AMD�̎�����CPU�ɂ��Č�낤 ��38����
�_.�Q�@ | �r�炵�E����E�~�[�͕��u����ԁB
�^|�Q|�@| �ނ�ꂸ�ɃX���[���܂��傤�B
|�Q�^�_! sage�i�s�Ń}�^�[�������܂��傤�B
���O�X��
AMD�̎�����CPU�ɂ��Č�낤 ��37����
http://pc11.2ch.net/test/read.cgi/jisaku/1275237092/
�����AMD�n�X���b�h�ߋ����O�ۑ��T�C�g�l
http://amd.jisakuita.net/
���֘A�X��
Intel�̎�����CPU�ɂ��Č�낤 43
http://pc11.2ch.net/test/read.cgi/jisaku/1270976684/
CPU�A�[�L�e�N�`���ɂ��Č�� 16
http://pc11.2ch.net/test/read.cgi/jisaku/1253517890/
�^|�Q|�@| �ނ�ꂸ�ɃX���[���܂��傤�B
|�Q�^�_! sage�i�s�Ń}�^�[�������܂��傤�B
���O�X��
AMD�̎�����CPU�ɂ��Č�낤 ��37����
http://pc11.2ch.net/test/read.cgi/jisaku/1275237092/
�����AMD�n�X���b�h�ߋ����O�ۑ��T�C�g�l
http://amd.jisakuita.net/
���֘A�X��
Intel�̎�����CPU�ɂ��Č�낤 43
http://pc11.2ch.net/test/read.cgi/jisaku/1270976684/
CPU�A�[�L�e�N�`���ɂ��Č�� 16
http://pc11.2ch.net/test/read.cgi/jisaku/1253517890/
|
|
|
2 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 12:24:09 ID:CD7Cz7EO
2��ʓ������s
http://up3.viploader.net/pic/src/viploader1195840.jpg
8600GT���ǂ�GPU���ƃt���[�����[�g�ǂ��Ȃ�̂������ė~������
http://up3.viploader.net/pic/src/viploader1195840.jpg
{kind=link}
8600GT���ǂ�GPU���ƃt���[�����[�g�ǂ��Ȃ�̂������ė~������
3�Ȃ�AMD�|�Y
���N���N�|�Y�ƌ�����������AMD�B
���N���N������������������邩���ˁB
���N���N������������������邩���ˁB
6 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 12:36:57 ID:CD7Cz7EO
�ꂵ������_���ׂĂȂ��Ŏ�����Ńx���`���ʎ����Ă݂���ǂ��Ȃ́H
8 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 12:39:28 ID:CD7Cz7EO
�s�\��
9 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 12:43:05 ID:CD7Cz7EO
�^�X�N�}�l�[�W����1�R�A�ɌŒ肵�Ď��s������CPU���[�^�[70%���x�ɒB����
Athlon�i�j����CPU����������
Athlon�i�j����CPU����������
�܂����̝s�����撣��n���������
11 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 12:59:37 ID:CD7Cz7EO
�N1�l�Ƃ���AMD�̔n���L��D����IE9�x���`�̌��ʏo���Ȃ��ˁB�Ȃ�ŁH
�P�D8600GT����X�y�b�N��GPU���g������
�Q�DCPU���x�����ăt���[�����[�g�o�Ȃ�
�R�D������DirectX11�Ȃ�đΉ����炵�ĂȂ�WindowsXP���g���Ă��邩�瓮���Ȃ�
AMD�̃f���Ɠ���100 Images�Ȃ�2��ʓ������s�ł�60fps���ʂɉz���܂���
http://up3.viploader.net/pic/src/viploader1195841.jpg
Ontario�͑���CPU���x����Ȃ��́H
�P�D8600GT����X�y�b�N��GPU���g������
�Q�DCPU���x�����ăt���[�����[�g�o�Ȃ�
�R�D������DirectX11�Ȃ�đΉ����炵�ĂȂ�WindowsXP���g���Ă��邩�瓮���Ȃ�
AMD�̃f���Ɠ���100 Images�Ȃ�2��ʓ������s�ł�60fps���ʂɉz���܂���
http://up3.viploader.net/pic/src/viploader1195841.jpg
{kind=link}
Ontario�͑���CPU���x����Ȃ��́H
�_�C�T�C�Y������ƕ����܂�オ��
�X����24���Ԝp�j����Η����i��������j����ƃC�J�_���X�i�o����ƐM���Ă���j
���ꂪ�m�\0�̃L���z��
�X����24���Ԝp�j����Η����i��������j����ƃC�J�_���X�i�o����ƐM���Ă���j
���ꂪ�m�\0�̃L���z��
13 �FSocket774�F2010/06/20(��) 13:05:39 ID:nT1bBXQX
�S�D�c�q�̑�����������Ȃ�
�N���o�����
�N���o�����
14 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 13:06:24 ID:CD7Cz7EO
>>13
���O�͏o���Ȃ��Ȃ���
���O�͏o���Ȃ��Ȃ���
15 �FSocket774�F2010/06/20(��) 13:07:34 ID:nT1bBXQX
�����1��
�C�J�_���X�ŃO�O�����畁�ʂɃq�b�g�����͈̂ӊO������
���������Ō����Ă�̂̓C�J�L���_���X�̂��Ƃ�
���������Ō����Ă�̂̓C�J�L���_���X�̂��Ƃ�
�����������𑜓x������
���C���Ɠ���p�ʼn𑜓x�߂��Ⴍ���Ⴞ��256 Images�œ����N���ł���Ȃ���
ttp://img194.imageshack.us/img194/6942/24177058.jpg
���̓���̉𑜓x�������炩�͒m���30fps�͒Ⴂ�Ǝv��
ttp://img19.imageshack.us/img19/1527/23619396.jpg
���C���Ɠ���p�ʼn𑜓x�߂��Ⴍ���Ⴞ��256 Images�œ����N���ł���Ȃ���
ttp://img194.imageshack.us/img194/6942/24177058.jpg
{kind=link}
���̓���̉𑜓x�������炩�͒m���30fps�͒Ⴂ�Ǝv��
ttp://img19.imageshack.us/img19/1527/23619396.jpg
{kind=link}
���ς�炸�̊�n�O���Ղ�����Ă�˒c�q�͂�
�V�v���ɒc�q���f����ď����Ƃ��悗
�V�v���ɒc�q���f����ď����Ƃ��悗
�c�q���K���Ƃ������Ƃ͂��ꂾ��Llano�͊��҂ł�����Ă��Ƃ���
�ق�60fps
ttp://img19.imageshack.us/img19/1527/23619396.jpg
��̂��47fps
ttp://img517.imageshack.us/img517/4060/51093656.jpg
ttp://img19.imageshack.us/img19/1527/23619396.jpg
��̂��47fps
ttp://img517.imageshack.us/img517/4060/51093656.jpg
{kind=link}
������Intel GPU�Ɋ��҂���Ƃ����ɂ��قǂ�����
�ǂ�Ȃɍ����\�ɍ���Ă��̐S�̃h���C�o����������Q�[������g���Ȃ�
Dx10�o���ɂP�N�ȏォ����ADX10.1�ȏ�Ή��͖���ALarrabee�̃\�t�g���͍ň���������w
�ǂ�Ȃɍ����\�ɍ���Ă��̐S�̃h���C�o����������Q�[������g���Ȃ�
Dx10�o���ɂP�N�ȏォ����ADX10.1�ȏ�Ή��͖���ALarrabee�̃\�t�g���͍ň���������w
22 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 13:25:23 ID:CD7Cz7EO
�܂��A���sCore i3/i5��IGP����GeForce 9400G���z������x�̐��\�͂���悤����
IE��Office�Ȃǂ��g�����ɂ͏\�����Ȃ����낤�Ȃ�
�f���A���f�B�X�v���C���z�͂ǂ݂̂��f�B�X�N���[�g�J�[�h�͎h�����Ƃ��������낤��
IE��Office�Ȃǂ��g�����ɂ͏\�����Ȃ����낤�Ȃ�
�f���A���f�B�X�v���C���z�͂ǂ݂̂��f�B�X�N���[�g�J�[�h�͎h�����Ƃ��������낤��
�͂��͂��AIE��Office�Ȃ��G965�ł������Ă��
24 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 13:30:17 ID:CD7Cz7EO
���ႠAMD�̍L���IE9/Office2010�̃f���͉��������H��
����GMA�ł���]�T�œ���GPU���ׂ̌y���A�v���Œp���N�����������H
����GMA�ł���]�T�œ���GPU���ׂ̌y���A�v���Œp���N�����������H
���N�ȍ~�̃��[�J�[�����ƌ���
Llano 2�R�A(120mm2�O��) vs Sandy 2�R�A/4T (150mm2�O��) vs Llano 4�R�A(160mm2�O��)
Ontario(2�R�A+DX11GPU) vs Atom(2�R�A+DX10GPU)
�Ő��\�I�ɂ͏\��������A�̗p�͖w��2�R�A����
Ontario vs Atom 2�R�A���Đ��\�͂ǂ��l���Ă�Ontario�D��
Llano vs Sandy�̓N���b�N�ꂵ���ꍇ
�E���\
Llano 4�R�A > Sandy 2�R�A/4T > Llano 2�R�A
�E����d��
Llano 2�R�A < Sandy 2�R�A/4T < Llano 4�R�A
�ŁA���b�g�p�t�H�[�}���X�I�ɂ͖w�Ǔ���ŁAGPU�̕�Llano���L��
Sandy4�R�A/8T���Ăǂ̕ӂɎ��v�����邩����炠�܂蔄��Ȃ�
�R�A�ƃL���b�V���̃f�J���ƁAGPU�̕����\�������Ђ��ς���Sandy�͔����ȑ��݂ɂȂ�
Llano 2�R�A(120mm2�O��) vs Sandy 2�R�A/4T (150mm2�O��) vs Llano 4�R�A(160mm2�O��)
Ontario(2�R�A+DX11GPU) vs Atom(2�R�A+DX10GPU)
�Ő��\�I�ɂ͏\��������A�̗p�͖w��2�R�A����
Ontario vs Atom 2�R�A���Đ��\�͂ǂ��l���Ă�Ontario�D��
Llano vs Sandy�̓N���b�N�ꂵ���ꍇ
�E���\
Llano 4�R�A > Sandy 2�R�A/4T > Llano 2�R�A
�E����d��
Llano 2�R�A < Sandy 2�R�A/4T < Llano 4�R�A
�ŁA���b�g�p�t�H�[�}���X�I�ɂ͖w�Ǔ���ŁAGPU�̕�Llano���L��
Sandy4�R�A/8T���Ăǂ̕ӂɎ��v�����邩����炠�܂蔄��Ȃ�
�R�A�ƃL���b�V���̃f�J���ƁAGPU�̕����\�������Ђ��ς���Sandy�͔����ȑ��݂ɂȂ�
26 �FSocket774�F2010/06/20(��) 13:33:14 ID:nT1bBXQX
����͑��v�H
27 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 13:34:27 ID:CD7Cz7EO
���O�猋�lj�ꂽ�^���e�[�v����
28 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 13:36:19 ID:CD7Cz7EO
������������AMD�̗̍p�����������̂�Core i3/i5�̋����s���̌����߂ł����Ȃ������
http://ednjapan.rbi-j.com/news/2010/4/6680
http://ednjapan.rbi-j.com/news/2010/4/6680
���\�̂Ăďȓd�͂Ɖ��i��������̂�������Atom��
���\��������̂̓o�J�̏��Ƃ��Ǝv����ł����ˁB
���\��������̂̓o�J�̏��Ƃ��Ǝv����ł����ˁB
�����o�������ׂŋC�ɂȂ�����G965��������1FPS���Ă���
>8600GT���ǂ�GPU���ƃt���[�����[�g�ǂ��Ȃ�̂������ė~������
GT240�ł���
100�͗]�T
ttp://img580.imageshack.us/img580/7638/96496671.jpg
256�͂�������CPU(E8400)�����AGPU���ׂ�45%���x
ttp://img689.imageshack.us/img689/6658/88524036.jpg
ttp://img641.imageshack.us/img641/6004/32028529.jpg
GT240�ł���
100�͗]�T
ttp://img580.imageshack.us/img580/7638/96496671.jpg
{kind=link}
256�͂�������CPU(E8400)�����AGPU���ׂ�45%���x
ttp://img689.imageshack.us/img689/6658/88524036.jpg
{kind=link}
ttp://img641.imageshack.us/img641/6004/32028529.jpg
{kind=link}
32 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 13:40:47 ID:CD7Cz7EO
>>30
�X�N�V���グ�Ă݁H
�X�N�V���グ�Ă݁H
>>22
IE��Office�Ȃ�Ontario�ŏ\��������w
>>23
IE9��AMD�Ȃ瑬������Ă�����ەt��
�������A�܂����c����~���c�q�̃��m�}�l����Ă��
����旧�������Ďx���ŗ�w
IE��Office�Ȃ�Ontario�ŏ\��������w
>>23
IE9��AMD�Ȃ瑬������Ă�����ەt��
�������A�܂����c����~���c�q�̃��m�}�l����Ă��
����旧�������Ďx���ŗ�w
34 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 13:42:09 ID:CD7Cz7EO
Fusion�̉����̔炪�������ꂽ�Ȃ�
4550��������2�܂ŗ���������
37 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 13:49:26 ID:CD7Cz7EO
Radeon��IE9�����ĂȂ��^�f����
�ق�clarkdale
ttp://img690.imageshack.us/img690/7815/84246126.jpg
ttp://img444.imageshack.us/img444/6294/64731098.jpg
ttp://img3.imageshack.us/img3/635/45875209.jpg
ttp://img690.imageshack.us/img690/7815/84246126.jpg
{kind=link}
ttp://img444.imageshack.us/img444/6294/64731098.jpg
{kind=link}
ttp://img3.imageshack.us/img3/635/45875209.jpg
{kind=link}
http://www.aist.go.jp/aist_j/new_research/nr20080929/nr20080929.html
���������Z�p�Ń`�b�v��������o���������₹���
GPU����CPU���������`���l�����₹��悤�ɂȂ��ċ��ш���������ł����Ȃ����B
���������Z�p�Ń`�b�v��������o���������₹���
GPU����CPU���������`���l�����₹��悤�ɂȂ��ċ��ш���������ł����Ȃ����B
41 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 13:59:23 ID:CD7Cz7EO
i920��DELL�@��HD4550����62�ł���
�{������@�͂����x�܂��Ă�邩��
�m��915��DELL�@�Ȃ炠�邪�������̖ʓ|��
GMA�͒c�q�����ɂ܂�����
�{������@�͂����x�܂��Ă�邩��
�m��915��DELL�@�Ȃ炠�邪�������̖ʓ|��
GMA�͒c�q�����ɂ܂�����
���X�Ɠ���������Ă邪�AFusion�̃f����Llano��Ontario������Ȃ���Ӗ�����������
�c�q�͂܂��A���ꂪ�wLlano�Ȃ̂ɒx���x�Ȃ̂��wOntario�ł����Ă��x���x�̂��_�_���͂����肵����������
�c�q�͂܂��A���ꂪ�wLlano�Ȃ̂ɒx���x�Ȃ̂��wOntario�ł����Ă��x���x�̂��_�_���͂����肵����������
Llano��Ontario���������ł��Ȃ��J�����̐��i�̃x���`�}�[�N�f���Ȃ�
�������]�X���Ă��k�J���낤��B
�J�����̒i�K�ł��łɑ����Ȃ�Ƃ������B
�������]�X���Ă��k�J���낤��B
�J�����̒i�K�ł��łɑ����Ȃ�Ƃ������B
4image�܂ʼn����Ă�64FPS
��̑����f����
��̑����f����
46 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 14:17:17 ID:CD7Cz7EO
�EIntel�̓���GPU���܂ތ��s���i�ł�100 Images��60fps�͏\���o����
�E���̃f����Fusion�͌����đ����Ȃ�
�����炱��ȏ�͖��Ӗ�����B
�E���̃f����Fusion�͌����đ����Ȃ�
�����炱��ȏ�͖��Ӗ�����B
Atom�̐����o����
atom��vista�Ȃ���7����Ă镨�D��������������ǂ�w
49 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 14:19:57 ID:CD7Cz7EO
�܂�Q�l�ɂȂ��x���`��
���ꂪOntario�Ȃ�AIntel��Atom�Ɋ|�����������蕥��Ȃ���Ȃ��������
��Ŋ뜜��̃l�b�g�u�b�N����Ղ̕����Ƃ����邩��
��Ŋ뜜��̃l�b�g�u�b�N����Ղ̕����Ƃ����邩��
�܂��l�b�g�u�b�N�������Ƃ͎v���ĂȂ���
53 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 14:28:11 ID:CD7Cz7EO
Web�u���E�U�̐��i���炷��ΐl�Ԃ̔F�����E��60fps��傫���z����t���[�����[�g�o�����Ƃ��A�C�h��������������
�v�Ƃ��Ă͐������������ǂˁB
�m�[�gPC�Ńo�b�e������̂��Ƃ�������B
�v�Ƃ��Ă͐������������ǂˁB
�m�[�gPC�Ńo�b�e������̂��Ƃ�������B
�u�_�C�T�C�Y������ƕ����܂�オ��v
�ihttp://pc11.2ch.net/test/read.cgi/jisaku/1275237092/968
���L���b�V�����傫�����璷���Ŏ����I�ȕ����܂肤���j
����l�����
12<16���o����ǂ��납16<12���ƐM���Ă��炢��������
�ihttp://pc11.2ch.net/test/read.cgi/jisaku/1275237092/968
���L���b�V�����傫�����璷���Ŏ����I�ȕ����܂肤���j
����l�����
12<16���o����ǂ��납16<12���ƐM���Ă��炢��������
55 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 14:45:37 ID:CD7Cz7EO
Sandy Bridge��L3�������I��2MB/core����̂�3MB�Ȃ���6MB�ŏo�ׂ���͉̂��̂�������Ȃ��낤��
>>40
�`���l���𑝂₵�ăo���h���A�b�v�ƂȂ�ƃ��W���[�������ꂾ����������ςނ��Ă��ƁH
������Ƃ���͌������C������Ȃ��BTSV��VRAM���ڂƂ��Ȃ�܂������B
�`���l���𑝂₵�ăo���h���A�b�v�ƂȂ�ƃ��W���[�������ꂾ����������ςނ��Ă��ƁH
������Ƃ���͌������C������Ȃ��BTSV��VRAM���ڂƂ��Ȃ�܂������B
SandyL3��3MB�̘b�́A�璷���ɂ��Ă͖����������傫�����ē���Ă��Ƃ������悤�ȁB
�u�����܂肤���v�Ȃǂƌ����Ă�����
������Ɂu3MB�ŏo���Ȃ��Ƃ����Ȃ��v
�����@���ǂ��납���������炨�������̂�������
������Ɂu3MB�ŏo���Ȃ��Ƃ����Ȃ��v
�����@���ǂ��납���������炨�������̂�������
>>56
���C����DDR3�~2ch�Ƃ͕ʂɁAGDDR5��GPU���[�J�����������ςށB
����œ����^�ł����[�G���h�̃f�B�X�N���[�g���炢�̐��\�͏o����悤�ɂȂ�B
�\�P�b�g�K�i�����̖��͂��Ă����B
���C����DDR3�~2ch�Ƃ͕ʂɁAGDDR5��GPU���[�J�����������ςށB
����œ����^�ł����[�G���h�̃f�B�X�N���[�g���炢�̐��\�͏o����悤�ɂȂ�B
�\�P�b�g�K�i�����̖��͂��Ă����B
60 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 14:55:45 ID:CD7Cz7EO
61 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 14:57:55 ID:CD7Cz7EO
http://pc.watch.impress.co.jp/img/pcw/docs/361/133/html/04.jpg.html
http://tech.icrontic.com/files/2009/11/amd_llano_die_block_diagram.png
�f�b�h�X�y�[�X�̖ʐϔ�ׂĂ݁H
{kind=link}
http://tech.icrontic.com/files/2009/11/amd_llano_die_block_diagram.png
{kind=link}
�f�b�h�X�y�[�X�̖ʐϔ�ׂĂ݁H
�̐S�̃������ш悪�p�ӂł��Ȃ��̂ɁA
DX11�Ή�GPU�ڂ�������Q�[���ł��܂����Ę_�����悭�킩���̂���ȁc�c
DX11�Ή�GPU�ڂ�������Q�[���ł��܂����Ę_�����悭�킩���̂���ȁc�c
63 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 15:03:43 ID:CD7Cz7EO
�����t���e�ʂ�1.5MB/core���Ƃ���ƁASandy Bridge�̃_�C�T�C�Y�͌듚���̑����ꃋ�[�}�[�\�z��
75%���x�Ƃ������Ƃ����肤���
75%���x�Ƃ������Ƃ����肤���
64 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 15:04:57 ID:CD7Cz7EO
�璷�������邩��璷�����Ȃ��������܂�オ��͂킩�邯�ǁA
�璷��������Ń_�C�T�C�Y�ł����̂ƁA�璷�����Ȃ��Ń_�C�T�C�Y������������̂Ƃ���
�ǂ����������܂��Ȃ낤���B
����1�E�G�n�������`�b�v�������邵�A���ۓI�ɘb����Ă����܂�Ӗ��Ȃ��悤�ȁB
�璷��������Ń_�C�T�C�Y�ł����̂ƁA�璷�����Ȃ��Ń_�C�T�C�Y������������̂Ƃ���
�ǂ����������܂��Ȃ낤���B
����1�E�G�n�������`�b�v�������邵�A���ۓI�ɘb����Ă����܂�Ӗ��Ȃ��悤�ȁB
Sandy�}��Dead Space?�������ĉ��̂����에��
����ɂ�����
�Ђ���Ƃ��đ��̉����ꂪ���A�ɂ���ăf�b�h�X�y�[�X��������̂��H
����ɂ�����
�Ђ���Ƃ��đ��̉����ꂪ���A�ɂ���ăf�b�h�X�y�[�X��������̂��H
67 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 15:26:26 ID:CD7Cz7EO
>>65
90nm��Cell��240mm²���z����_�C�T�C�Y��������SPE1�R�A�E����100mm²���݂̕����܂藦��B�������Ƃ��]�X�B
�܂�Intel�͋����s���ɂȂ�قǔ����Ȃ�_�C�T�C�Y������������ȑO�ɃE�F�n�Y���邾��B
AMD�͓���v���Z�X���[���ł�SOI�H���̕��������R�X�g�ɂ͕ς����������ʂ̋����ɋ����Ƃ͎v����
90nm��Cell��240mm²���z����_�C�T�C�Y��������SPE1�R�A�E����100mm²���݂̕����܂藦��B�������Ƃ��]�X�B
�܂�Intel�͋����s���ɂȂ�قǔ����Ȃ�_�C�T�C�Y������������ȑO�ɃE�F�n�Y���邾��B
AMD�͓���v���Z�X���[���ł�SOI�H���̕��������R�X�g�ɂ͕ς����������ʂ̋����ɋ����Ƃ͎v����
>>65
�ɒ[�Șb
�S�Ẵ��\�[�X�ɂ��̂������璷������������1�E�F�n1�_�C�ł��C�ɂ����v�����
�����܂��100%�Ɍ���Ȃ��ߕt��
�X�y�b�N�i�L�����\�[�X�j���ɂ��ė\���������킰�u�����܂�v�͗����邯�nj����͏オ��
Deneb�ł�4�R�A�Ƃ��č���đS��2�R�A�Ŕ������2�R�A�Ƃ��č�����ق������v���͗ǂ����낤��
�����������ƌ�����ǂ������i�Ƃ��đI�ʂ��Ă�����
�ɒ[�Șb
�S�Ẵ��\�[�X�ɂ��̂������璷������������1�E�F�n1�_�C�ł��C�ɂ����v�����
�����܂��100%�Ɍ���Ȃ��ߕt��
�X�y�b�N�i�L�����\�[�X�j���ɂ��ė\���������킰�u�����܂�v�͗����邯�nj����͏オ��
Deneb�ł�4�R�A�Ƃ��č���đS��2�R�A�Ŕ������2�R�A�Ƃ��č�����ق������v���͗ǂ����낤��
�����������ƌ�����ǂ������i�Ƃ��đI�ʂ��Ă�����
69 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 15:30:44 ID:CD7Cz7EO
�m�������Ԃ�L�^�[
>>68�̍Ō�̍s
�I�ʂ���Ȃ��ă��f����������
�I�ʂ���Ȃ��ă��f����������
71 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 15:32:59 ID:CD7Cz7EO
�����Ēp�̏�h��
72 �FSocket774�F2010/06/20(��) 15:35:32 ID:X2VJAgRH
AMD�M�҂͐����R�s�y�Ɛ���Ɏア����y������
73 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 15:36:46 ID:CD7Cz7EO
���Ȃ݂ɁA340mm²���z����6�R�A������đI�ʗ�����4�R�A�Ƃ��Ĕ����Ă��Ƃ������
Sandy������ROHAN�����K�ɂȂ�w�����l���Ȃ����Ƃ��Ȃ��ȁ[
75 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 15:40:51 ID:CD7Cz7EO
Ivy Bridge 2�R�A+IGP����100mm²��̂��ȁH
���1�N�x�����
���1�N�x�����
���f�b�h�X�y�[�X�̖ʐϔ�ׂĂ݁H
Sandy�ɂ̓f�b�h�X�y�[�X������I
�����̉�����i���Ŗ��܂��ė��p�s�j�Ƃ���Ȃ��I
Llano�ɂ͑S�������I�v�M���[�I�I�I
����������
Sandy�ɂ̓f�b�h�X�y�[�X������I
�����̉�����i���Ŗ��܂��ė��p�s�j�Ƃ���Ȃ��I
Llano�ɂ͑S�������I�v�M���[�I�I�I
����������
77 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 15:43:06 ID:CD7Cz7EO
�A�����̓Ɖ���
�����܂��ŃR�A�E���͓̂d�͓I�ɕs�����Ǝv���̂ł���
���Ƃ���GPU���ׂ̏��Ȃ��f��������A�c�q��8600GT�Ƒ卷���Ȃ�
8600GT������ڂ��킯�ł�Llano���������킯�ł��Ȃ��B
8600GT������ڂ��킯�ł�Llano���������킯�ł��Ȃ��B
PC�n��blog�̃R�����g��������ƁA
llano���o����amd�����������@�݂����Ȃ��Ƃ������Ă���l�����āA�ʔ����ˁB
llano���o����amd�����������@�݂����Ȃ��Ƃ������Ă���l�����āA�ʔ����ˁB
���m����cpu��k10�x�[�X�Ȃ�ˁB
�l�I�ɂ͂��̂��Ƃ̃u���Ɋ��҂��Ă�!!
�l�I�ɂ͂��̂��Ƃ̃u���Ɋ��҂��Ă�!!
82 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 16:30:22 ID:CD7Cz7EO
�ŁA256 Images�Ńt���[�����[�g�������ނ̂�CPU�̃V���O���X���b�h���\�l�b�N�Ȃ�H
Web�A�v���P�[�V������CPU���\���l�b�N�ł��葱������ĉ��̎��_�ʂ肶���
Web�A�v���P�[�V������CPU���\���l�b�N�ł��葱������ĉ��̎��_�ʂ肶���
>>80
Macmini�݂����ȏ��^�^�C�v�ł͗L���u��������Ȃ��v���u�����������v�ɔ]���ϊ�����Ă�낤��
Macmini�݂����ȏ��^�^�C�v�ł͗L���u��������Ȃ��v���u�����������v�ɔ]���ϊ�����Ă�낤��
>>72
����ς�A�~�̍r�����������B�ł����̍����ʔ������B
����ς�A�~�̍r�����������B�ł����̍����ʔ������B
���N����AMD GPU�̍Œ�C����DX11�Ή�
DirectX��m���Ă���l�����ɁA����͌v��m��Ȃ��A�h�o���e�[�W
OpenGL��CL�ɂ����đΉ����Ă��邩��A�G���R�[�h��CAD�p�r�ɂ����Ďg����
�����\�����߂Ȃ����C�g�Q�[�}�[��G���R���[�U�[�ɂ͍œK�Ȉ�i�ɂȂ�
�t��Sandy�P�̂̔�����ĉ�������̂��Ċ�������
�����_��G���R�͒ǂ����ꂽ�A�Q�[���͏o���Ȃ��A��ƌ����ɍ����\�͕K�v�Ȃ�
DirectX��m���Ă���l�����ɁA����͌v��m��Ȃ��A�h�o���e�[�W
OpenGL��CL�ɂ����đΉ����Ă��邩��A�G���R�[�h��CAD�p�r�ɂ����Ďg����
�����\�����߂Ȃ����C�g�Q�[�}�[��G���R���[�U�[�ɂ͍œK�Ȉ�i�ɂȂ�
�t��Sandy�P�̂̔�����ĉ�������̂��Ċ�������
�����_��G���R�͒ǂ����ꂽ�A�Q�[���͏o���Ȃ��A��ƌ����ɍ����\�͕K�v�Ȃ�
87 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 17:27:03 ID:CD7Cz7EO
> ���N����AMD GPU�̍Œ�C����DX11�Ή�
> DirectX��m���Ă���l�����ɁA����͌v��m��Ȃ��A�h�o���e�[�W
> OpenGL��CL�ɂ����đΉ����Ă��邩��A�G���R�[�h��CAD�p�r�ɂ����Ďg����
> �����\�����߂Ȃ����C�g�Q�[�}�[��G���R���[�U�[�ɂ͍œK�Ȉ�i�ɂȂ�
�́H�u�����\�����߂Ȃ��v�̂ɐ��\���K�v�H�n������Ȃ��́H
> �t��Sandy�P�̂̔�����ĉ�������̂��Ċ�������
> �����_��G���R�͒ǂ����ꂽ�A�Q�[���͏o���Ȃ��A��ƌ����ɍ����\�͕K�v�Ȃ�
��ƌ�����DX11�͕K�v�Ȃ��B���z���\�����[�V������CPU���\�̎��v�͐L�т�
> DirectX��m���Ă���l�����ɁA����͌v��m��Ȃ��A�h�o���e�[�W
> OpenGL��CL�ɂ����đΉ����Ă��邩��A�G���R�[�h��CAD�p�r�ɂ����Ďg����
> �����\�����߂Ȃ����C�g�Q�[�}�[��G���R���[�U�[�ɂ͍œK�Ȉ�i�ɂȂ�
�́H�u�����\�����߂Ȃ��v�̂ɐ��\���K�v�H�n������Ȃ��́H
> �t��Sandy�P�̂̔�����ĉ�������̂��Ċ�������
> �����_��G���R�͒ǂ����ꂽ�A�Q�[���͏o���Ȃ��A��ƌ����ɍ����\�͕K�v�Ȃ�
��ƌ�����DX11�͕K�v�Ȃ��B���z���\�����[�V������CPU���\�̎��v�͐L�т�
88 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 17:29:12 ID:CD7Cz7EO
GPU���\��GMA�ŏ\��
DX11��DX10�����GPU�ł����ߓI��API���g����̂ł��ꂱ�����\���K�v���Ȃ��Ȃ���Ȃ���
DX11��DX10�����GPU�ł����ߓI��API���g����̂ł��ꂱ�����\���K�v���Ȃ��Ȃ���Ȃ���
89 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 17:31:35 ID:CD7Cz7EO
Llano�̃^�[�Q�b�g��5000�~���x�̃A�h�I���J�[�h���P�`��Ȃ��Ə��i�͂̂Ȃ��悤�ȃj�b�`�s�ꂾ���Ď����Ō����Ă���
���\���K�v�Ȃ�GeForce�ł��h���Ă���������BFusion��GPU�͂ǂ����8600GT�����̒ᐫ�\�炵�����B
���\���K�v�Ȃ�GeForce�ł��h���Ă���������BFusion��GPU�͂ǂ����8600GT�����̒ᐫ�\�炵�����B
���l�܂�̉�����͂Ƃ������������E�͂����������������낤��
ttp://www.coneco.net/special/d082/
ttp://www.coneco.net/special/d082/
91 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 17:37:25 ID:CD7Cz7EO
�Ă��A���ɂȂ�����Radeon HD5750�ł�IE9�x���`�o���Ă����́H
�܂���30fps�����o�Ȃ��̂��H
iHDG�ł���60fps�o��̂ɂ�����
�܂���30fps�����o�Ȃ��̂��H
iHDG�ł���60fps�o��̂ɂ�����
92 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 17:46:43 ID:CD7Cz7EO
���Ȃ݂ɃR���V���[�}�����E�r�W�l�X������킸CPU���\�̎��v�ɏI���ȂǂȂ��B
���Ƃ��E�B���X��\�t�g�͔N�X�d���Ȃ葱���邩��ȁB
���Ƃ��E�B���X��\�t�g�͔N�X�d���Ȃ葱���邩��ȁB
Intel������CPU�X����ǂ��z�������Ȑ�������
94 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 17:52:09 ID:CD7Cz7EO
�Ă��A���ɂȂ�����Radeon HD5750�ł�IE9�x���`�o���Ă����́H
�܂���30fps�����o�Ȃ��̂��H
Phenom X4 + Radeon HD5750������ł��肢���܂�������
���R4��ʂ�60fps���炢�]�T�ł���ˁH������
�܂���30fps�����o�Ȃ��̂��H
Phenom X4 + Radeon HD5750������ł��肢���܂�������
���R4��ʂ�60fps���炢�]�T�ł���ˁH������
�_���S���߂��Ⴍ������������ɘA�����Ă邗
96 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 17:54:22 ID:CD7Cz7EO
���RIE9�̕`�搫�\��Core 2 Duo�ɕ����Ă���Ă��Ƃ͖����ł���H
Llano�͔�����Ȃ�H
Llano�͔�����Ȃ�H
97 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 17:56:14 ID:CD7Cz7EO
Core 2 Duo�i�j�{8600GT�i�j�̃V���{PC��2��ʓ������s
http://up3.viploader.net/pic/src/viploader1195840.jpg
����Ƃ�Phenom X4�{Radeon�ł��肢���܂�������
http://up3.viploader.net/pic/src/viploader1195840.jpg
����Ƃ�Phenom X4�{Radeon�ł��肢���܂�������
windows7�g����Ő�ɕK�v��GPU�p�t�H�[�}���X����
Aero�������������Ă��Ƃ�������H
Aero�������������Ă��Ƃ�������H
99 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 18:04:52 ID:CD7Cz7EO
���A���Ȃ݂Ƀe�b�Z���[�^�i�j���ĕ�����̒��_�������c��ނ̂��l�b�N�Ō��Ǒ債�Đ��\�オ��Ȃ����
���_�V�F�[�_�͂���Ȃ�ɉ��Z���x���d�v������Radeon�ɂ͕s�������ˁB
���ꂱ��Cell��SPU���x�̓Ɨ������V�[�P���X�������s�o����V���[�g�x�N�g���^�̉��Z�R�A�̂ق����L�����낤��
Sandy Bridge�̃\�t�g�E�F�A�V�F�[�_�͂��Ȃ�オ�邾�낤���B
���_�V�F�[�_�͂���Ȃ�ɉ��Z���x���d�v������Radeon�ɂ͕s�������ˁB
���ꂱ��Cell��SPU���x�̓Ɨ������V�[�P���X�������s�o����V���[�g�x�N�g���^�̉��Z�R�A�̂ق����L�����낤��
Sandy Bridge�̃\�t�g�E�F�A�V�F�[�_�͂��Ȃ�オ�邾�낤���B
�e�b�Z���[�^�i�j�Ő��\���オ��̂�������i���݂̓f�b�h�X�y�[�X�Ȃ̂ł��̃X�����㊘�炵���j
�e�b�Z���[�^�i�����Ń|���S�����₷�j�Ō����ڂ��ǂ��Ȃ�i���ׂ͑�����j�̂��������E
�e�b�Z���[�^�i�����Ń|���S�����₷�j�Ō����ڂ��ǂ��Ȃ�i���ׂ͑�����j�̂��������E
101 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 18:15:48 ID:CD7Cz7EO
�܁A�e�b�Z���[�^�̉��b������̂̓A�b�p�[�~�h�������W�ȏ�̃f�B�X�N���[�g���炢�����ǂ�
�e�N�X�`�����G�t�F�N�g�����Ƃ��Ē��_���������Ă��|�����Ȃ����B
DX11�ɖ��͂�������l�ԂȂ�Ȃ��̂���Llano�͑I�����ɂȂ��B
GPU���\�͂������CPU�̐��\���d�v�ł��邱�Ƃ�m���Ă邩��ȁB
�e�N�X�`�����G�t�F�N�g�����Ƃ��Ē��_���������Ă��|�����Ȃ����B
DX11�ɖ��͂�������l�ԂȂ�Ȃ��̂���Llano�͑I�����ɂȂ��B
GPU���\�͂������CPU�̐��\���d�v�ł��邱�Ƃ�m���Ă邩��ȁB
�e�b�Z���[�^�i�j�͍��ł�GS�̌������i�L���b�V������݂Łj��ԗǂ�S3��
DX11���̂��o���Ɩʔ������ɂȂ邾�낤�v���Ă�
nv�͂����`���b�Ƃ����܂��傤
DX11���̂��o���Ɩʔ������ɂȂ邾�낤�v���Ă�
nv�͂����`���b�Ƃ����܂��傤
�e�b�Z���[�^�i�j���āA���Ǖ��G��shading��GPU�ł�点��̂������Ȃ��
������Ɠʉ������Ă݂܂������Ă��̂��Ǝv����
���C�Ȃ�DX10��GS�g���Ă��ł������̂�����
������Ɠʉ������Ă݂܂������Ă��̂��Ǝv����
���C�Ȃ�DX10��GS�g���Ă��ł������̂�����
104 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 18:21:13 ID:CD7Cz7EO
���A���R������DX11���̗p���Ă���悤�ȃQ�[���Ȃ�Ȃ��̂���AVX�̑Ή���������B
�ł����L���b�V�����������
CPU���ł������ǂ���Ȃ�
�Ȃ�Ďv���̂���
�������̂�
CPU���ł������ǂ���Ȃ�
�Ȃ�Ďv���̂���
�������̂�
106 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 18:30:54 ID:CD7Cz7EO
�Ă��A���nj����ڂȂ�H
��������Radeon�ɍœK�ȕ������Z�G���W�����������ǂ��ɂ����ׂ����낤�B
http://pc.nikkeibp.co.jp/article/news/20090126/1011690/
OpenCL Havok��Radeon�Ŏ��s����ƍ������ƂɂȂ��Ă���
����CPU��SIMD���\���݂Ȃ�Sandy Bridge�ȊO�ɑI�������Ȃ�
��������Radeon�ɍœK�ȕ������Z�G���W�����������ǂ��ɂ����ׂ����낤�B
http://pc.nikkeibp.co.jp/article/news/20090126/1011690/
OpenCL Havok��Radeon�Ŏ��s����ƍ������ƂɂȂ��Ă���
����CPU��SIMD���\���݂Ȃ�Sandy Bridge�ȊO�ɑI�������Ȃ�
OpenCL,Open Physics�Ƃ�
Open���Ă͕̂������͂�����
���ǂ��������ɂ����Ȃ�����A���肳���Ă��炢�܂����Ă��Ƃ��
Open���Ă͕̂������͂�����
���ǂ��������ɂ����Ȃ�����A���肳���Ă��炢�܂����Ă��Ƃ��
108 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 19:09:45 ID:CD7Cz7EO
PS3��Cell�ɂ��\�t�gGPU�͂���Ȃ�ɐ��ʏo���Ă�悤�����A�f�B�X�v���[�X�����g�}�b�v�Ƃ��e�b�Z���[�V�������������Ă���B
VS���Ƃ�GS���Ƃ��́i�X���[�v�b�g���\���Ȃ�jCPU��SIMD���j�b�g�ɂ�点����������ۂnj����I���Ǝv����B
Sandy Bridge�͔ėp�v���Z�b�T�R�A�ł���Ȃ���4�R�A��PS3��Cell������200GFLOPS����������킯��
��葽���̑����̉\�����߂Ă�ˁB
�e�b�Z���[�V�����Ƃ����܂߂đO������CPU�������Ă��܂����ق����ǂ��������Ǝv���B
VS���Ƃ�GS���Ƃ��́i�X���[�v�b�g���\���Ȃ�jCPU��SIMD���j�b�g�ɂ�点����������ۂnj����I���Ǝv����B
Sandy Bridge�͔ėp�v���Z�b�T�R�A�ł���Ȃ���4�R�A��PS3��Cell������200GFLOPS����������킯��
��葽���̑����̉\�����߂Ă�ˁB
�e�b�Z���[�V�����Ƃ����܂߂đO������CPU�������Ă��܂����ق����ǂ��������Ǝv���B
PS3��RSX���ш摫��Ȃ��̂ŁA���_�Ƃ�Cell�ŏo���邱�Ƃ�Cell�ł�炴���
���Ȃ��Ƃ���������B
���Ȃ��Ƃ���������B
���X200G���x�o�������
���Ȃ݂Ɍ��̃x���`��BE2300 GF7050
1280x960��10�`15fps������
���Ȃ݂Ɍ��̃x���`��BE2300 GF7050
1280x960��10�`15fps������
�ш���Ă�����VS�̐����̂����Ȃ��̂�8���
��������360�͈ꉞ16��̔ėpshader�̃A���C��3�{������
�Œ�̏ꍇ�ł��P����2�{�̍����o�Ă��܂���
(PS��24��32���Ă��ɐ��邯�ǂˁj
PS3��SPE�������_�����ȊO�łǂ��g���Ă�̂��͂悭�m���
�Z�\�����I�Ŗʔ�����Ȃ�����
�J�[�N�Ɛ���N�̑Βk�L��
ttp://game.watch.impress.co.jp/docs/20050519/ps3_r.htm
��������360�͈ꉞ16��̔ėpshader�̃A���C��3�{������
�Œ�̏ꍇ�ł��P����2�{�̍����o�Ă��܂���
(PS��24��32���Ă��ɐ��邯�ǂˁj
PS3��SPE�������_�����ȊO�łǂ��g���Ă�̂��͂悭�m���
�Z�\�����I�Ŗʔ�����Ȃ�����
�J�[�N�Ɛ���N�̑Βk�L��
ttp://game.watch.impress.co.jp/docs/20050519/ps3_r.htm
112 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 20:56:09 ID:CD7Cz7EO
���Ƃ���Cell�����ł��\�肾��������RSX��VS���ア�͕̂ʂɃA������Ȃ��H
�i���̗\��Ƃ������v�v�z���ǂ��������ǂ����͂��Ă����j
�i���̗\��Ƃ������v�v�z���ǂ��������ǂ����͂��Ă����j
113 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 21:12:38 ID:CD7Cz7EO
�Ȃ�Ƃ������A�uPixel Shader�_�����ɂ��Ή����������́v��CPU�������_�����Ɍ����Ă邩�Ƃ����ƁA
�����Ƃ͌����Ȃ��C������ˁB
Cell�ɂ��Vertex Shader��ւ�SPE 2�ł��\�����p�I�Ȑ��\���ł����Ƃ����b����
�z�̃V�~�����[�V�����Ƃ������Ē��_�����̉��AOpenCL�ɂ��Havok Cloth�̃f����
�n�C�G���h��Radeon����g���Ă��N�A�b�h�R�ACPU�ɋy�Ȃ�����
GPU�̐��c��FLOPS���ȂǓ��ĂɂȂ��
�����Ƃ͌����Ȃ��C������ˁB
Cell�ɂ��Vertex Shader��ւ�SPE 2�ł��\�����p�I�Ȑ��\���ł����Ƃ����b����
�z�̃V�~�����[�V�����Ƃ������Ē��_�����̉��AOpenCL�ɂ��Havok Cloth�̃f����
�n�C�G���h��Radeon����g���Ă��N�A�b�h�R�ACPU�ɋy�Ȃ�����
GPU�̐��c��FLOPS���ȂǓ��ĂɂȂ��
�P���ɃN���b�N���g���̍������
115 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 21:28:04 ID:CD7Cz7EO
�܂�Ƃ��날����x�͒�������̐��\�Ɉ��������镔��������Ƃ������Ƃ���
>>112
�����������̂��A��������ƍ����PC�ł�CPU�ōs���l�ɂȂ��Ă����̂��H
�����������̂��A��������ƍ����PC�ł�CPU�ōs���l�ɂȂ��Ă����̂��H
���v����Cell����CPU����Ȃ�APU��������
PS3���Ē��g�ɖ����������l�܂��ĂĂ��������Č����Ă邯��
�ǂ�����XBOX360�ɔ�ׂė������̂����o���ĂȂ��낤
�ǂ�����XBOX360�ɔ�ׂė������̂����o���ĂȂ��낤
119 �F,,�E�L�́M�E,,�j��-�������F2010/06/20(��) 21:42:07 ID:CD7Cz7EO
���Ƃ���MMX/3DNow!�Ƃ�SSE��DirectX�̑O�������������I�ɍs���ׂ̂��̂�����
���������ꏊ�ɋA�邾���ł���
DirectX�͂Ƃ��������p�Q�[���G���W�����x���ł�SSE�̊��p�͕��ʂɂ���Ă�B
VS/GS�̏������S���y����������GPU�����\�������o���邵�ˁB
���������ꏊ�ɋA�邾���ł���
DirectX�͂Ƃ��������p�Q�[���G���W�����x���ł�SSE�̊��p�͕��ʂɂ���Ă�B
VS/GS�̏������S���y����������GPU�����\�������o���邵�ˁB
Intel��CPU���g�����Q�[�������̕������Z�𗧂��グ�Ă���
�����r�[�����������AIntel��OpenCL��Havok�͉��Ђ��ɂ�������ǂ�����
�����r�[�����������AIntel��OpenCL��Havok�͉��Ђ��ɂ�������ǂ�����
�������Z����Ȃ��Ď��o���ʂ���������
���o�p�̉�����
���o�p�̉�����
122 �FSocket774�F2010/06/20(��) 22:03:31 ID:nT1bBXQX
�Ȃ�ŏ��p�Q�[���G���W���������PC�ŕ��y���Ȃ��́H
�c�q�͒N�Ɖ�b���Ă��
�ŋ߂͓��ɍ����c1����90�߂����X�͂������Ɏ��d���Ă���
�ŋ߂͓��ɍ����c1����90�߂����X�͂������Ɏ��d���Ă���
Xbox��Wii��CPU��GPU�̊W��PC�Ɠ����ł���
AMD�̃u���h�[�U�[�̓R�A������̐��\�������āA���̂����R�A����������Ă��Ƃł������H
�c�q�͈�l�Ŏ₵������N���ɍ\���Ăق����낗
�m���͂����Ă��A��n�O�����琢�̒��ł������܂����ĒN�ɂ�����ɂ�����Ȃ����炗
�m���͂����Ă��A��n�O�����琢�̒��ł������܂����ĒN�ɂ�����ɂ�����Ȃ����炗
�R�A��������̂͂������A
�ڋq�̖]�݂́u�V���O���X���b�h���\���]���ɂ��Ȃ��v���R�A���Ȃ̂ŁA
Bulldozer�͂�����Ƃ���Ă�B
����ł��o�ׂł���Ό�̎����낤�B
�G�L�Z���g���b�N�ȃA�[�L�e�B�N�`���͈łɏ����Ă����Ă��܂����������B
�ڋq�̖]�݂́u�V���O���X���b�h���\���]���ɂ��Ȃ��v���R�A���Ȃ̂ŁA
Bulldozer�͂�����Ƃ���Ă�B
����ł��o�ׂł���Ό�̎����낤�B
�G�L�Z���g���b�N�ȃA�[�L�e�B�N�`���͈łɏ����Ă����Ă��܂����������B
�s�[�N���\�o���o���Ɏg���\�t�g���������ŁA
�u�s�[�N���\���茩�Ă����_�v�����猸�炵���킯�����B
�����悭�R�A���g����Ȃ�A���l�����́u�s�[�N���\�v���A
��ʓI�ȏ������X���[�Y�ɏ��������A
�o�����X���o���Ƃ����ꡂ��ɗǂ��킯�����B
���������A��ʌ����\�t�g�ʼn������V���O���X���b�h�̃s�[�N���\��
��������o���悤�ȃ\�t�g�Ȃ�āA���݂��Ȃ����낤�ƁB
�u�s�[�N���\���茩�Ă����_�v�����猸�炵���킯�����B
�����悭�R�A���g����Ȃ�A���l�����́u�s�[�N���\�v���A
��ʓI�ȏ������X���[�Y�ɏ��������A
�o�����X���o���Ƃ����ꡂ��ɗǂ��킯�����B
���������A��ʌ����\�t�g�ʼn������V���O���X���b�h�̃s�[�N���\��
��������o���悤�ȃ\�t�g�Ȃ�āA���݂��Ȃ����낤�ƁB
����v�Z��60�b�ŏI��点��V���O���R�A��CPU���������Ƃ��悤�B
�����g�����W�X�^�ʂŁA�V���O���X���b�h���\��2/3�ɗ��Ƃ���������
2�{�̃R�A��ς��nj^CPU���ƁA�����v�Z���}���`�X���b�h�ŕ��s���s�����
45�b�ŏI��点�邱�Ƃ��ł���B���ꂪBulldozer�̔��z���B
�Ƃ��낪�����ɂ̓t���ɕ��s���s�ł���P�[�X�͏��Ȃ�(�A���_�[���̖@��)�B
���Ƃ���60�b�̏����̂����̔�������MT���ł��Ȃ��ƁA
67.5�b�������Ă��܂��B
�ߏ�ȃV���O���X���b�h���\�̒Nj��̓g�����W�X�^���\����d�͐��\�������������B
�������R�A��������قǃR�A�ԒʐM�̃I�[�o�[�w�b�h������Ȃ��̂ɂȂ邩��A
���R�A����������ł͂Ȃ��B
��{�I�ɃA�v���P�[�V�����͂܂��V���O���X���b�h�ŏ������̂ł���A
�����V���O���X���b�h���\�͏�ɑP�B���Ƃ̓o�����X���B
�����g�����W�X�^�ʂŁA�V���O���X���b�h���\��2/3�ɗ��Ƃ���������
2�{�̃R�A��ς��nj^CPU���ƁA�����v�Z���}���`�X���b�h�ŕ��s���s�����
45�b�ŏI��点�邱�Ƃ��ł���B���ꂪBulldozer�̔��z���B
�Ƃ��낪�����ɂ̓t���ɕ��s���s�ł���P�[�X�͏��Ȃ�(�A���_�[���̖@��)�B
���Ƃ���60�b�̏����̂����̔�������MT���ł��Ȃ��ƁA
67.5�b�������Ă��܂��B
�ߏ�ȃV���O���X���b�h���\�̒Nj��̓g�����W�X�^���\����d�͐��\�������������B
�������R�A��������قǃR�A�ԒʐM�̃I�[�o�[�w�b�h������Ȃ��̂ɂȂ邩��A
���R�A����������ł͂Ȃ��B
��{�I�ɃA�v���P�[�V�����͂܂��V���O���X���b�h�ŏ������̂ł���A
�����V���O���X���b�h���\�͏�ɑP�B���Ƃ̓o�����X���B
��A52.5�b����?
