������\�}���Ē�TDP�ɂ��Ă�̂��A���Ɏn�܂���������Ȃ��Ƃ����̂ɁB
>TDP35W�N���X���f�X�N�g�b�v��փm�[�g�pCPU�̎嗬�Ȃ̂́A���Ɏn�܂���������Ȃ��Ƃ����̂ɁB
10�N�ʑO���炠�����˂�
�����̃Z��600MHz�m�[�g�̓f�X�N�g�b�v�pCPU����w
10�N�ʑO���炠�����˂�
�����̃Z��600MHz�m�[�g�̓f�X�N�g�b�v�pCPU����w
>>935
TDP100W��GPU�������ĐՌ`���Ȃ��R���s���܂�
TDP100W��GPU�������ĐՌ`���Ȃ��R���s���܂�
>>947
AMD�X��������NVIDIA�̂���͏����Ȃ������̂ɂ�
AMD�X��������NVIDIA�̂���͏����Ȃ������̂ɂ�
949 �FSocket774�F2010/09/04(�y) 21:52:51 ID:sJPs0ACu
>922
Llano-shy���ĂȂ悗
�@�܂��Ȃ��Ȃ��o�Ă��Ȃ������ǂ�
Llano-shy���ĂȂ悗
�@�܂��Ȃ��Ȃ��o�Ă��Ȃ������ǂ�
Llano���������ǁAGigano���ˁB
ttp://homepage3.nifty.com/higano-nouen/
ttp://homepage3.nifty.com/higano-nouen/
�gOntario�h���gZacate�h���m�[�gPC��g�ђ[������CPU�H
>>852
�f�X�N�g�b�v�������ł����ALlano�҂��Ȃ���Zacate�ł������Ȃ�
�f�X�N�g�b�v�������ł����ALlano�҂��Ȃ���Zacate�ł������Ȃ�
�҂������B�����o���B
955 �FSocket774�F2010/09/05(��) 13:03:10 ID:ZNjvTGe2
�G���b�^��4�P�^�̏�Ԃŏo���ꂽ��ł�������ǂ�����̂�
�v���I�łȂ�����e����B
CPU�Ƀo�O�Ȃ���킯�Ȃ�����
�v���O�����ł��d���܂�Ă���킯�ł�����܂���
�v���O�����ł��d���܂�Ă���킯�ł�����܂���
���Ƀf�X�N�g�b�v�͂Ȃ�����
�G���b�^���炢���ʂɂ����B
>>958
ATOM���ڂ̏��^�f�X�N�g�b�v�@�Ȃ�Ċ��ł�����̂Ɂc�B
ATOM���ڂ̏��^�f�X�N�g�b�v�@�Ȃ�Ċ��ł�����̂Ɂc�B
����̓f�X�N�g�b�v�Ƃ������A�t���̂Ȃ��l�b�g�u�b�N�Ƃ�������
�����t����̌^�f�X�N�g�b�v�Ƃ�����Ȃ��́H�̗p������ł���̂́B
���Ƃ́A�@�l�Ƃ��ő�ʂɔ���ꂻ���ȃX�����^�C�v�̂�B
���Ƃ́A�@�l�Ƃ��ő�ʂɔ���ꂻ���ȃX�����^�C�v�̂�B
AM3�{�}�U�[�܂��[�H
�G���b�^�Ȃ�3���ȏ゠��킯�Ȃ�����
�h���������ł�����܂���
�h���������ł�����܂���
��ԃl�^��>>957�Ƀ}�W���X�Ԃ��Ȃ�E�E�E
>>966
�ӊO�Ƃ��̃R�s�y�͒m���ĂȂ������
�ӊO�Ƃ��̃R�s�y�͒m���ĂȂ������
>>967
�L��������R�s�y���낗
�L��������R�s�y���낗
���̕ӂ܂ŃR�s�y�ɂ��Ă�������
Llano��Zacate��CPU���\�ǂꂮ�炢�Ⴄ��
����GPU���ꉞ�Ⴄ��ȁH
����GPU���ꉞ�Ⴄ��ȁH
�ŋ߂͓���GPU�̌X�����������ǁA
����\�͂����߂�l�͎��v��������ɔM���Ə���d�͂������邾���ŕs�ւȋC��������
����\�͂����߂�l�͎��v��������ɔM���Ə���d�͂������邾���ŕs�ւȋC��������
����GPU�ɂ�CnQ�̂悤�ȏȓd�͋@�\��݂��Ă����Ȃ�A
�Z�ʂ̗����Ȃ�IGP��肸���Ɗ��}���邼�Ȃ����B
�Z�ʂ̗����Ȃ�IGP��肸���Ɗ��}���邼�Ȃ����B
http://www.semiaccurate.com/2010/09/01/more-llano-wafer-picture/
Llano�̃E�F�n�[�ʐ^�B230mm^2�ȉ��炵��
