AMD�̎�����CPU�ɂ��Č�낤 ��8����
���������[�h�}�b�v
���i���[�h�}�b�v �i�Z���j
ttp://www.amdcompare.com/prodoutlook/
�e�N�m���W�E���[�h�}�b�v �i3�N�j
ttp://www.amdcompare.com/techoutlook/
���O�X��
7 http://pc7.2ch.net/test/read.cgi/jisaku/1161618220/
6 http://pc7.2ch.net/test/read.cgi/jisaku/1157327883/
5 http://pc7.2ch.net/test/read.cgi/jisaku/1150393478/
4 http://pc7.2ch.net/test/read.cgi/jisaku/1145187468/
3 http://pc7.2ch.net/test/read.cgi/jisaku/1138983969/
2 http://pc7.2ch.net/test/read.cgi/jisaku/1133374045/
1 http://pc7.2ch.net/test/read.cgi/jisaku/1124542812/
�����AMD�n�X���b�h�ߋ����O�ۑ��T�C�g�l
http://amd.jisakuita.net/
���֘A�X��
CPU�A�[�L�e�N�`���ɂ��Č�� 5
http://pc7.2ch.net/test/read.cgi/jisaku/1159238563/
Intel�̎�����CPU�ɂ��Č�낤 26
http://pc7.2ch.net/test/read.cgi/jisaku/1157019837/
�Q�Q�Q_
�_.�Q�@ | �r�炵�E����E�~�[�͕��u����ԁB
�^|�Q|�@| �ނ�ꂸ�ɃX���[���܂��傤�B
|�Q�^�_! sage�i�s�Ń}�^�[�������܂��傤
���i���[�h�}�b�v �i�Z���j
ttp://www.amdcompare.com/prodoutlook/
�e�N�m���W�E���[�h�}�b�v �i3�N�j
ttp://www.amdcompare.com/techoutlook/
���O�X��
7 http://pc7.2ch.net/test/read.cgi/jisaku/1161618220/
6 http://pc7.2ch.net/test/read.cgi/jisaku/1157327883/
5 http://pc7.2ch.net/test/read.cgi/jisaku/1150393478/
4 http://pc7.2ch.net/test/read.cgi/jisaku/1145187468/
3 http://pc7.2ch.net/test/read.cgi/jisaku/1138983969/
2 http://pc7.2ch.net/test/read.cgi/jisaku/1133374045/
1 http://pc7.2ch.net/test/read.cgi/jisaku/1124542812/
�����AMD�n�X���b�h�ߋ����O�ۑ��T�C�g�l
http://amd.jisakuita.net/
���֘A�X��
CPU�A�[�L�e�N�`���ɂ��Č�� 5
http://pc7.2ch.net/test/read.cgi/jisaku/1159238563/
Intel�̎�����CPU�ɂ��Č�낤 26
http://pc7.2ch.net/test/read.cgi/jisaku/1157019837/
�Q�Q�Q_
�_.�Q�@ | �r�炵�E����E�~�[�͕��u����ԁB
�^|�Q|�@| �ނ�ꂸ�ɃX���[���܂��傤�B
|�Q�^�_! sage�i�s�Ń}�^�[�������܂��傤
|
|
|
�@�@�@ ,-'�P�P�P�R/"�_�A
�@�@�^�@�Q�R�_�@�@Ɂ@|_ �R�A�X�N�G�j�̋~���傱�Ɠc���O���l��2�Q�b�g�I
�@/ ��\�@�@�@�R | |/�@�@�@�R
/�@�@,,,,,,,,,,,,,,,,---"�R�@�@�@�@|�@>>1��7���͎��̒a�����ł���ł�낵��
|�@/�@//�@�@�@�@:::::::::::| �_�@|�@�f�r����>>3�Ɛ��N�������ꏏ�B���t�^�����B
|�@|:::�R�@�@�@�@ ..::::::::::�k�R�@ |�@ >>4���[�g�Ŏ��𑝂₵���̂Ŗ��͉�������B
|�@|/==�A�@ , ==�R�@::::::|_ �@|�@ >>5���y���z�[���ɂ͖���s���B
�_|-���R�@ -��z�@ ::::::|_| �j�@ �f���[�v���Y>>6�ʔ����ł���
�@ | �P� | |�@�R-'�@�@:::: || |�@�@�����>>7�C�g�𒆐S�ɃW���u�o�����X�̒��������܂�
�@ |�@�@/ | |�@�j�@�@�@�@:::� "�@�@>>8�@�C�i���t�@���^�W�[1�`3������ĉ������ˁB
�@ '�A�@�@�O_�O�@�@�@�@�@ /�@�@�@�@>>9���m�N���X����낵��
�@�@�R�@ -==-�@�@�@�@/
�@�@�@�_ �P �@�@�@�^�@�@�@�@�@����>>1000�@�͑z��O
�@_, �]'�L�@ �_�@ /�@`��_
/ '�P�MY�L�P�MY�L�P�M���܁R
{�@��@ ɤ�@ �@ |�@�@_,,�,_�@�l
'���@�S`�[�`'�L�P__�����@�
�_�R��@�@ �[�@�^�@�[�@�@�r
�@�@�_�M�R-�]'�L�P�M�k�-��
�@�@�^�@�Q�R�_�@�@Ɂ@|_ �R�A�X�N�G�j�̋~���傱�Ɠc���O���l��2�Q�b�g�I
�@/ ��\�@�@�@�R | |/�@�@�@�R
/�@�@,,,,,,,,,,,,,,,,---"�R�@�@�@�@|�@>>1��7���͎��̒a�����ł���ł�낵��
|�@/�@//�@�@�@�@:::::::::::| �_�@|�@�f�r����>>3�Ɛ��N�������ꏏ�B���t�^�����B
|�@|:::�R�@�@�@�@ ..::::::::::�k�R�@ |�@ >>4���[�g�Ŏ��𑝂₵���̂Ŗ��͉�������B
|�@|/==�A�@ , ==�R�@::::::|_ �@|�@ >>5���y���z�[���ɂ͖���s���B
�_|-���R�@ -��z�@ ::::::|_| �j�@ �f���[�v���Y>>6�ʔ����ł���
�@ | �P� | |�@�R-'�@�@:::: || |�@�@�����>>7�C�g�𒆐S�ɃW���u�o�����X�̒��������܂�
�@ |�@�@/ | |�@�j�@�@�@�@:::� "�@�@>>8�@�C�i���t�@���^�W�[1�`3������ĉ������ˁB
�@ '�A�@�@�O_�O�@�@�@�@�@ /�@�@�@�@>>9���m�N���X����낵��
�@�@�R�@ -==-�@�@�@�@/
�@�@�@�_ �P �@�@�@�^�@�@�@�@�@����>>1000�@�͑z��O
�@_, �]'�L�@ �_�@ /�@`��_
/ '�P�MY�L�P�MY�L�P�M���܁R
{�@��@ ɤ�@ �@ |�@�@_,,�,_�@�l
'���@�S`�[�`'�L�P__�����@�
�_�R��@�@ �[�@�^�@�[�@�@�r
�@�@�_�M�R-�]'�L�P�M�k�-��
3��������3�R�A�̂��o��
�`�l�c�̂U�T�����v���Z�X�i�j
AMD�}���Z�[�����N�b�\���~�ǂ����I��
6 �F1000�F2006/12/25(��) 19:55:20 ID:hYDjvGwj
6��������AMD������
7 �FSocket774�F2006/12/25(��) 20:11:35 ID:Df/U2VRM
�uAMD Athlon64 65nm(by IBM) SOI(by IBM)�v���Z�b�T�[�v
8 �FSocket774�F2006/12/25(��) 20:19:57 ID:hYDjvGwj
8��������IBM�ɔ��������
9��������т�9�{�z������K9�̊���
K9���Ă�̂��ƂȂ�ˁH
�с[������
�n�Q�b�A���B
�n�Q�b�A���B
�Ȃ�Řb����Ȃ����X�����Ă�̂��Ӗ��s��
�r�炵�����Ă��̂��H
�G�k�X���ŏ\�����낤
�r�炵�����Ă��̂��H
�G�k�X���ŏ\�����낤
�O�X�����Ă݂�H
�������A�z���ȁB
�������A�z���ȁB
�������A�����̖ϑz��Intel�@���̃X������Ȃ���
��������PenD�̘b����肾����
�ŐV�s��QUAD FX�Ɋւ���}���Z�[�b���Ȃ�
��������PenD�̘b����肾����
�ŐV�s��QUAD FX�Ɋւ���}���Z�[�b���Ȃ�
���Ⴀ���N��U��Ԃ�
5���B�\�P�b�gAM2�ƃ��r�W����F���o��BOpteron���\�P�b�gF�Ɉڍs�B
11���BFX�u�����h���\�P�b�gF�Ɉڍs�i���\�̂݁j�B
12���B65nm�ł����\�i�̂݁j�B
����\�ȋZ�p�I�v�V��AM2�������ȁB
5���B�\�P�b�gAM2�ƃ��r�W����F���o��BOpteron���\�P�b�gF�Ɉڍs�B
11���BFX�u�����h���\�P�b�gF�Ɉڍs�i���\�̂݁j�B
12���B65nm�ł����\�i�̂݁j�B
����\�ȋZ�p�I�v�V��AM2�������ȁB
�ł��܂��c�ƓI�ɂ͂��܂��������N����ˁ[�́H
�܂����l�����̌��Z�͏o�ĂȂ����ǁB
�܂����l�����̌��Z�͏o�ĂȂ����ǁB
����ł����玟���ザ��Ȃ���K�X
>>14
�������A�z����
�������A�z����
AMD�ЁA300mm�E�G�n�[�Ή��H����j���[���[�N�B�ɐV�݂�
ttp://www.eetimes.jp/contents/200612/13779_1_20061227174631.cfm
ttp://www.eetimes.jp/contents/200612/13779_1_20061227174631.cfm
�b�肪�Ȃ��̂ɖ������ē\��Ȃ��Ă�����
K8L�ւ̈ڍs�͊ɂ₩��
http://northwood.blog60.fc2.com/blog-entry-457.html
�����̐V�f�X�N�g�b�vCPU��SocketAM2+���̗p���A���݂̃v���b�g�t�H�[���Ƃ͌݊������Ȃ��Ƃ����i���j�B
SocketAM2+ CPU��2007�N��4�l������AMD�́i�f�X�N�g�b�v�i�H�j�jCPU�o�חʂ�20���ƂȂ�A
2008�N��1�l�������ɂ�60���ȏ�ƂȂ�B
���̏�������Ƃ���ƁAAMD�͐V�A�[�L�e�N�`���E�V�v���b�g�t�H�[����60�`70����
��߂�悤�ɂȂ�܂ł�3�l�����������邱�ƂɂȂ�B
�f�X�N�g�b�vCPU��Socket754 / 939����
SocketAM2�֎�����2�l�����ňڍs���Ă��܂����̂Ƃ͑ΏƓI�ł���B
http://northwood.blog60.fc2.com/blog-entry-457.html
�����̐V�f�X�N�g�b�vCPU��SocketAM2+���̗p���A���݂̃v���b�g�t�H�[���Ƃ͌݊������Ȃ��Ƃ����i���j�B
SocketAM2+ CPU��2007�N��4�l������AMD�́i�f�X�N�g�b�v�i�H�j�jCPU�o�חʂ�20���ƂȂ�A
2008�N��1�l�������ɂ�60���ȏ�ƂȂ�B
���̏�������Ƃ���ƁAAMD�͐V�A�[�L�e�N�`���E�V�v���b�g�t�H�[����60�`70����
��߂�悤�ɂȂ�܂ł�3�l�����������邱�ƂɂȂ�B
�f�X�N�g�b�vCPU��Socket754 / 939����
SocketAM2�֎�����2�l�����ňڍs���Ă��܂����̂Ƃ͑ΏƓI�ł���B
AMD��̗��j
���Ɋ肢���`K8L��DDR2-1066��SSE4A���T�|�[�g����
http://northwood.blog60.fc2.com/blog-entry-460.html
http://northwood.blog60.fc2.com/blog-entry-460.html
�ǂ����Ă�Fantasmic�ł�
�{���ɂ��肪�Ƃ��������܂���
�{���ɂ��肪�Ƃ��������܂���
�\�P�b�g�ύX�̃��[�h�}�b�v�͔��ɃA�O���b�V�u����Ȃ���
AM2�FDDR2�AHT2,0
AM2+�FDDR2�AHT3.0�AAM2�ƌ݊�
AM3�FDDR3�AHT3.0�AAM2+�ƌ݊��AAM2�Ƃ͌݊��Ȃ�
���HDDR3���x��邩��HT3.0���ɓ������悤�Ɓc�ш�s��������ȁH
AM2+�FDDR2�AHT3.0�AAM2�ƌ݊�
AM3�FDDR3�AHT3.0�AAM2+�ƌ݊��AAM2�Ƃ͌݊��Ȃ�
���HDDR3���x��邩��HT3.0���ɓ������悤�Ɓc�ш�s��������ȁH
�}���`Socket�ȃV�X�e���ł́AHT�̑��x�̓������̑��x�ɔ�ׂ��
��ɑш�s������B
��ɑш�s������B
DDR3-1066����DDR2-800��萫�\�ቺ����Ƃ��B
������O�B
�Ƃ����Fantasmic���ĉ��H
�ǂ����̗m�y�̖��O�̂悤�����E�E�E�B
�ǂ����̗m�y�̖��O�̂悤�����E�E�E�B
32 �FSocket774�F2006/12/29(��) 17:21:47 ID:h5YCXuaR
Wish upon a star�ł͂��܂�Nightwish�̋�
33 �FSocket774�F2006/12/30(�y) 17:40:41 ID:WHiNF7PB
���H���������_�܂����H
34 �FSocket774�F2006/12/30(�y) 20:44:57 ID:ssqZ7UR0
>29 ���O�FSocket774 ���e���F2006/12/29(��) 16:27:22 ID:jC+S4yxT
>DDR3-1066����DDR2-800��萫�\�ቺ����Ƃ��B
>
>30 ���O�FSocket774 ���e���F2006/12/29(��) 16:51:56 ID:7CsHTMQF
>������O�B
�����Ȃ́H
>DDR3-1066����DDR2-800��萫�\�ቺ����Ƃ��B
>
>30 ���O�FSocket774 ���e���F2006/12/29(��) 16:51:56 ID:7CsHTMQF
>������O�B
�����Ȃ́H
�o�[�X�g���\��x�O�������ꍇ�A
DDR-400 = DDR2-800 = DDR3-1600 �ɂȂ�B
���C�e���V�̂������Œ��ח��x���\�����Ȃ�DDR-400���g�b�v�ɂȂ����������B
DDR-400 = DDR2-800 = DDR3-1600 �ɂȂ�B
���C�e���V�̂������Œ��ח��x���\�����Ȃ�DDR-400���g�b�v�ɂȂ����������B
�����ȂB���ɂȂ�����B
�ЂƂ����Ȃ����B
���肪�Ƃ��B
�ЂƂ����Ȃ����B
���肪�Ƃ��B
>>35
> �o�[�X�g���\��x�O�������ꍇ
�x�O��������_������w
����AM2��939��萫�\�����A���̍����Ƃ��ă������ш敝�̋����ɂ��
RAM Bandwidth Test�ł�C2D��2�{���x�̐��\�ƂȂ��Ă�B
�t��939��C2D������Ă邵�B
> �o�[�X�g���\��x�O�������ꍇ
�x�O��������_������w
����AM2��939��萫�\�����A���̍����Ƃ��ă������ш敝�̋����ɂ��
RAM Bandwidth Test�ł�C2D��2�{���x�̐��\�ƂȂ��Ă�B
�t��939��C2D������Ă邵�B
39 �FSocket774�F2007/01/02(��) 13:13:53 ID:lYU6FwYd
�o�[�X�g�]�����Ă���ȂɗL���Ȃ́H
���ɃQ�[���ŁB
���ɃQ�[���ŁB
>>39
�܂����Ă݂�B
X2 3800+(939) vs X2 3800+(AM2)
> ttp://www23.tomshardware.com/cpu.html?modelx=33&model1=471&model2=480&chart=170
�܂����Ă݂�B
X2 3800+(939) vs X2 3800+(AM2)
> ttp://www23.tomshardware.com/cpu.html?modelx=33&model1=471&model2=480&chart=170
DDR2-800�ł̘b����H���C�e���V�������������������Ă̂́AAMD���F�߂ĂȂ����������H
DDR2-667�Ȃ�Ƃ������A533���ƁADDR-400�̕�������Č��ʂ������Ǝv�����B
DDR2-667�Ȃ�Ƃ������A533���ƁADDR-400�̕�������Č��ʂ������Ǝv�����B
�����A���������ǂ߂ĂȂ������̂��B
���X��DDR3-1066��DDR2-800���x����ˁ[�̂��ă��X����������A
DDR2-800��DDR-400��葬�����ē�����O�̂��ƌ����Ăǂ�������Ċ��Ⴂ������B
���X��DDR3-1066��DDR2-800���x����ˁ[�̂��ă��X����������A
DDR2-800��DDR-400��葬�����ē�����O�̂��ƌ����Ăǂ�������Ċ��Ⴂ������B
DDR3-1066�̂������\���ȓd��
http://www.hkepc.com/bbs/itnews.php?tid=687974&starttime=0&endtime=0
http://www.hkepc.com/bbs/itnews.php?tid=687974&starttime=0&endtime=0
�ȓd�͂��낤���ǁA�ǂ���1600���ł�܂ł݂�ȗl�q�����H
AMD���S�̓��߂��̂��H
�����������茈�肵���̂ɈӖ��˂�����Ȃ���
�����������茈�肵���̂ɈӖ��˂�����Ȃ���
����g��
�~L2�̃��C�e���V���A12�T�C�N����20�T�C�N���ɑ���
��L2�̃��C�e���V���A12�T�C�N����14�T�C�N���ɑ���
�x���`�}�[�N�ɐ��\�̒ቺ���قƂ�ǂłȂ��̂́A
���C�e���V���قƂ�Ǒ������ĂȂ����������̂��Ƃ�������
��L2�̃��C�e���V���A12�T�C�N����14�T�C�N���ɑ���
�x���`�}�[�N�ɐ��\�̒ቺ���قƂ�ǂłȂ��̂́A
���C�e���V���قƂ�Ǒ������ĂȂ����������̂��Ƃ�������
>>48
�R�A�̃^�[�Q�b�g��2.4GHz����2.8GHz�ɕς�����ƍl��������̂��ȁH
�R�A�̃^�[�Q�b�g��2.4GHz����2.8GHz�ɕς�����ƍl��������̂��ȁH
90nm��3.2GHz�܂ŗ\�肳��Ă錻��ł��̃^�[�Q�b�g�͂�������
>>50
Northwood�̓^�[�Q�b�g2.8GHz�������̂ɁA3.4GHz�܂œ���������Ȃ����B
Presco�̂悤�Ƀ^�[�Q�b�g4.0GHz�ɓ͂��Ȃ������厸�s����܂�ɂ��邯�ǁB
Northwood�̓^�[�Q�b�g2.8GHz�������̂ɁA3.4GHz�܂œ���������Ȃ����B
Presco�̂悤�Ƀ^�[�Q�b�g4.0GHz�ɓ͂��Ȃ������厸�s����܂�ɂ��邯�ǁB
>>51
�v���X�R��4GHz�o���Ȃ������̂ƁA
90nm��3.2GHz���o�����Ƃ��Ă�͎̂��Ă�C��������
�v���X�R�͖����ɏo���Ȃ�����
FX�͖������ďo��
�v���X�R��4GHz�o���Ȃ������̂ƁA
90nm��3.2GHz���o�����Ƃ��Ă�͎̂��Ă�C��������
�v���X�R�͖����ɏo���Ȃ�����
FX�͖������ďo��
�������ďo���@3.0�@�|�`���܂�
��������
��������
��������AMD�~�ƌĂ��A����Netburst��@�ŏ��Ă�����̂�
Prescott����������������(���m�ɂ�90nm�̃��[�N����intel�����s����������)
����������Netburst�̍ŐV�R�ACedarmill�������[�X����Ă���ȏ�A
Prescott�̘b�肷����Ɏ���x��������Ƃ���̂悤�ȋC��������A
Core2�ɎU�X�Ȗڂɂ����Ă��鍡�ł���������o���͉̂��̂���?
�m�M�ƓI�ɁA����ȍ��������������o���̂���?
Prescott����������������(���m�ɂ�90nm�̃��[�N����intel�����s����������)
����������Netburst�̍ŐV�R�ACedarmill�������[�X����Ă���ȏ�A
Prescott�̘b�肷����Ɏ���x��������Ƃ���̂悤�ȋC��������A
Core2�ɎU�X�Ȗڂɂ����Ă��鍡�ł���������o���͉̂��̂���?
�m�M�ƓI�ɁA����ȍ��������������o���̂���?
���ł�PenD�Ɣ�ׂ�͔̂n���ȊO�̉��҂ł��Ȃ���ȁB
C2D�ɂƂ��Ēǂ����������̂�DDR2�̗p�Ń��������̂̃��C�e���V���オ���āA
�m�[�X�o�R�ł������܂ő傫�ȍ����o�Ȃ��Ȃ������Ă��ƁB
����ɑ傫��2���L���b�V����Pen3�啝���̐V�R�A�B
�����64�ɕ����Ă��炻�ꂱ���b�ɂȂ��B
��Ђ̋K�͂��l������AMD�͂������撣���Ă�B
Intel�݂����Ȓ������ƂƓ����y�[�X�ŊJ���ł���킯�Ȃ���ŁA
AMD�͐��N�Ɉ�x�̃y�[�X�Ŗ��i����B
����ł�������Ȃ����B
L3�L���b�V�����ڃR�A�ɂ͊��҂��Ă��B
C2D�ɂƂ��Ēǂ����������̂�DDR2�̗p�Ń��������̂̃��C�e���V���オ���āA
�m�[�X�o�R�ł������܂ő傫�ȍ����o�Ȃ��Ȃ������Ă��ƁB
����ɑ傫��2���L���b�V����Pen3�啝���̐V�R�A�B
�����64�ɕ����Ă��炻�ꂱ���b�ɂȂ��B
��Ђ̋K�͂��l������AMD�͂������撣���Ă�B
Intel�݂����Ȓ������ƂƓ����y�[�X�ŊJ���ł���킯�Ȃ���ŁA
AMD�͐��N�Ɉ�x�̃y�[�X�Ŗ��i����B
����ł�������Ȃ����B
L3�L���b�V�����ڃR�A�ɂ͊��҂��Ă��B
> C2D�ɂƂ��Ēǂ����������̂�DDR2�̗p�Ń��������̂̃��C�e���V���オ���āA
> �m�[�X�o�R�ł������܂ő傫�ȍ����o�Ȃ��Ȃ������Ă��ƁB
����͔[���ł��Ȃ��Ȃ��B
X2(939)��X2(AM2)���ׂ�Ƃ�͂�AM2�̕��������A���C�e�V�͂���Ȃɑ傫�Ȗ��ł͂Ȃ������B
Netburst�ɖ�肪��������������B
�����Athlon64��AthlonXP���ׂĂ݂Ă��ɒ[�ɐ��\�����������킯�ł͂Ȃ�����
�����R�����ڂɂ�郌�C�e���V�팸���ʂ��ߑ�]������������B
K8L��L3�������ŁA4Way�ȏ�Ȃ�傫�ȃ����b�g�ނ��낤��2Way���x�܂łȂ瑛���悤�Ȃ��̂���Ȃ��B
> �m�[�X�o�R�ł������܂ő傫�ȍ����o�Ȃ��Ȃ������Ă��ƁB
����͔[���ł��Ȃ��Ȃ��B
X2(939)��X2(AM2)���ׂ�Ƃ�͂�AM2�̕��������A���C�e�V�͂���Ȃɑ傫�Ȗ��ł͂Ȃ������B
Netburst�ɖ�肪��������������B
�����Athlon64��AthlonXP���ׂĂ݂Ă��ɒ[�ɐ��\�����������킯�ł͂Ȃ�����
�����R�����ڂɂ�郌�C�e���V�팸���ʂ��ߑ�]������������B
K8L��L3�������ŁA4Way�ȏ�Ȃ�傫�ȃ����b�g�ނ��낤��2Way���x�܂łȂ瑛���悤�Ȃ��̂���Ȃ��B
>57
>Athlon64��AthlonXP���ׂĂ݂Ă��ɒ[�ɐ��\�����������킯�ł͂Ȃ�
ttp://www23.tomshardware.com/cpu_2004.html?modelx=33&model1=76&model2=70&chart=17
�܂��B���ꂪ���������̂Ȃ�AC2D��Athlon64�����債�č��͖����ȁB
>Athlon64��AthlonXP���ׂĂ݂Ă��ɒ[�ɐ��\�����������킯�ł͂Ȃ�
ttp://www23.tomshardware.com/cpu_2004.html?modelx=33&model1=76&model2=70&chart=17
�܂��B���ꂪ���������̂Ȃ�AC2D��Athlon64�����債�č��͖����ȁB
�܂��AIntel�̑��݂������AMD�͂܂�����Ƃ��Ē����Ȑi�������Ă���̂ł́H
���̎��ӂ�Intel���h��ɃA�N���o�b�g���Ă��邩�犴�o��������邯�ǁB
���̎��ӂ�Intel���h��ɃA�N���o�b�g���Ă��邩�犴�o��������邯�ǁB
>>59
1�N��2.4GHz��2.8GHz�Ƃ����������A�덷�͈̔͂��炿����Ƃ����͂ݏo�����炢�Ȃ��c
2002���̌v��ł́A2003�N���̎��_��Socket754�L���b�V��256KB�ł�4000+�o���͂��������炵����
1�N��2.4GHz��2.8GHz�Ƃ����������A�덷�͈̔͂��炿����Ƃ����͂ݏo�����炢�Ȃ��c
2002���̌v��ł́A2003�N���̎��_��Socket754�L���b�V��256KB�ł�4000+�o���͂��������炵����
>>59
K8�̒x�ꂪK9&K10�ɑS�ĉe���������ǂȁB
���̉ߒ��ł܂����Ȃɂ��F�X���w������
AMD�̒��̐l�̍X�ɒ��ŋN���āA
�ǂ������������������c�B
>>60
�v��͗\��ʂ�ɂ͍s���Ȃ��̂��c�B
������Intel�̖����ɔ�ׂ���܂������B
K8�̒x�ꂪK9&K10�ɑS�ĉe���������ǂȁB
���̉ߒ��ł܂����Ȃɂ��F�X���w������
AMD�̒��̐l�̍X�ɒ��ŋN���āA
�ǂ������������������c�B
>>60
�v��͗\��ʂ�ɂ͍s���Ȃ��̂��c�B
������Intel�̖����ɔ�ׂ���܂������B
K9��K10���č����S�Ƀ��[�h�}�b�v��������Ă��ȁH
���Ƃ����o��������
���Ƃ����o��������
>>57
AM2��65nm��90nm�ɎS�s���Ă�̂́H
AM2��65nm��90nm�ɎS�s���Ă�̂́H
>>62
���X��K9/K10�̓L�����Z������Ȃ��́H����90nm�ł̃u���[�L�������̂��O���
�A�[�L�e�N�`���������Ǝv����
�B
�ŁA���͌��X��K8���}���`�R�A�����Ď��Ԃ��҂��AK8L��������Fusion��������́A
����̕��ʂ̋����ɑ���ƁB
���X��K9/K10�̓L�����Z������Ȃ��́H����90nm�ł̃u���[�L�������̂��O���
�A�[�L�e�N�`���������Ǝv����
�B
�ŁA���͌��X��K8���}���`�R�A�����Ď��Ԃ��҂��AK8L��������Fusion��������́A
����̕��ʂ̋����ɑ���ƁB
>>63
���̍��́u�͍��v���u�S�s�v�Ƃ����悤�ɂȂ����̂��B
�������u�����Ă��鍀�ځv�Ɓu�����Ă��鍀�ځv���A
�������Ă���̂ɕЕ��������Ȃ��̂��f�t�H�Ȃ̂��c�B
�A�~�I�ȃx���`���ʂ̌������ȁB
���̍��́u�͍��v���u�S�s�v�Ƃ����悤�ɂȂ����̂��B
�������u�����Ă��鍀�ځv�Ɓu�����Ă��鍀�ځv���A
�������Ă���̂ɕЕ��������Ȃ��̂��f�t�H�Ȃ̂��c�B
�A�~�I�ȃx���`���ʂ̌������ȁB
>>58
> ttp://www23.tomshardware.com/cpu_2004.html?modelx=33&model1=76&model2=70&chart=17
> �܂��B���ꂪ���������̂Ȃ�AC2D��Athlon64�����債�č��͖����ȁB
��ׂ���̂��Ⴄ����B
��ׂ�̂Ȃ�Athlon64�͏���̂��o����w
> ttp://www23.tomshardware.com/cpu_2004.html?modelx=33&model1=76&model2=70&chart=17
> �܂��B���ꂪ���������̂Ȃ�AC2D��Athlon64�����債�č��͖����ȁB
��ׂ���̂��Ⴄ����B
��ׂ�̂Ȃ�Athlon64�͏���̂��o����w
�́H
Newcastle�ł͂Ȃ�ClawHammer�Ɣ�ׂȂ��ƕς���
���̂��߂�MN���Ǝv���Ă�킯�H
�܂������ClawHammer�͂����ƍڂ��Ă�
�܂������ClawHammer�͂����ƍڂ��Ă�
���\�͂���ȂɈ��Ȃ��B
> ttp://www23.tomshardware.com/cpu_2004.html?modelx=33&model1=75&model2=67&chart=14
> ttp://www23.tomshardware.com/cpu_2004.html?modelx=33&model1=75&model2=67&chart=14
72 �FSocket774�F2007/01/12(��) 08:04:56 ID:3wPpUt0K
2012�N�ɂ�16�R�A��
http://northwood.blog60.fc2.com/blog-entry-482.html
Intel��2008�N���ɂ�Nehalem�j�R�C�`��8�R�A��\�肵�Ă���̂�
16�R�A��2012�N�Ƃ�AMD�͂����Ԃ�̂�т肾�ȁB
http://northwood.blog60.fc2.com/blog-entry-482.html
Intel��2008�N���ɂ�Nehalem�j�R�C�`��8�R�A��\�肵�Ă���̂�
16�R�A��2012�N�Ƃ�AMD�͂����Ԃ�̂�т肾�ȁB
���ۃR�A���̓v���Z�X���[���Ɉ˂�Ƃ�����傫���낤����A
intel���͒x�߂Ȃ̂�������B
�����̓R�A���ȏ�ɐ��\�̏���d�͔䗦���d�v���ۂ�����A
������intel�ƑΓ��ɂȂ�Ȃ�����A�t���O�V�b�v�ŗ���������̂�
�����ǂ����悤���Ȃ����B
�Â��オ��قǂ̈����肩�A�����ETDP130W���Ԃ������邵����́c
�����������i�E�́E�j��!!
intel���͒x�߂Ȃ̂�������B
�����̓R�A���ȏ�ɐ��\�̏���d�͔䗦���d�v���ۂ�����A
������intel�ƑΓ��ɂȂ�Ȃ�����A�t���O�V�b�v�ŗ���������̂�
�����ǂ����悤���Ȃ����B
�Â��オ��قǂ̈����肩�A�����ETDP130W���Ԃ������邵����́c
�����������i�E�́E�j��!!
>>58
AthlonXP 3200+(Barton 2200MHz) = 765
Athlon64 3200+(Newcastle 2200MHz) = 892
�����N���b�N�̔�r��17���サ�����サ�ĂȂ��킯����
AthlonXP 3200+(Barton 2200MHz) = 765
Athlon64 3200+(Newcastle 2200MHz) = 892
�����N���b�N�̔�r��17���サ�����サ�ĂȂ��킯����
>>72
���̗������ƁA���N����16�R�A��POWER���o�邱�ƂɂȂ�킯����
���̗������ƁA���N����16�R�A��POWER���o�邱�ƂɂȂ�킯����
Nehalem��8�R�A��2008�N�ŏo��\���Ⴂ��Ȃ����ȁB
FSB��CSI�ɕύX�ŁA�]���̃j�R�C�`�Ƃ͈Ⴄ�Z�p���K�v���낤���A�����R�����ړ��A�g�����W�X�^��������̂ɁA
����45nm��Yorkfield���TDP������ɉ�����Ƃ͎v���B
HTT�����ڂ���炵���̂ŁA�o�Ă����Ƃ��Ă��I�����̒�N���b�N�ł��R�A���������悢�p�r�����ɂȂ肻���B
FSB��CSI�ɕύX�ŁA�]���̃j�R�C�`�Ƃ͈Ⴄ�Z�p���K�v���낤���A�����R�����ړ��A�g�����W�X�^��������̂ɁA
����45nm��Yorkfield���TDP������ɉ�����Ƃ͎v���B
HTT�����ڂ���炵���̂ŁA�o�Ă����Ƃ��Ă��I�����̒�N���b�N�ł��R�A���������悢�p�r�����ɂȂ肻���B
�R�A���͂Ƃ�����Nehalem�ł���ɖ����̂�����ł��낤�d�͌�����
AMD�͂��Ă�����̂�?
�������R���g���[�������̃A�h�o���e�[�W�͍X�ɔ��炮���낤���c
((( �G߄D�)))����
AMD�͂��Ă�����̂�?
�������R���g���[�������̃A�h�o���e�[�W�͍X�ɔ��炮���낤���c
((( �G߄D�)))����
AMD�A��4�l�������Z�̓A�i���X�g�\�z������錩�ʂ�
ttp://japan.cnet.com/news/biz/story/0,2000056020,20340654,00.htm
ttp://japan.cnet.com/news/biz/story/0,2000056020,20340654,00.htm
>>78
�b���͂��čs���Ȃ����ǁA�܂����̂����߂��Ă���ł��傤�B
K6-2/III�̍��Ƃ��AAthlonXP�̍��Ƃ��A����I�ɒǂ��l�߂���̂����܂ł̃p�^�[�����������B
�b���͂��čs���Ȃ����ǁA�܂����̂����߂��Ă���ł��傤�B
K6-2/III�̍��Ƃ��AAthlonXP�̍��Ƃ��A����I�ɒǂ��l�߂���̂����܂ł̃p�^�[�����������B
����Intel����K�͂ȃ��X�g�������s������ő̗͏����ɏo�Ă����A
���\�œ���}�����Ă���AMD�����܂ł̂悤�ɐL�ё�����킯�Ȃ���
��ʍɕ����ĂĂ�����Ȑݔ�������������Ő��Y�������ł��Ȃ�
��7000�~���オ�ė����邩���ˁc
���\�œ���}�����Ă���AMD�����܂ł̂悤�ɐL�ё�����킯�Ȃ���
��ʍɕ����ĂĂ�����Ȑݔ�������������Ő��Y�������ł��Ȃ�
��7000�~���オ�ė����邩���ˁc
��������ɖ߂�̂͂������A���̑O��Athlon64��Sempron�u�����h�ɂ��Ă����Ȃ��Ƃ܂�������
�]�k�����AXP3200+�Ɠ��X�y�b�N��Semrpron3200+���Ă̂�����
�]�k�����AXP3200+�Ɠ��X�y�b�N��Semrpron3200+���Ă̂�����
Sempron�u�����h�̂Ă�Athlon 64�̂܂���Sempron�������������
�܂��A65nm���L�܂�A�V���O���R�A=Semp�����낤�B
Intel�����Ă��̂��炢�܂ł�Pen4���������Ă���킯�����B
Intel�����Ă��̂��炢�܂ł�Pen4���������Ă���킯�����B
>>86
Intel����Ƀf���A���������̂ɂ��̊Ԃɂ��t�]����Ƃ�Ȃ�
Intel����Ƀf���A���������̂ɂ��̊Ԃɂ��t�]����Ƃ�Ȃ�
Fusion�̐��i����2009�N�㔼
ttp://mypage.odn.ne.jp/www/k/8/k8_hammer_trans/files/Hammer-Info.html
ttp://mypage.odn.ne.jp/www/k/8/k8_hammer_trans/files/Hammer-Info.html
�ŏ��̍���2008�N������2009�N���߂ƌ����Ă��C������Ȃ��B
���߂��炱�̗\��ł͂������낤���B
���߂��炱�̗\��ł͂������낤���B
�� �ŏ��Ƀt�H�[�J�X����Z�O�����g�́A�m�[�g�u�b�N���Ƃ������Ƃł�
���o�C���n�͏ȓd�͋@�\�A�������Ή��f�o�C�X������V�X�e���Ƃ��Ă̕]�����ڂ��������B
�oރ��f�[�V�����ɂƂĂ����Ԃ�������B
������l�����2009�N�㔼�ł��������炢���B
���o�C���n�͏ȓd�͋@�\�A�������Ή��f�o�C�X������V�X�e���Ƃ��Ă̕]�����ڂ��������B
�oރ��f�[�V�����ɂƂĂ����Ԃ�������B
������l�����2009�N�㔼�ł��������炢���B
AMD���܂��߂Ƀo���f�[�V��������Ƃ͎v���Ȃ��A����܂łǂ���Œ���x�������Ȃ��Ǝv���B
AMD�͂܂��߂Ƀo���f�[�V���������Ȃ���������Intel�ɔ�ׂăG���b�^�����Ȃ���ł��ˁB
AMD+ATi��DAMiT���Ă�ɂȂ�Ȃ��悤�ɂȁc
���܂����ƌ��������肩�H
>>95
�U�X���o
�U�X���o
>>94
�l�Ԃ̃��\�[�X�͌����Ă邩��`�s�h�̂ق����w�{���Ƃ��肦�邩�獢��
�����`�b�v�Z�b�g�ŐV�����b�o�t�����Ȃ���������
�Г��łЂ��������悤�ɂȂ邩��b�o�t����̃��\�[�X�͌y���Ȃ�\���͔�߂Ă�
�u�f�`�̂`�s�h���Ƃ���v���Z�X�ו����ƃt�@�u���g���邱�Ƃ̃����b�g�����邯�ǂ�
�l�Ԃ̃��\�[�X�͌����Ă邩��`�s�h�̂ق����w�{���Ƃ��肦�邩�獢��
�����`�b�v�Z�b�g�ŐV�����b�o�t�����Ȃ���������
�Г��łЂ��������悤�ɂȂ邩��b�o�t����̃��\�[�X�͌y���Ȃ�\���͔�߂Ă�
�u�f�`�̂`�s�h���Ƃ���v���Z�X�ו����ƃt�@�u���g���邱�Ƃ̃����b�g�����邯�ǂ�
ATI�ȑO��AMD��K7����w��CPU�̃A�[�L�e�N�`����ς��Ă��Ȃ��B
Athlon64�Ń����R��������HT�����ő������\�͌��サ�������ꂩ���������E�E�E
K8L�ł�Intel�̕��^�����x�̋����A�������ȒP�ȕ��ʂ����E�E�E
L3���L�L���b�V�����P�ɃR�q�[�����V�����h�~���x��2Way���x�܂ł��Ɩw�ǐ��\�Ɋ�^���Ȃ��B
���ہAAMD�����ꂩ���AIntel�ɑR�o�����鎟����CPU���J���ł���̂��͐r���^�₾�B
IBM�������Đv���ĖႤ�ɂ��Ă�2010�N�x���炢�ɂȂ肻���B
Athlon64�Ń����R��������HT�����ő������\�͌��サ�������ꂩ���������E�E�E
K8L�ł�Intel�̕��^�����x�̋����A�������ȒP�ȕ��ʂ����E�E�E
L3���L�L���b�V�����P�ɃR�q�[�����V�����h�~���x��2Way���x�܂ł��Ɩw�ǐ��\�Ɋ�^���Ȃ��B
���ہAAMD�����ꂩ���AIntel�ɑR�o�����鎟����CPU���J���ł���̂��͐r���^�₾�B
IBM�������Đv���ĖႤ�ɂ��Ă�2010�N�x���炢�ɂȂ肻���B
>>98
����Ȃ���
����intel��F6����l�g�o�ɂ����Ăe6���i�o�d�m�@�l�j
�e6���ɂ��ꂱ�ꂭ���t����conroe������
�A�[�L�e�N�`���I�ɂ����Η����Â���
���\�݊p�����ȁB
���ӂ̃`�b�v�Z�b�g�Ƃ��������̂ق������\�A�b�v�Ɋ�^���Ă銴���炠��
IBM���b�o�t�v�o���Ȃ��Ǝv���i���Ȃ��Ƃ��`�l�c�Ƃ�intel�قǂɂ́j
45nm�̂Ƃ��ɂh�a�l�ƋZ�p��g������alpha�c�}�����邵�`�l�c�`�F�b�N��
���Ƃb�o�t���₷�̂�4core�łƂ߂ė~����
����Ȃ���
����intel��F6����l�g�o�ɂ����Ăe6���i�o�d�m�@�l�j
�e6���ɂ��ꂱ�ꂭ���t����conroe������
�A�[�L�e�N�`���I�ɂ����Η����Â���
���\�݊p�����ȁB
���ӂ̃`�b�v�Z�b�g�Ƃ��������̂ق������\�A�b�v�Ɋ�^���Ă銴���炠��
IBM���b�o�t�v�o���Ȃ��Ǝv���i���Ȃ��Ƃ��`�l�c�Ƃ�intel�قǂɂ́j
45nm�̂Ƃ��ɂh�a�l�ƋZ�p��g������alpha�c�}�����邵�`�l�c�`�F�b�N��
���Ƃb�o�t���₷�̂�4core�łƂ߂ė~����
100 �FSocket774�F2007/01/13(�y) 22:29:08 ID:8U8YH1oU
�~F6
��P6
��P6
http://pc.watch.impress.co.jp/docs/2006/0721/kaigai289.htm
���v���Z�b�T�R�A�̉��v�̓p�[�c�P�ʂōs�Ȃ��Ă䂭
�@�͂����āAAMD�̓v���Z�b�T�R�A���̂̔��{�I�ȍ��V�͂����s�Ȃ�Ȃ��̂��낤���B����Ƃ��A�j���[�R�A�̂��ƁA
�v���Z�b�T�R�A�����̍��{�I�ȃR�A�`�F���W���v�悵�Ă���̂��낤���B���̖₢�ɁAHester���͎��̂悤�ɓ�����B
�@�u�g�R�A�`�F���W�h�Ƃ������t�́A�l�ɂ���ĈقȂ邱�Ƃ��Ӗ�����B����𒍈ӂ��Ȃ���Ȃ�Ȃ����낤�B
�@�����ŋ^��́A�����A(�R�A�ɑ���)������x�̕����̕ύX���s�Ȃ�����A���̃R�A�́g�j���[�R�A�h�ƌĂׂ�̂��ǂ����A
�Ƃ����_�ɂȂ�B���ǁA���������ăj���[�R�A�ƌĂԂ��Ƃ�����`�̖��ƂȂ邾�낤�v
�@�v��ƁA���̂悤�ɂȂ�BAMD�́A���s��CPU�}�C�N���A�[�L�e�N�`���̃x�[�X�͔��ɗǍD�Ȃ̂ŁA
�S�����ւ���K�v�͂Ȃ��ƌ��Ă���B�������Ȃǂ̕ύX�ɉ����āA
�v���Z�b�T�R�A���O�̕K�v�ȃu���b�N���������V����ςނƔ��f�����B�܂�A�v���Z�b�T�R�A�S�̂����ւ���̂ł͂Ȃ��A
�v���Z�b�T�R�A�̕������������ǂ��čs���H�����BAMD�ł́A���̂悤�Ƀv���Z�b�T�R�A�̈ꕔ�̃s�[�X�����V�����ꍇ���A
�R�A�`�F���W���ƍl���Ă���Ǝ������Ă���B
���ƌÂ��L������AMD�̐헪���悭�킩�錾�t��
�v�͂��ꂩ���K8�����ǂ���������������킯��
�t�Ɍ����R�v���⏬���ǂ��ǂꂾ�����ʂ��邩�őS�Ă����܂��
���v���Z�b�T�R�A�̉��v�̓p�[�c�P�ʂōs�Ȃ��Ă䂭
�@�͂����āAAMD�̓v���Z�b�T�R�A���̂̔��{�I�ȍ��V�͂����s�Ȃ�Ȃ��̂��낤���B����Ƃ��A�j���[�R�A�̂��ƁA
�v���Z�b�T�R�A�����̍��{�I�ȃR�A�`�F���W���v�悵�Ă���̂��낤���B���̖₢�ɁAHester���͎��̂悤�ɓ�����B
�@�u�g�R�A�`�F���W�h�Ƃ������t�́A�l�ɂ���ĈقȂ邱�Ƃ��Ӗ�����B����𒍈ӂ��Ȃ���Ȃ�Ȃ����낤�B
�@�����ŋ^��́A�����A(�R�A�ɑ���)������x�̕����̕ύX���s�Ȃ�����A���̃R�A�́g�j���[�R�A�h�ƌĂׂ�̂��ǂ����A
�Ƃ����_�ɂȂ�B���ǁA���������ăj���[�R�A�ƌĂԂ��Ƃ�����`�̖��ƂȂ邾�낤�v
�@�v��ƁA���̂悤�ɂȂ�BAMD�́A���s��CPU�}�C�N���A�[�L�e�N�`���̃x�[�X�͔��ɗǍD�Ȃ̂ŁA
�S�����ւ���K�v�͂Ȃ��ƌ��Ă���B�������Ȃǂ̕ύX�ɉ����āA
�v���Z�b�T�R�A���O�̕K�v�ȃu���b�N���������V����ςނƔ��f�����B�܂�A�v���Z�b�T�R�A�S�̂����ւ���̂ł͂Ȃ��A
�v���Z�b�T�R�A�̕������������ǂ��čs���H�����BAMD�ł́A���̂悤�Ƀv���Z�b�T�R�A�̈ꕔ�̃s�[�X�����V�����ꍇ���A
�R�A�`�F���W���ƍl���Ă���Ǝ������Ă���B
���ƌÂ��L������AMD�̐헪���悭�킩�錾�t��
�v�͂��ꂩ���K8�����ǂ���������������킯��
�t�Ɍ����R�v���⏬���ǂ��ǂꂾ�����ʂ��邩�őS�Ă����܂��
>>102
> ���ƌÂ��L������AMD�̐헪���悭�킩�錾�t��
> �v�͂��ꂩ���K8�����ǂ���������������킯��
> �t�Ɍ����R�v���⏬���ǂ��ǂꂾ�����ʂ��邩�őS�Ă����܂��
�c�O�����ǂ��̂悤�ɂ͓ǂ߂Ȃ������ȁA�u����グ�錾�v�ɂ����������Ă��Ȃ�������B
> ���ƌÂ��L������AMD�̐헪���悭�킩�錾�t��
> �v�͂��ꂩ���K8�����ǂ���������������킯��
> �t�Ɍ����R�v���⏬���ǂ��ǂꂾ�����ʂ��邩�őS�Ă����܂��
�c�O�����ǂ��̂悤�ɂ͓ǂ߂Ȃ������ȁA�u����グ�錾�v�ɂ����������Ă��Ȃ�������B
�����炸���ƔS���ł����H�^���搶�A503���S�z���Ă���I
>>102
Linux�Ō�����Kernel2.2�����錾���Ȃ�
Linux�Ō�����Kernel2.2�����錾���Ȃ�
>>102
�����Ƃ����ǂ߂Ȃ��̂́A���O����̔��z���Â����炩�A
���̒��̓lj�͂�����Ȃ�����B
���ʂ́u����������肭���������H�v���Ǝv�����H
�����Ƃ����ǂ߂Ȃ��̂́A���O����̔��z���Â����炩�A
���̒��̓lj�͂�����Ȃ�����B
���ʂ́u����������肭���������H�v���Ǝv�����H
���_���肫�œǂ�ł�z�ɉ��������Ă�����
AMD�I���̂��m�点
�Ĕ����̂`�l�c��9.5�������A�C���e���Ƃ̉��i��������
http://news20.2ch.net/test/read.cgi/news/1168703501/
�Ĕ����̂`�l�c��9.5�������A�C���e���Ƃ̉��i��������
http://news20.2ch.net/test/read.cgi/news/1168703501/
Dell���@�ɕt�������ȏケ���Ȃ邱�Ƃ�
AMD�I����A�Ă�����ɂ́A
AMD�X���ɔS������̂Ȃ�
AMD�X���ɔS������̂Ȃ�
���肪����ɂ����Ă����̂����ꂩ������҂���̂�
��ƂƂ��Ă͂��蓾�Ȃ�����A
�R�A�̉��ǂ����ł͂ǂ����Ă�(�s���)�����c��Ȃ��Ȃ��
�ׂ�邩�A�V���������������[�X���悤�Ƌ�S����ł��B
���ہA���̉��������K���ɊJ�����Ȃ���������?
K8�R�A���Ljȍ~�̐�����B
�����炻��Ɋ��҂���̂͂ǂ����Ǝv�����B
��ƂƂ��Ă͂��蓾�Ȃ�����A
�R�A�̉��ǂ����ł͂ǂ����Ă�(�s���)�����c��Ȃ��Ȃ��
�ׂ�邩�A�V���������������[�X���悤�Ƌ�S����ł��B
���ہA���̉��������K���ɊJ�����Ȃ���������?
K8�R�A���Ljȍ~�̐�����B
�����炻��Ɋ��҂���̂͂ǂ����Ǝv�����B
���\�����Ђ��オ�����ł�����A�p���I�ɁB
112 �FSocket774�F2007/01/14(��) 12:47:29 ID:ePAm4l3G
�@�@�@�@�@�@ �@ �Q�㨁�)),�@���@�M�R�@�^�@�@�M�� �((_r���R
�@�@�@�@�@�@�@/�@��=� ��__�@�@ �M�@�@�@�@�@�@�L���� {f��}�r�j�_
.�@�@�@�@ �@ /�@ �s�U�c爁[�@�@�@�@ �@ �@ �@ � ��P�@�M��((_) ��_
�@�@�@�@�@ /�@/�@((�N�L�@�@�P�@ �@ �@ �@ ���@�@�@�@�@��Ĥ�@�@ �Ɂ@ }�@ i
.�@�@�@�@ /�@/�@(__))�@ �@ i �@ i�@|�@���@l i|�@|li�b�bil| | i�@�@ }�@ ,���b
�@�@�@�@ '�@/�@�@ �@ |�@i|�@l �@ i�@|�@|�@l l|�@|li�b�bil| | l ���@/�@ {�@�@ ,
�@�@�@ �q�@�o�@�@/�@ i|�@l|�@|�@�� i�@|�@|�@l l|�@|li�b�bil| | l i�@{�@�@�R �@ �R
�@�@�@�@ ,�@',�@/�@�@��|�@l|�@|�@| l�@| ))�� �� ��|�@|li�b�bil| | l�@l�n�@�@ .�@�@ }
�@ �@ �@ ʁ@i {�@�@ il|�@l|�@���@|, =�e�b! l| ,�li�ہہ�L!�@l�@ā@�@}�@�@,��
�@�@�@ /�@l�@�� �R�@ il| ! |�@| r{爃g� | | ��|�@| l�ہ�_! l |�@���@�� }�R�@�@/!
.�@ �^���@! ���@ �g ��nl|�@l/��Y^�g{�@| �i �Cf��_�P�Ml �R���@ / /�@ //
�^ /�@�@�@}�ȁ@�R�@�R�R�@�U�T�\�\�@ �@ �@ ` �k'�O �� l�@ { /�@ / ��
.�@/�@�@ �^�@ ,�@�@�j�@} �n �M�P)�j�@�@�A�@�@�@�@ �@ /�@}ʁ@ʁ@�@'�@|
�@���@�i �@ �@ }�@/�@//�@�ȁ@((�@�@ ��Q,�@�@�@�@ ��@��@'�A�n�@l�@ !
�@ �@ �@ �R�@ / /�@ { �@ /�@ > �A�@�@�@�@�@�@�@�C �/,���A �_j�@���@ �
�@ �@ �@ �� '�^{�@�@�R�@{ .�B�MY�L ���@..�@��Ɂ܁L// i|�@�M����_�R�@�_
�@ �@ �^ �^ ��@�j(�܁R.i.=fjfjfjfjfjfjfjfjfjfjfjfjfjfjfjfjfj=.i: r�ʁ@) �j�@',�@ �R
.�@�^ �^�@// /�^��) .|�@�@�@�@Conroe�́@�@�@�@�@�@|_�j �o_ .��@�@���@���b
�@ �^�@�@ '/.�^�@ �@ �T.|�@�@���|�I���\�ƈ����@ �@ .| �j�A�[- �A|�@l�n
' /�@�@�@/ /�@�@�@�@�@�@|�@�@�@�����Ēᐫ�\�@�@�@�@�@.|�@ �@ �R�@} } �R�� '�A
/�@ �@ /�@���@�@�@ .r�]���������d�͂�64�EAM2�^�L�R�@ �@} ' �n�@�R�R.�_
�@ �@ /�@�I�@�@�@�@(�M �� �RAMD����_(^o^)�^ �^�R } �^ .��@���@�@i�@}�@ �_
�@�@ {�@ �@ �R�^�@ .r'�-� �T',�@�@�@�@ �@�@�@ �@�@(_.�^ �^�@ |�^ /�@ ! �@ l � �@ �R�R
�@�@�ȁ@�@ �q�@�@�@�@�r- ..__�M�)�@�@�@�@�@�@�@�@�@�@ �T-�L__ -'�o�@�q�@ /�@ �^�@��@�@���b
�@�@�@�@�@�@�@/�@��=� ��__�@�@ �M�@�@�@�@�@�@�L���� {f��}�r�j�_
.�@�@�@�@ �@ /�@ �s�U�c爁[�@�@�@�@ �@ �@ �@ � ��P�@�M��((_) ��_
�@�@�@�@�@ /�@/�@((�N�L�@�@�P�@ �@ �@ �@ ���@�@�@�@�@��Ĥ�@�@ �Ɂ@ }�@ i
.�@�@�@�@ /�@/�@(__))�@ �@ i �@ i�@|�@���@l i|�@|li�b�bil| | i�@�@ }�@ ,���b
�@�@�@�@ '�@/�@�@ �@ |�@i|�@l �@ i�@|�@|�@l l|�@|li�b�bil| | l ���@/�@ {�@�@ ,
�@�@�@ �q�@�o�@�@/�@ i|�@l|�@|�@�� i�@|�@|�@l l|�@|li�b�bil| | l i�@{�@�@�R �@ �R
�@�@�@�@ ,�@',�@/�@�@��|�@l|�@|�@| l�@| ))�� �� ��|�@|li�b�bil| | l�@l�n�@�@ .�@�@ }
�@ �@ �@ ʁ@i {�@�@ il|�@l|�@���@|, =�e�b! l| ,�li�ہہ�L!�@l�@ā@�@}�@�@,��
�@�@�@ /�@l�@�� �R�@ il| ! |�@| r{爃g� | | ��|�@| l�ہ�_! l |�@���@�� }�R�@�@/!
.�@ �^���@! ���@ �g ��nl|�@l/��Y^�g{�@| �i �Cf��_�P�Ml �R���@ / /�@ //
�^ /�@�@�@}�ȁ@�R�@�R�R�@�U�T�\�\�@ �@ �@ ` �k'�O �� l�@ { /�@ / ��
.�@/�@�@ �^�@ ,�@�@�j�@} �n �M�P)�j�@�@�A�@�@�@�@ �@ /�@}ʁ@ʁ@�@'�@|
�@���@�i �@ �@ }�@/�@//�@�ȁ@((�@�@ ��Q,�@�@�@�@ ��@��@'�A�n�@l�@ !