�܂������ₗ���������������������Ƃ͂킩������傗����������
�܂������ₗ���������������������Ƃ͂킩������傗����������
131 �F,,�E�L�́M�E,,�j��-�������F2010/06/21(��) 00:39:32 ID:Ki7ZS8Ag
�W�����}�͂�����B���͂�����ǂ��������邩���B
���t�F�C�Y(�tHTT)�ŃV���O�����}���`������
>>127
�ڋq�̖]�݂͂���Ȃ�̃V���O���X���b�h���\�Ƒ����̃}���`�X���b�h
��ʌ����̂���Ȃ�̃V���O���X���b�h���\���Ă̂�K10��2.4GHz�ANehalem��2GHz���x
�}���`�X���b�h��2T�`4T���x
����ȏ�����߂�w�ɂ��Ă�k10��3GHz������Εs���͖w�ǔ������Ȃ�
Bulldozer��IPC��N���b�N�͕s�������A�V���O�����}���`��1090T����̂��O��ɂȂ��Zambezi��
��������Ȃ��ƒN������ɂ��Ȃ�������Ȃ������
����ƁA�łɏ����čs���̂͑�͓̂o�ꎞ�����x���������̂��A�����\���w���������ď���d�͂�R�X�g�������`�b�v
�O�҂̓N���[�\�[�̃G�t�B�V�I���A��҂�PenD��GF100��Larrabee
AMD�̎�����͂ǂ�����A�ǂ���ɂ����Ă͂܂�Ȃ�������v
�ڋq�̖]�݂͂���Ȃ�̃V���O���X���b�h���\�Ƒ����̃}���`�X���b�h
��ʌ����̂���Ȃ�̃V���O���X���b�h���\���Ă̂�K10��2.4GHz�ANehalem��2GHz���x
�}���`�X���b�h��2T�`4T���x
����ȏ�����߂�w�ɂ��Ă�k10��3GHz������Εs���͖w�ǔ������Ȃ�
Bulldozer��IPC��N���b�N�͕s�������A�V���O�����}���`��1090T����̂��O��ɂȂ��Zambezi��
��������Ȃ��ƒN������ɂ��Ȃ�������Ȃ������
����ƁA�łɏ����čs���̂͑�͓̂o�ꎞ�����x���������̂��A�����\���w���������ď���d�͂�R�X�g�������`�b�v
�O�҂̓N���[�\�[�̃G�t�B�V�I���A��҂�PenD��GF100��Larrabee
AMD�̎�����͂ǂ�����A�ǂ���ɂ����Ă͂܂�Ȃ�������v
�^�[�{�u�[�X�g���Ă̂̓V���v�������ǃi�C�X�A�C�f�B�A�����
�����̃X�������Č㓡�O�Ύ��̋L���Ƃ��D����������
>�ڋq�̖]�݂͂���Ȃ�̃V���O���X���b�h���\�Ƒ����̃}���`�X���b�h
(��)
(��)
XBox��Fusion�ɂȂ�����������ǃv���O���~���O�Ƃ����̕ӂǂ��Ȃ�
360�Ɋւ��Ă͕ς��Ȃ���Ȃ�
�ߋ��Ƃ̌݊����������Ȃ��Ⴂ���Ȃ���
�ߋ��Ƃ̌݊����������Ȃ��Ⴂ���Ȃ���
���Ƃ��ƁA�ǂ��ɂ��Ȃ���
�J���̂��₷���A�掿�̸��è��PS3�͔����܂��܂��������Ȃ��Ƃ������Ƃ�
�\�t�g���}�C�N���\�t�g�������Ă�iXNA�Ή����Ă�j����CPU�͉��ł�����
�[��XBOX360��Fusion�ɂȂ����̂�
�uMicrosoft�̃A�[�L�e�N�`���̏ꍇ�A45nm�̃`�b�v�ł͌ʃ`�b�v�ɂ��邱�Ƃ��ł����A�����`�b�v�ɂ���K�v���������v�Ƃ�������
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20100616_374574.html
�uMicrosoft�̃A�[�L�e�N�`���̏ꍇ�A45nm�̃`�b�v�ł͌ʃ`�b�v�ɂ��邱�Ƃ��ł����A�����`�b�v�ɂ���K�v���������v�Ƃ�������
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20100616_374574.html
���������Q�[���R���\�[��������̌㔼��CPU�EGPU����1�`�b�v������̂͂悭���邱��
������PS2�ɂ͌݊����̂��߂́u1�`�b�vPS�v���ڂ��Ă���
PS2��CPU��EE��GPU��GS��1�`�b�v������
������PS2�ɂ͌݊����̂��߂́u1�`�b�vPS�v���ڂ��Ă���
PS2��CPU��EE��GPU��GS��1�`�b�v������
����̌㔼���Ă��o�X�ł�����x�ȏ�̃_�C�T�C�Y�K�v�ɂȂ邩��
�_�C�T�C�Y�ێ��̂��߂ɑ��̃`�b�v��荞�ފ�������Ȃ��̂���
�_�C�T�C�Y�ێ��̂��߂ɑ��̃`�b�v��荞�ފ�������Ȃ��̂���
�Ȃ�قǎ��R�Ƃ����Ȃ����Ⴄ�̂�
fusion���Ă����炮�炢�ɂȂ�\��Ȃ́H
������œo�d�������{AMD�̋{�{�[�u��\������В��́C
�u�wPC���g���ĉ������������x�Ƃ�������ɑ��CPC���[�J�[�͂���܂ŁC�X�y�b�N��
�X�e�b�J�[�������Ă������C����ł͉ɂȂ��Ă��Ȃ��v�ƈ��A�B�u�v���Z�b�T��
�X�y�b�N�ɂ��Č��̂͂�߂āC�p�r�ɂ��Č��v���Ƃ��CVISION�̖����ł���ƁC
���炽�߂Đ�������B
http://www.4gamer.net/games/017/G001762/20100622016/
�����ɂ��݂ł����H
�u�wPC���g���ĉ������������x�Ƃ�������ɑ��CPC���[�J�[�͂���܂ŁC�X�y�b�N��
�X�e�b�J�[�������Ă������C����ł͉ɂȂ��Ă��Ȃ��v�ƈ��A�B�u�v���Z�b�T��
�X�y�b�N�ɂ��Č��̂͂�߂āC�p�r�ɂ��Č��v���Ƃ��CVISION�̖����ł���ƁC
���炽�߂Đ�������B
http://www.4gamer.net/games/017/G001762/20100622016/
�����ɂ��݂ł����H
������A�[�L�e�N�`���ɂȂ��FF14�x���`�ŃC���e�����D�ʂɗ��Ă�́H
���[�J�[��PC�����̃v���O�����Ȃ�VISION�̂����͍����Ă�Ǝv�����ǂ�
���ʂ̋q�́w�������������ǂ���PC��OK�Ȃ̂��ȁH�x���ď���L��Ώ\��
���ꂪ�Ȍ��ɔ���悤�ɂȂ�ΗL��
�ł��ATVCM�Ƃ��ł������Ȃ�����́A���[�J�[�͂��̂���ڂɏ��Ȃ�����Ӗ���������
�X����POP�u�����炢���Ⴡ�[�J�[�͓����Ȃ����낤
���ʂ̋q�́w�������������ǂ���PC��OK�Ȃ̂��ȁH�x���ď���L��Ώ\��
���ꂪ�Ȍ��ɔ���悤�ɂȂ�ΗL��
�ł��ATVCM�Ƃ��ł������Ȃ�����́A���[�J�[�͂��̂���ڂɏ��Ȃ�����Ӗ���������
�X����POP�u�����炢���Ⴡ�[�J�[�͓����Ȃ����낤
�����������̂��H�͗ǂ�����N���Ƃ͎v�����ǂ��E�E�E�B
AMD�͉����������H
AMD�͉����������H
��ʐl�ɂƂ��Ă�CPU�����AGPU�����Ƃ��ǂ��ł��������Ƃ������
�����o����̂���������₷���̂͏�肢�헪
�����o����̂���������₷���̂͏�肢�헪
>>147
�����ɂ��݂�������т��Ă��̎p�������B
�u���̎��g�݁v�����Ƃ��Ƃ��A���Ȃ����ł�
>>148
�����BFF�x���`�̒��[�J�[������B
>>150
>>147�̒ʂ�Ɂu�p�r�v�Ƃ��Ă�PC������Ă��邪�A
���ԂɑS���L�܂��Ă��Ȃ���ł��B
AMD�͖{���Ƀr�b�N������قǐ�`�x�^�B
�����ɂ��݂�������т��Ă��̎p�������B
�u���̎��g�݁v�����Ƃ��Ƃ��A���Ȃ����ł�
>>148
�����BFF�x���`�̒��[�J�[������B
>>150
>>147�̒ʂ�Ɂu�p�r�v�Ƃ��Ă�PC������Ă��邪�A
���ԂɑS���L�܂��Ă��Ȃ���ł��B
AMD�͖{���Ƀr�b�N������قǐ�`�x�^�B
PC�ʼn����������̂��I�~�~���Ȃ灛���ł���I�܂Ō���Ȃ��Ƃȁ[�B
���������Ӗ��Ō�����Mac�͐�`�͂��܂��B
���������Ӗ��Ō�����Mac�͐�`�͂��܂��B
�ŋ߂�AMD�͐�D������
HD5000��X6�͕i�s���ɂȂ�قǔ���Ă��āAFF14�͔^�Ȃ̂�Nv���Ԃ������肾��������
Vision�ɂ��Ă��悤�₭�������[�J�[�̃\�j�[��x�m�ʂō̗p���f�����o���̂͑傫��
���Ă̐�`���肶��Ȃ��A���≽��������肢��`���肵�Ă����
HD5000��X6�͕i�s���ɂȂ�قǔ���Ă��āAFF14�͔^�Ȃ̂�Nv���Ԃ������肾��������
Vision�ɂ��Ă��悤�₭�������[�J�[�̃\�j�[��x�m�ʂō̗p���f�����o���̂͑傫��
���Ă̐�`���肶��Ȃ��A���≽��������肢��`���肵�Ă����
AMD�͐�`����ƌ������A���{AMD�ɂ͑�X�I�ɍL����ł����̊��蓖�Ă�������
AMD�ł��č��⒆���ł�Intel���x�̍L��������A���ۂɂ����ł�AMD�̃V�F�A�͑傫��
VISION�������̒n��ł͌��ʂ��グ�Ă���낤
�ł����{�ł͂�����������x�ŏI����Ă��܂����Ęb
AMD�ł��č��⒆���ł�Intel���x�̍L��������A���ۂɂ����ł�AMD�̃V�F�A�͑傫��
VISION�������̒n��ł͌��ʂ��グ�Ă���낤
�ł����{�ł͂�����������x�ŏI����Ă��܂����Ęb
AMDCPU����PC���������Intel����L���⏕���o�Ȃ������
�v���b�g�t�H�[���헪���Ă̂�Intel��Pen4������
��̓I�ȃX�y�b�N���܂������߂ɂ���Ă���
��̓I�ȃX�y�b�N���܂������߂ɂ���Ă���
AMD LIVE! �Ƃ��������˂���������
>>154
������AMD�p�\�R�����o�Ă�̂́A�Ƌ֖@����݂���ˁ[�́B
������AMD�p�\�R�����o�Ă�̂́A�Ƌ֖@����݂���ˁ[�́B
>>154
> FF14�͔^�Ȃ̂�Nv���Ԃ������肾��������
�����܂�������
>Vision�ɂ��Ă��悤�₭�������[�J�[�̃\�j�[��x�m�ʂō̗p���f�����o���̂͑傫��
�����͖@���������������������瓖�R����
> FF14�͔^�Ȃ̂�Nv���Ԃ������肾��������
�����܂�������
>Vision�ɂ��Ă��悤�₭�������[�J�[�̃\�j�[��x�m�ʂō̗p���f�����o���̂͑傫��
�����͖@���������������������瓖�R����
���{�̓Z�������V��
����ȏꏊ�ōL���łӖ����Ȃ��낤��
����ȏꏊ�ōL���łӖ����Ȃ��낤��
4x4�Ƃ��Y��Ȃ��ł˂�
>>162
������������Ȃ̂������ȁI
������������Ȃ̂������ȁI
intel�������헪�ŁA�Ȃ��������̐��i�̂ق������s���x�������ł�
���Ĕ��������Ă��܂��Ɩڂ����Ă��Ȃ����c
�ǂ̘H���ł���͂�ቿ�i�ł��邱�Ƃ�����҂ɂ����ƃA�s�[��������Ȃ��Ȃ�
���Ĕ��������Ă��܂��Ɩڂ����Ă��Ȃ����c
�ǂ̘H���ł���͂�ቿ�i�ł��邱�Ƃ�����҂ɂ����ƃA�s�[��������Ȃ��Ȃ�
�uIntel GMA��Radeon�ɉ߁I�v�Ƃ����������킯�킩���܂������Ă�̂�
�K���̂������c�q�ɂ��H�삪���Ȃ���
ttp://www.fudzilla.com/processors/processors/fusion-dual-and-quad-are-32nm
fudzilla�̘b�Ȃ�Ŕ�������Llano�ȓd�͔ł�20W�炵��
����͌��\�����Ă��ł͂Ȃ����낤��
fudzilla�̘b�Ȃ�Ŕ�������Llano�ȓd�͔ł�20W�炵��
����͌��\�����Ă��ł͂Ȃ����낤��
�O�X���ɕ\������
Llano�̍ʼn���Onta�ŏオ20W
Llano�̍ʼn���Onta�ŏオ20W
�����\������
ttp://www.softnology.biz/work/fusion_details.png
�ǂ������T�C�g���m��Ǐ��Ȃ��Ƃ�fudzilla�ł͂Ȃ�
���A���Ƃ����Family�̔ԍ��ł����ăR�[�h�l�[�����ǂ��Ȃ̂��͈ꉞ�܂�������
{kind=link}
�ǂ������T�C�g���m��Ǐ��Ȃ��Ƃ�fudzilla�ł͂Ȃ�
���A���Ƃ����Family�̔ԍ��ł����ăR�[�h�l�[�����ǂ��Ȃ̂��͈ꉞ�܂�������
4�R�A��30W���ă}�W��
Llano��CPU�R�A���Ȃ菬�������B
Llano��2�R�A�ŁAL3��2MB���Ƃ͂���Westmere��1�R�A����肿����Ƒ傫�����x�B
Llano��2�R�A�ŁAL3��2MB���Ƃ͂���Westmere��1�R�A����肿����Ƒ傫�����x�B
�N���b�N�������30�ł�20�ł������邾��
���͂��̃N���b�N���ɏ��i�I���͂����邩�ǂ�������
���͂��̃N���b�N���ɏ��i�I���͂����邩�ǂ�������
AMD�A99�h�������1way/2way�pCPU�uOpteron 4100�v�V���[�Y
http://pc.watch.impress.co.jp/docs/news/20100623_376237.html
http://pc.watch.impress.co.jp/docs/news/20100623_376237.html
�܂������肩
LIano��L3�͕t���Ȃ��͂��B
�������ш�̐���͂��邾�낤����
HD5670�N���X�����Ă��邩��
4670���̐��\�͏o���Ă��邩�ȁH
�������ш�̐���͂��邾�낤����
HD5670�N���X�����Ă��邩��
4670���̐��\�͏o���Ă��邩�ȁH
32nSOIHKMG��GPU�R�A��OC�ϐ��Ɋ���
������GPU�Ɣ�ׂ�Ƌ��e����d�͔{���A�N�[���[��p�\�͐��{�B
���̂ł�1G�s�����肵�Ă邩��1.5GHz���炢�͏\���_���邾�낤�B
������GPU�Ɣ�ׂ�Ƌ��e����d�͔{���A�N�[���[��p�\�͐��{�B
���̂ł�1G�s�����肵�Ă邩��1.5GHz���炢�͏\���_���邾�낤�B
Fusion��GPU��OC����AMD��Optimus technology�̕��Ɋ��҂��Ă�
>>175
�u�����h�Ƃ���Opteron�̖�ڂ͏I������Ƃ�������
�u�����h�Ƃ���Opteron�̖�ڂ͏I������Ƃ�������
>>175
�Ƃ������d���x�́uAMD�̃o�J�������v���y���ȁB
��������������u�����h���l�������Ȃ邾�낤�Ɓc�B
����B���{����CPU2��3��+M/B��3�����炢��2way�͊��������ǂ��B
�Ƃ������d���x�́uAMD�̃o�J�������v���y���ȁB
��������������u�����h���l�������Ȃ邾�낤�Ɓc�B
����B���{����CPU2��3��+M/B��3�����炢��2way�͊��������ǂ��B
�T�[�o�[�p����������܂���Ɛ錾���Ă����悤�ȋC�����邪
�}���`�\�P�b�g�ɂ��v���~�A�t���Ȃ����l�i�������}�����
�헪�I�ɂ͕ʂɊԈ���ĂȂ����
�t�@�u�ɓ�������K�v���Ȃ��Ȃ�������J�������������o�������
�Ƃ����������o��
�T�[�o�[����CPU�̉��i�̌n������Ă�AMD�Ƃ��Ă͒m������������Ȃ�����
�}���`�\�P�b�g�ɂ��v���~�A�t���Ȃ����l�i�������}�����
�헪�I�ɂ͕ʂɊԈ���ĂȂ����
�t�@�u�ɓ�������K�v���Ȃ��Ȃ�������J�������������o�������
�Ƃ����������o��
�T�[�o�[����CPU�̉��i�̌n������Ă�AMD�Ƃ��Ă͒m������������Ȃ�����
6xxx�V���[�Y����Ȃ���4xxx�V���[�Y�ł���H
�f�X�N�g�b�v�p�R�A�̎I�p������ʂ点�������̃o�[�W�����ł���
Xeon�����Ă��̃N���X�̓f�X�N�g�b�v�p�Ɠ����l�i����
�f�X�N�g�b�v�p�R�A�̎I�p������ʂ点�������̃o�[�W�����ł���
Xeon�����Ă��̃N���X�̓f�X�N�g�b�v�p�Ɠ����l�i����
intel��Xeon��2P�\�ō����Opteron�ɑR�ł���R�X�g�p�t�H�[�}���X�̐��i�Ȃ�ĂȂ����ǁB
�f�X�N�g�b�v�Ɠ����l�i�Ȃ̂�2P�̂ł��Ȃ���3000�ԑ�B
�f�X�N�g�b�v�Ɠ����l�i�Ȃ̂�2P�̂ł��Ȃ���3000�ԑ�B
CPU������980X�̔��l�ŕ���6+6�R�A�̊��ɂł���̂͋��������B
�����ɂȂ�MB�̉��i�����z�ɂ����ۂ���܂邵�B
�����ɂȂ�MB�̉��i�����z�ɂ����ۂ���܂邵�B
bulldozer�̃R�A�ɂ�4�̐������Z�N���X�^��������2�̃X���b�h�ŋ��L���邻�������ǁA
�ғ����̃X���b�h��������Ȃ��Ƃ��ɂ͈�̃X���b�h��4�̐������Z�N���X�^���L�ł���̂��ȁH
�ғ����̃X���b�h��������Ȃ��Ƃ��ɂ͈�̃X���b�h��4�̐������Z�N���X�^���L�ł���̂��ȁH
�ڋq���ǂ�����I�Ԃ����ȁB
>188
�}�U�[�������ςޕ��A���ʂ�PhenomII�I�Ԃ�ˁH
1�����傢��945��������B
�����I��ECC�Ȃ�Ă���w�Ȃ���͗v���B
�}�U�[�������ςޕ��A���ʂ�PhenomII�I�Ԃ�ˁH
1�����傢��945��������B
�����I��ECC�Ȃ�Ă���w�Ȃ���͗v���B
>>187
Bulldozer�͂��������\������Ȃ�
Bulldozer�͂��������\������Ȃ�
�x�����͈̂������邵���Ȃ�
RADEON�͂͂₢���牿�i�ێ����Ă�����
PenD820��38k���炢����������
>>187
�킩���B�܂��B����łł��Ȃ��Ă�������ł͂�肻�������B
�킩���B�܂��B����łł��Ȃ��Ă�������ł͂�肻�������B
Fusion�Ƃ���GPU���������ꂽ���̂��ł���A�\�t�g�E�F�A������͂ǂ��F�������́H
�h���C�o���Ă���ς荡����K�v�ɂȂ�̂��ȁH
����Ƃ�APU�Ȃ��œ����ŏ�������āA���Ƃ���͌����Ȃ��悤�ɉB�������́H
�n�[�h�E�F�A�ɏڂ����l�����Ă�������
�h���C�o���Ă���ς荡����K�v�ɂȂ�̂��ȁH
����Ƃ�APU�Ȃ��œ����ŏ�������āA���Ƃ���͌����Ȃ��悤�ɉB�������́H
�n�[�h�E�F�A�ɏڂ����l�����Ă�������
�����ς��Ƃł��v���Ă�́H
LIano�ɂȂ�ƁA����GPU��PCI-E�o�R�̐ڑ��ł͖����Ȃ�̂ŁA
PCI-E�ڑ��O��̍��̃h���C�o���f���͂��̂܂g���Ȃ��B
�Ƃ��A�Ȃ�Ƃ��A�ǂ����œǂ��ǁA
�ڑ���PCI-E����Ȃ��Ȃ邾����
�h���C�o�̍����āA����Ȃɂ�������Ȃ́H
���Ƃ�����A���炭�̓h���C�o�̊����x�Ⴛ���ȋC��������ǁc
�t��PCI-E���o�R���Ȃ��Ȃ�̂ŁAMem��CPU�Ƃ̊Ԃ�
���C�e���V��ш悪�L���ɂȂ�Ƃ��A�Ȃ�Ƃ��c
PCI-E�ڑ��O��̍��̃h���C�o���f���͂��̂܂g���Ȃ��B
�Ƃ��A�Ȃ�Ƃ��A�ǂ����œǂ��ǁA
�ڑ���PCI-E����Ȃ��Ȃ邾����
�h���C�o�̍����āA����Ȃɂ�������Ȃ́H
���Ƃ�����A���炭�̓h���C�o�̊����x�Ⴛ���ȋC��������ǁc
�t��PCI-E���o�R���Ȃ��Ȃ�̂ŁAMem��CPU�Ƃ̊Ԃ�
���C�e���V��ш悪�L���ɂȂ�Ƃ��A�Ȃ�Ƃ��c
CyberGarden����
���̃T�C�g�͈�����ނ�̂����܂�
���̃T�C�g�͈�����ނ�̂����܂�
�݂Ȃ��肪�Ƃ��������܂��B
�����ł����B����ς肱�ꂩ����h���C�o�͕K�v�Ȃ�ł��ˁB
�Ă�����A�����h���C�o�����ɂ��낢��ł���悤�ɂȂ�̂��Ȃ��Ǝv���Ă܂����B
����UNIX�n��ǂ��g���̂ŁA����������UNIX�n��Clarldale�t����GPU���X�N���ł��邩�ǂ����A���ׂĂ݂܂������A
Gentoo linux�ł͎g�p�ł����Ƃ����b���݂��܂����B�ǂ̃h���C�o���g�p�����̂��͕�����܂���ł������ǁA�����炭xorg��video-intel�̂͂��ł��B
�ł����̃h���C�o�ł�http://www.x.org/wiki/IntelGraphicsDriver�݂�����Intel GMA500�n�͂܂��قƂ�ǖ��Ή��Ȃ̂ŁA�L�c�C���ȂƎv���Ă��̂ł����ȊO�ł����B
�����A�����炭3D Accel���s���S��������Ƃ��͂���ς肠��Ǝv���܂��B
Fusion�ɂȂ��Ă��A���܂Œʂ�A���[�J�[���Z�p�d�l�����J���h���C�o�J���Ǝg�p����܂ł��Ȃ莞�Ԃ����肻���ł��ˁB
�����ł����B����ς肱�ꂩ����h���C�o�͕K�v�Ȃ�ł��ˁB
�Ă�����A�����h���C�o�����ɂ��낢��ł���悤�ɂȂ�̂��Ȃ��Ǝv���Ă܂����B
����UNIX�n��ǂ��g���̂ŁA����������UNIX�n��Clarldale�t����GPU���X�N���ł��邩�ǂ����A���ׂĂ݂܂������A
Gentoo linux�ł͎g�p�ł����Ƃ����b���݂��܂����B�ǂ̃h���C�o���g�p�����̂��͕�����܂���ł������ǁA�����炭xorg��video-intel�̂͂��ł��B
�ł����̃h���C�o�ł�http://www.x.org/wiki/IntelGraphicsDriver�݂�����Intel GMA500�n�͂܂��قƂ�ǖ��Ή��Ȃ̂ŁA�L�c�C���ȂƎv���Ă��̂ł����ȊO�ł����B
�����A�����炭3D Accel���s���S��������Ƃ��͂���ς肠��Ǝv���܂��B
Fusion�ɂȂ��Ă��A���܂Œʂ�A���[�J�[���Z�p�d�l�����J���h���C�o�J���Ǝg�p����܂ł��Ȃ莞�Ԃ����肻���ł��ˁB
>>198
���S�ȃf�^����
���S�ȃf�^����
PCIE�o�R���Ȃ��ł������h���C�o�̍\���̓V���v���ɂȂ肻���ȋC������
204 �FSocket774�F2010/06/25(��) 08:30:54 ID:OHBhqg9J
LIano�͑����o����I
���AP�V-800�g���Ă邩�猀�I�ɕς����
���AP�V-800�g���Ă邩�猀�I�ɕς����
>>204
���܂���Ontario�ŏ\����������
���܂���Ontario�ŏ\����������
>>187
2�̃R���s���[�e�B���O���j�b�g�ŋ��L����͕̂��������_���Z�p�C�v�Ő������Z�ł͂Ȃ���B�������Z�̕��͊����̃A�[�L�e�N�`���Ɗ�{�I�ɓ����B
2�̃R���s���[�e�B���O���j�b�g�ŋ��L����͕̂��������_���Z�p�C�v�Ő������Z�ł͂Ȃ���B�������Z�̕��͊����̃A�[�L�e�N�`���Ɗ�{�I�ɓ����B
>>195
IGP��CPU�������������������炢�܂܂łƕς����B
PCIE���o�R���Ȃ��Ȃ���ď�����Ă邯�ǁA�����Ȃ�̂�HT�u���b�W�����B��������Ƃ��ƃ\�t�g�E�F�A����̓g�����X�y�A�����g������A�\�t�g�E�F�A�I�ɂ͕ς��Ȃ��B
IGP��CPU�������������������炢�܂܂łƕς����B
PCIE���o�R���Ȃ��Ȃ���ď�����Ă邯�ǁA�����Ȃ�̂�HT�u���b�W�����B��������Ƃ��ƃ\�t�g�E�F�A����̓g�����X�y�A�����g������A�\�t�g�E�F�A�I�ɂ͕ς��Ȃ��B
�Ă��������̃`�b�v�Z�b�g�̃r�f�I��������PCI-E�o�R���Ă�́H
�����I�ɂ͂���ĂȂ�����B�Ӗ�����������B
�C���^�[�t�F�C�X���x���̏��ł�����Ă���Ƃ͎v���Ȃ��B
�C���^�[�t�F�C�X���x���̏��ł�����Ă���Ƃ͎v���Ȃ��B
�����Ȃ�����Intel�����Ȃ�
AMD Fusion: Sockel, TDP, Speicher, Launch
http://www.hardware-infos.com/news.php?news=3600
http://www.hardware-infos.com/news.php?news=3600
200SP�ɕς�����́H
�ȑO�o�Ă�4�R�A�̃_�C�ʐ^���炷���
2�R�A�ł�GPU���������ɂȂ邩��
2�R�A�ł�200SP��4�R�A�ł�400SP���낤
2�R�A�ł�GPU���������ɂȂ邩��
2�R�A�ł�200SP��4�R�A�ł�400SP���낤
217 �F,,�E�L�́M�E,,�j��-�������F2010/06/26(�y) 03:29:31 ID:7i3hTE5T
�ȂA��������@��������
AMD�~���ߏ�Ɏ����グ�镨�œ����������������������H
AMD�~���ߏ�Ɏ����グ�镨�œ����������������������H
���̂�3��4��45W65W�݂����ȓ��ʘg�����E�E�E
��480SP�Ƃ�400SP�Ƃ��ŏ��Ɍ����o�����̂͒N�Ȃ̂�����H
�삯�����Ă䂭����Llano
�N���ے肵�Ȃ�����(?)���炤������M���Ă�����
���ׂ���V���O���_�C�ō���5870��1600SP��
400SP�������1/4��������
�~�h���N���X�̏ȓd��CPU��1/3�̖ʐςŔ��MGPU�n�C�G���h��1/4�H
���Ȃ肨�������Ȃ���
�Ƃ����>215�́u2�R�ATDP100W�������o���v�ƌ����Ă�̂�
�u75W�ȉ��v�Ɓu75W�����v�����Ⴆ�Ă�̂�
�삯�����Ă䂭����Llano
�N���ے肵�Ȃ�����(?)���炤������M���Ă�����
���ׂ���V���O���_�C�ō���5870��1600SP��
400SP�������1/4��������
�~�h���N���X�̏ȓd��CPU��1/3�̖ʐςŔ��MGPU�n�C�G���h��1/4�H
���Ȃ肨�������Ȃ���
�Ƃ����>215�́u2�R�ATDP100W�������o���v�ƌ����Ă�̂�
�u75W�ȉ��v�Ɓu75W�����v�����Ⴆ�Ă�̂�
��{�c����400�Ȃ�Ĕ��\�Ȃǖ��������̂ɉ��������ւ��Ă�낤��
Z�Ȃ���A���������}�W�˂����݂��Ă����傤���Ȃ�����
223 �FSocket774�F2010/06/26(�y) 08:52:58 ID:ahtwNoOW
32nm������
40nm400SP��Redwood��120mm2��3/4��90mm2�����ɂȂ�
Propus��L2���ʓ����邪45nm169mm2��2/3�ɂȂ����Ƃ��Ă�112mm2
���킹��200mm2�Ȃ�f�X�N�g�b�v�p�Ȃ�\��������
westmere��32nm2�R�A��CPU��81mm2�������
40nm400SP��Redwood��120mm2��3/4��90mm2�����ɂȂ�
Propus��L2���ʓ����邪45nm169mm2��2/3�ɂȂ����Ƃ��Ă�112mm2
���킹��200mm2�Ȃ�f�X�N�g�b�v�p�Ȃ�\��������
westmere��32nm2�R�A��CPU��81mm2�������
Llano��CPU �R�A+L2��17mm2�ʂ�����4�R�A�Ŗ�70mm2�B
GPU�R�A�͖ڎZ��50mm2�ʂ���������A���Z�킾���Ȃ獇�v120mm2
�����R����N���X�o�[�Ȃǂ̃A���R�A����50mm2�ʂ���
�ʐς̍��v��170mm2�ʂɂȂ�B
2�R�A�ł��v�Z����ƁA�R�A����������60mm2�A�A���R�A�͂��̂܂܂��Ƃ��č��v110mm2�ʁB
GPU�R�A�͖ڎZ��50mm2�ʂ���������A���Z�킾���Ȃ獇�v120mm2
�����R����N���X�o�[�Ȃǂ̃A���R�A����50mm2�ʂ���
�ʐς̍��v��170mm2�ʂɂȂ�B
2�R�A�ł��v�Z����ƁA�R�A����������60mm2�A�A���R�A�͂��̂܂܂��Ƃ��č��v110mm2�ʁB
200SP���ăf���A���R�A�łȂ�Ȃ��́B
��������400SP?��4�R�A�łƂ������Ă��A
���s�̃��o�C����Phenom�U X4�݂����ɁA
�قƂ�Ǎ̗p���郁�[�J�[���Ȃ������ȋC��
��������400SP?��4�R�A�łƂ������Ă��A
���s�̃��o�C����Phenom�U X4�݂����ɁA
�قƂ�Ǎ̗p���郁�[�J�[���Ȃ������ȋC��
�܂�480SP����Ȃ��ƌ��܂����킯����Ȃ���H
�������ш悩�炷��ƁA5570��5670�̐��\��r���l����A200SP�ł��\�����Ǝv�����ǁB
>>218
���̕��N���b�N�Ⴂ���낤����h�܂��܂��h�ł͂Ȃ�
�����܂�CPU�̕�����Ȃ���
���̂���GPU���Ȃ������N���b�N�ł��E�E����
����Llano�łȂ��ȁ@����႗
���̕��N���b�N�Ⴂ���낤����h�܂��܂��h�ł͂Ȃ�
�����܂�CPU�̕�����Ȃ���
���̂���GPU���Ȃ������N���b�N�ł��E�E����
����Llano�łȂ��ȁ@����႗
>>228
�����܂�Llano�̓o�����[�сA�n�C�p�t�H�[�}���X�̓u�����낤�����
�����܂�Llano�̓o�����[�сA�n�C�p�t�H�[�}���X�̓u�����낤�����
�����u���͂����\�z���܂����v�Ƃ������e�����
GPU�̃��C����������������ƒ��ׂĂ݂����ǁA
����1���~�O��ōw���ł���HD5670��5750�ł���4GHz��4.8GHz��GDDR5���g���Ă��
Llano�����C����������4GHz�ʂ�GDDR5�ɂ�����������\�o�������ȋC������
�l�i��DDR3��荂���Ȃ肻�������ǁADDR3 1600 4GB��GDDR5 4000 2GB���������i�Ȃ�GDDR5���~������
�C�ɂȂ�̂�GDDR5����CPU�ɂƂ��Ăǂ�ȃf�����b�g�����邩����
����1���~�O��ōw���ł���HD5670��5750�ł���4GHz��4.8GHz��GDDR5���g���Ă��
Llano�����C����������4GHz�ʂ�GDDR5�ɂ�����������\�o�������ȋC������
�l�i��DDR3��荂���Ȃ肻�������ǁADDR3 1600 4GB��GDDR5 4000 2GB���������i�Ȃ�GDDR5���~������
�C�ɂȂ�̂�GDDR5����CPU�ɂƂ��Ăǂ�ȃf�����b�g�����邩����
GDDR5�͊���t�����獂�����ł���̂ŁADIMM�͂Ȃ��B
CPU�����\�P�b�g������A�����������t�ł��g���邩�ǂ����B
�ŁA���t�����烁�����e�ʂ̓����R����bit���Ɉˑ��Ȃ̂ŁA
�����Ƒ����V�X�e��������1GB�Ƃ��ɂȂ�B
�e�ʑ������邽�߂�128bit��葽������ƂȂ�ƁA
�\�P�b�g�̃s������������̂Ń��C���X�g���[����������Ȃ��Ȃ�B
CPU�����\�P�b�g������A�����������t�ł��g���邩�ǂ����B
�ŁA���t�����烁�����e�ʂ̓����R����bit���Ɉˑ��Ȃ̂ŁA
�����Ƒ����V�X�e��������1GB�Ƃ��ɂȂ�B
�e�ʑ������邽�߂�128bit��葽������ƂȂ�ƁA
�\�P�b�g�̃s������������̂Ń��C���X�g���[����������Ȃ��Ȃ�B
200sp���m�肶�ᖳ�����A�����܂ł܂��܂��y���߂�����
����200sp���Ƃ����炠�܂��������ɂ͉��߂�H
>>223-224�������
��͂�ʐϓI��200SP���炢�Ȃ�Ȃ��̂�
480SP�Ȃ炻��������߂�GDDR�̃����R�����ڂ��邾�낤�Ǝv���Ă�����
DDR3�n�����݂��������i�܂��`�����l�����͕s�������j
�ėp��������GDDR�Ɣ�ׂđш拷�������C�e���V�Ⴂ�炵������
�f�[�^���[�h�E���Z�̃T�C�N�������܂�
�����ш�ł�GDDR�i�����C�e���V�H�j�������Ȃ����Z��ōςނ͂�
��͂�ʐϓI��200SP���炢�Ȃ�Ȃ��̂�
480SP�Ȃ炻��������߂�GDDR�̃����R�����ڂ��邾�낤�Ǝv���Ă�����
DDR3�n�����݂��������i�܂��`�����l�����͕s�������j
�ėp��������GDDR�Ɣ�ׂđш拷�������C�e���V�Ⴂ�炵������
�f�[�^���[�h�E���Z�̃T�C�N�������܂�
�����ш�ł�GDDR�i�����C�e���V�H�j�������Ȃ����Z��ōςނ͂�
>���C����������4GHz�ʂ�GDDR5�ɂ�����������\�o�������ȋC������
���C�e���V������GDDR�����C���������Ɏg����
���������\�o�������J���Ȃ���
���C�e���V������GDDR�����C���������Ɏg����
���������\�o�������J���Ȃ���
>>236
�l�b�g��ɔėpDDR��GDDR�̓����̈Ⴂ�Ȃ�Ă�����ł�����̂ɂȂ�Œ��ׂȂ��낤��w
�l�b�g��ɔėpDDR��GDDR�̓����̈Ⴂ�Ȃ�Ă�����ł�����̂ɂȂ�Œ��ׂȂ��낤��w
Llano�͌��X59W�ȉ��A2�R�A�Ɋւ��Ă�35W�ȉ��Ƃ��ŏ����Ă��������
100W��75W���Č����Ă����܂�s���Ɨ��Ȃ�
2�R�A 75W����4GHz�B���ł����������ljʂ����Ăǂ��Ȃ邩��
100W��75W���Č����Ă����܂�s���Ɨ��Ȃ�
2�R�A 75W����4GHz�B���ł����������ljʂ����Ăǂ��Ȃ邩��
http://northwood.blog60.fc2.com/blog-entry-3955.html
LIano����PCI-E���Ăǂ��ɂ���낤�H���Ďv���Ă�����
APU���œ��ڂ��ă`�b�v�Z�b�g�͂P�`�b�v�ɂȂ�̂ˁB
���Ȃ݂�
LIano
Llano
�ǂ������������́H
LIano����PCI-E���Ăǂ��ɂ���낤�H���Ďv���Ă�����
APU���œ��ڂ��ă`�b�v�Z�b�g�͂P�`�b�v�ɂȂ�̂ˁB
���Ȃ݂�
LIano
Llano
�ǂ������������́H
241 �F,,�E�L�́M�E,,�j��-�������F2010/06/26(�y) 14:33:12 ID:7i3hTE5T
�ĊO30fps�����łȂ��̂�Llano�Ȃ̂��������ˁB
�u���W���̒��g���f�b�h�X�y�[�X�v����
���ς�炸�Ӗ��s��
CPU��fps����Ȃ�Hz�ł�
���ς�炸�Ӗ��s��
CPU��fps����Ȃ�Hz�ł�
243 �F,,�E�L�́M�E,,�j��-�������F2010/06/26(�y) 15:43:23 ID:7i3hTE5T
IE9�̃x���`�̓V�F�[�_�[���\�W�Ȃ������
�Œ�@�\��UVD�̐��\�ł����Ȃ�
�Œ�@�\��UVD�̐��\�ł����Ȃ�
�Ȃ��8600�̌��ʂƔ�r�Ȃ낤���H
246 �F,,�E�L�́M�E,,�j��-�������F2010/06/26(�y) 16:12:58 ID:7i3hTE5T
200SP����400SP�����Ă�32SP�ɕ�����̂��H
�c�q�̓��̒������̎���Ŏ~�܂��Ă邩��B
���̂����őO�X���ő�p�����ăE���R�R�炵�Ȃ��瓦���������ǂ˂�
���̂����őO�X���ő�p�����ăE���R�R�炵�Ȃ��瓦���������ǂ˂�
����������NVDIA��ATI��SP�̐�����...
249 �F,,�E�L�́M�E,,�j��-�������F2010/06/26(�y) 16:20:21 ID:7i3hTE5T
���ɘ_�j���ꂽ�z�Ȃ�m���Ă邪
250 �F,,�E�L�́M�E,,�j��-�������F2010/06/26(�y) 16:24:28 ID:7i3hTE5T
>>248
32 MAD + 32 MUL����
�N���b�N���AVLIW�̌��������ɂ��Ă�200SP(5Way-VLIW 40��)�����32SP�i4SM�j���炢�ɂ͏����Ă�������ȁH
32 MAD + 32 MUL����
�N���b�N���AVLIW�̌��������ɂ��Ă�200SP(5Way-VLIW 40��)�����32SP�i4SM�j���炢�ɂ͏����Ă�������ȁH
251 �FSocket774�F2010/06/26(�y) 16:28:06 ID:cbkJyoyO
���̓��悪�ǂ�fusion��������Ȃ����ē˂����ݓ����Ă�̂ɂȂ��200or400���āH
���SP80��4550�̗Ⴞ���ďo�Ă邶���
���SP80��4550�̗Ⴞ���ďo�Ă邶���
252 �F,,�E�L�́M�E,,�j��-�������F2010/06/26(�y) 16:30:46 ID:7i3hTE5T
���Ⴀ�t�ɕ�����80SP�ł�32SP���ᐫ�\�Ȃ̂��H
�Ȃ�ł���Ȍ����̈���GPU���́H
FLOPS���������������́H
������Ȃ��́H
�Ȃ�ł���Ȍ����̈���GPU���́H
FLOPS���������������́H
������Ȃ��́H
253 �FSocket774�F2010/06/26(�y) 16:31:48 ID:cbkJyoyO
�܂����������̂܂�
254 �F,,�E�L�́M�E,,�j��-�������F2010/06/26(�y) 16:34:28 ID:7i3hTE5T
MAD��SFU(MUL)��dual issue���s�o����p�^�[���͌����Ă邱�Ƃ��m���Ă��ˁH
���������O���������������
����Ȏd�l�Ȃ̂ɒ��ڔ�r���Ăǂ�����́H
����ɉ�SP��30fps�����������ĂȂ��̂ɉ����������́H
����Ȏd�l�Ȃ̂ɒ��ڔ�r���Ăǂ�����́H
����ɉ�SP��30fps�����������ĂȂ��̂ɉ����������́H
���������U�c�q�̌��c�肷��̂͂�߂��w
�c�q�̗\�z�L�{��
�����ł��߂Ă�́H
������Ɠ��W�̃f�b�h�X�y�[�X���~����̂͗����i��������j�����炵��
ID:7i3hTE5T�������C���������E���R���ꗬ���Ă�̂͂��̎q����{������
ID:7i3hTE5T�������C���������E���R���ꗬ���Ă�̂͂��̎q����{������
260 �F,,�E�L�́M�E,,�j��-�������F2010/06/26(�y) 17:23:39 ID:7i3hTE5T
���Ȃ݂ɂ����ł�issue�̈Ӗ������s�Ȃ̂œ��ɂ��ɂ�
���_�͉��H
���_
400SP���ڂ�Ontario��������ɓ������ނƒ��̃E���R���y��
400SP���ڂ�Ontario��������ɓ������ނƒ��̃E���R���y��
263 �FSocket774�F2010/06/26(�y) 17:32:02 ID:i5x9F79b
3500+ ,2.2GHz,Single-Core ,L2.512KB,,62W
32nm�̎���ɂ́AL2��2MB�ɂ��āA����d�͂�25W���炢�ɂ��Ăق����B
32nm�̎���ɂ́AL2��2MB�ɂ��āA����d�͂�25W���炢�ɂ��Ăق����B
264 �F,,�E�L�́M�E,,�j��-�������F2010/06/26(�y) 17:36:22 ID:7i3hTE5T
400SP��Sandy Bridge�Ɉ�������Ȃ������̂�
�Ԃ����ႯGeForce��24SP���x��SIMD���\��Sandy Bridge 1�R�A�����ł��d���邩���
�Ԃ����ႯGeForce��24SP���x��SIMD���\��Sandy Bridge 1�R�A�����ł��d���邩���
Radeon�����T�C�Y��IntelGPU�Ɉ����͂����Ă�
Ontario��Sandy�Ɉ����͖�����
������̒��̐��E����
Ontario��Sandy�Ɉ����͖�����
������̒��̐��E����
�����A�̂̒c�q�ƈႤ�̂͋U���Ȃ̂��B
�Ȃ�قǁA�n����U��܂��������ʂ�����킯���ȁB
������̂�߂��A�n���n��������
�Ȃ�قǁA�n����U��܂��������ʂ�����킯���ȁB
������̂�߂��A�n���n��������
267 �F,,�E�L�́M�E,,�j��-�������F2010/06/26(�y) 17:50:52 ID:7i3hTE5T
�������Ă�̂��M���Ă�̂������̗���𗝉����悤
�Ȃ�����Ɗ��҂��Ă��̂ɁA�������B
�������炵�炭�҂����Ȃ��ȁB
�������炵�炭�҂����Ȃ��ȁB
Intel scores own goal against Core i7 in NVIDIA spat
ttp://arstechnica.com/business/news/2010/06/intel-scores-own-goal-against-core-i7-in-nvidia-spat.ars
Intel�@���@GPU���CPU�̕���10�{������I(CPU�ɍœK������GPU�ɂ͍œK������ĂȂ��R�[�h���g�p)
nVidia�@���@CPU���GPU(GPGPU)�̕���100�{������I(GPU�ɍœK������CPU�ɂ͍œK������ĂȂ��R�[�h���g�p)
ISCA�@���@���Ⴀ14��̉Ȋw�Z�p�n�̃v���O�������ǂ�����œK��������ԂŃx���`�Ƃ��Ă���
ISCA�@���@GPU(i7��GTX280)�ł�������ǁAGPU�̕�������2.5�{����������
Intel�@���@�E�E�E
NV�@���@�������I�������I
100�{�͂ǂ��Ȃ���
�@�@�@�@�@�@,,,
(�@߄t�)��
ttp://arstechnica.com/business/news/2010/06/intel-scores-own-goal-against-core-i7-in-nvidia-spat.ars
Intel�@���@GPU���CPU�̕���10�{������I(CPU�ɍœK������GPU�ɂ͍œK������ĂȂ��R�[�h���g�p)
nVidia�@���@CPU���GPU(GPGPU)�̕���100�{������I(GPU�ɍœK������CPU�ɂ͍œK������ĂȂ��R�[�h���g�p)
ISCA�@���@���Ⴀ14��̉Ȋw�Z�p�n�̃v���O�������ǂ�����œK��������ԂŃx���`�Ƃ��Ă���
ISCA�@���@GPU(i7��GTX280)�ł�������ǁAGPU�̕�������2.5�{����������
Intel�@���@�E�E�E
NV�@���@�������I�������I
100�{�͂ǂ��Ȃ���
�@�@�@�@�@�@,,,
(�@߄t�)��
270 �F,,�E�L�́M�E,,�j��-�������F2010/06/26(�y) 23:10:27 ID:7i3hTE5T
�����_��2.5�{���Ď����I����Ă��ȁB
GPU�̓������ш�l�b�N�łǂ�l�܂肾���ACPU�̓R�A�����������łȂ�AVX/FMA�ŃR�A������̃x�N�g�����Z���\��2�{�A4�{�Ƒ��₵�Ă�����B
GPU�̓������ш�l�b�N�łǂ�l�܂肾���ACPU�̓R�A�����������łȂ�AVX/FMA�ŃR�A������̃x�N�g�����Z���\��2�{�A4�{�Ƒ��₵�Ă�����B
>>215
200SP�̃r�f�I���݂�75W�����猈���Ĉ��������ł͂Ȃ��ł���
�܂����ɗǂ������ł��Ȃ�����
�m���ɗ��NQ1�`Q2�ɃR���o���Ă��C���p�N�g�͖�����
200SP�̃r�f�I���݂�75W�����猈���Ĉ��������ł͂Ȃ��ł���
�܂����ɗǂ������ł��Ȃ�����
�m���ɗ��NQ1�`Q2�ɃR���o���Ă��C���p�N�g�͖�����
�K�ޓK��
���~���͉����Ȃ�ł�200sp�ŃC�}�C�`���Ă��Ƃɂ������炵����w
�܂��A200sp�ł�Sandybridge���y���ɍ����\�����ǂ�w
�܂��A200sp�ł�Sandybridge���y���ɍ����\�����ǂ�w
>269
����d�͓I�ɂ͂ǂ��Ȃ낤�A����
����d�͓I�ɂ͂ǂ��Ȃ낤�A����
Fermi�o��O�̘b�ł���
Fermi vs Gulftown�ł����ʂ͎����悤�Ȃ��̂ɂȂ�C������
277 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 03:39:58 ID:Iw7f5ZOt
Sandy Bridge�ł�AVX���������CPU�����h�ȃV�F�[�_���j�b�g����
200SP���ď��F�s�[�N300�`400GFLOPS���Ŏ���100GFLOPS�������炢����
CPU�iAVX�j�ŏ\���R�ł��邶�����
200SP���ď��F�s�[�N300�`400GFLOPS���Ŏ���100GFLOPS�������炢����
CPU�iAVX�j�ŏ\���R�ł��邶�����
�ǂ���amd�͐��������ł������
��244 �FSocket774 [��] �F2010/06/26(�y) 15:51:40 ID:sQjuo1FN
��IE9�̃x���`�̓V�F�[�_�[���\�W�Ȃ������
���Œ�@�\��UVD�̐��\�ł����Ȃ�
uvd���Ȃ�Ȃ̂�����킩���ĂȂ��̂˂�
��IE9�̃x���`�̓V�F�[�_�[���\�W�Ȃ������
���Œ�@�\��UVD�̐��\�ł����Ȃ�
uvd���Ȃ�Ȃ̂�����킩���ĂȂ��̂˂�
���Ȃ݂ɂ��Aclarkdale��gpu�����Ȃ��12EU(48SP����)��
�Œ�x���̌Œ�@�\4TMU,4ROP(733MHz)���낤��60fps�ȏ���}�[�N���Ă���
���̓����GPU�̃X�y�b�N�\�z���������Ȃ�
40SP,4 ROP,4 TMU
�N���b�N��366MHz�ȉ�
����������1920x1200�ł��̓���͂�����𑜓x�Ⴛ��������
�Œ�x���̌Œ�@�\4TMU,4ROP(733MHz)���낤��60fps�ȏ���}�[�N���Ă���
���̓����GPU�̃X�y�b�N�\�z���������Ȃ�
40SP,4 ROP,4 TMU
�N���b�N��366MHz�ȉ�
����������1920x1200�ł��̓���͂�����𑜓x�Ⴛ��������
>>269
ttp://www.brightsideofnews.com/Data/2010_3_16/ATI-Radeon-HD-5970-king-of-iPhone-Wi-Fi-password-cracking/ElcomSoft_GPU_Performance_6.jpg
�p�X��́H
���e�͕�����̒��������Z���낤���ǂ����20�{��
float�g���Ȃǂ�����GPU�L���ȏ����ɂȂ��100�{�����ۂɂ����ł�
�Ȋw�Z�p�v�Z�̓f�[�^���c�傾�ƌ����Ă�Ƃ���������
���ς���Α債�����Ɩ������Č����Ƃ������邵�ǂ������\�����œK�Ȃ̂��͕s��
�������۹�̫���ǂ�ǂ�CPU�Ɏ����ė��Ă邱�Ƃ��l�����
��̫�ł͖��ՂȂ����ĂĂ��叟�͏o���Ȃ��Ȃ��Ă��Ă���
ttp://www.brightsideofnews.com/Data/2010_3_16/ATI-Radeon-HD-5970-king-of-iPhone-Wi-Fi-password-cracking/ElcomSoft_GPU_Performance_6.jpg
{kind=link}
�p�X��́H
���e�͕�����̒��������Z���낤���ǂ����20�{��
float�g���Ȃǂ�����GPU�L���ȏ����ɂȂ��100�{�����ۂɂ����ł�
�Ȋw�Z�p�v�Z�̓f�[�^���c�傾�ƌ����Ă�Ƃ���������
���ς���Α債�����Ɩ������Č����Ƃ������邵�ǂ������\�����œK�Ȃ̂��͕s��
�������۹�̫���ǂ�ǂ�CPU�Ɏ����ė��Ă邱�Ƃ��l�����
��̫�ł͖��ՂȂ����ĂĂ��叟�͏o���Ȃ��Ȃ��Ă��Ă���
�c�q���Ĕn���Q�{�~�Ɠ�������������
AVX�Ȃ�GPGPU�ʼn����A�s�[������C�ȂR�R�́H��
AVX�Ȃ�GPGPU�ʼn����A�s�[������C�ȂR�R�́H��
284 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 09:48:41 ID:Iw7f5ZOt
>>282
AMD��Fusion�̕���������ے肷��Ȃ�B
���R�����ǁA�u�����������������v�Ŋ�������Ȃ����B
CPU��GPU�̐������ɍő��Ӗ��͂Ȃ��Ȃ�B
AMD��Fusion�̕���������ے肷��Ȃ�B
���R�����ǁA�u�����������������v�Ŋ�������Ȃ����B
CPU��GPU�̐������ɍő��Ӗ��͂Ȃ��Ȃ�B
�����������邾���Ő���t�ł�����
��������������Ȃ�Ď�����ǂ��낶��Ȃ���
��������������Ȃ�Ď�����ǂ��낶��Ȃ���
CPU�̃s�[�N���\�Ⴂ����܂��]�T������ď�ԂȂ������ƁB
Sandy��8�R�A������ł��낻��������Ȃ��Ȃ��H
Sandy��8�R�A������ł��낻��������Ȃ��Ȃ��H
�����͂������������ł���
GPGPU���p�Ƃ��͌����_�ł͌��O��
�{���̓p�b�h�m�ۂƉ��i�ێ��̂��߂̓����Ȃ�
GPGPU���p�Ƃ��͌����_�ł͌��O��
�{���̓p�b�h�m�ۂƉ��i�ێ��̂��߂̓����Ȃ�
>>287
�����̓R�A�ʃL���b�V���Ɏ��܂���x�̃f�[�^�ʂ��g���܂킷�x���`������
C2Q�iL2���L�ƌ����Ă�2�R�A���x�ő�e�ʁj�J���o�b�N
�����̓R�A�ʃL���b�V���Ɏ��܂���x�̃f�[�^�ʂ��g���܂킷�x���`������
C2Q�iL2���L�ƌ����Ă�2�R�A���x�ő�e�ʁj�J���o�b�N
>>283
> �x���Ă������o���Ă�Ǝv��Ȃ����Ƃ��Ȃ��B
���N�ł��ʂɒx���͂Ȃ�
> ���N�̍����ɗ���CPU�Ƃ͂���K10�R�A�Ő키�̂͌������B
�V�������N+HK/MG+�p���[�Q�[�e�B���O+�ł��Ȃ���d�͉����i�݁ATurboCore�����p�I�ɂȂ�A
GPU�̐��\��CPU�̕]���ɉ���邩�炻��ȂɌ������͂Ȃ�
�V���O���X���b�h�ł��傢�����A�}���`�X���b�h�Ō��\�����ASSE�͌݊p�AGPU�͈����ɂȂ�
��������������ALlano�̓G��Sandy 2�R�A�ł����āASandy 4�R�A�͑��݊��������瑽�����u�����
> �x���Ă������o���Ă�Ǝv��Ȃ����Ƃ��Ȃ��B
���N�ł��ʂɒx���͂Ȃ�
> ���N�̍����ɗ���CPU�Ƃ͂���K10�R�A�Ő키�̂͌������B
�V�������N+HK/MG+�p���[�Q�[�e�B���O+�ł��Ȃ���d�͉����i�݁ATurboCore�����p�I�ɂȂ�A
GPU�̐��\��CPU�̕]���ɉ���邩�炻��ȂɌ������͂Ȃ�
�V���O���X���b�h�ł��傢�����A�}���`�X���b�h�Ō��\�����ASSE�͌݊p�AGPU�͈����ɂȂ�
��������������ALlano�̓G��Sandy 2�R�A�ł����āASandy 4�R�A�͑��݊��������瑽�����u�����
291 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 12:22:11 ID:Iw7f5ZOt
>>286
���Z���j�b�g�̃X���[�v�b�g������̊O���������ш��CPU�̂ق����f�R�]�T�����B
���Ȃ݂ɁALlano��Sandy Bridge��2�`4�R�A��胁�����ш悪�L���Ȃ炻�����낤�����ۂ͓���DDR3 2ch����H
���W������Llano��GPU��肩�����ėL���Ȃ��炢�����i���x�E����N���b�N���E�L���b�V���e�ʂȂǁj
�e�b�Z���[�^���g���������Đ��\�ʂŎ�_�ɂȂ邵�A�����I�ɂ͑債�����ЂɂȂ���B
�܂��ǂ����唼�̃Q�[����CPU��1�`2�X���b�h�����g��Ȃ����A
�c���CPU�R�A���V�F�[�_��ւɎg���͕̂������Ƃ��Đ���������B
���Z���j�b�g�̃X���[�v�b�g������̊O���������ш��CPU�̂ق����f�R�]�T�����B
���Ȃ݂ɁALlano��Sandy Bridge��2�`4�R�A��胁�����ш悪�L���Ȃ炻�����낤�����ۂ͓���DDR3 2ch����H
���W������Llano��GPU��肩�����ėL���Ȃ��炢�����i���x�E����N���b�N���E�L���b�V���e�ʂȂǁj
�e�b�Z���[�^���g���������Đ��\�ʂŎ�_�ɂȂ邵�A�����I�ɂ͑債�����ЂɂȂ���B
�܂��ǂ����唼�̃Q�[����CPU��1�`2�X���b�h�����g��Ȃ����A
�c���CPU�R�A���V�F�[�_��ւɎg���͕̂������Ƃ��Đ���������B
292 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 12:37:32 ID:Iw7f5ZOt
�Y�킵�܂�
�~��������������ALlano�̓G��Sandy 2�R�A�ł����āA
��Llano4�R�A�͋�g���Ă�2�R�A���̐��\�����o���Ȃ��i���̒��x����o���Ȃ������H�j
�~Sandy 4�R�A�͑��݊��������瑽�����u�����
��Sandy 4�R�A�ɏ��ĂȂ�����~�b�h�����W�ȏ�͑_���Ȃ�
��������Sandy Bridge��2�R�A����4�R�A��2�R�A�E���ł��Ǝv���Ă����
�~��������������ALlano�̓G��Sandy 2�R�A�ł����āA
��Llano4�R�A�͋�g���Ă�2�R�A���̐��\�����o���Ȃ��i���̒��x����o���Ȃ������H�j
�~Sandy 4�R�A�͑��݊��������瑽�����u�����
��Sandy 4�R�A�ɏ��ĂȂ�����~�b�h�����W�ȏ�͑_���Ȃ�
��������Sandy Bridge��2�R�A����4�R�A��2�R�A�E���ł��Ǝv���Ă����
������\�����ɁA���N��CPU�̋��������Ă݂�
�EAMD vs Intel
Ontario vs Atom
Llano 2�R�A vs CelelonDC
Llano 4�R�A vs Sandy 2�R�A
Zambezi 6�R�A vs Sandy 4�R�A
Zambezi 8�R�A vs Sandy 6�R�A
Interlagos 16�R�A vs sandy 8�R�A
Llano vs Bulldozer vs Sandy�̃R�A���\��r(TDP����)
�E�V���O���X���b�h
Bull =< Llano < Sandy
�E�}���`�X���b�h(�X���b�h����)
Sandy < Bull =< K10.5
�ESSE
Llano <Bull = Sandy
�EAVX
Bull << Sandy
�E����GPU
Sandy <<< Llano
�EAMD vs Intel
Ontario vs Atom
Llano 2�R�A vs CelelonDC
Llano 4�R�A vs Sandy 2�R�A
Zambezi 6�R�A vs Sandy 4�R�A
Zambezi 8�R�A vs Sandy 6�R�A
Interlagos 16�R�A vs sandy 8�R�A
Llano vs Bulldozer vs Sandy�̃R�A���\��r(TDP����)
�E�V���O���X���b�h
Bull =< Llano < Sandy
�E�}���`�X���b�h(�X���b�h����)
Sandy < Bull =< K10.5
�ESSE
Llano <Bull = Sandy
�EAVX
Bull << Sandy
�E����GPU
Sandy <<< Llano
>>293
���̃}���`�X���b�h�̔�r�͓����i������̕����R�A���H
���̃}���`�X���b�h�̔�r�͓����i������̕����R�A���H
295 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 12:48:13 ID:Iw7f5ZOt
�܂��ABulldozer�̓}���`�X���b�h��������ȋC�����邯�ǂ�
Sun Microsystems
Sun Blade X6440 (AMD Opteron 8389 2.9GHz)
Compiler: PGI Server Complete Version 8.0 x86 Open64 4.2.2 Compiler Suite (from AMD)�@��AMD����
SPECintR_rate2006 = 292
SPECint_rate_base2006 = 226
http://www.spec.org/cpu2006/results/res2009q3/cpu2006-20090914-08593.html
Sun Microsystems
Sun Blade X6275 (Intel Xeon X5570 2.93GHz)
Compiler: Sun Studio 12 Update 1(backend build 20090309)
SPECintR_rate2006 = 478
SPECint_rate_base2006 = 410
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090413-07024.html
���W���[���i�R�A�j������̃X���[�v�b�g��K10��1.5�`1.8�{�~�܂�炵����
Sun Microsystems
Sun Blade X6440 (AMD Opteron 8389 2.9GHz)
Compiler: PGI Server Complete Version 8.0 x86 Open64 4.2.2 Compiler Suite (from AMD)�@��AMD����
SPECintR_rate2006 = 292
SPECint_rate_base2006 = 226
http://www.spec.org/cpu2006/results/res2009q3/cpu2006-20090914-08593.html
Sun Microsystems
Sun Blade X6275 (Intel Xeon X5570 2.93GHz)
Compiler: Sun Studio 12 Update 1(backend build 20090309)
SPECintR_rate2006 = 478
SPECint_rate_base2006 = 410
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090413-07024.html
���W���[���i�R�A�j������̃X���[�v�b�g��K10��1.5�`1.8�{�~�܂�炵����
AVX���ĕ��y����̂��ˁH
297 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 13:00:56 ID:Iw7f5ZOt
Core 2 Quad+G3x/G4x�����肩�烊�v���[�X����Ȃ����Sandy Bridge������ȁB
PC�s��Ȃ�Ė@�l������7�����B
CPU���\������Ȃ��Ȃ���ł����Ȃ����蔃�������Ȃ�����B
GPU���\�Ȃ�đS�����҂��ĂȂ����B
�܂菭�Ȃ��Ƃ�AMD��I�Ȃ��Ƃ������ƁB
PC�s��Ȃ�Ė@�l������7�����B
CPU���\������Ȃ��Ȃ���ł����Ȃ����蔃�������Ȃ�����B
GPU���\�Ȃ�đS�����҂��ĂȂ����B
�܂菭�Ȃ��Ƃ�AMD��I�Ȃ��Ƃ������ƁB
298 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 13:03:08 ID:Iw7f5ZOt
>>296
SSE5�͕��y���Ȃ��Ǝv��������AMD�͑�1����Bulldozer�����ځ[��AVX�����s�o����悤�ɍĐv�����킯����
SSE5�͕��y���Ȃ��Ǝv��������AMD�͑�1����Bulldozer�����ځ[��AVX�����s�o����悤�ɍĐv�����킯����
�@�l�Ȃ�Ĉ�������������
300 �FSocket774�F2010/06/27(��) 13:06:51 ID:LtqE6ZYy
neo��Atom�݂�����
�}�U�{���o���̂ł��傤���B
�}�U�{���o���̂ł��傤���B
>>292
�Y�킵�܂�w
�~Llano4�R�A�͋�g���Ă�2�R�A���̐��\�����o���Ȃ��i���̒��x����o���Ȃ������H�j
��Llano 4�R�A��Sandy 2�R�A�ɏ��Ă�
Sandy 2�R�A/4T < Llano 4�R�A < Sandy 4�R�A/8T��������
���Ȃ݂ɁALlano 2�R�A��Sandy 1�R�A�͂قړ��T�C�Yw(��30mm2)
Sandy�̃R�A���ł���������Ă���w
�~Sandy 4�R�A�ɏ��ĂȂ�����~�b�h�����W�ȏ�͑_���Ȃ�
��Sandy 4�R�A�̓j�b�`�ȃ~�h���n�C�����疳��
��ʌ����ɂ͍����\�߂��A�v�������ɂ͏�ʂ�6�R�A��8�R�A�����邩���
�������Ă����Ȃ��قǂ̋�CCPU�Ɖ���w
> ��������Sandy Bridge��2�R�A����4�R�A��2�R�A�E���ł��Ǝv���Ă����
Sandy4�R�A�̃T�C�Y��220mm2�ʂ����āA
�ł��V�F�A�����郍�[�G���h��m�[�g�������J�o�[�o����傫������Ȃ����炠�肦�Ȃ�w
�_�C�T�C�Y�͂���Ȋ���
Llano 2�R�A(120mm2) vs ����
Llano 4�R�A(170mm2) vs Sandy 2�R�A (150mm2)
���� vs Sandy 4�R�A(220mm2)
Sandy 4�R�A�� �������x��Llano 2�R�A�ƃ��[�G���h�ň����荇�킷�����Ȃ̂���w
�Y�킵�܂�w
�~Llano4�R�A�͋�g���Ă�2�R�A���̐��\�����o���Ȃ��i���̒��x����o���Ȃ������H�j
��Llano 4�R�A��Sandy 2�R�A�ɏ��Ă�
Sandy 2�R�A/4T < Llano 4�R�A < Sandy 4�R�A/8T��������
���Ȃ݂ɁALlano 2�R�A��Sandy 1�R�A�͂قړ��T�C�Yw(��30mm2)
Sandy�̃R�A���ł���������Ă���w
�~Sandy 4�R�A�ɏ��ĂȂ�����~�b�h�����W�ȏ�͑_���Ȃ�
��Sandy 4�R�A�̓j�b�`�ȃ~�h���n�C�����疳��
��ʌ����ɂ͍����\�߂��A�v�������ɂ͏�ʂ�6�R�A��8�R�A�����邩���
�������Ă����Ȃ��قǂ̋�CCPU�Ɖ���w
> ��������Sandy Bridge��2�R�A����4�R�A��2�R�A�E���ł��Ǝv���Ă����
Sandy4�R�A�̃T�C�Y��220mm2�ʂ����āA
�ł��V�F�A�����郍�[�G���h��m�[�g�������J�o�[�o����傫������Ȃ����炠�肦�Ȃ�w
�_�C�T�C�Y�͂���Ȋ���
Llano 2�R�A(120mm2) vs ����
Llano 4�R�A(170mm2) vs Sandy 2�R�A (150mm2)
���� vs Sandy 4�R�A(220mm2)
Sandy 4�R�A�� �������x��Llano 2�R�A�ƃ��[�G���h�ň����荇�킷�����Ȃ̂���w
302 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 13:20:59 ID:Iw7f5ZOt
>>299
�����Ă�Ǝv������
Intel�͐̂���CPU���\�͗~��������GPU���\�͂���ȂɕK�v�Ȃ����Ă����@�l�����j�[�Y
�ŗD��Ő��i����Ă�̂�B
AES�A�N�Z�����[�V�����Ȃ͊�ƃj�[�Y���N�o����Ǝv�����ǂˁB
�iBulldozer��32nm����ŃT�|�[�g���邩�ǂ����s���j
�����Ă�Ǝv������
Intel�͐̂���CPU���\�͗~��������GPU���\�͂���ȂɕK�v�Ȃ����Ă����@�l�����j�[�Y
�ŗD��Ő��i����Ă�̂�B
AES�A�N�Z�����[�V�����Ȃ͊�ƃj�[�Y���N�o����Ǝv�����ǂˁB
�iBulldozer��32nm����ŃT�|�[�g���邩�ǂ����s���j
303 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 13:21:57 ID:Iw7f5ZOt
��Llano 4�R�A(170mm2) vs Sandy 4�R�A(220mm2)
Intel�̐����L���p���炷��Ώ\���]�T����
Intel�̐����L���p���炷��Ώ\���]�T����
304 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 13:24:50 ID:Iw7f5ZOt
���m�Ɍ�����
��Llano 4�R�A vs Sandy 2�R�AHT�L�� / 4�R�AHT����
��Llano 4�R�A vs Sandy 2�R�AHT�L�� / 4�R�AHT����
>>297
�@�l�����Ȃ�Llano 2�R�A��Ontario�ŏ\���Ȃ���
���Ƃ͉c�Ǝ��悾���A�a�����Ĉ��͂��y����������̗p�������邾��
�@�l�����Ȃ�Llano 2�R�A��Ontario�ŏ\���Ȃ���
���Ƃ͉c�Ǝ��悾���A�a�����Ĉ��͂��y����������̗p�������邾��
306 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 13:37:57 ID:Iw7f5ZOt
Intel�ɂƂ���Sandy Bridge��32nm�v���Z�X�ɂ�����u�㔼��v�����B
Sandy Bridge�������_�ŕ����܂藦�̓s�[�N�ɒB���Ă邾�낤����]�T����B
4�R�A�ł�Lynnfield���3������������
AMD�͗��N�悤�₭32nm�𓊓�����B���̎��_�Ő��Y�͂ɍ��������B
�X��2011�N�㔼�ɂ�Intel��22nm�̐��Y���J�n����B
Ivy Bridge��4�R�A�{IGP�ł�160mm²���x�ɂȂ邾�낤
�i���ꂱ��2�R�A�ŏ������_�C�ɂ�����[���`���_�ł����n�ʂ��グ���邾�낤�j
Sandy Bridge�������_�ŕ����܂藦�̓s�[�N�ɒB���Ă邾�낤����]�T����B
4�R�A�ł�Lynnfield���3������������
AMD�͗��N�悤�₭32nm�𓊓�����B���̎��_�Ő��Y�͂ɍ��������B
�X��2011�N�㔼�ɂ�Intel��22nm�̐��Y���J�n����B
Ivy Bridge��4�R�A�{IGP�ł�160mm²���x�ɂȂ邾�낤
�i���ꂱ��2�R�A�ŏ������_�C�ɂ�����[���`���_�ł����n�ʂ��グ���邾�낤�j
307 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 13:38:40 ID:Iw7f5ZOt
���@�l�����Ȃ�Llano 2�R�A��Ontario�ŏ\���Ȃ���
Core 2 Duo��Quad��萫�\�����镨�Ȃ�ėv���ł��傗
Core 2 Duo��Quad��萫�\�����镨�Ȃ�ėv���ł��傗
308 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 13:43:17 ID:Iw7f5ZOt
���Ȃ݂Ɋ�ƌ���PC�͑��4�`5�N�T�C�N���Ń��v���[�X���邩��CPU���\�ɂ͗]�T����������̂����ʂ���B
Core 2 Duo/Quad�Ɩw�ǐ��\�ς���GPU���t�����Ƃ���ŗv���
�����s�̃N���E�h�i�j�Ȃ��p����Ȃ炻�ꂱ���N���C�A���g�T�C�h��AES�A�N�Z�����[�V�����͗~�����Ȃ邾�낤�ȁB
Core 2 Duo/Quad�Ɩw�ǐ��\�ς���GPU���t�����Ƃ���ŗv���
�����s�̃N���E�h�i�j�Ȃ��p����Ȃ炻�ꂱ���N���C�A���g�T�C�h��AES�A�N�Z�����[�V�����͗~�����Ȃ邾�낤�ȁB
310 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 13:54:30 ID:Iw7f5ZOt
�}�V����1�`2�N�Ŕ��������鎩�슴�o�ōl����Ȃ�
�������ł���Ƃł���ʓ�������Ƃ����5�N�͌����Ŏg����X�y�b�N��I�ԁB
�������ł���Ƃł���ʓ�������Ƃ����5�N�͌����Ŏg����X�y�b�N��I�ԁB
>>309
�ꕔ���C���i�b�v�ŗ��v�����炵�Ă����ŃJ�o�[���邩��Aintel�̑e����������Ȃ��́H
intel�ɉ��i�����ŋꂵ���Ǝv�킹��ɂ́A�̗p����AMD�����ł��S�ʓI��
���i�����͂�������Ȃ����ďɂȂ�Ȃ��Ƃ����Ȃ����낤���B
�ꕔ���C���i�b�v�ŗ��v�����炵�Ă����ŃJ�o�[���邩��Aintel�̑e����������Ȃ��́H
intel�ɉ��i�����ŋꂵ���Ǝv�킹��ɂ́A�̗p����AMD�����ł��S�ʓI��
���i�����͂�������Ȃ����ďɂȂ�Ȃ��Ƃ����Ȃ����낤���B
312 �FSocket774�F2010/06/27(��) 14:02:03 ID:tWKQ6zSN
�܂��@�l=�n�C�X�y�b�NCPU�ƃ��[�X�y�b�NGPU���Č����o����
���O�̉�Ђ��ĉ�����Ă�́H
���O�̉�Ђ��ĉ�����Ă�́H
313 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 14:07:42 ID:Iw7f5ZOt
�������͑��݂ł���BHDD�����݂ł���B�O���{�����݂ł���B
CPU�͉��肷���}�V�����Ƃ��B
�������y����GPU�̐��\����Ȃ����甃��������z�Ȃ�Ă̂͂��蓾�Ȃ��I�����B
OS(Vista)��IGP�ŊԂɍ���Ȃ��悤�Ȗ��ʂɍ���GPU���\��K�v�Ƃ���Ȃ�Â�OS(Windows XP)���g��������B
���ꂪ�@�l����B
���A���Ȃ݂�Office 2010��GMA4k���x�ł�����Ȃ���B
CPU�͉��肷���}�V�����Ƃ��B
�������y����GPU�̐��\����Ȃ����甃��������z�Ȃ�Ă̂͂��蓾�Ȃ��I�����B
OS(Vista)��IGP�ŊԂɍ���Ȃ��悤�Ȗ��ʂɍ���GPU���\��K�v�Ƃ���Ȃ�Â�OS(Windows XP)���g��������B
���ꂪ�@�l����B
���A���Ȃ݂�Office 2010��GMA4k���x�ł�����Ȃ���B
�O���t�B�b�N�K�v�ȗp�r�Ȃ畁�ʂɃr�f�I�J�[�h�h���܂���
Llano�ɖ@�l�̎��v�͂Ȃ����ƁE�E�E
���Ă�Llano����Sandy�ƍ��ʉ��ł���ق�GPU���\�������ȁB
Llano�ɖ@�l�̎��v�͂Ȃ����ƁE�E�E
���Ă�Llano����Sandy�ƍ��ʉ��ł���ق�GPU���\�������ȁB
>>313
�m����XP�g���Ă�ȁB
>>312
�n�C�X�y�b�NCPU���Ă킯����Ȃ��Ǝv���B
AMD�ɂƂ��Ă�Turion�̓��o�C�������n�C�G���h��������Ȃ�����
Intel�ɂƂ���Core2Duo�̓��o�C�������n�C�G���h����Ȃ����ȁB
Turion�����������������Ȃ��ǁ���������Core2Duo�����ǂ��B
�m����XP�g���Ă�ȁB
>>312
�n�C�X�y�b�NCPU���Ă킯����Ȃ��Ǝv���B
AMD�ɂƂ��Ă�Turion�̓��o�C�������n�C�G���h��������Ȃ�����
Intel�ɂƂ���Core2Duo�̓��o�C�������n�C�G���h����Ȃ����ȁB
Turion�����������������Ȃ��ǁ���������Core2Duo�����ǂ��B
��������ꎞ���̓C���e������Ȃ�CPU�����Ă���
������ւ�
������ւ�
Atom��Sandy�̂������̉��i�ݒ�A�ȃG�l�A�ȃX�y�[�X�������ł�����������>�@�l����
318 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 14:17:52 ID:Iw7f5ZOt
1�`2�N�ň����}�V�������ւ���ƁA�}�V���ڍs�R�X�g������PC�̒P�����Ă��܂�����
�P�`��Ӗ��Ȃ�ĂȂ���B
�����ƌ����f�X�N�g�b�v�ł͌��\�̗p����Ă�����Nehalem/Westmere����ɂ�
�uCore 2 Quad + GMA�v�ɑ���I�������Ȃ���ˁBi5�ɂ���i7�ɂ���f�B�X�N���[�gGPU���K�v�B
2�R�A�����łȂ��킴�킴4�R�A��GPU���������̂͑傫�Ȏ��v�����邩��Ɍ��܂��Ă邾��B
�P�`��Ӗ��Ȃ�ĂȂ���B
�����ƌ����f�X�N�g�b�v�ł͌��\�̗p����Ă�����Nehalem/Westmere����ɂ�
�uCore 2 Quad + GMA�v�ɑ���I�������Ȃ���ˁBi5�ɂ���i7�ɂ���f�B�X�N���[�gGPU���K�v�B
2�R�A�����łȂ��킴�킴4�R�A��GPU���������̂͑傫�Ȏ��v�����邩��Ɍ��܂��Ă邾��B
>>309
AMD��SOI�v���Z�X�Ń}�X�N�����������������ƃ_�C�T�C�Y�������ł���A�O���͍��R�X�g
�����苣��������m����AMD�������邗
AMD��SOI�v���Z�X�Ń}�X�N�����������������ƃ_�C�T�C�Y�������ł���A�O���͍��R�X�g
�����苣��������m����AMD�������邗
320 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 14:24:09 ID:Iw7f5ZOt
�����Ńo���N�̂��낤�i�j�ł���
>>319
�u���R�X�g�v�Ƃ͌����Ă�"��������"�݂��炳�قǁc�B
�u���R�X�g�v�Ƃ͌����Ă�"��������"�݂��炳�قǁc�B
322 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 14:30:26 ID:Iw7f5ZOt
���͐ݔ�������
�C���e������Ȃ��Ⴂ���Ȃ����R
AMD����Ȃ��Ⴂ���Ȃ����R
�Ȃ�Ă͕̂ʂɂȂ���ˁc
office�\�t�g�������Ȃ��Ă�����
AMD����Ȃ��Ⴂ���Ȃ����R
�Ȃ�Ă͕̂ʂɂȂ���ˁc
office�\�t�g�������Ȃ��Ă�����
���x�����̓V���R���R�X�g����
�ݔ��������GF�����S���܂�!(�د
���Ǝ����I�Ɍ��J��Ƃ̐Ԏ��̔���J��Ƃւ̓]�łƂ������ƂɂȂ邪�A
��v�I�ɂ͍��@�Ȃ낤���B
�ݔ��������GF�����S���܂�!(�د
���Ǝ����I�Ɍ��J��Ƃ̐Ԏ��̔���J��Ƃւ̓]�łƂ������ƂɂȂ邪�A
��v�I�ɂ͍��@�Ȃ낤���B
325 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 14:48:41 ID:Iw7f5ZOt
����A�����������N�̎��_��AMD��32nm�v���Z�X����2�N�ڂ�Intel�Ɠ����̕����܂藦�������ł���Ȃ�
����͊�ՂƂ��������悤���Ȃ�
����͊�ՂƂ��������悤���Ȃ�
Intel��蓱���͒x�����Ǘ����オ�肪�����A���Ď��̂��Ă���AMD�B
�E�F�n�܂邲�Ƃ���Ȃ��Đ��i��������GF���甃���A
�����܂胊�X�N��AMD����]�łł���C������B
�E�F�n�܂邲�Ƃ���Ȃ��Đ��i��������GF���甃���A
�����܂胊�X�N��AMD����]�łł���C������B
>>318
>1�`2�N�ň����}�V�������ւ���ƁA�}�V���ڍs�R�X�g������PC�̒P�����Ă��܂�����
�Ȃ��1�`2�N�œ���ւ���K�v�������?
