�y�Q�[���n�[�h�z������@�e�N�m���W�[10�y�X���z
1 �F����������K�������F
�O�X��
�y�Q�[���n�[�h�z������@�e�N�m���W�[9�y�X���z
http://game10.2ch.net/test/read.cgi/ghard/1120348765/
���łɑ��@��Ԃ̔�r�����鏑�����݂̓X���[�̕�����
�y�Q�[���n�[�h�z������@�e�N�m���W�[9�y�X���z
http://game10.2ch.net/test/read.cgi/ghard/1120348765/
���łɑ��@��Ԃ̔�r�����鏑�����݂̓X���[�̕�����
|
|
|
2 �F����������K�������F2005/07/07(��) 12:58:35 ID:UtbtAPl4
2get�I
3 �F����������K�������F2005/07/07(��) 13:19:01 ID:VSQOErfJ
http://www.pcpop.com/doc/0/90/90528.shtml
sm4.0�Ή��ō���5�N�Ԃ�xenos�ɏ���GPU�Ȃ�
sm4.0�Ή��ō���5�N�Ԃ�xenos�ɏ���GPU�Ȃ�
4 �F����������K�������F2005/07/07(��) 13:29:30 ID:OCHQwqCz
5 �F����������K�������F2005/07/07(��) 14:56:45 ID:0PDR5C+g
SM4.0���ĂȂH
6 �F����������K�������F2005/07/07(��) 15:20:39 ID:M/6Ta75k
DirectX 10�Ɠ����l�Ȃ��ƁB
7 �F����������K�������F2005/07/07(��) 15:36:26 ID:oycdOqFP
cell�͂���������
�Ȃ������d�͂ŗ��_�l�㐫�\�����`���N�`������
PS3�ɍڂ�ʂɉ��i�������̂Ɏ��Ԃ��łĂ��Ȃ��̂��E�E�E
360CPU�����Ȃ薳�����Ă������낤�����
������œK������ʂ��PC�ɂ͎g���܂���Ȃ��
��{�I��linux�Ȃg���z��1��2���炢�̗p�r�ł���
�g��Ȃ������������̍œK���Ȃ�Ă�����ł��ł��邾��
��{�I�Ƀ��[�N�X�e�[�W�����̍l���ɋ߂����낤�����
cell��SGI��CPU�݂�����
�Ȃ������d�͂ŗ��_�l�㐫�\�����`���N�`������
PS3�ɍڂ�ʂɉ��i�������̂Ɏ��Ԃ��łĂ��Ȃ��̂��E�E�E
360CPU�����Ȃ薳�����Ă������낤�����
������œK������ʂ��PC�ɂ͎g���܂���Ȃ��
��{�I��linux�Ȃg���z��1��2���炢�̗p�r�ł���
�g��Ȃ������������̍œK���Ȃ�Ă�����ł��ł��邾��
��{�I�Ƀ��[�N�X�e�[�W�����̍l���ɋ߂����낤�����
cell��SGI��CPU�݂�����
8 �F����������K�������F2005/07/07(��) 15:38:37 ID:QQcY91V9
�V�F�[�_�[���f��4.0�A�V�F�[�_�[���f���Ƃ����̂̓s�N�Z���V�F�[�_�[��
�o�[�e�b�N�X�V�F�[�_�[���ǂꂾ���̋@�\�������Ƃ�����ŁA
�}�C�N���\�t�g�̒�߂����E�E�E����������
�K�肳��Ă���@�\�����Ă�����̃o�[�W�����Ή����Ď��ɂȂ�
�܂��AGPU�̐��\��SM�����Ō��܂��Ȃ��A�Ή����ĂĂ��x���Ďg������
�Ȃ�Ȃ��Ƃ�������̂ŁA�����܂őΉ����Ă���@�\�̍Œ���̖ڈ������A
PC��DirectX���g���ꍇ�͎g����̂����͈̔͂ɐ��������
OpenGL��Q�[���@�̓Ǝ�API��GPU���g���ꍇ�́AGPU�̎����Ă���\�͂��g����
���߂�SM�ɔ����鎖�͖���
�o�[�e�b�N�X�V�F�[�_�[���ǂꂾ���̋@�\�������Ƃ�����ŁA
�}�C�N���\�t�g�̒�߂����E�E�E����������
�K�肳��Ă���@�\�����Ă�����̃o�[�W�����Ή����Ď��ɂȂ�
�܂��AGPU�̐��\��SM�����Ō��܂��Ȃ��A�Ή����ĂĂ��x���Ďg������
�Ȃ�Ȃ��Ƃ�������̂ŁA�����܂őΉ����Ă���@�\�̍Œ���̖ڈ������A
PC��DirectX���g���ꍇ�͎g����̂����͈̔͂ɐ��������
OpenGL��Q�[���@�̓Ǝ�API��GPU���g���ꍇ�́AGPU�̎����Ă���\�͂��g����
���߂�SM�ɔ����鎖�͖���
9 �F����������K�������F2005/07/07(��) 15:41:28 ID:QQcY91V9
>>7
�g���܂���Ȃ�ĒN�������ĂȂ���
����Cell���ڂ̃R���s���[�^�[�V�X�e���͊J������Ă���
ttp://pc.watch.impress.co.jp/docs/2005/0629/mercury.htm
�܂��p�[�\�i���R���s���[�^�[�Ƃ͐F�X�ƈႤ���낤��
�ŁA���njN�͉������������ˁH
�g���܂���Ȃ�ĒN�������ĂȂ���
����Cell���ڂ̃R���s���[�^�[�V�X�e���͊J������Ă���
ttp://pc.watch.impress.co.jp/docs/2005/0629/mercury.htm
�܂��p�[�\�i���R���s���[�^�[�Ƃ͐F�X�ƈႤ���낤��
�ŁA���njN�͉������������ˁH
10 �F����������K�������F2005/07/07(��) 15:47:10 ID:Qi6mGJY+
�[���ARadeonX850 ��SM2.0�����ˁB
11 �F����������K�������F2005/07/07(��) 15:47:47 ID:B+bVZfmr
>>7
�̗pCPU�͕K���������\�E����d�͂ł͌��܂�Ȃ��B
��������Ō��܂�̂ł����Mac�ł��AIntel���ނ���AMD�̗p����ł���B
DD1�e�[�v�A�E�g�����N�āADD2�e�[�v�A�E�g�����N�t�A��������ʎY�J�n���āA
���Ȃ��Ƃ��\�j�[���Y����PS3�ɍڂ邵�A�������\���͏\������B
����Ɠd�APC�����ɑ�ʋ������Â炢�Ƃ�����������邵�A
���������o�ꂵ��������Ȃ̂��������Ȃ��̂��d���Ȃ��ł���B
�ł�IBM���I�[�v�����ƌ����Ă�̂ŁA���ꂩ���F�X�o�Ă���B
�̗pCPU�͕K���������\�E����d�͂ł͌��܂�Ȃ��B
��������Ō��܂�̂ł����Mac�ł��AIntel���ނ���AMD�̗p����ł���B
DD1�e�[�v�A�E�g�����N�āADD2�e�[�v�A�E�g�����N�t�A��������ʎY�J�n���āA
���Ȃ��Ƃ��\�j�[���Y����PS3�ɍڂ邵�A�������\���͏\������B
����Ɠd�APC�����ɑ�ʋ������Â炢�Ƃ�����������邵�A
���������o�ꂵ��������Ȃ̂��������Ȃ��̂��d���Ȃ��ł���B
�ł�IBM���I�[�v�����ƌ����Ă�̂ŁA���ꂩ���F�X�o�Ă���B
12 �F����������K�������F2005/07/07(��) 15:48:48 ID:k4OpcKdD
>>7
�͂��͂��B�������Ƃ����ł��˂�
�͂��͂��B�������Ƃ����ł��˂�
13 �F����������K�������F2005/07/07(��) 15:51:06 ID:oycdOqFP
�܂肾
���\�����Ȃ�n�b�^���L����
N64����X�I�Ƀ��[�N�X�e�[�V�����p��
����CPU���Ɛ�`���������Ԃ�
PS�̃V���M���Ƃ����悤�ȃ\�t�g�����肾��
�������̖����������낤���E�E�E
�܂莟����@�̃Q�[���푈��CPU�̐��\
�Ȃ��܂���ł͂Ȃ�GPU�Ō��܂��
cell�͕����Ƃ������Ƃ�
���\�����Ȃ�n�b�^���L����
N64����X�I�Ƀ��[�N�X�e�[�V�����p��
����CPU���Ɛ�`���������Ԃ�
PS�̃V���M���Ƃ����悤�ȃ\�t�g�����肾��
�������̖����������낤���E�E�E
�܂莟����@�̃Q�[���푈��CPU�̐��\
�Ȃ��܂���ł͂Ȃ�GPU�Ō��܂��
cell�͕����Ƃ������Ƃ�
14 �F����������K�������F2005/07/07(��) 15:54:03 ID:Ei2znPN/
�r���̐����̂����ł܂����������͂Ȃ��Ȃ������������^^
�܂�1�s�����̂ĂĂ����������܂�������������
�܂�1�s�����̂ĂĂ����������܂�������������
15 �F����������K�������F2005/07/07(��) 15:55:51 ID:k4OpcKdD
���_��Cell���N�\���Ƃ��Ă�PS3���ŋ����Ƃ������Ƃ��B
����ɂ����ȁB
����ɂ����ȁB
16 �F����������K�������F2005/07/07(��) 15:55:58 ID:QQcY91V9
>>10
�m��SM2.0b������2.0�g���������悤��
>>13
���ۂ�IntelCPU��100�{�̐��\��@��������CPU���n�b�^���ł����E�E�E
�܁A���������������͗������܂������A��ς݂̂ō\������Ă���
���̂悤�Ȉӌ���vs�X���Ŏv�������ǂ���
�m��SM2.0b������2.0�g���������悤��
>>13
���ۂ�IntelCPU��100�{�̐��\��@��������CPU���n�b�^���ł����E�E�E
�܁A���������������͗������܂������A��ς݂̂ō\������Ă���
���̂悤�Ȉӌ���vs�X���Ŏv�������ǂ���
17 �F����������K�������F2005/07/07(��) 15:56:39 ID:fj5f3bwn
PS3��GPU��������B
18 �F����������K�������F2005/07/07(��) 15:56:51 ID:HrEvukYx
>PS�̃V���M
19 �F����������K�������F2005/07/07(��) 16:01:16 ID:xwndrQzn
���{�l���b���Ă���C�����˂�(�G�L�D�M) �E�E�E
20 �F����������K�������F2005/07/07(��) 16:01:16 ID:OCHQwqCz
R4300�͍����\CPU�B
�R�v���Z�b�T���D�G�B
�����v���O���}�[�̕��S���l���Ė�������
�����Ȃ�}���I64���o��������
���ꂭ�炢�ł��ē�����O���Ǝv�킹��
�R�v���Z�b�T���D�G�B
�����v���O���}�[�̕��S���l���Ė�������
�����Ȃ�}���I64���o��������
���ꂭ�炢�ł��ē�����O���Ǝv�킹��
21 �F����������K�������F2005/07/07(��) 16:04:26 ID:Hl7IE6ZC
��������Cell�i�����Ɍ���Ȃ��j���A����p�r�ɂ����Ă͑����Ȕ\�͂�����
�����Ȃ��p�r�ɂ����Ă͕��ł���ȂA������O������b����Ȃ��̂��H
�Ă����̂������œ����x�̉��i�i�ʐρj�����¼غ݂őS�Ăɂ�����
�ō����\�ł���Ȃ�Ė��@�̋Z�p������킯�Ȃ������B
�Źްїp�r�ɂ��ڂ�����Cell�͂��������������ø����Ȃ�˂��Ď���
ܰ��ð��݂���PC���̂ōō��ł���K�v�͂��炳��Ȃ��Ǝv������
�����Ȃ��p�r�ɂ����Ă͕��ł���ȂA������O������b����Ȃ��̂��H
�Ă����̂������œ����x�̉��i�i�ʐρj�����¼غ݂őS�Ăɂ�����
�ō����\�ł���Ȃ�Ė��@�̋Z�p������킯�Ȃ������B
�Źްїp�r�ɂ��ڂ�����Cell�͂��������������ø����Ȃ�˂��Ď���
ܰ��ð��݂���PC���̂ōō��ł���K�v�͂��炳��Ȃ��Ǝv������
22 �F����������K�������F2005/07/07(��) 16:06:58 ID:HrEvukYx
>>���ۂ�IntelCPU��100�{
300GHz�����Ƃ���ƁA��������L2�Ƃ��S�Ă��{�g���l�b�N�ɂȂ�悤�ȋC���B
PS2���o��Ƃ��������悤�Ȏ������Ă����ǔ�r�Ɏg��ꂽPen3�Ƒ卷�Ȃ�XBOX���x���������B
�m�������̂ŕ����������ǁA�ǂ�ȗp�r�̏ꍇ��100�{�̍����o��́H
300GHz�����Ƃ���ƁA��������L2�Ƃ��S�Ă��{�g���l�b�N�ɂȂ�悤�ȋC���B
PS2���o��Ƃ��������悤�Ȏ������Ă����ǔ�r�Ɏg��ꂽPen3�Ƒ卷�Ȃ�XBOX���x���������B
�m�������̂ŕ����������ǁA�ǂ�ȗp�r�̏ꍇ��100�{�̍����o��́H
23 �F����������K�������F2005/07/07(��) 16:09:35 ID:oycdOqFP
cell�͐���������Ȃ�intel�ɑR�ł��Ȃ��́��œK���ł��Ȃ����灨
�œK���Ȃ�Ă��ł���恨linux������ς����灨����ł�cell�͐���
EE�̓�̕�����
�œK���Ȃ�Ă��ł���恨linux������ς����灨����ł�cell�͐���
EE�̓�̕�����
24 �F����������K�������F2005/07/07(��) 16:12:23 ID:W+x4qcks
Cell��300GHz�����Ƃ݂Ȃ����A
Cell��3GHz�~7�Ȃ̂ɑ���P4��200MHz�����̓����������Ă��Ȃ��A�ƍl��������
100�{�̍����ǂ����Đ����邩�l���₷�������B
��������CPU���x�̃M���b�v�����肷���āA�`���I�ȊK�w�^�L���b�V���@�\�����ł�
����������CPU�̑��x������ł��܂��̂ł���B(�X�g���[�������̏ꍇ�A��)
Cell��3GHz�~7�Ȃ̂ɑ���P4��200MHz�����̓����������Ă��Ȃ��A�ƍl��������
100�{�̍����ǂ����Đ����邩�l���₷�������B
��������CPU���x�̃M���b�v�����肷���āA�`���I�ȊK�w�^�L���b�V���@�\�����ł�
����������CPU�̑��x������ł��܂��̂ł���B(�X�g���[�������̏ꍇ�A��)
25 �F����������K�������F2005/07/07(��) 16:13:12 ID:B+bVZfmr
>>23
>cell�͐���������Ȃ�intel�ɑR�ł��Ȃ��́��œK���ł��Ȃ����灨
>�œK���Ȃ�Ă��ł���恨linux������ς����灨����ł�cell�͐���
��ԈႢ�B
�������́Acell�͐���������Ȃ�intel�ɑR�ł��Ȃ��́��y�U���Ⴄ����
�œK���Ɋւ��Ă�PC�ɂ�����œK���ƃQ�[���@�̍œK���͈Ⴄ�B
>cell�͐���������Ȃ�intel�ɑR�ł��Ȃ��́��œK���ł��Ȃ����灨
>�œK���Ȃ�Ă��ł���恨linux������ς����灨����ł�cell�͐���
��ԈႢ�B
�������́Acell�͐���������Ȃ�intel�ɑR�ł��Ȃ��́��y�U���Ⴄ����
�œK���Ɋւ��Ă�PC�ɂ�����œK���ƃQ�[���@�̍œK���͈Ⴄ�B
26 �F����������K�������F2005/07/07(��) 16:14:18 ID:B+bVZfmr
�Ƃ������ALinux�������ςƂ͒N�������ĂȂ����B
27 �F����������K�������F2005/07/07(��) 16:17:14 ID:1WUkNxTA
�h�����\��������S�Ă̗p�r�ɂ����čō��łȂ���E�\�h�ł����B
�������_�ł��ˁ`�B
�������_�ł��ˁ`�B
28 �F����������K�������F2005/07/07(��) 16:18:25 ID:Ei2znPN/
�䖝����64�̓�̕����Ă����Ă��̂ɂ���EE�̓�̕��ɂȂ����������
���炦���̂Ȃ��D�P���Ȃ�
���炦���̂Ȃ��D�P���Ȃ�
29 �F����������K�������F2005/07/07(��) 16:20:36 ID:oycdOqFP
�Ⴄ����Q�[���p�t�H�[�}���X���D��Ă���Ȃ�
PC�Ƃ��Ă��D��Ă���Ƃ������Ƃ͂�����x�����ł���
PenM��64�݂Ă�������
�����PC�A�v���Ȃ�Ă���ȕ��G�Ȍv�Z����킯�ł��Ȃ�
cell�͐���������Ȃ�intel�ɑR�ł��Ȃ��́��n�b�^��������
PC�Ƃ��Ă��D��Ă���Ƃ������Ƃ͂�����x�����ł���
PenM��64�݂Ă�������
�����PC�A�v���Ȃ�Ă���ȕ��G�Ȍv�Z����킯�ł��Ȃ�
cell�͐���������Ȃ�intel�ɑR�ł��Ȃ��́��n�b�^��������
30 �F����������K�������F2005/07/07(��) 16:22:16 ID:MZHC731r
�ȂA�����W�J�ɂȂ��Ă���
31 �F����������K�������F2005/07/07(��) 16:22:43 ID:HrEvukYx
>>24
���ۂɂ͂Q�O�OMH���Ƃ����肦�Ȃ��킯�ŁB
PPE�{SPE*7 = Pen4*100 �����藧�Ƃ��āAPPE�P�̂�Pen4�̖�12�{���Ă��肦��́H
�N���b�N��3.2G�Ƃ��Ă��B
100�{�����o��̂̓X�g���[��(���_�X�g���[���H)�����H
�������Ǐ��I�ȕ�����100�{�Ȃ����ł���ˁH
���ۂɂ͂Q�O�OMH���Ƃ����肦�Ȃ��킯�ŁB
PPE�{SPE*7 = Pen4*100 �����藧�Ƃ��āAPPE�P�̂�Pen4�̖�12�{���Ă��肦��́H
�N���b�N��3.2G�Ƃ��Ă��B
100�{�����o��̂̓X�g���[��(���_�X�g���[���H)�����H
�������Ǐ��I�ȕ�����100�{�Ȃ����ł���ˁH
32 �F����������K�������F2005/07/07(��) 16:23:41 ID:xwndrQzn
CELL�́A���W�ϊ��i3DCG�j��|���Z�i���[�N�X�e�[�V�����j�ł͎g�p���邪�A
PC�̃A�v���ł͎g�p���Ȃ����������_�v�Z�����ӂȂ�B
PC�̃A�v���ł͎g�p���Ȃ����������_�v�Z�����ӂȂ�B
33 �F����������K�������F2005/07/07(��) 16:24:25 ID:k4OpcKdD
�Z�p�I�Șb���ł��Ȃ��̂Ȃ�VS�X���ɍs���Ηǂ��B
34 �F����������K�������F2005/07/07(��) 16:25:26 ID:D8bu+cWv
ID:oycdOqFP���ʔ������錏�ɂ���
35 �F����������K�������F2005/07/07(��) 16:28:06 ID:xwndrQzn
�ł��APC�p�ɂ����Ȃ��ł���B�Ȃ�Ƃ����Ă��p���[PC��3.2GH���Ȃ킯������
36 �F����������K�������F2005/07/07(��) 16:28:32 ID:1WUkNxTA
Windows�ƌ���OS�A�h���C�o�̕����ł̃��X
PC�A�[�L�e�N�`���̃��X���܂܂��ł���B
CS�@�̌����̗ǂ����R�ɂ́B
PC�A�[�L�e�N�`���̃��X���܂܂��ł���B
CS�@�̌����̗ǂ����R�ɂ́B
37 �F����������K�������F2005/07/07(��) 16:29:15 ID:HrEvukYx
38 �F����������K�������F2005/07/07(��) 16:29:40 ID:W+x4qcks
> ���ۂɂ͂Q�O�OMH���Ƃ����肦�Ȃ��킯�ŁB
���₢��B���ꂮ�炢�A������CPU���L���b�V���~�X�̃y�i���e�B�Ŏ~�܂��Ă鎞�Ԃ�
�ӊO�ɒ����̂ł��B���̃{�g���l�b�N�̉��������݂��̂�SPE��LS��DMA�B
���₢��B���ꂮ�炢�A������CPU���L���b�V���~�X�̃y�i���e�B�Ŏ~�܂��Ă鎞�Ԃ�
�ӊO�ɒ����̂ł��B���̃{�g���l�b�N�̉��������݂��̂�SPE��LS��DMA�B
39 �F����������K�������F2005/07/07(��) 16:31:08 ID:HrEvukYx
�L���b�V���ʂ��Ȃ��Ă��x�[�X�N���b�N�̂S�O�O�`�P�O�R�R�Ƃ��œ��������ł������
40 �F����������K�������F2005/07/07(��) 16:38:21 ID:W+x4qcks
DRAM�̓��C�e���V������ł���B�f�[�^�o���Ƃ����Ă����o�Ă���킯����Ȃ��B
�Ƃ������u���C����������CPU��肩�Ȃ�x���v�Ƃ������Ƃ������������������Ȃ̂ŁA
200MHz�Ƃ��������ɂ͂��܂肱�����Ȃ��ł���������ƗL��B
�Ƃ������u���C����������CPU��肩�Ȃ�x���v�Ƃ������Ƃ������������������Ȃ̂ŁA
200MHz�Ƃ��������ɂ͂��܂肱�����Ȃ��ł���������ƗL��B
41 �F����������K�������F2005/07/07(��) 16:39:49 ID:HejGTBDS
42 �F����������K�������F2005/07/07(��) 16:40:40 ID:oycdOqFP
PPC��GC�ɍ̗p����Ă����������\�����ł��Ă���̂�
�����͂Ȃ��Ǝv�����B
���ꂪ������R�R�A�ł��낤�ƊJ���҂͈Ӓn�ł��œK�����Ă���
�ł���B���͂킯�̂킩��Ȃ�CPU,cell
���ƃQ�[���@�ɂȂ�Ƃ߂��Ⴍ����C���[�������Ȃ萫�\��
�P�^�Ⴂ�ɏオ��Ǝv�������ԈႢ
PS2�͂قƂ��640x480�̏������ĂȂ�������640x480�Ő���t
���̓����̃n�b�^���x���`
http://www.watch.impress.co.jp/mobile/column/ps2/2000/03/14/comp.jpg
�����͂Ȃ��Ǝv�����B
���ꂪ������R�R�A�ł��낤�ƊJ���҂͈Ӓn�ł��œK�����Ă���
�ł���B���͂킯�̂킩��Ȃ�CPU,cell
���ƃQ�[���@�ɂȂ�Ƃ߂��Ⴍ����C���[�������Ȃ萫�\��
�P�^�Ⴂ�ɏオ��Ǝv�������ԈႢ
PS2�͂قƂ��640x480�̏������ĂȂ�������640x480�Ő���t
���̓����̃n�b�^���x���`
http://www.watch.impress.co.jp/mobile/column/ps2/2000/03/14/comp.jpg
{kind=link}
43 �F����������K�������F2005/07/07(��) 16:45:04 ID:k4OpcKdD
44 �F����������K�������F2005/07/07(��) 16:49:17 ID:lm64HGVr
>>22
���̕ӂ̘b��́ACELL �X���� 34 �� 35 �ӂ�ŏo���B
100�{�Ƃ����̂� FFT �����̎��ŁA���� IBM �̃v���[�������́A
http://www.beyond3d.com/forum/viewtopic.php?t=23845&sid=b5addcbd654a97e434ffd98af6358cc3
�Ō�����B
���̕ӂ̘b��́ACELL �X���� 34 �� 35 �ӂ�ŏo���B
100�{�Ƃ����̂� FFT �����̎��ŁA���� IBM �̃v���[�������́A
http://www.beyond3d.com/forum/viewtopic.php?t=23845&sid=b5addcbd654a97e434ffd98af6358cc3
�Ō�����B
45 �F����������K�������F2005/07/07(��) 16:53:43 ID:HrEvukYx
��ŁA����100�{������������P�[�X���Ă̂́E�E�E
>>43
�������̑��x�Ɉ���������킯�ł���ˁB
�������Ă�PC�̓������N���b�N�S�O�OMH���Ȃ�łS�O�OMH�������ɂȂ�A�ƁB
SPE��3.2G��LS��3.2G�œ���ł����H
DMA�Ńf�[�^�������߂��E�ǂݎ��Ŕ�������X�g�[���͏������ɂ��Ă�����킯�ł����A
�X�g���[�����ƃf�[�^�̍ė��p���������A�L���b�V���̌��ʂ��o�ɂ����Ǝv����ł����B
�Ȃ��S�Ҋۏo���̎��������Ő\����Ȃ���ł����E�E�E�B
ROM���Ă������ǂ��ł����ˁA����ς�B
>>43
�������̑��x�Ɉ���������킯�ł���ˁB
�������Ă�PC�̓������N���b�N�S�O�OMH���Ȃ�łS�O�OMH�������ɂȂ�A�ƁB
SPE��3.2G��LS��3.2G�œ���ł����H
DMA�Ńf�[�^�������߂��E�ǂݎ��Ŕ�������X�g�[���͏������ɂ��Ă�����킯�ł����A
�X�g���[�����ƃf�[�^�̍ė��p���������A�L���b�V���̌��ʂ��o�ɂ����Ǝv����ł����B
�Ȃ��S�Ҋۏo���̎��������Ő\����Ȃ���ł����E�E�E�B
ROM���Ă������ǂ��ł����ˁA����ς�B
46 �F����������K�������F2005/07/07(��) 16:55:20 ID:cGz36+QS
�Ȃ�ō��XFFT�x���`��m��Ȃ��z��������̃X���ɁE�E�E
47 �F����������K�������F2005/07/07(��) 16:58:05 ID:oycdOqFP
FFT���ăL���b�V�����x�ɉe������₷���x���`����
48 �F����������K�������F2005/07/07(��) 17:01:01 ID:W+x4qcks
> DMA�Ńf�[�^�������߂��E�ǂݎ��Ŕ�������X�g�[���͏������ɂ��Ă�����킯�ł����A
���̒x���̓_�u���o�b�t�@�ʼnB���ł���B�Е���DMA�����C���������Ɠǂݏ�������
�����Е��ŃR�A���v�Z�B
���̒x���̓_�u���o�b�t�@�ʼnB���ł���B�Е���DMA�����C���������Ɠǂݏ�������
�����Е��ŃR�A���v�Z�B
49 �F����������K�������F2005/07/07(��) 17:02:37 ID:OCHQwqCz
�����t�[���G�ϊ��@�yFFT�z
�@1965�N�Ƀx����������James W. Cooley����John W. Tukey�����l�Ă����A
���U�I�t�[���G�ϊ��Ƌt�ϊ��������Ɍv�Z�����@�B
�@�摜�≹���A�f���Ȃǂ̃}���`���f�B�A�f�[�^�̏����ő��p����� �d�v�ȃA���S���Y���ł���B
��K��FFT���Z�̎��s���\�����C�o���Ђ�3.2GHz��CPU�EPC�V�X�e���Ŏ��s��r�B
ttp://img126.echo.cx/img126/634/slide150on.jpg
�L���͂�͂�A���S���Y���ƃ������A�N�Z�X�ɂ��邻���ȁB
�@1965�N�Ƀx����������James W. Cooley����John W. Tukey�����l�Ă����A
���U�I�t�[���G�ϊ��Ƌt�ϊ��������Ɍv�Z�����@�B
�@�摜�≹���A�f���Ȃǂ̃}���`���f�B�A�f�[�^�̏����ő��p����� �d�v�ȃA���S���Y���ł���B
��K��FFT���Z�̎��s���\�����C�o���Ђ�3.2GHz��CPU�EPC�V�X�e���Ŏ��s��r�B
ttp://img126.echo.cx/img126/634/slide150on.jpg
{kind=link}
�L���͂�͂�A���S���Y���ƃ������A�N�Z�X�ɂ��邻���ȁB
50 �F����������K�������F2005/07/07(��) 17:06:01 ID:HrEvukYx
�t�[���G�ϊ����ăQ�[���ł���܂�g��Ȃ��悤�ȋC��������ǥ���B
>>48
�Ȃ�قǁE�E�E�B
���AGekko�ɂ����b�N�h�L���b�V�������������Ǝv����ł����A�������Ȃ�ɓ����Ȃ��Ƃ��ł�����Ď������ˁB
�ƂȂ�ƁA������{�ł��o���Ă��������Ȃ��C���B
>>48
�Ȃ�قǁE�E�E�B
���AGekko�ɂ����b�N�h�L���b�V�������������Ǝv����ł����A�������Ȃ�ɓ����Ȃ��Ƃ��ł�����Ď������ˁB
�ƂȂ�ƁA������{�ł��o���Ă��������Ȃ��C���B
51 �F����������K�������F2005/07/07(��) 17:09:29 ID:l4JRUvjI
>>49
SRAM�͌��X�݊����ێ��ɂ��v���O�����̕��S���炷�ׁA
���\�]���ɂ��Ď��������ăL���b�V���ƂȂ������ǁB
CELL�͒P��n�[�h���Ď��Ő��\�d���̃v���O���}�u������������B
������ӍœK������ΒP���ȃX�y�b�N�ȏ�̍����o��낤�ȁB
SRAM�͌��X�݊����ێ��ɂ��v���O�����̕��S���炷�ׁA
���\�]���ɂ��Ď��������ăL���b�V���ƂȂ������ǁB
CELL�͒P��n�[�h���Ď��Ő��\�d���̃v���O���}�u������������B
������ӍœK������ΒP���ȃX�y�b�N�ȏ�̍����o��낤�ȁB
52 �F����������K�������F2005/07/07(��) 17:11:42 ID:Qi6mGJY+
�܂��Aintel�ɂ��Ȃ�Ȃ����R�͂�����AWindows�݊�����Ȃ�����B
apple���̗p���Ȃ��ő�̗��R�́A�m�[�g��������Ȃ�����B
apple���̗p���Ȃ��ő�̗��R�́A�m�[�g��������Ȃ�����B
53 �F����������K�������F2005/07/07(��) 17:11:50 ID:OCHQwqCz
�t�[���G�ϊ��� �܂��ɉ摜�E����̃G���R���ˁB
���̕���ł͕����ʂ� �P�^�O��ɑ����\���E�E
���[ �G���R�J�[�h�o���[�[���I�I
���̕���ł͕����ʂ� �P�^�O��ɑ����\���E�E
���[ �G���R�J�[�h�o���[�[���I�I
54 �F����������K�������F2005/07/07(��) 17:15:11 ID:oycdOqFP
�܂��킯�̂킩��Ȃ����Ƃ���Ă�̂�
�t�[���G�ϊ��ŃG���R�������Ȃ�Ȃ�Pen4��
���y�����H
���̃x���`��apple��G3��G4�̎��ɂ���Ă����y�e���x���`
�ɋ߂����̂�����
�t�[���G�ϊ��ŃG���R�������Ȃ�Ȃ�Pen4��
���y�����H
���̃x���`��apple��G3��G4�̎��ɂ���Ă����y�e���x���`
�ɋ߂����̂�����
55 �F����������K�������F2005/07/07(��) 17:17:55 ID:6ADfSgIL
>>54���C�V���M�҂Ȃ̂͗����o����
56 �F����������K�������F2005/07/07(��) 17:20:44 ID:9cVXiCMC
>>29
�N�͊��Ɏ����œ����ɋ߂Â��Ă���B
> �����PC�A�v���Ȃ�Ă���ȕ��G�Ȍv�Z����킯�ł��Ȃ�
�����B���G�Ȍv�Z�����Ȃ����Cell�̗͈͂Ӗ��������B
�����̃A�[�L�e�N�`����CPU�ŏ\�����������Ă���B
���\���K�v�ȕ��G�Ȍv�Z��K�v�Ƃ��鎞�ɁA
���̃^�C�g���[�v��SPE�Ɉڂ��čœK�����鎖��Cell�̃L���Ȃ킯�B
���������FFT�̃x���`��MPEG2����48�{�Đ��̂悤�ɗ͂�����B
�����̃R�[�h�����̂܂ܑ��点�č���������킯����Ȃ�����ˁB
�N�͊��Ɏ����œ����ɋ߂Â��Ă���B
> �����PC�A�v���Ȃ�Ă���ȕ��G�Ȍv�Z����킯�ł��Ȃ�
�����B���G�Ȍv�Z�����Ȃ����Cell�̗͈͂Ӗ��������B
�����̃A�[�L�e�N�`����CPU�ŏ\�����������Ă���B
���\���K�v�ȕ��G�Ȍv�Z��K�v�Ƃ��鎞�ɁA
���̃^�C�g���[�v��SPE�Ɉڂ��čœK�����鎖��Cell�̃L���Ȃ킯�B
���������FFT�̃x���`��MPEG2����48�{�Đ��̂悤�ɗ͂�����B
�����̃R�[�h�����̂܂ܑ��点�č���������킯����Ȃ�����ˁB
57 �F����������K�������F2005/07/07(��) 17:22:29 ID:D8bu+cWv
oycdOqFP�͂ǂ��炩�ƌ����Βs���Ɍ�����
58 �F����������K�������F2005/07/07(��) 17:23:06 ID:9cVXiCMC
> �t�[���G�ϊ��ŃG���R�������Ȃ�Ȃ�Pen4��
>���y�����H
Intel�̐����́B����Pentium4�̓G���R�[�h�ɂ����đ���CPU�Ƃ���Ă��B
����SSE2/SSE3�ȂɍœK�����ꂽ�\�t�g�ł�AMD���������B
���̎��_��Cell�ɑ��āA���Ɏs�������Đ��N�o�߂��ď\���͂�Ă���CPU��
�����o���Ă��d���Ȃ�����B�N�͋c�_������O�ɁA�����̘_���̔j�]�ɋC�t���B
>���y�����H
Intel�̐����́B����Pentium4�̓G���R�[�h�ɂ����đ���CPU�Ƃ���Ă��B
����SSE2/SSE3�ȂɍœK�����ꂽ�\�t�g�ł�AMD���������B
���̎��_��Cell�ɑ��āA���Ɏs�������Đ��N�o�߂��ď\���͂�Ă���CPU��
�����o���Ă��d���Ȃ�����B�N�͋c�_������O�ɁA�����̘_���̔j�]�ɋC�t���B
59 �F����������K�������F2005/07/07(��) 17:25:30 ID:OCHQwqCz
>>54
��H
MPEG�����JPEG�摜�� �ЂƂ܂Ƃ܂�̉�f�f�[�^�ɑ���
���G�ȃt�[���G�ϊ����s���A���̌� �ʎq�����ăf�[�^�T�C�Y�����炷���B
P4��Athron�� ���̃t�[���G�ϊ������ɉ��Z�\�͂��₵�A�G���R�ɖc��Ȏ��Ԃ�������̂��B
���t�[���G�ϊ��ŃG���R�������Ȃ�Ȃ�Pen4�����y�����H
�������A���������Ă�̂��S���Ӗ��s���E�E
��H
MPEG�����JPEG�摜�� �ЂƂ܂Ƃ܂�̉�f�f�[�^�ɑ���
���G�ȃt�[���G�ϊ����s���A���̌� �ʎq�����ăf�[�^�T�C�Y�����炷���B
P4��Athron�� ���̃t�[���G�ϊ������ɉ��Z�\�͂��₵�A�G���R�ɖc��Ȏ��Ԃ�������̂��B
���t�[���G�ϊ��ŃG���R�������Ȃ�Ȃ�Pen4�����y�����H
�������A���������Ă�̂��S���Ӗ��s���E�E
60 �F����������K�������F2005/07/07(��) 17:25:53 ID:lm64HGVr
>>54
> �t�[���G�ϊ��ŃG���R�������Ȃ�Ȃ�Pen4��
> ���y�����H
�Ȃ�� Intel CPU �͕��y���āADEC �� Alpha �͑ʖڂ�������ł��傤�ˁB
> �t�[���G�ϊ��ŃG���R�������Ȃ�Ȃ�Pen4��
> ���y�����H
�Ȃ�� Intel CPU �͕��y���āADEC �� Alpha �͑ʖڂ�������ł��傤�ˁB
61 �F����������K�������F2005/07/07(��) 17:27:48 ID:xwndrQzn
�P��x86�n���������炾��
62 �F����������K�������F2005/07/07(��) 17:33:06 ID:W+x4qcks
> �Ȃ�� Intel CPU �͕��y���āADEC �� Alpha �͑ʖڂ�������ł��傤�ˁB
�{�����[���}�W�b�N�BAlpha�ɂ͊J���R�X�g�𐳓����ł��邾���̗p�r���Ȃ������B
Cell��PS3�̎��v�������Ă����J�����\�������B
�{�����[���}�W�b�N�BAlpha�ɂ͊J���R�X�g�𐳓����ł��邾���̗p�r���Ȃ������B
Cell��PS3�̎��v�������Ă����J�����\�������B
63 �F����������K�������F2005/07/07(��) 17:38:02 ID:OCHQwqCz
[email protected]�� [email protected]�ł� �J�^���O�X�y�b�N�ɂ�15�`20�{���x�̍������Ȃ��̂ɁA
�Ⴆ�}���`���f�B�A�����̓T�^�ł���FFT���Z�Ȃǂ� �����܂ł̑卷���J�����̂�
�A���S���Y�������邱�ƂȂ���A��͂胁�����A�N�Z�X�ɂ�閳�ʁE�{�g���l�b�N��
�O��I�ɒጸ����A�[�L�e�N�`�����̂�������ł͂Ȃ����B
�}���`���f�B�A�����̐\���q�̂悤��CPU���Ƃ͌�����B
�����A���̑��̂ǂ�ȏ����ł������A�Ƃ����킯�ł͖����͓̂��R�B
�u�������߂邩�H�����̂Ă邩�H�v���Ă̂� �v�i�K�œO��I�ɍl�����ꂽ�̂��낤�B
������A�I�t�B�XPC�p�r�ɂ� ���������Ė����B
Mac�ɂ́E�E ���邢�͌����Ă�����������A
�C���e���ɂ� ����ɏ��閣�͂��������̂��낤�B
���i�Ƃ��A�����\�͂Ƃ��A�`�b�v�̐₦�ԂȂ��������Ƃ��B
�Ⴆ�}���`���f�B�A�����̓T�^�ł���FFT���Z�Ȃǂ� �����܂ł̑卷���J�����̂�
�A���S���Y�������邱�ƂȂ���A��͂胁�����A�N�Z�X�ɂ�閳�ʁE�{�g���l�b�N��
�O��I�ɒጸ����A�[�L�e�N�`�����̂�������ł͂Ȃ����B
�}���`���f�B�A�����̐\���q�̂悤��CPU���Ƃ͌�����B
�����A���̑��̂ǂ�ȏ����ł������A�Ƃ����킯�ł͖����͓̂��R�B
�u�������߂邩�H�����̂Ă邩�H�v���Ă̂� �v�i�K�œO��I�ɍl�����ꂽ�̂��낤�B
������A�I�t�B�XPC�p�r�ɂ� ���������Ė����B
Mac�ɂ́E�E ���邢�͌����Ă�����������A
�C���e���ɂ� ����ɏ��閣�͂��������̂��낤�B
���i�Ƃ��A�����\�͂Ƃ��A�`�b�v�̐₦�ԂȂ��������Ƃ��B
64 �F����������K�������F2005/07/07(��) 17:40:25 ID:W+x4qcks
�В��鏑�����l�������Ƃ�
65 �F����������K�������F2005/07/07(��) 17:42:11 ID:3EcBH0hf
>>63
�I�t�B�X�p�r�ɂ͖��ʂȋ@�\�̕t���ĂȂ��A�f���C����PC�������Ă���B
OA�@��ɉ߂��Ȃ�PC���}���`���f�B�A�p�r�����ݍ������Ƃ��Ĕ�剻
�������A���ǂ͂�������ł��B����͎����p�r�ƃ}���`���f�B�A�p�r��
�����邾�낤�B
�I�t�B�X�p�r�ɂ͖��ʂȋ@�\�̕t���ĂȂ��A�f���C����PC�������Ă���B
OA�@��ɉ߂��Ȃ�PC���}���`���f�B�A�p�r�����ݍ������Ƃ��Ĕ�剻
�������A���ǂ͂�������ł��B����͎����p�r�ƃ}���`���f�B�A�p�r��
�����邾�낤�B
66 �F����������K�������F2005/07/07(��) 17:42:22 ID:oycdOqFP
�x���`�����ʖڂ�
apple�̂悤�Ƀt�H�g�V���̂ڂ����t�B���^�������
��ׂĂ��ʖڂ�
�ǂ������\�͂ǂ������ǂ��������낤��
apple�̂悤�Ƀt�H�g�V���̂ڂ����t�B���^�������
��ׂĂ��ʖڂ�
�ǂ������\�͂ǂ������ǂ��������낤��
67 �F����������K�������F2005/07/07(��) 17:43:28 ID:3EcBH0hf
>>66
���Ⴀ�A������CPU��MPEG2��48�{�����Đ�������Ă݂�K�v������ȁB
���Ⴀ�A������CPU��MPEG2��48�{�����Đ�������Ă݂�K�v������ȁB
68 �F����������K�������F2005/07/07(��) 17:44:26 ID:QQcY91V9
69 �F����������K�������F2005/07/07(��) 17:48:10 ID:9cVXiCMC
�x���`�Ƃ�����̎w�W������Ƃ����̂ł���A
���ɍ����������Ă��Ȃ��ƈӖ��������B
>�ǂ������\�͂ǂ������ǂ��������낤��
�������ɂ����������������o���̂�VS�X�������B
���ɍ����������Ă��Ȃ��ƈӖ��������B
>�ǂ������\�͂ǂ������ǂ��������낤��
�������ɂ����������������o���̂�VS�X�������B
70 �F����������K�������F2005/07/07(��) 17:48:28 ID:/3A9XzGR
71 �F����������K�������F2005/07/07(��) 17:48:51 ID:FE23fBAN
����P�i��3D�Q�[���G�N�X�^�V�[ GeForce 7800 GTX�̃p�C�v���C�����ׂ������Ă݂�i��ҁj
http://www.4gamer.net/specials/3de/050706_gf7800/002/050707_gf7800_02.shtml
http://www.4gamer.net/specials/3de/050706_gf7800/002/050707_gf7800_02.shtml
72 �F����������K�������F2005/07/07(��) 17:49:35 ID:OCHQwqCz
>>66
IBM�̑�K��FFT�f����
���ۂ̃A�v���P�[�V�����̌`�Ŏ��������̂�
���ł�MPEG2�Đ��f���B
DVD�T�C�Y��48�{�AHDTV�T�C�Y��12�{�A�����f�R�[�h�\�B
�x���`�P�ł͂܂��킩��Ȃ��A�Ƃ����͓̂��������A
�ł͌N�� ���̃x���`�����ė~�����H
����́A�Ƃ������̂�����Ύ����ė~�����B
IBM�̑�K��FFT�f����
���ۂ̃A�v���P�[�V�����̌`�Ŏ��������̂�
���ł�MPEG2�Đ��f���B
DVD�T�C�Y��48�{�AHDTV�T�C�Y��12�{�A�����f�R�[�h�\�B
�x���`�P�ł͂܂��킩��Ȃ��A�Ƃ����͓̂��������A
�ł͌N�� ���̃x���`�����ė~�����H
����́A�Ƃ������̂�����Ύ����ė~�����B
73 �F����������K�������F2005/07/07(��) 17:51:59 ID:QQcY91V9
>>50
���b�N���č������[�J���������Ƃ��Ďg�����͂ł��邩������܂���
�������ɂ��{�g���l�b�N���������ꂽ�ꍇ�́A�����ɏ����\�͂̏����ɂȂ�킯��
�����Ȃ�Ɨ��_�l�������ق����L���ɂȂ鎖�͂킩��܂����
�܂�Cell�̓{�g���l�b�N�ɂ��e�����ł�����茸�炵�āA�������Z���\�������܂�
�L�����p�ł���悤�ɍ��ꂽ��
���b�N���č������[�J���������Ƃ��Ďg�����͂ł��邩������܂���
�������ɂ��{�g���l�b�N���������ꂽ�ꍇ�́A�����ɏ����\�͂̏����ɂȂ�킯��
�����Ȃ�Ɨ��_�l�������ق����L���ɂȂ鎖�͂킩��܂����
�܂�Cell�̓{�g���l�b�N�ɂ��e�����ł�����茸�炵�āA�������Z���\�������܂�
�L�����p�ł���悤�ɍ��ꂽ��
74 �F����������K�������F2005/07/07(��) 18:02:56 ID:oycdOqFP
���ʂ̐l�Ԃ̍l����
Pen3 �Ȃ��Ȃ�����
PenM 15w�̏���d�͂̊��ɂ͂������v�Z�\�͂�
Pen4 �d�͐H���������\���C�}�C�`
��������ׂĂقړ������\�ɂȂ�悤�ɃN���b�N�A�b�v
Pen3 �d�͐H�������A�M����
PenM ���҂͂���
Pen4 �d�͐H���������\���C�}�C�`
�܂�CPU�Ȃ�ď��F�͏���d�͂ȂƑ傢�ɑ��֊W��������
intel��Pen4���̂�Pen3�̃v���Z�X�Z�p���グ���̂�PenMOC�œ�������
����邾�낤�B���������������Ƃ͂��Ȃ����ł��Ȃ�
�Ȃ��Ȃ疲�̂悤�ȃR�A�Ȃ�đ��݂���cell���܂��ɂ���
�N���b�N���̎d�������ł��Ȃ�
Pen3 �Ȃ��Ȃ�����
PenM 15w�̏���d�͂̊��ɂ͂������v�Z�\�͂�
Pen4 �d�͐H���������\���C�}�C�`
��������ׂĂقړ������\�ɂȂ�悤�ɃN���b�N�A�b�v
Pen3 �d�͐H�������A�M����
PenM ���҂͂���
Pen4 �d�͐H���������\���C�}�C�`
�܂�CPU�Ȃ�ď��F�͏���d�͂ȂƑ傢�ɑ��֊W��������
intel��Pen4���̂�Pen3�̃v���Z�X�Z�p���グ���̂�PenMOC�œ�������
����邾�낤�B���������������Ƃ͂��Ȃ����ł��Ȃ�
�Ȃ��Ȃ疲�̂悤�ȃR�A�Ȃ�đ��݂���cell���܂��ɂ���
�N���b�N���̎d�������ł��Ȃ�
75 �F����������K�������F2005/07/07(��) 18:04:59 ID:3EcBH0hf
>>74
�ǂ�����˂�����ł�����炢���낤�E�E�E��
�ǂ�����˂�����ł�����炢���낤�E�E�E��
76 �F����������K�������F2005/07/07(��) 18:07:29 ID:/3A9XzGR
�Ƃ肠�����A���֎~�ȁB
>>74
�قړ������\�Ȃ琫�\�����҂͂��ꂾ�����萫�\�����܂����̂������肷���Ȃ�����c
�قړ������\�Ȃ���B
�������������H
>>74
�قړ������\�Ȃ琫�\�����҂͂��ꂾ�����萫�\�����܂����̂������肷���Ȃ�����c
�قړ������\�Ȃ���B
�������������H
77 �F����������K�������F2005/07/07(��) 18:07:30 ID:OCHQwqCz
������������ׂĂقړ������\�ɂȂ�悤�ɃN���b�N�A�b�v
Cell�ł�������ƁA�������\�ɂȂ�悤�ɃN���b�N�h�_�E���h ����ȁH
����ƁA�u�����d�͂Ȃ̂ɁA�����\�v���Ă��ƂɂȂ�̂ł́B
Cell�̓d�͂��Ⴂ�Ƃ͌���A���\/�d�͔�� �����D�G���Ǝv���E�E
P4��肸���ƒႢ�Ǝv�������d�͂ŁA�y���ɍ����}���`���f�B�A���\�B
�E�E�E�[���A��̉������������̂��H(�@�L��`)
Cell�ł�������ƁA�������\�ɂȂ�悤�ɃN���b�N�h�_�E���h ����ȁH
����ƁA�u�����d�͂Ȃ̂ɁA�����\�v���Ă��ƂɂȂ�̂ł́B
Cell�̓d�͂��Ⴂ�Ƃ͌���A���\/�d�͔�� �����D�G���Ǝv���E�E
P4��肸���ƒႢ�Ǝv�������d�͂ŁA�y���ɍ����}���`���f�B�A���\�B
�E�E�E�[���A��̉������������̂��H(�@�L��`)
78 �F����������K�������F2005/07/07(��) 18:07:40 ID:QQcY91V9
>>75
NG���[�h�܂ނ̂ŃX���[����������w
NG���[�h�܂ނ̂ŃX���[����������w
79 �F����������K�������F2005/07/07(��) 18:07:52 ID:3EcBH0hf
>>74
�Ƃ肠�����A����AT�݊��@��CPU�Ƃ���Intel��CPU���������d�͂�
���p�t�H�[�}���X��@���o���Ă�AMD��Athlon�̂��Ƃ�Y��ĂȂ��H
�Ƃ肠�����A����AT�݊��@��CPU�Ƃ���Intel��CPU���������d�͂�
���p�t�H�[�}���X��@���o���Ă�AMD��Athlon�̂��Ƃ�Y��ĂȂ��H
80 �F����������K�������F2005/07/07(��) 18:07:49 ID:lm64HGVr
81 �F����������K�������F2005/07/07(��) 18:10:17 ID:OCHQwqCz
���i�P���P�G�j �������I �R�C�c�h���֊W�h���b�I�I
��������I
|�c�@
��������I
|�c�@
82 �F����������K�������F2005/07/07(��) 18:11:53 ID:oycdOqFP
�Ӗ����킩��Ȃ����Ȃ�
�N���b�N���グ��Đ��\/�d�͔���߂��Ⴍ����悭��
�ᔭ�M�Ȃ�Ă���CPU�Ȃ�đ��݂��Ȃ���
�N���b�N���グ��Đ��\/�d�͔���߂��Ⴍ����悭��
�ᔭ�M�Ȃ�Ă���CPU�Ȃ�đ��݂��Ȃ���
83 �F����������K�������F2005/07/07(��) 18:12:32 ID:3EcBH0hf
>>74�͐��\������d�͂Ƌ����ɂ������ăA�[�L�e�N�`���̗D�������
Cell��Pentium4�Ɓu�ǂ������ǂ��������_�v�Ɏ������݂������Ă���悤������
Intel�̊eCPU�̔�r���o���Ă������_�ŃA�[�L�e�N�`�������̂�������
�����Ȃ莩���Ŕj�]�����Ă��܂��Ă邼��
Cell��Pentium4�Ɓu�ǂ������ǂ��������_�v�Ɏ������݂������Ă���悤������
Intel�̊eCPU�̔�r���o���Ă������_�ŃA�[�L�e�N�`�������̂�������
�����Ȃ莩���Ŕj�]�����Ă��܂��Ă邼��
84 �F����������K�������F2005/07/07(��) 18:13:20 ID:HrEvukYx
>>73
�����ɃN���b�N�ӂ�̖��ߌ�������Cell�̕�����360��{��荂����ł����ˁB
SPE����R����Ă�Cell�̕����������ȋC�͂����ł����APPC�x�[�X�ł���ȏ�
�傫�ȍ��͏o�Ȃ��Ǝv����ł����ǁB
flops�ł͔�360�̔{�߂�PS3l�̕��������Ă��܂������ǁA�R�R�A��1�R�A+7�ł�����
�L���b�V���̉��b���傫���Ȃ琔�l�������������Ă��ǂ��悤�ȋC�������ł����B
�����ɃN���b�N�ӂ�̖��ߌ�������Cell�̕�����360��{��荂����ł����ˁB
SPE����R����Ă�Cell�̕����������ȋC�͂����ł����APPC�x�[�X�ł���ȏ�
�傫�ȍ��͏o�Ȃ��Ǝv����ł����ǁB
flops�ł͔�360�̔{�߂�PS3l�̕��������Ă��܂������ǁA�R�R�A��1�R�A+7�ł�����
�L���b�V���̉��b���傫���Ȃ琔�l�������������Ă��ǂ��悤�ȋC�������ł����B
85 �F����������K�������F2005/07/07(��) 18:13:44 ID:OCHQwqCz
86 �F����������K�������F2005/07/07(��) 18:17:39 ID:3EcBH0hf
>>82
�ȒP�Ȃ��Ƃ���B
Intel�͐v�ɖ��ʂ���������N���b�N���グ���Ȃ��Đ��\/�d�͔���߂���߂��ራ����
�v���Z�X�������Ă����[�N�d���������܂���ŋt�ɍ����M�ɂȂ����Ⴄ�����Ȃ�B
�ȒP�Ȃ��Ƃ���B
Intel�͐v�ɖ��ʂ���������N���b�N���グ���Ȃ��Đ��\/�d�͔���߂���߂��ራ����
�v���Z�X�������Ă����[�N�d���������܂���ŋt�ɍ����M�ɂȂ����Ⴄ�����Ȃ�B
87 �F����������K�������F2005/07/07(��) 18:20:25 ID:y817h2G8
RSX is G70, 90 nanometre tweaked
http://theinquirer.net/?article=24445
ATI taped out R520, again
http://theinquirer.net/?article=24446
http://theinquirer.net/?article=24445
ATI taped out R520, again
http://theinquirer.net/?article=24446
88 �F����������K�������F2005/07/07(��) 18:24:46 ID:/3A9XzGR
���ACell����Pen4��萫�\�����Ēᔭ�M������A���\/�d�͔�͂߂��Ⴍ����ǂ��Ǝv�����ǁc
89 �F����������K�������F2005/07/07(��) 18:30:38 ID:r6PNX/wY
>>82
�Ƃ肠�������ꂭ�炢�͓ǂ�ł����B
ttp://pc.watch.impress.co.jp/docs/2005/0218/kaigai158.htm
ttp://pc.watch.impress.co.jp/docs/2005/0225/kaigai159.htm
>Cell��������悤�ȃw�e���W�j�A�X�}���`�R�A�ŃX�g���[���^�f�[�^�����̐��\�����߂�A�v���[�`�́A
>����I�Ƀp�t�H�[�}���X/�d�͂����コ���邱�Ƃ��ł���B������PC����CPU�̃A�v���[�`�ł́A���̌����ɂ͒ǂ����Ȃ��B
>�����x86�nCPU�ŁACell��256GFLOPS��B���ł���}���`�R�ACPU������ō�낤�Ƃ�����A�c��ȏ���d�́A
>���ꂱ��1,000W�N���X��CPU�ɂȂ��Ă��܂����낤�B
�݂�ȕ���Ă邵�B
�Ƃ肠�������ꂭ�炢�͓ǂ�ł����B
ttp://pc.watch.impress.co.jp/docs/2005/0218/kaigai158.htm
ttp://pc.watch.impress.co.jp/docs/2005/0225/kaigai159.htm
>Cell��������悤�ȃw�e���W�j�A�X�}���`�R�A�ŃX�g���[���^�f�[�^�����̐��\�����߂�A�v���[�`�́A
>����I�Ƀp�t�H�[�}���X/�d�͂����コ���邱�Ƃ��ł���B������PC����CPU�̃A�v���[�`�ł́A���̌����ɂ͒ǂ����Ȃ��B
>�����x86�nCPU�ŁACell��256GFLOPS��B���ł���}���`�R�ACPU������ō�낤�Ƃ�����A�c��ȏ���d�́A
>���ꂱ��1,000W�N���X��CPU�ɂȂ��Ă��܂����낤�B
�݂�ȕ���Ă邵�B
90 �F����������K�������F2005/07/07(��) 18:31:08 ID:oycdOqFP
Pen4�͗Ⴆ�@PPC������ł��邯��
�v�ɖ��ʂ��Ȃ��Ă�athlon�̂悤��
���݂����ɔ��M����CPU������
CPU�͔��M����ƈ��蓮�삪�ł��Ȃ��Ȃ邽��
����ɓd�����グ�Ȃꂯ��Ȃ�Ȃ�
�����Ă���ɔ��M����
�R�A���ɐ��\/�d�͂̃x�X�g�ȏ�Ԃ����݂���
�v�ɖ��ʂ��Ȃ��Ă�athlon�̂悤��
���݂����ɔ��M����CPU������
CPU�͔��M����ƈ��蓮�삪�ł��Ȃ��Ȃ邽��
����ɓd�����グ�Ȃꂯ��Ȃ�Ȃ�
�����Ă���ɔ��M����
�R�A���ɐ��\/�d�͂̃x�X�g�ȏ�Ԃ����݂���
91 �F����������K�������F2005/07/07(��) 18:32:12 ID:BFQ0V07B
ttp://www.4gamer.net/news.php?url=/specials/3de/050706_gf7800/002/050707_gf7800_02.shtml
>�s�N�Z���V�F�[�_�v���O�����̎��s�������I�ɃX�g�[������i�~�܂�j�ƁC���̃s�N�Z���V�F�[�_���ʂ̃s�N�Z���̏������s���悤�ɃX���b�h�͐�ւ�����Ƃ̂��ƁB
�ȂAG70��Xenos�Ɠ����Ńe�N�X�`���[�t�F�b�`�̃X�g�[�������X�P�W���[���@�\���������Ă���̂ˁB
����甠�M�҂��K����Xenos�̗D�ʐ�������Ă������������ꂽ�B
>�s�N�Z���V�F�[�_�v���O�����̎��s�������I�ɃX�g�[������i�~�܂�j�ƁC���̃s�N�Z���V�F�[�_���ʂ̃s�N�Z���̏������s���悤�ɃX���b�h�͐�ւ�����Ƃ̂��ƁB
�ȂAG70��Xenos�Ɠ����Ńe�N�X�`���[�t�F�b�`�̃X�g�[�������X�P�W���[���@�\���������Ă���̂ˁB
����甠�M�҂��K����Xenos�̗D�ʐ�������Ă������������ꂽ�B
92 �F����������K�������F2005/07/07(��) 18:38:30 ID:OCHQwqCz
>>87
��̂܂Ƃ�
RSX��nVIDIA�ɏ\���Ȏ��Ԃ�^�����ɒZ���Ԃ�G70��]�p�B
�������AXENOS�Ƃǂ������D��Ă��邩�͂܂����Ƃ������Ȃ��B
���̂܂Ƃ�
ATi ��2�x�ڂ�R520�̐v�蒼���B600MHz�ȏ�ŋ쓮�����邱�Ƃ�ڎw���Ă���B
�������A����ł�90nm�v���Z�X�ł̕����܂肪�ǂ��ɂ��オ��Ȃ��B
R500�������v���Z�X���낤�H
��̂ǂ�����ĉ��S����XENOS��MS�ɋ����ł���Ƃ����̂��H
��̂܂Ƃ�
RSX��nVIDIA�ɏ\���Ȏ��Ԃ�^�����ɒZ���Ԃ�G70��]�p�B
�������AXENOS�Ƃǂ������D��Ă��邩�͂܂����Ƃ������Ȃ��B
���̂܂Ƃ�
ATi ��2�x�ڂ�R520�̐v�蒼���B600MHz�ȏ�ŋ쓮�����邱�Ƃ�ڎw���Ă���B
�������A����ł�90nm�v���Z�X�ł̕����܂肪�ǂ��ɂ��オ��Ȃ��B
R500�������v���Z�X���낤�H
��̂ǂ�����ĉ��S����XENOS��MS�ɋ����ł���Ƃ����̂��H
93 �F����������K�������F2005/07/07(��) 18:39:59 ID:oycdOqFP
>>89
Cell�̐����ɂ���āA���݂�Cell�v���Z�b�T�ȊO�ɂ�Cell�^�̃A�v���[�`���L�܂�B
SPE�^CPU�R�A�𓋍ڂ��ACell���C�N�ȍ\����������CPU���A
���sCell�ȊO�ɂ������o�ꂵ�n�߂�BPowerPC G5�N���X�̃��b�`��
PowerPC�R�A�{SPE�𓋍ڂ���Macintosh������CPU��A�����ƃV���v����
PPE��4���x��SPE���ڂ��������g�ݍ��ݔłȂǂ����肤�邩������Ȃ�
�R��ꂿ������E�E�E
Cell�̐����ɂ���āA���݂�Cell�v���Z�b�T�ȊO�ɂ�Cell�^�̃A�v���[�`���L�܂�B
SPE�^CPU�R�A�𓋍ڂ��ACell���C�N�ȍ\����������CPU���A
���sCell�ȊO�ɂ������o�ꂵ�n�߂�BPowerPC G5�N���X�̃��b�`��
PowerPC�R�A�{SPE�𓋍ڂ���Macintosh������CPU��A�����ƃV���v����
PPE��4���x��SPE���ڂ��������g�ݍ��ݔłȂǂ����肤�邩������Ȃ�
�R��ꂿ������E�E�E
94 �F����������K�������F2005/07/07(��) 18:40:00 ID:/3A9XzGR
>>90
�����ł����B�����O��Ƃ��Ă��Ȃ��͉������������̂ł����H
�����ł����B�����O��Ƃ��Ă��Ȃ��͉������������̂ł����H
95 �F����������K�������F2005/07/07(��) 18:40:48 ID:oycdOqFP
>>94
cell���b
cell���b
96 �F����������K�������F2005/07/07(��) 18:41:19 ID:fm/HWvJG
�I�I�T���V���E�E�I�Q�T�U�C�m�F�A���Ɍ����ی���
http://www.yomiuri.co.jp/main/news/20050707i307.htm
http://www.yomiuri.co.jp/main/news/20050707i307.htm
97 �F����������K�������F2005/07/07(��) 18:43:27 ID:9cVXiCMC
256�Ȃ�ăL���̂���������������Ē���Ȃ��悤�ɁB
98 �F����������K�������F2005/07/07(��) 18:44:21 ID:QQcY91V9
>>84
Cell��SPE��PPC�x�[�X����Ȃ��A���S�ɐV�����A�[�L�e�N�`������
SPE1������̏����\�͗��_�l�́@4�v�fx2���Zx3.2G��25.6Gflops
Cell��PPE�́@(4�v�f+2�v�f)x2���Z��38.4Gflops
PS3��PPE+SPEx7�� 38.4+25.6��7��217.6��218Gflops
XBOX360��PPE��3�ς�� 38.4x3��115.2Gflops
Cell�̐v�ł�SPE�������ł�PPE�ŕ����Ă��A���𑝂₷���ʼn��Z�\�͂�
�������������I��
���ꂩ�痝�_�l�ɂ̓L���b�V���̌��ʂ͑S���W������
Cell��SPE��PPC�x�[�X����Ȃ��A���S�ɐV�����A�[�L�e�N�`������
SPE1������̏����\�͗��_�l�́@4�v�fx2���Zx3.2G��25.6Gflops
Cell��PPE�́@(4�v�f+2�v�f)x2���Z��38.4Gflops
PS3��PPE+SPEx7�� 38.4+25.6��7��217.6��218Gflops
XBOX360��PPE��3�ς�� 38.4x3��115.2Gflops
Cell�̐v�ł�SPE�������ł�PPE�ŕ����Ă��A���𑝂₷���ʼn��Z�\�͂�
�������������I��
���ꂩ�痝�_�l�ɂ̓L���b�V���̌��ʂ͑S���W������
99 �F����������K�������F2005/07/07(��) 18:45:00 ID:D8bu+cWv
>>91
����GPU�Ł���PS3�Ȃ�ĕ���Ă�Ǝv����
����GPU�Ł���PS3�Ȃ�ĕ���Ă�Ǝv����
100 �F����������K�������F2005/07/07(��) 18:45:21 ID:r6PNX/wY
>>920
����R520��R500(Xenos)�Ɠ������ǂ����܂��������ĂȂ���ˁB
�����Xenos�̓R�A������2��������ƂŁAeDRAM��1�����炢��߂�B
���AeDRAM�𓋍ڂł��Ȃ�R520�̓R�A������3������ƌ����Ă�B
������R420�̐i���n���Ƃ����b������B
����R520��R500(Xenos)�Ɠ������ǂ����܂��������ĂȂ���ˁB
�����Xenos�̓R�A������2��������ƂŁAeDRAM��1�����炢��߂�B
���AeDRAM�𓋍ڂł��Ȃ�R520�̓R�A������3������ƌ����Ă�B
������R420�̐i���n���Ƃ����b������B
101 �F����������K�������F2005/07/07(��) 18:45:47 ID:W+x4qcks
> R500�������v���Z�X���낤�H
> ��̂ǂ�����ĉ��S����XENOS��MS�ɋ����ł���Ƃ����̂��H
����́u�傫�Ȃ����b�v�ȋC������ȁc�B�Ⴄ�`�b�v�Ȃ̂ɁB
> ��̂ǂ�����ĉ��S����XENOS��MS�ɋ����ł���Ƃ����̂��H
����́u�傫�Ȃ����b�v�ȋC������ȁc�B�Ⴄ�`�b�v�Ȃ̂ɁB
>>92�̊ԈႢ�B
103 �F����������K�������F2005/07/07(��) 18:46:02 ID:DMqtMvYv
>>100
��������
��������
104 �F����������K�������F2005/07/07(��) 18:47:21 ID:33zr2Fhs
R500��NEC������
105 �F����������K�������F2005/07/07(��) 18:49:24 ID:QQcY91V9
>>95
����Cell�^�A�v���[�`�ō��ꂽCPU��XBOX360�ɏ��킯����Ȃ��ł���
�����������烌�{�����[�V�����ɂ͍ڂ邩������Ȃ����� ;-p
�܂��ACell�^���L�����Ɣ������Ă���v�n�߂���o�Ă���͓̂����悾��
Cell�̕��y�ɂ͉e�����Ȃ����낤��
����Cell�^�A�v���[�`�ō��ꂽCPU��XBOX360�ɏ��킯����Ȃ��ł���
�����������烌�{�����[�V�����ɂ͍ڂ邩������Ȃ����� ;-p
�܂��ACell�^���L�����Ɣ������Ă���v�n�߂���o�Ă���͓̂����悾��
Cell�̕��y�ɂ͉e�����Ȃ����낤��
106 �F����������K�������F2005/07/07(��) 18:52:05 ID:4j11OtxO
Cell�͂���ς葼�̂ǂ������̗p���Ă���Ȃ���
EE�Ɠ�������H��悤�ȋC������B
EE�Ɠ�������H��悤�ȋC������B
107 �F����������K�������F2005/07/07(��) 18:52:06 ID:/3A9XzGR
>>90 >>95
�v���Z�b�T���ɐ��\/�d�͂̃x�X�g�ȏ�Ԃ����݂��邩��cell���b�B
�Ȃ��肪�S��������Ȃ��c(���\/�d��)��Cell�̕������Ȃ荂�����B
�v���Z�b�T���ɐ��\/�d�͂̃x�X�g�ȏ�Ԃ����݂��邩��cell���b�B
�Ȃ��肪�S��������Ȃ��c(���\/�d��)��Cell�̕������Ȃ荂�����B
108 �F����������K�������F2005/07/07(��) 18:55:32 ID:OCHQwqCz
>>107
�����痼�҂ɂ́h���֊ւ��퉽������q�����������������ӂ��������G��
�����痼�҂ɂ́h���֊ւ��퉽������q�����������������ӂ��������G��
109 �F����������K�������F2005/07/07(��) 18:55:44 ID:UEIjZC5M
>>107
�������_�����Ǝv������_�����ƌ����Ă�z�Ȃ�ď��F����Ȃ��̂ł���
�������_�����Ǝv������_�����ƌ����Ă�z�Ȃ�ď��F����Ȃ��̂ł���
110 �F����������K�������F2005/07/07(��) 18:57:29 ID:W+x4qcks
R520�ɂ��Ă͈����\���������Ă���̂ɁAR500�ɂ��Ă͕������Ă��Ȃ��Ȃ�A
Xenos�̐��Y�͏����A�ƍl����̂������Ȃ�Ȃ��̂��˂��B
ATI/TSMC�̕�������̓_�_�R��A�Ƃ����O��ŁB
Xenos�̐��Y�͏����A�ƍl����̂������Ȃ�Ȃ��̂��˂��B
ATI/TSMC�̕�������̓_�_�R��A�Ƃ����O��ŁB
111 �F����������K�������F2005/07/07(��) 18:59:57 ID:9cVXiCMC
>>110
Xenos���ǂ����͂Ƃ������A��������_�_�R��͂Ȃ��ł���B
ATi��R520�̃X�P�W���[�����A�i�E���X���Ă�킯������A
����ɒx��Ă鎖�ɑ��鎖������Ƃ��͕K�v�����ˁB
Xenos���ǂ����͂Ƃ������A��������_�_�R��͂Ȃ��ł���B
ATi��R520�̃X�P�W���[�����A�i�E���X���Ă�킯������A
����ɒx��Ă鎖�ɑ��鎖������Ƃ��͕K�v�����ˁB