�@ �@ �@ �R�@ / /�@ { �@ /�@ > �A�@�@�@�@�@�@�@�C �/,���A �_j�@���@ �
�@ �@ �@ �� '�^{�@�@�R�@{ .�B�MY�L ���@..�@��Ɂ܁L// i|�@�M����_�R�@�_
�@ �@ �^ �^ ��@�j(�܁R.i.=fjfjfjfjfjfjfjfjfjfjfjfjfjfjfjfjfj=.i: r�ʁ@) �j�@',�@ �R
.�@�^ �^�@// /�^��) .|�@�@�@�@Conroe�́@�@�@�@�@�@|_�j �o_ .��@�@���@���b
�@ �^�@�@ '/.�^�@ �@ �T.|�@�@���|�I���\�ƈ����@ �@ .| �j�A�[- �A|�@l�n
' /�@�@�@/ /�@�@�@�@�@�@|�@�@�@�����Ēᐫ�\�@�@�@�@�@.|�@ �@ �R�@} } �R�� '�A
/�@ �@ /�@���@�@�@ .r�]���������d�͂�64�EAM2�^�L�R�@ �@} ' �n�@�R�R.�_
�@ �@ /�@�I�@�@�@�@(�M �� �RAMD����_(^o^)�^ �^�R } �^ .��@���@�@i�@}�@ �_
�@�@ {�@ �@ �R�^�@ .r'�-� �T',�@�@�@�@ �@�@�@ �@�@(_.�^ �^�@ |�^ /�@ ! �@ l � �@ �R�R
�@�@�ȁ@�@ �q�@�@�@�@�r- ..__�M�)�@�@�@�@�@�@�@�@�@�@ �T-�L__ -'�o�@�q�@ /�@ �^�@��@�@���b
>>101
�R���64bit�����鎞�ɂ����Ɣėp���W�X�^�𑝂₷�Z�i�����ė~�����������ǂȁB
RISC�v���Z�b�T�̍����\�ɂ́A���W�X�^�̑��������\��^���Ă��������B
�܂�INC/DEC���߂�64bit���p�̃v���t�B�b�N�X�ɓ]�p��������A���W�X�^�w��p��
�g����bit���ɐ��L�����̂��낤���A���W�X�^��{���ȏ�ɂ��Ă����\�A�b�v��
���قnj����߂Ȃ������̂�������B
����RISC�̓��W�X�^���Q�ɕ����āA�X���b�h�⊄�荞�ݖ��Ƀ��W�X�^�Q���ւ���
���Ń��W�X�^�̃Z�[�u���J�o���̏������������������ʂ����邩��A������h�`��
��荞�ނ͓̂�������C�����邪�B
�R���64bit�����鎞�ɂ����Ɣėp���W�X�^�𑝂₷�Z�i�����ė~�����������ǂȁB
RISC�v���Z�b�T�̍����\�ɂ́A���W�X�^�̑��������\��^���Ă��������B
�܂�INC/DEC���߂�64bit���p�̃v���t�B�b�N�X�ɓ]�p��������A���W�X�^�w��p��
�g����bit���ɐ��L�����̂��낤���A���W�X�^��{���ȏ�ɂ��Ă����\�A�b�v��
���قnj����߂Ȃ������̂�������B
����RISC�̓��W�X�^���Q�ɕ����āA�X���b�h�⊄�荞�ݖ��Ƀ��W�X�^�Q���ւ���
���Ń��W�X�^�̃Z�[�u���J�o���̏������������������ʂ����邩��A������h�`��
��荞�ނ͓̂�������C�����邪�B
���F�ď���d�͈ȊO�͂���܂�A64x2�ɑ���A�h�o���e�[�W�Ȃ��Ǝv���͉̂������H
�܂�AMD���啝�l�������������Ȃ�������
�܂�AMD���啝�l�������������Ȃ�������
>>113
x86���������������s�������_�ŏI��
x86���������������s�������_�ŏI��
ttp://pc.watch.impress.co.jp/docs/article/20010829/kaigai02.htm
x86���i������ƌ����Ă�̂̓C���e��
AMD������ɓ��悵������
x86���i������ƌ����Ă�̂̓C���e��
AMD������ɓ��悵������
x86������܂ŏ��������Ă����̂́A���̃��W�X�^�̏��Ȃ����v����1�B
�A�E�g�I�u�I�[�_�[�A�Ƃ��������W�X�^���l�[�~���O��^�C�A�����g���܂�
���߂̃X�P�[�W���[�����i�����邱�Ƃ��ł����B
�A�E�g�I�u�I�[�_�[�A�Ƃ��������W�X�^���l�[�~���O��^�C�A�����g���܂�
���߂̃X�P�[�W���[�����i�����邱�Ƃ��ł����B
���W�X�^���₵���烁�j�C�R�A���������ɍ���
> ���F�ď���d�͈ȊO�͂���܂�A64x2�ɑ���A�h�o���e�[�W�Ȃ��Ǝv���͉̂������H
���O��������w
C2D�͓��N���b�N��X2���2���ȏ㍂���A4MB�L���b�V������2.5���ɒB����P�[�X�������A�X��OC�ϐ����y���ɍ���3.6GHz�ŋ���p�ғ����Ă��������Ȃ��Ȃ��B
���Ȃ݂�AthlonXP����Athlon64�ւ̈ڍs�ł̐��\�����2���ɖ����Ȃ��B
���O��������w
C2D�͓��N���b�N��X2���2���ȏ㍂���A4MB�L���b�V������2.5���ɒB����P�[�X�������A�X��OC�ϐ����y���ɍ���3.6GHz�ŋ���p�ғ����Ă��������Ȃ��Ȃ��B
���Ȃ݂�AthlonXP����Athlon64�ւ̈ڍs�ł̐��\�����2���ɖ����Ȃ��B
IA64������_����Yamhill���j�����ꂽ�����
>>116
�ܔN���O�̋��`��M���Ă���l�Ɍ����̂��Ȃ�
�����ł���x86�̉i�����Ă̂����́A�Ԃ����Ⴏ
�@�uIA32����IA64�ւ̈ȍ~�ɂ͎��s���܂����v
���Ă����Ȃ��ǂ�
�ܔN���O�̋��`��M���Ă���l�Ɍ����̂��Ȃ�
�����ł���x86�̉i�����Ă̂����́A�Ԃ����Ⴏ
�@�uIA32����IA64�ւ̈ȍ~�ɂ͎��s���܂����v
���Ă����Ȃ��ǂ�
�ڍs�A��
�n�C�G���h�I�L���[�Ƃ�����SPARC�L���[�Ƃ��Ă͈��̐��������߂���
�f�X�N�g�b�v�ɂ͉��낹�Ȃ������Ƃ������R�̌����ł���
�ߋ��̐����̌���_�b�ɑ������������Ă��܂����Ƃ�������
�����炱��AMD�̖��i���������킯����
�n�C�G���h�I�L���[�Ƃ�����SPARC�L���[�Ƃ��Ă͈��̐��������߂���
�f�X�N�g�b�v�ɂ͉��낹�Ȃ������Ƃ������R�̌����ł���
�ߋ��̐����̌���_�b�ɑ������������Ă��܂����Ƃ�������
�����炱��AMD�̖��i���������킯����
SPARC �L���[�Ƃ��Đ��������̂� IBM ����B
IPF �͂ǂ��炩�Ƃ����� PA �̃��v���[�X�ɉ߂���B
Sun �� CPU �J���ł��낢��~�X�������A��V�F�A��H���������������
�v�����A����ɂ��ւ�炸 SPARC �L���[�Ƃ����̂ɂ͒���������Ȃ����B
�������� IPF �Ɋ��҂���Ă����̂́A���� CPU �ɔ�ׂău�b�`�M����
�����\�ň��|�I�ȃV�F�A��͂ނƂ��������Ƃ������������APOWER �Ƀ��[�h��
�����A����ǂ��납�A�������Z���\�ł� x86 ���u�b�`�M���ɑ����Ƃ���
�ł́A�̂̊��҂ɂ͒������B
IPF �͂ǂ��炩�Ƃ����� PA �̃��v���[�X�ɉ߂���B
Sun �� CPU �J���ł��낢��~�X�������A��V�F�A��H���������������
�v�����A����ɂ��ւ�炸 SPARC �L���[�Ƃ����̂ɂ͒���������Ȃ����B
�������� IPF �Ɋ��҂���Ă����̂́A���� CPU �ɔ�ׂău�b�`�M����
�����\�ň��|�I�ȃV�F�A��͂ނƂ��������Ƃ������������APOWER �Ƀ��[�h��
�����A����ǂ��납�A�������Z���\�ł� x86 ���u�b�`�M���ɑ����Ƃ���
�ł́A�̂̊��҂ɂ͒������B
�n�C�G���h�I�ł�x86�̔ߎS�ȏ���l�����IA64�͗ǂ��撣�����Ƃ�����
IPF�͂��O���v���Ă����蔄��Ă��邵�A�������PA-RISC�����肤��Ă���B
POWER�͂��O���������Ă�قǔ���ĂȂ��B
POWER��IPF�Ɠ������炢����Ă���A�j���[�X�ł͑唄��Ƃ��ďЉ�ɂȂ邪�A
IPF�ł͔���ĂȂ��ƂȂ�B�U�X�����Ă���悤�ɑO�]������ғx�̖��B
POWER�͂��O���������Ă�قǔ���ĂȂ��B
POWER��IPF�Ɠ������炢����Ă���A�j���[�X�ł͑唄��Ƃ��ďЉ�ɂȂ邪�A
IPF�ł͔���ĂȂ��ƂȂ�B�U�X�����Ă���悤�ɑO�]������ғx�̖��B
�ꌾ�����BAIX��HP-UX���V�K�J��͂Ȃ��B
�k�Ăł������݂�����>HP-UX
���Ɋu���X�������Ă邩��ȁB
CPU������Ȃ�����r�f�I�J�[�h�����o���Ă�������B
R600�͏���d�͂����o���ĐÉ��u���̉��ɂ͎肪�o�Ȃ�orz
>>133
�X���Ⴂ�����AG88��肩�͒Ⴂ��Ȃ����������H
�X���Ⴂ�����AG88��肩�͒Ⴂ��Ȃ����������H
G88�ĕ��ʂ�GeForce8800�̗�����Ȃ��̂��H
>>136
�����G80���Ă����悤�Ȃ�������B
�����G80���Ă����悤�Ȃ�������B
8800��G80�ɑ���8600�Ƃ���G86���ČĂ�Ă邩��A�Ȃ�ƂȂ�G88�ɂ��Ă݂�
������ɂ��������݂����ŃX�}�\
������ɂ��������݂����ŃX�}�\
���O134������orz
>>138
G86�̓R�[�h�l�[���Ȃ킯����
G86�̓R�[�h�l�[���Ȃ킯����
�����[��
nvidia�А��i�R�[�h�l�[��
G80/G83/G86
134�̐��E
G88��GeForce8800
G86��GeForce8600
G71��7100
G79.5��7950
GG79.5��GeForce Go 7950
G80/G83/G86
134�̐��E
G88��GeForce8800
G86��GeForce8600
G71��7100
G79.5��7950
GG79.5��GeForce Go 7950
>>136�̐��E����Ȃ��āH
��������
���̐��E
����l��߂��܂���� = �E��
����l�����t����� = �E��
����l�������� = �E��
����l�ɋ߂Â��� = �E��
����l��߂��܂���� = �E��
����l�����t����� = �E��
����l�������� = �E��
����l�ɋ߂Â��� = �E��
>>134�̖��m��������B
�ꉞ�x���`�}�[�N�ł�G80�������Ă邯�ǁAATI�����Ȃ�
���ۂ̃Q�[���łǂ��Ȃ鎖���
���ۂ̃Q�[���łǂ��Ȃ鎖���
�ӋC����Ȃ͂���AMD�������������ȗ��R
http://japan.cnet.com/news/biz/story/0,2000056020,20340763,00.htm
http://japan.cnet.com/news/biz/story/0,2000056020,20340763,00.htm
AMD�Ă��������ӋC����Ȃ́H
A64x2�͌����Ă�ق�Core2���_�����Ă킯����Ȃ��Ǝv������Core2�ɑ��ĂȂ�̃A�h�o���e�[�W��������
A64x2�͌����Ă�ق�Core2���_�����Ă킯����Ȃ��Ǝv������Core2�ɑ��ĂȂ�̃A�h�o���e�[�W��������
�����i�т�E6600��5200+���ׂ��ꍇ
E6600���Asuper�������̂͑������A����ȊO�Ȃ�5200+�������Ă�ˁB
A64x2������ȂɈ������Đ��\����Ȃ��Ǝv�����ǂȁB�B�B
E6600���Asuper�������̂͑������A����ȊO�Ȃ�5200+�������Ă�ˁB
A64x2������ȂɈ������Đ��\����Ȃ��Ǝv�����ǂȁB�B�B
�s��̕]���͂����ɂ���悤�ȼ����蔼�N�x�ꂭ�炢�ł�
150�݂����Ȓ����܂��܂������ς����邩��AMD�͈��ׂ���
>>152
���̔�r�͎����ł���B
���̔�r�͎����ł���B
�܂�2�N�O��Pen4��A64�قǐ�]�I�ȍ�������킯�ł�����܂���
http://www.matbe.com/articles/lire/306/merom-et-conroe-test-des-core-2-duo/page1.php
5200+����FX62��葬���̂��H
5200+����FX62��葬���̂��H
>>155
�I�}�C�͗⍓���ȋS�{��Y����
�I�}�C�͗⍓���ȋS�{��Y����
>>153
150�������{�l�Ɍ����Ă������͂Ȃ���
150�������{�l�Ɍ����Ă������͂Ȃ���
>155
���܂��́@�S�{�炵����
���܂��́@�S�{�炵����
159 �FSocket774�F2007/01/17(��) 03:39:09 ID:Lb3BF/8O
�@�@�@�@�@�@ �^::�O'�L::::::::::::i�::::::::::::::::::::::::::::�_
�@�@�@�@�@�]'7::::::::::::::::::::::::�n:�::|�R:::;�::::::::::::��
�@�@�@�@ �^::::::::::::::/!i::/|/�@ ! �S�@n:|;!�:::::::l
�@�@�@�@/�L7::::::::::�V|!/_,,�A�@�@ ''"�J_�O`''`�]ly:::ā@�@�@
�@�@�@ �@ /|;�:::::N,��]'�J_,,.�_�@�@ �L''""'�R�@ !;�j
�@ �@ �@ �@ ! |�āq �@,r''"�J�@ ,�@�@�@�@�@�@�@ز)|�@�@�@�@���˂����Ǝv����
�@�@ �@ �@ �@ �@`y't�@�@�@�@ �R' �@ �@ �@ �@ /�^
�@�@�@�@�@�@�@�@ ! ��� �@ �@ �;:=����@�@ �V�@�@�@�@�@
�@�@�@�@�@�@�@�@�@�M'' �ցA �@ ` �] '�K �@ .�
�@�@�@�@�@�@�@�@�@�@�@ �@ `i;��@�@ �@ �^ l�@�@�@�@�@�@�@�@�@
�@�@�@�@�@�@�@�@ �@�@ �@ �@ �r�@` �] �L �@ l`�R
�@�@�@�@�@�@�@�@�@�@�@�@�^�@!�@ �@ �@ �@ �' �R_
���ۂǂ��Ȃ낤�B5200+��6600E
�����Ăˁ[����킩��Ȃ��R(�L�[�M)�m
�����Ăˁ[����킩��Ȃ��R(�L�[�M)�m
���̉��i�т��Ⴀ����C2D�̕����R�X�g�p�t�H�[�}���X�ǂ��Ȃ��H
A64�̂������̂�20k�ȉ����Ǝv�����i��23k�ȉ���C2D���Ė������j
A64�̂������̂�20k�ȉ����Ǝv�����i��23k�ȉ���C2D���Ė������j
160�݂����Ȓ����܂��܂������ς����邩��AMD�͈��ׂ���
�ق��ق��B�����ĂȂ����番��Ȃ��z�������ς������AMD�ׂ͖���̂��B
>>155�̔����Ȑl�C�Ɏ��i
K8L�̃x���`�}�[�N�܂������́H
http://search.mimizun.com:82/perl/dattohtml.pl?http://mimizun.com:81/log/2ch/jisaku/pc7.2ch.net/jisaku/kako/1140/11408/1140884070.dat
721 �FSocket774�F2006/03/08(��) 08:44:24 ID:4uWUMo/X
Spring IDF 2006 Conroe Preview: Intel Regains the Performance Crown
ttp://www.anandtech.com/tradeshows/showdoc.aspx?i=2713&p=1
ttp://www.anandtech.com/tradeshows/showdoc.aspx?i=2713&p=2
ttp://www.anandtech.com/tradeshows/showdoc.aspx?i=2713&p=3
ttp://www.anandtech.com/tradeshows/showdoc.aspx?i=2713&p=4
ttp://www.anandtech.com/tradeshows/showdoc.aspx?i=2713&p=5
Conroe������
838 �FSocket774�F2006/03/09(��) 01:25:19 ID:Uuw0GzwI
>Conroe�̔��\�\��͑�3�l�����ŁA�P��ʂ�Ȃ�Intel�̋Z�p�J���t�@�����X
>�uIntel Developer Forum(IDF)�v(9��26���`28��)��̔����ƂȂ�B
10���ł��ȁB
conroe�̃x���`�͏o��̂����������ȁA����10���\�肾�����i��ɑO�|���ɂȂ邪�j
������3���Ƀx���`���o���Ă�
721 �FSocket774�F2006/03/08(��) 08:44:24 ID:4uWUMo/X
Spring IDF 2006 Conroe Preview: Intel Regains the Performance Crown
ttp://www.anandtech.com/tradeshows/showdoc.aspx?i=2713&p=1
ttp://www.anandtech.com/tradeshows/showdoc.aspx?i=2713&p=2
ttp://www.anandtech.com/tradeshows/showdoc.aspx?i=2713&p=3
ttp://www.anandtech.com/tradeshows/showdoc.aspx?i=2713&p=4
ttp://www.anandtech.com/tradeshows/showdoc.aspx?i=2713&p=5
Conroe������
838 �FSocket774�F2006/03/09(��) 01:25:19 ID:Uuw0GzwI
>Conroe�̔��\�\��͑�3�l�����ŁA�P��ʂ�Ȃ�Intel�̋Z�p�J���t�@�����X
>�uIntel Developer Forum(IDF)�v(9��26���`28��)��̔����ƂȂ�B
10���ł��ȁB
conroe�̃x���`�͏o��̂����������ȁA����10���\�肾�����i��ɑO�|���ɂȂ邪�j
������3���Ƀx���`���o���Ă�
K8L�̃x���`���Penryn�̕�����ɏo���肵�Ă�
���������Ȃ��āA������ʂŕ����Ă���ߎS���ȁB
���o�C����Penryn��DualCore��Wolfdale�ł�AMD�ɏ����ڂ͖����ȁB
���͂܂����m�̕���������YorkField����ȁB
�܂�YorkField��Wolfdale�����ׂ����̂Ȃ̂��A�L���b�V����4�̃R�A��
���L�������̂Ȃ̂��n�b�L�����Ă��Ȃ���ˁH
���͂܂����m�̕���������YorkField����ȁB
�܂�YorkField��Wolfdale�����ׂ����̂Ȃ̂��A�L���b�V����4�̃R�A��
���L�������̂Ȃ̂��n�b�L�����Ă��Ȃ���ˁH
>>170
�ǂ������낤�ƃN���b�N�����萫�\�̓L���b�V�������ōŒ�ł�Kents�Ɠ����A
Kents��肩�Ȃ�N���b�N���オ��L���b�V���������Ă�B
K8L���ő���ɂȂ�Ƃ͎v����B
�ǂ������낤�ƃN���b�N�����萫�\�̓L���b�V�������ōŒ�ł�Kents�Ɠ����A
Kents��肩�Ȃ�N���b�N���オ��L���b�V���������Ă�B
K8L���ő���ɂȂ�Ƃ͎v����B
>>169
>>172
�H
�ȑO�̃v���Z�X�Ȃ炢���m�炸�A90nm�ȉ��ł͔��������Ő�s���ĂĂ�
���\�ɂ͊W�Ȃ����B�R�X�g�ɂ͉e�����邯�ǁB
�ȑO�̃v���Z�X�Ŕ����Ő�s���ƃ��C�o�������ꂽ�̂́A
�����ŏ���ƃN���b�N�����ꂽ���炾�B
���͂��̃����b�g�������B
�ނ��덡�ł͘c�݃V���R���Ƃ��Q�[�g���ޗ��Ƃ��A�����������v���Z�X����������Z�p���d�v�B
>>172
�H
�ȑO�̃v���Z�X�Ȃ炢���m�炸�A90nm�ȉ��ł͔��������Ő�s���ĂĂ�
���\�ɂ͊W�Ȃ����B�R�X�g�ɂ͉e�����邯�ǁB
�ȑO�̃v���Z�X�Ŕ����Ő�s���ƃ��C�o�������ꂽ�̂́A
�����ŏ���ƃN���b�N�����ꂽ���炾�B
���͂��̃����b�g�������B
�ނ��덡�ł͘c�݃V���R���Ƃ��Q�[�g���ޗ��Ƃ��A�����������v���Z�X����������Z�p���d�v�B
�����Ł@�N���b�N�������邱�Ƃ́@�Ȃ��낤
>>173
�n����
�n����
�����������c�͋�̓I�ɉ����ǂ��Ԉ���Ă邩�w�E����z�B
175�݂����̂͑�l�ɂȂ��Ă��u���܂��̂��[�����Ł[�ׂ��v�̃��x������i�����ĂȂ������̒�IQw
175�݂����̂͑�l�ɂȂ��Ă��u���܂��̂��[�����Ł[�ׂ��v�̃��x������i�����ĂȂ������̒�IQw
�㓡�ȉ��̔n���������m�b�i���Đ����Ă������Ă��炦�Ȃ�������
>>175
���m��
ttp://pc.watch.impress.co.jp/docs/2006/0425/kaigai264.htm
�����v���Z�X�̔����ł͑����Ȃ�Ȃ��g�����W�X�^
���@�ȑO�́A�v���Z�X�m�[�h��1����i�ނƃg�����W�X�^���X�P�[���_�E�����A
�� ���̌��ʃQ�[�g�����Z���Ȃ�g�����W�X�^�̐��\�������I�ɏオ�����B
��
�� �Ƃ��낪�A���݂̓g�����W�X�^���������Ȃ肷�������߂ɁA
�� �g�����W�X�^���k������ƃ��[�N�d���������Ă��܂��A�����}�����悤��
�� ����ƍ��������ł��Ȃ��B�܂�A�v���Z�X�̔������A�g�����W�X�^��
�� �������Ƀ_�C���N�g�ɂ͂Ȃ���Ȃ��Ȃ��Ă��܂����B
�� �����ŁA�c�݃V���R���Ȃǂ̋Z�p���g�����ƂŁA���[�N�d����}���Ȃ���
�� �g�����W�X�^������������K�v���o�����B
���m��
ttp://pc.watch.impress.co.jp/docs/2006/0425/kaigai264.htm
�����v���Z�X�̔����ł͑����Ȃ�Ȃ��g�����W�X�^
���@�ȑO�́A�v���Z�X�m�[�h��1����i�ނƃg�����W�X�^���X�P�[���_�E�����A
�� ���̌��ʃQ�[�g�����Z���Ȃ�g�����W�X�^�̐��\�������I�ɏオ�����B
��
�� �Ƃ��낪�A���݂̓g�����W�X�^���������Ȃ肷�������߂ɁA
�� �g�����W�X�^���k������ƃ��[�N�d���������Ă��܂��A�����}�����悤��
�� ����ƍ��������ł��Ȃ��B�܂�A�v���Z�X�̔������A�g�����W�X�^��
�� �������Ƀ_�C���N�g�ɂ͂Ȃ���Ȃ��Ȃ��Ă��܂����B
�� �����ŁA�c�݃V���R���Ȃǂ̋Z�p���g�����ƂŁA���[�N�d����}���Ȃ���
�� �g�����W�X�^������������K�v���o�����B
179 �FSocket774�F2007/01/18(��) 02:12:27 ID:SQpBlLcr
�����Ȃ̂͐��E���Ō㓡���B9VvMNxK�̂����������ƌ����Ă����z��
�{�l�ȊO��l�����Ȃ����Ƃ���
���m�N���Ă����˂����܂ꂽ������ăo�J���K��������
�{�l�ȊO��l�����Ȃ����Ƃ���
���m�N���Ă����˂����܂ꂽ������ăo�J���K��������
>�� �v���Z�X�̔������A�g�����W�X�^�̍������Ƀ_�C���N�g�ɂ͂Ȃ���Ȃ��Ȃ��Ă��܂���
���{�ꂪ�ǂ߂Ȃ��炵����
���{�ꂪ�ǂ߂Ȃ��炵����
�͂��͂�
�u�_�C���N�g�ɂ͂Ȃ���Ȃ����ǂ�����Ƃ͉e�����邾��H�v���āH
�A�t�H��w
�u�_�C���N�g�ɂ͂Ȃ���Ȃ����ǂ�����Ƃ͉e�����邾��H�v���āH
�A�t�H��w
�@�@�@�@�@�@�@�@ �-'""""''''��='�,_�@�@�@�@�@�@�@�@�@ , ��''''""'�R��,,,_�@�@�@�@�@ �@�@ ,�-�]
�@�@�@�@�@�@�@�@�^�@�@�@�@�@�@�@�@�@ �M'�] ��@�@ �@�@�@ i' � i�ܤ____�@��_ _,,,��@,�- '�L-�]-,
�@�@�@�@ �@�@ r'�@�@�@�@�@�@�@�@�@�@�''- �_ �R��@�@ ,,i'�Li�@, |i�@�@�@�@�_'�@`i,�@ �M!r'''(�L �^~
�@�@�@�@ �=''�L�@�@�@�@�@�@�@�@�@�@�@�S��S '���r-'~�S, i�@'! "'�@�@ r�]'_""`y�S!�R�S,r'�L
�@�@�@ �^�@�@�@�@�@�@�@��=_�]''''�~�S�M�@�@�~�~`�_�R�R. �_|�@�@ �^i'�L �P�R�r '"; } i�@�@ �_
�@�@�@, '�@�@�@�@�@�@�@�@�R�G '7�@, ;,� ��@�@ �' ��R�R �R�'�_. �q. �l;,�@�@�@�_�@� |�@ �]+==
.�@�@�@��@�@�@�@�@�@�@�@�@Ё@!�@{ {,'! ,�R�@�@�@�@�@ �M�S�R�@/ r�R;�]�M;;�_�@�@ �@ Yڃw �a
�@�@�@ |�@�@�@�@�@�@�@�@Ѓ~� ��''�@�@�@�@, �@ 'i � �@�@} �w�L�@;;;;;''�@ �m �m}�@ �@�@ i'''7�Li�@+��
�@�@ �m�@�@�@�@ �@�@ �M�SЃ~�@�@�@ , �@ �J '�@�@�M�@�@ /�L,, �_�@�@�^�m'�� |�@�@�@;.,'�R~"'''''''
�@;;;;'�@�@�@�@�@�@�@�@�@�@�_���@r'!, t,,!` , �@ ,,,,;�@/;;,,�''"~�''"�t'''f�]-;|�@ �@ ;,'-=�,'_�@,,,;;;;
�@ ���@�@�@�@�@�@�@�@ �@ `�R��@{:���S�@' ___:;;;;�^;;;''''�@'�L,�@ 7�@r'�@�@ |�@�@ ;;,'�@�@�@ �M'''�]-
�@ -='_�@�@�@�@�@�@�@�@�@�@�@�~ЁR_,,,��]''";=����]�]'''''�]-'�,,,,,i��{;;;;;;;;;;i�@�@.;,'
�@�@�P���-�]�_�@�@�@�@�@�@�@�@�@�@�@ �ƁL�@�@�@�@�@�@�@�@�@�@�@�@�@�@ |�@�@;,'�P�M�M�M`'''''''��
"""""""""""`"�J'''''''''''''''''''''''''''''''�L-�]�]�]�]''''''''''''''''''''''''''''''''''''','r'~�L�@�@,''''''''''''''''''''''''''''''
�Ȃ��CPU�ł�GPU�ł��`�b�v�Z�b�g�ł�Intel�ɕ����Ă��.... ,�@ i
Intel�ɏ��Ă镔�����Ă����...... �@�@�@�@//�@�@'��';"'''-'7' ,�@, ,'
�����_����................�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�S�R.�@ �p ( ;;,,, Ɂ^//�
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�M''''""�M~"" `~~�P
�@�@�@�@�@�@�@�@�^�@�@�@�@�@�@�@�@�@ �M'�] ��@�@ �@�@�@ i' � i�ܤ____�@��_ _,,,��@,�- '�L-�]-,
�@�@�@�@ �@�@ r'�@�@�@�@�@�@�@�@�@�@�''- �_ �R��@�@ ,,i'�Li�@, |i�@�@�@�@�_'�@`i,�@ �M!r'''(�L �^~
�@�@�@�@ �=''�L�@�@�@�@�@�@�@�@�@�@�@�S��S '���r-'~�S, i�@'! "'�@�@ r�]'_""`y�S!�R�S,r'�L
�@�@�@ �^�@�@�@�@�@�@�@��=_�]''''�~�S�M�@�@�~�~`�_�R�R. �_|�@�@ �^i'�L �P�R�r '"; } i�@�@ �_
�@�@�@, '�@�@�@�@�@�@�@�@�R�G '7�@, ;,� ��@�@ �' ��R�R �R�'�_. �q. �l;,�@�@�@�_�@� |�@ �]+==
.�@�@�@��@�@�@�@�@�@�@�@�@Ё@!�@{ {,'! ,�R�@�@�@�@�@ �M�S�R�@/ r�R;�]�M;;�_�@�@ �@ Yڃw �a
�@�@�@ |�@�@�@�@�@�@�@�@Ѓ~� ��''�@�@�@�@, �@ 'i � �@�@} �w�L�@;;;;;''�@ �m �m}�@ �@�@ i'''7�Li�@+��
�@�@ �m�@�@�@�@ �@�@ �M�SЃ~�@�@�@ , �@ �J '�@�@�M�@�@ /�L,, �_�@�@�^�m'�� |�@�@�@;.,'�R~"'''''''
�@;;;;'�@�@�@�@�@�@�@�@�@�@�_���@r'!, t,,!` , �@ ,,,,;�@/;;,,�''"~�''"�t'''f�]-;|�@ �@ ;,'-=�,'_�@,,,;;;;
�@ ���@�@�@�@�@�@�@�@ �@ `�R��@{:���S�@' ___:;;;;�^;;;''''�@'�L,�@ 7�@r'�@�@ |�@�@ ;;,'�@�@�@ �M'''�]-
�@ -='_�@�@�@�@�@�@�@�@�@�@�@�~ЁR_,,,��]''";=����]�]'''''�]-'�,,,,,i��{;;;;;;;;;;i�@�@.;,'
�@�@�P���-�]�_�@�@�@�@�@�@�@�@�@�@�@ �ƁL�@�@�@�@�@�@�@�@�@�@�@�@�@�@ |�@�@;,'�P�M�M�M`'''''''��
"""""""""""`"�J'''''''''''''''''''''''''''''''�L-�]�]�]�]''''''''''''''''''''''''''''''''''''','r'~�L�@�@,''''''''''''''''''''''''''''''
�Ȃ��CPU�ł�GPU�ł��`�b�v�Z�b�g�ł�Intel�ɕ����Ă��.... ,�@ i
Intel�ɏ��Ă镔�����Ă����...... �@�@�@�@//�@�@'��';"'''-'7' ,�@, ,'
�����_����................�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�S�R.�@ �p ( ;;,,, Ɂ^//�
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�M''''""�M~"" `~~�P
>>182
���O�������{��ǂ߂ĂȂ������B�N������Ȏ��������H�H�H��
�o�J�܂邾��
B9VvMNxK�́A0.18�ʂ̍��̘b�����̂܂ܒʗp����Ǝv���Ă�H
���O�������{��ǂ߂ĂȂ������B�N������Ȏ��������H�H�H��
�o�J�܂邾��
B9VvMNxK�́A0.18�ʂ̍��̘b�����̂܂ܒʗp����Ǝv���Ă�H
��̔N���̌����J�����5�{�ȏ�̊J��������̂�>>173�݂����ȏ������݂��o�����Ⴄ���_�ŃA�z
�����ȊO�ł������̊J����������Ă̂�
>>184
AMD�̎�����90nm�ł�Intel��65nm�ɓ����ŏ��ĂȂ�����(@IEDM2006)�˂�
�����ȊO�ł������̊J����������Ă̂�
>>184
AMD�̎�����90nm�ł�Intel��65nm�ɓ����ŏ��ĂȂ�����(@IEDM2006)�˂�
B9VvMNxK�͎����������ŗU�����Ă�����ɍs���Ȃ��ƃL���Đ���ȊO�̔��������Ȃ��Ȃ�
�T�^�I�ȎG������
�T�^�I�ȎG������
>>185
(߄D�)ʧ?
���̐l�ȂɌ����Ă�́H
�ȂC���������Ȃ��Ă����ȁB
�����J����P���{���낤��Intel���F�������������[�˂��ẮB
���b���Ă����̂́u�v���Z�X�̔����v�B������ޮ�ށH
(߄D�)ʧ?
���̐l�ȂɌ����Ă�́H
�ȂC���������Ȃ��Ă����ȁB
�����J����P���{���낤��Intel���F�������������[�˂��ẮB
���b���Ă����̂́u�v���Z�X�̔����v�B������ޮ�ށH
>185
�Ă�������Intel�Ƃ�AMD�Ƃ��W�˂���
�Ă�������Intel�Ƃ�AMD�Ƃ��W�˂���
�Q�[�g�̒����͈ȑO�̃y�[�X�ł͏������ł��Ȃ��Ȃ邩�������
�z�������Z���Ȃ镪�͐�ΓI�Ȃ̂ŁA���ꎩ�̂̉��b�͂���͂��B
������A�����ō��N���b�N��_���Ȃ��A�Ƃ����̂͂ǂ����Ǝv����B
�ȑO�̃y�[�X�ł͑_���Ȃ��A�����������?
�z�������Z���Ȃ镪�͐�ΓI�Ȃ̂ŁA���ꎩ�̂̉��b�͂���͂��B
������A�����ō��N���b�N��_���Ȃ��A�Ƃ����̂͂ǂ����Ǝv����B
�ȑO�̃y�[�X�ł͑_���Ȃ��A�����������?
>>189
����������A�Q�[�g�x�������ɂ�鉶�b�͌����Ă�ǂ��납�A�ȑO�ƕς�炸����ł���B
�x���͕����I�Ȕz�������̖�肾����A���R����������Α����Ȃ�B
�����A���̓N���b�N����̓V�䂪�A���[�N�d���ɂȂ��Ă���̂�
�Q�[�g�x���������Ă�������Ȃ��ƃN���b�N���グ���Ȃ��̂ŁA
�x���������Ă��N���b�N����̉��b�ɂȂ��ĂȂ��B
�܂�A��H�̐M���x�����̂̓V��́A���i�Ƃ��Ĕ����Ă���b�o�t���
�����Ə�ɂȂ��Ă�̂Œx��������ȏ㌸���Ă��ʂɉ��b���Ȃ��B
�v����ɂP�O�O�O�O��]�o����G���W���͐v�o�������ǁA����ɑς�����
�ԑ̂��Ȃ��悤�ȏ�ԂȂ̂ŁA����ȏ�G���W���̉�]���オ���Ă�
�����̏���͕ς��Ȃ��A�ƌ������ƁB
�i�����疳������ƁA�}�U�[�����ς�������̂b�o�t���Ďv�������N���b�N��������H
�@�M���x�����̂͏������Ȃ��Ă邩�瓮��͂���\��������j
���N���b�N���グ�Ă���̂̓��[�N�d�������炷���߂�
�c�݃V���R����Low�|k�≏���ASOI�Ȃǂ̎��ӗv�f�Z�p�B
����������A�Q�[�g�x�������ɂ�鉶�b�͌����Ă�ǂ��납�A�ȑO�ƕς�炸����ł���B
�x���͕����I�Ȕz�������̖�肾����A���R����������Α����Ȃ�B
�����A���̓N���b�N����̓V�䂪�A���[�N�d���ɂȂ��Ă���̂�
�Q�[�g�x���������Ă�������Ȃ��ƃN���b�N���グ���Ȃ��̂ŁA
�x���������Ă��N���b�N����̉��b�ɂȂ��ĂȂ��B
�܂�A��H�̐M���x�����̂̓V��́A���i�Ƃ��Ĕ����Ă���b�o�t���
�����Ə�ɂȂ��Ă�̂Œx��������ȏ㌸���Ă��ʂɉ��b���Ȃ��B
�v����ɂP�O�O�O�O��]�o����G���W���͐v�o�������ǁA����ɑς�����
�ԑ̂��Ȃ��悤�ȏ�ԂȂ̂ŁA����ȏ�G���W���̉�]���オ���Ă�
�����̏���͕ς��Ȃ��A�ƌ������ƁB
�i�����疳������ƁA�}�U�[�����ς�������̂b�o�t���Ďv�������N���b�N��������H
�@�M���x�����̂͏������Ȃ��Ă邩�瓮��͂���\��������j
���N���b�N���グ�Ă���̂̓��[�N�d�������炷���߂�
�c�݃V���R����Low�|k�≏���ASOI�Ȃǂ̎��ӗv�f�Z�p�B
�ЂƂ⑫�B
���M���x�����̂͏������Ȃ��Ă邩�瓮��͂���\��������
�Ƃ͂����Ă����̂b�o�t�͍��N���b�N���l�������v�ɂȂ��ĂȂ����炻�̕����E�͂���B
���M���x�����̂͏������Ȃ��Ă邩�瓮��͂���\��������
�Ƃ͂����Ă����̂b�o�t�͍��N���b�N���l�������v�ɂȂ��ĂȂ����炻�̕����E�͂���B
Low-k�w�Ԑ≏����SOI��[�N�d���Ɨ��߂Č����̂͂ǂ����c
193 �FSocket774�F2007/01/18(��) 06:09:57 ID:RUbvYY5t
���܂���݂�Ȃ��ĉ��{�P���܂��Ă�́B
�v���Z�X��65n��45n��TDP��������B����͂�����ȁH
Intel�͂������AMD�ł�90n��65n��TDP�͂������艺�����Ă�B
���݂�CPU�̃N���b�N�����TDP�Ō��܂��Ă���B���C���X�g���[���Ȃ�65W�A
�p�t�H�[�}���X�Ȃ�95W�A�G�N�X�g���[���Ȃ�130W�A�Ƃ��ˁB
�����������ȁH
Kentsfield�̃N���b�N�Ȃ�Ă����TDP�Ő�������Ă���p�^�[��������A
���ꂪYorkfield�ɂȂ�����N���b�N����͏オ��B
�c�_�̗]�n�Ȃ��B
�v���Z�X��65n��45n��TDP��������B����͂�����ȁH
Intel�͂������AMD�ł�90n��65n��TDP�͂������艺�����Ă�B
���݂�CPU�̃N���b�N�����TDP�Ō��܂��Ă���B���C���X�g���[���Ȃ�65W�A
�p�t�H�[�}���X�Ȃ�95W�A�G�N�X�g���[���Ȃ�130W�A�Ƃ��ˁB
�����������ȁH
Kentsfield�̃N���b�N�Ȃ�Ă����TDP�Ő�������Ă���p�^�[��������A
���ꂪYorkfield�ɂȂ�����N���b�N����͏オ��B
�c�_�̗]�n�Ȃ��B
194 �FSocket774�F2007/01/18(��) 06:38:32 ID:u/AMXWnW
����A�v���X�R�́E�E
�I�[�o�[�N���b�N����Ηǂ������B
196 �FSocket774�F2007/01/18(��) 09:05:31 ID:xc/ue00S
AMD Athlon64 X2 65nm(IBM) SOI(IBM)�v���Z�X�Ő�������܂��B
AMD�̓}�g���ȃ`�b�v�Z�b�g�o���Ă���ɂ��Ă���B
198 �FSocket774�F2007/01/18(��) 09:33:14 ID:zcJI/e7E
TDP135W����PentiumD�ł�������Athlon64x2
>>193
�k�X�i90nm�j�@���@�v���X�R�i60nm�j
����d�͏オ������H�@���̂������ŃN���b�N���オ��Ȃ��������H
�v���X�R������d�͂��������Ă����̂͂��̑����ӋZ�p�_���H
�k�X�i90nm�j�@���@�v���X�R�i60nm�j
����d�͏オ������H�@���̂������ŃN���b�N���オ��Ȃ��������H
�v���X�R������d�͂��������Ă����̂͂��̑����ӋZ�p�_���H
��ׁB�f�ŊԈႦ���I�I�I�I�I�I�I�I�I�I�I�I
�k�X�i130nm�j���v���X�R�i90nm�j
�������B
�k�X�i130nm�j���v���X�R�i90nm�j
�������B
Cedarmill�ȁB
>����d�͏オ������H�@���̂������ŃN���b�N���オ��Ȃ��������H
�{���Ƀv���Z�X�̐�������������ׂȂ��̂���A�܂������ˁB
�g�����W�X�^����������W���}�C�J�B
�P����r�Ȃ点�߂ăV�������N���ꂽ���̂Ŕ�ׂĂ��������B
>����d�͏オ������H�@���̂������ŃN���b�N���オ��Ȃ��������H
�{���Ƀv���Z�X�̐�������������ׂȂ��̂���A�܂������ˁB
�g�����W�X�^����������W���}�C�J�B
�P����r�Ȃ点�߂ăV�������N���ꂽ���̂Ŕ�ׂĂ��������B
�N���b�N����̗v���͂����܂Ńv���Z�X���[���̏k���ɂ��X�C�b�`���O���x�̌���B
���ӋZ�p�͊O�I�ȑj�Q�v���̉����B
�����H���ŕ���������ύX���ăN���b�N���L�т�ꍇ�����邪��O�I�B
���ӋZ�p�͊O�I�ȑj�Q�v���̉����B
�����H���ŕ���������ύX���ăN���b�N���L�т�ꍇ�����邪��O�I�B
>>203
�c�P����r�ŃV�������N�u�����v���ꂽCPU�Ȃ�Ăˁ[����B
�c�P����r�ŃV�������N�u�����v���ꂽCPU�Ȃ�Ăˁ[����B
Intel�������P��45nm�v���Z�X�ɏk��������킯�Ȃ�����
Intel�A45nm�v���Z�X�Z�p��High-k�Q�[�g�≏��/���^���Q�[�g�d�ɂ��̗p
http://journal.mycom.co.jp/news/2003/11/05/51.html
�͂��R����>>167���������悤��K8L�̃x���`���Penryn�̕�����ɏo����
������ʂ�AMD��CPU�͕����܂�
�܂��A�o�Ȃ����낤���ǂ��Ԃ�
Intel�A45nm�v���Z�X�Z�p��High-k�Q�[�g�≏��/���^���Q�[�g�d�ɂ��̗p
http://journal.mycom.co.jp/news/2003/11/05/51.html
�͂��R����>>167���������悤��K8L�̃x���`���Penryn�̕�����ɏo����
������ʂ�AMD��CPU�͕����܂�
�܂��A�o�Ȃ����낤���ǂ��Ԃ�
207 �FSocket774�F2007/01/18(��) 13:50:20 ID:HueiK4Pa
http://journal.mycom.co.jp�̓��W��2007�N�̗\������Ă�
����܂�i�����Ȃ��炵��
����܂�i�����Ȃ��炵��
>�k�X�i130nm�j���v���X�R�i90nm�j
��
>Prescott�i90nm�j��Cedarmill�i65nm�j
�ɑւ��邾���ŗǂ��b�Ȃ̂Ɂc
NetBurst=Prescott�̍ō��Ɉ����������N���[�Y�A�b�v���������A�Ƃ����Ӑ}�͋��ނ��B
����͂܂��ɁA�v���Z�X�ڍs�ƃR�A�ύX�Ƃ�����̓�ւ��ɃN���A���悤�Ƃ����ӗ~��ł��邱�Ƃ͊ԈႢ�Ȃ���
�N���\�z�����Ȃ�����90nm����̃��[�N�̍���������ɑ��������������ˁB
FX74�Ƃ��o����Ă��܂������ł͂����ǂ��v���o�ł����B
��
>Prescott�i90nm�j��Cedarmill�i65nm�j
�ɑւ��邾���ŗǂ��b�Ȃ̂Ɂc
NetBurst=Prescott�̍ō��Ɉ����������N���[�Y�A�b�v���������A�Ƃ����Ӑ}�͋��ނ��B
����͂܂��ɁA�v���Z�X�ڍs�ƃR�A�ύX�Ƃ�����̓�ւ��ɃN���A���悤�Ƃ����ӗ~��ł��邱�Ƃ͊ԈႢ�Ȃ���
�N���\�z�����Ȃ�����90nm����̃��[�N�̍���������ɑ��������������ˁB
FX74�Ƃ��o����Ă��܂������ł͂����ǂ��v���o�ł����B
���߁A����
>Prescott-2M�i90nm�j��Cedarmill�i65nm�j
���m�ɂ͑����������Ǝv���B
����Nortwood����Prescott�ւ̕ύX�ő������g�����W�X�^��
�O��5500���ɑ��A���1��2500���������ŁB
�ǂ����Ă��{�ȏ�ł��A�{����(ry
Prescott����Prescott-2M��TDP�ω��͂ǂ����������ȁB
�o���ĂȂ����A�オ���ĂȂ��Ƃ�����A���̑��Z�p�̉��P���A
�v���Z�X���̂̏n�����i��ł��傤�ȁB
AMD�������������Ȃ��ŁA���ʋC�ŃL���b�V�����ʂ��Ă݂悤��B
>Prescott-2M�i90nm�j��Cedarmill�i65nm�j
���m�ɂ͑����������Ǝv���B
����Nortwood����Prescott�ւ̕ύX�ő������g�����W�X�^��
�O��5500���ɑ��A���1��2500���������ŁB
�ǂ����Ă��{�ȏ�ł��A�{����(ry
Prescott����Prescott-2M��TDP�ω��͂ǂ����������ȁB
�o���ĂȂ����A�オ���ĂȂ��Ƃ�����A���̑��Z�p�̉��P���A
�v���Z�X���̂̏n�����i��ł��傤�ȁB
AMD�������������Ȃ��ŁA���ʋC�ŃL���b�V�����ʂ��Ă݂悤��B
210 �FSocket774�F2007/01/18(��) 15:08:59 ID:ZIbHfxmW
100W�������v���X�q���ו����Ɖ��ǂ�65W�܂ʼn��������̂͋�����
>>209
���₹�ΐ��\�オ�邪
���₳�Ȃ��Ă����C�e���V���Ⴂ����卷�Ȃ�
�Ƃ����̂�����܂ł̘b
65nm���烌�C�e���V�������オ�����炵������
���₹����Ȃ�ɐ��\�����o�Ă���
���ǂ킴�ƂȂ�ˁB�k2�Ő��\���ł�悤�ɕύX
�܂��intel�݂����Ȃ��Ƃ���Ȃ�E�E�E�`�l�c
���₹�ΐ��\�オ�邪
���₳�Ȃ��Ă����C�e���V���Ⴂ����卷�Ȃ�
�Ƃ����̂�����܂ł̘b
65nm���烌�C�e���V�������オ�����炵������
���₹����Ȃ�ɐ��\�����o�Ă���
���ǂ킴�ƂȂ�ˁB�k2�Ő��\���ł�悤�ɕύX
�܂��intel�݂����Ȃ��Ƃ���Ȃ�E�E�E�`�l�c
�v���X�R�̓o�O��C1E OFF�̎���130w�������̂��o�O�Ƃ��C1E ON�ɂȂ�����
95w�ɂȂ�܂����I�Ƃ������o��������ۂ�TDP�͒��M�p�o����B
95w�ɂȂ�܂����I�Ƃ������o��������ۂ�TDP�͒��M�p�o����B
213 �FSocket774�F2007/01/18(��) 16:47:58 ID:xz1iYDjy
>�v���X�R
�v���Z������Ȃ��̂��H
�v���X�R=���̑㖼���ɂȂ��Ă�̂��ˁH
�v���Z������Ȃ��̂��H
�v���X�R=���̑㖼���ɂȂ��Ă�̂��ˁH
>>204
���N���b�N����̗v���͂����܂Ńv���Z�X���[���̏k���ɂ��X�C�b�`���O���x�̌���B
�����ӋZ�p�͊O�I�ȑj�Q�v���̉����B
�������Ƃ��āA���݃N���b�N�����j�Q���Ă�̂��X�C�b�`���O���x�łȂ���
���̗v�f�Ȃ���A���̘b���������Ȃ����H(-_-)
�u�Ԃ̑��x�����߂�̂̓G���W���̔n�͂����ׂāA��͂Ƃ��V���[�V�[�Ƃ��͑j�Q�v���̉��������v����
�����Ă�悤�Ȃ����B
���������A�N���b�N�ōl������p�C�v���C���̕����Ƃ��v�ʂ����R�W���邵
�Ȃ�ŃX�C�b�`���O���x�̌��ゾ���ɍi���Ă�̂����P���J���B
���N���b�N����̗v���͂����܂Ńv���Z�X���[���̏k���ɂ��X�C�b�`���O���x�̌���B
�����ӋZ�p�͊O�I�ȑj�Q�v���̉����B
�������Ƃ��āA���݃N���b�N�����j�Q���Ă�̂��X�C�b�`���O���x�łȂ���
���̗v�f�Ȃ���A���̘b���������Ȃ����H(-_-)
�u�Ԃ̑��x�����߂�̂̓G���W���̔n�͂����ׂāA��͂Ƃ��V���[�V�[�Ƃ��͑j�Q�v���̉��������v����
�����Ă�悤�Ȃ����B
���������A�N���b�N�ōl������p�C�v���C���̕����Ƃ��v�ʂ����R�W���邵
�Ȃ�ŃX�C�b�`���O���x�̌��ゾ���ɍi���Ă�̂����P���J���B
�܂��A�Q�[�g�̃X�C�b�`���x�̌��E���N���b�N����̑j�Q�v���̈�ɉ߂�����
DDR2�Ή������R�����������v���Z�b�T��AM2���o��O���炯����������������
DDR3�Ή��̂͂܂��o�ĂȂ������Ǝv������A���y����̂��C���e����������Ȃ��āA���ɂ���邩����
�C���e���ȊO�őΉ�����̂��o��ADDR3�̉��i�������邾�낤��
DDR3�Ή��̂͂܂��o�ĂȂ������Ǝv������A���y����̂��C���e����������Ȃ��āA���ɂ���邩����
�C���e���ȊO�őΉ�����̂��o��ADDR3�̉��i�������邾�낤��
�딚�����@�X�}�\
���̏��R�����N���b�N�����e��H�̃X�L���[�����ɐ���n�߂Ă�
��ISSCC��AMD�����\������WinPC�ɏ����Ă�����
��ISSCC��AMD�����\������WinPC�ɏ����Ă�����
���{�ŊJ�����Ă����Č��������d�̓R�A�͂ǂ����������H
>>219
�����I�ɂ������A�Ƃ������Ă����ǁA���肵���Ƃ�������Ȃ��̂ł����Ԑ悩�ƁB
�����I�ɂ������A�Ƃ������Ă����ǁA���肵���Ƃ�������Ȃ��̂ł����Ԑ悩�ƁB
���{�ŊJ�����Ă��̓t�@�[�X�g�V���R����2007�N����08�N���߂ɂȂ����
�̂��l�������Ă���
���i�ɂȂ�ɂ͂�������1�N���炢�������łȂ��́H
�̂��l�������Ă���
���i�ɂȂ�ɂ͂�������1�N���炢�������łȂ��́H
222 �FSocket774�F2007/01/21(��) 07:45:27 ID:TGBVwFPq
'�@ l | !_�^�l |, �@ l ',�@�@| �. �@ l�@ �@�@�@/ |�@ ;���@ ,�@�@�@ | l
�@ ,l/,r�]'�L!.| ',|�R�@| �R�@ ���@�R�@�b �@ �@ l�@l�@/���@ l, �@ �@ ���b
�@/ /�@ �@',| �\' �� ��ςs�L�@�R.|!�@ �@ / ��/-l�_,|�@ �@ /! !
,/ /���@�@�@ |�@���@�_ �Q�_�@ �@'|l �@�^ �]�'�L�@|/lj �@�^ /'�
. / |'�A�@ �@ ', �]��\r����` �@ �@ i�^�@ �]/_�]__/ /-�]'i�@/
/�@ ! �R.�@ �@́@��=��' �L�@ �@ �@ �@ �@ �T'-�cρL�@/�@ �@ �@ /'�R�@�@�@Conroe�̈��|�I���\�ƈ���
�@ �@! l�@�_ �@ �R�@ �@ �@ �@ �@ �@ �@�@�@�@�@�@�V�@ /!�@�@�@�@/�@ |�@�@�����Ēᐫ�\�@������d��64�EAM2�@�@�@�@
�@ l�@| l�@ �@�_�@ �_�@ �@ �@�@�@�@/�@ �@ �@ �^�@�^i�b�@ �@ /�@ /�@�@�@�@AMD����_(^o^)�^
�@���@ l�b �@ |�@�g�P�L�@�@�@�A�Q, �Q,�@ - '�L-�]�C �@ ��|.�@ �@/�@ /
�[ � l l�@ �@| /�_�_ �@ �@�@�L ��L�@ �@�^�@�@�b �@ ���@�@/ �@/�Q�Q, --�[
:::::::::::| l�@ �@|::::::�@�_ ށ@ �A�@�@ _�@�B �L�b�@ �@ l�@ �@, -:/�@, �;:::::::::::::::::::::::
::::::::::::l�b �@ !::::�@::::::::�|�Q�V �@ �@! �@ |�@�@�@l�^�L::::::/�@/�L |�-�------
:::::::::::::', l�@ �@|:�@::::::::/�L:|:::/�ul�_ �@ ! �@ !�@ �@l�Q�Q::/�^�@ /�@ �@�_::::::::::
:::::::::::::::',�@ �@ l�@::::::/::::::l:/�@l|::� �r�Q;-:::|�@ �@!::::::::::;'/�@�@,:'�@ �Ɂ@./�_::::
:�_:::::::::�ȁ@�@l�:::::::!:::::::l;' �@ l!::��>:::::::::l�@ �@l::::::::::��/ �@ ��@�R/�@ /�@ /�R
::::::�R:::/:::::� �@V�_:l�Q_�|�@�@l�x�::l>|�_::l �@ /:::::::::/�@�@�b �@ ! �/___/�@�1
::::::::::V:::::::::���_ �R�]Ĥ:::/|�@ �@�R�_!>�[��|�@/��::::::::::l�@ �@ �@�A�@l!_/�['-�C /
:::::::::::�:::::::::l/ �_�R�k.V�a�@ �@ �R�@ �@ / /!|:::::::::::l�@ �@ �@���@�@�@�@�@ځL
�@ ,l/,r�]'�L!.| ',|�R�@| �R�@ ���@�R�@�b �@ �@ l�@l�@/���@ l, �@ �@ ���b
�@/ /�@ �@',| �\' �� ��ςs�L�@�R.|!�@ �@ / ��/-l�_,|�@ �@ /! !
,/ /���@�@�@ |�@���@�_ �Q�_�@ �@'|l �@�^ �]�'�L�@|/lj �@�^ /'�
. / |'�A�@ �@ ', �]��\r����` �@ �@ i�^�@ �]/_�]__/ /-�]'i�@/
/�@ ! �R.�@ �@́@��=��' �L�@ �@ �@ �@ �@ �T'-�cρL�@/�@ �@ �@ /'�R�@�@�@Conroe�̈��|�I���\�ƈ���
�@ �@! l�@�_ �@ �R�@ �@ �@ �@ �@ �@ �@�@�@�@�@�@�V�@ /!�@�@�@�@/�@ |�@�@�����Ēᐫ�\�@������d��64�EAM2�@�@�@�@
�@ l�@| l�@ �@�_�@ �_�@ �@ �@�@�@�@/�@ �@ �@ �^�@�^i�b�@ �@ /�@ /�@�@�@�@AMD����_(^o^)�^
�@���@ l�b �@ |�@�g�P�L�@�@�@�A�Q, �Q,�@ - '�L-�]�C �@ ��|.�@ �@/�@ /
�[ � l l�@ �@| /�_�_ �@ �@�@�L ��L�@ �@�^�@�@�b �@ ���@�@/ �@/�Q�Q, --�[
:::::::::::| l�@ �@|::::::�@�_ ށ@ �A�@�@ _�@�B �L�b�@ �@ l�@ �@, -:/�@, �;:::::::::::::::::::::::
::::::::::::l�b �@ !::::�@::::::::�|�Q�V �@ �@! �@ |�@�@�@l�^�L::::::/�@/�L |�-�------
:::::::::::::', l�@ �@|:�@::::::::/�L:|:::/�ul�_ �@ ! �@ !�@ �@l�Q�Q::/�^�@ /�@ �@�_::::::::::
:::::::::::::::',�@ �@ l�@::::::/::::::l:/�@l|::� �r�Q;-:::|�@ �@!::::::::::;'/�@�@,:'�@ �Ɂ@./�_::::
:�_:::::::::�ȁ@�@l�:::::::!:::::::l;' �@ l!::��>:::::::::l�@ �@l::::::::::��/ �@ ��@�R/�@ /�@ /�R
::::::�R:::/:::::� �@V�_:l�Q_�|�@�@l�x�::l>|�_::l �@ /:::::::::/�@�@�b �@ ! �/___/�@�1
::::::::::V:::::::::���_ �R�]Ĥ:::/|�@ �@�R�_!>�[��|�@/��::::::::::l�@ �@ �@�A�@l!_/�['-�C /
:::::::::::�:::::::::l/ �_�R�k.V�a�@ �@ �R�@ �@ / /!|:::::::::::l�@ �@ �@���@�@�@�@�@ځL
>>222
������������
�f���A���R�A��20k�ȉ��Ŕ�����̂�AMD����
�������E6700��x5000���ׂ���O�҂̂����|�I�ɍ����\�����E�E�E
������������
�f���A���R�A��20k�ȉ��Ŕ�����̂�AMD����
�������E6700��x5000���ׂ���O�҂̂����|�I�ɍ����\�����E�E�E
PenD�Ȃ�2���ȉ������邪�c
�G�k�X���ł�X2�������Ĕ����Ȃ������805�ɓ��U���Ă��Ƃ�������
�G�k�X���ł�X2�������Ĕ����Ȃ������805�ɓ��U���Ă��Ƃ�������
PenD�̓d�A���R�A(ry
>>219
�u�����d�̓v���b�g�t�H�[���v�Ȃ����ŁA�R�A�ł͂Ȃ����c�B
�u�����d�̓v���b�g�t�H�[���v�Ȃ����ŁA�R�A�ł͂Ȃ����c�B
227 �FSocket774�F2007/01/21(��) 22:43:16 ID:DNXg/4Fm
�f���A���_�CQuad�R�A���ĈӖ�����̂��H
�_�C���m��P4�o�X�Ń`�b�v�Z�b�g�ɂ���ē�������PentiumD�ł����
�_�C���m��P4�o�X�Ń`�b�v�Z�b�g�ɂ���ē�������PentiumD�ł����
������Ɛ摖������������ȁH�@��AMD
�Ȃ�b���q�����ĂȂ���
>>227
������1�\�P�b�g�̃}�U�[��4�v���Z�b�T���h����Ƃ������_�ŏ\�����l������
Windows�Ȃ�Home���C�Z���X���g����i4x4����Professional�ȏオ�K�v�j
������1�\�P�b�g�̃}�U�[��4�v���Z�b�T���h����Ƃ������_�ŏ\�����l������
Windows�Ȃ�Home���C�Z���X���g����i4x4����Professional�ȏオ�K�v�j
���N��܂ŗ\��̏o�Ă�b�o�t�͂܂��Ǝv���������̍��B
�B���ʐF�X�d����ł�����ƂȁB�����C��������B
�B���ʐF�X�d����ł�����ƂȁB�����C��������B
>231
�G���ǂނ�
�Q�����Ɂ@�����
���܂��́@��]���@���Ȃ�
�G���ǂނ�
�Q�����Ɂ@�����
���܂��́@��]���@���Ȃ�
�G���L���̗��������悤�Ȃ̂𗊂ނ��Ď�����
�����ƕ��ǂ�
�����ƕ��ǂ�
>�G���L���̗��������悤�Ȃ̂𗊂ނ��Ď�����
����Ȃ��Ƃ́@�������
��232
�̂悤�ɂ�������
����Ȃ��Ƃ��킩���̂�
���܂��@�A�z���
����Ȃ��Ƃ́@�������
��232
�̂悤�ɂ�������
����Ȃ��Ƃ��킩���̂�
���܂��@�A�z���
���㓡�O��Weekly�C�O�j���[�X��
AMD���gFusion�h�v���Z�b�T�ƃI�N�^�R�A�ɐi�ޗ��R
http://pc.watch.impress.co.jp/docs/2007/0122/kaigai330.htm
AMD���gFusion�h�v���Z�b�T�ƃI�N�^�R�A�ɐi�ޗ��R
http://pc.watch.impress.co.jp/docs/2007/0122/kaigai330.htm
��u�I�N�^�R�A���I�^�N�R�A�Ɍ�����
���O�͉���
238 �FSocket774�F2007/01/22(��) 03:28:09 ID:UEUAwl0D
�����R���܂߂ă��W�����[�\����
HPC�p�r��2�`�����l���ȏ�̃V���A���C���^�[�t�F�[�XDRAM�Ƒ�GPU�R�A��Mathlon
�T�[�o�[�p�r��2�`�����l���̎�����DDR DRAM�Ƒ��ėp�R�A��Opteron
�R���V���[�}��2�`�����l���܂ł̎�����DDR DRAM��
GPU�E�ėp�R�A�̃Z�b�g��2�܂ł�Athlon64 X2��Athlon64
���Ċ����Ŗϑz���Ă����Ǘ\�z�ʂ蕲�ӂ��ꂽ��
HPC�p�r��2�`�����l���ȏ�̃V���A���C���^�[�t�F�[�XDRAM�Ƒ�GPU�R�A��Mathlon
�T�[�o�[�p�r��2�`�����l���̎�����DDR DRAM�Ƒ��ėp�R�A��Opteron
�R���V���[�}��2�`�����l���܂ł̎�����DDR DRAM��
GPU�E�ėp�R�A�̃Z�b�g��2�܂ł�Athlon64 X2��Athlon64
���Ċ����Ŗϑz���Ă����Ǘ\�z�ʂ蕲�ӂ��ꂽ��
�㓡������Ȃ��āAAMD�̍\�z���낤�B
�Z�p�I�ɂ͊Ԉ���ĂȂ��B
�R�c�����Ȃ����肸���ƗV�т܂����Ă�g�����W�X�^��
�������o�b�ɍڂ��Ă����A�킴�킴�g�����W�X�^�����炽�Ɏg����
128bit�p�b�N����256bit�p�b�N���̂̂��܂��P�ʂ�
SSE5�ESSE6�E�E�ESSE15�Ƃ��łb�o�t�ɂ��܂��܂ƃX�g���[�������n��
�������Ă������A�ǂ��[���512���������ł���GPU��
�ėp�ɂ����܂����ق����鉶�b�͂͂��肵��Ȃ��قǂł����B
���͂ǂꂾ���J���҂ɑf�����A�ǎ��Ȏ����������邩�A
�R���p�C���Ȃǂ̑Ή��̍��A���W���[�ȃ\�t�g�̑Ή��̓��������A���X
���ӂ̐������낤�ȁB
AMD�͂��̕ӂ̗͂��ア����Ȃ��B
�Z�p�I�ɂ͊Ԉ���ĂȂ��B
�R�c�����Ȃ����肸���ƗV�т܂����Ă�g�����W�X�^��
�������o�b�ɍڂ��Ă����A�킴�킴�g�����W�X�^�����炽�Ɏg����
128bit�p�b�N����256bit�p�b�N���̂̂��܂��P�ʂ�
SSE5�ESSE6�E�E�ESSE15�Ƃ��łb�o�t�ɂ��܂��܂ƃX�g���[�������n��
�������Ă������A�ǂ��[���512���������ł���GPU��
�ėp�ɂ����܂����ق����鉶�b�͂͂��肵��Ȃ��قǂł����B
���͂ǂꂾ���J���҂ɑf�����A�ǎ��Ȏ����������邩�A
�R���p�C���Ȃǂ̑Ή��̍��A���W���[�ȃ\�t�g�̑Ή��̓��������A���X
���ӂ̐������낤�ȁB
AMD�͂��̕ӂ̗͂��ア����Ȃ��B
>�R���p�C���Ȃǂ̑Ή��̍��A���W���[�ȃ\�t�g�̑Ή��̓��������A���X
�����intel���펪�������ɕ֏悵��(�R���p�C����SSE�̕��y�ȂǍ��܂ł͂قڃ^�_���)
�����j�~���ꂽ��"�Ƌ֖@�ᔽ"���Ċ�����
��i���邩����Ȃ��B
���Ă邩�ǂ����͂��ꂾ���A�ٔ��̌��ʂ��o��܂łɂ�
AMD���g�ʼn��Ƃ�����Ƃ����ژ_���B
�����AMD���D����(�L���M)
�����intel���펪�������ɕ֏悵��(�R���p�C����SSE�̕��y�ȂǍ��܂ł͂قڃ^�_���)
�����j�~���ꂽ��"�Ƌ֖@�ᔽ"���Ċ�����
��i���邩����Ȃ��B
���Ă邩�ǂ����͂��ꂾ���A�ٔ��̌��ʂ��o��܂łɂ�
AMD���g�ʼn��Ƃ�����Ƃ����ژ_���B
�����AMD���D����(�L���M)
>>242
CPU+GPU��AMD��������̂�����^�_��肵�悤���Ȃ�����Ȃ���
CPU+GPU��AMD��������̂�����^�_��肵�悤���Ȃ�����Ȃ���
>>241
�Ԉ���Ă邳w
����̂͏��F���_�v�Z���x�A�ƂĂ��ėp�I�ɂ͂Ȃ肦�Ȃ��B
�����ł������ėp���̂�����͍̂��l�F�̂͂���܂ł̐i���̉ߒ����ؖ����Ă���B
�Ԉ���Ă邳w
����̂͏��F���_�v�Z���x�A�ƂĂ��ėp�I�ɂ͂Ȃ肦�Ȃ��B
�����ł������ėp���̂�����͍̂��l�F�̂͂���܂ł̐i���̉ߒ����ؖ����Ă���B
>>242
���̔����̎�����E�p���悤�Ƃ��Ă邩��A����\�����ł����Ȃ��Ă�킯����
���̔����̎�����E�p���悤�Ƃ��Ă邩��A����\�����ł����Ȃ��Ă�킯����
>>244
�m�b�x�ꐙ���륥�������Ȃ�ł॥�
�m�b�x�ꐙ���륥�������Ȃ�ł॥�
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ _,...-�]----�_
�@�@�@�@�@�@�@�@�@ �@ �@ _,-�]'�L�@�@�@�@�@�@�@�M�R�A
�@�@�@�@�@�@�@�@ �@ _,.-'�L�@�@�@�@�@�@�@�@�@�@ ,�j�R�R�
�@�@�@�@�@�@�@�@ ,i�L�@ ,--..�_�@�@�@�@�@�@ _,�'�L�@�@ �R�R�A
�@�@�@�@�@�@�@ ,i�L�@,��L�@�@�@`�-----�]'�L�@�@�@ �@�@ �R�R
�@�@�@�@�@�@�@,l�@�@i�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@!� `i
�@�@ �@ �@ �@ |�@�@ l�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ |�@ |
.�@�@�@�@�@�@ |�@�@ l�@�@�@�@�@�@�@�@�@�A�@ �@ �@ �@ �@ �@ |�@ |
.�@�@�@ �@ �@ | �@�@l�@�@ �@ �@ ,,, �A � �R�@� ,,;;;,,,�@�@�@�@ !�@ |
�@�@�@�@�@�@�b�@ Ɂ@�@,;;;ii!!!''" �L�@�@�A__ ,�@ """!!!ii;,,�@ `i _|___
�@�@�@�@�@i'�L`�-|�_____,�'�L�P�P`�R�_____,r�]�]�]�]--�_�@�@l,!' -��R
�@�@�@�@�@| `,� V�@�@�@l�@-�]'�L��M�Ɂ]�]�]l ''�L��`�- ,�r�]'�L!�)��
�@�@�@�@�@�R��i�@�@�@�@ `-�_______,�m ,�@�@�R�__�@ �@ ,�m �@ |l���
�@ �@ �@ �@ !��@!�@�@�@�@�@�@�@�@ ,-�]'�@�@�@�@�R�M�P�L�@�@�@| ' j'
�@�@ �@ �@ �@ !�@i�A�@�@�@�@�@ _,-�A�@�@�@ �@ �@ ) �M�R�A�@�@l�@ l
�@�@ �@ �@ �@ `�'i�A�@�@�@�@,�@�@ �M�P�M��]'�P�L �M�R�Al �@�@l�M'�L
�@�@�@�@�@�@�@�@�@|�@�@�@ l l �___,..---�]�]�]�]---���� �@ ,!