Atom���x���Ȃ�Ƃ������A�z�r�[����ƌ������A�Ɉꕔ��������
Core2���x���ȏ��CPU�̐��\�Ƃ����߂��Ă��Ȃ����A������x
�̐��\�ŏȃG�l�A��R�X�g�Ȃ�\�����v�͂���Ǝv���B
�Ƃ������AApple�Ƃ�MS�̓��������Ă����������AAcer�̎В����͂������
�u�[���̃v���Z�b�T�̐��\�ȂǁA�ő��ǂ��ł������v�����Ă邵�B
>1�`2�N�ň����}�V�������ւ���ƁA�}�V���ڍs�R�X�g������PC�̒P�����Ă��܂�����
�Ȃ��1�`2�N�œ���ւ���K�v�������?
Atom���x���Ȃ�Ƃ������A�z�r�[����ƌ������A�Ɉꕔ��������
Core2���x���ȏ��CPU�̐��\�Ƃ����߂��Ă��Ȃ����A������x
�̐��\�ŏȃG�l�A��R�X�g�Ȃ�\�����v�͂���Ǝv���B
�Ƃ������AApple�Ƃ�MS�̓��������Ă����������AAcer�̎В����͂������
�u�[���̃v���Z�b�T�̐��\�ȂǁA�ő��ǂ��ł������v�����Ă邵�B
328 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 15:11:52 ID:Iw7f5ZOt
>>326
SOI-HKMG�̍����\�v���Z�X��AMD�ȊO�̌ڋq�����Ă�Ȃ��
SOI-HKMG�̍����\�v���Z�X��AMD�ȊO�̌ڋq�����Ă�Ȃ��
��Ђ�PC�ɑ��݂��Ă�����Ђ���
OS���I�t�B�X����������܂ł��̂܂g���|���܂���
�c�q�̋ߐ���Ăǂ�ȋƊE�Ȃ�
OS���I�t�B�X����������܂ł��̂܂g���|���܂���
�c�q�̋ߐ���Ăǂ�ȋƊE�Ȃ�
330 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 15:33:10 ID:Iw7f5ZOt
��������HDD�̑��݁E�����͕��ʂ���ˁi���[�X�i�ȊO�j
�䖝���낪���ʂ�
HDD�͂Ƃ������������͂Ȃ�Ƃ��Ȃ�ȁB
�@�l������4�R�A�̗p����悤�ȃ}�k�P�Ȋ�ƂȂw�Ǒ��݂��Ȃ���c
�f���A���R�A 3GHz��������ނ肪�o��قǃX�y�b�N�K�v�Ȃ��s���Sandy 4�R�A�Ȃ��ꏊ�͂Ȃ�
��������Llano�̓m�[�g�������C���ASandy�̓f�X�N�������C��������A��ׂĂ��d���Ȃ��C������
�f���A���R�A 3GHz��������ނ肪�o��قǃX�y�b�N�K�v�Ȃ��s���Sandy 4�R�A�Ȃ��ꏊ�͂Ȃ�
��������Llano�̓m�[�g�������C���ASandy�̓f�X�N�������C��������A��ׂĂ��d���Ȃ��C������
Sandy�̓m�[�g�����Ɉ�Ԃ�������o�ׂ���邾��
��������
��������
�E���R�i�ڕW�F�X���Z�l�j�Ɛ��q�i�ڕW�F�����i��������j����j�̋���ȏL�����X���ɏ[������
�������f�b�h�X�y�[�X���̊�@
�������f�b�h�X�y�[�X���̊�@
��Ƃ̗p�r�Ȃm�[�gPC�ŏ\������B�d�C��������ςނ��B
�m�[�gPC�Ő��\�̃l�b�N��HDD���炢������A���Ɗ��ɂ���Ⴢ�[�}���^�C�����B
�m�[�gPC�Ő��\�̃l�b�N��HDD���炢������A���Ɗ��ɂ���Ⴢ�[�}���^�C�����B
��Ƃ̗p�r�ł������Ă��A�������ǂ�
Sandy2�R�A����20W���x��CULV�̒u�����͏���d�͂�R�X�g�ʂŖ���
Llano 2�R�A�Ȃ�o����
35W���ȏ�̃��C���X�g���[���m�[�g��Llano��Sandy 2�R�A�����藐�ꂻ�������ǁA
�Q�[���⓮��n��GPU���\���]�܂�邱�Ƃ���������AGPU�ɗD���Llano���L��
����GPU���C�ɂ���l�̊S�̓Q�t�H�����f�������
AMD��Radeon�����������_�ŁA��ʌ����̍����i�т�Intel�ɏ����͂Ȃ�
�ő�s�ꂾ���ǐ��\�͒Ⴍ�Ă������@�l�������A�n�C�G���hGPU���g����������s��ɂ������ꏊ�Ȃ���
�f���A���R�AAtom��Ontario�ł��J�o�[�ł������Ȗ@�l������Sandy���ʂ����ăV�F�A���l���ł���̂���w
���łɁA��ʌ����ɂ�i5�ł���HD5450�Ƒg������邱�Ƃ����邩��A
Sandy+HD5450�Ȃ�ċ��J�I�ȍ\�������肦��������w
Llano 2�R�A�Ȃ�o����
35W���ȏ�̃��C���X�g���[���m�[�g��Llano��Sandy 2�R�A�����藐�ꂻ�������ǁA
�Q�[���⓮��n��GPU���\���]�܂�邱�Ƃ���������AGPU�ɗD���Llano���L��
����GPU���C�ɂ���l�̊S�̓Q�t�H�����f�������
AMD��Radeon�����������_�ŁA��ʌ����̍����i�т�Intel�ɏ����͂Ȃ�
�ő�s�ꂾ���ǐ��\�͒Ⴍ�Ă������@�l�������A�n�C�G���hGPU���g����������s��ɂ������ꏊ�Ȃ���
�f���A���R�AAtom��Ontario�ł��J�o�[�ł������Ȗ@�l������Sandy���ʂ����ăV�F�A���l���ł���̂���w
���łɁA��ʌ����ɂ�i5�ł���HD5450�Ƒg������邱�Ƃ����邩��A
Sandy+HD5450�Ȃ�ċ��J�I�ȍ\�������肦��������w
339 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 16:41:57 ID:Iw7f5ZOt
��Ƃ��Č����Ă��F��Ȋ�Ƃ����邩��ȁB
�܂��A���C���X�g���[���m�[�g�ł�4�R�A���x�͕W���ɂȂ�i�Ƃ������˂����ށj����B
�]�͂������GPU�̕⏕�ł���点������B
�܂��A���C���X�g���[���m�[�g�ł�4�R�A���x�͕W���ɂȂ�i�Ƃ������˂����ށj����B
�]�͂������GPU�̕⏕�ł���点������B
>>338
Arrandale��CULV������̂ɁA�Ȃ���SandyBridge���ƃ_���ȂH
Arrandale��CULV������̂ɁA�Ȃ���SandyBridge���ƃ_���ȂH
341 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 16:44:21 ID:Iw7f5ZOt
>>338
���Ԕ����r�炷�悤�Ő\����Ȃ����A������Fusion��GPU���\���f�B�X�N���[�g���݂̐��\�ɂȂ�����ł����H
����AMD��CPU�����ATi�̂��܂��ɂȂ����ȁB
�_�Z�F��B
���Ԕ����r�炷�悤�Ő\����Ȃ����A������Fusion��GPU���\���f�B�X�N���[�g���݂̐��\�ɂȂ�����ł����H
����AMD��CPU�����ATi�̂��܂��ɂȂ����ȁB
�_�Z�F��B
342 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 16:45:04 ID:Iw7f5ZOt
>>340
�ނ̔]���ł͑��݂��Ȃ����ƂɂȂ��Ă邩��
�ނ̔]���ł͑��݂��Ȃ����ƂɂȂ��Ă邩��
Llano��GPU���̐��\������������A�u�f�B�X�N���[�g����GPU���\�͋��߂��Ă��Ȃ��v
�Ƃ������o����10�փN�^�[�B
�Ƃ������o����10�փN�^�[�B
�܂����̐��ォ�O����̃f�B�X�N���[�g�̍ʼn������݂̐��\�͒����Ă��邾��
�Ƃ�����Core2����̍ʼn����f�B�X�N���[�g�̐��\�Ȃ�Sandy��GPU�ł��璴���Ă��
�Ƃ�����Core2����̍ʼn����f�B�X�N���[�g�̐��\�Ȃ�Sandy��GPU�ł��璴���Ă��
������ł̏o�����������
780G�Ńf�B�X�N���[�g���[�G���h�ɕ�����
�u�f�B�X�N���[�g����GPU���\�͋��߂��Ă��Ȃ��v�ȂǂƂԂ₫�Ȃ���
�L���L���E�����Ă���Ȃ���
780G�Ńf�B�X�N���[�g���[�G���h�ɕ�����
�u�f�B�X�N���[�g����GPU���\�͋��߂��Ă��Ȃ��v�ȂǂƂԂ₫�Ȃ���
�L���L���E�����Ă���Ȃ���
346 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 17:31:25 ID:Iw7f5ZOt
����Radeon��200SP�Ɠ����̎������\�Ȃ炢����GMA��������ڂ��Ă�CPU2�`3�R�A�ŕ⏕����Ώ\���Ԃɍ�������
BuII����Ȃ�����Bull���o�Ă�����
�u�f�B�X�N���[�g����GPU���\�͋��߂��Ă��Ȃ��v
�Ƃ�������Zambezi�����z�͏o�邩���m����
�@�\�g��Ȃ��z�ɂƂ��Ă̗]�v�Ȑ��\�Ȃ��
������x���`�ő���CPU�i�K��1/6�̃}�U�[�I���{�����C�o���H�j�{�R�邽�߂����ɂ���悤�Ȃ���
�u�f�B�X�N���[�g����GPU���\�͋��߂��Ă��Ȃ��v
�Ƃ�������Zambezi�����z�͏o�邩���m����
�@�\�g��Ȃ��z�ɂƂ��Ă̗]�v�Ȑ��\�Ȃ��
������x���`�ő���CPU�i�K��1/6�̃}�U�[�I���{�����C�o���H�j�{�R�邽�߂����ɂ���悤�Ȃ���
348 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 17:58:39 ID:Iw7f5ZOt
Sandy Bridge��SIMD�P���x���Z���\�́A1�R�A������8ADD+8MUL(+DIV)�ŁA�s�[�N���\�������Ă�1�R�A������GeForce�̃V�F�[�_���Z8SP�{�����x�͂���B
�������ߔ��s���i4����/clk)��A���x�ׂ̍����A�L���b�V���e�ʂ��l����Ύ������\�͂���ȏ�B
�N���b�N�����l�����2�`3�{�B
Clarksdale/Arrandale��CPU�T�|�[�g����ł̐��\�l����A�Ԃ蓢���ɂł��邾���̃p���[�͂����B
4�R�A�Ȃ�ĕK�v�Ȃ�����GPU���\���~�������ăj�[�Y�ƁAGPU�͂���ڂ��Ă���������R�A���^�X���b�h���͗~�������ăj�[�Y��
�����ɂ��Ȃ��邱�Ƃ��ł���킯������A�\�������I���B
�������ߔ��s���i4����/clk)��A���x�ׂ̍����A�L���b�V���e�ʂ��l����Ύ������\�͂���ȏ�B
�N���b�N�����l�����2�`3�{�B
Clarksdale/Arrandale��CPU�T�|�[�g����ł̐��\�l����A�Ԃ蓢���ɂł��邾���̃p���[�͂����B
4�R�A�Ȃ�ĕK�v�Ȃ�����GPU���\���~�������ăj�[�Y�ƁAGPU�͂���ڂ��Ă���������R�A���^�X���b�h���͗~�������ăj�[�Y��
�����ɂ��Ȃ��邱�Ƃ��ł���킯������A�\�������I���B
fusion���Ċ�炮�炢�ɂȂ�̂��ȁH
350 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 18:14:49 ID:Iw7f5ZOt
�����苍�i�j���͈����Ȃ��Ȃ��́H
��ʌ���PC�ɗv�������̂�
1. ��R�X�g���ŗD��ŁA���̂��߂̒�TDP�A���Ȃ������ʐ�
2. �s���̂Ȃ����쐫�̂��߂̕K�v�\����CPU���\�A�K�v�\����GPU���\
3. �����̕t�����l
�V���O���`�b�v�Ό��Ȃ�1.2.�͑�̌݊p�Ȃ̂ŁA�D���̒ቿ�i���Ր�ɂȂ�
���̂��߂̃R�A��100�`120mm2���낤Llano 2�R�A
Intel���ǂ��撣�낤�ƁA150mm2��������Sandy 2�R�A�ł͌�������
�t�����l�ōl�����
Sandy��AVX��HTT�̃}���`�X���b�h���\
Llano�͍ŐV��3D�Q�[�����y���ׂȂ�o����GPU���\
�v��HTT�ɂ��}���`�X���b�h���\ vs �l�b�g�Q�[�����o����GPU���\�ɂȂ肻��
1. ��R�X�g���ŗD��ŁA���̂��߂̒�TDP�A���Ȃ������ʐ�
2. �s���̂Ȃ����쐫�̂��߂̕K�v�\����CPU���\�A�K�v�\����GPU���\
3. �����̕t�����l
�V���O���`�b�v�Ό��Ȃ�1.2.�͑�̌݊p�Ȃ̂ŁA�D���̒ቿ�i���Ր�ɂȂ�
���̂��߂̃R�A��100�`120mm2���낤Llano 2�R�A
Intel���ǂ��撣�낤�ƁA150mm2��������Sandy 2�R�A�ł͌�������
�t�����l�ōl�����
Sandy��AVX��HTT�̃}���`�X���b�h���\
Llano�͍ŐV��3D�Q�[�����y���ׂȂ�o����GPU���\
�v��HTT�ɂ��}���`�X���b�h���\ vs �l�b�g�Q�[�����o����GPU���\�ɂȂ肻��
352 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 18:26:21 ID:Iw7f5ZOt
> 1. ��R�X�g���ŗD��ŁA���̂��߂̒�TDP�A���Ȃ������ʐ�
Phenom II��������������Ă����[�J�[PC�ɍ̗p����Ȃ����R�̐����ł���
Phenom II��������������Ă����[�J�[PC�ɍ̗p����Ȃ����R�̐����ł���
>>349
�_�C�T�C�Y�I�ɂ�X2��X4�Ɠ������炢������f�X�N�g�b�v������1.5���~�ȉ����ĂƂ��낾�낤��
sh�s�����N�ŃN���b�N�͌��シ�邵�AHD5570�N���X��GPU���\�ɂȂ邩��2���~�߂����i�ɂȂ肻��
(PhenomII + HD5570)
�_�C�T�C�Y�I�ɂ�X2��X4�Ɠ������炢������f�X�N�g�b�v������1.5���~�ȉ����ĂƂ��낾�낤��
sh�s�����N�ŃN���b�N�͌��シ�邵�AHD5570�N���X��GPU���\�ɂȂ邩��2���~�߂����i�ɂȂ肻��
(PhenomII + HD5570)
> ���̂��߂̃R�A��100�`120mm2���낤Llano 2�R�A
����̑����80mm^2��Westmere�n�R�A����Ȃ��������B
����̑����80mm^2��Westmere�n�R�A����Ȃ��������B
355 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 18:33:11 ID:Iw7f5ZOt
���o�C�������ɐv���ꂽCore MA�̔��W�^�ł���Sandy Bridge�Ɣ�ׂ���K10�R�A�̎��_�Ŗ���
>>351
�Ȃ��CPU�����ōl����́H
CULV�̓`�b�v�Z�b�g�Ƃ̃Z�b�g���i�Ȃ���A���v���Z�X��Fab�ň�������`�b�v�Z�b�g�̕���
���v���m�ۂł���Ȃ��������邾�낤�B
�����CULV�̈ꕔ���C���i�b�v�̗��v�������낤���A���ŃJ�o�[����Ƃ����̂�intel�̉��i�t�������B
�Ȃ��CPU�����ōl����́H
CULV�̓`�b�v�Z�b�g�Ƃ̃Z�b�g���i�Ȃ���A���v���Z�X��Fab�ň�������`�b�v�Z�b�g�̕���
���v���m�ۂł���Ȃ��������邾�낤�B
�����CULV�̈ꕔ���C���i�b�v�̗��v�������낤���A���ŃJ�o�[����Ƃ����̂�intel�̉��i�t�������B
���r���[��Llano�����AIntel�I�ɂ�bobcat�̕������ق���ˁB
Atom��Core�̈Öق̋��E����j���\��������(�Ƃ������A����)
Atom�͂������ɐ��\���Ⴗ����ʂ����邯�ǁAK7�`K8���x�̐��\��
RS880�N���X��GPU(�l�g�Q�A����Đ��x���͏\��)��ς�Ő�W�A
�ʐς�100mm^2�ȉ��Ƃ��ŗ�����ƁACore����R�ł��Ȃ����A
Atom�ł͐��\�ŕ�������
Atom��Core�̈Öق̋��E����j���\��������(�Ƃ������A����)
Atom�͂������ɐ��\���Ⴗ����ʂ����邯�ǁAK7�`K8���x�̐��\��
RS880�N���X��GPU(�l�g�Q�A����Đ��x���͏\��)��ς�Ő�W�A
�ʐς�100mm^2�ȉ��Ƃ��ŗ�����ƁACore����R�ł��Ȃ����A
Atom�ł͐��\�ŕ�������
������AMD��CPU�����ATi�̂��܂��ɂȂ����ȁB
���i����̃g�b�v�͌�ATI�̃o�[�O�}��������
��4�R�A�Ȃ�ĕK�v�Ȃ�����GPU���\���~�������ăj�[�Y�ƁAGPU�͂���ڂ��Ă���������R�A���^�X���b�h���͗~�������ăj�[�Y��
�������ɂ��Ȃ��邱�Ƃ��ł���킯������A�\�������I���B
���C�ɂ����d�v�|�C���g������
GPU��SP�Ȃ�Ċ��ς�ł悤���Q�[�����Ȃ��Ⴝ�����ʂȃX�y�[�X������
���i����̃g�b�v�͌�ATI�̃o�[�O�}��������
��4�R�A�Ȃ�ĕK�v�Ȃ�����GPU���\���~�������ăj�[�Y�ƁAGPU�͂���ڂ��Ă���������R�A���^�X���b�h���͗~�������ăj�[�Y��
�������ɂ��Ȃ��邱�Ƃ��ł���킯������A�\�������I���B
���C�ɂ����d�v�|�C���g������
GPU��SP�Ȃ�Ċ��ς�ł悤���Q�[�����Ȃ��Ⴝ�����ʂȃX�y�[�X������
359 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 18:49:04 ID:Iw7f5ZOt
���������s�[�N���߂����l�b�g�u�b�N�s���Intel�ɂƂ��Ă͎̂ĂĂ��ɂ��Ȃ��
GPU�̃V�F�A
Intel�F43%
AMD��Nvidia�̃I���{�̃V�F�A�͂��̔������x���낤����A�I���{�S�̂̃V�F�A�͍����Ă�60%���ĂƂ�����
�܂�O��GPU�̃V�F�A��40%�ʂɂȂ�
Sandy 2�R�A��GPU���\= Sandy 4�R�A�̔��� = i5��GPU���\���Ɖ��肷��ƁA
���[�G���h�ɂ���y�Ȃ�����O��GPU�̃V�F�A��������Ƃ͕s�\
�t��Llano��HD5570�܂ł̎s���D�����Ƃ��o����
��̓I�Ɍ����ƁA�I���{�S�ʁAion/ion2�AG210�`GT220�AHD4350�`HD5570���g���Ă���s���D����
���Ȃ݂�Llano 4�R�A��2�R�A�ŃV�F�[�_�[�������ɂȂ��Ă����͂��܂�GPU�̐��\�͒ቺ���Ȃ��B
�����͂���
Llano 4�R�A 480sp 128bit ROP�F8 DDR3 1333/1600
Llano 2�R�A 240sp 128bit ROP�F8 DDR3 1066/1333
�ߏ��sp�������ɂȂ��Ă��{�g���l�b�N�ɂȂ�Ȃ�����A���������\�ɔ�Ⴕ�Č��邾�����낤
Intel�������͓��������A�V�F�[�_�[���M���M�����ۂ�48sp����24sp�ɂȂ��đ������ɂȂ邩�琫�\����������B
Intel�F43%
AMD��Nvidia�̃I���{�̃V�F�A�͂��̔������x���낤����A�I���{�S�̂̃V�F�A�͍����Ă�60%���ĂƂ�����
�܂�O��GPU�̃V�F�A��40%�ʂɂȂ�
Sandy 2�R�A��GPU���\= Sandy 4�R�A�̔��� = i5��GPU���\���Ɖ��肷��ƁA
���[�G���h�ɂ���y�Ȃ�����O��GPU�̃V�F�A��������Ƃ͕s�\
�t��Llano��HD5570�܂ł̎s���D�����Ƃ��o����
��̓I�Ɍ����ƁA�I���{�S�ʁAion/ion2�AG210�`GT220�AHD4350�`HD5570���g���Ă���s���D����
���Ȃ݂�Llano 4�R�A��2�R�A�ŃV�F�[�_�[�������ɂȂ��Ă����͂��܂�GPU�̐��\�͒ቺ���Ȃ��B
�����͂���
Llano 4�R�A 480sp 128bit ROP�F8 DDR3 1333/1600
Llano 2�R�A 240sp 128bit ROP�F8 DDR3 1066/1333
�ߏ��sp�������ɂȂ��Ă��{�g���l�b�N�ɂȂ�Ȃ�����A���������\�ɔ�Ⴕ�Č��邾�����낤
Intel�������͓��������A�V�F�[�_�[���M���M�����ۂ�48sp����24sp�ɂȂ��đ������ɂȂ邩�琫�\����������B
>>354
Westmere�R�A�������ᓮ���Ȃ�(�����R�����ėp�o�X����)
80mm2��Westmere + 110mm2��GPU�R�A��Llano 120mm2�̑��肾��
Westmere�R�A�������ᓮ���Ȃ�(�����R�����ėp�o�X����)
80mm2��Westmere + 110mm2��GPU�R�A��Llano 120mm2�̑��肾��
>>360
���̉����intelCPU�̃V�F�A���ƒD��Ȃ��Ƃ����Ȃ��̂łǂ����Ǝv�����B
���ƁAintel�̓���GPU�̃V�F�A��5���߂�����̂́A���ꂾ��GPU���\���t�����l�ɂȂ�Ȃ��s�ꂪ
����������Ă��ƂŁALlano��GPU���\������ɂȂ�Ȃ����ƂȂ��ǁB
���̉����intelCPU�̃V�F�A���ƒD��Ȃ��Ƃ����Ȃ��̂łǂ����Ǝv�����B
���ƁAintel�̓���GPU�̃V�F�A��5���߂�����̂́A���ꂾ��GPU���\���t�����l�ɂȂ�Ȃ��s�ꂪ
����������Ă��ƂŁALlano��GPU���\������ɂȂ�Ȃ����ƂȂ��ǁB
363 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 18:54:36 ID:Iw7f5ZOt
�ާ�����
GPU������Sandy Bridge��CPU�����ꂽ���_�Ŗ�������GPU�V�F�A�ɃJ�E���g�����
�f�B�X�N���[�g�g�������g���܂����A��
GPU������Sandy Bridge��CPU�����ꂽ���_�Ŗ�������GPU�V�F�A�ɃJ�E���g�����
�f�B�X�N���[�g�g�������g���܂����A��
�_���S�̐l�i������e�w�ɋA�����Ă�c�B
������ǂ��l�߂��Ă���Ƃ͂����e���p�萙w
������ǂ��l�߂��Ă���Ƃ͂����e���p�萙w
365 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 19:00:00 ID:Iw7f5ZOt
ID:zt8MZVJX�͂��܂�CPU�ɂ��V�F�[�_�⏕�@�\�̑��݂���������́H
���Ȃ́H���ʂ́H
���Ȃ́H���ʂ́H
366 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 19:02:49 ID:Iw7f5ZOt
CPU��GPU�̋@�\�Z���Ƃ���AMD�̂�낤�Ƃ������Ƃ��ɂ���Ă��܂����̂ňӐ}�I�ɖ����������̂���
�Ȃ��Ƃ��i��
�Ȃ��Ƃ��i��
���͂ȁ[�����Ă���������������ł�����
DX�̂ǂ��܂œ������͂���Ȃ�ɋ������邯�ǂ�
�j�[�Y�ɑ��ăI�[�o�X�y�b�N�ɂȂ����b�o�t����J�����Ă����傤���Ȃ���
DX�̂ǂ��܂œ������͂���Ȃ�ɋ������邯�ǂ�
�j�[�Y�ɑ��ăI�[�o�X�y�b�N�ɂȂ����b�o�t����J�����Ă����傤���Ȃ���
368 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 19:28:55 ID:Iw7f5ZOt
RIA�̑䓪�ŕ��ʂ�CPU���\�v���͏オ���Ă܂����B
�������瓝��GPU�Ȃ��
Aero��������\���Ȃ�
Aero��������\���Ȃ�
�c�q�̊G�����Ƃ��������疼�O���ɂȂɂ������Ȃ��ł����H
�l�ɂ͂���Ȃ��Ƃ��������Ȃ����ǁA
�����݂�ȟT�������Ƃ������Ă��H
�Ȃ�ł���ȂɎ������A�s�[�����������m��Ȃ����ǂ��B
�l�ɂ͂���Ȃ��Ƃ��������Ȃ����ǁA
�����݂�ȟT�������Ƃ������Ă��H
�Ȃ�ł���ȂɎ������A�s�[�����������m��Ȃ����ǂ��B
>>356
TSMC��65nm�o���N�g���Ă��邩��A
AMD�̃`�b�v�Z�b�g���i���\��������
>>357
Ontario�̃R�A�T�C�Y�̓f���A���R�AAtom�Ɠ����ȉ��炵����
Pineview�F86.6mm2
Ontario�炵���R�A�F80mm2�ȉ�
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20100604_371991.html
http://pc.watch.impress.co.jp/img/pcw/docs/371/991/33.jpg
�u�E�F�n��Ń_�C�͏c�����ꂼ���36����33�オ�z�u����Ă���B
�_�C�T�C�Y(�����̖{�̖̂ʐ�)�́A�v�Z��ł�80����mm���B
����́A Intel��45nm�v���Z�X��Atom�n��GPU�������i(Pineview�̓f���A���R�A��86.6����mm)��
�����x���̃_�C�T�C�Y���B �v
TSMC��65nm�o���N�g���Ă��邩��A
AMD�̃`�b�v�Z�b�g���i���\��������
>>357
Ontario�̃R�A�T�C�Y�̓f���A���R�AAtom�Ɠ����ȉ��炵����
Pineview�F86.6mm2
Ontario�炵���R�A�F80mm2�ȉ�
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20100604_371991.html
http://pc.watch.impress.co.jp/img/pcw/docs/371/991/33.jpg
{kind=link}
�u�E�F�n��Ń_�C�͏c�����ꂼ���36����33�オ�z�u����Ă���B
�_�C�T�C�Y(�����̖{�̖̂ʐ�)�́A�v�Z��ł�80����mm���B
����́A Intel��45nm�v���Z�X��Atom�n��GPU�������i(Pineview�̓f���A���R�A��86.6����mm)��
�����x���̃_�C�T�C�Y���B �v
�c�q�̊G�����Ƃ��������疼�O���ɂȂɂ������Ȃ��ł����H
�l�ɂ͂���Ȃ��Ƃ��������Ȃ����ǁA
�����݂�ȟT�������Ƃ������Ă��H
�Ȃ�ł���ȂɎ������A�s�[�����������m��Ȃ����ǂ��B
�l�ɂ͂���Ȃ��Ƃ��������Ȃ����ǁA
�����݂�ȟT�������Ƃ������Ă��H
�Ȃ�ł���ȂɎ������A�s�[�����������m��Ȃ����ǂ��B
373 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 19:37:37 ID:Iw7f5ZOt
CPU���\�͕K�v�Ȃ��Ȃ�Č����Ă�z�͂��܂ł�Windows XP���g��������^�C�v
����Ȃ�DX11�i�j�Ƃ�
����Ȃ�DX11�i�j�Ƃ�
Atom�̐��\�͗��ɃA�����Ǝv�����A����Ȃ�CPU���\�������ĉ��Ɏg���́H
Win7���g����E7200��X2��5000+�Ŗ������Ă�
Win7���g����E7200��X2��5000+�Ŗ������Ă�
375 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 19:44:32 ID:Iw7f5ZOt
>>371
�ŁA�s���̈������Ƃ͓ǂ܂Ȃ���`�Ȃ�ł��˂�
>�@�������A����AAMD�͖��m��Llano�Ƃ킩����J�́A�V���R���ł��f���ł��s�Ȃ����Ƃ��ł��Ȃ������B
> ����̂ǂ�����肩�Ƃ����ƁA AMD���AIntel�̃��C���X�g���[����Sandy Bridge�ɑR���鐻�i��
> ���n�x���������Ƃ��ł��Ȃ��������炾�B���̂��߁AAMD��Llano��\��ʂ�ł��邩�ǂ����Ƃ����_�ɁA
> �^�╄���������ƂɂȂ�B
>
>�@AMD�͍�N(2009�N)��45nm��K10�t�@�~���𓊓����Ĉȗ��A���C���X�g���[���f�X�N�g�b�v�����ɂ�
> �قƂ�ǐV���i���Ȃ��B��O�́A��^�_�C(�����̖{��)��6�R�ACPU�uPhenom II X6(Thuban:�g�D�o��)�v�������B
> AMD��2011�N�㔼�ɁA�p�t�H�[�}���X�f�X�N�g�b�v�����ɁuBulldozer(�u���h�[�U)�v�R�A����������B
> �������ABulldozer�R�A�́A�V���O���X���b�h���\�����}���`�X���b�h���\�ɏd�_��u���Ă��邽�߁A
> ���C���X�g���[���ɂ̓t�B�b�g���ɂ����B
>
>�@���̂��߁A�����ALlano�̓������x���ƁAAMD��2�N�߂����C���X�g���[���f�X�N�g�b�v�ł̃��t���b�V����
> �s�Ȃ��Ȃ����ƂɂȂ��Ă��܂��BIntel�́A���̗̈���J�o�[����Sandy Bridge�𒅁X�Ɛi�߂Ă��邾���ɁA
> AMD��Llano��ł��o���Ȃ����Ƃ͕s����������B
�܂��A�V���i��L3�̂Ȃ�K10�̃V�������N�ł����Ȃ����_�ł��������o�������o���܂������҂Ȃ�Ă��ĂȂ��킯�ł����ǂ�
�l�I�ɂ�
�ŁA�s���̈������Ƃ͓ǂ܂Ȃ���`�Ȃ�ł��˂�
>�@�������A����AAMD�͖��m��Llano�Ƃ킩����J�́A�V���R���ł��f���ł��s�Ȃ����Ƃ��ł��Ȃ������B
> ����̂ǂ�����肩�Ƃ����ƁA AMD���AIntel�̃��C���X�g���[����Sandy Bridge�ɑR���鐻�i��
> ���n�x���������Ƃ��ł��Ȃ��������炾�B���̂��߁AAMD��Llano��\��ʂ�ł��邩�ǂ����Ƃ����_�ɁA
> �^�╄���������ƂɂȂ�B
>
>�@AMD�͍�N(2009�N)��45nm��K10�t�@�~���𓊓����Ĉȗ��A���C���X�g���[���f�X�N�g�b�v�����ɂ�
> �قƂ�ǐV���i���Ȃ��B��O�́A��^�_�C(�����̖{��)��6�R�ACPU�uPhenom II X6(Thuban:�g�D�o��)�v�������B
> AMD��2011�N�㔼�ɁA�p�t�H�[�}���X�f�X�N�g�b�v�����ɁuBulldozer(�u���h�[�U)�v�R�A����������B
> �������ABulldozer�R�A�́A�V���O���X���b�h���\�����}���`�X���b�h���\�ɏd�_��u���Ă��邽�߁A
> ���C���X�g���[���ɂ̓t�B�b�g���ɂ����B
>
>�@���̂��߁A�����ALlano�̓������x���ƁAAMD��2�N�߂����C���X�g���[���f�X�N�g�b�v�ł̃��t���b�V����
> �s�Ȃ��Ȃ����ƂɂȂ��Ă��܂��BIntel�́A���̗̈���J�o�[����Sandy Bridge�𒅁X�Ɛi�߂Ă��邾���ɁA
> AMD��Llano��ł��o���Ȃ����Ƃ͕s����������B
�܂��A�V���i��L3�̂Ȃ�K10�̃V�������N�ł����Ȃ����_�ł��������o�������o���܂������҂Ȃ�Ă��ĂȂ��킯�ł����ǂ�
�l�I�ɂ�
>>373
���̒��̕]���̎����ς���Ă���̂ɁA�����܂ł��ߋ��̕]�����ł���
�����������Ȃ��̂ȁB����Atom����͐��i�ɂ��邭�炢�̐�������Ȃ��ƁA
iPad�Ƃ��AARM�^�u���b�g�ɏ��ĂȂ���B
���̒��̕]���̎����ς���Ă���̂ɁA�����܂ł��ߋ��̕]�����ł���
�����������Ȃ��̂ȁB����Atom����͐��i�ɂ��邭�炢�̐�������Ȃ��ƁA
iPad�Ƃ��AARM�^�u���b�g�ɏ��ĂȂ���B
377 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 19:50:40 ID:Iw7f5ZOt
>>374
������邩�ɂ����ˁB
�l��PC�ł�NetBeans���g����RTS�Ƃ��̃w�r�[��Flash�Q�[����邩��
�܂��܂�CPU���\���������C�����܂���
�܁A����d�͗v���̂ǂ�ǂ�オ���Ă���GPU�͎�ɕ����܂���
������CPU���d�͌����Nj����Ă�GPU���S�đ䖳���ɂ���i�j
������邩�ɂ����ˁB
�l��PC�ł�NetBeans���g����RTS�Ƃ��̃w�r�[��Flash�Q�[����邩��
�܂��܂�CPU���\���������C�����܂���
�܁A����d�͗v���̂ǂ�ǂ�オ���Ă���GPU�͎�ɕ����܂���
������CPU���d�͌����Nj����Ă�GPU���S�đ䖳���ɂ���i�j
378 �FSocket774�F2010/06/27(��) 19:58:02 ID:IZtOrfA/
�Ƃ���ǂ낱���ځ`��Ō����Ȃ����ǂ����܂ł̗�����܂Ƃ߂��
Apple�݂�����OS��CPU��GPU�����₭�p�ӂł���Ƃ��낪���҂ɂȂ���Ă��Ƃ��ȁH
Apple�݂�����OS��CPU��GPU�����₭�p�ӂł���Ƃ��낪���҂ɂȂ���Ă��Ƃ��ȁH
379 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 20:00:07 ID:Iw7f5ZOt
>>376
�����������̃����W�̐��i�͔����������v�ł����ă��C���X�g���[���N���X��x86 PC�̎��v�͖W���ĂȂ��킯�ł����B
���N���狎�N�͈��PC�����܂蔄�ꂸ�Ƀl�b�g�u�b�N�����ꂽ���ǐ��E�����s���ɂ�锃���T�������܂���
�d�Ȃ���������������
�ǂ����̔n���A�i���X�g������PC�s�ꂪ�l�b�g�u�b�N�ɐH��ꂽ�Ƃ������Ă����ǂȂ�����
�[���A���̎�̃f�W�^���K�W�F�b�g�́u�ʕ��v����B
Windows CE�n���h�w���hPC�@�����s�������ǐ��N�Ŕp�ꂽ��H
iPad�����܂ł���������Ǝv���̂��H
����ȃ\�t�g�L�[�{�[�h�Ŏd���Ȃ�Ăł��邩�H
����������Âɍl���Ȃ��Ƃ�
�����������̃����W�̐��i�͔����������v�ł����ă��C���X�g���[���N���X��x86 PC�̎��v�͖W���ĂȂ��킯�ł����B
���N���狎�N�͈��PC�����܂蔄�ꂸ�Ƀl�b�g�u�b�N�����ꂽ���ǐ��E�����s���ɂ�锃���T�������܂���
�d�Ȃ���������������
�ǂ����̔n���A�i���X�g������PC�s�ꂪ�l�b�g�u�b�N�ɐH��ꂽ�Ƃ������Ă����ǂȂ�����
�[���A���̎�̃f�W�^���K�W�F�b�g�́u�ʕ��v����B
Windows CE�n���h�w���hPC�@�����s�������ǐ��N�Ŕp�ꂽ��H
iPad�����܂ł���������Ǝv���̂��H
����ȃ\�t�g�L�[�{�[�h�Ŏd���Ȃ�Ăł��邩�H
����������Âɍl���Ȃ��Ƃ�
>�l��PC�ł�NetBeans���g����RTS�Ƃ��̃w�r�[��Flash�Q�[����邩��
>�܂��܂�CPU���\���������C�����܂���
����ȃL�����^���v�͒��j�b�`������AiPad�������낤�ȁB
Intel���g�A�u�R���V���}�[�ɕK�v�Ȃ̂̓��f�B�A���v���Č������Ă邵�B
>�܂��܂�CPU���\���������C�����܂���
����ȃL�����^���v�͒��j�b�`������AiPad�������낤�ȁB
Intel���g�A�u�R���V���}�[�ɕK�v�Ȃ̂̓��f�B�A���v���Č������Ă邵�B
381 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 20:02:54 ID:Iw7f5ZOt
> RTS�Ƃ��̃w�r�[��Flash�Q�[����邩��
����J�W���A���Q�[�̕��ނ����ǁB
iPad��Flash�������Ȃ����Ƃɕs����������[�U�[�͑�����
����J�W���A���Q�[�̕��ނ����ǁB
iPad��Flash�������Ȃ����Ƃɕs����������[�U�[�͑�����
�ŋ߂l�`�b�I�^���݂����Ȃ���
>>362
����50%�̃V�F�A�͐��\�������i���d�v�Ȏs�ꂾ����ˁA
Sandy�����R�A�T�C�Y��������Llano�̕����L��
�t�Ɏc���40%��GPU���\���d�v�Ȏs�ꂾ����AGPU�������\��Llano�̕����L��
CPU���\�������ق����L���Ȏs��͎��͗]�薳���̂�����
i7��X6�̃����W�����ǁA�V�F�A��5%���Ȃ�
����������CPU+����������GPU�̃V�F�A�Ȃ�20%�O�゠�肻�������ǁACPU�Ɠ������炢�̒l�i��GPU������邩��
����CPU�ŗ���Ă��C�ɂ��邱�Ƃ͂Ȃ���
���Ȃ݂�Llano�̃`�b�v�Z�b�g��SATA3 6�|�[�g&USB3�ɑΉ�����̂��m�肵�Ă���
Sandy�̃`�b�v�Z�b�g��B2�����ł���SATA3 ��2�|�[�g�~�܂�AUSB3�͖�������
CPU�̃V���O���X���b�h���\�ŗD�ʂɗ��Ă�̂͂��낻��I��肻���Ȋ���
����GPU��`�b�v�Z�b�g�̑��@�\�����v���b�g�t�H�[���Ƃ��Ẵo�����X�̗ǂ�������͏d�v�ɂȂ��Ă�����
����50%�̃V�F�A�͐��\�������i���d�v�Ȏs�ꂾ����ˁA
Sandy�����R�A�T�C�Y��������Llano�̕����L��
�t�Ɏc���40%��GPU���\���d�v�Ȏs�ꂾ����AGPU�������\��Llano�̕����L��
CPU���\�������ق����L���Ȏs��͎��͗]�薳���̂�����
i7��X6�̃����W�����ǁA�V�F�A��5%���Ȃ�
����������CPU+����������GPU�̃V�F�A�Ȃ�20%�O�゠�肻�������ǁACPU�Ɠ������炢�̒l�i��GPU������邩��
����CPU�ŗ���Ă��C�ɂ��邱�Ƃ͂Ȃ���
���Ȃ݂�Llano�̃`�b�v�Z�b�g��SATA3 6�|�[�g&USB3�ɑΉ�����̂��m�肵�Ă���
Sandy�̃`�b�v�Z�b�g��B2�����ł���SATA3 ��2�|�[�g�~�܂�AUSB3�͖�������
CPU�̃V���O���X���b�h���\�ŗD�ʂɗ��Ă�̂͂��낻��I��肻���Ȋ���
����GPU��`�b�v�Z�b�g�̑��@�\�����v���b�g�t�H�[���Ƃ��Ẵo�����X�̗ǂ�������͏d�v�ɂȂ��Ă�����
�|�b�P�ɓ���Ȃ����o�C���Ȃ�^�u���b�g���Đ�������̂��ȁH
�Ă�ipad���ĂȂɂ��ł���́H
������l tell me(darude��)
�Ă�ipad���ĂȂɂ��ł���́H
������l tell me(darude��)
385 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 20:10:59 ID:Iw7f5ZOt
SOI�͐ݔ�������������R�X�g���o���N���s���B�n�C�I���B
>>364
�\��Ă���̂̓e�w���c�q�̃t�����Ă�U�c�q����
�\��Ă���̂̓e�w���c�q�̃t�����Ă�U�c�q����
387 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 20:12:49 ID:Iw7f5ZOt
388 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 20:22:16 ID:Iw7f5ZOt
Intel��USB3.0�ɑΉ����ĂȂ��Ƃ���̂ǂ��َ̈����̐l�Ȃ�ł��傤��
�m�[�gPC�ł���Ή��@�킪�o�Ă�̂�
http://journal.mycom.co.jp/news/2010/02/23/045/index.html
�m�[�gPC�ł���Ή��@�킪�o�Ă�̂�
http://journal.mycom.co.jp/news/2010/02/23/045/index.html
�l�I�ɂ͂��A���{�̏ꍇ�g�т����ɉߏ�ɑ��@�\�����Ă�
GPS���ʐ^��������B�e�ł��A�܂��Đ����\�Ŗ���lan�Ȃ��g���Ă��܂�
�������ʘb�A���[������M�\�APC�T�C�g�̉{���܂ʼn\�AWORD,EXCEL,PDF���\�����x�͉\
���̏�X�}�[�g�t�H���Ȃ�A�^�u���b�g���Ă͎̂��v�͂���̂��ȁH
�Ƌ^�₪����
apple�̐��i�͂����̃t�@�b�V�����Ȃ�@��������������
�ǂ��ɂ���
news�Ŏ��グ���肷�邵
GPS���ʐ^��������B�e�ł��A�܂��Đ����\�Ŗ���lan�Ȃ��g���Ă��܂�
�������ʘb�A���[������M�\�APC�T�C�g�̉{���܂ʼn\�AWORD,EXCEL,PDF���\�����x�͉\
���̏�X�}�[�g�t�H���Ȃ�A�^�u���b�g���Ă͎̂��v�͂���̂��ȁH
�Ƌ^�₪����
apple�̐��i�͂����̃t�@�b�V�����Ȃ�@��������������
�ǂ��ɂ���
news�Ŏ��グ���肷�邵
390 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 20:26:44 ID:Iw7f5ZOt
�܁A����O���R���g���[�����݂����ǂȁB
�uCougar Point�v�ŃO�O�������
�uCougar Point�v�ŃO�O�������
SOI�ŃE�F�n�R�X�g�͏オ��B
�ł��E�F���`�����K�v�����Ȃ�����Z���T�C�Y���������Ȃ�����Ƃ������R�X�g�ʂł̃����b�g������B
�����SOI�̓����Ƃ��č����\���A�����d�͉��ł̃����b�g������B
�g�[�^���Ń����b�g�f�����b�g�f����̂̓v���ł��������f�l���f��I�Ɍ��̂͂��n���B
�ł��E�F���`�����K�v�����Ȃ�����Z���T�C�Y���������Ȃ�����Ƃ������R�X�g�ʂł̃����b�g������B
�����SOI�̓����Ƃ��č����\���A�����d�͉��ł̃����b�g������B
�g�[�^���Ń����b�g�f�����b�g�f����̂̓v���ł��������f�l���f��I�Ɍ��̂͂��n���B
392 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 20:35:16 ID:Iw7f5ZOt
> �����SOI�̓����Ƃ��č����\���A�����d�͉��ł̃����b�g������B
�܂��32nm�ŏ��߂�SOI�𓊓�����݂����Ȍ������ł���
65nm, 45nm�ł���o���N�v���Z�X��Intel�v���Z�b�T�̓d�͌����ɋy�Ȃ������̂�Y�ꂽ�́H
�}�C�N���A�[�L�e�N�`�����x���Ńe�R���ꂵ�Ȃ��Ƙb�ɂȂ�Ȃ��B
�܂��32nm�ŏ��߂�SOI�𓊓�����݂����Ȍ������ł���
65nm, 45nm�ł���o���N�v���Z�X��Intel�v���Z�b�T�̓d�͌����ɋy�Ȃ������̂�Y�ꂽ�́H
�}�C�N���A�[�L�e�N�`�����x���Ńe�R���ꂵ�Ȃ��Ƙb�ɂȂ�Ȃ��B
�t�ɍl����B
SOI������������}�C�N���A�[�L�e�B�N�`�����A���Ȃ̂�Intel���o�ɂȂ炸�ɍςƍl����B
SOI������������}�C�N���A�[�L�e�B�N�`�����A���Ȃ̂�Intel���o�ɂȂ炸�ɍςƍl����B
�m����SOI�ŃX�^���o�C���[�N�͗}�������A��
�A�C�h���͒Ⴂ���炻�������P�킵�������
�������͂����{���{��������
�A�C�h���͒Ⴂ���炻�������P�킵�������
�������͂����{���{��������
395 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 21:06:53 ID:Iw7f5ZOt
65nm��SOI���o���N�̕����܂�SRAM�̓����ǂ������Ȃ�Ęb������ˁ��\�j�[
�d�������Ȃ��Ɠd�q�̈ړ��x��������Ȃ��āAAthlon�̃��C����L2�L���b�V�������Ă�̂�90nm��背�C�e���V�����債����A
Barcelona/Agena��\�����N���b�N�ŏo������ƁAAMD�����Q���o�Ă��ˁB
����͎��s��������Ȃ��́H
���X���o�C�������ɐv���ꂽ��Ȃ�K7�̊g�����Ⴛ�낻�떳������Ȃ���
�܂��Ȃ�ɂ���Integer/FP�ŃX�P�W���[���������ꂽ�\�����ēd�͌����������Ƃ͎v�����
���Ƃ����[�h����FP/SIMD���Z���ė����̃X�P�W���[���Ƀ�OP�����s������
���̎��_�Ŋ��ɓd�͌��������C�������
FP���Z��Integer�N���X�^�ł̃��[�h�I�y���[�V�����Ɉˑ����鎞�_�ňˑ��W��f����ĂȂ��B
�ŁA�u���b�N�_�C�A�O�����������Bulldozer��K7�p�C�v���C���̓��������̂܂�܈��������Ă�킯����
�����N���X�^��issue���E����2���ׂ������Ő��\�オ��قNJÂ��͂Ȃ�����
�d�������Ȃ��Ɠd�q�̈ړ��x��������Ȃ��āAAthlon�̃��C����L2�L���b�V�������Ă�̂�90nm��背�C�e���V�����債����A
Barcelona/Agena��\�����N���b�N�ŏo������ƁAAMD�����Q���o�Ă��ˁB
����͎��s��������Ȃ��́H
���X���o�C�������ɐv���ꂽ��Ȃ�K7�̊g�����Ⴛ�낻�떳������Ȃ���
�܂��Ȃ�ɂ���Integer/FP�ŃX�P�W���[���������ꂽ�\�����ēd�͌����������Ƃ͎v�����
���Ƃ����[�h����FP/SIMD���Z���ė����̃X�P�W���[���Ƀ�OP�����s������
���̎��_�Ŋ��ɓd�͌��������C�������
FP���Z��Integer�N���X�^�ł̃��[�h�I�y���[�V�����Ɉˑ����鎞�_�ňˑ��W��f����ĂȂ��B
�ŁA�u���b�N�_�C�A�O�����������Bulldozer��K7�p�C�v���C���̓��������̂܂�܈��������Ă�킯����
�����N���X�^��issue���E����2���ׂ������Ő��\�オ��قNJÂ��͂Ȃ�����
396 �FSocket774�F2010/06/27(��) 21:10:19 ID:tWKQ6zSN
�c�q����CPU�ɕ`���������Ȃ�ĎG������v�����Ȃ��a�V���������
>>391
���Z���T�C�Y���������Ȃ�����
������ăL���b�V���ɂ�������́H
���Ƃ���ƃo���N�Ȃ̂�AMD��SOI���L���b�V����荂���x�����\��Intel�L���b�V���͂܂��Ń~���N������
�v�o�����X�����`���N�`����
���̂��߃L���b�V�������ɗ����Ȃ�������Ă�������̓I�Ɍ��������ފ��Ɏ���ł�̂�
CPU�����̓L���b�V���̂��A�ő嗲���i��イ�����j
���Z���T�C�Y���������Ȃ�����
������ăL���b�V���ɂ�������́H
���Ƃ���ƃo���N�Ȃ̂�AMD��SOI���L���b�V����荂���x�����\��Intel�L���b�V���͂܂��Ń~���N������
�v�o�����X�����`���N�`����
���̂��߃L���b�V�������ɗ����Ȃ�������Ă�������̓I�Ɍ��������ފ��Ɏ���ł�̂�
CPU�����̓L���b�V���̂��A�ő嗲���i��イ�����j
398 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 21:17:01 ID:Iw7f5ZOt
�c�q���ߋ���Larrabee�}���Z�[���܂�������@�������ʼn���
����፡�x�͊J�����~����
����፡�x�͊J�����~����
�U�c�q��1����2ch������邱�Ƃ��Ȃ��̂�
�u0��3�s�v�����ē������̓z�݂������Ȃ�
403 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 21:37:25 ID:Iw7f5ZOt
���@������
Llano�̂��Ƃł�������
480SP�Ȃ�Ă���ς薳�����������������Ȃ�
Llano�̂��Ƃł�������
480SP�Ȃ�Ă���ς薳�����������������Ȃ�
{kind=link}
405 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 21:42:13 ID:Iw7f5ZOt
���C�h�V���[�ɏo�Ă��P�o���o�����A�C�h���̂ق�������ۂǃT�b�J�[�������Ă���
���₢��A����ȕ⏕���璴���锭�z�ł�����
�l�̖@�����ĉ䂪�@�����Ȃ�Ƃ��
�l�̖@�����ĉ䂪�@�����Ȃ�Ƃ��
�t�ɍl����B
�Z���������J�I�\�z�������炱�����{��\�����N�����ƍl��r
�Z���������J�I�\�z�������炱�����{��\�����N�����ƍl��r
408 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 21:50:00 ID:Iw7f5ZOt
14 �F�R�E�L�́M�E,,�j����������������[sage]�F2008/06 /24(��) 18:52:02 ID:UAl3M5Yx
����AGPU��SSE5�]�X�̓u���t�̈���o�Ȃ��A�Ǝv���Ă���B
CPU�A�[�L�e�N�`���ɕs�ē��ȓ�������t�@���{�[�C��ނ邽�߂̉a����
������ReverseHT�̂悤�ȁA�ˁB
�����ł���x86�ɂ����ĕ����������Z�̓��C�e���V�傫���ăp�C�v���C���n�U�[�h���N�����₷���B
����FPU����������Ƃ����̂͂����������\����̍�ł͂Ȃ��B
�x�N�^���𑝂₵����SMT�ɂ�郌�C�e���V�B���̂ق������ʓI���B
������SSE5�͊�����SSE�̉�����128bit SIMD�ł���AGPU���ӎ������悤�Ȑv�ł͂Ȃ��B
�܂�AVX���̗p��������AMD�ɂƂ��Ă������b�g�͑傫���B
�Ȃ����4�I�y�����h�Ȃ�Ďg�������Ȃ���\�t�g�J���҂����āB
���̎��_��SSE5�|�V����AVX�Ή���\�����Ă������ǂǂ��v�����H
����AGPU��SSE5�]�X�̓u���t�̈���o�Ȃ��A�Ǝv���Ă���B
CPU�A�[�L�e�N�`���ɕs�ē��ȓ�������t�@���{�[�C��ނ邽�߂̉a����
������ReverseHT�̂悤�ȁA�ˁB
�����ł���x86�ɂ����ĕ����������Z�̓��C�e���V�傫���ăp�C�v���C���n�U�[�h���N�����₷���B
����FPU����������Ƃ����̂͂����������\����̍�ł͂Ȃ��B
�x�N�^���𑝂₵����SMT�ɂ�郌�C�e���V�B���̂ق������ʓI���B
������SSE5�͊�����SSE�̉�����128bit SIMD�ł���AGPU���ӎ������悤�Ȑv�ł͂Ȃ��B
�܂�AVX���̗p��������AMD�ɂƂ��Ă������b�g�͑傫���B
�Ȃ����4�I�y�����h�Ȃ�Ďg�������Ȃ���\�t�g�J���҂����āB
���̎��_��SSE5�|�V����AVX�Ή���\�����Ă������ǂǂ��v�����H
�c�q���đO���炱��Ȋ����������H
�c�q�N�͕������邩��
�c�q����@�����������̂���AVX����Ȃ���Larrabee�Ȃ̂�...
