【GPGPU】CUDA/ATI STREAM 速度・画質検証スレ
952 :,,・´∀`・,,)っ-●◎○:2009/04/11(土) 02:34:22 ID:4rAUMB1v
科学技術計算まわりの需要としては、本当は倍精度もっと使いたいけど
単精度でもがんばれば精度補完できるから仕方なく使う類のもの。
たとえば今のx86のSSE*の実装なんかは単精度8:倍精度4だけど
単精度の仮数部は24ビット、倍精度は半分のスループットでも53ビットになるので
差し引きで単精度より上回るんだ。
だからx86で多倍長演算には普通倍精度しか使わない。
単精度と倍精度のスループットが逆転するのはスループット比4倍か
それ以上の差があるくらいが相場。
逆にいうとLarrabeeが単精度2TFの倍精度1TFあたり超えたらみんなそっちに流れますよ。
Teslaに入れ込んでた学者さんだって、切り捨てるときにはあっさり切り捨てる
単精度でもがんばれば精度補完できるから仕方なく使う類のもの。
たとえば今のx86のSSE*の実装なんかは単精度8:倍精度4だけど
単精度の仮数部は24ビット、倍精度は半分のスループットでも53ビットになるので
差し引きで単精度より上回るんだ。
だからx86で多倍長演算には普通倍精度しか使わない。
単精度と倍精度のスループットが逆転するのはスループット比4倍か
それ以上の差があるくらいが相場。
逆にいうとLarrabeeが単精度2TFの倍精度1TFあたり超えたらみんなそっちに流れますよ。
Teslaに入れ込んでた学者さんだって、切り捨てるときにはあっさり切り捨てる
科学技術計算する人は、その時点で少しでも高速なものを求めるから、
SPをひたすら大量に詰め込んだだけで性能の出ないGPUは選ばない
SPをひたすら大量に詰め込んだだけで性能の出ないGPUは選ばない
954 :,,・´∀`・,,)っ-●◎○:2009/04/11(土) 02:37:45 ID:4rAUMB1v
>>950
いいや、東工大は消費電力が予算の限界に達してて
効率のために仕方なくTeslaに置き換えた。
現状Opteronよりも倍精度も含めて浮動小数のスループット稼げるからね。
Teslaを導入したきっかけは来年か再来年あたりにはTeslaを見捨てる
理由にもなってしまうかもしれない
いいや、東工大は消費電力が予算の限界に達してて
効率のために仕方なくTeslaに置き換えた。
現状Opteronよりも倍精度も含めて浮動小数のスループット稼げるからね。
Teslaを導入したきっかけは来年か再来年あたりにはTeslaを見捨てる
理由にもなってしまうかもしれない
>既に指摘した通り、科学技術計算する人は電力効率なんて最初から問題にしないよ
これも嘘 大学の研究室なんかたいていの場合予算はカツカツでランニングコストを少しでも抑えたいと思っている
それにDCと違って空調が最適化されてないことも多いし電源もショボイんだぜ
HPCという言葉の響きから連想されるお洒落な事例は現実にはあんまりない
これも嘘 大学の研究室なんかたいていの場合予算はカツカツでランニングコストを少しでも抑えたいと思っている
それにDCと違って空調が最適化されてないことも多いし電源もショボイんだぜ
HPCという言葉の響きから連想されるお洒落な事例は現実にはあんまりない
なぁ、CPU+GPUのハイブリッドチップって実際問題どうなんだ?
cell的な制御でGPUの能力を効率よく制御しようってのはわかるのだが、
本来の高性能GPUの役割果たすためには256bit幅や512bit幅みたいな
基地外じみたバス幅かそれに相当するメモリ帯域を確保する必要があるわけだろ?
cellの様に各演算器の下にそれなりのローカルメモリをぶら下げるのは
一つの解だと思うけど、x86系のアーキテクチャにはあわん様な気がするし、
そこら辺の実装を解決しないとどうしようもないと思うのだけど。
>>942
PC台数に対するサウンドカードの出荷数の比率自体は減ってね?