Llano�̃E�F�n�[�ʐ^�B230mm^2�ȉ��炵��
>>970
"Llano"�͊ȒP�Ɍ������܂�Athlon X4�̉��ǔŁB
"Ontario"�̓��C���X�g���[����90%�̐��\�B
���C���X�g���[�����������w�����͓�B
>>971
���������l��"Bulldozer"��"Sandy Bridge H2"���ĂˁI
"Llano"�͊ȒP�Ɍ������܂�Athlon X4�̉��ǔŁB
"Ontario"�̓��C���X�g���[����90%�̐��\�B
���C���X�g���[�����������w�����͓�B
>>971
���������l��"Bulldozer"��"Sandy Bridge H2"���ĂˁI
>>975
��������Ontario�����C���X�g���[����90%���炢�����Č����Ă�����C�ɂȂ��Ă�
�ȓd�͂����AOntario��萫�\�������炵��Zacate����Llano�Ƃ���Ȃɕς��Ȃ����Ȃ��Ďv���Ă�
GPU���\��Ontario��5450���炢���Č����Ă�����҂��Ă���
��������Ontario�����C���X�g���[����90%���炢�����Č����Ă�����C�ɂȂ��Ă�
�ȓd�͂����AOntario��萫�\�������炵��Zacate����Llano�Ƃ���Ȃɕς��Ȃ����Ȃ��Ďv���Ă�
GPU���\��Ontario��5450���炢���Č����Ă�����҂��Ă���
Ontario�����C���X�g���[����90%�̐��\���ď�����H
Bobcat�R�A�����C���X�g���[���̔����̃_�C�T�C�Y��90%�̐��\���Ă̂́A
�ȑO����AMD���X���C�h�ɏ����Ă��邯�ǁB
Bobcat�R�A�����C���X�g���[���̔����̃_�C�T�C�Y��90%�̐��\���Ă̂́A
�ȑO����AMD���X���C�h�ɏ����Ă��邯�ǁB
>>977
�m���ɂ��̒ʂ肾�B"Bobcat"�A�[�L�e�B�N�`���̂ǂ̃R�A���A
�u���C���X�g���[����90%�̐��\���v�͌��y����Ă��Ȃ��ȁB
"Zacate"�Ȃ̂�"Ontario"�Ȃ̂��c�B�����ɍl������"Zacate"�̕����B
�m���ɂ��̒ʂ肾�B"Bobcat"�A�[�L�e�B�N�`���̂ǂ̃R�A���A
�u���C���X�g���[����90%�̐��\���v�͌��y����Ă��Ȃ��ȁB
"Zacate"�Ȃ̂�"Ontario"�Ȃ̂��c�B�����ɍl������"Zacate"�̕����B
�ǂ����ɂ��Ă����ꂮ�炢�̐��\������Ȃ牴�̗p�r�I�ɂ͏\�������炢�����ǂ�
�v����ɂ������̕����������������Ă��Ƃł���
ttp://chip-architect.com/news/Llano_comp2.jpg
����Llano 4�R�A��Sandy 4�R�A�Ɠ����x�̋K�͂��Ă��Ƃŗ��������̂�
ttp://chip-architect.com/news/Llano_comp2.jpg
{kind=link}
����Llano 4�R�A��Sandy 4�R�A�Ɠ����x�̋K�͂��Ă��Ƃŗ��������̂�
GPU���̉������͂Ƃ��Ă����l�Ȍ`���Ă��
�T�C�h�ہX�V��ł邵
�T�C�h�ہX�V��ł邵
987 �FSocket774�F2010/09/06(��) 20:54:45 ID:D5yoLgM7
2011�N���u���h�[�U�[��RADEON6550���Z�������
{kind=link}
�������E�E�E
Ontario���U�TW�܂ŃV�o���������ALlano��葬���Ⴄ��
991 �FSocket774�F2010/09/07(��) 00:18:39 ID:kei1x2jH
GPU�ł͗D�G�Ȃ̂����瑁���������Ȃ����ȁB
Intel�Ƃ͋t��GPU��CPU�܂ŕ₤�`��CPUGPU�����҂������B
Intel�Ƃ͋t��GPU��CPU�܂ŕ₤�`��CPUGPU�����҂������B
bobcat�̓^�[�Q�b�g���g��2GHz���炢������ȉ�����ˁ[��
�ȓd�͂ɐU���Ă�炵������p�C�v���C���i�������Ȃ����������N���b�N���삵�Ȃ�����
�ȓd�͂ɐU���Ă�炵������p�C�v���C���i�������Ȃ����������N���b�N���삵�Ȃ�����
Llano��4�R�A75W�ł͂��Ȃ�N���b�N���Ⴛ��
45nm��X6 2.8GHz��95W���o���Ă邩�炻��Ȃ�ɂ������Ȃ��̂��H
CPU�Ƀo�O����������v�Z�ԈႦ�邾�낗
>>991
GPU�Ɍ����I�ɕ�킹�ꂽ��Intel�ɏ����ڂ͂Ȃ��Ȃ肻����Ȃ��B
GPU���\���K�v�ɂȂ��Ă���킯�����AATI�����Ă邵�B
�܂��A����ȗp�r�͌����Ă�̂��ȁB
GPU�Ɍ����I�ɕ�킹�ꂽ��Intel�ɏ����ڂ͂Ȃ��Ȃ肻����Ȃ��B
GPU���\���K�v�ɂȂ��Ă���킯�����AATI�����Ă邵�B
�܂��A����ȗp�r�͌����Ă�̂��ȁB
���_�}���Ȃ�
What is AMD's Northern Islands?
http://www.semiaccurate.com/2010/09/06/what-amds-northern-islands/
What is AMD's Northern Islands?
http://www.semiaccurate.com/2010/09/06/what-amds-northern-islands/
1000 �FSocket774�F2010/09/07(��) 14:38:21 ID:aUinItQr
�@ �@ ���]���@ �@ �@ �@ �@ �@ ���]���@�@�@�@�@�@�@�@���]��
�@ �@ |�Q|.�@�@�@ �Q_�@�@ .__|�@ |__�@�@�@�@ �@ �@ .|�@ |
�@ �@ |�P| |�P!'�L.�@�@�M�R |__�@�@__|�@ �@ �@ �@ �@ |�@ |
�@ �@ |�@ | |.�@.r"�܁R�@.|�@ |�@ |.�@�@�@ �Q__�@�@ |�@ |
�@ �@ |�@ | |�@ |�@�@�@|�@ |�@ |�@ |�@ ,r''"�@�@ .�M�R |�@ |
�@ �@ |�@ | |�@ |�@�@�@|�@ |�@ |�@ !__i'.�@,r"�܁R�@ i|�@ |
�@ �@ |�Q| |�Q|�@�@�@|�Q|�@ !��Q__ �@ _�P�P �Q�Q.,|
�@�@�@�@ �@ �@ �@ �@ �@ �@ �@ �@ �@ !�@ !��P�P,�\,
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �@ �T�A_ �P�@_�m
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �@ �@ �P�P
�@ �@ |�Q|.�@�@�@ �Q_�@�@ .__|�@ |__�@�@�@�@ �@ �@ .|�@ |
�@ �@ |�P| |�P!'�L.�@�@�M�R |__�@�@__|�@ �@ �@ �@ �@ |�@ |
�@ �@ |�@ | |.�@.r"�܁R�@.|�@ |�@ |.�@�@�@ �Q__�@�@ |�@ |
�@ �@ |�@ | |�@ |�@�@�@|�@ |�@ |�@ |�@ ,r''"�@�@ .�M�R |�@ |
�@ �@ |�@ | |�@ |�@�@�@|�@ |�@ |�@ !__i'.�@,r"�܁R�@ i|�@ |
�@ �@ |�Q| |�Q|�@�@�@|�Q|�@ !��Q__ �@ _�P�P �Q�Q.,|
�@�@�@�@ �@ �@ �@ �@ �@ �@ �@ �@ �@ !�@ !��P�P,�\,
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �@ �T�A_ �P�@_�m
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �@ �@ �P�P
1001 �F�P�O�O�P�F
1��̃}�V�����g�ݏオ��܂����B�B�B
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://pc11.2ch.net/jisaku/
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://pc11.2ch.net/jisaku/