��̘b��ɋC������Ղ���
��̘b��ɋC������Ղ���
412 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 22:00:00 ID:Iw7f5ZOt
MIC�͓�����������ނ�����������
HPC�����H�����z���
�ėp�R�A��AVX�ł�������xGPU��ւł���Ȃ�債�ĕK�v�Ȃ���
HPC�����H�����z���
�ėp�R�A��AVX�ł�������xGPU��ւł���Ȃ�債�ĕK�v�Ȃ���
413 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 22:04:15 ID:Iw7f5ZOt
�~�F�u480SP��Sandy Bridge�Ɉ����I�v�@
��
����ς�200SP�ł���
��
����H�\�t�gGPU���p������Sandy Bridge�ł�Llano��GPU�R�U�点���ˁH��������
��
����ς�200SP�ł���
��
����H�\�t�gGPU���p������Sandy Bridge�ł�Llano��GPU�R�U�点���ˁH��������
�����̒�]�����R�s�y�Ƃ͉�����A���r���ȏ�̉�������
>>393
�������������HK/MG������������AMD�ɒǂ��z����Ȃ��čςɂ��Ȃ��Ă��܂�
�������������HK/MG������������AMD�ɒǂ��z����Ȃ��čςɂ��Ȃ��Ă��܂�
�������Llano���Ēf�肳�ꂽ�H
417 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 22:08:55 ID:Iw7f5ZOt
�܂��A�\�t�gGPU�Ƃ͌����Ă邪
���XDirectX�̑O��������CPU��SIMD���\�ŏ�������Ă�
GPU�̕����i����GPU�ł��悤�ɂȂ���
CPU�̃}���`�R�A��SIMD�����ŃX���[�v�b�g���ǂ����Ă�����������
���̗����ʒu�ɖ߂���邾�������ǂ�
>>415
Intel��65nm�v���Z�X��HKMG�Ȃ�Ďg���Ă܂��i�j
���XDirectX�̑O��������CPU��SIMD���\�ŏ�������Ă�
GPU�̕����i����GPU�ł��悤�ɂȂ���
CPU�̃}���`�R�A��SIMD�����ŃX���[�v�b�g���ǂ����Ă�����������
���̗����ʒu�ɖ߂���邾�������ǂ�
>>415
Intel��65nm�v���Z�X��HKMG�Ȃ�Ďg���Ă܂��i�j
>>413
200SP���������Ƃ�����A�����������肾��ȁB
200SP���������Ƃ�����A�����������肾��ȁB
>>415
intel��SOI���̗p���Ȃ��̂�AMD��HKMG���̗p���ĂȂ��͓̂���Ȃ̂��H
intel��SOI���̗p���Ȃ��̂�AMD��HKMG���̗p���ĂȂ��͓̂���Ȃ̂��H
��GPU��SSE5
SSE5�ɂ̓V�F�[�_�������߂��������Ƃ������ƂȂ�����
AMD�̗\��́uGPU��FPU�Ɂv
��ReverseHT
���\��
���p�C�v���C���n�U�[�h
ttp://ja.wikipedia.org/wiki/%E3%83%91%E3%82%A4%E3%83%97%E3%83%A9%E3%82%A4%E3%83%B3%E5%87%A6%E7%90%86#.E3.83.91.E3.82.A4.E3.83.97.E3.83.A9.E3.82.A4.E3.83.B3.E3.83.8F.E3.82.B6.E3.83.BC.E3.83.89
�ˑ��╪��̏��Ȃ������Ńn�U�[�h�Ƃ͗��A������S�J�A����S�H
������FPU����������
��������H
��AVX���̗p��������AMD�ɂƂ��Ă������b�g�͑傫��
SSE5���\���AVX���\������
���̐▭�ȃ^�C�~���O�䂦��
����SSE���S�~������\�肾�����̂ɂ���ɃS�~��AVX��ی��Ƃ��ē��ꂴ��Ȃ��Ȃ���
�܂��܂�����Ƃق�ƃX�Q�[
�m�\0�ǂ��납�}�C�i�X�l�s����Ȃ����H
SSE5�ɂ̓V�F�[�_�������߂��������Ƃ������ƂȂ�����
AMD�̗\��́uGPU��FPU�Ɂv
��ReverseHT
���\��
���p�C�v���C���n�U�[�h
ttp://ja.wikipedia.org/wiki/%E3%83%91%E3%82%A4%E3%83%97%E3%83%A9%E3%82%A4%E3%83%B3%E5%87%A6%E7%90%86#.E3.83.91.E3.82.A4.E3.83.97.E3.83.A9.E3.82.A4.E3.83.B3.E3.83.8F.E3.82.B6.E3.83.BC.E3.83.89
�ˑ��╪��̏��Ȃ������Ńn�U�[�h�Ƃ͗��A������S�J�A����S�H
������FPU����������
��������H
��AVX���̗p��������AMD�ɂƂ��Ă������b�g�͑傫��
SSE5���\���AVX���\������
���̐▭�ȃ^�C�~���O�䂦��
����SSE���S�~������\�肾�����̂ɂ���ɃS�~��AVX��ی��Ƃ��ē��ꂴ��Ȃ��Ȃ���
�܂��܂�����Ƃق�ƃX�Q�[
�m�\0�ǂ��납�}�C�i�X�l�s����Ȃ����H
421 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 22:23:36 ID:Iw7f5ZOt
��SSE5�ɃV�F�[�_��������
���݂��܂���
���݂��܂���
5-way�ł��Ȃ����Ȃ��B
423 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 22:37:19 ID:Iw7f5ZOt
5Way-VLIW�~64����̃x�N�g���A���C����������4�`8�����x86��SIMD���ߌo�R�Ŏg���Ƃ��ǂ��l���Ă����蓾�Ȃ��̂͒��w���ł����闝���B
NVIDIA�̉��Z���j�b�g�\���Ȃ�CPU�ɂ�����x�߂�����܂������Ȃ����ȂƎv�����ǂ�
NVIDIA�̉��Z���j�b�g�\���Ȃ�CPU�ɂ�����x�߂�����܂������Ȃ����ȂƎv�����ǂ�
>>323
�͂��ǁ[
�͂��ǁ[
SSE5�ɂ������i�炵���j�����x�ϊ���
�f�[�^�T�C�Y���ɂ������Ɏl�̌ܓ��ȂǂŒl�̐��x�������
�`��Ȃ�ш�d�v�������������������Ă��h�b�g��������u�o����x�Ȃ̂Ŗ�薳��
�������ėp���Z�ł͂��̖��߂͎g���h��
���������Ӗ��ŃV�F�[�_�������Ƃ̂���
������3�A�E���R�ɂƂ��Ă͗����i��������j����ƃf�b�h�X�y�[�X�ƃx���`�������d�v������
�uCPU�Ŏg���ĉ��̖�肪����H�v���Ă��ƂȂ낤��
�f�[�^�T�C�Y���ɂ������Ɏl�̌ܓ��ȂǂŒl�̐��x�������
�`��Ȃ�ш�d�v�������������������Ă��h�b�g��������u�o����x�Ȃ̂Ŗ�薳��
�������ėp���Z�ł͂��̖��߂͎g���h��
���������Ӗ��ŃV�F�[�_�������Ƃ̂���
������3�A�E���R�ɂƂ��Ă͗����i��������j����ƃf�b�h�X�y�[�X�ƃx���`�������d�v������
�uCPU�Ŏg���ĉ��̖�肪����H�v���Ă��ƂȂ낤��
�L���������Łu������ˁH�v�Ƃ������d�삩�E�E�E
428 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 23:08:34 ID:Iw7f5ZOt
��������128�r�b�g4�����SIMD���߂��̂��̂�GPU�Ɍ����ĂȂ����B
4�l���̕s���̍�Ƃ��l4�l�ł����q��320�l�ɗ^�������������Ȃ�Ȃ�Č������獼�\�t�ȊO�̂Ȃ�ł��Ȃ��B
4�l���̕s���̍�Ƃ��l4�l�ł����q��320�l�ɗ^�������������Ȃ�Ȃ�Č������獼�\�t�ȊO�̂Ȃ�ł��Ȃ��B
429 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 23:12:01 ID:Iw7f5ZOt
�����x�ϊ��i�j�����܂��ɔ����x4����̃x�N�g���ƒP���x4����̃x�N�g���𑊌ݕϊ����鑀�삪
320����̉��Z���j�b�g�ő����Ȃ�Ƃ��ǂ��r��
320����̉��Z���j�b�g�ő����Ȃ�Ƃ��ǂ��r��
Fusion����SIMD��GPU�ɕ��荞�ނ�
�������`
�������`
431 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 23:18:46 ID:Iw7f5ZOt
>>427
����قǐ��x���K�v�Ȃ��f�[�^�����Ǒ�ʂɓǂݏ�������ꍇ�A
�������ш搧��������������ׂ�GPU�łȂ��Ƃ�CPU�ł��g���܂���A���k�t�H�[�}�b�g�́B
SIMD���j�b�g�̃X���[�v�b�g�ɑ���DRAM�ш拷���̂�CPU����������
���Ȃ݂�Intel Compiler�ł������x�̈��k�W�J�͑g�ݍ��݊����x���őΉ����Ă܂���B
�\�t�g�����Ȃ̂�SSE2�ȏ�Ŏg���܂��B
�Q�[���Ƃ��ŕ`��p�C�v���C���̑O����CPU�Ŏ��O�ł���Ă�l�Ȃ炻��Ȃ�Ɏg����������Ȃ��B
�ǂ������Ƃ�����GPU�ɔ��s���閽�߂���Ȃ���GPU��������Ƃɂ��閽�߂����ǂ�
����قǐ��x���K�v�Ȃ��f�[�^�����Ǒ�ʂɓǂݏ�������ꍇ�A
�������ш搧��������������ׂ�GPU�łȂ��Ƃ�CPU�ł��g���܂���A���k�t�H�[�}�b�g�́B
SIMD���j�b�g�̃X���[�v�b�g�ɑ���DRAM�ш拷���̂�CPU����������
���Ȃ݂�Intel Compiler�ł������x�̈��k�W�J�͑g�ݍ��݊����x���őΉ����Ă܂���B
�\�t�g�����Ȃ̂�SSE2�ȏ�Ŏg���܂��B
�Q�[���Ƃ��ŕ`��p�C�v���C���̑O����CPU�Ŏ��O�ł���Ă�l�Ȃ炻��Ȃ�Ɏg����������Ȃ��B
�ǂ������Ƃ�����GPU�ɔ��s���閽�߂���Ȃ���GPU��������Ƃɂ��閽�߂����ǂ�
432 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 23:25:34 ID:Iw7f5ZOt
���Ȃ݂ɂ����
http://www.intel.com/software/products/compilers/docs/clin/main_cls/intref_cls/common/intref_halffloat_overview.htm
GPU�ɔ��s�i�j���đ�����
http://www.intel.com/software/products/compilers/docs/clin/main_cls/intref_cls/common/intref_halffloat_overview.htm
GPU�ɔ��s�i�j���đ�����
Intel�̃I�E���S�[��
http://www.geocities.jp/andosprocinfo/wadai10/20100626.htm
http://www.geocities.jp/andosprocinfo/wadai10/20100626.htm
434 �F,,�E�L�́M�E,,�j��-�������F2010/06/27(��) 23:47:11 ID:Iw7f5ZOt
>>433
�ނ���]�T�̌��ꂾ��
�ނ���]�T�̌��ꂾ��
����Sandy����GPU��������Ⴂ�Ȃ��Ďv��������
NVIDIA�Ƃ����܂���
�u�[�h�D�[�ƂƂ�
�u�[�h�D�[�ƂƂ�
ttp://www.freepatentsonline.com/20090172370.pdf
Bulldozer�͗����̎��s���j�b�g�ɖ��T�C�N��4���߃f�B�X�p�b�`�ł���\��������
����4���߂�������̃�ops�Ȃ̂�����O��Macro Ops�Ȃ̂��ɂ���Đ��\�͈���Ă���
Bulldozer�͗����̎��s���j�b�g�ɖ��T�C�N��4���߃f�B�X�p�b�`�ł���\��������
����4���߂�������̃�ops�Ȃ̂�����O��Macro Ops�Ȃ̂��ɂ���Đ��\�͈���Ă���
���T�C�N��x86�}�N��4���߃f�B�X�p�b�`�������I�ȃg�����W�X�^�R�X�g�ʼn\���Ǝv���܂���?
>>433
�I�E���S�[�����Ă�����ׂ��݂����Ȃ̂�������Ȃ���
�u�S���\�t�g�E�F�A����������v���O���}�ɕ��S�|����ΐ������Ƃ��o����i�\��������j�v
�ux86�f�R�[�_�ς�ł邩��n�[�h�E�F�A�I�ɂ��Ȃ�̕��S�����v���O���}�̕��S�͌���i��������Ȃ��j�v
�ȂǂƎU�X�����ł��Ǝv�����炢�̂܂ɂ����ł��Ă����Ö��p�⒴�X�s�[�h�ȊO�̉���
���������͎̂��M���X�ɓo�ꂵ�Ă������Ȃ������U�R�G�p�^�[���ł���Intel�̓`���|�\�i��ɑi�זʁj
�I�E���S�[�����Ă�����ׂ��݂����Ȃ̂�������Ȃ���
�u�S���\�t�g�E�F�A����������v���O���}�ɕ��S�|����ΐ������Ƃ��o����i�\��������j�v
�ux86�f�R�[�_�ς�ł邩��n�[�h�E�F�A�I�ɂ��Ȃ�̕��S�����v���O���}�̕��S�͌���i��������Ȃ��j�v
�ȂǂƎU�X�����ł��Ǝv�����炢�̂܂ɂ����ł��Ă����Ö��p�⒴�X�s�[�h�ȊO�̉���
���������͎̂��M���X�ɓo�ꂵ�Ă������Ȃ������U�R�G�p�^�[���ł���Intel�̓`���|�\�i��ɑi�זʁj
�܁AAMD�͉ᒠ�̊O�Ȃ�ł�����
http://pc.watch.impress.co.jp/docs/news/event/20100628_377262.html
Q: ���ɓd�͂Ɋւ��āB�����m�̒ʂ�NVIDIA��Fermi�`�b�v���o���܂������A���ꂪ�P�̂�300W��v������Ƃ������̂ł��B
�������ނ�͂�����ڂ����{�[�h���o�����Ƃ��Ă��܂��B
A: (���肦�Ȃ��A�Ƃ�����œV����)�B
Q: �����Ƃ������NVIDIA�݂̂Ȃ炸AMD�₻�̑��̃A�N�Z�����[�^�x���_�[������͓����ŁA
�Ȃ̂ʼn\�Ȃ��300W����d�͋�����~���Ă��܂��B
���PCIe��CEM�ł́A����300W�܂ł�����`����Ă��܂���B����ɂ��Ăǂ��v���܂����B
A: ����GPU�ɂ͏ڂ����Ȃ����A�ł�300W�͔���ȓd�͂Ȃ��B
Q: �܂������Ȃ�ł����A���Ƃ��J�^���O�X�y�b�N�ł�290W�Ƃ��ɂȂ��Ă��Ă��A
�x���`�}�[�N���Əu�ԓI�ɂ�300W�����肷�邱�Ƃ�����킯�ł��B
�ŁA��荂�������d�͂�CEM���`����Ƃ������\���?
A: �Ȃ�!! 300W�ŏ\�����B
Q: ���ƁAATI��NVIDIA�̃��t�@�����X�J�[�h�͂����Ȃ��Ă܂��A
�s��ɏo�Ă��鐻�i�̒��ɂ́A2x4�̓d���R�l�N�^��2�����̂�����A
����ɑΉ����ēd�����[�J�[��2x4���[����2�Ƃ�4�o������̂������Ă��܂��B������ǂ��v���܂�?
A: �ǂ�ȃt�H�[���t�@�N�^�[������ȋ��낵�����̂��g����?
Q: ����͂܂�����ȃP�[�X�ł��˂��B
������1,000W����d���������ĂāA�����2�~4�R�l�N�^��2���ڂ��ꂽ�J�[�h��2����������Ă���Ƃ����B
�ŋ߂͂��������\�����n�C�G���h�}�V���̃f�t�@�N�g�X�^���_�[�h�ɂȂ����̂ł����B
A: ������G���h���[�U�[���[�����čw������̂Ȃ�A������Ȃ����ȁB
�������Ȃ��Ƃ�CEM�Ɋւ��ẮA��������(2�~4�R�l�N�^��2���ڂ���)�\���� 300W����d�͋����Ƃ�������Ă͑��݂��Ȃ��B
���Ȃ��Ƃ����݁A���������j�[�Y�͂���߂Č���ꂽ�}�[�P�b�g�����ˁB
Q: ���ɓd�͂Ɋւ��āB�����m�̒ʂ�NVIDIA��Fermi�`�b�v���o���܂������A���ꂪ�P�̂�300W��v������Ƃ������̂ł��B
�������ނ�͂�����ڂ����{�[�h���o�����Ƃ��Ă��܂��B
A: (���肦�Ȃ��A�Ƃ�����œV����)�B
Q: �����Ƃ������NVIDIA�݂̂Ȃ炸AMD�₻�̑��̃A�N�Z�����[�^�x���_�[������͓����ŁA
�Ȃ̂ʼn\�Ȃ��300W����d�͋�����~���Ă��܂��B
���PCIe��CEM�ł́A����300W�܂ł�����`����Ă��܂���B����ɂ��Ăǂ��v���܂����B
A: ����GPU�ɂ͏ڂ����Ȃ����A�ł�300W�͔���ȓd�͂Ȃ��B
Q: �܂������Ȃ�ł����A���Ƃ��J�^���O�X�y�b�N�ł�290W�Ƃ��ɂȂ��Ă��Ă��A
�x���`�}�[�N���Əu�ԓI�ɂ�300W�����肷�邱�Ƃ�����킯�ł��B
�ŁA��荂�������d�͂�CEM���`����Ƃ������\���?
A: �Ȃ�!! 300W�ŏ\�����B
Q: ���ƁAATI��NVIDIA�̃��t�@�����X�J�[�h�͂����Ȃ��Ă܂��A
�s��ɏo�Ă��鐻�i�̒��ɂ́A2x4�̓d���R�l�N�^��2�����̂�����A
����ɑΉ����ēd�����[�J�[��2x4���[����2�Ƃ�4�o������̂������Ă��܂��B������ǂ��v���܂�?
A: �ǂ�ȃt�H�[���t�@�N�^�[������ȋ��낵�����̂��g����?
Q: ����͂܂�����ȃP�[�X�ł��˂��B
������1,000W����d���������ĂāA�����2�~4�R�l�N�^��2���ڂ��ꂽ�J�[�h��2����������Ă���Ƃ����B
�ŋ߂͂��������\�����n�C�G���h�}�V���̃f�t�@�N�g�X�^���_�[�h�ɂȂ����̂ł����B
A: ������G���h���[�U�[���[�����čw������̂Ȃ�A������Ȃ����ȁB
�������Ȃ��Ƃ�CEM�Ɋւ��ẮA��������(2�~4�R�l�N�^��2���ڂ���)�\���� 300W����d�͋����Ƃ�������Ă͑��݂��Ȃ��B
���Ȃ��Ƃ����݁A���������j�[�Y�͂���߂Č���ꂽ�}�[�P�b�g�����ˁB
442 �FSocket774�F2010/06/28(��) 12:45:27 ID:pNfkLKwX
��AM3�����͎̂�����������ok?
939�����������
939�����������
�ꎮ�����ւ��Ȃ玞������������
�Ƃ�����AMD��I������̂͂���Ӗ��唎�ł���
�u���h�U�[�̐��\���U�X�������ꍇ���l����Ɓi�T���f�B�̈��|�I�ȍ����\���\�z����邾���Ɂj
�\�Z������Ȃ�3���~�ŏo��12CPU�Ai7 970���ڂ�1366��930������őg�ނ̂��x�^�[����
�Ƃ�����AMD��I������̂͂���Ӗ��唎�ł���
�u���h�U�[�̐��\���U�X�������ꍇ���l����Ɓi�T���f�B�̈��|�I�ȍ����\���\�z����邾���Ɂj
�\�Z������Ȃ�3���~�ŏo��12CPU�Ai7 970���ڂ�1366��930������őg�ނ̂��x�^�[����
����ψꎮ������ɂ͎������������[�B
�u����T���f�B�҂Ɨ��N�ɂȂ�����B
AthlonIIX2�ł�������̍�낤�Ǝv�������ǁA�ڂ����d�l�o��܂ő҂��ȁB
�u����T���f�B�҂Ɨ��N�ɂȂ�����B
AthlonIIX2�ł�������̍�낤�Ǝv�������ǁA�ڂ����d�l�o��܂ő҂��ȁB
AM3r2���o���
����AM3�Ƃ�AM2+��AM2�̂悤�ȊW�ɂȂ�͂�
������������������
����AM3�Ƃ�AM2+��AM2�̂悤�ȊW�ɂȂ�͂�
������������������
�Ԃ�₳��ł����łĈ����Ȃ����������_������
�V�����̂��D�����[���Đl�͐V����ɔ�ѕt���̂��ǂ�
�݊����C�ɂ���Ȃ獡��intel���i�̓X���[����
AMD��AM3�ł̂邩������Ȃ����ǃt���ɋ@�\���ł��Ȃ����낤���A�����������ډ\�����������̂ł���ς�V���i�҂��������߂���
�V�����̂��D�����[���Đl�͐V����ɔ�ѕt���̂��ǂ�
�݊����C�ɂ���Ȃ獡��intel���i�̓X���[����
AMD��AM3�ł̂邩������Ȃ����ǃt���ɋ@�\���ł��Ȃ����낤���A�����������ډ\�����������̂ł���ς�V���i�҂��������߂���
AM2+��AM2r2�͓���������AAM3��AM3��2���������낤
BIOS�X�V�������Ƃ��鏊�̔�������
BIOS�X�V�������Ƃ��鏊�̔�������
�Ԉ�����BAM2��AM2+��AM3��AM3��2�̊W�͓������Ă��Ƃ�
G34��Bull�ɑΉ�����݂�������AMD 800�ԑ�̃}�U�[�Ȃ�BIOS�̍X�V�����ōڂ肻������
�܂��݊����������Ă����\���o�Ȃ���ΈӖ��̖������Ƃ����A���̓������̉��i���������Ȃ�ʼn\�Ȃ�҂����ق���������
�܂��݊����������Ă����\���o�Ȃ���ΈӖ��̖������Ƃ����A���̓������̉��i���������Ȃ�ʼn\�Ȃ�҂����ق���������
450 �FSocket774�F2010/06/28(��) 16:01:43 ID:5ra7tLIY
>>433
2.5�{���x�̍��Ȃ�sandybridge�ɂȂ�AAVX��FPU�{�����R�A�������Œǂ�����ƌ���������ˁB
2.5�{���x�̍��Ȃ�sandybridge�ɂȂ�AAVX��FPU�{�����R�A�������Œǂ�����ƌ���������ˁB
451 �F,,�E�L�́M�E,,�j��-�������F2010/06/28(��) 17:00:21 ID:vvW5sVNH
Intel�͕��ʂ�C/C++�Ńv���O���~���O�ł��Ȃ����Y���̈������O�X����w�E���Ă��
Cell�́u�����N���b�N�E��������d�͂�Pentium 4�̏\���{�v�ɔ�ׂ��
�X�ɓ���ȃv���O���~���O�X�^�C����v������̂ɏ]��CPU�̕���2.5�{���Ă̂�
�Ќ����Ȃ��ɂ��قǂ�����B
HPC�ɂ�����Tesla(Fermi)�̃R�X�g�p�t�H�[�}���X�̔��������w�E����ɂ͏\���Ȍ��ʂ͂���Ǝv���B
Cell�́u�����N���b�N�E��������d�͂�Pentium 4�̏\���{�v�ɔ�ׂ��
�X�ɓ���ȃv���O���~���O�X�^�C����v������̂ɏ]��CPU�̕���2.5�{���Ă̂�
�Ќ����Ȃ��ɂ��قǂ�����B
HPC�ɂ�����Tesla(Fermi)�̃R�X�g�p�t�H�[�}���X�̔��������w�E����ɂ͏\���Ȍ��ʂ͂���Ǝv���B
>>444
�܂�880��IIX2�̂��Ƃ��A���ƎO�N�̓l�b�g�̓���Đ��ō��邱�Ƃ͂Ȃ��B
�}�U�[�̏������ł����Ȃ�AIntel�̂ق����������Ȃ����B
������CPU���o�Ă��}�U�[�̎g���A�܂���������B
�܂�880��IIX2�̂��Ƃ��A���ƎO�N�̓l�b�g�̓���Đ��ō��邱�Ƃ͂Ȃ��B
�}�U�[�̏������ł����Ȃ�AIntel�̂ق����������Ȃ����B
������CPU���o�Ă��}�U�[�̎g���A�܂���������B
AM����FM���������
bulldozer��AM3�Ȃ�llano�̃\�P�b�g��llano��p�ŏI��肩���H
����Ƃ�2015�N�ȍ~�̑�2����ȍ~���g����́H
��������5�N�ȏ�ς�炸�H
bulldozer��AM3�Ȃ�llano�̃\�P�b�g��llano��p�ŏI��肩���H
����Ƃ�2015�N�ȍ~�̑�2����ȍ~���g����́H
��������5�N�ȏ�ς�炸�H
455 �F,,�E�L�́M�E,,�j��-�������F2010/06/28(��) 20:27:48 ID:vvW5sVNH
Phenom II���V���O���X���b�h�������Z���\�������邩������Ȃ�CPU�ɍڂ��ւ��\�Ȃ��Ƃ͊m���Ƀ����b�g�ł���
�܂��AIntel�Ȃ�Ă����A�ƍߍs�טa����Ƃ���Ȃ������ł��ȁB
�ЂƂƂ��Ă̑��������Ȃ����Ă̂Ȃ�ʂ����B
�ЂƂƂ��Ă̑��������Ȃ����Ă̂Ȃ�ʂ����B
���肪�シ����̂����Ȃ�Ȃ��̂���
458 �F,,�E�L�́M�E,,�j��-�������F2010/06/28(��) 20:42:59 ID:vvW5sVNH
>>454
HPC�ŏd�v�Ȃ͓̂d�͓����萫�\�B
�o��͓����R�X�g��胉�j���O�R�X�g�̂ق�������B
Nehalem��4�R�A��100GFLOPS�Ƃ���ƁAWestmere��6�R�A��150GFLOPS�ASandy Bridge�͓�6�R�A��400GFLOPS�ȁB
���̃C���p�N�g�͑傫���B
Fermi��GTX280��2�{�����s�[�NFP���Z���\�͂ނ��뗎���Ă�iSFU�ł�MUL�����s�o���Ȃ��Ȃ����ׁj��
����d�͂�GTX280��葝���Ă���B
���͂ǂ�ǂ�l�܂�B
HPC�ŏd�v�Ȃ͓̂d�͓����萫�\�B
�o��͓����R�X�g��胉�j���O�R�X�g�̂ق�������B
Nehalem��4�R�A��100GFLOPS�Ƃ���ƁAWestmere��6�R�A��150GFLOPS�ASandy Bridge�͓�6�R�A��400GFLOPS�ȁB
���̃C���p�N�g�͑傫���B
Fermi��GTX280��2�{�����s�[�NFP���Z���\�͂ނ��뗎���Ă�iSFU�ł�MUL�����s�o���Ȃ��Ȃ����ׁj��
����d�͂�GTX280��葝���Ă���B
���͂ǂ�ǂ�l�܂�B
�����i��������j����f�b�h�X�y�[�X���ړ��Ăŗ���̂͂����ǂ����悤���Ȃ��Ƃ��Ă�
���߂Ė��Ғœ����̐������x�̒m�\�͔������
���߂Ė��Ғœ����̐������x�̒m�\�͔������
460 �F,,�E�L�́M�E,,�j��-�������F2010/06/28(��) 20:46:52 ID:vvW5sVNH
8�R�A��400���ȁB���܂�B
������Westmere 6�R�A��Sandy Bridge 8�R�A������TDP�œ����N���b�N�o����̂��͋^��
������Westmere 6�R�A��Sandy Bridge 8�R�A������TDP�œ����N���b�N�o����̂��͋^��
���`���~��28nm�ɼ��ݸ����ł���
�����炭Northern Islands + Bulldozer�̃Z�b�g���肷�邾�낤����܂��܂����S�ł��Ȃ�nv
�����炭Northern Islands + Bulldozer�̃Z�b�g���肷�邾�낤����܂��܂����S�ł��Ȃ�nv
462 �F,,�E�L�́M�E,,�j��-�������F2010/06/28(��) 21:11:22 ID:vvW5sVNH
Intel��22nm���V�������N���čX��FMA�T�|�[�g��FP���\�X��2�{
���̂�����ɂȂ��GPGPU�̓Q�[���I�[�o�[����
���̂�����ɂȂ��GPGPU�̓Q�[���I�[�o�[����
>>458
GTX280��GTX480��ׂ����ʂȂ�Ăǂ̃e�X�g�ł�GTX480���������Ă邵
���ɂ���Ă͂��ꂱ���d�͂̑����ȂC�ɂ��Ȃ�Ȃ����炢���\�オ���Ă����
�s�[�N�p�t�H�[�}���X�������Ă�Ƃ��Ď��ۂɂ��ꂪ�o�Ă錋�ʂȂ����L����������
�ȂŒ��ꒃ�����Ȍ��_���ĂȂ�������
GTX280��GTX480��ׂ����ʂȂ�Ăǂ̃e�X�g�ł�GTX480���������Ă邵
���ɂ���Ă͂��ꂱ���d�͂̑����ȂC�ɂ��Ȃ�Ȃ����炢���\�オ���Ă����
�s�[�N�p�t�H�[�}���X�������Ă�Ƃ��Ď��ۂɂ��ꂪ�o�Ă錋�ʂȂ����L����������
�ȂŒ��ꒃ�����Ȍ��_���ĂȂ�������
3Dmark�̉�����GTX280�ɕ����ĂȂ���������
�Ƃ����GTX495�݂����ȃf���A���`�b�v���ďo��낤��
�Ƃ����GTX495�݂����ȃf���A���`�b�v���ďo��낤��
466 �F,,�E�L�́M�E,,�j��-�������F2010/06/28(��) 21:27:00 ID:vvW5sVNH
> GTX280��GTX480��ׂ����ʂȂ�Ăǂ̃e�X�g�ł�GTX480���������Ă邵
280����Ȃ͓̂�����O���B
295�Ɣ�ׂ��
�Ă��AHPC�̃x���`�}�[�N����ˁ[����
280����Ȃ͓̂�����O���B
295�Ɣ�ׂ��
�Ă��AHPC�̃x���`�}�[�N����ˁ[����
2005�N�Ȃ�X2���o�邩�Ȃ��ĂƂ��낾��
468 �F,,�E�L�́M�E,,�j��-�������F2010/06/28(��) 21:49:17 ID:vvW5sVNH
http://www.microway.com/pdfs/TeslaC2050-Fermi-Performance.pdf
���ꂩ
�܂��ACPU��2�{���x�������������ĂȂ�����͊m���Ɏ��ʂ��
���ꂩ
�܂��ACPU��2�{���x�������������ĂȂ�����͊m���Ɏ��ʂ��
470 �FSocket774�F2010/06/28(��) 21:52:16 ID:/5eZAroa
�����r���v��Ȃ��q���ؖ����ꂽ�̂�
471 �F,,�E�L�́M�E,,�j��-�������F2010/06/28(��) 21:55:03 ID:vvW5sVNH
> sandy��GTX280�Ȃ�ڋ߂��邩������Ȃ�����sandy��GTX480�Ȃ�
> ���ǁu����2.5�{�����v�܂܂������������Ȃ�ł́H
�Ƃ肠��������͓P�悤��
Sandy Bridge��Nehalem�Ɣ�r���ăR�A��1.5�`2�{�A�R�A�������SIMD���Z���\��2�{
> ���ǁu����2.5�{�����v�܂܂������������Ȃ�ł́H
�Ƃ肠��������͓P�悤��
Sandy Bridge��Nehalem�Ɣ�r���ăR�A��1.5�`2�{�A�R�A�������SIMD���Z���\��2�{
�܂��A�P���ɂ����Ɛ��\���͔����Ɍ���Ƃ������Ƃ��낤�ȁB
�����A����GTX280�Ƃ�GTX480�̂悤�Ȕ��M�ȍ�����d�͂�GPU�Ɣ�r���Ă���i�K�ł�����ƈُ�ł����Ȃ�
�d�͌����̗ǂ�GPU�Ƃ̔�r�łȂ��ƈӖ����Ȃ��̂��낤�Ǝv���B
�����A����GTX280�Ƃ�GTX480�̂悤�Ȕ��M�ȍ�����d�͂�GPU�Ɣ�r���Ă���i�K�ł�����ƈُ�ł����Ȃ�
�d�͌����̗ǂ�GPU�Ƃ̔�r�łȂ��ƈӖ����Ȃ��̂��낤�Ǝv���B
473 �F,,�E�L�́M�E,,�j��-�������F2010/06/28(��) 22:40:18 ID:vvW5sVNH
��������GPU�Ȃ�ĉ��Z���j�b�g�̕��ɂ�鐫�\�̐L�т���Ȃ�čŏ�������g����������Ă邵
�{�g���l�b�N�̃������ш�̖������ǂ�l�܂��Ԃ�����
SIMD���Z���\�̍��͋l�܂������B
���Z���j�b�g������̃������ш�Ƃ����_�ł́A��e�ʃL���b�V�������镪�܂��]�T�����邵�ˁB
>>468�����ǁATesla C2050��SGEMM���\�A���N��Larrabee�f���i��i��700GFLOPS�ȏ�AOC��1TFLOPS)�ɑS���y��łȂ���
�iDGEMM���낤�����낤�j
�����GPU����߂�HPC�ɍœK�����邱�Ƃ����܂������ATesla��HPC�s�ꂩ����ߏo�����̂����Ԃ̖�肾�ȁB
�{�g���l�b�N�̃������ш�̖������ǂ�l�܂��Ԃ�����
SIMD���Z���\�̍��͋l�܂������B
���Z���j�b�g������̃������ш�Ƃ����_�ł́A��e�ʃL���b�V�������镪�܂��]�T�����邵�ˁB
>>468�����ǁATesla C2050��SGEMM���\�A���N��Larrabee�f���i��i��700GFLOPS�ȏ�AOC��1TFLOPS)�ɑS���y��łȂ���
�iDGEMM���낤�����낤�j
�����GPU����߂�HPC�ɍœK�����邱�Ƃ����܂������ATesla��HPC�s�ꂩ����ߏo�����̂����Ԃ̖�肾�ȁB
�y�ϓI������Ǝv��
475 �F,,�E�L�́M�E,,�j��-�������F2010/06/28(��) 23:03:04 ID:vvW5sVNH
NVIDIA�ɂƂ��Ă͋��z�x�[�X�̑傫��HPC�s�ꂪ�_���Ȃ����GPGPU�𑱂���Ӗ����̂������Ȃ�
476 �F,,�E�L�́M�E,,�j��-�������F2010/06/28(��) 23:09:14 ID:vvW5sVNH
���ʂ�C/C++�ŃR�[�h��������v���Z�b�T�ɕ������玖����Q�[���I�[�o�[����
�v���O���~���O�̓�Փx�ň��|�I�ȕs���ȕ��A�����������ł͂Ȃ��u�����v�łȂ�������Ȃ��B
�v���O���~���O�̓�Փx�ň��|�I�ȕs���ȕ��A�����������ł͂Ȃ��u�����v�łȂ�������Ȃ��B
>>453
2015�N�̑��͂Ȃ����낤���ǁA��ꐢ��̓���Bull+APU �Ȃ���\���͂�����
�ꉞ�AK10��Bull�ɂ͌݊������L����Ęb�������AAPU�����オ�ς������V�\�P���ă��m�ł͂Ȃ��͂��i���Ȃ��Ƃ��f�X�N�g�b�v�����ł́j
2015�N�̑��͂Ȃ����낤���ǁA��ꐢ��̓���Bull+APU �Ȃ���\���͂�����
�ꉞ�AK10��Bull�ɂ͌݊������L����Ęb�������AAPU�����オ�ς������V�\�P���ă��m�ł͂Ȃ��͂��i���Ȃ��Ƃ��f�X�N�g�b�v�����ł́j
�[��APU���ĈӖ��s���Ȃ�ł�����w
�A�v���P�[�V�����v���Z�b�T���j�b�g���ĉ��ł����H
CPU�Ɖ����Ⴄ�̂ł����H
�A�v���P�[�V�����v���Z�b�T���j�b�g���ĉ��ł����H
CPU�Ɖ����Ⴄ�̂ł����H
�����̓������ш悪DDR3/128bit/1333-1600MHz�̖�30Gbps�ǂ܂肾����
�}���`�R�A�H���ŃR�A���₵�Ă��A���\�̓��j�A�ɐL�тɂ����Ȃ肻��
����Ƃ��L���b�V���̌��ʂ��������烁�����̒x���͖�肶��Ȃ��̂���
Tesla��Sandy���ǂ��ł��������AFusion�͂ǂ�����ă������ш�̖����N���A�������Ȃ낤
Llano�ł�DDR3�̑ш悶��ǂ�Ȃɍ��N���b�N�ł��������ɂȂ��Ă���炵������
32nm����ł͂������������ɂ��āA�����チ�����⋤�L�L���b�V���Ȃǂ̃{�g���l�b�N�����̃M�~�b�N��22nm����҂�����
����Ƃ�Llano�ɉ��炩�̑{����Ă��肷��̂���
�}���`�R�A�H���ŃR�A���₵�Ă��A���\�̓��j�A�ɐL�тɂ����Ȃ肻��
����Ƃ��L���b�V���̌��ʂ��������烁�����̒x���͖�肶��Ȃ��̂���
Tesla��Sandy���ǂ��ł��������AFusion�͂ǂ�����ă������ш�̖����N���A�������Ȃ낤
Llano�ł�DDR3�̑ш悶��ǂ�Ȃɍ��N���b�N�ł��������ɂȂ��Ă���炵������
32nm����ł͂������������ɂ��āA�����チ�����⋤�L�L���b�V���Ȃǂ̃{�g���l�b�N�����̃M�~�b�N��22nm����҂�����
����Ƃ�Llano�ɉ��炩�̑{����Ă��肷��̂���
480 �F,,�E�L�́M�E,,�j��-�������F2010/06/28(��) 23:48:16 ID:vvW5sVNH
��ʓI�ɍs��ς݂����ȃ|�s�����[�Ȗ��̓L���b�V���������₷����GPU�̓��[�J�������������̗܂قǂ��Ȃ����烁�������l�b�N�ɂȂ�B
HPC�̂��߂�SRAM�𑝂₹���̕�GPU�Ƃ��Ă��P�����オ���Ď������B
HPC�̂��߂�SRAM�𑝂₹���̕�GPU�Ƃ��Ă��P�����オ���Ď������B
���[�J���������͌������������
>>453>>477
AM2��AM2+��AM3��AM3r2�����5�N���炢������AFM�V���[�Y���������5�N���炢�����Ǝv��
AM2/3�̓������Ⴂ���z���ł���_������������璷�����ł���
FM�V���[�Y���A���l�̎v�z�Ń\�P�b�g���J�����Ă��邾�낤
FM�\�P�b�g�́ASB�ڑ��o�X�A�d�����C���A�f�B�X�v���C�o�́A�������o�X�ō\������Ă��āA
�V�������K�i�̗p�ɂ�郁�����o�X�ύX�ȊO�́A�݊����̂���g����������Ȃ����낤����A
DDR3�ł���Ԃ̓\�P�b�g�`��͕ς��Ȃ����낤
�����������獡�܂łƓ����悤��DDR3�Ǝ�����̃R���p�`�u�������R�����ڂ��Ă��肵��
AM2��AM2+��AM3��AM3r2�����5�N���炢������AFM�V���[�Y���������5�N���炢�����Ǝv��
AM2/3�̓������Ⴂ���z���ł���_������������璷�����ł���
FM�V���[�Y���A���l�̎v�z�Ń\�P�b�g���J�����Ă��邾�낤
FM�\�P�b�g�́ASB�ڑ��o�X�A�d�����C���A�f�B�X�v���C�o�́A�������o�X�ō\������Ă��āA
�V�������K�i�̗p�ɂ�郁�����o�X�ύX�ȊO�́A�݊����̂���g����������Ȃ����낤����A
DDR3�ł���Ԃ̓\�P�b�g�`��͕ς��Ȃ����낤
�����������獡�܂łƓ����悤��DDR3�Ǝ�����̃R���p�`�u�������R�����ڂ��Ă��肵��
483 �F,,�E�L�́M�E,,�j��-�������F2010/06/29(��) 00:02:33 ID:NEuBiObk
���A���Ȃ݂ɒP����2�����s��ϖ��ł�FLOPS������̊O���������ш�̗v����
�L���b�V�����邢�̓��[�J���������e�ʂ�2��ɔ���Ⴗ��
�X�ɓ����ш�E�e�ʂȂ�Ɨ��L���b�V����苤�L�L���b�V���̕������|�I�Ɍ������ǂ��B
���̓_GPU�̃��[�J���������͖{���I�ɏ��Ȃ�����킯�����A���W�X�^�{���ƃ������ш�ŃS���������Ă�̂�����
�L���b�V�����邢�̓��[�J���������e�ʂ�2��ɔ���Ⴗ��
�X�ɓ����ш�E�e�ʂȂ�Ɨ��L���b�V����苤�L�L���b�V���̕������|�I�Ɍ������ǂ��B
���̓_GPU�̃��[�J���������͖{���I�ɏ��Ȃ�����킯�����A���W�X�^�{���ƃ������ш�ŃS���������Ă�̂�����
484 �F,,�E�L�́M�E,,�j��-�������F2010/06/29(��) 00:15:03 ID:NEuBiObk
���߂�A�L���b�V���e�ʂ�1.5�悾����
���Ƃ���4x4�̍s��ς�64��̐ρi�a�j�Z���K�v����8x8����512��
�܂�L���b�V���e�ʂ�4�{�ɂȂ�ΊO���������ш�e�ʂ̗v����1/8���x�Ɍ���B
������SIMD���j�b�g�̕���x���オ��قǗL���B
���ƁA���̓��W�X�^�{�������\�d�v��������
�i512�r�b�g��SIMD�Ȃ�Larrabee�݂�����32�{��SIMD���W�X�^�͍Œ���~�����BRISC�^ISA�Ȃ炻��ȏ�j
���Ƃ���4x4�̍s��ς�64��̐ρi�a�j�Z���K�v����8x8����512��
�܂�L���b�V���e�ʂ�4�{�ɂȂ�ΊO���������ш�e�ʂ̗v����1/8���x�Ɍ���B
������SIMD���j�b�g�̕���x���オ��قǗL���B
���ƁA���̓��W�X�^�{�������\�d�v��������
�i512�r�b�g��SIMD�Ȃ�Larrabee�݂�����32�{��SIMD���W�X�^�͍Œ���~�����BRISC�^ISA�Ȃ炻��ȏ�j
DDR3��GDDR5�̔{�ȏ�̐��\�̃��������o�Ă��Ȃ��Ƃ��낻��CPU��GPU�����\�����ł��ɂȂ��
128bit DDR3 2ch�̏ꍇ�A�X�J��������12�X���b�h�A�X���b�h�ӂ�2M�̃L���b�V���A�x�N�g������(SIIMD)��500GFlops
�w�e���W�j�A�X�̏ꍇLlano�����ɏ���ɋ߂���
Llano��480sp�́A���C�����������\���瓋�ڂł��邬�肬��̃X�y�b�N�ŁA
K10 4�R�A�Ƃ̑g�����̓X�y�b�N�A�_�C�T�C�Y�ATDP���l��������ł̊�ՓI�ȃo�����X�̍\������
128bit DDR3 2ch�̏ꍇ�A�X�J��������12�X���b�h�A�X���b�h�ӂ�2M�̃L���b�V���A�x�N�g������(SIIMD)��500GFlops
�w�e���W�j�A�X�̏ꍇLlano�����ɏ���ɋ߂���
Llano��480sp�́A���C�����������\���瓋�ڂł��邬�肬��̃X�y�b�N�ŁA
K10 4�R�A�Ƃ̑g�����̓X�y�b�N�A�_�C�T�C�Y�ATDP���l��������ł̊�ՓI�ȃo�����X�̍\������
486 �F,,�E�L�́M�E,,�j��-�������F2010/06/29(��) 00:31:02 ID:NEuBiObk
Rambus�����X�Ƃ��Ă����������Ă���
�Q�n�~����X�Ƃ��ďo�Ă����Ȃ��n�[�h�E�F�A�Ő��\�_�������Ă���
488 �FSocket774�F2010/06/29(��) 06:05:32 ID:p3VrPR9n
�x�N�g���Ȃ�ĕʕ��ɂ܂Ŋ��ݕt���Ă�Ƃ�....
489 �FSocket774�F2010/06/29(��) 08:58:15 ID:5NrfVHwk
����Llano��30w�ȉ��̃��f�������ł�����
> Llano��480sp�́A���C�����������\���瓋�ڂł��邬�肬��̃X�y�b�N�ŁA
DDR3 2ch�̑ш�Ȃ��CPU4�R�A�����Ŏg���������Ⴂ�܂���B
480SP�ڂ��Ă��g�����W�X�^�ʂɌ����������\���o���ɏ��邾���ł���B
DDR3 2ch�̑ш�Ȃ��CPU4�R�A�����Ŏg���������Ⴂ�܂���B
480SP�ڂ��Ă��g�����W�X�^�ʂɌ����������\���o���ɏ��邾���ł���B
400SP��5570������SP����5670�Ɣ�ׂăR�A�N���b�N�̒ቺ�ȏ�ɐ��\�������Ă��邩��A
�������ш��5670���݂ɂȂ���480SP�̐��\�͎g������Ȃ�
�������ш��5670���݂ɂȂ���480SP�̐��\�͎g������Ȃ�
�܂�uTDP���l��������ł̊�ՓI�ȃo�����X�̍\���v�Ƃ����̂͑�R�Ƃ������Ƃ����w
200SP�Ȃ�g�������̂��H
494 �F,,�E�L�́M�E,,�j��-�������F2010/06/29(��) 12:18:12 ID:NEuBiObk
>>488
�u�x�N�g���X�p�R���̗Y�v���ǂ�ȓ��������Ă邩���m��Ȃ��Ƃ�
�債�����n������ł���
Intel�F�@AVX�̎d�l���\
��
Cray�F�@2011�N�̃n�C�G���h�X�p�R���V�V���[�Y�Ɍ�����Intel�ƕ��g
��
AMD�F�@Bulldozer��SSE5���L�����Z����AVX�݊���
��ł����ăx�N�g���v���Z�b�T�̍Ō�̍Ԃł���NEC��Intel�Ƒg�B
�Ԃ����Ⴏ���b�AKnights Corner���������SX10
�u�x�N�g���X�p�R���̗Y�v���ǂ�ȓ��������Ă邩���m��Ȃ��Ƃ�
�債�����n������ł���
Intel�F�@AVX�̎d�l���\
��
Cray�F�@2011�N�̃n�C�G���h�X�p�R���V�V���[�Y�Ɍ�����Intel�ƕ��g
��
AMD�F�@Bulldozer��SSE5���L�����Z����AVX�݊���
��ł����ăx�N�g���v���Z�b�T�̍Ō�̍Ԃł���NEC��Intel�Ƒg�B
�Ԃ����Ⴏ���b�AKnights Corner���������SX10
>>484
���ӗ͎U�����Ȃ��B
�s��̃T�C�Y��4�{�ɑ�����Γ]���ʂ�4�{�ɑ�������B
�u�L���b�V���e�ʂ̕������ɔ���Ⴗ��v�����B
���ӗ͎U�����Ȃ��B
�s��̃T�C�Y��4�{�ɑ�����Γ]���ʂ�4�{�ɑ�������B
�u�L���b�V���e�ʂ̕������ɔ���Ⴗ��v�����B
>>490
�t���������̑O��200SP�Ƃ������̕���
�܂���ՓI�ȃo�����X�̍\���Ƃ��ɋ߂��B
�Ƃ�����CPU�D�悷��Ȃ�W0SP���炢�����x�ǂ����B
(DDR3-1600�g�p��)
�t���������̑O��200SP�Ƃ������̕���
�܂���ՓI�ȃo�����X�̍\���Ƃ��ɋ߂��B
�Ƃ�����CPU�D�悷��Ȃ�W0SP���炢�����x�ǂ����B
(DDR3-1600�g�p��)
497 �FSocket774�F2010/06/29(��) 12:30:59 ID:VIVs1Yvm
�܂�Intel��CPU�����Ƃ��ᐫ�\�܂߂Ă��ׂĂ̖ʂň��S���Ă��Ƃ���
AMD��CPU�͐��\�܂߂Ă��ׂĂ̖ʂŐ�ׂ�ŕs���ȑ��݂ɂȂ��Ă�����
AMD��CPU�͐��\�܂߂Ă��ׂĂ̖ʂŐ�ׂ�ŕs���ȑ��݂ɂȂ��Ă�����
�D���ȃ��[�J�[�̂��Ȃ���
���̍��K���ȃl�K�L���������Ă���ƁA
������Ɣ��܂����C���ɂȂ�B
������Ɣ��܂����C���ɂȂ�B
500 �F,,�E�L�́M�E,,�j��-�������F2010/06/29(��) 12:45:45 ID:NEuBiObk
>>495
���ӗ͎U���Ȃ̂͂��O���B
�����s��̃T�C�Y��4�{�Ȃ�A�I���_�C�̃f�[�^�ɑ��鉉�Z�͍ő�8�{�ɑ�����B
�T�C�Y9�{�Ȃ�27�{�B
�܂艉�Z������̃������ш�̓������e�ʂ�2/3��ɔ��ō����Ă�
���ӗ͎U���Ȃ̂͂��O���B
�����s��̃T�C�Y��4�{�Ȃ�A�I���_�C�̃f�[�^�ɑ��鉉�Z�͍ő�8�{�ɑ�����B
�T�C�Y9�{�Ȃ�27�{�B
�܂艉�Z������̃������ш�̓������e�ʂ�2/3��ɔ��ō����Ă�
501 �F,,�E�L�́M�E,,�j��-�������F2010/06/29(��) 12:52:54 ID:NEuBiObk
�Ǝv������
(N ^ (3/2)) / N = ��N
���B
�T�[�Z��������������
(N ^ (3/2)) / N = ��N
���B
�T�[�Z��������������
>>436
���̐S�́H
���̐S�́H
���₨�⎩�̔N��5�疜�~�v���O���}�[����͍������A���d���͂��x�݂ł����H
�����ƋK������Ă��悩�����̂�
505 �FSocket774�F2010/06/29(��) 16:22:27 ID:8Oh5HKGO
GPU���\��5450�ȏ�5550�����Ȑ��\�ł���
�Ƃɂ����ȃG�l��
�Ƃɂ����ȃG�l��
NEC�̓x�N�g���������낪��
�x�m�ʂɍ̗p����Ă��猾��
�x�m�ʂɍ̗p����Ă��猾��
507 �F,,�E�L�́M�E,,�j��-�������F2010/06/29(��) 17:00:05 ID:NEuBiObk
��������Opteron��PRIMAGY�ɍ̗p����ĂȂ��ˁi�j
��������NEC�������~�肽�̂�SX�̃��[�U�[���S�������ɏW�����邱�Ƃ����ꂽ�ׂ�
�C���^�[�R�l�N�g�Z�p��Intel�ɋ��^�����ق��������b�g�傫�����炾
��������NEC�������~�肽�̂�SX�̃��[�U�[���S�������ɏW�����邱�Ƃ����ꂽ�ׂ�
�C���^�[�R�l�N�g�Z�p��Intel�ɋ��^�����ق��������b�g�傫�����炾
�[�������瓝���Ƀ����b�g�Ȃ�Ă�����Ȃ�����w
�P�Ƀ_�C�T�C�Y���]�邩��GPU�ł��������Ă������Ƃ������x�ł����Ȃ��B
�P�Ƀ_�C�T�C�Y���]�邩��GPU�ł��������Ă������Ƃ������x�ł����Ȃ��B
�i�X�ƐV�l�^�������Ă邪NVIDIA�Ɋ��ݕt����������Ɨ���邪�Ȃ�
���̃e�w�̕����}�g�������
���̃e�w�̕����}�g�������
�����͋߂ɏo�Ăāi��͐Q�Ȃ���2ch�j
�Ƃ����U���H����̂ĂĂ܂ŗ����i��������j����{���ɏ��o�����l���f�b�h�X�y�[�X
�Ƃ����U���H����̂ĂĂ܂ŗ����i��������j����{���ɏ��o�����l���f�b�h�X�y�[�X
AM3�}�U�[�ɗ��N�o��8�R�A�͂̂��H
200SP��500MHz����4 core sndy 3GHz�Ɣ�ׂĂ������ȃJ�^���O�X�y�b�N
>>513
4core Sandy�Ƃ͋������Ȃ�����C�ɂ����
Sandy 4�R�A�̓X�y�b�N��������2���~�ȉ��ɂ͗��Ȃ���
(HTT����750�I�Ȃ̂��h�����Đ邭�炢)
Llano 4�R�A�̓_�C�T�C�Y��\�I��1�`2���~�ȉ�
����Ƃ��Ă�AthlonIIX4 �� i7�ɋ߂��Ȃ�Ǝv��
4core Sandy�Ƃ͋������Ȃ�����C�ɂ����
Sandy 4�R�A�̓X�y�b�N��������2���~�ȉ��ɂ͗��Ȃ���
(HTT����750�I�Ȃ̂��h�����Đ邭�炢)
Llano 4�R�A�̓_�C�T�C�Y��\�I��1�`2���~�ȉ�
����Ƃ��Ă�AthlonIIX4 �� i7�ɋ߂��Ȃ�Ǝv��
�܂��A4�R�A��Sandy�Ƌ�����ԂɂȂ�̂�8�R�A��Bulldozer�����ȁc
����8�R�A��Bulldozer�̕����͌��܂����悤�Ȃ����ǂ��c
����8�R�A��Bulldozer�̕����͌��܂����悤�Ȃ����ǂ��c
�Ȃ�قǁA�Ƃ������Ƃ́A���ނ͎��S����킯���ȁB
�װ��ްقł��łɓ��ł����Ă����ȁ`
������Sandy4�R�A�Ƃ��ő��N��CPU����
�������炢�̐��\��Bull 6�R�A��AM3���[�U�[�̗����ȃA�b�v�O���[�h�Ώۂł���Ȃ�ɔ��ꂻ�������ǁA
Sandy 4�R�A�̓n�C�G���h����Ȃ����ǒl�i�������ŁA��IGP�t�����������������[�Ȃ���
��������Sandy�w���\��̓z����Ėw�ǂ�B2�_������
Sandy�X�����Ă��S�����҂���ĂȂ����A�Ӗ��s���ȑ��݂ɂȂ��Ă��
�������炢�̐��\��Bull 6�R�A��AM3���[�U�[�̗����ȃA�b�v�O���[�h�Ώۂł���Ȃ�ɔ��ꂻ�������ǁA
Sandy 4�R�A�̓n�C�G���h����Ȃ����ǒl�i�������ŁA��IGP�t�����������������[�Ȃ���
��������Sandy�w���\��̓z����Ėw�ǂ�B2�_������
Sandy�X�����Ă��S�����҂���ĂȂ����A�Ӗ��s���ȑ��݂ɂȂ��Ă��
�Q�n�~����X�Ƃ��ďo�Ă����Ȃ��n�[�h�E�F�A�ŏ��s��������Ă���
> ������Sandy4�R�A�Ƃ��ő��N��CPU���ȓ������炢�̐��\��Bull 6�R�A
�ϑz���r�������̂Ŗ������ȁH�A6�R�A��Sandy��4�R�A�Ɠ������炢�̐��\�H
�ϑz���قǂقǂɂ��Ă����A�����ĂĔ�������B
�ϑz���r�������̂Ŗ������ȁH�A6�R�A��Sandy��4�R�A�Ɠ������炢�̐��\�H
�ϑz���قǂقǂɂ��Ă����A�����ĂĔ�������B
521 �F,,�E�L�́M�E,,�j��-�������F2010/06/29(��) 22:35:30 ID:NEuBiObk
�t���O�V�b�v�𐧂����A�[�L�e�N�`���̉��ʐ��i�̓��[�G���h�s��ł������@���B
���j�I�ɂ����ʃ����W��AMD�̂ق����������\�ǂ��Ă�Celeron�����ꂽ�B
GPU�ł���������H
���j�I�ɂ����ʃ����W��AMD�̂ق����������\�ǂ��Ă�Celeron�����ꂽ�B
GPU�ł���������H
522 �F,,�E�L�́M�E,,�j��-�������F2010/06/29(��) 22:38:37 ID:NEuBiObk
>>522
TYPO���낤���ǒP��
TYPO���낤���ǒP��
524 �F,,�E�L�́M�E,,�j��-�������F2010/06/29(��) 22:39:28 ID:NEuBiObk
���܂�AGHz����Ȃ���MHz��
�Ȃ�ŃC���e����D���R�e��������������AMD�@���Ă�́H
�����̓A���`�X������Ȃ����AIntel������X���ł������̂�
�����̓A���`�X������Ȃ����AIntel������X���ł������̂�
�@���Ă�킯����Ȃ��A������������Ă��邾���̂���
Bull 6�R�A��Bull 3���W���[����128bit SSE���j�b�g�̓��ڐ���6
���ꂪ�����Ȃ�B
Bull 6�R�A��Bull 3���W���[����128bit SSE���j�b�g�̓��ڐ���6
���ꂪ�����Ȃ�B
528 �F,,�E�L�́M�E,,�j��-�������F2010/06/29(��) 23:42:38 ID:NEuBiObk
>>526
���̃X���ł�Llano��Bulldozer���b��ɂ���Ȃ�Ȃ�
���̃X���ł�Llano��Bulldozer���b��ɂ���Ȃ�Ȃ�
�܂������͒u���Ƃ��Ƃ��āA�Ȃ��Intel������X���ł��Ȃ��́H
�C���e���̑f���炵�����A�s�[���������Ȃ炠�����ő����ɂ�����
�C���e���̑f���炵�����A�s�[���������Ȃ炠�����ő����ɂ�����
�����A�Ƃ������c�q�N�́��������Ă邶���w
532 �F,,�E�L�́M�E,,�j��-�������F2010/06/29(��) 23:58:32 ID:NEuBiObk
�ߋ����O�ǂ݂����Ȃ���������
�Ӗ����������
Intel���D���Ȃ�C���e���̃X���ł���Ă���
AMD�������Ȃ�A���`�X�����ĂĂ���Ă���
���ꂪ�ł��Ȃ��Ȃ炽���̍r�炵�����
Intel���D���Ȃ�C���e���̃X���ł���Ă���
AMD�������Ȃ�A���`�X�����ĂĂ���Ă���
���ꂪ�ł��Ȃ��Ȃ炽���̍r�炵�����
�V�v���ɂ��̊�n�O��l������悤�ɂ��Ƃ��悗
���A�������������炱���ŗV��łق����Ă��傤���Ȃ���
Intel�X�����ᑊ��ɂ�����Ȃ�������Ă����ȋ���
���A�������������炱���ŗV��łق����Ă��傤���Ȃ���
Intel�X�����ᑊ��ɂ�����Ȃ�������Ă����ȋ���
http://citavia.blog.de/2010/06/29/llano-tri-core-and-ontario-dual-core-spotted-8884456/
Llano3�R�A��Ontario2�R�A��BONIC�������Ă���炵���B
BONIC�͋����Ȃ������̂ŃO���t���Ă����ɂ͂悭�킩��Ȃ����B
�Ō�̃p���O���t�ɂ�PhenomII�Ƃ̔�r�������Ă��邯�ǁA�N���b�N���킩��Ȃ��̂ŁA
Ontario�̐��i�ł̂ǂꂭ�炢���͂܂��悭�킩��Ȃ��ȁB
Llano3�R�A��Ontario2�R�A��BONIC�������Ă���炵���B
BONIC�͋����Ȃ������̂ŃO���t���Ă����ɂ͂悭�킩��Ȃ����B
�Ō�̃p���O���t�ɂ�PhenomII�Ƃ̔�r�������Ă��邯�ǁA�N���b�N���킩��Ȃ��̂ŁA
Ontario�̐��i�ł̂ǂꂭ�炢���͂܂��悭�킩��Ȃ��ȁB
538 �FSocket774�F2010/06/30(��) 00:52:23 ID:AjqJ5xeE
�T���f�B��6�R�A���č���980X��萫�\������I�H
�u����8�R�A�Ő킦��N���X����Ȃ����낗�����������Ⴂ�����邗����
�u����12�R�A���炢�ł���Ɠ������炢����ˁ[�́H����Ȃ̏o���Ȃ����낤���ǂ�����
�T���f�B��8�R�A�������ȁ[�����C���e�����o�m�肾��ȁ[
�u����8�R�A�Ő킦��N���X����Ȃ����낗�����������Ⴂ�����邗����
�u����12�R�A���炢�ł���Ɠ������炢����ˁ[�́H����Ȃ̏o���Ȃ����낤���ǂ�����
�T���f�B��8�R�A�������ȁ[�����C���e�����o�m�肾��ȁ[
Sandy�͓��ʂ̓~�h���n�C�܂ł����o�Ȃ���
Sandy�͍��N���b�N�ł͏o�Ȃ��A���̃J�e�S����32nm����̃n�C�G���h��Westmere�����������S��
�I�p�ł�Sandy�R�A��4P�ł܂ł����o�Ȃ��A������ȈՐڑ��^�ł���
�E���g���n�C�G���h��Westmere�̌��Sandy�̓X�L�b�v����Haswell�ɔ��
Sandy�͍��N���b�N�ł͏o�Ȃ��A���̃J�e�S����32nm����̃n�C�G���h��Westmere�����������S��
�I�p�ł�Sandy�R�A��4P�ł܂ł����o�Ȃ��A������ȈՐڑ��^�ł���
�E���g���n�C�G���h��Westmere�̌��Sandy�̓X�L�b�v����Haswell�ɔ��
���������b����Intel�X���ł��Ηǂ�����B
AMD�W�̘b��ɑ��������Ƃ͎v���܂���ȁB
AMD�W�̘b��ɑ��������Ƃ͎v���܂���ȁB
>>538
�ϑz�������܂ŗ���Ƒf���炵���Ȃ��B
�ϑz�������܂ŗ���Ƒf���炵���Ȃ��B
�[���ABulldozer�̊J���헪�Ƃ��ă��W���[���� Vs Intel�̕����R�A���ł���
Bulldozer�̃R�A�� VS Intel�̘_���R�A������Ȃ��̂��ȁH
�������ς܂�B
Bulldozer�̃R�A�� VS Intel�̘_���R�A������Ȃ��̂��ȁH
�������ς܂�B
����ȂƂ��낾�낤��
Bulldozer4���W���[��8�R�A�ƌ����Ă��A�g�����W�X�^���ł�Sandy4�R�A�����炢�����������낤
�ƌ������A�����v���Z�X�Ŕ����x��Ă����A���̂��炢���������Ă����Ȃ��Ə����ɂȂ�Ȃ��ł���
Bulldozer4���W���[��8�R�A�ƌ����Ă��A�g�����W�X�^���ł�Sandy4�R�A�����炢�����������낤
�ƌ������A�����v���Z�X�Ŕ����x��Ă����A���̂��炢���������Ă����Ȃ��Ə����ɂȂ�Ȃ��ł���
SIMD��SIMM�̈Ⴂ������Ȃ�K10STAT��K10START�ƌĂ�
����Ȕn�������炻���ɉ��������Ă�낤�˂�
����Ȕn�������炻���ɉ��������Ă�낤�˂�
�t�Ɍ����A������AMD��Intel�̂悤�ȑ�^�R�A���̗p�����������A
�v���Z�X�����x��̎��ɂ̓��b�g�p�t�H�[�}���X�̍����J�������ĔߎS�Ȃ��ƂɂȂ��
�v���Z�X�����x��̎��ɂ̓��b�g�p�t�H�[�}���X�̍����J�������ĔߎS�Ȃ��ƂɂȂ��
Bulldozer��Intel�̂��u��^�R�A�v�ƌ�����قǍ��ĂȂ�����
�t�ɍ�����Ⴄ�ƃV���O���X���b�h�Ńp�t�H�[�}���X���ǂ����悤���Ȃ��Ȃ�
�t�ɍ�����Ⴄ�ƃV���O���X���b�h�Ńp�t�H�[�}���X���ǂ����悤���Ȃ��Ȃ�
AMD��HD 3xxx�V���[�Y������j��]�����ă_�C�T�C�Y��}���A�j�b�`�ȃn�C�G���h�ɂ̓~�h����2����Ă���
���������헪��CPU�ɂ��K�p������������
���������헪��CPU�ɂ��K�p������������
Llano��Sandy�͂ǂ����GPU���������瓖�R�Q�[���x���`�����Ȃ����邾�낤��
Sandy�̈��|�I�卷�őS�ł��ڂɌ�����w
���Ȃ݂�Sandy 4�R�A��GPU���\��Clark���͍����������A2�R�A�̐��\�͔����ȉ��ɂȂ��ĒႭ�Ȃ�
�����\CPU��v������̂̓G���R���Q�[���ʂŁA�s��K�͂̓Q�[���̕������|�I�ɑ傫��
����Ȃ̂ɃQ�[�����o���Ȃ��Ƃ����v���I�Ȗ��������Sandy�ɑ��݉��l�͂قƂ�ǂȂ�
���ǃV���O���X���b�h���\�]�X�ƌ����Ă��A
Office��IE�����C���̐��\�����܂�K�v����Ȃ���ʌ����ɂ������v���Ȃ����̎�������߂����
��������Intel��32nm�̐ݔ���220mm2��150mm2��CPU�ŃV�F�A�m�ۂł��邾���̐����ł���̂���
���݂�Clarkdale�̃V�F�A��10�`20%�ʂŁA5���߂���Core2�n�������͂�
20%�̃V�F�A��80mm2���x��Westmere�R�A�ł���s�����Ă����(GPU��45nm�Ȃ̂ŊW�Ȃ�)
�����܂���サ�āA�ݔ��������Ă��ǂ����悤���Ȃ��قǑ���Ȃ���Ȃ�����
��ʌ����̌��_�Ƃ��ẮA
Llano�F��R�X�g�Ń��[�G���h���J�o�[�A����Ȃ�̃Q�[�����\�Ń~�h���܂ŃJ�o�[
Sandy�F���R�X�g�Ȃ̂Ń��[�G���h�͖����A�Q�[�����o���Ȃ��̂Ń~�h���ȏ�͖���
�������
Llano�F��R�X�g��ȓd�͎w���A�l�b�g��C�g�Q�[�}�[�ɑ�l�C
Sandy�F2�R�A��Llano�Ǝ����悤�Ȋ���(�Q�[�}�[����)�A�n�C�G���h�u����6/8�R�A�������Ȃ�
Sandy 4�R�A�̎��v�͉����H
Sandy�̈��|�I�卷�őS�ł��ڂɌ�����w
���Ȃ݂�Sandy 4�R�A��GPU���\��Clark���͍����������A2�R�A�̐��\�͔����ȉ��ɂȂ��ĒႭ�Ȃ�
�����\CPU��v������̂̓G���R���Q�[���ʂŁA�s��K�͂̓Q�[���̕������|�I�ɑ傫��
����Ȃ̂ɃQ�[�����o���Ȃ��Ƃ����v���I�Ȗ��������Sandy�ɑ��݉��l�͂قƂ�ǂȂ�
���ǃV���O���X���b�h���\�]�X�ƌ����Ă��A
Office��IE�����C���̐��\�����܂�K�v����Ȃ���ʌ����ɂ������v���Ȃ����̎�������߂����
��������Intel��32nm�̐ݔ���220mm2��150mm2��CPU�ŃV�F�A�m�ۂł��邾���̐����ł���̂���
���݂�Clarkdale�̃V�F�A��10�`20%�ʂŁA5���߂���Core2�n�������͂�
20%�̃V�F�A��80mm2���x��Westmere�R�A�ł���s�����Ă����(GPU��45nm�Ȃ̂ŊW�Ȃ�)
�����܂���サ�āA�ݔ��������Ă��ǂ����悤���Ȃ��قǑ���Ȃ���Ȃ�����
��ʌ����̌��_�Ƃ��ẮA
Llano�F��R�X�g�Ń��[�G���h���J�o�[�A����Ȃ�̃Q�[�����\�Ń~�h���܂ŃJ�o�[
Sandy�F���R�X�g�Ȃ̂Ń��[�G���h�͖����A�Q�[�����o���Ȃ��̂Ń~�h���ȏ�͖���
�������
Llano�F��R�X�g��ȓd�͎w���A�l�b�g��C�g�Q�[�}�[�ɑ�l�C
Sandy�F2�R�A��Llano�Ǝ����悤�Ȋ���(�Q�[�}�[����)�A�n�C�G���h�u����6/8�R�A�������Ȃ�
Sandy 4�R�A�̎��v�͉����H
�l�I�ɂ�Llano��FF14�x���`Low�ݒ��2500�ȏ�o�����
���̂��炢�̐��\�ɂȂ�����m�[�gPC���[�J�[���������č̗p���邾�낤��
���̂��炢�̐��\�ɂȂ�����m�[�gPC���[�J�[���������č̗p���邾�낤��
550 �FSocket774�F2010/06/30(��) 04:17:50 ID:poRiNGxC
��������FF14���V�ׂ郌�x���ɂ͂Ȃ�Ȃ���Ȃ���
��ʌ����ɂ�web��u���E�U�Q�[�łǂ��܂�3D�����y���邩
�r�W�l�X�����ɂ�IE��office��GPU�Ή����ǂ̒��x�̊��ň���Ă��邩�ɂ������Ă�����
��ʌ����ɂ�web��u���E�U�Q�[�łǂ��܂�3D�����y���邩
�r�W�l�X�����ɂ�IE��office��GPU�Ή����ǂ̒��x�̊��ň���Ă��邩�ɂ������Ă�����
>>546
�R�A�������\�Ƃ��s���Ă�Ȃ�Ƃ�����
��������R�A�������ŃR�A�T�C�Y�𑪂�͓̂����
�R�A�T�C�Y��K10��肠����x���ĂĂ����₵�Ă����̃R�A���Ŕ[�܂�Ƃ�����
L3�̗e�ʂƂ��L���b�V���̖��x���T�C�Y�ɉe���o�邵
�R�A�������\�Ƃ��s���Ă�Ȃ�Ƃ�����
��������R�A�������ŃR�A�T�C�Y�𑪂�͓̂����
�R�A�T�C�Y��K10��肠����x���ĂĂ����₵�Ă����̃R�A���Ŕ[�܂�Ƃ�����
L3�̗e�ʂƂ��L���b�V���̖��x���T�C�Y�ɉe���o�邵
>Llano��FF14�x���`Low�ݒ��2500�ȏ�
�܂���������
�܂Ƃ��ɓ������ǂ������������
�܂���������
�܂Ƃ��ɓ������ǂ������������
555 �FSocket774�F2010/06/30(��) 07:18:22 ID:gO3dyEXA
Llano�̓t��HD�̓��悪60�t���Ńk���k�������Ώ\���I
556 �FSocket774�F2010/06/30(��) 07:58:37 ID:oe+Zobj6
�e�w�̃G�ABull���Ăǂ�ȑ傫���H
�݂�ȂȂ��60�t���[���ɂ������́H
�����Z�O����15�t���[�������ǂ��ꂢ����ˁH
�e���r30�t���[�������ǂ��ꂢ�����B
60������Ȃ��Ȃ����H
�����Z�O����15�t���[�������ǂ��ꂢ����ˁH
�e���r30�t���[�������ǂ��ꂢ�����B
60������Ȃ��Ȃ����H
>>547
GPU�͉��Z�̕���x���ɂ߂č����̂ʼn��Z�R�A������̐��\��������X���[�v�b�g�̂ق����d�v
CPU�̓T�[�o�ł��Ȃ����肻���ł͂Ȃ�
�ꏏ�����ɂ����
GPU�͉��Z�̕���x���ɂ߂č����̂ʼn��Z�R�A������̐��\��������X���[�v�b�g�̂ق����d�v
CPU�̓T�[�o�ł��Ȃ����肻���ł͂Ȃ�
�ꏏ�����ɂ����
>>548
���Ȃ݂�Intel��45nm��Core 2�̂Ƃ��������オ�肪�x�����炭�i����������
�ŏ��͒P���̍���MCM��Core 2 Extreme�����������Ă��̌��Core 2 Duo��������������v�ߑ�
��ʌ�����Core 2 Quad���ł�܂Ŕ��N��������
�v�����32nm�ł������i���������̂͏]���ʂ�
2�N�ڂ܂ŕ����܂肪�����Ȃ�Ă悭����Ȗϑz�v�����Ȃ�
�v����ɂ��n��
���Ȃ݂�Intel��45nm��Core 2�̂Ƃ��������オ�肪�x�����炭�i����������
�ŏ��͒P���̍���MCM��Core 2 Extreme�����������Ă��̌��Core 2 Duo��������������v�ߑ�
��ʌ�����Core 2 Quad���ł�܂Ŕ��N��������
�v�����32nm�ł������i���������̂͏]���ʂ�
2�N�ڂ܂ŕ����܂肪�����Ȃ�Ă悭����Ȗϑz�v�����Ȃ�
�v����ɂ��n��
>>558
����Ȃ��Ƃ����Ă����ۂ���Ă���ǂ�
����Ȃ��Ƃ����Ă����ۂ���Ă���ǂ�
�c�q�̓G�C�v�����t�[���̃l�^�L������������M�����Ⴄ�ق�Bull�ɋ��ق������Ă�낤�Ȃ�
>>561
�r�炵����������Ȃ�
�r�炵����������Ȃ�
565 �FSocket774�F2010/06/30(��) 13:01:32 ID:OZHnNG5F
�U�c�q�N����
�I�N�Y�߂��ė�߂���
���ꂩ��͖{�c��������
���ꂩ��͖{�c��������
�������{����Bull�̓f���A���R�Ak10��菬�����Ȃ�̂��H
�����p�C�v��3��2�Ɍ��������ǃg�[�^����4�{�AFPU��2�{�A�f�R�[�_�[�������B����ɍ��N���b�N�����ڎw���ăp�C�v���C����[������Ȃ�_�C�T�C�Y�͂����Ƒ傫���Ȃ�B����2�R�Ak10�Ƒ卷�Ȃ��傫���ɂȂ�Ƒz��������ǂ��v���H
�����p�C�v��3��2�Ɍ��������ǃg�[�^����4�{�AFPU��2�{�A�f�R�[�_�[�������B����ɍ��N���b�N�����ڎw���ăp�C�v���C����[������Ȃ�_�C�T�C�Y�͂����Ƒ傫���Ȃ�B����2�R�Ak10�Ƒ卷�Ȃ��傫���ɂȂ�Ƒz��������ǂ��v���H
AVX�Ƃ��ςފ��ɂ͏������܂Ƃ߂��邾�낤���Ă����ŁAK10��菬�����͂Ȃ��ł���
>>568
�\���݂�킩��B�f�R�[�_��FPU�͋��L������B
�\���݂�킩��B�f�R�[�_��FPU�͋��L������B
1090T��荂���\��Bull���Ă��o��́H
�����Ȃ�8�R�A��3.6GH���iTB4.0GH���jTDP125W���炢�̏o���Ă����Ȃ�
�����Ȃ�8�R�A��3.6GH���iTB4.0GH���jTDP125W���炢�̏o���Ă����Ȃ�
�N���b�N���͏オ��Ȃ��Ǝv�����B
���������N���b�N��8�R�A(4���W���[��)�͏o�ė���̂ł͂Ȃ����ȁH
�������1090T���͍����\�Ƃ������ƂŁc
���������N���b�N��8�R�A(4���W���[��)�͏o�ė���̂ł͂Ȃ����ȁH
�������1090T���͍����\�Ƃ������ƂŁc
573 �F,,�E�L�́M�E,,�j��-�������F2010/07/01(��) 01:58:24 ID:qfnxFrhe
���������C�X���G���`�[����Core MA����IPC�H���ɐU�����̂�
�������\�Ȃ�IPC�������グ�Ă��̕��N���b�N�𗎂Ƃ��������ȓd�͂��Ɣ��f�������炾
�m�[�gPC�����̃v���b�g�t�H�[���͗e�Ղ�TDP���グ�邱�Ƃ��o���Ȃ��B
Sandy Bridge��Thin&Light�m�[�g�Ŏ嗬�ɂȂ肻����2�R�A+HT��2�`2.4GHz���x�Ɠ�����
�V���O���X���b�h���\��Bulldozer�x�[�X�Ŏ�������̂ɁA���Ƃ���3GHz�K�v�������肷��A
�Ȃ�Ă̂͑S�R���������Ȃ��B
�N���b�N���グ�Ă������d�͂ɂȂ�悤�Ȗ��@�ł�����Ȃ�ʂ����ǂˁB
>>561
�����т�ꂽ���ȁB
����Bulldozer�ɑ��Ďv���Ă邱�Ƃ́A���قł����Ђł��Ȃ��u�����v���B
XOP/FMA4�Ή��̃R�[�h�Ƃ������Ɏ��삵�Ă��ˁB
�������W���X�e�B�X���B
����͊���v�Z�����ǁASIMD�������Z�̈ꕔ�ł�Bulldozer��8�R�A�i4���W���[���j�́A
XOP���t���Ɏg�����Ƃ��A���N���b�N��Sandy Bridge 4�R�A���������Ȃ�E�E�E�E�Ƃ��������ꕔ����
FP��Sandy Bridge�L��������
�܂��L���b�V���̃q�b�g���Ƃ������̗^����e���̕����傫���̂łǂ��Ƃ�������B
�������\�Ȃ�IPC�������グ�Ă��̕��N���b�N�𗎂Ƃ��������ȓd�͂��Ɣ��f�������炾
�m�[�gPC�����̃v���b�g�t�H�[���͗e�Ղ�TDP���グ�邱�Ƃ��o���Ȃ��B
Sandy Bridge��Thin&Light�m�[�g�Ŏ嗬�ɂȂ肻����2�R�A+HT��2�`2.4GHz���x�Ɠ�����
�V���O���X���b�h���\��Bulldozer�x�[�X�Ŏ�������̂ɁA���Ƃ���3GHz�K�v�������肷��A
�Ȃ�Ă̂͑S�R���������Ȃ��B
�N���b�N���グ�Ă������d�͂ɂȂ�悤�Ȗ��@�ł�����Ȃ�ʂ����ǂˁB
>>561
�����т�ꂽ���ȁB
����Bulldozer�ɑ��Ďv���Ă邱�Ƃ́A���قł����Ђł��Ȃ��u�����v���B
XOP/FMA4�Ή��̃R�[�h�Ƃ������Ɏ��삵�Ă��ˁB
�������W���X�e�B�X���B
����͊���v�Z�����ǁASIMD�������Z�̈ꕔ�ł�Bulldozer��8�R�A�i4���W���[���j�́A
XOP���t���Ɏg�����Ƃ��A���N���b�N��Sandy Bridge 4�R�A���������Ȃ�E�E�E�E�Ƃ��������ꕔ����
FP��Sandy Bridge�L��������
�܂��L���b�V���̃q�b�g���Ƃ������̗^����e���̕����傫���̂łǂ��Ƃ�������B
�ȓd�͂ł��������W���X�e�B�X
����Ȃ��H
����Ȃ��H
>>567
�Ӗ��s���E�E�E
�Ӗ��s���E�E�E
576 �F,,�E�L�́M�E,,�j��-�������F2010/07/01(��) 02:42:16 ID:qfnxFrhe
����̓I�Ɍ����ƁA����v�Z�ɂ��ƒP���xN-Body�ł�Sandy Bridge��1�R�A�͓��N���b�N��Bulldozer1���W���[�����4�{���x����
FMA���L���Ɏg���Ȃ������ł�Bulldozer�s��
�i������Radix-64�N���X�̋��͂ȏ��Z��H�ł��ςނȂ�A�t���������̕K�v���x�ɂ���Ă�Bulldozer�̋t�]�����肤��j
�t��256�r�b�gSIMD���L���Ɏg�����Ȃ�����FMA�̗��p�p�x�̍��������Ȃ�Bulldozer�L���B
�i�����܂ł��Ȃ����A256�r�b�g��SIMD����K�p�ł��Ȃ����͓��RGPGPU���K�p�s�\�j
FMA���L���Ɏg���Ȃ������ł�Bulldozer�s��
�i������Radix-64�N���X�̋��͂ȏ��Z��H�ł��ςނȂ�A�t���������̕K�v���x�ɂ���Ă�Bulldozer�̋t�]�����肤��j
�t��256�r�b�gSIMD���L���Ɏg�����Ȃ�����FMA�̗��p�p�x�̍��������Ȃ�Bulldozer�L���B
�i�����܂ł��Ȃ����A256�r�b�g��SIMD����K�p�ł��Ȃ����͓��RGPGPU���K�p�s�\�j
577 �F,,�E�L�́M�E,,�j��-�������F2010/07/01(��) 02:43:00 ID:qfnxFrhe
��4�{���x����
����A����͂Ȃ���B4���ɒ�����
����A����͂Ȃ���B4���ɒ�����
>>572
���O�{������A�Ⴆ�Ă邶��Ȃ���.�B
�����A�ŏI�I�ɂ�32nm�Ń��[�N���������N���b�N�͏グ�Ă���Ǝv���B
>>573
�C�X���G���`�[���̓m�[�g����Ă��́B
���ꂪ�l�g�o��5GHZ�z�����Z�p�I�ɖ������Ƃ킩�����̂�
���������M�ŋ}篔��H�̖�������̂��B
>>574
�Ȃɂɑ������Ƃ����̂����邾��
pentium M�͐������Z�����͏ȃG�l�ō������������B
SSE�������������畂�������_���Z�͂����ς肾�������ǁB
intel�Ƃ��Ă��l�g�o�V���[�Y�̓`�������W���O�Ȏ��݂�������
���ǁAPen�V����A�Ȃ�A�[�L�e�N�`���������Ȃ��܂łɉ�������pentium M�̌n��Ői��ł�B
���O�{������A�Ⴆ�Ă邶��Ȃ���.�B
�����A�ŏI�I�ɂ�32nm�Ń��[�N���������N���b�N�͏グ�Ă���Ǝv���B
>>573
�C�X���G���`�[���̓m�[�g����Ă��́B
���ꂪ�l�g�o��5GHZ�z�����Z�p�I�ɖ������Ƃ킩�����̂�
���������M�ŋ}篔��H�̖�������̂��B
>>574
�Ȃɂɑ������Ƃ����̂����邾��
pentium M�͐������Z�����͏ȃG�l�ō������������B
SSE�������������畂�������_���Z�͂����ς肾�������ǁB
intel�Ƃ��Ă��l�g�o�V���[�Y�̓`�������W���O�Ȏ��݂�������
���ǁAPen�V����A�Ȃ�A�[�L�e�N�`���������Ȃ��܂łɉ�������pentium M�̌n��Ői��ł�B
>578
> 32nm���[�N��
> pentium M��
> SSE����������
��������́H
> 32nm���[�N��
> pentium M��
> SSE����������
��������́H
581 �FSocket774�F2010/07/01(��) 12:48:03 ID:afRCSIK5
���[�N�d���̑傫���B22nm>32nm>45nm>65nm>90nm �B
45nm�ŏ��߂�MGHK���̗p���ꂽ�B
45nm�ŏ��߂�MGHK���̗p���ꂽ�B
AMD�Ƃ�����GF��45nm��MGHK�������ĂȂ�����A
32nm��45nm��胊�[�N�d���팸������Ȃ��́H
intel�̕���45nm���炾����A32nm��45nm�Ɣ�r���Ăǂ��Ȃ̂��m��Ȃ����ǁB
32nm��45nm��胊�[�N�d���팸������Ȃ��́H
intel�̕���45nm���炾����A32nm��45nm�Ɣ�r���Ăǂ��Ȃ̂��m��Ȃ����ǁB
�����I�ɂ̓��[�N�͔������i�߂ǂ�ǂ���킯��
���ꂪ�}�����Ă�Ƃ������Ƃ͂�����Ƒł��Ă�Ƃ����؋�
���ꂪ�}�����Ă�Ƃ������Ƃ͂�����Ƒł��Ă�Ƃ����؋�
�́H
>>585
> ��������́H
�㓡�����k�قԂ肪�ǂ�������L������
�u32nm�œ��v���Z�X�ł�K10�n�R�A���A�͂邩�ɏ��������Ƃ͊m�����v���k�ق�M���ĕK���ɑ����ł��邾���̘b�ɉ߂��Ȃ��B
����������������K10�͏������Ȃ����̂��H�A�P��L3�����O���ď������������Ƒ����ł����ɉ߂����n���炵���ɂ���������B
> ��������́H
�㓡�����k�قԂ肪�ǂ�������L������
�u32nm�œ��v���Z�X�ł�K10�n�R�A���A�͂邩�ɏ��������Ƃ͊m�����v���k�ق�M���ĕK���ɑ����ł��邾���̘b�ɉ߂��Ȃ��B
����������������K10�͏������Ȃ����̂��H�A�P��L3�����O���ď������������Ƒ����ł����ɉ߂����n���炵���ɂ���������B
����C�J�L��
Llano�̃R�A�ɂ�L3������łȂ��́H
590 �FSocket774�F2010/07/01(��) 17:39:37 ID:I1kT5TRU
�V�������N�����珬�����Ȃ邵�����L3������
���ɓ�����O�ȋL���Ɋ��ݕt���Ă邗
���ɓ�����O�ȋL���Ɋ��ݕt���Ă邗
>>590
> �V�������N�����珬�����Ȃ邵�����L3������
�V�������N�����珬�����Ȃ�̂�Intel������
> ���ɓ�����O�ȋL��
�܂艽�̗��R���Ȃ��u�͂邩�ɏ������v�Ƒ����ł���n���L���Ȃ�w
> �V�������N�����珬�����Ȃ邵�����L3������
�V�������N�����珬�����Ȃ�̂�Intel������
> ���ɓ�����O�ȋL��
�܂艽�̗��R���Ȃ��u�͂邩�ɏ������v�Ƒ����ł���n���L���Ȃ�w
�ǂ���ւ��Ȃ̂���
Sandy�̃R�A��Llano�̃R�A���r������傫���͑��2�F1
Sandy�̃L���b�V�������̓R�A�ɂ͊܂߂Ȃ��Ƃ����g����Ȍv�Z�h������܂��b�͕ς�邯�ǂ�
Sandy�̃R�A��Llano�̃R�A���r������傫���͑��2�F1
Sandy�̃L���b�V�������̓R�A�ɂ͊܂߂Ȃ��Ƃ����g����Ȍv�Z�h������܂��b�͕ς�邯�ǂ�
Llano��CPU�R�A��32nm�ŁA1MB��L2�L���b�V��(�v���X�V������������p���[�Q�[�e�B���O�����O)�ƍ��킹��17.7����mm
Nehalem�nCPU�R�A��32nm�ŁA256KB��L2�L���b�V�����݂̃T�C�Y��17����mm��H
Nehalem�nCPU�R�A��32nm�ŁA256KB��L2�L���b�V�����݂̃T�C�Y��17����mm��H
�u������O�Ȃ��Ƃ������Ɣn���v�Ȃ̂�������̍��ł���
�G�i�\�t�g�ɖO�������]�Ȑ܁iPC���r���[�L�ғ��F�X�j
���݂͗����i��������j����ɂ��M�ȋC���������z���̏펯
�E���R�̏L����q�̏L���������肷��
�G�i�\�t�g�ɖO�������]�Ȑ܁iPC���r���[�L�ғ��F�X�j
���݂͗����i��������j����ɂ��M�ȋC���������z���̏펯
�E���R�̏L����q�̏L���������肷��
595 �F,,�E�L�́M�E,,�j��-�������F2010/07/01(��) 17:57:12 ID:qfnxFrhe
�m�[�h����7�����x�ɏk���Ƃ��������ȃV�������N���Ɍ����邪
http://pc.watch.impress.co.jp/img/pcw/docs/348/705/html/2.jpg.html
Llano��C�X�e�[�g�͐�pSRAM����Ȃ��ă��C���������ɑҔ�����d�g�݂����獂���ȃX�e�[�g�ؑւ͖���
�܂�ASandy Bridge�قǓd�͌����͏オ��Ȃ�
> Sandy�̃R�A��Llano�̃R�A���r������傫���͑��2�F1
Sandy��L2���܂ރR�A��Llano��L2���܂܂Ȃ��R�A���r��������Ȍv�Z��
http://pc.watch.impress.co.jp/img/pcw/docs/348/705/html/2.jpg.html
{kind=link}
Llano��C�X�e�[�g�͐�pSRAM����Ȃ��ă��C���������ɑҔ�����d�g�݂����獂���ȃX�e�[�g�ؑւ͖���
�܂�ASandy Bridge�قǓd�͌����͏オ��Ȃ�
> Sandy�̃R�A��Llano�̃R�A���r������傫���͑��2�F1
Sandy��L2���܂ރR�A��Llano��L2���܂܂Ȃ��R�A���r��������Ȍv�Z��
�S�L�u�������̒m�\�S�L�u�����߂ȋC���������̃z��������
�P�Ȃ�C���������ԈႢ�T���Ȃ̂Ŗ������悤
ttp://chip-architect.com/news/Shanghai_Nehalem.jpg
45nm��L1����ʂ��ĂȂ����������E�̘b�͂��̐}��
Intel�̓~���N���ȃL���b�V�����R���p�N�g�ɓ��ڂ��Ă��邪
���̕��R�A���W�b�N���ł���
�o�b�t�@�i�L���b�V���Ǝ����悤�Ȃ���j�����ǂ��Ȃ��Ă�̂��F�ڔ���Ȃ���
�Ƃ肠�����L���b�V�������ʂɂ����Intel�R�A�͕��ł���
�P�Ȃ�C���������ԈႢ�T���Ȃ̂Ŗ������悤
ttp://chip-architect.com/news/Shanghai_Nehalem.jpg
{kind=link}
45nm��L1����ʂ��ĂȂ����������E�̘b�͂��̐}��
Intel�̓~���N���ȃL���b�V�����R���p�N�g�ɓ��ڂ��Ă��邪
���̕��R�A���W�b�N���ł���
�o�b�t�@�i�L���b�V���Ǝ����悤�Ȃ���j�����ǂ��Ȃ��Ă�̂��F�ڔ���Ȃ���
�Ƃ肠�����L���b�V�������ʂɂ����Intel�R�A�͕��ł���
>>595
����A2�F1���Ă̂�Sandy��Llano�o���Ƃ��L���b�V�����܂߂��ꍇ�̂���
����A2�F1���Ă̂�Sandy��Llano�o���Ƃ��L���b�V�����܂߂��ꍇ�̂���
�L���b�V���܂Ŋ܂߂���r��Sandy��29.5�o2�ALlano��16�o2��������Ă��Ƃ�����A2�F1���͎���͏�������
�ł�Westmere�̎��_��28.5�o2���钆�ŁASandy��29.5�o2�ɂ܂Ƃ߂ė������Ă̂͑f���炵����
�[��Sandy�Ɣ�r���Ă���i�K�Ŋ����k�ق��̂��̂���w
Llano�������Ȓᐫ�\CPU����r���ėǂ��̂͂ǂ�ȂɊ撣���Ă�Clarkdale��Arrandale����B
�k�ق�M����ׂɕK���Ȃ͕̂����邪����������������w
Llano�������Ȓᐫ�\CPU����r���ėǂ��̂͂ǂ�ȂɊ撣���Ă�Clarkdale��Arrandale����B
�k�ق�M����ׂɕK���Ȃ͕̂����邪����������������w
ttp://www.chip-architect.com/news/Llano_vs_SandyBridge_vs_Westmere_s.jpg
����͂����
�uSandy��L3���܂ރR�A��K10��L3���܂܂Ȃ��R�A���r��������Ȍv�Z���v�ɂ͂Ȃ��
>596�̐}
K10L1�L���b�V�����i�q��̕������낤��
L2�Ƃقړ����傫���̊i�q
�e��4�{���Ȃ̂ɓ��T�C�Y
�uK10��L1�������\������L2�ȉ������v�Ƃ������Ă��݂���������
���x�l����Δ[��
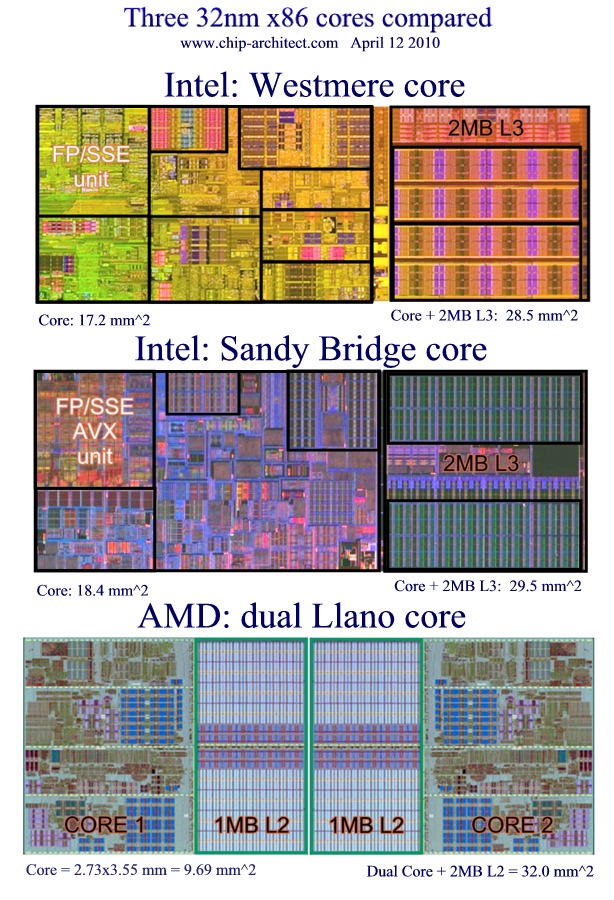{kind=link}
����͂����
�uSandy��L3���܂ރR�A��K10��L3���܂܂Ȃ��R�A���r��������Ȍv�Z���v�ɂ͂Ȃ��
>596�̐}
K10L1�L���b�V�����i�q��̕������낤��
L2�Ƃقړ����傫���̊i�q
�e��4�{���Ȃ̂ɓ��T�C�Y
�uK10��L1�������\������L2�ȉ������v�Ƃ������Ă��݂���������
���x�l����Δ[��
602 �F,,�E�L�́M�E,,�j��-�������F2010/07/01(��) 18:26:16 ID:qfnxFrhe
>>597
Llano��L2 1MB�~2��Sandy Bridge��L3 2MB(1.5MB�H�j���������x�̖ʐςŁA�������������
Llano �F�@���W�b�N�{L1
Sandy Bridge �F�@���W�b�N�{L1�{L2
�f�G�Ȕ�r����
Llano��L2 1MB�~2��Sandy Bridge��L3 2MB(1.5MB�H�j���������x�̖ʐςŁA�������������
Llano �F�@���W�b�N�{L1
Sandy Bridge �F�@���W�b�N�{L1�{L2
�f�G�Ȕ�r����
>>600
Sandy����2�R�A�`8�R�A�܂œ��������A�[�L�e�N�`���̖��O�ł����āA
Clarkdale��Arrandale�̂悤�Ȑ��i�̖��O����Ȃ���
�Ȃ̂�Llano��Sandy�̒��ł��~�h���`�G���g���[�N���X�Ƃ͋������邱�Ƃɂ�
Sandy����2�R�A�`8�R�A�܂œ��������A�[�L�e�N�`���̖��O�ł����āA
Clarkdale��Arrandale�̂悤�Ȑ��i�̖��O����Ȃ���
�Ȃ̂�Llano��Sandy�̒��ł��~�h���`�G���g���[�N���X�Ƃ͋������邱�Ƃɂ�
�܂��A�����܂��k�ق�M�����L���͂������㓡���Ƃ������Ƃ��낤���c
�㓡���Ƃ��Ă�AMD���V���O���X���b�h���\���]���ɂ����R�A���i�ނ��Ƃ̑Ó������u��菬���ȃ_�C�T�C�Y�v�Ƃ����k�قŕ₨���Ƃ��Ă���̂��Ǝv���B
�܂��A����J�Ȃ����Ăƌ���������w
�㓡���Ƃ��Ă�AMD���V���O���X���b�h���\���]���ɂ����R�A���i�ނ��Ƃ̑Ó������u��菬���ȃ_�C�T�C�Y�v�Ƃ����k�قŕ₨���Ƃ��Ă���̂��Ǝv���B
�܂��A����J�Ȃ����Ăƌ���������w
>>602
����A2�F1���Ă̂�Sandy��Llano�o���Ƃ��L���b�V�����܂߂��ꍇ�̂���
����A2�F1���Ă̂�Sandy��Llano�o���Ƃ��L���b�V�����܂߂��ꍇ�̂���
>>601
> ttp://www.chip-architect.com/news/Llano_vs_SandyBridge_vs_Westmere_s.jpg
dual Llano�R�A 32m�u
����ꂨ�������ȁc
> ttp://pc.watch.impress.co.jp/docs/column/kaigai/20100215_348705.html
������̋L������Llano�R�A��17.7m�u������x2�����35.4m�u�ȉ��ɂȂ锤���Ȃ��̂����c
�K���ɂȂ��ď��������������悤�Ƃ��Ă���͉̂��̂��H
> ttp://www.chip-architect.com/news/Llano_vs_SandyBridge_vs_Westmere_s.jpg
dual Llano�R�A 32m�u
����ꂨ�������ȁc
> ttp://pc.watch.impress.co.jp/docs/column/kaigai/20100215_348705.html
������̋L������Llano�R�A��17.7m�u������x2�����35.4m�u�ȉ��ɂȂ锤���Ȃ��̂����c
�K���ɂȂ��ď��������������悤�Ƃ��Ă���͉̂��̂��H
607 �F,,�E�L�́M�E,,�j��-�������F2010/07/01(��) 18:48:43 ID:qfnxFrhe
1�b�s���}�W�ŃC�J�L��
L1 32k? 64k??
+
L2 256k
+
L3 2M(share)
��
L1 32k? 64k??
+
L2 1M
�ǂ��������\�����낤�ˁH�i�����L���b�V�����\�Ƃ��āj
����L2���������傫�������Ń��C�e���V��������ƃT�C�Y�傫�����Ƃɂ��
�q�b�g���̌��㕪�E���Ă��܂���������
+
L2 256k
+
L3 2M(share)
��
L1 32k? 64k??