だからクリエイティブも高級化路線に行っているわけだし。
その意味では3D進化の止まらないVGAも同じかもね。
需要は作り出すもの、、、、って事か?
cell的な制御でGPUの能力を効率よく制御しようってのはわかるのだが、
本来の高性能GPUの役割果たすためには256bit幅や512bit幅みたいな
基地外じみたバス幅かそれに相当するメモリ帯域を確保する必要があるわけだろ?
cellの様に各演算器の下にそれなりのローカルメモリをぶら下げるのは
一つの解だと思うけど、x86系のアーキテクチャにはあわん様な気がするし、
そこら辺の実装を解決しないとどうしようもないと思うのだけど。
>>942
PC台数に対するサウンドカードの出荷数の比率自体は減ってね?
だからクリエイティブも高級化路線に行っているわけだし。
その意味では3D進化の止まらないVGAも同じかもね。
需要は作り出すもの、、、、って事か?
>>952
>科学技術計算まわりの需要としては、本当は倍精度もっと使いたいけど
>単精度でもがんばれば精度補完できるから仕方なく使う類のもの。
そういう科学技術計算の分野もあるかも知れないが、寡聞にして知らないな。
もともと高速な演算を必要とする科学技術計算というのは大抵、
計算式が非線形で解析的には解けない分野なんだよね。
非線形な計算をする時に桁を倍にするなど無意味以外の何物でもない。
簡単な例を挙げると、天文学では桁が合えば両者はほぼ等しいとみなされるし、
気象予報では温度や気圧を倍精度で表わしても全然意味がない。
より正しい結果を得たければ、増やすべきは精度ではなく要素数(塵の数や
分割するメッシュの数)だ。
>>953
SPをひたすら大量に詰め込んだってことは、上記の要素数がより大きくなるってこと。
個々のSPの性能よりも、このより多くの要素を並列して処理できることこそが重要だ。
マルチコアCPUは、ビジネスソフトその他にその高性能さを発揮すればいいんだよ。
そちらでは絶大な効果をもたらせるし、GPUじゃ逆立ちしてもできないことなんだから。
>科学技術計算まわりの需要としては、本当は倍精度もっと使いたいけど
>単精度でもがんばれば精度補完できるから仕方なく使う類のもの。
そういう科学技術計算の分野もあるかも知れないが、寡聞にして知らないな。
もともと高速な演算を必要とする科学技術計算というのは大抵、
計算式が非線形で解析的には解けない分野なんだよね。
非線形な計算をする時に桁を倍にするなど無意味以外の何物でもない。
簡単な例を挙げると、天文学では桁が合えば両者はほぼ等しいとみなされるし、
気象予報では温度や気圧を倍精度で表わしても全然意味がない。
より正しい結果を得たければ、増やすべきは精度ではなく要素数(塵の数や
分割するメッシュの数)だ。
>>953
SPをひたすら大量に詰め込んだってことは、上記の要素数がより大きくなるってこと。
個々のSPの性能よりも、このより多くの要素を並列して処理できることこそが重要だ。
マルチコアCPUは、ビジネスソフトその他にその高性能さを発揮すればいいんだよ。
そちらでは絶大な効果をもたらせるし、GPUじゃ逆立ちしてもできないことなんだから。
958 :,,・´∀`・,,)っ-●◎○:2009/04/11(土) 02:53:47 ID:4rAUMB1v
本来ワークステーション向けのマルチGPUなんて個人に売るとか狂気の沙汰だな
でもそうまでやらないと生き残れない
でもそうまでやらないと生き残れない
959 :,,・´∀`・,,)っ-●◎○:2009/04/11(土) 02:59:00 ID:4rAUMB1v
>>957
たぶん一般ピープルに最もメジャーなHPCアプリケーションって円周率計算があるじゃん。
あれは主にFFTとか使ってるんだけど、単精度なんて使ったら逆に性能が落ちる
まだSSE2が出る前だと、数学やさんはlong double(Intel独自の例の80ビット精度)とか
使ってたりした。
たぶん一般ピープルに最もメジャーなHPCアプリケーションって円周率計算があるじゃん。
あれは主にFFTとか使ってるんだけど、単精度なんて使ったら逆に性能が落ちる
まだSSE2が出る前だと、数学やさんはlong double(Intel独自の例の80ビット精度)とか
使ってたりした。
>>954>>955
それは、もしも東工大がもっと金持ちだったらTeslaではなくスパコンを導入しただろう、
ってことでしかないよ。少なくとも、GPUの代わりにCPUを使うって選択肢はない。
実際、東工大はOpteronよりもTeslaを選んだわけでしょ。
何人もが言っているように、GPUのFLOPS曲線がCPUのそれを上回っている限りは、
GPUの需要は0にはならないだろう。
>>958
それは認める。個人でTesla買う人って、個人でHPCやることに何の意義を感じてんだろ?