112 �F����������K�������F2005/07/07(��) 19:00:56 ID:HrEvukYx
>>98
�݊�����������ۂ����PPC�x�[�X���Ǝv���Ă܂����B
>���ꂩ�痝�_�l�ɂ̓L���b�V���̌��ʂ͑S���W������
�����ł������B
�Ă��Ƃ́A�L���b�V�����K�b�c����ŗL�����p�ł���Cell�A
�]����CPU���l�̃L���b�V�������̔�360��CPU�ł́A
Cell�̕��������l�͗����ɂ����A���͂���������ƊJ�����Ă��Ƃ����ˁB
���A�T�C�Y�̖�肪�o��Ǝv���܂����ǁA��360�^�C�v�Ŋe�R�A�Ƀ��b�N�\�ȃL���b�V����
DMA���t�����\�����o����ACell���_��Ŏ����l������������CPU�ɂȂ�܂��ˁB
���z�_�Ȃ�ł����ǁB
�݊�����������ۂ����PPC�x�[�X���Ǝv���Ă܂����B
>���ꂩ�痝�_�l�ɂ̓L���b�V���̌��ʂ͑S���W������
�����ł������B
�Ă��Ƃ́A�L���b�V�����K�b�c����ŗL�����p�ł���Cell�A
�]����CPU���l�̃L���b�V�������̔�360��CPU�ł́A
Cell�̕��������l�͗����ɂ����A���͂���������ƊJ�����Ă��Ƃ����ˁB
���A�T�C�Y�̖�肪�o��Ǝv���܂����ǁA��360�^�C�v�Ŋe�R�A�Ƀ��b�N�\�ȃL���b�V����
DMA���t�����\�����o����ACell���_��Ŏ����l������������CPU�ɂȂ�܂��ˁB
���z�_�Ȃ�ł����ǁB
113 �F����������K�������F2005/07/07(��) 19:02:57 ID:QQcY91V9
>>106
�Ƃ肠����
Cell���ڂ�IBM���u���[�h�T�[�o�[��
ttp://pc.watch.impress.co.jp/docs/2005/0629/mercury.htm
����Ȃ̂ɂ��̗p�����܂��Ă邩��AEE�݂����ɊO�̂ł��Ȃ����Ď��͖�������
�E�E�E�Ȃ�cell�X���̕����ӂ��킵���C�����Ă���
�Ƃ肠����
Cell���ڂ�IBM���u���[�h�T�[�o�[��
ttp://pc.watch.impress.co.jp/docs/2005/0629/mercury.htm
����Ȃ̂ɂ��̗p�����܂��Ă邩��AEE�݂����ɊO�̂ł��Ȃ����Ď��͖�������
�E�E�E�Ȃ�cell�X���̕����ӂ��킵���C�����Ă���
114 �F����������K�������F2005/07/07(��) 19:02:57 ID:4UcCENb3
oycdOqFP�ɍ\���Ă���Ă邠��₳������
115 �F����������K�������F2005/07/07(��) 19:03:08 ID:/vr50/T4
R520��Xbox360��GPU�iR500�j���S���Ⴄ���̂Ȃ�
�Ȃ��uR5xx�v�Ƃ����J���R�[�h�ɂ����̂��^��ȂƂ��낾��
>>110
R520�͌��X�͏t���\��7���ɂ͔������Ă�Ƃ����b����������ʎY��90nm�v���Z�X�Ń��[�N�d��
�Ƃ����b���o���낤
R500�̗ʎY�J�n��8���`9�����낾�낤����R500���̖̂��͏o�悤���Ȃ����낤
�Ȃ��uR5xx�v�Ƃ����J���R�[�h�ɂ����̂��^��ȂƂ��낾��
>>110
R520�͌��X�͏t���\��7���ɂ͔������Ă�Ƃ����b����������ʎY��90nm�v���Z�X�Ń��[�N�d��
�Ƃ����b���o���낤
R500�̗ʎY�J�n��8���`9�����낾�낤����R500���̖̂��͏o�悤���Ȃ����낤
116 �F����������K�������F2005/07/07(��) 19:03:53 ID:9cVXiCMC
���b�N�\�ȃL���b�V���ƌ����Ă��A�R�q�[�����V�̖��Ƃ������邵�Ȃ��B
117 �F����������K�������F2005/07/07(��) 19:04:59 ID:IhBIHqaP
mpeg2��48�{�����f�R�[�h�A�k�����āA�����Ă���T���l�C������ׂ�1080�����
���Č����Ă�����Ă����̂�cell�����ӂȏ���������o���Ă��邾���ŁA
�ʂ̏�����������Pen4�ɗ]�T�œG��Ȃ��Ȃ�Ă������Ƃ͂Ȃ��̂�����B
���Č����Ă�����Ă����̂�cell�����ӂȏ���������o���Ă��邾���ŁA
�ʂ̏�����������Pen4�ɗ]�T�œG��Ȃ��Ȃ�Ă������Ƃ͂Ȃ��̂�����B
118 �F����������K�������F2005/07/07(��) 19:06:10 ID:UEIjZC5M
R520����J���Ă�̂̓��[�N�d���B�V�v�{�X�Onm�v���Z�X���ɍs�����ׂƌ�����B
Xenos�̂ق���Tr�������Ȃ��Ƃ͂����V�v�{�X�Onm�v���Z�X�ł��邱�Ƃ͓�������㐶�Y����
���Ⴂ�Ȉȏ�A���Ȃ�ʎY�ɐԐM���������Ă���ƍl����̂͂��������Ȃ��Ǝv���B
Xenos�̂ق���Tr�������Ȃ��Ƃ͂����V�v�{�X�Onm�v���Z�X�ł��邱�Ƃ͓�������㐶�Y����
���Ⴂ�Ȉȏ�A���Ȃ�ʎY�ɐԐM���������Ă���ƍl����̂͂��������Ȃ��Ǝv���B
119 �F����������K�������F2005/07/07(��) 19:07:53 ID:W+x4qcks
>>117
�������ASPE�ɃI�t���[�h���ĂȂ�/�ł��Ȃ������͗]�T�œG��Ȃ��B
Cell�̗D�ʂ́A�v���O�������̃z�b�g�X�|�b�g(�p�ɂɎ��s�����)��
SPE������C/C++�ŏ��������A�Ƃ����̂���O��B
�������ASPE�ɃI�t���[�h���ĂȂ�/�ł��Ȃ������͗]�T�œG��Ȃ��B
Cell�̗D�ʂ́A�v���O�������̃z�b�g�X�|�b�g(�p�ɂɎ��s�����)��
SPE������C/C++�ŏ��������A�Ƃ����̂���O��B
120 �F����������K�������F2005/07/07(��) 19:09:30 ID:GLxm2rCd
�X�e�B�[�u�E�W���u�X����CELL�v���Z�b�T�Ɏ��]
http://news.teamxbox.com/xbox/8504/Steve-Jobs-Not-Impressed-with-the-Cell-Processor/
New York Times�ɂ��ƁA�A�b�v�� CEO�̃X�e�B�[�u�E�W���u�Y����PS3�ɓ��ڂ����CELL�v���Z�b�T�Ɍ������]���������������ł��B
�W���u�Y����SCE�̋v���ǖ؎�����CELL�v���Z�b�T�̗p�̓��������������̂́A���̃f�U�C���ɗ��_���APowerPC����������Ɣ��f�����Ƃ��B
�A�b�v���͍���C���e����CPU�֓]�����邱�Ƃ𖾂炩�ɂ��Ă��܂��B
http://news.teamxbox.com/xbox/8504/Steve-Jobs-Not-Impressed-with-the-Cell-Processor/
New York Times�ɂ��ƁA�A�b�v�� CEO�̃X�e�B�[�u�E�W���u�Y����PS3�ɓ��ڂ����CELL�v���Z�b�T�Ɍ������]���������������ł��B
�W���u�Y����SCE�̋v���ǖ؎�����CELL�v���Z�b�T�̗p�̓��������������̂́A���̃f�U�C���ɗ��_���APowerPC����������Ɣ��f�����Ƃ��B
�A�b�v���͍���C���e����CPU�֓]�����邱�Ƃ𖾂炩�ɂ��Ă��܂��B
121 �F����������K�������F2005/07/07(��) 19:09:39 ID:HrEvukYx
>>116
�R�q�[�����V�̖����āA
�E���̓��e�̏����߂�
�E�K�v�ȃf�[�^�̎�荞��
�E����
�̎菇�ōs�����瓯�ꐫ�ɖ��͏o�Ȃ��Ǝv�����ǁE�E�B
���b�N���Ȃ����Ȃ������_�ŃL���b�V���̃t���b�V������������B
���ĈႤ���ł����H
�R�q�[�����V�̖����āA
�E���̓��e�̏����߂�
�E�K�v�ȃf�[�^�̎�荞��
�E����
�̎菇�ōs�����瓯�ꐫ�ɖ��͏o�Ȃ��Ǝv�����ǁE�E�B
���b�N���Ȃ����Ȃ������_�ŃL���b�V���̃t���b�V������������B
���ĈႤ���ł����H
122 �F����������K�������F2005/07/07(��) 19:14:13 ID:GLxm2rCd
844 ���O�FSocket774[sage] ���e���F2005/06/18(�y) 00:03:04 ID:NywvqZB5
761 �FIt's������������ �F2005/06/15(��) 10:24:51
>>757
�܂����́h��360�̔{�ȏ�h�̏����\�͂͂����܂Ŋ���̗��_�l��
���g�p��ł͂قڂ��肦�Ȃ��l�ł����Ȃ��A�A�v���x�[�X�ł͂���
�����\�͂�60%���V��ł��܂��Ă��邨�e���ȃn�[�h�v��SDK
�Ȃ��ǂȁB�������n�[�h�̎d�l��̖��i���ׂƌ����Ă����j
������A���������Ɋւ��Ă͑啝�ȉ��P�̌����݂͂Ȃ��A
����́h�g����Ƃ��낾�����g���h�A�v���v�𑱂��邵����͂Ȃ��B
360�ɂ��Ă͂������������ʂȐv�i�����̏�ɉ��������݂����ȁj���Ȃ��A
�������J���������Ȃ�Ă��邩��A�����_�ł��J�������ăn�[�h������70�`80%�قǂ�
�p�t�H�[�}���X���������邵�A�n�[�h�̉�͂������߂���������悹���\�A�̂͂��B
���{�ɂ������Ă̓R���X�^���g�Ƀn�[�h�̃p�t�H�[�}���X��80%�ȏ���o����݂��������H
�i�C�V���Ɋւ��Ă̓m�[�^�b�`�Ȃ̂ł����܂œ`���j
761 �FIt's������������ �F2005/06/15(��) 10:24:51
>>757
�܂����́h��360�̔{�ȏ�h�̏����\�͂͂����܂Ŋ���̗��_�l��
���g�p��ł͂قڂ��肦�Ȃ��l�ł����Ȃ��A�A�v���x�[�X�ł͂���
�����\�͂�60%���V��ł��܂��Ă��邨�e���ȃn�[�h�v��SDK
�Ȃ��ǂȁB�������n�[�h�̎d�l��̖��i���ׂƌ����Ă����j
������A���������Ɋւ��Ă͑啝�ȉ��P�̌����݂͂Ȃ��A
����́h�g����Ƃ��낾�����g���h�A�v���v�𑱂��邵����͂Ȃ��B
360�ɂ��Ă͂������������ʂȐv�i�����̏�ɉ��������݂����ȁj���Ȃ��A
�������J���������Ȃ�Ă��邩��A�����_�ł��J�������ăn�[�h������70�`80%�قǂ�
�p�t�H�[�}���X���������邵�A�n�[�h�̉�͂������߂���������悹���\�A�̂͂��B
���{�ɂ������Ă̓R���X�^���g�Ƀn�[�h�̃p�t�H�[�}���X��80%�ȏ���o����݂��������H
�i�C�V���Ɋւ��Ă̓m�[�^�b�`�Ȃ̂ł����܂œ`���j
123 �F����������K�������F2005/07/07(��) 19:17:58 ID:QQcY91V9
>>112
����Ȋ�������Ȃ�����
Cell��SPE����LS��L1�L���b�V�����̑��x�A���C�e���V��256KB���̗e�ʐς�ł��
�l����ƁALS���ōςޏ����͎��s���\���������Ƒz���ł���ł���
���b�`�ȃR�A���ڂ���Ə���d�͂�_�C��̃T�C�Y�̖�肪�o�Ă���̂ŁA
���\���L�т�\���͂��邯��ǁA���M������܂肪���ɂȂ�\��������
Cell�͒P���ɐ��\�������l������ł͂Ȃ��A���Y�������d�͂̎����l���ɂ����
����Ă邩���
����Ȋ�������Ȃ�����
Cell��SPE����LS��L1�L���b�V�����̑��x�A���C�e���V��256KB���̗e�ʐς�ł��
�l����ƁALS���ōςޏ����͎��s���\���������Ƒz���ł���ł���
���b�`�ȃR�A���ڂ���Ə���d�͂�_�C��̃T�C�Y�̖�肪�o�Ă���̂ŁA
���\���L�т�\���͂��邯��ǁA���M������܂肪���ɂȂ�\��������
Cell�͒P���ɐ��\�������l������ł͂Ȃ��A���Y�������d�͂̎����l���ɂ����
����Ă邩���
124 �F����������K�������F2005/07/07(��) 19:19:02 ID:W+x4qcks
90nm�v���Z�X�ł̐��Y�ɂ��Č����ASONY+���ł�����3���g�����W�X�^�̋���GPU��������o����
�Ȃ���ˁBEE+GS��5000���g�����W�X�^���炢?
Cell�̑�ꐢ���IBM�̍H�ꂾ�낤��(�����܂���͉ߋ��ɂ��낢�날����)�A
�j�n��Ȃ̂͂ǂ����ꏏ����Ȃ����ƁB
�Ȃ���ˁBEE+GS��5000���g�����W�X�^���炢?
Cell�̑�ꐢ���IBM�̍H�ꂾ�낤��(�����܂���͉ߋ��ɂ��낢�날����)�A
�j�n��Ȃ̂͂ǂ����ꏏ����Ȃ����ƁB
125 �F����������K�������F2005/07/07(��) 19:19:56 ID:/vr50/T4
���������܂ł��čĐv�������Ă��Ƃ�ATI��90nm�v���Z�X����̃��[�N�d���ɑ��錩�ʂ����Â������Ƃ������ƂȂ낤
���ꂪATI�̈�̃`�[���̖�肾�����Ƃ���̂Ȃ�ǂ����A
�Г��S�̂ŔF�����Â������Ƃ������Ƃ��ƁA����90nm�v���Z�X�ŐV�A�[�L��R500�ɂ��v��œ����悤�Ȗ�肪
�Ƃ������Ă݂���
���ꂪATI�̈�̃`�[���̖�肾�����Ƃ���̂Ȃ�ǂ����A
�Г��S�̂ŔF�����Â������Ƃ������Ƃ��ƁA����90nm�v���Z�X�ŐV�A�[�L��R500�ɂ��v��œ����悤�Ȗ�肪
�Ƃ������Ă݂���
126 �F����������K�������F2005/07/07(��) 19:23:32 ID:HvxFdNts
127 �F����������K�������F2005/07/07(��) 19:24:15 ID:QQcY91V9
�X���[���ׂ������ǁA������Ƃ���
���s���\�ŗ��_�l��40%�o��Ȃ�Cell�� 218x0.4��87Gflops�A
1�R�A��OS��p�炵��Xbox360CPU�� 38.4x2x0.8��61Gflops
���Ď��ł����̂��ȁH;-p
���s���\�ŗ��_�l��40%�o��Ȃ�Cell�� 218x0.4��87Gflops�A
1�R�A��OS��p�炵��Xbox360CPU�� 38.4x2x0.8��61Gflops
���Ď��ł����̂��ȁH;-p
128 �F����������K�������F2005/07/07(��) 19:24:44 ID:XZgtKNHX
Cell,RSX����90nm�ő�̖��ł��郊�[�N�d���Ɋւ��đ������K�v������
���ꂾ���ł��A�h�o���e�[�W�͑傫����
���ꂾ���ł��A�h�o���e�[�W�͑傫����
129 �F����������K�������F2005/07/07(��) 19:26:47 ID:3tMVI3cs
�����܂�̘b���r��邩�炷���
130 �F����������K�������F2005/07/07(��) 19:28:30 ID:W+x4qcks
360�́u1�R�AOS��p�v���Ă̂́A
�u�V�X�e���R�[���ŃJ�[�l�����[�h�ɑJ�ڂł���R�A������R�A�����v
�̈Ӗ����Ǝv�����ǁA�ǂ��Ȃ̂��Ȃ��B
360�̃J�[�l�����āANT�J�[�l��������Xbox�̂��̂̊g���ł��Ă�������A
�����炭SMP�Ή����ĂȂ����̂ł���(�I�[�o�[�w�b�h���邩��)�B
�X���b�h�̓R�A�ɌŒ�Ŋ���t������Ǝv������ǂ��B
�u�V�X�e���R�[���ŃJ�[�l�����[�h�ɑJ�ڂł���R�A������R�A�����v
�̈Ӗ����Ǝv�����ǁA�ǂ��Ȃ̂��Ȃ��B
360�̃J�[�l�����āANT�J�[�l��������Xbox�̂��̂̊g���ł��Ă�������A
�����炭SMP�Ή����ĂȂ����̂ł���(�I�[�o�[�w�b�h���邩��)�B
�X���b�h�̓R�A�ɌŒ�Ŋ���t������Ǝv������ǂ��B
131 �F����������K�������F2005/07/07(��) 19:30:40 ID:MZHC731r
�ȂA�R�U�O�͕ʂɈ�R�A��OS��p�ɂ��Ȃ��Ă��ǂ����ď������݂�������
�悭�킩���
�悭�킩���
132 �F����������K�������F2005/07/07(��) 19:31:33 ID:MtbSxyqo
MS�͍ŋߐ��\�ɂ͌������Live��җ�Ƀv�b�V�����Ă�
�ǂ���������ɒu����Ă�̂��͐����đ���ׂ�����
�ǂ���������ɒu����Ă�̂��͐����đ���ׂ�����
133 �F����������K�������F2005/07/07(��) 19:31:53 ID:0PDR5C+g
134 �F����������K�������F2005/07/07(��) 19:32:40 ID:HrEvukYx
>>123
�Ȃ�قǁA���������܂Ō`�������Ă��܂����B
Cell�̊̂ɂȂ�SPE�ł����ǁA�R�[�h�̈���Ă���ς�LS�ɒu������ł����ˁB
�˂����b�ɂȂ�܂����ǁALS�ɒu�����ƂȂ�ƃv���O�����̓���ւ��͎��s����
�ʒu�ɏ㏑���ł���Ƃ��v���Ȃ��̂ŁAPPE����̓��ւ��ɂȂ�Ɨ\�z���܂����A
�����Ȃ��PPE�Ɋ��荞�݂������ē��ւ����N�G�X�g���s�ESPE���X���[�v�E
DMA�I�����荞�݂�SPE�N���A�݂����Ȏ菇���\�z����܂����A
���ւ����p������悤�ȏꍇ��PPE�̏��������\�j�Q����Ă��܂��悤�Ɏv���܂��B
�����܂ŗ\�z�Ȃ�ł����ǁA�Ȃp�t�H�[�}���X�������o���ɂ������̗l�ȋC�����܂��B
�R�[�h�̈悪���C���������Ɏ���Ȃ�S�R���Ȃ���ł����ǁB
�Ȃ�قǁA���������܂Ō`�������Ă��܂����B
Cell�̊̂ɂȂ�SPE�ł����ǁA�R�[�h�̈���Ă���ς�LS�ɒu������ł����ˁB
�˂����b�ɂȂ�܂����ǁALS�ɒu�����ƂȂ�ƃv���O�����̓���ւ��͎��s����
�ʒu�ɏ㏑���ł���Ƃ��v���Ȃ��̂ŁAPPE����̓��ւ��ɂȂ�Ɨ\�z���܂����A
�����Ȃ��PPE�Ɋ��荞�݂������ē��ւ����N�G�X�g���s�ESPE���X���[�v�E
DMA�I�����荞�݂�SPE�N���A�݂����Ȏ菇���\�z����܂����A
���ւ����p������悤�ȏꍇ��PPE�̏��������\�j�Q����Ă��܂��悤�Ɏv���܂��B
�����܂ŗ\�z�Ȃ�ł����ǁA�Ȃp�t�H�[�}���X�������o���ɂ������̗l�ȋC�����܂��B
�R�[�h�̈悪���C���������Ɏ���Ȃ�S�R���Ȃ���ł����ǁB
135 �F����������K�������F2005/07/07(��) 19:35:25 ID:QQcY91V9
>>130
���ʂɍl���������R�A��1�X���b�h���AOS�Ăяo���ŃX���b�h��ւ����N����
�I�[�o�[�w�b�h����ׂ̈ɗ\����Ď����Ǝv����ł����ǂ�
�܂��A>127�́A�\�[�X�������l�^�ɂ̓l�^���X���Ď���
���ʂɍl���������R�A��1�X���b�h���AOS�Ăяo���ŃX���b�h��ւ����N����
�I�[�o�[�w�b�h����ׂ̈ɗ\����Ď����Ǝv����ł����ǂ�
�܂��A>127�́A�\�[�X�������l�^�ɂ̓l�^���X���Ď���
136 �F����������K�������F2005/07/07(��) 19:35:48 ID:NiuTJ3UF
�A�v���P�[�V�����p�R�[�h�̈���_�u���o�b�t�@�ɂ���Ƃ��B
���������DMA�Ŏ����I�ɃR�[�h�ƃf�[�^������Ă��ď����ł���B
�������̃����N���͍X�ɑ�ς�����ǁB
���������DMA�Ŏ����I�ɃR�[�h�ƃf�[�^������Ă��ď����ł���B
�������̃����N���͍X�ɑ�ς�����ǁB
137 �F����������K�������F2005/07/07(��) 19:36:26 ID:W+x4qcks
>>134
������SPE�̃X���b�h�ؑւ̗��x�͍r���Ȃ�A
�ʏ��OS�̃X���b�h�̂悤�Ɏ������ł͂Ȃ��A�^�X�N����������܂Ŏ��s��������̂�
��{�ɂȂ�B
������SPE�̃X���b�h�ؑւ̗��x�͍r���Ȃ�A
�ʏ��OS�̃X���b�h�̂悤�Ɏ������ł͂Ȃ��A�^�X�N����������܂Ŏ��s��������̂�
��{�ɂȂ�B
138 �F����������K�������F2005/07/07(��) 19:38:06 ID:WYHJn+zB
����ȃX���킴�킴�\��܂ł̃\�[�X
�ȂK�v�Ȃ���
�܂��߂ɓ��_��������cell�X��������
�����Ƃ��ߑa�����i��ł��邪����
�ȂK�v�Ȃ���
�܂��߂ɓ��_��������cell�X��������
�����Ƃ��ߑa�����i��ł��邪����
139 �F����������K�������F2005/07/07(��) 19:39:00 ID:1WUkNxTA
PPE�p�R�[�h��SPE�p�R�[�h�͈Ⴄ�̂ł́H
140 �F����������K�������F2005/07/07(��) 19:40:51 ID:HvxFdNts
>>134
�Q�[���v���O�����Ɍ��肷��ƁASPE�̃X���b�h�i�v���O�������j��
�p�ɂɓ���ւ����肵�Ȃ��ł���B�����̃X���b�h��u���Ƃ����Ƃ��o���邵�B
�i�ǂ̃X���b�h�����s���邩�̎w��͕K�v���낤���ǁj
�V�F�[�_�̓��I����Ή��ɂ������āA�V�F�[�_�̕p�ɂȓ���ւ���
�������ʂ�����킯�ŁB
�Q�[���v���O�����Ɍ��肷��ƁASPE�̃X���b�h�i�v���O�������j��
�p�ɂɓ���ւ����肵�Ȃ��ł���B�����̃X���b�h��u���Ƃ����Ƃ��o���邵�B
�i�ǂ̃X���b�h�����s���邩�̎w��͕K�v���낤���ǁj
�V�F�[�_�̓��I����Ή��ɂ������āA�V�F�[�_�̕p�ɂȓ���ւ���
�������ʂ�����킯�ŁB
141 �F����������K�������F2005/07/07(��) 19:44:03 ID:16+jBJbE
>>132
���̘b�����ŕ������H
���̘b�����ŕ������H
142 �F����������K�������F2005/07/07(��) 19:45:41 ID:9cVXiCMC
>>121
Xbox360 CPU�̏ڂ����d�l��m��Ȃ��̂łȂ�Ƃ��Ȃ��ǁA
���������g�������o������̂Ȃ́H
�������̎��������ƁAL2�L���b�V���̗̈悻�ꂼ����w�肵�ă��b�N����킯�H
>>130
SMP���Ή��̃J�[�l���łǂ������3�R�A�������́H
���Ƃ����SMT���ʖڂȂ킯�����B
Xbox360 CPU�̏ڂ����d�l��m��Ȃ��̂łȂ�Ƃ��Ȃ��ǁA
���������g�������o������̂Ȃ́H
�������̎��������ƁAL2�L���b�V���̗̈悻�ꂼ����w�肵�ă��b�N����킯�H
>>130
SMP���Ή��̃J�[�l���łǂ������3�R�A�������́H
���Ƃ����SMT���ʖڂȂ킯�����B
143 �F����������K�������F2005/07/07(��) 19:46:24 ID:TlGEh/fK
1�R�AOS��p�Ȃ�ăf�}���낤�ɁB���OS��p���ċ�̓I�ɉ������B
���Ȃ݂ɉ����������͖̂���1�R�A2�X���b�h�̓��A
1�X���b�h��LIVE�ŁA1�X���b�h�̓T�E���h�B
�܂��ǂ����ɂ���J���҂̍ٗʂɔC����Ă邾�낤���ǁB
���Ȃ݂ɉ����������͖̂���1�R�A2�X���b�h�̓��A
1�X���b�h��LIVE�ŁA1�X���b�h�̓T�E���h�B
�܂��ǂ����ɂ���J���҂̍ٗʂɔC����Ă邾�낤���ǁB
144 �F����������K�������F2005/07/07(��) 19:49:42 ID:D4NJhtpc
�X���b�h���͑�����悢
�Ȃ��Ȃ炤�܂����ΐ��\�ቺ���h���邩��
N64��CPU�ŃT�E���h���܂�܂鏈�������̂�
���s���\���ቺ���܂�����
�Ȃ��Ȃ炤�܂����ΐ��\�ቺ���h���邩��
N64��CPU�ŃT�E���h���܂�܂鏈�������̂�
���s���\���ቺ���܂�����
145 �F����������K�������F2005/07/07(��) 19:51:29 ID:HrEvukYx
>>137
�T��134�̔F���͊Ԉ���ĂȂ��ƁB
�X���b�h��ւ���}����`�ƂȂ�ƁA��^�����ʼn̂������I�Ȃ�ł����ˁB
���[�V���������A�J�����O�E�R���W�����E�V�F�[�_�[�Ƃ����ȂƁB
���̕ӂ�̃f�[�^���ĕ��ɂ���Ă�256KB���Ⴗ�܂Ȃ����Ǝv����ł����A��������
��荞��ł����ƃf�[�^�̈��������\��ςȋC�����܂����E�E�E�B
�ȂA�ϑz����ƂƃL�����Ȃ��悤�Ȃ�
�T��134�̔F���͊Ԉ���ĂȂ��ƁB
�X���b�h��ւ���}����`�ƂȂ�ƁA��^�����ʼn̂������I�Ȃ�ł����ˁB
���[�V���������A�J�����O�E�R���W�����E�V�F�[�_�[�Ƃ����ȂƁB
���̕ӂ�̃f�[�^���ĕ��ɂ���Ă�256KB���Ⴗ�܂Ȃ����Ǝv����ł����A��������
��荞��ł����ƃf�[�^�̈��������\��ςȋC�����܂����E�E�E�B
�ȂA�ϑz����ƂƃL�����Ȃ��悤�Ȃ�
146 �F����������K�������F2005/07/07(��) 19:53:27 ID:mni8rgTD
>>144
����̓T�E���h�łP�X���b�h�g�������Ď��ł����
����̓T�E���h�łP�X���b�h�g�������Ď��ł����
147 �F����������K�������F2005/07/07(��) 19:54:16 ID:cHBZ2cKi
148 �F����������K�������F2005/07/07(��) 19:54:28 ID:HvxFdNts
149 �F����������K�������F2005/07/07(��) 19:54:52 ID:W+x4qcks
> SMP���Ή��̃J�[�l���łǂ������3�R�A�������́H
�J�[�l���ւ̑J�ڂ������ꂽ(�n�[�h�E�F�A)�X���b�h��������āA
����ȊO��5�̃X���b�h�͊�{�I��OS�̊Ǘ��O�ɂȂ�A�Ƃ������ƁB
�������A�R���e�L�X�g�X�C�b�`��r�������OS���ʓ|�݂Ă���邾�낤���ǁA
SMP�J�[�l���̂悤�ɁA�J�[�l�����ŃX���b�h�����������āA������I/O��
�����ɏ���������͂ł��Ȃ���A�ƁB
�J�[�l���ւ̑J�ڂ������ꂽ(�n�[�h�E�F�A)�X���b�h��������āA
����ȊO��5�̃X���b�h�͊�{�I��OS�̊Ǘ��O�ɂȂ�A�Ƃ������ƁB
�������A�R���e�L�X�g�X�C�b�`��r�������OS���ʓ|�݂Ă���邾�낤���ǁA
SMP�J�[�l���̂悤�ɁA�J�[�l�����ŃX���b�h�����������āA������I/O��
�����ɏ���������͂ł��Ȃ���A�ƁB
150 �F����������K�������F2005/07/07(��) 19:57:50 ID:0PDR5C+g
>>145
�����������ɂ��܂���邩��cell�v���O���~���O�̃L���ł���B
�܂�256KB������Α��̂��Ƃ͂���Ƃ������B
�Q�[���v���O���}�Ƃ����̂�4KB�Ƃ�8KB�ł����Ƃ����Ă����l�B�Ȃ̂ŁB
�����������ɂ��܂���邩��cell�v���O���~���O�̃L���ł���B
�܂�256KB������Α��̂��Ƃ͂���Ƃ������B
�Q�[���v���O���}�Ƃ����̂�4KB�Ƃ�8KB�ł����Ƃ����Ă����l�B�Ȃ̂ŁB
151 �F����������K�������F2005/07/07(��) 19:58:42 ID:D4NJhtpc
840XE�������Ȃ�CPU�Ȃ낤���ǂ�
���i�K�ł͍œK���ł��ĂȂ���ł���
���i�K�ł͍œK���ł��ĂȂ���ł���
152 �F����������K�������F2005/07/07(��) 20:00:08 ID:QQcY91V9
>>134
SPE�����s�ł���̂�LS��̃v���O���������ł�
SPE�͒P�̂�DMA�o�R�̃��C���������A�N�Z�X�ł���̂ŁA��{�I�ɂ�PPE�Ɋ��荞�݂�
������K�v�͖����ł��傤
�ŁA�m���ɓ���ւ��̕p������悤�ȏ��Ɛ��\�ቺ�͔������Ȃ��Ǝv���܂���
���̂悤�ȏɂȂ�Ȃ��悤�ɗ��p����̂�Cell�̗L���Ȏg�����ł��傤��
���ꂩ��v���O�����̗L���Ȗ@���Ƃ���10�|90�̖@���Ƃ����̂�����܂��āA
>�����Ă��̃v���O�����̏ꍇ�A�v���O�����̈ꕔ���i��10���j��
>�قƂ�ǂ̏������ԁi��90%�j������Ă���Ƃ����@�����B
�Ȃ̂ŁA�d�������̕����������o����256KB�ŏ\���Ɛv�҂����f�����̂ł��傤
SPE�����s�ł���̂�LS��̃v���O���������ł�
SPE�͒P�̂�DMA�o�R�̃��C���������A�N�Z�X�ł���̂ŁA��{�I�ɂ�PPE�Ɋ��荞�݂�
������K�v�͖����ł��傤
�ŁA�m���ɓ���ւ��̕p������悤�ȏ��Ɛ��\�ቺ�͔������Ȃ��Ǝv���܂���
���̂悤�ȏɂȂ�Ȃ��悤�ɗ��p����̂�Cell�̗L���Ȏg�����ł��傤��
���ꂩ��v���O�����̗L���Ȗ@���Ƃ���10�|90�̖@���Ƃ����̂�����܂��āA
>�����Ă��̃v���O�����̏ꍇ�A�v���O�����̈ꕔ���i��10���j��
>�قƂ�ǂ̏������ԁi��90%�j������Ă���Ƃ����@�����B
�Ȃ̂ŁA�d�������̕����������o����256KB�ŏ\���Ɛv�҂����f�����̂ł��傤
153 �F����������K�������F2005/07/07(��) 20:02:33 ID:9cVXiCMC
SMP�Ή��J�[�l�����Ă����Ă��A�J�[�l�����v���G���v�V��������Ƃ͌���Ȃ��킯�ŁB
FreeBSD��Linux�̌Â��o�[�W�����Ȃ̓J�[�l�����̓W���C�A���g���b�N�����Ȃ��A
�J�[�l�����ł͕����̃X���b�h�͑���Ȃ��\�����������ˁB
���̃o�[�W�����ł͗��x�ׂ̍������b�N���g���悤�ɂȂ��ăv���G���v�V�����ł���悤�ɂȂ������ǂˁB
����ɃJ�[�l�����v���G���v�V������������A
���\�[�X�҂����Ԃ̉B���ł��邵�����Ǝv�����ǂȁB
> ����ȊO��5�̃X���b�h�͊�{�I��OS�̊Ǘ��O�ɂȂ�A�Ƃ������ƁB
�V�X�e���R�[���Ƃ��g���Ȃ��Ȃ邵�A������ƌ������悤�ȁB
FreeBSD��Linux�̌Â��o�[�W�����Ȃ̓J�[�l�����̓W���C�A���g���b�N�����Ȃ��A
�J�[�l�����ł͕����̃X���b�h�͑���Ȃ��\�����������ˁB
���̃o�[�W�����ł͗��x�ׂ̍������b�N���g���悤�ɂȂ��ăv���G���v�V�����ł���悤�ɂȂ������ǂˁB
����ɃJ�[�l�����v���G���v�V������������A
���\�[�X�҂����Ԃ̉B���ł��邵�����Ǝv�����ǂȁB
> ����ȊO��5�̃X���b�h�͊�{�I��OS�̊Ǘ��O�ɂȂ�A�Ƃ������ƁB
�V�X�e���R�[���Ƃ��g���Ȃ��Ȃ邵�A������ƌ������悤�ȁB
154 �F����������K�������F2005/07/07(��) 20:03:12 ID:HvxFdNts
155 �F����������K�������F2005/07/07(��) 20:04:16 ID:zCSB5mOh
>>143
218 ���O�F����������K������[sage] ���e���F2005/06/20(��) 20:52:14 ID:CLMnUZDz
>>211
NE�̋L������Ȃ����ȁB
7�Ɍ��܂�O�͍ň��̃P�[�X���l������6���������Ă��͗l�B
��������������̓��e�̕����C�ɂȂ�B�����NE�̋L������Ȃ��A
����PPE3�̓�1��WinNT�J�[�l���Ɋ�Â�OS�Ɋ��蓖�ĂāA
�c��2���Q�[���v���O���}�ɊJ������B(���Ă��Ƃ͊��Ɋ��o����)
����Ɋ֘A���āAPS3�ł���ɂ��uSPE�̂���6���Q�[��
�v���O�����p�Ɋm�ۂ�����ŁA�c��1���pOS�̎��s�Ɏg���v
���āB����OS��PPE�œ���OS�Ƃ̊֘A�͕s���Ƃ̂��ƁB
218 ���O�F����������K������[sage] ���e���F2005/06/20(��) 20:52:14 ID:CLMnUZDz
>>211
NE�̋L������Ȃ����ȁB
7�Ɍ��܂�O�͍ň��̃P�[�X���l������6���������Ă��͗l�B
��������������̓��e�̕����C�ɂȂ�B�����NE�̋L������Ȃ��A
����PPE3�̓�1��WinNT�J�[�l���Ɋ�Â�OS�Ɋ��蓖�ĂāA
�c��2���Q�[���v���O���}�ɊJ������B(���Ă��Ƃ͊��Ɋ��o����)
����Ɋ֘A���āAPS3�ł���ɂ��uSPE�̂���6���Q�[��
�v���O�����p�Ɋm�ۂ�����ŁA�c��1���pOS�̎��s�Ɏg���v
���āB����OS��PPE�œ���OS�Ƃ̊֘A�͕s���Ƃ̂��ƁB
156 �F����������K�������F2005/07/07(��) 20:06:12 ID:QQcY91V9
>>145
���̕ӂ̏������ƃf�[�^�̃A�N�Z�X���V�[�P���V�����A�N�Z�X�ɋ߂��Ȃ�̂ŁA
�_�u���o�b�t�@��DMA���ǂ݂łȂ�Ƃ��Ȃ邩��
���S�Ƀ����_���ł��ƌ������ł��傤���ǁA���̏ꍇ��SPE��2�X���b�h��������̂�
���p���ĕЕ��̓ǂݍ��ݒx�����͂����Е�������������ADMA���C�e���V��
�B���ł��܂���
���̕ӂ̏������ƃf�[�^�̃A�N�Z�X���V�[�P���V�����A�N�Z�X�ɋ߂��Ȃ�̂ŁA
�_�u���o�b�t�@��DMA���ǂ݂łȂ�Ƃ��Ȃ邩��
���S�Ƀ����_���ł��ƌ������ł��傤���ǁA���̏ꍇ��SPE��2�X���b�h��������̂�
���p���ĕЕ��̓ǂݍ��ݒx�����͂����Е�������������ADMA���C�e���V��
�B���ł��܂���
157 �F����������K�������F2005/07/07(��) 20:12:00 ID:W+x4qcks
�J�[�l����SMP�Ή�������Ɣr�����䂪���G�ɂȂ�A�I�[�o�[�w�b�h�������ł��Ȃ��قǂ���B
�T�[�o�pOS��SMP�@�ŃJ�[�l���������X�P�[�������Ȃ��Ⴂ���Ȃ��̂ł�����d���Ȃ����A
�Q�[���@�Ȃ�唼�����[�U�v���O�����̉��Z����������A�J�[�l���̓V���v���Ȃ܂܂ł����B
�łȂ��ƃ��A���^�C�������Ȃ�Ăł��Ȃ��B
360�ł��A�}���`�R�A�ő��������̃X���b�h�́A
���Z���������C���X���b�h����I�t���[�h������p�r�Ŏg���̂���ł͂Ȃ����ƁB
�T�[�o�pOS��SMP�@�ŃJ�[�l���������X�P�[�������Ȃ��Ⴂ���Ȃ��̂ł�����d���Ȃ����A
�Q�[���@�Ȃ�唼�����[�U�v���O�����̉��Z����������A�J�[�l���̓V���v���Ȃ܂܂ł����B
�łȂ��ƃ��A���^�C�������Ȃ�Ăł��Ȃ��B
360�ł��A�}���`�R�A�ő��������̃X���b�h�́A
���Z���������C���X���b�h����I�t���[�h������p�r�Ŏg���̂���ł͂Ȃ����ƁB
158 �F����������K�������F2005/07/07(��) 20:14:51 ID:HrEvukYx
>>152
����A���s����SPE�̃R�[�h�̓��ւ��͂͂����ɖ�������Ȃ��̂��A�Ƃ����Ӗ��ł��B
�������㏑��������ɐ擪������s�ł���@�\������Ώo�������ł����B
>>150
�������ɐ̂Ƃ͂���Ă��邱�Ƃ̓�Փx���傫�����Ⴄ�Ǝv���܂����A
���̎�̃J���J���`���[�j���O��PS2�Ō����Ă����A�~���������Ă����Ƃ��낪
����Ǝv����ł����ǂˁB
�����܂ł�炸�Ƃ��X�y�b�N�������o����̂����z�ł����B
>>156
���[�V�������ăV�[�P���V�����ɏo���܂��H
�K�w���s�����肫���肷��̂œ��ւ��͐T�d�ɂ��Ȃ��Ƃ����Ȃ��Ǝv����ł����B
����A���������f�[�^�͈���Ȃ���Ηǂ��̂��B
����A���s����SPE�̃R�[�h�̓��ւ��͂͂����ɖ�������Ȃ��̂��A�Ƃ����Ӗ��ł��B
�������㏑��������ɐ擪������s�ł���@�\������Ώo�������ł����B
>>150
�������ɐ̂Ƃ͂���Ă��邱�Ƃ̓�Փx���傫�����Ⴄ�Ǝv���܂����A
���̎�̃J���J���`���[�j���O��PS2�Ō����Ă����A�~���������Ă����Ƃ��낪
����Ǝv����ł����ǂˁB
�����܂ł�炸�Ƃ��X�y�b�N�������o����̂����z�ł����B
>>156
���[�V�������ăV�[�P���V�����ɏo���܂��H
�K�w���s�����肫���肷��̂œ��ւ��͐T�d�ɂ��Ȃ��Ƃ����Ȃ��Ǝv����ł����B
����A���������f�[�^�͈���Ȃ���Ηǂ��̂��B
159 �F����������K�������F2005/07/07(��) 20:21:08 ID:9cVXiCMC
>>157
PS3�Ȃ�PC�̃Q�[���Ƃ̌݊����݂����Ȃ��̂��C�ɂ��Ȃ��Ă������ǁA
PC�v���b�g�t�H�[���̃Q�[������SMP/SMT�Ή��̃J�[�l�����g���āA
�ǂ̃X���b�h���V�X�e���R�[���̔��s���ł���悤�ɂ����ˁB
Xbox360���V���O���ȃJ�[�l����œ����ƂȂ��PC�Ƃ̌݊����������Ȃ�ł���B
���������헪��PS3�������Ȃ�킩����ǁAXbox360�ł��ȁH
PS3�Ȃ�PC�̃Q�[���Ƃ̌݊����݂����Ȃ��̂��C�ɂ��Ȃ��Ă������ǁA
PC�v���b�g�t�H�[���̃Q�[������SMP/SMT�Ή��̃J�[�l�����g���āA
�ǂ̃X���b�h���V�X�e���R�[���̔��s���ł���悤�ɂ����ˁB
Xbox360���V���O���ȃJ�[�l����œ����ƂȂ��PC�Ƃ̌݊����������Ȃ�ł���B
���������헪��PS3�������Ȃ�킩����ǁAXbox360�ł��ȁH
160 �F����������K�������F2005/07/07(��) 20:24:41 ID:W+x4qcks
>>159
PC�ł�1���C���X���b�h+�������Z�X���b�h �Ƃ����g��������ɂȂ�̂ł͂Ȃ����ƁB
http://www.itmedia.co.jp/pcupdate/articles/0507/01/news030.html
PC�ł�1���C���X���b�h+�������Z�X���b�h �Ƃ����g��������ɂȂ�̂ł͂Ȃ����ƁB
http://www.itmedia.co.jp/pcupdate/articles/0507/01/news030.html
161 �F����������K�������F2005/07/07(��) 20:27:30 ID:QQcY91V9
>>158
SPE���̃v���O�����������ŁA�����̃R�[�h�̈ꕔ�����ւ����鎖�́A�s�\����
�����Ƃ͎v���܂����ǁA���Ӗ��������ł��傤���E�E�E�H
���[�V�����ƌ����Ă��F�X����̂łǂ̃��[�V�������ɂ����Ƃ͎v���܂����ǁA
LS��256KB����A���L�������̃f�[�^�͏�����Ȃ��ł��傤���H
SPE���̃v���O�����������ŁA�����̃R�[�h�̈ꕔ�����ւ����鎖�́A�s�\����
�����Ƃ͎v���܂����ǁA���Ӗ��������ł��傤���E�E�E�H
���[�V�����ƌ����Ă��F�X����̂łǂ̃��[�V�������ɂ����Ƃ͎v���܂����ǁA
LS��256KB����A���L�������̃f�[�^�͏�����Ȃ��ł��傤���H
162 �F����������K�������F2005/07/07(��) 20:33:10 ID:W+x4qcks
�P�ɃR�[�h���傫������LS�Ɏ��܂�Ȃ��Ȃ�A�����PPE�Ŏ��s���鐫���̂��̂��Ǝv���B
�σ^���p���̂��߂ɁA�O������Ւf���ꂽSPE���A�Í������ꂽ���s�R�[�h�����ȏ���������
��������A�Ƃ����̂͂��邾�낤�ˁB�Z�L�����e�B�̂��߂̎d�|���͔���J�ł��낢��
�p�ӂ���Ă����������B
�σ^���p���̂��߂ɁA�O������Ւf���ꂽSPE���A�Í������ꂽ���s�R�[�h�����ȏ���������
��������A�Ƃ����̂͂��邾�낤�ˁB�Z�L�����e�B�̂��߂̎d�|���͔���J�ł��낢��
�p�ӂ���Ă����������B
163 �F����������K�������F2005/07/07(��) 20:36:25 ID:9cVXiCMC
>>160
���ꂼ��̑g�ݕ��͂Ƃ������AMS�������I�ɃX���b�h�̈��������肵�Ă����Ȃ��Ƃ����Ȃ��킯�����ǁA
�����PC���ʂł��������ʒB�Ƃ��ł��o�Ă�H
������A�݊����ɋꂵ�ރn���ɂȂ�Ǝv���̂����ǁB
�܂�Xbox360�����������������ł����ƂȂ�A
�啪Cell�Ƃ̐e�a���̍����l�����ȋC�͂���ȁB
���ꂼ��̑g�ݕ��͂Ƃ������AMS�������I�ɃX���b�h�̈��������肵�Ă����Ȃ��Ƃ����Ȃ��킯�����ǁA
�����PC���ʂł��������ʒB�Ƃ��ł��o�Ă�H
������A�݊����ɋꂵ�ރn���ɂȂ�Ǝv���̂����ǁB
�܂�Xbox360�����������������ł����ƂȂ�A
�啪Cell�Ƃ̐e�a���̍����l�����ȋC�͂���ȁB
164 �F����������K�������F2005/07/07(��) 20:39:24 ID:HrEvukYx
>>161
�悭�l������7�����邩��ق���SPE�ɔC���������ł��ˁB
�ғ������グ�܂���Ȃ�A�肪����v���O��������ւ��Ăł�
�Ԃ�̂��ȁ[�Ǝv���Ă���ł����A������Ɠ�������Ȃ����������ł��B
�R�[�h�͌ʂɂR�QKB���x�ł��L���b�V���������ă��C��������������s�ł����
���Ȃ�_��ɂȂ�C�������ł����ǁA���X�����č��̌`�ɂȂ����낤�ȁ[�B
�悭�l������7�����邩��ق���SPE�ɔC���������ł��ˁB
�ғ������グ�܂���Ȃ�A�肪����v���O��������ւ��Ăł�
�Ԃ�̂��ȁ[�Ǝv���Ă���ł����A������Ɠ�������Ȃ����������ł��B
�R�[�h�͌ʂɂR�QKB���x�ł��L���b�V���������ă��C��������������s�ł����
���Ȃ�_��ɂȂ�C�������ł����ǁA���X�����č��̌`�ɂȂ����낤�ȁ[�B
165 �F����������K�������F2005/07/07(��) 20:42:12 ID:90aHtrhe
���ł�CELL�J�����ɂ���Ȏd�g�݂�����
��256KB��LS�e�ʂɂ����܂�Ȃ����Ƃ��l�����邽�߁A�uSPE�I�[�o�[���C�v�ƌĂԎd�g�݂������B
�v���O������f�[�^����L����ɔz�u���A���̈ꕔ�̊����������s����LS�ɓ��I�Ƀ��[�h���Ď��s����B
SPE�I�[�o�[���C�ɂ�������̓���ւ��́ADMA�R���g���[�����s���B
��256KB��LS�e�ʂɂ����܂�Ȃ����Ƃ��l�����邽�߁A�uSPE�I�[�o�[���C�v�ƌĂԎd�g�݂������B
�v���O������f�[�^����L����ɔz�u���A���̈ꕔ�̊����������s����LS�ɓ��I�Ƀ��[�h���Ď��s����B
SPE�I�[�o�[���C�ɂ�������̓���ւ��́ADMA�R���g���[�����s���B
166 �F����������K�������F2005/07/07(��) 20:44:40 ID:BlbWBD3Q
�uPower�͍��A���r�L�^�X�ȏ�ԂɂȂ��Ă���v�\�\���{IBM�A
�gPower Everywhere Forum 2005�h���J��
http://ascii24.com/news/i/topi/article/2005/07/07/656844-000.html
�f���A���R�A�ł́wPowerPC 970MP�x
http://ascii24.com/news/i/topi/article/2005/07/07/images/images779599.jpg
�gPower Everywhere Forum 2005�h���J��
http://ascii24.com/news/i/topi/article/2005/07/07/656844-000.html
�f���A���R�A�ł́wPowerPC 970MP�x
http://ascii24.com/news/i/topi/article/2005/07/07/images/images779599.jpg
{kind=link}
167 �F����������K�������F2005/07/07(��) 20:49:58 ID:7qButmlC
cell�͖Y�ꋎ���܂���
168 �F����������K�������F2005/07/07(��) 20:56:52 ID:BY5+jcxC
169 �F����������K�������F2005/07/07(��) 21:07:11 ID:Qi6mGJY+
cell��power�Ȃ��B
170 �F����������K�������F2005/07/07(��) 21:14:27 ID:/0U26P3U
PPE�͖����ŁASPE10�̂ق����Q�[���@�Ɍ����Ă���Ǝv���B
�w�e���R�A��PPE�ɂ����镔�����ĒP�Ɍ݊����Ƃ邾���ł���ȏ㐫�\���オ�錩���݂��Ȃ��̂ɂ���܂Ȃ����B
�w�e���R�A��PPE�ɂ����镔�����ĒP�Ɍ݊����Ƃ邾���ł���ȏ㐫�\���オ�錩���݂��Ȃ��̂ɂ���܂Ȃ����B
171 �F����������K�������F2005/07/07(��) 21:15:09 ID:Vd+gF7yT
���AIBM��HD����AV�@������ɁA�Ɠd�e�Ђɔ��荞�݂��Ă���̂�CELL����Ȃ���360CPU��1.6�`2.4Ghz�ł�����Ȃ�
CELL�Ɠd�̓\�j�[���炵���o�Ȃ����낤��
CELL�Ɠd�̓\�j�[���炵���o�Ȃ����낤��
172 �F����������K�������F2005/07/07(��) 21:17:46 ID:90aHtrhe
>>171
�i�@�L,_�T`�j
�i�@�L,_�T`�j
173 �F����������K�������F2005/07/07(��) 21:19:28 ID:OCHQwqCz
�ǂ��̊e�Ђ��悗
174 �F����������K�������F2005/07/07(��) 21:19:39 ID:UEIjZC5M
175 �F����������K�������F2005/07/07(��) 21:20:03 ID:Qi6mGJY+
>>170
���ƌ݊��Ƃ�悗
���ƌ݊��Ƃ�悗
176 �F����������K�������F2005/07/07(��) 21:24:20 ID:HvxFdNts
>>170
SPE�����ڃ��C���������Q�Ƃł�����ˁB
�Q�[���v���O�����ŃX�g���[�������ł���ӏ���
�������̂́A�P�O�O���Ƃ����̂͐�ɗL�蓾�B
PPE2�ASPE4�ӂ肪�l�I�Ƀx�X�g���Ǝv���B
SPE�����ڃ��C���������Q�Ƃł�����ˁB
�Q�[���v���O�����ŃX�g���[�������ł���ӏ���
�������̂́A�P�O�O���Ƃ����̂͐�ɗL�蓾�B
PPE2�ASPE4�ӂ肪�l�I�Ƀx�X�g���Ǝv���B
177 �F����������K�������F2005/07/07(��) 21:24:46 ID:9cVXiCMC
178 �F����������K�������F2005/07/07(��) 21:29:05 ID:HvxFdNts
179 �F����������K�������F2005/07/07(��) 21:30:00 ID:OCHQwqCz
���Ȃ݂ɁALS��512KB�Ȃ� �����`�b�v�ʐς��ێ����Ȃ��� SPE 6�A
LS��1MB�Ȃ� 4���炢�̌v�Z�ɂȂ�܂��B
�������H
LS��1MB�Ȃ� 4���炢�̌v�Z�ɂȂ�܂��B
�������H
180 �F����������K�������F2005/07/07(��) 21:30:49 ID:90aHtrhe
>>170
����A���C�����������炢DMA�ŎQ�Ƃł�����āB
�������X�Q�ڂ������ƌ����ĂH
����Ȃ��Ƃ��OS�𑖂点�Ȃ���Ȃ��ȏ�A
PPE�͕K�{���낤�B
����A���C�����������炢DMA�ŎQ�Ƃł�����āB
�������X�Q�ڂ������ƌ����ĂH
����Ȃ��Ƃ��OS�𑖂点�Ȃ���Ȃ��ȏ�A
PPE�͕K�{���낤�B
181 �F����������K�������F2005/07/07(��) 21:37:27 ID:HvxFdNts
>>180
������A���C�����������炢DMA�ŎQ�Ƃł�����āB
�m���Ă܂����ȁB
�����ڃ��C���������Q��
������A���ڂƒf����Ă�킯�ŁB
DMA�ŎQ�Ƃ������A�L�͈͂̃����_���A�N�Z�X�͌��������낤����
�A�������f�[�^�̃X�g���[���������S�ɂȂ邾�낤�Ƃ������ƁB
������A���C�����������炢DMA�ŎQ�Ƃł�����āB
�m���Ă܂����ȁB
�����ڃ��C���������Q��
������A���ڂƒf����Ă�킯�ŁB
DMA�ŎQ�Ƃ������A�L�͈͂̃����_���A�N�Z�X�͌��������낤����
�A�������f�[�^�̃X�g���[���������S�ɂȂ邾�낤�Ƃ������ƁB
182 �F����������K�������F2005/07/07(��) 21:38:40 ID:OCHQwqCz
>>178
���̂܂ܓ��ځA�Ƃ�
���̂܂ܓ��ځA�Ƃ�
183 �F����������K�������F2005/07/07(��) 21:38:56 ID:g1xmviED
>>165
SPE�I�[�o�[���C���A���Ǘ��̎d�g�͂ǂ��Ȃ��Ă���̂���
��̃^�O�P�ʊǗ��ł����̃T�C�Y�������z����ꍇ�͂ǂ�����̂�
���s���̃R�[�h�X���b�v�͂��Ȃ����낤���A�������ʂɂ�镪���Ŋ�
�R�[������ꍇDMA�̃��[�h�҂����L��ƁA���̊Ԃ͑���SPE����Ď���
XDR��Z������
PPE -> XDR <- DMA -> LS (256KB) <- SPE x7
SPE�I�[�o�[���C���A���Ǘ��̎d�g�͂ǂ��Ȃ��Ă���̂���
��̃^�O�P�ʊǗ��ł����̃T�C�Y�������z����ꍇ�͂ǂ�����̂�
���s���̃R�[�h�X���b�v�͂��Ȃ����낤���A�������ʂɂ�镪���Ŋ�
�R�[������ꍇDMA�̃��[�h�҂����L��ƁA���̊Ԃ͑���SPE����Ď���
XDR��Z������
PPE -> XDR <- DMA -> LS (256KB) <- SPE x7
184 �F����������K�������F2005/07/07(��) 21:42:51 ID:OCHQwqCz
�������A�N�Z�X�͑Ë����B
�X�p�R���̂悤�ɂ͂������B
�����镪�ʼn䖝���邵���Ȃ��B
Cell�� �܂��}�V�ȕ����낤�E�E
Cell���ꂵ�����A xenon�Ȃǂ����ƔߎS�����B
�X�p�R���̂悤�ɂ͂������B
�����镪�ʼn䖝���邵���Ȃ��B
Cell�� �܂��}�V�ȕ����낤�E�E
Cell���ꂵ�����A xenon�Ȃǂ����ƔߎS�����B
185 �F����������K�������F2005/07/07(��) 21:56:56 ID:mni8rgTD
970MP��1.6GHz���M�v����d�͂͏o�Ȃ��̂�
��ڂ��[����[��
��ڂ��[����[��
186 �F����������K�������F2005/07/07(��) 22:31:11 ID:pmn0pmmq
>>185
PPC970�͓d�͌�������������A���{��PPC750�x�[�X�ŗ���悤�ȋC��������Ƃ���
PPC970�͓d�͌�������������A���{��PPC750�x�[�X�ŗ���悤�ȋC��������Ƃ���
187 �F����������K�������F2005/07/07(��) 23:01:44 ID:1P+4WlnU
���������A���Ă����̂ɁAID:oycdOqFP�����Ȃ��Ȃ��Ă�(�L��֥�M)
188 �F����������K�������F2005/07/07(��) 23:23:40 ID:h1iCIpPV
oycdOqFP����Ȃ����ǁA�����́u������@�e�N�m���W�[�v�X���Ȃ̂ɁAFFT�x���`��MPEG2����48�{�Đ������ꂵ�����R���ĉ��H
������CELL�X���Ȃ痝���o���邯�ǁA������Q�[�����ă��[�r�[��R�����ɍĐ������蓮��G���R�[�h������̂Ȃ̂��H
������CELL�X���Ȃ痝���o���邯�ǁA������Q�[�����ă��[�r�[��R�����ɍĐ������蓮��G���R�[�h������̂Ȃ̂��H
189 �F����������K�������F2005/07/07(��) 23:32:31 ID:yAugGCSq
�����������Ƃ��ł���A���Ă̂�������@�̃e�N�m���W�[�Ɋ܂܂�邩�炶��Ȃ��H
���̐��\���Q�[���ɂǂ��𗧂Ă��邩���l����̂����l�̎d���ł���B
���̐��\���Q�[���ɂǂ��𗧂Ă��邩���l����̂����l�̎d���ł���B
190 �F����������K�������F2005/07/07(��) 23:35:16 ID:0PDR5C+g
�g��������ŕ����ʂ茅�O��̐��\��@���o����ʔ����v���Z�b�T�ł��邱�Ƃ͊m���B
������@�e�N�m���W�[�̘b��Ƃ��Ă͒��S�Ɉʒu����Ƃ����Ă����B
������@�e�N�m���W�[�̘b��Ƃ��Ă͒��S�Ɉʒu����Ƃ����Ă����B
191 �F����������K�������F2005/07/07(��) 23:36:15 ID:fsrn1LfO
>>188
��FFT�x���`��MPEG2����48�{�Đ������ꂵ�����R���ĉ��H
�܂�A���������_���Z���K�v�ȃX�g���[���������哾�ӂƁB
���_���Z�A�����v�Z�A�������Z�A���������Aetc
�Q�[���v���O�������Ɖ��b�L��܂���ł���B
��FFT�x���`��MPEG2����48�{�Đ������ꂵ�����R���ĉ��H
�܂�A���������_���Z���K�v�ȃX�g���[���������哾�ӂƁB
���_���Z�A�����v�Z�A�������Z�A���������Aetc
�Q�[���v���O�������Ɖ��b�L��܂���ł���B
192 �F����������K�������F2005/07/07(��) 23:37:40 ID:5dNL6MlN
������ĔC�V�����킭�A�u�V�����V�сv���ł��邩�����Ă��Ƃ���Ȃ��́B
193 �F����������K�������F2005/07/07(��) 23:38:40 ID:W+x4qcks
�ǂ����̃X���̏Z�l�݂����Ɂu���̂Ƃ��̂��������v�u����A�������̂͂��������v��
���������ĂĂ����|���_�Ȃ̂ŁA��ʓI�Ȏw�W�ł��݂��̐��\��]�����悤�Ƃ����
�܂���MIPS, FLOPS�Ƃ����悤�ȃs�[�N���\�ł���A����FFT��MPEG�̃A���S���Y����
���ۂɎ��s���邱�ƂɂȂ�킯���B���ۂɂ�����g�����ǂ����ł͂Ȃ��āB
Cell�����łȂ��A���̃n�[�h�E�F�A�ł����ʂ����\�����A�����Ɨ������[�܂�̂����B
���������ĂĂ����|���_�Ȃ̂ŁA��ʓI�Ȏw�W�ł��݂��̐��\��]�����悤�Ƃ����
�܂���MIPS, FLOPS�Ƃ����悤�ȃs�[�N���\�ł���A����FFT��MPEG�̃A���S���Y����
���ۂɎ��s���邱�ƂɂȂ�킯���B���ۂɂ�����g�����ǂ����ł͂Ȃ��āB
Cell�����łȂ��A���̃n�[�h�E�F�A�ł����ʂ����\�����A�����Ɨ������[�܂�̂����B
194 �F����������K�������F2005/07/07(��) 23:42:09 ID:9cVXiCMC
PC�ƈ���ĕs���ȑ��͌��\���Ȃ����낤�ˁB
PS3�́APS3-Linux���o��킯�����A�������PS3-Linux��ł̃x���`�Ȃ��o�邾�낤�ˁB
PS3�́APS3-Linux���o��킯�����A�������PS3-Linux��ł̃x���`�Ȃ��o�邾�낤�ˁB
195 �F����������K�������F2005/07/07(��) 23:43:18 ID:HrEvukYx
>>191
�����͕��������͂����ł���B
���_�������CPU�͍ŋ߂͂�疳���Ă��ǂ���Ȃ��HGPU�̕����������B
�������Z�͉��C����܂���B������܂���B
���ɂ����낢�뉶�b����ł���B
�Ƃ������X�y�b�N���������Ȃ炠���������ǂ����B
�ނ��Ē艿���オ��܂����Ă����邯�ǁB
�����͕��������͂����ł���B
���_�������CPU�͍ŋ߂͂�疳���Ă��ǂ���Ȃ��HGPU�̕����������B
�������Z�͉��C����܂���B������܂���B
���ɂ����낢�뉶�b����ł���B
�Ƃ������X�y�b�N���������Ȃ炠���������ǂ����B
�ނ��Ē艿���オ��܂����Ă����邯�ǁB
196 �F����������K�������F2005/07/07(��) 23:43:49 ID:UltmjHYy
PS3��CPU�͕s�Ǖi���Ƃ������Ƃ����Y��Ȃ�
197 �F����������K�������F2005/07/07(��) 23:44:27 ID:fsrn1LfO
198 �F����������K�������F2005/07/07(��) 23:45:11 ID:OCHQwqCz
�[���Axenon�Ɋւ��ĉ��̏��������Ă��Ȃ��̂��A���Ȃ�E�E
�ǁ[����IBM�B
�������Ə����o��
�ǁ[����IBM�B
�������Ə����o��
>�Q�[���v���O�������Ɖ��b�L��܂���ł���B
���̊��ɋ[���R�[�h�̈���������Ɩ����̂ŁA�{���ɉ��p����܂���Ȃ̂����������v���Ă��܂���ŁB
���ɗ����m�͖������A�������e�N�m���W�[�Ȃ̂͊m��Ȃ̂ŃX���I�ɂ̓I�b�P�[���Ď��Ȃ̂��ȁB
CELL�X�����ƌ��\���^�I�Ɍ����Ă�̂ŁA���炢���x������Ȃ��Ǝv���Ď��₵������ł��B
���������ăX���I��CELL��J�ߏ̂��Ă��ł͂Ȃ��E�U�C�s��������̂ŁA���ΓI�ɂ��������邾���Ȃ̂��H
���̊��ɋ[���R�[�h�̈���������Ɩ����̂ŁA�{���ɉ��p����܂���Ȃ̂����������v���Ă��܂���ŁB
���ɗ����m�͖������A�������e�N�m���W�[�Ȃ̂͊m��Ȃ̂ŃX���I�ɂ̓I�b�P�[���Ď��Ȃ̂��ȁB
CELL�X�����ƌ��\���^�I�Ɍ����Ă�̂ŁA���炢���x������Ȃ��Ǝv���Ď��₵������ł��B
���������ăX���I��CELL��J�ߏ̂��Ă��ł͂Ȃ��E�U�C�s��������̂ŁA���ΓI�ɂ��������邾���Ȃ̂��H
200 �F����������K�������F2005/07/07(��) 23:48:54 ID:W+x4qcks
Cell�͊O�̂�����ėpCPU�����ǁA360 CPU�͓��萻�i�����̑g��CPU�����ŁA
���Ȃ��Ƃ����i���o��܂ł�IBM����͂قƂ�Ǐ��łȂ��̂����B
���Ȃ��Ƃ����i���o��܂ł�IBM����͂قƂ�Ǐ��łȂ��̂����B
201 �F����������K�������F2005/07/07(��) 23:48:57 ID:fsrn1LfO
>>195
�������͕��������͂����ł���B
������@�ł͕������������ɂ����킷��ł���B
5.1ch�ׂ̈̉��̈ړ��ɂ��g���邾�낤���B
LS�ɒu�����g�`�������̑��d������A���k���ꂽ�ȃf�[�^��
�X�g���[�~���O�𓀂����ł́A3GHz���ܑ̖����B
�������͕��������͂����ł���B
������@�ł͕������������ɂ����킷��ł���B
5.1ch�ׂ̈̉��̈ړ��ɂ��g���邾�낤���B
LS�ɒu�����g�`�������̑��d������A���k���ꂽ�ȃf�[�^��
�X�g���[�~���O�𓀂����ł́A3GHz���ܑ̖����B
202 �F����������K�������F2005/07/07(��) 23:49:28 ID:fPbBuDuP
����ł�cell�X�������Ă݂�Ƃ���
203 �F����������K�������F2005/07/07(��) 23:51:33 ID:fsrn1LfO
>>199
�����̊��ɋ[���R�[�h�̈���������Ɩ����̂ŁA
���{���ɉ��p����܂���Ȃ̂����������v���Ă��܂���ŁB
E3�J���t�@�����X�Ŏ�������Ă܂������ȁB
����Ƃ��ACorC++�R�[�h���̂��̂����J����ƁH
�����̊��ɋ[���R�[�h�̈���������Ɩ����̂ŁA
���{���ɉ��p����܂���Ȃ̂����������v���Ă��܂���ŁB
E3�J���t�@�����X�Ŏ�������Ă܂������ȁB
����Ƃ��ACorC++�R�[�h���̂��̂����J����ƁH
>����Ƃ��ACorC++�R�[�h���̂��̂����J����ƁH
�f���̃\�[�X�R�[�h�����[�N����Ƃ͌����ĂȂ��ł����B
���܂łƃp���_�C���̈Ⴄ�A�[�L�e�N�`���Ȃ���A�[���R�[�h�ł��ǂ��̂ŏ����̗��ꂪ����Ȃ��ƐM�p�ł��Ȃ��Ǝv���̂����ʂ���Ȃ��H
���l�̌������Ƃ��̂܂ܐM���ă}���Z�[����͖̂ӐM����B
�f���̃\�[�X�R�[�h�����[�N����Ƃ͌����ĂȂ��ł����B
���܂łƃp���_�C���̈Ⴄ�A�[�L�e�N�`���Ȃ���A�[���R�[�h�ł��ǂ��̂ŏ����̗��ꂪ����Ȃ��ƐM�p�ł��Ȃ��Ǝv���̂����ʂ���Ȃ��H
���l�̌������Ƃ��̂܂ܐM���ă}���Z�[����͖̂ӐM����B
205 �F����������K�������F2005/07/07(��) 23:57:14 ID:1WUkNxTA
206 �F����������K�������F2005/07/07(��) 23:58:13 ID:1WUkNxTA
�~SSESSE
��SSE
�_�u�����B
��SSE
�_�u�����B
207 �F����������K�������F2005/07/07(��) 23:59:56 ID:W+x4qcks
���܂łƃp���_�C���̈Ⴄ�A�[�L�e�B�N�`��������A�݂�ȓ��oNE�̓��W�Ƃ�
�ǂ�ŁA�Ƃ��ƂƓ��ɓ���Ă����w�͂������Ⴄ�ȁB
�ǂ�ŁA�Ƃ��ƂƓ��ɓ���Ă����w�͂������Ⴄ�ȁB
208 �F����������K�������F2005/07/08(��) 00:00:19 ID:NOxx0Y7p
209 �F����������K�������F2005/07/08(��) 00:02:17 ID:5cHZ36OG
>>204
�������̗��ꂪ����Ȃ�
�����̗���B
http://pc.watch.impress.co.jp/docs/2005/0310/kaigai165.htm
�����l�̌������Ƃ��̂܂ܐM���ă}���Z�[����͖̂ӐM����B
�v���O�����m�����Ȃ��l�ɂ́A�{�����R���̌�����o���܂����B
�O�̂��߂ɕ����Ƃ����ǁA�v���O���}����ł���ˁH
�������̗��ꂪ����Ȃ�
�����̗���B
http://pc.watch.impress.co.jp/docs/2005/0310/kaigai165.htm
�����l�̌������Ƃ��̂܂ܐM���ă}���Z�[����͖̂ӐM����B
�v���O�����m�����Ȃ��l�ɂ́A�{�����R���̌�����o���܂����B
�O�̂��߂ɕ����Ƃ����ǁA�v���O���}����ł���ˁH
210 �F����������K�������F2005/07/08(��) 00:05:09 ID:3Hc6sMZ2
>>201
ProLogicII��Q�T���E���h��BBE�ł��Œ菬���_�����ǂˁB
�����A���������_��艉�Z��������
�Q�[���ł����ǃ`���[�����ČŒ菬���_�����Ă��܂��̂��낤�E�E�E
ProLogicII��Q�T���E���h��BBE�ł��Œ菬���_�����ǂˁB
�����A���������_��艉�Z��������
�Q�[���ł����ǃ`���[�����ČŒ菬���_�����Ă��܂��̂��낤�E�E�E
211 �F����������K�������F2005/07/08(��) 00:08:02 ID:ykLrEG/E
>>209
�v���O���}����Ȃ����炱�������ڒ����Ȏ�������ł́B
�v���O���}����Ȃ����炱�������ڒ����Ȏ�������ł́B
212 �F����������K�������F2005/07/08(��) 00:08:59 ID:Z6LBPFmN
>>195
AV�A���v�Ƃ��ł̓A�i�f�o�̕��������_DSP���悭�g���Ă��B
CreamWare �Ƃ����\�t�g�V���Z�p PCI DSP �{�[�h�ɂ��g���Ă邵�B
�����≹�����̂������������鉹�Q�[�Ƃ��o���肷���Ȃ�?