+
L2 1M
�ǂ��������\�����낤�ˁH�i�����L���b�V�����\�Ƃ��āj
����L2���������傫�������Ń��C�e���V��������ƃT�C�Y�傫�����Ƃɂ��
�q�b�g���̌��㕪�E���Ă��܂���������
>>607
Sandy��Phenom�U���ׂ����́H
Sandy��Phenom�U���ׂ����́H
611 �F,,�E�L�́M�E,,�j��-�������F2010/07/01(��) 19:02:51 ID:qfnxFrhe
�Ă��A���{�I�Șb�Ƃ��āA�R�A�̃T�C�Y��r���ĉ��ɂȂ�́H
�R�A������̐��\�������̈Ⴂ�����B
�R�A������̐��\�������̈Ⴂ�����B
>>609
�L���b�V���e�ʂƃ��x�����̈�ʓI�ȃ��C�e���V���������ׂ����Ȃ�
Phe2X2��Ath2X2�Ŕ�ׂ�Α啪�Q�l�ɂȂ�
Intel��AMD�̃L���b�V���A�[�L���ׂ��Ȃ���������������Ȃ�Ⴄ���낤���牽�Ƃ������Ȃ�
���ƍ��{�I�Șb�������
���܂ꂽ������f�b�h�X�y�[�X�ȋC���������m�\0�̃V���^�z���͖{���ɃC�J�L��
�L���b�V���e�ʂƃ��x�����̈�ʓI�ȃ��C�e���V���������ׂ����Ȃ�
Phe2X2��Ath2X2�Ŕ�ׂ�Α啪�Q�l�ɂȂ�
Intel��AMD�̃L���b�V���A�[�L���ׂ��Ȃ���������������Ȃ�Ⴄ���낤���牽�Ƃ������Ȃ�
���ƍ��{�I�Șb�������
���܂ꂽ������f�b�h�X�y�[�X�ȋC���������m�\0�̃V���^�z���͖{���ɃC�J�L��
>AMD���V���O���X���b�h���\���]���ɂ����R�A���i�ނ��Ƃ̑Ó���
���������]���ɂ��Ȃ��Ă��}���`�R�A���o������B
����Intel������Ă邶���B
�㓡�ɂ�����Ɖ��̂��}���`�R�A���ɕ����邢���ɂ��ɂ���Ă��܂��B
���������]���ɂ��Ȃ��Ă��}���`�R�A���o������B
����Intel������Ă邶���B
�㓡�ɂ�����Ɖ��̂��}���`�R�A���ɕ����邢���ɂ��ɂ���Ă��܂��B
614 �FSocket774�F2010/07/01(��) 19:13:55 ID:I1kT5TRU
�V�������N���܂������ē��e�Ȃ����Ȃ̂ɂ˂�
�K���ɃL���b�V���Ƃ������o���Ăǂ������́H
�K���ɃL���b�V���Ƃ������o���Ăǂ������́H
615 �F,,�E�L�́M�E,,�j��-�������F2010/07/01(��) 19:18:38 ID:qfnxFrhe
��������Nehalem�̃R�A���̑傫����B45nm�̎��_�łȁB
�ł��A�傫�����Ƃʼn����s�s�����������H
�ł��A�傫�����Ƃʼn����s�s�����������H
>>613
�㓡���ɂ��Ă݂���Bulldozer��8�R�A�i4���W���[���j Vs Sandy Bridge 4�R�A(8�_���R�A)�̍\�}���\�z����Ă���
���̎���Bulldozer��8�R�A�i4���W���[���j�̓_�C�T�C�Y���������ċ����͂�����̂��Ǝv�킹�����̂��낤�ȁc
���ɂ͂��ꂮ�炢�����㓡�����k�ق�M���Ă��闝�R�͎v��������Ȃ��B
�܂��AAMD�ɂ͋����͂�����ƌ������������̂��낤��c
�㓡���ɂ��Ă݂���Bulldozer��8�R�A�i4���W���[���j Vs Sandy Bridge 4�R�A(8�_���R�A)�̍\�}���\�z����Ă���
���̎���Bulldozer��8�R�A�i4���W���[���j�̓_�C�T�C�Y���������ċ����͂�����̂��Ǝv�킹�����̂��낤�ȁc
���ɂ͂��ꂮ�炢�����㓡�����k�ق�M���Ă��闝�R�͎v��������Ȃ��B
�܂��AAMD�ɂ͋����͂�����ƌ������������̂��낤��c
�V���O���X���b�h���\�ƃ}���`�X���b�h���\
���܂ŗ����ł���̂���
�ėp�Ɛ�p�̂����Ƃ��ǂ�Ŏ��猂�����������~�̓�̕��͔��������Ƃ���
���܂ŗ����ł���̂���
�ėp�Ɛ�p�̂����Ƃ��ǂ�Ŏ��猂�����������~�̓�̕��͔��������Ƃ���
��������Ԃ��������ԈႢ�T���Ȃ�ďo�肷��ȃy�h�z��
619 �F,,�E�L�́M�E,,�j��-�������F2010/07/01(��) 19:24:13 ID:qfnxFrhe
>>609
K10�̏ꍇ�AL3���Ȃ����������x���`���炠����
Phenom�ɂ�����L3�̌��ʂ��āA�ǂ������Ƃ����Ɛ��\���グ��ׂƌ������
�������g���t�B�b�N�̍��G�ɂ�鐫�\�ቺ��h���ׂƂ����Ӗ��������傫���Ǝv���B
���̈Ӗ��őш��H�炢��GPU������Llano�ɂ���L3�͕K�v����Ȃ����Ǝv���̂����E�E�E
�ς�łȂ������I���̂��I
K10�̏ꍇ�AL3���Ȃ����������x���`���炠����
Phenom�ɂ�����L3�̌��ʂ��āA�ǂ������Ƃ����Ɛ��\���グ��ׂƌ������
�������g���t�B�b�N�̍��G�ɂ�鐫�\�ቺ��h���ׂƂ����Ӗ��������傫���Ǝv���B
���̈Ӗ��őш��H�炢��GPU������Llano�ɂ���L3�͕K�v����Ȃ����Ǝv���̂����E�E�E
�ς�łȂ������I���̂��I
>>618��>616�i�Ƃ�����>606�j�ւ̃��X
�wSandy�ł̓R�A�̈ꕔ�͖ʐόv�Z�Ɋ܂߂�ׂ��ł͂Ȃ��x�Ƃ������o���������������r�ꂽ������
Nehalem���_���Ȃ�Ęb�͏��Ȃ��Ƃ������͏o�ĂȂ���
Nehalem���_���Ȃ�Ęb�͏��Ȃ��Ƃ������͏o�ĂȂ���
GPU�ɃL���b�V������
�܂�GPGPU�Ɋ�]���H
�܂�GPGPU�Ɋ�]���H
�㓡���̋L���Ŗʔ��������̂͂��ꂩ�Ȃ��c
http://pc.watch.impress.co.jp/img/pcw/docs/377/488/html/6.jpg.html
10MB��eDRAM�`�b�v�������L���b�V���Ƃ���MCM���邱�Ƃœ���GPU�̃������ш�s����₤���Ęb
����͌��\����̃g�����h�ɂȂ��Ă���悤�Ɏv���̂����c
http://pc.watch.impress.co.jp/img/pcw/docs/377/488/html/6.jpg.html
{kind=link}
10MB��eDRAM�`�b�v�������L���b�V���Ƃ���MCM���邱�Ƃœ���GPU�̃������ш�s����₤���Ęb
����͌��\����̃g�����h�ɂȂ��Ă���悤�Ɏv���̂����c
>>619
�����̈Ӗ��őш��H�炢��GPU������
�����G���A�̃������ɑ��ĉ��x���A�N�Z�X���邩��L���b�V���͉��l������
�f�o�t�̎g���f�[�^�́A�������A�N�Z�X�̋Ǐ������R�����̂ŃL���b�V���������Ă�
�����ш�̌���Ƃ��ɂ͂قƂ�NJ�^���Ȃ��@�Ȃ�Ę_�����L���������L������Ȃ�
�V�~�����[�V�����Ƃ��ł�����x�m���߂Ă����Ŗ����́H
�����̈Ӗ��őш��H�炢��GPU������
�����G���A�̃������ɑ��ĉ��x���A�N�Z�X���邩��L���b�V���͉��l������
�f�o�t�̎g���f�[�^�́A�������A�N�Z�X�̋Ǐ������R�����̂ŃL���b�V���������Ă�
�����ш�̌���Ƃ��ɂ͂قƂ�NJ�^���Ȃ��@�Ȃ�Ę_�����L���������L������Ȃ�
�V�~�����[�V�����Ƃ��ł�����x�m���߂Ă����Ŗ����́H
625 �F,,�E�L�́M�E,,�j��-�������F2010/07/01(��) 19:32:06 ID:qfnxFrhe
�����������N��32nm�Ń^���͂�邩�ǂ����Ȃ�ċc�_���Ă��AIntel��22nm�𓊓����闂�N�ɂ͑S���Ӗ����Ȃ��Ȃ�B
�ނ���v���Z�X���[���Œx��Ă镪�����p�t�H�[�}���X�Ń��[�h���Ȃ��Ƙb�ɂȂ��Ƃ��Ⴄ��
�ނ���v���Z�X���[���Œx��Ă镪�����p�t�H�[�}���X�Ń��[�h���Ȃ��Ƙb�ɂȂ��Ƃ��Ⴄ��
626 �F,,�E�L�́M�E,,�j��-�������F2010/07/01(��) 19:34:04 ID:qfnxFrhe
>>624
�O���t�B�b�N�����́u���x���A�N�Z�X���Ȃ��v���Ƃ���
�u�X���b�h�c�偁�ް��c��v�Ȃ��Ƃ̂ق���������Ǝv����
�����f�[�^����x���Z���������ŏI����Ă��܂��Ȃ�
������L�ш惁�����g���Ă�����PCIE�̑ш�̃l�b�N�ŏI�����Ă��܂��͂�
���x���ǂݏ��������邩�烁������ς�ł���
GPU�ɃL���b�V�����s�����ȗ��R�͕��̂ق�
�O���t�B�b�N�����́u���x���A�N�Z�X���Ȃ��v���Ƃ���
�u�X���b�h�c�偁�ް��c��v�Ȃ��Ƃ̂ق���������Ǝv����
�����f�[�^����x���Z���������ŏI����Ă��܂��Ȃ�
������L�ш惁�����g���Ă�����PCIE�̑ш�̃l�b�N�ŏI�����Ă��܂��͂�
���x���ǂݏ��������邩�烁������ς�ł���
GPU�ɃL���b�V�����s�����ȗ��R�͕��̂ق�
Llano��L3���ڂ���Ƃ��āA���̕��������̂���
629 �F,,�E�L�́M�E,,�j��-�������F2010/07/01(��) 19:42:32 ID:qfnxFrhe
Llano�L�`�̐l��������4�R�A�����Ă��G���h���[�U�[�͈Ӗ��������炵���̂�
�l�C�e�B�u3�R�A�ɂ���1�R�A���̖ʐς�L3�����������ˁ[�́H
�X��1�R�A�����ɂ��邾���Ńf���A���R�A�̏o���オ��
�l�C�e�B�u3�R�A�ɂ���1�R�A���̖ʐς�L3�����������ˁ[�́H
�X��1�R�A�����ɂ��邾���Ńf���A���R�A�̏o���オ��
Llano��3�����Ė{���]�|�����
�R�X�g�グ�Ăǂ������
�R�X�g�グ�Ăǂ������
631 �F,,�E�L�́M�E,,�j��-�������F2010/07/01(��) 19:45:03 ID:qfnxFrhe
���邢�͏���Phenom�݂�����L2 512K�~4�{L3 2MB���H
SRAM�T�C�Y�I�ɂ�1MB�~4�ƕς���
SRAM�T�C�Y�I�ɂ�1MB�~4�ƕς���
>>626
�b�o�t���ɂ�L3�͂���قǎ|�݂��������Ď�����ˁH
���Ȃ��Ƃ�K10�A�[�L�e�N�`���̉�����̏ꍇ��
>>627
�Ō�ɕ��Əo�Ă��邪�A����������Ƃ��Ă��邩�s���Ŕ��Ǐo���Ȃ��̂���
�b�o�t���ɂ�L3�͂���قǎ|�݂��������Ď�����ˁH
���Ȃ��Ƃ�K10�A�[�L�e�N�`���̉�����̏ꍇ��
>>627
�Ō�ɕ��Əo�Ă��邪�A����������Ƃ��Ă��邩�s���Ŕ��Ǐo���Ȃ��̂���
>623�̂Â�
�����A>623�̕����ɐi�ނƊm���ɓ���GPU���\�̒�グ�Ɍq���邪���ꂾ��GPU�s�ꂪ�H���Ă��܂��ˁB
�����Ȃ��AMD�Ђɂ��Ă݂�Βɂ��y�����c�A�_�����Ȃ����
�����A>623�̕����ɐi�ނƊm���ɓ���GPU���\�̒�グ�Ɍq���邪���ꂾ��GPU�s�ꂪ�H���Ă��܂��ˁB
�����Ȃ��AMD�Ђɂ��Ă݂�Βɂ��y�����c�A�_�����Ȃ����
�L�`�K�C�̗��܂��
>>632
���偁�X���b�h�������f�[�^�ʑ�
���偁�X���b�h�������f�[�^�ʑ�
>>635
�����̌��t�ɒ��������̂ˁB
���������A�N�Z�X�̋Ǐ������R����
����ƈӖ��͓�������Ȃ��́H
�摜�����̓f�[�^�A�N�Z�X�ʂ��c��Ȃ�Ă̂͗ǂ��m���Ă���B
���́A�ʂ����łȂ����̖��Łc�Ƃ������Ƃ����B
�����̌��t�ɒ��������̂ˁB
���������A�N�Z�X�̋Ǐ������R����
����ƈӖ��͓�������Ȃ��́H
�摜�����̓f�[�^�A�N�Z�X�ʂ��c��Ȃ�Ă̂͗ǂ��m���Ă���B
���́A�ʂ����łȂ����̖��Łc�Ƃ������Ƃ����B
>>636
�f�[�^�A�N�Z�X�ʂ���Ȃ��f�[�^�ʂƌ����Ă��
�������A�N�Z�X�̋Ǐ����������Ă��f�[�^�ʎ��̂������ăL���b�V������𗧂�����
�ƌ����Ă��
�ʂ̂ق������Ȃ�Ȃ���
�ƌ����Ă��
�f�[�^�A�N�Z�X�ʂ���Ȃ��f�[�^�ʂƌ����Ă��
�������A�N�Z�X�̋Ǐ����������Ă��f�[�^�ʎ��̂������ăL���b�V������𗧂�����
�ƌ����Ă��
�ʂ̂ق������Ȃ�Ȃ���
�ƌ����Ă��
638 �FSocket774�F2010/07/01(��) 20:07:13 ID:bRy61479
�����Ǔ�ɁA���̔N���ɏo��i7 970�Ƃ̐��\�����|�C�����ɂȂ�Ǝv���̂�
������3���ۂ�����ŏo�����T���f�[4�R�A��u���h�U�[8�R�A��2�`3���ŏo���Ƃ����
���\�I�ɕ����Ă��ᔄ��ˁ[������Ă��ƁA�݂��970�őg����Ď�����A�[�L�܂ŃX���[����ˁH
����z���g�̘b�A�ŏI�S�{�̖��͈ɒB����Ȃ��Ǝv���̂�
������3���ۂ�����ŏo�����T���f�[4�R�A��u���h�U�[8�R�A��2�`3���ŏo���Ƃ����
���\�I�ɕ����Ă��ᔄ��ˁ[������Ă��ƁA�݂��970�őg����Ď�����A�[�L�܂ŃX���[����ˁH
����z���g�̘b�A�ŏI�S�{�̖��͈ɒB����Ȃ��Ǝv���̂�
>>637
�摜�f�[�^�͑傫�����[�v�ő傫���e�[�u���ւ̏������J��Ԃ��A
���g�����炩�Ȃ�̎��Ԃ̌�ɂ܂��g���̂�
�f�[�^�A�N�Z�X�̋Ǐ������Ⴍ�A�L���b�V�����w�ǖ��Ӗ��B
CPU�͏��������[�v�łقړ����̈�ւ̃A�N�Z�X���������A���ʂ̃��[�v��
���ʂ̗̈�ւ̃A�N�Z�X������B�@����ŃL���b�V���������B
���������A���C���������Q�f�a�قǗ~������ԂɂȂ��Ă���̂́AWINDOWS��
���Ȃ��������邪CPU���Ȃ̂����H
�摜�����̃������A�N�Z�X�̋Ǐ�����������L���b�V���͗L���Ɍ��܂��Ă���B
�Ǐ��������Ȃ��ă��C�e���V������̂��A���ɒ������ăX���b�h���₵�Ă���̂�
�ŋ߂�GPU�̃g�����h
�摜�f�[�^�͑傫�����[�v�ő傫���e�[�u���ւ̏������J��Ԃ��A
���g�����炩�Ȃ�̎��Ԃ̌�ɂ܂��g���̂�
�f�[�^�A�N�Z�X�̋Ǐ������Ⴍ�A�L���b�V�����w�ǖ��Ӗ��B
CPU�͏��������[�v�łقړ����̈�ւ̃A�N�Z�X���������A���ʂ̃��[�v��
���ʂ̗̈�ւ̃A�N�Z�X������B�@����ŃL���b�V���������B
���������A���C���������Q�f�a�قǗ~������ԂɂȂ��Ă���̂́AWINDOWS��
���Ȃ��������邪CPU���Ȃ̂����H
�摜�����̃������A�N�Z�X�̋Ǐ�����������L���b�V���͗L���Ɍ��܂��Ă���B
�Ǐ��������Ȃ��ă��C�e���V������̂��A���ɒ������ăX���b�h���₵�Ă���̂�
�ŋ߂�GPU�̃g�����h
>>639
> �摜�f�[�^�͑傫�����[�v�ő傫���e�[�u���ւ̏������J��Ԃ��A
> ���g�����炩�Ȃ�̎��Ԃ̌�ɂ܂��g���̂�
> �f�[�^�A�N�Z�X�̋Ǐ������Ⴍ�A�L���b�V�����w�ǖ��Ӗ��B
�㓡���̋L����ǂތ��肻���͎v���Ȃ��Ȃ��c
http://pc.watch.impress.co.jp/docs/column/kaigai/20100701_377756.html
> �J�X�^��eDRAM�`�b�v�ō����]�����������邱�ƂŁA�������`�b�v����}���Ȃ��璴�L�ш惁��������������Ƃ����A�C�f�A���B
> �A���t�@��Z�e�X�g�A�A���`�G�C���A�V���O�Ƃ����������́A�������A�N�Z�X���p�����邽�߁A�������ш�ւ̕��S���傫���B�����ŁA
> Xbox 360�ł́A�s�N�Z�������v���Z�b�T�Q��eDRAM�u���b�N�̊Ԃ��A�`�b�v���̒��L�ш�C���^�[�t�F�C�X�Ō���ł���B
> eDRAM�ւ̃`�b�v�����̃������ш��256GB/sec�Ƌɂ߂čL���B���������C���e���W�F���g�O���t�B�b�N�X�������́A�ȑO�A
> �O�H�d�@�����i�����Ă������AXbox 360�͗ގ��̋Z�p�̃�������GPU�ƃp�b�P�[�W���ɔ[�߂邱�ƂŁA���L���ȋZ�p�ɂ����B
> �摜�f�[�^�͑傫�����[�v�ő傫���e�[�u���ւ̏������J��Ԃ��A
> ���g�����炩�Ȃ�̎��Ԃ̌�ɂ܂��g���̂�
> �f�[�^�A�N�Z�X�̋Ǐ������Ⴍ�A�L���b�V�����w�ǖ��Ӗ��B
�㓡���̋L����ǂތ��肻���͎v���Ȃ��Ȃ��c
http://pc.watch.impress.co.jp/docs/column/kaigai/20100701_377756.html
> �J�X�^��eDRAM�`�b�v�ō����]�����������邱�ƂŁA�������`�b�v����}���Ȃ��璴�L�ш惁��������������Ƃ����A�C�f�A���B
> �A���t�@��Z�e�X�g�A�A���`�G�C���A�V���O�Ƃ����������́A�������A�N�Z�X���p�����邽�߁A�������ш�ւ̕��S���傫���B�����ŁA
> Xbox 360�ł́A�s�N�Z�������v���Z�b�T�Q��eDRAM�u���b�N�̊Ԃ��A�`�b�v���̒��L�ш�C���^�[�t�F�C�X�Ō���ł���B
> eDRAM�ւ̃`�b�v�����̃������ш��256GB/sec�Ƌɂ߂čL���B���������C���e���W�F���g�O���t�B�b�N�X�������́A�ȑO�A
> �O�H�d�@�����i�����Ă������AXbox 360�͗ގ��̋Z�p�̃�������GPU�ƃp�b�P�[�W���ɔ[�߂邱�ƂŁA���L���ȋZ�p�ɂ����B
641 �F,,�E�L�́M�E,,�j��-�������F2010/07/01(��) 20:25:44 ID:qfnxFrhe
���̃g�����h���ǂ�l�܂�Ń^�C�������_�Ɉڍs���悤�Ƃ������������
�C���e����PC�ł��^�C���̈ڍs�����炻���Ȃ낤��
>>639
����ł��ǂ�ł�
ttp://pc.watch.impress.co.jp/docs/2007/0515/nvidia.htm
���Ă��A�[�L�I�Ɏ��s������̫���̔���������Ċ������邯��
����͂��߂��Ȃ������Ă��Ƃ�
�`��ł��ˑ����͂�����x����Ƃ�������
���Ɉˑ���������CPU������GPU�����œ������Ƃ��Ă�
CPU�̕���x��1.5
GPU�̕���x�͖������⑽��
����ŃL���b�V���̉��l���ꏏ���Ƃ��v���Ă�Ƃ���������ˁE�E�E
����ł��ǂ�ł�
ttp://pc.watch.impress.co.jp/docs/2007/0515/nvidia.htm
���Ă��A�[�L�I�Ɏ��s������̫���̔���������Ċ������邯��
����͂��߂��Ȃ������Ă��Ƃ�
�`��ł��ˑ����͂�����x����Ƃ�������
���Ɉˑ���������CPU������GPU�����œ������Ƃ��Ă�
CPU�̕���x��1.5
GPU�̕���x�͖������⑽��
����ŃL���b�V���̉��l���ꏏ���Ƃ��v���Ă�Ƃ���������ˁE�E�E
>>643
���O���A���̋L���̉��������āA�����̔����̕���x�Ɨ��߂Ă��邩�͒肩�łȂ����A
����x�Ƃ����������ɍS���āA�������A�N�Z�X�̋Ǐ�����F�߂����Ȃ����R���s�����ȁB
Direct-X�ׂ̍����d�l�͗ǂ�������A�^�C�������_�̗l�ɏ��������̈�ɂ���
�L���b�V�����������Ȃ��珈�����Ă����Ƃ�������̓������A�N�Z�X���Ǐ������邽�߂�
�A�v���[�`�Ƃ��ėǂ���������Ȃ��B
SLI�Ńp�t�H�[�}���X�グ��̂��A�`�b�v���Ń^�C�����O�������������z�f�o�t�����`��
�u����������ĈӖ��ŁB
���O���A���̋L���̉��������āA�����̔����̕���x�Ɨ��߂Ă��邩�͒肩�łȂ����A
����x�Ƃ����������ɍS���āA�������A�N�Z�X�̋Ǐ�����F�߂����Ȃ����R���s�����ȁB
Direct-X�ׂ̍����d�l�͗ǂ�������A�^�C�������_�̗l�ɏ��������̈�ɂ���
�L���b�V�����������Ȃ��珈�����Ă����Ƃ�������̓������A�N�Z�X���Ǐ������邽�߂�
�A�v���[�`�Ƃ��ėǂ���������Ȃ��B
SLI�Ńp�t�H�[�}���X�グ��̂��A�`�b�v���Ń^�C�����O�������������z�f�o�t�����`��
�u����������ĈӖ��ŁB
����f�[�^���ǂ��g�����Ō���̈Ⴂ�Ȃ�ĊW������
�������ˑ������Ǐ����ɂ��Ă��������x�������Ă�̂�
��������
�������ˑ������Ǐ����ɂ��Ă��������x�������Ă�̂�
��������
646 �F,,�E�L�́M�E,,�j��-�������F2010/07/01(��) 21:03:57 ID:qfnxFrhe
�^�C�����Ċi�q�̋��E�������ꗂ������₷�����狫�E�������d�����ă����_�����O���Č�ō����
�d�ˍ��킹��݂����ȑΉ����K�v�����
�܂��A���Z���j�b�g�̃X���[�v�b�g�ɔ�ׂă������X���[�v�b�g����ΓI�ɕs�������錻��ł͂���ł��\������
�d�ˍ��킹��݂����ȑΉ����K�v�����
�܂��A���Z���j�b�g�̃X���[�v�b�g�ɔ�ׂă������X���[�v�b�g����ΓI�ɕs�������錻��ł͂���ł��\������
�C���e�����^�C����eDRAM���̗p��������̂�
�c�q�����A�C���e���ɓ{�荞��H
�c�q�����A�C���e���ɓ{�荞��H
648 �F,,�E�L�́M�E,,�j��-�������F2010/07/01(��) 21:08:03 ID:qfnxFrhe
Larrabee�����̃^�C���x�[�X��GPU�E�E�E�E�̐U�������HPC�����v���Z�b�T����Ȃ���
Intel�̐V����GMA����PowerVR�݊�����Ȃ����������H
�܊p�̃����r��������ɐς܂Ȃ������Ȃ�Ď₵�����
GMA500�������H
���ꂪSandy�ɗ���́H
������Ɩʔ�����
���ꂪSandy�ɗ���́H
������Ɩʔ�����
>>651
GMA500��Atom�̑g�ݍ��ݗp��PowerVR��IP�g���Ă��邯�ǁA
Sandy�͏]���ʂ�Ɠ���Unified Shader�B
>>652
Haswell��Larrabee�݊��R�A���ڂ���Ęb�����������ǁALarrabee�L�����Z����A
GMA�n����GPU���ڂ���Ęb���o�Ă��Ăǂ������킩��Ȃ��B
GMA500��Atom�̑g�ݍ��ݗp��PowerVR��IP�g���Ă��邯�ǁA
Sandy�͏]���ʂ�Ɠ���Unified Shader�B
>>652
Haswell��Larrabee�݊��R�A���ڂ���Ęb�����������ǁALarrabee�L�����Z����A
GMA�n����GPU���ڂ���Ęb���o�Ă��Ăǂ������킩��Ȃ��B
>>654
GMA�̌n����intel�������Ǝ��O�ŊJ�����Ă������PowerVR�Ȃł͂Ȃ����ǁB
GMA�̌n����intel�������Ǝ��O�ŊJ�����Ă������PowerVR�Ȃł͂Ȃ����ǁB
PowerVR SGX���낤��Intel GMA���낤��UnifiedShader�ɂ͕ς��˂���I�Ƃ��]�X
Sandy�̂�PowerVR����Ȃ������悤��
22n��Ivy���o�Ă��Ă��A����GPU�̐��\��sandy�Ƃ���قǕς��Ȃ��������
(Dx10�~�܂�A���h���C�o�A�ᐫ�\)
�܂�A����d�͂���������������Sandy�ł��������A�l�b�g�Q�[�����̒ቿ�i�Q�[��PC�ւ̓��ڂ͖������낤��
HD5570���x�ŏ\���ȃQ�[���ɂ�Llano�ɑ�Sandy��Ivy�͑S������ɂȂ�Ȃ�
�Q�[��������GPU���\���_���ȓ���CPU�Ȃs�ꂶ�Ⴈ�Ăт���Ȃ��Ȃ肻��
�Q�[�����Ȃ��Ȃ�4�X���b�h�A3GHz�ȏ�̐��\�͕K�v�Ȃ�����ˁAOntario�ŕK�v�\��
(Dx10�~�܂�A���h���C�o�A�ᐫ�\)
�܂�A����d�͂���������������Sandy�ł��������A�l�b�g�Q�[�����̒ቿ�i�Q�[��PC�ւ̓��ڂ͖������낤��
HD5570���x�ŏ\���ȃQ�[���ɂ�Llano�ɑ�Sandy��Ivy�͑S������ɂȂ�Ȃ�
�Q�[��������GPU���\���_���ȓ���CPU�Ȃs�ꂶ�Ⴈ�Ăт���Ȃ��Ȃ肻��
�Q�[�����Ȃ��Ȃ�4�X���b�h�A3GHz�ȏ�̐��\�͕K�v�Ȃ�����ˁAOntario�ŕK�v�\��
Ivy�̍��ɂ�Dx10�~�܂肶��MS����v���~�A�����S�̔F����Ȃ����낤����Dx10�~�܂�͂Ȃ���Ȃ���
Ivy��Intel�̐^�ł���
�C������Ă��Ȃ���
�C������Ă��Ȃ���
���m�̎������Ǝv�����ANehalem�n��Atom�n�̐��\�̃M���b�v���傫������
Atom�͒�R�X�g�����ǐ��\�Ⴗ���Ďg���Â炢�ANehalem�n�̓R�X�g���ŃI�[�o�[�X�y�b�N�C���A
���Ԃ̒��x�����̂����݂��Ȃ�
Ontario��Llano�͂��̃M���b�v�߂�▭�Ȉʒu�ɂ���Ǝv��
����GPU���\����������A�O��GPU�ō��ʉ������Ă���悤�ȃ��[�J�[�̏�ʋ@��̃V�F�A����C�ɒD����ύ���������
������Intel�̐����ݔ��������Ă��ALlano vs Sandy+HD5570�@�Ƃ��ŃR�X�g�����d�͂̏��������Ă����ĂȂ�����
Atom�͒�R�X�g�����ǐ��\�Ⴗ���Ďg���Â炢�ANehalem�n�̓R�X�g���ŃI�[�o�[�X�y�b�N�C���A
���Ԃ̒��x�����̂����݂��Ȃ�
Ontario��Llano�͂��̃M���b�v�߂�▭�Ȉʒu�ɂ���Ǝv��
����GPU���\����������A�O��GPU�ō��ʉ������Ă���悤�ȃ��[�J�[�̏�ʋ@��̃V�F�A����C�ɒD����ύ���������
������Intel�̐����ݔ��������Ă��ALlano vs Sandy+HD5570�@�Ƃ��ŃR�X�g�����d�͂̏��������Ă����ĂȂ�����
658�̂悤�Ȑ���͎G�����Ăяo�����߂̎����ł����Ȃ�
> ���Ԃ̒��x�����̂����݂��Ȃ�
�ȂɐQ���������Ă�̂��Ai3 530�����邶���
> ������Intel�̐����ݔ��������Ă��ALlano vs Sandy+HD5570�@�Ƃ��ŃR�X�g�����d�͂̏��������Ă����ĂȂ�����
Llano����Ȃ�i3 530�ŏ\�����Ǝv���̂����c
�ȂɐQ���������Ă�̂��Ai3 530�����邶���
> ������Intel�̐����ݔ��������Ă��ALlano vs Sandy+HD5570�@�Ƃ��ŃR�X�g�����d�͂̏��������Ă����ĂȂ�����
Llano����Ȃ�i3 530�ŏ\�����Ǝv���̂����c
>�ቿ�i�Q�[��PC
����ȃ����̎s�ꉟ�����Ă����傤���Ȃ���
����ȃ����̎s�ꉟ�����Ă����傤���Ȃ���
FF14�̐����ł��A��ݒ�Ȃ�HD5570�N���X�ł��V�ׂ�ʂɕ��ׂ��Ⴍ�Ȃ��Ă���ALlano��q�b�g���������ȁB
>>665
�ǂ������w�̐l��FF14�̂��߂�Llano���đ�q�b�g����H
�ǂ������w�̐l��FF14�̂��߂�Llano���đ�q�b�g����H
�Ȃ�AMD�̎���CPU�ɉߏ�Ȋ��҂����Ă鍁��t�������Ȃ���
�C���e�����قڈ�N�x��Ă���悤�Ȃ��������������s�v�c�ł��傤���Ȃ���
Llano vs Sandy+HD5570�H���₢�∳�|�I�Ɍ�҂̕������͓I���悗������Ƃł��Q�[�����Ȃ�Ȃ����炾
�D����ATI�̃O���{�ɑ��Ė��炩��AMD��CPU�̓{�g���l�b�N�ɂȂ��Ă邩���
�C���e�����قڈ�N�x��Ă���悤�Ȃ��������������s�v�c�ł��傤���Ȃ���
Llano vs Sandy+HD5570�H���₢�∳�|�I�Ɍ�҂̕������͓I���悗������Ƃł��Q�[�����Ȃ�Ȃ����炾
�D����ATI�̃O���{�ɑ��Ė��炩��AMD��CPU�̓{�g���l�b�N�ɂȂ��Ă邩���
�ƁA�Z�������g�����\���Ă���܂�
�l�b�g�u�b�N�N���X��Llano�ς�PC��FF14�Ƃ��������甄�ꂻ������
����K7����Ȃ牽�����͖���
�Ƃ������������\�����Ă��������炢�����������ւ�����
�M��
�����d�����ׂ�����������
�Ƃ������������\�����Ă��������炢�����������ւ�����
�M��
�����d�����ׂ�����������
���ɂ�MMORPG�Ȃ���ł������łĂ郍�[����~�h���N���X��GPU�ŃT�N�T�N�����Ă�����Ƃ�
Llano��HD5570���̐��\��@���o������}�W�v����Intel��NVIDIA���S�̂��m�点����
�����͂���ȂɗD�����Ȃ��Ǝv��
�����͂���ȂɗD�����Ȃ��Ǝv��
GF9600M GS�Ȃ�
�قƂ�ǂ�MMO��1920�~1080�ŃO���t�B�b�NALL���ݒ�ŕ��ʂɗV�ׂ�
�p���h���T�[�K�̐l�̑����L��͂߂��Ⴍ����d������
Llano�͂��ꂭ�炢�̃��x��������ȏ�Ȃ炿����ƍw�����l���Ă�����
�قƂ�ǂ�MMO��1920�~1080�ŃO���t�B�b�NALL���ݒ�ŕ��ʂɗV�ׂ�
�p���h���T�[�K�̐l�̑����L��͂߂��Ⴍ����d������
Llano�͂��ꂭ�炢�̃��x��������ȏ�Ȃ炿����ƍw�����l���Ă�����
���5�N����������ăX�y�b�N���߂Ă���Ęb������
5770��GTX260��LOW�ł܂Ƃ��ɗV�ׂ�Œ�C�����낤
5770��GTX260��LOW�ł܂Ƃ��ɗV�ׂ�Œ�C�����낤
����܂ŋc�_���ė����ʂ�Llano���ڂ�GPU�̓������ш�s�����ɑΏ����Ȃ����菊�F�̓��[���x���ł����Ȃ��B
�܂���҂͏o���ʂƂ������Ƃł���B
�܂���҂͏o���ʂƂ������Ƃł���B
AMD�������Ǝv���̂͂���ς�UNIX�n�A�Ƃ������Agcc�Ƃ̑����ɂ���Ǝv���܂��B
UNIX���[�U�ł��鎩���ɂɂƂ��Ă�AMD�n��CPU���g���ăJ�[�l���œK��������A
-march=amdfam10�Ƃ�-march=barcerola�Ƃ��t���ăp�b�P�[�W����Ă݂����ł��B
���A���Ȃ݂ɍ���Intel���[�U�B
UNIX���[�U�ł��鎩���ɂɂƂ��Ă�AMD�n��CPU���g���ăJ�[�l���œK��������A
-march=amdfam10�Ƃ�-march=barcerola�Ƃ��t���ăp�b�P�[�W����Ă݂����ł��B
���A���Ȃ݂ɍ���Intel���[�U�B
>>675
���g�ς�����Ƃ����v���Ȃ��قǍႦ�Ă�ȁB
�C���e����i5�ł���Ă����̂ɖт����������\��
�O�̃I���{�[�h�`�b�v�Z�b�g����Ȃ����_���܂������������Ȃ����炢�̕��ɂȂ�Ƒz���B
�����ŃI���{�[�h��CPU�ɂ��ꂽGPU�ƃ����N�����āA���\�������Ă����Ȃ����ȁB
�ǂ���ɂ��Ă���߂肠�x���`��12000���x�̊O�t���̈���VGA���x�̐��\�����o�Ȃ��Ǝv����B
����ł��m�[�g���[�U�[�ɂ͏[�����ɂȂ��Ȃ����ȁB�t��HD���Đ��ł���킯���B
���g�ς�����Ƃ����v���Ȃ��قǍႦ�Ă�ȁB
�C���e����i5�ł���Ă����̂ɖт����������\��
�O�̃I���{�[�h�`�b�v�Z�b�g����Ȃ����_���܂������������Ȃ����炢�̕��ɂȂ�Ƒz���B
�����ŃI���{�[�h��CPU�ɂ��ꂽGPU�ƃ����N�����āA���\�������Ă����Ȃ����ȁB
�ǂ���ɂ��Ă���߂肠�x���`��12000���x�̊O�t���̈���VGA���x�̐��\�����o�Ȃ��Ǝv����B
����ł��m�[�g���[�U�[�ɂ͏[�����ɂȂ��Ȃ����ȁB�t��HD���Đ��ł���킯���B
���A�ԈႦ��-marc=barcelona�ł���
opteron�̃R�[�h�ł��������H
���̂����Ashanghai�Ƃ�istanbul,magny-cours,lisbon�Ƃ����ł���̂ł��傤��
����������Opteron�̓T�[�o�����ŃO���t�B�b�N�Ƃ��W�Ȃ�Opteron��Fusion����łǂ��ς���ł��傤���H
GPU�͓������Ȃ����ǁAJava�݂����ȃ}���`�X���b�h���\���v���������̂ɑΉ��ł���悤�ɁA
bulldozer�݂����Ƀ��W���[�����₵�Ă��̂ł��傤���ˁH
opteron�̃R�[�h�ł��������H
���̂����Ashanghai�Ƃ�istanbul,magny-cours,lisbon�Ƃ����ł���̂ł��傤��
����������Opteron�̓T�[�o�����ŃO���t�B�b�N�Ƃ��W�Ȃ�Opteron��Fusion����łǂ��ς���ł��傤���H
GPU�͓������Ȃ����ǁAJava�݂����ȃ}���`�X���b�h���\���v���������̂ɑΉ��ł���悤�ɁA
bulldozer�݂����Ƀ��W���[�����₵�Ă��̂ł��傤���ˁH
gentoo�g����
����Ƃ��P�Ȃ�n����
����Ƃ��P�Ȃ�n����
>>679
�����̔n������
�����̔n������
>>625
�����ɒǂ����ǂ��z�����낤
�f�e�͐��E�ő勉�̓������邩��ȁ@���ǂ͎��������ʂ����ׂā@�T���\�����������̂Ɠ���
�����炉���������ł��P���T�O�O�O���~�̓����͖����@�l�ނ�������������@�ŐV�s�@�퓊��������̂f�e
�A���u�͖{�C����
�����ɒǂ����ǂ��z�����낤
�f�e�͐��E�ő勉�̓������邩��ȁ@���ǂ͎��������ʂ����ׂā@�T���\�����������̂Ɠ���
�����炉���������ł��P���T�O�O�O���~�̓����͖����@�l�ނ�������������@�ŐV�s�@�퓊��������̂f�e
�A���u�͖{�C����
>>681
���Ă���͂ǂ����Ȃ��c
�ꎞ�I�ɏW������1��5000���~�̓���������̂Ɩ��N5000���~�̌����J�����P�o���Ă���Intel�Ƃł͂ǂ��炪�����̂��낤���H
���͌�҂��Ǝv���̂����c
���Ă���͂ǂ����Ȃ��c
�ꎞ�I�ɏW������1��5000���~�̓���������̂Ɩ��N5000���~�̌����J�����P�o���Ă���Intel�Ƃł͂ǂ��炪�����̂��낤���H
���͌�҂��Ǝv���̂����c
�@�܂��̓_�b�V���Œǂ����ǂ��z��
�@��
�A���m�������
�@���@�@�@�@��
�B���v����J�����P�o
�A+�B�̃��[�v�ɓ���ׂɏW�������͕K�R�Ǝv����
�@��
�A���m�������
�@���@�@�@�@��
�B���v����J�����P�o
�A+�B�̃��[�v�ɓ���ׂɏW�������͕K�R�Ǝv����
�[���AGF�̏ꍇ�̓����͑S�Ă��Ő�[�ɉ킯����Ȃ����Ȃ��c
Intel�Ƃ͍��{�I�ɐ������قȂ��Ă�Ǝv���̂�B
�����AMD��GF�̊������������Ă��Ȃ����炻����ɗD�����ĖႦ�锤���Ȃ�
AMD�ׂ̈����Ɍ����J����P�o����邱�Ƃ��l�����Ȃ����c
��������AMD���̂�����ȗ��v���o��̎��ɒZ���Ԃŕϖe����Ƃ͎v���Ȃ�����
����ς�AMD���������J�������ɗp�ӂł���Ƃ͎v���Ȃ��c
��[�A�Ȃ���^���Â��Ǝv���̂����c
Intel�Ƃ͍��{�I�ɐ������قȂ��Ă�Ǝv���̂�B
�����AMD��GF�̊������������Ă��Ȃ����炻����ɗD�����ĖႦ�锤���Ȃ�
AMD�ׂ̈����Ɍ����J����P�o����邱�Ƃ��l�����Ȃ����c
��������AMD���̂�����ȗ��v���o��̎��ɒZ���Ԃŕϖe����Ƃ͎v���Ȃ�����
����ς�AMD���������J�������ɗp�ӂł���Ƃ͎v���Ȃ��c
��[�A�Ȃ���^���Â��Ǝv���̂����c
>>684
�����������̂��߂̂q�c���S���قڂO�ɂȂ��H�v�������l����悢
���W�b�N������͔{���ł����Ȃ���Ȃ��H
���̈�������������͂q�c�̂��Ȃ�̕������ɉȂ��Ƃ����Ȃ����疳���ꒃ���
��͂�݂͖݉��@�����͐������ɔC����̂���Ԍ���
���ہA�����Ɋւ��Ă͂f�e����ԂɂȂ肻���@�����������{�ɏW���@�R�N�łP�T�O�������炢��
��������������͐����ւ̓����͔N�R�O���@���W�b�N�J���͂Q�O�����炢�ł́H
�����Ɋւ��Ă͂f�e�ɍ������������ɂȂ肻���@�ǂ�ǂ����������@�@
�����������̂��߂̂q�c���S���قڂO�ɂȂ��H�v�������l����悢
���W�b�N������͔{���ł����Ȃ���Ȃ��H
���̈�������������͂q�c�̂��Ȃ�̕������ɉȂ��Ƃ����Ȃ����疳���ꒃ���
��͂�݂͖݉��@�����͐������ɔC����̂���Ԍ���
���ہA�����Ɋւ��Ă͂f�e����ԂɂȂ肻���@�����������{�ɏW���@�R�N�łP�T�O�������炢��
��������������͐����ւ̓����͔N�R�O���@���W�b�N�J���͂Q�O�����炢�ł́H
�����Ɋւ��Ă͂f�e�ɍ������������ɂȂ肻���@�ǂ�ǂ����������@�@
>>667
�R�X�g���{�ŗ����Ȃ������Ȃ����������őg�ނ�
�ő命���̃m�[�g�W�J�͂��̑g�ݍ��킹�ł͖������낤��
���N��m�[�g�ŏo�Ă�Llano vs Sandy+HD5570��5�`7���~�@�����@15�`20���~����
Llano ���e�̐��\�͂���ڂ��Ă�Llano �U�A�V�Ɣ���I�ɐ��\�͏オ���@
�V���̂������͏�ɕێ�I�Ȑv���烍�[���`���邩��ˁ@����������������������
�{�̔�����2���3��ڂ���
�R�X�g���{�ŗ����Ȃ������Ȃ����������őg�ނ�
�ő命���̃m�[�g�W�J�͂��̑g�ݍ��킹�ł͖������낤��
���N��m�[�g�ŏo�Ă�Llano vs Sandy+HD5570��5�`7���~�@�����@15�`20���~����
Llano ���e�̐��\�͂���ڂ��Ă�Llano �U�A�V�Ɣ���I�ɐ��\�͏オ���@
�V���̂������͏�ɕێ�I�Ȑv���烍�[���`���邩��ˁ@����������������������
�{�̔�����2���3��ڂ���
�S�p�͊�n�O�Ɛ̂̈̂��l�͌��������m���ɂ��̂悤����
2010�N��Intel�̓����z
�@�ݔ��@�@�@�@48���h��
�@�����J���@62���h��
��\�肵�Ă邻�����B
�m����GF�̓����z�͐������ǁA�܂�Intel��ǂ��グ�Ă�̂�����B
TSMC�����N�̐ݔ�������48���h�����炢�B
���͂�Ő�[�Ő키�Ȃ�N��50���h���̐ݔ������͓�����O�Ƃ������낵�����E�B
���Ȃ݂�Samsung�͔����̈ȊO���S���Ђ�����߂Ă����Ǎ��N�̐ݔ�������159���h�����������B
�@�ݔ��@�@�@�@48���h��
�@�����J���@62���h��
��\�肵�Ă邻�����B
�m����GF�̓����z�͐������ǁA�܂�Intel��ǂ��グ�Ă�̂�����B
TSMC�����N�̐ݔ�������48���h�����炢�B
���͂�Ő�[�Ő키�Ȃ�N��50���h���̐ݔ������͓�����O�Ƃ������낵�����E�B
���Ȃ݂�Samsung�͔����̈ȊO���S���Ђ�����߂Ă����Ǎ��N�̐ݔ�������159���h�����������B
>>688
intel�̌����J���ɂ͐����Ɋւ�����̂�6�����x�܂�ł̂��̂��낤
�f�e�̌����J����100�������Ɋւ��Ă�����f�e���ǂ����ǂ��z���͎̂��Ԃ̖��
���̓����z�Ő����ɓ��������ƒN���ǂ����Ȃ�
intel�̌����J���ɂ͐����Ɋւ�����̂�6�����x�܂�ł̂��̂��낤
�f�e�̌����J����100�������Ɋւ��Ă�����f�e���ǂ����ǂ��z���͎̂��Ԃ̖��
���̓����z�Ő����ɓ��������ƒN���ǂ����Ȃ�
��[�v���Z�X�̌����͗v��Ȃ��́H
Llano�ɇU��V�͖�������
Bulldozer+APU�Œu���������ăt�F�[�h�A�E�g�ł���
Bulldozer+APU�Œu���������ăt�F�[�h�A�E�g�ł���
�e�w��>>527�݂����Ȏ��������Ȃ���A�I�n��ϓI��AMD���������������Ă�悤�ȃ��X���肾��
���������A���`�X�����ĂĂ������ł���Ă����
���������A���`�X�����ĂĂ������ł���Ă����
>>690
GF�����Č����J����͕K�v�Ɍ��܂��Ă�
�������A�����̊�ƂŘA���g��ŋ����ŊJ�����Ă�̂ƁAIntel��ǂ��`�ŊJ�����Ă���̂�
�Ɨ́���s���ĊJ�����Ă���Intel�قǂɂ͔�p�͂�����Ȃ����낤��
���Ȃ݂�Intel�̐ݔ�����48���j���Ă͍̂H��1������
4�H��펞�ғ��̐����ێ�����ɂ͖��N���̂��炢�K�v�Ȃ̂����A
�V�F�A�łقړƐ��Ԃɂ���A����ȏ�V�F�A��D���Ă����v�Ɍq����Ȃ��̂�
Intel�͍������v���������Ă��̔�p��P�o���邵���Ȃ��A�n���݂����Ȓl�����͂��邱�Ƃ��o���Ȃ�
������Intel�̗B��̃E�B�[�N�|�C���g
GF�����Č����J����͕K�v�Ɍ��܂��Ă�
�������A�����̊�ƂŘA���g��ŋ����ŊJ�����Ă�̂ƁAIntel��ǂ��`�ŊJ�����Ă���̂�
�Ɨ́���s���ĊJ�����Ă���Intel�قǂɂ͔�p�͂�����Ȃ����낤��
���Ȃ݂�Intel�̐ݔ�����48���j���Ă͍̂H��1������
4�H��펞�ғ��̐����ێ�����ɂ͖��N���̂��炢�K�v�Ȃ̂����A
�V�F�A�łقړƐ��Ԃɂ���A����ȏ�V�F�A��D���Ă����v�Ɍq����Ȃ��̂�
Intel�͍������v���������Ă��̔�p��P�o���邵���Ȃ��A�n���݂����Ȓl�����͂��邱�Ƃ��o���Ȃ�
������Intel�̗B��̃E�B�[�N�|�C���g
intel�̏ꍇ�A������Fab�̐����ݔ��̓]��������AGF�قǓ������Ȃ��Ă��A
�Ő�[�v���Z�X�ł̐����\�͂��������Ȃ��́H
GF����U�����ł���A�����z�ߖ�ł���悤�ɂȂ邾�낤���ǁB
�Ő�[�v���Z�X�ł̐����\�͂��������Ȃ��́H
GF����U�����ł���A�����z�ߖ�ł���悤�ɂȂ邾�낤���ǁB
>>681
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20100608_372754.html
���̓����b���Ă���̂��Ƃł����́H ���̘b�H
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20100608_372754.html
���̓����b���Ă���̂��Ƃł����́H ���̘b�H
>>694
�y�n��ƍl����Γ��{�قǍ����Ȃ��̂ł����܂ŏd�v�ȃt�@�N�^�[���^��B
�y�n��ƍl����Γ��{�قǍ����Ȃ��̂ł����܂ŏd�v�ȃt�@�N�^�[���^��B
>>696
���O�͘I���@�̒l�i��m��Ȃ��c
���O�͘I���@�̒l�i��m��Ȃ��c
48���h���ȓ���2��Fab��32nm�֓]�����������AFab�P��24���h�����炢�B
�����ꂩ��Fab�����Ă�Fab 8 Module 1 Phase 1��48���h���ŁA
Module 1 Phase 2��30���h���ȏゾ����A
��Ђ��Ⴄ�̂ŒP���ɂ͌����Ȃ����ǁA�ꂩ�猚�Ă��肩�͌��\�����Ȃ���ۂ��B
�����ꂩ��Fab�����Ă�Fab 8 Module 1 Phase 1��48���h���ŁA
Module 1 Phase 2��30���h���ȏゾ����A
��Ђ��Ⴄ�̂ŒP���ɂ͌����Ȃ����ǁA�ꂩ�猚�Ă��肩�͌��\�����Ȃ���ۂ��B
699 �FSocket774�F2010/07/02(��) 12:59:16 ID:PHrUq8d6
Intel's Sandy Bridge, AVX Extensions On Track For Q4 2010
http://hothardware.com/News/Intels-Sandy-Bridge-AVX-Extensions-On-Track-For-Q4-2010/
��������
http://hothardware.com/News/Intels-Sandy-Bridge-AVX-Extensions-On-Track-For-Q4-2010/
��������
>>699
����͂����ł͂Ȃ�Intel�̎�����CPU�X����SandyBridge�X���ɓ\��ׂ��ł́H
����͂����ł͂Ȃ�Intel�̎�����CPU�X����SandyBridge�X���ɓ\��ׂ��ł́H
ID:gnyL+wQQ
>>695
�܂��A���̋L����ǂތ���㓡�����t�@�r�����Ă邾���Ŋ��҂�����͖̂w�ǂȂ��Ǝv���̂����c
��������Foundry�Ƃ��Ẳ��l�͂���Ǝv�������ꂾ���̂悤�Ɍ�����ˁB
�܂��A���̋L����ǂތ���㓡�����t�@�r�����Ă邾���Ŋ��҂�����͖̂w�ǂȂ��Ǝv���̂����c
��������Foundry�Ƃ��Ẳ��l�͂���Ǝv�������ꂾ���̂悤�Ɍ�����ˁB
704 �FSocket774�F2010/07/02(��) 14:53:38 ID:Qqz/tDOe
�C�c���t���r���b�e�C��Z
>>693
>Intel�͍������v���������Ă��̔�p��P�o���邵���Ȃ�
�����肵�Ă�AMD�͔�p��P�o�ł��Ȃ����ʂ��Ă��Ƃł���
IBM�Ƃ̋����J������p���S�̉�����IBM�ɋ������Ă����
>Intel�͍������v���������Ă��̔�p��P�o���邵���Ȃ�
�����肵�Ă�AMD�͔�p��P�o�ł��Ȃ����ʂ��Ă��Ƃł���
IBM�Ƃ̋����J������p���S�̉�����IBM�ɋ������Ă����
�v���Z�X�����̋����J������瓖�RGF���o���Ǝv����
> �v���Z�X�����̋����J������瓖�RGF���o���Ǝv����
�����GF�Ƀ����b�g������̂Ȃ�Ƃ����O������t������ˁH
�����GF�Ƀ����b�g������̂Ȃ�Ƃ����O������t������ˁH
708 �FSocket774�F2010/07/02(��) 17:07:56 ID:AQatrckf
�G����URL��\����������L���͂�������Ɠǂ߂�����
�v���Z�X�J���̘_���Ƃ��O��IBM/AMD�̖��O�ŏo���Ă����Ǎ���IBM/GF�̖��O�ŏo���Ă�B
���RIBM�ɋ������Ă�̂�AMD����Ȃ���GF�ɕς���Ă邾��B
���RIBM�ɋ������Ă�̂�AMD����Ȃ���GF�ɕς���Ă邾��B
�Ԏq�����ԈႢ�T���̃l�^���ɂ����Ƃ������R������
���x�͌㓡�ɐ��q�Ԃ������邱�Ƃɂ����C���������V���^�z��
�y�h�����l�܂Ŏ���͈͍L��
���x�͌㓡�ɐ��q�Ԃ������邱�Ƃɂ����C���������V���^�z��
�y�h�����l�܂Ŏ���͈͍L��
>>690
�@�����̂̐���������[�v���Z�X�������Ȃ��킯�Ȃ�����@�@�����͂̌���
�@�����̂̐���������[�v���Z�X�������Ȃ��킯�Ȃ�����@�@�����͂̌���
>>703
���ꂾ���̖�Ȃ�����@�ʎY������邾�������̈������̂q�c��͉�����@
�܂�ʎY���ʂ��n���ł���
�����̐����͈���Ɏ��Ă镔�������邩���
���ꂾ���̖�Ȃ�����@�ʎY������邾�������̈������̂q�c��͉�����@
�܂�ʎY���ʂ��n���ł���
�����̐����͈���Ɏ��Ă镔�������邩���
>>712
> �ʎY����
�����炻��͋����Foundry�Ƃ��Ẳ��l����
�����Ƃ��ʎY����ɂ͎��v���Ȃ��Əo���Ȃ��b�����炳�A���ꂪ������AMDCPU�̃R�X�g�_�E���q����Ƃ͎v���Ă��Ȃ��B
> �ʎY����
�����炻��͋����Foundry�Ƃ��Ẳ��l����
�����Ƃ��ʎY����ɂ͎��v���Ȃ��Əo���Ȃ��b�����炳�A���ꂪ������AMDCPU�̃R�X�g�_�E���q����Ƃ͎v���Ă��Ȃ��B
> ���͂f�e�����S���邩�炁�����͉�H�v�ɐ�O
�[����H�v�ɐ�O�o�����Ɏ�������Ƃ͎v���Ȃ����c
����ȕ������Ă���͍̂��������ł����āA���v���w�Ǐo�Ă��Ȃ��̂������H
�[����H�v�ɐ�O�o�����Ɏ�������Ƃ͎v���Ȃ����c
����ȕ������Ă���͍̂��������ł����āA���v���w�Ǐo�Ă��Ȃ��̂������H
716 �F,,�E�L�́M�E,,�j��-�������F2010/07/02(��) 18:22:19 ID:2cqE09Cm
�Ő�[�v���Z�X�̊J���̓t�@�u���X��Ƃɂ͒��ڊW�̂Ȃ��b�ɂȂ邩������Ȃ���
�u�Ő�[�v���Z�X���������W�b�N�v�v�̓t�@�u���X��Ƃ��܂߂��ۑ�
�u�Ő�[�v���Z�X���������W�b�N�v�v�̓t�@�u���X��Ƃ��܂߂��ۑ�
�{���̖{�i�I�Ȏː����J�n����܂���
GPU�̕��͂Ƃ������ACPU��SOI������AAMD�ȊO��SOI�ō�郆�[�U�[�������Ȃ��ƁA
GF�ɂƂ���SOI�̊J����ɂ��ėʎY���ʂ͌����Ȃ��Ⴀ�H
GF�ɂƂ���SOI�̊J����ɂ��ėʎY���ʂ͌����Ȃ��Ⴀ�H
719 �F,,�E�L�́M�E,,�j��-�������F2010/07/02(��) 19:14:54 ID:2cqE09Cm
�ESOI�̌������n�߂Ă邩����
>>718
IBM��Fab������Ƃ����\���ȑO�����C������B
IBM��Fab������Ƃ����\���ȑO�����C������B
�ǂ����݂�28nm�ȍ~�͎g��Ȃ���
AMD�́g���z�̕��h���ĉ����낤
SOI��22nm�ł��g���܂�
�ނ��낱�ꂩ��͎g���Ă����Ȃ��Ɣ������L�c�C�Ƃ������Ă���
�ނ��낱�ꂩ��͎g���Ă����Ȃ��Ɣ������L�c�C�Ƃ������Ă���
SOI��SOI�ł���X�K�v�Ȃ̂�FD-SOI�����Ȃ�
AMD��PD-SOI
AMD��PD-SOI
>>724
�ŋ߂̂��ƃR���Ƃ�
�yVLSI�z22nm�ȍ~��S��FD-SOI�f�o�C�X�ƃt�B��FET�C���p���ԋ߂̋Z�p�����X
http://techon.nikkeibp.co.jp/article/NEWS/20100616/183509/
>�@���s�̃o���NMOSFET�̔���������Ȃ�22nm����ȍ~��
> �g�����W�X�^�Z�p�Ƃ��āC�v���[�i�i���ʁj�^��FD-SOI
> �i���S��R�^SOI�j�f�o�C�X�Ɨ��̃`���l���ɂ��t�B��FET��
> ���ڂ��W�߂Ă���B��������C�`���l���ɕs������Y�����Ȃ���
> �ςނ��Ƃ�������̂����}���₷���C22nm ����ȍ~��
> �g�����W�X�^�Z�p�̗L�͌��ƂȂ��Ă���B
>>725
����ł��o���͗ǂ��Ƃ����]��
http://eetimes.jp/article/23107/
�ŋ߂̂��ƃR���Ƃ�
�yVLSI�z22nm�ȍ~��S��FD-SOI�f�o�C�X�ƃt�B��FET�C���p���ԋ߂̋Z�p�����X
http://techon.nikkeibp.co.jp/article/NEWS/20100616/183509/
>�@���s�̃o���NMOSFET�̔���������Ȃ�22nm����ȍ~��
> �g�����W�X�^�Z�p�Ƃ��āC�v���[�i�i���ʁj�^��FD-SOI
> �i���S��R�^SOI�j�f�o�C�X�Ɨ��̃`���l���ɂ��t�B��FET��
> ���ڂ��W�߂Ă���B��������C�`���l���ɕs������Y�����Ȃ���
> �ςނ��Ƃ�������̂����}���₷���C22nm ����ȍ~��
> �g�����W�X�^�Z�p�̗L�͌��ƂȂ��Ă���B
>>725
����ł��o���͗ǂ��Ƃ����]��
http://eetimes.jp/article/23107/
>>725
�����郂�m�ƁA���ꂩ��̃��m�����x���Ŕ�r����̂͒m�������薳�������낤�B
�����郂�m�ƁA���ꂩ��̃��m�����x���Ŕ�r����̂͒m�������薳�������낤�B
>>726
���̋L�����������A�������̓t�B��FET�̕������邯�ǒ��߂̈ڍs��FD-SOI�̕������₷���������B
�Z�p�I��FD�̕�������悤�����ǁA���܂�PD�ł���Ă�������ڍs��intel���͂��₷���̂��ȁB
���̋L�����������A�������̓t�B��FET�̕������邯�ǒ��߂̈ڍs��FD-SOI�̕������₷���������B
�Z�p�I��FD�̕�������悤�����ǁA���܂�PD�ł���Ă�������ڍs��intel���͂��₷���̂��ȁB
729 �FSocket774�F2010/07/02(��) 22:19:24 ID:YQEPLMvu
>>729
�����������͍���h�����낤�ȁ@�P���Q�O�O�O���~���̐ݔ��Ƃq�c�ɂ�����f�e�ɏ��Ă�Ƃ͂ƂĂ��v���Ȃ�
�L�[�ɂȂ�l�ނ�����������܂����Ȃ�����
�����������͍���h�����낤�ȁ@�P���Q�O�O�O���~���̐ݔ��Ƃq�c�ɂ�����f�e�ɏ��Ă�Ƃ͂ƂĂ��v���Ȃ�
�L�[�ɂȂ�l�ނ�����������܂����Ȃ�����
�꒛��牭��2�N�ԕ������A���̂�����4000����͋��v���Z�X��Chartered�̔�����p������A
�N�Ԃ̐ݔ������z����intel�Ƃ���Ȃɕς��Ȃ��B
�N�Ԃ̐ݔ������z����intel�Ƃ���Ȃɕς��Ȃ��B
ATIC���������܂����Ăijρ`���ˁc
http://citavia.blog.de/2010/07/01/some-updates-regarding-ontario-boinc-and-bobcat-8899248/
Comparing the Bobcat core to an Atom core at 1.66 GHz (as this one), the benchmarked Bobcat cores are about 2x the integer performance and 3x the FP performance of Atom.
2x the integer performance
3x the FP performance
Comparing the Bobcat core to an Atom core at 1.66 GHz (as this one), the benchmarked Bobcat cores are about 2x the integer performance and 3x the FP performance of Atom.