まあ、蓼喰う虫も好き好きだから、他人が口を挟むことじゃないが。
>>959
確かに円周率計算は一般にもよく知られたHPCアプリだが、ただ知られているだけのことだ。
円周率を何兆桁も計算すること自体に科学的な意義はないよ。
観測可能な宇宙の円周をプランク長で割っても、円周率は60桁で足りてしまうんだから。
あれは、計算機の性能を計るための計算なんだよ。つまり、計算のための計算だ。
それはそれでコンピュータ工学的な意義はあるが、今の議論とは別の話だろう。
>>949氏や俺が指摘した「間に合わない時は倍精度で間に合わない」例ってことでしかない。
それは、もしも東工大がもっと金持ちだったらTeslaではなくスパコンを導入しただろう、
ってことでしかないよ。少なくとも、GPUの代わりにCPUを使うって選択肢はない。
実際、東工大はOpteronよりもTeslaを選んだわけでしょ。
何人もが言っているように、GPUのFLOPS曲線がCPUのそれを上回っている限りは、
GPUの需要は0にはならないだろう。
>>958
それは認める。個人でTesla買う人って、個人でHPCやることに何の意義を感じてんだろ?
まあ、蓼喰う虫も好き好きだから、他人が口を挟むことじゃないが。
>>959
確かに円周率計算は一般にもよく知られたHPCアプリだが、ただ知られているだけのことだ。
円周率を何兆桁も計算すること自体に科学的な意義はないよ。
観測可能な宇宙の円周をプランク長で割っても、円周率は60桁で足りてしまうんだから。
あれは、計算機の性能を計るための計算なんだよ。つまり、計算のための計算だ。
それはそれでコンピュータ工学的な意義はあるが、今の議論とは別の話だろう。
>>949氏や俺が指摘した「間に合わない時は倍精度で間に合わない」例ってことでしかない。
961 :,,・´∀`・,,)っ-○◎●:2009/04/11(土) 03:39:05 ID:4rAUMB1v
倍精度で間に合わない精度を補完する場合、単精度:倍精度=2:1程度なら倍精度使うでしょって話。
単精度はそんなに変わらなかったとしてもね。
FFTってよく使うライブラリの一つだと思ってたが。
灯台のサイトから落とせるSSE3対応のライブラリは倍精度×2のFFTであって単精度×4は無い
単精度はそんなに変わらなかったとしてもね。
FFTってよく使うライブラリの一つだと思ってたが。
灯台のサイトから落とせるSSE3対応のライブラリは倍精度×2のFFTであって単精度×4は無い
x64のfpはsse2ですが
964 :,,・´∀`・,,)っ-○◎●:2009/04/11(土) 03:53:31 ID:4rAUMB1v
>こんなもんこそ本来CPUに必要ない機能で
強烈な馬鹿を見た。
DirectXのレンダリングパイプラインの前半部分をCPUでやってきた歴史も知らないんだろうな
そういえばPenIII時代のノートでよくあったYAMAHAのXG音源って
MMX/SSEでソフト処理やってたんだよね。
やたら音質良かった。
GPUもLRBniに引導を渡す時代がくるんだろうな
強烈な馬鹿を見た。
DirectXのレンダリングパイプラインの前半部分をCPUでやってきた歴史も知らないんだろうな
そういえばPenIII時代のノートでよくあったYAMAHAのXG音源って
MMX/SSEでソフト処理やってたんだよね。
やたら音質良かった。
GPUもLRBniに引導を渡す時代がくるんだろうな
S3 chrome400のshader部分はcentaurが設計したという夢を見た
なんでか、積和算器じゃないのと、やたら高効率なので
sseを参考にしたユニットを8個並べたという夢を見た
たかだか、5千円程度のサウンドカードでVL(物理モデル音源)使えたってのは当時衝撃だった
でも、13年位たついまでもVL70-mっていうモデルは電子楽器としては珍しく、生産終了もせずいまでも残ってるってのは凄い。
なんでか、積和算器じゃないのと、やたら高効率なので
sseを参考にしたユニットを8個並べたという夢を見た
たかだか、5千円程度のサウンドカードでVL(物理モデル音源)使えたってのは当時衝撃だった
でも、13年位たついまでもVL70-mっていうモデルは電子楽器としては珍しく、生産終了もせずいまでも残ってるってのは凄い。
>>964
おおわらwww
SSEなんて物を積んできたからこそ
協業で使われるようになっただけの事
鶏か卵かも分からんとは酷い
SSEなんてなくてもソフトウェアは動きますよ?