�@�@�@�@�@�@�@�@ �l�@�@�@!��R`�<�l�Hl�Hl��'�L�@!� �@ �
�@�@�@�@�@�@ _,��L�@ !�A�@�@ �R�R�M�R------'�L�@�@�@�@ �m
�@�@_,..-�]'"�L�@�@�@�@�Mi�A�@�@ �R���@�@�@�@�@�@�@�@_�^`�-�___
'"�L�@�@�@�@�@�@�@�@�@�@�M�-�_�@�R �M�@�@�@�@�@�@�m�@�@�@�@�@�@�M`�-
�@�@�@�@�@�@�@�@�@ �@ �@ _,-�]'�L�@�@�@�@�@�@�@�M�R�A
�@�@�@�@�@�@�@�@ �@ _,.-'�L�@�@�@�@�@�@�@�@�@�@ ,�j�R�R�
�@�@�@�@�@�@�@�@ ,i�L�@ ,--..�_�@�@�@�@�@�@ _,�'�L�@�@ �R�R�A
�@�@�@�@�@�@�@ ,i�L�@,��L�@�@�@`�-----�]'�L�@�@�@ �@�@ �R�R
�@�@�@�@�@�@�@,l�@�@i�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@!� `i
�@�@ �@ �@ �@ |�@�@ l�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ |�@ |
.�@�@�@�@�@�@ |�@�@ l�@�@�@�@�@�@�@�@�@�A�@ �@ �@ �@ �@ �@ |�@ |
.�@�@�@ �@ �@ | �@�@l�@�@ �@ �@ ,,, �A � �R�@� ,,;;;,,,�@�@�@�@ !�@ |
�@�@�@�@�@�@�b�@ Ɂ@�@,;;;ii!!!''" �L�@�@�A__ ,�@ """!!!ii;,,�@ `i _|___
�@�@�@�@�@i'�L`�-|�_____,�'�L�P�P`�R�_____,r�]�]�]�]--�_�@�@l,!' -��R
�@�@�@�@�@| `,� V�@�@�@l�@-�]'�L��M�Ɂ]�]�]l ''�L��`�- ,�r�]'�L!�)��
�@�@�@�@�@�R��i�@�@�@�@ `-�_______,�m ,�@�@�R�__�@ �@ ,�m �@ |l���
�@ �@ �@ �@ !��@!�@�@�@�@�@�@�@�@ ,-�]'�@�@�@�@�R�M�P�L�@�@�@| ' j'
�@�@ �@ �@ �@ !�@i�A�@�@�@�@�@ _,-�A�@�@�@ �@ �@ ) �M�R�A�@�@l�@ l
�@�@ �@ �@ �@ `�'i�A�@�@�@�@,�@�@ �M�P�M��]'�P�L �M�R�Al �@�@l�M'�L
�@�@�@�@�@�@�@�@�@|�@�@�@ l l �___,..---�]�]�]�]---���� �@ ,!
�@�@�@�@�@�@�@�@ �l�@�@�@!��R`�<�l�Hl�Hl��'�L�@!� �@ �
�@�@�@�@�@�@ _,��L�@ !�A�@�@ �R�R�M�R------'�L�@�@�@�@ �m
�@�@_,..-�]'"�L�@�@�@�@�Mi�A�@�@ �R���@�@�@�@�@�@�@�@_�^`�-�___
'"�L�@�@�@�@�@�@�@�@�@�@�M�-�_�@�R �M�@�@�@�@�@�@�m�@�@�@�@�@�@�M`�-
244�̔\�V�C���Ɏ��i
Fusion���ăQ�[���������ۂ��v���Z�b�T�݂���������
X-Box360�̎��̓z�Ƃ��ɏ悹��
�Q�[�����x�����畁�y��}�点����Ă̂���������
X-Box360�̎��̓z�Ƃ��ɏ悹��
�Q�[�����x�����畁�y��}�点����Ă̂���������
GPU���j�b�`�Ƃ́A�������B
AMD��GPU��CPU�Ɠ��������̂�����
Intel�݂����Ɍ���@�\���i���ď��^�������Ƃ����R�v���Z�b�T����������悹��̂���������
Intel��4�R�A�E�v���Z�T��11���ɏo�J�n�C80�R�A��1�e��FLOPS�v���Z�T������
http://itpro.nikkeibp.co.jp/article/USNEWS/20060927/249038/
�Q�l
����A1�`�b�v��512G FLOPS��B������512�R�A�v���Z�b�T
http://pc.watch.impress.co.jp/docs/2006/1106/tokyou.htm
C����Ńv���O�����ł���500GFLOPS�̃v���Z�b�TGeForce 8800
http://pc.watch.impress.co.jp/docs/2006/1109/kaigai316.htm
Intel�݂����Ɍ���@�\���i���ď��^�������Ƃ����R�v���Z�b�T����������悹��̂���������
Intel��4�R�A�E�v���Z�T��11���ɏo�J�n�C80�R�A��1�e��FLOPS�v���Z�T������
http://itpro.nikkeibp.co.jp/article/USNEWS/20060927/249038/
�Q�l
����A1�`�b�v��512G FLOPS��B������512�R�A�v���Z�b�T
http://pc.watch.impress.co.jp/docs/2006/1106/tokyou.htm
C����Ńv���O�����ł���500GFLOPS�̃v���Z�b�TGeForce 8800
http://pc.watch.impress.co.jp/docs/2006/1109/kaigai316.htm
Intel�̎嗬�͂��ꂶ��Ȃ�
>>253
�C���e����GPU��CPU�ɓ�������
�C���e����GPU��CPU�ɓ�������
{kind=link}
�����̎������悗��
>>250
���Ƃ��A�Q�[�������i�Q�[���̍����Ɋւ�镨�������j��
���ʕ����i�������̃G�t�F�N�g�j����������ꍇ
�Q�[�������́ACPU������GPU�ŏ�������̂����z����
���ʕ����́A�O�t��GPU�ŏ����������ق����ǂ��B
�Ȃ�Ďg���������o����A�Ȃ�����ǂ��ˁB
�T�E���h������GPU�ōs���悤�ɂȂ�E�E�E
�i�Đ��͕ʁB������G�t�F�N�g�����̂��Ɓj
���Ƃ��A�Q�[�������i�Q�[���̍����Ɋւ�镨�������j��
���ʕ����i�������̃G�t�F�N�g�j����������ꍇ
�Q�[�������́ACPU������GPU�ŏ�������̂����z����
���ʕ����́A�O�t��GPU�ŏ����������ق����ǂ��B
�Ȃ�Ďg���������o����A�Ȃ�����ǂ��ˁB
�T�E���h������GPU�ōs���悤�ɂȂ�E�E�E
�i�Đ��͕ʁB������G�t�F�N�g�����̂��Ɓj
Sound Blaster X-Fi �ɍڂ��Ă���
Creative X-Fi Xtreme Fidelity �I�[�f�B�I�v���Z�b�T
���Y�ꋎ���Ă���E�E�E�E�E�E
Creative X-Fi Xtreme Fidelity �I�[�f�B�I�v���Z�b�T
���Y�ꋎ���Ă���E�E�E�E�E�E
>>244
���������A��Â��ɂ��Ă����x�����邾��E�E�T�N�O�ɂ͂��ł�
DirectX�Ƀv���O���}�u���d�l���ڂ��o�Ă��Ă����Ƃ����̂ɁE�E
���ǂ����_�v�Z�����o���Ȃ��n�[�h���C�A�[�h�I�����[��GPU�����ڂ��ĂȂ��r�f�I�{�[�h�ȂǂȂ��B
DirectX10�ȍ~�̐����GPU�̃V�F�[�_�[�̓v���O���}�u�����K�{�����ŁA
������x�̏������o����悤�ɂȂ��Ă��Ă�B
�Q�c�n�̉摜�t�B���^�Ȃ͍���GPU�ł������ɉ\���B
���������A��Â��ɂ��Ă����x�����邾��E�E�T�N�O�ɂ͂��ł�
DirectX�Ƀv���O���}�u���d�l���ڂ��o�Ă��Ă����Ƃ����̂ɁE�E
���ǂ����_�v�Z�����o���Ȃ��n�[�h���C�A�[�h�I�����[��GPU�����ڂ��ĂȂ��r�f�I�{�[�h�ȂǂȂ��B
DirectX10�ȍ~�̐����GPU�̃V�F�[�_�[�̓v���O���}�u�����K�{�����ŁA
������x�̏������o����悤�ɂȂ��Ă��Ă�B
�Q�c�n�̉摜�t�B���^�Ȃ͍���GPU�ł������ɉ\���B
>>260
DX10�����GPU���L���
����̃T�E���h�J�[�h�Ɉˑ����Ȃ����_���E�E�E
���ہAATI��Radeon SDK March 2006��
�T�E���h��EQ�i�C�R���C�U�j�����̃f�����������肷��E�E�E
DX10�����GPU���L���
����̃T�E���h�J�[�h�Ɉˑ����Ȃ����_���E�E�E
���ہAATI��Radeon SDK March 2006��
�T�E���h��EQ�i�C�R���C�U�j�����̃f�����������肷��E�E�E
�Q�[���̂��߂Ɏd���Ȃ�X-Fi��Audigy�g���Ă�g�Ƃ��Ă̓T�E���h�����̎����͔ߊ肾�Ȃ��B
�����N���G�C�e�B�u�̃h���C�o�͌�������݁B
�����N���G�C�e�B�u�̃h���C�o�͌�������݁B
>>260
Creative��DirectX10��API�̍���ɂ�����낤�Ƃ������Ɏ��c�����
DirectX�x�[�X��EAX���g����Vista�h���C�o���̂Ɏ�Ԏ��Ȃ�ĕ挊�@���Ă�݂��������B
���`���ł�EAX�̍X�V���Ƃ�DirectX��DirectSound�̃T�u�Z�b�g���Ă���J���Ȃ��������̂��B
�Ǝ��H������L�c�C�����Ɋ�@���������B�}�W��GPU�ɋ@�\�H��ꂩ�˂�B
Creative��DirectX10��API�̍���ɂ�����낤�Ƃ������Ɏ��c�����
DirectX�x�[�X��EAX���g����Vista�h���C�o���̂Ɏ�Ԏ��Ȃ�ĕ挊�@���Ă�݂��������B
���`���ł�EAX�̍X�V���Ƃ�DirectX��DirectSound�̃T�u�Z�b�g���Ă���J���Ȃ��������̂��B
�Ǝ��H������L�c�C�����Ɋ�@���������B�}�W��GPU�ɋ@�\�H��ꂩ�˂�B
http://www.steampowered.com/status/survey.html
�Q�[�}�[�ł����I���{�����ŃT�E���h�J�[�h���̂����Ƀ}�C�i�[�B
Creative���ǂ����~���Ă�MS�̕����̗p���Ȃ����낤�B
�Q�[�}�[�ł����I���{�����ŃT�E���h�J�[�h���̂����Ƀ}�C�i�[�B
Creative���ǂ����~���Ă�MS�̕����̗p���Ȃ����낤�B
>>265
���m�ȉ����炷��ƃT�E���h�J�[�h���Č����ڂŔ����C���Ȃ��B
CPU��O���{�݂����Ȑ����N�[���[�Ƃ�������Ȃ��`�b�v�Ŏ��ې����������Ă�́H
���m�ȉ����炷��ƃT�E���h�J�[�h���Č����ڂŔ����C���Ȃ��B
CPU��O���{�݂����Ȑ����N�[���[�Ƃ�������Ȃ��`�b�v�Ŏ��ې����������Ă�́H
�p�Q�[�}�[�̓T�E���h�J�[�h�ςޏꍇ��������Ȃ����������B
CPU�ł���Ă�T�E���h�֘A�̏�����C�����邩��FPS��������B
CPU�ł���Ă�T�E���h�֘A�̏�����C�����邩��FPS��������B
>>267 CPU�I�o�N��������ɋ����ق���FPS���������Ȃ��́H
����Ȃ�FPS�ɍ����ł����Ȃ́H�ꊄ�ȏ�Ƃ��B
����Ȃ�FPS�ɍ����ł����Ȃ́H�ꊄ�ȏ�Ƃ��B
��Ȃ���S�ċ���������ŃT�E���h�J�[�h���t����B
X-Fi����Ȃ���64����128���o���Ȃ��Q�[��������B
�����̍������������߂���������ŁB
�X���Ⴂ�X�}���B
X-Fi����Ȃ���64����128���o���Ȃ��Q�[��������B
�����̍������������߂���������ŁB
�X���Ⴂ�X�}���B
�D�揇�ʓI�ɍŌ�̈����Ă킯�ˁB�[���B
�X���Ⴂ�ł�������Ȃ��H
�������Z�g���������Ƃ��R�v���R�A�Ƃ��ď悹�ĂĂق������B
�T�E���h�J�[�h�ɋ��������̂͋@�\�̕����������邵�B
�����Ƃ�128���Ƃ����A�Q�[�����̃I�u�W�F�N�g�̍d���Ƃ��f���Ĕ��ˉ���
��������Ƃ��̂��ʔ����B
�T�E���h���Ă������������ɔ��W���Ȃ��̂��Ȃ��H
�R�������̌ł��ɉ����Ă����Ɖ��Z���ĉ����ς��Ƃ����B
�X���Ⴂ�ł�������Ȃ��H
�������Z�g���������Ƃ��R�v���R�A�Ƃ��ď悹�ĂĂق������B
�T�E���h�J�[�h�ɋ��������̂͋@�\�̕����������邵�B
�����Ƃ�128���Ƃ����A�Q�[�����̃I�u�W�F�N�g�̍d���Ƃ��f���Ĕ��ˉ���
��������Ƃ��̂��ʔ����B
�T�E���h���Ă������������ɔ��W���Ȃ��̂��Ȃ��H
�R�������̌ł��ɉ����Ă����Ɖ��Z���ĉ����ς��Ƃ����B
>�Q�[�����̃I�u�W�F�N�g�̍d���Ƃ��f���Ĕ��ˉ�����������Ƃ��̂��ʔ����B
���ꂢ����w
���ꂢ����w
�mA3D 2.0
273 �FSocket774�F2007/01/23(��) 12:35:39 ID:Zia+d6vQ
Sun��Intel���헪�I��g
�܂���g��Sun��Java�ANetBeans�\�t�g�E�F�A�A���Ђ̋����G���W�j�A�����O��v�A
�}�[�P�e�B���O�ɂ��y�ԍL�͈͂ȓ��e�̂��̂ƂȂ����B
Sun��Intel�v���Z�b�T�AOS�ɂ�Solaris�AWindows�ALinux�𓋍ڂ���
�T�[�o�ƃ��[�N�X�e�[�V��������Ă����v��B
�܂����Ђ�Solaris�����ɍœK�������A4�v���Z�b�T�ȏ�̃V�X�e����
�����J������\��Ƃ����B
http://www.itmedia.co.jp/enterprise/articles/0701/23/news013.html
�܂���g��Sun��Java�ANetBeans�\�t�g�E�F�A�A���Ђ̋����G���W�j�A�����O��v�A
�}�[�P�e�B���O�ɂ��y�ԍL�͈͂ȓ��e�̂��̂ƂȂ����B
Sun��Intel�v���Z�b�T�AOS�ɂ�Solaris�AWindows�ALinux�𓋍ڂ���
�T�[�o�ƃ��[�N�X�e�[�V��������Ă����v��B
�܂����Ђ�Solaris�����ɍœK�������A4�v���Z�b�T�ȏ�̃V�X�e����
�����J������\��Ƃ����B
http://www.itmedia.co.jp/enterprise/articles/0701/23/news013.html
274 �FSocket774�F2007/01/23(��) 12:57:26 ID:NHu3ZTX/
5000�~�̃{�[�h�ł�
���yCD�������ł����炩�ȉ����̍�������B
���yCD�������ł����炩�ȉ����̍�������B
C2D�ł���Ă��e�ʋ��L�L���b�V�����Ă̂͂ǂ��Ȃ�B
���ʂ�����������Ȃ��̂��A����Ƃ��������ŏo�����ɂ���̂��ȁH
���ʂ�����������Ȃ��̂��A����Ƃ��������ŏo�����ɂ���̂��ȁH
>>275
Hammer�n�ł́A���C���������[��CPU�ɒ�������Ă���̂ŁA
�L���b�V���ʂ����Ƃ���ő債�����������B
�c�Ƃ������f�炵���B
�������c���������ĂȂH
�u�L���b�V���e�ʂ𑝂₷�v�̂ɁA�N�ɓ�����Ȃ�������Ȃ����Ď����H
���������u�L���b�V���e�ʂ𑝂₷�v�������ĂȂH
Hammer�n�ł́A���C���������[��CPU�ɒ�������Ă���̂ŁA
�L���b�V���ʂ����Ƃ���ő債�����������B
�c�Ƃ������f�炵���B
�������c���������ĂȂH
�u�L���b�V���e�ʂ𑝂₷�v�̂ɁA�N�ɓ�����Ȃ�������Ȃ����Ď����H
���������u�L���b�V���e�ʂ𑝂₷�v�������ĂȂH
>>276
������OS��\�t�g�ɂ���邯�ǁAK8����256KB��512KB�ŕǂ����銴������
������OS��\�t�g�ɂ���邯�ǁAK8����256KB��512KB�ŕǂ����銴������
�ł������I��8�R�A���́A�����Ă��̗p�r��4(2)�R�A+��e�ʃL���b�V����
�ق��������C�������ȑf�l�l��������
�ق��������C�������ȑf�l�l��������
�R�A�𑝂₷�ɂ͑�e�ʂ̋��L�L���b�V�����s��
������AMD��4�R�A��2MB���L3���L���b�V�����ڂ��Ă���
����Ăǂ����ɏ����Ă��悤�ȋC������
������AMD��4�R�A��2MB���L3���L���b�V�����ڂ��Ă���
����Ăǂ����ɏ����Ă��悤�ȋC������
7���~�̃r�f�I�J�[�h�{�I���{�[�h�T�E���h
����Ȋ��̂������ƃu�����肽���Ȃ�
����Ȋ��̂������ƃu�����肽���Ȃ�
> Hammer�n�ł́A���C���������[��CPU�ɒ�������Ă���̂ŁA
> �L���b�V���ʂ����Ƃ���ő債�����������B
�Ⴄ�A�r���L���b�V���ł���L1��C2D�̔{�e�ʂ��邩��L2�����Ă�C2D�̂悤�ɑ傫�ȉe�����Ȃ������B
�����������o����킯�ł��Ȃ��AX2���{����L2��傫���������̂��{���B
�A�����i�ቺ�ɔ��������팸���l������_�C�T�C�Y�͏������������̂Ŏd�������ɏ��������Ă���̂�����낤�B
> �L���b�V���ʂ����Ƃ���ő債�����������B
�Ⴄ�A�r���L���b�V���ł���L1��C2D�̔{�e�ʂ��邩��L2�����Ă�C2D�̂悤�ɑ傫�ȉe�����Ȃ������B
�����������o����킯�ł��Ȃ��AX2���{����L2��傫���������̂��{���B
�A�����i�ቺ�ɔ��������팸���l������_�C�T�C�Y�͏������������̂Ŏd�������ɏ��������Ă���̂�����낤�B
45nm�ւ̈ڍs���C���e���Ɠ������Ȃ�Ȃ�
>>273
�������Y�͂̍��ŏ�芷����ꂽ�낤�ˁB
Sun���ǂ��������Ă�AMD���I�v�����ʈȏ㋟������\�͂���������A
�Ɛт����ł��ɂȂ��Ă��܂�����Ȃ��B
>>282
������Z-RAM�ɃK���K�b�e�Ⴂ�����Ƃ���Ȃ̂����B
�������Y�͂̍��ŏ�芷����ꂽ�낤�ˁB
Sun���ǂ��������Ă�AMD���I�v�����ʈȏ㋟������\�͂���������A
�Ɛт����ł��ɂȂ��Ă��܂�����Ȃ��B
>>282
������Z-RAM�ɃK���K�b�e�Ⴂ�����Ƃ���Ȃ̂����B
>>284
����͐��Y�͂�萫�\�ʂ̔��f�ł͂Ȃ����ƁB
����͐��Y�͂�萫�\�ʂ̔��f�ł͂Ȃ����ƁB
>>285
���炟���������B
�T�[�o�[�̂悤�ȁA�����_���W�����v�������p�r�ł�
K8�̂ق��������B
���ۃx���`�ł��Ȋw�Z�p�v�Z�n��T�[�o�[�n��K8�������Ă���B
�T�C�G���X�}�[�N�Ȃǂ̌��ʂ����Ă݁B
���炟���������B
�T�[�o�[�̂悤�ȁA�����_���W�����v�������p�r�ł�
K8�̂ق��������B
���ۃx���`�ł��Ȋw�Z�p�v�Z�n��T�[�o�[�n��K8�������Ă���B
�T�C�G���X�}�[�N�Ȃǂ̌��ʂ����Ă݁B
>>286
�Ƃ������w�E���Ă��镪��̓T�[�o�[�p�r�̒��ł��ɏ����h����H
�Ƃ������w�E���Ă��镪��̓T�[�o�[�p�r�̒��ł��ɏ����h����H
�w�E���Ă��镪����āE�E�����w�E���Ă��镪����Ă��Ƃ��H
�T�[�o�[���T�[�o�[�Ƃ��Ďg���̂��ċɏ����h�Ȃ̂��H
�T�[�o�[���T�[�o�[�Ƃ��Ďg���̂��ċɏ����h�Ȃ̂��H
Sun�̊�ƃ��[�U�[��Java�֘A�̃\�����[�V���������C��������B
SPEC��Woodcrest�̂ق����������яo���Ă��ȁB
SPEC��Woodcrest�̂ق����������яo���Ă��ȁB
ID:Gi8qqI2k�̓����ƁA�T�[�o�[��Java�Ȃǎg��Ȃ�
PC�ȊO�Ŏg�����̂Ȃ�Geode���A�g�ݍ������Ŕ���܂����Ă�Ƃ�������������
x86����Ȃ���Γ��p�t�H�[�}���X�ŏ���d�͐����̈�̂����邵�A������d�͂Ȃ�����ƃp�t�H�[�}���X����̂������ς����邩���
PC�ȊO�Ŏg�����̂Ȃ�Geode���A�g�ݍ������Ŕ���܂����Ă�Ƃ�������������
x86����Ȃ���Γ��p�t�H�[�}���X�ŏ���d�͐����̈�̂����邵�A������d�͂Ȃ�����ƃp�t�H�[�}���X����̂������ς����邩���
>>290
�����Ȃ�o�Ă��ĉ������Ă�̂����H
�܂���ɂ���āAIntel vs AMD�̍\�}�ł������̂�����Ȃ����
������ǂ܂Ȃ��a�l��w
�Ă�������b�̓L���b�`�{�[���Ȃ́A�킩��H
�P�Ɂu���\�ŁiConroe���T�[�o�[�Ɂj�̗p������Ȃ��H�v�Ƃ���285�̔����ɂ�������
�u�T�[�o�[�Ɏg���̂Ȃ�K8�Ɓi���Ȃ��Ƃ���芷����قǁj���\���͂Ȃ��E���邢�͗L���v�Ƃ���
������܂��̈ӌ����o���Ă邾���B
�����Ȃ�o�Ă��ĉ������Ă�̂����H
�܂���ɂ���āAIntel vs AMD�̍\�}�ł������̂�����Ȃ����
������ǂ܂Ȃ��a�l��w
�Ă�������b�̓L���b�`�{�[���Ȃ́A�킩��H
�P�Ɂu���\�ŁiConroe���T�[�o�[�Ɂj�̗p������Ȃ��H�v�Ƃ���285�̔����ɂ�������
�u�T�[�o�[�Ɏg���̂Ȃ�K8�Ɓi���Ȃ��Ƃ���芷����قǁj���\���͂Ȃ��E���邢�͗L���v�Ƃ���
������܂��̈ӌ����o���Ă邾���B
> �T�[�o�[���T�[�o�[�Ƃ��Ďg���̂��ċɏ����h�Ȃ̂��H
�T�[�o�[�̑����Ƃ��������|�I�����͒�����Ƃ̋Ɩ��p�Ƃ��Ďg���Ă���2Way�܂ł̍\�����w�ǁB
���̕���Ńf�[�^�x�[�X���\��APP���\���ׂ��Woodcrest�̕���Opteron���ǂ����ʂɂȂ��Ă���B
���ꂪ�T�[�o�[�̃��W���[�ł���B
�T�[�o�[�̑����Ƃ��������|�I�����͒�����Ƃ̋Ɩ��p�Ƃ��Ďg���Ă���2Way�܂ł̍\�����w�ǁB
���̕���Ńf�[�^�x�[�X���\��APP���\���ׂ��Woodcrest�̕���Opteron���ǂ����ʂɂȂ��Ă���B
���ꂪ�T�[�o�[�̃��W���[�ł���B
293 �FSocket774�F2007/01/24(��) 03:34:38 ID:YDRxG1JE
ID:Gi8qqI2k
�����FIntel vs AMD�̍\�}�ł����i���O���j���̂������Ȃ�
��̒��̊^����
���āA>>287�ɕԓ����Ă��炨�����H
�����FIntel vs AMD�̍\�}�ł����i���O���j���̂������Ȃ�
��̒��̊^����
���āA>>287�ɕԓ����Ă��炨�����H
>>293
�ԓ����Ă��炨�����H���Ă��܂��Ȃɂ��u�w�E���ĂȂ��v�����B�P�Ɍ��������Ă邾���B
���_�ɂ���Ȃɂ��Ȃ��Ă��Ȃ�w
���̔����ɊԈႢ������Ƃ��Ă������
�uIntel vs AMD�̍\�}�ł����i���O���j���̂������Ȃ��v
�Ƃ������Ƃւ̂Ȃ��肪�܂�łȂ��B�o�J���H
�Č��������[�A����Ȗ钆�ɒP��ID�ŘA���X����Ă��˂��i��
�ނ��AJAVA��SPEC�ŏ����Ă邩�炶��Ȃ��H�Ƃ���>>289�݂����Ȃ̂Ȃ�
�u���_�v�ɂ��u��b�v�ɂ��Ȃ��Ă��邪�E�E
���O�̂悤�ɂȂ�ŏ����ւ�����A��������悤�Ȕn���ȗ���ɂȂ�̂��Ӗ��s���B
�G�����H
�ԓ����Ă��炨�����H���Ă��܂��Ȃɂ��u�w�E���ĂȂ��v�����B�P�Ɍ��������Ă邾���B
���_�ɂ���Ȃɂ��Ȃ��Ă��Ȃ�w
���̔����ɊԈႢ������Ƃ��Ă������
�uIntel vs AMD�̍\�}�ł����i���O���j���̂������Ȃ��v
�Ƃ������Ƃւ̂Ȃ��肪�܂�łȂ��B�o�J���H
�Č��������[�A����Ȗ钆�ɒP��ID�ŘA���X����Ă��˂��i��
�ނ��AJAVA��SPEC�ŏ����Ă邩�炶��Ȃ��H�Ƃ���>>289�݂����Ȃ̂Ȃ�
�u���_�v�ɂ��u��b�v�ɂ��Ȃ��Ă��邪�E�E
���O�̂悤�ɂȂ�ŏ����ւ�����A��������悤�Ȕn���ȗ���ɂȂ�̂��Ӗ��s���B
�G�����H
�����C���Ȃ��Ƃł��������̂��B�����ꂳ��i��
���O���u�C���Ȃ��Ɓv����w
�N����N���l�b�g�ɒ���t���ė��܂�Ă����Ȃ�
�i���������J����B
���Ƃ��[���̃X���̃X���^�C�m���Ă�H
�N����N���l�b�g�ɒ���t���ė��܂�Ă����Ȃ�
�i���������J����B
���Ƃ��[���̃X���̃X���^�C�m���Ă�H
�ςȓz�����������Ă��܂��āA�X���Z�l�ɂ͂��܂Ȃ����Ƃ������B
�[���ASPECjbb�Ȃ�đ�O�ҋ@�ւł܂Ƃ��ɔ�r���Ă�݂̂����ƂȂ��ȁB
Intel�����\���Ă�̂͒m���Ă邪�B
Intel�����\���Ă�̂͒m���Ă邪�B
300 �FSocket774�F2007/01/24(��) 04:04:21 ID:HCvZApOa
>>297
�X���Z�l�ɐ\����Ȃ��A�Ȃ�Ă�����ۂ������v���ĂȂ�����B
���O�͍ŏ�����Intel�i�삷�邽�߂ɂ͒N��s�����ɂ��Ă�
�C�ɂ���悤�Ȃ܂Ƃ��Ȑl�Ԃł�Ȃ��B
�b�ʂ��Ȃ�����
�X���Z�l�ɐ\����Ȃ��A�Ȃ�Ă�����ۂ������v���ĂȂ�����B
���O�͍ŏ�����Intel�i�삷�邽�߂ɂ͒N��s�����ɂ��Ă�
�C�ɂ���悤�Ȃ܂Ƃ��Ȑl�Ԃł�Ȃ��B
�b�ʂ��Ȃ�����
�Ȃ��x���Ⴂ�Ȃ�w
�ϑz�Ɩ��m�Ɛ���A���ꂾ�������˂����x�̈����r�炵����̂ł��ȁB
���ĂƁA�b�����ɖ߂����B
AMD�͗ǂ�CPU����邪�ߍ��͂���ς�ρB
�X�P�[���r���e�B���グ��̂͌��\�����̐S�v�̃R���V���[�}�s��Ŋ撣��Ȃ��ƃ_������H
��ʐ��Y��ʔ̔��Ƃ����ƂȂ̂�����j�b�`�ȃn�C�G���h���삾����ǂ������Ă���_�����Ƃ��������ȁB
K8L�ɂ��Ă����̐��AM3�H�ɂ��Ă����A�n�C�G���h����ł����킦�l�F��_�������B
�ϑz�Ɩ��m�Ɛ���A���ꂾ�������˂����x�̈����r�炵����̂ł��ȁB
���ĂƁA�b�����ɖ߂����B
AMD�͗ǂ�CPU����邪�ߍ��͂���ς�ρB
�X�P�[���r���e�B���グ��̂͌��\�����̐S�v�̃R���V���[�}�s��Ŋ撣��Ȃ��ƃ_������H
��ʐ��Y��ʔ̔��Ƃ����ƂȂ̂�����j�b�`�ȃn�C�G���h���삾����ǂ������Ă���_�����Ƃ��������ȁB
K8L�ɂ��Ă����̐��AM3�H�ɂ��Ă����A�n�C�G���h����ł����킦�l�F��_�������B
�n�C�G���h�̕����������傫����
��]�͖ق��
��]�͖ق��
>>303
������������̂���]���ۂ��Ȃ����H
������������̂���]���ۂ��Ȃ����H
>>304
���x�Ђ����Ȃ���
���x�Ђ����Ȃ���
>>306
���ł�2Way�܂ł�Intel�������A����Ŏs���9�����߂Ă��邩�炻��ŏ\������Ȃ����H
���ł�2Way�܂ł�Intel�������A����Ŏs���9�����߂Ă��邩�炻��ŏ\������Ȃ����H
MAC�I�^��G�������Ȃ��Ă��A���̐l���P���J�����߂čr���B
�����A���̘b���v���o���Ă��܂����B
�����A���̘b���v���o���Ă��܂����B
Clovertown�ɑR�ł��鐻�i��AMD�ɂ͂܂��Ȃ��悤�ȁB
�f���A���R�A�~4Way�Ȃ�܂��킩�邪�A8Way�Ƃ��ɂȂ��Tulsa��������
SPECjbb�����܂�A�J�f�~�b�N�Ȑl�Ɏ��悭�Ȃ��̂�
Java���̂�Sun�̏��Ɛ헪�̂��߂̃\�t�g���������炾�낤
�I�[�v���\�[�X�ɂȂ����ɂ��擖����Sun�̉e���͋�����
(�ނ���MS.NET�R�̂��߂�GNU�𖡕��ɂ����Ƃ����߂ł���)
�f���A���R�A�~4Way�Ȃ�܂��킩�邪�A8Way�Ƃ��ɂȂ��Tulsa��������
SPECjbb�����܂�A�J�f�~�b�N�Ȑl�Ɏ��悭�Ȃ��̂�
Java���̂�Sun�̏��Ɛ헪�̂��߂̃\�t�g���������炾�낤
�I�[�v���\�[�X�ɂȂ����ɂ��擖����Sun�̉e���͋�����
(�ނ���MS.NET�R�̂��߂�GNU�𖡕��ɂ����Ƃ����߂ł���)
�����̎G��ID:paXo7hyq
����������ȉ��̂����ĎG�����ڗ����Ȃ���w
���͎I��Java�g��Ȃ��ȁB�S��C��sh���B����Op�̃����R����L3�t�����o����
��������\��BXeon�H����̓x���`��pCPU������g���C���Ȃ��B
����������ȉ��̂����ĎG�����ڗ����Ȃ���w
���͎I��Java�g��Ȃ��ȁB�S��C��sh���B����Op�̃����R����L3�t�����o����
��������\��BXeon�H����̓x���`��pCPU������g���C���Ȃ��B
�͂��͂�����\��PV�̎���I��
���̃��x������C7���x�ŏ\�����ȁB
���]����PenIII��SDRAM��2��~�I(ry
23 �F���������� �F2007/01/21(��) 01:38:34
��190�� Core MicroArchitecture������������
http://journal.mycom.co.jp/column/sopinion/190/
26 �F���������� �F2007/01/21(��) 04:13:03
REV.F��DualCore�@2MB�@L2��227.4M�g�����W�X�^
1MB L2�ŁA153.8M�g�����W�X�^�ƌ����Ă���B
�܂�A227.4-153.8=73.6M�g�����W�X�^���A1MB L2�̗e�ʂƎv����B
2MB���Ƃ�2��147.2
227.4-147.2=80.2��L2���������g�����W�X�^���B
41.1M��1�R�A������̃g�����W�X�^���ƂȂ�B
���Ȃ݂ɁA512KB�̃V���O���R�A��81.1M�ƌ����Ă���̂�
81.1-36.8=44.3�ق�DualCore�̐��l�Ɣ�ׁA�����������A
��q���郁���R���Ȃǂ̋��p�����́A1�R�A�ł�1���̂ŁA���Ƃ����Ă邩������Ȃ��B
��������匴���̂���L1�L���b�V���̗e��7M������������34.1M�g�����W�X�^
����Ƀ����R��������L2�ȊO�̃_�C�ʐςɐ�߂銄�����炷���14���Ȃ̂ŁA
�P���v�Z��5.75M�A����𗼃R�A�ŋ��L���邽�߁A�����Ƃ���2.88M�g�����W�X�^�B
34.1-2.875��31.22M�ł���B
�����R���̃g�����W�X�^���ɂ��ẮA�O�q�̐��l�Ō����A
DualCore��SingleCore�ŃR�A�ӂ�3.2M�̍�������̂ŁA
�����炸�������炸���ȁB
27 �F���������� �F2007/01/21(��) 04:15:27
����Ɠ������Ƃ�Core2�ł���
Core2 4MB�ł�291M
Core2 2MB�ł�167M
�ł��邩��A(291-167)*2��248M�g�����W�X�^
�i291-248�j/2=21.5M
�ߋ���P6�A�[�L�e�N�`���̂���ׂ�ƁA���R�A�̋��p���������������Ă����Ȃ��悤�Ɏv���B
���̑�Core2�̃L���b�V���v�Z�@����A�ߋ���CPU�̃g�����W�X�^���𐄒肷���
2MB��CoreDuo���A(151.6-124M)/2=13.8M
2MB�̃h�^��,PentiumM���A140-124M=16M
1MB�̃o�j�A�X,PentiumM���A77M-62M=15M
256KB��Pentium3���A28.1M-15.5=12.6M
L2�O�t����Pentium3���A9.5M
Penteium4����
�v���Z����(376-248)/2=64M
�v���X�R�b�g��125-62=63M
���Ƃ��������ƌ������A�قڂ҂�����I
�������g�����W�X�^����Core2��3�{�ɒB���邱�ƂɂȂ邪�B
��190�� Core MicroArchitecture������������
http://journal.mycom.co.jp/column/sopinion/190/
26 �F���������� �F2007/01/21(��) 04:13:03
REV.F��DualCore�@2MB�@L2��227.4M�g�����W�X�^
1MB L2�ŁA153.8M�g�����W�X�^�ƌ����Ă���B
�܂�A227.4-153.8=73.6M�g�����W�X�^���A1MB L2�̗e�ʂƎv����B
2MB���Ƃ�2��147.2
227.4-147.2=80.2��L2���������g�����W�X�^���B
41.1M��1�R�A������̃g�����W�X�^���ƂȂ�B
���Ȃ݂ɁA512KB�̃V���O���R�A��81.1M�ƌ����Ă���̂�
81.1-36.8=44.3�ق�DualCore�̐��l�Ɣ�ׁA�����������A
��q���郁���R���Ȃǂ̋��p�����́A1�R�A�ł�1���̂ŁA���Ƃ����Ă邩������Ȃ��B
��������匴���̂���L1�L���b�V���̗e��7M������������34.1M�g�����W�X�^
����Ƀ����R��������L2�ȊO�̃_�C�ʐςɐ�߂銄�����炷���14���Ȃ̂ŁA
�P���v�Z��5.75M�A����𗼃R�A�ŋ��L���邽�߁A�����Ƃ���2.88M�g�����W�X�^�B
34.1-2.875��31.22M�ł���B
�����R���̃g�����W�X�^���ɂ��ẮA�O�q�̐��l�Ō����A
DualCore��SingleCore�ŃR�A�ӂ�3.2M�̍�������̂ŁA
�����炸�������炸���ȁB
27 �F���������� �F2007/01/21(��) 04:15:27
����Ɠ������Ƃ�Core2�ł���
Core2 4MB�ł�291M
Core2 2MB�ł�167M
�ł��邩��A(291-167)*2��248M�g�����W�X�^
�i291-248�j/2=21.5M
�ߋ���P6�A�[�L�e�N�`���̂���ׂ�ƁA���R�A�̋��p���������������Ă����Ȃ��悤�Ɏv���B
���̑�Core2�̃L���b�V���v�Z�@����A�ߋ���CPU�̃g�����W�X�^���𐄒肷���
2MB��CoreDuo���A(151.6-124M)/2=13.8M
2MB�̃h�^��,PentiumM���A140-124M=16M
1MB�̃o�j�A�X,PentiumM���A77M-62M=15M
256KB��Pentium3���A28.1M-15.5=12.6M
L2�O�t����Pentium3���A9.5M
Penteium4����
�v���Z����(376-248)/2=64M
�v���X�R�b�g��125-62=63M
���Ƃ��������ƌ������A�قڂ҂�����I
�������g�����W�X�^����Core2��3�{�ɒB���邱�ƂɂȂ邪�B
30 �F���������� �F2007/01/21(��) 14:47:40
�匴���̌����������ǂ������킩��Ȃ����ACore2�̃g�����W�X�^�������Ȃ��͎̂����ł��낤�B
������ɂ���ACore2�̃g�����W�X�^�����͂��Ȃ�ǂ��B
K8��60-70%���x�̉��Z�p�C�v���C���g�����W�X�^���ŁA120���̐��\�����Ă���̂�����B
�k��AK7 2200���g�����W�X�^�ɑ��āAPen3 950���g�����W�X�^�ŁA
�N���b�N�����萫�\���قڌ݊p�������̂�����AAMD�̃A�[�L�e�N�`���[�ɂ͖��ʂ������̂����ȁB
K8�̃u���b�N�}�����Ă�
�R���v���b�N�X�f�R�[�_�[*3
�Ώ̌^ALU*3
AGU*3
�n�������v�ƌ����邩������Ȃ��B
38 �F���������� �F2007/01/21(��) 23:32:22
>>23
4issue��CPU�ʼn��Z�p�C�v���C�����펞IPC4�ʼn��Ƃ����蓾�Ȃ��̂�
���R�̂��Ƃ��Ǝv���̂����A�Ӑ}�I�ɊԈႦ�Ă�̂��H
���������Ӗ�����Core2��K8��IPC3����S���B���ł��ĂȂ�/����C���Ȃ��B
����Ƃ͕ʂɁA�p�C�v���C����3��4�ɋ����������������̂͊ԈႢ�Ȃ��B
���̍������ɑ��āAIPC4+�̃P�[�X�����邱�Ƃ��A��������Ȃ����Ƃ��v�����Ă���B
���̑��F�X�ȋ�����ςݏd�˂āACore2�͂��̃X�s�[�h����ɓ��ꂽ�̂��B
K8������Core2�����āAIPC��1.4�̂Ƃ����1.5�ɂ��悤�ƕK���Ɋ撣���č�����͂��B
�匴���̌����������ǂ������킩��Ȃ����ACore2�̃g�����W�X�^�������Ȃ��͎̂����ł��낤�B
������ɂ���ACore2�̃g�����W�X�^�����͂��Ȃ�ǂ��B
K8��60-70%���x�̉��Z�p�C�v���C���g�����W�X�^���ŁA120���̐��\�����Ă���̂�����B
�k��AK7 2200���g�����W�X�^�ɑ��āAPen3 950���g�����W�X�^�ŁA
�N���b�N�����萫�\���قڌ݊p�������̂�����AAMD�̃A�[�L�e�N�`���[�ɂ͖��ʂ������̂����ȁB
K8�̃u���b�N�}�����Ă�
�R���v���b�N�X�f�R�[�_�[*3
�Ώ̌^ALU*3
AGU*3
�n�������v�ƌ����邩������Ȃ��B
38 �F���������� �F2007/01/21(��) 23:32:22
>>23
4issue��CPU�ʼn��Z�p�C�v���C�����펞IPC4�ʼn��Ƃ����蓾�Ȃ��̂�
���R�̂��Ƃ��Ǝv���̂����A�Ӑ}�I�ɊԈႦ�Ă�̂��H
���������Ӗ�����Core2��K8��IPC3����S���B���ł��ĂȂ�/����C���Ȃ��B
����Ƃ͕ʂɁA�p�C�v���C����3��4�ɋ����������������̂͊ԈႢ�Ȃ��B
���̍������ɑ��āAIPC4+�̃P�[�X�����邱�Ƃ��A��������Ȃ����Ƃ��v�����Ă���B
���̑��F�X�ȋ�����ςݏd�˂āACore2�͂��̃X�s�[�h����ɓ��ꂽ�̂��B
K8������Core2�����āAIPC��1.4�̂Ƃ����1.5�ɂ��悤�ƕK���Ɋ撣���č�����͂��B
���ƁA���͂ނ���K8�̉��Z��i(ALU+L/S)*3�j���ߏ�Ńo�����X�������Ɗ�����B
�����Ƃ��A���ꂪK8�̃p���[�̌����Ƃ��v�����A���ۂɂ͂��������Ȃ��̂��낤�B
�悭�����邱�Ƃ����ǁAALU���ߏ�Ƃ��L���b�V�����������Ƃ������̂�
�v�v�z�̈Ⴂ�ŁA�ǂ��炪�ǂ������Ƃ������̂ł͂Ȃ��B
�o�����X�������ƃ_�������ǁAK8��Core2�������܂Ńo�����X�������Ƃ͎v��Ȃ��B
�Ƃ���ŁA�匴����͕ʂ�Core2���Ȃ��Ă�킯����Ȃ���ˁB
�����A�uCore2�́ix86���߂ŁjIPC4��_�����v�ł͂Ȃ��v�Ǝ咣���Ă邾���ŁA
4issue�͖��ʂ��Ƃ��AK8��萫�\�����Ƃ��A�v�������Ƃ��́A�����ĂȂ��B
�Ȃ������咣�������̂����A�����ς�킩��Ȃ����ǁB
���x��K8L�́A�u���m����IPC3���o�������邱�Ƃ�_����CPU�v���Ǝv���B
����K8L�ƁA�uIPC4��_���ăf�R�[�h�E�X�P�W���[���ł܂Â��vCore2�̐킢�͊y���݂��B
41 �F���������� �F2007/01/21(��) 23:54:41
�����AIntel processor�����ʃs�[�L�[��(�▭��)�v�Ȃ���ȁ[
AMD�Ɍ��炸�ARISC processor�ł��n�������Ƃ������玸�炾���ǁA��G�c�Ȃ���̂����������B
Intel processor�́A�`���I�ɑ����Ȃ�Ƃ���͂��ꂾ���������邵�A�����Ȃ�Ȃ��Ƃ���͍ו��ł��ϋɓI�ɃP�`��B
�Г��Ŏ��v���O�����̓��삪�������s������Ă��āA�J���\�͂ɗ]�T���Ȃ���ł��Ȃ��|���B
decode BW�݂����ɋǏ��v���nbenchmark�̒P���Ȗ��߂̗���ł͂܂��������͂��킩���B
Intel processor�́A�������J�����architecture�I��spec����\�z�������������\�������B
�����compiler�̏o�������̖��ł͂Ȃ��B
���ƁA�匴��IPC�Ƃ������t�̎g��������낵���Ȃ��B
IPC xx��_����architecture�Ƃ����l�������������̂ċ���Ȃ��Ɓc�B
����3IPC��4IPC�Ȃ�čŏ�����N���l�����Ⴂ�Ȃ��̂ɁB
�����Ƃ��A���ꂪK8�̃p���[�̌����Ƃ��v�����A���ۂɂ͂��������Ȃ��̂��낤�B
�悭�����邱�Ƃ����ǁAALU���ߏ�Ƃ��L���b�V�����������Ƃ������̂�
�v�v�z�̈Ⴂ�ŁA�ǂ��炪�ǂ������Ƃ������̂ł͂Ȃ��B
�o�����X�������ƃ_�������ǁAK8��Core2�������܂Ńo�����X�������Ƃ͎v��Ȃ��B
�Ƃ���ŁA�匴����͕ʂ�Core2���Ȃ��Ă�킯����Ȃ���ˁB
�����A�uCore2�́ix86���߂ŁjIPC4��_�����v�ł͂Ȃ��v�Ǝ咣���Ă邾���ŁA
4issue�͖��ʂ��Ƃ��AK8��萫�\�����Ƃ��A�v�������Ƃ��́A�����ĂȂ��B
�Ȃ������咣�������̂����A�����ς�킩��Ȃ����ǁB
���x��K8L�́A�u���m����IPC3���o�������邱�Ƃ�_����CPU�v���Ǝv���B
����K8L�ƁA�uIPC4��_���ăf�R�[�h�E�X�P�W���[���ł܂Â��vCore2�̐킢�͊y���݂��B
41 �F���������� �F2007/01/21(��) 23:54:41
�����AIntel processor�����ʃs�[�L�[��(�▭��)�v�Ȃ���ȁ[
AMD�Ɍ��炸�ARISC processor�ł��n�������Ƃ������玸�炾���ǁA��G�c�Ȃ���̂����������B
Intel processor�́A�`���I�ɑ����Ȃ�Ƃ���͂��ꂾ���������邵�A�����Ȃ�Ȃ��Ƃ���͍ו��ł��ϋɓI�ɃP�`��B
�Г��Ŏ��v���O�����̓��삪�������s������Ă��āA�J���\�͂ɗ]�T���Ȃ���ł��Ȃ��|���B
decode BW�݂����ɋǏ��v���nbenchmark�̒P���Ȗ��߂̗���ł͂܂��������͂��킩���B
Intel processor�́A�������J�����architecture�I��spec����\�z�������������\�������B
�����compiler�̏o�������̖��ł͂Ȃ��B
���ƁA�匴��IPC�Ƃ������t�̎g��������낵���Ȃ��B
IPC xx��_����architecture�Ƃ����l�������������̂ċ���Ȃ��Ɓc�B
����3IPC��4IPC�Ȃ�čŏ�����N���l�����Ⴂ�Ȃ��̂ɁB
�匴�́uCore2�́ix86���߂ŁjIPC4��_�����v�ł͂Ȃ��v�̓s�[�N���\�ł̘b���������̂��낤�B
�����Ƃ����ǂ߂Ȃ����A�����������ׂɑ����������Ă����킯�����A
���̌�́u��190�� Core MicroArchitecture�������������v�ł́A���̎咣���ԈႢ�ł��邱�Ƃ��������A
�����ɓ����̎咣�̎�|��ς��Ď��U���Ă���Ƃ����̂��Ó����낤�B
�ǂ�łāu�R�C�c�͒p��m��ʔy���ȁv�Ǝv�����ˁB
�����Ƃ����ǂ߂Ȃ����A�����������ׂɑ����������Ă����킯�����A
���̌�́u��190�� Core MicroArchitecture�������������v�ł́A���̎咣���ԈႢ�ł��邱�Ƃ��������A
�����ɓ����̎咣�̎�|��ς��Ď��U���Ă���Ƃ����̂��Ó����낤�B
�ǂ�łāu�R�C�c�͒p��m��ʔy���ȁv�Ǝv�����ˁB
>>317
����͂�����Ȃ�ł��א��������B
�匴���͍ŏ�����s�[�N��4IPC���o�邱�Ƃ��������Ă邵�A9/5��5IPC�̗�����L�Ŏw�E����Ă���̂ŁA
�x���Ƃ��A�ڂ̑O�܂ł�5IPC���o��R�[�h���m���Ă���͂��B
�ŁA�A��2��ڂɁA
http://journal.mycom.co.jp/column/sopinion/178/
Sustained Performance���d������Ƃ��āA���̈Ӗ���IPC���g���A
Core2Duo��Athlon64�̍������������Ƃ��w�E������A�Ꭶ�̃R�[�h�𑖂点���肵�āA
Core2Duo��4IPC����Ȃ��ƌ��_�Â��Ă���B
���́A���Ⴀ�AAthlon64��3�ɋ߂�IPC��
���C�ӂ̖��߂�g�ݍ��킹�����ɁA�A���I�Ɉێ��ł���IPC
�Ƃ����Ӗ��ŏo�Ă�̂��Ƃ����Ƃ���Ȃ킯�Ȃ��̂ɁA���ᔻ��Athlon64��3IPC�̂悤�ɏ����Ă��邩��A
�˂����܂�܂���킯�ŁB
����͂�����Ȃ�ł��א��������B
�匴���͍ŏ�����s�[�N��4IPC���o�邱�Ƃ��������Ă邵�A9/5��5IPC�̗�����L�Ŏw�E����Ă���̂ŁA
�x���Ƃ��A�ڂ̑O�܂ł�5IPC���o��R�[�h���m���Ă���͂��B
�ŁA�A��2��ڂɁA
http://journal.mycom.co.jp/column/sopinion/178/
Sustained Performance���d������Ƃ��āA���̈Ӗ���IPC���g���A
Core2Duo��Athlon64�̍������������Ƃ��w�E������A�Ꭶ�̃R�[�h�𑖂点���肵�āA
Core2Duo��4IPC����Ȃ��ƌ��_�Â��Ă���B
���́A���Ⴀ�AAthlon64��3�ɋ߂�IPC��
���C�ӂ̖��߂�g�ݍ��킹�����ɁA�A���I�Ɉێ��ł���IPC
�Ƃ����Ӗ��ŏo�Ă�̂��Ƃ����Ƃ���Ȃ킯�Ȃ��̂ɁA���ᔻ��Athlon64��3IPC�̂悤�ɏ����Ă��邩��A
�˂����܂�܂���킯�ŁB
http://mypage.odn.ne.jp/www/k/8/k8_hammer_trans/files/Hammer-Info.html
�iBarcelona�Ƃ��̒��Ԃ������������x�p�t�H�[�}���X���[�h��D���Ԃ��̂��ǂ����A�݂�Ȓ��ڂ��Ă���j
Meyer�@���Ђ̐��i�ɂ��Ēm���Ă��邱�ƁA�y�сA�e�\�[�X����m�肦�����C�o���̃��[�h�}�b�v��
���Ă̒m������ɂ���ƁA���N����native 4-core���o�����Ƃ��̌��ʂ��͔��ɖ��邢�B
���Ђ́A�͂�����ƃp�t�H�[�}���X���[�h��D���Ԃ��B
AMD: Go to 'Barcelona' over 'Clovertown'
http://news.com.com/AMD+Go+to+Barcelona+over+Clovertown/2100-1006_3-6152645.html?tag=nefd.top
"We expect across a wide variety of workloads for Barcelona to outperform Clovertown by 40 percent," Allen said.
�iBarcelona�Ƃ��̒��Ԃ������������x�p�t�H�[�}���X���[�h��D���Ԃ��̂��ǂ����A�݂�Ȓ��ڂ��Ă���j
Meyer�@���Ђ̐��i�ɂ��Ēm���Ă��邱�ƁA�y�сA�e�\�[�X����m�肦�����C�o���̃��[�h�}�b�v��
���Ă̒m������ɂ���ƁA���N����native 4-core���o�����Ƃ��̌��ʂ��͔��ɖ��邢�B
���Ђ́A�͂�����ƃp�t�H�[�}���X���[�h��D���Ԃ��B
AMD: Go to 'Barcelona' over 'Clovertown'
http://news.com.com/AMD+Go+to+Barcelona+over+Clovertown/2100-1006_3-6152645.html?tag=nefd.top
"We expect across a wide variety of workloads for Barcelona to outperform Clovertown by 40 percent," Allen said.
320 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2007/01/24(��) 21:34:43 ID:9GDZn44Z
�R�s�y��
ttp://pc10.2ch.net/test/read.cgi/tech/1168399966/
���́u�f�t�H���g�̖���������v�Ȃ̂Ƀ��O�s������Ȃ�
�[����̂ɂ��̃X���Ƃ������̔��Ă�����x�Z�l���Ԃ��Ă邩��
���p���Ă��Ӗ��Ȃ��Ǝv����
ttp://pc10.2ch.net/test/read.cgi/tech/1168399966/
���́u�f�t�H���g�̖���������v�Ȃ̂Ƀ��O�s������Ȃ�
�[����̂ɂ��̃X���Ƃ������̔��Ă�����x�Z�l���Ԃ��Ă邩��
���p���Ă��Ӗ��Ȃ��Ǝv����
���X�̗�����܂邲�ƈ��p����͖̂��ʂł����Ȃ���ȁB
�A�h���X�\��t����ΏI���̂ɁB
����͂�����Barcelona�͉��Ƃ�Q2���ɏo����ۂ��ˁB
���\���ǂ��݂����H
�A�h���X�\��t����ΏI���̂ɁB
����͂�����Barcelona�͉��Ƃ�Q2���ɏo����ۂ��ˁB
���\���ǂ��݂����H
��پ�ł͂������ǁA��į�ߔł͂��ł�H
wolfdale���Ă̂������낤�H
��������
��������
>>322
Q3 2007
AMD�fs next-generation Star supports DDR2-1066 & SSE4A
http://www.hkepc.com/bbs/news.php?tid=718770&starttime=0&endtime=0
Q3 2007
AMD�fs next-generation Star supports DDR2-1066 & SSE4A
http://www.hkepc.com/bbs/news.php?tid=718770&starttime=0&endtime=0
�g�����W�X�^���̍��̓A�[�L����ʂ���������̐v�c�[���̍�����
ttp://www.theinquirer.net/default.aspx?article=37154
AMD ramping Barcelona
Wafers in 'real soon'
If really soon is defined as the end of the month, and you add in the 1
0-12 weeks it takes from shiny silicon pizzas in to pin laden
chunks out, that would mean parts are available at the beginning of May.
AMD ramping Barcelona
Wafers in 'real soon'
If really soon is defined as the end of the month, and you add in the 1
0-12 weeks it takes from shiny silicon pizzas in to pin laden
chunks out, that would mean parts are available at the beginning of May.