���܂��� for PS3 �Ƃ��B
AV�A���v�Ƃ��ł̓A�i�f�o�̕��������_DSP���悭�g���Ă��B
CreamWare �Ƃ����\�t�g�V���Z�p PCI DSP �{�[�h�ɂ��g���Ă邵�B
�����≹�����̂������������鉹�Q�[�Ƃ��o���肷���Ȃ�?
���܂��� for PS3 �Ƃ��B
213 �F(�@�E)3�@ ���E )�F2005/07/08(��) 00:10:22 ID:M7yql5Cl
0.1�̕\������덷�̏o��Œ菬���_����
>�����̗���B
>http://pc.watch.impress.co.jp/docs/2005/0310/kaigai165.htm
���₢��A����SPE�̃X�P�W���[�����O�ŏ����̗��ꂶ��Ȃ��ł���B
���Ƃ���AI�������烿���@���ǂ�SPE�Ŏ�������Ƃ��A���������b�Ȃ��ǁB
���߁H
>http://pc.watch.impress.co.jp/docs/2005/0310/kaigai165.htm
���₢��A����SPE�̃X�P�W���[�����O�ŏ����̗��ꂶ��Ȃ��ł���B
���Ƃ���AI�������烿���@���ǂ�SPE�Ŏ�������Ƃ��A���������b�Ȃ��ǁB
���߁H
215 �F����������K�������F2005/07/08(��) 00:15:40 ID:8zYgQFQv
���f�B�A�����n���Ɛ��x���������x���ŕۂĂ�Ό������
���������_�����������n�ł������ł�������
���������_�����������n�ł������ł�������
216 �F����������K�������F2005/07/08(��) 00:17:13 ID:49aFnj0o
�������Ă݂����ł��ˁD�[���R�[�h�ł�������D
209���v���O���}�݂����Ȃ�ŁC���ҁD
209���v���O���}�݂����Ȃ�ŁC���ҁD
217 �F����������K�������F2005/07/08(��) 00:18:25 ID:M1R+UN05
���㓡�O��Weekly�C�O�j���[�X��
�ΏƓI�ȃA�[�L�e�N�`���łԂ���NVIDIA��ATI
http://pc.watch.impress.co.jp/docs/2005/0708/kaigai196.htm
�ΏƓI�ȃA�[�L�e�N�`���łԂ���NVIDIA��ATI
http://pc.watch.impress.co.jp/docs/2005/0708/kaigai196.htm
218 �F����������K�������F2005/07/08(��) 00:19:53 ID:YZU3prp2
�]������SPE�Ŏ����\���ǂ���(�K���ǂ���)�ɂ��Ǝv����B
219 �F����������K�������F2005/07/08(��) 00:20:03 ID:NOxx0Y7p
�f�[�^��float�Ŏ��̂��ȁB
ADPCM�̂悤�Ȉ��k������FP8�݂����Ȃ̂ł��̂��ȁB
����̂�����ǁB
�������Ɏ�����@�Ƃ͂��������k�Ŏ��̂͂��܂�ɖ��ʂ��Ǝv�����ǁB
PS3/360�̉�������ĉ�����Ă܂��������H
ADPCM�̂悤�Ȉ��k������FP8�݂����Ȃ̂ł��̂��ȁB
����̂�����ǁB
�������Ɏ�����@�Ƃ͂��������k�Ŏ��̂͂��܂�ɖ��ʂ��Ǝv�����ǁB
PS3/360�̉�������ĉ�����Ă܂��������H
220 �F����������K�������F2005/07/08(��) 00:20:10 ID:6pvwGyBO
�[���R�[�h���邳�����ǁASPE��C����ł�����c
256KB�Ɏ��܂�悤�ɕ��ʂɏ����悵�B
IBM�����R���p�C��������ɍœK�����Ă���܂��B
256KB�Ɏ��܂�悤�ɕ��ʂɏ����悵�B
IBM�����R���p�C��������ɍœK�����Ă���܂��B
221 �F����������K�������F2005/07/08(��) 00:22:25 ID:5cHZ36OG
>>214
����SPE�ւ�AI�R�[�h������܂ŁASCE��IBM�������Ȃ���Ȃ�Ȃ��́H
�����ASPE�����Ƃ��鏈���Ȃ�APPE�ŏ�������Ηǂ��B
���ꂾ���̘b�B
���Ȃ��̂ق����Z���v�l�ɂȂ��Ă�B
����SPE�ւ�AI�R�[�h������܂ŁASCE��IBM�������Ȃ���Ȃ�Ȃ��́H
�����ASPE�����Ƃ��鏈���Ȃ�APPE�ŏ�������Ηǂ��B
���ꂾ���̘b�B
���Ȃ��̂ق����Z���v�l�ɂȂ��Ă�B
>256KB�Ɏ��܂�悤�ɕ��ʂɏ����悵�B
���C����������DMA�ł����A�N�Z�X�o���Ȃ���Ȃ����������H
�R���p�C���̍œK���Ń��C�e���V�B���Ă����́H
���C����������DMA�ł����A�N�Z�X�o���Ȃ���Ȃ����������H
�R���p�C���̍œK���Ń��C�e���V�B���Ă����́H
223 �F����������K�������F2005/07/08(��) 00:23:40 ID:6pvwGyBO
>>214
SPE���t�����p���邮�炢������A�����[���ɂȂ�ł���B
�ォ��3���x���܂ł̃m�[�h��PPE�A����ȉ���SPE�B
PPE��SPE����message box�ŒʐM����Ε��ʂɂł��邶���B
SPE���t�����p���邮�炢������A�����[���ɂȂ�ł���B
�ォ��3���x���܂ł̃m�[�h��PPE�A����ȉ���SPE�B
PPE��SPE����message box�ŒʐM����Ε��ʂɂł��邶���B
224 �F����������K�������F2005/07/08(��) 00:24:41 ID:49aFnj0o
225 �F����������K�������F2005/07/08(��) 00:26:25 ID:6pvwGyBO
>>222
�T�����Ȃ�ĕ����e�ՂȂ���ASPE����99.9%�͎��܂�B
�c��0.1%���炢���C�e���V�����������Ƃ���łǂ����Ƃ����B
SPE���_���ƌ��������Ȃ�A�����ƕ���������̂������Ă��Ȃ����B
�T�����Ȃ�ĕ����e�ՂȂ���ASPE����99.9%�͎��܂�B
�c��0.1%���炢���C�e���V�����������Ƃ���łǂ����Ƃ����B
SPE���_���ƌ��������Ȃ�A�����ƕ���������̂������Ă��Ȃ����B
>����SPE�ւ�AI�R�[�h������܂ŁASCE��IBM�������Ȃ���Ȃ�Ȃ��́H
SCE��IBM�Ȃ�Ĉꌾ�������ĂȂ����ǁE�E�E�B
SCE��IBM�Ȃ�Ĉꌾ�������ĂȂ����ǁE�E�E�B
227 �F����������K�������F2005/07/08(��) 00:28:20 ID:QqHAO7+l
>>214
�Ⴆ�A�{�i�I�ȃQ�[������҂��킴�킴�R�[�h�������ɗ���킯�������B
Cell�ŃA�C�f�A���������Ă݂悤�Ƃ����l�������̎���킴�킴���炩�ɂ͂��Ȃ��B
���Ⴀ�ǂ������Ȃ�R�[�h���o�Ă���̂��B
����͎������瓮���l�����ď��߂ďo�Ă���B
���͖{��ȓz���u�R�[�h�����Ă����`�v�Ȃ�Č����Ă��N���������B
�����2ch�̑��̐F�X�ȔE�X���ł��������Ǝv�����ǂˁB
���������X���݂����Ȃ̂������������Ă݁H
�O�����ɁA���������R�[�h�Ȃ瓮�����������ǂǂ��H�Ƃ����������̂Ȃ�A
�C�܂���ŒN�����A�h�o�C�X�����ꂽ��A�����x���̓z���A
���Ȃ炱�����������݂����Ȃ̂������Ă���邩������Ȃ��B
�Ƃ肠�������̂܂܂Ȃ�A�ԈႢ�Ȃ��N�������͂��Ȃ��B�����b�g�Ȃ����B
�Ⴆ�A�{�i�I�ȃQ�[������҂��킴�킴�R�[�h�������ɗ���킯�������B
Cell�ŃA�C�f�A���������Ă݂悤�Ƃ����l�������̎���킴�킴���炩�ɂ͂��Ȃ��B
���Ⴀ�ǂ������Ȃ�R�[�h���o�Ă���̂��B
����͎������瓮���l�����ď��߂ďo�Ă���B
���͖{��ȓz���u�R�[�h�����Ă����`�v�Ȃ�Č����Ă��N���������B
�����2ch�̑��̐F�X�ȔE�X���ł��������Ǝv�����ǂˁB
���������X���݂����Ȃ̂������������Ă݁H
�O�����ɁA���������R�[�h�Ȃ瓮�����������ǂǂ��H�Ƃ����������̂Ȃ�A
�C�܂���ŒN�����A�h�o�C�X�����ꂽ��A�����x���̓z���A
���Ȃ炱�����������݂����Ȃ̂������Ă���邩������Ȃ��B
�Ƃ肠�������̂܂܂Ȃ�A�ԈႢ�Ȃ��N�������͂��Ȃ��B�����b�g�Ȃ����B
228 �F����������K�������F2005/07/08(��) 00:29:15 ID:Y+nPtwIC
���ʂ̊��i�������d�������j�Ƃ��Ď�������Ȃ�A256KB������Ώ\�����Ǝv���B
229 �F����������K�������F2005/07/08(��) 00:31:25 ID:5cHZ36OG
>>224
�������͗�Ƃ���AI�������o���ꂽ���R��������B
SPE�ŕW���I�ȃv���O���~���O���f����
�f�[�^�̓_�u���o�b�t�@�A�Е��̃o�b�t�@���������Ă�Ԃ�
DMA�ŁA�����Е��̃o�b�t�@�����ւ���B���̌J��Ԃ��B
����ŁA�ǂ̂悤�Ȏ�����o���Ȃ���[�������Ȃ��́H
�������͗�Ƃ���AI�������o���ꂽ���R��������B
SPE�ŕW���I�ȃv���O���~���O���f����
�f�[�^�̓_�u���o�b�t�@�A�Е��̃o�b�t�@���������Ă�Ԃ�
DMA�ŁA�����Е��̃o�b�t�@�����ւ���B���̌J��Ԃ��B
����ŁA�ǂ̂悤�Ȏ�����o���Ȃ���[�������Ȃ��́H
231 �F����������K�������F2005/07/08(��) 00:34:55 ID:i0/45Hyp
>>188�͑��l�ɑ��Ă��荪�������߂�
�����̈ӌ��̍�����琳�����ɂ��Ă͊��S�ɖڂ���炵�Ă�Ȃ�
�����̈ӌ��̍�����琳�����ɂ��Ă͊��S�ɖڂ���炵�Ă�Ȃ�
232 �F(�@�E)3�@ ���E )�F2005/07/08(��) 00:35:39 ID:rzGt2iIQ
AI������ŏo�Ă���͕̂ς����A���̂Ƃ���SPE�ł����\�C�P��A������
233 �F����������K�������F2005/07/08(��) 00:36:36 ID:h90zU47n
�����ȑO�ɒT���͐߂̍����ʂ���ׂɃO���[�o���ȃn�b�V�����Q�Ƃł��Ȃ��Ƃ����Ȃ�����
SPE����ނ��Ⴍ���������B����Ȃ��Ƃ�������Ȃ��A�z����CELL�ݾ��h�ɂ͂��Ȃ��悤���ȁB
SPE����ނ��Ⴍ���������B����Ȃ��Ƃ�������Ȃ��A�z����CELL�ݾ��h�ɂ͂��Ȃ��悤���ȁB
234 �F����������K�������F2005/07/08(��) 00:38:17 ID:Hs5YH8zn
>>219
PS3��PS2�̃f�t�H���g�Ɠ���ADPCM��PSP�Ƃ̘A�g����AAC�ӂ�ɂȂ��Ȃ��́H
�����kPCM��BD�ƌ����ǖ��ʂɐ�����ł��B
PS3��PS2�̃f�t�H���g�Ɠ���ADPCM��PSP�Ƃ̘A�g����AAC�ӂ�ɂȂ��Ȃ��́H
�����kPCM��BD�ƌ����ǖ��ʂɐ�����ł��B
235 �F����������K�������F2005/07/08(��) 00:39:01 ID:2ww5Ol2q
>>233
���̃O���[�o���l��LS�Ɉꏏ�ɓ������܂Ȃ�������Ȃ����Ă��ƁH
���̃O���[�o���l��LS�Ɉꏏ�ɓ������܂Ȃ�������Ȃ����Ă��ƁH
236 �F����������K�������F2005/07/08(��) 00:40:16 ID:Y+nPtwIC
�Ⴆ�A���̂`�A�a�̊��ŁA
main() {
���`() // 1ns
�@���a() // 1ms
}
�������Ԃ������Ƃ���Ȃ�A���a()��SPE�Ɋ��蓖�Ă�悢�B
���Ɋ��a()��SPE�ɓW�J�ł��Ȃ��傫�Ȼ��ނ��Ƃ���A
���a() {
���b() // 10ns
�@���c() // 90ns
}
���a���̊��c()��SPE�Ɋ��蓖�Ă邾���B
��������ȯ��ɂȂ�ӏ����̂́A����قǑ傫�ȗe�ʂ�K�v�Ƃ��Ȃ��Ǝv���B
main() {
���`() // 1ns
�@���a() // 1ms
}
�������Ԃ������Ƃ���Ȃ�A���a()��SPE�Ɋ��蓖�Ă�悢�B
���Ɋ��a()��SPE�ɓW�J�ł��Ȃ��傫�Ȼ��ނ��Ƃ���A
���a() {
���b() // 10ns
�@���c() // 90ns
}
���a���̊��c()��SPE�Ɋ��蓖�Ă邾���B
��������ȯ��ɂȂ�ӏ����̂́A����قǑ傫�ȗe�ʂ�K�v�Ƃ��Ȃ��Ǝv���B
237 �F����������K�������F2005/07/08(��) 00:41:51 ID:Y+nPtwIC
���c�i�j // 990ns
�̊ԈႢ���B�Borz
�̊ԈႢ���B�Borz
238 �F����������K�������F2005/07/08(��) 00:41:55 ID:6pvwGyBO
>>233
�킴�킴�������ꂽ�}�Ƃ̍����ʂ���K�v�Ȃ�ĂȂ���
SPE���̎}�����ʂ���悵
�Ƃ������T�����̕��Ȃ�Ă�����Ε���قǏo�Ă���Ƃ����̂�
�킴�킴�������ꂽ�}�Ƃ̍����ʂ���K�v�Ȃ�ĂȂ���
SPE���̎}�����ʂ���悵
�Ƃ������T�����̕��Ȃ�Ă�����Ε���قǏo�Ă���Ƃ����̂�
239 �F����������K�������F2005/07/08(��) 00:42:33 ID:YZU3prp2
�R�A�̓����ʐM���K�v���ƍ��������������B
240 �F����������K�������F2005/07/08(��) 00:43:28 ID:m4sgE6Un
>>234
ADPCM���̈��k�f�[�^�͈�xPCM�ɓW�J���Ȃ��ƍ����ł��Ȃ��B
�������������ΐ�PCM�f�[�^�g���������y�B
�Q�[���@�ł̓������D�悾���爳�k�`���ɂ͂Ȃ邾�낤���ǁB
ADPCM���̈��k�f�[�^�͈�xPCM�ɓW�J���Ȃ��ƍ����ł��Ȃ��B
�������������ΐ�PCM�f�[�^�g���������y�B
�Q�[���@�ł̓������D�悾���爳�k�`���ɂ͂Ȃ邾�낤���ǁB
>�����̈ӌ��̍�����琳�����ɂ��Ă͊��S�ɖڂ���炵�Ă�Ȃ�
�{����CELL���Q�[���������ǂ����^��Ɏv�����Ƃ����̃X���I�ɂ͖����Ď��H
�{����CELL���Q�[���������ǂ����^��Ɏv�����Ƃ����̃X���I�ɂ͖����Ď��H
242 �F����������K�������F2005/07/08(��) 00:47:33 ID:oQ6uEJ6P
���������O���[�o���ɎU������������Ƀ����_���A�N�Z�X���悤�Ǝv������A�ǂ�Ȃb�o�t�ł����C���������A�N�Z�X���x�ȏ�͏o�Ȃ��Ǝv���B
�k�r�ɏ��Ȃ����Ă��Ƃ̓L���b�V���ɂ����Ȃ��ł���H
�L���b�V���ɏ�郌�x���Ȃ�>238�������悤�ɒT���^�X�N�̕����čו������k�r�ɑ����łc�l�`�Ԃ�Ƃ����@�ŃL���b�V���Ɠ����̌��ʂ͏o��B
��������Ȃ����ǂˁB
�k�r�ɏ��Ȃ����Ă��Ƃ̓L���b�V���ɂ����Ȃ��ł���H
�L���b�V���ɏ�郌�x���Ȃ�>238�������悤�ɒT���^�X�N�̕����čו������k�r�ɑ����łc�l�`�Ԃ�Ƃ����@�ŃL���b�V���Ɠ����̌��ʂ͏o��B
��������Ȃ����ǂˁB
243 �F����������K�������F2005/07/08(��) 00:47:34 ID:PTJBXFZ+
>>241
>�����̈ӌ��́u������琳�����v�ɂ���
�����ǂ��v����cell���Q�[���Ɍ����ĂȂ��ƍl�����̂��A�����Ă�������̐������Ǝv�����̂��B
>�����̈ӌ��́u������琳�����v�ɂ���
�����ǂ��v����cell���Q�[���Ɍ����ĂȂ��ƍl�����̂��A�����Ă�������̐������Ǝv�����̂��B
244 �F����������K�������F2005/07/08(��) 00:47:43 ID:i0/45Hyp
�����́u������@�e�N�m���W�[�v�X���Ȃ̂ɁAFFT�x���`��MPEG2����48�{�Đ������ꂵ�����R���ĉ��H
��
�܂�A���������_���Z���K�v�ȃX�g���[���������哾�ӂƁB
���_���Z�A�����v�Z�A�������Z�A���������Aetc
�Q�[���v���O�������Ɖ��b�L��܂���ł���B
��
���̊��ɋ[���R�[�h�̈���������Ɩ����̂ŁA�{���ɉ��p����܂���Ȃ̂����������v���Ă��܂���ŁB
���܂łƃp���_�C���̈Ⴄ�A�[�L�e�N�`���Ȃ���A�[���R�[�h�ł��ǂ��̂ŏ����̗��ꂪ����Ȃ��ƐM�p�ł��Ȃ��Ǝv���̂����ʂ���Ȃ��H
�i���������Ă���Ȃ��Ɠ��Ӌ��߂��Ă�����������j
��
�����̗���B
http://pc.watch.impress.co.jp/docs/2005/0310/kaigai165.htm
��
���₢��A����SPE�̃X�P�W���[�����O�ŏ����̗��ꂶ��Ȃ��ł���B
���Ƃ���AI�������烿���@���ǂ�SPE�Ŏ�������Ƃ��A���������b�Ȃ��ǁB
�i�����Ȃ苭���Ș_�_���炵���I�j
��
����SPE�ւ�AI�R�[�h������܂ŁASCE��IBM�������Ȃ���Ȃ�Ȃ��́H
��
SCE��IBM�Ȃ�Ĉꌾ�������ĂȂ����ǁE�E�E�B
�i���Ⴀ�N�������悗���j
��
�܂�A���������_���Z���K�v�ȃX�g���[���������哾�ӂƁB
���_���Z�A�����v�Z�A�������Z�A���������Aetc
�Q�[���v���O�������Ɖ��b�L��܂���ł���B
��
���̊��ɋ[���R�[�h�̈���������Ɩ����̂ŁA�{���ɉ��p����܂���Ȃ̂����������v���Ă��܂���ŁB
���܂łƃp���_�C���̈Ⴄ�A�[�L�e�N�`���Ȃ���A�[���R�[�h�ł��ǂ��̂ŏ����̗��ꂪ����Ȃ��ƐM�p�ł��Ȃ��Ǝv���̂����ʂ���Ȃ��H
�i���������Ă���Ȃ��Ɠ��Ӌ��߂��Ă�����������j
��
�����̗���B
http://pc.watch.impress.co.jp/docs/2005/0310/kaigai165.htm
��
���₢��A����SPE�̃X�P�W���[�����O�ŏ����̗��ꂶ��Ȃ��ł���B
���Ƃ���AI�������烿���@���ǂ�SPE�Ŏ�������Ƃ��A���������b�Ȃ��ǁB
�i�����Ȃ苭���Ș_�_���炵���I�j
��
����SPE�ւ�AI�R�[�h������܂ŁASCE��IBM�������Ȃ���Ȃ�Ȃ��́H
��
SCE��IBM�Ȃ�Ĉꌾ�������ĂȂ����ǁE�E�E�B
�i���Ⴀ�N�������悗���j
245 �F����������K�������F2005/07/08(��) 00:49:24 ID:zcWzLQPy
>>241
�ǂ��g����̂��͂܂��킩��Ȃ����ǁA���̋@�\���Q�[���ɐ��������\�����Ȃ��킯����Ȃ��B
CELL�̔\�͂�m�邤���ŎQ�l�ƂȂ�f�[�^���o���ꂽ���Ƃɑ��āA
���������P�`����̂���邾�Ǝv�����ǂȂ��B
�ǂ��g����̂��͂܂��킩��Ȃ����ǁA���̋@�\���Q�[���ɐ��������\�����Ȃ��킯����Ȃ��B
CELL�̔\�͂�m�邤���ŎQ�l�ƂȂ�f�[�^���o���ꂽ���Ƃɑ��āA
���������P�`����̂���邾�Ǝv�����ǂȂ��B
246 �F(�@�E)3�@ ���E )�F2005/07/08(��) 00:49:29 ID:rzGt2iIQ
�������]�����̏���������˂����ق���
247 �F����������K�������F2005/07/08(��) 00:50:41 ID:h90zU47n
>>242
�펞�O���[�o���ȃ������������_���A�N�Z�X�͕K�v�Ȃ��B
�������K�v�Ȏ��͕K�v���Ƃ��������B
SPE�łǂ��������邩�Ƃ����l�^�Ȃ�Ӗ��͂��邪
SPE�őS�����Ȃ��ƌ�������A�z�ɂ͂��������肾�B
�펞�O���[�o���ȃ������������_���A�N�Z�X�͕K�v�Ȃ��B
�������K�v�Ȏ��͕K�v���Ƃ��������B
SPE�łǂ��������邩�Ƃ����l�^�Ȃ�Ӗ��͂��邪
SPE�őS�����Ȃ��ƌ�������A�z�ɂ͂��������肾�B
248 �F����������K�������F2005/07/08(��) 00:50:59 ID:5cHZ36OG
>>236
���a��c���g����������SPE���Ŏ��܂��Ă�Ȃ���ʓI���Ǝv�����ǁA���̃O���[�o���ȃf�[�^�Q�Ƃ��Ă�ƃ}�Y���Ȃ��H
��x���[�h�����������ʂȂ������Ɏg���̂�SPE�̐^�������ƍl����ƁA�����Ƃ����W���[�����ł��Ȃ��Ɠ�������ˁB
����Ӗ��I�u�W�F�N�g�w���I�Ȃ̂��ȁB
���a��c���g����������SPE���Ŏ��܂��Ă�Ȃ���ʓI���Ǝv�����ǁA���̃O���[�o���ȃf�[�^�Q�Ƃ��Ă�ƃ}�Y���Ȃ��H
��x���[�h�����������ʂȂ������Ɏg���̂�SPE�̐^�������ƍl����ƁA�����Ƃ����W���[�����ł��Ȃ��Ɠ�������ˁB
����Ӗ��I�u�W�F�N�g�w���I�Ȃ̂��ȁB
250 �F����������K�������F2005/07/08(��) 00:53:06 ID:6pvwGyBO
�Ǐ��������Ȃ��t�@�C�������A���S���Y����SPE�ʼn����ł��邩�H
���c�_�̗]�n����
�T�����̂悤�ȋǏ����������āA���łɂ��������A���S���Y������������Ă����
���c�_�̗]�n�Ȃ��S�����Ȃ�
���c�_�̗]�n����
�T�����̂悤�ȋǏ����������āA���łɂ��������A���S���Y������������Ă����
���c�_�̗]�n�Ȃ��S�����Ȃ�
251 �F����������K�������F2005/07/08(��) 00:56:10 ID:Y+nPtwIC
�ŋ߁A��۰��ٕϐ����Ă���܂�g���̂ōl�����ĂȂ������B
>>244
�܂Ƃ߂Ă���Ă��肪�Ƃ��B
�[���R�[�h���ď����Ă�̂ɂ܂����X�P�W���[�����O�̘b���o��Ƃ͎v���ĂȂ��������̂ŁB
�����R�[�h���ď����Ă邩��A��̓I�ȗ�Ƃ��ă����@�Ƃ��o�������ǁA�_�_���炵�Ă�悤�Ɍ����܂������B
���܂����B
�܂Ƃ߂Ă���Ă��肪�Ƃ��B
�[���R�[�h���ď����Ă�̂ɂ܂����X�P�W���[�����O�̘b���o��Ƃ͎v���ĂȂ��������̂ŁB
�����R�[�h���ď����Ă邩��A��̓I�ȗ�Ƃ��ă����@�Ƃ��o�������ǁA�_�_���炵�Ă�悤�Ɍ����܂������B
���܂����B
253 �F����������K�������F2005/07/08(��) 00:58:23 ID:Nj8goKm3
�v���O���}�͗^����ꂽ�����̒��ŁA���̓s�x�����I�ȃA�v���[�`��͍�����̂��d��������A
�uSPE��AI�Ɍ����Ă��邩�v�Ƃ�����G�c������c�_�͖��Ӗ��ȋC������B
�Ƃ肠����SPE�́A���Z�ʑ��߁A�������A�N�Z�X���Ȃ߂̖�肪���ӂł���Ƃ������Ƃ���
�킩��Ȃ��킯�����B
�uSPE��AI�Ɍ����Ă��邩�v�Ƃ�����G�c������c�_�͖��Ӗ��ȋC������B
�Ƃ肠����SPE�́A���Z�ʑ��߁A�������A�N�Z�X���Ȃ߂̖�肪���ӂł���Ƃ������Ƃ���
�킩��Ȃ��킯�����B
254 �F����������K�������F2005/07/08(��) 01:00:19 ID:YZU3prp2
�ނ͂ނ��냁�����A�N�Z�X�������̕����������B
�_�u���o�b�t�@�Ō��݂ɁB�x�݂Ȃ��B
�������������ʂ��Ǝv�����B
�_�u���o�b�t�@�Ō��݂ɁB�x�݂Ȃ��B
�������������ʂ��Ǝv�����B
255 �F(�@�E)3�@ ���E )�F2005/07/08(��) 01:01:12 ID:rzGt2iIQ
������SuperPenisErection
256 �F����������K�������F2005/07/08(��) 01:01:34 ID:PTJBXFZ+
>>245-255
���
���
257 �F����������K�������F2005/07/08(��) 01:01:54 ID:oQ6uEJ6P
>253
�������A�N�Z�X�͑����Ă����Ȃ��ł���B
�����_���A�N�Z�X�������ƃX�P�W���[�����O���߂�ǂ����Ă�������B
�������A�N�Z�X�͑����Ă����Ȃ��ł���B
�����_���A�N�Z�X�������ƃX�P�W���[�����O���߂�ǂ����Ă�������B
�r�o�d�̂������ŃX�������V���Ă��܂��܂����B
259 �F����������K�������F2005/07/08(��) 01:03:58 ID:iXKfXl5i
>>217
����R520���܂߁AATI�̍���̐V����GPU�́AUnified-Shader�\�����p������ƌ����Ă���B
R520�� ����܂ŕ����V�F�[�_�̂܂܂ōs���A
�Ƃ������ĂȂ������H �����V�F�[�_�������̂��H
�������A���҂̌������͖ʔ����ȁ[
�@�����Q�[���̒��ł���ʂɂ���Ē��_�V�F�[�_�ƃs�N�Z���V�F�[�_�̕��ׂ�����Ă���B
������A�����V�F�[�_���A�ƁB �����A�[���ł���B
�@����ŁA�����V�F�[�_�ɂ��h���ʁh�͂���A�ƁB
�S�ẴV�F�[�_���s�N�Z�������Ő�L����邱�ƂȂnj����Ė����B
�ɂ�������炸�A�����V�F�[�_�ł� �S�ẴV�F�[�_�Ƀs�N�Z�������@�\���ڂ��Ȃ��ƂȂ�Ȃ��B
�P�̃V�F�[�_�ɉ���������点�悤�Ƃ���ƁA�������āh��p�n�R�h�A�g�����W�X�^�̖��ʂɂȂ�A�ƁB
�����E�E ������[���ł���B
�܁A���ǂ͎��s���\�Ō������t���낤���ǁE�E
����R520���܂߁AATI�̍���̐V����GPU�́AUnified-Shader�\�����p������ƌ����Ă���B
R520�� ����܂ŕ����V�F�[�_�̂܂܂ōs���A
�Ƃ������ĂȂ������H �����V�F�[�_�������̂��H
�������A���҂̌������͖ʔ����ȁ[
�@�����Q�[���̒��ł���ʂɂ���Ē��_�V�F�[�_�ƃs�N�Z���V�F�[�_�̕��ׂ�����Ă���B
������A�����V�F�[�_���A�ƁB �����A�[���ł���B
�@����ŁA�����V�F�[�_�ɂ��h���ʁh�͂���A�ƁB
�S�ẴV�F�[�_���s�N�Z�������Ő�L����邱�ƂȂnj����Ė����B
�ɂ�������炸�A�����V�F�[�_�ł� �S�ẴV�F�[�_�Ƀs�N�Z�������@�\���ڂ��Ȃ��ƂȂ�Ȃ��B
�P�̃V�F�[�_�ɉ���������点�悤�Ƃ���ƁA�������āh��p�n�R�h�A�g�����W�X�^�̖��ʂɂȂ�A�ƁB
�����E�E ������[���ł���B
�܁A���ǂ͎��s���\�Ō������t���낤���ǁE�E
260 �F����������K�������F2005/07/08(��) 01:04:10 ID:5cHZ36OG
>>253
���������A�N�Z�X���Ȃ߂̖�肪���ӂł���Ƃ������Ƃ���
�u�������̃����_���A�N�Z�X���Ȃ߁v�ł��ȁB
�A�������A�h���X�̃������A�N�Z�X��
LS�_�u���o�b�t�@�ɂ�郌�C�e���V�B���܂Ŋ܂߂��瓾�ӂƂ������邵�B
���������A�N�Z�X���Ȃ߂̖�肪���ӂł���Ƃ������Ƃ���
�u�������̃����_���A�N�Z�X���Ȃ߁v�ł��ȁB
�A�������A�h���X�̃������A�N�Z�X��
LS�_�u���o�b�t�@�ɂ�郌�C�e���V�B���܂Ŋ܂߂��瓾�ӂƂ������邵�B
>SPE��AI�Ɍ����ĂȂ��ƁACell�̓Q�[���@��������Ȃ��Ƃ������ƁH
����A�O�̃X����AI���������Z���K�V�K�V������݂����Șb�肪�o�Ă��̂ŁA��ɂ����������B
�������Z�̕��̓R�[�h�ɂ���Ƃǂ��Ȃ邩�ǂ��킩���ĂȂ��̂ŁA��ɂ����܂���ł����B
����A�O�̃X����AI���������Z���K�V�K�V������݂����Șb�肪�o�Ă��̂ŁA��ɂ����������B
�������Z�̕��̓R�[�h�ɂ���Ƃǂ��Ȃ邩�ǂ��킩���ĂȂ��̂ŁA��ɂ����܂���ł����B
262 �F����������K�������F2005/07/08(��) 01:04:48 ID:Hs5YH8zn
>>250
���Ǐ��������Ȃ��t�@�C�������A���S���Y��
�ʏ�A������x�ȏ�K�͂̑傫���f�[�^�x�[�X��
�����Ȃ葍������ŕЂ��[����f�[�^�r�߂Ă����̂ł͂Ȃ���
�f�[�^�x�[�X�\�z���Ɏ��f�[�^�Ƃ͕ʂɌ����L�[�ʂ�
�����ƃR���p�N�g�Ȍ����e�[�u�����������Ă�̂ł́H
�O�[�O���Ƃ��Ђ��[����S�f�[�^�r�߂Ă�킫�ᖳ���Ǝv�����B
���Ǐ��������Ȃ��t�@�C�������A���S���Y��
�ʏ�A������x�ȏ�K�͂̑傫���f�[�^�x�[�X��
�����Ȃ葍������ŕЂ��[����f�[�^�r�߂Ă����̂ł͂Ȃ���
�f�[�^�x�[�X�\�z���Ɏ��f�[�^�Ƃ͕ʂɌ����L�[�ʂ�
�����ƃR���p�N�g�Ȍ����e�[�u�����������Ă�̂ł́H
�O�[�O���Ƃ��Ђ��[����S�f�[�^�r�߂Ă�킫�ᖳ���Ǝv�����B
263 �F����������K�������F2005/07/08(��) 01:06:48 ID:6rDmKiwg
ttp://techon.nikkeibp.co.jp/article/NEWS/20050707/106552/
CELL�̉��p�၄�v�����^�iw
�V���{�C�A���܂�ɂ��V���{�߂���B
�v�����^�ɏ悹����x�̒ᐫ�\�`�b�v�ŃQ�[���@�����Ȃ�
CELL�̉��p�၄�v�����^�iw
�V���{�C�A���܂�ɂ��V���{�߂���B
�v�����^�ɏ悹����x�̒ᐫ�\�`�b�v�ŃQ�[���@�����Ȃ�
264 �F����������K�������F2005/07/08(��) 01:07:30 ID:76vPqr+e
>>259
ATI�̃`�F�b�N�����beyond3d�̋L����R520�͓����V�F�[�_����Ȃ��ƌ����Ă�
����㓡�̑s��Ȋ��Ⴂ�ł���B�O���㓡��NVIDIA�������V�F�[�_�����A
�Ƃ������Ă����Ȃ���Ă�B
ATI�̃`�F�b�N�����beyond3d�̋L����R520�͓����V�F�[�_����Ȃ��ƌ����Ă�
����㓡�̑s��Ȋ��Ⴂ�ł���B�O���㓡��NVIDIA�������V�F�[�_�����A
�Ƃ������Ă����Ȃ���Ă�B
265 �F����������K�������F2005/07/08(��) 01:07:45 ID:5cHZ36OG
>>261
��AI���������Z���K�V�K�V������݂�����
���l�^�͑�������ł��ȁB
http://spin.s2c.ne.jp/stoday/stoday06.html
���܂��A���������̉����̉ߒ������ł��܂��B
���܂�A�����V�~����AI�̏����͕����̗v�f�����m�ł���
�������Ɍ����Ă��܂��B
���̕��͂őz�肳��Ă�AI�����̒��g�͒m��Ȃ����ǁB
�iAI�����͎�ޑ������Ȃ�Łj
��AI���������Z���K�V�K�V������݂�����
���l�^�͑�������ł��ȁB
http://spin.s2c.ne.jp/stoday/stoday06.html
���܂��A���������̉����̉ߒ������ł��܂��B
���܂�A�����V�~����AI�̏����͕����̗v�f�����m�ł���
�������Ɍ����Ă��܂��B
���̕��͂őz�肳��Ă�AI�����̒��g�͒m��Ȃ����ǁB
�iAI�����͎�ޑ������Ȃ�Łj
266 �F����������K�������F2005/07/08(��) 01:08:25 ID:D+Jh+MKR
G70�̓V�F�[�_�[�𑖂点�Ȃ��Ɩ��ʂ��Ƃ����Ӗ��Ȃ�
���Ƃ��Ό��s���ł��V�F�[�_�[�o���o���̃\�t�g�Ȃ�ĉ�������H
���Ƃ��Ό��s���ł��V�F�[�_�[�o���o���̃\�t�g�Ȃ�ĉ�������H
267 �F����������K�������F2005/07/08(��) 01:08:44 ID:YZU3prp2
�㓡�^���̌�������Ȃ����AATI�̌^�Ԃ̂����ɂ���肠��C������
>LS�_�u���o�b�t�@�ɂ�郌�C�e���V�B���܂Ŋ܂߂��瓾�ӂƂ������邵�B
LS�_�u���o�b�t�@����256K���Ɋ�����Ď��ł����H
����������DMA�ł̃A�N�Z�X�̃I�[�o�[�w�b�h���Ăǂ�Ȃ���Ȃ�ł��傤�ˁH
CELL���I�[�v���\�[�X�ɂ�����Č�������A���̂����ڂ��������Ƃ��o��̂��ȁB
>�V���{�C�A���܂�ɂ��V���{�߂���B
�v�����^�Ȃ߂��炢����B
LS�_�u���o�b�t�@����256K���Ɋ�����Ď��ł����H
����������DMA�ł̃A�N�Z�X�̃I�[�o�[�w�b�h���Ăǂ�Ȃ���Ȃ�ł��傤�ˁH
CELL���I�[�v���\�[�X�ɂ�����Č�������A���̂����ڂ��������Ƃ��o��̂��ȁB
>�V���{�C�A���܂�ɂ��V���{�߂���B
�v�����^�Ȃ߂��炢����B
269 �F����������K�������F2005/07/08(��) 01:12:11 ID:Hs5YH8zn
270 �F����������K�������F2005/07/08(��) 01:12:14 ID:br3dPTc0
�v�����^�n���ɂ��Ă�z�̓v�����^���Ɏӂꂗ
271 �F����������K�������F2005/07/08(��) 01:13:07 ID:iXKfXl5i
R500��R520���� �m���ɓ����n�����Ǝv���Ă��d����������ȁE�E
���ۂ͂ǂ��Ȃ�H
���ۂ͂ǂ��Ȃ�H
272 �F����������K�������F2005/07/08(��) 01:14:20 ID:D+Jh+MKR
�v�����^���Ƃ����n���݂����ɏ���d�͐H���悤�ɂȂ�����I��肾��
�������͂Ƃ�����������CPU�Ȃ�ĕK�v�Ȃ���
�������͂Ƃ�����������CPU�Ȃ�ĕK�v�Ȃ���
273 �F����������K�������F2005/07/08(��) 01:14:59 ID:FESYEsGE
��������ނ͍��𑜓x�ɂ��Ή����Ȃ���Ȃ�Ȃ�PC����܂������͓̂��ӁB
HDTV�𑜓x���܂����y������Ă��Ȃ��R���V���[�}������ł�����̂��ˁB
HDTV�𑜓x���܂����y������Ă��Ȃ��R���V���[�}������ł�����̂��ˁB
274 �F����������K�������F2005/07/08(��) 01:15:34 ID:76vPqr+e
>>271
R400(�L�����Z�����ꂽSM3.0�Ή��`�b�v)��R420���Ⴄ�킯�ŁB
R400(�L�����Z�����ꂽSM3.0�Ή��`�b�v)��R420���Ⴄ�킯�ŁB
275 �F����������K�������F2005/07/08(��) 01:15:39 ID:5cHZ36OG
>>268
��LS�_�u���o�b�t�@����256K���Ɋ�����Ď��ł����H
�ő�A(256KB-�v���O����)/2
�o�b�t�@�T�C�Y�̓f�[�^�ɑ���SPE�̏����ʂɂ���ĕς��B
60����1�b�Ő��\�o�C�g���������ł��Ȃ���A���̔{���������B
��LS�_�u���o�b�t�@����256K���Ɋ�����Ď��ł����H
�ő�A(256KB-�v���O����)/2
�o�b�t�@�T�C�Y�̓f�[�^�ɑ���SPE�̏����ʂɂ���ĕς��B
60����1�b�Ő��\�o�C�g���������ł��Ȃ���A���̔{���������B
276 �F����������K�������F2005/07/08(��) 01:16:46 ID:zcWzLQPy
277 �F����������K�������F2005/07/08(��) 01:17:01 ID:PTJBXFZ+
>>272
�Ɩ��p�̃v�����^�[����1000w�]�T�Œ����Ă��ł����E�E�E
�Ɩ��p�̃v�����^�[����1000w�]�T�Œ����Ă��ł����E�E�E
278 �F����������K�������F2005/07/08(��) 01:17:08 ID:76vPqr+e
279 �F����������K�������F2005/07/08(��) 01:17:33 ID:Y+nPtwIC
>>272
ڰ�ް������̓d���͋����ł��B
������ײ݂�PLC��ؾ�Ă��ďł����B
�܂��e�ʖ����������������̂���������
500w�����x����S�R����ˁB�Borz
ڰ�ް������̓d���͋����ł��B
������ײ݂�PLC��ؾ�Ă��ďł����B
�܂��e�ʖ����������������̂���������
500w�����x����S�R����ˁB�Borz
280 �F����������K�������F2005/07/08(��) 01:19:18 ID:kbte9H3q
>>268
���S�ɃX�g���[���I�ȃV�[�P���V�����A�N�Z�X�ł����Ȃ�A�����O�o�b�t�@�ł��ǂ�
DMA�̓��C���̃X���b�h�̗��œ������āA�K�v�Ȏ��ɕK�v�ȃf�[�^����������ɗp�ӂ���
�Ă����ԂɂȂ肳������A�o�b�t�@�����͉��ł��ǂ�����
���S�ɃX�g���[���I�ȃV�[�P���V�����A�N�Z�X�ł����Ȃ�A�����O�o�b�t�@�ł��ǂ�
DMA�̓��C���̃X���b�h�̗��œ������āA�K�v�Ȏ��ɕK�v�ȃf�[�^����������ɗp�ӂ���
�Ă����ԂɂȂ肳������A�o�b�t�@�����͉��ł��ǂ�����
281 �F����������K�������F2005/07/08(��) 01:20:36 ID:iXKfXl5i
282 �F����������K�������F2005/07/08(��) 01:22:40 ID:6VKD79Rf
���̂Ƃ��딻������Cell�̗p�r
SPE8�@WS�A��×p�摜�����@��
SPE7�@PS3
6�ȉ��@HP�̕����v�����^
��@�g���^�̎ԍڃV�X�e��
4�����O�Ɏd�l�����J���ꂽ����̃`�b�v�Ȃ̂ɏ�������
SPE8�@WS�A��×p�摜�����@��
SPE7�@PS3
6�ȉ��@HP�̕����v�����^
��@�g���^�̎ԍڃV�X�e��
4�����O�Ɏd�l�����J���ꂽ����̃`�b�v�Ȃ̂ɏ�������
283 �F����������K�������F2005/07/08(��) 01:23:30 ID:D+Jh+MKR
R520��WGF2.0����Ȃ���
���Ȃ݂�WGF2.0��DirectX10�̂���
���Ȃ݂�WGF2.0��DirectX10�̂���
284 �F����������K�������F2005/07/08(��) 01:23:35 ID:YZU3prp2
R1050�Ƃ����Ă����ΒN���݂Ă������V�F�[�_���Ă킩��̂ɂȁB
285 �F����������K�������F2005/07/08(��) 01:24:18 ID:49aFnj0o
>>280
>DMA�̓��C���̃X���b�h�̗��œ������āA�K�v�Ȏ��ɕK�v�ȃf�[�^����������ɗp�ӂ���
>�Ă����ԂɂȂ肳�������
�����������������Z���\�ɗ^����e���Ƃ����̂͂ǂ�Ȃ���Ȃ�ł���D
�X��SPE���Ń}���`�X���b�h���Ă��Ƃł���ˁD
>DMA�̓��C���̃X���b�h�̗��œ������āA�K�v�Ȏ��ɕK�v�ȃf�[�^����������ɗp�ӂ���
>�Ă����ԂɂȂ肳�������
�����������������Z���\�ɗ^����e���Ƃ����̂͂ǂ�Ȃ���Ȃ�ł���D
�X��SPE���Ń}���`�X���b�h���Ă��Ƃł���ˁD
286 �F����������K�������F2005/07/08(��) 01:24:39 ID:oQ6uEJ6P
>280
�������d�d�̗������c�l�`�ɃC���e���W�F���g�Ȏ����]���@�\�����ĂĂ����������Ȃ��B
�������d�d�̗������c�l�`�ɃC���e���W�F���g�Ȏ����]���@�\�����ĂĂ����������Ȃ��B
>>275
>>280
�Ȃ�قǁA�����Ȃ��SPE�ɍڂ��Ă�DMA���L���Ȃ�ł��ˁB
XDR�Ȃ�\���ȃ������ш悠�肻�������B
�f�o�b�N����SPE�̃���������Ȃ��Ƒ�ς������Ȃ��B
�����͓��ł�IBM��������Ă����̂��ȁB
>>280
�Ȃ�قǁA�����Ȃ��SPE�ɍڂ��Ă�DMA���L���Ȃ�ł��ˁB
XDR�Ȃ�\���ȃ������ш悠�肻�������B
�f�o�b�N����SPE�̃���������Ȃ��Ƒ�ς������Ȃ��B
�����͓��ł�IBM��������Ă����̂��ȁB
288 �F����������K�������F2005/07/08(��) 01:32:05 ID:YZU3prp2
289 �F����������K�������F2005/07/08(��) 01:32:07 ID:oQ6uEJ6P
>285,287
�d�d�ł͂c�l�`�ő���f�[�^��Ƀp�P�b�g�i�����P�ʁj���ɓ]�����邽�߂̃^�O�⎟�̃f�[�^��փW�����v���邽�߂̃����N����ߍ��߂��͂��B
������c�l�`����͂��ē]�����R���g���[���B
�����f�B�X�v���C���X�g�ɂ͂���Ȋ����̍���͂��������ǂc�l�`�̂悤�ȃn�[�h�E�F�A�A�V�X�g������̂��͒m��Ȃ��B
�d�d�ł͂c�l�`�ő���f�[�^��Ƀp�P�b�g�i�����P�ʁj���ɓ]�����邽�߂̃^�O�⎟�̃f�[�^��փW�����v���邽�߂̃����N����ߍ��߂��͂��B
������c�l�`����͂��ē]�����R���g���[���B
�����f�B�X�v���C���X�g�ɂ͂���Ȋ����̍���͂��������ǂc�l�`�̂悤�ȃn�[�h�E�F�A�A�V�X�g������̂��͒m��Ȃ��B
290 �F����������K�������F2005/07/08(��) 01:33:16 ID:6pvwGyBO
>>284
���܂��I
���܂��I
291 �F����������K�������F2005/07/08(��) 01:33:39 ID:iXKfXl5i
>>288
�n�n�n�A����߁I
�n�n�n�A����߁I
�~���
���@�\
���ƁA289�͈ȑO�͂������������玟���Ȃ����������i�͓����Ă����Ȃ����Ƃ����Ӗ��B
���@�\
���ƁA289�͈ȑO�͂������������玟���Ȃ����������i�͓����Ă����Ȃ����Ƃ����Ӗ��B
293 �F����������K�������F2005/07/08(��) 01:35:39 ID:ayQGDqjj
>>265
�r�����[�h��[�X�Q�[���̂悤�ȍ�p����p�����ŕ����͗L��Ȃ́H
�r�����[�h��[�X�Q�[���̂悤�ȍ�p����p�����ŕ����͗L��Ȃ́H
294 �F����������K�������F2005/07/08(��) 01:36:50 ID:6pvwGyBO
>>293
��������قǃR�X�g���傫���Ȃ��Ǝv���
��������قǃR�X�g���傫���Ȃ��Ǝv���
295 �F����������K�������F2005/07/08(��) 01:38:06 ID:6wosZonT
>>289
Cell��EIB�̓f�[�^128bit������64bit���̃^�O���������Ă邵�ˁB
Cell��EIB�̓f�[�^128bit������64bit���̃^�O���������Ă邵�ˁB
296 �F����������K�������F2005/07/08(��) 01:48:02 ID:5cHZ36OG
297 �F����������K�������F2005/07/08(��) 01:54:31 ID:Hs5YH8zn
>>295
http://ascii24.com/news/i/tech/article/2005/02/09/654178-000.html
�����ꂼ��64bit�̃^�O��128bit�̃f�[�^����Ȃ�v192bit�̃p�P�b�g���o�X���𑖂�B
http://ascii24.com/news/i/tech/article/2005/02/09/654178-000.html
�����ꂼ��64bit�̃^�O��128bit�̃f�[�^����Ȃ�v192bit�̃p�P�b�g���o�X���𑖂�B
298 �F����������K�������F2005/07/08(��) 01:57:03 ID:ucMx7jvF
Xbox 360 Beta Development Kit Picture Leaked?
http://news.teamxbox.com/xbox/8661/Xbox-360-Beta-Development-Kit-Picture-Leaked/
http://news.teamxbox.com/xbox/8661/Xbox-360-Beta-Development-Kit-Picture-Leaked/
299 �F����������K�������F2005/07/08(��) 02:42:00 ID:oUj4ykTi
�҂��Ă�Ύ��@���o��̂ɂȂ������X�y�b�N���C�ɂȂ鍡�����̍��B
http://pc.watch.impress.co.jp/docs/2005/0622/kaigai193.htm
��
������ǂ��ǂނ�RSX�̃V�F�[�_�[���Z���\�ɂ́AFP16 normalize�����p
�̃��j�b�g�����܂܂�Ă܂��ˁB
FP16 normalize���܂܂Ȃ��V�F�[�_�[���\
�s�N�Z���V�F�[�_�[���\ 24��~20Flops�~550MHz=264GFlops
�i20Flops=4way�~2��=8MADD=16Flops + 1way�~2��=2MADD=4Flops)
�o�[�e�b�N�X�V�F�[�_�[���\ 8��~10Flops�~550MHz=44GFlops
(10Flops=4way�~1��=4MADD=8Flops + 1way�~1��=1MADD=2Flops)
���v=264GFlops + 44 GFlops = 308GFlops
FP16 normalize�������j�b�g�̐��\��Nvidia�ɂ���
7Flops�~24��~550MHz=92.4GFlops �Ƃ������Ȃ̂ł���𑫂���
308GFlops + 92.4GFlops= 400.4GFlops�ƂȂ�܂��ˁB
http://pc.watch.impress.co.jp/docs/2005/0622/kaigai193.htm
��
������ǂ��ǂނ�RSX�̃V�F�[�_�[���Z���\�ɂ́AFP16 normalize�����p
�̃��j�b�g�����܂܂�Ă܂��ˁB
FP16 normalize���܂܂Ȃ��V�F�[�_�[���\
�s�N�Z���V�F�[�_�[���\ 24��~20Flops�~550MHz=264GFlops
�i20Flops=4way�~2��=8MADD=16Flops + 1way�~2��=2MADD=4Flops)
�o�[�e�b�N�X�V�F�[�_�[���\ 8��~10Flops�~550MHz=44GFlops
(10Flops=4way�~1��=4MADD=8Flops + 1way�~1��=1MADD=2Flops)
���v=264GFlops + 44 GFlops = 308GFlops
FP16 normalize�������j�b�g�̐��\��Nvidia�ɂ���
7Flops�~24��~550MHz=92.4GFlops �Ƃ������Ȃ̂ł���𑫂���
308GFlops + 92.4GFlops= 400.4GFlops�ƂȂ�܂��ˁB
300 �F����������K�������F2005/07/08(��) 02:49:16 ID:ayQGDqjj
>>294
�ŋ߂̃V�~�����[�^�[�v�f���������[�X�Q�[���͂ǂ����낤
>>296
���`�A����ȁB
���Ƃ��A�����̎Ԃ��N���b�V�����đ��̎Ԃ��������ގ�
���̎Ԃ̃N���b�V���������ɏ����o�����ł����H
�r�����[�h�������l����Ώo�������ɂȂ��Ǝv���̂ł���
�ŋ߂̃V�~�����[�^�[�v�f���������[�X�Q�[���͂ǂ����낤
>>296
���`�A����ȁB
���Ƃ��A�����̎Ԃ��N���b�V�����đ��̎Ԃ��������ގ�
���̎Ԃ̃N���b�V���������ɏ����o�����ł����H
�r�����[�h�������l����Ώo�������ɂȂ��Ǝv���̂ł���
301 �F����������K�������F2005/07/08(��) 02:54:04 ID:oUj4ykTi
299�̑����ł��B
http://www.beyond3d.com/articles/xenos
����ŎU�X���o�ł����A��L�L����ǂނƁA
Xenos�̃V�F�[�_�[���\��
�����V�F�[�_�[���\�@48��~10Flops�~500MHz=240GFlops
(10Flops=4way�~1��=4MADD=8Flops + 1way�~1��=1MADD=2Flops)
Xenos�͓����V�F�[�_�[�Ȃ̂ő��v��240GFlops�ƂȂ�܂��B
http://www.beyond3d.com/articles/xenos/index.php?p=07
�������A��������ǂނ�ATI�̓V�F�[�_�[���j�b�g�ƕ����pixel shader
interpolation calculations�����s�\�ȕʃ��j�b�g�𓋍ڂ��Ă���Ƃ̎��B
������J�E���g����ƃs�N�Z���V�F�[�_�[���Z���\��33%���シ��Ƃ��B
���̃��j�b�g���S�����V�F�[�_�[�ɒ����Ă���̂��͕s���Ƃ��Ă�ATI��
�������ʂ肾�ƍő��
240GFlops�~0.33=79.2GFlops������悹����鎖�ɂȂ�܂��B
����đ��v��240+79.2GFlops = 319.2GFlops??��
http://www.beyond3d.com/articles/xenos
����ŎU�X���o�ł����A��L�L����ǂނƁA
Xenos�̃V�F�[�_�[���\��
�����V�F�[�_�[���\�@48��~10Flops�~500MHz=240GFlops
(10Flops=4way�~1��=4MADD=8Flops + 1way�~1��=1MADD=2Flops)
Xenos�͓����V�F�[�_�[�Ȃ̂ő��v��240GFlops�ƂȂ�܂��B
http://www.beyond3d.com/articles/xenos/index.php?p=07
�������A��������ǂނ�ATI�̓V�F�[�_�[���j�b�g�ƕ����pixel shader
interpolation calculations�����s�\�ȕʃ��j�b�g�𓋍ڂ��Ă���Ƃ̎��B
������J�E���g����ƃs�N�Z���V�F�[�_�[���Z���\��33%���シ��Ƃ��B
���̃��j�b�g���S�����V�F�[�_�[�ɒ����Ă���̂��͕s���Ƃ��Ă�ATI��
�������ʂ肾�ƍő��
240GFlops�~0.33=79.2GFlops������悹����鎖�ɂȂ�܂��B
����đ��v��240+79.2GFlops = 319.2GFlops??��
302 �F����������K�������F2005/07/08(��) 02:54:53 ID:oUj4ykTi
301�̑����ł��B�����Ă����܂���O�O�G�@����ōŌ�ł��B
RSX��FP16 normalize���j�b�g�@�Ɓ@Xenos��pixel shader interpolation
calculations���j�b�g�̂ǂ�����t���ғ�����悤�ȃP�[�X�͂��܂�z��
�ł��܂��A�ʏ�̃Q�[���A�v���삳����ꍇ�ɂǂ��炪��葽��
���p���ꂻ�����Ƃ����\�z���Ă��l��������Ⴂ�܂����H�H
�P�[�X�o�C�P�[�X���Ƃ͎v���܂����E�E�B
�i�����V�F�[�_�[�̌������Ƃ��ш悤��ʂ�Ƃ��͕ʂ̘b�Ƃ��đf�̃V�F�[
�_�[���\�ɉe�����镔���Ȃ̂ł�����Ƌ������j
RSX��FP16 normalize���j�b�g�@�Ɓ@Xenos��pixel shader interpolation
calculations���j�b�g�̂ǂ�����t���ғ�����悤�ȃP�[�X�͂��܂�z��
�ł��܂��A�ʏ�̃Q�[���A�v���삳����ꍇ�ɂǂ��炪��葽��
���p���ꂻ�����Ƃ����\�z���Ă��l��������Ⴂ�܂����H�H
�P�[�X�o�C�P�[�X���Ƃ͎v���܂����E�E�B
�i�����V�F�[�_�[�̌������Ƃ��ш悤��ʂ�Ƃ��͕ʂ̘b�Ƃ��đf�̃V�F�[
�_�[���\�ɉe�����镔���Ȃ̂ł�����Ƌ������j
303 �F����������K�������F2005/07/08(��) 02:56:12 ID:6pvwGyBO
>>299
normalize�Ƃ����̂Ȃėp���j�b�g����Ȃ��悤�ɕ������邯�ǁA
����Ă�v�Z���Ă̂́A
x=v1*h1+v2*h2+v3*h3+v4*h4
��4�̐ω��Z�ƂR�̘a���Z
3D�v�Z�ł͂����Ƃ��p�o����SIMD���Z�ł���
���̃\�[�X�ł�norm���Ă��������ǁAnormalize����Ȃ���
�x�N�g���̃m�����v�Z�Ƃ����Ӗ��̂ق����߂��Ǝv���B
normalize�ɂ�������Ax=v1*v1+v2*v2+v3*v3+v4*v4�ƈ������ɂ���悢�B
normalize�Ƃ����̂Ȃėp���j�b�g����Ȃ��悤�ɕ������邯�ǁA
����Ă�v�Z���Ă̂́A
x=v1*h1+v2*h2+v3*h3+v4*h4
��4�̐ω��Z�ƂR�̘a���Z
3D�v�Z�ł͂����Ƃ��p�o����SIMD���Z�ł���
���̃\�[�X�ł�norm���Ă��������ǁAnormalize����Ȃ���
�x�N�g���̃m�����v�Z�Ƃ����Ӗ��̂ق����߂��Ǝv���B
normalize�ɂ�������Ax=v1*v1+v2*v2+v3*v3+v4*v4�ƈ������ɂ���悢�B
304 �F����������K�������F2005/07/08(��) 03:00:06 ID:6pvwGyBO
>>301
��interpolation calculations
���̉p�P��m��Ȃ��������玫�����������ǁA�⊮�݂������ˁB
���̂����`�⊮�Ȃ̂��A�����ƍ��x�ȕ⊮�Ȃ̂��͒m��Ȃ����ǁB
�A���t�@�u�����f�B���O�͐��`�⊮�B
���Ɏg���̂��͒m��Ȃ����ǁA���ɂ�ROS�����̈ꕔ���Ƃ����v���Ȃ��B
�����������Ƃ�����Œ�@�\�̈ꕔ�Ƃ��ăJ�E���g����ׂ�����ˁB
��interpolation calculations
���̉p�P��m��Ȃ��������玫�����������ǁA�⊮�݂������ˁB
���̂����`�⊮�Ȃ̂��A�����ƍ��x�ȕ⊮�Ȃ̂��͒m��Ȃ����ǁB
�A���t�@�u�����f�B���O�͐��`�⊮�B
���Ɏg���̂��͒m��Ȃ����ǁA���ɂ�ROS�����̈ꕔ���Ƃ����v���Ȃ��B
�����������Ƃ�����Œ�@�\�̈ꕔ�Ƃ��ăJ�E���g����ׂ�����ˁB
305 �F����������K�������F2005/07/08(��) 03:03:15 ID:6pvwGyBO
>>303�̕⑫
���������{���̈Ӗ��ł�normalize�i���K���j���Ă̂́B
x=��(v1*v1+v2*v2+v3*v3+v4*v4)
v1/=x,v2/=x,v3/=x,v4/=x
�̂P�Q���������_���Z���K�v�B
���̃\�[�X�ɂ�norm�͂V���������_���Z���Ə�����Ă�������A
normalize�Ɖ��肷��Ƃ����������ƂɂȂ�
���������{���̈Ӗ��ł�normalize�i���K���j���Ă̂́B
x=��(v1*v1+v2*v2+v3*v3+v4*v4)
v1/=x,v2/=x,v3/=x,v4/=x
�̂P�Q���������_���Z���K�v�B
���̃\�[�X�ɂ�norm�͂V���������_���Z���Ə�����Ă�������A
normalize�Ɖ��肷��Ƃ����������ƂɂȂ�
306 �F����������K�������F2005/07/08(��) 03:16:56 ID:FG2ZW7mL
>>301
�����Ƃ��A�����̎Ԃ��N���b�V�����đ��̎Ԃ��������ގ�
�����̎Ԃ̃N���b�V���������ɏ����o�����ł����H
�ړ��v�Z���Փ˔��聨�Փˉ����͕ʁX�̏����B
��������̂́A���ꂼ��̒i�K�B
�����Ƃ��A�����̎Ԃ��N���b�V�����đ��̎Ԃ��������ގ�
�����̎Ԃ̃N���b�V���������ɏ����o�����ł����H
�ړ��v�Z���Փ˔��聨�Փˉ����͕ʁX�̏����B
��������̂́A���ꂼ��̒i�K�B
307 �F����������K�������F2005/07/08(��) 03:18:12 ID:oUj4ykTi
>>305
���w�E�ǂ����ł��B
���̃\�[�X�Ƃ����̂͂ǂ���ɂȂ�܂��ł��傤���H
�iNvidia�̎����Ƃ��ł����H�j
������x�Q�X�X�o�������\�[�X��ǂݒ����Ă݂����̂ł����A
������̐}�ɂ�+Free FP16 normalize�ƋL�ڂ���Ă��܂����A
��
http://pc.watch.impress.co.jp/docs/2005/0622/kaigai06l.gif
�{�����̉��̂ق��ɉ��L�̂悤�ɋL�ڂ���Ă����̂�normalize�����p����
�v��������ł��B
[����ɁATamasi���ɂ��ƁA7��FP16 normalize(���K��)�����������
�\���Ƃ����B]
���w�E�ǂ����ł��B
���̃\�[�X�Ƃ����̂͂ǂ���ɂȂ�܂��ł��傤���H
�iNvidia�̎����Ƃ��ł����H�j
������x�Q�X�X�o�������\�[�X��ǂݒ����Ă݂����̂ł����A
������̐}�ɂ�+Free FP16 normalize�ƋL�ڂ���Ă��܂����A
��
http://pc.watch.impress.co.jp/docs/2005/0622/kaigai06l.gif
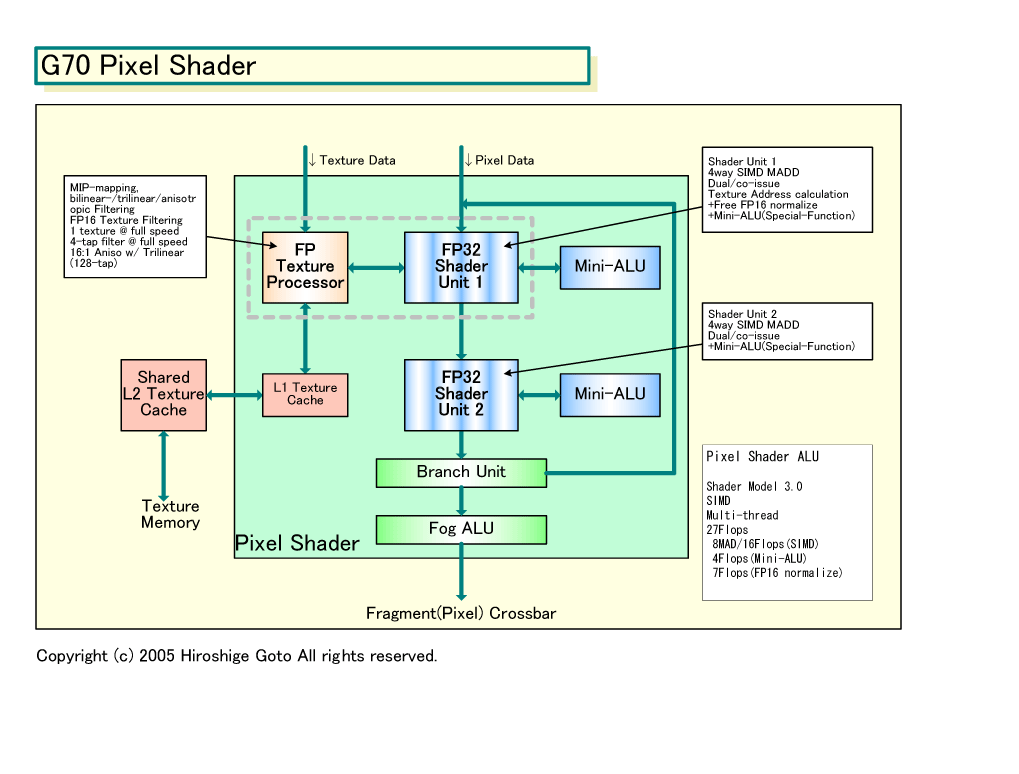{kind=link}
�{�����̉��̂ق��ɉ��L�̂悤�ɋL�ڂ���Ă����̂�normalize�����p����
�v��������ł��B
[����ɁATamasi���ɂ��ƁA7��FP16 normalize(���K��)�����������
�\���Ƃ����B]
308 �F����������K�������F2005/07/08(��) 03:19:28 ID:oUj4ykTi
>>307
�����@
������x�Q�X�X�o�������\�[�X��ǂݒ����Ă݂����̂ł����A
��
������x�Q�X�X�ŏo�����\�[�X��ǂݒ����Ă݂��̂ł����A
�����@
������x�Q�X�X�o�������\�[�X��ǂݒ����Ă݂����̂ł����A
��
������x�Q�X�X�ŏo�����\�[�X��ǂݒ����Ă݂��̂ł����A
309 �F����������K�������F2005/07/08(��) 03:19:59 ID:6pvwGyBO
310 �F����������K�������F2005/07/08(��) 03:23:18 ID:6pvwGyBO
>>307
���߂�A�������̃\�[�X��URL�����O�����B
norm��7fp�Ə�����Ă�����m�����v�Z���Ƃ�����v���Ă���A
�㓡����normalize�Ƃ������̂ŃA���H����
���߂�A�������̃\�[�X��URL�����O�����B
norm��7fp�Ə�����Ă�����m�����v�Z���Ƃ�����v���Ă���A
�㓡����normalize�Ƃ������̂ŃA���H����
311 �F����������K�������F2005/07/08(��) 03:24:03 ID:Fmbw4Z06
���ړ��v�Z���Փ˔��聨�Փˉ����͕ʁX�̏����B
����������̂́A���ꂼ��̒i�K�B
���Ƃ���ƁA�Փ˔��聨�Փˉ������ċA�I�ɋN����ꍇ�́A�w�Ǖ��o���Ȃ��Ƃ������H
����������̂́A���ꂼ��̒i�K�B
���Ƃ���ƁA�Փ˔��聨�Փˉ������ċA�I�ɋN����ꍇ�́A�w�Ǖ��o���Ȃ��Ƃ������H
312 �Fsage�F2005/07/08(��) 03:26:24 ID:oUj4ykTi
>>310
NVIDIA�i�S���啶���Ȃ�ł��ˁO�O�G�j�̎��������Ă��܂������A
����ς�FP16 normalize���ď����Ă���܂��ˁB
��
http://www.4gamer.net/specials/3de/050706_gf7800/002/img/pixel_g70.jpg
Xenos��pixel shader interpolation calculations�ɂ��Ă͏��߂ĕ���
�P��Ő��̕s���ł��BFlops���Ƃ��łȂ��ĂR�R�����Ă�������������ł���
�E�E�B
NVIDIA�i�S���啶���Ȃ�ł��ˁO�O�G�j�̎��������Ă��܂������A
����ς�FP16 normalize���ď����Ă���܂��ˁB
��
http://www.4gamer.net/specials/3de/050706_gf7800/002/img/pixel_g70.jpg
{kind=link}
Xenos��pixel shader interpolation calculations�ɂ��Ă͏��߂ĕ���
�P��Ő��̕s���ł��BFlops���Ƃ��łȂ��ĂR�R�����Ă�������������ł���
�E�E�B
313 �F����������K�������F2005/07/08(��) 03:29:01 ID:oUj4ykTi
�������ԈႦ�܂���m(_ _)m
314 �F����������K�������F2005/07/08(��) 03:30:40 ID:76HaHgNc
>>303
����͗B�̓��ςł���ˁH
����Ȃ�Geforce3�ł�
�X���[�v�b�g1�ŏo���Ă����Ǝv���܂����B
(8bit�Œ菬���_�ł���)
G70�ł�16bit���������_���ςׂ̈�
��p���Z���݂��Ă����ł����ˁH
����͗B�̓��ςł���ˁH
����Ȃ�Geforce3�ł�
�X���[�v�b�g1�ŏo���Ă����Ǝv���܂����B
(8bit�Œ菬���_�ł���)
G70�ł�16bit���������_���ςׂ̈�
��p���Z���݂��Ă����ł����ˁH
315 �F����������K�������F2005/07/08(��) 03:31:27 ID:6pvwGyBO
>>312
������ς�FP16 normalize���ď����Ă���܂��ˁB
�{�����B���ꂾ������7fp�Ƃ����̂��ԈႢ�Ȃ낤���c
�ł����K�������Ȃ�Ă����܂ŏo���p�x�����Ȃ���
�łĂ����Ƃ��Ă�simd*2+alu��1clock�łł���������
������ς�FP16 normalize���ď����Ă���܂��ˁB
�{�����B���ꂾ������7fp�Ƃ����̂��ԈႢ�Ȃ낤���c
�ł����K�������Ȃ�Ă����܂ŏo���p�x�����Ȃ���
�łĂ����Ƃ��Ă�simd*2+alu��1clock�łł���������
316 �F����������K�������F2005/07/08(��) 03:34:32 ID:FG2ZW7mL
317 �F����������K�������F2005/07/08(��) 03:35:31 ID:6pvwGyBO
>>314
shader�v���O�����ł͓��ς̎g�p�p�x��TOP
����simd unit���P�ɂ͓��ψȊO�ɂ����������߂�p�ӂ���K�v������B
���ꂶ�Ⴀ���ς������P���j�b�g�ɂ���A���\/�_�C�ʐς̌���Ɍq����̂ł͂Ƃ����A
���f���Ǝv����
shader�v���O�����ł͓��ς̎g�p�p�x��TOP
����simd unit���P�ɂ͓��ψȊO�ɂ����������߂�p�ӂ���K�v������B
���ꂶ�Ⴀ���ς������P���j�b�g�ɂ���A���\/�_�C�ʐς̌���Ɍq����̂ł͂Ƃ����A
���f���Ǝv����
318 �F����������K�������F2005/07/08(��) 03:40:03 ID:Fmbw4Z06
319 �F����������K�������F2005/07/08(��) 03:40:56 ID:dPcTLbK7
���K���͎g���܂���ł́B�RDc�ł��g��������B
320 �F����������K�������F2005/07/08(��) 03:43:34 ID:6pvwGyBO
�g���܂�����āA����͉��Ɣ�r���Ă��ɂ��
���Ȃ��Ƃ����ς��g�����Ă��Ƃ͂Ȃ�
���Ȃ��Ƃ����ς��g�����Ă��Ƃ͂Ȃ�
321 �F����������K�������F2005/07/08(��) 03:46:56 ID:oUj4ykTi
>>315
���낻��Q�܂����A7fp����ł����A
������̐}������ƁAfp16 normalize unit��Shader Unit1�ɂ��������ĂȂ�
�����ł��ˁB�iShader Unit1�̓e�N�X�`���������p���ۂ��j
��
http://www.4gamer.net/specials/3de/050706_gf7800/002/img/pixel_g70.jpg
�ƂȂ�ƂQ�S��S�Ăɒ����Ă�Ƃ��Čv�Z���Ă���㓡���̋L���͈Ⴄ��
���ȁH�H�����ĕ�����ʁE�E
���낻��Q�܂����A7fp����ł����A
������̐}������ƁAfp16 normalize unit��Shader Unit1�ɂ��������ĂȂ�
�����ł��ˁB�iShader Unit1�̓e�N�X�`���������p���ۂ��j
��
http://www.4gamer.net/specials/3de/050706_gf7800/002/img/pixel_g70.jpg
�ƂȂ�ƂQ�S��S�Ăɒ����Ă�Ƃ��Čv�Z���Ă���㓡���̋L���͈Ⴄ��
���ȁH�H�����ĕ�����ʁE�E
322 �F����������K�������F2005/07/08(��) 03:49:59 ID:76HaHgNc
>>315
�t���������͗���1�N���b�N�͖��������B
SSE���ƃX���[�v�b�g4�݂����ł����B
�����6�{�����炢�̐�p���j�b�g�ɂ���
�X���[�v�b�g1�ɂ����肵�āB
�t���������͗���1�N���b�N�͖��������B
SSE���ƃX���[�v�b�g4�݂����ł����B
�����6�{�����炢�̐�p���j�b�g�ɂ���
�X���[�v�b�g1�ɂ����肵�āB
323 �F����������K�������F2005/07/08(��) 03:50:27 ID:6pvwGyBO
324 �F����������K�������F2005/07/08(��) 03:51:13 ID:oUj4ykTi
>>319
3Dc�Ƃ��Ŏg���Ƃ������ł���A�}�̏�ł̓e�N�X�`�������p�v���Z�b�T��
�ڑ�����Ă���Shader Unit1�ɓ��ڂ���Ă��闝�R�ɂȂ肻���ł��ˁB
3Dc�Ƃ��Ŏg���Ƃ������ł���A�}�̏�ł̓e�N�X�`�������p�v���Z�b�T��
�ڑ�����Ă���Shader Unit1�ɓ��ڂ���Ă��闝�R�ɂȂ肻���ł��ˁB
325 �F����������K�������F2005/07/08(��) 03:52:33 ID:MdtinKG0
GeForce 7800 GTX�̃p�C�v���C�����ׂ������Ă݂�i��ҁj
ttp://www.4gamer.net/specials/3de/050706_gf7800/002/050707_gf7800_02.shtml
ttp://www.4gamer.net/specials/3de/050706_gf7800/002/050707_gf7800_02.shtml
326 �F����������K�������F2005/07/08(��) 03:52:34 ID:FG2ZW7mL
>>318
������@���ƁA�ǂ��Ȃ�Ǝv���Ă��́H
���̏����T�v�������Ă݁B
�Ԃ����Ⴏ�A��������蕨�����Z�����ł���I�u�W�F�N�g����������ق���
���o�C���p�N�g���傫���킯�Łi������A�P�O�O�{�A�P�O�O�O�{�̐��E�j
������@���ƁA�ǂ��Ȃ�Ǝv���Ă��́H
���̏����T�v�������Ă݁B
�Ԃ����Ⴏ�A��������蕨�����Z�����ł���I�u�W�F�N�g����������ق���
���o�C���p�N�g���傫���킯�Łi������A�P�O�O�{�A�P�O�O�O�{�̐��E�j
327 �F����������K�������F2005/07/08(��) 03:53:50 ID:oUj4ykTi
328 �F����������K�������F2005/07/08(��) 04:12:11 ID:xFhS6Jf5
�F�l���͂悤�������܂�
329 �F����������K�������F2005/07/08(��) 04:21:51 ID:ayQGDqjj
>>306
�����I�ɂ͂����ł���
�P�P�������ĉ��Z���ʂ��o���Ȃ���Αʖ�
���Z����o���Ă������͕��o���Ȃ�
>>316
�Ȃ�Cell�͕������Z�̕������`���Ęb����
�悭�����p����p�ȃr�����[�h�������v���o���ď����Ă݂�
���̑O�̃f�B�[�v�C���p�N�g���Đ�����ȁA�v�Z�ʂ�F���̔ޕ���
�Փ˂���������ȁA�Q����N���ꖳ�����E�E�ǂ����悤�O�����邢
�����I�ɂ͂����ł���
�P�P�������ĉ��Z���ʂ��o���Ȃ���Αʖ�
���Z����o���Ă������͕��o���Ȃ�
>>316
�Ȃ�Cell�͕������Z�̕������`���Ęb����
�悭�����p����p�ȃr�����[�h�������v���o���ď����Ă݂�
���̑O�̃f�B�[�v�C���p�N�g���Đ�����ȁA�v�Z�ʂ�F���̔ޕ���
�Փ˂���������ȁA�Q����N���ꖳ�����E�E�ǂ����悤�O�����邢
330 �F����������K�������F2005/07/08(��) 04:39:52 ID:FG2ZW7mL
>>329
�����Z����o���Ă������͕��o���Ȃ�
���Z�̕��́A���Z�����ƌ����Ă܂���B
���ƁA�R�̏����������K�v�͍ŏ�����Ȃ��ł��B
�i������SPE�������ɓ��������邱�Ƃɂ͕ς��Ȃ��̂Łj
���悭�����p����p�ȃr�����[�h�������v���o���ď����Ă݂�
�Q�̖��͋��ȏ��ɂ��ڂ��Ă܂���
���Փ˔��聨�Փˉ������ċA�I�ɋN����ꍇ��
����͑��̖��ɂ����W������
�悭����b����Ȃ��ł��B
�����Z����o���Ă������͕��o���Ȃ�
���Z�̕��́A���Z�����ƌ����Ă܂���B
���ƁA�R�̏����������K�v�͍ŏ�����Ȃ��ł��B
�i������SPE�������ɓ��������邱�Ƃɂ͕ς��Ȃ��̂Łj
���悭�����p����p�ȃr�����[�h�������v���o���ď����Ă݂�
�Q�̖��͋��ȏ��ɂ��ڂ��Ă܂���
���Փ˔��聨�Փˉ������ċA�I�ɋN����ꍇ��
����͑��̖��ɂ����W������
�悭����b����Ȃ��ł��B
331 �F����������K�������F2005/07/08(��) 05:11:30 ID:ayQGDqjj
>>330
�����ƁA�R�̏����������K�v�͍ŏ�����Ȃ��ł��B
����3�̏���������ĈӖ�����Ȃ��āE�E
���݂̏������ʂ����̋��������߂�킯��
���Q�̖��͋��ȏ��ɂ��ڂ��Ă܂���
�ȒP�ȗ�Ńr�����[�h�o��������
9�{�[������Ȃ���4096�{�[���Ń��A���^�C���������Z���ĉ�ʂ�
�������Ƃ��i�Ԃł��j
�����ƁA�R�̏����������K�v�͍ŏ�����Ȃ��ł��B
����3�̏���������ĈӖ�����Ȃ��āE�E
���݂̏������ʂ����̋��������߂�킯��
���Q�̖��͋��ȏ��ɂ��ڂ��Ă܂���
�ȒP�ȗ�Ńr�����[�h�o��������
9�{�[������Ȃ���4096�{�[���Ń��A���^�C���������Z���ĉ�ʂ�
�������Ƃ��i�Ԃł��j
332 �F����������K�������F2005/07/08(��) 05:19:28 ID:ayQGDqjj
333 �F����������K�������F2005/07/08(��) 05:19:41 ID:QqHAO7+l
1�t���[���̊Ԃɂ���Ȃɕ��G�ɂԂ��镨�Ȃ́H
���̃V�~�����[�V�����Ƃ��̂悤�ȗ��x�ł��Ȃ��āA
���F�r�����[�h���̂ł���H
�t���[���P�ʂőʖڂȂ�A>>316�ɂ���悤�ɍׂ����ϕ����鎖�őΏ��ł��邾�낤���B
���̃V�~�����[�V�����Ƃ��̂悤�ȗ��x�ł��Ȃ��āA
���F�r�����[�h���̂ł���H
�t���[���P�ʂőʖڂȂ�A>>316�ɂ���悤�ɍׂ����ϕ����鎖�őΏ��ł��邾�낤���B
334 �F����������K�������F2005/07/08(��) 05:32:39 ID:wYMvu35Q
�ׂ����ϕ����ĂȂH
335 �F����������K�������F2005/07/08(��) 05:43:35 ID:FG2ZW7mL
>>334
�ϕ�dt������������B
�ϕ�dt������������B
336 �F����������K�������F2005/07/08(��) 06:40:51 ID:wYMvu35Q
����T�C�N�����ׂ���������Ă��Ƃ���
337 �F����������K�������F2005/07/08(��) 06:45:30 ID:wYMvu35Q
���������Ԃ��ƂɈړ�������������Ă�������ϕ����Č����̂�
338 �F����������K�������F2005/07/08(��) 08:30:17 ID:AwCMTawc
RSX�����[�N�d����ŋ�J���Ă���݂����B
110nm����90nm�ɃV�������N���������ł͑ʖڂ��������悤�B
110nm450MHz�Ŕ�����?
110nm����90nm�ɃV�������N���������ł͑ʖڂ��������悤�B
110nm450MHz�Ŕ�����?
339 �F����������K�������F2005/07/08(��) 08:32:17 ID:7mf92KjL
���[�N�d����肻�̐��������ȂɊȒP�Ƀ��[�N�o����Ǝv���Ă邨�O�̂�����
340 �F����������K�������F2005/07/08(��) 08:47:01 ID:8lOPOEnI
����������RSX���ĂȂ�ł���Ȏ��Ԃ������Ă�?
�v��G70����B
�v��G70����B
341 �F����������K�������F2005/07/08(��) 09:34:19 ID:oQ6uEJ6P
�I�u�W�F�N�g�������Ƃ��̏Փˏ������I�u�W�F�N�g���Ƃɂ���Ă���A���Z���ԂŌ��ʂ������B
���ʂ�>306�̂悤�ɏ������ĕ�����B
���x�グ��Ƃ��͊F�����Ă���ʂ肄��������������i�P�t���[���ɐ�������j
���ʂ�>306�̂悤�ɏ������ĕ�����B
���x�グ��Ƃ��͊F�����Ă���ʂ肄��������������i�P�t���[���ɐ�������j
342 �F����������K�������F2005/07/08(��) 09:48:05 ID:LumHw70N
PC�p��GPU��CPU���璼��VRAM��ǂݏ����o����v�ɂȂ��Ă��Ȃ�����ˁAG70���̂܂܂Ƃ����킯�ɂ͂����Ȃ��ł���B
�P��FloxIO�ƌq�������Ȃ�Ƃ�����NUMA�Ƃ����̂��l�b�N�ɂȂ��Ă���̂ł�?
���Ƃ�110nm�̎��_��90nm�ɃV�������N���邱�Ƃ��l���Đv����Ă����̂��Ƃ����̂��l�����Ȃ����Ȃ��B
�P��FloxIO�ƌq�������Ȃ�Ƃ�����NUMA�Ƃ����̂��l�b�N�ɂȂ��Ă���̂ł�?
���Ƃ�110nm�̎��_��90nm�ɃV�������N���邱�Ƃ��l���Đv����Ă����̂��Ƃ����̂��l�����Ȃ����Ȃ��B
343 �F����������K�������F2005/07/08(��) 10:20:23 ID:YZU3prp2
G70�ƃA�[�L�e�B�N�`�������L���A�v�͕ʁA�Ƃ����b�ł́B
�܂�110��90nm�V�������N�ł͂Ȃ�90nm�ŐV�K�̐v�B
FlexIO�ɉ����ďȓd�͂�����Ă��邩������Ȃ��B
�܂�110��90nm�V�������N�ł͂Ȃ�90nm�ŐV�K�̐v�B
FlexIO�ɉ����ďȓd�͂�����Ă��邩������Ȃ��B
344 �F����������K�������F2005/07/08(��) 10:48:52 ID:YZU3prp2
GDDR3��ATI�哱�̋K�i�ł��邱�Ƃ��l���ƁA
�E nVidia��VRAM�Ƃ���XDR2���̗p
�E 65nm�v���Z�X��RSX��XDR2�̗p
�E Cell�ARSX�Ƃ��Ƀ�������XDR2��1Gbit�i 2���ɕύX
�Ƃ����R�X�g�_�E���̋؏������肤�邩�B������Ƒ�ς����邩�B
�E nVidia��VRAM�Ƃ���XDR2���̗p
�E 65nm�v���Z�X��RSX��XDR2�̗p
�E Cell�ARSX�Ƃ��Ƀ�������XDR2��1Gbit�i 2���ɕύX
�Ƃ����R�X�g�_�E���̋؏������肤�邩�B������Ƒ�ς����邩�B
345 �F����������K�������F2005/07/08(��) 10:53:23 ID:kW9pV1KT
�v���Z�X�ύX�����邯�ǃ\���ɉ�����redwood�Ή��̂�������Ȃ��́H
���܂���PCI-E�ڑ��Ȃ�ł���H
���܂���PCI-E�ڑ��Ȃ�ł���H
346 �F����������K�������F2005/07/08(��) 12:20:42 ID:tpbfBbIV
>>344
�[���A���͂���ǂ�ł���AnVIDIA��G70��XDR-DRAM�Ɉڍs����ƐM���Ă��B
ttp://pc.watch.impress.co.jp/docs/2004/0716/kaigai103.htm
�[���A���͂���ǂ�ł���AnVIDIA��G70��XDR-DRAM�Ɉڍs����ƐM���Ă��B
ttp://pc.watch.impress.co.jp/docs/2004/0716/kaigai103.htm
347 �F����������K�������F2005/07/08(��) 12:40:12 ID:bVOEB1kx
>>346
nVIDIA�ɂ��Ă��A�܂�XDR�̃m�E�n�E���~�ς���ĂȂ�����A�܂���RSX��FlexIO�iSLI�����j��
Cell�Ƃ̘A�g��XIO�̎����f�[�^���Q�l�ɂ���G80���炢����XDR2�ɑΉ������Ȃ��H
nVIDIA�ɂ��Ă��A�܂�XDR�̃m�E�n�E���~�ς���ĂȂ�����A�܂���RSX��FlexIO�iSLI�����j��
Cell�Ƃ̘A�g��XIO�̎����f�[�^���Q�l�ɂ���G80���炢����XDR2�ɑΉ������Ȃ��H
348 �F����������K�������F2005/07/08(��) 13:26:35 ID:YZU3prp2
XDR(2)�ւ̈ڍs���Z�p�I�ɐ������Ȃ���AnVidia�����Ă��낤���ǂˁB
������GDDR�ł́A�O���j�������e�B�Ƒш摬�x�̖�肪�ǂ̒��x������̂���
��������?
������GDDR�ł́A�O���j�������e�B�Ƒш摬�x�̖�肪�ǂ̒��x������̂���
��������?
349 �F����������K�������F2005/07/08(��) 14:05:41 ID:m4sgE6Un
XDR2�̉��i����ł��傤�ȁB�}�C�N���X���b�f�B���O�Ƃ��ǂ̂��炢Rambun�ɕ������ɂȂ�̂�
�킩��B�������[�͍����\���A�ʎY�ቿ�i�����������\�����߂��邵�B
�킩��B�������[�͍����\���A�ʎY�ቿ�i�����������\�����߂��邵�B
350 �F����������K�������F2005/07/08(��) 14:39:15 ID:sT69XnRM
351 �F����������K�������F2005/07/08(��) 17:13:18 ID:+eGeCTC9
GDDR�n�́A���낻�듙���z�����L�c���Ȃ��Ă��ĂȂ����H
�ш�Ɨe�ʂ��l�����玟����GPU��XDR�n�����I�����͖����������Ǝv�����ǁB
����GDDR�n�ł��̕ӂ̐V�Z�p�Ƃ������������H
�ш�Ɨe�ʂ��l�����玟����GPU��XDR�n�����I�����͖����������Ǝv�����ǁB
����GDDR�n�ł��̕ӂ̐V�Z�p�Ƃ������������H
352 �F����������K�������F2005/07/08(��) 17:14:22 ID:bmGa59tX
>>350
>Rambus�̗\���ł́AGDDR�̓�����g����8GHz����̂�2015�N�Ɨ\������Ă��邪�A
>XDR2�ł�2007�N�ŁA2015�N�ɂ͂�荂���Ȏ��g���������ł���
>Rambus�̗\���ł́AGDDR�̓�����g����8GHz����̂�2015�N�Ɨ\������Ă��邪�A
>XDR2�ł�2007�N�ŁA2015�N�ɂ͂�荂���Ȏ��g���������ł���
353 �F����������K�������F2005/07/08(��) 17:19:35 ID:m4sgE6Un
�ႦXDR2�̗p���Đ��\�オ���Ă����i���オ��A�ł̓n�C�G���h�ȊO�Ő킦�Ȃ��B
XDR2�Ɉڍs����ɂ��Ă��`�L�����[�X�ɂȂ邾�낤�ˁB
XDR2�Ɉڍs����ɂ��Ă��`�L�����[�X�ɂȂ邾�낤�ˁB
354 �F����������K�������F2005/07/08(��) 18:11:48 ID:YZU3prp2
XDR2�̃��C�Z���X���͂���Ȃɍ����̂�?
�������́u�����v�͂����Ă��u���ʂłȂ����獂���v�ŁA
PS3���炢�̃{�����[��������ƁA����͂Ȃ�Ƃ��Ȃ�炵�����B
�������́u�����v�͂����Ă��u���ʂłȂ����獂���v�ŁA
PS3���炢�̃{�����[��������ƁA����͂Ȃ�Ƃ��Ȃ�炵�����B
355 �F����������K�������F2005/07/08(��) 18:15:26 ID:NkKXUMyq
356 �F����������K�������F2005/07/08(��) 18:20:33 ID:m4sgE6Un
�������ш�͏d�v�����ŗD��ł͂Ȃ����Ƃ�RD��PC�̃��C���X�g���[���ɂȂ�Ȃ������������
�킩��B���i�������Ȃ遁��ʐ��Y�Ȃ��AXDR2���ǂ̒��x�̉��i���i�ɂȂ邩�͖��m���B
�킩��B���i�������Ȃ遁��ʐ��Y�Ȃ��AXDR2���ǂ̒��x�̉��i���i�ɂȂ邩�͖��m���B
357 �F����������K�������F2005/07/08(��) 18:36:31 ID:QqHAO7+l
RDRAM�����s��Ȃ������̂́AIntel�̊J�����s����ԑ傫���悤�ȁB
�J����x��������������ˁB�ł��AXDR�ł͂��ꂪ�t�]���鎖�ɂȂ�ł���B
XDR�̕����J�����y������A��͒l�i���ǂ�ʂ̕��ɂȂ邩���悩�ƁB
�J����x��������������ˁB�ł��AXDR�ł͂��ꂪ�t�]���鎖�ɂȂ�ł���B
XDR�̕����J�����y������A��͒l�i���ǂ�ʂ̕��ɂȂ邩���悩�ƁB
358 �F����������K�������F2005/07/08(��) 18:48:18 ID:ZXSxBB4y
RDRAM�Ɋւ��Ă͓����Ƃ��Ă͎��s���\��DDR�Ɣ�r���ĕʒi�����Ȃ�
�l�i�͔�тʂ��č��������̂Ŏs��Ɏ����Ȃ������̂ł́B
�l�i�͔�тʂ��č��������̂Ŏs��Ɏ����Ȃ������̂ł́B
359 �F����������K�������F2005/07/08(��) 19:01:21 ID:qkkknA1e
RDRAM�͍����ADDR�͈����ADDR�ł��{�g���l�b�N�ɂ͂��܂�Ȃ�Ȃ��������A�C���e����RDRAM�ŋ��s�B
�����ق��������Ƃ����s��ɕ������Ƃ������ꂾ���������B
�����ق��������Ƃ����s��ɕ������Ƃ������ꂾ���������B
360 �F����������K�������F2005/07/08(��) 19:13:19 ID:UoLMrq7n
�����RDRAM�͍ŏ��̍���ϻް���������̂��Ȃ�
Intel�Ō��������������̂��ꂮ�炢����ˁH
Intel�Ō��������������̂��ꂮ�炢����ˁH
361 �F����������K�������F2005/07/08(��) 20:35:51 ID:gTsE6b7U
�݂�ȁA�T�����������o�X�ɗ]�v�ȋ��������Ȃ�������B
362 �F����������K�������F2005/07/08(��) 22:58:44 ID:k54YQCmc
�Q�[���v���O�����̕����āA�ǂ���������ɂȂ�ˁB
�~�h���E�F�A��}���`�X���b�h�����ꂽ���C�u�������g���Ƃ������B���Ȃ��̂łȂ��A�o����A�Z���u�����x���܂ō~��Č����Ă݂������ǁB
���Ȃ݂Ɍ����ړI�Ȃ̂ŁA���p�I�łȂ��Ƃ������͖̂����̕����ŁB
�~�h���E�F�A��}���`�X���b�h�����ꂽ���C�u�������g���Ƃ������B���Ȃ��̂łȂ��A�o����A�Z���u�����x���܂ō~��Č����Ă݂������ǁB
���Ȃ݂Ɍ����ړI�Ȃ̂ŁA���p�I�łȂ��Ƃ������͖̂����̕����ŁB
363 �F����������K�������F2005/07/08(��) 23:07:24 ID:pqIlqnLw
�Ȃ��̕Ò���́H
364 �F����������K�������F2005/07/08(��) 23:08:19 ID:mOLSu1+0
���ꂩ�n�[�h�̂��ƂƂ�
�v���O�����̂��₷����r�Ƃ�
�F�ɕ�����悤�Ƀ`���R�ɗႦ�Đ������Ă���
�v���O�����̂��₷����r�Ƃ�
�F�ɕ�����悤�Ƀ`���R�ɗႦ�Đ������Ă���
365 �F����������K�������F2005/07/08(��) 23:10:04 ID:NkKXUMyq
>>364
��Ȃ���������Ȃ��̂ɂǂ�Șb����ƁH
��Ȃ���������Ȃ��̂ɂǂ�Șb����ƁH
366 �F����������K�������F2005/07/08(��) 23:10:14 ID:HAzl1q5q
����Ȃ�A�R���g���[���[����̓��͂���ɂȂ邩�ȁB
�����1�v���C���[�̏ꍇ�͕��o���Ȃ��A�����̏ꍇ���܂��A�V���O���X���b�h����LS�Ƀ��[�h�����v���O����������SPE���ʼnAXDR�̓A�N�Z�X���Ȃ��B
�����1�v���C���[�̏ꍇ�͕��o���Ȃ��A�����̏ꍇ���܂��A�V���O���X���b�h����LS�Ƀ��[�h�����v���O����������SPE���ʼnAXDR�̓A�N�Z�X���Ȃ��B
367 �F����������K�������F2005/07/08(��) 23:30:32 ID:/bCKKRXs
>>364
360��GPU�͂��O�̃`���R�݂����Ȃ��B�a�V�ȍ\��������x���g���Ė����̂Ŗ������m��
360��GPU�͂��O�̃`���R�݂����Ȃ��B�a�V�ȍ\��������x���g���Ė����̂Ŗ������m��
368 �F����������K�������F2005/07/08(��) 23:31:03 ID:gE8CBjDU
���͂̌�́A�s�����[�`�����B
�������畨�����Z�Ƃ������Ă����ȁB
�������畨�����Z�Ƃ������Ă����ȁB
369 �F����������K�������F2005/07/08(��) 23:32:33 ID:bmGa59tX
�a�V�ȍ\���̂������Ăǂ�Ȃ̂��낤�B
370 �F����������K�������F2005/07/08(��) 23:33:20 ID:r2f4QE2F
>>369
�J���g����s
�J���g����s
371 �F����������K�������F2005/07/08(��) 23:34:43 ID:kbte9H3q
I/O����ǂݍ���Ō��ʂ��������Ɋi�[���邾���̏�����SPE�Ɋ��蓖�Ă���
�I�[�o�[�w�b�h�̕����������낤
���Ԃ�PPE�ŃT�N���ƏI��点��Ǝv���
�I�[�o�[�w�b�h�̕����������낤
���Ԃ�PPE�ŃT�N���ƏI��点��Ǝv���
372 �F����������K�������F2005/07/08(��) 23:39:05 ID:XduoBLD7
�����蔻����W�̔z��g�ނ��ǃf�[�^�[�ʂ��猩��LS�ɂ͓��肫��Ȃ���ȁB
����ς�XDR�ǂ݂ɂ����̂�?
����ς�XDR�ǂ݂ɂ����̂�?
373 �F����������K�������F2005/07/08(��) 23:49:00 ID:76HaHgNc
>>362
�X�b�h���̗��x�͊����x���ł���B
>>372
LS�Ɏ��܂�悤�ׂ����ǂ�ł��������Ȃ���Ȃ��H
PenIII��32�o�C�g���Ƃɓǂݍ��ރv���t�F�`�݂����ȃC���[�W�ŁB
�X�b�h���̗��x�͊����x���ł���B
>>372
LS�Ɏ��܂�悤�ׂ����ǂ�ł��������Ȃ���Ȃ��H
PenIII��32�o�C�g���Ƃɓǂݍ��ރv���t�F�`�݂����ȃC���[�W�ŁB
374 �F����������K�������F2005/07/08(��) 23:59:34 ID:kbte9H3q
������L1�L���b�V���ƈ���āALS��256KB���邩��_�u���o�b�t�@�ɂ��Ă�
100KB���炢�͂͂����邾�낤
��������W����Ɏg�������̃v���O�����Ȃ�10K�ɂ��Ȃ�Ȃ����낤��
100KB���炢�͂͂����邾�낤
��������W����Ɏg�������̃v���O�����Ȃ�10K�ɂ��Ȃ�Ȃ����낤��
375 �F����������K�������F2005/07/09(�y) 00:29:29 ID:PyKK4/4e
�C�V����MS�͖{�C���[�h
SONY�͖����鉳�����[�h
��������HGK�����
SONY�͖����鉳�����[�h
��������HGK�����
376 �F����������K�������F2005/07/09(�y) 00:32:14 ID:lOPdqeVv
vs�X���łǂ����B
377 �F����������K�������F2005/07/09(�y) 00:40:24 ID:lw6jCr59
G70���ł́A���ꂼ��قȂ�N���b�N�X�s�[�h�œ��삷�镡���̕���
http://www.bit-tech.net/news/2005/07/07/g70_clock_speed/
http://www.bit-tech.net/news/2005/07/07/g70_clock_speed/
378 �F����������K�������F2005/07/09(�y) 00:47:28 ID:UGeVkpH1
>>377
���ꂩ�������˂������܂� orz
���ꂩ�������˂������܂� orz
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@,,...-�@''''''' ''' �[---
�@�@�@�@�@�@�@�@�@�@�@��ٷ�ف@�@�@�@�@�@�@�@�@ _,,,,.../
�@�@�@�c�@�@�@�@�@�@�@�@�@�c�@ �c�@,,,......-..:::':'::"�@ _�m
�@�@�@�@�O�O�O�O�O�O�G�G�G===�T:�A:,:,:.:- ' "
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �@�i
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�_�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ;
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�R �A�@�@�@�@�@�@�@�@_,,,,.......Ƀm�A,,,_
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ " '''---�@''''''"
380 �F����������K�������F2005/07/09(�y) 01:06:41 ID:6RKdsQMI
�ȓd�͂Ɗe���̏����X�s�[�h�o�����X���Ƃ邽�߂ɁA���ʂɂ���ăN���b�N�X�s�[�h��
�Ⴄ�����A�N���b�N�\������\�t�g���Ή��o���ĂȂ��̂ŁA�ςȕ\���ɂȂ�悤��
�����̂Ƃ��Ă͕ʂɒ�����������Ȃ��ACPU�����ĕ����I�ɂ͔{���������肷�邵
�Ⴄ�����A�N���b�N�\������\�t�g���Ή��o���ĂȂ��̂ŁA�ςȕ\���ɂȂ�悤��
�����̂Ƃ��Ă͕ʂɒ�����������Ȃ��ACPU�����ĕ����I�ɂ͔{���������肷�邵
381 �F����������K�������F2005/07/09(�y) 01:27:06 ID:fYeWimpv
382 �F����������K�������F2005/07/09(�y) 02:25:20 ID:tQAKG4dE
�y���{�����[�V�����@�n�[�h���i���[�N�j�z
CPU�F4�R�A �i�e2.5GHz�j�ꎟ�L���b�V����128KB�A�L���b�V����512KB
GPU�FRN520�~2�R�A�i16MB���ځj
��F512MB���L
PPU�F�����Эڰ��ݐ�p����۾���i32MB�j
�E�ł��v���I�ȕ����́u�����̃I�����C���V�X�e���v
�E���\�I�ɂ�Xbox360���y���ɏ�
�E720p(�v���O���b�V�u)��1080i(�C���^�[���[�X)HDTV�K�i�ɑΉ�
�EE3�ł̃R���g���[���[�̔��\�͖���
�E�R���g���[���[���������Ƃ�����
�EDS���i�������u�����F���@�\�v
�E�����ɂ��u�c�r�Ƃ̘A���v
ttp://www.unika.com.cn/article/article.php/2572
�I������E�E�E�@���S�ɏՂ�˂��ꂽ�ȁE�E�E
CPU�F4�R�A �i�e2.5GHz�j�ꎟ�L���b�V����128KB�A�L���b�V����512KB
GPU�FRN520�~2�R�A�i16MB���ځj
��F512MB���L
PPU�F�����Эڰ��ݐ�p����۾���i32MB�j
�E�ł��v���I�ȕ����́u�����̃I�����C���V�X�e���v
�E���\�I�ɂ�Xbox360���y���ɏ�
�E720p(�v���O���b�V�u)��1080i(�C���^�[���[�X)HDTV�K�i�ɑΉ�
�EE3�ł̃R���g���[���[�̔��\�͖���
�E�R���g���[���[���������Ƃ�����
�EDS���i�������u�����F���@�\�v
�E�����ɂ��u�c�r�Ƃ̘A���v
ttp://www.unika.com.cn/article/article.php/2572
�I������E�E�E�@���S�ɏՂ�˂��ꂽ�ȁE�E�E
383 �F����������K�������F2005/07/09(�y) 03:09:57 ID:V779SQ7l
>>382
�����̃R���Z�v�g���f��
ttp://www.1up.com/media?id=1897381&type=lg
�`�b�v��h���C�u�ނ̎����܂��Đ��@�ƔM������������ŐV�v���g�^�C�v
ttp://www.clubic.com/photo/00101697.jpg
������LED�̕����őo���̑傫���̈Ⴂ����r�ł���ȁB
�����̃R���Z�v�g���f��
ttp://www.1up.com/media?id=1897381&type=lg
�`�b�v��h���C�u�ނ̎����܂��Đ��@�ƔM������������ŐV�v���g�^�C�v
ttp://www.clubic.com/photo/00101697.jpg
{kind=link}
������LED�̕����őo���̑傫���̈Ⴂ����r�ł���ȁB
384 �F����������K�������F2005/07/09(�y) 03:12:54 ID:KccXX2ya
�C���`�L���[�N�ɕK������o���������Z�`�b�v���ĂȂ���������́H
�В�������Ȃ��Ƃ���킹���Ƃ����B
�В�������Ȃ��Ƃ���킹���Ƃ����B
385 �F����������K�������F2005/07/09(�y) 03:19:19 ID:arJxY8Vj
>>384
��N���b�N�ł����\�I�ɑR�ł������ȉ\���͂��ꂾ��������B
�ł��A�������Z�`�b�v���ĂRD�Q�[������鎞�ɂ����p����������
�QD�Q�[���₻�̑��̗p�r�ł͑S���g���Ȃ��Ӓ��`�b�v�B
Cell��SPE�┠��GPU�̓����V�F�[�_�̂悤�ȏ_��͖����B
��N���b�N�ł����\�I�ɑR�ł������ȉ\���͂��ꂾ��������B
�ł��A�������Z�`�b�v���ĂRD�Q�[������鎞�ɂ����p����������
�QD�Q�[���₻�̑��̗p�r�ł͑S���g���Ȃ��Ӓ��`�b�v�B
Cell��SPE�┠��GPU�̓����V�F�[�_�̂悤�ȏ_��͖����B
386 �F����������K�������F2005/07/09(�y) 03:24:17 ID:ZPqhZpRw
�Ƃ������������Z�`�b�v���ڂ���R�X�g���l������A
���N���b�N��CPU��GPU���ڂ�������R�X�g�p�t�H�[�}���X���ǂ��B
�R�X�g�d���H���̔C�V�����A����Ȗ��ʂɃR�X�g�̂����镨���ڂ��鎖�͖����B
���N���b�N��CPU��GPU���ڂ�������R�X�g�p�t�H�[�}���X���ǂ��B
�R�X�g�d���H���̔C�V�����A����Ȗ��ʂɃR�X�g�̂����镨���ڂ��鎖�͖����B
387 �F����������K�������F2005/07/09(�y) 03:27:09 ID:bhrObCc5
�C�V�����������Z��
�Q�[�����ʔ����Ȃ�ƈ�Ԏv���Ė����ł���
�Q�[�����ʔ����Ȃ�ƈ�Ԏv���Ė����ł���
388 �F����������K�������F2005/07/09(�y) 03:29:50 ID:arJxY8Vj
>>383
���`�b�v��h���C�u�ނ̎����܂��Đ��@�ƔM������������ŐV�v���g�^�C�v
��ttp://www.clubic.com/photo/00101697.jpg
���@�̃��{�̓t�@�����X�Ȃ�{�C�ł��̉摜�݂����ȃS�c��➑̂ɂȂ邩���ȁB
���̃��b�N�A�b�v��I/O�|�[�g�̈ʒu�Ƃ��ׂ����Ƃ���Ő��Ȃ�����ĂȂ��悤��
�v���邩��A�啝�ȕύX�͖����ɂ����B
���`�b�v��h���C�u�ނ̎����܂��Đ��@�ƔM������������ŐV�v���g�^�C�v
��ttp://www.clubic.com/photo/00101697.jpg
���@�̃��{�̓t�@�����X�Ȃ�{�C�ł��̉摜�݂����ȃS�c��➑̂ɂȂ邩���ȁB
���̃��b�N�A�b�v��I/O�|�[�g�̈ʒu�Ƃ��ׂ����Ƃ���Ő��Ȃ�����ĂȂ��悤��
�v���邩��A�啝�ȕύX�͖����ɂ����B
389 �F����������K�������F2005/07/09(�y) 03:37:49 ID:4a2cobSq
2D�Ŏg����Ƃ������͖����Ǝv����
�I�u�W�F�N�g�ꕽ�ʏ�ɑ�����������������H
�I�u�W�F�N�g�ꕽ�ʏ�ɑ�����������������H
390 �F����������K�������F2005/07/09(�y) 03:43:40 ID:arJxY8Vj
391 �F����������K�������F2005/07/09(�y) 03:46:03 ID:4a2cobSq
> �ł��A�������Z�`�b�v���ĂRD�Q�[������鎞�ɂ����p����������
> �QD�Q�[���₻�̑��̗p�r�ł͑S���g���Ȃ��Ӓ��`�b�v�B
�R���ɑ��郌�X������ėp�`�b�v�̂������Ƃ��͂���m���
> �QD�Q�[���₻�̑��̗p�r�ł͑S���g���Ȃ��Ӓ��`�b�v�B
�R���ɑ��郌�X������ėp�`�b�v�̂������Ƃ��͂���m���
392 �F����������K�������F2005/07/09(�y) 03:47:11 ID:arJxY8Vj
>>391
�u�g���Ȃ��v����Ȃ��āu�g�����ɂȂ�Ȃ��v�̂ق����ǂ��������ȁH
�u�g���Ȃ��v����Ȃ��āu�g�����ɂȂ�Ȃ��v�̂ق����ǂ��������ȁH
393 �F����������K�������F2005/07/09(�y) 03:50:33 ID:fYeWimpv
394 �F����������K�������F2005/07/09(�y) 03:52:51 ID:gu14F09u
��{�I�ɃQ�[���L���[�u�̓��P�Ȃ낤����
1T-SRAM�͂ǂꂭ�炢��e�ʉ����\�Ȃ낤
1T-SRAM�͂ǂꂭ�炢��e�ʉ����\�Ȃ낤
395 �F����������K�������F2005/07/09(�y) 03:58:34 ID:4a2cobSq
������768Mbit�`�b�v�~�Q�Ƃ���
396 �F����������K�������F2005/07/09(�y) 05:06:22 ID:Q4vD/CpZ
397 �F����������K�������F2005/07/09(�y) 06:22:39 ID:FZMMPzco
>>387
�����I�Ȗʔ�����Njy�����ŁA�������Z�͔��ɗL���Ȏ�i�B
�ނ���O���t�B�b�N�̕ς��ɔC�V����������ň�ԗ͂����ꂻ���ȕ��삾�Ǝv���Ă����B
���������Ӗ��ł͐��\���d�����Ȃ��ƌ����郌�{�͈ӊO�B
�����I�Ȗʔ�����Njy�����ŁA�������Z�͔��ɗL���Ȏ�i�B
�ނ���O���t�B�b�N�̕ς��ɔC�V����������ň�ԗ͂����ꂻ���ȕ��삾�Ǝv���Ă����B
���������Ӗ��ł͐��\���d�����Ȃ��ƌ����郌�{�͈ӊO�B
398 �F����������K�������F2005/07/09(�y) 07:09:59 ID:4a2cobSq
�\����PPC970MP��1.6GHz���������H
���ꂾ���ł������̃m�[�p�\���R�{������
VMX���ӂ��ڂ��Ă邵
���Ђ������Ɛ�������R���ŏ\���Ȃ�ĂƂĂ������Ȃ�����
������ɂ͈Ⴂ�Ȃ���Ȃ�
���ꂾ���ł������̃m�[�p�\���R�{������
VMX���ӂ��ڂ��Ă邵
���Ђ������Ɛ�������R���ŏ\���Ȃ�ĂƂĂ������Ȃ�����
������ɂ͈Ⴂ�Ȃ���Ȃ�
399 �F����������K�������F2005/07/09(�y) 07:26:41 ID:lw6jCr59
�����_�ŏo�Ă郌���H�̐��\�ɂ��Ă̏��͗�O�Ȃ��f�}�B�Ȃ��
�����ɂ��̃X���ɌJ��Ԃ��o�Ă���낤��
�����ɂ��̃X���ɌJ��Ԃ��o�Ă���낤��
400 �F����������K�������F2005/07/09(�y) 07:38:58 ID:emFn94wI
>>399
����Ȃ��Ă��݂�Ȃ킩���Ă܂�����E�E�E�B
����Ȃ��Ă��݂�Ȃ킩���Ă܂�����E�E�E�B
401 �F����������K�������F2005/07/09(�y) 08:39:31 ID:w89pmAQu
�������Z�Ŗʔ����Q�[���E�E�E
FANFUN���炢�����L���ɖ����Ȃ�
FANFUN���炢�����L���ɖ����Ȃ�
402 �F����������K�������F2005/07/09(�y) 09:02:05 ID:T8/vLQHw
403 �F����������K�������F2005/07/09(�y) 09:17:57 ID:gc9KSmve
���{�����[�V�����̃X�y�b�N
http://www.gamesindustry.biz/content_page.php?aid=9485
�E1.8Ghz IBM PowerPC G5�v���Z�b�T��2�iGC��IBM PowerPC�uGEKKO�v485MHz�j
�E600Mhz ATI�O���t�B�b�N�`�b�v�iGC�́uFlipper�v162MHz�j
�E7.1�f�W�^���T�E���h�`�b�v�Z�b�g
�E128MB 1T SRAM�iGC��1T SRAM�uSplash�v24M + �uA�������v16M�j
�E12MB �O���t�B�b�N�`�b�v��RAM
�E�p�i�\�j�b�N�v��6GB DVD�T�C�Y�f�B�X�N
http://www.gamesindustry.biz/content_page.php?aid=9485
�E1.8Ghz IBM PowerPC G5�v���Z�b�T��2�iGC��IBM PowerPC�uGEKKO�v485MHz�j
�E600Mhz ATI�O���t�B�b�N�`�b�v�iGC�́uFlipper�v162MHz�j
�E7.1�f�W�^���T�E���h�`�b�v�Z�b�g
�E128MB 1T SRAM�iGC��1T SRAM�uSplash�v24M + �uA�������v16M�j
�E12MB �O���t�B�b�N�`�b�v��RAM
�E�p�i�\�j�b�N�v��6GB DVD�T�C�Y�f�B�X�N
404 �F����������K�������F2005/07/09(�y) 09:19:54 ID:xv7Mqf2i
>>400
�ϑz�Ȃ̂ɍ���o�Ă鐻�i������
�����������x�̔��z�����o���Ȃ��̂��߂����B
REGE FURY MAXX�m���Ă�̂���
XGI Volari Duo V8 Ultra�m���Ă�̂��ƁB
�ϑz�Ȃ̂ɍ���o�Ă鐻�i������
�����������x�̔��z�����o���Ȃ��̂��߂����B
REGE FURY MAXX�m���Ă�̂���
XGI Volari Duo V8 Ultra�m���Ă�̂��ƁB
405 �F����������K�������F2005/07/09(�y) 09:23:59 ID:MswLjvAz
CELL�̓X�g���[�~���O�͓��ӂ�����
http://www.itmedia.co.jp/games/articles/0505/17/news075.html
������������̂̃L�������������Q�[���͋��ł��ˁB�Ƃ����������B
MPEG2����48�{�����f�R�[�h�̃f���݂����ȕ����ɂ͋������ǁB
http://www.itmedia.co.jp/games/articles/0505/17/news075.html
������������̂̃L�������������Q�[���͋��ł��ˁB�Ƃ����������B
MPEG2����48�{�����f�R�[�h�̃f���݂����ȕ����ɂ͋������ǁB
406 �F����������K�������F2005/07/09(�y) 09:43:59 ID:f/naLqaw
>>405
�]���r����͖̂����ł��A�A�q���⑫�y�Ȃ��R�����Ă����B
�]���r����͖̂����ł��A�A�q���⑫�y�Ȃ��R�����Ă����B
407 �F����������K�������F2005/07/09(�y) 09:51:12 ID:B46oczHh
�A�q���́AAI�̍ڂ��ĂȂ������̃I�u�W�F�N�g�Ȗ��
408 �F����������K�������F2005/07/09(�y) 10:00:13 ID:rlUn9Seb
>>405
�ݳ݁A�������Ƃ����ł��ˁi �L,_�T�M�j
�ݳ݁A�������Ƃ����ł��ˁi �L,_�T�M�j
409 �F����������K�������F2005/07/09(�y) 10:03:20 ID:3/ZalpJG
�Ȃ��360�̓L������ʂɏo����
PS3��360�قǃL���������Ȃ����ĂȂ��Ă�́B�ȂZ�p�I�؋�����̂��ȁB
PS3��360�قǃL���������Ȃ����ĂȂ��Ă�́B�ȂZ�p�I�؋�����̂��ȁB
410 �F����������K�������F2005/07/09(�y) 10:06:55 ID:eCmVD0HS
411 �F����������K�������F2005/07/09(�y) 10:10:50 ID:gSOuIRJ5
�]���r���e�L�p�L������
412 �F����������K�������F2005/07/09(�y) 10:14:23 ID:7IMnRyjh
ttp://www.scei.co.jp/corporate/release/pdf/050701b.pdf
�ǂ����{�C�ŃR���s���[�^���Ƃɏ��o���炵��
�ǂ����{�C�ŃR���s���[�^���Ƃɏ��o���炵��
413 �F����������K�������F2005/07/09(�y) 10:14:35 ID:WZRZ77zS
�ǂ��ł��������S���|����Ƃ�����ȑO�ɕ��L�Ŏ��˂�������
414 �F����������K�������F2005/07/09(�y) 10:17:30 ID:f6X1DeQw
415 �F����������K�������F2005/07/09(�y) 10:20:06 ID:WGDAl9rY
�����ł͔����ɍ������Ȃ��Ƃ˂�
416 �F����������K�������F2005/07/09(�y) 10:20:34 ID:NzOsoaOg
SPE�ɂ́A��������̃y�i���e�B���傫���Ƃ��A�R�[�h�T�C�Y��LS�Ő��������Ȃǂ�
AI���W�b�N�̎��s�ɕs���ƍl��������������邪�A
�܂������̃Q�[���ł͂ǁ[�Ƃł��Ȃ�ł��낤�B
>>413
�@��
AI���W�b�N�̎��s�ɕs���ƍl��������������邪�A
�܂������̃Q�[���ł͂ǁ[�Ƃł��Ȃ�ł��낤�B
>>413
�@��
417 �F����������K�������F2005/07/09(�y) 10:21:34 ID:rlUn9Seb
���̌��t�𑗂낤
�ׂ������Ό�����܂�
�ׂ������Ό�����܂�
418 �F����������K�������F2005/07/09(�y) 10:22:39 ID:xv7Mqf2i
419 �F����������K�������F2005/07/09(�y) 10:39:39 ID:CiSIHOOP
�[���A����̂̃]���r��AI�g���Ă�Ƃ͎v���Ȃ����ǁc
420 �F����������K�������F2005/07/09(�y) 10:50:53 ID:NzOsoaOg
�X�ɌW�����ݒ肳��Ă��āA�k�}��g��łނ����Ă���z������Έ�l�œ����Ă�
�z������A���炢�̂��Ƃ͊��҂��Ă������悤�ȋC������B�Q�[���Ƃ��Ėʔ����̂�
�ǂ�ȃ��f�����낤?
�z������A���炢�̂��Ƃ͊��҂��Ă������悤�ȋC������B�Q�[���Ƃ��Ėʔ����̂�
�ǂ�ȃ��f�����낤?
421 �F����������K�������F2005/07/09(�y) 10:53:25 ID:3/ZalpJG
422 �F����������K�������F2005/07/09(�y) 11:10:36 ID:f6X1DeQw
SPE�Ń��C������������f�[�^�ǂݍ��ގ���
struct list {
void *data;
struct list *prev;
struct list *next;
};
�݂����Ȏ��ȎQ�ƍ\���̂̃f�[�^�́A�f�[�^���A�����ĂȂ������̃f�[�^�ǂݍ��ނ܂ł��̎��̃f�[�^�ǂݍ��߂Ȃ����猵���������ˁB
�����ł悭�g���Q����W�������ȎQ�ƍ\���̂Ȃ��ǁA���̕ӂ�PPE�ŏ���������Ď��Ȃ̂��ȁH
�W�����Ēn�`�R���W�����ɂ悭�g���邩��A�R���W����������PPE�̎d���ɂȂ肻�����ˁB
struct list {
void *data;
struct list *prev;
struct list *next;
};
�݂����Ȏ��ȎQ�ƍ\���̂̃f�[�^�́A�f�[�^���A�����ĂȂ������̃f�[�^�ǂݍ��ނ܂ł��̎��̃f�[�^�ǂݍ��߂Ȃ����猵���������ˁB
�����ł悭�g���Q����W�������ȎQ�ƍ\���̂Ȃ��ǁA���̕ӂ�PPE�ŏ���������Ď��Ȃ̂��ȁH
�W�����Ēn�`�R���W�����ɂ悭�g���邩��A�R���W����������PPE�̎d���ɂȂ肻�����ˁB
423 �F����������K�������F2005/07/09(�y) 11:20:54 ID:3hsTR4Ur
Dead Rising�△�o�݂����ȃ��������Q�[����
AI���ǂ��̂����̂Ƃ��������A�P���Ƀ|���S�����ǂꂾ���o���邩
�Ƃ����̂��������Ǝv�����ǁB�����Ȃ�Έ��|�I��PS3�̂ق������ӂȂ킯�ŁB
AI���ǂ��̂����̂Ƃ��������A�P���Ƀ|���S�����ǂꂾ���o���邩
�Ƃ����̂��������Ǝv�����ǁB�����Ȃ�Έ��|�I��PS3�̂ق������ӂȂ킯�ŁB
424 �F����������K�������F2005/07/09(�y) 11:22:31 ID:pJ6EbQPz
425 �F����������K�������F2005/07/09(�y) 11:28:25 ID:f6X1DeQw
>424
�L���̈��A���ɂł�����̂�list�g��Ȃ���Ȃ��H
list�̎|���͑}���폜�ɃR�X�g������Ȃ��_���Ǝv���B
�̃T�C�Y��LS�Ɏ��܂�Ȃ�A�m���ɂ��̕��@�ŗǂ��Ǝv�����ǁB
�L���̈��A���ɂł�����̂�list�g��Ȃ���Ȃ��H
list�̎|���͑}���폜�ɃR�X�g������Ȃ��_���Ǝv���B
�̃T�C�Y��LS�Ɏ��܂�Ȃ�A�m���ɂ��̕��@�ŗǂ��Ǝv�����ǁB
426 �F����������K�������F2005/07/09(�y) 11:28:56 ID:NzOsoaOg
SPE�ł̏������郁���o�����ʂɎ��o���ĘA���ȃf�[�^�\���ɂ���Ƃ��A
�����ɕ����}�T�����ă��C���������A�N�Z�X�̃��C�e���V���B������Ƃ��A
�K�v�Ȃ���@�͐��ݏo�����ł��傤�B
��G�c�Ɍ����ASPE�̂��߂̍œK���͂������Ԃ͑傫�����A�����鐫�\���傫���B
��p�Ό��ʂōl����Ɗ��ɍ����̂ł͂Ȃ����ȁA�ƁB
�Ƃ肠�����v���O���}�I�ɂ͊y���������B
�����ɕ����}�T�����ă��C���������A�N�Z�X�̃��C�e���V���B������Ƃ��A
�K�v�Ȃ���@�͐��ݏo�����ł��傤�B
��G�c�Ɍ����ASPE�̂��߂̍œK���͂������Ԃ͑傫�����A�����鐫�\���傫���B
��p�Ό��ʂōl����Ɗ��ɍ����̂ł͂Ȃ����ȁA�ƁB
�Ƃ肠�����v���O���}�I�ɂ͊y���������B
427 �F����������K�������F2005/07/09(�y) 11:30:55 ID:5suOkruR
�|�C���^�A���C�n���̂������R�[�X����
428 �F����������K�������F2005/07/09(�y) 11:32:31 ID:5suOkruR
�K�w���[���Ȃ���Ζ��ˁ[��B�T�����̂��B�����͂������˂���B
429 �F����������K�������F2005/07/09(�y) 11:38:38 ID:pXASzork
����̂̃]���r�̏����Ȃ`�h�Ƃ����Ă��������Z�Ɠ����x�����낤�ȁB
�ʂɕ��ł��Ȃ���������ȁB
�ʂɕ��ł��Ȃ���������ȁB
430 �F����������K�������F2005/07/09(�y) 11:42:58 ID:pXASzork
�|�C���^�̍ċA�I�Q�ƂŃf�B�X�N���[�g�ȃ������G���A�ɃA�N�Z�X����̂́A���ʂ̂b�o�t�����ăL���b�V�������ň��ɂȂ邵�A�K�v�Ȃ�r�o�d�ł���ǂݏ������Ă����Ώ������x�͓�������Ȃ��H
�߂�ǂ������̂͊m�������ǎ�������������ꂻ�������R���p�C������������Ȃ����ȁB
�߂�ǂ������̂͊m�������ǎ�������������ꂻ�������R���p�C������������Ȃ����ȁB
431 �F����������K�������F2005/07/09(�y) 11:48:18 ID:6RKdsQMI
List�Ȃ�Ĉ�ԑΉ����ȒP�ȃp�^�[������
�P��List�����ɏ������邾���ŗǂ��Ȃ�ADMA�p�X���b�h�����C���̏����X���b�h�̗���
*next��*data�ǂݎ���āADMA���s���邾���ł�������
List����`�ɂȂ�A���C���X���b�h���������Ă��镔��������s����DMA���s���\
������A���S�Ƀf�[�^�]�����C�e���V���B���ł���p�^�[����
�����̂悤�ɕ��K�v�ȏꍇ�́A�Ⴆ�ŏ��ɑS�̂�2�ɕ������āA���̃c���[��
���݂�
����Ŏ��ɕK�v�ȃf�[�^������DMA���s���ʂ̃c���[�̔��聨DMA���s
�Ƃ������ŏ�������A�B���͉\��
�f�l�ł����̂��炢�v��������A�v���͂����Ƃ������@�v�������낤��
�P��List�����ɏ������邾���ŗǂ��Ȃ�ADMA�p�X���b�h�����C���̏����X���b�h�̗���
*next��*data�ǂݎ���āADMA���s���邾���ł�������
List����`�ɂȂ�A���C���X���b�h���������Ă��镔��������s����DMA���s���\
������A���S�Ƀf�[�^�]�����C�e���V���B���ł���p�^�[����
�����̂悤�ɕ��K�v�ȏꍇ�́A�Ⴆ�ŏ��ɑS�̂�2�ɕ������āA���̃c���[��
���݂�
����Ŏ��ɕK�v�ȃf�[�^������DMA���s���ʂ̃c���[�̔��聨DMA���s
�Ƃ������ŏ�������A�B���͉\��
�f�l�ł����̂��炢�v��������A�v���͂����Ƃ������@�v�������낤��
432 �F����������K�������F2005/07/09(�y) 11:49:29 ID:pJ6EbQPz
>>425
���g�p�m�[�h�̊Ǘ��͑債���R�X�g����Ȃ���B�폜����m�[�h��
���g�p�m�[�h�̃��X�g�Ɍq������������B�C�����C������
�W�J�ł�����x�B
���g�p�m�[�h�̊Ǘ��͑債���R�X�g����Ȃ���B�폜����m�[�h��
���g�p�m�[�h�̃��X�g�Ɍq������������B�C�����C������
�W�J�ł�����x�B
433 �F����������K�������F2005/07/09(�y) 11:53:50 ID:miiQnjkd
�����f�l�ł����ǁANUMA�Ȃ�ĒP�ɕ����������̊Ԃ�
�u���b�W�Ōq���ł邾���̂��̂���Ȃ��́H
�������Ⴀ����x���ʂ͂��肻�������֗����Ƃ��v�����ǁA
���GPU��p�̃��[�J�������������邾�낤����A
����ȂɌ��I�ȍ��ɂ͂Ȃ�Ȃ������ȋC�����܂��B
���Ƃ̊F�l�ǂ��Ȃ�ł���
�u���b�W�Ōq���ł邾���̂��̂���Ȃ��́H
�������Ⴀ����x���ʂ͂��肻�������֗����Ƃ��v�����ǁA
���GPU��p�̃��[�J�������������邾�낤����A
����ȂɌ��I�ȍ��ɂ͂Ȃ�Ȃ������ȋC�����܂��B
���Ƃ̊F�l�ǂ��Ȃ�ł���
434 �F����������K�������F2005/07/09(�y) 12:01:15 ID:pXASzork
>432
>425�͏����������̂�������Ȃ����A�����������Ƃ̓c���[�̓��I�ύX�Ɏ��R�x������Ƃ������Ƃł���H
�p�����ăm�[�h�̑傫�����ς���Ă��A�m�[�h�̐����ɒ[�ɑ������Ă�List�Ȃ烁�����̍Ċm�ەK�v�Ȃ����B
>424�ɑ���ӌ��Ȃ��A�z�ł��邩���Ęb�ł́H
>425�͏����������̂�������Ȃ����A�����������Ƃ̓c���[�̓��I�ύX�Ɏ��R�x������Ƃ������Ƃł���H
�p�����ăm�[�h�̑傫�����ς���Ă��A�m�[�h�̐����ɒ[�ɑ������Ă�List�Ȃ烁�����̍Ċm�ەK�v�Ȃ����B
>424�ɑ���ӌ��Ȃ��A�z�ł��邩���Ęb�ł́H
435 �F����������K�������F2005/07/09(�y) 12:01:59 ID:pJ6EbQPz
436 �F����������K�������F2005/07/09(�y) 12:02:40 ID:pJ6EbQPz
437 �F����������K�������F2005/07/09(�y) 12:26:16 ID:DqE0caew
>>402
�O�t��HDD�̎��́A�O�t���d�����j�b�g����I�I
����ȑO��DVD�P�[�X�R�����̑傫���Ƃ��͂���Ȃ�n�b�^���ŏI��点��C���H
�O�t��HDD�̎��́A�O�t���d�����j�b�g����I�I
����ȑO��DVD�P�[�X�R�����̑傫���Ƃ��͂���Ȃ�n�b�^���ŏI��点��C���H
438 �F����������K�������F2005/07/09(�y) 12:33:12 ID:sr4r+iQq
�����Q�[���̓X�}�b�V��TV�Ŋ�������Ă邩��Ȃ��B
439 �F����������K�������F2005/07/09(�y) 12:40:14 ID:sGlvG7m4
ATI taped out R520, again
http://www.theinquirer.net/?article=24446
2�x�ڂ̃e�[�v�A�E�g���A�����܂���P���Ȃ������̂�
�����
>I just cannot understand one thing. How come ATI was able to ship millions of R500,
>Xbox 360 chips to Microsoft's launch scheduled for October, when it seems to having
>trouble with yields for the R520? Both chips are using the same new 90 nanometre marchitecture.
http://www.theinquirer.net/?article=24446
2�x�ڂ̃e�[�v�A�E�g���A�����܂���P���Ȃ������̂�
�����
>I just cannot understand one thing. How come ATI was able to ship millions of R500,
>Xbox 360 chips to Microsoft's launch scheduled for October, when it seems to having
>trouble with yields for the R520? Both chips are using the same new 90 nanometre marchitecture.
440 �F����������K�������F2005/07/09(�y) 12:44:13 ID:lrLRvyX6
>>434
���������AList�̃m�[�h���Ɣz��̃������ʒu�������Ȃ�A���ł�List����Ȃ�������
�]���r�̗�Ō����ƁA�����ƕ��G�ȃV�[���O���t�Ȃ킯�ŁA�A�B
�V�[���̃g���o�[�X���ƃ������z�u�Ɉ��ʊW�Ȃ���Ă���A��������Ă��ˁ[��B
�g���o�[�X���Ȃ�āA������Ƃ������łǂ�ǂ�ω�������̂����B
���������AList�̃m�[�h���Ɣz��̃������ʒu�������Ȃ�A���ł�List����Ȃ�������
�]���r�̗�Ō����ƁA�����ƕ��G�ȃV�[���O���t�Ȃ킯�ŁA�A�B
�V�[���̃g���o�[�X���ƃ������z�u�Ɉ��ʊW�Ȃ���Ă���A��������Ă��ˁ[��B
�g���o�[�X���Ȃ�āA������Ƃ������łǂ�ǂ�ω�������̂����B
441 �F����������K�������F2005/07/09(�y) 12:49:30 ID:J4+wjTAn
>>439
��J���Ă�˂��B
��J���Ă�˂��B
442 �F����������K�������F2005/07/09(�y) 12:53:09 ID:rlUn9Seb
�����A���炢���������o���܂����悗
>746 ���O�F����������K������ sage ���e���F2005/07/09(�y) 12:36:47 ID:FszcfBG8
>>>737�݂����Ȃ��q�l�͉p�ꂪ�ǂ߂Ȃ��̂�www
>��XBOX360CPU=240Gflops�͍ŐV�J���@�ނɓY�t����Ă����X�y�b�N�V�[�g�ɏ�����Ă����B
>��360CPU�͍ŏI�I�ɁA1core������2����/clock�ɑ������ꂽ������(Cell��PPE��1����/2clock��2���ߓ������s�j
(Ɂ�`)����
>746 ���O�F����������K������ sage ���e���F2005/07/09(�y) 12:36:47 ID:FszcfBG8
>>>737�݂����Ȃ��q�l�͉p�ꂪ�ǂ߂Ȃ��̂�www
>��XBOX360CPU=240Gflops�͍ŐV�J���@�ނɓY�t����Ă����X�y�b�N�V�[�g�ɏ�����Ă����B
>��360CPU�͍ŏI�I�ɁA1core������2����/clock�ɑ������ꂽ������(Cell��PPE��1����/2clock��2���ߓ������s�j
(Ɂ�`)����
443 �F����������K�������F2005/07/09(�y) 12:57:32 ID:9N9E4b9m
>>426
�����̃A���S���Y�����g���Ȃ��̂͐E�ƃv���O���}�I�ɂ͐h�������Ȃ̂ł����E�E�E
�����̃A���S���Y�����g���Ȃ��̂͐E�ƃv���O���}�I�ɂ͐h�������Ȃ̂ł����E�E�E
444 �F����������K�������F2005/07/09(�y) 12:57:43 ID:eRE2Ysxr
���Ă��APS3�ł������Q�[���̃f�����������B
�m�������A���^�C���������炵�����Aheavenly sword��
�J������f���Ń��A���^�C���������ƔF�߂Ă邵�B
http://www.ninjatheory.com/blinkblink/index.php?option=com_content&task=view&id=38&Itemid=61
�m�������A���^�C���������炵�����Aheavenly sword��
�J������f���Ń��A���^�C���������ƔF�߂Ă邵�B
http://www.ninjatheory.com/blinkblink/index.php?option=com_content&task=view&id=38&Itemid=61
445 �F����������K�������F2005/07/09(�y) 13:01:31 ID:eRE2Ysxr
>>442
���o�l�^�BBeyond3D�ł����l�^�������l�͒@����܂����āA
�s�����Ă��܂���B
http://www.beyond3d.com/forum/viewtopic.php?t=24138
���o�l�^�BBeyond3D�ł����l�^�������l�͒@����܂����āA
�s�����Ă��܂���B
http://www.beyond3d.com/forum/viewtopic.php?t=24138
446 �F����������K�������F2005/07/09(�y) 13:01:58 ID:6RKdsQMI
>>443
�����A���S���Y���͎g����ł���ASPE�ɍ��킹�����ǂ��K�v���Ă�����
�o�������̃��[�`�������̂܂g���������o���Ȃ��悤�Ȑl�́A���Ƃ���v���O���}
�Ȃ�Č����ĂȂ��Ǝv���
�����A���S���Y���͎g����ł���ASPE�ɍ��킹�����ǂ��K�v���Ă�����
�o�������̃��[�`�������̂܂g���������o���Ȃ��悤�Ȑl�́A���Ƃ���v���O���}
�Ȃ�Č����ĂȂ��Ǝv���
447 �F����������K�������F2005/07/09(�y) 13:02:16 ID:jjtROd0G
>442
������ƑO�ɘb��ɂȂ��Ă����C�����邪�H
������ƑO�ɘb��ɂȂ��Ă����C�����邪�H
448 �F����������K�������F2005/07/09(�y) 13:02:55 ID:NY+Sz8as
>>442
���炭�Â��l�^���ȁE�E�E
���炭�Â��l�^���ȁE�E�E
449 �F����������K�������F2005/07/09(�y) 13:12:04 ID:rlUn9Seb
����A���܂��ɂ��̃l�^VS�X���ŐU�肩�����Ă�����ˁB�p��T�C�g�ɏ�����Ă�Ɛ����͂���炵����
>440
�����ƁA�Ȃ����Ƀ��X�H
>434��>432�ɑ��Ę_�_�����ݍ����Ă��Ȃ����Č�����������B
���Ȃ݂Ɏ�����>430�����ASPE�ł�List��z��I�ɘA���������胁�����G���A�ɉ������߂Ďg���Ӗ��͖����Ǝv���Ă�B
�����ƁA�Ȃ����Ƀ��X�H
>434��>432�ɑ��Ę_�_�����ݍ����Ă��Ȃ����Č�����������B
���Ȃ݂Ɏ�����>430�����ASPE�ł�List��z��I�ɘA���������胁�����G���A�ɉ������߂Ďg���Ӗ��͖����Ǝv���Ă�B
451 �F����������K�������F2005/07/09(�y) 13:29:03 ID:mp6vwTg8
>>429
���������Q�[���Ȃ�L���O�_���A���_�[�t�@�C�A�Ƃ��A
��1(�L���b�V�������P3)�ł�150�̓���������B
�Փ˃��f������肳��ɊȒP�Ȃ�B
���������Q�[���Ȃ�L���O�_���A���_�[�t�@�C�A�Ƃ��A
��1(�L���b�V�������P3)�ł�150�̓���������B
�Փ˃��f������肳��ɊȒP�Ȃ�B
452 �F����������K�������F2005/07/09(�y) 13:36:27 ID:pXASzork
>451
��������ˁA�ǂ������P�ʎ��ԓ�����̎��͂̏ɑ��鉞���������i�����̏�ԑJ�ڊ܂ށj���Ă������������B
�Ⴂ�Ƃ����AAI�͏ꍇ�i���x���j�ɂ���Ă͕��G�ȕ]�������������Ȃ���Ȃ�Ȃ��̂ƁA�Փ˔���Ȃ�P�ʎ��Ԃ�Z���Ƃ�Ȃ���Ȃ�Ȃ��\����������Ď����ȁB
��������ˁA�ǂ������P�ʎ��ԓ�����̎��͂̏ɑ��鉞���������i�����̏�ԑJ�ڊ܂ށj���Ă������������B
�Ⴂ�Ƃ����AAI�͏ꍇ�i���x���j�ɂ���Ă͕��G�ȕ]�������������Ȃ���Ȃ�Ȃ��̂ƁA�Փ˔���Ȃ�P�ʎ��Ԃ�Z���Ƃ�Ȃ���Ȃ�Ȃ��\����������Ď����ȁB
453 �F����������K�������F2005/07/09(�y) 13:39:57 ID:6RKdsQMI
ttp://www.ati.com/developer/demos/rx800.html
ATi��Crowd�Ƃ���Demo�͊�����PC�AGPU��1400�̂̃L�����N�^�[�o���Ă�
Mpeg�ł�����邵�AATi��X800�ȍ~�̃J�[�h�����Ă�l�Ȃ玩���Ŏ��s�ł����
�܁A�L�����N�^�[�����������o�������Ȃ�APS3��XBOX360���S����薳�����낤��
ATi��Crowd�Ƃ���Demo�͊�����PC�AGPU��1400�̂̃L�����N�^�[�o���Ă�
Mpeg�ł�����邵�AATi��X800�ȍ~�̃J�[�h�����Ă�l�Ȃ玩���Ŏ��s�ł����
�܁A�L�����N�^�[�����������o�������Ȃ�APS3��XBOX360���S����薳�����낤��
454 �F����������K�������F2005/07/09(�y) 13:45:05 ID:lrLRvyX6
>>446
�����ɃL���b�V���T�C�Y���Ƃ��]���Ƃ���M���Ď��Ȗ������Ă�A�����ǂ����Ǝv�����ǂˁB
���������̍D���Ȑl�킪�����̂͂킩�邪�A���������n�[�h�x���_���������d�������B
�����Ƃ���Ƃ����Ȃ������͑�R����Ǝv�����ˁB�C�O�ɐ�z����Ă�B
���ہA���ǂ͑��ł��g���Ȃ����색�C�u�����͎~�߂ă~�h���E�F�A�ɃV�t�g���Ă鏊�������B
>>450
�[���Ӗ��͂Ȃ���B
�����ɃL���b�V���T�C�Y���Ƃ��]���Ƃ���M���Ď��Ȗ������Ă�A�����ǂ����Ǝv�����ǂˁB
���������̍D���Ȑl�킪�����̂͂킩�邪�A���������n�[�h�x���_���������d�������B
�����Ƃ���Ƃ����Ȃ������͑�R����Ǝv�����ˁB�C�O�ɐ�z����Ă�B
���ہA���ǂ͑��ł��g���Ȃ����색�C�u�����͎~�߂ă~�h���E�F�A�ɃV�t�g���Ă鏊�������B
>>450
�[���Ӗ��͂Ȃ���B
455 �F����������K�������F2005/07/09(�y) 13:53:15 ID:6RKdsQMI
>>454
�C�O�ɐ�s����Ă��镪��́A���ꂱ�������ŐV�����A���S���Y�����l���Ȃ���
�Ȃ�Ȃ������������ASPE�̍œK���ŔY�ނ悤�ȃv���O���}�́A����ȃ��x����
�����Ǝv���E�E�E
�A���S���Y���ƃf�[�^�\���̍œK���̓v���O�����̊�{�Ȃ�
�C�O�ɐ�s����Ă��镪��́A���ꂱ�������ŐV�����A���S���Y�����l���Ȃ���
�Ȃ�Ȃ������������ASPE�̍œK���ŔY�ނ悤�ȃv���O���}�́A����ȃ��x����
�����Ǝv���E�E�E
�A���S���Y���ƃf�[�^�\���̍œK���̓v���O�����̊�{�Ȃ�
456 �F����������K�������F2005/07/09(�y) 14:01:50 ID:KccXX2ya
PS3�̊w�K�Ȑ���PS2���͂邩�Ɉ������낤�ȁB
�܂�PS3�̐��\�������\�t�g��PS3�����ɂ����o�Ă��Ȃ��\���������Ƃ������Ƃ��B
FLOPS�ɕΏd�������̎g���Â炢�n�[�h�������t��
printf�f�o�b�O�����v���Ă�����g���Â炢�Ƃ����J���҂\�Ă��B
���ꂪSCE&GK���è�B
�܂�PS3�̐��\�������\�t�g��PS3�����ɂ����o�Ă��Ȃ��\���������Ƃ������Ƃ��B
FLOPS�ɕΏd�������̎g���Â炢�n�[�h�������t��
printf�f�o�b�O�����v���Ă�����g���Â炢�Ƃ����J���҂\�Ă��B
���ꂪSCE&GK���è�B
457 �F����������K�������F2005/07/09(�y) 14:04:28 ID:bBdSd2ws
���\�ɈႢ�͂Ȃ�
�悭��GC�Ɣ����炢�̈Ⴂ
���̂Q�@���GC����30fps�Ƃ�����
�\�t�g���F��������
���F����Ȃ���
�悭��GC�Ɣ����炢�̈Ⴂ
���̂Q�@���GC����30fps�Ƃ�����
�\�t�g���F��������
���F����Ȃ���
458 �F����������K�������F2005/07/09(�y) 14:06:10 ID:WmAwB5Fv
�{����ID�FID:KccXX2ya
459 �F����������K�������F2005/07/09(�y) 14:06:47 ID:8lRWG0WR
PPE+SPEx1�ł���EE�Ɠ������炢�J��������ƌ����Ă�̂ɁA�J������PS2�̎��Ɠ����x�ƁA�\�j�[�������甭��
�{��64�̎��̔C�V�������y���ɃO�_�O�_����
�{��64�̎��̔C�V�������y���ɃO�_�O�_����
460 �F����������K�������F2005/07/09(�y) 14:06:59 ID:f6X1DeQw
>>454
����A���̎��Ȗ����ŏo���鎖��������Ȃ�v���O���}�ȊO����Ԃ���A���Ȗ������ᖳ���Ǝv����B
�m���Ƀn�[�h�x���_�[������Ă����ō��Ȃ��ǂˁB
�܂��ɖ��̊J�����B
>>456
�X�ւ��A��
����A���̎��Ȗ����ŏo���鎖��������Ȃ�v���O���}�ȊO����Ԃ���A���Ȗ������ᖳ���Ǝv����B
�m���Ƀn�[�h�x���_�[������Ă����ō��Ȃ��ǂˁB
�܂��ɖ��̊J�����B
>>456
�X�ւ��A��
461 �F����������K�������F2005/07/09(�y) 14:14:12 ID:hkGg+HJ2
cell��SPE���g�����\�t�g�͓����o�Ă��Ȃ�
�Ƃ��������o���Ȃ�
�Ƃ��������o���Ȃ�
462 �F����������K�������F2005/07/09(�y) 14:18:35 ID:8lRWG0WR
���ۂ̘b�A���̊J�����ł�SPE�̓Q�[���p�r�ł͔w�i����̍Đ����炢�ɂ����g���Ȃ�
463 �F����������K�������F2005/07/09(�y) 14:19:47 ID:lrLRvyX6
>>460
�d�l���B���o���ďI���B����Ȃ�����ˁB
�ėp���ƕێ炪�厖�B������܂ł��Ȃ��Ǝv�����B
����̓n�[�h�x���_�����Ȃ��ƁB
�ŁA���ǔj�����ă~�h���E�F�A�ɗ���Ȃ�A�ŏ�������Ȃ������ǂ��B
�R�X�g�̖��ʁB�v����Ɏ��Ȗ����B
�d�l���B���o���ďI���B����Ȃ�����ˁB
�ėp���ƕێ炪�厖�B������܂ł��Ȃ��Ǝv�����B
����̓n�[�h�x���_�����Ȃ��ƁB
�ŁA���ǔj�����ă~�h���E�F�A�ɗ���Ȃ�A�ŏ�������Ȃ������ǂ��B
�R�X�g�̖��ʁB�v����Ɏ��Ȗ����B
464 �F����������K�������F2005/07/09(�y) 14:21:04 ID:pXASzork
>PPE+SPEx1�ł���EE�Ɠ������炢�J��������ƌ����Ă�̂�
�������B
���܂ł̏�����ʂ茩�Ă����Ȍ��_�ɂ͂Ȃ�Ȃ��Ǝv�����B
�Ă��������X�����Ⴂ���Ȃ��l�݂������ȁB
�������B
���܂ł̏�����ʂ茩�Ă����Ȍ��_�ɂ͂Ȃ�Ȃ��Ǝv�����B
�Ă��������X�����Ⴂ���Ȃ��l�݂������ȁB
465 �F����������K�������F2005/07/09(�y) 14:23:44 ID:UGeVkpH1
���A���Ⴂ���Ă�̂�������
�ʂ�SPE��PPE�ɍœK�����ꂽ�R�[�h�����Ȃ��Ă�
Cell�͂���Ȃ�ɓ����Ă����킯�ł���
(�R���p�C���̖������邪)
�ʂ�SPE��PPE�ɍœK�����ꂽ�R�[�h�����Ȃ��Ă�
Cell�͂���Ȃ�ɓ����Ă����킯�ł���
(�R���p�C���̖������邪)
466 �F����������K�������F2005/07/09(�y) 14:25:31 ID:6RKdsQMI
>>463
���Ѓ��C�u�����������͖��ʂȂ̂��E�E�E
�~�h���E�F�A�����ЂȂ�Ƃ������A�Q�[���ƊE�Ȃ�ăn�[�h����ւ��Ήߋ���
���Y�Ȃ�Ďg�����ɂȂ�Ȃ��Ȃ違�Q�[���ȊO�̗p�r�Ɏg�����Ȃ�čl������
�œK������̂�������܂��̋ƊE�ŁA�ėp���ƕێ琫����ɍl����H
Cell���g�����T�[�o�[���APC�Ȃ�Ƃ������A�����̓Q�[���n�[�h�e�N�m���W�[�X������H
���Ѓ��C�u�����������͖��ʂȂ̂��E�E�E
�~�h���E�F�A�����ЂȂ�Ƃ������A�Q�[���ƊE�Ȃ�ăn�[�h����ւ��Ήߋ���
���Y�Ȃ�Ďg�����ɂȂ�Ȃ��Ȃ違�Q�[���ȊO�̗p�r�Ɏg�����Ȃ�čl������
�œK������̂�������܂��̋ƊE�ŁA�ėp���ƕێ琫����ɍl����H
Cell���g�����T�[�o�[���APC�Ȃ�Ƃ������A�����̓Q�[���n�[�h�e�N�m���W�[�X������H
467 �F����������K�������F2005/07/09(�y) 14:28:59 ID:hkGg+HJ2
�~�h���E�F�A�������Ȃ����s������
�܂���EE����Ȃ���
�܂���EE����Ȃ���
468 �F����������K�������F2005/07/09(�y) 14:35:31 ID:lrLRvyX6
>>466
���ʂƂ܂ł͌���Ȃ����A�g�`�k�w�̍œK���ɒ��͂��Ă�Ⴂ�����Đl�͂��������Ă�ƁB
��A�l�����������Â��Ȃ��H
���҂╜�������������A�ėp���ƕێ琫�͏d�v���オ���Ă�ł��傤�B�ԈႢ�Ȃ��B
�������̓Q�[���n�[�h�e�N�m���W�[�X������H
�n�[�h�ɓ������Ă�̂��A�A�B�Ȃ�\�t�g���̏o�開�͂Ȃ��ȁA�A�B
���ʂƂ܂ł͌���Ȃ����A�g�`�k�w�̍œK���ɒ��͂��Ă�Ⴂ�����Đl�͂��������Ă�ƁB
��A�l�����������Â��Ȃ��H
���҂╜�������������A�ėp���ƕێ琫�͏d�v���オ���Ă�ł��傤�B�ԈႢ�Ȃ��B
�������̓Q�[���n�[�h�e�N�m���W�[�X������H
�n�[�h�ɓ������Ă�̂��A�A�B�Ȃ�\�t�g���̏o�開�͂Ȃ��ȁA�A�B
469 �F����������K�������F2005/07/09(�y) 14:38:22 ID:UGeVkpH1
�ėp�R�[�h�łƂ肠�����g��ł��āA�K�v��������œK�����Ă����̂����̎嗬�@���ȁH
470 �F����������K�������F2005/07/09(�y) 14:56:27 ID:9PMnNr1S
�Q�[���G���W���̃~�h���E�F�A�ЂƂ��\���h���{���p�[�Z���g���̃C���Z���e�B�u�Ƃ������Ă�킯�ŁA
���������̂��{���ɕK�v�Ȓ����ɂƂ��Ă͌��\������ȁB
�̗͂̂�����͎��ЊJ�����āA�o���ӂ��߂ĉ�Ђ̎��Y�ɂ���������X���L�������B
���̃��g���Q�[�I�Ɍ�X�ɂȂ��čĔ̂��鏤�����l����A���܂ł��R�t���Ȃ͕̂|���b�ł����邵�ȁB
���������̂��{���ɕK�v�Ȓ����ɂƂ��Ă͌��\������ȁB
�̗͂̂�����͎��ЊJ�����āA�o���ӂ��߂ĉ�Ђ̎��Y�ɂ���������X���L�������B
���̃��g���Q�[�I�Ɍ�X�ɂȂ��čĔ̂��鏤�����l����A���܂ł��R�t���Ȃ͕̂|���b�ł����邵�ȁB
471 �F����������K�������F2005/07/09(�y) 15:18:11 ID:ja0G24u0
�Ă��Ƃ�FF11�Ƃ����ƹް���۸��ς͂ƁA�Ă��Ȃ��Ǝv���Ă����
���̂ւ��ؽĂ��ǂ��̂Ƃ������Ă�悤�Ȏ��́A�܂��������ɂȂ��Ǝv���
���̂ւ��ؽĂ��ǂ��̂Ƃ������Ă�悤�Ȏ��́A�܂��������ɂȂ��Ǝv���
472 �F����������K�������F2005/07/09(�y) 15:18:39 ID:/4Brz06L
http://www.theinquirer.net/?article=24446
>How come ATI was able to ship millions of R500, Xbox
>360 chips to Microsoft's launch scheduled for October,
>when it seems to having trouble with yields for the
>R520? Both chips are using the same new 90 nanometrem
> architecture.
R520�̍Đv�ɂ͂S�`�U�T�Ԃ�����BnVIDIA��G70�����O
�ɁAATI�͂��ł�R520�̍Đv���x�s���Ă������A����
�ł��A�����̂������ʂ������Ȃ������B
�i���j
R520�̐��Y�ł��ꂾ���g���u��������Ă�̂ɁA�P�O������
���\�肳��Ă���l�r��Xbox360�p�̃`�b�v�AR500�𐔕S��
����̂ǂ��������o�ׂ��邱�Ƃ��ł���Ƃ����̂��낤�H
���`�b�v�͓����V����90nm�A�[�L�e�N�`�����g���Ă���B
���Ƃ�����AR500�̐��Y�̓����|�Ƃ����ӌ����o�Ă����ˁB
Xbox360�A�܂����N�t�ȍ~�ɔ��������ɂȂ肻�����B
>How come ATI was able to ship millions of R500, Xbox
>360 chips to Microsoft's launch scheduled for October,
>when it seems to having trouble with yields for the
>R520? Both chips are using the same new 90 nanometrem
> architecture.
R520�̍Đv�ɂ͂S�`�U�T�Ԃ�����BnVIDIA��G70�����O
�ɁAATI�͂��ł�R520�̍Đv���x�s���Ă������A����
�ł��A�����̂������ʂ������Ȃ������B
�i���j
R520�̐��Y�ł��ꂾ���g���u��������Ă�̂ɁA�P�O������
���\�肳��Ă���l�r��Xbox360�p�̃`�b�v�AR500�𐔕S��
����̂ǂ��������o�ׂ��邱�Ƃ��ł���Ƃ����̂��낤�H
���`�b�v�͓����V����90nm�A�[�L�e�N�`�����g���Ă���B
���Ƃ�����AR500�̐��Y�̓����|�Ƃ����ӌ����o�Ă����ˁB
Xbox360�A�܂����N�t�ȍ~�ɔ��������ɂȂ肻�����B
473 �F����������K�������F2005/07/09(�y) 15:19:37 ID:ja0G24u0
�ǂ��ɋ�Ǔ_�ł��Ă��G
���l�ްт��тȂ���]�����Ă���D�D�D
���l�ްт��тȂ���]�����Ă���D�D�D
474 �F����������K�������F2005/07/09(�y) 15:23:50 ID:lrLRvyX6
>>471
FF11�͏����m���Ă���A�A���Ȃ�D�L��������Ă�B
�f�U�C�i������ł��o����悤�Ȏ����A���ƂŁB
���ꕷ���āA�u�ȂA����Ȃ��v�Ǝv�������ǂȁB
���̃f�U�C�i�ɓ������v��������A�u�ӂ�����ȁI�v���O�����ʼn��Ƃ��o���Ȃ��́H�v�Č�����悤�Ȏ��B
FF11�͏����m���Ă���A�A���Ȃ�D�L��������Ă�B
�f�U�C�i������ł��o����悤�Ȏ����A���ƂŁB
���ꕷ���āA�u�ȂA����Ȃ��v�Ǝv�������ǂȁB
���̃f�U�C�i�ɓ������v��������A�u�ӂ�����ȁI�v���O�����ʼn��Ƃ��o���Ȃ��́H�v�Č�����悤�Ȏ��B
475 �F����������K�������F2005/07/09(�y) 15:26:12 ID:/4Brz06L
GPU�̊J���x���ŁA�����̔����͗��N�������قڔZ�����BPS3��蔭����
�x�ꂽ��A���\�ŗ�锠���͂܂��ł���ˁB�e�N���Ƃ��A�����ɉגS
���Ă��郁�[�J�[����Ђ��Ɛтɉe�����o��͕̂K�����B
�x�ꂽ��A���\�ŗ�锠���͂܂��ł���ˁB�e�N���Ƃ��A�����ɉגS
���Ă��郁�[�J�[����Ђ��Ɛтɉe�����o��͕̂K�����B
476 �F����������K�������F2005/07/09(�y) 15:28:30 ID:6v3h8Tyu
�܂��܂��h���L���X�L���Y���Ă���
477 �F����������K�������F2005/07/09(�y) 15:30:56 ID:ja0G24u0
478 �F����������K�������F2005/07/09(�y) 15:33:29 ID:3ZuvGeTE
���̍�R600���ڂ��Ă���Ⴂ���̂�
DVD��HDDVD
DVD��HDDVD
479 �F����������K�������F2005/07/09(�y) 15:35:42 ID:8lRWG0WR
G70<>RSX�ƈ����
R500<>R520�͊��S�ȕʐv
�ڕW���\�ȊO�ɋ��ʓ_�͂Ȃ���
R500<>R520�͊��S�ȕʐv
�ڕW���\�ȊO�ɋ��ʓ_�͂Ȃ���
480 �F����������K�������F2005/07/09(�y) 15:40:24 ID:/4Brz06L
R500��R520���A����TSMC��90nm�v���Z�X�Ő����ŁAR520�̊J�����x������
����̂́A������̖�肾����AR500������ł���B
����̂́A������̖�肾����AR500������ł���B
481 �F����������K�������F2005/07/09(�y) 15:42:49 ID:lR4zUkaB
RSX��R500���Ȃp�b�g���Ȃ��B
X-GPU����Ԃ悩������
���ł��掿�̖ʂŌ���肵�Ȃ�
������V�F�[�_�[���\���オ���Ă����ꂾ���Ȃ�
������ƃv���[�������肷�邩�Ƃ��������̒��x��
�Ⴂ�B�T�N��ł�����肵�Ȃ�GPU�������ė~�����B
X-GPU����Ԃ悩������
���ł��掿�̖ʂŌ���肵�Ȃ�
������V�F�[�_�[���\���オ���Ă����ꂾ���Ȃ�
������ƃv���[�������肷�邩�Ƃ��������̒��x��
�Ⴂ�B�T�N��ł�����肵�Ȃ�GPU�������ė~�����B
482 �F����������K�������F2005/07/09(�y) 15:43:17 ID:ZPqhZpRw
>>479
R520�Ŗ�肪�����Ă���̂�TSMC 90nm�v���Z�X�ɂ����郊�[�N�d������H
�����R500�ɂ����R���ɂȂ��BR500�ɂ̂݉��炩�̃��[�N�d��������Ă��Ȃ��ƑʖځB
�������A�㓡�Ȃ�R520�������V�F�[�_���ƌ����Ă邯�ǂȁB
�������ꂪ�{���Ȃ�R500��R520�͋��ʓ_�������B
R520�Ŗ�肪�����Ă���̂�TSMC 90nm�v���Z�X�ɂ����郊�[�N�d������H
�����R500�ɂ����R���ɂȂ��BR500�ɂ̂݉��炩�̃��[�N�d��������Ă��Ȃ��ƑʖځB
�������A�㓡�Ȃ�R520�������V�F�[�_���ƌ����Ă邯�ǂȁB
�������ꂪ�{���Ȃ�R500��R520�͋��ʓ_�������B
483 �F����������K�������F2005/07/09(�y) 15:45:42 ID:ZPqhZpRw
484 �F����������K�������F2005/07/09(�y) 15:47:07 ID:pXASzork
>472
�\�[�X�͏o���Ȃ����ǁA�m���ɓ����m���Ă�l�Ԃɂ����܂Œx��Ă���Ƃ͕����Ȃ��������ǂȁB
R500��R520��eDRAM�ȊO�����悤�ȃA�[�L�e�N�`�����Ƃ������Ă��B
���������܂��ꂽ�����Ȃ̂��H
�\�[�X�͏o���Ȃ����ǁA�m���ɓ����m���Ă�l�Ԃɂ����܂Œx��Ă���Ƃ͕����Ȃ��������ǂȁB
R500��R520��eDRAM�ȊO�����悤�ȃA�[�L�e�N�`�����Ƃ������Ă��B
���������܂��ꂽ�����Ȃ̂��H
485 �F����������K�������F2005/07/09(�y) 16:00:30 ID:L+GKrPO9
ATI�̒��̐l�̃C���^�r���[�ł́A
Xenos��R520�͑S���قȂ�A�Ƃ����킯�ł͂Ȃ����Č����Ă��ȁB
����Xenos��R520������A�[�L�e�N�`�����Ƃ��Ă��A
24�p�C�v���m(Xenos�����H)�͒ʏ�̃n�C�G���hGPU���Ɏ���炵�����A
�N���b�N��500MH���ƒႢ�킯�ŁA����قǑ傫�Ȗ��ł͂Ȃ��悤�ȁB
Xenos��R520�͑S���قȂ�A�Ƃ����킯�ł͂Ȃ����Č����Ă��ȁB
����Xenos��R520������A�[�L�e�N�`�����Ƃ��Ă��A
24�p�C�v���m(Xenos�����H)�͒ʏ�̃n�C�G���hGPU���Ɏ���炵�����A
�N���b�N��500MH���ƒႢ�킯�ŁA����قǑ傫�Ȗ��ł͂Ȃ��悤�ȁB
486 �F����������K�������F2005/07/09(�y) 16:03:08 ID:RY5WXqPq
�Ƃ����ɔ��\�E�̔�����Ă���͂��̃`�b�v���x��Ă��邱�Ƃ͊m���B
PC�����`�b�v��BF2�����ɏ��Ă��Ȃ��̂͒ɂ��Ǝv���B
PC�����`�b�v��BF2�����ɏ��Ă��Ȃ��̂͒ɂ��Ǝv���B
487 �F����������K�������F2005/07/09(�y) 16:04:01 ID:WmAwB5Fv
>>484
�\�[�X���o���Ȃ��悤�ȏ����A�ǂ��M����ƁH
�\�[�X���o���Ȃ��悤�ȏ����A�ǂ��M����ƁH
488 �F����������K�������F2005/07/09(�y) 16:06:40 ID:8lRWG0WR
�ʏ�̃n�C�G���h�i�Ɠ����Ȃ�A�N300�����x�̐��Y�ʂ͂�����A
�����܂�͎��Ԃ����ɂ���シ��̂ŁA���͂قƂ�ǂȂ����낤
�����܂�͎��Ԃ����ɂ���シ��̂ŁA���͂قƂ�ǂȂ����낤
489 �F����������K�������F2005/07/09(�y) 16:07:59 ID:emFn94wI
>>484
��������m���Ă�l�Ԃ��A���ꂽ��Ɏ�ɂȂ�悤�Ȃ��Ƃ��O���̂��̂ɘb���킯�Ȃ��Ǝv�����B
��������m���Ă�l�Ԃ��A���ꂽ��Ɏ�ɂȂ�悤�Ȃ��Ƃ��O���̂��̂ɘb���킯�Ȃ��Ǝv�����B
490 �F����������K�������F2005/07/09(�y) 16:08:53 ID:C4YUWLyw
���Y���x���Ȃ�R500�̓{�c�ɂ�����
491 �F����������K�������F2005/07/09(�y) 16:09:52 ID:ucjV/EDl
�N300������ ���ĉ��Ŕ���3���ŕi�ꂾ�낗
����Ƃ��AXBOX360�ł͂���ŏ\���Ȃ̂��ȁH
����Ƃ��AXBOX360�ł͂���ŏ\���Ȃ̂��ȁH
492 �F����������K�������F2005/07/09(�y) 16:13:56 ID:fB9x/Iw5
��X���̃^�C�g����
�y�Q�[�������z������@�e�N�m���W�[11�y�X���z
�ɂł�����Ƃ��悤�B
�y�Q�[�������z������@�e�N�m���W�[11�y�X���z
�ɂł�����Ƃ��悤�B
493 �F����������K�������F2005/07/09(�y) 16:19:08 ID:VaaqOF11
RSX�����[�N�d���̖�肪�E�E�E
�}�110nm�ł𓊓���
�N���b�N�����Ƃ�
�}�110nm�ł𓊓���
�N���b�N�����Ƃ�
>487�A��
���߂�A�M���Ă��炢�����킯����Ȃ��̂œK���ɗ����āB
���߂�A�M���Ă��炢�����킯����Ȃ��̂œK���ɗ����āB
495 �F����������K�������F2005/07/09(�y) 16:21:08 ID:9N9E4b9m
>>446
�������A���̓v���O���}�ɂ͌����Ă��Ȃ������̂�orz
���ɉ��̏������R�[�h��100����ȏ�s��ɏo�Ă��邯�Ǖ|���ˁB
�ł��A��������ŋ߂͎d�l���������ĂȂ���B
�������A���̓v���O���}�ɂ͌����Ă��Ȃ������̂�orz
���ɉ��̏������R�[�h��100����ȏ�s��ɏo�Ă��邯�Ǖ|���ˁB
�ł��A��������ŋ߂͎d�l���������ĂȂ���B
496 �F����������K�������F2005/07/09(�y) 16:23:10 ID:8lRWG0WR
90nm�ł̍��N���b�N���i�̐��Y�\�͂ł�����
���т̂Ȃ��\�j�[����Fab��RSX�̕����y���Ɋ댯
���т̂Ȃ��\�j�[����Fab��RSX�̕����y���Ɋ댯
497 �F����������K�������F2005/07/09(�y) 16:25:05 ID:UGeVkpH1
>>496
�\�[�X�ł����������Ă��Ă��猾���Ă���
�\�[�X�ł����������Ă��Ă��猾���Ă���
498 �F����������K�������F2005/07/09(�y) 16:25:22 ID:CiSIHOOP
>>485
R520��32�p�C�v�Őv����Ă�炵������24�p�C�v�̕��͑�������B
���ǁAXenos�����߂���24�p�C�v�Őv����Ă��瑽�����Ȃ��̂ł́c�H
R520��32�p�C�v�Őv����Ă�炵������24�p�C�v�̕��͑�������B
���ǁAXenos�����߂���24�p�C�v�Őv����Ă��瑽�����Ȃ��̂ł́c�H
499 �F����������K�������F2005/07/09(�y) 16:26:47 ID:dwLyl/mO
���̃X���A�\�[�X�A�\�[�X�����z
�E�U����
�E�U����
500 �F����������K�������F2005/07/09(�y) 16:28:00 ID:/4Brz06L
�\�j�[�̓g�����X���^�̎Ј����ʂɌق��āA���[�N�d�����
LongRun2�̎��������Ă��邾�낤����AR500���͕����܂肢��
���낤�B
LongRun2�̎��������Ă��邾�낤����AR500���͕����܂肢��
���낤�B
501 �F����������K�������F2005/07/09(�y) 16:29:59 ID:8lRWG0WR
���̃X�����悭�ǂ߂킩�邯�ǁA���_�o���Ȃ����̓����̌��t�ł�����
���\�[�X���o��
���\�[�X���o��
502 �F����������K�������F2005/07/09(�y) 16:32:37 ID:RY5WXqPq
�l�b�g��ɂ��獪���̖����\�b�̂ق����E�U���ł�
503 �F����������K�������F2005/07/09(�y) 16:33:29 ID:cpJK0brP
R500��NEC��UX6�ł�����̂ł���
504 �F����������K�������F2005/07/09(�y) 16:34:32 ID:/4Brz06L
R520�͂��łɂQ�x�Đv���āA32�p�C�v�͂قƂ�ǎ�ꂸ�A24�p�C�v
��ꂽ�烉�b�L�[�A�唼��16�p�C�v�炵���A���O�x�ڂ̍Đv�ŁA
�v�������ꃖ������ꃖ����������A�����ɍs���ĂW�����{����X
���Ƀe�[�v�A�E�g�A���ꂩ�琻�i�����܂œ��Ƃ��ĂP�O�`�P�P��
�ɓX���ɕ��ԁB
����AR500�́i���������\�����P���ȁj48�p�C�v�̓����V�F�[�_�[�B
48�p�C�v�𐔕S���`�b�v�m�ۂ���͍̂��N�����ς��͖������낤�ˁB
��ꂽ�烉�b�L�[�A�唼��16�p�C�v�炵���A���O�x�ڂ̍Đv�ŁA
�v�������ꃖ������ꃖ����������A�����ɍs���ĂW�����{����X
���Ƀe�[�v�A�E�g�A���ꂩ�琻�i�����܂œ��Ƃ��ĂP�O�`�P�P��
�ɓX���ɕ��ԁB
����AR500�́i���������\�����P���ȁj48�p�C�v�̓����V�F�[�_�[�B
48�p�C�v�𐔕S���`�b�v�m�ۂ���͍̂��N�����ς��͖������낤�ˁB
505 �F����������K�������F2005/07/09(�y) 16:35:00 ID:CiSIHOOP
LR2�͋Z�p�I�ɂ܂��ڂ���Ȃ���Ȃ����Ƃ������b���̂������C�����邯�ǁA
�������eDRAM���������Ă�ꍇ�������H
�������eDRAM���������Ă�ꍇ�������H
506 �F����������K�������F2005/07/09(�y) 16:35:16 ID:/4Brz06L
��R500��NEC��UX6�ł�����̂ł���
����͕ʃ_�C��eDRAM���������BGPU�{�̂�TSMC�B
����͕ʃ_�C��eDRAM���������BGPU�{�̂�TSMC�B
507 �F����������K�������F2005/07/09(�y) 16:36:30 ID:CiSIHOOP
>>503
eDRAM+���W�b�N��������NEC�ŁA���C���͑�p����Ȃ����������H
eDRAM+���W�b�N��������NEC�ŁA���C���͑�p����Ȃ����������H
508 �F����������K�������F2005/07/09(�y) 16:36:46 ID:L+GKrPO9
509 �F����������K�������F2005/07/09(�y) 16:38:42 ID:PZJ/gLDq
ID:8lRWG0WR�̔����Ȃǂ�ǂ�ł����
�����Ƀ\�[�X���厖���Ɋ��������܂�w
�����Ƀ\�[�X���厖���Ɋ��������܂�w
510 �F����������K�������F2005/07/09(�y) 16:39:47 ID:AlTZ22OS
511 �F����������K�������F2005/07/09(�y) 16:41:02 ID:c/vBPfxs
�\�[�X�̂Ȃ��p��̏������݂��Ȃ������̃X���ł̓\�[�X�ɂȂ��Ă��܂���
512 �F����������K�������F2005/07/09(�y) 16:41:13 ID:tBfivVw7
UX6�͍H��ł͂���܂���
513 �F����������K�������F2005/07/09(�y) 16:41:24 ID:WmAwB5Fv
>>501
yokattane
yokattane
514 �F����������K�������F2005/07/09(�y) 16:44:49 ID:9AkcIPnr
�\�[�X�Ȃ�Ċ�{�I�ɒ����Ă������ǂ��ɂ�������
�Y��邵���������A�h���X�܂ł��ۑ����Ă���̂��H
�ߋ����O������T���̂��߂�ǂ�����
�Y��邵���������A�h���X�܂ł��ۑ����Ă���̂��H
�ߋ����O������T���̂��߂�ǂ�����
515 �F����������K�������F2005/07/09(�y) 16:45:05 ID:flLdZdn7
RSX��TSMC?
516 �F����������K�������F2005/07/09(�y) 16:46:38 ID:QiO2xBwr
>>504
���{�͔����x������A����ŕʂɑ傫�Ȗ��͂Ȃ���ˁH
���{�͔����x������A����ŕʂɑ傫�Ȗ��͂Ȃ���ˁH
517 �F����������K�������F2005/07/09(�y) 16:47:20 ID:A6mV1iGt
518 �F����������K�������F2005/07/09(�y) 16:47:30 ID:QiO2xBwr
>>516
���܂�AR500�̂ق��̘b���B���Ⴂ������
���܂�AR500�̂ق��̘b���B���Ⴂ������
519 �F����������K�������F2005/07/09(�y) 16:48:01 ID:CiSIHOOP
>>515
SCEI����c
���������APS2�Ƃ̌݊����Ƃ�Ƃ��AGS��48MB/s�Ƃ����ш悪���ɂȂ肻�������ǁA
�����͂ǂ�����낤�HSB�Ƃ���4MB��eDRAM����Ă���̂��ȁH
SCEI����c
���������APS2�Ƃ̌݊����Ƃ�Ƃ��AGS��48MB/s�Ƃ����ш悪���ɂȂ肻�������ǁA
�����͂ǂ�����낤�HSB�Ƃ���4MB��eDRAM����Ă���̂��ȁH
520 �F����������K�������F2005/07/09(�y) 16:49:47 ID:bFuj06S1
521 �F����������K�������F2005/07/09(�y) 16:50:04 ID:mp6vwTg8
522 �F����������K�������F2005/07/09(�y) 16:52:50 ID:CiSIHOOP
>>510
�T���N�X�B
ttp://pc.watch.impress.co.jp/docs/2004/1220/kaigai142.htm
SOI��eDRAM�̋���������Ƃ������Ƃ�eDRAM+LR2�̉\��������̂��B
�T���N�X�B
ttp://pc.watch.impress.co.jp/docs/2004/1220/kaigai142.htm
SOI��eDRAM�̋���������Ƃ������Ƃ�eDRAM+LR2�̉\��������̂��B
523 �F����������K�������F2005/07/09(�y) 16:55:46 ID:6hm7MCNo
���O�̃��[�N���͎��͒����o�R�Ȃ�
524 �F����������K�������F2005/07/09(�y) 17:00:05 ID:RY5WXqPq
PC�֘A�₻�̎��ӂ̃��[�N�Ȃ璆���o�R�̏��͂��Ȃ�m�x�������B
GPU��CPU�A�}�U�[�{�[�h�֘A�̃x���`�Ȃǂ͎���̏��ƂقƂ�Ǐd�Ȃ�B
���Z�L�����e�B���Â��ďd�v���_�_�R��̗��Ԃ��ł͂��邪�B
GPU��CPU�A�}�U�[�{�[�h�֘A�̃x���`�Ȃǂ͎���̏��ƂقƂ�Ǐd�Ȃ�B
���Z�L�����e�B���Â��ďd�v���_�_�R��̗��Ԃ��ł͂��邪�B
525 �F����������K�������F2005/07/09(�y) 17:54:07 ID:ciU6C++3
>>524
����ȊǗ����Â��Ƃ���ō���Ă���RSX���Ă��������D�D�D�B
����ȊǗ����Â��Ƃ���ō���Ă���RSX���Ă��������D�D�D�B
526 �F����������K�������F2005/07/09(�y) 18:13:29 ID:ZWjyKR6F
>>525
��p�ō���Ă���^�Q�[���@�̘b����
PS3�̒��̐l������̂�SONY�iCell+RSX)��IBM�iCell)����
�[��RSX�́h�m���ȃ��[�N���h�Ȃ���̃p�b�P�ʐ^�ȊO�ɉ����Ȃ�
��p�ō���Ă���^�Q�[���@�̘b����
PS3�̒��̐l������̂�SONY�iCell+RSX)��IBM�iCell)����
�[��RSX�́h�m���ȃ��[�N���h�Ȃ���̃p�b�P�ʐ^�ȊO�ɉ����Ȃ�
527 �F����������K�������F2005/07/09(�y) 18:36:05 ID:VoOMGPL4
NEC�Ő�������̕��̉\�͑S�R�`����Ă��Ȃ���
���[��[�ꍇ�͏����ɂ����Ă�؋�����
���[��[�ꍇ�͏����ɂ����Ă�؋�����
528 �F����������K�������F2005/07/09(�y) 19:26:33 ID:6RKdsQMI
>>468
���҂͂Ƃ������A�������l���Č������]���ɂ��ėp����ێ琫��D�悷��̂�
���ʂł��������Ƃ�������
�����Ȃ�v���O�������̂��̂ł͂Ȃ��A�h�L�������g��f�[�^�A�ڍd�l�̕���
���|�I�ɏd�v����Ȃ����H�ǂ����R�[�h�͂��̂܂܂���g���Ȃ����A�ڍׂȃh�L�������g��
���f�[�^������ΈڐA�v���O�������̂͑債�ē���������낤
�܂��A�ėp����ێ琫�ɂ������āA�S�Ă�Cell�x�b�^���ɂ���K�v�͖����̂�����
���������K�v�ȕ��������Ή�����悤�ɂ���A����Ȃɋ]���ɂȂ�Ƃ��v���Ȃ���
���҂͂Ƃ������A�������l���Č������]���ɂ��ėp����ێ琫��D�悷��̂�
���ʂł��������Ƃ�������
�����Ȃ�v���O�������̂��̂ł͂Ȃ��A�h�L�������g��f�[�^�A�ڍd�l�̕���
���|�I�ɏd�v����Ȃ����H�ǂ����R�[�h�͂��̂܂܂���g���Ȃ����A�ڍׂȃh�L�������g��
���f�[�^������ΈڐA�v���O�������̂͑債�ē���������낤
�܂��A�ėp����ێ琫�ɂ������āA�S�Ă�Cell�x�b�^���ɂ���K�v�͖����̂�����
���������K�v�ȕ��������Ή�����悤�ɂ���A����Ȃɋ]���ɂȂ�Ƃ��v���Ȃ���
529 �F����������K�������F2005/07/09(�y) 19:27:36 ID:f/naLqaw
>>527
�܂��S�R����ĂȂ�����A�S�R�`����Ă��Ȃ��B
�ł��A�{����R500���C�����ɐv�ύX����������A
NEC���̐����ɂ��e���͂��邩���B
�܂��S�R����ĂȂ�����A�S�R�`����Ă��Ȃ��B
�ł��A�{����R500���C�����ɐv�ύX����������A
NEC���̐����ɂ��e���͂��邩���B
530 �F����������K�������F2005/07/09(�y) 20:13:04 ID:lrLRvyX6
>>528
���������b�����܂�����ŁA
���Q�[���ƊE�Ȃ�ăn�[�h����ւ��Ήߋ���
���Y�Ȃ�Ďg�����ɂȂ�Ȃ��Ȃ�
�Ƃ����͈̂Ⴄ��H�ƌ����Ă��B
�Q�[���G���W�����ŃJ���J���̍œK�����K�v���Ƃ͎v���Ȃ����A
�G���W�������Ǝd�l�͕�����Ղ�������ׂ������B
�ŁACell�A�[�L�e�N�`�����ǂꂾ���ėp�������]���ɂ��邩��
������Ƒz���t���Ȃ��B���A����肩�͈ˑ������������B
���݂ɁAC++��X�}�[�g�|�C���^�͎^���h�H���Δh�H���͐��i�h�B
�Ƃ���~�h���E�F�A�ł́A���낵���N���X�̃l�X�g���[���\���ɂȂ��Ă�B
�ł��A�p�t�H�[�}���X�͑S�R������ˁB
�����̖ʂ��猾���ƁA�R�[�h�ł̍œK���Ȃ�āA�]���n�[�h���ȕ����ȊO�̓i���Z���X�����A
�������������ɂȂ��ė��Ă�Ǝv�����B�N�̎���ł͂�������Ȃ��H
���������b�����܂�����ŁA
���Q�[���ƊE�Ȃ�ăn�[�h����ւ��Ήߋ���
���Y�Ȃ�Ďg�����ɂȂ�Ȃ��Ȃ�
�Ƃ����͈̂Ⴄ��H�ƌ����Ă��B
�Q�[���G���W�����ŃJ���J���̍œK�����K�v���Ƃ͎v���Ȃ����A
�G���W�������Ǝd�l�͕�����Ղ�������ׂ������B
�ŁACell�A�[�L�e�N�`�����ǂꂾ���ėp�������]���ɂ��邩��
������Ƒz���t���Ȃ��B���A����肩�͈ˑ������������B
���݂ɁAC++��X�}�[�g�|�C���^�͎^���h�H���Δh�H���͐��i�h�B
�Ƃ���~�h���E�F�A�ł́A���낵���N���X�̃l�X�g���[���\���ɂȂ��Ă�B
�ł��A�p�t�H�[�}���X�͑S�R������ˁB
�����̖ʂ��猾���ƁA�R�[�h�ł̍œK���Ȃ�āA�]���n�[�h���ȕ����ȊO�̓i���Z���X�����A
�������������ɂȂ��ė��Ă�Ǝv�����B�N�̎���ł͂�������Ȃ��H
531 �F����������K�������F2005/07/09(�y) 20:29:05 ID:NzOsoaOg
SPE�����ɍœK�����ꂽ���C�u�������������\�œ��삷��A
�J���҂͍�������PPE�R�[�h�����������ł悭�Ȃ�A�Ƃ����l����������Ǝv�����ǂˁB
Cell�ˑ��̃R�[�h���Ǐ����ł��Ȃ��A�Ƃ������Ƃ͂Ȃ��̂ŁA�v�͏������A�g�������Ǝv�����ǁB
�J���҂͍�������PPE�R�[�h�����������ł悭�Ȃ�A�Ƃ����l����������Ǝv�����ǂˁB
Cell�ˑ��̃R�[�h���Ǐ����ł��Ȃ��A�Ƃ������Ƃ͂Ȃ��̂ŁA�v�͏������A�g�������Ǝv�����ǁB
532 �F����������K�������F2005/07/09(�y) 20:32:33 ID:6RKdsQMI
>>530
��[�A����Ȃ�J���J���̍œK�����K�v����Ȃ�������PPE�ŏ��������
������Ȃ����ȁHCell��PPE�܂Ŋ܂߂�Cell�Ȃ̂���
�ŁASPE�����p�ł��镔���̓��[�`���P�ʂ�SPE�ɓ�����悤�ɂ���A����y��
�������\�@��
���Ȃ݂ɁAC++��X�}�[�g�|�C���^�͎^���h����A�������X�}�[�g�|�C���^�Ƀx�b�^��
���邮�炢�Ȃ�ʂ̌���g���h������
���ƁA�N���X�̃l�X�g���Čp���W�̎��Ȃ�A��������v����Ă���A���z����
��ʂɎg��Ȃ�����A������l�X�g���Ă��p�t�H�[�}���X�ւ̉e���͑債���������̂ł́H
�v���O���~���O�̎�ԂƂ�����������l����A�n�[�h�E�F�A�x�b�^���̍œK��������̂�
�i���Z���X�ƌ������͂킩�邯�ǁA�n�[�h�\�͂���������Ɗ��p���鎖���]�܂��Q�[��
�v���O���~���O�ł̓i���Z���X�Ƃ͎v��Ȃ��Ȃ�
�����A�y�ɑg�߂�ɉz�������͖������ǂ�
��[�A����Ȃ�J���J���̍œK�����K�v����Ȃ�������PPE�ŏ��������
������Ȃ����ȁHCell��PPE�܂Ŋ܂߂�Cell�Ȃ̂���
�ŁASPE�����p�ł��镔���̓��[�`���P�ʂ�SPE�ɓ�����悤�ɂ���A����y��
�������\�@��
���Ȃ݂ɁAC++��X�}�[�g�|�C���^�͎^���h����A�������X�}�[�g�|�C���^�Ƀx�b�^��
���邮�炢�Ȃ�ʂ̌���g���h������
���ƁA�N���X�̃l�X�g���Čp���W�̎��Ȃ�A��������v����Ă���A���z����
��ʂɎg��Ȃ�����A������l�X�g���Ă��p�t�H�[�}���X�ւ̉e���͑債���������̂ł́H
�v���O���~���O�̎�ԂƂ�����������l����A�n�[�h�E�F�A�x�b�^���̍œK��������̂�
�i���Z���X�ƌ������͂킩�邯�ǁA�n�[�h�\�͂���������Ɗ��p���鎖���]�܂��Q�[��
�v���O���~���O�ł̓i���Z���X�Ƃ͎v��Ȃ��Ȃ�
�����A�y�ɑg�߂�ɉz�������͖������ǂ�
533 �F����������K�������F2005/07/09(�y) 20:36:14 ID:4a2cobSq
�w�b�h���[���I
�w�b�h���[���I
�w�b�h���[���I
534 �F����������K�������F2005/07/09(�y) 20:46:33 ID:pJ6EbQPz
���������Max Headroom���Ă������Ȃ�
535 �F����������K�������F2005/07/09(�y) 20:52:18 ID:lrLRvyX6
>>532
��SPE�����p�ł��镔���̓��[�`���P�ʂ�SPE�ɓ�����悤�ɂ���A����y��
�������\
���������ł���̂ł���A�������ǁB
�X�N���b�`�p�b�h�X�^�b�N�̂悤�ɁA�R�[�h�T�C�Y���I�[�o�[�����r�[�\���B�Ƃ��͊��ق��ė~�����B
�����z�����ʂɎg��Ȃ�����A������l�X�g���Ă��p�t�H�[�}���X�ւ̉e���͑債���������̂ł́H
���������ǁA���邳���l�͍ی��Ȃ��������ˁB
���n�[�h�\�͂���������Ɗ��p���鎖���]�܂��Q�[��
�v���O���~���O�ł̓i���Z���X�Ƃ͎v��Ȃ��Ȃ�
���Ȃ��Ƃ��A���̍����Q�[���̃��x���ƃn�[�h�\�͂���l����A
�c�ȃR�[�h�����Ȃ��Ƃ����Ȃ��悤�ȃP�[�X�́A�����͂Ȃ����ƁB
������łǂ��ς��̂��͂킩��Ȃ����ǁA����̗�����t�����ė~�����͖����ȁB�ƁB
��SPE�����p�ł��镔���̓��[�`���P�ʂ�SPE�ɓ�����悤�ɂ���A����y��
�������\
���������ł���̂ł���A�������ǁB
�X�N���b�`�p�b�h�X�^�b�N�̂悤�ɁA�R�[�h�T�C�Y���I�[�o�[�����r�[�\���B�Ƃ��͊��ق��ė~�����B
�����z�����ʂɎg��Ȃ�����A������l�X�g���Ă��p�t�H�[�}���X�ւ̉e���͑債���������̂ł́H
���������ǁA���邳���l�͍ی��Ȃ��������ˁB
���n�[�h�\�͂���������Ɗ��p���鎖���]�܂��Q�[��
�v���O���~���O�ł̓i���Z���X�Ƃ͎v��Ȃ��Ȃ�
���Ȃ��Ƃ��A���̍����Q�[���̃��x���ƃn�[�h�\�͂���l����A
�c�ȃR�[�h�����Ȃ��Ƃ����Ȃ��悤�ȃP�[�X�́A�����͂Ȃ����ƁB
������łǂ��ς��̂��͂킩��Ȃ����ǁA����̗�����t�����ė~�����͖����ȁB�ƁB
536 �F����������K�������F2005/07/09(�y) 20:56:16 ID:xv7Mqf2i
>>530
�h�Q�[���h�ƈꊇ��ɂ��Ă��邪
30�t���[���ŗǂ�2D��RPG��
60�t�B�[���h�o�͂����߂���
3D�̃X�|�[�c��A�N�V�����ł�
�œK���̕K�v���͓����Ɍ��Ȃ��̂ł́H
�h�Q�[���h�ƈꊇ��ɂ��Ă��邪
30�t���[���ŗǂ�2D��RPG��
60�t�B�[���h�o�͂����߂���
3D�̃X�|�[�c��A�N�V�����ł�
�œK���̕K�v���͓����Ɍ��Ȃ��̂ł́H
537 �F����������K�������F2005/07/09(�y) 21:13:59 ID:dSegLIo0
538 �F����������K�������F2005/07/09(�y) 21:20:39 ID:6RKdsQMI
>>535
���X�N���b�`�p�b�h�X�^�b�N�̂悤�ɁA�R�[�h�T�C�Y���I�[�o�[�����r�[�\���B�Ƃ��͊��ق��ė~�����B
�������Ƀt����C,C++���T�|�[�g����Ă�����Ȃ̂�����A����Ȏ��͖����Ǝv�����ǂ�
IBM��SCE�Ɠ��ł��ǂ��܂Ńv���O���~���O���𐮂��邩���悾��IBM��Cell�u���[�h
�T�[�o�[������Ă�̂�����A����Ȃɍ������ƌ������͖����Ǝv����A
�������l�I�Ȑ���(�ϑz)�����ǂ�
�������ɁA��PS3��G���悤�Ȑl����̃��[�N�͂��肦�Ȃ����낤��
������̗�����t�����ė~�����͖����ȁB�ƁB
���z�Ō������������ǁA������x�̍œK���͂ǂ�ȕ��ɂł��t����������˂�
�R���p�C�����f���炵�������Ȃ��Ă����A�����I�ɂ͂����Ȃ�̂�������Ȃ������
TLP�Ɍ��������錻��ł��A�Y��ɃX���b�h�������Ă����R���p�C���Ȃ�Ė������
���\������Ȃɋ��߂Ȃ��Ȃ�\�Ȃ낤���ǁA�Q�[�����Ƃǂ����Ă����\��ǂ����߂�
�����ɂȂ����Ⴄ���낤��
���X�N���b�`�p�b�h�X�^�b�N�̂悤�ɁA�R�[�h�T�C�Y���I�[�o�[�����r�[�\���B�Ƃ��͊��ق��ė~�����B
�������Ƀt����C,C++���T�|�[�g����Ă�����Ȃ̂�����A����Ȏ��͖����Ǝv�����ǂ�
IBM��SCE�Ɠ��ł��ǂ��܂Ńv���O���~���O���𐮂��邩���悾��IBM��Cell�u���[�h
�T�[�o�[������Ă�̂�����A����Ȃɍ������ƌ������͖����Ǝv����A
�������l�I�Ȑ���(�ϑz)�����ǂ�
�������ɁA��PS3��G���悤�Ȑl����̃��[�N�͂��肦�Ȃ����낤��
������̗�����t�����ė~�����͖����ȁB�ƁB
���z�Ō������������ǁA������x�̍œK���͂ǂ�ȕ��ɂł��t����������˂�
�R���p�C�����f���炵�������Ȃ��Ă����A�����I�ɂ͂����Ȃ�̂�������Ȃ������
TLP�Ɍ��������錻��ł��A�Y��ɃX���b�h�������Ă����R���p�C���Ȃ�Ė������
���\������Ȃɋ��߂Ȃ��Ȃ�\�Ȃ낤���ǁA�Q�[�����Ƃǂ����Ă����\��ǂ����߂�
�����ɂȂ����Ⴄ���낤��
539 �F����������K�������F2005/07/09(�y) 21:22:27 ID:6RKdsQMI
>>536
���n�[�h�\�͂���������Ɗ��p���鎖���]�܂��Q�[�� "��"�v���O���~���O�ł�
�ƌ�������
2DRPG�Ȃł́A���ꂱ��SPE�g��Ȃ��Ă��\��������قǂ̃p���[�����邾�낤��
���n�[�h�\�͂���������Ɗ��p���鎖���]�܂��Q�[�� "��"�v���O���~���O�ł�
�ƌ�������
2DRPG�Ȃł́A���ꂱ��SPE�g��Ȃ��Ă��\��������قǂ̃p���[�����邾�낤��
540 �F����������K�������F2005/07/09(�y) 21:56:23 ID:AlTZ22OS
>>537
�Ȃ�CPU�Ɋւ��Ă͂ǂ������{���J�X�Ɍ����Ă܂��ȁB
XBOX360��CPU���߰����\�i��۸�߯��j�d���APen4�AAthlon64�N���X�ɋy�Ȃ������\
Cell��SPE�͂���܂�g���Ȃ��ADMA�͒x���BLS��������PPE���Ⴆ�Ȃ��B
�J������PS��PS2�̑听��������������A�ςȱ���ł��J���҂͋C�ɂ����ɃQ�[���J�����邾�낤
XBOX360�͊J���҂̗v�]���܂����Ă��̂ɁA�����o�Ă�����]��ł����̂���Ȃ������B�}���`�R�A�Ȃ�Ă���Ȃ��̂ɁE�E�E
GPU��RSX����������ς�90nm��G70�B�o���͂����Ԃ�ǂ��B
1080p���ڕW�����A�w�ǂ̊J���҂�720p��ڕW�ɂ��Ă�BAAx4�͂���܂�d�v�ł͂Ȃ��B
Xenon�������炵���BRSX�Ɠ������炢
�Ȃ�CPU�Ɋւ��Ă͂ǂ������{���J�X�Ɍ����Ă܂��ȁB
XBOX360��CPU���߰����\�i��۸�߯��j�d���APen4�AAthlon64�N���X�ɋy�Ȃ������\
Cell��SPE�͂���܂�g���Ȃ��ADMA�͒x���BLS��������PPE���Ⴆ�Ȃ��B
�J������PS��PS2�̑听��������������A�ςȱ���ł��J���҂͋C�ɂ����ɃQ�[���J�����邾�낤
XBOX360�͊J���҂̗v�]���܂����Ă��̂ɁA�����o�Ă�����]��ł����̂���Ȃ������B�}���`�R�A�Ȃ�Ă���Ȃ��̂ɁE�E�E
GPU��RSX����������ς�90nm��G70�B�o���͂����Ԃ�ǂ��B
1080p���ڕW�����A�w�ǂ̊J���҂�720p��ڕW�ɂ��Ă�BAAx4�͂���܂�d�v�ł͂Ȃ��B
Xenon�������炵���BRSX�Ɠ������炢
541 �F����������K�������F2005/07/09(�y) 22:14:57 ID:b3diNHad
DMA���x���Ƃ��N�������Ă�́H���̒��ɂ���l���H
542 �F����������K�������F2005/07/09(�y) 22:19:11 ID:6RKdsQMI
��Ƃ��ČӎU��������
�}���`�R�A�ɂ��Ȃ��ł����\���オ�����߂�Ȃ�Ƃ������A�N���b�N���オ��Ȃ�
����A�ǂ��ɂ��Ȃ�Ȃ��Ɖ����Ă邾�낤�ɁE�E�E
RSX���^�[�{�L���b�V���ς�G70�Ƃ������͋C�ɂȂ����ǂ�
�}���`�R�A�ɂ��Ȃ��ł����\���オ�����߂�Ȃ�Ƃ������A�N���b�N���オ��Ȃ�
����A�ǂ��ɂ��Ȃ�Ȃ��Ɖ����Ă邾�낤�ɁE�E�E
RSX���^�[�{�L���b�V���ς�G70�Ƃ������͋C�ɂȂ����ǂ�
543 �F����������K�������F2005/07/09(�y) 22:20:34 ID:b3diNHad
From those that have had experience with the PS3 development kits,
this access takes far too long to be used in many real world scenarios.
�������ꂩ�Breal world scenarios�Ƃ��������������ȁB
this access takes far too long to be used in many real world scenarios.
�������ꂩ�Breal world scenarios�Ƃ��������������ȁB
544 �F����������K�������F2005/07/09(�y) 22:24:09 ID:NzOsoaOg
Cell�͂Ƃ������A360 CPU���Ȃ����łɂ���PPC970�R�A�����V���O���X���b�h���\�̒Ⴂ
(���N���b�N�Ŕ���?)PPE���̗p�����̂��A�Ƃ����^��͊m���ɂ���B
(���N���b�N�Ŕ���?)PPE���̗p�����̂��A�Ƃ����^��͊m���ɂ���B
545 �F����������K�������F2005/07/09(�y) 22:30:14 ID:rlUn9Seb
>>544
�T�C�Y���ł������A�����M�ɂȂ邩�炾��BPPEx3�ł�����ƌ����Ă����B
�T�C�Y���ł������A�����M�ɂȂ邩�炾��BPPEx3�ł�����ƌ����Ă����B
546 �F����������K�������F2005/07/09(�y) 22:32:24 ID:NzOsoaOg
�s�[�N���\�͎̂ĂāA970�R�A+��e��L2�L���b�V���ŏ�������̂��B
����ł����J���҂̂��߂̃n�[�h�E�F�A�ł��낤�B
�܂��A������₵�����B
����ł����J���҂̂��߂̃n�[�h�E�F�A�ł��낤�B
�܂��A������₵�����B
547 �F����������K�������F2005/07/09(�y) 22:34:28 ID:ucjV/EDl
PPE 3�� ���āA�ނ���o�����X�����������ˁE�E
SIMD���Z�������������Ȃ�ACell���������A
�R�A�Ƃ��Ă̐��\��L���Ȃ� �ȗ���������G5�����Ăł�3�ڂ���Ηǂ������B
�������A������������ PS3��xenon��CPU���ڂ��Ă��\�����������킯����ȁA�����̐v�Ăł́E�E
SIMD���Z�������������Ȃ�ACell���������A
�R�A�Ƃ��Ă̐��\��L���Ȃ� �ȗ���������G5�����Ăł�3�ڂ���Ηǂ������B
�������A������������ PS3��xenon��CPU���ڂ��Ă��\�����������킯����ȁA�����̐v�Ăł́E�E
548 �F����������K�������F2005/07/09(�y) 22:34:44 ID:AlTZ22OS
>>544
The one statement that we heard over and over again was that Microsoft was sold on the peak theoretical performance of the Xenon CPU.
�ɗ̓R�X�g���������A�s�[�N���\���d���������炶��ˁH
VMX�ŊȒP�Ƀs�[�N���\����UP
The one statement that we heard over and over again was that Microsoft was sold on the peak theoretical performance of the Xenon CPU.
�ɗ̓R�X�g���������A�s�[�N���\���d���������炶��ˁH
VMX�ŊȒP�Ƀs�[�N���\����UP
549 �F����������K�������F2005/07/09(�y) 22:40:08 ID:ZG3KC3T0
>>540
�������́A�Q�[���v���O�����̎��s��z�肵����Œ��J��
���͂��Ă�̂Ɂi���̒��g�́A���̃X����Cell�X���Ő�������Ă������Ƃɋ߂��j
��XBOX360��CPU���߰����\�i��۸�߯��j�d���APen4�AAthlon64�N���X�ɋy�Ȃ������\
��Cell��SPE�͂���܂�g���Ȃ��ADMA�͒x���BLS��������PPE���Ⴆ�Ȃ��B
�����̒Ⴂ�v��Ȃ�B�v�����Č��n�����������B
�������́A�Q�[���v���O�����̎��s��z�肵����Œ��J��
���͂��Ă�̂Ɂi���̒��g�́A���̃X����Cell�X���Ő�������Ă������Ƃɋ߂��j
��XBOX360��CPU���߰����\�i��۸�߯��j�d���APen4�AAthlon64�N���X�ɋy�Ȃ������\
��Cell��SPE�͂���܂�g���Ȃ��ADMA�͒x���BLS��������PPE���Ⴆ�Ȃ��B
�����̒Ⴂ�v��Ȃ�B�v�����Č��n�����������B
550 �F����������K�������F2005/07/09(�y) 22:41:54 ID:AlTZ22OS
551 �F����������K�������F2005/07/09(�y) 22:41:55 ID:NzOsoaOg
SPE��DMA�͗��x���r���̂�(128�o�C�g������?)�A
���ʂɃ��C����������4�o�C�g�����A�N�Z�X�������Ƃ��́u�x���v���낤�B
���ʂɃ��C����������4�o�C�g�����A�N�Z�X�������Ƃ��́u�x���v���낤�B
552 �F����������K�������F2005/07/09(�y) 22:44:11 ID:eHrj/6rM
MS-Intel�Ԃ̌����s���ɏI���
��
IBM�Ƃ̌��ɋً}�ɐ�ւ�
��
PPC970����Q�[���@�ɂ���Ȃ��������J�b�g���K�v�ȋ@�\���g���������̂��I�[�_�[
��
�Q�[���@�ɕs�v�ȕ������J�b�g�������̂�PPE�Ȃ炠�邪�A�g���ƂȂ�Ɛv�̎��Ԃ�������
��
PPE*3�̃}���`�R�A�őΉ�
����Ȋ�������ˁH
��
IBM�Ƃ̌��ɋً}�ɐ�ւ�
��
PPC970����Q�[���@�ɂ���Ȃ��������J�b�g���K�v�ȋ@�\���g���������̂��I�[�_�[
��
�Q�[���@�ɕs�v�ȕ������J�b�g�������̂�PPE�Ȃ炠�邪�A�g���ƂȂ�Ɛv�̎��Ԃ�������
��
PPE*3�̃}���`�R�A�őΉ�
����Ȋ�������ˁH
553 �F����������K�������F2005/07/09(�y) 22:46:39 ID:NzOsoaOg
970�R�A��Apple�Ƃ̗��݂ŁA�Q�[���@�p�̒l�i�ł͔���Ȃ��̂��������ˁB
554 �F����������K�������F2005/07/09(�y) 22:49:12 ID:AlTZ22OS
>>552
PS3��GPU�݂����Ȋ������B
cellGPU�̃p�t�H�[�}���X�����܂��낵���Ȃ�
��
Nvidia�Ƃ̌��ɋً}�ɐ�ւ�
��
cell�Ƌ�������ł���V����GPU���I�[�_�[
��
6800�̉��ǔł�G70�Ȃ炠�邪�A�V�v�ƂȂ�Ɛv�̎��Ԃ�������
��
G70�N���b�N�A�b�v�łőΉ�
PS3��GPU�݂����Ȋ������B
cellGPU�̃p�t�H�[�}���X�����܂��낵���Ȃ�
��
Nvidia�Ƃ̌��ɋً}�ɐ�ւ�
��
cell�Ƌ�������ł���V����GPU���I�[�_�[
��
6800�̉��ǔł�G70�Ȃ炠�邪�A�V�v�ƂȂ�Ɛv�̎��Ԃ�������
��
G70�N���b�N�A�b�v�łőΉ�
555 �F����������K�������F2005/07/09(�y) 22:52:14 ID:znyot5Sh
cell��GPU�ɂ���������Ɛ��\�łȂ�������
���̉p���ł̓{���J�X�ɂ����Ă邩��
nvidia�͂����d��������
���̉p���ł̓{���J�X�ɂ����Ă邩��
nvidia�͂����d��������
556 �F����������K�������F2005/07/09(�y) 22:57:48 ID:ucjV/EDl
���ہARSX�� �v�����\���\�ɖ������Ă邾�낤�H
�����v����B�Q�[������҂��������S�����̂ł́B
�ň��ł��A�ǂ�ȋZ�p�s���ȉ�Ђł�PPE��RSX�����Ȃ爵���邾�낤�B
PPE�����ł�P4��荂���\�Ȃ�H
�����v����B�Q�[������҂��������S�����̂ł́B
�ň��ł��A�ǂ�ȋZ�p�s���ȉ�Ђł�PPE��RSX�����Ȃ爵���邾�낤�B
PPE�����ł�P4��荂���\�Ȃ�H
557 �F����������K�������F2005/07/09(�y) 22:58:01 ID:LXeiiPIZ
����O�ɶ��̋L�������
���̋L�����������z�͌㓡�ȉ���
�O�m���̎����傾�Ə������o��������
���̋L�����������z�͌㓡�ȉ���
�O�m���̎����傾�Ə������o��������
558 �F����������K�������F2005/07/09(�y) 23:04:29 ID:5CQ9jR+P
���ʂɍl���ė��҂̃p�t�H�[�}���X���ڍׂɒm���Ăă��[�N�����Ȃ�Ă��Ȃ�����
559 �F����������K�������F2005/07/09(�y) 23:05:19 ID:AlTZ22OS
560 �F����������K�������F2005/07/09(�y) 23:05:45 ID:NzOsoaOg
����Ȃ̂͂��̃X�������Ĉꏏ��
561 �F����������K�������F2005/07/09(�y) 23:09:25 ID:znyot5Sh
Attend����Ƃ������ɍڂ����L�����H
562 �F����������K�������F2005/07/09(�y) 23:49:28 ID:0dRvHwSz
������m���Ȏ���ID:AlTZ22OS��ID:oycdOqFP�ȉ��̃c�}��������t�����Ă��Ƃ��B
563 �F����������K�������F2005/07/10(��) 01:38:18 ID:yL6T4WTd
>>556
�Ƃ�����RSX�͋��N�܂ł�SCE�̔�������
���Ԃ�������܂��ш�P�`����eDRAM��������C�������ۂ����ȁB
���ʓI�ɃR�X�g���ł����W�b�N���ڃ`�b�v�ς̂̓Q�[�}�[�I�Ɍ�̎��B
�Ƃ�����RSX�͋��N�܂ł�SCE�̔�������
���Ԃ�������܂��ш�P�`����eDRAM��������C�������ۂ����ȁB
���ʓI�ɃR�X�g���ł����W�b�N���ڃ`�b�v�ς̂̓Q�[�}�[�I�Ɍ�̎��B
564 �F����������K�������F2005/07/10(��) 01:46:58 ID:RmUTmFy8
���Ă����ʂɍl����CELL�ւڂł��傤�H
565 �F����������K�������F2005/07/10(��) 01:49:42 ID:pMmXtq6z
RmUTmFy8�@���@oycdOqFP
���B�����̐l���B�@�L�~�̔]���ł̓w�{�Ȃ낤�Ȃ���
���B�����̐l���B�@�L�~�̔]���ł̓w�{�Ȃ낤�Ȃ���
566 �F����������K�������F2005/07/10(��) 01:55:07 ID:uKMPKnBC
MS���čŏ��̓C���e��CPU�ōs�����Ƃ��Ă��́H
567 �F����������K�������F2005/07/10(��) 02:03:37 ID:pMmXtq6z
�@��
568 �F����������K�������F2005/07/10(��) 02:04:00 ID:AERAYsFo
>>567
�H
�H
569 �F����������K�������F2005/07/10(��) 02:09:03 ID:xapwisCe
>>566
Intel�̐l���̎Z������Ȃ�����ƍ~�肽�Ƃ̋L����ǂ��Ƃ�����B
Intel�̐l���̎Z������Ȃ�����ƍ~�肽�Ƃ̋L����ǂ��Ƃ�����B
570 �F����������K�������F2005/07/10(��) 02:21:49 ID:Z9uiFo7N
����Intel�`�b�v���Ƃ�����PenD�悹���鏊�������낤����
���[�U�[�Ƃ��Ă�Intel���R���Ă���ď���������Ȃ��H
���[�U�[�Ƃ��Ă�Intel���R���Ă���ď���������Ȃ��H
571 �F����������K�������F2005/07/10(��) 02:25:23 ID:uKMPKnBC
PS4�ł� �ŏ�����IBM�EnVIDIA�Ƌ��͂��Ă���Ăق����B
572 �F����������K�������F2005/07/10(��) 03:17:48 ID:G7pKTaot
>>556
PPE�������Ɗm����P4�ɕ�����AVMX�����ł̔���PPE�ɂ�����������B
PPE�������Ɗm����P4�ɕ�����AVMX�����ł̔���PPE�ɂ�����������B
573 �F����������K�������F2005/07/10(��) 03:20:03 ID:SnqYBU76
�N�^�̘b����RSX��NVIDIA�Ƒg�ނ��Ƃ̑����݂����Ȃ��ƌ����Ă����B
IBM�̕��В������o�̃C���^�r���[�ŁA����Cell�̑��̐v�v�z
�ɂ��ă\�j�[�Ƌc�_���n�߂��Ƃ������Ă��B
���ۂ�5�N��̂��̐��E���ǂ��Ȃ邩�Ȃ�đS���킩��B
IBM�̕��В������o�̃C���^�r���[�ŁA����Cell�̑��̐v�v�z
�ɂ��ă\�j�[�Ƌc�_���n�߂��Ƃ������Ă��B
���ۂ�5�N��̂��̐��E���ǂ��Ȃ邩�Ȃ�đS���킩��B
574 �F����������K�������F2005/07/10(��) 03:25:11 ID:JsMbxSIG
>>572
������PPC��Cell��PPE���ăX�y�b�N�I�ɂ�
���������_���Z�\�͓���������VMX�̂ǂ���ւ�ō������Ă�̂��ȁH
���W�X�^�̖{���H
������PPC��Cell��PPE���ăX�y�b�N�I�ɂ�
���������_���Z�\�͓���������VMX�̂ǂ���ւ�ō������Ă�̂��ȁH
���W�X�^�̖{���H
575 �F����������K�������F2005/07/10(��) 04:23:38 ID:zau2tjeQ
����VMX��32�{����128�{�փ��W�X�^���������Ă邯�ǁA
CELL��VMX�͎d�l�����J����ĂȂ������ׂ悤���Ȃ��B
�����A�X�y�b�N�\����ǂݎ���VMX�̉��Z���\���̂�
�ǂ���������B
CELL��VMX�͎d�l�����J����ĂȂ������ׂ悤���Ȃ��B
�����A�X�y�b�N�\����ǂݎ���VMX�̉��Z���\���̂�
�ǂ���������B
576 �F����������K�������F2005/07/10(��) 06:07:52 ID:DS6FPTKS
����VMX�̃��W�X�^��128�{���Ă̂��悭�킩���̂�B
PowerPC ISA�ł͘_�����W�X�^32�{����Ȃ��ƃt�H�[�}�b�g�I�ɂ܂�����ł́H
������PowerPC970�͕����I�ɂ͂��ꂼ��80�{�������͂������琔���̂͂��������Ȃ��Ǝv�����ǁB
PowerPC ISA�ł͘_�����W�X�^32�{����Ȃ��ƃt�H�[�}�b�g�I�ɂ܂�����ł́H
������PowerPC970�͕����I�ɂ͂��ꂼ��80�{�������͂������琔���̂͂��������Ȃ��Ǝv�����ǁB
577 �F����������K�������F2005/07/10(��) 07:47:19 ID:M/o5EqWn
http://pc.watch.impress.co.jp/docs/2005/0514/kaigai178.htm
> VMX���̂��g������Ă���BPowerPC�n��VMX�́A���Ƃ���128bit���W�X�^��
> 32�{�����Ă����B�������AXenon CPU��VMX�́A�eCPU�R�A��128�{��VMX���W�X
> �^(VRF)������B���L����Ă��Ȃ����A����͕������W�X�^�����łȂ��_����
> �W�X�^��128�{�ɂȂ��Ă���ƌ�����B
���̏��������ƁA���ɍ����͂Ȃ���Ȃ����Ƃ����C���c
> VMX���̂��g������Ă���BPowerPC�n��VMX�́A���Ƃ���128bit���W�X�^��
> 32�{�����Ă����B�������AXenon CPU��VMX�́A�eCPU�R�A��128�{��VMX���W�X
> �^(VRF)������B���L����Ă��Ȃ����A����͕������W�X�^�����łȂ��_����
> �W�X�^��128�{�ɂȂ��Ă���ƌ�����B
���̏��������ƁA���ɍ����͂Ȃ���Ȃ����Ƃ����C���c
578 �F����������K�������F2005/07/10(��) 09:10:15 ID:YMCzGSHk
CELL��VMX��32�{(IBM�̃T�C�g���ǂ����Ō����L���L��)�AXenon�̂�128�{(���[�N����)�B
579 �F����������K�������F2005/07/10(��) 09:36:53 ID:M/o5EqWn
360 CPU��VMX�̃��W�X�^128�{�͌����ɔ��\����Ă����ǂ��A
���X��VMX�̖��߃t�H�[�}�b�g�̓��W�X�^32�{�p������A�ǂ��Ή����Ă�낤��? �Ƃ����b�B
���W�X�^�w���5bit��7bit�Ɋg������VMX���߂Ȃ̂��Aregister renaming�ňÖقɎg���̂��B
���X��VMX�̖��߃t�H�[�}�b�g�̓��W�X�^32�{�p������A�ǂ��Ή����Ă�낤��? �Ƃ����b�B
���W�X�^�w���5bit��7bit�Ɋg������VMX���߂Ȃ̂��Aregister renaming�ňÖقɎg���̂��B
580 �F����������K�������F2005/07/10(��) 09:56:28 ID:THuGnuOd
�Q�[���@�p�ɖ��߃Z�b�g�g�������Ⴂ���͖�����
581 �F����������K�������F2005/07/10(��) 10:26:06 ID:M/o5EqWn
���W�X�^7bit�ɂ����Ⴄ��PowerPC�̖��߃t�H�[�}�b�g�����E�����ɁA
VMX���ă\�[�X3�A�f�X�e�B�l�[�V����1��4���W�X�^�w�肷���ŁA
opcode�Ƃ��킹��32bit�ɂ����܂�Ȃ��B
�J�X�^�����ߒlj��̂悤�ɂ͊ȒP�Ɋg���ł��Ȃ��ł���B
���߃Z�b�g�͂��̂܂܂ɁA970��32+48������VMX���W�X�^���A
32+96�ɑ��₵���ƍl����̂��Ó��ł͂Ȃ����ƁB
�ǂ̒��x�g����̂��͂킩��܂��B
�㓡�^���A���ɂ��uXenon��PPC970�R�A�̃J�X�^���Łv�Ƃ������Ă��肷����(�܂���������
�Ȃ�)�A360�l�^�͂����������Ă����ۂ��Ȋ����B
VMX���ă\�[�X3�A�f�X�e�B�l�[�V����1��4���W�X�^�w�肷���ŁA
opcode�Ƃ��킹��32bit�ɂ����܂�Ȃ��B
�J�X�^�����ߒlj��̂悤�ɂ͊ȒP�Ɋg���ł��Ȃ��ł���B
���߃Z�b�g�͂��̂܂܂ɁA970��32+48������VMX���W�X�^���A
32+96�ɑ��₵���ƍl����̂��Ó��ł͂Ȃ����ƁB
�ǂ̒��x�g����̂��͂킩��܂��B
�㓡�^���A���ɂ��uXenon��PPC970�R�A�̃J�X�^���Łv�Ƃ������Ă��肷����(�܂���������
�Ȃ�)�A360�l�^�͂����������Ă����ۂ��Ȋ����B
582 �F����������K�������F2005/07/10(��) 10:36:20 ID:7Zem9daS
�㓡�^����Xenon�Ɋ�肷�����Ǝv�����ǂȁE�E�E�L���Ƃ��Ă͖ʔ��������m��ARSX�������Ɨ���Ă�悤�ȍ��o���N��������
583 �F����������K�������F2005/07/10(��) 10:38:00 ID:THuGnuOd
�[���Ƃ�Cell��SPE��32+96�Ȃ�
584 �F����������K�������F2005/07/10(��) 10:44:34 ID:M/o5EqWn
Cell��PPE��SIMD���\����������K�v���������AVMX�g����MS�����̕ʃ��j���[�����B
�J�^���O�X�y�b�N�͗��_�s�[�N�l�Ȃ̂ŁA���̂ւ�̍��������Ɍ���ĂȂ��Ă�
�s�v�c�͂Ȃ��B
�J�^���O�X�y�b�N�͗��_�s�[�N�l�Ȃ̂ŁA���̂ւ�̍��������Ɍ���ĂȂ��Ă�
�s�v�c�͂Ȃ��B
585 �F����������K�������F2005/07/10(��) 10:51:04 ID:qCQnxRX/
Cell��SPE��PPC�Ƃ͂܂��������W�B
586 �F����������K�������F2005/07/10(��) 10:55:15 ID:0vpfvpqT
>>582
����͎d���Ȃ���Ȃ��B
RSX�͖w�Ǐ��łĂȂ��݂���������AG70����z�肵���o���Ȃ���
���������̍���������J�ɂ����͂��邾�낤�B
����͎d���Ȃ���Ȃ��B
RSX�͖w�Ǐ��łĂȂ��݂���������AG70����z�肵���o���Ȃ���
���������̍���������J�ɂ����͂��邾�낤�B
587 �F����������K�������F2005/07/10(��) 10:55:57 ID:JsMbxSIG
>>582
�㓡�^����CPU�Ɋւ��ẮACell�ɓ��ꍞ���
GPU�Ɋւ��Ă�Xenos�ɓ��ꍞ��ł邯��
�n�[�h���^�I�ɂ͕��ʂ̎p�ƈႤ���ȁH
���Ɍ㓡����̏ꍇ�A�ߋ��L�������
�����V�F�[�_�͐S�҂��ɂ��Ă����������B
Cell���\�@(߁��)=3 ѯʰ�@�@���@�@�����PentiumD���\�@('A`)
Xenos���\�@(߁��)=3 ѯʰ�@�@���@�@RSX���\�@('A`)
���̋L���̃e���V�����̗����͓ǂ�łď���w
�㓡�^����CPU�Ɋւ��ẮACell�ɓ��ꍞ���
GPU�Ɋւ��Ă�Xenos�ɓ��ꍞ��ł邯��
�n�[�h���^�I�ɂ͕��ʂ̎p�ƈႤ���ȁH
���Ɍ㓡����̏ꍇ�A�ߋ��L�������
�����V�F�[�_�͐S�҂��ɂ��Ă����������B
Cell���\�@(߁��)=3 ѯʰ�@�@���@�@�����PentiumD���\�@('A`)
Xenos���\�@(߁��)=3 ѯʰ�@�@���@�@RSX���\�@('A`)
���̋L���̃e���V�����̗����͓ǂ�łď���w
588 �F����������K�������F2005/07/10(��) 11:03:05 ID:I6N6a8+3
589 �F����������K�������F2005/07/10(��) 11:08:27 ID:6KoMe+gC
>>582
�㓡���͐V�������D��������ȁB
�V�Z�p�Ƀ`�������W�Ƃ��A�Â����M�~�b�N�Ƃ��A���������̂ɖG�����B
���i�̉��l�Ƃ��ẮA�����̋Z�p�ł����܂��܂Ƃߏグ�����̂ق���
�����ꍇ�������āA�ނ����̉��l�͂�����ƔF�߂���ǁA�G���Ȃ��B
�㓡�����V���i�̃��r���[�Ƃ����Ȃ��̂́A�ގ��g������������ƔF�����Ă��邩��
��������Ȃ��B
�㓡���͐V�������D��������ȁB
�V�Z�p�Ƀ`�������W�Ƃ��A�Â����M�~�b�N�Ƃ��A���������̂ɖG�����B
���i�̉��l�Ƃ��ẮA�����̋Z�p�ł����܂��܂Ƃߏグ�����̂ق���
�����ꍇ�������āA�ނ����̉��l�͂�����ƔF�߂���ǁA�G���Ȃ��B
�㓡�����V���i�̃��r���[�Ƃ����Ȃ��̂́A�ގ��g������������ƔF�����Ă��邩��
��������Ȃ��B
590 �F����������K�������F2005/07/10(��) 11:16:37 ID:yAiqpeDg
>>582
�㓡����Xenos�Ώd�ƌ������ǁA���̐��܂����ق�
Cell�Ώd�Ԃ�ɂ���ׂ�A�S�R�����������ƂȂ��ł��B
ttp://pc.watch.impress.co.jp/docs/2005/0208/kaigai153.htm
ttp://pc.watch.impress.co.jp/docs/2005/0209/kaigai154.htm
ttp://pc.watch.impress.co.jp/docs/2005/0211/kaigai155.htm
ttp://pc.watch.impress.co.jp/docs/2005/0212/kaigai156.htm
ttp://pc.watch.impress.co.jp/docs/2005/0212/kaigai157.htm
ttp://pc.watch.impress.co.jp/docs/2005/0218/kaigai158.htm
ttp://pc.watch.impress.co.jp/docs/2005/0225/kaigai159.htm
ttp://pc.watch.impress.co.jp/docs/2005/0228/kaigai160.htm
ttp://pc.watch.impress.co.jp/docs/2005/0308/kaigai163.htm
ttp://pc.watch.impress.co.jp/docs/2005/0310/kaigai165.htm
�㓡����Xenos�Ώd�ƌ������ǁA���̐��܂����ق�
Cell�Ώd�Ԃ�ɂ���ׂ�A�S�R�����������ƂȂ��ł��B
ttp://pc.watch.impress.co.jp/docs/2005/0208/kaigai153.htm
ttp://pc.watch.impress.co.jp/docs/2005/0209/kaigai154.htm
ttp://pc.watch.impress.co.jp/docs/2005/0211/kaigai155.htm
ttp://pc.watch.impress.co.jp/docs/2005/0212/kaigai156.htm
ttp://pc.watch.impress.co.jp/docs/2005/0212/kaigai157.htm
ttp://pc.watch.impress.co.jp/docs/2005/0218/kaigai158.htm
ttp://pc.watch.impress.co.jp/docs/2005/0225/kaigai159.htm
ttp://pc.watch.impress.co.jp/docs/2005/0228/kaigai160.htm
ttp://pc.watch.impress.co.jp/docs/2005/0308/kaigai163.htm
ttp://pc.watch.impress.co.jp/docs/2005/0310/kaigai165.htm
591 �F����������K�������F2005/07/10(��) 11:23:13 ID:YHcfE2Pu
�㓡�݂�PS��肾�������ǁAGPU�������̑z�����Ă��̂Ƃ܂�����������̂������������������݂����B
�ŏ���PS3�X�y�b�N���\���ARSX�������낵�����Xenos���ݾ��U�肪�����ЁB
�������ǂ�����z���ŕM���点�Ă邠�肳�܁B
�ŏ���PS3�X�y�b�N���\���ARSX�������낵�����Xenos���ݾ��U�肪�����ЁB
�������ǂ�����z���ŕM���点�Ă邠�肳�܁B
592 �F����������K�������F2005/07/10(��) 11:42:17 ID:YMCzGSHk
593 �F����������K�������F2005/07/10(��) 11:56:42 ID:JsMbxSIG
>>377�ʼn��C�ɃX���[����Ă邯��
http://www.bit-tech.net/news/2005/07/07/g70_clock_speed/
���̋L���̓��e�A���\�����낵���ˁH
>The clock speeds within the chip are dynamic
>three visible clocks did (that's the ROP clock, pixel clock and geometry clock if you're still playing catchup).
�ȂW�I���g���[���A�s�N�Z�����AROP���̃N���b�N��
���ׂɉ����Ă��ꂼ�ꓮ�I�ɕς��炵���B
�Ȃ܂�Ŕ��N���b�N�`�b�v���v���o�����銴���B
http://www.bit-tech.net/news/2005/07/07/g70_clock_speed/
���̋L���̓��e�A���\�����낵���ˁH
>The clock speeds within the chip are dynamic
>three visible clocks did (that's the ROP clock, pixel clock and geometry clock if you're still playing catchup).
�ȂW�I���g���[���A�s�N�Z�����AROP���̃N���b�N��
���ׂɉ����Ă��ꂼ�ꓮ�I�ɕς��炵���B
�Ȃ܂�Ŕ��N���b�N�`�b�v���v���o�����銴���B
594 �F����������K�������F2005/07/10(��) 12:14:35 ID:85xmBuTE
Xenos�̃e�N�X�`���[�p�C�v����
�e�N�X�`���[�t�B���^�[�Ƃ��s����̂ł����ˁH
����Ƃ��t�F�b�`�݂̂�SIMD���Z�@�ōs���H
�e�N�X�`���[�t�B���^�[�Ƃ��s����̂ł����ˁH
����Ƃ��t�F�b�`�݂̂�SIMD���Z�@�ōs���H
595 �F����������K�������F2005/07/10(��) 12:15:14 ID:JcB+yY4u
CELL���Ė{���ɐ��\�ǂ��̂��ˁE�E
CELL�ɂ�����ė~�������ǁA�C�O������̕��͌���Ƒ����ʖڂ��ۂ��̂ŕs�����Ȃ�
CELL�ɂ�����ė~�������ǁA�C�O������̕��͌���Ƒ����ʖڂ��ۂ��̂ŕs�����Ȃ�
596 �F����������K�������F2005/07/10(��) 12:15:39 ID:THuGnuOd
�X���Ⴂ���C�ɂ��Ă������ɂ��������͕̂����邪
���˓I�ɂ����̃}���`�|�X�g�Ɍ����Ă��܂��Q�����˂�]�̔߂���
���˓I�ɂ����̃}���`�|�X�g�Ɍ����Ă��܂��Q�����˂�]�̔߂���
597 �F����������K�������F2005/07/10(��) 12:17:55 ID:mk5TLWQ0
����GI����
598 �F����������K�������F2005/07/10(��) 12:20:03 ID:p037LVXI
RSX�̃��W�X�^�����\���Ȃ̂ŁA
�V���[�Y�p�������^���W�X�^�����O���t��p�������@�A
���𒊏o�E���W�X�^���������Ă��ǂ����ʁA�x�N�g���v���Z�b�T�̓��W�X�^�������ɑ�����ɁA
�x�N�g�����Z�ł��邪�̂Ƀ��W�X�^�ɕK�v�ȃg�����W�X�^�����x�N�g�����{���������̂ŁA�R�U�O���y�ł��B
�V���[�Y�p�������^���W�X�^�����O���t��p�������@�A
���𒊏o�E���W�X�^���������Ă��ǂ����ʁA�x�N�g���v���Z�b�T�̓��W�X�^�������ɑ�����ɁA
�x�N�g�����Z�ł��邪�̂Ƀ��W�X�^�ɕK�v�ȃg�����W�X�^�����x�N�g�����{���������̂ŁA�R�U�O���y�ł��B
599 �F����������K�������F2005/07/10(��) 12:25:02 ID:jWOjz1m5
Cell�̓x���`���ʂ������̂ŁA�J���҂����ꂽ�胉�C�u���������������悭�����邾�낤
600 �F����������K�������F2005/07/10(��) 12:30:43 ID:85xmBuTE
CELL��GPU�ł͂Ȃ�RSX���̗p�������R
�P�ʃf�[�^�ɑ��鉉�Z�ʂ͏��Ȃ���
��ʂɃf�[�^���������Ȃ���Ȃ�Ȃ��ꍇ�A
����ς�CELL�ł͕s�����Ɣ��f�����̂ł͂Ȃ����E�E
�P�ʃf�[�^�ɑ��鉉�Z�ʂ͏��Ȃ���
��ʂɃf�[�^���������Ȃ���Ȃ�Ȃ��ꍇ�A
����ς�CELL�ł͕s�����Ɣ��f�����̂ł͂Ȃ����E�E
601 �F����������K�������F2005/07/10(��) 12:31:51 ID:NgWNRmYx
602 �F����������K�������F2005/07/10(��) 12:33:50 ID:mk5TLWQ0
���̒����p��̒�������
603 �F����������K�������F2005/07/10(��) 12:35:51 ID:JsMbxSIG
XBOX360�̃R�A�͎��ۂ̃Q�[���ł�
������g���Ȃ�����Ƃ������Ă��L���ˁB
���̋L���͂ǂ����c
������g���Ȃ�����Ƃ������Ă��L���ˁB
���̋L���͂ǂ����c
604 �F����������K�������F2005/07/10(��) 12:42:28 ID:yYJNj32y
�x���`���ăA�e�ɂȂ�Ȃ���ˁA������œ���\�t�g�Ŏ��s�����
������x�M�����͂���낤���ǁA���ĕs����₿����Ƃ������Ő��l
�͕ς�邵�B���[�J�[�����������Ȃ�Ă͂Ȃ�������O����
�Q�[���Ƃ�������ȃA�v���ł���ȏ�A�ėp���ƌ��������}���Ă��邩�A
���Ƃ̓n�[�h�����̏��J��������邩�ۂ��B
���\�ǂ��ł��A�ł�����̕��@�ɂ����ꍇ�݂̂��ăn�[�h�͖��O����
������x�M�����͂���낤���ǁA���ĕs����₿����Ƃ������Ő��l
�͕ς�邵�B���[�J�[�����������Ȃ�Ă͂Ȃ�������O����
�Q�[���Ƃ�������ȃA�v���ł���ȏ�A�ėp���ƌ��������}���Ă��邩�A
���Ƃ̓n�[�h�����̏��J��������邩�ۂ��B
���\�ǂ��ł��A�ł�����̕��@�ɂ����ꍇ�݂̂��ăn�[�h�͖��O����
605 �F����������K�������F2005/07/10(��) 13:01:48 ID:uKMPKnBC
>>593
���o�C���̋Z�p���������
�N���b�N���ςɂ��邱�Ƃœd�͏���̒ጸ�A�q�[�g�V���N�̏��^��
�t�@���̐É����ɍv�������A�݂����ȓ��e�ł��ˁB
�d�͂�6800����啝�_�E�������ƌ������A�����ɔ閧������̂��ˁB
�N���b�N��550MHz�܂ŏグ�Ă����v�Ȃ悤�ɏo���Ă�悤���B
���o�C���̋Z�p���������
�N���b�N���ςɂ��邱�Ƃœd�͏���̒ጸ�A�q�[�g�V���N�̏��^��
�t�@���̐É����ɍv�������A�݂����ȓ��e�ł��ˁB
�d�͂�6800����啝�_�E�������ƌ������A�����ɔ閧������̂��ˁB
�N���b�N��550MHz�܂ŏグ�Ă����v�Ȃ悤�ɏo���Ă�悤���B
606 �F����������K�������F2005/07/10(��) 13:10:47 ID:sx2ZkOEu
607 �F����������K�������F2005/07/10(��) 13:33:32 ID:7Zem9daS
>>606
����͐������ƂȂ̂��H
����͐������ƂȂ̂��H
608 �F����������K�������F2005/07/10(��) 13:41:52 ID:uKMPKnBC
��Shader Clock�F430MHz/Rop Clock�F430MHz/Geometry Clock�F470MHz
����Geometry���Ă̂� �ǂ��ɂ���́H
�V�F�[�_��ROP�Ƃ͈Ⴄ�ꏊ�ɂ��鉉�Z�@�H
����Geometry���Ă̂� �ǂ��ɂ���́H
�V�F�[�_��ROP�Ƃ͈Ⴄ�ꏊ�ɂ��鉉�Z�@�H
609 �F����������K�������F2005/07/10(��) 13:44:44 ID:Z9uiFo7N
���g�̎g�p�����Ȃ���N���b�N��ς��Ă�̂�����
�����Q�[���Ȃ�I�[�o�[�N���b�N���Ă����g�̎g�����͈��Ȃ�����
�e���j�b�g�iShader,Rop,Geometry�j�̃N���b�N��͕ς��Ȃ�
��~�����Ƃ����{��430�ɂ��ǂ�
��������`
�����Q�[���Ȃ�I�[�o�[�N���b�N���Ă����g�̎g�����͈��Ȃ�����
�e���j�b�g�iShader,Rop,Geometry�j�̃N���b�N��͕ς��Ȃ�
��~�����Ƃ����{��430�ɂ��ǂ�
��������`
610 �F����������K�������F2005/07/10(��) 13:46:27 ID:DIQjAlBv
>>599
FFT�x���`��Cell�ɗL���ȃx���`�ŔėpCPU��Pen4���r�Ώ̂Ƃ��Ă��鎞�_��
���������Ǝv���A�������ш悪�S�R�Ⴄ�̂�Cell�����[�Ƃ������Ă�
�Ӂ[����Ċ����B
���߂ē��������R�����ڂ��Ă���Athlon64�Ƃ��ׂ�����Ȃ����ȁB
FFT�x���`��Cell�ɗL���ȃx���`�ŔėpCPU��Pen4���r�Ώ̂Ƃ��Ă��鎞�_��
���������Ǝv���A�������ш悪�S�R�Ⴄ�̂�Cell�����[�Ƃ������Ă�
�Ӂ[����Ċ����B
���߂ē��������R�����ڂ��Ă���Athlon64�Ƃ��ׂ�����Ȃ����ȁB
611 �F����������K�������F2005/07/10(��) 13:53:27 ID:RQNe6Dq1
��i��3.2G���삷��Athlon64���Ă����������H
612 �F����������K�������F2005/07/10(��) 13:59:14 ID:luJrZYsS
>>610
�ʂɃ������ш悪�����͖̂��Ȃ����낗
�Q�[���Ɩ��W�ȃx���`��������ĂȂ��̂����Ȃ�B
���߂�MS���炢�@�ޑ݂���3DMark����Ă�����ăQ�[���G����DVD��
�v���O�������̂Ƙ^�惀�[�r�[�z�z���Ă��������̂ɁB
�ʂɃ������ш悪�����͖̂��Ȃ����낗
�Q�[���Ɩ��W�ȃx���`��������ĂȂ��̂����Ȃ�B
���߂�MS���炢�@�ޑ݂���3DMark����Ă�����ăQ�[���G����DVD��
�v���O�������̂Ƙ^�惀�[�r�[�z�z���Ă��������̂ɁB
613 �F����������K�������F2005/07/10(��) 14:01:00 ID:fisSELOz
614 �F����������K�������F2005/07/10(��) 14:03:46 ID:uKMPKnBC
�����������ш悪�S�R�Ⴄ�̂�
������������ɂ܂��B
�܂��ɁA�{�g���l�b�N�ƂȂ��Ă��郁�����ш�����コ�����̂�Cell�A�[�L�e�N�`���Ȃ�B
���̓��A�uSPE���g���Ȃ�Ĕڋ����B PPE�����ŏ�������I�v�Ƃ������o����Ȃ�����ȁH
������������ɂ܂��B
�܂��ɁA�{�g���l�b�N�ƂȂ��Ă��郁�����ш�����コ�����̂�Cell�A�[�L�e�N�`���Ȃ�B
���̓��A�uSPE���g���Ȃ�Ĕڋ����B PPE�����ŏ�������I�v�Ƃ������o����Ȃ�����ȁH
615 �F����������K�������F2005/07/10(��) 14:04:06 ID:yMiJ3zvG
616 �F����������K�������F2005/07/10(��) 14:05:04 ID:iLzPIHST
>>611
AthlonFX2.8GHz�Ɣ�r����������ƍ����k�܂��ˁB
�����x��Pen4�Ƃ��႟��r�ɂȂ��̂���Ȃ����Ǝv���B
�t�F�A�ɂ��Ȃ�PenM�APower5�AAthlon64FX�ACell2.4GHz�J���@�Ŕ�ׂ�ׂ��A
AthlonFX2.8GHz�Ɣ�r����������ƍ����k�܂��ˁB
�����x��Pen4�Ƃ��႟��r�ɂȂ��̂���Ȃ����Ǝv���B
�t�F�A�ɂ��Ȃ�PenM�APower5�AAthlon64FX�ACell2.4GHz�J���@�Ŕ�ׂ�ׂ��A
617 �F����������K�������F2005/07/10(��) 14:09:07 ID:fisSELOz
618 �F����������K�������F2005/07/10(��) 14:11:14 ID:yMiJ3zvG
ttp://www.fftw.org/speed/g5-2GHz/ PPC G5(970) 2GHz Dual
ttp://www.fftw.org/speed/itanium2-900MHz/ Itanium II, 900 MHz
ttp://www.fftw.org/speed/p3-550MHz/ Pentium III (Katmai), 550MHz
PenM�͖�������Pen3�Ɏ��g���̃X�P�[�������Ă݂邮�炢���������˂�
�܂��A�ǂ�ɂ��Ă�Cell�����|�I�Ȃ�
ttp://www.fftw.org/speed/itanium2-900MHz/ Itanium II, 900 MHz
ttp://www.fftw.org/speed/p3-550MHz/ Pentium III (Katmai), 550MHz
PenM�͖�������Pen3�Ɏ��g���̃X�P�[�������Ă݂邮�炢���������˂�
�܂��A�ǂ�ɂ��Ă�Cell�����|�I�Ȃ�
619 �F����������K�������F2005/07/10(��) 14:11:47 ID:6HOlqQLD
620 �F����������K�������F2005/07/10(��) 14:14:29 ID:U0kNyyWw
�Q�[���J���ɊW�����x���`�ł����Ă��邱������Ă��������D�D�D�B
621 �F����������K�������F2005/07/10(��) 14:15:13 ID:Z9uiFo7N
���_�Ƃ��Ă͌����G���W������g���Ȃ��q����ROM���ĂȂ����ƌ������ł���
622 �F����������K�������F2005/07/10(��) 14:21:07 ID:yMiJ3zvG
�Q�[���J���ɊW�̂���x���`�}�[�N�Ȃ�āA�ߋ��̃Q�[���@�ɂ����ďo����
�����������H
���Ȃ��Ƃ������ɂȂ�炩�̃x���`�}�[�N���ʂ\�����Q�[���@�Ȃ�āA�����Ǝv����
���\�����̂̓s�[�N���Z�\�͂ƁA�s�[�N�\���\�|���S�������炢����Ȃ��E�E�E
�������\�̐��l�ƌ����镨���A�ǂ�ȃ\�t�g�g�������������Ȃ���Ԃł�
�������\�ł͖����B���Ȑ��������������ƂȂ���
�����������H
���Ȃ��Ƃ������ɂȂ�炩�̃x���`�}�[�N���ʂ\�����Q�[���@�Ȃ�āA�����Ǝv����
���\�����̂̓s�[�N���Z�\�͂ƁA�s�[�N�\���\�|���S�������炢����Ȃ��E�E�E
�������\�̐��l�ƌ����镨���A�ǂ�ȃ\�t�g�g�������������Ȃ���Ԃł�
�������\�ł͖����B���Ȑ��������������ƂȂ���
623 �F����������K�������F2005/07/10(��) 14:25:10 ID:EsvI3Uh1
�܂�FFT�x���`�̓\�[�X�ɂ͂Ȃ肦�Ȃ����Ď���FA�H
624 �F����������K�������F2005/07/10(��) 14:26:14 ID:Kefi5FJo
����ȃ}�C�i�[�ȃx���`�ł����Ă��E�E�E
625 �F����������K�������F2005/07/10(��) 14:26:45 ID:6HOlqQLD
FFT�x���`���Ă̂�
�摜�⓮��A�����Ȃǂ̈��k��𓀂Ƃ����������̍ۂɂ�����B
CELL���ڂ̃G���R�V�X�e���o���āE�E
�摜�⓮��A�����Ȃǂ̈��k��𓀂Ƃ����������̍ۂɂ�����B
CELL���ڂ̃G���R�V�X�e���o���āE�E
626 �F����������K�������F2005/07/10(��) 14:26:53 ID:n40+gLbM
�����炳�܂ȒP��ID���b�V���۽������
627 �F����������K�������F2005/07/10(��) 14:28:20 ID:yMiJ3zvG
���ۂɃQ�[���@�ɓ��ڂ����CPU�ł̎������\���A�����ȃx���`�}�[�N�Ƃ��Ĕ��\����
���ɗL�v�ȏ���FA
����CPU�̗��_�s�[�N���\�Ǝ��s���\�̔�ƁACell�̏ꍇ�̔���ׂ�Ɩʔ���������
���ɗL�v�ȏ���FA
����CPU�̗��_�s�[�N���\�Ǝ��s���\�̔�ƁACell�̏ꍇ�̔���ׂ�Ɩʔ���������
628 �F����������K�������F2005/07/10(��) 14:29:17 ID:Kefi5FJo
�Ӗ��Ȃ��x���`�݂�������
629 �F����������K�������F2005/07/10(��) 14:30:06 ID:uKMPKnBC
���̑��̃x���`�Ȃ畉���Ȃ������A
�ƌ��������̂��낤�B
��낵���B ���������ɗL���ȃx���`��T���Ă��Ȃ����B
�҂��Ă��
�ƌ��������̂��낤�B
��낵���B ���������ɗL���ȃx���`��T���Ă��Ȃ����B
�҂��Ă��
630 �F����������K�������F2005/07/10(��) 14:30:39 ID:yMiJ3zvG
>>628
>>624
>>623
�����̈Ӗ����ǂݎ��Ȃ��l�ɂƂ��ẮA�ǂ�ȃx���`���Ӗ���������
���Ȃ��B�ɂƂ��Ă͂����FA���Ǝv����;-p
>>624
>>623
�����̈Ӗ����ǂݎ��Ȃ��l�ɂƂ��ẮA�ǂ�ȃx���`���Ӗ���������
���Ȃ��B�ɂƂ��Ă͂����FA���Ǝv����;-p
631 �F����������K�������F2005/07/10(��) 14:31:17 ID:KU/xeHMy
�x���`�����o���Ȃ�CPU���͂����Ǝv�����ǂˁB
����ƁA�������ш�𗝗R��Cell���ʖڂ��ƌ����Ă��n�����������ǁA
128MB�̃������A�N�Z�X�������Ă��������\���\���o���Ƃ����ؖ��ɂȂ������B
����ƁA�������ш�𗝗R��Cell���ʖڂ��ƌ����Ă��n�����������ǁA
128MB�̃������A�N�Z�X�������Ă��������\���\���o���Ƃ����ؖ��ɂȂ������B
632 �F����������K�������F2005/07/10(��) 14:31:29 ID:yysRcZ4O
>>623
�t�[���G�ϊ��ȂQ�[�����Ⴠ�[�r�[���炢�ɂ����g��Ȃ�����Ȃ��B
Cell�M�җB��̐S�̋��菊���ے肳��Ă��܂��܂����i��
�����A�ǂ�����H
�t�[���G�ϊ��ȂQ�[�����Ⴠ�[�r�[���炢�ɂ����g��Ȃ�����Ȃ��B
Cell�M�җB��̐S�̋��菊���ے肳��Ă��܂��܂����i��
�����A�ǂ�����H
633 �F����������K�������F2005/07/10(��) 14:31:41 ID:fisSELOz
�}�C�i�[�ȃx���`���āE�E�E
FFT��HPC�`�������W�x���`�ł����\�]�����ڂ�
�����Ă�قǏd�v�Ȍv�Z�ł���B
FFT��HPC�`�������W�x���`�ł����\�]�����ڂ�
�����Ă�قǏd�v�Ȍv�Z�ł���B
634 �F����������K�������F2005/07/10(��) 14:32:44 ID:M/o5EqWn
�����炭���܍s���Ă���ł��낤UE3�G���W����Cell�œK������̎������B
���ꂪ�ǂ̒��x��ςŁA�ǂ̒��x�̌��ʂ�����̂��킩��A
PS3�̏������ǂ����Ȃ̂��������Ă��邾�낤�B
���ꂪ�ǂ̒��x��ςŁA�ǂ̒��x�̌��ʂ�����̂��킩��A
PS3�̏������ǂ����Ȃ̂��������Ă��邾�낤�B
635 �F����������K�������F2005/07/10(��) 14:33:12 ID:Kefi5FJo
���t�[���G�ϊ��ȂQ�[�����Ⴠ�[�r�[���炢�ɂ����g��Ȃ�����Ȃ��B
�Ȃ�ق�
��͂�x���`�ɈӖ��Ȃ�������
�Ȃ�ق�
��͂�x���`�ɈӖ��Ȃ�������
636 �F����������K�������F2005/07/10(��) 14:33:37 ID:yysRcZ4O
>>633
����ł��Q�[���ɂ͊W�����A�����ǂ�����H
����ł��Q�[���ɂ͊W�����A�����ǂ�����H
637 �F����������K�������F2005/07/10(��) 14:33:54 ID:yMiJ3zvG
>>632
�t�[���G�ϊ������ۂɂǂ��������Z�����Ă��邩�m������ł���Ȏ������Ă�Ȃ�
�I���f�^�C�l���E�E�E �Ϙa���Z���Ēm���Ă�H
�t�[���G�ϊ������ۂɂǂ��������Z�����Ă��邩�m������ł���Ȏ������Ă�Ȃ�
�I���f�^�C�l���E�E�E �Ϙa���Z���Ēm���Ă�H
638 �F����������K�������F2005/07/10(��) 14:36:12 ID:RQNe6Dq1
>>616
�[���ACell�̐��\���������߂ɓ��N���b�N��Pen4����������o�������B
���t�F�A�ɂ��Ȃ�
�Ƃ����O��ɈӖ����Ȃ������ȁB
�[���ACell�̐��\���������߂ɓ��N���b�N��Pen4����������o�������B
���t�F�A�ɂ��Ȃ�
�Ƃ����O��ɈӖ����Ȃ������ȁB
639 �F����������K�������F2005/07/10(��) 14:36:17 ID:yysRcZ4O
>>637
���̑O�Ƀt�[���G�ϊ������ۃQ�[���ɂǂ��������ɗ��̂������Ȃ����i��
���̑O�Ƀt�[���G�ϊ������ۃQ�[���ɂǂ��������ɗ��̂������Ȃ����i��
640 �F����������K�������F2005/07/10(��) 14:36:18 ID:fisSELOz
641 �F����������K�������F2005/07/10(��) 14:36:29 ID:KU/xeHMy
ID:yysRcZ4O
�����̐l�H
�N�ɂ�VS�X���̕��������Ǝv�����ǂȁB
�x���`�̒��g�𗝉��ł��Ȃ��z�́A�w�L�т��Ă����ɗ��Ă��d���Ȃ���B
�����̐l�H
�N�ɂ�VS�X���̕��������Ǝv�����ǂȁB
�x���`�̒��g�𗝉��ł��Ȃ��z�́A�w�L�т��Ă����ɗ��Ă��d���Ȃ���B
642 �F����������K�������F2005/07/10(��) 14:36:45 ID:JsMbxSIG
������VS�X��������̂�('A`)
643 �F����������K�������F2005/07/10(��) 14:37:12 ID:yMiJ3zvG
���ꂩ��ACell�̐��\�ے�ޗ��Ƃ��Ďg���₷���ALS�ɏ���Ȃ��ʂ̃f�[�^��
��������Ƃ��āA���\�ቺ�����̒��x�ōς�ł���Ƃ����Ӗ��ł����ɗL�v�ȏ��
�Ȃ̂ɁE�E�E
��������Ƃ��āA���\�ቺ�����̒��x�ōς�ł���Ƃ����Ӗ��ł����ɗL�v�ȏ��
�Ȃ̂ɁE�E�E
644 �F����������K�������F2005/07/10(��) 14:37:41 ID:ApCQmk/k
�܂����̔ɂ���X���ł���ȏ�d���Ȃ��Ƃ���B
645 �F����������K�������F2005/07/10(��) 14:38:51 ID:yysRcZ4O
>>641
�u�\�[�X���o���v�uVS�X���֍s���v��Cell�M�҂̔s�k�錾�B
�u�\�[�X���o���v�uVS�X���֍s���v��Cell�M�҂̔s�k�錾�B
646 �F����������K�������F2005/07/10(��) 14:39:26 ID:yMiJ3zvG
����I�ɗ���̂͂��d��������Ȃ̂���
647 �F����������K�������F2005/07/10(��) 14:40:28 ID:yMiJ3zvG
648 �F����������K�������F2005/07/10(��) 14:40:29 ID:ucjz7WTt
�A���`�Ȃ�\�j�[�炵���n�b�^�����Ĕ[�����Ƃ��A����ʒp�������Ȃ��ōς�
�ɁA�u�r�X���ɶ�ځB
�ɁA�u�r�X���ɶ�ځB
649 �F����������K�������F2005/07/10(��) 14:40:33 ID:ZTIojovw
�A���`Cell�̐l��
�����Ŋ撣��Ί撣��ق�
�������v���m�炳��邱�ƂɂȂ��Ă�̂Ɂc
���Ȃ��ƌ������c
�����Ŋ撣��Ί撣��ق�
�������v���m�炳��邱�ƂɂȂ��Ă�̂Ɂc
���Ȃ��ƌ������c
650 �F����������K�������F2005/07/10(��) 14:40:42 ID:7nLZ8LpC
��������Hcell��Itanium2������
���U�R���s���[�e�B���O����Ԏ������Ă���
���U�R���s���[�e�B���O����Ԏ������Ă���
651 �F����������K�������F2005/07/10(��) 14:41:12 ID:ApCQmk/k
>>645
�\�[�X�o���A���Ă͓̂�����O����Ȃ��̂��H
�\�[�X�o���A���Ă͓̂�����O����Ȃ��̂��H
652 �F����������K�������F2005/07/10(��) 14:44:02 ID:fisSELOz
http://ascii24.com/news/i/topi/article/2004/09/06/651405-000.html
�g�̕\���ɂ́AGerstner(�K�[�X�i�[)�g�`�v�Z��FFT
(�����t�[���G�ϊ�)�̓��v���f�������邪�A�����ł�Gerstner�g�`
���̗p���Ă���B���̗��R�Ƃ��Ĉ��c���́AFFT�̓��v���f���ł́A
���A���Ȕg��\���ł��锼�ʁA�v�Z(�v�������_�����O)�Ɏ��Ԃ�
�����邱�ƁA�����g���J��Ԃ��o�Ă��Ă��܂����ƂȂǂ��������B
�����A���A���^�C�������_�����O�̕K�v���Ȃ��f��Ȃǂł�FFT
�̓��v���f�����g���Ă���A�����g�̌J��Ԃ��̓J�����ʒu
���ւ��邱�ƂȂǂŃJ�o�[���Ă��邱�Ƃ����������B
CELL�ł���A���A���Ȑ��ʔg�V�~�����[�V�����������ł�����
�ł��ˁB�܂��Ƀv�������_�Ɠ�����@���g�����ł��B
�g�̕\���ɂ́AGerstner(�K�[�X�i�[)�g�`�v�Z��FFT
(�����t�[���G�ϊ�)�̓��v���f�������邪�A�����ł�Gerstner�g�`
���̗p���Ă���B���̗��R�Ƃ��Ĉ��c���́AFFT�̓��v���f���ł́A
���A���Ȕg��\���ł��锼�ʁA�v�Z(�v�������_�����O)�Ɏ��Ԃ�
�����邱�ƁA�����g���J��Ԃ��o�Ă��Ă��܂����ƂȂǂ��������B
�����A���A���^�C�������_�����O�̕K�v���Ȃ��f��Ȃǂł�FFT
�̓��v���f�����g���Ă���A�����g�̌J��Ԃ��̓J�����ʒu
���ւ��邱�ƂȂǂŃJ�o�[���Ă��邱�Ƃ����������B
CELL�ł���A���A���Ȑ��ʔg�V�~�����[�V�����������ł�����
�ł��ˁB�܂��Ƀv�������_�Ɠ�����@���g�����ł��B
653 �F����������K�������F2005/07/10(��) 14:51:28 ID:M/o5EqWn
SPE��FFT�̂悤�ȘA���f�[�^�̏����ɍD�K�Ȃ̂͂�������Ȃ�Ȃ̂����A
�l�I�ɂ́A(��������ŘA�����Ă��Ȃ�)linked list��
���p�I�ȑ��x�ň�����̂��ǂ����ɋ���������B
�l�I�ɂ́A(��������ŘA�����Ă��Ȃ�)linked list��
���p�I�ȑ��x�ň�����̂��ǂ����ɋ���������B
654 �F����������K�������F2005/07/10(��) 14:52:23 ID:7Zem9daS
���̂Ƃ���A�A���`Cell�h�ɂ͎��̒ɂ������肾��
655 �F����������K�������F2005/07/10(��) 14:54:14 ID:yMiJ3zvG
656 �F����������K�������F2005/07/10(��) 14:57:08 ID:M/o5EqWn
����A��ʓI�ɁA�ǂ̎�@�łǂ̒��x�̃R�[�h�̕��G���Ƒ��x����(��PPE���)��
����̂��ȁA�ƁB
����̂��ȁA�ƁB
657 �F����������K�������F2005/07/10(��) 14:57:46 ID:doVpEinN
http://forum.teamxbox.com/showthread.php?t=357095
�����̘b�͖������E�E�E
�����̘b�͖������E�E�E
658 �F����������K�������F2005/07/10(��) 14:58:40 ID:J8CuN6AJ
>>657
100���X���炢�O�ɏo�Ă���
100���X���炢�O�ɏo�Ă���
659 �F����������K�������F2005/07/10(��) 14:59:29 ID:M/o5EqWn
>>657 ���̃X���b�h�͎��ۂɃR�[�h�����Č������b����Ȃ���ŁA
������̃X���Ɠ����x���Ƃ������c
������̃X���Ɠ����x���Ƃ������c
660 �F����������K�������F2005/07/10(��) 15:00:57 ID:BUtsK8/f
>>658
�\�[�X������
�\�[�X������
661 �F����������K�������F2005/07/10(��) 15:01:43 ID:J8CuN6AJ
>>660
���̃\�[�X�H
���̃\�[�X�H
662 �F����������K�������F2005/07/10(��) 15:02:09 ID:M/o5EqWn
663 �F����������K�������F2005/07/10(��) 15:02:23 ID:yMiJ3zvG
XBOX360��CPU��XBOX��CPU��2�{���x�̎������\�����o�Ȃ��Ə����Ă��鎞�_�ŁE�E�E
664 �F����������K�������F2005/07/10(��) 15:04:36 ID:1RXN1pvp
2�{���x�͂Ȃ���
����Ȃ�kameo�̌Q�W�V�[���Ȃł���킯�Ȃ��͂���
����ł����܂����L�b�g�炵������
����Ȃ�kameo�̌Q�W�V�[���Ȃł���킯�Ȃ��͂���
����ł����܂����L�b�g�炵������
665 �F����������K�������F2005/07/10(��) 15:05:49 ID:M/o5EqWn
���������ACell��PPE�̃x���`�����Ă����������B
���N���b�N���Z��G5��肾���Ԉ����̂ł͂Ȃ����Ǝv���̂����B
���N���b�N���Z��G5��肾���Ԉ����̂ł͂Ȃ����Ǝv���̂����B
666 �F����������K�������F2005/07/10(��) 15:08:33 ID:/Qxhm2aB
���͊J�����y���ǂ��������
���\�����낤���Ⴉ�낤���\�t�g���x�����Ⴝ���������͂Ȃ�
���\�����낤���Ⴉ�낤���\�t�g���x�����Ⴝ���������͂Ȃ�
667 �F����������K�������F2005/07/10(��) 15:09:58 ID:J8CuN6AJ
�N���b�N���S�D�R�{�ɂȂ��Ă�̂ɁA�����\����{��������ň�����ȁB
���肦��Ƃ�����AXBOXCPU�̗��_���l�̓�{�̎����\���Ď�����
���肦��Ƃ�����AXBOXCPU�̗��_���l�̓�{�̎����\���Ď�����
668 �F����������K�������F2005/07/10(��) 15:11:04 ID:yMiJ3zvG
PPE�P�̂͌������Ɩ�����
�F�X�Ȏ������琄������ɁAXBOX360 CPU�̃R�A�ɋ߂��悤�����A���\�ɂ��Ă�
�L�q�͌������Ɩ�����
�F�X�Ȏ������琄������ɁAXBOX360 CPU�̃R�A�ɋ߂��悤�����A���\�ɂ��Ă�
�L�q�͌������Ɩ�����
669 �F����������K�������F2005/07/10(��) 15:13:09 ID:KU/xeHMy
���\��������A�x���I�v���O���~���O�̂悤�Ȏ�@���I���ł���悤�ɂȂ�B
670 �F����������K�������F2005/07/10(��) 15:18:42 ID:uKMPKnBC
PPE�P�̂̐��\���l���� ���قǂ̈Ӗ�������̂��ȁH
�S�̂łP��CPU�Ȃ̂ɁB ��̉��Ɣ�r����̂��B
�܂����{����SPE���g�킸�ɃQ�[���������肩�B
�S�̂łP��CPU�Ȃ̂ɁB ��̉��Ɣ�r����̂��B
�܂����{����SPE���g�킸�ɃQ�[���������肩�B
671 �F����������K�������F2005/07/10(��) 15:20:44 ID:yMiJ3zvG
>>670
2D�A�h�x���`���[�Q�[���Ȃ炻��ł��\�����낤�ȁA������M�����Q�[�̗ނƂ�
2D�A�h�x���`���[�Q�[���Ȃ炻��ł��\�����낤�ȁA������M�����Q�[�̗ނƂ�
672 �F����������K�������F2005/07/10(��) 15:21:39 ID:M/o5EqWn
�����炭�قړ����R�A�ł��낤360 CPU�̃V���O���X���b�h���\���ސ��ł���B
�uXBOX��CPU��2�{���x�̎������\�����o�Ȃ��v���́A�����炭�V���O���X���b�h��
VMX���g��Ȃ��R�[�h�Ŕ�r�������̘b���낤�B
PPE�̊��������l����ƁA��������肤�鐔������Ȃ����Ǝv���Ă���̂����c
�uXBOX��CPU��2�{���x�̎������\�����o�Ȃ��v���́A�����炭�V���O���X���b�h��
VMX���g��Ȃ��R�[�h�Ŕ�r�������̘b���낤�B
PPE�̊��������l����ƁA��������肤�鐔������Ȃ����Ǝv���Ă���̂����c
673 �F����������K�������F2005/07/10(��) 15:30:41 ID:3MkTvFUs
�J�����y�`���Č����Ă�z�͉������������H
��Ƃ��炷��A��Ԕ���Ă�n�[�h�ɊJ����������Ɍ��܂��Ă邾��
�J���҂��y�`�ŊJ�������悪���܂�Ƃł��v���Ă�̂���
��Ƃ��炷��A��Ԕ���Ă�n�[�h�ɊJ����������Ɍ��܂��Ă邾��
�J���҂��y�`�ŊJ�������悪���܂�Ƃł��v���Ă�̂���
674 �F����������K�������F2005/07/10(��) 15:32:41 ID:pgbN/qY6
cell�M�Ҍ����ꂵ��
675 �F����������K�������F2005/07/10(��) 15:36:31 ID:M/o5EqWn
�J���R�X�g����������Ȃ瑹�v����_��������킯�ŁA
���ɂ܂����҂Ƃ��V�F�A0%�̏�Ԃł́A�J���̗e�Ղ��͋@��I��̏�ł���Ȃ��
�d�v�ȃt�@�N�^�[�ł��傤�B
���Ƃ�����Windows�ł���̃x�^�ڐA���e�Ղ���Ȃ�������A����360�p��FF11���o���Ȃ�
���낤�Ǝv���B
��������ē����\�t�g�����܂�A���[���`�����������莸�s�����肵�ĕ��y�䐔��
��܂��Ă����킯�ŁA�J���̗e�Ղ��Ƃ����̂�(����łł͂Ȃ��Ƃ�)
�܂邫�薳�ʂƂ����킯�ł͂Ȃ��̂ł́B
���ɂ܂����҂Ƃ��V�F�A0%�̏�Ԃł́A�J���̗e�Ղ��͋@��I��̏�ł���Ȃ��
�d�v�ȃt�@�N�^�[�ł��傤�B
���Ƃ�����Windows�ł���̃x�^�ڐA���e�Ղ���Ȃ�������A����360�p��FF11���o���Ȃ�
���낤�Ǝv���B
��������ē����\�t�g�����܂�A���[���`�����������莸�s�����肵�ĕ��y�䐔��
��܂��Ă����킯�ŁA�J���̗e�Ղ��Ƃ����̂�(����łł͂Ȃ��Ƃ�)
�܂邫�薳�ʂƂ����킯�ł͂Ȃ��̂ł́B
676 �F����������K�������F2005/07/10(��) 15:39:25 ID:7RaEs9ZB
>>672
���႟�ACell��PPE��P3��2�{���x�̎������\���Ă��ƁH
���႟�ACell��PPE��P3��2�{���x�̎������\���Ă��ƁH
677 �F����������K�������F2005/07/10(��) 15:41:35 ID:KU/xeHMy
�J���R�X�g�̐�߂銄���̒��ŁA�v���O���~���O�̗e�Ղ��͂��قlje����������B
�������AWindows�̃x�^�ڐA���Č����Ă��AWindows�ŃQ�[��������ĂāA
�Q�[���@�ɂ��̂܂܈ڐA�ł���悤�Ȓe�������Ă郁�[�J�[�͏����h�ł���B
�������AWindows�̃x�^�ڐA���Č����Ă��AWindows�ŃQ�[��������ĂāA
�Q�[���@�ɂ��̂܂܈ڐA�ł���悤�Ȓe�������Ă郁�[�J�[�͏����h�ł���B
678 �F����������K�������F2005/07/10(��) 15:42:59 ID:qMx7ntCq
>>674
�t�[���G�ϊ����Q�[���ɖ𗧂�������疳���������_�Ŕs�k���Ă���킯�����i��
�Ȍ�AFFT�x���`�̓\�[�X�ɂȂ�Ȃ��Ƃ��������ŁB
�t�[���G�ϊ����Q�[���ɖ𗧂�������疳���������_�Ŕs�k���Ă���킯�����i��
�Ȍ�AFFT�x���`�̓\�[�X�ɂȂ�Ȃ��Ƃ��������ŁB
679 �F����������K�������F2005/07/10(��) 15:44:18 ID:ZAYlAaKd
��������PC�ƃR���V���[�}�@�Ƀ}���`�ŏo���Ă鏊�����̂���?
���{�͖w�ǂȂ���˃R���V���[�}�����PC�ڐA�Ƃ��J�v�R��������Ă��
���{�͖w�ǂȂ���˃R���V���[�}�����PC�ڐA�Ƃ��J�v�R��������Ă��
680 �F����������K�������F2005/07/10(��) 15:44:35 ID:pgbN/qY6
�v���O���~���O�̗e�Ղ͉e������܂���
�܂��ςȉ��������Ȃ��Ȃ�A�œK�����e��
GT4�̐��쌻��TV�ɏo�Ă����Njꂵ������������
�o�O�������̃I���p���[�h
�܂��ςȉ��������Ȃ��Ȃ�A�œK�����e��
GT4�̐��쌻��TV�ɏo�Ă����Njꂵ������������
�o�O�������̃I���p���[�h
681 �F����������K�������F2005/07/10(��) 15:47:07 ID:ri3mQ6Zf
���{��PC�Q�[�̒��S�̓G���Q�ł�����
CS�@�ƃ}���`���ł��Ȃ�
CS�@�ƃ}���`���ł��Ȃ�
682 �F����������K�������F2005/07/10(��) 15:48:14 ID:0vpfvpqT
���E�ɂ�PC�ƃR���\�[���������Ă�Q�[���͎R�قǂ���B
���{���[�J�[�ł��R�i�~��MGS��SH�Ȃǂ�PC�����ɂ��ڐA���Ă�B
�܂����{�ł͔����ĂȂ����B
���{���[�J�[�ł��R�i�~��MGS��SH�Ȃǂ�PC�����ɂ��ڐA���Ă�B
�܂����{�ł͔����ĂȂ����B
683 �F����������K�������F2005/07/10(��) 15:49:15 ID:tH5N7wHM
GT4�N���X���ƁA�J��������̂����邱�ƂȂ���PS2�ł͐��\����Ȃ��āA�M���M���܂Ő��\���o���n���ɂȂ��Ă邩���q������ˁB
684 �F����������K�������F2005/07/10(��) 15:49:29 ID:yMiJ3zvG
685 �F����������K�������F2005/07/10(��) 15:50:28 ID:hWuVGBJM
�s��͊J���҂����߂Ă�Ƃł��v���Ă�̂�
���Ⴂ�������Ƃ��낾��
�X���Ⴂ������M�Ҋu��VS�X���ւǂ���
���Ⴂ�������Ƃ��낾��
�X���Ⴂ������M�Ҋu��VS�X���ւǂ���
686 �F����������K�������F2005/07/10(��) 15:51:01 ID:KU/xeHMy
>>678
>>652
>>682
PC�ŏo���ꍇ�AOpenGL�Ƃ�����i������킯�ŁB
����Mac�ł��Q�[�����o���悤�ȏꍇ�ɂ�OpenGL�����Ȃ��B
MS��Halo��Mac�ł�OpenGL�ŏ����Ă����ˁB
>>652
>>682
PC�ŏo���ꍇ�AOpenGL�Ƃ�����i������킯�ŁB
����Mac�ł��Q�[�����o���悤�ȏꍇ�ɂ�OpenGL�����Ȃ��B
MS��Halo��Mac�ł�OpenGL�ŏ����Ă����ˁB
687 �F����������K�������F2005/07/10(��) 15:51:37 ID:pgbN/qY6
�s��͊J���҂̌��f�ɂ������Ă�̂�������
688 �F����������K�������F2005/07/10(��) 15:54:17 ID:YMCzGSHk
689 �F����������K�������F2005/07/10(��) 15:55:14 ID:fisSELOz
690 �F����������K�������F2005/07/10(��) 15:55:58 ID:J8CuN6AJ
���Ɋւ��Ắi�J�����������Ƃ���j�J�����e�Ղ��e�ՂłȂ����́A���܂�W�Ȃ����낤��
�����Ǐ��������[�J�[���ƁA���Ȃ�C�ɂȂ�Ƃ��낾�Ǝv���B
�����Ǐ��������[�J�[���ƁA���Ȃ�C�ɂȂ�Ƃ��낾�Ǝv���B
691 �F����������K�������F2005/07/10(��) 15:56:58 ID:zRGUvbRi
����PS2����l���������ǁA�J�����������Ƃł��H
�J�����Ŏs����݂�Ȃ�A���������Ă�͂��ł���
����H��
�J�����Ŏs����݂�Ȃ�A���������Ă�͂��ł���
����H��
692 �F����������K�������F2005/07/10(��) 15:58:02 ID:ApCQmk/k
�������₠���ƃ��{�̊J�����ǂ����������Ƃ����Ęb�����Ȃ��˂�
693 �F����������K�������F2005/07/10(��) 15:59:16 ID:0vpfvpqT
>>686
PC��OpenGL�͐�Ŋ뜜��Ȃ�B
Halo�̓z���g�ɓ��ʂȗ�ŁA����͌��XMac�����ɊJ������Ă����̂�
MS�ɔ��������XBOX�^�C�g���ɉ������Ă��܂����B
OpenGL��ϋɓI�Ɏg���̂���Carmack���炢�Ȃ��̂ŁA
�����ŋ�OpenGL�������^�C�g���Ȃ��D3���炢�����m��Ȃ��B
Linux��Mac�����Ɍ�ɈڐA�����OpenGL�g���̂͂ǂ��ł����ʂ��ˁB
PC��OpenGL�͐�Ŋ뜜��Ȃ�B
Halo�̓z���g�ɓ��ʂȗ�ŁA����͌��XMac�����ɊJ������Ă����̂�
MS�ɔ��������XBOX�^�C�g���ɉ������Ă��܂����B
OpenGL��ϋɓI�Ɏg���̂���Carmack���炢�Ȃ��̂ŁA
�����ŋ�OpenGL�������^�C�g���Ȃ��D3���炢�����m��Ȃ��B
Linux��Mac�����Ɍ�ɈڐA�����OpenGL�g���̂͂ǂ��ł����ʂ��ˁB
694 �F����������K�������F2005/07/10(��) 16:00:27 ID:KU/xeHMy
�m��GC����OpenGL�g���Ă���Ȃ��B
���{����������OpenGL�g������Ď����ȁB
���{����������OpenGL�g������Ď����ȁB
695 �F����������K�������F2005/07/10(��) 16:03:17 ID:UV4VGp47
���̃X����>>191�ȍ~�ł����o�̘b��������Ԃ��ł���
191 ���O�F����������K������[sage] ���e���F2005/07/07(��) 23:36:15 ID:fsrn1LfO
>>188
��FFT�x���`��MPEG2����48�{�Đ������ꂵ�����R���ĉ��H
�܂�A���������_���Z���K�v�ȃX�g���[���������哾�ӂƁB
���_���Z�A�����v�Z�A�������Z�A���������Aetc
�Q�[���v���O�������Ɖ��b�L��܂���ł���B
191 ���O�F����������K������[sage] ���e���F2005/07/07(��) 23:36:15 ID:fsrn1LfO
>>188
��FFT�x���`��MPEG2����48�{�Đ������ꂵ�����R���ĉ��H
�܂�A���������_���Z���K�v�ȃX�g���[���������哾�ӂƁB
���_���Z�A�����v�Z�A�������Z�A���������Aetc
�Q�[���v���O�������Ɖ��b�L��܂���ł���B
696 �F����������K�������F2005/07/10(��) 16:05:22 ID:YMCzGSHk
697 �F����������K�������F2005/07/10(��) 16:05:59 ID:tmLFn6A5
>>678�Ȃ��Ă�ƁA�A���`��
FFT�x���`�̌��ʂ�K����
�Ȃ����̂ɂ��������Ă�Ȃ�
�Ƃ����̂�������w
����ۂǏՌ��I�������̂��˂��H
FFT�x���`�̌��ʂ�K����
�Ȃ����̂ɂ��������Ă�Ȃ�
�Ƃ����̂�������w
����ۂǏՌ��I�������̂��˂��H
698 �F����������K�������F2005/07/10(��) 16:07:08 ID:uKMPKnBC
>>632
�t�[���G�ϊ��͉摜�E�����M���̎��g����͂����邽�߂́u�Ϙa���Z�v�̈��A����e
�ŋ߂̃Q�[���ɂ����� 3D�̍��W�ϊ��E�x�N�g�����Z�� ���́u�Ϙa���Z�v���J��Ԃ��s�����ƂŎ��s�����
���_���Z��s�N�Z���������s�� GPU�̃V�F�[�_���j�b�g�̃��C���� ���̂��߂́u�Ϙa���Z��v
�V�F�[�_���\�����߂� �Ƃ́A�V�F�[�_���j�b�g����� �u�Ϙa���Z�@�\�v�����߂邱��
���ہAG70�ł�GF6800�ɔ�ׂ� �s�N�Z���V�F�[�_���̐Ϙa���Z��̐��� 16�� �� 48�� �� 3�{�ɑ��₳��Ă�
���̂���Ȃ��Ƃ��������ƌ����ƁAnVIDIA����\�I��1300�̃Q�[���̃V�F�[�_������������������
�Ϙa���Z�@�\����������� �Q�[���̐��\���ł��オ��₷���Ɣ��f��������
�܂�AFFT�i�����t�[���G�ϊ��j������ �� �Ϙa���Z������ �� �Q�[���ɂ�����3D����������
�ƁA�܂��ɃQ�[�����\�ɒ������Ă���
SPE�́AGPU�ł����u�V�F�[�_���j�b�g�v�̂悤�Ȃ��̂��ƍl���Ă���
�����āA���FFT�̌��ʂ�
�hCell�� �i�Q�[�����\�ɒ�������j�Ϙa���Z�́i�J�^���O�l�����łȂ��j�u�������\�v�������h�A�Ƃ����Ӗ��Ȃ̂�
�t�[���G�ϊ��͉摜�E�����M���̎��g����͂����邽�߂́u�Ϙa���Z�v�̈��A����e
�ŋ߂̃Q�[���ɂ����� 3D�̍��W�ϊ��E�x�N�g�����Z�� ���́u�Ϙa���Z�v���J��Ԃ��s�����ƂŎ��s�����
���_���Z��s�N�Z���������s�� GPU�̃V�F�[�_���j�b�g�̃��C���� ���̂��߂́u�Ϙa���Z��v
�V�F�[�_���\�����߂� �Ƃ́A�V�F�[�_���j�b�g����� �u�Ϙa���Z�@�\�v�����߂邱��
���ہAG70�ł�GF6800�ɔ�ׂ� �s�N�Z���V�F�[�_���̐Ϙa���Z��̐��� 16�� �� 48�� �� 3�{�ɑ��₳��Ă�
���̂���Ȃ��Ƃ��������ƌ����ƁAnVIDIA����\�I��1300�̃Q�[���̃V�F�[�_������������������
�Ϙa���Z�@�\����������� �Q�[���̐��\���ł��オ��₷���Ɣ��f��������
�܂�AFFT�i�����t�[���G�ϊ��j������ �� �Ϙa���Z������ �� �Q�[���ɂ�����3D����������
�ƁA�܂��ɃQ�[�����\�ɒ������Ă���
SPE�́AGPU�ł����u�V�F�[�_���j�b�g�v�̂悤�Ȃ��̂��ƍl���Ă���
�����āA���FFT�̌��ʂ�
�hCell�� �i�Q�[�����\�ɒ�������j�Ϙa���Z�́i�J�^���O�l�����łȂ��j�u�������\�v�������h�A�Ƃ����Ӗ��Ȃ̂�
699 �F����������K�������F2005/07/10(��) 16:07:35 ID:ApCQmk/k
�悭�킩��ǂȂ��]�����ۂ�����
�Q�[���ɂ�W�ˁ[���Ē@���Ƃ��A�����������
�Q�[���ɂ�W�ˁ[���Ē@���Ƃ��A�����������
700 �F����������K�������F2005/07/10(��) 16:09:54 ID:nImNIti4
�\�j�[��@���������������b��̐l��������ł���
701 �F����������K�������F2005/07/10(��) 16:10:37 ID:UR2cuWl9
Cell�ɕ�����Ă锠���M�҂͂ǂ����悤���˂��ȁB
����CPU�̓x���`���ʌ��\���Ă�̂��ƁB
�����x���`�������ACell�ɂԂ�������ŕ����邩����\�ł��܂����ˁB
���߂āA�M�ҞH�����ӂȕ���ł̃x���`���ʂ��Ă̂��������ˁB
����CPU�̓x���`���ʌ��\���Ă�̂��ƁB
�����x���`�������ACell�ɂԂ�������ŕ����邩����\�ł��܂����ˁB
���߂āA�M�ҞH�����ӂȕ���ł̃x���`���ʂ��Ă̂��������ˁB
702 �F����������K�������F2005/07/10(��) 16:12:24 ID:ZTIojovw
703 �F����������K�������F2005/07/10(��) 16:13:55 ID:M/o5EqWn
>>657�ɏ�����Ă�݂�����
�u�����牉�Z�����Ă��ASPE�ł܂Ƃ��ȏ����ł��邩�v�I�ӌ���
����Ȃ�ɗ����ł��邯�ǂˁB���Ƃ���C++�I�u�W�F�N�g��1�����o��
SPE�̃R�[�h����A�N�Z�X�������A�Ƃ����ƁA���Ȃ�ʓ|�Ȃ̂ł͂Ȃ����B
360�̂悤�ȑΏ̌^�}���`�X���b�h�Ȃ牽�̑�����Ȃ����ƂȂ̂ɁB
�u�����牉�Z�����Ă��ASPE�ł܂Ƃ��ȏ����ł��邩�v�I�ӌ���
����Ȃ�ɗ����ł��邯�ǂˁB���Ƃ���C++�I�u�W�F�N�g��1�����o��
SPE�̃R�[�h����A�N�Z�X�������A�Ƃ����ƁA���Ȃ�ʓ|�Ȃ̂ł͂Ȃ����B
360�̂悤�ȑΏ̌^�}���`�X���b�h�Ȃ牽�̑�����Ȃ����ƂȂ̂ɁB
704 �F����������K�������F2005/07/10(��) 16:16:39 ID:pgbN/qY6
������PPE���̂܂�Ȃ���
XBOX��PS2�̎�����r�x���`�͂�������
XBOX��PS2�̎�����r�x���`�͂�������
705 �F����������K�������F2005/07/10(��) 16:17:44 ID:uKMPKnBC
PPE�����܂��Ȃ��ƁAxenon����������悗
706 �F����������K�������F2005/07/10(��) 16:18:34 ID:yMiJ3zvG
ttp://game10.2ch.net/test/read.cgi/ghard/1117970733/422
�I�}�P�ŁA�e�N�m���W�[�X���炵��XBOX360�ɓ��ڂ����CPU�R�A�̐����𐄑����Ă݂�
���ڂ����CPU�R�A�ɋ߂��Ǝv����PowerPC G5 (970), 2GHz Dual�@���琄��
�܂��A�ő�l�ōl����Ɨv�f��512�̎���10MFlops�o�Ă���̂ŁA���j�A�ɐ��\��
�L�т�(���ۂɂ͂��肦�Ȃ�)�Ɖ��肵���ꍇ�ADual����3�R�A�֒P���ɐ��\��1.5�{�A
�N���b�N��3.2G�Ȃ̂ł����1.6�{��10x1.5x1.6=24GFlops�@���̒��x���ő�l���낤
�ŁA���Cell�̌��ʂ͗v�f����2^24�̎��̂��̂Ȃ̂ŁA�Ȃ�ׂ��v�f�����傫������
�T���Ă݂�ƁA2^18�̎���1.75GFlops�Ɠǂݎ���̂ŁA1.75��1.5x1.6=4.2GFlops
���������Ƒ�������ȉ��ɂȂ�Ǝv����
�����XBOX360���ɂ��肦�Ȃ��قǗL���ȏ����肵����ł̌��ʂ����ǁA����ł�
10�{���x�̍����t�����ɂȂ�
�I�}�P�ŁA�e�N�m���W�[�X���炵��XBOX360�ɓ��ڂ����CPU�R�A�̐����𐄑����Ă݂�
���ڂ����CPU�R�A�ɋ߂��Ǝv����PowerPC G5 (970), 2GHz Dual�@���琄��
�܂��A�ő�l�ōl����Ɨv�f��512�̎���10MFlops�o�Ă���̂ŁA���j�A�ɐ��\��
�L�т�(���ۂɂ͂��肦�Ȃ�)�Ɖ��肵���ꍇ�ADual����3�R�A�֒P���ɐ��\��1.5�{�A
�N���b�N��3.2G�Ȃ̂ł����1.6�{��10x1.5x1.6=24GFlops�@���̒��x���ő�l���낤
�ŁA���Cell�̌��ʂ͗v�f����2^24�̎��̂��̂Ȃ̂ŁA�Ȃ�ׂ��v�f�����傫������
�T���Ă݂�ƁA2^18�̎���1.75GFlops�Ɠǂݎ���̂ŁA1.75��1.5x1.6=4.2GFlops
���������Ƒ�������ȉ��ɂȂ�Ǝv����
�����XBOX360���ɂ��肦�Ȃ��قǗL���ȏ����肵����ł̌��ʂ����ǁA����ł�
10�{���x�̍����t�����ɂȂ�
707 �F����������K�������F2005/07/10(��) 16:19:03 ID:0vpfvpqT
>>698
G70�̓V�F�[�_�[���Z��̉�݂����Ȃ��̂��Ǝv�����A
G70�����Œǂ������ACell�ɂ܂ʼn���Ă��邱�Ƃ�����̂��^��B
�Q�[���ɂ�����Cell�̖�����3D�����ł͖����A
�ނ����O���t�B�b�N����AAI�╨���v�Z�Ȃǂ��傾�낤�B
G70�̓V�F�[�_�[���Z��̉�݂����Ȃ��̂��Ǝv�����A
G70�����Œǂ������ACell�ɂ܂ʼn���Ă��邱�Ƃ�����̂��^��B
�Q�[���ɂ�����Cell�̖�����3D�����ł͖����A
�ނ����O���t�B�b�N����AAI�╨���v�Z�Ȃǂ��傾�낤�B
708 �F����������K�������F2005/07/10(��) 16:19:04 ID:yMiJ3zvG
����
115.2 GFlops�Ɣ��\����Ă��鐫�\���炷��ƁA�ő�Ńs�[�N���\��20.8%�ACell�Ɠ�����
�ɋ߂��Ƃ���3.6%�����Ŗ������ƂȂ�
�܂��A���ۂ̃Q�[���ł��̂܂܂̍����t�����ǂ����͕ʂ̘b�����ACell�����̏����Œ@���o����
20%�A41GFlops�Ƃ����������ǂꂾ���������Ƃ������������ɂ͏\�����낤
����Ȏ��Z���ߋ��ɂ���Ă���
115.2 GFlops�Ɣ��\����Ă��鐫�\���炷��ƁA�ő�Ńs�[�N���\��20.8%�ACell�Ɠ�����
�ɋ߂��Ƃ���3.6%�����Ŗ������ƂȂ�
�܂��A���ۂ̃Q�[���ł��̂܂܂̍����t�����ǂ����͕ʂ̘b�����ACell�����̏����Œ@���o����
20%�A41GFlops�Ƃ����������ǂꂾ���������Ƃ������������ɂ͏\�����낤
����Ȏ��Z���ߋ��ɂ���Ă���
709 �F����������K�������F2005/07/10(��) 16:19:33 ID:JsMbxSIG
>http://forum.teamxbox.com/showthread.php?t=357095
>�����̘b�͖������E�E�E
XBOX360��Cell��PowerPC�R�A�̓V���v���߂��ŃV���{�b�I�I�b�ɂȂ��B
���Ęb���c
�㓡�^���Ƃ͌�����180�x�Ⴄ�ȁB
>http://pc.watch.impress.co.jp/docs/2005/0218/kaigai158.htm
>�����̘b�͖������E�E�E
XBOX360��Cell��PowerPC�R�A�̓V���v���߂��ŃV���{�b�I�I�b�ɂȂ��B
���Ęb���c
�㓡�^���Ƃ͌�����180�x�Ⴄ�ȁB
>http://pc.watch.impress.co.jp/docs/2005/0218/kaigai158.htm
710 �F����������K�������F2005/07/10(��) 16:19:54 ID:RIOs/nc4
PPE��GC�݂�����Ǝv����
711 �F����������K�������F2005/07/10(��) 16:20:38 ID:A2FYMLkk
712 �F����������K�������F2005/07/10(��) 16:21:02 ID:yMiJ3zvG
713 �F����������K�������F2005/07/10(��) 16:22:11 ID:yMiJ3zvG
714 �F����������K�������F2005/07/10(��) 16:23:45 ID:JsMbxSIG
>http://forum.teamxbox.com/showthread.php?t=357095
���łɌ����Ƃ��̋L���̐l�A�X�[�p�[�X�J���[�̎��s
�p�C�v���C����2�{�ɂȂ�V���O���X���b�h���\���A
���̂܂�2�{�߂��ɂȂ�ƍl����ނ̐l�Ȃ̂��낤���H
�����R�[�h�𑖂点�Ȃ��P�[�X�ł�Out-Of-Order�̗L���́A
����قǑ傫���Ȃ����Ă��Ƃɂ��v������Ȃ��̂��낤���H
���łɌ����Ƃ��̋L���̐l�A�X�[�p�[�X�J���[�̎��s
�p�C�v���C����2�{�ɂȂ�V���O���X���b�h���\���A
���̂܂�2�{�߂��ɂȂ�ƍl����ނ̐l�Ȃ̂��낤���H
�����R�[�h�𑖂点�Ȃ��P�[�X�ł�Out-Of-Order�̗L���́A
����قǑ傫���Ȃ����Ă��Ƃɂ��v������Ȃ��̂��낤���H
715 �F����������K�������F2005/07/10(��) 16:25:19 ID:KU/xeHMy
716 �F����������K�������F2005/07/10(��) 16:26:12 ID:UV4VGp47
���Ȃ݂�Epic Games�̕��В���PhysX�iNovodeX�j��Cell�͑����������̂ňڐA���e�Ղ��Ƃ͌����Ă���
3D�Q�[���t�@���̂��߂̍ŐV�����G���W���u��
�`3D�Q�[���̂��߂̕����G���W���A�N�Z�����[�^�uPhysX�v�̓u���C�N���邩?
http://www.watch.impress.co.jp/game/docs/20050318/ageia.htm
���@�����ŁAAGEIA���J�������̂́A���E���̕����G���W���A�N�Z�����[�^�`�b�v�uPhysX�v���B
����{�I�ɂ�SIMD�x�[�X�̕��������_�����x�N�g�����Z��̉�(�A���C)�̂悤�����A������
���ŏq�ׂĂ����悤�ȘA�������I�ɔ������镨���v�Z�ɓ��������A�[�L�e�N�`���ɂȂ��Ă���Ƃ����B
�uSIMD�x�[�X�̕��������_�����x�N�g�����Z��̉�v���Ă܂���Cell�̂��Ƃ�����
3D�Q�[���t�@���̂��߂̍ŐV�����G���W���u��
�`3D�Q�[���̂��߂̕����G���W���A�N�Z�����[�^�uPhysX�v�̓u���C�N���邩?
http://www.watch.impress.co.jp/game/docs/20050318/ageia.htm
���@�����ŁAAGEIA���J�������̂́A���E���̕����G���W���A�N�Z�����[�^�`�b�v�uPhysX�v���B
����{�I�ɂ�SIMD�x�[�X�̕��������_�����x�N�g�����Z��̉�(�A���C)�̂悤�����A������
���ŏq�ׂĂ����悤�ȘA�������I�ɔ������镨���v�Z�ɓ��������A�[�L�e�N�`���ɂȂ��Ă���Ƃ����B
�uSIMD�x�[�X�̕��������_�����x�N�g�����Z��̉�v���Ă܂���Cell�̂��Ƃ�����
717 �F����������K�������F2005/07/10(��) 16:29:01 ID:M/o5EqWn
>>710
GC��Gecko��PowerPC 750�J�X�^���B970�݊���PPE�Ƃ͂��Ȃ�Ⴄ�B
GC��Gecko��PowerPC 750�J�X�^���B970�݊���PPE�Ƃ͂��Ȃ�Ⴄ�B
718 �F����������K�������F2005/07/10(��) 16:29:40 ID:2gkv2AvL
719 �F����������K�������F2005/07/10(��) 16:32:01 ID:TvlctE2p
HD DVD�̎R�c����݂����ȕ�����
720 �F����������K�������F2005/07/10(��) 16:33:39 ID:uKMPKnBC
>>707
�����GPU�̕������Ƃ���
�E����Đ��x���̋���
�E�������Z�@�\�̋���
����������B
���͂������肵���̂��܂��� Cell
�������Z�ŏd�v�ȉ��Z��
�E�͊w�v�Z
�E�Փ˔���
���̓��A�Փ˔���͘b��́hPhysX�`�b�v�h�Ȃǂ̂悤��
�������Z��p�`�b�v�ɂ͂��Ȃ�Ȃ���������Ȃ����A
�͊w���Z�ɂ� Cell�̖c��ȃp���[����������������邾�낤�B
���Ȃ��Ƃ��Axenon�`�b�v�ɂ� �������Z���u�[�X�g����悤��
�@�\�͉����t���Ă��Ȃ��̂ł͂Ȃ����B
�����GPU�̕������Ƃ���
�E����Đ��x���̋���
�E�������Z�@�\�̋���
����������B
���͂������肵���̂��܂��� Cell
�������Z�ŏd�v�ȉ��Z��
�E�͊w�v�Z
�E�Փ˔���
���̓��A�Փ˔���͘b��́hPhysX�`�b�v�h�Ȃǂ̂悤��
�������Z��p�`�b�v�ɂ͂��Ȃ�Ȃ���������Ȃ����A
�͊w���Z�ɂ� Cell�̖c��ȃp���[����������������邾�낤�B
���Ȃ��Ƃ��Axenon�`�b�v�ɂ� �������Z���u�[�X�g����悤��
�@�\�͉����t���Ă��Ȃ��̂ł͂Ȃ����B
721 �F����������K�������F2005/07/10(��) 16:35:10 ID:M/o5EqWn
�R���p�C����PPE�����œK���Ŗ��߂���ׂ�����A
in-order���ߎ��s�̃C���p�N�g�͏�����? ����Ȃ��̂��ˁB
in-order���ߎ��s�̃C���p�N�g�͏�����? ����Ȃ��̂��ˁB
722 �F����������K�������F2005/07/10(��) 16:38:32 ID:yAiqpeDg
����������PPC970����RISC���߂̂͂���PPC���߃Z�b�g�ł���A
���͂╡�G�߂���悤�ŁA�킴�킴�V���v���ȓ������߂ɍӂ��Ď��s����ƌ���
����x86�nCPU�݂����Ȃ��Ƃ���ĂāA����������RISC�Ƃ͌��������B
PPC���߃Z�b�g�Ƃ̌݊��ł���A���ƂȂ��Ă͐��\�I�Ȃȑ��g�ƌ������Ƃ��B
������SPE�́A200�ȉ��ɍi�荞�̂����ȁB
���͂╡�G�߂���悤�ŁA�킴�킴�V���v���ȓ������߂ɍӂ��Ď��s����ƌ���
����x86�nCPU�݂����Ȃ��Ƃ���ĂāA����������RISC�Ƃ͌��������B
PPC���߃Z�b�g�Ƃ̌݊��ł���A���ƂȂ��Ă͐��\�I�Ȃȑ��g�ƌ������Ƃ��B
������SPE�́A200�ȉ��ɍi�荞�̂����ȁB
723 �F����������K�������F2005/07/10(��) 16:41:23 ID:uKMPKnBC
100�ȉ��A����Ȃ������H �����߃Z�b�g
�V����IBM�A�[�L�e�N�^�� ����ő����Ƃ������āB
�\�����V���v���ɁA���߃Z�b�g���V���v���ɁB
�����̂ł͂Ȃ����B
�V����IBM�A�[�L�e�N�^�� ����ő����Ƃ������āB
�\�����V���v���ɁA���߃Z�b�g���V���v���ɁB
�����̂ł͂Ȃ����B
724 �F����������K�������F2005/07/10(��) 16:47:52 ID:UV4VGp47
�����̓��o�G���̋L����
���̃~�[�e�B���O�̓I�[�X�e�B���BSCE��u����c���ɓ���ƁA
IBM�̐Ȃɏ��V�̃G���W�j�A���B30�A40�オ�������A��ۖڗ��B
���܍l�����݂Ȃ���A��S�s���Ƀy���𑖂点�Ă���B
�u����͒N���낤�H�v
IBM���Ă���鏇�ԂɁB����ƁA���̏��V�������オ��B
�u�Ƃ������R���p�C���������₷�����߃Z�b�g�ɂ��ׂ��B200�ł�
��������B���̎��Z�ł�100�ȉ��Ŏ������v
��قǂ܂Ńy���𑖂点�Ă��������f���Ȃ������������B
�����ɂ͋@�B��ŋL�q�����菑���̃T���v���v���O�������B
���̋S�C����p�ɒN�������|�����B
�X�ɑ����E�E�E
���̃~�[�e�B���O�̓I�[�X�e�B���BSCE��u����c���ɓ���ƁA
IBM�̐Ȃɏ��V�̃G���W�j�A���B30�A40�オ�������A��ۖڗ��B
���܍l�����݂Ȃ���A��S�s���Ƀy���𑖂点�Ă���B
�u����͒N���낤�H�v
IBM���Ă���鏇�ԂɁB����ƁA���̏��V�������オ��B
�u�Ƃ������R���p�C���������₷�����߃Z�b�g�ɂ��ׂ��B200�ł�
��������B���̎��Z�ł�100�ȉ��Ŏ������v
��قǂ܂Ńy���𑖂点�Ă��������f���Ȃ������������B
�����ɂ͋@�B��ŋL�q�����菑���̃T���v���v���O�������B
���̋S�C����p�ɒN�������|�����B
�X�ɑ����E�E�E
725 �F����������K�������F2005/07/10(��) 16:48:03 ID:M/o5EqWn
����ATLP�����߂邩��Ƃ�����ILP���̂Ă�̂͂���܂�ǂ����Ƃł͂Ȃ�����ǁB
�g�����W�X�^����`�b�v�J���R�X�g�Ƃ̃g���[�h�I�t�ł�ނ������A�Ƃ������B
���ہACell����2�����PPE��2���ߓ������s�ɉ��P�����B
1���߂ł͂���܂肾�Ǝv�����낤�B
�g�����W�X�^����`�b�v�J���R�X�g�Ƃ̃g���[�h�I�t�ł�ނ������A�Ƃ������B
���ہACell����2�����PPE��2���ߓ������s�ɉ��P�����B
1���߂ł͂���܂肾�Ǝv�����낤�B
726 �F����������K�������F2005/07/10(��) 16:50:36 ID:UV4VGp47
����
��������̂͂��AAPU���߃Z�b�g�̒�`�͂��̃G���W�j�A��
�\�t�g�Z�p�҂Ƃ��ẴL�����A�̒��߂�����Ƃ��đI�d��
�������̂��B�ނ̖���Marty Hopkins�B���E����RISC�^
CPU�uIBM801�v�̊J���҂̈�l�ł���A���̓��ł͒m��l��
�m��l���B�V���Z�p�҂̌����ɋZ�p�ҒB�̖ڂ�����B
�R���p�C����m��s����Marty�̃A�h�o�C�X�����Z�p��
���V�~�����[�V�����Ō�����B
���̌���A�R���p�C���̍œK����Ƃ������邽�߂ɃA�h���b�V���O
���[�h��lj�����ȂNjM�d�ȏ������c�����B�����āAAPU��
���߃Z�b�g���قڌł܂����̂����͂��āA30�N�Ζ�����IBM��
��ɂ����B
RISC�̎Y�݂̐e�̈�l�ł���IBM�̃G���W�j�A��
�Ō�̎d���ł���Cell�̐v�Ŏ����̔��w�����߂Č�����������Ƃ������Ƃ�
��������̂͂��AAPU���߃Z�b�g�̒�`�͂��̃G���W�j�A��
�\�t�g�Z�p�҂Ƃ��ẴL�����A�̒��߂�����Ƃ��đI�d��
�������̂��B�ނ̖���Marty Hopkins�B���E����RISC�^
CPU�uIBM801�v�̊J���҂̈�l�ł���A���̓��ł͒m��l��
�m��l���B�V���Z�p�҂̌����ɋZ�p�ҒB�̖ڂ�����B
�R���p�C����m��s����Marty�̃A�h�o�C�X�����Z�p��
���V�~�����[�V�����Ō�����B
���̌���A�R���p�C���̍œK����Ƃ������邽�߂ɃA�h���b�V���O
���[�h��lj�����ȂNjM�d�ȏ������c�����B�����āAAPU��
���߃Z�b�g���قڌł܂����̂����͂��āA30�N�Ζ�����IBM��
��ɂ����B
RISC�̎Y�݂̐e�̈�l�ł���IBM�̃G���W�j�A��
�Ō�̎d���ł���Cell�̐v�Ŏ����̔��w�����߂Č�����������Ƃ������Ƃ�
727 �F����������K�������F2005/07/10(��) 16:56:22 ID:uKMPKnBC
�g�����W�X�^�A������ȁB��Cell
�܂�SRAM��2.5MB������Ă�̂����E�E
�ʐς�RSX���傫���Ȃ邾�낤�ˁB
�܂�SRAM��2.5MB������Ă�̂����E�E
�ʐς�RSX���傫���Ȃ邾�낤�ˁB
728 �F����������K�������F2005/07/10(��) 17:03:24 ID:JsMbxSIG
>>657�̋L���̐l�ɍX�ɓ˂����ނ�
XBOX360��CPU�̓v���X�R�̔������炢�̑傫�������Ȃ��ăV���{�b�I�I
�݂����Ȃ��ƌ����Ă邯�ǁA�v���X�R�����K�V�[�̂��߂�
�����ɖ��ʂȃg�����W�X�^�������Ă邩�l���~����
ttp://rerere.sytes.net/up/source/up8267.jpg
�X�P�W���[���[�A���߃f�R�[�_�A����\����H�ƌ�����
����s���j�b�g�����s���j�b�g��2�{���炢�ʐς�H���Ă�
���̏���قǂ̖����I�c
XBOX360��CPU�̓v���X�R�̔������炢�̑傫�������Ȃ��ăV���{�b�I�I
�݂����Ȃ��ƌ����Ă邯�ǁA�v���X�R�����K�V�[�̂��߂�
�����ɖ��ʂȃg�����W�X�^�������Ă邩�l���~����
ttp://rerere.sytes.net/up/source/up8267.jpg
{kind=link}
�X�P�W���[���[�A���߃f�R�[�_�A����\����H�ƌ�����
����s���j�b�g�����s���j�b�g��2�{���炢�ʐς�H���Ă�
���̏���قǂ̖����I�c
729 �F����������K�������F2005/07/10(��) 17:04:17 ID:LZFVhLxL
>>727
����HCell��2��5000�����炢�ŁARSX��3���z���������悤�ȁH
����HCell��2��5000�����炢�ŁARSX��3���z���������悤�ȁH
730 �F����������K�������F2005/07/10(��) 17:06:07 ID:RIOs/nc4
�v���X�R�̓L���b�V��2M�ɂ��Ă����̃U�}
�g�����W�X�^�̑������ĈӖ�����̂��H
�g�����W�X�^�̑������ĈӖ�����̂��H
731 �F����������K�������F2005/07/10(��) 17:14:58 ID:M/o5EqWn
�ǂ�����g�����W�X�^���������ǁA����ł�GS���̓_�C�T�C�Y���������Ȃ��Ă���B
�Ƃ肠����G70�͖��Ȃ��o�ׂ��Ă�ˁB
�������nVidia�Ƃ͑�Ⴂ�B�ނ�͎��s����w�K����g�D�Ȃ낤���B
�Ƃ肠����G70�͖��Ȃ��o�ׂ��Ă�ˁB
�������nVidia�Ƃ͑�Ⴂ�B�ނ�͎��s����w�K����g�D�Ȃ낤���B
732 �F����������K�������F2005/07/10(��) 17:15:00 ID:uKMPKnBC
>>729
����B
Cell�iDD2�j�� 2��5000���g�����W�X�^�E 235mm~2�A
RSX��3���g�����W�X�^��E ���� 200�`240mm~2���x����Ȃ����ȁB
���m�ɂ͂킩��ǁE�E
�ǂ�����90nm�v���Z�X�B
�g�����W�X�^���Ɩʐς͕K��������v���Ȃ��B
����B
Cell�iDD2�j�� 2��5000���g�����W�X�^�E 235mm~2�A
RSX��3���g�����W�X�^��E ���� 200�`240mm~2���x����Ȃ����ȁB
���m�ɂ͂킩��ǁE�E
�ǂ�����90nm�v���Z�X�B
�g�����W�X�^���Ɩʐς͕K��������v���Ȃ��B
733 �F����������K�������F2005/07/10(��) 17:18:47 ID:LZFVhLxL
>>728
ttp://pcweb.mycom.co.jp/special/2004/prescott/003.html
Prescott����90nm�v���Z�X��1��2500��(L2 1M)�����ǁAXbox360��CPU���Ă���ȏ������́H
ttp://pcweb.mycom.co.jp/special/2004/prescott/003.html
Prescott����90nm�v���Z�X��1��2500��(L2 1M)�����ǁAXbox360��CPU���Ă���ȏ������́H
734 �F����������K�������F2005/07/10(��) 17:22:35 ID:JsMbxSIG
735 �F����������K�������F2005/07/10(��) 17:25:41 ID:Fstyiy4Z
>>720
Xbox360�̊J���L�b�g�ɂ̓��A�N�^�[�Ƃ����������Z�G���W�������Ă����AUE3�ɂ��ˁB
�������Z�̓\�t�g�ł̌����̂ق������\�ɒ������邩��~�h���E�F�A�̐��\����B
���ɃQ�[���̏ꍇ�A�|���S���̃J�����O�Ɠ����ł������ɗ͊w�v�Z�Ȃ���Ă���g�����ɂȂ�Ȃ���B
Xbox360�̊J���L�b�g�ɂ̓��A�N�^�[�Ƃ����������Z�G���W�������Ă����AUE3�ɂ��ˁB
�������Z�̓\�t�g�ł̌����̂ق������\�ɒ������邩��~�h���E�F�A�̐��\����B
���ɃQ�[���̏ꍇ�A�|���S���̃J�����O�Ɠ����ł������ɗ͊w�v�Z�Ȃ���Ă���g�����ɂȂ�Ȃ���B
736 �F����������K�������F2005/07/10(��) 17:27:02 ID:M/o5EqWn
����ȑ��U�Ř_�j����邱�Ƃ��킴�킴�����ɗ��Ȃ��Ă��A�Ǝv�����B
737 �F����������K�������F2005/07/10(��) 17:36:41 ID:uKMPKnBC
>>735
���₳�E�E
�uCell�͓���̃G���R�����g���Ȃ��v �ƒN������������
�u3D�Q�[���̉��Z�ɂ�������v ��������A
�uGPU�I�ȋ@�\�͑���Ă��B Cell�͕������Z�͏o���Ȃ��̂��H�v ��������A
�u����A��������ӂ���B Cell�̓��ӕ��삾�v ���ē����������ł��E�E
�`�b�v�{�̂ɕ������Z���u�[�X�g����悤�ȋ@�\���t���ĂȂ��̂ɁA
�~�h���E�F�A�ŕt���Ă邩��S�z�����A�ނ���Cell�Ŕn�������Ƀ��A���^�C�����Z����͖̂��ʁA
�Ȃ�Č����Ă��E�E�E
�u���������ł����A�撣���Ă��������v�A�Ƃ��������悤���Ȃ��B
���₳�E�E
�uCell�͓���̃G���R�����g���Ȃ��v �ƒN������������
�u3D�Q�[���̉��Z�ɂ�������v ��������A
�uGPU�I�ȋ@�\�͑���Ă��B Cell�͕������Z�͏o���Ȃ��̂��H�v ��������A
�u����A��������ӂ���B Cell�̓��ӕ��삾�v ���ē����������ł��E�E
�`�b�v�{�̂ɕ������Z���u�[�X�g����悤�ȋ@�\���t���ĂȂ��̂ɁA
�~�h���E�F�A�ŕt���Ă邩��S�z�����A�ނ���Cell�Ŕn�������Ƀ��A���^�C�����Z����͖̂��ʁA
�Ȃ�Č����Ă��E�E�E
�u���������ł����A�撣���Ă��������v�A�Ƃ��������悤���Ȃ��B
738 �F����������K�������F2005/07/10(��) 17:38:45 ID:SGsfZGQd
>>737
�����G���W�����u�`�b�v�v���Ǝv���Ă�Ɉ�[�B
�����G���W�����u�`�b�v�v���Ǝv���Ă�Ɉ�[�B
739 �F����������K�������F2005/07/10(��) 17:51:47 ID:uKMPKnBC
>>738
�����E�E
�Ⴆ�� �uNovodeX�G���W���v�ƁuPhysX�`�b�v�v���������Ă�̂��E�E
���������ł� ��p�`�b�v��ς߂�60fps�ł�̂��A
P4�Ƃ����̎��CPU�����ōs���� 1�`2fps�����o�Ȃ����Ă��Ƃ����邼�B
�������Z�A�N�Z�����[�V�����@�\�͎������Ă��ق��������B
���������̃~�h���E�F�A�����Ӗ��ɂȂ��Ă��܂��B
�����E�E
�Ⴆ�� �uNovodeX�G���W���v�ƁuPhysX�`�b�v�v���������Ă�̂��E�E
���������ł� ��p�`�b�v��ς߂�60fps�ł�̂��A
P4�Ƃ����̎��CPU�����ōs���� 1�`2fps�����o�Ȃ����Ă��Ƃ����邼�B
�������Z�A�N�Z�����[�V�����@�\�͎������Ă��ق��������B
���������̃~�h���E�F�A�����Ӗ��ɂȂ��Ă��܂��B
740 �F����������K�������F2005/07/10(��) 17:54:55 ID:8/z8II6N
Cell�̃\�t�g���̏[���x�͂ǂ�Ȃ��˂��B
���Ȃ݂�DirectX��HLSL�R���p�C����
�ƂĂ��悭�o���Ă�Ǝv����
���܂���auto�ϐ���const����t�����Ȃ��B
����2�N�ȏ���j������͂��Ȃ̂����B
IBM��������v�͂�����Ɗy�ϓI������Ǝv���̂����E�E�B
���Ȃ݂�DirectX��HLSL�R���p�C����
�ƂĂ��悭�o���Ă�Ǝv����
���܂���auto�ϐ���const����t�����Ȃ��B
����2�N�ȏ���j������͂��Ȃ̂����B
IBM��������v�͂�����Ɗy�ϓI������Ǝv���̂����E�E�B
741 �F����������K�������F2005/07/10(��) 17:55:38 ID:SxIPeAp/
�������Z�����������ƃo�[�`���̐l�`������������H
������ɂ͂�����ӊ��҂��������ǁA�����ɗ͊w�v�Z���Ȃ��Ă������Ȃ́H
������ɂ͂�����ӊ��҂��������ǁA�����ɗ͊w�v�Z���Ȃ��Ă������Ȃ́H
742 �F����������K�������F2005/07/10(��) 17:59:11 ID:uKMPKnBC
����n�̃\�t�g�����s���Ă݂�킩��Ǝv�����ǁA
�P���ȃ|���S�����f���ł� �C�����������炢�N�l�N�l�������B
�����I�ɉ��Z���Ȃ���E�E
�Y��ȃe�N�X�`���������L�����œ���������
��ۂ͑S���Ⴄ�Q�[���̂悤�Ɍ����邾�낤�B
Cell�� ���̂����肪�y���݁B
�P���ȃ|���S�����f���ł� �C�����������炢�N�l�N�l�������B
�����I�ɉ��Z���Ȃ���E�E
�Y��ȃe�N�X�`���������L�����œ���������
��ۂ͑S���Ⴄ�Q�[���̂悤�Ɍ����邾�낤�B
Cell�� ���̂����肪�y���݁B
743 �F����������K�������F2005/07/10(��) 18:00:25 ID:8/z8II6N
744 �F����������K�������F2005/07/10(��) 18:03:48 ID:D7hc5JcB
�{���Ɍ����Ɠ����������Z�����Ńo�[�`���������
�������x����HP�Q�[�W�̈Ӗ��̖������̂ɂȂ肻�����B
�������x����HP�Q�[�W�̈Ӗ��̖������̂ɂȂ肻�����B
745 �F����������K�������F2005/07/10(��) 18:05:27 ID:uKMPKnBC
������� �X�p�R������Ȃ�����A
���Z�\�͂̋����͈͂̕������Z����
�܁A�Q�[�����x�Ȃ� ���������������̂��ł��邩��
���Z�\�͂̋����͈͂̕������Z����
�܁A�Q�[�����x�Ȃ� ���������������̂��ł��邩��
746 �F����������K�������F2005/07/10(��) 18:06:09 ID:ZTIojovw
��������Ȃ�����Q�[���͊y�����Ƃ������������邵�ˁB
�ʂɃ��A���ȉ��荇�������߂Ă�킯����Ȃ���
�ʂɃ��A���ȉ��荇�������߂Ă�킯����Ȃ���
747 �F����������K�������F2005/07/10(��) 18:07:39 ID:R+hYO/m9
�i���Q�[���ɕ������Z�̂悤�Ȋm���ւ̈ˑ����������v�f������͔̂����Ȃ悤�ȁE�E�E�B
���������v�f���������i�Q�[������ƌ�������Ȃ��A�o�[�`���̂悤�ɗ��j��
����\�t�g�͉���Ɋv�V�I�ȗv�f�荞�߂Ȃ��������Ƃ���B
���������v�f���������i�Q�[������ƌ�������Ȃ��A�o�[�`���̂悤�ɗ��j��
����\�t�g�͉���Ɋv�V�I�ȗv�f�荞�߂Ȃ��������Ƃ���B
748 �F����������K�������F2005/07/10(��) 18:18:14 ID:E1cHK8dU
�i���Q�[���̃X��������킩�邯�ǁu���̋Z��������d�����t����XX�Z�m��v�Ȃ�Đ��E��
�������Z�͋��߂��Ă��Ȃ��C������ȁB
�������Z�͋��߂��Ă��Ȃ��C������ȁB
749 �F����������K�������F2005/07/10(��) 18:31:05 ID:L2kM2+jR
������@�̊i�Q�[���^�̊Ԃł̓t���[��������Ȃ���
�������Z�̓����̒��œǂ݂Ȃ���키�悤�ɂȂ�
�Ƃ��������ɂȂ�̂�������Ȃ�
���ɂ����ꂪ�ǂ��������Ƃ����悭�킩��i�Q�[���^�̔\�͂͐��������
�������Z�̓����̒��œǂ݂Ȃ���키�悤�ɂȂ�
�Ƃ��������ɂȂ�̂�������Ȃ�
���ɂ����ꂪ�ǂ��������Ƃ����悭�킩��i�Q�[���^�̔\�͂͐��������
750 �F����������K�������F2005/07/10(��) 18:32:29 ID:M/o5EqWn
�V�т���Ȃ�
751 �F����������K�������F2005/07/10(��) 18:34:28 ID:E1cHK8dU
��1�ɕ������Z�������ꂽ�i�����l���Ă̂��������Ǝv��������͂ǂ��]������Ă��̂��ȁH
����������ݖ������ꂽ���ȊO�m��Ȃ����A�Q�[���V�X�e���I�ɂǂ��������̂��ƁB
����������ݖ������ꂽ���ȊO�m��Ȃ����A�Q�[���V�X�e���I�ɂǂ��������̂��ƁB
752 �F����������K�������F2005/07/10(��) 18:41:04 ID:SGsfZGQd
�P�ɕ������Z������̂ł͂Ȃ��āA�������Z���g����+�����Ȃ����
�Q�[���Ƃ��Ă̖ʔ����͂Ȃ��Ǝv��
�Q�[���Ƃ��Ă̖ʔ����͂Ȃ��Ǝv��
753 �F����������K�������F2005/07/10(��) 18:41:54 ID:D7hc5JcB
�i�Q�[�ɕ������Z�����Ȃ�w�i�Ɠ��h�ꂮ�炢����B
754 �F����������K�������F2005/07/10(��) 18:46:09 ID:xchullbC
�RD�i�Q�[�ɍׂ����������Z�g������
�R���{�Ȃo���Ȃ��Ǝv����
�R���{�Ȃo���Ȃ��Ǝv����
755 �F����������K�������F2005/07/10(��) 19:02:31 ID:9fhNQisk
>>754
���ȁB
�y���͂����������Ől�����X�ƕ����Ă��܂����_�ŕ����@���ɔ����Ă�B
�ł����A���ɂ���ƋR���{���̂��̂��������Ȃ��Ȃ��Ėʔ����Ȃ��Ȃ��Ă��܂��B
�i���Q�[����ʔ������邽�߂ɂ͂ނ���V�X�e���ʂ̉��ǂ̕������ʂ��傫���Ǝv���ˁB
�K�[�h����ƌł܂��Ă��܂������Ƃ��A�������s���[�V���������炩�ɕs���R�Ƃ��A
�N���オ��̍U�h���P���Ƃ��B������ւ�̉��ǂ̕����ʔ����𑝂��Ɨ\�z�B
���ȁB
�y���͂����������Ől�����X�ƕ����Ă��܂����_�ŕ����@���ɔ����Ă�B
�ł����A���ɂ���ƋR���{���̂��̂��������Ȃ��Ȃ��Ėʔ����Ȃ��Ȃ��Ă��܂��B
�i���Q�[����ʔ������邽�߂ɂ͂ނ���V�X�e���ʂ̉��ǂ̕������ʂ��傫���Ǝv���ˁB
�K�[�h����ƌł܂��Ă��܂������Ƃ��A�������s���[�V���������炩�ɕs���R�Ƃ��A
�N���オ��̍U�h���P���Ƃ��B������ւ�̉��ǂ̕����ʔ����𑝂��Ɨ\�z�B
756 �F����������K�������F2005/07/10(��) 19:05:57 ID:LW/tRNtn
�������Z���邩��j���[�g���͊w�ɉ��������������ł��Ȃ��Ȃ���Ă킯�ł��Ȃ�����B
757 �F����������K�������F2005/07/10(��) 19:07:56 ID:E1cHK8dU
�i�Q�[�Ȃ�Ă��͂�L�����Q�[�Ȃ��ǂȁB��
�����X�^�[�E�H�[�YEP3�̃Q�[�������Ă��܂������������Ă݂邗
�����X�^�[�E�H�[�YEP3�̃Q�[�������Ă��܂������������Ă݂邗
758 �F����������K�������F2005/07/10(��) 19:08:13 ID:rSl5/my0
1��1�̌�����Ƃ���܌��ʂ͂Ȃ��B�O�����o�݂����Ȃ�̂ق������ʓI���낤�B
RTS�Ƃ��ˁB
�o����o���Ȃ��Ǝg���g��Ȃ��͕ʖ�肾���B�Q�[���f�U�C���Ɋւ��Ă͂܂��ʂ�
�X�����ӂ��킵���Ǝv�����H
RTS�Ƃ��ˁB
�o����o���Ȃ��Ǝg���g��Ȃ��͕ʖ�肾���B�Q�[���f�U�C���Ɋւ��Ă͂܂��ʂ�
�X�����ӂ��킵���Ǝv�����H
759 �F����������K�������F2005/07/10(��) 19:09:55 ID:og4NzZCv
�i�Q�[�ɕ����G���W���̗�Ȃ炷�ł�EA��Fight Night�Ŏ����Ă�B
�X���[���[�V������KO�V�[�������Ƀ��A���ȃo�[�`���Ƃ��ǂ���B
�X���[���[�V������KO�V�[�������Ƀ��A���ȃo�[�`���Ƃ��ǂ���B
760 �F����������K�������F2005/07/10(��) 19:13:58 ID:9fhNQisk
�Ⴆ�~�h���L�b�N���K�[�h�����ꍇ�A�{���ɕ������Z���d������Ȃ�
���̒����̕������L���������Ɍ�ނ��Ȃ��Ƃ����Ȃ���ˁB
�ł�����́A���ߋ����Ń~�h���L�b�N���K�[�h���Ă�����������ނ��Ȃ��B
�����L�����̂̂߂荞����Ă�̂�����B
��������A���ɂ��邾���ł��Q�[�����͂��Ȃ�ς��͂��B
���̒����̕������L���������Ɍ�ނ��Ȃ��Ƃ����Ȃ���ˁB
�ł�����́A���ߋ����Ń~�h���L�b�N���K�[�h���Ă�����������ނ��Ȃ��B
�����L�����̂̂߂荞����Ă�̂�����B
��������A���ɂ��邾���ł��Q�[�����͂��Ȃ�ς��͂��B
761 �F����������K�������F2005/07/10(��) 19:14:13 ID:G0fZdk1F
>>756
�Q�[���ɋ��߂��Ă��镨�����Z�͌����ɗ͊w�v�Z���Ȃ��Ă������悤�ȋC������ȁB
��������ƁA�������Z���u�[�X�g����@�\�͓��ʕK�v����Ȃ��ăt�F�C�N��
�ق��������������ăQ�[���������Ƃ������ɂȂ�B
�Q�[���ɋ��߂��Ă��镨�����Z�͌����ɗ͊w�v�Z���Ȃ��Ă������悤�ȋC������ȁB
��������ƁA�������Z���u�[�X�g����@�\�͓��ʕK�v����Ȃ��ăt�F�C�N��
�ق��������������ăQ�[���������Ƃ������ɂȂ�B
762 �F�L�t�@�C�g�F2005/07/10(��) 19:16:53 ID:ecEOjoLP
�u�������Z�v�Ō�������Ƃ������낢�̂�����ȁB
winny�̍�҂��i�Q�[�ƕ������Z�Ƃ̊W�ɒ��ڂ��Ă����悤���B
winny�̍�҂��i�Q�[�ƕ������Z�Ƃ̊W�ɒ��ڂ��Ă����悤���B
�������L�����̂̂߂荞����Ă�̂�����B
��
�����L�����ɂ̂߂荞����Ă�̂�����B
>>761
�������Z�����̂��߂ɕK�v���A�Ƃ����Ƃ܂�̓��A�����̌��ゾ��B
�ł��i���Q�[���̏ꍇ�A����L�����̓�����V�X�e���ʂ̕������A������j�Q���Ă�킯���B
�܂����ǂ��ׂ��͂�����ł��傤�B�������Z��胂�[�V�����̉��ǂ̕������A�����𑝂��B
��
�����L�����ɂ̂߂荞����Ă�̂�����B
>>761
�������Z�����̂��߂ɕK�v���A�Ƃ����Ƃ܂�̓��A�����̌��ゾ��B
�ł��i���Q�[���̏ꍇ�A����L�����̓�����V�X�e���ʂ̕������A������j�Q���Ă�킯���B
�܂����ǂ��ׂ��͂�����ł��傤�B�������Z��胂�[�V�����̉��ǂ̕������A�����𑝂��B
764 �F����������K�������F2005/07/10(��) 19:17:23 ID:M/o5EqWn
�R��u�Ԃɑ��̎��ʂ�500Kg�ɑ������āA���̏Փ˂����Z�Ō����Ɍv�Z������
�Q�[���I�ʔ������o�Ȃ����ȁB
�Q�[���I�ʔ������o�Ȃ����ȁB
765 �F����������K�������F2005/07/10(��) 19:22:38 ID:og4NzZCv
�ނ���Q�[���ɕ����G���W���̖ʔ����͌����ł͂��肦�Ȃ�
�@�����\�z�ł���Ƃ��������ɂ����邩��A
�ǂ����Ƀt�F�C�N�Ȃ薟��I����������͕̂K�{��������Ȃ��B
�@�����\�z�ł���Ƃ��������ɂ����邩��A
�ǂ����Ƀt�F�C�N�Ȃ薟��I����������͕̂K�{��������Ȃ��B
766 �F����������K�������F2005/07/10(��) 19:23:21 ID:9fhNQisk
�܂����A��������ʔ����������Ƃ͌���Ȃ�����ˁB
�Q�[���Ƃ��Ẵt�F�C�N�͂ǂ����ɕK�v�B
�l�I�ɂ́A�i���Q�[���̏ꍇ�̃t�F�C�N�́u�L�����̃p���[�v�����ł悢�Ǝv���B
�s���R�ȃ��[�V�����͋ɗ͔z�����ׂ��B
�Q�[���Ƃ��Ẵt�F�C�N�͂ǂ����ɕK�v�B
�l�I�ɂ́A�i���Q�[���̏ꍇ�̃t�F�C�N�́u�L�����̃p���[�v�����ł悢�Ǝv���B
�s���R�ȃ��[�V�����͋ɗ͔z�����ׂ��B
�~�s���R�ȃ��[�V�����͋ɗ͔z�����ׂ��B�����s���R�ȃ��[�V�����͋ɗ͔r�����ׂ��B
�����̓L�[���̓~�X�������E�E�E
�����̓L�[���̓~�X�������E�E�E
768 �F����������K�������F2005/07/10(��) 19:29:51 ID:TO9iUiov
�r�����[�h�Ƃ��d�͂��V���~���[�g���������Q�[�Ƃ��Ȃ畨�����Z���Q�[����
�ʔ������邩������Ȃ����A�����̃Q�[���͕����w�������Ƃ���ɖʔ�����
����̂Ńt���[���V�e�B�݂����Ɍ������h�����ʂ����A���ɂ��낪��Ƃ�����
�͈̂Ӗ��������Ƃ������ȁB
���������͔̂C�V���̓��ӕ���Ȃ�SCE�͓�����O�̎g�����������Ȃ�����Ȃ��B
�ʔ������邩������Ȃ����A�����̃Q�[���͕����w�������Ƃ���ɖʔ�����
����̂Ńt���[���V�e�B�݂����Ɍ������h�����ʂ����A���ɂ��낪��Ƃ�����
�͈̂Ӗ��������Ƃ������ȁB
���������͔̂C�V���̓��ӕ���Ȃ�SCE�͓�����O�̎g�����������Ȃ�����Ȃ��B
769 �F����������K�������F2005/07/10(��) 19:31:07 ID:LW/tRNtn
�i���̐l�ΐl�̏����͕����G���W����肳��ɓ����������i�V�~�����[�^���o�Ă��邩���ȁB
�f�̃G���W�����Ƒ�G�c�߂��Ďg���Â炢�����B
���ɕ����G���W�������C�����e�B�[�t���[�ŕW�����ڂ����Ȃ�
���ւ̃��A���Ȋ��i�u���b�N����ꂽ����Ԃ��Ђ��Ⴐ����j�͓�����O�ɂȂ��Ȃ��́B
�f�̃G���W�����Ƒ�G�c�߂��Ďg���Â炢�����B
���ɕ����G���W�������C�����e�B�[�t���[�ŕW�����ڂ����Ȃ�
���ւ̃��A���Ȋ��i�u���b�N����ꂽ����Ԃ��Ђ��Ⴐ����j�͓�����O�ɂȂ��Ȃ��́B
770 �F����������K�������F2005/07/10(��) 19:33:47 ID:xchullbC
���肪���������ɉ���ꏊ���ς������ǂ����ł������킩���Ǝv����
���������Ɏ������U�������ꏊ������������肾�����肷��킯�����
�����܂ōׂ���������ʔ����Ȃ���
���������Ɏ������U�������ꏊ������������肾�����肷��킯�����
�����܂ōׂ���������ʔ����Ȃ���
771 �F����������K�������F2005/07/10(��) 19:43:39 ID:zGNw+bgz
�������Z�͂������A���͊i���Q�[�}�[���[���ł���ΐ�o�����X���\�z�ł��邩�ǂ������B
�J���Ҏ��g���\�����Ȃ����삪��ʂɔ������Ă��܂��킯������A�o�����X�����͂���ςɂȂ�B
�J���Ҏ��g���\�����Ȃ����삪��ʂɔ������Ă��܂��킯������A�o�����X�����͂���ςɂȂ�B
772 �F����������K�������F2005/07/10(��) 19:45:14 ID:9fhNQisk
>>768
�����������͔̂C�V���̓��ӕ���Ȃ�SCE�͓�����O�̎g�����������Ȃ�����Ȃ��B
���̕��������悭�킩���B�C�V���Ȃ�ăL�����Ŕ����Ă邾���B
�Q�[���f�U�C���̍S��ȂǂƂ͍ł������Ƃ���ɂ���Q�[�������Ǝv�����B
�����������͔̂C�V���̓��ӕ���Ȃ�SCE�͓�����O�̎g�����������Ȃ�����Ȃ��B
���̕��������悭�킩���B�C�V���Ȃ�ăL�����Ŕ����Ă邾���B
�Q�[���f�U�C���̍S��ȂǂƂ͍ł������Ƃ���ɂ���Q�[�������Ǝv�����B
773 �F����������K�������F2005/07/10(��) 19:45:48 ID:EFxBuWP+
�@Xenon�Ŏg�p�����̂́C�O�̃R�A���܂Ƃ߂�PowerPC�n�̃v���Z�b�T�ŁC1�R�A������2���߂����s�ł���Ƃ����B���ꂪ3.5GHz�ȏ�ŋ쓮�����̂ŁC��{���\��21G����/sec�ȏ�Ƃ������ƂɂȂ�B
��{�I�ɎO�̃R�A�ł͂��邪�C�R�A���Ƃ�2�X���b�h�������ƂŁC�S�̂�6�X���b�h�������s����Ƃ����C���[�W���B
�@����ɁC�x�N�g�����W�X�^���X���b�h���Ƃ�128���ڂ���Ă���Ƃ����BVMX�Ƃ���̂ŁC����͂����炭128�r�b�g���W�X�^�Ńx�N�g�����Z���s��AltiVec�iVelocityEngine�j�����Ă���Ƃ����Ӗ����Ǝv����
�iAltiVec��128�r�b�g���W�X�^��32�r�b�g���������_���Z����4���s����PowerPC�n�̃}���`���f�B�A���ߎ��s���j�b�g�j�B���̏ꍇ�̉��Z���\��84GFLOPS�ƂȂ�iPlayStation2��EmotionEngine��6.4GFLOPS���x�j�B
���W�X�^�����s���R�ɑ����悤�ɂ��v���邪�C���ꂪ���ɕ����̃��W�X�^�ɑ��ē����ɉ��Z���ł���d�l�ł���Ȃ�C�ő�10.5TFLOPS�̉��Z���\������\��������B
��{�I�ɎO�̃R�A�ł͂��邪�C�R�A���Ƃ�2�X���b�h�������ƂŁC�S�̂�6�X���b�h�������s����Ƃ����C���[�W���B
�@����ɁC�x�N�g�����W�X�^���X���b�h���Ƃ�128���ڂ���Ă���Ƃ����BVMX�Ƃ���̂ŁC����͂����炭128�r�b�g���W�X�^�Ńx�N�g�����Z���s��AltiVec�iVelocityEngine�j�����Ă���Ƃ����Ӗ����Ǝv����
�iAltiVec��128�r�b�g���W�X�^��32�r�b�g���������_���Z����4���s����PowerPC�n�̃}���`���f�B�A���ߎ��s���j�b�g�j�B���̏ꍇ�̉��Z���\��84GFLOPS�ƂȂ�iPlayStation2��EmotionEngine��6.4GFLOPS���x�j�B
���W�X�^�����s���R�ɑ����悤�ɂ��v���邪�C���ꂪ���ɕ����̃��W�X�^�ɑ��ē����ɉ��Z���ł���d�l�ł���Ȃ�C�ő�10.5TFLOPS�̉��Z���\������\��������B
774 �F����������K�������F2005/07/10(��) 19:47:07 ID:eNLeHor3
�������Z�ň�Ԗʔ��݂������Ƃ�����N���X�V������Ȃ����Ǝv�����B
�炪�ό`����Ƃ���菗�L�����̃R�X���̂ɉ����ĂՂ�Ղ�̂��邷���
�����̂������猩�Ă݂����B
�炪�ό`����Ƃ���菗�L�����̃R�X���̂ɉ����ĂՂ�Ղ�̂��邷���
�����̂������猩�Ă݂����B
775 �F����������K�������F2005/07/10(��) 19:48:26 ID:M/o5EqWn
�p���`����NG�Ȃ�A�p���c�E���������̂�
776 �F����������K�������F2005/07/10(��) 19:55:12 ID:I6N6a8+3
���ł�胊�b�`�ɂȂ������Z�\�͂ƃ������̎g�������i�Q�[���A����ӓ|�ȂH
�r���̔��j��̂ł��A�t�ɒz��V�~�����[�^�ł�
���함SLG�ł��G����茫��������
�n�`���̑��̃p�����[�^�̎�ނƐ��x���オ�邾���ł��f�B�e�B�[�����ׂ����o������
�����ƃ}�V�Ȏg�����͊��ł��L�邾�낤�B
�r���̔��j��̂ł��A�t�ɒz��V�~�����[�^�ł�
���함SLG�ł��G����茫��������
�n�`���̑��̃p�����[�^�̎�ނƐ��x���オ�邾���ł��f�B�e�B�[�����ׂ����o������
�����ƃ}�V�Ȏg�����͊��ł��L�邾�낤�B
777 �F����������K�������F2005/07/10(��) 20:01:32 ID:9fhNQisk
>>770
�����Ƃ�����Ȃ�����B
�R���{�ŁA�̂����������Ǝ���������Ƃ��Ő�����ѕ���������Ƃ��Ă�
�ʔ������j�Q�����Ƃ͎v��Ȃ��B
VF4������ł��R���{�Ńq�b�g������Z�̎�ނɂ���Đ�����ѕ����Ⴄ��B
���̃o���G�[�V�������X�ɑ�����킯������A�R���{�̑��l���Ƃ����Ӗ��ł�
�������Z�͖ʔ����Ƀv���X�ɓ����Ǝv����B
�����Ƃ�����Ȃ�����B
�R���{�ŁA�̂����������Ǝ���������Ƃ��Ő�����ѕ���������Ƃ��Ă�
�ʔ������j�Q�����Ƃ͎v��Ȃ��B
VF4������ł��R���{�Ńq�b�g������Z�̎�ނɂ���Đ�����ѕ����Ⴄ��B
���̃o���G�[�V�������X�ɑ�����킯������A�R���{�̑��l���Ƃ����Ӗ��ł�
�������Z�͖ʔ����Ƀv���X�ɓ����Ǝv����B
778 �F����������K�������F2005/07/10(��) 20:04:21 ID:J8CuN6AJ
�ő�10.5TFLOPS�̉��Z���\
^^^^^^^^^^^^^
������
^^^^^^^^^^^^^
������
779 �F����������K�������F2005/07/10(��) 20:07:41 ID:9fhNQisk
�i���Q�[���̏ꍇ�A�q�b�g����Q�[���f�U�C���̏������[�̂́A
�@����A���[����������x�V���v���ł��邱�Ɓi���S�҂̕~�����Ⴂ�j
�A�Z�p����̗]�n�������i�㋉�҂���肱�݂�������j
�Ƃ����̂�����Ǝv���B
�������Z�́A�@�ɑ��Ă͉e����^���Ȃ����A�A�ɑ��Ă͉e����^����B
�������Z�����l�ȃ��[�V���������ݏo���A���l�ȃ��[�V���������l�ȏݏo���͂��B
�e�ɑΉ������œK�ȍs�����[�̂͏㋉�҂������̂����������邾��B
�@����A���[����������x�V���v���ł��邱�Ɓi���S�҂̕~�����Ⴂ�j
�A�Z�p����̗]�n�������i�㋉�҂���肱�݂�������j
�Ƃ����̂�����Ǝv���B
�������Z�́A�@�ɑ��Ă͉e����^���Ȃ����A�A�ɑ��Ă͉e����^����B
�������Z�����l�ȃ��[�V���������ݏo���A���l�ȃ��[�V���������l�ȏݏo���͂��B
�e�ɑΉ������œK�ȍs�����[�̂͏㋉�҂������̂����������邾��B
780 �F����������K�������F2005/07/10(��) 20:12:53 ID:THuGnuOd
�q�b�g�����ꏊ�ňЗ͂␁����т��Ⴄ����
�悤�̓X�}�u������
�悤�̓X�}�u������
781 �F����������K�������F2005/07/10(��) 20:21:27 ID:9fhNQisk
�X�}�u���̓L�����Q�[�B
�Q�[�����e�͊��҂���ĂȂ���B
�Q�[�����e�͊��҂���ĂȂ���B
782 �F����������K�������F2005/07/10(��) 20:22:45 ID:A2FYMLkk
>>769
�������Z�ƃ��f���ɑ�����H�͕ʎ����̘b�̂悤�ȋC�����܂����B
�������Z�ƃ��f���ɑ�����H�͕ʎ����̘b�̂悤�ȋC�����܂����B
783 �F����������K�������F2005/07/10(��) 20:26:51 ID:GV/cRwKR
>>776�@9fhNQisk����肽������ł���A���ہA�i���Q�[����
���̎�̃A�v���[�`�͊i�����l�Ƃ��ł�����������悤��
���Ă��肵�����ǁA���������i�����Ȃ��i���Q�[�����}���l����
�L�����Q�[�ɐ��艺�����Ă邵�B�C�O�͂Ƃ��������{�Ŋi���Q�[����
�Q�[�����|���S���ɗ���邫�������������W�����������B
�l�I�ɂ�����ŋZ�p���r�W���A���ɔ��f���ꌩ�h�����ς��Ȃ�
FPS�ŕ������A���ɉ�ꂽ�薳�o�݂����Ȃ̂ŃL������1000�̂ł��茩�Ă݂����B
�ł����̓��{�̊i�Q�[�����Ă�Ƃ���ɂ���ȋZ�p����Ƃ͎v���Ȃ����ǁB
���̎�̃A�v���[�`�͊i�����l�Ƃ��ł�����������悤��
���Ă��肵�����ǁA���������i�����Ȃ��i���Q�[�����}���l����
�L�����Q�[�ɐ��艺�����Ă邵�B�C�O�͂Ƃ��������{�Ŋi���Q�[����
�Q�[�����|���S���ɗ���邫�������������W�����������B
�l�I�ɂ�����ŋZ�p���r�W���A���ɔ��f���ꌩ�h�����ς��Ȃ�
FPS�ŕ������A���ɉ�ꂽ�薳�o�݂����Ȃ̂ŃL������1000�̂ł��茩�Ă݂����B
�ł����̓��{�̊i�Q�[�����Ă�Ƃ���ɂ���ȋZ�p����Ƃ͎v���Ȃ����ǁB
784 �F����������K�������F2005/07/10(��) 20:47:21 ID:0KFhO7TJ
���Q�C����CM�̂悤��CG�����Ƀ��A���Ȃ̂��l��������
ttp://regain.jp/jiten/cm/index.html
ttp://regain.jp/jiten/cm/index.html
785 �F����������K�������F2005/07/10(��) 20:49:24 ID:LZFVhLxL
�t�@�C�e�B���O���p�c����A�Ȃ�ł��Ȃ��B
786 �F����������K�������F2005/07/10(��) 20:49:32 ID:+flq4pCn
�Ȃ�ł��H
�K�R����
�K�R����
787 �F����������K�������F2005/07/10(��) 20:49:47 ID:I6N6a8+3
>>783
���Z�p���r�W���A���ɔ��f���ꌩ�h�����ς��
�t�@�C�g�i�C�g�R�������ł́H
�i�Q�[�ł���ȏ�A���A���^�C���ɔ����ł���قǂ͂����荷���o��
���A�Q�[���p�b�h�ő��삵�Ȃ�������Ȃ�����
�����⑀����ׂ������鎖�̓Q�[�����̖W���ɂ����Ȃ�Ȃ�������B
���Z�p���r�W���A���ɔ��f���ꌩ�h�����ς��
�t�@�C�g�i�C�g�R�������ł́H
�i�Q�[�ł���ȏ�A���A���^�C���ɔ����ł���قǂ͂����荷���o��
���A�Q�[���p�b�h�ő��삵�Ȃ�������Ȃ�����
�����⑀����ׂ������鎖�̓Q�[�����̖W���ɂ����Ȃ�Ȃ�������B
788 �F����������K�������F2005/07/10(��) 20:52:52 ID:XrOV4zer
�u���[�X�E���[��CG�f��{�c�ɂȂ����H
789 �F����������K�������F2005/07/10(��) 20:56:01 ID:9fhNQisk
>>783
�����̎�̃A�v���[�`�͊i�����l�Ƃ��ł�����������悤�Ƃ��Ă��肵������
���������i�Q�[�̖ʔ����̊j�S�͑ΐ�ɂ���킯������
�ΐ�l���[���̊i�Q�[�Ȃ������͂��������B
���ƃL�����������y���ւڂւڂ�������B
�����̎�̃A�v���[�`�͊i�����l�Ƃ��ł�����������悤�Ƃ��Ă��肵������
���������i�Q�[�̖ʔ����̊j�S�͑ΐ�ɂ���킯������
�ΐ�l���[���̊i�Q�[�Ȃ������͂��������B
���ƃL�����������y���ւڂւڂ�������B
790 �F����������K�������F2005/07/10(��) 20:58:33 ID:KABhKhxZ
�i�Q�[�ɕ������Z�i�G���W���H�j���Ă̂́A��Ƀo�����X�����̖�肶��Ȃ��̂��ƁB
���Ȃ��Ƃ������ڂɂ�胊�A���Ɂi�j�]�����j�Ȃ�̂͊m�����Ƃ͎v�����ǁA�v���C���[�̓���
�ɂ���ċN�����Ԃ̉\���������ɑ��������āA�����S�ĊǗ�������邩���Ă̂���肾�ƁB
�����ڂɔ�����������Ԃ̂͗ǂ����ǁA���̐�����ѕ��̓Q�[���Ƃ��ĕs�������������A
�L�������Ȃ������ĕ����̒������w�Ǖs�\�ɂȂ�B
�����ƃA�o�E�g�Ƀo�����X������o����Q�[���AVS�Q�O�݂����Ȗ��o���̃Q�[���Ȃ�
�������Z�̎�荞�݂悤�����邩������Ȃ����ǁA�ׂ��Ȃ�����S�Ă̋����܂ł�
�Q�[���o�����X�Ƃ��Ē������Ȃ���Ȃ��i�Q�[�ł́i���̂܂܂ł́j�����Ȃ����Ǝv���B
���Ȃ��Ƃ������ڂɂ�胊�A���Ɂi�j�]�����j�Ȃ�̂͊m�����Ƃ͎v�����ǁA�v���C���[�̓���
�ɂ���ċN�����Ԃ̉\���������ɑ��������āA�����S�ĊǗ�������邩���Ă̂���肾�ƁB
�����ڂɔ�����������Ԃ̂͗ǂ����ǁA���̐�����ѕ��̓Q�[���Ƃ��ĕs�������������A
�L�������Ȃ������ĕ����̒������w�Ǖs�\�ɂȂ�B
�����ƃA�o�E�g�Ƀo�����X������o����Q�[���AVS�Q�O�݂����Ȗ��o���̃Q�[���Ȃ�
�������Z�̎�荞�݂悤�����邩������Ȃ����ǁA�ׂ��Ȃ�����S�Ă̋����܂ł�
�Q�[���o�����X�Ƃ��Ē������Ȃ���Ȃ��i�Q�[�ł́i���̂܂܂ł́j�����Ȃ����Ǝv���B
791 �F����������K�������F2005/07/10(��) 21:00:42 ID:9fhNQisk
�i���Q�[���̏ꍇ�A�Q�[���f�U�C�����d�v�����ǁA
����ȏ�ɑΐ���y���߂����ΐ��グ��V�X�e���̕����d�v�B
�i�����l�͂��̕ӂ��_���_���������B
�܂��A����ȑO�Ɂu�i�����l�v���Ă��C���������ȃ^�C�g���ł��鎞�_��
�I����Ă邯�ǁE�E�E
����ȏ�ɑΐ���y���߂����ΐ��グ��V�X�e���̕����d�v�B
�i�����l�͂��̕ӂ��_���_���������B
�܂��A����ȑO�Ɂu�i�����l�v���Ă��C���������ȃ^�C�g���ł��鎞�_��
�I����Ă邯�ǁE�E�E
792 �F����������K�������F2005/07/10(��) 21:01:47 ID:XymhsClF
�i�����l�ł���Ă邱�Ƃ��āA�o�E���T�[�ł���Ă邱�Ƃƈꏏ����Ȃ����������H
���ꃂ�[�V�������p�ӂ���ĂȂ����Č����B
�N���オ��܂ł̍d�����ԂƂ��R���{�̕�����Ƃ��A�����Ђ��ɕK�v�ȏ��͊W�Ȃ�������ł́H
���ꃂ�[�V�������p�ӂ���ĂȂ����Č����B
�N���オ��܂ł̍d�����ԂƂ��R���{�̕�����Ƃ��A�����Ђ��ɕK�v�ȏ��͊W�Ȃ�������ł́H
793 �F����������K�������F2005/07/10(��) 21:02:58 ID:fMIt/Npi
>>772
���܂�����A�C�V�̃Q�[���������ƂȂ��́H
�L�����Q�[���Ă����̂̓Q�[�������N�ł��Ȃ����̂ł��A
�L�����̗͂Ŕ����Q�[���̂��Ƃ���H
���i�ǂ�ȃQ�[�����Ă�̂�
���܂�����A�C�V�̃Q�[���������ƂȂ��́H
�L�����Q�[���Ă����̂̓Q�[�������N�ł��Ȃ����̂ł��A
�L�����̗͂Ŕ����Q�[���̂��Ƃ���H
���i�ǂ�ȃQ�[�����Ă�̂�
794 �F����������K�������F2005/07/10(��) 21:06:58 ID:9fhNQisk
�C�V���̃Q�[�����Č����ڎq���������ۂ�����ȁB
�q���x�����Ă�H��l���y���߂�{�i�h���Ċ��������Ȃ���
���ۗV��Ŋ��������������ȁB
�q���x�����Ă�H��l���y���߂�{�i�h���Ċ��������Ȃ���
���ۗV��Ŋ��������������ȁB
795 �F����������K�������F2005/07/10(��) 21:10:51 ID:9fhNQisk
>>790
���̕ӂ̒����ׂ͍����o�[�W�����グ�Ă������őΉ��\�Ȃ̂ł́H
���ꂱ���o�[�`���S�݂����ɁB
�o�[�`���S�����čŏ��̃o�[�W�����ł͋��߂���Z�����\������
�o�����X�I�ɂ͍����������B
���̕ӂ̒����ׂ͍����o�[�W�����グ�Ă������őΉ��\�Ȃ̂ł́H
���ꂱ���o�[�`���S�݂����ɁB
�o�[�`���S�����čŏ��̃o�[�W�����ł͋��߂���Z�����\������
�o�����X�I�ɂ͍����������B
796 �F����������K�������F2005/07/10(��) 21:11:21 ID:THuGnuOd
���̃^�N�g�ŎM��R�b�v�̋�����1G���ł̋������ۂ�������悤�ɂȂ����ł���
797 �F����������K�������F2005/07/10(��) 21:16:17 ID:9fhNQisk
���^�N�Ƀ��A�����Ȃ�ĕs�K�v�B
������G�ƃL���������Ŕ���L�����Q�[���ȁB
������G�ƃL���������Ŕ���L�����Q�[���ȁB
798 �F����������K�������F2005/07/10(��) 21:18:27 ID:THuGnuOd
�Ȃ���ID:9fhNQisk(14)
799 �F����������K�������F2005/07/10(��) 21:21:40 ID:ZTIojovw
800 �F����������K�������F2005/07/10(��) 21:26:06 ID:9fhNQisk
�C�V���݂����ɃL�����ƒm���x�𗊂�ɖʔ����Ȃ��Q�[���낤�Ƃ��Ă�
�l�b�g�S���̂������ł͕��Q�[�͂����ɒ@�����^���ł��邩��
����҂��x���ɂ����E��������Ď����B
�l�b�g�S���̂������ł͕��Q�[�͂����ɒ@�����^���ł��邩��
����҂��x���ɂ����E��������Ď����B
801 �F����������K�������F2005/07/10(��) 21:28:28 ID:SGsfZGQd
>>800
�X�}�u���͖ʔ������H
�X�}�u���͖ʔ������H
802 �F����������K�������F2005/07/10(��) 21:30:15 ID:KABhKhxZ
�j���e���h�E�Q�[���_�͗��ɂ��Ȃ范�����X���Ⴂ���ᖳ�����Ǝv���ł��B�B�B
803 �F����������K�������F2005/07/10(��) 21:31:59 ID:PM2enMCH
���������Q�[���_�H���̃X���Ⴂ
804 �F����������K�������F2005/07/10(��) 21:34:44 ID:9fhNQisk
�������Q�[���@�ň�ԑ�Ȃ̂̓Q�[���Ƃ������\�t�g�E�F�A
�ł���̂͋^���]�n�������킯�ŁB
�\�t�g�E�F�A�Ƃ����v������������̂Ƀn�[�h�E�F�A��
�����Ƃ�����A�\�t�g�E�F�A�A�܂�Q�[�����v������
���m���������Ă����͔̂��ɏd�v�ł���Ǝv���ˁB
�ł���̂͋^���]�n�������킯�ŁB
�\�t�g�E�F�A�Ƃ����v������������̂Ƀn�[�h�E�F�A��
�����Ƃ�����A�\�t�g�E�F�A�A�܂�Q�[�����v������
���m���������Ă����͔̂��ɏd�v�ł���Ǝv���ˁB
805 �F����������K�������F2005/07/10(��) 21:37:22 ID:9fhNQisk
���ɔC�V���B���{�݂����Ɂu�ቿ�i�A�ᐫ�\�v
�H���ōs�������{���ɐ������̂��H
�����\���������郊�A�����̓Q�[���̖ʔ�����
�{���Ɍq����Ȃ��ƌ�����̂��A
�C�V���͂�����ƌ��������̂��낤���E�E�E
�H���ōs�������{���ɐ������̂��H
�����\���������郊�A�����̓Q�[���̖ʔ�����
�{���Ɍq����Ȃ��ƌ�����̂��A
�C�V���͂�����ƌ��������̂��낤���E�E�E
806 �F����������K�������F2005/07/10(��) 21:39:00 ID:ZTIojovw
�����A�N���X�C�b�`���ꂽ��
807 �F����������K�������F2005/07/10(��) 21:39:33 ID:PM2enMCH
�ԈႢ�Ȃ��A���Ȃ����L�\�ȋƊE�̐l���^���ɂ͌������Ă�Ǝv���܂���
808 �F����������K�������F2005/07/10(��) 21:48:01 ID:9fhNQisk
>>807
�ƌ����A�C�V���͎q���x���I�ȔA�����Q�[������葱���Ă���킯�����B
���A���X�e�B�b�N�ȃQ�[������ڎw���������Ȃ��C�V���Ȃ�
�u���A�����̓Q�[���ɕs�K�v�v�Ƃ����l���������Ă����������Ȃ��B
����Ȃ���C�V���͎q�������̃��b�e����\����B
�ƌ����A�C�V���͎q���x���I�ȔA�����Q�[������葱���Ă���킯�����B
���A���X�e�B�b�N�ȃQ�[������ڎw���������Ȃ��C�V���Ȃ�
�u���A�����̓Q�[���ɕs�K�v�v�Ƃ����l���������Ă����������Ȃ��B
����Ȃ���C�V���͎q�������̃��b�e����\����B
809 �F����������K�������F2005/07/10(��) 21:49:53 ID:sMpnWFoV
>9fhNQisk
�C�V�����X���Ⴂ�Ȃ͕̂����邪�A
���O���X���Ⴂ
�C�V�����X���Ⴂ�Ȃ͕̂����邪�A
���O���X���Ⴂ
810 �F����������K�������F2005/07/10(��) 21:50:38 ID:I7gzAGnd
�����A�N�ɂ��~�߂��Ȃ��B
811 �F����������K�������F2005/07/10(��) 21:52:13 ID:9fhNQisk
��x���ꂪ�o�������������d���Ȃ��ׁB
�V�����Z�p�I�ȃl�^����������Ȃ����肱�̗���͑����B
�V�����Z�p�I�ȃl�^����������Ȃ����肱�̗���͑����B
812 �F����������K�������F2005/07/10(��) 21:53:46 ID:ZTIojovw
>>808
����A������ˁH�q�������ŁB
�������Ǝv����A�C�V���̕������Ƃ��āB
�����e�Ȃ�ԈႢ�Ȃ�3�@��̒��Ń��{�������B
�Ƒ��ŗV�ׂ����ȃQ�[�������邵�B
����A������ˁH�q�������ŁB
�������Ǝv����A�C�V���̕������Ƃ��āB
�����e�Ȃ�ԈႢ�Ȃ�3�@��̒��Ń��{�������B
�Ƒ��ŗV�ׂ����ȃQ�[�������邵�B
813 �F����������K�������F2005/07/10(��) 21:58:30 ID:PM2enMCH
9fhNQisk
�����̗��_���S�Đ������̂ł���
�����̗��_���S�Đ������̂ł���
814 �F����������K�������F2005/07/10(��) 21:58:39 ID:rg6I0tmd
ID:9fhNQisk
���������h�ǁh�f�l���x���̒��w���ł��o����Q�[���f�U�C���l�͎~�߂�B
�v���Ȃ���ɋc�_����s�����Ă郌�x���̂��̂��������X���ӂ��ɏ�������ł�H
���������h�ǁh�f�l���x���̒��w���ł��o����Q�[���f�U�C���l�͎~�߂�B
�v���Ȃ���ɋc�_����s�����Ă郌�x���̂��̂��������X���ӂ��ɏ�������ł�H
815 �F����������K�������F2005/07/10(��) 22:03:37 ID:9fhNQisk
�킩�����悶�Ⴀ������Ɨ�����C�����ċZ�p�I�Șb�����悤�B
http://www.watch.impress.co.jp/game/docs/20050318/ageia.htm
���̂悤�ȕ������Z����������̂ɁACELL��XBOX360CPU�ǂ�����
���������Ǝv���H
CELL��LS�̓��C���������Ƃ̃R�q�[�����V���ۂ���Ă��Ȃ������Ȃ̂ŁA
�������Z�Ƒ����������悤�ŁA���͂��܂�悭�Ȃ��Ǝv���B
SPE�����Z�Ɏg�����f�[�^��p�ɂɃ��C���������Ƃ���肵�Ȃ��Ƃ����Ȃ��̂ŁA
���C���������̑ш悪�N�����邾�낤�B
http://www.watch.impress.co.jp/game/docs/20050318/ageia.htm
���̂悤�ȕ������Z����������̂ɁACELL��XBOX360CPU�ǂ�����
���������Ǝv���H
CELL��LS�̓��C���������Ƃ̃R�q�[�����V���ۂ���Ă��Ȃ������Ȃ̂ŁA
�������Z�Ƒ����������悤�ŁA���͂��܂�悭�Ȃ��Ǝv���B
SPE�����Z�Ɏg�����f�[�^��p�ɂɃ��C���������Ƃ���肵�Ȃ��Ƃ����Ȃ��̂ŁA
���C���������̑ш悪�N�����邾�낤�B
816 �F����������K�������F2005/07/10(��) 22:07:01 ID:9fhNQisk
CELL��SPE���������Z�Ő������Ȃ��ƂȂ���A
�J���҂�CELL��������Ӑ}�̑唼�͎�������Ȃ�������
�������ƂȂ̂ł͂Ȃ��́H
���ꂶ��XBOX360��CPU�Ƒ卷�����B
CELL�ւ̓����͖��ʂ������A�Ƃ������Ȃ̂ł́E�E�E
�J���҂�CELL��������Ӑ}�̑唼�͎�������Ȃ�������
�������ƂȂ̂ł͂Ȃ��́H
���ꂶ��XBOX360��CPU�Ƒ卷�����B
CELL�ւ̓����͖��ʂ������A�Ƃ������Ȃ̂ł́E�E�E
817 �F����������K�������F2005/07/10(��) 22:10:05 ID:9fhNQisk
�Z�p�I�Șb�ɂ͑a���̂ł��܂蒷�������Ȃ��̂����A
���_�V�F�[�_�[�̑�p�╨�����Z�Ƃ����p�r��CELL�i�Ƃ�����SPE�j��
�ǂ̒��x������̂��A���܂����悭�킩���B
�Ƃ������A����ł͐������Ȃ��̂ł͂Ȃ����A�Ǝv���Ă���̂����B
���̕ӂ̂��Ƃ��ڂ����l�ɉ�����ė~�����B
���_�V�F�[�_�[�̑�p�╨�����Z�Ƃ����p�r��CELL�i�Ƃ�����SPE�j��
�ǂ̒��x������̂��A���܂����悭�킩���B
�Ƃ������A����ł͐������Ȃ��̂ł͂Ȃ����A�Ǝv���Ă���̂����B
���̕ӂ̂��Ƃ��ڂ����l�ɉ�����ė~�����B
818 �F����������K�������F2005/07/10(��) 22:11:27 ID:4nWuwOtt
���������u�������Z�v�ƌ������A�̃\�����A��̋�̓I�ɂǂ�ȏ����Ȃ̂�����
�̂�������Ȃ��B
�܂��A������ȒP�ɐ����o����A�_�u�X�`����ꂿ�Ⴄ�̂��낤���ǁE�E
�̂�������Ȃ��B
�܂��A������ȒP�ɐ����o����A�_�u�X�`����ꂿ�Ⴄ�̂��낤���ǁE�E
819 �F����������K�������F2005/07/10(��) 22:12:00 ID:M/o5EqWn
�ш�Ƃ����ւƂ��G���f�B�A���̘b�̓X���[�������N��
820 �F����������K�������F2005/07/10(��) 22:17:03 ID:THuGnuOd
���錳�f�[�^��������
��������ƂɌv�Z�������ʂ�f���o���Ƃ������Ƃ�����Ƃ�
���f�[�^���Ȃ������낱�돑���������Ă���ɒǏ]���Ȃ��Ⴂ���Ȃ��Ȃ�
�R�q�[�����V��ۂ����ɏo�������ʂ͉�ꂽ�f�[�^�Ƃ������ƂɂȂ����Ⴄ
�ł��������Z���鎞�́u���f�[�^�v�͕s�ςł��邱�Ƃ��O��ł���
�����Č��f�[�^������A�v�Z�̑O����
�R�q�[�����V���ۂ���Ȃ����Ƃ��������Z�̏�Q�ɂȂ�Ƃ͎v���Ȃ�
��������ƂɌv�Z�������ʂ�f���o���Ƃ������Ƃ�����Ƃ�
���f�[�^���Ȃ������낱�돑���������Ă���ɒǏ]���Ȃ��Ⴂ���Ȃ��Ȃ�
�R�q�[�����V��ۂ����ɏo�������ʂ͉�ꂽ�f�[�^�Ƃ������ƂɂȂ����Ⴄ
�ł��������Z���鎞�́u���f�[�^�v�͕s�ςł��邱�Ƃ��O��ł���
�����Č��f�[�^������A�v�Z�̑O����
�R�q�[�����V���ۂ���Ȃ����Ƃ��������Z�̏�Q�ɂȂ�Ƃ͎v���Ȃ�
821 �F����������K�������F2005/07/10(��) 22:17:06 ID:rg6I0tmd
822 �F����������K�������F2005/07/10(��) 22:17:13 ID:9fhNQisk
>>815�̃����N�ɂ���@�ԗ�����vs.Ragdoll(���p�n)�@��
�_�u�X�`�Ȃł��g�������ȋC������B
��{�I�ɁARagdoll����(��{�n)�@�̓q�g�̓����ɊW����
�����Ȃ̂ŁA�����������ȃV�[���͑������B
HALO2�ł��`�[�t�̂��ꃂ�[�V�����Ŏg���Ă������ȁB
�_�u�X�`�Ȃł��g�������ȋC������B
��{�I�ɁARagdoll����(��{�n)�@�̓q�g�̓����ɊW����
�����Ȃ̂ŁA�����������ȃV�[���͑������B
HALO2�ł��`�[�t�̂��ꃂ�[�V�����Ŏg���Ă������ȁB
823 �F����������K�������F2005/07/10(��) 22:20:30 ID:9fhNQisk
>>820
���f�[�^���s�ςƂ����̂��Ⴄ�Ǝv�����B
�������Z�������ʂ̃��f���ɍX��
�A�N�V�������������ĕω�����Ƃ���
�\�������čl�����邾��B
���f�[�^���s�ςƂ����̂��Ⴄ�Ǝv�����B
�������Z�������ʂ̃��f���ɍX��
�A�N�V�������������ĕω�����Ƃ���
�\�������čl�����邾��B
824 �F����������K�������F2005/07/10(��) 22:25:07 ID:NJS26p1c
������CPU��
��������UMA�ł���Ƀ������ɒ�������Ă��Ȃ��̂�
�_�O�E�E�E�E����肪�������I�I�ǂ�����ƁE�E�E
��������UMA�ł���Ƀ������ɒ�������Ă��Ȃ��̂�
�_�O�E�E�E�E����肪�������I�I�ǂ�����ƁE�E�E
825 �F����������K�������F2005/07/10(��) 22:25:28 ID:ixFnPX0B
>>623-632
�������s���ۼ�wwwwwwwwwwwwww
�������s���ۼ�wwwwwwwwwwwwww
�~�\�������čl�����邾��B �����\�������čl�����邾��B
�������Z��AI���ď����̓��C���������ɂ��鋤�L�f�[�^��
�p�ɂɎQ�Ƃ��Ȃ��Ƃ����Ȃ��͂��ŁA��������������LS�̂悤��
�ꎞ�̈�I�ȃ������͂��܂萶���Ȃ�����B
�Ƃ���ƁASPE���ĉ��ɐ�������̂����ċ^�₪�o�Ă���킯���B
�������Z��AI���ď����̓��C���������ɂ��鋤�L�f�[�^��
�p�ɂɎQ�Ƃ��Ȃ��Ƃ����Ȃ��͂��ŁA��������������LS�̂悤��
�ꎞ�̈�I�ȃ������͂��܂萶���Ȃ�����B
�Ƃ���ƁASPE���ĉ��ɐ�������̂����ċ^�₪�o�Ă���킯���B
827 �F����������K�������F2005/07/10(��) 22:26:05 ID:THuGnuOd
�Ȃ�łP��ڂ̉��Z�ƂQ��ڂ̉��Z���ЂƂ�����ɍl�����Ⴄ�̂�
828 �F����������K�������F2005/07/10(��) 22:30:52 ID:9fhNQisk
CELL���ʖڂȂ�XBOX360CPU�͂ǂ��Ȃ�́H
�ƌ�����ƁACELL���X�ɑʖڂ��Ď��ɂȂ邗
�������A���̂���CPU���{�g���l�b�N�ɂȂ�悤��
�V�[�����ǂ̒��x����̂��ƁE�E�E
XBOX360��CPU�ł��L����2000�̃�����������������ĉ\������̂ɂȁB
����ȏ�CPU�̐��\�グ�Ă��g���������������ł́B
�ƌ�����ƁACELL���X�ɑʖڂ��Ď��ɂȂ邗
�������A���̂���CPU���{�g���l�b�N�ɂȂ�悤��
�V�[�����ǂ̒��x����̂��ƁE�E�E
XBOX360��CPU�ł��L����2000�̃�����������������ĉ\������̂ɂȁB
����ȏ�CPU�̐��\�グ�Ă��g���������������ł́B
829 �F����������K�������F2005/07/10(��) 22:32:12 ID:og4NzZCv
�ق�ƒN����X�C�b�`���ꂽ��
830 �F����������K�������F2005/07/10(��) 22:32:19 ID:E1cHK8dU
������ȏ�CPU�̐��\�グ�Ă��g���������������ł́B
������ȏ�CPU�̐��\�グ�Ă��g���������������ł́B
������ȏ�CPU�̐��\�グ�Ă��g���������������ł́B
�����A����]
������ȏ�CPU�̐��\�グ�Ă��g���������������ł́B
������ȏ�CPU�̐��\�グ�Ă��g���������������ł́B
�����A����]
831 �F����������K�������F2005/07/10(��) 22:32:26 ID:THuGnuOd
���_�͂����ɍs�����Ⴄ�̂���
832 �F����������K�������F2005/07/10(��) 22:32:53 ID:1ZFNTLey
�Ȃ����Ƃ��l�̈ӌ������Ȃ��Ƃ��Ƃ����E�E�E�̐l�݂��������H
833 �F����������K�������F2005/07/10(��) 22:40:37 ID:I6N6a8+3
834 �F����������K�������F2005/07/10(��) 22:41:46 ID:9fhNQisk
�������AXBOX360��CPU���ʖڂƌ����Ă��A
XBOX360�̏ꍇGPU��CPU�I�Ȏd����������x�ł���̂�
�����I�ɂ͂���Ȃɑʖڂ���Ȃ��B
���_�ƃs�N�Z���͓����ɍ����ׂɂ͂Ȃ�Ȃ��Ƃ���ATI��
���͂͑f���炵���ł��ȁB
XBOX360�̏ꍇGPU��CPU�I�Ȏd����������x�ł���̂�
�����I�ɂ͂���Ȃɑʖڂ���Ȃ��B
���_�ƃs�N�Z���͓����ɍ����ׂɂ͂Ȃ�Ȃ��Ƃ���ATI��
���͂͑f���炵���ł��ȁB
835 �F����������K�������F2005/07/10(��) 22:46:36 ID:I6N6a8+3
>>ID:9fhNQisk
���O�A�ȑOCELL�X���Œ��X�ƍ����Ɠ����������ĂȂ��������H
���̂ɕ��������o����������H
���O�A�ȑOCELL�X���Œ��X�ƍ����Ɠ����������ĂȂ��������H
���̂ɕ��������o����������H
836 �F����������K�������F2005/07/10(��) 22:48:53 ID:9fhNQisk
���[CELL�X���ɂ����傭���傭��������ł��邩�瑽������������Ȃ��B
�܁A���[�ł��������ǂȁB���F�ꖼ���������B
�܁A���[�ł��������ǂȁB���F�ꖼ���������B
�~�܁A���[�ł��������ǂȁB���F�ꖼ���������B �����܁A�ǁ[�ł��������ǂȁB���F�ꖼ���������B
>>830
�������Q�[���@�ł�CPU���{�g���l�b�N�ɂȂ鏈�����Ă�������܂薳����ƈႤ�̂��H
�f�B�X�v���[�X�}�b�s���O�n�̏�����GPU����OK�����A�������Z�Ȃ�Half-Life2�̎��_��
������x��������Ă��邵�B
��������Ȃ�CPU�p���[���K�v�Ƃ�����ʂ��Ė����悤�ȋC���B
>>830
�������Q�[���@�ł�CPU���{�g���l�b�N�ɂȂ鏈�����Ă�������܂薳����ƈႤ�̂��H
�f�B�X�v���[�X�}�b�s���O�n�̏�����GPU����OK�����A�������Z�Ȃ�Half-Life2�̎��_��
������x��������Ă��邵�B
��������Ȃ�CPU�p���[���K�v�Ƃ�����ʂ��Ė����悤�ȋC���B
838 �F����������K�������F2005/07/10(��) 22:58:59 ID:LZFVhLxL
�[���A�ŋ߂̃x���`���đ��CPU���{�g���l�b�N����Ȃ����������H
839 �F����������K�������F2005/07/10(��) 23:00:06 ID:Y4HotUtq
7800GTX��CPU���{�g���l�b�N���������
840 �F����������K�������F2005/07/10(��) 23:02:49 ID:KABhKhxZ
�������Z�Ȃ�Ăǂ��l���Ă������蔻��̑O�����݂����ȕ��Ȃ��A
����邾��CPU���K�v�Ȃ�čl���Ȃ��Ă����[�Ȃᖳ���̂��B
�������Z�]�X�����o����CPU���K�v�Ȃ����ēW�J�͈Ӗ��킩���B
����邾��CPU���K�v�Ȃ�čl���Ȃ��Ă����[�Ȃᖳ���̂��B
�������Z�]�X�����o����CPU���K�v�Ȃ����ēW�J�͈Ӗ��킩���B
841 �F����������K�������F2005/07/10(��) 23:02:59 ID:1ZFNTLey
������ł����Ă��������E�Ƃ̊G�̍��͂܂��܂�ꡂ��ɂ���B
���̍��߂čs���ɂ��b�o�t�f�o�t�Ƃ��ɂ����Ƃ����Ɛi������K�v��
�����Ȃ��̂��H
���̍��߂čs���ɂ��b�o�t�f�o�t�Ƃ��ɂ����Ƃ����Ɛi������K�v��
�����Ȃ��̂��H
842 �F����������K�������F2005/07/10(��) 23:05:11 ID:YMCzGSHk
>>833 �����o
�Ƃ���ŁAXbox 360�J���Ҍ����́Aalpha�L�b�g�Ǝ��@�Ƃ̑�����������
�h�L�������g���o����Ă���炵��
http://www.beyond3d.com/forum/viewtopic.php?p=569006#569006
����ɂ��ƁAalpha�L�b�g�͎��@�̎O���̈�̐��\�����A�ėp�R�[�h���\��alpha�L�b�g
(PowerPC G5 dual)�̕�����Ƃ̂��ƁB���ƃL���b�V���̃R���g���[���Ȃ���肭���
�Ȃ��Ɛ��\���o�Ȃ��Ƃ��B
�Ƃ���ŁAXbox 360�J���Ҍ����́Aalpha�L�b�g�Ǝ��@�Ƃ̑�����������
�h�L�������g���o����Ă���炵��
http://www.beyond3d.com/forum/viewtopic.php?p=569006#569006
����ɂ��ƁAalpha�L�b�g�͎��@�̎O���̈�̐��\�����A�ėp�R�[�h���\��alpha�L�b�g
(PowerPC G5 dual)�̕�����Ƃ̂��ƁB���ƃL���b�V���̃R���g���[���Ȃ���肭���
�Ȃ��Ɛ��\���o�Ȃ��Ƃ��B
843 �F����������K�������F2005/07/10(��) 23:08:19 ID:LZFVhLxL
>>842
�E�L���b�V���̃R���g���[���Ȃ���肭���Ȃ��Ɛ��\���o�Ȃ�
��������3�R�A��L2���p�����瓖����O�Ƃ��āB
�C�ɂȂ�̂́A
�E�ėp�R�[�h���\��alpha�L�b�g(PowerPC G5 dual)�̕�����
���ȁB
����ς�970�R�A����Ȃ���PPE�����ƍl���ėǂ��̂��B
�E�L���b�V���̃R���g���[���Ȃ���肭���Ȃ��Ɛ��\���o�Ȃ�
��������3�R�A��L2���p�����瓖����O�Ƃ��āB
�C�ɂȂ�̂́A
�E�ėp�R�[�h���\��alpha�L�b�g(PowerPC G5 dual)�̕�����
���ȁB
����ς�970�R�A����Ȃ���PPE�����ƍl���ėǂ��̂��B
844 �F����������K�������F2005/07/10(��) 23:10:23 ID:9fhNQisk
XBOX360��CPU�R�A��PowerPC G5�Ɠ����x�̐��\���o���邩���m������
������������o���Ȃ��̂�������Ȃ��ȁE�E�E
x86�nCPU�Ɠ��l�A�L���b�V����������x���₵��2�R�A�ɂ�������
���s���\�͍��������̂ł́B
������������o���Ȃ��̂�������Ȃ��ȁE�E�E
x86�nCPU�Ɠ��l�A�L���b�V����������x���₵��2�R�A�ɂ�������
���s���\�͍��������̂ł́B
845 �F����������K�������F2005/07/10(��) 23:13:45 ID:XrOV4zer
�f�B�A���R�A�̃����b�g�͐��\�ቺ��
�h���邱��
intel�̐l�Ԃ������Ă邶���
�h���邱��
intel�̐l�Ԃ������Ă邶���
846 �F����������K�������F
PPC970�͂Q�R�A���킹�Ă�L2�L���b�V����XBOX360�Ƃ���Ȃ�1MB�ł���