むしろCPUが高速になった今となっては邪魔で仕方がない代物
CUDAにしたってUVDにしたって
昔からあるWindowアクセラレーションにしたって
その時代の標準的なハードウェアで性能が追いつかないなら
外付けで補うのがPCATのアーキテクチャだろうがwww
大体な
現在最高峰の790GXだってWindow描画では遅くて使いもんにならんし
3D処理にしても他のオンボよりは多少はマシ程度
Fusionになった所で構造的には何も変わらん
遠いメインメモリをシェアして他のデバイスとバス帯域を食い合う以上はな
Fusionになったら専用メモリを直結するとか
そんな情報でもどこかで見たのか?
今の段階ではどう見たって単純にオンダイになるだけ
それにな
YAMAHAのXGが音良いだあ?耳大丈夫か?
初期のLA-GSまでの機器でさえソフトウェア音源がかなうかよwww
標準で入ってるGS Tableの方が余程音良いというのにwwwwwwwwww
あのおまけのようなソフトウェアXG音源が音良いとかくるっとるwwwwww
おおわらwww
SSEなんて物を積んできたからこそ
協業で使われるようになっただけの事
鶏か卵かも分からんとは酷い
SSEなんてなくてもソフトウェアは動きますよ?
むしろCPUが高速になった今となっては邪魔で仕方がない代物
CUDAにしたってUVDにしたって
昔からあるWindowアクセラレーションにしたって
その時代の標準的なハードウェアで性能が追いつかないなら
外付けで補うのがPCATのアーキテクチャだろうがwww
大体な
現在最高峰の790GXだってWindow描画では遅くて使いもんにならんし
3D処理にしても他のオンボよりは多少はマシ程度
Fusionになった所で構造的には何も変わらん
遠いメインメモリをシェアして他のデバイスとバス帯域を食い合う以上はな
Fusionになったら専用メモリを直結するとか
そんな情報でもどこかで見たのか?
今の段階ではどう見たって単純にオンダイになるだけ
それにな
YAMAHAのXGが音良いだあ?耳大丈夫か?
初期のLA-GSまでの機器でさえソフトウェア音源がかなうかよwww
標準で入ってるGS Tableの方が余程音良いというのにwwwwwwwwww
あのおまけのようなソフトウェアXG音源が音良いとかくるっとるwwwwww
という、強烈な馬鹿を見た。
>>966
最近のコンパイラだと浮動小数点なんかはSSEのスカラー演算を使ってきます。
FPUは極力使わない傾向がトレンドのようです。
動画編集ソフトのフィルタ書いているものとしてはSSEは便利なんですけど。
最近のコンパイラだと浮動小数点なんかはSSEのスカラー演算を使ってきます。
FPUは極力使わない傾向がトレンドのようです。
動画編集ソフトのフィルタ書いているものとしてはSSEは便利なんですけど。
>>964
Pen3に SSE あったっけ?
Pen3に SSE あったっけ?
>>962
SSEは本来必要無いまで言い切るのはどうかね。正直バカとしか。
これだけ普及してそれこそ矛盾じゃないかね。本来とかいうのは初めから
全く必要無かったって事ですよ?