���N���DDR2-1066���c
�܂��ǂ����ɂ��Ă�C2D�̍�IPC��32bit���肶��H
>>319�̓��{���
> AMD: Go to 'Barcelona' over 'Clovertown'
> http://news.com.com/AMD+Go+to+Barcelona+over+Clovertown/2100-1006_3-6152645.html?tag=nefd.top
AMD�A����4�R�A�v���Z�b�T�uBarcelona�v�ŃC���e���œ|��ڎw�� - CNET Japan
http://japan.cnet.com/news/ent/story/0,2000056022,20341458,00.htm
> AMD: Go to 'Barcelona' over 'Clovertown'
> http://news.com.com/AMD+Go+to+Barcelona+over+Clovertown/2100-1006_3-6152645.html?tag=nefd.top
AMD�A����4�R�A�v���Z�b�T�uBarcelona�v�ŃC���e���œ|��ڎw�� - CNET Japan
http://japan.cnet.com/news/ent/story/0,2000056022,20341458,00.htm
������������
> AMD�ł�Barcelona�̃R�A���Đv�����B����́A���Ђ�2003�N��32�r�b�g�uAthlon�v��
> �v���Z�b�T�����s��64�r�b�g�Ɉڍs���Ĉȗ��A�ő�̕ω����B
> ����̍Đv�̋K�͂́AAMD��Opteron�ɑ����N�ɂ����Ď{���Ă��������Ȓ����ƁA
> Intel���uNetBurst�v�A�[�L�e�N�`�����猻�݂́uCore�v�f�U�C���Ɉڍs����ۂɍs�����A
> �����̏�Ԃ���̍Đv�Ƃ̒��Ԃ��炢���ƁAAllen���͏q�ׂĂ���B
�@~~~~~~~~~~~~~~~~~~~~~~~~~
> AMD�ł�Barcelona�̃R�A���Đv�����B����́A���Ђ�2003�N��32�r�b�g�uAthlon�v��
> �v���Z�b�T�����s��64�r�b�g�Ɉڍs���Ĉȗ��A�ő�̕ω����B
> ����̍Đv�̋K�͂́AAMD��Opteron�ɑ����N�ɂ����Ď{���Ă��������Ȓ����ƁA
> Intel���uNetBurst�v�A�[�L�e�N�`�����猻�݂́uCore�v�f�U�C���Ɉڍs����ۂɍs�����A
> �����̏�Ԃ���̍Đv�Ƃ̒��Ԃ��炢���ƁAAllen���͏q�ׂĂ���B
�@~~~~~~~~~~~~~~~~~~~~~~~~~
�ʂɂ����ނƂ��낶��Ȃ��B
���������͂�N���b�N��3GHz���邱�Ƃ͂Ȃ������ȓ_���C�ɂȂ�B
�\�ʂ�2.9GHz�܂ŏo��ȁB
���������͂�N���b�N��3GHz���邱�Ƃ͂Ȃ������ȓ_���C�ɂȂ�B
�\�ʂ�2.9GHz�܂ŏo��ȁB
>>330��AMD���uCMA�͉���I����Ȃ��v�Ƃ������Ă��̂��l�^�ɂ����������낤����
��Intel���uNetBurst�v�A�[�L�e�N�`�����猻�݂́uCore�v�f�U�C���Ɉڍs����ۂ�
���������߁B�����������Ȃ炱����܂߂Ȃ��Ɯ��ӓI�ȑ���ɂ����Ȃ��
��Intel���uNetBurst�v�A�[�L�e�N�`�����猻�݂́uCore�v�f�U�C���Ɉڍs����ۂ�
���������߁B�����������Ȃ炱����܂߂Ȃ��Ɯ��ӓI�ȑ���ɂ����Ȃ��
> ���s��AMD���f���A���R�A�v���Z�b�T�uOpteron�v�Ɣ�ׂĂ��A
> �N���b�N���g���������Ȃ�Barcelona�̕���3.6�{�́u���������_�v�v�Z�����Ȃ��\�͂�����Ƃ����B
Clovertown��4�{���z����u���������_�v�v�Z�����Ȃ��\�͂�������ǂˁB
> �N���b�N���g���������Ȃ�Barcelona�̕���3.6�{�́u���������_�v�v�Z�����Ȃ��\�͂�����Ƃ����B
Clovertown��4�{���z����u���������_�v�v�Z�����Ȃ��\�͂�������ǂˁB
>>333
���N���b�N�Ȃ�Bercelona��Clovertown�̕��������_���Z�s�[�N���\�͓�������Ȃ��H
���N���b�N�Ȃ�Bercelona��Clovertown�̕��������_���Z�s�[�N���\�͓�������Ȃ��H
�Ă��R�A�ӂ�1.8�{���Ă̂͂ǂ������v�Z�H
Core2��SSE���ƃR�A������X2��2�{�ɂȂ邯�ǁA
Barcelona��SSE��Core2�ɂ͋y�Ȃ��Ƃ������ƁH
�܂��A1.8�{�ł�����肾���Ԑ���Ԃ�����
Barcelona��SSE��Core2�ɂ͋y�Ȃ��Ƃ������ƁH
�܂��A1.8�{�ł�����肾���Ԑ���Ԃ�����
3DNow!�ɂ��2������SSE�ɂ��4����ɒu�������邾���ŃX���[�v�b�g2�{
�����2�R�A��4�R�A����������ł��s�[�N���\��4�{�����Ȃ��Ƃ����������B
�����2�R�A��4�R�A����������ł��s�[�N���\��4�{�����Ȃ��Ƃ����������B
SSE�Ɋւ��Ă�CoreMA���K8L�̕����ǂ��Ƃ����b�B
���s���j�b�g�̃X���[�v�b�g�͕ς��ǁA���߂̎�荞�ݗ��Ƃ��B
���s���j�b�g�̃X���[�v�b�g�͕ς��ǁA���߂̎�荞�ݗ��Ƃ��B
���ۂɐ키����ł��낤Penryn�t�@�~���[�̃x���`�͂܂��o�ĂȂ����A
AMD�W�҂ɂ͓`����Ă���̂�?
Merom���肶��O���V���Ƃ��ɂȂ肩�˂�B
���ꂷ��������������B
AMD�W�҂ɂ͓`����Ă���̂�?
Merom���肶��O���V���Ƃ��ɂȂ肩�˂�B
���ꂷ��������������B
Barcelona�̑��肪Penryn�H
4���I������2����ٌ������ׂĂ��d���Ȃ��悤�ȁc
Intel�̑R�͍��N���\���45nmȲè��4�����낤
4���I������2����ٌ������ׂĂ��d���Ȃ��悤�ȁc
Intel�̑R�͍��N���\���45nmȲè��4�����낤
572 �FSocket774�F2006/12/03(��) 00:31:54 ID:70uwS2Di
http://i17.tinypic.com/2eq51k5.jpg
http://i16.tinypic.com/4d6wjmo.jpg
http://www.chip-architect.com/news/K8L_floorplan.jpg
573 �FSocket774�F2006/12/03(��) 00:35:14 ID:Pr8XaNc1
Xeon�T�P�������Ƃn������������22xx���ɒu���Ă鎞�_�Œm�肾��
�O�X���ɏo���x���`�A���Đ�������悤������
������ăX���Z�����炷��ƑÓ��Ȑ����Ȃ́H
http://i17.tinypic.com/2eq51k5.jpg
{kind=link}
http://i16.tinypic.com/4d6wjmo.jpg
{kind=link}
http://www.chip-architect.com/news/K8L_floorplan.jpg
{kind=link}
573 �FSocket774�F2006/12/03(��) 00:35:14 ID:Pr8XaNc1
Xeon�T�P�������Ƃn������������22xx���ɒu���Ă鎞�_�Œm�肾��
�O�X���ɏo���x���`�A���Đ�������悤������
������ăX���Z�����炷��ƑÓ��Ȑ����Ȃ́H
SPEC_fp�����B
�܂�Ó��H
�T�[�o�[�n�x���`�͂悭�킩���
�T�[�o�[�n�x���`�͂悭�킩���
�Ó����Ƃ������base����Ȃ��Ƃ��F�X�˂����ލ���t�͋����������B
�Ƃ肠�����A�T�[�o�[�n�x���`����Ȃ����Ƃ͊m������
�Ƃ肠�����A�T�[�o�[�n�x���`����Ȃ����Ƃ͊m������
�T�[�o�[�n�x���`���Ƃ����Ǝv���Ă��A�A�A
���������璆���̔�c���c�̂̂���Ă�x���`�������̂�
�p�����������Ⴂ�A�A�A
���������璆���̔�c���c�̂̂���Ă�x���`�������̂�
�p�����������Ⴂ�A�A�A
�������Ďv�����̂̓}�WItanium2����ȁE�E�E�Ƶ��
���{��ƘA�����������Ęb�Ȃ��������H
>>348
�ŏ����炾��
�ŏ����炾��
���₢��A�n�܂�����
�Ռ��̃v���Z�b�T����\�\�C���e��R ItaniumR 2 �v���Z�b�T�Ƃ����g���f
http://www.itmedia.co.jp/enterprise/articles/0602/20/news007.html
�v�킸�C���e�� Itanium �v���Z�b�T �t�@�~����I���������Ȃ邱�ꂾ���̗��R
http://www.itmedia.co.jp/enterprise/articles/0610/31/news001.html
HP�̐헪�Ɍ���C���e�� Itanium �v���Z�b�T �t�@�~���̐^�̃����b�g
http://www.itmedia.co.jp/enterprise/articles/0611/13/news003.html
�����q�͈ψ���A�f���A���R�AItanium 2�N���X�^����
http://www.itmedia.co.jp/news/articles/0412/09/news033.html
���Y��Itanium 2�A�g���^��Opteron�A�X�Y�L��SX-8
http://www.itmedia.co.jp/news/articles/0504/07/news052.html
��Q�������y�V�،��A�DB��PA����Itanium 2�ɐ�ւ�
http://www.itmedia.co.jp/news/articles/0511/09/news076.html
�C�m�����J���@�\�C�f���A���R�A��Itanium2��1280���ڂ�����^�v�Z�@��
http://techon.nikkeibp.co.jp/article/NEWS/20060905/120826/
�_��Ɗg�����ɉ������S����]�� ������n�V�X�e����Itanium 2���̗p
http://primeserver.fujitsu.com/primequest/casestudies/2006/1031/
�����،��������2009�N�ɉғ��\��̎����㔄���V�X�e����Itanium2
http://itpro.nikkeibp.co.jp/article/NEWS/20061220/257456/
��Intel VP�A�u�m���Ă��Ȃ���Itanium�͔���Ă܂��v
http://enterprise.watch.impress.co.jp/cda/topic/2005/12/16/6853.html
2007�N�܂ł�RISC�T�[�o�[�s���5���l����ڎw��
http://enterprise.watch.impress.co.jp/cda/topic/2006/02/07/7170.html
Itanium�T�[�o�[���}�����ցA��IDC����
http://enterprise.watch.impress.co.jp/cda/foreign/2006/02/21/7251.html
Itanium�x�[�X�E�V�X�e���̌ڋq�����o���z�̐���
http://enterprise.watch.impress.co.jp/cda/parts/image_for_link/17938-7574-9-2.html
2007�N���܂ł�RISC�s���6���ڎw��
http://enterprise.watch.impress.co.jp/cda/topic/2006/10/05/8787.html
�Ռ��̃v���Z�b�T����\�\�C���e��R ItaniumR 2 �v���Z�b�T�Ƃ����g���f
http://www.itmedia.co.jp/enterprise/articles/0602/20/news007.html
�v�킸�C���e�� Itanium �v���Z�b�T �t�@�~����I���������Ȃ邱�ꂾ���̗��R
http://www.itmedia.co.jp/enterprise/articles/0610/31/news001.html
HP�̐헪�Ɍ���C���e�� Itanium �v���Z�b�T �t�@�~���̐^�̃����b�g
http://www.itmedia.co.jp/enterprise/articles/0611/13/news003.html
�����q�͈ψ���A�f���A���R�AItanium 2�N���X�^����
http://www.itmedia.co.jp/news/articles/0412/09/news033.html
���Y��Itanium 2�A�g���^��Opteron�A�X�Y�L��SX-8
http://www.itmedia.co.jp/news/articles/0504/07/news052.html
��Q�������y�V�،��A�DB��PA����Itanium 2�ɐ�ւ�
http://www.itmedia.co.jp/news/articles/0511/09/news076.html
�C�m�����J���@�\�C�f���A���R�A��Itanium2��1280���ڂ�����^�v�Z�@��
http://techon.nikkeibp.co.jp/article/NEWS/20060905/120826/
�_��Ɗg�����ɉ������S����]�� ������n�V�X�e����Itanium 2���̗p
http://primeserver.fujitsu.com/primequest/casestudies/2006/1031/
�����،��������2009�N�ɉғ��\��̎����㔄���V�X�e����Itanium2
http://itpro.nikkeibp.co.jp/article/NEWS/20061220/257456/
��Intel VP�A�u�m���Ă��Ȃ���Itanium�͔���Ă܂��v
http://enterprise.watch.impress.co.jp/cda/topic/2005/12/16/6853.html
2007�N�܂ł�RISC�T�[�o�[�s���5���l����ڎw��
http://enterprise.watch.impress.co.jp/cda/topic/2006/02/07/7170.html
Itanium�T�[�o�[���}�����ցA��IDC����
http://enterprise.watch.impress.co.jp/cda/foreign/2006/02/21/7251.html
Itanium�x�[�X�E�V�X�e���̌ڋq�����o���z�̐���
http://enterprise.watch.impress.co.jp/cda/parts/image_for_link/17938-7574-9-2.html
2007�N���܂ł�RISC�s���6���ڎw��
http://enterprise.watch.impress.co.jp/cda/topic/2006/10/05/8787.html
���㓡�O��Weekly�C�O�j���[�X��
Vista�ƃX�g���[���v���Z�b�V���O��FUSION�𐄐i����
http://pc.watch.impress.co.jp/docs/2007/0126/kaigai331.htm
Vista�ƃX�g���[���v���Z�b�V���O��FUSION�𐄐i����
http://pc.watch.impress.co.jp/docs/2007/0126/kaigai331.htm
> �u�R�v���Z�b�T(Coprocessor)�v�A�u�A�N�Z�����[�^(Accelerator)�v�A�uxPU�v�BAMD�̕\���͂��܂��܂����Ӗ����Ă���͓̂������̂��B
> �ėpCPU�Ƃ͈قȂ�A����̏�����A�v���P�[�V�����ɓ��������v���Z�b�T���B
> AMD�́A�R�v���Z�b�T�Ƃ���Java�AXML�A�{���x(DP)�ƒP���x(SP)�̕��������_�x�N�^���Z�A
> ���f�B�A�v���Z�b�V���O�A�Z�L�����e�B�Ȃǂ̃A�N�Z�����[�^�������Ă���B�T�[�o�[�ł́A
> �����̃R�v���Z�b�T�͓��ʂ́uTorrenza(�g�����U)�v�C�j�V�A�`�u�̌��AAMD CPU�\�P�b�g�AHTX(HyperTransport�̊g���X���b�g�d�l)�A
> PCI Express�ȂǕW���o�X�Őڑ������B
> ����A�N���C�A���g�ł́AFUSION�ŁA�P���x(SP)���������_���Z�ɓ�������Shader GPU�R�A������B
���悢��j�b�`��CPU�i�ݏo���悤���ȁB
�����Ɏg����̂̓I���{�[�hGPU��菭���������\���悭����d�͂ɗD������GPU�R�v�Z�b�T�ʂ��ȁH
���̑��͑Ή��\�t�g�������ɋ������ꂸ�A�j�b�`�Ń��_�Ȃ��̂ɂȂ邾�낤�ȁB
> �ėpCPU�Ƃ͈قȂ�A����̏�����A�v���P�[�V�����ɓ��������v���Z�b�T���B
> AMD�́A�R�v���Z�b�T�Ƃ���Java�AXML�A�{���x(DP)�ƒP���x(SP)�̕��������_�x�N�^���Z�A
> ���f�B�A�v���Z�b�V���O�A�Z�L�����e�B�Ȃǂ̃A�N�Z�����[�^�������Ă���B�T�[�o�[�ł́A
> �����̃R�v���Z�b�T�͓��ʂ́uTorrenza(�g�����U)�v�C�j�V�A�`�u�̌��AAMD CPU�\�P�b�g�AHTX(HyperTransport�̊g���X���b�g�d�l)�A
> PCI Express�ȂǕW���o�X�Őڑ������B
> ����A�N���C�A���g�ł́AFUSION�ŁA�P���x(SP)���������_���Z�ɓ�������Shader GPU�R�A������B
���悢��j�b�`��CPU�i�ݏo���悤���ȁB
�����Ɏg����̂̓I���{�[�hGPU��菭���������\���悭����d�͂ɗD������GPU�R�v�Z�b�T�ʂ��ȁH
���̑��͑Ή��\�t�g�������ɋ������ꂸ�A�j�b�`�Ń��_�Ȃ��̂ɂȂ邾�낤�ȁB
�t�����g�G���h�T�[�o���ƁA�Í��W�̃A�N�Z�����[�^�͂����Ă��ǂ������B
Visual Computing Group
Create next-gen graphics and gaming experiences
http://www.intel.com/jobs/careers/visualcomputing/
Intel confirms discrete graphics
http://www.theinquirer.net/default.aspx?article=37133
Intel discrete graphics chips confirmed
http://www.beyond3d.com/forum/showthread.php?t=37889
Intel Gets Serious w/ Discrete GPUs Business
http://www.vr-zone.com/?i=4517
Intel career page confirms discrete GPU plans
http://www.techreport.com/onearticle.x/11683
Intel Job Openings Hint at Discrete GPU
http://www.dailytech.com/Intel+Job+Openings+Hint+at+Discrete+GPU/article5811.htm
Intel�r�f�I�J�[�h�s��Q����Fusion�R��CPU+GPU�����`�b�v
���ς�炸Intel�͌�ǂ����Ă����
Create next-gen graphics and gaming experiences
http://www.intel.com/jobs/careers/visualcomputing/
Intel confirms discrete graphics
http://www.theinquirer.net/default.aspx?article=37133
Intel discrete graphics chips confirmed
http://www.beyond3d.com/forum/showthread.php?t=37889
Intel Gets Serious w/ Discrete GPUs Business
http://www.vr-zone.com/?i=4517
Intel career page confirms discrete GPU plans
http://www.techreport.com/onearticle.x/11683
Intel Job Openings Hint at Discrete GPU
http://www.dailytech.com/Intel+Job+Openings+Hint+at+Discrete+GPU/article5811.htm
Intel�r�f�I�J�[�h�s��Q����Fusion�R��CPU+GPU�����`�b�v
���ς�炸Intel�͌�ǂ����Ă����
Intel�͐����ȑO��GPU�Ƃ̕������킹���i���K�i���\���A�s��j�[�Y���R�������ۂɂ͐��i������Ȃ��������j�������Ă��Ǝv�����ǂȁB
��ǂ���AMD����w
��ǂ���AMD����w
>>355
Torrenza�R�Ńu�`�グ��FSB���C�Z���X�Ƃ�����������������
����܂�{�C�͊������Ȃ�
�܂��ł��ꉞ�ی��͂����Ƃ��݂�����
Torrenza�R�Ńu�`�グ��FSB���C�Z���X�Ƃ�����������������
����܂�{�C�͊������Ȃ�
�܂��ł��ꉞ�ی��͂����Ƃ��݂�����
�����R�������Ȃ�Ă̂͐헪�ł����Ȃ��AIntel�I�Ɍ��킹��`�b�v�Z�b�g�����Ƃ̌��ˍ����ō��オ���܂�B
�������p�������͌��E�ɗ��Ă邩��V���A�������}���Ȃ��Ă͂����Ȃ��w�i������B
�܂��A��ǂ��Ƃ��Ƃ������x������˂��ȁA�Z�p�I�ɂ͒P���ȒP�̐��E���B
�������p�������͌��E�ɗ��Ă邩��V���A�������}���Ȃ��Ă͂����Ȃ��w�i������B
�܂��A��ǂ��Ƃ��Ƃ������x������˂��ȁA�Z�p�I�ɂ͒P���ȒP�̐��E���B
����Ȃ��Ă��F�����Ă�Ǝv���������̃A��ID:Q3thE13q
�������������͂ǂ��ł��悭�āA
��ǂ��Ɍ����Ă��܂����̃t�B���^�[�����Ȃ�B
�݊��ł��܂��`�z���Ă����āA64bit�g���ň���������ɖ^�Ђ͌݊����[�J�[�A�Ƃ�
��������x���`�}�[�N�Ŗ^�Ђ��L���A�������Ă����!�A�Ɛ������̂����̊ԁA
���\���t�]�����₢�Ȃ�A�ƊE�W���Ƃ�����x���`�}�[�N�͂Ȃ��̂ŃR�����g�ł��Ȃ��Ƃ�����
�̂��l�̂����Ђ̂�邱�Ƃ����ׂĐ��`�Ƃ݂��h�ɂ�
�����܂�ʔ����Ȃ��Ȃ͓̂���邪�B
��ǂ��Ɍ����Ă��܂����̃t�B���^�[�����Ȃ�B
�݊��ł��܂��`�z���Ă����āA64bit�g���ň���������ɖ^�Ђ͌݊����[�J�[�A�Ƃ�
��������x���`�}�[�N�Ŗ^�Ђ��L���A�������Ă����!�A�Ɛ������̂����̊ԁA
���\���t�]�����₢�Ȃ�A�ƊE�W���Ƃ�����x���`�}�[�N�͂Ȃ��̂ŃR�����g�ł��Ȃ��Ƃ�����
�̂��l�̂����Ђ̂�邱�Ƃ����ׂĐ��`�Ƃ݂��h�ɂ�
�����܂�ʔ����Ȃ��Ȃ͓̂���邪�B
>�݊��ł��܂��`�z���Ă�����
K5�ł�����
K5�ł�����
���ꂪ��ǂ��Ɍ����Ȃ��Ȃ�t�B���^�[����肾�Ȃ�
���݊��ł��܂��`�z���Ă����āA64bit�g���ň���������ɖ^�Ђ͌݊����[�J�[
�݊����p�`�����A���Č����Ă���݊����[�J�[�ɐ��艺����������˂��A�C�̓ł�
�����\���t�]�����₢�Ȃ�A�ƊE�W���Ƃ�����x���`�}�[�N�͂Ȃ��̂ŃR�����g�ł��Ȃ�
����͕����������������A���������悤�Ȏ��������Ă��Ȃ�
���݊��ł��܂��`�z���Ă����āA64bit�g���ň���������ɖ^�Ђ͌݊����[�J�[
�݊����p�`�����A���Č����Ă���݊����[�J�[�ɐ��艺����������˂��A�C�̓ł�
�����\���t�]�����₢�Ȃ�A�ƊE�W���Ƃ�����x���`�}�[�N�͂Ȃ��̂ŃR�����g�ł��Ȃ�
����͕����������������A���������悤�Ȏ��������Ă��Ȃ�
>361,363
���ꂪ���������
���̂��߂̃x���`�}�[�N���Ǝv���Ă�H
���[�J�[�͉��̂��߂ɐ��N�O����J����i�߂Ă�H
�J���҂̓I�[�o�[�N�{�b�J�[�Ȃ̂��H
���ꂪ���������
���̂��߂̃x���`�}�[�N���Ǝv���Ă�H
���[�J�[�͉��̂��߂ɐ��N�O����J����i�߂Ă�H
�J���҂̓I�[�o�[�N�{�b�J�[�Ȃ̂��H
>>363
����AMD���̔����ɂ�̨����������̂��킩��Ȃ����A
�m����Core2���������o�Ă������ɂ���Ȕ�����������
AM2���o�����́A
�u�������蕉������͎d�����Ȃ��B�܂�AMD�����Ă鎞������ƐM���Ă���v
�݂����Ȕ��������Ă���
ϲ�����������H
�M�҂��u�����Ă��Ȃ��v�Ƒ������A��{�c�̔s�k�錾�͂ނ��납�����悩����
����AMD���̔����ɂ�̨����������̂��킩��Ȃ����A
�m����Core2���������o�Ă������ɂ���Ȕ�����������
AM2���o�����́A
�u�������蕉������͎d�����Ȃ��B�܂�AMD�����Ă鎞������ƐM���Ă���v
�݂����Ȕ��������Ă���
ϲ�����������H
�M�҂��u�����Ă��Ȃ��v�Ƒ������A��{�c�̔s�k�錾�͂ނ��납�����悩����
���Ă��AIntel��GPU�J���ɂ̂肾���A��������������ɂȂ��Ă���B
���Ƃ��ƃ`�b�v�Z�b�g�ɂ��ł�GPU�͏���Ă����
�����CPU���Ɉڂ����Ƃ���ŃR�X�g�����b�g�͂Ȃ���ȁB
GPU���O���t�B�N�X�ȊO�̗p�r�Ŏg���ď��߂�Fusion�������Ӗ�������B
�����CPU���Ɉڂ����Ƃ���ŃR�X�g�����b�g�͂Ȃ���ȁB
GPU���O���t�B�N�X�ȊO�̗p�r�Ŏg���ď��߂�Fusion�������Ӗ�������B
> GPU���O���t�B�N�X�ȊO�̗p�r�Ŏg���ď��߂�Fusion�������Ӗ�������B
�����炻��͊��҂��邾�����_�Ȃ�w
�����炻��͊��҂��邾�����_�Ȃ�w
>>365
http://pc.watch.impress.co.jp/docs/2006/0608/amd.htm
���ƊE�ɂ����Ă͐��\���ؖ��ł���W���I�ȃx���`�}�[�N���Ȃ����ߔ��f�ł��Ȃ�
���ꂾ��H
���̌�AMD�́A����d�͓�����̐��\��AMD�̕�����A�Ƃ����咣�ɕς��B
�ŁAK8L�Ŏ��M�����߂����̂��A�ŋ߂͂܂��x���`�}�[�N�ɂ��ĐG��Ă�ˁB
>>367
CPU�Ƀ����R���������ƁAGPU���`�b�v�Z�b�g����CPU�ɂ���������\���o��ƌ����Ă���B
intel��Nehalem����Ń����R�������̉\������̂ŁAGPU������ڎw���̂͂��������͂Ȃ��̂��낤�B
http://pc.watch.impress.co.jp/docs/2006/0608/amd.htm
���ƊE�ɂ����Ă͐��\���ؖ��ł���W���I�ȃx���`�}�[�N���Ȃ����ߔ��f�ł��Ȃ�
���ꂾ��H
���̌�AMD�́A����d�͓�����̐��\��AMD�̕�����A�Ƃ����咣�ɕς��B
�ŁAK8L�Ŏ��M�����߂����̂��A�ŋ߂͂܂��x���`�}�[�N�ɂ��ĐG��Ă�ˁB
>>367
CPU�Ƀ����R���������ƁAGPU���`�b�v�Z�b�g����CPU�ɂ���������\���o��ƌ����Ă���B
intel��Nehalem����Ń����R�������̉\������̂ŁAGPU������ڎw���̂͂��������͂Ȃ��̂��낤�B
������HT�̑ш�ߖ�ɂ��Ȃ邵�B����ɑш�ߖ��������͏オ��B
�ł��������ш�Ƃ��ǂ����ˁH
�ł��������ш�Ƃ��ǂ����ˁH
��̔ނ̓��́ADX7�̌Œ�@�\����ŁA�~�܂��Ă�ȁB
CPU��GPU�ŁA����v�Z���Ă鎞��ɁE�E
CPU��GPU�ŁA����v�Z���Ă鎞��ɁE�E
CPU - �m�[�X�u���b�W�Ԃ̃o�X�̏���d�͂����点�邩�炢����ˁH
�O���t�B�b�N�X�̂��߂ɏ펞����Ȃ�̍����o�X�̓d�͂��Ƃ�Ȃ��Ă�������
�O���t�B�b�N�X�̂��߂ɏ펞����Ȃ�̍����o�X�̓d�͂��Ƃ�Ȃ��Ă�������
CPU��GPU�ƃ����R���������Ƃ���ɏ���Ă��System Mem <-> Video Mem�̓]����
�{�g���l�b�N�ɂȂ��Ă���GPGPU�̌�����ȒP�ɑŔj�ł��邾�낤�ˁB
�{�g���l�b�N�ɂȂ��Ă���GPGPU�̌�����ȒP�ɑŔj�ł��邾�낤�ˁB
�����Ƽ�����̊W�͂ǂ��Ȃ�H
>>375
���O�A�b�������Ă���l���Ȃ�����H
���O�A�b�������Ă���l���Ȃ�����H
>>374
���Ԃ�A�ς��Ȃ�
BIOS�ŗe�ʂ�ݒ肷�邱�ƂɂȂ�͂�
�P����CPU-North-bridge�Ԃ�ʂ�Ȃ��Ȃ邾�����낤
CPU��GPU����������
���߂܂ŗZ�������킯����Ȃ��Ȃ�
�������͕ʂɂ��Ƃ��Ȃ���
���Ԃ�A�ς��Ȃ�
BIOS�ŗe�ʂ�ݒ肷�邱�ƂɂȂ�͂�
�P����CPU-North-bridge�Ԃ�ʂ�Ȃ��Ȃ邾�����낤
CPU��GPU����������
���߂܂ŗZ�������킯����Ȃ��Ȃ�
�������͕ʂɂ��Ƃ��Ȃ���
ttp://www.4gamer.net/news/history/2006.12/20061215144454detail.html
>CPU��GPU�����邱�ƂŁC�iDirectX�̂悤�ȁj�O��API�Z�b�g��@����GPU���쓮����̂ł͂Ȃ��C
>�ƊE���ʂ�API�Z�b�g�C���邢��CPU�̊g�����߂̌`�ŁC
>GPU�����ڃv���O��������쓮�����d�g�݂����Ƃ����B
���߃Z�b�g��������������ł���悤�ł��B
>CPU��GPU�����邱�ƂŁC�iDirectX�̂悤�ȁj�O��API�Z�b�g��@����GPU���쓮����̂ł͂Ȃ��C
>�ƊE���ʂ�API�Z�b�g�C���邢��CPU�̊g�����߂̌`�ŁC
>GPU�����ڃv���O��������쓮�����d�g�݂����Ƃ����B
���߃Z�b�g��������������ł���悤�ł��B
CPU��GPU�Ń������ш�Ƃ肠�����瑫��Ȃ��C�����邯�ǁA
CPU�g�����߂��炢�܂œ���������ш�ߖ�Ƃ��ł���́H
CPU�g�����߂��炢�܂œ���������ш�ߖ�Ƃ��ł���́H
���s��
256bit-GDDR3-1500MHz
�Ȃ̂�
128bit-DDR3-1333MHz
������ɗ����鎖�ɂȂ�̂ŁA
���������ɕq���Ȃ��̂͐��\�����鈫��
�N�������Ԉ���Ă�Ƃ����Ă���
256bit-GDDR3-1500MHz
�Ȃ̂�
128bit-DDR3-1333MHz
������ɗ����鎖�ɂȂ�̂ŁA
���������ɕq���Ȃ��̂͐��\�����鈫��
�N�������Ԉ���Ă�Ƃ����Ă���
>>381�����Ă�B2009�N�Ȃ烍�[�G���h�B
�������APC�p�x�N�^���Z�@�Ƃ��Ă͏\���B
�s���Ȃ�A�O�t��GPU�𑫂��Ηǂ��B
�ŁA�ʂ̘b
ttp://www.dailytech.com/Article.aspx?newsid=5863
AMD Expects Quad-Core "Barcelona" to "Outperform Clovertown by 40%"
�������APC�p�x�N�^���Z�@�Ƃ��Ă͏\���B
�s���Ȃ�A�O�t��GPU�𑫂��Ηǂ��B
�ŁA�ʂ̘b
ttp://www.dailytech.com/Article.aspx?newsid=5863
AMD Expects Quad-Core "Barcelona" to "Outperform Clovertown by 40%"
AMD��
�u�n�C�G���h���[�U�[�͏]���ʂ�O���{��}���Ηǂ��Aati�̃O���{�͂��ꂩ�������Ă����v
�u�܂��̓m�[�g����fusion���ڂ���B�m�[�g����Ԍ��ʓI�����炾�B�v
���Ĕ������Ă�ʂ�A��ʃ��[�U�[�����̋@�\�ł���Afusion���āB
�Ȃ�Ŏ���ł���Ȃɑ������́H
�u�n�C�G���h���[�U�[�͏]���ʂ�O���{��}���Ηǂ��Aati�̃O���{�͂��ꂩ�������Ă����v
�u�܂��̓m�[�g����fusion���ڂ���B�m�[�g����Ԍ��ʓI�����炾�B�v
���Ĕ������Ă�ʂ�A��ʃ��[�U�[�����̋@�\�ł���Afusion���āB
�Ȃ�Ŏ���ł���Ȃɑ������́H
����A�ꕔ�̐M�k�ȊO�͑����ł��Ȃ��B
���������҂��A�������Ă���l�������ł��邾���A���̑���������Ă���̂��㓡���ȁH
�ނ͂ǂ���玟�̃g�����h��s���������炵���B
�ł�������x�m���̂���l�͗�߂Ă�̂����ǂȁB
���������҂��A�������Ă���l�������ł��邾���A���̑���������Ă���̂��㓡���ȁH
�ނ͂ǂ���玟�̃g�����h��s���������炵���B
�ł�������x�m���̂���l�͗�߂Ă�̂����ǂȁB
More AMD Next Generation Desktop Details Leaked
ttp://www.dailytech.com/article.aspx?newsid=5874
ttp://www.dailytech.com/article.aspx?newsid=5874
387 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2007/01/27(�y) 01:36:12 ID:eU7W84nT
> �y�R��zAMD������f�X�N�g�b�v�y�o�Ă��郊�[�N�z
�܂œǂ�
�܂œǂ�
�^���ƒc�q��������
389 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2007/01/27(�y) 01:46:46 ID:eU7W84nT
�Ƃ肠����ATI�͔ėp�x�N�g�����Z�v���Z�b�T�o���Ă���
�������Z��1000GOPS�ȏア�����B
�������Z��1000GOPS�ȏア�����B
>>385
�m���Ɍ㓡�͑������������A�A�A
�m���Ɍ㓡�͑������������A�A�A
391 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2007/01/27(�y) 02:04:06 ID:eU7W84nT
����ł��匴�^���͕i������Ǝv���Ă邪�ȉ���
������ɂ���A�V�F�[�_���u�v���O���}�u���Ȕėp�x�N�g���R�A�Ƃ��āv����������ɂ�
MS�Ȃ�Intel�Ȃ肪ISA���T�|�[�g���Ȃ��Ƒʖڂ���Ȃ�����
�܂�CQ�o�ŎЂ̑g�ݍ��n�����G�������Ă�悤�ȍ���t�i���܂ށj�̃z�r�[�p�r��
���艺����̂����肩
������ɂ���A�V�F�[�_���u�v���O���}�u���Ȕėp�x�N�g���R�A�Ƃ��āv����������ɂ�
MS�Ȃ�Intel�Ȃ肪ISA���T�|�[�g���Ȃ��Ƒʖڂ���Ȃ�����
�܂�CQ�o�ŎЂ̑g�ݍ��n�����G�������Ă�悤�ȍ���t�i���܂ށj�̃z�r�[�p�r��
���艺����̂����肩
�匴�̂̓}�X�^�[�x�[�V�����ɉ߂��Ȃ������w
ttp://journal.mycom.co.jp/column/sopinion/177/
> �ő�̃e�[�}�͕M�҂����W�̍l�@�ŏq�ׂ��u�����I�ɂ�x86���߂�3����/Cycle��_�����A�[�L�e�N�`���ł���v���Ó����ۂ��A�Ƃ���������ł��낤�B
�匴���o�J�Ȃ̂́A�u�����I�ɂ�x86���߂�3����/Cycle��_�����A�[�L�e�N�`���ł���v�ƌ����Ă�_�ł���w
X2�ɂ��Ă�C2D�ɂ��Ă��u�����I�ɂ�x86���߂�3����/Cycle�v�Ȃ�č������͂���Ă��Ȃ�w
�s�[�N���\��X2�Ȃ�uOP��3����/Cycle�AC2D�Ȃ�uOP��5����/Cycle(Macro-Fusion�ɂ�錋�������Čv�Z)�ł��邱�Ƃ͖����B
�����ē��N���b�N�ł̐��\��C2D��X2��蕽�ς���1.2�{�`1.25�{�����Ƃ�������������w
�A�v���P�[�V�����Ō�����I/O�҂�����߂鎞�Ԃ͔��ɑ傫���AI/O�҂����Ԃ̂Ȃ��\�t�g�Ȃ�Ă͖̂w�ǂȂ��ėp�����R����������K�v���Ȃ��B
I/O�҂��̊Ԃł��f�R�[�h�����͎��s����Ă����ŁA������uOP�̓o�b�t�@�e�ʏ���܂Œ��܂�B
�����ĕK�v�ȃf�[�^���S�ďW�܂����i�K�ň�C�Ɏ����Z�p�C�v���C���֓��������C�ɉ��Z����킯�Ńs�[�N���\�ŏ���C2D�������̃x���`���ʂ�
X2��葬���Ȃ�͓̂�����O�����B
ttp://journal.mycom.co.jp/column/sopinion/177/
> �ő�̃e�[�}�͕M�҂����W�̍l�@�ŏq�ׂ��u�����I�ɂ�x86���߂�3����/Cycle��_�����A�[�L�e�N�`���ł���v���Ó����ۂ��A�Ƃ���������ł��낤�B
�匴���o�J�Ȃ̂́A�u�����I�ɂ�x86���߂�3����/Cycle��_�����A�[�L�e�N�`���ł���v�ƌ����Ă�_�ł���w
X2�ɂ��Ă�C2D�ɂ��Ă��u�����I�ɂ�x86���߂�3����/Cycle�v�Ȃ�č������͂���Ă��Ȃ�w
�s�[�N���\��X2�Ȃ�uOP��3����/Cycle�AC2D�Ȃ�uOP��5����/Cycle(Macro-Fusion�ɂ�錋�������Čv�Z)�ł��邱�Ƃ͖����B
�����ē��N���b�N�ł̐��\��C2D��X2��蕽�ς���1.2�{�`1.25�{�����Ƃ�������������w
�A�v���P�[�V�����Ō�����I/O�҂�����߂鎞�Ԃ͔��ɑ傫���AI/O�҂����Ԃ̂Ȃ��\�t�g�Ȃ�Ă͖̂w�ǂȂ��ėp�����R����������K�v���Ȃ��B
I/O�҂��̊Ԃł��f�R�[�h�����͎��s����Ă����ŁA������uOP�̓o�b�t�@�e�ʏ���܂Œ��܂�B
�����ĕK�v�ȃf�[�^���S�ďW�܂����i�K�ň�C�Ɏ����Z�p�C�v���C���֓��������C�ɉ��Z����킯�Ńs�[�N���\�ŏ���C2D�������̃x���`���ʂ�
X2��葬���Ȃ�͓̂�����O�����B
�匴�����������̂�CoreMA�ŃX�P�W���[����x86���߂�3����/cycle���ǂ����Ƃ����_����B
���\�̘b�͂��ĂȂ��Ǝv�����B
�ŁA���ۃX�P�W���[���͂ǂ��Ȃ��Ă�̂��ˁB
���\�̘b�͂��ĂȂ��Ǝv�����B
�ŁA���ۃX�P�W���[���͂ǂ��Ȃ��Ă�̂��ˁB
�N���������Ă������S�ɃT�C�����g�}�W�����e�B�[�n�������\���@>O��
>>393
�X�P�W���[���ւ̓�����X2�Ȃ�3uOP/Cycle�AC2D����4uOP/Cycle�AMacro-Fusion�ł̌�����2uOP�ƍl����̂Ȃ�4uOP/Cycle�B
�X�P�W���[���ւ̓�����X2�Ȃ�3uOP/Cycle�AC2D����4uOP/Cycle�AMacro-Fusion�ł̌�����2uOP�ƍl����̂Ȃ�4uOP/Cycle�B
�������X�P�W���[���ւ̓�����X2�Ȃ�3uOP/Cycle�AC2D����4uOP/Cycle�AMacro-Fusion�ł̌�����2uOP�ƍl����̂Ȃ�5uOP/Cycle�B
C2D�̃X�P�W���[�������ۂɃp�C�v���C���֖��߂𓊓�����^�C�~���O
store���߂�uOP��store���߂��Ƀp�C�v���C���֓������ǂݍ��܂ꂽ�i�K(���^�C���̑O)�ʼn��ZuOP�𓊓��B
��s����store�̒l�ƈˑ��W�ɂ���uOP�͐�s����store���߂ɂ��ǂݍ��܂ꂽ�i�K(���^�C���̑O)�œ����B
���ꓙ��uOP��store���߂����^�C������܂ŒP�Ƃł̃��^�C���͕ۗ������B
��������肭����Ă��ȁB
store���߂�uOP��store���߂��Ƀp�C�v���C���֓������ǂݍ��܂ꂽ�i�K(���^�C���̑O)�ʼn��ZuOP�𓊓��B
��s����store�̒l�ƈˑ��W�ɂ���uOP�͐�s����store���߂ɂ��ǂݍ��܂ꂽ�i�K(���^�C���̑O)�œ����B
���ꓙ��uOP��store���߂����^�C������܂ŒP�Ƃł̃��^�C���͕ۗ������B
��������肭����Ă��ȁB
ttp://www.dailytech.com/Intel+Job+Openings+Hint+at+Discrete+GPU/article5811.htm
>Intel Job Openings Hint at Discrete GPU
>Intel recruiting for upcoming discrete graphics solutions and a hybrid CPU/GPU product
Intel�����������ɐi��ł���悤�ł��BAMD�ƁB
>Intel Job Openings Hint at Discrete GPU
>Intel recruiting for upcoming discrete graphics solutions and a hybrid CPU/GPU product
Intel�����������ɐi��ł���悤�ł��BAMD�ƁB
�����Ƃ��������A�I���{�[�h���x����GPU��CPU�Ɠ����_�C�ɑg�ݍ��܂�Ă�����֗����Ǝv���B
���͂�GPU���K�v�Ȃ�GPU�{�[�h���������A���ꂪ�̏Ⴕ���Ƃ��Ă�CPU�_�C�ɍڂ��Ă���GPU���g���čŒ���x�̓���͂��邩�̂������ȁB
GPU���\���s�v�Ȃ炻�ꂱ������d�͂ŗL����CPU�_�C�ɍڂ��Ă���GPU���g����������ˁB
�_�C�T�C�Y�ɗ]�T������ڂ��Ă���͕̂��ʂ���Ȃ����ȁH
���͂�GPU���K�v�Ȃ�GPU�{�[�h���������A���ꂪ�̏Ⴕ���Ƃ��Ă�CPU�_�C�ɍڂ��Ă���GPU���g���čŒ���x�̓���͂��邩�̂������ȁB
GPU���\���s�v�Ȃ炻�ꂱ������d�͂ŗL����CPU�_�C�ɍڂ��Ă���GPU���g����������ˁB
�_�C�T�C�Y�ɗ]�T������ڂ��Ă���͕̂��ʂ���Ȃ����ȁH
�m�[�X�ɂ����������R����CPU�Ɏ����ė��邩��A���������GPU�������ė��܂��傤�Ƃ����A
���ꂾ���̘b�ł́B�Ƃ��Ƀ��o�C���ł͏���d�͓I��CPU�Ɏ����Ă����������������낤�B
���ꂾ���̘b�ł́B�Ƃ��Ƀ��o�C���ł͏���d�͓I��CPU�Ɏ����Ă����������������낤�B
NIC�ƃT�E�X��������A�u�����`�b�v�v�p�\�R���̂ł�������B
�J�V�I���m�[�gPC�Q�����B
�J�V�I���m�[�gPC�Q�����B
CPU�������R����VGA�����Ȃ�A�m�[�X�ƃT�E�X�̓����`�b�v�ł�����
PCI-Express x16�Ƃ�
��p��GPU��ς߂Ȃ��d�l�ɂ���A�قڃT�E�X���̂��̂���
�g�����Ȃ��m�[�g�ɂ͓s�����ǂ�
��p��GPU��ς߂Ȃ��d�l�ɂ���A�قڃT�E�X���̂��̂���
�g�����Ȃ��m�[�g�ɂ͓s�����ǂ�
�ӊO��GPU�t��CPU��Intel�̕�����ɏo�����肵�āB
����GPU���R�v���I�Ɏg���Ȃ�ė~�o�����ɒP��Penryn�Ƀ����R����VGA��MCM�ŕt����
���o�C����pCPU�ɂ��邾���Ȃ�2008�N���ɂł����肻���Șb�B
����GPU���R�v���I�Ɏg���Ȃ�ė~�o�����ɒP��Penryn�Ƀ����R����VGA��MCM�ŕt����
���o�C����pCPU�ɂ��邾���Ȃ�2008�N���ɂł����肻���Șb�B
>>401
PowerPC�Ń����R���APCI-E�A�M�K�r�b�g�C�[�T�����f���A���R�ACPU���łɂ����
PowerPC�Ń����R���APCI-E�A�M�K�r�b�g�C�[�T�����f���A���R�ACPU���łɂ����
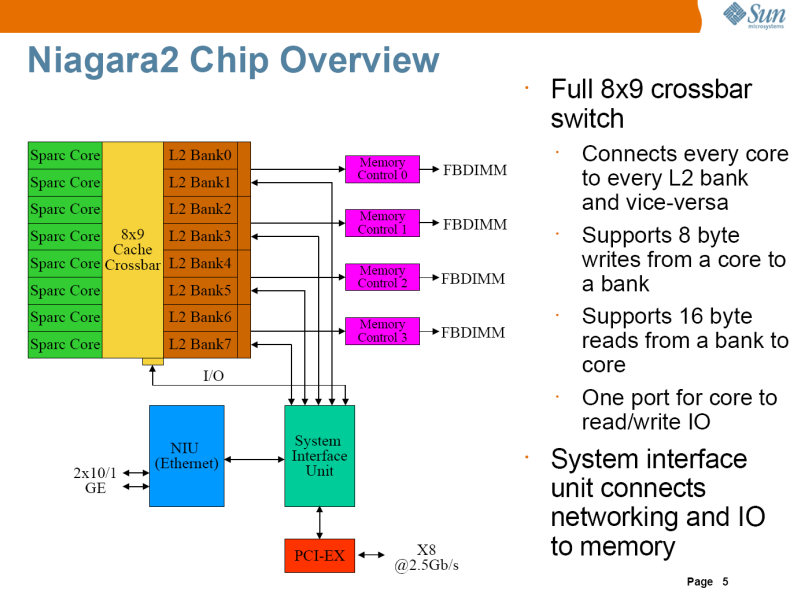{kind=link}
�Ƃ������A�N�B�Ax86�������߂Ȃ�VIA����s���Ă邱�Ƃ�Y(r
�����`�b�v�Ȃ�AMD������GeodeLX���B
�������A�n�R��OC�~�͂قƂ�ǎ��b��������Ȃ���
>>401
���߂āu�ĎQ���v���Č����Ă���Ă���B
���߂āu�ĎQ���v���Č����Ă���Ă���B
FIVA��������
ʲ�߰��������ɰ�
�̨��݂ͷ�������MMXPentium��̊e�n����۾��������
ʲ�߰��������ɰ�
�̨��݂ͷ�������MMXPentium��̊e�n����۾��������
FIVA�ɂ��̃v���Z�b�T�͍ڂ������Ƃ���܂��ǂ�
�H
�����A�ٰ����������
���������Ă��̂͊m��206V�Ȃ�Ƃ��݂����Ȍ^��
C3�ƈ����i686�ł���ْ߲ʂ邯�ǁADMA66�ɂ���Ɣ�������f�G�Ȉ�i
�����A�ٰ����������
���������Ă��̂͊m��206V�Ȃ�Ƃ��݂����Ȍ^��
C3�ƈ����i686�ł���ْ߲ʂ邯�ǁADMA66�ɂ���Ɣ�������f�G�Ȉ�i
�f�X�N�g�b�v����K8L�\�gStars Processor�h�ɂ���
http://northwood.blog60.fc2.com/blog-entry-524.html
http://northwood.blog60.fc2.com/blog-entry-524.html
������agena�łQCPU�Ƃ��������
CPU�����łQ�T�OW����E�E
�d���Ɣr�M�ǂ�����Ⴂ����E�E
CPU�����łQ�T�OW����E�E
�d���Ɣr�M�ǂ�����Ⴂ����E�E
417 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2007/01/27(�y) 21:10:53 ID:eU7W84nT
Transmeta Efficeon�����[�J�[�m�[�g�ɍڂ����̂���Muramasa���������
�iAMD Efficeon�Ƃ��Ă̎��т͒m���j
�|�V������ULV Pentium M�ɂȂ��Ă���FF�x���`�̎��s�p�t�H�[�}���X���啝�ɉ��P���ꂽ
�iAMD Efficeon�Ƃ��Ă̎��т͒m���j
�|�V������ULV Pentium M�ɂȂ��Ă���FF�x���`�̎��s�p�t�H�[�}���X���啝�ɉ��P���ꂽ
>>416
FX-74���}�V����ˁH
FX-74���}�V����ˁH
>>418
���\�͂Ƃ��������M�͓���
���\�͂Ƃ��������M�͓���
420 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2007/01/27(�y) 21:15:48 ID:eU7W84nT
�V�������N�ɂ�����d�͒ቺ���`�����ɂ���ق�K8L�̊g���͖c��Ȃ̂�
�܂��A�債�ė����ĂȂ��Ƃ������߂����邪�B
�܂��A�債�ė����ĂȂ��Ƃ������߂����邪�B
>>420
�Q�R�A���S�R�A����
�Q�R�A���S�R�A����
K8L��2�R�A�o�[�W�����Ɋ���
423 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2007/01/27(�y) 21:29:26 ID:eU7W84nT
�t�ɂ�TDP�̊�Â��ˁH
�t�����[�h������]�T�͂����ꂻ��
�t�����[�h������]�T�͂����ꂻ��
>>422
KUMA��
KUMA��
�t�����[�h����4�R�A�g���������H
�m���N�����͐�s����1�R�A���Ǝv�����E�E�E
�m���N�����͐�s����1�R�A���Ǝv�����E�E�E
http://journal.mycom.co.jp/special/2007/trendspring/005.html
HyperTransport Link�Ɋւ��ẮAVersion 1.x��Version 2.0��Version 3.0�ŗl�X�ȋ@�\���lj�����Ă��邪�A
�i�����j���������ۂ�Version 3.0��4GHz�̑��x���K�v�Ȃ̂�Dual Processor�Ԃ�HT Link�Ōq��Athlon 64 FX�́u4x4�v����
Quad FX�\���݂̂ł���A���ʂ̗��p���ɂ͂��܂�W�Ȃ��Ǝv����B
HT3,0�̓N�A�b�hFX�p���Ă��Ƃ�
�Ă����ꂩ����N�A�b�hFX������C���X�Ȃ�
HyperTransport Link�Ɋւ��ẮAVersion 1.x��Version 2.0��Version 3.0�ŗl�X�ȋ@�\���lj�����Ă��邪�A
�i�����j���������ۂ�Version 3.0��4GHz�̑��x���K�v�Ȃ̂�Dual Processor�Ԃ�HT Link�Ōq��Athlon 64 FX�́u4x4�v����
Quad FX�\���݂̂ł���A���ʂ̗��p���ɂ͂��܂�W�Ȃ��Ǝv����B
HT3,0�̓N�A�b�hFX�p���Ă��Ƃ�
�Ă����ꂩ����N�A�b�hFX������C���X�Ȃ�
�ϰ�R�A
>>426
�N�A�b�hFX���i���E�҂̃��|�[�g���������Ƃ��낾�ȁB
�N�A�b�hFX���i���E�҂̃��|�[�g���������Ƃ��낾�ȁB
�N�A�b�hCPU1��10���~�͍s�����낤���ȁB
431 �FSocket774�F2007/01/28(��) 02:44:20 ID:b3qRoxQ9
�@�@�@ �@�@ ,. �B�L�܁R�@�@�@�@ /:::::::::::/�@ �@�@�@�@�@�@�@/�R�@)::::::::::::::::::::::::::::1
�@�@�@�@�@j�^ (__�@�@�@�@�@�@/::::::::::::/�@�@�@�@�@�@_ �@ /::_i_�m'�R:::::::::::::::: _:::�m
�@�@�@�@�@�S r ' �N�@�@�@�@�@/::::::::::::/ :::::::::::::::::�Y__�@ �R�@�@�@�@�_::::::::::���
�@�@�@�@�@�@ |...:::::::::::�^ �@':::::::::::::::l__,:: - �����@�n�@Ɂ@�@�@�@ �@�R::::::__�
�@�@�@�@�@ �@r-�� "�@ �@ |:::::::::::::: |�@�@�@�@�@ _�@�R� '�@�S. �@�@�@�@ �:::�R
�@�@�@�@�@�@ �T_ �@ �@ �@_ |:::::::::::::: |�@�@�@�@�t_j�@� �@�@ �@,.�@�@�@ �@ ځ�
�@�@�@�@�@�@l�@/�T :::: ��_.|:::::::::::::: | ::::::::::"j �L T���@�@�@ |�@�@�@, �@ l
�@�@�@�@�@�@| l:::;/�M ��_�@ |:::__ :::::: |�@�@ _�m ,�R�S. �@ �@ ,�j_ �@ //�@,
�@�@�@�@�@�@| Lj! |�@ '' ����r��R::::|�@_�m�]!- !-!�l! �@ �زi/ �m .�,/
�@�@�@�@�@�@|�@�@ l�@�@�S�@�T�j�N:::::|�l�n!j_�T! �T�R�mj�rj�C/ l/ j/
�@�@�@�@�@�@|�@�@.�@ �@ | �_`�[".::::| �R�::��`�@�@�@�@ ˹ j �n
�@�@�@�@�@�@|�@ /�@�@�@|�@�@�R �_::::!�@ʁM �L�@�@�@�@�@,�@�@/ | | �@�@�@�@ Conroe�̈��|�I���\�ƈ���
�@�@�@�@�@�@|�@,�@�@ �@ |�@�@�@|` �[�T �R�R�@�@ �@_ _�@�@ � .�.|�@�@�@�@ �����Ēᐫ�\�@������d��64�EAM2
�@�@�@�@�@�m /�@�@�@�@ | !�@�@�R�m^� |�@|ā@�_ �@�@�@�^ _j�@| !|�@�@�@�@�@ AMD����_(^o^)�^
�@ �@ .�^,.j/ �@�@�@ �@ | |�R�@/�T.�@ |�@ �R.�_ �R��� �P"|�@l!�S.�
�@ �^ �@ / �@�@�@ �@�@�R�R�m �@ �@�@L�@�@ �_�R �R:.:�!:.:. l ,,� �@!l
�^�@�@., '�@�@�@�@�@�@�@ �^�@�C�@�@ �n �R.�@�@�_�_�_:.:.:| ɤ._ l|
�@�@�^�@�@�@�@�@�@�@�@'�@�@:::/�@�@ /:::::�@�@�M�[� �M�[ ��R( `-���� �
,�^�@�@�@�@�@- ��@_�m�@::::::/�@�@�@{::::::::::�@�@�@ �@��- �� �M�t��"��
�@�@�@�@�@ / �@_ �m�@ .::::::/�@ ��@�@�R:::::�@�@�@�@�@|�U_��'_�L�@�@_�� �
�@�@�@�@r�@�L�@�@ �@ ::::::�m�@ /::! �@ �@):::::! �@ �@�@ |�@�@�@j,._)�@ �M�Sj
�@�@�@�@�R-����'�@�^�@ �^::::�@�@ /:::::: !�@�@�@�@ �R�_ �S�R�@�@ ('�
�@�@�@�@�@j�^ (__�@�@�@�@�@�@/::::::::::::/�@�@�@�@�@�@_ �@ /::_i_�m'�R:::::::::::::::: _:::�m
�@�@�@�@�@�S r ' �N�@�@�@�@�@/::::::::::::/ :::::::::::::::::�Y__�@ �R�@�@�@�@�_::::::::::���
�@�@�@�@�@�@ |...:::::::::::�^ �@':::::::::::::::l__,:: - �����@�n�@Ɂ@�@�@�@ �@�R::::::__�
�@�@�@�@�@ �@r-�� "�@ �@ |:::::::::::::: |�@�@�@�@�@ _�@�R� '�@�S. �@�@�@�@ �:::�R
�@�@�@�@�@�@ �T_ �@ �@ �@_ |:::::::::::::: |�@�@�@�@�t_j�@� �@�@ �@,.�@�@�@ �@ ځ�
�@�@�@�@�@�@l�@/�T :::: ��_.|:::::::::::::: | ::::::::::"j �L T���@�@�@ |�@�@�@, �@ l
�@�@�@�@�@�@| l:::;/�M ��_�@ |:::__ :::::: |�@�@ _�m ,�R�S. �@ �@ ,�j_ �@ //�@,
�@�@�@�@�@�@| Lj! |�@ '' ����r��R::::|�@_�m�]!- !-!�l! �@ �زi/ �m .�,/
�@�@�@�@�@�@|�@�@ l�@�@�S�@�T�j�N:::::|�l�n!j_�T! �T�R�mj�rj�C/ l/ j/
�@�@�@�@�@�@|�@�@.�@ �@ | �_`�[".::::| �R�::��`�@�@�@�@ ˹ j �n
�@�@�@�@�@�@|�@ /�@�@�@|�@�@�R �_::::!�@ʁM �L�@�@�@�@�@,�@�@/ | | �@�@�@�@ Conroe�̈��|�I���\�ƈ���
�@�@�@�@�@�@|�@,�@�@ �@ |�@�@�@|` �[�T �R�R�@�@ �@_ _�@�@ � .�.|�@�@�@�@ �����Ēᐫ�\�@������d��64�EAM2
�@�@�@�@�@�m /�@�@�@�@ | !�@�@�R�m^� |�@|ā@�_ �@�@�@�^ _j�@| !|�@�@�@�@�@ AMD����_(^o^)�^
�@ �@ .�^,.j/ �@�@�@ �@ | |�R�@/�T.�@ |�@ �R.�_ �R��� �P"|�@l!�S.�
�@ �^ �@ / �@�@�@ �@�@�R�R�m �@ �@�@L�@�@ �_�R �R:.:�!:.:. l ,,� �@!l
�^�@�@., '�@�@�@�@�@�@�@ �^�@�C�@�@ �n �R.�@�@�_�_�_:.:.:| ɤ._ l|
�@�@�^�@�@�@�@�@�@�@�@'�@�@:::/�@�@ /:::::�@�@�M�[� �M�[ ��R( `-���� �
,�^�@�@�@�@�@- ��@_�m�@::::::/�@�@�@{::::::::::�@�@�@ �@��- �� �M�t��"��
�@�@�@�@�@ / �@_ �m�@ .::::::/�@ ��@�@�R:::::�@�@�@�@�@|�U_��'_�L�@�@_�� �
�@�@�@�@r�@�L�@�@ �@ ::::::�m�@ /::! �@ �@):::::! �@ �@�@ |�@�@�@j,._)�@ �M�Sj
�@�@�@�@�R-����'�@�^�@ �^::::�@�@ /:::::: !�@�@�@�@ �R�_ �S�R�@�@ ('�
432 �FSocket774�F2007/01/28(��) 04:53:17 ID:/rqi0W5U
4�R�A��CPU�̖ʐς�
�Q�R�A+��e�ʃL���b�V���̂��̂��o���Ăق�����
�Q�R�A+��e�ʃL���b�V���̂��̂��o���Ăق�����
4�R�A��CPU�̖ʐς�
�P�R�A+��e�ʃL���b�V���}�W������
�P�R�A+��e�ʃL���b�V���}�W������
�m��3�R�A+��e�ʃL���b�V����4�R�A�̔�r�͂������Ȃ��������ȁB
�ŁA4�R�A�̕����ǂ��Ƃ̌��_�ɁB
�ŁA4�R�A�̕����ǂ��Ƃ̌��_�ɁB
x86�ɂ������Ȃ��Ȃ�Acell�݂����ɍ����������������Ď���������
x86�łȂ���AMD�i��C���e���j�I�ԈӖ�����܂��Ȃ�����Ȃ�
x86�łȂ���AMD�i��C���e���j�I�ԈӖ�����܂��Ȃ�����Ȃ�
�N�A�b�h�ȏ�����ɂ͂ǂ��������̃\�[�X�͎g���Ȃ��킯�ŁA
����������i�����肾�Ǝv���B
����������i�����肾�Ǝv���B
HyperThreading��Penryn�ŕ�������炵�����A
�^���̕��A�����R�����g���肢���܂��B
�^���̕��A�����R�����g���肢���܂��B
���m�x15��
Core2Duo���o�����̏T���ɂ́A������HT�����ڂ����A�ƒf�蒲���������ǁA�ǂ��Ȃ�
�����ł����A�g������Ȃ��قǃR�A���ڂ����̂ɂ��H
����X2���g���Ă���ǁA���̗��p���@�ł́A�����\���ȋC������B
�������Â������ˁB
4�̃R�A���ڂ������������ĉ��Ɏg����
�������Â������ˁB
4�̃R�A���ڂ������������ĉ��Ɏg����
����p�AWS�p�A�I�p
1�ԖڈȊO�͎���PC���e�O����
1�ԖڈȊO�͎���PC���e�O����
3DCG�̃����_�����O����Ă��
4�R�A���낤��8�R�A���낤�Ɗ��Ƀ\�t�g�͑Ή��ς�
4�R�A���낤��8�R�A���낤�Ɗ��Ƀ\�t�g�͑Ή��ς�
>>437
2�R�A4�X���b�h�̓C���e���ȊO�ɂ��̗p����Ă邪
2�R�A4�X���b�h�̓C���e���ȊO�ɂ��̗p����Ă邪
20����50�������郏�[�N�X�e�[�V�����\�t�g�A�v�������\�t�g���ɂ�����
�u�I���͊��p���Ă�v
�݂����Ɍ�������Ă悭������
�u�I���͊��p���Ă�v
�݂����Ɍ�������Ă悭������
���͕��ʂ�CentOS+VMWare�ŊJ���������Ă邪�c
�܂��A���i�g���Ă�̂�Core2ThinkPad�ł܂�ŕs���R���ĂȂ��Ƃ���������
�܂��A���i�g���Ă�̂�Core2ThinkPad�ł܂�ŕs���R���ĂȂ��Ƃ���������
>>435
��������PS3��HDD�o�ڂ�Linux���������邩��APC��Linux�Ɛ��\��r�o����
�Ǝv�����A���̂�����̏����ĉ������ɗL�邩�Ȃ��H
��������PS3��HDD�o�ڂ�Linux���������邩��APC��Linux�Ɛ��\��r�o����
�Ǝv�����A���̂�����̏����ĉ������ɗL�邩�Ȃ��H
PS3��RSX���g���Ȃ��S�~����
�����PPE��1�R�A����
�����PPE��1�R�A����
PPE���ĂQ�X���b�h����Ȃ����������H
http://pc.watch.impress.co.jp/docs/2005/0514/kaigai178.htm