2x the integer performance
3x the FP performance
�E�E�E$885�Ƃ͂��܂�������Ȃ����ł��B���ɍŋ߂ł͑�3�l�����ɂ܂�$562�œo�ꂵ�A���̌�Core i7 980�i6-core / 3.33GHz�j�̓o��ƂƂ���$316�ɂȂ�Ƃ��������������̂Ŋ��҂��Ă����l�͂Ȃ�����ł��傤�B
>>733
�����������S
�����������S
bull����AVX�Ƃ�XOP�Ƃ�FMA4�Ƃ����Ďg����́H
�܂����\����ĂȂ��H
�܂����\����ĂȂ��H
Bulldozer��AVX�̂��܂���
���ǓƎ��̖��߂��Ђ�����lj����܂���
����Ȃ�������
���ǓƎ��̖��߂��Ђ�����lj����܂���
����Ȃ�������
>>737
�Ǝ��̖��߁H
AMD�̂Ƃ���ɂ��郊�t�@�����X�ɂ�
AVX���߂��ڂ��ĂȂ���ˁB
XOP��FMA4�͍ڂ��Ă���ǁB
�C���e����AVX�ɑ��Ă����Ƌ����Ǝ��̖��߂��lj������낤���H
�ł�����܂�B���Ă�ƃ\�t�g���o��̂��x���Ǝv�����B
�Ǝ��̖��߁H
AMD�̂Ƃ���ɂ��郊�t�@�����X�ɂ�
AVX���߂��ڂ��ĂȂ���ˁB
XOP��FMA4�͍ڂ��Ă���ǁB
�C���e����AVX�ɑ��Ă����Ƌ����Ǝ��̖��߂��lj������낤���H
�ł�����܂�B���Ă�ƃ\�t�g���o��̂��x���Ǝv�����B
������
�ǂ��˂����߂����̂�������Ȃ�
XOP�AFMA4���Ǝ��g�����ŁAAVX���̂�intel�Ɠ����B
Bobcat cores�Ƃ��邩��f���A���R�A��Bobcat��������2x�{�Ƃ����̂�
����܂萦���Ȃ��悤�ȁc
����܂萦���Ȃ��悤�ȁc
��r��D510������A2.x�{�͏\���������Ǝv�����ǁB
���Ƃ͂���Ontario��TDP��W�̃��f�����ł��������ς�邭�炢���ƁB
���Ƃ͂���Ontario��TDP��W�̃��f�����ł��������ς�邭�炢���ƁB
�����N���b�N��TDP�̃��m�Ōv�����Ă����Ȃ�����
�ނ��덡��Atom�̓V�������N�������N���b�N����]�n���܂��܂����邾��B
���ĂقǃV�������N�̌��ʂ��傫���Ȃ��ƌ����Ă����B
���ĂقǃV�������N�̌��ʂ��傫���Ȃ��ƌ����Ă����B
>>744
Ontario2�R�A��BOINC�̌��ʂ��킩���Ă��邾���ŁA�N���b�N��TDP�͂킩���Ă��Ȃ��B
>>745
Atom��CPU�ȊO�̕������V�������N���������ŁACPU������32nm�łł�܂ňꏏ�����ǁB
Ontario2�R�A��BOINC�̌��ʂ��킩���Ă��邾���ŁA�N���b�N��TDP�͂킩���Ă��Ȃ��B
>>745
Atom��CPU�ȊO�̕������V�������N���������ŁACPU������32nm�łł�܂ňꏏ�����ǁB
>>745
�����N���b�N��������������
�����N���b�N��������������
���N��ɂ͂��������������������啝�K�͏k������
���������������[�������܂�ɂ��֗������邵�R�X�g���������R������
���Ɋy���@�g�тƂ��V�[�����X���������̒��������烂�g���[���@sony�@�T���\���@�V���[�v�܂ŌQ�Y����
�s�ւȋ����͖łт�݂̂��ȁ@
���������������[�������܂�ɂ��֗������邵�R�X�g���������R������
���Ɋy���@�g�тƂ��V�[�����X���������̒��������烂�g���[���@sony�@�T���\���@�V���[�v�܂ŌQ�Y����
�s�ւȋ����͖łт�݂̂��ȁ@
45nm HK/MG��Atom D510(13W)�ɑ��A40nm �o���N Ontario (W�s��)��2�`3�{�̐��\���Ă̂͂�������
����Ontario�̍ō�TDP��18W�i�ł̍��������Ƃ��Ă�5���ȏ�͑������ƂɂȂ��
����Ontario�̍ō�TDP��18W�i�ł̍��������Ƃ��Ă�5���ȏ�͑������ƂɂȂ��
>>746
Atom��CPU�ȊO�̕������V�������N���������ŁACPU������32nm�łł�܂ňꏏ�����ǁB
���[�������B���Ⴂ���Ă��B
�t��Fusion�̐��\�ɐM�ߐ����o�Ă���ȁB
Atom��CPU�ȊO�̕������V�������N���������ŁACPU������32nm�łł�܂ňꏏ�����ǁB
���[�������B���Ⴂ���Ă��B
�t��Fusion�̐��\�ɐM�ߐ����o�Ă���ȁB
���p������́������Y�ꂽorz
���߂ċL����ǂݒ����Č����̂���AMD��K10���S���i�����Ă��炸�����͂͋}���ɖ����Ȃ��Ă��Ă���Ǝv���̂ł���B
http://pc.watch.impress.co.jp/docs/column/kaigai/20100427_364107.html
�㓡���̍I�݂Ȍ�����6�R�A�������͂����肻���Ɋ��Ⴂ���Ă��܂����ǥ��
���������������AMD��6�R�A�̐��\��Intel��4�R�A���x���ł����Ȃ��V���O���X���b�h���\�Ɏ����Ă�1.3�{�ȏ�̍���t�����Ă���ƌ���������B
������AMD��6�R�A��45nm�v���Z�X�ł���_�C�T�C�Y��346mm2�ł���B
���āAIntel��6�R�A��32nm�v���Z�X�ł���_�C�T�C�Y��240mm2�ɉ߂��Ȃ��B
AMD��346mm2��6�R�A�i��$300�ȉ��̉��i�тŔ̔�����헪����������A����͂͂����茾���Ă���ȏ�̉��i���Ɣ���錩���݂��Ȃ������̂���
Intel��4�R�A�i�Ƌ�������x�̐��\�����Ȃ��̂�����ł��荂���i�i�Ƃ��Ẳ��l��������L���Ă��Ȃ��̂����̍��{�I�ȗ��R���B
Intel�͍X�ɍ����\����������ɐi��ł���Sandy Bridge�ł�256bitSSE���j�b�g����������AVX���쉺�ł����SSE���\��2�{�ւƐi������������B
����ɑ�AMD��Bulldozer�ŃR�A�����X�ɑ��₷�����Ɍ������Ă���B
�������ڂ����SSE���j�b�g���₻�̐��\���猩�Ă��R�A���𑝂₵�����x��Intel�ɉ����y�Ȃ��Ɛ�������Ă��܂��̂�����ł͂Ȃ����낤���H
��{�I��AMD��K10����i�����Ă��Ȃ��̂ł��肻�����l�b�N�ɂȂ��Ă���ƌ��ĊԈႢ�Ȃ����낤�B
http://pc.watch.impress.co.jp/docs/column/kaigai/20100427_364107.html
�㓡���̍I�݂Ȍ�����6�R�A�������͂����肻���Ɋ��Ⴂ���Ă��܂����ǥ��
���������������AMD��6�R�A�̐��\��Intel��4�R�A���x���ł����Ȃ��V���O���X���b�h���\�Ɏ����Ă�1.3�{�ȏ�̍���t�����Ă���ƌ���������B
������AMD��6�R�A��45nm�v���Z�X�ł���_�C�T�C�Y��346mm2�ł���B
���āAIntel��6�R�A��32nm�v���Z�X�ł���_�C�T�C�Y��240mm2�ɉ߂��Ȃ��B
AMD��346mm2��6�R�A�i��$300�ȉ��̉��i�тŔ̔�����헪����������A����͂͂����茾���Ă���ȏ�̉��i���Ɣ���錩���݂��Ȃ������̂���
Intel��4�R�A�i�Ƌ�������x�̐��\�����Ȃ��̂�����ł��荂���i�i�Ƃ��Ẳ��l��������L���Ă��Ȃ��̂����̍��{�I�ȗ��R���B
Intel�͍X�ɍ����\����������ɐi��ł���Sandy Bridge�ł�256bitSSE���j�b�g����������AVX���쉺�ł����SSE���\��2�{�ւƐi������������B
����ɑ�AMD��Bulldozer�ŃR�A�����X�ɑ��₷�����Ɍ������Ă���B
�������ڂ����SSE���j�b�g���₻�̐��\���猩�Ă��R�A���𑝂₵�����x��Intel�ɉ����y�Ȃ��Ɛ�������Ă��܂��̂�����ł͂Ȃ����낤���H
��{�I��AMD��K10����i�����Ă��Ȃ��̂ł��肻�����l�b�N�ɂȂ��Ă���ƌ��ĊԈႢ�Ȃ����낤�B
753 �FSocket774�F2010/07/03(�y) 01:53:05 ID:QVM/wPjm
AMD������������������������������������������������������������
Atom��Intel�̓s���Ő��\�A�b�v���}�����Ă�����������
Bobcat�̓o��Ő��\���グ�Ă���̂�����
���[�U�[�ɂƂ��Ă͗ǂ����Ƃ���Ȃ���
��͂苣�����Ȃ��Ƒʖڂ���
Bobcat�̓o��Ő��\���グ�Ă���̂�����
���[�U�[�ɂƂ��Ă͗ǂ����Ƃ���Ȃ���
��͂苣�����Ȃ��Ƒʖڂ���
AMD��32nm�v���Z�X�܂�����
���̂Ƃ���Bulldozer��Intel�̌�ǂ��ł����Ȃ����
�X���[�v�b�g��HTT�ɒǂ����̂ƃ}�[�P�e�B���O�ʂł̃����b�g�̂�
���߂�HTT�������Ă����X���[�v�b�g�ň���������̂�
�X���[�v�b�g��HTT�ɒǂ����̂ƃ}�[�P�e�B���O�ʂł̃����b�g�̂�
���߂�HTT�������Ă����X���[�v�b�g�ň���������̂�
�������������|���X���b�h�Ȃ�ėv��Ȃ������B
>>756
> ���߂�HTT�������Ă����X���[�v�b�g�ň���������̂�
HTT��Intel�̏��W������AMD�ɂ͖�����
�Ɩ��p�̎I����ւ���HTT��on/off���ăp�t�H�[�}���X�v�����Ă����ǁA�C�������x�����オ���ĂȂ������ȁB
�A�����x�����̂�>>443���炢���낤�B
> ���߂�HTT�������Ă����X���[�v�b�g�ň���������̂�
HTT��Intel�̏��W������AMD�ɂ͖�����
�Ɩ��p�̎I����ւ���HTT��on/off���ăp�t�H�[�}���X�v�����Ă����ǁA�C�������x�����オ���ĂȂ������ȁB
�A�����x�����̂�>>443���炢���낤�B
SMT�����͒u���Ƃ���
�G���R����_�����O�Ƃ���ʓI�ȗp�r��HTT�̌��ʂ�����͎̂��m�Ȃ̂�
��������Ȃ��ӂ肷��̂͂ǂ����Ǝv������
�G���R����_�����O�Ƃ���ʓI�ȗp�r��HTT�̌��ʂ�����͎̂��m�Ȃ̂�
��������Ȃ��ӂ肷��̂͂ǂ����Ǝv������
1���W���[����1�R�A�̑Ό���������SMT�����B
���Ă邩�͒m���B
���Ă邩�͒m���B
�Ă��A���Ƃ��ƎI�pCPU���f�X�N�g�b�|CPU�ɂ��Č��܂����݂����Ȃ�����ˁB
�����l�����HyTh�͂�����Ɨv��Ȃ������B
�������ǁ[����͂胁���R���E�L���b�V�����肪�ア�C������B
���̕ӂ��炢��OPTERON�����������Ă���ėǂ��Ǝv���̂����E�E�E
�����l�����HyTh�͂�����Ɨv��Ȃ������B
�������ǁ[����͂胁���R���E�L���b�V�����肪�ア�C������B
���̕ӂ��炢��OPTERON�����������Ă���ėǂ��Ǝv���̂����E�E�E
>>761
32nm�ɂ����炢�܂܂ł̃f�X�N�g�b�v�̃T�C�Y��12�R�A���ڂ����邺���Ă����̂�
�v��̔��[�̂悤�ȋC������B
����͂���ł�����Ȃ��H�ړI���킩���ĂĂ�邱�Ƃ�
�ߏ�̌��ʂ͂Ȃ��Ȃ���������B
32nm�ɂ����炢�܂܂ł̃f�X�N�g�b�v�̃T�C�Y��12�R�A���ڂ����邺���Ă����̂�
�v��̔��[�̂悤�ȋC������B
����͂���ł�����Ȃ��H�ړI���킩���ĂĂ�邱�Ƃ�
�ߏ�̌��ʂ͂Ȃ��Ȃ���������B
763 �FSocket774�F2010/07/03(�y) 08:40:51 ID:4ve6foS5
Bull�̍\����HTT���ăA�z�ۏo��
Andy Glew�̖����܂��Ă���
>>758
�I�ł����z���I�ł́AHTT��ON�ɂ��Ă��������Z�̐��\�͏オ��Ȃ��炵����
HTT��ON�ɂ���Ɛ��\���㗦��������d�͏㏸���̕����������Ⴄ�̂ʼn��b�͏��Ȃ�
�������A�ߕ��ׁi���j���|�����Ƃ��ɂ͎HTT�̌��ʂ�����B
�����z�R�A���̐ݒ萔���~�X���ĕ����R�A���ȏ�ɐݒ肵���ꍇ�ȂǁB�I�S�̂̐��\������������̒ʏ�͂ł��Ȃ�
�I�ł����z���I�ł́AHTT��ON�ɂ��Ă��������Z�̐��\�͏オ��Ȃ��炵����
HTT��ON�ɂ���Ɛ��\���㗦��������d�͏㏸���̕����������Ⴄ�̂ʼn��b�͏��Ȃ�
�������A�ߕ��ׁi���j���|�����Ƃ��ɂ͎HTT�̌��ʂ�����B
�����z�R�A���̐ݒ萔���~�X���ĕ����R�A���ȏ�ɐݒ肵���ꍇ�ȂǁB�I�S�̂̐��\������������̒ʏ�͂ł��Ȃ�
>>759
�܂��AHTT��Intel��SMT�ɑ��ĕt�����ʂ薼
�ł����āA�G���R����_�����O�Ɏg����SIMD�iSSE�Ȃǁj�̕����ɂ��Ă�
Bulldozer�ł͋@�\�I�ɂ�SMT�Ɠ���
�܂��AHTT��Intel��SMT�ɑ��ĕt�����ʂ薼
�ł����āA�G���R����_�����O�Ɏg����SIMD�iSSE�Ȃǁj�̕����ɂ��Ă�
Bulldozer�ł͋@�\�I�ɂ�SMT�Ɠ���
�g�s�s���ł�̂͂Ǒf�l�@���\��������ꍇ�����Ă���
�ł��ASMT�������Ă���I����CPU��intel�ȊO�ɂ�����A
HTT�̎������ւڂ������Ȃ�Ȃ������ċC������B
HTT�̎������ւڂ������Ȃ�Ȃ������ċC������B
769 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 10:14:16 ID:koawV+us
>>754
Atom�̐��\���グ����āA����d�͂��グ�Ă܂Ń}�C�N���A�[�L�e�N�`�������ǂ���Ƃł��H
���ʂ�CULV�����ŏ\������
Atom�͂��̂܂܃V�������N���ăX�}�[�g�t�H����Ɠd�����ɍœK�����Ǝv����
Atom��萫�\�������ƃn�b�^�����܂��Ă郌���W�̃n�C�G���hCortex A9-MP�͂��������ڋq�͌����������ĂȂ��B
Atom�̐��\���グ����āA����d�͂��グ�Ă܂Ń}�C�N���A�[�L�e�N�`�������ǂ���Ƃł��H
���ʂ�CULV�����ŏ\������
Atom�͂��̂܂܃V�������N���ăX�}�[�g�t�H����Ɠd�����ɍœK�����Ǝv����
Atom��萫�\�������ƃn�b�^�����܂��Ă郌���W�̃n�C�G���hCortex A9-MP�͂��������ڋq�͌����������ĂȂ��B
���ꂾ���p�C�v���C���[����2G�O�������E���Ă܂�����
���܂��ɒm�I��Q�M�҂Ɂu�`�b�v�Z�b�g�ɑ����������Ă�v�Ƃ����킹�Ă�n��
���܂��ɒm�I��Q�M�҂Ɂu�`�b�v�Z�b�g�ɑ����������Ă�v�Ƃ����킹�Ă�n��
771 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 10:32:01 ID:koawV+us
>>767
Andy Glew���w�E���Ă邯�ǁA���Ȃ�L1�L���b�V�����������X��2�X���b�h�ŕ�������X�y�b�N�����ŃX���b�V���O�p���Ő��\�ቺ�����ˁB
�������A���̓_�����Ɋւ��Č�����4-Way�Z�b�g�A�\�V�G�C�e�B�u��16KB��L1D���X���b�h���Ɏ��͕̂ʂɔ��������Ȃ���B
�Ȃ��Ȃ�A���xNehalem�`Sandy Bridge�̔���������B
�L���b�V�����[�J���e�B�ɉ������o�����V���O���o���镪8-Way�Z�b�g�A�\�V�G�C�e�B�u��32KB�̃L���b�V����
2�X���b�h�ŕ���������܂��q�b�g���͏グ����B
�t�Ɍ����ƁAIntel�v���Z�b�T�ł̓X���b�h���蓖�Ă����点�ΐ��\���P����P�[�X�ł�
Bulldozer���Ƃǂ����悤���Ȃ��Ƃ������ƂɂȂ�B
Andy Glew���w�E���Ă邯�ǁA���Ȃ�L1�L���b�V�����������X��2�X���b�h�ŕ�������X�y�b�N�����ŃX���b�V���O�p���Ő��\�ቺ�����ˁB
�������A���̓_�����Ɋւ��Č�����4-Way�Z�b�g�A�\�V�G�C�e�B�u��16KB��L1D���X���b�h���Ɏ��͕̂ʂɔ��������Ȃ���B
�Ȃ��Ȃ�A���xNehalem�`Sandy Bridge�̔���������B
�L���b�V�����[�J���e�B�ɉ������o�����V���O���o���镪8-Way�Z�b�g�A�\�V�G�C�e�B�u��32KB�̃L���b�V����
2�X���b�h�ŕ���������܂��q�b�g���͏グ����B
�t�Ɍ����ƁAIntel�v���Z�b�T�ł̓X���b�h���蓖�Ă����点�ΐ��\���P����P�[�X�ł�
Bulldozer���Ƃǂ����悤���Ȃ��Ƃ������ƂɂȂ�B
>>769
ARM�͂����ʂ蔭�\���Ă��炠����x���Ԃ������č̗p���i���o����ăp�^�[���Ȃ����ł́H
����Snapdragon�ł�CortexA9���̗p�����悤�����B
>>770
�g���Ă���g�����W�X�^�̓��[�N�d�������������ǁA�x����炵������A
�x���g�����W�X�^�̊��ɂ̓N���b�N������Ȃ�ɏo����Ē��x�Ȃ�Ȃ��́H
���C���͑g�ݍ������ŁANetbook�Ƃ��͖{�����܂��̐v�B
ARM�͂����ʂ蔭�\���Ă��炠����x���Ԃ������č̗p���i���o����ăp�^�[���Ȃ����ł́H
����Snapdragon�ł�CortexA9���̗p�����悤�����B
>>770
�g���Ă���g�����W�X�^�̓��[�N�d�������������ǁA�x����炵������A
�x���g�����W�X�^�̊��ɂ̓N���b�N������Ȃ�ɏo����Ē��x�Ȃ�Ȃ��́H
���C���͑g�ݍ������ŁANetbook�Ƃ��͖{�����܂��̐v�B
773 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 10:36:11 ID:koawV+us
�ᑬ�g�����W�X�^�ł����N���b�N�œ������ׂɃp�C�v���C���i���𑝂₵�Ă��ł�����
�����g�����W�X�^�̂���Ɣ�ׂ�̂͂����̈���
�����g�����W�X�^�̂���Ɣ�ׂ�̂͂����̈���
Atom�ɔ�ׂ�Cortex�x������
�Ƃ������Ă�c�q�������ėǂ��䎌�ł͂Ȃ�����E�E�E
�Ƃ������Ă�c�q�������ėǂ��䎌�ł͂Ȃ�����E�E�E
PATCH: Support AVX Programming Reference (June, 2010)
http://sourceware.org/ml/binutils-cvs/2010-07/msg00008.html
AVX Programming Reference ��7��
http://software.intel.com/file/28986
�������̖��߂��lj�����Ă��邪
AVX�Ƃ͕ʂ̎��ʃt���O���^�����Ă���
http://sourceware.org/ml/binutils-cvs/2010-07/msg00008.html
AVX Programming Reference ��7��
http://software.intel.com/file/28986
�������̖��߂��lj�����Ă��邪
AVX�Ƃ͕ʂ̎��ʃt���O���^�����Ă���
776 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 11:06:00 ID:koawV+us
>>774
�����Ă��̎�̃f���͏��F�n�b�^�������́B
ARM��CPU�������ďI���ł͂Ȃ��A�p�[�g�i�[��Ƃɒ��Ă���SoC�J�����n�܂邩��A���ۂ����Ɏg����킯�ł͂Ȃ��B
�����i�Ƃ��ďo�Ă�̂̓n�C�G���h�ł�A9��1GHz��O�����炢����B
���N�O�ɔ��\���ꂽ���i���Ǝv���Ă�B
�܂�2GHz��MP-Core�����ۂ̐��i�ɓ�������鍠�ɂ�Atom�������ƃv���Z�X���[�����i��ł邾�낤�����r���Ă��Ӗ����Ȃ���
�����Ƃ��AARM��IP���[�U�[���炷��v���Z�X���[�����g���Â���Ă���̂ق����E�F�n�P���������Ȃ��ăE�}�[�A�Ƃ����ʂ�����̂��낤���B
�����Ă��̎�̃f���͏��F�n�b�^�������́B
ARM��CPU�������ďI���ł͂Ȃ��A�p�[�g�i�[��Ƃɒ��Ă���SoC�J�����n�܂邩��A���ۂ����Ɏg����킯�ł͂Ȃ��B
�����i�Ƃ��ďo�Ă�̂̓n�C�G���h�ł�A9��1GHz��O�����炢����B
���N�O�ɔ��\���ꂽ���i���Ǝv���Ă�B
�܂�2GHz��MP-Core�����ۂ̐��i�ɓ�������鍠�ɂ�Atom�������ƃv���Z�X���[�����i��ł邾�낤�����r���Ă��Ӗ����Ȃ���
�����Ƃ��AARM��IP���[�U�[���炷��v���Z�X���[�����g���Â���Ă���̂ق����E�F�n�P���������Ȃ��ăE�}�[�A�Ƃ����ʂ�����̂��낤���B
>>772
�������������̂͂ނ���2�s�ڂ���
�u�`�b�v�Z�b�g�̂������v�u�}�C�N���A�[�L�e�N�`���̂������v
����ɉ����čŐV���X�i���l�̂��́j��4���ŖY��ē����������J��Ԃ�
���q�T���U�炵�z�����C������������
�������������̂͂ނ���2�s�ڂ���
�u�`�b�v�Z�b�g�̂������v�u�}�C�N���A�[�L�e�N�`���̂������v
����ɉ����čŐV���X�i���l�̂��́j��4���ŖY��ē����������J��Ԃ�
���q�T���U�炵�z�����C������������
778 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 11:16:13 ID:koawV+us
����ID���ځ[��]�T�ł���
779 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 11:17:29 ID:koawV+us
�����ׂ��}���`�X���b�h���o����Ȃ�Bulldozer�A�[�L�e�N�`���͗L���B�t�ɃV���O���X���b�h�Ńs�[�N���\�����߂���p�r�Ȃ�s���B���ꂾ���̘b
> �����ׂ��}���`�X���b�h���o����Ȃ�Bulldozer�A�[�L�e�N�`���͗L���B
�����ׂɂ���׃R�A���\�𗎂Ƃ����Ƃ��v���Ă�́H
�}���`�R�A������ƃR�q�[�����V�ێ��ɑ傫�ȃR�X�g���|�邩��R�A���\���]���ɂ����ʂɃR�A�����₵�Ă��ǂ����Ƃ͂Ȃ��Ǝv�����B
�����ׂɂ���׃R�A���\�𗎂Ƃ����Ƃ��v���Ă�́H
�}���`�R�A������ƃR�q�[�����V�ێ��ɑ傫�ȃR�X�g���|�邩��R�A���\���]���ɂ����ʂɃR�A�����₵�Ă��ǂ����Ƃ͂Ȃ��Ǝv�����B
783 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 11:34:25 ID:koawV+us
AMD�ɊW���肻���ȂƂ���������Č����Ȃ�
VCVTPH2PS/VCVTPS2PH��Intel�̖��߃Z�b�g�g���̎d�l�Ƀ}�[�W���ꂽ���ĂƂ��납�B
imm8�̈����d�l�����X��AMD�̂Ɠ����B
������XOP�ł͂Ȃ�VEX�v���t�B�N�X�Ƀ}�b�s���O����Ă�B
VCVTPH2PS/VCVTPS2PH��Intel�̖��߃Z�b�g�g���̎d�l�Ƀ}�[�W���ꂽ���ĂƂ��납�B
imm8�̈����d�l�����X��AMD�̂Ɠ����B
������XOP�ł͂Ȃ�VEX�v���t�B�N�X�Ƀ}�b�s���O����Ă�B
Atom��ARM�̔�r�Ȃ�Intel�X���ł��
������AMD�̃X����
������AMD�̃X����
785 �FSocket774�F2010/07/03(�y) 11:41:55 ID:4ve6foS5
Bull��16�R�A�Ƃ��Ɍ�����́H
������AMD�A���`�X������Ȃ��̂Ɋ��Ⴂ���Ă�l�ԑ��߂�����
��������Intel�EAMD������CPU�Ό��X���ł����ĂĂ������ł������̂�
��������Intel�EAMD������CPU�Ό��X���ł����ĂĂ������ł������̂�
NVIDIA�~vsATI�~vsS3�~vsIntel�~ Part74
http://pc11.2ch.net/test/read.cgi/jisaku/1266945234/
GPU���S�̘b�ɂȂ肪���Ȃ̂�Intel��S3���ᒠ�̊O��
http://pc11.2ch.net/test/read.cgi/jisaku/1266945234/
GPU���S�̘b�ɂȂ肪���Ȃ̂�Intel��S3���ᒠ�̊O��
Intel�X���̐Â���������ƁE�E�E
�܂�́A�������������B
�܂�́A�������������B
Opteron�̍ŐV�^���Ă����B
MCM�����ǂȂ��Ȃ��ǂ��ȁA����ň��g��ł݂����B
���������i�ƃV���O���\�P�b�gMB���l�b�N���ˁB
�肪�o�Ȃ��̂�AM3r2�҂��B
MCM�����ǂȂ��Ȃ��ǂ��ȁA����ň��g��ł݂����B
���������i�ƃV���O���\�P�b�gMB���l�b�N���ˁB
�肪�o�Ȃ��̂�AM3r2�҂��B
790 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 12:00:58 ID:koawV+us
>>785
���⎩��16�R�A�̗\�肠�邾�낗
CbMT�Ƃ�����SMT�ɖт����������Ƃ�����
�Z�p�I�D�ʐ������邩�ǂ����́A�T�[�o�ɂ����������Ă�IBM��POWER�����ʂ�SMT�Ȃ̂��|�C���g�B
�܂�嗬����傫���O��Ă�Ƃ������ƁB
�t�Ɍ����A����Bulldozer�̕��������������̂ł�����㐔�N�ɂ킽���ċƊE�����[�h���鑶�݂ɂȂ��B
���⎩��16�R�A�̗\�肠�邾�낗
CbMT�Ƃ�����SMT�ɖт����������Ƃ�����
�Z�p�I�D�ʐ������邩�ǂ����́A�T�[�o�ɂ����������Ă�IBM��POWER�����ʂ�SMT�Ȃ̂��|�C���g�B
�܂�嗬����傫���O��Ă�Ƃ������ƁB
�t�Ɍ����A����Bulldozer�̕��������������̂ł�����㐔�N�ɂ킽���ċƊE�����[�h���鑶�݂ɂȂ��B
�����̓X���Ⴂ�Ɣ�ׂĈ��|�I�Ɂu�����Ⴂ�v����������V���b�N�ʼnߕq�ɂȂ�z���o�Ă���낤����
�X���Ⴂ���x�Ȃ�ʂɑ����͂�����Ȃ����H
�X���Ⴂ���x�Ȃ�ʂɑ����͂�����Ȃ����H
>>782
HTT�Ɣ�ׂāA��
HTT�Ɣ�ׂāA��
793 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 12:30:26 ID:koawV+us
HTT�Ɣ�ׂėL�����ǂ����͂킩���
�X���b�h�̕��ׂ͏�ɋψ�ł͂Ȃ��B
���Ƃ�����������̃��[�h�҂��ŃX�g�[�����邱�Ƃ���������イ���邵�A�����Ȃ����ꍇ�ɂ����Е��̃X���b�h�ɉ��Z���\�[�X����ł�������L�����낤�B
���Ȃ��Ƃ�1���W���[����K10��1�R�A��1.8�{�~�܂�ł̓T�[�o�s��ŏ��Ă�B
�X���b�h�̕��ׂ͏�ɋψ�ł͂Ȃ��B
���Ƃ�����������̃��[�h�҂��ŃX�g�[�����邱�Ƃ���������イ���邵�A�����Ȃ����ꍇ�ɂ����Е��̃X���b�h�ɉ��Z���\�[�X����ł�������L�����낤�B
���Ȃ��Ƃ�1���W���[����K10��1�R�A��1.8�{�~�܂�ł̓T�[�o�s��ŏ��Ă�B
794 �FSocket774�F2010/07/03(�y) 12:30:51 ID:QVM/wPjm
3D����Ȃ��嗬�ɂȂ�e���r���Q�[�����l�b�g���G���^��PC�͂܂��܂����p�t�H�[�}���X�����߂���̂�
�V���O�����\���}���`���\���アAMD�ɖ����͖�����
�܂��C���e���̊J���͂����|�I�ɋ���������Ă��Ƃ���
AMD�͎嗬����O�ꂲ�������ꕔ�̍���t��pCPU�Ƃ��ă}�C�i�[�ȕ����i��Ő������Ⴄ�낤��
�V���O�����\���}���`���\���アAMD�ɖ����͖�����
�܂��C���e���̊J���͂����|�I�ɋ���������Ă��Ƃ���
AMD�͎嗬����O�ꂲ�������ꕔ�̍���t��pCPU�Ƃ��ă}�C�i�[�ȕ����i��Ő������Ⴄ�낤��
795 �FSocket774�F2010/07/03(�y) 12:37:25 ID:4ve6foS5
3D�����GPU�Ƀ|�C�ł�����
3D����Ȃ��嗬�ɂȂ�e���r���Q�[�����l�b�g���G���^��PC�͂܂��܂����p�t�H�[�}���X�����߂���Ȃ�
�C���e���͂ǂ�����̂��B
�C���e���͂ǂ�����̂��B
�z���O����������
���ق��ᖳ������
���ق��ᖳ������
>>780
�S�����̒ʂ肾��
�S�����̒ʂ肾��
>>796
�����������v�X�������ڂꂻ����
�����������v�X�������ڂꂻ����
������
Intel����K10��1.8�{�Ȃ̂�
Intel����K10��1.8�{�Ȃ̂�
801 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 12:59:42 ID:koawV+us
�h��G�ɓ�������GPU�Ɛ��㗎���v���Z�b�T�������Ă�ꍇ�ł��Ȃ�����
802 �FSocket774�F2010/07/03(�y) 13:02:13 ID:4ve6foS5
3D����̘b�̎��ɓˑR�ǂ������́H
803 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 13:03:35 ID:koawV+us
>>800
����16�R�A�ł����X�R�A���Ⴆ�����Ȃ낤��
Sun Microsystems
Sun Blade X6440 (AMD Opteron 8389 2.9GHz)
Compiler: PGI Server Complete Version 8.0 x86 Open64 4.2.2 Compiler Suite (from AMD)
SPECintR_rate2006 = 292
SPECint_rate_base2006 = 226
http://www.spec.org/cpu2006/results/res2009q3/cpu2006-20090914-08593.html
Sun Microsystems
Sun Blade X6275 (Intel Xeon X5570 2.93GHz)
Compiler: Sun Studio 12 Update 1(backend build 20090309)
SPECintR_rate2006 = 478
SPECint_rate_base2006 = 410
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090413-07024.html
�����X���b�h��g�����ꍇ�̃X���[�v�b�g���㗦��SMT���CbMT�̂ق����傫����
��������1�X���b�h������̐��\���Ⴂ�̂Łi�ȉ���
����16�R�A�ł����X�R�A���Ⴆ�����Ȃ낤��
Sun Microsystems
Sun Blade X6440 (AMD Opteron 8389 2.9GHz)
Compiler: PGI Server Complete Version 8.0 x86 Open64 4.2.2 Compiler Suite (from AMD)
SPECintR_rate2006 = 292
SPECint_rate_base2006 = 226
http://www.spec.org/cpu2006/results/res2009q3/cpu2006-20090914-08593.html
Sun Microsystems
Sun Blade X6275 (Intel Xeon X5570 2.93GHz)
Compiler: Sun Studio 12 Update 1(backend build 20090309)
SPECintR_rate2006 = 478
SPECint_rate_base2006 = 410
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090413-07024.html
�����X���b�h��g�����ꍇ�̃X���[�v�b�g���㗦��SMT���CbMT�̂ق����傫����
��������1�X���b�h������̐��\���Ⴂ�̂Łi�ȉ���
���܂�嗬����傫���O��Ă�Ƃ������ƁB
�܂��������̒ʂ�Ȃ̂łނ�����Ă��܂����B
SMT�J�����s���Ă�Ȃ��̂�AMD�́B
�Ƃ͂����AAMD��SMT����Ȃ����@�ɑǐ�������
AMD�M�҂͊��҂��邵���Ȃ���ȁB
�܂��������̒ʂ�Ȃ̂łނ�����Ă��܂����B
SMT�J�����s���Ă�Ȃ��̂�AMD�́B
�Ƃ͂����AAMD��SMT����Ȃ����@�ɑǐ�������
AMD�M�҂͊��҂��邵���Ȃ���ȁB
����i7����AMD�̂ɔ�ׂ�1/25�X�s�[�h�Ȃ�ł���
806 �FSocket774�F2010/07/03(�y) 13:06:25 ID:QVM/wPjm
>>801
�܂��ɂ��̂Ƃ���Ȃ�ˁI
�ꐢ��O��GPU��2����O��CPU�������Ċ��ł鍁��t�Ȃ�Ă���̂��Ƃ�
2011�N�ɂ����Llano��Intel�̍ŐV�Z�p�̌���Sandy�Ƃ܂Ƃ��ɐ킨���Ƃ��Ă�AMD�͂ǂ������Ă邗
�܂��ɂ��̂Ƃ���Ȃ�ˁI
�ꐢ��O��GPU��2����O��CPU�������Ċ��ł鍁��t�Ȃ�Ă���̂��Ƃ�
2011�N�ɂ����Llano��Intel�̍ŐV�Z�p�̌���Sandy�Ƃ܂Ƃ��ɐ킨���Ƃ��Ă�AMD�͂ǂ������Ă邗
�����琔�ɂ܂������
http://pc.watch.impress.co.jp/docs/column/ubiq/20100122_343853.html
���̋L���ǂތ���́Aintel�̓���GPU�ł���ʐ��i�Ȃ�Blu-ray 3D���Đ��ł�����ۂ��B
3D����ł�AMD�ANVIDIA�Aintel�Ƃ��Ɏ����゠����ł͑����Ȃ���Ȃ����낤���B
���̋L���ǂތ���́Aintel�̓���GPU�ł���ʐ��i�Ȃ�Blu-ray 3D���Đ��ł�����ۂ��B
3D����ł�AMD�ANVIDIA�Aintel�Ƃ��Ɏ����゠����ł͑����Ȃ���Ȃ����낤���B
809 �FSocket774�F2010/07/03(�y) 13:10:25 ID:4ve6foS5
>>806
Intel�̍ŐVGPU�Ȃ�ă��N���N������
Intel�̍ŐVGPU�Ȃ�ă��N���N������
����AMD��SMT�̑I�����͖�����
���Ƃ��Z�p�I�ɉ\�ł����Ă���
AMD��IBM�Ƃ��Ƃ͊�Ƃ̌`�Ԃ��Y�ƍ\�����Ⴄ�̂������
AMD�Ɋւ��Č�����SMT���̗p���郁���b�g�͖���
���Ƃ��Z�p�I�ɉ\�ł����Ă���
AMD��IBM�Ƃ��Ƃ͊�Ƃ̌`�Ԃ��Y�ƍ\�����Ⴄ�̂������
AMD�Ɋւ��Č�����SMT���̗p���郁���b�g�͖���
>>806
�V�������͖`�����Ȃ��̂Ɍ��܂��Ă邾��
�Q��ڂƂȂ�Ƃ����������t�������Ă����Ȃ��
�e���r�ł���R���ɂȂ�̂ɂ����������̂����Ƃ����炗
�V�������͖`�����Ȃ��̂Ɍ��܂��Ă邾��
�Q��ڂƂȂ�Ƃ����������t�������Ă����Ȃ��
�e���r�ł���R���ɂȂ�̂ɂ����������̂����Ƃ����炗
�N���X�^�[�h�A�[�L�e�N�`���[��AMD�ŊJ�����Ă�Andy Glew���g��SpMT�g��Ȃ��Ȃ�A
SMT�͈Ӗ����Ȃ����ăR�����g���Ă�����ASMT�P�̂Ŏ�������\���͂��܂�Ȃ���Ȃ��́H
SMT�͈Ӗ����Ȃ����ăR�����g���Ă�����ASMT�P�̂Ŏ�������\���͂��܂�Ȃ���Ȃ��́H
813 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 13:22:29 ID:koawV+us
>>810
�Y�ƍ\���̈Ⴂ�������Ȃ�Ȃ��̂��ƃR���V���[�}PC�̂悤�ȃX���b�h�v�������Ȃ��ꍇ�ł��p�t�H�[�}���X�����₷��
3�`4issue�p�C�v���C���{SMT�����̂ق����L���Ȃ��B
�Y�ƍ\���̈Ⴂ�������Ȃ�Ȃ��̂��ƃR���V���[�}PC�̂悤�ȃX���b�h�v�������Ȃ��ꍇ�ł��p�t�H�[�}���X�����₷��
3�`4issue�p�C�v���C���{SMT�����̂ق����L���Ȃ��B
>>814
���̗����ł�����Atom�ŏ\���Ƃ������ƂɂȂ�ȁB
������Atom��i7 980X�Ԃ̐��i�Q�Ȃ���v�ɉ������i����������Ηǂ������̘b�ł����ċc�_���鉿�l���Ȃ����Ă��Ƃ���w
���̗����ł�����Atom�ŏ\���Ƃ������ƂɂȂ�ȁB
������Atom��i7 980X�Ԃ̐��i�Q�Ȃ���v�ɉ������i����������Ηǂ������̘b�ł����ċc�_���鉿�l���Ȃ����Ă��Ƃ���w
>>811
http://pc.watch.impress.co.jp/docs/news/20100527_369625.html
�ʂ̋L���ǂ�łĒm�������ǁANEC��3DPC����intel�̓���GPU�������B
http://pc.watch.impress.co.jp/docs/news/20100527_369625.html
�ʂ̋L���ǂ�łĒm�������ǁANEC��3DPC����intel�̓���GPU�������B
>>813
����̓��C�o���Ɠ����x�̐����Z�p�������Ă��邩�A
���邢�͎��Ђ݂̂ŃV�X�e������T�[�r�X�܂ł̐��������^
�܂���̌ڋq���͂����N���[�Y�Ȏs��������Ă��邩�̂ǂ��炩�������Ǝ��Ȃ��I��
����̓��C�o���Ɠ����x�̐����Z�p�������Ă��邩�A
���邢�͎��Ђ݂̂ŃV�X�e������T�[�r�X�܂ł̐��������^
�܂���̌ڋq���͂����N���[�Y�Ȏs��������Ă��邩�̂ǂ��炩�������Ǝ��Ȃ��I��
>>817
> Atom���Ƃ��܂�ɂ���͉߂��邵�A����Đ��x���ɂ���������Ă邩��
����͌N�l�̊��z�ł����Ȃ���A������Atom�𓋍ڂ����l�b�g�u�b�N�̔���s���͍D�������ȁB
> Atom���Ƃ��܂�ɂ���͉߂��邵�A����Đ��x���ɂ���������Ă邩��
����͌N�l�̊��z�ł����Ȃ���A������Atom�𓋍ڂ����l�b�g�u�b�N�̔���s���͍D�������ȁB
�������Intel�Ɛ����ʂ�v���Z�X�Œǂ������Ƃ�����A
��^�R�A�Ƃ����I�������������邪����AMD�̔\�͂���s�\��
��^�R�A�Ƃ����I�������������邪����AMD�̔\�͂���s�\��
>>819
>����͌N�l�̊��z�ł����Ȃ���
�� http://img3.wiredvision.jp/news/201005/2010050722-2.png
�����s�[�N�͉߂��Ă�
>����͌N�l�̊��z�ł����Ȃ���
�� http://img3.wiredvision.jp/news/201005/2010050722-2.png
{kind=link}
�����s�[�N�͉߂��Ă�
>>818
���ǁAAMD�͋Z�p�͕s���Ǝ����s�������g�ƂȂ��Ă邩�瓯���y�U�ł͏����ɂȂ�Ȃ��̂Ō��ԏ�����͍����Ă�����Ă��Ƃł����Ȃ��ȥ��
���ꂪ�����Č����Ă��܂��Ă邩����҂ł��Ȃ��Ȃ��Ă��܂�����Ԃɒu����Ă���̂�����륥��Ȃ�Ƃ������AMD
���ǁAAMD�͋Z�p�͕s���Ǝ����s�������g�ƂȂ��Ă邩�瓯���y�U�ł͏����ɂȂ�Ȃ��̂Ō��ԏ�����͍����Ă�����Ă��Ƃł����Ȃ��ȥ��
���ꂪ�����Č����Ă��܂��Ă邩����҂ł��Ȃ��Ȃ��Ă��܂�����Ԃɒu����Ă���̂�����륥��Ȃ�Ƃ������AMD
�l�b�g�u�b�N���Č����Ă�iPAD�̂悤�ȃs���A�^�u���b�g�����O����Ək�������Ⴄ���ǂ�
���R�Ȃ���AOntario�ɂƂ��Ă����������ɂȂ肻��
���R�Ȃ���AOntario�ɂƂ��Ă����������ɂȂ肻��
824 �FSocket774�F2010/07/03(�y) 13:57:19 ID:4ve6foS5
Atom�ŏ\���Ȃ獡��Intel��CPU�̔�����������s�\�����
>>822
AMD�͓��{�Ō����ΎO�m�d�@���x�̋K�͂���������
Intel�Ƃ�2�`30�{�̊i��������
AMD��Intel���x���̎��������Č����Ă�����͖�����
AMD�͓��{�Ō����ΎO�m�d�@���x�̋K�͂���������
Intel�Ƃ�2�`30�{�̊i��������
AMD��Intel���x���̎��������Č����Ă�����͖�����
>>761
>�������ǁ[����͂胁���R���E�L���b�V�����肪�ア�C������B
�ア���H�A���M�����O�h�g���邵L3�̓X�k�[�v�o�b�t�@�Ƃ��Ă͑�������ʂ������Ȃ��Ǝv�����B
>�������ǁ[����͂胁���R���E�L���b�V�����肪�ア�C������B
�ア���H�A���M�����O�h�g���邵L3�̓X�k�[�v�o�b�t�@�Ƃ��Ă͑�������ʂ������Ȃ��Ǝv�����B
827 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 14:00:18 ID:koawV+us
������^�R�A�Ȃ�邾�����ʂȂ悤��
�R�X�g���������J���Ɏ��Ԃ�������
�O���t�B�b�N�X�Ɠ����悤�Ƀn�C�G���h�͒��^�R�A��Ő��\�m�ۂ�����j�Ȃ�Ȃ�
�R�X�g���������J���Ɏ��Ԃ�������
�O���t�B�b�N�X�Ɠ����悤�Ƀn�C�G���h�͒��^�R�A��Ő��\�m�ۂ�����j�Ȃ�Ȃ�
TDP20W���炢��Ontario�̒l�i�̂�������ł́A�����m�[�gPC�p�ɔ�����Ȃ��́H
AMD�̕��������悭�킩��Ȃ�����
���\�ŏ��ĂȂ��̂ŃR�X�p�����ɓ���������Bulldozer�ɂȂ�܂���
���ĔF���ł����́H
���\�ŏ��ĂȂ��̂ŃR�X�p�����ɓ���������Bulldozer�ɂȂ�܂���
���ĔF���ł����́H
832 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 14:03:26 ID:koawV+us
>>828
�R���V���[�}PC�ɂ�����CPU�̃��[�N���[�h�̓O���t�B�b�N�قǕ���x�͍����Ȃ����B
�����炱��Turbo Boost�̂悤�ȏ��X���b�h�̐��\�������グ��Z�p�����Ě������킯���B
�R���V���[�}PC�ɂ�����CPU�̃��[�N���[�h�̓O���t�B�b�N�قǕ���x�͍����Ȃ����B
�����炱��Turbo Boost�̂悤�ȏ��X���b�h�̐��\�������グ��Z�p�����Ě������킯���B
���ƃI���G���^�������h�A�����A�_�C���n�E�X�A�R�j�J�����肪AMD�Ɠ����x�̋K�͂���
>>928
> TDP20W���炢��Ontario�̒l�i�̂�������ł́A�����m�[�gPC�p�ɔ�����Ȃ��́H
�����̌��ԐH���͉\���낤���{�i�I�Ȕ���ؕi�ɂ���͕̂s�\�Ǝv���B
���������l�t�������Ŏs���{�i�I�ɍr����킯���Ȃ��A������n������Ȃ�����e���x���傫���Ɣ��f���ꂽ�牿�i�R����邩��ȁB
> TDP20W���炢��Ontario�̒l�i�̂�������ł́A�����m�[�gPC�p�ɔ�����Ȃ��́H
�����̌��ԐH���͉\���낤���{�i�I�Ȕ���ؕi�ɂ���͕̂s�\�Ǝv���B
���������l�t�������Ŏs���{�i�I�ɍr����킯���Ȃ��A������n������Ȃ�����e���x���傫���Ɣ��f���ꂽ�牿�i�R����邩��ȁB
�Ȃ�AMD���Q�[�������������z�����Č��������Ȋ����͂����
���Ƃ��̌��Ԃ͂ł����Ǝv���B���{�ɂ����ẮB
���b�c�m�[�g�݂����Ȃ̗~�����Ǝv���l�b�g�u�b�N�����Ă��w��
10���~�O��̌y�ʃm�[�g�g���悤�ɂȂ����瑶�݊��͂���B
AMD�̗����͔������Ȃ̂ł����炵�Ȃ����낤���ǂ�
���b�c�m�[�g�݂����Ȃ̗~�����Ǝv���l�b�g�u�b�N�����Ă��w��
10���~�O��̌y�ʃm�[�g�g���悤�ɂȂ����瑶�݊��͂���B
AMD�̗����͔������Ȃ̂ł����炵�Ȃ����낤���ǂ�
���ԑ_���͊Ԉ���ĂȂ��헪�����
�n�������ɐ^���ʂ������Ă����傤���Ȃ�
�n�������ɐ^���ʂ������Ă����傤���Ȃ�
�݂���x�����Ȃ�
��ʌ����ɂ����ăV���O���X���b�h���\�Ȃ�K10���x���ŏ\��
�}���`�X���b�h��4�X���b�h�o����Ώ\��
�v��2�`4�X���b�h��CPU���ȉ��Ɉ����A�ǂꂾ���ȓd�͂ŏ����o���邩����
�T�[�o�[�����́A�t�Ƀ}���`�X���b�h���\���ŏd�v
�}���`���\ > �V���O�����\��
�V���O�����\������Ă��A�R�A���������Č����������ق�������
������ʌ�����65W�ȉ��A�T�[�o�[��HPC��130W�ł̍ő�R�A(�X���b�h��)��N���b�N�����ߎ�ɂȂ��
���Ȃ݂ɁA�N���b�N�ƃX���b�h�����ꏏ�Ȃ� K10 > Nehalem�̐��\�ɂȂ�
�}�j�N�[����Xeon 5600�ɏ��ĂȂ��̂̓N���b�N��5�����炢�������邩��ł����āA
�N���b�N�������ɂȂ�Interlagos vs Sandy 8�R�A��Interlagos���D�ʂɗ��Ă�\��������
(6100��5600��5���̐��\���͂Ȃ����N���b�N��5���オ��Ώ��Ă�)
��ʌ����ɂ����ăV���O���X���b�h���\�Ȃ�K10���x���ŏ\��
�}���`�X���b�h��4�X���b�h�o����Ώ\��
�v��2�`4�X���b�h��CPU���ȉ��Ɉ����A�ǂꂾ���ȓd�͂ŏ����o���邩����
�T�[�o�[�����́A�t�Ƀ}���`�X���b�h���\���ŏd�v
�}���`���\ > �V���O�����\��
�V���O�����\������Ă��A�R�A���������Č����������ق�������
������ʌ�����65W�ȉ��A�T�[�o�[��HPC��130W�ł̍ő�R�A(�X���b�h��)��N���b�N�����ߎ�ɂȂ��
���Ȃ݂ɁA�N���b�N�ƃX���b�h�����ꏏ�Ȃ� K10 > Nehalem�̐��\�ɂȂ�
�}�j�N�[����Xeon 5600�ɏ��ĂȂ��̂̓N���b�N��5�����炢�������邩��ł����āA
�N���b�N�������ɂȂ�Interlagos vs Sandy 8�R�A��Interlagos���D�ʂɗ��Ă�\��������
(6100��5600��5���̐��\���͂Ȃ����N���b�N��5���オ��Ώ��Ă�)
Ontario�͌��Ԃ���ˁ[��w
Atom+Ion2��CULV+Ion�Ɠ����̐��\��Atom�ȉ��̉��i�Ŏ����ł��邩��ȁA
�����ʎ���ň�C�Ƀ��C�����
�R�A�T�C�Y��Atom Dual�ȉ��Ȃ̂Œ�R�X�g��Ǖi����Atom�Ɠ����ȏ�
����Nvidia�̌����点��TSMC�̃��C�����w�ǎg���Ȃ��Ȃ�����Ă��Ƃ������c
Atom+Ion2��CULV+Ion�Ɠ����̐��\��Atom�ȉ��̉��i�Ŏ����ł��邩��ȁA
�����ʎ���ň�C�Ƀ��C�����
�R�A�T�C�Y��Atom Dual�ȉ��Ȃ̂Œ�R�X�g��Ǖi����Atom�Ɠ����ȏ�
����Nvidia�̌����点��TSMC�̃��C�����w�ǎg���Ȃ��Ȃ�����Ă��Ƃ������c
Bulldozer���Č��ǂ͌��s��AM3�ɂ͏�炸�ɐV�`�b�v�Z�b�g���o��
AM3r2�Ƃ��ĕʃ\�P�����ɂȂ����Ⴄ�́H
���ꂾ��Intel��AMD���}�U�[�̔��������܂��܂��悾�ȁB
AM3r2�Ƃ��ĕʃ\�P�����ɂȂ����Ⴄ�́H
���ꂾ��Intel��AMD���}�U�[�̔��������܂��܂��悾�ȁB
> ���Ȃ݂ɁA�N���b�N�ƃX���b�h�����ꏏ�Ȃ� K10 > Nehalem�̐��\�ɂȂ�
���̉��d�g�Ȃ�Ƃ����Ă���w
���̉��d�g�Ȃ�Ƃ����Ă���w
�Ƃ��Ƃ�12<16���o����y�h�z��
�N���b�N�ƃX���b�h�����ꏏ�Ƃ��������t��������12�Ƃ�16�͖��W����w
�͂����茾���ăR�A���\��r���ĈӖ�����
�͂����茾���ăR�A���\��r���ĈӖ�����
���X�Ɣ����҂̒m�\�̊W������Ȃ�
��ɒm�\0�ŃC�J�L���y�h�z���C�������߂�
�Ƃ��Ƃ�12<16���o����
��ɒm�\0�ŃC�J�L���y�h�z���C�������߂�
�Ƃ��Ƃ�12<16���o����
846 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 15:14:29 ID:koawV+us
�N���b�N�قړ����A�X���b�h�������ł�K10���ĂĂȂ���
Sun Microsystems
Sun Blade X6275 (Intel Xeon X5570 2.93GHz)
Compiler: Sun Studio 12 Update 1 (internal build 39.0)
SPECintR_rate2006 = 253
SPECint_rate_base2006 = 238
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090414-07079.html
Sun Microsystems
Sun Blade X6440 (AMD Opteron 8389 2.9GHz)
Compiler: PGI Server Complete Version 8.0 x86 Open64 4.2.2 Compiler Suite (from AMD)�@��AMD����
SPECintR_rate2006 = 292
SPECint_rate_base2006 = 226
http://www.spec.org/cpu2006/results/res2009q3/cpu2006-20090914-08593.html
Sun Microsystems
Sun Blade X6275 (Intel Xeon X5570 2.93GHz)
Compiler: Sun Studio 12 Update 1 (internal build 39.0)
SPECintR_rate2006 = 253
SPECint_rate_base2006 = 238
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090414-07079.html
Sun Microsystems
Sun Blade X6440 (AMD Opteron 8389 2.9GHz)
Compiler: PGI Server Complete Version 8.0 x86 Open64 4.2.2 Compiler Suite (from AMD)�@��AMD����
SPECintR_rate2006 = 292
SPECint_rate_base2006 = 226
http://www.spec.org/cpu2006/results/res2009q3/cpu2006-20090914-08593.html
�Ȃ��1.8�{����Ȃ��́H
848 �FSocket774�F2010/07/03(�y) 15:16:48 ID:QVM/wPjm
�V���O�����\���}���`���\�����N���b�N���Ꮯ���ɂȂ���
�䂦��3.4GHz��965BE�ł�2.66GH����750�Ƀ{�������邵��ڂ��Ȃ̂�
����AMD�ɃC���e���Ɠ��N���b�N�œ������\�ɂ��邱�Ƃ͖����ł��s�\�ł��n�C
���N���b�N���R�A�ŏ������邵���Ȃ��낤�������h�c�{�ɛƂ��Đ����Ă�C�����ĂȂ�Ȃ�
�䂦��3.4GHz��965BE�ł�2.66GH����750�Ƀ{�������邵��ڂ��Ȃ̂�
����AMD�ɃC���e���Ɠ��N���b�N�œ������\�ɂ��邱�Ƃ͖����ł��s�\�ł��n�C
���N���b�N���R�A�ŏ������邵���Ȃ��낤�������h�c�{�ɛƂ��Đ����Ă�C�����ĂȂ�Ȃ�
849 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 15:20:11 ID:koawV+us
>>847
���Ȃ݂Ɂu���W���[��������ő�80%�̃X���[�v�b�g����v���Č����Ă��̂�AMD�̎������B
�܂����R���[�X�g�P�[�X�������ȁB
���Ȃ݂Ɂu���W���[��������ő�80%�̃X���[�v�b�g����v���Č����Ă��̂�AMD�̎������B
�܂����R���[�X�g�P�[�X�������ȁB
850 �FSocket774�F2010/07/03(�y) 15:35:11 ID:1ftNxHnN
intel�ƈ����AMD�͏���Ȃ���Ɏ��O�̏��ȉ��̐��\�����łȂ���
�������肷��W�J����������S�z��
�������肷��W�J����������S�z��
>>818
�����Z�p�Ȃ炷���ǂ����ǂ��z�����낤�@�f�e�����Ă邩��ȁ@�P�Q�O�O�O�������̂q�c�ɓ������邵
�����Z�p�Ȃ炷���ǂ����ǂ��z�����낤�@�f�e�����Ă邩��ȁ@�P�Q�O�O�O�������̂q�c�ɓ������邵
sage�����ĂȂ��̂͑啔�����y�̐l�ƌ��Ă����H
Llano �̓���GPU�̐��\�ɋ߂�HD5570/5550�̃Q�[�����\
ttp://www.4gamer.net/games/098/G009886/20100208044/
ttp://www.4gamer.net/games/098/G009886/20100402057/
�ᕉ�אݒ�Ƃ͂���
L4D�A�o�C�I�n�U�[�h5�ACall of Durty�ӂ�͕��ʂɃv���C�ł�������
���Ȃ݂�i5 661�̐��\
ttp://www.anandtech.com/Show/Index/2952?cPage=2&all=False&sort=0&page=2&slug=
�����悻HD5450��1/2�`2/3���x
Sandy��GPU���\��661���炢������サ�Ă�HD5450�ɓ͂����ǂ���������A
�{���ɃQ�[���ړI�Ŕ������l�͑S���Ȃ���
ttp://www.4gamer.net/games/098/G009886/20100208044/
ttp://www.4gamer.net/games/098/G009886/20100402057/
�ᕉ�אݒ�Ƃ͂���
L4D�A�o�C�I�n�U�[�h5�ACall of Durty�ӂ�͕��ʂɃv���C�ł�������
���Ȃ݂�i5 661�̐��\
ttp://www.anandtech.com/Show/Index/2952?cPage=2&all=False&sort=0&page=2&slug=
�����悻HD5450��1/2�`2/3���x
Sandy��GPU���\��661���炢������サ�Ă�HD5450�ɓ͂����ǂ���������A
�{���ɃQ�[���ړI�Ŕ������l�͑S���Ȃ���
854 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 15:41:29 ID:koawV+us
�{����400����480SP���Ƃ����ł���
>>828
�����������W���[�����@������o�J��������ȓd�C��H���������Ȃ�Ė]��łȂ�
�f�[�^�Z���^�[�ł���ǂ�ǂ��R�X�g�ȃG�l�������ɑ�����v�ɃV�t�g���Ă邵
���R�X�g����`�b�v�~������̂̓o�J�������������t�@���ƋɈꕔ�̃}�j�A(�����������t�@���̈ꕔ)����
�����������W���[�����@������o�J��������ȓd�C��H���������Ȃ�Ė]��łȂ�
�f�[�^�Z���^�[�ł���ǂ�ǂ��R�X�g�ȃG�l�������ɑ�����v�ɃV�t�g���Ă邵
���R�X�g����`�b�v�~������̂̓o�J�������������t�@���ƋɈꕔ�̃}�j�A(�����������t�@���̈ꕔ)����
����HotChips���ȁB�Aulldozer�̏��o��̂́B
���N��Magny-Cours�͊�����CPU��MCM�ł��������炩�A���\�ڂ������o���Ă����ǁA
Bulldozer�͐V�A�[�L�e�N�`��������A�ǂꂭ�炢�̏��o���̂��낤���B
���N��Magny-Cours�͊�����CPU��MCM�ł��������炩�A���\�ڂ������o���Ă����ǁA
Bulldozer�͐V�A�[�L�e�N�`��������A�ǂꂭ�炢�̏��o���̂��낤���B
>>846
R_rate2006��20%����
rate_base2006��5%����
5%������462 libquantum�����̍�
462 libquantum���ǂ�ȏ������͒m��A����ȊO�ōl�����K10���D���ƍl���Ă悳��������w
R_rate2006��20%����
rate_base2006��5%����
5%������462 libquantum�����̍�
462 libquantum���ǂ�ȏ������͒m��A����ȊO�ōl�����K10���D���ƍl���Ă悳��������w
858 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 15:51:20 ID:koawV+us
AMD��AVX�Ǝ��g���̃}�j���A������CVT16�̋L�q���폜���ꂽ�̂͋��N��10�����炢������
Intel��CVT16�݊����߁iF16C�j���T�|�[�g���邱�Ƃ�AMD�Ǝd�l���C�荇�킹����
�l���ėǂ��Ǝv�����ǂ���
Intel��CVT16�݊����߁iF16C�j���T�|�[�g���邱�Ƃ�AMD�Ǝd�l���C�荇�킹����
�l���ėǂ��Ǝv�����ǂ���
859 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 15:52:52 ID:koawV+us
860 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 16:12:30 ID:koawV+us
���łɌ�����
����d�͂�K10�@4�R�A��Nehalem 4�R�A�@���������
�듚�̉���ɂ���Llano��32nm SOI+HKMG��45nm��K10�̃R�A������80%���x�܂ł�������d�͗����ĂȂ��炵����
����ŁA�R�A��1.5�{�ɂȂ��Ă�������d�͉������Ă�Nehalem��Westmere
http://www.2cpu.com/contentteller.php?ct=articles&action=pages&page=118,5.html
����d�͂�K10�@4�R�A��Nehalem 4�R�A�@���������
�듚�̉���ɂ���Llano��32nm SOI+HKMG��45nm��K10�̃R�A������80%���x�܂ł�������d�͗����ĂȂ��炵����
����ŁA�R�A��1.5�{�ɂȂ��Ă�������d�͉������Ă�Nehalem��Westmere
http://www.2cpu.com/contentteller.php?ct=articles&action=pages&page=118,5.html
WinPC���������ł́A980�̏���d�͂�1090T���A�C�h����20W������ƁA������40W������ƍ�����
980��HTT-ON�̏ꍇ��
863 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 16:21:40 ID:koawV+us
�܂�����ł�980�̓����_�����O��G���R�̐��\���ǂ��̂ŁA���b�g�p�t�H�[�}���X�ł͗ǂ�
�ł��A45nm��1090T��32nm��980������d�͂��Ⴉ�����̂͂��Ȃ�ӊO������
�ł��A45nm��1090T��32nm��980������d�͂��Ⴉ�����̂͂��Ȃ�ӊO������
865 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 16:33:28 ID:koawV+us
�����̐��\�����{�I�ɈႤ�̂ɔ�ׂĂ��Ȃ��E�E�E
����45nm i7�ł�9xx���̓������̃`���l������QPI�̋@�\��������Ă�8xx�̂ق�������d�͒Ⴂ����
������Thuban��4�R�A�iZosma�j��i5, i7���ʂ̔�r�ł�����Ȃ���
����45nm i7�ł�9xx���̓������̃`���l������QPI�̋@�\��������Ă�8xx�̂ق�������d�͒Ⴂ����
������Thuban��4�R�A�iZosma�j��i5, i7���ʂ̔�r�ł�����Ȃ���
���ƁACore-i�̃R�A���傫���̂���_���Ęb���o�Ă邪�AIntel�Ƃ��Ă͑�^�R�A�������ł���
���鐫�\���o���ꍇ�A��^�Œ�N���b�N�̃R�A�͏��^�ō��N���b�N�̃R�A�̏���d��1�敪�����Ⴍ�ς�
��^�R�A�����邾���̔\�͂�����Intel�ɂƂ��Ă͑�^��N���b�N�ō��t�����l�̏��i���œK����
���鐫�\���o���ꍇ�A��^�Œ�N���b�N�̃R�A�͏��^�ō��N���b�N�̃R�A�̏���d��1�敪�����Ⴍ�ς�
��^�R�A�����邾���̔\�͂�����Intel�ɂƂ��Ă͑�^��N���b�N�ō��t�����l�̏��i���œK����
�ł����āA�N���b�N������������TB�łǂ���ƈ����グ�Ă��Ηǂ�
Sandy��������������������
Sandy��������������������
�܂�AMD������헪����Ȃ�
������
X5670 (15���A2.93GHz�A6C/12T) vs Op4186 (4.5���A2.9GHz�A6C)*2�ɂȂ���
15�� 1���A5�� 2�Ƃ̏����ɂȂ�
�\�P�b�g�������킹��Ȃ�
L5640 (9���A2.26GHz�A12T) vs op 6176(14���A2.3GHz�A12C)�ɂȂ��
�E12�X���b�h���m�̔�r
L5640
http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100315-09793.html
SPECintR_rate2006 = 281
SPECint_rate_base2006 = 261
6176
http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100315-10002.html
SPECintR_rate2006 = 398
SPECint_rate_base2006 = 309
����H�N���b�N���킹����2�`3�����x Opteron�̕���������
�X���b�h�ƃN���b�N���킹����K10 > Nehalem�͊m�肵���ƌ��Ă�����w
X5670 (15���A2.93GHz�A6C/12T) vs Op4186 (4.5���A2.9GHz�A6C)*2�ɂȂ���
15�� 1���A5�� 2�Ƃ̏����ɂȂ�
�\�P�b�g�������킹��Ȃ�
L5640 (9���A2.26GHz�A12T) vs op 6176(14���A2.3GHz�A12C)�ɂȂ��
�E12�X���b�h���m�̔�r
L5640
http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100315-09793.html
SPECintR_rate2006 = 281
SPECint_rate_base2006 = 261
6176
http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100315-10002.html
SPECintR_rate2006 = 398
SPECint_rate_base2006 = 309
����H�N���b�N���킹����2�`3�����x Opteron�̕���������
�X���b�h�ƃN���b�N���킹����K10 > Nehalem�͊m�肵���ƌ��Ă�����w
�܂��ǂ݂̂��卷�ȂǕt�����B�s���ƌ����R�\�����[�V�����o���Ă�����́B
Intel���s���Ȏ��ɂ�Intel�͔��M�����邵�AAMD���s���Ȏ��ɂ̓_���s���O����B
Intel���s���Ȏ��ɂ�Intel�͔��M�����邵�AAMD���s���Ȏ��ɂ̓_���s���O����B
���X�����؈�ࣂ������̎��ザ��Ȃ�
�f�[�^�Z���^�[�ł���ȃG�l��R�X�g�u��
���܂ł���Ƃ����卂�R�X�g���������肪�������Ĕ������ザ��Ȃ�
intel���K��bulldozer�헪�^�����Ă���@�@����͍�����
�������\���s�[�N���\�ɂ������͔̂n���ȑf�l����
intel���K��bulldozer�헪�^�����Ă���@
�f�[�^�Z���^�[�ł���ȃG�l��R�X�g�u��
���܂ł���Ƃ����卂�R�X�g���������肪�������Ĕ������ザ��Ȃ�
intel���K��bulldozer�헪�^�����Ă���@�@����͍�����
�������\���s�[�N���\�ɂ������͔̂n���ȑf�l����
intel���K��bulldozer�헪�^�����Ă���@
872 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 16:50:24 ID:koawV+us
L5640��TDP60W
����ς�n������
����ς�n������
873 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 16:55:27 ID:koawV+us
�d�͌����ň������K10
>>804
AMD��Bulldozer���u2�R�A��1���W���[���v�ƌĂ�ł��邪�A
����͂ǂ��l���Ă��u�}�[�P�e�B���O�I�ȈӖ��v�ł����Ȃ��B
���ʂɍl������u1���W���[��=1�R�A�v����B�A���B
AMD��Bulldozer���u2�R�A��1���W���[���v�ƌĂ�ł��邪�A
����͂ǂ��l���Ă��u�}�[�P�e�B���O�I�ȈӖ��v�ł����Ȃ��B
���ʂɍl������u1���W���[��=1�R�A�v����B�A���B
875 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 17:01:06 ID:koawV+us
AMD��Magny Cours��Westmere�����d�͌����L���Ƃ��ӂ����Ă����Ǒ�O�ҕ]�����Ƃ����Ȃ�
SPECpower_ssj2008
PowerEdge R710 (Intel Xeon X5670, 2.93 GHz) �E�E�E�E�@2,963
http://www.spec.org/power_ssj2008/results/res2010q2/power_ssj2008-20100504-00259.html
PowerEdge R815 (AMD Opteron 6174, 2.20 GHz)�@�E�E�E�@2,357
http://www.spec.org/power_ssj2008/results/res2010q2/power_ssj2008-20100615-00269.html
SPECpower_ssj2008
PowerEdge R710 (Intel Xeon X5670, 2.93 GHz) �E�E�E�E�@2,963
http://www.spec.org/power_ssj2008/results/res2010q2/power_ssj2008-20100504-00259.html
PowerEdge R815 (AMD Opteron 6174, 2.20 GHz)�@�E�E�E�@2,357
http://www.spec.org/power_ssj2008/results/res2010q2/power_ssj2008-20100615-00269.html
�����X�����؈�ࣂ������̎��ザ��Ȃ�
�V���O���X���b�h���\�����ɂ���̂͂�����
CPU�����̕���IPC1.5�Ȓ���ALU�i�X�P�W���[���j��3��4�����₷�͔̂n��
��ɏo����K7�͂Ƃ�����
���������
���f�����ł͂Ȃ��P�ɒ��荇���ĺ�ۏo����Intel�͂�͂肢���ʂ�̔n��
�Ƃ�������
�܂����̑�ǂ�ł�Ԃ���Bull��1�R�A��ALU4�ς�ł�����ǂ����悤��
�V���O���X���b�h���\�����ɂ���̂͂�����
CPU�����̕���IPC1.5�Ȓ���ALU�i�X�P�W���[���j��3��4�����₷�͔̂n��
��ɏo����K7�͂Ƃ�����
���������
���f�����ł͂Ȃ��P�ɒ��荇���ĺ�ۏo����Intel�͂�͂肢���ʂ�̔n��
�Ƃ�������
�܂����̑�ǂ�ł�Ԃ���Bull��1�R�A��ALU4�ς�ł�����ǂ����悤��
�����R�A�����{��2�C3���������ĂĂȂ��̂ɁAK10��Nehalem���č���ł���̂́A
ID:klabAOD7���炢���낤�ȁB
AMD�̒��̐l����`�̂��߂Ƃ͂����A�������ɂ���Ȓp�������������͂ł��Ȃ����낤�B
ID:klabAOD7���炢���낤�ȁB
AMD�̒��̐l����`�̂��߂Ƃ͂����A�������ɂ���Ȓp�������������͂ł��Ȃ����낤�B
878 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 17:05:51 ID:koawV+us
AMD�̃o�C�g�Ȃ�Ȃ���
������Ƃ������{�ꂪ�s���R�ȗ��w�����Ȃ�
������Ƃ������{�ꂪ�s���R�ȗ��w�����Ȃ�
���X���b�h����������2�C3���������ĂĂȂ��̂ɁAK10��Nehalem���č���ł���̂́A
��ID:klabAOD7���炢���낤�ȁB
������x�m�\����z�͊F�����v������
��ID:klabAOD7���炢���낤�ȁB
������x�m�\����z�͊F�����v������
>>873
bulldozer�ɋ��ꂨ�̂̂��@�����Ă��̉��i�ɂ�
bulldozer�ɋ��ꂨ�̂̂��@�����Ă��̉��i�ɂ�
>>879
�����Ă�{�l�ȊO�ƌ������Ă��ǂ����Ƃ�
�����Ă�{�l�ȊO�ƌ������Ă��ǂ����Ƃ�
>>877
��ƂɂƂ��Ă͉��i�ƃp�t�H�[�}���X���S�ā@�R�A�̐��Ȃ�Ăǂ��ł�����
�����ăp�t�H�[�}���X�Ⴂ���̂����܂ł�����Ȃ���
��ƂɂƂ��Ă͉��i�ƃp�t�H�[�}���X���S�ā@�R�A�̐��Ȃ�Ăǂ��ł�����
�����ăp�t�H�[�}���X�Ⴂ���̂����܂ł�����Ȃ���
885 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 17:11:28 ID:koawV+us
> �����ăp�t�H�[�}���X�Ⴂ���̂����܂ł�����Ȃ���
Opteron 8xxx�V���[�Y��n���ɂ���ȁI�n���ɂ���ȁI
Opteron 8xxx�V���[�Y��n���ɂ���ȁI�n���ɂ���ȁI
>>839���N���b�N�ƃX���b�h�����ꏏ�Ȃ� K10 > Nehalem�̐��\
��
>877�������R�A�����{��2�C3���������ĂĂȂ�
�v�Z���o���Ȃ��C�J�L�������̃z����
����Ƃ����b�Œs���o���邢���̃z�������ĂƂ�����
��
>877�������R�A�����{��2�C3���������ĂĂȂ�
�v�Z���o���Ȃ��C�J�L�������̃z����
����Ƃ����b�Œs���o���邢���̃z�������ĂƂ�����
>>882
bulldozer�̓��b�`�ȃR�A�ł͂Ȃ�
������R�X�g�Ő��Y�ł���@�����_���Đv���Ă���
���݂����ȃ��b�`�R�A�����܂ł������c���Ƃ͎v��Ȃ�
�h���������͊�ƋK�͂������݂����ɕ��ł��������Ƀ��b�`�ō����i�̃v���Z�b�T�[�𐔑�������Ȃ��Ƒ����ł��Ȃ��h��
��R�X�g�����������s�������ΐ▽����
bulldozer�̓��b�`�ȃR�A�ł͂Ȃ�
������R�X�g�Ő��Y�ł���@�����_���Đv���Ă���
���݂����ȃ��b�`�R�A�����܂ł������c���Ƃ͎v��Ȃ�
�h���������͊�ƋK�͂������݂����ɕ��ł��������Ƀ��b�`�ō����i�̃v���Z�b�T�[�𐔑�������Ȃ��Ƒ����ł��Ȃ��h��
��R�X�g�����������s�������ΐ▽����
�X���b�h���������Łc�悵Xeon��HTT���I�t�ɂ��悤��
>>886
�X���b�h���ō��킹�āAK10�������Č����Ă��������ǁA
>>869�������ŏ����Ă邯�ǁA�����i�тȂ̂�Opteron 6176����Xeon X5670�B
>>883�������Ă�Ƃ���A�����\�Ȃ͓̂����i�тɂȂ��Ă���B
�Ƃ������A�������Ȃ���2P�s�����������AG34�Ƀv���~�A�������Ȃ��Ȃ����̂ɁB
�X���b�h���ō��킹�āAK10�������Č����Ă��������ǁA
>>869�������ŏ����Ă邯�ǁA�����i�тȂ̂�Opteron 6176����Xeon X5670�B
>>883�������Ă�Ƃ���A�����\�Ȃ͓̂����i�тɂȂ��Ă���B
�Ƃ������A�������Ȃ���2P�s�����������AG34�Ƀv���~�A�������Ȃ��Ȃ����̂ɁB
>>875
�����������ʂ������w
PowerEdge R815 (AMD Opteron 6174, 2.20 GHz)�@�E�E�E�@2,696
ttp://www.spec.org/power_ssj2008/results/res2010q2/power_ssj2008-20100615-00270.html
�܂��A�v���Z�X���Ⴄ���畉����͎̂d���Ȃ����A��3000��2700�Ȃ炻���܂Ŕߊς���قǍ�������Ƃ����킯����Ȃ���
���Ȃ݂�4�R�A��5500�V���[�Y��2000�O�ゾ����
�����������ʂ������w
PowerEdge R815 (AMD Opteron 6174, 2.20 GHz)�@�E�E�E�@2,696
ttp://www.spec.org/power_ssj2008/results/res2010q2/power_ssj2008-20100615-00270.html
�܂��A�v���Z�X���Ⴄ���畉����͎̂d���Ȃ����A��3000��2700�Ȃ炻���܂Ŕߊς���قǍ�������Ƃ����킯����Ȃ���
���Ȃ݂�4�R�A��5500�V���[�Y��2000�O�ゾ����
891 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 17:29:54 ID:koawV+us
>>875�̔�r��BTO�Ō��ς����Ă݂�����
http://configure.apj.dell.com/dellstore/config.aspx?c=jp&l=ja&s=pad&cs=jppad1&oc=6382SStandard
http://configure.apj.dell.com/dellstore/config.aspx?c=jp&l=ja&s=pad&cs=jppad1&oc=6327SStandard
�ǂ�����1���b�N100�����傢����
�g�[�^�����i�ɑ卷�Ȃ��A�d�͌����ɍ�����
http://configure.apj.dell.com/dellstore/config.aspx?c=jp&l=ja&s=pad&cs=jppad1&oc=6382SStandard
http://configure.apj.dell.com/dellstore/config.aspx?c=jp&l=ja&s=pad&cs=jppad1&oc=6327SStandard
�ǂ�����1���b�N100�����傢����
�g�[�^�����i�ɑ卷�Ȃ��A�d�͌����ɍ�����
892 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 17:31:17 ID:koawV+us
�ʂ�Intel��PC�pCPU�݂̂����Ȃ��Ⴂ���Ȃ��ƌ����@�͖���
SSD�Ƃ��ł�Intel�̔\�͂��������镪��͑�����
PC�̏o�א����̂͑����Ă����AIntel���炵�Ă݂��PC�s��̒��ł��@������̂悤�ȕ���͎̂ĂĂ�OK��
�V�F�A�͎����Ă��A�o�א��x�[�X�ł͗����Ȃ����낤
�ނ��동�X�ɍ��t�����l���i�Ɏ�����U���������ׂ��邾�낤
SSD�Ƃ��ł�Intel�̔\�͂��������镪��͑�����
PC�̏o�א����̂͑����Ă����AIntel���炵�Ă݂��PC�s��̒��ł��@������̂悤�ȕ���͎̂ĂĂ�OK��
�V�F�A�͎����Ă��A�o�א��x�[�X�ł͗����Ȃ����낤
�ނ��동�X�ɍ��t�����l���i�Ɏ�����U���������ׂ��邾�낤
>>893
�ŁH�@���ɂ���̉�����AMD������CPU�X���Ɨ��߂�́H
�ŁH�@���ɂ���̉�����AMD������CPU�X���Ɨ��߂�́H
895 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 17:41:25 ID:koawV+us
������BTO�ŗV��łċC�Â������ǁAOpteron�T�[�o�ɂ�Intel��NIC�h���邺������
������Intel��RISC�v���Z�b�T�𗘕������ď�����������Ȃ��G���v���s��ɉ�������āA
�����J���R�X�g�S�ł��Ȃ��Ȃ�܂Ŏ��v�����Ēׂ��Ă������j������킯�ŁA
�G���v���݂̂Ŗׂ��悤�Ƃ����̂����E�ɑ��Ȃ�Ȃ������炢�킩���Ă邾�낤�B
�����J���R�X�g�S�ł��Ȃ��Ȃ�܂Ŏ��v�����Ēׂ��Ă������j������킯�ŁA
�G���v���݂̂Ŗׂ��悤�Ƃ����̂����E�ɑ��Ȃ�Ȃ������炢�킩���Ă邾�낤�B
897 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 17:45:31 ID:koawV+us
Intel��Atom�Ƃ������ɂ̔��������v���Z�b�T�������Ă���ł�
>>894
Intel�ɂƂ��Ă͗��v�ł͂Ȃ����v�����������Ȃ�
������A���ʂɍl����ΑS�J�e�S����AMD�ƈ����荇���������͂��Ȃ�
��ʂ�葹�Q�̂ق����y���ɂł��������
������AAMD�ɂƂ��Ă͉��i�����ɂ���ď��@���o�Ă�����Ęb
Intel�ɂƂ��Ă͗��v�ł͂Ȃ����v�����������Ȃ�
������A���ʂɍl����ΑS�J�e�S����AMD�ƈ����荇���������͂��Ȃ�
��ʂ�葹�Q�̂ق����y���ɂł��������
������AAMD�ɂƂ��Ă͉��i�����ɂ���ď��@���o�Ă�����Ęb
�c�q�ƎG���Ƃ��ƂƎ��Ȃˁ[����
900 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 17:52:18 ID:koawV+us
�����N���E�h�i�j�����i�ނȂ炻��͂���Ńn�C�G���h�T�[�o�s��̓j�b�`�s��ł͂Ȃ��Ȃ�
RISC�̓N���b�N�����̒��ŃI�y���[�V�������x�̒Ⴓ�̂����Ő��\���o�����Ɏ��ł���
1���߂�����̃I�y���[�V�������x���Ⴂ���N���b�N�Ő��\���҂������Ȃ����A�N���b�N�̌��E����������
��������ł��Ȃ��Ȃ邗
POWER��ARM����r�ICISC���i�I�y���[�V�������x�������j��RISC��
RISC�̓N���b�N�����̒��ŃI�y���[�V�������x�̒Ⴓ�̂����Ő��\���o�����Ɏ��ł���
1���߂�����̃I�y���[�V�������x���Ⴂ���N���b�N�Ő��\���҂������Ȃ����A�N���b�N�̌��E����������
��������ł��Ȃ��Ȃ邗
POWER��ARM����r�ICISC���i�I�y���[�V�������x�������j��RISC��
�������͌�����@�@��8�o����������f���A���z�肵�Ă���
������7�N���炢�O���烂�W���[�����������Ă���
K10����8�̊�{�v�ς�炸�����ǂ̐ςݏd�˂ł����܂ŗ���
�u���ł͍X�ɖ��ʍ팸�ō����������Ė{�i���W���[���v
���������啝�A�b�v�ƃ����j���O�R�X�g�啝�팸��_���Ă�
��Ƃ��炷��ƂP�j�ł��R�X�g���팸���������낤���烊�b�`�ȃR�A�͊肢����
intel�͒�R�X�gcpu�̗��s�͔����������낤���ǎ���̔g�ɂ͏��ĂȂ����낤�ˁ@�_�E�������葱���Ă�����E�o�ς͊�@�I������
������7�N���炢�O���烂�W���[�����������Ă���
K10����8�̊�{�v�ς�炸�����ǂ̐ςݏd�˂ł����܂ŗ���
�u���ł͍X�ɖ��ʍ팸�ō����������Ė{�i���W���[���v
���������啝�A�b�v�ƃ����j���O�R�X�g�啝�팸��_���Ă�
��Ƃ��炷��ƂP�j�ł��R�X�g���팸���������낤���烊�b�`�ȃR�A�͊肢����
intel�͒�R�X�gcpu�̗��s�͔����������낤���ǎ���̔g�ɂ͏��ĂȂ����낤�ˁ@�_�E�������葱���Ă�����E�o�ς͊�@�I������
���ہA����1�N�]���AMD�̊����̏㏸�i5�{�z���j�́A�s�ꂩ�獡�̘H���Ƀ_���o���͏o�ĂȂ����Ă��Ƃ��낤
�܂��A�����グ�̍ő�̗v����GPU�̔���グ����GF�̖\���̂��������낤���ǂ�
�܂��A�����グ�̍ő�̗v����GPU�̔���グ����GF�̖\���̂��������낤���ǂ�
INTEL��NIC�͔F�߂邪�A�ł�CPU�ƃ`�b�v�Z�b�g(MB)�͂���ς荂���Ǝv���B
�\�P�b�g�Ɍ݊��������ނ��A�n�R�l�ɂ͐h���B
���ꂩ��s�[�N���\�������Ă���������������ƒx���Ȃ�ɂ������Ă���B
�\�P�b�g�Ɍ݊��������ނ��A�n�R�l�ɂ͐h���B
���ꂩ��s�[�N���\�������Ă���������������ƒx���Ȃ�ɂ������Ă���B
���������A��Ɠ������T�[�o�[�s��͏k���ɓ]������
�N���E�h�ւ̈ڍs���n�܂����̂ł��̎s��͉��錩���݂͖����Ƃ̂���
�N���E�h�ւ̈ڍs���n�܂����̂ł��̎s��͉��錩���݂͖����Ƃ̂���
���܂ł̂܂Ƃ�
�X���b�h�A�N���b�N�ꏏ�Ȃ� K10 = Nehalem*1.2�ȏ� (>>866�Q��)
�E���āA�{��ɂł��ڂ邩��
Bull 1���W���[��(2T)��K10�@1�R�A��1.8�{�̐��\
�V�������N�ɂ��80%�֏���d�͒ቺ��20%�̃N���b�N���オ�o����
�܂�AK10�ɑ��N���b�N������80%�̐��\�ŁA20%���N���b�N�����猋��96%�̐��\�ɂȂ�A
�قړ����̃s�[�N���\�ɂȂ�
Sandy��Nehalem��1.1�{���x�ȋC������
�E�������16�X���b�h�Ό���K10�̃}���`�X���b�h���\�����ɍl�@
K10=Bull�Ɠ�������%��(*1.04)
K10=Nehalem*1.2��Sandy=Nehalem*1.1�ŁAK10=Sandy*1.09
Bull*1.04=Sandy*1.09��Bull=Sandy*1.05��Bull�̕����������\��
�X���b�h�A�N���b�N�ꏏ�Ȃ� K10 = Nehalem*1.2�ȏ� (>>866�Q��)
�E���āA�{��ɂł��ڂ邩��
Bull 1���W���[��(2T)��K10�@1�R�A��1.8�{�̐��\
�V�������N�ɂ��80%�֏���d�͒ቺ��20%�̃N���b�N���オ�o����
�܂�AK10�ɑ��N���b�N������80%�̐��\�ŁA20%���N���b�N�����猋��96%�̐��\�ɂȂ�A
�قړ����̃s�[�N���\�ɂȂ�
Sandy��Nehalem��1.1�{���x�ȋC������
�E�������16�X���b�h�Ό���K10�̃}���`�X���b�h���\�����ɍl�@
K10=Bull�Ɠ�������%��(*1.04)
K10=Nehalem*1.2��Sandy=Nehalem*1.1�ŁAK10=Sandy*1.09
Bull*1.04=Sandy*1.09��Bull=Sandy*1.05��Bull�̕����������\��
908 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 17:59:31 ID:koawV+us
�n����
Atom�̑_���s���PC�ł͂Ȃ��X�}�[�g�t�H����^�u���b�g��
Ontario�̉��z�G��CULV����B
Atom�͏���d�͂𗎂Ƃ��C�͂����Ă����{���琫�\���グ��C�ȂǂȂ��B
Atom�̑_���s���PC�ł͂Ȃ��X�}�[�g�t�H����^�u���b�g��
Ontario�̉��z�G��CULV����B
Atom�͏���d�͂𗎂Ƃ��C�͂����Ă����{���琫�\���グ��C�ȂǂȂ��B
909 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 18:00:54 ID:koawV+us
> �X���b�h�A�N���b�N�ꏏ�Ȃ� K10 = Nehalem*1.2�ȏ�
����d�͔͂{�����ǂ�
����d�͔͂{�����ǂ�
910 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 18:02:26 ID:koawV+us
Bulldozer��50%�̃g�����W�X�^������80�p�[�Z���g�̃X���[�v�b�g����A�炵���̂�
�d�͌��������������ǂ��Ȃ�Ȃ���
�d�͌��������������ǂ��Ȃ�Ȃ���
�⑫���Ă������A�I�Ƃ�CPU�Ƃ��V�X�e���̒u���ꏊ���ڂ���Ă����̘b������
CPU�Ȃ̔���グ��������Ęb�ł͖���
�����Ȃ݂�PC�̃��������ڗʂ̕��ϒl�͏k�����o����
CPU�Ȃ̔���グ��������Ęb�ł͖���
�����Ȃ݂�PC�̃��������ڗʂ̕��ϒl�͏k�����o����
>>892
�X���b�h���W�ˁ[��o�Jw
12�X���b�h2927
24�X���b�h3038
48�X���b�h3008
5670 12/24/48�X���b�h�Ō덷���x�̍������ˁ[
�X���b�h���W�ˁ[��o�Jw
12�X���b�h2927
24�X���b�h3038
48�X���b�h3008
5670 12/24/48�X���b�h�Ō덷���x�̍������ˁ[
913 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 18:06:40 ID:koawV+us
�悭�킩���Ă邶��Ȃ����B
�܂�A������R�A�����₵�Ă��d�͌����̍��͏k�܂Ȃ��悗
�܂�A������R�A�����₵�Ă��d�͌����̍��͏k�܂Ȃ��悗
�n��(�c�q)�̑��肷��Ȃ�
�L�`�K�C�ʼn��Ɋ����ē�����̂��I�`�Ȃ���
�G���̃L�`�K�C�x��10�{�ʂɑ��₵���̂��c�q
�L�`�K�C�ʼn��Ɋ����ē�����̂��I�`�Ȃ���
�G���̃L�`�K�C�x��10�{�ʂɑ��₵���̂��c�q
��������Tegra��Atom�ȃX�}�[�g�t�H�����Đi��ł�́H
>>907
�Ȃ�ւ��A�킩��₷��THX
���āA���ۂǂ̒��x������̂��B�R�ꂪ�C�ɂ��Ă�̂�HTLink�ƃ����R�����ǂ��Ȃ邩���ĂƂ����ȁB
����������HT3.1�ɂ����Ăق����Ƃ���B
�Ȃ�ւ��A�킩��₷��THX
���āA���ۂǂ̒��x������̂��B�R�ꂪ�C�ɂ��Ă�̂�HTLink�ƃ����R�����ǂ��Ȃ邩���ĂƂ����ȁB
����������HT3.1�ɂ����Ăق����Ƃ���B
917 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 18:09:45 ID:koawV+us
�܂�Atom�x�[�X��STB�Ȃ̗̍p�͕��ʂɐi��ł邵�i�r�Ȃ����Ԃ̖�肩����
���ʐ��Y�E�Z���J���Ȃ�Atom���L���B
���ʐ��Y�E�Z���J���Ȃ�Atom���L���B
918 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 18:14:41 ID:koawV+us
>>916
������������d�͂̊T�O�������ł�ާ��̌������Ƃ��܂ɂ������
������������d�͂̊T�O�������ł�ާ��̌������Ƃ��܂ɂ������
���������[�̂��������ǁA
�c�q�I�ɂ́A�����PC(CPU)�̃g�����h�͂ǂ��Ȃ�Ǝv���Ă�̂�?
�c�q�I�ɂ́A�����PC(CPU)�̃g�����h�͂ǂ��Ȃ�Ǝv���Ă�̂�?
��Ȕ��R�Ƃ���������������c�q�����邾�낤�B
��̓�N������HT�̐V�K�i�����肳��邩��3.2��4.0���������ȋC������
>>887
> bulldozer�̓��b�`�ȃR�A�ł͂Ȃ�
���̂Ƃ���
> ������R�X�g�Ő��Y�ł���@�����_���Đv���Ă���
����͌㓡���ȊO�N���M���Ă��Ȃ��A�\�����e���������_�C�T�C�Y�͂�����������Ȃ�Ȃ��Ɨ\�z���Ă���B
> bulldozer�̓��b�`�ȃR�A�ł͂Ȃ�
���̂Ƃ���
> ������R�X�g�Ő��Y�ł���@�����_���Đv���Ă���
����͌㓡���ȊO�N���M���Ă��Ȃ��A�\�����e���������_�C�T�C�Y�͂�����������Ȃ�Ȃ��Ɨ\�z���Ă���B
>>907
Bull���W���[���^�͎��s�p�C�v1�Z�b�g���̍\����
����Ɏ��s�p�C�v����1�Z�b�g�t�����80%���\�������Ă��Ƃ���������
Bull���W���[���^�͎��s�p�C�v1�Z�b�g���̍\����
����Ɏ��s�p�C�v����1�Z�b�g�t�����80%���\�������Ă��Ƃ���������
>>918
����A���͏���d�͂Ȃ�ĕ���u�߂Ȃ����x�Ȃ�ǂ��ł����Ă��ǂ�����B
�����Ă��̌��M��ȊO�͕n�R�Ȃ��Ɂ[�����INTEL����͐h����ł��AMB��CPU���ゲ�ƌ��݂Ɍ����ł��Ȃ�����B
����A���͏���d�͂Ȃ�ĕ���u�߂Ȃ����x�Ȃ�ǂ��ł����Ă��ǂ�����B
�����Ă��̌��M��ȊO�͕n�R�Ȃ��Ɂ[�����INTEL����͐h����ł��AMB��CPU���ゲ�ƌ��݂Ɍ����ł��Ȃ�����B
�X�}�[�g�t�H���͖������悗
>>907�̉��肪������������A4�R�A8�X���b�h��Sandy�̍ŏ�ʂ̃N���b�N����ł́A
Bulldozer8�R�A����ԓ��ӂ̃}���`�X���b�h���\�ł�������\�����o�Ă������Ȃ��ǁc�B
Bulldozer8�R�A����ԓ��ӂ̃}���`�X���b�h���\�ł�������\�����o�Ă������Ȃ��ǁc�B
��芸�����ABull 8M/16T��Sandy 8C/16T�ƌ݊p�ȏ�ɂȂ肻������
�����\���K�v�Ƃ����s��
�E��ʂ̓Q�[����Llano���
�E�����
�n�C�G���h�Q�[����GPU�͂ǂ���HD5800��6800
�G���R��8�R�A��Intel�̓Ƃ菟�����ۂ����ǁA5���ȉ��Ȃ�݊p
�����\����Ȃ��Ă������Ȃ�
Atom vs Ontario
�����ɂȂ�Ȃ��ق�Ontario�̈���
�����������ʕs����Atom�̃V�F�A���������ĂƂ���
�����\���K�v�Ƃ����s��
�E��ʂ̓Q�[����Llano���
�E�����
�n�C�G���h�Q�[����GPU�͂ǂ���HD5800��6800
�G���R��8�R�A��Intel�̓Ƃ菟�����ۂ����ǁA5���ȉ��Ȃ�݊p
�����\����Ȃ��Ă������Ȃ�
Atom vs Ontario
�����ɂȂ�Ȃ��ق�Ontario�̈���
�����������ʕs����Atom�̃V�F�A���������ĂƂ���
>>926
1���W���[����1�R�A���Z�ŏ����錾�����
�K�L����Ȃ�����>>907�݂����Ȏ����������Ă鏊�͕����Ă��
�����ƌ��ݓI�Șb����Ⴂ���̂�
1���W���[����1�R�A���Z�ŏ����錾�����
�K�L����Ȃ�����>>907�݂����Ȏ����������Ă鏊�͕����Ă��
�����ƌ��ݓI�Șb����Ⴂ���̂�
�����W���[���P�ʂ�Intel�Ɛ키�̂�AMD�̐헪���Ǝv���Ă����B
931 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 18:28:27 ID:koawV+us
���W�b�N�̃g�����W�X�^1.5�{�Ȃ�A45nm�ł�K10 1�R�A��32nm Bulldozer��1���W���[�����r����
�R�A�T�C�Y�͋͂��ɏk���A�N���b�N���������d�͂͂���Ƃ������Ƃ��낶��Ȃ��́B
�܂�Interagos 16�R�A�ł�2.5GHz���x���ւ̎R����
�R�A�T�C�Y�͋͂��ɏk���A�N���b�N���������d�͂͂���Ƃ������Ƃ��낶��Ȃ��́B
�܂�Interagos 16�R�A�ł�2.5GHz���x���ւ̎R����
>>926
�\�����x�̍�������A�D���ȕ�����������
���Ȃ݂�Bull�Ȃ�Bios����Ŋ����̃}�U�[�ɏ�邩�瓊���z��CPU�̐����~����
(���� 8�R�A�ł� 2�`5���~���x���낤)
Sandy 4�R�A�����������悤�Ȓl�i�����ǃ}�U�[���w������K�v������
���łɃS�~�݂�����GPU���t���Ă��邯�lj䖝���Ă�
�\�����x�̍�������A�D���ȕ�����������
���Ȃ݂�Bull�Ȃ�Bios����Ŋ����̃}�U�[�ɏ�邩�瓊���z��CPU�̐����~����
(���� 8�R�A�ł� 2�`5���~���x���낤)
Sandy 4�R�A�����������悤�Ȓl�i�����ǃ}�U�[���w������K�v������
���łɃS�~�݂�����GPU���t���Ă��邯�lj䖝���Ă�
>>931
Sandy��8�R�A��2.8GHz���x�����炢���������Ǝv����
Sandy��8�R�A��2.8GHz���x�����炢���������Ǝv����
935 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 18:34:55 ID:koawV+us
K10�Ɣ�ׂăg�����W�X�^�����萫�\���㗦��1.2�{���x����AMD���g�����_�o���Ă邾��
�n����
�n����
K10 �� Bull�́A�V�������N�AHK/MG�A�p���[�Q�[�e�B���O�A�R�A�k���ł��Ȃ�d�͌������オ�肻���Ŋy���݂�
West��Sandy�̓R�A�̏����ǂ�������x�Ŋ��҂͂ł��Ȃ�
K10����啝�Ƀ��b�g�p�t�H�[�}���X�������Bull
West����w�Ǖς��Ȃ�Sandy
���b�g�p�t�H�[�}���X�I�ɂ͂�����������������
West��Sandy�̓R�A�̏����ǂ�������x�Ŋ��҂͂ł��Ȃ�
K10����啝�Ƀ��b�g�p�t�H�[�}���X�������Bull
West����w�Ǖς��Ȃ�Sandy
���b�g�p�t�H�[�}���X�I�ɂ͂�����������������
937 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 18:45:03 ID:koawV+us
>>934
45nm��Nehalem-EX��8�R�A�ł���2.66GHz�o�Ă��������
�܂�65nm��Core 2 Quad��95W�g��2.66GHz�A�X��45nm��3GHz�B�����Ă邱�ƍl�����
����TDP�g���Ȃ�3GHz�͌ł��
45nm��Nehalem-EX��8�R�A�ł���2.66GHz�o�Ă��������
�܂�65nm��Core 2 Quad��95W�g��2.66GHz�A�X��45nm��3GHz�B�����Ă邱�ƍl�����
����TDP�g���Ȃ�3GHz�͌ł��
938 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 18:46:40 ID:koawV+us
> ���b�g�p�t�H�[�}���X�I�ɂ͂�����������������
100�������ėǂ��������Ă�Intel��22nm�����Ŕ��N�V���ł����ǂ˂�����
100�������ėǂ��������Ă�Intel��22nm�����Ŕ��N�V���ł����ǂ˂�����
�Ƃ肠�����m�\0�̃C�J�L���ċC���������V���^�z���͂��̕ӂɎ̂Ă�
Bull��80%�����1���W��1�R�A����2�R�A�����ׂ�����
Bull��80%�����1���W��1�R�A����2�R�A�����ׂ�����
AMD�����Ԃ�ڎw���Ă��邱��
Nehalem (�P�R�A)
�V���O���F********************
___�}���`�F******
Bulldozer (1���W���[��)
�V���O���F****************
___�}���`�F************
Nehalem (�P�R�A)
�V���O���F********************
___�}���`�F******
Bulldozer (1���W���[��)
�V���O���F****************
___�}���`�F************
941 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 18:57:08 ID:koawV+us
>>940
�X���[�v�b�g�R���s���[�e�B���O�p��x86�R�A�Ȃ炻�ꂱ��Intel�̂ق�����s���Ă邪�H
���͂ȃR�A2�`4�R�A�{�X���[���R�A���\�Ƃ����I������������H
�X���[�v�b�g�R���s���[�e�B���O�p��x86�R�A�Ȃ炻�ꂱ��Intel�̂ق�����s���Ă邪�H
���͂ȃR�A2�`4�R�A�{�X���[���R�A���\�Ƃ����I������������H
�܂��c�q�͋x�݂Ȃ̂Ɉ������t���ăX���Ⴂ�̌����点����
����������a�@�ɍs���ė��Ȃ�
����������a�@�ɍs���ė��Ȃ�
45nm����32nm�ւ̏k�ڗ���32nm��Westmere 6C(240mm2)��45nm��Bloomfield(262mm2)�Ōv�Z����ƥ��
240��(262�~1.5)=61%�ƂȂ�B
Phenom�U X6�̃_�C�T�C�Y��346mm2�ł��邩�炱���Bulldozer�ɒu��������ƥ��
346�~1.5�~0.61=316mm2�Ɨ\�z�����BBulldozer(6���W���[��,12�R�A)
������Bulldozer(6���W���[��,12�R�A)�̐��\��Phenom�U X6��1.8�{�ƌ����Ă���B
���݂�Phenom�U X6�̐��\��Bloomfield 4�R�A�Ɠ����x�ł����Ȃ����Ƃ��l������ƥ��
Bulldozer(6���W���[��,12�R�A)��Sandy Bridge��6�R�A��萫�\�����Ƒz�肳���B
Sandy Bridge��4�R�A��GPU���܂߂Ă�230mm2�����ł����Ȃ��A������L3���܂߂�1�R�A�̐�L����
2.85��18.4=15.5%�ł��肻������Sandy Bridge��6�R�A�̃_�C�T�C�Y�����߂�ƥ��
(230�~0.155)�~2+230=301.2mm2�ƂȂ�B
Bulldozer(6���W���[��,12�R�A)��GPU����316mm2�Ȃ̂ɑ�Sandy Bridge��6�R�A��GPU�t����301.2mm2
�_�C�T�C�Y�I�ɂ�Sandy Bridge��6�R�A���L���ł��萫�\�I��Sandy Bridge��6�R�A�̕����D��Ă��邱�ƂɂȂ�B
240��(262�~1.5)=61%�ƂȂ�B
Phenom�U X6�̃_�C�T�C�Y��346mm2�ł��邩�炱���Bulldozer�ɒu��������ƥ��
346�~1.5�~0.61=316mm2�Ɨ\�z�����BBulldozer(6���W���[��,12�R�A)
������Bulldozer(6���W���[��,12�R�A)�̐��\��Phenom�U X6��1.8�{�ƌ����Ă���B
���݂�Phenom�U X6�̐��\��Bloomfield 4�R�A�Ɠ����x�ł����Ȃ����Ƃ��l������ƥ��
Bulldozer(6���W���[��,12�R�A)��Sandy Bridge��6�R�A��萫�\�����Ƒz�肳���B
Sandy Bridge��4�R�A��GPU���܂߂Ă�230mm2�����ł����Ȃ��A������L3���܂߂�1�R�A�̐�L����
2.85��18.4=15.5%�ł��肻������Sandy Bridge��6�R�A�̃_�C�T�C�Y�����߂�ƥ��
(230�~0.155)�~2+230=301.2mm2�ƂȂ�B
Bulldozer(6���W���[��,12�R�A)��GPU����316mm2�Ȃ̂ɑ�Sandy Bridge��6�R�A��GPU�t����301.2mm2
�_�C�T�C�Y�I�ɂ�Sandy Bridge��6�R�A���L���ł��萫�\�I��Sandy Bridge��6�R�A�̕����D��Ă��邱�ƂɂȂ�B
944 �FSocket774�F2010/07/03(�y) 19:05:10 ID:QVM/wPjm
945 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 19:05:48 ID:koawV+us
Sandy Bridge��GPU�t����6�R�A�̐��i�̗\��͂Ȃ��ł��B�������炸
>>930
���W���[�������Ė��ʂȕ��������L�����ă��\�[�X���炷�̂��ړI����ˁH
�R�A�P�ʂłԂ���Ȃ�Intel���_�C�T�C�Y������������R�X�p�ŏ����ɂȂ邯��
���W���[���P�ʂŐ키��Intel���͂��ɐ��\��Ń_�C�T�C�Y��1.5�{�߂�����
���v����Ĕ��邱�ƂɂȂ��Č���̋ꂵ����Ԃƕς��Ȃ��悤��
���W���[�������Ė��ʂȕ��������L�����ă��\�[�X���炷�̂��ړI����ˁH
�R�A�P�ʂłԂ���Ȃ�Intel���_�C�T�C�Y������������R�X�p�ŏ����ɂȂ邯��
���W���[���P�ʂŐ키��Intel���͂��ɐ��\��Ń_�C�T�C�Y��1.5�{�߂�����
���v����Ĕ��邱�ƂɂȂ��Č���̋ꂵ����Ԃƕς��Ȃ��悤��
>>945
> Sandy Bridge��GPU�t����6�R�A�̐��i�̗\��͂Ȃ��ł��B�������炸
�������ˁA�����I�Șb����GPU���Ȃ��Ă�8�R�A��Bulldozer(6���W���[��,12�R�A)�̑R�n�ƂȂ邾�낤�B
������̏ꍇ�ł��_�C�T�C�Y���܂߂�Sandy Bridge�̈����ł��邱�Ƃ͋^���Ȃ����낤�B
> Sandy Bridge��GPU�t����6�R�A�̐��i�̗\��͂Ȃ��ł��B�������炸
�������ˁA�����I�Șb����GPU���Ȃ��Ă�8�R�A��Bulldozer(6���W���[��,12�R�A)�̑R�n�ƂȂ邾�낤�B
������̏ꍇ�ł��_�C�T�C�Y���܂߂�Sandy Bridge�̈����ł��邱�Ƃ͋^���Ȃ����낤�B
45nm����32nm����50.6%�����...
�Ȃ��̃L�e���c�Ȍv�Z��
�Ȃ��̃L�e���c�Ȍv�Z��
Atom�̃o���G�[�V������Aubrey Isle
���W���[�����̐��ʂ��o���Ă�̂�Intel���Ƃ���������
���W���[�����̐��ʂ��o���Ă�̂�Intel���Ƃ���������
>>948
�P���v�Z�ǂ���ɂ͏k�ڂ����킯����Ȃ������w
(32x32)��45x45=50.56%�͗��_�l�ł����Ȃ����̒ʂ�ɏk�ڂ����킯����Ȃ���B
�P���v�Z�ǂ���ɂ͏k�ڂ����킯����Ȃ������w
(32x32)��45x45=50.56%�͗��_�l�ł����Ȃ����̒ʂ�ɏk�ڂ����킯����Ȃ���B
>>908
�S���������ĂȂ��Ȃ�
�������n�̎����R�X�g����сA���i��Ƃ�킯����d�͂ɂ͓���ǂ����Ȃ����낤
�������P�łQ�O�O�h���Ƃ�����s�ꂶ��Ȃ��������J���R�X�g������Ηǂ��Ƃ������̂ł͂Ȃ��Ȃ�
�S���������ĂȂ��Ȃ�
�������n�̎����R�X�g����сA���i��Ƃ�킯����d�͂ɂ͓���ǂ����Ȃ����낤
�������P�łQ�O�O�h���Ƃ�����s�ꂶ��Ȃ��������J���R�X�g������Ηǂ��Ƃ������̂ł͂Ȃ��Ȃ�
952 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 19:15:40 ID:koawV+us
Bulldozer��1���W���[����Sandy Bridge��1�R�A�͎����悤�ȃT�C�Y�ɂȂ���
���Ƃ̓L���b�V���e�ʂƂ������Ń_�C�T�C�Y�����܂�A�I��
���Ƃ̓L���b�V���e�ʂƂ������Ń_�C�T�C�Y�����܂�A�I��
>>935
�V�������N�Ńg�����W�X�^���͔{�������(�T�C�Y�����̏ꍇ)
�܂�_�C�S�̂ł͔{�ȏ�̐��\�ɂȂ���Ă��Ƃ���>>938
>>938
���̍��ɂ�Fusion�T�[�o�[�̘b���o�Ă���������
GPGPU���T�[�o�[�����ɂǂ�قnj��ʂ����邩�͕s��������
HPC�����Ȃ�L���ŁACPU�̃������ш悾��500GFlops�������������낤����A
���̐��\�ɑ��Ăǂꂾ����R�X�g��d�͂ɏo���邩�Ɋ|�����Ă����
���������A�{���x�ƒP���x�œ��ꃁ�����ш�ɂ��X���[�v�b�g���\�̓V��͂��܂荷���Ȃ��̂���
����Ƃ��{���x�͈Ⴄ�H
DDR3 128Bit 1600MHz�ӂ肪���N�̕W���d�l�ɂȂ肻�������ǁA
�ǂ̒��x������ɂȂ�̂��N���m��Ȃ��H
�l�I�ɂ�Llano 480sp �P���x500GFlops������ȋC������
�{���x�͂��̔�����250GFlops�ʂ���
�v��Llano��480sp�̏ꍇ�A���������{�g���l�b�N�ɂȂ�̂��ǂ������m�肽��
�����{�g���l�b�N�Ȃ�ALlano�ȏ�̃x�N�g�����\�͈Ӗ����������ƂɂȂ�
�V�������N�Ńg�����W�X�^���͔{�������(�T�C�Y�����̏ꍇ)
�܂�_�C�S�̂ł͔{�ȏ�̐��\�ɂȂ���Ă��Ƃ���>>938
>>938
���̍��ɂ�Fusion�T�[�o�[�̘b���o�Ă���������
GPGPU���T�[�o�[�����ɂǂ�قnj��ʂ����邩�͕s��������
HPC�����Ȃ�L���ŁACPU�̃������ш悾��500GFlops�������������낤����A
���̐��\�ɑ��Ăǂꂾ����R�X�g��d�͂ɏo���邩�Ɋ|�����Ă����
���������A�{���x�ƒP���x�œ��ꃁ�����ш�ɂ��X���[�v�b�g���\�̓V��͂��܂荷���Ȃ��̂���
����Ƃ��{���x�͈Ⴄ�H
DDR3 128Bit 1600MHz�ӂ肪���N�̕W���d�l�ɂȂ肻�������ǁA
�ǂ̒��x������ɂȂ�̂��N���m��Ȃ��H
�l�I�ɂ�Llano 480sp �P���x500GFlops������ȋC������
�{���x�͂��̔�����250GFlops�ʂ���
�v��Llano��480sp�̏ꍇ�A���������{�g���l�b�N�ɂȂ�̂��ǂ������m�肽��
�����{�g���l�b�N�Ȃ�ALlano�ȏ�̃x�N�g�����\�͈Ӗ����������ƂɂȂ�
�f�����悤
�����������͂������̌�ǂ�����
���������̎v�z����荞�܂���Ȃ��Ȃ�
���b�`�łȂ��������̃R�A�ŏȃG�l��R�X�g
��K�͂ȃ��X�g���K�����Ȃ�
�����������͂������̌�ǂ�����
���������̎v�z����荞�܂���Ȃ��Ȃ�
���b�`�łȂ��������̃R�A�ŏȃG�l��R�X�g
��K�͂ȃ��X�g���K�����Ȃ�
�e�w�ƒc�q����c�q�̕����܂Ƃ��ȗ\�z���낤��
957 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 19:23:06 ID:koawV+us
>>956
http://plusd.itmedia.co.jp/pcuser/articles/1006/08/news089.html
GPU�t���ł��ARadeon�ڂ��Ă���B
CPU���\�A�s�[���̂��߂ɁA����GPU�g��Ȃ��ŁATurboBoost�ŃN���b�N�������������̂��낤���B
http://plusd.itmedia.co.jp/pcuser/articles/1006/08/news089.html
GPU�t���ł��ARadeon�ڂ��Ă���B
CPU���\�A�s�[���̂��߂ɁA����GPU�g��Ȃ��ŁATurboBoost�ŃN���b�N�������������̂��낤���B
>>937
Gulftown��130W��6�R�A��3.3GHz�Ȃ�A
�R�A�ӂ�w�Ǖς��Ȃ�Sandy 8�R�A�Ȃ� 3GHz�͍s���Ȃ�����B
�P���ɍl�����
6�R�A*3.3GHz=8�R�A*XGHz
X=8/20=2.5�ő��2.5GHz�ɂȂ�
�����܂��ɂȂ����Ƃ��Ă�2.8GHz�������������낤��
Gulftown��130W��6�R�A��3.3GHz�Ȃ�A
�R�A�ӂ�w�Ǖς��Ȃ�Sandy 8�R�A�Ȃ� 3GHz�͍s���Ȃ�����B
�P���ɍl�����
6�R�A*3.3GHz=8�R�A*XGHz
X=8/20=2.5�ő��2.5GHz�ɂȂ�
�����܂��ɂȂ����Ƃ��Ă�2.8GHz�������������낤��
>>959
B2��SandyBridge��PCIe3.0 x24�ڂ��邩��A�R�A�����ȏ�ɒ�i�N���b�N�͉������Ȃ��́H
B2��SandyBridge��PCIe3.0 x24�ڂ��邩��A�R�A�����ȏ�ɒ�i�N���b�N�͉������Ȃ��́H
961 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 19:30:02 ID:koawV+us
Nehalem��Westmere�͂����̃V�������N����Westmere��Sandy Bridge�̓}�C�N���A�[�L�e�N�`���̍��V��
����ɂ���d�͌����̍œK�������邩��8�R�A��3.2GHz���x�����ʂɂ��蓾�邯�ǂ�
����ɂ���d�͌����̍œK�������邩��8�R�A��3.2GHz���x�����ʂɂ��蓾�邯�ǂ�
�c�q�̎咣�̍ő�̖��͌��́E�����\���̑o���ɂ���Intel�ɂ��Ă�best case�AAMD�ɂ��Ă�worst case�������������ɏo�����ɔ�r��c�_��i�߂悤�Ƃ���Ƃ���Ȃ��
963 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 19:34:03 ID:koawV+us
����v���Z�X���[���ł��X�e�b�s���O�̍��V��TDP������������͂��邵��
�悭�����K10������Bull�̃R�A�T�C�Y�\�z����
�V�������N�̊����ǂ��낶��˂���
�V�������N�̊����ǂ��낶��˂���
965 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 19:36:10 ID:koawV+us
���[�X�g�P�[�X�Ȃ�Č������������
�uALU��2�Ɍ���������V���O���X���b�h���\2/3���I�v
�ɂȂ邯�ǂȁB
�܂��ASandra��ALU�x���`�Ȃł͎��ۂɂ����Ȃ肻������
�uALU��2�Ɍ���������V���O���X���b�h���\2/3���I�v
�ɂȂ邯�ǂȁB
�܂��ASandra��ALU�x���`�Ȃł͎��ۂɂ����Ȃ肻������
>>964
> �悭�����K10������Bull�̃R�A�T�C�Y�\�z����
��������AAMD�Ђ����\���Ă���_�C�T�C�Y50%����80%�̐��\����������ĎZ�o�������ʂł���
���傪����Ȃ�AMD�ЂɌ����ĂˁB�v���Z�X���[���ύX�ɂ��k�ڗ���Intel�̃_�C�ŗ\�������l�ł��B(61%)
> �悭�����K10������Bull�̃R�A�T�C�Y�\�z����
��������AAMD�Ђ����\���Ă���_�C�T�C�Y50%����80%�̐��\����������ĎZ�o�������ʂł���
���傪����Ȃ�AMD�ЂɌ����ĂˁB�v���Z�X���[���ύX�ɂ��k�ڗ���Intel�̃_�C�ŗ\�������l�ł��B(61%)
���̃X���ɎT���U�炳�ꂽ�����������q�̋���AMD�ɂȂ���t����y�h�z��
968 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 19:49:28 ID:koawV+us
�Ă�Intel��32nm�̂ق���IBM�A����28nm���g�����W�X�^���x������Ȃ���������
>>966
61����50���ɂ��邽�߂ɍH�i�F�X������j�����̂��u�����Ǝv�����B
61����50���ɂ��邽�߂ɍH�i�F�X������j�����̂��u�����Ǝv�����B
> AMD�ɂ��Ă�worst case�������������ɏo����
����͈Ⴄ��Ȃ��́H
Bulldozer�̐��\�\���́AAMD�Ђ̔��\�l�����ɂ��Ĕ������Ă��锤����B
�����Ă���ȊO�ɐ��\�\���̂��悤���Ȃ����낤�A1���W���[���Ō��s��50%���̃_�C�T�C�Y�ƂȂ肻�̐��\�͌��s��180%�ɒB����Ƃ������Ƃ���{�Ŕ�r���Ă���B
������ď펯�I�Ɍ��ăx�X�g�P�[�X�Ȃ�Ȃ��́H
����͈Ⴄ��Ȃ��́H
Bulldozer�̐��\�\���́AAMD�Ђ̔��\�l�����ɂ��Ĕ������Ă��锤����B
�����Ă���ȊO�ɐ��\�\���̂��悤���Ȃ����낤�A1���W���[���Ō��s��50%���̃_�C�T�C�Y�ƂȂ肻�̐��\�͌��s��180%�ɒB����Ƃ������Ƃ���{�Ŕ�r���Ă���B
������ď펯�I�Ɍ��ăx�X�g�P�[�X�Ȃ�Ȃ��́H
971 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 19:58:08 ID:koawV+us
Bulldozer��1���W���[����K10��1�R�A��肩�Ȃ胊�\�[�X�������ȁH
L1�̗e�ʈȊO��
L1�̗e�ʈȊO��
>>961
> Nehalem��Westmere�͂����̃V�������N����Westmere��Sandy Bridge�̓}�C�N���A�[�L�e�N�`���̍��V��
����ȑ�w�Ȃ���Ȃ�����
AVX�lj��ȊO�͑債�����Ƃ��Ė��������͂�����
> Nehalem��Westmere�͂����̃V�������N����Westmere��Sandy Bridge�̓}�C�N���A�[�L�e�N�`���̍��V��
����ȑ�w�Ȃ���Ȃ�����
AVX�lj��ȊO�͑債�����Ƃ��Ė��������͂�����
>>971
50%�����邯��80%���\���シ�邩����͑S���Ȃ���w
50%�����邯��80%���\���シ�邩����͑S���Ȃ���w
974 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 20:01:44 ID:koawV+us
Nehalem��Westmere�͂قڌ��w�V�������N����
Sandy Bridge��32nm��O��ɍœK������Ă邩��
Westmere���1�R�A������̏���d�͂��X�ɗ����邱�Ƃ͎��m�̎������Ǝv������
Sandy Bridge��32nm��O��ɍœK������Ă邩��
Westmere���1�R�A������̏���d�͂��X�ɗ����邱�Ƃ͎��m�̎������Ǝv������
>>969
> 61����50���ɂ��邽�߂ɍH�i�F�X������j�����̂��u�����Ǝv�����B
�Ⴄ�Ǝv�����A61%�̓v���Z�X���[���ɂ��k�ڗ��̂��Ƃ������ABulldozer��1���W���[��2�R�A�ɂ��邱�Ƃɂ��50%�̃g�����W�X�^����80%�̐��\�����ڎw���Ă���̂�����
�����̌v�Z�͂܂��ʂ̘b�ł��B
>943�̌v�Z�Ŗ�肪����Ƃ���̂Ȃ炻���L3�̗e�ʂ��炢�ł����āA���s��6MB����Bulldozer(6���W���[��,12�R�A)��9MB�ɂȂ邱�Ƃ�O��Ɍv�Z���ꂽ���ʂł��B
������12�R�A�ł��邱�Ƃ��l�������L3��9MB���x�Ȃ��ƂȂ��Ǝv���͎̂��R�ł͂Ȃ��ł��傤���H
�܂��A�_�C�T�C�Y���P�`��ׂ�L3�����������Ă���\��������̂�AMD�Ȃ��ǂ�w
> 61����50���ɂ��邽�߂ɍH�i�F�X������j�����̂��u�����Ǝv�����B
�Ⴄ�Ǝv�����A61%�̓v���Z�X���[���ɂ��k�ڗ��̂��Ƃ������ABulldozer��1���W���[��2�R�A�ɂ��邱�Ƃɂ��50%�̃g�����W�X�^����80%�̐��\�����ڎw���Ă���̂�����
�����̌v�Z�͂܂��ʂ̘b�ł��B
>943�̌v�Z�Ŗ�肪����Ƃ���̂Ȃ炻���L3�̗e�ʂ��炢�ł����āA���s��6MB����Bulldozer(6���W���[��,12�R�A)��9MB�ɂȂ邱�Ƃ�O��Ɍv�Z���ꂽ���ʂł��B
������12�R�A�ł��邱�Ƃ��l�������L3��9MB���x�Ȃ��ƂȂ��Ǝv���͎̂��R�ł͂Ȃ��ł��傤���H
�܂��A�_�C�T�C�Y���P�`��ׂ�L3�����������Ă���\��������̂�AMD�Ȃ��ǂ�w
976 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 20:03:05 ID:koawV+us
>>973
������g�����W�X�^������̐��\���㗦��2����������ȁH���Č����Ă�킯�����B
�}���`�X���b�h�ł���Nehalem/Westmere�ɁiSandy Bridge�ɂł͂Ȃ��j�ǂ����Ȃ��\��
������g�����W�X�^������̐��\���㗦��2����������ȁH���Č����Ă�킯�����B
�}���`�X���b�h�ł���Nehalem/Westmere�ɁiSandy Bridge�ɂł͂Ȃ��j�ǂ����Ȃ��\��
K10��Bull��r�Ȃ̂ɃV�������N61%�Ȃ�ĂĒf��ł���H
�����ǂ݂��邽�тɈُ픭���A���̃L���z��
�����i��������j���㓡�ւ̐��~����������
�ނ��{�����邽�ߏ�ɎT���U�炳��鐸�q������܂��L�߂���
�Ƃ肠�����������E��AMD�̔��\
ttp://pc.watch.impress.co.jp/img/pcw/docs/328/392/html/kaigai5.jpg.html
�����i��������j���㓡�ւ̐��~����������
�ނ��{�����邽�ߏ�ɎT���U�炳��鐸�q������܂��L�߂���
�Ƃ肠�����������E��AMD�̔��\
ttp://pc.watch.impress.co.jp/img/pcw/docs/328/392/html/kaigai5.jpg.html
{kind=link}
�c�q�Ȃ�Z�p�I�ɓ����ꂻ�������畷����
>>953
> ���������A�{���x�ƒP���x�œ��ꃁ�����ш�ɂ��X���[�v�b�g���\�̓V��͂��܂荷���Ȃ��̂���
> ����Ƃ��{���x�͈Ⴄ�H
> DDR3 128Bit 1600MHz�ӂ肪���N�̕W���d�l�ɂȂ肻�������ǁA
> �ǂ̒��x������ɂȂ�̂��N���m��Ȃ��H
�ɂ��ĉ����m���Ă邩�H
>>953
> ���������A�{���x�ƒP���x�œ��ꃁ�����ш�ɂ��X���[�v�b�g���\�̓V��͂��܂荷���Ȃ��̂���
> ����Ƃ��{���x�͈Ⴄ�H
> DDR3 128Bit 1600MHz�ӂ肪���N�̕W���d�l�ɂȂ肻�������ǁA
> �ǂ̒��x������ɂȂ�̂��N���m��Ȃ��H
�ɂ��ĉ����m���Ă邩�H
980 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 20:05:31 ID:koawV+us
Propus��Llano�ł�6����������債�Ă�����
��ł����ăg�����W�X�^��1.5�{�Ȃ�R�A���W�b�N���̃T�C�Y��45nm��K10�Ƃǂ��������x���B
��ł����ăg�����W�X�^��1.5�{�Ȃ�R�A���W�b�N���̃T�C�Y��45nm��K10�Ƃǂ��������x���B
>>977
�V�������N61%�̓v���Z�X���[������ɂ��k�����ł�����45nm����32nm�ւ̏k�ڗ��Ƃ��đÓ��ł���w
�[���A�N���Ĕn���Ȃ́H
�V�������N61%�̓v���Z�X���[������ɂ��k�����ł�����45nm����32nm�ւ̏k�ڗ��Ƃ��đÓ��ł���w
�[���A�N���Ĕn���Ȃ́H
Intel��Sandy�ł�Westmere���N���b�N�����������A�����TB�̃N���b�N�㏸����傫������
>>974
> Sandy Bridge��32nm��O��ɍœK������Ă邩��
> Westmere���1�R�A������̏���d�͂��X�ɗ����邱�Ƃ͎��m�̎������Ǝv������
�ǂ��������œK���ŁA�ǂ̒��x���\���シ��̂������Ȃ�
> Sandy Bridge��32nm��O��ɍœK������Ă邩��
> Westmere���1�R�A������̏���d�͂��X�ɗ����邱�Ƃ͎��m�̎������Ǝv������
�ǂ��������œK���ŁA�ǂ̒��x���\���シ��̂������Ȃ�
AMD��32nm��CPU�̃f�W�^���d�̓��j�^��H�́ACPU�R�A�̊e���̓d�͏�������j�^���āA�œK�ȓd�͐����Z���C�e���V�ōs�Ȃ��B
Nehalem�̏ꍇ�Ɠ����ŁACPU�����Ƀn�[�h�E�F�A��������Ă��邽�߁A����̃��C�e���V���Z���A���ߍׂ��Ȑ��䂪�ł���B
�������A���j�^�̕����́ANehalem�Ƃ͑傫���قȂ��Ă���B
�@AMD��32nm��CPU�ł́ACPU�R�A�̊e���̓���̃|�C���g�̃X�C�b�`���O�L���p�V�^���X�𑪒肵�ēd�͂̌��ς�����s�Ȃ��B
Intel���̂��Ă���悤�ȁA�T�[�}���Z���T�[�ɂ��_�C���x�����d���ʂƂ������]���̎�@�͍̂�Ȃ������B
AMD�ł́ACPU�R�A��95���̃|�C���g���T���v�����邱�ƂŁA�덷2%�ȓ��Ƃ����ɂ߂č����x�̓d�͌��ς��肪�\�ɂȂ�Ƃ����B
�T���v�����O�͊e�T�C�N�����ł͂Ȃ��A��莞�Ԓu���ɍs�Ȃ����ߕ��S�͏��Ȃ��Ƃ����B
�@AMD��32nm CPU�ł́A�����x�̃f�W�^���d�̓��j�^���j�b�g�ɂ���āA���ɐ��x�̍����d�͐��䂪�\�ɂȂ�Ɛ��肳���B
���̂��߁A�^�[�{���[�h�����S�}�[�W�������Ȃ��Ƃ��āA��荂�����g���ɑJ�ڂ����邱�Ƃ������I�ɗe�ՂƂȂ�
http://pc.watch.impress.co.jp/docs/column/kaigai/20100427_364107.html
�ȃG�l�Z�p�������������ɐ�s���������ˁ@�s�[�N���\��ǂ킸�������ɓI���i�����v������\�ɂȂ�
�ŏ����炻���{
�s�[�N���\�ǂ��Ăǂ�ǂ�R�A�����b�`�ɂȂ邉���������͎���ɋt�s���Ă�ˁ@�R�X�g���������낤��
Nehalem�̏ꍇ�Ɠ����ŁACPU�����Ƀn�[�h�E�F�A��������Ă��邽�߁A����̃��C�e���V���Z���A���ߍׂ��Ȑ��䂪�ł���B
�������A���j�^�̕����́ANehalem�Ƃ͑傫���قȂ��Ă���B
�@AMD��32nm��CPU�ł́ACPU�R�A�̊e���̓���̃|�C���g�̃X�C�b�`���O�L���p�V�^���X�𑪒肵�ēd�͂̌��ς�����s�Ȃ��B
Intel���̂��Ă���悤�ȁA�T�[�}���Z���T�[�ɂ��_�C���x�����d���ʂƂ������]���̎�@�͍̂�Ȃ������B
AMD�ł́ACPU�R�A��95���̃|�C���g���T���v�����邱�ƂŁA�덷2%�ȓ��Ƃ����ɂ߂č����x�̓d�͌��ς��肪�\�ɂȂ�Ƃ����B
�T���v�����O�͊e�T�C�N�����ł͂Ȃ��A��莞�Ԓu���ɍs�Ȃ����ߕ��S�͏��Ȃ��Ƃ����B
�@AMD��32nm CPU�ł́A�����x�̃f�W�^���d�̓��j�^���j�b�g�ɂ���āA���ɐ��x�̍����d�͐��䂪�\�ɂȂ�Ɛ��肳���B
���̂��߁A�^�[�{���[�h�����S�}�[�W�������Ȃ��Ƃ��āA��荂�����g���ɑJ�ڂ����邱�Ƃ������I�ɗe�ՂƂȂ�
http://pc.watch.impress.co.jp/docs/column/kaigai/20100427_364107.html
�ȃG�l�Z�p�������������ɐ�s���������ˁ@�s�[�N���\��ǂ킸�������ɓI���i�����v������\�ɂȂ�
�ŏ����炻���{
�s�[�N���\�ǂ��Ăǂ�ǂ�R�A�����b�`�ɂȂ邉���������͎���ɋt�s���Ă�ˁ@�R�X�g���������낤��
>>981
�܂�A�[�L�̑啝�ȕω��ł̉e���͖������Ēf��ł�����
�܂�A�[�L�̑啝�ȕω��ł̉e���͖������Ēf��ł�����
>>984
���s�[�N���\�ǂ��Ăǂ�ǂ�R�A�����b�`�ɂȂ邉���������͎���ɋt�s���Ă�ˁ@�R�X�g���������낤��
���ꂪCPU�̖{�����Ă��B
�t������o���閇���Ɠ����ŁA�l�i�����������_�C�T�C�Y���Ă����̂͊m���ɑ��݂���킯��
����ɗ��V�ɂ��킹�Ă����Ă�̂��ޗ��オ�قړ�{��AMD��
�K���ɂ���Ă�̂�intel���Ǝv�����B
���s�[�N���\�ǂ��Ăǂ�ǂ�R�A�����b�`�ɂȂ邉���������͎���ɋt�s���Ă�ˁ@�R�X�g���������낤��
���ꂪCPU�̖{�����Ă��B
�t������o���閇���Ɠ����ŁA�l�i�����������_�C�T�C�Y���Ă����̂͊m���ɑ��݂���킯��
����ɗ��V�ɂ��킹�Ă����Ă�̂��ޗ��オ�قړ�{��AMD��
�K���ɂ���Ă�̂�intel���Ǝv�����B
988 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 20:12:09 ID:koawV+us
>>979
���Z���j�b�g�̃X���[�v�b�g���P���x�F�{���x���Q�F�P�ł���A�Ȃ����P���x�̃f�[�^�T�C�Y���{���x�̒��x�����ł���ȏ�
�X���[�v�b�g�䗦�͕ς��Ȃ�
�L�����x������Ɨ��Ƃ��ėǂ����Ď��ɂȂ���ꂱ�������x�t�H�[�}�b�g�̈��k�W�J���߂����ɗ���
���Z���j�b�g�̃X���[�v�b�g���P���x�F�{���x���Q�F�P�ł���A�Ȃ����P���x�̃f�[�^�T�C�Y���{���x�̒��x�����ł���ȏ�
�X���[�v�b�g�䗦�͕ς��Ȃ�
�L�����x������Ɨ��Ƃ��ėǂ����Ď��ɂȂ���ꂱ�������x�t�H�[�}�b�g�̈��k�W�J���߂����ɗ���
>>985
> �܂�A�[�L�̑啝�ȕω��ł̉e���͖������Ēf��ł�����
�A�[�L�̑啝�ȕω��ł̉e����AMD�Ђ����\���Ă���50%����80%���̐��\����Ƃ������l���g���ĎZ�o���Ă邶���w
�ȂɌ����Ă�́H�A�����������́H
> �܂�A�[�L�̑啝�ȕω��ł̉e���͖������Ēf��ł�����
�A�[�L�̑啝�ȕω��ł̉e����AMD�Ђ����\���Ă���50%����80%���̐��\����Ƃ������l���g���ĎZ�o���Ă邶���w
�ȂɌ����Ă�́H�A�����������́H
990 �F�N�����X�����ĂĂ����F2010/07/03(�y) 20:13:28 ID:n7O1EZag
�_.�Q�@ | �r�炵�E����E�~�[�͕��u����ԁB
�^|�Q|�@| �ނ�ꂸ�ɃX���[���܂��傤�B
|�Q�^�_! sage�i�s�Ń}�^�[�������܂��傤�B
���O�X��
AMD�̎�����CPU�ɂ��Č�낤 ��38����
http://pc11.2ch.net/test/read.cgi/jisaku/1277004119/
�����AMD�n�X���b�h�ߋ����O�ۑ��T�C�g�l
http://amd.jisakuita.net/
���֘A�X��
Intel�̎�����CPU�ɂ��Č�낤 43
http://pc11.2ch.net/test/read.cgi/jisaku/1270976684/
CPU�A�[�L�e�N�`���ɂ��Č�� 17
http://pc11.2ch.net/test/read.cgi/jisaku/1274809074/
�^|�Q|�@| �ނ�ꂸ�ɃX���[���܂��傤�B
|�Q�^�_! sage�i�s�Ń}�^�[�������܂��傤�B
���O�X��
AMD�̎�����CPU�ɂ��Č�낤 ��38����
http://pc11.2ch.net/test/read.cgi/jisaku/1277004119/
�����AMD�n�X���b�h�ߋ����O�ۑ��T�C�g�l
http://amd.jisakuita.net/
���֘A�X��
Intel�̎�����CPU�ɂ��Č�낤 43
http://pc11.2ch.net/test/read.cgi/jisaku/1270976684/
CPU�A�[�L�e�N�`���ɂ��Č�� 17
http://pc11.2ch.net/test/read.cgi/jisaku/1274809074/
>>990
�C����w
�C����w
�N���X�����ė��ށB���X���́u��40����v�ł��B
36���オ�d�������������v�Z���Ă��Ȃ��I
�ǂ��ł������b�����ǂ�
36���オ�d�������������v�Z���Ă��Ȃ��I
�ǂ��ł������b�����ǂ�
994 �F,,�E�L�́M�E,,�j��-�������F2010/07/03(�y) 20:15:51 ID:koawV+us
>>987
�����̂�Intel�̗ʎY������80mm²�O�ザ���
Sandy Bridge�����Ԃ�CULV����������ɏ������_�C�̃}�X�N����Ă��ˁH
1�`2�R�A�{GPU(6EU)������ŁB
�����̂�Intel�̗ʎY������80mm²�O�ザ���
Sandy Bridge�����Ԃ�CULV����������ɏ������_�C�̃}�X�N����Ă��ˁH
1�`2�R�A�{GPU(6EU)������ŁB
8������ɂ́@Intel�̎�����CPU�ɂ��Č�낤 ��ǂ��z����������
������ƒx���������B�����l�ł����B���X���B
AMD�̎�����CPU�ɂ��Č�낤 ��39����
http://pc11.2ch.net/test/read.cgi/jisaku/1278155706/
AMD�̎�����CPU�ɂ��Č�낤 ��39����
http://pc11.2ch.net/test/read.cgi/jisaku/1278155706/
�X�����Ă����ꂳ�܂ł�
>>976
> >>973
> �}���`�X���b�h�ł���Nehalem/Westmere�ɁiSandy Bridge�ɂł͂Ȃ��j�ǂ����Ȃ��\��
>>869�œ����N���b�N�Ȃ�K10��20�`30%�����Ȃ̂͏ؖ����ꂽ��
> >>973
> �}���`�X���b�h�ł���Nehalem/Westmere�ɁiSandy Bridge�ɂł͂Ȃ��j�ǂ����Ȃ��\��
>>869�œ����N���b�N�Ȃ�K10��20�`30%�����Ȃ̂͏ؖ����ꂽ��
>>991=993
���肪�Ƃ����X�����ĉ�
���肪�Ƃ����X�����ĉ�
1001 �F�P�O�O�P�F
1��̃}�V�����g�ݏオ��܂����B�B�B
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://pc11.2ch.net/jisaku/
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://pc11.2ch.net/jisaku/