それと芝(ww)生やすのやめたほうが良いですよ。いくら正論言ったとしても痛い人にしか見えなくなるから。
>Fusionになったら専用メモリを直結するとか
>そんな情報でもどこかで見たのか?
>今の段階ではどう見たって単純にオンダイになるだけ
なんでまたFusionだの790GXがどうだのなんかAMDに絞ってるのかね。
現段階ではオンダイだけって別に次ぎだすものの事を誰もどうこう言ってるわけ
じゃ無いし。将来的にはそうなるのが必然でしょ。
intelの構想にもCPU+GPU+DRAMの構想はあるし。技術的にまだまだ問題を抱えてるが。
http://pc.watch.impress.co.jp/docs/2008/1226/kaigai_7.jpg
http://pc.watch.impress.co.jp/docs/2008/1226/kaigai_8l.gif
SSEは本来必要無いまで言い切るのはどうかね。正直バカとしか。
これだけ普及してそれこそ矛盾じゃないかね。本来とかいうのは初めから
全く必要無かったって事ですよ?
それと芝(ww)生やすのやめたほうが良いですよ。いくら正論言ったとしても痛い人にしか見えなくなるから。
>Fusionになったら専用メモリを直結するとか
>そんな情報でもどこかで見たのか?
>今の段階ではどう見たって単純にオンダイになるだけ
なんでまたFusionだの790GXがどうだのなんかAMDに絞ってるのかね。
現段階ではオンダイだけって別に次ぎだすものの事を誰もどうこう言ってるわけ
じゃ無いし。将来的にはそうなるのが必然でしょ。
intelの構想にもCPU+GPU+DRAMの構想はあるし。技術的にまだまだ問題を抱えてるが。
http://pc.watch.impress.co.jp/docs/2008/1226/kaigai_7.jpg
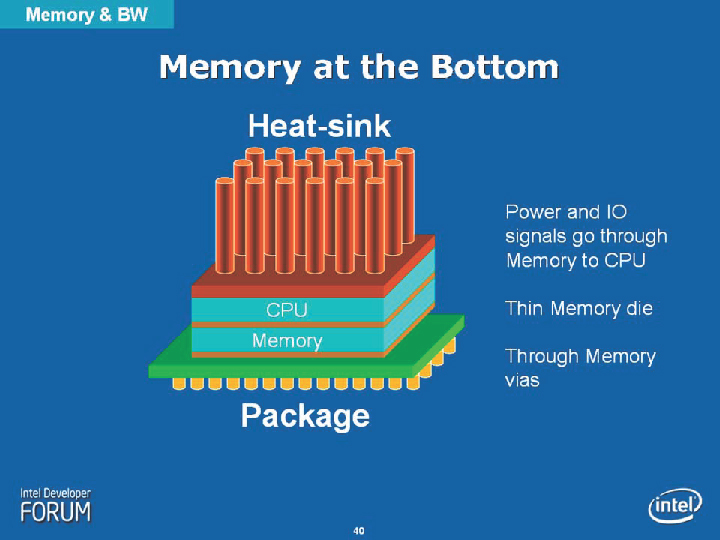{kind=link}
http://pc.watch.impress.co.jp/docs/2008/1226/kaigai_8l.gif
{kind=link}
>>970
ちょ・・SSEはPen3からだろ。
ちょ・・SSEはPen3からだろ。
sseのないpen3なんてpen2だろ
それもどうかと…w
976 :,,・´∀`・,,)っ-●◎○:2009/04/11(土) 16:38:19 ID:4rAUMB1v
>>969
弊害?ww
単精度で代替するほうが弊害大きいだろ
ハイエンドコンピューティングでは普通浮動小数といったらdouble
たとえば、SSE3の水平加算命令には倍精度haddpdがあるとは書いてるが
基本的に単精度のhaddpsには言及してない。全て倍精度前提で書かれてる。
これは東大の計算機センターの利用マニュアルの話だよ。
倍精度が弱くて単精度だけ速いハードってのは基本、問題児でしょ。
そりゃ単精度で事足りるものなら単精度で充分だろうけど、倍精度を単精度に置換したときの
精度落ちの影響はでかい
いまTeslaが選ばれる理由は、1TFLOPSと単精度が圧倒してて、
倍精度でも80GFLOPS程度と、そんなに悪くないからだろ。
単精度が圧倒してるのと同レベルで倍精度が圧倒してるハードが出たら
みんなそっち選ぶよって話。
単精度で1TFLOPSなら倍精度は500GFLOPSは出て欲しいんだよ。
弊害?ww
単精度で代替するほうが弊害大きいだろ
ハイエンドコンピューティングでは普通浮動小数といったらdouble
たとえば、SSE3の水平加算命令には倍精度haddpdがあるとは書いてるが
基本的に単精度のhaddpsには言及してない。全て倍精度前提で書かれてる。
これは東大の計算機センターの利用マニュアルの話だよ。
倍精度が弱くて単精度だけ速いハードってのは基本、問題児でしょ。
そりゃ単精度で事足りるものなら単精度で充分だろうけど、倍精度を単精度に置換したときの