�b�Ⴆ�ACell��PowerPC�R�A�ł���PPE(Power Processor Element)�́A2�X���b�h��
�b���߂�1�T�C�N�����ɐ�ւ��Ď��s����uFine-Grain�v�^�̃}���`�X���b�f�B���O
�b���s�Ȃ��Ă���B
���A�ł����ꂶ��Ӗ��������ȁH�@�ꉞ���������C�e���V�̉B�����ʂ͂���݂��������B
http://pc.watch.impress.co.jp/docs/2005/0514/kaigai178.htm
�b�Ⴆ�ACell��PowerPC�R�A�ł���PPE(Power Processor Element)�́A2�X���b�h��
�b���߂�1�T�C�N�����ɐ�ւ��Ď��s����uFine-Grain�v�^�̃}���`�X���b�f�B���O
�b���s�Ȃ��Ă���B
���A�ł����ꂶ��Ӗ��������ȁH�@�ꉞ���������C�e���V�̉B�����ʂ͂���݂��������B
450 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2007/01/28(��) 21:24:16 ID:gfifHECw
�����̃N���b�N��PPC��2�ڂ����Ǝv������
K8L�̓��_�ɏI��肻���Ȋ���������B
Intel��45nm�̓N���b�N���\���ɏオ�肻������K8L�͋t�ɃN���b�N�オ�肻�����Ȃ��B
Intel preps five 45 nm dual- and quad-core processors
ttp://www.tgdaily.com/2007/01/27/intel_45nm_penryn_details/
Intel��45nm�̓N���b�N���\���ɏオ�肻������K8L�͋t�ɃN���b�N�オ�肻�����Ȃ��B
Intel preps five 45 nm dual- and quad-core processors
ttp://www.tgdaily.com/2007/01/27/intel_45nm_penryn_details/
���ʂ��Ă��Ƃ͂Ȃ�����c
�킸�����N�ł܂�į�ߐ��\��D���Ԃ���邩������Ȃ��ŁA
���N�ɂ͂�����ʰ�݂ɒǂ��ł�����������
�Ȃ����ׂȂ��s��邩������Ȃ��Ƃ��Ă��A��
�킸�����N�ł܂�į�ߐ��\��D���Ԃ���邩������Ȃ��ŁA
���N�ɂ͂�����ʰ�݂ɒǂ��ł�����������
�Ȃ����ׂȂ��s��邩������Ȃ��Ƃ��Ă��A��
>445
3DCG�n�Ȃ�A1�����傢�̃\�t�g�ł������S�R�A���炢�Ή����Ă邼
3DCG�n�Ȃ�A1�����傢�̃\�t�g�ł������S�R�A���炢�Ή����Ă邼
>>447
��������
ttp://rian.s26.xrea.com/nicky200611.html
��11��21��
> ���_�Ƃ��ẮALinux�}�V�����~���������Ȃ�A����PC�������ق��������B
> Cell���G�肽���Ȃ�APS3 Linux�Ƃ������Ƃ���ł��傤���B
��������
ttp://rian.s26.xrea.com/nicky200611.html
��11��21��
> ���_�Ƃ��ẮALinux�}�V�����~���������Ȃ�A����PC�������ق��������B
> Cell���G�肽���Ȃ�APS3 Linux�Ƃ������Ƃ���ł��傤���B
Intel�A45nm�v���Z�X�̎���CPU�uPenryn�v�̎���ɐ���
http://pc.watch.impress.co.jp/docs/2007/0129/intel.htm
�A���h�������
http://pc.watch.impress.co.jp/docs/2007/0129/intel.htm
�A���h�������
>>455
�T���N�X�B
���[�[��A�P���x�ł�Athlon64�ɂ͂Ƃǂ������B
�܂�PC�����̈�ʓI�ȃx���`�}�[�N������Acell�̓��ӋZ�i����\�́H�j��
�������ĂȂ��̂�������ALinux���PS3�Ȃ�ł́A�̎g�����������
�ʔ������ł��ˁB
>>456
���{��DRAM���[�J�[���T���\���ɂ��ꂽ�\�}��f�i�������܂��ˁB
�T���N�X�B
���[�[��A�P���x�ł�Athlon64�ɂ͂Ƃǂ������B
�܂�PC�����̈�ʓI�ȃx���`�}�[�N������Acell�̓��ӋZ�i����\�́H�j��
�������ĂȂ��̂�������ALinux���PS3�Ȃ�ł́A�̎g�����������
�ʔ������ł��ˁB
>>456
���{��DRAM���[�J�[���T���\���ɂ��ꂽ�\�}��f�i�������܂��ˁB
http://pc.watch.impress.co.jp/docs/2007/0129/ibm.htm
�v���Z�X�Z�p�̒x������AK8L�̎����Ȃ��̂���肾��B
���܂̂܂܂��ƁAAMD��Fusion�ŏȓd�̓m�[�g�p�\�R���ƒቿ�i�p�\�R���ɑi�����Ă�������������ԁB
�n�C�X�y�b�N�}�V���́A�y�������l�n�[�����̓ƒd��ɁE�E�E�E�E�E�E�E
�������A�C���e�����r�f�I�`�b�v�s��Q���\�������A�C���e����Fusion�����i���o���̂͊ȒP������A�m�[�g�p�\�R���A�ቿ�i�p�\�R���s�ꂾ���Ĉ��ׂ���Ȃ��B
�܂�AMD����_(^o^)�^
�v���Z�X�Z�p�̒x������AK8L�̎����Ȃ��̂���肾��B
���܂̂܂܂��ƁAAMD��Fusion�ŏȓd�̓m�[�g�p�\�R���ƒቿ�i�p�\�R���ɑi�����Ă�������������ԁB
�n�C�X�y�b�N�}�V���́A�y�������l�n�[�����̓ƒd��ɁE�E�E�E�E�E�E�E
�������A�C���e�����r�f�I�`�b�v�s��Q���\�������A�C���e����Fusion�����i���o���̂͊ȒP������A�m�[�g�p�\�R���A�ቿ�i�p�\�R���s�ꂾ���Ĉ��ׂ���Ȃ��B
�܂�AMD����_(^o^)�^
AMD����_(^o^)�^���Ă��Ƃ�Intel�Ɛ�ŏ���ҵ���_(^o^)�^���Ă��Ƃł���������~�ǂ��I��
�d���˂���AAMD���w�|�Ȃ��ȁB
�ł�CPU�R�A�P�̂̐��\���A�b�v���āA���������b�g�͂���̂��H
�����PC�ŏ����\�͂��v�������̂́AFusion����荞�����Ƃ��Ă�
�@�\���肾���A�̊����x�ɂ�HDD���\�₻����t���b�V����������
�⍲����d�g�݂̕������ʂ͑傫�����B
���ǁA�Q�[���@��Wii�Ɠ����ŃL�[�{�[�h���g��Ȃ��ōςޕ�����PC
�ŁA���p�҂𑝂₷�������W���͖����낤�BPC�̎g�����肪��{�I��
�ς��Ȃ�Vista�ȂAWin2K/XP����킴�킴��芷����C������
��ʃ��[�U�[�ɂ͖������낤���B
�����PC�ŏ����\�͂��v�������̂́AFusion����荞�����Ƃ��Ă�
�@�\���肾���A�̊����x�ɂ�HDD���\�₻����t���b�V����������
�⍲����d�g�݂̕������ʂ͑傫�����B
���ǁA�Q�[���@��Wii�Ɠ����ŃL�[�{�[�h���g��Ȃ��ōςޕ�����PC
�ŁA���p�҂𑝂₷�������W���͖����낤�BPC�̎g�����肪��{�I��
�ς��Ȃ�Vista�ȂAWin2K/XP����킴�킴��芷����C������
��ʃ��[�U�[�ɂ͖������낤���B
�l����PC����ׂ肻��������AAMD�ʹ���݂݂����ȼ����r������
�@�l�����̎I�ɒ��͂��Ă����킯�����c
�@�l�����̎I�ɒ��͂��Ă����킯�����c
�������AFUSION��2009�N�ȍ~�ɂ��ꍞ�ނ悤�����Ȃ�
DDR3-1600��z�肵�Ă����悤�����ǁADDR3�̕��y�ƒl������JEDEC�̍����
Intel�̐V���߂̔���s������
�ł��AIntel��Ҳݽ�ذь���DDR3�Ή����߂�2008�N�������ȍ~�c
DDR3-1600��z�肵�Ă����悤�����ǁADDR3�̕��y�ƒl������JEDEC�̍����
Intel�̐V���߂̔���s������
�ł��AIntel��Ҳݽ�ذь���DDR3�Ή����߂�2008�N�������ȍ~�c
TI�Ђ��Ő�[�v���Z�X�J���������痣�E�A
45nm�Z�p�J���𒆎~ (2007/01/26)
http://www.eetimes.jp/contents/200701/14217_1_20070128194425.cfm
45nm�Z�p�J���𒆎~ (2007/01/26)
http://www.eetimes.jp/contents/200701/14217_1_20070128194425.cfm
45nm�͂�قǓ����
>>458
K8L�̎��͂��邼�c�B
K8L�̎��͂��邼�c�B
���C���e����Fusion�����i���o���̂͊ȒP������A
�A�z�H
G965��Driver�������ɏ����Ȃ�Intel��GPU�ɉ������҂��Ă�킯�H
�����AIntel��nVidia�����鑼��Fusion�ɑR�����͖����Ǝv���B
�A�z�H
G965��Driver�������ɏ����Ȃ�Intel��GPU�ɉ������҂��Ă�킯�H
�����AIntel��nVidia�����鑼��Fusion�ɑR�����͖����Ǝv���B
>>467
GPU���ǂ��g�����̓\�t�g�̖�肾�Ƃ��Ă��AVGA�����v���Z�b�T�����������̂ł��Ȃ����Ȃ�
GPU���ǂ��g�����̓\�t�g�̖�肾�Ƃ��Ă��AVGA�����v���Z�b�T�����������̂ł��Ȃ����Ȃ�
timuna�̂��Ƃ�
timna��
471 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2007/01/30(��) 02:15:34 ID:jXKsa1Hn
GPU�����]�X���ă��[�G���hPC����̘b�Ȃ��ǂˁB
�_�C�������������������HT�Ƃ������R���݂����ȕ��̍L��
�p�������O���C���^�[�t�F�C�X�����邽�߂Ɉ��̕��͊m�ۂ��Ȃ��Ƃ����Ȃ��B
�ł����̃_�C�T�C�Y�̒���1�R�A2�R�A����_�C���]��B
������GPU�˂����߂悭�ˁH���Ă̂�AMD�̔��z�B
�_�C�����������Ă����̂Ȃ��R�A����Ă�ΊW�̂Ȃ��b�Ȃ悾��ˁB
�n�C�G���hPC��T�[�o���܂߂Ė{�������GPU��������Ȃ�
�t��Intel��GPU�̃l�C�e�B�uISA���T�|�[�g���Ȃ��ƕ��y�����
MS��GPU��ISA�Ɋւ��ăl�C�e�B�u����̑w�̃V�F�[�_���f����
���Ă邾���ł����Ȃ�����Cx86-64�̂悤�ɂ͂������B
�_�C�������������������HT�Ƃ������R���݂����ȕ��̍L��
�p�������O���C���^�[�t�F�C�X�����邽�߂Ɉ��̕��͊m�ۂ��Ȃ��Ƃ����Ȃ��B
�ł����̃_�C�T�C�Y�̒���1�R�A2�R�A����_�C���]��B
������GPU�˂����߂悭�ˁH���Ă̂�AMD�̔��z�B
�_�C�����������Ă����̂Ȃ��R�A����Ă�ΊW�̂Ȃ��b�Ȃ悾��ˁB
�n�C�G���hPC��T�[�o���܂߂Ė{�������GPU��������Ȃ�
�t��Intel��GPU�̃l�C�e�B�uISA���T�|�[�g���Ȃ��ƕ��y�����
MS��GPU��ISA�Ɋւ��ăl�C�e�B�u����̑w�̃V�F�[�_���f����
���Ă邾���ł����Ȃ�����Cx86-64�̂悤�ɂ͂������B
ISA��GPU���ƂɈႤ���AGPU���̂܂��܂����W�r��B
ISA�͍�����A�ω�����\�����傫���B
���̂��߁AATI��DPVM��GPU���ƂɃ����^�C����p�ӂ���
���z�}�V���^�C�v�ƂȂ�\�肾�B
��{�I�ɁA�����GPU���Ƃ̍��ق͊W�Ȃ��Ȃ�B
ISA�͍�����A�ω�����\�����傫���B
���̂��߁AATI��DPVM��GPU���ƂɃ����^�C����p�ӂ���
���z�}�V���^�C�v�ƂȂ�\�肾�B
��{�I�ɁA�����GPU���Ƃ̍��ق͊W�Ȃ��Ȃ�B
�N���C�A���g�p�r�ł�GPU�͕K�{����
�T�[�o�[�p�r�ł͕K�{�ł͂Ȃ��B
�N���C�A���g�����ɁAGPU�����������͎̂��R����
�T�[�o�[�����͑g�ݍ��ދ@�\���A�܂�����ł��Ȃ�����
���ʂ͔ėp�R�A�𑝂₵�Ă����܂�����āA�����ł���B
��������ɂ��Ă��A�㓡�����`���N�`���N������
���G�ȁi�V�[�P���T�̑���ɔėp�R�A���g����悤�ȁj�`�ł�
�����ł͂Ȃ��AGPU���̂܂܃^�C�v���낤�B
���G�^�͔ėp�R�A��shader�̐ڑ����A�N���X�o�[�ڑ��̂܂܂ł͕��G�ɂȂ�߂���
���Ƃ����āACell�̂悤�Ƀ����O�o�X�ɂ��邩�Ƃ�����
������������܂ŁA��C�e���V�ł���Ă������̈Ӗ����Ȃ��Ȃ�E�E�E
�܂�A���C�e���V���F�ł���GPU�ƁA�G�ł���CPU���������邱�ƂɂȂ�B
�����Ƃ��A�������ш�̖��ŁA���Ƃ��Ƒ�����shader��ςނ��Ƃ͏o���Ȃ��B
����ɃN���b�N�������Ȃ�Ȃ�A���Ȃ�Shader�ł�
�p�t�H�[�}���X�������p�t�H�[�}���X���o�����Ƃ��\�B
Fusion�ɓ��������Sahder�̐��͌��\���Ȃ��i16shader 4Quad���x�H�j���낤�B
AMD�́A����܂łƂ̓^�C�v�̈ႤGPU���J�����Ȃ���Ȃ�Ȃ��Ȃ�B
���Ȃ�shader�Ȃ�A�㓡���̕��G�^�̓������\��������Ȃ��B
�T�[�o�[�p�r�ł͕K�{�ł͂Ȃ��B
�N���C�A���g�����ɁAGPU�����������͎̂��R����
�T�[�o�[�����͑g�ݍ��ދ@�\���A�܂�����ł��Ȃ�����
���ʂ͔ėp�R�A�𑝂₵�Ă����܂�����āA�����ł���B
��������ɂ��Ă��A�㓡�����`���N�`���N������
���G�ȁi�V�[�P���T�̑���ɔėp�R�A���g����悤�ȁj�`�ł�
�����ł͂Ȃ��AGPU���̂܂܃^�C�v���낤�B
���G�^�͔ėp�R�A��shader�̐ڑ����A�N���X�o�[�ڑ��̂܂܂ł͕��G�ɂȂ�߂���
���Ƃ����āACell�̂悤�Ƀ����O�o�X�ɂ��邩�Ƃ�����
������������܂ŁA��C�e���V�ł���Ă������̈Ӗ����Ȃ��Ȃ�E�E�E
�܂�A���C�e���V���F�ł���GPU�ƁA�G�ł���CPU���������邱�ƂɂȂ�B
�����Ƃ��A�������ш�̖��ŁA���Ƃ��Ƒ�����shader��ςނ��Ƃ͏o���Ȃ��B
����ɃN���b�N�������Ȃ�Ȃ�A���Ȃ�Shader�ł�
�p�t�H�[�}���X�������p�t�H�[�}���X���o�����Ƃ��\�B
Fusion�ɓ��������Sahder�̐��͌��\���Ȃ��i16shader 4Quad���x�H�j���낤�B
AMD�́A����܂łƂ̓^�C�v�̈ႤGPU���J�����Ȃ���Ȃ�Ȃ��Ȃ�B
���Ȃ�shader�Ȃ�A�㓡���̕��G�^�̓������\��������Ȃ��B
GPU�������Ă��A�ި���ڲ�ݼ�݂⓮��̱���ڰ��͋��炭���߾�đ������A
�ш�̖��͕ς��Ȃ��悤��
����ɱ�۸ޏo�͂��悤�Ƃ���ƕϊ����K�v�ɂȂ��Ȃ��́H
�ш�̖��͕ς��Ȃ��悤��
����ɱ�۸ޏo�͂��悤�Ƃ���ƕϊ����K�v�ɂȂ��Ȃ��́H
�Ⴄ�^�C�v���Ă������A���j�b�g�����Ȃ��Ȃ�
�����O�o�X�ɂ���K�v�́A�Ȃ��Ȃ邾�낤�B
�����A�L���b�V���ƃ��W�X�^�́A�O�t��GPU�ȏ�ɐςނ����ȁB
�����ɓ������Ă����A����܂łƂ͕ς���Ă��������ȁB
�����O�o�X�ɂ���K�v�́A�Ȃ��Ȃ邾�낤�B
�����A�L���b�V���ƃ��W�X�^�́A�O�t��GPU�ȏ�ɐςނ����ȁB
�����ɓ������Ă����A����܂łƂ͕ς���Ă��������ȁB
>>474
>��ި���ڲ�ݼ�݂⓮��̱���ڰ��͋��炭���߾�đ�
������O�t���ɂ�����CPU�ɓ�������Ӗ������܂�Ȃ��C���B
�ш�̖���HT3.0�₻�̐�̋Z�p�ł�����x�����ł����ˁH
�_���̓n�C�G���h�ł͂Ȃ��āA���[�G���h�Ȃ��B
>��ި���ڲ�ݼ�݂⓮��̱���ڰ��͋��炭���߾�đ�
������O�t���ɂ�����CPU�ɓ�������Ӗ������܂�Ȃ��C���B
�ш�̖���HT3.0�₻�̐�̋Z�p�ł�����x�����ł����ˁH
�_���̓n�C�G���h�ł͂Ȃ��āA���[�G���h�Ȃ��B
>>476
���[�G���h���Ă̂��Q�N��ɂǂ̒��x���Ă̂���肶��ˁH
�`�b�v�Z�b�g�̃O���t�B�b�N���\�ȏ�̐��\���o���ď�����
�ȃG�l�ɂ��Ȃ��ƈӖ��Ȃ�
���R���o�C���p�r�̕����琻�i�ɂȂ��Ă���Ǝv�����A�f�X�N����
�ł͕�����Ȃ��Ȃ�Ǝv���B
���[�G���h���Ă̂��Q�N��ɂǂ̒��x���Ă̂���肶��ˁH
�`�b�v�Z�b�g�̃O���t�B�b�N���\�ȏ�̐��\���o���ď�����
�ȃG�l�ɂ��Ȃ��ƈӖ��Ȃ�
���R���o�C���p�r�̕����琻�i�ɂȂ��Ă���Ǝv�����A�f�X�N����
�ł͕�����Ȃ��Ȃ�Ǝv���B
>>477
�f�X�N�����ŕ�����Ȃ��Ȃ�Ƃ����Ă��A���[�U�[���悾��B
�`�b�v�Z�b�g����GPU���g���Ă�l�ȁA�Ɩ��p��������S�R���[�}���^�C�����A
����ȏオ�K�v�Ȃ�Video�J�[�h�lj��ŃI�P����B
������Video�h���C�o���悾���A�`�b�v�Z�b�g����GPU��PC��Video�J�[�h��
�lj����Ă��`�b�v�Z�b�g����GPU�͎�������邾�������AFusion��GPU�Ȃ�
���U�����Ɏg����B
�f�X�N�����ŕ�����Ȃ��Ȃ�Ƃ����Ă��A���[�U�[���悾��B
�`�b�v�Z�b�g����GPU���g���Ă�l�ȁA�Ɩ��p��������S�R���[�}���^�C�����A
����ȏオ�K�v�Ȃ�Video�J�[�h�lj��ŃI�P����B
������Video�h���C�o���悾���A�`�b�v�Z�b�g����GPU��PC��Video�J�[�h��
�lj����Ă��`�b�v�Z�b�g����GPU�͎�������邾�������AFusion��GPU�Ȃ�
���U�����Ɏg����B
>Fusion��GPU�Ȃ番�U�����Ɏg����B
���肦�Ȃ�
���肦�Ȃ�
Multi GPU�̂��Ƃ��AGPGPU�̂��Ƃ�����Ȃ�����
DX10.1�̉��z����Multi GPU�����₷���Ȃ�B
S3�AATI(AMD)��DX10.1����Ń}���`�_�C�ɐ���Ƃ����Ă���B
�i����nVIDIA���j
DX10.1�̉��z����Multi GPU�����₷���Ȃ�B
S3�AATI(AMD)��DX10.1����Ń}���`�_�C�ɐ���Ƃ����Ă���B
�i����nVIDIA���j
����ɂ���CPU�ɓ����������ł͂ł��ă`�b�v�Z�b�g�ɓ����������ł͂ł��Ȃ����Ėϑz�̓o�C�A�X�����肷����
�u��X�̉�Ђ肽���Ƃ͎v��Ȃ��v�C��NVIDIA�Ђ��u���̉\�v��ے�
http://techon.nikkeibp.co.jp/article/NEWS/20070130/127117/?ST=lsi
�\�\����NVIDIA�Ђɂ̓}�C�N���v���Z�T���Ȃ��B����C�����_�̃��C�o���ł���
AMD�Ђ́u�}�C�N���v���Z�T�ƃO���t�B�b�N�XLSI�̓����v��v�𐄐i���Ă���B
�}�C�N���v���Z�T���Ȃ������CAMD�ЂɑR�ł��Ȃ��Ȃ�̂ł͂Ȃ����H
Hara���@����ȋ����ɂ͂܂������������Ȃ��B���R�͑傫�������B
��́C�}�C�N���v���Z�T�ƃO���t�B�b�N�XLSI�͖�������{�I�ɈႤ���̂����炾�B
�}�C�N���v���Z�T�́C�f�[�^�̏o������������G�ȉ��Z���������邱�Ƃɏd�_��
�u�����v���Z�T�ł���̂ɑ��C�O���t�B�b�N�XLSI�́i���Ƃ��ėp�I�Ȑ��l���Z��
�ł���悤�ɂȂ��Ă��j��e�ʂ̃f�[�^�������ɏ����ł��邱�Ƃ���Ԃ̓������B
���̓�͏ɉ����ďd�݂�ς��Ďg���̂��悢�B�����Ɉ�ɂ܂Ƃ߂�C
�v�̏_��������Ďs��̗v���ւ̐v���ȑΉ����x���B
������̗��R�́C�}�C�N���v���Z�T�ƃO���t�B�b�N�XLSI�̓�����
��X���Nj����Ă����u���l�v�������Ȃ����Ƃ��B
http://techon.nikkeibp.co.jp/article/NEWS/20070130/127117/?ST=lsi
�\�\����NVIDIA�Ђɂ̓}�C�N���v���Z�T���Ȃ��B����C�����_�̃��C�o���ł���
AMD�Ђ́u�}�C�N���v���Z�T�ƃO���t�B�b�N�XLSI�̓����v��v�𐄐i���Ă���B
�}�C�N���v���Z�T���Ȃ������CAMD�ЂɑR�ł��Ȃ��Ȃ�̂ł͂Ȃ����H
Hara���@����ȋ����ɂ͂܂������������Ȃ��B���R�͑傫�������B
��́C�}�C�N���v���Z�T�ƃO���t�B�b�N�XLSI�͖�������{�I�ɈႤ���̂����炾�B
�}�C�N���v���Z�T�́C�f�[�^�̏o������������G�ȉ��Z���������邱�Ƃɏd�_��
�u�����v���Z�T�ł���̂ɑ��C�O���t�B�b�N�XLSI�́i���Ƃ��ėp�I�Ȑ��l���Z��
�ł���悤�ɂȂ��Ă��j��e�ʂ̃f�[�^�������ɏ����ł��邱�Ƃ���Ԃ̓������B
���̓�͏ɉ����ďd�݂�ς��Ďg���̂��悢�B�����Ɉ�ɂ܂Ƃ߂�C
�v�̏_��������Ďs��̗v���ւ̐v���ȑΉ����x���B
������̗��R�́C�}�C�N���v���Z�T�ƃO���t�B�b�N�XLSI�̓�����
��X���Nj����Ă����u���l�v�������Ȃ����Ƃ��B
���������傫�ȕǂƂȂ�AMD��FUSION�v���Z�b�T
http://pc.watch.impress.co.jp/docs/2007/0131/kaigai332.htm
http://pc.watch.impress.co.jp/docs/2007/0131/kaigai332.htm
nVIDIA�͌Ǘ������ɁA���������t���B
Intel����������������Ȃ̂ɁE�E
CUDA�́A�y�[�p�[�����[�X�ɏI��肩�B
����Ȃ�nVIDIA�B
Intel����������������Ȃ̂ɁE�E
CUDA�́A�y�[�p�[�����[�X�ɏI��肩�B
����Ȃ�nVIDIA�B
AMD(ATI)�AIntel�AnVIDIA��3�Ђ̒��ł�
nVIDIA���Ó��Ō����ȑI�������Ă�Ǝv����
nVIDIA���Ó��Ō����ȑI�������Ă�Ǝv����
>>485
�������ɐ^���ʂ���Intel��AMD�ɗ����������̗͖͂��������
CUDA��CPUGPU�̓�����ɂ����Ă͂��Ȃ��ƃA�s�[�����Ă邾����
���Ȃ��Ƃ��AIntel��AMD�ɐH�킹�Ă�����Ă闧���A
�����������܂킵�Ȕ�������ނȂ��Ƃ������Ƃ��낾�낤
�������ɐ^���ʂ���Intel��AMD�ɗ����������̗͖͂��������
CUDA��CPUGPU�̓�����ɂ����Ă͂��Ȃ��ƃA�s�[�����Ă邾����
���Ȃ��Ƃ��AIntel��AMD�ɐH�킹�Ă�����Ă闧���A
�����������܂킵�Ȕ�������ނȂ��Ƃ������Ƃ��낾�낤
>>482
�������͒��D�NJ��NVIDIA�B
�W���n�̖��ɓq���ɏo�������V�F�[�_���������Đg���肵��ATI�Ƃ͈Ⴄ�B
�����o���Ėׂ���Ƃ���ƋZ�p�̃t���b�O�V�b�v����邱�Ƃ̃o�����X��ǂ��������Ă�B
8800�̌�p�������������ASIMD�A�N�Z�����[�^�Ƃ��Č����ꍇ�ł�Cell�Ȃ���ɂ������Ċ������B
�������͒��D�NJ��NVIDIA�B
�W���n�̖��ɓq���ɏo�������V�F�[�_���������Đg���肵��ATI�Ƃ͈Ⴄ�B
�����o���Ėׂ���Ƃ���ƋZ�p�̃t���b�O�V�b�v����邱�Ƃ̃o�����X��ǂ��������Ă�B
8800�̌�p�������������ASIMD�A�N�Z�����[�^�Ƃ��Č����ꍇ�ł�Cell�Ȃ���ɂ������Ċ������B
K8L���ޭ�ٺ��ۯ��������
�������Z�͂قƂ�Ǖς��Ȃ��̂ł́H�Ƃ����b������A
�����ɂ���ẮA�܂�����939�Ƒ卷�̂Ȃ����ʂɂȂ肻����
�������Z�͂قƂ�Ǖς��Ȃ��̂ł́H�Ƃ����b������A
�����ɂ���ẮA�܂�����939�Ƒ卷�̂Ȃ����ʂɂȂ肻����
>>488
�N���b�N������̂�Quad�BSingle��Sempron��p�B
�N���b�N������̂�Quad�BSingle��Sempron��p�B
�Ƃ����K8L����Conroe�Œlj����ꂽSSSE3�ɂ͑Ή�����́H
����͂��A�I���^ww
���������傫�ȕǂƂȂ�AMD��FUSION�v���Z�b�T
http://pc.watch.impress.co.jp/docs/2007/0131/kaigai332.htm
���������傫�ȕǂƂȂ�AMD��FUSION�v���Z�b�T
http://pc.watch.impress.co.jp/docs/2007/0131/kaigai332.htm
Fusion�͊�{�I��ɰČ���������A��؎���͍X�Ɍ�������łȂ��H
Intel��ɰČ���DDR3�Ή����߂��o���ĕ��y�����Ă���Ȃ��Ƃ����Ȃ��킯�����A
�c�����Ă�2008�N�㔼���낤
Intel��ɰČ���DDR3�Ή����߂��o���ĕ��y�����Ă���Ȃ��Ƃ����Ȃ��킯�����A
�c�����Ă�2008�N�㔼���낤
������Z-RAM�ł���
DDR2�̗����グ���Ȃ�DDR�����������C������B
���������ʂ͊y�ώ����Ă�����Ȃ��H
�ނ���DDR3�̑ш�ł��瑫��Ȃ��\���͂��邪�c�c
���������ʂ͊y�ώ����Ă�����Ȃ��H
�ނ���DDR3�̑ш�ł��瑫��Ȃ��\���͂��邪�c�c
DDR-3 1600�Ƃ��z�肵�Ă邵�Ȃ��c
ɰĂłł�킯�Ȃ��̂�
�ł��A�����͂���ł��낤��
ɰĂłł�킯�Ȃ��̂�
�ł��A�����͂���ł��낤��
XBOX�|�[�^�u��(��)�ɍ̗p������Ƃ��E�E�E
����XBOX�݊��ŁB
����XBOX�݊��ŁB
�������ш悪�ǂɂȂ�Ȃ�āB
GPGPU�~�̖Џ@�ł����A�w�E���Ă���B
nVIDIA�ƈ����AMD�Ȃ�A��肭��邳w
GPGPU�~�̖Џ@�ł����A�w�E���Ă���B
nVIDIA�ƈ����AMD�Ȃ�A��肭��邳w
��肭���Ƃ��������A�����̔��\��㓡�̔����Ƃ͈Ⴂ�����Ɩ��̖͂������̂ɂȂ肻���B
�m�[�g���Ɖ]�X�Ƃ������Ă邪�A���̒��x�̏ȓd�͂��R�X�g���Ȃ�v���b�g�t�H�[���S�̂Ƃ��č����\��Intel��
�R�o����悤�ɂ͎v���Ȃ��AIntel�����ăm�[�g�pCPU�ɂ�GPU���ڂ��Ă��邾�낤���E�E�E
�Ȃ����Ȃ��l�q�ł���B
�m�[�g���Ɖ]�X�Ƃ������Ă邪�A���̒��x�̏ȓd�͂��R�X�g���Ȃ�v���b�g�t�H�[���S�̂Ƃ��č����\��Intel��
�R�o����悤�ɂ͎v���Ȃ��AIntel�����ăm�[�g�pCPU�ɂ�GPU���ڂ��Ă��邾�낤���E�E�E
�Ȃ����Ȃ��l�q�ł���B
�܂��A�ʂɍ���VGA�����^�`�b�v�Z�b�g�����@���g���Ă���킯�ł��Ȃ����ȁB
Fusion�Ƃ������̂́A������South�`�b�v�ƃ����������Ă��邾���Ńm�[�gPC
���܂���Ƃ����Ƃ��낾�낤���B
Fusion�Ƃ������̂́A������South�`�b�v�ƃ����������Ă��邾���Ńm�[�gPC
���܂���Ƃ����Ƃ��낾�낤���B
501 �FSocket774�F2007/01/31(��) 11:28:39 ID:vxdayi13
http://pc.watch.impress.co.jp/docs/2006/0609/comp09.htm
�����āARadeon�ł̓r�f�I�J�[�h3���\�����\�ƂȂ�B���̏ꍇ�́A
.2����CrossFire�Ƃ��ăO���t�B�b�N�����Ɋ��蓖�āA�c���1����
.�������Ɋ��蓖�Ă�B���ۂɓ��Ђ́ARadeon X1900 CrossFire+Radeon X1600�A
�����Radeon X1900 CrossFire+Radeon X1900�Ƃ����\���̃f���@��W���A
���삳���Ă����B
�����āARadeon�ł̓r�f�I�J�[�h3���\�����\�ƂȂ�B���̏ꍇ�́A
.2����CrossFire�Ƃ��ăO���t�B�b�N�����Ɋ��蓖�āA�c���1����
.�������Ɋ��蓖�Ă�B���ۂɓ��Ђ́ARadeon X1900 CrossFire+Radeon X1600�A
�����Radeon X1900 CrossFire+Radeon X1900�Ƃ����\���̃f���@��W���A
���삳���Ă����B
502 �FSocket774�F2007/01/31(��) 11:59:49 ID:lN8FRMLn
Fusion�͓��ʐ�̘b�ɂȂ邾�낤
���_��茇�_�̂ق��������Ȃ肻��
������V�^�𑁂�����ė~������
C2D����悤�Ȑ��\�ƍ��M��AMD�炵����̌����ė~����
���_��茇�_�̂ق��������Ȃ肻��
������V�^�𑁂�����ė~������
C2D����悤�Ȑ��\�ƍ��M��AMD�炵����̌����ė~����
> ������V�^�𑁂�����ė~������
Fusion�œ�������悤������A
�ǂ�Ȃɑ����Ă�2015�N�ȍ~���炢�ɂȂ肻���H
Fusion�œ�������悤������A
�ǂ�Ȃɑ����Ă�2015�N�ȍ~���炢�ɂȂ肻���H
>>504
�������V�v�H
CPU�̉�H�̓��W���[�����ɂ������ύX�w�ǂ��Ȃ������A�V�v���Č����邩�H
���N���b�N���Ɛ��\�w�Ǖς��Ȃ���B
�������V�v�H
CPU�̉�H�̓��W���[�����ɂ������ύX�w�ǂ��Ȃ������A�V�v���Č����邩�H
���N���b�N���Ɛ��\�w�Ǖς��Ȃ���B
i815�̍���AGP�X���b�g�ɑ��݂���VRAM���W���[�����������Ƃ����������A
PCI-Express�~16�Ɋg�����������݂Ƃ��ł�����ȁE�E�E>Fusion
PCI-Express�~16�Ɋg�����������݂Ƃ��ł�����ȁE�E�E>Fusion
�ނ���A�������R���g���[�����t���āA�Е����r�f�I�`�b�v��p�����R���ɂ���Ƃ��B
���[������A�������ш�̖������I
������ƒቿ�i�pPC�ɂ͎g���Ȃ��Ȃ邵�A�����iPC�̓t���[�W�������ᐫ�\����Ȃ������B
���߂��킱��B
���[������A�������ш�̖������I
������ƒቿ�i�pPC�ɂ͎g���Ȃ��Ȃ邵�A�����iPC�̓t���[�W�������ᐫ�\����Ȃ������B
���߂��킱��B
X2600������Fusion < VRAM�lj���Fusion < X3300(�V����8000�~)
2015�N�ɂ�AMD�Ȃ�đ��݂��Ă܂���i�����j
�V���O���X���b�h�̑��x�������邱�ƂȂ�ĊȒP����
����ŃI�[�o�[�N���b�N���������
�t����(�݂����ȉ�����)�ŗ�p�A���ꂵ���Ȃ���
����ŃI�[�o�[�N���b�N���������
�t����(�݂����ȉ�����)�ŗ�p�A���ꂵ���Ȃ���
>>507
DIMM��1�X���b�g�̂݁A���������₵����Ȃ�
�������������ւ��邵���Ȃ��悤�ɂ���
DDR3�@1600Mhz�Ƃ��ɂ���������ш�͗]�T
�Ȃ��A���C���������ƃr�f�I������������
�����̂ق����͌��������Ǝv��
DIMM��1�X���b�g�̂݁A���������₵����Ȃ�
�������������ւ��邵���Ȃ��悤�ɂ���
DDR3�@1600Mhz�Ƃ��ɂ���������ш�͗]�T
�Ȃ��A���C���������ƃr�f�I������������
�����̂ق����͌��������Ǝv��
>>506
8GB/sec����ƂĂ�����Ȃ���H
8GB/sec����ƂĂ�����Ȃ���H
GPU�ɔėp��؎g���Ă�GDDR�ɂ͏��Ă܂���
���[�G���h��GPU������̂����C���̃��[�h�}�b�v�ł́AAMD�̏����͂����Ǝv���B
���Z���\���ǂ��オ��̂����A�����Ȃ��B
���͓���Ȃ��Ă������A�n����CPU�̐^�̐��\���グ������ɖ߂��Ăق����B
���Z���\���ǂ��オ��̂����A�����Ȃ��B
���͓���Ȃ��Ă������A�n����CPU�̐^�̐��\���グ������ɖ߂��Ăق����B
���ǁAFUSION�v���Z�b�T��PC�͑����Ȃ�̂��H
�Ƃ������Ƃ��d�v���Ǝv���B
�Ƃ������Ƃ��d�v���Ǝv���B
�����Ȃ�����CPU�ƃ����������A�ŃO���t�B�b�N�{�[�h�ɑR����
CPU�{�[�h�����B
CPU�{�[�h�����B
���ǁAFUSION�v���Z�b�T�Ńm�[�gPC�͈����Ȃ�̂��H
�Ƃ������Ƃ������I���Ǝv���B
�Ƃ������Ƃ������I���Ǝv���B
�e��̃R�v���Z�b�T�������Ă��A���r���[�Ȃ��̂���CPU�̐��\�����サ�Ďg���Ȃ��Ȃ�B
�t�ɍ����\��_���ƃ_�C�ʐς������B���ΓI�ɔėp�R�A���キ�Ȃ�B
FUSION�v���Z�b�T�͎��s����Ǝv���B
�t�ɍ����\��_���ƃ_�C�ʐς������B���ΓI�ɔėp�R�A���キ�Ȃ�B
FUSION�v���Z�b�T�͎��s����Ǝv���B
��������GPU��CPU�ł܂��Ȃ��͖̂��������āB
���[�G���h��GPU�̋@�\�ł��n�C�G���h��CPU�̔����p���[�����Ă��d����B
���[�G���h��GPU�̋@�\�ł��n�C�G���h��CPU�̔����p���[�����Ă��d����B
������XDR DRAM�̗p�ł���
GPU����CPU�{�ėp���������ƁA���[�G���h��3D�\�͂ɂ����Ȃ�Ȃ��B
GPU����CPU�{��p�������Ȃ�A
�ʏ��CPU�{GPU�̕������\����ŁA���i�������Ǝv���B
GPU����CPU�{��p�������Ȃ�A
�ʏ��CPU�{GPU�̕������\����ŁA���i�������Ǝv���B
Robson�݂����ɒᑬ�ȃ��C���������̃L���b�V���Ƃ��Ďg����>XDR
>GPU����CPU�{�ėp���������ƁA���[�G���h��3D�\�͂ɂ����Ȃ�Ȃ��B
FUSION���_���Ă�̂͂����B
���������n�C�G���hGPU�̐��\����������قǃ_�C�ʐς���������͂��炳��Ȃ��B
45nm�Ńf���A���R�A���ƃ_�C���]�邩�猊���߂�GPU�悹����Ă����B
FUSION���_���Ă�̂͂����B
���������n�C�G���hGPU�̐��\����������قǃ_�C�ʐς���������͂��炳��Ȃ��B
45nm�Ńf���A���R�A���ƃ_�C���]�邩�猊���߂�GPU�悹����Ă����B
���[�G���h�Ȃ�A�����`�b�v�Z�b�g�ŏ\�����Ǝv���B
527 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2007/02/01(��) 00:10:46 ID:EwCMqD2+
XDR�͑ш�͂Ƃ��������C�e���V�͌����ď������Ȃ�
AMD�̏ꍇ�̓I���_�C�̃������R���g���[��������CPU��VPU���ڂ����ق��������I�ł���
>>527
VGA�̃L���b�V���Ƃ��Ďg�����ɂ͑�敝�̕����d�v�ł����
VGA�̃L���b�V���Ƃ��Ďg�����ɂ͑�敝�̕����d�v�ł����
��敝���ĂȂc�ш敝�ł�
�X�}�\
�X�}�\
�����߂ŏ悹��GPU�̂��߂�XDR DRAM�悹�ăR�X�g�A�b�v������킯�Ȃ�����B
�{���]�|�B
�{���]�|�B
>>526
�����瓝���`�b�v�Z�b�g��GPU�������R���̂���CPU���Ɉڂ�������������
�����瓝���`�b�v�Z�b�g��GPU�������R���̂���CPU���Ɉڂ�������������
533 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2007/02/01(��) 00:18:24 ID:EwCMqD2+
nVIDIA�̍ŐV�s��GPU�Ə�������Ȃ痊��Ȃ���
Intel GMA������Ȃ�\���ʗp���邾�낤��
ATI���킴�킴���S���h���Ŕ������č����̂����[�G���h������
�����v���Z�b�T�����Ȃ�A���_�����邾�낤��
Intel�����ȗ͂������Ă�m�[�g�s��ɑ�ʓ������悤��
�l���Ă�̂�����
Intel GMA������Ȃ�\���ʗp���邾�낤��
ATI���킴�킴���S���h���Ŕ������č����̂����[�G���h������
�����v���Z�b�T�����Ȃ�A���_�����邾�낤��
Intel�����ȗ͂������Ă�m�[�g�s��ɑ�ʓ������悤��
�l���Ă�̂�����
>527
Opteron��FB-DIMM���̗p����Ă�����炵���̂ł����A
XDR��FB-DIMM�ł͂ǂ���̃��C�e���V���傫���̂ł��傤��?
Opteron��FB-DIMM���̗p����Ă�����炵���̂ł����A
XDR��FB-DIMM�ł͂ǂ���̃��C�e���V���傫���̂ł��傤��?
535 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2007/02/01(��) 00:29:07 ID:EwCMqD2+
�ΏۂƂ�����̂��ʕ����Ǝv���B
XDR�͑�ʂɓ��ڂ���ɂ͌����Ȃ��悤�ȁB
DDR/DDR2�Ȃ��͈��|�I�ɑ�������Q�[����p�@�ɂ͌����Ă�B
FB-DIMM�͒��g��DDR2�����ǁA��ʂɐςނ��Ƃőш���҂��A�v���[�`�B
Fusion�ɂ�XDR�͗L�������m��Ȃ����A��ʂɃ�������ςރT�[�o�Ȃ�
FB-DIMM�͏\������ł��傤�B
XDR�͑�ʂɓ��ڂ���ɂ͌����Ȃ��悤�ȁB
DDR/DDR2�Ȃ��͈��|�I�ɑ�������Q�[����p�@�ɂ͌����Ă�B
FB-DIMM�͒��g��DDR2�����ǁA��ʂɐςނ��Ƃőш���҂��A�v���[�`�B
Fusion�ɂ�XDR�͗L�������m��Ȃ����A��ʂɃ�������ςރT�[�o�Ȃ�
FB-DIMM�͏\������ł��傤�B
�[�����A�m�[�gPC��DIMM�X���b�g����Ȃ��ˁH
1GB���}�U�{���t�ŏ\������ˁH
���t�Ȃ�`�����l����ш�����Ƒ��₹���ˁH
1GB���}�U�{���t�ŏ\������ˁH
���t�Ȃ�`�����l����ш�����Ƒ��₹���ˁH
http://pc.watch.impress.co.jp/docs/2006/0104/rambus.htm
�@��RAMBUS��3��(���n����)�AAMD��5�N�Ԃɓn��7,500���h���̓������C�Z���X�_�����������Ɣ��\�����B
�@�_��̏ڍׂ͖��炩�ɂ���Ă��Ȃ����A�����[�X�ɂ��A�������ȊO�̂��ׂẴ`�b�v���J�o�[����Ƃ��Ă���B�܂��ADDR2�ADDR3�AFB-DIMM�APCI Express�AXDR�A����ь��݂Ə����̍����������ƃC���^�[�t�F�C�X�Ɋւ���RAMBUS�̓������܂ނƂ��Ă���B
�@����̃��C�Z���X�_��͍L���͈͂ɓn����̂����A2006�N�ɓo�ꂪ�\�肳��Ă���FB-DIMM�Ɋւ���������܂܂�Ă���_�����ڂ����B
�@��RAMBUS��3��(���n����)�AAMD��5�N�Ԃɓn��7,500���h���̓������C�Z���X�_�����������Ɣ��\�����B
�@�_��̏ڍׂ͖��炩�ɂ���Ă��Ȃ����A�����[�X�ɂ��A�������ȊO�̂��ׂẴ`�b�v���J�o�[����Ƃ��Ă���B�܂��ADDR2�ADDR3�AFB-DIMM�APCI Express�AXDR�A����ь��݂Ə����̍����������ƃC���^�[�t�F�C�X�Ɋւ���RAMBUS�̓������܂ނƂ��Ă���B
�@����̃��C�Z���X�_��͍L���͈͂ɓn����̂����A2006�N�ɓo�ꂪ�\�肳��Ă���FB-DIMM�Ɋւ���������܂܂�Ă���_�����ڂ����B
�����̒Ⴂ���[�G���h�s��ɁA���z�̔����E�J����𓊓���������Ή�Ђ͌X���B
539 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2007/02/01(��) 00:34:35 ID:EwCMqD2+
��������DIMM���ăm�[�gPC�̂��߂ɊJ�����ꂽ���ǂ�
�������N�A�㓡���̎����グ��Z�p���āA�K�������Ă��ȁB
��ʂɂ́A�n�C�G���h���i�ɒ��ڂ��Ă���̂͏��F�I�^�N����������FUSION������Ȃ��Ƃ͌���Ȃ��Ǝv�����ǁB
��ʂɂ́A�n�C�G���h���i�ɒ��ڂ��Ă���̂͏��F�I�^�N����������FUSION������Ȃ��Ƃ͌���Ȃ��Ǝv�����ǁB
�㓡�͍D���Ȃ���fusion�Ɋւ��Ă͂܂�������ƃI�`�c�P�Ǝv��
�㓡�͍D���Ȃ���cell�Ɋւ��Ă͂܂�������ƃI�`�c�P�Ǝv��
�Ⴆ�AJava��p�R�v�����������ꂽ�Ƃ��āA
Java�̎��s���x�͓����i�̃C���e��CPU��荂���B
����ȊO�̎��s���x�͑S�Ēᑬ�B
�����l�͂���Ǝv���A�����j�b�`���Ǝv���B
Java�̎��s���x�͓����i�̃C���e��CPU��荂���B
����ȊO�̎��s���x�͑S�Ēᑬ�B
�����l�͂���Ǝv���A�����j�b�`���Ǝv���B
>>518
���̎�͕̂��ʂɂ��邯��
���̎�͕̂��ʂɂ��邯��
>>512-513
�n�C�G���hGPU���ڂ����Ȃ�����A�\������˂��́H
�����K8���ł��AGPU�����`�b�v��HT�ƃ����R���o�R�Ń��C���������g���Ă��B
HT�̃o�X����16bit������A�N�Z�X���x�̓_�ł�64bit����DIMM�A�N�Z�X��肢���̂����H
�n�C�G���hGPU���ڂ����Ȃ�����A�\������˂��́H
�����K8���ł��AGPU�����`�b�v��HT�ƃ����R���o�R�Ń��C���������g���Ă��B
HT�̃o�X����16bit������A�N�Z�X���x�̓_�ł�64bit����DIMM�A�N�Z�X��肢���̂����H
Fusion2��SLI�Ƃ��ɂ���Αш�����ɘa�����B
�ɘa����邾���ʼn������Ȃ����ǁB
�ɘa����邾���ʼn������Ȃ����ǁB
�������R���g���[����Fusion����ł͉��P����K�v������B
DDR3����Ŏg�����ɂȂ�悤��R580�̂悤��32bit�Ǘ��ɂ���K�v���B
���ƁAFusion�o��܂ł�AMD(ATI)�͋ƊE���ʂ́iGPGPU�jAPI�iDPVM�H�j�����Ƃ����˂E�E�E
ttp://ati.amd.com/developer/siggraph06/dpvm_sketch_siggraph.pdf
ttp://ati.amd.com/developer/siggraph06/dpvm_e.pdf
DDR3����Ŏg�����ɂȂ�悤��R580�̂悤��32bit�Ǘ��ɂ���K�v���B
���ƁAFusion�o��܂ł�AMD(ATI)�͋ƊE���ʂ́iGPGPU�jAPI�iDPVM�H�j�����Ƃ����˂E�E�E
ttp://ati.amd.com/developer/siggraph06/dpvm_sketch_siggraph.pdf
ttp://ati.amd.com/developer/siggraph06/dpvm_e.pdf
�ް���ނ�������낤
�����ǂ��炩�����s������ƊE�͈Í��̐��E�ɂȂ鎞�ゾ��
AMD�����ł����悤�ɂȂ�Ȃ�قǁAIntel��AMD�����ł����邱�Ƃɖ�N�ɂȂ邾�낤
�|���ƊE�����S����������Ȃ��c
����ڰ��ɏ��Ă�MS������۰قł���悤�ɂȂ邾�낤
�����ǂ��炩�����s������ƊE�͈Í��̐��E�ɂȂ鎞�ゾ��
AMD�����ł����悤�ɂȂ�Ȃ�قǁAIntel��AMD�����ł����邱�Ƃɖ�N�ɂȂ邾�낤
�|���ƊE�����S����������Ȃ��c
����ڰ��ɏ��Ă�MS������۰قł���悤�ɂȂ邾�낤
�n�����@��������
AMD�́AAMD64�ȗ�MS�ƒ����ǂ��B
ATI�́A���킸�����ȁB
���炭�AMS������ł���B
Intel��GPU�Q�킪�A������L�킹��B
ATI�́A���킸�����ȁB
���炭�AMS������ł���B
Intel��GPU�Q�킪�A������L�킹��B
�������ɂ�FUSION�݂����ȃ��[�G���h�����R�A�͂ǂ��ł������I
CPU+GPU�Ȃ�Ύ����ʐς��啝�Ɍ��邵�A���[�G���h+�m�[�gPC�ɂ͂������낤�I
�����A����������I�^�ɂ̓f�X�N�g�b�v����CPU���ǂ��ς���čs������������I
CPU+GPU�Ȃ�Ύ����ʐς��啝�Ɍ��邵�A���[�G���h+�m�[�gPC�ɂ͂������낤�I
�����A����������I�^�ɂ̓f�X�N�g�b�v����CPU���ǂ��ς���čs������������I
�R�v���Z�b�T��ς�Ń\�t�g���Ή����Ă��鏈�����������āA
���̑��c��̏����͑S���x���j�b�`��CPU�B
SETI��UD���̕��U�R���s���[�e�B���O��10�{�����Ȃ�R�v���̓����Ȃ�A
�ꕔ�̐l�͊��Ŕ����Ǝv���B����ς�j�b�`����...
���̑��c��̏����͑S���x���j�b�`��CPU�B
SETI��UD���̕��U�R���s���[�e�B���O��10�{�����Ȃ�R�v���̓����Ȃ�A
�ꕔ�̐l�͊��Ŕ����Ǝv���B����ς�j�b�`����...
����GPU�̓��ʂ̎g�����Ƃ��ẮA�{���̗p�r�ȊO����HD����̍Đ��x�������肩�ˁH
3D���̓������ш�K�v�Ȃ����������B
3D���̓������ш�K�v�Ȃ����������B
>>548
Mac�Ƃ�������œƋ֖@����̂��߂Ƀ��C�o����Ƃ��片�������I�`�B
Mac�Ƃ�������œƋ֖@����̂��߂Ƀ��C�o����Ƃ��片�������I�`�B
>>550
�ʂɒ����ǂ����猨���ꂵ�Ă�킯����Ȃ�
Intel��x86�̂��߂ɕʂ̊g����p�ӂ��Ă��͂�����
MS��IA64�̎��͂��ꂩ�Ǝ�Ԃ��葝�₷Intel�Ƀu�`��
����I��AMD64�����T�|�[�g�����I�����I�Ɛ錾
MS�͎����̗��v�ɂȂ�ق���I�Ԃ����ő����
AMD�ł�Intel�ł��ǂ����ł����������}���Ȃ�
�����ł����̂�AMD�Ȃ瓯���悤�Ɍ������Ɍ��܂��Ă�
�P�Ȃ�c����Ɠ��m�Ȃ����
�ʂɒ����ǂ����猨���ꂵ�Ă�킯����Ȃ�
Intel��x86�̂��߂ɕʂ̊g����p�ӂ��Ă��͂�����
MS��IA64�̎��͂��ꂩ�Ǝ�Ԃ��葝�₷Intel�Ƀu�`��
����I��AMD64�����T�|�[�g�����I�����I�Ɛ錾
MS�͎����̗��v�ɂȂ�ق���I�Ԃ����ő����
AMD�ł�Intel�ł��ǂ����ł����������}���Ȃ�
�����ł����̂�AMD�Ȃ瓯���悤�Ɍ������Ɍ��܂��Ă�
�P�Ȃ�c����Ɠ��m�Ȃ����
MS��������XBOX�p�ɂ����������߃Z�b�g�����`�Ɩ��߂��A
�����̂�PC�ɂ��̗p�A�e�Q�[�����[�J�[���x���Ƃ������ꂪ���邩������Ȃ��B
MS�̌����Ȃ�ɂȂ��Ă���ŋC�ɂ���Ȃ����B
�����̂�PC�ɂ��̗p�A�e�Q�[�����[�J�[���x���Ƃ������ꂪ���邩������Ȃ��B
MS�̌����Ȃ�ɂȂ��Ă���ŋC�ɂ���Ȃ����B
http://gcc.gnu.org/ml/gcc-patches/2007-01/msg02432.html
gcc��family10�Ή��p�b�`ktkr
Advanced Bit Manipulation (ABM) ���ĉ�?
�N��athlon.md����family10���ǂ�Ȋ����Ȃ̂��ǂݎ���Ă���B
gcc��family10�Ή��p�b�`ktkr
Advanced Bit Manipulation (ABM) ���ĉ�?
�N��athlon.md����family10���ǂ�Ȋ����Ȃ̂��ǂݎ���Ă���B
�P����r�ł������ȃC���X�g���N�V�����R�X�g���炢�����킩��ˁ[�B
http://gcc.gnu.org/ml/gcc-patches/2007-01/msg02434/gcc-amdfam10-2.patch
http://gcc.gnu.org/ml/gcc-patches/2007-01/msg02434/gcc-amdfam10-2.patch
SSE4��POPCNT����Ȃ��́H
�ƃ����N��ǂ܂Ȃ��œK���Ƀ��X
White Paper
Intel Architecture Extending the World�fs Most Popular Processor Architecture
New innovations that improve the performance and energy efficiency of Intel architecture
ftp://download.intel.com/technology/architecture/new-instructions-paper.pdf
�ƃ����N��ǂ܂Ȃ��œK���Ƀ��X
White Paper
Intel Architecture Extending the World�fs Most Popular Processor Architecture
New innovations that improve the performance and energy efficiency of Intel architecture
ftp://download.intel.com/technology/architecture/new-instructions-paper.pdf
>which include popcnt and lzcnt instructions
�����āA�A�t�H�ł��܂��B
�����āA�A�t�H�ł��܂��B
���������Ă��A3D�̓��[�G���h�ő����Ȃ�ˁ[���B
563 �FSocket774�F2007/02/01(��) 18:35:21 ID:wiqTue21
��N��̃��[�G���h���Ď��͌���̃~�h���ȏ�̐��\�ɂ͂Ȃ邾��
45nm�ō���Ă邩��f���A���ȏ�̃R�A��GPU���ڂ��Ă���͂�
GPU���f���A���ɂ��ĉ��Z���ł���Ȃ�ʔ����ȁB
45nm�ō���Ă邩��f���A���ȏ�̃R�A��GPU���ڂ��Ă���͂�
GPU���f���A���ɂ��ĉ��Z���ł���Ȃ�ʔ����ȁB
۰���ނ�3D���\�ȂȂ��Ă���������
�ނ��듮��̱���ڰ����[�����Ă��ꂽ�ق�������ۂǂ���
�ނ��듮��̱���ڰ����[�����Ă��ꂽ�ق�������ۂǂ���
������܂߂Ă��ł��哖�R
>>543
Windows�}�[�P�b�g�ł� .NET MSIL �R�v���Ȃ�L�]�Ȃ�W���}�C�J�H
Windows�}�[�P�b�g�ł� .NET MSIL �R�v���Ȃ�L�]�Ȃ�W���}�C�J�H
�N���C�A���g�T�C�h�ł��c�H
CCC���y���Ȃ����肷��Ƃ���
CCC���y���Ȃ����肷��Ƃ���
Fusion������Ă����͂��Ȃ̂ɏo�����͉̂��̂�GeodeFX
�����AFusion��geode�̖����łł���
�낭�Ɏg�����������̂ɁA�����R�A4����
���납�ȏ��i�ʂɔ��邮�炢�A
CPU���Ⴀ�A�������g�����W�X�^�̎g�������Ȃ��Ȃ��Ă錻��
���̂܂܂��ƁACPU�����͎Ηz�Y�Ɖ��܂�������
intel��VIA���卷�Ȃ��Ƃ�����ꂩ�˂Ȃ�����
���傤���Ȃ�����A�t�����l��T���Ă�
������geode�́A�ȒP�ȉ̂ЂƂ�
�낭�Ɏg�����������̂ɁA�����R�A4����
���납�ȏ��i�ʂɔ��邮�炢�A
CPU���Ⴀ�A�������g�����W�X�^�̎g�������Ȃ��Ȃ��Ă錻��
���̂܂܂��ƁACPU�����͎Ηz�Y�Ɖ��܂�������
intel��VIA���卷�Ȃ��Ƃ�����ꂩ�˂Ȃ�����
���傤���Ȃ�����A�t�����l��T���Ă�
������geode�́A�ȒP�ȉ̂ЂƂ�
�n�܂�O������
>>570
�P�Ƀg�����W�X�^���]���Ă邾���Ȃ�A�L���b�V�����ǂ�ǂ₹�ςނ��A
�������ꂾ�ƁA����e�ʈȏ�ł́u���\�g�����W�X�^�ʁ{���M�v�����������
�ɂȂ�낤�ˁB
�P�Ƀg�����W�X�^���]���Ă邾���Ȃ�A�L���b�V�����ǂ�ǂ₹�ςނ��A
�������ꂾ�ƁA����e�ʈȏ�ł́u���\�g�����W�X�^�ʁ{���M�v�����������
�ɂȂ�낤�ˁB
4�R�A8�R�A�Ƃ����炭�͑唼�̐l�͂���Ȃ����ˁB
2�R�A������Έ�ʐl�ɂ͏\���ȋC������B
10�N��ɕ��ʂ̐l��8�R�A�Ƃ��g���Ă�납
����ۂǃR�A�ȃQ�[���Ƃ��A�v����4�R�A8�R�A�Ή����Ă������܂ŁE�E
Vista���}���`�R�A�����܂ňȏ�Ɍ��I�ɗL���Ɏg���Ă����킯�ł��Ȃ���
�P�̂ő����ق����֗��Ȃ����E�E�B
�N���b�N���������Ȃ����A����œK����VGA�����Ĉ����A���Ă��ƂȂ̂���
2�R�A������Έ�ʐl�ɂ͏\���ȋC������B
10�N��ɕ��ʂ̐l��8�R�A�Ƃ��g���Ă�납
����ۂǃR�A�ȃQ�[���Ƃ��A�v����4�R�A8�R�A�Ή����Ă������܂ŁE�E
Vista���}���`�R�A�����܂ňȏ�Ɍ��I�ɗL���Ɏg���Ă����킯�ł��Ȃ���
�P�̂ő����ق����֗��Ȃ����E�E�B
�N���b�N���������Ȃ����A����œK����VGA�����Ĉ����A���Ă��ƂȂ̂���
���[�G���h�ł�2����O�̃n�C�G���h�ɕC�G�����
���[�G���h���Ȃ߂��
7600�����̂��̂͐ς܂���Ȃ��H
���[�G���h���Ȃ߂��
7600�����̂��̂͐ς܂���Ȃ��H
http://japan.cnet.com/special/biz/story/0,2000056932,20342098,00.htm
AMD�̃A�v���[�`�ł́A�^�[�Q�b�g�ƂȂ�ڋq�w�͋����Ȃ�B
���i���d�����A����ɃO���t�B�b�N�X���\�ɋ����������w���w���B
�����ɗ]�T�������ăO���t�B�b�N�X���d������ڋq�A�܂���NVIDIA��ATI��
�m���Ă���ڋq�ł���APC�ɓ��ڂ���Ă���̂�Intel��AMD���ɊW�Ȃ��A
��p�̃O���t�B�b�N�X�J�[�h����肵�����Ǝv�����낤�B
�o���}���悤�Ƃ���w���҂̂قƂ�ǂ́A�O���t�B�b�N�X���\���d�����Ă��Ȃ��B
�ǂ��炩�̊�Ƃ�����ł������ȉ��i�̂��̂�I�Ԃ��낤�B
Peddie���́A�O���t�B�b�N�X���\�̃x���`�}�[�N�l�ł�AMD���D���
���邩������Ȃ����A�f�l�̖ڂŁA�����X�ɕ���2���PC������
���̗D�ʐ��f����͓̂�����낤�ƌ����B
AMD�̃A�v���[�`�ł́A�^�[�Q�b�g�ƂȂ�ڋq�w�͋����Ȃ�B
���i���d�����A����ɃO���t�B�b�N�X���\�ɋ����������w���w���B
�����ɗ]�T�������ăO���t�B�b�N�X���d������ڋq�A�܂���NVIDIA��ATI��
�m���Ă���ڋq�ł���APC�ɓ��ڂ���Ă���̂�Intel��AMD���ɊW�Ȃ��A
��p�̃O���t�B�b�N�X�J�[�h����肵�����Ǝv�����낤�B
�o���}���悤�Ƃ���w���҂̂قƂ�ǂ́A�O���t�B�b�N�X���\���d�����Ă��Ȃ��B
�ǂ��炩�̊�Ƃ�����ł������ȉ��i�̂��̂�I�Ԃ��낤�B
Peddie���́A�O���t�B�b�N�X���\�̃x���`�}�[�N�l�ł�AMD���D���
���邩������Ȃ����A�f�l�̖ڂŁA�����X�ɕ���2���PC������
���̗D�ʐ��f����͓̂�����낤�ƌ����B
2����O�̃n�C�G���h�ł�FUSION����ł̓��[�G���h�Ƃ�����ŁA
FUSION����̃Q�[���ɂ͕͗s���ɂȂ�Ǝv���̂����B
M/B����O���t�B�b�N�`�b�v�����S�ɊO����A
CPU�Řd���Ƃ����̂ł���Ύg�����͂��肻���B
�����[�G���hPC�ɂ����g�������Ȃ������Ƃ͎v�����B
�����\���ꂽ���\������ƒ��r���[�Ȋ����ۂ߂Ȃ��̂������B
���ǂ̓O���t�B�b�N�W�͍��܂ŊO���w�����Z�I���[�Ȃ̂��ȁB
�O���ȊO�̂��̑��̋@�\�荞�ގ��������^�̖ړI�Ȃ낤�ˁB
FUSION����̃Q�[���ɂ͕͗s���ɂȂ�Ǝv���̂����B
M/B����O���t�B�b�N�`�b�v�����S�ɊO����A
CPU�Řd���Ƃ����̂ł���Ύg�����͂��肻���B
�����[�G���hPC�ɂ����g�������Ȃ������Ƃ͎v�����B
�����\���ꂽ���\������ƒ��r���[�Ȋ����ۂ߂Ȃ��̂������B
���ǂ̓O���t�B�b�N�W�͍��܂ŊO���w�����Z�I���[�Ȃ̂��ȁB
�O���ȊO�̂��̑��̋@�\�荞�ގ��������^�̖ړI�Ȃ낤�ˁB
5950ultra vs 7300GS
9800XT vs X1300pro
��O�̃n�C�G���h�̕����ザ��Ȃ��H
9800XT vs X1300pro
��O�̃n�C�G���h�̕����ザ��Ȃ��H
>>576
���߂�Fusion���݂̋L���ł��ǂ�ł��珑�����߂楥�
���߂�Fusion���݂̋L���ł��ǂ�ł��珑�����߂楥�
>>574,577
GPU�̓n�C�G���h�̓R�X�g���グ���\���グ�A���[�G���h�̓R�X�g�ێ��ł���͈͓��Ő��\�グ�Ă��������
GPU�̓n�C�G���h�̓R�X�g���グ���\���グ�A���[�G���h�̓R�X�g�ێ��ł���͈͓��Ő��\�グ�Ă��������
580 �FSocket774�F2007/02/02(��) 00:19:33 ID:QrvXW7Qh
�Ȃ�ǂ��������݂��邯�ǁAFUSION�̓��o�C�������������
�f�X�N�����͊O�t���̃O���{�������̓A�N�Z���[�^�����邱
�Ƃɂ��n�C�G���h�ɂ��ł���d�l�ɂ��Ă���͂��B
GPU���������Z�����Ȃ������Ȃ��Ȃ������r�̌������H
��{�I�ɂ͔�r�ΏƂ̓`�b�v�Z�b�g�̃O���t�B�b�N���\����ˁH��
�f�X�N�����͊O�t���̃O���{�������̓A�N�Z���[�^�����邱
�Ƃɂ��n�C�G���h�ɂ��ł���d�l�ɂ��Ă���͂��B
GPU���������Z�����Ȃ������Ȃ��Ȃ������r�̌������H
��{�I�ɂ͔�r�ΏƂ̓`�b�v�Z�b�g�̃O���t�B�b�N���\����ˁH��
PC����I�^�łȂ���A�O���t�B�b�N�X���\���Ⴂ=���[�G���h�R���s���[�^���Ă̂͂��܂�v��Ȃ����?