精度落ちの影響はでかい
いまTeslaが選ばれる理由は、1TFLOPSと単精度が圧倒してて、
倍精度でも80GFLOPS程度と、そんなに悪くないからだろ。
単精度が圧倒してるのと同レベルで倍精度が圧倒してるハードが出たら
みんなそっち選ぶよって話。
単精度で1TFLOPSなら倍精度は500GFLOPSは出て欲しいんだよ。
977 :,,・´∀`・,,)っ-●◎○:2009/04/11(土) 16:39:57 ID:4rAUMB1v
>>974
いいや、Pentium IIにSSEを追加しただけのものだよ。
L2キャッシュ統合自体はPentium IIコアのCeleronであるMontecinoあたりでやってるし。
それでPentium IIより速くなっちゃったりしてw
いいや、Pentium IIにSSEを追加しただけのものだよ。
L2キャッシュ統合自体はPentium IIコアのCeleronであるMontecinoあたりでやってるし。
それでPentium IIより速くなっちゃったりしてw
978 :,,・´∀`・,,)っ-●◎○:2009/04/11(土) 16:42:55 ID:4rAUMB1v
* 高性能プログラミング(I)入門編
o http://www.cc.u-tokyo.ac.jp/publication/news/VOL10/No4/200807tuning.pdf
* 高性能プログラミング(II)上級編
o http://www.cc.u-tokyo.ac.jp/publication/news/VOL10/No5/200809tuning.pdf
ひつもん。
どこで単精度ますか?
SSEはもともとKatmai New Instructions(KNI)と呼ばれていたもの
んでこのKatmaiってのが何かというと初代PentiumIIIのコードネーム。
でPentiumIIIの中身は何なんだっつーと、PentiumII + KNI (SSE)
つまりSSEが無ければ、それはただのPentiumIIなわけだな。
んでこのKatmaiってのが何かというと初代PentiumIIIのコードネーム。
でPentiumIIIの中身は何なんだっつーと、PentiumII + KNI (SSE)
つまりSSEが無ければ、それはただのPentiumIIなわけだな。
980 :Socket774:2009/04/11(土) 17:20:38 ID:2bM2d4U2
元のMMXがゲームとか向きなんでSSEも倍精度は高速化の対象になっていないというか
FPU廃止したいがためにとってつけたような感じがする。
FPUはスタック形式なのでパイプラインによる高速化を阻害するかららしい。
インテルはIntel AVXでレジスタ長倍の256bitにしてくるので
倍精度4ユニット同時演算も可能になる。
CPUのSIMD処理能力は強化されるばっかりだわな。
というかクロックはこれ以上早くならんのでマルチコア化や命令セットの改良で
パフォーマンス上げるしかないようだ。
FPU廃止したいがためにとってつけたような感じがする。
FPUはスタック形式なのでパイプラインによる高速化を阻害するかららしい。
インテルはIntel AVXでレジスタ長倍の256bitにしてくるので
倍精度4ユニット同時演算も可能になる。
CPUのSIMD処理能力は強化されるばっかりだわな。
というかクロックはこれ以上早くならんのでマルチコア化や命令セットの改良で
パフォーマンス上げるしかないようだ。
981 :,,・´∀`・,,)っ-○◎●:2009/04/11(土) 17:39:31 ID:4rAUMB1v
ドライバ経由でベクトルをセットアップしてやんないといけないGPGPUは
レジスタ間転送命令一発で汎用レジスタ・XMMレジスタ間を転送できて
汎用演算ユニットと等速で動作するSSEの代用にはならないよ
むしろ高速なセットアップのためにSSEのシャッフル命令が使われたりする現状。
本当はIntelはカーネルモードではSSE使うなって言ってるんだけどww
レジスタ間転送命令一発で汎用レジスタ・XMMレジスタ間を転送できて
汎用演算ユニットと等速で動作するSSEの代用にはならないよ
むしろ高速なセットアップのためにSSEのシャッフル命令が使われたりする現状。
本当はIntelはカーネルモードではSSE使うなって言ってるんだけどww
過疎スレと思ってたら短期間にえらい伸びてるww
基地害が暴れてるからな。
三連続あぼーんワロタw
どんだけ必死なんだ
どんだけ必死なんだ
何のスレかわからなくなってるなw
【レポート】 見えてきた日本の次世代スパコン - GPUなどのアクセラレータを活用
http://journal.mycom.co.jp/articles/2009/03/18/riken_symposium2009/001.html
NVIDIA、CUDA 2.2β版を発表 - ハードウェア・デバッガなどを搭載
http://journal.mycom.co.jp/news/2009/04/10/057/index.html
http://journal.mycom.co.jp/articles/2009/03/18/riken_symposium2009/001.html
NVIDIA、CUDA 2.2β版を発表 - ハードウェア・デバッガなどを搭載
http://journal.mycom.co.jp/news/2009/04/10/057/index.html
988 :,,・´∀`・,,)っ-○◎●:2009/04/11(土) 21:29:28 ID:4rAUMB1v
なんのけんきゅうですか?
なつやすみのしゅくだいですか?
富士通が開発してるSPARC64 VIIIfxって最大128GFLOPSなんだけど
アレ倍精度の値な。
単精度のほうがFLOPS数稼げるのになんで倍精度のスペックを前面にだすかって?
ハイエンドコンピューティング市場ってのはそういうものだからだ。
TOP500の根拠となるLINPACKスコアも倍精度。
単精度(笑)がメインで使われる世界の方がニッチですよ。
なつやすみのしゅくだいですか?
富士通が開発してるSPARC64 VIIIfxって最大128GFLOPSなんだけど
アレ倍精度の値な。
単精度のほうがFLOPS数稼げるのになんで倍精度のスペックを前面にだすかって?
ハイエンドコンピューティング市場ってのはそういうものだからだ。
TOP500の根拠となるLINPACKスコアも倍精度。
単精度(笑)がメインで使われる世界の方がニッチですよ。
>>988
はい? 残念ながら、東大大学院出の研究員などが集まって、
日本で三本の指に入る売り上げを誇る研究所なんですけど?
で、おまえ、倍精度による弊害って「どんなこと」か理解してないだろ?
やーい、バーカ。
はい? 残念ながら、東大大学院出の研究員などが集まって、
日本で三本の指に入る売り上げを誇る研究所なんですけど?
で、おまえ、倍精度による弊害って「どんなこと」か理解してないだろ?
やーい、バーカ。
何言っても通じない馬鹿なんだからあぼーんしとけよ。
このスレ自体あぼ〜んしてもいいけどね
992 :,,・´∀`・,,)っ-○◎●:2009/04/11(土) 22:19:17 ID:4rAUMB1v
3本の指っていうのは保険金かけて指チョンパしちゃった人なんですか?
5本とは言うけど3本とは言わないんだよね。
あと、1位や2位は「3大〜」なんて言わない法則がある。
あと「研究所」で売上げとかさ・・・
ちなみに理研や産総研、あと国立大学なんかはいくら独立行政法人化したとはいえ、
「売上」なんて言わないんですよ。公共機関の会計はあくまで「歳入」です。
ようは国営でない真空タンクさんなんでしょ。
登記上「株式会社●●研究所」を名乗るのは自由だからね。
でその、三菱総研の人がどんなアプリ作ってるの?