����E�ł̓Q�[�������Ȃ��l�Ԃł��ACPU�ɂ��˂�����Ȃ�GPU�ɂ����������Ȃ���A���o�����X�������邯�ǁA
���ہA���[�J�[PC�ł��A�m�[�g�ł��A�T�[�o�ł�GPU�͈����������͎̂��������A���Ȃ��Ƃ�XP�N���X��OS�Ȃ�
����ŏ\���������킯���B���XGUI�̑̊����x�Ȃ�ċC�ɂ��Ă���̂��I�^�N���������ˁB
����d�͂��l�����GPU�̓��[�G���h���`���C�X����������Ȃ��ȁB�I�^�N�̎v�l�����܂łÂ����킩���B
GPU���������ł͂��܂�C���p�N�g�͂Ȃ�����North���S�����܂ł����A�`�b�v��1���点��킯�ŁA
����̓����b�g�����肻�B
����E�ł̓Q�[�������Ȃ��l�Ԃł��ACPU�ɂ��˂�����Ȃ�GPU�ɂ����������Ȃ���A���o�����X�������邯�ǁA
���ہA���[�J�[PC�ł��A�m�[�g�ł��A�T�[�o�ł�GPU�͈����������͎̂��������A���Ȃ��Ƃ�XP�N���X��OS�Ȃ�
����ŏ\���������킯���B���XGUI�̑̊����x�Ȃ�ċC�ɂ��Ă���̂��I�^�N���������ˁB
����d�͂��l�����GPU�̓��[�G���h���`���C�X����������Ȃ��ȁB�I�^�N�̎v�l�����܂łÂ����킩���B
GPU���������ł͂��܂�C���p�N�g�͂Ȃ�����North���S�����܂ł����A�`�b�v��1���点��킯�ŁA
����̓����b�g�����肻�B
������ׂ��炻���Ȃ邪�AFUSION����ł͌��ǂ̓��[�G���h�ɂȂ��ł���B
>>575�̋L���ƏƂ炵���킹�Ă��A
�p�\�R���̒��ł���ʑw�̕��ނɃO�������^�i���[�G���h�jCPU�Ƃ���
���Ɛ�M/B���o���Ă�Intel�̗l�ɁAPC=Intel�ő����C���[�W���A
�O������CPU��������CPU=AMD��蒅�����A��ƂȂ�CPU�肽����������Ȃ��̂��ȁB
����ɂ́A�ŏI�I�Ƀ`�b�v�Z�b�g����O�����ڍs�����������ł͑ʖڂ�
���\�̖ʂł��A�s�[���ł���K�v���łĂ���B�����ŁA�����O���͈�ʎd�l�Ɋ������邾���ŏ\����
����ȏ�̕��͍��܂Œʂ�ʔ}�̂ŋ������ACPU�̐��\�𑼂̃R�v���ŋǏ��I�ɏグ�ăA�s�[������K�v������B
�ǂ��l���Ă��O���t�B�b�N�ɂ����Č��铝���^CPU�͊�{�A�����^�`�b�v�Z�b�g�̑���ł����Ȃ��A
��ʂɕ�����Ղ��A�s�[������ׂɃO�����A�����đ��̃R�v���ɂ��ACPU�Ƃ��Ă̖{���I�ȕ]����
���͂�菟����肽����Ȃ��̂��ȁB
>>575�̋L���ƏƂ炵���킹�Ă��A
�p�\�R���̒��ł���ʑw�̕��ނɃO�������^�i���[�G���h�jCPU�Ƃ���
���Ɛ�M/B���o���Ă�Intel�̗l�ɁAPC=Intel�ő����C���[�W���A
�O������CPU��������CPU=AMD��蒅�����A��ƂȂ�CPU�肽����������Ȃ��̂��ȁB
����ɂ́A�ŏI�I�Ƀ`�b�v�Z�b�g����O�����ڍs�����������ł͑ʖڂ�
���\�̖ʂł��A�s�[���ł���K�v���łĂ���B�����ŁA�����O���͈�ʎd�l�Ɋ������邾���ŏ\����
����ȏ�̕��͍��܂Œʂ�ʔ}�̂ŋ������ACPU�̐��\�𑼂̃R�v���ŋǏ��I�ɏグ�ăA�s�[������K�v������B
�ǂ��l���Ă��O���t�B�b�N�ɂ����Č��铝���^CPU�͊�{�A�����^�`�b�v�Z�b�g�̑���ł����Ȃ��A
��ʂɕ�����Ղ��A�s�[������ׂɃO�����A�����đ��̃R�v���ɂ��ACPU�Ƃ��Ă̖{���I�ȕ]����
���͂�菟����肽����Ȃ��̂��ȁB
�O��GPU���p����Physix�����Ƃ��ĉғ�����̂���
�[��FUSION�̂ǂ��ɃR�X�g�����b�g������̂������ς茩���Ȃ����B
�\���`�b�v��������킯�ł��Ȃ����B
�\���`�b�v��������킯�ł��Ȃ����B
��������A�����GPU�́A����ȏ��K�͂ɂȂ炸�ɁA
��r�I���K�͂Ȃ�ʏ����Ń{�[�h�ɏ悹������ɂȂ�Ƃ������b�������ȁB
�����H���ł������l���ŁA���W���[�����ׂĐ��\�҂����Ă̂̓v���Z�X�̐i���Ŕ�r�I�e�Ղɉ\��������Ȃ��B
��r�I���K�͂Ȃ�ʏ����Ń{�[�h�ɏ悹������ɂȂ�Ƃ������b�������ȁB
�����H���ł������l���ŁA���W���[�����ׂĐ��\�҂����Ă̂̓v���Z�X�̐i���Ŕ�r�I�e�Ղɉ\��������Ȃ��B
VPU���m�[�X�u���b�W�ɓ���������v���Z�X���[�����������̂�
�R�X�g�I�Ɉ����������\���オ�����߂���ĂƂ���Ȃ�łȂ���
�f���A���\�P�b�gCPU�Ŏ�y��SLI�ł���悤�ɂȂ邩��
�R�X�g�I�Ɉ����������\���オ�����߂���ĂƂ���Ȃ�łȂ���
�f���A���\�P�b�gCPU�Ŏ�y��SLI�ł���悤�ɂȂ邩��
�m�[�g�p���[�G���h�̂��܂��R�v���Ȃɂ킴�킴�v���O�����������Ă����
�����ȃ\�t�g���[�J�[�Ȃ���킯�Ȃ��낤�B
FUSION�����グ���̓R�v���Ƃ��Ă̈Ӗ��͂܂������Ȃ��ƍl������B
�����ȃ\�t�g���[�J�[�Ȃ���킯�Ȃ��낤�B
FUSION�����グ���̓R�v���Ƃ��Ă̈Ӗ��͂܂������Ȃ��ƍl������B
�����O���O��������
������A�܂��͕�����₷�������^�`�b�v�Z�b�g�̑���Ƃ��ăO���t�B�b�N������̂ł́B
���͂ɔF�m������K�v������킯�����B
���͂ɔF�m������K�v������킯�����B
>>590
����͂������A����K8L�R�A�Ȃ̂��H
����͂������A����K8L�R�A�Ȃ̂��H
>>587�@MS�����ł��傗
�ǂ݂̂�intel�������Ɍ������Ă邵�ACPU���̂��R�v���d�l�Ɍ������͂�����
�ǂ݂̂�intel�������Ɍ������Ă邵�ACPU���̂��R�v���d�l�Ɍ������͂�����
>>596
���N����č��ł��m�[�gPC>�f�X�N�g�b�vPC�ɂȂ錩���݂���Ȃ�������?
��i���ł́A2008�N���ɂ�PC=�m�[�gPC�Ƃ����l�������Z�����n�߂Ă��邭�炢���ȁB
���_�A���{�͂Ƃ����Ƀm�[�g�̕�������Ă��邯�ǁB���{�s������AMD��Intel��CPU�����Ă�킯����Ȃ���ŁB
���N����č��ł��m�[�gPC>�f�X�N�g�b�vPC�ɂȂ錩���݂���Ȃ�������?
��i���ł́A2008�N���ɂ�PC=�m�[�gPC�Ƃ����l�������Z�����n�߂Ă��邭�炢���ȁB
���_�A���{�͂Ƃ����Ƀm�[�g�̕�������Ă��邯�ǁB���{�s������AMD��Intel��CPU�����Ă�킯����Ȃ���ŁB
Intel���m�[�g�pcpu�ɒ��͂��Ă��āA���N����Meorm��XE�ł�2.8GHz�܂ł����炵���ˁB�T�[�o�p��K8L��荂��]���B
���Ɨ]�k�Ƃ��ă_�C�ʐ�=�R�X�g�ł͂Ȃ���ȁB�z���w�����e�X�g�ʂ��Ⴄ�B
�㓡�����O�ɏ����Ă����悤�Ƀx���`���[�ł�����GPU�ƁA���ł���ɕ����Ȃ��Ȃ��Ă��Ă���ŋ߂�MPU�Ƃ�
�B�ꂽ�Z�p�����̈Ⴂ�Ɋ��ҁB�g�����W�X�^���x�����畽���ɂȂ�Ƃǂ��Ȃ�̂��B
����ȊO�ł͊m���ɂ������Ċ��҂ł��Ȃ������B
���Ɨ]�k�Ƃ��ă_�C�ʐ�=�R�X�g�ł͂Ȃ���ȁB�z���w�����e�X�g�ʂ��Ⴄ�B
�㓡�����O�ɏ����Ă����悤�Ƀx���`���[�ł�����GPU�ƁA���ł���ɕ����Ȃ��Ȃ��Ă��Ă���ŋ߂�MPU�Ƃ�
�B�ꂽ�Z�p�����̈Ⴂ�Ɋ��ҁB�g�����W�X�^���x�����畽���ɂȂ�Ƃǂ��Ȃ�̂��B
����ȊO�ł͊m���ɂ������Ċ��҂ł��Ȃ������B
MS�AAMD�AIntel ��3�҂ŃO���t�B�b�N�p���߃Z�b�g�ꂵ�Ȃ��ƃ_������܂����H
���ǂ̂Ƃ���Afab���B
��xfab���������t����]���������Ȃ���Ȃ�Ȃ��B
���̏�fab�𑝂₵�A����グ��L�����v���o�����Ƃ��g��B
����Ȃ��ƁA�������낻����E�Ȃ�B
������킩���Ă��Ȃ��̂��A����킩���Ă��邩�炱��
�r�W���i���[�ǂ����������������Z�p���A�s�[������B
�����̃v���Z�X�̔����Ƌ��ɊJ����͌����B�����@���̌��E���߂��B
�E���ґ��o�̃`�L�����[�X�B�q�����O���Ɖ�Ђ��X����M�����u���B
�ݔ��̏��p���Ԃ�v���Z�X�̊J�����Ԃ�{�ɂ���Ƃ��A
�V�������N�Ƌ��Ƀ`�b�v���̃g�����W�X�^���͑��₳��fab�����炷�Ƃ��A
�������v���オ���邱�Ƃ�O��ɁA����������ƌ����I�ȘH����͍����ė~�����B
��xfab���������t����]���������Ȃ���Ȃ�Ȃ��B
���̏�fab�𑝂₵�A����グ��L�����v���o�����Ƃ��g��B
����Ȃ��ƁA�������낻����E�Ȃ�B
������킩���Ă��Ȃ��̂��A����킩���Ă��邩�炱��
�r�W���i���[�ǂ����������������Z�p���A�s�[������B
�����̃v���Z�X�̔����Ƌ��ɊJ����͌����B�����@���̌��E���߂��B
�E���ґ��o�̃`�L�����[�X�B�q�����O���Ɖ�Ђ��X����M�����u���B
�ݔ��̏��p���Ԃ�v���Z�X�̊J�����Ԃ�{�ɂ���Ƃ��A
�V�������N�Ƌ��Ƀ`�b�v���̃g�����W�X�^���͑��₳��fab�����炷�Ƃ��A
�������v���オ���邱�Ƃ�O��ɁA����������ƌ����I�ȘH����͍����ė~�����B
�������Ȃ���success�݂����ɓˑR���ځ[��
140����mm�O��i�����C���X�g���[���j�̃V���R���������i�Ŕ���
�r�W�l�X���f�����ێ����������������߂̉R��`��֑�L���B
�����Ȃ肷�����n�[�h�E�F�A�w�̃R�X�g���\�t�g�E�F�A�w�ւ�
������肽���C�����͗����ł��邪�A
�\�t�g�E�F�A�r�W�l�X�����藧���Ȃ��㕨�ł͈Ӗ����Ȃ��B
���j�C�R�A�AFusion�AGPGPU�ATorrenza�B
�͂��Ȋ��҂͂���B�ł����͌���Ȃ��B
�r�W�l�X���f�����ێ����������������߂̉R��`��֑�L���B
�����Ȃ肷�����n�[�h�E�F�A�w�̃R�X�g���\�t�g�E�F�A�w�ւ�
������肽���C�����͗����ł��邪�A
�\�t�g�E�F�A�r�W�l�X�����藧���Ȃ��㕨�ł͈Ӗ����Ȃ��B
���j�C�R�A�AFusion�AGPGPU�ATorrenza�B
�͂��Ȋ��҂͂���B�ł����͌���Ȃ��B
�R���V���[�}�s��̓f�X�N�g�b�v����m�[�g�A���o�C���Ɉڍs���i��ł���B
��
���o�C�������V�F�AIntel���|�I�AAMD�����ŃV�F�A���Ȃ��ƃR���V���[�}�������S
��
�ʎY�ŃR�X�g�̏��p�ł��Ȃ��ƍ���̂ŕK��(�V�H������Ă��������)
��
Fusion�o��\��2�N���2009�N��Vista�v���C���X�g�[���}�V�����ǂ��l���Ă��嗬
��
�m�[�g��3D�̃C���^�[�t�F�C�X���삩�����d��
��
nvidia�̃O���t�B�b�N�����`�b�v�Z�b�g�͔M�߂��Ďg���Ȃ�
��
���O(ATI����)�ł��
Intel �`�b�v�Z�b�g����GPU vs AMD CPU����GPU
�EIntel�`�b�v�Z�b�g�ɗp���锼���̃v���Z�X��CPU�������O����̂���
�EAMD�͍ŐV�v���Z�X�g�p+�������R���g���[������
��
���\�A����d�͋���AMD�ɗL��
��
AMD���Ƃ��������т�H
��
���o�C�������V�F�AIntel���|�I�AAMD�����ŃV�F�A���Ȃ��ƃR���V���[�}�������S
��
�ʎY�ŃR�X�g�̏��p�ł��Ȃ��ƍ���̂ŕK��(�V�H������Ă��������)
��
Fusion�o��\��2�N���2009�N��Vista�v���C���X�g�[���}�V�����ǂ��l���Ă��嗬
��
�m�[�g��3D�̃C���^�[�t�F�C�X���삩�����d��
��
nvidia�̃O���t�B�b�N�����`�b�v�Z�b�g�͔M�߂��Ďg���Ȃ�
��
���O(ATI����)�ł��
Intel �`�b�v�Z�b�g����GPU vs AMD CPU����GPU
�EIntel�`�b�v�Z�b�g�ɗp���锼���̃v���Z�X��CPU�������O����̂���
�EAMD�͍ŐV�v���Z�X�g�p+�������R���g���[������
��
���\�A����d�͋���AMD�ɗL��
��
AMD���Ƃ��������т�H
605 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2007/02/02(��) 02:18:25 ID:00b9tM3E
CPU�̔����̃v���Z�X��1�N�x��Ă邩��g�[�^���ł͎����������肾������
CPU�������`�b�v�Z�b�g�������D�ʉ]�X�ȑO�ɁA����Radeon Xpress��GMA�����B
CPU�������`�b�v�Z�b�g�������D�ʉ]�X�ȑO�ɁA����Radeon Xpress��GMA�����B
>>558
�Ƃ肠�����C���X�g���N�V�����R�X�g����킩�邱��
http://pc.watch.impress.co.jp/docs/2006/1013/kaigai07l.gif
# cost of divide/mod
QI 18 -> 19 (+1)
HI 26 -> 35 (+9)
SI 42 -> 51 (+9)
DI 74 -> 83 (+9)
�������Z�̃R�X�g��������
� Data-dependent divide latency
�̕���p��?
# cost of loading SSE registers in SImode, DImode and TImode
{4, 3, 6} -> {4, 4, 3} (0, +1 ,-3)
128bit�̃��[�h��������
#MMX or SSE register to integer
5 -> 3 (-2)
� More Fastpath
�@- Data movement between FP & INT
�Ƃ͂���̂��Ƃ�?
�Ƃ肠�����C���X�g���N�V�����R�X�g����킩�邱��
http://pc.watch.impress.co.jp/docs/2006/1013/kaigai07l.gif
{kind=link}
# cost of divide/mod
QI 18 -> 19 (+1)
HI 26 -> 35 (+9)
SI 42 -> 51 (+9)
DI 74 -> 83 (+9)
�������Z�̃R�X�g��������
� Data-dependent divide latency
�̕���p��?
# cost of loading SSE registers in SImode, DImode and TImode
{4, 3, 6} -> {4, 4, 3} (0, +1 ,-3)
128bit�̃��[�h��������
#MMX or SSE register to integer
5 -> 3 (-2)
� More Fastpath
�@- Data movement between FP & INT
�Ƃ͂���̂��Ƃ�?
607 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2007/02/02(��) 02:28:53 ID:00b9tM3E
�����̃��C�e���V�܂��[�H
����SIMD�̃��C�e���V��2�̂܂܂ł�
609 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2007/02/02(��) 02:33:38 ID:00b9tM3E
�S�͂ňނ���
���\��40%�A�b�v�ƕ����܂������ACore2Duo���甃���ւ�����̂��̂ł͂Ȃ������ł���
��������667����1066�ɔ�ׂ�40%���\�_�E���݂����ł���
��������667����1066�ɔ�ׂ�40%���\�_�E���݂����ł���
�T�����̂��H���G�^��D
Fusion�o���ɑΉ��\�t�g���o��̂ł͂Ȃ��B
DX10����DX10.1����́AGPU�Ŏ��s�\��GPGPU
ATI�Ȃ�CTM�A���炭�ƊE�W����ڎw��DPVM��������������
Fusion���o�ꂷ��B
AMD�ɂƂ��Ẳۑ�́A2009�N�܂łɂǂꂾ��GPGPU�܂����ł߂��邩�B
DX10����DX10.1����́AGPU�Ŏ��s�\��GPGPU
ATI�Ȃ�CTM�A���炭�ƊE�W����ڎw��DPVM��������������
Fusion���o�ꂷ��B
AMD�ɂƂ��Ẳۑ�́A2009�N�܂łɂǂꂾ��GPGPU�܂����ł߂��邩�B
�V�A�[�L�e�N�`���̉��Z�R�A�p�̃\�t�g������Ȃ����ɊJ���ł���킯�Ȃ��낤�B
x86���ߓ��m�̃}���`�R�A�ɂ����ă\�t�g���̑Ή����Ȃ��Ȃ��i��łȂ��̂ɁB
x86���ߓ��m�̃}���`�R�A�ɂ����ă\�t�g���̑Ή����Ȃ��Ȃ��i��łȂ��̂ɁB
�ǂ�����낤�ˁB����ό������Ƃ���NVIDIA�Ƒg���GPGPU�p�J���C���^�[�t�F�[�X
�ƃ��W���[���̐��`���̂��ȁH
�ƃ��W���[���̐��`���̂��ȁH
���⑽���܂��߂ɍl���ĂȂ��t�F�B�N�Ƃ��ăO�_�O�^�����Ă邾������B
�{����������GPU�̓����̓m�[�g��o�C���p�r�ł����l���ĂȂ��Ǝv���B
����GPU�ȊO�̗p�r�͓K���Ȃ��ƌ������x����Ĕ����Ă����������x�ɂ����l���ĂȂ�����B
���܂�ɂ��������y�����邩�炻���v�������Ȃ��B
�{����������GPU�̓����̓m�[�g��o�C���p�r�ł����l���ĂȂ��Ǝv���B
����GPU�ȊO�̗p�r�͓K���Ȃ��ƌ������x����Ĕ����Ă����������x�ɂ����l���ĂȂ�����B
���܂�ɂ��������y�����邩�炻���v�������Ȃ��B
�}���`�X���b�h�ʼn��Z���Ȃ���Ȃ�Ȃ��A�v�����Ă̂���ʂɎg����悤�ɂȂ�̂��H
�G���R�Ƃ�����HD���l�b�N�ɂȂ��Ă���������
�O���t�B�b�N�W���炢�����v������B
�G���R�Ƃ�����HD���l�b�N�ɂȂ��Ă���������
�O���t�B�b�N�W���炢�����v������B
���ꂩ��OS���ǂ�ǂ�g���Ă���܂��B
����OS�Ȃ��������Bvista�Ƃ����������ȁB
�G���R�[�h��HDD���l�b�N���āA�Đ����x�̐����̈�œǂݏ������Ă�̂ɁH
�P���v�Z����30���̓����1���Ԃ�����1Mbps�ɃG���R�[�h����ꍇ�A
��b�������HDD�ɏ������ރf�[�^�ʂ�500kbit(64KB)���ȁB
��b�������HDD�ɏ������ރf�[�^�ʂ�500kbit(64KB)���ȁB
�������cFUSION�̔̔��^�[�Q�b�g�����Ⴂ���Ă��郄�c�����������ȁB
���O��͈�ʓd�C���ɂ����āA���ʂ̐l�����������ȁA
10���ȉ���PC��m�[�gPC�̊�{�\�������ė����B
����������I�^�Ƃ������A��ʐl�͓����`�b�v�Z�b�g��
�\�����������Ȃ��Ŏg���Ă����B
����������I�^��FUSION����Ȃ��āA���ʂ�CPU�ł������āA
�����Ƃ����O�t��GPU�łԂ�Ζ��Ȃ���B
���O��͈�ʓd�C���ɂ����āA���ʂ̐l�����������ȁA
10���ȉ���PC��m�[�gPC�̊�{�\�������ė����B
����������I�^�Ƃ������A��ʐl�͓����`�b�v�Z�b�g��
�\�����������Ȃ��Ŏg���Ă����B
����������I�^��FUSION����Ȃ��āA���ʂ�CPU�ł������āA
�����Ƃ����O�t��GPU�łԂ�Ζ��Ȃ���B
���ʂ�CPU�́AGPU�Ƃ��ė]�v�ȃ_�C�ʐςƂ��ĂȂ��A�R�A�̐v���V����
�C���e��CPU�Ō��܂肾�ˁB
�C���e��CPU�Ō��܂肾�ˁB
FUSION�̈�Ԃ̔���͐��\����Ȃ��ďȃG�l�ł���
�r�f�I�J�[�h��t���Ă���Ƃ��́A
���zPC��Fusion��GPU�������Ăł����肷��Ɩʔ�����������Ȃ��B
�E�E�E�ł����ǁAWin9x�p�̃h���C�o���Ȃ���ΐ̂̃Q�[���͕s�\���B(�̂�Radeon�݊����[�h�������������)
�f�B�X�v���C���ʁX�ɂȂ邵���v�͂���܂�Ȃ����Ȃ��B
���zPC��Fusion��GPU�������Ăł����肷��Ɩʔ�����������Ȃ��B
�E�E�E�ł����ǁAWin9x�p�̃h���C�o���Ȃ���ΐ̂̃Q�[���͕s�\���B(�̂�Radeon�݊����[�h�������������)
�f�B�X�v���C���ʁX�ɂȂ邵���v�͂���܂�Ȃ����Ȃ��B
���܂���Q�����Ȃ�HFusion�ŏ\������
���ł�2ch��Web�Ȃǂ̌y��Ɗ���VirtualPC��ɍ\�z���āAXP��Vista�̗�������g���Ă�B
���ł��I��/�ĊJ�ł��ĉ��K����B
�����Q�[����VirtualPC���I�����ăz�X�g�Ŏ��s���Ă邯�ǁA
�\�Ȃ炱���VirtualPC�ɂ����Ă��������B
���z���Z�p�̔��W�Ɋ��҂��Ă���B
���ł��I��/�ĊJ�ł��ĉ��K����B
�����Q�[����VirtualPC���I�����ăz�X�g�Ŏ��s���Ă邯�ǁA
�\�Ȃ炱���VirtualPC�ɂ����Ă��������B
���z���Z�p�̔��W�Ɋ��҂��Ă���B
>>624
�c�f�B�X�v���C���ʁX���āH
�c�f�B�X�v���C���ʁX���āH
>>622
�������ȁH
FPU����n�܂���MMX,SSE �Ȃ�āA�d�߂ȉ摜�����Ŏg���Ă鎞�ȊO��
�V��ł�C���B
SIMD�@�\��GPU�@�\�ƁA�K�v�Ƃ���摜�����ŏd�����镔���͑�������A
Fusion�Ŏ�荞��GPU����肭SIMD�@�\��d����A���̕��̃g�����W
�X�^���������o�������ȋC�����邪�B
�m�������b�V��FPU�@�\��SIMD�@�\���G�~�����[�g���鎖�ŁAFPU���\
�A�b�v��FPU�p�g�����W�X�^�̍팸��_���Ă��������B
�������ȁH
FPU����n�܂���MMX,SSE �Ȃ�āA�d�߂ȉ摜�����Ŏg���Ă鎞�ȊO��
�V��ł�C���B
SIMD�@�\��GPU�@�\�ƁA�K�v�Ƃ���摜�����ŏd�����镔���͑�������A
Fusion�Ŏ�荞��GPU����肭SIMD�@�\��d����A���̕��̃g�����W
�X�^���������o�������ȋC�����邪�B
�m�������b�V��FPU�@�\��SIMD�@�\���G�~�����[�g���鎖�ŁAFPU���\
�A�b�v��FPU�p�g�����W�X�^�̍팸��_���Ă��������B
>>625
����������Ă��܂��ƁAXBOX��PS�ł��[���Ƃ����b�ɂȂ��ȁB
���ہA�R�ꂪ�C���^�[�l�b�g�ň�ԏd��̂͒��ו������鎞�����A
������Ƃ������Ńf�X�N�g�b�vPC�̋N���͟T����������B
�N���̑����m�[�gPC���~�����Ȃ邵�A�Q�[���@�̋N�����X�ɑ����Ȃ�
���ǂ������B
����������Ă��܂��ƁAXBOX��PS�ł��[���Ƃ����b�ɂȂ��ȁB
���ہA�R�ꂪ�C���^�[�l�b�g�ň�ԏd��̂͒��ו������鎞�����A
������Ƃ������Ńf�X�N�g�b�vPC�̋N���͟T����������B
�N���̑����m�[�gPC���~�����Ȃ邵�A�Q�[���@�̋N�����X�ɑ����Ȃ�
���ǂ������B
>>627
Fusion�̃r�f�I���}�U�[�{�[�h��̃R�l�N�^����o��
�r�f�I�J�[�h���r�f�I�J�[�h��̃R�l�N�^����o��
Fusion�̉�ʃC���[�W���r�f�I�J�[�h�֓]������Ƃ���������邾�낤���ǁB
Fusion�̃r�f�I���}�U�[�{�[�h��̃R�l�N�^����o��
�r�f�I�J�[�h���r�f�I�J�[�h��̃R�l�N�^����o��
Fusion�̉�ʃC���[�W���r�f�I�J�[�h�֓]������Ƃ���������邾�낤���ǁB
�܂��r�X�^�����y���n�߂鍠�ɂ́A������Ȃ��H��FUSION
���[�J�[PC���r�f�I�J�[�h���������A�R�X�g���������邵
�܂�����ł̘A���ɂ́A�W�Ȃ�������W�Ȃ�����
���[�J�[PC���r�f�I�J�[�h���������A�R�X�g���������邵
�܂�����ł̘A���ɂ́A�W�Ȃ�������W�Ȃ�����
���z�}�V���ォ�畁�ʂ̃r�f�I�J�[�h�̂悤�Ɍ�������āA�m����CPU�Ɏ�荞��ԂȂ�ł���ˁB
���łɁA�����R�A�̓��̈�����z�}�V���p�ɐ藣���ē��삳����Ƃ��B
���łɁA�����R�A�̓��̈�����z�}�V���p�ɐ藣���ē��삳����Ƃ��B
{kind=link}
���z�}�V���Ńz�X�g�@���̃r�f�I���\���o��A�唼�̍�Ƃ͉��z�}�V���ŊԂɍ����Ă��܂��ˁB
�l�p�r�ʼn��z�}�V���������郁���b�g������Ȃ�
�R�X�g�l������ƁA����˂��Ǝv���B
�R�X�g�l������ƁA����˂��Ǝv���B
���x��OS����꒼���W�T�J�[�ɂ͂����[�֗�����B
VPC���C���X�g�[�����邾���ł����̊����A���Ă���B
VPC���C���X�g�[�����邾���ł����̊����A���Ă���B
>>630
�o�J���H�@�O����GPU������ꍇ�͓������ꂽGPU�̓R�v���I�Ȏg�����ɂȂ��āA
GPU�����̈ꕔ�����ɂȂ�v��Ȃ�B
���ꂪ�L�����ǂ����͂킩��ȁB
�o�J���H�@�O����GPU������ꍇ�͓������ꂽGPU�̓R�v���I�Ȏg�����ɂȂ��āA
GPU�����̈ꕔ�����ɂȂ�v��Ȃ�B
���ꂪ�L�����ǂ����͂킩��ȁB
����630��624����̗���̒��ł̘b������B
���̃}�U�[�ł��I���{�[�h�r�f�I�{�r�f�I�J�[�h�Ń}���`���j�^�[�\�����A�ʂɎg���Ƃ������Ƃ͂��邾�낤�B
Fusion�{AMD(ATI) GPU���ƁA�V���O��GPU�{�[�h�ł�
SLI�I�ɓ����Ă����3D�p�t�H�[�}���X�A�b�v���ƁA
�ꕔ�̃Q�[�}�[�ɂ͎邩����
SLI�I�ɓ����Ă����3D�p�t�H�[�}���X�A�b�v���ƁA
�ꕔ�̃Q�[�}�[�ɂ͎邩����
>>628
C7����Ȃ��ACN(Isaiah)�ˁB
�܂��łĂȂ����ǁE�E�E
VIA��Centaur(CPU)��S3(GPU)�����Ă邩��
������́A����Ă���͂��B
Isaiah�̒x��́A�Ђ���Ƃ��Ă��̂������H
�Ƃ��v������E�E�E
C7����Ȃ��ACN(Isaiah)�ˁB
�܂��łĂȂ����ǁE�E�E
VIA��Centaur(CPU)��S3(GPU)�����Ă邩��
������́A����Ă���͂��B
Isaiah�̒x��́A�Ђ���Ƃ��Ă��̂������H
�Ƃ��v������E�E�E
643 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2007/02/02(��) 23:22:59 ID:00b9tM3E
AMD��SMT�Ƃ��������Ȃ��́H
���₳���SIMD���߂̃��C�e���V�B���ɋ��
���₳���SIMD���߂̃��C�e���V�B���ɋ��
http://gcc.gnu.org/ml/gcc-patches/2007-01/msg02444.html
gcc-amdfam10-7.patch
���
insertq
latency 5
vector path
gcc-amdfam10-7.patch
���
insertq
latency 5
vector path
645 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2007/02/02(��) 23:54:43 ID:00b9tM3E
�x���I
��ɂ����Intel�͍̗p���Ȃ��낤��
movntss/movntsd���ʂɂǂ����Ă��K�v�Ȗ��߂���Ȃ���
movntss�F
movd eax, xmm0
movntd [mem], 'eax
movntsd�F
movdq2q mm0, xmm0
movntq [mem], mm0
emms
��ɂ����Intel�͍̗p���Ȃ��낤��
movntss/movntsd���ʂɂǂ����Ă��K�v�Ȗ��߂���Ȃ���
movntss�F
movd eax, xmm0
movntd [mem], 'eax
movntsd�F
movdq2q mm0, xmm0
movntq [mem], mm0
emms
646 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2007/02/02(��) 23:56:26 ID:00b9tM3E
�~movntd
��movnti
��movnti
>>643
AMD�uPOWER��SMT�݂��Ă��������G�G�v
AMD�uPOWER��SMT�݂��Ă��������G�G�v
Fusion�̌v��ɂ͉��z�}�V���x���������Ă��邾�낤�ȁB
���݂�����CPU���g����Trio64���G�~�����[�g������������������B
MS���ߋ��̃\�t�g�̃T�|�[�g�ʓ|������VirtualPC�g�����ĕ��j�ɂȂ��Ă�݂��������B
���݂�����CPU���g����Trio64���G�~�����[�g������������������B
MS���ߋ��̃\�t�g�̃T�|�[�g�ʓ|������VirtualPC�g�����ĕ��j�ɂȂ��Ă�݂��������B
VGA���g�ɴЭڰ�Ӱ�ނ݂����Ȃ̂��K�v�ɂȂ��Ȃ��́H
�܂��ARAGEXL�݊��œ����Ă��ꂽ�炢�����A
�Â�OS�̂��߂ɂ������傢�Â����������̂���
�܂��ARAGEXL�݊��œ����Ă��ꂽ�炢�����A
�Â�OS�̂��߂ɂ������傢�Â����������̂���
Laguna�݊��ł�����
NV1�݊���Voodoo�݊���PowerVR�݊�������
652 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2007/02/04(��) 00:27:45 ID:HuuOXOBE
Voodoo�͂悩������
�Ȃɂ���DirectX�̃��t�@�����X���[�h�����ʂɓ����Ă��܂�����Ȃ̂�
�݊��@�\���킴�킴����K�v���Ȃ��̂ł���B
�݊��@�\���킴�킴����K�v���Ȃ��̂ł���B
654 �FSocket774�F2007/02/04(��) 11:30:39 ID:IBilpoQQ
�@�@�@�@�@�@�@�@�@�@�@�@�@ .�@�@�L�@�@�@�@�@�@�@�M�~=�-� �Q
�@�@�@�@ �@ �@ �@ �@ �@ �^�@�@�@�@�@�@�@�@_�Q�u�M�R��_ɁO���� �A
�@�@�@�@ �@ �@ �@ �@ , '�@�@�@�@�@�@,�@�@�L�@�@-́@�@�i�@f�L�P�M�R��z
�@�@�@�@�@�@�@�@�@ /�@�@�@�@�@ �^�@�@�@�@ __ -́@�@��́A�@ rfY��Ĥ
�@ �@ �@ �@ �@ �@ /�@�@�@�@ �^�@�@�@,�@ �L�^�@�@ �_�@ �k_Y�O!ʁU=�� �
�@�@�@�@�@�@�@�@ ���@�@�@/�@ �@ �^ . �^�@ �@ �@ �@ �M�R �R����`���i��
�@�@�@�@�@�@�@�@i�@�@ �@ /�@�@�^ �^/ _�Q_�@�@�@�@�@ �@ �_��́@ �@ ���
�@�@�@�@�@�@�@�@|.�@ �@ /�@�^ ,�C ,/'�L�@�@�@�M�R�@�@�@�@�@�@ �Y�___/�\
�@�@�@�@�@�@�@�@|:::. �@ {��_ �m / ʁ����~� �@ �@ �@ �@ ___�@ Y爓�
�@�@�@�@�@�@�@�@��::::.�@/ '�O�R X_ ��Y�OY )�P} i�p �@ �@ �@ �@ �@ �R}/ /�
.�@�@�@ �@ �@ �@ ',:::::�q�@ / �V�@ |,�T��c��@�@ �@ �@ �B��Ф_ /�c'�m
�@ �@ �@ �@ �@ �@ �A:::�R �R{{�@�@ !�A�P �M�@ �@ �@ �@ �`r��' �.��P�L�@�@Conroe�̈��|�I���\�ƈ���
�@�@�@�@�@�@�@�@�@�R:::::::`�́^�@ �_�@ �@ �@ �@ �@ �U߃C ��=.��@�����Ēᐫ�\�@������d��64�EAM2
�@�@�@�@�@�@�@ �@ �@ �_::::�^ �^�@ �@ >/�P��@�@�@�@ �@ '�M__}�p�@�@�@�@AMD����_(^o^)�^
�@�@�@�@�@�@�@�@�@�@�@�@�{�@ '�@ �@ �^:�_`��]'���@�@�@ �l_�@ ��_
�@�@�@�@�@�@�@ �@ �@ �^�P�@���^:�ځR �Rr�]r r����___�@ �q ,�n�_�Q�Q�Q_
�@�@�@�@�@�@�@�@�@ /�@�@�@�@�@�@Y�L�P�M�� '�@__��`������� �@ �@ �@ �@ �@ __�MY
�@ �@ �@ �@ �@ �@ /�@�@�@�@�@�@�@�k._Ĥ/�@Y�L�@�@ ����]���q�@�@�@�@�@ �@ �V�L ��
�@�@�@�@�@�@�@�@ ���@�@�@�@�@�@ [_��@,�@-�]���]- ��@ ��'�B�@ Ɂ[��@ '���@ i |:.',
�@�@ �@ �@ �@ �@ |�@�@�@�@�@�@�@ �T_�@/�^�L�P�P�M�R�_�@ �Ѳ�@�@_�^�@�@�@�@�U!:::.�A
�@�@�@�@�@�@�@�@ �_�@�@�@�@�@�@�i�i�QY�@�@�@�@�@�@�@�R �_ �ṔN�L�@�@�@�@�@�@ l ::::::.�R
�@�@�@�@�@�@�@�@�@�@`�[�]r�d �@ �M�]�Y�@�@�@�@�@�@�@�@ �R �R���@�@ �@ �@ �@ �@ �@ ::::::::�@�_
�@�@�@�@�@�@�@�@�@�@�@ �@ �R.�@�@�@�@�|�@ �@ �@ �@ �@ �@ �b�b �_�@�@ �@ �@ �@ �@ ::::::�@�@ �q�A
�@�@�@�@ �@ �@ �@ �@ �@ �^�@�@�@�@�@�@�@�@_�Q�u�M�R��_ɁO���� �A
�@�@�@�@ �@ �@ �@ �@ , '�@�@�@�@�@�@,�@�@�L�@�@-́@�@�i�@f�L�P�M�R��z
�@�@�@�@�@�@�@�@�@ /�@�@�@�@�@ �^�@�@�@�@ __ -́@�@��́A�@ rfY��Ĥ
�@ �@ �@ �@ �@ �@ /�@�@�@�@ �^�@�@�@,�@ �L�^�@�@ �_�@ �k_Y�O!ʁU=�� �
�@�@�@�@�@�@�@�@ ���@�@�@/�@ �@ �^ . �^�@ �@ �@ �@ �M�R �R����`���i��
�@�@�@�@�@�@�@�@i�@�@ �@ /�@�@�^ �^/ _�Q_�@�@�@�@�@ �@ �_��́@ �@ ���
�@�@�@�@�@�@�@�@|.�@ �@ /�@�^ ,�C ,/'�L�@�@�@�M�R�@�@�@�@�@�@ �Y�___/�\
�@�@�@�@�@�@�@�@|:::. �@ {��_ �m / ʁ����~� �@ �@ �@ �@ ___�@ Y爓�
�@�@�@�@�@�@�@�@��::::.�@/ '�O�R X_ ��Y�OY )�P} i�p �@ �@ �@ �@ �@ �R}/ /�
.�@�@�@ �@ �@ �@ ',:::::�q�@ / �V�@ |,�T��c��@�@ �@ �@ �B��Ф_ /�c'�m
�@ �@ �@ �@ �@ �@ �A:::�R �R{{�@�@ !�A�P �M�@ �@ �@ �@ �`r��' �.��P�L�@�@Conroe�̈��|�I���\�ƈ���
�@�@�@�@�@�@�@�@�@�R:::::::`�́^�@ �_�@ �@ �@ �@ �@ �U߃C ��=.��@�����Ēᐫ�\�@������d��64�EAM2
�@�@�@�@�@�@�@ �@ �@ �_::::�^ �^�@ �@ >/�P��@�@�@�@ �@ '�M__}�p�@�@�@�@AMD����_(^o^)�^
�@�@�@�@�@�@�@�@�@�@�@�@�{�@ '�@ �@ �^:�_`��]'���@�@�@ �l_�@ ��_
�@�@�@�@�@�@�@ �@ �@ �^�P�@���^:�ځR �Rr�]r r����___�@ �q ,�n�_�Q�Q�Q_
�@�@�@�@�@�@�@�@�@ /�@�@�@�@�@�@Y�L�P�M�� '�@__��`������� �@ �@ �@ �@ �@ __�MY
�@ �@ �@ �@ �@ �@ /�@�@�@�@�@�@�@�k._Ĥ/�@Y�L�@�@ ����]���q�@�@�@�@�@ �@ �V�L ��
�@�@�@�@�@�@�@�@ ���@�@�@�@�@�@ [_��@,�@-�]���]- ��@ ��'�B�@ Ɂ[��@ '���@ i |:.',
�@�@ �@ �@ �@ �@ |�@�@�@�@�@�@�@ �T_�@/�^�L�P�P�M�R�_�@ �Ѳ�@�@_�^�@�@�@�@�U!:::.�A
�@�@�@�@�@�@�@�@ �_�@�@�@�@�@�@�i�i�QY�@�@�@�@�@�@�@�R �_ �ṔN�L�@�@�@�@�@�@ l ::::::.�R
�@�@�@�@�@�@�@�@�@�@`�[�]r�d �@ �M�]�Y�@�@�@�@�@�@�@�@ �R �R���@�@ �@ �@ �@ �@ �@ ::::::::�@�_
�@�@�@�@�@�@�@�@�@�@�@ �@ �R.�@�@�@�@�|�@ �@ �@ �@ �@ �@ �b�b �_�@�@ �@ �@ �@ �@ ::::::�@�@ �q�A
���ꂱ�����z�}�V���x���Ȃ�Fusion�ł���K�R���͖���
���z�}�V���ł����S��DirectX��API��������Ƃ����������Ȃ�
DirectX10.1�Ŏ��������GPU�̉��z���������̑�{��
���z�}�V���ł����S��DirectX��API��������Ƃ����������Ȃ�
DirectX10.1�Ŏ��������GPU�̉��z���������̑�{��
>>655
���O���ӋC�Ȃ�A���l�����̖�Y
���O���ӋC�Ȃ�A���l�����̖�Y
>>656
Microsoft�l�ɂ��肢�ɍs����i�j
Microsoft�l�ɂ��肢�ɍs����i�j
>>657
���^���ԂȊ炵�ĈӖ��킩��˂����Ə����Ă�r��
���^���ԂȊ炵�ĈӖ��킩��˂����Ə����Ă�r��
>>658
AMD�uMicrosoft�l�ADirectX10.1��AMD��Fusion�ł����g���Ȃ��d�l�ɂ��Ă��������v
AMD�uMicrosoft�l�ADirectX10.1��AMD��Fusion�ł����g���Ȃ��d�l�ɂ��Ă��������v
>>659
���O�͉��z�����ꂽ�}�V����3D�Q�[���ł���肽���̂��H�o�J��������
���O�͉��z�����ꂽ�}�V����3D�Q�[���ł���肽���̂��H�o�J��������
���z�����āA�����������z������Ȃ�����E�E
Windows�����ăA�v���͉��z�����ꂽ�n�[�h�E�F�A�𑀍삷���Ȃ����B
7600���x�̂��̂��ς܂��ȁH
�h���C���[�A5900�ȏオ�ς܂��݂�����
�h���C���[�A5900�ȏオ�ς܂��݂�����
>>662
�����A����GPU�Ń}���`�X���b�h�������Ď��B
Aero���g���A����������A�Q�[�������������
���z�����Ή��ȁADX10�ȑO��GPU���A�����Ɖ��K�ɂȂ�B
�܂��AMulti GPU���T�|�[�g�����B
����́AMulti CPU�Ɠ��l�̈Ӗ������B
���Ȃ킿�A����܂�CPU�œ�����O�ɂ���Ă�����
GPU�ł��\�ɂȂ���Ď��ł��B
�����A����GPU�Ń}���`�X���b�h�������Ď��B
Aero���g���A����������A�Q�[�������������
���z�����Ή��ȁADX10�ȑO��GPU���A�����Ɖ��K�ɂȂ�B
�܂��AMulti GPU���T�|�[�g�����B
����́AMulti CPU�Ɠ��l�̈Ӗ������B
���Ȃ킿�A����܂�CPU�œ�����O�ɂ���Ă�����
GPU�ł��\�ɂȂ���Ď��ł��B
>���Ȃ킿�A����܂�CPU�œ�����O�ɂ���Ă�����
>GPU�ł��\�ɂȂ���Ď��ł��B
�ϑz��
>GPU�ł��\�ɂȂ���Ď��ł��B
�ϑz��
���>>664�̕߂炦���ō����Ă�B
����������Έȉ����Q��
ttp://www.4gamer.net/news.php?url=/news/history/2006.05/20060530200736detail.html
>Windows Vista�ɂ����āC�O���t�B�b�N�X�`�b�v�́g��l�C�ő�Z���h�ȃn�[�h�E�F�A�f�o�C�X�ƂȂ�C
>Windows Vista�̏������X���[�X�ɍs���Ă������߂ɂ́C
>�O���t�B�b�N�X�`�b�v���X���[�X�ɓ������K�v�������Ă���킯���B
>�@������������邽�߂̋ߓ����C�O���t�B�b�N�X�`�b�v�̉��z���Ƃ������z���B
>����͖�����ł��Ȃ�ł��Ȃ��C��̃��|�[�g�ł��Љ���Ƃ���C
>Windows Vista�̃��C�t�X�p�����ɁC�m���Ɏ��������B
>�O���t�B�b�N�X�`�b�v�̊��S�ȉ��z����B������C
>�ŏI�I�ȃS�[���Ƃ��Đݒ肳��Ă���̂�WDDM 2.1���B
>DirectX 10.1����̃O���t�B�b�N�X�`�b�v�ɂ���Ď�������邱�Ƃ��C
>���ʂ̖ڕW�Ƃ���Ă���B
����������Έȉ����Q��
ttp://www.4gamer.net/news.php?url=/news/history/2006.05/20060530200736detail.html
>Windows Vista�ɂ����āC�O���t�B�b�N�X�`�b�v�́g��l�C�ő�Z���h�ȃn�[�h�E�F�A�f�o�C�X�ƂȂ�C
>Windows Vista�̏������X���[�X�ɍs���Ă������߂ɂ́C
>�O���t�B�b�N�X�`�b�v���X���[�X�ɓ������K�v�������Ă���킯���B
>�@������������邽�߂̋ߓ����C�O���t�B�b�N�X�`�b�v�̉��z���Ƃ������z���B
>����͖�����ł��Ȃ�ł��Ȃ��C��̃��|�[�g�ł��Љ���Ƃ���C
>Windows Vista�̃��C�t�X�p�����ɁC�m���Ɏ��������B
>�O���t�B�b�N�X�`�b�v�̊��S�ȉ��z����B������C
>�ŏI�I�ȃS�[���Ƃ��Đݒ肳��Ă���̂�WDDM 2.1���B
>DirectX 10.1����̃O���t�B�b�N�X�`�b�v�ɂ���Ď�������邱�Ƃ��C
>���ʂ̖ڕW�Ƃ���Ă���B
�ʂ�Fusion���Ȃ��Ă������
�v����ɁA�O�t����GPU�J�[�h���}���`�R�A�����Ă������ꂾ�Ƃ������Ƃ��낤�H
PCIEx1�̃J�[�h�����y���Ă������ł������C������
PCIEx1�̃J�[�h�����y���Ă������ł������C������
���z�����̂�DX10.1�Ŏ���������AFusion�͕K�{�ł͂Ȃ��B
�t�ɁA�����Ă����ʂɂ͂Ȃ�Ȃ��B
�t�ɁA�����Ă����ʂɂ͂Ȃ�Ȃ��B
GPU�̃X���b�h�@�\���i�����闬�ꂾ�Ƃ�������
>>666
�R���s���[�^�\�t�g������������̔�
�R���s���[�^�\�t�g������������̔�
672 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2007/02/04(��) 14:00:53 ID:HuuOXOBE
�����A���ȃt���C�g�V�~�����[�^�ł��o���Ă�����ł��傤����
>>668
S3,ATI(AMD)��DX10.1����͉��z�������������}���`�_�C�̗\��B
nVIDIA�������E�E�E
ttp://www.theinquirer.net/default.aspx?article=35932
S3 roadmap reveals DX10 and 10.1 chips
Multicore GPUs clocked to stratospheric levels
���Ȃ݂�Crysis��Core 2 Quad QX6700�A8800GTX��SLI�ʼn��Ƃ��Q�[�����ł�����x�̗l�q�B
ttp://sg.vr-zone.com/?i=4555
First DX10 Crysis Benchmarks Appear
S3,ATI(AMD)��DX10.1����͉��z�������������}���`�_�C�̗\��B
nVIDIA�������E�E�E
ttp://www.theinquirer.net/default.aspx?article=35932
S3 roadmap reveals DX10 and 10.1 chips
Multicore GPUs clocked to stratospheric levels
���Ȃ݂�Crysis��Core 2 Quad QX6700�A8800GTX��SLI�ʼn��Ƃ��Q�[�����ł�����x�̗l�q�B
ttp://sg.vr-zone.com/?i=4555
First DX10 Crysis Benchmarks Appear
> ���z�����̂�DX10.1�Ŏ���������AFusion�͕K�{�ł͂Ȃ��B
> �t�ɁA�����Ă����ʂɂ͂Ȃ�Ȃ��B
�K�{����Ȃ��Ƃ����_�ɂȂ�Ȃ��Ƃ��ł͂Ȃ��A�S�����W�Ȃ��Ȃ��̂�Fusion
�Ƃ��������AFusion���ĉ�w
AMD�������Ă邱�Ƃ͖w�ǖϑz�ɋ߂��n�[�h�I�Ɏ����o���Ă��\�t�g�͒N�����Ȃ�����Ӗ��������B
���̈Ӗ����Ɩ����l�Ȃ̂�B
�܂��AGPU�����ăm�[�g�E���o�C������ł̏ȃG�l�ƒቿ�i�H���ŏ����̓V�F�A�D���邩�����Ǝv���Ă���x�̂��Ƃł����Ȃ��B
���������A�m�[�g�E���o�C������Ɍ����Intel�����ĒP��1�p�b�P�[�W�Ɏ��߂������̎���Fusion�őR���邾�낤���A����ŏ\���B
�܂�AMD�͔߂����ˁB
> �t�ɁA�����Ă����ʂɂ͂Ȃ�Ȃ��B
�K�{����Ȃ��Ƃ����_�ɂȂ�Ȃ��Ƃ��ł͂Ȃ��A�S�����W�Ȃ��Ȃ��̂�Fusion
�Ƃ��������AFusion���ĉ�w
AMD�������Ă邱�Ƃ͖w�ǖϑz�ɋ߂��n�[�h�I�Ɏ����o���Ă��\�t�g�͒N�����Ȃ�����Ӗ��������B
���̈Ӗ����Ɩ����l�Ȃ̂�B
�܂��AGPU�����ăm�[�g�E���o�C������ł̏ȃG�l�ƒቿ�i�H���ŏ����̓V�F�A�D���邩�����Ǝv���Ă���x�̂��Ƃł����Ȃ��B
���������A�m�[�g�E���o�C������Ɍ����Intel�����ĒP��1�p�b�P�[�W�Ɏ��߂������̎���Fusion�őR���邾�낤���A����ŏ\���B
�܂�AMD�͔߂����ˁB
>>674
����������
����������
Fusion(��)
Fusion�ׂ̈ɉ����V������������K�v�͂Ȃ��B
�Œ�ł�DX10.1����̋@�\�͓��ڂ���̂��낤����
��{�I��DX10.1�����GPU�Ŏ鉶�b�́AFusion�ł�����B
�`���GPGPU���B
������A�N���C�A���g�����ɂ́AGPU��������B
�������Aintel�̓���CPU�ł��ˁB
���Ƃ́AGPU�̐��\�ƌ����̍��B
�Œ�ł�DX10.1����̋@�\�͓��ڂ���̂��낤����
��{�I��DX10.1�����GPU�Ŏ鉶�b�́AFusion�ł�����B
�`���GPGPU���B
������A�N���C�A���g�����ɂ́AGPU��������B
�������Aintel�̓���CPU�ł��ˁB
���Ƃ́AGPU�̐��\�ƌ����̍��B
678 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2007/02/04(��) 15:39:55 ID:HuuOXOBE
Fusion���̂������V�������Ƃ��킯����Ȃ���
�]��_�C�ߍ��킹��Ƃ������ɓI�ȗ��R���唼�Ȃ���B
�]��_�C�ߍ��킹��Ƃ������ɓI�ȗ��R���唼�Ȃ���B
> ������A�N���C�A���g�����ɂ́AGPU��������B
����������Ȃ́H
�����̕K�v�͑S�����������A��荂���\�Ȃ̂����߂�ƌ��ǂ̓r�f�I�J�[�h�������ƂɂȂ�B
����GPU�Ƀ_�C�����ʂȂ�p�r�͏��Ȃ��Ă��R�A�����₵�Ăė~������B
����������Ȃ́H
�����̕K�v�͑S�����������A��荂���\�Ȃ̂����߂�ƌ��ǂ̓r�f�I�J�[�h�������ƂɂȂ�B
����GPU�Ƀ_�C�����ʂȂ�p�r�͏��Ȃ��Ă��R�A�����₵�Ăė~������B
680 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2007/02/04(��) 15:47:19 ID:HuuOXOBE
�ނ���L���b�V�����₹�����Ǝv����
�܂�Sempron��p��z�肵�����������E�����̃A�[�L�ɂȂ�낤����
�܂�Sempron��p��z�肵�����������E�����̃A�[�L�ɂȂ�낤����
����ŕ`��ȊO��GPGPU�����A�v�����ĂȂɂ�B
�����AMD������Ă����́H
�m�[�g�̂����ꕔ�ɂ����V�F�A�̂Ȃ��@���p�Ƀ\�t�g���[�J�[��
�Ή�����Ƃ��v���Ă�H
�����AMD������Ă����́H
�m�[�g�̂����ꕔ�ɂ����V�F�A�̂Ȃ��@���p�Ƀ\�t�g���[�J�[��
�Ή�����Ƃ��v���Ă�H
>>679
������GPU�݂ł��Ȃ����4�R�A�ȏ�͖w�LjӖ������������i���v�����������j�ȃm�[�gPC�����Ȃ�B
��́APC��3D�Q�[���Ȃ�Ă��z�͂������Ă��Ȃ�����B
������GPU�݂ł��Ȃ����4�R�A�ȏ�͖w�LjӖ������������i���v�����������j�ȃm�[�gPC�����Ȃ�B
��́APC��3D�Q�[���Ȃ�Ă��z�͂������Ă��Ȃ�����B
>>678
L2��Intel�̔����i�Ȃ�������ȉ��j�����ς�łȂ��̂�
�_�C���]��Ƃ������Ă鎞�_�łǂ���AMD�̌������Ƃ͐M�p�ł���̂���Ȃ��B
L2��Intel�̔����i�Ȃ�������ȉ��j�����ς�łȂ��̂�
�_�C���]��Ƃ������Ă鎞�_�łǂ���AMD�̌������Ƃ͐M�p�ł���̂���Ȃ��B
�����R�����炢�ς�ł��猾������
�m�[�g�����ɍl����L���b�V�����₷����GPU�������������������ȁ[���Ē��x�Ȃ�łȂ��́H
��p�ӏ����W���ł��邩��y�ɂȂ�c��˂��H
��p�ӏ����W���ł��邩��y�ɂȂ�c��˂��H
686 �FSocket774�F2007/02/04(��) 16:18:57 ID:IBilpoQQ
Conroe�̈��|�I���\�ƈ���
�@�@�@�@�@�@65�i�m�ł������Ēᐫ�\�@������d��64�EAM2�@�@�@�@�@�@�@�@�@�@�@�@�@
�@�@�@�@�@�@�@�@�@�@�@�@�@AMD����_(^o^)�^ �@�@�@
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ , -�
.�@�@�@�@�@�@ �@ , --��@�@�@ �@ �@, -��@�@�@_�@�@�@�@�@ �i�@�@j
�@�@�@�@�@�@�@ �i�@ �@j�@�@�@�@ �^�@�@ �܁L�@ �_�@�@�@ /�@/�L
�@�@�@�@�@ �@ �@ �_�@�_.�@ �ځ@�@�@� M�@,�@ �@',�@�@/�@/
�@�@�@�@�@�@�@�@ �@ �_�@�_�@/�@�R Ĥ���@!/ |�@�@ʁ@/�@/
�@�@�@�@�@�@�@�@�@�@�@ �_�@�R!�@l���܁Q��ف@��/�@/
�@�@�@�@�@�@�@�@�@�@�@�@�@�_��{l � �@V_Ɂ@� j�ȁ�/
�@�@�@�@�@�@�@�@�@�@�@�@ �@ // .�R { ���]�� j/ �_�R
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�_�@ ��/^<>^',�R�@ �^
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �M{ �@�r f::l .�qo Y
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ } /�@l::::���@V .}
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@���.�@�Ɂ@ }!�l
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ {=����=}�@�@�_
�@�@�@�@�@�@65�i�m�ł������Ēᐫ�\�@������d��64�EAM2�@�@�@�@�@�@�@�@�@�@�@�@�@
�@�@�@�@�@�@�@�@�@�@�@�@�@AMD����_(^o^)�^ �@�@�@
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ , -�
.�@�@�@�@�@�@ �@ , --��@�@�@ �@ �@, -��@�@�@_�@�@�@�@�@ �i�@�@j
�@�@�@�@�@�@�@ �i�@ �@j�@�@�@�@ �^�@�@ �܁L�@ �_�@�@�@ /�@/�L
�@�@�@�@�@ �@ �@ �_�@�_.�@ �ځ@�@�@� M�@,�@ �@',�@�@/�@/
�@�@�@�@�@�@�@�@ �@ �_�@�_�@/�@�R Ĥ���@!/ |�@�@ʁ@/�@/
�@�@�@�@�@�@�@�@�@�@�@ �_�@�R!�@l���܁Q��ف@��/�@/
�@�@�@�@�@�@�@�@�@�@�@�@�@�_��{l � �@V_Ɂ@� j�ȁ�/
�@�@�@�@�@�@�@�@�@�@�@�@ �@ // .�R { ���]�� j/ �_�R
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�_�@ ��/^<>^',�R�@ �^
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �M{ �@�r f::l .�qo Y
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ } /�@l::::���@V .}
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@���.�@�Ɂ@ }!�l
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ {=����=}�@�@�_
�N���C�A���g�p�r�ŁA�ėp�R�A���ނ�݂ɂӂ₵�Ă����ʁB
���ʂ�����̂��A���ǃG���R�[�h�Ȃǂ̓���p�r�B
�_�C�T�C�Y��2�{�ɂ��A�ėp�R�A��2�{�ɂ��Ă�
���̓���p�r�ł��A���ʂ�2�{�ȉ��B
�L���b�V����2�{�ɂ��Ă��A����܂ł̌o���ŕ�����悤��
10-20%���x�Ɏ~�܂�B
������A����܂ł̎�@�Ŋg�����Ă��A�_�C�T�C�Y�ɑ��āA
������p�t�H�[�}���X�͏������B
����Ȃ�A�p�r�ɓ��������R�A�݂��悤�Ƃ����̂���{�v�z�B
Fusion�ɂ���āA�N���C�A���g����CPU�̓��f�B�A�v���Z�b�V���O��
vector���Z�\�͂̒�グ���Ȃ����B
���āA��ɑ����̎d�������Ȃ��T�[�o�[�p�r�ł́A
�ėp�R�A�݂��Ă��A���ʂ͍����B
���ʂ�����̂��A���ǃG���R�[�h�Ȃǂ̓���p�r�B
�_�C�T�C�Y��2�{�ɂ��A�ėp�R�A��2�{�ɂ��Ă�
���̓���p�r�ł��A���ʂ�2�{�ȉ��B
�L���b�V����2�{�ɂ��Ă��A����܂ł̌o���ŕ�����悤��
10-20%���x�Ɏ~�܂�B
������A����܂ł̎�@�Ŋg�����Ă��A�_�C�T�C�Y�ɑ��āA
������p�t�H�[�}���X�͏������B
����Ȃ�A�p�r�ɓ��������R�A�݂��悤�Ƃ����̂���{�v�z�B
Fusion�ɂ���āA�N���C�A���g����CPU�̓��f�B�A�v���Z�b�V���O��
vector���Z�\�͂̒�グ���Ȃ����B
���āA��ɑ����̎d�������Ȃ��T�[�o�[�p�r�ł́A
�ėp�R�A�݂��Ă��A���ʂ͍����B
>������p�t�H�[�}���X�͏������B
�u��������p�t�H�[�}���X�͏������v�̕��������ˁB
�u��������p�t�H�[�}���X�͏������v�̕��������ˁB
689 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2007/02/04(��) 16:34:04 ID:HuuOXOBE
�p�������������C���^�[�t�F�C�X�͐ς܂Ȃ������v���b�g�t�H�[���̕ω��ɑΉ����₷�����
�ɂ��Ă�Intel�̓R���R���ς��������Ǝv�����B
�ɂ��Ă�Intel�̓R���R���ς��������Ǝv�����B
SSE�ł������
215 �FSocket774 [sage] �F2007/02/02(��) 21:11:20 ID:jAYNkG+5
>>194
����CPU�Ƀr�f�I�t������ă����b�g���悭�������B
�����̃��[�J�[PC�͓����`�b�v�Z�b�g�Ŏ�����Ă邵�B
�_�C�T�C�Y�傫�����ĒP���㏸������
�ǂ̃Z�O�����g�Ɏ��v��������B
217 �FSocket774 [sage] �F2007/02/02(��) 22:23:42 ID:rQqW4jQq
>>215
�����b�g������Ƃ�����UMPC�Ƃ�����ˁHGMCH + ULV PentiumM�Ƃ����\���ł�TDP10w�ʂ����Ă�͂��B
�����㓡���g�ALPIA�ɂ��Ă������Ă��Ȃ��B
UMPC�ɓ��������̂͂��������낤���B
���� Bloomfield + GPU�Ƃ�Wolfdale + GMCH�Ƃ��̃|�W�V�����͂悭�킩���ȁB
Penryn��TDP�����Ȃ�(�f�X�N�g�b�v��65w�ŏ\���Ⴂ)�Ƃ������Ă錻�炵��Intel�I�ɂ̓R�X�g�������邾���Ń����b�g��������B
221 �F217 [sage] �F2007/02/03(�y) 00:38:12 ID:/Qx/FzvJ
Nehalem��IMC��PCI-Express��I/F�������Ă�̂��B
������������Nehalem-C��Geneseo�Ńr�f�I�J�[�h��CPU���ł���̂����B
�����Ȃ�ƌ��݂�GPGPU�̃o�X���{�g���l�b�N�Ƃ�������Fusion�̃��������{�g���l�b�N�Ƃ������̗����������ł���B
>>194
����CPU�Ƀr�f�I�t������ă����b�g���悭�������B
�����̃��[�J�[PC�͓����`�b�v�Z�b�g�Ŏ�����Ă邵�B
�_�C�T�C�Y�傫�����ĒP���㏸������
�ǂ̃Z�O�����g�Ɏ��v��������B
217 �FSocket774 [sage] �F2007/02/02(��) 22:23:42 ID:rQqW4jQq
>>215
�����b�g������Ƃ�����UMPC�Ƃ�����ˁHGMCH + ULV PentiumM�Ƃ����\���ł�TDP10w�ʂ����Ă�͂��B
�����㓡���g�ALPIA�ɂ��Ă������Ă��Ȃ��B
UMPC�ɓ��������̂͂��������낤���B
���� Bloomfield + GPU�Ƃ�Wolfdale + GMCH�Ƃ��̃|�W�V�����͂悭�킩���ȁB
Penryn��TDP�����Ȃ�(�f�X�N�g�b�v��65w�ŏ\���Ⴂ)�Ƃ������Ă錻�炵��Intel�I�ɂ̓R�X�g�������邾���Ń����b�g��������B
221 �F217 [sage] �F2007/02/03(�y) 00:38:12 ID:/Qx/FzvJ
Nehalem��IMC��PCI-Express��I/F�������Ă�̂��B
������������Nehalem-C��Geneseo�Ńr�f�I�J�[�h��CPU���ł���̂����B
�����Ȃ�ƌ��݂�GPGPU�̃o�X���{�g���l�b�N�Ƃ�������Fusion�̃��������{�g���l�b�N�Ƃ������̗����������ł���B
263 �FSocket774 [sage] �F2007/02/03(�y) 23:31:17 ID:9UzVYhAE
>>217
�㓡���̂��̐����������̂�
Intel�`�b�v�Z�b�g�̃��[�h�}�b�v���Ă�����
����GPU��CPU�ɓ������闝�R���iIntel�ɂ́j���N��������Ȃ����B
����Barelake�Ŏ�����DVD�Đ��x�����t����
45nm��CPU�ڍs������ɁA��65nm���C���Ő������郄�c��
�ꉞ�͖{�i�IGPU�ɂȂ邵�B
�����㓡���uAMD�̓�����Intel���t�������Ă��ꂽ�炢���Ȃ��v
�ƌl�I��]�������Ă邾���Ȃ�ʂɂǂ��ł��������B
265 �FSocket774 [sage] �F2007/02/03(�y) 23:50:16 ID:nD4d2d58
>>263�ɕ֏�B
���Ƃ��ƃx�N�g���v���Z�b�T�̕����Ă�����Ă̂́u���͂ȃ������A�N�Z�X���\�̂��߂ɂ����������邱�Ɓv�𐳓�������̂�����Ƃ������̂Ȃ킯�B
�Ⴆ��ClearSpeed����12.8GB/s����Ȃ���6.4GB/s�ł����\���o�邩��艿���������悤�Ƃ����b�ɂȂ�B
����Ȃ킯�Ń������o���h����PC��2�`8�{�Ƃ��Ȃ̂ɂ��l�i��1�`9���~�Ƃ����r�f�I�J�[�h�ɒ��ڂ��W�܂����B
���̃r�f�I�J�[�h�̓������������̂��Ƃ����ƃr�f�I�J�[�h�̗p�r��99%���߂�3D�Q�[���ɕK�v������B
���̃r�f�I�J�[�h�̓������������̂Ɉ����̂��Ƃ�����3D�Q�[�}�[�l���̓x�N�g���v�Z�@���g�������l��舳�|�I�ɑ�������B(�{���͑��ɑ傫�ȗ��R��������ǂ����ł͊����B)
������������Ⴂ�����̂��ǂ����̉�Ђ�CPU�ɓ�������Ƃ������o�����B
x86�v���Z�b�T�Ȃ�u���͂ȃ������A�N�Z�X���\�̂��߂ɂ����������邱�Ɓv���������ł��܂����H(��:�ł��܂���B)
>>217
�㓡���̂��̐����������̂�
Intel�`�b�v�Z�b�g�̃��[�h�}�b�v���Ă�����
����GPU��CPU�ɓ������闝�R���iIntel�ɂ́j���N��������Ȃ����B
����Barelake�Ŏ�����DVD�Đ��x�����t����
45nm��CPU�ڍs������ɁA��65nm���C���Ő������郄�c��
�ꉞ�͖{�i�IGPU�ɂȂ邵�B
�����㓡���uAMD�̓�����Intel���t�������Ă��ꂽ�炢���Ȃ��v
�ƌl�I��]�������Ă邾���Ȃ�ʂɂǂ��ł��������B
265 �FSocket774 [sage] �F2007/02/03(�y) 23:50:16 ID:nD4d2d58
>>263�ɕ֏�B
���Ƃ��ƃx�N�g���v���Z�b�T�̕����Ă�����Ă̂́u���͂ȃ������A�N�Z�X���\�̂��߂ɂ����������邱�Ɓv�𐳓�������̂�����Ƃ������̂Ȃ킯�B
�Ⴆ��ClearSpeed����12.8GB/s����Ȃ���6.4GB/s�ł����\���o�邩��艿���������悤�Ƃ����b�ɂȂ�B
����Ȃ킯�Ń������o���h����PC��2�`8�{�Ƃ��Ȃ̂ɂ��l�i��1�`9���~�Ƃ����r�f�I�J�[�h�ɒ��ڂ��W�܂����B
���̃r�f�I�J�[�h�̓������������̂��Ƃ����ƃr�f�I�J�[�h�̗p�r��99%���߂�3D�Q�[���ɕK�v������B
���̃r�f�I�J�[�h�̓������������̂Ɉ����̂��Ƃ�����3D�Q�[�}�[�l���̓x�N�g���v�Z�@���g�������l��舳�|�I�ɑ�������B(�{���͑��ɑ傫�ȗ��R��������ǂ����ł͊����B)
������������Ⴂ�����̂��ǂ����̉�Ђ�CPU�ɓ�������Ƃ������o�����B
x86�v���Z�b�T�Ȃ�u���͂ȃ������A�N�Z�X���\�̂��߂ɂ����������邱�Ɓv���������ł��܂����H(��:�ł��܂���B)
287 �FSocket774 [sage] �F2007/02/04(��) 00:49:37 ID:uxq0Kmag
>>265
>������������Ⴂ�����̂��ǂ����̉�Ђ�CPU�ɓ�������Ƃ������o�����B
�����܂Ōl�I�ɂ́A�ƍŏ��̒f���Ă�����
CPU+GPU�Ȃ鏤�i�͑��݂��Ă��\��Ȃ��Ǝv���Ă�B
�����㓡�̘b���L�ۂ݂ɂ���Ȃ�
AMD�̖��͐��\�v��������
�e�Z�O�����g�ɂ��̃l�^CPU��W�J���悤�Ƃ��Ă鏊���B
�G�N�Z���ƃp���|�ƃ��[���[���������Ηǂ�
��ƌ����N���C�A���g�}�V���ɂ����CPU�v���B
�i�t�����������炱��Celeron�ɋ���Ȏ��v���L��j
�m�[�gPC��DR�ȊO�����CPU�ς߂�(65n����ł́j�B
�{���ɃX�y�b�N�~�����A���͊O�t���r�f�I�g���B
�|�����������i�͂����ɓ��������Ǝv�����B
297 �FSocket774 [sage] �F2007/02/04(��) 01:09:36 ID:iAWjmp+p
>>286�̍Ō�̍s�����B
��Merom�̍����\���s�[�NIPC5�����ɋ�����̂��Ƃ��v��Ȃ����B
>>287
"�������Ⴂ�����̂�"���Ă̂́ux86�v���Z�b�T���l�̂قƂ�ǑS�����Q�[��������킯�ł͂Ȃ���B�r�f�I�J�[�h�Ƃ͈Ⴄ��B�v���Ă��ƂˁB
�܂��܂�SSE�ɑ��Ĉ��̃A�h�o���e�[�W������̂��H����Ƃ��Ă����i�͏]���ʂ�Ȃ̂��H�Ƃ������Ƃł��B
>>265
>������������Ⴂ�����̂��ǂ����̉�Ђ�CPU�ɓ�������Ƃ������o�����B
�����܂Ōl�I�ɂ́A�ƍŏ��̒f���Ă�����
CPU+GPU�Ȃ鏤�i�͑��݂��Ă��\��Ȃ��Ǝv���Ă�B
�����㓡�̘b���L�ۂ݂ɂ���Ȃ�
AMD�̖��͐��\�v��������
�e�Z�O�����g�ɂ��̃l�^CPU��W�J���悤�Ƃ��Ă鏊���B
�G�N�Z���ƃp���|�ƃ��[���[���������Ηǂ�
��ƌ����N���C�A���g�}�V���ɂ����CPU�v���B
�i�t�����������炱��Celeron�ɋ���Ȏ��v���L��j
�m�[�gPC��DR�ȊO�����CPU�ς߂�(65n����ł́j�B
�{���ɃX�y�b�N�~�����A���͊O�t���r�f�I�g���B
�|�����������i�͂����ɓ��������Ǝv�����B
297 �FSocket774 [sage] �F2007/02/04(��) 01:09:36 ID:iAWjmp+p
>>286�̍Ō�̍s�����B
��Merom�̍����\���s�[�NIPC5�����ɋ�����̂��Ƃ��v��Ȃ����B
>>287
"�������Ⴂ�����̂�"���Ă̂́ux86�v���Z�b�T���l�̂قƂ�ǑS�����Q�[��������킯�ł͂Ȃ���B�r�f�I�J�[�h�Ƃ͈Ⴄ��B�v���Ă��ƂˁB
�܂��܂�SSE�ɑ��Ĉ��̃A�h�o���e�[�W������̂��H����Ƃ��Ă����i�͏]���ʂ�Ȃ̂��H�Ƃ������Ƃł��B
���ǂ��A�㓡�̃A�t�H��AMD�̃t�F�B�N�ɕ֏悵�Č֑�ɑ����ł邾�������B
�A�C�c������������ΒN��AMD�̃t�F�B�N�Ɉ����|���邱�Ɩ��������Ǝv�����A�����Ă邱�Ƃ��������̂܂����������B
�L���b�V���e�ʑ��₵�Ă�10%���x�Ƃ������Ă�z���邯�ǂ��A����10%���傫�����ᐫ�\��GPU��������͗y���Ƀ}�V���B
�L���b�V���e�ʑ��Ȃ�R�A�����Ƃ��ႢTDP�ւ̉e�������Ȃ�����D�s�������ȁB
�����I�ɂ�����GPU�̓����ł�����x�����b�g�������ނ̂Ȃ�m�[�g��o�C���n�p�r�ł����Ȃ��B
������������債�����̂���Ȃ��B
�A�C�c������������ΒN��AMD�̃t�F�B�N�Ɉ����|���邱�Ɩ��������Ǝv�����A�����Ă邱�Ƃ��������̂܂����������B
�L���b�V���e�ʑ��₵�Ă�10%���x�Ƃ������Ă�z���邯�ǂ��A����10%���傫�����ᐫ�\��GPU��������͗y���Ƀ}�V���B
�L���b�V���e�ʑ��Ȃ�R�A�����Ƃ��ႢTDP�ւ̉e�������Ȃ�����D�s�������ȁB
�����I�ɂ�����GPU�̓����ł�����x�����b�g�������ނ̂Ȃ�m�[�g��o�C���n�p�r�ł����Ȃ��B
������������債�����̂���Ȃ��B
�܂��m�[�X���ŐV�̃v���Z�X�ō��邱�Ƃ̏���d�͌��ƁA
�L���b�V�����₷���Ƃɂ�鐫�\�A�b�v������d�͑��A
�ǂ�����邩����B
�L���b�V�����₷���Ƃɂ�鐫�\�A�b�v������d�͑��A
�ǂ�����邩����B
�����𑝂₵���ꍇ�́A�K�����̖ʓ|�����Ă�����
"���C�A�[�h���W�b�N|�R���p�C��|�v���O���}"���X��
�J���R�X�g�E�^�p�R�X�g���ӂ݂Ȃ���ȂȂ�Ȃ��B
���������A����Ƃ����邨�Ԕ����_���J��L���邱�Ƃ��ł���B
�u�Ƭ�ׂ�xx�{�ɂ���A�Ƭ�ׂ���������A��̫��ݽ�́`�v
���̎�̑f�l�l���͉��̉��l���Ȃ��B
���̐l�ł���O�̐l�ł���A��������Ȃ����@�̐��t�ɔ�т��̂͒p���������B
"���C�A�[�h���W�b�N|�R���p�C��|�v���O���}"���X��
�J���R�X�g�E�^�p�R�X�g���ӂ݂Ȃ���ȂȂ�Ȃ��B
���������A����Ƃ����邨�Ԕ����_���J��L���邱�Ƃ��ł���B
�u�Ƭ�ׂ�xx�{�ɂ���A�Ƭ�ׂ���������A��̫��ݽ�́`�v
���̎�̑f�l�l���͉��̉��l���Ȃ��B
���̐l�ł���O�̐l�ł���A��������Ȃ����@�̐��t�ɔ�т��̂͒p���������B
>>696
���͑f�l�ł��e�ՂɎv�����A�v���P�[�V�����Ή��̍����
�������ш�s����I�ɂ����āi�܂����v�����Ȃ��قǔn������Ȃ����낤�j
�}���Z�[���Ă�㓡�B
���͑f�l�ł��e�ՂɎv�����A�v���P�[�V�����Ή��̍����
�������ш�s����I�ɂ����āi�܂����v�����Ȃ��قǔn������Ȃ����낤�j
�}���Z�[���Ă�㓡�B
>>697
���������傫�ȕǂƂȂ�AMD��FUSION�v���Z�b�T
ttp://pc.watch.impress.co.jp/docs/2007/0131/kaigai332.htm
> ����Ȃ��������ш�Ƒ傫�����郁�����A�N�Z�X���x
���������傫�ȕǂƂȂ�AMD��FUSION�v���Z�b�T
ttp://pc.watch.impress.co.jp/docs/2007/0131/kaigai332.htm
> ����Ȃ��������ш�Ƒ傫�����郁�����A�N�Z�X���x
���[�G���h�̏��Z�ɂ��Ă͋c�_�͂���Ƃ��Ă��A
�~�h���ȏ�̃f�X�N�g�b�v�A�T�[�o�[�ŃC���e���ɏ����\�͂̍����ŏ��Ă錩���݂���H
�~�h���ȏ�̃f�X�N�g�b�v�A�T�[�o�[�ŃC���e���ɏ����\�͂̍����ŏ��Ă錩���݂���H
Intel�ɂƂ��Ă̓L���b�V���𑝂₷�̂�P6�ȍ~���㖈�ɌJ��Ԃ��Ă��Ċm���������@�_�B
�i���C�e���V�������܂߂Đ��\�ێ��E���シ��̂Ɏ��ۂ͂���Ȃ�̋�J�͂���Ǝv�����j
>>697
�ނ̋L����10�N��ǂɂƁA�Ȃ�قǂȂ��Ǝv���ӏ������Ԃ�25%���炢�͂���Ƃ͎v���̂����A
�ŋ߂͖ϑz�}�����ɂ��Ԕ����_��W�J���錴�e���҂��L�����唼�Ȃ�Ȃ��B
�i���C�e���V�������܂߂Đ��\�ێ��E���シ��̂Ɏ��ۂ͂���Ȃ�̋�J�͂���Ǝv�����j
>>697
�ނ̋L����10�N��ǂɂƁA�Ȃ�قǂȂ��Ǝv���ӏ������Ԃ�25%���炢�͂���Ƃ͎v���̂����A
�ŋ߂͖ϑz�}�����ɂ��Ԕ����_��W�J���錴�e���҂��L�����唼�Ȃ�Ȃ��B
>>699
�������Nehalem�̐��̂��S���s���Ȃ̂ɉ��������Ă�H
�������Nehalem�̐��̂��S���s���Ȃ̂ɉ��������Ă�H
���������T�[�o�[��8�R�A����
>>698
���N�O��
AMD��ATI�̃v���Z�b�T��1�ɗZ������
http://pc.watch.impress.co.jp/docs/2006/0725/kaigai290.htm
���̋L���̒i�K�ł��̃X���ł�
�EGPU�����v���Z�b�T�͍ŏ��̓��o�C���p�ƂȂ邱��
�E�������ш悪���ɂȂ邱��
�͎w�E����Ă���ˁB
���N�O��
AMD��ATI�̃v���Z�b�T��1�ɗZ������
http://pc.watch.impress.co.jp/docs/2006/0725/kaigai290.htm
���̋L���̒i�K�ł��̃X���ł�
�EGPU�����v���Z�b�T�͍ŏ��̓��o�C���p�ƂȂ邱��
�E�������ш悪���ɂȂ邱��
�͎w�E����Ă���ˁB
> CPU��GPU�̓����A����������ƃX�J���v���Z�b�T�ƃx�N�^�v���Z�b�T�̓����́A�����炭�A����5�`10�N�̃v���Z�b�T�ƊE�̑傫�ȃg�����h�ƂȂ�B
�Ȃ�˂���w
�Ȃ�˂���w
AMD�̃t�F�B�N�Ɍ㓡�ƃC���e���̃o�J��������H
>>705
Intel��CPU��GPU���P�p�b�P�[�W�ɂ������i�����o�C���s������ɊJ�����ƌ����Ă邾���ŁA
�����GPU���R�v���I�Ɏg����Ȃ�Ă��Ƃ͈ꌾ�������ĂȂ��B
Intel��CPU��GPU���P�p�b�P�[�W�ɂ������i�����o�C���s������ɊJ�����ƌ����Ă邾���ŁA
�����GPU���R�v���I�Ɏg����Ȃ�Ă��Ƃ͈ꌾ�������ĂȂ��B
708 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2007/02/04(��) 18:08:24 ID:HuuOXOBE
�Ƃ肠�����͂₢�Ƃ�SDK�ƃV�~�����[�^���J���Ă���
���̃X���ł����x���w�E����Ă邪�㓡��fusion�ɑ���ԓx�͂�����ƁH�H�H���Ċ���
�������Ȏ��O��������B
���̋L���͌��\�N�I���e�B�����Ǝv�����ǂ�
�������Ȏ��O��������B
���̋L���͌��\�N�I���e�B�����Ǝv�����ǂ�
>>706
�Z���I�ɂ͂������낤�������I�ɂ�Fixed Function Units���ڂ���B
���ꂪ�����w���Ă�̂��͂킩��ǁA�w�e���W�j�A�X�}���`�R�A�ƌ��������ȋC������B
�Z���I�ɂ͂������낤�������I�ɂ�Fixed Function Units���ڂ���B
���ꂪ�����w���Ă�̂��͂킩��ǁA�w�e���W�j�A�X�}���`�R�A�ƌ��������ȋC������B
711 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2007/02/04(��) 18:11:48 ID:HuuOXOBE
TCP/IP�Ƃ��̌Œ�@�\�̃A�N�Z�����[�^�Ɣc��
�w�e�����낤�����R�A���낤���������ш�̃{�g���l�b�N��
���{�I�ɉ��P���Ȃ��Ƃǂ��ɂ��Ȃ��ȁB
���{�I�ɉ��P���Ȃ��Ƃǂ��ɂ��Ȃ��ȁB
713 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2007/02/04(��) 18:14:32 ID:HuuOXOBE
�L���b�V�����₹�悭�ˁH
���C���������H�X���b�v�̈悾��B
���C���������H�X���b�v�̈悾��B
>>712
�N�݂����Ȑl�̂��߂ɓV����NEC��SX-8i������Ă���̂���
�N�݂����Ȑl�̂��߂ɓV����NEC��SX-8i������Ă���̂���
2006�N11���X�p�R�������L���OTop500
Opteron�{ClearSpeed��CSX-600�Ƃ����w�e���ȃN���X�^�\�����Ƃ�
TSUBAME�͊撣���ă`���[�j���O�������ʁA�O��i6���j��
38.18TFlops����47.38TFlops��9.2TFlops�p���[�A�b�v���܂���
http://journal.mycom.co.jp/articles/2007/01/08/tsubame/005.html �����̐l�̊撣��
���̌��ʁA���ʂ͑O���7�ʂ��牽�ʏオ�����̂ł��傤���H
������ -2 �ʏオ����
�܂�9�ʂɗ������̂ł�
�Ȃ��Ȃ瑼�̕��ʂ̃N���X�^�}�V��������ȏ�ɐi����������ł�
Opteron�{ClearSpeed��CSX-600�Ƃ����w�e���ȃN���X�^�\�����Ƃ�
TSUBAME�͊撣���ă`���[�j���O�������ʁA�O��i6���j��
38.18TFlops����47.38TFlops��9.2TFlops�p���[�A�b�v���܂���
http://journal.mycom.co.jp/articles/2007/01/08/tsubame/005.html �����̐l�̊撣��
���̌��ʁA���ʂ͑O���7�ʂ��牽�ʏオ�����̂ł��傤���H
������ -2 �ʏオ����
�܂�9�ʂɗ������̂ł�
�Ȃ��Ȃ瑼�̕��ʂ̃N���X�^�}�V��������ȏ�ɐi����������ł�
�ŏ��\���łP�Q�O�O�������B�����낤�˂���ł��B
718 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2007/02/04(��) 18:29:03 ID:HuuOXOBE
Cedarmill�t�@�~����Tulsa��L3������ŃT�[�o�n�x���`�Ő��\�L�т܂����Ă邱�ƍl�����
�L���b�V���̑��ʂ͌��ʂ��邾�낤�B
1�_�C��20MB��SRAM���߂�Z�p��R&D�̒i�K�Ƃ͂���
Intel���J�����Ă邵��
�L���b�V���̑��ʂ͌��ʂ��邾�낤�B
1�_�C��20MB��SRAM���߂�Z�p��R&D�̒i�K�Ƃ͂���
Intel���J�����Ă邵��
����Ȃ��Memory eXpansion Technology�H
L3��20MB����������f�R�[�_�̊�����VLIW+CMS�̂����������ǂ������ł��ˁB
IPC���₷�̂��y����
IPC���₷�̂��y����
Windows3.1���炢�Ȃ�L���b�V����œ������H
�����̂̐����\�͂��]���Ă�Ȃ�A���낻�냁�C����������DRAM����SRAM��
�ڍs������ǂ��l�Ɏv���̂����B
�ł��]���Ă�̂�CPU���[�J�[�̐����\�͂ł����āA���������[�J�[����
�Ȃ�����Ȃ��B
�ڍs������ǂ��l�Ɏv���̂����B
�ł��]���Ă�̂�CPU���[�J�[�̐����\�͂ł����āA���������[�J�[����
�Ȃ�����Ȃ��B
�����\�͂��]���Ă�̂Ɖ��i�������Ȃ�͕̂ʖ�肾��
DRAM1GB�̃R�X�g�ŁA�撣���Ă�128MB���炢�̗e�ʂɂȂ����Ⴄ�̂ł́H
���Ɣz���ǂ�����́B
���Ɣz���ǂ�����́B
>>723
������1��100w�Ƃ��ł������̂��H
������1��100w�Ƃ��ł������̂��H
>>724
�܂��m����HDD�A�N�Z�X�����炷�ׂɁA�����DRAM���K���K����ʂɈ���
����̂��APC���\���A�b�v�����i�����A����̓t���b�V����������
���������B
>>725
�ǂ��Ȃ낤�H�@�ꉞSRAM�ɕK�v�ȃg�����W�X�^����DRAM�̂S�{���Ă�
������Ȕ������B���Ɣz���Ɋւ��Ă͐����\�̘͂b�Ƃ͕ʂ���B
>>726
���̂����܂ő����Ȃ�H�@FET��N-MOS/P-MOS�ō��A�Ƃ͌����ĂȂ����B
�t���b�v�t���b�v��H�̃I���^�I�t�̕����ADRAM�L���p�V�^�̕��d�^
�`���[�W�����d���𑴏��܂ő��������̂��H
�܂��m����HDD�A�N�Z�X�����炷�ׂɁA�����DRAM���K���K����ʂɈ���
����̂��APC���\���A�b�v�����i�����A����̓t���b�V����������
���������B
>>725
�ǂ��Ȃ낤�H�@�ꉞSRAM�ɕK�v�ȃg�����W�X�^����DRAM�̂S�{���Ă�
������Ȕ������B���Ɣz���Ɋւ��Ă͐����\�̘͂b�Ƃ͕ʂ���B
>>726
���̂����܂ő����Ȃ�H�@FET��N-MOS/P-MOS�ō��A�Ƃ͌����ĂȂ����B
�t���b�v�t���b�v��H�̃I���^�I�t�̕����ADRAM�L���p�V�^�̕��d�^
�`���[�W�����d���𑴏��܂ő��������̂��H
FUSION�v�z�͐̂�Intel���ۂ������
Timna�̎v�z�Ɠ������Ƃ��������H
���ƁA�������A�N�Z�X�̖��͓����`�b�v�Z�b�g�ł������������B
�����ɒ@���Ă�����������킩���B
�܂��B�u���邩�v�u����Ȃ����v���ꂽ��A����l�I�ɂ̓C�����B
�ł��A���PC�������[�G���h�ł͎g�����̓S���S�����Ă���Ǝv�����ˁB
Timna�̎v�z�Ɠ������Ƃ��������H
���ƁA�������A�N�Z�X�̖��͓����`�b�v�Z�b�g�ł������������B
�����ɒ@���Ă�����������킩���B
�܂��B�u���邩�v�u����Ȃ����v���ꂽ��A����l�I�ɂ̓C�����B
�ł��A���PC�������[�G���h�ł͎g�����̓S���S�����Ă���Ǝv�����ˁB
���ƌ����DRAM�̂܂܂Ń������A�N�Z�X���x�����߂�ɂ́A�������Z����
��x�ɃA�N�Z�X���鐔�𑝂₳����Ȃ�����A�������A�N�Z�X���x��
��肪�o��B
����DRAM����SRAM�ɂ���A�������Z�����̂̑��x��DRAM���͑����H����
������A�������A�N�Z�X���x�̖��i���������A�N�Z�X���x�j�������b��
�摗��o����̂ł́H
��x�ɃA�N�Z�X���鐔�𑝂₳����Ȃ�����A�������A�N�Z�X���x��
��肪�o��B
����DRAM����SRAM�ɂ���A�������Z�����̂̑��x��DRAM���͑����H����
������A�������A�N�Z�X���x�̖��i���������A�N�Z�X���x�j�������b��
�摗��o����̂ł́H
>>728
Timna���ۂ�������̂́A�v�v�z����������������ł��v�S������������������ł��Ȃ��A
DRDRAM���ƊE�̎嗬�ɂȂ�Ɠǂ����炢����̏��ׁB
Timna��Fusion���������Ă����̂́A�����B
�m�[�gPC�ƊE�ƃ��[�G���hPC�ƊE�́A���Ȃ��Ƃ��̗p���܂����łˁH
Timna���ۂ�������̂́A�v�v�z����������������ł��v�S������������������ł��Ȃ��A
DRDRAM���ƊE�̎嗬�ɂȂ�Ɠǂ����炢����̏��ׁB
Timna��Fusion���������Ă����̂́A�����B
�m�[�gPC�ƊE�ƃ��[�G���hPC�ƊE�́A���Ȃ��Ƃ��̗p���܂����łˁH
�̗p���܂��邩�ǂ����͉��i����
�Ƃ����������l����ς���Ă��Ă��ȁB
���[�J�[����PC���݂�킩�邪CPU��`�b�v�Z�b�g�̉��i��葼�̍\�����i�����R�X�g�ɂȂ����B
���XGPU�������Ƃ���ő傫�ȃ����b�g������Ƃ͎v���Ȃ��B
���[�J�[����PC���݂�킩�邪CPU��`�b�v�Z�b�g�̉��i��葼�̍\�����i�����R�X�g�ɂȂ����B
���XGPU�������Ƃ���ő傫�ȃ����b�g������Ƃ͎v���Ȃ��B
���R�X�g�ȑ��̍\�����i�̑�\���
�������ƃf�B�X�v���C����
���ۓI�ȃJ���e�����o���オ���Ă�
�������ƃf�B�X�v���C����
���ۓI�ȃJ���e�����o���オ���Ă�
>>734
���̓�i�Ɋւ��Ă̓J���e���Ƃ�����蓊���^�C�~���O�̏�̕K�R�������̂ł͂Ȃ����ƁB
elpida-�͏��̃������H��Asamsung-sony�̉t��G8�H�ꂪ�ғ��n�߂�᎖�Ԃ͕ς���B
���̓�i�Ɋւ��Ă̓J���e���Ƃ�����蓊���^�C�~���O�̏�̕K�R�������̂ł͂Ȃ����ƁB
elpida-�͏��̃������H��Asamsung-sony�̉t��G8�H�ꂪ�ғ��n�߂�᎖�Ԃ͕ς���B
�O���{�̔��M�₠�̃f�J�����匙��������AFUSION�̖����Ɋ��҂���
���������A���̉��Z�����Ȃ�GPU�������ATimna�Ɠ���Ɉ��������̂��ԈႢ�B
���[�G���h�Ƃ͌����Ă��A200-300gflop�Ȃ�R520���x��shader�p�t�H�[�}���X�ɂȂ�B
ROP��4����x���낤���ǂˁB
�x���`�͂��܂���������ɂ��������Ȃ����A���_�l���̓C���[�W���₷�����낤����ꉞ�B
�P��x���`�̌����L�^�Ƃ��āAnvidia��G70��Pen4 3.0GHz�̊���6Gflop
��CPU�ɑ���6�{�̃p�t�H�[�}���X�ƂȂ�B
�܂��A�^Brook�ŕP��x���`�́AG70��4Gflop�ɑ���RV515��30Gflop���}�[�N�����B
�܂��A���̍���GPU�̃A�[�L�e�N�`���̈Ⴂ�����������B
�ėp�R�A�œ����p�t�H�[�}���X���o���ɂ�
���R�A�K�v�ɂȂ邩�ȁE�E
�܂��A�{���x�͈����Ȃ������ǂˁE�E���̂܂܂ł́B
����ƁA����܂ł�GPGPU�́AOpenGL��DirectX�o�R�B
���GPU�ɋ߂�CTM�Ȃ�A�X�Ƀp�t�H�[�}���X�͏オ����悤�B
���[�G���h�Ƃ͌����Ă��A200-300gflop�Ȃ�R520���x��shader�p�t�H�[�}���X�ɂȂ�B
ROP��4����x���낤���ǂˁB
�x���`�͂��܂���������ɂ��������Ȃ����A���_�l���̓C���[�W���₷�����낤����ꉞ�B
�P��x���`�̌����L�^�Ƃ��āAnvidia��G70��Pen4 3.0GHz�̊���6Gflop
��CPU�ɑ���6�{�̃p�t�H�[�}���X�ƂȂ�B
�܂��A�^Brook�ŕP��x���`�́AG70��4Gflop�ɑ���RV515��30Gflop���}�[�N�����B
�܂��A���̍���GPU�̃A�[�L�e�N�`���̈Ⴂ�����������B
�ėp�R�A�œ����p�t�H�[�}���X���o���ɂ�
���R�A�K�v�ɂȂ邩�ȁE�E
�܂��A�{���x�͈����Ȃ������ǂˁE�E���̂܂܂ł́B
����ƁA����܂ł�GPGPU�́AOpenGL��DirectX�o�R�B
���GPU�ɋ߂�CTM�Ȃ�A�X�Ƀp�t�H�[�}���X�͏オ����悤�B
�����炻�������h���[�~�[�ȗ\�z�̓f�X�N�g�b�v�ɍڂ��Ă���ɂ�����āB
�ŏ��̓m�[�g�̂�������[�G���h��p�Ȃ���B
�ŏ��̓m�[�g�̂�������[�G���h��p�Ȃ���B
>>737
�����A����݂ď����������B
�m���ɓ������Đ�p�̃x���`�\�t�g��AMD�Ђ̗����ō�����ł͂Ȃ����ȁH
�����Ă��u���̑����������A����!�v�Ƃ����������ł���ˁB
�ł��A�v���P�[�V�����͔����ĂȂ������肷���Ȃ��E�E�E�E�E�E�E�E(�����
�����A����݂ď����������B
�m���ɓ������Đ�p�̃x���`�\�t�g��AMD�Ђ̗����ō�����ł͂Ȃ����ȁH
�����Ă��u���̑����������A����!�v�Ƃ����������ł���ˁB
�ł��A�v���P�[�V�����͔����ĂȂ������肷���Ȃ��E�E�E�E�E�E�E�E(�����
>�t���b�v�t���b�v��H�̃I���^�I�t�̕����ADRAM�L���p�V�^�̕��d�^
>�`���[�W�����d���𑴏��܂ő��������̂��H
��10�{�ł��B
>�`���[�W�����d���𑴏��܂ő��������̂��H
��10�{�ł��B
CPU�Ƀx�N�g�����Z����R�قǐςނ̂��������������͂Ƃ������A
�o���炱�̏�œ������C�g���\�t�g�����Ă݂�����B
�o���炱�̏�œ������C�g���\�t�g�����Ă݂�����B
���b�h�N�B�[���Ƃ��Ȃ炻�̂܂g�������ȋC�K�X
744 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2007/02/04(��) 23:49:15 ID:HuuOXOBE
�������������͂��邪
�������Z���ߗp�ӂ��Ă���Ȃ��Ɖ��̑z�肷�����p�r�ł͎g���Ȃ�
�������Z���ߗp�ӂ��Ă���Ȃ��Ɖ��̑z�肷�����p�r�ł͎g���Ȃ�
>>729
����Ȗʓ|�Ȃ��Ƃ����Ȃ��Ă��L���b�V�����C���T�C�Y�ς��邾���ł��������\���f���ɏオ��
���_:GPU�����Ȃ���Ηǂ�
����Ȗʓ|�Ȃ��Ƃ����Ȃ��Ă��L���b�V�����C���T�C�Y�ς��邾���ł��������\���f���ɏオ��
���_:GPU�����Ȃ���Ηǂ�
CPU��GPU��_�C�ɂ���̂͂������ǂ��A���C���������ƃr�f�I��������
�����Ȃ��Ƒʖڂ���B
������������Ɣz�����Ƃ�ł��Ȃ����ƂɁB
�����Ȃ��Ƒʖڂ���B
������������Ɣz�����Ƃ�ł��Ȃ����ƂɁB
���ڑ��n�C�p�[�g�����X�|�[�g���Ԃɍ����Έ����́E�E�E�E
�܁A�������낤�ȁB
���A���e�B����̂��Ƃ����Z-RAM���H�ł����������VGA�Ƃ��Ă̔\�͂́E�E
���xPS2��EE�݂����Ȋ����ɂȂ����Ⴄ�ȁB���̕ӂ�����C���������Ɛ▭��
�������ɂ��Ăǂꂾ�����\���o���邩���ď����ȁB����Fusion�́B
�܁A�������낤�ȁB
���A���e�B����̂��Ƃ����Z-RAM���H�ł����������VGA�Ƃ��Ă̔\�͂́E�E
���xPS2��EE�݂����Ȋ����ɂȂ����Ⴄ�ȁB���̕ӂ�����C���������Ɛ▭��
�������ɂ��Ăǂꂾ�����\���o���邩���ď����ȁB����Fusion�́B
>> 749
> ���A���e�B����̂��Ƃ����Z-RAM���H�ł����������VGA�Ƃ��Ă̔\�͂́E�E
> ���xPS2��EE�݂����Ȋ����ɂȂ����Ⴄ�ȁB
eDRAM���ڂ�GPU�Ƃ�����ATi��Xbox 360-GPU�ł��傤�B
ttp://www.watch.impress.co.jp/game/docs/20050520/x360_g.htm
> ���A���e�B����̂��Ƃ����Z-RAM���H�ł����������VGA�Ƃ��Ă̔\�͂́E�E
> ���xPS2��EE�݂����Ȋ����ɂȂ����Ⴄ�ȁB
eDRAM���ڂ�GPU�Ƃ�����ATi��Xbox 360-GPU�ł��傤�B
ttp://www.watch.impress.co.jp/game/docs/20050520/x360_g.htm
Vista�ɂȂ�����Œ�ł�256MB�͓��ڂ��Ȃ��ƁB
>>723
SRAM�̓g�����W�X�^6��
DRAM�̓R���f���T1��
���ꂼ��1�r�b�g������
���x�͑f�q���ȏ�̍�������
SRAM�����C���������ɂ��Ă�
��e�ʂ�����A�o�b�t�@���`�b�v�Z�b�g�Ƃ̊Ԃ�
�����ς����܂��Ȃ����Ⴂ���Ȃ���
��C�e���V�̃����b�g�͂łȂ��Ǝv��
SRAM�̓g�����W�X�^6��
DRAM�̓R���f���T1��
���ꂼ��1�r�b�g������
���x�͑f�q���ȏ�̍�������
SRAM�����C���������ɂ��Ă�
��e�ʂ�����A�o�b�t�@���`�b�v�Z�b�g�Ƃ̊Ԃ�
�����ς����܂��Ȃ����Ⴂ���Ȃ���
��C�e���V�̃����b�g�͂łȂ��Ǝv��
DX10����́A�������Z���\�B
>>737
�����������̂��E�E�E
�������������Ƃ��܂����B
ttp://accc.riken.jp/HPC/Symposium/2005/benchmark.pdf
Brook�̕��̓��[�G���h��RV515�ƁA�~�h����RV530�ŕς��Ȃ����ʂɂȂ�����ˁE�E�E
Folding@Home��Brook�g���Ă邯�ǁAshader�̍��̓n�b�L���o�邵�E�E�E
driver7.1�ɂ�����A������RV570�ł͓����Ȃ��Ȃ���������E�E�E
>>755
�������Z�͏o���Ă��ACPU�Ɠ������Ƃ������悤�Ɂi���������Łj�o����킯�ł͖������낤���ǂˁB
�C���[�W�I�ɂ�CPU�͉��M���̃y���n�AGPU�̓n�P���̃u���V�n�ƕ߂炦�Ă܂��B
�p�r�ɂ���Ă̎g�������́A�K�{�B
�����������̂��E�E�E
�������������Ƃ��܂����B
ttp://accc.riken.jp/HPC/Symposium/2005/benchmark.pdf
Brook�̕��̓��[�G���h��RV515�ƁA�~�h����RV530�ŕς��Ȃ����ʂɂȂ�����ˁE�E�E
Folding@Home��Brook�g���Ă邯�ǁAshader�̍��̓n�b�L���o�邵�E�E�E
driver7.1�ɂ�����A������RV570�ł͓����Ȃ��Ȃ���������E�E�E
>>755
�������Z�͏o���Ă��ACPU�Ɠ������Ƃ������悤�Ɂi���������Łj�o����킯�ł͖������낤���ǂˁB
�C���[�W�I�ɂ�CPU�͉��M���̃y���n�AGPU�̓n�P���̃u���V�n�ƕ߂炦�Ă܂��B
�p�r�ɂ���Ă̎g�������́A�K�{�B
�c�q��Mac��Windows��Linux��gcc�̑��x��r����Ă݂�Ƃ�����
>>740
����͒m��Ȃ������B
���ꂪ�{���Ȃ�A�m���Ƀ��C����������SRAM�ɂ���͖̂������L�肻�������A
����������CPU�̃L���b�V������������ɂ��ĂȂ����H
�L���b�V���������͊�{�I��CPU�Ɠ��N���b�N�œ��삳���邩��A���x�D���
����d�͂��]���ɂ��Ă锤�Ȃ̂ŁA�����܂ł̓���N���b�N�͕s�v�i�ő�ł�
�������o�X�N���b�N�j�ȃ��C���������Ȃ�A�����Əȓd�͂ȍ��������肻��
�����B
>>741
�L���p�V�^�̏[���d�̑��x���������������Ă�̃W���}�C�J�B
�I���`�b�v�p�r������1T-SRAM�ł��ADRAM���������g�ɂȂ��đ��x���グ��ꂸ
�d�����݂��������B
>>754
�������U�{���A������ƌ����������Ȃ��B
�ł���e�ʂ̖��́A���Ƃ��Ɛ����\�͂��]����Ă̂��O��̘b��������v���ƁB
����͒m��Ȃ������B
���ꂪ�{���Ȃ�A�m���Ƀ��C����������SRAM�ɂ���͖̂������L�肻�������A
����������CPU�̃L���b�V������������ɂ��ĂȂ����H
�L���b�V���������͊�{�I��CPU�Ɠ��N���b�N�œ��삳���邩��A���x�D���
����d�͂��]���ɂ��Ă锤�Ȃ̂ŁA�����܂ł̓���N���b�N�͕s�v�i�ő�ł�
�������o�X�N���b�N�j�ȃ��C���������Ȃ�A�����Əȓd�͂ȍ��������肻��
�����B
>>741
�L���p�V�^�̏[���d�̑��x���������������Ă�̃W���}�C�J�B
�I���`�b�v�p�r������1T-SRAM�ł��ADRAM���������g�ɂȂ��đ��x���グ��ꂸ
�d�����݂��������B
>>754
�������U�{���A������ƌ����������Ȃ��B
�ł���e�ʂ̖��́A���Ƃ��Ɛ����\�͂��]����Ă̂��O��̘b��������v���ƁB
759 �F�W���}�C�J��Y�F2007/02/05(��) 14:11:38 ID:Hh7hU64E
203 �FSocket774[sage]�F2007/01/18(��) 11:06:20 ID:nlZ2ZAtK
Cedarmill�ȁB
>����d�͏オ������H�@���̂������ŃN���b�N���オ��Ȃ��������H
�{���Ƀv���Z�X�̐�������������ׂȂ��̂���A�܂������ˁB
�g�����W�X�^����������W���}�C�J�B
�P����r�Ȃ点�߂ăV�������N���ꂽ���̂Ŕ�ׂĂ��������B
566 �FSocket774[sage]�F2007/02/01(��) 20:10:39 ID:0cslN4KW
>>543
Windows�}�[�P�b�g�ł� .NET MSIL �R�v���Ȃ�L�]�Ȃ�W���}�C�J�H
758 �FSocket774[sage]�F2007/02/05(��) 12:43:18 ID:71hAnE2S
>>740
����͒m��Ȃ������B
���ꂪ�{���Ȃ�A�m���Ƀ��C����������SRAM�ɂ���͖̂������L�肻�������A
����������CPU�̃L���b�V������������ɂ��ĂȂ����H
�L���b�V���������͊�{�I��CPU�Ɠ��N���b�N�œ��삳���邩��A���x�D���
����d�͂��]���ɂ��Ă锤�Ȃ̂ŁA�����܂ł̓���N���b�N�͕s�v�i�ő�ł�
�������o�X�N���b�N�j�ȃ��C���������Ȃ�A�����Əȓd�͂ȍ��������肻��
�����B
>>741
�L���p�V�^�̏[���d�̑��x���������������Ă�̃W���}�C�J�B
�I���`�b�v�p�r������1T-SRAM�ł��ADRAM���������g�ɂȂ��đ��x���グ��ꂸ
�d�����݂��������B
>>754
�������U�{���A������ƌ����������Ȃ��B
�ł���e�ʂ̖��́A���Ƃ��Ɛ����\�͂��]����Ă̂��O��̘b��������v���ƁB
Cedarmill�ȁB
>����d�͏オ������H�@���̂������ŃN���b�N���オ��Ȃ��������H
�{���Ƀv���Z�X�̐�������������ׂȂ��̂���A�܂������ˁB
�g�����W�X�^����������W���}�C�J�B
�P����r�Ȃ点�߂ăV�������N���ꂽ���̂Ŕ�ׂĂ��������B
566 �FSocket774[sage]�F2007/02/01(��) 20:10:39 ID:0cslN4KW
>>543
Windows�}�[�P�b�g�ł� .NET MSIL �R�v���Ȃ�L�]�Ȃ�W���}�C�J�H
758 �FSocket774[sage]�F2007/02/05(��) 12:43:18 ID:71hAnE2S
>>740
����͒m��Ȃ������B
���ꂪ�{���Ȃ�A�m���Ƀ��C����������SRAM�ɂ���͖̂������L�肻�������A
����������CPU�̃L���b�V������������ɂ��ĂȂ����H
�L���b�V���������͊�{�I��CPU�Ɠ��N���b�N�œ��삳���邩��A���x�D���
����d�͂��]���ɂ��Ă锤�Ȃ̂ŁA�����܂ł̓���N���b�N�͕s�v�i�ő�ł�
�������o�X�N���b�N�j�ȃ��C���������Ȃ�A�����Əȓd�͂ȍ��������肻��
�����B
>>741
�L���p�V�^�̏[���d�̑��x���������������Ă�̃W���}�C�J�B
�I���`�b�v�p�r������1T-SRAM�ł��ADRAM���������g�ɂȂ��đ��x���グ��ꂸ
�d�����݂��������B
>>754
�������U�{���A������ƌ����������Ȃ��B
�ł���e�ʂ̖��́A���Ƃ��Ɛ����\�͂��]����Ă̂��O��̘b��������v���ƁB
�W���}�C�J��Y������l�����ƌ��������킯��?
�������ɔ�Q�ϑz���߂���B
�G���̖S�삪������A���Ƒ債�ĕς���B
�������ɔ�Q�ϑz���߂���B
�G���̖S�삪������A���Ƒ債�ĕς���B
>>758
SRAM�ɂ�1bit�L������̂ɂS�g�����W�X�^�K�v�ȃ^�C�v�ƂU�g�����W�X�^�K�v�ȃ^�C�v������B
CPU������L1��L2�ɂ͂U�g�����W�X�^�^���g����B
SRAM�ɂ�1bit�L������̂ɂS�g�����W�X�^�K�v�ȃ^�C�v�ƂU�g�����W�X�^�K�v�ȃ^�C�v������B
CPU������L1��L2�ɂ͂U�g�����W�X�^�^���g����B
> �S�g�����W�X�^�K�v�ȃ^�C�v
���߂ĕ������ڂ���
���߂ĕ������ڂ���
>>762
�uSRAM�@�S�g�����W�X�^�v���邢�́u4T-SRAM�v�ł������낵
�uSRAM�@�S�g�����W�X�^�v���邢�́u4T-SRAM�v�ł������낵
���Ȃ݂�1T-SRAM���Ă̂����邯�ǂ����SRAM�̃����b�g�̂�����������DRAM�ŁA
4T-SRAM�͂ق���̂�SRAM
4T-SRAM�͂ق���̂�SRAM
�W�Ȃ����A���Ɍ㓡�����ʂɒ@�������������̂��Ȃ�
�������}���Z�[�������㓡���A��������l�Œ@���n�߂Ă������N�ɂȂ邩�E�E�E
�ŋ߂́A�A�z�炵������S�R�@���ĂȂ�������
�������}���Z�[�������㓡���A��������l�Œ@���n�߂Ă������N�ɂȂ邩�E�E�E
�ŋ߂́A�A�z�炵������S�R�@���ĂȂ�������
766 �F�P�P�P�P�P�P�P�ɁP�P�P�P�P�P�P�F2007/02/05(��) 21:57:32 ID:ljQFsZWE
�@�@�@�@�@�@�@�@�@�@�Q�Q�Q�Q�Q�Q�Q�Q
�@�@�@�@�@�@�@�@ /�L:::::::::::::::::::::::::::::::::::::::::::�M�R
�@�@�@�@�@�@�@�^::::::::::::::::::::::::::::::::::::::::::::::::::::::::�_
�@�@�@�@ �@ �i:::::::::::�l�m�R�m�R�m�R�m�R�l::::::::::::::::�j
�@�@�@ �@�@�i:::::::::::/�@�@�@�@�@�@�@�@�@�@�@�_:::::::::::::�j
�@�@�@ �@ �i::::::::::/�@�@�@�@�@�@�@�@�@�@�@�@�@�_:::::::::::�j
�@�@�@�@ �i::::::::::/�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�R::::::::�j
�@�@�@�@�@|:::::::/�@,,;;;;;;;;;;;;;;,�@�@�@�@ ,,;;;;;;;;;;;;;;,�@ |:::::::::|
�@�@�@�@�@|:::::�������������@ ������������:::::|
�@�@�@�@�@|::=ہ@�@ -=�E=- ������ -=�E=- �@�@�=::|
�@�@�@�@ /|:::/�R�@�@�@�@�@�@/Ɂ@ �R�@�@�@�@�@�@/�@�R|�R
�@�@�@�@.| |/�@�@�M�P�P�P�L/�@�@�@ �M�P�P�P�L�@�@�@| |
�@�@�@�@�R| �@�@�@�@�@�@�@ �i. o��o .�j�@�@�@�@�@�@�@ .|�
�@�@�@�@�@ �_�@�@ �@ �@ :::::::::::::U::::::::::::::�@�@�@�@�@�^
�@�@�@�@ �@�@|�_�@�@�@ ::::--������--::::�@�@�@�^|
�@�@�@�@�@�@ |.�@�_. �@�@�@�@�������@�@�@�@.�^�@.|
�@�@�@�@�@�@ �_�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �@�^
�@�@�@�@�@�@�@�@�_ �@�@�@ �L�P�P�P�M �@�@�@.�^
�@�@�@�@�@�@�@ �@�@�_�@�@�@�@�@�@�@�@�@�@ �^
�@�@�@�@ �Q�Q�Q�^|.�_�Q�Q�Q�Q�Q_�^|�_�Q�Q�Q
�@�@�@�^;;;;;;;;;;;;;;; �_�_�@�@�@�@�@�@�@�@ �^�^;;;;;;;;;;;;;;;;;�_
�@ �^;;;;;;;;;;;;;;;;;;;;;;;;;;;�_�_ �@�@�@�@�@ �^�^;;;;;;;;;;;;;;;;;;;;;;;;;;;�_
�@�@�@�@�@�@�@�@ /�L:::::::::::::::::::::::::::::::::::::::::::�M�R
�@�@�@�@�@�@�@�^::::::::::::::::::::::::::::::::::::::::::::::::::::::::�_
�@�@�@�@ �@ �i:::::::::::�l�m�R�m�R�m�R�m�R�l::::::::::::::::�j
�@�@�@ �@�@�i:::::::::::/�@�@�@�@�@�@�@�@�@�@�@�_:::::::::::::�j
�@�@�@ �@ �i::::::::::/�@�@�@�@�@�@�@�@�@�@�@�@�@�_:::::::::::�j
�@�@�@�@ �i::::::::::/�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�R::::::::�j
�@�@�@�@�@|:::::::/�@,,;;;;;;;;;;;;;;,�@�@�@�@ ,,;;;;;;;;;;;;;;,�@ |:::::::::|
�@�@�@�@�@|:::::�������������@ ������������:::::|
�@�@�@�@�@|::=ہ@�@ -=�E=- ������ -=�E=- �@�@�=::|
�@�@�@�@ /|:::/�R�@�@�@�@�@�@/Ɂ@ �R�@�@�@�@�@�@/�@�R|�R
�@�@�@�@.| |/�@�@�M�P�P�P�L/�@�@�@ �M�P�P�P�L�@�@�@| |
�@�@�@�@�R| �@�@�@�@�@�@�@ �i. o��o .�j�@�@�@�@�@�@�@ .|�
�@�@�@�@�@ �_�@�@ �@ �@ :::::::::::::U::::::::::::::�@�@�@�@�@�^
�@�@�@�@ �@�@|�_�@�@�@ ::::--������--::::�@�@�@�^|
�@�@�@�@�@�@ |.�@�_. �@�@�@�@�������@�@�@�@.�^�@.|
�@�@�@�@�@�@ �_�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �@�^
�@�@�@�@�@�@�@�@�_ �@�@�@ �L�P�P�P�M �@�@�@.�^
�@�@�@�@�@�@�@ �@�@�_�@�@�@�@�@�@�@�@�@�@ �^
�@�@�@�@ �Q�Q�Q�^|.�_�Q�Q�Q�Q�Q_�^|�_�Q�Q�Q
�@�@�@�^;;;;;;;;;;;;;;; �_�_�@�@�@�@�@�@�@�@ �^�^;;;;;;;;;;;;;;;;;�_
�@ �^;;;;;;;;;;;;;;;;;;;;;;;;;;;�_�_ �@�@�@�@�@ �^�^;;;;;;;;;;;;;;;;;;;;;;;;;;;�_
�c�q�͂����ƕs�H�ł�
�㓡�������|�l�Ƃ��Ă͕]�����Ă�
�܂����ʘ_�ł�����ł��P�`�����邵�A�����Ŕ����ɐӔC���Ȃ��ėǂ����C�y����ȁB
�}�b�N�I�^�ɂ��Ă������Ȃ������Ȃ��ĈႤ�r�W�����Ȃ�Ĉ�،��Ȃ������i�B
�}�b�N�I�^�ɂ��Ă������Ȃ������Ȃ��ĈႤ�r�W�����Ȃ�Ĉ�،��Ȃ������i�B
�����Ƃ����A���͌㓡��@���ĂȂ���
�������K�v�S����������
����Ƃ݂�ȋC�������Ȃ��Ƃ�����|
�������K�v�S����������
����Ƃ݂�ȋC�������Ȃ��Ƃ�����|
�@���Ă�͔̂n�������Ɍ����邯�ǂ�
�܂��A�v�̓C���e�����̔����Ȃ�@����Ȃ�
AMD���Ȃ�A�@�������Ă����̂悤�ȋC�����邪��
AMD���Ȃ�A�@�������Ă����̂悤�ȋC�����邪��
�����ݖ�������Ȃ���ˁA������Q�����œ˕t�����B
���̃W���[�i���X�g������������ƌ㓡�ϑz��}������悤�ȋL���������Ă����������ǁB
���̃W���[�i���X�g������������ƌ㓡�ϑz��}������悤�ȋL���������Ă����������ǁB
���[�����C�^�[�Ԃ̑����V�X�e���݂����ȃ��c���~������
���C�^�[���m�����������K�`���I�[�v����
�����Ԃ��Č��܂���悤�ɂȂ�����
PC���C�^�[�ƊE�����悩�}�V�ɂȂ�낤��
���C�^�[���m�����������K�`���I�[�v����
�����Ԃ��Č��܂���悤�ɂȂ�����
PC���C�^�[�ƊE�����悩�}�V�ɂȂ�낤��
AMD��ATI���������ƂŁA���|�I�Ɍ㓡�D�݂̃��[�J�[�ɂȂ���
���������āA���炭�㓡�̖ϑz���[�h�͑�������
���~�͊o�債�Ƃ�
���������āA���炭�㓡�̖ϑz���[�h�͑�������
���~�͊o�債�Ƃ�
���������܂��猾���������肾�Ȃ�
�����낢���炢�����ǂ�
�����낢���炢�����ǂ�
�����A�q��AIzumida�A�匴
���̕ӂ̃n�[�h��\�t�g�̐v�A�J���A�^�p�Ɍg��������Ƃ̂���l��
���X���ɂ����Ɓu�㓡����A����͈Ⴄ��v�ĂȊ������s�Ԃɍ��߂ď����Ă��肷��
���̕ӂ̃n�[�h��\�t�g�̐v�A�J���A�^�p�Ɍg��������Ƃ̂���l��
���X���ɂ����Ɓu�㓡����A����͈Ⴄ��v�ĂȊ������s�Ԃɍ��߂ď����Ă��肷��
�㓡���n�ő��ɃC�C�������C�^�[���Ȃ������B
�l�I�Ȋ��z���ƁA�A�㓡���͑f�l�ɂ��ǂ܂���L���̎d�������Ă��邵���C�^�[�������Ǝv���B
���ƁA�q�쎁�̕��������B���߂Ȃ̂͂��̒��ł��߂Ȃ̂͂܂��킩��Ƃ���������(ry�����ȁB
�l�I�Ȋ��z���ƁA�A�㓡���͑f�l�ɂ��ǂ܂���L���̎d�������Ă��邵���C�^�[�������Ǝv���B
���ƁA�q�쎁�̕��������B���߂Ȃ̂͂��̒��ł��߂Ȃ̂͂܂��킩��Ƃ���������(ry�����ȁB
�R�ꂪ�D���Ȃ̂�Izumida
�ƊE�A�s��A�Z�p�A����
���̃o�����X���o���ǂ�
�ƊE�A�s��A�Z�p�A����
���̃o�����X���o���ǂ�
781 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2007/02/05(��) 23:25:57 ID:jJeB1z2Y
>>757
10.4�t����GCC4�̓A�z�݂����ɒx����B
PPC�̘b�����ǁA10.3�Ńr���h���Ă�������o�C�i���̂ق����f�R�����B
�܂�xcode 2.4�͓���ĂȂ����玎���Ă݂邩�ȁB
Intel Mac�܂��茳�ɂȂ��̂�B
Apple��GCC4��x86�����̃R�[�h�̐��\��Intel�R���p�C����
�O���t�������ł͑啪�������ۂ��ˁB
Windows�̂��ƁACygwin��MinGW�ɂȂ邾�낤����
�ŐV���܂�3.3���炢����Ȃ����������B
10.4�t����GCC4�̓A�z�݂����ɒx����B
PPC�̘b�����ǁA10.3�Ńr���h���Ă�������o�C�i���̂ق����f�R�����B
�܂�xcode 2.4�͓���ĂȂ����玎���Ă݂邩�ȁB
Intel Mac�܂��茳�ɂȂ��̂�B
Apple��GCC4��x86�����̃R�[�h�̐��\��Intel�R���p�C����
�O���t�������ł͑啪�������ۂ��ˁB
Windows�̂��ƁACygwin��MinGW�ɂȂ邾�낤����
�ŐV���܂�3.3���炢����Ȃ����������B
Fusion�̓C�\�e����SSE�g�����₵�Ă��h���C�o�őΉ��ł����ۂ��ˁH
GPGPU�̎g�����Ƃ��ĂȂ�œ���Đ��x�����łĂ��Ȃ��낤���H
�����A�r�f�I�J�[�h�����r�f�I�J�[�h�̓���Đ��x���@�\�����p����DVD�Đ��\�t�g��
������O�̂悤�Ƀo���h������Ă�̂ɂȁB
DVD��CPU�̐i������Ԍ��������ɏ{����������A�����ɂ����������ׂɂ��Ȃ�Ȃ��Ȃ������A
������ȍ~�̓���K�i��GPGPU�̎x�������ł͂����낤�Ǝv�����B
�����A�r�f�I�J�[�h�����r�f�I�J�[�h�̓���Đ��x���@�\�����p����DVD�Đ��\�t�g��
������O�̂悤�Ƀo���h������Ă�̂ɂȁB
DVD��CPU�̐i������Ԍ��������ɏ{����������A�����ɂ����������ׂɂ��Ȃ�Ȃ��Ȃ������A
������ȍ~�̓���K�i��GPGPU�̎x�������ł͂����낤�Ǝv�����B
>>767�@�@�@�@�@�@)�@�@�@�@))�@�@�@�@�@(( �@�@ �j
�@�@�@�@�@�@�@�@�^:::::::::::::)(:::)(:::::::::::)(::::::�O:::::::::::::::::::�_( �@
�@�@�@�@�@�@�@ ))(:::::::::::::::::::::::::(:::):::::::::::::::::(:::):�@::::::::::::::�_�`
�@�@�@�@�@�@/::::::::::/�m::::::::�::::::::�R:�l::::::::::�R::::::::::::::::::::::::))�j
�@�@�@�@�@�@�i:::::::::::::::::::::::::/�@�@�j:::�m::::Ɂ@) ��@�S:::::::::��::::�R
�@�@�@�@�@�@(�i:::::::::::::::./�@�c�@�@� ���@Ɂ@�@::�@�c:/)):::::::):�j �@�@ �Ձ`�`��
�@�@�@�@�@�@�i::::::::::/ �~�~�~�~�~�~�~.�B�c�c�c�c�c�@ :::::::::::�j�@�@�@�`
�@�@�@�@�`�i(::::::://�P�P�P�P�R===/�P�P�P�P�R |:::::::::�j))
�@�@�@�@�@ �@|==� �@�@-=�E==- �a�@�a�@-===�E=-�@�===
�@�@�@ /�� |:/ �a�@�@�@--�^�@/Ɂ@ �R�@�_----�@�a �@�R|�R�܁R
�@�@�@�q �@�@|/�@ �R�M======/�@ .�܁@�M ========�. �@ ..| | �@�@ �r�@�@�@
�@�@�@ �R �@.�i�@�B �E�F�E�e�Bc �i ���@�@�� �j�@�G�h�Eu�B*@�E�F�A�e�j�@ /�@�@
�@�@�@�@|�@�i�@�F�B�E�G���F�E�B/::: ::::::| |::::::�R�@�@�G 8@ �E�B�F���@�j�@|�@
�@�@�@�@�_�i �B�G�E�O�h*�Eo�G�^::::::::::l l::: ::: �_�@�F�B�E�G���F�E�B. �j�^�@ �@
�@�@�@�@�@�@ �i�G8@�E�B�F�@ �^�P�P�P�P�P�_:�@�h�E�F�B�G�h�E.�j
�@�@�@�@�@�@�@�i�O�h*�E o�^�@�@�@�@�@�@�@�@�@�@�_�@�O�h*�Eo�F�j
�@�@�@�@�@.�@�@�i�E�F��,:�j|.�@�@�P|�P|�P|�P�@�@ | :�i:���h�E�F�j�@�@
�@�@�@�@�@�@�@:�i�G 8@�E �_�@�@�@�P�P�@�@�@�@�^�G8@ *�E�E�j
�@�@�@�@�@�@�@�@�_:::o ::::�@�_�Q�Q�Q�Q�Q�^:::::::::::::::�^
�@�@�@�@�@�@�@�@�@ �R �R:::: _-�@::::: ��::�@::::::::::-_ �@�m
�@�@�@�@�@�@�@�@�@�@�@�_�@:::::::::::::::::�@:::::::::: ::: ::_�^
�@�@�@�@�@�@�@�@ �@, �]'��`^�V/��" �Q�^ '�L�@ �P ` �
�@�@�@�@�@�@�@�@�@�^�@/�@ �@ l.l.�Q__�L�^'�L�@�@ �@ �@ �@ �R
�@�@�@�@�@�@ ,-�]'�L,r ' �L�@�@ �@ �P�P�@�@�@�@�@.|:l:�@�@ . : ::!
�@�@�@�@�@ ,.�ցR.!: . .�@ �@ �@ l /�@�@�@�@�@�@ . �R|�@. :/ : : !
�@�@ �@ �^�@�@ �R�R�A: : : : ,�: : : . . . . . . . : : : :<: �^:/: : ::�r
�@�@�@�@�@�@�@�@�^:::::::::::::)(:::)(:::::::::::)(::::::�O:::::::::::::::::::�_( �@
�@�@�@�@�@�@�@ ))(:::::::::::::::::::::::::(:::):::::::::::::::::(:::):�@::::::::::::::�_�`
�@�@�@�@�@�@/::::::::::/�m::::::::�::::::::�R:�l::::::::::�R::::::::::::::::::::::::))�j
�@�@�@�@�@�@�i:::::::::::::::::::::::::/�@�@�j:::�m::::Ɂ@) ��@�S:::::::::��::::�R
�@�@�@�@�@�@(�i:::::::::::::::./�@�c�@�@� ���@Ɂ@�@::�@�c:/)):::::::):�j �@�@ �Ձ`�`��
�@�@�@�@�@�@�i::::::::::/ �~�~�~�~�~�~�~.�B�c�c�c�c�c�@ :::::::::::�j�@�@�@�`
�@�@�@�@�`�i(::::::://�P�P�P�P�R===/�P�P�P�P�R |:::::::::�j))
�@�@�@�@�@ �@|==� �@�@-=�E==- �a�@�a�@-===�E=-�@�===
�@�@�@ /�� |:/ �a�@�@�@--�^�@/Ɂ@ �R�@�_----�@�a �@�R|�R�܁R
�@�@�@�q �@�@|/�@ �R�M======/�@ .�܁@�M ========�. �@ ..| | �@�@ �r�@�@�@
�@�@�@ �R �@.�i�@�B �E�F�E�e�Bc �i ���@�@�� �j�@�G�h�Eu�B*@�E�F�A�e�j�@ /�@�@
�@�@�@�@|�@�i�@�F�B�E�G���F�E�B/::: ::::::| |::::::�R�@�@�G 8@ �E�B�F���@�j�@|�@
�@�@�@�@�_�i �B�G�E�O�h*�Eo�G�^::::::::::l l::: ::: �_�@�F�B�E�G���F�E�B. �j�^�@ �@
�@�@�@�@�@�@ �i�G8@�E�B�F�@ �^�P�P�P�P�P�_:�@�h�E�F�B�G�h�E.�j
�@�@�@�@�@�@�@�i�O�h*�E o�^�@�@�@�@�@�@�@�@�@�@�_�@�O�h*�Eo�F�j
�@�@�@�@�@.�@�@�i�E�F��,:�j|.�@�@�P|�P|�P|�P�@�@ | :�i:���h�E�F�j�@�@
�@�@�@�@�@�@�@:�i�G 8@�E �_�@�@�@�P�P�@�@�@�@�^�G8@ *�E�E�j
�@�@�@�@�@�@�@�@�_:::o ::::�@�_�Q�Q�Q�Q�Q�^:::::::::::::::�^
�@�@�@�@�@�@�@�@�@ �R �R:::: _-�@::::: ��::�@::::::::::-_ �@�m
�@�@�@�@�@�@�@�@�@�@�@�_�@:::::::::::::::::�@:::::::::: ::: ::_�^
�@�@�@�@�@�@�@�@ �@, �]'��`^�V/��" �Q�^ '�L�@ �P ` �
�@�@�@�@�@�@�@�@�@�^�@/�@ �@ l.l.�Q__�L�^'�L�@�@ �@ �@ �@ �R
�@�@�@�@�@�@ ,-�]'�L,r ' �L�@�@ �@ �P�P�@�@�@�@�@.|:l:�@�@ . : ::!
�@�@�@�@�@ ,.�ցR.!: . .�@ �@ �@ l /�@�@�@�@�@�@ . �R|�@. :/ : : !
�@�@ �@ �^�@�@ �R�R�A: : : : ,�: : : . . . . . . . : : : :<: �^:/: : ::�r
���Ԃ�HD�x���@�\�͂�����܂������ĒN������Ȃ���
�[��Fusion����PC�͂܂������Ȃ����̂������ɂ��Ă���
�悭�l����ƁA�}���`���f�B�APC�Ɣ��ɑ������悳���������
�[��Fusion����PC�͂܂������Ȃ����̂������ɂ��Ă���
�悭�l����ƁA�}���`���f�B�APC�Ɣ��ɑ������悳���������
>>783
> GPGPU�̎g�����Ƃ��ĂȂ�œ���Đ��x�����łĂ��Ȃ��낤���H
�o�Ă邶���
> �����A�r�f�I�J�[�h�����r�f�I�J�[�h�̓���Đ��x���@�\�����p����DVD�Đ��\�t�g��
> ������O�̂悤�Ƀo���h������Ă�̂ɂȁB
> GPGPU�̎g�����Ƃ��ĂȂ�œ���Đ��x�����łĂ��Ȃ��낤���H
�o�Ă邶���
> �����A�r�f�I�J�[�h�����r�f�I�J�[�h�̓���Đ��x���@�\�����p����DVD�Đ��\�t�g��
> ������O�̂悤�Ƀo���h������Ă�̂ɂȁB
AMD�͎��O�ŃR���p�C�����Ȃ��́H
>>778
�����v���Z�b�T�ւ̑��w�͓����ˏo���Ă���
�㓡�̓}�[�P�e�B���O�ɐU���Ȃ�����͐^�����Ȏ������Ă�Ǝv���D
�}�[�P�e�B���O�����e�N�m���W�ɐU���Ď��X�ςȂ��Ə��������e�͈͓��D
�����v���Z�b�T�ւ̑��w�͓����ˏo���Ă���
�㓡�̓}�[�P�e�B���O�ɐU���Ȃ�����͐^�����Ȏ������Ă�Ǝv���D
�}�[�P�e�B���O�����e�N�m���W�ɐU���Ď��X�ςȂ��Ə��������e�͈͓��D
�U���Ă��Ȃ��Ă킩���Ăď����Ă��B
���������Ȃ��̂���{�Ȃ���B
���������Ȃ��̂���{�Ȃ���B
�킩���Ăď����Ă���Ȃ爫���ɂ܂�Ȃ���w
�}�W���X����Ƃ��������̂�ǂݎ��Ȃ��l�������B
�o���F�̖��������������X�ɒ��ӓ_�������Ă�̂ɁA�L���̈ꕔ�������グ�Ėϑz���Ɣᔻ�B
������Ď����̖��\���N���Ă邾���B
�o���F�̖��������������X�ɒ��ӓ_�������Ă�̂ɁA�L���̈ꕔ�������グ�Ėϑz���Ɣᔻ�B
������Ď����̖��\���N���Ă邾���B
����A��אF�ݾ��L������������A�������炦����ʂ̎d�����炦���肷��킯�����瓖�R����
AMD���낤��Intel���낤����������
AMD���낤��Intel���낤����������
�ᔻ�����o���Ȃ��n�����ϑz����Ă��̂ق��������ʔ��������}�V
>>791
�܂薳�\�ȃA���~�͗i�삷��K�v���������\���̂��x���ꂽ�A���~�ɑS�Ă̐ӂ�����Ƃ����킯����w
�܂薳�\�ȃA���~�͗i�삷��K�v���������\���̂��x���ꂽ�A���~�ɑS�Ă̐ӂ�����Ƃ����킯����w
795 �FSocket774�F2007/02/06(��) 09:13:48 ID:XUPRNJ2s
���\�A��\�ȂǂƐ��肾���̂͂������~
����ȓz�炪����Ǝv����intel���ǂ�Ȃɗǂ����i�����Ă��X���[���Ă��܂�
����ȓz�炪����Ǝv����intel���ǂ�Ȃɗǂ����i�����Ă��X���[���Ă��܂�
��אF�̖������E�ł́AXBOX��GPU��MS��AMDATi(��IBM)�ŊJ�����Ă���̂��L���ɓ�����B
�����͌݊��̂���`��PC��GPGPU�ɂ���������āA���ʂ̊J�������p�ӂ����B
NVIDIA�͓G�w�c�Ȃ̂őΉ�������x���B
�\�j�[�}���Z�[�̌㓡�݂Ƃ��Ă͂܂�Ȃ���������Ȃ��B
�����͌݊��̂���`��PC��GPGPU�ɂ���������āA���ʂ̊J�������p�ӂ����B
NVIDIA�͓G�w�c�Ȃ̂őΉ�������x���B
�\�j�[�}���Z�[�̌㓡�݂Ƃ��Ă͂܂�Ȃ���������Ȃ��B
���[�G���hGPU�ł��AVector�n���Z�p�t�H�[�}���X��
CPU�̗y����Ȃ��E�E�E
CPU�̗y����Ȃ��E�E�E
FUSION+�`�b�v�Z�b�g+VGA�ŁA�hTriple FUSION �h���Ă����@�\���o���������Ȃ�
>>796
XBOX�̏���Wii�ɒu�������Ă��ʗp����悤�ȕ��͂����B
XBOX�̏���Wii�ɒu�������Ă��ʗp����悤�ȕ��͂����B
Wii�͐��\�I�ɑ��Ђ�ǂ������闧�ꂾ����A�ǂ����Ȃ��H
PC�ƊE�ւ̉e���͂��Ȃ����B
PC�ƊE�ւ̉e���͂��Ȃ����B
������GPU�̒�`���Ă�͉̂����ł��邩���l�����
���GPU�̃p�t�H�[�}���X�ɁA�ڂ����Ă���̂������ł��邩��������͂��B
������Intel�����̂��߂ɁA�ǂ������s���ɏo�����B
���GPU�̃p�t�H�[�}���X�ɁA�ڂ����Ă���̂������ł��邩��������͂��B
������Intel�����̂��߂ɁA�ǂ������s���ɏo�����B
>>800
Wii�̃R���Z�v�g�͐��\�v����Ȃ�����A�u�ǂ�������v�Ƃ͈Ⴄ�Ǝv�����H
Wii�̃R���Z�v�g�͐��\�v����Ȃ�����A�u�ǂ�������v�Ƃ͈Ⴄ�Ǝv�����H
>>761
����ς����ł����A���T���N�X�B
��CMOS��H������Ă����ɁASRAM�͂S�g�����W�X�^���Ęb����
�o�����L���������Ȃ̂ŁA�����ᗠ�Â��ɂȂ�m�����疳�����甽�_
�o���Ȃ�������B
����ς����ł����A���T���N�X�B
��CMOS��H������Ă����ɁASRAM�͂S�g�����W�X�^���Ęb����
�o�����L���������Ȃ̂ŁA�����ᗠ�Â��ɂȂ�m�����疳�����甽�_
�o���Ȃ�������B
>>795
�����͗L�\������A�D�ꂽ�C���e�����i��I��ł���B
���\�ȃA���~�Ƃ͈Ⴄ�B
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�Ƃ����A�������Ȏ��ӎ��ȊO�A�����Ȃ��̂����~������ȁB
�����͗L�\������A�D�ꂽ�C���e�����i��I��ł���B
���\�ȃA���~�Ƃ͈Ⴄ�B
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�Ƃ����A�������Ȏ��ӎ��ȊO�A�����Ȃ��̂����~������ȁB
>>805
�̂������̍���t�قǍŋ߂̎��͂��Ղ肵���������~��ʔ����ɓ��S��肫���Ă��Ȃ��H
�̂������̍���t�قǍŋ߂̎��͂��Ղ肵���������~��ʔ����ɓ��S��肫���Ă��Ȃ��H
�����Winchester�R�A�o�ꂠ����̃A���~���͐}�Ɠ����ł���
AMD=�����́AϲŰ�A�s���A�Љ�A���`�A�����A�����A�����A�����A���a�A������
Intel=���́AҼެ��A���{�A�����A���A�ǔ��A�E���A�����A�ꕔ���A�c���A�c�q
Intel=���́AҼެ��A���{�A�����A���A�ǔ��A�E���A�����A�ꕔ���A�c���A�c�q
����hummer-Info ��AMD ��45nm�������Ƃ������Ă邪�AHigh-k+�����Q�[�g����
�� Intel �ɑR�o����̂��H
Intel�� High-k+�����Q�[�g��45nm ���A�ȓd�́����N���b�N��CPU�����܂�����
��AAMD��32nm �܂ő���Ȃ����ꂪ�E�E�E�E�B
�� Intel �ɑR�o����̂��H
Intel�� High-k+�����Q�[�g��45nm ���A�ȓd�́����N���b�N��CPU�����܂�����
��AAMD��32nm �܂ő���Ȃ����ꂪ�E�E�E�E�B
High-k�{���^���Q�[�g�͊m���ɐ����Z�p�����ǂ��ꂾ�����ᐫ�\�͌��܂�Ȃ��B
���[�N�̍팸�ȊO�ɖڂ��҂�쓮�d������������@�͑��ɂ�����B�c��Si�Ƃ��B
����AMD��ultra Low-k������B
Intel����`���ĂȂ��Ƃ��������Ƃ��̓_�ł�Intel�ɏ����Ă��Ȃ��낤���B
�܂����\���ǂ�قnj��シ�邩�͒m��ǁB
�v�͎g���Ă�Z�p�̎�ނ���Ȃ��Ď��ۂ̐��\���d�v���Ƃ������ɓ�����O�̌��_�Ȃ�ł����B
���[�N�̍팸�ȊO�ɖڂ��҂�쓮�d������������@�͑��ɂ�����B�c��Si�Ƃ��B
����AMD��ultra Low-k������B
Intel����`���ĂȂ��Ƃ��������Ƃ��̓_�ł�Intel�ɏ����Ă��Ȃ��낤���B
�܂����\���ǂ�قnj��シ�邩�͒m��ǁB
�v�͎g���Ă�Z�p�̎�ނ���Ȃ��Ď��ۂ̐��\���d�v���Ƃ������ɓ�����O�̌��_�Ȃ�ł����B
���\�ȑO�Ƀ����[�X�������܂���肾��
K8L 2.9GHz��Core2 3GHz�̑Ό�����������
�Z�M��dual��K8�̓������Č����Ă��
http://www.watch.impress.co.jp/Akiba/hotline/20061223/etc_akibax2006b.html
http://www.watch.impress.co.jp/Akiba/hotline/20061223/etc_akibax2006b.html
>>814
Quad��2.5GHz���x�炵�����A�����͒l�i���A���Ȃ̂Ń��C���X�g���[���̃f���A�����C�ɂȂ�̂�
�܂����\�͂悭�ăg���g���i���N���b�N�j���낤
Core2 3GHz��E6850 TDP65W�Ƃ��ďo�����̂ŁATDP130W�ɔ[�߂�ꂻ����QX6800��AMD����ł͏o�����̂�����
AMD 45nm�̉\���o�Ă邪�A���܂ł̗��ꂩ�猾���Ă܂��x��邩�Ȃ�
�b�͕ς�邪
X2 3800+���t�F�[�h�A�E�g����b�͂ǂ��Ȃ����H�܂��������H
4200+��3800+�̉��i�ɉ�������3800+�͏�����ǂ��납�A���i������ʏo�ׂ��Ă��
65nm��Athlon 3200+�������Ă邵�A���낻��Sempron���S��Athlon���ˑRSempron�ɂȂ邩��
Radeon X1600pro/X1300XT/X1650�݂����Ɂc
Quad��2.5GHz���x�炵�����A�����͒l�i���A���Ȃ̂Ń��C���X�g���[���̃f���A�����C�ɂȂ�̂�
�܂����\�͂悭�ăg���g���i���N���b�N�j���낤
Core2 3GHz��E6850 TDP65W�Ƃ��ďo�����̂ŁATDP130W�ɔ[�߂�ꂻ����QX6800��AMD����ł͏o�����̂�����
AMD 45nm�̉\���o�Ă邪�A���܂ł̗��ꂩ�猾���Ă܂��x��邩�Ȃ�
�b�͕ς�邪
X2 3800+���t�F�[�h�A�E�g����b�͂ǂ��Ȃ����H�܂��������H
4200+��3800+�̉��i�ɉ�������3800+�͏�����ǂ��납�A���i������ʏo�ׂ��Ă��
65nm��Athlon 3200+�������Ă邵�A���낻��Sempron���S��Athlon���ˑRSempron�ɂȂ邩��
Radeon X1600pro/X1300XT/X1650�݂����Ɂc
K8L��Turion64���Ӗ����Ă����BL��low-power�̈Ӗ��������B
K9�́ATurion�� (��2005�N) �ɏo����A��dual-core�v���Z�b�T�̃R�[�h�l�[���������B
K8L�ƍL����̂���Ă��� (Barcelona�ȍ~��) Cities and Stars�A�[�L�e�N�`���́AK10�ł���B
ttp://mypage.odn.ne.jp/www/k/8/k8_hammer_trans/files/Hammer-Info.html
K9�́ATurion�� (��2005�N) �ɏo����A��dual-core�v���Z�b�T�̃R�[�h�l�[���������B
K8L�ƍL����̂���Ă��� (Barcelona�ȍ~��) Cities and Stars�A�[�L�e�N�`���́AK10�ł���B
ttp://mypage.odn.ne.jp/www/k/8/k8_hammer_trans/files/Hammer-Info.html
>>817
>���@�^�����ǂ����͐}�肩�˂�Ƃ��낪����܂����AK8L�ƌĂ�łق����Ȃ��Ƃ����Ӑ}�͏\��������܂����B
>�ŁA������ɂȂ���K10�Ƃ������O���o���Ă����Ӑ}���悭������܂���B
>K10�Ƃ����ď̂��L�܂��Ăق����Ǝv���Ă���̂��ȂƂ����ƁA�����������͋C�͑S�R����܂��B
>������ɂ��Ă��A������ɂȂ��Ă���Ȃ��Ƃ������Ă��A������ƒx�����B
AMD�}�[�P�e�B���O����͂������Ɋi�������
>���@�^�����ǂ����͐}�肩�˂�Ƃ��낪����܂����AK8L�ƌĂ�łق����Ȃ��Ƃ����Ӑ}�͏\��������܂����B
>�ŁA������ɂȂ���K10�Ƃ������O���o���Ă����Ӑ}���悭������܂���B
>K10�Ƃ����ď̂��L�܂��Ăق����Ǝv���Ă���̂��ȂƂ����ƁA�����������͋C�͑S�R����܂��B
>������ɂ��Ă��A������ɂȂ��Ă���Ȃ��Ƃ������Ă��A������ƒx�����B
AMD�}�[�P�e�B���O����͂������Ɋi�������
>������ɂ��Ă��A������ɂȂ��Ă���Ȃ��Ƃ������Ă��A������ƒx�����B
Add amdfam10 instructions
http://sources.redhat.com/ml/binutils-cvs/2006-07/msg00051.html
��N��7���ɂ�10�Ԗڂ̃v���Z�b�T�[�ł��邱�Ƃ��킩���Ă����͂������H
Add amdfam10 instructions
http://sources.redhat.com/ml/binutils-cvs/2006-07/msg00051.html
��N��7���ɂ�10�Ԗڂ̃v���Z�b�T�[�ł��邱�Ƃ��킩���Ă����͂������H
���Ⴂ���鐢�Ԃ�������
AMD�}�[�P�e�B���O����͂������Ɋi�������
AMD�}�[�P�e�B���O����͂������Ɋi�������
>>810
SOI������intel�̓Q�[�g���[�N���High-k���g���������ł���
AMD�̓I�t���[�N��SOI�g���Ă邩�炻��ȂɋC�ɂ��鎖�����̂ł́H
SOI������intel�̓Q�[�g���[�N���High-k���g���������ł���
AMD�̓I�t���[�N��SOI�g���Ă邩�炻��ȂɋC�ɂ��鎖�����̂ł́H
�Ƃ肠�������̃X���ł�K8L��K10�ƌĂԕ����ł����̂�
>>823
�F�ł�����
�F�ł�����
>>778
���̒��ő匴��
���͖S�������A�X�L�[�Ō㓡�ƑΒk������B
�㓡�͓��R
�uCell�͊v�V�I��CPU�v
���������킯����
�u�v���O���~���O�l����ƃR�A�Q�܂ł͊y
����ȏ�ɂȂ�Ɛ����g�����Ȃ��͓̂���v�I�Ȕ�����
�匴�����������˂�����ł��B
���̒��ő匴��
���͖S�������A�X�L�[�Ō㓡�ƑΒk������B
�㓡�͓��R
�uCell�͊v�V�I��CPU�v
���������킯����
�u�v���O���~���O�l����ƃR�A�Q�܂ł͊y
����ȏ�ɂȂ�Ɛ����g�����Ȃ��͓̂���v�I�Ȕ�����
�匴�����������˂�����ł��B
K7�Ƃ�K8�Ƃ�P6�Ƃ����������ł܂�Ȃ����i�����j
>>822
�Q�[�g���[�N��SOI�͌����Ȃ���
�Q�[�g���[�N��SOI�͌����Ȃ���
>>827
�����Ȃ��̂͒m���Ă邪�AAMD�����[�N������Ė����l�ȃ��X������������c
�����Ȃ��̂͒m���Ă邪�AAMD�����[�N������Ė����l�ȃ��X������������c
>>826
�ȂX�^�[�t�@�~���[�Ƃ��Ă�ł�����ۂ�����K8L�Ƃ������AK10?
���AAM2�}�U�[�̌^�ԂɁuK9�v���ē����Ă����̂͂����������Ƃ������ˁB
�ȂX�^�[�t�@�~���[�Ƃ��Ă�ł�����ۂ�����K8L�Ƃ������AK10?
���AAM2�}�U�[�̌^�ԂɁuK9�v���ē����Ă����̂͂����������Ƃ������ˁB
��������}�U�[��K9�������ȁA�A�A
�Ȃ����݂�ȐG��Ȃ���������
�Ȃ����݂�ȐG��Ȃ���������
http://pc.watch.impress.co.jp/docs/2006/0119/kaigai233.htm
���X��K9�͐V�}�C�N���A�[�L�e�N�`�����������ǃL�����Z��
��
��փv�����Ƃ���K8�f���A���R�A��K9�ƌĂюn�߂�
����ȂƂ��ł���B
�ꎞ��AMD��K8�f���A���R�A�̂��Ƃ�K9�ƌ����Ă��炵�����B
�㓡���G���ŏ����Ă��B
���X��K9�͐V�}�C�N���A�[�L�e�N�`�����������ǃL�����Z��
��
��փv�����Ƃ���K8�f���A���R�A��K9�ƌĂюn�߂�
����ȂƂ��ł���B
�ꎞ��AMD��K8�f���A���R�A�̂��Ƃ�K9�ƌ����Ă��炵�����B
�㓡���G���ŏ����Ă��B
�܂�Intel������Nehalem�Ƃ����^�Ƃǂ߂ĂȂ���
���`�Ƃǂ߂ĂȂ����Ă����̂͌����o�Ă���łȂ��Ƃ��ɂ���ɂ傷�銴�o���c��ȁB
�S���ʕ��ɁA�����R�[�h�l�[�����������������B
�S���ʕ��ɁA�����R�[�h�l�[�����������������B
�I���W�i����Nehalem�����i�Ƃ��ďo��Ȃ�
���������̈��~�݂����ɖ\��邩���m���Ȃ�
�N���b�N�͍Œ�8GHz�ł��
���������̈��~�݂����ɖ\��邩���m���Ȃ�
�N���b�N�͍Œ�8GHz�ł��
>>834
POWER6��5GHz����TDP80W���x�炵�����B
6�N�O��POWER4�Ńf���A���R�A���APOWER5��SMT(HTT�̂悤�Ȃ���)�Ɨ��đ�O�����2�{�ȏ�̍��N���b�N
�ǂ����C���e���Ǝ��Ă�C�����邺
POWER6��5GHz����TDP80W���x�炵�����B
6�N�O��POWER4�Ńf���A���R�A���APOWER5��SMT(HTT�̂悤�Ȃ���)�Ɨ��đ�O�����2�{�ȏ�̍��N���b�N
�ǂ����C���e���Ǝ��Ă�C�����邺
>>836�͉������������낤�H
>>833�́u�S���ʕ��ɁA�����R�[�h�l�[�����������������B�v��
�{����{nehalem,K9}�Ƃ͂܂������ʕ���
{�V����nehalem�ƌĂ�����,�P�Ȃ�f���A���R�AAthlon64}����t��
{nehalem,K9}�Ƃ��������R�[�h�l�[����������������
�����Ă��Ȃ��́H
>>833�́u�S���ʕ��ɁA�����R�[�h�l�[�����������������B�v��
�{����{nehalem,K9}�Ƃ͂܂������ʕ���
{�V����nehalem�ƌĂ�����,�P�Ȃ�f���A���R�AAthlon64}����t��
{nehalem,K9}�Ƃ��������R�[�h�l�[����������������
�����Ă��Ȃ��́H
�S���ʕ��Ȃ���K9����Ȃ���J9���ČĂڂ����I
����p
��������A��ATi�͐��i���ς��ƃR�[�h�l�[�����ς��Ă���
R400�̃L�����Z����R420
R400�̃L�����Z����R420
939�͂����VCPU�̓����͂Ȃ��̂ł������E�E�E�H
����Ȱт;�r(ry
�P�[�i�C���b
�n�Q�b��
�n�Q�b��
>>842
��������Ă����������A���ɂ�����܂����c�c
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@Socket754
��������Ă����������A���ɂ�����܂����c�c
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@Socket754
�c�t���Ȃ�
�S�R�b�͕ς�邪�A�T�E�X�`�b�v�̋tFusion���Ă͖̂������ȁH
SCSI��Intel100Pro��LAN�J�[�h�Ȃ́AMCU�̗ނ��ڂ��ăC���e���W�F���g
���삵�Ă�����ACPU���ׂ������Ă��̂�����A���̃T�E�X�ɂ�SATA�₽GbE
��炪�W�ς��Ă邩��A������C���e���W�F���g������ׂ�CPU�R�A��Fusion
����A���ʓI��CPU���\�A�b�v���o����Ǝv���̂����B
SCSI��Intel100Pro��LAN�J�[�h�Ȃ́AMCU�̗ނ��ڂ��ăC���e���W�F���g
���삵�Ă�����ACPU���ׂ������Ă��̂�����A���̃T�E�X�ɂ�SATA�₽GbE
��炪�W�ς��Ă邩��A������C���e���W�F���g������ׂ�CPU�R�A��Fusion
����A���ʓI��CPU���\�A�b�v���o����Ǝv���̂����B
���̂��߂ɔėpCPU���T�E�X�ɓ�������́H
�E�E�E
�E�E�E
850 �F�E�́E�j��-{}@{}@{}@ ��DanGorION6 �F2007/02/07(��) 22:11:59 ID:zesqwyzZ
�{���]�|�B��p���W�b�N�ɂ��Ă��܂��������܂������B
x86 Everywhere����������AMD�ɂƂ��Đ�p���W�b�N�͔s�k
>>825
�܂�CPU�̓\�t�g���炷���߂̓���ɉ߂���
�A�[�L�e�N�`��"����"����Ă��Ӗ�������ȁB
�\�t�g�J�����ɗ���������������匴��
CPU�������Ė������Ă�㓡
���̓�l�̋c�_�����ݍ������͉i���ɂȂ��낤�E�E�E�E
�܂�CPU�̓\�t�g���炷���߂̓���ɉ߂���
�A�[�L�e�N�`��"����"����Ă��Ӗ�������ȁB
�\�t�g�J�����ɗ���������������匴��
CPU�������Ė������Ă�㓡
���̓�l�̋c�_�����ݍ������͉i���ɂȂ��낤�E�E�E�E
>>848
x86����C7���C�t�B�̔��z�ɋ߂��ȁB
x86����C7���C�t�B�̔��z�ɋ߂��ȁB
�t���Č��������u�T�E�X���ɂ�CPU���ڂ���̂��Ǝv����
���̒ʂ肾��
�����������T�E���h�`�b�v���T�E�X�`�b�v���m�[�X�`�b�v���S��CPU�ɂ��悤
���o�����m���
ttp://nueda.main.jp/blog/archives/002498.html
ttp://nueda.main.jp/blog/archives/002498.html
>>848
SATA �͂Ȃ��B
�X�g���[�W�n�͊���CPU���ׂ͂��Ȃ�Ⴍ�ăC���e���W�F���g������
�Ӗ��͂��܂�Ȃ�����B
NIC�͂��肤��B
���[�J�[�n�̌����������X�o���Ă� TCP offload engine �Ȃ�Ă̂́A
�܂��ɂ����������z�B
�ł��A�L�܂�Ƃ�����A�N���C�A���g�n���炶��Ȃ��ăT�[�o�n����
���낤�ˁB�N���C�A���g�̕��̓G���R���Q�[���ł����Ȃ�����ACPU��
�]��܂���ł���B
SATA �͂Ȃ��B
�X�g���[�W�n�͊���CPU���ׂ͂��Ȃ�Ⴍ�ăC���e���W�F���g������
�Ӗ��͂��܂�Ȃ�����B
NIC�͂��肤��B
���[�J�[�n�̌����������X�o���Ă� TCP offload engine �Ȃ�Ă̂́A
�܂��ɂ����������z�B
�ł��A�L�܂�Ƃ�����A�N���C�A���g�n���炶��Ȃ��ăT�[�o�n����
���낤�ˁB�N���C�A���g�̕��̓G���R���Q�[���ł����Ȃ�����ACPU��
�]��܂���ł���B
�܂����i�͂��܂�܂���Ȃ킯�����G���R��Q�[��������ƂƂ���ɃJ�c�J�c�ɂȂ�Ƃ���
�����������Ȃ��Ă���Ƃ����̂�
HDD���D�b��Ȃ��Ƃ�����c
HDD���D�b��Ȃ��Ƃ�����c
>>849
�ėp�Ƃ����قǍ����\�Ȃ̂͗v��Ȃ����A�}���`�X���b�h�Ή���MCU�͗~�������ȁH
>>859
���ׂ����l������PATA��UDMA�����ꂽ���_�ő啝�Ɍ����Ă�Ǝv�����B
������CPU�g�p���͂Ƃ������ACPU�̖��߂�f�[�^�̃X�g���[�~���O���ɗ͗������A
�y�уL���b�V���̃t���b�V�������炷�Ӗ��ł̖������l���Ă�B
>>860 �̗l�ȃp�^�[���̎��ɏd�v���ƁB
����HDD�́A�Í����Ɋւ��Ă�HDD���ŃC���e���W�F���g������b���������ˁB
�ėp�Ƃ����قǍ����\�Ȃ̂͗v��Ȃ����A�}���`�X���b�h�Ή���MCU�͗~�������ȁH
>>859
���ׂ����l������PATA��UDMA�����ꂽ���_�ő啝�Ɍ����Ă�Ǝv�����B
������CPU�g�p���͂Ƃ������ACPU�̖��߂�f�[�^�̃X�g���[�~���O���ɗ͗������A
�y�уL���b�V���̃t���b�V�������炷�Ӗ��ł̖������l���Ă�B
>>860 �̗l�ȃp�^�[���̎��ɏd�v���ƁB
����HDD�́A�Í����Ɋւ��Ă�HDD���ŃC���e���W�F���g������b���������ˁB
�������� SerialATA �� Native Command Queuing ���āAHDD���ōs���Ă�
�����H�@����Ƃ��h���C�o���H
�h���C�o���Ȃ�T�E�X�`�b�v�̋tFusion���𗧂����������B
�����H�@����Ƃ��h���C�o���H
�h���C�o���Ȃ�T�E�X�`�b�v�̋tFusion���𗧂����������B
3�N�O�ɔ��\���ꂽ�t���[�X�P�[���̃f���A���R�APPC�ƁA�ŋ�P.A�Z�~���甭�\���ꂽPPC�ɂ͂Q�̃����R���ڂ��Ă邯�ǁA
�f���A���R�A/�N�A�b�h/�I�N�g�R�AOpteron�ɍڂ�����ƌ��ʂ������肷��H
�f���A���R�A/�N�A�b�h/�I�N�g�R�AOpteron�ɍڂ�����ƌ��ʂ������肷��H
IntelR RAID Controller SRCSAS144E
http://download.intel.com/design/servers/RAID/srcsas144e/31358601.pdf
�C���e�� IOP333 I/O �v���Z�b�T�[�E�`�b�v�Z�b�g
http://www.intel.co.jp/jp/design/iio/iop333.htm
LSISAS1064E PCI Express to 4-Port Serial Attached SCSI Controller
http://www.lsi.com/files/docs/techdocs/storage_stand_prod/sas/lsisas1064E_ds.pdf
http://download.intel.com/design/servers/RAID/srcsas144e/31358601.pdf
�C���e�� IOP333 I/O �v���Z�b�T�[�E�`�b�v�Z�b�g
http://www.intel.co.jp/jp/design/iio/iop333.htm
LSISAS1064E PCI Express to 4-Port Serial Attached SCSI Controller
http://www.lsi.com/files/docs/techdocs/storage_stand_prod/sas/lsisas1064E_ds.pdf
> ������CPU�g�p���͂Ƃ������ACPU�̖��߂�f�[�^�̃X�g���[�~���O���ɗ͗������A
> �y�уL���b�V���̃t���b�V�������炷�Ӗ��ł̖������l���Ă�B
������ӂ́A�X�g���[�W�� HBA �����C���e���W�F���g�����Ă�����܂�ς���B
�ǂ����ɂ��� HBA �Ɏw�߂��o�������� CPU ������K�v�����邩��ˁB
���Ȃ݂ɁARAID �� SCSI �n�� HBA �͂Ƃ����̐̂ɃC���e���W�F���g�����Ă�B
(�C���e���W�F���g����Ȃ��z�����邪)
NIC�̕��́A���̂Ƃ���v���g�R��������CPU�ł���Ă�̂ŁA�����̂Ƃ����
�����ԕς��B
> �y�уL���b�V���̃t���b�V�������炷�Ӗ��ł̖������l���Ă�B
������ӂ́A�X�g���[�W�� HBA �����C���e���W�F���g�����Ă�����܂�ς���B
�ǂ����ɂ��� HBA �Ɏw�߂��o�������� CPU ������K�v�����邩��ˁB
���Ȃ݂ɁARAID �� SCSI �n�� HBA �͂Ƃ����̐̂ɃC���e���W�F���g�����Ă�B
(�C���e���W�F���g����Ȃ��z�����邪)
NIC�̕��́A���̂Ƃ���v���g�R��������CPU�ł���Ă�̂ŁA�����̂Ƃ����
�����ԕς��B
����A�m���Ă邵�B
�����H
��CPU�ŕ��ʂɂ���Ă邱�Ƃ́A�ςȃA�[�L�e�N�`����������悩
�}���`�R�A�������ł���E�E�E
�}���`�R�A�������ł���E�E�E
�A�v�����Ή����Ă�����Ȃ炻��ł��܂�Ȃ�����
>>866
���ꂾ�Ɖ��ׂ̈�RAID �� SCSI �n�� HBA���C���e���W�F���g������Ă�̂��H
����Ȃ�ɈӖ������邩�炵�Ă�̂ł́H
�Ƃ���Ő̂�SCSI�̕�������G���R�[�h�Ƃ�����ꍇ�ɁACPU���ׂ����Ȃ���
���������b���L�����Ǝv�����A�����HBA �����C���e���W�F���g������Ă�
���A�������̂ł́H
���͂�������Ȃ����Ęb���A�P��CPU���\���オ��������A�Ƃ������R�Ȃ�A
�b�̑O�����̂����B
�����܂ł�����CPU���\�A�b�v�̈�Ԃ̃l�b�N���A���C���������ւ̃A�N�Z�X
������A����CPU�ł��A�b�v�A�b�v�ȏ������s���ꍇ�ɁA�tFusion���𗧂�
�ł́H�Ƃ����z�肩��b���n�߂��̂����B
>>869
�}���`�R�A�ɂ�����ɂ͕��ׂ����������Ėܑ̂Ȃ����낤���A�X�g���[�~���O
�𗐂��Ȃ��A�Ƃ����ژ_�݂������o���Ȃ��C���B
���ꂾ�Ɖ��ׂ̈�RAID �� SCSI �n�� HBA���C���e���W�F���g������Ă�̂��H
����Ȃ�ɈӖ������邩�炵�Ă�̂ł́H
�Ƃ���Ő̂�SCSI�̕�������G���R�[�h�Ƃ�����ꍇ�ɁACPU���ׂ����Ȃ���
���������b���L�����Ǝv�����A�����HBA �����C���e���W�F���g������Ă�
���A�������̂ł́H
���͂�������Ȃ����Ęb���A�P��CPU���\���オ��������A�Ƃ������R�Ȃ�A
�b�̑O�����̂����B
�����܂ł�����CPU���\�A�b�v�̈�Ԃ̃l�b�N���A���C���������ւ̃A�N�Z�X
������A����CPU�ł��A�b�v�A�b�v�ȏ������s���ꍇ�ɁA�tFusion���𗧂�
�ł́H�Ƃ����z�肩��b���n�߂��̂����B
>>869
�}���`�R�A�ɂ�����ɂ͕��ׂ����������Ėܑ̂Ȃ����낤���A�X�g���[�~���O
�𗐂��Ȃ��A�Ƃ����ژ_�݂������o���Ȃ��C���B
���������ACPU���g���鏈������Ă�Œ��ɁA
IO�ł��ACPU�ɂ₽��ɕ��ׂ��������Ă���
�Ȃ�Ă��Ƃ���{�I�ɖ����̂�
����Ȃ��Ƃ��Ă��ACPU�͂����Ƃ������Ȃ��
IO�ł��ACPU�ɂ₽��ɕ��ׂ��������Ă���
�Ȃ�Ă��Ƃ���{�I�ɖ����̂�
����Ȃ��Ƃ��Ă��ACPU�͂����Ƃ������Ȃ��
Winny���Ȃ����҂ł�ݺ���Ă��
>>871
>���ꂾ�Ɖ��ׂ̈�RAID �� SCSI �n�� HBA���C���e���W�F���g������Ă�̂��H
I/O�A�N�Z�X���C�e���V�B���̂��߂���
�f�B�X�N��ms�̃V�[�N�^�C���Ȃ�Ă̂�
CPU�ł͈�疜�T�C�N���ɑ�������
�f�B�X�N�A�N�Z�X���N�G�X�g���o����
�f�[�^�҂����ɑ��̎����ɂ��Ă�
��疜�T�C�N������ɂ������]�f�[�^�����Ȃ��Ⴠ�_�߂���
�C���e���W�F���g�łق�̂�����Ƃł�
���C�e���V�̉B�����ł���Ȃ��̎�����
>���ꂾ�Ɖ��ׂ̈�RAID �� SCSI �n�� HBA���C���e���W�F���g������Ă�̂��H
I/O�A�N�Z�X���C�e���V�B���̂��߂���
�f�B�X�N��ms�̃V�[�N�^�C���Ȃ�Ă̂�
CPU�ł͈�疜�T�C�N���ɑ�������
�f�B�X�N�A�N�Z�X���N�G�X�g���o����
�f�[�^�҂����ɑ��̎����ɂ��Ă�
��疜�T�C�N������ɂ������]�f�[�^�����Ȃ��Ⴠ�_�߂���
�C���e���W�F���g�łق�̂�����Ƃł�
���C�e���V�̉B�����ł���Ȃ��̎�����
ttp://mypage.odn.ne.jp/www/k/8/k8_hammer_trans/files/Hammer-Info.html
AM2+�ȃ`�b�v�Z�b�g���Ăǂ��Ȃ�낤�ˁB
DDR3�ւ̑Ή��͌��ɂ��ꍞ���AM3�̑��݂����������ȁBFusion����Ȃ�w�c�q�Ƃ��̗p����������
�\�P�b�g���ւ��ėǂ��Ǝv�����ǁBAM2>AM2+>AM3>�V�\�P���ĂȂ��B�ւ���^�C�~���O���������͂�����
���ė~�������ǁB������AM3����Ă����Ⴂ�����ǁB
AM2+�ȃ`�b�v�Z�b�g���Ăǂ��Ȃ�낤�ˁB
DDR3�ւ̑Ή��͌��ɂ��ꍞ���AM3�̑��݂����������ȁBFusion����Ȃ�w�c�q�Ƃ��̗p����������
�\�P�b�g���ւ��ėǂ��Ǝv�����ǁBAM2>AM2+>AM3>�V�\�P���ĂȂ��B�ւ���^�C�~���O���������͂�����
���ė~�������ǁB������AM3����Ă����Ⴂ�����ǁB
�ϑz�͂��̕ӂ�
>>874
AMD�͂킩��AIntel����Nehalem����ɂȂ�ƃf�X�N�g�b�v��
�W���łS�R�A�W�X���b�h�ɂȂ�̂ł��̂ւ��CPU�ɂ��܂����ł�����ˁB
AMD�͂킩��AIntel����Nehalem����ɂȂ�ƃf�X�N�g�b�v��
�W���łS�R�A�W�X���b�h�ɂȂ�̂ł��̂ւ��CPU�ɂ��܂����ł�����ˁB
>>876
�w�c�q�͌���ϑz�����ǁA�c�c�q�R�̓C���e���������R����������܂Ń��C���X�g���[��
�ɂ�Ȃ��̂���B45nm���炾�����Q�O�O�W�N�p�P�`�`�l�c��45nm���Q�O�O�W�N���Ղ�����
�C���e���̎d�l�����܂�����`�l�c�̃����R���͘M��Ȃ��B�����܂Œx����V�\�P�ł������B
�c�c�q�R���ăC���e���̃m�[�g�ō��N�̒��Ս̗p���邾���ł��B���\��肩�́A�d�͏���̖��ŁB
�܂������⎩�Ȋ��������C������B�`�l�Q�{����������ȋK�i�Ƃ��Ĕ���o���Ӗ����킩���ȁB
�w�c�q�͌���ϑz�����ǁA�c�c�q�R�̓C���e���������R����������܂Ń��C���X�g���[��
�ɂ�Ȃ��̂���B45nm���炾�����Q�O�O�W�N�p�P�`�`�l�c��45nm���Q�O�O�W�N���Ղ�����
�C���e���̎d�l�����܂�����`�l�c�̃����R���͘M��Ȃ��B�����܂Œx����V�\�P�ł������B
�c�c�q�R���ăC���e���̃m�[�g�ō��N�̒��Ս̗p���邾���ł��B���\��肩�́A�d�͏���̖��ŁB
�܂������⎩�Ȋ��������C������B�`�l�Q�{����������ȋK�i�Ƃ��Ĕ���o���Ӗ����킩���ȁB
>>879
Intel�̃����R��������Nehalem�����2008�N�㔼����
DDR3�̃{�����[���o�ׂ͂��ꂷ��Ԃɍ���Ȃ��Ƃ����b�����B
�Ή��`�b�v�Z�b�g���̂�2007Q2�`Q3��X38����B�m�[�g�őΉ��Ƃ����b�͒m���B
Intel�̃����R��������Nehalem�����2008�N�㔼����
DDR3�̃{�����[���o�ׂ͂��ꂷ��Ԃɍ���Ȃ��Ƃ����b�����B
�Ή��`�b�v�Z�b�g���̂�2007Q2�`Q3��X38����B�m�[�g�őΉ��Ƃ����b�͒m���B
ttp://www.theinquirer.net/default.aspx?article=37548
Meet Larrabee, Intel's answer to a GPU
Hello CGPUs, goodbye Nvidia
CGPU??
Meet Larrabee, Intel's answer to a GPU
Hello CGPUs, goodbye Nvidia
CGPU??
DDR3���܂Ƃ��ɏo�Ă��Ȃ����_��Fusion�͏o��O�ɏI�������������
�I������I������撣���Č����Ă��郄�c�����邪�A
�Ȃ�ς��Ȃ����Ă�������B
�Ȃ�ς��Ȃ����Ă�������B
884 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2007/02/10(�y) 12:37:00 ID:rv9wcSJq
������I/F���V���A��������������̋K�i���ǂ��Ȃ낤��
�t���b�V��ROM���������őΉ��ł������
�t���b�V��ROM���������őΉ��ł������
�������̃V���A�����͒x�����S�z��
���C�e���V�͉B���ł��邪�ш�͂����͂����Ȃ��̂ŁB
>>874
�����Ȃ痝�R�͈Ⴄ���A�tFusion�̃����b�g�͗L����Ęb�ɂȂ肻�������B
�����Ȃ痝�R�͈Ⴄ���A�tFusion�̃����b�g�͗L����Ęb�ɂȂ肻�������B
>>887
��CPU������Ă��Ƃ��t Fusion���ă`�b�v�Z�b�g�ɓ��������Ƃ����
�ǂ����������b�g������H
�}���`�R�ACPU�̃��\�[�X�̗]�����R�A�ł��ł��Ȃ�����
�t Fusion����Ƃł���悤�ɂȂ�Ƃł��H
��CPU������Ă��Ƃ��t Fusion���ă`�b�v�Z�b�g�ɓ��������Ƃ����
�ǂ����������b�g������H
�}���`�R�ACPU�̃��\�[�X�̗]�����R�A�ł��ł��Ȃ�����
�t Fusion����Ƃł���悤�ɂȂ�Ƃł��H
>>888
�o�X������ɃT�E�X�`�b�v�Ń��[�J����IO�����s��
�I�t���[�h��p�`�b�v�Ƃ��Ĕėp86�v���Z�b�T�g�����Ă��Ƃ����
86�Ȃ猻��h���C�o�����̕����̃R�[�h�̒u���������y��������
�o�X������ɃT�E�X�`�b�v�Ń��[�J����IO�����s��
�I�t���[�h��p�`�b�v�Ƃ��Ĕėp86�v���Z�b�T�g�����Ă��Ƃ����
86�Ȃ猻��h���C�o�����̕����̃R�[�h�̒u���������y��������
�T�E�X�̑ш�Ȃ�Ēm��Ă邩��CPU�ł���Ă��ς���
>>888 >>890
�ߋ����O��ǂ�ŗ������ĂȂ��̂��H�@���x�������Ă邾��B
�����܂ł�CPU���A�b�v�A�b�v���Ă�l�ȏ�ԂŁA���\�A�b�v�̈�Ԃ�
�l�b�N�ɂȂ��Ă郁�C���������ւ̃A�N�Z�X���A���߂�f�[�^�̃X�g��
�[�~���O���ז����Ȃ����ŁA���\�A�b�v���ʂ�_���Ă̘b�Ȗ��B
CPU�̏����\�͂��]���Ă��Ԃ�O��ɂ��Ă�Ȃ�A���̃X���̎�|��
���鎟����CPU����C�����Ƃ����b�ɂȂ�̂ł́H
>>889
�����܂ł͍l���ĂȂ��������A�����������p���A���i�B
�ߋ����O��ǂ�ŗ������ĂȂ��̂��H�@���x�������Ă邾��B
�����܂ł�CPU���A�b�v�A�b�v���Ă�l�ȏ�ԂŁA���\�A�b�v�̈�Ԃ�
�l�b�N�ɂȂ��Ă郁�C���������ւ̃A�N�Z�X���A���߂�f�[�^�̃X�g��
�[�~���O���ז����Ȃ����ŁA���\�A�b�v���ʂ�_���Ă̘b�Ȗ��B
CPU�̏����\�͂��]���Ă��Ԃ�O��ɂ��Ă�Ȃ�A���̃X���̎�|��
���鎟����CPU����C�����Ƃ����b�ɂȂ�̂ł́H
>>889
�����܂ł͍l���ĂȂ��������A�����������p���A���i�B
>>891
���܂���V���O���R�A�O��Řb����Ă���
���܂���V���O���R�A�O��Řb����Ă���
>>892
���܂��͂��������˂Ă鏬�w����
���܂��͂��������˂Ă鏬�w����
>>891
�K�����Ȃ�
�K�����Ȃ�
�R�X�g�p�t�H�[�}���X������
>>893
���������ޑO�ɂ��ł�888�������Ă����
���������ޑO�ɂ��ł�888�������Ă����
>>896
�����炢�܂ł��O�_�O�_�����������Ă����Ă����
�����炢�܂ł��O�_�O�_�����������Ă����Ă����
�̂�80286�Ƃ��𓋍ڂ��Ă���IDE�J�[�h���������Ȃ��B
SIMM�ŃL���b�V���������݂ł����肵�āB
SIMM�ŃL���b�V���������݂ł����肵�āB
>>891
�V���O���R�A�Ȃ�A�b�v�A�b�v���������
���ꂩ�瑽�R�A�ɂȂ�Ό��ł��]��܂���悤�ɂȂ��
�\�t�g���g����Ȃ��Ȃ邩���
������R�A��P�ɑ��₷�̂ł͂Ȃ�
Fusion��GPU�R�A���`�Ƃ����������o�Ă��
�S�z���Ȃ��Ă�����̓A�b�v�A�b�v�Ƃ͖�����
�V���O���R�A�Ȃ�A�b�v�A�b�v���������
���ꂩ�瑽�R�A�ɂȂ�Ό��ł��]��܂���悤�ɂȂ��
�\�t�g���g����Ȃ��Ȃ邩���
������R�A��P�ɑ��₷�̂ł͂Ȃ�
Fusion��GPU�R�A���`�Ƃ����������o�Ă��
�S�z���Ȃ��Ă�����̓A�b�v�A�b�v�Ƃ͖�����
>���\�A�b�v�̈�Ԃ�
>�l�b�N�ɂȂ��Ă郁�C���������ւ̃A�N�Z�X���A���߂�f�[�^�̃X�g��
>�[�~���O���ז����Ȃ����ŁA���\�A�b�v���ʂ�_���Ă̘b�Ȗ��B
�ؗ�ɃX���[�ł��Ȃ�����
>�l�b�N�ɂȂ��Ă郁�C���������ւ̃A�N�Z�X���A���߂�f�[�^�̃X�g��
>�[�~���O���ז����Ȃ����ŁA���\�A�b�v���ʂ�_���Ă̘b�Ȗ��B
�ؗ�ɃX���[�ł��Ȃ�����
�����[�T�E�X�̎d����CPU�̃��C����Ƃ̃������ш������������̂Ȃ�ĂȂ�����Ȃ�
���܂���K���������ʂ�
���͑S�Ăɂ����Ă��܂�����D��Ă���
���܂��炪�ǂ�Ȃɉ��Ɏ��i�����Ȃ����Ƃ��Ă�����
���͑S�Ăɂ����Ă��܂�����D��Ă���
���܂��炪�ǂ�Ȃɉ��Ɏ��i�����Ȃ����Ƃ��Ă�����
>902
���܂��@������������
���܂��@������������
AMD talks up Barcelona power
http://www.theinquirer.net/default.aspx?article=37574
http://www.theinquirer.net/default.aspx?article=37574
�������A��������ISSCC�̋G�߂���
�F�X�y���݂�
�F�X�y���݂�
����K8L����Ȃ��AK10���ČĂ�ł��
907 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2007/02/12(��) 15:29:42 ID:22DFMDXJ
K8 Rev.H�ł͂Ȃ�
AMD64 Rev.H
���Č��������������̂���
PS3����������L�v�ȏ��W�߂悤�Ǝv���ăQ�n��Cell�X������������
����ς�L��
AMD64 Rev.H
���Č��������������̂���
PS3����������L�v�ȏ��W�߂悤�Ǝv���ăQ�n��Cell�X������������
����ς�L��
>>907
�����Q�n�ɍs�����_�ŊԈ���Ă�B
�Q�[���̂��ƒm�肽����e�W�������n�̔����A
�v���O�����̂��ƂȂ�Q�[������Z�p���B
�����Q�n�ɍs�����_�ŊԈ���Ă�B
�Q�[���̂��ƒm�肽����e�W�������n�̔����A
�v���O�����̂��ƂȂ�Q�[������Z�p���B
����͒N�ł��m���Ă邱�Ƃ�����ȁ[�E�E�E�P�ɏL����k���ɂ������낤�E�E�E�B
�����ł��Ȃ���Q�n�Ȃ�đI��B
�X�J�g����Ȃ̂�������Ȃ��ȁB
�����ł��Ȃ���Q�n�Ȃ�đI��B
�X�J�g����Ȃ̂�������Ȃ��ȁB