あらゆる科学技術計算のベンチマークは倍精度基準ですよ。
大学、旧国研しかり。予算規模が違いますって。
私企業はコスト重視だから単精度でも無理して頑張るんだろw
赤ポスにありつけた人間はシンクタンクなんて馬鹿にしてるのが現実だったり。
で、君らより数段エリートな人間の意見がこれだ
http://www.human.nagoya-u.ac.jp/~yasudak/QCGPU-1.html
> GPU計算の欠点
>
> 1. 単精度計算は高速だが、倍精度計算は遅い。つまりかなりの計算を単精度で
> 行える場合は高速化できる。倍精度演算器は単精度の5倍の規模が必要な事、
> 科学技術計算の市場の狭さを考えると、倍精度で価格性能比が悪くなるのはやむを得まい。
> 2. 汎用CPUとは異なり、メモリーアクセスは遅く、threadに割り当てられるリソースも僅かである。
> Pipeline stallを隠すため、細粒度で多数の並列処理が必要である。ハードウェアが
> 汎用CPUとかなり異なり、別のアルゴリズムやプログラムが必要である。
> また GPUの計算速度(数百GLOPS)に比べて、CPU-GPU間の通信速度(PCI Express, 数十GB/sec)
> はとても遅い。
> 3. ホストで行う逐次処理は遅いので、アムダールの法則から、全計算の殆どを
> GPUで行わないと速くならない。つまり計算の核心部分は、GPU用に再度書き直す必要がある。
5本とは言うけど3本とは言わないんだよね。
あと、1位や2位は「3大〜」なんて言わない法則がある。
あと「研究所」で売上げとかさ・・・
ちなみに理研や産総研、あと国立大学なんかはいくら独立行政法人化したとはいえ、
「売上」なんて言わないんですよ。公共機関の会計はあくまで「歳入」です。
ようは国営でない真空タンクさんなんでしょ。
登記上「株式会社●●研究所」を名乗るのは自由だからね。
でその、三菱総研の人がどんなアプリ作ってるの?
あらゆる科学技術計算のベンチマークは倍精度基準ですよ。
大学、旧国研しかり。予算規模が違いますって。
私企業はコスト重視だから単精度でも無理して頑張るんだろw
赤ポスにありつけた人間はシンクタンクなんて馬鹿にしてるのが現実だったり。
で、君らより数段エリートな人間の意見がこれだ
http://www.human.nagoya-u.ac.jp/~yasudak/QCGPU-1.html
> GPU計算の欠点
>
> 1. 単精度計算は高速だが、倍精度計算は遅い。つまりかなりの計算を単精度で
> 行える場合は高速化できる。倍精度演算器は単精度の5倍の規模が必要な事、
> 科学技術計算の市場の狭さを考えると、倍精度で価格性能比が悪くなるのはやむを得まい。
> 2. 汎用CPUとは異なり、メモリーアクセスは遅く、threadに割り当てられるリソースも僅かである。
> Pipeline stallを隠すため、細粒度で多数の並列処理が必要である。ハードウェアが
> 汎用CPUとかなり異なり、別のアルゴリズムやプログラムが必要である。
> また GPUの計算速度(数百GLOPS)に比べて、CPU-GPU間の通信速度(PCI Express, 数十GB/sec)
> はとても遅い。
> 3. ホストで行う逐次処理は遅いので、アムダールの法則から、全計算の殆どを
> GPUで行わないと速くならない。つまり計算の核心部分は、GPU用に再度書き直す必要がある。
ume
994 :,,・´∀`・,,)っ-○◎●:2009/04/11(土) 22:26:16 ID:4rAUMB1v
単精度(笑)あげ
995 :,,・´∀`・,,)っ-○◎●:2009/04/11(土) 22:29:48 ID:4rAUMB1v
単精度番長あげ(笑)
996 :Socket774:2009/04/11(土) 22:34:57 ID:nukDJ3HN
一言で言うとNASを導入してLANの激遅さに驚いている状態なんですよ。
団子顔真っ赤あげ1000げっと
今
時代は
1000 :,,・´∀`・,,)っ-○◎●:2009/04/11(土) 22:46:32 ID:4rAUMB1v
俺の時代
1001 :1001: